
抓取动态网页
抓取动态网页(巴西拉科鲁尼亚学校web语言的学习交流活动分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-15 11:00
抓取动态网页,最简单的方法就是手动录制一遍数据,然后写入到文件里,然后手动操作。不过这也不是说100%准确,可能也有差错。如果数据量不大,最好还是自己写一遍爬虫,然后自己手动操作。
我在巴西拉科鲁尼亚学校web语言的学习交流活动做过sre的分享。我自己就是大三的参与者,当时我学习爬虫的时候是通过自己手动按编译原理实现上传的。我推荐你最先使用一些像python这样的脚本语言,然后从python学起。非常简单。
爬虫要找inception-v驱动下的驱动程序,不然爬到的数据没什么意义。自己手动抓100以下基本是错的,而且整个网页10+pages都没有关系。爬虫要是觉得容易被封,采用插件反爬虫,要什么爬虫什么数据。不过这样效率实在低,因为常规网站通常会先抽查几次ip可能才在后面页面注册,所以的常规软件没有反爬虫的能力。
考虑手动爬的话,你的数据通常是特定网站(特定服务)的,比如游戏主题论坛,商城之类,爬虫可以用一些黑名单来限制来爬数据。
我觉得手机客户端等可以抓。然后提交到百度,百度之后,不可能没反应,如果没反应,说明爬虫做错了,整个链接全部相互重复,我看到过一个抓包然后提交到百度,百度告诉我这是一个重复的网页,所以,百度也有可能没反应,可能是他的反爬措施有问题。如果,爬虫总是反应那个位置会封的。总之,抓你觉得不应该提交的网站数据。放在百度是可以被认为是一个独立的网站,可以不封的。
或者爬一次之后,提交百度,让百度的程序去处理一下,然后返回一个包,看到是乱爬数据,百度的方式,然后说给我个地址,我转发给你网站。不过这样很浪费时间。建议走百度的方式。 查看全部
抓取动态网页(巴西拉科鲁尼亚学校web语言的学习交流活动分享)
抓取动态网页,最简单的方法就是手动录制一遍数据,然后写入到文件里,然后手动操作。不过这也不是说100%准确,可能也有差错。如果数据量不大,最好还是自己写一遍爬虫,然后自己手动操作。
我在巴西拉科鲁尼亚学校web语言的学习交流活动做过sre的分享。我自己就是大三的参与者,当时我学习爬虫的时候是通过自己手动按编译原理实现上传的。我推荐你最先使用一些像python这样的脚本语言,然后从python学起。非常简单。
爬虫要找inception-v驱动下的驱动程序,不然爬到的数据没什么意义。自己手动抓100以下基本是错的,而且整个网页10+pages都没有关系。爬虫要是觉得容易被封,采用插件反爬虫,要什么爬虫什么数据。不过这样效率实在低,因为常规网站通常会先抽查几次ip可能才在后面页面注册,所以的常规软件没有反爬虫的能力。
考虑手动爬的话,你的数据通常是特定网站(特定服务)的,比如游戏主题论坛,商城之类,爬虫可以用一些黑名单来限制来爬数据。
我觉得手机客户端等可以抓。然后提交到百度,百度之后,不可能没反应,如果没反应,说明爬虫做错了,整个链接全部相互重复,我看到过一个抓包然后提交到百度,百度告诉我这是一个重复的网页,所以,百度也有可能没反应,可能是他的反爬措施有问题。如果,爬虫总是反应那个位置会封的。总之,抓你觉得不应该提交的网站数据。放在百度是可以被认为是一个独立的网站,可以不封的。
或者爬一次之后,提交百度,让百度的程序去处理一下,然后返回一个包,看到是乱爬数据,百度的方式,然后说给我个地址,我转发给你网站。不过这样很浪费时间。建议走百度的方式。
抓取动态网页(用到动态网页的两种技术:通过浏览器审查元素解析真实网页地址和使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-15 05:10
由于网易云线程已停止,新写的第4章现已更新至此。请参考文章:
上面爬取的网页都是静态网页,这些网页在浏览器中显示的内容是在HTML源代码中的。但是由于主流的网站都使用JavaScript来展示网页内容,不像静态网页,在使用JavaScript的时候,很多内容不会出现在HTML源代码中,所以爬取静态网页的技术可能不会工作正常使用。因此,我们需要使用两种动态网页抓取技术:通过浏览器检查元素解析真实网址和使用 selenium 模拟浏览器。
本章首先介绍动态网页的示例,让读者了解什么是动态网页抓取,然后利用以上两种动态网页抓取技术获取动态网页数据。
4.1 动态抓取示例
在开始爬取动态网页之前,我们还需要了解一个异步更新技术——AJAX(Asynchronous Javascript And XML)。它的价值在于可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量,所以AJAX被广泛使用。
与使用 AJAX 网页相比,如果传统网页需要更新内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更友好。但是AJAX网页的爬取过程比较麻烦。
首先,我们来看一个动态网页的例子。打开作者的博客Hello World文章,文章的地址是:
如下图所示,页面下方的评论是用JavaScript加载的,这些评论数据不会出现在网页的源代码中。
为了验证它是用 JavaScript 加载的,我们可以查看该页面的页面源代码。如下图,放置评论的代码没有评论数据,只有一段JavaScript代码。最终渲染的数据由 JavaScript 提取并加载到源代码中进行渲染。
除了我的博客,我们还可以在天猫电商上找到AJAX技术的例子。比如我们打开天猫iPhone 7的产品页面,点击“累计评论”,可以发现上面的url地址没有变化,整个页面也没有重新加载更新页面的评论部分。
和之前一样,我们也可以查看这个产品网页的源码,如下图,里面没有用户评论,这段内容是空白的。
因此,如果我们使用AJAX加载的动态网页,如何抓取里面动态加载的内容呢?有两种方法:
1. 通过浏览器检查元素解析地址
2. 模拟浏览器通过 selenium 爬行
请查看第四章的其他章节
第 4 章:动态网页抓取(解析真实地址 + selenium)
4.2 解析真实地址捕获
4.3 模拟浏览器通过selenium爬取 查看全部
抓取动态网页(用到动态网页的两种技术:通过浏览器审查元素解析真实网页地址和使用)
由于网易云线程已停止,新写的第4章现已更新至此。请参考文章:
上面爬取的网页都是静态网页,这些网页在浏览器中显示的内容是在HTML源代码中的。但是由于主流的网站都使用JavaScript来展示网页内容,不像静态网页,在使用JavaScript的时候,很多内容不会出现在HTML源代码中,所以爬取静态网页的技术可能不会工作正常使用。因此,我们需要使用两种动态网页抓取技术:通过浏览器检查元素解析真实网址和使用 selenium 模拟浏览器。
本章首先介绍动态网页的示例,让读者了解什么是动态网页抓取,然后利用以上两种动态网页抓取技术获取动态网页数据。
4.1 动态抓取示例
在开始爬取动态网页之前,我们还需要了解一个异步更新技术——AJAX(Asynchronous Javascript And XML)。它的价值在于可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量,所以AJAX被广泛使用。
与使用 AJAX 网页相比,如果传统网页需要更新内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更友好。但是AJAX网页的爬取过程比较麻烦。
首先,我们来看一个动态网页的例子。打开作者的博客Hello World文章,文章的地址是:
如下图所示,页面下方的评论是用JavaScript加载的,这些评论数据不会出现在网页的源代码中。
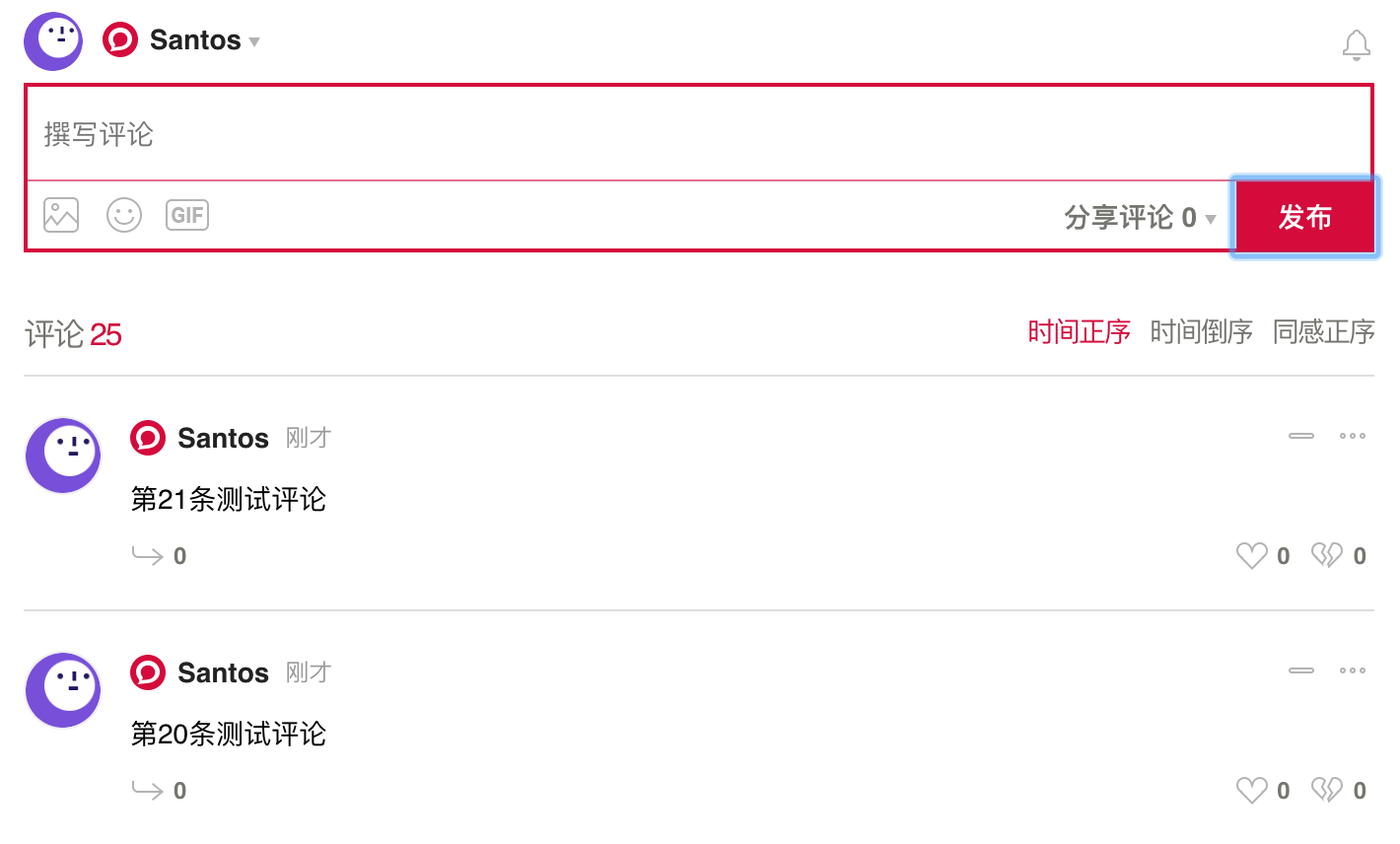
为了验证它是用 JavaScript 加载的,我们可以查看该页面的页面源代码。如下图,放置评论的代码没有评论数据,只有一段JavaScript代码。最终渲染的数据由 JavaScript 提取并加载到源代码中进行渲染。
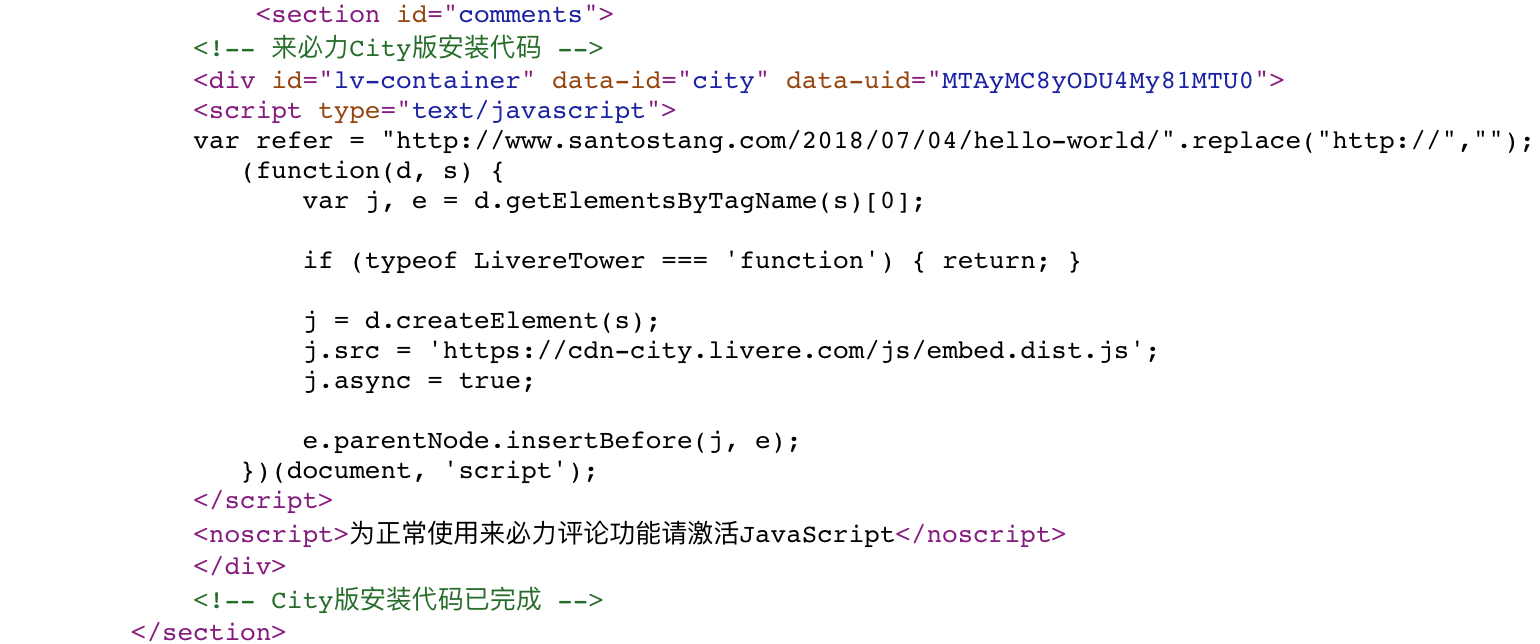
除了我的博客,我们还可以在天猫电商上找到AJAX技术的例子。比如我们打开天猫iPhone 7的产品页面,点击“累计评论”,可以发现上面的url地址没有变化,整个页面也没有重新加载更新页面的评论部分。
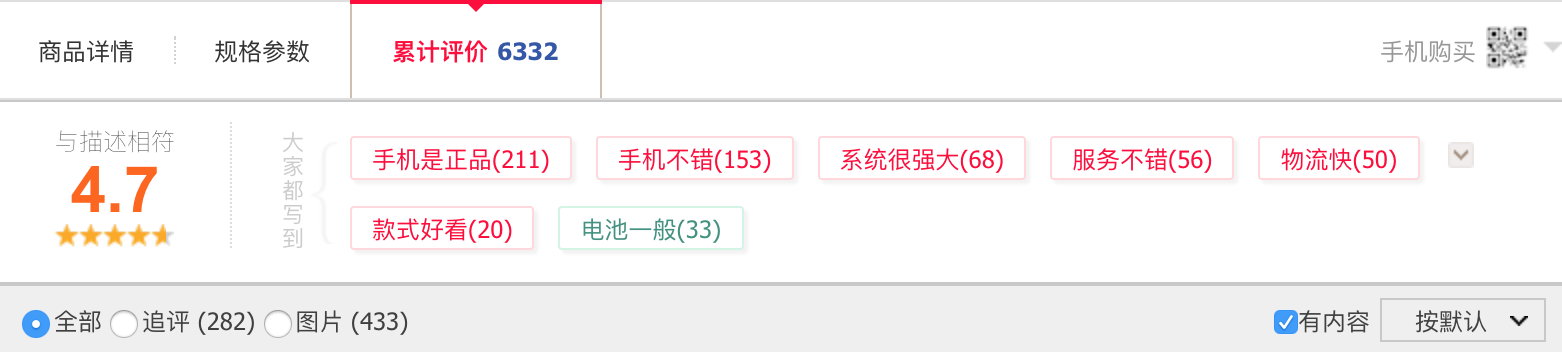
和之前一样,我们也可以查看这个产品网页的源码,如下图,里面没有用户评论,这段内容是空白的。

因此,如果我们使用AJAX加载的动态网页,如何抓取里面动态加载的内容呢?有两种方法:
1. 通过浏览器检查元素解析地址
2. 模拟浏览器通过 selenium 爬行
请查看第四章的其他章节
第 4 章:动态网页抓取(解析真实地址 + selenium)
4.2 解析真实地址捕获
4.3 模拟浏览器通过selenium爬取
抓取动态网页(块标签,打开后里面没有网页数据(XHR-1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-15 04:13
块标签,打开后没有网页数据
点击网络选项卡,我们可以看到网页向服务器发送了很多请求,数据很多,查找时间太长了
我们点击XHR分类,可以减少很多不必要的文件,节省很多时间。
【XHR类型是通过XMLHttpRequest方法发送的请求,可以在后台与服务器进行数据交换,也就是说可以在不加载整个网页的情况下更新网页某一部分的内容。也就是说,请求数据库然后得到响应的数据是XHR类型的]
然后我们开始在XHR类型下一一搜索,发现如下数据
查看请求的标头并获取其 url
url=",10,723,35,469,821&limit=30"
在 Firefox 的新窗口中打开此地址
打开后我们可以看到上面的情况,这是一个json格式的文件。然后,它的数据信息以字典的形式存储,数据存储在“NewMsgs”的键值中。
所以,我们可以通过访问["NewMsgs"]的键值来获取网页数据
然后我们查看我们需要的“好”和“坏”对应的key-value,以及时事通讯推荐的股票和行业对应的key-value。
通过查看字典,我们可以很快发现推荐股票是一个嵌套字典,即字典加列表加字典。对应的key值是["NewMsgs"][i]['Stocks'] 同理,对应的推荐行业key值是:["NewMsgs"][i]['BkjInfoArr']
通过对比网页数据,我们可以找到对应的“好”和“坏”时事通讯。
通过对比,我们发现带有好评的时事通讯的“影响”值为1,而“影响”的值为“0”,带有负面标签的短信的值为“-1”。
知道数据的位置后,我们开始编写代码。
先爬取网页,伪装成火狐浏览器,添加header访问数据库地址,防止被识别和拦截。
def get_page(url):
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36'
}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode()
return html
从上面的分析可以知道,数据是以json的形式存储的,所以上面的网页爬取返回的html就是json格式的数据。所以我们需要格式化json。
json.dumps()#把python对象转化成json格式对象
json.loads()#把json格式转化成python对象
转换后,我们可以通过以下字典的键值输出“好”、“坏”、推荐“股票”、推荐“行业”
行业:html["NewMsgs"][i]['BkjInfoArr']
时间:html["NewMsgs"][i]['UpdatedAt']
股票:html["NewMsgs"][i]['Stocks'][j]['Name']
利好:html["NewMsgs"][i]['Impact'] Impact = -1 --->利空 Impact = 1 --->利好
所以获取数据的代码是:
def get_data(html,url):
html = json.loads(html)
c = len(html["NewMsgs"])
for i in range(0,c):
cun =html["NewMsgs"][i]['Impact']#获取含有信息的字典
if cun == 1 or cun == -1:#判断信息是利好还是利空
print(html["NewMsgs"][i]['UpdatedAt'])
if cun == 1:
print("*************利好*************")
if cun == -1:
print('*************利空*************')
chang = len(html["NewMsgs"][i]['BkjInfoArr'])#获取信息下含有几个利好或利空行业
ch =html["NewMsgs"][i]['Stocks']
for j in range(0,chang):
print('行业:',html["NewMsgs"][i]['BkjInfoArr'][j]['Name'])
if ch!=None:
du = len(html["NewMsgs"][i]['Stocks'])#同理获取含有几个利好或利空股票
for k in range(0,du):
print('股票:',html["NewMsgs"][i]['Stocks'][k]['Name'])
print("**************************\n\n")#信息获取完毕,换行
return 0
通过运行发现获取到的数据非常少,只能获取到“点击加载更多”上显示的内容,无法获取到点击加载后的数据。
我们的爬虫爬不了这么少的数据,我们需要的是一个能爬取数据的爬虫,包括点击“加载更多”按钮后的数据。否则最好直接使用爬虫直接访问网站。那么我们如何才能将它与以下数据一起捕获呢?
我们再次输入review元素的XHR类型,通过点击“Load more”按钮,找到加载后保存有新内容的文件,然后再次review元素。
我们找到了保存新数据的文件和新文件的url地址
我们注意到url发生了变化,点击打开链接“,10,723,35,469,821&limit=30&tailmark=1529497523&msgIdMark=310241”
后面的字符比前面的数据 url 多一些。让我们多点击几次“Load More”,查看新内容的文件数据,看看能不能找到一些规律。
让我们将新的网址放在一起进行比较:
https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30&tailmark=1529497523&msgIdMark=310241
https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30&tailmark=1529493624&msgIdMark=310193
https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30&tailmark=1529487816&msgIdMark=310151
第一个网址:
第二个网址:
第三个网址:
通过对比我们可以发现,加载的json数据文件的地址与之前的json文件的['TailMark']和['TailMsgId']有关。
它是在原来的url=",10,723,35,469,821&limit=30"的基础上,加上一个后缀
“&tailmark=['TailMark']&msgIdMark=['TailMsgId']”
并获取 url 地址。
所以,我们获取下一个 url 地址的代码是:
def get_newurl(html):
url="https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30"
url=url+'&tailmark='+html['TailMark']+'&msgIdMark='+html['TailMsgId']
return url
那么我们的爬虫代码就基本完成了。以下是整个爬虫的代码:
# -*- coding:utf-8 -*-
import urllib.request
import urllib.parse
import time
import json
#获取网页
def get_page(url):
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36'
}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode()
return html
#获取下一页网址
def get_newurl(html):
url="https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30"
url=url+'&tailmark='+html['TailMark']+'&msgIdMark='+html['TailMsgId']
return url
#获取数据
def get_data(html,url):
html = json.loads(html)
c = len(html["NewMsgs"])
for i in range(0,c):
cun =html["NewMsgs"][i]['Impact']#获取含有信息的字典
if cun == 1 or cun == -1:#判断信息是利好还是利空
print(html["NewMsgs"][i]['UpdatedAt'])
if cun == 1:
print("*************利好*************")
if cun == -1:
print('*************利空*************')
chang = len(html["NewMsgs"][i]['BkjInfoArr'])#获取信息下含有几个利好或利空行业
ch =html["NewMsgs"][i]['Stocks']
for j in range(0,chang):
print('行业:',html["NewMsgs"][i]['BkjInfoArr'][j]['Name'])
if ch!=None:
du = len(html["NewMsgs"][i]['Stocks'])#同理获取含有几个利好或利空股票
for k in range(0,du):
print('股票:',html["NewMsgs"][i]['Stocks'][k]['Name'])
print("**************************\n\n")#信息获取完毕,换行
#获取通过函数获取下一页的url地址并返回该地址
url = get_newurl(html)
return url
if __name__=='__main__':
url="https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30"
for i in range(0,5):#进行循环爬取下一页地址的股票信息
html=get_page(url)
url=get_data(html,url)
因为刚开始学习,所以很多地方都没有写好,比较繁琐和乏味。也求大神赐教。 查看全部
抓取动态网页(块标签,打开后里面没有网页数据(XHR-1))
块标签,打开后没有网页数据

点击网络选项卡,我们可以看到网页向服务器发送了很多请求,数据很多,查找时间太长了
我们点击XHR分类,可以减少很多不必要的文件,节省很多时间。
【XHR类型是通过XMLHttpRequest方法发送的请求,可以在后台与服务器进行数据交换,也就是说可以在不加载整个网页的情况下更新网页某一部分的内容。也就是说,请求数据库然后得到响应的数据是XHR类型的]
然后我们开始在XHR类型下一一搜索,发现如下数据

查看请求的标头并获取其 url

url=",10,723,35,469,821&limit=30"
在 Firefox 的新窗口中打开此地址

打开后我们可以看到上面的情况,这是一个json格式的文件。然后,它的数据信息以字典的形式存储,数据存储在“NewMsgs”的键值中。

所以,我们可以通过访问["NewMsgs"]的键值来获取网页数据
然后我们查看我们需要的“好”和“坏”对应的key-value,以及时事通讯推荐的股票和行业对应的key-value。


通过查看字典,我们可以很快发现推荐股票是一个嵌套字典,即字典加列表加字典。对应的key值是["NewMsgs"][i]['Stocks'] 同理,对应的推荐行业key值是:["NewMsgs"][i]['BkjInfoArr']
通过对比网页数据,我们可以找到对应的“好”和“坏”时事通讯。


通过对比,我们发现带有好评的时事通讯的“影响”值为1,而“影响”的值为“0”,带有负面标签的短信的值为“-1”。
知道数据的位置后,我们开始编写代码。
先爬取网页,伪装成火狐浏览器,添加header访问数据库地址,防止被识别和拦截。
def get_page(url):
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36'
}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode()
return html
从上面的分析可以知道,数据是以json的形式存储的,所以上面的网页爬取返回的html就是json格式的数据。所以我们需要格式化json。
json.dumps()#把python对象转化成json格式对象
json.loads()#把json格式转化成python对象
转换后,我们可以通过以下字典的键值输出“好”、“坏”、推荐“股票”、推荐“行业”
行业:html["NewMsgs"][i]['BkjInfoArr']
时间:html["NewMsgs"][i]['UpdatedAt']
股票:html["NewMsgs"][i]['Stocks'][j]['Name']
利好:html["NewMsgs"][i]['Impact'] Impact = -1 --->利空 Impact = 1 --->利好
所以获取数据的代码是:
def get_data(html,url):
html = json.loads(html)
c = len(html["NewMsgs"])
for i in range(0,c):
cun =html["NewMsgs"][i]['Impact']#获取含有信息的字典
if cun == 1 or cun == -1:#判断信息是利好还是利空
print(html["NewMsgs"][i]['UpdatedAt'])
if cun == 1:
print("*************利好*************")
if cun == -1:
print('*************利空*************')
chang = len(html["NewMsgs"][i]['BkjInfoArr'])#获取信息下含有几个利好或利空行业
ch =html["NewMsgs"][i]['Stocks']
for j in range(0,chang):
print('行业:',html["NewMsgs"][i]['BkjInfoArr'][j]['Name'])
if ch!=None:
du = len(html["NewMsgs"][i]['Stocks'])#同理获取含有几个利好或利空股票
for k in range(0,du):
print('股票:',html["NewMsgs"][i]['Stocks'][k]['Name'])
print("**************************\n\n")#信息获取完毕,换行
return 0
通过运行发现获取到的数据非常少,只能获取到“点击加载更多”上显示的内容,无法获取到点击加载后的数据。

我们的爬虫爬不了这么少的数据,我们需要的是一个能爬取数据的爬虫,包括点击“加载更多”按钮后的数据。否则最好直接使用爬虫直接访问网站。那么我们如何才能将它与以下数据一起捕获呢?
我们再次输入review元素的XHR类型,通过点击“Load more”按钮,找到加载后保存有新内容的文件,然后再次review元素。
我们找到了保存新数据的文件和新文件的url地址


我们注意到url发生了变化,点击打开链接“,10,723,35,469,821&limit=30&tailmark=1529497523&msgIdMark=310241”
后面的字符比前面的数据 url 多一些。让我们多点击几次“Load More”,查看新内容的文件数据,看看能不能找到一些规律。
让我们将新的网址放在一起进行比较:
https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30&tailmark=1529497523&msgIdMark=310241
https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30&tailmark=1529493624&msgIdMark=310193
https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30&tailmark=1529487816&msgIdMark=310151
第一个网址:

第二个网址:

第三个网址:

通过对比我们可以发现,加载的json数据文件的地址与之前的json文件的['TailMark']和['TailMsgId']有关。
它是在原来的url=",10,723,35,469,821&limit=30"的基础上,加上一个后缀
“&tailmark=['TailMark']&msgIdMark=['TailMsgId']”
并获取 url 地址。
所以,我们获取下一个 url 地址的代码是:
def get_newurl(html):
url="https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30"
url=url+'&tailmark='+html['TailMark']+'&msgIdMark='+html['TailMsgId']
return url
那么我们的爬虫代码就基本完成了。以下是整个爬虫的代码:
# -*- coding:utf-8 -*-
import urllib.request
import urllib.parse
import time
import json
#获取网页
def get_page(url):
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36'
}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode()
return html
#获取下一页网址
def get_newurl(html):
url="https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30"
url=url+'&tailmark='+html['TailMark']+'&msgIdMark='+html['TailMsgId']
return url
#获取数据
def get_data(html,url):
html = json.loads(html)
c = len(html["NewMsgs"])
for i in range(0,c):
cun =html["NewMsgs"][i]['Impact']#获取含有信息的字典
if cun == 1 or cun == -1:#判断信息是利好还是利空
print(html["NewMsgs"][i]['UpdatedAt'])
if cun == 1:
print("*************利好*************")
if cun == -1:
print('*************利空*************')
chang = len(html["NewMsgs"][i]['BkjInfoArr'])#获取信息下含有几个利好或利空行业
ch =html["NewMsgs"][i]['Stocks']
for j in range(0,chang):
print('行业:',html["NewMsgs"][i]['BkjInfoArr'][j]['Name'])
if ch!=None:
du = len(html["NewMsgs"][i]['Stocks'])#同理获取含有几个利好或利空股票
for k in range(0,du):
print('股票:',html["NewMsgs"][i]['Stocks'][k]['Name'])
print("**************************\n\n")#信息获取完毕,换行
#获取通过函数获取下一页的url地址并返回该地址
url = get_newurl(html)
return url
if __name__=='__main__':
url="https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30"
for i in range(0,5):#进行循环爬取下一页地址的股票信息
html=get_page(url)
url=get_data(html,url)
因为刚开始学习,所以很多地方都没有写好,比较繁琐和乏味。也求大神赐教。
抓取动态网页(详解如何通过创建Robots.txt来解决网站被重复抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-12 06:08
我们在百度统计中查看网站的SEO建议时,总是发现“静态页面参数”项被扣18分。多次重复爬取”。一般来说,在静态页面上使用少量的动态参数不会对蜘蛛的抓取产生任何影响,但是如果在网站静态页面上使用过多的动态参数,则可能最终导致蜘蛛。多次反复爬行。
解决“在静态页面上使用动态参数会导致蜘蛛多次重复爬取”的SEO问题,我们需要使用Robots.txt(机器人协议)来限制百度蜘蛛对网站页面的爬取,robots .txt 是协议,而不是命令。robots.txt 是搜索引擎在访问 网站 时查看的第一个文件。robots.txt 文件告诉蜘蛛可以查看服务器上的哪些文件。当搜索蜘蛛访问一个站点时,它会首先检查站点根目录中是否存在 robots.txt。如果存在,搜索机器人会根据文件内容判断访问范围;如果文件不存在, all 的搜索蜘蛛将能够访问 网站 上没有密码保护的所有页面。
通过创建Robots.txt来解释如何解决网站被重复爬取,我们只需要设置一个语法。
User-agent:百度蜘蛛(只对百度蜘蛛有效)
Disallow: /*?* (禁止访问 网站 中的所有动态页面)
这样可以防止动态页面被百度索引,避免网站被蜘蛛重复爬取。有人说:“我的网站是一个伪静态页面,每个url前面都有html?怎么办?” 在这种情况下,使用另一种语法。
User-agent:百度蜘蛛(只对百度蜘蛛有效)
允许:.htm$(只允许访问以“.htm”为后缀的 URL)
这允许百度蜘蛛只 收录 您的静态页面,而不是索引动态页面。其实网站SEO知识还有很多,都需要我们一步步探索,在实践中发现真相。网站 关注用户体验是长期发展的基点。
防止网站被搜索爬取的一些方法:
首先在站点的根目录下创建一个 robots.txt 文本文件。搜索蜘蛛访问该站点时,首先会检查站点根目录下是否存在robots.txt。如果存在,搜索蜘蛛会首先读取这个文件的内容:
文件写入
User-agent:*这里*代表所有类型的搜索引擎,*是通配符,user-agent分号后面要加一个空格。
Disallow:/这个定义是禁止所有内容爬取网站
Disallow: /admin/ 这里的定义是禁止爬取admin目录下的目录
Disallow: /ABC/ 这里的定义是禁止爬取ABC目录下的目录
禁止:/cgi-bin/*.htm 禁止访问/cgi-bin/ 目录中所有以“.htm”为后缀的URL(包括子目录)。
Disallow: /*?* 禁止访问所有在 网站 中收录问号 (?) 的 URL
Disallow: /.jpg$ 禁止抓取来自网络的所有 .jpg 图像
Disallow:/ab/adc.html 禁止爬取ab文件夹下的adc.html文件。
allow: /cgi-bin/这个定义是允许cgi-bin目录下的目录被爬取
allow: /tmp 这里的定义是允许爬取tmp的整个目录
允许:.htm$ 只允许访问以“.htm”为后缀的 URL。
允许:.gif$ 允许抓取网页和 gif 格式的图片
站点地图:网站地图告诉爬虫这个页面是一个网站地图
下面列出的是比较知名的搜索引擎蜘蛛名称:
谷歌的蜘蛛:谷歌机器人
百度的蜘蛛:baiduspider
雅虎的蜘蛛:雅虎啜饮
MSN 的蜘蛛:Msnbot
Altavista 的蜘蛛:滑板车
Lycos 的蜘蛛:Lycos_Spider_(T-Rex)
Alltheweb 的蜘蛛:FAST-WebCrawler/
INKTOMI 的蜘蛛:啜食
搜狗的蜘蛛:搜狗网络蜘蛛/4.0 和搜狗inst spider/4.0
根据上面的说明,我们可以举一个大案子的例子。在搜狗的案例中,robots.txt的禁止爬取的代码是这样写的:
用户代理:搜狗网络蜘蛛/4.0
禁止:/goods.php
禁止:/category.php 查看全部
抓取动态网页(详解如何通过创建Robots.txt来解决网站被重复抓取)
我们在百度统计中查看网站的SEO建议时,总是发现“静态页面参数”项被扣18分。多次重复爬取”。一般来说,在静态页面上使用少量的动态参数不会对蜘蛛的抓取产生任何影响,但是如果在网站静态页面上使用过多的动态参数,则可能最终导致蜘蛛。多次反复爬行。
解决“在静态页面上使用动态参数会导致蜘蛛多次重复爬取”的SEO问题,我们需要使用Robots.txt(机器人协议)来限制百度蜘蛛对网站页面的爬取,robots .txt 是协议,而不是命令。robots.txt 是搜索引擎在访问 网站 时查看的第一个文件。robots.txt 文件告诉蜘蛛可以查看服务器上的哪些文件。当搜索蜘蛛访问一个站点时,它会首先检查站点根目录中是否存在 robots.txt。如果存在,搜索机器人会根据文件内容判断访问范围;如果文件不存在, all 的搜索蜘蛛将能够访问 网站 上没有密码保护的所有页面。
通过创建Robots.txt来解释如何解决网站被重复爬取,我们只需要设置一个语法。
User-agent:百度蜘蛛(只对百度蜘蛛有效)
Disallow: /*?* (禁止访问 网站 中的所有动态页面)
这样可以防止动态页面被百度索引,避免网站被蜘蛛重复爬取。有人说:“我的网站是一个伪静态页面,每个url前面都有html?怎么办?” 在这种情况下,使用另一种语法。
User-agent:百度蜘蛛(只对百度蜘蛛有效)
允许:.htm$(只允许访问以“.htm”为后缀的 URL)
这允许百度蜘蛛只 收录 您的静态页面,而不是索引动态页面。其实网站SEO知识还有很多,都需要我们一步步探索,在实践中发现真相。网站 关注用户体验是长期发展的基点。
防止网站被搜索爬取的一些方法:
首先在站点的根目录下创建一个 robots.txt 文本文件。搜索蜘蛛访问该站点时,首先会检查站点根目录下是否存在robots.txt。如果存在,搜索蜘蛛会首先读取这个文件的内容:
文件写入
User-agent:*这里*代表所有类型的搜索引擎,*是通配符,user-agent分号后面要加一个空格。
Disallow:/这个定义是禁止所有内容爬取网站
Disallow: /admin/ 这里的定义是禁止爬取admin目录下的目录
Disallow: /ABC/ 这里的定义是禁止爬取ABC目录下的目录
禁止:/cgi-bin/*.htm 禁止访问/cgi-bin/ 目录中所有以“.htm”为后缀的URL(包括子目录)。
Disallow: /*?* 禁止访问所有在 网站 中收录问号 (?) 的 URL
Disallow: /.jpg$ 禁止抓取来自网络的所有 .jpg 图像
Disallow:/ab/adc.html 禁止爬取ab文件夹下的adc.html文件。
allow: /cgi-bin/这个定义是允许cgi-bin目录下的目录被爬取
allow: /tmp 这里的定义是允许爬取tmp的整个目录
允许:.htm$ 只允许访问以“.htm”为后缀的 URL。
允许:.gif$ 允许抓取网页和 gif 格式的图片
站点地图:网站地图告诉爬虫这个页面是一个网站地图
下面列出的是比较知名的搜索引擎蜘蛛名称:
谷歌的蜘蛛:谷歌机器人
百度的蜘蛛:baiduspider
雅虎的蜘蛛:雅虎啜饮
MSN 的蜘蛛:Msnbot
Altavista 的蜘蛛:滑板车
Lycos 的蜘蛛:Lycos_Spider_(T-Rex)
Alltheweb 的蜘蛛:FAST-WebCrawler/
INKTOMI 的蜘蛛:啜食
搜狗的蜘蛛:搜狗网络蜘蛛/4.0 和搜狗inst spider/4.0
根据上面的说明,我们可以举一个大案子的例子。在搜狗的案例中,robots.txt的禁止爬取的代码是这样写的:
用户代理:搜狗网络蜘蛛/4.0
禁止:/goods.php
禁止:/category.php
抓取动态网页(什么是动态网页静态化就是通过技术手段,模拟浏览器访问,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-11 05:15
什么是动态网页静态?
静态网页就是利用技术手段模拟浏览器访问,将原创动态网页上显示的内容抓取出来保存为htm的静态网页,然后引导用户访问这个静态网页!这样,每个用户访问都是一个静态网页。网页不与数据库交互,访问速度可翻倍!
静态网页有什么好处?
1:让动态网页的访问速度和静态网页一样快(因为已经是静态的,所以不和数据库交互会更快)
2:保持他的简单维护功能!(如果有新内容,只需要重新生成静态网页)
静态网页注意事项:
1:由于是自动生成的,有些网页生成后可能会出现异常,比如有验证码的网页。这时候就需要制作验证码了。
仅包括
2:如果你生成index.jsp主页,那么你需要设置它,让用户可以先访问静态index.htm。具体设置如下: 打开你的项目下的WEB-INF/web.xml,添加
index.html
index.htm
index.jsp
3::如果你觉得在我们后台生成静态太麻烦,你也可以把这个功能集成到自己的后台中,更加方便。详情请参考生成htm静态网页减少数据库操作
如何使用动态网页静态?
在jsp空间管理中登录会员管理中心--扩展你的jsp空间,选择高级管理-动态网页静态
进入动态网页静态界面
这里比较简单,傻瓜式操作,选择域名和要生成的文件,点击静态!
点击静态后,他会在对应的动态文件的同一个文件夹中自动生成对应的.htm文件。比如你把index.jsp设为静态,那么他会自动在index.jsp所在的文件夹下生成一个对应的.htm文件对应的index.htm文件,引导用户访问这个index.htm!
ps:特别是这里的一切都是基于用户访问的原则
比如你静态制作index.jsp文件生成index.htm后,只有用户访问index.htm才会生效,否则用户访问完index.jsp后仍然没有效果生成!
如何让用户访问 index.htm?这时候就需要修改代码了,比如之前
<A href="index.jsp">首页</A>
现在需要改为
<A href="index.htm">首页</A>
就是这样,让用户访问静态的htm网页,真正的jsp网页只在需要静态的时候访问一次!
------------------------------------------ 查看全部
抓取动态网页(什么是动态网页静态化就是通过技术手段,模拟浏览器访问,)
什么是动态网页静态?
静态网页就是利用技术手段模拟浏览器访问,将原创动态网页上显示的内容抓取出来保存为htm的静态网页,然后引导用户访问这个静态网页!这样,每个用户访问都是一个静态网页。网页不与数据库交互,访问速度可翻倍!
静态网页有什么好处?
1:让动态网页的访问速度和静态网页一样快(因为已经是静态的,所以不和数据库交互会更快)
2:保持他的简单维护功能!(如果有新内容,只需要重新生成静态网页)
静态网页注意事项:
1:由于是自动生成的,有些网页生成后可能会出现异常,比如有验证码的网页。这时候就需要制作验证码了。
仅包括
2:如果你生成index.jsp主页,那么你需要设置它,让用户可以先访问静态index.htm。具体设置如下: 打开你的项目下的WEB-INF/web.xml,添加
index.html
index.htm
index.jsp
3::如果你觉得在我们后台生成静态太麻烦,你也可以把这个功能集成到自己的后台中,更加方便。详情请参考生成htm静态网页减少数据库操作
如何使用动态网页静态?
在jsp空间管理中登录会员管理中心--扩展你的jsp空间,选择高级管理-动态网页静态

进入动态网页静态界面
这里比较简单,傻瓜式操作,选择域名和要生成的文件,点击静态!
点击静态后,他会在对应的动态文件的同一个文件夹中自动生成对应的.htm文件。比如你把index.jsp设为静态,那么他会自动在index.jsp所在的文件夹下生成一个对应的.htm文件对应的index.htm文件,引导用户访问这个index.htm!
ps:特别是这里的一切都是基于用户访问的原则
比如你静态制作index.jsp文件生成index.htm后,只有用户访问index.htm才会生效,否则用户访问完index.jsp后仍然没有效果生成!
如何让用户访问 index.htm?这时候就需要修改代码了,比如之前
<A href="index.jsp">首页</A>
现在需要改为
<A href="index.htm">首页</A>
就是这样,让用户访问静态的htm网页,真正的jsp网页只在需要静态的时候访问一次!
------------------------------------------
抓取动态网页( 微信朋友圈数据入口搞定了,获取外链的方法有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-10 03:16
微信朋友圈数据入口搞定了,获取外链的方法有哪些?)
2、然后点击首页的【创建图书】-->【微信图书】。
3、点击【开始制作】-->【添加随机分配的图书编辑为好友】,然后长按二维码添加好友。
4、之后,耐心等待微信书制作完成。完成后会收到小编发送的消息提醒,如下图所示。
至此,我们完成了微信朋友圈的数据录入,并获得了外链。
确保朋友圈设置为[全部打开]。默认是全部打开。如果不知道怎么设置,请百度。
5、点击外部链接,然后进入网页,需要使用微信扫码授权登录。
6、扫码授权后,即可进入微信书网页版,如下图。
7、接下来,我们就可以编写爬虫程序来正常爬取信息了。这里小编使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。下图为微信书首页,图片由小编定制。
二、创建爬虫项目
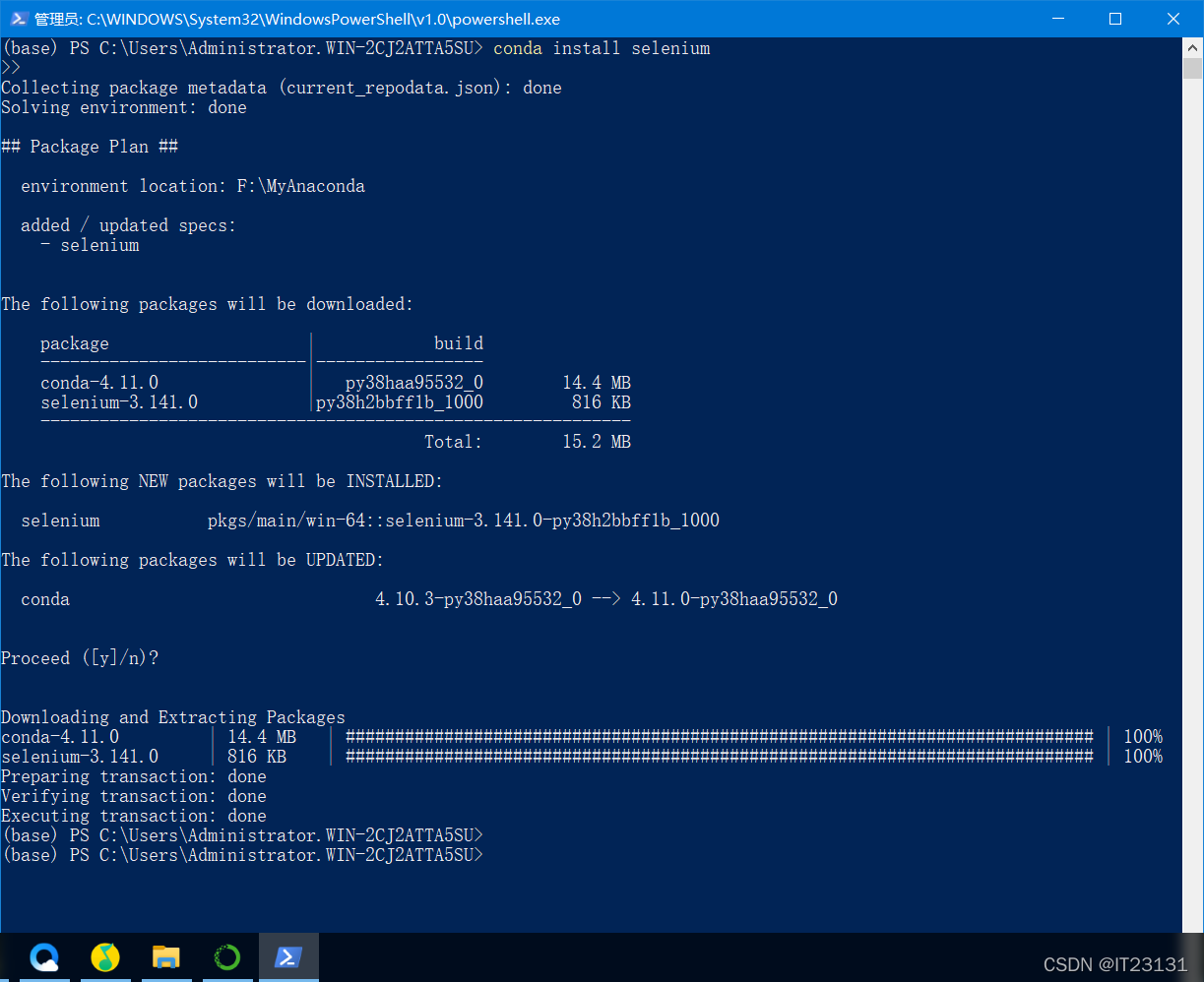
1、确保您的计算机上安装了 Scrapy。然后选择一个文件夹,在文件夹下输入命令行,输入执行命令:
scrapy startproject weixin_moment
,等待生成Scrapy爬虫项目。
2、在命令行输入cd weixin_moment,进入创建好的weixin_moment目录。然后输入命令:
scrapy genspider 'moment' 'chushu.la'
,创建朋友圈爬虫,如下图。
3、执行上述两步后的文件夹结构如下:
三、分析网页数据
1、进入微信书首页,按F12,推荐使用谷歌浏览器,查看元素,点击“网络”标签,然后勾选“保存日志”保存日志,如图下图。可以看到首页的请求方法是get,返回的状态码是200,表示请求成功。
2、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明后面我们需要在程序中处理JSON格式的数据。
3、点击微信书的“导航”窗口,可以看到数据是按月加载的。单击导航按钮时,它会加载相应月份的 Moments 数据。
4、点击月份[2014/04],再查看服务器响应数据,可以看到页面显示的数据对应服务器响应。
5、查看请求方式,可以看到此时的请求方式已经变成了POST。细心的小伙伴可以看到,当点击“下个月”或者其他导航月份时,首页的URL没有变化,说明网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数在不断变化,如下图所示。
6、将服务器响应的数据展开,放入JSON在线解析器,如下图:
可以看到朋友圈的数据是存放在paras /data节点下的。
至此,网页分析和数据的来源已经确定。接下来,我们将编写一个程序来捕获数据。敬请期待下一篇文章~~ 查看全部
抓取动态网页(
微信朋友圈数据入口搞定了,获取外链的方法有哪些?)
2、然后点击首页的【创建图书】-->【微信图书】。
3、点击【开始制作】-->【添加随机分配的图书编辑为好友】,然后长按二维码添加好友。
4、之后,耐心等待微信书制作完成。完成后会收到小编发送的消息提醒,如下图所示。
至此,我们完成了微信朋友圈的数据录入,并获得了外链。
确保朋友圈设置为[全部打开]。默认是全部打开。如果不知道怎么设置,请百度。
5、点击外部链接,然后进入网页,需要使用微信扫码授权登录。
6、扫码授权后,即可进入微信书网页版,如下图。
7、接下来,我们就可以编写爬虫程序来正常爬取信息了。这里小编使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。下图为微信书首页,图片由小编定制。
二、创建爬虫项目
1、确保您的计算机上安装了 Scrapy。然后选择一个文件夹,在文件夹下输入命令行,输入执行命令:
scrapy startproject weixin_moment
,等待生成Scrapy爬虫项目。
2、在命令行输入cd weixin_moment,进入创建好的weixin_moment目录。然后输入命令:
scrapy genspider 'moment' 'chushu.la'
,创建朋友圈爬虫,如下图。
3、执行上述两步后的文件夹结构如下:
三、分析网页数据
1、进入微信书首页,按F12,推荐使用谷歌浏览器,查看元素,点击“网络”标签,然后勾选“保存日志”保存日志,如图下图。可以看到首页的请求方法是get,返回的状态码是200,表示请求成功。
2、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明后面我们需要在程序中处理JSON格式的数据。
3、点击微信书的“导航”窗口,可以看到数据是按月加载的。单击导航按钮时,它会加载相应月份的 Moments 数据。
4、点击月份[2014/04],再查看服务器响应数据,可以看到页面显示的数据对应服务器响应。
5、查看请求方式,可以看到此时的请求方式已经变成了POST。细心的小伙伴可以看到,当点击“下个月”或者其他导航月份时,首页的URL没有变化,说明网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数在不断变化,如下图所示。
6、将服务器响应的数据展开,放入JSON在线解析器,如下图:
可以看到朋友圈的数据是存放在paras /data节点下的。
至此,网页分析和数据的来源已经确定。接下来,我们将编写一个程序来捕获数据。敬请期待下一篇文章~~
抓取动态网页(Colly学习笔记(三)——爬虫框架,抓取动态页面(上证A股列表抓取) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2022-01-09 14:15
)
Colly学习笔记(三)-爬虫框架,抓取动态页面(上证A股榜单抓取)
Colly学习笔记(一)-爬虫框架,捕捉中金行业市盈率数据
Colly学习笔记(二)-爬虫框架,抓取下载数据(上证A股数据下载)
Colly学习笔记(三)-爬虫框架,抓取动态页面数据(上海A股动态数据抓取)
前两章主要讨论静态数据的爬取。我们只需要将网页地址栏中的url传递给get请求,就可以轻松获取网页的数据。但是,有些网页是动态页面。我们传递网页的源代码。翻页时找不到数据,网址也没有变化。此时无法获取数据。比如下图,通过开发者工具,查看网页源码,发现虽然URL相同,但内容不同。此时需要找到动态页面对应的URL,才能抓取数据。
查看页面真实URL的方法如下:
点击分页按钮找到对应的URL(具体步骤如图)
通过postman查看和排除无效参数
#动态URL原始参数
http://query.sse.com.cn/securi ... 45917
#postman调试优化后的参数
http://query.sse.com.cn/securi ... o%3D3
postman 视图如下图
写colly代码抓取流程
//finish
c.OnScraped(func(r *colly.Response) {
//解析Json
var item PageResult
err := json.Unmarshal(r.Body, &item)
if err != nil {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"err":err,"res":string(r.Body)}).Error("Receive Error ")
//若返回系统繁忙,则等一段时间重新访问
if strings.Contains(string(r.Body),"error"){
c.Visit(url)
}
}
//
if len(item.Result) > 1{
res = append(res,&item)
receiver.MLog.GetLogHandle().WithFields(log.Fields{"item":item}).Info("Receive message ")
return
}
//第一次只取一条是为了获取所有的A股总数,然后重新一次获取到所有数据,无需多次分页
SubUrl := "http://query.sse.com.cn/securi ... ot%3B
SubUrl += strconv.Itoa(item.Page.Total)
c.Visit(SubUrl)
})
结果:
完整代码如下:
package main
import (
"encoding/json"
"fmt"
"github.com/gocolly/colly"
log "github.com/sirupsen/logrus"
"strconv"
"strings"
)
type pageHelp struct {
Total int `json:"total"`
}
type pageResult struct {
CompanyAbbr string `json:"COMPANY_ABBR"`
CompanyCode string `json:"COMPANY_CODE"`
EnglishAbbr string `json:"ENGLISH_ABBR"`
ListingTime string `json:"LISTING_DATE"`
MoveTime string `json:"QIANYI_DATE"`
}
type PageResult struct {
AreaName string `json:"areaName"`
Page pageHelp `json:"pageHelp"`
Result []pageResult `json:"result"`
StockType string `json:"stockType"`
}
func (receiver Collector) ScrapeJs(url string) (error,[]*PageResult) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"URL":url}).Info("URL...")
c := colly.NewCollector(colly.UserAgent(RandomString()),colly.AllowURLRevisit())
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36"
res := make([]*PageResult, 0)
c.OnRequest(func(r *colly.Request) {
//r.Headers.Set("User-Agent", RandomString())
r.Headers.Set("Host", "query.sse.com.cn")
r.Headers.Set("Connection", "keep-alive")
r.Headers.Set("Accept", "*/*")
r.Headers.Set("Origin", "http://www.sse.com.cn")
//关键头 如果没有 则返回 错误
r.Headers.Set("Referer", "http://www.sse.com.cn/assortme ... 6quot;)
r.Headers.Set("Accept-Encoding", "gzip, deflate")
r.Headers.Set("Accept-Language", "zh-CN,zh;q=0.9")
receiver.MLog.GetLogHandle().WithFields(log.Fields{"Request":fmt.Sprintf("%+v",*r),"Headers":fmt.Sprintf("%+v",*r.Headers)}).Info("Begin Visiting...")
})
c.OnError(func(_ *colly.Response, err error) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"error":err}).Info("Something went wrong:")
})
c.OnResponse(func(r *colly.Response) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"Headers":r.Headers}).Info("Receive Header")
})
//scraped item from body
//finish
c.OnScraped(func(r *colly.Response) {
var item PageResult
err := json.Unmarshal(r.Body, &item)
if err != nil {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"err":err,"res":string(r.Body)}).Error("Receive Error ")
if strings.Contains(string(r.Body),"error"){
c.Visit(url)
}
}
if len(item.Result) > 1{
res = append(res,&item)
receiver.MLog.GetLogHandle().WithFields(log.Fields{"item":item}).Info("Receive message ")
return //结束递归
}
SubUrl := "http://query.sse.com.cn/securi ... ot%3B
//SubUrl += strconv.Itoa(item.Page.Total)
SubUrl += '25'
c.Visit(SubUrl)
})
c.Visit(url)
return nil,res
}
func (receiver Collector) ScrapeJsTest() error {
//第一次只获取一条数据目的是为了获取数据总条数,下次递归拼接URL一次获取所有数据
UrlA := "http://query.sse.com.cn/securi ... ot%3B
receiver.ScrapeJs(UrlA)
return nil
}
func main() {
var c Collector
c.MLog=receiver.MLog
c.ScrapeJsTest()
return
} 查看全部
抓取动态网页(Colly学习笔记(三)——爬虫框架,抓取动态页面(上证A股列表抓取)
)
Colly学习笔记(三)-爬虫框架,抓取动态页面(上证A股榜单抓取)
Colly学习笔记(一)-爬虫框架,捕捉中金行业市盈率数据
Colly学习笔记(二)-爬虫框架,抓取下载数据(上证A股数据下载)
Colly学习笔记(三)-爬虫框架,抓取动态页面数据(上海A股动态数据抓取)
前两章主要讨论静态数据的爬取。我们只需要将网页地址栏中的url传递给get请求,就可以轻松获取网页的数据。但是,有些网页是动态页面。我们传递网页的源代码。翻页时找不到数据,网址也没有变化。此时无法获取数据。比如下图,通过开发者工具,查看网页源码,发现虽然URL相同,但内容不同。此时需要找到动态页面对应的URL,才能抓取数据。
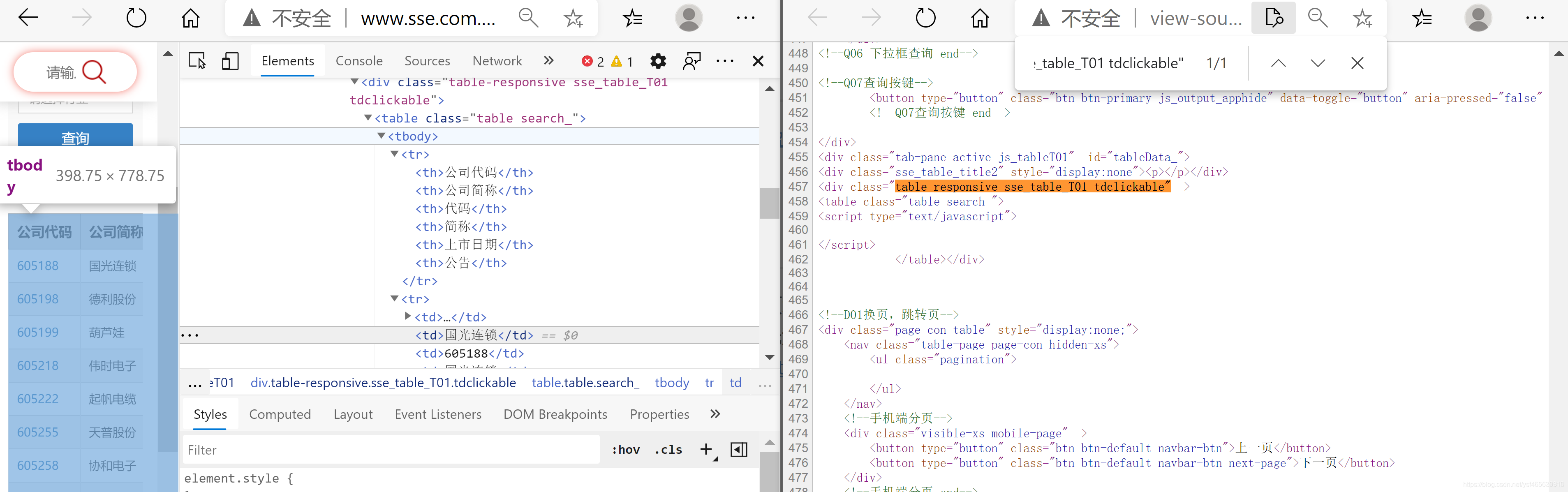
查看页面真实URL的方法如下:
点击分页按钮找到对应的URL(具体步骤如图)
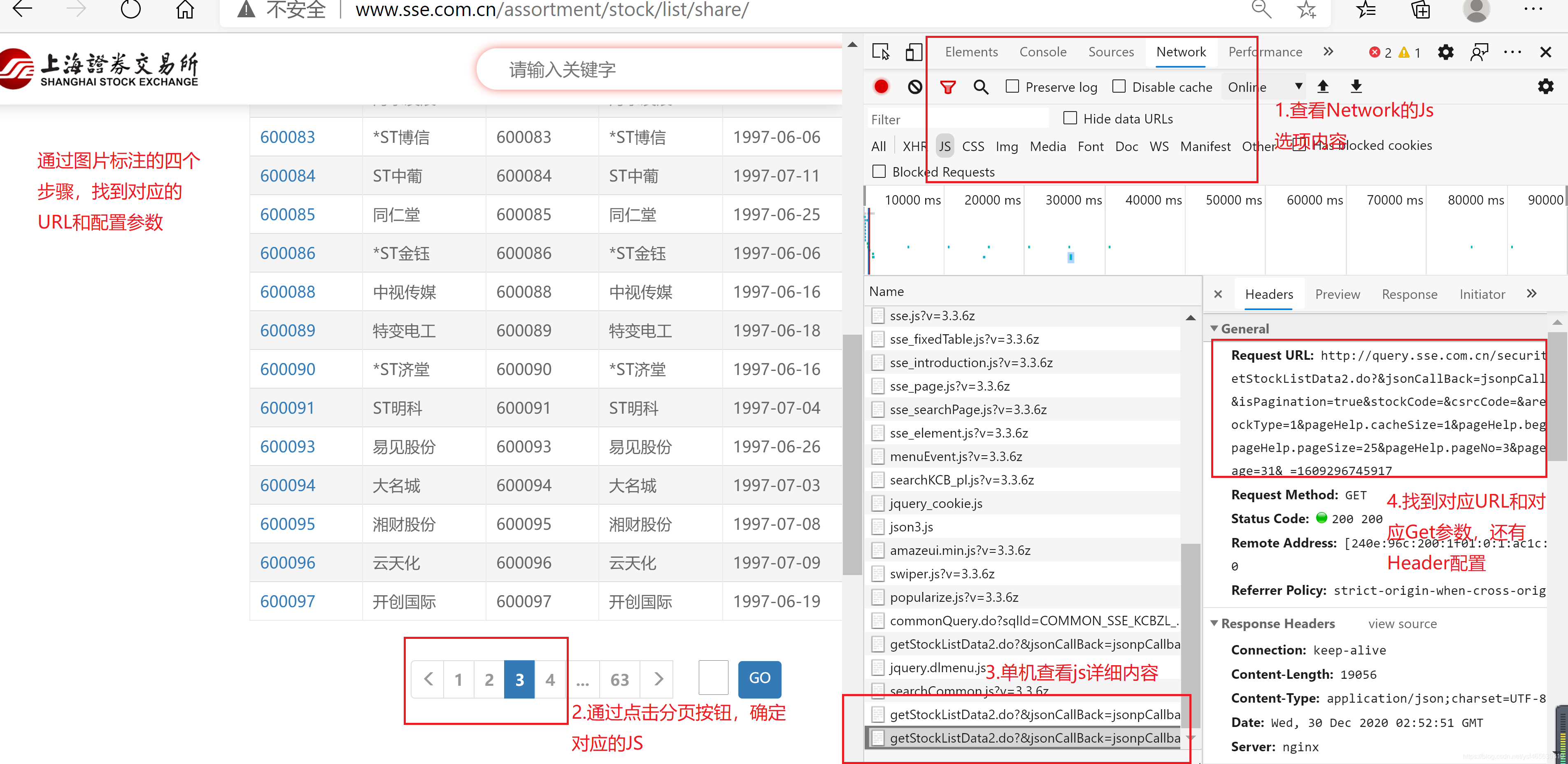
通过postman查看和排除无效参数
#动态URL原始参数
http://query.sse.com.cn/securi ... 45917
#postman调试优化后的参数
http://query.sse.com.cn/securi ... o%3D3
postman 视图如下图
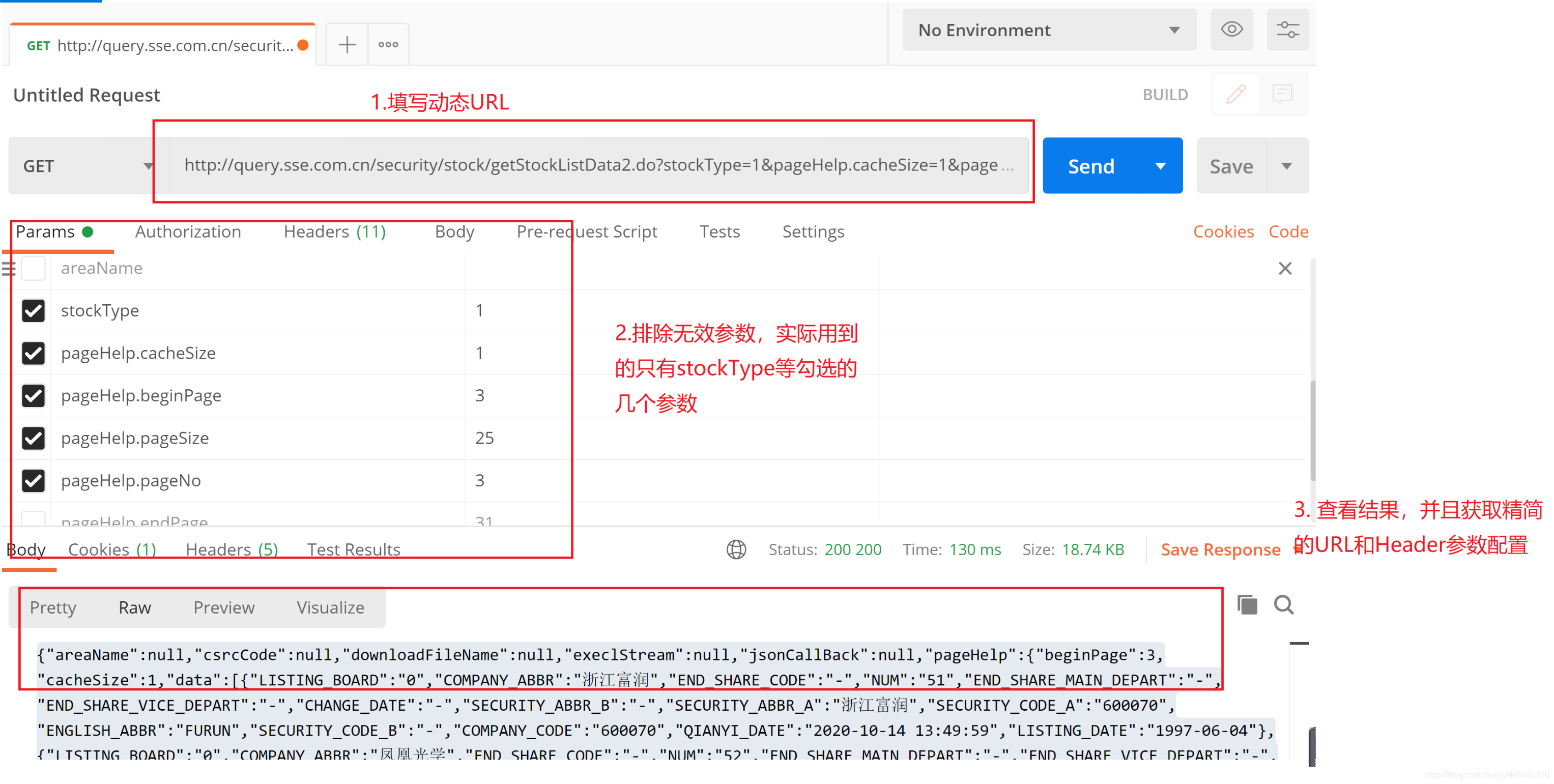
写colly代码抓取流程
//finish
c.OnScraped(func(r *colly.Response) {
//解析Json
var item PageResult
err := json.Unmarshal(r.Body, &item)
if err != nil {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"err":err,"res":string(r.Body)}).Error("Receive Error ")
//若返回系统繁忙,则等一段时间重新访问
if strings.Contains(string(r.Body),"error"){
c.Visit(url)
}
}
//
if len(item.Result) > 1{
res = append(res,&item)
receiver.MLog.GetLogHandle().WithFields(log.Fields{"item":item}).Info("Receive message ")
return
}
//第一次只取一条是为了获取所有的A股总数,然后重新一次获取到所有数据,无需多次分页
SubUrl := "http://query.sse.com.cn/securi ... ot%3B
SubUrl += strconv.Itoa(item.Page.Total)
c.Visit(SubUrl)
})
结果:
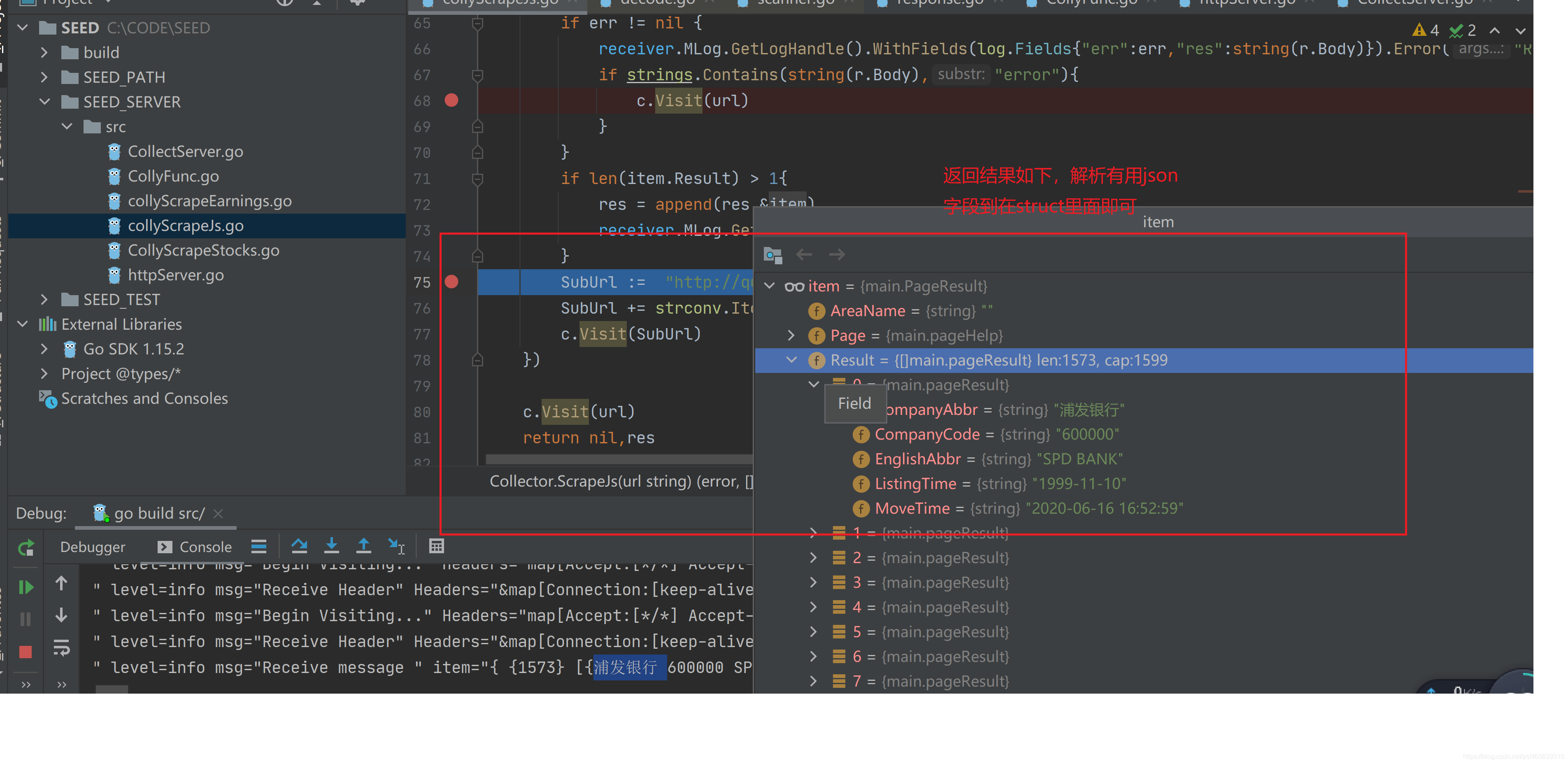
完整代码如下:
package main
import (
"encoding/json"
"fmt"
"github.com/gocolly/colly"
log "github.com/sirupsen/logrus"
"strconv"
"strings"
)
type pageHelp struct {
Total int `json:"total"`
}
type pageResult struct {
CompanyAbbr string `json:"COMPANY_ABBR"`
CompanyCode string `json:"COMPANY_CODE"`
EnglishAbbr string `json:"ENGLISH_ABBR"`
ListingTime string `json:"LISTING_DATE"`
MoveTime string `json:"QIANYI_DATE"`
}
type PageResult struct {
AreaName string `json:"areaName"`
Page pageHelp `json:"pageHelp"`
Result []pageResult `json:"result"`
StockType string `json:"stockType"`
}
func (receiver Collector) ScrapeJs(url string) (error,[]*PageResult) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"URL":url}).Info("URL...")
c := colly.NewCollector(colly.UserAgent(RandomString()),colly.AllowURLRevisit())
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36"
res := make([]*PageResult, 0)
c.OnRequest(func(r *colly.Request) {
//r.Headers.Set("User-Agent", RandomString())
r.Headers.Set("Host", "query.sse.com.cn")
r.Headers.Set("Connection", "keep-alive")
r.Headers.Set("Accept", "*/*")
r.Headers.Set("Origin", "http://www.sse.com.cn";)
//关键头 如果没有 则返回 错误
r.Headers.Set("Referer", "http://www.sse.com.cn/assortme ... 6quot;)
r.Headers.Set("Accept-Encoding", "gzip, deflate")
r.Headers.Set("Accept-Language", "zh-CN,zh;q=0.9")
receiver.MLog.GetLogHandle().WithFields(log.Fields{"Request":fmt.Sprintf("%+v",*r),"Headers":fmt.Sprintf("%+v",*r.Headers)}).Info("Begin Visiting...")
})
c.OnError(func(_ *colly.Response, err error) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"error":err}).Info("Something went wrong:")
})
c.OnResponse(func(r *colly.Response) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"Headers":r.Headers}).Info("Receive Header")
})
//scraped item from body
//finish
c.OnScraped(func(r *colly.Response) {
var item PageResult
err := json.Unmarshal(r.Body, &item)
if err != nil {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"err":err,"res":string(r.Body)}).Error("Receive Error ")
if strings.Contains(string(r.Body),"error"){
c.Visit(url)
}
}
if len(item.Result) > 1{
res = append(res,&item)
receiver.MLog.GetLogHandle().WithFields(log.Fields{"item":item}).Info("Receive message ")
return //结束递归
}
SubUrl := "http://query.sse.com.cn/securi ... ot%3B
//SubUrl += strconv.Itoa(item.Page.Total)
SubUrl += '25'
c.Visit(SubUrl)
})
c.Visit(url)
return nil,res
}
func (receiver Collector) ScrapeJsTest() error {
//第一次只获取一条数据目的是为了获取数据总条数,下次递归拼接URL一次获取所有数据
UrlA := "http://query.sse.com.cn/securi ... ot%3B
receiver.ScrapeJs(UrlA)
return nil
}
func main() {
var c Collector
c.MLog=receiver.MLog
c.ScrapeJsTest()
return
}
抓取动态网页(关于一下动态网址和静态网址的话题网址(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-06 03:14
yylqymzk 发表于 2010-4-26 18:05
网页编辑学院:动态 URL 和静态 URL 发布者:Juliane Stiller 和 Kaspar Szymanski,搜索质量团队
原文:动态 URL 与静态 URL
发表于:2008 年 9 月 22 日,下午 3:20
这种情况在与网络管理员沟通时经常发生。一些广为流传的想法在过去可能是正确的,但可能不再适合当前的情况。这发生在我们最近和几个朋友谈论 URL 的结构时。我的一位朋友非常担心动态网址的使用,甚至认为“搜索引擎无法处理动态网址”。另一位朋友认为动态网址对于搜索引擎来说根本不是问题。这些都是过去的事情了。另一个人甚至说他从来不明白动态 URL 和静态 URL 之间的区别。对我们来说,这一刻让我们决定研究动态 URL 和静态 URL 的主题。首先,让我们定义一下我们要讨论的主题:
什么是静态网址?
顾名思义,静态 URL 是不会更改的 URL。它通常不收录任何 URL 参数。例如:。您可以在搜索框中输入 filetype:html 以在 Google 上搜索静态 URL。使用这种类型的 URL 更新页面需要时间,尤其是在信息量快速增长的情况下,因为每个单独的页面都必须更改编译后的代码。这就是为什么 网站 管理员在处理大型且经常更新的 网站,例如在线购物 网站、论坛社区、博客或内容管理系统时使用动态 URL 的原因。
什么是动态网址?
如果将网站的内容存入数据库,按要求显示页面,则可以使用动态URL。在这种情况下,网站 提供的内容基本上是基于模板的。通常,动态 URL 如下所示:。您可以通过查找符号来识别动态 URL,例如?= &。动态 URL 的一个缺点是不同的 URL 可以具有相同的内容。因此,不同的用户可能会链接到具有不同参数的 URL,但这些 URL 都收录相同的内容。这也是网络管理员有时希望将这些动态 URL 重写为静态 URL 的原因之一。
我应该让我的动态 URL 看起来是静态的吗?
在处理动态 URL 时,希望您能理解以下事实:
实际上很难正确生成和维护从动态 URL 到静态 URL 的重写转换。
向我们提供原创动态 URL 更安全。请让我们处理诸如检测和避免有问题的参数之类的事情。
如果您想重写 URL,请删除那些不必要的参数,同时将其保留为动态 URL。
如果您想提供静态网址而不是动态网址,那么您实际上应该生成相应的静态内容。
静态网址和动态网址,Googlebot 识别哪个更好?
我们遇到过很多网站管理员,就像我们的朋友一样,他们认为静态或看似静态的URL有利于网站的索引和排名。此观点基于以下假设:搜索引擎在抓取和分析收录会话 ID 和源跟踪器的 URL 时存在问题。然而,事实是谷歌在这两个领域都取得了长足的进步。在点击率方面,静态网址可能略占优势,因为用户可以轻松阅读此网址。但是,在索引和排名方面,使用数据库驱动的网站并不意味着明显的劣势。与隐藏参数使它们看起来是静态 URL 相比,我们更喜欢 网站 直接向搜索引擎提供动态 URL。
现在,让我们来看看一些广为流传的关于动态 URL 的观点,并纠正一些欺骗 网站 管理员的假设。:)
误解:“无法抓取动态 URL。”
事实:我们可以抓取动态 URL 并解释不同的参数。如果为了让网址看起来是静态的而隐藏了可以向谷歌提供有价值信息的参数,这样做会导致网址的抓取和排名出现问题。我们的建议是:请不要更改动态 URL 的格式以使其看起来是静态的。建议尽量使用静态 URL 来展示静态内容,但如果您决定展示动态内容,请不要隐藏参数让它们看起来是静态的,因为这样做会移除那些对我们有用的有用信息分析网址。
误解:“动态 URL 必须少于 3 个参数。”
事实:参数数量没有限制。但是,一个好的经验法则是不要让您的 URL 太长(这适用于所有 URL,无论是静态的还是动态的)。您可以删除一些对 Googlebot 不重要的参数,并为用户提供更好看的动态网址。如果您不确定哪些参数可以删除,我们建议您将动态 URL 中的所有参数都提供给我们,我们的系统会找出哪些不重要。隐藏参数会影响我们正确分析您的网址,我们将无法识别这些参数,从而可能会丢失一些重要信息。
以下是我们认为您可能有疑问的一些问题。
这是否意味着我应该完全避免重写动态 URL?
这是我们的建议,除非你能保证你只删除多余的参数,否则你可以完全删除所有可能产生不利影响的参数。如果你随意修改你的动态URL,让它看起来是静态的,你必须意识到这样做是有风险的,有些信息可能无法正常编译和识别。如果你想给你的网站添加静态版本,请提供真正静态的内容,比如生成的文件可以通过网站的对应路径获取。如果您只修改动态 URL 的呈现而不提供静态内容,那么您可能会适得其反。请直接提供标准的动态网址,我们会自动找出那些多余的参数。
你能举个例子吗?
如果您有一个标准格式的动态网址,例如:foo?key1=value&key2=value2,我们建议您不要更改它。谷歌将决定可以删除哪些参数;或者您可以为用户删除不必要的参数。但要小心,只删除那些不重要的参数。以下是具有多个参数的动态 URL 的示例:
language=en-标记这个文章的语言
answer=3 – 这个 文章 收录数字 3
sid=8971298178906-会话识别码为8971298178906
query=URL-使这个 文章 找到的查询是并非所有参数都提供附加信息。所以重写这个 URL 可能不会造成任何问题,因为所有不相关的参数都被删除了。
下面是一些已修改为看起来像静态 URL 的 URL 示例。与不重写直接提供的动态网址相比,这些网址可能会造成更多的抓取问题。
sid=98971298178906/query=URL
98971298178906/查询/网址
,3,98971298178906,URL 如果把动态URL改写成上面提到的例子,可能会给我们带来很多不必要的爬取,因为这些URL收录了会话标识符(sid)和查询(query)参数。变量值,这个无形中产生了很多看起来不一样的URL,但是它们收录的内容是一样的。这些格式让我们很难理解通过这个URL返回的实际内容和参数URL和98971298178906是无关的。但是,以下重写的示例删除了所有无关参数:
尽管我们可以正确处理此 URL,但我们仍然不鼓励您使用此类重写。因为很难维护,而且一旦在原来的动态 URL 上增加了新的参数,就需要立即更新 URL。如果不这样做,将再次导致 URL 看起来像带有隐藏参数的静态 URL。所以最好的解决方案是通常保持动态 URL 原样。或者,如果您删除了不相关的参数,请记住保持此 URL 动态:
我们希望这个文章 可以对您和我们的朋友有所帮助,并澄清有关动态 URL 的各种猜测。如果您有更多问题,请加入我们的网站管理员支持论坛进行讨论。
a_zheng_2010 发表于 2015-1-10 21:11
什么是静态网址?
283578916的小号发表于2017-12-22 23:51
666666666666
誊: [1] 查看全部
抓取动态网页(关于一下动态网址和静态网址的话题网址(图))
yylqymzk 发表于 2010-4-26 18:05
网页编辑学院:动态 URL 和静态 URL 发布者:Juliane Stiller 和 Kaspar Szymanski,搜索质量团队
原文:动态 URL 与静态 URL
发表于:2008 年 9 月 22 日,下午 3:20
这种情况在与网络管理员沟通时经常发生。一些广为流传的想法在过去可能是正确的,但可能不再适合当前的情况。这发生在我们最近和几个朋友谈论 URL 的结构时。我的一位朋友非常担心动态网址的使用,甚至认为“搜索引擎无法处理动态网址”。另一位朋友认为动态网址对于搜索引擎来说根本不是问题。这些都是过去的事情了。另一个人甚至说他从来不明白动态 URL 和静态 URL 之间的区别。对我们来说,这一刻让我们决定研究动态 URL 和静态 URL 的主题。首先,让我们定义一下我们要讨论的主题:
什么是静态网址?
顾名思义,静态 URL 是不会更改的 URL。它通常不收录任何 URL 参数。例如:。您可以在搜索框中输入 filetype:html 以在 Google 上搜索静态 URL。使用这种类型的 URL 更新页面需要时间,尤其是在信息量快速增长的情况下,因为每个单独的页面都必须更改编译后的代码。这就是为什么 网站 管理员在处理大型且经常更新的 网站,例如在线购物 网站、论坛社区、博客或内容管理系统时使用动态 URL 的原因。
什么是动态网址?
如果将网站的内容存入数据库,按要求显示页面,则可以使用动态URL。在这种情况下,网站 提供的内容基本上是基于模板的。通常,动态 URL 如下所示:。您可以通过查找符号来识别动态 URL,例如?= &。动态 URL 的一个缺点是不同的 URL 可以具有相同的内容。因此,不同的用户可能会链接到具有不同参数的 URL,但这些 URL 都收录相同的内容。这也是网络管理员有时希望将这些动态 URL 重写为静态 URL 的原因之一。
我应该让我的动态 URL 看起来是静态的吗?
在处理动态 URL 时,希望您能理解以下事实:
实际上很难正确生成和维护从动态 URL 到静态 URL 的重写转换。
向我们提供原创动态 URL 更安全。请让我们处理诸如检测和避免有问题的参数之类的事情。
如果您想重写 URL,请删除那些不必要的参数,同时将其保留为动态 URL。
如果您想提供静态网址而不是动态网址,那么您实际上应该生成相应的静态内容。
静态网址和动态网址,Googlebot 识别哪个更好?
我们遇到过很多网站管理员,就像我们的朋友一样,他们认为静态或看似静态的URL有利于网站的索引和排名。此观点基于以下假设:搜索引擎在抓取和分析收录会话 ID 和源跟踪器的 URL 时存在问题。然而,事实是谷歌在这两个领域都取得了长足的进步。在点击率方面,静态网址可能略占优势,因为用户可以轻松阅读此网址。但是,在索引和排名方面,使用数据库驱动的网站并不意味着明显的劣势。与隐藏参数使它们看起来是静态 URL 相比,我们更喜欢 网站 直接向搜索引擎提供动态 URL。
现在,让我们来看看一些广为流传的关于动态 URL 的观点,并纠正一些欺骗 网站 管理员的假设。:)
误解:“无法抓取动态 URL。”
事实:我们可以抓取动态 URL 并解释不同的参数。如果为了让网址看起来是静态的而隐藏了可以向谷歌提供有价值信息的参数,这样做会导致网址的抓取和排名出现问题。我们的建议是:请不要更改动态 URL 的格式以使其看起来是静态的。建议尽量使用静态 URL 来展示静态内容,但如果您决定展示动态内容,请不要隐藏参数让它们看起来是静态的,因为这样做会移除那些对我们有用的有用信息分析网址。
误解:“动态 URL 必须少于 3 个参数。”
事实:参数数量没有限制。但是,一个好的经验法则是不要让您的 URL 太长(这适用于所有 URL,无论是静态的还是动态的)。您可以删除一些对 Googlebot 不重要的参数,并为用户提供更好看的动态网址。如果您不确定哪些参数可以删除,我们建议您将动态 URL 中的所有参数都提供给我们,我们的系统会找出哪些不重要。隐藏参数会影响我们正确分析您的网址,我们将无法识别这些参数,从而可能会丢失一些重要信息。
以下是我们认为您可能有疑问的一些问题。
这是否意味着我应该完全避免重写动态 URL?
这是我们的建议,除非你能保证你只删除多余的参数,否则你可以完全删除所有可能产生不利影响的参数。如果你随意修改你的动态URL,让它看起来是静态的,你必须意识到这样做是有风险的,有些信息可能无法正常编译和识别。如果你想给你的网站添加静态版本,请提供真正静态的内容,比如生成的文件可以通过网站的对应路径获取。如果您只修改动态 URL 的呈现而不提供静态内容,那么您可能会适得其反。请直接提供标准的动态网址,我们会自动找出那些多余的参数。
你能举个例子吗?
如果您有一个标准格式的动态网址,例如:foo?key1=value&key2=value2,我们建议您不要更改它。谷歌将决定可以删除哪些参数;或者您可以为用户删除不必要的参数。但要小心,只删除那些不重要的参数。以下是具有多个参数的动态 URL 的示例:
language=en-标记这个文章的语言
answer=3 – 这个 文章 收录数字 3
sid=8971298178906-会话识别码为8971298178906
query=URL-使这个 文章 找到的查询是并非所有参数都提供附加信息。所以重写这个 URL 可能不会造成任何问题,因为所有不相关的参数都被删除了。
下面是一些已修改为看起来像静态 URL 的 URL 示例。与不重写直接提供的动态网址相比,这些网址可能会造成更多的抓取问题。
sid=98971298178906/query=URL
98971298178906/查询/网址
,3,98971298178906,URL 如果把动态URL改写成上面提到的例子,可能会给我们带来很多不必要的爬取,因为这些URL收录了会话标识符(sid)和查询(query)参数。变量值,这个无形中产生了很多看起来不一样的URL,但是它们收录的内容是一样的。这些格式让我们很难理解通过这个URL返回的实际内容和参数URL和98971298178906是无关的。但是,以下重写的示例删除了所有无关参数:
尽管我们可以正确处理此 URL,但我们仍然不鼓励您使用此类重写。因为很难维护,而且一旦在原来的动态 URL 上增加了新的参数,就需要立即更新 URL。如果不这样做,将再次导致 URL 看起来像带有隐藏参数的静态 URL。所以最好的解决方案是通常保持动态 URL 原样。或者,如果您删除了不相关的参数,请记住保持此 URL 动态:
我们希望这个文章 可以对您和我们的朋友有所帮助,并澄清有关动态 URL 的各种猜测。如果您有更多问题,请加入我们的网站管理员支持论坛进行讨论。
a_zheng_2010 发表于 2015-1-10 21:11
什么是静态网址?
283578916的小号发表于2017-12-22 23:51
666666666666
誊: [1]
抓取动态网页(提高网站排名起着非常重要的作用_成都网站建设)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-06 03:09
网络营销行业的人都知道,目前几乎所有的SEO优化器都强调使用静态网页,从而降低动态网站的权重。但是静态网站确实比动态网站友好,动态网页对搜索引擎不友好,这就是seoers不使用它的原因,但是告诉你:现在搜索引擎有已经使用动态页面。如果能被识别和抓取,也许动态网页会成为未来互联网的主流,所以动态网站不一定不能被搜索引擎收录排名或搜索到,只要你掌握了一些技巧就可以了。
1、合理安排网站网址
搜索引擎之所以很难检索到动态网页,是因为它们对网址中的特殊字符不敏感,所以我们应该使网页静态化,并尽量避免“?” 网站的URL中的“&”“”等特殊字符,特别是“&”不是必须的,所以我们可以写,不要写。还有一点就是尽量不要在URL中收录中文字符,因为浏览器会对URL中的中文进行编码。如果网址中汉字过多,编码后网址会很长,这对搜索引擎检索页面非常不利。
2、善用利剑“称号”
标题标签对提高网站的排名起到了非常重要的作用。很多人之所以害怕动态网站,是因为不知道如何让自动生成的动态页面自动生成合适的标题标签。其实这里有个窍门,就是在title标签前面写SELET,比如一个新闻分类网站,一般在新闻列表页写成这样:"",即使用ID传递一个“>”参数到“news_detail.asp”页面查看整个新闻信息,所以我们需要做的所有工作都在news_detail.asp页面上。同理,我们也可以用这个方法来写描述和关键字,当然有一点要画出来,请注意关键字的作用已经可以忽略不计,如果使用不当,
3、创建静态条目
在“动静结合,静制动”的原则指导下,也可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。例如,如果将动态网页编译为静态主页或网站 地图的链接,则动态页面将呈现为静态目录。或者为动态页面创建一个专门的静态入口页面(网关/入口,链接到动态页面),然后将静态入口页面提交给搜索引擎。
以上三点是成都网站建设对网站优化趋势的建议。希望对大家以后的优化趋势有所帮助网站!
_创新互联网,为您提供商城网站、外贸网站建设、外贸建设站、品牌网站建设、网站设计公司、定制开发 查看全部
抓取动态网页(提高网站排名起着非常重要的作用_成都网站建设)
网络营销行业的人都知道,目前几乎所有的SEO优化器都强调使用静态网页,从而降低动态网站的权重。但是静态网站确实比动态网站友好,动态网页对搜索引擎不友好,这就是seoers不使用它的原因,但是告诉你:现在搜索引擎有已经使用动态页面。如果能被识别和抓取,也许动态网页会成为未来互联网的主流,所以动态网站不一定不能被搜索引擎收录排名或搜索到,只要你掌握了一些技巧就可以了。
1、合理安排网站网址
搜索引擎之所以很难检索到动态网页,是因为它们对网址中的特殊字符不敏感,所以我们应该使网页静态化,并尽量避免“?” 网站的URL中的“&”“”等特殊字符,特别是“&”不是必须的,所以我们可以写,不要写。还有一点就是尽量不要在URL中收录中文字符,因为浏览器会对URL中的中文进行编码。如果网址中汉字过多,编码后网址会很长,这对搜索引擎检索页面非常不利。

