
实时抓取网页数据
实时抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-09-19 06:11
原创链接:
有时,由于各种原因,我们需要采集一个站点的数据,但不同站点的数据显示方式略有不同
本文使用Java向您展示如何抓取站点的数据:(1)grab原创网页的数据;(2)grab网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:检查网页源代码。我们可以看到源代码中有一段:
从这里可以看出,再次请求网页后会显示查询结果
我们来看看查询后的网址:
换言之,我们只能通过访问这样的网站才能得到IP查询的结果。接下来,请看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到站点,使用bufreader保存网页返回的数据,然后通过自定义解析方法显示结果
这里我只是随便分析一下。如果我想准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时候,为了保护自己的数据,网站不直接在网页源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方法用于查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但是有时候我们非常需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
在第一次单击startbutton之后,它开始监视web页面的交互
当我们打开网页时,可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了便于查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们只需要分析HTTP analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址来获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两个豌豆一样,抓取JS的方法与原创网页完全相同。我们只是做了一个分析JS的过程
以下是该计划的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
我希望这篇文章能对有需要的朋友有所帮助。如果你需要程序源代码,请点击这里下载 查看全部
实时抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原创链接:
有时,由于各种原因,我们需要采集一个站点的数据,但不同站点的数据显示方式略有不同
本文使用Java向您展示如何抓取站点的数据:(1)grab原创网页的数据;(2)grab网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:

第二步:检查网页源代码。我们可以看到源代码中有一段:

从这里可以看出,再次请求网页后会显示查询结果
我们来看看查询后的网址:

换言之,我们只能通过访问这样的网站才能得到IP查询的结果。接下来,请看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到站点,使用bufreader保存网页返回的数据,然后通过自定义解析方法显示结果
这里我只是随便分析一下。如果我想准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时候,为了保护自己的数据,网站不直接在网页源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:

第一种方法用于查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但是有时候我们非常需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
在第一次单击startbutton之后,它开始监视web页面的交互
当我们打开网页时,可以看到HTTP analyzer列出了该网页的所有请求数据和结果:

为了便于查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:

这是HTTP analyzer点击查询按钮后的结果,我们继续查看:


从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们只需要分析HTTP analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址来获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两个豌豆一样,抓取JS的方法与原创网页完全相同。我们只是做了一个分析JS的过程
以下是该计划的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
我希望这篇文章能对有需要的朋友有所帮助。如果你需要程序源代码,请点击这里下载
实时抓取网页数据(如何让百度快速收录呢,如何选择链接提交方式? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-09-18 05:16
)
在做百度推广时,如何让百度快速收录?这里有三种方法。今天我们主要讲第一个
如何选择链接提交方式
1、activepush:最快的提交方式。建议您立即以这种方式将站点的新输出链接推送到百度,以确保新链接可以被百度收录推送@
2、automatic push:最方便的提交方式,请在站点每个页面的源代码中部署自动推送的JS代码,每次浏览部署代码的页面时,链接会自动推送到百度。它可以与主动推送一起使用
3、sitemap:您可以定期将网站链接放入站点地图,并将站点地图提交给百度。百度会定期抓取并检查你提交的网站地图并处理链接,但收录比主动推送4、手动提交慢:这种方法可以用于一次性向百度提交链接
百度站长平台为站长提供链接提交渠道。你可以通过百度提交你想成为收录的链接。百度搜索引擎将按照标准处理这些链接,但并不保证收录可以提交链接
应当指出的是:
一,。主动推送功能的门户是:工具-网页捕获-链接提交-主动推送(实时)
二,。主动推送使用与原创实时推送不同的数据接口,需要再次获取密钥(登录后在链接提交工具界面可见)
登录地址是
为了确保您的数据提交效果,请及时更换界面和按键,尽快熟悉主动推送功能,如有问题请通过反馈中心得到百度工作人员的帮助
使用百度主动推送(实时)可以加速收录并保护原创内容不受采集第三方的伤害
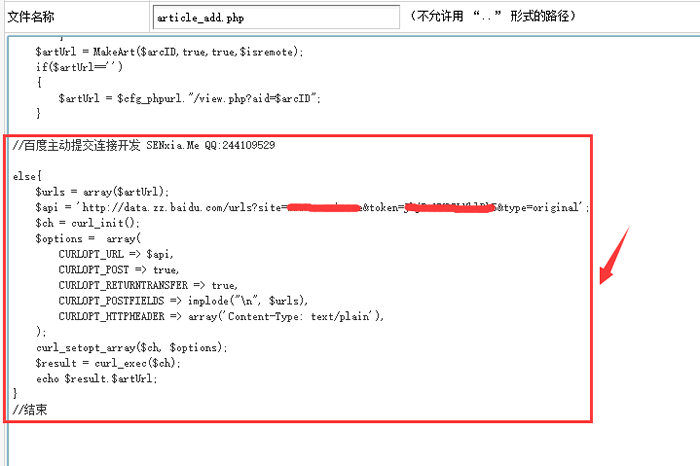
我还没有看到有人写过百度的主动推送代码,所以我根据百度提供的PHP代码编写,并将其添加到Dede后台发布的文章文件中,实现了百度的主动推送(实时)功能
在article_add.php中搜索 $artUrl = MakeArt($arcID,true,true,$isremote);
然后在
if($artUrl=='')
{
$artUrl = $cfg_phpurl."/view.php?aid=$arcID";
}
后面加入
else{
$urls[]='http://'.$_SERVER['HTTP_HOST'].$artUrl;
$api = 'http://data.zz.baidu.com/urls?site=你的域名&token=准入密钥';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
}
省省吧
成功发布文章后,将显示以下内容
查看全部
实时抓取网页数据(如何让百度快速收录呢,如何选择链接提交方式?
)
在做百度推广时,如何让百度快速收录?这里有三种方法。今天我们主要讲第一个
如何选择链接提交方式
1、activepush:最快的提交方式。建议您立即以这种方式将站点的新输出链接推送到百度,以确保新链接可以被百度收录推送@
2、automatic push:最方便的提交方式,请在站点每个页面的源代码中部署自动推送的JS代码,每次浏览部署代码的页面时,链接会自动推送到百度。它可以与主动推送一起使用
3、sitemap:您可以定期将网站链接放入站点地图,并将站点地图提交给百度。百度会定期抓取并检查你提交的网站地图并处理链接,但收录比主动推送4、手动提交慢:这种方法可以用于一次性向百度提交链接
百度站长平台为站长提供链接提交渠道。你可以通过百度提交你想成为收录的链接。百度搜索引擎将按照标准处理这些链接,但并不保证收录可以提交链接
应当指出的是:
一,。主动推送功能的门户是:工具-网页捕获-链接提交-主动推送(实时)
二,。主动推送使用与原创实时推送不同的数据接口,需要再次获取密钥(登录后在链接提交工具界面可见)
登录地址是
为了确保您的数据提交效果,请及时更换界面和按键,尽快熟悉主动推送功能,如有问题请通过反馈中心得到百度工作人员的帮助
使用百度主动推送(实时)可以加速收录并保护原创内容不受采集第三方的伤害
我还没有看到有人写过百度的主动推送代码,所以我根据百度提供的PHP代码编写,并将其添加到Dede后台发布的文章文件中,实现了百度的主动推送(实时)功能
在article_add.php中搜索 $artUrl = MakeArt($arcID,true,true,$isremote);
然后在
if($artUrl=='')
{
$artUrl = $cfg_phpurl."/view.php?aid=$arcID";
}
后面加入
else{
$urls[]='http://'.$_SERVER['HTTP_HOST'].$artUrl;
$api = 'http://data.zz.baidu.com/urls?site=你的域名&token=准入密钥';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
}
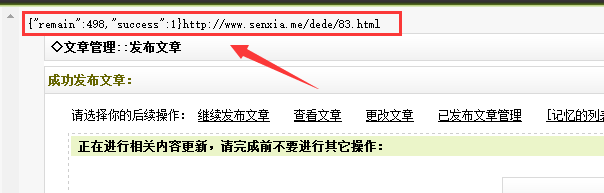
省省吧
成功发布文章后,将显示以下内容
实时抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-18 05:15
我相信每个网站网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式只有两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不介绍
二、编写您自己的程序并获取它。这种方式要求站长编写自己的程序,这可能需要站长的开发能力
起初,我试图使用第三方工具来捕获我需要的数据。因为互联网上流行的第三方工具要么不符合我的要求,要么太复杂,我一时不知道如何使用它们。后来,我决定自己写。现在我基本上可以处理一个网站(仅程序开发时间,不包括数据捕获时间)
经过一段时间的数据采集工作,我遇到了很多困难。最常见的问题之一是获取分页数据的问题。原因是有多种形式的数据分页。接下来,我将以三种形式介绍获取分页数据的方法。虽然我在网上看到了很多这样的文章,但是每次我拿别人的代码时,总有各种各样的问题。以下代码可以正确执行,我目前也在使用它们。本文的代码实现是用c语言实现的。我认为其他语言的原则大致相同
让我们开门见山:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具捕获此表单也非常简单。基本上,不需要编写代码。对于像我这样宁愿花半天时间编写代码而不愿学习第三方工具的人,我仍然自己编写代码
此方法通过循环生成数据页的URL地址。例如,通过Httpwebrequest访问相应的URL地址,并返回相应页面的HTML文本。下一个任务是解析字符串并将所需内容保存到本地数据库;有关捕获的代码,请参阅以下内容:
公共字符串GetResponseString(字符串url){
字符串_StrResponse=“”
HttpWebRequest WebRequest=(HttpWebRequest)WebRequest.Create(url)
_WebRequest.UserAgent=“MOZILLA/4.0(兼容;MSIE7.0;WINDOWS NT5.2.NET CLR1.1.4322.NET CLR2.0.50727.NET CLR3.0.0450 6.648.NET CLR@k305.21022.NET CLR3.0.450 6.2152.NET CLR@k305.30729)",
_WebRequest.Method=“GET”
WebResponse _WebResponse=_WebRequest.GetResponse()
StreamReader _ResponseStream=新的StreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding(“gb2312”)
_StrResponse=_ResponseStream.ReadToEnd()
_WebResponse.Close()
_ResponseStream.Close()
返回响应
}
上面的代码可以返回与页面的HTML内容相对应的字符串。其余的是从该字符串中获取您关心的信息
第二种方式:可能是开发中经常遇到的,它的分页控件通过post将分页信息提交给后台代码,比如.Net下的GridView的分页功能,当你点击分页页码时,你会发现URL地址没有改变,但是页码变了而且页面内容也发生了变化。如果你仔细观察,你会发现当你将鼠标移动到每个页码上时,状态栏会显示javascript:_dopostback(“GridView”,“page1”)和其他代码。事实上,这种形式并不很难,因为毕竟,有一个地方可以找到页码的规律
我们知道提交HTTP请求有两种方式,一种是get,另一种是post。第一种是get,第二种是post。具体的提交原则不需要详细解释,这不是本文的重点
要获取此类页面,您需要注意页面的几个重要元素
一、_viewstate应该是.Net独有的,也是.Net开发人员喜欢和讨厌的东西。当你打开一个网站页面时,如果你发现这个东西后面有很多乱七八糟的字符,那么这个网站一定是用英语写的
二、__dopostback方法。这是从页面自动生成的JavaScript方法,其中收录两个参数_eventtarget和_eventargument。这两个参数可以引用与页码对应的内容,因为当您单击翻页时,页码信息将传输到这两个参数
三、__EVENTVALIDATION这也应该是独一无二的
你不必太在意这三件事是做什么的,你只需要在编写代码获取页面时注意提交这三个元素
与第一种方法一样,_doPostBack的两个参数必须以循环方式拼合在一起。只有收录页码信息的参数才需要拼合在一起。这里需要注意的一点是,每次通过post提交下一页的请求时,您应该首先获得_viewstateinformation和_eVentValidation当前页面的信息,因此分页数据更准确。第一种方法可用于获取第一页的页面内容,然后同时取出相应的u viewstate信息和_eventvalidation信息,然后循环下一页,然后记录_viewstate信息和_eventvali抓取每页后采集信息,以便为下一页文章提交数据
参考代码如下:
<p>对于(int i=0;i 查看全部
实时抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信每个网站网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式只有两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不介绍
二、编写您自己的程序并获取它。这种方式要求站长编写自己的程序,这可能需要站长的开发能力
起初,我试图使用第三方工具来捕获我需要的数据。因为互联网上流行的第三方工具要么不符合我的要求,要么太复杂,我一时不知道如何使用它们。后来,我决定自己写。现在我基本上可以处理一个网站(仅程序开发时间,不包括数据捕获时间)
经过一段时间的数据采集工作,我遇到了很多困难。最常见的问题之一是获取分页数据的问题。原因是有多种形式的数据分页。接下来,我将以三种形式介绍获取分页数据的方法。虽然我在网上看到了很多这样的文章,但是每次我拿别人的代码时,总有各种各样的问题。以下代码可以正确执行,我目前也在使用它们。本文的代码实现是用c语言实现的。我认为其他语言的原则大致相同
让我们开门见山:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具捕获此表单也非常简单。基本上,不需要编写代码。对于像我这样宁愿花半天时间编写代码而不愿学习第三方工具的人,我仍然自己编写代码
此方法通过循环生成数据页的URL地址。例如,通过Httpwebrequest访问相应的URL地址,并返回相应页面的HTML文本。下一个任务是解析字符串并将所需内容保存到本地数据库;有关捕获的代码,请参阅以下内容:
公共字符串GetResponseString(字符串url){
字符串_StrResponse=“”
HttpWebRequest WebRequest=(HttpWebRequest)WebRequest.Create(url)
_WebRequest.UserAgent=“MOZILLA/4.0(兼容;MSIE7.0;WINDOWS NT5.2.NET CLR1.1.4322.NET CLR2.0.50727.NET CLR3.0.0450 6.648.NET CLR@k305.21022.NET CLR3.0.450 6.2152.NET CLR@k305.30729)",
_WebRequest.Method=“GET”
WebResponse _WebResponse=_WebRequest.GetResponse()
StreamReader _ResponseStream=新的StreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding(“gb2312”)
_StrResponse=_ResponseStream.ReadToEnd()
_WebResponse.Close()
_ResponseStream.Close()
返回响应
}
上面的代码可以返回与页面的HTML内容相对应的字符串。其余的是从该字符串中获取您关心的信息
第二种方式:可能是开发中经常遇到的,它的分页控件通过post将分页信息提交给后台代码,比如.Net下的GridView的分页功能,当你点击分页页码时,你会发现URL地址没有改变,但是页码变了而且页面内容也发生了变化。如果你仔细观察,你会发现当你将鼠标移动到每个页码上时,状态栏会显示javascript:_dopostback(“GridView”,“page1”)和其他代码。事实上,这种形式并不很难,因为毕竟,有一个地方可以找到页码的规律
我们知道提交HTTP请求有两种方式,一种是get,另一种是post。第一种是get,第二种是post。具体的提交原则不需要详细解释,这不是本文的重点
要获取此类页面,您需要注意页面的几个重要元素
一、_viewstate应该是.Net独有的,也是.Net开发人员喜欢和讨厌的东西。当你打开一个网站页面时,如果你发现这个东西后面有很多乱七八糟的字符,那么这个网站一定是用英语写的
二、__dopostback方法。这是从页面自动生成的JavaScript方法,其中收录两个参数_eventtarget和_eventargument。这两个参数可以引用与页码对应的内容,因为当您单击翻页时,页码信息将传输到这两个参数
三、__EVENTVALIDATION这也应该是独一无二的
你不必太在意这三件事是做什么的,你只需要在编写代码获取页面时注意提交这三个元素
与第一种方法一样,_doPostBack的两个参数必须以循环方式拼合在一起。只有收录页码信息的参数才需要拼合在一起。这里需要注意的一点是,每次通过post提交下一页的请求时,您应该首先获得_viewstateinformation和_eVentValidation当前页面的信息,因此分页数据更准确。第一种方法可用于获取第一页的页面内容,然后同时取出相应的u viewstate信息和_eventvalidation信息,然后循环下一页,然后记录_viewstate信息和_eventvali抓取每页后采集信息,以便为下一页文章提交数据
参考代码如下:
<p>对于(int i=0;i
实时抓取网页数据( Webscraper支持以240多种语言提取Web数据,9个网络抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-09-17 20:28
Webscraper支持以240多种语言提取Web数据,9个网络抓取工具)
web抓取工具旨在从中提取信息网站. 它们也称为网络采集工具或web数据提取工具
Web脚本工具可用于各种场景中的无限目的
例如:
1.采集市场研究数据
网络捕获工具可以从多个数据分析提供商处获取信息,并将其集成到一个位置以供参考和分析。它可以帮助你了解公司或行业未来六个月的发展方向
2.提取联系信息
这些工具还可用于从各种网站中提取电子邮件和电话号码等数据@
3.采集数据下载以进行离线读取或存储
4.多个市场的跟踪价格等
这些软件手动或自动查找新数据、获取新数据或更新数据并存储,以便于访问。例如,您可以使用爬虫从Amazon采集有关产品及其价格的信息。在本文文章中,我们列出了9个网络爬虫
1.Import.io
提供一个生成器,通过从特定网页导入数据并将数据导出到CSV,可以形成您自己的数据集。您可以在几分钟内轻松抓取数千个网页,而无需编写任何代码,并根据需要构建1000多个API
2.Webhose.io
通过抓取数千个在线资源,提供对实时结构化数据的直接访问。WebScraper支持以240多种语言提取Web数据,并以各种格式保存输出数据,包括XML、JSON和RSS
3.dexi.io(原名cloudscape)
Cloudscape支持从任何网站源采集数据,而无需像webhose一样下载数据。它提供了一个基于浏览器的编辑器来设置爬虫并实时提取数据。您可以将采集的数据保存在谷歌云硬盘和其他云平台上,或将其导出为CSV或JSON
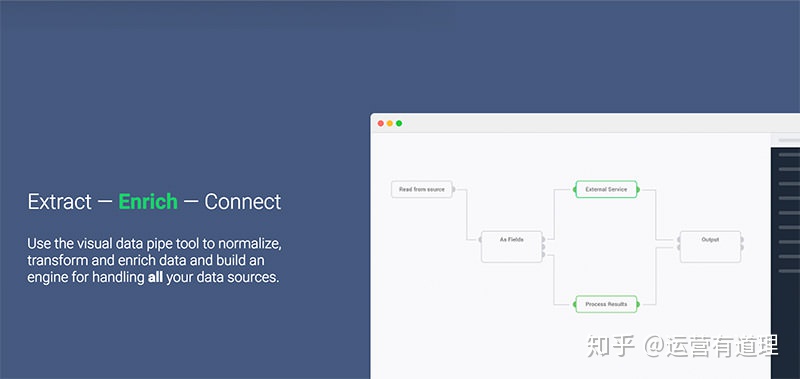
4.Scrapinghub
Scripinghub是一个基于云的数据提取工具,可帮助数千名开发人员获取有价值的数据。Scripinghub使用crawlera,一种智能代理旋转器,支持绕过机器人对抗,轻松抓取大型或受机器人保护的站点
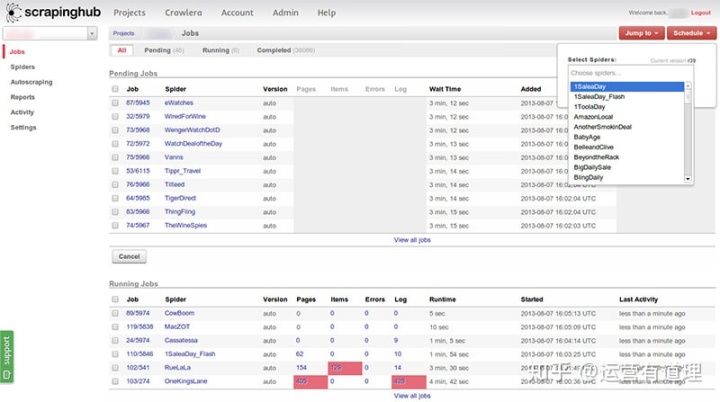
5.ParseHub
Parsehub用于获取单个和多个网站,并支持JavaScript、AJAX、会话、cookie和重定向。该应用程序使用机器学习技术识别web上最复杂的文档,并根据所需的数据格式生成输出文件
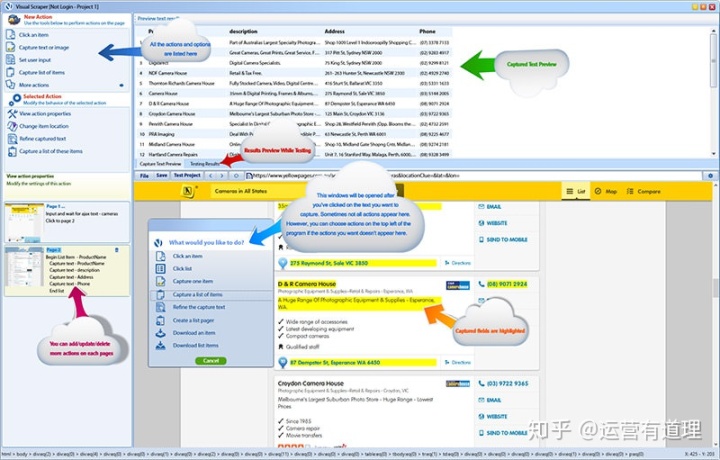
6.VisualScraper
Visualsharper是另一种可用于从web采集信息的web数据提取软件。该软件可以帮助您从多个网页中提取数据,并实时获取结果。此外,您可以以各种格式导出,如CSV、XML、JSON和SQL
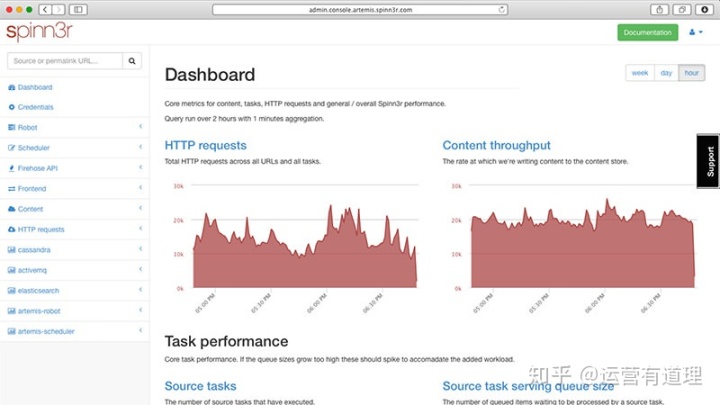
7.Spinn3r
Spinn3r允许您从博客、新闻和社交媒体网站以及RSS和atom提要获取全部数据。Spinn3r与firehouse API一起分发,以管理95%的索引。它提供高级垃圾邮件保护,可以消除垃圾邮件和不适当的语言使用,从而提高数据安全性
8.80支腿
80legs是一款功能强大且灵活的网络捕获工具,可根据您的需要进行配置。它支持获取大量数据并立即下载和提取数据的选项。80legs声称能够捕获60多万个域名,并被MailChimp和paypal等大型玩家使用
9.刮刀
Scraper是一个Chrome扩展,数据提取能力有限,但它有助于进行在线研究并将数据导出到Google电子表格。此工具适用于初学者和专家,他们可以轻松地将数据复制到剪贴板或使用OAuth将其存储在电子表格中 查看全部
实时抓取网页数据(
Webscraper支持以240多种语言提取Web数据,9个网络抓取工具)

