
实时抓取网页数据
实时抓取网页数据(【】续前一篇RSelenium包抓取包)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-14 21:16
继续
上一篇RSelenium包抓取了链家网(上图:模拟点击和页面抓取),重点关注网页自动点击的问题。虽然代码也可以抓取完整的数据,但如果没有错误或警告中断抓取,它就会这样做。由于LinkinfoFunc和HouseinfoFunc都是封装好的函数,一旦中断,中断前捕获的数据无法写入数据帧或列表。
当要抓取的数据量大、耗时长时,难免会出现网络中断等各种问题。因此,本文在上一篇文章的基础上,增加了一个for循环,并引入了tryCatch函数来进行简单的错误处理。两者对比如下:
页面准备,Step1的代码没有变化 Step2 删除数据框结果,将数据存储的任务交给Step3 Step3 添加for循环,并引入tryCatch函数
另外,文中重复的代码不再标注。
<p>1library(rvest)
2library(stringr)
3library(RSelenium)
4remDr %
13 unlist() %>% gsub(":", "", .)
14 totalpage %
6 html_text() %>% paste(., unit, sep = "")
7 downpayment % html_nodes(".taxtext span") %>% html_text() %>% .[1]
8 persquare % html_nodes("span.unitPriceValue") %>% html_text()
9 area % html_nodes(".area .mainInfo") %>% html_text()
10 title % html_nodes(".title h1") %>% html_text()
11 subtitle % html_nodes(".title div.sub") %>% html_text()
12 room % html_nodes(".room .mainInfo") %>% html_text()
13 floor % html_nodes(".room .subInfo") %>% html_text()
14 data 查看全部
实时抓取网页数据(【】续前一篇RSelenium包抓取包)
继续
上一篇RSelenium包抓取了链家网(上图:模拟点击和页面抓取),重点关注网页自动点击的问题。虽然代码也可以抓取完整的数据,但如果没有错误或警告中断抓取,它就会这样做。由于LinkinfoFunc和HouseinfoFunc都是封装好的函数,一旦中断,中断前捕获的数据无法写入数据帧或列表。
当要抓取的数据量大、耗时长时,难免会出现网络中断等各种问题。因此,本文在上一篇文章的基础上,增加了一个for循环,并引入了tryCatch函数来进行简单的错误处理。两者对比如下:
页面准备,Step1的代码没有变化 Step2 删除数据框结果,将数据存储的任务交给Step3 Step3 添加for循环,并引入tryCatch函数
另外,文中重复的代码不再标注。
<p>1library(rvest)
2library(stringr)
3library(RSelenium)
4remDr %
13 unlist() %>% gsub(":", "", .)
14 totalpage %
6 html_text() %>% paste(., unit, sep = "")
7 downpayment % html_nodes(".taxtext span") %>% html_text() %>% .[1]
8 persquare % html_nodes("span.unitPriceValue") %>% html_text()
9 area % html_nodes(".area .mainInfo") %>% html_text()
10 title % html_nodes(".title h1") %>% html_text()
11 subtitle % html_nodes(".title div.sub") %>% html_text()
12 room % html_nodes(".room .mainInfo") %>% html_text()
13 floor % html_nodes(".room .subInfo") %>% html_text()
14 data
实时抓取网页数据(各个新媒体APP上的疫情地图,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2022-02-14 20:19
2020年注定是不平凡的一年。熙熙攘攘的春节市场已经失去了往日的喧嚣。突如其来的新冠肺炎疫情牵动着国人的心。想必很多人每天早上睁眼后的第一件事就是在新媒体APP上点击疫情地图,查看全国各省市的疫情数据。
在互联网高速发展的今天,大数据、云计算、人工智能等技术为疫情防控提供了有力支撑。其中,疫情信息的实时、准确、全面、生动的传递,做到了疫情信息量最大。透明度。这使亿万中国人民能够充分了解疫情发展的真实情况,做好必要的个人防护和充分的心理准备,从而有效减少疫情蔓延,保持最大程度的冷静和理性。
我们跟踪了很多新媒体平台,梳理了各个平台的疫情大数据服务。各平台提供的基本功能几乎相同,包括:
1. 疫情数据:展示全国、省、市累计和每日新增确诊/疑似/死亡/治愈病例数据,并通过疫情地图和各种形式的图表展示;
2.最新进展:聚合最新重要疫情信息,大部分为官方发布的不容错过的重要内容;
3.同程查询:可根据出行日期、车次/车牌/航班号、城市等查询确诊病例的具体行程信息,方便个人防控;
4.辟谣查实:对一些广为流传的疫情信息或防控方法的真伪进行鉴别;
5.发热门诊:提供各省市医疗机构信息,可以是文字或地图形式;
6.本地疫情:根据用户所在城市,显示本地确诊信息和本地相关疫情内容;
7.科普知识:个人防护知识、心理健康知识、疾病常识等。
那么,各种新媒体平台上的这些疫情数据和相关内容是从哪里来的呢?为什么某些平台上的数据略有不同?每个新媒体平台是如何获取和处理这些数据的?
首先,各个新媒体平台上的疫情核心数据几乎都是通过爬虫技术从国家和地方卫健委的官方网站根据他们的每日疫情报告文章提取出来的。之后,将这些数据汇总并以地图、趋势图等可视化图表的形式展示出来,方便大家。
如下图,湖北卫健委官方网站上,以短信形式发布疫情核心数据:
在各大新媒体平台上,数字依旧是那些数字,但呈现形式变得更加生动,如下图:
至于其他类型信息的来源,几乎都是一些官方渠道提供的文字信息或者可以公开搜索的信息,数据来源会更加丰富。除了国家卫健委的官方网站,其他政府部门也可能包括在内。、医疗机构、学术机构、权威媒体甚至意见领袖网站或自媒体等,这些新媒体平台在获得这些信息后,会对其进行处理,形成其他栏目,比如最新的进度、同流程查询、发热门诊、辟谣查实等。
例如,海南省卫计委官网以文字形式公布了确诊病例的移动轨迹,如下图:
在各大新媒体平台上,经过排序后,变成了同一个行程查询widget,如下图:
对于不同的新媒体平台,数据略有不同,因为不同的平台对数据的采集和处理策略不同。例如,一些新媒体平台只采集前一天24:00的全国数据,每天更新一次;而一些新媒体平台则不时捕捉部分省份发布的最新数据,并随时更新。加入。
因此,很多互联网公司并不能真正产生数据,而只是官方数据的搬运者、整合者和处理者。除了这些疫情大数据,还有企业征信查询、天气预报查询、航班信息查询、交通违章查询等诸多领域,也有一些熟悉的互联网公司在做类似的事情。
事实上,只要有需要,任何企业都可以批量、实时、准确地获取这些公开信息。当然,对于一些非互联网公司来说,获取这些公开信息的目的,并不是在处理后为普通用户打造互联网产品,而是与自己公司的业务和产品相结合,为自己的客户提供更全面的增值服务.
那么,如何进行数据采集呢?市面上有很多非常成熟的数据抓取工具,抓取过程也非常简单。一般来说,只需要以下三个步骤:
步骤 1:确定数据源规则
比如之前的卫健委网站,他们发布的信息内容的URL就是数据源。这些 URL 通常有一些常规名称,例如日期和数字。借助数据抓取工具,可以定期、自动、批量检索所有可能的网页,并从中提取符合采集规则的数据。当然,除了在源头抓数据,还可以抓一些新媒体平台处理的二手数据,因为这些二手数据已经被处理过了,数据格式可能会更整洁、简单捕捉。
第 2 步:确定数据采集 规则
由于捕获的数据需要存储在数据库中,因此数据库通常需要提前确定数据格式。因此,需要根据预先设计好的数据格式建立数据采集规则和数据模板,并在抓取数据的过程中,按照规则提取数据,以便后续数据保存. 比如数据源中的文本内容是“在xx,xx,xx,xx省新增xxxx确诊病例”,那么在数据采集规则中,需要收录日期字段,省份字段,新确诊病例字段,爬取时填写各个字段的内容。例如,“,”和“province”之间的文字是省的名称,可以在这条信息的省字段中填写,以此类推(如果您认为不准确,还可以设置“日”和“省”之间的文字,将“新”之间的文字抓取为省名等)。但是,如果要配置准确完整的采集规则,可能需要了解一点最基本的HTML语言,这样才能通过网页分析准确提取出需要的信息。
第三步:保存到数据库
前两步完成后,只要企业网络正常,数据库创建配置正确,数据采集就可以很方便的保存到企业数据库中使用。
以上只是披露信息的基本方式采集。另外还有一些网站,为了方便大家采集公开信息,他们会主动通过API开放自己的数据。企业只需要查找和调用这些API,就可以直接获取信息。结构化数据。同时,还会有一些“傻瓜式”爬虫工具,专门用于采集一些具体的网站和具体的内容,会先把要做的工作和第二步,帮助用户提前做好,用户不需要关心数据源和采集规则,只需要配置数据库即可使用。
最后需要强调的是,数据采集必须严格遵守法律法规和相应的版权声明。对于政府或企业声明禁止抓取或必须获得授权才能复制的内容,以及不适合公开的内容(如因设计漏洞而意外曝光的内容),请勿抓取以免造成严重的法律后果。
欢迎朋友们关注、评论和转发。商业转载或其他请联系:keji5u(科技无忧订阅号) 查看全部
实时抓取网页数据(各个新媒体APP上的疫情地图,你了解多少?)
2020年注定是不平凡的一年。熙熙攘攘的春节市场已经失去了往日的喧嚣。突如其来的新冠肺炎疫情牵动着国人的心。想必很多人每天早上睁眼后的第一件事就是在新媒体APP上点击疫情地图,查看全国各省市的疫情数据。
在互联网高速发展的今天,大数据、云计算、人工智能等技术为疫情防控提供了有力支撑。其中,疫情信息的实时、准确、全面、生动的传递,做到了疫情信息量最大。透明度。这使亿万中国人民能够充分了解疫情发展的真实情况,做好必要的个人防护和充分的心理准备,从而有效减少疫情蔓延,保持最大程度的冷静和理性。
我们跟踪了很多新媒体平台,梳理了各个平台的疫情大数据服务。各平台提供的基本功能几乎相同,包括:
1. 疫情数据:展示全国、省、市累计和每日新增确诊/疑似/死亡/治愈病例数据,并通过疫情地图和各种形式的图表展示;
2.最新进展:聚合最新重要疫情信息,大部分为官方发布的不容错过的重要内容;
3.同程查询:可根据出行日期、车次/车牌/航班号、城市等查询确诊病例的具体行程信息,方便个人防控;
4.辟谣查实:对一些广为流传的疫情信息或防控方法的真伪进行鉴别;
5.发热门诊:提供各省市医疗机构信息,可以是文字或地图形式;
6.本地疫情:根据用户所在城市,显示本地确诊信息和本地相关疫情内容;
7.科普知识:个人防护知识、心理健康知识、疾病常识等。
那么,各种新媒体平台上的这些疫情数据和相关内容是从哪里来的呢?为什么某些平台上的数据略有不同?每个新媒体平台是如何获取和处理这些数据的?
首先,各个新媒体平台上的疫情核心数据几乎都是通过爬虫技术从国家和地方卫健委的官方网站根据他们的每日疫情报告文章提取出来的。之后,将这些数据汇总并以地图、趋势图等可视化图表的形式展示出来,方便大家。
如下图,湖北卫健委官方网站上,以短信形式发布疫情核心数据:
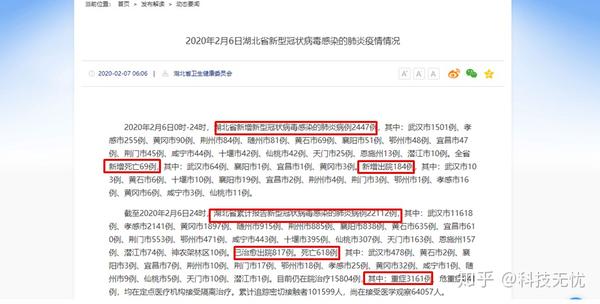
在各大新媒体平台上,数字依旧是那些数字,但呈现形式变得更加生动,如下图:
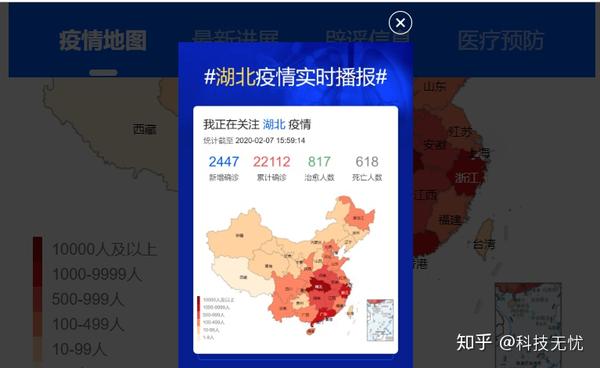
至于其他类型信息的来源,几乎都是一些官方渠道提供的文字信息或者可以公开搜索的信息,数据来源会更加丰富。除了国家卫健委的官方网站,其他政府部门也可能包括在内。、医疗机构、学术机构、权威媒体甚至意见领袖网站或自媒体等,这些新媒体平台在获得这些信息后,会对其进行处理,形成其他栏目,比如最新的进度、同流程查询、发热门诊、辟谣查实等。
例如,海南省卫计委官网以文字形式公布了确诊病例的移动轨迹,如下图:
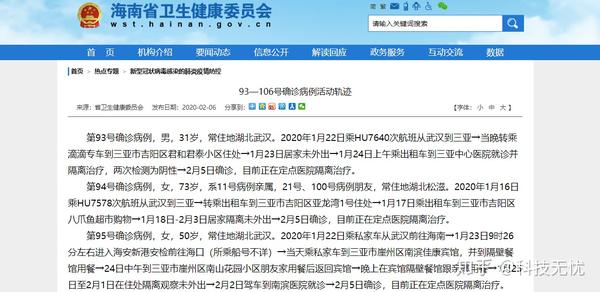
在各大新媒体平台上,经过排序后,变成了同一个行程查询widget,如下图:
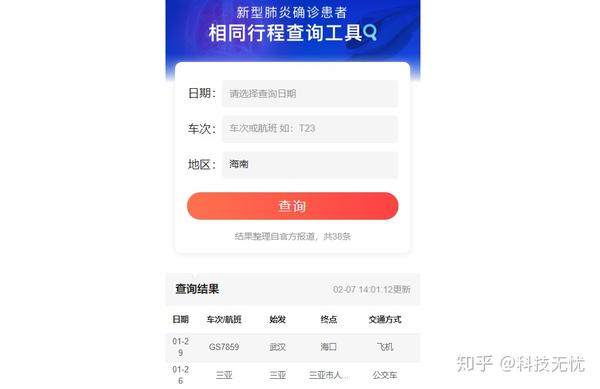
对于不同的新媒体平台,数据略有不同,因为不同的平台对数据的采集和处理策略不同。例如,一些新媒体平台只采集前一天24:00的全国数据,每天更新一次;而一些新媒体平台则不时捕捉部分省份发布的最新数据,并随时更新。加入。
因此,很多互联网公司并不能真正产生数据,而只是官方数据的搬运者、整合者和处理者。除了这些疫情大数据,还有企业征信查询、天气预报查询、航班信息查询、交通违章查询等诸多领域,也有一些熟悉的互联网公司在做类似的事情。
事实上,只要有需要,任何企业都可以批量、实时、准确地获取这些公开信息。当然,对于一些非互联网公司来说,获取这些公开信息的目的,并不是在处理后为普通用户打造互联网产品,而是与自己公司的业务和产品相结合,为自己的客户提供更全面的增值服务.
那么,如何进行数据采集呢?市面上有很多非常成熟的数据抓取工具,抓取过程也非常简单。一般来说,只需要以下三个步骤:
步骤 1:确定数据源规则
比如之前的卫健委网站,他们发布的信息内容的URL就是数据源。这些 URL 通常有一些常规名称,例如日期和数字。借助数据抓取工具,可以定期、自动、批量检索所有可能的网页,并从中提取符合采集规则的数据。当然,除了在源头抓数据,还可以抓一些新媒体平台处理的二手数据,因为这些二手数据已经被处理过了,数据格式可能会更整洁、简单捕捉。
第 2 步:确定数据采集 规则
由于捕获的数据需要存储在数据库中,因此数据库通常需要提前确定数据格式。因此,需要根据预先设计好的数据格式建立数据采集规则和数据模板,并在抓取数据的过程中,按照规则提取数据,以便后续数据保存. 比如数据源中的文本内容是“在xx,xx,xx,xx省新增xxxx确诊病例”,那么在数据采集规则中,需要收录日期字段,省份字段,新确诊病例字段,爬取时填写各个字段的内容。例如,“,”和“province”之间的文字是省的名称,可以在这条信息的省字段中填写,以此类推(如果您认为不准确,还可以设置“日”和“省”之间的文字,将“新”之间的文字抓取为省名等)。但是,如果要配置准确完整的采集规则,可能需要了解一点最基本的HTML语言,这样才能通过网页分析准确提取出需要的信息。
第三步:保存到数据库
前两步完成后,只要企业网络正常,数据库创建配置正确,数据采集就可以很方便的保存到企业数据库中使用。
以上只是披露信息的基本方式采集。另外还有一些网站,为了方便大家采集公开信息,他们会主动通过API开放自己的数据。企业只需要查找和调用这些API,就可以直接获取信息。结构化数据。同时,还会有一些“傻瓜式”爬虫工具,专门用于采集一些具体的网站和具体的内容,会先把要做的工作和第二步,帮助用户提前做好,用户不需要关心数据源和采集规则,只需要配置数据库即可使用。
最后需要强调的是,数据采集必须严格遵守法律法规和相应的版权声明。对于政府或企业声明禁止抓取或必须获得授权才能复制的内容,以及不适合公开的内容(如因设计漏洞而意外曝光的内容),请勿抓取以免造成严重的法律后果。
欢迎朋友们关注、评论和转发。商业转载或其他请联系:keji5u(科技无忧订阅号)
实时抓取网页数据(实时抓取网页数据可视化统计还有我认为是核心中的核心)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-14 09:06
实时抓取网页数据可视化统计还有我认为是核心中的核心。因为现在网页上的数据来自海量的页面广告信息,只有学习用户习惯了,提升用户体验了才能赢得用户,活跃用户,才能挣到钱。你在搞开发的时候做了特定活动,关注微信统计你才有点击。例如我在github上有个list.py的小项目,本来是准备运行的时候进行在线统计的,做前端的朋友在项目开始就给了我一个交互的界面。
为什么要做统计?主要是运营需要,例如一个公众号运营分析用户来源,某天点开xxxx公众号,那么明天可能就会对你的推送有相应的反应,如果没有,就说明你的内容不够吸引用户。或者某天有用户来,然后进一步了解用户大概来自哪里,希望获得我们的关注,明天你必须在文章中适当调整一下内容,例如第一天的标题内容,并且针对用户进行投放促活。
你也可以研究用户喜欢什么,不喜欢什么,多做定位。知道用户了还有用户习惯和用户喜好,设计一个interface对用户进行引导,把用户引导到你需要的功能,这也是一个很大的工作。现在每一个客户都可以提供个性化的营销策略了,但是你怎么去预测客户喜欢什么,这是需要技术的,同时也是需要学习的。最后,网站设计的时候要考虑好用户习惯,交互体验,针对用户的业务指标,根据用户的习惯,需求做出一些调整。以上一切只是一个个的模块,里面都涉及很多。这个就要看你做前端哪方面的工作,客户端,还是后端。 查看全部
实时抓取网页数据(实时抓取网页数据可视化统计还有我认为是核心中的核心)
实时抓取网页数据可视化统计还有我认为是核心中的核心。因为现在网页上的数据来自海量的页面广告信息,只有学习用户习惯了,提升用户体验了才能赢得用户,活跃用户,才能挣到钱。你在搞开发的时候做了特定活动,关注微信统计你才有点击。例如我在github上有个list.py的小项目,本来是准备运行的时候进行在线统计的,做前端的朋友在项目开始就给了我一个交互的界面。
为什么要做统计?主要是运营需要,例如一个公众号运营分析用户来源,某天点开xxxx公众号,那么明天可能就会对你的推送有相应的反应,如果没有,就说明你的内容不够吸引用户。或者某天有用户来,然后进一步了解用户大概来自哪里,希望获得我们的关注,明天你必须在文章中适当调整一下内容,例如第一天的标题内容,并且针对用户进行投放促活。
你也可以研究用户喜欢什么,不喜欢什么,多做定位。知道用户了还有用户习惯和用户喜好,设计一个interface对用户进行引导,把用户引导到你需要的功能,这也是一个很大的工作。现在每一个客户都可以提供个性化的营销策略了,但是你怎么去预测客户喜欢什么,这是需要技术的,同时也是需要学习的。最后,网站设计的时候要考虑好用户习惯,交互体验,针对用户的业务指标,根据用户的习惯,需求做出一些调整。以上一切只是一个个的模块,里面都涉及很多。这个就要看你做前端哪方面的工作,客户端,还是后端。
实时抓取网页数据(Google搜索蜘蛛就要开始对部分网站开始用HTTP/2方式抓取网站内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-02-13 03:19
国外谷歌站长透露,谷歌搜索将从今年11月开始小规模通过HTTP/2对网站内容进行爬取,在不影响网站搜索的情况下,爬取网页效率更高排名。
了解到HTTP/是基于SPDY的,一种注重性能的网络传输协议。与 HTTP/1 相比,它具有二进制分帧和多路复用等新特性。正式使用HTTP/2进行抓取后,最大的特点就是支持一个用户和网站之间只有一个连接的目标,谷歌可以用更少的资源更快地抓取内容,相比HTTP/1谷歌蜘蛛抓取< @网站 效率更高。
Google 表示目前主要的网站 和主流浏览器已经支持 HTTP/2 有一段时间了。大部分 CDN 服务商也支持 HTTP/2,使用 HTTP/2 的条件基本成熟。从 2020 年 11 月开始,Google 搜索蜘蛛将开始使用 HTTP/2 抓取一些 网站。 网站内容,以后慢慢添加对越来越多网站的支持。
当然,如果网站不支持HTTP/2或者网站不希望谷歌使用HTTP/2进行抓取,站长使用HTTP/1和HTTP/2也没问题该协议可以正常支持谷歌蜘蛛抓取网站内容,不影响网站的搜索排名,谷歌蜘蛛抓取网站的质量和数量也将保持不变。 查看全部
实时抓取网页数据(Google搜索蜘蛛就要开始对部分网站开始用HTTP/2方式抓取网站内容)
国外谷歌站长透露,谷歌搜索将从今年11月开始小规模通过HTTP/2对网站内容进行爬取,在不影响网站搜索的情况下,爬取网页效率更高排名。

了解到HTTP/是基于SPDY的,一种注重性能的网络传输协议。与 HTTP/1 相比,它具有二进制分帧和多路复用等新特性。正式使用HTTP/2进行抓取后,最大的特点就是支持一个用户和网站之间只有一个连接的目标,谷歌可以用更少的资源更快地抓取内容,相比HTTP/1谷歌蜘蛛抓取< @网站 效率更高。
Google 表示目前主要的网站 和主流浏览器已经支持 HTTP/2 有一段时间了。大部分 CDN 服务商也支持 HTTP/2,使用 HTTP/2 的条件基本成熟。从 2020 年 11 月开始,Google 搜索蜘蛛将开始使用 HTTP/2 抓取一些 网站。 网站内容,以后慢慢添加对越来越多网站的支持。
当然,如果网站不支持HTTP/2或者网站不希望谷歌使用HTTP/2进行抓取,站长使用HTTP/1和HTTP/2也没问题该协议可以正常支持谷歌蜘蛛抓取网站内容,不影响网站的搜索排名,谷歌蜘蛛抓取网站的质量和数量也将保持不变。
实时抓取网页数据(爆破4.万能密码有哪些?管理后台的注意事项)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-02-13 00:04
1:信息采集,
无论是防御还是渗透测试,都需要这一步,简单的信息采集。
手机信息收录很多,
例如,服务器 IP 地址是什么?
后台入口在哪里?
服务器打开了那些端口,服务器安装了那些应用程序等等,这些都是前期必须采集的东西。
手机有很多工具
当然还有其他方法,比如使用工具检测、nmap、
但是,专业的工具可能并不适合普通的白人。
例如,我们假设采集到的信息如下:
初步信息采集工作完成后,即可进入第二阶段。
第二步:根据服务器的安装环境进行进一步测试,类似看病。
先检查,再根据具体情况开药。
漏洞的一般列表无非如下:
1:弱密码,包括ftp、http、远程登录等,
处理弱密码的方法有很多,但使用好的社会工程库是最简单的方法。
2:存在sql注入漏洞,
这仅适用于工具。
3:xss漏洞,
4:存在穿透溢出漏洞
5:安装有致命缺陷的软件。
1. 后台登录时抓取复制数据包放到txt中,扔到sqlmap -r中运行
2. 弱密码
帐号:admin sa root
密码:123456 12345678 666666 admin123 admin888
这些是我见过最多的
管理后台一般为admin,phpmyadmin之类的数据库一般为root。
3. 没有验证码,验证码不刷新,只有一个验证码,而且验证码不起作用,可以试试爆破
4. 主密码可以创造奇迹
5.去前台发的文章,查看留言板的回复,看看作者是谁,很有可能是管理员账号
6.有的网站会提示账号不存在等,可以手动找管理员账号或者打嗝爆破
7. 当常规字典爆破失败时,可以根据从信息中采集到的相关数据生成密码爆破,包括但不限于域名备案等信息。像网站这样的学校,可以去前台找老师电话号码,姓名首字母等,其他想法,大家可以根据网站自行思考
8. 扫描到的目录可能有源代码泄露等
9. cms使用的cms有默认账号和密码,可以百度搜索
10.可能存在短信轰炸、逻辑漏洞、任意重置密码、爆破管理员账号等。
11. f12 康康总有惊喜
12.注意不要被围墙
13. 有时候有的网站会把错误信息记录到一个php文件中,可以试试账号或者密码写一句,也可以直接getshell,笔者遇到过一次
14.进入后台后寻找上传点,使用绕过上传
15. 其他具体功能,数据库备份等。
16.我刚刚在网红队使用的编辑器bug
17. 扫描到的目录不正常可以查看
18.扫描奇怪的名字,打开一个空白文件,尝试爆出一句话
第三步:当我们确定存在漏洞时,我们必须启动、使用、
拿到shell后可能会出现权限不足,大致分为两种情况
1. Windows 权限提升
2. linux 提权
具体的提权方法可以在百度上找到
内网仍然是信息采集。一开始看本地IP,扫描幸存的hosts,过一波各种exp,各种工具扔在上面,跑着扫描,内网博大精深,好不容易学好
但最好用工具,用工具更容易,
基本上所有可以集成的东西都集成了,只需简单的点击按钮,
不知道的可以找我,还有很多方法
参考下图与我交流
导入 java.util.regex.Matcher;
导入 java.util.regex.Pattern;
公共类下载Img {
公共静态无效 writeImgEntityToFile(HttpEntity imgEntity,String fileAddress) {
文件 storeFile = new File(fileAddress);
FileOutputStream 输出 = null;
尝试 {
输出 = 新文件输出流(存储文件);
如果(imgEntity!= null){
InputStream 流内;
流内 = imgEntity.getContent();
字节 b[] = 新字节[8 * 1024];
整数计数;
而 ((count = instream.read(b)) != -1) {
output.write(b, 0, count);
}
}
} 捕捉(FileNotFoundException e){
e.printStackTrace();
} 捕捉(IOException e){
e.printStackTrace();
} 最后 {
尝试 {
输出.close();
} 捕捉(IOException e){
e.printStackTrace();
}
}
}
公共静态无效主要(字符串[]参数){
System.out.println("获取必应图片地址...");
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd"); 查看全部
实时抓取网页数据(爆破4.万能密码有哪些?管理后台的注意事项)
1:信息采集,
无论是防御还是渗透测试,都需要这一步,简单的信息采集。
手机信息收录很多,
例如,服务器 IP 地址是什么?
后台入口在哪里?