2、善用利剑“称号”
标题标签对提高网站的排名起到了非常重要的作用。很多人之所以害怕动态网站,是因为不知道如何让自动生成的动态页面自动生成合适的标题标签。其实这里有个窍门,就是在title标签前面写SELET,比如一个新闻分类网站,一般在新闻列表页写成这样:"",即使用ID传递一个“>”参数到“news_detail.asp”页面查看整个新闻信息,所以我们需要做的所有工作都在news_detail.asp页面上。同理,我们也可以用这个方法来写描述和关键字,当然有一点要画出来,请注意关键字的作用已经可以忽略不计,如果使用不当,
3、创建静态条目
在“动静结合,静制动”的原则指导下,也可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。例如,如果将动态网页编译为静态主页或网站 地图的链接,则动态页面将呈现为静态目录。或者为动态页面创建一个专门的静态入口页面(网关/入口,链接到动态页面),然后将静态入口页面提交给搜索引擎。
以上三点是成都网站建设对网站优化趋势的建议。希望对大家以后的优化趋势有所帮助网站!
_创新互联网,为您提供商城网站、外贸网站建设、外贸建设站、品牌网站建设、网站设计公司、定制开发
抓取动态网页(基于改进Single-Pass算法的噪声链接去除算法进行研究)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-04 16:13
[摘要]:互联网上Web2.0技术的出现和社交平台的兴起,极大地促进了动态网页的使用和普及。动态网页中的Ajax技术实现了客户端和服务器之间数据的异步操作,既满足了新时代的技术需求,又提高了用户体验,促进了互联网的发展。然而,传统的网络爬虫无法应对动态网页带来的新特性,因此研究支持动态页面的网络爬虫具有一定的现实意义。对于话题网络爬虫来说,噪声链接不仅毫无价值,而且消耗大量资源,尤其是采集和噪声链接对应网页上的网络爬虫分析,这大大降低了网络爬虫的效率。针对以上问题,本文的主要研究内容如下: 一、解决动态网页中Ajax异步操作原理的关键技术,以及如何让网络爬虫支持动态网页爬取的问题。本文通过HTTP请求获取网页,然后在本地构建网页的DOM树,分析脚本并提取URL,并修改HtmlUnit的源码解析需要点击触发的脚本,从而解决了传统网络爬虫对于动态网页中动态生成的网址难以获取的问题;其次,由于噪声链接大大降低了网络爬虫的效率,本文研究了去除网页噪声的算法。传统的网页去噪算法处理网页的整体结构,去噪效率低。本文通过聚类后的相似度计算对提取的URL结果进行去噪,在改进的Single-Pass算法的基础上提出了噪声链接去除算法,在去噪精度上取得了较好的效果;最后,实现了一个支持动态页面URL主题快速提取的网络爬虫系统,并针对动态网页分析和动态生成的URL提取、去噪算法的效果对比以及主题网络爬虫系统进行了设计和实现在快速提取 URL 的三个方面。实验。实验结果数据表明,本文实现的网络爬虫系统支持动态网页网址的提取, 查看全部
抓取动态网页(基于改进Single-Pass算法的噪声链接去除算法进行研究)
[摘要]:互联网上Web2.0技术的出现和社交平台的兴起,极大地促进了动态网页的使用和普及。动态网页中的Ajax技术实现了客户端和服务器之间数据的异步操作,既满足了新时代的技术需求,又提高了用户体验,促进了互联网的发展。然而,传统的网络爬虫无法应对动态网页带来的新特性,因此研究支持动态页面的网络爬虫具有一定的现实意义。对于话题网络爬虫来说,噪声链接不仅毫无价值,而且消耗大量资源,尤其是采集和噪声链接对应网页上的网络爬虫分析,这大大降低了网络爬虫的效率。针对以上问题,本文的主要研究内容如下: 一、解决动态网页中Ajax异步操作原理的关键技术,以及如何让网络爬虫支持动态网页爬取的问题。本文通过HTTP请求获取网页,然后在本地构建网页的DOM树,分析脚本并提取URL,并修改HtmlUnit的源码解析需要点击触发的脚本,从而解决了传统网络爬虫对于动态网页中动态生成的网址难以获取的问题;其次,由于噪声链接大大降低了网络爬虫的效率,本文研究了去除网页噪声的算法。传统的网页去噪算法处理网页的整体结构,去噪效率低。本文通过聚类后的相似度计算对提取的URL结果进行去噪,在改进的Single-Pass算法的基础上提出了噪声链接去除算法,在去噪精度上取得了较好的效果;最后,实现了一个支持动态页面URL主题快速提取的网络爬虫系统,并针对动态网页分析和动态生成的URL提取、去噪算法的效果对比以及主题网络爬虫系统进行了设计和实现在快速提取 URL 的三个方面。实验。实验结果数据表明,本文实现的网络爬虫系统支持动态网页网址的提取,
抓取动态网页(如何帮助我从以下链接中获取结果,你知道吗 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-04 10:16
)
如果您能帮助我从以下链接获取结果,我将不胜感激:
我正在使用 python3.7、beautifulsoup4 和 Selenium。你知道吗
我写了一个程序来提取酒店用户评论的特征,比如评论者姓名、评论日期、评论者评分、评论者国家、入住日期、评论标题和评论本身(在这个例子中,评论分为正面和负部分)。我使用beautifulsoup4从HTML标签中提取文本,依靠Selenium点击“cookienotification”按钮并循环浏览页面结果。你知道吗
当我成功循环浏览页面结果时,我没有提取第一页后检索到的内容。每 N 个页面从第一个结果页面检索相同的内容,我敢打赌这可能是因为内容是通过 JQuery 加载的。在这一点上,我不确定行为是什么,或者我需要在页面源代码中寻找什么,或者如何继续寻找解决方案。你知道吗
任何提示或建议将不胜感激!你知道吗
我的代码片段:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait, Select
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
import time
driver = webdriver.Chrome('/Users/admin/Desktop/chrome_driver/chromedriver')
#initiate driver-browser via Selenium - with original url
driver.get('link1')
def acceptCookies():
time.sleep(3)
element = driver.find_elements_by_xpath("//button[@class='cookie-warning-v2__banner-cta bui-button bui-button--wide bui-button--secondary close_warning']")
if element != None:
element = driver.find_elements_by_xpath("//button[@class='cookie-warning-v2__banner-cta bui-button bui-button--wide bui-button--secondary close_warning']")
element[0].click()
def getData(count, soup):
try:
for line in soup.find_all('li', class_='review_item'):
count += 1
review={}
review["review_metadata"]={}
review["review_metadata"]["review_date"] = line.find('p', class_='review_item_date').text.strip()
if line.find('p', class_='review_staydate') != None:
review["review_metadata"]["review_staydate"] = line.find('p', class_='review_staydate').text.strip()
review["review_metadata"]["reviewer_name"] = line.find('p', class_='reviewer_name').text.strip()
print(review["review_metadata"]["reviewer_name"])
review["review_metadata"]["reviewer_country"] = line.find('span', class_='reviewer_country').text.strip()
review["review_metadata"]["reviewer_score"] = line.find('span', class_='review-score-badge').text.strip()
if line.find('p', class_='review_pos') != None:
review["review_metadata"]["review_pos"] = line.find('p', class_='review_pos').text.strip()
if line.find('p', class_='review_neg') != None:
review["review_metadata"]["review_neg"] = line.find('p', class_='review_neg').text.strip()
scoreword = line.find('span', class_='review_item_header_scoreword')
if scoreword != None :
review["review_metadata"]["review_header"] = scoreword.text.strip()
else:
review["review_metadata"]["review_header"] = ""
hotel_reviews[count] = review
return hotel_reviews
except Exception as e:
return print('the error is', e)
# Finds max-range of pagination (number of result pages retrieved)
def find_max_pages():
max_pages = driver.find_elements_by_xpath("//div[@class='bui-pagination__list']//div//span")
max_pages = max_pages[-1].text
max_pages = max_pages.split()
max_pages = int(max_pages[1])
return max_pages
hotel_reviews= {}
count = 0
review_page = {}
hotel_reviews_2 = []
# Accept on Cookie-Notification
acceptCookies()
# Find Max Pages
max_pages = find_max_pages()
# Find every pagination link in order to loop through each review page carousel
element = driver.find_elements_by_xpath("//a[@class='bui-pagination__link']")
for item in range(max_pages-1):
review_page = getData(count, soup)
hotel_reviews_2.extend(review_page)
time.sleep(2)
element = driver.find_elements_by_xpath("//a[@class='bui-pagination__link']")
element[item].click()
driver.get(url=driver.current_url)
print(driver.page_source)
print(driver.current_url)
soup = BeautifulSoup(driver.page_source, 'lxml') 查看全部
抓取动态网页(如何帮助我从以下链接中获取结果,你知道吗
)
如果您能帮助我从以下链接获取结果,我将不胜感激:
我正在使用 python3.7、beautifulsoup4 和 Selenium。你知道吗
我写了一个程序来提取酒店用户评论的特征,比如评论者姓名、评论日期、评论者评分、评论者国家、入住日期、评论标题和评论本身(在这个例子中,评论分为正面和负部分)。我使用beautifulsoup4从HTML标签中提取文本,依靠Selenium点击“cookienotification”按钮并循环浏览页面结果。你知道吗
当我成功循环浏览页面结果时,我没有提取第一页后检索到的内容。每 N 个页面从第一个结果页面检索相同的内容,我敢打赌这可能是因为内容是通过 JQuery 加载的。在这一点上,我不确定行为是什么,或者我需要在页面源代码中寻找什么,或者如何继续寻找解决方案。你知道吗
任何提示或建议将不胜感激!你知道吗
我的代码片段:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait, Select
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
import time
driver = webdriver.Chrome('/Users/admin/Desktop/chrome_driver/chromedriver')
#initiate driver-browser via Selenium - with original url
driver.get('link1')
def acceptCookies():
time.sleep(3)
element = driver.find_elements_by_xpath("//button[@class='cookie-warning-v2__banner-cta bui-button bui-button--wide bui-button--secondary close_warning']")
if element != None:
element = driver.find_elements_by_xpath("//button[@class='cookie-warning-v2__banner-cta bui-button bui-button--wide bui-button--secondary close_warning']")
element[0].click()
def getData(count, soup):
try:
for line in soup.find_all('li', class_='review_item'):
count += 1
review={}
review["review_metadata"]={}
review["review_metadata"]["review_date"] = line.find('p', class_='review_item_date').text.strip()
if line.find('p', class_='review_staydate') != None:
review["review_metadata"]["review_staydate"] = line.find('p', class_='review_staydate').text.strip()
review["review_metadata"]["reviewer_name"] = line.find('p', class_='reviewer_name').text.strip()
print(review["review_metadata"]["reviewer_name"])
review["review_metadata"]["reviewer_country"] = line.find('span', class_='reviewer_country').text.strip()
review["review_metadata"]["reviewer_score"] = line.find('span', class_='review-score-badge').text.strip()
if line.find('p', class_='review_pos') != None:
review["review_metadata"]["review_pos"] = line.find('p', class_='review_pos').text.strip()
if line.find('p', class_='review_neg') != None:
review["review_metadata"]["review_neg"] = line.find('p', class_='review_neg').text.strip()
scoreword = line.find('span', class_='review_item_header_scoreword')
if scoreword != None :
review["review_metadata"]["review_header"] = scoreword.text.strip()
else:
review["review_metadata"]["review_header"] = ""
hotel_reviews[count] = review
return hotel_reviews
except Exception as e:
return print('the error is', e)
# Finds max-range of pagination (number of result pages retrieved)
def find_max_pages():
max_pages = driver.find_elements_by_xpath("//div[@class='bui-pagination__list']//div//span")
max_pages = max_pages[-1].text
max_pages = max_pages.split()
max_pages = int(max_pages[1])
return max_pages
hotel_reviews= {}
count = 0
review_page = {}
hotel_reviews_2 = []
# Accept on Cookie-Notification
acceptCookies()
# Find Max Pages
max_pages = find_max_pages()
# Find every pagination link in order to loop through each review page carousel
element = driver.find_elements_by_xpath("//a[@class='bui-pagination__link']")
for item in range(max_pages-1):
review_page = getData(count, soup)
hotel_reviews_2.extend(review_page)
time.sleep(2)
element = driver.find_elements_by_xpath("//a[@class='bui-pagination__link']")
element[item].click()
driver.get(url=driver.current_url)
print(driver.page_source)
print(driver.current_url)
soup = BeautifulSoup(driver.page_source, 'lxml')
抓取动态网页(小编来告诉你静态网站和动态网站的区别(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-03 13:12
大多数人认为,如果一个网页有动画或一些动态效果,那么它就是一个动态网页,否则就是一个静态网页。这是大多数人错误认为的动态页面。下面就跟小编一起来告诉你静态网站和动态网站
的区别
静态网站和动态网站的区别
在网站的设计中,纯HTML格式的网页通常被称为“静态网页”,早期的网站一般都是由静态网页制作而成。静态网页的URL形式通常是:后缀.htm、.html等。在HTML格式的网页上,还可以出现各种动态效果,如.GIF格式动画、FLASH、移动字母等。这些“动态效果”只是视觉效果,你可以跟网站 动态网页是一个不同的概念。静态网页是实际保存在服务器上的文件,每个网页都是一个独立的文件等。所谓静态网页是指网页文件中没有程序,只有HTML代码,一般是带有.html或.htm的后缀,网站的静态内容制作完成后不会改变,任何人访问都会显示。如果您的内容发生变化,您必须修改原创代码,然后将其上传到服务器。
动态网页与网页上的各种动画、动态字幕等视觉“动态效果”没有直接关系。动态网页还可以收录纯文本内容或收录各种动画的内容。这些只是网页详细内容的形式,无论网页是否具有动态效果,以动态网站技术而生的网页都称为动态网页。所谓动态网页,是指网页文件不仅有HTML标记,还收录程序代码。通过数据库连接,动态网页可以根据不同的时间和不同的访问者显示不同的内容。动态网站更新方便,一般在后台直接更新。
静态网站简要说明
·每个静态网页都有一个固定的URL,文件名后缀为htm、html、shtml等;
·静态网页一旦发布到服务器上,无论是否被访问,都是一个独立的文件;
·静态网页内容相对稳定,不收录特殊代码,容易被搜索引擎检索到; HTML更适合SEO搜索引擎优化。
·静态网站没有数据库支持,在网站的生产和维护上有很多工作;
·由于不需要通过数据库工作,静态网页的访问速度比较快;
流行的cms都支持静态网页,有利于搜索引擎收录,提高访问速度,但占用服务器空间大,程序运行时消耗大量时间生成html服务器资源,建议在服务器空闲时进行此类操作。
动态简述网站
Dynamic网站不是指具有动画功能的网站,而是指网站,其内容可以根据不同情况动态变化网站,一般来说,动态的网站 架构师通过数据库。动态网站除了设计网页之外,还需要借助数据库和编程,让网站具备更多的自动化和高级功能。动态网站体现在网页一般以asp、jsp、php、aspx等结尾,而静态网页一般以HTML(标准通用标记语言的一个子集)结尾。动态网站服务器空间配置比静态网页要求高,相应的成本也高,但动态网页有利于更新网站的内容,适合企业建网站。动态相对于静态网站。
动态网站功能
动态网站可实现用户注册、信息发布、产品展示、订单管理等交互功能;
动态网页不是独立存在于服务器上的网页文件,而是浏览器发送请求时反馈的网页;
动态网页收录服务器端脚本,因此页面文件名往往以asp、jsp、php等为后缀。但是您也可以使用 URL 静态技术将网页后缀显示为 HTML。因此,不能以页面文件的后缀作为判断网站动静态的唯一标准。
由于动态网页需要进行数据库处理,动态网站的访问速度大大减慢;
由于代码的特殊性,动态网页对搜索引擎的友好度低于静态网页。
但随着计算机性能的提升和网络带宽的增加,后两项基本得到解决。
动态主要特点网站
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件,服务器只有在用户请求时才返回一个完整的网页;
(4)动态网页中的“?”对搜索引擎检索有一定的问题。搜索引擎一般不可能访问网站数据库中的所有网页,或者由于技术原因考虑搜索蜘蛛不会抓取网址中“?”后的内容,因此网站使用动态网页在进行搜索引擎推广时需要做一定的技术处理,以满足搜索引擎的要求
什么是静态网页?静态网页的特点是什么?
在网站的设计中,纯HTML格式的网页通常被称为“静态网页”。早期的网站一般都是由静态网页制作而成。
静态网页的 URL 形式通常是:
以.htm、.html、.shtml、.xml等为后缀,在HTML格式的网页上,还可以出现各种动态效果,如.GIF格式动画、FLASH、滚动字母等。这些“动态效果” ”只是视觉效果,与下面介绍的动态网页是不同的概念。 .
我们简单总结一下静态网页的特点如下:
(1)静态网页每个网页都有一个固定的网址,网页网址以.htm、.html、.shtml等常见形式为后缀,不收录“?”;
(2)一旦网页内容发布在网站服务器上,无论是否有用户访问,每个静态网页的内容都存储在网站服务器上,也就是说,静态网页是服务器上实际保存的一个文件,每个网页都是一个独立的文件;
(3)静态网页的内容比较稳定,容易被搜索引擎检索到;
(4)静态网页不支持数据库,网站的制作和维护工作量很大,所以信息量大的时候,比较静态网页制作方法完全依赖于困难;
(5)静态网页交互性较差,在功能上有较大限制。
看过静态网站和动态网站区别的人会看到:
1.旅游产品推广计划范文
2.腾达路由器新界面如何升级
3.路由器tel402部分网页打不开怎么办
4.3篇会议纪要范文
5.如何学习期货交易的意识 查看全部
抓取动态网页(小编来告诉你静态网站和动态网站的区别(图))
大多数人认为,如果一个网页有动画或一些动态效果,那么它就是一个动态网页,否则就是一个静态网页。这是大多数人错误认为的动态页面。下面就跟小编一起来告诉你静态网站和动态网站
的区别