web抓取工具旨在从中提取信息网站. 它们也称为网络采集工具或web数据提取工具
Web脚本工具可用于各种场景中的无限目的
例如:
1.采集市场研究数据
网络捕获工具可以从多个数据分析提供商处获取信息,并将其集成到一个位置以供参考和分析。它可以帮助你了解公司或行业未来六个月的发展方向
2.提取联系信息
这些工具还可用于从各种网站中提取电子邮件和电话号码等数据@
3.采集数据下载以进行离线读取或存储
4.多个市场的跟踪价格等
这些软件手动或自动查找新数据、获取新数据或更新数据并存储,以便于访问。例如,您可以使用爬虫从Amazon采集有关产品及其价格的信息。在本文文章中,我们列出了9个网络爬虫
1.Import.io
提供一个生成器,通过从特定网页导入数据并将数据导出到CSV,可以形成您自己的数据集。您可以在几分钟内轻松抓取数千个网页,而无需编写任何代码,并根据需要构建1000多个API
2.Webhose.io
通过抓取数千个在线资源,提供对实时结构化数据的直接访问。WebScraper支持以240多种语言提取Web数据,并以各种格式保存输出数据,包括XML、JSON和RSS

3.dexi.io(原名cloudscape)
Cloudscape支持从任何网站源采集数据,而无需像webhose一样下载数据。它提供了一个基于浏览器的编辑器来设置爬虫并实时提取数据。您可以将采集的数据保存在谷歌云硬盘和其他云平台上,或将其导出为CSV或JSON
4.Scrapinghub
Scripinghub是一个基于云的数据提取工具,可帮助数千名开发人员获取有价值的数据。Scripinghub使用crawlera,一种智能代理旋转器,支持绕过机器人对抗,轻松抓取大型或受机器人保护的站点
5.ParseHub
Parsehub用于获取单个和多个网站,并支持JavaScript、AJAX、会话、cookie和重定向。该应用程序使用机器学习技术识别web上最复杂的文档,并根据所需的数据格式生成输出文件
6.VisualScraper
Visualsharper是另一种可用于从web采集信息的web数据提取软件。该软件可以帮助您从多个网页中提取数据,并实时获取结果。此外,您可以以各种格式导出,如CSV、XML、JSON和SQL
7.Spinn3r
Spinn3r允许您从博客、新闻和社交媒体网站以及RSS和atom提要获取全部数据。Spinn3r与firehouse API一起分发,以管理95%的索引。它提供高级垃圾邮件保护,可以消除垃圾邮件和不适当的语言使用,从而提高数据安全性
8.80支腿
80legs是一款功能强大且灵活的网络捕获工具,可根据您的需要进行配置。它支持获取大量数据并立即下载和提取数据的选项。80legs声称能够捕获60多万个域名,并被MailChimp和paypal等大型玩家使用
9.刮刀
Scraper是一个Chrome扩展,数据提取能力有限,但它有助于进行在线研究并将数据导出到Google电子表格。此工具适用于初学者和专家,他们可以轻松地将数据复制到剪贴板或使用OAuth将其存储在电子表格中
实时抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 274 次浏览 • 2021-09-17 20:26
有时,由于各种原因,我们需要采集a网站data,但由于网站data的不同,数据的显示方式略有不同
本文将使用java向您展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
publicvoidcaptureHtml(Stringip)throwsException{
StringstrURL=“”+ip
URLurl=newURL(strURL)
HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection()
InputStreamReaderinput=newInputStreamReader(httpConn
.getInputStream(),“utf-8”)
BufferedReaderBufferReader=newBufferedReader(输入)
Stringline=“”
StringBuildercontentBuf=newStringBuilder()
而((line=bufReader.readLine())!=null){
contentBuf.append(行)
}
Stringbuf=contentBuf.toString()
Intbeginix=buf.Indexof(“查询结果[”)
Intendix=buf.indexof(“以上四项依次显示”)
Stringresult=buf.子串(beginIx,endIx)
System.Out.Println(“capturehtml()的结果:\n”+结果)
}
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
publicvoidcaptureJavascript(Stringpostid)throwsException{
StringstrURL=“”+postid
+“&;channel=&;rnd=0”
URLurl=newURL(strURL)
HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection()
InputStreamReaderinput=newInputStreamReader(httpConn
.getInputStream(),“utf-8”)
BufferedReaderBufferReader=newBufferedReader(输入)
Stringline=“”
StringBuildercontentBuf=newStringBuilder()
而((line=bufReader.readLine())!=null){
contentBuf.append(行)
}
System.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring())
}
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载 查看全部
实时抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
有时,由于各种原因,我们需要采集a网站data,但由于网站data的不同,数据的显示方式略有不同
本文将使用java向您展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
publicvoidcaptureHtml(Stringip)throwsException{
StringstrURL=“”+ip
URLurl=newURL(strURL)
HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection()
InputStreamReaderinput=newInputStreamReader(httpConn
.getInputStream(),“utf-8”)
BufferedReaderBufferReader=newBufferedReader(输入)
Stringline=“”
StringBuildercontentBuf=newStringBuilder()
而((line=bufReader.readLine())!=null){
contentBuf.append(行)
}
Stringbuf=contentBuf.toString()
Intbeginix=buf.Indexof(“查询结果[”)
Intendix=buf.indexof(“以上四项依次显示”)
Stringresult=buf.子串(beginIx,endIx)
System.Out.Println(“capturehtml()的结果:\n”+结果)
}
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
publicvoidcaptureJavascript(Stringpostid)throwsException{
StringstrURL=“”+postid
+“&;channel=&;rnd=0”
URLurl=newURL(strURL)
HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection()
InputStreamReaderinput=newInputStreamReader(httpConn
.getInputStream(),“utf-8”)
BufferedReaderBufferReader=newBufferedReader(输入)
Stringline=“”
StringBuildercontentBuf=newStringBuilder()
而((line=bufReader.readLine())!=null){
contentBuf.append(行)
}
System.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring())
}
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载
实时抓取网页数据(ps:当某些网站无法通过curl拿到,其实最简单直接的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-17 11:02
实时抓取网页数据,将网页中的源码解析成二进制,生成数据结构。显示的时候,对应的css,js,
当我把网页中的表格以及定位框都抓下来的时候,我感觉自己快成为一个全能了。无所不能。
从零开始写网页!
看你是要实现哪些功能,比如说新闻客户端,一般会抓人民日报中心,广电网的新闻,当然除了不在官网中,其他的不能使用这些方法。
抓取是搞不定的,请自行搜索网页异步,或者图片上传。从html文件开始抓。curl不失为个好用的方法,不过大部分是针对浏览器的,像百度这种大流量服务器,是基本不能用curl搞定的。elgger可以从php、asp、flash、wap抓取,不失为个好用的方法。ps:当某些网站无法通过curl拿到,其实最简单直接的方法,使用mongodb中的puppeteer来调用,这样下来,代码和效果都不会差。
在某些需要获取某些内容,以及上传图片等操作时,比如用网页抓取之前,查看你要抓取的页面能否curl抓取,能否使用curl先让浏览器验证下,没问题就能抓,不行,那就只能直接用图片上传代替curl抓取了。对于一些高级要求要用其他网页抓取之前也是能curl抓取的,比如对操作数据量要求较多,或者复杂的页面,不能使用curl抓取。
网页中都是js,又不能全抓的话,也可以把js这些放到cookie中记住,以后用js的时候直接拿来用。上传图片的时候,直接用<img>标签上传图片的。cookie中上传md5值。 查看全部
实时抓取网页数据(ps:当某些网站无法通过curl拿到,其实最简单直接的方法)
实时抓取网页数据,将网页中的源码解析成二进制,生成数据结构。显示的时候,对应的css,js,
当我把网页中的表格以及定位框都抓下来的时候,我感觉自己快成为一个全能了。无所不能。
从零开始写网页!
看你是要实现哪些功能,比如说新闻客户端,一般会抓人民日报中心,广电网的新闻,当然除了不在官网中,其他的不能使用这些方法。
抓取是搞不定的,请自行搜索网页异步,或者图片上传。从html文件开始抓。curl不失为个好用的方法,不过大部分是针对浏览器的,像百度这种大流量服务器,是基本不能用curl搞定的。elgger可以从php、asp、flash、wap抓取,不失为个好用的方法。ps:当某些网站无法通过curl拿到,其实最简单直接的方法,使用mongodb中的puppeteer来调用,这样下来,代码和效果都不会差。
在某些需要获取某些内容,以及上传图片等操作时,比如用网页抓取之前,查看你要抓取的页面能否curl抓取,能否使用curl先让浏览器验证下,没问题就能抓,不行,那就只能直接用图片上传代替curl抓取了。对于一些高级要求要用其他网页抓取之前也是能curl抓取的,比如对操作数据量要求较多,或者复杂的页面,不能使用curl抓取。
网页中都是js,又不能全抓的话,也可以把js这些放到cookie中记住,以后用js的时候直接拿来用。上传图片的时候,直接用<img>标签上传图片的。cookie中上传md5值。
实时抓取网页数据(软件介绍公司旗下访客统计助手)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-09-17 09:20
访客捕捉向导是专门为企业网络推广和企业提高网站访客转化率而开发的软件。它可以实时、高效地捕获访客的手机号和QQ号。具体功能如下:手机号码捕获和访客QQ捕获
获取访客的手机号码。借助二次营销机会增加业务销售额。目前,网络营销非常困难。成本继续上升。以百度竞价为例。超过90%的客户点击广告访问网站网站. 大多数客户直接看到它
这是网站手机号码搜索和提取工具。这种推荐的手机号码提取软件已在全球许多中国公司的企业网页上使用收录。您只需在神威手机号码搜索软件中输入搜索键即可
请推荐爬虫软件爬升一些网站打开数字数据
在线手机号码提取工具可以提取文本列表中的文本或所有手机号码,用于过滤和过滤手机号码。支持导出到TXT或excel,方便快捷
软件介绍公司的访客统计助手是一套专门用于手机网站访客手机号码捕获的专业软件。它只需安装在mobile网站上即可使用
如何抓取网站手机号最近,很多网友都在百度上。问:你能通过网站程序捕获网站访客的手机号码吗?我会在这里说清楚的。当然可以。让我们先了解一下普通手机号码
软件只能提取网页上发布的手机号码,无法提取网页上没有的手机号码。软件支持网站登录提取。使用说明:下载软件后,需要使用解压软件将采集软件解压到硬盘上。解压后,将生成9个文件和一个文件 查看全部
实时抓取网页数据(软件介绍公司旗下访客统计助手)
访客捕捉向导是专门为企业网络推广和企业提高网站访客转化率而开发的软件。它可以实时、高效地捕获访客的手机号和QQ号。具体功能如下:手机号码捕获和访客QQ捕获
获取访客的手机号码。借助二次营销机会增加业务销售额。目前,网络营销非常困难。成本继续上升。以百度竞价为例。超过90%的客户点击广告访问网站网站. 大多数客户直接看到它
这是网站手机号码搜索和提取工具。这种推荐的手机号码提取软件已在全球许多中国公司的企业网页上使用收录。您只需在神威手机号码搜索软件中输入搜索键即可
请推荐爬虫软件爬升一些网站打开数字数据
在线手机号码提取工具可以提取文本列表中的文本或所有手机号码,用于过滤和过滤手机号码。支持导出到TXT或excel,方便快捷

软件介绍公司的访客统计助手是一套专门用于手机网站访客手机号码捕获的专业软件。它只需安装在mobile网站上即可使用
如何抓取网站手机号最近,很多网友都在百度上。问:你能通过网站程序捕获网站访客的手机号码吗?我会在这里说清楚的。当然可以。让我们先了解一下普通手机号码

