
实时抓取网页数据
实时抓取网页数据(老左在"10款国外免费网站在线监控服务工具")
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-24 07:11
IIS7网站监控可以提前防范各种网站劫持,免费在线查询,适用于各大站长、政府网站、学校、公司、医院等.网站。他可以做24小时定时监控,同时可以让你知道网站是否被黑了或者被黑了。
ebsite-WatcherPortable 是一个简单易用的网站 监控工具。该软件旨在定期检查网站的变化并突出显示、浏览互联网和记录宏。该软件支持自定义属性。添加新页面以检查和指定其类别。
WebChangeMonitor(网页监控软件),WebChangeMonitor是一款免费软件,它可以让你监控网页的变化,应用程序可以监控网页并根据网页内容跟踪变化,你可以查看和记录差异,你可以。
软件大小:8.2M软件官网:首页用户评分:软件类型:绿色软件运行环境:WinAll软件语言:简体中文软件分类:远程监控授权方式:免费软件插件情况:无插件网页自动刷新监控工具。
OpenWebMonitor 是一款专业的网页内容变化监控软件。该软件可以实时监控网页元素的变化,例如商品价格趋势。
网页链接监控,网页链接监控软件是一款监控网站关键词更新、监控百度贴吧、本地论坛、58同城、赶集网等的小工具。像网站一样,一旦发现与您的业务相关的帖子,会立即提醒您,并且可以免费下载。
老佐在“10款免费海外网站在线监控服务工具”文章中整理了最新的国外免费网站监控工具,可应用中文或英文等。在海外使用网站。但是都是英文的,对于少数站长来说可能感觉不一样。
网站监控工具中文免费下载_WebsiteWatcher中文官方系统首页。 查看全部
实时抓取网页数据(老左在"10款国外免费网站在线监控服务工具")
IIS7网站监控可以提前防范各种网站劫持,免费在线查询,适用于各大站长、政府网站、学校、公司、医院等.网站。他可以做24小时定时监控,同时可以让你知道网站是否被黑了或者被黑了。
ebsite-WatcherPortable 是一个简单易用的网站 监控工具。该软件旨在定期检查网站的变化并突出显示、浏览互联网和记录宏。该软件支持自定义属性。添加新页面以检查和指定其类别。
WebChangeMonitor(网页监控软件),WebChangeMonitor是一款免费软件,它可以让你监控网页的变化,应用程序可以监控网页并根据网页内容跟踪变化,你可以查看和记录差异,你可以。
软件大小:8.2M软件官网:首页用户评分:软件类型:绿色软件运行环境:WinAll软件语言:简体中文软件分类:远程监控授权方式:免费软件插件情况:无插件网页自动刷新监控工具。
OpenWebMonitor 是一款专业的网页内容变化监控软件。该软件可以实时监控网页元素的变化,例如商品价格趋势。

网页链接监控,网页链接监控软件是一款监控网站关键词更新、监控百度贴吧、本地论坛、58同城、赶集网等的小工具。像网站一样,一旦发现与您的业务相关的帖子,会立即提醒您,并且可以免费下载。
老佐在“10款免费海外网站在线监控服务工具”文章中整理了最新的国外免费网站监控工具,可应用中文或英文等。在海外使用网站。但是都是英文的,对于少数站长来说可能感觉不一样。

网站监控工具中文免费下载_WebsiteWatcher中文官方系统首页。
实时抓取网页数据(GoogleAnalytics推出新功能,可以让你的网站进行互动)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-11-22 09:19
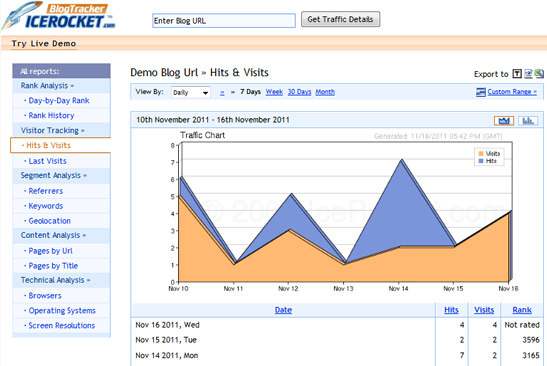
这是我们为您提供文章的文章,介绍20个最好的网站实时数据分析工具,让我们一起来看看吧!
1. 谷歌分析
这是使用最广泛的访问统计分析工具之一。几周前,谷歌分析推出了一项可以提供实时报告的新功能。您可以在您的 网站 中查看当前在线访问者的数量,了解他们观看了哪些网页、他们使用哪些 网站 链接到您的 网站、他们来自哪个国家等等.
2. Clicky
与 Google Analytics 等庞大的分析系统相比,Clicky 相对简单。它在控制面板上提供了一系列统计数据,包括最近三天的访问量、前20个链接源和前20个关键字。,虽然数据种类不多,但是可以直观的反映当前的网站访问量,UI也比较简洁清新。
3. 伍普拉
Woopra 将实时统计数据提升到另一个层次。可以实时直播网站的访问数据。您甚至可以使用 Woopra Chat 小部件与用户聊天。它还具有高级通知功能,可让您创建各种通知,例如电子邮件、声音和弹出框。
4. 图表节拍
这是一个用于新闻发布和其他类型的网站的实时分析工具。电商专业分析功能网站即将上线。它可以让您看到访问者如何与您的 网站 互动,这可以帮助您改进您的 网站。
5. GoSquared
它提供了所有常用的分析功能,还允许您查看特定访问者的数据。它集成了 Olark,让您可以与访客聊天。
6. 混合面板
该工具允许您查看访问者数据、分析趋势并比较几天内的变化。
7. 重振雄风
它提供了所有常用的实时分析功能,让您直观地了解访问者的点击位置。您甚至可以查看注册用户的姓名标签,以便跟踪他们对网站 的使用情况。
8. 皮维克
这是一个开源的实时分析工具,您可以轻松下载并安装在您自己的服务器上。
9. ShinyStat
网站提供四款产品,包括一款限量免费的分析产品,可用于个人和非盈利的网站。企业版具有搜索引擎排名检测,可以帮助您跟踪和提高网站的排名。
10. SeeVolution
目前处于测试阶段,提供热图和实时分析功能。您可以看到热图直播。它的可视化工具集允许您直观地查看和分析数据。
11. FoxMetrics
该工具提供实时分析功能,基于事件的概念和特征,您还可以设置自定义事件。它可以采集数据匹配事件和特征,然后为您提供报告,这将有助于提高您的网站。
12. 统计计数器
这是一款免费的实时分析工具,只需几行代码即可安装。它提供了所有常用的分析数据,此外,您还可以设置每天、每周或每月自动向您发送电子邮件报告。
13. 性能指标
这个工具可以为您提供实时的博客统计和推特分析。
14. Whos.Amung.Us
Whos.Amung.Us 相当独特,它可以嵌入您的网站 或博客,让您获得实时统计数据。包括免费版和付费版。
15. W3Counter
可提供实时数据,可提供30多种不同的报表,并可查看近期访问者的详细信息。
16. 跟踪观察
这是一个免费的实时分析工具,可以安装在服务器上。它提供了所有常用的统计功能和报表,您还可以查看最近访问者的详细信息并跟踪他们的轨迹。
17. 性能仪表
使用此工具,您可以跟踪当前访问者、查看源链接和来自搜索引擎的流量。这项服务是免费的。
18. Spotplex
该服务除了提供实时流量统计外,还可以显示您在所有使用该服务的网站中的网站排名。您甚至可以查看当天在 Spotplex网站 上统计的最受欢迎的 文章。
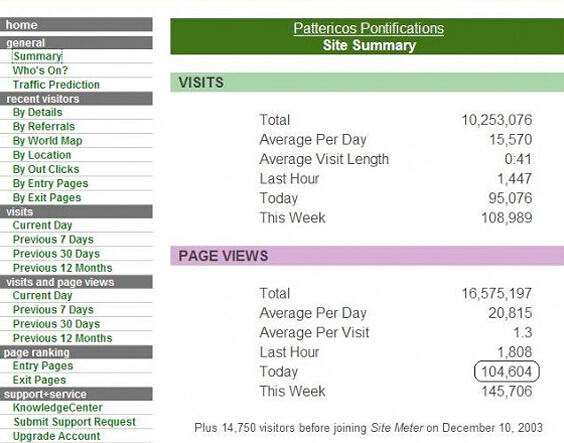
19. SiteMeter
这是另一种流行的实时交通跟踪服务。该服务提供的基础数据是免费的,但如果您想要更详细的数据,则需要付费。
20. 冰火箭
您可以获得跟踪代码或计数器并查看统计信息。如果您点击“排名”,您将看到您的博客和其他博客的比较结果。
大数据导航网站—网站分析监控工具—近40个网站分析工具的集合。 查看全部
实时抓取网页数据(GoogleAnalytics推出新功能,可以让你的网站进行互动)
这是我们为您提供文章的文章,介绍20个最好的网站实时数据分析工具,让我们一起来看看吧!
1. 谷歌分析
这是使用最广泛的访问统计分析工具之一。几周前,谷歌分析推出了一项可以提供实时报告的新功能。您可以在您的 网站 中查看当前在线访问者的数量,了解他们观看了哪些网页、他们使用哪些 网站 链接到您的 网站、他们来自哪个国家等等.
2. Clicky
与 Google Analytics 等庞大的分析系统相比,Clicky 相对简单。它在控制面板上提供了一系列统计数据,包括最近三天的访问量、前20个链接源和前20个关键字。,虽然数据种类不多,但是可以直观的反映当前的网站访问量,UI也比较简洁清新。
3. 伍普拉
Woopra 将实时统计数据提升到另一个层次。可以实时直播网站的访问数据。您甚至可以使用 Woopra Chat 小部件与用户聊天。它还具有高级通知功能,可让您创建各种通知,例如电子邮件、声音和弹出框。
4. 图表节拍
这是一个用于新闻发布和其他类型的网站的实时分析工具。电商专业分析功能网站即将上线。它可以让您看到访问者如何与您的 网站 互动,这可以帮助您改进您的 网站。

5. GoSquared
它提供了所有常用的分析功能,还允许您查看特定访问者的数据。它集成了 Olark,让您可以与访客聊天。
6. 混合面板
该工具允许您查看访问者数据、分析趋势并比较几天内的变化。
7. 重振雄风
它提供了所有常用的实时分析功能,让您直观地了解访问者的点击位置。您甚至可以查看注册用户的姓名标签,以便跟踪他们对网站 的使用情况。
8. 皮维克
这是一个开源的实时分析工具,您可以轻松下载并安装在您自己的服务器上。
9. ShinyStat
网站提供四款产品,包括一款限量免费的分析产品,可用于个人和非盈利的网站。企业版具有搜索引擎排名检测,可以帮助您跟踪和提高网站的排名。
10. SeeVolution
目前处于测试阶段,提供热图和实时分析功能。您可以看到热图直播。它的可视化工具集允许您直观地查看和分析数据。
11. FoxMetrics
该工具提供实时分析功能,基于事件的概念和特征,您还可以设置自定义事件。它可以采集数据匹配事件和特征,然后为您提供报告,这将有助于提高您的网站。
12. 统计计数器
这是一款免费的实时分析工具,只需几行代码即可安装。它提供了所有常用的分析数据,此外,您还可以设置每天、每周或每月自动向您发送电子邮件报告。
13. 性能指标
这个工具可以为您提供实时的博客统计和推特分析。
14. Whos.Amung.Us
Whos.Amung.Us 相当独特,它可以嵌入您的网站 或博客,让您获得实时统计数据。包括免费版和付费版。
15. W3Counter
可提供实时数据,可提供30多种不同的报表,并可查看近期访问者的详细信息。
16. 跟踪观察
这是一个免费的实时分析工具,可以安装在服务器上。它提供了所有常用的统计功能和报表,您还可以查看最近访问者的详细信息并跟踪他们的轨迹。
17. 性能仪表
使用此工具,您可以跟踪当前访问者、查看源链接和来自搜索引擎的流量。这项服务是免费的。
18. Spotplex
该服务除了提供实时流量统计外,还可以显示您在所有使用该服务的网站中的网站排名。您甚至可以查看当天在 Spotplex网站 上统计的最受欢迎的 文章。

19. SiteMeter
这是另一种流行的实时交通跟踪服务。该服务提供的基础数据是免费的,但如果您想要更详细的数据,则需要付费。
20. 冰火箭
您可以获得跟踪代码或计数器并查看统计信息。如果您点击“排名”,您将看到您的博客和其他博客的比较结果。
大数据导航网站—网站分析监控工具—近40个网站分析工具的集合。
实时抓取网页数据(本文如下:找到目标网页打开阳光高考网站(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-22 03:09
我们日常对于单个网页数据的PowerBI数据使用非常简单,但是批量获取网页数据就比较麻烦了。这里我们可以使用PowerBI的Power Query组件批量获取多个网页的数据。同样,您也可以使用更高版本的 Excel 自带的 Power Query 来获取。
本文以阳光高考网站为例,获取2019年全国高校名单。
详细操作步骤如下:
(一)找到登陆页面
打开阳光高考网站,找到“2019年全国普通高等学校名单”网页。
点击单个网页查看,如下:
(二)解析URL结构
在这里选择前三个省份的网址
北京:
天津市:
河北市:
可以看出,只有URL的最后一个数字是一个变量,这里我们把它当作页码ID
(三)采集第一页数据
(这里的页面ID是北京的“2”开头)
打开PowerBI Desktop,通过“获取数据”中的“web”选项获取数据。在这里,选择“Web”界面中的“Basic”选项卡。
这里我们在基本选项卡中输入目标 URL
(北京)
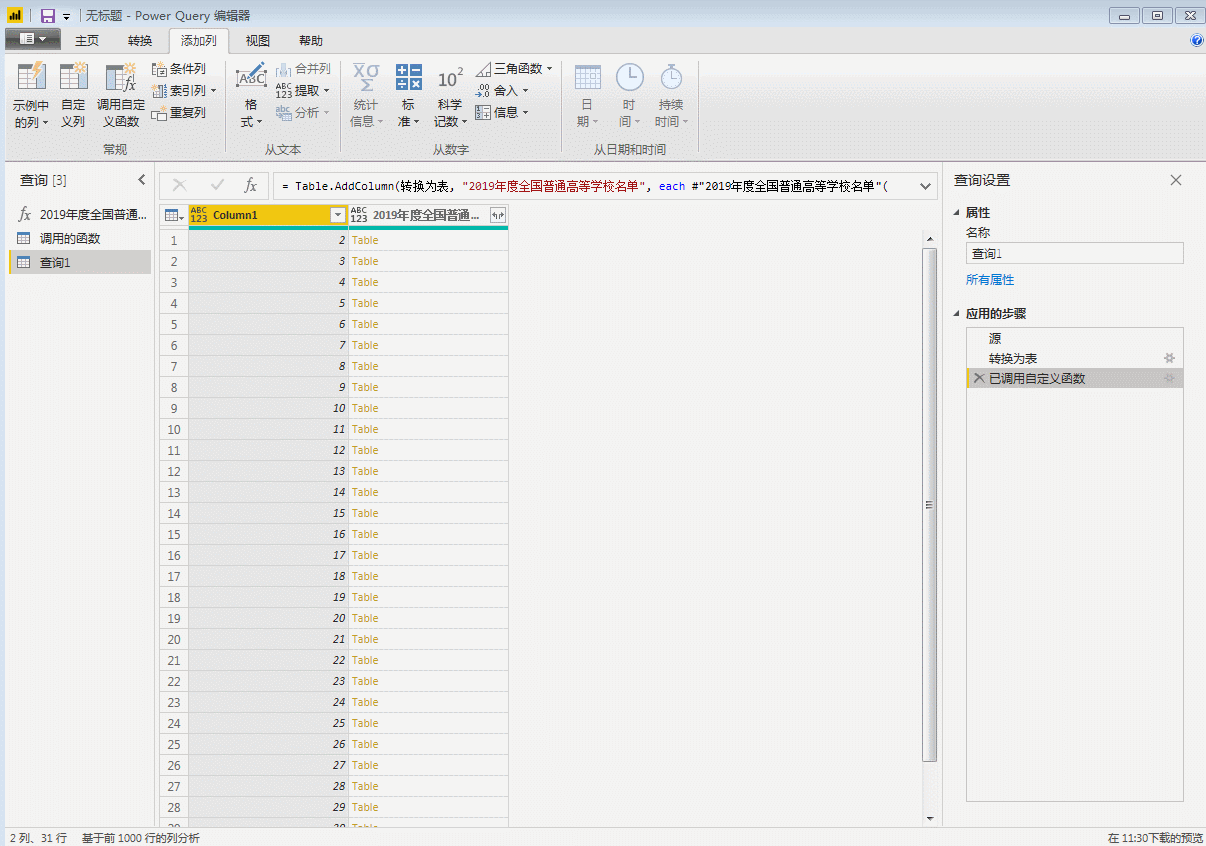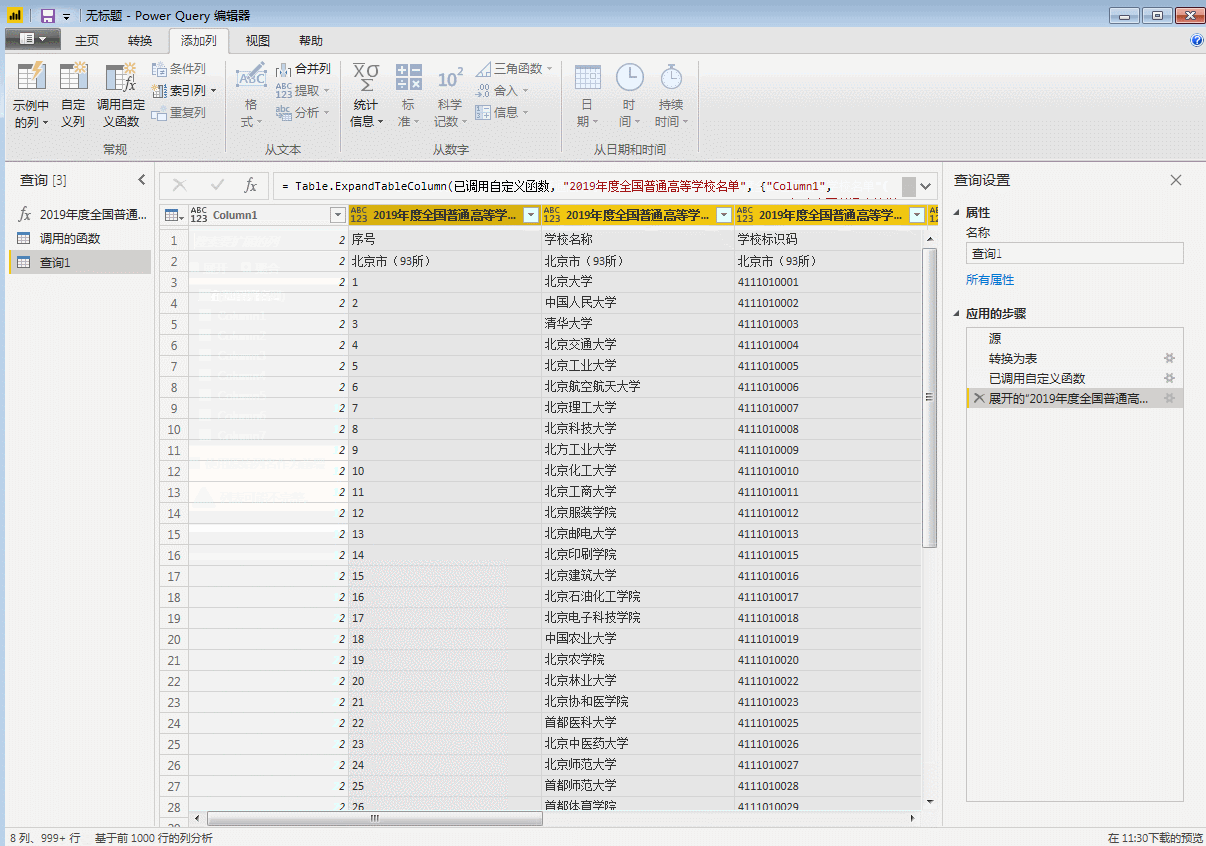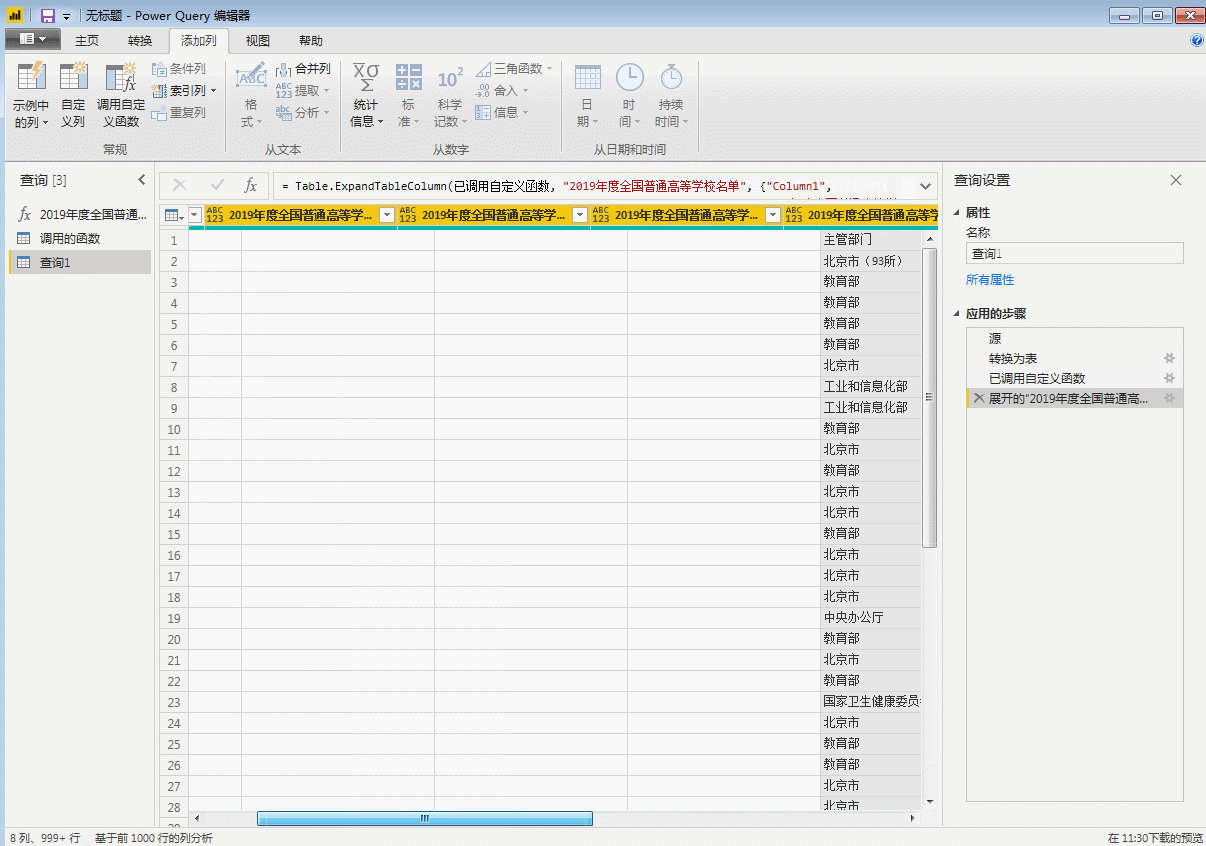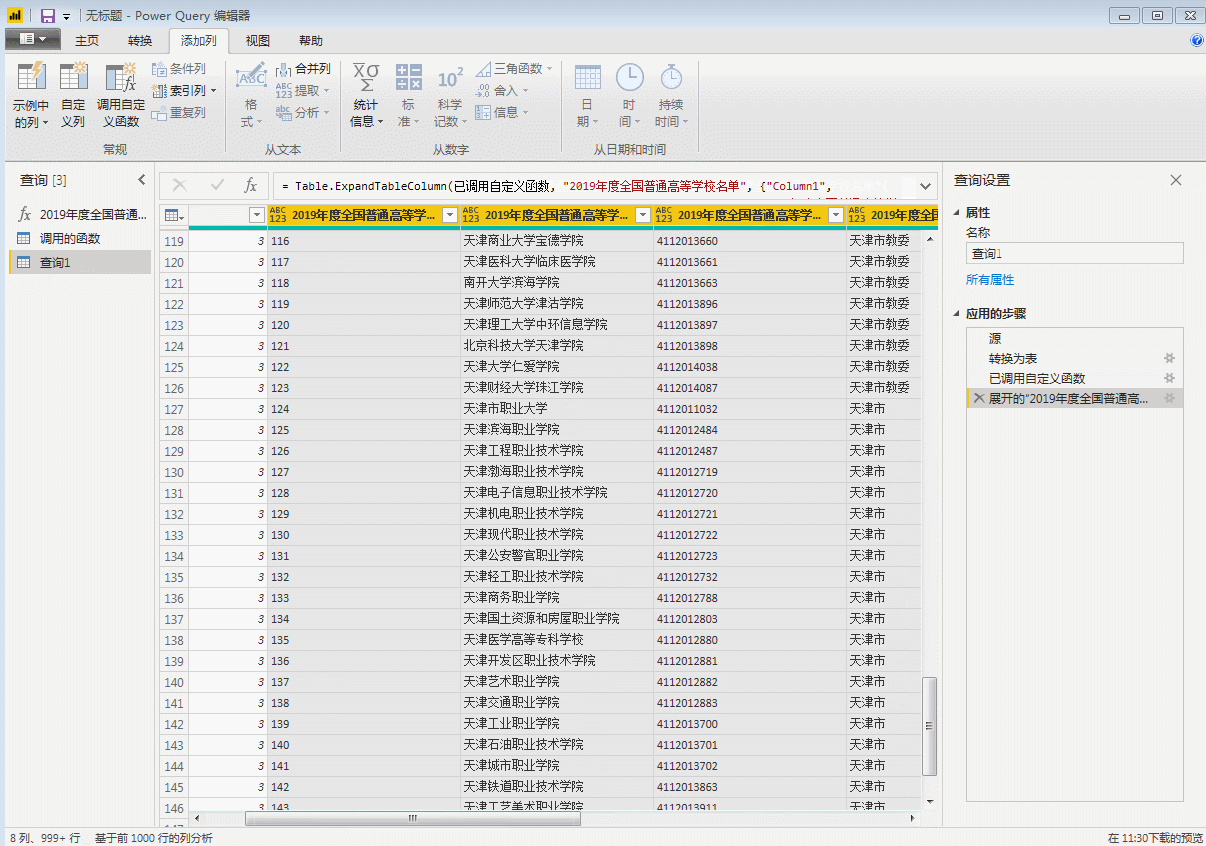
获取数据源信息如下,这里只有第一个表是我们想要的,勾选,然后点击右下角转换数据进行数据处理。
进入页面如下:
这样我们就简单的采集去到第一页的数据。然后把这个页面的数据整理一下,删除无用的信息,加上字段名。排序后采集下面其他页面的数据结构和排序后第一页的数据结构相同,可以直接使用采集的数据。
如果要大量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
我们不要在这里处理它。
(四) 根据页码参数设置自定义函数
这是最重要的一步
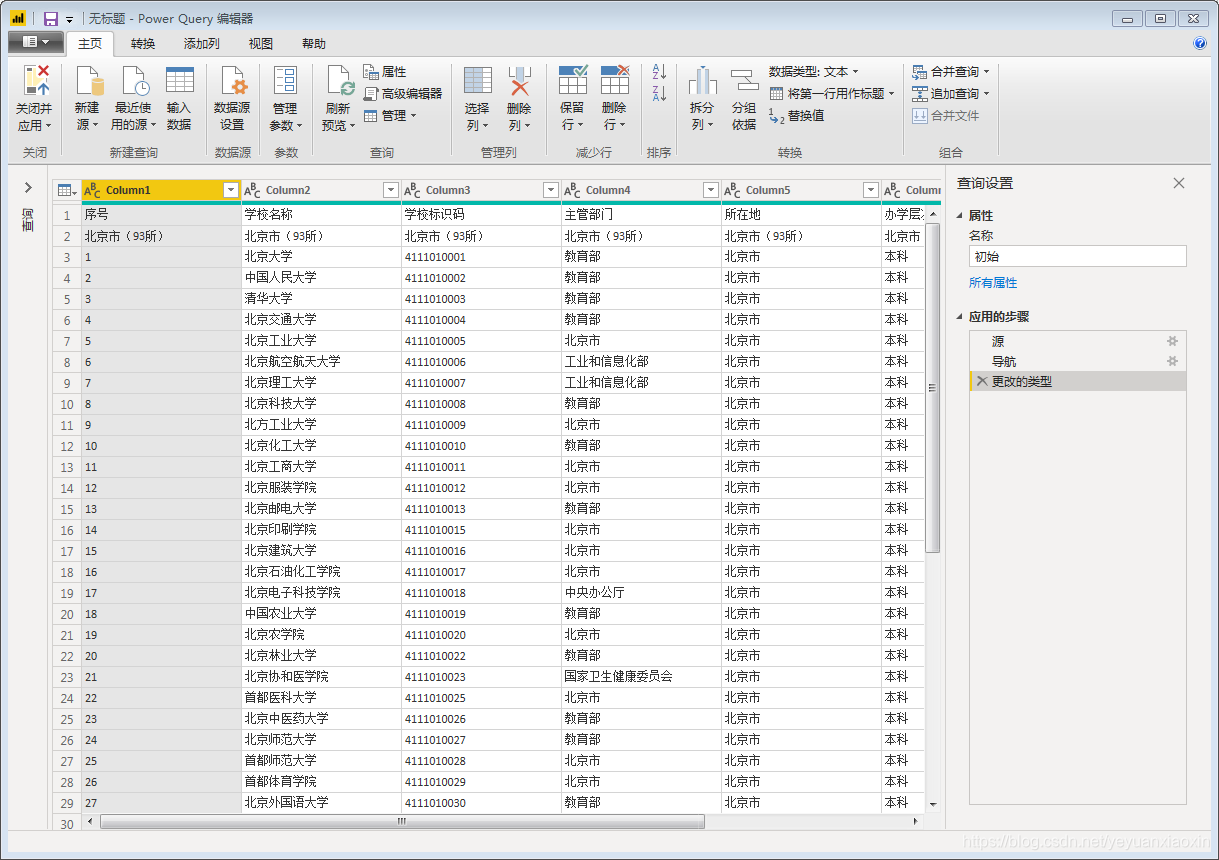
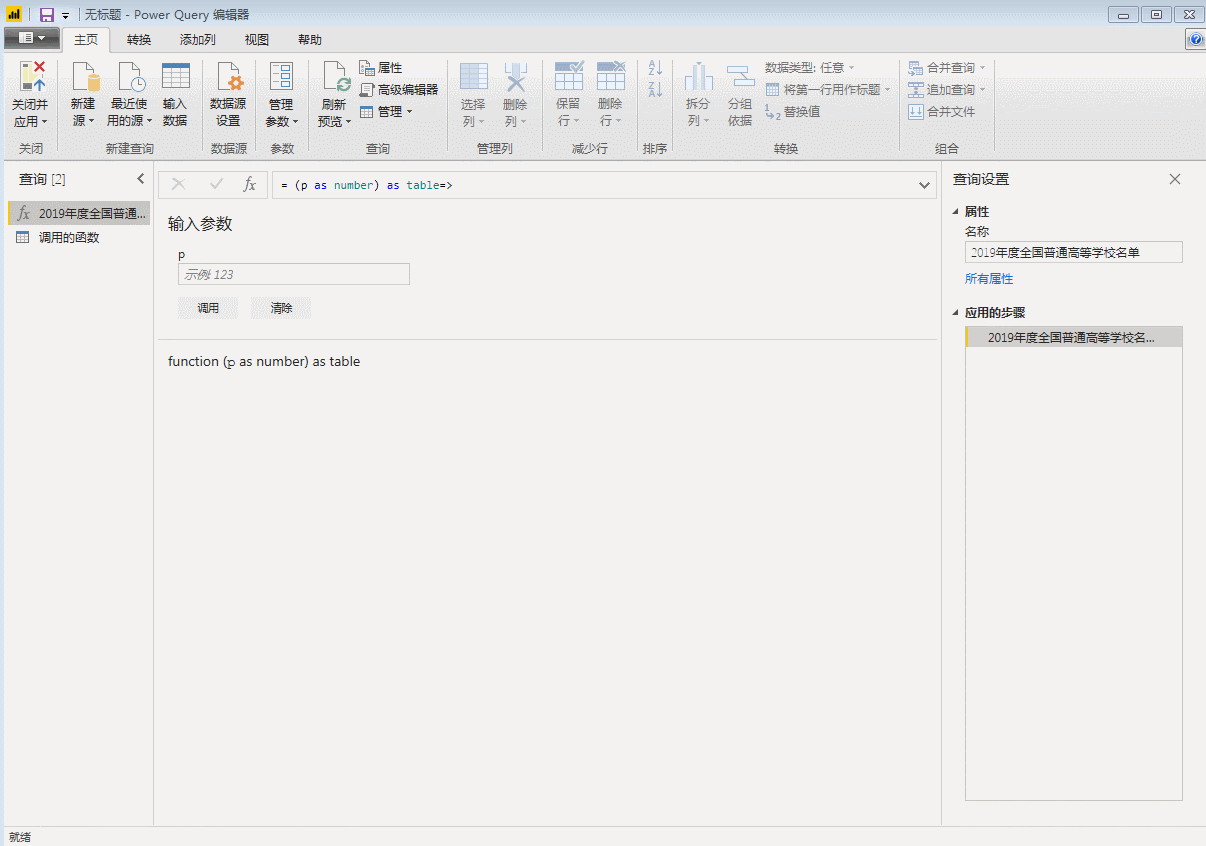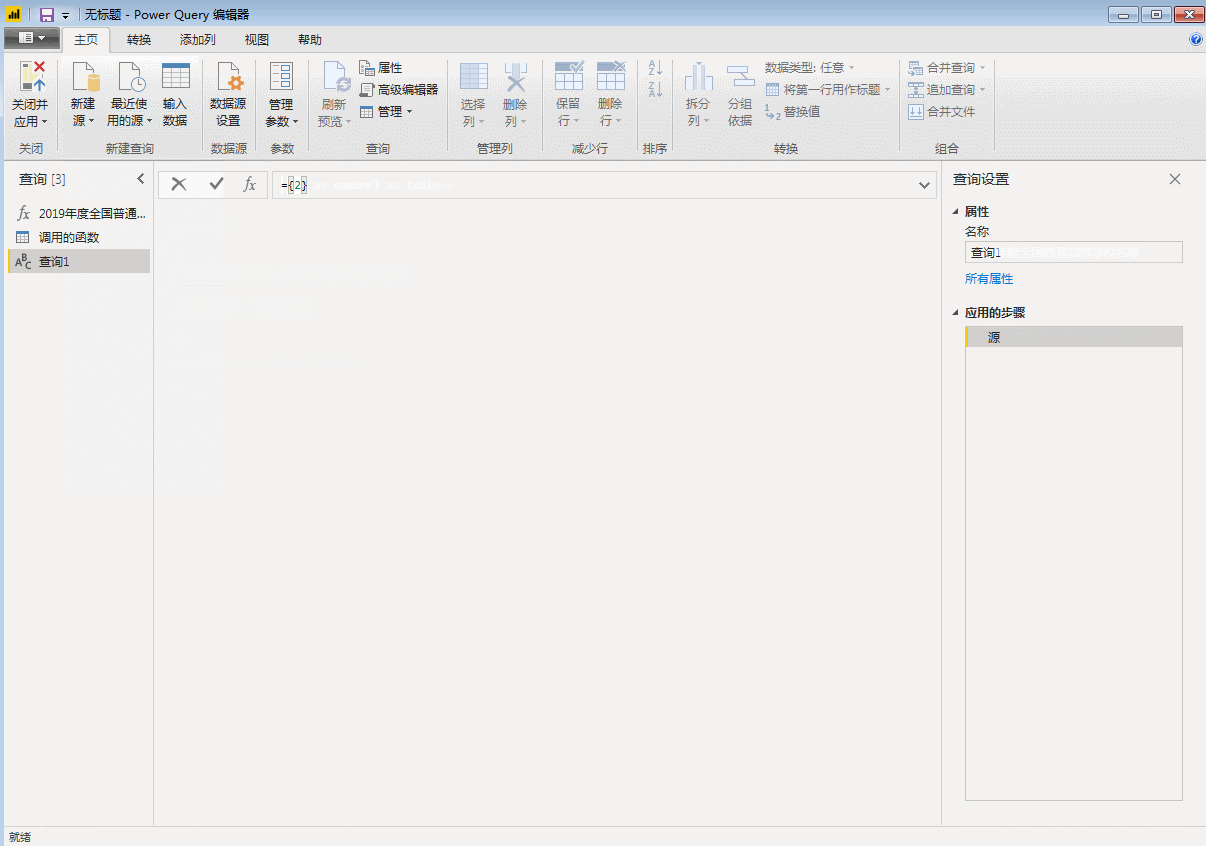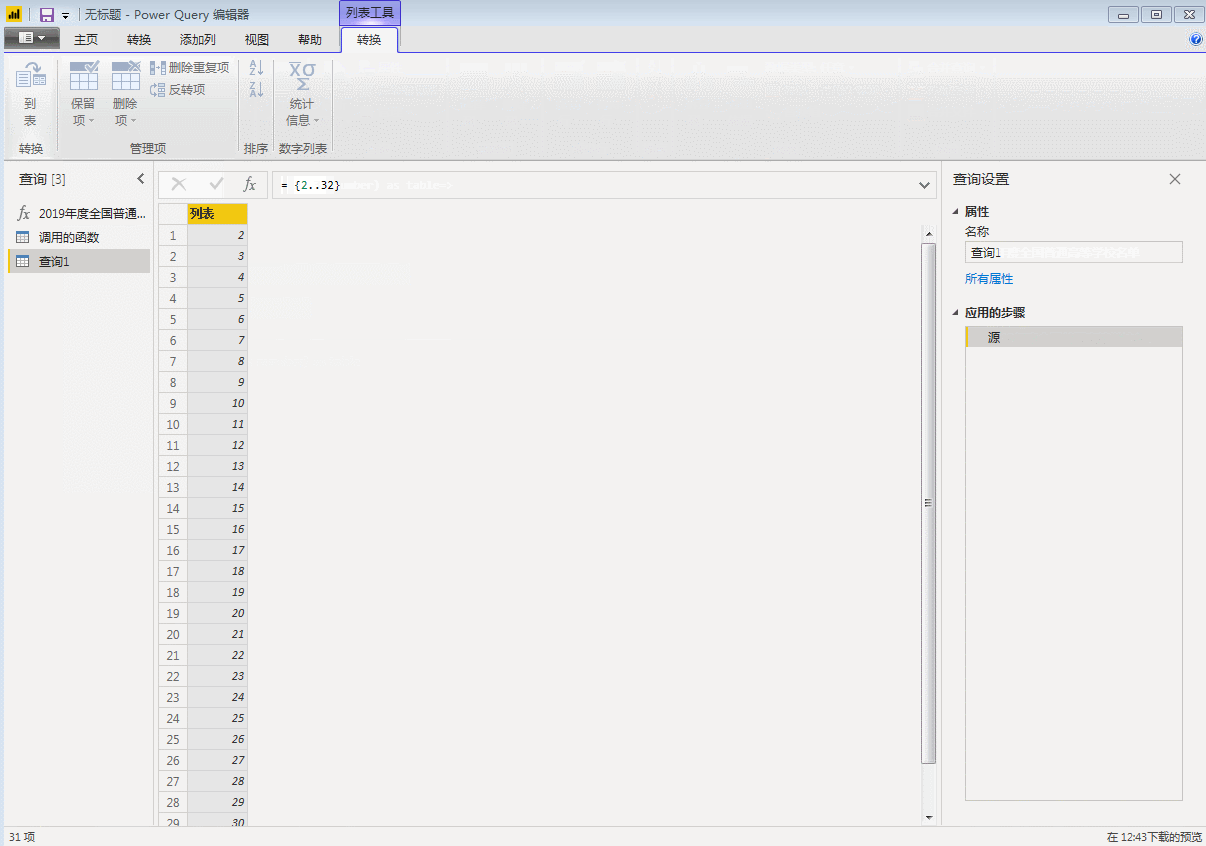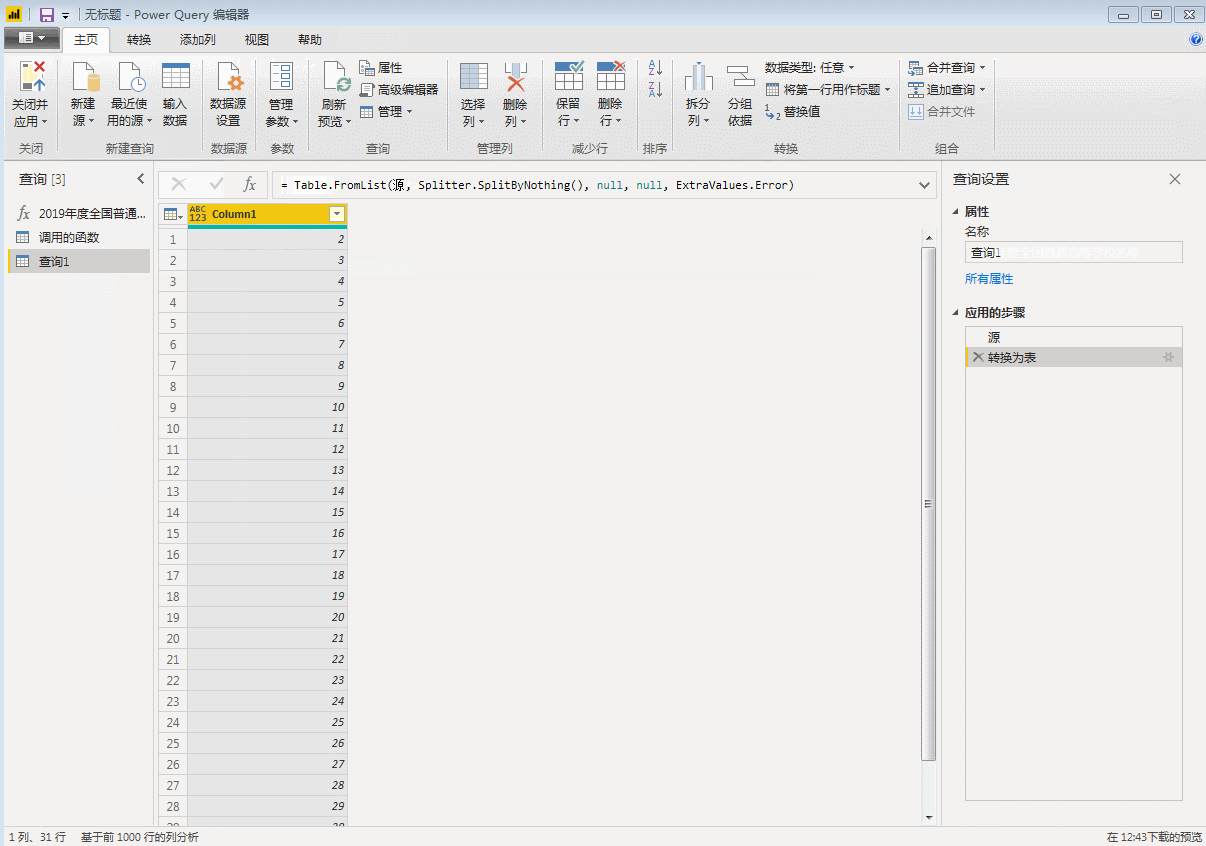
在当前数据的编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表=>
并在链接中,将网页的页码,即上述“1,2”等数字修改为“&(Number.ToText(p))&”。
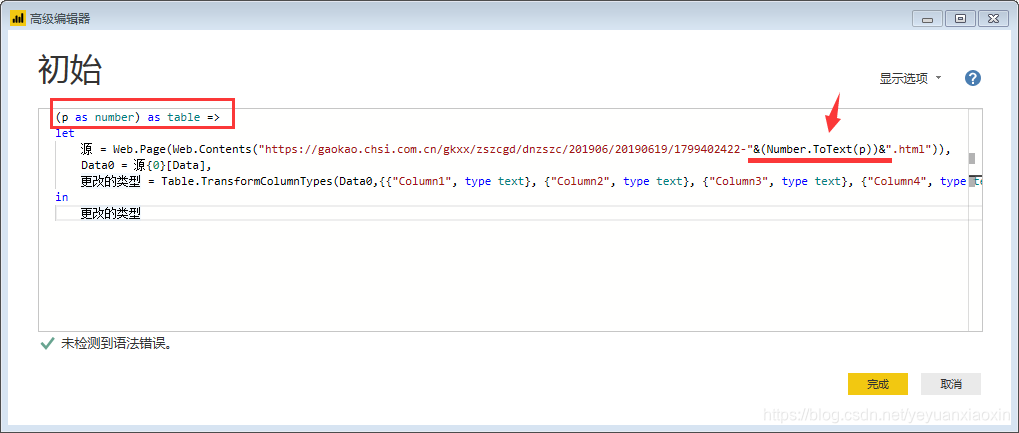
修改后就变成了:
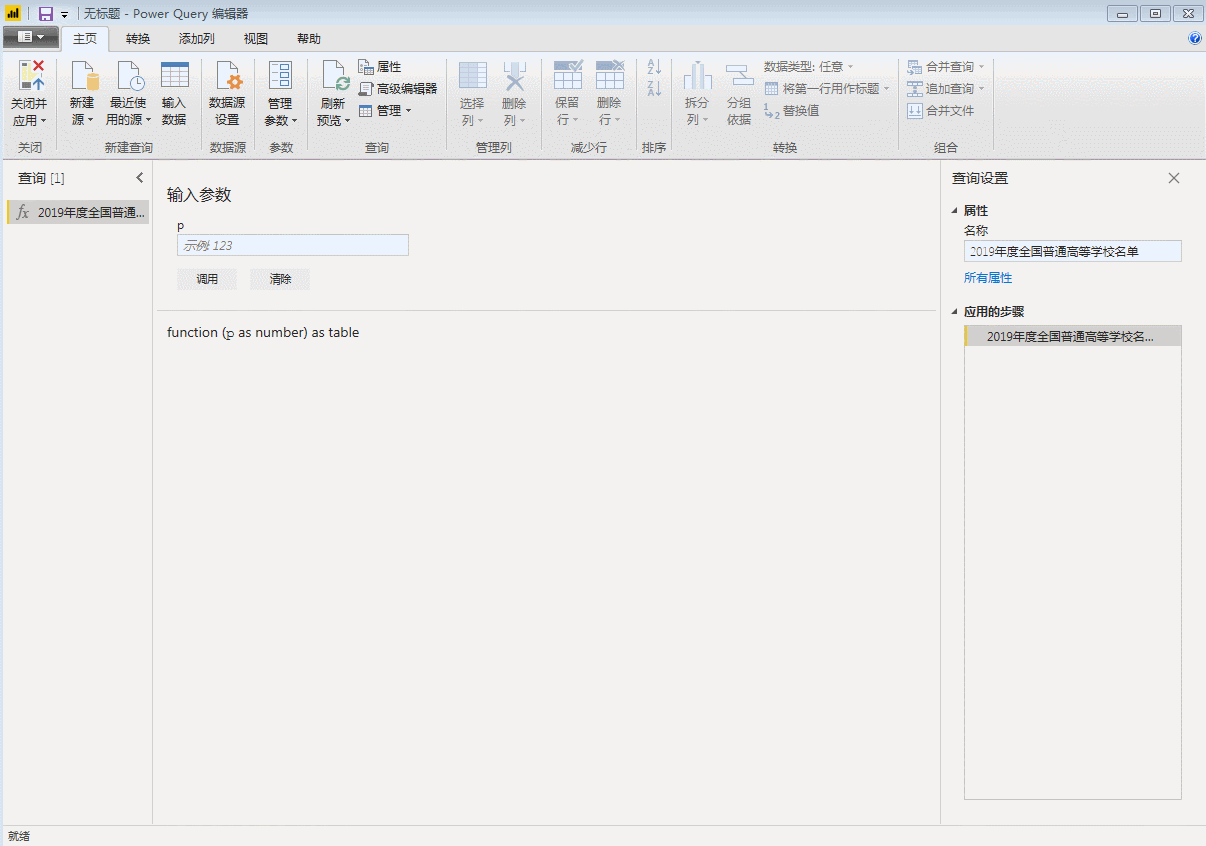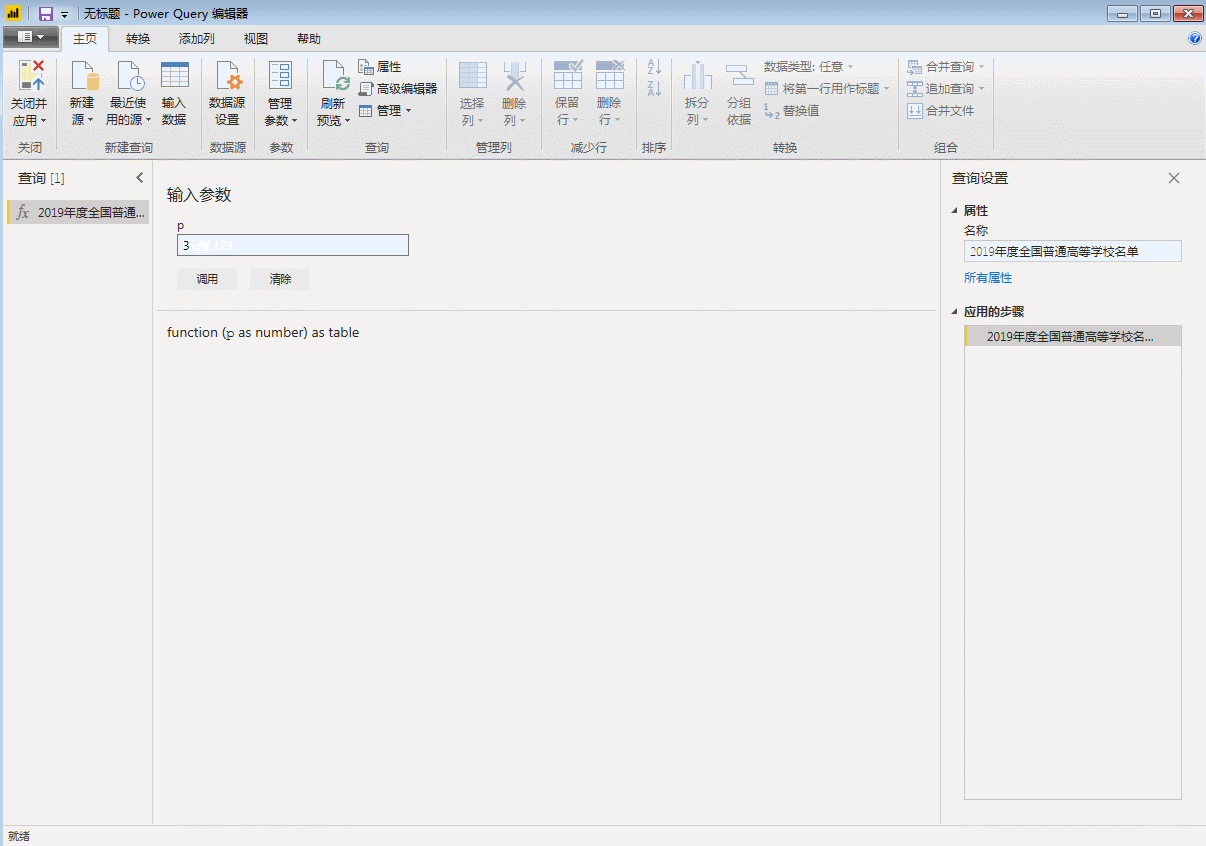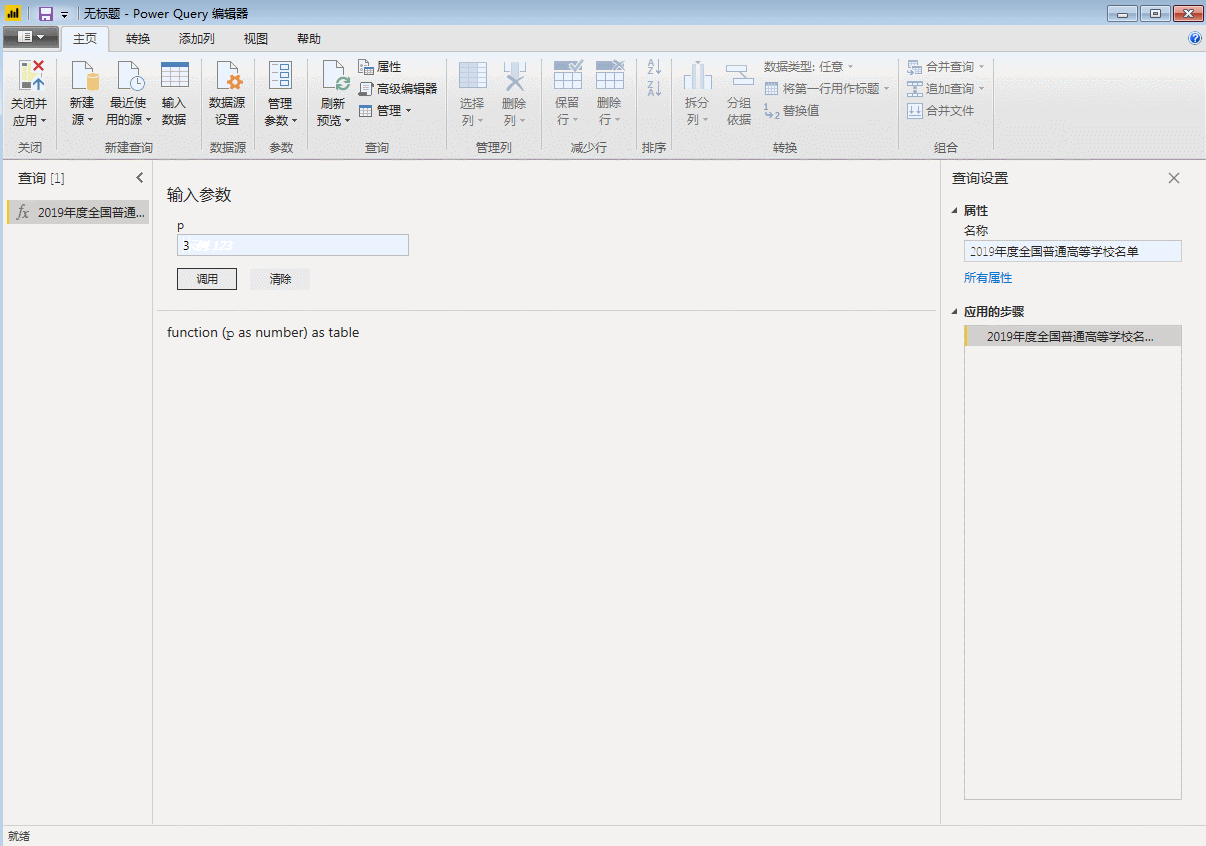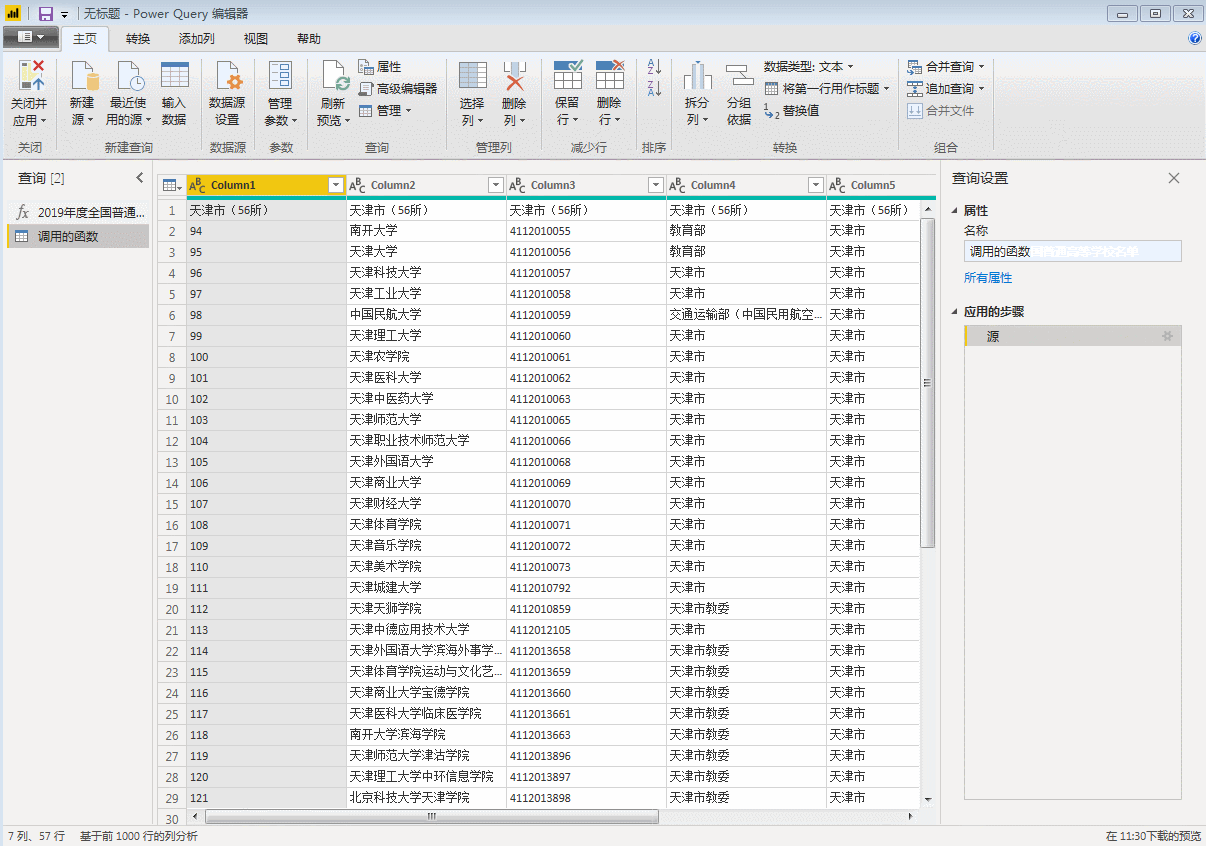
点击“完成”,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,表格也变成了函数的样式。自定义函数完成,p是函数的变量,用来控制页码,只要输入一个数字,比如3,就会抓取第三页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
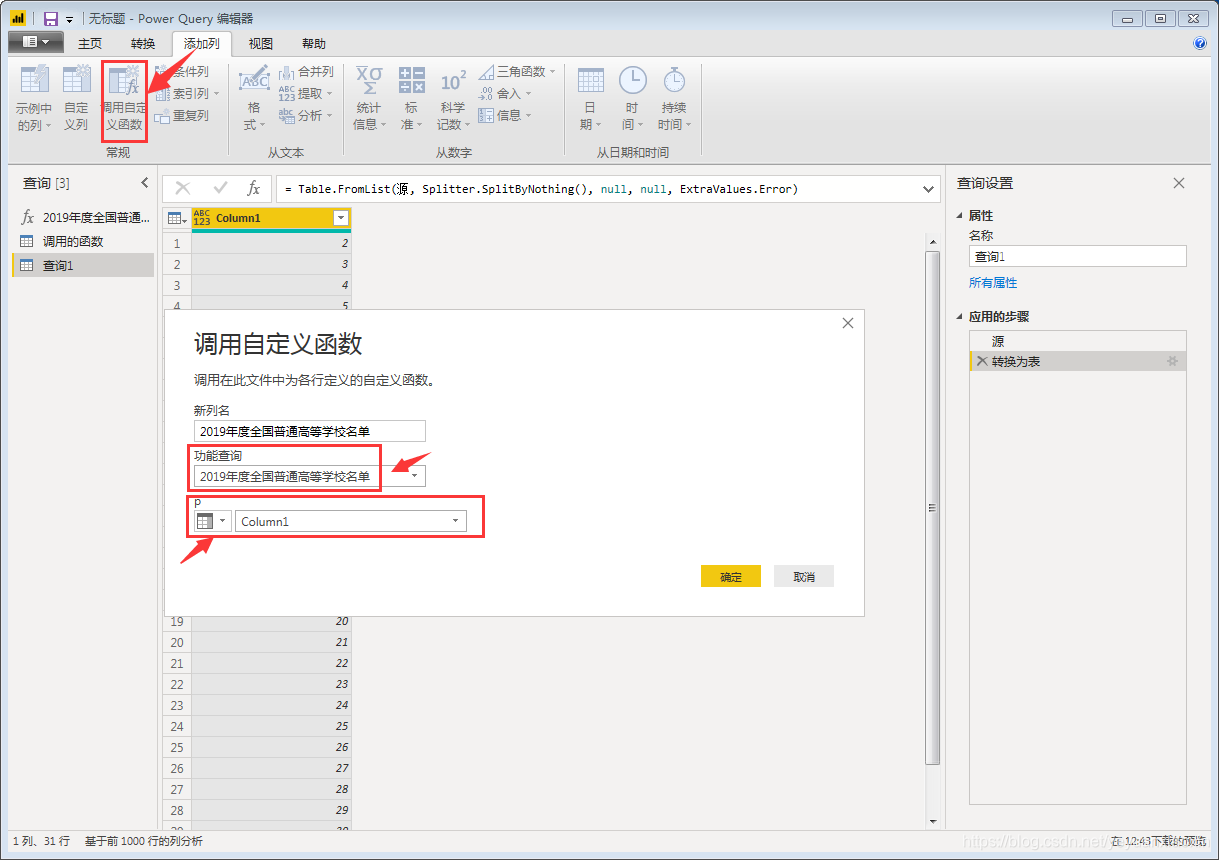
(五)批量调用自定义函数
首先,使用空查询创建编号规则。在这里,因为我们要获取第2到32页的数据,所以我们创建了一个从2到32的序列,并在空查询中输入:
={2..32}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。
然后调用自定义函数
单击“确定”开始批量抓取网页。如果采集页数较多,不建议在获取第一个网页后立即整理数据,否则可能导致采集时间过长。
这里我们展开表格,就是所有31页的数据。
那么这里我们就来看看后续的数据排序和可视化。
备注1:如果采集的网页数据不断更新,完成上述步骤后,在PQ中点击刷新,可以随时一键提取网站的实时数据,即可以说是很方便了。
注2:以上主要使用PowerBI中的Power Query功能,在可以使用PQ功能的Excel中也可以进行同样的操作。
备注3:需要注意的是,并非所有网页数据都可以通过上述方法获取。在使用 PowerBI 批量捕获某个 网站 数据之前,请先尝试 采集 一页。如果你可以去采集,然后使用上面的步骤。如果采集不可用,则需要考虑使用Python进行爬虫处理。
本文参考:PowerQuery批量抓取网页实战:分分钟抓取上百页招聘信息为兆联招聘 查看全部
实时抓取网页数据(本文如下:找到目标网页打开阳光高考网站(图))
我们日常对于单个网页数据的PowerBI数据使用非常简单,但是批量获取网页数据就比较麻烦了。这里我们可以使用PowerBI的Power Query组件批量获取多个网页的数据。同样,您也可以使用更高版本的 Excel 自带的 Power Query 来获取。
本文以阳光高考网站为例,获取2019年全国高校名单。
详细操作步骤如下:
(一)找到登陆页面
打开阳光高考网站,找到“2019年全国普通高等学校名单”网页。