静态网站和动态网站的区别
在网站的设计中,纯HTML格式的网页通常被称为“静态网页”,早期的网站一般都是由静态网页制作而成。静态网页的URL形式通常是:后缀.htm、.html等。在HTML格式的网页上,还可以出现各种动态效果,如.GIF格式动画、FLASH、移动字母等。这些“动态效果”只是视觉效果,你可以跟网站 动态网页是一个不同的概念。静态网页是实际保存在服务器上的文件,每个网页都是一个独立的文件等。所谓静态网页是指网页文件中没有程序,只有HTML代码,一般是带有.html或.htm的后缀,网站的静态内容制作完成后不会改变,任何人访问都会显示。如果您的内容发生变化,您必须修改原创代码,然后将其上传到服务器。
动态网页与网页上的各种动画、动态字幕等视觉“动态效果”没有直接关系。动态网页还可以收录纯文本内容或收录各种动画的内容。这些只是网页详细内容的形式,无论网页是否具有动态效果,以动态网站技术而生的网页都称为动态网页。所谓动态网页,是指网页文件不仅有HTML标记,还收录程序代码。通过数据库连接,动态网页可以根据不同的时间和不同的访问者显示不同的内容。动态网站更新方便,一般在后台直接更新。
静态网站简要说明
·每个静态网页都有一个固定的URL,文件名后缀为htm、html、shtml等;
·静态网页一旦发布到服务器上,无论是否被访问,都是一个独立的文件;
·静态网页内容相对稳定,不收录特殊代码,容易被搜索引擎检索到; HTML更适合SEO搜索引擎优化。
·静态网站没有数据库支持,在网站的生产和维护上有很多工作;
·由于不需要通过数据库工作,静态网页的访问速度比较快;
流行的cms都支持静态网页,有利于搜索引擎收录,提高访问速度,但占用服务器空间大,程序运行时消耗大量时间生成html服务器资源,建议在服务器空闲时进行此类操作。
动态简述网站
Dynamic网站不是指具有动画功能的网站,而是指网站,其内容可以根据不同情况动态变化网站,一般来说,动态的网站 架构师通过数据库。动态网站除了设计网页之外,还需要借助数据库和编程,让网站具备更多的自动化和高级功能。动态网站体现在网页一般以asp、jsp、php、aspx等结尾,而静态网页一般以HTML(标准通用标记语言的一个子集)结尾。动态网站服务器空间配置比静态网页要求高,相应的成本也高,但动态网页有利于更新网站的内容,适合企业建网站。动态相对于静态网站。
动态网站功能
动态网站可实现用户注册、信息发布、产品展示、订单管理等交互功能;
动态网页不是独立存在于服务器上的网页文件,而是浏览器发送请求时反馈的网页;
动态网页收录服务器端脚本,因此页面文件名往往以asp、jsp、php等为后缀。但是您也可以使用 URL 静态技术将网页后缀显示为 HTML。因此,不能以页面文件的后缀作为判断网站动静态的唯一标准。
由于动态网页需要进行数据库处理,动态网站的访问速度大大减慢;
由于代码的特殊性,动态网页对搜索引擎的友好度低于静态网页。
但随着计算机性能的提升和网络带宽的增加,后两项基本得到解决。
动态主要特点网站
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件,服务器只有在用户请求时才返回一个完整的网页;
(4)动态网页中的“?”对搜索引擎检索有一定的问题。搜索引擎一般不可能访问网站数据库中的所有网页,或者由于技术原因考虑搜索蜘蛛不会抓取网址中“?”后的内容,因此网站使用动态网页在进行搜索引擎推广时需要做一定的技术处理,以满足搜索引擎的要求
什么是静态网页?静态网页的特点是什么?
在网站的设计中,纯HTML格式的网页通常被称为“静态网页”。早期的网站一般都是由静态网页制作而成。
静态网页的 URL 形式通常是:
以.htm、.html、.shtml、.xml等为后缀,在HTML格式的网页上,还可以出现各种动态效果,如.GIF格式动画、FLASH、滚动字母等。这些“动态效果” ”只是视觉效果,与下面介绍的动态网页是不同的概念。 .
我们简单总结一下静态网页的特点如下:
(1)静态网页每个网页都有一个固定的网址,网页网址以.htm、.html、.shtml等常见形式为后缀,不收录“?”;
(2)一旦网页内容发布在网站服务器上,无论是否有用户访问,每个静态网页的内容都存储在网站服务器上,也就是说,静态网页是服务器上实际保存的一个文件,每个网页都是一个独立的文件;
(3)静态网页的内容比较稳定,容易被搜索引擎检索到;
(4)静态网页不支持数据库,网站的制作和维护工作量很大,所以信息量大的时候,比较静态网页制作方法完全依赖于困难;
(5)静态网页交互性较差,在功能上有较大限制。
看过静态网站和动态网站区别的人会看到:
1.旅游产品推广计划范文
2.腾达路由器新界面如何升级
3.路由器tel402部分网页打不开怎么办
4.3篇会议纪要范文
5.如何学习期货交易的意识
抓取动态网页(关于动态网站优化的一些优化技巧:合理的安排网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-02 06:12
网络营销行业的人都知道,目前几乎所有的seo优化者都强调使用静态网页,从而降低动态网站的权重。不过静态网站确实比动态网站友好,动态网页对搜索引擎不友好,这也是seoers不使用的原因,但是网络营销教学网告诉你: 现在的搜索引擎对于可以识别和爬取的动态页面,或许动态页面将来会成为互联网的主流,所以动态网站不一定是搜索引擎无法排名或者搜索不到的< @收录,只要掌握了一些技巧就行。现在商七云给大家分享一些关于动态网站优化的优化技巧:
1、合理安排网站网址
搜索引擎之所以难以检索到动态网页,是因为它们对网址中的特殊字符不敏感。因此,我们应该使网页静态化,并尽量避免“?”在 网站 的 URL 中。 “&”等特殊字符,特别是“&”不是必须的,所以我们可以不写,另外就是尽量不要在URL中收录中文字符,因为浏览器会在URL Encoding中对待中文,如果网址中汉字过多,编码后网址会很长,对搜索引擎检索页面非常不利。
2、善用利剑“称号”
title标签对于提升网站的排名起到了非常重要的作用。很多人之所以害怕动态网站,是因为不知道如何让自动生成的动态页面自动生成一个合适的标题标签,其实这里还有一个技巧,就是写标题标签前面的SELET,比如一个新闻分类网站,在新闻列表页上通常是这样写的:“”,即用ID传递一个“>”参数给“news_detail.txt”。 asp”页面查看整个新闻信息,所以我们要做的所有工作都在news_detail.asp页面上。同样的方式我们也可以用这个方法来写描述和关键字,当然还有我想要的提醒大家的是,关键词的作用微乎其微,如果使用不当,只会害你而不是帮助你,所以不要用这种动态技术来滥用关键词标签。
3、创建静态条目
在“动静结合,静制动”的原则指导下,也可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。例如,如果将动态网页编译为静态主页或网站 地图的链接,则动态页面将呈现为静态目录。或者创建一个专门的静态入口页面(网关/入口,为动态页面链接到动态页面,然后将静态入口页面提交给搜索引擎。
以上三点是关于如何优化网络营销知识网动态网站的建议。希望对你优化动态网站有帮助! 查看全部
抓取动态网页(关于动态网站优化的一些优化技巧:合理的安排网站)
网络营销行业的人都知道,目前几乎所有的seo优化者都强调使用静态网页,从而降低动态网站的权重。不过静态网站确实比动态网站友好,动态网页对搜索引擎不友好,这也是seoers不使用的原因,但是网络营销教学网告诉你: 现在的搜索引擎对于可以识别和爬取的动态页面,或许动态页面将来会成为互联网的主流,所以动态网站不一定是搜索引擎无法排名或者搜索不到的< @收录,只要掌握了一些技巧就行。现在商七云给大家分享一些关于动态网站优化的优化技巧:
1、合理安排网站网址
搜索引擎之所以难以检索到动态网页,是因为它们对网址中的特殊字符不敏感。因此,我们应该使网页静态化,并尽量避免“?”在 网站 的 URL 中。 “&”等特殊字符,特别是“&”不是必须的,所以我们可以不写,另外就是尽量不要在URL中收录中文字符,因为浏览器会在URL Encoding中对待中文,如果网址中汉字过多,编码后网址会很长,对搜索引擎检索页面非常不利。

2、善用利剑“称号”
title标签对于提升网站的排名起到了非常重要的作用。很多人之所以害怕动态网站,是因为不知道如何让自动生成的动态页面自动生成一个合适的标题标签,其实这里还有一个技巧,就是写标题标签前面的SELET,比如一个新闻分类网站,在新闻列表页上通常是这样写的:“”,即用ID传递一个“>”参数给“news_detail.txt”。 asp”页面查看整个新闻信息,所以我们要做的所有工作都在news_detail.asp页面上。同样的方式我们也可以用这个方法来写描述和关键字,当然还有我想要的提醒大家的是,关键词的作用微乎其微,如果使用不当,只会害你而不是帮助你,所以不要用这种动态技术来滥用关键词标签。
3、创建静态条目
在“动静结合,静制动”的原则指导下,也可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。例如,如果将动态网页编译为静态主页或网站 地图的链接,则动态页面将呈现为静态目录。或者创建一个专门的静态入口页面(网关/入口,为动态页面链接到动态页面,然后将静态入口页面提交给搜索引擎。
以上三点是关于如何优化网络营销知识网动态网站的建议。希望对你优化动态网站有帮助!
抓取动态网页(Java高并发编程入门为啥写这篇文章?(09))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-01 07:10
您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连。
1. 社区里走一走,每周都有福利,每周都有惊喜。马农飞阁社区飞跃计划
2. Python基础专栏,基础知识一应俱全。 Python从入门到精通
❤️ 3. Ceph实战,从原理到实战,无所不包。 Ceph实战
❤️ 4. Java高并发编程介绍,点进来学习Java高并发。 Java高并发编程简介
为什么要写这个文章?
前两篇文章我们分别介绍了
使用正则表达式爬取古诗词散文网站,玩玩学习【python爬虫入门进阶】(09)
使用生产者-消费者模式抓取bucket图片,一下子获取大量表情【python爬虫入门进阶】(11)
还没来得及看的朋友可以再看一波。
本文以小凡表网站为例介绍如何从动态网页中抓取数据。上面说的数据爬取是为了说明哪些是静态网页,即接口直接返回一个Html页面。我们只需要通过Xpath等方式提取页面内容即可。
今天要讲的另一种网站就是页面数据通过ajax返回。对于这种网站,我们如何抓取他的数据?
为什么要写这个文章?分析页面 ajax获取ajax数据的方法是什么 获取数据汇总分析页面
首先打开这个网站,经过简单的分析,我们可以得出三个结论。
点击查看更多数据后,页面地址不变,页面不会刷新。单击以查看更多一次将请求该接口一次。页面的数据以application/json的形式由接口返回。 p 参数控制返回哪一页数据。 n 参数控制每页返回的数据项数。什么是ajax
AJAX(Asynchronouse JavaScript And XML)中文称为异步JavaScript和XML。主要用于前端和服务器端进行少量数据交互。 Ajax 可以实现网页的异步加载,这意味着可以在不重新加载整个网页的情况下部分更新网页的某个部分。传统网页(不使用 Ajax)如果需要更新内容,需要重新加载整个网页。
因为传统的数据传输格式是XML语法,所以叫做AJAX。其实现在数据交互基本都是用JSON。使用ajax加载的数据,即使使用js,数据渲染到浏览器中,右键---->查看网页源码,仍然看不到通过ajax加载的数据,只加载了html使用网址代码。
如何获取ajax数据直接分析ajax调用的接口,然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。 (文章后面会详细介绍)获取数据
这个小餐桌网站的界面比较简单。没有加密认证什么的,直接通过requests请求即可。这是一个示例代码:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36"
}
requests.packages.urllib3.disable_warnings()
if __name__ == '__main__':
for i in range(1,10):
url = "https://www.xfz.cn/api/website/articles/?p={0}&n=20&type=".format(str(i))
resp = requests.get(url, headers=headers, verify=False)
print(resp.json())
运行结果:
总结
本文以小凡表网站为例,简单介绍一下如何抓取动态网页的数据。 查看全部
抓取动态网页(Java高并发编程入门为啥写这篇文章?(09))
您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连。
1. 社区里走一走,每周都有福利,每周都有惊喜。马农飞阁社区飞跃计划
2. Python基础专栏,基础知识一应俱全。 Python从入门到精通
❤️ 3. Ceph实战,从原理到实战,无所不包。 Ceph实战
❤️ 4. Java高并发编程介绍,点进来学习Java高并发。 Java高并发编程简介
为什么要写这个文章?
前两篇文章我们分别介绍了
使用正则表达式爬取古诗词散文网站,玩玩学习【python爬虫入门进阶】(09)
使用生产者-消费者模式抓取bucket图片,一下子获取大量表情【python爬虫入门进阶】(11)
还没来得及看的朋友可以再看一波。
本文以小凡表网站为例介绍如何从动态网页中抓取数据。上面说的数据爬取是为了说明哪些是静态网页,即接口直接返回一个Html页面。我们只需要通过Xpath等方式提取页面内容即可。
今天要讲的另一种网站就是页面数据通过ajax返回。对于这种网站,我们如何抓取他的数据?
为什么要写这个文章?分析页面 ajax获取ajax数据的方法是什么 获取数据汇总分析页面
首先打开这个网站,经过简单的分析,我们可以得出三个结论。
点击查看更多数据后,页面地址不变,页面不会刷新。单击以查看更多一次将请求该接口一次。页面的数据以application/json的形式由接口返回。 p 参数控制返回哪一页数据。 n 参数控制每页返回的数据项数。什么是ajax
AJAX(Asynchronouse JavaScript And XML)中文称为异步JavaScript和XML。主要用于前端和服务器端进行少量数据交互。 Ajax 可以实现网页的异步加载,这意味着可以在不重新加载整个网页的情况下部分更新网页的某个部分。传统网页(不使用 Ajax)如果需要更新内容,需要重新加载整个网页。
因为传统的数据传输格式是XML语法,所以叫做AJAX。其实现在数据交互基本都是用JSON。使用ajax加载的数据,即使使用js,数据渲染到浏览器中,右键---->查看网页源码,仍然看不到通过ajax加载的数据,只加载了html使用网址代码。
如何获取ajax数据直接分析ajax调用的接口,然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。 (文章后面会详细介绍)获取数据
这个小餐桌网站的界面比较简单。没有加密认证什么的,直接通过requests请求即可。这是一个示例代码:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36"
}
requests.packages.urllib3.disable_warnings()
if __name__ == '__main__':
for i in range(1,10):
url = "https://www.xfz.cn/api/website/articles/?p={0}&n=20&type=".format(str(i))
resp = requests.get(url, headers=headers, verify=False)
print(resp.json())
运行结果:
总结
本文以小凡表网站为例,简单介绍一下如何抓取动态网页的数据。
抓取动态网页(让百度蜘蛛抓取我们的网站,那么最重要的就是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-30 06:21
在网站建设的过程中,很多企业网主和企业主都希望自己的优质网站能够被百度收录,有时除了发一些文章,不知道该怎么办。其实被收录还是有点难度的。今天小编就来给大家分析一下。
其实我们想让百度蜘蛛抓取我们的网站,所以最重要的是我们要了解百度蜘蛛是什么!注意这里的蜘蛛不是我们生活中的蜘蛛动物,这里的蜘蛛是一个程序!我们认为互联网是一个大网,蜘蛛是在这里活跃的程序蜘蛛。所以我们用好引擎蜘蛛,我们的优化和包容会事半功倍。
对于互联网,蜘蛛爬行我们网站所有栏目站点的概率非常低。毕竟,蜘蛛只是一个程序,不可能像我们的人脑一样聪明。其实在我们希望蜘蛛的爬行过程中,我要注意以下三个最重要的事情。
蜘蛛:引擎蜘蛛
1. 网站的扁平化设计
因为蜘蛛在抓取网页的过程中有两种方法,广度和深度。大家很容易理解,广度爬取就是按顺序爬取,然后在一个完整页面的末尾进行下一页。一个简单的例子就是我们网站首页的所有内容蜘蛛在开始下一级之前都已经查看过我们,比如产品中心的爬取。就是这样一个链接。但是深度是从首页直接到产品中心再到具体产品的一个层次。对于SEO来说,深度更好,每一层的内容蜘蛛都会不停地爬行。这样,外部网站的内容被收录的概率非常高。所以关键是外部扁平化网站设计风格是一种符合百度爬虫的机制。因为在设计过程中布局简洁。降低运算能耗,提高计算速度,让蜘蛛爬行更顺畅。因此,我们在网站设计的初期就需要考虑很多内容。比如我们的爬取,在前期建站的过程中就应该考虑到。所以扁平化的网站建设风格更受企业欢迎,当然蜘蛛也喜欢。
二、 站点地图
网站管理员可以创建网站地图,很多引擎的蜘蛛都会跟随网站地图。我们把网站内容的所有链接都放在这个文件夹中。这样蜘蛛在爬行的过程中会很流畅,爬行率还是很高的。我们的搜索引擎在抓取时抓取的网页形式有很多种,比如我们的PDF、DOC、JPG等多种网站形式。这些文件在被收录
之前经过处理以提取信息。
三、 站点安全
有时我们发现上面两点我们做得比较好,但是如果蜘蛛爬行的数量和宽度都不深怎么办?此时,我们必须保证我们网站的某些内容和安全性。
我们网站的服务器和网络服务商呢?不能说网站经常打不开。无论在时间上付出多少努力,都是白费力气。因此,服务器的安全和网络运营商的稳定性非常重要。
我们网站是否存在死链接和异常跳转。当然,死链接的存在不仅会影响蜘蛛爬行,还会影响我们网站目标客户的满意度。不知道蜘蛛被异常的跳跃引到哪里去了。蜘蛛是一个程序,不会自己回头。
当然,还有IP阻塞、DNS异常和UA阻塞。这些问题出现的概率非常小。网站公司会处理这些问题,所以不用担心。
网站安全很重要
结合以上两个方面,引擎蜘蛛爬行更加顺畅。对内,是网站的质量和服务器的稳定性,保证网站不会出现异常问题。对外,就是建立一个站点地图,方便我们的蜘蛛爬取。事实上,仔细分析搜索引擎的一些规则,可以更好地帮助我们应用这些内容。帮助我们的网站更好地被搜索引擎收录。 查看全部
抓取动态网页(让百度蜘蛛抓取我们的网站,那么最重要的就是)
在网站建设的过程中,很多企业网主和企业主都希望自己的优质网站能够被百度收录,有时除了发一些文章,不知道该怎么办。其实被收录还是有点难度的。今天小编就来给大家分析一下。
其实我们想让百度蜘蛛抓取我们的网站,所以最重要的是我们要了解百度蜘蛛是什么!注意这里的蜘蛛不是我们生活中的蜘蛛动物,这里的蜘蛛是一个程序!我们认为互联网是一个大网,蜘蛛是在这里活跃的程序蜘蛛。所以我们用好引擎蜘蛛,我们的优化和包容会事半功倍。
对于互联网,蜘蛛爬行我们网站所有栏目站点的概率非常低。毕竟,蜘蛛只是一个程序,不可能像我们的人脑一样聪明。其实在我们希望蜘蛛的爬行过程中,我要注意以下三个最重要的事情。
蜘蛛:引擎蜘蛛
1. 网站的扁平化设计
因为蜘蛛在抓取网页的过程中有两种方法,广度和深度。大家很容易理解,广度爬取就是按顺序爬取,然后在一个完整页面的末尾进行下一页。一个简单的例子就是我们网站首页的所有内容蜘蛛在开始下一级之前都已经查看过我们,比如产品中心的爬取。就是这样一个链接。但是深度是从首页直接到产品中心再到具体产品的一个层次。对于SEO来说,深度更好,每一层的内容蜘蛛都会不停地爬行。这样,外部网站的内容被收录的概率非常高。所以关键是外部扁平化网站设计风格是一种符合百度爬虫的机制。因为在设计过程中布局简洁。降低运算能耗,提高计算速度,让蜘蛛爬行更顺畅。因此,我们在网站设计的初期就需要考虑很多内容。比如我们的爬取,在前期建站的过程中就应该考虑到。所以扁平化的网站建设风格更受企业欢迎,当然蜘蛛也喜欢。
二、 站点地图
网站管理员可以创建网站地图,很多引擎的蜘蛛都会跟随网站地图。我们把网站内容的所有链接都放在这个文件夹中。这样蜘蛛在爬行的过程中会很流畅,爬行率还是很高的。我们的搜索引擎在抓取时抓取的网页形式有很多种,比如我们的PDF、DOC、JPG等多种网站形式。这些文件在被收录
之前经过处理以提取信息。
三、 站点安全
有时我们发现上面两点我们做得比较好,但是如果蜘蛛爬行的数量和宽度都不深怎么办?此时,我们必须保证我们网站的某些内容和安全性。
我们网站的服务器和网络服务商呢?不能说网站经常打不开。无论在时间上付出多少努力,都是白费力气。因此,服务器的安全和网络运营商的稳定性非常重要。
我们网站是否存在死链接和异常跳转。当然,死链接的存在不仅会影响蜘蛛爬行,还会影响我们网站目标客户的满意度。不知道蜘蛛被异常的跳跃引到哪里去了。蜘蛛是一个程序,不会自己回头。
当然,还有IP阻塞、DNS异常和UA阻塞。这些问题出现的概率非常小。网站公司会处理这些问题,所以不用担心。
网站安全很重要
结合以上两个方面,引擎蜘蛛爬行更加顺畅。对内,是网站的质量和服务器的稳定性,保证网站不会出现异常问题。对外,就是建立一个站点地图,方便我们的蜘蛛爬取。事实上,仔细分析搜索引擎的一些规则,可以更好地帮助我们应用这些内容。帮助我们的网站更好地被搜索引擎收录。
抓取动态网页(Selenium自动化动态网页的数据代码代码结果四.总结(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-28 13:10
内容
前言
学习Selenium自动化测试框架,在Anaconda的虚拟环境中安装selenium和webdrive等必要的库。熟悉浏览器的开发者模式(Chrome和Edge浏览器按F12)分析网页结构,找到对应网页元素的技巧。然后完成以下任务:
1)自动测试网页。比如在百度网页上自动填写搜索关键词,完成自动搜索。
2) 爬取一个动态网页的数据,根据附件的要求实现代码。
3) 抓取京东网站上感兴趣的书籍信息(如关键词“python编程”的前200本书)并保存。
一.Selenium 1. 简介
Selenium 是一个 Web 自动化测试工具。它最初是为自动化网站测试而开发的。类型就像我们用来玩游戏的按钮向导。可根据指定指令自动运行。不同的是,Selenium 可以直接在浏览器上运行。支持所有主流浏览器(包括PhantomJS等非接口浏览器)。
Selenium 可以根据我们的指示让浏览器自动加载页面,获取所需的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些操作。
Selenium 没有浏览器,不支持浏览器的功能。需要配合第三方浏览器使用。但是我们有时需要让它嵌入到代码中运行,所以我们可以使用一个叫做 PhantomJS 的工具来代替真正的浏览器。
2.环境配置
打开 Anaconda 提示
conda install selenium
3.安装驱动
Selenium 官网驱动下载(下载 | Selenium)
适用于 Chrome 的 ChromeDriver 镜像
二. 爬取动态网页的数据
代码
def write_csv(csv_head,csv_content,csv_path):
with open(csv_path, 'w', newline='',encoding='utf-8') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(csv_head)
fileWriter.writerows(csv_content)
print('爬取信息成功')
quote=driver.find_elements_by_class_name("quote")
#将要收集的信息放在quote_content里
for i in tqdm(range(len(quote))):
quote_text=quote[i].find_element_by_class_name("text")
quote_author=quote[i].find_element_by_class_name("author")
temp=[]
temp.append(quote_text.text)
temp.append(quote_author.text)
quote_content.append(temp)
write_csv(quote_head,quote_content,quote_path)
三. 在京东网站上爬取感兴趣的书籍信息
代码
<p>driver = webdriver.Chrome("E:\GoogleDownload\chromedriver_win32\chromedriver.exe")
driver.set_window_size(1920,1080)
# 京东网站
driver.get("https://www.jd.com/")
# 输入需要查找的关键字
key=driver.find_element_by_id("key").send_keys("python编程")
time.sleep(1)
# 点击搜素按钮
button=driver.find_element_by_class_name("button").click()
time.sleep(1)
# 获取所有窗口
windows = driver.window_handles
# 切换到最新的窗口
driver.switch_to.window(windows[-1])
time.sleep(1)
# js语句
js = 'return document.body.scrollHeight'
# 获取body高度
max_height = driver.execute_script(js)
max_height=(int(max_height/1000))*1000
# 当前滚动条高度
tmp_height=1000
# 所有书籍的字典
res_dict={}
# 需要爬取的数量
num=200
while len(res_dict) 查看全部
抓取动态网页(Selenium自动化动态网页的数据代码代码结果四.总结(一))
内容
前言
学习Selenium自动化测试框架,在Anaconda的虚拟环境中安装selenium和webdrive等必要的库。熟悉浏览器的开发者模式(Chrome和Edge浏览器按F12)分析网页结构,找到对应网页元素的技巧。然后完成以下任务:
1)自动测试网页。比如在百度网页上自动填写搜索关键词,完成自动搜索。
2) 爬取一个动态网页的数据,根据附件的要求实现代码。
3) 抓取京东网站上感兴趣的书籍信息(如关键词“python编程”的前200本书)并保存。
一.Selenium 1. 简介
Selenium 是一个 Web 自动化测试工具。它最初是为自动化网站测试而开发的。类型就像我们用来玩游戏的按钮向导。可根据指定指令自动运行。不同的是,Selenium 可以直接在浏览器上运行。支持所有主流浏览器(包括PhantomJS等非接口浏览器)。
Selenium 可以根据我们的指示让浏览器自动加载页面,获取所需的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些操作。
Selenium 没有浏览器,不支持浏览器的功能。需要配合第三方浏览器使用。但是我们有时需要让它嵌入到代码中运行,所以我们可以使用一个叫做 PhantomJS 的工具来代替真正的浏览器。
2.环境配置
打开 Anaconda 提示
conda install selenium
3.安装驱动
Selenium 官网驱动下载(下载 | Selenium)
适用于 Chrome 的 ChromeDriver 镜像

二. 爬取动态网页的数据

代码
def write_csv(csv_head,csv_content,csv_path):
with open(csv_path, 'w', newline='',encoding='utf-8') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(csv_head)
fileWriter.writerows(csv_content)
print('爬取信息成功')
quote=driver.find_elements_by_class_name("quote")
#将要收集的信息放在quote_content里
for i in tqdm(range(len(quote))):
quote_text=quote[i].find_element_by_class_name("text")
quote_author=quote[i].find_element_by_class_name("author")
temp=[]
temp.append(quote_text.text)
temp.append(quote_author.text)
quote_content.append(temp)
write_csv(quote_head,quote_content,quote_path)
三. 在京东网站上爬取感兴趣的书籍信息
代码
<p>driver = webdriver.Chrome("E:\GoogleDownload\chromedriver_win32\chromedriver.exe")
driver.set_window_size(1920,1080)
# 京东网站
driver.get("https://www.jd.com/";)
# 输入需要查找的关键字
key=driver.find_element_by_id("key").send_keys("python编程")
time.sleep(1)
# 点击搜素按钮
button=driver.find_element_by_class_name("button").click()
time.sleep(1)
# 获取所有窗口
windows = driver.window_handles
# 切换到最新的窗口
driver.switch_to.window(windows[-1])
time.sleep(1)
# js语句
js = 'return document.body.scrollHeight'
# 获取body高度
max_height = driver.execute_script(js)
max_height=(int(max_height/1000))*1000
# 当前滚动条高度
tmp_height=1000
# 所有书籍的字典
res_dict={}
# 需要爬取的数量
num=200
while len(res_dict)
抓取动态网页(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-28 07:12
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。
大大地
优势
缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。pip install selenium install chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。安装 Selenium 和 chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,所以在网页上用鼠标点击。所以,如果要选中checkbox标签,先选中这个标签,再执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
记住Tag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
fromselenium.webdriver.support.ui importSelect
#选中这个标签,然后用Select创建一个对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
#根据索引选择
selectTag.select_by_index(1)
# 按值选择
selectTag.select_by_value("")
# 根据可见文本选择
selectTag.select_by_visible_text("95 显示客户端")
# 取消所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
2/显示等待:显示等待是表示在执行获取元素的操作之前已经建立了某种条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
更多条件参考:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。
Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('https://www.baidu.com')")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。
screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
. 查看全部
抓取动态网页(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。
大大地
优势
缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。pip install selenium install chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。安装 Selenium 和 chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,所以在网页上用鼠标点击。所以,如果要选中checkbox标签,先选中这个标签,再执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
记住Tag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
fromselenium.webdriver.support.ui importSelect
#选中这个标签,然后用Select创建一个对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
#根据索引选择
selectTag.select_by_index(1)
# 按值选择
selectTag.select_by_value("")
# 根据可见文本选择
selectTag.select_by_visible_text("95 显示客户端")
# 取消所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
2/显示等待:显示等待是表示在执行获取元素的操作之前已经建立了某种条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
更多条件参考:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。
Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('https://www.baidu.com')")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。
screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
.
抓取动态网页(ajax横行的年代,我们的网页是残缺的吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-28 07:10
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html。其中有
跳过js加载部分,表示爬虫爬取的网页不完整,不完整。可以在下方看到博客园主页
从首页加载可以看出,页面渲染后,会有5个ajax异步请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候想要获取就必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎具有三大支柱。
Trident:是IE核心,WebBrowser就是基于这个核心,但是加载性比较差。
Gecko:FF的核心,性能优于Trident。
WebKit:Safari 和 Chrome 的核心。性能如你所知,在真实场景中依然是主要特色。
好了,为了简单方便,这里就用WebBrowser来玩,大家在使用WebBrowser的时候要注意以下几点:
第一:因为WebBrowser是System.Windows.Forms中的winform控件,所以需要设置STAThread标签。
第二:Winform 是事件驱动的,Console 不响应事件。所有事件都在 windows 消息队列中等待执行。为防止程序假死,
我们需要调用DoEvents方法来转移控制权,让操作系统执行其他事件。
第三:WebBrowser中的内容,我们需要使用DomDocument查看,而不是DocumentText。
判断一个动态网页是否已经加载,通常有两种方法:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们需要在这里
只需将计数值记录在
.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们也可以通过设置一个Timer来判断,比如3s、4s、5s以后。
WEBbrowser 是否已加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然效果还是一样的,所以就不截图了。从上面两种写法来看,我们的WebBrowser是放在主线程上的。来看看如何把它放到工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
原文: 查看全部
抓取动态网页(ajax横行的年代,我们的网页是残缺的吗?)
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html。其中有
跳过js加载部分,表示爬虫爬取的网页不完整,不完整。可以在下方看到博客园主页

从首页加载可以看出,页面渲染后,会有5个ajax异步请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候想要获取就必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎具有三大支柱。
Trident:是IE核心,WebBrowser就是基于这个核心,但是加载性比较差。
Gecko:FF的核心,性能优于Trident。
WebKit:Safari 和 Chrome 的核心。性能如你所知,在真实场景中依然是主要特色。
好了,为了简单方便,这里就用WebBrowser来玩,大家在使用WebBrowser的时候要注意以下几点:
第一:因为WebBrowser是System.Windows.Forms中的winform控件,所以需要设置STAThread标签。
第二:Winform 是事件驱动的,Console 不响应事件。所有事件都在 windows 消息队列中等待执行。为防止程序假死,
我们需要调用DoEvents方法来转移控制权,让操作系统执行其他事件。
第三:WebBrowser中的内容,我们需要使用DomDocument查看,而不是DocumentText。
判断一个动态网页是否已经加载,通常有两种方法:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们需要在这里
只需将计数值记录在
.