服务器打开了那些端口,服务器安装了那些应用程序等等,这些都是前期必须采集的东西。
手机有很多工具
当然还有其他方法,比如使用工具检测、nmap、
但是,专业的工具可能并不适合普通的白人。
例如,我们假设采集到的信息如下:
初步信息采集工作完成后,即可进入第二阶段。
第二步:根据服务器的安装环境进行进一步测试,类似看病。
先检查,再根据具体情况开药。
漏洞的一般列表无非如下:
1:弱密码,包括ftp、http、远程登录等,
处理弱密码的方法有很多,但使用好的社会工程库是最简单的方法。
2:存在sql注入漏洞,
这仅适用于工具。
3:xss漏洞,
4:存在穿透溢出漏洞
5:安装有致命缺陷的软件。
1. 后台登录时抓取复制数据包放到txt中,扔到sqlmap -r中运行
2. 弱密码
帐号:admin sa root
密码:123456 12345678 666666 admin123 admin888
这些是我见过最多的
管理后台一般为admin,phpmyadmin之类的数据库一般为root。
3. 没有验证码,验证码不刷新,只有一个验证码,而且验证码不起作用,可以试试爆破
4. 主密码可以创造奇迹
5.去前台发的文章,查看留言板的回复,看看作者是谁,很有可能是管理员账号
6.有的网站会提示账号不存在等,可以手动找管理员账号或者打嗝爆破
7. 当常规字典爆破失败时,可以根据从信息中采集到的相关数据生成密码爆破,包括但不限于域名备案等信息。像网站这样的学校,可以去前台找老师电话号码,姓名首字母等,其他想法,大家可以根据网站自行思考
8. 扫描到的目录可能有源代码泄露等
9. cms使用的cms有默认账号和密码,可以百度搜索
10.可能存在短信轰炸、逻辑漏洞、任意重置密码、爆破管理员账号等。
11. f12 康康总有惊喜
12.注意不要被围墙
13. 有时候有的网站会把错误信息记录到一个php文件中,可以试试账号或者密码写一句,也可以直接getshell,笔者遇到过一次
14.进入后台后寻找上传点,使用绕过上传
15. 其他具体功能,数据库备份等。
16.我刚刚在网红队使用的编辑器bug
17. 扫描到的目录不正常可以查看
18.扫描奇怪的名字,打开一个空白文件,尝试爆出一句话
第三步:当我们确定存在漏洞时,我们必须启动、使用、
拿到shell后可能会出现权限不足,大致分为两种情况
1. Windows 权限提升
2. linux 提权
具体的提权方法可以在百度上找到
内网仍然是信息采集。一开始看本地IP,扫描幸存的hosts,过一波各种exp,各种工具扔在上面,跑着扫描,内网博大精深,好不容易学好
但最好用工具,用工具更容易,
基本上所有可以集成的东西都集成了,只需简单的点击按钮,
不知道的可以找我,还有很多方法
参考下图与我交流

导入 java.util.regex.Matcher;
导入 java.util.regex.Pattern;
公共类下载Img {
公共静态无效 writeImgEntityToFile(HttpEntity imgEntity,String fileAddress) {
文件 storeFile = new File(fileAddress);
FileOutputStream 输出 = null;
尝试 {
输出 = 新文件输出流(存储文件);
如果(imgEntity!= null){
InputStream 流内;
流内 = imgEntity.getContent();
字节 b[] = 新字节[8 * 1024];
整数计数;
而 ((count = instream.read(b)) != -1) {
output.write(b, 0, count);
}
}
} 捕捉(FileNotFoundException e){
e.printStackTrace();
} 捕捉(IOException e){
e.printStackTrace();
} 最后 {
尝试 {
输出.close();
} 捕捉(IOException e){
e.printStackTrace();
}
}
}
公共静态无效主要(字符串[]参数){
System.out.println("获取必应图片地址...");
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd");
实时抓取网页数据(实时抓取网页追踪页面上的标题、图片地址、页面比对、插入或更新的链接等信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-11 12:00
实时抓取网页数据是每个网页追踪页面上的标题、图片地址、页面比对、插入或更新的链接等信息。全部数据可以保存在github,采用对象存储系统对全部页面进行存储和交换。可以在工作流中轻松查看、修改、导出导航链接(如:按标题搜索、按页码搜索等)。本项目涵盖了以下工作内容:首先,抓取所有经过网页url验证的url,然后,从github开发项目目录下读取该页面的链接并完成链接的格式化。
链接格式化主要采用gulp负责完成构建,其中包括解析url中的type参数,并把整个url打包成一个png图片文件,这里,由click部署。在其中click会根据type参数的不同被划分为多种格式,比如,name是url文件中的type,title是url文件中的title字段,或者是type和title都是一致的格式。
如:url中type是text,title是favicon。click会负责配置css、html、cssoutputstream、style,将各种数据对格式化后的javascript的样式样式按文件名进行命名。这样,整个javascript代码样式是数组,以顺序存放在同一个文件中,便于扩展和理解。接下来,把页面的html文件抓取下来,如:html文件主要分为三个部分,分别是图片、链接、标题。
图片从github下载,即可直接拖拽到浏览器上进行爬取。链接采用七牛云的代理,即://sitemap.js/.html:://webpack.config.js{"require":{"node_env":"development","entry":"./sitemap.js","script":"javascript:;","src":"./webpack-dev-server-schema.conf.js","script-loader":"babel-loader","loaders":["babel-loader","babel-loader-loader","babel-loader-loader","babel-loader-loader","lodash","log-generator","file","ready","reading","release","sass","less","sass","less-release","options","minify","prettier","pip","swig","squeezes","fetch","actions","gulp","gulp","webpack","webpack-cli","test","require","test-path","cheers","path.join","require-resolve","git","travis-dependencies","mock","gulp","then","babel-polyfill","require-resolve","gzip","babel-preset-env","output","python","。 查看全部
实时抓取网页数据(实时抓取网页追踪页面上的标题、图片地址、页面比对、插入或更新的链接等信息)
实时抓取网页数据是每个网页追踪页面上的标题、图片地址、页面比对、插入或更新的链接等信息。全部数据可以保存在github,采用对象存储系统对全部页面进行存储和交换。可以在工作流中轻松查看、修改、导出导航链接(如:按标题搜索、按页码搜索等)。本项目涵盖了以下工作内容:首先,抓取所有经过网页url验证的url,然后,从github开发项目目录下读取该页面的链接并完成链接的格式化。
链接格式化主要采用gulp负责完成构建,其中包括解析url中的type参数,并把整个url打包成一个png图片文件,这里,由click部署。在其中click会根据type参数的不同被划分为多种格式,比如,name是url文件中的type,title是url文件中的title字段,或者是type和title都是一致的格式。
如:url中type是text,title是favicon。click会负责配置css、html、cssoutputstream、style,将各种数据对格式化后的javascript的样式样式按文件名进行命名。这样,整个javascript代码样式是数组,以顺序存放在同一个文件中,便于扩展和理解。接下来,把页面的html文件抓取下来,如:html文件主要分为三个部分,分别是图片、链接、标题。
图片从github下载,即可直接拖拽到浏览器上进行爬取。链接采用七牛云的代理,即://sitemap.js/.html:://webpack.config.js{"require":{"node_env":"development","entry":"./sitemap.js","script":"javascript:;","src":"./webpack-dev-server-schema.conf.js","script-loader":"babel-loader","loaders":["babel-loader","babel-loader-loader","babel-loader-loader","babel-loader-loader","lodash","log-generator","file","ready","reading","release","sass","less","sass","less-release","options","minify","prettier","pip","swig","squeezes","fetch","actions","gulp","gulp","webpack","webpack-cli","test","require","test-path","cheers","path.join","require-resolve","git","travis-dependencies","mock","gulp","then","babel-polyfill","require-resolve","gzip","babel-preset-env","output","python","。
实时抓取网页数据(抓取网站数据不再难(其实是想死的!))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-11 09:22
首先,从标题开始,为什么抓网站数据不再难(其实抓网站数据很难),SO EASY!!!使用 Fizzler 可以做到这一切。我相信大多数人或公司应该都有捕获他人网站数据的经验。比如我们博客园每次发布文章都会被其他网站给我抢,不信你看就知道了。还有人在网站上抢别人的邮箱、电话、QQ等有用信息。这些信息绝对可以卖钱或做其他事情。我们每天都会不时收到垃圾短信或电子邮件。就是这样,同感,O(∩_∩)O哈哈~。
前段时间写了两个程序,一个程序是采集彩票网站(双色球)的数据,另一个是采集求职网站(猎聘,54Worry,智联招聘, etc.)数据,写这两个程序的时候显示特别棘手,看到一堆HTML标签真想死。首先,让我们回顾一下我之前是如何解析 HTML 的。通过WebRequest获取HTML内容,然后使用HTML标签一步步截取你想要的内容,是一种很常见的做法。下面的代码是截取双色球的红球和篮球的代码。一旦网站的标签稍有变化,就有可能面临重新编程,使用起来很不方便。
下面是我在解析红球和篮球双色球的代码。我做的最多的就是截取(正则表达式)标签的对应内容。也许这段代码不是很复杂,因为截取的数据是有限的,而且非常规则,因此也比较简单。
1 #region * 在一个TR中,解析TD,获取一期的号码
2 ///
3 /// 在一个TR中,解析TD,获取一期的号码
4 ///
5 ///
6 ///
7 private void ResolveTd(ref WinNo wn, string trContent)
8 {
9 List redBoxList = null;
10 //匹配期号的表达式
11 string patternQiHao = "0)
17 {
18 info.Position = NodesMainContent1.ToArray()[0].InnerText;
19 }
20 //--公司名称
21 IEnumerable NodesMainContent2 = AnalyzeHTML.GetHtmlInfo(html, "div.title-info h3");
22 if (NodesMainContent2.Count() > 0)
23 {
24 info.Company = NodesMainContent2.ToArray()[0].InnerText;
25 }
26 //--公司性质/公司规模
27 IEnumerable NodesMainContent4 = AnalyzeHTML.GetHtmlInfo(html, "div.content.content-word ul li");
28 if (NodesMainContent4.Count() > 0)
29 {
30 foreach (var item in NodesMainContent4)
31 {
32 if (item.InnerHtml.Contains("企业性质"))
33 {
34 string nature = item.InnerText;
35 nature = nature.Replace("企业性质:", "");
36 info.Nature = nature;
37 }
38 if (item.InnerHtml.Contains("企业规模"))
39 {
40 string scale = item.InnerText;
41 scale = scale.Replace("企业规模:", "");
42 info.Scale = scale;
43 }
44 }
45 }
46 else//第二次解析企业性质和企业规模
47 {
48 IEnumerable NodesMainContent4_1 = AnalyzeHTML.GetHtmlInfo(html, "div.right-post-top div.content.content-word");
49 if (NodesMainContent4_1.Count() > 0)
50 {
51 foreach (var item_1 in NodesMainContent4_1)
52 {
53 string[] arr = item_1.InnerText.Split("\r\n".ToCharArray(), StringSplitOptions.RemoveEmptyEntries);
54 if (arr != null && arr.Length > 0)
55 {
56 foreach (string str in arr)
57 {
58 if (str.Trim().Contains("性质"))
59 {
60 info.Nature = str.Replace("性质:", "").Trim();
61 }
62 if (str.Trim().Contains("规模"))
63 {
64 info.Scale = str.Replace("规模:", "").Trim();
65 }
66 }
67 }
68 }
69 }
70 }
71 //--工作经验
72 IEnumerable NodesMainContent5 = AnalyzeHTML.GetHtmlInfo(html, "div.resume.clearfix span.noborder");
73 if (NodesMainContent5.Count() > 0)
74 {
75 info.Experience = NodesMainContent5.ToArray()[0].InnerText;
76 }
77 //--公司地址/最低学历
78 IEnumerable NodesMainContent6 = AnalyzeHTML.GetHtmlInfo(html, "div.resume.clearfix");
79 if (NodesMainContent6.Count() > 0)
80 {
81 foreach (var item in NodesMainContent6)
82 {
83 string lable = Regex.Replace(item.InnerHtml, "\\s", "");
84 lable = lable.Replace("", "");
85 string[] arr = lable.Split("".ToCharArray(), StringSplitOptions.RemoveEmptyEntries);
86 if (arr != null && arr.Length > 2)
87 {
88 info.Address = arr[0];//公司地址
89 info.Education = arr[1];//最低学历
90 }
91 }
92 }
93 //--月薪
94 IEnumerable NodesMainContent7 = AnalyzeHTML.GetHtmlInfo(html, "div.job-title-left p.job-main-title");
95 if (NodesMainContent7.Count() > 0)
96 {
97 info.Salary = NodesMainContent7.ToArray()[0].InnerText;
98 }
99 //--发布时间
100 IEnumerable NodesMainContent8 = AnalyzeHTML.GetHtmlInfo(html, "div.job-title-left p.release-time em");
101 if (NodesMainContent8.Count() > 0)
102 {
103 info.Time = NodesMainContent8.ToArray()[0].InnerText;
104 }
105 //--
106 if (GetJobEnd != null)
107 {
108 GetJobEnd("", info);
109 }
110 }
111 catch (Exception exMsg)
112 {
113 throw new Exception(exMsg.Message);
114 }
115 }
上面的方法也解析了一个招聘网站标签的内容,但是我已经看不到复杂的正则表达式来拦截HTML标签了,这使得代码更加干练和简单,整个配置页面可以应付爬取< @网站tag 频繁更换的问题,所以看来抓取别人的网站数据是一件很简单的事情,O(∩_∩)O哈哈~是不是!!!
以上只是我个人的看法!!!有兴趣可以加QQ群:(186841119),参与讨论学习交流 查看全部
实时抓取网页数据(抓取网站数据不再难(其实是想死的!))
首先,从标题开始,为什么抓网站数据不再难(其实抓网站数据很难),SO EASY!!!使用 Fizzler 可以做到这一切。我相信大多数人或公司应该都有捕获他人网站数据的经验。比如我们博客园每次发布文章都会被其他网站给我抢,不信你看就知道了。还有人在网站上抢别人的邮箱、电话、QQ等有用信息。这些信息绝对可以卖钱或做其他事情。我们每天都会不时收到垃圾短信或电子邮件。就是这样,同感,O(∩_∩)O哈哈~。
前段时间写了两个程序,一个程序是采集彩票网站(双色球)的数据,另一个是采集求职网站(猎聘,54Worry,智联招聘, etc.)数据,写这两个程序的时候显示特别棘手,看到一堆HTML标签真想死。首先,让我们回顾一下我之前是如何解析 HTML 的。通过WebRequest获取HTML内容,然后使用HTML标签一步步截取你想要的内容,是一种很常见的做法。下面的代码是截取双色球的红球和篮球的代码。一旦网站的标签稍有变化,就有可能面临重新编程,使用起来很不方便。
下面是我在解析红球和篮球双色球的代码。我做的最多的就是截取(正则表达式)标签的对应内容。也许这段代码不是很复杂,因为截取的数据是有限的,而且非常规则,因此也比较简单。
1 #region * 在一个TR中,解析TD,获取一期的号码
2 ///
3 /// 在一个TR中,解析TD,获取一期的号码
4 ///
5 ///
6 ///
7 private void ResolveTd(ref WinNo wn, string trContent)
8 {
9 List redBoxList = null;
10 //匹配期号的表达式
11 string patternQiHao = "0)
17 {
18 info.Position = NodesMainContent1.ToArray()[0].InnerText;
19 }
20 //--公司名称
21 IEnumerable NodesMainContent2 = AnalyzeHTML.GetHtmlInfo(html, "div.title-info h3");
22 if (NodesMainContent2.Count() > 0)
23 {
24 info.Company = NodesMainContent2.ToArray()[0].InnerText;
25 }
26 //--公司性质/公司规模
27 IEnumerable NodesMainContent4 = AnalyzeHTML.GetHtmlInfo(html, "div.content.content-word ul li");
28 if (NodesMainContent4.Count() > 0)
29 {
30 foreach (var item in NodesMainContent4)
31 {
32 if (item.InnerHtml.Contains("企业性质"))
33 {
34 string nature = item.InnerText;
35 nature = nature.Replace("企业性质:", "");
36 info.Nature = nature;
37 }
38 if (item.InnerHtml.Contains("企业规模"))
39 {
40 string scale = item.InnerText;
41 scale = scale.Replace("企业规模:", "");
42 info.Scale = scale;
43 }
44 }
45 }
46 else//第二次解析企业性质和企业规模
47 {
48 IEnumerable NodesMainContent4_1 = AnalyzeHTML.GetHtmlInfo(html, "div.right-post-top div.content.content-word");
49 if (NodesMainContent4_1.Count() > 0)
50 {
51 foreach (var item_1 in NodesMainContent4_1)
52 {
53 string[] arr = item_1.InnerText.Split("\r\n".ToCharArray(), StringSplitOptions.RemoveEmptyEntries);
54 if (arr != null && arr.Length > 0)
55 {
56 foreach (string str in arr)
57 {
58 if (str.Trim().Contains("性质"))
59 {
60 info.Nature = str.Replace("性质:", "").Trim();
61 }
62 if (str.Trim().Contains("规模"))
63 {
64 info.Scale = str.Replace("规模:", "").Trim();
65 }
66 }
67 }
68 }
69 }
70 }
71 //--工作经验
72 IEnumerable NodesMainContent5 = AnalyzeHTML.GetHtmlInfo(html, "div.resume.clearfix span.noborder");
73 if (NodesMainContent5.Count() > 0)
74 {
75 info.Experience = NodesMainContent5.ToArray()[0].InnerText;
76 }
77 //--公司地址/最低学历
78 IEnumerable NodesMainContent6 = AnalyzeHTML.GetHtmlInfo(html, "div.resume.clearfix");
79 if (NodesMainContent6.Count() > 0)
80 {
81 foreach (var item in NodesMainContent6)
82 {
83 string lable = Regex.Replace(item.InnerHtml, "\\s", "");
84 lable = lable.Replace("", "");
85 string[] arr = lable.Split("".ToCharArray(), StringSplitOptions.RemoveEmptyEntries);
86 if (arr != null && arr.Length > 2)
87 {
88 info.Address = arr[0];//公司地址
89 info.Education = arr[1];//最低学历
90 }
91 }
92 }
93 //--月薪
94 IEnumerable NodesMainContent7 = AnalyzeHTML.GetHtmlInfo(html, "div.job-title-left p.job-main-title");
95 if (NodesMainContent7.Count() > 0)
96 {
97 info.Salary = NodesMainContent7.ToArray()[0].InnerText;
98 }
99 //--发布时间
100 IEnumerable NodesMainContent8 = AnalyzeHTML.GetHtmlInfo(html, "div.job-title-left p.release-time em");
101 if (NodesMainContent8.Count() > 0)
102 {
103 info.Time = NodesMainContent8.ToArray()[0].InnerText;
104 }
105 //--
106 if (GetJobEnd != null)
107 {
108 GetJobEnd("", info);
109 }
110 }
111 catch (Exception exMsg)
112 {
113 throw new Exception(exMsg.Message);
114 }
115 }
上面的方法也解析了一个招聘网站标签的内容,但是我已经看不到复杂的正则表达式来拦截HTML标签了,这使得代码更加干练和简单,整个配置页面可以应付爬取< @网站tag 频繁更换的问题,所以看来抓取别人的网站数据是一件很简单的事情,O(∩_∩)O哈哈~是不是!!!
以上只是我个人的看法!!!有兴趣可以加QQ群:(186841119),参与讨论学习交流
实时抓取网页数据( Agenty网页代理2.变更检测代理网络爬虫代理如何使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-02-10 23:19
Agenty网页代理2.变更检测代理网络爬虫代理如何使用)
介绍:
Agenty 一个简单、强大的网页抓取应用程序,用于使用 CSS 选择器进行屏幕抓取和创建网页抓取代理 Agenty 是一个非常简单和高级的网页抓取扩展程序,使用 <从@k17@ 提取数据> 中的点击式 CSS 选择器,提取数据实时pview,快速导出数据为JSON/CSV/TSV。为 Agenty Cloud Platform() 创建免费的网页抓取代理,用于大数据提取和更高级的网页抓取功能:如调度、匿名 网站 抓取、网站 抓取,提取 100 或数百万个网页,同时获取多个 网站,将数据发布到服务器等...您可以创建的代理 - 1. 网络抓取代理2. 更改检测代理 3. 网络爬虫代理的工作原理-------------------------------- 1. 去找你 < @网站 提取,然后启动扩展。2. 在新建下选择代理类型,或者您可以使用我的代理下的示例代理模板。2. 点击你想提取的网页元素(它会变成绿色)。然后,Web 抓取应用程序将为该元素生成最佳 CSS 选择器,并将突出显示(黄色)与该选择器匹配的所有内容。3. 现在您可以单击突出显示的元素将其从选择器中移除(红色),或者单击未突出显示的元素将其添加到提取器中。然后,Web 抓取应用程序将为该元素生成最佳 CSS 选择器,并将突出显示(黄色)与该选择器匹配的所有内容。3. 现在您可以单击突出显示的元素将其从选择器中移除(红色),或者单击未突出显示的元素将其添加到提取器中。然后,Web 抓取应用程序将为该元素生成最佳 CSS 选择器,并将突出显示(黄色)与该选择器匹配的所有内容。3. 现在您可以单击突出显示的元素将其从选择器中移除(红色),或者单击未突出显示的元素将其添加到提取器中。
通过这个选择和拒绝过程,Web Scraping App 将帮助您为需要提取的项目提供完美的 CSS 选择器。4. 使用文本、HTML 或 ATTR(属性)提取任意数量的字段,并即时输出提取数据的视图。如何编辑您的网络抓取/更改检测代理------------------------------- 1. 转到创建代理网站 URL 2. 启动代理扩展3. 单击代理旁边的打开按钮以在代理中打开它。4. 现在您可以添加/更改任何内容并将其保存回您的帐户。功能-------------------------------- 1. 从网页中提取任意数量的字段。2.使用内置的 CSS 选择器一键生成模式。3. 编写您自己的自定义 CSS 选择器。4. 选择要提取的项目。例如文本、HTML 或 ATTR(属性)5. 选择 CSS 选择器后立即查看生成的 pview。5. 左右切换位置。7. 以最流行的文件格式 JSON、CSV 或 TSV 导出最好的网络爬虫 ------------- ---- --- 首先是用于 网站 抓取的 Jquery 样式 CSS 选择器扩展。
立即安装以使用最先进的屏幕抓取技术免费解析 HTML 和抓取/提取网站信息。例如价格抓取、电子邮件抓取、数据抓取、隐藏的 html 标签抓取。网页抓取也称为屏幕抓取、网页数据提取、网页采集等。无论您是使用 Agenty 抓取网站,还是 C#、Python、Node JS、Perl、Ruby、Java 中的 API,还是JavaScript 编程语言。您可以使用 chrome 扩展来生成 Jquery 样式的 CSS 选择器以进行 Web 抓取。查看更多详情: 查看全部
实时抓取网页数据(
Agenty网页代理2.变更检测代理网络爬虫代理如何使用)



介绍:
Agenty 一个简单、强大的网页抓取应用程序,用于使用 CSS 选择器进行屏幕抓取和创建网页抓取代理 Agenty 是一个非常简单和高级的网页抓取扩展程序,使用 <从@k17@ 提取数据> 中的点击式 CSS 选择器,提取数据实时pview,快速导出数据为JSON/CSV/TSV。为 Agenty Cloud Platform() 创建免费的网页抓取代理,用于大数据提取和更高级的网页抓取功能:如调度、匿名 网站 抓取、网站 抓取,提取 100 或数百万个网页,同时获取多个 网站,将数据发布到服务器等...您可以创建的代理 - 1. 网络抓取代理2. 更改检测代理 3. 网络爬虫代理的工作原理-------------------------------- 1. 去找你 < @网站 提取,然后启动扩展。2. 在新建下选择代理类型,或者您可以使用我的代理下的示例代理模板。2. 点击你想提取的网页元素(它会变成绿色)。然后,Web 抓取应用程序将为该元素生成最佳 CSS 选择器,并将突出显示(黄色)与该选择器匹配的所有内容。3. 现在您可以单击突出显示的元素将其从选择器中移除(红色),或者单击未突出显示的元素将其添加到提取器中。然后,Web 抓取应用程序将为该元素生成最佳 CSS 选择器,并将突出显示(黄色)与该选择器匹配的所有内容。3. 现在您可以单击突出显示的元素将其从选择器中移除(红色),或者单击未突出显示的元素将其添加到提取器中。然后,Web 抓取应用程序将为该元素生成最佳 CSS 选择器,并将突出显示(黄色)与该选择器匹配的所有内容。3. 现在您可以单击突出显示的元素将其从选择器中移除(红色),或者单击未突出显示的元素将其添加到提取器中。
通过这个选择和拒绝过程,Web Scraping App 将帮助您为需要提取的项目提供完美的 CSS 选择器。4. 使用文本、HTML 或 ATTR(属性)提取任意数量的字段,并即时输出提取数据的视图。如何编辑您的网络抓取/更改检测代理------------------------------- 1. 转到创建代理网站 URL 2. 启动代理扩展3. 单击代理旁边的打开按钮以在代理中打开它。4. 现在您可以添加/更改任何内容并将其保存回您的帐户。功能-------------------------------- 1. 从网页中提取任意数量的字段。2.使用内置的 CSS 选择器一键生成模式。3. 编写您自己的自定义 CSS 选择器。4. 选择要提取的项目。例如文本、HTML 或 ATTR(属性)5. 选择 CSS 选择器后立即查看生成的 pview。5. 左右切换位置。7. 以最流行的文件格式 JSON、CSV 或 TSV 导出最好的网络爬虫 ------------- ---- --- 首先是用于 网站 抓取的 Jquery 样式 CSS 选择器扩展。
立即安装以使用最先进的屏幕抓取技术免费解析 HTML 和抓取/提取网站信息。例如价格抓取、电子邮件抓取、数据抓取、隐藏的 html 标签抓取。网页抓取也称为屏幕抓取、网页数据提取、网页采集等。无论您是使用 Agenty 抓取网站,还是 C#、Python、Node JS、Perl、Ruby、Java 中的 API,还是JavaScript 编程语言。您可以使用 chrome 扩展来生成 Jquery 样式的 CSS 选择器以进行 Web 抓取。查看更多详情:
实时抓取网页数据(全网舆情分析系统设计中可能会遇到的的问题?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-09 16:25
摘要: 前言 在当前的互联网信息浪潮下,信息传播的速度远远超出我们的想象。一条微博大V的帖子,一条朋友圈的动态,一条热门论坛的新闻,或者购物平台的一条购物评论,都可能产生数以万计的转发、关注和点赞。如果是一些不合理的负面评论,就会激起人们的负面情绪,甚至影响消费者对企业品牌的认可。如果不能及时采取正确的措施,将会造成不可估量的损失。
前言
在当前的互联网信息浪潮下,信息传播的速度远远超出我们的想象。一条微博大V的帖子,一条朋友圈的动态,一条热门论坛的新闻,或者购物平台的一条购物评论,都可能产生数以万计的转发、关注和点赞。如果是一些不合理的负面评论,就会激起人们的负面情绪,甚至影响消费者对企业品牌的认可。如果不能及时采取正确的措施,将会造成不可估量的损失。因此,我们需要一个高效的全网舆情分析系统来帮助我们实时观察舆情。
这个全网舆情分析系统可以存储百亿网页数据,实时抓取和存储新网页,并为新网页实时提取元数据。随着提取结果,我们还需要进行进一步的挖掘分析,包括但不限于
舆情影响力诊断,从传播的幅度和传播趋势进行预测,判断舆情最终是否会形成。
传播路径分析,分析舆情传播的关键路径。
用户画像为舆论参与者提供了一个共同特征的轮廓,例如性别、年龄、地区和感兴趣的话题。
情绪分析,分析新闻或评论是正面还是负面。在情感分类之后进行统计聚合。
预警设置,我们支持设置舆情讨论量阈值,达到阈值后通知推送业务方,避免错过舆论的黄金参与时间。
这些挖掘出来的舆情结果会被推送到需求方,同时也提供了一个接口供各业务方搜索查询。接下来,我们将讨论系统设计中可能遇到的问题。我们将重点关注系统设计中与存储相关的话题,并为这些问题找到最优的解决方案。
系统设计
一个舆情系统,首先需要一个爬虫引擎去采集各大主流门户、购物网站、社区论坛、微博的原创页面内容、朋友圈的各种新闻资讯. 采集对于海量的网页,消息数据(上百亿)需要实时存储。在根据网站url获取网页之前,需要判断是否是之前爬过的页面,避免不必要的重复爬取。采集网页之后,我们需要提取网页,去除不必要的标签,提取标题、摘要、正文内容、评论等,提取的内容进入存储系统,方便后续查询。同时,新增的抽取结果需要推送到计算平台进行统计分析、报表生成或后续舆情检索等功能。根据算法,计算内容可能需要新数据或完整数据。舆论本身的时间敏感性决定了我们的系统必须能够高效地处理这些新内容。最好延迟几秒后检索新的热搜。
我们可以将整个数据流总结如下:
根据上图不难发现,要设计一个全网舆情的存储分析平台,我们需要处理爬取、存储、分析、搜索和展示。具体来说,我们需要解决以下问题:
如何高效存储百亿原创网页信息,为了提高舆情分析的全面性和准确性,我们往往希望尽可能多的抓取网页信息,然后按照我们设定的权重进行聚合。因此,整个网页的历史数据库会比较大,积累了数百亿的网页信息,数据量可以达到数百TB甚至数PB。在数据量如此之大的情况下,我们还需要做到读写毫秒级的低延迟,这使得传统数据库难以满足需求。
在爬虫爬取网页之前,如何判断之前是否被爬过?对于普通的网页,舆论关心的是时效性。或许我们只想爬取同一个网页一次,那我们就可以用网页地址来爬取Heavy,减少不必要的网页资源浪费。所以我们需要分布式存储来提供基于网页的高效随机查询。
如何在新的原创网页存储后进行实时结构化提取,并存储提取结果。这里我们的原创网页可能收录各种html标签,我们需要去掉这些html标签,提取出文章的标题、作者、发布时间等。这些内容为后续舆情情绪分析提供了必要的结构化数据。
如何高效连接计算平台,对新提取的结构化数据进行流式传输,进行实时计算。这里我们需要对网页内容和消息描述进行分类,进行情感识别,并对识别后的结果进行统计分析。由于全盘分析的时效性差,舆论往往关注最新的新闻和评论,所以必须做增量分析。
如何提供高效的舆情搜索,除了订阅固定的关键词舆情,用户还做一些关键词搜索。比如你想了解竞品公司新产品的一些舆情分析。
如何实现新舆论的实时推送?为了保证舆情的及时性,不仅要坚持舆情分析结果,还要支持舆情结果的推送。推送的内容通常是我们实时分析的新舆情。
系统结构
针对以上问题,我们来介绍一下如何基于阿里云上的各种云产品,搭建一个全网百亿级别的舆情分析平台。我们将重点关注存储产品的选择以及如何高效连接各类计算。,搜索平台。
我们使用ECS作为爬虫引擎,可以根据爬取的数量确定使用ECS的机器资源数量,也可以在每天的高峰期临时扩展资源用于网络爬取。抓取原创网页后,将原创网页地址和网页内容写入存储系统。同时,如果要避免重复爬取,爬虫引擎在爬取前要根据url列表去重。存储引擎需要支持低延迟的随机访问查询,判断当前url是否已经存在,如果存在,则无需再次爬取。
为了实现网页原创内容的实时提取,我们需要将新增的页面推送到计算平台。以前的架构往往需要应用层的双重写入,即原创网页数据存储在数据库中,我们反复将数据的副本写入计算平台。这样的架构需要我们维护两组编写逻辑。同样,结构化增量进入舆情分析平台也存在类似问题。提取的结构化元数据也需要双写入舆情分析平台。舆情分析结果也需要写入分布式存储,推送到搜索平台。在这里我们可以发现图中的三个红线会带来我们对三个数据源的双写需求。这会增加代码开发的工作量,也会导致复杂的系统实现和维护。每个数据源的双写需要知道下游的存在,或者使用消息服务通过双写消息做解耦。mysql等传统数据库支持增量日志binlog的订阅。如果分布式存储产品可以支持大的访问和存储容量,还可以提供增量订阅,可以大大简化我们的架构。每个数据源的双写需要知道下游的存在,或者使用消息服务通过双写消息做解耦。mysql等传统数据库支持增量日志binlog的订阅。如果分布式存储产品可以支持大的访问和存储容量,还可以提供增量订阅,可以大大简化我们的架构。每个数据源的双写需要知道下游的存在,或者使用消息服务通过双写消息做解耦。mysql等传统数据库支持增量日志binlog的订阅。如果分布式存储产品可以支持大的访问和存储容量,还可以提供增量订阅,可以大大简化我们的架构。
网页数据采集存储后,会增量流入我们的计算平台,实时提取元数据。这里我们可以使用函数计算。当有新的页面需要提取时,触发函数计算的托管函数执行网页元数据。提炼。提取出来的结果存入存储系统并持久化后,同时推送到MaxCompute进行舆情分析,如情感分析、文本聚类等。可能会有一些公共信息表数据、用户情绪数据统计等结果。舆情结果会写入存储系统和搜索引擎,部分报告和阈值告警会推送给订阅者。搜索引擎的数据提供给在线舆情检索系统。
介绍完完整的架构后,我们再来看看阿里云上如何进行存储选型。
存储选择
通过架构的介绍,我们总结一下存储选型的要求:
可支持海量数据存储(TB/PB级别)、高并发访问(10万到1000万TPS)、低访问延迟。
采集的数量会随着采集订阅的网页源的调整而动态调整。同时,爬虫在不同时间段爬取的网页数量在一天之内也会有明显的波峰和波谷,所以数据库需要能够灵活的扩缩容。
有了自由表属性结构,对于普通网页和社交平台页面的信息,我们需要注意的属性可能会有很大的不同。灵活的模式将有助于我们的扩展。
对于旧数据,您可以选择自动过期或分层存储。由于舆情数据往往集中在近期热点,旧数据的访问频率较低。
需要更好的增量通道,新增数据可以定期导出到计算平台。上图中有3条红色虚线。这三个部分有一个共同的特点。增量可以实时引导到相应的计算平台进行计算,并将计算结果写入相应的存储引擎。如果数据库引擎本身支持增量,可以大大简化架构,减少之前在全读区过滤增量,或者双写客户端实现增量的逻辑。
需要有更好的搜索解决方案(它支持自身或可以将数据无缝连接到搜索引擎)。
带着这些需求,我们需要使用分布式的NoSQL数据来解决海量数据的存储和访问。多链路增量数据访问的需求和业务高峰访问的波动进一步决定了灵活计费的表格存储是我们在这个架构中的最佳选择。表格存储的schema介绍请参考表格存储数据模型
与同类数据库相比,TableStore(表格存储)有一个很大的功能优势,就是TableStore(表格存储)有一个比较完整的增量接口,即Stream增量API。Stream的介绍请参考表格存储流概述。场景介绍可以参考Stream应用场景介绍,具体API使用可以参考JAVA SDK Stream。通过Stream接口,我们可以很方便的订阅TableStore(表存储)的所有修改操作,也就是各种新数据。同时,我们基于Stream构建了大量的数据通道,连接各种下游计算产品。用户甚至不需要直接调用Stream API,使用我们的channel直接订阅下游的增量数据,自然接入整个阿里云计算生态。上述架构中提到的函数计算,MaxCompute、ElasticSearch、DataV、TableStore(表存储)都支持。详情请参阅:
流与函数计算对接
Stream 和 MaxCompute
流和 Elasticsearch
通过DataV显示存储在表中的数据
TableStore(表存储)是属性列上的自由表结构。对于舆情分析的场景,随着舆情分析算法的升级,我们可能会增加新的属性字段,普通网页、微博等社交页面的属性也可能有所不同。因此,自由表结构与传统数据库相比,可以很好地满足我们的需求。
在架构中,我们有三个存储库需求。它们是原创页库、结构化元数据库和舆情结果库。前两个一般是离线存储和分析库,最后一个是在线数据库。它们对访问性能和存储成本有不同的要求。表格存储有两种支持存储分层的实例类型,高性能和容量。高性能适用于多写多读的场景,即作为在线业务存储。容量类型适用于写多读少的场景,即离线业务存储。它们的单线写入延迟可以控制在10毫秒以内,读取高性能可以保持在毫秒级。TableStore 还支持 TTL 并设置表级数据过期时间。根据需求,我们可以设置舆情结果的TTL,只提供最近数据的查询,旧的舆情会自动过期删除。
借助TableStore(表存储)的这些特性,可以很好地满足系统对存储选择的六大要求。基于TableStore(表存储),可以完美设计和实现全网舆情存储分析系统。
后记
本文总结了海量数据舆情分析场景中遇到的存储和分析问题,介绍了如何在满足业务基础数据量的前提下,使用阿里云自研的TableStore(表存储),通过Stream接口与计算平台的对接,实现了架构的简化。TableStore(表格存储)是阿里云自主研发的专业级分布式NoSQL数据库。它是一种基于共享存储的高性能、低成本、易扩展、全托管的半结构化数据存储平台。数据处理领域的重要应用之一。其他场景请参考TableStore进阶之路。 查看全部
实时抓取网页数据(全网舆情分析系统设计中可能会遇到的的问题?)
