
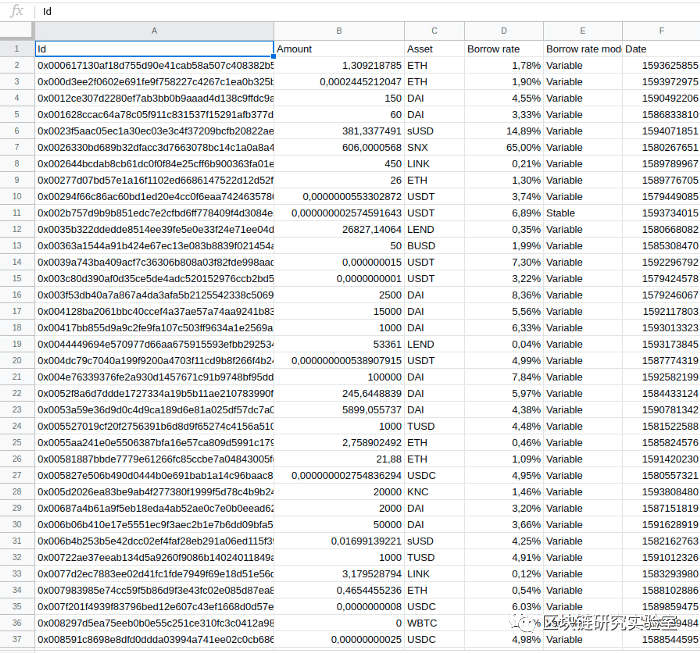
实时抓取网页数据
实时抓取网页数据(【干货】网页静态化的几种常见问题及解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-21 05:05
一、 静态页面
1、 动态和静态页面
静态页面
即静态网页是指加载了内容的HTML页面,直接加载到客户端浏览器上显示,不经过请求服务器数据和编译的过程。通俗的说就是生成一个独立的HTML页面,不需要与服务器进行数据交互。
优缺点说明:
动态页面
指一种网页编程技术,而不是静态网页。页面内容需要由服务器获取。在不考虑缓存的情况下,服务接口的数据发生变化,页面加载的内容也会实时发生变化,但显示的内容是数据库操作动态变化的结果。
优缺点说明:
动态页面和静态页面有很强的相关性,比较起来更容易理解。
2、应用场景
动态页面的静态处理有很多应用场景,例如:
静态技术基础:提示服务的响应速度,或者提前做好响应节点,比如一般流程、页面(客户端)请求服务、服务处理、响应数据、页面加载等一系列流程不仅复杂,而且耗时,如果基于静态技术处理后直接加载静态页面,则请求结束。
二、过程分析
静态页面转换是一个比较复杂的过程,核心过程如下:
主要流程大致如上。如果数据接口的响应参数发生变化,需要重新生成静态页面,因此数据加载的实时性会低很多。
三、代码实现案例
1、基本依赖
FreeMarker 是一个模板引擎:一个基于模板和要更改的数据的通用工具,用于生成输出文本(HTML 网页、电子邮件、配置文件、源代码等)。
org.springframework.boot
spring-boot-starter-freemarker
2、页面模板
这里都使用了 FreeMarker 开发的模板样式。
PageStatic
主题:${myTitle}
作者:${data.auth} 日期:${data.date}
规格描述
产品详情
${info.desc}
${info.imgUrl}
${imgIF}
FreeMarker 的语法与原来的 HTML 语法基本一致,但有自己的一套数据处理标签,使用起来并不复杂。
3、分析过程
通过分析,可以将页面模板和数据接口数据合并在一起。
@Service
public class PageServiceImpl implements PageService {
private static final Logger LOGGER = LoggerFactory.getLogger(PageServiceImpl.class) ;
private static final String PATH = "/templates/" ;
@Override
public void ftlToHtml() throws Exception {
// 创建配置类
Configuration configuration = new Configuration(Configuration.getVersion());
// 设置模板路径
String classpath = this.getClass().getResource("/").getPath();
configuration.setDirectoryForTemplateLoading(new File(classpath + PATH));
// 加载模板
Template template = configuration.getTemplate("my-page.ftl");
// 数据模型
Map map = new HashMap();
map.put("myTitle", "页面静态化(PageStatic)");
map.put("tableList",getList()) ;
map.put("imgList",getImgList()) ;
// 静态化页面内容
String content = FreeMarkerTemplateUtils.processTemplateIntoString(template, map);
LOGGER.info("content:{}",content);
InputStream inputStream = IOUtils.toInputStream(content,"UTF-8");
// 输出文件
FileOutputStream fileOutputStream = new FileOutputStream(new File("F:/page/newPage.html"));
IOUtils.copy(inputStream, fileOutputStream);
// 关闭流
inputStream.close();
fileOutputStream.close();
}
private List getList (){
List tableInfoList = new ArrayList() ;
tableInfoList.add(new TableInfo(Constant.desc1, Constant.img01));
tableInfoList.add(new TableInfo(Constant.desc2,Constant.img02));
return tableInfoList ;
}
private List getImgList (){
List imgList = new ArrayList() ;
imgList.add(Constant.img02) ;
imgList.add(Constant.img02) ;
return imgList ;
}
}
生成的HTML页面可以直接用浏览器打开,不再需要依赖任何数据接口服务。
四、源码地址
GitHub·地址
GitEE·地址
以上就是文章关于SpringBoot2集成FreeMarker实现页面静态化示例的介绍。更多SpringBoot2集成FreeMarker实现页面静态内容相关相关内容,请搜索之前的文章面圈教程或继续浏览下方相关文章,希望大家多多支持面条教程未来! 查看全部
实时抓取网页数据(【干货】网页静态化的几种常见问题及解决方法)
一、 静态页面
1、 动态和静态页面
静态页面
即静态网页是指加载了内容的HTML页面,直接加载到客户端浏览器上显示,不经过请求服务器数据和编译的过程。通俗的说就是生成一个独立的HTML页面,不需要与服务器进行数据交互。
优缺点说明:
动态页面
指一种网页编程技术,而不是静态网页。页面内容需要由服务器获取。在不考虑缓存的情况下,服务接口的数据发生变化,页面加载的内容也会实时发生变化,但显示的内容是数据库操作动态变化的结果。
优缺点说明:
动态页面和静态页面有很强的相关性,比较起来更容易理解。
2、应用场景
动态页面的静态处理有很多应用场景,例如:
静态技术基础:提示服务的响应速度,或者提前做好响应节点,比如一般流程、页面(客户端)请求服务、服务处理、响应数据、页面加载等一系列流程不仅复杂,而且耗时,如果基于静态技术处理后直接加载静态页面,则请求结束。
二、过程分析
静态页面转换是一个比较复杂的过程,核心过程如下:

主要流程大致如上。如果数据接口的响应参数发生变化,需要重新生成静态页面,因此数据加载的实时性会低很多。
三、代码实现案例
1、基本依赖
FreeMarker 是一个模板引擎:一个基于模板和要更改的数据的通用工具,用于生成输出文本(HTML 网页、电子邮件、配置文件、源代码等)。
org.springframework.boot
spring-boot-starter-freemarker
2、页面模板
这里都使用了 FreeMarker 开发的模板样式。
PageStatic
主题:${myTitle}
作者:${data.auth} 日期:${data.date}
规格描述
产品详情
${info.desc}
${info.imgUrl}
${imgIF}
FreeMarker 的语法与原来的 HTML 语法基本一致,但有自己的一套数据处理标签,使用起来并不复杂。
3、分析过程
通过分析,可以将页面模板和数据接口数据合并在一起。
@Service
public class PageServiceImpl implements PageService {
private static final Logger LOGGER = LoggerFactory.getLogger(PageServiceImpl.class) ;
private static final String PATH = "/templates/" ;
@Override
public void ftlToHtml() throws Exception {
// 创建配置类
Configuration configuration = new Configuration(Configuration.getVersion());
// 设置模板路径
String classpath = this.getClass().getResource("/").getPath();
configuration.setDirectoryForTemplateLoading(new File(classpath + PATH));
// 加载模板
Template template = configuration.getTemplate("my-page.ftl");
// 数据模型
Map map = new HashMap();
map.put("myTitle", "页面静态化(PageStatic)");
map.put("tableList",getList()) ;
map.put("imgList",getImgList()) ;
// 静态化页面内容
String content = FreeMarkerTemplateUtils.processTemplateIntoString(template, map);
LOGGER.info("content:{}",content);
InputStream inputStream = IOUtils.toInputStream(content,"UTF-8");
// 输出文件
FileOutputStream fileOutputStream = new FileOutputStream(new File("F:/page/newPage.html"));
IOUtils.copy(inputStream, fileOutputStream);
// 关闭流
inputStream.close();
fileOutputStream.close();
}
private List getList (){
List tableInfoList = new ArrayList() ;
tableInfoList.add(new TableInfo(Constant.desc1, Constant.img01));
tableInfoList.add(new TableInfo(Constant.desc2,Constant.img02));
return tableInfoList ;
}
private List getImgList (){
List imgList = new ArrayList() ;
imgList.add(Constant.img02) ;
imgList.add(Constant.img02) ;
return imgList ;
}
}
生成的HTML页面可以直接用浏览器打开,不再需要依赖任何数据接口服务。
四、源码地址
GitHub·地址
GitEE·地址
以上就是文章关于SpringBoot2集成FreeMarker实现页面静态化示例的介绍。更多SpringBoot2集成FreeMarker实现页面静态内容相关相关内容,请搜索之前的文章面圈教程或继续浏览下方相关文章,希望大家多多支持面条教程未来!
实时抓取网页数据(简单实现爬取网页数据的功能,发现猫眼实时票房展示的数据样本 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-21 05:04
)
学完python,准备练习爬虫项目。简单实现爬取网页数据的功能,发现猫眼实时票房显示的数据样本正好符合预期,然后记录遇到的困难和解决方法。
目标网址:
目标数据:绿色框是要获取的数据类型,红色框是具体需要获取的数据
通过F12查看网页源码,发现label里面的数据就是需要获取的数据
先通过scrapy shell命令:scrapy shell""
检查是否可以获取数据(我这里遇到了困难,导致无法获取动态加载的目标数据)
执行成功后进入交互模式,可以获取网页的内容,
输入命令:response.xpath("//div/div/div[2]/div[2]/table").extract()
可获取的数据类型
通过命令: response.xpath("//div/div/div[2]/div[2]/div/div/table").extract()
无法获取数据的具体数值信息:返回的数据为空
继续查看网页源代码。数据是实时加载的。发现数据存放在xhr类型的second-box文件中。你可以在这里获取数据
注意:XHR是什么,请参考这个文章:)
选择-右键-可以选择复制链接地址:
单独打开此页面地址,即可获取实时票房数据。
像红框这样的数据就是需要的。你只需要通过这个地址获取数据
这时候通过命令进入交互模式:scrapy shell ""
通过命令:response.body。查看具体数据信息(不显示中文,但不妨碍数据的获取)
查看全部
实时抓取网页数据(简单实现爬取网页数据的功能,发现猫眼实时票房展示的数据样本
)
学完python,准备练习爬虫项目。简单实现爬取网页数据的功能,发现猫眼实时票房显示的数据样本正好符合预期,然后记录遇到的困难和解决方法。
目标网址:
目标数据:绿色框是要获取的数据类型,红色框是具体需要获取的数据
通过F12查看网页源码,发现label里面的数据就是需要获取的数据
先通过scrapy shell命令:scrapy shell""
检查是否可以获取数据(我这里遇到了困难,导致无法获取动态加载的目标数据)
执行成功后进入交互模式,可以获取网页的内容,
输入命令:response.xpath("//div/div/div[2]/div[2]/table").extract()
可获取的数据类型
通过命令: response.xpath("//div/div/div[2]/div[2]/div/div/table").extract()
无法获取数据的具体数值信息:返回的数据为空
继续查看网页源代码。数据是实时加载的。发现数据存放在xhr类型的second-box文件中。你可以在这里获取数据
注意:XHR是什么,请参考这个文章:)
选择-右键-可以选择复制链接地址:
单独打开此页面地址,即可获取实时票房数据。
像红框这样的数据就是需要的。你只需要通过这个地址获取数据
这时候通过命令进入交互模式:scrapy shell ""
通过命令:response.body。查看具体数据信息(不显示中文,但不妨碍数据的获取)
实时抓取网页数据(如何从defi(去中心化金融)协议中提取相关defi数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-21 05:04
目前,我们获取区块链数据变得越来越容易和快捷。在这个文章中,我们将解释如何从defi(去中心化金融)协议中提取相关的defi数据,并使用谷歌电子表格创建数据集。通过它,我们将创建一个仪表板来实时显示这些数据,为我们提供有关 Aave 协议中要求的贷款的信息。
检索数据
为了获取数据,我们将使用 The graph 的 Api,如本文所述。
我们要提取的是与贷款申请相关的所有历史数据,以供以后分析。为此,我们必须创建以下查询:
{ borrows (first: 1000) { id, amount, reserve { id, symbol }, borrowRate, borrowRateMode, timestamp }}
通过这个查询,我们得到了前 1000 个结果,这是数据块中 The Graphs 允许的最大值,然后我们将不断迭代得到以下结果,直到我们恢复所有结果。
如果我们在这个操作上测试这个查询,我们可以看到它返回:
之后我们将获得所有贷款数据,以及请求的加密资产、它们的数量、利率和利率。
通过将这些数据直接导入 Google Sheets 中的文档,我们将拥有一个实时数据集来构建我们的分析模型。
创建数据集
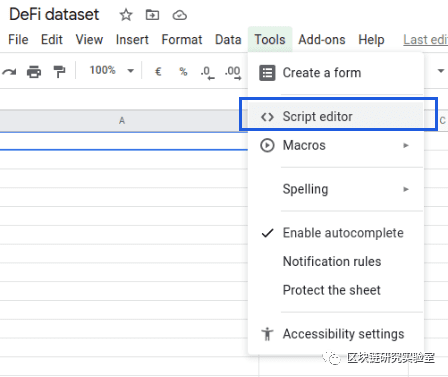
为了将数据保存在 Google excel 表中,我们将在其中创建一个带有以下选项的脚本:
在此脚本中,我们收录以下代码:
我们来看看每一行的详细信息:
第 4-22 行:将被调用以填充数据集的函数。在该函数中,定义了要调用的端点和用于获取数据和查询的查询。有了这些,我调用函数提取出来,然后用excel写出来。
第 30-37 行:构造在调用 API 时将传递选项的函数,为每次迭代调用一个动态参数“skip”,并使用这个新参数创建选项。
第 44-49 行:在 Excel 表格中写入数据的函数。以数组的形式接收数据作为参数,写入执行脚本的excel。
第 57-86 行:迭代历史中存在的所有数据块的函数。创建一个循环向api请求数据,如果有数据,将skip参数增加1000个单位。接收到数据后,将其存储为数组,并从 api 返回的 json 中检索该数组。
创建脚本后,执行脚本加载数据。我们通过以下方式执行它:
我们可以看到excel是如何填充数据的
分析数据
使用填充的数据集,我们可以分析我们的数据。最快、最简单的方法是使用 Google Data Studio 仪表板。
我们创建一个新报告并指定数据源将是电子表格。
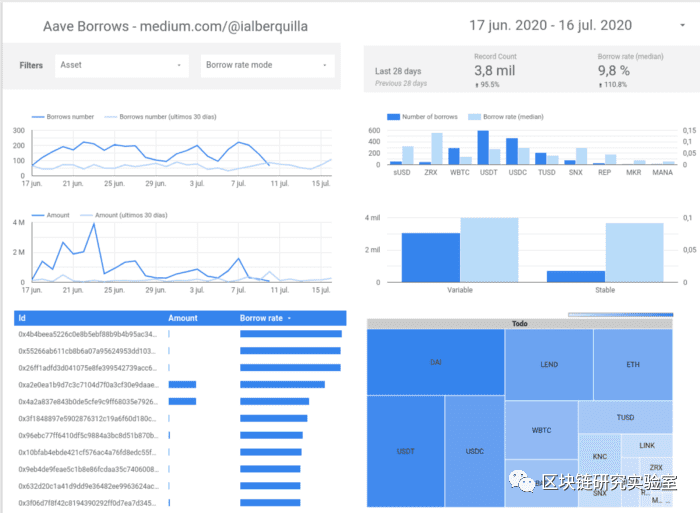
通过选择我们创建的工作表,我们可以使用 Google Data Studio 中存在的模板,然后创建一个仪表板,以一种简单且非常有吸引力的方式向我们展示数据。
通过这个简单的脚本,我们可以实时从协议 DeFi 中获取数据,并分析整个贷款历史中的数据。这是一条非常重要的信息,可以以完全可访问的方式创建模型。 查看全部
实时抓取网页数据(如何从defi(去中心化金融)协议中提取相关defi数据)
目前,我们获取区块链数据变得越来越容易和快捷。在这个文章中,我们将解释如何从defi(去中心化金融)协议中提取相关的defi数据,并使用谷歌电子表格创建数据集。通过它,我们将创建一个仪表板来实时显示这些数据,为我们提供有关 Aave 协议中要求的贷款的信息。
检索数据
为了获取数据,我们将使用 The graph 的 Api,如本文所述。
我们要提取的是与贷款申请相关的所有历史数据,以供以后分析。为此,我们必须创建以下查询:
{ borrows (first: 1000) { id, amount, reserve { id, symbol }, borrowRate, borrowRateMode, timestamp }}
通过这个查询,我们得到了前 1000 个结果,这是数据块中 The Graphs 允许的最大值,然后我们将不断迭代得到以下结果,直到我们恢复所有结果。
如果我们在这个操作上测试这个查询,我们可以看到它返回:
之后我们将获得所有贷款数据,以及请求的加密资产、它们的数量、利率和利率。
通过将这些数据直接导入 Google Sheets 中的文档,我们将拥有一个实时数据集来构建我们的分析模型。
创建数据集
为了将数据保存在 Google excel 表中,我们将在其中创建一个带有以下选项的脚本:
在此脚本中,我们收录以下代码:
我们来看看每一行的详细信息:
第 4-22 行:将被调用以填充数据集的函数。在该函数中,定义了要调用的端点和用于获取数据和查询的查询。有了这些,我调用函数提取出来,然后用excel写出来。
第 30-37 行:构造在调用 API 时将传递选项的函数,为每次迭代调用一个动态参数“skip”,并使用这个新参数创建选项。
第 44-49 行:在 Excel 表格中写入数据的函数。以数组的形式接收数据作为参数,写入执行脚本的excel。
第 57-86 行:迭代历史中存在的所有数据块的函数。创建一个循环向api请求数据,如果有数据,将skip参数增加1000个单位。接收到数据后,将其存储为数组,并从 api 返回的 json 中检索该数组。
创建脚本后,执行脚本加载数据。我们通过以下方式执行它:
我们可以看到excel是如何填充数据的
分析数据
使用填充的数据集,我们可以分析我们的数据。最快、最简单的方法是使用 Google Data Studio 仪表板。
我们创建一个新报告并指定数据源将是电子表格。
通过选择我们创建的工作表,我们可以使用 Google Data Studio 中存在的模板,然后创建一个仪表板,以一种简单且非常有吸引力的方式向我们展示数据。
通过这个简单的脚本,我们可以实时从协议 DeFi 中获取数据,并分析整个贷款历史中的数据。这是一条非常重要的信息,可以以完全可访问的方式创建模型。
实时抓取网页数据(如何让百度快速收录呢,如何选择链接提交方式? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-21 03:04
)
做百度推广时,如何让百度快速收录?这里有三种方法。今天我们主要讲第一个。
如何选择链接提交方式
1、主动推送:最快的提交方式。建议您立即通过此方式将本站产生的新链接推送给百度,以确保百度能及时收到新链接收录。
2、自动推送:最方便的提交方式,请将自动推送的JS代码部署在站点各个页面的源代码中。每次浏览部署代码的页面都会自动推送链接到百度。. 可与主动推送结合使用。
3、站点地图:您可以定期在站点地图中放置网站链接,然后将站点地图提交给百度。百度会定期抓取检查您提交的站点地图,并处理其中的链接,但收录的速度比主动推送要慢。4、 手动提交:一次性提交链接到百度,可以使用这种方式。
百度站长平台为站长提供了链接提交通道。你可以提交你想成为百度收录的链接。百度搜索引擎会按照标准进行处理,但不保证您提交的链接是收录。
需要注意的是:
1.主动推送功能入口为:工具-网页抓取-链接提交-主动推送(实时)
2.主动推送与原实时推送使用不同的数据接口,需要重新获取key(登录后链接提交工具界面可见)
登录地址是
为保证您提交数据的效果,请及时更换界面和密钥,尽快熟悉主动推送功能。如果有问题,您可以通过反馈中心向百度工作人员寻求帮助。
使用百度主动推送(实时)可以加速收录,保护原创的内容不被第三方采集伤害。
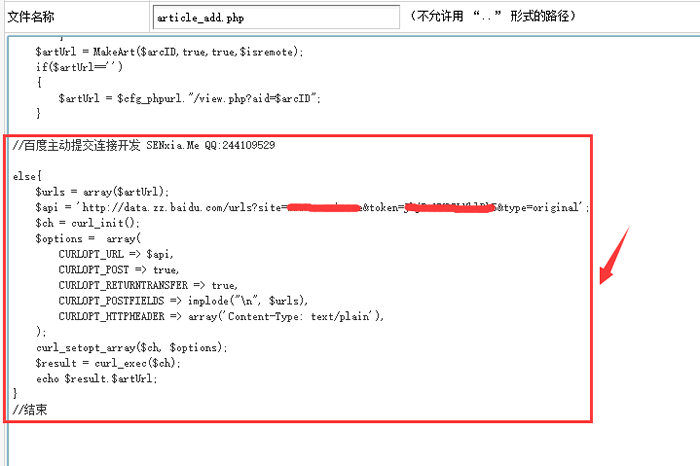
暂时没看到有人写百度的主动推送代码,所以根据百度提供的PHP代码编写,并添加到DEDE后端发布文章文件中,实现了主动推送(真实) -time) 功能与百度百度。
在article_add.php中搜索 $artUrl = MakeArt($arcID,true,true,$isremote);
然后在
if($artUrl=='')
{
$artUrl = $cfg_phpurl."/view.php?aid=$arcID";
}
后面加入
else{
$urls[]='http://'.$_SERVER['HTTP_HOST'].$artUrl;
$api = 'http://data.zz.baidu.com/urls?site=你的域名&token=准入密钥';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
}
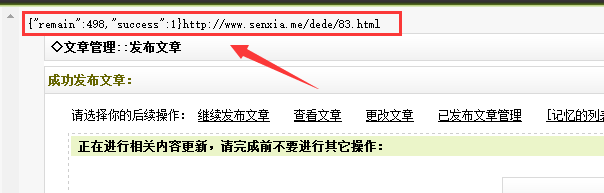
只需保存
文章发布成功后,会显示如下
查看全部
实时抓取网页数据(如何让百度快速收录呢,如何选择链接提交方式?
)
做百度推广时,如何让百度快速收录?这里有三种方法。今天我们主要讲第一个。
如何选择链接提交方式
1、主动推送:最快的提交方式。建议您立即通过此方式将本站产生的新链接推送给百度,以确保百度能及时收到新链接收录。
2、自动推送:最方便的提交方式,请将自动推送的JS代码部署在站点各个页面的源代码中。每次浏览部署代码的页面都会自动推送链接到百度。. 可与主动推送结合使用。
3、站点地图:您可以定期在站点地图中放置网站链接,然后将站点地图提交给百度。百度会定期抓取检查您提交的站点地图,并处理其中的链接,但收录的速度比主动推送要慢。4、 手动提交:一次性提交链接到百度,可以使用这种方式。
百度站长平台为站长提供了链接提交通道。你可以提交你想成为百度收录的链接。百度搜索引擎会按照标准进行处理,但不保证您提交的链接是收录。
需要注意的是:
1.主动推送功能入口为:工具-网页抓取-链接提交-主动推送(实时)
2.主动推送与原实时推送使用不同的数据接口,需要重新获取key(登录后链接提交工具界面可见)
登录地址是
为保证您提交数据的效果,请及时更换界面和密钥,尽快熟悉主动推送功能。如果有问题,您可以通过反馈中心向百度工作人员寻求帮助。
使用百度主动推送(实时)可以加速收录,保护原创的内容不被第三方采集伤害。
暂时没看到有人写百度的主动推送代码,所以根据百度提供的PHP代码编写,并添加到DEDE后端发布文章文件中,实现了主动推送(真实) -time) 功能与百度百度。
在article_add.php中搜索 $artUrl = MakeArt($arcID,true,true,$isremote);
然后在
if($artUrl=='')
{
$artUrl = $cfg_phpurl."/view.php?aid=$arcID";
}
后面加入
else{
$urls[]='http://'.$_SERVER['HTTP_HOST'].$artUrl;
$api = 'http://data.zz.baidu.com/urls?site=你的域名&token=准入密钥';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
}
只需保存
文章发布成功后,会显示如下
实时抓取网页数据(怎么把网页数据导入到Excel表格中6.excel表格序号如何)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-12-20 20:05
我们经常使用网页数据,但是每次打开网页查询都非常麻烦,而且我们需要的数据都是实时更新的,那么如何才能达到这个目的呢?Excel可以帮你完美解决。今天教大家如何在Excel中查询网页数据并实时更新。
Excel中查询网页数据并实时更新的操作步骤:
首先打开excel,点击数据,在获取外部数据选项卡下,点击来自网站,会弹出一个新的web查询对话框,如下图:
将网页地址复制到地址栏,点击前往打开网页。
在打开的网页中,找到要导入的数据,点击带黄框的箭头选择区域,然后点击右下角的导入。
在弹出的导入数据对话框中,点击指定导入位置将数据导入excel。
使用方法:数据导入excel后,如果要更改数据区域,可以右键编辑查询,重新指定区域。
数据导入excel后,在数据区右击,点击刷新,刷新数据。通过右键单击数据区域属性,可以打开外部数据区域属性对话框,设置刷新频率,以及打开文件时是否允许后台刷新或刷新。
另一种简单的方法是直接复制你需要的网页数据并粘贴到excel中。粘贴完成后,右下角有粘贴选项。有一个可刷新的网络查询。单击它以输入新的网络查询。界面,重复之前的操作即可。
Excel文章中查询网页数据并实时更新相关操作:
1.如何在Excel中查询网页数据并实时更新
2.如何使用excel2013web查询采集网页数据功能
3.Excel中如何批量更新数据
4.Excel表格中快速查询数据的操作方法
5.如何将网页数据导入Excel表格
6.如何自动更新excel表格的序号
7.如何使用Excel中的自动数据过滤功能 查看全部
实时抓取网页数据(怎么把网页数据导入到Excel表格中6.excel表格序号如何)
我们经常使用网页数据,但是每次打开网页查询都非常麻烦,而且我们需要的数据都是实时更新的,那么如何才能达到这个目的呢?Excel可以帮你完美解决。今天教大家如何在Excel中查询网页数据并实时更新。
Excel中查询网页数据并实时更新的操作步骤:
首先打开excel,点击数据,在获取外部数据选项卡下,点击来自网站,会弹出一个新的web查询对话框,如下图:

将网页地址复制到地址栏,点击前往打开网页。
在打开的网页中,找到要导入的数据,点击带黄框的箭头选择区域,然后点击右下角的导入。


在弹出的导入数据对话框中,点击指定导入位置将数据导入excel。

使用方法:数据导入excel后,如果要更改数据区域,可以右键编辑查询,重新指定区域。

数据导入excel后,在数据区右击,点击刷新,刷新数据。通过右键单击数据区域属性,可以打开外部数据区域属性对话框,设置刷新频率,以及打开文件时是否允许后台刷新或刷新。


另一种简单的方法是直接复制你需要的网页数据并粘贴到excel中。粘贴完成后,右下角有粘贴选项。有一个可刷新的网络查询。单击它以输入新的网络查询。界面,重复之前的操作即可。

Excel文章中查询网页数据并实时更新相关操作:
1.如何在Excel中查询网页数据并实时更新
2.如何使用excel2013web查询采集网页数据功能
3.Excel中如何批量更新数据
4.Excel表格中快速查询数据的操作方法
5.如何将网页数据导入Excel表格
6.如何自动更新excel表格的序号
7.如何使用Excel中的自动数据过滤功能
实时抓取网页数据( 大数据舆情系统对数据存储和计算系统会有哪些需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-19 03:00
大数据舆情系统对数据存储和计算系统会有哪些需求)
互联网的飞速发展促进了许多新媒体的发展。无论是知名大V、名人还是围观者,都可以用手机在微博、朋友圈或评论网站上发布动态,分享所见所想,让“人人有话筒”。 ” 无论是热点新闻还是娱乐八卦,传播速度都远超我们的想象。一条信息可以在短短几分钟内被数万人转发,数百万人阅读。海量信息是可以爆炸的,那么如何实时掌握信息并进行相应的处理呢?真的很难对付吗?今天,
大数据时代,除了媒体信息外,各个电商平台的产品订单和用户购买评论都会对后续消费者产生很大的影响。商家的产品设计师需要对各个平台的数据进行统计和分析,作为确定后续产品开发的依据。公司公关和营销部门也需要根据舆情做出相应的及时处理,而这一切也意味着将传统的舆情系统升级为大数据舆情采集和分析系统。细看大数据舆情系统,对我们的数据存储和计算系统提出以下要求:
本文主要提供架构设计。首先介绍当前主流的大数据计算架构,分析一些优缺点,然后介绍舆情大数据架构。
系统设计
需求分析
结合文章开头对舆情系统的描述,海量大数据舆情分析系统流程图大致如下:
图1 舆情系统业务流程
根据前面的介绍,舆情大数据分析系统需要两种计算。一是实时计算,包括实时提取海量网页内容、情感词分析、网页舆情结果存储等。另一种是离线计算。系统需要回溯历史数据,结合人工标注等方法优化情感词汇,对一些实时计算的结果进行修正。因此,在系统设计中,需要选择一个既可以进行实时计算又可以进行批量离线计算的系统。在开源大数据解决方案中,Lambda 架构可以满足这些需求。下面介绍一下 Lambda 架构。
Lambda 架构(维基)
图2 Lambda架构图
Lambda架构可以说是Hadoop、Spark系统下最火的大数据架构。这种架构的最大优点是支持海量数据批量计算处理(即离线处理),也支持流式实时处理(即热数据处理)。
它是如何实施的?首先,上游一般是kafka等队列服务,实时存储数据。Kafka队列会有两个订阅者,一个是全量数据,也就是图片的上半部分,全量数据会存储在HDFS这样的存储介质上。当离线计算任务到来时,计算资源(如Hadoop)会访问存储系统上的全量数据,执行全批量计算的处理逻辑。
map/reduce链接后,完整的结果会写入到Hbase等结构化存储引擎中,提供给业务方查询。队列的另一个消费者订阅者是流计算引擎。流计算引擎往往实时消费队列中的数据进行计算处理。比如Spark Streaming实时订阅Kafka数据,流计算的结果也写入结构化数据引擎。写入批量计算和流计算结果的结构化存储引擎就是上面注3所示的“Serving Layer”。该层主要提供结果数据的展示和查询。
在这套架构中,批量计算的特点是需要支持海量数据的处理,并根据业务的需要,关联一些其他的业务指标进行计算。批量计算的优点是计算逻辑可以根据业务需求灵活调整,计算结果可以重复计算,同一个计算逻辑不会多次变化。批量计算的缺点是计算周期比较长,难以满足实时结果的需求。因此,随着大数据计算的演进,提出了实时计算的需求。
实时计算是通过 Lambda 架构中的实时数据流来实现的。与批处理相比,增量数据流的处理方式决定了数据往往是新生成的数据,即热点数据。由于热数据的特性,流计算可以满足业务对计算的低时延需求。例如,在一个舆情分析系统中,我们往往希望可以从网页中检索舆情信息,并在分钟级得到计算结果,以便业务方有足够的时间进行舆情反馈。下面我们来具体看看如何基于Lambda架构的思想,实现一套完整的舆情大数据架构。
开源舆情大数据解决方案
通过这个流程图,我们了解到整个舆情系统的构建需要不同的存储和计算系统。对数据的组织和查询有不同的要求。基于业界开源的大数据系统,结合Lambda架构,整个系统可以设计如下:
图3 开源舆情架构图
1. 系统最上游是分布式爬虫引擎,根据爬取任务对订阅网页的原创内容进行爬取。爬虫会实时将爬取到的网页内容写入Kafka队列。进入Kafka队列的数据会根据上述计算需求实时流入流计算引擎(如Spark或Flink),也会持久化存储在Hbase中进行全量处理。数据存储。全量网页的存储,可以满足网页爬取和去重,批量离线计算的需要。
2. 流计算会提取原创网页的结构,将非结构化的网页内容转化为结构化数据并进行分词,如提取页面的标题、作者、摘要等,对文本进行分词和抽象的内容。提取和分词结果会写回Hbase。经过结构化提取和分词后,流计算引擎会结合情感词汇分析网页情感,判断是否有舆情。
3. 流计算引擎分析的舆情结果存储在Mysql或Hbase数据库中。为了方便搜索和查看结果集,需要将数据同步到Elasticsearch等搜索引擎,方便属性字段的组合查询。如果是重大舆情时间,需要写入Kafka队列触发舆情警报。
4. 全量结构化数据会定期通过Spark系统离线计算更新情感词汇或接受新的计算策略重新计算历史数据以修正实时计算的结果。
开源架构分析
上面的舆情大数据架构,通过Kafka对接流计算,Hbase对接批量计算实现了Lambda架构中的“批量查看”和“实时查看”,整个架构比较清晰,可以很好的满足线上和离线 两种类型的计算需求。但是,将该系统应用到生产中并不是一件容易的事,主要有以下几个原因:
整个架构涉及到很多存储和计算系统,包括:Kafka、Hbase、Spark、Flink、Elasticsearch。数据将在不同的存储和计算系统中流动。在整个架构中运行和维护每个开源产品是一个很大的挑战。任何一款产品或产品之间的通道出现故障都会影响整体舆情分析结果的及时性。
为了实现批量计算和流计算,原创网页需要分别存储在Kafka和Hbase中。离线计算消费HBase中的数据,流计算消费Kafka中的数据。这会带来存储资源的冗余,也会导致需要维护两套计算逻辑,会增加计算代码的开发和维护成本。
舆情的计算结果存储在Mysql或Hbase中。为了丰富组合查询语句,需要将数据同步并内置到Elasticsearch中。查询时,可能需要结合Mysql和Elasticsearch的查询结果。这里没有跳过数据库,结果数据直接写入Elasticsearch等搜索系统中,因为搜索系统的实时数据写入能力和数据可靠性不如数据库。行业通常将数据库和搜索系统集成在一起,集成系统兼具数据库和搜索系统的优点,但是两个引擎之间的数据同步和跨系统查询给运维和维护带来了很多额外的成本。发展。
全新大数据架构 Lambda plus
通过前面的分析,相信大家都会有一个疑问。有没有一种简化的大数据架构可以满足Lambda对计算需求的假设,同时减少存储计算和模块的数量?
Linkedin 的 Jay Kreps 提出了 Kappa 架构。Lambda和Kappa的对比可以参考文末文档。详细的比较这里就不展开了。简单来说,为了简化两个存储,Kappa取消了全量数据存储。通过将它们保存在 Kafka 中,对于较长的日志,当需要回溯重新计算时,再次从队列头部订阅数据,所有存储在 Kafka 队列中的数据再次在流中处理。这种设计的好处是解决了维护两套存储和两套计算逻辑的痛点。缺点是队列能保留的历史数据毕竟有限,没有时间限制很难回溯。
分析到此,我们沿用Kappa对Lambda的改进思路,更远的思考:如果有存储引擎,不仅可以满足数据库的高效写入和随机查询,还可以像队列服务一样,满足第一—— in first-out, yes 不是可以结合Lambda和Kappa架构来创建Lambda plus架构吗?
新架构可以在Lambda的基础上改进以下几点:
在支持流计算和批量计算的同时,可以复用计算逻辑,实现“一套代码,两类需求”。
统一存储全量历史数据和在线实时增量数据,实现“一存两算”。
为了方便舆情结果的查询需求,“批量查看”和“实时查看”的存储不仅可以支持高吞吐量实时写作,还可以支持多字段组合搜索和全文检索恢复。
综上所述,整个新架构的核心是解决存储问题,以及如何灵活连接计算。我们希望整个程序类似于以下架构:
图 4 Lambda Plus 架构
数据流实时写入分布式数据库。借助数据库查询能力,可以轻松将全量数据接入批量计算系统进行离线处理。
数据库支持通过数据库日志接口增量读取,并结合流计算引擎实现实时计算。
批计算和流计算的结果回写到分布式数据库中。分布式数据库提供丰富的查询语义,实现计算结果的交互查询。
在整个架构中,存储层通过结合数据库主表数据和数据库日志来替代大数据架构中的队列服务。计算系统选择自然支持batch和stream的计算引擎,如Flink或Spark。这样,我们不仅可以像 Lambda 那样进行历史数据回溯,还可以像 Kappa 架构那样进行一套逻辑来存储和处理两类计算任务。我们将这样一套架构命名为“Lambda plus”,下面详细介绍如何在阿里云上搭建这样一套大数据架构。
云舆情系统架构
在阿里云众多的存储和计算产品中,为了满足上述大数据架构的需求,我们选择了两款产品来实现整个舆情大数据系统。存储层使用阿里云自研的分布式多模型数据库Tablestore,计算层使用Blink实现流一体和批量计算。
图5 云舆情大数据架构
在存储层面,这个架构都是基于Tablestore的。一个数据库解决不同的存储需求。根据之前舆情系统的介绍,网络爬虫数据的系统流程会有四个阶段:原创网页内容、网页结构化数据、分析规则。元数据和舆情结果,舆情结果索引。
我们利用Tablestore的宽行和无模式特性将原创网页和网页结构化数据合并为一个网页数据。网页数据表和计算系统通过Tablestore新的功能通道服务连接起来。通道服务基于数据库日志,按照数据写入的顺序存储数据的组织结构。正是这个特性,让数据库具备了排队和流式消费的能力。这使得存储引擎既可以随机访问数据库,也可以按写入顺序访问队列,也满足了上面提到的集成Lambda和kappa架构的需求。分析规则元数据表由分析规则和情感词汇组层组成,
计算系统采用阿里云实时流计算产品Blink。Blink 是一款支持流计算和批量计算的实时计算产品。并且类似于Tablestore,它可以轻松实现分布式横向扩展,让计算资源随着业务数据的增长而灵活扩展。使用Tablestore+Blink的优势如下:
Tablestore与Blink深度集成,支持源表、维度表、目的表。无需为业务中的数据流开发代码。
整个架构大大减少了组件数量,从开源产品的6~7个组件减少到2个。Tablestore和Blink都是零运维的全托管产品,可以实现非常好的横向灵活性,没有业务扩张高峰。压力大大降低了大数据架构的运维成本。
业务侧只需要关注数据处理逻辑,Blink中已经集成了与Tablestore的交互逻辑。
在开源方案中,如果数据库源想要连接实时计算,还需要写一个队列,让流计算引擎消费队列中的数据。在我们的架构中,数据库既是数据表,也是实时增量数据消费的队列通道。大大简化了架构的开发和使用成本。
流式批处理集成,实时性在舆情系统中很重要,所以我们需要一个实时计算引擎,而Blink除了实时计算,还支持Tablestore数据的批处理,在低峰期业务的,往往也需要批量处理一些数据作为反馈结果写回Tablestore,比如情感分析反馈。所以一套架构可以同时支持流处理和批处理更好。一套架构的优势在于一套分析代码既可以用于实时流式计算,也可以用于离线批处理。
整个计算过程会产生实时的舆情计算结果。通过Tablestore与函数计算触发器的对接,实现重大舆情事件预警。Tablestore和函数计算做了增量数据的无缝对接。通过在结果表中写入事件,您可以通过函数计算轻松触发短信或电子邮件通知。完整的舆情分析结果和展示搜索使用Tablestore的新功能多索引,彻底解决了开源Hbase+Solr多引擎的痛点:
运维复杂,需要有hbase和solr两个系统的运维能力,还需要维护数据同步的链接。
Solr 数据一致性不如Hbase。Hbase 和 Solr 中数据的语义并不完全相同。另外,Solr/Elasticsearch 很难做到像数据库一样严格的数据一致性。在一些极端情况下,可能会出现数据不一致的情况,开源解决方案很难实现跨系统的一致性比较。
查询接口需要维护两套API。Hbase客户端和Solr客户端都需要用到。不在索引中的字段需要主动对照Hbase进行检查,不太好用。
参考
Lambda 大数据架构:
Kappa大数据架构:
Lambda 和 Kappa 架构比较:
【编辑推荐】
你只知道熊猫吗?数据科学家不容错过的 24 个 Python 库(第 1 部分)。在 Fedora 上构建 Jupyter 和数据科学环境。基于Python语言的大数据搜索引擎。使用 Python 加速数据分析的 10 个简单技巧。分布式文件服务器。你还在手工搭建分布式文件服务器吗?一步一步来试试Docker镜像 查看全部
实时抓取网页数据(
大数据舆情系统对数据存储和计算系统会有哪些需求)