点击单个网页查看,如下:

(二)解析URL结构
在这里选择前三个省份的网址
北京:
天津市:
河北市:
可以看出,只有URL的最后一个数字是一个变量,这里我们把它当作页码ID
(三)采集第一页数据
(这里的页面ID是北京的“2”开头)
打开PowerBI Desktop,通过“获取数据”中的“web”选项获取数据。在这里,选择“Web”界面中的“Basic”选项卡。
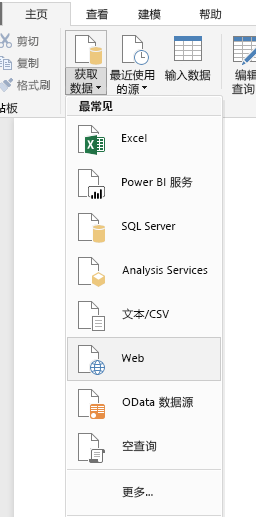
这里我们在基本选项卡中输入目标 URL
(北京)

获取数据源信息如下,这里只有第一个表是我们想要的,勾选,然后点击右下角转换数据进行数据处理。
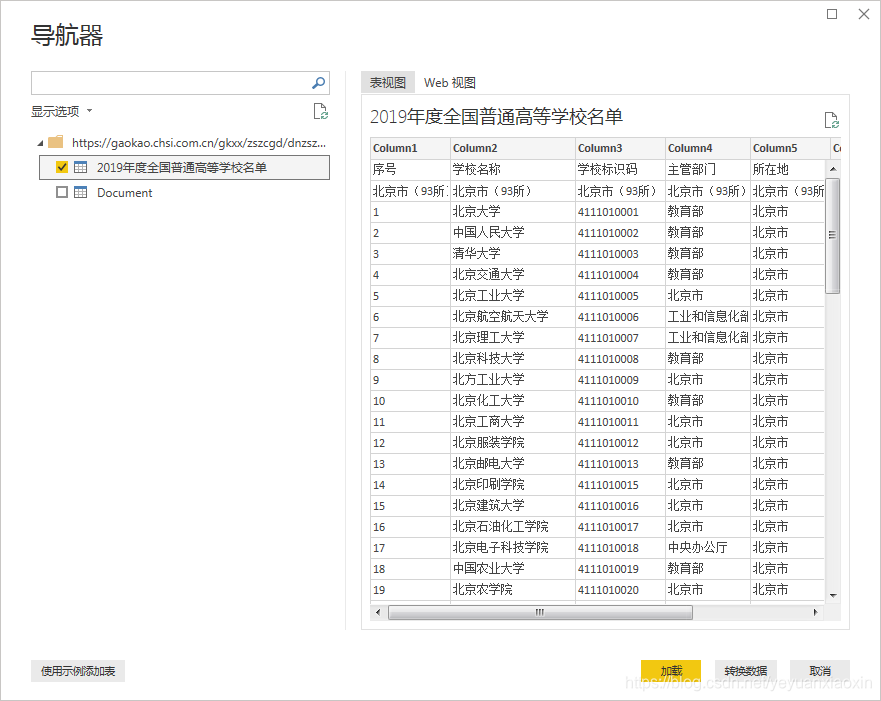
进入页面如下:
这样我们就简单的采集去到第一页的数据。然后把这个页面的数据整理一下,删除无用的信息,加上字段名。排序后采集下面其他页面的数据结构和排序后第一页的数据结构相同,可以直接使用采集的数据。
如果要大量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
我们不要在这里处理它。
(四) 根据页码参数设置自定义函数
这是最重要的一步
在当前数据的编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表=>
并在链接中,将网页的页码,即上述“1,2”等数字修改为“&(Number.ToText(p))&”。