摘要: 前言 在当前的互联网信息浪潮下,信息传播的速度远远超出我们的想象。一条微博大V的帖子,一条朋友圈的动态,一条热门论坛的新闻,或者购物平台的一条购物评论,都可能产生数以万计的转发、关注和点赞。如果是一些不合理的负面评论,就会激起人们的负面情绪,甚至影响消费者对企业品牌的认可。如果不能及时采取正确的措施,将会造成不可估量的损失。
前言
在当前的互联网信息浪潮下,信息传播的速度远远超出我们的想象。一条微博大V的帖子,一条朋友圈的动态,一条热门论坛的新闻,或者购物平台的一条购物评论,都可能产生数以万计的转发、关注和点赞。如果是一些不合理的负面评论,就会激起人们的负面情绪,甚至影响消费者对企业品牌的认可。如果不能及时采取正确的措施,将会造成不可估量的损失。因此,我们需要一个高效的全网舆情分析系统来帮助我们实时观察舆情。
这个全网舆情分析系统可以存储百亿网页数据,实时抓取和存储新网页,并为新网页实时提取元数据。随着提取结果,我们还需要进行进一步的挖掘分析,包括但不限于
舆情影响力诊断,从传播的幅度和传播趋势进行预测,判断舆情最终是否会形成。
传播路径分析,分析舆情传播的关键路径。
用户画像为舆论参与者提供了一个共同特征的轮廓,例如性别、年龄、地区和感兴趣的话题。
情绪分析,分析新闻或评论是正面还是负面。在情感分类之后进行统计聚合。
预警设置,我们支持设置舆情讨论量阈值,达到阈值后通知推送业务方,避免错过舆论的黄金参与时间。
这些挖掘出来的舆情结果会被推送到需求方,同时也提供了一个接口供各业务方搜索查询。接下来,我们将讨论系统设计中可能遇到的问题。我们将重点关注系统设计中与存储相关的话题,并为这些问题找到最优的解决方案。
系统设计
一个舆情系统,首先需要一个爬虫引擎去采集各大主流门户、购物网站、社区论坛、微博的原创页面内容、朋友圈的各种新闻资讯. 采集对于海量的网页,消息数据(上百亿)需要实时存储。在根据网站url获取网页之前,需要判断是否是之前爬过的页面,避免不必要的重复爬取。采集网页之后,我们需要提取网页,去除不必要的标签,提取标题、摘要、正文内容、评论等,提取的内容进入存储系统,方便后续查询。同时,新增的抽取结果需要推送到计算平台进行统计分析、报表生成或后续舆情检索等功能。根据算法,计算内容可能需要新数据或完整数据。舆论本身的时间敏感性决定了我们的系统必须能够高效地处理这些新内容。最好延迟几秒后检索新的热搜。
我们可以将整个数据流总结如下:
根据上图不难发现,要设计一个全网舆情的存储分析平台,我们需要处理爬取、存储、分析、搜索和展示。具体来说,我们需要解决以下问题:
如何高效存储百亿原创网页信息,为了提高舆情分析的全面性和准确性,我们往往希望尽可能多的抓取网页信息,然后按照我们设定的权重进行聚合。因此,整个网页的历史数据库会比较大,积累了数百亿的网页信息,数据量可以达到数百TB甚至数PB。在数据量如此之大的情况下,我们还需要做到读写毫秒级的低延迟,这使得传统数据库难以满足需求。
在爬虫爬取网页之前,如何判断之前是否被爬过?对于普通的网页,舆论关心的是时效性。或许我们只想爬取同一个网页一次,那我们就可以用网页地址来爬取Heavy,减少不必要的网页资源浪费。所以我们需要分布式存储来提供基于网页的高效随机查询。
如何在新的原创网页存储后进行实时结构化提取,并存储提取结果。这里我们的原创网页可能收录各种html标签,我们需要去掉这些html标签,提取出文章的标题、作者、发布时间等。这些内容为后续舆情情绪分析提供了必要的结构化数据。
如何高效连接计算平台,对新提取的结构化数据进行流式传输,进行实时计算。这里我们需要对网页内容和消息描述进行分类,进行情感识别,并对识别后的结果进行统计分析。由于全盘分析的时效性差,舆论往往关注最新的新闻和评论,所以必须做增量分析。
如何提供高效的舆情搜索,除了订阅固定的关键词舆情,用户还做一些关键词搜索。比如你想了解竞品公司新产品的一些舆情分析。
如何实现新舆论的实时推送?为了保证舆情的及时性,不仅要坚持舆情分析结果,还要支持舆情结果的推送。推送的内容通常是我们实时分析的新舆情。
系统结构
针对以上问题,我们来介绍一下如何基于阿里云上的各种云产品,搭建一个全网百亿级别的舆情分析平台。我们将重点关注存储产品的选择以及如何高效连接各类计算。,搜索平台。
我们使用ECS作为爬虫引擎,可以根据爬取的数量确定使用ECS的机器资源数量,也可以在每天的高峰期临时扩展资源用于网络爬取。抓取原创网页后,将原创网页地址和网页内容写入存储系统。同时,如果要避免重复爬取,爬虫引擎在爬取前要根据url列表去重。存储引擎需要支持低延迟的随机访问查询,判断当前url是否已经存在,如果存在,则无需再次爬取。
为了实现网页原创内容的实时提取,我们需要将新增的页面推送到计算平台。以前的架构往往需要应用层的双重写入,即原创网页数据存储在数据库中,我们反复将数据的副本写入计算平台。这样的架构需要我们维护两组编写逻辑。同样,结构化增量进入舆情分析平台也存在类似问题。提取的结构化元数据也需要双写入舆情分析平台。舆情分析结果也需要写入分布式存储,推送到搜索平台。在这里我们可以发现图中的三个红线会带来我们对三个数据源的双写需求。这会增加代码开发的工作量,也会导致复杂的系统实现和维护。每个数据源的双写需要知道下游的存在,或者使用消息服务通过双写消息做解耦。mysql等传统数据库支持增量日志binlog的订阅。如果分布式存储产品可以支持大的访问和存储容量,还可以提供增量订阅,可以大大简化我们的架构。每个数据源的双写需要知道下游的存在,或者使用消息服务通过双写消息做解耦。mysql等传统数据库支持增量日志binlog的订阅。如果分布式存储产品可以支持大的访问和存储容量,还可以提供增量订阅,可以大大简化我们的架构。每个数据源的双写需要知道下游的存在,或者使用消息服务通过双写消息做解耦。mysql等传统数据库支持增量日志binlog的订阅。如果分布式存储产品可以支持大的访问和存储容量,还可以提供增量订阅,可以大大简化我们的架构。
网页数据采集存储后,会增量流入我们的计算平台,实时提取元数据。这里我们可以使用函数计算。当有新的页面需要提取时,触发函数计算的托管函数执行网页元数据。提炼。提取出来的结果存入存储系统并持久化后,同时推送到MaxCompute进行舆情分析,如情感分析、文本聚类等。可能会有一些公共信息表数据、用户情绪数据统计等结果。舆情结果会写入存储系统和搜索引擎,部分报告和阈值告警会推送给订阅者。搜索引擎的数据提供给在线舆情检索系统。
介绍完完整的架构后,我们再来看看阿里云上如何进行存储选型。
存储选择
通过架构的介绍,我们总结一下存储选型的要求:
可支持海量数据存储(TB/PB级别)、高并发访问(10万到1000万TPS)、低访问延迟。
采集的数量会随着采集订阅的网页源的调整而动态调整。同时,爬虫在不同时间段爬取的网页数量在一天之内也会有明显的波峰和波谷,所以数据库需要能够灵活的扩缩容。
有了自由表属性结构,对于普通网页和社交平台页面的信息,我们需要注意的属性可能会有很大的不同。灵活的模式将有助于我们的扩展。
对于旧数据,您可以选择自动过期或分层存储。由于舆情数据往往集中在近期热点,旧数据的访问频率较低。
需要更好的增量通道,新增数据可以定期导出到计算平台。上图中有3条红色虚线。这三个部分有一个共同的特点。增量可以实时引导到相应的计算平台进行计算,并将计算结果写入相应的存储引擎。如果数据库引擎本身支持增量,可以大大简化架构,减少之前在全读区过滤增量,或者双写客户端实现增量的逻辑。
需要有更好的搜索解决方案(它支持自身或可以将数据无缝连接到搜索引擎)。
带着这些需求,我们需要使用分布式的NoSQL数据来解决海量数据的存储和访问。多链路增量数据访问的需求和业务高峰访问的波动进一步决定了灵活计费的表格存储是我们在这个架构中的最佳选择。表格存储的schema介绍请参考表格存储数据模型
与同类数据库相比,TableStore(表格存储)有一个很大的功能优势,就是TableStore(表格存储)有一个比较完整的增量接口,即Stream增量API。Stream的介绍请参考表格存储流概述。场景介绍可以参考Stream应用场景介绍,具体API使用可以参考JAVA SDK Stream。通过Stream接口,我们可以很方便的订阅TableStore(表存储)的所有修改操作,也就是各种新数据。同时,我们基于Stream构建了大量的数据通道,连接各种下游计算产品。用户甚至不需要直接调用Stream API,使用我们的channel直接订阅下游的增量数据,自然接入整个阿里云计算生态。上述架构中提到的函数计算,MaxCompute、ElasticSearch、DataV、TableStore(表存储)都支持。详情请参阅:
流与函数计算对接
Stream 和 MaxCompute
流和 Elasticsearch
通过DataV显示存储在表中的数据
TableStore(表存储)是属性列上的自由表结构。对于舆情分析的场景,随着舆情分析算法的升级,我们可能会增加新的属性字段,普通网页、微博等社交页面的属性也可能有所不同。因此,自由表结构与传统数据库相比,可以很好地满足我们的需求。
在架构中,我们有三个存储库需求。它们是原创页库、结构化元数据库和舆情结果库。前两个一般是离线存储和分析库,最后一个是在线数据库。它们对访问性能和存储成本有不同的要求。表格存储有两种支持存储分层的实例类型,高性能和容量。高性能适用于多写多读的场景,即作为在线业务存储。容量类型适用于写多读少的场景,即离线业务存储。它们的单线写入延迟可以控制在10毫秒以内,读取高性能可以保持在毫秒级。TableStore 还支持 TTL 并设置表级数据过期时间。根据需求,我们可以设置舆情结果的TTL,只提供最近数据的查询,旧的舆情会自动过期删除。
借助TableStore(表存储)的这些特性,可以很好地满足系统对存储选择的六大要求。基于TableStore(表存储),可以完美设计和实现全网舆情存储分析系统。
后记
本文总结了海量数据舆情分析场景中遇到的存储和分析问题,介绍了如何在满足业务基础数据量的前提下,使用阿里云自研的TableStore(表存储),通过Stream接口与计算平台的对接,实现了架构的简化。TableStore(表格存储)是阿里云自主研发的专业级分布式NoSQL数据库。它是一种基于共享存储的高性能、低成本、易扩展、全托管的半结构化数据存储平台。数据处理领域的重要应用之一。其他场景请参考TableStore进阶之路。
实时抓取网页数据(有时会有爬虫经常抓取网站却不收录的情况,这是什么原因)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-07 03:28
随着互联网的发展,很多企业开始重视网站推广,利用搜索引擎优化(SEO)来获取流量,完成转化。搜索引擎抓取网站和收录会影响网站的排名,所以SEO人员会经常关注网站的抓取频率和搜索引擎的收录情况,但是有时候爬虫经常爬到网站而不爬到收录,是什么原因?
一、低质量的内容
SEO人员都知道,为了让爬虫频繁地爬取网站,需要不断的更新网站的内容。然而,有些网站为了定期更新而忽略了内容的质量。众所周知,搜索引擎喜欢 原创 和有用的内容。当网站的内容更新时,虽然蜘蛛爬取了网站,但是在做内容评估的时候,网站的内容并没有被评估,没有收录。
为了避免这种情况,在更新网站内容时,尽量添加一些原创内容,或者对用户有帮助的优质内容,这样更容易被搜索引擎评价。受益 收录 和 网站 排名。
二、死链接太多
当蜘蛛爬行 网站 时,它们会沿着链接爬行。如果死链接太多,会影响蜘蛛的爬取,从而有爬取痕迹但没有收录。这种情况一般发生在网站修改后,页面链接处理不当,导致大量死链接,影响收录和网站的排名。因此,应经常检查网站链接,发现死链接时及时提交给搜索引擎,以利于网站的长远发展。
三、算法改变
搜索引擎经常不时更新他们的算法以改进他们的搜索引擎。当算法发生变化时,爬行频率很容易急剧增加。如果是由于算法调整而发生这种情况,您不必太担心。只需了解算法更新的细节,进行有针对性的调整,很快就会恢复正常。
四、对于被攻击
很多网站会为了提升自己的排名,使用一些作弊手段,比如蜘蛛池。这种攻击对手网站的方法会导致对手网站的爬取频率显着增加,甚至可能对搜索引擎收取点球,导致网站排名消失。
综上所述,这就是 网站 经常有人居住的四个原因中的一些,但 收录 却很低。SEO工作是一项细致的工作,除了做好基本的网站优化、内容更新、外链建设等,还需要定期检查网站。如果发现异常情况,要及时了解和处理,有利于网站的长期推广。搜索引擎获得稳定和持久的排名和流量。 查看全部
实时抓取网页数据(有时会有爬虫经常抓取网站却不收录的情况,这是什么原因)
随着互联网的发展,很多企业开始重视网站推广,利用搜索引擎优化(SEO)来获取流量,完成转化。搜索引擎抓取网站和收录会影响网站的排名,所以SEO人员会经常关注网站的抓取频率和搜索引擎的收录情况,但是有时候爬虫经常爬到网站而不爬到收录,是什么原因?
一、低质量的内容
SEO人员都知道,为了让爬虫频繁地爬取网站,需要不断的更新网站的内容。然而,有些网站为了定期更新而忽略了内容的质量。众所周知,搜索引擎喜欢 原创 和有用的内容。当网站的内容更新时,虽然蜘蛛爬取了网站,但是在做内容评估的时候,网站的内容并没有被评估,没有收录。
为了避免这种情况,在更新网站内容时,尽量添加一些原创内容,或者对用户有帮助的优质内容,这样更容易被搜索引擎评价。受益 收录 和 网站 排名。
二、死链接太多
当蜘蛛爬行 网站 时,它们会沿着链接爬行。如果死链接太多,会影响蜘蛛的爬取,从而有爬取痕迹但没有收录。这种情况一般发生在网站修改后,页面链接处理不当,导致大量死链接,影响收录和网站的排名。因此,应经常检查网站链接,发现死链接时及时提交给搜索引擎,以利于网站的长远发展。
三、算法改变
搜索引擎经常不时更新他们的算法以改进他们的搜索引擎。当算法发生变化时,爬行频率很容易急剧增加。如果是由于算法调整而发生这种情况,您不必太担心。只需了解算法更新的细节,进行有针对性的调整,很快就会恢复正常。
四、对于被攻击
很多网站会为了提升自己的排名,使用一些作弊手段,比如蜘蛛池。这种攻击对手网站的方法会导致对手网站的爬取频率显着增加,甚至可能对搜索引擎收取点球,导致网站排名消失。
综上所述,这就是 网站 经常有人居住的四个原因中的一些,但 收录 却很低。SEO工作是一项细致的工作,除了做好基本的网站优化、内容更新、外链建设等,还需要定期检查网站。如果发现异常情况,要及时了解和处理,有利于网站的长期推广。搜索引擎获得稳定和持久的排名和流量。
实时抓取网页数据( 基于Python的网络爬虫与反爬虫技术研究[J])
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-04 11:12
基于Python的网络爬虫与反爬虫技术研究[J])
基于Python爬虫技术的网页解析与数据获取研究
温雅娜、袁子良、何永辰、黄萌
(灾害预防与技术学院, 河北三河 065201)
摘要:网络的发展、大数据和人工智能的兴起让数据变得尤为重要。各行各业的发展都需要数据的支撑。任何一种深度学习和算法都需要大量数据作为模型。训练以得出更准确的结论。本文讨论了网络爬虫实现中的主要问题:了解网页的基本结构,使用直观的网页分析工具抓取和分析网页,如何使用正则表达式获取准确的字符串信息,以及使用Python实现简单的页面数据获取。
关键词:网络爬虫; Python;正则表达式;抓包分析
中国图书馆分类代码:TP391.3 文献识别代码:A 文章编号:2096-4706 (2020)01-0012-03
基于Python爬虫技术的网页分析与数据采集研究
温雅娜、袁子良、何永臣、黄萌
(中国防灾研究所,三河 065201)
摘要:随着网络的发展,大数据和人工智能的兴起,数据变得越来越重要。各行各业的发展需要数据的支撑。任何一种深度学习和算法都需要大量的数据作为模型进行训练,才能得到更准确的结论。本文讨论了网络爬虫实现中的主要问题:了解网页的基本结构,使用直观的网页分析工具分析网页,如何使用正则表达式获取准确的字符串信息,以及使用Python实现简单的页面数据获取。
关键词:网络爬虫; Python;正则表达式;抓包分析
资助单位:防震减灾专项;中央高校基本科研业务费专项资金(ZY20180124)
参考资料:
[1]郭尔强,李波。大数据环境下基于Python的网络爬虫技术[J].计算机产品与流通,2017 (12): 82.
[2]李沛。基于Python的网络爬虫与反爬虫技术研究[J].计算机与数字工程, 2019, 47 (6): 1415-1420+1496.
p>
[3] 王朝阳.基于Python的图书馆信息系统设计与实现[D].长春:吉林大学,2016.
[4] 徐衡.社交网络数据采集技术研究与实现[D].长春:吉林大学,2016.
[5] 孙建利,贾卓生。基于Python的Web爬虫实现与内容分析研究[C]//中国计算机用户协会网络应用分会2017年第21届网络新技术与应用年会。中国计算机用户协会网络应用分会2017年第21届网络新技术与应用年会论文集.河北雄安:计算机科学编辑部,2017:275-277+281.
[6] 陈琳,任芳。基于Python的新浪微博数据爬虫程序设计[J].信息系统工程,2016 (9): 97-99.
[7] 卢淑芬。基于Python的Web爬虫系统设计与实现[J].计算机编程技能与维护,2019 (2): 26-27+51.
[8] 熊畅。基于Python爬虫技术的Web数据采集与分析研究[J].数字技术与应用, 2017 (9): 35-36.
[9] 吴双。基于python语言的Web数据挖掘与分析研究[J].计算机知识与技术, 2018, 14 (27):1-2.
作者简介:文雅娜(1999.03-),女,汉族,内蒙古包头人,本科,学士,研究方向:人工智能与软件开发与应用。 查看全部
实时抓取网页数据(
基于Python的网络爬虫与反爬虫技术研究[J])
基于Python爬虫技术的网页解析与数据获取研究
温雅娜、袁子良、何永辰、黄萌
(灾害预防与技术学院, 河北三河 065201)
摘要:网络的发展、大数据和人工智能的兴起让数据变得尤为重要。各行各业的发展都需要数据的支撑。任何一种深度学习和算法都需要大量数据作为模型。训练以得出更准确的结论。本文讨论了网络爬虫实现中的主要问题:了解网页的基本结构,使用直观的网页分析工具抓取和分析网页,如何使用正则表达式获取准确的字符串信息,以及使用Python实现简单的页面数据获取。
关键词:网络爬虫; Python;正则表达式;抓包分析
中国图书馆分类代码:TP391.3 文献识别代码:A 文章编号:2096-4706 (2020)01-0012-03
基于Python爬虫技术的网页分析与数据采集研究
温雅娜、袁子良、何永臣、黄萌
(中国防灾研究所,三河 065201)
摘要:随着网络的发展,大数据和人工智能的兴起,数据变得越来越重要。各行各业的发展需要数据的支撑。任何一种深度学习和算法都需要大量的数据作为模型进行训练,才能得到更准确的结论。本文讨论了网络爬虫实现中的主要问题:了解网页的基本结构,使用直观的网页分析工具分析网页,如何使用正则表达式获取准确的字符串信息,以及使用Python实现简单的页面数据获取。
关键词:网络爬虫; Python;正则表达式;抓包分析
资助单位:防震减灾专项;中央高校基本科研业务费专项资金(ZY20180124)
参考资料:
[1]郭尔强,李波。大数据环境下基于Python的网络爬虫技术[J].计算机产品与流通,2017 (12): 82.
[2]李沛。基于Python的网络爬虫与反爬虫技术研究[J].计算机与数字工程, 2019, 47 (6): 1415-1420+1496.
p>
[3] 王朝阳.基于Python的图书馆信息系统设计与实现[D].长春:吉林大学,2016.
[4] 徐衡.社交网络数据采集技术研究与实现[D].长春:吉林大学,2016.
[5] 孙建利,贾卓生。基于Python的Web爬虫实现与内容分析研究[C]//中国计算机用户协会网络应用分会2017年第21届网络新技术与应用年会。中国计算机用户协会网络应用分会2017年第21届网络新技术与应用年会论文集.河北雄安:计算机科学编辑部,2017:275-277+281.
[6] 陈琳,任芳。基于Python的新浪微博数据爬虫程序设计[J].信息系统工程,2016 (9): 97-99.
[7] 卢淑芬。基于Python的Web爬虫系统设计与实现[J].计算机编程技能与维护,2019 (2): 26-27+51.
[8] 熊畅。基于Python爬虫技术的Web数据采集与分析研究[J].数字技术与应用, 2017 (9): 35-36.
[9] 吴双。基于python语言的Web数据挖掘与分析研究[J].计算机知识与技术, 2018, 14 (27):1-2.
作者简介:文雅娜(1999.03-),女,汉族,内蒙古包头人,本科,学士,研究方向:人工智能与软件开发与应用。
实时抓取网页数据(各大互联网公司各种团队的团队做的开放平台)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-03 11:03
实时抓取网页数据可以加入saas平台,如猿圈快数等。图片可以通过浏览器插件获取。百度地图中的数据量应该比较多,点开图片即可看到数据。数据可以通过百度开放平台获取。
联系我们吧,
百度地图的数据是大网络传输过来的.很多网站已经把数据封装好了,比如说qq.有些网站在接数据的时候只需要获取,不需要转发给每个网站.这样提高了互联网数据交换的效率.还有一个可能是,通过某种加密技术,运输过来的大量网站,先通过互联网传输进某些数据库,然后再转发给不同的网站.这样节省转发路由的时间.
这个服务我以前也很疑惑,但是我有不同的观点:第一,这其实是一种匿名的网络传输,方便传输,省时省力。第二,做出来的服务在不同国家可能不一样。至于说没必要,应该说不是必要,是不清楚某些国家怎么玩转。第三,这服务将来肯定也会有地图数据,就像现在的车牌一样。
有点不理解楼主的意思,百度地图数据源自哪里?人家是先有数据源,再要你们搞各种渠道弄了产品卖给你。比如cdn、数据库、存储、其他比如sns导航大数据之类的。
我不知道以后的百度地图数据是不是提供给各大互联网公司了,像腾讯、360之类的,他们分别搞各种各样的市场团队,里面可能有开放平台。腾讯地图和360地图目前已经拿到数据并开放免费数据了。我试用了一下各大互联网公司各种团队的团队做的开放平台。感觉有的提供一个百度apistore接口,有的提供各家公司api数据,数据质量层次不齐。 查看全部
实时抓取网页数据(各大互联网公司各种团队的团队做的开放平台)
实时抓取网页数据可以加入saas平台,如猿圈快数等。图片可以通过浏览器插件获取。百度地图中的数据量应该比较多,点开图片即可看到数据。数据可以通过百度开放平台获取。
联系我们吧,
百度地图的数据是大网络传输过来的.很多网站已经把数据封装好了,比如说qq.有些网站在接数据的时候只需要获取,不需要转发给每个网站.这样提高了互联网数据交换的效率.还有一个可能是,通过某种加密技术,运输过来的大量网站,先通过互联网传输进某些数据库,然后再转发给不同的网站.这样节省转发路由的时间.
这个服务我以前也很疑惑,但是我有不同的观点:第一,这其实是一种匿名的网络传输,方便传输,省时省力。第二,做出来的服务在不同国家可能不一样。至于说没必要,应该说不是必要,是不清楚某些国家怎么玩转。第三,这服务将来肯定也会有地图数据,就像现在的车牌一样。
有点不理解楼主的意思,百度地图数据源自哪里?人家是先有数据源,再要你们搞各种渠道弄了产品卖给你。比如cdn、数据库、存储、其他比如sns导航大数据之类的。
我不知道以后的百度地图数据是不是提供给各大互联网公司了,像腾讯、360之类的,他们分别搞各种各样的市场团队,里面可能有开放平台。腾讯地图和360地图目前已经拿到数据并开放免费数据了。我试用了一下各大互联网公司各种团队的团队做的开放平台。感觉有的提供一个百度apistore接口,有的提供各家公司api数据,数据质量层次不齐。
实时抓取网页数据(知乎ios端的效率可能更高的实时抓取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-02 21:02
实时抓取网页数据无论是互联网、pc端网页数据,还是移动端网页数据,通过分析你的电脑、手机、ipad的cookie记录以及浏览器的hook。都可以获取目标地址对应的页面。然后爬虫将爬取过的页面按照cookie记录的返回,还原出刚才的场景和内容。然后进行定制的渲染即可。这样就可以大致解决当前互联网数据抓取方面的问题。
真正工程实现上,这个估计是有技术难度的,主要是在大量ip抓取以及cookie记录上。如果不对于页面进行优化,应该抓取效率是很低的。
首先,手机端上常见的是:抓包解包分析header请求发送包加载包抓取源url后ajax返回包结合ajax回调过后,用正则匹配正则字符串抓取session里的header等进行抓取,有些是不抓取,有些是抓取ajax请求包,再根据返回地址抓取。知乎ios端的效率可能更高,因为有点历史原因,如果抓取数据实时保存,大多需要写代码抓取。
抓包分析请求地址,返回信息,人肉构造请求,判断,分析,静态页是这么一套链路,具体规范自己细细体会吧。如果要达到微信那种动态场景,估计不大可能实现。
很高兴这么多人回答这个问题,今天对微信的消息抓取进行了实现。目前开发使用了chrome浏览器,浏览器的hook机制和safari有所不同,但依然要满足hook机制的条件。ps:小程序有seuthread.js,内置了一个基本ui,可以作为各种界面交互的hook,然后通过getdata传递给hook来获取图片等响应数据。
可以抓取历史数据,接口响应返回有些延迟,但不影响用户体验,hook响应响应慢的场景时间在控制在2分钟。时间不够的情况下,会采用短连接,交互响应用textfield而不是传递fetchfrom{},短连接解决通信麻烦和重定向,这是实现最快的方案。定时判断请求连接是否连接,如果没连接,使用自己写的一个websocket服务,每天或每周进行一次流量控制,限制每次请求的时间。
通过这种一站式的解决方案,目前有些成果了,但这是需要一些时间的,我觉得微信微博朋友圈的数据抓取不大可能,因为没有准确的机制和规范,想要实现这个也只能试试。 查看全部
实时抓取网页数据(知乎ios端的效率可能更高的实时抓取网页数据)
实时抓取网页数据无论是互联网、pc端网页数据,还是移动端网页数据,通过分析你的电脑、手机、ipad的cookie记录以及浏览器的hook。都可以获取目标地址对应的页面。然后爬虫将爬取过的页面按照cookie记录的返回,还原出刚才的场景和内容。然后进行定制的渲染即可。这样就可以大致解决当前互联网数据抓取方面的问题。
真正工程实现上,这个估计是有技术难度的,主要是在大量ip抓取以及cookie记录上。如果不对于页面进行优化,应该抓取效率是很低的。
首先,手机端上常见的是:抓包解包分析header请求发送包加载包抓取源url后ajax返回包结合ajax回调过后,用正则匹配正则字符串抓取session里的header等进行抓取,有些是不抓取,有些是抓取ajax请求包,再根据返回地址抓取。知乎ios端的效率可能更高,因为有点历史原因,如果抓取数据实时保存,大多需要写代码抓取。
抓包分析请求地址,返回信息,人肉构造请求,判断,分析,静态页是这么一套链路,具体规范自己细细体会吧。如果要达到微信那种动态场景,估计不大可能实现。
很高兴这么多人回答这个问题,今天对微信的消息抓取进行了实现。目前开发使用了chrome浏览器,浏览器的hook机制和safari有所不同,但依然要满足hook机制的条件。ps:小程序有seuthread.js,内置了一个基本ui,可以作为各种界面交互的hook,然后通过getdata传递给hook来获取图片等响应数据。
可以抓取历史数据,接口响应返回有些延迟,但不影响用户体验,hook响应响应慢的场景时间在控制在2分钟。时间不够的情况下,会采用短连接,交互响应用textfield而不是传递fetchfrom{},短连接解决通信麻烦和重定向,这是实现最快的方案。定时判断请求连接是否连接,如果没连接,使用自己写的一个websocket服务,每天或每周进行一次流量控制,限制每次请求的时间。
通过这种一站式的解决方案,目前有些成果了,但这是需要一些时间的,我觉得微信微博朋友圈的数据抓取不大可能,因为没有准确的机制和规范,想要实现这个也只能试试。
实时抓取网页数据(为什么要学网络爬虫可以替代人工从网页中找到数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-02 13:08
为什么要学习网络爬虫
它可以代替人工从网页中查找数据并将其复制粘贴到excel中。这种重复性的工作,不仅浪费时间,而且一不留神,容易出错,解决了这些无法自动化、无法实时获取的公共数据的应用价值,我们可以借助KYC框架来了解,了解你的公司(了解您的公司),了解您的竞争对手(了解您的竞争对手),了解您的客户(了解您的客户)。这是通过理解和执行对公共数据的简单描述性分析可以带来的价值。此外,通过机器学习和统计算法分析,可以帮助企业在营销领域做4P(产品、价格、渠道)。地方)促销(促销))
网络爬虫的基本协议
robots协议
python爬虫的流程
主要可以分为三个部分:1.获取网页;2.解析网页(提取数据);3.存储数据;
1.获取网页就是向URL发送请求,会返回整个网页的数据
2.解析一个网页就是从整个网页的数据中提取出想要的数据
3.存数据就是存数据
三道工序的技术实现
1.获取网页
获取网页的基本技术:request、urllib和selenium(模拟浏览器)
获取网页先进技术:多进程多线程爬取、登录爬取、破IP封禁、服务器爬取
2.解析网页
解析网页的基本技术:re正则表达式、beautifulsoup和lxml
网页解析高级技术:解决中文乱码
3.存储的数据
数据存储的基本技术:存txt文件和存csv文件
存储数据的先进技术:存储在MySQL数据库中和存储在mongodb数据库中 查看全部
实时抓取网页数据(为什么要学网络爬虫可以替代人工从网页中找到数据?)