互联网的飞速发展促进了许多新媒体的发展。无论是知名大V、名人还是围观者,都可以用手机在微博、朋友圈或评论网站上发布动态,分享所见所想,让“人人有话筒”。 ” 无论是热点新闻还是娱乐八卦,传播速度都远超我们的想象。一条信息可以在短短几分钟内被数万人转发,数百万人阅读。海量信息是可以爆炸的,那么如何实时掌握信息并进行相应的处理呢?真的很难对付吗?今天,
大数据时代,除了媒体信息外,各个电商平台的产品订单和用户购买评论都会对后续消费者产生很大的影响。商家的产品设计师需要对各个平台的数据进行统计和分析,作为确定后续产品开发的依据。公司公关和营销部门也需要根据舆情做出相应的及时处理,而这一切也意味着将传统的舆情系统升级为大数据舆情采集和分析系统。细看大数据舆情系统,对我们的数据存储和计算系统提出以下要求:
本文主要提供架构设计。首先介绍当前主流的大数据计算架构,分析一些优缺点,然后介绍舆情大数据架构。
系统设计
需求分析
结合文章开头对舆情系统的描述,海量大数据舆情分析系统流程图大致如下:

图1 舆情系统业务流程
根据前面的介绍,舆情大数据分析系统需要两种计算。一是实时计算,包括实时提取海量网页内容、情感词分析、网页舆情结果存储等。另一种是离线计算。系统需要回溯历史数据,结合人工标注等方法优化情感词汇,对一些实时计算的结果进行修正。因此,在系统设计中,需要选择一个既可以进行实时计算又可以进行批量离线计算的系统。在开源大数据解决方案中,Lambda 架构可以满足这些需求。下面介绍一下 Lambda 架构。
Lambda 架构(维基)

图2 Lambda架构图
Lambda架构可以说是Hadoop、Spark系统下最火的大数据架构。这种架构的最大优点是支持海量数据批量计算处理(即离线处理),也支持流式实时处理(即热数据处理)。
它是如何实施的?首先,上游一般是kafka等队列服务,实时存储数据。Kafka队列会有两个订阅者,一个是全量数据,也就是图片的上半部分,全量数据会存储在HDFS这样的存储介质上。当离线计算任务到来时,计算资源(如Hadoop)会访问存储系统上的全量数据,执行全批量计算的处理逻辑。
map/reduce链接后,完整的结果会写入到Hbase等结构化存储引擎中,提供给业务方查询。队列的另一个消费者订阅者是流计算引擎。流计算引擎往往实时消费队列中的数据进行计算处理。比如Spark Streaming实时订阅Kafka数据,流计算的结果也写入结构化数据引擎。写入批量计算和流计算结果的结构化存储引擎就是上面注3所示的“Serving Layer”。该层主要提供结果数据的展示和查询。
在这套架构中,批量计算的特点是需要支持海量数据的处理,并根据业务的需要,关联一些其他的业务指标进行计算。批量计算的优点是计算逻辑可以根据业务需求灵活调整,计算结果可以重复计算,同一个计算逻辑不会多次变化。批量计算的缺点是计算周期比较长,难以满足实时结果的需求。因此,随着大数据计算的演进,提出了实时计算的需求。
实时计算是通过 Lambda 架构中的实时数据流来实现的。与批处理相比,增量数据流的处理方式决定了数据往往是新生成的数据,即热点数据。由于热数据的特性,流计算可以满足业务对计算的低时延需求。例如,在一个舆情分析系统中,我们往往希望可以从网页中检索舆情信息,并在分钟级得到计算结果,以便业务方有足够的时间进行舆情反馈。下面我们来具体看看如何基于Lambda架构的思想,实现一套完整的舆情大数据架构。
开源舆情大数据解决方案
通过这个流程图,我们了解到整个舆情系统的构建需要不同的存储和计算系统。对数据的组织和查询有不同的要求。基于业界开源的大数据系统,结合Lambda架构,整个系统可以设计如下:

图3 开源舆情架构图
1. 系统最上游是分布式爬虫引擎,根据爬取任务对订阅网页的原创内容进行爬取。爬虫会实时将爬取到的网页内容写入Kafka队列。进入Kafka队列的数据会根据上述计算需求实时流入流计算引擎(如Spark或Flink),也会持久化存储在Hbase中进行全量处理。数据存储。全量网页的存储,可以满足网页爬取和去重,批量离线计算的需要。
2. 流计算会提取原创网页的结构,将非结构化的网页内容转化为结构化数据并进行分词,如提取页面的标题、作者、摘要等,对文本进行分词和抽象的内容。提取和分词结果会写回Hbase。经过结构化提取和分词后,流计算引擎会结合情感词汇分析网页情感,判断是否有舆情。
3. 流计算引擎分析的舆情结果存储在Mysql或Hbase数据库中。为了方便搜索和查看结果集,需要将数据同步到Elasticsearch等搜索引擎,方便属性字段的组合查询。如果是重大舆情时间,需要写入Kafka队列触发舆情警报。
4. 全量结构化数据会定期通过Spark系统离线计算更新情感词汇或接受新的计算策略重新计算历史数据以修正实时计算的结果。
开源架构分析
上面的舆情大数据架构,通过Kafka对接流计算,Hbase对接批量计算实现了Lambda架构中的“批量查看”和“实时查看”,整个架构比较清晰,可以很好的满足线上和离线 两种类型的计算需求。但是,将该系统应用到生产中并不是一件容易的事,主要有以下几个原因:
整个架构涉及到很多存储和计算系统,包括:Kafka、Hbase、Spark、Flink、Elasticsearch。数据将在不同的存储和计算系统中流动。在整个架构中运行和维护每个开源产品是一个很大的挑战。任何一款产品或产品之间的通道出现故障都会影响整体舆情分析结果的及时性。
为了实现批量计算和流计算,原创网页需要分别存储在Kafka和Hbase中。离线计算消费HBase中的数据,流计算消费Kafka中的数据。这会带来存储资源的冗余,也会导致需要维护两套计算逻辑,会增加计算代码的开发和维护成本。
舆情的计算结果存储在Mysql或Hbase中。为了丰富组合查询语句,需要将数据同步并内置到Elasticsearch中。查询时,可能需要结合Mysql和Elasticsearch的查询结果。这里没有跳过数据库,结果数据直接写入Elasticsearch等搜索系统中,因为搜索系统的实时数据写入能力和数据可靠性不如数据库。行业通常将数据库和搜索系统集成在一起,集成系统兼具数据库和搜索系统的优点,但是两个引擎之间的数据同步和跨系统查询给运维和维护带来了很多额外的成本。发展。
全新大数据架构 Lambda plus
通过前面的分析,相信大家都会有一个疑问。有没有一种简化的大数据架构可以满足Lambda对计算需求的假设,同时减少存储计算和模块的数量?
Linkedin 的 Jay Kreps 提出了 Kappa 架构。Lambda和Kappa的对比可以参考文末文档。详细的比较这里就不展开了。简单来说,为了简化两个存储,Kappa取消了全量数据存储。通过将它们保存在 Kafka 中,对于较长的日志,当需要回溯重新计算时,再次从队列头部订阅数据,所有存储在 Kafka 队列中的数据再次在流中处理。这种设计的好处是解决了维护两套存储和两套计算逻辑的痛点。缺点是队列能保留的历史数据毕竟有限,没有时间限制很难回溯。
分析到此,我们沿用Kappa对Lambda的改进思路,更远的思考:如果有存储引擎,不仅可以满足数据库的高效写入和随机查询,还可以像队列服务一样,满足第一—— in first-out, yes 不是可以结合Lambda和Kappa架构来创建Lambda plus架构吗?
新架构可以在Lambda的基础上改进以下几点:
在支持流计算和批量计算的同时,可以复用计算逻辑,实现“一套代码,两类需求”。
统一存储全量历史数据和在线实时增量数据,实现“一存两算”。
为了方便舆情结果的查询需求,“批量查看”和“实时查看”的存储不仅可以支持高吞吐量实时写作,还可以支持多字段组合搜索和全文检索恢复。
综上所述,整个新架构的核心是解决存储问题,以及如何灵活连接计算。我们希望整个程序类似于以下架构:

图 4 Lambda Plus 架构
数据流实时写入分布式数据库。借助数据库查询能力,可以轻松将全量数据接入批量计算系统进行离线处理。
数据库支持通过数据库日志接口增量读取,并结合流计算引擎实现实时计算。
批计算和流计算的结果回写到分布式数据库中。分布式数据库提供丰富的查询语义,实现计算结果的交互查询。
在整个架构中,存储层通过结合数据库主表数据和数据库日志来替代大数据架构中的队列服务。计算系统选择自然支持batch和stream的计算引擎,如Flink或Spark。这样,我们不仅可以像 Lambda 那样进行历史数据回溯,还可以像 Kappa 架构那样进行一套逻辑来存储和处理两类计算任务。我们将这样一套架构命名为“Lambda plus”,下面详细介绍如何在阿里云上搭建这样一套大数据架构。
云舆情系统架构
在阿里云众多的存储和计算产品中,为了满足上述大数据架构的需求,我们选择了两款产品来实现整个舆情大数据系统。存储层使用阿里云自研的分布式多模型数据库Tablestore,计算层使用Blink实现流一体和批量计算。

图5 云舆情大数据架构
在存储层面,这个架构都是基于Tablestore的。一个数据库解决不同的存储需求。根据之前舆情系统的介绍,网络爬虫数据的系统流程会有四个阶段:原创网页内容、网页结构化数据、分析规则。元数据和舆情结果,舆情结果索引。
我们利用Tablestore的宽行和无模式特性将原创网页和网页结构化数据合并为一个网页数据。网页数据表和计算系统通过Tablestore新的功能通道服务连接起来。通道服务基于数据库日志,按照数据写入的顺序存储数据的组织结构。正是这个特性,让数据库具备了排队和流式消费的能力。这使得存储引擎既可以随机访问数据库,也可以按写入顺序访问队列,也满足了上面提到的集成Lambda和kappa架构的需求。分析规则元数据表由分析规则和情感词汇组层组成,
计算系统采用阿里云实时流计算产品Blink。Blink 是一款支持流计算和批量计算的实时计算产品。并且类似于Tablestore,它可以轻松实现分布式横向扩展,让计算资源随着业务数据的增长而灵活扩展。使用Tablestore+Blink的优势如下:
Tablestore与Blink深度集成,支持源表、维度表、目的表。无需为业务中的数据流开发代码。
整个架构大大减少了组件数量,从开源产品的6~7个组件减少到2个。Tablestore和Blink都是零运维的全托管产品,可以实现非常好的横向灵活性,没有业务扩张高峰。压力大大降低了大数据架构的运维成本。
业务侧只需要关注数据处理逻辑,Blink中已经集成了与Tablestore的交互逻辑。
在开源方案中,如果数据库源想要连接实时计算,还需要写一个队列,让流计算引擎消费队列中的数据。在我们的架构中,数据库既是数据表,也是实时增量数据消费的队列通道。大大简化了架构的开发和使用成本。
流式批处理集成,实时性在舆情系统中很重要,所以我们需要一个实时计算引擎,而Blink除了实时计算,还支持Tablestore数据的批处理,在低峰期业务的,往往也需要批量处理一些数据作为反馈结果写回Tablestore,比如情感分析反馈。所以一套架构可以同时支持流处理和批处理更好。一套架构的优势在于一套分析代码既可以用于实时流式计算,也可以用于离线批处理。

整个计算过程会产生实时的舆情计算结果。通过Tablestore与函数计算触发器的对接,实现重大舆情事件预警。Tablestore和函数计算做了增量数据的无缝对接。通过在结果表中写入事件,您可以通过函数计算轻松触发短信或电子邮件通知。完整的舆情分析结果和展示搜索使用Tablestore的新功能多索引,彻底解决了开源Hbase+Solr多引擎的痛点:
运维复杂,需要有hbase和solr两个系统的运维能力,还需要维护数据同步的链接。
Solr 数据一致性不如Hbase。Hbase 和 Solr 中数据的语义并不完全相同。另外,Solr/Elasticsearch 很难做到像数据库一样严格的数据一致性。在一些极端情况下,可能会出现数据不一致的情况,开源解决方案很难实现跨系统的一致性比较。
查询接口需要维护两套API。Hbase客户端和Solr客户端都需要用到。不在索引中的字段需要主动对照Hbase进行检查,不太好用。
参考
Lambda 大数据架构:
Kappa大数据架构:
Lambda 和 Kappa 架构比较:
【编辑推荐】
你只知道熊猫吗?数据科学家不容错过的 24 个 Python 库(第 1 部分)。在 Fedora 上构建 Jupyter 和数据科学环境。基于Python语言的大数据搜索引擎。使用 Python 加速数据分析的 10 个简单技巧。分布式文件服务器。你还在手工搭建分布式文件服务器吗?一步一步来试试Docker镜像
实时抓取网页数据(如何抓取网页实时数据?(网页数据抓取软件)(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-18 01:09
)
优采云(网页数据抓取软件)是一款非常实用的在线网页数据抓取助手。如何抓取网页的实时数据?优采云(网页数据抓取软件)供用户快速抓取。他可以帮助用户批量处理采集站点的页面数据。这个过程是全自动的,非常智能,帮助用户快速采集他们想要的信息。
使用说明:
登录优采云客户端->点击方式创建爬虫->点击要爬取的数据->启动爬虫
第一步:登录优采云客户端
打开安装好的优采云客户端,输入优采云的账号和密码,登录后进入控制台
第 2 步:创建一个点击式爬虫
点击“新建应用程序”>选择“爬虫”,点击“下一步”>选择“自己开发”>选择“点击模式”。输入爬虫名称,点击“创建”
第三步:点击要爬取的数据
1、 打开创建好的爬虫,进入并打开点击面板
2、 在点击面板中,进行点击操作
首先输入收录所需数据的url,回车加载显示内容:
然后,在显示的网页内容中,点击选择数据为采集,例如选择采集文章的标题和内容:
点击左侧高级设置,设置爬虫的列表页、内容页url正则表达式、是否自动JS渲染等,提高爬虫效率:
第四步启动爬虫
点击后,点击开始爬取。稍等片刻,爬虫会自动开始运行
查看全部
实时抓取网页数据(如何抓取网页实时数据?(网页数据抓取软件)(组图)
)
优采云(网页数据抓取软件)是一款非常实用的在线网页数据抓取助手。如何抓取网页的实时数据?优采云(网页数据抓取软件)供用户快速抓取。他可以帮助用户批量处理采集站点的页面数据。这个过程是全自动的,非常智能,帮助用户快速采集他们想要的信息。
使用说明:
登录优采云客户端->点击方式创建爬虫->点击要爬取的数据->启动爬虫
第一步:登录优采云客户端
打开安装好的优采云客户端,输入优采云的账号和密码,登录后进入控制台
第 2 步:创建一个点击式爬虫
点击“新建应用程序”>选择“爬虫”,点击“下一步”>选择“自己开发”>选择“点击模式”。输入爬虫名称,点击“创建”
第三步:点击要爬取的数据
1、 打开创建好的爬虫,进入并打开点击面板
2、 在点击面板中,进行点击操作
首先输入收录所需数据的url,回车加载显示内容:
然后,在显示的网页内容中,点击选择数据为采集,例如选择采集文章的标题和内容:
点击左侧高级设置,设置爬虫的列表页、内容页url正则表达式、是否自动JS渲染等,提高爬虫效率:
第四步启动爬虫
点击后,点击开始爬取。稍等片刻,爬虫会自动开始运行

实时抓取网页数据(本文对实时垂直搜索引擎数据抓取任务调度相关技术进行总结和研究)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-14 04:29
摘要 实时垂直搜索引擎的发展解决了互联网用户对海量、时效性数据的搜索需求,爬行任务调度相关技术是实时垂直搜索引擎的关键技术,决定了其性能的优劣。和实时垂直搜索引擎的用户体验。. 然而,目前学术界对实时垂直搜索引擎数据抓取任务的调度还没有开展研究,导致现有的实时垂直搜索引擎数据过期,浪费爬取资源的现象非常严重。 . 本文对实时垂直搜索引擎的爬虫任务调度相关技术进行了详细的总结和研究。第一的,系统总结分析了数据捕捉的基本问题,总结了实时垂直搜索引擎的捕捉策略和数据变化规律的预测方法。然后提出了一种新的实时垂直搜索引擎爬取分布优化策略:策略,基于对象及其属性之间的关联,设计流行对象预测模型来预测流行对象的趋势;基于用户查询和对象变化根据泊松过程的特点,推导出数据新鲜度最大化的计算方法,从理论上给出资源分配和动态平衡的最优策略。最后,基于该策略,一个自适应的实时垂直搜索引擎任务捕获和分发模型:模型提出。该模型巧妙地运用了小白适配的思想,有效解决了实时垂直搜索引擎的抓取分发模块。配置复杂,维护成本高。本文利用实际数据对所提出的理论和观点进行了详细的实验测试,验证了该策略和模型在处理实时数据时,用户查询结果的平均数据新鲜度和准确率明显优于传统的垂直搜索。发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 该模型巧妙地运用了小白适配的思想,有效解决了实时垂直搜索引擎的抓取分发模块。配置复杂,维护成本高。本文利用实际数据对所提出的理论和观点进行了详细的实验测试,验证了该策略和模型在处理实时数据时,用户查询结果的平均数据新鲜度和准确率明显优于传统的垂直搜索。发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 该模型巧妙地运用了小白适配的思想,有效解决了实时垂直搜索引擎的抓取分发模块。配置复杂,维护成本高。本文利用实际数据对所提出的理论和观点进行了详细的实验测试,验证了该策略和模型在处理实时数据时,用户查询结果的平均数据新鲜度和准确率明显优于传统的垂直搜索。发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 本文利用实际数据对所提出的理论和观点进行了详细的实验测试,验证了该策略和模型在处理实时数据时,用户查询结果的平均数据新鲜度和准确率明显优于传统的垂直搜索。发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 本文利用实际数据对所提出的理论和观点进行了详细的实验测试,验证了该策略和模型在处理实时数据时,用户查询结果的平均数据新鲜度和准确率明显优于传统的垂直搜索。发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文
:; 浙江大学硕士论文——. 畉 · , . 痶,瓼。, ; 瑆。, : 籧 ; 阛
图 目录 图:数据对象的数据新鲜度和年龄变化趋势……图:同一对象用户间间隔分布曲线……图 Query Driven 演示非查询驱动数据捕获的区别。...... 整体模型架构....... 图。流行预测模型的预测偏差。效果比较... 图。平均数据新鲜度效果对比……垂直搜索引擎的整体系统结构…………………………………………………………………………………………………………………… 对象。数据新鲜度预期值随时间变化的趋势......................本文重点研究思路....... .... 数字。增量爬取策略数据新鲜度的变化....... 连续爬取策略数据新鲜度的变化...................... .... 数字。查询总数随时间变化的关系..........日本苦恼的趋势..寡妇的变化趋势... 引擎整体架构.................................图.数据变化区间规律与泊松分布验证.................................. ..在批量更新期间持续捕获临时数据数据集和在线数据机的数据新鲜度的变化。图.批量抓取和批量更新。临时数据集和在线数据机的数据新鲜度变化。批量更新期间持续捕获临时数据 数据集和在线数据机的数据新鲜度变化。图.批量抓取和批量更新。临时数据集和在线数据机的数据新鲜度变化。批量更新期间持续捕获临时数据 数据集和在线数据机的数据新鲜度变化。图.批量抓取和批量更新。临时数据集和在线数据机的数据新鲜度变化。
目录表。数据捕获和更新的基本策略比较...查询等待时间比较...
栾章:垂直搜索引擎技术简介:实时垂直搜索引擎的开发与架构。随着互联网规模的快速增长和互联网技术的飞速发展,用户对信息检索和整合的需求越来越迫切。以此为契机,搜索引擎、搜索引擎等搜索引擎产品相继推出。搜索引擎从整个互联网抓取各种信息,有针对性地将信息编入索引,针对不同的查询关键词,向用户呈现不同的信息集。搜索引擎的出现极大地推动了互联网的发展;而互联网的巨大发展也推动了搜索引擎技术的不断更新。网页动态等新技术的出现和推广对传统搜索引擎提出了新的挑战,而垂直搜索引擎的发展正好弥补了传统搜索引擎的不足:网页动态数据实时生成,而传统搜索引擎仅依靠固定链接进行网页抓取,无法有效抓取动态网页中的数据;而垂直搜索引擎可以查找和抓取页面中的动态数据,因此可以轻松索引和检索这些数据。·传统搜索引擎统一处理网页的非结构化文本信息,但无法处理页面中的动态结构化数据。垂直搜索引擎可以抓取和提取网页中的结构化数据,因此他们可以轻松地检索和处理结构化数据中的特定域。·传统搜索引擎专注于整个互联网的信息,无法对特定领域进行深入分析和挖掘。垂直搜索引擎一般专注于某个领域 查看全部
实时抓取网页数据(本文对实时垂直搜索引擎数据抓取任务调度相关技术进行总结和研究)
摘要 实时垂直搜索引擎的发展解决了互联网用户对海量、时效性数据的搜索需求,爬行任务调度相关技术是实时垂直搜索引擎的关键技术,决定了其性能的优劣。和实时垂直搜索引擎的用户体验。. 然而,目前学术界对实时垂直搜索引擎数据抓取任务的调度还没有开展研究,导致现有的实时垂直搜索引擎数据过期,浪费爬取资源的现象非常严重。 . 本文对实时垂直搜索引擎的爬虫任务调度相关技术进行了详细的总结和研究。第一的,系统总结分析了数据捕捉的基本问题,总结了实时垂直搜索引擎的捕捉策略和数据变化规律的预测方法。然后提出了一种新的实时垂直搜索引擎爬取分布优化策略:策略,基于对象及其属性之间的关联,设计流行对象预测模型来预测流行对象的趋势;基于用户查询和对象变化根据泊松过程的特点,推导出数据新鲜度最大化的计算方法,从理论上给出资源分配和动态平衡的最优策略。最后,基于该策略,一个自适应的实时垂直搜索引擎任务捕获和分发模型:模型提出。该模型巧妙地运用了小白适配的思想,有效解决了实时垂直搜索引擎的抓取分发模块。配置复杂,维护成本高。本文利用实际数据对所提出的理论和观点进行了详细的实验测试,验证了该策略和模型在处理实时数据时,用户查询结果的平均数据新鲜度和准确率明显优于传统的垂直搜索。发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 该模型巧妙地运用了小白适配的思想,有效解决了实时垂直搜索引擎的抓取分发模块。配置复杂,维护成本高。本文利用实际数据对所提出的理论和观点进行了详细的实验测试,验证了该策略和模型在处理实时数据时,用户查询结果的平均数据新鲜度和准确率明显优于传统的垂直搜索。发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 该模型巧妙地运用了小白适配的思想,有效解决了实时垂直搜索引擎的抓取分发模块。配置复杂,维护成本高。本文利用实际数据对所提出的理论和观点进行了详细的实验测试,验证了该策略和模型在处理实时数据时,用户查询结果的平均数据新鲜度和准确率明显优于传统的垂直搜索。发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 本文利用实际数据对所提出的理论和观点进行了详细的实验测试,验证了该策略和模型在处理实时数据时,用户查询结果的平均数据新鲜度和准确率明显优于传统的垂直搜索。发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 本文利用实际数据对所提出的理论和观点进行了详细的实验测试,验证了该策略和模型在处理实时数据时,用户查询结果的平均数据新鲜度和准确率明显优于传统的垂直搜索。发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文
:; 浙江大学硕士论文——. 畉 · , . 痶,瓼。, ; 瑆。, : 籧 ; 阛
图 目录 图:数据对象的数据新鲜度和年龄变化趋势……图:同一对象用户间间隔分布曲线……图 Query Driven 演示非查询驱动数据捕获的区别。...... 整体模型架构....... 图。流行预测模型的预测偏差。效果比较... 图。平均数据新鲜度效果对比……垂直搜索引擎的整体系统结构…………………………………………………………………………………………………………………… 对象。数据新鲜度预期值随时间变化的趋势......................本文重点研究思路....... .... 数字。增量爬取策略数据新鲜度的变化....... 连续爬取策略数据新鲜度的变化...................... .... 数字。查询总数随时间变化的关系..........日本苦恼的趋势..寡妇的变化趋势... 引擎整体架构.................................图.数据变化区间规律与泊松分布验证.................................. ..在批量更新期间持续捕获临时数据数据集和在线数据机的数据新鲜度的变化。图.批量抓取和批量更新。临时数据集和在线数据机的数据新鲜度变化。批量更新期间持续捕获临时数据 数据集和在线数据机的数据新鲜度变化。图.批量抓取和批量更新。临时数据集和在线数据机的数据新鲜度变化。批量更新期间持续捕获临时数据 数据集和在线数据机的数据新鲜度变化。图.批量抓取和批量更新。临时数据集和在线数据机的数据新鲜度变化。
目录表。数据捕获和更新的基本策略比较...查询等待时间比较...
栾章:垂直搜索引擎技术简介:实时垂直搜索引擎的开发与架构。随着互联网规模的快速增长和互联网技术的飞速发展,用户对信息检索和整合的需求越来越迫切。以此为契机,搜索引擎、搜索引擎等搜索引擎产品相继推出。搜索引擎从整个互联网抓取各种信息,有针对性地将信息编入索引,针对不同的查询关键词,向用户呈现不同的信息集。搜索引擎的出现极大地推动了互联网的发展;而互联网的巨大发展也推动了搜索引擎技术的不断更新。网页动态等新技术的出现和推广对传统搜索引擎提出了新的挑战,而垂直搜索引擎的发展正好弥补了传统搜索引擎的不足:网页动态数据实时生成,而传统搜索引擎仅依靠固定链接进行网页抓取,无法有效抓取动态网页中的数据;而垂直搜索引擎可以查找和抓取页面中的动态数据,因此可以轻松索引和检索这些数据。·传统搜索引擎统一处理网页的非结构化文本信息,但无法处理页面中的动态结构化数据。垂直搜索引擎可以抓取和提取网页中的结构化数据,因此他们可以轻松地检索和处理结构化数据中的特定域。·传统搜索引擎专注于整个互联网的信息,无法对特定领域进行深入分析和挖掘。垂直搜索引擎一般专注于某个领域
实时抓取网页数据(高德和百度地图实时路况数据的研究进展及应用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-12-08 15:22
1. 简介
最近老师有一个需求,就是想抓取实时矢量交通流数据进行分析,类似于百度地图和高德地图的“实时路况”。通常的网络爬虫工作一般都是抓取网页上现成的数据,但是流量数据只有栅格切片,没有矢量数据,数据购买成本每年几十W,也就是基本不可能获得。实验室里的兄弟们都忙于事情,所以这项艰巨的任务自然是交给了我。
图1.高德和百度地图实时路况数据
因为网上能查到的数据只有切片数据,这个问题转化为如何对切片数据进行向量化。如果直接使用ArcGIS Engine将栅格数据转换为矢量数据,基本上是不可能的。一是计算量过大,二是转换后的矢量数据不准确。更重要的是,每次转换的矢量道路都不一样。没有办法分析它。但是我们注意到流量切片有两个特点:
a) 也是一种地图切片,所以可以使用地图切片算法来计算每个切片的经纬度;
b) 它是一个透明的 PNG 图像,用四种颜色表示交通拥堵。我只需要识别每一段路的颜色,判断交通拥堵情况就可以完成“矢量化”工作。
接下来的工作可以分为以下几个步骤:
a) 准备某城市详细的矢量道路数据;
b) 下载城市交通流切片,拼成大图;
c) 在网格上标记需要检测颜色的像素点,并计算这些像素点的经纬度;
d) 将每条道路的矢量数据与像素一一匹配,检测交通流情况并写入数据库。
2. 地图切片系统和实时交通流
地图切片也称为地图图块。这方面的文章和机制已经很成熟了。详细算法内容请参考这个文章。本文以高德切片为例。高德的实时交通流使用动态切片,但与一般的切片系统略有不同。切片的缩放级别越小,缩放级别越大,反之亦然。
当然我们也可以自己计算不同,建议使用类库
3. 主要思想
高德的交通流数据(图1.(a))一般都很简单。用“绿”、“黄”、“红”三种颜色表示交通拥堵。分离非常明显。但是直接将切片转换为向量是非常不现实的。但是我有北京提供的非常详细的矢量数据(图2.(b))。如果将交通流切片与矢量数据进行匹配,则可以生成实时交通流矢量数据。最后,交通流数据可以切片发布,也可以向量发布。所以现在的主要任务是找到匹配流量切片和矢量数据的中间件。
图2. 交通流切片和矢量数据
虽然高德切片数据是以编码方式组织的,但每张图片、每一个像素都有严格固定的坐标。只要选取一部分有值的像素,将像素安装公式转化为点阵,然后将每个A点与一条矢量道路进行匹配,即在每个点上添加一个RouteId字段。图3(a)是我生成的点阵的一部分,图3(b)是点阵的属性表,它收录三个字段:x、y和routeid。具体步骤如下:
a) 定期下载交通流切片数据并保存在本地文件夹中;
b) 根据点阵数据读取指定切片的指定像素,判断像素的颜色,得到拥塞情况;
c) 根据拥塞情况和RouteId生成交通流表,包括RouteId和Traffic两个字段;
d) 根据RouteId匹配交通流表和矢量数据,得到矢量交通流数据;
e) 使用切片工具从矢量数据中生成天津师范大学所需的切片数据。
图3.(a)交通流切片数据和矢量道路数据用点阵叠加,(b)点阵的属性表
这是我用一个程序捕捉2014年12月5日晚上8点左右的交通流量数据,然后对北京四环的交通流量进行矢量化处理的地方。从结果可以看出,交通流量的总体趋势相似,但在一些细节上存在一些差异。矢量化的结果取决于晶格的细度。
图4. (a) 交通流切片数据 (b) 生成的矢量交通流数据
4. 总结
当时我是抱着完成任务的心态做这个的,所以整个事情做的很粗糙,代码也很乱,所以就厚颜无耻的分享一下代码吧。大家慢慢看官喷,以后有空我再安排。
转载于: 查看全部
实时抓取网页数据(高德和百度地图实时路况数据的研究进展及应用方法)
1. 简介
最近老师有一个需求,就是想抓取实时矢量交通流数据进行分析,类似于百度地图和高德地图的“实时路况”。通常的网络爬虫工作一般都是抓取网页上现成的数据,但是流量数据只有栅格切片,没有矢量数据,数据购买成本每年几十W,也就是基本不可能获得。实验室里的兄弟们都忙于事情,所以这项艰巨的任务自然是交给了我。