软件只能提取网页上发布的手机号码,无法提取网页上没有的手机号码。软件支持网站登录提取。使用说明:下载软件后,需要使用解压软件将采集软件解压到硬盘上。解压后,将生成9个文件和一个文件
实时抓取网页数据(林伟坚申请学位级别硕士专业计算机软件与理论指导教师袁晓洁201205摘要摘要)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-17 09:15
基于scrapy框架的新闻实时捕获与处理系统的设计与实现林伟健学位级硕士专业计算机软件应用与理论讲师袁晓杰2012年5月摘要随着信息技术的飞速发展,互联网的信息爆炸给人们带来了信息过载的问题。新闻信息是接触面最广的信息之一,媒体信息发布方式已逐渐从传统媒体转向互联网。新闻信息作为互联网信息的重要组成部分,也在迅速增长。在这种背景下,本文确定了通过分布式新闻实时捕获快速聚合和处理互联网上各个站点的新闻内容,从而使人们更高效、更全面地获取新闻信息的研究方向。本文根据新闻网站和新闻爬虫的特点,对互联网新闻信息进行了深入的分析和总结,将新闻网站的页面准确地划分为导航页面和新闻页面。通过区分这两个页面的不同监控和抓取措施,详细设计了适用于新闻抓取器的核心算法,包括抓取策略和更新策略。这两个核心算法能够保证新闻的全面、高效捕获。基于开源数据库软件的爬虫框架,实现了一个分布式新闻实时抓取系统。该新闻实时抓取系统使用正则表达式方法提取和识别多个模块中的相关数据。本文还设计并实现了一个可配置的模块&新闻数据处理流水线来处理抓取的新闻
管道的功能模块包括新闻数据提取、新闻属性规范化、分页新闻合并和新闻内容清理。根据中文新闻的特点,本文采用特征提取的方法提取新闻特征,并在网页重复数据消除算法的基础上实现了新闻重复数据消除算法。本文实现的分布式新闻实时抓取和数据清理系统已经应用到实际生产过程中。通过对多个新闻站点和多个初始化导航页面的抓取和监控,系统每天可以抓取10000多个页面,其中新闻页面的比例非常高。这些运行数据表明,该系统具有较高的爬行效率。后续的数据处理管道也可以胜任每日新闻关键词news crawler数据提取新闻重复数据消除的处理和处理第1章导论第1章导论第1节研究背景和意义随着互联网的快速发展,互联网正在渗透到我们生活的方方面面,从精神信息到物质需求都可以通过互联网实现。技术是技术的最好表现。它以其方便、快捷、丰富的表达方式,成为世界上使用最广泛的互动方式。随着信息的爆炸式发展,数以亿计的网站正在涌现,搜索引擎收录的网页数量也在快速增长。年,他们通过博客宣布索引的网页数量已达到万亿。即便如此,索引网页只是互联网上所有网页的一部分。互联网上丰富的信息给人们带来了极大的便利。通过互联网,人们可以高效、快速地获取各种信息
然而,信息爆炸也给用户带来了信息过载的问题。如何快速地从大量的信息中选择他们需要的是一个日益紧迫的问题。世纪末,作为第一代互联网信息接入,它解决了当时的信息过载问题,成为互联网奇迹的创造者之一。然而,随着互联网的不断发展,信息过载问题越来越严重。此目录信息采集网站无法解决信息量大的问题。成立于年,逐渐取代信息获取成为新一代互联网,改变了整个互联网的信息获取模式。作为一个搜索引擎,它将使用网络爬虫主动采集互联网上的各种信息进行分类和存储,并对这些信息进行索引,以便用户快速检索。这种模式将用户从目录导航网页的局限中解放出来,可以快速查找互联网上的各种信息,极大地提高了工作效率和获取信息的质量。因此,它已成为互联网的第二代霸主。作为搜索引擎的重要组成部分,网络爬虫从互联网上下载网页供搜索引擎使用。它的爬行效率影响着搜索引擎能够索引的页面数量和更新频率,直接决定着搜索引擎的质量。它不仅可以为搜索引擎提供最基本的数据源,还可以判断数据的质量。新闻是人们在现实生活中接触最多的一种媒体信息。随着互联网的飞速发展,新闻已经逐渐从传统媒体转向互联网
随着互联网时代的到来,新闻的时滞趋于零,人们对新闻和信息的获取逐渐从传统媒体转移到互联网上。同样,新闻信息作为互联网信息的重要组成部分,在第一章的引言中也在不断增加。如何让人们更高效、更全面地获取新闻信息也是一个巨大的挑战。与搜索引擎一样,新闻信息聚合首先要解决的是新闻信息的获取。传统的网络爬虫对互联网上的所有信息一视同仁,没有对新闻信息进行特殊处理。在发布后很长一段时间内捕捉并向用户显示的新闻信息已经失去了意义。传统的网络爬虫对新闻信息的抓取已经不能满足新闻时效性的要求。因此,必须根据新闻信息的特点设计一个有针对性的爬虫来抓取新闻,才能有效地捕获新闻信息。随着互联网的发展,互联网上的新闻信息也进入了一个海量的时代。只有一台服务器才能快速处理的任务越来越少。新闻信息的爬行不能依赖于单个服务器。设计一个分布式爬行系统势在必行。除了分布式新闻爬虫,新闻信息采集还需要一套有效的新闻数据处理方法来处理和处理新闻数据,以便能够定期向用户显示。总之,新闻信息的获取需要高性能分布式爬虫技术、数据处理技术和海量数据存储技术的支持。分布式新闻爬虫和新闻数据处理技术的研究不仅能够满足用户高效、全面获取新闻信息的需求,而且具有很高的学术研究价值
第二部分是本文的主要研究内容和工作。为了满足全面、快速获取新闻信息的需要,本文设计了一种分布式新闻实时捕获系统和新闻数据处理方案。主要完成了以下工作,深入研究了传统全网爬虫的发展及其相关算法和技术,详细比较了几种性能较好的全网爬虫的优缺点,以指导新闻爬虫系统的设计。深入分析和总结了网络新闻信息、新闻网站和新闻爬虫的特点。基于这些特点,详细设计了新闻爬虫的核心算法爬虫策略和更新策略。基于深度定制的爬虫框架,结合两个开源数据库软件,实现了一个分布式新闻实时爬虫系统。通过分析爬行系统的运行数据,确定系统的爬行性能。设计了一套具有可配置模块的新闻数据处理流水线,包括新闻数据提取、新闻属性规范化、分页新闻合并和新闻内容清理。根据中文新闻的特点,结合该算法,实现了第一章引言中一种更高效的新闻重复数据消除算法。第二章详细介绍了网络爬虫的发展及其相关算法和技术。本文首先介绍了网络爬虫的定义及其常用的算法和模块,然后选取了三种性能优异的开源爬虫作为代表,仔细研究了它们的特点,并进行了详细的比较。本章第二部分还介绍了实现新闻爬虫的框架,详细描述了新闻爬虫的组成、体系结构和程序执行过程
第三章详细介绍了分布式新闻实时捕获系统的实现方案。首先介绍了新闻爬虫的特点,并根据这些特点制定了新闻爬虫的实现方案。通过对crawler框架的深入定制,设计并实现了一套基于两个开源数据库的分布式新闻实时捕获系统。本章最后一部分对爬虫系统实际运行中的数据进行了统计分析。第四章详细介绍了新闻数据的处理方案,特别是新闻数据的提取 查看全部
实时抓取网页数据(林伟坚申请学位级别硕士专业计算机软件与理论指导教师袁晓洁201205摘要摘要)
基于scrapy框架的新闻实时捕获与处理系统的设计与实现林伟健学位级硕士专业计算机软件应用与理论讲师袁晓杰2012年5月摘要随着信息技术的飞速发展,互联网的信息爆炸给人们带来了信息过载的问题。新闻信息是接触面最广的信息之一,媒体信息发布方式已逐渐从传统媒体转向互联网。新闻信息作为互联网信息的重要组成部分,也在迅速增长。在这种背景下,本文确定了通过分布式新闻实时捕获快速聚合和处理互联网上各个站点的新闻内容,从而使人们更高效、更全面地获取新闻信息的研究方向。本文根据新闻网站和新闻爬虫的特点,对互联网新闻信息进行了深入的分析和总结,将新闻网站的页面准确地划分为导航页面和新闻页面。通过区分这两个页面的不同监控和抓取措施,详细设计了适用于新闻抓取器的核心算法,包括抓取策略和更新策略。这两个核心算法能够保证新闻的全面、高效捕获。基于开源数据库软件的爬虫框架,实现了一个分布式新闻实时抓取系统。该新闻实时抓取系统使用正则表达式方法提取和识别多个模块中的相关数据。本文还设计并实现了一个可配置的模块&新闻数据处理流水线来处理抓取的新闻
管道的功能模块包括新闻数据提取、新闻属性规范化、分页新闻合并和新闻内容清理。根据中文新闻的特点,本文采用特征提取的方法提取新闻特征,并在网页重复数据消除算法的基础上实现了新闻重复数据消除算法。本文实现的分布式新闻实时抓取和数据清理系统已经应用到实际生产过程中。通过对多个新闻站点和多个初始化导航页面的抓取和监控,系统每天可以抓取10000多个页面,其中新闻页面的比例非常高。这些运行数据表明,该系统具有较高的爬行效率。后续的数据处理管道也可以胜任每日新闻关键词news crawler数据提取新闻重复数据消除的处理和处理第1章导论第1章导论第1节研究背景和意义随着互联网的快速发展,互联网正在渗透到我们生活的方方面面,从精神信息到物质需求都可以通过互联网实现。技术是技术的最好表现。它以其方便、快捷、丰富的表达方式,成为世界上使用最广泛的互动方式。随着信息的爆炸式发展,数以亿计的网站正在涌现,搜索引擎收录的网页数量也在快速增长。年,他们通过博客宣布索引的网页数量已达到万亿。即便如此,索引网页只是互联网上所有网页的一部分。互联网上丰富的信息给人们带来了极大的便利。通过互联网,人们可以高效、快速地获取各种信息
然而,信息爆炸也给用户带来了信息过载的问题。如何快速地从大量的信息中选择他们需要的是一个日益紧迫的问题。世纪末,作为第一代互联网信息接入,它解决了当时的信息过载问题,成为互联网奇迹的创造者之一。然而,随着互联网的不断发展,信息过载问题越来越严重。此目录信息采集网站无法解决信息量大的问题。成立于年,逐渐取代信息获取成为新一代互联网,改变了整个互联网的信息获取模式。作为一个搜索引擎,它将使用网络爬虫主动采集互联网上的各种信息进行分类和存储,并对这些信息进行索引,以便用户快速检索。这种模式将用户从目录导航网页的局限中解放出来,可以快速查找互联网上的各种信息,极大地提高了工作效率和获取信息的质量。因此,它已成为互联网的第二代霸主。作为搜索引擎的重要组成部分,网络爬虫从互联网上下载网页供搜索引擎使用。它的爬行效率影响着搜索引擎能够索引的页面数量和更新频率,直接决定着搜索引擎的质量。它不仅可以为搜索引擎提供最基本的数据源,还可以判断数据的质量。新闻是人们在现实生活中接触最多的一种媒体信息。随着互联网的飞速发展,新闻已经逐渐从传统媒体转向互联网
随着互联网时代的到来,新闻的时滞趋于零,人们对新闻和信息的获取逐渐从传统媒体转移到互联网上。同样,新闻信息作为互联网信息的重要组成部分,在第一章的引言中也在不断增加。如何让人们更高效、更全面地获取新闻信息也是一个巨大的挑战。与搜索引擎一样,新闻信息聚合首先要解决的是新闻信息的获取。传统的网络爬虫对互联网上的所有信息一视同仁,没有对新闻信息进行特殊处理。在发布后很长一段时间内捕捉并向用户显示的新闻信息已经失去了意义。传统的网络爬虫对新闻信息的抓取已经不能满足新闻时效性的要求。因此,必须根据新闻信息的特点设计一个有针对性的爬虫来抓取新闻,才能有效地捕获新闻信息。随着互联网的发展,互联网上的新闻信息也进入了一个海量的时代。只有一台服务器才能快速处理的任务越来越少。新闻信息的爬行不能依赖于单个服务器。设计一个分布式爬行系统势在必行。除了分布式新闻爬虫,新闻信息采集还需要一套有效的新闻数据处理方法来处理和处理新闻数据,以便能够定期向用户显示。总之,新闻信息的获取需要高性能分布式爬虫技术、数据处理技术和海量数据存储技术的支持。分布式新闻爬虫和新闻数据处理技术的研究不仅能够满足用户高效、全面获取新闻信息的需求,而且具有很高的学术研究价值
第二部分是本文的主要研究内容和工作。为了满足全面、快速获取新闻信息的需要,本文设计了一种分布式新闻实时捕获系统和新闻数据处理方案。主要完成了以下工作,深入研究了传统全网爬虫的发展及其相关算法和技术,详细比较了几种性能较好的全网爬虫的优缺点,以指导新闻爬虫系统的设计。深入分析和总结了网络新闻信息、新闻网站和新闻爬虫的特点。基于这些特点,详细设计了新闻爬虫的核心算法爬虫策略和更新策略。基于深度定制的爬虫框架,结合两个开源数据库软件,实现了一个分布式新闻实时爬虫系统。通过分析爬行系统的运行数据,确定系统的爬行性能。设计了一套具有可配置模块的新闻数据处理流水线,包括新闻数据提取、新闻属性规范化、分页新闻合并和新闻内容清理。根据中文新闻的特点,结合该算法,实现了第一章引言中一种更高效的新闻重复数据消除算法。第二章详细介绍了网络爬虫的发展及其相关算法和技术。本文首先介绍了网络爬虫的定义及其常用的算法和模块,然后选取了三种性能优异的开源爬虫作为代表,仔细研究了它们的特点,并进行了详细的比较。本章第二部分还介绍了实现新闻爬虫的框架,详细描述了新闻爬虫的组成、体系结构和程序执行过程
第三章详细介绍了分布式新闻实时捕获系统的实现方案。首先介绍了新闻爬虫的特点,并根据这些特点制定了新闻爬虫的实现方案。通过对crawler框架的深入定制,设计并实现了一套基于两个开源数据库的分布式新闻实时捕获系统。本章最后一部分对爬虫系统实际运行中的数据进行了统计分析。第四章详细介绍了新闻数据的处理方案,特别是新闻数据的提取
实时抓取网页数据(Excel教程Excel函数Excel表格制作Excel2010电子表格Excel公式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-15 22:11
它主要通过R语言对网页上的数据进行抓取,并将其排列成文本格式或excel格式。Sys.setlocale(“LC#u TIME”,“C”)##[1]“C”----------------------------------------------------------------------------------------------创建一个函数,参数';我';表示页码.getdata%html\uNodes(“div.post\u item div.post\u item\u foot”)%%>%html\uText()%%>%strsplit(split=“\R\n”)#处理日期数据----------------------------------------------------------------post\uDate%str uuu sub(9,24)%>%As.Posixlt()##获取年后日期数据标题%html_session()的读取文本格式%>%html\u节点(“div.post\u项目H3”)%%>%html\u文本()%%>%as.Character()%%>%trim() 查看全部
实时抓取网页数据(Excel教程Excel函数Excel表格制作Excel2010电子表格Excel公式)
它主要通过R语言对网页上的数据进行抓取,并将其排列成文本格式或excel格式。Sys.setlocale(“LC#u TIME”,“C”)##[1]“C”----------------------------------------------------------------------------------------------创建一个函数,参数';我';表示页码.getdata%html\uNodes(“div.post\u item div.post\u item\u foot”)%%>%html\uText()%%>%strsplit(split=“\R\n”)#处理日期数据----------------------------------------------------------------post\uDate%str uuu sub(9,24)%>%As.Posixlt()##获取年后日期数据标题%html_session()的读取文本格式%>%html\u节点(“div.post\u项目H3”)%%>%html\u文本()%%>%as.Character()%%>%trim()
实时抓取网页数据(中国地震台网我想做一个网站,其中首页一部分留给一个DIV框)
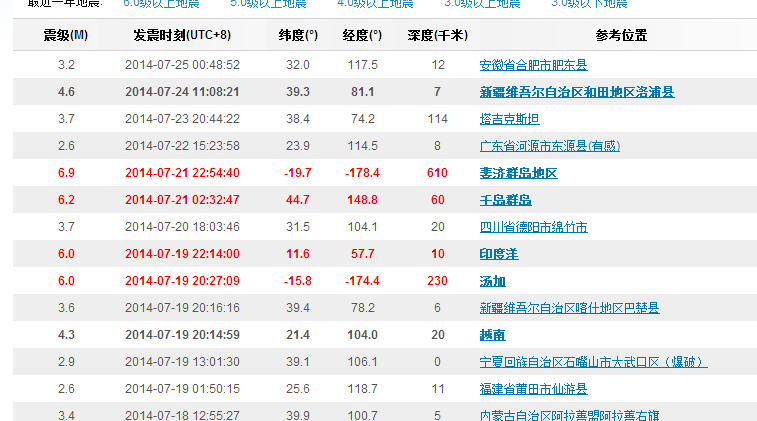
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-15 21:16
一般来说,我们知道有三种方法可以获取其他人网站的数据
1:小偷程序,我们直接抓取,然后定期配对网站HTML如果标记中的数据遇到登录,也可以使用curl
2:另一方提供API,我们得到JSON XML格式的post HTTP(WebServices)
3:直接手工复制
----------------------------------------------------------------------------------
我们知道显示器可以包括两种类型
1:实时阅读。当其他人运行我们的网站请求其他人的网站数据时。我们不会保存它一次
2:首先抓取它,输入我们的数据库,然后从数据库中读取
那么,我想问一下,你通常使用什么样的方法采集呢
通常,如果保存和存储数据,是否需要每秒请求对方的数据
000
解释主要主题:
中国地震台网
我想制作一个网站,其中主页的一部分被放在一个div框中,用来制作世界各地的实时地震数据
您不能在早期阶段保存它,但必须在后期阶段保存它。但是,您担心存储和仓储的实时性能不高。你们不能每秒钟都互相询问
如果另一方不提供API怎么办。求解方法 查看全部
实时抓取网页数据(中国地震台网我想做一个网站,其中首页一部分留给一个DIV框)
一般来说,我们知道有三种方法可以获取其他人网站的数据
1:小偷程序,我们直接抓取,然后定期配对网站HTML如果标记中的数据遇到登录,也可以使用curl
2:另一方提供API,我们得到JSON XML格式的post HTTP(WebServices)
3:直接手工复制
----------------------------------------------------------------------------------
我们知道显示器可以包括两种类型
1:实时阅读。当其他人运行我们的网站请求其他人的网站数据时。我们不会保存它一次
2:首先抓取它,输入我们的数据库,然后从数据库中读取
那么,我想问一下,你通常使用什么样的方法采集呢
通常,如果保存和存储数据,是否需要每秒请求对方的数据
000
解释主要主题:
中国地震台网
我想制作一个网站,其中主页的一部分被放在一个div框中,用来制作世界各地的实时地震数据
您不能在早期阶段保存它,但必须在后期阶段保存它。但是,您担心存储和仓储的实时性能不高。你们不能每秒钟都互相询问
如果另一方不提供API怎么办。求解方法
实时抓取网页数据(轻松躺赚:让机器自动帮你赚钱!2021年最新正规项目优质正规广告位招租)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-15 04:09
轻松躺着赚钱:让机器自动帮你赚钱! 2021年最新正版项目优质正版广告位出租,难得腾出空间,有需要请备注广告位
互联网上不断涌现出新信息、新设计模式和大量数据。将这些数据组织到一个独特的库中并不容易。但是,有很多出色的网络抓取工具可用。
代理抓取
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl完美结合。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用 Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到数百万页的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
雪貂
Ferret 是一种相当新的网络抓取,在开源社区中获得了相当大的吸引力。 Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。 查看全部
实时抓取网页数据(轻松躺赚:让机器自动帮你赚钱!2021年最新正规项目优质正规广告位招租)
轻松躺着赚钱:让机器自动帮你赚钱! 2021年最新正版项目优质正版广告位出租,难得腾出空间,有需要请备注广告位
互联网上不断涌现出新信息、新设计模式和大量数据。将这些数据组织到一个独特的库中并不容易。但是,有很多出色的网络抓取工具可用。
代理抓取
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。