为什么要学习网络爬虫
它可以代替人工从网页中查找数据并将其复制粘贴到excel中。这种重复性的工作,不仅浪费时间,而且一不留神,容易出错,解决了这些无法自动化、无法实时获取的公共数据的应用价值,我们可以借助KYC框架来了解,了解你的公司(了解您的公司),了解您的竞争对手(了解您的竞争对手),了解您的客户(了解您的客户)。这是通过理解和执行对公共数据的简单描述性分析可以带来的价值。此外,通过机器学习和统计算法分析,可以帮助企业在营销领域做4P(产品、价格、渠道)。地方)促销(促销))
网络爬虫的基本协议
robots协议
python爬虫的流程
主要可以分为三个部分:1.获取网页;2.解析网页(提取数据);3.存储数据;
1.获取网页就是向URL发送请求,会返回整个网页的数据
2.解析一个网页就是从整个网页的数据中提取出想要的数据
3.存数据就是存数据
三道工序的技术实现
1.获取网页
获取网页的基本技术:request、urllib和selenium(模拟浏览器)
获取网页先进技术:多进程多线程爬取、登录爬取、破IP封禁、服务器爬取
2.解析网页
解析网页的基本技术:re正则表达式、beautifulsoup和lxml
网页解析高级技术:解决中文乱码
3.存储的数据
数据存储的基本技术:存txt文件和存csv文件
存储数据的先进技术:存储在MySQL数据库中和存储在mongodb数据库中
实时抓取网页数据(SpiderDuck如何工作?Twitter的工程问题及解决方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-01 06:14
推文通常收录指向网络上各种内容的链接,包括图像、视频、新闻文章 和博客文章。SpiderDuck 是一项 Twitter 服务,它实时抓取这些链接,解析下载内容并提取有趣的元数据,并在几秒钟内将这些数据提供给其他 Twitter 服务。
Twitter 的许多团队都需要访问链接的内容,尤其是要通过实时内容改进 Twitter 的产品。例如:
背景
在 SpiderDuck 之前,Twitter 有一项服务,通过发送 HEAD 请求和跟踪重定向来解析所有推文中的 URL。服务很简单,满足了当时公司的需求,但也有几个局限:
显然,我们需要构建一个真正的 URL 抓取工具,能够克服上述限制并满足公司的长期目标。我们最初的想法是使用或构建一些开源抓取代码,但我们意识到几乎每个可用的开源抓取工具都有两个我们不需要的功能:
因此,我们决定设计一个新系统来满足 Twitter 的实时需求,并随着它的发展而横向扩展。为了避免重新发明轮子,我们主要在开源模块上构建了新系统,以便我们可以继续利用开源社区的贡献。
这是 Twitter 的典型工程问题——它们与其他大型互联网公司的问题类似,但要求一切都实时工作提出了独特而有趣的挑战。
系统总览
以下是 SpiderDuck 工作原理的概述。下图显示了它的主要组成部分。
Kestrel:这是 Twitter 广泛使用的消息队列系统,用于对新推文进行排队。
调度程序:这些工作单元决定是否抓取 URL、调度抓取时间和跟踪重定向跳转(如果有)。抓取后,它解析下载的内容,提取元数据,将元数据写回元数据存储,并将原创数据写入内容存储。每个调度器独立工作;也就是说,我们可以向系统添加任意数量的调度程序,随着推文和 URL 数量的增加,水平扩展系统。
Fetcher:这些是 Thrift 服务器,用于维护短期 URL 获取队列,它们发送实际的 HTTP 获取请求并实现速率控制和处理 robots.txt。就像调度程序一样,它们可以随抓取速度水平扩展。
Memcached:这是 fetcher 用来临时存储 robots.txt 文件的分布式缓存。
Metadata Store:这是一个基于 Cassandra 的分布式哈希表,用于存储网页元数据和 URL 索引的解析信息,以及系统最近遇到的每个 URL 的爬取状态。该商店归 Twitter 所有,用于所有需要实时访问 URL 数据的客户服务。
内容存储:这是一个 HDFS 集群,用于存储下载的内容和所有爬取信息。
现在我们将详细介绍 SpiderDuck 的两个主要组件 - URL Scheduler 和 URLFetcher。
网址调度程序
下图描述了 SpiderDuck Scheduler 中的几个处理阶段。
与大多数 SpiderDuck 一样,Scheduler 构建在由 Twitter 开发的名为 Finagle 的开源异步 RPC 框架之上。(实际上,这是最早使用 Finagle 的项目之一)。上图中的每个块,除了 KestrelReader 之外,都是一个 Finagle 过滤器 - 一种抽象,它允许将一系列处理阶段连接到一个完全异步的管道中。完全异步允许 SpiderDuck 使用少量、固定数量的线程来处理高流量。
Kestrel Reader 会不断要求新的推文。当推文进入时,它们被发送到 TweetProcessor,它从中提取 URL。然后将每个 URL 发送到 Crawl Decider 阶段。此阶段从 MetadataStore 中读取 URL 的爬取状态,以确定 SpiderDuck 之前是否已看到该 URL。然后,Crawl Decider 根据预定义的爬取策略决定是否应该爬取 URL(也就是说,如果 SpiderDuck 在过去 X 天内看到了该 URL,则不再对其进行爬取)。如果 Decider 决定不抓取 URL,它会记录一个状态以指示处理已完成。如果它决定获取 URL,它将把 URL 发送到 Fetcher Client 阶段。
Fetcher Client 阶段使用客户端库与 Fetcher 对话。客户端库实现逻辑来决定使用哪个 Fetcher 来获取 URL;它还可以处理重定向。(重定向跳转链很常见,因为 Twitter 帖子上的 URL 大多被缩短。)通过调度程序的每个 URL 都有一个关联的上下文对象。Fetcher 客户端将包括状态、下载的标头和内容在内的获取信息添加到上下文对象,并将其传递给后处理器。后处理器将下载的数据交给元数据提取器,后者检测页面的编码并使用开源 HTML5 解析器解析页面的内容。提取库实现了一系列启发式方法来提取元数据,例如标题、介绍和代表性图像。然后后处理器将所有元数据和抓取信息写入元数据存储。如果需要,后处理器还会安排一系列相关的提取。相关抓取的一个示例是嵌入的媒体内容,例如图像。
在后处理之后,URL 上下文对象被传递到下一个阶段,该阶段使用一个名为 Scribe 的开源日志聚合器将所有信息(包括完整内容)记录在 ContentStore (HDFS) 日志中。此阶段还通知所有感兴趣的听众 URL 处理已完成。通知使用简单的发布者-订阅者模型,通过 Kestrel 的分散队列实现。
所有处理阶段都是异步运行的——没有线程会等待一个阶段完成。与正在处理的每个 URL 关联的状态都存储在关联的上下文对象中,因此线程模型也非常简单。异步实现还受益于 Finagle 和 Twitter Util 库提供的方便的抽象和构造。
网址提取器
让我们看看 Fetcher 如何处理 URL。
Fetcher 通过 Thrift 接口接收 URL。经过一些简单的确认后,Thrift 处理程序将 URL 传递给请求队列管理器,请求队列管理器将 URL 分配给适当的请求队列。计划任务将以固定速率从请求队列中读取。一旦从队列中取出 URL,它将被发送到 HTTPService 进行处理。基于 Finagle 构建的 HTTP 服务首先检查与 URL 关联的主机是否已经在缓存中。如果没有,那么它会为其创建一个 Finagle 客户端并安排对 robots.txt 文件的获取。下载 robots.txt 后,HTTP 服务会获取允许的 URL。robots.txt文件本身是缓存的,进程内Host Cache各一份,Memcached一份,防止每次有新的主机URL进来时重复爬取。
一些名为 Vulture 的任务会定期检查 Request Queue 和 Host Cache 中是否有一段时间未使用的队列和主机;如果找到,它们将被删除。Vulture 还通过日志和 Twitter Commons 状态输出库报告有用的统计数据。
Fetcher 的 Request Queue 还有一个重要的目标:速率限制。SpiderDuck 会限制对每个域名的 HTTP 抓取请求,以确保它不会使 Web 服务器过载。为了准确地限制速率,SpiderDuck 确保在任何时候每个 RequestQueue 都被分配给一个 Fetcher,并且在 Fetcher 失败时可以自动重新分配给另一个 Fetcher。一个名为 Pacemaker 的集群包将请求队列分配给 Fetcher 并管理故障转移。Fetcher 客户端库根据域名将 URL 分配给不同的请求队列。为整个网络设置的默认速率限制也可以根据需要被为特定域名设置的速率限制覆盖。也就是说,如果 URL 的进入速度超过了它们的处理速度,它们将拒绝告诉客户端它应该收敛的请求,
为了安全起见,Fetcher 被部署在 Twitter 数据中心内的一个特殊区域 DMZ 中。这意味着 Fetcher 无法访问 Twitter 的产品群和服务。因此,确保它们是轻量级和自力更生是非常重要的,这是指导设计的许多方面的原则。
Twitter 如何使用 SpiderDuck
Twitter 服务以多种方式使用 SpiderDuck 的数据。大多数将直接查询元数据存储以获取 URL 的元数据(例如,标题)和解析信息(所有重定向后的最终标准化 URL)。元数据存储是实时填充的,通常在推文中发布 URL 的几秒钟内。这些服务不直接与 Cassandra 通信,而是通过代理这些请求的 Spiderduck Thrift 服务器。这个中间层为 SpiderDuck 提供了在需要时透明地切换存储系统的灵活性。它还支持比直接访问 Cassandra 更高级别的 API 抽象。
其他服务会定期处理 SpiderDuck 在 HDFS 上的日志,以生成汇总统计信息,用于 Twitter 的内部测量仪表板或其他批处理分析。仪表板帮助我们回答诸如“每天在 Twitter 上分享多少张图片?”、“Twitter 用户最常链接到哪些新闻 网站?”之类的问题。和“昨天我们从某个 网站 上刮了多少?” 网页?”等等。
需要注意的是,这些服务通常不会告诉 SpiderDuck 要抓取什么。SpiderDuck 已经抓取了所有访问 Twitter 的 URL。相反,这些服务会在 URL 可用后要求他们提供信息。SpiderDuck 还允许这些服务直接请求 Fetcher 通过 HTTP 获取任意内容(因此它们可以从我们的数据中心设置、速率限制、robot.txt 支持等中受益),但这种用法并不普遍。
性能数据
SpiderDuck 每秒处理数百个 URL。其中大部分在 SpiderDuck 获取策略定义的时间窗口内是唯一的,因此它们将被获取。对于抓取的 URL,SpiderDuck 的中位处理延迟低于 2 秒,其中 99% 的处理延迟低于 5 秒。延迟是根据推文发布时间来衡量的,即在用户点击“推文”按钮后的 5 秒内,推文中的 URL 被提取出来,准备爬取,并捕获所有重定向跳转。内容被下载和解析,元数据被提取,并且已经通过 MetadataStore 提供给客户。大部分时间要么花在 Fetcher 请求队列中(由于速率限制),要么实际从外部 Web 服务器获取 URL。
SpiderDuck 基于 Cassandra 的元数据存储每秒可以处理近 10,000 个请求。这些请求通常针对单个或小批量(少于 20 个)的 URL,但它也可以处理大批量(200-300 个 URL)的请求。该存储系统的读取延迟中值约为 4 到 5 秒,第 99 个百分位范围约为 50 到 60 毫秒。
谢谢
SpiderDuck 的核心团队包括以下成员:Abhi Khune、Michael Busch、Paul Burstein、Raghavendra Prabhu、Tian Wang 和 YiZhuang。此外,我们要感谢公司中的以下人员,他们直接为该项目做出了贡献,帮助设置了 SpiderDuck 直接依赖的部分(例如 Cassandra、Finagle、Pacemaker 和 Scribe),或者帮助构建SpiderDuck 独特的数据中心设置:Alan Liang、Brady Catherman、Chris Goffinet、Dmitriy Ryaboy、Gilad Mishne、John Corwin、John Sirois、Jonathan Boulle、Jonathan Reichhold、Marius Eriksen、Nick Kallen、Ryan King、Samuel Luckenbill、Steve Jiang、Stu Hood和特拉维斯克劳福德。我们还要感谢整个 Twitter 搜索团队的宝贵设计反馈和支持。如果你也想参与这样的项目,
原文地址::///2011/11/spiderduck-twitters-real-time-url.html 查看全部
实时抓取网页数据(SpiderDuck如何工作?Twitter的工程问题及解决方案)
推文通常收录指向网络上各种内容的链接,包括图像、视频、新闻文章 和博客文章。SpiderDuck 是一项 Twitter 服务,它实时抓取这些链接,解析下载内容并提取有趣的元数据,并在几秒钟内将这些数据提供给其他 Twitter 服务。
Twitter 的许多团队都需要访问链接的内容,尤其是要通过实时内容改进 Twitter 的产品。例如:
背景
在 SpiderDuck 之前,Twitter 有一项服务,通过发送 HEAD 请求和跟踪重定向来解析所有推文中的 URL。服务很简单,满足了当时公司的需求,但也有几个局限:
显然,我们需要构建一个真正的 URL 抓取工具,能够克服上述限制并满足公司的长期目标。我们最初的想法是使用或构建一些开源抓取代码,但我们意识到几乎每个可用的开源抓取工具都有两个我们不需要的功能:
因此,我们决定设计一个新系统来满足 Twitter 的实时需求,并随着它的发展而横向扩展。为了避免重新发明轮子,我们主要在开源模块上构建了新系统,以便我们可以继续利用开源社区的贡献。
这是 Twitter 的典型工程问题——它们与其他大型互联网公司的问题类似,但要求一切都实时工作提出了独特而有趣的挑战。
系统总览
以下是 SpiderDuck 工作原理的概述。下图显示了它的主要组成部分。
Kestrel:这是 Twitter 广泛使用的消息队列系统,用于对新推文进行排队。
调度程序:这些工作单元决定是否抓取 URL、调度抓取时间和跟踪重定向跳转(如果有)。抓取后,它解析下载的内容,提取元数据,将元数据写回元数据存储,并将原创数据写入内容存储。每个调度器独立工作;也就是说,我们可以向系统添加任意数量的调度程序,随着推文和 URL 数量的增加,水平扩展系统。
Fetcher:这些是 Thrift 服务器,用于维护短期 URL 获取队列,它们发送实际的 HTTP 获取请求并实现速率控制和处理 robots.txt。就像调度程序一样,它们可以随抓取速度水平扩展。
Memcached:这是 fetcher 用来临时存储 robots.txt 文件的分布式缓存。
Metadata Store:这是一个基于 Cassandra 的分布式哈希表,用于存储网页元数据和 URL 索引的解析信息,以及系统最近遇到的每个 URL 的爬取状态。该商店归 Twitter 所有,用于所有需要实时访问 URL 数据的客户服务。
内容存储:这是一个 HDFS 集群,用于存储下载的内容和所有爬取信息。
现在我们将详细介绍 SpiderDuck 的两个主要组件 - URL Scheduler 和 URLFetcher。
网址调度程序
下图描述了 SpiderDuck Scheduler 中的几个处理阶段。
与大多数 SpiderDuck 一样,Scheduler 构建在由 Twitter 开发的名为 Finagle 的开源异步 RPC 框架之上。(实际上,这是最早使用 Finagle 的项目之一)。上图中的每个块,除了 KestrelReader 之外,都是一个 Finagle 过滤器 - 一种抽象,它允许将一系列处理阶段连接到一个完全异步的管道中。完全异步允许 SpiderDuck 使用少量、固定数量的线程来处理高流量。
Kestrel Reader 会不断要求新的推文。当推文进入时,它们被发送到 TweetProcessor,它从中提取 URL。然后将每个 URL 发送到 Crawl Decider 阶段。此阶段从 MetadataStore 中读取 URL 的爬取状态,以确定 SpiderDuck 之前是否已看到该 URL。然后,Crawl Decider 根据预定义的爬取策略决定是否应该爬取 URL(也就是说,如果 SpiderDuck 在过去 X 天内看到了该 URL,则不再对其进行爬取)。如果 Decider 决定不抓取 URL,它会记录一个状态以指示处理已完成。如果它决定获取 URL,它将把 URL 发送到 Fetcher Client 阶段。
Fetcher Client 阶段使用客户端库与 Fetcher 对话。客户端库实现逻辑来决定使用哪个 Fetcher 来获取 URL;它还可以处理重定向。(重定向跳转链很常见,因为 Twitter 帖子上的 URL 大多被缩短。)通过调度程序的每个 URL 都有一个关联的上下文对象。Fetcher 客户端将包括状态、下载的标头和内容在内的获取信息添加到上下文对象,并将其传递给后处理器。后处理器将下载的数据交给元数据提取器,后者检测页面的编码并使用开源 HTML5 解析器解析页面的内容。提取库实现了一系列启发式方法来提取元数据,例如标题、介绍和代表性图像。然后后处理器将所有元数据和抓取信息写入元数据存储。如果需要,后处理器还会安排一系列相关的提取。相关抓取的一个示例是嵌入的媒体内容,例如图像。
在后处理之后,URL 上下文对象被传递到下一个阶段,该阶段使用一个名为 Scribe 的开源日志聚合器将所有信息(包括完整内容)记录在 ContentStore (HDFS) 日志中。此阶段还通知所有感兴趣的听众 URL 处理已完成。通知使用简单的发布者-订阅者模型,通过 Kestrel 的分散队列实现。
所有处理阶段都是异步运行的——没有线程会等待一个阶段完成。与正在处理的每个 URL 关联的状态都存储在关联的上下文对象中,因此线程模型也非常简单。异步实现还受益于 Finagle 和 Twitter Util 库提供的方便的抽象和构造。
网址提取器
让我们看看 Fetcher 如何处理 URL。
Fetcher 通过 Thrift 接口接收 URL。经过一些简单的确认后,Thrift 处理程序将 URL 传递给请求队列管理器,请求队列管理器将 URL 分配给适当的请求队列。计划任务将以固定速率从请求队列中读取。一旦从队列中取出 URL,它将被发送到 HTTPService 进行处理。基于 Finagle 构建的 HTTP 服务首先检查与 URL 关联的主机是否已经在缓存中。如果没有,那么它会为其创建一个 Finagle 客户端并安排对 robots.txt 文件的获取。下载 robots.txt 后,HTTP 服务会获取允许的 URL。robots.txt文件本身是缓存的,进程内Host Cache各一份,Memcached一份,防止每次有新的主机URL进来时重复爬取。
一些名为 Vulture 的任务会定期检查 Request Queue 和 Host Cache 中是否有一段时间未使用的队列和主机;如果找到,它们将被删除。Vulture 还通过日志和 Twitter Commons 状态输出库报告有用的统计数据。
Fetcher 的 Request Queue 还有一个重要的目标:速率限制。SpiderDuck 会限制对每个域名的 HTTP 抓取请求,以确保它不会使 Web 服务器过载。为了准确地限制速率,SpiderDuck 确保在任何时候每个 RequestQueue 都被分配给一个 Fetcher,并且在 Fetcher 失败时可以自动重新分配给另一个 Fetcher。一个名为 Pacemaker 的集群包将请求队列分配给 Fetcher 并管理故障转移。Fetcher 客户端库根据域名将 URL 分配给不同的请求队列。为整个网络设置的默认速率限制也可以根据需要被为特定域名设置的速率限制覆盖。也就是说,如果 URL 的进入速度超过了它们的处理速度,它们将拒绝告诉客户端它应该收敛的请求,
为了安全起见,Fetcher 被部署在 Twitter 数据中心内的一个特殊区域 DMZ 中。这意味着 Fetcher 无法访问 Twitter 的产品群和服务。因此,确保它们是轻量级和自力更生是非常重要的,这是指导设计的许多方面的原则。
Twitter 如何使用 SpiderDuck
Twitter 服务以多种方式使用 SpiderDuck 的数据。大多数将直接查询元数据存储以获取 URL 的元数据(例如,标题)和解析信息(所有重定向后的最终标准化 URL)。元数据存储是实时填充的,通常在推文中发布 URL 的几秒钟内。这些服务不直接与 Cassandra 通信,而是通过代理这些请求的 Spiderduck Thrift 服务器。这个中间层为 SpiderDuck 提供了在需要时透明地切换存储系统的灵活性。它还支持比直接访问 Cassandra 更高级别的 API 抽象。
其他服务会定期处理 SpiderDuck 在 HDFS 上的日志,以生成汇总统计信息,用于 Twitter 的内部测量仪表板或其他批处理分析。仪表板帮助我们回答诸如“每天在 Twitter 上分享多少张图片?”、“Twitter 用户最常链接到哪些新闻 网站?”之类的问题。和“昨天我们从某个 网站 上刮了多少?” 网页?”等等。
需要注意的是,这些服务通常不会告诉 SpiderDuck 要抓取什么。SpiderDuck 已经抓取了所有访问 Twitter 的 URL。相反,这些服务会在 URL 可用后要求他们提供信息。SpiderDuck 还允许这些服务直接请求 Fetcher 通过 HTTP 获取任意内容(因此它们可以从我们的数据中心设置、速率限制、robot.txt 支持等中受益),但这种用法并不普遍。
性能数据
SpiderDuck 每秒处理数百个 URL。其中大部分在 SpiderDuck 获取策略定义的时间窗口内是唯一的,因此它们将被获取。对于抓取的 URL,SpiderDuck 的中位处理延迟低于 2 秒,其中 99% 的处理延迟低于 5 秒。延迟是根据推文发布时间来衡量的,即在用户点击“推文”按钮后的 5 秒内,推文中的 URL 被提取出来,准备爬取,并捕获所有重定向跳转。内容被下载和解析,元数据被提取,并且已经通过 MetadataStore 提供给客户。大部分时间要么花在 Fetcher 请求队列中(由于速率限制),要么实际从外部 Web 服务器获取 URL。
SpiderDuck 基于 Cassandra 的元数据存储每秒可以处理近 10,000 个请求。这些请求通常针对单个或小批量(少于 20 个)的 URL,但它也可以处理大批量(200-300 个 URL)的请求。该存储系统的读取延迟中值约为 4 到 5 秒,第 99 个百分位范围约为 50 到 60 毫秒。
谢谢
SpiderDuck 的核心团队包括以下成员:Abhi Khune、Michael Busch、Paul Burstein、Raghavendra Prabhu、Tian Wang 和 YiZhuang。此外,我们要感谢公司中的以下人员,他们直接为该项目做出了贡献,帮助设置了 SpiderDuck 直接依赖的部分(例如 Cassandra、Finagle、Pacemaker 和 Scribe),或者帮助构建SpiderDuck 独特的数据中心设置:Alan Liang、Brady Catherman、Chris Goffinet、Dmitriy Ryaboy、Gilad Mishne、John Corwin、John Sirois、Jonathan Boulle、Jonathan Reichhold、Marius Eriksen、Nick Kallen、Ryan King、Samuel Luckenbill、Steve Jiang、Stu Hood和特拉维斯克劳福德。我们还要感谢整个 Twitter 搜索团队的宝贵设计反馈和支持。如果你也想参与这样的项目,
原文地址::///2011/11/spiderduck-twitters-real-time-url.html
实时抓取网页数据(Python3基本语法,抓取境外投资企业(机构)名录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-31 06:09
【新手任务】
老板:我们在海外市场,吸引投资人很重要。你去把所有的海外投资企业(机构)都抄给我。
任务.png
一共2606页,点击下一页,然后ctrl+C,再Ctrl+V,准备复制到黎明。环顾四周,新来的实习生们都回学校做毕业论文了。
【解决方案】
知识点:Python 3基础语法、splinter库和xpath基础知识
情况1:
Python 使用 splinter 库来控制 chrome 浏览器,打开网页,获取数据。抢占境外投资企业(机构)名录。
思路分析:
第 1 步:安装碎片
百度splinter安装,建议先安装anaconda(python常用库基本都有),然后再安装splinter
第二步:使用splinter打开chrome并访问链接
from splinter import Browser
browser = Browser('chrome') #打开谷歌浏览器
browser.visit('http://femhzs.mofcom.gov.cn/fecpmvc/pages/fem/CorpJWList.html') #访问链接
打开谷歌浏览器并访问link.png
第 3 步:获取信息
# 通过谷歌浏览器的检查功能,可以很迅速地获取所需元素的地址。
# find_by_xpath(XPath地址) 返回值是储存在列表中的
# 这里是只有一个元素的列表,所以要选择列表第一个元素的值
r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.value # 取得1行1列的值
r1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.value # 取得1行2列的值
r1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.value# 取得1行3列的值
browser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click() # 点击下一页
# 打印数据,并退出浏览器
print(r1c1,r1c2,r1c3)
browser.quit()
【结论】
本文简要介绍了如何使用python splinter库来操作谷歌浏览器,然后定位到想要的元素,然后获取元素的值。采集完成后,打印数据并退出浏览器。数据存储请参考插上翅膀让Excel飞起来-xlwings(一)。完整的上百页数据的获取只是在代码中加了一个循环,有需要我再讨论下次详细说。。完整代码如下:
from splinter import Browser
browser = Browser('chrome')
browser.visit('http://femhzs.mofcom.gov.cn/fecpmvc/pages/fem/CorpJWList.html')
r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.value
r1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.value
r1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.value
browser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click()
# 打印数据,并退出浏览器
print(r1c1,r1c2,r1c3)
browser.quit()
参考
Xpath 实例
分裂官方文档 查看全部
实时抓取网页数据(Python3基本语法,抓取境外投资企业(机构)名录)
【新手任务】
老板:我们在海外市场,吸引投资人很重要。你去把所有的海外投资企业(机构)都抄给我。

任务.png
一共2606页,点击下一页,然后ctrl+C,再Ctrl+V,准备复制到黎明。环顾四周,新来的实习生们都回学校做毕业论文了。
【解决方案】
知识点:Python 3基础语法、splinter库和xpath基础知识
情况1:
Python 使用 splinter 库来控制 chrome 浏览器,打开网页,获取数据。抢占境外投资企业(机构)名录。
思路分析:
第 1 步:安装碎片
百度splinter安装,建议先安装anaconda(python常用库基本都有),然后再安装splinter
第二步:使用splinter打开chrome并访问链接
from splinter import Browser
browser = Browser('chrome') #打开谷歌浏览器
browser.visit('http://femhzs.mofcom.gov.cn/fecpmvc/pages/fem/CorpJWList.html') #访问链接
打开谷歌浏览器并访问link.png
第 3 步:获取信息
# 通过谷歌浏览器的检查功能,可以很迅速地获取所需元素的地址。
# find_by_xpath(XPath地址) 返回值是储存在列表中的
# 这里是只有一个元素的列表,所以要选择列表第一个元素的值
r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.value # 取得1行1列的值
r1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.value # 取得1行2列的值
r1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.value# 取得1行3列的值
browser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click() # 点击下一页
# 打印数据,并退出浏览器
print(r1c1,r1c2,r1c3)
browser.quit()
【结论】
本文简要介绍了如何使用python splinter库来操作谷歌浏览器,然后定位到想要的元素,然后获取元素的值。采集完成后,打印数据并退出浏览器。数据存储请参考插上翅膀让Excel飞起来-xlwings(一)。完整的上百页数据的获取只是在代码中加了一个循环,有需要我再讨论下次详细说。。完整代码如下:
from splinter import Browser
browser = Browser('chrome')
browser.visit('http://femhzs.mofcom.gov.cn/fecpmvc/pages/fem/CorpJWList.html')
r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.value
r1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.value
r1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.value
browser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click()
# 打印数据,并退出浏览器
print(r1c1,r1c2,r1c3)
browser.quit()
参考
Xpath 实例
分裂官方文档
实时抓取网页数据(不转售客户资料网站手机号码抓取软件抓取你网站手机号的原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-29 16:04
浏览页面后,如果要获取客户的手机号和手机号,可以100%抓取网站访客的手机号。有没有这样的手机号获取系统?
当然还有:我们的老师可以通过数据的实现来抓取自己公司的手机号网站,也可以实现中国同行之间的相互抓取,APP抓取指定的抓取也是没问题的网站 和应用的电话号码
郑重声明:不转售客户资料,不转售客户资料,不转售客户资料网站手机号码抓取软件
抓取你的网站手机号的原理是在网站的头部插入一个设计码。当访问者访问 网站 页面时,他们会询问用户的手机号码。
同行公司相互爬取和APP爬取的工作原理:互联网大数据运营商与代理商合作,基本技术原理是当访问者使用手机3G总流量浏览信息时网站设计或APP软件的情况下,会影响到属于公司自身的https报告。访客的手机号码,浏览和访问我们的区别是什么网站,停留了多长时间,都可以由访客计算,最终计算。需求和实体经济模型。
无论您想要什么,我们都有一个系统来获取 网站 的移动流量。
任何在网上做任何事的人都摆脱不了运营商
运营商存储每个人的在线行为、电话、短信交互、实时位置等
每一个行为都反映了客户的需求
您希望客户解决什么问题行为,无非是为需要我们的国家寻找和提取
网站掌握手机号,低成本客源+高效改造,解决客户问题,利润翻倍 查看全部
实时抓取网页数据(不转售客户资料网站手机号码抓取软件抓取你网站手机号的原理)
浏览页面后,如果要获取客户的手机号和手机号,可以100%抓取网站访客的手机号。有没有这样的手机号获取系统?
当然还有:我们的老师可以通过数据的实现来抓取自己公司的手机号网站,也可以实现中国同行之间的相互抓取,APP抓取指定的抓取也是没问题的网站 和应用的电话号码
郑重声明:不转售客户资料,不转售客户资料,不转售客户资料网站手机号码抓取软件
抓取你的网站手机号的原理是在网站的头部插入一个设计码。当访问者访问 网站 页面时,他们会询问用户的手机号码。
同行公司相互爬取和APP爬取的工作原理:互联网大数据运营商与代理商合作,基本技术原理是当访问者使用手机3G总流量浏览信息时网站设计或APP软件的情况下,会影响到属于公司自身的https报告。访客的手机号码,浏览和访问我们的区别是什么网站,停留了多长时间,都可以由访客计算,最终计算。需求和实体经济模型。
无论您想要什么,我们都有一个系统来获取 网站 的移动流量。
任何在网上做任何事的人都摆脱不了运营商
运营商存储每个人的在线行为、电话、短信交互、实时位置等
每一个行为都反映了客户的需求
您希望客户解决什么问题行为,无非是为需要我们的国家寻找和提取
网站掌握手机号,低成本客源+高效改造,解决客户问题,利润翻倍
实时抓取网页数据(为什么要学网络爬虫可以替代人工从网页中找到数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-29 07:09
为什么要学习网络爬虫
它可以代替人工从网页中查找数据并将其复制粘贴到excel中。这种重复性的工作,不仅浪费时间,而且一不留神,容易出错,解决了这些无法自动化、无法实时获取的公共数据的应用价值,我们可以借助KYC框架来了解,了解你的公司(了解您的公司),了解您的竞争对手(了解您的竞争对手),了解您的客户(了解您的客户)。这是通过理解和执行对公共数据的简单描述性分析可以带来的价值。进一步,通过机器学习和统计算法分析,可以帮助企业做4Ps(产品)、价格(price)、渠道(place)推广(promotion))
网络爬虫的基本协议
robots协议
python爬虫的流程
主要可以分为三个部分:1.获取网页;2.解析网页(提取数据);3.存储数据;
1.获取网页就是向URL发送请求,会返回整个网页的数据
2.解析一个网页就是从整个网页的数据中提取出想要的数据
3.存数据就是存数据
三道工序的技术实现
1.获取网页
获取网页的基本技术:request、urllib和selenium(模拟浏览器)
网页获取先进技术:多进程多线程爬取、登录爬取、突破IP封禁、服务器爬取
2.解析网页
解析网页的基本技术:re正则表达式、beautifulsoup和lxml
网页解析高级技术:解决中文乱码
3.存储的数据
数据存储的基本技术:存txt文件和存csv文件
存储数据的先进技术:存储在MySQL数据库中和存储在mongodb数据库中 查看全部
实时抓取网页数据(为什么要学网络爬虫可以替代人工从网页中找到数据?)
为什么要学习网络爬虫
它可以代替人工从网页中查找数据并将其复制粘贴到excel中。这种重复性的工作,不仅浪费时间,而且一不留神,容易出错,解决了这些无法自动化、无法实时获取的公共数据的应用价值,我们可以借助KYC框架来了解,了解你的公司(了解您的公司),了解您的竞争对手(了解您的竞争对手),了解您的客户(了解您的客户)。这是通过理解和执行对公共数据的简单描述性分析可以带来的价值。进一步,通过机器学习和统计算法分析,可以帮助企业做4Ps(产品)、价格(price)、渠道(place)推广(promotion))
网络爬虫的基本协议
robots协议
python爬虫的流程
主要可以分为三个部分:1.获取网页;2.解析网页(提取数据);3.存储数据;
1.获取网页就是向URL发送请求,会返回整个网页的数据
2.解析一个网页就是从整个网页的数据中提取出想要的数据
3.存数据就是存数据
三道工序的技术实现
1.获取网页
获取网页的基本技术:request、urllib和selenium(模拟浏览器)
网页获取先进技术:多进程多线程爬取、登录爬取、突破IP封禁、服务器爬取
2.解析网页
解析网页的基本技术:re正则表达式、beautifulsoup和lxml
网页解析高级技术:解决中文乱码
3.存储的数据
数据存储的基本技术:存txt文件和存csv文件
存储数据的先进技术:存储在MySQL数据库中和存储在mongodb数据库中
实时抓取网页数据(33款常用的大数据分析工具推荐(最新)-可用来抓数据的开源爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-29 07:05
链接提交工具可以实时向百度推送数据,创建并提交站点地图,提交收录网页链接,帮助百度发现和了解你的网站。
来自.wkwm17c48105ed5{display:none;font-size:12px;}百度文库。
特点:网页抓取、信息提取、数据提取工具包,操作简单 11、Playfishplayfish是Java技术,综合应用多种开源。
我想抓取一个国外网站的数据,有什么好的数据抓取工具推荐吗?.
33个用于抓取数据的开源爬虫软件工具 每个人都是产品经理。
如何防止恶意爬虫窃取我的 网站 上的所有数据?我不太关心 SEO,虽然我不想阻止合法的抓取。
刮:开始数据刮工作。ExportdataCSV:以 CSV 格式导出捕获的数据。在这里,有一个简单的了解就足够了。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
呵呵,楼上说的很清楚了,你得先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据采集,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据采集系统,可以搜索详情,它们是国内信息的采集 的创始人。
比如等待事件或点击某些项目,而不仅仅是抓取数据,MechanicalSoup 确实为这款浏览器提供了网络抓取能力。 查看全部
实时抓取网页数据(33款常用的大数据分析工具推荐(最新)-可用来抓数据的开源爬虫)
链接提交工具可以实时向百度推送数据,创建并提交站点地图,提交收录网页链接,帮助百度发现和了解你的网站。
来自.wkwm17c48105ed5{display:none;font-size:12px;}百度文库。
特点:网页抓取、信息提取、数据提取工具包,操作简单 11、Playfishplayfish是Java技术,综合应用多种开源。
我想抓取一个国外网站的数据,有什么好的数据抓取工具推荐吗?.