图1.高德和百度地图实时路况数据
因为网上能查到的数据只有切片数据,这个问题转化为如何对切片数据进行向量化。如果直接使用ArcGIS Engine将栅格数据转换为矢量数据,基本上是不可能的。一是计算量过大,二是转换后的矢量数据不准确。更重要的是,每次转换的矢量道路都不一样。没有办法分析它。但是我们注意到流量切片有两个特点:
a) 也是一种地图切片,所以可以使用地图切片算法来计算每个切片的经纬度;
b) 它是一个透明的 PNG 图像,用四种颜色表示交通拥堵。我只需要识别每一段路的颜色,判断交通拥堵情况就可以完成“矢量化”工作。
接下来的工作可以分为以下几个步骤:
a) 准备某城市详细的矢量道路数据;
b) 下载城市交通流切片,拼成大图;
c) 在网格上标记需要检测颜色的像素点,并计算这些像素点的经纬度;
d) 将每条道路的矢量数据与像素一一匹配,检测交通流情况并写入数据库。
2. 地图切片系统和实时交通流
地图切片也称为地图图块。这方面的文章和机制已经很成熟了。详细算法内容请参考这个文章。本文以高德切片为例。高德的实时交通流使用动态切片,但与一般的切片系统略有不同。切片的缩放级别越小,缩放级别越大,反之亦然。
当然我们也可以自己计算不同,建议使用类库

3. 主要思想
高德的交通流数据(图1.(a))一般都很简单。用“绿”、“黄”、“红”三种颜色表示交通拥堵。分离非常明显。但是直接将切片转换为向量是非常不现实的。但是我有北京提供的非常详细的矢量数据(图2.(b))。如果将交通流切片与矢量数据进行匹配,则可以生成实时交通流矢量数据。最后,交通流数据可以切片发布,也可以向量发布。所以现在的主要任务是找到匹配流量切片和矢量数据的中间件。

图2. 交通流切片和矢量数据
虽然高德切片数据是以编码方式组织的,但每张图片、每一个像素都有严格固定的坐标。只要选取一部分有值的像素,将像素安装公式转化为点阵,然后将每个A点与一条矢量道路进行匹配,即在每个点上添加一个RouteId字段。图3(a)是我生成的点阵的一部分,图3(b)是点阵的属性表,它收录三个字段:x、y和routeid。具体步骤如下:
a) 定期下载交通流切片数据并保存在本地文件夹中;
b) 根据点阵数据读取指定切片的指定像素,判断像素的颜色,得到拥塞情况;
c) 根据拥塞情况和RouteId生成交通流表,包括RouteId和Traffic两个字段;
d) 根据RouteId匹配交通流表和矢量数据,得到矢量交通流数据;
e) 使用切片工具从矢量数据中生成天津师范大学所需的切片数据。


图3.(a)交通流切片数据和矢量道路数据用点阵叠加,(b)点阵的属性表
这是我用一个程序捕捉2014年12月5日晚上8点左右的交通流量数据,然后对北京四环的交通流量进行矢量化处理的地方。从结果可以看出,交通流量的总体趋势相似,但在一些细节上存在一些差异。矢量化的结果取决于晶格的细度。


图4. (a) 交通流切片数据 (b) 生成的矢量交通流数据
4. 总结
当时我是抱着完成任务的心态做这个的,所以整个事情做的很粗糙,代码也很乱,所以就厚颜无耻的分享一下代码吧。大家慢慢看官喷,以后有空我再安排。
转载于:
实时抓取网页数据(之前抓取百度疫情数据的代码已经无法运行,怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-05 12:00
有朋友反映,抓取百度疫情数据的代码不能用了。没有看过的朋友可以点击下方链接查看。
Python抓取实时数据并绘制地图
我看了一下,因为百度调整了部分页面信息,代码调整后就可以使用了。如果下次调整呢?你觉得这个概率大吗?
我觉得它很大,那么有没有办法稳定它?
这样问,肯定有一些,就是用另一种方式获取疫情的实时数据。
这次我们将抓取网易JSON流行病数据。
链接是这个
打开网站,看到是这样的。如果您是第一次接触 JSON 数据,您会感到困惑。不过没关系,如果你用的是火狐,还可以发现上面有JSON,美化输出等功能。
这就是美化输出的效果。看起来好一点了,但是还是傻眼了,因为你还没有接触到JSON数据。
这个有点JSON效果,颜色不同,看起来更舒服。
好的,让我们开始数据捕获和导入。首先导入所需的模块。
import json
import requests
from pandas.io.json import json_normalize
然后开始抓取数据
url="https://c.m.163.com/ug/api/wuh ... ot%3B
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36'}
ret=requests.get(url, headers=headers)
result=json.loads(ret.content)
查看抓到的数据结果,可以看到是一个字典,我们要的数据在key=data中。
继续双击打开数据,我们要的数据在areaTree中。
继续双击打开areaTree,这个areaTree是一个列表,在我们想要的数据的第一行。
继续双击打开areaTree的第一行。这次又变成了字典。你看到中国了吗?哈哈,我们要的数据在key=children里面。
继续双击打开children,这是我们要的数据,这个又变成了一个列表,每一行都是一个省的数据
我们点第一行,看看湖北有没有出现。
如果继续点击儿童,就会是湖北各城市的数据。如果不点击,我们只需要省份数据。我们怎样才能提出来?继续数据处理,提取我们想要的数据。
t= result['data']['areaTree'][0]['children']
sf=json_normalize(t)
就出来了两行代码,哈哈!我们来看看数据。
那么我们要的字段是name,total.confirm,name是省名,
total.confirm是累计确诊数,如果换成taday.confirm就是新确诊数。直接将name和total.confirm替换为用于绘制地图的代码对应的位置。
# 将数据转换为二元的列表
list1 = list(zip(sf['name'],sf['total.confirm']))
# 创建一个地图对象
map_1 = Map()
#对全局进行设置
map_1.set_global_opts(
#设置标题
title_opts=opts.TitleOpts(title="全国疫情地图"),
#设置最大数据范围
visualmap_opts=opts.VisualMapOpts(max_=2500,range_color=["#FFFFFF","#FFCC00","#CC0000"]))
# 使用add方法添加地图数据与地图类型
map_1.add("累计确诊人数", list1, maptype="china")
# 地图创建完成后,通过render()方法可以将地图渲染为html
map_1.render('全国疫情地图.html')
然后地图绘制结果出来了。
如果你喜欢这篇文章,可以点击右下角查看
如果您正在关注学习,请在留言区留言:签到
如果你刚看完这篇文章,你可以查看这个系列的历史文章 并关注:
从小白-Anaconda安装学习Python数据分析
从小白学Python数据分析-使用spyder
从小白学Python数据分析-数据导入1
从小白学Python数据分析-数据导入2
从小白学Python数据分析-描述性统计分析
从小白-群分析学Python数据分析
8行Python代码轻松映射新冠疫情
动态新冠疫情图Python易画
Python绘制16个省份支持湖北地图
湖北动态新冠疫情地图Python易画
Python抓取实时数据并绘制地图
世界动态疫情图Python易画 查看全部
实时抓取网页数据(之前抓取百度疫情数据的代码已经无法运行,怎么办?)
有朋友反映,抓取百度疫情数据的代码不能用了。没有看过的朋友可以点击下方链接查看。
Python抓取实时数据并绘制地图
我看了一下,因为百度调整了部分页面信息,代码调整后就可以使用了。如果下次调整呢?你觉得这个概率大吗?
我觉得它很大,那么有没有办法稳定它?
这样问,肯定有一些,就是用另一种方式获取疫情的实时数据。
这次我们将抓取网易JSON流行病数据。
链接是这个
打开网站,看到是这样的。如果您是第一次接触 JSON 数据,您会感到困惑。不过没关系,如果你用的是火狐,还可以发现上面有JSON,美化输出等功能。

这就是美化输出的效果。看起来好一点了,但是还是傻眼了,因为你还没有接触到JSON数据。

这个有点JSON效果,颜色不同,看起来更舒服。

好的,让我们开始数据捕获和导入。首先导入所需的模块。
import json
import requests
from pandas.io.json import json_normalize
然后开始抓取数据
url="https://c.m.163.com/ug/api/wuh ... ot%3B
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36'}
ret=requests.get(url, headers=headers)
result=json.loads(ret.content)
查看抓到的数据结果,可以看到是一个字典,我们要的数据在key=data中。

继续双击打开数据,我们要的数据在areaTree中。

继续双击打开areaTree,这个areaTree是一个列表,在我们想要的数据的第一行。

继续双击打开areaTree的第一行。这次又变成了字典。你看到中国了吗?哈哈,我们要的数据在key=children里面。

继续双击打开children,这是我们要的数据,这个又变成了一个列表,每一行都是一个省的数据

我们点第一行,看看湖北有没有出现。

如果继续点击儿童,就会是湖北各城市的数据。如果不点击,我们只需要省份数据。我们怎样才能提出来?继续数据处理,提取我们想要的数据。
t= result['data']['areaTree'][0]['children']
sf=json_normalize(t)
就出来了两行代码,哈哈!我们来看看数据。

那么我们要的字段是name,total.confirm,name是省名,
total.confirm是累计确诊数,如果换成taday.confirm就是新确诊数。直接将name和total.confirm替换为用于绘制地图的代码对应的位置。
# 将数据转换为二元的列表
list1 = list(zip(sf['name'],sf['total.confirm']))
# 创建一个地图对象
map_1 = Map()
#对全局进行设置
map_1.set_global_opts(
#设置标题
title_opts=opts.TitleOpts(title="全国疫情地图"),
#设置最大数据范围
visualmap_opts=opts.VisualMapOpts(max_=2500,range_color=["#FFFFFF","#FFCC00","#CC0000"]))
# 使用add方法添加地图数据与地图类型
map_1.add("累计确诊人数", list1, maptype="china")
# 地图创建完成后,通过render()方法可以将地图渲染为html
map_1.render('全国疫情地图.html')
然后地图绘制结果出来了。


如果你喜欢这篇文章,可以点击右下角查看
如果您正在关注学习,请在留言区留言:签到
如果你刚看完这篇文章,你可以查看这个系列的历史文章 并关注:
从小白-Anaconda安装学习Python数据分析
从小白学Python数据分析-使用spyder
从小白学Python数据分析-数据导入1
从小白学Python数据分析-数据导入2
从小白学Python数据分析-描述性统计分析
从小白-群分析学Python数据分析
8行Python代码轻松映射新冠疫情
动态新冠疫情图Python易画
Python绘制16个省份支持湖北地图
湖北动态新冠疫情地图Python易画
Python抓取实时数据并绘制地图
世界动态疫情图Python易画
实时抓取网页数据(一下网页抓取为电子商务行业带来的优势网页数据分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-03 14:36
大数据分析对电子商务行业非常重要。通过捕获其他网站 数据进行分析,它可以帮助企业更好地了解客户、预测市场趋势并帮助增加收入。本文将向您介绍网页抓取给电子商务行业带来的优势。
1、追踪购物者的购买历史
通过对浏览活动数据的数据抓取和分析,企业可以了解购物者的购物习惯,洞察近期哪些产品需求旺盛,以及年内某些产品的需求何时上升。
2、个性化体验
通过捕获购物者的相关数据,您可以创建满足用户需求的个性化体验。个性化体验策略包括向用户发送定制邮件、提供特别折扣和优惠、向不同人群展示针对性广告等。
3、了解卖家满意度
从客户评论中采集和挖掘数据,利用自然语言处理技术进行文本挖掘和分析,使企业能够准确了解买家对其产品的意见,帮助电商业主更好地与买家建立联系。
4、更好的客户服务
通过分析采集收到的数据,有助于改善客户服务。通过监测平均响应速度,客服人员可以提高整体响应的及时性;通过发放问卷和采集客户反馈,提供第一手信息,帮助提高服务质量,减少不良服务的机会。
5、优化定价
设定的价格决定了您是否能够保持竞争力并直接影响您的产品销售。通过网络爬虫,企业可以纵览全局,实时监控竞争对手的定价,从而制定更好的营销方式。
6、需求预测
大数据可以帮助企业根据过去的经验估计未来的库存,提前规划营销活动。
综上所述,网络爬虫的好处有很多,但是现在很多网站都设置了反爬虫,让你无法高效爬取数据。目前,使用住宅轮换代理是提高爬虫效率的最佳方式。Ipidea是一家海外爬虫代理,与多家公司和爬虫企业合作,也支持免费测试。 查看全部
实时抓取网页数据(一下网页抓取为电子商务行业带来的优势网页数据分析)
大数据分析对电子商务行业非常重要。通过捕获其他网站 数据进行分析,它可以帮助企业更好地了解客户、预测市场趋势并帮助增加收入。本文将向您介绍网页抓取给电子商务行业带来的优势。

1、追踪购物者的购买历史
通过对浏览活动数据的数据抓取和分析,企业可以了解购物者的购物习惯,洞察近期哪些产品需求旺盛,以及年内某些产品的需求何时上升。
2、个性化体验
通过捕获购物者的相关数据,您可以创建满足用户需求的个性化体验。个性化体验策略包括向用户发送定制邮件、提供特别折扣和优惠、向不同人群展示针对性广告等。
3、了解卖家满意度
从客户评论中采集和挖掘数据,利用自然语言处理技术进行文本挖掘和分析,使企业能够准确了解买家对其产品的意见,帮助电商业主更好地与买家建立联系。
4、更好的客户服务
通过分析采集收到的数据,有助于改善客户服务。通过监测平均响应速度,客服人员可以提高整体响应的及时性;通过发放问卷和采集客户反馈,提供第一手信息,帮助提高服务质量,减少不良服务的机会。
5、优化定价
设定的价格决定了您是否能够保持竞争力并直接影响您的产品销售。通过网络爬虫,企业可以纵览全局,实时监控竞争对手的定价,从而制定更好的营销方式。
6、需求预测
大数据可以帮助企业根据过去的经验估计未来的库存,提前规划营销活动。
综上所述,网络爬虫的好处有很多,但是现在很多网站都设置了反爬虫,让你无法高效爬取数据。目前,使用住宅轮换代理是提高爬虫效率的最佳方式。Ipidea是一家海外爬虫代理,与多家公司和爬虫企业合作,也支持免费测试。
实时抓取网页数据(#如何用excel获得股票实时数据#首先找一个提供股票数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-03 14:34
#如何使用excel获取实时股票数据#
首先,找到一个提供股票数据的网站。各种金融网站都有股票数据。我们以东方财富网为例:
对于沪深A股数据,我们在谷歌浏览器中查看真实网址:
找到与股票数据对应的jQuery行,然后查看头文件中的URL:
将此 URL 复制到 Excel,数据 ==> 来自 网站:
单击以确认,Power Query 编辑器将打开。如果一切顺利,数据会直接出现:
虽然不是表,但证明爬取成功。下一步是如何解析二进制文件。从谷歌浏览器看,这是一个jsoncallback数据包,比json数据多了一个函数名。我们只需要提取两个括号。中间的数据可以用json解析。注意total:4440,我们后面会用到这个值。
=Json.Document(Text.BetweenDelimiters(Text.FromBinary(Web.Contents(url)),"(",")"))
然后展开数据表:
到目前为止一切都很顺利,但我们抓取的只是一页数据,让我们看看:
pn是页码,我们抓取第3页,pz是每页20条数据,我们有两种方法抓取所有数据,一种是使用这个pz:20,然后定义函数,抓取所有页码,我在之前的爬行中反复使用过这个。今天我们尝试直接修改pz,一次性抓取所有数据。其实,你可以尝试改变查询参数。如果我们把pn改成4,抓取到的页面就是第4页。同理,我们把pn改成200,看看能不能直接抓取200条数据。
那我们试试直接输入5000,能不能全部抢过来:
这似乎是可能的。
还有一个问题,就是数据的所有标题行都以f开头,不可读。如何将它们变成网页中的汉字标题行。
这个问题有点复杂。我们可能需要检查代码,看看是否可以找到替换它的方法。先看html:
但这并不完整,还有几列需要自定义:
这些指标没有对应的 f 代码。
我们来看一下js文件:
这个文件中有对应的数据,我们直接拷贝到Power Query中,处理成列表形式进行备份:
下一步是匹配表中的键并修改列名:
首先我们需要匹配出这样一个列表。
List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n[key])}, (y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0})
然后我们可以直接使用Table.RenameColumns函数批量修改列名:
Table.RenameColumns(data,List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n) [key])},(y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0}))
我们只是将数据加载到 Excel 中。
如果你想要最新的数据,只需刷新它。 查看全部
实时抓取网页数据(#如何用excel获得股票实时数据#首先找一个提供股票数据)
#如何使用excel获取实时股票数据#
首先,找到一个提供股票数据的网站。各种金融网站都有股票数据。我们以东方财富网为例:

对于沪深A股数据,我们在谷歌浏览器中查看真实网址:
找到与股票数据对应的jQuery行,然后查看头文件中的URL:
将此 URL 复制到 Excel,数据 ==> 来自 网站:
单击以确认,Power Query 编辑器将打开。如果一切顺利,数据会直接出现:
虽然不是表,但证明爬取成功。下一步是如何解析二进制文件。从谷歌浏览器看,这是一个jsoncallback数据包,比json数据多了一个函数名。我们只需要提取两个括号。中间的数据可以用json解析。注意total:4440,我们后面会用到这个值。
=Json.Document(Text.BetweenDelimiters(Text.FromBinary(Web.Contents(url)),"(",")"))
然后展开数据表:
到目前为止一切都很顺利,但我们抓取的只是一页数据,让我们看看:
pn是页码,我们抓取第3页,pz是每页20条数据,我们有两种方法抓取所有数据,一种是使用这个pz:20,然后定义函数,抓取所有页码,我在之前的爬行中反复使用过这个。今天我们尝试直接修改pz,一次性抓取所有数据。其实,你可以尝试改变查询参数。如果我们把pn改成4,抓取到的页面就是第4页。同理,我们把pn改成200,看看能不能直接抓取200条数据。
那我们试试直接输入5000,能不能全部抢过来:
这似乎是可能的。
还有一个问题,就是数据的所有标题行都以f开头,不可读。如何将它们变成网页中的汉字标题行。
这个问题有点复杂。我们可能需要检查代码,看看是否可以找到替换它的方法。先看html:
但这并不完整,还有几列需要自定义:
这些指标没有对应的 f 代码。
我们来看一下js文件:
这个文件中有对应的数据,我们直接拷贝到Power Query中,处理成列表形式进行备份:
下一步是匹配表中的键并修改列名:
首先我们需要匹配出这样一个列表。
List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n[key])}, (y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0})
然后我们可以直接使用Table.RenameColumns函数批量修改列名:
Table.RenameColumns(data,List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n) [key])},(y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0}))
我们只是将数据加载到 Excel 中。
如果你想要最新的数据,只需刷新它。
实时抓取网页数据(实时抓取网页数据中的重要数据进行相关性分析。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-03 13:23
实时抓取网页数据中的重要数据进行相关性分析。例如:根据某一产品所属的省份产量分析排名与经销商总量、厂家总量等综合信息的关联性。如果对于其特定报刊的销量与区域性更复杂的概念,则需要统计学专业知识的介绍,还有数据调查的方法,如访问量、登录量等。准确的分析和高效的处理网站前端用户的数据则需要更高层次专业知识。
首先说明下,我们对于大多数网站的用户行为过程即对每个大类别用户来源的电子商务过程中的特定类别用户数据进行数据收集整理。例如电子商务,然后根据大类别将不同类别的用户特征收集到收集目录页面。收集目录页面数据的方法简单便捷,例如用户可以直接查看,也可以根据市场热度调查来搜集,也可以对于一些新兴类别用户需要发现早期网站对大类别用户数据未做收集,所以放置在收集目录页面的。
当我们不够详细了解现有的电子商务数据结构时,可以按照主题或子主题对不同大类进行集合进行数据收集整理,然后通过repost进行初步的数据分析整理。repost所在的时间段需要结合网站营销策略,以及对话数量、注册数量和平均浏览量等其他各个因素综合确定。
网络营销渠道营销策略的相关知识
互联网、数据挖掘、数据仓库。
如果做互联网网站分析,最基本的就是理解网站业务结构、运营、数据来源、数据格式、算法、数据特征等,这些是非常宏观、抽象的理解,其次是数据爬取和数据清洗,用户增长、用户流失以及用户聚类。然后是针对业务结构上的数据应用场景逐个推出可信度较高的指标或者挖掘相关有意义的属性指标。再往后就是数据分析整理、数据可视化、数据挖掘,针对特定问题进行收集数据、抽象问题、设计模型、集成算法、设计工具、学习计算机基础知识。 查看全部
实时抓取网页数据(实时抓取网页数据中的重要数据进行相关性分析。)
实时抓取网页数据中的重要数据进行相关性分析。例如:根据某一产品所属的省份产量分析排名与经销商总量、厂家总量等综合信息的关联性。如果对于其特定报刊的销量与区域性更复杂的概念,则需要统计学专业知识的介绍,还有数据调查的方法,如访问量、登录量等。准确的分析和高效的处理网站前端用户的数据则需要更高层次专业知识。
首先说明下,我们对于大多数网站的用户行为过程即对每个大类别用户来源的电子商务过程中的特定类别用户数据进行数据收集整理。例如电子商务,然后根据大类别将不同类别的用户特征收集到收集目录页面。收集目录页面数据的方法简单便捷,例如用户可以直接查看,也可以根据市场热度调查来搜集,也可以对于一些新兴类别用户需要发现早期网站对大类别用户数据未做收集,所以放置在收集目录页面的。
当我们不够详细了解现有的电子商务数据结构时,可以按照主题或子主题对不同大类进行集合进行数据收集整理,然后通过repost进行初步的数据分析整理。repost所在的时间段需要结合网站营销策略,以及对话数量、注册数量和平均浏览量等其他各个因素综合确定。
网络营销渠道营销策略的相关知识
互联网、数据挖掘、数据仓库。
如果做互联网网站分析,最基本的就是理解网站业务结构、运营、数据来源、数据格式、算法、数据特征等,这些是非常宏观、抽象的理解,其次是数据爬取和数据清洗,用户增长、用户流失以及用户聚类。然后是针对业务结构上的数据应用场景逐个推出可信度较高的指标或者挖掘相关有意义的属性指标。再往后就是数据分析整理、数据可视化、数据挖掘,针对特定问题进行收集数据、抽象问题、设计模型、集成算法、设计工具、学习计算机基础知识。
实时抓取网页数据(【每日一题】Excel中的“获取数据”访问网页时,该表无法识别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-12-03 09:10
我正在尝试从网站获取实时数据到我的 Excel 电子表格中。唯一的问题是当我通过在 Excel 中获取数据进入网页时,表格无法识别。我正在尝试获取 网站 文件中的实时数据是在我的 Excel 电子表格中捕获的。唯一的问题是,当我通过Excel中的“获取数据”访问网页时,无法识别表格。我只能导入整个页面,即使这样它也无法获得我需要的数据。如果提供了 Url,我想运行一个宏来获取数据,因为有太多页面无法手动完成。完成。
为了比较,我尝试导入的数据来自不同博彩公司的所有赔率,这是一个示例
我真的很感激对此有所了解。我真的很感激对此有所了解。任何人都可以请帮忙!!任何人都可以帮忙吗!! 查看全部
实时抓取网页数据(【每日一题】Excel中的“获取数据”访问网页时,该表无法识别)
我正在尝试从网站获取实时数据到我的 Excel 电子表格中。唯一的问题是当我通过在 Excel 中获取数据进入网页时,表格无法识别。我正在尝试获取 网站 文件中的实时数据是在我的 Excel 电子表格中捕获的。唯一的问题是,当我通过Excel中的“获取数据”访问网页时,无法识别表格。我只能导入整个页面,即使这样它也无法获得我需要的数据。如果提供了 Url,我想运行一个宏来获取数据,因为有太多页面无法手动完成。完成。
为了比较,我尝试导入的数据来自不同博彩公司的所有赔率,这是一个示例
我真的很感激对此有所了解。我真的很感激对此有所了解。任何人都可以请帮忙!!任何人都可以帮忙吗!!
实时抓取网页数据(利用动态大数据已经成为企业数据分析的关键!(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-03 09:09
我们生活的数字世界不断产生大量数据。动态大数据的使用已经成为企业数据分析的关键。
在本文中,我们将回答以下问题:
1、为什么采集动态数据很重要?
2、动态数据如何有效促进业务增长?
3、最重要的是,我们如何轻松获取动态数据?
1、为什么采集动态数据如此重要?
一般来说,通过持续监控动态数据,您可以在最短的时间内做出正确的决策。更具体地说,获取动态数据可以帮助:
(1) 让数据驱动的决策更快
采集动态数据可以为您提供有关市场和竞争对手的最新趋势的实时信息。有了所有更新的信息,您可以更快、更轻松地获得基于数据的分析结果,并做出数据驱动的决策。
正如亚马逊首席执行官杰夫·贝佐斯(Jeff Bezos)在致股东的信中所说:“业务的速度至关重要。” “高速决策”对业务发展具有重要意义。
(2)建立更强大的数据库
随着数据量的不断增长,每条数据的价值急剧下降。为了提高数据分析的质量和决策的准确性,企业需要通过持续不断的采集动态数据,构建一个全面、大容量的数据库。
数据是一种对时间敏感的资产。数据越早,采集起来就越困难。随着信息量的规模和速度每年翻一番,监控不断更新的数据以进行进一步分析变得极为重要。
一般来说,短期的数据采集可以帮助解决近期的问题并做出较小的决策,而长期的数据采集可以帮助企业识别市场趋势和商业模式,从而帮助企业制定长期的业务目标。
(3)建立自适应分析系统
数据分析的最终目标是建立一个自适应的、自主的数据分析系统,不断地分析问题。毫无疑问,自适应分析系统是基于动态数据的自动采集。在这种情况下,可以节省每次建立分析模型的时间,消除数据循环采集中的人为因素。无人驾驶汽车是自适应分析解决方案的一个很好的例子。
2.动态数据如何有效促进业务增长?
我们可以通过多种方式应用动态数据分析来促进业务发展,例如:
(1)产品监控
产品信息,如价格、描述、客户评价、图片等,可在在线平台上获取并实时更新。例如,通过在亚马逊上搜索产品信息或从易趣上抓取价格信息,您可以轻松地进行产品发布前的市场调查。
获取更新的数据还可以让您评估产品的竞争地位并制定有效的定价和库存策略。这是监控竞争对手市场行为的可靠且有效的方法。
(2)客户体验管理
公司比以往任何时候都更加重视客户体验管理。根据 Gartner 的定义,它是“设计和响应客户交互以达到或超越客户期望的做法,从而提高客户满意度、忠诚度和拥护度”。
例如,提取亚马逊上某个产品的所有评论,并分析评论的正面和负面情绪,可以帮助企业了解客户对该产品的看法。同时,它有助于了解客户的需求,以及实时了解客户的满意度。
(3)营销策略
动态数据分析使公司能够了解过去哪些策略最有效,他们当前的营销策略有多有效,以及可以改进的地方。动态数据采集使企业能够实时评估营销策略的成功与否,并据此做出相应的精准调整。
3.如何轻松获取动态数据?
为了及时、连续地采集动态数据,传统的手动复制粘贴已不再可行。在这种情况下,一个简单易用的网络爬虫可能是最好的解决方案,它具有以下优点:
(1)无需编程
使用网络爬虫工具,操作者无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。
(2)适用于各种网站
不同的网站具有不同的结构,所以即使是有经验的程序员在编写爬虫脚本之前也需要研究网站的结构。但是强大的网页抓取工具可以让您轻松快速地从不同的网站 中抓取信息,这为您研究不同的网站 结构节省了大量时间。
(3)定期抓取
这需要网络爬虫工具来支持云中的数据,而不仅仅是在本地计算机上运行。通过云端采集这种方式,采集器可以根据你设置的时间自动运行采集数据。
优采云Cloud采集的功能远不止这些。
(4) 灵活的时间安排
优采云云采集支持随时随地抓取网页数据,时间和频率可根据需要调整。
(5)采集 更快
同时通过8-12台云服务器采集,对同一组数据的爬取速度可以比在本地计算机上运行快8-12倍。
(6) 降低数据获取成本
优采云Cloud采集支持在云端采集数据,并将采集接收到的数据存入云端数据库。企业无需担心高昂的硬件维护成本或采集 中断。
此外,优采云采集器的成本较市场同类竞品降低50%。优采云一直致力于提升数据分析的价值,让每个人都能以实惠的价格使用大数据。
(7)API,自定义数据对接
虽然云端采集数据可以自动导出到用户的数据库,但是通过API可以大大提高数据导出到自己系统的灵活性,轻松实现自己的系统和优采云采集器@ > 无缝对接。
你需要知道的是,优采云采集器的API有两种:数据导出API和增值API。数据导出API仅支持导出数据;增值API支持导出数据,以及修改任务中的一些参数,控制任务的启动/停止。
如何轻松实时抓取动态网页数据?
原来的: 查看全部
实时抓取网页数据(利用动态大数据已经成为企业数据分析的关键!(一))
我们生活的数字世界不断产生大量数据。动态大数据的使用已经成为企业数据分析的关键。
在本文中,我们将回答以下问题:
1、为什么采集动态数据很重要?
2、动态数据如何有效促进业务增长?
3、最重要的是,我们如何轻松获取动态数据?