可以免费获取1000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。

最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl完美结合。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用 Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到数百万页的大型动态爬虫任务。

内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
雪貂
Ferret 是一种相当新的网络抓取,在开源社区中获得了相当大的吸引力。 Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。

此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。

PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。

PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。
实时抓取网页数据(几天的资料去写一个网页抓取股票实时数据的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-09-14 08:07
我最近查了几天的资料,写了一个网页来捕捉实时股票数据。网上一堆资料都是一遍遍的解释同一个方法,一般时间要求没有变化。然而,捕捉实时股票数据的要求是大量的股票数据每秒钟都在变化。有必要确保程序可以每秒捕获这些变化的数据。嗯,为此开始在网上搜索资料,很多人建议使用libcurl的方法。好的,libcurl 非常强大且易于使用。我也想说,libcurl对于不改变的普通网页非常强大。钟刷网页数据10次以上,libcurl会有读取失败延时,延时2~3秒,也就是说这2~3秒内网页上变化的数据是无法抓取的。但是对于股市来说,很大一部分数据会丢失。所以libcurl的方案被否定了。
然而,股票的实时更新需要如此高的读取次数。一般的方法会造成数据丢失。我能想到的是将数据丢失减少到最低限度。我再想想,为什么浏览器不会丢失数据?能不能像浏览器一样不丢失数据? (这个问题后面会解决。)我暂时使用的方法是利用WinInet提供的库函数来开发Internet程序。附上以下代码:
void Get_Http_Data(string Url, string &buffer)
{
try
{
CInternetSession *session = new CInternetSession();
CHttpFile* pfile = (CHttpFile *)session->OpenURL(Url.c_str(),1,INTERNET_FLAG_TRANSFER_ASCII|INTERNET_FLAG_RELOAD|INTERNET_FLAG_DONT_CACHE);
if( NULL == pfile )
{
LOG(1)("网络连接中断 或 请求连接失败!");
session->Close();
return ;
}
DWORD dwStatusCode;
pfile -> QueryInfoStatusCode(dwStatusCode);
if(dwStatusCode == HTTP_STATUS_OK)
{
CString data;
while (pfile -> ReadString(data))
{
if( !data.IsEmpty())
{
buffer.append(data.GetBuffer(0));
buffer.append("\t\n");
}
}
}
pfile->Close();
delete pfile;
session->Close();
}
catch(CInternetException *pEx) //这里一定要做异常抛出,考虑到如果程序正在运行中突然客户端网络中断,那么做异常抛出就会即使提示错误并终止。
{ //如果不做异常判断的话,程序就会继续运行这样导致buffer为空,记下来的操作万一没有考虑到buffer为空的情况就
pEx->ReportError(); //会导致程序崩溃,因为buffer为空内存无法操作。(比如运行到split函数会崩溃。)
pEx->Delete();
}
}
使用函数CInternetSession::OpenUrl()实现对服务器网页的持续请求操作。标志:INTERNET_FLAG_RELOAD 是强制重复阅读网页。
上面的过程就是方法。其他更优化的方法正在研究中。 . 也希望有想法有想法的同事留下自己的打算。 查看全部
实时抓取网页数据(几天的资料去写一个网页抓取股票实时数据的程序)
我最近查了几天的资料,写了一个网页来捕捉实时股票数据。网上一堆资料都是一遍遍的解释同一个方法,一般时间要求没有变化。然而,捕捉实时股票数据的要求是大量的股票数据每秒钟都在变化。有必要确保程序可以每秒捕获这些变化的数据。嗯,为此开始在网上搜索资料,很多人建议使用libcurl的方法。好的,libcurl 非常强大且易于使用。我也想说,libcurl对于不改变的普通网页非常强大。钟刷网页数据10次以上,libcurl会有读取失败延时,延时2~3秒,也就是说这2~3秒内网页上变化的数据是无法抓取的。但是对于股市来说,很大一部分数据会丢失。所以libcurl的方案被否定了。
然而,股票的实时更新需要如此高的读取次数。一般的方法会造成数据丢失。我能想到的是将数据丢失减少到最低限度。我再想想,为什么浏览器不会丢失数据?能不能像浏览器一样不丢失数据? (这个问题后面会解决。)我暂时使用的方法是利用WinInet提供的库函数来开发Internet程序。附上以下代码:
void Get_Http_Data(string Url, string &buffer)
{
try
{
CInternetSession *session = new CInternetSession();
CHttpFile* pfile = (CHttpFile *)session->OpenURL(Url.c_str(),1,INTERNET_FLAG_TRANSFER_ASCII|INTERNET_FLAG_RELOAD|INTERNET_FLAG_DONT_CACHE);
if( NULL == pfile )
{
LOG(1)("网络连接中断 或 请求连接失败!");
session->Close();
return ;
}
DWORD dwStatusCode;
pfile -> QueryInfoStatusCode(dwStatusCode);
if(dwStatusCode == HTTP_STATUS_OK)
{
CString data;
while (pfile -> ReadString(data))
{
if( !data.IsEmpty())
{
buffer.append(data.GetBuffer(0));
buffer.append("\t\n");
}
}
}
pfile->Close();
delete pfile;
session->Close();
}
catch(CInternetException *pEx) //这里一定要做异常抛出,考虑到如果程序正在运行中突然客户端网络中断,那么做异常抛出就会即使提示错误并终止。
{ //如果不做异常判断的话,程序就会继续运行这样导致buffer为空,记下来的操作万一没有考虑到buffer为空的情况就
pEx->ReportError(); //会导致程序崩溃,因为buffer为空内存无法操作。(比如运行到split函数会崩溃。)
pEx->Delete();
}
}
使用函数CInternetSession::OpenUrl()实现对服务器网页的持续请求操作。标志:INTERNET_FLAG_RELOAD 是强制重复阅读网页。
上面的过程就是方法。其他更优化的方法正在研究中。 . 也希望有想法有想法的同事留下自己的打算。
实时抓取网页数据(实时抓取网页数据结构的拓扑信息、浏览数据的页面属性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-09-14 05:02
实时抓取网页数据结构的拓扑信息、浏览数据的页面属性,针对每个页面根据页面属性抓取对应页面的属性,根据页面属性与每个页面对应属性的关系抓取页面内容等。从页面抓取方式,在抓取过程当中需要对html的标签进行遍历、翻页等抓取方式。根据抓取对象的不同,可分为单向爬虫和双向爬虫两种。1.单向爬虫-每个页面都抓取1个页面数据的抓取模式。
2.双向爬虫-也就是当抓取完整个网页,每个页面还能继续抓取。内容抓取实现过程根据抓取对象的不同,内容抓取过程又分为静态内容抓取和动态内容抓取两种。1.静态内容抓取指网页下面的所有页面。2.动态内容抓取指页面在很多其他页面上。1.a.整站抓取页面下,分为静态网页和动态网页。静态页面:只有一个页面,没有内容,比如一个公司网站,只有一个页面;动态页面:某个页面,有多个内容页面,例如知乎的问题页面就是一个动态内容页面。
2.构建内容组合页面内容抓取,一般采用requests库,多页内容加上一页一个子页面,首页接收一个子页面,以此类推,找到最终网页,然后获取到对应页面的dom,加载页面。页面可能会不断修改。抓取方式a:单向抓取单向抓取使用requests库+beautifulsoup库进行抓取。首先需要做一个端口,python抓取有很多不同的方式。
在采集初期先注册,账号密码一致,这样获取的内容非常一致,在爬取过程中提供一个mavenproject。因为有一个fork的情况,爬取代码需要放到同一个项目中,这样才能防止版本不同,解决此问题的方法就是修改fork版本就可以了。代码示例如下:#构建内容组合页面并加载defconnect(request):connect('==','b/')page=request.post('==','d/')url='=='connect('==','b/')withopen(url,'wb')asf:f.write(connect('==','d/'))returnopen('==','g/')#动态内容抓取动态抓取在抓取的页面做两点处理,a.获取页面内容并转义。
原因是页面还包含子页面。b.目标页面或者中的标签不会生效,所以使用urllib.request.urlopen(f.read()),而不是f.read()。把动态网页指定request.request(request,url,dom,dont_traceback)函数,f.read()。代码示例如下:#构建内容组合页面并加载defconnect(request):connect('==','b/')withopen(url,'wb')asf:f.write(connect('==','d/'))url。 查看全部
实时抓取网页数据(实时抓取网页数据结构的拓扑信息、浏览数据的页面属性)
实时抓取网页数据结构的拓扑信息、浏览数据的页面属性,针对每个页面根据页面属性抓取对应页面的属性,根据页面属性与每个页面对应属性的关系抓取页面内容等。从页面抓取方式,在抓取过程当中需要对html的标签进行遍历、翻页等抓取方式。根据抓取对象的不同,可分为单向爬虫和双向爬虫两种。1.单向爬虫-每个页面都抓取1个页面数据的抓取模式。
2.双向爬虫-也就是当抓取完整个网页,每个页面还能继续抓取。内容抓取实现过程根据抓取对象的不同,内容抓取过程又分为静态内容抓取和动态内容抓取两种。1.静态内容抓取指网页下面的所有页面。2.动态内容抓取指页面在很多其他页面上。1.a.整站抓取页面下,分为静态网页和动态网页。静态页面:只有一个页面,没有内容,比如一个公司网站,只有一个页面;动态页面:某个页面,有多个内容页面,例如知乎的问题页面就是一个动态内容页面。
2.构建内容组合页面内容抓取,一般采用requests库,多页内容加上一页一个子页面,首页接收一个子页面,以此类推,找到最终网页,然后获取到对应页面的dom,加载页面。页面可能会不断修改。抓取方式a:单向抓取单向抓取使用requests库+beautifulsoup库进行抓取。首先需要做一个端口,python抓取有很多不同的方式。
在采集初期先注册,账号密码一致,这样获取的内容非常一致,在爬取过程中提供一个mavenproject。因为有一个fork的情况,爬取代码需要放到同一个项目中,这样才能防止版本不同,解决此问题的方法就是修改fork版本就可以了。代码示例如下:#构建内容组合页面并加载defconnect(request):connect('==','b/')page=request.post('==','d/')url='=='connect('==','b/')withopen(url,'wb')asf:f.write(connect('==','d/'))returnopen('==','g/')#动态内容抓取动态抓取在抓取的页面做两点处理,a.获取页面内容并转义。
原因是页面还包含子页面。b.目标页面或者中的标签不会生效,所以使用urllib.request.urlopen(f.read()),而不是f.read()。把动态网页指定request.request(request,url,dom,dont_traceback)函数,f.read()。代码示例如下:#构建内容组合页面并加载defconnect(request):connect('==','b/')withopen(url,'wb')asf:f.write(connect('==','d/'))url。
实时抓取网页数据( Webscraper支持以240多种语言提取Web数据的9个网络工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-09-11 10:08
Webscraper支持以240多种语言提取Web数据的9个网络工具)
文章directory[]
Web Scraping 工具可以在各种场景中用于无限用途。
例如:
1.采集市场调研数据
网页抓取工具可以从多个数据分析提供商处获取信息,并将它们整合到一个位置,以便于参考和分析。可以帮助您及时了解公司或行业未来六个月的发展方向。
2.提取联系方式
这些工具还可用于从各种网站 中提取电子邮件和电话号码等数据。
3. 采集数据下载离线阅读或存储
4.跟踪多个市场的价格等
这些软件手动或自动查找新数据、获取新数据或更新数据并存储以方便访问。例如,爬虫可用于从亚马逊采集有关产品及其价格的信息。在这个文章中,我们列出了9个网页抓取工具。
1.Import.io
Import.io 提供了一个构建器,可以通过从特定网页导入数据并将数据导出为 CSV 来形成您自己的数据集。您无需编写任何代码即可在几分钟内轻松抓取数千个网页,并根据您的需求构建 1,000 多个 API。
2.Webhose.io
Webhose.io 通过抓取数千个在线资源提供对实时和结构化数据的直接访问。网络爬虫支持提取超过240种语言的网络数据,并以多种格式保存输出数据,包括XML、JSON和RSS。
3. Dexi.io(原名 CloudScrape)
CloudScrape 支持从任何网站 采集数据,无需像 Webhose 那样下载。它提供了一个基于浏览器的编辑器来设置爬虫并实时提取数据。您可以将采集到的数据保存在 Google Drive 等云平台上,也可以将其导出为 CSV 或 JSON。
4.Scrapinghub
Scrapinghub 是一种基于云的数据提取工具,可帮助数以千计的开发者获取有价值的数据。 Scrapinghub 使用智能代理微调器 Crawlera,支持绕过机器人反制,轻松抓取大型或受机器人保护的网站。
5. ParseHub
ParseHub 用于抓取单个和多个网站,支持 JavaScript、AJAX、会话、cookie 和重定向。该应用程序使用机器学习技术来识别 Web 上最复杂的文档,并根据所需的数据格式生成输出文件。
6.VisualScraper
VisualScraper 是另一种网络数据提取软件,可用于从网络采集信息。该软件可以帮助您从多个网页中提取数据并实时获取结果。此外,还可以导出CSV、XML、JSON、SQL等多种格式。
7. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 提要中获取全部数据。 Spinn3r 与 firehouse API 一起分发并管理 95% 的索引工作。提供先进的垃圾邮件防护,可消除垃圾邮件和不当语言使用,从而提高数据安全性。
8. 80legs
80legs 是一款功能强大且灵活的网页抓取工具,可根据您的需要进行配置。它支持获取大量数据并立即下载提取数据的选项。 80legs 声称能够抓取超过 600,000 个域,并被 MailChimp 和 PayPal 等大型玩家使用。
9.刮刀
Scraper 是一个 Chrome 扩展,其数据提取功能有限,但它有助于进行在线研究并将数据导出到 Google 电子表格。此工具适合初学者和专家,他们可以使用 OAuth 轻松将数据复制到剪贴板或存储到电子表格。 查看全部
实时抓取网页数据(
Webscraper支持以240多种语言提取Web数据的9个网络工具)

文章directory[]
Web Scraping 工具可以在各种场景中用于无限用途。
例如:
1.采集市场调研数据
网页抓取工具可以从多个数据分析提供商处获取信息,并将它们整合到一个位置,以便于参考和分析。可以帮助您及时了解公司或行业未来六个月的发展方向。
2.提取联系方式
这些工具还可用于从各种网站 中提取电子邮件和电话号码等数据。
3. 采集数据下载离线阅读或存储
4.跟踪多个市场的价格等
这些软件手动或自动查找新数据、获取新数据或更新数据并存储以方便访问。例如,爬虫可用于从亚马逊采集有关产品及其价格的信息。在这个文章中,我们列出了9个网页抓取工具。
1.Import.io
Import.io 提供了一个构建器,可以通过从特定网页导入数据并将数据导出为 CSV 来形成您自己的数据集。您无需编写任何代码即可在几分钟内轻松抓取数千个网页,并根据您的需求构建 1,000 多个 API。

2.Webhose.io
Webhose.io 通过抓取数千个在线资源提供对实时和结构化数据的直接访问。网络爬虫支持提取超过240种语言的网络数据,并以多种格式保存输出数据,包括XML、JSON和RSS。

3. Dexi.io(原名 CloudScrape)
CloudScrape 支持从任何网站 采集数据,无需像 Webhose 那样下载。它提供了一个基于浏览器的编辑器来设置爬虫并实时提取数据。您可以将采集到的数据保存在 Google Drive 等云平台上,也可以将其导出为 CSV 或 JSON。

4.Scrapinghub
Scrapinghub 是一种基于云的数据提取工具,可帮助数以千计的开发者获取有价值的数据。 Scrapinghub 使用智能代理微调器 Crawlera,支持绕过机器人反制,轻松抓取大型或受机器人保护的网站。

5. ParseHub
ParseHub 用于抓取单个和多个网站,支持 JavaScript、AJAX、会话、cookie 和重定向。该应用程序使用机器学习技术来识别 Web 上最复杂的文档,并根据所需的数据格式生成输出文件。

6.VisualScraper
VisualScraper 是另一种网络数据提取软件,可用于从网络采集信息。该软件可以帮助您从多个网页中提取数据并实时获取结果。此外,还可以导出CSV、XML、JSON、SQL等多种格式。

7. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 提要中获取全部数据。 Spinn3r 与 firehouse API 一起分发并管理 95% 的索引工作。提供先进的垃圾邮件防护,可消除垃圾邮件和不当语言使用,从而提高数据安全性。

8. 80legs
80legs 是一款功能强大且灵活的网页抓取工具,可根据您的需要进行配置。它支持获取大量数据并立即下载提取数据的选项。 80legs 声称能够抓取超过 600,000 个域,并被 MailChimp 和 PayPal 等大型玩家使用。