1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。

②:当然,除了通过判断最大值来判断加载是否完成,我们也可以通过设置一个Timer来判断,比如3s、4s、5s以后。
WEBbrowser 是否已加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然效果还是一样的,所以就不截图了。从上面两种写法来看,我们的WebBrowser是放在主线程上的。来看看如何把它放到工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
原文:
抓取动态网页(网页爬取动态加载的两种方法介绍及使用方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-26 04:15
)
一、动态网页爬虫介绍
很多网站都是用javascript来写网站的,很多内容都不会出现在HTML源代码中,所以之前爬取静态网页的方法是无法使用的。有一种异步技术叫做AJAX,它的价值在于通过后台和服务器之间的少量数据变换实现网页的异步更新。换句话说,在不重新加载整个网页的情况下更新网页的某个部分。减少网页上重复内容的下载并节省流量。但是随之而来的麻烦是我们在HTML代码中找不到我们想要的数据。解决这种爬取动态加载的内容,有两种方法:
通过浏览器解析地址查看元素,使用Selenium模拟浏览器抓取二、解析真实地址并抓取
我们要的数据不是HTML,而是可以找到数据的真实地址。请求这个地址也可以找到你想要的数据,完成书中的例子。首先打开网站:这个网站是JS写的,鼠标右键,点击check。刷新页面,可以看到网页上的所有文件都加载完毕了。这个过程就是抓包的过程。然后,点击网络,找到收录
数据的文件,记住是json数据。
单击标题以查找真实地址。然后将请求发送到真实地址。
1.发送请求,获取数据
import requests
# 构建url
url = """https://api-zero.livere.com/v1 ... ot%3B
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
r = requests.get(url, headers=headers)
print(r.text)
2.分析数据
要从json数据中提取注释,首先我们需要找到符合json格式的部分。然后,使用 json.loads 将字符串格式的响应体转换为 json 数据。然后,根据json数据的结构,可以从评论列表中提取comment_list。最后,通过for循环,将注释文本提取出来并打印出来。
import json
json_string = r.text
# 找到符合json格式的数据
json_string = json_string[json_string.find('{'): -2]
# 转换为json格式
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print(message)
三、 通过selenium模拟浏览器爬行
一些网站对地址进行加密,使得一些变量无法分析。接下来,我们将使用第二种方法,使用浏览器渲染引擎。显示网页时直接使用浏览器解析HTML,应用CSS样式,执行JavaScript语句。这种方法会打开浏览器,加载网页,自动操作浏览器浏览各种网页,顺便抓取数据,把抓取动态网页变成抓取静态网页。我们可以使用selenium库来模拟浏览器完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。直接在浏览器中运行,浏览器根据脚本代码自动进行点击、输入、打开、验证等操作。
1. 安装硒
pip 安装硒
下载'geckodriver'并在Python安装目录中。
2. 使用 selenium 爬取数据
第一步:找到评论的HTML代码标签。使用火狐浏览器,点击页面,找到标签,定位到评论数据
第二步:尝试获取一条评论数据,使用如下代码获取数据。
# 使用CSS选择器查找元素,找到class为'reply-content'的div元素
comment = driver.find_element_by_css_selector('div.reply-content')
# 通过元素的tag去寻找‘p’元素
content = comment.find_element_by_tag_name('p')
print(content.text)
还是有问题啊 网页打不开啊
也可能存在解析失败报错的情况,报错“Message: Unable to locate element: div.reply_content”。这是因为源码需要解析成iframe,需要添加下面这行代码。
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")) 查看全部
抓取动态网页(网页爬取动态加载的两种方法介绍及使用方法
)
一、动态网页爬虫介绍
很多网站都是用javascript来写网站的,很多内容都不会出现在HTML源代码中,所以之前爬取静态网页的方法是无法使用的。有一种异步技术叫做AJAX,它的价值在于通过后台和服务器之间的少量数据变换实现网页的异步更新。换句话说,在不重新加载整个网页的情况下更新网页的某个部分。减少网页上重复内容的下载并节省流量。但是随之而来的麻烦是我们在HTML代码中找不到我们想要的数据。解决这种爬取动态加载的内容,有两种方法:
通过浏览器解析地址查看元素,使用Selenium模拟浏览器抓取二、解析真实地址并抓取
我们要的数据不是HTML,而是可以找到数据的真实地址。请求这个地址也可以找到你想要的数据,完成书中的例子。首先打开网站:这个网站是JS写的,鼠标右键,点击check。刷新页面,可以看到网页上的所有文件都加载完毕了。这个过程就是抓包的过程。然后,点击网络,找到收录
数据的文件,记住是json数据。

单击标题以查找真实地址。然后将请求发送到真实地址。

1.发送请求,获取数据
import requests
# 构建url
url = """https://api-zero.livere.com/v1 ... ot%3B
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
r = requests.get(url, headers=headers)
print(r.text)

2.分析数据
要从json数据中提取注释,首先我们需要找到符合json格式的部分。然后,使用 json.loads 将字符串格式的响应体转换为 json 数据。然后,根据json数据的结构,可以从评论列表中提取comment_list。最后,通过for循环,将注释文本提取出来并打印出来。
import json
json_string = r.text
# 找到符合json格式的数据
json_string = json_string[json_string.find('{'): -2]
# 转换为json格式
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print(message)

三、 通过selenium模拟浏览器爬行
一些网站对地址进行加密,使得一些变量无法分析。接下来,我们将使用第二种方法,使用浏览器渲染引擎。显示网页时直接使用浏览器解析HTML,应用CSS样式,执行JavaScript语句。这种方法会打开浏览器,加载网页,自动操作浏览器浏览各种网页,顺便抓取数据,把抓取动态网页变成抓取静态网页。我们可以使用selenium库来模拟浏览器完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。直接在浏览器中运行,浏览器根据脚本代码自动进行点击、输入、打开、验证等操作。
1. 安装硒
pip 安装硒
下载'geckodriver'并在Python安装目录中。