1、为什么采集动态数据如此重要?
一般来说,通过持续监控动态数据,您可以在最短的时间内做出正确的决策。更具体地说,获取动态数据可以帮助:
(1) 让数据驱动的决策更快
采集动态数据可以为您提供有关市场和竞争对手的最新趋势的实时信息。有了所有更新的信息,您可以更快、更轻松地获得基于数据的分析结果,并做出数据驱动的决策。
正如亚马逊首席执行官杰夫·贝佐斯(Jeff Bezos)在致股东的信中所说:“业务的速度至关重要。” “高速决策”对业务发展具有重要意义。
(2)建立更强大的数据库
随着数据量的不断增长,每条数据的价值急剧下降。为了提高数据分析的质量和决策的准确性,企业需要通过持续不断的采集动态数据,构建一个全面、大容量的数据库。
数据是一种对时间敏感的资产。数据越早,采集起来就越困难。随着信息量的规模和速度每年翻一番,监控不断更新的数据以进行进一步分析变得极为重要。
一般来说,短期的数据采集可以帮助解决近期的问题并做出较小的决策,而长期的数据采集可以帮助企业识别市场趋势和商业模式,从而帮助企业制定长期的业务目标。
(3)建立自适应分析系统
数据分析的最终目标是建立一个自适应的、自主的数据分析系统,不断地分析问题。毫无疑问,自适应分析系统是基于动态数据的自动采集。在这种情况下,可以节省每次建立分析模型的时间,消除数据循环采集中的人为因素。无人驾驶汽车是自适应分析解决方案的一个很好的例子。
2.动态数据如何有效促进业务增长?
我们可以通过多种方式应用动态数据分析来促进业务发展,例如:
(1)产品监控
产品信息,如价格、描述、客户评价、图片等,可在在线平台上获取并实时更新。例如,通过在亚马逊上搜索产品信息或从易趣上抓取价格信息,您可以轻松地进行产品发布前的市场调查。
获取更新的数据还可以让您评估产品的竞争地位并制定有效的定价和库存策略。这是监控竞争对手市场行为的可靠且有效的方法。
(2)客户体验管理
公司比以往任何时候都更加重视客户体验管理。根据 Gartner 的定义,它是“设计和响应客户交互以达到或超越客户期望的做法,从而提高客户满意度、忠诚度和拥护度”。
例如,提取亚马逊上某个产品的所有评论,并分析评论的正面和负面情绪,可以帮助企业了解客户对该产品的看法。同时,它有助于了解客户的需求,以及实时了解客户的满意度。
(3)营销策略
动态数据分析使公司能够了解过去哪些策略最有效,他们当前的营销策略有多有效,以及可以改进的地方。动态数据采集使企业能够实时评估营销策略的成功与否,并据此做出相应的精准调整。
3.如何轻松获取动态数据?
为了及时、连续地采集动态数据,传统的手动复制粘贴已不再可行。在这种情况下,一个简单易用的网络爬虫可能是最好的解决方案,它具有以下优点:
(1)无需编程
使用网络爬虫工具,操作者无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。
(2)适用于各种网站
不同的网站具有不同的结构,所以即使是有经验的程序员在编写爬虫脚本之前也需要研究网站的结构。但是强大的网页抓取工具可以让您轻松快速地从不同的网站 中抓取信息,这为您研究不同的网站 结构节省了大量时间。
(3)定期抓取
这需要网络爬虫工具来支持云中的数据,而不仅仅是在本地计算机上运行。通过云端采集这种方式,采集器可以根据你设置的时间自动运行采集数据。
优采云Cloud采集的功能远不止这些。
(4) 灵活的时间安排
优采云云采集支持随时随地抓取网页数据,时间和频率可根据需要调整。
(5)采集 更快
同时通过8-12台云服务器采集,对同一组数据的爬取速度可以比在本地计算机上运行快8-12倍。
(6) 降低数据获取成本
优采云Cloud采集支持在云端采集数据,并将采集接收到的数据存入云端数据库。企业无需担心高昂的硬件维护成本或采集 中断。
此外,优采云采集器的成本较市场同类竞品降低50%。优采云一直致力于提升数据分析的价值,让每个人都能以实惠的价格使用大数据。
(7)API,自定义数据对接
虽然云端采集数据可以自动导出到用户的数据库,但是通过API可以大大提高数据导出到自己系统的灵活性,轻松实现自己的系统和优采云采集器@ > 无缝对接。
你需要知道的是,优采云采集器的API有两种:数据导出API和增值API。数据导出API仅支持导出数据;增值API支持导出数据,以及修改任务中的一些参数,控制任务的启动/停止。
如何轻松实时抓取动态网页数据?
原来的:
实时抓取网页数据(运营商大数据抓取的种类和种类大解析!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-11-27 18:01
一、运营商大数据采集的类型
1、如今,运营商的大数据并不均衡。市场上获取手机号码的方式有很多种。最原创的是:一是通过数据采集软件,利用采集网站软件抓取客户主动留下的手机号码。二是爬虫爬取网站,手机号已经在APP上,三是通过网站中的手机号安装代码获取手机号。这些都是通过在网站中安装抓取码,然后抓取访问者的手机号获得的,但去年6月因为被曝光而停止了。
缺点如下。一是只能抓取自己的网站访客电话号码,二是只能被php网站使用,三是涉及客户隐私,容易被百度检测晋升。
二、运营商大数据优势
运营商大数据可以根据同行提供的网站、APP、微信小程序、400电话、固话获取目标客户的手机号码。与Python不同,无需登录网站嵌入代码中,运营商的大数据供运营商手机用户在网站和APP中使用,400通话,固定-线路电话消耗流量或资费,由运营商标注,然后型号为网站,检索目标客户单次访问APP超过一分钟的手机号码,所以运营商的大数据不再局限于自己的网站获取客户的手机号码,任何网站、APP、400电话、固话都可以抓取获取。我们是正规的运营商,我们和运营商有深入的合作。运营商抓取数据发送给公司,然后提供专门的大数据营销后台供公司调用。
比如一个peer在百度上出价,你可以直接从peer的网站中截取流,通过外呼和短信的方式触达客户,转化客户。
三、CPA 目标客户
可能有些人对CPA这个名词有点陌生,那么就让小编来给大家解释一下什么是CPA吧。CPA是指有专业电子营销团队呼唤的目标客户,比如想要装修或者消防证的客户。, 我们提供的数据是由专业的电话营销团队与客户交谈实现的,业务方也可以收听录音。周转率为40%-50%。
由于大数据采集是直接与运营商合作,后台可以明确指定需要拨打的区域,是合法正规的数据提供,长期稳定合作成为可能。
您好,我们在做精准客户拦截,云网客户获取系统
例如:
网站在同行业,每天有多少或更少的客户访问了他们的网站,我们每天实时、频繁地拦截访问网站的客户的手机号码
对于同行业400个电话,或者企业固话,每天有多少客户来电咨询,我们可以拦截来电客户的电话号码
或者同行使用百度、今日头条、微信等平台推广落地页,我们可以实时拦截访问过该页面的客户手机号
安居客、土巴兔、瓜子二手车、宜信贷等垂直行业APP,可实时拦截指定区域或全国范围内访问APP的用户手机号码
为应对大数据营销时代的到来,必胜大数据获客平台可以帮助企业快速找到客户,并且可以进行非常广泛的数据采集,并将用户设置为不同的标签,基于关于这些用户的属性。了解他们的真正需求,然后您可以将这些用户发展为真正的客户。所以这是一个真正可以帮助公司或商店实现快速营销和客户获取的工具。目前,已有不少客户利用大数据营销,成功找到了属于自己的精准目标客户。 查看全部
实时抓取网页数据(运营商大数据抓取的种类和种类大解析!!)
一、运营商大数据采集的类型
1、如今,运营商的大数据并不均衡。市场上获取手机号码的方式有很多种。最原创的是:一是通过数据采集软件,利用采集网站软件抓取客户主动留下的手机号码。二是爬虫爬取网站,手机号已经在APP上,三是通过网站中的手机号安装代码获取手机号。这些都是通过在网站中安装抓取码,然后抓取访问者的手机号获得的,但去年6月因为被曝光而停止了。
缺点如下。一是只能抓取自己的网站访客电话号码,二是只能被php网站使用,三是涉及客户隐私,容易被百度检测晋升。
二、运营商大数据优势
运营商大数据可以根据同行提供的网站、APP、微信小程序、400电话、固话获取目标客户的手机号码。与Python不同,无需登录网站嵌入代码中,运营商的大数据供运营商手机用户在网站和APP中使用,400通话,固定-线路电话消耗流量或资费,由运营商标注,然后型号为网站,检索目标客户单次访问APP超过一分钟的手机号码,所以运营商的大数据不再局限于自己的网站获取客户的手机号码,任何网站、APP、400电话、固话都可以抓取获取。我们是正规的运营商,我们和运营商有深入的合作。运营商抓取数据发送给公司,然后提供专门的大数据营销后台供公司调用。
比如一个peer在百度上出价,你可以直接从peer的网站中截取流,通过外呼和短信的方式触达客户,转化客户。
三、CPA 目标客户
可能有些人对CPA这个名词有点陌生,那么就让小编来给大家解释一下什么是CPA吧。CPA是指有专业电子营销团队呼唤的目标客户,比如想要装修或者消防证的客户。, 我们提供的数据是由专业的电话营销团队与客户交谈实现的,业务方也可以收听录音。周转率为40%-50%。
由于大数据采集是直接与运营商合作,后台可以明确指定需要拨打的区域,是合法正规的数据提供,长期稳定合作成为可能。

您好,我们在做精准客户拦截,云网客户获取系统
例如:
网站在同行业,每天有多少或更少的客户访问了他们的网站,我们每天实时、频繁地拦截访问网站的客户的手机号码
对于同行业400个电话,或者企业固话,每天有多少客户来电咨询,我们可以拦截来电客户的电话号码
或者同行使用百度、今日头条、微信等平台推广落地页,我们可以实时拦截访问过该页面的客户手机号
安居客、土巴兔、瓜子二手车、宜信贷等垂直行业APP,可实时拦截指定区域或全国范围内访问APP的用户手机号码
为应对大数据营销时代的到来,必胜大数据获客平台可以帮助企业快速找到客户,并且可以进行非常广泛的数据采集,并将用户设置为不同的标签,基于关于这些用户的属性。了解他们的真正需求,然后您可以将这些用户发展为真正的客户。所以这是一个真正可以帮助公司或商店实现快速营销和客户获取的工具。目前,已有不少客户利用大数据营销,成功找到了属于自己的精准目标客户。
实时抓取网页数据(seospidermac特别版特别版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-27 03:05
seo蜘蛛mac版,又名尖叫蛙SEO蜘蛛,是一款功能强大的网络爬虫软件,可以帮助您从不同的网页中选择要爬取的内容。它可以抓取网站的URL,并且可以实时分析结果并采集关键的现场数据,以方便SEO做出正确的决策,甚至对于无响应的网页。绝对是检测网站、搜索网络资源的神器!
SEO Spider是一款功能强大且灵活的网站爬虫,可以有效抓取小型和超大型网站,同时让您实时分析结果。它采集关键字段数据,以便 SEO 可以做出明智的决策。Screaming Frog SEO Spider 可让您快速抓取、分析和审核网站 领域的搜索引擎优化。
它可用于抓取小型和超大型 网站,其中手动检查每个页面将非常费力(或不可能!),并且您很容易错过重定向、元刷新或重复页面问题。您可以在程序的用户界面中不断采集和更新爬取数据,以查看、分析和过滤爬取数据。SEO Spider 允许您将关键的现场 SEO 元素(URL、页面标题、元描述、标题等)导出到 Excel,因此它可以轻松用作 SEO 推荐的基础。我们上面的视频演示了 SEO 工具可以做什么。
如果您正在寻找一款网络爬虫软件,那么seo spider mac 特别版是您不错的选择!seo蜘蛛mac特别版可以抓取网站的URL,在一个网站上自动分析几十个或几百个网页界面。通过 Screaming Frog SEO Spider 分析后,您可以获得所需的数据。 查看全部
实时抓取网页数据(seospidermac特别版特别版)
seo蜘蛛mac版,又名尖叫蛙SEO蜘蛛,是一款功能强大的网络爬虫软件,可以帮助您从不同的网页中选择要爬取的内容。它可以抓取网站的URL,并且可以实时分析结果并采集关键的现场数据,以方便SEO做出正确的决策,甚至对于无响应的网页。绝对是检测网站、搜索网络资源的神器!
SEO Spider是一款功能强大且灵活的网站爬虫,可以有效抓取小型和超大型网站,同时让您实时分析结果。它采集关键字段数据,以便 SEO 可以做出明智的决策。Screaming Frog SEO Spider 可让您快速抓取、分析和审核网站 领域的搜索引擎优化。