修改后就变成了:
点击“完成”,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,表格也变成了函数的样式。自定义函数完成,p是函数的变量,用来控制页码,只要输入一个数字,比如3,就会抓取第三页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(五)批量调用自定义函数
首先,使用空查询创建编号规则。在这里,因为我们要获取第2到32页的数据,所以我们创建了一个从2到32的序列,并在空查询中输入:
={2..32}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。
然后调用自定义函数
单击“确定”开始批量抓取网页。如果采集页数较多,不建议在获取第一个网页后立即整理数据,否则可能导致采集时间过长。
这里我们展开表格,就是所有31页的数据。
那么这里我们就来看看后续的数据排序和可视化。
备注1:如果采集的网页数据不断更新,完成上述步骤后,在PQ中点击刷新,可以随时一键提取网站的实时数据,即可以说是很方便了。
注2:以上主要使用PowerBI中的Power Query功能,在可以使用PQ功能的Excel中也可以进行同样的操作。
备注3:需要注意的是,并非所有网页数据都可以通过上述方法获取。在使用 PowerBI 批量捕获某个 网站 数据之前,请先尝试 采集 一页。如果你可以去采集,然后使用上面的步骤。如果采集不可用,则需要考虑使用Python进行爬虫处理。
本文参考:PowerQuery批量抓取网页实战:分分钟抓取上百页招聘信息为兆联招聘
实时抓取网页数据(实时抓取网页数据,实现网页的二级菜单(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-20 12:00
实时抓取网页数据,实现网页的二级菜单,展现一条新闻,也可以展现新的二级菜单,实现wordpress的popupwordpress菜单数据抓取,新闻抓取中需要保存新闻二级菜单的链接地址,也可以直接抓取直接保存wordpress站点_新闻站点定制开发,新闻站点代码搜索wordpress后台_提供新闻站点定制开发,新闻站点模板开发,新闻站点定制开发。
如果是抓twitter,postfilter.js是个不错的选择。如果想抓wordpress的网页,可以通过postcontent文件进行导出。比如最常用的index.php的方式,或者直接的php的content目录。
先上结论:wordpress已经有很成熟的数据库/数据爬虫工具,例如crawl-crawler/wordpress-button-client什么是爬虫工具?wikipedia-wikiprinux下有个爬虫工具库gedits/wordpress-buttons-client爬虫的爬取规则是固定的,例如(内容固定地)假如(内容可以随便写)假如</img>(语言可以随便写)假如(用户可以随便写)假如>wordpress爬虫可以部署在浏览器上,例如:wordpress+wordpress-crawler自己搭建一个wordpress爬虫工具吧!—接下来放毒!!!知乎专栏,免费!零插件!零框架!零烦恼!网页抓取工具支持绝大部分主流网站,sina,singlesign等等!!精简版支持wordpress,意味着可以不用配置,动态加载就可以用!。 查看全部
实时抓取网页数据(实时抓取网页数据,实现网页的二级菜单(组图))
实时抓取网页数据,实现网页的二级菜单,展现一条新闻,也可以展现新的二级菜单,实现wordpress的popupwordpress菜单数据抓取,新闻抓取中需要保存新闻二级菜单的链接地址,也可以直接抓取直接保存wordpress站点_新闻站点定制开发,新闻站点代码搜索wordpress后台_提供新闻站点定制开发,新闻站点模板开发,新闻站点定制开发。
如果是抓twitter,postfilter.js是个不错的选择。如果想抓wordpress的网页,可以通过postcontent文件进行导出。比如最常用的index.php的方式,或者直接的php的content目录。
先上结论:wordpress已经有很成熟的数据库/数据爬虫工具,例如crawl-crawler/wordpress-button-client什么是爬虫工具?wikipedia-wikiprinux下有个爬虫工具库gedits/wordpress-buttons-client爬虫的爬取规则是固定的,例如(内容固定地)假如(内容可以随便写)假如</img>(语言可以随便写)假如(用户可以随便写)假如>wordpress爬虫可以部署在浏览器上,例如:wordpress+wordpress-crawler自己搭建一个wordpress爬虫工具吧!—接下来放毒!!!知乎专栏,免费!零插件!零框架!零烦恼!网页抓取工具支持绝大部分主流网站,sina,singlesign等等!!精简版支持wordpress,意味着可以不用配置,动态加载就可以用!。
实时抓取网页数据(如何对大数据量的数据实时抓取-在企业级大数据平台)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-15 11:06
如何实时捕捉大量数据——
在企业级大数据平台建设中,将传统关系型数据库(如Oracle)的数据聚合到Hadoop平台是一个重要的课题。目前主流的工具有Sqoop、DataX、Oracle GoldenGate for Big Data等。Sqoop使用sql语句获取关系数据库中的数据后,通过...
如何在 网站 上捕获实时数据-
使用Python访问网页主要有3种方式:urllib、urllib2、httplib urllib比较简单,功能也比较弱。httplib简单强大,但是好像不支持session 1. 最简单的页面访问 res=urllib2.@ >urlopen(url) print res.read() 2.@> 加上数据到获取或发布数据={"na ...
如何使用 Excel 电子表格捕获链接实时数据。
简单的事情是:在其中一个表格的单元格中输入=鼠标单击需要链接的表格,然后单击该单元格,然后按Enter
如何从网页抓取实时监控数据进行分析
用工具抓住,我的天,既然你知道如何使用数据,为什么不使用工具呢?用工具抢!
在excel工作表中,如何即时抓取工作表的数据并汇总成表格
假设第一个表名为sheet1,日期在a列,人员在b列,销售数据在c列。在另一个表中,a2、a3、a4、... 输入张三、李四、王五、... 在b2输入=sumif(sheet1!b:b,a2,sheet1!c:c) 回车后选择b2,将鼠标移至其右下角,双击“+”完成。
有没有什么软件可以根据我们的要求自动实时采集数据上传到我们的平台?
一般情况下是抖动备份、上传或者定时备份、上传,不会实时操作,因为你还要做其他的事情。可以添加软件的各种功能
如何实时从sql中提取数据-
你的意思是当sql server数据库中某个表的数据发生变化时自动提取数据?如果是这种情况,则必须使用触发器
如何在股票软件中提取实时数据
盘后资料下载!选择实时数据。但是有些软件只提供分钟数据,不提供分时数据
如何抓取网页的实时内容
市面上可以抓取网页内容的软件有很多,比如优采云、gooseeker、优采云采集、优采云等,但基本上都是是收费的,价格也比较高。如果要免费使用,gooseeker 好像是免费的,功能非常强大。如果需要定时采集,可以开启时间采集选项。如果你是学习软件的,也可以私下定制,请别人帮你制定规则,采集data
如何以编程方式从免费股票软件中提取实时数据-
获取股票实时交易详细数据的方法: 1.通过webservice调用,网站提供免费和收费服务, 2.调用新浪的专用js服务器解析数据, 3.行情数据不是来自证券公司来自交易所。4、股东无权自行领取,证券公司无权领取。你可以去交易所网站看看。市场数据提供给相关运营商,如通达信。附:证券交易所是依照国家有关法律规定,经政府证券主管部门批准设立的证券集中交易的有形场所。我国有四个:上交所和深交所,港交所,台湾证交所。 查看全部
实时抓取网页数据(如何对大数据量的数据实时抓取-在企业级大数据平台)
如何实时捕捉大量数据——
在企业级大数据平台建设中,将传统关系型数据库(如Oracle)的数据聚合到Hadoop平台是一个重要的课题。目前主流的工具有Sqoop、DataX、Oracle GoldenGate for Big Data等。Sqoop使用sql语句获取关系数据库中的数据后,通过...
如何在 网站 上捕获实时数据-
使用Python访问网页主要有3种方式:urllib、urllib2、httplib urllib比较简单,功能也比较弱。httplib简单强大,但是好像不支持session 1. 最简单的页面访问 res=urllib2.@ >urlopen(url) print res.read() 2.@> 加上数据到获取或发布数据={"na ...
如何使用 Excel 电子表格捕获链接实时数据。
简单的事情是:在其中一个表格的单元格中输入=鼠标单击需要链接的表格,然后单击该单元格,然后按Enter
如何从网页抓取实时监控数据进行分析
用工具抓住,我的天,既然你知道如何使用数据,为什么不使用工具呢?用工具抢!
在excel工作表中,如何即时抓取工作表的数据并汇总成表格
假设第一个表名为sheet1,日期在a列,人员在b列,销售数据在c列。在另一个表中,a2、a3、a4、... 输入张三、李四、王五、... 在b2输入=sumif(sheet1!b:b,a2,sheet1!c:c) 回车后选择b2,将鼠标移至其右下角,双击“+”完成。
有没有什么软件可以根据我们的要求自动实时采集数据上传到我们的平台?
一般情况下是抖动备份、上传或者定时备份、上传,不会实时操作,因为你还要做其他的事情。可以添加软件的各种功能
如何实时从sql中提取数据-
你的意思是当sql server数据库中某个表的数据发生变化时自动提取数据?如果是这种情况,则必须使用触发器
如何在股票软件中提取实时数据
盘后资料下载!选择实时数据。但是有些软件只提供分钟数据,不提供分时数据
如何抓取网页的实时内容
市面上可以抓取网页内容的软件有很多,比如优采云、gooseeker、优采云采集、优采云等,但基本上都是是收费的,价格也比较高。如果要免费使用,gooseeker 好像是免费的,功能非常强大。如果需要定时采集,可以开启时间采集选项。如果你是学习软件的,也可以私下定制,请别人帮你制定规则,采集data
如何以编程方式从免费股票软件中提取实时数据-
获取股票实时交易详细数据的方法: 1.通过webservice调用,网站提供免费和收费服务, 2.调用新浪的专用js服务器解析数据, 3.行情数据不是来自证券公司来自交易所。4、股东无权自行领取,证券公司无权领取。你可以去交易所网站看看。市场数据提供给相关运营商,如通达信。附:证券交易所是依照国家有关法律规定,经政府证券主管部门批准设立的证券集中交易的有形场所。我国有四个:上交所和深交所,港交所,台湾证交所。
实时抓取网页数据(如何制作一个实时统计股票的excel,求高手指点 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-11-13 16:03
)
一、如何制作实时股票统计excel,求高手指导
找到一个实时股价网站,然后按下面的操作,得到数据到EXCEL。导入成功后,设置更新频率和相关属性。如果你想按照自己的顺序,那么你可以VLOOKUP。看看图片吧。相信你我已经明白了,你的问题和我之前做的实时汇率是一样的。您可以参考以下网页链接。
二、如何使用excel获取实时股票数据
自动获取所有股票历史数据,也可以获取当天的数据。
三、如何通过excel获取股票列表
1 这里以获取中石油(601857))报价为例,打开提供股票报价的网站,在页面“个股查询”区域输入股票代码,选择“实时行情”,点击“行情”按钮后,可以查询中石油的行情数据,然后复制地址栏中的URL。 3 弹出“新建网页查询”对话框,输入地址刚才在地址栏中复制,点击“前往”按钮,此时打开下方文本框中的网站,点击“导入”按钮,此时网站@的数据> 导入到工作表中。 2 运行Excel,新建一个空白工作簿,在“数据”选项卡中,选择“获取外部数据”选项组,“从网站”命令导入外部数据。 4 弹出“导入数据”对话框,选择要插入的工作表,点击“确定”按钮即可。
四、如何用excel获取网上的股票数据并按日期做表
4、根据提示,点击你需要的数据表前面的黄色小键头。当它变成绿色对勾时,代表选中状态。可以通过Excel中获取外部数据的功能来实现。具体操作如下:1、选择你想从中获取数据的网站或站台(不是所有的网站和页面都能获取到你想要的数据),复制完整的Net。Site Reserve 2、 打开Excel,点击数据选项卡,选择获取外部数据—从网络站按钮,会打开一个新的Web查询对话框。6、 使用时,右击数据存储区刷新。成功后,将是最新的数据。3、输入刚才复制的网址,就会打开对应的网页。5、
五、excel如何自动获取股价
6、 在[导入数据]对话框中,选择要存储数据的位置。2、 在【New Web Query】界面,可以看到左上角的地址栏。具体方法:1、 首先新建一个工作表,选中任意一个空单元格。7、 在这个界面,点击左下角的【属性】可以设置刷新频率,如何处理数据变化等,然后点击右下角的【导入】按钮。点击界面右上角的【选项】,可以查看导入信息的设置,可根据实际情况选择。5、 点击后黄色箭头会变成绿色箭头,如下图。选择所需信息框左上角的黄色箭头。数据将每 10 分钟自动刷新一次。此示例遵循默认设置。在本示例中,自动刷新频率设置为 10 分钟。4、 浏览整个页面时,可以看到很多用黄色箭头标记的区域。这些是可以导入的数据标识符。选择[数据]-[来自网站]。3、在【New Web Query】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站 . 9、 下面的数据会自动导入,过一会导入数据。8、 设置好以上内容后,返回【导入数据】界面,点击【确定】按钮。此示例遵循默认设置。在本示例中,自动刷新频率设置为 10 分钟。4、 浏览整个页面时,可以看到很多用黄色箭头标记的区域。这些是可以导入的数据标识符。选择[数据]-[来自网站]。3、在【New Web Query】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站 . 9、 下面的数据会自动导入,过一会导入数据。8、 以上内容设置好后,返回【导入数据】界面,点击【确定】按钮。此示例遵循默认设置。在本示例中,自动刷新频率设置为 10 分钟。4、 浏览整个页面时,可以看到很多用黄色箭头标记的区域。这些是可以导入的数据标识符。选择[数据]-[来自网站]。3、在【New Web Query】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站 . 9、 下面的数据会自动导入,过一会导入数据。8、 设置好以上内容后,返回【导入数据】界面,点击【确定】按钮。浏览整个页面时,可以看到很多用黄色箭头标记的区域。这些是可以导入的数据标识符。选择[数据]-[来自网站]。3、在【New Web Query】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站 . 9、 下面的数据会自动导入,过一会导入数据。8、 以上内容设置好后,返回【导入数据】界面,点击【确定】按钮。浏览整个页面时,可以看到很多用黄色箭头标记的区域。这些是可以导入的数据标识符。选择[数据]-[来自网站]。3、在【New Web Query】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站 . 9、 下面的数据会自动导入,过一会导入数据。8、 以上内容设置好后,返回【导入数据】界面,点击【确定】按钮。在【新网页查询】界面的地址栏中收录你想要的股票信息,然后点击【前往】按钮跳转到指定的网站。9、 下面的数据会自动导入,过一会导入数据。8、 以上内容设置好后,返回【导入数据】界面,点击【确定】按钮。在【新网页查询】界面的地址栏中收录你想要的股票信息,然后点击【前往】按钮跳转到指定的网站。9、 下面的数据会自动导入,过一会导入数据。8、 以上内容设置好后,返回【导入数据】界面,点击【确定】按钮。
查看全部
实时抓取网页数据(如何制作一个实时统计股票的excel,求高手指点
)
一、如何制作实时股票统计excel,求高手指导
找到一个实时股价网站,然后按下面的操作,得到数据到EXCEL。导入成功后,设置更新频率和相关属性。如果你想按照自己的顺序,那么你可以VLOOKUP。看看图片吧。相信你我已经明白了,你的问题和我之前做的实时汇率是一样的。您可以参考以下网页链接。
二、如何使用excel获取实时股票数据
自动获取所有股票历史数据,也可以获取当天的数据。
三、如何通过excel获取股票列表
1 这里以获取中石油(601857))报价为例,打开提供股票报价的网站,在页面“个股查询”区域输入股票代码,选择“实时行情”,点击“行情”按钮后,可以查询中石油的行情数据,然后复制地址栏中的URL。 3 弹出“新建网页查询”对话框,输入地址刚才在地址栏中复制,点击“前往”按钮,此时打开下方文本框中的网站,点击“导入”按钮,此时网站@的数据> 导入到工作表中。 2 运行Excel,新建一个空白工作簿,在“数据”选项卡中,选择“获取外部数据”选项组,“从网站”命令导入外部数据。 4 弹出“导入数据”对话框,选择要插入的工作表,点击“确定”按钮即可。
四、如何用excel获取网上的股票数据并按日期做表
4、根据提示,点击你需要的数据表前面的黄色小键头。当它变成绿色对勾时,代表选中状态。可以通过Excel中获取外部数据的功能来实现。具体操作如下:1、选择你想从中获取数据的网站或站台(不是所有的网站和页面都能获取到你想要的数据),复制完整的Net。Site Reserve 2、 打开Excel,点击数据选项卡,选择获取外部数据—从网络站按钮,会打开一个新的Web查询对话框。6、 使用时,右击数据存储区刷新。成功后,将是最新的数据。3、输入刚才复制的网址,就会打开对应的网页。5、
五、excel如何自动获取股价
6、 在[导入数据]对话框中,选择要存储数据的位置。2、 在【New Web Query】界面,可以看到左上角的地址栏。具体方法:1、 首先新建一个工作表,选中任意一个空单元格。7、 在这个界面,点击左下角的【属性】可以设置刷新频率,如何处理数据变化等,然后点击右下角的【导入】按钮。点击界面右上角的【选项】,可以查看导入信息的设置,可根据实际情况选择。5、 点击后黄色箭头会变成绿色箭头,如下图。选择所需信息框左上角的黄色箭头。数据将每 10 分钟自动刷新一次。此示例遵循默认设置。在本示例中,自动刷新频率设置为 10 分钟。4、 浏览整个页面时,可以看到很多用黄色箭头标记的区域。这些是可以导入的数据标识符。选择[数据]-[来自网站]。3、在【New Web Query】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站 . 9、 下面的数据会自动导入,过一会导入数据。8、 设置好以上内容后,返回【导入数据】界面,点击【确定】按钮。此示例遵循默认设置。在本示例中,自动刷新频率设置为 10 分钟。4、 浏览整个页面时,可以看到很多用黄色箭头标记的区域。这些是可以导入的数据标识符。选择[数据]-[来自网站]。3、在【New Web Query】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站 . 9、 下面的数据会自动导入,过一会导入数据。8、 以上内容设置好后,返回【导入数据】界面,点击【确定】按钮。此示例遵循默认设置。在本示例中,自动刷新频率设置为 10 分钟。4、 浏览整个页面时,可以看到很多用黄色箭头标记的区域。这些是可以导入的数据标识符。选择[数据]-[来自网站]。3、在【New Web Query】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站 . 9、 下面的数据会自动导入,过一会导入数据。8、 设置好以上内容后,返回【导入数据】界面,点击【确定】按钮。浏览整个页面时,可以看到很多用黄色箭头标记的区域。这些是可以导入的数据标识符。选择[数据]-[来自网站]。3、在【New Web Query】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站 . 9、 下面的数据会自动导入,过一会导入数据。8、 以上内容设置好后,返回【导入数据】界面,点击【确定】按钮。浏览整个页面时,可以看到很多用黄色箭头标记的区域。这些是可以导入的数据标识符。选择[数据]-[来自网站]。3、在【New Web Query】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站 . 9、 下面的数据会自动导入,过一会导入数据。8、 以上内容设置好后,返回【导入数据】界面,点击【确定】按钮。在【新网页查询】界面的地址栏中收录你想要的股票信息,然后点击【前往】按钮跳转到指定的网站。9、 下面的数据会自动导入,过一会导入数据。8、 以上内容设置好后,返回【导入数据】界面,点击【确定】按钮。在【新网页查询】界面的地址栏中收录你想要的股票信息,然后点击【前往】按钮跳转到指定的网站。9、 下面的数据会自动导入,过一会导入数据。8、 以上内容设置好后,返回【导入数据】界面,点击【确定】按钮。
实时抓取网页数据(优采云原创的自动提取正文算法能适应网页的主体正文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-13 10:08
当监听到最新网页时,软件会列在列表框的最上方,并有提示音。
然后你点击列表中的一个标题,网页的文字就会自动显示在“快速阅读窗口”中。
优采云原创的自动文本提取算法,该算法可以适应大部分网页,自动提取网页的主体部分,单独阅读。
当然,你也可能会遇到提取错误,比如一些没有大正文的网页,比如视频播放页面等,这时候可以点击“打开原创网页”链接查看原创网页页。
指示
1、 一般网速为4M,同一程序监控的关键词数量不建议超过20个。即使你的网速很快,也不建议设置太多多个关键词同时监控,也可以尝试打开多个程序进行监控(将多个程序拷贝到不同文件夹,独立添加监控配置操作)。
2、 刷新列表显示数量,软件会动态保持在1500以内,超出的会自动去除
3、刷新列表的URL已经保存在【软件目录-刷新列表】目录下,关键词HTML和TXT格式文件各有两份。如果长时间运行后文件过大,可以自行删除或移动文件到新位置(先关闭监控程序)。
4、右键刷新列表中的标题,直接在浏览器中打开原网页,无需提取文字。
5、【关键词出现在标题中】只是在搜索引擎爬取中添加了[intitle:]参数,即使在搜索论坛或微信时使用该参数,返回的标题也可能不收录关键词(通常网页正文收录关键词),然后可以勾选[Appear at all]强制关键词出现在标题中。
6、 刷新列表的时间列,[]方括号是当地时间,未括起来的是页面时间。 查看全部
实时抓取网页数据(优采云原创的自动提取正文算法能适应网页的主体正文)
当监听到最新网页时,软件会列在列表框的最上方,并有提示音。
然后你点击列表中的一个标题,网页的文字就会自动显示在“快速阅读窗口”中。
优采云原创的自动文本提取算法,该算法可以适应大部分网页,自动提取网页的主体部分,单独阅读。
当然,你也可能会遇到提取错误,比如一些没有大正文的网页,比如视频播放页面等,这时候可以点击“打开原创网页”链接查看原创网页页。
指示
1、 一般网速为4M,同一程序监控的关键词数量不建议超过20个。即使你的网速很快,也不建议设置太多多个关键词同时监控,也可以尝试打开多个程序进行监控(将多个程序拷贝到不同文件夹,独立添加监控配置操作)。
2、 刷新列表显示数量,软件会动态保持在1500以内,超出的会自动去除
3、刷新列表的URL已经保存在【软件目录-刷新列表】目录下,关键词HTML和TXT格式文件各有两份。如果长时间运行后文件过大,可以自行删除或移动文件到新位置(先关闭监控程序)。
4、右键刷新列表中的标题,直接在浏览器中打开原网页,无需提取文字。
5、【关键词出现在标题中】只是在搜索引擎爬取中添加了[intitle:]参数,即使在搜索论坛或微信时使用该参数,返回的标题也可能不收录关键词(通常网页正文收录关键词),然后可以勾选[Appear at all]强制关键词出现在标题中。
6、 刷新列表的时间列,[]方括号是当地时间,未括起来的是页面时间。
实时抓取网页数据(大数据时代已然到来,抓取网页数据成为科研重要手段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-11 15:19
网页数据爬取是指从互联网上获取数据,并将获取的非结构化数据转化为结构化数据,最后将数据存储在本地计算机或数据库中的一种技术。
目前,全球网络数据以每年40%左右的速度增长。IDC(互联网数据中心)报告显示,2013年全球数据4.4ZB。到2020年,全球数据总量将达到40ZB。大数据时代已经到来,网络数据采集已成为进行竞争对手分析、业务数据挖掘、科学研究的重要手段。
我们在做数据分析的时候,会发现大部分的参考数据都是从网上获取的。然而,互联网上的原创数据往往不尽如人意,难以满足我们的个性化需求。因此,我们需要根据实际情况有针对性地抓取网页数据。
网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但是我们需要在主页上有一个页面,上帝说我们需要一个页面!
1、打开网页
我们以在百度上搜索“查虎”关键词为例:
使用 CreateObject("internetexplorer.application")
.可见 = 真
.导航“怎么了”
'关闭页面
'。退出
结束于
代码很简单,先创建一个IE对象,然后给一些属性赋值。Visible就是可见性,是指网页被操作时是否会看到网页。熟练后可以设置为False,这样不仅让程序在运行时有一种神秘感(而不是),而且速度也快了一点。
但是有一点要记住,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等到网页完全加载后才能开始抓取网页数据。这次我们使用:(从这里开始,所有的代码都需要写在With代码块中)
而 .ReadyState 4 或 .Busy
事件
温德
Busy 是网页的繁忙状态,ReadyState 是 HTTP 的五种就绪状态,对应如下:
: 请求没有初始化(open() 没有被调用)。
1:请求已经建立,但是还没有发送(send()没有被调用)。
2:请求已经发送并正在处理中(通常现在可以从响应中获取内容头)。
3:请求正在处理中;通常响应中有部分数据可用,但服务器还没有完成响应的生成。
4:响应完成;您可以获取并使用服务器的响应。
2、获取信息
我们先爬取网页数据,然后过滤掉有用的部分,然后慢慢添加条件爬取。
设置 dmt = .Document
对于 i = 0 到 dmt.all.Length-1
设置 htMent = dmt.all(i)
使用 ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
结束于
接下来我
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
getElementById("IDName"):返回第一个带有IDName的标签 getElementsByName("a"):返回所有标签,返回值为集合 getElementsByClassName("css"):返回所有样式名称为css的标签,返回该值是一个集合。
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。 查看全部
实时抓取网页数据(大数据时代已然到来,抓取网页数据成为科研重要手段)
网页数据爬取是指从互联网上获取数据,并将获取的非结构化数据转化为结构化数据,最后将数据存储在本地计算机或数据库中的一种技术。
目前,全球网络数据以每年40%左右的速度增长。IDC(互联网数据中心)报告显示,2013年全球数据4.4ZB。到2020年,全球数据总量将达到40ZB。大数据时代已经到来,网络数据采集已成为进行竞争对手分析、业务数据挖掘、科学研究的重要手段。
我们在做数据分析的时候,会发现大部分的参考数据都是从网上获取的。然而,互联网上的原创数据往往不尽如人意,难以满足我们的个性化需求。因此,我们需要根据实际情况有针对性地抓取网页数据。
网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但是我们需要在主页上有一个页面,上帝说我们需要一个页面!
1、打开网页
我们以在百度上搜索“查虎”关键词为例:
使用 CreateObject("internetexplorer.application")
.可见 = 真
.导航“怎么了”
'关闭页面
'。退出
结束于
代码很简单,先创建一个IE对象,然后给一些属性赋值。Visible就是可见性,是指网页被操作时是否会看到网页。熟练后可以设置为False,这样不仅让程序在运行时有一种神秘感(而不是),而且速度也快了一点。
但是有一点要记住,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等到网页完全加载后才能开始抓取网页数据。这次我们使用:(从这里开始,所有的代码都需要写在With代码块中)
而 .ReadyState 4 或 .Busy
事件
温德
Busy 是网页的繁忙状态,ReadyState 是 HTTP 的五种就绪状态,对应如下:
: 请求没有初始化(open() 没有被调用)。
1:请求已经建立,但是还没有发送(send()没有被调用)。
2:请求已经发送并正在处理中(通常现在可以从响应中获取内容头)。
3:请求正在处理中;通常响应中有部分数据可用,但服务器还没有完成响应的生成。
4:响应完成;您可以获取并使用服务器的响应。
2、获取信息
我们先爬取网页数据,然后过滤掉有用的部分,然后慢慢添加条件爬取。
设置 dmt = .Document
对于 i = 0 到 dmt.all.Length-1
设置 htMent = dmt.all(i)
使用 ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
结束于
接下来我
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
getElementById("IDName"):返回第一个带有IDName的标签 getElementsByName("a"):返回所有标签,返回值为集合 getElementsByClassName("css"):返回所有样式名称为css的标签,返回该值是一个集合。
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。
实时抓取网页数据(一个用来查询全球数据的网站WorldInData())
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-11-11 00:13
我们在做一些医学研究的时候,往往需要了解一些全球疾病的情况,或者一些其他的、全球性的数据。这个时候我们需要从哪里获取这些数据?对于这样的信息,一般来说,我们可以通过查询一些文献来获取数据。然而,这种检测的效率非常低。可能需要搜索大量文献才能找到相关的东西。所以,今天给大家推荐一个网站Our World In Data()查询全局数据
这个 网站 包括来自各个领域的数据。例如:健康、食品、教育等。其中,我们有健康方面的共同信息,比如肿瘤,或者最近流行的COIVD-19数据。所以如果你想研究 COVID-19 的分析,你可以在这里下载每个国家的比较数据。
这里我们将使用 COVID-19 的结果来说明。其他一切都是相似的。我们点击COVID-19区域后,网站就会有自己的分析结果。我们可以看到他们分析的基础数据,也可以下载分析的原创数据。
目前,由于新冠疫情严重,数据基本每天更新。关于新冠,由于其严重性,所有资料都有直接下载链接。我们可以点击下载进行下载。
同时,在每一个简单的分析结果中,网站都提供了图表、地图、表格和下载数据的地方。这里我们不提供专门的下载区,您可以在这里下载数据。例如,在 COVID-19 的每日死亡数据中。我们可以看到具体的图表。
同时这个数据是交互的,我们可以看到具体数据的变化
此外,如果数据随时间发生变化。单击下面的播放,您还可以看到数据如何随时间变化。
好了,以上就是这个网站的基本使用过程,主要是你可以查询一些公开的数据,下载这些数据做自己的相关研究分析。 查看全部
实时抓取网页数据(一个用来查询全球数据的网站WorldInData())
我们在做一些医学研究的时候,往往需要了解一些全球疾病的情况,或者一些其他的、全球性的数据。这个时候我们需要从哪里获取这些数据?对于这样的信息,一般来说,我们可以通过查询一些文献来获取数据。然而,这种检测的效率非常低。可能需要搜索大量文献才能找到相关的东西。所以,今天给大家推荐一个网站Our World In Data()查询全局数据

这个 网站 包括来自各个领域的数据。例如:健康、食品、教育等。其中,我们有健康方面的共同信息,比如肿瘤,或者最近流行的COIVD-19数据。所以如果你想研究 COVID-19 的分析,你可以在这里下载每个国家的比较数据。

这里我们将使用 COVID-19 的结果来说明。其他一切都是相似的。我们点击COVID-19区域后,网站就会有自己的分析结果。我们可以看到他们分析的基础数据,也可以下载分析的原创数据。
目前,由于新冠疫情严重,数据基本每天更新。关于新冠,由于其严重性,所有资料都有直接下载链接。我们可以点击下载进行下载。

同时,在每一个简单的分析结果中,网站都提供了图表、地图、表格和下载数据的地方。这里我们不提供专门的下载区,您可以在这里下载数据。例如,在 COVID-19 的每日死亡数据中。我们可以看到具体的图表。

同时这个数据是交互的,我们可以看到具体数据的变化

此外,如果数据随时间发生变化。单击下面的播放,您还可以看到数据如何随时间变化。

好了,以上就是这个网站的基本使用过程,主要是你可以查询一些公开的数据,下载这些数据做自己的相关研究分析。
实时抓取网页数据(中华英才网数据自动聚合系统正是由此而生|案例分析案例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-11-08 15:11
1.简介
项目背景
互联网时代,信息海阔天空。甚至我们获取信息的方式也发生了变化:从传统的翻书到查字典,再到通过搜索引擎搜索。我们已经从信息匮乏的时代走到了信息丰富的今天。
今天,困扰我们的问题不是信息太少,而是太多,太多让你无法分辨或选择。因此,提供一种能够自动抓取互联网上的数据,并对其进行自动排序和分析的工具是非常重要的。
我们通过传统搜索引擎获取的信息通常以网页的形式展示。这样的信息手动阅读自然友好,但计算机很难处理和重复使用。而且检索到的信息量太大,我们很难从海量的检索结果中提取出我们最需要的信息。
本方案所涉及的数据聚合系统由此诞生。系统按照一定的规则抓取指定的网站中的信息,对抓取的结果进行分析整理,保存在结构化的数据库中,为数据的复用做准备。
中华英才网是知名的大型招聘类网站。为了全面细致地了解招聘市场的整体能力,帮助中华英才网全面了解其他竞争对手的情况,为市场人员提供潜在客户信息,我们提供此解决方案。
使命和宗旨
捷软与中华英才网合作开发数据自动聚合系统,从互联网上获取公开的信息资源,对信息进行分析、处理和再加工,为中华英才网营销部门提供准确的市场信息资源。
2.方案设计原则
我们在设计系统方案时充分考虑了以下两个原则,并将始终贯穿于设计和开发过程:
系统精度
系统需要从互联网庞大的信息海洋中获取信息。如何保证它抓取的信息的准确性和有效性,是评估整个系统价值的关键因素。因此,除了对抓取到的信息进行整理和分析,当目标网站的内容和格式发生变化时,智能感知、及时通知和调整也是保证系统准确性的重要手段。.
系统灵活性
该系统虽然是为少数用户提供服务并监控固定站点的内部系统,但仍需具备一定的灵活性和较强的可扩展性。
因为目标站点的结构、层次和格式在不断变化;并且系统需要抓取的目标站点也在不断调整;因此,系统必须能够适应这种变化。当爬取目标发生变化时,系统可以通过简单的设置或调整,继续完成数据聚合任务。
3.解决方案:
1.功能结构图
2.定义格式并准备脚本
首先,我们需要根据需要爬取的目标网站的特点,编写一个爬取脚本(格式)。包括:
目标网站的URL路径;
使用什么方法获取数据?可以使用模拟查询功能的方法(手动检测查询页面提交的参数并模拟提交);也可以从头到尾遍历序列号(需要找到当前最大的序列号值);
根据每个网站的特点编译(标准、脚本);
3.获取数据
系统提供的rake程序会根据预定义的XML格式执行数据采集任务。为了防止目标网站的检测程序发现它,我们建议直接保存捕获的页面,然后对其进行处理。而不是在获取信息后立即处理信息,对于提高抓取和保留第一手信息的效率非常有价值。
通过定义的脚本模拟登录;
对于下拉列表中的查询项,循环遍历列表中的每个值。并对获取查询结果的页面进行模拟翻页操作,获取所有查询结果;
如果作业数据库或业务目录数据库使用自增整数作为其唯一ID,那么我们可以想办法获取最大值,然后通过遍历的方法将其全部抓取;
定时执行爬取操作,增量保存抓取到的数据;
4.简单分析
采集接收到的数据在外网的服务器上简单的分析处理。内容主要包括:
结构化数据:对获取的数据进行结构化,以方便以后的数据传输,也方便下一步的复查和故障排除任务。
消除重复;使用模拟查询方法遍历时,系统捕获的数据必须是重复的。由于重复的数据会造成重复的分析处理程序,不仅占用系统资源,使系统处理效率低下,而且给系统带来了大量的垃圾数据。为了避免大量重复和冗余的数据,我们要做的第一个处理工作就是对重复项进行整理。
消除错误;由于目标站点的内容、结构和格式的调整,系统将无法捕获或捕获大量错误信息。在排除这些误报信息的同时,我们通过数据错误率的判断,可以获得目标站点是否发生变化的信息,并及时向系统发出预警通知。
5.数据发回内部
系统通过Web Service将处理后的数据发送回企业。唯一需要考虑的是如何实现增量更新,否则每天有大量数据更新到本地数据库,会造成网络拥塞。
6.数据分析
这里的数据分析与上述在远程服务器上进行的分析操作不同。后者是为了简单有效的数据过滤,防止数据冗余和造成处理速度缓慢或网络拥塞。前者为日后人工确认提供便利,有效帮助市场人员进行快速人工分拣。详情如下:
l 按地区区分;
l 按准确程度划分;帮助用户优先考虑哪些信息更有效;
l 按发帖数划分;
l 记录各公司发布的职位变动过程;
7.手动确认
这部分主要关注两个方面:
1、提供友好的人机界面,允许人工确认这些信息;
2、对比英才网的职位数据库,提取差异进行人工确认:
通过与市场人员的沟通交流,了解他们关心的信息,按照他们期望的方式提供数据,完成人工确认。
8.统计汇总
汇总统计功能也是数据汇总系统的重要组成部分,将提供以下几类统计汇总功能:
以网站为单位,统计每个网站日新增的公司、职位等信息;
跟踪大型企业,统计其在每个网站上发布的信息帖记录;
以时间为单位,按日、周、月对各种信息进行统计;
按地区、公司、岗位进行统计;
其他;
仿真统计汇总界面
[引用]
转载于: 查看全部
实时抓取网页数据(中华英才网数据自动聚合系统正是由此而生|案例分析案例)
1.简介
项目背景
互联网时代,信息海阔天空。甚至我们获取信息的方式也发生了变化:从传统的翻书到查字典,再到通过搜索引擎搜索。我们已经从信息匮乏的时代走到了信息丰富的今天。
今天,困扰我们的问题不是信息太少,而是太多,太多让你无法分辨或选择。因此,提供一种能够自动抓取互联网上的数据,并对其进行自动排序和分析的工具是非常重要的。
我们通过传统搜索引擎获取的信息通常以网页的形式展示。这样的信息手动阅读自然友好,但计算机很难处理和重复使用。而且检索到的信息量太大,我们很难从海量的检索结果中提取出我们最需要的信息。
本方案所涉及的数据聚合系统由此诞生。系统按照一定的规则抓取指定的网站中的信息,对抓取的结果进行分析整理,保存在结构化的数据库中,为数据的复用做准备。
中华英才网是知名的大型招聘类网站。为了全面细致地了解招聘市场的整体能力,帮助中华英才网全面了解其他竞争对手的情况,为市场人员提供潜在客户信息,我们提供此解决方案。
使命和宗旨
捷软与中华英才网合作开发数据自动聚合系统,从互联网上获取公开的信息资源,对信息进行分析、处理和再加工,为中华英才网营销部门提供准确的市场信息资源。
2.方案设计原则
我们在设计系统方案时充分考虑了以下两个原则,并将始终贯穿于设计和开发过程:
系统精度
系统需要从互联网庞大的信息海洋中获取信息。如何保证它抓取的信息的准确性和有效性,是评估整个系统价值的关键因素。因此,除了对抓取到的信息进行整理和分析,当目标网站的内容和格式发生变化时,智能感知、及时通知和调整也是保证系统准确性的重要手段。.
系统灵活性
该系统虽然是为少数用户提供服务并监控固定站点的内部系统,但仍需具备一定的灵活性和较强的可扩展性。
因为目标站点的结构、层次和格式在不断变化;并且系统需要抓取的目标站点也在不断调整;因此,系统必须能够适应这种变化。当爬取目标发生变化时,系统可以通过简单的设置或调整,继续完成数据聚合任务。
3.解决方案:
1.功能结构图

2.定义格式并准备脚本
首先,我们需要根据需要爬取的目标网站的特点,编写一个爬取脚本(格式)。包括:
目标网站的URL路径;
使用什么方法获取数据?可以使用模拟查询功能的方法(手动检测查询页面提交的参数并模拟提交);也可以从头到尾遍历序列号(需要找到当前最大的序列号值);
根据每个网站的特点编译(标准、脚本);
3.获取数据
系统提供的rake程序会根据预定义的XML格式执行数据采集任务。为了防止目标网站的检测程序发现它,我们建议直接保存捕获的页面,然后对其进行处理。而不是在获取信息后立即处理信息,对于提高抓取和保留第一手信息的效率非常有价值。
通过定义的脚本模拟登录;
对于下拉列表中的查询项,循环遍历列表中的每个值。并对获取查询结果的页面进行模拟翻页操作,获取所有查询结果;
如果作业数据库或业务目录数据库使用自增整数作为其唯一ID,那么我们可以想办法获取最大值,然后通过遍历的方法将其全部抓取;
定时执行爬取操作,增量保存抓取到的数据;
4.简单分析
采集接收到的数据在外网的服务器上简单的分析处理。内容主要包括:
结构化数据:对获取的数据进行结构化,以方便以后的数据传输,也方便下一步的复查和故障排除任务。
消除重复;使用模拟查询方法遍历时,系统捕获的数据必须是重复的。由于重复的数据会造成重复的分析处理程序,不仅占用系统资源,使系统处理效率低下,而且给系统带来了大量的垃圾数据。为了避免大量重复和冗余的数据,我们要做的第一个处理工作就是对重复项进行整理。
消除错误;由于目标站点的内容、结构和格式的调整,系统将无法捕获或捕获大量错误信息。在排除这些误报信息的同时,我们通过数据错误率的判断,可以获得目标站点是否发生变化的信息,并及时向系统发出预警通知。
5.数据发回内部
系统通过Web Service将处理后的数据发送回企业。唯一需要考虑的是如何实现增量更新,否则每天有大量数据更新到本地数据库,会造成网络拥塞。
6.数据分析
这里的数据分析与上述在远程服务器上进行的分析操作不同。后者是为了简单有效的数据过滤,防止数据冗余和造成处理速度缓慢或网络拥塞。前者为日后人工确认提供便利,有效帮助市场人员进行快速人工分拣。详情如下:
l 按地区区分;
l 按准确程度划分;帮助用户优先考虑哪些信息更有效;
l 按发帖数划分;
l 记录各公司发布的职位变动过程;
7.手动确认
这部分主要关注两个方面:
1、提供友好的人机界面,允许人工确认这些信息;
2、对比英才网的职位数据库,提取差异进行人工确认:
通过与市场人员的沟通交流,了解他们关心的信息,按照他们期望的方式提供数据,完成人工确认。
8.统计汇总
汇总统计功能也是数据汇总系统的重要组成部分,将提供以下几类统计汇总功能:
以网站为单位,统计每个网站日新增的公司、职位等信息;
跟踪大型企业,统计其在每个网站上发布的信息帖记录;
以时间为单位,按日、周、月对各种信息进行统计;
按地区、公司、岗位进行统计;
其他;
仿真统计汇总界面

