
完整的采集神器
完整的采集神器(开发一个专属数据爬虫,用java不多python可以)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-13 02:04
完整的采集神器,包括设置,爬虫,爬虫的实现,爬虫的更新以及稳定,获取数据速度,读取方式,复杂网站的读取,目录的打包整理。以上是我自己做的爬虫,喜欢的可以关注一下。开发一个专属数据爬虫,用java不多,python可以。自己准备自己操作,计划尝试自己写爬虫。计划是下面2个方面。读取写入一起。问题的答案,我会在下面写下我的看法。
引言最近需要爬取某物业发布的房源信息,然后做数据分析,那么我将我们爬取的数据再进行变成csv文件,以便之后的对比。整体文件目录是。要下载什么东西呢?1、mongo下载,下载原始数据。2、json文件,转成csv。json能支持这种下载方式。不能再用xml,太麻烦了。json简介json,是javascriptobjectnotation的缩写,翻译成中文,即“javascript对象标记语言”,是一种xml文档格式,是一种规范的xml风格xml文档,一般用javascript语言编写,所以称json为javascript格式。
json最初是用于进行信息交换的,但json和xml不仅可以通过xmlhttprequest对象传递,还可以通过另一个对象传递,且它俩可以通过自定义的标记格式(tags)来组织,tags是json所采用的标记语言。本文接下来只涉及通过xmlhttprequest对象来解析json数据。json文件的目录分为。
一个json文件是由一个或多个大括号标记的,是由一个或多个大括号和一个小括号表示的。该文件是用一个或多个大括号和一个小括号分隔的。例如:1</a>它的大括号是<a>,小括号是<a>,虽然a不是大括号,但它却是json所定义的所有元素的标记。一个json文件中的元素包括每个元素的标记jsonpath和一个由该元素标记来表示的元素的数组或一个值eval表示json格式,例如jsonpath=jsonpath["element"],jsonpath["element"]=1表示当前元素的一个二元运算符(=,+,*)。
json文件本身可以无法通过浏览器直接打开,需要安装jsonlite(一款json解析器),才能获取json文件,当然这种情况并不是每次都能打开成功。下面是获取到json文件的源代码,其中遇到过的一些坑,大家共同探讨。===。 查看全部
完整的采集神器(开发一个专属数据爬虫,用java不多python可以)
完整的采集神器,包括设置,爬虫,爬虫的实现,爬虫的更新以及稳定,获取数据速度,读取方式,复杂网站的读取,目录的打包整理。以上是我自己做的爬虫,喜欢的可以关注一下。开发一个专属数据爬虫,用java不多,python可以。自己准备自己操作,计划尝试自己写爬虫。计划是下面2个方面。读取写入一起。问题的答案,我会在下面写下我的看法。
引言最近需要爬取某物业发布的房源信息,然后做数据分析,那么我将我们爬取的数据再进行变成csv文件,以便之后的对比。整体文件目录是。要下载什么东西呢?1、mongo下载,下载原始数据。2、json文件,转成csv。json能支持这种下载方式。不能再用xml,太麻烦了。json简介json,是javascriptobjectnotation的缩写,翻译成中文,即“javascript对象标记语言”,是一种xml文档格式,是一种规范的xml风格xml文档,一般用javascript语言编写,所以称json为javascript格式。
json最初是用于进行信息交换的,但json和xml不仅可以通过xmlhttprequest对象传递,还可以通过另一个对象传递,且它俩可以通过自定义的标记格式(tags)来组织,tags是json所采用的标记语言。本文接下来只涉及通过xmlhttprequest对象来解析json数据。json文件的目录分为。
一个json文件是由一个或多个大括号标记的,是由一个或多个大括号和一个小括号表示的。该文件是用一个或多个大括号和一个小括号分隔的。例如:1</a>它的大括号是<a>,小括号是<a>,虽然a不是大括号,但它却是json所定义的所有元素的标记。一个json文件中的元素包括每个元素的标记jsonpath和一个由该元素标记来表示的元素的数组或一个值eval表示json格式,例如jsonpath=jsonpath["element"],jsonpath["element"]=1表示当前元素的一个二元运算符(=,+,*)。
json文件本身可以无法通过浏览器直接打开,需要安装jsonlite(一款json解析器),才能获取json文件,当然这种情况并不是每次都能打开成功。下面是获取到json文件的源代码,其中遇到过的一些坑,大家共同探讨。===。
完整的采集神器(CaptureSaver破解版功能介绍功能六:制作电子书收集的资料)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-10-12 02:25
CaptureSaver破解版是一款功能实用的图文信息采集软件,可以帮助用户快速抓取您指定的网页内容,然后完整保存,还可以对网页中的内容进行编辑。
CaptureSaver免费版具有采集、管理、浏览等功能,很好的满足了用户的需求。此外,还可以通过软件进行全屏、窗口和区域截屏。用户可以根据自己的需要进行选择。
CaptureSaver破解版功能介绍
功能一:抓取网页
使用capturesaver,你可以通过简单的鼠标拖拽或者点击,完整抓取当前页面或者页面中选中的内容,也可以抓取页面中的所有链接或者链接的选中部分,汁源(包括网页中的图片)一起下载保存,也支持批量下载。Capturesaver 是您最好的网页保存工具。
功能二:抓屏
使用 capturesaver 来捕获全屏、窗口捕获和区域捕获。
功能3:抓取文本
使用capturesaver,可以自由的抓取任意窗口的文字、控件中的文字、剪贴板中的文字……也可以使用mircosoft word、wordpad、adobe acrobat reader、ie browser、chm document、outlook 摘录文字来自Capturesaver 中的电子邮件和 等应用程序。
功能四:离线浏览
Capturesaver 将捕获的网页完整下载并保存在本地库中以供离线浏览。
功能五:数据管理
Capturesaver 存储您平时的杂乱信息、图片等,并统一管理,方便您的查找和使用。使用capturesaver的树状目录结构,可以很方便的进行整理。通过关键字全文搜索,您可以从采集到的数据中快速检索到您需要的内容。
功能六:制作电子书
有很多材料要采集。你可以把它们做成chm电子书,可以自己采集,也可以分享给同事或朋友,甚至可以发布到网上。 查看全部
完整的采集神器(CaptureSaver破解版功能介绍功能六:制作电子书收集的资料)
CaptureSaver破解版是一款功能实用的图文信息采集软件,可以帮助用户快速抓取您指定的网页内容,然后完整保存,还可以对网页中的内容进行编辑。

CaptureSaver免费版具有采集、管理、浏览等功能,很好的满足了用户的需求。此外,还可以通过软件进行全屏、窗口和区域截屏。用户可以根据自己的需要进行选择。
CaptureSaver破解版功能介绍
功能一:抓取网页
使用capturesaver,你可以通过简单的鼠标拖拽或者点击,完整抓取当前页面或者页面中选中的内容,也可以抓取页面中的所有链接或者链接的选中部分,汁源(包括网页中的图片)一起下载保存,也支持批量下载。Capturesaver 是您最好的网页保存工具。
功能二:抓屏
使用 capturesaver 来捕获全屏、窗口捕获和区域捕获。
功能3:抓取文本
使用capturesaver,可以自由的抓取任意窗口的文字、控件中的文字、剪贴板中的文字……也可以使用mircosoft word、wordpad、adobe acrobat reader、ie browser、chm document、outlook 摘录文字来自Capturesaver 中的电子邮件和 等应用程序。
功能四:离线浏览
Capturesaver 将捕获的网页完整下载并保存在本地库中以供离线浏览。
功能五:数据管理
Capturesaver 存储您平时的杂乱信息、图片等,并统一管理,方便您的查找和使用。使用capturesaver的树状目录结构,可以很方便的进行整理。通过关键字全文搜索,您可以从采集到的数据中快速检索到您需要的内容。
功能六:制作电子书
有很多材料要采集。你可以把它们做成chm电子书,可以自己采集,也可以分享给同事或朋友,甚至可以发布到网上。
完整的采集神器( 一下file_get_contents函数可以获取远程链接数据的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-10-12 00:43
一下file_get_contents函数可以获取远程链接数据的方法)
php采集cURL使用方法详解,采集curl
对于做过数据采集的人来说,curl一定不陌生。PHP中虽然有file_get_contents函数可以获取远程链接数据,但是可控性太差。对于各种复杂的情况,file_get_contents 似乎有点无能为力。因此,本文将向您介绍采集 神器cURL 的使用。
给大家补充一下file_get_contents函数获取远程链接数据的方法。
这段代码会直接使用curl来显示文件的内容,但是问题来了。因为 curl 是 PHP 的扩展,所以一些主机为了安全会使用 curl。本地调试宁外PHP的时候,curl也是关闭的,所以会报错。所以这段代码是不可取的,所以云落给他改写了
修改后的版本是对curl扩展做一个判断,看服务器有没有打开curl扩展。如果打开,则直接显示文件,如果未打开,则显示提示文本。
虽然问题解决了,但还有一个问题。我只是显示了一段文字。我没做什么大事,为什么要写这么多代码??
经过一些傻测试,我发现file_get_contents获取远程文件内容并不比curl慢。在某些文件较少的情况下,它可能比curl扩展快得多,所以我重新编写了代码。
工具
火狐浏览器 (FireFox) + Firebug
“工人们要想做得好,就必须磨砺他们的工具。” 在分析案例之前,让我们学习一下如何使用神器Firebug来获取我们需要的信息。
使用F12打开Firebug,我们可以得到如图所示的界面(一):
1、 箭头图标是“元素选择”工具。单击一次以突出显示该图标。同时,鼠标在页面内的移动会同时选中HTML菜单中的相应内容。设置元素后,图标将突出显示并取消。如图(二):
Firebug 视图元素
2、控制面板
JS中console.log系列函数的打印输出在这里。
3、HTML
HTML内容,注意这里看到的不一定是采集要解析的内容。采集 时对内容的分析将始终基于查看源代码(Ctrl+U)。这里只是为了快速定位元素。然后选择一个比较特殊的引用,在源码中定位到对应的位置。
例如,如果您在 HTML 中看到一个标签
演示
, 但是你查看源码看到的可能是
演示
, 如果按照前者对采集的内容进行正则匹配,则不会得到任何结果。
4、CSS
这是CSS文件的内容
5、脚本
这是Javascript文件的内容
6、DOM
Dom 节点内容
7、网络
每个请求链接的数据,这里是我们采集应该注意和分析的地方。它可以显示每个请求的参数、请求头、cookie数据等。在页面提交会刷新的情况下,需要使用hold,让页面请求的内容刷新后保留在控制台中,如图(三):
此外,Firefox 有一个 Tamper 数据扩展,也可以获取请求数据,需要时可以安装和使用。
8、饼干
饼干数据
图片中(一),你也可以看到下面有很多可选的小菜单项,其中保留是我们要注意的。选择时,即使提交表单后刷新页面,下面内容区的数据仍会保留,这对于分析提交的数据尤为关键。
总结
我们在分析采集请求时,主要关心的是“Network”菜单中的请求数据。必要时,使用“Keep”查看刷新页面的请求数据。您可以在请求前使用“清除”清除以下内容。
案例分析
一、简单采集
这里所说的简单采集指的是单页GET请求的采集。如此简单,即使通过file_get_contents函数,也可以轻松获取页面返回结果。
代码片段 file_get_contents
<p> 查看全部
完整的采集神器(
一下file_get_contents函数可以获取远程链接数据的方法)
php采集cURL使用方法详解,采集curl
对于做过数据采集的人来说,curl一定不陌生。PHP中虽然有file_get_contents函数可以获取远程链接数据,但是可控性太差。对于各种复杂的情况,file_get_contents 似乎有点无能为力。因此,本文将向您介绍采集 神器cURL 的使用。
给大家补充一下file_get_contents函数获取远程链接数据的方法。
这段代码会直接使用curl来显示文件的内容,但是问题来了。因为 curl 是 PHP 的扩展,所以一些主机为了安全会使用 curl。本地调试宁外PHP的时候,curl也是关闭的,所以会报错。所以这段代码是不可取的,所以云落给他改写了
修改后的版本是对curl扩展做一个判断,看服务器有没有打开curl扩展。如果打开,则直接显示文件,如果未打开,则显示提示文本。
虽然问题解决了,但还有一个问题。我只是显示了一段文字。我没做什么大事,为什么要写这么多代码??
经过一些傻测试,我发现file_get_contents获取远程文件内容并不比curl慢。在某些文件较少的情况下,它可能比curl扩展快得多,所以我重新编写了代码。
工具
火狐浏览器 (FireFox) + Firebug
“工人们要想做得好,就必须磨砺他们的工具。” 在分析案例之前,让我们学习一下如何使用神器Firebug来获取我们需要的信息。
使用F12打开Firebug,我们可以得到如图所示的界面(一):
1、 箭头图标是“元素选择”工具。单击一次以突出显示该图标。同时,鼠标在页面内的移动会同时选中HTML菜单中的相应内容。设置元素后,图标将突出显示并取消。如图(二):
Firebug 视图元素
2、控制面板
JS中console.log系列函数的打印输出在这里。
3、HTML
HTML内容,注意这里看到的不一定是采集要解析的内容。采集 时对内容的分析将始终基于查看源代码(Ctrl+U)。这里只是为了快速定位元素。然后选择一个比较特殊的引用,在源码中定位到对应的位置。
例如,如果您在 HTML 中看到一个标签
演示
, 但是你查看源码看到的可能是
演示
, 如果按照前者对采集的内容进行正则匹配,则不会得到任何结果。
4、CSS
这是CSS文件的内容
5、脚本
这是Javascript文件的内容
6、DOM
Dom 节点内容
7、网络
每个请求链接的数据,这里是我们采集应该注意和分析的地方。它可以显示每个请求的参数、请求头、cookie数据等。在页面提交会刷新的情况下,需要使用hold,让页面请求的内容刷新后保留在控制台中,如图(三):
此外,Firefox 有一个 Tamper 数据扩展,也可以获取请求数据,需要时可以安装和使用。
8、饼干
饼干数据
图片中(一),你也可以看到下面有很多可选的小菜单项,其中保留是我们要注意的。选择时,即使提交表单后刷新页面,下面内容区的数据仍会保留,这对于分析提交的数据尤为关键。
总结
我们在分析采集请求时,主要关心的是“Network”菜单中的请求数据。必要时,使用“Keep”查看刷新页面的请求数据。您可以在请求前使用“清除”清除以下内容。
案例分析
一、简单采集
这里所说的简单采集指的是单页GET请求的采集。如此简单,即使通过file_get_contents函数,也可以轻松获取页面返回结果。
代码片段 file_get_contents
<p>
完整的采集神器(智能采集优采云采集可根据不同网站公开数据(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-11 03:35
特征:
简单采集
简单的采集模式内置了数百个主流的网站数据源,如京东、天猫、大众点评等流行的采集网站,只需参考模板并简单地设置参数。您可以快速获取网站公开数据。
智能采集
优采云采集 针对不同的网站,提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集流程实现数据的完整性和稳定性。
云采集
云采集支持5000多台云服务器,7*24小时不间断运行,可实现定时采集,无人值守,灵活适配业务场景,助您提升采集 效率,保证数据的及时性。
API接口
通过优采云 API,您可以轻松获取优采云任务信息和采集接收到的数据,灵活调度任务,如远程控制任务启停,高效实现数据< @采集 和存档。基于强大的API系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax 、页面滚动、条件判断等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
方便的定时功能
简单几步,即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集,你可以同时自由设置多个任务,根据自己的需要进行多种选择时间组合,灵活部署自己的采集任务。
全自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集全自动处理过程中,无需人工干预,即可得到所需格式的数据。
多级采集
许多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;无论网站有多少层,优采云都可以拥有无限层的采集数据,满足各种业务采集的需求。
采集登录后支持网站
优采云内置采集登录模块,只需要配置目标网站的账号和密码,即可使用该模块对采集进行数据登录;同时优采云还带有采集Cookie自定义功能,首次登录后可以自动记住cookie,免去多次输入密码的繁琐,支持更多网站< @采集。 查看全部
完整的采集神器(智能采集优采云采集可根据不同网站公开数据(组图))
特征:
简单采集
简单的采集模式内置了数百个主流的网站数据源,如京东、天猫、大众点评等流行的采集网站,只需参考模板并简单地设置参数。您可以快速获取网站公开数据。
智能采集
优采云采集 针对不同的网站,提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集流程实现数据的完整性和稳定性。
云采集
云采集支持5000多台云服务器,7*24小时不间断运行,可实现定时采集,无人值守,灵活适配业务场景,助您提升采集 效率,保证数据的及时性。
API接口
通过优采云 API,您可以轻松获取优采云任务信息和采集接收到的数据,灵活调度任务,如远程控制任务启停,高效实现数据< @采集 和存档。基于强大的API系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax 、页面滚动、条件判断等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
方便的定时功能
简单几步,即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集,你可以同时自由设置多个任务,根据自己的需要进行多种选择时间组合,灵活部署自己的采集任务。
全自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集全自动处理过程中,无需人工干预,即可得到所需格式的数据。
多级采集
许多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;无论网站有多少层,优采云都可以拥有无限层的采集数据,满足各种业务采集的需求。
采集登录后支持网站
优采云内置采集登录模块,只需要配置目标网站的账号和密码,即可使用该模块对采集进行数据登录;同时优采云还带有采集Cookie自定义功能,首次登录后可以自动记住cookie,免去多次输入密码的繁琐,支持更多网站< @采集。
完整的采集神器(智能采集优采云采集可根据不同网站公开数据(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-09 22:36
软件特点
模板采集