9.刮刀
Scraper 是一个 Chrome 扩展,其数据提取功能有限,但它有助于进行在线研究并将数据导出到 Google 电子表格。此工具适合初学者和专家,他们可以使用 OAuth 轻松将数据复制到剪贴板或存储到电子表格。
实时抓取网页数据( WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-09-11 05:08
WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))
WebSpider 蓝蜘蛛网络爬虫工具5.1 可以爬取互联网上的任何网页,wap网站,包括登录后可以访问的页面。分析爬取的页面内容,获取新闻等结构化信息标题、作者、出处、正文等,支持列表页自动翻页抓取、文本页多页合并、图片和文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
用户指定要爬取的网站、要爬取的网页类型(固定页面、分页展示页面等),并配置如何解析数据项(如新闻标题、作者、来源等) , body 等),系统可以根据配置信息实时自动采集数据,也可以通过配置设置开始采集的时间,真正做到了“按需采集,一个配置,和永久捕获”。捕获的数据可以保存在数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等
该工具可以完全替代传统的编辑人工信息处理模式。 24*60全天候实时、准确地为企业提供最新的信息和情报,真正为企业降低成本,提高竞争力。
该工具的主要特点如下:
*应用广泛,可以抓取任何网页(包括登录后可以访问的网页)
*处理速度快。网络畅通,1小时可抓取解析1万个网页
*采用独特的重复数据过滤技术,支持增量数据抓取,可抓取实时数据,如:股票交易信息、天气预报等
*抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
*支持断点恢复爬行,崩溃或异常情况后恢复爬行,继续后续爬行工作,提高系统爬行效率
*对于列表页,支持翻页,可以获取所有列表页中的数据。对于body页面,可以自动合并分页显示的内容;
*支持深度页面爬取,可以逐层爬取页面。比如通过列表页面抓取body页面的URL,然后再抓取body页面。各级页面可单独存放;
*WEB操作界面,一站式安装,随处使用
*分步分析,分步存储
*配置一次,永久抓取,一劳永逸 查看全部
实时抓取网页数据(
WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))