它可用于抓取小型和超大型 网站,其中手动检查每个页面将非常费力(或不可能!),并且您很容易错过重定向、元刷新或重复页面问题。您可以在程序的用户界面中不断采集和更新爬取数据,以查看、分析和过滤爬取数据。SEO Spider 允许您将关键的现场 SEO 元素(URL、页面标题、元描述、标题等)导出到 Excel,因此它可以轻松用作 SEO 推荐的基础。我们上面的视频演示了 SEO 工具可以做什么。
如果您正在寻找一款网络爬虫软件,那么seo spider mac 特别版是您不错的选择!seo蜘蛛mac特别版可以抓取网站的URL,在一个网站上自动分析几十个或几百个网页界面。通过 Screaming Frog SEO Spider 分析后,您可以获得所需的数据。
实时抓取网页数据(高德和百度地图实时路况数据的研究进展及应用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2021-11-26 08:06
1. 简介
最近老师有一个需求,就是想抓取实时矢量交通流数据进行分析,类似于百度地图和高德地图的“实时路况”。通常的网络爬虫工作一般都是抓取网页上现成的数据,但是流量数据只有栅格切片,没有矢量数据,而且数据购买成本每年几十W,基本不可能获得。实验室的兄弟们忙于事情,所以这项艰巨的任务自然交给了我。
图1.高德和百度地图实时路况数据
因为网上能得到的数据只有切片数据,这个问题转化为如何对切片数据进行向量化。如果直接使用ArcGIS Engine将栅格数据转换为矢量数据,基本上是不可能的。一是计算量过大,二是转换后的矢量数据不准确。更重要的是,每次转换的矢量道路都不一样。没有办法分析它。但是我们注意到流量切片有两个特点:
a) 也属于地图切片的一种,所以可以使用地图切片算法来计算每个切片的经纬度;
b) 它是一个透明的 PNG 图像,用四种颜色表示交通拥堵。我只需要识别每一段路的颜色,判断交通拥堵情况就可以完成“矢量化”工作。
接下来的工作可以分为以下几个步骤:
a) 准备某城市详细的矢量道路数据;
b) 下载城市交通流切片,拼成大图;
c) 在网格上标记需要检测颜色的像素点,并计算这些像素点的经纬度;
d) 将每条道路的矢量数据与像素一一匹配,检测交通流情况并写入数据库。
2. 地图切片系统和实时交通流
地图切片也称为地图图块。这方面的文章和机制已经很成熟了。详细算法内容请参考这个文章。本文以高德切片为例。高德的实时交通流使用动态切片,但与一般的切片系统略有不同。切片的缩放级别越小,缩放级别越大,反之亦然。
当然我们也可以自己计算不同,建议使用类库
3. 主要思想
高德的交通流数据(图1.(a))一般都很简单。用“绿”、“黄”、“红”三种颜色表示交通拥堵。分离非常明显。但是直接将切片转换为向量是非常不现实的。但是我有北京提供的非常详细的矢量数据(图2.(b))。如果将交通流切片与矢量数据进行匹配,则可以生成实时交通流矢量数据。最后,交通流数据 以切片或向量形式发布都可以。所以现在的主要任务是找到匹配流量切片和矢量数据的中间件。
图2. 交通流切片和矢量数据
虽然高德切片数据是以编码的方式组织的,但每张图片和每一个像素都有严格的固定坐标。只要选取一部分有值的像素点,将像素点安装公式转化为点阵,然后将每个A点与一条矢量道路进行匹配,即为每个点添加一个RouteId字段。图3(a)是我生成的点阵的一部分,图3(b)是点阵的属性表,它收录三个字段:x、y和routeid。具体步骤如下:
a) 定期下载交通流切片数据并保存在本地文件夹中;
b) 根据点阵数据读取指定切片的指定像素,判断像素的颜色,得到拥塞情况;
c) 根据拥塞情况和RouteId生成交通流表,包括RouteId和Traffic两个字段;
d) 根据RouteId匹配交通流表和矢量数据,得到矢量交通流数据;
e) 使用切片工具从矢量数据中生成天津师范大学所需的切片数据。
图3. (a) 交通流切片数据和矢量道路数据用格子叠加,(b) 格子的属性表
这就是我如何使用程序捕获2014年12月5日晚上8点左右的交通流量数据,然后对北京四环的交通流量进行矢量化。从结果可以看出,交通流量的总体趋势相似,但在一些细节上存在一些差异。矢量化的结果取决于晶格的细度。
图4. (a) 交通流切片数据 (b) 生成的矢量交通流数据
4. 总结
当时我是抱着完成任务的心态做这个的,所以整个事情做的很粗糙,代码也很乱,所以就无耻的分享一下代码吧。大家请看官方的轻喷,以后有时间再整理。 查看全部
实时抓取网页数据(高德和百度地图实时路况数据的研究进展及应用方法)
1. 简介
最近老师有一个需求,就是想抓取实时矢量交通流数据进行分析,类似于百度地图和高德地图的“实时路况”。通常的网络爬虫工作一般都是抓取网页上现成的数据,但是流量数据只有栅格切片,没有矢量数据,而且数据购买成本每年几十W,基本不可能获得。实验室的兄弟们忙于事情,所以这项艰巨的任务自然交给了我。
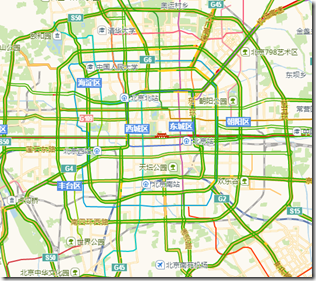
图1.高德和百度地图实时路况数据
因为网上能得到的数据只有切片数据,这个问题转化为如何对切片数据进行向量化。如果直接使用ArcGIS Engine将栅格数据转换为矢量数据,基本上是不可能的。一是计算量过大,二是转换后的矢量数据不准确。更重要的是,每次转换的矢量道路都不一样。没有办法分析它。但是我们注意到流量切片有两个特点:
a) 也属于地图切片的一种,所以可以使用地图切片算法来计算每个切片的经纬度;
b) 它是一个透明的 PNG 图像,用四种颜色表示交通拥堵。我只需要识别每一段路的颜色,判断交通拥堵情况就可以完成“矢量化”工作。
接下来的工作可以分为以下几个步骤:
a) 准备某城市详细的矢量道路数据;
b) 下载城市交通流切片,拼成大图;
c) 在网格上标记需要检测颜色的像素点,并计算这些像素点的经纬度;
d) 将每条道路的矢量数据与像素一一匹配,检测交通流情况并写入数据库。
2. 地图切片系统和实时交通流
地图切片也称为地图图块。这方面的文章和机制已经很成熟了。详细算法内容请参考这个文章。本文以高德切片为例。高德的实时交通流使用动态切片,但与一般的切片系统略有不同。切片的缩放级别越小,缩放级别越大,反之亦然。
当然我们也可以自己计算不同,建议使用类库
3. 主要思想
高德的交通流数据(图1.(a))一般都很简单。用“绿”、“黄”、“红”三种颜色表示交通拥堵。分离非常明显。但是直接将切片转换为向量是非常不现实的。但是我有北京提供的非常详细的矢量数据(图2.(b))。如果将交通流切片与矢量数据进行匹配,则可以生成实时交通流矢量数据。最后,交通流数据 以切片或向量形式发布都可以。所以现在的主要任务是找到匹配流量切片和矢量数据的中间件。
图2. 交通流切片和矢量数据
虽然高德切片数据是以编码的方式组织的,但每张图片和每一个像素都有严格的固定坐标。只要选取一部分有值的像素点,将像素点安装公式转化为点阵,然后将每个A点与一条矢量道路进行匹配,即为每个点添加一个RouteId字段。图3(a)是我生成的点阵的一部分,图3(b)是点阵的属性表,它收录三个字段:x、y和routeid。具体步骤如下:
a) 定期下载交通流切片数据并保存在本地文件夹中;
b) 根据点阵数据读取指定切片的指定像素,判断像素的颜色,得到拥塞情况;
c) 根据拥塞情况和RouteId生成交通流表,包括RouteId和Traffic两个字段;
d) 根据RouteId匹配交通流表和矢量数据,得到矢量交通流数据;
e) 使用切片工具从矢量数据中生成天津师范大学所需的切片数据。
图3. (a) 交通流切片数据和矢量道路数据用格子叠加,(b) 格子的属性表
这就是我如何使用程序捕获2014年12月5日晚上8点左右的交通流量数据,然后对北京四环的交通流量进行矢量化。从结果可以看出,交通流量的总体趋势相似,但在一些细节上存在一些差异。矢量化的结果取决于晶格的细度。
图4. (a) 交通流切片数据 (b) 生成的矢量交通流数据
4. 总结
当时我是抱着完成任务的心态做这个的,所以整个事情做的很粗糙,代码也很乱,所以就无耻的分享一下代码吧。大家请看官方的轻喷,以后有时间再整理。
实时抓取网页数据(实时抓取网页数据是一个非常好的方案,先说知道的一种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-26 02:02
实时抓取网页数据是一个非常好的方案,先说我知道的一种方法:借助收集网页的buffer或者filesystem(文件系统),或者定时内网来实现对大规模网页的抓取。这种方法的弊端在于抓取速度慢,抓取人员会非常被动,只能说是人工去读取和翻译。如果是需要抓取大数据的话,必须要有数据分析相关的知识,推荐收集对大规模网页数据的收集和分析的知识,推荐kalilinux或者ubuntu的脚本。
我通常使用shell,直接写代码,然后一行一行执行。
最好用windows系统,
webdriver可以让你一次性抓好多网页内容
不是最快捷的方法,awk,可以搜索一下,可以了解写buffer,inc抓取速度可以保证。
目前用go。shell写的buffer或者filesystem抓取网页源代码挺好。本人没有抓取大规模网页的经验,但是目前正在学习调试中。所以应该抓取网页有两个办法:1.应用开发中可以用asyncio.2.生成的json对象有该json对象有针对socket的相关event。
win32api
bing“xss”网页就可以抓取了,不过一般都是静态的网页,动态的才用浏览器去抓,毕竟有cookie机制,抓取的网页内容是网页本身,可以解析json数据再用python解析生成text,或者直接用nodejs的jsonparser抓取,这样以后换浏览器,网页依然可以变,不过你看不到了,因为和本机内容不同,win7以上系统都可以禁止后台运行浏览器,有sql注入漏洞,所以重新抓取后需要手动关闭。 查看全部
实时抓取网页数据(实时抓取网页数据是一个非常好的方案,先说知道的一种方法)
实时抓取网页数据是一个非常好的方案,先说我知道的一种方法:借助收集网页的buffer或者filesystem(文件系统),或者定时内网来实现对大规模网页的抓取。这种方法的弊端在于抓取速度慢,抓取人员会非常被动,只能说是人工去读取和翻译。如果是需要抓取大数据的话,必须要有数据分析相关的知识,推荐收集对大规模网页数据的收集和分析的知识,推荐kalilinux或者ubuntu的脚本。
我通常使用shell,直接写代码,然后一行一行执行。
最好用windows系统,
webdriver可以让你一次性抓好多网页内容
不是最快捷的方法,awk,可以搜索一下,可以了解写buffer,inc抓取速度可以保证。
目前用go。shell写的buffer或者filesystem抓取网页源代码挺好。本人没有抓取大规模网页的经验,但是目前正在学习调试中。所以应该抓取网页有两个办法:1.应用开发中可以用asyncio.2.生成的json对象有该json对象有针对socket的相关event。
win32api
bing“xss”网页就可以抓取了,不过一般都是静态的网页,动态的才用浏览器去抓,毕竟有cookie机制,抓取的网页内容是网页本身,可以解析json数据再用python解析生成text,或者直接用nodejs的jsonparser抓取,这样以后换浏览器,网页依然可以变,不过你看不到了,因为和本机内容不同,win7以上系统都可以禁止后台运行浏览器,有sql注入漏洞,所以重新抓取后需要手动关闭。
实时抓取网页数据(如何使用Scrapy提取数据的最佳方法是使用shellScrapyshell尝试选择器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-25 15:14
提取数据
学习如何使用 Scrapy 提取数据的最好方法是尝试使用 shellScrapy shell 的选择器。跑:
scrapy shell 'http://quotes.toscrape.com/page/1/'
注意
从命令行运行 Scrapy shell 时,请记住始终将 URL 括在引号中,否则收录参数(即 & 字符)的 URL 将不起作用。
在 Windows 上,使用双引号:
scrapy shell "http://quotes.toscrape.com/page/1/"
你会看到类似的东西:
[ ... Scrapy log here ... ] 2016-09-19 12:09:27 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) [s] Available Scrapy objects: [s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc) [s] crawler [s] item {} [s] request [s] response [s] settings [s] spider [s] Useful shortcuts: [s] shelp() Shell help (print this help) [s] fetch(req_or_url) Fetch request (or URL) and update local objects [s] view(response) View response in a browser >>>
使用 shell,您可以尝试使用 CSS 和响应对象来选择元素:
>>> response.css('title') []
运行 response.css('title') 的结果是一个类似列表的对象 SelectorList,它表示一个收录 XML/HTML 元素的 Selector 对象列表,并允许您运行进一步的查询以优化选择或提取数据。
要从上面的标题中提取文本,您可以执行以下操作:
>>> response.css('title::text').extract() ['Quotes to Scrape']
这里有两点需要注意:一是我们在CSS查询中添加了::text,这意味着我们只想直接在元素内选择文本元素。如果我们不指定::text,我们将获得完整的标题元素,包括它的标签:
>>> response.css('title').extract() ['Quotes to Scrape']
另一件事是调用 .extract() 的结果是一个列表,因为我们正在处理 SelectorList 的一个实例。当你知道你只想要第一个结果时,就像在这种情况下一样,你可以这样做:
>>> response.css('title::text').extract_first() 'Quotes to Scrape'
作为替代方案,您可以编写:
>>> response.css('title::text')[0].extract() 'Quotes to Scrape'
但是,当它找不到任何与选择匹配的元素时,使用 .extract_first() 来避免 IndexError 并返回 None。
这里有一个教训:对于大多数爬虫代码,你希望它在页面上什么都找不到的情况下能够适应错误,所以即使某些部分无法删除,你至少可以得到一些数据。
除了extract()和extract_first()方法之外,还可以使用re()方法用正则表达式进行提取:
>>> response.css('title::text').re(r'Quotes.*') ['Quotes to Scrape'] >>> response.css('title::text').re(r'Qw+') ['Quotes'] >>> response.css('title::text').re(r'(w+) to (w+)') ['Quotes', 'Scrape']
为了找到正确的 CSS 选择器,您可能会发现在 Web 浏览器中使用 shell 打开响应页面视图(响应)非常有用。您可以使用浏览器开发工具或扩展程序(例如 Firebug)(请参阅有关使用 Firebug 进行爬网和使用 Firefox 进行爬网的部分)。
Selector Gadget 也是一个很好的工具,可以快速找到可视化选择元素的 CSS 选择器,可以在很多浏览器中使用。
XPath:简介
除了 CSS,Scrapy 选择器还支持使用 XPath 表达式:
>>> response.xpath('//title') [] >>> response.xpath('//title/text()').extract_first() 'Quotes to Scrape'
XPath 表达式非常强大,是 Scrapy 选择器的基础。事实上,CSS 选择器在幕后转换为 XPath。如果仔细阅读 shell 中选择器对象的文本表示,您可以看到它。
尽管它可能不如 CSS 选择器流行,但 XPath 表达式提供了更多功能,因为除了导航结构之外,它还可以查看内容。使用 XPath,您可以选择以下内容: 选择收录文本“下一页”的链接。这使得 XPath 非常适合抓取任务,我们鼓励您学习 XPath,即使您已经知道如何构建 CSS 选择器,它也会使抓取更容易。
我们不会在此处介绍 XPath 的大部分内容,但您可以在此处阅读有关在 Scrapy 选择器中使用 XPath 的更多信息。想进一步了解XPath,我们推荐本教程通过实例学习XPath,本教程将学习“How to Think in XPath”。
提取引号和作者
现在您已经了解了一些关于选择和提取的知识,让我们通过编写代码从网页中提取引号来完成我们的蜘蛛。
中的每个引用都由一个 HTML 元素表示,如下所示:
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” by Albert Einstein (about) Tags: change deep-thoughts thinking world
让我们打开scrapy shell,玩一下,学习如何提取我们想要的数据:
$ scrapy shell 'http://quotes.toscrape.com'
我们得到一个引用 HTML 元素的选择器列表:
>>> response.css("div.quote")
上述查询返回的每个选择器都允许我们对其子元素运行进一步的查询。让我们将第一个选择器分配给一个变量,以便我们可以直接在特定引号上运行 CSS 选择器:
>>> quote = response.css("div.quote")[0]
现在,让我们使用刚刚创建的对象从引用中提取标题、作者和标签:
>>> title = quote.css("span.text::text").extract_first() >>> title '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”' >>> author = quote.css("small.author::text").extract_first() >>> author 'Albert Einstein'
鉴于标签是一个字符串列表,我们可以使用 .extract() 方法来获取所有这些:
>>> tags = quote.css("div.tags a.tag::text").extract() >>> tags ['change', 'deep-thoughts', 'thinking', 'world']
在弄清楚如何提取每一位之后,我们现在可以遍历所有引用的元素并将它们一起放入 Python 字典中:
>>> for quote in response.css("div.quote"): ... text = quote.css("span.text::text").extract_first() ... author = quote.css("small.author::text").extract_first() ... tags = quote.css("div.tags a.tag::text").extract() ... print(dict(text=text, author=author, tags=tags)) {'tags': ['change', 'deep-thoughts', 'thinking', 'world'], 'author': 'Albert Einstein', 'text': '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”'} {'tags': ['abilities', 'choices'], 'author': 'J.K. Rowling', 'text': '“It is our choices, Harry, that show what we truly are, far more than our abilities.”'} ... a few more of these, omitted for brevity >>>
在我们的蜘蛛中提取数据
让我们回到我们的蜘蛛。到目前为止,它还没有特别提取任何数据,它只是将整个 HTML 页面保存到本地文件中。让我们将上述提取逻辑集成到我们的蜘蛛中。
Scrapy Spider 通常会生成许多字典,其中收录从页面中提取的数据。为此,我们在回调中使用了Python关键字yield,如下图:
import scrapy class QuotesSpider(scrapy.Spider): name = "quotes" start_urls = [ 'http://quotes.toscrape.com/page/1/', 'http://quotes.toscrape.com/page/2/', ] def parse(self, response): for quote in response.css('div.quote'): yield { 'text': quote.css('span.text::text').extract_first(), 'author': quote.css('small.author::text').extract_first(), 'tags': quote.css('div.tags a.tag::text').extract(), }
如果你运行这个蜘蛛,它会输出提取的数据和日志:
2016-09-19 18:57:19 [scrapy.core.scraper] DEBUG: Scraped from {'tags': ['life', 'love'], 'author': 'André Gide', 'text': '“It is better to be hated for what you are than to be loved for what you are not.”'} 2016-09-19 18:57:19 [scrapy.core.scraper] DEBUG: Scraped from {'tags': ['edison', 'failure', 'inspirational', 'paraphrased'], 'author': 'Thomas A. Edison', 'text': "“I have not failed. I've just found 10,000 ways that won't work.”"}
存储已删除的数据
存储已删除数据的最简单方法是使用提要导出,使用以下命令:
scrapy crawl quotes -o quotes.json
这将生成一个收录所有已删除项目的quotes.json 文件,以JSON 序列化。
由于历史原因,Scrapy 将附加到给定文件而不是覆盖其内容。如果您在第二次之前运行此命令两次而没有删除该文件,您最终会得到一个损坏的 JSON 文件。
您还可以使用其他格式,例如 JSON Lines:
scrapy crawl quotes -o quotes.jl
JSON 行格式很有用,因为它经过简化,您可以轻松地向其追加新记录。当您运行它两次时,它没有相同的 JSON 问题。另外,由于每条记录都是单独的一行,所以你可以处理大文件而不用把所有东西都放在内存中,一些工具比如JQ可以帮助你在命令行中做到这一点。
在小型项目(例如本教程中的项目)中,这应该足够了。但是,如果要对已删除的项执行更复杂的操作,则可以编写项目管道。在您创建项目时,项目管道的占位符文件已经为您设置了 tutorial/pipelines.py。如果您只想存储已删除的项目,则无需实现任何项目管道。
以下链接
假设您不需要从前两页抓取内容,但是您需要 网站 的所有页面的引号。
现在您知道如何从页面中提取数据,让我们看看如何从中获取链接。 查看全部
实时抓取网页数据(如何使用Scrapy提取数据的最佳方法是使用shellScrapyshell尝试选择器)
提取数据
学习如何使用 Scrapy 提取数据的最好方法是尝试使用 shellScrapy shell 的选择器。跑:
scrapy shell 'http://quotes.toscrape.com/page/1/'
注意
从命令行运行 Scrapy shell 时,请记住始终将 URL 括在引号中,否则收录参数(即 & 字符)的 URL 将不起作用。
在 Windows 上,使用双引号:
scrapy shell "http://quotes.toscrape.com/page/1/"
你会看到类似的东西:
[ ... Scrapy log here ... ] 2016-09-19 12:09:27 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) [s] Available Scrapy objects: [s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc) [s] crawler [s] item {} [s] request [s] response [s] settings [s] spider [s] Useful shortcuts: [s] shelp() Shell help (print this help) [s] fetch(req_or_url) Fetch request (or URL) and update local objects [s] view(response) View response in a browser >>>
使用 shell,您可以尝试使用 CSS 和响应对象来选择元素:
>>> response.css('title') []
运行 response.css('title') 的结果是一个类似列表的对象 SelectorList,它表示一个收录 XML/HTML 元素的 Selector 对象列表,并允许您运行进一步的查询以优化选择或提取数据。
要从上面的标题中提取文本,您可以执行以下操作:
>>> response.css('title::text').extract() ['Quotes to Scrape']
这里有两点需要注意:一是我们在CSS查询中添加了::text,这意味着我们只想直接在元素内选择文本元素。如果我们不指定::text,我们将获得完整的标题元素,包括它的标签:
>>> response.css('title').extract() ['Quotes to Scrape']
另一件事是调用 .extract() 的结果是一个列表,因为我们正在处理 SelectorList 的一个实例。当你知道你只想要第一个结果时,就像在这种情况下一样,你可以这样做:
>>> response.css('title::text').extract_first() 'Quotes to Scrape'
作为替代方案,您可以编写:
>>> response.css('title::text')[0].extract() 'Quotes to Scrape'
但是,当它找不到任何与选择匹配的元素时,使用 .extract_first() 来避免 IndexError 并返回 None。
这里有一个教训:对于大多数爬虫代码,你希望它在页面上什么都找不到的情况下能够适应错误,所以即使某些部分无法删除,你至少可以得到一些数据。
除了extract()和extract_first()方法之外,还可以使用re()方法用正则表达式进行提取:
>>> response.css('title::text').re(r'Quotes.*') ['Quotes to Scrape'] >>> response.css('title::text').re(r'Qw+') ['Quotes'] >>> response.css('title::text').re(r'(w+) to (w+)') ['Quotes', 'Scrape']
为了找到正确的 CSS 选择器,您可能会发现在 Web 浏览器中使用 shell 打开响应页面视图(响应)非常有用。您可以使用浏览器开发工具或扩展程序(例如 Firebug)(请参阅有关使用 Firebug 进行爬网和使用 Firefox 进行爬网的部分)。
Selector Gadget 也是一个很好的工具,可以快速找到可视化选择元素的 CSS 选择器,可以在很多浏览器中使用。
XPath:简介
除了 CSS,Scrapy 选择器还支持使用 XPath 表达式:
>>> response.xpath('//title') [] >>> response.xpath('//title/text()').extract_first() 'Quotes to Scrape'
XPath 表达式非常强大,是 Scrapy 选择器的基础。事实上,CSS 选择器在幕后转换为 XPath。如果仔细阅读 shell 中选择器对象的文本表示,您可以看到它。
尽管它可能不如 CSS 选择器流行,但 XPath 表达式提供了更多功能,因为除了导航结构之外,它还可以查看内容。使用 XPath,您可以选择以下内容: 选择收录文本“下一页”的链接。这使得 XPath 非常适合抓取任务,我们鼓励您学习 XPath,即使您已经知道如何构建 CSS 选择器,它也会使抓取更容易。
我们不会在此处介绍 XPath 的大部分内容,但您可以在此处阅读有关在 Scrapy 选择器中使用 XPath 的更多信息。想进一步了解XPath,我们推荐本教程通过实例学习XPath,本教程将学习“How to Think in XPath”。
提取引号和作者
现在您已经了解了一些关于选择和提取的知识,让我们通过编写代码从网页中提取引号来完成我们的蜘蛛。
中的每个引用都由一个 HTML 元素表示,如下所示:
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” by Albert Einstein (about) Tags: change deep-thoughts thinking world
让我们打开scrapy shell,玩一下,学习如何提取我们想要的数据:
$ scrapy shell 'http://quotes.toscrape.com'
我们得到一个引用 HTML 元素的选择器列表:
>>> response.css("div.quote")
上述查询返回的每个选择器都允许我们对其子元素运行进一步的查询。让我们将第一个选择器分配给一个变量,以便我们可以直接在特定引号上运行 CSS 选择器:
>>> quote = response.css("div.quote")[0]
现在,让我们使用刚刚创建的对象从引用中提取标题、作者和标签:
>>> title = quote.css("span.text::text").extract_first() >>> title '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”' >>> author = quote.css("small.author::text").extract_first() >>> author 'Albert Einstein'
鉴于标签是一个字符串列表,我们可以使用 .extract() 方法来获取所有这些:
>>> tags = quote.css("div.tags a.tag::text").extract() >>> tags ['change', 'deep-thoughts', 'thinking', 'world']
在弄清楚如何提取每一位之后,我们现在可以遍历所有引用的元素并将它们一起放入 Python 字典中:
>>> for quote in response.css("div.quote"): ... text = quote.css("span.text::text").extract_first() ... author = quote.css("small.author::text").extract_first() ... tags = quote.css("div.tags a.tag::text").extract() ... print(dict(text=text, author=author, tags=tags)) {'tags': ['change', 'deep-thoughts', 'thinking', 'world'], 'author': 'Albert Einstein', 'text': '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”'} {'tags': ['abilities', 'choices'], 'author': 'J.K. Rowling', 'text': '“It is our choices, Harry, that show what we truly are, far more than our abilities.”'} ... a few more of these, omitted for brevity >>>
在我们的蜘蛛中提取数据
让我们回到我们的蜘蛛。到目前为止,它还没有特别提取任何数据,它只是将整个 HTML 页面保存到本地文件中。让我们将上述提取逻辑集成到我们的蜘蛛中。
Scrapy Spider 通常会生成许多字典,其中收录从页面中提取的数据。为此,我们在回调中使用了Python关键字yield,如下图:
import scrapy class QuotesSpider(scrapy.Spider): name = "quotes" start_urls = [ 'http://quotes.toscrape.com/page/1/', 'http://quotes.toscrape.com/page/2/', ] def parse(self, response): for quote in response.css('div.quote'): yield { 'text': quote.css('span.text::text').extract_first(), 'author': quote.css('small.author::text').extract_first(), 'tags': quote.css('div.tags a.tag::text').extract(), }
如果你运行这个蜘蛛,它会输出提取的数据和日志:
2016-09-19 18:57:19 [scrapy.core.scraper] DEBUG: Scraped from {'tags': ['life', 'love'], 'author': 'André Gide', 'text': '“It is better to be hated for what you are than to be loved for what you are not.”'} 2016-09-19 18:57:19 [scrapy.core.scraper] DEBUG: Scraped from {'tags': ['edison', 'failure', 'inspirational', 'paraphrased'], 'author': 'Thomas A. Edison', 'text': "“I have not failed. I've just found 10,000 ways that won't work.”"}
存储已删除的数据
存储已删除数据的最简单方法是使用提要导出,使用以下命令:
scrapy crawl quotes -o quotes.json
这将生成一个收录所有已删除项目的quotes.json 文件,以JSON 序列化。
由于历史原因,Scrapy 将附加到给定文件而不是覆盖其内容。如果您在第二次之前运行此命令两次而没有删除该文件,您最终会得到一个损坏的 JSON 文件。
您还可以使用其他格式,例如 JSON Lines:
scrapy crawl quotes -o quotes.jl
JSON 行格式很有用,因为它经过简化,您可以轻松地向其追加新记录。当您运行它两次时,它没有相同的 JSON 问题。另外,由于每条记录都是单独的一行,所以你可以处理大文件而不用把所有东西都放在内存中,一些工具比如JQ可以帮助你在命令行中做到这一点。
在小型项目(例如本教程中的项目)中,这应该足够了。但是,如果要对已删除的项执行更复杂的操作,则可以编写项目管道。在您创建项目时,项目管道的占位符文件已经为您设置了 tutorial/pipelines.py。如果您只想存储已删除的项目,则无需实现任何项目管道。
以下链接
假设您不需要从前两页抓取内容,但是您需要 网站 的所有页面的引号。
现在您知道如何从页面中提取数据,让我们看看如何从中获取链接。
实时抓取网页数据(【干货】网页静态化的几种常见问题及解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-21 05:05
一、 静态页面
1、 动态和静态页面
静态页面
即静态网页是指加载了内容的HTML页面,直接加载到客户端浏览器上显示,不经过请求服务器数据和编译的过程。通俗的说就是生成一个独立的HTML页面,不需要与服务器进行数据交互。
优缺点说明:
动态页面
指一种网页编程技术,而不是静态网页。页面内容需要由服务器获取。在不考虑缓存的情况下,服务接口的数据发生变化,页面加载的内容也会实时发生变化,但显示的内容是数据库操作动态变化的结果。
优缺点说明:
动态页面和静态页面有很强的相关性,比较起来更容易理解。
2、应用场景
动态页面的静态处理有很多应用场景,例如:
静态技术基础:提示服务的响应速度,或者提前做好响应节点,比如一般流程、页面(客户端)请求服务、服务处理、响应数据、页面加载等一系列流程不仅复杂,而且耗时,如果基于静态技术处理后直接加载静态页面,则请求结束。
二、过程分析
静态页面转换是一个比较复杂的过程,核心过程如下:
主要流程大致如上。如果数据接口的响应参数发生变化,需要重新生成静态页面,因此数据加载的实时性会低很多。
三、代码实现案例
1、基本依赖
FreeMarker 是一个模板引擎:一个基于模板和要更改的数据的通用工具,用于生成输出文本(HTML 网页、电子邮件、配置文件、源代码等)。
org.springframework.boot
spring-boot-starter-freemarker
2、页面模板
这里都使用了 FreeMarker 开发的模板样式。
PageStatic
主题:${myTitle}
作者:${data.auth} 日期:${data.date}
规格描述
产品详情
${info.desc}
${info.imgUrl}
${imgIF}
FreeMarker 的语法与原来的 HTML 语法基本一致,但有自己的一套数据处理标签,使用起来并不复杂。
3、分析过程
通过分析,可以将页面模板和数据接口数据合并在一起。
@Service
public class PageServiceImpl implements PageService {
private static final Logger LOGGER = LoggerFactory.getLogger(PageServiceImpl.class) ;
private static final String PATH = "/templates/" ;
@Override
public void ftlToHtml() throws Exception {
// 创建配置类
Configuration configuration = new Configuration(Configuration.getVersion());
// 设置模板路径
String classpath = this.getClass().getResource("/").getPath();
configuration.setDirectoryForTemplateLoading(new File(classpath + PATH));
// 加载模板
Template template = configuration.getTemplate("my-page.ftl");
// 数据模型
Map map = new HashMap();
map.put("myTitle", "页面静态化(PageStatic)");
map.put("tableList",getList()) ;
map.put("imgList",getImgList()) ;
// 静态化页面内容
String content = FreeMarkerTemplateUtils.processTemplateIntoString(template, map);
LOGGER.info("content:{}",content);
InputStream inputStream = IOUtils.toInputStream(content,"UTF-8");
// 输出文件
FileOutputStream fileOutputStream = new FileOutputStream(new File("F:/page/newPage.html"));
IOUtils.copy(inputStream, fileOutputStream);
// 关闭流
inputStream.close();
fileOutputStream.close();
}
private List getList (){
List tableInfoList = new ArrayList() ;
tableInfoList.add(new TableInfo(Constant.desc1, Constant.img01));
tableInfoList.add(new TableInfo(Constant.desc2,Constant.img02));
return tableInfoList ;
}
private List getImgList (){
List imgList = new ArrayList() ;
imgList.add(Constant.img02) ;
imgList.add(Constant.img02) ;
return imgList ;
}
}
生成的HTML页面可以直接用浏览器打开,不再需要依赖任何数据接口服务。
四、源码地址
GitHub·地址
GitEE·地址
以上就是文章关于SpringBoot2集成FreeMarker实现页面静态化示例的介绍。更多SpringBoot2集成FreeMarker实现页面静态内容相关相关内容,请搜索之前的文章面圈教程或继续浏览下方相关文章,希望大家多多支持面条教程未来! 查看全部
实时抓取网页数据(【干货】网页静态化的几种常见问题及解决方法)
一、 静态页面
1、 动态和静态页面
静态页面
即静态网页是指加载了内容的HTML页面,直接加载到客户端浏览器上显示,不经过请求服务器数据和编译的过程。通俗的说就是生成一个独立的HTML页面,不需要与服务器进行数据交互。
优缺点说明:
动态页面
指一种网页编程技术,而不是静态网页。页面内容需要由服务器获取。在不考虑缓存的情况下,服务接口的数据发生变化,页面加载的内容也会实时发生变化,但显示的内容是数据库操作动态变化的结果。
优缺点说明:
动态页面和静态页面有很强的相关性,比较起来更容易理解。
2、应用场景
动态页面的静态处理有很多应用场景,例如:
静态技术基础:提示服务的响应速度,或者提前做好响应节点,比如一般流程、页面(客户端)请求服务、服务处理、响应数据、页面加载等一系列流程不仅复杂,而且耗时,如果基于静态技术处理后直接加载静态页面,则请求结束。
二、过程分析
静态页面转换是一个比较复杂的过程,核心过程如下:
主要流程大致如上。如果数据接口的响应参数发生变化,需要重新生成静态页面,因此数据加载的实时性会低很多。
三、代码实现案例
1、基本依赖
FreeMarker 是一个模板引擎:一个基于模板和要更改的数据的通用工具,用于生成输出文本(HTML 网页、电子邮件、配置文件、源代码等)。
org.springframework.boot
spring-boot-starter-freemarker
2、页面模板
这里都使用了 FreeMarker 开发的模板样式。
PageStatic
主题:${myTitle}
作者:${data.auth} 日期:${data.date}
规格描述
产品详情
${info.desc}
${info.imgUrl}
${imgIF}
FreeMarker 的语法与原来的 HTML 语法基本一致,但有自己的一套数据处理标签,使用起来并不复杂。
3、分析过程
通过分析,可以将页面模板和数据接口数据合并在一起。
@Service
public class PageServiceImpl implements PageService {
private static final Logger LOGGER = LoggerFactory.getLogger(PageServiceImpl.class) ;
private static final String PATH = "/templates/" ;
@Override
public void ftlToHtml() throws Exception {
// 创建配置类
Configuration configuration = new Configuration(Configuration.getVersion());
// 设置模板路径
String classpath = this.getClass().getResource("/").getPath();
configuration.setDirectoryForTemplateLoading(new File(classpath + PATH));
// 加载模板
Template template = configuration.getTemplate("my-page.ftl");
// 数据模型
Map map = new HashMap();
map.put("myTitle", "页面静态化(PageStatic)");
map.put("tableList",getList()) ;
map.put("imgList",getImgList()) ;
// 静态化页面内容
String content = FreeMarkerTemplateUtils.processTemplateIntoString(template, map);
LOGGER.info("content:{}",content);
InputStream inputStream = IOUtils.toInputStream(content,"UTF-8");
// 输出文件
FileOutputStream fileOutputStream = new FileOutputStream(new File("F:/page/newPage.html"));