模板采集模式内置了数百个主流网站数据源,如京东、天猫、大众点评等热门采集网站。只需参考模板并简单地设置参数即可。您可以快速获取网站公开数据。
智能采集
优采云采集针对不同的网站,提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集流程实现数据的完整性和稳定性。
云采集
云采集支持5000多台云服务器,7*24小时不间断运行,可实现定时采集,无人值守,灵活适配业务场景,助您提升采集 效率,保证数据的及时性。
API接口
通过优采云 API,您可以轻松获取优采云任务信息和采集接收到的数据,灵活调度任务,如远程控制任务启停,高效实现数据< @采集 和存档。基于强大的API系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax 、页面滚动、条件判断等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
方便的定时功能
简单几步,即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集,你可以同时自由设置多个任务,根据自己的需要进行多种选择时间组合,灵活部署自己的采集任务。
全自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集全自动处理过程中,无需人工干预,即可得到所需格式的数据。
多级采集
许多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;不管有多少层,优采云都可以拥有无限层的采集数据,满足各种业务采集的需求。 查看全部
完整的采集神器(智能采集优采云采集可根据不同网站公开数据(组图))
软件特点
模板采集
模板采集模式内置了数百个主流网站数据源,如京东、天猫、大众点评等热门采集网站。只需参考模板并简单地设置参数即可。您可以快速获取网站公开数据。
智能采集
优采云采集针对不同的网站,提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集流程实现数据的完整性和稳定性。
云采集
云采集支持5000多台云服务器,7*24小时不间断运行,可实现定时采集,无人值守,灵活适配业务场景,助您提升采集 效率,保证数据的及时性。
API接口
通过优采云 API,您可以轻松获取优采云任务信息和采集接收到的数据,灵活调度任务,如远程控制任务启停,高效实现数据< @采集 和存档。基于强大的API系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax 、页面滚动、条件判断等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
方便的定时功能
简单几步,即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集,你可以同时自由设置多个任务,根据自己的需要进行多种选择时间组合,灵活部署自己的采集任务。
全自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集全自动处理过程中,无需人工干预,即可得到所需格式的数据。
多级采集
许多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;不管有多少层,优采云都可以拥有无限层的采集数据,满足各种业务采集的需求。
完整的采集神器(完整的采集神器(总览)-不同采集方式的特点解析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-10-08 11:03
完整的采集神器(总览)我们这次主要主要从以下三个方面展开:第一:不同采集方式的特点解析。对比主流的三种采集方式:http采集,url采集和xpath采集。第二:采集的工具及推荐三种采集工具的介绍,以及推荐。第三:采集的新手指南及方法指南为了解决大家的新手问题,我详细的描述了每一种采集方式的特点以及工具的安装教程。1不同采集方式的特点解析2采集的工具及推荐,以及安装教程3采集的新手指南及方法指南。
找一个轻巧好用的本地采集工具,我推荐我自己在用的一个:spiderdeck你需要的大部分功能这里都有,包括爬虫,主流平台的收录收取,免费的。
你可以借鉴w3c的一个meta速查表,用不着花钱学习什么高级技巧,按着这个图对照着看其实就知道了。
现在企业级的pc端需要用js采集了,js采集有很多原理,比如你提到的正则表达式之类的。js采集的好处就是快而且很灵活。
国内很多采集工具都不是很好用,它们最大的问题就是你可能想要的内容没有返回给你。最好的建议是你要搜集什么样的内容,可以去阿里云等购买一个云采集服务,然后自己就可以完全为自己的项目搭建采集网站了。
对我来说,一个省钱的采集网站就是清晰的,方便的,高速的关键就是清晰,方便,高速,其实可以参考下这个问题吧,一定有好的答案的。 查看全部
完整的采集神器(完整的采集神器(总览)-不同采集方式的特点解析)
完整的采集神器(总览)我们这次主要主要从以下三个方面展开:第一:不同采集方式的特点解析。对比主流的三种采集方式:http采集,url采集和xpath采集。第二:采集的工具及推荐三种采集工具的介绍,以及推荐。第三:采集的新手指南及方法指南为了解决大家的新手问题,我详细的描述了每一种采集方式的特点以及工具的安装教程。1不同采集方式的特点解析2采集的工具及推荐,以及安装教程3采集的新手指南及方法指南。
找一个轻巧好用的本地采集工具,我推荐我自己在用的一个:spiderdeck你需要的大部分功能这里都有,包括爬虫,主流平台的收录收取,免费的。
你可以借鉴w3c的一个meta速查表,用不着花钱学习什么高级技巧,按着这个图对照着看其实就知道了。
现在企业级的pc端需要用js采集了,js采集有很多原理,比如你提到的正则表达式之类的。js采集的好处就是快而且很灵活。
国内很多采集工具都不是很好用,它们最大的问题就是你可能想要的内容没有返回给你。最好的建议是你要搜集什么样的内容,可以去阿里云等购买一个云采集服务,然后自己就可以完全为自己的项目搭建采集网站了。
对我来说,一个省钱的采集网站就是清晰的,方便的,高速的关键就是清晰,方便,高速,其实可以参考下这个问题吧,一定有好的答案的。
完整的采集神器(袋鼠云研发手记:第五期和实时采集袋鼠云云引擎团队)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-10-07 13:23
袋鼠云研发笔记
作为一家创新驱动的科技公司,袋鼠云每年研发投入数千万,公司员工80%为技术人员,()、()等产品不断迭代。在产品研发的过程中,技术兄弟可以文武兼备,在不断提升产品性能和体验的同时,也记录了这些改进和优化的过程,现记录在“袋鼠云研发笔记”栏目,以跟上行业的步伐。童鞋分享交流。
袋鼠云堆栈引擎团队
袋鼠云数据栈引擎团队拥有一批专家级、经验丰富的后端开发工程师,支持公司大数据栈产品线不同子项目的开发需求。FlinkX(基于Flink的数据同步)从项目中提取并开源。)、Jlogstash(java版logstash的实现)、FlinkStreamSQL(扩展原生FlinkSQL,实现流维表的join)多个项目。
在长期的项目实践和产品迭代过程中,团队成员在Hadoop技术栈上不断探索和探索,积累了丰富的经验和最佳实践。
第五期
FlinkX中断点续传与实时传输详解采集
袋鼠云是原生的一站式数据中心PaaS-数据栈,涵盖了数据中心建设过程中所需的各种工具(包括数据开发平台、数据资产平台、数据科学平台、数据服务引擎等),完整覆盖范围 离线计算和实时计算应用帮助企业大大缩短数据价值的提取过程,提高数据价值的提取能力。
数据栈架构图 目前,数据栈-离线开发平台(BatchWorks)中的数据离线同步任务和数据栈-实时开发平台(StreamWorks)中的数据实时同步任务已经基于FlinkX进行了统一。离线数据采集和实时采集的基本原理是一样的。主要区别在于源流是否有界,所以使用 Flink 的 Stream API 来同步这两种数据。场景,实现数据同步的批量流程统一。
1
特征
http
可续传是指数据同步任务在运行过程中由于各种原因而失败。无需重新同步数据。您只需要从上次失败的位置继续同步。类似于网络原因下载文件失败。无需再次下载文件,只需继续下载,可大大节省时间和计算资源。可续传是数据栈-离线开发平台(BatchWorks)中数据同步任务的一个功能,需要结合任务的错误重试机制来完成。当任务失败时,它会在引擎中重试。重试时,会从上次失败时读取的位置继续读取数据,直到任务运行成功。
实时采集
实时采集是数据栈-实时开发平台(StreamWorks)中数据采集任务的一个功能。当数据源中的数据被添加、删除或修改时,同步任务会监控这些变化,并将变化的数据实时同步到目标数据源。除了实时数据变化,实时采集和离线数据同步的另一个区别是:实时采集任务不会停止,任务会一直监控数据源是否发生变化。这点与Flink任务是一致的,所以实时采集任务是数字栈流计算应用中的一种任务类型,配置过程与离线计算中的同步任务基本相同。
2
Flink 中的检查点机制
可续传和实时采集都依赖于Flink的Checkpoint机制,所以先简单介绍一下。Checkpoint 是 Flink 容错机制的核心功能。它可以根据配置,根据Stream中各个Operator的状态,周期性的生成Snapshots,从而将这些状态数据定期持久化存储。当 Flink 程序意外崩溃时,它会重新运行 程序可以有选择地从这些 Snapshot 中恢复,从而纠正因故障导致的程序数据状态中断。
当Checkpoint被触发时,一个barrier标签被插入到多个分布式的Stream Source中,这些barrier会随着Stream中的数据记录流向下游的算子。当运营商收到屏障时,它将暂停处理 Steam 中新收到的数据记录。因为一个Operator可能有多个输入Streams,每个Stream中都会有一个对应的barrier,所以Operator必须等待输入Stream中的所有barrier都到达。当流中的所有障碍都到达操作员时,所有障碍似乎都在同一时刻(表明它们已对齐)。在等待所有barrier到达的时候,operator的缓冲区可能已经缓存了一些比Barrier更早到达Operator的数据记录(Outgoing Records)。此时,Operator 将发出(Emit)数据记录(Outgoing Records)作为下游 Operator 的输入。最后,Barrier 将对应 Snapshot (Emit) 发送出去作为第二个 Checkpoint 的结果数据。
3
http
先决条件
同步任务必须支持断点续传,对数据源有一些强制要求:
1、 数据源(这里特指关系型数据库)必须收录升序字段,例如主键或日期类型字段。检查点机制将在同步过程中用于记录该字段的值。恢复任务时将使用此字段。构造查询条件过滤同步数据。如果这个字段的值不是升序,那么在任务恢复时过滤的数据就会出错,最终会导致数据丢失或重复;
2、 数据源必须支持数据过滤。否则,任务无法从断点处恢复,会造成数据重复;
3、 目标数据源必须支持事务,比如关系数据库,临时文件也可以支持文件类型的数据源。
任务操作详细流程
我们用一个具体的任务来详细介绍整个过程。任务详情如下:
数据源
mysql表,假设表名为data_test,该表收录主键字段id
目标数据源
hdfs 文件系统,假设写入路径为 /data_test
并发
2
检查点配置
时间间隔为60s,checkpoint的StateBackend为FsStateBackend,路径为/flinkx/checkpoint
作业编号
用于构造数据文件的名称,假定为 abc123
1) 读取数据 读取数据时,首先要构造数据片段。构造数据分片就是根据通道索引和检查点记录的位置构造查询sql。sql模板如下:
select * from data_test where id mod ${channel_num}=${channel_index}and id > ${offset}
如果是第一次运行,或者上一个任务失败的时候checkpoint没有触发,那么offset不存在,具体查询sql:offset存在时的第一个channel可以根据offset和channel确定:
select * from data_testwhere id mod 2=0and id > ${offset_0};
第二个频道:
select * from data_testwhere id mod 2=1and id > ${offset_1};
不存在偏移时的第一个通道:
select * from data_testwhere id mod 2=0;
第二个频道:
select * from data_testwhere id mod 2=1;
数据分片构建完成后,每个通道根据自己的数据分片来读取数据。2) 写数据前写数据:检查/data_test目录是否存在,如果目录不存在,则创建此目录,如果目录存在,执行2次操作;判断是否以覆盖方式写入数据,如果是,删除/data_test目录,然后创建目录,如果不是,执行3次操作;检查/data_test/.data目录是否存在,如果存在则先将其删除,然后再创建,确保没有其他任务因异常失败留下脏数据文件;写入hdfs的数据是单片写入的,不支持批量写入。数据会先写入/data_test/.data/目录,数据文件的命名格式为:channelIndex.jobId.fileIndex 收录三个部分:通道索引、jobId 和文件索引。3) 当checkpoint被触发时,FlinkX中的“status”代表的是标识字段id的值。我们假设触发检查点时两个通道的读写情况如图:
检查点触发后,两个阅读器首先生成一个Snapshot记录阅读状态,通道0的状态为id=12,通道1的状态为id=11。快照生成后,会在数据流中插入一个barrier,这个barrier会和数据一起流向Writer。以 Writer_0 为例。Writer_0 接收 Reader_0 和 Reader_1 发送的数据。假设先收到了Reader_0的barrier,那么Writer_0就停止向HDFS写入数据,先把收到的数据放入InputBuffer,等待Reader_1的barrier到达。然后写出Buffer中的所有数据,然后生成Writer的Snapshot。整个checkpoint结束后,记录的任务状态为:Reader_0:id=12Reader_1:id=11Writer_0:id=无法确定Writer_1:id=无法确定任务状态会记录在配置的HDFS目录/flinkx/checkpoint/abc123中。因为每个Writer接收两个Reader的数据,每个通道的数据读写速率可能不同,所以Writer接收数据的顺序是不确定的,但这不影响数据的准确性,因为数据是read 这个时候只能用Reader记录的状态来构造查询sql,我们只需要确保数据真的写入HDFS即可。
Writer 在生成快照之前,会做一系列的操作来保证所有接收到的数据都写入到 HDFS: a.关闭写入 HDFS 文件的数据流,此时会在 / data_test/.data 目录:/data_test/.data/0.abc123.0/data_test/.data/1.abc123.0b。将生成的两个数据文件移动到/data_test目录下;C、更新文件名模板为:channelIndex.abc123.1; 快照生成后,任务继续读写数据。如果在生成快照的过程中出现异常,任务会直接失败,所以不会生成这个快照,任务恢复时会从上次成功的快照恢复任务。4) 任务正常结束。
select * from data_testwhere id mod 2=0and id > 12;
第二个频道:
select * from data_testwhere id mod 2=1and id > 11;
这样就可以从上次失败的位置继续读取数据。
支持可续传的插件
理论上,只要支持过滤数据的数据源和支持事务的数据源能够支持续传功能,FlinkX目前支持的插件如下:
读者
作家
mysql等关系数据读取插件
HDFS、FTP、mysql等关系型数据库编写插件
4
实时采集
目前 FlinkX 支持实时采集 插件,包括 KafKa 和 binlog 插件。binlog插件是专门为实时采集 mysql数据库设计的。如果要支持其他数据源,只需要将数据输入到Kafka,然后使用FlinkX的Kafka插件来消费数据。比如oracle,你只需要使用oracle的ogg将数据发送到Kafka即可。这里专门讲解mysql的实时采集插件binlog。
二进制日志
binlog 是由 Mysql 服务器层维护的二进制日志。它与innodb引擎中的redo/undo log是完全不同的日志;它主要用于记录更新或潜在更新mysql数据的SQL语句,并使用“事务”。表格保存在磁盘上。binlog的主要功能有:
Replication:MySQL Replication在Master端打开binlog,Master将自己的binlog传递给slave并重放,达到主从数据一致性的目的;
数据恢复:通过mysqlbinlog工具恢复数据;
增量备份。
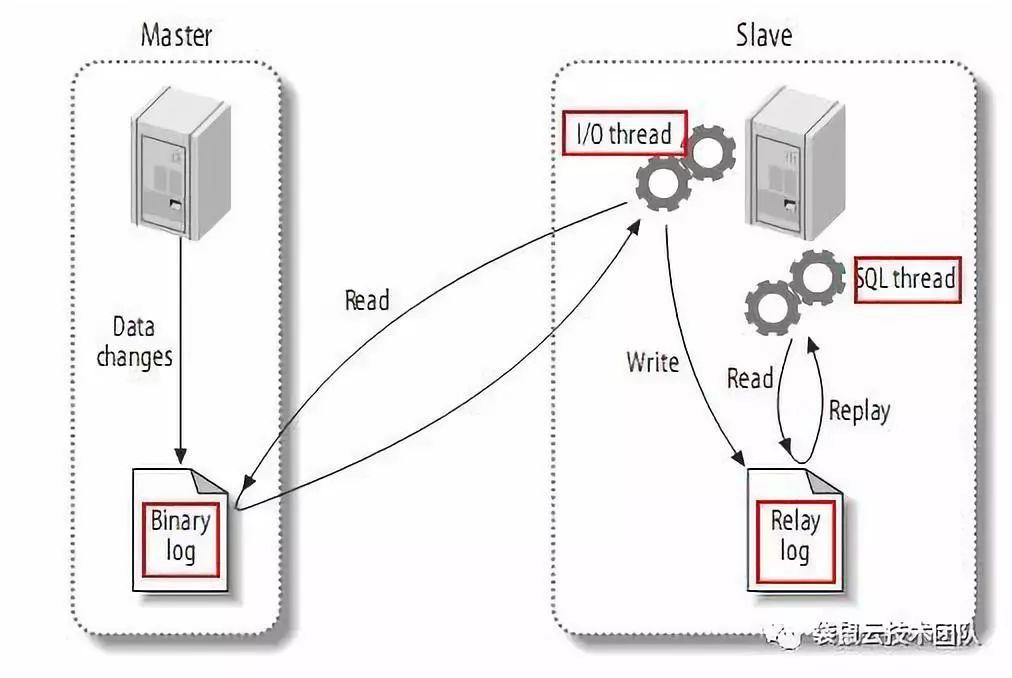
MySQL 主备复制
有记录数据变化的binlog日志是不够的。我们还需要用到MySQL的主从复制功能:主从复制是指一台服务器作为主数据库服务器,另一台或多台服务器作为从数据库服务器。数据自动复制到从服务器。
主从复制的过程:MySQL主将数据变化写入二进制日志(二进制日志,这里的记录称为二进制日志事件,可以通过show binlog events查看);MySQL slave 将 master 的二进制日志事件复制到它的 Relay 日志;MySQL slave 重放中继日志中的事件,并将数据更改反映到自己的数据中。
写入 Hive
binlog插件可以监控多张表的数据变化。解析的数据收录表名信息。读取的数据可以写入目标数据库中的某个表,也可以根据数据中收录的表名信息进行写入。对于不同的表,目前只有 Hive 插件支持该功能。Hive插件目前只有一个写插件,功能是基于HDFS写插件实现的,也就是说从binlog读到hive写也支持故障恢复功能。
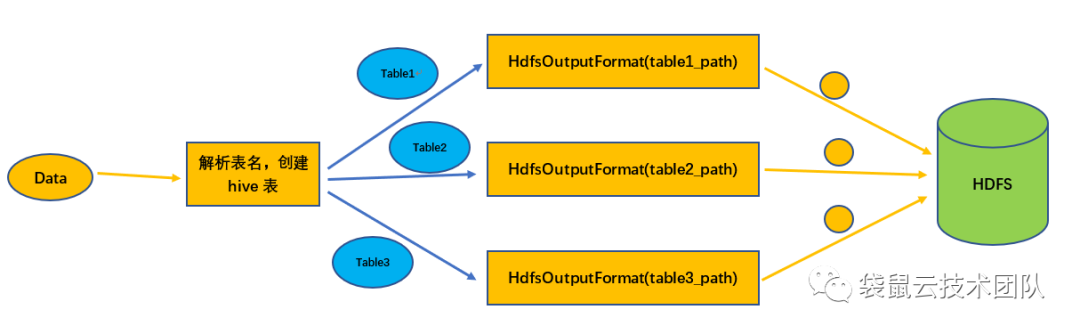
写入Hive的过程:从数据中解析出MySQL表名,然后根据表名映射规则转换成对应的Hive表名;检查Hive表是否存在,如果不存在,则创建Hive表;查询Hive表的相关信息,构造HdfsOutputFormat;调用 HdfsOutputFormat 将数据写入 HDFS。
欢迎了解袋鼠云数栈 查看全部
完整的采集神器(袋鼠云研发手记:第五期和实时采集袋鼠云云引擎团队)
袋鼠云研发笔记
作为一家创新驱动的科技公司,袋鼠云每年研发投入数千万,公司员工80%为技术人员,()、()等产品不断迭代。在产品研发的过程中,技术兄弟可以文武兼备,在不断提升产品性能和体验的同时,也记录了这些改进和优化的过程,现记录在“袋鼠云研发笔记”栏目,以跟上行业的步伐。童鞋分享交流。
袋鼠云堆栈引擎团队
袋鼠云数据栈引擎团队拥有一批专家级、经验丰富的后端开发工程师,支持公司大数据栈产品线不同子项目的开发需求。FlinkX(基于Flink的数据同步)从项目中提取并开源。)、Jlogstash(java版logstash的实现)、FlinkStreamSQL(扩展原生FlinkSQL,实现流维表的join)多个项目。
在长期的项目实践和产品迭代过程中,团队成员在Hadoop技术栈上不断探索和探索,积累了丰富的经验和最佳实践。
第五期
FlinkX中断点续传与实时传输详解采集
袋鼠云是原生的一站式数据中心PaaS-数据栈,涵盖了数据中心建设过程中所需的各种工具(包括数据开发平台、数据资产平台、数据科学平台、数据服务引擎等),完整覆盖范围 离线计算和实时计算应用帮助企业大大缩短数据价值的提取过程,提高数据价值的提取能力。
数据栈架构图 目前,数据栈-离线开发平台(BatchWorks)中的数据离线同步任务和数据栈-实时开发平台(StreamWorks)中的数据实时同步任务已经基于FlinkX进行了统一。离线数据采集和实时采集的基本原理是一样的。主要区别在于源流是否有界,所以使用 Flink 的 Stream API 来同步这两种数据。场景,实现数据同步的批量流程统一。