WebSpider 蓝蜘蛛网络爬虫工具5.1 可以爬取互联网上的任何网页,wap网站,包括登录后可以访问的页面。分析爬取的页面内容,获取新闻等结构化信息标题、作者、出处、正文等,支持列表页自动翻页抓取、文本页多页合并、图片和文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
用户指定要爬取的网站、要爬取的网页类型(固定页面、分页展示页面等),并配置如何解析数据项(如新闻标题、作者、来源等) , body 等),系统可以根据配置信息实时自动采集数据,也可以通过配置设置开始采集的时间,真正做到了“按需采集,一个配置,和永久捕获”。捕获的数据可以保存在数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等
该工具可以完全替代传统的编辑人工信息处理模式。 24*60全天候实时、准确地为企业提供最新的信息和情报,真正为企业降低成本,提高竞争力。
该工具的主要特点如下:
*应用广泛,可以抓取任何网页(包括登录后可以访问的网页)
*处理速度快。网络畅通,1小时可抓取解析1万个网页
*采用独特的重复数据过滤技术,支持增量数据抓取,可抓取实时数据,如:股票交易信息、天气预报等
*抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
*支持断点恢复爬行,崩溃或异常情况后恢复爬行,继续后续爬行工作,提高系统爬行效率
*对于列表页,支持翻页,可以获取所有列表页中的数据。对于body页面,可以自动合并分页显示的内容;
*支持深度页面爬取,可以逐层爬取页面。比如通过列表页面抓取body页面的URL,然后再抓取body页面。各级页面可单独存放;
*WEB操作界面,一站式安装,随处使用
*分步分析,分步存储
*配置一次,永久抓取,一劳永逸
实时抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-09-19 06:11
原创链接:
有时,由于各种原因,我们需要采集一个站点的数据,但不同站点的数据显示方式略有不同
本文使用Java向您展示如何抓取站点的数据:(1)grab原创网页的数据;(2)grab网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:检查网页源代码。我们可以看到源代码中有一段:
从这里可以看出,再次请求网页后会显示查询结果
我们来看看查询后的网址:
换言之,我们只能通过访问这样的网站才能得到IP查询的结果。接下来,请看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到站点,使用bufreader保存网页返回的数据,然后通过自定义解析方法显示结果
这里我只是随便分析一下。如果我想准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时候,为了保护自己的数据,网站不直接在网页源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方法用于查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但是有时候我们非常需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
在第一次单击startbutton之后,它开始监视web页面的交互
当我们打开网页时,可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了便于查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们只需要分析HTTP analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址来获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两个豌豆一样,抓取JS的方法与原创网页完全相同。我们只是做了一个分析JS的过程
以下是该计划的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
我希望这篇文章能对有需要的朋友有所帮助。如果你需要程序源代码,请点击这里下载 查看全部
实时抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原创链接:
有时,由于各种原因,我们需要采集一个站点的数据,但不同站点的数据显示方式略有不同
本文使用Java向您展示如何抓取站点的数据:(1)grab原创网页的数据;(2)grab网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:检查网页源代码。我们可以看到源代码中有一段:
从这里可以看出,再次请求网页后会显示查询结果
我们来看看查询后的网址:
换言之,我们只能通过访问这样的网站才能得到IP查询的结果。接下来,请看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到站点,使用bufreader保存网页返回的数据,然后通过自定义解析方法显示结果
这里我只是随便分析一下。如果我想准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时候,为了保护自己的数据,网站不直接在网页源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方法用于查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但是有时候我们非常需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
在第一次单击startbutton之后,它开始监视web页面的交互
当我们打开网页时,可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了便于查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们只需要分析HTTP analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址来获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两个豌豆一样,抓取JS的方法与原创网页完全相同。我们只是做了一个分析JS的过程
以下是该计划的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
我希望这篇文章能对有需要的朋友有所帮助。如果你需要程序源代码,请点击这里下载
实时抓取网页数据(如何让百度快速收录呢,如何选择链接提交方式? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-09-18 05:16
)
在做百度推广时,如何让百度快速收录?这里有三种方法。今天我们主要讲第一个
如何选择链接提交方式
1、activepush:最快的提交方式。建议您立即以这种方式将站点的新输出链接推送到百度,以确保新链接可以被百度收录推送@
2、automatic push:最方便的提交方式,请在站点每个页面的源代码中部署自动推送的JS代码,每次浏览部署代码的页面时,链接会自动推送到百度。它可以与主动推送一起使用
3、sitemap:您可以定期将网站链接放入站点地图,并将站点地图提交给百度。百度会定期抓取并检查你提交的网站地图并处理链接,但收录比主动推送4、手动提交慢:这种方法可以用于一次性向百度提交链接
百度站长平台为站长提供链接提交渠道。你可以通过百度提交你想成为收录的链接。百度搜索引擎将按照标准处理这些链接,但并不保证收录可以提交链接
应当指出的是:
一,。主动推送功能的门户是:工具-网页捕获-链接提交-主动推送(实时)
二,。主动推送使用与原创实时推送不同的数据接口,需要再次获取密钥(登录后在链接提交工具界面可见)
登录地址是
为了确保您的数据提交效果,请及时更换界面和按键,尽快熟悉主动推送功能,如有问题请通过反馈中心得到百度工作人员的帮助
使用百度主动推送(实时)可以加速收录并保护原创内容不受采集第三方的伤害
我还没有看到有人写过百度的主动推送代码,所以我根据百度提供的PHP代码编写,并将其添加到Dede后台发布的文章文件中,实现了百度的主动推送(实时)功能
在article_add.php中搜索 $artUrl = MakeArt($arcID,true,true,$isremote);
然后在
if($artUrl=='')
{
$artUrl = $cfg_phpurl."/view.php?aid=$arcID";
}
后面加入
else{
$urls[]='http://'.$_SERVER['HTTP_HOST'].$artUrl;
$api = 'http://data.zz.baidu.com/urls?site=你的域名&token=准入密钥';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
}
省省吧
成功发布文章后,将显示以下内容
查看全部
实时抓取网页数据(如何让百度快速收录呢,如何选择链接提交方式?
)
在做百度推广时,如何让百度快速收录?这里有三种方法。今天我们主要讲第一个
如何选择链接提交方式
1、activepush:最快的提交方式。建议您立即以这种方式将站点的新输出链接推送到百度,以确保新链接可以被百度收录推送@
2、automatic push:最方便的提交方式,请在站点每个页面的源代码中部署自动推送的JS代码,每次浏览部署代码的页面时,链接会自动推送到百度。它可以与主动推送一起使用
3、sitemap:您可以定期将网站链接放入站点地图,并将站点地图提交给百度。百度会定期抓取并检查你提交的网站地图并处理链接,但收录比主动推送4、手动提交慢:这种方法可以用于一次性向百度提交链接
百度站长平台为站长提供链接提交渠道。你可以通过百度提交你想成为收录的链接。百度搜索引擎将按照标准处理这些链接,但并不保证收录可以提交链接
应当指出的是:
一,。主动推送功能的门户是:工具-网页捕获-链接提交-主动推送(实时)
二,。主动推送使用与原创实时推送不同的数据接口,需要再次获取密钥(登录后在链接提交工具界面可见)
登录地址是
为了确保您的数据提交效果,请及时更换界面和按键,尽快熟悉主动推送功能,如有问题请通过反馈中心得到百度工作人员的帮助
使用百度主动推送(实时)可以加速收录并保护原创内容不受采集第三方的伤害
我还没有看到有人写过百度的主动推送代码,所以我根据百度提供的PHP代码编写,并将其添加到Dede后台发布的文章文件中,实现了百度的主动推送(实时)功能
在article_add.php中搜索 $artUrl = MakeArt($arcID,true,true,$isremote);
然后在
if($artUrl=='')
{
$artUrl = $cfg_phpurl."/view.php?aid=$arcID";
}
后面加入
else{
$urls[]='http://'.$_SERVER['HTTP_HOST'].$artUrl;
$api = 'http://data.zz.baidu.com/urls?site=你的域名&token=准入密钥';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
}
省省吧
成功发布文章后,将显示以下内容
实时抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-18 05:15
我相信每个网站网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式只有两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不介绍
二、编写您自己的程序并获取它。这种方式要求站长编写自己的程序,这可能需要站长的开发能力
起初,我试图使用第三方工具来捕获我需要的数据。因为互联网上流行的第三方工具要么不符合我的要求,要么太复杂,我一时不知道如何使用它们。后来,我决定自己写。现在我基本上可以处理一个网站(仅程序开发时间,不包括数据捕获时间)
经过一段时间的数据采集工作,我遇到了很多困难。最常见的问题之一是获取分页数据的问题。原因是有多种形式的数据分页。接下来,我将以三种形式介绍获取分页数据的方法。虽然我在网上看到了很多这样的文章,但是每次我拿别人的代码时,总有各种各样的问题。以下代码可以正确执行,我目前也在使用它们。本文的代码实现是用c语言实现的。我认为其他语言的原则大致相同
让我们开门见山:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具捕获此表单也非常简单。基本上,不需要编写代码。对于像我这样宁愿花半天时间编写代码而不愿学习第三方工具的人,我仍然自己编写代码
此方法通过循环生成数据页的URL地址。例如,通过Httpwebrequest访问相应的URL地址,并返回相应页面的HTML文本。下一个任务是解析字符串并将所需内容保存到本地数据库;有关捕获的代码,请参阅以下内容:
公共字符串GetResponseString(字符串url){
字符串_StrResponse=“”
HttpWebRequest WebRequest=(HttpWebRequest)WebRequest.Create(url)
_WebRequest.UserAgent=“MOZILLA/4.0(兼容;MSIE7.0;WINDOWS NT5.2.NET CLR1.1.4322.NET CLR2.0.50727.NET CLR3.0.0450 6.648.NET CLR@k305.21022.NET CLR3.0.450 6.2152.NET CLR@k305.30729)",
_WebRequest.Method=“GET”
WebResponse _WebResponse=_WebRequest.GetResponse()
StreamReader _ResponseStream=新的StreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding(“gb2312”)
_StrResponse=_ResponseStream.ReadToEnd()
_WebResponse.Close()
_ResponseStream.Close()
返回响应
}
上面的代码可以返回与页面的HTML内容相对应的字符串。其余的是从该字符串中获取您关心的信息
第二种方式:可能是开发中经常遇到的,它的分页控件通过post将分页信息提交给后台代码,比如.Net下的GridView的分页功能,当你点击分页页码时,你会发现URL地址没有改变,但是页码变了而且页面内容也发生了变化。如果你仔细观察,你会发现当你将鼠标移动到每个页码上时,状态栏会显示javascript:_dopostback(“GridView”,“page1”)和其他代码。事实上,这种形式并不很难,因为毕竟,有一个地方可以找到页码的规律
我们知道提交HTTP请求有两种方式,一种是get,另一种是post。第一种是get,第二种是post。具体的提交原则不需要详细解释,这不是本文的重点
要获取此类页面,您需要注意页面的几个重要元素
一、_viewstate应该是.Net独有的,也是.Net开发人员喜欢和讨厌的东西。当你打开一个网站页面时,如果你发现这个东西后面有很多乱七八糟的字符,那么这个网站一定是用英语写的
二、__dopostback方法。这是从页面自动生成的JavaScript方法,其中收录两个参数_eventtarget和_eventargument。这两个参数可以引用与页码对应的内容,因为当您单击翻页时,页码信息将传输到这两个参数
三、__EVENTVALIDATION这也应该是独一无二的
你不必太在意这三件事是做什么的,你只需要在编写代码获取页面时注意提交这三个元素
与第一种方法一样,_doPostBack的两个参数必须以循环方式拼合在一起。只有收录页码信息的参数才需要拼合在一起。这里需要注意的一点是,每次通过post提交下一页的请求时,您应该首先获得_viewstateinformation和_eVentValidation当前页面的信息,因此分页数据更准确。第一种方法可用于获取第一页的页面内容,然后同时取出相应的u viewstate信息和_eventvalidation信息,然后循环下一页,然后记录_viewstate信息和_eventvali抓取每页后采集信息,以便为下一页文章提交数据
参考代码如下:
<p>对于(int i=0;i 查看全部
实时抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信每个网站网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式只有两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不介绍
二、编写您自己的程序并获取它。这种方式要求站长编写自己的程序,这可能需要站长的开发能力
起初,我试图使用第三方工具来捕获我需要的数据。因为互联网上流行的第三方工具要么不符合我的要求,要么太复杂,我一时不知道如何使用它们。后来,我决定自己写。现在我基本上可以处理一个网站(仅程序开发时间,不包括数据捕获时间)
经过一段时间的数据采集工作,我遇到了很多困难。最常见的问题之一是获取分页数据的问题。原因是有多种形式的数据分页。接下来,我将以三种形式介绍获取分页数据的方法。虽然我在网上看到了很多这样的文章,但是每次我拿别人的代码时,总有各种各样的问题。以下代码可以正确执行,我目前也在使用它们。本文的代码实现是用c语言实现的。我认为其他语言的原则大致相同
让我们开门见山:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具捕获此表单也非常简单。基本上,不需要编写代码。对于像我这样宁愿花半天时间编写代码而不愿学习第三方工具的人,我仍然自己编写代码
此方法通过循环生成数据页的URL地址。例如,通过Httpwebrequest访问相应的URL地址,并返回相应页面的HTML文本。下一个任务是解析字符串并将所需内容保存到本地数据库;有关捕获的代码,请参阅以下内容:
公共字符串GetResponseString(字符串url){
字符串_StrResponse=“”
HttpWebRequest WebRequest=(HttpWebRequest)WebRequest.Create(url)
_WebRequest.UserAgent=“MOZILLA/4.0(兼容;MSIE7.0;WINDOWS NT5.2.NET CLR1.1.4322.NET CLR2.0.50727.NET CLR3.0.0450 6.648.NET CLR@k305.21022.NET CLR3.0.450 6.2152.NET CLR@k305.30729)",
_WebRequest.Method=“GET”
WebResponse _WebResponse=_WebRequest.GetResponse()
StreamReader _ResponseStream=新的StreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding(“gb2312”)
_StrResponse=_ResponseStream.ReadToEnd()
_WebResponse.Close()
_ResponseStream.Close()
返回响应
}
上面的代码可以返回与页面的HTML内容相对应的字符串。其余的是从该字符串中获取您关心的信息
第二种方式:可能是开发中经常遇到的,它的分页控件通过post将分页信息提交给后台代码,比如.Net下的GridView的分页功能,当你点击分页页码时,你会发现URL地址没有改变,但是页码变了而且页面内容也发生了变化。如果你仔细观察,你会发现当你将鼠标移动到每个页码上时,状态栏会显示javascript:_dopostback(“GridView”,“page1”)和其他代码。事实上,这种形式并不很难,因为毕竟,有一个地方可以找到页码的规律
我们知道提交HTTP请求有两种方式,一种是get,另一种是post。第一种是get,第二种是post。具体的提交原则不需要详细解释,这不是本文的重点
要获取此类页面,您需要注意页面的几个重要元素
一、_viewstate应该是.Net独有的,也是.Net开发人员喜欢和讨厌的东西。当你打开一个网站页面时,如果你发现这个东西后面有很多乱七八糟的字符,那么这个网站一定是用英语写的
二、__dopostback方法。这是从页面自动生成的JavaScript方法,其中收录两个参数_eventtarget和_eventargument。这两个参数可以引用与页码对应的内容,因为当您单击翻页时,页码信息将传输到这两个参数
三、__EVENTVALIDATION这也应该是独一无二的
你不必太在意这三件事是做什么的,你只需要在编写代码获取页面时注意提交这三个元素
与第一种方法一样,_doPostBack的两个参数必须以循环方式拼合在一起。只有收录页码信息的参数才需要拼合在一起。这里需要注意的一点是,每次通过post提交下一页的请求时,您应该首先获得_viewstateinformation和_eVentValidation当前页面的信息,因此分页数据更准确。第一种方法可用于获取第一页的页面内容,然后同时取出相应的u viewstate信息和_eventvalidation信息,然后循环下一页,然后记录_viewstate信息和_eventvali抓取每页后采集信息,以便为下一页文章提交数据
参考代码如下:
<p>对于(int i=0;i
实时抓取网页数据( Webscraper支持以240多种语言提取Web数据,9个网络抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-09-17 20:28
Webscraper支持以240多种语言提取Web数据,9个网络抓取工具)
web抓取工具旨在从中提取信息网站. 它们也称为网络采集工具或web数据提取工具
Web脚本工具可用于各种场景中的无限目的
例如:
1.采集市场研究数据
网络捕获工具可以从多个数据分析提供商处获取信息,并将其集成到一个位置以供参考和分析。它可以帮助你了解公司或行业未来六个月的发展方向
2.提取联系信息
这些工具还可用于从各种网站中提取电子邮件和电话号码等数据@
3.采集数据下载以进行离线读取或存储
4.多个市场的跟踪价格等
这些软件手动或自动查找新数据、获取新数据或更新数据并存储,以便于访问。例如,您可以使用爬虫从Amazon采集有关产品及其价格的信息。在本文文章中,我们列出了9个网络爬虫
1.Import.io
提供一个生成器,通过从特定网页导入数据并将数据导出到CSV,可以形成您自己的数据集。您可以在几分钟内轻松抓取数千个网页,而无需编写任何代码,并根据需要构建1000多个API
2.Webhose.io
通过抓取数千个在线资源,提供对实时结构化数据的直接访问。WebScraper支持以240多种语言提取Web数据,并以各种格式保存输出数据,包括XML、JSON和RSS
3.dexi.io(原名cloudscape)
Cloudscape支持从任何网站源采集数据,而无需像webhose一样下载数据。它提供了一个基于浏览器的编辑器来设置爬虫并实时提取数据。您可以将采集的数据保存在谷歌云硬盘和其他云平台上,或将其导出为CSV或JSON
4.Scrapinghub
Scripinghub是一个基于云的数据提取工具,可帮助数千名开发人员获取有价值的数据。Scripinghub使用crawlera,一种智能代理旋转器,支持绕过机器人对抗,轻松抓取大型或受机器人保护的站点
5.ParseHub
Parsehub用于获取单个和多个网站,并支持JavaScript、AJAX、会话、cookie和重定向。该应用程序使用机器学习技术识别web上最复杂的文档,并根据所需的数据格式生成输出文件
6.VisualScraper
Visualsharper是另一种可用于从web采集信息的web数据提取软件。该软件可以帮助您从多个网页中提取数据,并实时获取结果。此外,您可以以各种格式导出,如CSV、XML、JSON和SQL
7.Spinn3r
Spinn3r允许您从博客、新闻和社交媒体网站以及RSS和atom提要获取全部数据。Spinn3r与firehouse API一起分发,以管理95%的索引。它提供高级垃圾邮件保护,可以消除垃圾邮件和不适当的语言使用,从而提高数据安全性
8.80支腿
80legs是一款功能强大且灵活的网络捕获工具,可根据您的需要进行配置。它支持获取大量数据并立即下载和提取数据的选项。80legs声称能够捕获60多万个域名,并被MailChimp和paypal等大型玩家使用
9.刮刀
Scraper是一个Chrome扩展,数据提取能力有限,但它有助于进行在线研究并将数据导出到Google电子表格。此工具适用于初学者和专家,他们可以轻松地将数据复制到剪贴板或使用OAuth将其存储在电子表格中 查看全部
实时抓取网页数据(
Webscraper支持以240多种语言提取Web数据,9个网络抓取工具)
web抓取工具旨在从中提取信息网站. 它们也称为网络采集工具或web数据提取工具
Web脚本工具可用于各种场景中的无限目的
例如:
1.采集市场研究数据
网络捕获工具可以从多个数据分析提供商处获取信息,并将其集成到一个位置以供参考和分析。它可以帮助你了解公司或行业未来六个月的发展方向
2.提取联系信息
这些工具还可用于从各种网站中提取电子邮件和电话号码等数据@
3.采集数据下载以进行离线读取或存储
4.多个市场的跟踪价格等
这些软件手动或自动查找新数据、获取新数据或更新数据并存储,以便于访问。例如,您可以使用爬虫从Amazon采集有关产品及其价格的信息。在本文文章中,我们列出了9个网络爬虫
1.Import.io
提供一个生成器,通过从特定网页导入数据并将数据导出到CSV,可以形成您自己的数据集。您可以在几分钟内轻松抓取数千个网页,而无需编写任何代码,并根据需要构建1000多个API
2.Webhose.io
通过抓取数千个在线资源,提供对实时结构化数据的直接访问。WebScraper支持以240多种语言提取Web数据,并以各种格式保存输出数据,包括XML、JSON和RSS
3.dexi.io(原名cloudscape)
Cloudscape支持从任何网站源采集数据,而无需像webhose一样下载数据。它提供了一个基于浏览器的编辑器来设置爬虫并实时提取数据。您可以将采集的数据保存在谷歌云硬盘和其他云平台上,或将其导出为CSV或JSON
4.Scrapinghub
Scripinghub是一个基于云的数据提取工具,可帮助数千名开发人员获取有价值的数据。Scripinghub使用crawlera,一种智能代理旋转器,支持绕过机器人对抗,轻松抓取大型或受机器人保护的站点
5.ParseHub
Parsehub用于获取单个和多个网站,并支持JavaScript、AJAX、会话、cookie和重定向。该应用程序使用机器学习技术识别web上最复杂的文档,并根据所需的数据格式生成输出文件
6.VisualScraper
Visualsharper是另一种可用于从web采集信息的web数据提取软件。该软件可以帮助您从多个网页中提取数据,并实时获取结果。此外,您可以以各种格式导出,如CSV、XML、JSON和SQL
7.Spinn3r
Spinn3r允许您从博客、新闻和社交媒体网站以及RSS和atom提要获取全部数据。Spinn3r与firehouse API一起分发,以管理95%的索引。它提供高级垃圾邮件保护,可以消除垃圾邮件和不适当的语言使用,从而提高数据安全性
8.80支腿