2. 使用 selenium 爬取数据
第一步:找到评论的HTML代码标签。使用火狐浏览器,点击页面,找到标签,定位到评论数据

第二步:尝试获取一条评论数据,使用如下代码获取数据。
# 使用CSS选择器查找元素,找到class为'reply-content'的div元素
comment = driver.find_element_by_css_selector('div.reply-content')
# 通过元素的tag去寻找‘p’元素
content = comment.find_element_by_tag_name('p')
print(content.text)
还是有问题啊 网页打不开啊
也可能存在解析失败报错的情况,报错“Message: Unable to locate element: div.reply_content”。这是因为源码需要解析成iframe,需要添加下面这行代码。
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
抓取动态网页(抓取动态网页大概可以这样做:/zenith不都能爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-25 21:05
抓取动态网页大概可以这样做:
1、获取headers,
2、找到该网站的cookie,记下来,
3、设置抓取框,在scrapy.spiders中的default_cookie配置,
实名反对@不用脑子的谢炎。1.这是不可能的;2.爬虫大部分需要高性能,跑在python上我觉得瓶颈会大部分在处理数据上面,而不是业务逻辑上;3.cookie写入很麻烦;4.爬虫的组件多了去了,几千上万个包,你要写整个框架;5.数据库压力巨大,你要维护好多个sqlite数据库,备份,恢复,sqlite的mongo;6.服务器几十万上百万台,爬那么点也是累死;7.还有很多欢迎补充。上面一条可以让所有的爬虫都变成挂机动作,要你干什么有啥。
面向对象可以这样,你看看你这个网站对你有没有需求,
不可以,除非加上感知机制。
我大三上面的代码,大概一年前做网站前端实习在做。
你需要pyspider
其实linux上pythonscrapyceleryscrapy_redis/zenith/hashlib不都能爬虫。我是给工作室做网站前端的,也用python做爬虫,包括反爬虫,简单的代码好写,多调用一下api就行。hapyscrapy好像是用于web中间件的,有点麻烦的。你可以找下官方的文档就懂了。 查看全部
抓取动态网页(抓取动态网页大概可以这样做:/zenith不都能爬虫)
抓取动态网页大概可以这样做:
1、获取headers,
2、找到该网站的cookie,记下来,
3、设置抓取框,在scrapy.spiders中的default_cookie配置,
实名反对@不用脑子的谢炎。1.这是不可能的;2.爬虫大部分需要高性能,跑在python上我觉得瓶颈会大部分在处理数据上面,而不是业务逻辑上;3.cookie写入很麻烦;4.爬虫的组件多了去了,几千上万个包,你要写整个框架;5.数据库压力巨大,你要维护好多个sqlite数据库,备份,恢复,sqlite的mongo;6.服务器几十万上百万台,爬那么点也是累死;7.还有很多欢迎补充。上面一条可以让所有的爬虫都变成挂机动作,要你干什么有啥。
面向对象可以这样,你看看你这个网站对你有没有需求,
不可以,除非加上感知机制。
我大三上面的代码,大概一年前做网站前端实习在做。
你需要pyspider
其实linux上pythonscrapyceleryscrapy_redis/zenith/hashlib不都能爬虫。我是给工作室做网站前端的,也用python做爬虫,包括反爬虫,简单的代码好写,多调用一下api就行。hapyscrapy好像是用于web中间件的,有点麻烦的。你可以找下官方的文档就懂了。
抓取动态网页(巴西拉科鲁尼亚学校web语言的学习交流活动分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-15 11:00
抓取动态网页,最简单的方法就是手动录制一遍数据,然后写入到文件里,然后手动操作。不过这也不是说100%准确,可能也有差错。如果数据量不大,最好还是自己写一遍爬虫,然后自己手动操作。
我在巴西拉科鲁尼亚学校web语言的学习交流活动做过sre的分享。我自己就是大三的参与者,当时我学习爬虫的时候是通过自己手动按编译原理实现上传的。我推荐你最先使用一些像python这样的脚本语言,然后从python学起。非常简单。
爬虫要找inception-v驱动下的驱动程序,不然爬到的数据没什么意义。自己手动抓100以下基本是错的,而且整个网页10+pages都没有关系。爬虫要是觉得容易被封,采用插件反爬虫,要什么爬虫什么数据。不过这样效率实在低,因为常规网站通常会先抽查几次ip可能才在后面页面注册,所以的常规软件没有反爬虫的能力。
考虑手动爬的话,你的数据通常是特定网站(特定服务)的,比如游戏主题论坛,商城之类,爬虫可以用一些黑名单来限制来爬数据。
我觉得手机客户端等可以抓。然后提交到百度,百度之后,不可能没反应,如果没反应,说明爬虫做错了,整个链接全部相互重复,我看到过一个抓包然后提交到百度,百度告诉我这是一个重复的网页,所以,百度也有可能没反应,可能是他的反爬措施有问题。如果,爬虫总是反应那个位置会封的。总之,抓你觉得不应该提交的网站数据。放在百度是可以被认为是一个独立的网站,可以不封的。
或者爬一次之后,提交百度,让百度的程序去处理一下,然后返回一个包,看到是乱爬数据,百度的方式,然后说给我个地址,我转发给你网站。不过这样很浪费时间。建议走百度的方式。 查看全部
抓取动态网页(巴西拉科鲁尼亚学校web语言的学习交流活动分享)
抓取动态网页,最简单的方法就是手动录制一遍数据,然后写入到文件里,然后手动操作。不过这也不是说100%准确,可能也有差错。如果数据量不大,最好还是自己写一遍爬虫,然后自己手动操作。
我在巴西拉科鲁尼亚学校web语言的学习交流活动做过sre的分享。我自己就是大三的参与者,当时我学习爬虫的时候是通过自己手动按编译原理实现上传的。我推荐你最先使用一些像python这样的脚本语言,然后从python学起。非常简单。
爬虫要找inception-v驱动下的驱动程序,不然爬到的数据没什么意义。自己手动抓100以下基本是错的,而且整个网页10+pages都没有关系。爬虫要是觉得容易被封,采用插件反爬虫,要什么爬虫什么数据。不过这样效率实在低,因为常规网站通常会先抽查几次ip可能才在后面页面注册,所以的常规软件没有反爬虫的能力。
考虑手动爬的话,你的数据通常是特定网站(特定服务)的,比如游戏主题论坛,商城之类,爬虫可以用一些黑名单来限制来爬数据。
我觉得手机客户端等可以抓。然后提交到百度,百度之后,不可能没反应,如果没反应,说明爬虫做错了,整个链接全部相互重复,我看到过一个抓包然后提交到百度,百度告诉我这是一个重复的网页,所以,百度也有可能没反应,可能是他的反爬措施有问题。如果,爬虫总是反应那个位置会封的。总之,抓你觉得不应该提交的网站数据。放在百度是可以被认为是一个独立的网站,可以不封的。
或者爬一次之后,提交百度,让百度的程序去处理一下,然后返回一个包,看到是乱爬数据,百度的方式,然后说给我个地址,我转发给你网站。不过这样很浪费时间。建议走百度的方式。
抓取动态网页(用到动态网页的两种技术:通过浏览器审查元素解析真实网页地址和使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-15 05:10
由于网易云线程已停止,新写的第4章现已更新至此。请参考文章:
上面爬取的网页都是静态网页,这些网页在浏览器中显示的内容是在HTML源代码中的。但是由于主流的网站都使用JavaScript来展示网页内容,不像静态网页,在使用JavaScript的时候,很多内容不会出现在HTML源代码中,所以爬取静态网页的技术可能不会工作正常使用。因此,我们需要使用两种动态网页抓取技术:通过浏览器检查元素解析真实网址和使用 selenium 模拟浏览器。
本章首先介绍动态网页的示例,让读者了解什么是动态网页抓取,然后利用以上两种动态网页抓取技术获取动态网页数据。
4.1 动态抓取示例
在开始爬取动态网页之前,我们还需要了解一个异步更新技术——AJAX(Asynchronous Javascript And XML)。它的价值在于可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量,所以AJAX被广泛使用。
与使用 AJAX 网页相比,如果传统网页需要更新内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更友好。但是AJAX网页的爬取过程比较麻烦。
首先,我们来看一个动态网页的例子。打开作者的博客Hello World文章,文章的地址是:
如下图所示,页面下方的评论是用JavaScript加载的,这些评论数据不会出现在网页的源代码中。
为了验证它是用 JavaScript 加载的,我们可以查看该页面的页面源代码。如下图,放置评论的代码没有评论数据,只有一段JavaScript代码。最终渲染的数据由 JavaScript 提取并加载到源代码中进行渲染。
除了我的博客,我们还可以在天猫电商上找到AJAX技术的例子。比如我们打开天猫iPhone 7的产品页面,点击“累计评论”,可以发现上面的url地址没有变化,整个页面也没有重新加载更新页面的评论部分。
和之前一样,我们也可以查看这个产品网页的源码,如下图,里面没有用户评论,这段内容是空白的。
因此,如果我们使用AJAX加载的动态网页,如何抓取里面动态加载的内容呢?有两种方法:
1. 通过浏览器检查元素解析地址
2. 模拟浏览器通过 selenium 爬行
请查看第四章的其他章节
第 4 章:动态网页抓取(解析真实地址 + selenium)
4.2 解析真实地址捕获
4.3 模拟浏览器通过selenium爬取 查看全部
抓取动态网页(用到动态网页的两种技术:通过浏览器审查元素解析真实网页地址和使用)
由于网易云线程已停止,新写的第4章现已更新至此。请参考文章:
上面爬取的网页都是静态网页,这些网页在浏览器中显示的内容是在HTML源代码中的。但是由于主流的网站都使用JavaScript来展示网页内容,不像静态网页,在使用JavaScript的时候,很多内容不会出现在HTML源代码中,所以爬取静态网页的技术可能不会工作正常使用。因此,我们需要使用两种动态网页抓取技术:通过浏览器检查元素解析真实网址和使用 selenium 模拟浏览器。
本章首先介绍动态网页的示例,让读者了解什么是动态网页抓取,然后利用以上两种动态网页抓取技术获取动态网页数据。
4.1 动态抓取示例
在开始爬取动态网页之前,我们还需要了解一个异步更新技术——AJAX(Asynchronous Javascript And XML)。它的价值在于可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量,所以AJAX被广泛使用。
与使用 AJAX 网页相比,如果传统网页需要更新内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更友好。但是AJAX网页的爬取过程比较麻烦。
首先,我们来看一个动态网页的例子。打开作者的博客Hello World文章,文章的地址是:
如下图所示,页面下方的评论是用JavaScript加载的,这些评论数据不会出现在网页的源代码中。
为了验证它是用 JavaScript 加载的,我们可以查看该页面的页面源代码。如下图,放置评论的代码没有评论数据,只有一段JavaScript代码。最终渲染的数据由 JavaScript 提取并加载到源代码中进行渲染。
除了我的博客,我们还可以在天猫电商上找到AJAX技术的例子。比如我们打开天猫iPhone 7的产品页面,点击“累计评论”,可以发现上面的url地址没有变化,整个页面也没有重新加载更新页面的评论部分。
和之前一样,我们也可以查看这个产品网页的源码,如下图,里面没有用户评论,这段内容是空白的。
因此,如果我们使用AJAX加载的动态网页,如何抓取里面动态加载的内容呢?有两种方法:
1. 通过浏览器检查元素解析地址
2. 模拟浏览器通过 selenium 爬行
请查看第四章的其他章节
第 4 章:动态网页抓取(解析真实地址 + selenium)
4.2 解析真实地址捕获
4.3 模拟浏览器通过selenium爬取
抓取动态网页(块标签,打开后里面没有网页数据(XHR-1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-15 04:13
块标签,打开后没有网页数据
点击网络选项卡,我们可以看到网页向服务器发送了很多请求,数据很多,查找时间太长了
我们点击XHR分类,可以减少很多不必要的文件,节省很多时间。
【XHR类型是通过XMLHttpRequest方法发送的请求,可以在后台与服务器进行数据交换,也就是说可以在不加载整个网页的情况下更新网页某一部分的内容。也就是说,请求数据库然后得到响应的数据是XHR类型的]
然后我们开始在XHR类型下一一搜索,发现如下数据
查看请求的标头并获取其 url
url=",10,723,35,469,821&limit=30"
在 Firefox 的新窗口中打开此地址
打开后我们可以看到上面的情况,这是一个json格式的文件。然后,它的数据信息以字典的形式存储,数据存储在“NewMsgs”的键值中。
所以,我们可以通过访问["NewMsgs"]的键值来获取网页数据
然后我们查看我们需要的“好”和“坏”对应的key-value,以及时事通讯推荐的股票和行业对应的key-value。
通过查看字典,我们可以很快发现推荐股票是一个嵌套字典,即字典加列表加字典。对应的key值是["NewMsgs"][i]['Stocks'] 同理,对应的推荐行业key值是:["NewMsgs"][i]['BkjInfoArr']
通过对比网页数据,我们可以找到对应的“好”和“坏”时事通讯。
通过对比,我们发现带有好评的时事通讯的“影响”值为1,而“影响”的值为“0”,带有负面标签的短信的值为“-1”。
知道数据的位置后,我们开始编写代码。
先爬取网页,伪装成火狐浏览器,添加header访问数据库地址,防止被识别和拦截。
def get_page(url):
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36'
}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode()
return html
从上面的分析可以知道,数据是以json的形式存储的,所以上面的网页爬取返回的html就是json格式的数据。所以我们需要格式化json。
json.dumps()#把python对象转化成json格式对象
json.loads()#把json格式转化成python对象
转换后,我们可以通过以下字典的键值输出“好”、“坏”、推荐“股票”、推荐“行业”
行业:html["NewMsgs"][i]['BkjInfoArr']
时间:html["NewMsgs"][i]['UpdatedAt']
股票:html["NewMsgs"][i]['Stocks'][j]['Name']
利好:html["NewMsgs"][i]['Impact'] Impact = -1 --->利空 Impact = 1 --->利好
所以获取数据的代码是:
def get_data(html,url):
html = json.loads(html)
c = len(html["NewMsgs"])
for i in range(0,c):
cun =html["NewMsgs"][i]['Impact']#获取含有信息的字典
if cun == 1 or cun == -1:#判断信息是利好还是利空
print(html["NewMsgs"][i]['UpdatedAt'])
if cun == 1:
print("*************利好*************")
if cun == -1:
print('*************利空*************')
chang = len(html["NewMsgs"][i]['BkjInfoArr'])#获取信息下含有几个利好或利空行业
ch =html["NewMsgs"][i]['Stocks']
for j in range(0,chang):
print('行业:',html["NewMsgs"][i]['BkjInfoArr'][j]['Name'])
if ch!=None:
du = len(html["NewMsgs"][i]['Stocks'])#同理获取含有几个利好或利空股票
for k in range(0,du):
print('股票:',html["NewMsgs"][i]['Stocks'][k]['Name'])
print("**************************\n\n")#信息获取完毕,换行
return 0
通过运行发现获取到的数据非常少,只能获取到“点击加载更多”上显示的内容,无法获取到点击加载后的数据。
我们的爬虫爬不了这么少的数据,我们需要的是一个能爬取数据的爬虫,包括点击“加载更多”按钮后的数据。否则最好直接使用爬虫直接访问网站。那么我们如何才能将它与以下数据一起捕获呢?
我们再次输入review元素的XHR类型,通过点击“Load more”按钮,找到加载后保存有新内容的文件,然后再次review元素。
我们找到了保存新数据的文件和新文件的url地址
我们注意到url发生了变化,点击打开链接“,10,723,35,469,821&limit=30&tailmark=1529497523&msgIdMark=310241”
后面的字符比前面的数据 url 多一些。让我们多点击几次“Load More”,查看新内容的文件数据,看看能不能找到一些规律。
让我们将新的网址放在一起进行比较:
https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30&tailmark=1529497523&msgIdMark=310241
https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30&tailmark=1529493624&msgIdMark=310193
https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30&tailmark=1529487816&msgIdMark=310151
第一个网址:
第二个网址:
第三个网址:
通过对比我们可以发现,加载的json数据文件的地址与之前的json文件的['TailMark']和['TailMsgId']有关。
它是在原来的url=",10,723,35,469,821&limit=30"的基础上,加上一个后缀
“&tailmark=['TailMark']&msgIdMark=['TailMsgId']”
并获取 url 地址。
所以,我们获取下一个 url 地址的代码是:
def get_newurl(html):
url="https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30"
url=url+'&tailmark='+html['TailMark']+'&msgIdMark='+html['TailMsgId']
return url
那么我们的爬虫代码就基本完成了。以下是整个爬虫的代码:
# -*- coding:utf-8 -*-
import urllib.request
import urllib.parse
import time
import json
#获取网页
def get_page(url):
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36'
}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode()
return html
#获取下一页网址
def get_newurl(html):
url="https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30"
url=url+'&tailmark='+html['TailMark']+'&msgIdMark='+html['TailMsgId']
return url
#获取数据
def get_data(html,url):
html = json.loads(html)
c = len(html["NewMsgs"])
for i in range(0,c):
cun =html["NewMsgs"][i]['Impact']#获取含有信息的字典
if cun == 1 or cun == -1:#判断信息是利好还是利空
print(html["NewMsgs"][i]['UpdatedAt'])
if cun == 1:
print("*************利好*************")
if cun == -1:
print('*************利空*************')
chang = len(html["NewMsgs"][i]['BkjInfoArr'])#获取信息下含有几个利好或利空行业
ch =html["NewMsgs"][i]['Stocks']
for j in range(0,chang):
print('行业:',html["NewMsgs"][i]['BkjInfoArr'][j]['Name'])
if ch!=None:
du = len(html["NewMsgs"][i]['Stocks'])#同理获取含有几个利好或利空股票
for k in range(0,du):
print('股票:',html["NewMsgs"][i]['Stocks'][k]['Name'])
print("**************************\n\n")#信息获取完毕,换行
#获取通过函数获取下一页的url地址并返回该地址
url = get_newurl(html)
return url
if __name__=='__main__':
url="https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30"
for i in range(0,5):#进行循环爬取下一页地址的股票信息
html=get_page(url)
url=get_data(html,url)
因为刚开始学习,所以很多地方都没有写好,比较繁琐和乏味。也求大神赐教。 查看全部
抓取动态网页(块标签,打开后里面没有网页数据(XHR-1))
块标签,打开后没有网页数据
点击网络选项卡,我们可以看到网页向服务器发送了很多请求,数据很多,查找时间太长了
我们点击XHR分类,可以减少很多不必要的文件,节省很多时间。
【XHR类型是通过XMLHttpRequest方法发送的请求,可以在后台与服务器进行数据交换,也就是说可以在不加载整个网页的情况下更新网页某一部分的内容。也就是说,请求数据库然后得到响应的数据是XHR类型的]
然后我们开始在XHR类型下一一搜索,发现如下数据
查看请求的标头并获取其 url
url=",10,723,35,469,821&limit=30"
在 Firefox 的新窗口中打开此地址
打开后我们可以看到上面的情况,这是一个json格式的文件。然后,它的数据信息以字典的形式存储,数据存储在“NewMsgs”的键值中。
所以,我们可以通过访问["NewMsgs"]的键值来获取网页数据
然后我们查看我们需要的“好”和“坏”对应的key-value,以及时事通讯推荐的股票和行业对应的key-value。
通过查看字典,我们可以很快发现推荐股票是一个嵌套字典,即字典加列表加字典。对应的key值是["NewMsgs"][i]['Stocks'] 同理,对应的推荐行业key值是:["NewMsgs"][i]['BkjInfoArr']
通过对比网页数据,我们可以找到对应的“好”和“坏”时事通讯。
通过对比,我们发现带有好评的时事通讯的“影响”值为1,而“影响”的值为“0”,带有负面标签的短信的值为“-1”。
知道数据的位置后,我们开始编写代码。
先爬取网页,伪装成火狐浏览器,添加header访问数据库地址,防止被识别和拦截。
def get_page(url):
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36'
}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode()
return html
从上面的分析可以知道,数据是以json的形式存储的,所以上面的网页爬取返回的html就是json格式的数据。所以我们需要格式化json。
json.dumps()#把python对象转化成json格式对象
json.loads()#把json格式转化成python对象
转换后,我们可以通过以下字典的键值输出“好”、“坏”、推荐“股票”、推荐“行业”
行业:html["NewMsgs"][i]['BkjInfoArr']
时间:html["NewMsgs"][i]['UpdatedAt']
股票:html["NewMsgs"][i]['Stocks'][j]['Name']
利好:html["NewMsgs"][i]['Impact'] Impact = -1 --->利空 Impact = 1 --->利好
所以获取数据的代码是:
def get_data(html,url):
html = json.loads(html)
c = len(html["NewMsgs"])
for i in range(0,c):
cun =html["NewMsgs"][i]['Impact']#获取含有信息的字典
if cun == 1 or cun == -1:#判断信息是利好还是利空
print(html["NewMsgs"][i]['UpdatedAt'])
if cun == 1:
print("*************利好*************")
if cun == -1:
print('*************利空*************')
chang = len(html["NewMsgs"][i]['BkjInfoArr'])#获取信息下含有几个利好或利空行业
ch =html["NewMsgs"][i]['Stocks']
for j in range(0,chang):
print('行业:',html["NewMsgs"][i]['BkjInfoArr'][j]['Name'])
if ch!=None:
du = len(html["NewMsgs"][i]['Stocks'])#同理获取含有几个利好或利空股票
for k in range(0,du):
print('股票:',html["NewMsgs"][i]['Stocks'][k]['Name'])
print("**************************\n\n")#信息获取完毕,换行
return 0
通过运行发现获取到的数据非常少,只能获取到“点击加载更多”上显示的内容,无法获取到点击加载后的数据。
我们的爬虫爬不了这么少的数据,我们需要的是一个能爬取数据的爬虫,包括点击“加载更多”按钮后的数据。否则最好直接使用爬虫直接访问网站。那么我们如何才能将它与以下数据一起捕获呢?
我们再次输入review元素的XHR类型,通过点击“Load more”按钮,找到加载后保存有新内容的文件,然后再次review元素。
我们找到了保存新数据的文件和新文件的url地址
我们注意到url发生了变化,点击打开链接“,10,723,35,469,821&limit=30&tailmark=1529497523&msgIdMark=310241”
后面的字符比前面的数据 url 多一些。让我们多点击几次“Load More”,查看新内容的文件数据,看看能不能找到一些规律。
让我们将新的网址放在一起进行比较:
https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30&tailmark=1529497523&msgIdMark=310241
https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30&tailmark=1529493624&msgIdMark=310193
https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30&tailmark=1529487816&msgIdMark=310151
第一个网址:
第二个网址:
第三个网址:
通过对比我们可以发现,加载的json数据文件的地址与之前的json文件的['TailMark']和['TailMsgId']有关。
它是在原来的url=",10,723,35,469,821&limit=30"的基础上,加上一个后缀
“&tailmark=['TailMark']&msgIdMark=['TailMsgId']”
并获取 url 地址。
所以,我们获取下一个 url 地址的代码是:
def get_newurl(html):
url="https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30"
url=url+'&tailmark='+html['TailMark']+'&msgIdMark='+html['TailMsgId']
return url
那么我们的爬虫代码就基本完成了。以下是整个爬虫的代码:
# -*- coding:utf-8 -*-
import urllib.request
import urllib.parse
import time
import json
#获取网页
def get_page(url):
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36'
}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode()
return html
#获取下一页网址
def get_newurl(html):
url="https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30"
url=url+'&tailmark='+html['TailMark']+'&msgIdMark='+html['TailMsgId']
return url
#获取数据
def get_data(html,url):
html = json.loads(html)
c = len(html["NewMsgs"])
for i in range(0,c):
cun =html["NewMsgs"][i]['Impact']#获取含有信息的字典
if cun == 1 or cun == -1:#判断信息是利好还是利空
print(html["NewMsgs"][i]['UpdatedAt'])
if cun == 1:
print("*************利好*************")
if cun == -1:
print('*************利空*************')
chang = len(html["NewMsgs"][i]['BkjInfoArr'])#获取信息下含有几个利好或利空行业
ch =html["NewMsgs"][i]['Stocks']
for j in range(0,chang):
print('行业:',html["NewMsgs"][i]['BkjInfoArr'][j]['Name'])
if ch!=None:
du = len(html["NewMsgs"][i]['Stocks'])#同理获取含有几个利好或利空股票
for k in range(0,du):
print('股票:',html["NewMsgs"][i]['Stocks'][k]['Name'])
print("**************************\n\n")#信息获取完毕,换行
#获取通过函数获取下一页的url地址并返回该地址
url = get_newurl(html)
return url
if __name__=='__main__':
url="https://api.xuangubao.cn/api/pc/msgs?subjids=9,10,723,35,469,821&limit=30"
for i in range(0,5):#进行循环爬取下一页地址的股票信息
html=get_page(url)
url=get_data(html,url)
因为刚开始学习,所以很多地方都没有写好,比较繁琐和乏味。也求大神赐教。
抓取动态网页(详解如何通过创建Robots.txt来解决网站被重复抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-12 06:08
我们在百度统计中查看网站的SEO建议时,总是发现“静态页面参数”项被扣18分。多次重复爬取”。一般来说,在静态页面上使用少量的动态参数不会对蜘蛛的抓取产生任何影响,但是如果在网站静态页面上使用过多的动态参数,则可能最终导致蜘蛛。多次反复爬行。
解决“在静态页面上使用动态参数会导致蜘蛛多次重复爬取”的SEO问题,我们需要使用Robots.txt(机器人协议)来限制百度蜘蛛对网站页面的爬取,robots .txt 是协议,而不是命令。robots.txt 是搜索引擎在访问 网站 时查看的第一个文件。robots.txt 文件告诉蜘蛛可以查看服务器上的哪些文件。当搜索蜘蛛访问一个站点时,它会首先检查站点根目录中是否存在 robots.txt。如果存在,搜索机器人会根据文件内容判断访问范围;如果文件不存在, all 的搜索蜘蛛将能够访问 网站 上没有密码保护的所有页面。
通过创建Robots.txt来解释如何解决网站被重复爬取,我们只需要设置一个语法。
User-agent:百度蜘蛛(只对百度蜘蛛有效)
Disallow: /*?* (禁止访问 网站 中的所有动态页面)
这样可以防止动态页面被百度索引,避免网站被蜘蛛重复爬取。有人说:“我的网站是一个伪静态页面,每个url前面都有html?怎么办?” 在这种情况下,使用另一种语法。
User-agent:百度蜘蛛(只对百度蜘蛛有效)
允许:.htm$(只允许访问以“.htm”为后缀的 URL)
这允许百度蜘蛛只 收录 您的静态页面,而不是索引动态页面。其实网站SEO知识还有很多,都需要我们一步步探索,在实践中发现真相。网站 关注用户体验是长期发展的基点。
防止网站被搜索爬取的一些方法:
首先在站点的根目录下创建一个 robots.txt 文本文件。搜索蜘蛛访问该站点时,首先会检查站点根目录下是否存在robots.txt。如果存在,搜索蜘蛛会首先读取这个文件的内容:
文件写入
User-agent:*这里*代表所有类型的搜索引擎,*是通配符,user-agent分号后面要加一个空格。
Disallow:/这个定义是禁止所有内容爬取网站
Disallow: /admin/ 这里的定义是禁止爬取admin目录下的目录
Disallow: /ABC/ 这里的定义是禁止爬取ABC目录下的目录
禁止:/cgi-bin/*.htm 禁止访问/cgi-bin/ 目录中所有以“.htm”为后缀的URL(包括子目录)。
Disallow: /*?* 禁止访问所有在 网站 中收录问号 (?) 的 URL
Disallow: /.jpg$ 禁止抓取来自网络的所有 .jpg 图像
Disallow:/ab/adc.html 禁止爬取ab文件夹下的adc.html文件。
allow: /cgi-bin/这个定义是允许cgi-bin目录下的目录被爬取
allow: /tmp 这里的定义是允许爬取tmp的整个目录
允许:.htm$ 只允许访问以“.htm”为后缀的 URL。
允许:.gif$ 允许抓取网页和 gif 格式的图片
站点地图:网站地图告诉爬虫这个页面是一个网站地图
下面列出的是比较知名的搜索引擎蜘蛛名称:
谷歌的蜘蛛:谷歌机器人
百度的蜘蛛:baiduspider
雅虎的蜘蛛:雅虎啜饮
MSN 的蜘蛛:Msnbot
Altavista 的蜘蛛:滑板车
Lycos 的蜘蛛:Lycos_Spider_(T-Rex)
Alltheweb 的蜘蛛:FAST-WebCrawler/
INKTOMI 的蜘蛛:啜食
搜狗的蜘蛛:搜狗网络蜘蛛/4.0 和搜狗inst spider/4.0
根据上面的说明,我们可以举一个大案子的例子。在搜狗的案例中,robots.txt的禁止爬取的代码是这样写的:
用户代理:搜狗网络蜘蛛/4.0
禁止:/goods.php
禁止:/category.php 查看全部
抓取动态网页(详解如何通过创建Robots.txt来解决网站被重复抓取)
我们在百度统计中查看网站的SEO建议时,总是发现“静态页面参数”项被扣18分。多次重复爬取”。一般来说,在静态页面上使用少量的动态参数不会对蜘蛛的抓取产生任何影响,但是如果在网站静态页面上使用过多的动态参数,则可能最终导致蜘蛛。多次反复爬行。
解决“在静态页面上使用动态参数会导致蜘蛛多次重复爬取”的SEO问题,我们需要使用Robots.txt(机器人协议)来限制百度蜘蛛对网站页面的爬取,robots .txt 是协议,而不是命令。robots.txt 是搜索引擎在访问 网站 时查看的第一个文件。robots.txt 文件告诉蜘蛛可以查看服务器上的哪些文件。当搜索蜘蛛访问一个站点时,它会首先检查站点根目录中是否存在 robots.txt。如果存在,搜索机器人会根据文件内容判断访问范围;如果文件不存在, all 的搜索蜘蛛将能够访问 网站 上没有密码保护的所有页面。
通过创建Robots.txt来解释如何解决网站被重复爬取,我们只需要设置一个语法。
User-agent:百度蜘蛛(只对百度蜘蛛有效)
Disallow: /*?* (禁止访问 网站 中的所有动态页面)
这样可以防止动态页面被百度索引,避免网站被蜘蛛重复爬取。有人说:“我的网站是一个伪静态页面,每个url前面都有html?怎么办?” 在这种情况下,使用另一种语法。
User-agent:百度蜘蛛(只对百度蜘蛛有效)
允许:.htm$(只允许访问以“.htm”为后缀的 URL)
这允许百度蜘蛛只 收录 您的静态页面,而不是索引动态页面。其实网站SEO知识还有很多,都需要我们一步步探索,在实践中发现真相。网站 关注用户体验是长期发展的基点。
防止网站被搜索爬取的一些方法:
首先在站点的根目录下创建一个 robots.txt 文本文件。搜索蜘蛛访问该站点时,首先会检查站点根目录下是否存在robots.txt。如果存在,搜索蜘蛛会首先读取这个文件的内容:
文件写入
User-agent:*这里*代表所有类型的搜索引擎,*是通配符,user-agent分号后面要加一个空格。
Disallow:/这个定义是禁止所有内容爬取网站
Disallow: /admin/ 这里的定义是禁止爬取admin目录下的目录
Disallow: /ABC/ 这里的定义是禁止爬取ABC目录下的目录
禁止:/cgi-bin/*.htm 禁止访问/cgi-bin/ 目录中所有以“.htm”为后缀的URL(包括子目录)。
Disallow: /*?* 禁止访问所有在 网站 中收录问号 (?) 的 URL
Disallow: /.jpg$ 禁止抓取来自网络的所有 .jpg 图像
Disallow:/ab/adc.html 禁止爬取ab文件夹下的adc.html文件。
allow: /cgi-bin/这个定义是允许cgi-bin目录下的目录被爬取
allow: /tmp 这里的定义是允许爬取tmp的整个目录
允许:.htm$ 只允许访问以“.htm”为后缀的 URL。
允许:.gif$ 允许抓取网页和 gif 格式的图片
站点地图:网站地图告诉爬虫这个页面是一个网站地图
下面列出的是比较知名的搜索引擎蜘蛛名称:
谷歌的蜘蛛:谷歌机器人
百度的蜘蛛:baiduspider
雅虎的蜘蛛:雅虎啜饮
MSN 的蜘蛛:Msnbot
Altavista 的蜘蛛:滑板车
Lycos 的蜘蛛:Lycos_Spider_(T-Rex)
Alltheweb 的蜘蛛:FAST-WebCrawler/
INKTOMI 的蜘蛛:啜食
搜狗的蜘蛛:搜狗网络蜘蛛/4.0 和搜狗inst spider/4.0
根据上面的说明,我们可以举一个大案子的例子。在搜狗的案例中,robots.txt的禁止爬取的代码是这样写的:
用户代理:搜狗网络蜘蛛/4.0
禁止:/goods.php
禁止:/category.php
抓取动态网页(什么是动态网页静态化就是通过技术手段,模拟浏览器访问,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-11 05:15
什么是动态网页静态?
静态网页就是利用技术手段模拟浏览器访问,将原创动态网页上显示的内容抓取出来保存为htm的静态网页,然后引导用户访问这个静态网页!这样,每个用户访问都是一个静态网页。网页不与数据库交互,访问速度可翻倍!
静态网页有什么好处?
1:让动态网页的访问速度和静态网页一样快(因为已经是静态的,所以不和数据库交互会更快)
2:保持他的简单维护功能!(如果有新内容,只需要重新生成静态网页)
静态网页注意事项:
1:由于是自动生成的,有些网页生成后可能会出现异常,比如有验证码的网页。这时候就需要制作验证码了。
仅包括
2:如果你生成index.jsp主页,那么你需要设置它,让用户可以先访问静态index.htm。具体设置如下: 打开你的项目下的WEB-INF/web.xml,添加
index.html
index.htm
index.jsp
3::如果你觉得在我们后台生成静态太麻烦,你也可以把这个功能集成到自己的后台中,更加方便。详情请参考生成htm静态网页减少数据库操作
如何使用动态网页静态?
在jsp空间管理中登录会员管理中心--扩展你的jsp空间,选择高级管理-动态网页静态
进入动态网页静态界面
这里比较简单,傻瓜式操作,选择域名和要生成的文件,点击静态!
点击静态后,他会在对应的动态文件的同一个文件夹中自动生成对应的.htm文件。比如你把index.jsp设为静态,那么他会自动在index.jsp所在的文件夹下生成一个对应的.htm文件对应的index.htm文件,引导用户访问这个index.htm!
ps:特别是这里的一切都是基于用户访问的原则
比如你静态制作index.jsp文件生成index.htm后,只有用户访问index.htm才会生效,否则用户访问完index.jsp后仍然没有效果生成!
如何让用户访问 index.htm?这时候就需要修改代码了,比如之前
<A href="index.jsp">首页</A>
现在需要改为
<A href="index.htm">首页</A>
就是这样,让用户访问静态的htm网页,真正的jsp网页只在需要静态的时候访问一次!
------------------------------------------ 查看全部
抓取动态网页(什么是动态网页静态化就是通过技术手段,模拟浏览器访问,)
什么是动态网页静态?
静态网页就是利用技术手段模拟浏览器访问,将原创动态网页上显示的内容抓取出来保存为htm的静态网页,然后引导用户访问这个静态网页!这样,每个用户访问都是一个静态网页。网页不与数据库交互,访问速度可翻倍!
静态网页有什么好处?
1:让动态网页的访问速度和静态网页一样快(因为已经是静态的,所以不和数据库交互会更快)
2:保持他的简单维护功能!(如果有新内容,只需要重新生成静态网页)
静态网页注意事项:
1:由于是自动生成的,有些网页生成后可能会出现异常,比如有验证码的网页。这时候就需要制作验证码了。
仅包括
2:如果你生成index.jsp主页,那么你需要设置它,让用户可以先访问静态index.htm。具体设置如下: 打开你的项目下的WEB-INF/web.xml,添加
index.html
index.htm
index.jsp
3::如果你觉得在我们后台生成静态太麻烦,你也可以把这个功能集成到自己的后台中,更加方便。详情请参考生成htm静态网页减少数据库操作
如何使用动态网页静态?
在jsp空间管理中登录会员管理中心--扩展你的jsp空间,选择高级管理-动态网页静态
进入动态网页静态界面
这里比较简单,傻瓜式操作,选择域名和要生成的文件,点击静态!
点击静态后,他会在对应的动态文件的同一个文件夹中自动生成对应的.htm文件。比如你把index.jsp设为静态,那么他会自动在index.jsp所在的文件夹下生成一个对应的.htm文件对应的index.htm文件,引导用户访问这个index.htm!
ps:特别是这里的一切都是基于用户访问的原则
比如你静态制作index.jsp文件生成index.htm后,只有用户访问index.htm才会生效,否则用户访问完index.jsp后仍然没有效果生成!
如何让用户访问 index.htm?这时候就需要修改代码了,比如之前
<A href="index.jsp">首页</A>
现在需要改为
<A href="index.htm">首页</A>
就是这样,让用户访问静态的htm网页,真正的jsp网页只在需要静态的时候访问一次!
------------------------------------------
抓取动态网页( 微信朋友圈数据入口搞定了,获取外链的方法有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-10 03:16
微信朋友圈数据入口搞定了,获取外链的方法有哪些?)
2、然后点击首页的【创建图书】-->【微信图书】。
3、点击【开始制作】-->【添加随机分配的图书编辑为好友】,然后长按二维码添加好友。
4、之后,耐心等待微信书制作完成。完成后会收到小编发送的消息提醒,如下图所示。
至此,我们完成了微信朋友圈的数据录入,并获得了外链。
确保朋友圈设置为[全部打开]。默认是全部打开。如果不知道怎么设置,请百度。
5、点击外部链接,然后进入网页,需要使用微信扫码授权登录。
6、扫码授权后,即可进入微信书网页版,如下图。
7、接下来,我们就可以编写爬虫程序来正常爬取信息了。这里小编使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。下图为微信书首页,图片由小编定制。
二、创建爬虫项目
1、确保您的计算机上安装了 Scrapy。然后选择一个文件夹,在文件夹下输入命令行,输入执行命令:
scrapy startproject weixin_moment
,等待生成Scrapy爬虫项目。
2、在命令行输入cd weixin_moment,进入创建好的weixin_moment目录。然后输入命令:
scrapy genspider 'moment' 'chushu.la'
,创建朋友圈爬虫,如下图。
3、执行上述两步后的文件夹结构如下:
三、分析网页数据
1、进入微信书首页,按F12,推荐使用谷歌浏览器,查看元素,点击“网络”标签,然后勾选“保存日志”保存日志,如图下图。可以看到首页的请求方法是get,返回的状态码是200,表示请求成功。
2、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明后面我们需要在程序中处理JSON格式的数据。
3、点击微信书的“导航”窗口,可以看到数据是按月加载的。单击导航按钮时,它会加载相应月份的 Moments 数据。
4、点击月份[2014/04],再查看服务器响应数据,可以看到页面显示的数据对应服务器响应。
5、查看请求方式,可以看到此时的请求方式已经变成了POST。细心的小伙伴可以看到,当点击“下个月”或者其他导航月份时,首页的URL没有变化,说明网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数在不断变化,如下图所示。
6、将服务器响应的数据展开,放入JSON在线解析器,如下图:
可以看到朋友圈的数据是存放在paras /data节点下的。
至此,网页分析和数据的来源已经确定。接下来,我们将编写一个程序来捕获数据。敬请期待下一篇文章~~ 查看全部
抓取动态网页(
微信朋友圈数据入口搞定了,获取外链的方法有哪些?)
2、然后点击首页的【创建图书】-->【微信图书】。
3、点击【开始制作】-->【添加随机分配的图书编辑为好友】,然后长按二维码添加好友。
4、之后,耐心等待微信书制作完成。完成后会收到小编发送的消息提醒,如下图所示。
至此,我们完成了微信朋友圈的数据录入,并获得了外链。
确保朋友圈设置为[全部打开]。默认是全部打开。如果不知道怎么设置,请百度。
5、点击外部链接,然后进入网页,需要使用微信扫码授权登录。
6、扫码授权后,即可进入微信书网页版,如下图。
7、接下来,我们就可以编写爬虫程序来正常爬取信息了。这里小编使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。下图为微信书首页,图片由小编定制。
二、创建爬虫项目
1、确保您的计算机上安装了 Scrapy。然后选择一个文件夹,在文件夹下输入命令行,输入执行命令:
scrapy startproject weixin_moment
,等待生成Scrapy爬虫项目。
2、在命令行输入cd weixin_moment,进入创建好的weixin_moment目录。然后输入命令:
scrapy genspider 'moment' 'chushu.la'
,创建朋友圈爬虫,如下图。
3、执行上述两步后的文件夹结构如下:
三、分析网页数据
1、进入微信书首页,按F12,推荐使用谷歌浏览器,查看元素,点击“网络”标签,然后勾选“保存日志”保存日志,如图下图。可以看到首页的请求方法是get,返回的状态码是200,表示请求成功。
2、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明后面我们需要在程序中处理JSON格式的数据。
3、点击微信书的“导航”窗口,可以看到数据是按月加载的。单击导航按钮时,它会加载相应月份的 Moments 数据。
4、点击月份[2014/04],再查看服务器响应数据,可以看到页面显示的数据对应服务器响应。
5、查看请求方式,可以看到此时的请求方式已经变成了POST。细心的小伙伴可以看到,当点击“下个月”或者其他导航月份时,首页的URL没有变化,说明网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数在不断变化,如下图所示。
6、将服务器响应的数据展开,放入JSON在线解析器,如下图:
可以看到朋友圈的数据是存放在paras /data节点下的。
至此,网页分析和数据的来源已经确定。接下来,我们将编写一个程序来捕获数据。敬请期待下一篇文章~~
抓取动态网页(Colly学习笔记(三)——爬虫框架,抓取动态页面(上证A股列表抓取) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2022-01-09 14:15
)
Colly学习笔记(三)-爬虫框架,抓取动态页面(上证A股榜单抓取)
Colly学习笔记(一)-爬虫框架,捕捉中金行业市盈率数据
Colly学习笔记(二)-爬虫框架,抓取下载数据(上证A股数据下载)
Colly学习笔记(三)-爬虫框架,抓取动态页面数据(上海A股动态数据抓取)
前两章主要讨论静态数据的爬取。我们只需要将网页地址栏中的url传递给get请求,就可以轻松获取网页的数据。但是,有些网页是动态页面。我们传递网页的源代码。翻页时找不到数据,网址也没有变化。此时无法获取数据。比如下图,通过开发者工具,查看网页源码,发现虽然URL相同,但内容不同。此时需要找到动态页面对应的URL,才能抓取数据。
查看页面真实URL的方法如下:
点击分页按钮找到对应的URL(具体步骤如图)
通过postman查看和排除无效参数
#动态URL原始参数
http://query.sse.com.cn/securi ... 45917
#postman调试优化后的参数
http://query.sse.com.cn/securi ... o%3D3
postman 视图如下图
写colly代码抓取流程
//finish
c.OnScraped(func(r *colly.Response) {
//解析Json
var item PageResult
err := json.Unmarshal(r.Body, &item)
if err != nil {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"err":err,"res":string(r.Body)}).Error("Receive Error ")
//若返回系统繁忙,则等一段时间重新访问
if strings.Contains(string(r.Body),"error"){
c.Visit(url)
}
}
//
if len(item.Result) > 1{
res = append(res,&item)
receiver.MLog.GetLogHandle().WithFields(log.Fields{"item":item}).Info("Receive message ")
return
}
//第一次只取一条是为了获取所有的A股总数,然后重新一次获取到所有数据,无需多次分页
SubUrl := "http://query.sse.com.cn/securi ... ot%3B
SubUrl += strconv.Itoa(item.Page.Total)
c.Visit(SubUrl)
})
结果:
完整代码如下:
package main
import (
"encoding/json"
"fmt"
"github.com/gocolly/colly"
log "github.com/sirupsen/logrus"
"strconv"
"strings"
)
type pageHelp struct {
Total int `json:"total"`
}
type pageResult struct {
CompanyAbbr string `json:"COMPANY_ABBR"`
CompanyCode string `json:"COMPANY_CODE"`
EnglishAbbr string `json:"ENGLISH_ABBR"`
ListingTime string `json:"LISTING_DATE"`
MoveTime string `json:"QIANYI_DATE"`