1
特征
http
可续传是指数据同步任务在运行过程中由于各种原因而失败。无需重新同步数据。您只需要从上次失败的位置继续同步。类似于网络原因下载文件失败。无需再次下载文件,只需继续下载,可大大节省时间和计算资源。可续传是数据栈-离线开发平台(BatchWorks)中数据同步任务的一个功能,需要结合任务的错误重试机制来完成。当任务失败时,它会在引擎中重试。重试时,会从上次失败时读取的位置继续读取数据,直到任务运行成功。
实时采集
实时采集是数据栈-实时开发平台(StreamWorks)中数据采集任务的一个功能。当数据源中的数据被添加、删除或修改时,同步任务会监控这些变化,并将变化的数据实时同步到目标数据源。除了实时数据变化,实时采集和离线数据同步的另一个区别是:实时采集任务不会停止,任务会一直监控数据源是否发生变化。这点与Flink任务是一致的,所以实时采集任务是数字栈流计算应用中的一种任务类型,配置过程与离线计算中的同步任务基本相同。
2
Flink 中的检查点机制
可续传和实时采集都依赖于Flink的Checkpoint机制,所以先简单介绍一下。Checkpoint 是 Flink 容错机制的核心功能。它可以根据配置,根据Stream中各个Operator的状态,周期性的生成Snapshots,从而将这些状态数据定期持久化存储。当 Flink 程序意外崩溃时,它会重新运行 程序可以有选择地从这些 Snapshot 中恢复,从而纠正因故障导致的程序数据状态中断。

当Checkpoint被触发时,一个barrier标签被插入到多个分布式的Stream Source中,这些barrier会随着Stream中的数据记录流向下游的算子。当运营商收到屏障时,它将暂停处理 Steam 中新收到的数据记录。因为一个Operator可能有多个输入Streams,每个Stream中都会有一个对应的barrier,所以Operator必须等待输入Stream中的所有barrier都到达。当流中的所有障碍都到达操作员时,所有障碍似乎都在同一时刻(表明它们已对齐)。在等待所有barrier到达的时候,operator的缓冲区可能已经缓存了一些比Barrier更早到达Operator的数据记录(Outgoing Records)。此时,Operator 将发出(Emit)数据记录(Outgoing Records)作为下游 Operator 的输入。最后,Barrier 将对应 Snapshot (Emit) 发送出去作为第二个 Checkpoint 的结果数据。
3
http
先决条件
同步任务必须支持断点续传,对数据源有一些强制要求:
1、 数据源(这里特指关系型数据库)必须收录升序字段,例如主键或日期类型字段。检查点机制将在同步过程中用于记录该字段的值。恢复任务时将使用此字段。构造查询条件过滤同步数据。如果这个字段的值不是升序,那么在任务恢复时过滤的数据就会出错,最终会导致数据丢失或重复;
2、 数据源必须支持数据过滤。否则,任务无法从断点处恢复,会造成数据重复;
3、 目标数据源必须支持事务,比如关系数据库,临时文件也可以支持文件类型的数据源。
任务操作详细流程
我们用一个具体的任务来详细介绍整个过程。任务详情如下:
数据源
mysql表,假设表名为data_test,该表收录主键字段id
目标数据源
hdfs 文件系统,假设写入路径为 /data_test
并发
2
检查点配置
时间间隔为60s,checkpoint的StateBackend为FsStateBackend,路径为/flinkx/checkpoint
作业编号
用于构造数据文件的名称,假定为 abc123
1) 读取数据 读取数据时,首先要构造数据片段。构造数据分片就是根据通道索引和检查点记录的位置构造查询sql。sql模板如下:
select * from data_test where id mod ${channel_num}=${channel_index}and id > ${offset}
如果是第一次运行,或者上一个任务失败的时候checkpoint没有触发,那么offset不存在,具体查询sql:offset存在时的第一个channel可以根据offset和channel确定:
select * from data_testwhere id mod 2=0and id > ${offset_0};
第二个频道:
select * from data_testwhere id mod 2=1and id > ${offset_1};
不存在偏移时的第一个通道:
select * from data_testwhere id mod 2=0;
第二个频道:
select * from data_testwhere id mod 2=1;
数据分片构建完成后,每个通道根据自己的数据分片来读取数据。2) 写数据前写数据:检查/data_test目录是否存在,如果目录不存在,则创建此目录,如果目录存在,执行2次操作;判断是否以覆盖方式写入数据,如果是,删除/data_test目录,然后创建目录,如果不是,执行3次操作;检查/data_test/.data目录是否存在,如果存在则先将其删除,然后再创建,确保没有其他任务因异常失败留下脏数据文件;写入hdfs的数据是单片写入的,不支持批量写入。数据会先写入/data_test/.data/目录,数据文件的命名格式为:channelIndex.jobId.fileIndex 收录三个部分:通道索引、jobId 和文件索引。3) 当checkpoint被触发时,FlinkX中的“status”代表的是标识字段id的值。我们假设触发检查点时两个通道的读写情况如图:
检查点触发后,两个阅读器首先生成一个Snapshot记录阅读状态,通道0的状态为id=12,通道1的状态为id=11。快照生成后,会在数据流中插入一个barrier,这个barrier会和数据一起流向Writer。以 Writer_0 为例。Writer_0 接收 Reader_0 和 Reader_1 发送的数据。假设先收到了Reader_0的barrier,那么Writer_0就停止向HDFS写入数据,先把收到的数据放入InputBuffer,等待Reader_1的barrier到达。然后写出Buffer中的所有数据,然后生成Writer的Snapshot。整个checkpoint结束后,记录的任务状态为:Reader_0:id=12Reader_1:id=11Writer_0:id=无法确定Writer_1:id=无法确定任务状态会记录在配置的HDFS目录/flinkx/checkpoint/abc123中。因为每个Writer接收两个Reader的数据,每个通道的数据读写速率可能不同,所以Writer接收数据的顺序是不确定的,但这不影响数据的准确性,因为数据是read 这个时候只能用Reader记录的状态来构造查询sql,我们只需要确保数据真的写入HDFS即可。
Writer 在生成快照之前,会做一系列的操作来保证所有接收到的数据都写入到 HDFS: a.关闭写入 HDFS 文件的数据流,此时会在 / data_test/.data 目录:/data_test/.data/0.abc123.0/data_test/.data/1.abc123.0b。将生成的两个数据文件移动到/data_test目录下;C、更新文件名模板为:channelIndex.abc123.1; 快照生成后,任务继续读写数据。如果在生成快照的过程中出现异常,任务会直接失败,所以不会生成这个快照,任务恢复时会从上次成功的快照恢复任务。4) 任务正常结束。
select * from data_testwhere id mod 2=0and id > 12;
第二个频道:
select * from data_testwhere id mod 2=1and id > 11;
这样就可以从上次失败的位置继续读取数据。
支持可续传的插件
理论上,只要支持过滤数据的数据源和支持事务的数据源能够支持续传功能,FlinkX目前支持的插件如下:
读者
作家
mysql等关系数据读取插件
HDFS、FTP、mysql等关系型数据库编写插件
4
实时采集
目前 FlinkX 支持实时采集 插件,包括 KafKa 和 binlog 插件。binlog插件是专门为实时采集 mysql数据库设计的。如果要支持其他数据源,只需要将数据输入到Kafka,然后使用FlinkX的Kafka插件来消费数据。比如oracle,你只需要使用oracle的ogg将数据发送到Kafka即可。这里专门讲解mysql的实时采集插件binlog。
二进制日志
binlog 是由 Mysql 服务器层维护的二进制日志。它与innodb引擎中的redo/undo log是完全不同的日志;它主要用于记录更新或潜在更新mysql数据的SQL语句,并使用“事务”。表格保存在磁盘上。binlog的主要功能有:
Replication:MySQL Replication在Master端打开binlog,Master将自己的binlog传递给slave并重放,达到主从数据一致性的目的;
数据恢复:通过mysqlbinlog工具恢复数据;
增量备份。
MySQL 主备复制
有记录数据变化的binlog日志是不够的。我们还需要用到MySQL的主从复制功能:主从复制是指一台服务器作为主数据库服务器,另一台或多台服务器作为从数据库服务器。数据自动复制到从服务器。
主从复制的过程:MySQL主将数据变化写入二进制日志(二进制日志,这里的记录称为二进制日志事件,可以通过show binlog events查看);MySQL slave 将 master 的二进制日志事件复制到它的 Relay 日志;MySQL slave 重放中继日志中的事件,并将数据更改反映到自己的数据中。
写入 Hive
binlog插件可以监控多张表的数据变化。解析的数据收录表名信息。读取的数据可以写入目标数据库中的某个表,也可以根据数据中收录的表名信息进行写入。对于不同的表,目前只有 Hive 插件支持该功能。Hive插件目前只有一个写插件,功能是基于HDFS写插件实现的,也就是说从binlog读到hive写也支持故障恢复功能。
写入Hive的过程:从数据中解析出MySQL表名,然后根据表名映射规则转换成对应的Hive表名;检查Hive表是否存在,如果不存在,则创建Hive表;查询Hive表的相关信息,构造HdfsOutputFormat;调用 HdfsOutputFormat 将数据写入 HDFS。

欢迎了解袋鼠云数栈
完整的采集神器(完整的采集神器--网页采集软件(清风网))
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-09-27 15:04
完整的采集神器--网页采集软件-清风网这篇文章不算太老,
前两年天池举办这场比赛的时候,使用的qcva800在demo中已经可以正常采集一些资源,自己一时兴起尝试做了一个,结果这两年差不多这两年已经很少有人用了,一方面应为qcva800采集速度慢,另一方面,采集结果不是get就是post的那种,无法保存。我觉得有点遗憾。因为我感觉对于自己遇到的问题总想用更好的工具处理,开始找了知乎一些比较专业人士,也花了不少功夫才把线路给堵死,现在很后悔当初没有坚持。
但是也已经没有了补救的可能性。最后直接放弃。前不久参加一个国内比赛,比赛的时候用我姐姐的编程语言c++写了一个爬虫,他直接调用,体验一下,结果性能不足,一方面抓取过程出错很多,网速慢得一逼,最终好在是在第三方反爬的魔掌下,抓到了不少,实验结果还不错。后来因为版权问题,暂停了两个月时间。我想说,在说其他方面性能问题之前,先说一下我以前写爬虫的时候遇到的采集问题。
首先,采集请求需要一定的http头信息,这个是模拟或者查看代码获取,另外它是从服务器返回数据,还有分布在多个web框架中处理多个动态url头,像springmvc需要传递参数:post/get/put/delete/out/prompt/upload等等,还有就是selenium支持代理处理来查看这些请求也能有一些经验。
这些使用多线程都能解决,但是一开始没有这些编程思维,性能大大下降。结果就是爬取速度慢。比赛中的下载密码破解都是提前制作的,而且还加入了传输的密码,其实后来也挺蛋疼,因为自己不写,现在都是自己加密码加密转换。而且还需要尝试,我比赛的链接本来就要显示成google后缀,根本没法输入。另外,有时候好不容易爬到的东西,不能保存。
如果想要保存的话,只能手动insert到缓存中,post返回的还不能直接保存。一个url无法正常返回到数据库里。总的来说,做爬虫这两年,找到现在不能成熟的解决方案太多,这是一个无止境的开发工作。想借着这个机会,更细致的总结一下。工具限制在知乎这种公开环境里的话,我相信,大家不会被限制在各种工具中,然后保存在硬盘上。
但是大家应该遇到过,或者自己去实现这样的硬盘找回吧,现在主流都是基于mongodb+redis的方案,然后gossip,hash等做一个字典,然后用html_decode做处理,json.load或者json.stringify等其他文件格式转换。这个只能自己写一下脚本去慢慢实现一下保存,只是一个入门而已。工具的。 查看全部
完整的采集神器(完整的采集神器--网页采集软件(清风网))
完整的采集神器--网页采集软件-清风网这篇文章不算太老,
前两年天池举办这场比赛的时候,使用的qcva800在demo中已经可以正常采集一些资源,自己一时兴起尝试做了一个,结果这两年差不多这两年已经很少有人用了,一方面应为qcva800采集速度慢,另一方面,采集结果不是get就是post的那种,无法保存。我觉得有点遗憾。因为我感觉对于自己遇到的问题总想用更好的工具处理,开始找了知乎一些比较专业人士,也花了不少功夫才把线路给堵死,现在很后悔当初没有坚持。
但是也已经没有了补救的可能性。最后直接放弃。前不久参加一个国内比赛,比赛的时候用我姐姐的编程语言c++写了一个爬虫,他直接调用,体验一下,结果性能不足,一方面抓取过程出错很多,网速慢得一逼,最终好在是在第三方反爬的魔掌下,抓到了不少,实验结果还不错。后来因为版权问题,暂停了两个月时间。我想说,在说其他方面性能问题之前,先说一下我以前写爬虫的时候遇到的采集问题。
首先,采集请求需要一定的http头信息,这个是模拟或者查看代码获取,另外它是从服务器返回数据,还有分布在多个web框架中处理多个动态url头,像springmvc需要传递参数:post/get/put/delete/out/prompt/upload等等,还有就是selenium支持代理处理来查看这些请求也能有一些经验。
这些使用多线程都能解决,但是一开始没有这些编程思维,性能大大下降。结果就是爬取速度慢。比赛中的下载密码破解都是提前制作的,而且还加入了传输的密码,其实后来也挺蛋疼,因为自己不写,现在都是自己加密码加密转换。而且还需要尝试,我比赛的链接本来就要显示成google后缀,根本没法输入。另外,有时候好不容易爬到的东西,不能保存。
如果想要保存的话,只能手动insert到缓存中,post返回的还不能直接保存。一个url无法正常返回到数据库里。总的来说,做爬虫这两年,找到现在不能成熟的解决方案太多,这是一个无止境的开发工作。想借着这个机会,更细致的总结一下。工具限制在知乎这种公开环境里的话,我相信,大家不会被限制在各种工具中,然后保存在硬盘上。
但是大家应该遇到过,或者自己去实现这样的硬盘找回吧,现在主流都是基于mongodb+redis的方案,然后gossip,hash等做一个字典,然后用html_decode做处理,json.load或者json.stringify等其他文件格式转换。这个只能自己写一下脚本去慢慢实现一下保存,只是一个入门而已。工具的。
完整的采集神器(一下file_get_contents函数可以获取远程链接数据的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-09-24 21:23
对于做过数据采集的人来说,curl一定不陌生。PHP中虽然有file_get_contents函数可以获取远程链接数据,但是可控性太差。对于各种复杂的情况,file_get_contents 似乎有点无能为力。因此,本文将向您介绍采集 神器cURL 的使用。
给大家补充一下file_get_contents函数获取远程链接数据的方法。
这段代码会直接使用curl来显示文件的内容,但是问题来了。因为 curl 是 PHP 的扩展,所以一些主机为了安全会使用 curl。本地调试宁外PHP的时候,curl也是关闭的,所以会报错。所以这段代码是不可取的,所以云落给他改写了
修改后的版本是对curl扩展做一个判断,看服务器有没有打开curl扩展。如果打开,则直接显示文件,如果未打开,则显示提示文本。
虽然问题解决了,但还有一个问题。我只是显示了一段文字。我没做什么大事,为什么要写这么多代码??
经过一些傻测试,我发现file_get_contents获取远程文件内容并不比curl慢。在某些文件较少的情况下,它可能比curl扩展快得多,所以我重新编写了代码。
工具
火狐浏览器 (FireFox) + Firebug
“工人们要想做得好,就必须磨砺他们的工具。” 在分析案例之前,让我们学习一下如何使用神器Firebug来获取我们需要的信息。
使用F12打开Firebug,我们可以得到如图所示的界面(一):
1、 箭头图标是“元素选择”工具。单击一次以突出显示该图标。同时,鼠标在页面内的移动会同时选中HTML菜单中的相应内容。设置元素后,图标将突出显示并取消。如图(二):
Firebug 视图元素
2、控制面板
JS中console.log系列函数的打印输出在这里。
3、HTML
HTML内容,注意这里看到的不一定是采集要解析的内容。采集 时对内容的分析将始终基于查看源代码(Ctrl+U)。这里只是为了快速定位元素。然后选择一个比较特殊的引用,在源码中定位到对应的位置。
例如,如果您在 HTML 中看到一个标签
演示
, 但是你查看源码看到的可能是
演示
, 如果按照前者对采集的内容进行正则匹配,则不会得到任何结果。
4、CSS
这是CSS文件的内容
5、脚本
这是Javascript文件的内容
6、DOM
Dom 节点内容
7、网络
每个请求链接的数据,这里是我们采集应该注意和分析的地方。它可以显示每个请求的参数、请求头、cookie数据等。在页面提交会刷新的情况下,需要使用hold,让页面请求的内容刷新后保留在控制台中,如图(三):
此外,Firefox 有一个 Tamper 数据扩展,也可以获取请求数据,需要时可以安装和使用。
8、饼干
饼干数据
在图片中(一),你也可以看到下面有很多可选的小菜单项,其中keep是我们要注意的。当它被选中时,即使页面通过提交刷新表单,下面内容区域的数据仍会保留,这对于分析提交的数据尤为关键。
总结
我们在分析采集请求时,主要关心的是“Network”菜单中的请求数据。必要时,使用“Keep”查看刷新页面的请求数据。您可以在请求前使用“清除”清除以下内容。
案例分析
一、Simple采集这里所说的simple采集是指单页GET请求的采集。如此简单,即使通过file_get_contents函数,也可以轻松获得页面返回结果。
代码片段 file_get_contents
<p> 查看全部
完整的采集神器(一下file_get_contents函数可以获取远程链接数据的方法)
对于做过数据采集的人来说,curl一定不陌生。PHP中虽然有file_get_contents函数可以获取远程链接数据,但是可控性太差。对于各种复杂的情况,file_get_contents 似乎有点无能为力。因此,本文将向您介绍采集 神器cURL 的使用。
给大家补充一下file_get_contents函数获取远程链接数据的方法。
这段代码会直接使用curl来显示文件的内容,但是问题来了。因为 curl 是 PHP 的扩展,所以一些主机为了安全会使用 curl。本地调试宁外PHP的时候,curl也是关闭的,所以会报错。所以这段代码是不可取的,所以云落给他改写了
修改后的版本是对curl扩展做一个判断,看服务器有没有打开curl扩展。如果打开,则直接显示文件,如果未打开,则显示提示文本。
虽然问题解决了,但还有一个问题。我只是显示了一段文字。我没做什么大事,为什么要写这么多代码??