80legs是一款功能强大且灵活的网络捕获工具,可根据您的需要进行配置。它支持获取大量数据并立即下载和提取数据的选项。80legs声称能够捕获60多万个域名,并被MailChimp和paypal等大型玩家使用
9.刮刀
Scraper是一个Chrome扩展,数据提取能力有限,但它有助于进行在线研究并将数据导出到Google电子表格。此工具适用于初学者和专家,他们可以轻松地将数据复制到剪贴板或使用OAuth将其存储在电子表格中
实时抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 274 次浏览 • 2021-09-17 20:26
有时,由于各种原因,我们需要采集a网站data,但由于网站data的不同,数据的显示方式略有不同
本文将使用java向您展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
publicvoidcaptureHtml(Stringip)throwsException{
StringstrURL=“”+ip
URLurl=newURL(strURL)
HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection()
InputStreamReaderinput=newInputStreamReader(httpConn
.getInputStream(),“utf-8”)
BufferedReaderBufferReader=newBufferedReader(输入)
Stringline=“”
StringBuildercontentBuf=newStringBuilder()
而((line=bufReader.readLine())!=null){
contentBuf.append(行)
}
Stringbuf=contentBuf.toString()
Intbeginix=buf.Indexof(“查询结果[”)
Intendix=buf.indexof(“以上四项依次显示”)
Stringresult=buf.子串(beginIx,endIx)
System.Out.Println(“capturehtml()的结果:\n”+结果)
}
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
publicvoidcaptureJavascript(Stringpostid)throwsException{
StringstrURL=“”+postid
+“&;channel=&;rnd=0”
URLurl=newURL(strURL)
HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection()
InputStreamReaderinput=newInputStreamReader(httpConn
.getInputStream(),“utf-8”)
BufferedReaderBufferReader=newBufferedReader(输入)
Stringline=“”
StringBuildercontentBuf=newStringBuilder()
而((line=bufReader.readLine())!=null){
contentBuf.append(行)
}
System.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring())
}
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载 查看全部
实时抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
有时,由于各种原因,我们需要采集a网站data,但由于网站data的不同,数据的显示方式略有不同
本文将使用java向您展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
publicvoidcaptureHtml(Stringip)throwsException{
StringstrURL=“”+ip
URLurl=newURL(strURL)
HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection()
InputStreamReaderinput=newInputStreamReader(httpConn
.getInputStream(),“utf-8”)
BufferedReaderBufferReader=newBufferedReader(输入)
Stringline=“”
StringBuildercontentBuf=newStringBuilder()
而((line=bufReader.readLine())!=null){
contentBuf.append(行)
}
Stringbuf=contentBuf.toString()
Intbeginix=buf.Indexof(“查询结果[”)
Intendix=buf.indexof(“以上四项依次显示”)
Stringresult=buf.子串(beginIx,endIx)
System.Out.Println(“capturehtml()的结果:\n”+结果)
}
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
publicvoidcaptureJavascript(Stringpostid)throwsException{
StringstrURL=“”+postid
+“&;channel=&;rnd=0”
URLurl=newURL(strURL)
HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection()
InputStreamReaderinput=newInputStreamReader(httpConn
.getInputStream(),“utf-8”)
BufferedReaderBufferReader=newBufferedReader(输入)
Stringline=“”
StringBuildercontentBuf=newStringBuilder()
而((line=bufReader.readLine())!=null){
contentBuf.append(行)
}
System.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring())
}
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载
实时抓取网页数据(ps:当某些网站无法通过curl拿到,其实最简单直接的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-17 11:02
实时抓取网页数据,将网页中的源码解析成二进制,生成数据结构。显示的时候,对应的css,js,
当我把网页中的表格以及定位框都抓下来的时候,我感觉自己快成为一个全能了。无所不能。
从零开始写网页!
看你是要实现哪些功能,比如说新闻客户端,一般会抓人民日报中心,广电网的新闻,当然除了不在官网中,其他的不能使用这些方法。
抓取是搞不定的,请自行搜索网页异步,或者图片上传。从html文件开始抓。curl不失为个好用的方法,不过大部分是针对浏览器的,像百度这种大流量服务器,是基本不能用curl搞定的。elgger可以从php、asp、flash、wap抓取,不失为个好用的方法。ps:当某些网站无法通过curl拿到,其实最简单直接的方法,使用mongodb中的puppeteer来调用,这样下来,代码和效果都不会差。
在某些需要获取某些内容,以及上传图片等操作时,比如用网页抓取之前,查看你要抓取的页面能否curl抓取,能否使用curl先让浏览器验证下,没问题就能抓,不行,那就只能直接用图片上传代替curl抓取了。对于一些高级要求要用其他网页抓取之前也是能curl抓取的,比如对操作数据量要求较多,或者复杂的页面,不能使用curl抓取。
网页中都是js,又不能全抓的话,也可以把js这些放到cookie中记住,以后用js的时候直接拿来用。上传图片的时候,直接用<img>标签上传图片的。cookie中上传md5值。 查看全部
实时抓取网页数据(ps:当某些网站无法通过curl拿到,其实最简单直接的方法)
实时抓取网页数据,将网页中的源码解析成二进制,生成数据结构。显示的时候,对应的css,js,
当我把网页中的表格以及定位框都抓下来的时候,我感觉自己快成为一个全能了。无所不能。
从零开始写网页!
看你是要实现哪些功能,比如说新闻客户端,一般会抓人民日报中心,广电网的新闻,当然除了不在官网中,其他的不能使用这些方法。
抓取是搞不定的,请自行搜索网页异步,或者图片上传。从html文件开始抓。curl不失为个好用的方法,不过大部分是针对浏览器的,像百度这种大流量服务器,是基本不能用curl搞定的。elgger可以从php、asp、flash、wap抓取,不失为个好用的方法。ps:当某些网站无法通过curl拿到,其实最简单直接的方法,使用mongodb中的puppeteer来调用,这样下来,代码和效果都不会差。
在某些需要获取某些内容,以及上传图片等操作时,比如用网页抓取之前,查看你要抓取的页面能否curl抓取,能否使用curl先让浏览器验证下,没问题就能抓,不行,那就只能直接用图片上传代替curl抓取了。对于一些高级要求要用其他网页抓取之前也是能curl抓取的,比如对操作数据量要求较多,或者复杂的页面,不能使用curl抓取。
网页中都是js,又不能全抓的话,也可以把js这些放到cookie中记住,以后用js的时候直接拿来用。上传图片的时候,直接用<img>标签上传图片的。cookie中上传md5值。
实时抓取网页数据(软件介绍公司旗下访客统计助手)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-09-17 09:20
访客捕捉向导是专门为企业网络推广和企业提高网站访客转化率而开发的软件。它可以实时、高效地捕获访客的手机号和QQ号。具体功能如下:手机号码捕获和访客QQ捕获
获取访客的手机号码。借助二次营销机会增加业务销售额。目前,网络营销非常困难。成本继续上升。以百度竞价为例。超过90%的客户点击广告访问网站网站. 大多数客户直接看到它
这是网站手机号码搜索和提取工具。这种推荐的手机号码提取软件已在全球许多中国公司的企业网页上使用收录。您只需在神威手机号码搜索软件中输入搜索键即可
请推荐爬虫软件爬升一些网站打开数字数据
在线手机号码提取工具可以提取文本列表中的文本或所有手机号码,用于过滤和过滤手机号码。支持导出到TXT或excel,方便快捷
软件介绍公司的访客统计助手是一套专门用于手机网站访客手机号码捕获的专业软件。它只需安装在mobile网站上即可使用
如何抓取网站手机号最近,很多网友都在百度上。问:你能通过网站程序捕获网站访客的手机号码吗?我会在这里说清楚的。当然可以。让我们先了解一下普通手机号码
软件只能提取网页上发布的手机号码,无法提取网页上没有的手机号码。软件支持网站登录提取。使用说明:下载软件后,需要使用解压软件将采集软件解压到硬盘上。解压后,将生成9个文件和一个文件 查看全部
实时抓取网页数据(软件介绍公司旗下访客统计助手)
访客捕捉向导是专门为企业网络推广和企业提高网站访客转化率而开发的软件。它可以实时、高效地捕获访客的手机号和QQ号。具体功能如下:手机号码捕获和访客QQ捕获
获取访客的手机号码。借助二次营销机会增加业务销售额。目前,网络营销非常困难。成本继续上升。以百度竞价为例。超过90%的客户点击广告访问网站网站. 大多数客户直接看到它
这是网站手机号码搜索和提取工具。这种推荐的手机号码提取软件已在全球许多中国公司的企业网页上使用收录。您只需在神威手机号码搜索软件中输入搜索键即可
请推荐爬虫软件爬升一些网站打开数字数据
在线手机号码提取工具可以提取文本列表中的文本或所有手机号码,用于过滤和过滤手机号码。支持导出到TXT或excel,方便快捷
软件介绍公司的访客统计助手是一套专门用于手机网站访客手机号码捕获的专业软件。它只需安装在mobile网站上即可使用
如何抓取网站手机号最近,很多网友都在百度上。问:你能通过网站程序捕获网站访客的手机号码吗?我会在这里说清楚的。当然可以。让我们先了解一下普通手机号码
软件只能提取网页上发布的手机号码,无法提取网页上没有的手机号码。软件支持网站登录提取。使用说明:下载软件后,需要使用解压软件将采集软件解压到硬盘上。解压后,将生成9个文件和一个文件
实时抓取网页数据(林伟坚申请学位级别硕士专业计算机软件与理论指导教师袁晓洁201205摘要摘要)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-17 09:15
基于scrapy框架的新闻实时捕获与处理系统的设计与实现林伟健学位级硕士专业计算机软件应用与理论讲师袁晓杰2012年5月摘要随着信息技术的飞速发展,互联网的信息爆炸给人们带来了信息过载的问题。新闻信息是接触面最广的信息之一,媒体信息发布方式已逐渐从传统媒体转向互联网。新闻信息作为互联网信息的重要组成部分,也在迅速增长。在这种背景下,本文确定了通过分布式新闻实时捕获快速聚合和处理互联网上各个站点的新闻内容,从而使人们更高效、更全面地获取新闻信息的研究方向。本文根据新闻网站和新闻爬虫的特点,对互联网新闻信息进行了深入的分析和总结,将新闻网站的页面准确地划分为导航页面和新闻页面。通过区分这两个页面的不同监控和抓取措施,详细设计了适用于新闻抓取器的核心算法,包括抓取策略和更新策略。这两个核心算法能够保证新闻的全面、高效捕获。基于开源数据库软件的爬虫框架,实现了一个分布式新闻实时抓取系统。该新闻实时抓取系统使用正则表达式方法提取和识别多个模块中的相关数据。本文还设计并实现了一个可配置的模块&新闻数据处理流水线来处理抓取的新闻
管道的功能模块包括新闻数据提取、新闻属性规范化、分页新闻合并和新闻内容清理。根据中文新闻的特点,本文采用特征提取的方法提取新闻特征,并在网页重复数据消除算法的基础上实现了新闻重复数据消除算法。本文实现的分布式新闻实时抓取和数据清理系统已经应用到实际生产过程中。通过对多个新闻站点和多个初始化导航页面的抓取和监控,系统每天可以抓取10000多个页面,其中新闻页面的比例非常高。这些运行数据表明,该系统具有较高的爬行效率。后续的数据处理管道也可以胜任每日新闻关键词news crawler数据提取新闻重复数据消除的处理和处理第1章导论第1章导论第1节研究背景和意义随着互联网的快速发展,互联网正在渗透到我们生活的方方面面,从精神信息到物质需求都可以通过互联网实现。技术是技术的最好表现。它以其方便、快捷、丰富的表达方式,成为世界上使用最广泛的互动方式。随着信息的爆炸式发展,数以亿计的网站正在涌现,搜索引擎收录的网页数量也在快速增长。年,他们通过博客宣布索引的网页数量已达到万亿。即便如此,索引网页只是互联网上所有网页的一部分。互联网上丰富的信息给人们带来了极大的便利。通过互联网,人们可以高效、快速地获取各种信息
然而,信息爆炸也给用户带来了信息过载的问题。如何快速地从大量的信息中选择他们需要的是一个日益紧迫的问题。世纪末,作为第一代互联网信息接入,它解决了当时的信息过载问题,成为互联网奇迹的创造者之一。然而,随着互联网的不断发展,信息过载问题越来越严重。此目录信息采集网站无法解决信息量大的问题。成立于年,逐渐取代信息获取成为新一代互联网,改变了整个互联网的信息获取模式。作为一个搜索引擎,它将使用网络爬虫主动采集互联网上的各种信息进行分类和存储,并对这些信息进行索引,以便用户快速检索。这种模式将用户从目录导航网页的局限中解放出来,可以快速查找互联网上的各种信息,极大地提高了工作效率和获取信息的质量。因此,它已成为互联网的第二代霸主。作为搜索引擎的重要组成部分,网络爬虫从互联网上下载网页供搜索引擎使用。它的爬行效率影响着搜索引擎能够索引的页面数量和更新频率,直接决定着搜索引擎的质量。它不仅可以为搜索引擎提供最基本的数据源,还可以判断数据的质量。新闻是人们在现实生活中接触最多的一种媒体信息。随着互联网的飞速发展,新闻已经逐渐从传统媒体转向互联网
随着互联网时代的到来,新闻的时滞趋于零,人们对新闻和信息的获取逐渐从传统媒体转移到互联网上。同样,新闻信息作为互联网信息的重要组成部分,在第一章的引言中也在不断增加。如何让人们更高效、更全面地获取新闻信息也是一个巨大的挑战。与搜索引擎一样,新闻信息聚合首先要解决的是新闻信息的获取。传统的网络爬虫对互联网上的所有信息一视同仁,没有对新闻信息进行特殊处理。在发布后很长一段时间内捕捉并向用户显示的新闻信息已经失去了意义。传统的网络爬虫对新闻信息的抓取已经不能满足新闻时效性的要求。因此,必须根据新闻信息的特点设计一个有针对性的爬虫来抓取新闻,才能有效地捕获新闻信息。随着互联网的发展,互联网上的新闻信息也进入了一个海量的时代。只有一台服务器才能快速处理的任务越来越少。新闻信息的爬行不能依赖于单个服务器。设计一个分布式爬行系统势在必行。除了分布式新闻爬虫,新闻信息采集还需要一套有效的新闻数据处理方法来处理和处理新闻数据,以便能够定期向用户显示。总之,新闻信息的获取需要高性能分布式爬虫技术、数据处理技术和海量数据存储技术的支持。分布式新闻爬虫和新闻数据处理技术的研究不仅能够满足用户高效、全面获取新闻信息的需求,而且具有很高的学术研究价值
第二部分是本文的主要研究内容和工作。为了满足全面、快速获取新闻信息的需要,本文设计了一种分布式新闻实时捕获系统和新闻数据处理方案。主要完成了以下工作,深入研究了传统全网爬虫的发展及其相关算法和技术,详细比较了几种性能较好的全网爬虫的优缺点,以指导新闻爬虫系统的设计。深入分析和总结了网络新闻信息、新闻网站和新闻爬虫的特点。基于这些特点,详细设计了新闻爬虫的核心算法爬虫策略和更新策略。基于深度定制的爬虫框架,结合两个开源数据库软件,实现了一个分布式新闻实时爬虫系统。通过分析爬行系统的运行数据,确定系统的爬行性能。设计了一套具有可配置模块的新闻数据处理流水线,包括新闻数据提取、新闻属性规范化、分页新闻合并和新闻内容清理。根据中文新闻的特点,结合该算法,实现了第一章引言中一种更高效的新闻重复数据消除算法。第二章详细介绍了网络爬虫的发展及其相关算法和技术。本文首先介绍了网络爬虫的定义及其常用的算法和模块,然后选取了三种性能优异的开源爬虫作为代表,仔细研究了它们的特点,并进行了详细的比较。本章第二部分还介绍了实现新闻爬虫的框架,详细描述了新闻爬虫的组成、体系结构和程序执行过程
第三章详细介绍了分布式新闻实时捕获系统的实现方案。首先介绍了新闻爬虫的特点,并根据这些特点制定了新闻爬虫的实现方案。通过对crawler框架的深入定制,设计并实现了一套基于两个开源数据库的分布式新闻实时捕获系统。本章最后一部分对爬虫系统实际运行中的数据进行了统计分析。第四章详细介绍了新闻数据的处理方案,特别是新闻数据的提取 查看全部
实时抓取网页数据(林伟坚申请学位级别硕士专业计算机软件与理论指导教师袁晓洁201205摘要摘要)
基于scrapy框架的新闻实时捕获与处理系统的设计与实现林伟健学位级硕士专业计算机软件应用与理论讲师袁晓杰2012年5月摘要随着信息技术的飞速发展,互联网的信息爆炸给人们带来了信息过载的问题。新闻信息是接触面最广的信息之一,媒体信息发布方式已逐渐从传统媒体转向互联网。新闻信息作为互联网信息的重要组成部分,也在迅速增长。在这种背景下,本文确定了通过分布式新闻实时捕获快速聚合和处理互联网上各个站点的新闻内容,从而使人们更高效、更全面地获取新闻信息的研究方向。本文根据新闻网站和新闻爬虫的特点,对互联网新闻信息进行了深入的分析和总结,将新闻网站的页面准确地划分为导航页面和新闻页面。通过区分这两个页面的不同监控和抓取措施,详细设计了适用于新闻抓取器的核心算法,包括抓取策略和更新策略。这两个核心算法能够保证新闻的全面、高效捕获。基于开源数据库软件的爬虫框架,实现了一个分布式新闻实时抓取系统。该新闻实时抓取系统使用正则表达式方法提取和识别多个模块中的相关数据。本文还设计并实现了一个可配置的模块&新闻数据处理流水线来处理抓取的新闻
管道的功能模块包括新闻数据提取、新闻属性规范化、分页新闻合并和新闻内容清理。根据中文新闻的特点,本文采用特征提取的方法提取新闻特征,并在网页重复数据消除算法的基础上实现了新闻重复数据消除算法。本文实现的分布式新闻实时抓取和数据清理系统已经应用到实际生产过程中。通过对多个新闻站点和多个初始化导航页面的抓取和监控,系统每天可以抓取10000多个页面,其中新闻页面的比例非常高。这些运行数据表明,该系统具有较高的爬行效率。后续的数据处理管道也可以胜任每日新闻关键词news crawler数据提取新闻重复数据消除的处理和处理第1章导论第1章导论第1节研究背景和意义随着互联网的快速发展,互联网正在渗透到我们生活的方方面面,从精神信息到物质需求都可以通过互联网实现。技术是技术的最好表现。它以其方便、快捷、丰富的表达方式,成为世界上使用最广泛的互动方式。随着信息的爆炸式发展,数以亿计的网站正在涌现,搜索引擎收录的网页数量也在快速增长。年,他们通过博客宣布索引的网页数量已达到万亿。即便如此,索引网页只是互联网上所有网页的一部分。互联网上丰富的信息给人们带来了极大的便利。通过互联网,人们可以高效、快速地获取各种信息
然而,信息爆炸也给用户带来了信息过载的问题。如何快速地从大量的信息中选择他们需要的是一个日益紧迫的问题。世纪末,作为第一代互联网信息接入,它解决了当时的信息过载问题,成为互联网奇迹的创造者之一。然而,随着互联网的不断发展,信息过载问题越来越严重。此目录信息采集网站无法解决信息量大的问题。成立于年,逐渐取代信息获取成为新一代互联网,改变了整个互联网的信息获取模式。作为一个搜索引擎,它将使用网络爬虫主动采集互联网上的各种信息进行分类和存储,并对这些信息进行索引,以便用户快速检索。这种模式将用户从目录导航网页的局限中解放出来,可以快速查找互联网上的各种信息,极大地提高了工作效率和获取信息的质量。因此,它已成为互联网的第二代霸主。作为搜索引擎的重要组成部分,网络爬虫从互联网上下载网页供搜索引擎使用。它的爬行效率影响着搜索引擎能够索引的页面数量和更新频率,直接决定着搜索引擎的质量。它不仅可以为搜索引擎提供最基本的数据源,还可以判断数据的质量。新闻是人们在现实生活中接触最多的一种媒体信息。随着互联网的飞速发展,新闻已经逐渐从传统媒体转向互联网
随着互联网时代的到来,新闻的时滞趋于零,人们对新闻和信息的获取逐渐从传统媒体转移到互联网上。同样,新闻信息作为互联网信息的重要组成部分,在第一章的引言中也在不断增加。如何让人们更高效、更全面地获取新闻信息也是一个巨大的挑战。与搜索引擎一样,新闻信息聚合首先要解决的是新闻信息的获取。传统的网络爬虫对互联网上的所有信息一视同仁,没有对新闻信息进行特殊处理。在发布后很长一段时间内捕捉并向用户显示的新闻信息已经失去了意义。传统的网络爬虫对新闻信息的抓取已经不能满足新闻时效性的要求。因此,必须根据新闻信息的特点设计一个有针对性的爬虫来抓取新闻,才能有效地捕获新闻信息。随着互联网的发展,互联网上的新闻信息也进入了一个海量的时代。只有一台服务器才能快速处理的任务越来越少。新闻信息的爬行不能依赖于单个服务器。设计一个分布式爬行系统势在必行。除了分布式新闻爬虫,新闻信息采集还需要一套有效的新闻数据处理方法来处理和处理新闻数据,以便能够定期向用户显示。总之,新闻信息的获取需要高性能分布式爬虫技术、数据处理技术和海量数据存储技术的支持。分布式新闻爬虫和新闻数据处理技术的研究不仅能够满足用户高效、全面获取新闻信息的需求,而且具有很高的学术研究价值
第二部分是本文的主要研究内容和工作。为了满足全面、快速获取新闻信息的需要,本文设计了一种分布式新闻实时捕获系统和新闻数据处理方案。主要完成了以下工作,深入研究了传统全网爬虫的发展及其相关算法和技术,详细比较了几种性能较好的全网爬虫的优缺点,以指导新闻爬虫系统的设计。深入分析和总结了网络新闻信息、新闻网站和新闻爬虫的特点。基于这些特点,详细设计了新闻爬虫的核心算法爬虫策略和更新策略。基于深度定制的爬虫框架,结合两个开源数据库软件,实现了一个分布式新闻实时爬虫系统。通过分析爬行系统的运行数据,确定系统的爬行性能。设计了一套具有可配置模块的新闻数据处理流水线,包括新闻数据提取、新闻属性规范化、分页新闻合并和新闻内容清理。根据中文新闻的特点,结合该算法,实现了第一章引言中一种更高效的新闻重复数据消除算法。第二章详细介绍了网络爬虫的发展及其相关算法和技术。本文首先介绍了网络爬虫的定义及其常用的算法和模块,然后选取了三种性能优异的开源爬虫作为代表,仔细研究了它们的特点,并进行了详细的比较。本章第二部分还介绍了实现新闻爬虫的框架,详细描述了新闻爬虫的组成、体系结构和程序执行过程
第三章详细介绍了分布式新闻实时捕获系统的实现方案。首先介绍了新闻爬虫的特点,并根据这些特点制定了新闻爬虫的实现方案。通过对crawler框架的深入定制,设计并实现了一套基于两个开源数据库的分布式新闻实时捕获系统。本章最后一部分对爬虫系统实际运行中的数据进行了统计分析。第四章详细介绍了新闻数据的处理方案,特别是新闻数据的提取
实时抓取网页数据(Excel教程Excel函数Excel表格制作Excel2010电子表格Excel公式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-15 22:11
它主要通过R语言对网页上的数据进行抓取,并将其排列成文本格式或excel格式。Sys.setlocale(“LC#u TIME”,“C”)##[1]“C”----------------------------------------------------------------------------------------------创建一个函数,参数';我';表示页码.getdata%html\uNodes(“div.post\u item div.post\u item\u foot”)%%>%html\uText()%%>%strsplit(split=“\R\n”)#处理日期数据----------------------------------------------------------------post\uDate%str uuu sub(9,24)%>%As.Posixlt()##获取年后日期数据标题%html_session()的读取文本格式%>%html\u节点(“div.post\u项目H3”)%%>%html\u文本()%%>%as.Character()%%>%trim() 查看全部
实时抓取网页数据(Excel教程Excel函数Excel表格制作Excel2010电子表格Excel公式)
它主要通过R语言对网页上的数据进行抓取,并将其排列成文本格式或excel格式。Sys.setlocale(“LC#u TIME”,“C”)##[1]“C”----------------------------------------------------------------------------------------------创建一个函数,参数';我';表示页码.getdata%html\uNodes(“div.post\u item div.post\u item\u foot”)%%>%html\uText()%%>%strsplit(split=“\R\n”)#处理日期数据----------------------------------------------------------------post\uDate%str uuu sub(9,24)%>%As.Posixlt()##获取年后日期数据标题%html_session()的读取文本格式%>%html\u节点(“div.post\u项目H3”)%%>%html\u文本()%%>%as.Character()%%>%trim()
实时抓取网页数据(中国地震台网我想做一个网站,其中首页一部分留给一个DIV框)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-15 21:16