IOUtils.copy(inputStream, fileOutputStream);
// 关闭流
inputStream.close();
fileOutputStream.close();
}
private List getList (){
List tableInfoList = new ArrayList() ;
tableInfoList.add(new TableInfo(Constant.desc1, Constant.img01));
tableInfoList.add(new TableInfo(Constant.desc2,Constant.img02));
return tableInfoList ;
}
private List getImgList (){
List imgList = new ArrayList() ;
imgList.add(Constant.img02) ;
imgList.add(Constant.img02) ;
return imgList ;
}
}
生成的HTML页面可以直接用浏览器打开,不再需要依赖任何数据接口服务。
四、源码地址
GitHub·地址
GitEE·地址
以上就是文章关于SpringBoot2集成FreeMarker实现页面静态化示例的介绍。更多SpringBoot2集成FreeMarker实现页面静态内容相关相关内容,请搜索之前的文章面圈教程或继续浏览下方相关文章,希望大家多多支持面条教程未来!
实时抓取网页数据(简单实现爬取网页数据的功能,发现猫眼实时票房展示的数据样本 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-21 05:04
)
学完python,准备练习爬虫项目。简单实现爬取网页数据的功能,发现猫眼实时票房显示的数据样本正好符合预期,然后记录遇到的困难和解决方法。
目标网址:
目标数据:绿色框是要获取的数据类型,红色框是具体需要获取的数据
通过F12查看网页源码,发现label里面的数据就是需要获取的数据
先通过scrapy shell命令:scrapy shell""
检查是否可以获取数据(我这里遇到了困难,导致无法获取动态加载的目标数据)
执行成功后进入交互模式,可以获取网页的内容,
输入命令:response.xpath("//div/div/div[2]/div[2]/table").extract()
可获取的数据类型
通过命令: response.xpath("//div/div/div[2]/div[2]/div/div/table").extract()
无法获取数据的具体数值信息:返回的数据为空
继续查看网页源代码。数据是实时加载的。发现数据存放在xhr类型的second-box文件中。你可以在这里获取数据
注意:XHR是什么,请参考这个文章:)
选择-右键-可以选择复制链接地址:
单独打开此页面地址,即可获取实时票房数据。
像红框这样的数据就是需要的。你只需要通过这个地址获取数据
这时候通过命令进入交互模式:scrapy shell ""
通过命令:response.body。查看具体数据信息(不显示中文,但不妨碍数据的获取)
查看全部
实时抓取网页数据(简单实现爬取网页数据的功能,发现猫眼实时票房展示的数据样本
)
学完python,准备练习爬虫项目。简单实现爬取网页数据的功能,发现猫眼实时票房显示的数据样本正好符合预期,然后记录遇到的困难和解决方法。
目标网址:
目标数据:绿色框是要获取的数据类型,红色框是具体需要获取的数据
通过F12查看网页源码,发现label里面的数据就是需要获取的数据
先通过scrapy shell命令:scrapy shell""
检查是否可以获取数据(我这里遇到了困难,导致无法获取动态加载的目标数据)
执行成功后进入交互模式,可以获取网页的内容,
输入命令:response.xpath("//div/div/div[2]/div[2]/table").extract()
可获取的数据类型
通过命令: response.xpath("//div/div/div[2]/div[2]/div/div/table").extract()
无法获取数据的具体数值信息:返回的数据为空
继续查看网页源代码。数据是实时加载的。发现数据存放在xhr类型的second-box文件中。你可以在这里获取数据
注意:XHR是什么,请参考这个文章:)
选择-右键-可以选择复制链接地址:
单独打开此页面地址,即可获取实时票房数据。
像红框这样的数据就是需要的。你只需要通过这个地址获取数据
这时候通过命令进入交互模式:scrapy shell ""
通过命令:response.body。查看具体数据信息(不显示中文,但不妨碍数据的获取)
实时抓取网页数据(如何从defi(去中心化金融)协议中提取相关defi数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-21 05:04
目前,我们获取区块链数据变得越来越容易和快捷。在这个文章中,我们将解释如何从defi(去中心化金融)协议中提取相关的defi数据,并使用谷歌电子表格创建数据集。通过它,我们将创建一个仪表板来实时显示这些数据,为我们提供有关 Aave 协议中要求的贷款的信息。
检索数据
为了获取数据,我们将使用 The graph 的 Api,如本文所述。
我们要提取的是与贷款申请相关的所有历史数据,以供以后分析。为此,我们必须创建以下查询:
{ borrows (first: 1000) { id, amount, reserve { id, symbol }, borrowRate, borrowRateMode, timestamp }}
通过这个查询,我们得到了前 1000 个结果,这是数据块中 The Graphs 允许的最大值,然后我们将不断迭代得到以下结果,直到我们恢复所有结果。
如果我们在这个操作上测试这个查询,我们可以看到它返回:
之后我们将获得所有贷款数据,以及请求的加密资产、它们的数量、利率和利率。
通过将这些数据直接导入 Google Sheets 中的文档,我们将拥有一个实时数据集来构建我们的分析模型。
创建数据集
为了将数据保存在 Google excel 表中,我们将在其中创建一个带有以下选项的脚本:
在此脚本中,我们收录以下代码:
我们来看看每一行的详细信息:
第 4-22 行:将被调用以填充数据集的函数。在该函数中,定义了要调用的端点和用于获取数据和查询的查询。有了这些,我调用函数提取出来,然后用excel写出来。
第 30-37 行:构造在调用 API 时将传递选项的函数,为每次迭代调用一个动态参数“skip”,并使用这个新参数创建选项。
第 44-49 行:在 Excel 表格中写入数据的函数。以数组的形式接收数据作为参数,写入执行脚本的excel。
第 57-86 行:迭代历史中存在的所有数据块的函数。创建一个循环向api请求数据,如果有数据,将skip参数增加1000个单位。接收到数据后,将其存储为数组,并从 api 返回的 json 中检索该数组。
创建脚本后,执行脚本加载数据。我们通过以下方式执行它:
我们可以看到excel是如何填充数据的
分析数据
使用填充的数据集,我们可以分析我们的数据。最快、最简单的方法是使用 Google Data Studio 仪表板。
我们创建一个新报告并指定数据源将是电子表格。
通过选择我们创建的工作表,我们可以使用 Google Data Studio 中存在的模板,然后创建一个仪表板,以一种简单且非常有吸引力的方式向我们展示数据。
通过这个简单的脚本,我们可以实时从协议 DeFi 中获取数据,并分析整个贷款历史中的数据。这是一条非常重要的信息,可以以完全可访问的方式创建模型。 查看全部
实时抓取网页数据(如何从defi(去中心化金融)协议中提取相关defi数据)
目前,我们获取区块链数据变得越来越容易和快捷。在这个文章中,我们将解释如何从defi(去中心化金融)协议中提取相关的defi数据,并使用谷歌电子表格创建数据集。通过它,我们将创建一个仪表板来实时显示这些数据,为我们提供有关 Aave 协议中要求的贷款的信息。
检索数据
为了获取数据,我们将使用 The graph 的 Api,如本文所述。
我们要提取的是与贷款申请相关的所有历史数据,以供以后分析。为此,我们必须创建以下查询:
{ borrows (first: 1000) { id, amount, reserve { id, symbol }, borrowRate, borrowRateMode, timestamp }}
通过这个查询,我们得到了前 1000 个结果,这是数据块中 The Graphs 允许的最大值,然后我们将不断迭代得到以下结果,直到我们恢复所有结果。
如果我们在这个操作上测试这个查询,我们可以看到它返回:
之后我们将获得所有贷款数据,以及请求的加密资产、它们的数量、利率和利率。
通过将这些数据直接导入 Google Sheets 中的文档,我们将拥有一个实时数据集来构建我们的分析模型。
创建数据集
为了将数据保存在 Google excel 表中,我们将在其中创建一个带有以下选项的脚本:
在此脚本中,我们收录以下代码:
我们来看看每一行的详细信息:
第 4-22 行:将被调用以填充数据集的函数。在该函数中,定义了要调用的端点和用于获取数据和查询的查询。有了这些,我调用函数提取出来,然后用excel写出来。
第 30-37 行:构造在调用 API 时将传递选项的函数,为每次迭代调用一个动态参数“skip”,并使用这个新参数创建选项。
第 44-49 行:在 Excel 表格中写入数据的函数。以数组的形式接收数据作为参数,写入执行脚本的excel。
第 57-86 行:迭代历史中存在的所有数据块的函数。创建一个循环向api请求数据,如果有数据,将skip参数增加1000个单位。接收到数据后,将其存储为数组,并从 api 返回的 json 中检索该数组。
创建脚本后,执行脚本加载数据。我们通过以下方式执行它:
我们可以看到excel是如何填充数据的
分析数据
使用填充的数据集,我们可以分析我们的数据。最快、最简单的方法是使用 Google Data Studio 仪表板。
我们创建一个新报告并指定数据源将是电子表格。
通过选择我们创建的工作表,我们可以使用 Google Data Studio 中存在的模板,然后创建一个仪表板,以一种简单且非常有吸引力的方式向我们展示数据。
通过这个简单的脚本,我们可以实时从协议 DeFi 中获取数据,并分析整个贷款历史中的数据。这是一条非常重要的信息,可以以完全可访问的方式创建模型。
实时抓取网页数据(如何让百度快速收录呢,如何选择链接提交方式? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-21 03:04
)
做百度推广时,如何让百度快速收录?这里有三种方法。今天我们主要讲第一个。
如何选择链接提交方式
1、主动推送:最快的提交方式。建议您立即通过此方式将本站产生的新链接推送给百度,以确保百度能及时收到新链接收录。
2、自动推送:最方便的提交方式,请将自动推送的JS代码部署在站点各个页面的源代码中。每次浏览部署代码的页面都会自动推送链接到百度。. 可与主动推送结合使用。
3、站点地图:您可以定期在站点地图中放置网站链接,然后将站点地图提交给百度。百度会定期抓取检查您提交的站点地图,并处理其中的链接,但收录的速度比主动推送要慢。4、 手动提交:一次性提交链接到百度,可以使用这种方式。
百度站长平台为站长提供了链接提交通道。你可以提交你想成为百度收录的链接。百度搜索引擎会按照标准进行处理,但不保证您提交的链接是收录。
需要注意的是:
1.主动推送功能入口为:工具-网页抓取-链接提交-主动推送(实时)
2.主动推送与原实时推送使用不同的数据接口,需要重新获取key(登录后链接提交工具界面可见)
登录地址是
为保证您提交数据的效果,请及时更换界面和密钥,尽快熟悉主动推送功能。如果有问题,您可以通过反馈中心向百度工作人员寻求帮助。
使用百度主动推送(实时)可以加速收录,保护原创的内容不被第三方采集伤害。
暂时没看到有人写百度的主动推送代码,所以根据百度提供的PHP代码编写,并添加到DEDE后端发布文章文件中,实现了主动推送(真实) -time) 功能与百度百度。
在article_add.php中搜索 $artUrl = MakeArt($arcID,true,true,$isremote);
然后在
if($artUrl=='')
{
$artUrl = $cfg_phpurl."/view.php?aid=$arcID";
}
后面加入
else{
$urls[]='http://'.$_SERVER['HTTP_HOST'].$artUrl;
$api = 'http://data.zz.baidu.com/urls?site=你的域名&token=准入密钥';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
}
只需保存
文章发布成功后,会显示如下
查看全部
实时抓取网页数据(如何让百度快速收录呢,如何选择链接提交方式?
)
做百度推广时,如何让百度快速收录?这里有三种方法。今天我们主要讲第一个。
如何选择链接提交方式
1、主动推送:最快的提交方式。建议您立即通过此方式将本站产生的新链接推送给百度,以确保百度能及时收到新链接收录。
2、自动推送:最方便的提交方式,请将自动推送的JS代码部署在站点各个页面的源代码中。每次浏览部署代码的页面都会自动推送链接到百度。. 可与主动推送结合使用。
3、站点地图:您可以定期在站点地图中放置网站链接,然后将站点地图提交给百度。百度会定期抓取检查您提交的站点地图,并处理其中的链接,但收录的速度比主动推送要慢。4、 手动提交:一次性提交链接到百度,可以使用这种方式。
百度站长平台为站长提供了链接提交通道。你可以提交你想成为百度收录的链接。百度搜索引擎会按照标准进行处理,但不保证您提交的链接是收录。
需要注意的是:
1.主动推送功能入口为:工具-网页抓取-链接提交-主动推送(实时)
2.主动推送与原实时推送使用不同的数据接口,需要重新获取key(登录后链接提交工具界面可见)
登录地址是
为保证您提交数据的效果,请及时更换界面和密钥,尽快熟悉主动推送功能。如果有问题,您可以通过反馈中心向百度工作人员寻求帮助。
使用百度主动推送(实时)可以加速收录,保护原创的内容不被第三方采集伤害。
暂时没看到有人写百度的主动推送代码,所以根据百度提供的PHP代码编写,并添加到DEDE后端发布文章文件中,实现了主动推送(真实) -time) 功能与百度百度。
在article_add.php中搜索 $artUrl = MakeArt($arcID,true,true,$isremote);
然后在
if($artUrl=='')
{
$artUrl = $cfg_phpurl."/view.php?aid=$arcID";
}
后面加入
else{
$urls[]='http://'.$_SERVER['HTTP_HOST'].$artUrl;
$api = 'http://data.zz.baidu.com/urls?site=你的域名&token=准入密钥';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
}
只需保存
文章发布成功后,会显示如下
实时抓取网页数据(怎么把网页数据导入到Excel表格中6.excel表格序号如何)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-12-20 20:05
我们经常使用网页数据,但是每次打开网页查询都非常麻烦,而且我们需要的数据都是实时更新的,那么如何才能达到这个目的呢?Excel可以帮你完美解决。今天教大家如何在Excel中查询网页数据并实时更新。
Excel中查询网页数据并实时更新的操作步骤:
首先打开excel,点击数据,在获取外部数据选项卡下,点击来自网站,会弹出一个新的web查询对话框,如下图:
将网页地址复制到地址栏,点击前往打开网页。
在打开的网页中,找到要导入的数据,点击带黄框的箭头选择区域,然后点击右下角的导入。
在弹出的导入数据对话框中,点击指定导入位置将数据导入excel。
使用方法:数据导入excel后,如果要更改数据区域,可以右键编辑查询,重新指定区域。
数据导入excel后,在数据区右击,点击刷新,刷新数据。通过右键单击数据区域属性,可以打开外部数据区域属性对话框,设置刷新频率,以及打开文件时是否允许后台刷新或刷新。
另一种简单的方法是直接复制你需要的网页数据并粘贴到excel中。粘贴完成后,右下角有粘贴选项。有一个可刷新的网络查询。单击它以输入新的网络查询。界面,重复之前的操作即可。
Excel文章中查询网页数据并实时更新相关操作:
1.如何在Excel中查询网页数据并实时更新
2.如何使用excel2013web查询采集网页数据功能
3.Excel中如何批量更新数据
4.Excel表格中快速查询数据的操作方法
5.如何将网页数据导入Excel表格
6.如何自动更新excel表格的序号
7.如何使用Excel中的自动数据过滤功能 查看全部
实时抓取网页数据(怎么把网页数据导入到Excel表格中6.excel表格序号如何)
我们经常使用网页数据,但是每次打开网页查询都非常麻烦,而且我们需要的数据都是实时更新的,那么如何才能达到这个目的呢?Excel可以帮你完美解决。今天教大家如何在Excel中查询网页数据并实时更新。
Excel中查询网页数据并实时更新的操作步骤:
首先打开excel,点击数据,在获取外部数据选项卡下,点击来自网站,会弹出一个新的web查询对话框,如下图:
将网页地址复制到地址栏,点击前往打开网页。
在打开的网页中,找到要导入的数据,点击带黄框的箭头选择区域,然后点击右下角的导入。
在弹出的导入数据对话框中,点击指定导入位置将数据导入excel。
使用方法:数据导入excel后,如果要更改数据区域,可以右键编辑查询,重新指定区域。
数据导入excel后,在数据区右击,点击刷新,刷新数据。通过右键单击数据区域属性,可以打开外部数据区域属性对话框,设置刷新频率,以及打开文件时是否允许后台刷新或刷新。
另一种简单的方法是直接复制你需要的网页数据并粘贴到excel中。粘贴完成后,右下角有粘贴选项。有一个可刷新的网络查询。单击它以输入新的网络查询。界面,重复之前的操作即可。
Excel文章中查询网页数据并实时更新相关操作:
1.如何在Excel中查询网页数据并实时更新
2.如何使用excel2013web查询采集网页数据功能
3.Excel中如何批量更新数据
4.Excel表格中快速查询数据的操作方法
5.如何将网页数据导入Excel表格
6.如何自动更新excel表格的序号
7.如何使用Excel中的自动数据过滤功能
实时抓取网页数据( 大数据舆情系统对数据存储和计算系统会有哪些需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-19 03:00
大数据舆情系统对数据存储和计算系统会有哪些需求)
互联网的飞速发展促进了许多新媒体的发展。无论是知名大V、名人还是围观者,都可以用手机在微博、朋友圈或评论网站上发布动态,分享所见所想,让“人人有话筒”。 ” 无论是热点新闻还是娱乐八卦,传播速度都远超我们的想象。一条信息可以在短短几分钟内被数万人转发,数百万人阅读。海量信息是可以爆炸的,那么如何实时掌握信息并进行相应的处理呢?真的很难对付吗?今天,
大数据时代,除了媒体信息外,各个电商平台的产品订单和用户购买评论都会对后续消费者产生很大的影响。商家的产品设计师需要对各个平台的数据进行统计和分析,作为确定后续产品开发的依据。公司公关和营销部门也需要根据舆情做出相应的及时处理,而这一切也意味着将传统的舆情系统升级为大数据舆情采集和分析系统。细看大数据舆情系统,对我们的数据存储和计算系统提出以下要求:
本文主要提供架构设计。首先介绍当前主流的大数据计算架构,分析一些优缺点,然后介绍舆情大数据架构。
系统设计
需求分析
结合文章开头对舆情系统的描述,海量大数据舆情分析系统流程图大致如下:
图1 舆情系统业务流程
根据前面的介绍,舆情大数据分析系统需要两种计算。一是实时计算,包括实时提取海量网页内容、情感词分析、网页舆情结果存储等。另一种是离线计算。系统需要回溯历史数据,结合人工标注等方法优化情感词汇,对一些实时计算的结果进行修正。因此,在系统设计中,需要选择一个既可以进行实时计算又可以进行批量离线计算的系统。在开源大数据解决方案中,Lambda 架构可以满足这些需求。下面介绍一下 Lambda 架构。
Lambda 架构(维基)
图2 Lambda架构图
Lambda架构可以说是Hadoop、Spark系统下最火的大数据架构。这种架构的最大优点是支持海量数据批量计算处理(即离线处理),也支持流式实时处理(即热数据处理)。
它是如何实施的?首先,上游一般是kafka等队列服务,实时存储数据。Kafka队列会有两个订阅者,一个是全量数据,也就是图片的上半部分,全量数据会存储在HDFS这样的存储介质上。当离线计算任务到来时,计算资源(如Hadoop)会访问存储系统上的全量数据,执行全批量计算的处理逻辑。
map/reduce链接后,完整的结果会写入到Hbase等结构化存储引擎中,提供给业务方查询。队列的另一个消费者订阅者是流计算引擎。流计算引擎往往实时消费队列中的数据进行计算处理。比如Spark Streaming实时订阅Kafka数据,流计算的结果也写入结构化数据引擎。写入批量计算和流计算结果的结构化存储引擎就是上面注3所示的“Serving Layer”。该层主要提供结果数据的展示和查询。
在这套架构中,批量计算的特点是需要支持海量数据的处理,并根据业务的需要,关联一些其他的业务指标进行计算。批量计算的优点是计算逻辑可以根据业务需求灵活调整,计算结果可以重复计算,同一个计算逻辑不会多次变化。批量计算的缺点是计算周期比较长,难以满足实时结果的需求。因此,随着大数据计算的演进,提出了实时计算的需求。
实时计算是通过 Lambda 架构中的实时数据流来实现的。与批处理相比,增量数据流的处理方式决定了数据往往是新生成的数据,即热点数据。由于热数据的特性,流计算可以满足业务对计算的低时延需求。例如,在一个舆情分析系统中,我们往往希望可以从网页中检索舆情信息,并在分钟级得到计算结果,以便业务方有足够的时间进行舆情反馈。下面我们来具体看看如何基于Lambda架构的思想,实现一套完整的舆情大数据架构。
开源舆情大数据解决方案
通过这个流程图,我们了解到整个舆情系统的构建需要不同的存储和计算系统。对数据的组织和查询有不同的要求。基于业界开源的大数据系统,结合Lambda架构,整个系统可以设计如下:
图3 开源舆情架构图
1. 系统最上游是分布式爬虫引擎,根据爬取任务对订阅网页的原创内容进行爬取。爬虫会实时将爬取到的网页内容写入Kafka队列。进入Kafka队列的数据会根据上述计算需求实时流入流计算引擎(如Spark或Flink),也会持久化存储在Hbase中进行全量处理。数据存储。全量网页的存储,可以满足网页爬取和去重,批量离线计算的需要。
2. 流计算会提取原创网页的结构,将非结构化的网页内容转化为结构化数据并进行分词,如提取页面的标题、作者、摘要等,对文本进行分词和抽象的内容。提取和分词结果会写回Hbase。经过结构化提取和分词后,流计算引擎会结合情感词汇分析网页情感,判断是否有舆情。
3. 流计算引擎分析的舆情结果存储在Mysql或Hbase数据库中。为了方便搜索和查看结果集,需要将数据同步到Elasticsearch等搜索引擎,方便属性字段的组合查询。如果是重大舆情时间,需要写入Kafka队列触发舆情警报。
4. 全量结构化数据会定期通过Spark系统离线计算更新情感词汇或接受新的计算策略重新计算历史数据以修正实时计算的结果。
开源架构分析
上面的舆情大数据架构,通过Kafka对接流计算,Hbase对接批量计算实现了Lambda架构中的“批量查看”和“实时查看”,整个架构比较清晰,可以很好的满足线上和离线 两种类型的计算需求。但是,将该系统应用到生产中并不是一件容易的事,主要有以下几个原因:
整个架构涉及到很多存储和计算系统,包括:Kafka、Hbase、Spark、Flink、Elasticsearch。数据将在不同的存储和计算系统中流动。在整个架构中运行和维护每个开源产品是一个很大的挑战。任何一款产品或产品之间的通道出现故障都会影响整体舆情分析结果的及时性。
为了实现批量计算和流计算,原创网页需要分别存储在Kafka和Hbase中。离线计算消费HBase中的数据,流计算消费Kafka中的数据。这会带来存储资源的冗余,也会导致需要维护两套计算逻辑,会增加计算代码的开发和维护成本。
舆情的计算结果存储在Mysql或Hbase中。为了丰富组合查询语句,需要将数据同步并内置到Elasticsearch中。查询时,可能需要结合Mysql和Elasticsearch的查询结果。这里没有跳过数据库,结果数据直接写入Elasticsearch等搜索系统中,因为搜索系统的实时数据写入能力和数据可靠性不如数据库。行业通常将数据库和搜索系统集成在一起,集成系统兼具数据库和搜索系统的优点,但是两个引擎之间的数据同步和跨系统查询给运维和维护带来了很多额外的成本。发展。
全新大数据架构 Lambda plus
通过前面的分析,相信大家都会有一个疑问。有没有一种简化的大数据架构可以满足Lambda对计算需求的假设,同时减少存储计算和模块的数量?
Linkedin 的 Jay Kreps 提出了 Kappa 架构。Lambda和Kappa的对比可以参考文末文档。详细的比较这里就不展开了。简单来说,为了简化两个存储,Kappa取消了全量数据存储。通过将它们保存在 Kafka 中,对于较长的日志,当需要回溯重新计算时,再次从队列头部订阅数据,所有存储在 Kafka 队列中的数据再次在流中处理。这种设计的好处是解决了维护两套存储和两套计算逻辑的痛点。缺点是队列能保留的历史数据毕竟有限,没有时间限制很难回溯。
分析到此,我们沿用Kappa对Lambda的改进思路,更远的思考:如果有存储引擎,不仅可以满足数据库的高效写入和随机查询,还可以像队列服务一样,满足第一—— in first-out, yes 不是可以结合Lambda和Kappa架构来创建Lambda plus架构吗?
新架构可以在Lambda的基础上改进以下几点:
在支持流计算和批量计算的同时,可以复用计算逻辑,实现“一套代码,两类需求”。
统一存储全量历史数据和在线实时增量数据,实现“一存两算”。
为了方便舆情结果的查询需求,“批量查看”和“实时查看”的存储不仅可以支持高吞吐量实时写作,还可以支持多字段组合搜索和全文检索恢复。
综上所述,整个新架构的核心是解决存储问题,以及如何灵活连接计算。我们希望整个程序类似于以下架构:
图 4 Lambda Plus 架构
数据流实时写入分布式数据库。借助数据库查询能力,可以轻松将全量数据接入批量计算系统进行离线处理。
数据库支持通过数据库日志接口增量读取,并结合流计算引擎实现实时计算。
批计算和流计算的结果回写到分布式数据库中。分布式数据库提供丰富的查询语义,实现计算结果的交互查询。
在整个架构中,存储层通过结合数据库主表数据和数据库日志来替代大数据架构中的队列服务。计算系统选择自然支持batch和stream的计算引擎,如Flink或Spark。这样,我们不仅可以像 Lambda 那样进行历史数据回溯,还可以像 Kappa 架构那样进行一套逻辑来存储和处理两类计算任务。我们将这样一套架构命名为“Lambda plus”,下面详细介绍如何在阿里云上搭建这样一套大数据架构。
云舆情系统架构
在阿里云众多的存储和计算产品中,为了满足上述大数据架构的需求,我们选择了两款产品来实现整个舆情大数据系统。存储层使用阿里云自研的分布式多模型数据库Tablestore,计算层使用Blink实现流一体和批量计算。
图5 云舆情大数据架构
在存储层面,这个架构都是基于Tablestore的。一个数据库解决不同的存储需求。根据之前舆情系统的介绍,网络爬虫数据的系统流程会有四个阶段:原创网页内容、网页结构化数据、分析规则。元数据和舆情结果,舆情结果索引。
我们利用Tablestore的宽行和无模式特性将原创网页和网页结构化数据合并为一个网页数据。网页数据表和计算系统通过Tablestore新的功能通道服务连接起来。通道服务基于数据库日志,按照数据写入的顺序存储数据的组织结构。正是这个特性,让数据库具备了排队和流式消费的能力。这使得存储引擎既可以随机访问数据库,也可以按写入顺序访问队列,也满足了上面提到的集成Lambda和kappa架构的需求。分析规则元数据表由分析规则和情感词汇组层组成,
计算系统采用阿里云实时流计算产品Blink。Blink 是一款支持流计算和批量计算的实时计算产品。并且类似于Tablestore,它可以轻松实现分布式横向扩展,让计算资源随着业务数据的增长而灵活扩展。使用Tablestore+Blink的优势如下:
Tablestore与Blink深度集成,支持源表、维度表、目的表。无需为业务中的数据流开发代码。
整个架构大大减少了组件数量,从开源产品的6~7个组件减少到2个。Tablestore和Blink都是零运维的全托管产品,可以实现非常好的横向灵活性,没有业务扩张高峰。压力大大降低了大数据架构的运维成本。
业务侧只需要关注数据处理逻辑,Blink中已经集成了与Tablestore的交互逻辑。
在开源方案中,如果数据库源想要连接实时计算,还需要写一个队列,让流计算引擎消费队列中的数据。在我们的架构中,数据库既是数据表,也是实时增量数据消费的队列通道。大大简化了架构的开发和使用成本。
流式批处理集成,实时性在舆情系统中很重要,所以我们需要一个实时计算引擎,而Blink除了实时计算,还支持Tablestore数据的批处理,在低峰期业务的,往往也需要批量处理一些数据作为反馈结果写回Tablestore,比如情感分析反馈。所以一套架构可以同时支持流处理和批处理更好。一套架构的优势在于一套分析代码既可以用于实时流式计算,也可以用于离线批处理。
整个计算过程会产生实时的舆情计算结果。通过Tablestore与函数计算触发器的对接,实现重大舆情事件预警。Tablestore和函数计算做了增量数据的无缝对接。通过在结果表中写入事件,您可以通过函数计算轻松触发短信或电子邮件通知。完整的舆情分析结果和展示搜索使用Tablestore的新功能多索引,彻底解决了开源Hbase+Solr多引擎的痛点:
运维复杂,需要有hbase和solr两个系统的运维能力,还需要维护数据同步的链接。
Solr 数据一致性不如Hbase。Hbase 和 Solr 中数据的语义并不完全相同。另外,Solr/Elasticsearch 很难做到像数据库一样严格的数据一致性。在一些极端情况下,可能会出现数据不一致的情况,开源解决方案很难实现跨系统的一致性比较。
查询接口需要维护两套API。Hbase客户端和Solr客户端都需要用到。不在索引中的字段需要主动对照Hbase进行检查,不太好用。
参考
Lambda 大数据架构:
Kappa大数据架构:
Lambda 和 Kappa 架构比较:
【编辑推荐】
你只知道熊猫吗?数据科学家不容错过的 24 个 Python 库(第 1 部分)。在 Fedora 上构建 Jupyter 和数据科学环境。基于Python语言的大数据搜索引擎。使用 Python 加速数据分析的 10 个简单技巧。分布式文件服务器。你还在手工搭建分布式文件服务器吗?一步一步来试试Docker镜像 查看全部
实时抓取网页数据(
大数据舆情系统对数据存储和计算系统会有哪些需求)
互联网的飞速发展促进了许多新媒体的发展。无论是知名大V、名人还是围观者,都可以用手机在微博、朋友圈或评论网站上发布动态,分享所见所想,让“人人有话筒”。 ” 无论是热点新闻还是娱乐八卦,传播速度都远超我们的想象。一条信息可以在短短几分钟内被数万人转发,数百万人阅读。海量信息是可以爆炸的,那么如何实时掌握信息并进行相应的处理呢?真的很难对付吗?今天,
大数据时代,除了媒体信息外,各个电商平台的产品订单和用户购买评论都会对后续消费者产生很大的影响。商家的产品设计师需要对各个平台的数据进行统计和分析,作为确定后续产品开发的依据。公司公关和营销部门也需要根据舆情做出相应的及时处理,而这一切也意味着将传统的舆情系统升级为大数据舆情采集和分析系统。细看大数据舆情系统,对我们的数据存储和计算系统提出以下要求:
本文主要提供架构设计。首先介绍当前主流的大数据计算架构,分析一些优缺点,然后介绍舆情大数据架构。
系统设计
需求分析
结合文章开头对舆情系统的描述,海量大数据舆情分析系统流程图大致如下:
图1 舆情系统业务流程
根据前面的介绍,舆情大数据分析系统需要两种计算。一是实时计算,包括实时提取海量网页内容、情感词分析、网页舆情结果存储等。另一种是离线计算。系统需要回溯历史数据,结合人工标注等方法优化情感词汇,对一些实时计算的结果进行修正。因此,在系统设计中,需要选择一个既可以进行实时计算又可以进行批量离线计算的系统。在开源大数据解决方案中,Lambda 架构可以满足这些需求。下面介绍一下 Lambda 架构。
Lambda 架构(维基)
图2 Lambda架构图
Lambda架构可以说是Hadoop、Spark系统下最火的大数据架构。这种架构的最大优点是支持海量数据批量计算处理(即离线处理),也支持流式实时处理(即热数据处理)。
它是如何实施的?首先,上游一般是kafka等队列服务,实时存储数据。Kafka队列会有两个订阅者,一个是全量数据,也就是图片的上半部分,全量数据会存储在HDFS这样的存储介质上。当离线计算任务到来时,计算资源(如Hadoop)会访问存储系统上的全量数据,执行全批量计算的处理逻辑。
map/reduce链接后,完整的结果会写入到Hbase等结构化存储引擎中,提供给业务方查询。队列的另一个消费者订阅者是流计算引擎。流计算引擎往往实时消费队列中的数据进行计算处理。比如Spark Streaming实时订阅Kafka数据,流计算的结果也写入结构化数据引擎。写入批量计算和流计算结果的结构化存储引擎就是上面注3所示的“Serving Layer”。该层主要提供结果数据的展示和查询。
在这套架构中,批量计算的特点是需要支持海量数据的处理,并根据业务的需要,关联一些其他的业务指标进行计算。批量计算的优点是计算逻辑可以根据业务需求灵活调整,计算结果可以重复计算,同一个计算逻辑不会多次变化。批量计算的缺点是计算周期比较长,难以满足实时结果的需求。因此,随着大数据计算的演进,提出了实时计算的需求。
实时计算是通过 Lambda 架构中的实时数据流来实现的。与批处理相比,增量数据流的处理方式决定了数据往往是新生成的数据,即热点数据。由于热数据的特性,流计算可以满足业务对计算的低时延需求。例如,在一个舆情分析系统中,我们往往希望可以从网页中检索舆情信息,并在分钟级得到计算结果,以便业务方有足够的时间进行舆情反馈。下面我们来具体看看如何基于Lambda架构的思想,实现一套完整的舆情大数据架构。
开源舆情大数据解决方案
通过这个流程图,我们了解到整个舆情系统的构建需要不同的存储和计算系统。对数据的组织和查询有不同的要求。基于业界开源的大数据系统,结合Lambda架构,整个系统可以设计如下:
图3 开源舆情架构图
1. 系统最上游是分布式爬虫引擎,根据爬取任务对订阅网页的原创内容进行爬取。爬虫会实时将爬取到的网页内容写入Kafka队列。进入Kafka队列的数据会根据上述计算需求实时流入流计算引擎(如Spark或Flink),也会持久化存储在Hbase中进行全量处理。数据存储。全量网页的存储,可以满足网页爬取和去重,批量离线计算的需要。
2. 流计算会提取原创网页的结构,将非结构化的网页内容转化为结构化数据并进行分词,如提取页面的标题、作者、摘要等,对文本进行分词和抽象的内容。提取和分词结果会写回Hbase。经过结构化提取和分词后,流计算引擎会结合情感词汇分析网页情感,判断是否有舆情。
3. 流计算引擎分析的舆情结果存储在Mysql或Hbase数据库中。为了方便搜索和查看结果集,需要将数据同步到Elasticsearch等搜索引擎,方便属性字段的组合查询。如果是重大舆情时间,需要写入Kafka队列触发舆情警报。
4. 全量结构化数据会定期通过Spark系统离线计算更新情感词汇或接受新的计算策略重新计算历史数据以修正实时计算的结果。
开源架构分析
上面的舆情大数据架构,通过Kafka对接流计算,Hbase对接批量计算实现了Lambda架构中的“批量查看”和“实时查看”,整个架构比较清晰,可以很好的满足线上和离线 两种类型的计算需求。但是,将该系统应用到生产中并不是一件容易的事,主要有以下几个原因:
整个架构涉及到很多存储和计算系统,包括:Kafka、Hbase、Spark、Flink、Elasticsearch。数据将在不同的存储和计算系统中流动。在整个架构中运行和维护每个开源产品是一个很大的挑战。任何一款产品或产品之间的通道出现故障都会影响整体舆情分析结果的及时性。
为了实现批量计算和流计算,原创网页需要分别存储在Kafka和Hbase中。离线计算消费HBase中的数据,流计算消费Kafka中的数据。这会带来存储资源的冗余,也会导致需要维护两套计算逻辑,会增加计算代码的开发和维护成本。
舆情的计算结果存储在Mysql或Hbase中。为了丰富组合查询语句,需要将数据同步并内置到Elasticsearch中。查询时,可能需要结合Mysql和Elasticsearch的查询结果。这里没有跳过数据库,结果数据直接写入Elasticsearch等搜索系统中,因为搜索系统的实时数据写入能力和数据可靠性不如数据库。行业通常将数据库和搜索系统集成在一起,集成系统兼具数据库和搜索系统的优点,但是两个引擎之间的数据同步和跨系统查询给运维和维护带来了很多额外的成本。发展。
全新大数据架构 Lambda plus
通过前面的分析,相信大家都会有一个疑问。有没有一种简化的大数据架构可以满足Lambda对计算需求的假设,同时减少存储计算和模块的数量?
Linkedin 的 Jay Kreps 提出了 Kappa 架构。Lambda和Kappa的对比可以参考文末文档。详细的比较这里就不展开了。简单来说,为了简化两个存储,Kappa取消了全量数据存储。通过将它们保存在 Kafka 中,对于较长的日志,当需要回溯重新计算时,再次从队列头部订阅数据,所有存储在 Kafka 队列中的数据再次在流中处理。这种设计的好处是解决了维护两套存储和两套计算逻辑的痛点。缺点是队列能保留的历史数据毕竟有限,没有时间限制很难回溯。
分析到此,我们沿用Kappa对Lambda的改进思路,更远的思考:如果有存储引擎,不仅可以满足数据库的高效写入和随机查询,还可以像队列服务一样,满足第一—— in first-out, yes 不是可以结合Lambda和Kappa架构来创建Lambda plus架构吗?
新架构可以在Lambda的基础上改进以下几点:
在支持流计算和批量计算的同时,可以复用计算逻辑,实现“一套代码,两类需求”。
统一存储全量历史数据和在线实时增量数据,实现“一存两算”。
为了方便舆情结果的查询需求,“批量查看”和“实时查看”的存储不仅可以支持高吞吐量实时写作,还可以支持多字段组合搜索和全文检索恢复。
综上所述,整个新架构的核心是解决存储问题,以及如何灵活连接计算。我们希望整个程序类似于以下架构:
图 4 Lambda Plus 架构
数据流实时写入分布式数据库。借助数据库查询能力,可以轻松将全量数据接入批量计算系统进行离线处理。
数据库支持通过数据库日志接口增量读取,并结合流计算引擎实现实时计算。
批计算和流计算的结果回写到分布式数据库中。分布式数据库提供丰富的查询语义,实现计算结果的交互查询。
在整个架构中,存储层通过结合数据库主表数据和数据库日志来替代大数据架构中的队列服务。计算系统选择自然支持batch和stream的计算引擎,如Flink或Spark。这样,我们不仅可以像 Lambda 那样进行历史数据回溯,还可以像 Kappa 架构那样进行一套逻辑来存储和处理两类计算任务。我们将这样一套架构命名为“Lambda plus”,下面详细介绍如何在阿里云上搭建这样一套大数据架构。
云舆情系统架构
在阿里云众多的存储和计算产品中,为了满足上述大数据架构的需求,我们选择了两款产品来实现整个舆情大数据系统。存储层使用阿里云自研的分布式多模型数据库Tablestore,计算层使用Blink实现流一体和批量计算。
图5 云舆情大数据架构
在存储层面,这个架构都是基于Tablestore的。一个数据库解决不同的存储需求。根据之前舆情系统的介绍,网络爬虫数据的系统流程会有四个阶段:原创网页内容、网页结构化数据、分析规则。元数据和舆情结果,舆情结果索引。
我们利用Tablestore的宽行和无模式特性将原创网页和网页结构化数据合并为一个网页数据。网页数据表和计算系统通过Tablestore新的功能通道服务连接起来。通道服务基于数据库日志,按照数据写入的顺序存储数据的组织结构。正是这个特性,让数据库具备了排队和流式消费的能力。这使得存储引擎既可以随机访问数据库,也可以按写入顺序访问队列,也满足了上面提到的集成Lambda和kappa架构的需求。分析规则元数据表由分析规则和情感词汇组层组成,
计算系统采用阿里云实时流计算产品Blink。Blink 是一款支持流计算和批量计算的实时计算产品。并且类似于Tablestore,它可以轻松实现分布式横向扩展,让计算资源随着业务数据的增长而灵活扩展。使用Tablestore+Blink的优势如下:
Tablestore与Blink深度集成,支持源表、维度表、目的表。无需为业务中的数据流开发代码。
整个架构大大减少了组件数量,从开源产品的6~7个组件减少到2个。Tablestore和Blink都是零运维的全托管产品,可以实现非常好的横向灵活性,没有业务扩张高峰。压力大大降低了大数据架构的运维成本。
业务侧只需要关注数据处理逻辑,Blink中已经集成了与Tablestore的交互逻辑。
在开源方案中,如果数据库源想要连接实时计算,还需要写一个队列,让流计算引擎消费队列中的数据。在我们的架构中,数据库既是数据表,也是实时增量数据消费的队列通道。大大简化了架构的开发和使用成本。
流式批处理集成,实时性在舆情系统中很重要,所以我们需要一个实时计算引擎,而Blink除了实时计算,还支持Tablestore数据的批处理,在低峰期业务的,往往也需要批量处理一些数据作为反馈结果写回Tablestore,比如情感分析反馈。所以一套架构可以同时支持流处理和批处理更好。一套架构的优势在于一套分析代码既可以用于实时流式计算,也可以用于离线批处理。
整个计算过程会产生实时的舆情计算结果。通过Tablestore与函数计算触发器的对接,实现重大舆情事件预警。Tablestore和函数计算做了增量数据的无缝对接。通过在结果表中写入事件,您可以通过函数计算轻松触发短信或电子邮件通知。完整的舆情分析结果和展示搜索使用Tablestore的新功能多索引,彻底解决了开源Hbase+Solr多引擎的痛点:
运维复杂,需要有hbase和solr两个系统的运维能力,还需要维护数据同步的链接。
Solr 数据一致性不如Hbase。Hbase 和 Solr 中数据的语义并不完全相同。另外,Solr/Elasticsearch 很难做到像数据库一样严格的数据一致性。在一些极端情况下,可能会出现数据不一致的情况,开源解决方案很难实现跨系统的一致性比较。
查询接口需要维护两套API。Hbase客户端和Solr客户端都需要用到。不在索引中的字段需要主动对照Hbase进行检查,不太好用。
参考
Lambda 大数据架构:
Kappa大数据架构:
Lambda 和 Kappa 架构比较:
【编辑推荐】
你只知道熊猫吗?数据科学家不容错过的 24 个 Python 库(第 1 部分)。在 Fedora 上构建 Jupyter 和数据科学环境。基于Python语言的大数据搜索引擎。使用 Python 加速数据分析的 10 个简单技巧。分布式文件服务器。你还在手工搭建分布式文件服务器吗?一步一步来试试Docker镜像
实时抓取网页数据(如何抓取网页实时数据?(网页数据抓取软件)(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-18 01:09
)
优采云(网页数据抓取软件)是一款非常实用的在线网页数据抓取助手。如何抓取网页的实时数据?优采云(网页数据抓取软件)供用户快速抓取。他可以帮助用户批量处理采集站点的页面数据。这个过程是全自动的,非常智能,帮助用户快速采集他们想要的信息。
使用说明:
登录优采云客户端->点击方式创建爬虫->点击要爬取的数据->启动爬虫
第一步:登录优采云客户端
打开安装好的优采云客户端,输入优采云的账号和密码,登录后进入控制台
第 2 步:创建一个点击式爬虫
点击“新建应用程序”>选择“爬虫”,点击“下一步”>选择“自己开发”>选择“点击模式”。输入爬虫名称,点击“创建”
第三步:点击要爬取的数据
1、 打开创建好的爬虫,进入并打开点击面板
2、 在点击面板中,进行点击操作
首先输入收录所需数据的url,回车加载显示内容:
然后,在显示的网页内容中,点击选择数据为采集,例如选择采集文章的标题和内容:
点击左侧高级设置,设置爬虫的列表页、内容页url正则表达式、是否自动JS渲染等,提高爬虫效率:
第四步启动爬虫
点击后,点击开始爬取。稍等片刻,爬虫会自动开始运行
查看全部
实时抓取网页数据(如何抓取网页实时数据?(网页数据抓取软件)(组图)
)
优采云(网页数据抓取软件)是一款非常实用的在线网页数据抓取助手。如何抓取网页的实时数据?优采云(网页数据抓取软件)供用户快速抓取。他可以帮助用户批量处理采集站点的页面数据。这个过程是全自动的,非常智能,帮助用户快速采集他们想要的信息。
使用说明:
登录优采云客户端->点击方式创建爬虫->点击要爬取的数据->启动爬虫
第一步:登录优采云客户端
打开安装好的优采云客户端,输入优采云的账号和密码,登录后进入控制台
第 2 步:创建一个点击式爬虫
点击“新建应用程序”>选择“爬虫”,点击“下一步”>选择“自己开发”>选择“点击模式”。输入爬虫名称,点击“创建”
第三步:点击要爬取的数据
1、 打开创建好的爬虫,进入并打开点击面板
2、 在点击面板中,进行点击操作
首先输入收录所需数据的url,回车加载显示内容:
然后,在显示的网页内容中,点击选择数据为采集,例如选择采集文章的标题和内容:
点击左侧高级设置,设置爬虫的列表页、内容页url正则表达式、是否自动JS渲染等,提高爬虫效率:
第四步启动爬虫
点击后,点击开始爬取。稍等片刻,爬虫会自动开始运行
实时抓取网页数据(本文对实时垂直搜索引擎数据抓取任务调度相关技术进行总结和研究)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-14 04:29