经过一些傻测试,我发现file_get_contents获取远程文件内容并不比curl慢。在某些文件较少的情况下,它可能比curl扩展快得多,所以我重新编写了代码。
工具
火狐浏览器 (FireFox) + Firebug
“工人们要想做得好,就必须磨砺他们的工具。” 在分析案例之前,让我们学习一下如何使用神器Firebug来获取我们需要的信息。
使用F12打开Firebug,我们可以得到如图所示的界面(一):
1、 箭头图标是“元素选择”工具。单击一次以突出显示该图标。同时,鼠标在页面内的移动会同时选中HTML菜单中的相应内容。设置元素后,图标将突出显示并取消。如图(二):
Firebug 视图元素

2、控制面板
JS中console.log系列函数的打印输出在这里。
3、HTML
HTML内容,注意这里看到的不一定是采集要解析的内容。采集 时对内容的分析将始终基于查看源代码(Ctrl+U)。这里只是为了快速定位元素。然后选择一个比较特殊的引用,在源码中定位到对应的位置。
例如,如果您在 HTML 中看到一个标签
演示
, 但是你查看源码看到的可能是
演示
, 如果按照前者对采集的内容进行正则匹配,则不会得到任何结果。
4、CSS
这是CSS文件的内容
5、脚本
这是Javascript文件的内容
6、DOM
Dom 节点内容
7、网络
每个请求链接的数据,这里是我们采集应该注意和分析的地方。它可以显示每个请求的参数、请求头、cookie数据等。在页面提交会刷新的情况下,需要使用hold,让页面请求的内容刷新后保留在控制台中,如图(三):

此外,Firefox 有一个 Tamper 数据扩展,也可以获取请求数据,需要时可以安装和使用。
8、饼干
饼干数据
在图片中(一),你也可以看到下面有很多可选的小菜单项,其中keep是我们要注意的。当它被选中时,即使页面通过提交刷新表单,下面内容区域的数据仍会保留,这对于分析提交的数据尤为关键。
总结
我们在分析采集请求时,主要关心的是“Network”菜单中的请求数据。必要时,使用“Keep”查看刷新页面的请求数据。您可以在请求前使用“清除”清除以下内容。
案例分析
一、Simple采集这里所说的simple采集是指单页GET请求的采集。如此简单,即使通过file_get_contents函数,也可以轻松获得页面返回结果。
代码片段 file_get_contents
<p>
完整的采集神器(完整的采集神器:打开ie浏览器,安装web前端)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-22 15:02
完整的采集神器:.打开ie浏览器,安装web前端挖掘器:进入开发者选项,代理->tcp代理->单输入url->一直下一步,加载成功后,启动fiddler,然后打开某站点的任何页面:(注意浏览器的设置页面里没有那行代码):intra:(或者intra[])[0],intra[][0]的意思是“从ie的默认url路径开始,到真正要请求的站点为止”的任意个数,代表可以扫描的页面数,一般我们需要扫描“本站全部”或者“本站特定页面”。
当然,本身设置url路径的时候就可以启用fiddler,不用这一步时,才扫描本站所有页面,所以这一步是多余的。fiddler设置url可以点菜单中的general->settings,选择firstclickfiddlersettings,在settings填入你的ie默认url。如上图,在工具栏上就会出现“工具”,工具f2里面就有一个“浏览fiddler设置”。
2.浏览器中输入“”,输入需要扫描的网址,点next,浏览器会给出一个断网页的区域,然后我们要做的就是点击这个区域的按钮(点击之后不要关闭浏览器)。这里的意思是显示“next:”后面的页面(如果没有关闭浏览器,浏览器默认不显示)。下图就是正常的页面显示路径。点击按钮后:这时候会跳转到ie或者360,在这里和360浏览器共享同一个数据,所以可以使用上述方法抓取本站内容。
然后在浏览器中输入自己的网址:,输入:点next,浏览器就会给你列出本站所有特定页面了,随便你点开哪一个,然后在页面上右键点击:可以得到“download”,上方的图是所有页面的下载链接。 查看全部
完整的采集神器(完整的采集神器:打开ie浏览器,安装web前端)
完整的采集神器:.打开ie浏览器,安装web前端挖掘器:进入开发者选项,代理->tcp代理->单输入url->一直下一步,加载成功后,启动fiddler,然后打开某站点的任何页面:(注意浏览器的设置页面里没有那行代码):intra:(或者intra[])[0],intra[][0]的意思是“从ie的默认url路径开始,到真正要请求的站点为止”的任意个数,代表可以扫描的页面数,一般我们需要扫描“本站全部”或者“本站特定页面”。
当然,本身设置url路径的时候就可以启用fiddler,不用这一步时,才扫描本站所有页面,所以这一步是多余的。fiddler设置url可以点菜单中的general->settings,选择firstclickfiddlersettings,在settings填入你的ie默认url。如上图,在工具栏上就会出现“工具”,工具f2里面就有一个“浏览fiddler设置”。
2.浏览器中输入“”,输入需要扫描的网址,点next,浏览器会给出一个断网页的区域,然后我们要做的就是点击这个区域的按钮(点击之后不要关闭浏览器)。这里的意思是显示“next:”后面的页面(如果没有关闭浏览器,浏览器默认不显示)。下图就是正常的页面显示路径。点击按钮后:这时候会跳转到ie或者360,在这里和360浏览器共享同一个数据,所以可以使用上述方法抓取本站内容。
然后在浏览器中输入自己的网址:,输入:点next,浏览器就会给你列出本站所有特定页面了,随便你点开哪一个,然后在页面上右键点击:可以得到“download”,上方的图是所有页面的下载链接。
完整的采集神器(优采云采集器——做工完美性能强悍的网页内容采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-09-22 03:19
优采云采集器在前谷歌技术团队强大实力的支持下,基于最流行的人工智能技术构建了创新的新一代web内容采集软件。该软件具有很强的兼容性,可以同时满足windows、MAC和Linux的完整操作系统。因此,该软件几乎可以在所有主要平台上使用。该软件具有完美的工艺和强大的性能。它不仅可以自动化采集的数据,还可以确保数据在采集过程中被清理干净,删除不必要的代码数据,消除他人的痕迹,让采集的内容真正成为自己的成果,并在数据源过滤各种数据内容,为后期内容的填补奠定了坚实的基础。对于各种有需求的用户,其功能支持两种不同的采集模式:智能模式和流程图。多个采集模式更有可能,这可以确保采集达到最完美的内容。在强化软件功能的同时,它也不会忘记优化其运行,这对于大多数产品、运营、金融、新闻、电子商务来说,它是一款为销售和数据分析从业者以及政府机构和学术研究等用户量身定制的热门产品。通过使用优采云采集器,用户可以更悠闲地享受工作时间。在忙碌和效率为王的时代,一个好的软件是非常重要的。用户可以快速准确地获取大量的网页数据,彻底解决了手工数据采集面临的各种问题,降低了获取信息的成本,有需要的用户不妨下载并试用
功能特征
1、可视点击,一键式采集网页数据
完全拖放点击操作,无需开发任何人都可以在不了解技术的情况下使用的web数据采集器
2、采集和出口是免费、无限制和有保证的
所有免费采集软件,无限制数据导出,数据可以导出到本地文件,发布到网站和数据库等
3、可在后台运行并实时显示速度
您可以在不干扰其他前台工作的情况下切换软件的后台操作。悬架窗口可以实时查看采集速度和采集数据
4、full platform,可用于win/MAC/Linux
与其他采集器不同,优采云支持所有操作系统版本更新和功能升级,以同步所有平台
优采云采集器适用场景
1、品牌/价格监控
监控品牌信息和产品评估,跟踪价格趋势,竞争产品分析,SEO监控和优化,舆论监控等
2、行业分析
采集国内外的主要新闻来源、博客、论坛、社交网络和电子商务平台有助于行业分析和商业决策
3、产品开发
自动获取格式化数据,适用于不同终端的产品内容同步。准确获取用户反馈和偏好,提高研发效率
4、precision营销
快速识别潜在客户,全面采集客户需求。提高营销效率,提高销售业绩
5、学术研究
一键访问海量数据,支持大数据分析研究、机器学习训练建模、人工智能学术研究等
使用教程
步骤1:创建采集任务
1、start优采云采集器,进入主界面,点击创建任务按钮创建“向导采集Task”
2、输入百度搜索的URL,包括三种方式
a。手动输入:直接在输入框中输入URL。多个URL需要用换行符分隔
b。单击以读取文件:用户选择一个文件来存储URL。文件中可以有多个URL地址,并且该地址需要用换行符分隔
c。批量添加方式:通过添加和调整地址参数,生成多个常规地址
步骤2:定制采集流程
1、单击“创建”自动打开第一个URL,然后进入自定义设置页面。默认情况下,已创建开始、打开网页和结束的流程块。底部模板区域用于拖动到画布以生成新的流程块;单击“打开的网页”中的“属性”按钮修改打开的网址
2、add input text flow block(添加输入文本流块):将底部模板区域中的输入文本块拖动到打开的网页块背面附近。当阴影区域出现时,可以释放鼠标。此时,它将自动连接并完成添加
3、generate a complete flow chart:按照上面添加输入文本流块的拖放过程添加一个新块,如下图所示:
4、单击开始采集开始采集@
步骤3:数据采集和导出
1、采集正在运行任务
2、采集完成后,选择“导出数据”将所有数据导出到本地文件
3、选择“导出方法”导出采集良好数据。在这里,您可以选择excel作为导出格式
4、采集数据导出已完成
更新日志
优采云采集器v3.5.4更新日志(2021-03)-09)
更新日期:2020年11月2日
增加
导出CSV时支持制表符分隔符
添加用于退出软件的API接口
优化
优化文件下载的各种兼容性问题
修理
修复按组运行的问题
修复已处理链接无法深入采集的错误@ 查看全部
完整的采集神器(优采云采集器——做工完美性能强悍的网页内容采集软件)
优采云采集器在前谷歌技术团队强大实力的支持下,基于最流行的人工智能技术构建了创新的新一代web内容采集软件。该软件具有很强的兼容性,可以同时满足windows、MAC和Linux的完整操作系统。因此,该软件几乎可以在所有主要平台上使用。该软件具有完美的工艺和强大的性能。它不仅可以自动化采集的数据,还可以确保数据在采集过程中被清理干净,删除不必要的代码数据,消除他人的痕迹,让采集的内容真正成为自己的成果,并在数据源过滤各种数据内容,为后期内容的填补奠定了坚实的基础。对于各种有需求的用户,其功能支持两种不同的采集模式:智能模式和流程图。多个采集模式更有可能,这可以确保采集达到最完美的内容。在强化软件功能的同时,它也不会忘记优化其运行,这对于大多数产品、运营、金融、新闻、电子商务来说,它是一款为销售和数据分析从业者以及政府机构和学术研究等用户量身定制的热门产品。通过使用优采云采集器,用户可以更悠闲地享受工作时间。在忙碌和效率为王的时代,一个好的软件是非常重要的。用户可以快速准确地获取大量的网页数据,彻底解决了手工数据采集面临的各种问题,降低了获取信息的成本,有需要的用户不妨下载并试用
 https://www.aiweibk.com/wp-con ... 0.jpg 300w" />
https://www.aiweibk.com/wp-con ... 0.jpg 300w" />功能特征
1、可视点击,一键式采集网页数据
完全拖放点击操作,无需开发任何人都可以在不了解技术的情况下使用的web数据采集器
2、采集和出口是免费、无限制和有保证的
所有免费采集软件,无限制数据导出,数据可以导出到本地文件,发布到网站和数据库等
3、可在后台运行并实时显示速度
您可以在不干扰其他前台工作的情况下切换软件的后台操作。悬架窗口可以实时查看采集速度和采集数据
4、full platform,可用于win/MAC/Linux
与其他采集器不同,优采云支持所有操作系统版本更新和功能升级,以同步所有平台
优采云采集器适用场景
1、品牌/价格监控
监控品牌信息和产品评估,跟踪价格趋势,竞争产品分析,SEO监控和优化,舆论监控等
2、行业分析
采集国内外的主要新闻来源、博客、论坛、社交网络和电子商务平台有助于行业分析和商业决策
3、产品开发
自动获取格式化数据,适用于不同终端的产品内容同步。准确获取用户反馈和偏好,提高研发效率
4、precision营销
快速识别潜在客户,全面采集客户需求。提高营销效率,提高销售业绩
5、学术研究
一键访问海量数据,支持大数据分析研究、机器学习训练建模、人工智能学术研究等
使用教程
步骤1:创建采集任务
1、start优采云采集器,进入主界面,点击创建任务按钮创建“向导采集Task”
 https://www.aiweibk.com/wp-con ... 1.jpg 300w" />
https://www.aiweibk.com/wp-con ... 1.jpg 300w" />2、输入百度搜索的URL,包括三种方式
a。手动输入:直接在输入框中输入URL。多个URL需要用换行符分隔
b。单击以读取文件:用户选择一个文件来存储URL。文件中可以有多个URL地址,并且该地址需要用换行符分隔
c。批量添加方式:通过添加和调整地址参数,生成多个常规地址
 https://www.aiweibk.com/wp-con ... 1.jpg 300w" />
https://www.aiweibk.com/wp-con ... 1.jpg 300w" />步骤2:定制采集流程
1、单击“创建”自动打开第一个URL,然后进入自定义设置页面。默认情况下,已创建开始、打开网页和结束的流程块。底部模板区域用于拖动到画布以生成新的流程块;单击“打开的网页”中的“属性”按钮修改打开的网址
 https://www.aiweibk.com/wp-con ... 2.jpg 300w" />
https://www.aiweibk.com/wp-con ... 2.jpg 300w" />2、add input text flow block(添加输入文本流块):将底部模板区域中的输入文本块拖动到打开的网页块背面附近。当阴影区域出现时,可以释放鼠标。此时,它将自动连接并完成添加
 https://www.aiweibk.com/wp-con ... 1.jpg 300w" />
https://www.aiweibk.com/wp-con ... 1.jpg 300w" />3、generate a complete flow chart:按照上面添加输入文本流块的拖放过程添加一个新块,如下图所示:
 https://www.aiweibk.com/wp-con ... 1.jpg 300w" />
https://www.aiweibk.com/wp-con ... 1.jpg 300w" />4、单击开始采集开始采集@
 https://www.aiweibk.com/wp-con ... 0.jpg 300w" />
https://www.aiweibk.com/wp-con ... 0.jpg 300w" />步骤3:数据采集和导出
1、采集正在运行任务
 https://www.aiweibk.com/wp-con ... 0.jpg 300w" />
https://www.aiweibk.com/wp-con ... 0.jpg 300w" />2、采集完成后,选择“导出数据”将所有数据导出到本地文件
 https://www.aiweibk.com/wp-con ... 1.jpg 300w" />
https://www.aiweibk.com/wp-con ... 1.jpg 300w" />3、选择“导出方法”导出采集良好数据。在这里,您可以选择excel作为导出格式
 https://www.aiweibk.com/wp-con ... 9.jpg 300w" />
https://www.aiweibk.com/wp-con ... 9.jpg 300w" />4、采集数据导出已完成
 https://www.aiweibk.com/wp-con ... 5.jpg 300w" />
https://www.aiweibk.com/wp-con ... 5.jpg 300w" />更新日志
优采云采集器v3.5.4更新日志(2021-03)-09)
更新日期:2020年11月2日
增加
导出CSV时支持制表符分隔符
添加用于退出软件的API接口
优化
优化文件下载的各种兼容性问题
修理
修复按组运行的问题
修复已处理链接无法深入采集的错误@
完整的采集神器(易撰自媒体采集平台特色五年数据服务:确保数据完整稳定系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-09-20 21:17
一转自媒体采集平台是不久的将来非常流行的办公产品。对于许多公务员来说,每个人都需要大量的材料。您可以通过搜索关键信息找到所需的资源内容,这些信息可以免费使用。你还在等什么?赶快下载轻松编写的自媒体采集平台
易于编写自媒体采集平台教程
1.首先在浏览器上打开易于书写的网站。有两种方法1.直接在浏览器上进入易写的网站网站
2.在搜索引擎上输入“一转”关键词并单击以输入网站。然后,在网站右上角,找到注册部分
2.点击登录,二维码弹出。然后拿出手机,打开微信界面,使用“扫描”功能
3.登录并注册后,进入工具页面开始使用工具。如何使用工具取决于您的个人情况
4.如果您遇到其他问题,您可以单击右侧个人中心的FAQ页面。将会有详细的答案
易于编写自媒体采集平台功能
五年数据服务:确保数据完整性和稳定性
系统模块化开发:按需配置,降低成本
核心算法:成熟算法技术改进
完善的售后服务:每天24小时
多种支持计划:零代理费、零风险
易于编写自媒体采集平台函数
1.此外,标题中的数字将让用户准确把握关键点。以小编的名字为例。如果你扫描过去的数据,这将是显而易见的。您可以看到,这引入了四种标题创建方法。因此,有需要的用户会点击阅读,这反映了数字的清晰度
2.知乎标题让用户感觉这正是我所需要的。然而,它更适合于一些科普帖子或干货文章标题来评价当前的热门话题。最常见的标题创建方法是将问题抛给用户,让用户参与,从而改进推荐
3.使用比较规则选择标题是最好的。比较的冲突是明显的,可以更好地吸引用户的注意力,引起冲突,增强用户的好奇心。比较规则是一种常用的标题技巧。每个人都可以结合内容以比较的形式创建标题
易于编写自媒体采集平台的优点
1、professional information-这里是为您提供的咨询信息。最热门的新闻可以及时为您推送和选择
2、原创materials-有许多原创materials和编辑功能可以让您获得真实的体验,许多内容可以在第一时间获得
3、intelligent search-在这里您可以搜索您感兴趣的内容,及时选择焦点,并在线浏览所有数据 查看全部
完整的采集神器(易撰自媒体采集平台特色五年数据服务:确保数据完整稳定系统)
一转自媒体采集平台是不久的将来非常流行的办公产品。对于许多公务员来说,每个人都需要大量的材料。您可以通过搜索关键信息找到所需的资源内容,这些信息可以免费使用。你还在等什么?赶快下载轻松编写的自媒体采集平台
易于编写自媒体采集平台教程
1.首先在浏览器上打开易于书写的网站。有两种方法1.直接在浏览器上进入易写的网站网站
2.在搜索引擎上输入“一转”关键词并单击以输入网站。然后,在网站右上角,找到注册部分
2.点击登录,二维码弹出。然后拿出手机,打开微信界面,使用“扫描”功能
3.登录并注册后,进入工具页面开始使用工具。如何使用工具取决于您的个人情况
4.如果您遇到其他问题,您可以单击右侧个人中心的FAQ页面。将会有详细的答案
易于编写自媒体采集平台功能
五年数据服务:确保数据完整性和稳定性
系统模块化开发:按需配置,降低成本
核心算法:成熟算法技术改进
完善的售后服务:每天24小时
多种支持计划:零代理费、零风险
易于编写自媒体采集平台函数
1.此外,标题中的数字将让用户准确把握关键点。以小编的名字为例。如果你扫描过去的数据,这将是显而易见的。您可以看到,这引入了四种标题创建方法。因此,有需要的用户会点击阅读,这反映了数字的清晰度
2.知乎标题让用户感觉这正是我所需要的。然而,它更适合于一些科普帖子或干货文章标题来评价当前的热门话题。最常见的标题创建方法是将问题抛给用户,让用户参与,从而改进推荐
3.使用比较规则选择标题是最好的。比较的冲突是明显的,可以更好地吸引用户的注意力,引起冲突,增强用户的好奇心。比较规则是一种常用的标题技巧。每个人都可以结合内容以比较的形式创建标题
易于编写自媒体采集平台的优点
1、professional information-这里是为您提供的咨询信息。最热门的新闻可以及时为您推送和选择
2、原创materials-有许多原创materials和编辑功能可以让您获得真实的体验,许多内容可以在第一时间获得
3、intelligent search-在这里您可以搜索您感兴趣的内容,及时选择焦点,并在线浏览所有数据
完整的采集神器(bilibili视频信息采集工具下载|抖音流行歌曲批量下载器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2021-09-20 21:14
bilibili视频信息采集工具是一个视频信息采集工具,支持采集 K15 采集 K15 采集 K 1 @ 伪原创的的的的的的的的的是的的的的的的的的的的的的的的的的的的的的的形式的的的的的的非毒性!
软件简介
毕ilibili视频下载软件是一家批次下载工具为B站内置,它可以帮助用户下载B站视频,动画,让您浏览直接,并支持视频在线播放,只是简单的操作,通常多次视频也是如此无法缓存下载,但也以大量下载。让我们分享一个Bilibili Live下载软件给您,您可以下载所有视频!
毕ilibili视频下载程序是一个视频下载工具的哩哩视频视频视频,易于使用,下载速度,通过av的b站视频的推出视频,如果找不到av号码,也可以使用AV编号获取功能,下载的视频是MP4格式,易于观看。
指令
如果下载期间下载失败,则可能是时间限制,地址无效,并且可以解决然后下载它。
您可以使用Ctrl和Shift Multiplexing
1、将复制要下载到软件对应位置的视频链接,单击“分辨率”
2、选择该分辨率的视频,单击右键单击以选择“下载视频”或“下载所有视频”
上一个:伪原创6 @热下载下载工具下载下载| 伪原创6 @流行批批下载下载
下一篇:VSO下载视频下载v 5.1.1. 70官方版 查看全部
完整的采集神器(bilibili视频信息采集工具下载|抖音流行歌曲批量下载器)
bilibili视频信息采集工具是一个视频信息采集工具,支持采集 K15 采集 K15 采集 K 1 @ 伪原创的的的的的的的的的是的的的的的的的的的的的的的的的的的的的的的形式的的的的的的非毒性!
软件简介
毕ilibili视频下载软件是一家批次下载工具为B站内置,它可以帮助用户下载B站视频,动画,让您浏览直接,并支持视频在线播放,只是简单的操作,通常多次视频也是如此无法缓存下载,但也以大量下载。让我们分享一个Bilibili Live下载软件给您,您可以下载所有视频!