一般来说,我们知道有三种方法可以获取其他人网站的数据
1:小偷程序,我们直接抓取,然后定期配对网站HTML如果标记中的数据遇到登录,也可以使用curl
2:另一方提供API,我们得到JSON XML格式的post HTTP(WebServices)
3:直接手工复制
----------------------------------------------------------------------------------
我们知道显示器可以包括两种类型
1:实时阅读。当其他人运行我们的网站请求其他人的网站数据时。我们不会保存它一次
2:首先抓取它,输入我们的数据库,然后从数据库中读取
那么,我想问一下,你通常使用什么样的方法采集呢
通常,如果保存和存储数据,是否需要每秒请求对方的数据
000
解释主要主题:
中国地震台网
我想制作一个网站,其中主页的一部分被放在一个div框中,用来制作世界各地的实时地震数据
您不能在早期阶段保存它,但必须在后期阶段保存它。但是,您担心存储和仓储的实时性能不高。你们不能每秒钟都互相询问
如果另一方不提供API怎么办。求解方法 查看全部
实时抓取网页数据(中国地震台网我想做一个网站,其中首页一部分留给一个DIV框)
一般来说,我们知道有三种方法可以获取其他人网站的数据
1:小偷程序,我们直接抓取,然后定期配对网站HTML如果标记中的数据遇到登录,也可以使用curl
2:另一方提供API,我们得到JSON XML格式的post HTTP(WebServices)
3:直接手工复制
----------------------------------------------------------------------------------
我们知道显示器可以包括两种类型
1:实时阅读。当其他人运行我们的网站请求其他人的网站数据时。我们不会保存它一次
2:首先抓取它,输入我们的数据库,然后从数据库中读取
那么,我想问一下,你通常使用什么样的方法采集呢
通常,如果保存和存储数据,是否需要每秒请求对方的数据
000
解释主要主题:
中国地震台网
我想制作一个网站,其中主页的一部分被放在一个div框中,用来制作世界各地的实时地震数据
您不能在早期阶段保存它,但必须在后期阶段保存它。但是,您担心存储和仓储的实时性能不高。你们不能每秒钟都互相询问
如果另一方不提供API怎么办。求解方法
实时抓取网页数据(轻松躺赚:让机器自动帮你赚钱!2021年最新正规项目优质正规广告位招租)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-15 04:09
轻松躺着赚钱:让机器自动帮你赚钱! 2021年最新正版项目优质正版广告位出租,难得腾出空间,有需要请备注广告位
互联网上不断涌现出新信息、新设计模式和大量数据。将这些数据组织到一个独特的库中并不容易。但是,有很多出色的网络抓取工具可用。
代理抓取
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl完美结合。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用 Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到数百万页的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
雪貂
Ferret 是一种相当新的网络抓取,在开源社区中获得了相当大的吸引力。 Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。 查看全部
实时抓取网页数据(轻松躺赚:让机器自动帮你赚钱!2021年最新正规项目优质正规广告位招租)
轻松躺着赚钱:让机器自动帮你赚钱! 2021年最新正版项目优质正版广告位出租,难得腾出空间,有需要请备注广告位
互联网上不断涌现出新信息、新设计模式和大量数据。将这些数据组织到一个独特的库中并不容易。但是,有很多出色的网络抓取工具可用。
代理抓取
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl完美结合。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用 Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到数百万页的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
雪貂
Ferret 是一种相当新的网络抓取,在开源社区中获得了相当大的吸引力。 Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。
实时抓取网页数据(几天的资料去写一个网页抓取股票实时数据的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-09-14 08:07
我最近查了几天的资料,写了一个网页来捕捉实时股票数据。网上一堆资料都是一遍遍的解释同一个方法,一般时间要求没有变化。然而,捕捉实时股票数据的要求是大量的股票数据每秒钟都在变化。有必要确保程序可以每秒捕获这些变化的数据。嗯,为此开始在网上搜索资料,很多人建议使用libcurl的方法。好的,libcurl 非常强大且易于使用。我也想说,libcurl对于不改变的普通网页非常强大。钟刷网页数据10次以上,libcurl会有读取失败延时,延时2~3秒,也就是说这2~3秒内网页上变化的数据是无法抓取的。但是对于股市来说,很大一部分数据会丢失。所以libcurl的方案被否定了。
然而,股票的实时更新需要如此高的读取次数。一般的方法会造成数据丢失。我能想到的是将数据丢失减少到最低限度。我再想想,为什么浏览器不会丢失数据?能不能像浏览器一样不丢失数据? (这个问题后面会解决。)我暂时使用的方法是利用WinInet提供的库函数来开发Internet程序。附上以下代码:
void Get_Http_Data(string Url, string &buffer)
{
try
{
CInternetSession *session = new CInternetSession();
CHttpFile* pfile = (CHttpFile *)session->OpenURL(Url.c_str(),1,INTERNET_FLAG_TRANSFER_ASCII|INTERNET_FLAG_RELOAD|INTERNET_FLAG_DONT_CACHE);
if( NULL == pfile )
{
LOG(1)("网络连接中断 或 请求连接失败!");
session->Close();
return ;
}
DWORD dwStatusCode;
pfile -> QueryInfoStatusCode(dwStatusCode);
if(dwStatusCode == HTTP_STATUS_OK)
{
CString data;
while (pfile -> ReadString(data))
{
if( !data.IsEmpty())
{
buffer.append(data.GetBuffer(0));
buffer.append("\t\n");
}
}
}
pfile->Close();
delete pfile;
session->Close();
}
catch(CInternetException *pEx) //这里一定要做异常抛出,考虑到如果程序正在运行中突然客户端网络中断,那么做异常抛出就会即使提示错误并终止。
{ //如果不做异常判断的话,程序就会继续运行这样导致buffer为空,记下来的操作万一没有考虑到buffer为空的情况就
pEx->ReportError(); //会导致程序崩溃,因为buffer为空内存无法操作。(比如运行到split函数会崩溃。)
pEx->Delete();
}
}
使用函数CInternetSession::OpenUrl()实现对服务器网页的持续请求操作。标志:INTERNET_FLAG_RELOAD 是强制重复阅读网页。
上面的过程就是方法。其他更优化的方法正在研究中。 . 也希望有想法有想法的同事留下自己的打算。 查看全部
实时抓取网页数据(几天的资料去写一个网页抓取股票实时数据的程序)
我最近查了几天的资料,写了一个网页来捕捉实时股票数据。网上一堆资料都是一遍遍的解释同一个方法,一般时间要求没有变化。然而,捕捉实时股票数据的要求是大量的股票数据每秒钟都在变化。有必要确保程序可以每秒捕获这些变化的数据。嗯,为此开始在网上搜索资料,很多人建议使用libcurl的方法。好的,libcurl 非常强大且易于使用。我也想说,libcurl对于不改变的普通网页非常强大。钟刷网页数据10次以上,libcurl会有读取失败延时,延时2~3秒,也就是说这2~3秒内网页上变化的数据是无法抓取的。但是对于股市来说,很大一部分数据会丢失。所以libcurl的方案被否定了。
然而,股票的实时更新需要如此高的读取次数。一般的方法会造成数据丢失。我能想到的是将数据丢失减少到最低限度。我再想想,为什么浏览器不会丢失数据?能不能像浏览器一样不丢失数据? (这个问题后面会解决。)我暂时使用的方法是利用WinInet提供的库函数来开发Internet程序。附上以下代码:
void Get_Http_Data(string Url, string &buffer)
{
try
{
CInternetSession *session = new CInternetSession();
CHttpFile* pfile = (CHttpFile *)session->OpenURL(Url.c_str(),1,INTERNET_FLAG_TRANSFER_ASCII|INTERNET_FLAG_RELOAD|INTERNET_FLAG_DONT_CACHE);
if( NULL == pfile )
{
LOG(1)("网络连接中断 或 请求连接失败!");
session->Close();
return ;
}
DWORD dwStatusCode;
pfile -> QueryInfoStatusCode(dwStatusCode);
if(dwStatusCode == HTTP_STATUS_OK)
{
CString data;
while (pfile -> ReadString(data))
{
if( !data.IsEmpty())
{
buffer.append(data.GetBuffer(0));
buffer.append("\t\n");
}
}
}
pfile->Close();
delete pfile;
session->Close();
}
catch(CInternetException *pEx) //这里一定要做异常抛出,考虑到如果程序正在运行中突然客户端网络中断,那么做异常抛出就会即使提示错误并终止。
{ //如果不做异常判断的话,程序就会继续运行这样导致buffer为空,记下来的操作万一没有考虑到buffer为空的情况就
pEx->ReportError(); //会导致程序崩溃,因为buffer为空内存无法操作。(比如运行到split函数会崩溃。)
pEx->Delete();
}
}
使用函数CInternetSession::OpenUrl()实现对服务器网页的持续请求操作。标志:INTERNET_FLAG_RELOAD 是强制重复阅读网页。
上面的过程就是方法。其他更优化的方法正在研究中。 . 也希望有想法有想法的同事留下自己的打算。
实时抓取网页数据(实时抓取网页数据结构的拓扑信息、浏览数据的页面属性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-09-14 05:02
实时抓取网页数据结构的拓扑信息、浏览数据的页面属性,针对每个页面根据页面属性抓取对应页面的属性,根据页面属性与每个页面对应属性的关系抓取页面内容等。从页面抓取方式,在抓取过程当中需要对html的标签进行遍历、翻页等抓取方式。根据抓取对象的不同,可分为单向爬虫和双向爬虫两种。1.单向爬虫-每个页面都抓取1个页面数据的抓取模式。
2.双向爬虫-也就是当抓取完整个网页,每个页面还能继续抓取。内容抓取实现过程根据抓取对象的不同,内容抓取过程又分为静态内容抓取和动态内容抓取两种。1.静态内容抓取指网页下面的所有页面。2.动态内容抓取指页面在很多其他页面上。1.a.整站抓取页面下,分为静态网页和动态网页。静态页面:只有一个页面,没有内容,比如一个公司网站,只有一个页面;动态页面:某个页面,有多个内容页面,例如知乎的问题页面就是一个动态内容页面。
2.构建内容组合页面内容抓取,一般采用requests库,多页内容加上一页一个子页面,首页接收一个子页面,以此类推,找到最终网页,然后获取到对应页面的dom,加载页面。页面可能会不断修改。抓取方式a:单向抓取单向抓取使用requests库+beautifulsoup库进行抓取。首先需要做一个端口,python抓取有很多不同的方式。
在采集初期先注册,账号密码一致,这样获取的内容非常一致,在爬取过程中提供一个mavenproject。因为有一个fork的情况,爬取代码需要放到同一个项目中,这样才能防止版本不同,解决此问题的方法就是修改fork版本就可以了。代码示例如下:#构建内容组合页面并加载defconnect(request):connect('==','b/')page=request.post('==','d/')url='=='connect('==','b/')withopen(url,'wb')asf:f.write(connect('==','d/'))returnopen('==','g/')#动态内容抓取动态抓取在抓取的页面做两点处理,a.获取页面内容并转义。
原因是页面还包含子页面。b.目标页面或者中的标签不会生效,所以使用urllib.request.urlopen(f.read()),而不是f.read()。把动态网页指定request.request(request,url,dom,dont_traceback)函数,f.read()。代码示例如下:#构建内容组合页面并加载defconnect(request):connect('==','b/')withopen(url,'wb')asf:f.write(connect('==','d/'))url。 查看全部
实时抓取网页数据(实时抓取网页数据结构的拓扑信息、浏览数据的页面属性)
实时抓取网页数据结构的拓扑信息、浏览数据的页面属性,针对每个页面根据页面属性抓取对应页面的属性,根据页面属性与每个页面对应属性的关系抓取页面内容等。从页面抓取方式,在抓取过程当中需要对html的标签进行遍历、翻页等抓取方式。根据抓取对象的不同,可分为单向爬虫和双向爬虫两种。1.单向爬虫-每个页面都抓取1个页面数据的抓取模式。
2.双向爬虫-也就是当抓取完整个网页,每个页面还能继续抓取。内容抓取实现过程根据抓取对象的不同,内容抓取过程又分为静态内容抓取和动态内容抓取两种。1.静态内容抓取指网页下面的所有页面。2.动态内容抓取指页面在很多其他页面上。1.a.整站抓取页面下,分为静态网页和动态网页。静态页面:只有一个页面,没有内容,比如一个公司网站,只有一个页面;动态页面:某个页面,有多个内容页面,例如知乎的问题页面就是一个动态内容页面。
2.构建内容组合页面内容抓取,一般采用requests库,多页内容加上一页一个子页面,首页接收一个子页面,以此类推,找到最终网页,然后获取到对应页面的dom,加载页面。页面可能会不断修改。抓取方式a:单向抓取单向抓取使用requests库+beautifulsoup库进行抓取。首先需要做一个端口,python抓取有很多不同的方式。
在采集初期先注册,账号密码一致,这样获取的内容非常一致,在爬取过程中提供一个mavenproject。因为有一个fork的情况,爬取代码需要放到同一个项目中,这样才能防止版本不同,解决此问题的方法就是修改fork版本就可以了。代码示例如下:#构建内容组合页面并加载defconnect(request):connect('==','b/')page=request.post('==','d/')url='=='connect('==','b/')withopen(url,'wb')asf:f.write(connect('==','d/'))returnopen('==','g/')#动态内容抓取动态抓取在抓取的页面做两点处理,a.获取页面内容并转义。
原因是页面还包含子页面。b.目标页面或者中的标签不会生效,所以使用urllib.request.urlopen(f.read()),而不是f.read()。把动态网页指定request.request(request,url,dom,dont_traceback)函数,f.read()。代码示例如下:#构建内容组合页面并加载defconnect(request):connect('==','b/')withopen(url,'wb')asf:f.write(connect('==','d/'))url。
实时抓取网页数据( Webscraper支持以240多种语言提取Web数据的9个网络工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-09-11 10:08
Webscraper支持以240多种语言提取Web数据的9个网络工具)
文章directory[]
Web Scraping 工具可以在各种场景中用于无限用途。
例如:
1.采集市场调研数据
网页抓取工具可以从多个数据分析提供商处获取信息,并将它们整合到一个位置,以便于参考和分析。可以帮助您及时了解公司或行业未来六个月的发展方向。
2.提取联系方式
这些工具还可用于从各种网站 中提取电子邮件和电话号码等数据。
3. 采集数据下载离线阅读或存储
4.跟踪多个市场的价格等
这些软件手动或自动查找新数据、获取新数据或更新数据并存储以方便访问。例如,爬虫可用于从亚马逊采集有关产品及其价格的信息。在这个文章中,我们列出了9个网页抓取工具。
1.Import.io
Import.io 提供了一个构建器,可以通过从特定网页导入数据并将数据导出为 CSV 来形成您自己的数据集。您无需编写任何代码即可在几分钟内轻松抓取数千个网页,并根据您的需求构建 1,000 多个 API。
2.Webhose.io
Webhose.io 通过抓取数千个在线资源提供对实时和结构化数据的直接访问。网络爬虫支持提取超过240种语言的网络数据,并以多种格式保存输出数据,包括XML、JSON和RSS。
3. Dexi.io(原名 CloudScrape)
CloudScrape 支持从任何网站 采集数据,无需像 Webhose 那样下载。它提供了一个基于浏览器的编辑器来设置爬虫并实时提取数据。您可以将采集到的数据保存在 Google Drive 等云平台上,也可以将其导出为 CSV 或 JSON。
4.Scrapinghub
Scrapinghub 是一种基于云的数据提取工具,可帮助数以千计的开发者获取有价值的数据。 Scrapinghub 使用智能代理微调器 Crawlera,支持绕过机器人反制,轻松抓取大型或受机器人保护的网站。
5. ParseHub
ParseHub 用于抓取单个和多个网站,支持 JavaScript、AJAX、会话、cookie 和重定向。该应用程序使用机器学习技术来识别 Web 上最复杂的文档,并根据所需的数据格式生成输出文件。
6.VisualScraper
VisualScraper 是另一种网络数据提取软件,可用于从网络采集信息。该软件可以帮助您从多个网页中提取数据并实时获取结果。此外,还可以导出CSV、XML、JSON、SQL等多种格式。
7. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 提要中获取全部数据。 Spinn3r 与 firehouse API 一起分发并管理 95% 的索引工作。提供先进的垃圾邮件防护,可消除垃圾邮件和不当语言使用,从而提高数据安全性。
8. 80legs
80legs 是一款功能强大且灵活的网页抓取工具,可根据您的需要进行配置。它支持获取大量数据并立即下载提取数据的选项。 80legs 声称能够抓取超过 600,000 个域,并被 MailChimp 和 PayPal 等大型玩家使用。
9.刮刀
Scraper 是一个 Chrome 扩展,其数据提取功能有限,但它有助于进行在线研究并将数据导出到 Google 电子表格。此工具适合初学者和专家,他们可以使用 OAuth 轻松将数据复制到剪贴板或存储到电子表格。 查看全部
实时抓取网页数据(
Webscraper支持以240多种语言提取Web数据的9个网络工具)
文章directory[]
Web Scraping 工具可以在各种场景中用于无限用途。
例如:
1.采集市场调研数据
网页抓取工具可以从多个数据分析提供商处获取信息,并将它们整合到一个位置,以便于参考和分析。可以帮助您及时了解公司或行业未来六个月的发展方向。
2.提取联系方式
这些工具还可用于从各种网站 中提取电子邮件和电话号码等数据。
3. 采集数据下载离线阅读或存储
4.跟踪多个市场的价格等
这些软件手动或自动查找新数据、获取新数据或更新数据并存储以方便访问。例如,爬虫可用于从亚马逊采集有关产品及其价格的信息。在这个文章中,我们列出了9个网页抓取工具。
1.Import.io
Import.io 提供了一个构建器,可以通过从特定网页导入数据并将数据导出为 CSV 来形成您自己的数据集。您无需编写任何代码即可在几分钟内轻松抓取数千个网页,并根据您的需求构建 1,000 多个 API。
2.Webhose.io
Webhose.io 通过抓取数千个在线资源提供对实时和结构化数据的直接访问。网络爬虫支持提取超过240种语言的网络数据,并以多种格式保存输出数据,包括XML、JSON和RSS。
3. Dexi.io(原名 CloudScrape)
CloudScrape 支持从任何网站 采集数据,无需像 Webhose 那样下载。它提供了一个基于浏览器的编辑器来设置爬虫并实时提取数据。您可以将采集到的数据保存在 Google Drive 等云平台上,也可以将其导出为 CSV 或 JSON。
4.Scrapinghub
Scrapinghub 是一种基于云的数据提取工具,可帮助数以千计的开发者获取有价值的数据。 Scrapinghub 使用智能代理微调器 Crawlera,支持绕过机器人反制,轻松抓取大型或受机器人保护的网站。
5. ParseHub
ParseHub 用于抓取单个和多个网站,支持 JavaScript、AJAX、会话、cookie 和重定向。该应用程序使用机器学习技术来识别 Web 上最复杂的文档,并根据所需的数据格式生成输出文件。
6.VisualScraper
VisualScraper 是另一种网络数据提取软件,可用于从网络采集信息。该软件可以帮助您从多个网页中提取数据并实时获取结果。此外,还可以导出CSV、XML、JSON、SQL等多种格式。
7. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 提要中获取全部数据。 Spinn3r 与 firehouse API 一起分发并管理 95% 的索引工作。提供先进的垃圾邮件防护,可消除垃圾邮件和不当语言使用,从而提高数据安全性。
8. 80legs
80legs 是一款功能强大且灵活的网页抓取工具,可根据您的需要进行配置。它支持获取大量数据并立即下载提取数据的选项。 80legs 声称能够抓取超过 600,000 个域,并被 MailChimp 和 PayPal 等大型玩家使用。
9.刮刀
Scraper 是一个 Chrome 扩展,其数据提取功能有限,但它有助于进行在线研究并将数据导出到 Google 电子表格。此工具适合初学者和专家,他们可以使用 OAuth 轻松将数据复制到剪贴板或存储到电子表格。
实时抓取网页数据( WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-09-11 05:08
WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))
WebSpider 蓝蜘蛛网络爬虫工具5.1 可以爬取互联网上的任何网页,wap网站,包括登录后可以访问的页面。分析爬取的页面内容,获取新闻等结构化信息标题、作者、出处、正文等,支持列表页自动翻页抓取、文本页多页合并、图片和文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
用户指定要爬取的网站、要爬取的网页类型(固定页面、分页展示页面等),并配置如何解析数据项(如新闻标题、作者、来源等) , body 等),系统可以根据配置信息实时自动采集数据,也可以通过配置设置开始采集的时间,真正做到了“按需采集,一个配置,和永久捕获”。捕获的数据可以保存在数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等
该工具可以完全替代传统的编辑人工信息处理模式。 24*60全天候实时、准确地为企业提供最新的信息和情报,真正为企业降低成本,提高竞争力。
该工具的主要特点如下:
*应用广泛,可以抓取任何网页(包括登录后可以访问的网页)
*处理速度快。网络畅通,1小时可抓取解析1万个网页
*采用独特的重复数据过滤技术,支持增量数据抓取,可抓取实时数据,如:股票交易信息、天气预报等
*抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
*支持断点恢复爬行,崩溃或异常情况后恢复爬行,继续后续爬行工作,提高系统爬行效率
*对于列表页,支持翻页,可以获取所有列表页中的数据。对于body页面,可以自动合并分页显示的内容;
*支持深度页面爬取,可以逐层爬取页面。比如通过列表页面抓取body页面的URL,然后再抓取body页面。各级页面可单独存放;
*WEB操作界面,一站式安装,随处使用
*分步分析,分步存储
*配置一次,永久抓取,一劳永逸 查看全部
实时抓取网页数据(
WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))
WebSpider 蓝蜘蛛网络爬虫工具5.1 可以爬取互联网上的任何网页,wap网站,包括登录后可以访问的页面。分析爬取的页面内容,获取新闻等结构化信息标题、作者、出处、正文等,支持列表页自动翻页抓取、文本页多页合并、图片和文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
用户指定要爬取的网站、要爬取的网页类型(固定页面、分页展示页面等),并配置如何解析数据项(如新闻标题、作者、来源等) , body 等),系统可以根据配置信息实时自动采集数据,也可以通过配置设置开始采集的时间,真正做到了“按需采集,一个配置,和永久捕获”。捕获的数据可以保存在数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等
该工具可以完全替代传统的编辑人工信息处理模式。 24*60全天候实时、准确地为企业提供最新的信息和情报,真正为企业降低成本,提高竞争力。
该工具的主要特点如下:
*应用广泛,可以抓取任何网页(包括登录后可以访问的网页)
*处理速度快。网络畅通,1小时可抓取解析1万个网页
*采用独特的重复数据过滤技术,支持增量数据抓取,可抓取实时数据,如:股票交易信息、天气预报等
*抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
*支持断点恢复爬行,崩溃或异常情况后恢复爬行,继续后续爬行工作,提高系统爬行效率
*对于列表页,支持翻页,可以获取所有列表页中的数据。对于body页面,可以自动合并分页显示的内容;
*支持深度页面爬取,可以逐层爬取页面。比如通过列表页面抓取body页面的URL,然后再抓取body页面。各级页面可单独存放;
*WEB操作界面,一站式安装,随处使用
*分步分析,分步存储
*配置一次,永久抓取,一劳永逸