}
type PageResult struct {
AreaName string `json:"areaName"`
Page pageHelp `json:"pageHelp"`
Result []pageResult `json:"result"`
StockType string `json:"stockType"`
}
func (receiver Collector) ScrapeJs(url string) (error,[]*PageResult) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"URL":url}).Info("URL...")
c := colly.NewCollector(colly.UserAgent(RandomString()),colly.AllowURLRevisit())
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36"
res := make([]*PageResult, 0)
c.OnRequest(func(r *colly.Request) {
//r.Headers.Set("User-Agent", RandomString())
r.Headers.Set("Host", "query.sse.com.cn")
r.Headers.Set("Connection", "keep-alive")
r.Headers.Set("Accept", "*/*")
r.Headers.Set("Origin", "http://www.sse.com.cn")
//关键头 如果没有 则返回 错误
r.Headers.Set("Referer", "http://www.sse.com.cn/assortme ... 6quot;)
r.Headers.Set("Accept-Encoding", "gzip, deflate")
r.Headers.Set("Accept-Language", "zh-CN,zh;q=0.9")
receiver.MLog.GetLogHandle().WithFields(log.Fields{"Request":fmt.Sprintf("%+v",*r),"Headers":fmt.Sprintf("%+v",*r.Headers)}).Info("Begin Visiting...")
})
c.OnError(func(_ *colly.Response, err error) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"error":err}).Info("Something went wrong:")
})
c.OnResponse(func(r *colly.Response) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"Headers":r.Headers}).Info("Receive Header")
})
//scraped item from body
//finish
c.OnScraped(func(r *colly.Response) {
var item PageResult
err := json.Unmarshal(r.Body, &item)
if err != nil {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"err":err,"res":string(r.Body)}).Error("Receive Error ")
if strings.Contains(string(r.Body),"error"){
c.Visit(url)
}
}
if len(item.Result) > 1{
res = append(res,&item)
receiver.MLog.GetLogHandle().WithFields(log.Fields{"item":item}).Info("Receive message ")
return //结束递归
}
SubUrl := "http://query.sse.com.cn/securi ... ot%3B
//SubUrl += strconv.Itoa(item.Page.Total)
SubUrl += '25'
c.Visit(SubUrl)
})
c.Visit(url)
return nil,res
}
func (receiver Collector) ScrapeJsTest() error {
//第一次只获取一条数据目的是为了获取数据总条数,下次递归拼接URL一次获取所有数据
UrlA := "http://query.sse.com.cn/securi ... ot%3B
receiver.ScrapeJs(UrlA)
return nil
}
func main() {
var c Collector
c.MLog=receiver.MLog
c.ScrapeJsTest()
return
} 查看全部
抓取动态网页(Colly学习笔记(三)——爬虫框架,抓取动态页面(上证A股列表抓取)
)
Colly学习笔记(三)-爬虫框架,抓取动态页面(上证A股榜单抓取)
Colly学习笔记(一)-爬虫框架,捕捉中金行业市盈率数据
Colly学习笔记(二)-爬虫框架,抓取下载数据(上证A股数据下载)
Colly学习笔记(三)-爬虫框架,抓取动态页面数据(上海A股动态数据抓取)
前两章主要讨论静态数据的爬取。我们只需要将网页地址栏中的url传递给get请求,就可以轻松获取网页的数据。但是,有些网页是动态页面。我们传递网页的源代码。翻页时找不到数据,网址也没有变化。此时无法获取数据。比如下图,通过开发者工具,查看网页源码,发现虽然URL相同,但内容不同。此时需要找到动态页面对应的URL,才能抓取数据。
查看页面真实URL的方法如下:
点击分页按钮找到对应的URL(具体步骤如图)
通过postman查看和排除无效参数
#动态URL原始参数
http://query.sse.com.cn/securi ... 45917
#postman调试优化后的参数
http://query.sse.com.cn/securi ... o%3D3
postman 视图如下图
写colly代码抓取流程
//finish
c.OnScraped(func(r *colly.Response) {
//解析Json
var item PageResult
err := json.Unmarshal(r.Body, &item)
if err != nil {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"err":err,"res":string(r.Body)}).Error("Receive Error ")
//若返回系统繁忙,则等一段时间重新访问
if strings.Contains(string(r.Body),"error"){
c.Visit(url)
}
}
//
if len(item.Result) > 1{
res = append(res,&item)
receiver.MLog.GetLogHandle().WithFields(log.Fields{"item":item}).Info("Receive message ")
return
}
//第一次只取一条是为了获取所有的A股总数,然后重新一次获取到所有数据,无需多次分页
SubUrl := "http://query.sse.com.cn/securi ... ot%3B
SubUrl += strconv.Itoa(item.Page.Total)
c.Visit(SubUrl)
})
结果:
完整代码如下:
package main
import (
"encoding/json"
"fmt"
"github.com/gocolly/colly"
log "github.com/sirupsen/logrus"
"strconv"
"strings"
)
type pageHelp struct {
Total int `json:"total"`
}
type pageResult struct {
CompanyAbbr string `json:"COMPANY_ABBR"`
CompanyCode string `json:"COMPANY_CODE"`
EnglishAbbr string `json:"ENGLISH_ABBR"`
ListingTime string `json:"LISTING_DATE"`
MoveTime string `json:"QIANYI_DATE"`
}
type PageResult struct {
AreaName string `json:"areaName"`
Page pageHelp `json:"pageHelp"`
Result []pageResult `json:"result"`
StockType string `json:"stockType"`
}
func (receiver Collector) ScrapeJs(url string) (error,[]*PageResult) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"URL":url}).Info("URL...")
c := colly.NewCollector(colly.UserAgent(RandomString()),colly.AllowURLRevisit())
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36"
res := make([]*PageResult, 0)
c.OnRequest(func(r *colly.Request) {
//r.Headers.Set("User-Agent", RandomString())
r.Headers.Set("Host", "query.sse.com.cn")
r.Headers.Set("Connection", "keep-alive")
r.Headers.Set("Accept", "*/*")
r.Headers.Set("Origin", "http://www.sse.com.cn";)
//关键头 如果没有 则返回 错误
r.Headers.Set("Referer", "http://www.sse.com.cn/assortme ... 6quot;)
r.Headers.Set("Accept-Encoding", "gzip, deflate")
r.Headers.Set("Accept-Language", "zh-CN,zh;q=0.9")
receiver.MLog.GetLogHandle().WithFields(log.Fields{"Request":fmt.Sprintf("%+v",*r),"Headers":fmt.Sprintf("%+v",*r.Headers)}).Info("Begin Visiting...")
})
c.OnError(func(_ *colly.Response, err error) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"error":err}).Info("Something went wrong:")
})
c.OnResponse(func(r *colly.Response) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"Headers":r.Headers}).Info("Receive Header")
})
//scraped item from body
//finish
c.OnScraped(func(r *colly.Response) {
var item PageResult
err := json.Unmarshal(r.Body, &item)
if err != nil {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"err":err,"res":string(r.Body)}).Error("Receive Error ")
if strings.Contains(string(r.Body),"error"){
c.Visit(url)
}
}
if len(item.Result) > 1{
res = append(res,&item)
receiver.MLog.GetLogHandle().WithFields(log.Fields{"item":item}).Info("Receive message ")
return //结束递归
}
SubUrl := "http://query.sse.com.cn/securi ... ot%3B
//SubUrl += strconv.Itoa(item.Page.Total)
SubUrl += '25'
c.Visit(SubUrl)
})
c.Visit(url)
return nil,res
}
func (receiver Collector) ScrapeJsTest() error {
//第一次只获取一条数据目的是为了获取数据总条数,下次递归拼接URL一次获取所有数据
UrlA := "http://query.sse.com.cn/securi ... ot%3B
receiver.ScrapeJs(UrlA)
return nil
}
func main() {
var c Collector
c.MLog=receiver.MLog
c.ScrapeJsTest()
return
}
抓取动态网页(关于一下动态网址和静态网址的话题网址(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-06 03:14
yylqymzk 发表于 2010-4-26 18:05
网页编辑学院:动态 URL 和静态 URL 发布者:Juliane Stiller 和 Kaspar Szymanski,搜索质量团队
原文:动态 URL 与静态 URL
发表于:2008 年 9 月 22 日,下午 3:20
这种情况在与网络管理员沟通时经常发生。一些广为流传的想法在过去可能是正确的,但可能不再适合当前的情况。这发生在我们最近和几个朋友谈论 URL 的结构时。我的一位朋友非常担心动态网址的使用,甚至认为“搜索引擎无法处理动态网址”。另一位朋友认为动态网址对于搜索引擎来说根本不是问题。这些都是过去的事情了。另一个人甚至说他从来不明白动态 URL 和静态 URL 之间的区别。对我们来说,这一刻让我们决定研究动态 URL 和静态 URL 的主题。首先,让我们定义一下我们要讨论的主题:
什么是静态网址?
顾名思义,静态 URL 是不会更改的 URL。它通常不收录任何 URL 参数。例如:。您可以在搜索框中输入 filetype:html 以在 Google 上搜索静态 URL。使用这种类型的 URL 更新页面需要时间,尤其是在信息量快速增长的情况下,因为每个单独的页面都必须更改编译后的代码。这就是为什么 网站 管理员在处理大型且经常更新的 网站,例如在线购物 网站、论坛社区、博客或内容管理系统时使用动态 URL 的原因。
什么是动态网址?
如果将网站的内容存入数据库,按要求显示页面,则可以使用动态URL。在这种情况下,网站 提供的内容基本上是基于模板的。通常,动态 URL 如下所示:。您可以通过查找符号来识别动态 URL,例如?= &。动态 URL 的一个缺点是不同的 URL 可以具有相同的内容。因此,不同的用户可能会链接到具有不同参数的 URL,但这些 URL 都收录相同的内容。这也是网络管理员有时希望将这些动态 URL 重写为静态 URL 的原因之一。
我应该让我的动态 URL 看起来是静态的吗?
在处理动态 URL 时,希望您能理解以下事实:
实际上很难正确生成和维护从动态 URL 到静态 URL 的重写转换。
向我们提供原创动态 URL 更安全。请让我们处理诸如检测和避免有问题的参数之类的事情。
如果您想重写 URL,请删除那些不必要的参数,同时将其保留为动态 URL。
如果您想提供静态网址而不是动态网址,那么您实际上应该生成相应的静态内容。
静态网址和动态网址,Googlebot 识别哪个更好?
我们遇到过很多网站管理员,就像我们的朋友一样,他们认为静态或看似静态的URL有利于网站的索引和排名。此观点基于以下假设:搜索引擎在抓取和分析收录会话 ID 和源跟踪器的 URL 时存在问题。然而,事实是谷歌在这两个领域都取得了长足的进步。在点击率方面,静态网址可能略占优势,因为用户可以轻松阅读此网址。但是,在索引和排名方面,使用数据库驱动的网站并不意味着明显的劣势。与隐藏参数使它们看起来是静态 URL 相比,我们更喜欢 网站 直接向搜索引擎提供动态 URL。
现在,让我们来看看一些广为流传的关于动态 URL 的观点,并纠正一些欺骗 网站 管理员的假设。:)
误解:“无法抓取动态 URL。”
事实:我们可以抓取动态 URL 并解释不同的参数。如果为了让网址看起来是静态的而隐藏了可以向谷歌提供有价值信息的参数,这样做会导致网址的抓取和排名出现问题。我们的建议是:请不要更改动态 URL 的格式以使其看起来是静态的。建议尽量使用静态 URL 来展示静态内容,但如果您决定展示动态内容,请不要隐藏参数让它们看起来是静态的,因为这样做会移除那些对我们有用的有用信息分析网址。
误解:“动态 URL 必须少于 3 个参数。”
事实:参数数量没有限制。但是,一个好的经验法则是不要让您的 URL 太长(这适用于所有 URL,无论是静态的还是动态的)。您可以删除一些对 Googlebot 不重要的参数,并为用户提供更好看的动态网址。如果您不确定哪些参数可以删除,我们建议您将动态 URL 中的所有参数都提供给我们,我们的系统会找出哪些不重要。隐藏参数会影响我们正确分析您的网址,我们将无法识别这些参数,从而可能会丢失一些重要信息。
以下是我们认为您可能有疑问的一些问题。
这是否意味着我应该完全避免重写动态 URL?
这是我们的建议,除非你能保证你只删除多余的参数,否则你可以完全删除所有可能产生不利影响的参数。如果你随意修改你的动态URL,让它看起来是静态的,你必须意识到这样做是有风险的,有些信息可能无法正常编译和识别。如果你想给你的网站添加静态版本,请提供真正静态的内容,比如生成的文件可以通过网站的对应路径获取。如果您只修改动态 URL 的呈现而不提供静态内容,那么您可能会适得其反。请直接提供标准的动态网址,我们会自动找出那些多余的参数。
你能举个例子吗?
如果您有一个标准格式的动态网址,例如:foo?key1=value&key2=value2,我们建议您不要更改它。谷歌将决定可以删除哪些参数;或者您可以为用户删除不必要的参数。但要小心,只删除那些不重要的参数。以下是具有多个参数的动态 URL 的示例:
language=en-标记这个文章的语言
answer=3 – 这个 文章 收录数字 3
sid=8971298178906-会话识别码为8971298178906
query=URL-使这个 文章 找到的查询是并非所有参数都提供附加信息。所以重写这个 URL 可能不会造成任何问题,因为所有不相关的参数都被删除了。
下面是一些已修改为看起来像静态 URL 的 URL 示例。与不重写直接提供的动态网址相比,这些网址可能会造成更多的抓取问题。
sid=98971298178906/query=URL
98971298178906/查询/网址
,3,98971298178906,URL 如果把动态URL改写成上面提到的例子,可能会给我们带来很多不必要的爬取,因为这些URL收录了会话标识符(sid)和查询(query)参数。变量值,这个无形中产生了很多看起来不一样的URL,但是它们收录的内容是一样的。这些格式让我们很难理解通过这个URL返回的实际内容和参数URL和98971298178906是无关的。但是,以下重写的示例删除了所有无关参数:
尽管我们可以正确处理此 URL,但我们仍然不鼓励您使用此类重写。因为很难维护,而且一旦在原来的动态 URL 上增加了新的参数,就需要立即更新 URL。如果不这样做,将再次导致 URL 看起来像带有隐藏参数的静态 URL。所以最好的解决方案是通常保持动态 URL 原样。或者,如果您删除了不相关的参数,请记住保持此 URL 动态:
我们希望这个文章 可以对您和我们的朋友有所帮助,并澄清有关动态 URL 的各种猜测。如果您有更多问题,请加入我们的网站管理员支持论坛进行讨论。
a_zheng_2010 发表于 2015-1-10 21:11
什么是静态网址?
283578916的小号发表于2017-12-22 23:51
666666666666
誊: [1] 查看全部
抓取动态网页(关于一下动态网址和静态网址的话题网址(图))
yylqymzk 发表于 2010-4-26 18:05
网页编辑学院:动态 URL 和静态 URL 发布者:Juliane Stiller 和 Kaspar Szymanski,搜索质量团队
原文:动态 URL 与静态 URL
发表于:2008 年 9 月 22 日,下午 3:20
这种情况在与网络管理员沟通时经常发生。一些广为流传的想法在过去可能是正确的,但可能不再适合当前的情况。这发生在我们最近和几个朋友谈论 URL 的结构时。我的一位朋友非常担心动态网址的使用,甚至认为“搜索引擎无法处理动态网址”。另一位朋友认为动态网址对于搜索引擎来说根本不是问题。这些都是过去的事情了。另一个人甚至说他从来不明白动态 URL 和静态 URL 之间的区别。对我们来说,这一刻让我们决定研究动态 URL 和静态 URL 的主题。首先,让我们定义一下我们要讨论的主题:
什么是静态网址?
顾名思义,静态 URL 是不会更改的 URL。它通常不收录任何 URL 参数。例如:。您可以在搜索框中输入 filetype:html 以在 Google 上搜索静态 URL。使用这种类型的 URL 更新页面需要时间,尤其是在信息量快速增长的情况下,因为每个单独的页面都必须更改编译后的代码。这就是为什么 网站 管理员在处理大型且经常更新的 网站,例如在线购物 网站、论坛社区、博客或内容管理系统时使用动态 URL 的原因。
什么是动态网址?
如果将网站的内容存入数据库,按要求显示页面,则可以使用动态URL。在这种情况下,网站 提供的内容基本上是基于模板的。通常,动态 URL 如下所示:。您可以通过查找符号来识别动态 URL,例如?= &。动态 URL 的一个缺点是不同的 URL 可以具有相同的内容。因此,不同的用户可能会链接到具有不同参数的 URL,但这些 URL 都收录相同的内容。这也是网络管理员有时希望将这些动态 URL 重写为静态 URL 的原因之一。
我应该让我的动态 URL 看起来是静态的吗?
在处理动态 URL 时,希望您能理解以下事实:
实际上很难正确生成和维护从动态 URL 到静态 URL 的重写转换。
向我们提供原创动态 URL 更安全。请让我们处理诸如检测和避免有问题的参数之类的事情。
如果您想重写 URL,请删除那些不必要的参数,同时将其保留为动态 URL。
如果您想提供静态网址而不是动态网址,那么您实际上应该生成相应的静态内容。
静态网址和动态网址,Googlebot 识别哪个更好?
我们遇到过很多网站管理员,就像我们的朋友一样,他们认为静态或看似静态的URL有利于网站的索引和排名。此观点基于以下假设:搜索引擎在抓取和分析收录会话 ID 和源跟踪器的 URL 时存在问题。然而,事实是谷歌在这两个领域都取得了长足的进步。在点击率方面,静态网址可能略占优势,因为用户可以轻松阅读此网址。但是,在索引和排名方面,使用数据库驱动的网站并不意味着明显的劣势。与隐藏参数使它们看起来是静态 URL 相比,我们更喜欢 网站 直接向搜索引擎提供动态 URL。
现在,让我们来看看一些广为流传的关于动态 URL 的观点,并纠正一些欺骗 网站 管理员的假设。:)
误解:“无法抓取动态 URL。”
事实:我们可以抓取动态 URL 并解释不同的参数。如果为了让网址看起来是静态的而隐藏了可以向谷歌提供有价值信息的参数,这样做会导致网址的抓取和排名出现问题。我们的建议是:请不要更改动态 URL 的格式以使其看起来是静态的。建议尽量使用静态 URL 来展示静态内容,但如果您决定展示动态内容,请不要隐藏参数让它们看起来是静态的,因为这样做会移除那些对我们有用的有用信息分析网址。
误解:“动态 URL 必须少于 3 个参数。”
事实:参数数量没有限制。但是,一个好的经验法则是不要让您的 URL 太长(这适用于所有 URL,无论是静态的还是动态的)。您可以删除一些对 Googlebot 不重要的参数,并为用户提供更好看的动态网址。如果您不确定哪些参数可以删除,我们建议您将动态 URL 中的所有参数都提供给我们,我们的系统会找出哪些不重要。隐藏参数会影响我们正确分析您的网址,我们将无法识别这些参数,从而可能会丢失一些重要信息。
以下是我们认为您可能有疑问的一些问题。
这是否意味着我应该完全避免重写动态 URL?
这是我们的建议,除非你能保证你只删除多余的参数,否则你可以完全删除所有可能产生不利影响的参数。如果你随意修改你的动态URL,让它看起来是静态的,你必须意识到这样做是有风险的,有些信息可能无法正常编译和识别。如果你想给你的网站添加静态版本,请提供真正静态的内容,比如生成的文件可以通过网站的对应路径获取。如果您只修改动态 URL 的呈现而不提供静态内容,那么您可能会适得其反。请直接提供标准的动态网址,我们会自动找出那些多余的参数。
你能举个例子吗?
如果您有一个标准格式的动态网址,例如:foo?key1=value&key2=value2,我们建议您不要更改它。谷歌将决定可以删除哪些参数;或者您可以为用户删除不必要的参数。但要小心,只删除那些不重要的参数。以下是具有多个参数的动态 URL 的示例:
language=en-标记这个文章的语言
answer=3 – 这个 文章 收录数字 3
sid=8971298178906-会话识别码为8971298178906
query=URL-使这个 文章 找到的查询是并非所有参数都提供附加信息。所以重写这个 URL 可能不会造成任何问题,因为所有不相关的参数都被删除了。
下面是一些已修改为看起来像静态 URL 的 URL 示例。与不重写直接提供的动态网址相比,这些网址可能会造成更多的抓取问题。
sid=98971298178906/query=URL
98971298178906/查询/网址
,3,98971298178906,URL 如果把动态URL改写成上面提到的例子,可能会给我们带来很多不必要的爬取,因为这些URL收录了会话标识符(sid)和查询(query)参数。变量值,这个无形中产生了很多看起来不一样的URL,但是它们收录的内容是一样的。这些格式让我们很难理解通过这个URL返回的实际内容和参数URL和98971298178906是无关的。但是,以下重写的示例删除了所有无关参数:
尽管我们可以正确处理此 URL,但我们仍然不鼓励您使用此类重写。因为很难维护,而且一旦在原来的动态 URL 上增加了新的参数,就需要立即更新 URL。如果不这样做,将再次导致 URL 看起来像带有隐藏参数的静态 URL。所以最好的解决方案是通常保持动态 URL 原样。或者,如果您删除了不相关的参数,请记住保持此 URL 动态:
我们希望这个文章 可以对您和我们的朋友有所帮助,并澄清有关动态 URL 的各种猜测。如果您有更多问题,请加入我们的网站管理员支持论坛进行讨论。
a_zheng_2010 发表于 2015-1-10 21:11
什么是静态网址?
283578916的小号发表于2017-12-22 23:51
666666666666
誊: [1]
抓取动态网页(提高网站排名起着非常重要的作用_成都网站建设)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-06 03:09
网络营销行业的人都知道,目前几乎所有的SEO优化器都强调使用静态网页,从而降低动态网站的权重。但是静态网站确实比动态网站友好,动态网页对搜索引擎不友好,这就是seoers不使用它的原因,但是告诉你:现在搜索引擎有已经使用动态页面。如果能被识别和抓取,也许动态网页会成为未来互联网的主流,所以动态网站不一定不能被搜索引擎收录排名或搜索到,只要你掌握了一些技巧就可以了。
1、合理安排网站网址
搜索引擎之所以很难检索到动态网页,是因为它们对网址中的特殊字符不敏感,所以我们应该使网页静态化,并尽量避免“?” 网站的URL中的“&”“”等特殊字符,特别是“&”不是必须的,所以我们可以写,不要写。还有一点就是尽量不要在URL中收录中文字符,因为浏览器会对URL中的中文进行编码。如果网址中汉字过多,编码后网址会很长,这对搜索引擎检索页面非常不利。
2、善用利剑“称号”
标题标签对提高网站的排名起到了非常重要的作用。很多人之所以害怕动态网站,是因为不知道如何让自动生成的动态页面自动生成合适的标题标签。其实这里有个窍门,就是在title标签前面写SELET,比如一个新闻分类网站,一般在新闻列表页写成这样:"",即使用ID传递一个“>”参数到“news_detail.asp”页面查看整个新闻信息,所以我们需要做的所有工作都在news_detail.asp页面上。同理,我们也可以用这个方法来写描述和关键字,当然有一点要画出来,请注意关键字的作用已经可以忽略不计,如果使用不当,
3、创建静态条目
在“动静结合,静制动”的原则指导下,也可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。例如,如果将动态网页编译为静态主页或网站 地图的链接,则动态页面将呈现为静态目录。或者为动态页面创建一个专门的静态入口页面(网关/入口,链接到动态页面),然后将静态入口页面提交给搜索引擎。
以上三点是成都网站建设对网站优化趋势的建议。希望对大家以后的优化趋势有所帮助网站!
_创新互联网,为您提供商城网站、外贸网站建设、外贸建设站、品牌网站建设、网站设计公司、定制开发 查看全部
抓取动态网页(提高网站排名起着非常重要的作用_成都网站建设)
网络营销行业的人都知道,目前几乎所有的SEO优化器都强调使用静态网页,从而降低动态网站的权重。但是静态网站确实比动态网站友好,动态网页对搜索引擎不友好,这就是seoers不使用它的原因,但是告诉你:现在搜索引擎有已经使用动态页面。如果能被识别和抓取,也许动态网页会成为未来互联网的主流,所以动态网站不一定不能被搜索引擎收录排名或搜索到,只要你掌握了一些技巧就可以了。
1、合理安排网站网址
搜索引擎之所以很难检索到动态网页,是因为它们对网址中的特殊字符不敏感,所以我们应该使网页静态化,并尽量避免“?” 网站的URL中的“&”“”等特殊字符,特别是“&”不是必须的,所以我们可以写,不要写。还有一点就是尽量不要在URL中收录中文字符,因为浏览器会对URL中的中文进行编码。如果网址中汉字过多,编码后网址会很长,这对搜索引擎检索页面非常不利。
2、善用利剑“称号”
标题标签对提高网站的排名起到了非常重要的作用。很多人之所以害怕动态网站,是因为不知道如何让自动生成的动态页面自动生成合适的标题标签。其实这里有个窍门,就是在title标签前面写SELET,比如一个新闻分类网站,一般在新闻列表页写成这样:"",即使用ID传递一个“>”参数到“news_detail.asp”页面查看整个新闻信息,所以我们需要做的所有工作都在news_detail.asp页面上。同理,我们也可以用这个方法来写描述和关键字,当然有一点要画出来,请注意关键字的作用已经可以忽略不计,如果使用不当,
3、创建静态条目
在“动静结合,静制动”的原则指导下,也可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。例如,如果将动态网页编译为静态主页或网站 地图的链接,则动态页面将呈现为静态目录。或者为动态页面创建一个专门的静态入口页面(网关/入口,链接到动态页面),然后将静态入口页面提交给搜索引擎。
以上三点是成都网站建设对网站优化趋势的建议。希望对大家以后的优化趋势有所帮助网站!
_创新互联网,为您提供商城网站、外贸网站建设、外贸建设站、品牌网站建设、网站设计公司、定制开发
抓取动态网页(基于改进Single-Pass算法的噪声链接去除算法进行研究)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-04 16:13
[摘要]:互联网上Web2.0技术的出现和社交平台的兴起,极大地促进了动态网页的使用和普及。动态网页中的Ajax技术实现了客户端和服务器之间数据的异步操作,既满足了新时代的技术需求,又提高了用户体验,促进了互联网的发展。然而,传统的网络爬虫无法应对动态网页带来的新特性,因此研究支持动态页面的网络爬虫具有一定的现实意义。对于话题网络爬虫来说,噪声链接不仅毫无价值,而且消耗大量资源,尤其是采集和噪声链接对应网页上的网络爬虫分析,这大大降低了网络爬虫的效率。针对以上问题,本文的主要研究内容如下: 一、解决动态网页中Ajax异步操作原理的关键技术,以及如何让网络爬虫支持动态网页爬取的问题。本文通过HTTP请求获取网页,然后在本地构建网页的DOM树,分析脚本并提取URL,并修改HtmlUnit的源码解析需要点击触发的脚本,从而解决了传统网络爬虫对于动态网页中动态生成的网址难以获取的问题;其次,由于噪声链接大大降低了网络爬虫的效率,本文研究了去除网页噪声的算法。传统的网页去噪算法处理网页的整体结构,去噪效率低。本文通过聚类后的相似度计算对提取的URL结果进行去噪,在改进的Single-Pass算法的基础上提出了噪声链接去除算法,在去噪精度上取得了较好的效果;最后,实现了一个支持动态页面URL主题快速提取的网络爬虫系统,并针对动态网页分析和动态生成的URL提取、去噪算法的效果对比以及主题网络爬虫系统进行了设计和实现在快速提取 URL 的三个方面。实验。实验结果数据表明,本文实现的网络爬虫系统支持动态网页网址的提取, 查看全部
抓取动态网页(基于改进Single-Pass算法的噪声链接去除算法进行研究)
[摘要]:互联网上Web2.0技术的出现和社交平台的兴起,极大地促进了动态网页的使用和普及。动态网页中的Ajax技术实现了客户端和服务器之间数据的异步操作,既满足了新时代的技术需求,又提高了用户体验,促进了互联网的发展。然而,传统的网络爬虫无法应对动态网页带来的新特性,因此研究支持动态页面的网络爬虫具有一定的现实意义。对于话题网络爬虫来说,噪声链接不仅毫无价值,而且消耗大量资源,尤其是采集和噪声链接对应网页上的网络爬虫分析,这大大降低了网络爬虫的效率。针对以上问题,本文的主要研究内容如下: 一、解决动态网页中Ajax异步操作原理的关键技术,以及如何让网络爬虫支持动态网页爬取的问题。本文通过HTTP请求获取网页,然后在本地构建网页的DOM树,分析脚本并提取URL,并修改HtmlUnit的源码解析需要点击触发的脚本,从而解决了传统网络爬虫对于动态网页中动态生成的网址难以获取的问题;其次,由于噪声链接大大降低了网络爬虫的效率,本文研究了去除网页噪声的算法。传统的网页去噪算法处理网页的整体结构,去噪效率低。本文通过聚类后的相似度计算对提取的URL结果进行去噪,在改进的Single-Pass算法的基础上提出了噪声链接去除算法,在去噪精度上取得了较好的效果;最后,实现了一个支持动态页面URL主题快速提取的网络爬虫系统,并针对动态网页分析和动态生成的URL提取、去噪算法的效果对比以及主题网络爬虫系统进行了设计和实现在快速提取 URL 的三个方面。实验。实验结果数据表明,本文实现的网络爬虫系统支持动态网页网址的提取,
抓取动态网页(如何帮助我从以下链接中获取结果,你知道吗 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-04 10:16
)
如果您能帮助我从以下链接获取结果,我将不胜感激:
我正在使用 python3.7、beautifulsoup4 和 Selenium。你知道吗
我写了一个程序来提取酒店用户评论的特征,比如评论者姓名、评论日期、评论者评分、评论者国家、入住日期、评论标题和评论本身(在这个例子中,评论分为正面和负部分)。我使用beautifulsoup4从HTML标签中提取文本,依靠Selenium点击“cookienotification”按钮并循环浏览页面结果。你知道吗
当我成功循环浏览页面结果时,我没有提取第一页后检索到的内容。每 N 个页面从第一个结果页面检索相同的内容,我敢打赌这可能是因为内容是通过 JQuery 加载的。在这一点上,我不确定行为是什么,或者我需要在页面源代码中寻找什么,或者如何继续寻找解决方案。你知道吗
任何提示或建议将不胜感激!你知道吗
我的代码片段:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait, Select
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
import time
driver = webdriver.Chrome('/Users/admin/Desktop/chrome_driver/chromedriver')
#initiate driver-browser via Selenium - with original url
driver.get('link1')
def acceptCookies():
time.sleep(3)
element = driver.find_elements_by_xpath("//button[@class='cookie-warning-v2__banner-cta bui-button bui-button--wide bui-button--secondary close_warning']")
if element != None:
element = driver.find_elements_by_xpath("//button[@class='cookie-warning-v2__banner-cta bui-button bui-button--wide bui-button--secondary close_warning']")
element[0].click()
def getData(count, soup):
try:
for line in soup.find_all('li', class_='review_item'):
count += 1
review={}
review["review_metadata"]={}
review["review_metadata"]["review_date"] = line.find('p', class_='review_item_date').text.strip()
if line.find('p', class_='review_staydate') != None:
review["review_metadata"]["review_staydate"] = line.find('p', class_='review_staydate').text.strip()
review["review_metadata"]["reviewer_name"] = line.find('p', class_='reviewer_name').text.strip()
print(review["review_metadata"]["reviewer_name"])
review["review_metadata"]["reviewer_country"] = line.find('span', class_='reviewer_country').text.strip()
review["review_metadata"]["reviewer_score"] = line.find('span', class_='review-score-badge').text.strip()
if line.find('p', class_='review_pos') != None:
review["review_metadata"]["review_pos"] = line.find('p', class_='review_pos').text.strip()
if line.find('p', class_='review_neg') != None:
review["review_metadata"]["review_neg"] = line.find('p', class_='review_neg').text.strip()
scoreword = line.find('span', class_='review_item_header_scoreword')
if scoreword != None :
review["review_metadata"]["review_header"] = scoreword.text.strip()
else:
review["review_metadata"]["review_header"] = ""
hotel_reviews[count] = review
return hotel_reviews
except Exception as e:
return print('the error is', e)
# Finds max-range of pagination (number of result pages retrieved)
def find_max_pages():
max_pages = driver.find_elements_by_xpath("//div[@class='bui-pagination__list']//div//span")
max_pages = max_pages[-1].text
max_pages = max_pages.split()
max_pages = int(max_pages[1])
return max_pages
hotel_reviews= {}
count = 0
review_page = {}
hotel_reviews_2 = []
# Accept on Cookie-Notification
acceptCookies()
# Find Max Pages
max_pages = find_max_pages()
# Find every pagination link in order to loop through each review page carousel
element = driver.find_elements_by_xpath("//a[@class='bui-pagination__link']")
for item in range(max_pages-1):
review_page = getData(count, soup)
hotel_reviews_2.extend(review_page)
time.sleep(2)
element = driver.find_elements_by_xpath("//a[@class='bui-pagination__link']")
element[item].click()
driver.get(url=driver.current_url)
print(driver.page_source)
print(driver.current_url)
soup = BeautifulSoup(driver.page_source, 'lxml') 查看全部
抓取动态网页(如何帮助我从以下链接中获取结果,你知道吗
)
如果您能帮助我从以下链接获取结果,我将不胜感激:
我正在使用 python3.7、beautifulsoup4 和 Selenium。你知道吗
我写了一个程序来提取酒店用户评论的特征,比如评论者姓名、评论日期、评论者评分、评论者国家、入住日期、评论标题和评论本身(在这个例子中,评论分为正面和负部分)。我使用beautifulsoup4从HTML标签中提取文本,依靠Selenium点击“cookienotification”按钮并循环浏览页面结果。你知道吗
当我成功循环浏览页面结果时,我没有提取第一页后检索到的内容。每 N 个页面从第一个结果页面检索相同的内容,我敢打赌这可能是因为内容是通过 JQuery 加载的。在这一点上,我不确定行为是什么,或者我需要在页面源代码中寻找什么,或者如何继续寻找解决方案。你知道吗
任何提示或建议将不胜感激!你知道吗
我的代码片段:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait, Select
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
import time
driver = webdriver.Chrome('/Users/admin/Desktop/chrome_driver/chromedriver')
#initiate driver-browser via Selenium - with original url
driver.get('link1')
def acceptCookies():
time.sleep(3)
element = driver.find_elements_by_xpath("//button[@class='cookie-warning-v2__banner-cta bui-button bui-button--wide bui-button--secondary close_warning']")
if element != None:
element = driver.find_elements_by_xpath("//button[@class='cookie-warning-v2__banner-cta bui-button bui-button--wide bui-button--secondary close_warning']")
element[0].click()
def getData(count, soup):
try:
for line in soup.find_all('li', class_='review_item'):
count += 1
review={}
review["review_metadata"]={}
review["review_metadata"]["review_date"] = line.find('p', class_='review_item_date').text.strip()
if line.find('p', class_='review_staydate') != None:
review["review_metadata"]["review_staydate"] = line.find('p', class_='review_staydate').text.strip()
review["review_metadata"]["reviewer_name"] = line.find('p', class_='reviewer_name').text.strip()
print(review["review_metadata"]["reviewer_name"])
review["review_metadata"]["reviewer_country"] = line.find('span', class_='reviewer_country').text.strip()
review["review_metadata"]["reviewer_score"] = line.find('span', class_='review-score-badge').text.strip()
if line.find('p', class_='review_pos') != None:
review["review_metadata"]["review_pos"] = line.find('p', class_='review_pos').text.strip()
if line.find('p', class_='review_neg') != None:
review["review_metadata"]["review_neg"] = line.find('p', class_='review_neg').text.strip()
scoreword = line.find('span', class_='review_item_header_scoreword')
if scoreword != None :
review["review_metadata"]["review_header"] = scoreword.text.strip()
else:
review["review_metadata"]["review_header"] = ""
hotel_reviews[count] = review
return hotel_reviews
except Exception as e:
return print('the error is', e)
# Finds max-range of pagination (number of result pages retrieved)
def find_max_pages():
max_pages = driver.find_elements_by_xpath("//div[@class='bui-pagination__list']//div//span")
max_pages = max_pages[-1].text
max_pages = max_pages.split()
max_pages = int(max_pages[1])
return max_pages
hotel_reviews= {}
count = 0
review_page = {}
hotel_reviews_2 = []
# Accept on Cookie-Notification
acceptCookies()
# Find Max Pages
max_pages = find_max_pages()
# Find every pagination link in order to loop through each review page carousel
element = driver.find_elements_by_xpath("//a[@class='bui-pagination__link']")
for item in range(max_pages-1):
review_page = getData(count, soup)
hotel_reviews_2.extend(review_page)
time.sleep(2)
element = driver.find_elements_by_xpath("//a[@class='bui-pagination__link']")
element[item].click()
driver.get(url=driver.current_url)
print(driver.page_source)
print(driver.current_url)
soup = BeautifulSoup(driver.page_source, 'lxml')
抓取动态网页(小编来告诉你静态网站和动态网站的区别(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-03 13:12
大多数人认为,如果一个网页有动画或一些动态效果,那么它就是一个动态网页,否则就是一个静态网页。这是大多数人错误认为的动态页面。下面就跟小编一起来告诉你静态网站和动态网站
的区别
静态网站和动态网站的区别
在网站的设计中,纯HTML格式的网页通常被称为“静态网页”,早期的网站一般都是由静态网页制作而成。静态网页的URL形式通常是:后缀.htm、.html等。在HTML格式的网页上,还可以出现各种动态效果,如.GIF格式动画、FLASH、移动字母等。这些“动态效果”只是视觉效果,你可以跟网站 动态网页是一个不同的概念。静态网页是实际保存在服务器上的文件,每个网页都是一个独立的文件等。所谓静态网页是指网页文件中没有程序,只有HTML代码,一般是带有.html或.htm的后缀,网站的静态内容制作完成后不会改变,任何人访问都会显示。如果您的内容发生变化,您必须修改原创代码,然后将其上传到服务器。
动态网页与网页上的各种动画、动态字幕等视觉“动态效果”没有直接关系。动态网页还可以收录纯文本内容或收录各种动画的内容。这些只是网页详细内容的形式,无论网页是否具有动态效果,以动态网站技术而生的网页都称为动态网页。所谓动态网页,是指网页文件不仅有HTML标记,还收录程序代码。通过数据库连接,动态网页可以根据不同的时间和不同的访问者显示不同的内容。动态网站更新方便,一般在后台直接更新。
静态网站简要说明
·每个静态网页都有一个固定的URL,文件名后缀为htm、html、shtml等;
·静态网页一旦发布到服务器上,无论是否被访问,都是一个独立的文件;
·静态网页内容相对稳定,不收录特殊代码,容易被搜索引擎检索到; HTML更适合SEO搜索引擎优化。
·静态网站没有数据库支持,在网站的生产和维护上有很多工作;
·由于不需要通过数据库工作,静态网页的访问速度比较快;
流行的cms都支持静态网页,有利于搜索引擎收录,提高访问速度,但占用服务器空间大,程序运行时消耗大量时间生成html服务器资源,建议在服务器空闲时进行此类操作。
动态简述网站
Dynamic网站不是指具有动画功能的网站,而是指网站,其内容可以根据不同情况动态变化网站,一般来说,动态的网站 架构师通过数据库。动态网站除了设计网页之外,还需要借助数据库和编程,让网站具备更多的自动化和高级功能。动态网站体现在网页一般以asp、jsp、php、aspx等结尾,而静态网页一般以HTML(标准通用标记语言的一个子集)结尾。动态网站服务器空间配置比静态网页要求高,相应的成本也高,但动态网页有利于更新网站的内容,适合企业建网站。动态相对于静态网站。
动态网站功能
动态网站可实现用户注册、信息发布、产品展示、订单管理等交互功能;
动态网页不是独立存在于服务器上的网页文件,而是浏览器发送请求时反馈的网页;
动态网页收录服务器端脚本,因此页面文件名往往以asp、jsp、php等为后缀。但是您也可以使用 URL 静态技术将网页后缀显示为 HTML。因此,不能以页面文件的后缀作为判断网站动静态的唯一标准。
由于动态网页需要进行数据库处理,动态网站的访问速度大大减慢;
由于代码的特殊性,动态网页对搜索引擎的友好度低于静态网页。