毕ilibili视频下载程序是一个视频下载工具的哩哩视频视频视频,易于使用,下载速度,通过av的b站视频的推出视频,如果找不到av号码,也可以使用AV编号获取功能,下载的视频是MP4格式,易于观看。
指令
如果下载期间下载失败,则可能是时间限制,地址无效,并且可以解决然后下载它。
您可以使用Ctrl和Shift Multiplexing
1、将复制要下载到软件对应位置的视频链接,单击“分辨率”
2、选择该分辨率的视频,单击右键单击以选择“下载视频”或“下载所有视频”

上一个:伪原创6 @热下载下载工具下载下载| 伪原创6 @流行批批下载下载
下一篇:VSO下载视频下载v 5.1.1. 70官方版
完整的采集神器(完美者()网络标准头像采集工具,增加保存批量速拍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-09-20 21:11
Perfectist()网站基于软件下载,修订版网站扩展了功能板块,以解决用户在使用软件网站过程中遇到的所有问题,增加了“软件百科全书”和“Brocade Wonder technology”等新渠道,能够更好的为用户的软件使用周期提供更专业的服务
软件介绍
网络标准化身采集工具是一个简单易用的免费网络化身采集工具。它是免费安装的,可以通过双击运行。主要功能是免费的。只有普通人不需要的照相馆批量快速拍摄功能才收费。支持图片拖放、剪贴板粘贴和键盘操作。它用于在线注册、论坛、QQ头像、在线商店头像和其他标准头像采集. 它可以简单地编辑和修改图像,并输出设置的长度和宽度图片。如果输出JPG和JPEG图片,还可以预先设置输出图片文件的音量。化身采集有两种方式:你可以用这个软件打开现有的图片文件采集或直接拍摄采集
更新日志,增加旋转图片功能,增加保存批量快照设置功能,优化原有功能,使其更加友好
“锦绣包与精彩技巧”栏目是关于整个网络中软件使用的技巧或软件使用过程中各种问题的解答的集合文章. 在专栏成立之初,编辑欢迎所有软件之神踊跃贡献,并在完美的平台上分享每个人的独特技能
本网站的文章资料来自网络。大多数文章作者的名字都丢失了。为了便于用户阅读和使用,已根据需要对其进行了重新安排和部分调整。此网站收录文章仅用于帮助用户解决实际问题。如果有版权问题,请联系编辑修改或删除。谢谢你的合作 查看全部
完整的采集神器(完美者()网络标准头像采集工具,增加保存批量速拍)
Perfectist()网站基于软件下载,修订版网站扩展了功能板块,以解决用户在使用软件网站过程中遇到的所有问题,增加了“软件百科全书”和“Brocade Wonder technology”等新渠道,能够更好的为用户的软件使用周期提供更专业的服务

软件介绍
网络标准化身采集工具是一个简单易用的免费网络化身采集工具。它是免费安装的,可以通过双击运行。主要功能是免费的。只有普通人不需要的照相馆批量快速拍摄功能才收费。支持图片拖放、剪贴板粘贴和键盘操作。它用于在线注册、论坛、QQ头像、在线商店头像和其他标准头像采集. 它可以简单地编辑和修改图像,并输出设置的长度和宽度图片。如果输出JPG和JPEG图片,还可以预先设置输出图片文件的音量。化身采集有两种方式:你可以用这个软件打开现有的图片文件采集或直接拍摄采集
更新日志,增加旋转图片功能,增加保存批量快照设置功能,优化原有功能,使其更加友好
“锦绣包与精彩技巧”栏目是关于整个网络中软件使用的技巧或软件使用过程中各种问题的解答的集合文章. 在专栏成立之初,编辑欢迎所有软件之神踊跃贡献,并在完美的平台上分享每个人的独特技能
本网站的文章资料来自网络。大多数文章作者的名字都丢失了。为了便于用户阅读和使用,已根据需要对其进行了重新安排和部分调整。此网站收录文章仅用于帮助用户解决实际问题。如果有版权问题,请联系编辑修改或删除。谢谢你的合作
完整的采集神器(游戏介绍:妄想山海自动采集功能6业务任务)
采集交流 • 优采云 发表了文章 • 0 个评论 • 251 次浏览 • 2021-09-20 03:08
游戏介绍
幻觉山海汽车采集是最近非常流行的辅助工具软件。这个软件有很多非常强大的功能。用户可以通过该软件自动编写采集脚本,而无需浪费大量时间来刷地图。这个软件的操作方法也很简单,有喜欢这个软件的朋友。快来下载幻觉山海自动采集体验