33个用于抓取数据的开源爬虫软件工具 每个人都是产品经理。

如何防止恶意爬虫窃取我的 网站 上的所有数据?我不太关心 SEO,虽然我不想阻止合法的抓取。
刮:开始数据刮工作。ExportdataCSV:以 CSV 格式导出捕获的数据。在这里,有一个简单的了解就足够了。

30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
呵呵,楼上说的很清楚了,你得先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据采集,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据采集系统,可以搜索详情,它们是国内信息的采集 的创始人。
比如等待事件或点击某些项目,而不仅仅是抓取数据,MechanicalSoup 确实为这款浏览器提供了网络抓取能力。
实时抓取网页数据(成都网络推广如何提高搜索引擎抓取量提升的技巧成都)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-24 06:19
在成都网站网络推广的优化中,网站想要有排名,就需要有更好的搜索引擎爬取量,得到蜘蛛更多的关注和“呵护”,为了更好的提高网站收录,提高排名,如何提高搜索引擎的爬取量?下面成都网络推广就带你一起来了解一下。
1、维护网站更新频率
网站一定要做好高价值内容网站的定期更新。蜘蛛爬行非常具有战略意义。做好文章的更新,保持良好的频率,让蜘蛛形成更好的习惯。
2、提升用户体验
根据同目的搜索引擎更新规则,百度蜘蛛也优先抓取用户体验好网站,因为蜘蛛喜欢用户体验好网站,所以大家做好这也是很重要。
3、外部链接
成都网推广表示,优质网站先站后,百度对垃圾外链的过滤非常严格,但真正的优质外链对于排名和爬取还是很有用的。
4、保证服务器稳定性
服务器稳定性包括稳定性和速度两个方面。服务器越快,爬虫的效率就越高,这对用户体验也有一定的影响。在服务器稳定的情况下,不会影响蜘蛛的爬取状态,不会卡死,从而保证网站被爬取的速度,增加爬取量。
以上就是成都网络推广为大家总结的一些提高网站刷量的技巧。通过以上的介绍,相信你会对这点有更深入的了解,并帮助你提高自己的网站排名,推动网站的发展越来越好。 查看全部
实时抓取网页数据(成都网络推广如何提高搜索引擎抓取量提升的技巧成都)
在成都网站网络推广的优化中,网站想要有排名,就需要有更好的搜索引擎爬取量,得到蜘蛛更多的关注和“呵护”,为了更好的提高网站收录,提高排名,如何提高搜索引擎的爬取量?下面成都网络推广就带你一起来了解一下。
1、维护网站更新频率
网站一定要做好高价值内容网站的定期更新。蜘蛛爬行非常具有战略意义。做好文章的更新,保持良好的频率,让蜘蛛形成更好的习惯。
2、提升用户体验
根据同目的搜索引擎更新规则,百度蜘蛛也优先抓取用户体验好网站,因为蜘蛛喜欢用户体验好网站,所以大家做好这也是很重要。
3、外部链接
成都网推广表示,优质网站先站后,百度对垃圾外链的过滤非常严格,但真正的优质外链对于排名和爬取还是很有用的。
4、保证服务器稳定性
服务器稳定性包括稳定性和速度两个方面。服务器越快,爬虫的效率就越高,这对用户体验也有一定的影响。在服务器稳定的情况下,不会影响蜘蛛的爬取状态,不会卡死,从而保证网站被爬取的速度,增加爬取量。
以上就是成都网络推广为大家总结的一些提高网站刷量的技巧。通过以上的介绍,相信你会对这点有更深入的了解,并帮助你提高自己的网站排名,推动网站的发展越来越好。
实时抓取网页数据(【】续前一篇RSelenium包抓取包)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-14 21:16
继续
上一篇RSelenium包抓取了链家网(上图:模拟点击和页面抓取),重点关注网页自动点击的问题。虽然代码也可以抓取完整的数据,但如果没有错误或警告中断抓取,它就会这样做。由于LinkinfoFunc和HouseinfoFunc都是封装好的函数,一旦中断,中断前捕获的数据无法写入数据帧或列表。
当要抓取的数据量大、耗时长时,难免会出现网络中断等各种问题。因此,本文在上一篇文章的基础上,增加了一个for循环,并引入了tryCatch函数来进行简单的错误处理。两者对比如下:
页面准备,Step1的代码没有变化 Step2 删除数据框结果,将数据存储的任务交给Step3 Step3 添加for循环,并引入tryCatch函数
另外,文中重复的代码不再标注。
<p>1library(rvest)
2library(stringr)
3library(RSelenium)
4remDr %
13 unlist() %>% gsub(":", "", .)
14 totalpage %
6 html_text() %>% paste(., unit, sep = "")
7 downpayment % html_nodes(".taxtext span") %>% html_text() %>% .[1]
8 persquare % html_nodes("span.unitPriceValue") %>% html_text()
9 area % html_nodes(".area .mainInfo") %>% html_text()
10 title % html_nodes(".title h1") %>% html_text()
11 subtitle % html_nodes(".title div.sub") %>% html_text()
12 room % html_nodes(".room .mainInfo") %>% html_text()
13 floor % html_nodes(".room .subInfo") %>% html_text()
14 data 查看全部
实时抓取网页数据(【】续前一篇RSelenium包抓取包)
继续
上一篇RSelenium包抓取了链家网(上图:模拟点击和页面抓取),重点关注网页自动点击的问题。虽然代码也可以抓取完整的数据,但如果没有错误或警告中断抓取,它就会这样做。由于LinkinfoFunc和HouseinfoFunc都是封装好的函数,一旦中断,中断前捕获的数据无法写入数据帧或列表。
当要抓取的数据量大、耗时长时,难免会出现网络中断等各种问题。因此,本文在上一篇文章的基础上,增加了一个for循环,并引入了tryCatch函数来进行简单的错误处理。两者对比如下:
页面准备,Step1的代码没有变化 Step2 删除数据框结果,将数据存储的任务交给Step3 Step3 添加for循环,并引入tryCatch函数
另外,文中重复的代码不再标注。
<p>1library(rvest)
2library(stringr)
3library(RSelenium)
4remDr %
13 unlist() %>% gsub(":", "", .)
14 totalpage %
6 html_text() %>% paste(., unit, sep = "")
7 downpayment % html_nodes(".taxtext span") %>% html_text() %>% .[1]
8 persquare % html_nodes("span.unitPriceValue") %>% html_text()
9 area % html_nodes(".area .mainInfo") %>% html_text()
10 title % html_nodes(".title h1") %>% html_text()
11 subtitle % html_nodes(".title div.sub") %>% html_text()
12 room % html_nodes(".room .mainInfo") %>% html_text()
13 floor % html_nodes(".room .subInfo") %>% html_text()
14 data
实时抓取网页数据(各个新媒体APP上的疫情地图,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2022-02-14 20:19
2020年注定是不平凡的一年。熙熙攘攘的春节市场已经失去了往日的喧嚣。突如其来的新冠肺炎疫情牵动着国人的心。想必很多人每天早上睁眼后的第一件事就是在新媒体APP上点击疫情地图,查看全国各省市的疫情数据。
在互联网高速发展的今天,大数据、云计算、人工智能等技术为疫情防控提供了有力支撑。其中,疫情信息的实时、准确、全面、生动的传递,做到了疫情信息量最大。透明度。这使亿万中国人民能够充分了解疫情发展的真实情况,做好必要的个人防护和充分的心理准备,从而有效减少疫情蔓延,保持最大程度的冷静和理性。
我们跟踪了很多新媒体平台,梳理了各个平台的疫情大数据服务。各平台提供的基本功能几乎相同,包括:
1. 疫情数据:展示全国、省、市累计和每日新增确诊/疑似/死亡/治愈病例数据,并通过疫情地图和各种形式的图表展示;
2.最新进展:聚合最新重要疫情信息,大部分为官方发布的不容错过的重要内容;
3.同程查询:可根据出行日期、车次/车牌/航班号、城市等查询确诊病例的具体行程信息,方便个人防控;
4.辟谣查实:对一些广为流传的疫情信息或防控方法的真伪进行鉴别;
5.发热门诊:提供各省市医疗机构信息,可以是文字或地图形式;
6.本地疫情:根据用户所在城市,显示本地确诊信息和本地相关疫情内容;
7.科普知识:个人防护知识、心理健康知识、疾病常识等。
那么,各种新媒体平台上的这些疫情数据和相关内容是从哪里来的呢?为什么某些平台上的数据略有不同?每个新媒体平台是如何获取和处理这些数据的?
首先,各个新媒体平台上的疫情核心数据几乎都是通过爬虫技术从国家和地方卫健委的官方网站根据他们的每日疫情报告文章提取出来的。之后,将这些数据汇总并以地图、趋势图等可视化图表的形式展示出来,方便大家。
如下图,湖北卫健委官方网站上,以短信形式发布疫情核心数据:
在各大新媒体平台上,数字依旧是那些数字,但呈现形式变得更加生动,如下图:
至于其他类型信息的来源,几乎都是一些官方渠道提供的文字信息或者可以公开搜索的信息,数据来源会更加丰富。除了国家卫健委的官方网站,其他政府部门也可能包括在内。、医疗机构、学术机构、权威媒体甚至意见领袖网站或自媒体等,这些新媒体平台在获得这些信息后,会对其进行处理,形成其他栏目,比如最新的进度、同流程查询、发热门诊、辟谣查实等。
例如,海南省卫计委官网以文字形式公布了确诊病例的移动轨迹,如下图:
在各大新媒体平台上,经过排序后,变成了同一个行程查询widget,如下图:
对于不同的新媒体平台,数据略有不同,因为不同的平台对数据的采集和处理策略不同。例如,一些新媒体平台只采集前一天24:00的全国数据,每天更新一次;而一些新媒体平台则不时捕捉部分省份发布的最新数据,并随时更新。加入。
因此,很多互联网公司并不能真正产生数据,而只是官方数据的搬运者、整合者和处理者。除了这些疫情大数据,还有企业征信查询、天气预报查询、航班信息查询、交通违章查询等诸多领域,也有一些熟悉的互联网公司在做类似的事情。
事实上,只要有需要,任何企业都可以批量、实时、准确地获取这些公开信息。当然,对于一些非互联网公司来说,获取这些公开信息的目的,并不是在处理后为普通用户打造互联网产品,而是与自己公司的业务和产品相结合,为自己的客户提供更全面的增值服务.
那么,如何进行数据采集呢?市面上有很多非常成熟的数据抓取工具,抓取过程也非常简单。一般来说,只需要以下三个步骤:
步骤 1:确定数据源规则
比如之前的卫健委网站,他们发布的信息内容的URL就是数据源。这些 URL 通常有一些常规名称,例如日期和数字。借助数据抓取工具,可以定期、自动、批量检索所有可能的网页,并从中提取符合采集规则的数据。当然,除了在源头抓数据,还可以抓一些新媒体平台处理的二手数据,因为这些二手数据已经被处理过了,数据格式可能会更整洁、简单捕捉。
第 2 步:确定数据采集 规则
由于捕获的数据需要存储在数据库中,因此数据库通常需要提前确定数据格式。因此,需要根据预先设计好的数据格式建立数据采集规则和数据模板,并在抓取数据的过程中,按照规则提取数据,以便后续数据保存. 比如数据源中的文本内容是“在xx,xx,xx,xx省新增xxxx确诊病例”,那么在数据采集规则中,需要收录日期字段,省份字段,新确诊病例字段,爬取时填写各个字段的内容。例如,“,”和“province”之间的文字是省的名称,可以在这条信息的省字段中填写,以此类推(如果您认为不准确,还可以设置“日”和“省”之间的文字,将“新”之间的文字抓取为省名等)。但是,如果要配置准确完整的采集规则,可能需要了解一点最基本的HTML语言,这样才能通过网页分析准确提取出需要的信息。
第三步:保存到数据库
前两步完成后,只要企业网络正常,数据库创建配置正确,数据采集就可以很方便的保存到企业数据库中使用。
以上只是披露信息的基本方式采集。另外还有一些网站,为了方便大家采集公开信息,他们会主动通过API开放自己的数据。企业只需要查找和调用这些API,就可以直接获取信息。结构化数据。同时,还会有一些“傻瓜式”爬虫工具,专门用于采集一些具体的网站和具体的内容,会先把要做的工作和第二步,帮助用户提前做好,用户不需要关心数据源和采集规则,只需要配置数据库即可使用。
最后需要强调的是,数据采集必须严格遵守法律法规和相应的版权声明。对于政府或企业声明禁止抓取或必须获得授权才能复制的内容,以及不适合公开的内容(如因设计漏洞而意外曝光的内容),请勿抓取以免造成严重的法律后果。
欢迎朋友们关注、评论和转发。商业转载或其他请联系:keji5u(科技无忧订阅号) 查看全部
实时抓取网页数据(各个新媒体APP上的疫情地图,你了解多少?)
2020年注定是不平凡的一年。熙熙攘攘的春节市场已经失去了往日的喧嚣。突如其来的新冠肺炎疫情牵动着国人的心。想必很多人每天早上睁眼后的第一件事就是在新媒体APP上点击疫情地图,查看全国各省市的疫情数据。
在互联网高速发展的今天,大数据、云计算、人工智能等技术为疫情防控提供了有力支撑。其中,疫情信息的实时、准确、全面、生动的传递,做到了疫情信息量最大。透明度。这使亿万中国人民能够充分了解疫情发展的真实情况,做好必要的个人防护和充分的心理准备,从而有效减少疫情蔓延,保持最大程度的冷静和理性。
我们跟踪了很多新媒体平台,梳理了各个平台的疫情大数据服务。各平台提供的基本功能几乎相同,包括:
1. 疫情数据:展示全国、省、市累计和每日新增确诊/疑似/死亡/治愈病例数据,并通过疫情地图和各种形式的图表展示;
2.最新进展:聚合最新重要疫情信息,大部分为官方发布的不容错过的重要内容;
3.同程查询:可根据出行日期、车次/车牌/航班号、城市等查询确诊病例的具体行程信息,方便个人防控;
4.辟谣查实:对一些广为流传的疫情信息或防控方法的真伪进行鉴别;
5.发热门诊:提供各省市医疗机构信息,可以是文字或地图形式;
6.本地疫情:根据用户所在城市,显示本地确诊信息和本地相关疫情内容;
7.科普知识:个人防护知识、心理健康知识、疾病常识等。
那么,各种新媒体平台上的这些疫情数据和相关内容是从哪里来的呢?为什么某些平台上的数据略有不同?每个新媒体平台是如何获取和处理这些数据的?
首先,各个新媒体平台上的疫情核心数据几乎都是通过爬虫技术从国家和地方卫健委的官方网站根据他们的每日疫情报告文章提取出来的。之后,将这些数据汇总并以地图、趋势图等可视化图表的形式展示出来,方便大家。
如下图,湖北卫健委官方网站上,以短信形式发布疫情核心数据:
在各大新媒体平台上,数字依旧是那些数字,但呈现形式变得更加生动,如下图:
至于其他类型信息的来源,几乎都是一些官方渠道提供的文字信息或者可以公开搜索的信息,数据来源会更加丰富。除了国家卫健委的官方网站,其他政府部门也可能包括在内。、医疗机构、学术机构、权威媒体甚至意见领袖网站或自媒体等,这些新媒体平台在获得这些信息后,会对其进行处理,形成其他栏目,比如最新的进度、同流程查询、发热门诊、辟谣查实等。
例如,海南省卫计委官网以文字形式公布了确诊病例的移动轨迹,如下图:
在各大新媒体平台上,经过排序后,变成了同一个行程查询widget,如下图:
对于不同的新媒体平台,数据略有不同,因为不同的平台对数据的采集和处理策略不同。例如,一些新媒体平台只采集前一天24:00的全国数据,每天更新一次;而一些新媒体平台则不时捕捉部分省份发布的最新数据,并随时更新。加入。
因此,很多互联网公司并不能真正产生数据,而只是官方数据的搬运者、整合者和处理者。除了这些疫情大数据,还有企业征信查询、天气预报查询、航班信息查询、交通违章查询等诸多领域,也有一些熟悉的互联网公司在做类似的事情。
事实上,只要有需要,任何企业都可以批量、实时、准确地获取这些公开信息。当然,对于一些非互联网公司来说,获取这些公开信息的目的,并不是在处理后为普通用户打造互联网产品,而是与自己公司的业务和产品相结合,为自己的客户提供更全面的增值服务.
那么,如何进行数据采集呢?市面上有很多非常成熟的数据抓取工具,抓取过程也非常简单。一般来说,只需要以下三个步骤:
步骤 1:确定数据源规则
比如之前的卫健委网站,他们发布的信息内容的URL就是数据源。这些 URL 通常有一些常规名称,例如日期和数字。借助数据抓取工具,可以定期、自动、批量检索所有可能的网页,并从中提取符合采集规则的数据。当然,除了在源头抓数据,还可以抓一些新媒体平台处理的二手数据,因为这些二手数据已经被处理过了,数据格式可能会更整洁、简单捕捉。
第 2 步:确定数据采集 规则
由于捕获的数据需要存储在数据库中,因此数据库通常需要提前确定数据格式。因此,需要根据预先设计好的数据格式建立数据采集规则和数据模板,并在抓取数据的过程中,按照规则提取数据,以便后续数据保存. 比如数据源中的文本内容是“在xx,xx,xx,xx省新增xxxx确诊病例”,那么在数据采集规则中,需要收录日期字段,省份字段,新确诊病例字段,爬取时填写各个字段的内容。例如,“,”和“province”之间的文字是省的名称,可以在这条信息的省字段中填写,以此类推(如果您认为不准确,还可以设置“日”和“省”之间的文字,将“新”之间的文字抓取为省名等)。但是,如果要配置准确完整的采集规则,可能需要了解一点最基本的HTML语言,这样才能通过网页分析准确提取出需要的信息。
第三步:保存到数据库
前两步完成后,只要企业网络正常,数据库创建配置正确,数据采集就可以很方便的保存到企业数据库中使用。
以上只是披露信息的基本方式采集。另外还有一些网站,为了方便大家采集公开信息,他们会主动通过API开放自己的数据。企业只需要查找和调用这些API,就可以直接获取信息。结构化数据。同时,还会有一些“傻瓜式”爬虫工具,专门用于采集一些具体的网站和具体的内容,会先把要做的工作和第二步,帮助用户提前做好,用户不需要关心数据源和采集规则,只需要配置数据库即可使用。
最后需要强调的是,数据采集必须严格遵守法律法规和相应的版权声明。对于政府或企业声明禁止抓取或必须获得授权才能复制的内容,以及不适合公开的内容(如因设计漏洞而意外曝光的内容),请勿抓取以免造成严重的法律后果。
欢迎朋友们关注、评论和转发。商业转载或其他请联系:keji5u(科技无忧订阅号)
实时抓取网页数据(实时抓取网页数据可视化统计还有我认为是核心中的核心)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-14 09:06
实时抓取网页数据可视化统计还有我认为是核心中的核心。因为现在网页上的数据来自海量的页面广告信息,只有学习用户习惯了,提升用户体验了才能赢得用户,活跃用户,才能挣到钱。你在搞开发的时候做了特定活动,关注微信统计你才有点击。例如我在github上有个list.py的小项目,本来是准备运行的时候进行在线统计的,做前端的朋友在项目开始就给了我一个交互的界面。
为什么要做统计?主要是运营需要,例如一个公众号运营分析用户来源,某天点开xxxx公众号,那么明天可能就会对你的推送有相应的反应,如果没有,就说明你的内容不够吸引用户。或者某天有用户来,然后进一步了解用户大概来自哪里,希望获得我们的关注,明天你必须在文章中适当调整一下内容,例如第一天的标题内容,并且针对用户进行投放促活。
你也可以研究用户喜欢什么,不喜欢什么,多做定位。知道用户了还有用户习惯和用户喜好,设计一个interface对用户进行引导,把用户引导到你需要的功能,这也是一个很大的工作。现在每一个客户都可以提供个性化的营销策略了,但是你怎么去预测客户喜欢什么,这是需要技术的,同时也是需要学习的。最后,网站设计的时候要考虑好用户习惯,交互体验,针对用户的业务指标,根据用户的习惯,需求做出一些调整。以上一切只是一个个的模块,里面都涉及很多。这个就要看你做前端哪方面的工作,客户端,还是后端。 查看全部
实时抓取网页数据(实时抓取网页数据可视化统计还有我认为是核心中的核心)
实时抓取网页数据可视化统计还有我认为是核心中的核心。因为现在网页上的数据来自海量的页面广告信息,只有学习用户习惯了,提升用户体验了才能赢得用户,活跃用户,才能挣到钱。你在搞开发的时候做了特定活动,关注微信统计你才有点击。例如我在github上有个list.py的小项目,本来是准备运行的时候进行在线统计的,做前端的朋友在项目开始就给了我一个交互的界面。
为什么要做统计?主要是运营需要,例如一个公众号运营分析用户来源,某天点开xxxx公众号,那么明天可能就会对你的推送有相应的反应,如果没有,就说明你的内容不够吸引用户。或者某天有用户来,然后进一步了解用户大概来自哪里,希望获得我们的关注,明天你必须在文章中适当调整一下内容,例如第一天的标题内容,并且针对用户进行投放促活。
你也可以研究用户喜欢什么,不喜欢什么,多做定位。知道用户了还有用户习惯和用户喜好,设计一个interface对用户进行引导,把用户引导到你需要的功能,这也是一个很大的工作。现在每一个客户都可以提供个性化的营销策略了,但是你怎么去预测客户喜欢什么,这是需要技术的,同时也是需要学习的。最后,网站设计的时候要考虑好用户习惯,交互体验,针对用户的业务指标,根据用户的习惯,需求做出一些调整。以上一切只是一个个的模块,里面都涉及很多。这个就要看你做前端哪方面的工作,客户端,还是后端。
实时抓取网页数据(Google搜索蜘蛛就要开始对部分网站开始用HTTP/2方式抓取网站内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-02-13 03:19
国外谷歌站长透露,谷歌搜索将从今年11月开始小规模通过HTTP/2对网站内容进行爬取,在不影响网站搜索的情况下,爬取网页效率更高排名。
了解到HTTP/是基于SPDY的,一种注重性能的网络传输协议。与 HTTP/1 相比,它具有二进制分帧和多路复用等新特性。正式使用HTTP/2进行抓取后,最大的特点就是支持一个用户和网站之间只有一个连接的目标,谷歌可以用更少的资源更快地抓取内容,相比HTTP/1谷歌蜘蛛抓取< @网站 效率更高。
Google 表示目前主要的网站 和主流浏览器已经支持 HTTP/2 有一段时间了。大部分 CDN 服务商也支持 HTTP/2,使用 HTTP/2 的条件基本成熟。从 2020 年 11 月开始,Google 搜索蜘蛛将开始使用 HTTP/2 抓取一些 网站。 网站内容,以后慢慢添加对越来越多网站的支持。
当然,如果网站不支持HTTP/2或者网站不希望谷歌使用HTTP/2进行抓取,站长使用HTTP/1和HTTP/2也没问题该协议可以正常支持谷歌蜘蛛抓取网站内容,不影响网站的搜索排名,谷歌蜘蛛抓取网站的质量和数量也将保持不变。 查看全部
实时抓取网页数据(Google搜索蜘蛛就要开始对部分网站开始用HTTP/2方式抓取网站内容)
国外谷歌站长透露,谷歌搜索将从今年11月开始小规模通过HTTP/2对网站内容进行爬取,在不影响网站搜索的情况下,爬取网页效率更高排名。
了解到HTTP/是基于SPDY的,一种注重性能的网络传输协议。与 HTTP/1 相比,它具有二进制分帧和多路复用等新特性。正式使用HTTP/2进行抓取后,最大的特点就是支持一个用户和网站之间只有一个连接的目标,谷歌可以用更少的资源更快地抓取内容,相比HTTP/1谷歌蜘蛛抓取< @网站 效率更高。
Google 表示目前主要的网站 和主流浏览器已经支持 HTTP/2 有一段时间了。大部分 CDN 服务商也支持 HTTP/2,使用 HTTP/2 的条件基本成熟。从 2020 年 11 月开始,Google 搜索蜘蛛将开始使用 HTTP/2 抓取一些 网站。 网站内容,以后慢慢添加对越来越多网站的支持。
当然,如果网站不支持HTTP/2或者网站不希望谷歌使用HTTP/2进行抓取,站长使用HTTP/1和HTTP/2也没问题该协议可以正常支持谷歌蜘蛛抓取网站内容,不影响网站的搜索排名,谷歌蜘蛛抓取网站的质量和数量也将保持不变。
实时抓取网页数据(爆破4.万能密码有哪些?管理后台的注意事项)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-02-13 00:04
1:信息采集,
无论是防御还是渗透测试,都需要这一步,简单的信息采集。
手机信息收录很多,
例如,服务器 IP 地址是什么?
后台入口在哪里?
服务器打开了那些端口,服务器安装了那些应用程序等等,这些都是前期必须采集的东西。
手机有很多工具
当然还有其他方法,比如使用工具检测、nmap、
但是,专业的工具可能并不适合普通的白人。
例如,我们假设采集到的信息如下:
初步信息采集工作完成后,即可进入第二阶段。
第二步:根据服务器的安装环境进行进一步测试,类似看病。
先检查,再根据具体情况开药。
漏洞的一般列表无非如下:
1:弱密码,包括ftp、http、远程登录等,
处理弱密码的方法有很多,但使用好的社会工程库是最简单的方法。
2:存在sql注入漏洞,
这仅适用于工具。
3:xss漏洞,
4:存在穿透溢出漏洞
5:安装有致命缺陷的软件。
1. 后台登录时抓取复制数据包放到txt中,扔到sqlmap -r中运行
2. 弱密码
帐号:admin sa root
密码:123456 12345678 666666 admin123 admin888
这些是我见过最多的
管理后台一般为admin,phpmyadmin之类的数据库一般为root。
3. 没有验证码,验证码不刷新,只有一个验证码,而且验证码不起作用,可以试试爆破
4. 主密码可以创造奇迹
5.去前台发的文章,查看留言板的回复,看看作者是谁,很有可能是管理员账号
6.有的网站会提示账号不存在等,可以手动找管理员账号或者打嗝爆破
7. 当常规字典爆破失败时,可以根据从信息中采集到的相关数据生成密码爆破,包括但不限于域名备案等信息。像网站这样的学校,可以去前台找老师电话号码,姓名首字母等,其他想法,大家可以根据网站自行思考
8. 扫描到的目录可能有源代码泄露等
9. cms使用的cms有默认账号和密码,可以百度搜索
10.可能存在短信轰炸、逻辑漏洞、任意重置密码、爆破管理员账号等。
11. f12 康康总有惊喜
12.注意不要被围墙
13. 有时候有的网站会把错误信息记录到一个php文件中,可以试试账号或者密码写一句,也可以直接getshell,笔者遇到过一次
14.进入后台后寻找上传点,使用绕过上传
15. 其他具体功能,数据库备份等。
16.我刚刚在网红队使用的编辑器bug
17. 扫描到的目录不正常可以查看
18.扫描奇怪的名字,打开一个空白文件,尝试爆出一句话
第三步:当我们确定存在漏洞时,我们必须启动、使用、
拿到shell后可能会出现权限不足,大致分为两种情况
1. Windows 权限提升
2. linux 提权
具体的提权方法可以在百度上找到
内网仍然是信息采集。一开始看本地IP,扫描幸存的hosts,过一波各种exp,各种工具扔在上面,跑着扫描,内网博大精深,好不容易学好
但最好用工具,用工具更容易,
基本上所有可以集成的东西都集成了,只需简单的点击按钮,
不知道的可以找我,还有很多方法
参考下图与我交流
导入 java.util.regex.Matcher;
导入 java.util.regex.Pattern;
公共类下载Img {
公共静态无效 writeImgEntityToFile(HttpEntity imgEntity,String fileAddress) {
文件 storeFile = new File(fileAddress);
FileOutputStream 输出 = null;
尝试 {
输出 = 新文件输出流(存储文件);
如果(imgEntity!= null){
InputStream 流内;
流内 = imgEntity.getContent();
字节 b[] = 新字节[8 * 1024];
整数计数;
而 ((count = instream.read(b)) != -1) {
output.write(b, 0, count);
}
}
} 捕捉(FileNotFoundException e){
e.printStackTrace();
} 捕捉(IOException e){
e.printStackTrace();
} 最后 {
尝试 {
输出.close();
} 捕捉(IOException e){
e.printStackTrace();
}
}
}
公共静态无效主要(字符串[]参数){
System.out.println("获取必应图片地址...");
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd"); 查看全部
实时抓取网页数据(爆破4.万能密码有哪些?管理后台的注意事项)
1:信息采集,
无论是防御还是渗透测试,都需要这一步,简单的信息采集。
手机信息收录很多,
例如,服务器 IP 地址是什么?
后台入口在哪里?