摘要 实时垂直搜索引擎的发展解决了互联网用户对海量、时效性数据的搜索需求,爬行任务调度相关技术是实时垂直搜索引擎的关键技术,决定了其性能的优劣。和实时垂直搜索引擎的用户体验。. 然而,目前学术界对实时垂直搜索引擎数据抓取任务的调度还没有开展研究,导致现有的实时垂直搜索引擎数据过期,浪费爬取资源的现象非常严重。 . 本文对实时垂直搜索引擎的爬虫任务调度相关技术进行了详细的总结和研究。第一的,系统总结分析了数据捕捉的基本问题,总结了实时垂直搜索引擎的捕捉策略和数据变化规律的预测方法。然后提出了一种新的实时垂直搜索引擎爬取分布优化策略:策略,基于对象及其属性之间的关联,设计流行对象预测模型来预测流行对象的趋势;基于用户查询和对象变化根据泊松过程的特点,推导出数据新鲜度最大化的计算方法,从理论上给出资源分配和动态平衡的最优策略。最后,基于该策略,一个自适应的实时垂直搜索引擎任务捕获和分发模型:模型提出。该模型巧妙地运用了小白适配的思想,有效解决了实时垂直搜索引擎的抓取分发模块。配置复杂,维护成本高。本文利用实际数据对所提出的理论和观点进行了详细的实验测试,验证了该策略和模型在处理实时数据时,用户查询结果的平均数据新鲜度和准确率明显优于传统的垂直搜索。发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 该模型巧妙地运用了小白适配的思想,有效解决了实时垂直搜索引擎的抓取分发模块。配置复杂,维护成本高。本文利用实际数据对所提出的理论和观点进行了详细的实验测试,验证了该策略和模型在处理实时数据时,用户查询结果的平均数据新鲜度和准确率明显优于传统的垂直搜索。发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 该模型巧妙地运用了小白适配的思想,有效解决了实时垂直搜索引擎的抓取分发模块。配置复杂,维护成本高。本文利用实际数据对所提出的理论和观点进行了详细的实验测试,验证了该策略和模型在处理实时数据时,用户查询结果的平均数据新鲜度和准确率明显优于传统的垂直搜索。发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 本文利用实际数据对所提出的理论和观点进行了详细的实验测试,验证了该策略和模型在处理实时数据时,用户查询结果的平均数据新鲜度和准确率明显优于传统的垂直搜索。发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 本文利用实际数据对所提出的理论和观点进行了详细的实验测试,验证了该策略和模型在处理实时数据时,用户查询结果的平均数据新鲜度和准确率明显优于传统的垂直搜索。发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文
:; 浙江大学硕士论文——. 畉 · , . 痶,瓼。, ; 瑆。, : 籧 ; 阛
图 目录 图:数据对象的数据新鲜度和年龄变化趋势……图:同一对象用户间间隔分布曲线……图 Query Driven 演示非查询驱动数据捕获的区别。...... 整体模型架构....... 图。流行预测模型的预测偏差。效果比较... 图。平均数据新鲜度效果对比……垂直搜索引擎的整体系统结构…………………………………………………………………………………………………………………… 对象。数据新鲜度预期值随时间变化的趋势......................本文重点研究思路....... .... 数字。增量爬取策略数据新鲜度的变化....... 连续爬取策略数据新鲜度的变化...................... .... 数字。查询总数随时间变化的关系..........日本苦恼的趋势..寡妇的变化趋势... 引擎整体架构.................................图.数据变化区间规律与泊松分布验证.................................. ..在批量更新期间持续捕获临时数据数据集和在线数据机的数据新鲜度的变化。图.批量抓取和批量更新。临时数据集和在线数据机的数据新鲜度变化。批量更新期间持续捕获临时数据 数据集和在线数据机的数据新鲜度变化。图.批量抓取和批量更新。临时数据集和在线数据机的数据新鲜度变化。批量更新期间持续捕获临时数据 数据集和在线数据机的数据新鲜度变化。图.批量抓取和批量更新。临时数据集和在线数据机的数据新鲜度变化。
目录表。数据捕获和更新的基本策略比较...查询等待时间比较...
栾章:垂直搜索引擎技术简介:实时垂直搜索引擎的开发与架构。随着互联网规模的快速增长和互联网技术的飞速发展,用户对信息检索和整合的需求越来越迫切。以此为契机,搜索引擎、搜索引擎等搜索引擎产品相继推出。搜索引擎从整个互联网抓取各种信息,有针对性地将信息编入索引,针对不同的查询关键词,向用户呈现不同的信息集。搜索引擎的出现极大地推动了互联网的发展;而互联网的巨大发展也推动了搜索引擎技术的不断更新。网页动态等新技术的出现和推广对传统搜索引擎提出了新的挑战,而垂直搜索引擎的发展正好弥补了传统搜索引擎的不足:网页动态数据实时生成,而传统搜索引擎仅依靠固定链接进行网页抓取,无法有效抓取动态网页中的数据;而垂直搜索引擎可以查找和抓取页面中的动态数据,因此可以轻松索引和检索这些数据。·传统搜索引擎统一处理网页的非结构化文本信息,但无法处理页面中的动态结构化数据。垂直搜索引擎可以抓取和提取网页中的结构化数据,因此他们可以轻松地检索和处理结构化数据中的特定域。·传统搜索引擎专注于整个互联网的信息,无法对特定领域进行深入分析和挖掘。垂直搜索引擎一般专注于某个领域 查看全部
实时抓取网页数据(本文对实时垂直搜索引擎数据抓取任务调度相关技术进行总结和研究)
摘要 实时垂直搜索引擎的发展解决了互联网用户对海量、时效性数据的搜索需求,爬行任务调度相关技术是实时垂直搜索引擎的关键技术,决定了其性能的优劣。和实时垂直搜索引擎的用户体验。. 然而,目前学术界对实时垂直搜索引擎数据抓取任务的调度还没有开展研究,导致现有的实时垂直搜索引擎数据过期,浪费爬取资源的现象非常严重。 . 本文对实时垂直搜索引擎的爬虫任务调度相关技术进行了详细的总结和研究。第一的,系统总结分析了数据捕捉的基本问题,总结了实时垂直搜索引擎的捕捉策略和数据变化规律的预测方法。然后提出了一种新的实时垂直搜索引擎爬取分布优化策略:策略,基于对象及其属性之间的关联,设计流行对象预测模型来预测流行对象的趋势;基于用户查询和对象变化根据泊松过程的特点,推导出数据新鲜度最大化的计算方法,从理论上给出资源分配和动态平衡的最优策略。最后,基于该策略,一个自适应的实时垂直搜索引擎任务捕获和分发模型:模型提出。该模型巧妙地运用了小白适配的思想,有效解决了实时垂直搜索引擎的抓取分发模块。配置复杂,维护成本高。本文利用实际数据对所提出的理论和观点进行了详细的实验测试,验证了该策略和模型在处理实时数据时,用户查询结果的平均数据新鲜度和准确率明显优于传统的垂直搜索。发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 该模型巧妙地运用了小白适配的思想,有效解决了实时垂直搜索引擎的抓取分发模块。配置复杂,维护成本高。本文利用实际数据对所提出的理论和观点进行了详细的实验测试,验证了该策略和模型在处理实时数据时,用户查询结果的平均数据新鲜度和准确率明显优于传统的垂直搜索。发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 该模型巧妙地运用了小白适配的思想,有效解决了实时垂直搜索引擎的抓取分发模块。配置复杂,维护成本高。本文利用实际数据对所提出的理论和观点进行了详细的实验测试,验证了该策略和模型在处理实时数据时,用户查询结果的平均数据新鲜度和准确率明显优于传统的垂直搜索。发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 本文利用实际数据对所提出的理论和观点进行了详细的实验测试,验证了该策略和模型在处理实时数据时,用户查询结果的平均数据新鲜度和准确率明显优于传统的垂直搜索。发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 本文利用实际数据对所提出的理论和观点进行了详细的实验测试,验证了该策略和模型在处理实时数据时,用户查询结果的平均数据新鲜度和准确率明显优于传统的垂直搜索。发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文 发动机的各种策略具有很大的实用价值。关键词:数据抓取、缓存策略、垂直搜索、实时搜索、搜索引擎浙江大学硕士论文
:; 浙江大学硕士论文——. 畉 · , . 痶,瓼。, ; 瑆。, : 籧 ; 阛
图 目录 图:数据对象的数据新鲜度和年龄变化趋势……图:同一对象用户间间隔分布曲线……图 Query Driven 演示非查询驱动数据捕获的区别。...... 整体模型架构....... 图。流行预测模型的预测偏差。效果比较... 图。平均数据新鲜度效果对比……垂直搜索引擎的整体系统结构…………………………………………………………………………………………………………………… 对象。数据新鲜度预期值随时间变化的趋势......................本文重点研究思路....... .... 数字。增量爬取策略数据新鲜度的变化....... 连续爬取策略数据新鲜度的变化...................... .... 数字。查询总数随时间变化的关系..........日本苦恼的趋势..寡妇的变化趋势... 引擎整体架构.................................图.数据变化区间规律与泊松分布验证.................................. ..在批量更新期间持续捕获临时数据数据集和在线数据机的数据新鲜度的变化。图.批量抓取和批量更新。临时数据集和在线数据机的数据新鲜度变化。批量更新期间持续捕获临时数据 数据集和在线数据机的数据新鲜度变化。图.批量抓取和批量更新。临时数据集和在线数据机的数据新鲜度变化。批量更新期间持续捕获临时数据 数据集和在线数据机的数据新鲜度变化。图.批量抓取和批量更新。临时数据集和在线数据机的数据新鲜度变化。
目录表。数据捕获和更新的基本策略比较...查询等待时间比较...
栾章:垂直搜索引擎技术简介:实时垂直搜索引擎的开发与架构。随着互联网规模的快速增长和互联网技术的飞速发展,用户对信息检索和整合的需求越来越迫切。以此为契机,搜索引擎、搜索引擎等搜索引擎产品相继推出。搜索引擎从整个互联网抓取各种信息,有针对性地将信息编入索引,针对不同的查询关键词,向用户呈现不同的信息集。搜索引擎的出现极大地推动了互联网的发展;而互联网的巨大发展也推动了搜索引擎技术的不断更新。网页动态等新技术的出现和推广对传统搜索引擎提出了新的挑战,而垂直搜索引擎的发展正好弥补了传统搜索引擎的不足:网页动态数据实时生成,而传统搜索引擎仅依靠固定链接进行网页抓取,无法有效抓取动态网页中的数据;而垂直搜索引擎可以查找和抓取页面中的动态数据,因此可以轻松索引和检索这些数据。·传统搜索引擎统一处理网页的非结构化文本信息,但无法处理页面中的动态结构化数据。垂直搜索引擎可以抓取和提取网页中的结构化数据,因此他们可以轻松地检索和处理结构化数据中的特定域。·传统搜索引擎专注于整个互联网的信息,无法对特定领域进行深入分析和挖掘。垂直搜索引擎一般专注于某个领域
实时抓取网页数据(高德和百度地图实时路况数据的研究进展及应用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-12-08 15:22
1. 简介
最近老师有一个需求,就是想抓取实时矢量交通流数据进行分析,类似于百度地图和高德地图的“实时路况”。通常的网络爬虫工作一般都是抓取网页上现成的数据,但是流量数据只有栅格切片,没有矢量数据,数据购买成本每年几十W,也就是基本不可能获得。实验室里的兄弟们都忙于事情,所以这项艰巨的任务自然是交给了我。
图1.高德和百度地图实时路况数据
因为网上能查到的数据只有切片数据,这个问题转化为如何对切片数据进行向量化。如果直接使用ArcGIS Engine将栅格数据转换为矢量数据,基本上是不可能的。一是计算量过大,二是转换后的矢量数据不准确。更重要的是,每次转换的矢量道路都不一样。没有办法分析它。但是我们注意到流量切片有两个特点:
a) 也是一种地图切片,所以可以使用地图切片算法来计算每个切片的经纬度;
b) 它是一个透明的 PNG 图像,用四种颜色表示交通拥堵。我只需要识别每一段路的颜色,判断交通拥堵情况就可以完成“矢量化”工作。
接下来的工作可以分为以下几个步骤:
a) 准备某城市详细的矢量道路数据;
b) 下载城市交通流切片,拼成大图;
c) 在网格上标记需要检测颜色的像素点,并计算这些像素点的经纬度;
d) 将每条道路的矢量数据与像素一一匹配,检测交通流情况并写入数据库。
2. 地图切片系统和实时交通流
地图切片也称为地图图块。这方面的文章和机制已经很成熟了。详细算法内容请参考这个文章。本文以高德切片为例。高德的实时交通流使用动态切片,但与一般的切片系统略有不同。切片的缩放级别越小,缩放级别越大,反之亦然。
当然我们也可以自己计算不同,建议使用类库
3. 主要思想
高德的交通流数据(图1.(a))一般都很简单。用“绿”、“黄”、“红”三种颜色表示交通拥堵。分离非常明显。但是直接将切片转换为向量是非常不现实的。但是我有北京提供的非常详细的矢量数据(图2.(b))。如果将交通流切片与矢量数据进行匹配,则可以生成实时交通流矢量数据。最后,交通流数据可以切片发布,也可以向量发布。所以现在的主要任务是找到匹配流量切片和矢量数据的中间件。
图2. 交通流切片和矢量数据
虽然高德切片数据是以编码方式组织的,但每张图片、每一个像素都有严格固定的坐标。只要选取一部分有值的像素,将像素安装公式转化为点阵,然后将每个A点与一条矢量道路进行匹配,即在每个点上添加一个RouteId字段。图3(a)是我生成的点阵的一部分,图3(b)是点阵的属性表,它收录三个字段:x、y和routeid。具体步骤如下:
a) 定期下载交通流切片数据并保存在本地文件夹中;
b) 根据点阵数据读取指定切片的指定像素,判断像素的颜色,得到拥塞情况;
c) 根据拥塞情况和RouteId生成交通流表,包括RouteId和Traffic两个字段;
d) 根据RouteId匹配交通流表和矢量数据,得到矢量交通流数据;
e) 使用切片工具从矢量数据中生成天津师范大学所需的切片数据。
图3.(a)交通流切片数据和矢量道路数据用点阵叠加,(b)点阵的属性表
这是我用一个程序捕捉2014年12月5日晚上8点左右的交通流量数据,然后对北京四环的交通流量进行矢量化处理的地方。从结果可以看出,交通流量的总体趋势相似,但在一些细节上存在一些差异。矢量化的结果取决于晶格的细度。
图4. (a) 交通流切片数据 (b) 生成的矢量交通流数据
4. 总结
当时我是抱着完成任务的心态做这个的,所以整个事情做的很粗糙,代码也很乱,所以就厚颜无耻的分享一下代码吧。大家慢慢看官喷,以后有空我再安排。
转载于: 查看全部
实时抓取网页数据(高德和百度地图实时路况数据的研究进展及应用方法)
1. 简介
最近老师有一个需求,就是想抓取实时矢量交通流数据进行分析,类似于百度地图和高德地图的“实时路况”。通常的网络爬虫工作一般都是抓取网页上现成的数据,但是流量数据只有栅格切片,没有矢量数据,数据购买成本每年几十W,也就是基本不可能获得。实验室里的兄弟们都忙于事情,所以这项艰巨的任务自然是交给了我。
图1.高德和百度地图实时路况数据
因为网上能查到的数据只有切片数据,这个问题转化为如何对切片数据进行向量化。如果直接使用ArcGIS Engine将栅格数据转换为矢量数据,基本上是不可能的。一是计算量过大,二是转换后的矢量数据不准确。更重要的是,每次转换的矢量道路都不一样。没有办法分析它。但是我们注意到流量切片有两个特点:
a) 也是一种地图切片,所以可以使用地图切片算法来计算每个切片的经纬度;
b) 它是一个透明的 PNG 图像,用四种颜色表示交通拥堵。我只需要识别每一段路的颜色,判断交通拥堵情况就可以完成“矢量化”工作。
接下来的工作可以分为以下几个步骤:
a) 准备某城市详细的矢量道路数据;
b) 下载城市交通流切片,拼成大图;
c) 在网格上标记需要检测颜色的像素点,并计算这些像素点的经纬度;
d) 将每条道路的矢量数据与像素一一匹配,检测交通流情况并写入数据库。
2. 地图切片系统和实时交通流
地图切片也称为地图图块。这方面的文章和机制已经很成熟了。详细算法内容请参考这个文章。本文以高德切片为例。高德的实时交通流使用动态切片,但与一般的切片系统略有不同。切片的缩放级别越小,缩放级别越大,反之亦然。
当然我们也可以自己计算不同,建议使用类库
3. 主要思想
高德的交通流数据(图1.(a))一般都很简单。用“绿”、“黄”、“红”三种颜色表示交通拥堵。分离非常明显。但是直接将切片转换为向量是非常不现实的。但是我有北京提供的非常详细的矢量数据(图2.(b))。如果将交通流切片与矢量数据进行匹配,则可以生成实时交通流矢量数据。最后,交通流数据可以切片发布,也可以向量发布。所以现在的主要任务是找到匹配流量切片和矢量数据的中间件。
图2. 交通流切片和矢量数据
虽然高德切片数据是以编码方式组织的,但每张图片、每一个像素都有严格固定的坐标。只要选取一部分有值的像素,将像素安装公式转化为点阵,然后将每个A点与一条矢量道路进行匹配,即在每个点上添加一个RouteId字段。图3(a)是我生成的点阵的一部分,图3(b)是点阵的属性表,它收录三个字段:x、y和routeid。具体步骤如下:
a) 定期下载交通流切片数据并保存在本地文件夹中;
b) 根据点阵数据读取指定切片的指定像素,判断像素的颜色,得到拥塞情况;
c) 根据拥塞情况和RouteId生成交通流表,包括RouteId和Traffic两个字段;
d) 根据RouteId匹配交通流表和矢量数据,得到矢量交通流数据;
e) 使用切片工具从矢量数据中生成天津师范大学所需的切片数据。
图3.(a)交通流切片数据和矢量道路数据用点阵叠加,(b)点阵的属性表
这是我用一个程序捕捉2014年12月5日晚上8点左右的交通流量数据,然后对北京四环的交通流量进行矢量化处理的地方。从结果可以看出,交通流量的总体趋势相似,但在一些细节上存在一些差异。矢量化的结果取决于晶格的细度。
图4. (a) 交通流切片数据 (b) 生成的矢量交通流数据
4. 总结
当时我是抱着完成任务的心态做这个的,所以整个事情做的很粗糙,代码也很乱,所以就厚颜无耻的分享一下代码吧。大家慢慢看官喷,以后有空我再安排。
转载于:
实时抓取网页数据(之前抓取百度疫情数据的代码已经无法运行,怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-05 12:00
有朋友反映,抓取百度疫情数据的代码不能用了。没有看过的朋友可以点击下方链接查看。
Python抓取实时数据并绘制地图
我看了一下,因为百度调整了部分页面信息,代码调整后就可以使用了。如果下次调整呢?你觉得这个概率大吗?
我觉得它很大,那么有没有办法稳定它?
这样问,肯定有一些,就是用另一种方式获取疫情的实时数据。
这次我们将抓取网易JSON流行病数据。
链接是这个
打开网站,看到是这样的。如果您是第一次接触 JSON 数据,您会感到困惑。不过没关系,如果你用的是火狐,还可以发现上面有JSON,美化输出等功能。
这就是美化输出的效果。看起来好一点了,但是还是傻眼了,因为你还没有接触到JSON数据。
这个有点JSON效果,颜色不同,看起来更舒服。
好的,让我们开始数据捕获和导入。首先导入所需的模块。
import json
import requests
from pandas.io.json import json_normalize
然后开始抓取数据
url="https://c.m.163.com/ug/api/wuh ... ot%3B
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36'}
ret=requests.get(url, headers=headers)
result=json.loads(ret.content)
查看抓到的数据结果,可以看到是一个字典,我们要的数据在key=data中。
继续双击打开数据,我们要的数据在areaTree中。
继续双击打开areaTree,这个areaTree是一个列表,在我们想要的数据的第一行。
继续双击打开areaTree的第一行。这次又变成了字典。你看到中国了吗?哈哈,我们要的数据在key=children里面。
继续双击打开children,这是我们要的数据,这个又变成了一个列表,每一行都是一个省的数据
我们点第一行,看看湖北有没有出现。
如果继续点击儿童,就会是湖北各城市的数据。如果不点击,我们只需要省份数据。我们怎样才能提出来?继续数据处理,提取我们想要的数据。
t= result['data']['areaTree'][0]['children']
sf=json_normalize(t)
就出来了两行代码,哈哈!我们来看看数据。
那么我们要的字段是name,total.confirm,name是省名,
total.confirm是累计确诊数,如果换成taday.confirm就是新确诊数。直接将name和total.confirm替换为用于绘制地图的代码对应的位置。
# 将数据转换为二元的列表
list1 = list(zip(sf['name'],sf['total.confirm']))
# 创建一个地图对象
map_1 = Map()
#对全局进行设置
map_1.set_global_opts(
#设置标题
title_opts=opts.TitleOpts(title="全国疫情地图"),
#设置最大数据范围
visualmap_opts=opts.VisualMapOpts(max_=2500,range_color=["#FFFFFF","#FFCC00","#CC0000"]))
# 使用add方法添加地图数据与地图类型
map_1.add("累计确诊人数", list1, maptype="china")
# 地图创建完成后,通过render()方法可以将地图渲染为html
map_1.render('全国疫情地图.html')
然后地图绘制结果出来了。
如果你喜欢这篇文章,可以点击右下角查看
如果您正在关注学习,请在留言区留言:签到
如果你刚看完这篇文章,你可以查看这个系列的历史文章 并关注:
从小白-Anaconda安装学习Python数据分析
从小白学Python数据分析-使用spyder
从小白学Python数据分析-数据导入1
从小白学Python数据分析-数据导入2
从小白学Python数据分析-描述性统计分析
从小白-群分析学Python数据分析
8行Python代码轻松映射新冠疫情
动态新冠疫情图Python易画
Python绘制16个省份支持湖北地图
湖北动态新冠疫情地图Python易画
Python抓取实时数据并绘制地图
世界动态疫情图Python易画 查看全部
实时抓取网页数据(之前抓取百度疫情数据的代码已经无法运行,怎么办?)
有朋友反映,抓取百度疫情数据的代码不能用了。没有看过的朋友可以点击下方链接查看。
Python抓取实时数据并绘制地图
我看了一下,因为百度调整了部分页面信息,代码调整后就可以使用了。如果下次调整呢?你觉得这个概率大吗?
我觉得它很大,那么有没有办法稳定它?
这样问,肯定有一些,就是用另一种方式获取疫情的实时数据。
这次我们将抓取网易JSON流行病数据。
链接是这个
打开网站,看到是这样的。如果您是第一次接触 JSON 数据,您会感到困惑。不过没关系,如果你用的是火狐,还可以发现上面有JSON,美化输出等功能。
这就是美化输出的效果。看起来好一点了,但是还是傻眼了,因为你还没有接触到JSON数据。
这个有点JSON效果,颜色不同,看起来更舒服。
好的,让我们开始数据捕获和导入。首先导入所需的模块。
import json
import requests
from pandas.io.json import json_normalize
然后开始抓取数据
url="https://c.m.163.com/ug/api/wuh ... ot%3B
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36'}
ret=requests.get(url, headers=headers)
result=json.loads(ret.content)
查看抓到的数据结果,可以看到是一个字典,我们要的数据在key=data中。
继续双击打开数据,我们要的数据在areaTree中。
继续双击打开areaTree,这个areaTree是一个列表,在我们想要的数据的第一行。
继续双击打开areaTree的第一行。这次又变成了字典。你看到中国了吗?哈哈,我们要的数据在key=children里面。
继续双击打开children,这是我们要的数据,这个又变成了一个列表,每一行都是一个省的数据
我们点第一行,看看湖北有没有出现。
如果继续点击儿童,就会是湖北各城市的数据。如果不点击,我们只需要省份数据。我们怎样才能提出来?继续数据处理,提取我们想要的数据。
t= result['data']['areaTree'][0]['children']
sf=json_normalize(t)
就出来了两行代码,哈哈!我们来看看数据。
那么我们要的字段是name,total.confirm,name是省名,
total.confirm是累计确诊数,如果换成taday.confirm就是新确诊数。直接将name和total.confirm替换为用于绘制地图的代码对应的位置。
# 将数据转换为二元的列表
list1 = list(zip(sf['name'],sf['total.confirm']))
# 创建一个地图对象
map_1 = Map()
#对全局进行设置
map_1.set_global_opts(
#设置标题
title_opts=opts.TitleOpts(title="全国疫情地图"),
#设置最大数据范围
visualmap_opts=opts.VisualMapOpts(max_=2500,range_color=["#FFFFFF","#FFCC00","#CC0000"]))
# 使用add方法添加地图数据与地图类型
map_1.add("累计确诊人数", list1, maptype="china")
# 地图创建完成后,通过render()方法可以将地图渲染为html
map_1.render('全国疫情地图.html')
然后地图绘制结果出来了。
如果你喜欢这篇文章,可以点击右下角查看
如果您正在关注学习,请在留言区留言:签到
如果你刚看完这篇文章,你可以查看这个系列的历史文章 并关注:
从小白-Anaconda安装学习Python数据分析
从小白学Python数据分析-使用spyder
从小白学Python数据分析-数据导入1
从小白学Python数据分析-数据导入2
从小白学Python数据分析-描述性统计分析
从小白-群分析学Python数据分析
8行Python代码轻松映射新冠疫情
动态新冠疫情图Python易画
Python绘制16个省份支持湖北地图
湖北动态新冠疫情地图Python易画
Python抓取实时数据并绘制地图
世界动态疫情图Python易画
实时抓取网页数据(一下网页抓取为电子商务行业带来的优势网页数据分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-03 14:36
大数据分析对电子商务行业非常重要。通过捕获其他网站 数据进行分析,它可以帮助企业更好地了解客户、预测市场趋势并帮助增加收入。本文将向您介绍网页抓取给电子商务行业带来的优势。
1、追踪购物者的购买历史
通过对浏览活动数据的数据抓取和分析,企业可以了解购物者的购物习惯,洞察近期哪些产品需求旺盛,以及年内某些产品的需求何时上升。
2、个性化体验
通过捕获购物者的相关数据,您可以创建满足用户需求的个性化体验。个性化体验策略包括向用户发送定制邮件、提供特别折扣和优惠、向不同人群展示针对性广告等。
3、了解卖家满意度
从客户评论中采集和挖掘数据,利用自然语言处理技术进行文本挖掘和分析,使企业能够准确了解买家对其产品的意见,帮助电商业主更好地与买家建立联系。
4、更好的客户服务
通过分析采集收到的数据,有助于改善客户服务。通过监测平均响应速度,客服人员可以提高整体响应的及时性;通过发放问卷和采集客户反馈,提供第一手信息,帮助提高服务质量,减少不良服务的机会。
5、优化定价
设定的价格决定了您是否能够保持竞争力并直接影响您的产品销售。通过网络爬虫,企业可以纵览全局,实时监控竞争对手的定价,从而制定更好的营销方式。
6、需求预测
大数据可以帮助企业根据过去的经验估计未来的库存,提前规划营销活动。
综上所述,网络爬虫的好处有很多,但是现在很多网站都设置了反爬虫,让你无法高效爬取数据。目前,使用住宅轮换代理是提高爬虫效率的最佳方式。Ipidea是一家海外爬虫代理,与多家公司和爬虫企业合作,也支持免费测试。 查看全部
实时抓取网页数据(一下网页抓取为电子商务行业带来的优势网页数据分析)
大数据分析对电子商务行业非常重要。通过捕获其他网站 数据进行分析,它可以帮助企业更好地了解客户、预测市场趋势并帮助增加收入。本文将向您介绍网页抓取给电子商务行业带来的优势。
1、追踪购物者的购买历史
通过对浏览活动数据的数据抓取和分析,企业可以了解购物者的购物习惯,洞察近期哪些产品需求旺盛,以及年内某些产品的需求何时上升。
2、个性化体验
通过捕获购物者的相关数据,您可以创建满足用户需求的个性化体验。个性化体验策略包括向用户发送定制邮件、提供特别折扣和优惠、向不同人群展示针对性广告等。
3、了解卖家满意度
从客户评论中采集和挖掘数据,利用自然语言处理技术进行文本挖掘和分析,使企业能够准确了解买家对其产品的意见,帮助电商业主更好地与买家建立联系。
4、更好的客户服务
通过分析采集收到的数据,有助于改善客户服务。通过监测平均响应速度,客服人员可以提高整体响应的及时性;通过发放问卷和采集客户反馈,提供第一手信息,帮助提高服务质量,减少不良服务的机会。
5、优化定价
设定的价格决定了您是否能够保持竞争力并直接影响您的产品销售。通过网络爬虫,企业可以纵览全局,实时监控竞争对手的定价,从而制定更好的营销方式。
6、需求预测
大数据可以帮助企业根据过去的经验估计未来的库存,提前规划营销活动。
综上所述,网络爬虫的好处有很多,但是现在很多网站都设置了反爬虫,让你无法高效爬取数据。目前,使用住宅轮换代理是提高爬虫效率的最佳方式。Ipidea是一家海外爬虫代理,与多家公司和爬虫企业合作,也支持免费测试。
实时抓取网页数据(#如何用excel获得股票实时数据#首先找一个提供股票数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-03 14:34
#如何使用excel获取实时股票数据#
首先,找到一个提供股票数据的网站。各种金融网站都有股票数据。我们以东方财富网为例:
对于沪深A股数据,我们在谷歌浏览器中查看真实网址:
找到与股票数据对应的jQuery行,然后查看头文件中的URL:
将此 URL 复制到 Excel,数据 ==> 来自 网站:
单击以确认,Power Query 编辑器将打开。如果一切顺利,数据会直接出现:
虽然不是表,但证明爬取成功。下一步是如何解析二进制文件。从谷歌浏览器看,这是一个jsoncallback数据包,比json数据多了一个函数名。我们只需要提取两个括号。中间的数据可以用json解析。注意total:4440,我们后面会用到这个值。
=Json.Document(Text.BetweenDelimiters(Text.FromBinary(Web.Contents(url)),"(",")"))
然后展开数据表:
到目前为止一切都很顺利,但我们抓取的只是一页数据,让我们看看:
pn是页码,我们抓取第3页,pz是每页20条数据,我们有两种方法抓取所有数据,一种是使用这个pz:20,然后定义函数,抓取所有页码,我在之前的爬行中反复使用过这个。今天我们尝试直接修改pz,一次性抓取所有数据。其实,你可以尝试改变查询参数。如果我们把pn改成4,抓取到的页面就是第4页。同理,我们把pn改成200,看看能不能直接抓取200条数据。
那我们试试直接输入5000,能不能全部抢过来:
这似乎是可能的。
还有一个问题,就是数据的所有标题行都以f开头,不可读。如何将它们变成网页中的汉字标题行。
这个问题有点复杂。我们可能需要检查代码,看看是否可以找到替换它的方法。先看html:
但这并不完整,还有几列需要自定义:
这些指标没有对应的 f 代码。
我们来看一下js文件:
这个文件中有对应的数据,我们直接拷贝到Power Query中,处理成列表形式进行备份:
下一步是匹配表中的键并修改列名:
首先我们需要匹配出这样一个列表。
List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n[key])}, (y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0})
然后我们可以直接使用Table.RenameColumns函数批量修改列名:
Table.RenameColumns(data,List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n) [key])},(y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0}))
我们只是将数据加载到 Excel 中。
如果你想要最新的数据,只需刷新它。 查看全部
实时抓取网页数据(#如何用excel获得股票实时数据#首先找一个提供股票数据)
#如何使用excel获取实时股票数据#
首先,找到一个提供股票数据的网站。各种金融网站都有股票数据。我们以东方财富网为例:
对于沪深A股数据,我们在谷歌浏览器中查看真实网址:
找到与股票数据对应的jQuery行,然后查看头文件中的URL:
将此 URL 复制到 Excel,数据 ==> 来自 网站:
单击以确认,Power Query 编辑器将打开。如果一切顺利,数据会直接出现:
虽然不是表,但证明爬取成功。下一步是如何解析二进制文件。从谷歌浏览器看,这是一个jsoncallback数据包,比json数据多了一个函数名。我们只需要提取两个括号。中间的数据可以用json解析。注意total:4440,我们后面会用到这个值。
=Json.Document(Text.BetweenDelimiters(Text.FromBinary(Web.Contents(url)),"(",")"))
然后展开数据表:
到目前为止一切都很顺利,但我们抓取的只是一页数据,让我们看看:
pn是页码,我们抓取第3页,pz是每页20条数据,我们有两种方法抓取所有数据,一种是使用这个pz:20,然后定义函数,抓取所有页码,我在之前的爬行中反复使用过这个。今天我们尝试直接修改pz,一次性抓取所有数据。其实,你可以尝试改变查询参数。如果我们把pn改成4,抓取到的页面就是第4页。同理,我们把pn改成200,看看能不能直接抓取200条数据。
那我们试试直接输入5000,能不能全部抢过来:
这似乎是可能的。
还有一个问题,就是数据的所有标题行都以f开头,不可读。如何将它们变成网页中的汉字标题行。
这个问题有点复杂。我们可能需要检查代码,看看是否可以找到替换它的方法。先看html:
但这并不完整,还有几列需要自定义:
这些指标没有对应的 f 代码。
我们来看一下js文件:
这个文件中有对应的数据,我们直接拷贝到Power Query中,处理成列表形式进行备份:
下一步是匹配表中的键并修改列名:
首先我们需要匹配出这样一个列表。
List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n[key])}, (y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0})
然后我们可以直接使用Table.RenameColumns函数批量修改列名:
Table.RenameColumns(data,List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n) [key])},(y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0}))
我们只是将数据加载到 Excel 中。
如果你想要最新的数据,只需刷新它。
实时抓取网页数据(实时抓取网页数据中的重要数据进行相关性分析。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-03 13:23
实时抓取网页数据中的重要数据进行相关性分析。例如:根据某一产品所属的省份产量分析排名与经销商总量、厂家总量等综合信息的关联性。如果对于其特定报刊的销量与区域性更复杂的概念,则需要统计学专业知识的介绍,还有数据调查的方法,如访问量、登录量等。准确的分析和高效的处理网站前端用户的数据则需要更高层次专业知识。
首先说明下,我们对于大多数网站的用户行为过程即对每个大类别用户来源的电子商务过程中的特定类别用户数据进行数据收集整理。例如电子商务,然后根据大类别将不同类别的用户特征收集到收集目录页面。收集目录页面数据的方法简单便捷,例如用户可以直接查看,也可以根据市场热度调查来搜集,也可以对于一些新兴类别用户需要发现早期网站对大类别用户数据未做收集,所以放置在收集目录页面的。
当我们不够详细了解现有的电子商务数据结构时,可以按照主题或子主题对不同大类进行集合进行数据收集整理,然后通过repost进行初步的数据分析整理。repost所在的时间段需要结合网站营销策略,以及对话数量、注册数量和平均浏览量等其他各个因素综合确定。
网络营销渠道营销策略的相关知识
互联网、数据挖掘、数据仓库。
如果做互联网网站分析,最基本的就是理解网站业务结构、运营、数据来源、数据格式、算法、数据特征等,这些是非常宏观、抽象的理解,其次是数据爬取和数据清洗,用户增长、用户流失以及用户聚类。然后是针对业务结构上的数据应用场景逐个推出可信度较高的指标或者挖掘相关有意义的属性指标。再往后就是数据分析整理、数据可视化、数据挖掘,针对特定问题进行收集数据、抽象问题、设计模型、集成算法、设计工具、学习计算机基础知识。 查看全部
实时抓取网页数据(实时抓取网页数据中的重要数据进行相关性分析。)
实时抓取网页数据中的重要数据进行相关性分析。例如:根据某一产品所属的省份产量分析排名与经销商总量、厂家总量等综合信息的关联性。如果对于其特定报刊的销量与区域性更复杂的概念,则需要统计学专业知识的介绍,还有数据调查的方法,如访问量、登录量等。准确的分析和高效的处理网站前端用户的数据则需要更高层次专业知识。
首先说明下,我们对于大多数网站的用户行为过程即对每个大类别用户来源的电子商务过程中的特定类别用户数据进行数据收集整理。例如电子商务,然后根据大类别将不同类别的用户特征收集到收集目录页面。收集目录页面数据的方法简单便捷,例如用户可以直接查看,也可以根据市场热度调查来搜集,也可以对于一些新兴类别用户需要发现早期网站对大类别用户数据未做收集,所以放置在收集目录页面的。
当我们不够详细了解现有的电子商务数据结构时,可以按照主题或子主题对不同大类进行集合进行数据收集整理,然后通过repost进行初步的数据分析整理。repost所在的时间段需要结合网站营销策略,以及对话数量、注册数量和平均浏览量等其他各个因素综合确定。
网络营销渠道营销策略的相关知识
互联网、数据挖掘、数据仓库。
如果做互联网网站分析,最基本的就是理解网站业务结构、运营、数据来源、数据格式、算法、数据特征等,这些是非常宏观、抽象的理解,其次是数据爬取和数据清洗,用户增长、用户流失以及用户聚类。然后是针对业务结构上的数据应用场景逐个推出可信度较高的指标或者挖掘相关有意义的属性指标。再往后就是数据分析整理、数据可视化、数据挖掘,针对特定问题进行收集数据、抽象问题、设计模型、集成算法、设计工具、学习计算机基础知识。
实时抓取网页数据(【每日一题】Excel中的“获取数据”访问网页时,该表无法识别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-12-03 09:10
我正在尝试从网站获取实时数据到我的 Excel 电子表格中。唯一的问题是当我通过在 Excel 中获取数据进入网页时,表格无法识别。我正在尝试获取 网站 文件中的实时数据是在我的 Excel 电子表格中捕获的。唯一的问题是,当我通过Excel中的“获取数据”访问网页时,无法识别表格。我只能导入整个页面,即使这样它也无法获得我需要的数据。如果提供了 Url,我想运行一个宏来获取数据,因为有太多页面无法手动完成。完成。
为了比较,我尝试导入的数据来自不同博彩公司的所有赔率,这是一个示例
我真的很感激对此有所了解。我真的很感激对此有所了解。任何人都可以请帮忙!!任何人都可以帮忙吗!! 查看全部
实时抓取网页数据(【每日一题】Excel中的“获取数据”访问网页时,该表无法识别)
我正在尝试从网站获取实时数据到我的 Excel 电子表格中。唯一的问题是当我通过在 Excel 中获取数据进入网页时,表格无法识别。我正在尝试获取 网站 文件中的实时数据是在我的 Excel 电子表格中捕获的。唯一的问题是,当我通过Excel中的“获取数据”访问网页时,无法识别表格。我只能导入整个页面,即使这样它也无法获得我需要的数据。如果提供了 Url,我想运行一个宏来获取数据,因为有太多页面无法手动完成。完成。
为了比较,我尝试导入的数据来自不同博彩公司的所有赔率,这是一个示例
我真的很感激对此有所了解。我真的很感激对此有所了解。任何人都可以请帮忙!!任何人都可以帮忙吗!!
实时抓取网页数据(利用动态大数据已经成为企业数据分析的关键!(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-03 09:09
我们生活的数字世界不断产生大量数据。动态大数据的使用已经成为企业数据分析的关键。
在本文中,我们将回答以下问题:
1、为什么采集动态数据很重要?
2、动态数据如何有效促进业务增长?
3、最重要的是,我们如何轻松获取动态数据?
1、为什么采集动态数据如此重要?
一般来说,通过持续监控动态数据,您可以在最短的时间内做出正确的决策。更具体地说,获取动态数据可以帮助:
(1) 让数据驱动的决策更快
采集动态数据可以为您提供有关市场和竞争对手的最新趋势的实时信息。有了所有更新的信息,您可以更快、更轻松地获得基于数据的分析结果,并做出数据驱动的决策。
正如亚马逊首席执行官杰夫·贝佐斯(Jeff Bezos)在致股东的信中所说:“业务的速度至关重要。” “高速决策”对业务发展具有重要意义。
(2)建立更强大的数据库
随着数据量的不断增长,每条数据的价值急剧下降。为了提高数据分析的质量和决策的准确性,企业需要通过持续不断的采集动态数据,构建一个全面、大容量的数据库。
数据是一种对时间敏感的资产。数据越早,采集起来就越困难。随着信息量的规模和速度每年翻一番,监控不断更新的数据以进行进一步分析变得极为重要。
一般来说,短期的数据采集可以帮助解决近期的问题并做出较小的决策,而长期的数据采集可以帮助企业识别市场趋势和商业模式,从而帮助企业制定长期的业务目标。
(3)建立自适应分析系统
数据分析的最终目标是建立一个自适应的、自主的数据分析系统,不断地分析问题。毫无疑问,自适应分析系统是基于动态数据的自动采集。在这种情况下,可以节省每次建立分析模型的时间,消除数据循环采集中的人为因素。无人驾驶汽车是自适应分析解决方案的一个很好的例子。
2.动态数据如何有效促进业务增长?
我们可以通过多种方式应用动态数据分析来促进业务发展,例如:
(1)产品监控
产品信息,如价格、描述、客户评价、图片等,可在在线平台上获取并实时更新。例如,通过在亚马逊上搜索产品信息或从易趣上抓取价格信息,您可以轻松地进行产品发布前的市场调查。
获取更新的数据还可以让您评估产品的竞争地位并制定有效的定价和库存策略。这是监控竞争对手市场行为的可靠且有效的方法。
(2)客户体验管理
公司比以往任何时候都更加重视客户体验管理。根据 Gartner 的定义,它是“设计和响应客户交互以达到或超越客户期望的做法,从而提高客户满意度、忠诚度和拥护度”。
例如,提取亚马逊上某个产品的所有评论,并分析评论的正面和负面情绪,可以帮助企业了解客户对该产品的看法。同时,它有助于了解客户的需求,以及实时了解客户的满意度。
(3)营销策略
动态数据分析使公司能够了解过去哪些策略最有效,他们当前的营销策略有多有效,以及可以改进的地方。动态数据采集使企业能够实时评估营销策略的成功与否,并据此做出相应的精准调整。
3.如何轻松获取动态数据?
为了及时、连续地采集动态数据,传统的手动复制粘贴已不再可行。在这种情况下,一个简单易用的网络爬虫可能是最好的解决方案,它具有以下优点:
(1)无需编程
使用网络爬虫工具,操作者无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。
(2)适用于各种网站
不同的网站具有不同的结构,所以即使是有经验的程序员在编写爬虫脚本之前也需要研究网站的结构。但是强大的网页抓取工具可以让您轻松快速地从不同的网站 中抓取信息,这为您研究不同的网站 结构节省了大量时间。
(3)定期抓取
这需要网络爬虫工具来支持云中的数据,而不仅仅是在本地计算机上运行。通过云端采集这种方式,采集器可以根据你设置的时间自动运行采集数据。
优采云Cloud采集的功能远不止这些。
(4) 灵活的时间安排
优采云云采集支持随时随地抓取网页数据,时间和频率可根据需要调整。
(5)采集 更快
同时通过8-12台云服务器采集,对同一组数据的爬取速度可以比在本地计算机上运行快8-12倍。
(6) 降低数据获取成本
优采云Cloud采集支持在云端采集数据,并将采集接收到的数据存入云端数据库。企业无需担心高昂的硬件维护成本或采集 中断。
此外,优采云采集器的成本较市场同类竞品降低50%。优采云一直致力于提升数据分析的价值,让每个人都能以实惠的价格使用大数据。
(7)API,自定义数据对接
虽然云端采集数据可以自动导出到用户的数据库,但是通过API可以大大提高数据导出到自己系统的灵活性,轻松实现自己的系统和优采云采集器@ > 无缝对接。
你需要知道的是,优采云采集器的API有两种:数据导出API和增值API。数据导出API仅支持导出数据;增值API支持导出数据,以及修改任务中的一些参数,控制任务的启动/停止。
如何轻松实时抓取动态网页数据?
原来的: 查看全部
实时抓取网页数据(利用动态大数据已经成为企业数据分析的关键!(一))
我们生活的数字世界不断产生大量数据。动态大数据的使用已经成为企业数据分析的关键。
在本文中,我们将回答以下问题:
1、为什么采集动态数据很重要?
2、动态数据如何有效促进业务增长?
3、最重要的是,我们如何轻松获取动态数据?
1、为什么采集动态数据如此重要?
一般来说,通过持续监控动态数据,您可以在最短的时间内做出正确的决策。更具体地说,获取动态数据可以帮助:
(1) 让数据驱动的决策更快
采集动态数据可以为您提供有关市场和竞争对手的最新趋势的实时信息。有了所有更新的信息,您可以更快、更轻松地获得基于数据的分析结果,并做出数据驱动的决策。
正如亚马逊首席执行官杰夫·贝佐斯(Jeff Bezos)在致股东的信中所说:“业务的速度至关重要。” “高速决策”对业务发展具有重要意义。
(2)建立更强大的数据库
随着数据量的不断增长,每条数据的价值急剧下降。为了提高数据分析的质量和决策的准确性,企业需要通过持续不断的采集动态数据,构建一个全面、大容量的数据库。
数据是一种对时间敏感的资产。数据越早,采集起来就越困难。随着信息量的规模和速度每年翻一番,监控不断更新的数据以进行进一步分析变得极为重要。
一般来说,短期的数据采集可以帮助解决近期的问题并做出较小的决策,而长期的数据采集可以帮助企业识别市场趋势和商业模式,从而帮助企业制定长期的业务目标。
(3)建立自适应分析系统
数据分析的最终目标是建立一个自适应的、自主的数据分析系统,不断地分析问题。毫无疑问,自适应分析系统是基于动态数据的自动采集。在这种情况下,可以节省每次建立分析模型的时间,消除数据循环采集中的人为因素。无人驾驶汽车是自适应分析解决方案的一个很好的例子。
2.动态数据如何有效促进业务增长?
我们可以通过多种方式应用动态数据分析来促进业务发展,例如:
(1)产品监控
产品信息,如价格、描述、客户评价、图片等,可在在线平台上获取并实时更新。例如,通过在亚马逊上搜索产品信息或从易趣上抓取价格信息,您可以轻松地进行产品发布前的市场调查。
获取更新的数据还可以让您评估产品的竞争地位并制定有效的定价和库存策略。这是监控竞争对手市场行为的可靠且有效的方法。
(2)客户体验管理