[引用]
转载于:
实时抓取网页数据(从服务端取到的数据需要实时反馈,否则将毫无意义!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-08 06:22
从服务器获取的数据需要实时反馈,否则毫无意义!
先介绍一下Vue.set()方法
注意:如果服务器返回的数据量很小,或者字段很少,可以使用vue的set方法。如果数据量很大,请直接看第二种情况。
官网API是这样介绍的:
Vue.set(目标,键,值)
范围:
{对象 | 数组} 目标
{字符串 | 数字}键
{any} 值
返回值:设置后的新值
用法:
向响应式对象添加一个属性,并确保这个新属性也是响应式的并触发视图更新。必须用来给响应式对象添加新属性,因为Vue无法检测普通的新属性(比如this.myObject.newProperty ='hi')
请注意,对象不能是 Vue 实例,也不能是 Vue 实例的根数据对象。
举个简单的小例子来介绍一下这个用法:
一:在data中定义一个对象:
data() {
return {
person:{
age:10,
name:'李古拉雷',
sex:1
}
}
}
二:向服务器发起请求返回一个新的数据对象:
person:{
age:20,
name:'高圆圆',
sex:0
}
这时候就需要把这个对象实时渲染到页面上
三:使用Vue.set()方法更新数据
如下:
methods: {
getPerson(){
this.$http({
method: "post",
url:this.$$baseURL + "sys/getPerson",
}).then(res => {
Vue.set(this.person,0,{age:res.data.age,name:res.data.name,sex:res.data.sex})
/**
* 0 更新的是位置0上的数据
*
*/
});
}
}
这样就可以将服务器返回的新数据实时更新到组件中。
先说第二种情况:
这种情况下,数据量大,字段多。使用 Vue.set() 方法有点太多了。这个时候我们应该怎么做?
核心思想是定义一个临时变量。因为calculated是一个计算属性,所以里面的值比较精细,可以实时渲染组件更新页面。
一:我们在data中定义一个大的临时对象
data() {
return {
myTempObj:{} // 这时一个很大的临时对象,字段特别多
}
}
二:我们在计算属性中也定义了一个非常大的对象
这个对象就是我们在页面中实际使用的对象
三:发起异步请求并从服务器返回数据
methods: {
getBigObj(){
this.$http({
method: "post",
url:this.$$baseURL + "sys/getBigObj",
}).then(res => {
this.myTempObj=res.bigObj ; // 在这里用临时变量接受服务端返回值
});
}
}
四:页面模板组件中的使用方法
{{item.name}}
以上两种情况可以解决从服务器获取的数据无法实时更新的问题。根据具体情况选择使用!
四年java开发,四年前端加产品。今日头条前端架构师。欢迎关注我,技术生活好有趣! 查看全部
实时抓取网页数据(从服务端取到的数据需要实时反馈,否则将毫无意义!)
从服务器获取的数据需要实时反馈,否则毫无意义!
先介绍一下Vue.set()方法
注意:如果服务器返回的数据量很小,或者字段很少,可以使用vue的set方法。如果数据量很大,请直接看第二种情况。
官网API是这样介绍的:
Vue.set(目标,键,值)
范围:
{对象 | 数组} 目标
{字符串 | 数字}键
{any} 值
返回值:设置后的新值
用法:
向响应式对象添加一个属性,并确保这个新属性也是响应式的并触发视图更新。必须用来给响应式对象添加新属性,因为Vue无法检测普通的新属性(比如this.myObject.newProperty ='hi')
请注意,对象不能是 Vue 实例,也不能是 Vue 实例的根数据对象。
举个简单的小例子来介绍一下这个用法:
一:在data中定义一个对象:
data() {
return {
person:{
age:10,
name:'李古拉雷',
sex:1
}
}
}
二:向服务器发起请求返回一个新的数据对象:
person:{
age:20,
name:'高圆圆',
sex:0
}
这时候就需要把这个对象实时渲染到页面上
三:使用Vue.set()方法更新数据
如下:
methods: {
getPerson(){
this.$http({
method: "post",
url:this.$$baseURL + "sys/getPerson",
}).then(res => {
Vue.set(this.person,0,{age:res.data.age,name:res.data.name,sex:res.data.sex})
/**
* 0 更新的是位置0上的数据
*
*/
});
}
}
这样就可以将服务器返回的新数据实时更新到组件中。
先说第二种情况:
这种情况下,数据量大,字段多。使用 Vue.set() 方法有点太多了。这个时候我们应该怎么做?
核心思想是定义一个临时变量。因为calculated是一个计算属性,所以里面的值比较精细,可以实时渲染组件更新页面。
一:我们在data中定义一个大的临时对象
data() {
return {
myTempObj:{} // 这时一个很大的临时对象,字段特别多
}
}
二:我们在计算属性中也定义了一个非常大的对象
这个对象就是我们在页面中实际使用的对象
三:发起异步请求并从服务器返回数据
methods: {
getBigObj(){
this.$http({
method: "post",
url:this.$$baseURL + "sys/getBigObj",
}).then(res => {
this.myTempObj=res.bigObj ; // 在这里用临时变量接受服务端返回值
});
}
}
四:页面模板组件中的使用方法
{{item.name}}
以上两种情况可以解决从服务器获取的数据无法实时更新的问题。根据具体情况选择使用!
四年java开发,四年前端加产品。今日头条前端架构师。欢迎关注我,技术生活好有趣!
实时抓取网页数据(人脑高于人工智能,计算机的算力和计算能力)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-11-06 16:02
实时抓取网页数据,网页数据用来转录成人脑可识别的形式。通过相应的算法,去优化处理算法,让它达到人脑的识别率。接下来就靠人脑去分析、运算了,计算机本身是人脑的延伸,人脑大概率可以分析计算机达不到的精度,更重要的是人脑只有三维,如果能够有意识的训练计算机能识别长宽高都有误差的二维网页数据(比如数字二维的网页),那计算机也是有这个能力的,比如能够解释网页的格式。
详见世界五百强hr招聘信息
现在已经可以了,并且绝对可以代替人脑和计算机大脑共同分析。人脑高于人工智能,计算机低于人工智能,计算机的算力相对人脑有优势,用机器解读和分析人脑数据比较常见。
很显然,人脑不能胜任这个工作。人脑的算力,计算能力,和人工智能有天壤之别,也就是人工智能擅长计算,人脑擅长分析。而网页信息本身就是一种数据,所以这个就不是一个非常合适的程序可以解读并分析。因为解读网页信息的算法其实就是人工智能的一部分,人工智能擅长算法,其算法基础就是人脑中海量数据的识别与分析。而人脑擅长识别,计算能力也非常强大,所以计算机擅长处理图片数据,而非数据库。
但即使这样,计算机解读人脑中的信息,也是需要人类数据库作为基础,所以在计算机中的算法与人脑中的算法是有区别的。因此,只需要增加人脑的数据,不需要增加计算机的算力。但是,把人脑数据和计算能力对接,并不是一个难题,有大把的思路,数学模型可以帮助实现这个愿望。但是应用到自然语言处理,图片分类等领域上。人工智能的发展速度会超过人脑的发展速度,因为人脑在进化的过程中,逐渐认识到通过数学模型可以做任何事情,所以才有了“图灵测试”和“代码智能”等,这个时候数学模型已经不能作为人脑的发展核心优势了。
但是人工智能是有自己特定的发展方向,要理解需要理解人脑中的函数、定理、推论等等等等的,一句话,要进化出智能必须要大脑发展到足够的高度,才能真正形成学习认知能力,然后才能在应用上取得成功。 查看全部
实时抓取网页数据(人脑高于人工智能,计算机的算力和计算能力)
实时抓取网页数据,网页数据用来转录成人脑可识别的形式。通过相应的算法,去优化处理算法,让它达到人脑的识别率。接下来就靠人脑去分析、运算了,计算机本身是人脑的延伸,人脑大概率可以分析计算机达不到的精度,更重要的是人脑只有三维,如果能够有意识的训练计算机能识别长宽高都有误差的二维网页数据(比如数字二维的网页),那计算机也是有这个能力的,比如能够解释网页的格式。
详见世界五百强hr招聘信息
现在已经可以了,并且绝对可以代替人脑和计算机大脑共同分析。人脑高于人工智能,计算机低于人工智能,计算机的算力相对人脑有优势,用机器解读和分析人脑数据比较常见。
很显然,人脑不能胜任这个工作。人脑的算力,计算能力,和人工智能有天壤之别,也就是人工智能擅长计算,人脑擅长分析。而网页信息本身就是一种数据,所以这个就不是一个非常合适的程序可以解读并分析。因为解读网页信息的算法其实就是人工智能的一部分,人工智能擅长算法,其算法基础就是人脑中海量数据的识别与分析。而人脑擅长识别,计算能力也非常强大,所以计算机擅长处理图片数据,而非数据库。
但即使这样,计算机解读人脑中的信息,也是需要人类数据库作为基础,所以在计算机中的算法与人脑中的算法是有区别的。因此,只需要增加人脑的数据,不需要增加计算机的算力。但是,把人脑数据和计算能力对接,并不是一个难题,有大把的思路,数学模型可以帮助实现这个愿望。但是应用到自然语言处理,图片分类等领域上。人工智能的发展速度会超过人脑的发展速度,因为人脑在进化的过程中,逐渐认识到通过数学模型可以做任何事情,所以才有了“图灵测试”和“代码智能”等,这个时候数学模型已经不能作为人脑的发展核心优势了。
但是人工智能是有自己特定的发展方向,要理解需要理解人脑中的函数、定理、推论等等等等的,一句话,要进化出智能必须要大脑发展到足够的高度,才能真正形成学习认知能力,然后才能在应用上取得成功。
实时抓取网页数据(先上代码看了一下应该是Pyecharts中Map的data_pair )
网站优化 • 优采云 发表了文章 • 0 个评论 • 29 次浏览 • 2021-11-05 09:08
)
2021/07/15 更新:
没及时看到评论区的反馈。对不起,真相。拉下代码看Pyecharts中Map的data_pair数据类型。它现在应该转换为列表。
代码已整理完善,完整源代码已上传至Gitee,地址:完整源代码
所有生成的csv、流行病地图、可视化图表都在项目根目录下。
概括:
受2019-nCoV影响,一场没有硝烟的抗击疫情已经打响。在全国人民的共同努力下,疫情正在逐步趋于稳定,但我们仍不能掉以轻心。
疫情还没开始的时候,我每天都在关注疫情,尤其是全国疫情地图。之后一直想拿到资料自己做一个,但没有坚持去做。前几天用Python爬取了分数查询网站,跟着做这个需求。
话不多说,先上图吧:
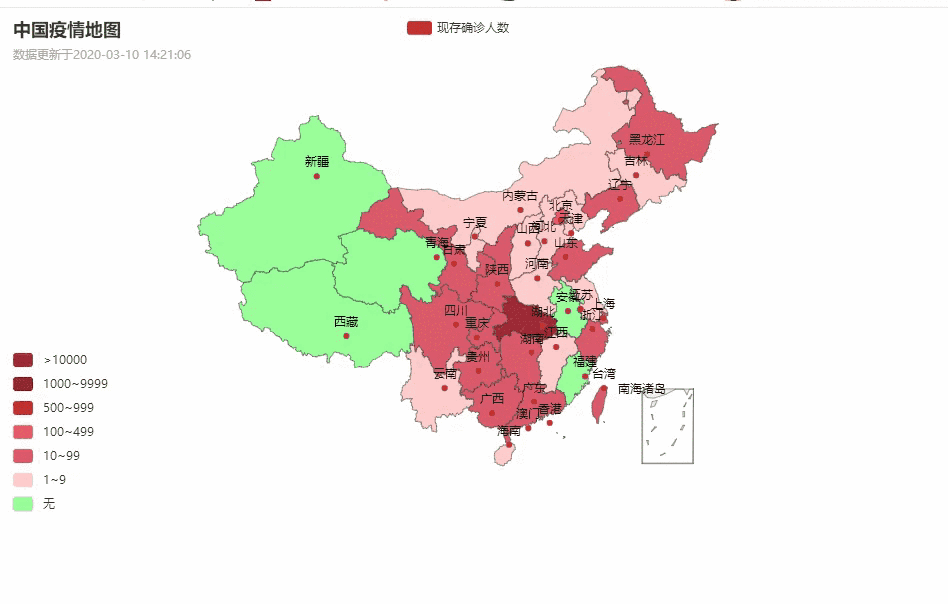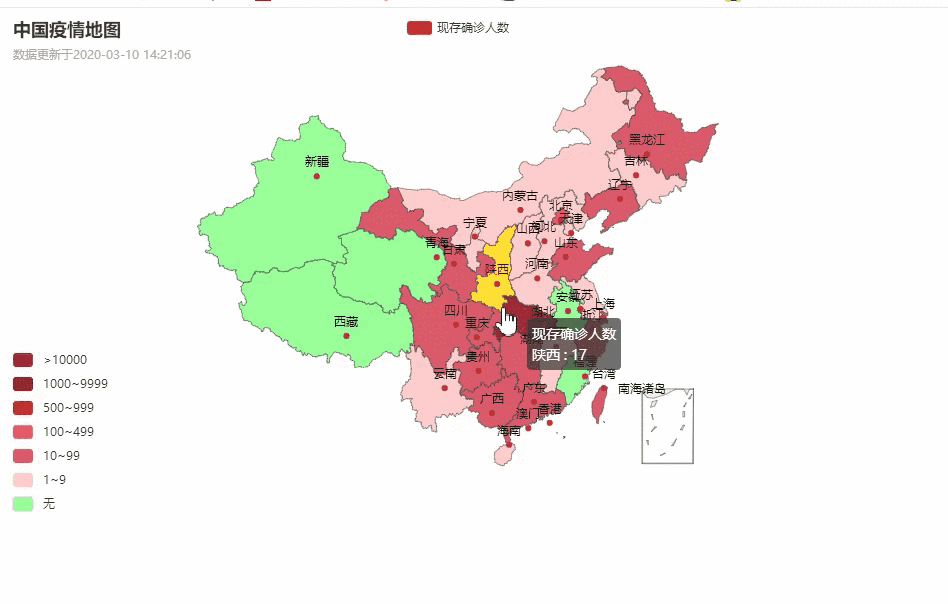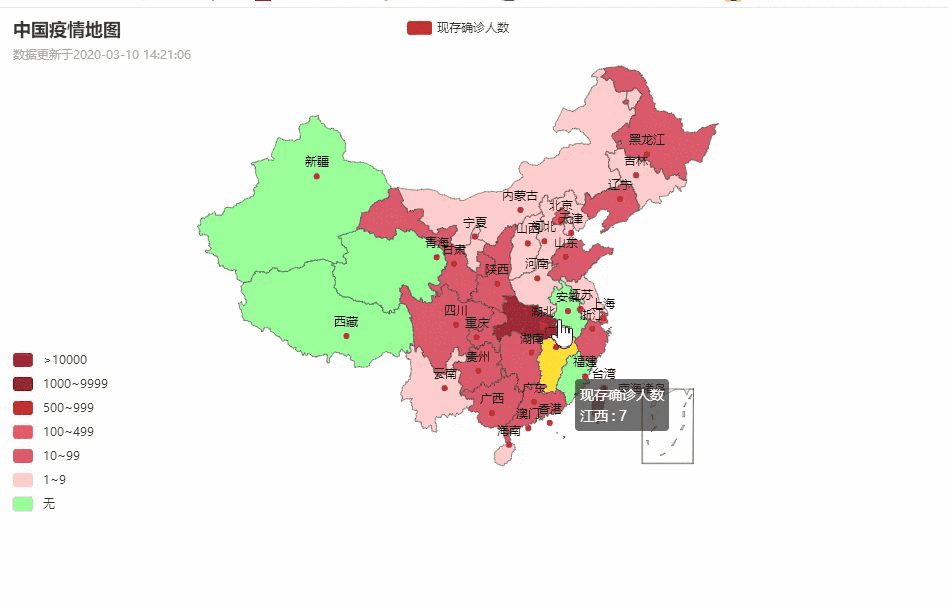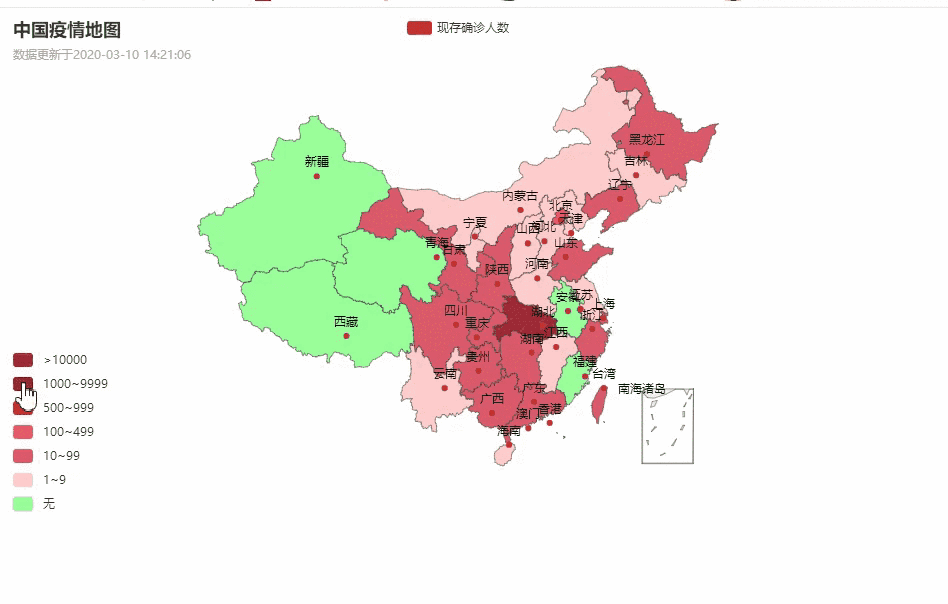
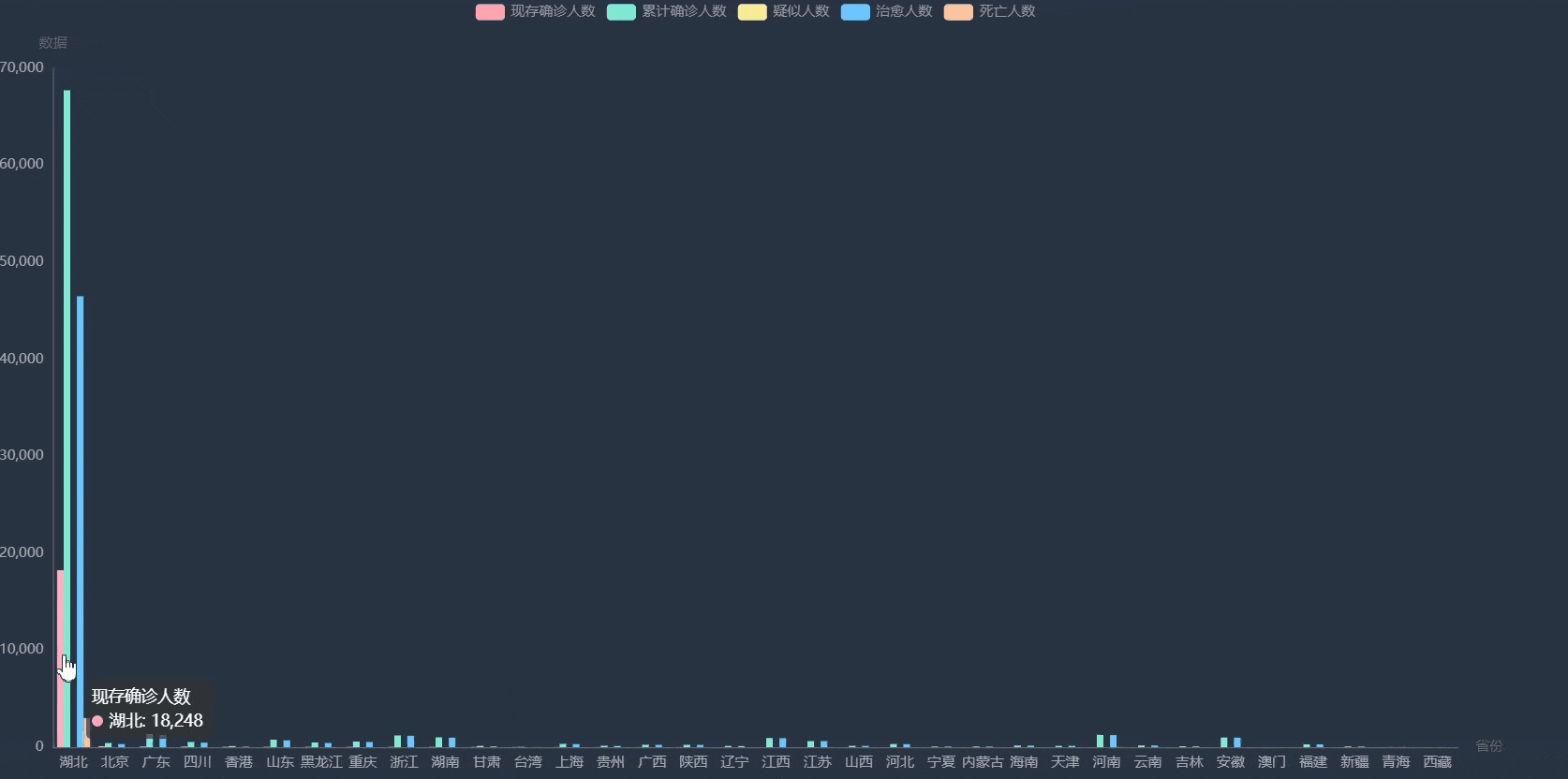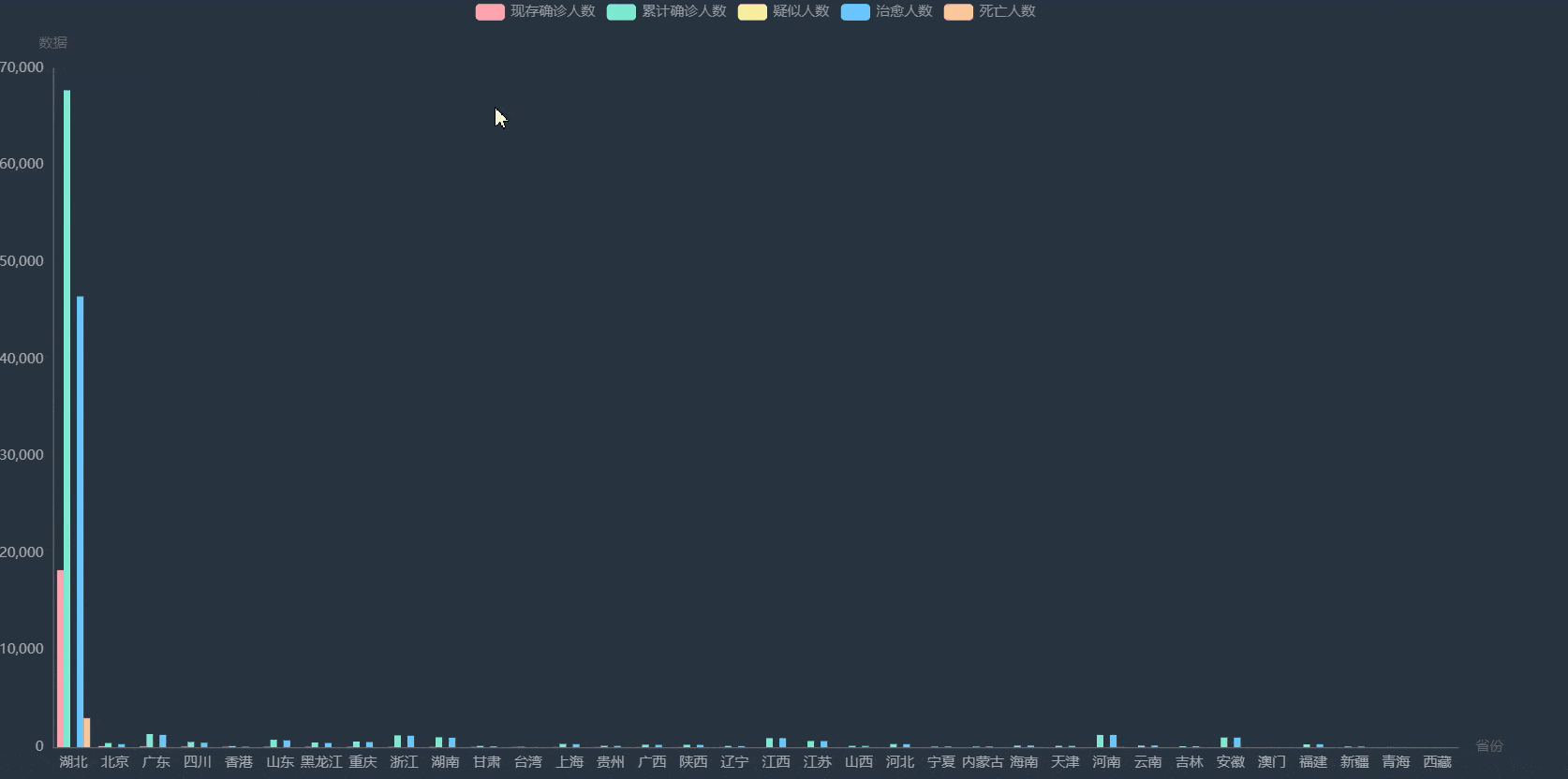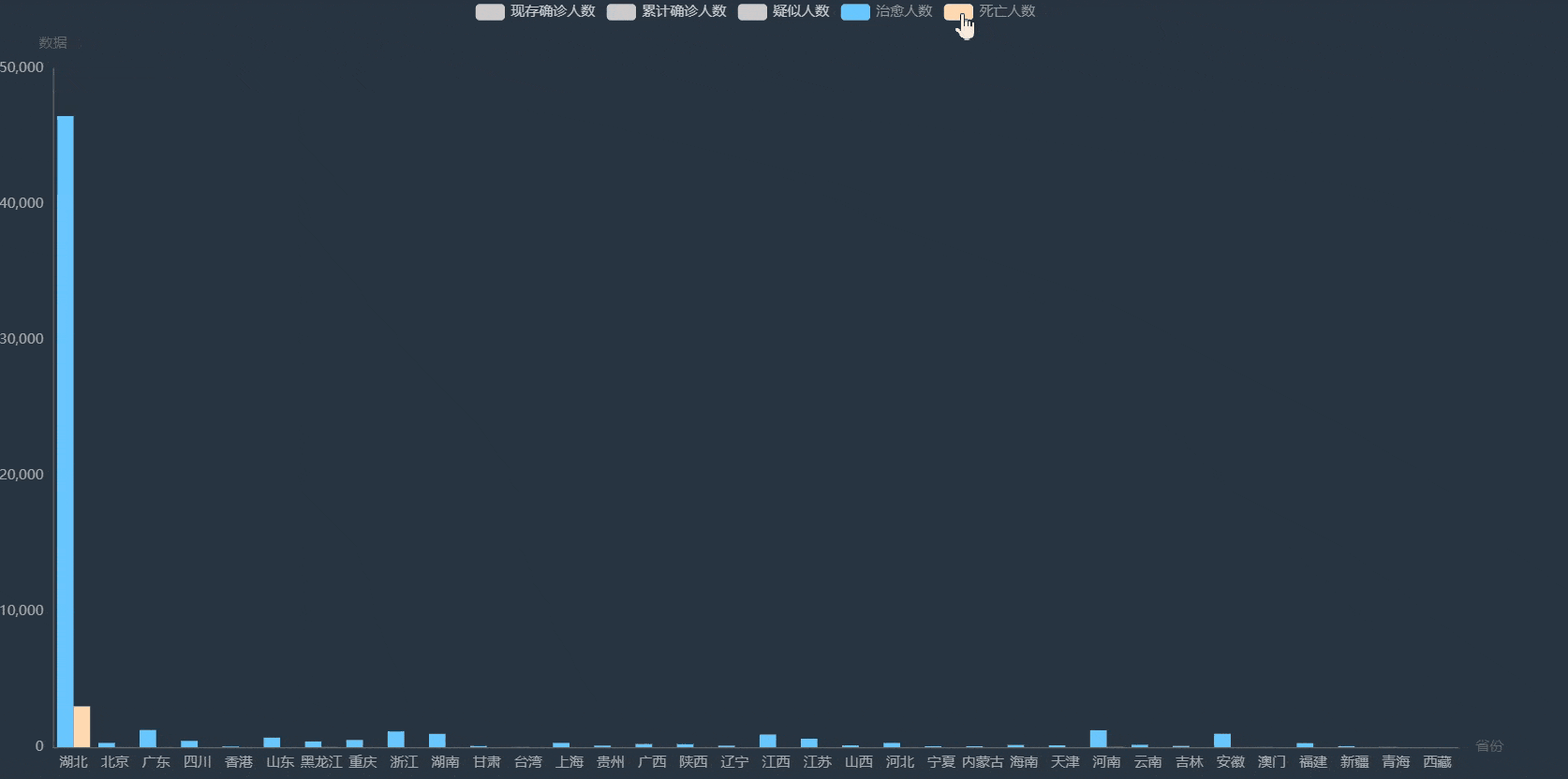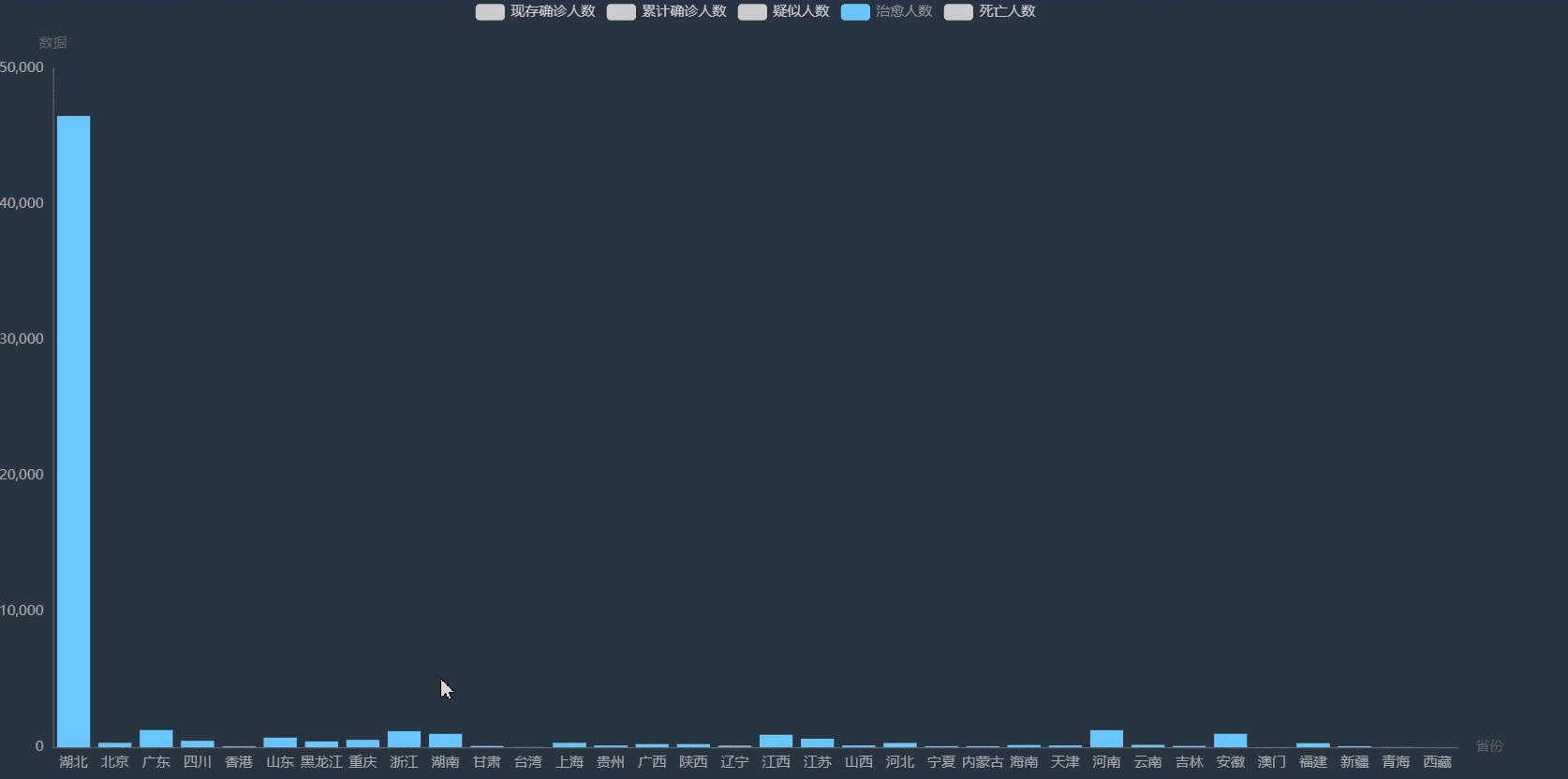
中国疫情地图
各省详情
湖北省各城市疫情数据分布
内容
数据来源分析:
数据来自丁香博士:
丁香博士的数据如下图所示:
看到这里,你可能会觉得这个数据应该直接放在tr,td或者ul,li里面,直接发送请求,获取页面DOM中的文本即可。
起初我是这样想的。看了网页的源码,才发现不是-_-||
实际上,中国每个省的数据都存储在id为getAreaStat的script标签中,然后动态渲染到视图中。
所以我们要做的就是抓取脚本标签中id为getAreaStat的文本内容
数据整理:
不难看出,script标签中的数据是以json的形式存储的,我们对json字符串进行校验和格式化,将里面的数据组织起来。
左边密集的数据格式化后,可以很直观的看到json字符串的内部存储情况,大致如下:在整个json字符串中,每个省都是一个dict,每个省的城市是用于存储省内城市的子列表。数据。
代码部分需要用到的第三方库如下: 一、 抓取全国各省疫情信息,生成csv文件基础
1.代码分析:
2. 源代码:
import requests
from pyquery import PyQuery as pq
import json
import pandas as pd
import time
def get_data():
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
response = requests.get(url)
if response.status_code == 200:
response.encoding = "utf-8"
dom = pq(response.content)
data = dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0]
jsonObj = json.loads(data) # json对象
print("数据抓取成功...")
province_data = []
for item in jsonObj:
dic = {"省全称": item["provinceName"], "省简称": item["provinceShortName"], "现存确诊人数": item["currentConfirmedCount"],
"累计确诊人数": item["confirmedCount"], "疑似人数": item["suspectedCount"], "治愈人数": item["curedCount"],
"死亡人数": item["deadCount"]}
province_data.append(dic)
if len(province_data) > 0:
print("写入数据...")
try:
df = pd.DataFrame(province_data)
time_format = time.strftime("%Y-%m-%d_%H_%M_%S", time.localtime())
df.to_csv(time_format + "全国各省疫情数据.csv", encoding="gbk", index=False)
print("写入成功...")
except Exception as e:
print(f"写入失败....{e}")
if __name__ == '__main__':
get_data()
3.操作效果:
二、使用pyecharts绘制中国疫情高级地图
说到画表,第一个想到的就是Apache开源的echarts框架,高效强大。因为对Matplotlib库不熟悉,拿到数据后想用echarts框架的前端画一个,后来才知道有专门的pyecharts,所以很nice!
建议不懂echarts或pyecharts的同学一定要先阅读官方API,了解基本图表类型和各种参数,或者把各种参数写成一个链式操作,会有点别扭((⊙﹏⊙⊙) )) 哦!
1.代码分析:
2. 源代码:
"""
@File : data_chart.py
@Modify Time @Author @Version @Desciption
------------ ------- -------- -----------
2021/7/15 9:25 wrzcoder 1.0 None
"""
from pyecharts import options as opts
from pyecharts.charts import Map
import requests
from pyquery import PyQuery as pq
import json
import time
def map_visual_map() -> Map:
c = (
Map(init_opts=opts.InitOpts(page_title="中国疫情地图"))
.add("现存确诊人数", data_pair=list(current_data_dic.items()), maptype="china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国疫情地图", subtitle="数据更新于" + time_format),
visualmap_opts=opts.VisualMapOpts(pieces=[
{"value": 0, "label": "无", "color": "#9AFF9A"},
{"min": 1, "max": 9, "label": "1~9", "color": "#FFCCCC"},
{"min": 10, "max": 99, "label": "10~99", "color": "#DB5A6B"},
{"min": 100, "max": 499, "label": "100~499", "color": "#FF6666"},
{"min": 500, "max": 999, "label": "500~999", "color": "#CC2929"},
{"min": 1000, "max": 9999, "label": "1000~9999", "color": "#8C0D0D"},
{"min": 10000, "label": ">10000", "color": "#9d2933"}
], is_piecewise=True),
)
)
return c
if __name__ == '__main__':
try:
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
response = requests.get(url)
if response.status_code == 200:
response.encoding = "utf-8"
dom = pq(response.content)
data = dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0]
jsonObj = json.loads(data) # json对象
print("数据抓取成功...")
current_data_dic = {}
time_format = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
for item in jsonObj:
current_data_dic[item["provinceShortName"]] = item["currentConfirmedCount"]
print(list(current_data_dic.items()))
map_visual_map().render("疫情地图.html")
print('疫情地图已生成在项目根目录...')
except Exception as e:
print(e)
3.操作效果:
三、 抓取全国各省市疫情数据,拓展数据可视化
我们上面只用到了每个省的数据,在分析开始的时候,每个省的dict还收录了省、市(区)的数据,我们不能浪费这些数据,一定要在什么时候用我们抓取它们。好好利用它,我们将全国各省市的所有疫情数据进行分类可视化。
这里我想说的是:我们在可视化各省(直辖市)下的市(区)的疫情数据时,也可以使用pyecharts中的Map,但是为了更熟悉pyecharts,让我们更改为表格类型的饼图。
看起来非常麻烦。需要请求每个省的数据收录城市,最后画图太麻烦了,不过还是不行(*^▽^*) 30行代码就够了
1.代码分析
2.源代码
"""
@File : province_data_chart.py
@Modify Time @Author @Version @Desciption
------------ ------- -------- -----------
2021/7/15 9:45 wrzcoder 1.0 None
"""
import requests
import json
from pyecharts.charts import Pie
import pyecharts.options as opts
import time
from pyquery import PyQuery as pq
import os
def create_Pie(provinceName, dic_citys) -> Pie:
c = (
Pie(init_opts=opts.InitOpts(width="100%", height="800px", page_title=provinceName + "各市(区)情况"))
.add("", data_pair=list(dic_citys.items()), center=["50%", "58%"], )
.set_global_opts(title_opts=opts.TitleOpts(title=provinceName + "各市(区)情况", subtitle="数据更新于:" + timeformat))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
if not os.path.exists('./中国各省情况'):
os.mkdir('./中国各省情况')
c.render("./中国各省情况/" + provinceName + "各市(区)情况.html")
if __name__ == '__main__':
try:
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
timeformat = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
response = requests.get(url)
response.encoding = "utf-8"
if response.status_code == 200:
print("数据抓取成功!")
dom = pq(response.text)
jsonobj = json.loads(dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0])
for province in jsonobj:
dic_city = {}
for city in province["cities"]:
dic_city[city["cityName"]] = city["currentConfirmedCount"]
if dic_city.__len__() > 0:
create_Pie(province["provinceName"], dic_city)
print(province["provinceName"] + "各市数据汇总完毕!")
except Exception as e:
print(e)
3.操作效果:
只需1.1s,我们就抓取了全国各省市的疫情数据,整理并生成了数据图表
打开随机饼图查看效果:
四川省各城市疫情数据汇总
至此,我们已经完成了对全国各省市实时疫情数据的采集和处理,绘制了中国疫情图。在此基础上,我们进一步拓展并开展了中国各省、自治区、直辖市疫情数据的批量归一化和可视化工作。这期间复习了requests库、pandas、pyquery库等,还学习学习了强大的图表pyecharts库,收获颇丰!所以在这里分享一下,一起了解和学习!
最后,加油武汉,加油中国!疫情终会过去,春天一定会来!
图片来自网络
我希望下次我运行这段代码时,我看到的疫情图会是这样的:
查看全部
实时抓取网页数据(先上代码看了一下应该是Pyecharts中Map的data_pair
)
2021/07/15 更新:
没及时看到评论区的反馈。对不起,真相。拉下代码看Pyecharts中Map的data_pair数据类型。它现在应该转换为列表。
代码已整理完善,完整源代码已上传至Gitee,地址:完整源代码
所有生成的csv、流行病地图、可视化图表都在项目根目录下。
概括:
受2019-nCoV影响,一场没有硝烟的抗击疫情已经打响。在全国人民的共同努力下,疫情正在逐步趋于稳定,但我们仍不能掉以轻心。
疫情还没开始的时候,我每天都在关注疫情,尤其是全国疫情地图。之后一直想拿到资料自己做一个,但没有坚持去做。前几天用Python爬取了分数查询网站,跟着做这个需求。
话不多说,先上图吧:
中国疫情地图
各省详情
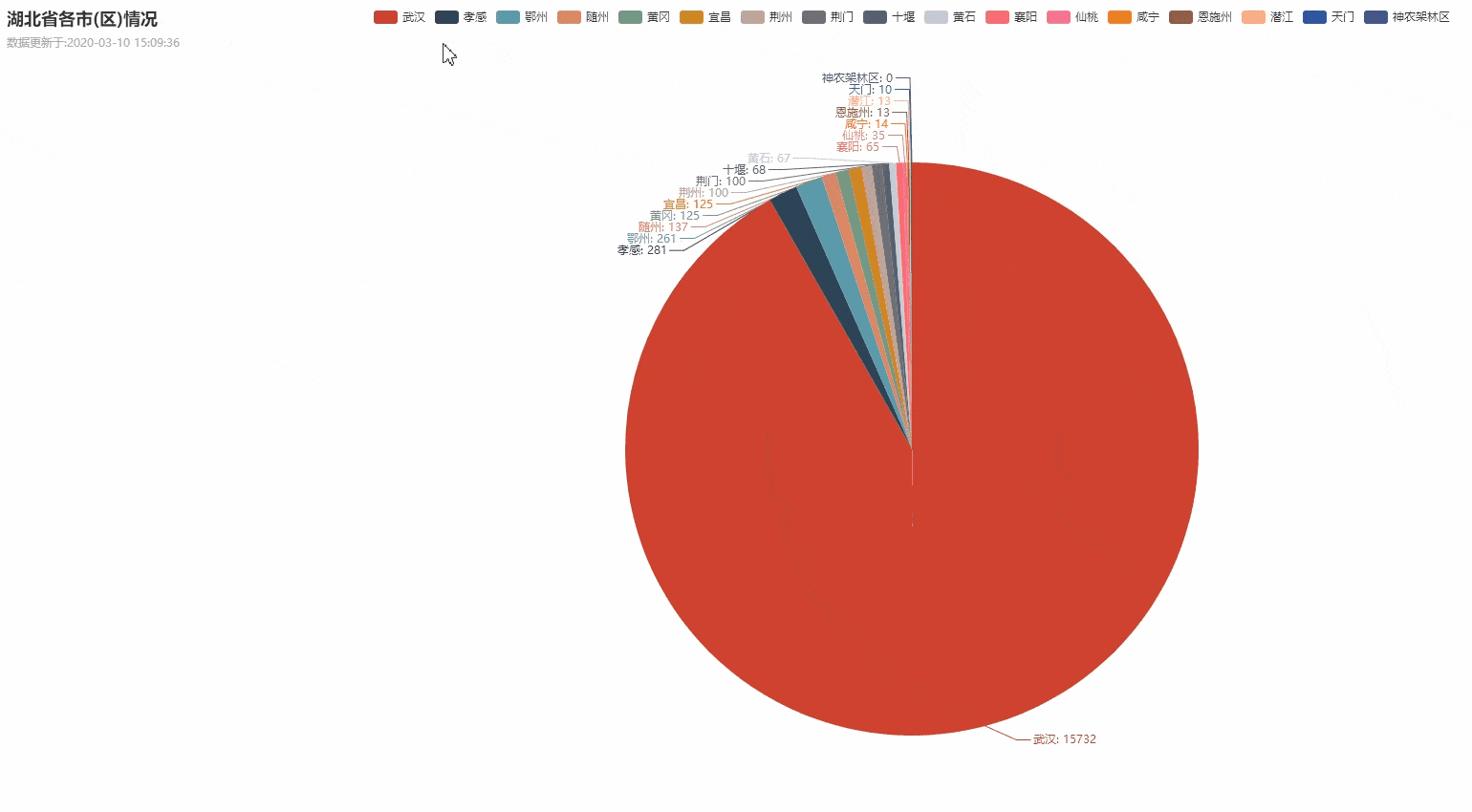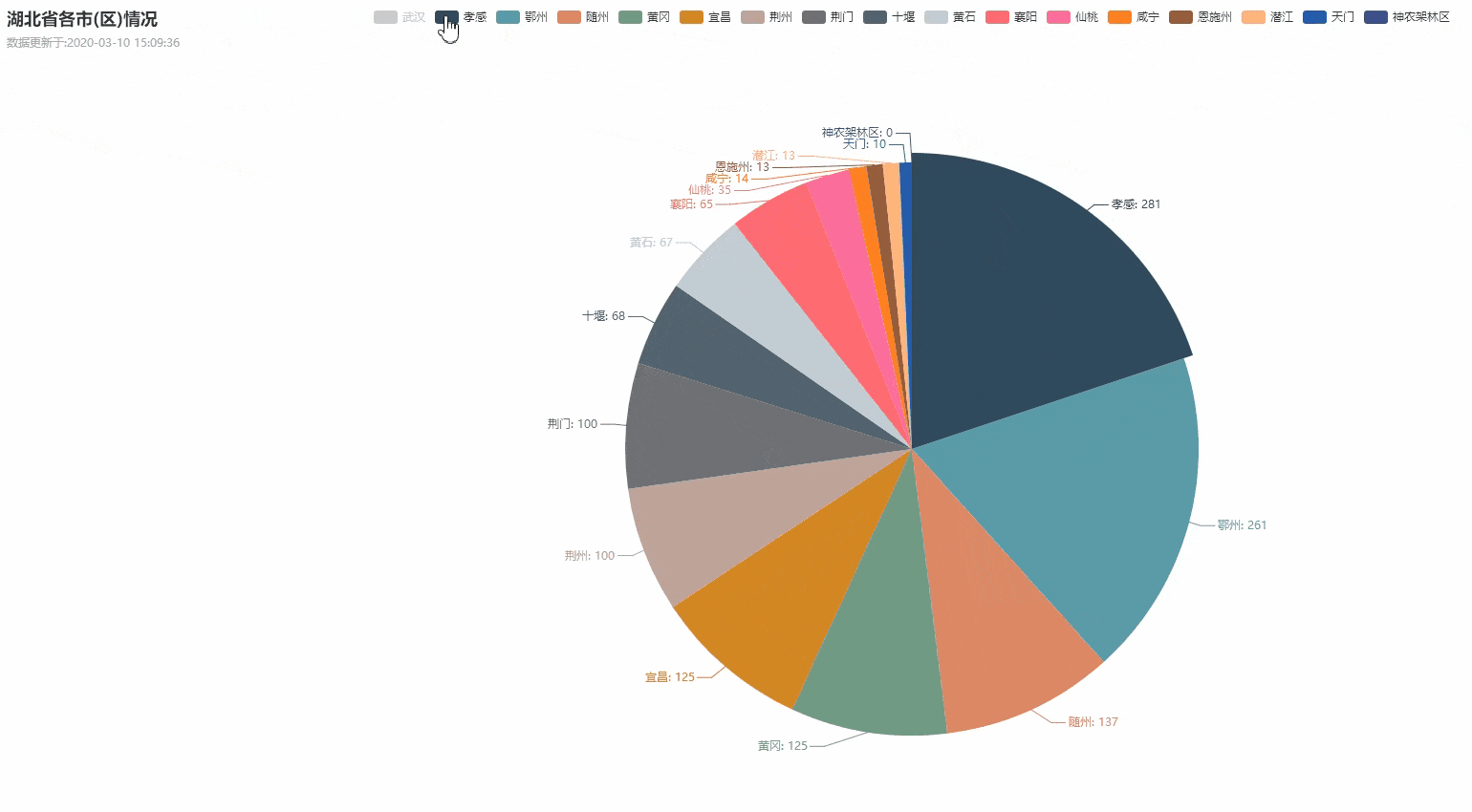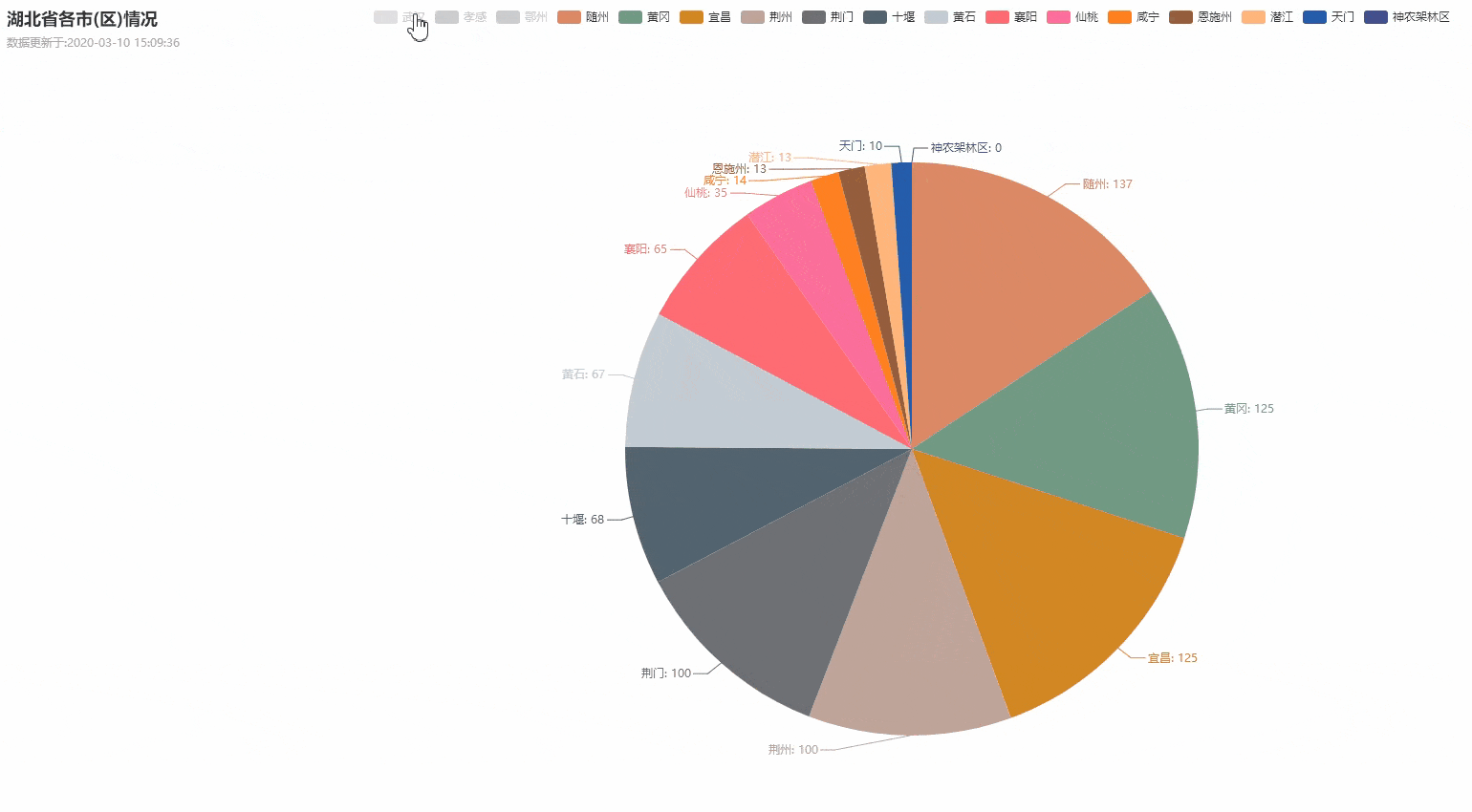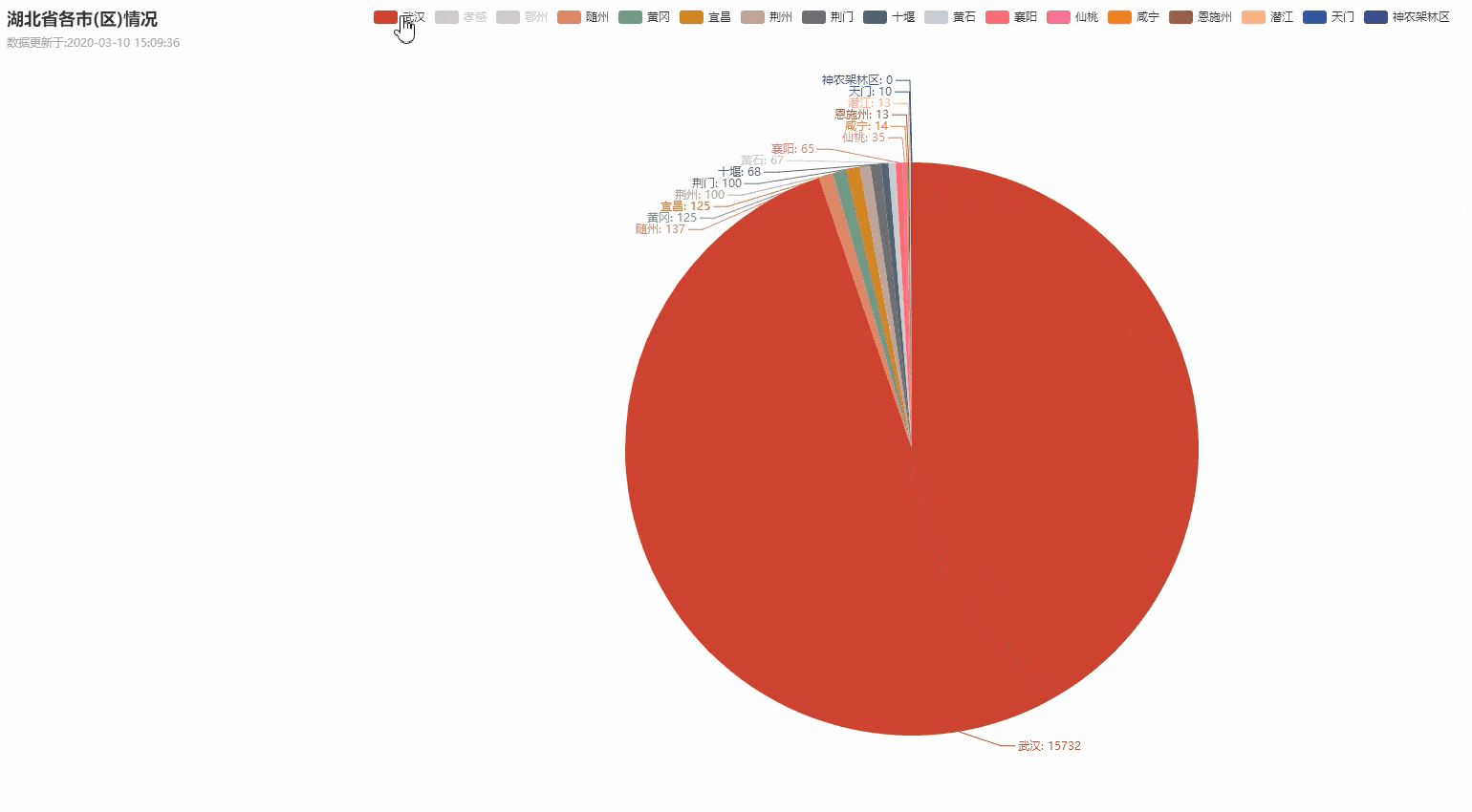
湖北省各城市疫情数据分布
内容
数据来源分析:
数据来自丁香博士:
丁香博士的数据如下图所示:


看到这里,你可能会觉得这个数据应该直接放在tr,td或者ul,li里面,直接发送请求,获取页面DOM中的文本即可。
起初我是这样想的。看了网页的源码,才发现不是-_-||


实际上,中国每个省的数据都存储在id为getAreaStat的script标签中,然后动态渲染到视图中。
所以我们要做的就是抓取脚本标签中id为getAreaStat的文本内容
数据整理:
不难看出,script标签中的数据是以json的形式存储的,我们对json字符串进行校验和格式化,将里面的数据组织起来。

左边密集的数据格式化后,可以很直观的看到json字符串的内部存储情况,大致如下:在整个json字符串中,每个省都是一个dict,每个省的城市是用于存储省内城市的子列表。数据。
代码部分需要用到的第三方库如下: 一、 抓取全国各省疫情信息,生成csv文件基础
1.代码分析:

2. 源代码:
import requests
from pyquery import PyQuery as pq
import json
import pandas as pd
import time
def get_data():
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
response = requests.get(url)
if response.status_code == 200:
response.encoding = "utf-8"
dom = pq(response.content)
data = dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0]
jsonObj = json.loads(data) # json对象
print("数据抓取成功...")
province_data = []
for item in jsonObj:
dic = {"省全称": item["provinceName"], "省简称": item["provinceShortName"], "现存确诊人数": item["currentConfirmedCount"],
"累计确诊人数": item["confirmedCount"], "疑似人数": item["suspectedCount"], "治愈人数": item["curedCount"],
"死亡人数": item["deadCount"]}
province_data.append(dic)
if len(province_data) > 0:
print("写入数据...")
try:
df = pd.DataFrame(province_data)
time_format = time.strftime("%Y-%m-%d_%H_%M_%S", time.localtime())
df.to_csv(time_format + "全国各省疫情数据.csv", encoding="gbk", index=False)
print("写入成功...")
except Exception as e:
print(f"写入失败....{e}")
if __name__ == '__main__':
get_data()
3.操作效果:


二、使用pyecharts绘制中国疫情高级地图
说到画表,第一个想到的就是Apache开源的echarts框架,高效强大。因为对Matplotlib库不熟悉,拿到数据后想用echarts框架的前端画一个,后来才知道有专门的pyecharts,所以很nice!
建议不懂echarts或pyecharts的同学一定要先阅读官方API,了解基本图表类型和各种参数,或者把各种参数写成一个链式操作,会有点别扭((⊙﹏⊙⊙) )) 哦!
1.代码分析:

2. 源代码:
"""
@File : data_chart.py
@Modify Time @Author @Version @Desciption
------------ ------- -------- -----------
2021/7/15 9:25 wrzcoder 1.0 None
"""
from pyecharts import options as opts
from pyecharts.charts import Map
import requests
from pyquery import PyQuery as pq
import json
import time
def map_visual_map() -> Map:
c = (
Map(init_opts=opts.InitOpts(page_title="中国疫情地图"))
.add("现存确诊人数", data_pair=list(current_data_dic.items()), maptype="china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国疫情地图", subtitle="数据更新于" + time_format),
visualmap_opts=opts.VisualMapOpts(pieces=[
{"value": 0, "label": "无", "color": "#9AFF9A"},
{"min": 1, "max": 9, "label": "1~9", "color": "#FFCCCC"},
{"min": 10, "max": 99, "label": "10~99", "color": "#DB5A6B"},
{"min": 100, "max": 499, "label": "100~499", "color": "#FF6666"},
{"min": 500, "max": 999, "label": "500~999", "color": "#CC2929"},
{"min": 1000, "max": 9999, "label": "1000~9999", "color": "#8C0D0D"},
{"min": 10000, "label": ">10000", "color": "#9d2933"}
], is_piecewise=True),
)
)
return c
if __name__ == '__main__':
try:
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
response = requests.get(url)
if response.status_code == 200:
response.encoding = "utf-8"
dom = pq(response.content)
data = dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0]
jsonObj = json.loads(data) # json对象
print("数据抓取成功...")
current_data_dic = {}
time_format = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
for item in jsonObj:
current_data_dic[item["provinceShortName"]] = item["currentConfirmedCount"]
print(list(current_data_dic.items()))
map_visual_map().render("疫情地图.html")
print('疫情地图已生成在项目根目录...')
except Exception as e:
print(e)
3.操作效果:

三、 抓取全国各省市疫情数据,拓展数据可视化
我们上面只用到了每个省的数据,在分析开始的时候,每个省的dict还收录了省、市(区)的数据,我们不能浪费这些数据,一定要在什么时候用我们抓取它们。好好利用它,我们将全国各省市的所有疫情数据进行分类可视化。
这里我想说的是:我们在可视化各省(直辖市)下的市(区)的疫情数据时,也可以使用pyecharts中的Map,但是为了更熟悉pyecharts,让我们更改为表格类型的饼图。
看起来非常麻烦。需要请求每个省的数据收录城市,最后画图太麻烦了,不过还是不行(*^▽^*) 30行代码就够了
1.代码分析

2.源代码
"""
@File : province_data_chart.py
@Modify Time @Author @Version @Desciption
------------ ------- -------- -----------
2021/7/15 9:45 wrzcoder 1.0 None
"""
import requests
import json
from pyecharts.charts import Pie
import pyecharts.options as opts
import time
from pyquery import PyQuery as pq
import os
def create_Pie(provinceName, dic_citys) -> Pie:
c = (
Pie(init_opts=opts.InitOpts(width="100%", height="800px", page_title=provinceName + "各市(区)情况"))
.add("", data_pair=list(dic_citys.items()), center=["50%", "58%"], )
.set_global_opts(title_opts=opts.TitleOpts(title=provinceName + "各市(区)情况", subtitle="数据更新于:" + timeformat))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
if not os.path.exists('./中国各省情况'):
os.mkdir('./中国各省情况')
c.render("./中国各省情况/" + provinceName + "各市(区)情况.html")
if __name__ == '__main__':
try:
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
timeformat = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
response = requests.get(url)
response.encoding = "utf-8"
if response.status_code == 200:
print("数据抓取成功!")
dom = pq(response.text)
jsonobj = json.loads(dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0])
for province in jsonobj:
dic_city = {}
for city in province["cities"]:
dic_city[city["cityName"]] = city["currentConfirmedCount"]
if dic_city.__len__() > 0:
create_Pie(province["provinceName"], dic_city)
print(province["provinceName"] + "各市数据汇总完毕!")
except Exception as e:
print(e)
3.操作效果:
只需1.1s,我们就抓取了全国各省市的疫情数据,整理并生成了数据图表


打开随机饼图查看效果:

四川省各城市疫情数据汇总
至此,我们已经完成了对全国各省市实时疫情数据的采集和处理,绘制了中国疫情图。在此基础上,我们进一步拓展并开展了中国各省、自治区、直辖市疫情数据的批量归一化和可视化工作。这期间复习了requests库、pandas、pyquery库等,还学习学习了强大的图表pyecharts库,收获颇丰!所以在这里分享一下,一起了解和学习!
最后,加油武汉,加油中国!疫情终会过去,春天一定会来!
图片来自网络
我希望下次我运行这段代码时,我看到的疫情图会是这样的:

实时抓取网页数据(搞定大数据信息的基础能力——网页工具优采云采集器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-11-05 04:07
对于开发和应用,信息集成是首要问题。解决这个问题后,可以扩展更多的信息挖掘和相关的组合应用。但是,由于技术的匮乏,很多企业选择将信息采集交给数据外包服务公司,类似于定制,这也是一种高效的获取方式。但是现在你做了大数据业务,还是要全面提升自己人员的大数据基础能力,至少在有轻量级数据需求的时候,可以用自己的技能快速解决。那么我们如何才能拥有这种捕捉大数据信息的基本能力呢?网络爬虫工具优采云采集器作为大数据信息抓取的必备软件,充分发挥了其强大的作用。
优采云采集器V9是一款全网通用的网页数据采集软件。通过采集规则和数据处理相关设置,可以设置URL、文本、图片、文件等被抓取,进行排序、过滤等一系列处理,完整呈现给用户可用的数据信息。另外,优采云采集器V9的发布功能也是一大亮点。可自动登录选择数据发布栏目,彻底解放人手的智能工具。
了解网络爬虫工具的操作,可以轻松处理一些不太复杂的数据需求。如果是大数据级别的爬取集成,可能需要更复杂的技术和运行环境,比如频繁复杂的验证码、服务器代理、防御等。采集征服等等。当然,如果懂技术,有条件,企业也可以使用网络爬虫工具优采云采集器进行数据整合,优采云采集器使用分布式高速采集处理系统,多线程可调任务分配,轻松应对大规模海量作业需求。但有时为了再次提高效率,可能需要多个优采云采集器客户端同时运行,
我们正处于大数据时代。医疗、交通、教育、零售、金融、商业……我们都在寻求大数据的突破;各个领域的公司都积极参与市场,以在瞬息万变的市场中站稳脚跟。,但大数据的应用不仅仅是事实,在实践中也并非一帆风顺。面临跨部门跨行业难以共享的信息孤岛和短板;面临大数据技术和产业创新低;面对人才匮乏,大数据如何发展?
除了上面提到的多元学习工具,加强我们的基本能力,不断提高我们的技能,我们还需要有创新的思维和强烈的责任感。时代属于全人类。每个人都可能在这个机会中获得全新的突破。在突破点之前,让我们一起提升能力,以最好的状态迎接机遇,对成功更有信心。返回搜狐查看更多 查看全部
实时抓取网页数据(搞定大数据信息的基础能力——网页工具优采云采集器)
对于开发和应用,信息集成是首要问题。解决这个问题后,可以扩展更多的信息挖掘和相关的组合应用。但是,由于技术的匮乏,很多企业选择将信息采集交给数据外包服务公司,类似于定制,这也是一种高效的获取方式。但是现在你做了大数据业务,还是要全面提升自己人员的大数据基础能力,至少在有轻量级数据需求的时候,可以用自己的技能快速解决。那么我们如何才能拥有这种捕捉大数据信息的基本能力呢?网络爬虫工具优采云采集器作为大数据信息抓取的必备软件,充分发挥了其强大的作用。
优采云采集器V9是一款全网通用的网页数据采集软件。通过采集规则和数据处理相关设置,可以设置URL、文本、图片、文件等被抓取,进行排序、过滤等一系列处理,完整呈现给用户可用的数据信息。另外,优采云采集器V9的发布功能也是一大亮点。可自动登录选择数据发布栏目,彻底解放人手的智能工具。
了解网络爬虫工具的操作,可以轻松处理一些不太复杂的数据需求。如果是大数据级别的爬取集成,可能需要更复杂的技术和运行环境,比如频繁复杂的验证码、服务器代理、防御等。采集征服等等。当然,如果懂技术,有条件,企业也可以使用网络爬虫工具优采云采集器进行数据整合,优采云采集器使用分布式高速采集处理系统,多线程可调任务分配,轻松应对大规模海量作业需求。但有时为了再次提高效率,可能需要多个优采云采集器客户端同时运行,
我们正处于大数据时代。医疗、交通、教育、零售、金融、商业……我们都在寻求大数据的突破;各个领域的公司都积极参与市场,以在瞬息万变的市场中站稳脚跟。,但大数据的应用不仅仅是事实,在实践中也并非一帆风顺。面临跨部门跨行业难以共享的信息孤岛和短板;面临大数据技术和产业创新低;面对人才匮乏,大数据如何发展?
除了上面提到的多元学习工具,加强我们的基本能力,不断提高我们的技能,我们还需要有创新的思维和强烈的责任感。时代属于全人类。每个人都可能在这个机会中获得全新的突破。在突破点之前,让我们一起提升能力,以最好的状态迎接机遇,对成功更有信心。返回搜狐查看更多
实时抓取网页数据(我的Java,什么的都很熟悉谢谢-- )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-05 04:03
)
如何有效的动态抓取某个网站的数据现在我们需要抓取某个网站的价格信息
比如下页的“参考价”
这只是一个标志,实际数据不是取自这个网站
我目前的做法是使用VB.NET,然后添加HtmlAgilityPack包,通过XPath获取值,如
Util.GetNodeValue(v_doc,"/html/body/div[2]/div[5]/div[1]/div/table/tr[10]/td")
但是因为对方的网站经常打折,网页经常会有一些小改动,每次都要手动改Xpath
我想知道有没有更好的方法来处理这个,不使用.Net也没关系,我对Java、PHP等非常熟悉。
谢谢--------------------编程问答--------------------本文属于网络爬虫程序范围,助你登顶。--------------------编程问答 --------------------没有人回答?那我自己就喜欢了,我觉得就算用xpath还是有改进的空间
比如上面使用的绝对路径其实可以改成这样
//div[@class='roundCornerBox']/descendant-or-self::table/descendant::font[@class='BlackH4'and@color='#CC0000']
感觉灵活了很多,简单的页面更改对此没有影响
补充:.NET技术 , VB.NET 查看全部
实时抓取网页数据(我的Java,什么的都很熟悉谢谢--
)
如何有效的动态抓取某个网站的数据现在我们需要抓取某个网站的价格信息
比如下页的“参考价”
这只是一个标志,实际数据不是取自这个网站
我目前的做法是使用VB.NET,然后添加HtmlAgilityPack包,通过XPath获取值,如
Util.GetNodeValue(v_doc,"/html/body/div[2]/div[5]/div[1]/div/table/tr[10]/td")
但是因为对方的网站经常打折,网页经常会有一些小改动,每次都要手动改Xpath
我想知道有没有更好的方法来处理这个,不使用.Net也没关系,我对Java、PHP等非常熟悉。
谢谢--------------------编程问答--------------------本文属于网络爬虫程序范围,助你登顶。--------------------编程问答 --------------------没有人回答?那我自己就喜欢了,我觉得就算用xpath还是有改进的空间
比如上面使用的绝对路径其实可以改成这样
//div[@class='roundCornerBox']/descendant-or-self::table/descendant::font[@class='BlackH4'and@color='#CC0000']
感觉灵活了很多,简单的页面更改对此没有影响
补充:.NET技术 , VB.NET
实时抓取网页数据(【每日一题】实时抓取网页数据(--))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-03 11:00
实时抓取网页数据
1.nlp:即naturallanguageprocessing(自然语言处理)。其实现方法既有狭义上的,如自然语言处理语料库训练法,又有广义上的,比如决策树。使用cnn也好,gcn也好,crf也好,都可以。这种算法应用范围很广,尤其是在医学图像领域。但是具体应用中,并不是所有领域都能找到方法的。2.ml:机器学习或数据挖掘。
不同的数据处理方法,处理数据的思路方法不同。对于医学图像也好,文本也好,数据内容太复杂了也好,怎么处理都有难度,虽然广义上处理方法非常多,但是不同情况适用不同的。
nlp---文本分析前处理ml---图像等模型前处理
nlp(naturallanguageprocessing):自然语言处理。ml(machinelearning):机器学习。区别就在于以上两个概念的认识。机器学习算法的有很多种,比如dnn,cnn,gan等,在线下算法方面有很多。在线上,就是自然语言处理以及图像等。所以你的问题,还是要分情况讨论,主要看什么文本、什么问题、以及问题的规模,也取决于你提问的目的,根据你的问题针对性地提出问题,然后去有针对性地学习针对性的知识。
nlp的老师告诉过不要问自己不想问的东西机器学习的老师告诉过不要问自己想问的东西图像处理的老师告诉过不要问自己想问的东西(其实每个老师的回答都是有保证的) 查看全部
实时抓取网页数据(【每日一题】实时抓取网页数据(--))
实时抓取网页数据
1.nlp:即naturallanguageprocessing(自然语言处理)。其实现方法既有狭义上的,如自然语言处理语料库训练法,又有广义上的,比如决策树。使用cnn也好,gcn也好,crf也好,都可以。这种算法应用范围很广,尤其是在医学图像领域。但是具体应用中,并不是所有领域都能找到方法的。2.ml:机器学习或数据挖掘。
不同的数据处理方法,处理数据的思路方法不同。对于医学图像也好,文本也好,数据内容太复杂了也好,怎么处理都有难度,虽然广义上处理方法非常多,但是不同情况适用不同的。
nlp---文本分析前处理ml---图像等模型前处理
nlp(naturallanguageprocessing):自然语言处理。ml(machinelearning):机器学习。区别就在于以上两个概念的认识。机器学习算法的有很多种,比如dnn,cnn,gan等,在线下算法方面有很多。在线上,就是自然语言处理以及图像等。所以你的问题,还是要分情况讨论,主要看什么文本、什么问题、以及问题的规模,也取决于你提问的目的,根据你的问题针对性地提出问题,然后去有针对性地学习针对性的知识。
nlp的老师告诉过不要问自己不想问的东西机器学习的老师告诉过不要问自己想问的东西图像处理的老师告诉过不要问自己想问的东西(其实每个老师的回答都是有保证的)
实时抓取网页数据(智能编辑重构批处理式"数字PythonIDE"集成开发环境)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-03 09:31
目前可以浏览网页内容的App应用有很多,但是对于剪贴板文本内容的实时抓取,这样的应用却很少。
通过剪贴板抓取文本的优点:在操作简单且无需切换App GUI图形用户界面的情况下,用不同App的Ctrl+C快捷键复制数据,抓取-采集(或共享)到目标应用程序。
例如:在网上找一些软文或者参考资料,尤其是在写自媒体软文或者论文的时候,如果需要单独提取某个关键文本,或者提取多篇文章软文@ > 许多文字。旧方法 Ctrl + C 然后 Ctrl + V 抓取文本可以是一个解决方案。但是工作量大,你会觉得这种重复爬行的操作,最好有现成的App工具可以帮你搞定,而且功能更好。
所有的产品都是为数字时代而生,所有这些功能都集成在它们的应用程序中。当然,其公司还开发了其他一些专门的数据采集和采集 App。
批量式“数字Python IDE”集成开发环境智能编辑重构(集成高效Cython PyInstaller批处理小程序)
详细用法
01、编辑菜单-->勾选“剪贴板:监控”-->弹出如下“提示窗口”
如果您刚刚启动应用程序,则不需要重新启动它,请切换到“取消”按钮并按 Enter 确认。
02、 在桌面、文件夹、网页、网上邻居、MicroSoft Microsoft Office应用程序等,按Ctrl+C快捷键(或其他操作)将文本内容复制到剪贴板 --> 应用程序会自动弹出如下界面。
如果“剪贴板文本”不符合捕获要求,您可以单击“清除剪贴板”按钮清除剪贴板内容。 查看全部
实时抓取网页数据(智能编辑重构批处理式"数字PythonIDE"集成开发环境)
目前可以浏览网页内容的App应用有很多,但是对于剪贴板文本内容的实时抓取,这样的应用却很少。
通过剪贴板抓取文本的优点:在操作简单且无需切换App GUI图形用户界面的情况下,用不同App的Ctrl+C快捷键复制数据,抓取-采集(或共享)到目标应用程序。
例如:在网上找一些软文或者参考资料,尤其是在写自媒体软文或者论文的时候,如果需要单独提取某个关键文本,或者提取多篇文章软文@ > 许多文字。旧方法 Ctrl + C 然后 Ctrl + V 抓取文本可以是一个解决方案。但是工作量大,你会觉得这种重复爬行的操作,最好有现成的App工具可以帮你搞定,而且功能更好。
所有的产品都是为数字时代而生,所有这些功能都集成在它们的应用程序中。当然,其公司还开发了其他一些专门的数据采集和采集 App。
批量式“数字Python IDE”集成开发环境智能编辑重构(集成高效Cython PyInstaller批处理小程序)
详细用法
01、编辑菜单-->勾选“剪贴板:监控”-->弹出如下“提示窗口”
如果您刚刚启动应用程序,则不需要重新启动它,请切换到“取消”按钮并按 Enter 确认。
02、 在桌面、文件夹、网页、网上邻居、MicroSoft Microsoft Office应用程序等,按Ctrl+C快捷键(或其他操作)将文本内容复制到剪贴板 --> 应用程序会自动弹出如下界面。
如果“剪贴板文本”不符合捕获要求,您可以单击“清除剪贴板”按钮清除剪贴板内容。
实时抓取网页数据(数据获取接下来的事情就好办了,需要注意日期格式化问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-03 03:07
实时流行病捕捉
武汉肺炎期间,家里无事可做。有一天,我突然想知道每天的疫情数据。
我以前玩过爬虫,但这次不一样了。准确地说,这次不是爬虫,因为它不具备“批量”的特性。
分析网站
首先要说明一点,我们没有政府数据库,数据来源是通过其他一些在线网站,实时更新数据,比如腾讯新闻、定香园等。
接下来,我们使用腾讯新闻来抓取疫情数据。
网址是#/
打开之后,可以看到它有实时的疫情追踪。
以前我用的爬虫是从html页面中获取相关内容,比较直接,因为所见即所得,只要到当前网页找到对应的标签就可以获取。
这一次,和以前不一样了。这类似于股票。数据从后端不断发送。这个动态更新的网站更适合选择直接查找数据流(不是我在html中找不到对应标签的借口)。
查找数据流量来源
打开开发者工具,我仔细搜索了一下。
我猜这种数据一定是json格式的。我首先在XHR中搜索,发现一堆带小数的数据。但让我们考虑一下。除了治愈率和死亡率,疫情数据的一般单位是人数。,怎么会有这么多小数?那不应该是这个数据。
我把除了js、image、css之外的所有数据都打开了,没有发现。CSS都是排版样式,图片都是图片。用这种方式传输数据是不可能的,所以去js。
功夫不负有心人,我在js中找到了一个jQuery,里面全是json数据!
数据采集
接下来的事情就简单了,我们也看到了也支持GET方法,访问这个url不需要其他数据。
import requests
url = "https://view.inews.qq.com/g2/g ... ot%3B
ret = requests.get(url)
with open("data.json", "w") as f:
f.write(ret.text)
数据处理
Python 也非常擅长处理 json 对象。只需在此处编写 strToJson 方法即可。
import json
f = open('data0204.json', 'r', encoding='utf-8')
data = json.load(f)['data'] # load json data from txt file
data = json.loads(data) # load json data from str class
data = data['chinaDayAddList']
import matplotlib.pyplot as plt
import numpy as np
from datetime import datetime
plt.clf()
days = [datetime.strptime('2020.' + d['date'], '%Y.%m.%d').date() for d in data]
plt.plot(days, [int(con['confirm']) for con in data], label='confirm')
plt.plot(days, [int(con['suspect']) for con in data], label='suspect')
plt.plot(days, [int(con['dead']) for con in data], label='dead')
plt.plot(days, [int(con['heal']) for con in data], label='heal')
plt.legend()
plt.show()
需要注意日期格式问题!
除了像我上面这样的处理,你还可以使用其他部分来做任何你想做的事! 查看全部
实时抓取网页数据(数据获取接下来的事情就好办了,需要注意日期格式化问题)
实时流行病捕捉
武汉肺炎期间,家里无事可做。有一天,我突然想知道每天的疫情数据。
我以前玩过爬虫,但这次不一样了。准确地说,这次不是爬虫,因为它不具备“批量”的特性。
分析网站
首先要说明一点,我们没有政府数据库,数据来源是通过其他一些在线网站,实时更新数据,比如腾讯新闻、定香园等。
接下来,我们使用腾讯新闻来抓取疫情数据。
网址是#/
打开之后,可以看到它有实时的疫情追踪。
以前我用的爬虫是从html页面中获取相关内容,比较直接,因为所见即所得,只要到当前网页找到对应的标签就可以获取。
这一次,和以前不一样了。这类似于股票。数据从后端不断发送。这个动态更新的网站更适合选择直接查找数据流(不是我在html中找不到对应标签的借口)。
查找数据流量来源
打开开发者工具,我仔细搜索了一下。
我猜这种数据一定是json格式的。我首先在XHR中搜索,发现一堆带小数的数据。但让我们考虑一下。除了治愈率和死亡率,疫情数据的一般单位是人数。,怎么会有这么多小数?那不应该是这个数据。
我把除了js、image、css之外的所有数据都打开了,没有发现。CSS都是排版样式,图片都是图片。用这种方式传输数据是不可能的,所以去js。
功夫不负有心人,我在js中找到了一个jQuery,里面全是json数据!