服务器打开了那些端口,服务器安装了那些应用程序等等,这些都是前期必须采集的东西。
手机有很多工具
当然还有其他方法,比如使用工具检测、nmap、
但是,专业的工具可能并不适合普通的白人。
例如,我们假设采集到的信息如下:
初步信息采集工作完成后,即可进入第二阶段。
第二步:根据服务器的安装环境进行进一步测试,类似看病。
先检查,再根据具体情况开药。
漏洞的一般列表无非如下:
1:弱密码,包括ftp、http、远程登录等,
处理弱密码的方法有很多,但使用好的社会工程库是最简单的方法。
2:存在sql注入漏洞,
这仅适用于工具。
3:xss漏洞,
4:存在穿透溢出漏洞
5:安装有致命缺陷的软件。
1. 后台登录时抓取复制数据包放到txt中,扔到sqlmap -r中运行
2. 弱密码
帐号:admin sa root
密码:123456 12345678 666666 admin123 admin888
这些是我见过最多的
管理后台一般为admin,phpmyadmin之类的数据库一般为root。
3. 没有验证码,验证码不刷新,只有一个验证码,而且验证码不起作用,可以试试爆破
4. 主密码可以创造奇迹
5.去前台发的文章,查看留言板的回复,看看作者是谁,很有可能是管理员账号
6.有的网站会提示账号不存在等,可以手动找管理员账号或者打嗝爆破
7. 当常规字典爆破失败时,可以根据从信息中采集到的相关数据生成密码爆破,包括但不限于域名备案等信息。像网站这样的学校,可以去前台找老师电话号码,姓名首字母等,其他想法,大家可以根据网站自行思考
8. 扫描到的目录可能有源代码泄露等
9. cms使用的cms有默认账号和密码,可以百度搜索
10.可能存在短信轰炸、逻辑漏洞、任意重置密码、爆破管理员账号等。
11. f12 康康总有惊喜
12.注意不要被围墙
13. 有时候有的网站会把错误信息记录到一个php文件中,可以试试账号或者密码写一句,也可以直接getshell,笔者遇到过一次
14.进入后台后寻找上传点,使用绕过上传
15. 其他具体功能,数据库备份等。
16.我刚刚在网红队使用的编辑器bug
17. 扫描到的目录不正常可以查看
18.扫描奇怪的名字,打开一个空白文件,尝试爆出一句话
第三步:当我们确定存在漏洞时,我们必须启动、使用、
拿到shell后可能会出现权限不足,大致分为两种情况
1. Windows 权限提升
2. linux 提权
具体的提权方法可以在百度上找到
内网仍然是信息采集。一开始看本地IP,扫描幸存的hosts,过一波各种exp,各种工具扔在上面,跑着扫描,内网博大精深,好不容易学好
但最好用工具,用工具更容易,
基本上所有可以集成的东西都集成了,只需简单的点击按钮,
不知道的可以找我,还有很多方法
参考下图与我交流
导入 java.util.regex.Matcher;
导入 java.util.regex.Pattern;
公共类下载Img {
公共静态无效 writeImgEntityToFile(HttpEntity imgEntity,String fileAddress) {
文件 storeFile = new File(fileAddress);
FileOutputStream 输出 = null;
尝试 {
输出 = 新文件输出流(存储文件);
如果(imgEntity!= null){
InputStream 流内;
流内 = imgEntity.getContent();
字节 b[] = 新字节[8 * 1024];
整数计数;
而 ((count = instream.read(b)) != -1) {
output.write(b, 0, count);
}
}
} 捕捉(FileNotFoundException e){
e.printStackTrace();
} 捕捉(IOException e){
e.printStackTrace();
} 最后 {
尝试 {
输出.close();
} 捕捉(IOException e){
e.printStackTrace();
}
}
}
公共静态无效主要(字符串[]参数){
System.out.println("获取必应图片地址...");
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd");
实时抓取网页数据(实时抓取网页追踪页面上的标题、图片地址、页面比对、插入或更新的链接等信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-11 12:00
实时抓取网页数据是每个网页追踪页面上的标题、图片地址、页面比对、插入或更新的链接等信息。全部数据可以保存在github,采用对象存储系统对全部页面进行存储和交换。可以在工作流中轻松查看、修改、导出导航链接(如:按标题搜索、按页码搜索等)。本项目涵盖了以下工作内容:首先,抓取所有经过网页url验证的url,然后,从github开发项目目录下读取该页面的链接并完成链接的格式化。
链接格式化主要采用gulp负责完成构建,其中包括解析url中的type参数,并把整个url打包成一个png图片文件,这里,由click部署。在其中click会根据type参数的不同被划分为多种格式,比如,name是url文件中的type,title是url文件中的title字段,或者是type和title都是一致的格式。
如:url中type是text,title是favicon。click会负责配置css、html、cssoutputstream、style,将各种数据对格式化后的javascript的样式样式按文件名进行命名。这样,整个javascript代码样式是数组,以顺序存放在同一个文件中,便于扩展和理解。接下来,把页面的html文件抓取下来,如:html文件主要分为三个部分,分别是图片、链接、标题。
图片从github下载,即可直接拖拽到浏览器上进行爬取。链接采用七牛云的代理,即://sitemap.js/.html:://webpack.config.js{"require":{"node_env":"development","entry":"./sitemap.js","script":"javascript:;","src":"./webpack-dev-server-schema.conf.js","script-loader":"babel-loader","loaders":["babel-loader","babel-loader-loader","babel-loader-loader","babel-loader-loader","lodash","log-generator","file","ready","reading","release","sass","less","sass","less-release","options","minify","prettier","pip","swig","squeezes","fetch","actions","gulp","gulp","webpack","webpack-cli","test","require","test-path","cheers","path.join","require-resolve","git","travis-dependencies","mock","gulp","then","babel-polyfill","require-resolve","gzip","babel-preset-env","output","python","。 查看全部
实时抓取网页数据(实时抓取网页追踪页面上的标题、图片地址、页面比对、插入或更新的链接等信息)
实时抓取网页数据是每个网页追踪页面上的标题、图片地址、页面比对、插入或更新的链接等信息。全部数据可以保存在github,采用对象存储系统对全部页面进行存储和交换。可以在工作流中轻松查看、修改、导出导航链接(如:按标题搜索、按页码搜索等)。本项目涵盖了以下工作内容:首先,抓取所有经过网页url验证的url,然后,从github开发项目目录下读取该页面的链接并完成链接的格式化。
链接格式化主要采用gulp负责完成构建,其中包括解析url中的type参数,并把整个url打包成一个png图片文件,这里,由click部署。在其中click会根据type参数的不同被划分为多种格式,比如,name是url文件中的type,title是url文件中的title字段,或者是type和title都是一致的格式。
如:url中type是text,title是favicon。click会负责配置css、html、cssoutputstream、style,将各种数据对格式化后的javascript的样式样式按文件名进行命名。这样,整个javascript代码样式是数组,以顺序存放在同一个文件中,便于扩展和理解。接下来,把页面的html文件抓取下来,如:html文件主要分为三个部分,分别是图片、链接、标题。
图片从github下载,即可直接拖拽到浏览器上进行爬取。链接采用七牛云的代理,即://sitemap.js/.html:://webpack.config.js{"require":{"node_env":"development","entry":"./sitemap.js","script":"javascript:;","src":"./webpack-dev-server-schema.conf.js","script-loader":"babel-loader","loaders":["babel-loader","babel-loader-loader","babel-loader-loader","babel-loader-loader","lodash","log-generator","file","ready","reading","release","sass","less","sass","less-release","options","minify","prettier","pip","swig","squeezes","fetch","actions","gulp","gulp","webpack","webpack-cli","test","require","test-path","cheers","path.join","require-resolve","git","travis-dependencies","mock","gulp","then","babel-polyfill","require-resolve","gzip","babel-preset-env","output","python","。
实时抓取网页数据(抓取网站数据不再难(其实是想死的!))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-11 09:22
首先,从标题开始,为什么抓网站数据不再难(其实抓网站数据很难),SO EASY!!!使用 Fizzler 可以做到这一切。我相信大多数人或公司应该都有捕获他人网站数据的经验。比如我们博客园每次发布文章都会被其他网站给我抢,不信你看就知道了。还有人在网站上抢别人的邮箱、电话、QQ等有用信息。这些信息绝对可以卖钱或做其他事情。我们每天都会不时收到垃圾短信或电子邮件。就是这样,同感,O(∩_∩)O哈哈~。
前段时间写了两个程序,一个程序是采集彩票网站(双色球)的数据,另一个是采集求职网站(猎聘,54Worry,智联招聘, etc.)数据,写这两个程序的时候显示特别棘手,看到一堆HTML标签真想死。首先,让我们回顾一下我之前是如何解析 HTML 的。通过WebRequest获取HTML内容,然后使用HTML标签一步步截取你想要的内容,是一种很常见的做法。下面的代码是截取双色球的红球和篮球的代码。一旦网站的标签稍有变化,就有可能面临重新编程,使用起来很不方便。
下面是我在解析红球和篮球双色球的代码。我做的最多的就是截取(正则表达式)标签的对应内容。也许这段代码不是很复杂,因为截取的数据是有限的,而且非常规则,因此也比较简单。
1 #region * 在一个TR中,解析TD,获取一期的号码
2 ///
3 /// 在一个TR中,解析TD,获取一期的号码
4 ///
5 ///
6 ///
7 private void ResolveTd(ref WinNo wn, string trContent)
8 {
9 List redBoxList = null;
10 //匹配期号的表达式
11 string patternQiHao = "0)
17 {
18 info.Position = NodesMainContent1.ToArray()[0].InnerText;
19 }
20 //--公司名称
21 IEnumerable NodesMainContent2 = AnalyzeHTML.GetHtmlInfo(html, "div.title-info h3");
22 if (NodesMainContent2.Count() > 0)
23 {
24 info.Company = NodesMainContent2.ToArray()[0].InnerText;
25 }
26 //--公司性质/公司规模
27 IEnumerable NodesMainContent4 = AnalyzeHTML.GetHtmlInfo(html, "div.content.content-word ul li");
28 if (NodesMainContent4.Count() > 0)
29 {
30 foreach (var item in NodesMainContent4)
31 {
32 if (item.InnerHtml.Contains("企业性质"))
33 {
34 string nature = item.InnerText;
35 nature = nature.Replace("企业性质:", "");
36 info.Nature = nature;
37 }
38 if (item.InnerHtml.Contains("企业规模"))
39 {
40 string scale = item.InnerText;
41 scale = scale.Replace("企业规模:", "");
42 info.Scale = scale;
43 }
44 }
45 }
46 else//第二次解析企业性质和企业规模
47 {
48 IEnumerable NodesMainContent4_1 = AnalyzeHTML.GetHtmlInfo(html, "div.right-post-top div.content.content-word");
49 if (NodesMainContent4_1.Count() > 0)
50 {
51 foreach (var item_1 in NodesMainContent4_1)
52 {
53 string[] arr = item_1.InnerText.Split("\r\n".ToCharArray(), StringSplitOptions.RemoveEmptyEntries);
54 if (arr != null && arr.Length > 0)
55 {
56 foreach (string str in arr)
57 {
58 if (str.Trim().Contains("性质"))
59 {
60 info.Nature = str.Replace("性质:", "").Trim();
61 }
62 if (str.Trim().Contains("规模"))
63 {
64 info.Scale = str.Replace("规模:", "").Trim();
65 }
66 }
67 }
68 }
69 }
70 }
71 //--工作经验
72 IEnumerable NodesMainContent5 = AnalyzeHTML.GetHtmlInfo(html, "div.resume.clearfix span.noborder");
73 if (NodesMainContent5.Count() > 0)
74 {
75 info.Experience = NodesMainContent5.ToArray()[0].InnerText;
76 }
77 //--公司地址/最低学历
78 IEnumerable NodesMainContent6 = AnalyzeHTML.GetHtmlInfo(html, "div.resume.clearfix");
79 if (NodesMainContent6.Count() > 0)
80 {
81 foreach (var item in NodesMainContent6)
82 {
83 string lable = Regex.Replace(item.InnerHtml, "\\s", "");
84 lable = lable.Replace("", "");
85 string[] arr = lable.Split("".ToCharArray(), StringSplitOptions.RemoveEmptyEntries);
86 if (arr != null && arr.Length > 2)
87 {
88 info.Address = arr[0];//公司地址
89 info.Education = arr[1];//最低学历
90 }
91 }
92 }
93 //--月薪
94 IEnumerable NodesMainContent7 = AnalyzeHTML.GetHtmlInfo(html, "div.job-title-left p.job-main-title");
95 if (NodesMainContent7.Count() > 0)
96 {
97 info.Salary = NodesMainContent7.ToArray()[0].InnerText;
98 }
99 //--发布时间
100 IEnumerable NodesMainContent8 = AnalyzeHTML.GetHtmlInfo(html, "div.job-title-left p.release-time em");
101 if (NodesMainContent8.Count() > 0)
102 {
103 info.Time = NodesMainContent8.ToArray()[0].InnerText;
104 }
105 //--
106 if (GetJobEnd != null)
107 {
108 GetJobEnd("", info);
109 }
110 }
111 catch (Exception exMsg)
112 {
113 throw new Exception(exMsg.Message);
114 }
115 }
上面的方法也解析了一个招聘网站标签的内容,但是我已经看不到复杂的正则表达式来拦截HTML标签了,这使得代码更加干练和简单,整个配置页面可以应付爬取< @网站tag 频繁更换的问题,所以看来抓取别人的网站数据是一件很简单的事情,O(∩_∩)O哈哈~是不是!!!
以上只是我个人的看法!!!有兴趣可以加QQ群:(186841119),参与讨论学习交流 查看全部
实时抓取网页数据(抓取网站数据不再难(其实是想死的!))
首先,从标题开始,为什么抓网站数据不再难(其实抓网站数据很难),SO EASY!!!使用 Fizzler 可以做到这一切。我相信大多数人或公司应该都有捕获他人网站数据的经验。比如我们博客园每次发布文章都会被其他网站给我抢,不信你看就知道了。还有人在网站上抢别人的邮箱、电话、QQ等有用信息。这些信息绝对可以卖钱或做其他事情。我们每天都会不时收到垃圾短信或电子邮件。就是这样,同感,O(∩_∩)O哈哈~。
前段时间写了两个程序,一个程序是采集彩票网站(双色球)的数据,另一个是采集求职网站(猎聘,54Worry,智联招聘, etc.)数据,写这两个程序的时候显示特别棘手,看到一堆HTML标签真想死。首先,让我们回顾一下我之前是如何解析 HTML 的。通过WebRequest获取HTML内容,然后使用HTML标签一步步截取你想要的内容,是一种很常见的做法。下面的代码是截取双色球的红球和篮球的代码。一旦网站的标签稍有变化,就有可能面临重新编程,使用起来很不方便。
下面是我在解析红球和篮球双色球的代码。我做的最多的就是截取(正则表达式)标签的对应内容。也许这段代码不是很复杂,因为截取的数据是有限的,而且非常规则,因此也比较简单。
1 #region * 在一个TR中,解析TD,获取一期的号码
2 ///
3 /// 在一个TR中,解析TD,获取一期的号码
4 ///
5 ///
6 ///
7 private void ResolveTd(ref WinNo wn, string trContent)
8 {
9 List redBoxList = null;
10 //匹配期号的表达式
11 string patternQiHao = "0)
17 {
18 info.Position = NodesMainContent1.ToArray()[0].InnerText;
19 }
20 //--公司名称
21 IEnumerable NodesMainContent2 = AnalyzeHTML.GetHtmlInfo(html, "div.title-info h3");
22 if (NodesMainContent2.Count() > 0)
23 {
24 info.Company = NodesMainContent2.ToArray()[0].InnerText;
25 }
26 //--公司性质/公司规模
27 IEnumerable NodesMainContent4 = AnalyzeHTML.GetHtmlInfo(html, "div.content.content-word ul li");
28 if (NodesMainContent4.Count() > 0)
29 {
30 foreach (var item in NodesMainContent4)
31 {
32 if (item.InnerHtml.Contains("企业性质"))
33 {
34 string nature = item.InnerText;
35 nature = nature.Replace("企业性质:", "");
36 info.Nature = nature;
37 }
38 if (item.InnerHtml.Contains("企业规模"))
39 {
40 string scale = item.InnerText;
41 scale = scale.Replace("企业规模:", "");
42 info.Scale = scale;
43 }
44 }
45 }
46 else//第二次解析企业性质和企业规模
47 {
48 IEnumerable NodesMainContent4_1 = AnalyzeHTML.GetHtmlInfo(html, "div.right-post-top div.content.content-word");
49 if (NodesMainContent4_1.Count() > 0)
50 {
51 foreach (var item_1 in NodesMainContent4_1)
52 {
53 string[] arr = item_1.InnerText.Split("\r\n".ToCharArray(), StringSplitOptions.RemoveEmptyEntries);
54 if (arr != null && arr.Length > 0)
55 {
56 foreach (string str in arr)
57 {
58 if (str.Trim().Contains("性质"))
59 {
60 info.Nature = str.Replace("性质:", "").Trim();
61 }
62 if (str.Trim().Contains("规模"))
63 {
64 info.Scale = str.Replace("规模:", "").Trim();
65 }
66 }
67 }
68 }
69 }
70 }
71 //--工作经验
72 IEnumerable NodesMainContent5 = AnalyzeHTML.GetHtmlInfo(html, "div.resume.clearfix span.noborder");
73 if (NodesMainContent5.Count() > 0)
74 {
75 info.Experience = NodesMainContent5.ToArray()[0].InnerText;
76 }
77 //--公司地址/最低学历
78 IEnumerable NodesMainContent6 = AnalyzeHTML.GetHtmlInfo(html, "div.resume.clearfix");
79 if (NodesMainContent6.Count() > 0)
80 {
81 foreach (var item in NodesMainContent6)
82 {
83 string lable = Regex.Replace(item.InnerHtml, "\\s", "");
84 lable = lable.Replace("", "");
85 string[] arr = lable.Split("".ToCharArray(), StringSplitOptions.RemoveEmptyEntries);
86 if (arr != null && arr.Length > 2)
87 {
88 info.Address = arr[0];//公司地址
89 info.Education = arr[1];//最低学历
90 }
91 }
92 }
93 //--月薪
94 IEnumerable NodesMainContent7 = AnalyzeHTML.GetHtmlInfo(html, "div.job-title-left p.job-main-title");
95 if (NodesMainContent7.Count() > 0)
96 {
97 info.Salary = NodesMainContent7.ToArray()[0].InnerText;
98 }
99 //--发布时间
100 IEnumerable NodesMainContent8 = AnalyzeHTML.GetHtmlInfo(html, "div.job-title-left p.release-time em");
101 if (NodesMainContent8.Count() > 0)
102 {
103 info.Time = NodesMainContent8.ToArray()[0].InnerText;
104 }
105 //--
106 if (GetJobEnd != null)
107 {
108 GetJobEnd("", info);
109 }
110 }
111 catch (Exception exMsg)
112 {
113 throw new Exception(exMsg.Message);
114 }
115 }
上面的方法也解析了一个招聘网站标签的内容,但是我已经看不到复杂的正则表达式来拦截HTML标签了,这使得代码更加干练和简单,整个配置页面可以应付爬取< @网站tag 频繁更换的问题,所以看来抓取别人的网站数据是一件很简单的事情,O(∩_∩)O哈哈~是不是!!!
以上只是我个人的看法!!!有兴趣可以加QQ群:(186841119),参与讨论学习交流
实时抓取网页数据( Agenty网页代理2.变更检测代理网络爬虫代理如何使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-02-10 23:19
Agenty网页代理2.变更检测代理网络爬虫代理如何使用)
介绍:
Agenty 一个简单、强大的网页抓取应用程序,用于使用 CSS 选择器进行屏幕抓取和创建网页抓取代理 Agenty 是一个非常简单和高级的网页抓取扩展程序,使用 <从@k17@ 提取数据> 中的点击式 CSS 选择器,提取数据实时pview,快速导出数据为JSON/CSV/TSV。为 Agenty Cloud Platform() 创建免费的网页抓取代理,用于大数据提取和更高级的网页抓取功能:如调度、匿名 网站 抓取、网站 抓取,提取 100 或数百万个网页,同时获取多个 网站,将数据发布到服务器等...您可以创建的代理 - 1. 网络抓取代理2. 更改检测代理 3. 网络爬虫代理的工作原理-------------------------------- 1. 去找你 < @网站 提取,然后启动扩展。2. 在新建下选择代理类型,或者您可以使用我的代理下的示例代理模板。2. 点击你想提取的网页元素(它会变成绿色)。然后,Web 抓取应用程序将为该元素生成最佳 CSS 选择器,并将突出显示(黄色)与该选择器匹配的所有内容。3. 现在您可以单击突出显示的元素将其从选择器中移除(红色),或者单击未突出显示的元素将其添加到提取器中。然后,Web 抓取应用程序将为该元素生成最佳 CSS 选择器,并将突出显示(黄色)与该选择器匹配的所有内容。3. 现在您可以单击突出显示的元素将其从选择器中移除(红色),或者单击未突出显示的元素将其添加到提取器中。然后,Web 抓取应用程序将为该元素生成最佳 CSS 选择器,并将突出显示(黄色)与该选择器匹配的所有内容。3. 现在您可以单击突出显示的元素将其从选择器中移除(红色),或者单击未突出显示的元素将其添加到提取器中。
通过这个选择和拒绝过程,Web Scraping App 将帮助您为需要提取的项目提供完美的 CSS 选择器。4. 使用文本、HTML 或 ATTR(属性)提取任意数量的字段,并即时输出提取数据的视图。如何编辑您的网络抓取/更改检测代理------------------------------- 1. 转到创建代理网站 URL 2. 启动代理扩展3. 单击代理旁边的打开按钮以在代理中打开它。4. 现在您可以添加/更改任何内容并将其保存回您的帐户。功能-------------------------------- 1. 从网页中提取任意数量的字段。2.使用内置的 CSS 选择器一键生成模式。3. 编写您自己的自定义 CSS 选择器。4. 选择要提取的项目。例如文本、HTML 或 ATTR(属性)5. 选择 CSS 选择器后立即查看生成的 pview。5. 左右切换位置。7. 以最流行的文件格式 JSON、CSV 或 TSV 导出最好的网络爬虫 ------------- ---- --- 首先是用于 网站 抓取的 Jquery 样式 CSS 选择器扩展。
立即安装以使用最先进的屏幕抓取技术免费解析 HTML 和抓取/提取网站信息。例如价格抓取、电子邮件抓取、数据抓取、隐藏的 html 标签抓取。网页抓取也称为屏幕抓取、网页数据提取、网页采集等。无论您是使用 Agenty 抓取网站,还是 C#、Python、Node JS、Perl、Ruby、Java 中的 API,还是JavaScript 编程语言。您可以使用 chrome 扩展来生成 Jquery 样式的 CSS 选择器以进行 Web 抓取。查看更多详情: 查看全部
实时抓取网页数据(
Agenty网页代理2.变更检测代理网络爬虫代理如何使用)
介绍:
Agenty 一个简单、强大的网页抓取应用程序,用于使用 CSS 选择器进行屏幕抓取和创建网页抓取代理 Agenty 是一个非常简单和高级的网页抓取扩展程序,使用 <从@k17@ 提取数据> 中的点击式 CSS 选择器,提取数据实时pview,快速导出数据为JSON/CSV/TSV。为 Agenty Cloud Platform() 创建免费的网页抓取代理,用于大数据提取和更高级的网页抓取功能:如调度、匿名 网站 抓取、网站 抓取,提取 100 或数百万个网页,同时获取多个 网站,将数据发布到服务器等...您可以创建的代理 - 1. 网络抓取代理2. 更改检测代理 3. 网络爬虫代理的工作原理-------------------------------- 1. 去找你 < @网站 提取,然后启动扩展。2. 在新建下选择代理类型,或者您可以使用我的代理下的示例代理模板。2. 点击你想提取的网页元素(它会变成绿色)。然后,Web 抓取应用程序将为该元素生成最佳 CSS 选择器,并将突出显示(黄色)与该选择器匹配的所有内容。3. 现在您可以单击突出显示的元素将其从选择器中移除(红色),或者单击未突出显示的元素将其添加到提取器中。然后,Web 抓取应用程序将为该元素生成最佳 CSS 选择器,并将突出显示(黄色)与该选择器匹配的所有内容。3. 现在您可以单击突出显示的元素将其从选择器中移除(红色),或者单击未突出显示的元素将其添加到提取器中。然后,Web 抓取应用程序将为该元素生成最佳 CSS 选择器,并将突出显示(黄色)与该选择器匹配的所有内容。3. 现在您可以单击突出显示的元素将其从选择器中移除(红色),或者单击未突出显示的元素将其添加到提取器中。
通过这个选择和拒绝过程,Web Scraping App 将帮助您为需要提取的项目提供完美的 CSS 选择器。4. 使用文本、HTML 或 ATTR(属性)提取任意数量的字段,并即时输出提取数据的视图。如何编辑您的网络抓取/更改检测代理------------------------------- 1. 转到创建代理网站 URL 2. 启动代理扩展3. 单击代理旁边的打开按钮以在代理中打开它。4. 现在您可以添加/更改任何内容并将其保存回您的帐户。功能-------------------------------- 1. 从网页中提取任意数量的字段。2.使用内置的 CSS 选择器一键生成模式。3. 编写您自己的自定义 CSS 选择器。4. 选择要提取的项目。例如文本、HTML 或 ATTR(属性)5. 选择 CSS 选择器后立即查看生成的 pview。5. 左右切换位置。7. 以最流行的文件格式 JSON、CSV 或 TSV 导出最好的网络爬虫 ------------- ---- --- 首先是用于 网站 抓取的 Jquery 样式 CSS 选择器扩展。
立即安装以使用最先进的屏幕抓取技术免费解析 HTML 和抓取/提取网站信息。例如价格抓取、电子邮件抓取、数据抓取、隐藏的 html 标签抓取。网页抓取也称为屏幕抓取、网页数据提取、网页采集等。无论您是使用 Agenty 抓取网站,还是 C#、Python、Node JS、Perl、Ruby、Java 中的 API,还是JavaScript 编程语言。您可以使用 chrome 扩展来生成 Jquery 样式的 CSS 选择器以进行 Web 抓取。查看更多详情:
实时抓取网页数据(全网舆情分析系统设计中可能会遇到的的问题?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-09 16:25
摘要: 前言 在当前的互联网信息浪潮下,信息传播的速度远远超出我们的想象。一条微博大V的帖子,一条朋友圈的动态,一条热门论坛的新闻,或者购物平台的一条购物评论,都可能产生数以万计的转发、关注和点赞。如果是一些不合理的负面评论,就会激起人们的负面情绪,甚至影响消费者对企业品牌的认可。如果不能及时采取正确的措施,将会造成不可估量的损失。
前言
在当前的互联网信息浪潮下,信息传播的速度远远超出我们的想象。一条微博大V的帖子,一条朋友圈的动态,一条热门论坛的新闻,或者购物平台的一条购物评论,都可能产生数以万计的转发、关注和点赞。如果是一些不合理的负面评论,就会激起人们的负面情绪,甚至影响消费者对企业品牌的认可。如果不能及时采取正确的措施,将会造成不可估量的损失。因此,我们需要一个高效的全网舆情分析系统来帮助我们实时观察舆情。
这个全网舆情分析系统可以存储百亿网页数据,实时抓取和存储新网页,并为新网页实时提取元数据。随着提取结果,我们还需要进行进一步的挖掘分析,包括但不限于
舆情影响力诊断,从传播的幅度和传播趋势进行预测,判断舆情最终是否会形成。
传播路径分析,分析舆情传播的关键路径。
用户画像为舆论参与者提供了一个共同特征的轮廓,例如性别、年龄、地区和感兴趣的话题。
情绪分析,分析新闻或评论是正面还是负面。在情感分类之后进行统计聚合。
预警设置,我们支持设置舆情讨论量阈值,达到阈值后通知推送业务方,避免错过舆论的黄金参与时间。
这些挖掘出来的舆情结果会被推送到需求方,同时也提供了一个接口供各业务方搜索查询。接下来,我们将讨论系统设计中可能遇到的问题。我们将重点关注系统设计中与存储相关的话题,并为这些问题找到最优的解决方案。
系统设计
一个舆情系统,首先需要一个爬虫引擎去采集各大主流门户、购物网站、社区论坛、微博的原创页面内容、朋友圈的各种新闻资讯. 采集对于海量的网页,消息数据(上百亿)需要实时存储。在根据网站url获取网页之前,需要判断是否是之前爬过的页面,避免不必要的重复爬取。采集网页之后,我们需要提取网页,去除不必要的标签,提取标题、摘要、正文内容、评论等,提取的内容进入存储系统,方便后续查询。同时,新增的抽取结果需要推送到计算平台进行统计分析、报表生成或后续舆情检索等功能。根据算法,计算内容可能需要新数据或完整数据。舆论本身的时间敏感性决定了我们的系统必须能够高效地处理这些新内容。最好延迟几秒后检索新的热搜。
我们可以将整个数据流总结如下:
根据上图不难发现,要设计一个全网舆情的存储分析平台,我们需要处理爬取、存储、分析、搜索和展示。具体来说,我们需要解决以下问题:
如何高效存储百亿原创网页信息,为了提高舆情分析的全面性和准确性,我们往往希望尽可能多的抓取网页信息,然后按照我们设定的权重进行聚合。因此,整个网页的历史数据库会比较大,积累了数百亿的网页信息,数据量可以达到数百TB甚至数PB。在数据量如此之大的情况下,我们还需要做到读写毫秒级的低延迟,这使得传统数据库难以满足需求。
在爬虫爬取网页之前,如何判断之前是否被爬过?对于普通的网页,舆论关心的是时效性。或许我们只想爬取同一个网页一次,那我们就可以用网页地址来爬取Heavy,减少不必要的网页资源浪费。所以我们需要分布式存储来提供基于网页的高效随机查询。
如何在新的原创网页存储后进行实时结构化提取,并存储提取结果。这里我们的原创网页可能收录各种html标签,我们需要去掉这些html标签,提取出文章的标题、作者、发布时间等。这些内容为后续舆情情绪分析提供了必要的结构化数据。
如何高效连接计算平台,对新提取的结构化数据进行流式传输,进行实时计算。这里我们需要对网页内容和消息描述进行分类,进行情感识别,并对识别后的结果进行统计分析。由于全盘分析的时效性差,舆论往往关注最新的新闻和评论,所以必须做增量分析。
如何提供高效的舆情搜索,除了订阅固定的关键词舆情,用户还做一些关键词搜索。比如你想了解竞品公司新产品的一些舆情分析。
如何实现新舆论的实时推送?为了保证舆情的及时性,不仅要坚持舆情分析结果,还要支持舆情结果的推送。推送的内容通常是我们实时分析的新舆情。
系统结构
针对以上问题,我们来介绍一下如何基于阿里云上的各种云产品,搭建一个全网百亿级别的舆情分析平台。我们将重点关注存储产品的选择以及如何高效连接各类计算。,搜索平台。
我们使用ECS作为爬虫引擎,可以根据爬取的数量确定使用ECS的机器资源数量,也可以在每天的高峰期临时扩展资源用于网络爬取。抓取原创网页后,将原创网页地址和网页内容写入存储系统。同时,如果要避免重复爬取,爬虫引擎在爬取前要根据url列表去重。存储引擎需要支持低延迟的随机访问查询,判断当前url是否已经存在,如果存在,则无需再次爬取。
为了实现网页原创内容的实时提取,我们需要将新增的页面推送到计算平台。以前的架构往往需要应用层的双重写入,即原创网页数据存储在数据库中,我们反复将数据的副本写入计算平台。这样的架构需要我们维护两组编写逻辑。同样,结构化增量进入舆情分析平台也存在类似问题。提取的结构化元数据也需要双写入舆情分析平台。舆情分析结果也需要写入分布式存储,推送到搜索平台。在这里我们可以发现图中的三个红线会带来我们对三个数据源的双写需求。这会增加代码开发的工作量,也会导致复杂的系统实现和维护。每个数据源的双写需要知道下游的存在,或者使用消息服务通过双写消息做解耦。mysql等传统数据库支持增量日志binlog的订阅。如果分布式存储产品可以支持大的访问和存储容量,还可以提供增量订阅,可以大大简化我们的架构。每个数据源的双写需要知道下游的存在,或者使用消息服务通过双写消息做解耦。mysql等传统数据库支持增量日志binlog的订阅。如果分布式存储产品可以支持大的访问和存储容量,还可以提供增量订阅,可以大大简化我们的架构。每个数据源的双写需要知道下游的存在,或者使用消息服务通过双写消息做解耦。mysql等传统数据库支持增量日志binlog的订阅。如果分布式存储产品可以支持大的访问和存储容量,还可以提供增量订阅,可以大大简化我们的架构。
网页数据采集存储后,会增量流入我们的计算平台,实时提取元数据。这里我们可以使用函数计算。当有新的页面需要提取时,触发函数计算的托管函数执行网页元数据。提炼。提取出来的结果存入存储系统并持久化后,同时推送到MaxCompute进行舆情分析,如情感分析、文本聚类等。可能会有一些公共信息表数据、用户情绪数据统计等结果。舆情结果会写入存储系统和搜索引擎,部分报告和阈值告警会推送给订阅者。搜索引擎的数据提供给在线舆情检索系统。
介绍完完整的架构后,我们再来看看阿里云上如何进行存储选型。
存储选择
通过架构的介绍,我们总结一下存储选型的要求:
可支持海量数据存储(TB/PB级别)、高并发访问(10万到1000万TPS)、低访问延迟。
采集的数量会随着采集订阅的网页源的调整而动态调整。同时,爬虫在不同时间段爬取的网页数量在一天之内也会有明显的波峰和波谷,所以数据库需要能够灵活的扩缩容。
有了自由表属性结构,对于普通网页和社交平台页面的信息,我们需要注意的属性可能会有很大的不同。灵活的模式将有助于我们的扩展。
对于旧数据,您可以选择自动过期或分层存储。由于舆情数据往往集中在近期热点,旧数据的访问频率较低。
需要更好的增量通道,新增数据可以定期导出到计算平台。上图中有3条红色虚线。这三个部分有一个共同的特点。增量可以实时引导到相应的计算平台进行计算,并将计算结果写入相应的存储引擎。如果数据库引擎本身支持增量,可以大大简化架构,减少之前在全读区过滤增量,或者双写客户端实现增量的逻辑。
需要有更好的搜索解决方案(它支持自身或可以将数据无缝连接到搜索引擎)。
带着这些需求,我们需要使用分布式的NoSQL数据来解决海量数据的存储和访问。多链路增量数据访问的需求和业务高峰访问的波动进一步决定了灵活计费的表格存储是我们在这个架构中的最佳选择。表格存储的schema介绍请参考表格存储数据模型
与同类数据库相比,TableStore(表格存储)有一个很大的功能优势,就是TableStore(表格存储)有一个比较完整的增量接口,即Stream增量API。Stream的介绍请参考表格存储流概述。场景介绍可以参考Stream应用场景介绍,具体API使用可以参考JAVA SDK Stream。通过Stream接口,我们可以很方便的订阅TableStore(表存储)的所有修改操作,也就是各种新数据。同时,我们基于Stream构建了大量的数据通道,连接各种下游计算产品。用户甚至不需要直接调用Stream API,使用我们的channel直接订阅下游的增量数据,自然接入整个阿里云计算生态。上述架构中提到的函数计算,MaxCompute、ElasticSearch、DataV、TableStore(表存储)都支持。详情请参阅:
流与函数计算对接
Stream 和 MaxCompute
流和 Elasticsearch
通过DataV显示存储在表中的数据
TableStore(表存储)是属性列上的自由表结构。对于舆情分析的场景,随着舆情分析算法的升级,我们可能会增加新的属性字段,普通网页、微博等社交页面的属性也可能有所不同。因此,自由表结构与传统数据库相比,可以很好地满足我们的需求。
在架构中,我们有三个存储库需求。它们是原创页库、结构化元数据库和舆情结果库。前两个一般是离线存储和分析库,最后一个是在线数据库。它们对访问性能和存储成本有不同的要求。表格存储有两种支持存储分层的实例类型,高性能和容量。高性能适用于多写多读的场景,即作为在线业务存储。容量类型适用于写多读少的场景,即离线业务存储。它们的单线写入延迟可以控制在10毫秒以内,读取高性能可以保持在毫秒级。TableStore 还支持 TTL 并设置表级数据过期时间。根据需求,我们可以设置舆情结果的TTL,只提供最近数据的查询,旧的舆情会自动过期删除。
借助TableStore(表存储)的这些特性,可以很好地满足系统对存储选择的六大要求。基于TableStore(表存储),可以完美设计和实现全网舆情存储分析系统。
后记
本文总结了海量数据舆情分析场景中遇到的存储和分析问题,介绍了如何在满足业务基础数据量的前提下,使用阿里云自研的TableStore(表存储),通过Stream接口与计算平台的对接,实现了架构的简化。TableStore(表格存储)是阿里云自主研发的专业级分布式NoSQL数据库。它是一种基于共享存储的高性能、低成本、易扩展、全托管的半结构化数据存储平台。数据处理领域的重要应用之一。其他场景请参考TableStore进阶之路。 查看全部
实时抓取网页数据(全网舆情分析系统设计中可能会遇到的的问题?)