公司比以往任何时候都更加重视客户体验管理。根据 Gartner 的定义,它是“设计和响应客户交互以达到或超越客户期望的做法,从而提高客户满意度、忠诚度和拥护度”。
例如,提取亚马逊上某个产品的所有评论,并分析评论的正面和负面情绪,可以帮助企业了解客户对该产品的看法。同时,它有助于了解客户的需求,以及实时了解客户的满意度。
(3)营销策略
动态数据分析使公司能够了解过去哪些策略最有效,他们当前的营销策略有多有效,以及可以改进的地方。动态数据采集使企业能够实时评估营销策略的成功与否,并据此做出相应的精准调整。
3.如何轻松获取动态数据?
为了及时、连续地采集动态数据,传统的手动复制粘贴已不再可行。在这种情况下,一个简单易用的网络爬虫可能是最好的解决方案,它具有以下优点:
(1)无需编程
使用网络爬虫工具,操作者无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。
(2)适用于各种网站
不同的网站具有不同的结构,所以即使是有经验的程序员在编写爬虫脚本之前也需要研究网站的结构。但是强大的网页抓取工具可以让您轻松快速地从不同的网站 中抓取信息,这为您研究不同的网站 结构节省了大量时间。
(3)定期抓取
这需要网络爬虫工具来支持云中的数据,而不仅仅是在本地计算机上运行。通过云端采集这种方式,采集器可以根据你设置的时间自动运行采集数据。
优采云Cloud采集的功能远不止这些。
(4) 灵活的时间安排
优采云云采集支持随时随地抓取网页数据,时间和频率可根据需要调整。
(5)采集 更快
同时通过8-12台云服务器采集,对同一组数据的爬取速度可以比在本地计算机上运行快8-12倍。
(6) 降低数据获取成本
优采云Cloud采集支持在云端采集数据,并将采集接收到的数据存入云端数据库。企业无需担心高昂的硬件维护成本或采集 中断。
此外,优采云采集器的成本较市场同类竞品降低50%。优采云一直致力于提升数据分析的价值,让每个人都能以实惠的价格使用大数据。
(7)API,自定义数据对接
虽然云端采集数据可以自动导出到用户的数据库,但是通过API可以大大提高数据导出到自己系统的灵活性,轻松实现自己的系统和优采云采集器@ > 无缝对接。
你需要知道的是,优采云采集器的API有两种:数据导出API和增值API。数据导出API仅支持导出数据;增值API支持导出数据,以及修改任务中的一些参数,控制任务的启动/停止。
如何轻松实时抓取动态网页数据?
原来的:
实时抓取网页数据(运营商大数据抓取的种类和种类大解析!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-11-27 18:01
一、运营商大数据采集的类型
1、如今,运营商的大数据并不均衡。市场上获取手机号码的方式有很多种。最原创的是:一是通过数据采集软件,利用采集网站软件抓取客户主动留下的手机号码。二是爬虫爬取网站,手机号已经在APP上,三是通过网站中的手机号安装代码获取手机号。这些都是通过在网站中安装抓取码,然后抓取访问者的手机号获得的,但去年6月因为被曝光而停止了。
缺点如下。一是只能抓取自己的网站访客电话号码,二是只能被php网站使用,三是涉及客户隐私,容易被百度检测晋升。
二、运营商大数据优势
运营商大数据可以根据同行提供的网站、APP、微信小程序、400电话、固话获取目标客户的手机号码。与Python不同,无需登录网站嵌入代码中,运营商的大数据供运营商手机用户在网站和APP中使用,400通话,固定-线路电话消耗流量或资费,由运营商标注,然后型号为网站,检索目标客户单次访问APP超过一分钟的手机号码,所以运营商的大数据不再局限于自己的网站获取客户的手机号码,任何网站、APP、400电话、固话都可以抓取获取。我们是正规的运营商,我们和运营商有深入的合作。运营商抓取数据发送给公司,然后提供专门的大数据营销后台供公司调用。
比如一个peer在百度上出价,你可以直接从peer的网站中截取流,通过外呼和短信的方式触达客户,转化客户。
三、CPA 目标客户
可能有些人对CPA这个名词有点陌生,那么就让小编来给大家解释一下什么是CPA吧。CPA是指有专业电子营销团队呼唤的目标客户,比如想要装修或者消防证的客户。, 我们提供的数据是由专业的电话营销团队与客户交谈实现的,业务方也可以收听录音。周转率为40%-50%。
由于大数据采集是直接与运营商合作,后台可以明确指定需要拨打的区域,是合法正规的数据提供,长期稳定合作成为可能。
您好,我们在做精准客户拦截,云网客户获取系统
例如:
网站在同行业,每天有多少或更少的客户访问了他们的网站,我们每天实时、频繁地拦截访问网站的客户的手机号码
对于同行业400个电话,或者企业固话,每天有多少客户来电咨询,我们可以拦截来电客户的电话号码
或者同行使用百度、今日头条、微信等平台推广落地页,我们可以实时拦截访问过该页面的客户手机号
安居客、土巴兔、瓜子二手车、宜信贷等垂直行业APP,可实时拦截指定区域或全国范围内访问APP的用户手机号码
为应对大数据营销时代的到来,必胜大数据获客平台可以帮助企业快速找到客户,并且可以进行非常广泛的数据采集,并将用户设置为不同的标签,基于关于这些用户的属性。了解他们的真正需求,然后您可以将这些用户发展为真正的客户。所以这是一个真正可以帮助公司或商店实现快速营销和客户获取的工具。目前,已有不少客户利用大数据营销,成功找到了属于自己的精准目标客户。 查看全部
实时抓取网页数据(运营商大数据抓取的种类和种类大解析!!)
一、运营商大数据采集的类型
1、如今,运营商的大数据并不均衡。市场上获取手机号码的方式有很多种。最原创的是:一是通过数据采集软件,利用采集网站软件抓取客户主动留下的手机号码。二是爬虫爬取网站,手机号已经在APP上,三是通过网站中的手机号安装代码获取手机号。这些都是通过在网站中安装抓取码,然后抓取访问者的手机号获得的,但去年6月因为被曝光而停止了。
缺点如下。一是只能抓取自己的网站访客电话号码,二是只能被php网站使用,三是涉及客户隐私,容易被百度检测晋升。
二、运营商大数据优势
运营商大数据可以根据同行提供的网站、APP、微信小程序、400电话、固话获取目标客户的手机号码。与Python不同,无需登录网站嵌入代码中,运营商的大数据供运营商手机用户在网站和APP中使用,400通话,固定-线路电话消耗流量或资费,由运营商标注,然后型号为网站,检索目标客户单次访问APP超过一分钟的手机号码,所以运营商的大数据不再局限于自己的网站获取客户的手机号码,任何网站、APP、400电话、固话都可以抓取获取。我们是正规的运营商,我们和运营商有深入的合作。运营商抓取数据发送给公司,然后提供专门的大数据营销后台供公司调用。
比如一个peer在百度上出价,你可以直接从peer的网站中截取流,通过外呼和短信的方式触达客户,转化客户。
三、CPA 目标客户
可能有些人对CPA这个名词有点陌生,那么就让小编来给大家解释一下什么是CPA吧。CPA是指有专业电子营销团队呼唤的目标客户,比如想要装修或者消防证的客户。, 我们提供的数据是由专业的电话营销团队与客户交谈实现的,业务方也可以收听录音。周转率为40%-50%。
由于大数据采集是直接与运营商合作,后台可以明确指定需要拨打的区域,是合法正规的数据提供,长期稳定合作成为可能。
您好,我们在做精准客户拦截,云网客户获取系统
例如:
网站在同行业,每天有多少或更少的客户访问了他们的网站,我们每天实时、频繁地拦截访问网站的客户的手机号码
对于同行业400个电话,或者企业固话,每天有多少客户来电咨询,我们可以拦截来电客户的电话号码
或者同行使用百度、今日头条、微信等平台推广落地页,我们可以实时拦截访问过该页面的客户手机号
安居客、土巴兔、瓜子二手车、宜信贷等垂直行业APP,可实时拦截指定区域或全国范围内访问APP的用户手机号码
为应对大数据营销时代的到来,必胜大数据获客平台可以帮助企业快速找到客户,并且可以进行非常广泛的数据采集,并将用户设置为不同的标签,基于关于这些用户的属性。了解他们的真正需求,然后您可以将这些用户发展为真正的客户。所以这是一个真正可以帮助公司或商店实现快速营销和客户获取的工具。目前,已有不少客户利用大数据营销,成功找到了属于自己的精准目标客户。
实时抓取网页数据(seospidermac特别版特别版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-27 03:05
seo蜘蛛mac版,又名尖叫蛙SEO蜘蛛,是一款功能强大的网络爬虫软件,可以帮助您从不同的网页中选择要爬取的内容。它可以抓取网站的URL,并且可以实时分析结果并采集关键的现场数据,以方便SEO做出正确的决策,甚至对于无响应的网页。绝对是检测网站、搜索网络资源的神器!
SEO Spider是一款功能强大且灵活的网站爬虫,可以有效抓取小型和超大型网站,同时让您实时分析结果。它采集关键字段数据,以便 SEO 可以做出明智的决策。Screaming Frog SEO Spider 可让您快速抓取、分析和审核网站 领域的搜索引擎优化。
它可用于抓取小型和超大型 网站,其中手动检查每个页面将非常费力(或不可能!),并且您很容易错过重定向、元刷新或重复页面问题。您可以在程序的用户界面中不断采集和更新爬取数据,以查看、分析和过滤爬取数据。SEO Spider 允许您将关键的现场 SEO 元素(URL、页面标题、元描述、标题等)导出到 Excel,因此它可以轻松用作 SEO 推荐的基础。我们上面的视频演示了 SEO 工具可以做什么。
如果您正在寻找一款网络爬虫软件,那么seo spider mac 特别版是您不错的选择!seo蜘蛛mac特别版可以抓取网站的URL,在一个网站上自动分析几十个或几百个网页界面。通过 Screaming Frog SEO Spider 分析后,您可以获得所需的数据。 查看全部
实时抓取网页数据(seospidermac特别版特别版)
seo蜘蛛mac版,又名尖叫蛙SEO蜘蛛,是一款功能强大的网络爬虫软件,可以帮助您从不同的网页中选择要爬取的内容。它可以抓取网站的URL,并且可以实时分析结果并采集关键的现场数据,以方便SEO做出正确的决策,甚至对于无响应的网页。绝对是检测网站、搜索网络资源的神器!
SEO Spider是一款功能强大且灵活的网站爬虫,可以有效抓取小型和超大型网站,同时让您实时分析结果。它采集关键字段数据,以便 SEO 可以做出明智的决策。Screaming Frog SEO Spider 可让您快速抓取、分析和审核网站 领域的搜索引擎优化。
它可用于抓取小型和超大型 网站,其中手动检查每个页面将非常费力(或不可能!),并且您很容易错过重定向、元刷新或重复页面问题。您可以在程序的用户界面中不断采集和更新爬取数据,以查看、分析和过滤爬取数据。SEO Spider 允许您将关键的现场 SEO 元素(URL、页面标题、元描述、标题等)导出到 Excel,因此它可以轻松用作 SEO 推荐的基础。我们上面的视频演示了 SEO 工具可以做什么。
如果您正在寻找一款网络爬虫软件,那么seo spider mac 特别版是您不错的选择!seo蜘蛛mac特别版可以抓取网站的URL,在一个网站上自动分析几十个或几百个网页界面。通过 Screaming Frog SEO Spider 分析后,您可以获得所需的数据。
实时抓取网页数据(高德和百度地图实时路况数据的研究进展及应用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2021-11-26 08:06
1. 简介
最近老师有一个需求,就是想抓取实时矢量交通流数据进行分析,类似于百度地图和高德地图的“实时路况”。通常的网络爬虫工作一般都是抓取网页上现成的数据,但是流量数据只有栅格切片,没有矢量数据,而且数据购买成本每年几十W,基本不可能获得。实验室的兄弟们忙于事情,所以这项艰巨的任务自然交给了我。
图1.高德和百度地图实时路况数据
因为网上能得到的数据只有切片数据,这个问题转化为如何对切片数据进行向量化。如果直接使用ArcGIS Engine将栅格数据转换为矢量数据,基本上是不可能的。一是计算量过大,二是转换后的矢量数据不准确。更重要的是,每次转换的矢量道路都不一样。没有办法分析它。但是我们注意到流量切片有两个特点:
a) 也属于地图切片的一种,所以可以使用地图切片算法来计算每个切片的经纬度;
b) 它是一个透明的 PNG 图像,用四种颜色表示交通拥堵。我只需要识别每一段路的颜色,判断交通拥堵情况就可以完成“矢量化”工作。
接下来的工作可以分为以下几个步骤:
a) 准备某城市详细的矢量道路数据;
b) 下载城市交通流切片,拼成大图;
c) 在网格上标记需要检测颜色的像素点,并计算这些像素点的经纬度;
d) 将每条道路的矢量数据与像素一一匹配,检测交通流情况并写入数据库。
2. 地图切片系统和实时交通流
地图切片也称为地图图块。这方面的文章和机制已经很成熟了。详细算法内容请参考这个文章。本文以高德切片为例。高德的实时交通流使用动态切片,但与一般的切片系统略有不同。切片的缩放级别越小,缩放级别越大,反之亦然。
当然我们也可以自己计算不同,建议使用类库
3. 主要思想
高德的交通流数据(图1.(a))一般都很简单。用“绿”、“黄”、“红”三种颜色表示交通拥堵。分离非常明显。但是直接将切片转换为向量是非常不现实的。但是我有北京提供的非常详细的矢量数据(图2.(b))。如果将交通流切片与矢量数据进行匹配,则可以生成实时交通流矢量数据。最后,交通流数据 以切片或向量形式发布都可以。所以现在的主要任务是找到匹配流量切片和矢量数据的中间件。
图2. 交通流切片和矢量数据
虽然高德切片数据是以编码的方式组织的,但每张图片和每一个像素都有严格的固定坐标。只要选取一部分有值的像素点,将像素点安装公式转化为点阵,然后将每个A点与一条矢量道路进行匹配,即为每个点添加一个RouteId字段。图3(a)是我生成的点阵的一部分,图3(b)是点阵的属性表,它收录三个字段:x、y和routeid。具体步骤如下:
a) 定期下载交通流切片数据并保存在本地文件夹中;
b) 根据点阵数据读取指定切片的指定像素,判断像素的颜色,得到拥塞情况;
c) 根据拥塞情况和RouteId生成交通流表,包括RouteId和Traffic两个字段;
d) 根据RouteId匹配交通流表和矢量数据,得到矢量交通流数据;
e) 使用切片工具从矢量数据中生成天津师范大学所需的切片数据。
图3. (a) 交通流切片数据和矢量道路数据用格子叠加,(b) 格子的属性表
这就是我如何使用程序捕获2014年12月5日晚上8点左右的交通流量数据,然后对北京四环的交通流量进行矢量化。从结果可以看出,交通流量的总体趋势相似,但在一些细节上存在一些差异。矢量化的结果取决于晶格的细度。
图4. (a) 交通流切片数据 (b) 生成的矢量交通流数据
4. 总结
当时我是抱着完成任务的心态做这个的,所以整个事情做的很粗糙,代码也很乱,所以就无耻的分享一下代码吧。大家请看官方的轻喷,以后有时间再整理。 查看全部
实时抓取网页数据(高德和百度地图实时路况数据的研究进展及应用方法)
1. 简介
最近老师有一个需求,就是想抓取实时矢量交通流数据进行分析,类似于百度地图和高德地图的“实时路况”。通常的网络爬虫工作一般都是抓取网页上现成的数据,但是流量数据只有栅格切片,没有矢量数据,而且数据购买成本每年几十W,基本不可能获得。实验室的兄弟们忙于事情,所以这项艰巨的任务自然交给了我。
图1.高德和百度地图实时路况数据
因为网上能得到的数据只有切片数据,这个问题转化为如何对切片数据进行向量化。如果直接使用ArcGIS Engine将栅格数据转换为矢量数据,基本上是不可能的。一是计算量过大,二是转换后的矢量数据不准确。更重要的是,每次转换的矢量道路都不一样。没有办法分析它。但是我们注意到流量切片有两个特点:
a) 也属于地图切片的一种,所以可以使用地图切片算法来计算每个切片的经纬度;
b) 它是一个透明的 PNG 图像,用四种颜色表示交通拥堵。我只需要识别每一段路的颜色,判断交通拥堵情况就可以完成“矢量化”工作。
接下来的工作可以分为以下几个步骤:
a) 准备某城市详细的矢量道路数据;
b) 下载城市交通流切片,拼成大图;
c) 在网格上标记需要检测颜色的像素点,并计算这些像素点的经纬度;
d) 将每条道路的矢量数据与像素一一匹配,检测交通流情况并写入数据库。
2. 地图切片系统和实时交通流
地图切片也称为地图图块。这方面的文章和机制已经很成熟了。详细算法内容请参考这个文章。本文以高德切片为例。高德的实时交通流使用动态切片,但与一般的切片系统略有不同。切片的缩放级别越小,缩放级别越大,反之亦然。
当然我们也可以自己计算不同,建议使用类库
3. 主要思想
高德的交通流数据(图1.(a))一般都很简单。用“绿”、“黄”、“红”三种颜色表示交通拥堵。分离非常明显。但是直接将切片转换为向量是非常不现实的。但是我有北京提供的非常详细的矢量数据(图2.(b))。如果将交通流切片与矢量数据进行匹配,则可以生成实时交通流矢量数据。最后,交通流数据 以切片或向量形式发布都可以。所以现在的主要任务是找到匹配流量切片和矢量数据的中间件。
图2. 交通流切片和矢量数据
虽然高德切片数据是以编码的方式组织的,但每张图片和每一个像素都有严格的固定坐标。只要选取一部分有值的像素点,将像素点安装公式转化为点阵,然后将每个A点与一条矢量道路进行匹配,即为每个点添加一个RouteId字段。图3(a)是我生成的点阵的一部分,图3(b)是点阵的属性表,它收录三个字段:x、y和routeid。具体步骤如下:
a) 定期下载交通流切片数据并保存在本地文件夹中;
b) 根据点阵数据读取指定切片的指定像素,判断像素的颜色,得到拥塞情况;
c) 根据拥塞情况和RouteId生成交通流表,包括RouteId和Traffic两个字段;
d) 根据RouteId匹配交通流表和矢量数据,得到矢量交通流数据;
e) 使用切片工具从矢量数据中生成天津师范大学所需的切片数据。
图3. (a) 交通流切片数据和矢量道路数据用格子叠加,(b) 格子的属性表
这就是我如何使用程序捕获2014年12月5日晚上8点左右的交通流量数据,然后对北京四环的交通流量进行矢量化。从结果可以看出,交通流量的总体趋势相似,但在一些细节上存在一些差异。矢量化的结果取决于晶格的细度。
图4. (a) 交通流切片数据 (b) 生成的矢量交通流数据
4. 总结
当时我是抱着完成任务的心态做这个的,所以整个事情做的很粗糙,代码也很乱,所以就无耻的分享一下代码吧。大家请看官方的轻喷,以后有时间再整理。
实时抓取网页数据(实时抓取网页数据是一个非常好的方案,先说知道的一种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-26 02:02
实时抓取网页数据是一个非常好的方案,先说我知道的一种方法:借助收集网页的buffer或者filesystem(文件系统),或者定时内网来实现对大规模网页的抓取。这种方法的弊端在于抓取速度慢,抓取人员会非常被动,只能说是人工去读取和翻译。如果是需要抓取大数据的话,必须要有数据分析相关的知识,推荐收集对大规模网页数据的收集和分析的知识,推荐kalilinux或者ubuntu的脚本。
我通常使用shell,直接写代码,然后一行一行执行。
最好用windows系统,
webdriver可以让你一次性抓好多网页内容
不是最快捷的方法,awk,可以搜索一下,可以了解写buffer,inc抓取速度可以保证。
目前用go。shell写的buffer或者filesystem抓取网页源代码挺好。本人没有抓取大规模网页的经验,但是目前正在学习调试中。所以应该抓取网页有两个办法:1.应用开发中可以用asyncio.2.生成的json对象有该json对象有针对socket的相关event。
win32api
bing“xss”网页就可以抓取了,不过一般都是静态的网页,动态的才用浏览器去抓,毕竟有cookie机制,抓取的网页内容是网页本身,可以解析json数据再用python解析生成text,或者直接用nodejs的jsonparser抓取,这样以后换浏览器,网页依然可以变,不过你看不到了,因为和本机内容不同,win7以上系统都可以禁止后台运行浏览器,有sql注入漏洞,所以重新抓取后需要手动关闭。 查看全部
实时抓取网页数据(实时抓取网页数据是一个非常好的方案,先说知道的一种方法)
实时抓取网页数据是一个非常好的方案,先说我知道的一种方法:借助收集网页的buffer或者filesystem(文件系统),或者定时内网来实现对大规模网页的抓取。这种方法的弊端在于抓取速度慢,抓取人员会非常被动,只能说是人工去读取和翻译。如果是需要抓取大数据的话,必须要有数据分析相关的知识,推荐收集对大规模网页数据的收集和分析的知识,推荐kalilinux或者ubuntu的脚本。
我通常使用shell,直接写代码,然后一行一行执行。
最好用windows系统,
webdriver可以让你一次性抓好多网页内容
不是最快捷的方法,awk,可以搜索一下,可以了解写buffer,inc抓取速度可以保证。
目前用go。shell写的buffer或者filesystem抓取网页源代码挺好。本人没有抓取大规模网页的经验,但是目前正在学习调试中。所以应该抓取网页有两个办法:1.应用开发中可以用asyncio.2.生成的json对象有该json对象有针对socket的相关event。
win32api
bing“xss”网页就可以抓取了,不过一般都是静态的网页,动态的才用浏览器去抓,毕竟有cookie机制,抓取的网页内容是网页本身,可以解析json数据再用python解析生成text,或者直接用nodejs的jsonparser抓取,这样以后换浏览器,网页依然可以变,不过你看不到了,因为和本机内容不同,win7以上系统都可以禁止后台运行浏览器,有sql注入漏洞,所以重新抓取后需要手动关闭。
实时抓取网页数据(如何使用Scrapy提取数据的最佳方法是使用shellScrapyshell尝试选择器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-25 15:14
提取数据
学习如何使用 Scrapy 提取数据的最好方法是尝试使用 shellScrapy shell 的选择器。跑:
scrapy shell 'http://quotes.toscrape.com/page/1/'
注意
从命令行运行 Scrapy shell 时,请记住始终将 URL 括在引号中,否则收录参数(即 & 字符)的 URL 将不起作用。
在 Windows 上,使用双引号:
scrapy shell "http://quotes.toscrape.com/page/1/"
你会看到类似的东西:
[ ... Scrapy log here ... ] 2016-09-19 12:09:27 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) [s] Available Scrapy objects: [s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc) [s] crawler [s] item {} [s] request [s] response [s] settings [s] spider [s] Useful shortcuts: [s] shelp() Shell help (print this help) [s] fetch(req_or_url) Fetch request (or URL) and update local objects [s] view(response) View response in a browser >>>
使用 shell,您可以尝试使用 CSS 和响应对象来选择元素:
>>> response.css('title') []
运行 response.css('title') 的结果是一个类似列表的对象 SelectorList,它表示一个收录 XML/HTML 元素的 Selector 对象列表,并允许您运行进一步的查询以优化选择或提取数据。
要从上面的标题中提取文本,您可以执行以下操作:
>>> response.css('title::text').extract() ['Quotes to Scrape']
这里有两点需要注意:一是我们在CSS查询中添加了::text,这意味着我们只想直接在元素内选择文本元素。如果我们不指定::text,我们将获得完整的标题元素,包括它的标签:
>>> response.css('title').extract() ['Quotes to Scrape']
另一件事是调用 .extract() 的结果是一个列表,因为我们正在处理 SelectorList 的一个实例。当你知道你只想要第一个结果时,就像在这种情况下一样,你可以这样做:
>>> response.css('title::text').extract_first() 'Quotes to Scrape'
作为替代方案,您可以编写:
>>> response.css('title::text')[0].extract() 'Quotes to Scrape'
但是,当它找不到任何与选择匹配的元素时,使用 .extract_first() 来避免 IndexError 并返回 None。
这里有一个教训:对于大多数爬虫代码,你希望它在页面上什么都找不到的情况下能够适应错误,所以即使某些部分无法删除,你至少可以得到一些数据。
除了extract()和extract_first()方法之外,还可以使用re()方法用正则表达式进行提取:
>>> response.css('title::text').re(r'Quotes.*') ['Quotes to Scrape'] >>> response.css('title::text').re(r'Qw+') ['Quotes'] >>> response.css('title::text').re(r'(w+) to (w+)') ['Quotes', 'Scrape']
为了找到正确的 CSS 选择器,您可能会发现在 Web 浏览器中使用 shell 打开响应页面视图(响应)非常有用。您可以使用浏览器开发工具或扩展程序(例如 Firebug)(请参阅有关使用 Firebug 进行爬网和使用 Firefox 进行爬网的部分)。
Selector Gadget 也是一个很好的工具,可以快速找到可视化选择元素的 CSS 选择器,可以在很多浏览器中使用。
XPath:简介
除了 CSS,Scrapy 选择器还支持使用 XPath 表达式:
>>> response.xpath('//title') [] >>> response.xpath('//title/text()').extract_first() 'Quotes to Scrape'
XPath 表达式非常强大,是 Scrapy 选择器的基础。事实上,CSS 选择器在幕后转换为 XPath。如果仔细阅读 shell 中选择器对象的文本表示,您可以看到它。
尽管它可能不如 CSS 选择器流行,但 XPath 表达式提供了更多功能,因为除了导航结构之外,它还可以查看内容。使用 XPath,您可以选择以下内容: 选择收录文本“下一页”的链接。这使得 XPath 非常适合抓取任务,我们鼓励您学习 XPath,即使您已经知道如何构建 CSS 选择器,它也会使抓取更容易。
我们不会在此处介绍 XPath 的大部分内容,但您可以在此处阅读有关在 Scrapy 选择器中使用 XPath 的更多信息。想进一步了解XPath,我们推荐本教程通过实例学习XPath,本教程将学习“How to Think in XPath”。
提取引号和作者
现在您已经了解了一些关于选择和提取的知识,让我们通过编写代码从网页中提取引号来完成我们的蜘蛛。
中的每个引用都由一个 HTML 元素表示,如下所示:
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” by Albert Einstein (about) Tags: change deep-thoughts thinking world
让我们打开scrapy shell,玩一下,学习如何提取我们想要的数据:
$ scrapy shell 'http://quotes.toscrape.com'
我们得到一个引用 HTML 元素的选择器列表:
>>> response.css("div.quote")
上述查询返回的每个选择器都允许我们对其子元素运行进一步的查询。让我们将第一个选择器分配给一个变量,以便我们可以直接在特定引号上运行 CSS 选择器:
>>> quote = response.css("div.quote")[0]
现在,让我们使用刚刚创建的对象从引用中提取标题、作者和标签:
>>> title = quote.css("span.text::text").extract_first() >>> title '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”' >>> author = quote.css("small.author::text").extract_first() >>> author 'Albert Einstein'
鉴于标签是一个字符串列表,我们可以使用 .extract() 方法来获取所有这些:
>>> tags = quote.css("div.tags a.tag::text").extract() >>> tags ['change', 'deep-thoughts', 'thinking', 'world']
在弄清楚如何提取每一位之后,我们现在可以遍历所有引用的元素并将它们一起放入 Python 字典中:
>>> for quote in response.css("div.quote"): ... text = quote.css("span.text::text").extract_first() ... author = quote.css("small.author::text").extract_first() ... tags = quote.css("div.tags a.tag::text").extract() ... print(dict(text=text, author=author, tags=tags)) {'tags': ['change', 'deep-thoughts', 'thinking', 'world'], 'author': 'Albert Einstein', 'text': '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”'} {'tags': ['abilities', 'choices'], 'author': 'J.K. Rowling', 'text': '“It is our choices, Harry, that show what we truly are, far more than our abilities.”'} ... a few more of these, omitted for brevity >>>
在我们的蜘蛛中提取数据
让我们回到我们的蜘蛛。到目前为止,它还没有特别提取任何数据,它只是将整个 HTML 页面保存到本地文件中。让我们将上述提取逻辑集成到我们的蜘蛛中。
Scrapy Spider 通常会生成许多字典,其中收录从页面中提取的数据。为此,我们在回调中使用了Python关键字yield,如下图:
import scrapy class QuotesSpider(scrapy.Spider): name = "quotes" start_urls = [ 'http://quotes.toscrape.com/page/1/', 'http://quotes.toscrape.com/page/2/', ] def parse(self, response): for quote in response.css('div.quote'): yield { 'text': quote.css('span.text::text').extract_first(), 'author': quote.css('small.author::text').extract_first(), 'tags': quote.css('div.tags a.tag::text').extract(), }
如果你运行这个蜘蛛,它会输出提取的数据和日志:
2016-09-19 18:57:19 [scrapy.core.scraper] DEBUG: Scraped from {'tags': ['life', 'love'], 'author': 'André Gide', 'text': '“It is better to be hated for what you are than to be loved for what you are not.”'} 2016-09-19 18:57:19 [scrapy.core.scraper] DEBUG: Scraped from {'tags': ['edison', 'failure', 'inspirational', 'paraphrased'], 'author': 'Thomas A. Edison', 'text': "“I have not failed. I've just found 10,000 ways that won't work.”"}
存储已删除的数据
存储已删除数据的最简单方法是使用提要导出,使用以下命令:
scrapy crawl quotes -o quotes.json
这将生成一个收录所有已删除项目的quotes.json 文件,以JSON 序列化。
由于历史原因,Scrapy 将附加到给定文件而不是覆盖其内容。如果您在第二次之前运行此命令两次而没有删除该文件,您最终会得到一个损坏的 JSON 文件。
您还可以使用其他格式,例如 JSON Lines:
scrapy crawl quotes -o quotes.jl
JSON 行格式很有用,因为它经过简化,您可以轻松地向其追加新记录。当您运行它两次时,它没有相同的 JSON 问题。另外,由于每条记录都是单独的一行,所以你可以处理大文件而不用把所有东西都放在内存中,一些工具比如JQ可以帮助你在命令行中做到这一点。
在小型项目(例如本教程中的项目)中,这应该足够了。但是,如果要对已删除的项执行更复杂的操作,则可以编写项目管道。在您创建项目时,项目管道的占位符文件已经为您设置了 tutorial/pipelines.py。如果您只想存储已删除的项目,则无需实现任何项目管道。
以下链接
假设您不需要从前两页抓取内容,但是您需要 网站 的所有页面的引号。
现在您知道如何从页面中提取数据,让我们看看如何从中获取链接。 查看全部
实时抓取网页数据(如何使用Scrapy提取数据的最佳方法是使用shellScrapyshell尝试选择器)
提取数据
学习如何使用 Scrapy 提取数据的最好方法是尝试使用 shellScrapy shell 的选择器。跑:
scrapy shell 'http://quotes.toscrape.com/page/1/'
注意
从命令行运行 Scrapy shell 时,请记住始终将 URL 括在引号中,否则收录参数(即 & 字符)的 URL 将不起作用。
在 Windows 上,使用双引号:
scrapy shell "http://quotes.toscrape.com/page/1/"
你会看到类似的东西:
[ ... Scrapy log here ... ] 2016-09-19 12:09:27 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) [s] Available Scrapy objects: [s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc) [s] crawler [s] item {} [s] request [s] response [s] settings [s] spider [s] Useful shortcuts: [s] shelp() Shell help (print this help) [s] fetch(req_or_url) Fetch request (or URL) and update local objects [s] view(response) View response in a browser >>>
使用 shell,您可以尝试使用 CSS 和响应对象来选择元素:
>>> response.css('title') []
运行 response.css('title') 的结果是一个类似列表的对象 SelectorList,它表示一个收录 XML/HTML 元素的 Selector 对象列表,并允许您运行进一步的查询以优化选择或提取数据。
要从上面的标题中提取文本,您可以执行以下操作:
>>> response.css('title::text').extract() ['Quotes to Scrape']
这里有两点需要注意:一是我们在CSS查询中添加了::text,这意味着我们只想直接在元素内选择文本元素。如果我们不指定::text,我们将获得完整的标题元素,包括它的标签:
>>> response.css('title').extract() ['Quotes to Scrape']
另一件事是调用 .extract() 的结果是一个列表,因为我们正在处理 SelectorList 的一个实例。当你知道你只想要第一个结果时,就像在这种情况下一样,你可以这样做:
>>> response.css('title::text').extract_first() 'Quotes to Scrape'
作为替代方案,您可以编写:
>>> response.css('title::text')[0].extract() 'Quotes to Scrape'
但是,当它找不到任何与选择匹配的元素时,使用 .extract_first() 来避免 IndexError 并返回 None。
这里有一个教训:对于大多数爬虫代码,你希望它在页面上什么都找不到的情况下能够适应错误,所以即使某些部分无法删除,你至少可以得到一些数据。
除了extract()和extract_first()方法之外,还可以使用re()方法用正则表达式进行提取:
>>> response.css('title::text').re(r'Quotes.*') ['Quotes to Scrape'] >>> response.css('title::text').re(r'Qw+') ['Quotes'] >>> response.css('title::text').re(r'(w+) to (w+)') ['Quotes', 'Scrape']
为了找到正确的 CSS 选择器,您可能会发现在 Web 浏览器中使用 shell 打开响应页面视图(响应)非常有用。您可以使用浏览器开发工具或扩展程序(例如 Firebug)(请参阅有关使用 Firebug 进行爬网和使用 Firefox 进行爬网的部分)。
Selector Gadget 也是一个很好的工具,可以快速找到可视化选择元素的 CSS 选择器,可以在很多浏览器中使用。
XPath:简介
除了 CSS,Scrapy 选择器还支持使用 XPath 表达式:
>>> response.xpath('//title') [] >>> response.xpath('//title/text()').extract_first() 'Quotes to Scrape'
XPath 表达式非常强大,是 Scrapy 选择器的基础。事实上,CSS 选择器在幕后转换为 XPath。如果仔细阅读 shell 中选择器对象的文本表示,您可以看到它。
尽管它可能不如 CSS 选择器流行,但 XPath 表达式提供了更多功能,因为除了导航结构之外,它还可以查看内容。使用 XPath,您可以选择以下内容: 选择收录文本“下一页”的链接。这使得 XPath 非常适合抓取任务,我们鼓励您学习 XPath,即使您已经知道如何构建 CSS 选择器,它也会使抓取更容易。
我们不会在此处介绍 XPath 的大部分内容,但您可以在此处阅读有关在 Scrapy 选择器中使用 XPath 的更多信息。想进一步了解XPath,我们推荐本教程通过实例学习XPath,本教程将学习“How to Think in XPath”。
提取引号和作者
现在您已经了解了一些关于选择和提取的知识,让我们通过编写代码从网页中提取引号来完成我们的蜘蛛。
中的每个引用都由一个 HTML 元素表示,如下所示:
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” by Albert Einstein (about) Tags: change deep-thoughts thinking world
让我们打开scrapy shell,玩一下,学习如何提取我们想要的数据:
$ scrapy shell 'http://quotes.toscrape.com'
我们得到一个引用 HTML 元素的选择器列表:
>>> response.css("div.quote")
上述查询返回的每个选择器都允许我们对其子元素运行进一步的查询。让我们将第一个选择器分配给一个变量,以便我们可以直接在特定引号上运行 CSS 选择器:
>>> quote = response.css("div.quote")[0]
现在,让我们使用刚刚创建的对象从引用中提取标题、作者和标签:
>>> title = quote.css("span.text::text").extract_first() >>> title '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”' >>> author = quote.css("small.author::text").extract_first() >>> author 'Albert Einstein'
鉴于标签是一个字符串列表,我们可以使用 .extract() 方法来获取所有这些:
>>> tags = quote.css("div.tags a.tag::text").extract() >>> tags ['change', 'deep-thoughts', 'thinking', 'world']
在弄清楚如何提取每一位之后,我们现在可以遍历所有引用的元素并将它们一起放入 Python 字典中:
>>> for quote in response.css("div.quote"): ... text = quote.css("span.text::text").extract_first() ... author = quote.css("small.author::text").extract_first() ... tags = quote.css("div.tags a.tag::text").extract() ... print(dict(text=text, author=author, tags=tags)) {'tags': ['change', 'deep-thoughts', 'thinking', 'world'], 'author': 'Albert Einstein', 'text': '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”'} {'tags': ['abilities', 'choices'], 'author': 'J.K. Rowling', 'text': '“It is our choices, Harry, that show what we truly are, far more than our abilities.”'} ... a few more of these, omitted for brevity >>>
在我们的蜘蛛中提取数据
让我们回到我们的蜘蛛。到目前为止,它还没有特别提取任何数据,它只是将整个 HTML 页面保存到本地文件中。让我们将上述提取逻辑集成到我们的蜘蛛中。
Scrapy Spider 通常会生成许多字典,其中收录从页面中提取的数据。为此,我们在回调中使用了Python关键字yield,如下图:
import scrapy class QuotesSpider(scrapy.Spider): name = "quotes" start_urls = [ 'http://quotes.toscrape.com/page/1/', 'http://quotes.toscrape.com/page/2/', ] def parse(self, response): for quote in response.css('div.quote'): yield { 'text': quote.css('span.text::text').extract_first(), 'author': quote.css('small.author::text').extract_first(), 'tags': quote.css('div.tags a.tag::text').extract(), }
如果你运行这个蜘蛛,它会输出提取的数据和日志:
2016-09-19 18:57:19 [scrapy.core.scraper] DEBUG: Scraped from {'tags': ['life', 'love'], 'author': 'André Gide', 'text': '“It is better to be hated for what you are than to be loved for what you are not.”'} 2016-09-19 18:57:19 [scrapy.core.scraper] DEBUG: Scraped from {'tags': ['edison', 'failure', 'inspirational', 'paraphrased'], 'author': 'Thomas A. Edison', 'text': "“I have not failed. I've just found 10,000 ways that won't work.”"}
存储已删除的数据
存储已删除数据的最简单方法是使用提要导出,使用以下命令:
scrapy crawl quotes -o quotes.json
这将生成一个收录所有已删除项目的quotes.json 文件,以JSON 序列化。
由于历史原因,Scrapy 将附加到给定文件而不是覆盖其内容。如果您在第二次之前运行此命令两次而没有删除该文件,您最终会得到一个损坏的 JSON 文件。
您还可以使用其他格式,例如 JSON Lines:
scrapy crawl quotes -o quotes.jl
JSON 行格式很有用,因为它经过简化,您可以轻松地向其追加新记录。当您运行它两次时,它没有相同的 JSON 问题。另外,由于每条记录都是单独的一行,所以你可以处理大文件而不用把所有东西都放在内存中,一些工具比如JQ可以帮助你在命令行中做到这一点。
在小型项目(例如本教程中的项目)中,这应该足够了。但是,如果要对已删除的项执行更复杂的操作,则可以编写项目管道。在您创建项目时,项目管道的占位符文件已经为您设置了 tutorial/pipelines.py。如果您只想存储已删除的项目,则无需实现任何项目管道。
以下链接
假设您不需要从前两页抓取内容,但是您需要 网站 的所有页面的引号。
现在您知道如何从页面中提取数据,让我们看看如何从中获取链接。