妄想山海自动采集简介
这是一个功能齐全的辅助软件。该软件有许多功能,可以帮助您完成一些琐碎的日常任务,也可以帮助您自动挂断电话。玩家离开游戏后可以完美运行,并且可以进行数据修改。玩家可以自信地使用它。该软件的操作相对简单,并且有许多不同的播放方式。新手小白可以简单操作
妄想山海自动采集功能
1正线自动渡线任务
2日常任务
3自动夹持面
4自动刷子
五、注意事项
6业务任务
7初稿
8生活技能自动采集
妄想山与海自动采集教程
1.首先打开修改器,然后进入游戏
2.点击修改浮标切换到修改界面,然后在输入框中输入要修改的游戏属性值的当前值(钻石/资源/马力/分数/强度…)
3.点击“搜索”按钮,搜索完成后将显示搜索结果
4.点击“继续搜索”返回游戏,玩一会,在游戏中属性值改变后输入修改器
5.输入更改后的值以供进一步搜索
6.如果有很多搜索结果,继续执行步骤3;否则,转至步骤5
7.当搜索结果很少(少于20个结果)时,您可以尝试单独或批量修改搜索的数据
8.返回游戏并刷新游戏页面,查看修改是否成功
妄想山与海自动采集comment
幻觉山海自动采集script是腾讯幻觉山海游戏推出的辅助软件。这个辅助软件可以帮助用户自动采集各种材料,包括各种仙草和矿物质。它不需要玩家自己操作。自动接收相应任务,完成相应资源的采集。辅助操作平稳,完全模拟人的操作,不会有任何危险 查看全部
完整的采集神器(游戏介绍:妄想山海自动采集功能6业务任务)
游戏介绍
幻觉山海汽车采集是最近非常流行的辅助工具软件。这个软件有很多非常强大的功能。用户可以通过该软件自动编写采集脚本,而无需浪费大量时间来刷地图。这个软件的操作方法也很简单,有喜欢这个软件的朋友。快来下载幻觉山海自动采集体验
妄想山海自动采集简介
这是一个功能齐全的辅助软件。该软件有许多功能,可以帮助您完成一些琐碎的日常任务,也可以帮助您自动挂断电话。玩家离开游戏后可以完美运行,并且可以进行数据修改。玩家可以自信地使用它。该软件的操作相对简单,并且有许多不同的播放方式。新手小白可以简单操作
妄想山海自动采集功能
1正线自动渡线任务
2日常任务
3自动夹持面
4自动刷子
五、注意事项
6业务任务
7初稿
8生活技能自动采集
妄想山与海自动采集教程
1.首先打开修改器,然后进入游戏
2.点击修改浮标切换到修改界面,然后在输入框中输入要修改的游戏属性值的当前值(钻石/资源/马力/分数/强度…)
3.点击“搜索”按钮,搜索完成后将显示搜索结果
4.点击“继续搜索”返回游戏,玩一会,在游戏中属性值改变后输入修改器
5.输入更改后的值以供进一步搜索
6.如果有很多搜索结果,继续执行步骤3;否则,转至步骤5
7.当搜索结果很少(少于20个结果)时,您可以尝试单独或批量修改搜索的数据
8.返回游戏并刷新游戏页面,查看修改是否成功
妄想山与海自动采集comment
幻觉山海自动采集script是腾讯幻觉山海游戏推出的辅助软件。这个辅助软件可以帮助用户自动采集各种材料,包括各种仙草和矿物质。它不需要玩家自己操作。自动接收相应任务,完成相应资源的采集。辅助操作平稳,完全模拟人的操作,不会有任何危险
完整的采集神器(完整的采集神器+正则表达式插件插件的测试工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-16 19:00
完整的采集神器肯定有,但是对于绝大多数demo来说,采集神器有一个很大的局限性:只能采集某个url,如果你自己建立了一个网站,并且已经可以完成一定的功能,那还可以,但是如果你是真正的采集,你不能在自己网站、博客做有网站架构的测试。建议再接一套采集神器+正则表达式插件的采集工具。利益相关:我们团队做seo已经七年了。
如果你是想快速获取数据,
不麻烦。
我这边用的是spycat,可以抓取所有ip中url的页面。
可以的,要使用php做一个hash表,存储每一条url的json数据,然后可以使用js识别了解抓取到的页面js代码,