摘要: 前言 在当前的互联网信息浪潮下,信息传播的速度远远超出我们的想象。一条微博大V的帖子,一条朋友圈的动态,一条热门论坛的新闻,或者购物平台的一条购物评论,都可能产生数以万计的转发、关注和点赞。如果是一些不合理的负面评论,就会激起人们的负面情绪,甚至影响消费者对企业品牌的认可。如果不能及时采取正确的措施,将会造成不可估量的损失。
前言
在当前的互联网信息浪潮下,信息传播的速度远远超出我们的想象。一条微博大V的帖子,一条朋友圈的动态,一条热门论坛的新闻,或者购物平台的一条购物评论,都可能产生数以万计的转发、关注和点赞。如果是一些不合理的负面评论,就会激起人们的负面情绪,甚至影响消费者对企业品牌的认可。如果不能及时采取正确的措施,将会造成不可估量的损失。因此,我们需要一个高效的全网舆情分析系统来帮助我们实时观察舆情。
这个全网舆情分析系统可以存储百亿网页数据,实时抓取和存储新网页,并为新网页实时提取元数据。随着提取结果,我们还需要进行进一步的挖掘分析,包括但不限于
舆情影响力诊断,从传播的幅度和传播趋势进行预测,判断舆情最终是否会形成。
传播路径分析,分析舆情传播的关键路径。
用户画像为舆论参与者提供了一个共同特征的轮廓,例如性别、年龄、地区和感兴趣的话题。
情绪分析,分析新闻或评论是正面还是负面。在情感分类之后进行统计聚合。
预警设置,我们支持设置舆情讨论量阈值,达到阈值后通知推送业务方,避免错过舆论的黄金参与时间。
这些挖掘出来的舆情结果会被推送到需求方,同时也提供了一个接口供各业务方搜索查询。接下来,我们将讨论系统设计中可能遇到的问题。我们将重点关注系统设计中与存储相关的话题,并为这些问题找到最优的解决方案。
系统设计
一个舆情系统,首先需要一个爬虫引擎去采集各大主流门户、购物网站、社区论坛、微博的原创页面内容、朋友圈的各种新闻资讯. 采集对于海量的网页,消息数据(上百亿)需要实时存储。在根据网站url获取网页之前,需要判断是否是之前爬过的页面,避免不必要的重复爬取。采集网页之后,我们需要提取网页,去除不必要的标签,提取标题、摘要、正文内容、评论等,提取的内容进入存储系统,方便后续查询。同时,新增的抽取结果需要推送到计算平台进行统计分析、报表生成或后续舆情检索等功能。根据算法,计算内容可能需要新数据或完整数据。舆论本身的时间敏感性决定了我们的系统必须能够高效地处理这些新内容。最好延迟几秒后检索新的热搜。
我们可以将整个数据流总结如下:
根据上图不难发现,要设计一个全网舆情的存储分析平台,我们需要处理爬取、存储、分析、搜索和展示。具体来说,我们需要解决以下问题:
如何高效存储百亿原创网页信息,为了提高舆情分析的全面性和准确性,我们往往希望尽可能多的抓取网页信息,然后按照我们设定的权重进行聚合。因此,整个网页的历史数据库会比较大,积累了数百亿的网页信息,数据量可以达到数百TB甚至数PB。在数据量如此之大的情况下,我们还需要做到读写毫秒级的低延迟,这使得传统数据库难以满足需求。
在爬虫爬取网页之前,如何判断之前是否被爬过?对于普通的网页,舆论关心的是时效性。或许我们只想爬取同一个网页一次,那我们就可以用网页地址来爬取Heavy,减少不必要的网页资源浪费。所以我们需要分布式存储来提供基于网页的高效随机查询。
如何在新的原创网页存储后进行实时结构化提取,并存储提取结果。这里我们的原创网页可能收录各种html标签,我们需要去掉这些html标签,提取出文章的标题、作者、发布时间等。这些内容为后续舆情情绪分析提供了必要的结构化数据。
如何高效连接计算平台,对新提取的结构化数据进行流式传输,进行实时计算。这里我们需要对网页内容和消息描述进行分类,进行情感识别,并对识别后的结果进行统计分析。由于全盘分析的时效性差,舆论往往关注最新的新闻和评论,所以必须做增量分析。
如何提供高效的舆情搜索,除了订阅固定的关键词舆情,用户还做一些关键词搜索。比如你想了解竞品公司新产品的一些舆情分析。
如何实现新舆论的实时推送?为了保证舆情的及时性,不仅要坚持舆情分析结果,还要支持舆情结果的推送。推送的内容通常是我们实时分析的新舆情。
系统结构
针对以上问题,我们来介绍一下如何基于阿里云上的各种云产品,搭建一个全网百亿级别的舆情分析平台。我们将重点关注存储产品的选择以及如何高效连接各类计算。,搜索平台。
我们使用ECS作为爬虫引擎,可以根据爬取的数量确定使用ECS的机器资源数量,也可以在每天的高峰期临时扩展资源用于网络爬取。抓取原创网页后,将原创网页地址和网页内容写入存储系统。同时,如果要避免重复爬取,爬虫引擎在爬取前要根据url列表去重。存储引擎需要支持低延迟的随机访问查询,判断当前url是否已经存在,如果存在,则无需再次爬取。
为了实现网页原创内容的实时提取,我们需要将新增的页面推送到计算平台。以前的架构往往需要应用层的双重写入,即原创网页数据存储在数据库中,我们反复将数据的副本写入计算平台。这样的架构需要我们维护两组编写逻辑。同样,结构化增量进入舆情分析平台也存在类似问题。提取的结构化元数据也需要双写入舆情分析平台。舆情分析结果也需要写入分布式存储,推送到搜索平台。在这里我们可以发现图中的三个红线会带来我们对三个数据源的双写需求。这会增加代码开发的工作量,也会导致复杂的系统实现和维护。每个数据源的双写需要知道下游的存在,或者使用消息服务通过双写消息做解耦。mysql等传统数据库支持增量日志binlog的订阅。如果分布式存储产品可以支持大的访问和存储容量,还可以提供增量订阅,可以大大简化我们的架构。每个数据源的双写需要知道下游的存在,或者使用消息服务通过双写消息做解耦。mysql等传统数据库支持增量日志binlog的订阅。如果分布式存储产品可以支持大的访问和存储容量,还可以提供增量订阅,可以大大简化我们的架构。每个数据源的双写需要知道下游的存在,或者使用消息服务通过双写消息做解耦。mysql等传统数据库支持增量日志binlog的订阅。如果分布式存储产品可以支持大的访问和存储容量,还可以提供增量订阅,可以大大简化我们的架构。
网页数据采集存储后,会增量流入我们的计算平台,实时提取元数据。这里我们可以使用函数计算。当有新的页面需要提取时,触发函数计算的托管函数执行网页元数据。提炼。提取出来的结果存入存储系统并持久化后,同时推送到MaxCompute进行舆情分析,如情感分析、文本聚类等。可能会有一些公共信息表数据、用户情绪数据统计等结果。舆情结果会写入存储系统和搜索引擎,部分报告和阈值告警会推送给订阅者。搜索引擎的数据提供给在线舆情检索系统。
介绍完完整的架构后,我们再来看看阿里云上如何进行存储选型。
存储选择
通过架构的介绍,我们总结一下存储选型的要求:
可支持海量数据存储(TB/PB级别)、高并发访问(10万到1000万TPS)、低访问延迟。
采集的数量会随着采集订阅的网页源的调整而动态调整。同时,爬虫在不同时间段爬取的网页数量在一天之内也会有明显的波峰和波谷,所以数据库需要能够灵活的扩缩容。
有了自由表属性结构,对于普通网页和社交平台页面的信息,我们需要注意的属性可能会有很大的不同。灵活的模式将有助于我们的扩展。
对于旧数据,您可以选择自动过期或分层存储。由于舆情数据往往集中在近期热点,旧数据的访问频率较低。
需要更好的增量通道,新增数据可以定期导出到计算平台。上图中有3条红色虚线。这三个部分有一个共同的特点。增量可以实时引导到相应的计算平台进行计算,并将计算结果写入相应的存储引擎。如果数据库引擎本身支持增量,可以大大简化架构,减少之前在全读区过滤增量,或者双写客户端实现增量的逻辑。
需要有更好的搜索解决方案(它支持自身或可以将数据无缝连接到搜索引擎)。
带着这些需求,我们需要使用分布式的NoSQL数据来解决海量数据的存储和访问。多链路增量数据访问的需求和业务高峰访问的波动进一步决定了灵活计费的表格存储是我们在这个架构中的最佳选择。表格存储的schema介绍请参考表格存储数据模型
与同类数据库相比,TableStore(表格存储)有一个很大的功能优势,就是TableStore(表格存储)有一个比较完整的增量接口,即Stream增量API。Stream的介绍请参考表格存储流概述。场景介绍可以参考Stream应用场景介绍,具体API使用可以参考JAVA SDK Stream。通过Stream接口,我们可以很方便的订阅TableStore(表存储)的所有修改操作,也就是各种新数据。同时,我们基于Stream构建了大量的数据通道,连接各种下游计算产品。用户甚至不需要直接调用Stream API,使用我们的channel直接订阅下游的增量数据,自然接入整个阿里云计算生态。上述架构中提到的函数计算,MaxCompute、ElasticSearch、DataV、TableStore(表存储)都支持。详情请参阅:
流与函数计算对接
Stream 和 MaxCompute
流和 Elasticsearch
通过DataV显示存储在表中的数据
TableStore(表存储)是属性列上的自由表结构。对于舆情分析的场景,随着舆情分析算法的升级,我们可能会增加新的属性字段,普通网页、微博等社交页面的属性也可能有所不同。因此,自由表结构与传统数据库相比,可以很好地满足我们的需求。
在架构中,我们有三个存储库需求。它们是原创页库、结构化元数据库和舆情结果库。前两个一般是离线存储和分析库,最后一个是在线数据库。它们对访问性能和存储成本有不同的要求。表格存储有两种支持存储分层的实例类型,高性能和容量。高性能适用于多写多读的场景,即作为在线业务存储。容量类型适用于写多读少的场景,即离线业务存储。它们的单线写入延迟可以控制在10毫秒以内,读取高性能可以保持在毫秒级。TableStore 还支持 TTL 并设置表级数据过期时间。根据需求,我们可以设置舆情结果的TTL,只提供最近数据的查询,旧的舆情会自动过期删除。
借助TableStore(表存储)的这些特性,可以很好地满足系统对存储选择的六大要求。基于TableStore(表存储),可以完美设计和实现全网舆情存储分析系统。
后记
本文总结了海量数据舆情分析场景中遇到的存储和分析问题,介绍了如何在满足业务基础数据量的前提下,使用阿里云自研的TableStore(表存储),通过Stream接口与计算平台的对接,实现了架构的简化。TableStore(表格存储)是阿里云自主研发的专业级分布式NoSQL数据库。它是一种基于共享存储的高性能、低成本、易扩展、全托管的半结构化数据存储平台。数据处理领域的重要应用之一。其他场景请参考TableStore进阶之路。
实时抓取网页数据(有时会有爬虫经常抓取网站却不收录的情况,这是什么原因)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-07 03:28
随着互联网的发展,很多企业开始重视网站推广,利用搜索引擎优化(SEO)来获取流量,完成转化。搜索引擎抓取网站和收录会影响网站的排名,所以SEO人员会经常关注网站的抓取频率和搜索引擎的收录情况,但是有时候爬虫经常爬到网站而不爬到收录,是什么原因?
一、低质量的内容
SEO人员都知道,为了让爬虫频繁地爬取网站,需要不断的更新网站的内容。然而,有些网站为了定期更新而忽略了内容的质量。众所周知,搜索引擎喜欢 原创 和有用的内容。当网站的内容更新时,虽然蜘蛛爬取了网站,但是在做内容评估的时候,网站的内容并没有被评估,没有收录。
为了避免这种情况,在更新网站内容时,尽量添加一些原创内容,或者对用户有帮助的优质内容,这样更容易被搜索引擎评价。受益 收录 和 网站 排名。
二、死链接太多
当蜘蛛爬行 网站 时,它们会沿着链接爬行。如果死链接太多,会影响蜘蛛的爬取,从而有爬取痕迹但没有收录。这种情况一般发生在网站修改后,页面链接处理不当,导致大量死链接,影响收录和网站的排名。因此,应经常检查网站链接,发现死链接时及时提交给搜索引擎,以利于网站的长远发展。
三、算法改变
搜索引擎经常不时更新他们的算法以改进他们的搜索引擎。当算法发生变化时,爬行频率很容易急剧增加。如果是由于算法调整而发生这种情况,您不必太担心。只需了解算法更新的细节,进行有针对性的调整,很快就会恢复正常。
四、对于被攻击
很多网站会为了提升自己的排名,使用一些作弊手段,比如蜘蛛池。这种攻击对手网站的方法会导致对手网站的爬取频率显着增加,甚至可能对搜索引擎收取点球,导致网站排名消失。
综上所述,这就是 网站 经常有人居住的四个原因中的一些,但 收录 却很低。SEO工作是一项细致的工作,除了做好基本的网站优化、内容更新、外链建设等,还需要定期检查网站。如果发现异常情况,要及时了解和处理,有利于网站的长期推广。搜索引擎获得稳定和持久的排名和流量。 查看全部
实时抓取网页数据(有时会有爬虫经常抓取网站却不收录的情况,这是什么原因)
随着互联网的发展,很多企业开始重视网站推广,利用搜索引擎优化(SEO)来获取流量,完成转化。搜索引擎抓取网站和收录会影响网站的排名,所以SEO人员会经常关注网站的抓取频率和搜索引擎的收录情况,但是有时候爬虫经常爬到网站而不爬到收录,是什么原因?
一、低质量的内容
SEO人员都知道,为了让爬虫频繁地爬取网站,需要不断的更新网站的内容。然而,有些网站为了定期更新而忽略了内容的质量。众所周知,搜索引擎喜欢 原创 和有用的内容。当网站的内容更新时,虽然蜘蛛爬取了网站,但是在做内容评估的时候,网站的内容并没有被评估,没有收录。
为了避免这种情况,在更新网站内容时,尽量添加一些原创内容,或者对用户有帮助的优质内容,这样更容易被搜索引擎评价。受益 收录 和 网站 排名。
二、死链接太多
当蜘蛛爬行 网站 时,它们会沿着链接爬行。如果死链接太多,会影响蜘蛛的爬取,从而有爬取痕迹但没有收录。这种情况一般发生在网站修改后,页面链接处理不当,导致大量死链接,影响收录和网站的排名。因此,应经常检查网站链接,发现死链接时及时提交给搜索引擎,以利于网站的长远发展。
三、算法改变
搜索引擎经常不时更新他们的算法以改进他们的搜索引擎。当算法发生变化时,爬行频率很容易急剧增加。如果是由于算法调整而发生这种情况,您不必太担心。只需了解算法更新的细节,进行有针对性的调整,很快就会恢复正常。
四、对于被攻击
很多网站会为了提升自己的排名,使用一些作弊手段,比如蜘蛛池。这种攻击对手网站的方法会导致对手网站的爬取频率显着增加,甚至可能对搜索引擎收取点球,导致网站排名消失。
综上所述,这就是 网站 经常有人居住的四个原因中的一些,但 收录 却很低。SEO工作是一项细致的工作,除了做好基本的网站优化、内容更新、外链建设等,还需要定期检查网站。如果发现异常情况,要及时了解和处理,有利于网站的长期推广。搜索引擎获得稳定和持久的排名和流量。
实时抓取网页数据( 基于Python的网络爬虫与反爬虫技术研究[J])
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-04 11:12
基于Python的网络爬虫与反爬虫技术研究[J])
基于Python爬虫技术的网页解析与数据获取研究
温雅娜、袁子良、何永辰、黄萌
(灾害预防与技术学院, 河北三河 065201)
摘要:网络的发展、大数据和人工智能的兴起让数据变得尤为重要。各行各业的发展都需要数据的支撑。任何一种深度学习和算法都需要大量数据作为模型。训练以得出更准确的结论。本文讨论了网络爬虫实现中的主要问题:了解网页的基本结构,使用直观的网页分析工具抓取和分析网页,如何使用正则表达式获取准确的字符串信息,以及使用Python实现简单的页面数据获取。
关键词:网络爬虫; Python;正则表达式;抓包分析
中国图书馆分类代码:TP391.3 文献识别代码:A 文章编号:2096-4706 (2020)01-0012-03
基于Python爬虫技术的网页分析与数据采集研究
温雅娜、袁子良、何永臣、黄萌
(中国防灾研究所,三河 065201)
摘要:随着网络的发展,大数据和人工智能的兴起,数据变得越来越重要。各行各业的发展需要数据的支撑。任何一种深度学习和算法都需要大量的数据作为模型进行训练,才能得到更准确的结论。本文讨论了网络爬虫实现中的主要问题:了解网页的基本结构,使用直观的网页分析工具分析网页,如何使用正则表达式获取准确的字符串信息,以及使用Python实现简单的页面数据获取。
关键词:网络爬虫; Python;正则表达式;抓包分析
资助单位:防震减灾专项;中央高校基本科研业务费专项资金(ZY20180124)
参考资料:
[1]郭尔强,李波。大数据环境下基于Python的网络爬虫技术[J].计算机产品与流通,2017 (12): 82.
[2]李沛。基于Python的网络爬虫与反爬虫技术研究[J].计算机与数字工程, 2019, 47 (6): 1415-1420+1496.
p>
[3] 王朝阳.基于Python的图书馆信息系统设计与实现[D].长春:吉林大学,2016.
[4] 徐衡.社交网络数据采集技术研究与实现[D].长春:吉林大学,2016.
[5] 孙建利,贾卓生。基于Python的Web爬虫实现与内容分析研究[C]//中国计算机用户协会网络应用分会2017年第21届网络新技术与应用年会。中国计算机用户协会网络应用分会2017年第21届网络新技术与应用年会论文集.河北雄安:计算机科学编辑部,2017:275-277+281.
[6] 陈琳,任芳。基于Python的新浪微博数据爬虫程序设计[J].信息系统工程,2016 (9): 97-99.
[7] 卢淑芬。基于Python的Web爬虫系统设计与实现[J].计算机编程技能与维护,2019 (2): 26-27+51.
[8] 熊畅。基于Python爬虫技术的Web数据采集与分析研究[J].数字技术与应用, 2017 (9): 35-36.
[9] 吴双。基于python语言的Web数据挖掘与分析研究[J].计算机知识与技术, 2018, 14 (27):1-2.
作者简介:文雅娜(1999.03-),女,汉族,内蒙古包头人,本科,学士,研究方向:人工智能与软件开发与应用。 查看全部
实时抓取网页数据(
基于Python的网络爬虫与反爬虫技术研究[J])
基于Python爬虫技术的网页解析与数据获取研究
温雅娜、袁子良、何永辰、黄萌
(灾害预防与技术学院, 河北三河 065201)
摘要:网络的发展、大数据和人工智能的兴起让数据变得尤为重要。各行各业的发展都需要数据的支撑。任何一种深度学习和算法都需要大量数据作为模型。训练以得出更准确的结论。本文讨论了网络爬虫实现中的主要问题:了解网页的基本结构,使用直观的网页分析工具抓取和分析网页,如何使用正则表达式获取准确的字符串信息,以及使用Python实现简单的页面数据获取。
关键词:网络爬虫; Python;正则表达式;抓包分析
中国图书馆分类代码:TP391.3 文献识别代码:A 文章编号:2096-4706 (2020)01-0012-03
基于Python爬虫技术的网页分析与数据采集研究
温雅娜、袁子良、何永臣、黄萌
(中国防灾研究所,三河 065201)
摘要:随着网络的发展,大数据和人工智能的兴起,数据变得越来越重要。各行各业的发展需要数据的支撑。任何一种深度学习和算法都需要大量的数据作为模型进行训练,才能得到更准确的结论。本文讨论了网络爬虫实现中的主要问题:了解网页的基本结构,使用直观的网页分析工具分析网页,如何使用正则表达式获取准确的字符串信息,以及使用Python实现简单的页面数据获取。
关键词:网络爬虫; Python;正则表达式;抓包分析
资助单位:防震减灾专项;中央高校基本科研业务费专项资金(ZY20180124)
参考资料:
[1]郭尔强,李波。大数据环境下基于Python的网络爬虫技术[J].计算机产品与流通,2017 (12): 82.
[2]李沛。基于Python的网络爬虫与反爬虫技术研究[J].计算机与数字工程, 2019, 47 (6): 1415-1420+1496.
p>
[3] 王朝阳.基于Python的图书馆信息系统设计与实现[D].长春:吉林大学,2016.
[4] 徐衡.社交网络数据采集技术研究与实现[D].长春:吉林大学,2016.
[5] 孙建利,贾卓生。基于Python的Web爬虫实现与内容分析研究[C]//中国计算机用户协会网络应用分会2017年第21届网络新技术与应用年会。中国计算机用户协会网络应用分会2017年第21届网络新技术与应用年会论文集.河北雄安:计算机科学编辑部,2017:275-277+281.
[6] 陈琳,任芳。基于Python的新浪微博数据爬虫程序设计[J].信息系统工程,2016 (9): 97-99.
[7] 卢淑芬。基于Python的Web爬虫系统设计与实现[J].计算机编程技能与维护,2019 (2): 26-27+51.
[8] 熊畅。基于Python爬虫技术的Web数据采集与分析研究[J].数字技术与应用, 2017 (9): 35-36.
[9] 吴双。基于python语言的Web数据挖掘与分析研究[J].计算机知识与技术, 2018, 14 (27):1-2.
作者简介:文雅娜(1999.03-),女,汉族,内蒙古包头人,本科,学士,研究方向:人工智能与软件开发与应用。
实时抓取网页数据(各大互联网公司各种团队的团队做的开放平台)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-03 11:03
实时抓取网页数据可以加入saas平台,如猿圈快数等。图片可以通过浏览器插件获取。百度地图中的数据量应该比较多,点开图片即可看到数据。数据可以通过百度开放平台获取。
联系我们吧,
百度地图的数据是大网络传输过来的.很多网站已经把数据封装好了,比如说qq.有些网站在接数据的时候只需要获取,不需要转发给每个网站.这样提高了互联网数据交换的效率.还有一个可能是,通过某种加密技术,运输过来的大量网站,先通过互联网传输进某些数据库,然后再转发给不同的网站.这样节省转发路由的时间.
这个服务我以前也很疑惑,但是我有不同的观点:第一,这其实是一种匿名的网络传输,方便传输,省时省力。第二,做出来的服务在不同国家可能不一样。至于说没必要,应该说不是必要,是不清楚某些国家怎么玩转。第三,这服务将来肯定也会有地图数据,就像现在的车牌一样。
有点不理解楼主的意思,百度地图数据源自哪里?人家是先有数据源,再要你们搞各种渠道弄了产品卖给你。比如cdn、数据库、存储、其他比如sns导航大数据之类的。
我不知道以后的百度地图数据是不是提供给各大互联网公司了,像腾讯、360之类的,他们分别搞各种各样的市场团队,里面可能有开放平台。腾讯地图和360地图目前已经拿到数据并开放免费数据了。我试用了一下各大互联网公司各种团队的团队做的开放平台。感觉有的提供一个百度apistore接口,有的提供各家公司api数据,数据质量层次不齐。 查看全部
实时抓取网页数据(各大互联网公司各种团队的团队做的开放平台)
实时抓取网页数据可以加入saas平台,如猿圈快数等。图片可以通过浏览器插件获取。百度地图中的数据量应该比较多,点开图片即可看到数据。数据可以通过百度开放平台获取。
联系我们吧,
百度地图的数据是大网络传输过来的.很多网站已经把数据封装好了,比如说qq.有些网站在接数据的时候只需要获取,不需要转发给每个网站.这样提高了互联网数据交换的效率.还有一个可能是,通过某种加密技术,运输过来的大量网站,先通过互联网传输进某些数据库,然后再转发给不同的网站.这样节省转发路由的时间.
这个服务我以前也很疑惑,但是我有不同的观点:第一,这其实是一种匿名的网络传输,方便传输,省时省力。第二,做出来的服务在不同国家可能不一样。至于说没必要,应该说不是必要,是不清楚某些国家怎么玩转。第三,这服务将来肯定也会有地图数据,就像现在的车牌一样。
有点不理解楼主的意思,百度地图数据源自哪里?人家是先有数据源,再要你们搞各种渠道弄了产品卖给你。比如cdn、数据库、存储、其他比如sns导航大数据之类的。
我不知道以后的百度地图数据是不是提供给各大互联网公司了,像腾讯、360之类的,他们分别搞各种各样的市场团队,里面可能有开放平台。腾讯地图和360地图目前已经拿到数据并开放免费数据了。我试用了一下各大互联网公司各种团队的团队做的开放平台。感觉有的提供一个百度apistore接口,有的提供各家公司api数据,数据质量层次不齐。
实时抓取网页数据(知乎ios端的效率可能更高的实时抓取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-02 21:02
实时抓取网页数据无论是互联网、pc端网页数据,还是移动端网页数据,通过分析你的电脑、手机、ipad的cookie记录以及浏览器的hook。都可以获取目标地址对应的页面。然后爬虫将爬取过的页面按照cookie记录的返回,还原出刚才的场景和内容。然后进行定制的渲染即可。这样就可以大致解决当前互联网数据抓取方面的问题。
真正工程实现上,这个估计是有技术难度的,主要是在大量ip抓取以及cookie记录上。如果不对于页面进行优化,应该抓取效率是很低的。
首先,手机端上常见的是:抓包解包分析header请求发送包加载包抓取源url后ajax返回包结合ajax回调过后,用正则匹配正则字符串抓取session里的header等进行抓取,有些是不抓取,有些是抓取ajax请求包,再根据返回地址抓取。知乎ios端的效率可能更高,因为有点历史原因,如果抓取数据实时保存,大多需要写代码抓取。
抓包分析请求地址,返回信息,人肉构造请求,判断,分析,静态页是这么一套链路,具体规范自己细细体会吧。如果要达到微信那种动态场景,估计不大可能实现。
很高兴这么多人回答这个问题,今天对微信的消息抓取进行了实现。目前开发使用了chrome浏览器,浏览器的hook机制和safari有所不同,但依然要满足hook机制的条件。ps:小程序有seuthread.js,内置了一个基本ui,可以作为各种界面交互的hook,然后通过getdata传递给hook来获取图片等响应数据。
可以抓取历史数据,接口响应返回有些延迟,但不影响用户体验,hook响应响应慢的场景时间在控制在2分钟。时间不够的情况下,会采用短连接,交互响应用textfield而不是传递fetchfrom{},短连接解决通信麻烦和重定向,这是实现最快的方案。定时判断请求连接是否连接,如果没连接,使用自己写的一个websocket服务,每天或每周进行一次流量控制,限制每次请求的时间。
通过这种一站式的解决方案,目前有些成果了,但这是需要一些时间的,我觉得微信微博朋友圈的数据抓取不大可能,因为没有准确的机制和规范,想要实现这个也只能试试。 查看全部
实时抓取网页数据(知乎ios端的效率可能更高的实时抓取网页数据)
实时抓取网页数据无论是互联网、pc端网页数据,还是移动端网页数据,通过分析你的电脑、手机、ipad的cookie记录以及浏览器的hook。都可以获取目标地址对应的页面。然后爬虫将爬取过的页面按照cookie记录的返回,还原出刚才的场景和内容。然后进行定制的渲染即可。这样就可以大致解决当前互联网数据抓取方面的问题。
真正工程实现上,这个估计是有技术难度的,主要是在大量ip抓取以及cookie记录上。如果不对于页面进行优化,应该抓取效率是很低的。
首先,手机端上常见的是:抓包解包分析header请求发送包加载包抓取源url后ajax返回包结合ajax回调过后,用正则匹配正则字符串抓取session里的header等进行抓取,有些是不抓取,有些是抓取ajax请求包,再根据返回地址抓取。知乎ios端的效率可能更高,因为有点历史原因,如果抓取数据实时保存,大多需要写代码抓取。
抓包分析请求地址,返回信息,人肉构造请求,判断,分析,静态页是这么一套链路,具体规范自己细细体会吧。如果要达到微信那种动态场景,估计不大可能实现。
很高兴这么多人回答这个问题,今天对微信的消息抓取进行了实现。目前开发使用了chrome浏览器,浏览器的hook机制和safari有所不同,但依然要满足hook机制的条件。ps:小程序有seuthread.js,内置了一个基本ui,可以作为各种界面交互的hook,然后通过getdata传递给hook来获取图片等响应数据。
可以抓取历史数据,接口响应返回有些延迟,但不影响用户体验,hook响应响应慢的场景时间在控制在2分钟。时间不够的情况下,会采用短连接,交互响应用textfield而不是传递fetchfrom{},短连接解决通信麻烦和重定向,这是实现最快的方案。定时判断请求连接是否连接,如果没连接,使用自己写的一个websocket服务,每天或每周进行一次流量控制,限制每次请求的时间。
通过这种一站式的解决方案,目前有些成果了,但这是需要一些时间的,我觉得微信微博朋友圈的数据抓取不大可能,因为没有准确的机制和规范,想要实现这个也只能试试。
实时抓取网页数据(为什么要学网络爬虫可以替代人工从网页中找到数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-02 13:08
为什么要学习网络爬虫
它可以代替人工从网页中查找数据并将其复制粘贴到excel中。这种重复性的工作,不仅浪费时间,而且一不留神,容易出错,解决了这些无法自动化、无法实时获取的公共数据的应用价值,我们可以借助KYC框架来了解,了解你的公司(了解您的公司),了解您的竞争对手(了解您的竞争对手),了解您的客户(了解您的客户)。这是通过理解和执行对公共数据的简单描述性分析可以带来的价值。此外,通过机器学习和统计算法分析,可以帮助企业在营销领域做4P(产品、价格、渠道)。地方)促销(促销))
网络爬虫的基本协议
robots协议
python爬虫的流程
主要可以分为三个部分:1.获取网页;2.解析网页(提取数据);3.存储数据;
1.获取网页就是向URL发送请求,会返回整个网页的数据
2.解析一个网页就是从整个网页的数据中提取出想要的数据
3.存数据就是存数据
三道工序的技术实现
1.获取网页
获取网页的基本技术:request、urllib和selenium(模拟浏览器)
获取网页先进技术:多进程多线程爬取、登录爬取、破IP封禁、服务器爬取
2.解析网页
解析网页的基本技术:re正则表达式、beautifulsoup和lxml
网页解析高级技术:解决中文乱码
3.存储的数据
数据存储的基本技术:存txt文件和存csv文件
存储数据的先进技术:存储在MySQL数据库中和存储在mongodb数据库中 查看全部
实时抓取网页数据(为什么要学网络爬虫可以替代人工从网页中找到数据?)