数据采集
接下来的事情就简单了,我们也看到了也支持GET方法,访问这个url不需要其他数据。
import requests
url = "https://view.inews.qq.com/g2/g ... ot%3B
ret = requests.get(url)
with open("data.json", "w") as f:
f.write(ret.text)
数据处理
Python 也非常擅长处理 json 对象。只需在此处编写 strToJson 方法即可。
import json
f = open('data0204.json', 'r', encoding='utf-8')
data = json.load(f)['data'] # load json data from txt file
data = json.loads(data) # load json data from str class
data = data['chinaDayAddList']
import matplotlib.pyplot as plt
import numpy as np
from datetime import datetime
plt.clf()
days = [datetime.strptime('2020.' + d['date'], '%Y.%m.%d').date() for d in data]
plt.plot(days, [int(con['confirm']) for con in data], label='confirm')
plt.plot(days, [int(con['suspect']) for con in data], label='suspect')
plt.plot(days, [int(con['dead']) for con in data], label='dead')
plt.plot(days, [int(con['heal']) for con in data], label='heal')
plt.legend()
plt.show()
需要注意日期格式问题!
除了像我上面这样的处理,你还可以使用其他部分来做任何你想做的事!
实时抓取网页数据(世界上最盛行的网络和谈阐发器!(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-03 02:28
Wireshark(原名Ethereal)是一款免费开源的网络嗅探捕捉工具,全球最流行的网络和谈分析器!网络包分析软件的作用是捕获网络包,尽可能显示最详细的网络包资料。Wireshark网络抓包工具以WinPCAP为接口,间接抓取网卡停止数据报文交换。它可以及时检测网络通信数据,检测它抓取的网络通信数据快照文件,并通过图形界面读取这些数据,检查网络通信。数据包中每一层的详细内容。其强大的功能:例如,它采集了强大的显示过滤器语言和检查TCP会话重建流程的能力,
工作过程
1.确定Wireshark的位置
如果您没有正确的位置,在您启动软件后,需要很长时间才能捕获一些与您无关的数据。
2.选择抓图界面
一般选择连接Internet网络的接口,这样就可以抓取到与网络相关的数据。否则,其他捕获的数据将不会以任何方式帮助您。
3.使用捕获过滤器
通过设置捕获过滤器,可以避免生成过大的捕获文件。这样,用户在分析数据时就不会受到其他数据的干扰。此外,它还可以为用户节省大量时间。
4.使用显示过滤器
捕获过滤器过滤的数据通常仍然非常复杂。为了使过滤后的数据包更加细致,此时使用显示过滤器进行过滤。
5.使用着色规则
显示过滤器过滤的数据通常是有用的数据包。如果您想更突出地突出显示一个会话,您可以使用着色规则来突出显示它。
6.构建图表
如果用户想更清楚地看到网络中数据的变化,可以很容易地以图表的形式显示数据分布。
7.重组数据 Wireshark 的重组功能可以重组一个会话中不同数据包的信息,或者重组一个完整的图片或文件。由于传输的文件往往很大,信息分布在多个数据包中。为了能够查看整个图片或文件,需要使用重新组织数据的方法来实现。 查看全部
实时抓取网页数据(世界上最盛行的网络和谈阐发器!(一))
Wireshark(原名Ethereal)是一款免费开源的网络嗅探捕捉工具,全球最流行的网络和谈分析器!网络包分析软件的作用是捕获网络包,尽可能显示最详细的网络包资料。Wireshark网络抓包工具以WinPCAP为接口,间接抓取网卡停止数据报文交换。它可以及时检测网络通信数据,检测它抓取的网络通信数据快照文件,并通过图形界面读取这些数据,检查网络通信。数据包中每一层的详细内容。其强大的功能:例如,它采集了强大的显示过滤器语言和检查TCP会话重建流程的能力,

工作过程
1.确定Wireshark的位置
如果您没有正确的位置,在您启动软件后,需要很长时间才能捕获一些与您无关的数据。
2.选择抓图界面
一般选择连接Internet网络的接口,这样就可以抓取到与网络相关的数据。否则,其他捕获的数据将不会以任何方式帮助您。
3.使用捕获过滤器
通过设置捕获过滤器,可以避免生成过大的捕获文件。这样,用户在分析数据时就不会受到其他数据的干扰。此外,它还可以为用户节省大量时间。
4.使用显示过滤器
捕获过滤器过滤的数据通常仍然非常复杂。为了使过滤后的数据包更加细致,此时使用显示过滤器进行过滤。
5.使用着色规则
显示过滤器过滤的数据通常是有用的数据包。如果您想更突出地突出显示一个会话,您可以使用着色规则来突出显示它。
6.构建图表
如果用户想更清楚地看到网络中数据的变化,可以很容易地以图表的形式显示数据分布。
7.重组数据 Wireshark 的重组功能可以重组一个会话中不同数据包的信息,或者重组一个完整的图片或文件。由于传输的文件往往很大,信息分布在多个数据包中。为了能够查看整个图片或文件,需要使用重新组织数据的方法来实现。
实时抓取网页数据(#如何用excel获得股票实时数据#首先找一个提供股票数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-03 02:20
#如何使用excel获取实时股票数据#
首先找到一个提供股票数据的网站。各种金融网站都有股票数据。我们以东方财富网为例:
对于沪深A股数据,我们在谷歌浏览器中查看真实网址:
找到与股票数据对应的jQuery行,然后查看头文件中的URL:
将此 URL 复制到 Excel,数据 ==> 来自 网站:
单击以确认,Power Query 编辑器将打开。如果一切顺利,数据会直接出现:
虽然不是表,但证明爬行成功。下一步是如何解析二进制文件。从谷歌浏览器看,这是一个jsoncallback数据包,比json数据多了一个函数名。我们只需要提取两个括号。中间的数据可以用json解析。注意total:4440,我们后面会用到这个值。
=Json.Document(Text.BetweenDelimiters(Text.FromBinary(Web.Contents(url)),"(",")"))
然后展开数据表:
到目前为止一切都很顺利,但我们抓取的只是一页数据,让我们看看:
pn是页码,我们抓取第3页,pz是每页20条数据,我们有两种方法抓取所有数据,一种是使用这个pz:20,然后定义函数,抓取所有页码,我在之前的爬行中反复使用过这个。今天我们尝试直接修改pz,一次性抓取所有数据。其实你可以尝试改变查询参数。如果我们把pn改成4,抓取到的页面就是第4页。同理,我们把pn改成200,看看能不能直接抓取200条数据。
那我们试试直接输入5000,能不能全部抢过来:
这似乎是可能的。
还有一个问题,就是数据的所有标题行都以f开头,不可读。如何将它们变成网页中的汉字标题行。
这个问题有点复杂。我们可能需要检查代码,看看是否可以找到替换它的方法。先看html:
但这并不完整,还有几列需要自定义:
这些指标没有对应的 f 代码。
我们来看一下js文件:
这个文件中有对应的数据,我们直接拷贝到Power Query中,处理成列表形式进行备份:
下一步是匹配表中的键并修改列名:
首先我们需要匹配出这样一个列表。
List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n[key])}, (y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0})
然后我们可以直接使用Table.RenameColumns函数批量修改列名:
Table.RenameColumns(data,List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n) [key])},(y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0}))
我们只是将数据加载到 Excel 中。
如果你想要最新的数据,只需刷新它。 查看全部
实时抓取网页数据(#如何用excel获得股票实时数据#首先找一个提供股票数据)
#如何使用excel获取实时股票数据#
首先找到一个提供股票数据的网站。各种金融网站都有股票数据。我们以东方财富网为例:

对于沪深A股数据,我们在谷歌浏览器中查看真实网址:

找到与股票数据对应的jQuery行,然后查看头文件中的URL:

将此 URL 复制到 Excel,数据 ==> 来自 网站:

单击以确认,Power Query 编辑器将打开。如果一切顺利,数据会直接出现:

虽然不是表,但证明爬行成功。下一步是如何解析二进制文件。从谷歌浏览器看,这是一个jsoncallback数据包,比json数据多了一个函数名。我们只需要提取两个括号。中间的数据可以用json解析。注意total:4440,我们后面会用到这个值。

=Json.Document(Text.BetweenDelimiters(Text.FromBinary(Web.Contents(url)),"(",")"))

然后展开数据表:

到目前为止一切都很顺利,但我们抓取的只是一页数据,让我们看看:

pn是页码,我们抓取第3页,pz是每页20条数据,我们有两种方法抓取所有数据,一种是使用这个pz:20,然后定义函数,抓取所有页码,我在之前的爬行中反复使用过这个。今天我们尝试直接修改pz,一次性抓取所有数据。其实你可以尝试改变查询参数。如果我们把pn改成4,抓取到的页面就是第4页。同理,我们把pn改成200,看看能不能直接抓取200条数据。

那我们试试直接输入5000,能不能全部抢过来:

这似乎是可能的。
还有一个问题,就是数据的所有标题行都以f开头,不可读。如何将它们变成网页中的汉字标题行。
这个问题有点复杂。我们可能需要检查代码,看看是否可以找到替换它的方法。先看html:
但这并不完整,还有几列需要自定义:

这些指标没有对应的 f 代码。
我们来看一下js文件:

这个文件中有对应的数据,我们直接拷贝到Power Query中,处理成列表形式进行备份:

下一步是匹配表中的键并修改列名:

首先我们需要匹配出这样一个列表。
List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n[key])}, (y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0})
然后我们可以直接使用Table.RenameColumns函数批量修改列名:

Table.RenameColumns(data,List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n) [key])},(y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0}))
我们只是将数据加载到 Excel 中。