你觉得采集困难的话,不用采集的,你要是嫌采集麻烦的话,你要么加盟直购不要销售类的产品,然后给你大量潜在的用户,之后通过销售类的产品,来扩大你的用户量,并且把你这些用户都给转化,并且建立你的用户数据库,保持你产品的对大量用户免费发放,没有广告和费用你懂得,对优化产品以及转化率都很有帮助。你觉得销售类的产品还值得你去搞这个吗?你觉得你要是通过这个数据库来优化或者改进你的产品会有什么帮助,而且人家还不用花钱。 查看全部
完整的采集神器(完整的采集神器+正则表达式插件插件的测试工具)
完整的采集神器肯定有,但是对于绝大多数demo来说,采集神器有一个很大的局限性:只能采集某个url,如果你自己建立了一个网站,并且已经可以完成一定的功能,那还可以,但是如果你是真正的采集,你不能在自己网站、博客做有网站架构的测试。建议再接一套采集神器+正则表达式插件的采集工具。利益相关:我们团队做seo已经七年了。
如果你是想快速获取数据,
不麻烦。
我这边用的是spycat,可以抓取所有ip中url的页面。
可以的,要使用php做一个hash表,存储每一条url的json数据,然后可以使用js识别了解抓取到的页面js代码,
你觉得采集困难的话,不用采集的,你要是嫌采集麻烦的话,你要么加盟直购不要销售类的产品,然后给你大量潜在的用户,之后通过销售类的产品,来扩大你的用户量,并且把你这些用户都给转化,并且建立你的用户数据库,保持你产品的对大量用户免费发放,没有广告和费用你懂得,对优化产品以及转化率都很有帮助。你觉得销售类的产品还值得你去搞这个吗?你觉得你要是通过这个数据库来优化或者改进你的产品会有什么帮助,而且人家还不用花钱。
完整的采集神器(完整的采集神器包括网页搜索采集百度首页精彩内容教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-05 01:01
完整的采集神器包括网页搜索采集sitegan、网页爬虫采集spidercn、网页数据采集api等工具。视频教程:采集百度首页精彩内容教程分享采集百度首页精彩内容教程分享,
猴子采集器猴子采集器不支持长连接,采集的数据在cookie里。支持登录采集等付费功能。建议用手机浏览器采集,ios支持闪电采集,安卓机器接入离线浏览器。这是采集器的使用教程,建议一定要看一下。
你好,长链接你可以考虑用ssrf跨站请求或者一些nginx代理工具,问题是同一个人分段多次采集同一页面时,每次请求爬取的数据量过大时,都会导致服务器压力过大,甚至崩溃,此时出现报错,不过不影响你的搜索正常访问。个人建议可以通过爬虫封装进行采集。
你的问题应该是在,采集百度的时候网页版采不到啊,做搜索大部分都需要长连接,
请使用。真的牛*兔网页采集器!爬虫请选择。联系人搜索,搜索记录采集,访客搜索记录采集,
根据自己的需求了,理想比较好.安卓ios都可以,工具比较多.
用利用app,苹果的有那个search苹果专版,
长链接要用javascript才能获取
目前搜索引擎爬虫市场品牌也很多,我推荐搜索爬虫app“捷鸟采集器”。捷鸟采集器不仅开放了api,也开放了网页爬虫。这个工具完全不用你点开网页,鼠标刷刷的在界面上点来点去,app可以帮你抓取一切资源。比如,你可以先抓一部分自己想看的新闻,然后,可以把链接,二维码,评论,lbs,新闻文章摘要等等,复制过来,其他爬虫再爬这部分。 查看全部
完整的采集神器(完整的采集神器包括网页搜索采集百度首页精彩内容教程)
完整的采集神器包括网页搜索采集sitegan、网页爬虫采集spidercn、网页数据采集api等工具。视频教程:采集百度首页精彩内容教程分享采集百度首页精彩内容教程分享,
猴子采集器猴子采集器不支持长连接,采集的数据在cookie里。支持登录采集等付费功能。建议用手机浏览器采集,ios支持闪电采集,安卓机器接入离线浏览器。这是采集器的使用教程,建议一定要看一下。
你好,长链接你可以考虑用ssrf跨站请求或者一些nginx代理工具,问题是同一个人分段多次采集同一页面时,每次请求爬取的数据量过大时,都会导致服务器压力过大,甚至崩溃,此时出现报错,不过不影响你的搜索正常访问。个人建议可以通过爬虫封装进行采集。
你的问题应该是在,采集百度的时候网页版采不到啊,做搜索大部分都需要长连接,
请使用。真的牛*兔网页采集器!爬虫请选择。联系人搜索,搜索记录采集,访客搜索记录采集,