为什么要学习网络爬虫
它可以代替人工从网页中查找数据并将其复制粘贴到excel中。这种重复性的工作,不仅浪费时间,而且一不留神,容易出错,解决了这些无法自动化、无法实时获取的公共数据的应用价值,我们可以借助KYC框架来了解,了解你的公司(了解您的公司),了解您的竞争对手(了解您的竞争对手),了解您的客户(了解您的客户)。这是通过理解和执行对公共数据的简单描述性分析可以带来的价值。此外,通过机器学习和统计算法分析,可以帮助企业在营销领域做4P(产品、价格、渠道)。地方)促销(促销))
网络爬虫的基本协议
robots协议
python爬虫的流程
主要可以分为三个部分:1.获取网页;2.解析网页(提取数据);3.存储数据;
1.获取网页就是向URL发送请求,会返回整个网页的数据
2.解析一个网页就是从整个网页的数据中提取出想要的数据
3.存数据就是存数据
三道工序的技术实现
1.获取网页
获取网页的基本技术:request、urllib和selenium(模拟浏览器)
获取网页先进技术:多进程多线程爬取、登录爬取、破IP封禁、服务器爬取
2.解析网页
解析网页的基本技术:re正则表达式、beautifulsoup和lxml
网页解析高级技术:解决中文乱码
3.存储的数据
数据存储的基本技术:存txt文件和存csv文件
存储数据的先进技术:存储在MySQL数据库中和存储在mongodb数据库中
实时抓取网页数据(SpiderDuck如何工作?Twitter的工程问题及解决方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-01 06:14
推文通常收录指向网络上各种内容的链接,包括图像、视频、新闻文章 和博客文章。SpiderDuck 是一项 Twitter 服务,它实时抓取这些链接,解析下载内容并提取有趣的元数据,并在几秒钟内将这些数据提供给其他 Twitter 服务。
Twitter 的许多团队都需要访问链接的内容,尤其是要通过实时内容改进 Twitter 的产品。例如:
背景
在 SpiderDuck 之前,Twitter 有一项服务,通过发送 HEAD 请求和跟踪重定向来解析所有推文中的 URL。服务很简单,满足了当时公司的需求,但也有几个局限:
显然,我们需要构建一个真正的 URL 抓取工具,能够克服上述限制并满足公司的长期目标。我们最初的想法是使用或构建一些开源抓取代码,但我们意识到几乎每个可用的开源抓取工具都有两个我们不需要的功能:
因此,我们决定设计一个新系统来满足 Twitter 的实时需求,并随着它的发展而横向扩展。为了避免重新发明轮子,我们主要在开源模块上构建了新系统,以便我们可以继续利用开源社区的贡献。
这是 Twitter 的典型工程问题——它们与其他大型互联网公司的问题类似,但要求一切都实时工作提出了独特而有趣的挑战。
系统总览
以下是 SpiderDuck 工作原理的概述。下图显示了它的主要组成部分。
Kestrel:这是 Twitter 广泛使用的消息队列系统,用于对新推文进行排队。
调度程序:这些工作单元决定是否抓取 URL、调度抓取时间和跟踪重定向跳转(如果有)。抓取后,它解析下载的内容,提取元数据,将元数据写回元数据存储,并将原创数据写入内容存储。每个调度器独立工作;也就是说,我们可以向系统添加任意数量的调度程序,随着推文和 URL 数量的增加,水平扩展系统。
Fetcher:这些是 Thrift 服务器,用于维护短期 URL 获取队列,它们发送实际的 HTTP 获取请求并实现速率控制和处理 robots.txt。就像调度程序一样,它们可以随抓取速度水平扩展。
Memcached:这是 fetcher 用来临时存储 robots.txt 文件的分布式缓存。
Metadata Store:这是一个基于 Cassandra 的分布式哈希表,用于存储网页元数据和 URL 索引的解析信息,以及系统最近遇到的每个 URL 的爬取状态。该商店归 Twitter 所有,用于所有需要实时访问 URL 数据的客户服务。
内容存储:这是一个 HDFS 集群,用于存储下载的内容和所有爬取信息。
现在我们将详细介绍 SpiderDuck 的两个主要组件 - URL Scheduler 和 URLFetcher。
网址调度程序
下图描述了 SpiderDuck Scheduler 中的几个处理阶段。
与大多数 SpiderDuck 一样,Scheduler 构建在由 Twitter 开发的名为 Finagle 的开源异步 RPC 框架之上。(实际上,这是最早使用 Finagle 的项目之一)。上图中的每个块,除了 KestrelReader 之外,都是一个 Finagle 过滤器 - 一种抽象,它允许将一系列处理阶段连接到一个完全异步的管道中。完全异步允许 SpiderDuck 使用少量、固定数量的线程来处理高流量。
Kestrel Reader 会不断要求新的推文。当推文进入时,它们被发送到 TweetProcessor,它从中提取 URL。然后将每个 URL 发送到 Crawl Decider 阶段。此阶段从 MetadataStore 中读取 URL 的爬取状态,以确定 SpiderDuck 之前是否已看到该 URL。然后,Crawl Decider 根据预定义的爬取策略决定是否应该爬取 URL(也就是说,如果 SpiderDuck 在过去 X 天内看到了该 URL,则不再对其进行爬取)。如果 Decider 决定不抓取 URL,它会记录一个状态以指示处理已完成。如果它决定获取 URL,它将把 URL 发送到 Fetcher Client 阶段。
Fetcher Client 阶段使用客户端库与 Fetcher 对话。客户端库实现逻辑来决定使用哪个 Fetcher 来获取 URL;它还可以处理重定向。(重定向跳转链很常见,因为 Twitter 帖子上的 URL 大多被缩短。)通过调度程序的每个 URL 都有一个关联的上下文对象。Fetcher 客户端将包括状态、下载的标头和内容在内的获取信息添加到上下文对象,并将其传递给后处理器。后处理器将下载的数据交给元数据提取器,后者检测页面的编码并使用开源 HTML5 解析器解析页面的内容。提取库实现了一系列启发式方法来提取元数据,例如标题、介绍和代表性图像。然后后处理器将所有元数据和抓取信息写入元数据存储。如果需要,后处理器还会安排一系列相关的提取。相关抓取的一个示例是嵌入的媒体内容,例如图像。
在后处理之后,URL 上下文对象被传递到下一个阶段,该阶段使用一个名为 Scribe 的开源日志聚合器将所有信息(包括完整内容)记录在 ContentStore (HDFS) 日志中。此阶段还通知所有感兴趣的听众 URL 处理已完成。通知使用简单的发布者-订阅者模型,通过 Kestrel 的分散队列实现。
所有处理阶段都是异步运行的——没有线程会等待一个阶段完成。与正在处理的每个 URL 关联的状态都存储在关联的上下文对象中,因此线程模型也非常简单。异步实现还受益于 Finagle 和 Twitter Util 库提供的方便的抽象和构造。
网址提取器
让我们看看 Fetcher 如何处理 URL。
Fetcher 通过 Thrift 接口接收 URL。经过一些简单的确认后,Thrift 处理程序将 URL 传递给请求队列管理器,请求队列管理器将 URL 分配给适当的请求队列。计划任务将以固定速率从请求队列中读取。一旦从队列中取出 URL,它将被发送到 HTTPService 进行处理。基于 Finagle 构建的 HTTP 服务首先检查与 URL 关联的主机是否已经在缓存中。如果没有,那么它会为其创建一个 Finagle 客户端并安排对 robots.txt 文件的获取。下载 robots.txt 后,HTTP 服务会获取允许的 URL。robots.txt文件本身是缓存的,进程内Host Cache各一份,Memcached一份,防止每次有新的主机URL进来时重复爬取。
一些名为 Vulture 的任务会定期检查 Request Queue 和 Host Cache 中是否有一段时间未使用的队列和主机;如果找到,它们将被删除。Vulture 还通过日志和 Twitter Commons 状态输出库报告有用的统计数据。
Fetcher 的 Request Queue 还有一个重要的目标:速率限制。SpiderDuck 会限制对每个域名的 HTTP 抓取请求,以确保它不会使 Web 服务器过载。为了准确地限制速率,SpiderDuck 确保在任何时候每个 RequestQueue 都被分配给一个 Fetcher,并且在 Fetcher 失败时可以自动重新分配给另一个 Fetcher。一个名为 Pacemaker 的集群包将请求队列分配给 Fetcher 并管理故障转移。Fetcher 客户端库根据域名将 URL 分配给不同的请求队列。为整个网络设置的默认速率限制也可以根据需要被为特定域名设置的速率限制覆盖。也就是说,如果 URL 的进入速度超过了它们的处理速度,它们将拒绝告诉客户端它应该收敛的请求,
为了安全起见,Fetcher 被部署在 Twitter 数据中心内的一个特殊区域 DMZ 中。这意味着 Fetcher 无法访问 Twitter 的产品群和服务。因此,确保它们是轻量级和自力更生是非常重要的,这是指导设计的许多方面的原则。
Twitter 如何使用 SpiderDuck
Twitter 服务以多种方式使用 SpiderDuck 的数据。大多数将直接查询元数据存储以获取 URL 的元数据(例如,标题)和解析信息(所有重定向后的最终标准化 URL)。元数据存储是实时填充的,通常在推文中发布 URL 的几秒钟内。这些服务不直接与 Cassandra 通信,而是通过代理这些请求的 Spiderduck Thrift 服务器。这个中间层为 SpiderDuck 提供了在需要时透明地切换存储系统的灵活性。它还支持比直接访问 Cassandra 更高级别的 API 抽象。
其他服务会定期处理 SpiderDuck 在 HDFS 上的日志,以生成汇总统计信息,用于 Twitter 的内部测量仪表板或其他批处理分析。仪表板帮助我们回答诸如“每天在 Twitter 上分享多少张图片?”、“Twitter 用户最常链接到哪些新闻 网站?”之类的问题。和“昨天我们从某个 网站 上刮了多少?” 网页?”等等。
需要注意的是,这些服务通常不会告诉 SpiderDuck 要抓取什么。SpiderDuck 已经抓取了所有访问 Twitter 的 URL。相反,这些服务会在 URL 可用后要求他们提供信息。SpiderDuck 还允许这些服务直接请求 Fetcher 通过 HTTP 获取任意内容(因此它们可以从我们的数据中心设置、速率限制、robot.txt 支持等中受益),但这种用法并不普遍。
性能数据
SpiderDuck 每秒处理数百个 URL。其中大部分在 SpiderDuck 获取策略定义的时间窗口内是唯一的,因此它们将被获取。对于抓取的 URL,SpiderDuck 的中位处理延迟低于 2 秒,其中 99% 的处理延迟低于 5 秒。延迟是根据推文发布时间来衡量的,即在用户点击“推文”按钮后的 5 秒内,推文中的 URL 被提取出来,准备爬取,并捕获所有重定向跳转。内容被下载和解析,元数据被提取,并且已经通过 MetadataStore 提供给客户。大部分时间要么花在 Fetcher 请求队列中(由于速率限制),要么实际从外部 Web 服务器获取 URL。
SpiderDuck 基于 Cassandra 的元数据存储每秒可以处理近 10,000 个请求。这些请求通常针对单个或小批量(少于 20 个)的 URL,但它也可以处理大批量(200-300 个 URL)的请求。该存储系统的读取延迟中值约为 4 到 5 秒,第 99 个百分位范围约为 50 到 60 毫秒。
谢谢
SpiderDuck 的核心团队包括以下成员:Abhi Khune、Michael Busch、Paul Burstein、Raghavendra Prabhu、Tian Wang 和 YiZhuang。此外,我们要感谢公司中的以下人员,他们直接为该项目做出了贡献,帮助设置了 SpiderDuck 直接依赖的部分(例如 Cassandra、Finagle、Pacemaker 和 Scribe),或者帮助构建SpiderDuck 独特的数据中心设置:Alan Liang、Brady Catherman、Chris Goffinet、Dmitriy Ryaboy、Gilad Mishne、John Corwin、John Sirois、Jonathan Boulle、Jonathan Reichhold、Marius Eriksen、Nick Kallen、Ryan King、Samuel Luckenbill、Steve Jiang、Stu Hood和特拉维斯克劳福德。我们还要感谢整个 Twitter 搜索团队的宝贵设计反馈和支持。如果你也想参与这样的项目,
原文地址::///2011/11/spiderduck-twitters-real-time-url.html 查看全部
实时抓取网页数据(SpiderDuck如何工作?Twitter的工程问题及解决方案)
推文通常收录指向网络上各种内容的链接,包括图像、视频、新闻文章 和博客文章。SpiderDuck 是一项 Twitter 服务,它实时抓取这些链接,解析下载内容并提取有趣的元数据,并在几秒钟内将这些数据提供给其他 Twitter 服务。
Twitter 的许多团队都需要访问链接的内容,尤其是要通过实时内容改进 Twitter 的产品。例如:
背景
在 SpiderDuck 之前,Twitter 有一项服务,通过发送 HEAD 请求和跟踪重定向来解析所有推文中的 URL。服务很简单,满足了当时公司的需求,但也有几个局限:
显然,我们需要构建一个真正的 URL 抓取工具,能够克服上述限制并满足公司的长期目标。我们最初的想法是使用或构建一些开源抓取代码,但我们意识到几乎每个可用的开源抓取工具都有两个我们不需要的功能:
因此,我们决定设计一个新系统来满足 Twitter 的实时需求,并随着它的发展而横向扩展。为了避免重新发明轮子,我们主要在开源模块上构建了新系统,以便我们可以继续利用开源社区的贡献。
这是 Twitter 的典型工程问题——它们与其他大型互联网公司的问题类似,但要求一切都实时工作提出了独特而有趣的挑战。
系统总览
以下是 SpiderDuck 工作原理的概述。下图显示了它的主要组成部分。
Kestrel:这是 Twitter 广泛使用的消息队列系统,用于对新推文进行排队。
调度程序:这些工作单元决定是否抓取 URL、调度抓取时间和跟踪重定向跳转(如果有)。抓取后,它解析下载的内容,提取元数据,将元数据写回元数据存储,并将原创数据写入内容存储。每个调度器独立工作;也就是说,我们可以向系统添加任意数量的调度程序,随着推文和 URL 数量的增加,水平扩展系统。
Fetcher:这些是 Thrift 服务器,用于维护短期 URL 获取队列,它们发送实际的 HTTP 获取请求并实现速率控制和处理 robots.txt。就像调度程序一样,它们可以随抓取速度水平扩展。
Memcached:这是 fetcher 用来临时存储 robots.txt 文件的分布式缓存。
Metadata Store:这是一个基于 Cassandra 的分布式哈希表,用于存储网页元数据和 URL 索引的解析信息,以及系统最近遇到的每个 URL 的爬取状态。该商店归 Twitter 所有,用于所有需要实时访问 URL 数据的客户服务。
内容存储:这是一个 HDFS 集群,用于存储下载的内容和所有爬取信息。
现在我们将详细介绍 SpiderDuck 的两个主要组件 - URL Scheduler 和 URLFetcher。
网址调度程序
下图描述了 SpiderDuck Scheduler 中的几个处理阶段。
与大多数 SpiderDuck 一样,Scheduler 构建在由 Twitter 开发的名为 Finagle 的开源异步 RPC 框架之上。(实际上,这是最早使用 Finagle 的项目之一)。上图中的每个块,除了 KestrelReader 之外,都是一个 Finagle 过滤器 - 一种抽象,它允许将一系列处理阶段连接到一个完全异步的管道中。完全异步允许 SpiderDuck 使用少量、固定数量的线程来处理高流量。
Kestrel Reader 会不断要求新的推文。当推文进入时,它们被发送到 TweetProcessor,它从中提取 URL。然后将每个 URL 发送到 Crawl Decider 阶段。此阶段从 MetadataStore 中读取 URL 的爬取状态,以确定 SpiderDuck 之前是否已看到该 URL。然后,Crawl Decider 根据预定义的爬取策略决定是否应该爬取 URL(也就是说,如果 SpiderDuck 在过去 X 天内看到了该 URL,则不再对其进行爬取)。如果 Decider 决定不抓取 URL,它会记录一个状态以指示处理已完成。如果它决定获取 URL,它将把 URL 发送到 Fetcher Client 阶段。
Fetcher Client 阶段使用客户端库与 Fetcher 对话。客户端库实现逻辑来决定使用哪个 Fetcher 来获取 URL;它还可以处理重定向。(重定向跳转链很常见,因为 Twitter 帖子上的 URL 大多被缩短。)通过调度程序的每个 URL 都有一个关联的上下文对象。Fetcher 客户端将包括状态、下载的标头和内容在内的获取信息添加到上下文对象,并将其传递给后处理器。后处理器将下载的数据交给元数据提取器,后者检测页面的编码并使用开源 HTML5 解析器解析页面的内容。提取库实现了一系列启发式方法来提取元数据,例如标题、介绍和代表性图像。然后后处理器将所有元数据和抓取信息写入元数据存储。如果需要,后处理器还会安排一系列相关的提取。相关抓取的一个示例是嵌入的媒体内容,例如图像。
在后处理之后,URL 上下文对象被传递到下一个阶段,该阶段使用一个名为 Scribe 的开源日志聚合器将所有信息(包括完整内容)记录在 ContentStore (HDFS) 日志中。此阶段还通知所有感兴趣的听众 URL 处理已完成。通知使用简单的发布者-订阅者模型,通过 Kestrel 的分散队列实现。
所有处理阶段都是异步运行的——没有线程会等待一个阶段完成。与正在处理的每个 URL 关联的状态都存储在关联的上下文对象中,因此线程模型也非常简单。异步实现还受益于 Finagle 和 Twitter Util 库提供的方便的抽象和构造。
网址提取器
让我们看看 Fetcher 如何处理 URL。
Fetcher 通过 Thrift 接口接收 URL。经过一些简单的确认后,Thrift 处理程序将 URL 传递给请求队列管理器,请求队列管理器将 URL 分配给适当的请求队列。计划任务将以固定速率从请求队列中读取。一旦从队列中取出 URL,它将被发送到 HTTPService 进行处理。基于 Finagle 构建的 HTTP 服务首先检查与 URL 关联的主机是否已经在缓存中。如果没有,那么它会为其创建一个 Finagle 客户端并安排对 robots.txt 文件的获取。下载 robots.txt 后,HTTP 服务会获取允许的 URL。robots.txt文件本身是缓存的,进程内Host Cache各一份,Memcached一份,防止每次有新的主机URL进来时重复爬取。
一些名为 Vulture 的任务会定期检查 Request Queue 和 Host Cache 中是否有一段时间未使用的队列和主机;如果找到,它们将被删除。Vulture 还通过日志和 Twitter Commons 状态输出库报告有用的统计数据。
Fetcher 的 Request Queue 还有一个重要的目标:速率限制。SpiderDuck 会限制对每个域名的 HTTP 抓取请求,以确保它不会使 Web 服务器过载。为了准确地限制速率,SpiderDuck 确保在任何时候每个 RequestQueue 都被分配给一个 Fetcher,并且在 Fetcher 失败时可以自动重新分配给另一个 Fetcher。一个名为 Pacemaker 的集群包将请求队列分配给 Fetcher 并管理故障转移。Fetcher 客户端库根据域名将 URL 分配给不同的请求队列。为整个网络设置的默认速率限制也可以根据需要被为特定域名设置的速率限制覆盖。也就是说,如果 URL 的进入速度超过了它们的处理速度,它们将拒绝告诉客户端它应该收敛的请求,
为了安全起见,Fetcher 被部署在 Twitter 数据中心内的一个特殊区域 DMZ 中。这意味着 Fetcher 无法访问 Twitter 的产品群和服务。因此,确保它们是轻量级和自力更生是非常重要的,这是指导设计的许多方面的原则。
Twitter 如何使用 SpiderDuck
Twitter 服务以多种方式使用 SpiderDuck 的数据。大多数将直接查询元数据存储以获取 URL 的元数据(例如,标题)和解析信息(所有重定向后的最终标准化 URL)。元数据存储是实时填充的,通常在推文中发布 URL 的几秒钟内。这些服务不直接与 Cassandra 通信,而是通过代理这些请求的 Spiderduck Thrift 服务器。这个中间层为 SpiderDuck 提供了在需要时透明地切换存储系统的灵活性。它还支持比直接访问 Cassandra 更高级别的 API 抽象。
其他服务会定期处理 SpiderDuck 在 HDFS 上的日志,以生成汇总统计信息,用于 Twitter 的内部测量仪表板或其他批处理分析。仪表板帮助我们回答诸如“每天在 Twitter 上分享多少张图片?”、“Twitter 用户最常链接到哪些新闻 网站?”之类的问题。和“昨天我们从某个 网站 上刮了多少?” 网页?”等等。
需要注意的是,这些服务通常不会告诉 SpiderDuck 要抓取什么。SpiderDuck 已经抓取了所有访问 Twitter 的 URL。相反,这些服务会在 URL 可用后要求他们提供信息。SpiderDuck 还允许这些服务直接请求 Fetcher 通过 HTTP 获取任意内容(因此它们可以从我们的数据中心设置、速率限制、robot.txt 支持等中受益),但这种用法并不普遍。
性能数据
SpiderDuck 每秒处理数百个 URL。其中大部分在 SpiderDuck 获取策略定义的时间窗口内是唯一的,因此它们将被获取。对于抓取的 URL,SpiderDuck 的中位处理延迟低于 2 秒,其中 99% 的处理延迟低于 5 秒。延迟是根据推文发布时间来衡量的,即在用户点击“推文”按钮后的 5 秒内,推文中的 URL 被提取出来,准备爬取,并捕获所有重定向跳转。内容被下载和解析,元数据被提取,并且已经通过 MetadataStore 提供给客户。大部分时间要么花在 Fetcher 请求队列中(由于速率限制),要么实际从外部 Web 服务器获取 URL。
SpiderDuck 基于 Cassandra 的元数据存储每秒可以处理近 10,000 个请求。这些请求通常针对单个或小批量(少于 20 个)的 URL,但它也可以处理大批量(200-300 个 URL)的请求。该存储系统的读取延迟中值约为 4 到 5 秒,第 99 个百分位范围约为 50 到 60 毫秒。
谢谢
SpiderDuck 的核心团队包括以下成员:Abhi Khune、Michael Busch、Paul Burstein、Raghavendra Prabhu、Tian Wang 和 YiZhuang。此外,我们要感谢公司中的以下人员,他们直接为该项目做出了贡献,帮助设置了 SpiderDuck 直接依赖的部分(例如 Cassandra、Finagle、Pacemaker 和 Scribe),或者帮助构建SpiderDuck 独特的数据中心设置:Alan Liang、Brady Catherman、Chris Goffinet、Dmitriy Ryaboy、Gilad Mishne、John Corwin、John Sirois、Jonathan Boulle、Jonathan Reichhold、Marius Eriksen、Nick Kallen、Ryan King、Samuel Luckenbill、Steve Jiang、Stu Hood和特拉维斯克劳福德。我们还要感谢整个 Twitter 搜索团队的宝贵设计反馈和支持。如果你也想参与这样的项目,
原文地址::///2011/11/spiderduck-twitters-real-time-url.html
实时抓取网页数据(Python3基本语法,抓取境外投资企业(机构)名录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-31 06:09
【新手任务】
老板:我们在海外市场,吸引投资人很重要。你去把所有的海外投资企业(机构)都抄给我。
任务.png
一共2606页,点击下一页,然后ctrl+C,再Ctrl+V,准备复制到黎明。环顾四周,新来的实习生们都回学校做毕业论文了。
【解决方案】
知识点:Python 3基础语法、splinter库和xpath基础知识
情况1:
Python 使用 splinter 库来控制 chrome 浏览器,打开网页,获取数据。抢占境外投资企业(机构)名录。
思路分析:
第 1 步:安装碎片
百度splinter安装,建议先安装anaconda(python常用库基本都有),然后再安装splinter
第二步:使用splinter打开chrome并访问链接
from splinter import Browser
browser = Browser('chrome') #打开谷歌浏览器
browser.visit('http://femhzs.mofcom.gov.cn/fecpmvc/pages/fem/CorpJWList.html') #访问链接
打开谷歌浏览器并访问link.png
第 3 步:获取信息
# 通过谷歌浏览器的检查功能,可以很迅速地获取所需元素的地址。
# find_by_xpath(XPath地址) 返回值是储存在列表中的
# 这里是只有一个元素的列表,所以要选择列表第一个元素的值
r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.value # 取得1行1列的值
r1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.value # 取得1行2列的值
r1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.value# 取得1行3列的值
browser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click() # 点击下一页
# 打印数据,并退出浏览器
print(r1c1,r1c2,r1c3)
browser.quit()
【结论】
本文简要介绍了如何使用python splinter库来操作谷歌浏览器,然后定位到想要的元素,然后获取元素的值。采集完成后,打印数据并退出浏览器。数据存储请参考插上翅膀让Excel飞起来-xlwings(一)。完整的上百页数据的获取只是在代码中加了一个循环,有需要我再讨论下次详细说。。完整代码如下:
from splinter import Browser
browser = Browser('chrome')
browser.visit('http://femhzs.mofcom.gov.cn/fecpmvc/pages/fem/CorpJWList.html')
r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.value
r1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.value
r1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.value
browser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click()
# 打印数据,并退出浏览器
print(r1c1,r1c2,r1c3)
browser.quit()
参考
Xpath 实例
分裂官方文档 查看全部
实时抓取网页数据(Python3基本语法,抓取境外投资企业(机构)名录)
【新手任务】
老板:我们在海外市场,吸引投资人很重要。你去把所有的海外投资企业(机构)都抄给我。
任务.png
一共2606页,点击下一页,然后ctrl+C,再Ctrl+V,准备复制到黎明。环顾四周,新来的实习生们都回学校做毕业论文了。
【解决方案】
知识点:Python 3基础语法、splinter库和xpath基础知识
情况1:
Python 使用 splinter 库来控制 chrome 浏览器,打开网页,获取数据。抢占境外投资企业(机构)名录。
思路分析:
第 1 步:安装碎片
百度splinter安装,建议先安装anaconda(python常用库基本都有),然后再安装splinter
第二步:使用splinter打开chrome并访问链接
from splinter import Browser
browser = Browser('chrome') #打开谷歌浏览器
browser.visit('http://femhzs.mofcom.gov.cn/fecpmvc/pages/fem/CorpJWList.html') #访问链接
打开谷歌浏览器并访问link.png
第 3 步:获取信息
# 通过谷歌浏览器的检查功能,可以很迅速地获取所需元素的地址。
# find_by_xpath(XPath地址) 返回值是储存在列表中的
# 这里是只有一个元素的列表,所以要选择列表第一个元素的值
r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.value # 取得1行1列的值
r1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.value # 取得1行2列的值
r1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.value# 取得1行3列的值
browser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click() # 点击下一页
# 打印数据,并退出浏览器
print(r1c1,r1c2,r1c3)
browser.quit()
【结论】
本文简要介绍了如何使用python splinter库来操作谷歌浏览器,然后定位到想要的元素,然后获取元素的值。采集完成后,打印数据并退出浏览器。数据存储请参考插上翅膀让Excel飞起来-xlwings(一)。完整的上百页数据的获取只是在代码中加了一个循环,有需要我再讨论下次详细说。。完整代码如下:
from splinter import Browser
browser = Browser('chrome')
browser.visit('http://femhzs.mofcom.gov.cn/fecpmvc/pages/fem/CorpJWList.html')
r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.value
r1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.value
r1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.value
browser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click()
# 打印数据,并退出浏览器
print(r1c1,r1c2,r1c3)
browser.quit()
参考
Xpath 实例
分裂官方文档
实时抓取网页数据(不转售客户资料网站手机号码抓取软件抓取你网站手机号的原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-29 16:04
浏览页面后,如果要获取客户的手机号和手机号,可以100%抓取网站访客的手机号。有没有这样的手机号获取系统?
当然还有:我们的老师可以通过数据的实现来抓取自己公司的手机号网站,也可以实现中国同行之间的相互抓取,APP抓取指定的抓取也是没问题的网站 和应用的电话号码
郑重声明:不转售客户资料,不转售客户资料,不转售客户资料网站手机号码抓取软件
抓取你的网站手机号的原理是在网站的头部插入一个设计码。当访问者访问 网站 页面时,他们会询问用户的手机号码。
同行公司相互爬取和APP爬取的工作原理:互联网大数据运营商与代理商合作,基本技术原理是当访问者使用手机3G总流量浏览信息时网站设计或APP软件的情况下,会影响到属于公司自身的https报告。访客的手机号码,浏览和访问我们的区别是什么网站,停留了多长时间,都可以由访客计算,最终计算。需求和实体经济模型。
无论您想要什么,我们都有一个系统来获取 网站 的移动流量。
任何在网上做任何事的人都摆脱不了运营商
运营商存储每个人的在线行为、电话、短信交互、实时位置等
每一个行为都反映了客户的需求
您希望客户解决什么问题行为,无非是为需要我们的国家寻找和提取
网站掌握手机号,低成本客源+高效改造,解决客户问题,利润翻倍 查看全部
实时抓取网页数据(不转售客户资料网站手机号码抓取软件抓取你网站手机号的原理)
浏览页面后,如果要获取客户的手机号和手机号,可以100%抓取网站访客的手机号。有没有这样的手机号获取系统?
当然还有:我们的老师可以通过数据的实现来抓取自己公司的手机号网站,也可以实现中国同行之间的相互抓取,APP抓取指定的抓取也是没问题的网站 和应用的电话号码
郑重声明:不转售客户资料,不转售客户资料,不转售客户资料网站手机号码抓取软件
抓取你的网站手机号的原理是在网站的头部插入一个设计码。当访问者访问 网站 页面时,他们会询问用户的手机号码。
同行公司相互爬取和APP爬取的工作原理:互联网大数据运营商与代理商合作,基本技术原理是当访问者使用手机3G总流量浏览信息时网站设计或APP软件的情况下,会影响到属于公司自身的https报告。访客的手机号码,浏览和访问我们的区别是什么网站,停留了多长时间,都可以由访客计算,最终计算。需求和实体经济模型。
无论您想要什么,我们都有一个系统来获取 网站 的移动流量。
任何在网上做任何事的人都摆脱不了运营商
运营商存储每个人的在线行为、电话、短信交互、实时位置等
每一个行为都反映了客户的需求
您希望客户解决什么问题行为,无非是为需要我们的国家寻找和提取
网站掌握手机号,低成本客源+高效改造,解决客户问题,利润翻倍
实时抓取网页数据(为什么要学网络爬虫可以替代人工从网页中找到数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-29 07:09
为什么要学习网络爬虫
它可以代替人工从网页中查找数据并将其复制粘贴到excel中。这种重复性的工作,不仅浪费时间,而且一不留神,容易出错,解决了这些无法自动化、无法实时获取的公共数据的应用价值,我们可以借助KYC框架来了解,了解你的公司(了解您的公司),了解您的竞争对手(了解您的竞争对手),了解您的客户(了解您的客户)。这是通过理解和执行对公共数据的简单描述性分析可以带来的价值。进一步,通过机器学习和统计算法分析,可以帮助企业做4Ps(产品)、价格(price)、渠道(place)推广(promotion))
网络爬虫的基本协议
robots协议
python爬虫的流程
主要可以分为三个部分:1.获取网页;2.解析网页(提取数据);3.存储数据;
1.获取网页就是向URL发送请求,会返回整个网页的数据
2.解析一个网页就是从整个网页的数据中提取出想要的数据
3.存数据就是存数据
三道工序的技术实现
1.获取网页
获取网页的基本技术:request、urllib和selenium(模拟浏览器)
网页获取先进技术:多进程多线程爬取、登录爬取、突破IP封禁、服务器爬取
2.解析网页
解析网页的基本技术:re正则表达式、beautifulsoup和lxml
网页解析高级技术:解决中文乱码
3.存储的数据
数据存储的基本技术:存txt文件和存csv文件
存储数据的先进技术:存储在MySQL数据库中和存储在mongodb数据库中 查看全部
实时抓取网页数据(为什么要学网络爬虫可以替代人工从网页中找到数据?)
为什么要学习网络爬虫
它可以代替人工从网页中查找数据并将其复制粘贴到excel中。这种重复性的工作,不仅浪费时间,而且一不留神,容易出错,解决了这些无法自动化、无法实时获取的公共数据的应用价值,我们可以借助KYC框架来了解,了解你的公司(了解您的公司),了解您的竞争对手(了解您的竞争对手),了解您的客户(了解您的客户)。这是通过理解和执行对公共数据的简单描述性分析可以带来的价值。进一步,通过机器学习和统计算法分析,可以帮助企业做4Ps(产品)、价格(price)、渠道(place)推广(promotion))
网络爬虫的基本协议
robots协议
python爬虫的流程
主要可以分为三个部分:1.获取网页;2.解析网页(提取数据);3.存储数据;
1.获取网页就是向URL发送请求,会返回整个网页的数据
2.解析一个网页就是从整个网页的数据中提取出想要的数据
3.存数据就是存数据
三道工序的技术实现
1.获取网页
获取网页的基本技术:request、urllib和selenium(模拟浏览器)
网页获取先进技术:多进程多线程爬取、登录爬取、突破IP封禁、服务器爬取
2.解析网页
解析网页的基本技术:re正则表达式、beautifulsoup和lxml
网页解析高级技术:解决中文乱码
3.存储的数据
数据存储的基本技术:存txt文件和存csv文件
存储数据的先进技术:存储在MySQL数据库中和存储在mongodb数据库中
实时抓取网页数据(33款常用的大数据分析工具推荐(最新)-可用来抓数据的开源爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-29 07:05
链接提交工具可以实时向百度推送数据,创建并提交站点地图,提交收录网页链接,帮助百度发现和了解你的网站。
来自.wkwm17c48105ed5{display:none;font-size:12px;}百度文库。
特点:网页抓取、信息提取、数据提取工具包,操作简单 11、Playfishplayfish是Java技术,综合应用多种开源。
我想抓取一个国外网站的数据,有什么好的数据抓取工具推荐吗?.
33个用于抓取数据的开源爬虫软件工具 每个人都是产品经理。
如何防止恶意爬虫窃取我的 网站 上的所有数据?我不太关心 SEO,虽然我不想阻止合法的抓取。
刮:开始数据刮工作。ExportdataCSV:以 CSV 格式导出捕获的数据。在这里,有一个简单的了解就足够了。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
呵呵,楼上说的很清楚了,你得先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据采集,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据采集系统,可以搜索详情,它们是国内信息的采集 的创始人。
比如等待事件或点击某些项目,而不仅仅是抓取数据,MechanicalSoup 确实为这款浏览器提供了网络抓取能力。 查看全部
实时抓取网页数据(33款常用的大数据分析工具推荐(最新)-可用来抓数据的开源爬虫)
链接提交工具可以实时向百度推送数据,创建并提交站点地图,提交收录网页链接,帮助百度发现和了解你的网站。
来自.wkwm17c48105ed5{display:none;font-size:12px;}百度文库。
特点:网页抓取、信息提取、数据提取工具包,操作简单 11、Playfishplayfish是Java技术,综合应用多种开源。
我想抓取一个国外网站的数据,有什么好的数据抓取工具推荐吗?.
33个用于抓取数据的开源爬虫软件工具 每个人都是产品经理。
如何防止恶意爬虫窃取我的 网站 上的所有数据?我不太关心 SEO,虽然我不想阻止合法的抓取。
刮:开始数据刮工作。ExportdataCSV:以 CSV 格式导出捕获的数据。在这里,有一个简单的了解就足够了。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
呵呵,楼上说的很清楚了,你得先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据采集,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据采集系统,可以搜索详情,它们是国内信息的采集 的创始人。
比如等待事件或点击某些项目,而不仅仅是抓取数据,MechanicalSoup 确实为这款浏览器提供了网络抓取能力。
实时抓取网页数据(成都网络推广如何提高搜索引擎抓取量提升的技巧成都)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-24 06:19
在成都网站网络推广的优化中,网站想要有排名,就需要有更好的搜索引擎爬取量,得到蜘蛛更多的关注和“呵护”,为了更好的提高网站收录,提高排名,如何提高搜索引擎的爬取量?下面成都网络推广就带你一起来了解一下。
1、维护网站更新频率
网站一定要做好高价值内容网站的定期更新。蜘蛛爬行非常具有战略意义。做好文章的更新,保持良好的频率,让蜘蛛形成更好的习惯。
2、提升用户体验
根据同目的搜索引擎更新规则,百度蜘蛛也优先抓取用户体验好网站,因为蜘蛛喜欢用户体验好网站,所以大家做好这也是很重要。
3、外部链接
成都网推广表示,优质网站先站后,百度对垃圾外链的过滤非常严格,但真正的优质外链对于排名和爬取还是很有用的。
4、保证服务器稳定性
服务器稳定性包括稳定性和速度两个方面。服务器越快,爬虫的效率就越高,这对用户体验也有一定的影响。在服务器稳定的情况下,不会影响蜘蛛的爬取状态,不会卡死,从而保证网站被爬取的速度,增加爬取量。
以上就是成都网络推广为大家总结的一些提高网站刷量的技巧。通过以上的介绍,相信你会对这点有更深入的了解,并帮助你提高自己的网站排名,推动网站的发展越来越好。 查看全部
实时抓取网页数据(成都网络推广如何提高搜索引擎抓取量提升的技巧成都)
在成都网站网络推广的优化中,网站想要有排名,就需要有更好的搜索引擎爬取量,得到蜘蛛更多的关注和“呵护”,为了更好的提高网站收录,提高排名,如何提高搜索引擎的爬取量?下面成都网络推广就带你一起来了解一下。
1、维护网站更新频率
网站一定要做好高价值内容网站的定期更新。蜘蛛爬行非常具有战略意义。做好文章的更新,保持良好的频率,让蜘蛛形成更好的习惯。
2、提升用户体验
根据同目的搜索引擎更新规则,百度蜘蛛也优先抓取用户体验好网站,因为蜘蛛喜欢用户体验好网站,所以大家做好这也是很重要。
3、外部链接
成都网推广表示,优质网站先站后,百度对垃圾外链的过滤非常严格,但真正的优质外链对于排名和爬取还是很有用的。
4、保证服务器稳定性
服务器稳定性包括稳定性和速度两个方面。服务器越快,爬虫的效率就越高,这对用户体验也有一定的影响。在服务器稳定的情况下,不会影响蜘蛛的爬取状态,不会卡死,从而保证网站被爬取的速度,增加爬取量。
以上就是成都网络推广为大家总结的一些提高网站刷量的技巧。通过以上的介绍,相信你会对这点有更深入的了解,并帮助你提高自己的网站排名,推动网站的发展越来越好。