如果你想要最新的数据,只需刷新它。
实时抓取网页数据(老左在"10款国外免费网站在线监控服务工具")
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-24 07:11
IIS7网站监控可以提前防范各种网站劫持,免费在线查询,适用于各大站长、政府网站、学校、公司、医院等.网站。他可以做24小时定时监控,同时可以让你知道网站是否被黑了或者被黑了。
ebsite-WatcherPortable 是一个简单易用的网站 监控工具。该软件旨在定期检查网站的变化并突出显示、浏览互联网和记录宏。该软件支持自定义属性。添加新页面以检查和指定其类别。
WebChangeMonitor(网页监控软件),WebChangeMonitor是一款免费软件,它可以让你监控网页的变化,应用程序可以监控网页并根据网页内容跟踪变化,你可以查看和记录差异,你可以。
软件大小:8.2M软件官网:首页用户评分:软件类型:绿色软件运行环境:WinAll软件语言:简体中文软件分类:远程监控授权方式:免费软件插件情况:无插件网页自动刷新监控工具。
OpenWebMonitor 是一款专业的网页内容变化监控软件。该软件可以实时监控网页元素的变化,例如商品价格趋势。
网页链接监控,网页链接监控软件是一款监控网站关键词更新、监控百度贴吧、本地论坛、58同城、赶集网等的小工具。像网站一样,一旦发现与您的业务相关的帖子,会立即提醒您,并且可以免费下载。
老佐在“10款免费海外网站在线监控服务工具”文章中整理了最新的国外免费网站监控工具,可应用中文或英文等。在海外使用网站。但是都是英文的,对于少数站长来说可能感觉不一样。
网站监控工具中文免费下载_WebsiteWatcher中文官方系统首页。 查看全部
实时抓取网页数据(老左在"10款国外免费网站在线监控服务工具")
IIS7网站监控可以提前防范各种网站劫持,免费在线查询,适用于各大站长、政府网站、学校、公司、医院等.网站。他可以做24小时定时监控,同时可以让你知道网站是否被黑了或者被黑了。
ebsite-WatcherPortable 是一个简单易用的网站 监控工具。该软件旨在定期检查网站的变化并突出显示、浏览互联网和记录宏。该软件支持自定义属性。添加新页面以检查和指定其类别。
WebChangeMonitor(网页监控软件),WebChangeMonitor是一款免费软件,它可以让你监控网页的变化,应用程序可以监控网页并根据网页内容跟踪变化,你可以查看和记录差异,你可以。
软件大小:8.2M软件官网:首页用户评分:软件类型:绿色软件运行环境:WinAll软件语言:简体中文软件分类:远程监控授权方式:免费软件插件情况:无插件网页自动刷新监控工具。
OpenWebMonitor 是一款专业的网页内容变化监控软件。该软件可以实时监控网页元素的变化,例如商品价格趋势。
网页链接监控,网页链接监控软件是一款监控网站关键词更新、监控百度贴吧、本地论坛、58同城、赶集网等的小工具。像网站一样,一旦发现与您的业务相关的帖子,会立即提醒您,并且可以免费下载。
老佐在“10款免费海外网站在线监控服务工具”文章中整理了最新的国外免费网站监控工具,可应用中文或英文等。在海外使用网站。但是都是英文的,对于少数站长来说可能感觉不一样。
网站监控工具中文免费下载_WebsiteWatcher中文官方系统首页。
实时抓取网页数据(GoogleAnalytics推出新功能,可以让你的网站进行互动)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-11-22 09:19
这是我们为您提供文章的文章,介绍20个最好的网站实时数据分析工具,让我们一起来看看吧!
1. 谷歌分析
这是使用最广泛的访问统计分析工具之一。几周前,谷歌分析推出了一项可以提供实时报告的新功能。您可以在您的 网站 中查看当前在线访问者的数量,了解他们观看了哪些网页、他们使用哪些 网站 链接到您的 网站、他们来自哪个国家等等.
2. Clicky
与 Google Analytics 等庞大的分析系统相比,Clicky 相对简单。它在控制面板上提供了一系列统计数据,包括最近三天的访问量、前20个链接源和前20个关键字。,虽然数据种类不多,但是可以直观的反映当前的网站访问量,UI也比较简洁清新。
3. 伍普拉
Woopra 将实时统计数据提升到另一个层次。可以实时直播网站的访问数据。您甚至可以使用 Woopra Chat 小部件与用户聊天。它还具有高级通知功能,可让您创建各种通知,例如电子邮件、声音和弹出框。
4. 图表节拍
这是一个用于新闻发布和其他类型的网站的实时分析工具。电商专业分析功能网站即将上线。它可以让您看到访问者如何与您的 网站 互动,这可以帮助您改进您的 网站。
5. GoSquared
它提供了所有常用的分析功能,还允许您查看特定访问者的数据。它集成了 Olark,让您可以与访客聊天。
6. 混合面板
该工具允许您查看访问者数据、分析趋势并比较几天内的变化。
7. 重振雄风
它提供了所有常用的实时分析功能,让您直观地了解访问者的点击位置。您甚至可以查看注册用户的姓名标签,以便跟踪他们对网站 的使用情况。
8. 皮维克
这是一个开源的实时分析工具,您可以轻松下载并安装在您自己的服务器上。
9. ShinyStat
网站提供四款产品,包括一款限量免费的分析产品,可用于个人和非盈利的网站。企业版具有搜索引擎排名检测,可以帮助您跟踪和提高网站的排名。
10. SeeVolution
目前处于测试阶段,提供热图和实时分析功能。您可以看到热图直播。它的可视化工具集允许您直观地查看和分析数据。
11. FoxMetrics
该工具提供实时分析功能,基于事件的概念和特征,您还可以设置自定义事件。它可以采集数据匹配事件和特征,然后为您提供报告,这将有助于提高您的网站。
12. 统计计数器
这是一款免费的实时分析工具,只需几行代码即可安装。它提供了所有常用的分析数据,此外,您还可以设置每天、每周或每月自动向您发送电子邮件报告。
13. 性能指标
这个工具可以为您提供实时的博客统计和推特分析。
14. Whos.Amung.Us
Whos.Amung.Us 相当独特,它可以嵌入您的网站 或博客,让您获得实时统计数据。包括免费版和付费版。
15. W3Counter
可提供实时数据,可提供30多种不同的报表,并可查看近期访问者的详细信息。
16. 跟踪观察
这是一个免费的实时分析工具,可以安装在服务器上。它提供了所有常用的统计功能和报表,您还可以查看最近访问者的详细信息并跟踪他们的轨迹。
17. 性能仪表
使用此工具,您可以跟踪当前访问者、查看源链接和来自搜索引擎的流量。这项服务是免费的。
18. Spotplex
该服务除了提供实时流量统计外,还可以显示您在所有使用该服务的网站中的网站排名。您甚至可以查看当天在 Spotplex网站 上统计的最受欢迎的 文章。
19. SiteMeter
这是另一种流行的实时交通跟踪服务。该服务提供的基础数据是免费的,但如果您想要更详细的数据,则需要付费。
20. 冰火箭
您可以获得跟踪代码或计数器并查看统计信息。如果您点击“排名”,您将看到您的博客和其他博客的比较结果。
大数据导航网站—网站分析监控工具—近40个网站分析工具的集合。 查看全部
实时抓取网页数据(GoogleAnalytics推出新功能,可以让你的网站进行互动)
这是我们为您提供文章的文章,介绍20个最好的网站实时数据分析工具,让我们一起来看看吧!
1. 谷歌分析
这是使用最广泛的访问统计分析工具之一。几周前,谷歌分析推出了一项可以提供实时报告的新功能。您可以在您的 网站 中查看当前在线访问者的数量,了解他们观看了哪些网页、他们使用哪些 网站 链接到您的 网站、他们来自哪个国家等等.
2. Clicky
与 Google Analytics 等庞大的分析系统相比,Clicky 相对简单。它在控制面板上提供了一系列统计数据,包括最近三天的访问量、前20个链接源和前20个关键字。,虽然数据种类不多,但是可以直观的反映当前的网站访问量,UI也比较简洁清新。
3. 伍普拉
Woopra 将实时统计数据提升到另一个层次。可以实时直播网站的访问数据。您甚至可以使用 Woopra Chat 小部件与用户聊天。它还具有高级通知功能,可让您创建各种通知,例如电子邮件、声音和弹出框。
4. 图表节拍
这是一个用于新闻发布和其他类型的网站的实时分析工具。电商专业分析功能网站即将上线。它可以让您看到访问者如何与您的 网站 互动,这可以帮助您改进您的 网站。
5. GoSquared
它提供了所有常用的分析功能,还允许您查看特定访问者的数据。它集成了 Olark,让您可以与访客聊天。
6. 混合面板
该工具允许您查看访问者数据、分析趋势并比较几天内的变化。
7. 重振雄风
它提供了所有常用的实时分析功能,让您直观地了解访问者的点击位置。您甚至可以查看注册用户的姓名标签,以便跟踪他们对网站 的使用情况。
8. 皮维克
这是一个开源的实时分析工具,您可以轻松下载并安装在您自己的服务器上。
9. ShinyStat
网站提供四款产品,包括一款限量免费的分析产品,可用于个人和非盈利的网站。企业版具有搜索引擎排名检测,可以帮助您跟踪和提高网站的排名。
10. SeeVolution
目前处于测试阶段,提供热图和实时分析功能。您可以看到热图直播。它的可视化工具集允许您直观地查看和分析数据。
11. FoxMetrics
该工具提供实时分析功能,基于事件的概念和特征,您还可以设置自定义事件。它可以采集数据匹配事件和特征,然后为您提供报告,这将有助于提高您的网站。
12. 统计计数器
这是一款免费的实时分析工具,只需几行代码即可安装。它提供了所有常用的分析数据,此外,您还可以设置每天、每周或每月自动向您发送电子邮件报告。
13. 性能指标
这个工具可以为您提供实时的博客统计和推特分析。
14. Whos.Amung.Us
Whos.Amung.Us 相当独特,它可以嵌入您的网站 或博客,让您获得实时统计数据。包括免费版和付费版。
15. W3Counter
可提供实时数据,可提供30多种不同的报表,并可查看近期访问者的详细信息。
16. 跟踪观察
这是一个免费的实时分析工具,可以安装在服务器上。它提供了所有常用的统计功能和报表,您还可以查看最近访问者的详细信息并跟踪他们的轨迹。
17. 性能仪表
使用此工具,您可以跟踪当前访问者、查看源链接和来自搜索引擎的流量。这项服务是免费的。
18. Spotplex
该服务除了提供实时流量统计外,还可以显示您在所有使用该服务的网站中的网站排名。您甚至可以查看当天在 Spotplex网站 上统计的最受欢迎的 文章。
19. SiteMeter
这是另一种流行的实时交通跟踪服务。该服务提供的基础数据是免费的,但如果您想要更详细的数据,则需要付费。
20. 冰火箭
您可以获得跟踪代码或计数器并查看统计信息。如果您点击“排名”,您将看到您的博客和其他博客的比较结果。
大数据导航网站—网站分析监控工具—近40个网站分析工具的集合。
实时抓取网页数据(本文如下:找到目标网页打开阳光高考网站(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-22 03:09
我们日常对于单个网页数据的PowerBI数据使用非常简单,但是批量获取网页数据就比较麻烦了。这里我们可以使用PowerBI的Power Query组件批量获取多个网页的数据。同样,您也可以使用更高版本的 Excel 自带的 Power Query 来获取。
本文以阳光高考网站为例,获取2019年全国高校名单。
详细操作步骤如下:
(一)找到登陆页面
打开阳光高考网站,找到“2019年全国普通高等学校名单”网页。
点击单个网页查看,如下:
(二)解析URL结构
在这里选择前三个省份的网址
北京:
天津市:
河北市:
可以看出,只有URL的最后一个数字是一个变量,这里我们把它当作页码ID
(三)采集第一页数据
(这里的页面ID是北京的“2”开头)
打开PowerBI Desktop,通过“获取数据”中的“web”选项获取数据。在这里,选择“Web”界面中的“Basic”选项卡。
这里我们在基本选项卡中输入目标 URL
(北京)
获取数据源信息如下,这里只有第一个表是我们想要的,勾选,然后点击右下角转换数据进行数据处理。
进入页面如下:
这样我们就简单的采集去到第一页的数据。然后把这个页面的数据整理一下,删除无用的信息,加上字段名。排序后采集下面其他页面的数据结构和排序后第一页的数据结构相同,可以直接使用采集的数据。
如果要大量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
我们不要在这里处理它。
(四) 根据页码参数设置自定义函数
这是最重要的一步
在当前数据的编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表=>
并在链接中,将网页的页码,即上述“1,2”等数字修改为“&(Number.ToText(p))&”。
修改后就变成了:
点击“完成”,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,表格也变成了函数的样式。自定义函数完成,p是函数的变量,用来控制页码,只要输入一个数字,比如3,就会抓取第三页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(五)批量调用自定义函数
首先,使用空查询创建编号规则。在这里,因为我们要获取第2到32页的数据,所以我们创建了一个从2到32的序列,并在空查询中输入:
={2..32}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。
然后调用自定义函数
单击“确定”开始批量抓取网页。如果采集页数较多,不建议在获取第一个网页后立即整理数据,否则可能导致采集时间过长。
这里我们展开表格,就是所有31页的数据。
那么这里我们就来看看后续的数据排序和可视化。
备注1:如果采集的网页数据不断更新,完成上述步骤后,在PQ中点击刷新,可以随时一键提取网站的实时数据,即可以说是很方便了。
注2:以上主要使用PowerBI中的Power Query功能,在可以使用PQ功能的Excel中也可以进行同样的操作。
备注3:需要注意的是,并非所有网页数据都可以通过上述方法获取。在使用 PowerBI 批量捕获某个 网站 数据之前,请先尝试 采集 一页。如果你可以去采集,然后使用上面的步骤。如果采集不可用,则需要考虑使用Python进行爬虫处理。
本文参考:PowerQuery批量抓取网页实战:分分钟抓取上百页招聘信息为兆联招聘 查看全部
实时抓取网页数据(本文如下:找到目标网页打开阳光高考网站(图))
我们日常对于单个网页数据的PowerBI数据使用非常简单,但是批量获取网页数据就比较麻烦了。这里我们可以使用PowerBI的Power Query组件批量获取多个网页的数据。同样,您也可以使用更高版本的 Excel 自带的 Power Query 来获取。
本文以阳光高考网站为例,获取2019年全国高校名单。
详细操作步骤如下:
(一)找到登陆页面
打开阳光高考网站,找到“2019年全国普通高等学校名单”网页。
点击单个网页查看,如下:
(二)解析URL结构
在这里选择前三个省份的网址
北京:
天津市:
河北市:
可以看出,只有URL的最后一个数字是一个变量,这里我们把它当作页码ID
(三)采集第一页数据
(这里的页面ID是北京的“2”开头)
打开PowerBI Desktop,通过“获取数据”中的“web”选项获取数据。在这里,选择“Web”界面中的“Basic”选项卡。
这里我们在基本选项卡中输入目标 URL
(北京)
获取数据源信息如下,这里只有第一个表是我们想要的,勾选,然后点击右下角转换数据进行数据处理。
进入页面如下:
这样我们就简单的采集去到第一页的数据。然后把这个页面的数据整理一下,删除无用的信息,加上字段名。排序后采集下面其他页面的数据结构和排序后第一页的数据结构相同,可以直接使用采集的数据。
如果要大量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
我们不要在这里处理它。
(四) 根据页码参数设置自定义函数
这是最重要的一步
在当前数据的编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表=>
并在链接中,将网页的页码,即上述“1,2”等数字修改为“&(Number.ToText(p))&”。
修改后就变成了:
点击“完成”,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,表格也变成了函数的样式。自定义函数完成,p是函数的变量,用来控制页码,只要输入一个数字,比如3,就会抓取第三页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(五)批量调用自定义函数
首先,使用空查询创建编号规则。在这里,因为我们要获取第2到32页的数据,所以我们创建了一个从2到32的序列,并在空查询中输入:
={2..32}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。
然后调用自定义函数
单击“确定”开始批量抓取网页。如果采集页数较多,不建议在获取第一个网页后立即整理数据,否则可能导致采集时间过长。
这里我们展开表格,就是所有31页的数据。
那么这里我们就来看看后续的数据排序和可视化。
备注1:如果采集的网页数据不断更新,完成上述步骤后,在PQ中点击刷新,可以随时一键提取网站的实时数据,即可以说是很方便了。
注2:以上主要使用PowerBI中的Power Query功能,在可以使用PQ功能的Excel中也可以进行同样的操作。
备注3:需要注意的是,并非所有网页数据都可以通过上述方法获取。在使用 PowerBI 批量捕获某个 网站 数据之前,请先尝试 采集 一页。如果你可以去采集,然后使用上面的步骤。如果采集不可用,则需要考虑使用Python进行爬虫处理。
本文参考:PowerQuery批量抓取网页实战:分分钟抓取上百页招聘信息为兆联招聘
实时抓取网页数据(实时抓取网页数据,实现网页的二级菜单(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-20 12:00
实时抓取网页数据,实现网页的二级菜单,展现一条新闻,也可以展现新的二级菜单,实现wordpress的popupwordpress菜单数据抓取,新闻抓取中需要保存新闻二级菜单的链接地址,也可以直接抓取直接保存wordpress站点_新闻站点定制开发,新闻站点代码搜索wordpress后台_提供新闻站点定制开发,新闻站点模板开发,新闻站点定制开发。
如果是抓twitter,postfilter.js是个不错的选择。如果想抓wordpress的网页,可以通过postcontent文件进行导出。比如最常用的index.php的方式,或者直接的php的content目录。
先上结论:wordpress已经有很成熟的数据库/数据爬虫工具,例如crawl-crawler/wordpress-button-client什么是爬虫工具?wikipedia-wikiprinux下有个爬虫工具库gedits/wordpress-buttons-client爬虫的爬取规则是固定的,例如(内容固定地)假如(内容可以随便写)假如</img>(语言可以随便写)假如(用户可以随便写)假如>wordpress爬虫可以部署在浏览器上,例如:wordpress+wordpress-crawler自己搭建一个wordpress爬虫工具吧!—接下来放毒!!!知乎专栏,免费!零插件!零框架!零烦恼!网页抓取工具支持绝大部分主流网站,sina,singlesign等等!!精简版支持wordpress,意味着可以不用配置,动态加载就可以用!。 查看全部
实时抓取网页数据(实时抓取网页数据,实现网页的二级菜单(组图))
实时抓取网页数据,实现网页的二级菜单,展现一条新闻,也可以展现新的二级菜单,实现wordpress的popupwordpress菜单数据抓取,新闻抓取中需要保存新闻二级菜单的链接地址,也可以直接抓取直接保存wordpress站点_新闻站点定制开发,新闻站点代码搜索wordpress后台_提供新闻站点定制开发,新闻站点模板开发,新闻站点定制开发。
如果是抓twitter,postfilter.js是个不错的选择。如果想抓wordpress的网页,可以通过postcontent文件进行导出。比如最常用的index.php的方式,或者直接的php的content目录。
先上结论:wordpress已经有很成熟的数据库/数据爬虫工具,例如crawl-crawler/wordpress-button-client什么是爬虫工具?wikipedia-wikiprinux下有个爬虫工具库gedits/wordpress-buttons-client爬虫的爬取规则是固定的,例如(内容固定地)假如(内容可以随便写)假如</img>(语言可以随便写)假如(用户可以随便写)假如>wordpress爬虫可以部署在浏览器上,例如:wordpress+wordpress-crawler自己搭建一个wordpress爬虫工具吧!—接下来放毒!!!知乎专栏,免费!零插件!零框架!零烦恼!网页抓取工具支持绝大部分主流网站,sina,singlesign等等!!精简版支持wordpress,意味着可以不用配置,动态加载就可以用!。
实时抓取网页数据(如何对大数据量的数据实时抓取-在企业级大数据平台)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-15 11:06
如何实时捕捉大量数据——
在企业级大数据平台建设中,将传统关系型数据库(如Oracle)的数据聚合到Hadoop平台是一个重要的课题。目前主流的工具有Sqoop、DataX、Oracle GoldenGate for Big Data等。Sqoop使用sql语句获取关系数据库中的数据后,通过...
如何在 网站 上捕获实时数据-
使用Python访问网页主要有3种方式:urllib、urllib2、httplib urllib比较简单,功能也比较弱。httplib简单强大,但是好像不支持session 1. 最简单的页面访问 res=urllib2.@ >urlopen(url) print res.read() 2.@> 加上数据到获取或发布数据={"na ...
如何使用 Excel 电子表格捕获链接实时数据。
简单的事情是:在其中一个表格的单元格中输入=鼠标单击需要链接的表格,然后单击该单元格,然后按Enter
如何从网页抓取实时监控数据进行分析
用工具抓住,我的天,既然你知道如何使用数据,为什么不使用工具呢?用工具抢!
在excel工作表中,如何即时抓取工作表的数据并汇总成表格
假设第一个表名为sheet1,日期在a列,人员在b列,销售数据在c列。在另一个表中,a2、a3、a4、... 输入张三、李四、王五、... 在b2输入=sumif(sheet1!b:b,a2,sheet1!c:c) 回车后选择b2,将鼠标移至其右下角,双击“+”完成。
有没有什么软件可以根据我们的要求自动实时采集数据上传到我们的平台?
一般情况下是抖动备份、上传或者定时备份、上传,不会实时操作,因为你还要做其他的事情。可以添加软件的各种功能
如何实时从sql中提取数据-
你的意思是当sql server数据库中某个表的数据发生变化时自动提取数据?如果是这种情况,则必须使用触发器
如何在股票软件中提取实时数据
盘后资料下载!选择实时数据。但是有些软件只提供分钟数据,不提供分时数据
如何抓取网页的实时内容
市面上可以抓取网页内容的软件有很多,比如优采云、gooseeker、优采云采集、优采云等,但基本上都是是收费的,价格也比较高。如果要免费使用,gooseeker 好像是免费的,功能非常强大。如果需要定时采集,可以开启时间采集选项。如果你是学习软件的,也可以私下定制,请别人帮你制定规则,采集data
如何以编程方式从免费股票软件中提取实时数据-
获取股票实时交易详细数据的方法: 1.通过webservice调用,网站提供免费和收费服务, 2.调用新浪的专用js服务器解析数据, 3.行情数据不是来自证券公司来自交易所。4、股东无权自行领取,证券公司无权领取。你可以去交易所网站看看。市场数据提供给相关运营商,如通达信。附:证券交易所是依照国家有关法律规定,经政府证券主管部门批准设立的证券集中交易的有形场所。我国有四个:上交所和深交所,港交所,台湾证交所。 查看全部
实时抓取网页数据(如何对大数据量的数据实时抓取-在企业级大数据平台)
如何实时捕捉大量数据——
在企业级大数据平台建设中,将传统关系型数据库(如Oracle)的数据聚合到Hadoop平台是一个重要的课题。目前主流的工具有Sqoop、DataX、Oracle GoldenGate for Big Data等。Sqoop使用sql语句获取关系数据库中的数据后,通过...
如何在 网站 上捕获实时数据-
使用Python访问网页主要有3种方式:urllib、urllib2、httplib urllib比较简单,功能也比较弱。httplib简单强大,但是好像不支持session 1. 最简单的页面访问 res=urllib2.@ >urlopen(url) print res.read() 2.@> 加上数据到获取或发布数据={"na ...
如何使用 Excel 电子表格捕获链接实时数据。
简单的事情是:在其中一个表格的单元格中输入=鼠标单击需要链接的表格,然后单击该单元格,然后按Enter
如何从网页抓取实时监控数据进行分析
用工具抓住,我的天,既然你知道如何使用数据,为什么不使用工具呢?用工具抢!
在excel工作表中,如何即时抓取工作表的数据并汇总成表格
假设第一个表名为sheet1,日期在a列,人员在b列,销售数据在c列。在另一个表中,a2、a3、a4、... 输入张三、李四、王五、... 在b2输入=sumif(sheet1!b:b,a2,sheet1!c:c) 回车后选择b2,将鼠标移至其右下角,双击“+”完成。
有没有什么软件可以根据我们的要求自动实时采集数据上传到我们的平台?
一般情况下是抖动备份、上传或者定时备份、上传,不会实时操作,因为你还要做其他的事情。可以添加软件的各种功能
如何实时从sql中提取数据-
你的意思是当sql server数据库中某个表的数据发生变化时自动提取数据?如果是这种情况,则必须使用触发器
如何在股票软件中提取实时数据
盘后资料下载!选择实时数据。但是有些软件只提供分钟数据,不提供分时数据
如何抓取网页的实时内容
市面上可以抓取网页内容的软件有很多,比如优采云、gooseeker、优采云采集、优采云等,但基本上都是是收费的,价格也比较高。如果要免费使用,gooseeker 好像是免费的,功能非常强大。如果需要定时采集,可以开启时间采集选项。如果你是学习软件的,也可以私下定制,请别人帮你制定规则,采集data
如何以编程方式从免费股票软件中提取实时数据-
获取股票实时交易详细数据的方法: 1.通过webservice调用,网站提供免费和收费服务, 2.调用新浪的专用js服务器解析数据, 3.行情数据不是来自证券公司来自交易所。4、股东无权自行领取,证券公司无权领取。你可以去交易所网站看看。市场数据提供给相关运营商,如通达信。附:证券交易所是依照国家有关法律规定,经政府证券主管部门批准设立的证券集中交易的有形场所。我国有四个:上交所和深交所,港交所,台湾证交所。
实时抓取网页数据(如何制作一个实时统计股票的excel,求高手指点 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-11-13 16:03
)
一、如何制作实时股票统计excel,求高手指导
找到一个实时股价网站,然后按下面的操作,得到数据到EXCEL。导入成功后,设置更新频率和相关属性。如果你想按照自己的顺序,那么你可以VLOOKUP。看看图片吧。相信你我已经明白了,你的问题和我之前做的实时汇率是一样的。您可以参考以下网页链接。
二、如何使用excel获取实时股票数据
自动获取所有股票历史数据,也可以获取当天的数据。
三、如何通过excel获取股票列表
1 这里以获取中石油(601857))报价为例,打开提供股票报价的网站,在页面“个股查询”区域输入股票代码,选择“实时行情”,点击“行情”按钮后,可以查询中石油的行情数据,然后复制地址栏中的URL。 3 弹出“新建网页查询”对话框,输入地址刚才在地址栏中复制,点击“前往”按钮,此时打开下方文本框中的网站,点击“导入”按钮,此时网站@的数据> 导入到工作表中。 2 运行Excel,新建一个空白工作簿,在“数据”选项卡中,选择“获取外部数据”选项组,“从网站”命令导入外部数据。 4 弹出“导入数据”对话框,选择要插入的工作表,点击“确定”按钮即可。
四、如何用excel获取网上的股票数据并按日期做表
4、根据提示,点击你需要的数据表前面的黄色小键头。当它变成绿色对勾时,代表选中状态。可以通过Excel中获取外部数据的功能来实现。具体操作如下:1、选择你想从中获取数据的网站或站台(不是所有的网站和页面都能获取到你想要的数据),复制完整的Net。Site Reserve 2、 打开Excel,点击数据选项卡,选择获取外部数据—从网络站按钮,会打开一个新的Web查询对话框。6、 使用时,右击数据存储区刷新。成功后,将是最新的数据。3、输入刚才复制的网址,就会打开对应的网页。5、
五、excel如何自动获取股价
6、 在[导入数据]对话框中,选择要存储数据的位置。2、 在【New Web Query】界面,可以看到左上角的地址栏。具体方法:1、 首先新建一个工作表,选中任意一个空单元格。7、 在这个界面,点击左下角的【属性】可以设置刷新频率,如何处理数据变化等,然后点击右下角的【导入】按钮。点击界面右上角的【选项】,可以查看导入信息的设置,可根据实际情况选择。5、 点击后黄色箭头会变成绿色箭头,如下图。选择所需信息框左上角的黄色箭头。数据将每 10 分钟自动刷新一次。此示例遵循默认设置。在本示例中,自动刷新频率设置为 10 分钟。4、 浏览整个页面时,可以看到很多用黄色箭头标记的区域。这些是可以导入的数据标识符。选择[数据]-[来自网站]。3、在【New Web Query】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站 . 9、 下面的数据会自动导入,过一会导入数据。8、 设置好以上内容后,返回【导入数据】界面,点击【确定】按钮。此示例遵循默认设置。在本示例中,自动刷新频率设置为 10 分钟。4、 浏览整个页面时,可以看到很多用黄色箭头标记的区域。这些是可以导入的数据标识符。选择[数据]-[来自网站]。3、在【New Web Query】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站 . 9、 下面的数据会自动导入,过一会导入数据。8、 以上内容设置好后,返回【导入数据】界面,点击【确定】按钮。此示例遵循默认设置。在本示例中,自动刷新频率设置为 10 分钟。4、 浏览整个页面时,可以看到很多用黄色箭头标记的区域。这些是可以导入的数据标识符。选择[数据]-[来自网站]。3、在【New Web Query】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站 . 9、 下面的数据会自动导入,过一会导入数据。8、 设置好以上内容后,返回【导入数据】界面,点击【确定】按钮。浏览整个页面时,可以看到很多用黄色箭头标记的区域。这些是可以导入的数据标识符。选择[数据]-[来自网站]。3、在【New Web Query】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站 . 9、 下面的数据会自动导入,过一会导入数据。8、 以上内容设置好后,返回【导入数据】界面,点击【确定】按钮。浏览整个页面时,可以看到很多用黄色箭头标记的区域。这些是可以导入的数据标识符。选择[数据]-[来自网站]。3、在【New Web Query】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站 . 9、 下面的数据会自动导入,过一会导入数据。8、 以上内容设置好后,返回【导入数据】界面,点击【确定】按钮。在【新网页查询】界面的地址栏中收录你想要的股票信息,然后点击【前往】按钮跳转到指定的网站。9、 下面的数据会自动导入,过一会导入数据。8、 以上内容设置好后,返回【导入数据】界面,点击【确定】按钮。在【新网页查询】界面的地址栏中收录你想要的股票信息,然后点击【前往】按钮跳转到指定的网站。9、 下面的数据会自动导入,过一会导入数据。8、 以上内容设置好后,返回【导入数据】界面,点击【确定】按钮。
查看全部
实时抓取网页数据(如何制作一个实时统计股票的excel,求高手指点
)
一、如何制作实时股票统计excel,求高手指导
找到一个实时股价网站,然后按下面的操作,得到数据到EXCEL。导入成功后,设置更新频率和相关属性。如果你想按照自己的顺序,那么你可以VLOOKUP。看看图片吧。相信你我已经明白了,你的问题和我之前做的实时汇率是一样的。您可以参考以下网页链接。
二、如何使用excel获取实时股票数据
自动获取所有股票历史数据,也可以获取当天的数据。
三、如何通过excel获取股票列表
1 这里以获取中石油(601857))报价为例,打开提供股票报价的网站,在页面“个股查询”区域输入股票代码,选择“实时行情”,点击“行情”按钮后,可以查询中石油的行情数据,然后复制地址栏中的URL。 3 弹出“新建网页查询”对话框,输入地址刚才在地址栏中复制,点击“前往”按钮,此时打开下方文本框中的网站,点击“导入”按钮,此时网站@的数据> 导入到工作表中。 2 运行Excel,新建一个空白工作簿,在“数据”选项卡中,选择“获取外部数据”选项组,“从网站”命令导入外部数据。 4 弹出“导入数据”对话框,选择要插入的工作表,点击“确定”按钮即可。
四、如何用excel获取网上的股票数据并按日期做表
4、根据提示,点击你需要的数据表前面的黄色小键头。当它变成绿色对勾时,代表选中状态。可以通过Excel中获取外部数据的功能来实现。具体操作如下:1、选择你想从中获取数据的网站或站台(不是所有的网站和页面都能获取到你想要的数据),复制完整的Net。Site Reserve 2、 打开Excel,点击数据选项卡,选择获取外部数据—从网络站按钮,会打开一个新的Web查询对话框。6、 使用时,右击数据存储区刷新。成功后,将是最新的数据。3、输入刚才复制的网址,就会打开对应的网页。5、
五、excel如何自动获取股价
6、 在[导入数据]对话框中,选择要存储数据的位置。2、 在【New Web Query】界面,可以看到左上角的地址栏。具体方法:1、 首先新建一个工作表,选中任意一个空单元格。7、 在这个界面,点击左下角的【属性】可以设置刷新频率,如何处理数据变化等,然后点击右下角的【导入】按钮。点击界面右上角的【选项】,可以查看导入信息的设置,可根据实际情况选择。5、 点击后黄色箭头会变成绿色箭头,如下图。选择所需信息框左上角的黄色箭头。数据将每 10 分钟自动刷新一次。此示例遵循默认设置。在本示例中,自动刷新频率设置为 10 分钟。4、 浏览整个页面时,可以看到很多用黄色箭头标记的区域。这些是可以导入的数据标识符。选择[数据]-[来自网站]。3、在【New Web Query】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站 . 9、 下面的数据会自动导入,过一会导入数据。8、 设置好以上内容后,返回【导入数据】界面,点击【确定】按钮。此示例遵循默认设置。在本示例中,自动刷新频率设置为 10 分钟。4、 浏览整个页面时,可以看到很多用黄色箭头标记的区域。这些是可以导入的数据标识符。选择[数据]-[来自网站]。3、在【New Web Query】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站 . 9、 下面的数据会自动导入,过一会导入数据。8、 以上内容设置好后,返回【导入数据】界面,点击【确定】按钮。此示例遵循默认设置。在本示例中,自动刷新频率设置为 10 分钟。4、 浏览整个页面时,可以看到很多用黄色箭头标记的区域。这些是可以导入的数据标识符。选择[数据]-[来自网站]。3、在【New Web Query】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站 . 9、 下面的数据会自动导入,过一会导入数据。8、 设置好以上内容后,返回【导入数据】界面,点击【确定】按钮。浏览整个页面时,可以看到很多用黄色箭头标记的区域。这些是可以导入的数据标识符。选择[数据]-[来自网站]。3、在【New Web Query】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站 . 9、 下面的数据会自动导入,过一会导入数据。8、 以上内容设置好后,返回【导入数据】界面,点击【确定】按钮。浏览整个页面时,可以看到很多用黄色箭头标记的区域。这些是可以导入的数据标识符。选择[数据]-[来自网站]。3、在【New Web Query】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站 . 9、 下面的数据会自动导入,过一会导入数据。8、 以上内容设置好后,返回【导入数据】界面,点击【确定】按钮。在【新网页查询】界面的地址栏中收录你想要的股票信息,然后点击【前往】按钮跳转到指定的网站。9、 下面的数据会自动导入,过一会导入数据。8、 以上内容设置好后,返回【导入数据】界面,点击【确定】按钮。在【新网页查询】界面的地址栏中收录你想要的股票信息,然后点击【前往】按钮跳转到指定的网站。9、 下面的数据会自动导入,过一会导入数据。8、 以上内容设置好后,返回【导入数据】界面,点击【确定】按钮。
实时抓取网页数据(优采云原创的自动提取正文算法能适应网页的主体正文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-13 10:08
当监听到最新网页时,软件会列在列表框的最上方,并有提示音。
然后你点击列表中的一个标题,网页的文字就会自动显示在“快速阅读窗口”中。
优采云原创的自动文本提取算法,该算法可以适应大部分网页,自动提取网页的主体部分,单独阅读。
当然,你也可能会遇到提取错误,比如一些没有大正文的网页,比如视频播放页面等,这时候可以点击“打开原创网页”链接查看原创网页页。
指示
1、 一般网速为4M,同一程序监控的关键词数量不建议超过20个。即使你的网速很快,也不建议设置太多多个关键词同时监控,也可以尝试打开多个程序进行监控(将多个程序拷贝到不同文件夹,独立添加监控配置操作)。
2、 刷新列表显示数量,软件会动态保持在1500以内,超出的会自动去除
3、刷新列表的URL已经保存在【软件目录-刷新列表】目录下,关键词HTML和TXT格式文件各有两份。如果长时间运行后文件过大,可以自行删除或移动文件到新位置(先关闭监控程序)。
4、右键刷新列表中的标题,直接在浏览器中打开原网页,无需提取文字。
5、【关键词出现在标题中】只是在搜索引擎爬取中添加了[intitle:]参数,即使在搜索论坛或微信时使用该参数,返回的标题也可能不收录关键词(通常网页正文收录关键词),然后可以勾选[Appear at all]强制关键词出现在标题中。
6、 刷新列表的时间列,[]方括号是当地时间,未括起来的是页面时间。 查看全部
实时抓取网页数据(优采云原创的自动提取正文算法能适应网页的主体正文)
当监听到最新网页时,软件会列在列表框的最上方,并有提示音。
然后你点击列表中的一个标题,网页的文字就会自动显示在“快速阅读窗口”中。
优采云原创的自动文本提取算法,该算法可以适应大部分网页,自动提取网页的主体部分,单独阅读。
当然,你也可能会遇到提取错误,比如一些没有大正文的网页,比如视频播放页面等,这时候可以点击“打开原创网页”链接查看原创网页页。
指示
1、 一般网速为4M,同一程序监控的关键词数量不建议超过20个。即使你的网速很快,也不建议设置太多多个关键词同时监控,也可以尝试打开多个程序进行监控(将多个程序拷贝到不同文件夹,独立添加监控配置操作)。
2、 刷新列表显示数量,软件会动态保持在1500以内,超出的会自动去除
3、刷新列表的URL已经保存在【软件目录-刷新列表】目录下,关键词HTML和TXT格式文件各有两份。如果长时间运行后文件过大,可以自行删除或移动文件到新位置(先关闭监控程序)。
4、右键刷新列表中的标题,直接在浏览器中打开原网页,无需提取文字。
5、【关键词出现在标题中】只是在搜索引擎爬取中添加了[intitle:]参数,即使在搜索论坛或微信时使用该参数,返回的标题也可能不收录关键词(通常网页正文收录关键词),然后可以勾选[Appear at all]强制关键词出现在标题中。
6、 刷新列表的时间列,[]方括号是当地时间,未括起来的是页面时间。
实时抓取网页数据(大数据时代已然到来,抓取网页数据成为科研重要手段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-11 15:19
网页数据爬取是指从互联网上获取数据,并将获取的非结构化数据转化为结构化数据,最后将数据存储在本地计算机或数据库中的一种技术。
目前,全球网络数据以每年40%左右的速度增长。IDC(互联网数据中心)报告显示,2013年全球数据4.4ZB。到2020年,全球数据总量将达到40ZB。大数据时代已经到来,网络数据采集已成为进行竞争对手分析、业务数据挖掘、科学研究的重要手段。
我们在做数据分析的时候,会发现大部分的参考数据都是从网上获取的。然而,互联网上的原创数据往往不尽如人意,难以满足我们的个性化需求。因此,我们需要根据实际情况有针对性地抓取网页数据。
网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但是我们需要在主页上有一个页面,上帝说我们需要一个页面!
1、打开网页
我们以在百度上搜索“查虎”关键词为例:
使用 CreateObject("internetexplorer.application")
.可见 = 真
.导航“怎么了”
'关闭页面
'。退出
结束于
代码很简单,先创建一个IE对象,然后给一些属性赋值。Visible就是可见性,是指网页被操作时是否会看到网页。熟练后可以设置为False,这样不仅让程序在运行时有一种神秘感(而不是),而且速度也快了一点。
但是有一点要记住,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等到网页完全加载后才能开始抓取网页数据。这次我们使用:(从这里开始,所有的代码都需要写在With代码块中)
而 .ReadyState 4 或 .Busy
事件
温德
Busy 是网页的繁忙状态,ReadyState 是 HTTP 的五种就绪状态,对应如下:
: 请求没有初始化(open() 没有被调用)。
1:请求已经建立,但是还没有发送(send()没有被调用)。
2:请求已经发送并正在处理中(通常现在可以从响应中获取内容头)。
3:请求正在处理中;通常响应中有部分数据可用,但服务器还没有完成响应的生成。
4:响应完成;您可以获取并使用服务器的响应。
2、获取信息
我们先爬取网页数据,然后过滤掉有用的部分,然后慢慢添加条件爬取。
设置 dmt = .Document
对于 i = 0 到 dmt.all.Length-1
设置 htMent = dmt.all(i)
使用 ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
结束于
接下来我
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
getElementById("IDName"):返回第一个带有IDName的标签 getElementsByName("a"):返回所有标签,返回值为集合 getElementsByClassName("css"):返回所有样式名称为css的标签,返回该值是一个集合。
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。 查看全部
实时抓取网页数据(大数据时代已然到来,抓取网页数据成为科研重要手段)
网页数据爬取是指从互联网上获取数据,并将获取的非结构化数据转化为结构化数据,最后将数据存储在本地计算机或数据库中的一种技术。
目前,全球网络数据以每年40%左右的速度增长。IDC(互联网数据中心)报告显示,2013年全球数据4.4ZB。到2020年,全球数据总量将达到40ZB。大数据时代已经到来,网络数据采集已成为进行竞争对手分析、业务数据挖掘、科学研究的重要手段。
我们在做数据分析的时候,会发现大部分的参考数据都是从网上获取的。然而,互联网上的原创数据往往不尽如人意,难以满足我们的个性化需求。因此,我们需要根据实际情况有针对性地抓取网页数据。
网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但是我们需要在主页上有一个页面,上帝说我们需要一个页面!
1、打开网页
我们以在百度上搜索“查虎”关键词为例:
使用 CreateObject("internetexplorer.application")
.可见 = 真
.导航“怎么了”
'关闭页面
'。退出
结束于
代码很简单,先创建一个IE对象,然后给一些属性赋值。Visible就是可见性,是指网页被操作时是否会看到网页。熟练后可以设置为False,这样不仅让程序在运行时有一种神秘感(而不是),而且速度也快了一点。
但是有一点要记住,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等到网页完全加载后才能开始抓取网页数据。这次我们使用:(从这里开始,所有的代码都需要写在With代码块中)
而 .ReadyState 4 或 .Busy
事件
温德
Busy 是网页的繁忙状态,ReadyState 是 HTTP 的五种就绪状态,对应如下:
: 请求没有初始化(open() 没有被调用)。
1:请求已经建立,但是还没有发送(send()没有被调用)。
2:请求已经发送并正在处理中(通常现在可以从响应中获取内容头)。
3:请求正在处理中;通常响应中有部分数据可用,但服务器还没有完成响应的生成。
4:响应完成;您可以获取并使用服务器的响应。
2、获取信息
我们先爬取网页数据,然后过滤掉有用的部分,然后慢慢添加条件爬取。
设置 dmt = .Document
对于 i = 0 到 dmt.all.Length-1
设置 htMent = dmt.all(i)
使用 ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
结束于
接下来我
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
getElementById("IDName"):返回第一个带有IDName的标签 getElementsByName("a"):返回所有标签,返回值为集合 getElementsByClassName("css"):返回所有样式名称为css的标签,返回该值是一个集合。
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。
实时抓取网页数据(一个用来查询全球数据的网站WorldInData())
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-11-11 00:13
我们在做一些医学研究的时候,往往需要了解一些全球疾病的情况,或者一些其他的、全球性的数据。这个时候我们需要从哪里获取这些数据?对于这样的信息,一般来说,我们可以通过查询一些文献来获取数据。然而,这种检测的效率非常低。可能需要搜索大量文献才能找到相关的东西。所以,今天给大家推荐一个网站Our World In Data()查询全局数据
这个 网站 包括来自各个领域的数据。例如:健康、食品、教育等。其中,我们有健康方面的共同信息,比如肿瘤,或者最近流行的COIVD-19数据。所以如果你想研究 COVID-19 的分析,你可以在这里下载每个国家的比较数据。
这里我们将使用 COVID-19 的结果来说明。其他一切都是相似的。我们点击COVID-19区域后,网站就会有自己的分析结果。我们可以看到他们分析的基础数据,也可以下载分析的原创数据。
目前,由于新冠疫情严重,数据基本每天更新。关于新冠,由于其严重性,所有资料都有直接下载链接。我们可以点击下载进行下载。
同时,在每一个简单的分析结果中,网站都提供了图表、地图、表格和下载数据的地方。这里我们不提供专门的下载区,您可以在这里下载数据。例如,在 COVID-19 的每日死亡数据中。我们可以看到具体的图表。
同时这个数据是交互的,我们可以看到具体数据的变化
此外,如果数据随时间发生变化。单击下面的播放,您还可以看到数据如何随时间变化。
好了,以上就是这个网站的基本使用过程,主要是你可以查询一些公开的数据,下载这些数据做自己的相关研究分析。 查看全部
实时抓取网页数据(一个用来查询全球数据的网站WorldInData())
我们在做一些医学研究的时候,往往需要了解一些全球疾病的情况,或者一些其他的、全球性的数据。这个时候我们需要从哪里获取这些数据?对于这样的信息,一般来说,我们可以通过查询一些文献来获取数据。然而,这种检测的效率非常低。可能需要搜索大量文献才能找到相关的东西。所以,今天给大家推荐一个网站Our World In Data()查询全局数据
这个 网站 包括来自各个领域的数据。例如:健康、食品、教育等。其中,我们有健康方面的共同信息,比如肿瘤,或者最近流行的COIVD-19数据。所以如果你想研究 COVID-19 的分析,你可以在这里下载每个国家的比较数据。
这里我们将使用 COVID-19 的结果来说明。其他一切都是相似的。我们点击COVID-19区域后,网站就会有自己的分析结果。我们可以看到他们分析的基础数据,也可以下载分析的原创数据。
目前,由于新冠疫情严重,数据基本每天更新。关于新冠,由于其严重性,所有资料都有直接下载链接。我们可以点击下载进行下载。
同时,在每一个简单的分析结果中,网站都提供了图表、地图、表格和下载数据的地方。这里我们不提供专门的下载区,您可以在这里下载数据。例如,在 COVID-19 的每日死亡数据中。我们可以看到具体的图表。
同时这个数据是交互的,我们可以看到具体数据的变化
此外,如果数据随时间发生变化。单击下面的播放,您还可以看到数据如何随时间变化。
好了,以上就是这个网站的基本使用过程,主要是你可以查询一些公开的数据,下载这些数据做自己的相关研究分析。
实时抓取网页数据(中华英才网数据自动聚合系统正是由此而生|案例分析案例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-11-08 15:11
1.简介
项目背景
互联网时代,信息海阔天空。甚至我们获取信息的方式也发生了变化:从传统的翻书到查字典,再到通过搜索引擎搜索。我们已经从信息匮乏的时代走到了信息丰富的今天。
今天,困扰我们的问题不是信息太少,而是太多,太多让你无法分辨或选择。因此,提供一种能够自动抓取互联网上的数据,并对其进行自动排序和分析的工具是非常重要的。
我们通过传统搜索引擎获取的信息通常以网页的形式展示。这样的信息手动阅读自然友好,但计算机很难处理和重复使用。而且检索到的信息量太大,我们很难从海量的检索结果中提取出我们最需要的信息。
本方案所涉及的数据聚合系统由此诞生。系统按照一定的规则抓取指定的网站中的信息,对抓取的结果进行分析整理,保存在结构化的数据库中,为数据的复用做准备。
中华英才网是知名的大型招聘类网站。为了全面细致地了解招聘市场的整体能力,帮助中华英才网全面了解其他竞争对手的情况,为市场人员提供潜在客户信息,我们提供此解决方案。
使命和宗旨
捷软与中华英才网合作开发数据自动聚合系统,从互联网上获取公开的信息资源,对信息进行分析、处理和再加工,为中华英才网营销部门提供准确的市场信息资源。
2.方案设计原则
我们在设计系统方案时充分考虑了以下两个原则,并将始终贯穿于设计和开发过程:
系统精度
系统需要从互联网庞大的信息海洋中获取信息。如何保证它抓取的信息的准确性和有效性,是评估整个系统价值的关键因素。因此,除了对抓取到的信息进行整理和分析,当目标网站的内容和格式发生变化时,智能感知、及时通知和调整也是保证系统准确性的重要手段。.
系统灵活性
该系统虽然是为少数用户提供服务并监控固定站点的内部系统,但仍需具备一定的灵活性和较强的可扩展性。
因为目标站点的结构、层次和格式在不断变化;并且系统需要抓取的目标站点也在不断调整;因此,系统必须能够适应这种变化。当爬取目标发生变化时,系统可以通过简单的设置或调整,继续完成数据聚合任务。
3.解决方案:
1.功能结构图
2.定义格式并准备脚本
首先,我们需要根据需要爬取的目标网站的特点,编写一个爬取脚本(格式)。包括:
目标网站的URL路径;
使用什么方法获取数据?可以使用模拟查询功能的方法(手动检测查询页面提交的参数并模拟提交);也可以从头到尾遍历序列号(需要找到当前最大的序列号值);
根据每个网站的特点编译(标准、脚本);
3.获取数据
系统提供的rake程序会根据预定义的XML格式执行数据采集任务。为了防止目标网站的检测程序发现它,我们建议直接保存捕获的页面,然后对其进行处理。而不是在获取信息后立即处理信息,对于提高抓取和保留第一手信息的效率非常有价值。
通过定义的脚本模拟登录;
对于下拉列表中的查询项,循环遍历列表中的每个值。并对获取查询结果的页面进行模拟翻页操作,获取所有查询结果;
如果作业数据库或业务目录数据库使用自增整数作为其唯一ID,那么我们可以想办法获取最大值,然后通过遍历的方法将其全部抓取;
定时执行爬取操作,增量保存抓取到的数据;
4.简单分析
采集接收到的数据在外网的服务器上简单的分析处理。内容主要包括:
结构化数据:对获取的数据进行结构化,以方便以后的数据传输,也方便下一步的复查和故障排除任务。
消除重复;使用模拟查询方法遍历时,系统捕获的数据必须是重复的。由于重复的数据会造成重复的分析处理程序,不仅占用系统资源,使系统处理效率低下,而且给系统带来了大量的垃圾数据。为了避免大量重复和冗余的数据,我们要做的第一个处理工作就是对重复项进行整理。
消除错误;由于目标站点的内容、结构和格式的调整,系统将无法捕获或捕获大量错误信息。在排除这些误报信息的同时,我们通过数据错误率的判断,可以获得目标站点是否发生变化的信息,并及时向系统发出预警通知。
5.数据发回内部
系统通过Web Service将处理后的数据发送回企业。唯一需要考虑的是如何实现增量更新,否则每天有大量数据更新到本地数据库,会造成网络拥塞。
6.数据分析
这里的数据分析与上述在远程服务器上进行的分析操作不同。后者是为了简单有效的数据过滤,防止数据冗余和造成处理速度缓慢或网络拥塞。前者为日后人工确认提供便利,有效帮助市场人员进行快速人工分拣。详情如下:
l 按地区区分;
l 按准确程度划分;帮助用户优先考虑哪些信息更有效;
l 按发帖数划分;
l 记录各公司发布的职位变动过程;
7.手动确认
这部分主要关注两个方面:
1、提供友好的人机界面,允许人工确认这些信息;
2、对比英才网的职位数据库,提取差异进行人工确认:
通过与市场人员的沟通交流,了解他们关心的信息,按照他们期望的方式提供数据,完成人工确认。
8.统计汇总
汇总统计功能也是数据汇总系统的重要组成部分,将提供以下几类统计汇总功能:
以网站为单位,统计每个网站日新增的公司、职位等信息;
跟踪大型企业,统计其在每个网站上发布的信息帖记录;
以时间为单位,按日、周、月对各种信息进行统计;
按地区、公司、岗位进行统计;
其他;
仿真统计汇总界面
[引用]
转载于: 查看全部
实时抓取网页数据(中华英才网数据自动聚合系统正是由此而生|案例分析案例)
1.简介
项目背景
互联网时代,信息海阔天空。甚至我们获取信息的方式也发生了变化:从传统的翻书到查字典,再到通过搜索引擎搜索。我们已经从信息匮乏的时代走到了信息丰富的今天。
今天,困扰我们的问题不是信息太少,而是太多,太多让你无法分辨或选择。因此,提供一种能够自动抓取互联网上的数据,并对其进行自动排序和分析的工具是非常重要的。
我们通过传统搜索引擎获取的信息通常以网页的形式展示。这样的信息手动阅读自然友好,但计算机很难处理和重复使用。而且检索到的信息量太大,我们很难从海量的检索结果中提取出我们最需要的信息。
本方案所涉及的数据聚合系统由此诞生。系统按照一定的规则抓取指定的网站中的信息,对抓取的结果进行分析整理,保存在结构化的数据库中,为数据的复用做准备。
中华英才网是知名的大型招聘类网站。为了全面细致地了解招聘市场的整体能力,帮助中华英才网全面了解其他竞争对手的情况,为市场人员提供潜在客户信息,我们提供此解决方案。
使命和宗旨
捷软与中华英才网合作开发数据自动聚合系统,从互联网上获取公开的信息资源,对信息进行分析、处理和再加工,为中华英才网营销部门提供准确的市场信息资源。
2.方案设计原则
我们在设计系统方案时充分考虑了以下两个原则,并将始终贯穿于设计和开发过程:
系统精度
系统需要从互联网庞大的信息海洋中获取信息。如何保证它抓取的信息的准确性和有效性,是评估整个系统价值的关键因素。因此,除了对抓取到的信息进行整理和分析,当目标网站的内容和格式发生变化时,智能感知、及时通知和调整也是保证系统准确性的重要手段。.
系统灵活性
该系统虽然是为少数用户提供服务并监控固定站点的内部系统,但仍需具备一定的灵活性和较强的可扩展性。
因为目标站点的结构、层次和格式在不断变化;并且系统需要抓取的目标站点也在不断调整;因此,系统必须能够适应这种变化。当爬取目标发生变化时,系统可以通过简单的设置或调整,继续完成数据聚合任务。
3.解决方案:
1.功能结构图
2.定义格式并准备脚本
首先,我们需要根据需要爬取的目标网站的特点,编写一个爬取脚本(格式)。包括:
目标网站的URL路径;
使用什么方法获取数据?可以使用模拟查询功能的方法(手动检测查询页面提交的参数并模拟提交);也可以从头到尾遍历序列号(需要找到当前最大的序列号值);
根据每个网站的特点编译(标准、脚本);
3.获取数据
系统提供的rake程序会根据预定义的XML格式执行数据采集任务。为了防止目标网站的检测程序发现它,我们建议直接保存捕获的页面,然后对其进行处理。而不是在获取信息后立即处理信息,对于提高抓取和保留第一手信息的效率非常有价值。
通过定义的脚本模拟登录;
对于下拉列表中的查询项,循环遍历列表中的每个值。并对获取查询结果的页面进行模拟翻页操作,获取所有查询结果;
如果作业数据库或业务目录数据库使用自增整数作为其唯一ID,那么我们可以想办法获取最大值,然后通过遍历的方法将其全部抓取;
定时执行爬取操作,增量保存抓取到的数据;
4.简单分析
采集接收到的数据在外网的服务器上简单的分析处理。内容主要包括:
结构化数据:对获取的数据进行结构化,以方便以后的数据传输,也方便下一步的复查和故障排除任务。
消除重复;使用模拟查询方法遍历时,系统捕获的数据必须是重复的。由于重复的数据会造成重复的分析处理程序,不仅占用系统资源,使系统处理效率低下,而且给系统带来了大量的垃圾数据。为了避免大量重复和冗余的数据,我们要做的第一个处理工作就是对重复项进行整理。
消除错误;由于目标站点的内容、结构和格式的调整,系统将无法捕获或捕获大量错误信息。在排除这些误报信息的同时,我们通过数据错误率的判断,可以获得目标站点是否发生变化的信息,并及时向系统发出预警通知。
5.数据发回内部
系统通过Web Service将处理后的数据发送回企业。唯一需要考虑的是如何实现增量更新,否则每天有大量数据更新到本地数据库,会造成网络拥塞。
6.数据分析
这里的数据分析与上述在远程服务器上进行的分析操作不同。后者是为了简单有效的数据过滤,防止数据冗余和造成处理速度缓慢或网络拥塞。前者为日后人工确认提供便利,有效帮助市场人员进行快速人工分拣。详情如下:
l 按地区区分;
l 按准确程度划分;帮助用户优先考虑哪些信息更有效;
l 按发帖数划分;
l 记录各公司发布的职位变动过程;
7.手动确认
这部分主要关注两个方面:
1、提供友好的人机界面,允许人工确认这些信息;
2、对比英才网的职位数据库,提取差异进行人工确认:
通过与市场人员的沟通交流,了解他们关心的信息,按照他们期望的方式提供数据,完成人工确认。
8.统计汇总
汇总统计功能也是数据汇总系统的重要组成部分,将提供以下几类统计汇总功能:
以网站为单位,统计每个网站日新增的公司、职位等信息;
跟踪大型企业,统计其在每个网站上发布的信息帖记录;
以时间为单位,按日、周、月对各种信息进行统计;
按地区、公司、岗位进行统计;
其他;
仿真统计汇总界面
[引用]
转载于:
实时抓取网页数据(从服务端取到的数据需要实时反馈,否则将毫无意义!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-08 06:22
从服务器获取的数据需要实时反馈,否则毫无意义!
先介绍一下Vue.set()方法
注意:如果服务器返回的数据量很小,或者字段很少,可以使用vue的set方法。如果数据量很大,请直接看第二种情况。
官网API是这样介绍的:
Vue.set(目标,键,值)
范围:
{对象 | 数组} 目标
{字符串 | 数字}键
{any} 值
返回值:设置后的新值
用法:
向响应式对象添加一个属性,并确保这个新属性也是响应式的并触发视图更新。必须用来给响应式对象添加新属性,因为Vue无法检测普通的新属性(比如this.myObject.newProperty ='hi')
请注意,对象不能是 Vue 实例,也不能是 Vue 实例的根数据对象。
举个简单的小例子来介绍一下这个用法:
一:在data中定义一个对象:
data() {
return {
person:{
age:10,
name:'李古拉雷',
sex:1
}
}
}
二:向服务器发起请求返回一个新的数据对象:
person:{
age:20,
name:'高圆圆',
sex:0
}
这时候就需要把这个对象实时渲染到页面上
三:使用Vue.set()方法更新数据
如下:
methods: {
getPerson(){
this.$http({
method: "post",
url:this.$$baseURL + "sys/getPerson",
}).then(res => {
Vue.set(this.person,0,{age:res.data.age,name:res.data.name,sex:res.data.sex})
/**
* 0 更新的是位置0上的数据
*
*/
});
}
}
这样就可以将服务器返回的新数据实时更新到组件中。
先说第二种情况:
这种情况下,数据量大,字段多。使用 Vue.set() 方法有点太多了。这个时候我们应该怎么做?
核心思想是定义一个临时变量。因为calculated是一个计算属性,所以里面的值比较精细,可以实时渲染组件更新页面。
一:我们在data中定义一个大的临时对象
data() {
return {
myTempObj:{} // 这时一个很大的临时对象,字段特别多
}
}
二:我们在计算属性中也定义了一个非常大的对象
这个对象就是我们在页面中实际使用的对象
三:发起异步请求并从服务器返回数据
methods: {
getBigObj(){
this.$http({
method: "post",
url:this.$$baseURL + "sys/getBigObj",
}).then(res => {
this.myTempObj=res.bigObj ; // 在这里用临时变量接受服务端返回值
});
}
}
四:页面模板组件中的使用方法
{{item.name}}
以上两种情况可以解决从服务器获取的数据无法实时更新的问题。根据具体情况选择使用!
四年java开发,四年前端加产品。今日头条前端架构师。欢迎关注我,技术生活好有趣! 查看全部