但随着计算机性能的提升和网络带宽的增加,后两项基本得到解决。
动态主要特点网站
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件,服务器只有在用户请求时才返回一个完整的网页;
(4)动态网页中的“?”对搜索引擎检索有一定的问题。搜索引擎一般不可能访问网站数据库中的所有网页,或者由于技术原因考虑搜索蜘蛛不会抓取网址中“?”后的内容,因此网站使用动态网页在进行搜索引擎推广时需要做一定的技术处理,以满足搜索引擎的要求
什么是静态网页?静态网页的特点是什么?
在网站的设计中,纯HTML格式的网页通常被称为“静态网页”。早期的网站一般都是由静态网页制作而成。
静态网页的 URL 形式通常是:
以.htm、.html、.shtml、.xml等为后缀,在HTML格式的网页上,还可以出现各种动态效果,如.GIF格式动画、FLASH、滚动字母等。这些“动态效果” ”只是视觉效果,与下面介绍的动态网页是不同的概念。 .
我们简单总结一下静态网页的特点如下:
(1)静态网页每个网页都有一个固定的网址,网页网址以.htm、.html、.shtml等常见形式为后缀,不收录“?”;
(2)一旦网页内容发布在网站服务器上,无论是否有用户访问,每个静态网页的内容都存储在网站服务器上,也就是说,静态网页是服务器上实际保存的一个文件,每个网页都是一个独立的文件;
(3)静态网页的内容比较稳定,容易被搜索引擎检索到;
(4)静态网页不支持数据库,网站的制作和维护工作量很大,所以信息量大的时候,比较静态网页制作方法完全依赖于困难;
(5)静态网页交互性较差,在功能上有较大限制。
看过静态网站和动态网站区别的人会看到:
1.旅游产品推广计划范文
2.腾达路由器新界面如何升级
3.路由器tel402部分网页打不开怎么办
4.3篇会议纪要范文
5.如何学习期货交易的意识 查看全部
抓取动态网页(小编来告诉你静态网站和动态网站的区别(图))
大多数人认为,如果一个网页有动画或一些动态效果,那么它就是一个动态网页,否则就是一个静态网页。这是大多数人错误认为的动态页面。下面就跟小编一起来告诉你静态网站和动态网站
的区别
静态网站和动态网站的区别
在网站的设计中,纯HTML格式的网页通常被称为“静态网页”,早期的网站一般都是由静态网页制作而成。静态网页的URL形式通常是:后缀.htm、.html等。在HTML格式的网页上,还可以出现各种动态效果,如.GIF格式动画、FLASH、移动字母等。这些“动态效果”只是视觉效果,你可以跟网站 动态网页是一个不同的概念。静态网页是实际保存在服务器上的文件,每个网页都是一个独立的文件等。所谓静态网页是指网页文件中没有程序,只有HTML代码,一般是带有.html或.htm的后缀,网站的静态内容制作完成后不会改变,任何人访问都会显示。如果您的内容发生变化,您必须修改原创代码,然后将其上传到服务器。
动态网页与网页上的各种动画、动态字幕等视觉“动态效果”没有直接关系。动态网页还可以收录纯文本内容或收录各种动画的内容。这些只是网页详细内容的形式,无论网页是否具有动态效果,以动态网站技术而生的网页都称为动态网页。所谓动态网页,是指网页文件不仅有HTML标记,还收录程序代码。通过数据库连接,动态网页可以根据不同的时间和不同的访问者显示不同的内容。动态网站更新方便,一般在后台直接更新。
静态网站简要说明
·每个静态网页都有一个固定的URL,文件名后缀为htm、html、shtml等;
·静态网页一旦发布到服务器上,无论是否被访问,都是一个独立的文件;
·静态网页内容相对稳定,不收录特殊代码,容易被搜索引擎检索到; HTML更适合SEO搜索引擎优化。
·静态网站没有数据库支持,在网站的生产和维护上有很多工作;
·由于不需要通过数据库工作,静态网页的访问速度比较快;
流行的cms都支持静态网页,有利于搜索引擎收录,提高访问速度,但占用服务器空间大,程序运行时消耗大量时间生成html服务器资源,建议在服务器空闲时进行此类操作。
动态简述网站
Dynamic网站不是指具有动画功能的网站,而是指网站,其内容可以根据不同情况动态变化网站,一般来说,动态的网站 架构师通过数据库。动态网站除了设计网页之外,还需要借助数据库和编程,让网站具备更多的自动化和高级功能。动态网站体现在网页一般以asp、jsp、php、aspx等结尾,而静态网页一般以HTML(标准通用标记语言的一个子集)结尾。动态网站服务器空间配置比静态网页要求高,相应的成本也高,但动态网页有利于更新网站的内容,适合企业建网站。动态相对于静态网站。
动态网站功能
动态网站可实现用户注册、信息发布、产品展示、订单管理等交互功能;
动态网页不是独立存在于服务器上的网页文件,而是浏览器发送请求时反馈的网页;
动态网页收录服务器端脚本,因此页面文件名往往以asp、jsp、php等为后缀。但是您也可以使用 URL 静态技术将网页后缀显示为 HTML。因此,不能以页面文件的后缀作为判断网站动静态的唯一标准。
由于动态网页需要进行数据库处理,动态网站的访问速度大大减慢;
由于代码的特殊性,动态网页对搜索引擎的友好度低于静态网页。
但随着计算机性能的提升和网络带宽的增加,后两项基本得到解决。
动态主要特点网站
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件,服务器只有在用户请求时才返回一个完整的网页;
(4)动态网页中的“?”对搜索引擎检索有一定的问题。搜索引擎一般不可能访问网站数据库中的所有网页,或者由于技术原因考虑搜索蜘蛛不会抓取网址中“?”后的内容,因此网站使用动态网页在进行搜索引擎推广时需要做一定的技术处理,以满足搜索引擎的要求
什么是静态网页?静态网页的特点是什么?
在网站的设计中,纯HTML格式的网页通常被称为“静态网页”。早期的网站一般都是由静态网页制作而成。
静态网页的 URL 形式通常是:
以.htm、.html、.shtml、.xml等为后缀,在HTML格式的网页上,还可以出现各种动态效果,如.GIF格式动画、FLASH、滚动字母等。这些“动态效果” ”只是视觉效果,与下面介绍的动态网页是不同的概念。 .
我们简单总结一下静态网页的特点如下:
(1)静态网页每个网页都有一个固定的网址,网页网址以.htm、.html、.shtml等常见形式为后缀,不收录“?”;
(2)一旦网页内容发布在网站服务器上,无论是否有用户访问,每个静态网页的内容都存储在网站服务器上,也就是说,静态网页是服务器上实际保存的一个文件,每个网页都是一个独立的文件;
(3)静态网页的内容比较稳定,容易被搜索引擎检索到;
(4)静态网页不支持数据库,网站的制作和维护工作量很大,所以信息量大的时候,比较静态网页制作方法完全依赖于困难;
(5)静态网页交互性较差,在功能上有较大限制。
看过静态网站和动态网站区别的人会看到:
1.旅游产品推广计划范文
2.腾达路由器新界面如何升级
3.路由器tel402部分网页打不开怎么办
4.3篇会议纪要范文
5.如何学习期货交易的意识
抓取动态网页(关于动态网站优化的一些优化技巧:合理的安排网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-02 06:12
网络营销行业的人都知道,目前几乎所有的seo优化者都强调使用静态网页,从而降低动态网站的权重。不过静态网站确实比动态网站友好,动态网页对搜索引擎不友好,这也是seoers不使用的原因,但是网络营销教学网告诉你: 现在的搜索引擎对于可以识别和爬取的动态页面,或许动态页面将来会成为互联网的主流,所以动态网站不一定是搜索引擎无法排名或者搜索不到的< @收录,只要掌握了一些技巧就行。现在商七云给大家分享一些关于动态网站优化的优化技巧:
1、合理安排网站网址
搜索引擎之所以难以检索到动态网页,是因为它们对网址中的特殊字符不敏感。因此,我们应该使网页静态化,并尽量避免“?”在 网站 的 URL 中。 “&”等特殊字符,特别是“&”不是必须的,所以我们可以不写,另外就是尽量不要在URL中收录中文字符,因为浏览器会在URL Encoding中对待中文,如果网址中汉字过多,编码后网址会很长,对搜索引擎检索页面非常不利。
2、善用利剑“称号”
title标签对于提升网站的排名起到了非常重要的作用。很多人之所以害怕动态网站,是因为不知道如何让自动生成的动态页面自动生成一个合适的标题标签,其实这里还有一个技巧,就是写标题标签前面的SELET,比如一个新闻分类网站,在新闻列表页上通常是这样写的:“”,即用ID传递一个“>”参数给“news_detail.txt”。 asp”页面查看整个新闻信息,所以我们要做的所有工作都在news_detail.asp页面上。同样的方式我们也可以用这个方法来写描述和关键字,当然还有我想要的提醒大家的是,关键词的作用微乎其微,如果使用不当,只会害你而不是帮助你,所以不要用这种动态技术来滥用关键词标签。
3、创建静态条目
在“动静结合,静制动”的原则指导下,也可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。例如,如果将动态网页编译为静态主页或网站 地图的链接,则动态页面将呈现为静态目录。或者创建一个专门的静态入口页面(网关/入口,为动态页面链接到动态页面,然后将静态入口页面提交给搜索引擎。
以上三点是关于如何优化网络营销知识网动态网站的建议。希望对你优化动态网站有帮助! 查看全部
抓取动态网页(关于动态网站优化的一些优化技巧:合理的安排网站)
网络营销行业的人都知道,目前几乎所有的seo优化者都强调使用静态网页,从而降低动态网站的权重。不过静态网站确实比动态网站友好,动态网页对搜索引擎不友好,这也是seoers不使用的原因,但是网络营销教学网告诉你: 现在的搜索引擎对于可以识别和爬取的动态页面,或许动态页面将来会成为互联网的主流,所以动态网站不一定是搜索引擎无法排名或者搜索不到的< @收录,只要掌握了一些技巧就行。现在商七云给大家分享一些关于动态网站优化的优化技巧:
1、合理安排网站网址
搜索引擎之所以难以检索到动态网页,是因为它们对网址中的特殊字符不敏感。因此,我们应该使网页静态化,并尽量避免“?”在 网站 的 URL 中。 “&”等特殊字符,特别是“&”不是必须的,所以我们可以不写,另外就是尽量不要在URL中收录中文字符,因为浏览器会在URL Encoding中对待中文,如果网址中汉字过多,编码后网址会很长,对搜索引擎检索页面非常不利。
2、善用利剑“称号”
title标签对于提升网站的排名起到了非常重要的作用。很多人之所以害怕动态网站,是因为不知道如何让自动生成的动态页面自动生成一个合适的标题标签,其实这里还有一个技巧,就是写标题标签前面的SELET,比如一个新闻分类网站,在新闻列表页上通常是这样写的:“”,即用ID传递一个“>”参数给“news_detail.txt”。 asp”页面查看整个新闻信息,所以我们要做的所有工作都在news_detail.asp页面上。同样的方式我们也可以用这个方法来写描述和关键字,当然还有我想要的提醒大家的是,关键词的作用微乎其微,如果使用不当,只会害你而不是帮助你,所以不要用这种动态技术来滥用关键词标签。
3、创建静态条目
在“动静结合,静制动”的原则指导下,也可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。例如,如果将动态网页编译为静态主页或网站 地图的链接,则动态页面将呈现为静态目录。或者创建一个专门的静态入口页面(网关/入口,为动态页面链接到动态页面,然后将静态入口页面提交给搜索引擎。
以上三点是关于如何优化网络营销知识网动态网站的建议。希望对你优化动态网站有帮助!
抓取动态网页(Java高并发编程入门为啥写这篇文章?(09))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-01 07:10
您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连。
1. 社区里走一走,每周都有福利,每周都有惊喜。马农飞阁社区飞跃计划
2. Python基础专栏,基础知识一应俱全。 Python从入门到精通
❤️ 3. Ceph实战,从原理到实战,无所不包。 Ceph实战
❤️ 4. Java高并发编程介绍,点进来学习Java高并发。 Java高并发编程简介
为什么要写这个文章?
前两篇文章我们分别介绍了
使用正则表达式爬取古诗词散文网站,玩玩学习【python爬虫入门进阶】(09)
使用生产者-消费者模式抓取bucket图片,一下子获取大量表情【python爬虫入门进阶】(11)
还没来得及看的朋友可以再看一波。
本文以小凡表网站为例介绍如何从动态网页中抓取数据。上面说的数据爬取是为了说明哪些是静态网页,即接口直接返回一个Html页面。我们只需要通过Xpath等方式提取页面内容即可。
今天要讲的另一种网站就是页面数据通过ajax返回。对于这种网站,我们如何抓取他的数据?
为什么要写这个文章?分析页面 ajax获取ajax数据的方法是什么 获取数据汇总分析页面
首先打开这个网站,经过简单的分析,我们可以得出三个结论。
点击查看更多数据后,页面地址不变,页面不会刷新。单击以查看更多一次将请求该接口一次。页面的数据以application/json的形式由接口返回。 p 参数控制返回哪一页数据。 n 参数控制每页返回的数据项数。什么是ajax
AJAX(Asynchronouse JavaScript And XML)中文称为异步JavaScript和XML。主要用于前端和服务器端进行少量数据交互。 Ajax 可以实现网页的异步加载,这意味着可以在不重新加载整个网页的情况下部分更新网页的某个部分。传统网页(不使用 Ajax)如果需要更新内容,需要重新加载整个网页。
因为传统的数据传输格式是XML语法,所以叫做AJAX。其实现在数据交互基本都是用JSON。使用ajax加载的数据,即使使用js,数据渲染到浏览器中,右键---->查看网页源码,仍然看不到通过ajax加载的数据,只加载了html使用网址代码。
如何获取ajax数据直接分析ajax调用的接口,然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。 (文章后面会详细介绍)获取数据
这个小餐桌网站的界面比较简单。没有加密认证什么的,直接通过requests请求即可。这是一个示例代码:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36"
}
requests.packages.urllib3.disable_warnings()
if __name__ == '__main__':
for i in range(1,10):
url = "https://www.xfz.cn/api/website/articles/?p={0}&n=20&type=".format(str(i))
resp = requests.get(url, headers=headers, verify=False)
print(resp.json())
运行结果:
总结
本文以小凡表网站为例,简单介绍一下如何抓取动态网页的数据。 查看全部
抓取动态网页(Java高并发编程入门为啥写这篇文章?(09))
您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连。
1. 社区里走一走,每周都有福利,每周都有惊喜。马农飞阁社区飞跃计划
2. Python基础专栏,基础知识一应俱全。 Python从入门到精通
❤️ 3. Ceph实战,从原理到实战,无所不包。 Ceph实战
❤️ 4. Java高并发编程介绍,点进来学习Java高并发。 Java高并发编程简介
为什么要写这个文章?
前两篇文章我们分别介绍了
使用正则表达式爬取古诗词散文网站,玩玩学习【python爬虫入门进阶】(09)
使用生产者-消费者模式抓取bucket图片,一下子获取大量表情【python爬虫入门进阶】(11)
还没来得及看的朋友可以再看一波。
本文以小凡表网站为例介绍如何从动态网页中抓取数据。上面说的数据爬取是为了说明哪些是静态网页,即接口直接返回一个Html页面。我们只需要通过Xpath等方式提取页面内容即可。
今天要讲的另一种网站就是页面数据通过ajax返回。对于这种网站,我们如何抓取他的数据?
为什么要写这个文章?分析页面 ajax获取ajax数据的方法是什么 获取数据汇总分析页面
首先打开这个网站,经过简单的分析,我们可以得出三个结论。
点击查看更多数据后,页面地址不变,页面不会刷新。单击以查看更多一次将请求该接口一次。页面的数据以application/json的形式由接口返回。 p 参数控制返回哪一页数据。 n 参数控制每页返回的数据项数。什么是ajax
AJAX(Asynchronouse JavaScript And XML)中文称为异步JavaScript和XML。主要用于前端和服务器端进行少量数据交互。 Ajax 可以实现网页的异步加载,这意味着可以在不重新加载整个网页的情况下部分更新网页的某个部分。传统网页(不使用 Ajax)如果需要更新内容,需要重新加载整个网页。
因为传统的数据传输格式是XML语法,所以叫做AJAX。其实现在数据交互基本都是用JSON。使用ajax加载的数据,即使使用js,数据渲染到浏览器中,右键---->查看网页源码,仍然看不到通过ajax加载的数据,只加载了html使用网址代码。
如何获取ajax数据直接分析ajax调用的接口,然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。 (文章后面会详细介绍)获取数据
这个小餐桌网站的界面比较简单。没有加密认证什么的,直接通过requests请求即可。这是一个示例代码:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36"
}
requests.packages.urllib3.disable_warnings()
if __name__ == '__main__':
for i in range(1,10):
url = "https://www.xfz.cn/api/website/articles/?p={0}&n=20&type=".format(str(i))
resp = requests.get(url, headers=headers, verify=False)
print(resp.json())
运行结果:
总结
本文以小凡表网站为例,简单介绍一下如何抓取动态网页的数据。
抓取动态网页(让百度蜘蛛抓取我们的网站,那么最重要的就是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-30 06:21
在网站建设的过程中,很多企业网主和企业主都希望自己的优质网站能够被百度收录,有时除了发一些文章,不知道该怎么办。其实被收录还是有点难度的。今天小编就来给大家分析一下。
其实我们想让百度蜘蛛抓取我们的网站,所以最重要的是我们要了解百度蜘蛛是什么!注意这里的蜘蛛不是我们生活中的蜘蛛动物,这里的蜘蛛是一个程序!我们认为互联网是一个大网,蜘蛛是在这里活跃的程序蜘蛛。所以我们用好引擎蜘蛛,我们的优化和包容会事半功倍。
对于互联网,蜘蛛爬行我们网站所有栏目站点的概率非常低。毕竟,蜘蛛只是一个程序,不可能像我们的人脑一样聪明。其实在我们希望蜘蛛的爬行过程中,我要注意以下三个最重要的事情。
蜘蛛:引擎蜘蛛
1. 网站的扁平化设计
因为蜘蛛在抓取网页的过程中有两种方法,广度和深度。大家很容易理解,广度爬取就是按顺序爬取,然后在一个完整页面的末尾进行下一页。一个简单的例子就是我们网站首页的所有内容蜘蛛在开始下一级之前都已经查看过我们,比如产品中心的爬取。就是这样一个链接。但是深度是从首页直接到产品中心再到具体产品的一个层次。对于SEO来说,深度更好,每一层的内容蜘蛛都会不停地爬行。这样,外部网站的内容被收录的概率非常高。所以关键是外部扁平化网站设计风格是一种符合百度爬虫的机制。因为在设计过程中布局简洁。降低运算能耗,提高计算速度,让蜘蛛爬行更顺畅。因此,我们在网站设计的初期就需要考虑很多内容。比如我们的爬取,在前期建站的过程中就应该考虑到。所以扁平化的网站建设风格更受企业欢迎,当然蜘蛛也喜欢。
二、 站点地图
网站管理员可以创建网站地图,很多引擎的蜘蛛都会跟随网站地图。我们把网站内容的所有链接都放在这个文件夹中。这样蜘蛛在爬行的过程中会很流畅,爬行率还是很高的。我们的搜索引擎在抓取时抓取的网页形式有很多种,比如我们的PDF、DOC、JPG等多种网站形式。这些文件在被收录
之前经过处理以提取信息。
三、 站点安全
有时我们发现上面两点我们做得比较好,但是如果蜘蛛爬行的数量和宽度都不深怎么办?此时,我们必须保证我们网站的某些内容和安全性。
我们网站的服务器和网络服务商呢?不能说网站经常打不开。无论在时间上付出多少努力,都是白费力气。因此,服务器的安全和网络运营商的稳定性非常重要。
我们网站是否存在死链接和异常跳转。当然,死链接的存在不仅会影响蜘蛛爬行,还会影响我们网站目标客户的满意度。不知道蜘蛛被异常的跳跃引到哪里去了。蜘蛛是一个程序,不会自己回头。
当然,还有IP阻塞、DNS异常和UA阻塞。这些问题出现的概率非常小。网站公司会处理这些问题,所以不用担心。
网站安全很重要
结合以上两个方面,引擎蜘蛛爬行更加顺畅。对内,是网站的质量和服务器的稳定性,保证网站不会出现异常问题。对外,就是建立一个站点地图,方便我们的蜘蛛爬取。事实上,仔细分析搜索引擎的一些规则,可以更好地帮助我们应用这些内容。帮助我们的网站更好地被搜索引擎收录。 查看全部
抓取动态网页(让百度蜘蛛抓取我们的网站,那么最重要的就是)
在网站建设的过程中,很多企业网主和企业主都希望自己的优质网站能够被百度收录,有时除了发一些文章,不知道该怎么办。其实被收录还是有点难度的。今天小编就来给大家分析一下。
其实我们想让百度蜘蛛抓取我们的网站,所以最重要的是我们要了解百度蜘蛛是什么!注意这里的蜘蛛不是我们生活中的蜘蛛动物,这里的蜘蛛是一个程序!我们认为互联网是一个大网,蜘蛛是在这里活跃的程序蜘蛛。所以我们用好引擎蜘蛛,我们的优化和包容会事半功倍。
对于互联网,蜘蛛爬行我们网站所有栏目站点的概率非常低。毕竟,蜘蛛只是一个程序,不可能像我们的人脑一样聪明。其实在我们希望蜘蛛的爬行过程中,我要注意以下三个最重要的事情。
蜘蛛:引擎蜘蛛
1. 网站的扁平化设计
因为蜘蛛在抓取网页的过程中有两种方法,广度和深度。大家很容易理解,广度爬取就是按顺序爬取,然后在一个完整页面的末尾进行下一页。一个简单的例子就是我们网站首页的所有内容蜘蛛在开始下一级之前都已经查看过我们,比如产品中心的爬取。就是这样一个链接。但是深度是从首页直接到产品中心再到具体产品的一个层次。对于SEO来说,深度更好,每一层的内容蜘蛛都会不停地爬行。这样,外部网站的内容被收录的概率非常高。所以关键是外部扁平化网站设计风格是一种符合百度爬虫的机制。因为在设计过程中布局简洁。降低运算能耗,提高计算速度,让蜘蛛爬行更顺畅。因此,我们在网站设计的初期就需要考虑很多内容。比如我们的爬取,在前期建站的过程中就应该考虑到。所以扁平化的网站建设风格更受企业欢迎,当然蜘蛛也喜欢。
二、 站点地图
网站管理员可以创建网站地图,很多引擎的蜘蛛都会跟随网站地图。我们把网站内容的所有链接都放在这个文件夹中。这样蜘蛛在爬行的过程中会很流畅,爬行率还是很高的。我们的搜索引擎在抓取时抓取的网页形式有很多种,比如我们的PDF、DOC、JPG等多种网站形式。这些文件在被收录
之前经过处理以提取信息。
三、 站点安全
有时我们发现上面两点我们做得比较好,但是如果蜘蛛爬行的数量和宽度都不深怎么办?此时,我们必须保证我们网站的某些内容和安全性。
我们网站的服务器和网络服务商呢?不能说网站经常打不开。无论在时间上付出多少努力,都是白费力气。因此,服务器的安全和网络运营商的稳定性非常重要。
我们网站是否存在死链接和异常跳转。当然,死链接的存在不仅会影响蜘蛛爬行,还会影响我们网站目标客户的满意度。不知道蜘蛛被异常的跳跃引到哪里去了。蜘蛛是一个程序,不会自己回头。
当然,还有IP阻塞、DNS异常和UA阻塞。这些问题出现的概率非常小。网站公司会处理这些问题,所以不用担心。
网站安全很重要
结合以上两个方面,引擎蜘蛛爬行更加顺畅。对内,是网站的质量和服务器的稳定性,保证网站不会出现异常问题。对外,就是建立一个站点地图,方便我们的蜘蛛爬取。事实上,仔细分析搜索引擎的一些规则,可以更好地帮助我们应用这些内容。帮助我们的网站更好地被搜索引擎收录。
抓取动态网页(Selenium自动化动态网页的数据代码代码结果四.总结(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-28 13:10
内容
前言
学习Selenium自动化测试框架,在Anaconda的虚拟环境中安装selenium和webdrive等必要的库。熟悉浏览器的开发者模式(Chrome和Edge浏览器按F12)分析网页结构,找到对应网页元素的技巧。然后完成以下任务:
1)自动测试网页。比如在百度网页上自动填写搜索关键词,完成自动搜索。
2) 爬取一个动态网页的数据,根据附件的要求实现代码。
3) 抓取京东网站上感兴趣的书籍信息(如关键词“python编程”的前200本书)并保存。
一.Selenium 1. 简介
Selenium 是一个 Web 自动化测试工具。它最初是为自动化网站测试而开发的。类型就像我们用来玩游戏的按钮向导。可根据指定指令自动运行。不同的是,Selenium 可以直接在浏览器上运行。支持所有主流浏览器(包括PhantomJS等非接口浏览器)。
Selenium 可以根据我们的指示让浏览器自动加载页面,获取所需的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些操作。
Selenium 没有浏览器,不支持浏览器的功能。需要配合第三方浏览器使用。但是我们有时需要让它嵌入到代码中运行,所以我们可以使用一个叫做 PhantomJS 的工具来代替真正的浏览器。
2.环境配置
打开 Anaconda 提示
conda install selenium
3.安装驱动
Selenium 官网驱动下载(下载 | Selenium)
适用于 Chrome 的 ChromeDriver 镜像
二. 爬取动态网页的数据
代码
def write_csv(csv_head,csv_content,csv_path):
with open(csv_path, 'w', newline='',encoding='utf-8') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(csv_head)
fileWriter.writerows(csv_content)
print('爬取信息成功')
quote=driver.find_elements_by_class_name("quote")
#将要收集的信息放在quote_content里
for i in tqdm(range(len(quote))):
quote_text=quote[i].find_element_by_class_name("text")
quote_author=quote[i].find_element_by_class_name("author")
temp=[]
temp.append(quote_text.text)
temp.append(quote_author.text)
quote_content.append(temp)
write_csv(quote_head,quote_content,quote_path)
三. 在京东网站上爬取感兴趣的书籍信息
代码
<p>driver = webdriver.Chrome("E:\GoogleDownload\chromedriver_win32\chromedriver.exe")
driver.set_window_size(1920,1080)
# 京东网站
driver.get("https://www.jd.com/")
# 输入需要查找的关键字
key=driver.find_element_by_id("key").send_keys("python编程")
time.sleep(1)
# 点击搜素按钮
button=driver.find_element_by_class_name("button").click()
time.sleep(1)
# 获取所有窗口
windows = driver.window_handles
# 切换到最新的窗口
driver.switch_to.window(windows[-1])
time.sleep(1)
# js语句
js = 'return document.body.scrollHeight'
# 获取body高度
max_height = driver.execute_script(js)
max_height=(int(max_height/1000))*1000
# 当前滚动条高度
tmp_height=1000
# 所有书籍的字典
res_dict={}
# 需要爬取的数量
num=200
while len(res_dict) 查看全部
抓取动态网页(Selenium自动化动态网页的数据代码代码结果四.总结(一))
内容
前言
学习Selenium自动化测试框架,在Anaconda的虚拟环境中安装selenium和webdrive等必要的库。熟悉浏览器的开发者模式(Chrome和Edge浏览器按F12)分析网页结构,找到对应网页元素的技巧。然后完成以下任务:
1)自动测试网页。比如在百度网页上自动填写搜索关键词,完成自动搜索。
2) 爬取一个动态网页的数据,根据附件的要求实现代码。
3) 抓取京东网站上感兴趣的书籍信息(如关键词“python编程”的前200本书)并保存。
一.Selenium 1. 简介
Selenium 是一个 Web 自动化测试工具。它最初是为自动化网站测试而开发的。类型就像我们用来玩游戏的按钮向导。可根据指定指令自动运行。不同的是,Selenium 可以直接在浏览器上运行。支持所有主流浏览器(包括PhantomJS等非接口浏览器)。
Selenium 可以根据我们的指示让浏览器自动加载页面,获取所需的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些操作。
Selenium 没有浏览器,不支持浏览器的功能。需要配合第三方浏览器使用。但是我们有时需要让它嵌入到代码中运行,所以我们可以使用一个叫做 PhantomJS 的工具来代替真正的浏览器。
2.环境配置
打开 Anaconda 提示
conda install selenium
3.安装驱动
Selenium 官网驱动下载(下载 | Selenium)
适用于 Chrome 的 ChromeDriver 镜像
二. 爬取动态网页的数据
代码
def write_csv(csv_head,csv_content,csv_path):
with open(csv_path, 'w', newline='',encoding='utf-8') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(csv_head)
fileWriter.writerows(csv_content)
print('爬取信息成功')
quote=driver.find_elements_by_class_name("quote")
#将要收集的信息放在quote_content里
for i in tqdm(range(len(quote))):
quote_text=quote[i].find_element_by_class_name("text")
quote_author=quote[i].find_element_by_class_name("author")
temp=[]
temp.append(quote_text.text)
temp.append(quote_author.text)
quote_content.append(temp)
write_csv(quote_head,quote_content,quote_path)
三. 在京东网站上爬取感兴趣的书籍信息
代码
<p>driver = webdriver.Chrome("E:\GoogleDownload\chromedriver_win32\chromedriver.exe")
driver.set_window_size(1920,1080)
# 京东网站
driver.get("https://www.jd.com/";)
# 输入需要查找的关键字
key=driver.find_element_by_id("key").send_keys("python编程")
time.sleep(1)
# 点击搜素按钮
button=driver.find_element_by_class_name("button").click()
time.sleep(1)
# 获取所有窗口
windows = driver.window_handles
# 切换到最新的窗口
driver.switch_to.window(windows[-1])
time.sleep(1)
# js语句
js = 'return document.body.scrollHeight'
# 获取body高度
max_height = driver.execute_script(js)
max_height=(int(max_height/1000))*1000
# 当前滚动条高度
tmp_height=1000
# 所有书籍的字典
res_dict={}
# 需要爬取的数量
num=200
while len(res_dict)
抓取动态网页(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-28 07:12
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。
大大地
优势
缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。pip install selenium install chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。安装 Selenium 和 chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,所以在网页上用鼠标点击。所以,如果要选中checkbox标签,先选中这个标签,再执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
记住Tag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
fromselenium.webdriver.support.ui importSelect
#选中这个标签,然后用Select创建一个对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
#根据索引选择
selectTag.select_by_index(1)
# 按值选择
selectTag.select_by_value("")
# 根据可见文本选择
selectTag.select_by_visible_text("95 显示客户端")
# 取消所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
2/显示等待:显示等待是表示在执行获取元素的操作之前已经建立了某种条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
更多条件参考:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。
Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('https://www.baidu.com')")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。
screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
. 查看全部
抓取动态网页(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。
大大地
优势
缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。pip install selenium install chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。安装 Selenium 和 chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,所以在网页上用鼠标点击。所以,如果要选中checkbox标签,先选中这个标签,再执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
记住Tag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
fromselenium.webdriver.support.ui importSelect
#选中这个标签,然后用Select创建一个对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
#根据索引选择
selectTag.select_by_index(1)
# 按值选择
selectTag.select_by_value("")
# 根据可见文本选择
selectTag.select_by_visible_text("95 显示客户端")
# 取消所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
2/显示等待:显示等待是表示在执行获取元素的操作之前已经建立了某种条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
更多条件参考:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。
Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('https://www.baidu.com')")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。
screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
.
抓取动态网页(ajax横行的年代,我们的网页是残缺的吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-28 07:10
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html。其中有
跳过js加载部分,表示爬虫爬取的网页不完整,不完整。可以在下方看到博客园主页
从首页加载可以看出,页面渲染后,会有5个ajax异步请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候想要获取就必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎具有三大支柱。
Trident:是IE核心,WebBrowser就是基于这个核心,但是加载性比较差。
Gecko:FF的核心,性能优于Trident。
WebKit:Safari 和 Chrome 的核心。性能如你所知,在真实场景中依然是主要特色。
好了,为了简单方便,这里就用WebBrowser来玩,大家在使用WebBrowser的时候要注意以下几点:
第一:因为WebBrowser是System.Windows.Forms中的winform控件,所以需要设置STAThread标签。
第二:Winform 是事件驱动的,Console 不响应事件。所有事件都在 windows 消息队列中等待执行。为防止程序假死,
我们需要调用DoEvents方法来转移控制权,让操作系统执行其他事件。
第三:WebBrowser中的内容,我们需要使用DomDocument查看,而不是DocumentText。
判断一个动态网页是否已经加载,通常有两种方法:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们需要在这里
只需将计数值记录在
.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们也可以通过设置一个Timer来判断,比如3s、4s、5s以后。
WEBbrowser 是否已加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然效果还是一样的,所以就不截图了。从上面两种写法来看,我们的WebBrowser是放在主线程上的。来看看如何把它放到工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
原文: 查看全部
抓取动态网页(ajax横行的年代,我们的网页是残缺的吗?)
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html。其中有
跳过js加载部分,表示爬虫爬取的网页不完整,不完整。可以在下方看到博客园主页
从首页加载可以看出,页面渲染后,会有5个ajax异步请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候想要获取就必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎具有三大支柱。
Trident:是IE核心,WebBrowser就是基于这个核心,但是加载性比较差。
Gecko:FF的核心,性能优于Trident。
WebKit:Safari 和 Chrome 的核心。性能如你所知,在真实场景中依然是主要特色。
好了,为了简单方便,这里就用WebBrowser来玩,大家在使用WebBrowser的时候要注意以下几点:
第一:因为WebBrowser是System.Windows.Forms中的winform控件,所以需要设置STAThread标签。
第二:Winform 是事件驱动的,Console 不响应事件。所有事件都在 windows 消息队列中等待执行。为防止程序假死,
我们需要调用DoEvents方法来转移控制权,让操作系统执行其他事件。
第三:WebBrowser中的内容,我们需要使用DomDocument查看,而不是DocumentText。
判断一个动态网页是否已经加载,通常有两种方法:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们需要在这里
只需将计数值记录在
.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们也可以通过设置一个Timer来判断,比如3s、4s、5s以后。
WEBbrowser 是否已加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然效果还是一样的,所以就不截图了。从上面两种写法来看,我们的WebBrowser是放在主线程上的。来看看如何把它放到工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
原文:
抓取动态网页(网页爬取动态加载的两种方法介绍及使用方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-26 04:15
)
一、动态网页爬虫介绍
很多网站都是用javascript来写网站的,很多内容都不会出现在HTML源代码中,所以之前爬取静态网页的方法是无法使用的。有一种异步技术叫做AJAX,它的价值在于通过后台和服务器之间的少量数据变换实现网页的异步更新。换句话说,在不重新加载整个网页的情况下更新网页的某个部分。减少网页上重复内容的下载并节省流量。但是随之而来的麻烦是我们在HTML代码中找不到我们想要的数据。解决这种爬取动态加载的内容,有两种方法:
通过浏览器解析地址查看元素,使用Selenium模拟浏览器抓取二、解析真实地址并抓取
我们要的数据不是HTML,而是可以找到数据的真实地址。请求这个地址也可以找到你想要的数据,完成书中的例子。首先打开网站:这个网站是JS写的,鼠标右键,点击check。刷新页面,可以看到网页上的所有文件都加载完毕了。这个过程就是抓包的过程。然后,点击网络,找到收录
数据的文件,记住是json数据。
单击标题以查找真实地址。然后将请求发送到真实地址。
1.发送请求,获取数据
import requests
# 构建url
url = """https://api-zero.livere.com/v1 ... ot%3B
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
r = requests.get(url, headers=headers)
print(r.text)
2.分析数据
要从json数据中提取注释,首先我们需要找到符合json格式的部分。然后,使用 json.loads 将字符串格式的响应体转换为 json 数据。然后,根据json数据的结构,可以从评论列表中提取comment_list。最后,通过for循环,将注释文本提取出来并打印出来。
import json
json_string = r.text
# 找到符合json格式的数据
json_string = json_string[json_string.find('{'): -2]
# 转换为json格式
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print(message)
三、 通过selenium模拟浏览器爬行
一些网站对地址进行加密,使得一些变量无法分析。接下来,我们将使用第二种方法,使用浏览器渲染引擎。显示网页时直接使用浏览器解析HTML,应用CSS样式,执行JavaScript语句。这种方法会打开浏览器,加载网页,自动操作浏览器浏览各种网页,顺便抓取数据,把抓取动态网页变成抓取静态网页。我们可以使用selenium库来模拟浏览器完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。直接在浏览器中运行,浏览器根据脚本代码自动进行点击、输入、打开、验证等操作。
1. 安装硒
pip 安装硒
下载'geckodriver'并在Python安装目录中。
2. 使用 selenium 爬取数据
第一步:找到评论的HTML代码标签。使用火狐浏览器,点击页面,找到标签,定位到评论数据
第二步:尝试获取一条评论数据,使用如下代码获取数据。
# 使用CSS选择器查找元素,找到class为'reply-content'的div元素
comment = driver.find_element_by_css_selector('div.reply-content')
# 通过元素的tag去寻找‘p’元素
content = comment.find_element_by_tag_name('p')
print(content.text)
还是有问题啊 网页打不开啊
也可能存在解析失败报错的情况,报错“Message: Unable to locate element: div.reply_content”。这是因为源码需要解析成iframe,需要添加下面这行代码。
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")) 查看全部
抓取动态网页(网页爬取动态加载的两种方法介绍及使用方法
)
一、动态网页爬虫介绍
很多网站都是用javascript来写网站的,很多内容都不会出现在HTML源代码中,所以之前爬取静态网页的方法是无法使用的。有一种异步技术叫做AJAX,它的价值在于通过后台和服务器之间的少量数据变换实现网页的异步更新。换句话说,在不重新加载整个网页的情况下更新网页的某个部分。减少网页上重复内容的下载并节省流量。但是随之而来的麻烦是我们在HTML代码中找不到我们想要的数据。解决这种爬取动态加载的内容,有两种方法:
通过浏览器解析地址查看元素,使用Selenium模拟浏览器抓取二、解析真实地址并抓取
我们要的数据不是HTML,而是可以找到数据的真实地址。请求这个地址也可以找到你想要的数据,完成书中的例子。首先打开网站:这个网站是JS写的,鼠标右键,点击check。刷新页面,可以看到网页上的所有文件都加载完毕了。这个过程就是抓包的过程。然后,点击网络,找到收录
数据的文件,记住是json数据。
单击标题以查找真实地址。然后将请求发送到真实地址。
1.发送请求,获取数据
import requests
# 构建url
url = """https://api-zero.livere.com/v1 ... ot%3B
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
r = requests.get(url, headers=headers)
print(r.text)
2.分析数据
要从json数据中提取注释,首先我们需要找到符合json格式的部分。然后,使用 json.loads 将字符串格式的响应体转换为 json 数据。然后,根据json数据的结构,可以从评论列表中提取comment_list。最后,通过for循环,将注释文本提取出来并打印出来。
import json
json_string = r.text
# 找到符合json格式的数据
json_string = json_string[json_string.find('{'): -2]
# 转换为json格式
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print(message)
三、 通过selenium模拟浏览器爬行
一些网站对地址进行加密,使得一些变量无法分析。接下来,我们将使用第二种方法,使用浏览器渲染引擎。显示网页时直接使用浏览器解析HTML,应用CSS样式,执行JavaScript语句。这种方法会打开浏览器,加载网页,自动操作浏览器浏览各种网页,顺便抓取数据,把抓取动态网页变成抓取静态网页。我们可以使用selenium库来模拟浏览器完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。直接在浏览器中运行,浏览器根据脚本代码自动进行点击、输入、打开、验证等操作。
1. 安装硒
pip 安装硒
下载'geckodriver'并在Python安装目录中。
2. 使用 selenium 爬取数据
第一步:找到评论的HTML代码标签。使用火狐浏览器,点击页面,找到标签,定位到评论数据
第二步:尝试获取一条评论数据,使用如下代码获取数据。
# 使用CSS选择器查找元素,找到class为'reply-content'的div元素
comment = driver.find_element_by_css_selector('div.reply-content')
# 通过元素的tag去寻找‘p’元素
content = comment.find_element_by_tag_name('p')
print(content.text)
还是有问题啊 网页打不开啊
也可能存在解析失败报错的情况,报错“Message: Unable to locate element: div.reply_content”。这是因为源码需要解析成iframe,需要添加下面这行代码。
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
抓取动态网页(抓取动态网页大概可以这样做:/zenith不都能爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-25 21:05
抓取动态网页大概可以这样做:
1、获取headers,
2、找到该网站的cookie,记下来,
3、设置抓取框,在scrapy.spiders中的default_cookie配置,
实名反对@不用脑子的谢炎。1.这是不可能的;2.爬虫大部分需要高性能,跑在python上我觉得瓶颈会大部分在处理数据上面,而不是业务逻辑上;3.cookie写入很麻烦;4.爬虫的组件多了去了,几千上万个包,你要写整个框架;5.数据库压力巨大,你要维护好多个sqlite数据库,备份,恢复,sqlite的mongo;6.服务器几十万上百万台,爬那么点也是累死;7.还有很多欢迎补充。上面一条可以让所有的爬虫都变成挂机动作,要你干什么有啥。
面向对象可以这样,你看看你这个网站对你有没有需求,
不可以,除非加上感知机制。
我大三上面的代码,大概一年前做网站前端实习在做。
你需要pyspider
其实linux上pythonscrapyceleryscrapy_redis/zenith/hashlib不都能爬虫。我是给工作室做网站前端的,也用python做爬虫,包括反爬虫,简单的代码好写,多调用一下api就行。hapyscrapy好像是用于web中间件的,有点麻烦的。你可以找下官方的文档就懂了。 查看全部
抓取动态网页(抓取动态网页大概可以这样做:/zenith不都能爬虫)
抓取动态网页大概可以这样做:
1、获取headers,
2、找到该网站的cookie,记下来,
3、设置抓取框,在scrapy.spiders中的default_cookie配置,
实名反对@不用脑子的谢炎。1.这是不可能的;2.爬虫大部分需要高性能,跑在python上我觉得瓶颈会大部分在处理数据上面,而不是业务逻辑上;3.cookie写入很麻烦;4.爬虫的组件多了去了,几千上万个包,你要写整个框架;5.数据库压力巨大,你要维护好多个sqlite数据库,备份,恢复,sqlite的mongo;6.服务器几十万上百万台,爬那么点也是累死;7.还有很多欢迎补充。上面一条可以让所有的爬虫都变成挂机动作,要你干什么有啥。
面向对象可以这样,你看看你这个网站对你有没有需求,
不可以,除非加上感知机制。
我大三上面的代码,大概一年前做网站前端实习在做。
你需要pyspider
其实linux上pythonscrapyceleryscrapy_redis/zenith/hashlib不都能爬虫。我是给工作室做网站前端的,也用python做爬虫,包括反爬虫,简单的代码好写,多调用一下api就行。hapyscrapy好像是用于web中间件的,有点麻烦的。你可以找下官方的文档就懂了。