实时抓取网页数据(从服务端取到的数据需要实时反馈,否则将毫无意义!)
从服务器获取的数据需要实时反馈,否则毫无意义!
先介绍一下Vue.set()方法
注意:如果服务器返回的数据量很小,或者字段很少,可以使用vue的set方法。如果数据量很大,请直接看第二种情况。
官网API是这样介绍的:
Vue.set(目标,键,值)
范围:
{对象 | 数组} 目标
{字符串 | 数字}键
{any} 值
返回值:设置后的新值
用法:
向响应式对象添加一个属性,并确保这个新属性也是响应式的并触发视图更新。必须用来给响应式对象添加新属性,因为Vue无法检测普通的新属性(比如this.myObject.newProperty ='hi')
请注意,对象不能是 Vue 实例,也不能是 Vue 实例的根数据对象。
举个简单的小例子来介绍一下这个用法:
一:在data中定义一个对象:
data() {
return {
person:{
age:10,
name:'李古拉雷',
sex:1
}
}
}
二:向服务器发起请求返回一个新的数据对象:
person:{
age:20,
name:'高圆圆',
sex:0
}
这时候就需要把这个对象实时渲染到页面上
三:使用Vue.set()方法更新数据
如下:
methods: {
getPerson(){
this.$http({
method: "post",
url:this.$$baseURL + "sys/getPerson",
}).then(res => {
Vue.set(this.person,0,{age:res.data.age,name:res.data.name,sex:res.data.sex})
/**
* 0 更新的是位置0上的数据
*
*/
});
}
}
这样就可以将服务器返回的新数据实时更新到组件中。
先说第二种情况:
这种情况下,数据量大,字段多。使用 Vue.set() 方法有点太多了。这个时候我们应该怎么做?
核心思想是定义一个临时变量。因为calculated是一个计算属性,所以里面的值比较精细,可以实时渲染组件更新页面。
一:我们在data中定义一个大的临时对象
data() {
return {
myTempObj:{} // 这时一个很大的临时对象,字段特别多
}
}
二:我们在计算属性中也定义了一个非常大的对象
这个对象就是我们在页面中实际使用的对象
三:发起异步请求并从服务器返回数据
methods: {
getBigObj(){
this.$http({
method: "post",
url:this.$$baseURL + "sys/getBigObj",
}).then(res => {
this.myTempObj=res.bigObj ; // 在这里用临时变量接受服务端返回值
});
}
}
四:页面模板组件中的使用方法
{{item.name}}
以上两种情况可以解决从服务器获取的数据无法实时更新的问题。根据具体情况选择使用!
四年java开发,四年前端加产品。今日头条前端架构师。欢迎关注我,技术生活好有趣!
实时抓取网页数据(人脑高于人工智能,计算机的算力和计算能力)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-11-06 16:02
实时抓取网页数据,网页数据用来转录成人脑可识别的形式。通过相应的算法,去优化处理算法,让它达到人脑的识别率。接下来就靠人脑去分析、运算了,计算机本身是人脑的延伸,人脑大概率可以分析计算机达不到的精度,更重要的是人脑只有三维,如果能够有意识的训练计算机能识别长宽高都有误差的二维网页数据(比如数字二维的网页),那计算机也是有这个能力的,比如能够解释网页的格式。
详见世界五百强hr招聘信息
现在已经可以了,并且绝对可以代替人脑和计算机大脑共同分析。人脑高于人工智能,计算机低于人工智能,计算机的算力相对人脑有优势,用机器解读和分析人脑数据比较常见。
很显然,人脑不能胜任这个工作。人脑的算力,计算能力,和人工智能有天壤之别,也就是人工智能擅长计算,人脑擅长分析。而网页信息本身就是一种数据,所以这个就不是一个非常合适的程序可以解读并分析。因为解读网页信息的算法其实就是人工智能的一部分,人工智能擅长算法,其算法基础就是人脑中海量数据的识别与分析。而人脑擅长识别,计算能力也非常强大,所以计算机擅长处理图片数据,而非数据库。
但即使这样,计算机解读人脑中的信息,也是需要人类数据库作为基础,所以在计算机中的算法与人脑中的算法是有区别的。因此,只需要增加人脑的数据,不需要增加计算机的算力。但是,把人脑数据和计算能力对接,并不是一个难题,有大把的思路,数学模型可以帮助实现这个愿望。但是应用到自然语言处理,图片分类等领域上。人工智能的发展速度会超过人脑的发展速度,因为人脑在进化的过程中,逐渐认识到通过数学模型可以做任何事情,所以才有了“图灵测试”和“代码智能”等,这个时候数学模型已经不能作为人脑的发展核心优势了。
但是人工智能是有自己特定的发展方向,要理解需要理解人脑中的函数、定理、推论等等等等的,一句话,要进化出智能必须要大脑发展到足够的高度,才能真正形成学习认知能力,然后才能在应用上取得成功。 查看全部
实时抓取网页数据(人脑高于人工智能,计算机的算力和计算能力)
实时抓取网页数据,网页数据用来转录成人脑可识别的形式。通过相应的算法,去优化处理算法,让它达到人脑的识别率。接下来就靠人脑去分析、运算了,计算机本身是人脑的延伸,人脑大概率可以分析计算机达不到的精度,更重要的是人脑只有三维,如果能够有意识的训练计算机能识别长宽高都有误差的二维网页数据(比如数字二维的网页),那计算机也是有这个能力的,比如能够解释网页的格式。
详见世界五百强hr招聘信息
现在已经可以了,并且绝对可以代替人脑和计算机大脑共同分析。人脑高于人工智能,计算机低于人工智能,计算机的算力相对人脑有优势,用机器解读和分析人脑数据比较常见。
很显然,人脑不能胜任这个工作。人脑的算力,计算能力,和人工智能有天壤之别,也就是人工智能擅长计算,人脑擅长分析。而网页信息本身就是一种数据,所以这个就不是一个非常合适的程序可以解读并分析。因为解读网页信息的算法其实就是人工智能的一部分,人工智能擅长算法,其算法基础就是人脑中海量数据的识别与分析。而人脑擅长识别,计算能力也非常强大,所以计算机擅长处理图片数据,而非数据库。
但即使这样,计算机解读人脑中的信息,也是需要人类数据库作为基础,所以在计算机中的算法与人脑中的算法是有区别的。因此,只需要增加人脑的数据,不需要增加计算机的算力。但是,把人脑数据和计算能力对接,并不是一个难题,有大把的思路,数学模型可以帮助实现这个愿望。但是应用到自然语言处理,图片分类等领域上。人工智能的发展速度会超过人脑的发展速度,因为人脑在进化的过程中,逐渐认识到通过数学模型可以做任何事情,所以才有了“图灵测试”和“代码智能”等,这个时候数学模型已经不能作为人脑的发展核心优势了。
但是人工智能是有自己特定的发展方向,要理解需要理解人脑中的函数、定理、推论等等等等的,一句话,要进化出智能必须要大脑发展到足够的高度,才能真正形成学习认知能力,然后才能在应用上取得成功。
实时抓取网页数据(先上代码看了一下应该是Pyecharts中Map的data_pair )
网站优化 • 优采云 发表了文章 • 0 个评论 • 29 次浏览 • 2021-11-05 09:08
)
2021/07/15 更新:
没及时看到评论区的反馈。对不起,真相。拉下代码看Pyecharts中Map的data_pair数据类型。它现在应该转换为列表。
代码已整理完善,完整源代码已上传至Gitee,地址:完整源代码
所有生成的csv、流行病地图、可视化图表都在项目根目录下。
概括:
受2019-nCoV影响,一场没有硝烟的抗击疫情已经打响。在全国人民的共同努力下,疫情正在逐步趋于稳定,但我们仍不能掉以轻心。
疫情还没开始的时候,我每天都在关注疫情,尤其是全国疫情地图。之后一直想拿到资料自己做一个,但没有坚持去做。前几天用Python爬取了分数查询网站,跟着做这个需求。
话不多说,先上图吧:
中国疫情地图
各省详情
湖北省各城市疫情数据分布
内容
数据来源分析:
数据来自丁香博士:
丁香博士的数据如下图所示:
看到这里,你可能会觉得这个数据应该直接放在tr,td或者ul,li里面,直接发送请求,获取页面DOM中的文本即可。
起初我是这样想的。看了网页的源码,才发现不是-_-||
实际上,中国每个省的数据都存储在id为getAreaStat的script标签中,然后动态渲染到视图中。
所以我们要做的就是抓取脚本标签中id为getAreaStat的文本内容
数据整理:
不难看出,script标签中的数据是以json的形式存储的,我们对json字符串进行校验和格式化,将里面的数据组织起来。
左边密集的数据格式化后,可以很直观的看到json字符串的内部存储情况,大致如下:在整个json字符串中,每个省都是一个dict,每个省的城市是用于存储省内城市的子列表。数据。
代码部分需要用到的第三方库如下: 一、 抓取全国各省疫情信息,生成csv文件基础
1.代码分析:
2. 源代码:
import requests
from pyquery import PyQuery as pq
import json
import pandas as pd
import time
def get_data():
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
response = requests.get(url)
if response.status_code == 200:
response.encoding = "utf-8"
dom = pq(response.content)
data = dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0]
jsonObj = json.loads(data) # json对象
print("数据抓取成功...")
province_data = []
for item in jsonObj:
dic = {"省全称": item["provinceName"], "省简称": item["provinceShortName"], "现存确诊人数": item["currentConfirmedCount"],
"累计确诊人数": item["confirmedCount"], "疑似人数": item["suspectedCount"], "治愈人数": item["curedCount"],
"死亡人数": item["deadCount"]}
province_data.append(dic)
if len(province_data) > 0:
print("写入数据...")
try:
df = pd.DataFrame(province_data)
time_format = time.strftime("%Y-%m-%d_%H_%M_%S", time.localtime())
df.to_csv(time_format + "全国各省疫情数据.csv", encoding="gbk", index=False)
print("写入成功...")
except Exception as e:
print(f"写入失败....{e}")
if __name__ == '__main__':
get_data()
3.操作效果:
二、使用pyecharts绘制中国疫情高级地图
说到画表,第一个想到的就是Apache开源的echarts框架,高效强大。因为对Matplotlib库不熟悉,拿到数据后想用echarts框架的前端画一个,后来才知道有专门的pyecharts,所以很nice!
建议不懂echarts或pyecharts的同学一定要先阅读官方API,了解基本图表类型和各种参数,或者把各种参数写成一个链式操作,会有点别扭((⊙﹏⊙⊙) )) 哦!
1.代码分析:
2. 源代码:
"""
@File : data_chart.py
@Modify Time @Author @Version @Desciption
------------ ------- -------- -----------
2021/7/15 9:25 wrzcoder 1.0 None
"""
from pyecharts import options as opts
from pyecharts.charts import Map
import requests
from pyquery import PyQuery as pq
import json
import time
def map_visual_map() -> Map:
c = (
Map(init_opts=opts.InitOpts(page_title="中国疫情地图"))
.add("现存确诊人数", data_pair=list(current_data_dic.items()), maptype="china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国疫情地图", subtitle="数据更新于" + time_format),
visualmap_opts=opts.VisualMapOpts(pieces=[
{"value": 0, "label": "无", "color": "#9AFF9A"},
{"min": 1, "max": 9, "label": "1~9", "color": "#FFCCCC"},
{"min": 10, "max": 99, "label": "10~99", "color": "#DB5A6B"},
{"min": 100, "max": 499, "label": "100~499", "color": "#FF6666"},
{"min": 500, "max": 999, "label": "500~999", "color": "#CC2929"},
{"min": 1000, "max": 9999, "label": "1000~9999", "color": "#8C0D0D"},
{"min": 10000, "label": ">10000", "color": "#9d2933"}
], is_piecewise=True),
)
)
return c
if __name__ == '__main__':
try:
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
response = requests.get(url)
if response.status_code == 200:
response.encoding = "utf-8"
dom = pq(response.content)
data = dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0]
jsonObj = json.loads(data) # json对象
print("数据抓取成功...")
current_data_dic = {}
time_format = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
for item in jsonObj:
current_data_dic[item["provinceShortName"]] = item["currentConfirmedCount"]
print(list(current_data_dic.items()))
map_visual_map().render("疫情地图.html")
print('疫情地图已生成在项目根目录...')
except Exception as e:
print(e)
3.操作效果:
三、 抓取全国各省市疫情数据,拓展数据可视化
我们上面只用到了每个省的数据,在分析开始的时候,每个省的dict还收录了省、市(区)的数据,我们不能浪费这些数据,一定要在什么时候用我们抓取它们。好好利用它,我们将全国各省市的所有疫情数据进行分类可视化。
这里我想说的是:我们在可视化各省(直辖市)下的市(区)的疫情数据时,也可以使用pyecharts中的Map,但是为了更熟悉pyecharts,让我们更改为表格类型的饼图。
看起来非常麻烦。需要请求每个省的数据收录城市,最后画图太麻烦了,不过还是不行(*^▽^*) 30行代码就够了
1.代码分析
2.源代码
"""
@File : province_data_chart.py
@Modify Time @Author @Version @Desciption
------------ ------- -------- -----------
2021/7/15 9:45 wrzcoder 1.0 None
"""
import requests
import json
from pyecharts.charts import Pie
import pyecharts.options as opts
import time
from pyquery import PyQuery as pq
import os
def create_Pie(provinceName, dic_citys) -> Pie:
c = (
Pie(init_opts=opts.InitOpts(width="100%", height="800px", page_title=provinceName + "各市(区)情况"))
.add("", data_pair=list(dic_citys.items()), center=["50%", "58%"], )
.set_global_opts(title_opts=opts.TitleOpts(title=provinceName + "各市(区)情况", subtitle="数据更新于:" + timeformat))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
if not os.path.exists('./中国各省情况'):
os.mkdir('./中国各省情况')
c.render("./中国各省情况/" + provinceName + "各市(区)情况.html")
if __name__ == '__main__':
try:
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
timeformat = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
response = requests.get(url)
response.encoding = "utf-8"
if response.status_code == 200:
print("数据抓取成功!")
dom = pq(response.text)
jsonobj = json.loads(dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0])
for province in jsonobj:
dic_city = {}
for city in province["cities"]:
dic_city[city["cityName"]] = city["currentConfirmedCount"]
if dic_city.__len__() > 0:
create_Pie(province["provinceName"], dic_city)
print(province["provinceName"] + "各市数据汇总完毕!")
except Exception as e:
print(e)
3.操作效果:
只需1.1s,我们就抓取了全国各省市的疫情数据,整理并生成了数据图表
打开随机饼图查看效果:
四川省各城市疫情数据汇总
至此,我们已经完成了对全国各省市实时疫情数据的采集和处理,绘制了中国疫情图。在此基础上,我们进一步拓展并开展了中国各省、自治区、直辖市疫情数据的批量归一化和可视化工作。这期间复习了requests库、pandas、pyquery库等,还学习学习了强大的图表pyecharts库,收获颇丰!所以在这里分享一下,一起了解和学习!
最后,加油武汉,加油中国!疫情终会过去,春天一定会来!
图片来自网络
我希望下次我运行这段代码时,我看到的疫情图会是这样的:
查看全部
实时抓取网页数据(先上代码看了一下应该是Pyecharts中Map的data_pair
)
2021/07/15 更新:
没及时看到评论区的反馈。对不起,真相。拉下代码看Pyecharts中Map的data_pair数据类型。它现在应该转换为列表。
代码已整理完善,完整源代码已上传至Gitee,地址:完整源代码
所有生成的csv、流行病地图、可视化图表都在项目根目录下。
概括:
受2019-nCoV影响,一场没有硝烟的抗击疫情已经打响。在全国人民的共同努力下,疫情正在逐步趋于稳定,但我们仍不能掉以轻心。
疫情还没开始的时候,我每天都在关注疫情,尤其是全国疫情地图。之后一直想拿到资料自己做一个,但没有坚持去做。前几天用Python爬取了分数查询网站,跟着做这个需求。
话不多说,先上图吧:
中国疫情地图
各省详情
湖北省各城市疫情数据分布
内容
数据来源分析:
数据来自丁香博士:
丁香博士的数据如下图所示:
看到这里,你可能会觉得这个数据应该直接放在tr,td或者ul,li里面,直接发送请求,获取页面DOM中的文本即可。
起初我是这样想的。看了网页的源码,才发现不是-_-||
实际上,中国每个省的数据都存储在id为getAreaStat的script标签中,然后动态渲染到视图中。
所以我们要做的就是抓取脚本标签中id为getAreaStat的文本内容
数据整理:
不难看出,script标签中的数据是以json的形式存储的,我们对json字符串进行校验和格式化,将里面的数据组织起来。
左边密集的数据格式化后,可以很直观的看到json字符串的内部存储情况,大致如下:在整个json字符串中,每个省都是一个dict,每个省的城市是用于存储省内城市的子列表。数据。
代码部分需要用到的第三方库如下: 一、 抓取全国各省疫情信息,生成csv文件基础
1.代码分析:
2. 源代码:
import requests
from pyquery import PyQuery as pq
import json
import pandas as pd
import time
def get_data():
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
response = requests.get(url)
if response.status_code == 200:
response.encoding = "utf-8"
dom = pq(response.content)
data = dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0]
jsonObj = json.loads(data) # json对象
print("数据抓取成功...")
province_data = []
for item in jsonObj:
dic = {"省全称": item["provinceName"], "省简称": item["provinceShortName"], "现存确诊人数": item["currentConfirmedCount"],
"累计确诊人数": item["confirmedCount"], "疑似人数": item["suspectedCount"], "治愈人数": item["curedCount"],
"死亡人数": item["deadCount"]}
province_data.append(dic)
if len(province_data) > 0:
print("写入数据...")
try:
df = pd.DataFrame(province_data)
time_format = time.strftime("%Y-%m-%d_%H_%M_%S", time.localtime())
df.to_csv(time_format + "全国各省疫情数据.csv", encoding="gbk", index=False)
print("写入成功...")
except Exception as e:
print(f"写入失败....{e}")
if __name__ == '__main__':
get_data()
3.操作效果:
二、使用pyecharts绘制中国疫情高级地图
说到画表,第一个想到的就是Apache开源的echarts框架,高效强大。因为对Matplotlib库不熟悉,拿到数据后想用echarts框架的前端画一个,后来才知道有专门的pyecharts,所以很nice!
建议不懂echarts或pyecharts的同学一定要先阅读官方API,了解基本图表类型和各种参数,或者把各种参数写成一个链式操作,会有点别扭((⊙﹏⊙⊙) )) 哦!
1.代码分析:
2. 源代码:
"""
@File : data_chart.py
@Modify Time @Author @Version @Desciption
------------ ------- -------- -----------
2021/7/15 9:25 wrzcoder 1.0 None
"""
from pyecharts import options as opts
from pyecharts.charts import Map
import requests
from pyquery import PyQuery as pq
import json
import time
def map_visual_map() -> Map:
c = (
Map(init_opts=opts.InitOpts(page_title="中国疫情地图"))
.add("现存确诊人数", data_pair=list(current_data_dic.items()), maptype="china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国疫情地图", subtitle="数据更新于" + time_format),
visualmap_opts=opts.VisualMapOpts(pieces=[
{"value": 0, "label": "无", "color": "#9AFF9A"},
{"min": 1, "max": 9, "label": "1~9", "color": "#FFCCCC"},
{"min": 10, "max": 99, "label": "10~99", "color": "#DB5A6B"},
{"min": 100, "max": 499, "label": "100~499", "color": "#FF6666"},
{"min": 500, "max": 999, "label": "500~999", "color": "#CC2929"},
{"min": 1000, "max": 9999, "label": "1000~9999", "color": "#8C0D0D"},
{"min": 10000, "label": ">10000", "color": "#9d2933"}
], is_piecewise=True),
)
)
return c
if __name__ == '__main__':
try:
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
response = requests.get(url)
if response.status_code == 200:
response.encoding = "utf-8"
dom = pq(response.content)
data = dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0]
jsonObj = json.loads(data) # json对象
print("数据抓取成功...")
current_data_dic = {}
time_format = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
for item in jsonObj:
current_data_dic[item["provinceShortName"]] = item["currentConfirmedCount"]
print(list(current_data_dic.items()))
map_visual_map().render("疫情地图.html")
print('疫情地图已生成在项目根目录...')
except Exception as e:
print(e)
3.操作效果:
三、 抓取全国各省市疫情数据,拓展数据可视化
我们上面只用到了每个省的数据,在分析开始的时候,每个省的dict还收录了省、市(区)的数据,我们不能浪费这些数据,一定要在什么时候用我们抓取它们。好好利用它,我们将全国各省市的所有疫情数据进行分类可视化。
这里我想说的是:我们在可视化各省(直辖市)下的市(区)的疫情数据时,也可以使用pyecharts中的Map,但是为了更熟悉pyecharts,让我们更改为表格类型的饼图。
看起来非常麻烦。需要请求每个省的数据收录城市,最后画图太麻烦了,不过还是不行(*^▽^*) 30行代码就够了
1.代码分析
2.源代码
"""
@File : province_data_chart.py
@Modify Time @Author @Version @Desciption
------------ ------- -------- -----------
2021/7/15 9:45 wrzcoder 1.0 None
"""
import requests
import json
from pyecharts.charts import Pie
import pyecharts.options as opts
import time
from pyquery import PyQuery as pq
import os
def create_Pie(provinceName, dic_citys) -> Pie:
c = (
Pie(init_opts=opts.InitOpts(width="100%", height="800px", page_title=provinceName + "各市(区)情况"))
.add("", data_pair=list(dic_citys.items()), center=["50%", "58%"], )
.set_global_opts(title_opts=opts.TitleOpts(title=provinceName + "各市(区)情况", subtitle="数据更新于:" + timeformat))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
if not os.path.exists('./中国各省情况'):
os.mkdir('./中国各省情况')
c.render("./中国各省情况/" + provinceName + "各市(区)情况.html")
if __name__ == '__main__':
try:
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
timeformat = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
response = requests.get(url)
response.encoding = "utf-8"
if response.status_code == 200:
print("数据抓取成功!")
dom = pq(response.text)
jsonobj = json.loads(dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0])
for province in jsonobj:
dic_city = {}
for city in province["cities"]:
dic_city[city["cityName"]] = city["currentConfirmedCount"]
if dic_city.__len__() > 0:
create_Pie(province["provinceName"], dic_city)
print(province["provinceName"] + "各市数据汇总完毕!")
except Exception as e:
print(e)
3.操作效果:
只需1.1s,我们就抓取了全国各省市的疫情数据,整理并生成了数据图表
打开随机饼图查看效果:
四川省各城市疫情数据汇总
至此,我们已经完成了对全国各省市实时疫情数据的采集和处理,绘制了中国疫情图。在此基础上,我们进一步拓展并开展了中国各省、自治区、直辖市疫情数据的批量归一化和可视化工作。这期间复习了requests库、pandas、pyquery库等,还学习学习了强大的图表pyecharts库,收获颇丰!所以在这里分享一下,一起了解和学习!
最后,加油武汉,加油中国!疫情终会过去,春天一定会来!
图片来自网络
我希望下次我运行这段代码时,我看到的疫情图会是这样的:
实时抓取网页数据(搞定大数据信息的基础能力——网页工具优采云采集器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-11-05 04:07
对于开发和应用,信息集成是首要问题。解决这个问题后,可以扩展更多的信息挖掘和相关的组合应用。但是,由于技术的匮乏,很多企业选择将信息采集交给数据外包服务公司,类似于定制,这也是一种高效的获取方式。但是现在你做了大数据业务,还是要全面提升自己人员的大数据基础能力,至少在有轻量级数据需求的时候,可以用自己的技能快速解决。那么我们如何才能拥有这种捕捉大数据信息的基本能力呢?网络爬虫工具优采云采集器作为大数据信息抓取的必备软件,充分发挥了其强大的作用。
优采云采集器V9是一款全网通用的网页数据采集软件。通过采集规则和数据处理相关设置,可以设置URL、文本、图片、文件等被抓取,进行排序、过滤等一系列处理,完整呈现给用户可用的数据信息。另外,优采云采集器V9的发布功能也是一大亮点。可自动登录选择数据发布栏目,彻底解放人手的智能工具。
了解网络爬虫工具的操作,可以轻松处理一些不太复杂的数据需求。如果是大数据级别的爬取集成,可能需要更复杂的技术和运行环境,比如频繁复杂的验证码、服务器代理、防御等。采集征服等等。当然,如果懂技术,有条件,企业也可以使用网络爬虫工具优采云采集器进行数据整合,优采云采集器使用分布式高速采集处理系统,多线程可调任务分配,轻松应对大规模海量作业需求。但有时为了再次提高效率,可能需要多个优采云采集器客户端同时运行,
我们正处于大数据时代。医疗、交通、教育、零售、金融、商业……我们都在寻求大数据的突破;各个领域的公司都积极参与市场,以在瞬息万变的市场中站稳脚跟。,但大数据的应用不仅仅是事实,在实践中也并非一帆风顺。面临跨部门跨行业难以共享的信息孤岛和短板;面临大数据技术和产业创新低;面对人才匮乏,大数据如何发展?
除了上面提到的多元学习工具,加强我们的基本能力,不断提高我们的技能,我们还需要有创新的思维和强烈的责任感。时代属于全人类。每个人都可能在这个机会中获得全新的突破。在突破点之前,让我们一起提升能力,以最好的状态迎接机遇,对成功更有信心。返回搜狐查看更多 查看全部
实时抓取网页数据(搞定大数据信息的基础能力——网页工具优采云采集器)
对于开发和应用,信息集成是首要问题。解决这个问题后,可以扩展更多的信息挖掘和相关的组合应用。但是,由于技术的匮乏,很多企业选择将信息采集交给数据外包服务公司,类似于定制,这也是一种高效的获取方式。但是现在你做了大数据业务,还是要全面提升自己人员的大数据基础能力,至少在有轻量级数据需求的时候,可以用自己的技能快速解决。那么我们如何才能拥有这种捕捉大数据信息的基本能力呢?网络爬虫工具优采云采集器作为大数据信息抓取的必备软件,充分发挥了其强大的作用。
优采云采集器V9是一款全网通用的网页数据采集软件。通过采集规则和数据处理相关设置,可以设置URL、文本、图片、文件等被抓取,进行排序、过滤等一系列处理,完整呈现给用户可用的数据信息。另外,优采云采集器V9的发布功能也是一大亮点。可自动登录选择数据发布栏目,彻底解放人手的智能工具。
了解网络爬虫工具的操作,可以轻松处理一些不太复杂的数据需求。如果是大数据级别的爬取集成,可能需要更复杂的技术和运行环境,比如频繁复杂的验证码、服务器代理、防御等。采集征服等等。当然,如果懂技术,有条件,企业也可以使用网络爬虫工具优采云采集器进行数据整合,优采云采集器使用分布式高速采集处理系统,多线程可调任务分配,轻松应对大规模海量作业需求。但有时为了再次提高效率,可能需要多个优采云采集器客户端同时运行,
我们正处于大数据时代。医疗、交通、教育、零售、金融、商业……我们都在寻求大数据的突破;各个领域的公司都积极参与市场,以在瞬息万变的市场中站稳脚跟。,但大数据的应用不仅仅是事实,在实践中也并非一帆风顺。面临跨部门跨行业难以共享的信息孤岛和短板;面临大数据技术和产业创新低;面对人才匮乏,大数据如何发展?
除了上面提到的多元学习工具,加强我们的基本能力,不断提高我们的技能,我们还需要有创新的思维和强烈的责任感。时代属于全人类。每个人都可能在这个机会中获得全新的突破。在突破点之前,让我们一起提升能力,以最好的状态迎接机遇,对成功更有信心。返回搜狐查看更多
实时抓取网页数据(我的Java,什么的都很熟悉谢谢-- )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-05 04:03
)
如何有效的动态抓取某个网站的数据现在我们需要抓取某个网站的价格信息
比如下页的“参考价”
这只是一个标志,实际数据不是取自这个网站
我目前的做法是使用VB.NET,然后添加HtmlAgilityPack包,通过XPath获取值,如
Util.GetNodeValue(v_doc,"/html/body/div[2]/div[5]/div[1]/div/table/tr[10]/td")
但是因为对方的网站经常打折,网页经常会有一些小改动,每次都要手动改Xpath
我想知道有没有更好的方法来处理这个,不使用.Net也没关系,我对Java、PHP等非常熟悉。
谢谢--------------------编程问答--------------------本文属于网络爬虫程序范围,助你登顶。--------------------编程问答 --------------------没有人回答?那我自己就喜欢了,我觉得就算用xpath还是有改进的空间
比如上面使用的绝对路径其实可以改成这样
//div[@class='roundCornerBox']/descendant-or-self::table/descendant::font[@class='BlackH4'and@color='#CC0000']
感觉灵活了很多,简单的页面更改对此没有影响
补充:.NET技术 , VB.NET 查看全部
实时抓取网页数据(我的Java,什么的都很熟悉谢谢--
)
如何有效的动态抓取某个网站的数据现在我们需要抓取某个网站的价格信息
比如下页的“参考价”
这只是一个标志,实际数据不是取自这个网站
我目前的做法是使用VB.NET,然后添加HtmlAgilityPack包,通过XPath获取值,如
Util.GetNodeValue(v_doc,"/html/body/div[2]/div[5]/div[1]/div/table/tr[10]/td")
但是因为对方的网站经常打折,网页经常会有一些小改动,每次都要手动改Xpath
我想知道有没有更好的方法来处理这个,不使用.Net也没关系,我对Java、PHP等非常熟悉。
谢谢--------------------编程问答--------------------本文属于网络爬虫程序范围,助你登顶。--------------------编程问答 --------------------没有人回答?那我自己就喜欢了,我觉得就算用xpath还是有改进的空间
比如上面使用的绝对路径其实可以改成这样
//div[@class='roundCornerBox']/descendant-or-self::table/descendant::font[@class='BlackH4'and@color='#CC0000']
感觉灵活了很多,简单的页面更改对此没有影响
补充:.NET技术 , VB.NET
实时抓取网页数据(【每日一题】实时抓取网页数据(--))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-03 11:00
实时抓取网页数据
1.nlp:即naturallanguageprocessing(自然语言处理)。其实现方法既有狭义上的,如自然语言处理语料库训练法,又有广义上的,比如决策树。使用cnn也好,gcn也好,crf也好,都可以。这种算法应用范围很广,尤其是在医学图像领域。但是具体应用中,并不是所有领域都能找到方法的。2.ml:机器学习或数据挖掘。
不同的数据处理方法,处理数据的思路方法不同。对于医学图像也好,文本也好,数据内容太复杂了也好,怎么处理都有难度,虽然广义上处理方法非常多,但是不同情况适用不同的。
nlp---文本分析前处理ml---图像等模型前处理
nlp(naturallanguageprocessing):自然语言处理。ml(machinelearning):机器学习。区别就在于以上两个概念的认识。机器学习算法的有很多种,比如dnn,cnn,gan等,在线下算法方面有很多。在线上,就是自然语言处理以及图像等。所以你的问题,还是要分情况讨论,主要看什么文本、什么问题、以及问题的规模,也取决于你提问的目的,根据你的问题针对性地提出问题,然后去有针对性地学习针对性的知识。
nlp的老师告诉过不要问自己不想问的东西机器学习的老师告诉过不要问自己想问的东西图像处理的老师告诉过不要问自己想问的东西(其实每个老师的回答都是有保证的) 查看全部
实时抓取网页数据(【每日一题】实时抓取网页数据(--))
实时抓取网页数据
1.nlp:即naturallanguageprocessing(自然语言处理)。其实现方法既有狭义上的,如自然语言处理语料库训练法,又有广义上的,比如决策树。使用cnn也好,gcn也好,crf也好,都可以。这种算法应用范围很广,尤其是在医学图像领域。但是具体应用中,并不是所有领域都能找到方法的。2.ml:机器学习或数据挖掘。
不同的数据处理方法,处理数据的思路方法不同。对于医学图像也好,文本也好,数据内容太复杂了也好,怎么处理都有难度,虽然广义上处理方法非常多,但是不同情况适用不同的。
nlp---文本分析前处理ml---图像等模型前处理
nlp(naturallanguageprocessing):自然语言处理。ml(machinelearning):机器学习。区别就在于以上两个概念的认识。机器学习算法的有很多种,比如dnn,cnn,gan等,在线下算法方面有很多。在线上,就是自然语言处理以及图像等。所以你的问题,还是要分情况讨论,主要看什么文本、什么问题、以及问题的规模,也取决于你提问的目的,根据你的问题针对性地提出问题,然后去有针对性地学习针对性的知识。
nlp的老师告诉过不要问自己不想问的东西机器学习的老师告诉过不要问自己想问的东西图像处理的老师告诉过不要问自己想问的东西(其实每个老师的回答都是有保证的)
实时抓取网页数据(智能编辑重构批处理式"数字PythonIDE"集成开发环境)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-03 09:31
目前可以浏览网页内容的App应用有很多,但是对于剪贴板文本内容的实时抓取,这样的应用却很少。
通过剪贴板抓取文本的优点:在操作简单且无需切换App GUI图形用户界面的情况下,用不同App的Ctrl+C快捷键复制数据,抓取-采集(或共享)到目标应用程序。
例如:在网上找一些软文或者参考资料,尤其是在写自媒体软文或者论文的时候,如果需要单独提取某个关键文本,或者提取多篇文章软文@ > 许多文字。旧方法 Ctrl + C 然后 Ctrl + V 抓取文本可以是一个解决方案。但是工作量大,你会觉得这种重复爬行的操作,最好有现成的App工具可以帮你搞定,而且功能更好。
所有的产品都是为数字时代而生,所有这些功能都集成在它们的应用程序中。当然,其公司还开发了其他一些专门的数据采集和采集 App。
批量式“数字Python IDE”集成开发环境智能编辑重构(集成高效Cython PyInstaller批处理小程序)
详细用法
01、编辑菜单-->勾选“剪贴板:监控”-->弹出如下“提示窗口”
如果您刚刚启动应用程序,则不需要重新启动它,请切换到“取消”按钮并按 Enter 确认。
02、 在桌面、文件夹、网页、网上邻居、MicroSoft Microsoft Office应用程序等,按Ctrl+C快捷键(或其他操作)将文本内容复制到剪贴板 --> 应用程序会自动弹出如下界面。
如果“剪贴板文本”不符合捕获要求,您可以单击“清除剪贴板”按钮清除剪贴板内容。 查看全部
实时抓取网页数据(智能编辑重构批处理式"数字PythonIDE"集成开发环境)
目前可以浏览网页内容的App应用有很多,但是对于剪贴板文本内容的实时抓取,这样的应用却很少。
通过剪贴板抓取文本的优点:在操作简单且无需切换App GUI图形用户界面的情况下,用不同App的Ctrl+C快捷键复制数据,抓取-采集(或共享)到目标应用程序。
例如:在网上找一些软文或者参考资料,尤其是在写自媒体软文或者论文的时候,如果需要单独提取某个关键文本,或者提取多篇文章软文@ > 许多文字。旧方法 Ctrl + C 然后 Ctrl + V 抓取文本可以是一个解决方案。但是工作量大,你会觉得这种重复爬行的操作,最好有现成的App工具可以帮你搞定,而且功能更好。
所有的产品都是为数字时代而生,所有这些功能都集成在它们的应用程序中。当然,其公司还开发了其他一些专门的数据采集和采集 App。
批量式“数字Python IDE”集成开发环境智能编辑重构(集成高效Cython PyInstaller批处理小程序)
详细用法
01、编辑菜单-->勾选“剪贴板:监控”-->弹出如下“提示窗口”
如果您刚刚启动应用程序,则不需要重新启动它,请切换到“取消”按钮并按 Enter 确认。
02、 在桌面、文件夹、网页、网上邻居、MicroSoft Microsoft Office应用程序等,按Ctrl+C快捷键(或其他操作)将文本内容复制到剪贴板 --> 应用程序会自动弹出如下界面。
如果“剪贴板文本”不符合捕获要求,您可以单击“清除剪贴板”按钮清除剪贴板内容。
实时抓取网页数据(数据获取接下来的事情就好办了,需要注意日期格式化问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-03 03:07
实时流行病捕捉
武汉肺炎期间,家里无事可做。有一天,我突然想知道每天的疫情数据。
我以前玩过爬虫,但这次不一样了。准确地说,这次不是爬虫,因为它不具备“批量”的特性。
分析网站
首先要说明一点,我们没有政府数据库,数据来源是通过其他一些在线网站,实时更新数据,比如腾讯新闻、定香园等。
接下来,我们使用腾讯新闻来抓取疫情数据。
网址是#/
打开之后,可以看到它有实时的疫情追踪。
以前我用的爬虫是从html页面中获取相关内容,比较直接,因为所见即所得,只要到当前网页找到对应的标签就可以获取。
这一次,和以前不一样了。这类似于股票。数据从后端不断发送。这个动态更新的网站更适合选择直接查找数据流(不是我在html中找不到对应标签的借口)。
查找数据流量来源
打开开发者工具,我仔细搜索了一下。
我猜这种数据一定是json格式的。我首先在XHR中搜索,发现一堆带小数的数据。但让我们考虑一下。除了治愈率和死亡率,疫情数据的一般单位是人数。,怎么会有这么多小数?那不应该是这个数据。
我把除了js、image、css之外的所有数据都打开了,没有发现。CSS都是排版样式,图片都是图片。用这种方式传输数据是不可能的,所以去js。
功夫不负有心人,我在js中找到了一个jQuery,里面全是json数据!
数据采集
接下来的事情就简单了,我们也看到了也支持GET方法,访问这个url不需要其他数据。
import requests
url = "https://view.inews.qq.com/g2/g ... ot%3B
ret = requests.get(url)
with open("data.json", "w") as f:
f.write(ret.text)
数据处理
Python 也非常擅长处理 json 对象。只需在此处编写 strToJson 方法即可。
import json
f = open('data0204.json', 'r', encoding='utf-8')
data = json.load(f)['data'] # load json data from txt file
data = json.loads(data) # load json data from str class
data = data['chinaDayAddList']
import matplotlib.pyplot as plt
import numpy as np
from datetime import datetime
plt.clf()
days = [datetime.strptime('2020.' + d['date'], '%Y.%m.%d').date() for d in data]
plt.plot(days, [int(con['confirm']) for con in data], label='confirm')
plt.plot(days, [int(con['suspect']) for con in data], label='suspect')
plt.plot(days, [int(con['dead']) for con in data], label='dead')
plt.plot(days, [int(con['heal']) for con in data], label='heal')
plt.legend()
plt.show()
需要注意日期格式问题!
除了像我上面这样的处理,你还可以使用其他部分来做任何你想做的事! 查看全部
实时抓取网页数据(数据获取接下来的事情就好办了,需要注意日期格式化问题)
实时流行病捕捉
武汉肺炎期间,家里无事可做。有一天,我突然想知道每天的疫情数据。
我以前玩过爬虫,但这次不一样了。准确地说,这次不是爬虫,因为它不具备“批量”的特性。
分析网站
首先要说明一点,我们没有政府数据库,数据来源是通过其他一些在线网站,实时更新数据,比如腾讯新闻、定香园等。
接下来,我们使用腾讯新闻来抓取疫情数据。
网址是#/
打开之后,可以看到它有实时的疫情追踪。
以前我用的爬虫是从html页面中获取相关内容,比较直接,因为所见即所得,只要到当前网页找到对应的标签就可以获取。
这一次,和以前不一样了。这类似于股票。数据从后端不断发送。这个动态更新的网站更适合选择直接查找数据流(不是我在html中找不到对应标签的借口)。
查找数据流量来源
打开开发者工具,我仔细搜索了一下。
我猜这种数据一定是json格式的。我首先在XHR中搜索,发现一堆带小数的数据。但让我们考虑一下。除了治愈率和死亡率,疫情数据的一般单位是人数。,怎么会有这么多小数?那不应该是这个数据。
我把除了js、image、css之外的所有数据都打开了,没有发现。CSS都是排版样式,图片都是图片。用这种方式传输数据是不可能的,所以去js。
功夫不负有心人,我在js中找到了一个jQuery,里面全是json数据!
数据采集
接下来的事情就简单了,我们也看到了也支持GET方法,访问这个url不需要其他数据。
import requests
url = "https://view.inews.qq.com/g2/g ... ot%3B
ret = requests.get(url)
with open("data.json", "w") as f:
f.write(ret.text)
数据处理
Python 也非常擅长处理 json 对象。只需在此处编写 strToJson 方法即可。
import json
f = open('data0204.json', 'r', encoding='utf-8')
data = json.load(f)['data'] # load json data from txt file
data = json.loads(data) # load json data from str class
data = data['chinaDayAddList']
import matplotlib.pyplot as plt
import numpy as np
from datetime import datetime
plt.clf()
days = [datetime.strptime('2020.' + d['date'], '%Y.%m.%d').date() for d in data]
plt.plot(days, [int(con['confirm']) for con in data], label='confirm')
plt.plot(days, [int(con['suspect']) for con in data], label='suspect')
plt.plot(days, [int(con['dead']) for con in data], label='dead')
plt.plot(days, [int(con['heal']) for con in data], label='heal')
plt.legend()
plt.show()
需要注意日期格式问题!
除了像我上面这样的处理,你还可以使用其他部分来做任何你想做的事!
实时抓取网页数据(世界上最盛行的网络和谈阐发器!(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-03 02:28
Wireshark(原名Ethereal)是一款免费开源的网络嗅探捕捉工具,全球最流行的网络和谈分析器!网络包分析软件的作用是捕获网络包,尽可能显示最详细的网络包资料。Wireshark网络抓包工具以WinPCAP为接口,间接抓取网卡停止数据报文交换。它可以及时检测网络通信数据,检测它抓取的网络通信数据快照文件,并通过图形界面读取这些数据,检查网络通信。数据包中每一层的详细内容。其强大的功能:例如,它采集了强大的显示过滤器语言和检查TCP会话重建流程的能力,
工作过程
1.确定Wireshark的位置
如果您没有正确的位置,在您启动软件后,需要很长时间才能捕获一些与您无关的数据。
2.选择抓图界面
一般选择连接Internet网络的接口,这样就可以抓取到与网络相关的数据。否则,其他捕获的数据将不会以任何方式帮助您。
3.使用捕获过滤器
通过设置捕获过滤器,可以避免生成过大的捕获文件。这样,用户在分析数据时就不会受到其他数据的干扰。此外,它还可以为用户节省大量时间。
4.使用显示过滤器
捕获过滤器过滤的数据通常仍然非常复杂。为了使过滤后的数据包更加细致,此时使用显示过滤器进行过滤。
5.使用着色规则
显示过滤器过滤的数据通常是有用的数据包。如果您想更突出地突出显示一个会话,您可以使用着色规则来突出显示它。
6.构建图表
如果用户想更清楚地看到网络中数据的变化,可以很容易地以图表的形式显示数据分布。
7.重组数据 Wireshark 的重组功能可以重组一个会话中不同数据包的信息,或者重组一个完整的图片或文件。由于传输的文件往往很大,信息分布在多个数据包中。为了能够查看整个图片或文件,需要使用重新组织数据的方法来实现。 查看全部
实时抓取网页数据(世界上最盛行的网络和谈阐发器!(一))
Wireshark(原名Ethereal)是一款免费开源的网络嗅探捕捉工具,全球最流行的网络和谈分析器!网络包分析软件的作用是捕获网络包,尽可能显示最详细的网络包资料。Wireshark网络抓包工具以WinPCAP为接口,间接抓取网卡停止数据报文交换。它可以及时检测网络通信数据,检测它抓取的网络通信数据快照文件,并通过图形界面读取这些数据,检查网络通信。数据包中每一层的详细内容。其强大的功能:例如,它采集了强大的显示过滤器语言和检查TCP会话重建流程的能力,
工作过程
1.确定Wireshark的位置
如果您没有正确的位置,在您启动软件后,需要很长时间才能捕获一些与您无关的数据。
2.选择抓图界面
一般选择连接Internet网络的接口,这样就可以抓取到与网络相关的数据。否则,其他捕获的数据将不会以任何方式帮助您。
3.使用捕获过滤器
通过设置捕获过滤器,可以避免生成过大的捕获文件。这样,用户在分析数据时就不会受到其他数据的干扰。此外,它还可以为用户节省大量时间。
4.使用显示过滤器
捕获过滤器过滤的数据通常仍然非常复杂。为了使过滤后的数据包更加细致,此时使用显示过滤器进行过滤。
5.使用着色规则
显示过滤器过滤的数据通常是有用的数据包。如果您想更突出地突出显示一个会话,您可以使用着色规则来突出显示它。
6.构建图表
如果用户想更清楚地看到网络中数据的变化,可以很容易地以图表的形式显示数据分布。
7.重组数据 Wireshark 的重组功能可以重组一个会话中不同数据包的信息,或者重组一个完整的图片或文件。由于传输的文件往往很大,信息分布在多个数据包中。为了能够查看整个图片或文件,需要使用重新组织数据的方法来实现。
实时抓取网页数据(#如何用excel获得股票实时数据#首先找一个提供股票数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-03 02:20
#如何使用excel获取实时股票数据#
首先找到一个提供股票数据的网站。各种金融网站都有股票数据。我们以东方财富网为例:
对于沪深A股数据,我们在谷歌浏览器中查看真实网址:
找到与股票数据对应的jQuery行,然后查看头文件中的URL:
将此 URL 复制到 Excel,数据 ==> 来自 网站:
单击以确认,Power Query 编辑器将打开。如果一切顺利,数据会直接出现:
虽然不是表,但证明爬行成功。下一步是如何解析二进制文件。从谷歌浏览器看,这是一个jsoncallback数据包,比json数据多了一个函数名。我们只需要提取两个括号。中间的数据可以用json解析。注意total:4440,我们后面会用到这个值。
=Json.Document(Text.BetweenDelimiters(Text.FromBinary(Web.Contents(url)),"(",")"))
然后展开数据表:
到目前为止一切都很顺利,但我们抓取的只是一页数据,让我们看看:
pn是页码,我们抓取第3页,pz是每页20条数据,我们有两种方法抓取所有数据,一种是使用这个pz:20,然后定义函数,抓取所有页码,我在之前的爬行中反复使用过这个。今天我们尝试直接修改pz,一次性抓取所有数据。其实你可以尝试改变查询参数。如果我们把pn改成4,抓取到的页面就是第4页。同理,我们把pn改成200,看看能不能直接抓取200条数据。
那我们试试直接输入5000,能不能全部抢过来:
这似乎是可能的。
还有一个问题,就是数据的所有标题行都以f开头,不可读。如何将它们变成网页中的汉字标题行。
这个问题有点复杂。我们可能需要检查代码,看看是否可以找到替换它的方法。先看html:
但这并不完整,还有几列需要自定义:
这些指标没有对应的 f 代码。
我们来看一下js文件:
这个文件中有对应的数据,我们直接拷贝到Power Query中,处理成列表形式进行备份:
下一步是匹配表中的键并修改列名:
首先我们需要匹配出这样一个列表。
List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n[key])}, (y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0})
然后我们可以直接使用Table.RenameColumns函数批量修改列名:
Table.RenameColumns(data,List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n) [key])},(y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0}))
我们只是将数据加载到 Excel 中。
如果你想要最新的数据,只需刷新它。 查看全部
实时抓取网页数据(#如何用excel获得股票实时数据#首先找一个提供股票数据)
#如何使用excel获取实时股票数据#
首先找到一个提供股票数据的网站。各种金融网站都有股票数据。我们以东方财富网为例:
对于沪深A股数据,我们在谷歌浏览器中查看真实网址:
找到与股票数据对应的jQuery行,然后查看头文件中的URL:
将此 URL 复制到 Excel,数据 ==> 来自 网站:
单击以确认,Power Query 编辑器将打开。如果一切顺利,数据会直接出现:
虽然不是表,但证明爬行成功。下一步是如何解析二进制文件。从谷歌浏览器看,这是一个jsoncallback数据包,比json数据多了一个函数名。我们只需要提取两个括号。中间的数据可以用json解析。注意total:4440,我们后面会用到这个值。
=Json.Document(Text.BetweenDelimiters(Text.FromBinary(Web.Contents(url)),"(",")"))
然后展开数据表:
到目前为止一切都很顺利,但我们抓取的只是一页数据,让我们看看:
pn是页码,我们抓取第3页,pz是每页20条数据,我们有两种方法抓取所有数据,一种是使用这个pz:20,然后定义函数,抓取所有页码,我在之前的爬行中反复使用过这个。今天我们尝试直接修改pz,一次性抓取所有数据。其实你可以尝试改变查询参数。如果我们把pn改成4,抓取到的页面就是第4页。同理,我们把pn改成200,看看能不能直接抓取200条数据。
那我们试试直接输入5000,能不能全部抢过来:
这似乎是可能的。
还有一个问题,就是数据的所有标题行都以f开头,不可读。如何将它们变成网页中的汉字标题行。
这个问题有点复杂。我们可能需要检查代码,看看是否可以找到替换它的方法。先看html:
但这并不完整,还有几列需要自定义:
这些指标没有对应的 f 代码。
我们来看一下js文件:
这个文件中有对应的数据,我们直接拷贝到Power Query中,处理成列表形式进行备份:
下一步是匹配表中的键并修改列名:
首先我们需要匹配出这样一个列表。
List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n[key])}, (y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0})
然后我们可以直接使用Table.RenameColumns函数批量修改列名:
Table.RenameColumns(data,List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n) [key])},(y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0}))
我们只是将数据加载到 Excel 中。
如果你想要最新的数据,只需刷新它。