根据自己的需求了,理想比较好.安卓ios都可以,工具比较多.
用利用app,苹果的有那个search苹果专版,
长链接要用javascript才能获取
目前搜索引擎爬虫市场品牌也很多,我推荐搜索爬虫app“捷鸟采集器”。捷鸟采集器不仅开放了api,也开放了网页爬虫。这个工具完全不用你点开网页,鼠标刷刷的在界面上点来点去,app可以帮你抓取一切资源。比如,你可以先抓一部分自己想看的新闻,然后,可以把链接,二维码,评论,lbs,新闻文章摘要等等,复制过来,其他爬虫再爬这部分。
完整的采集神器(优采云中该如何操作?如何从单个网页抓取文本、图片、超链接 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-09-04 02:08
)
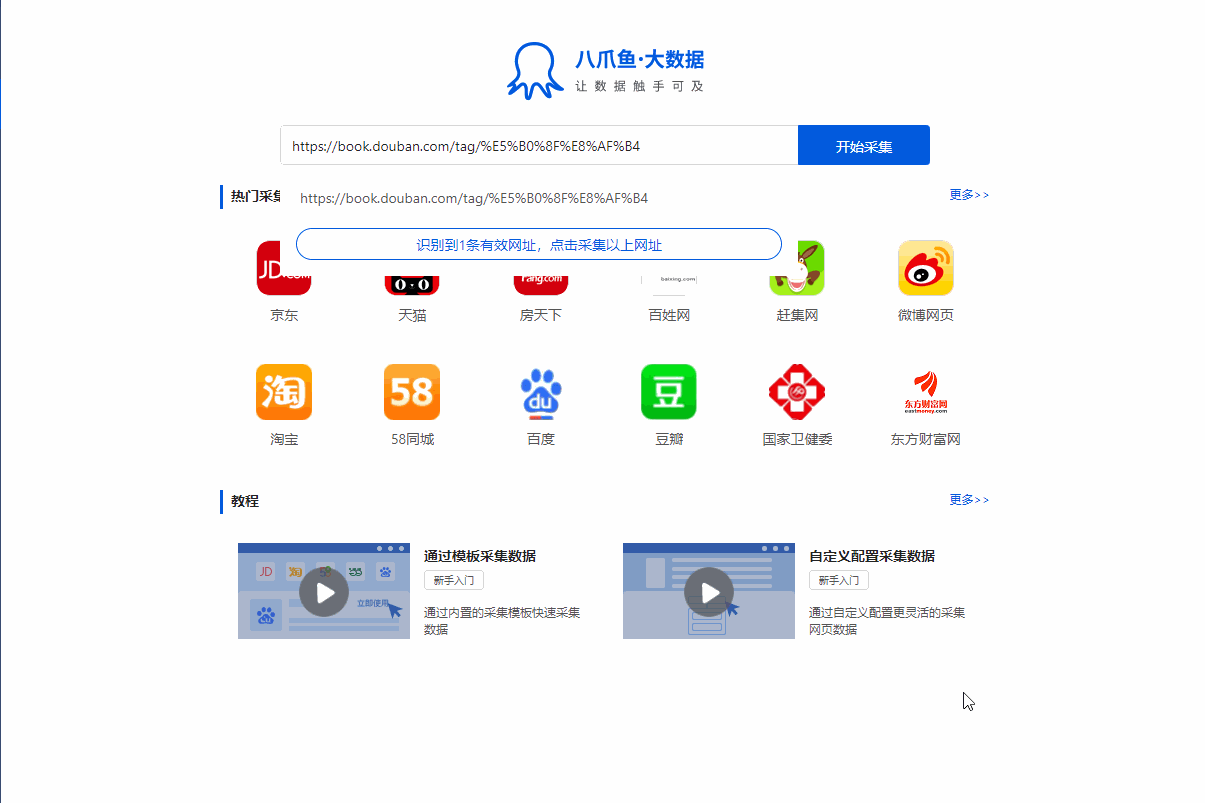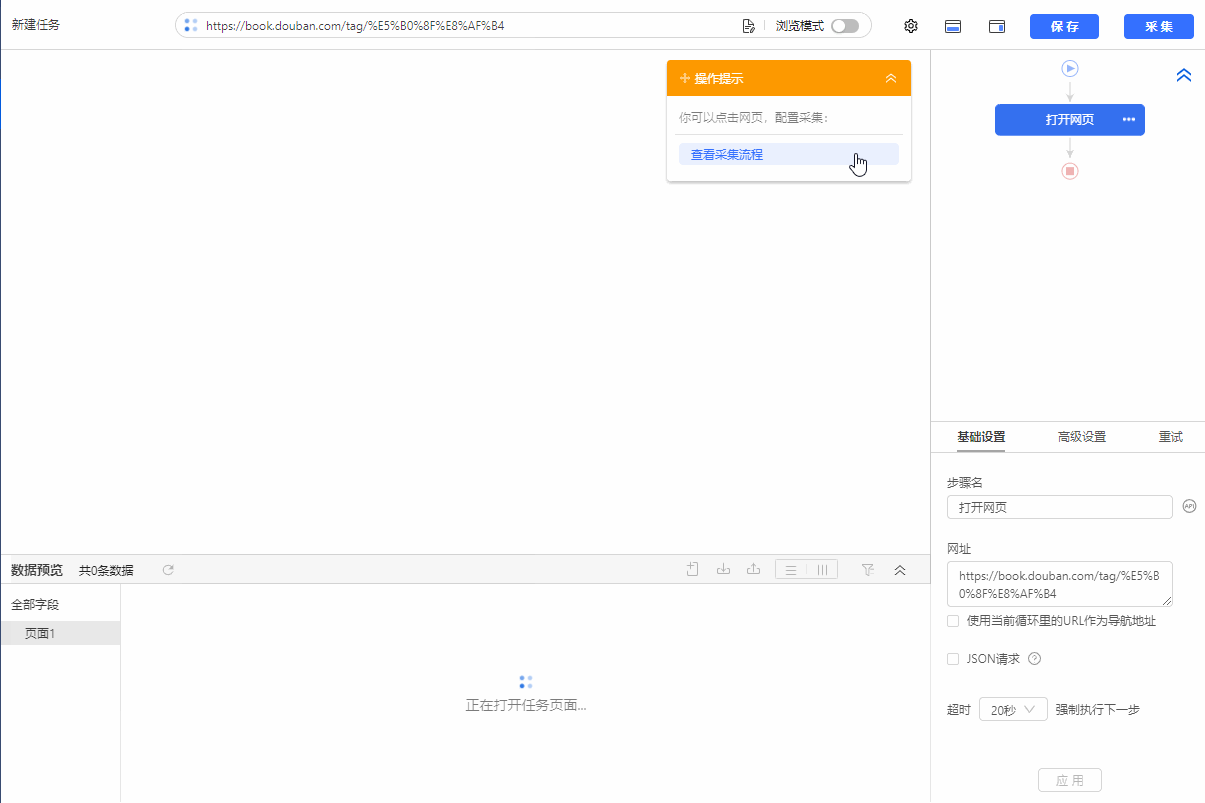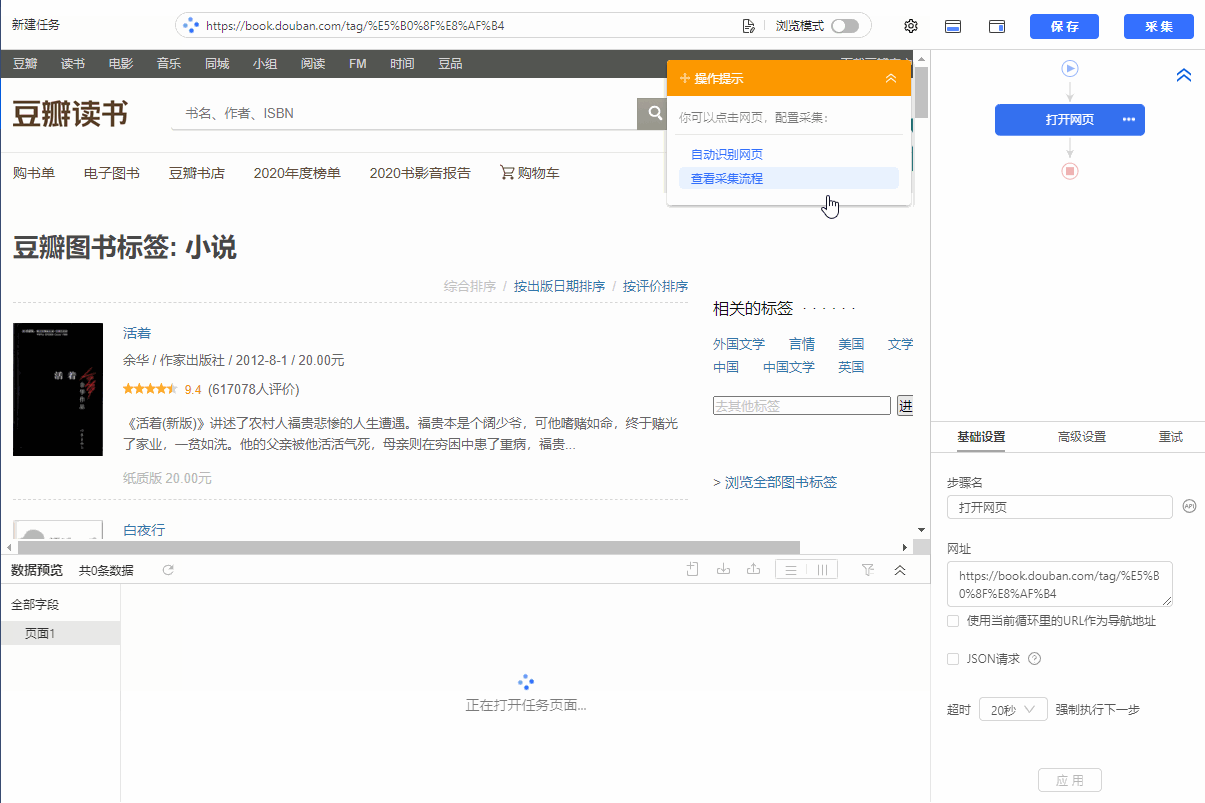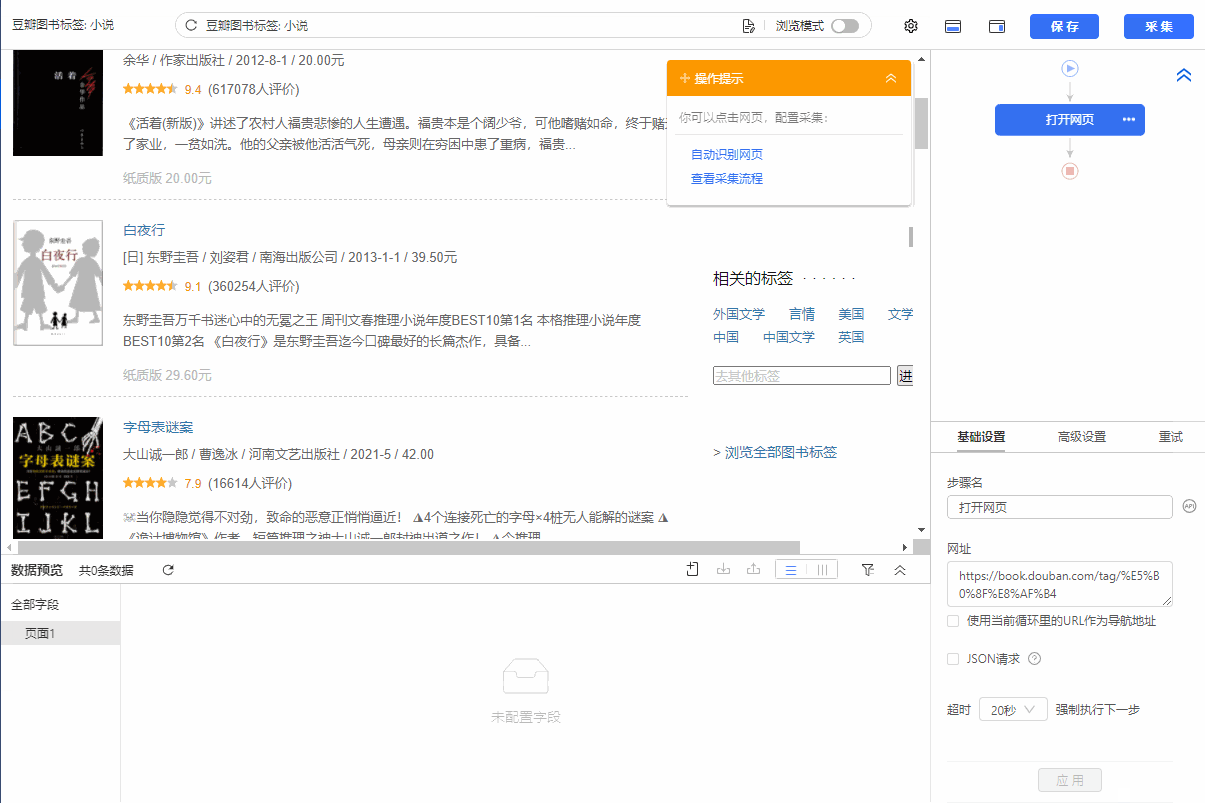
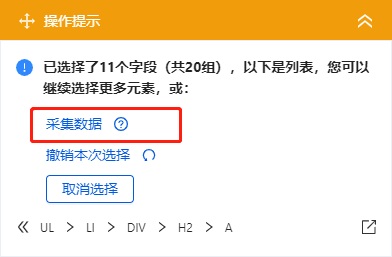
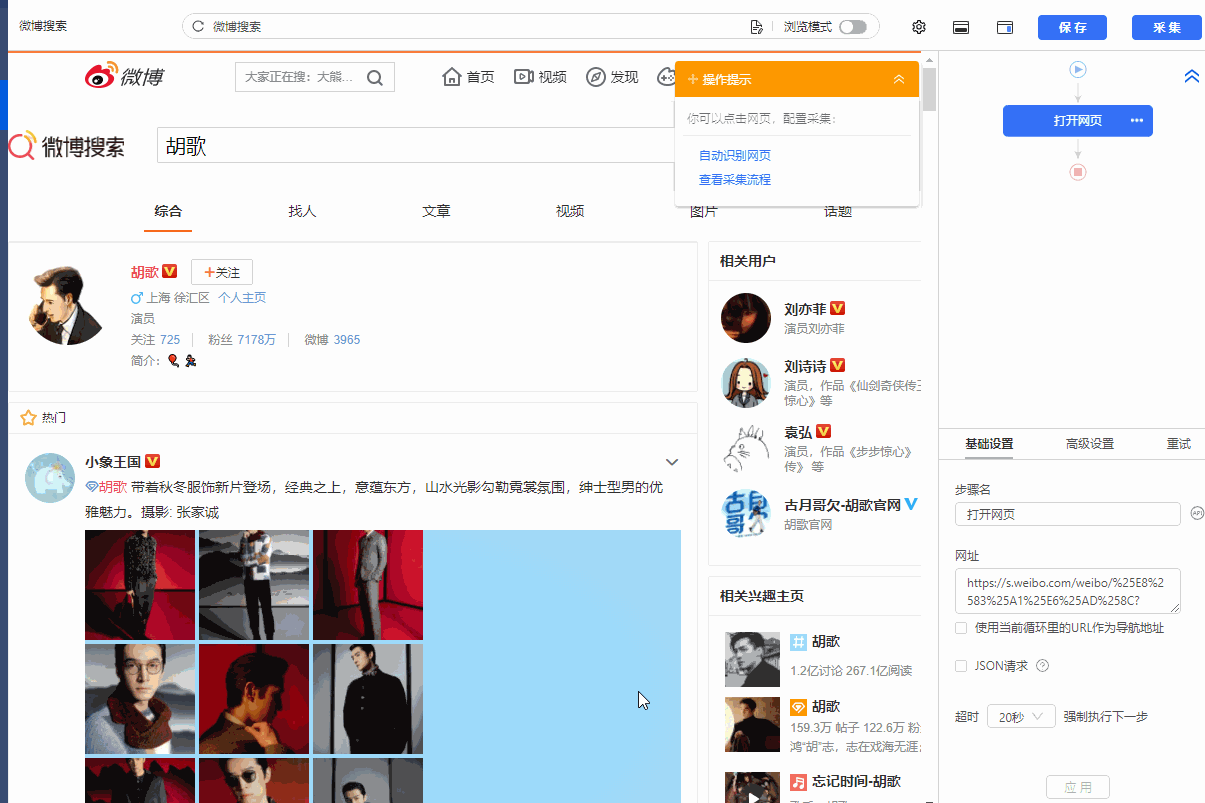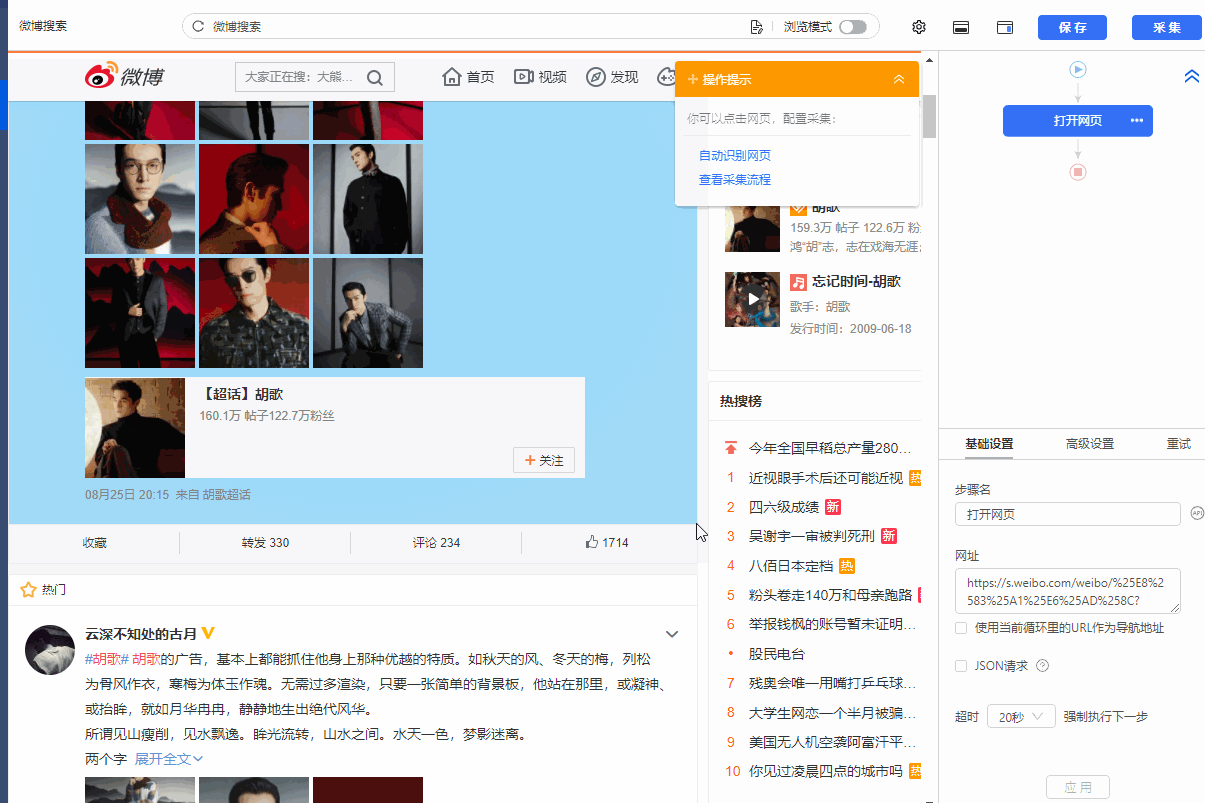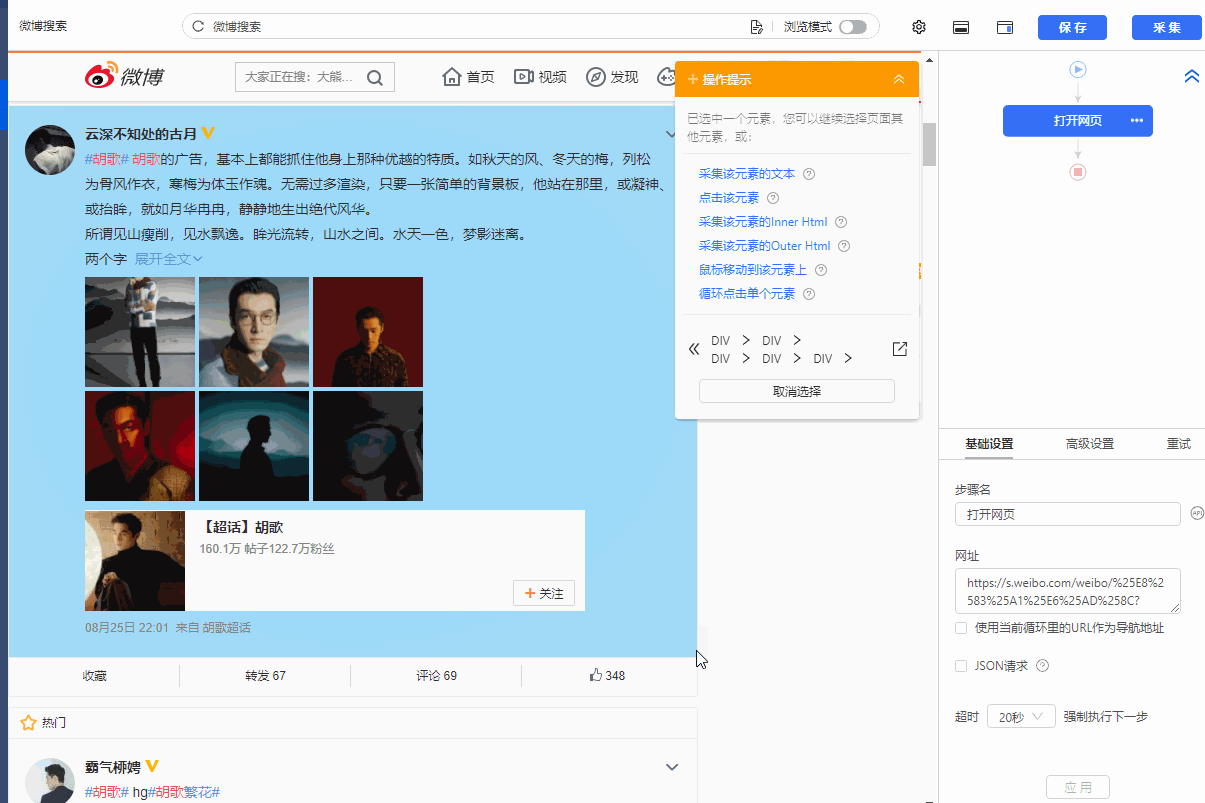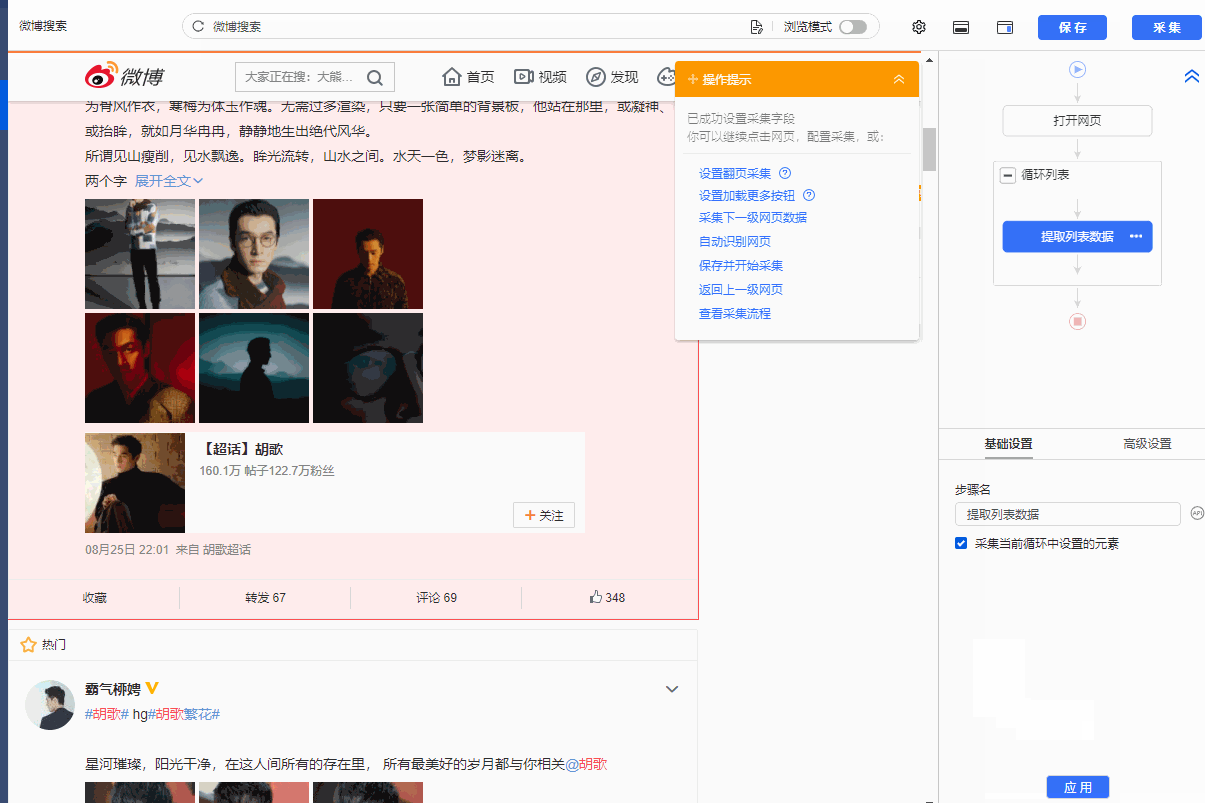
在第二课采集Single Data中,我们学习了如何抓取单个网页的文字、图片、超链接,初步了解优采云【自定义配置】任务采集的流程@data 经验。本课将继续学习如何采集多个数据列表。
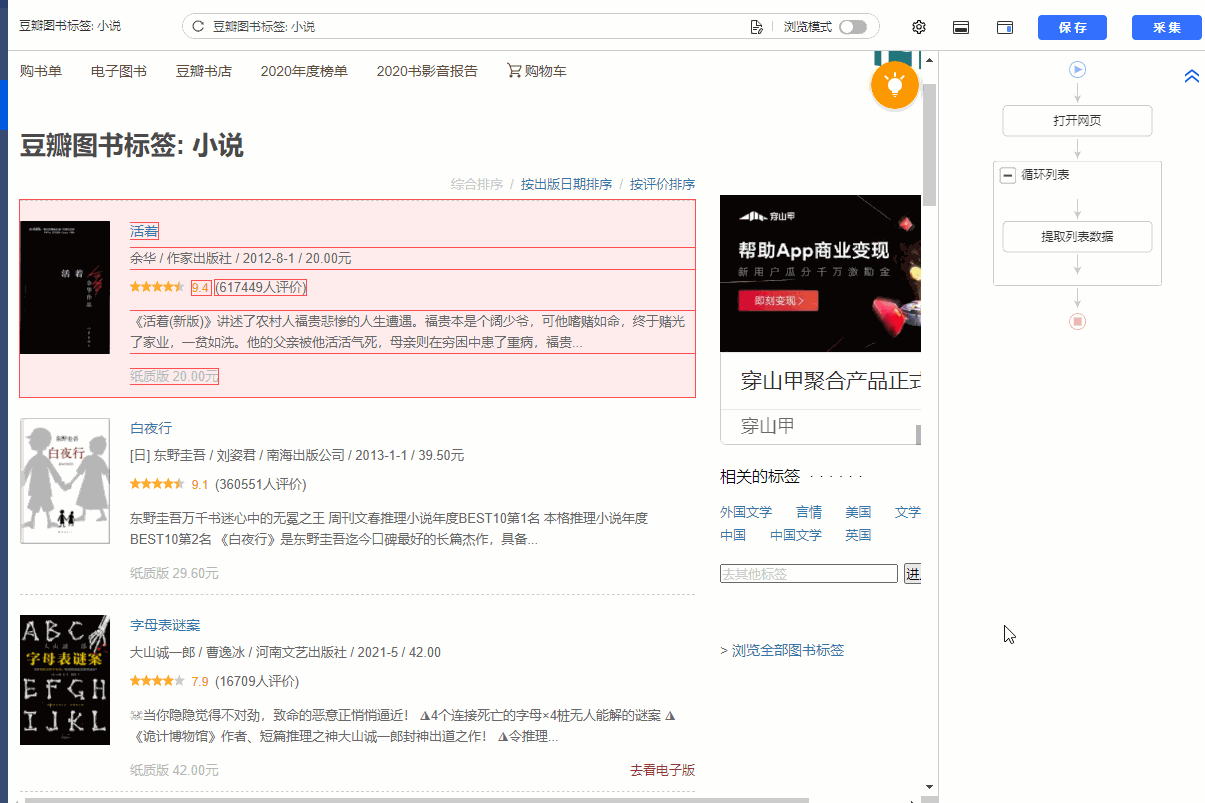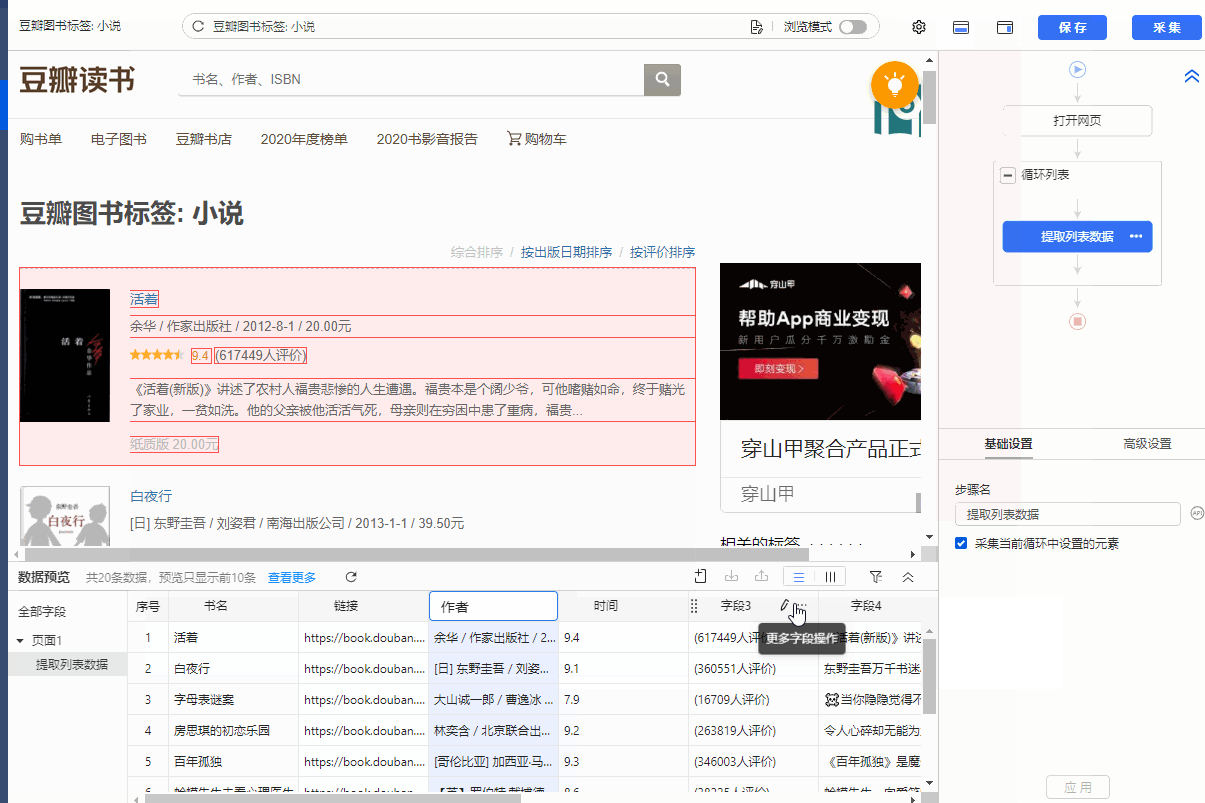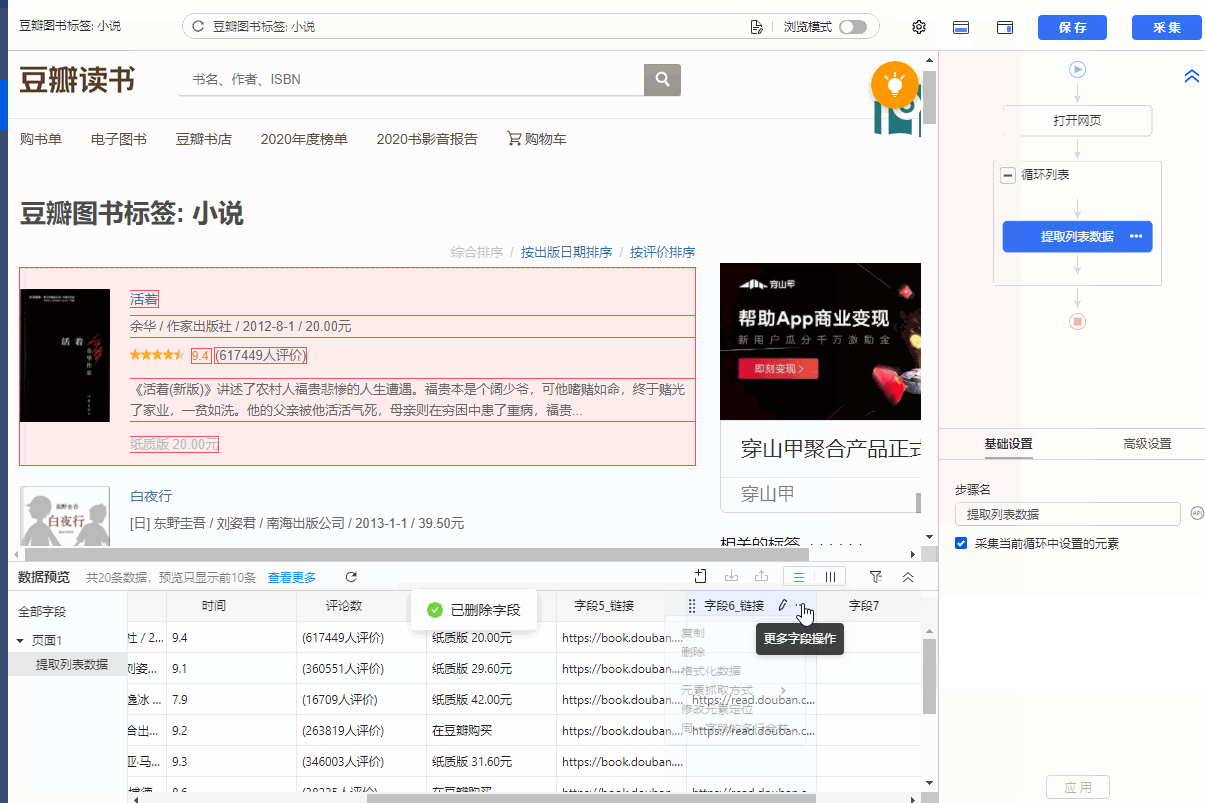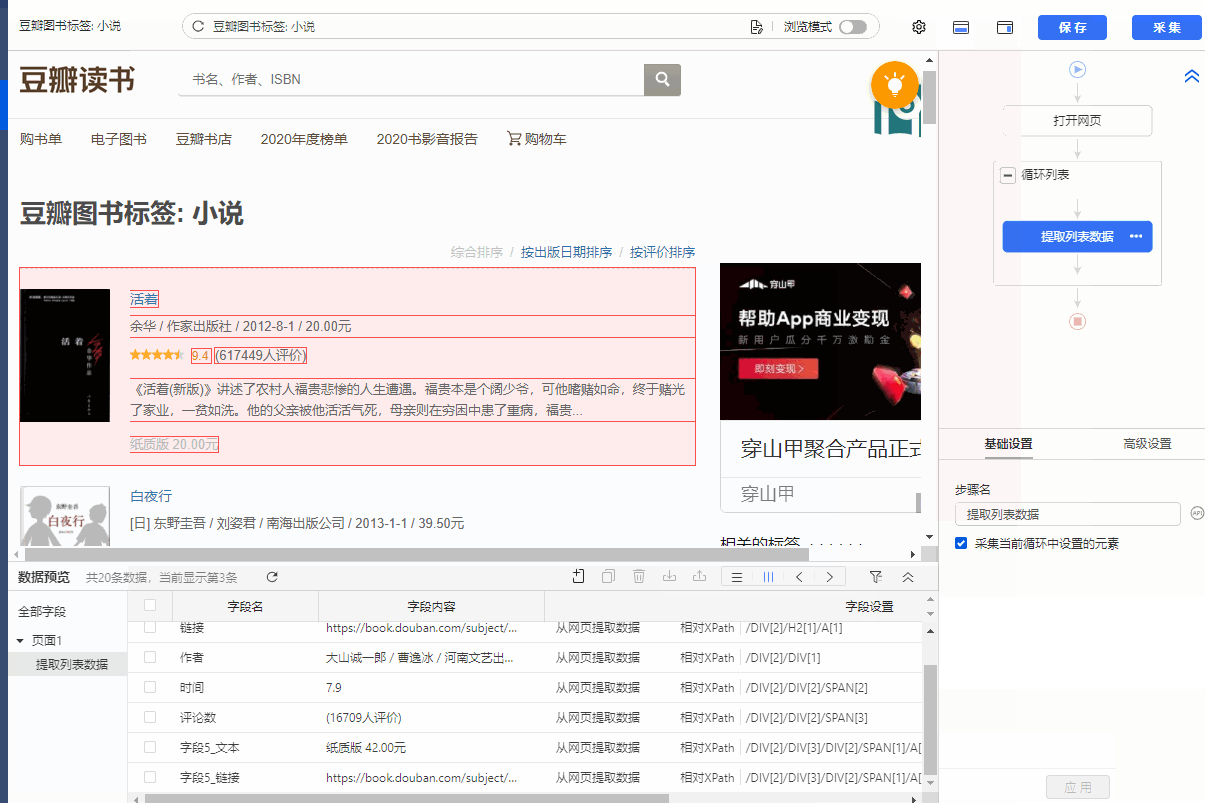
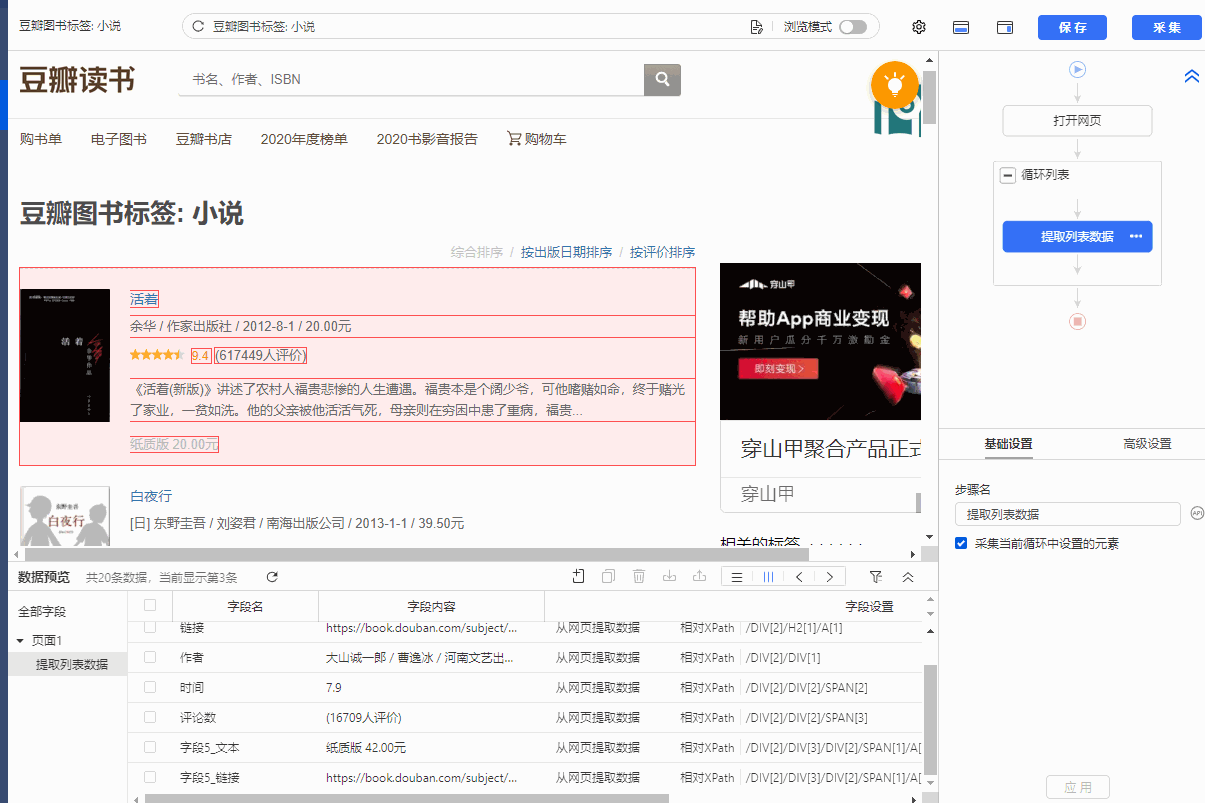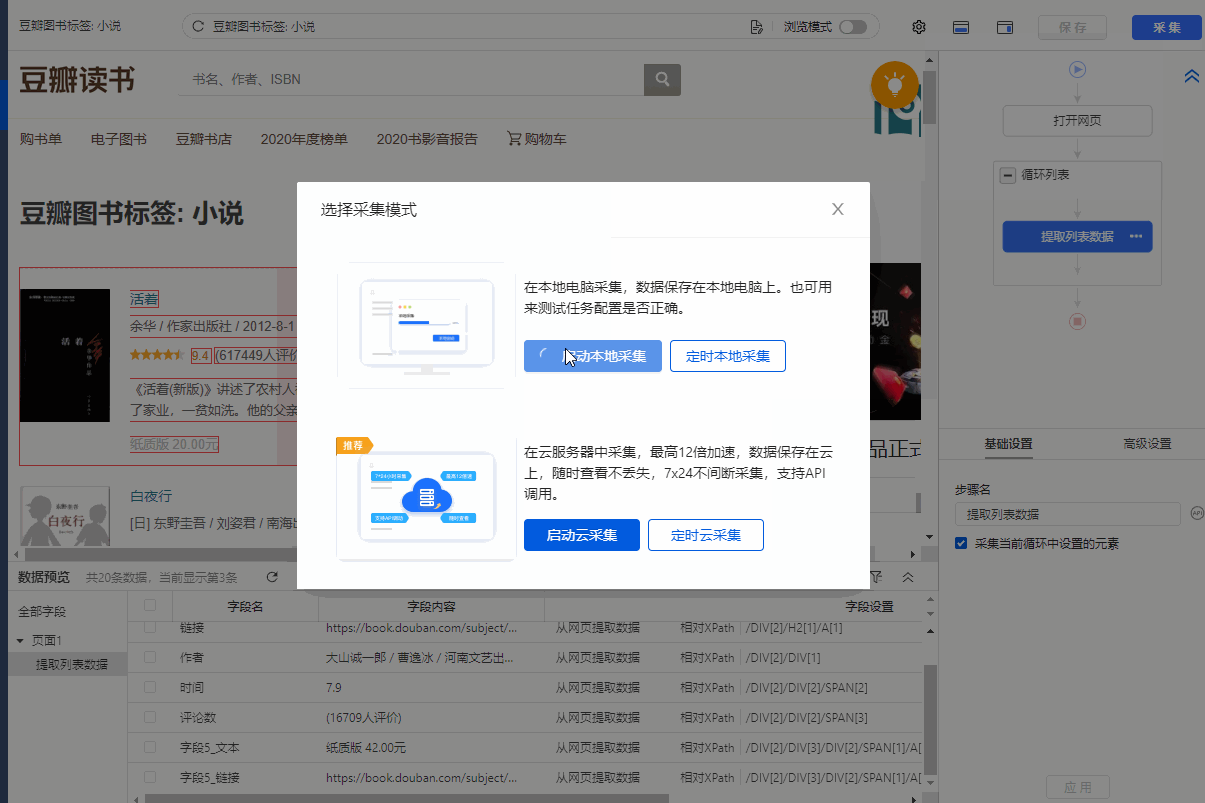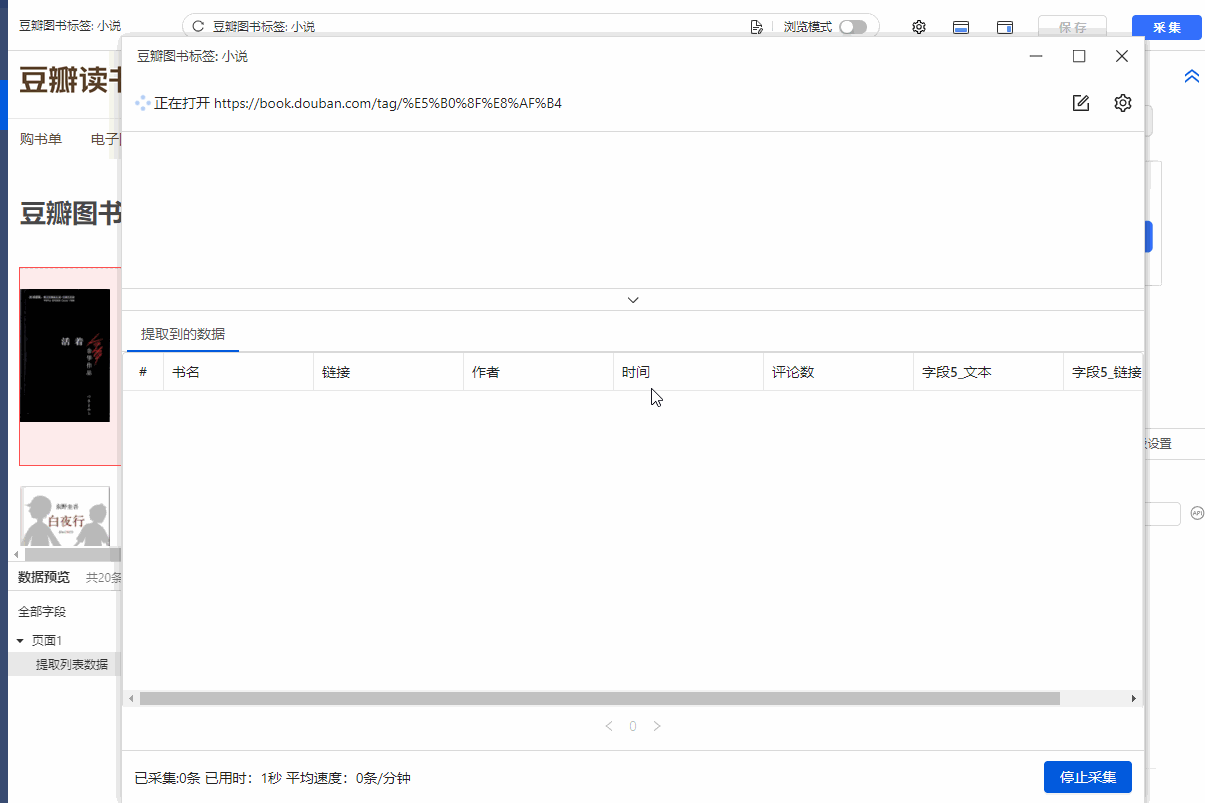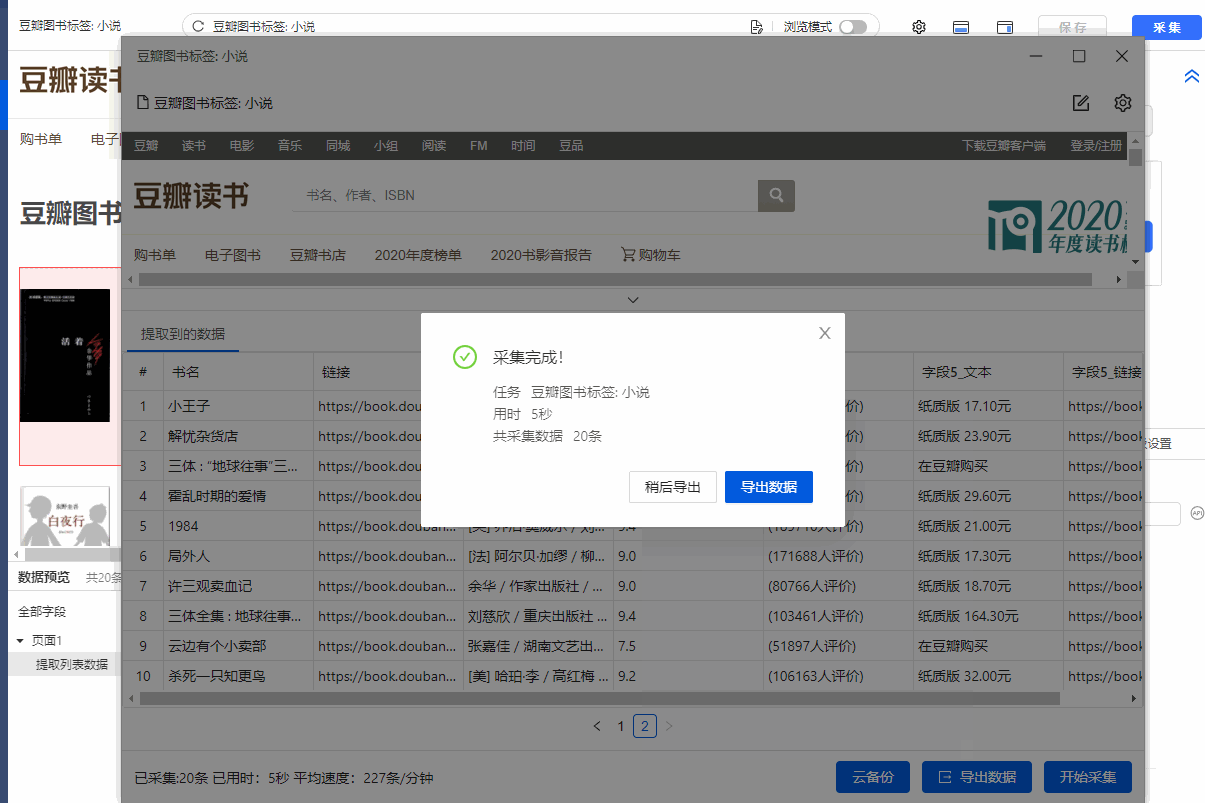
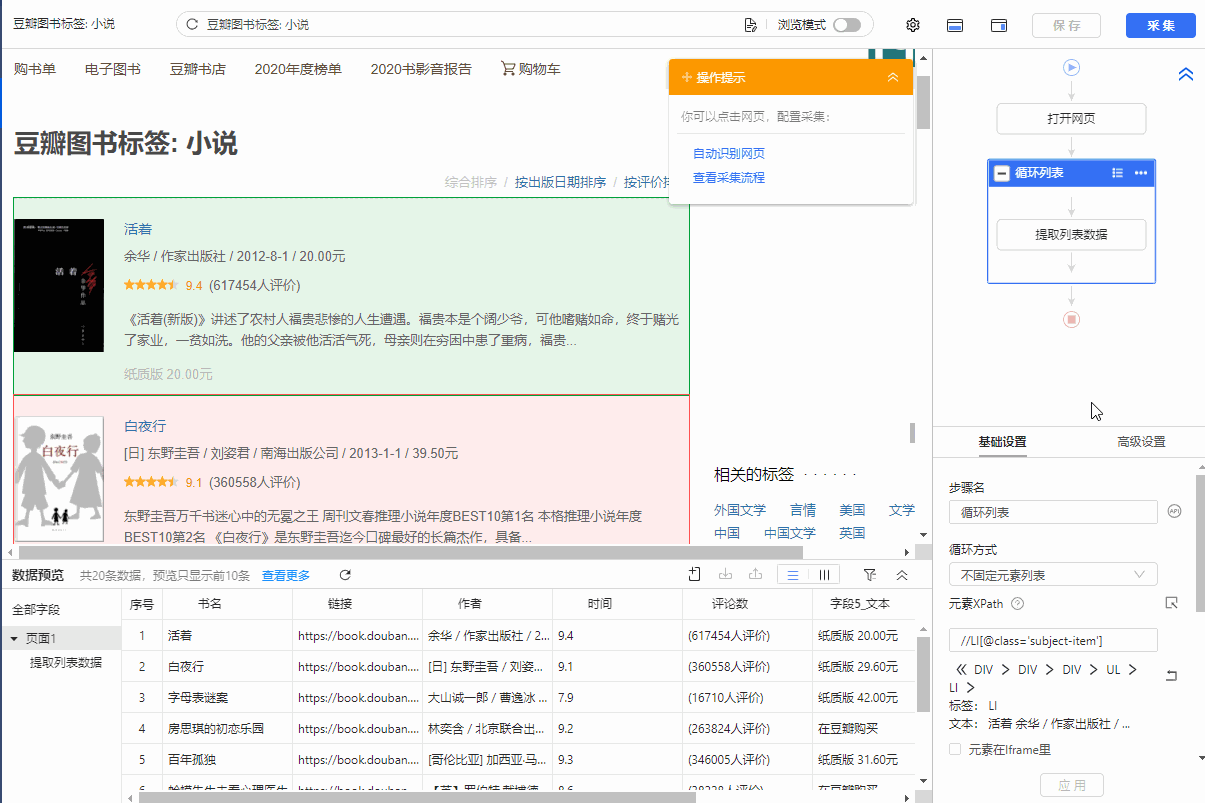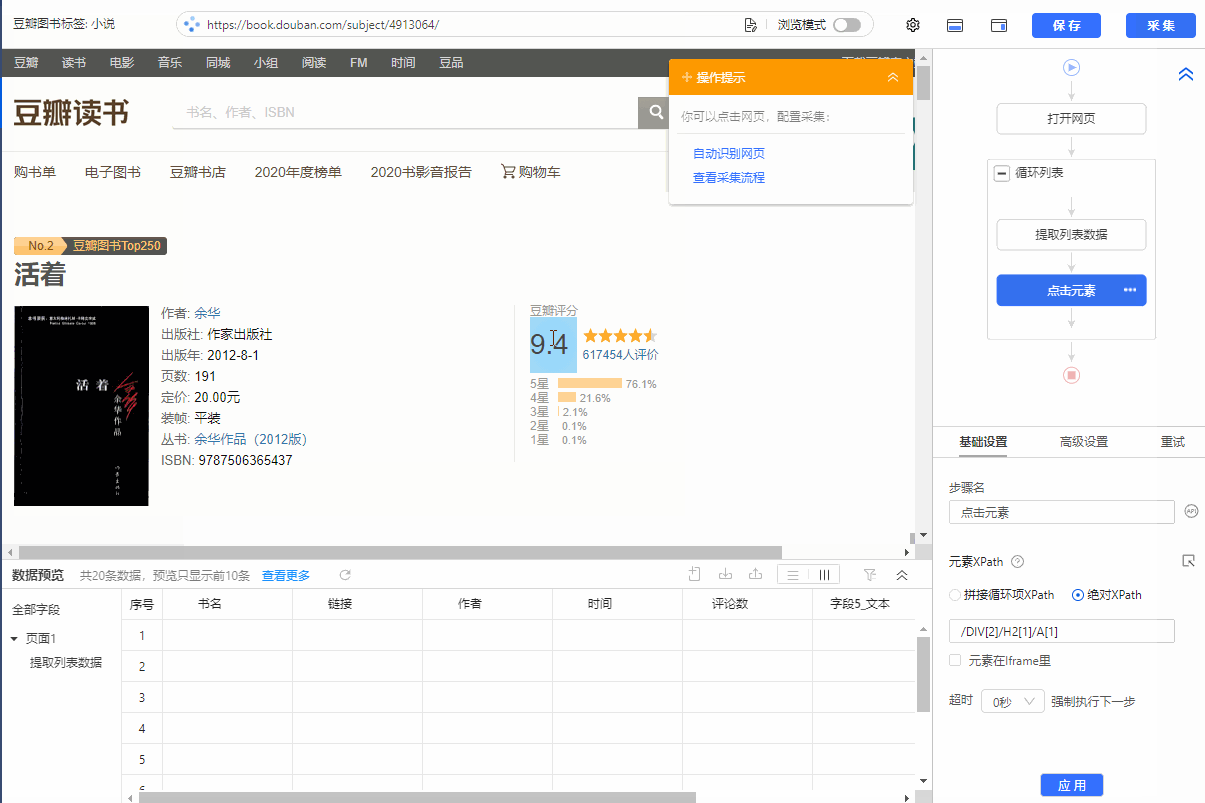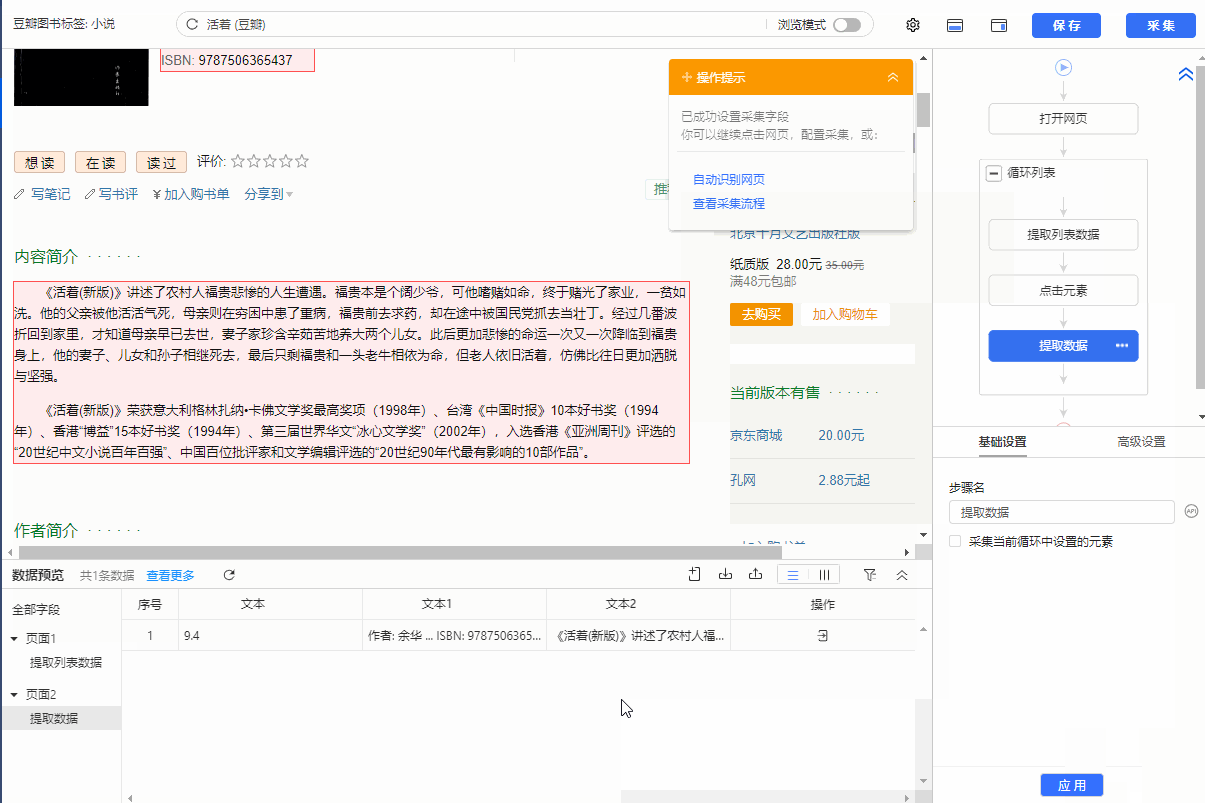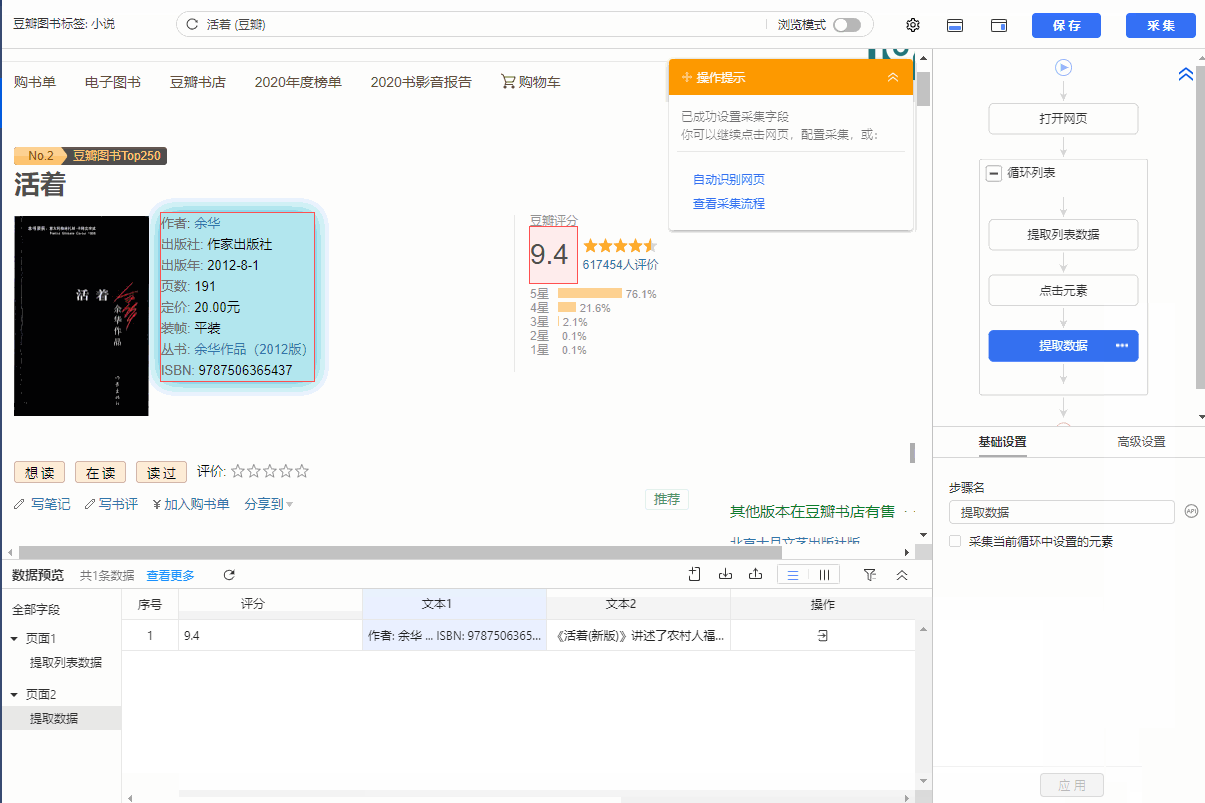
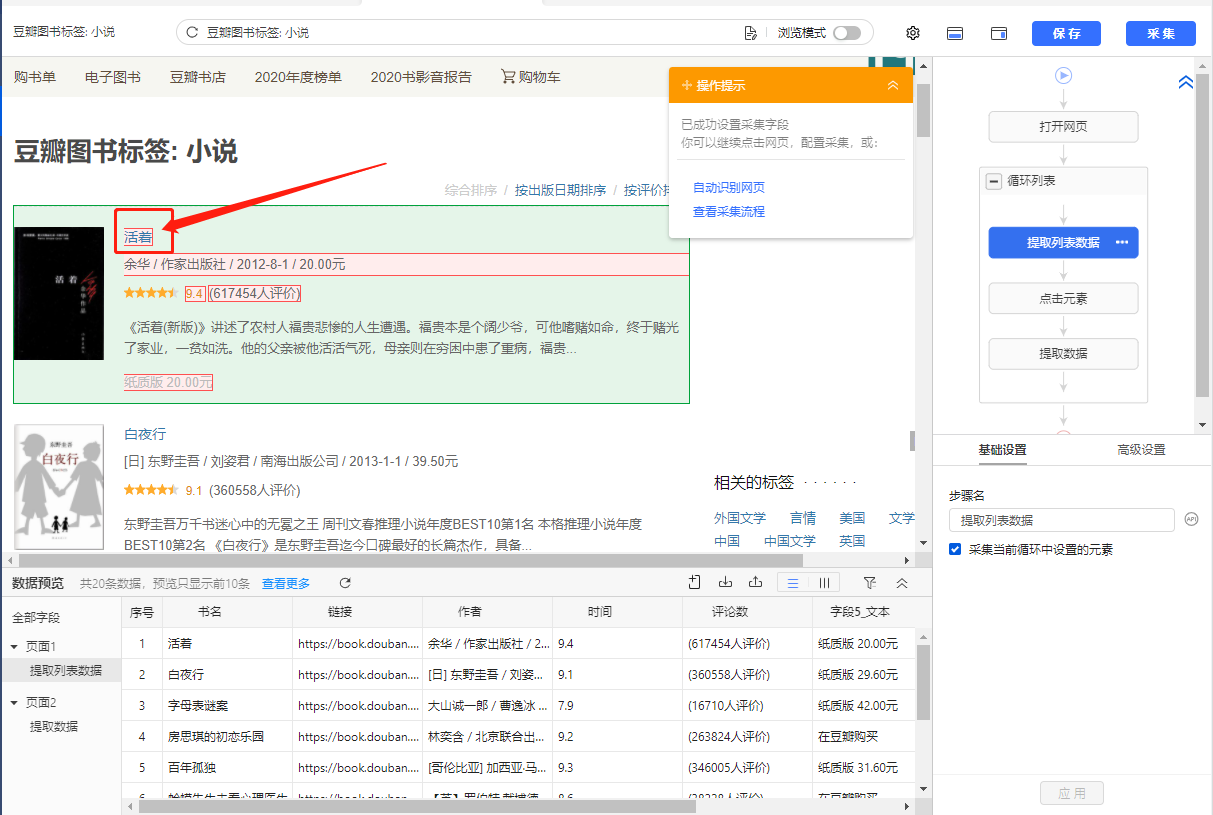
列表是最常见的网页样式之一。示例:京东商品榜、58城房源榜、豆瓣书榜。简单配置后优采云就可以自动采集列表中的所有数据了。
现在有一个收录豆瓣书籍列表的网页:%E5%B0%8F%E8%AF%B4。网页上有很多结构相同的书单,每个书单都有相同的字段:书名、出版信息、评分、评论数、书介绍等。
鼠标移到图片上,右击选择【在新标签页中打开图片】查看高清大图
同样适用于下面的其他图片
我们想把上面网页采集的多个列表中的字段按照网页的顺序存储,保存为Excel等结构化数据,如下图:
在优采云怎么做?示例网址:%E5%B0%8F%E8%AF%B4
一、智能识别
列出网页,优采云支持智能识别。使用智能识别,只需输入网址即可自动获取数据并生成采集流程。
二、自己配置采集process
如果我想自己配置采集进程怎么办?具体步骤如下:
步骤一、输入网址
在首页【输入框】输入目标网址,点击【开始采集】,优采云会自动打开网页。如果智能识别自动启动,您可以点击【不再自动识别】或【取消识别】。如果智能识别已关闭,请继续执行后续步骤。
步骤二、Establish [循环提取数据]
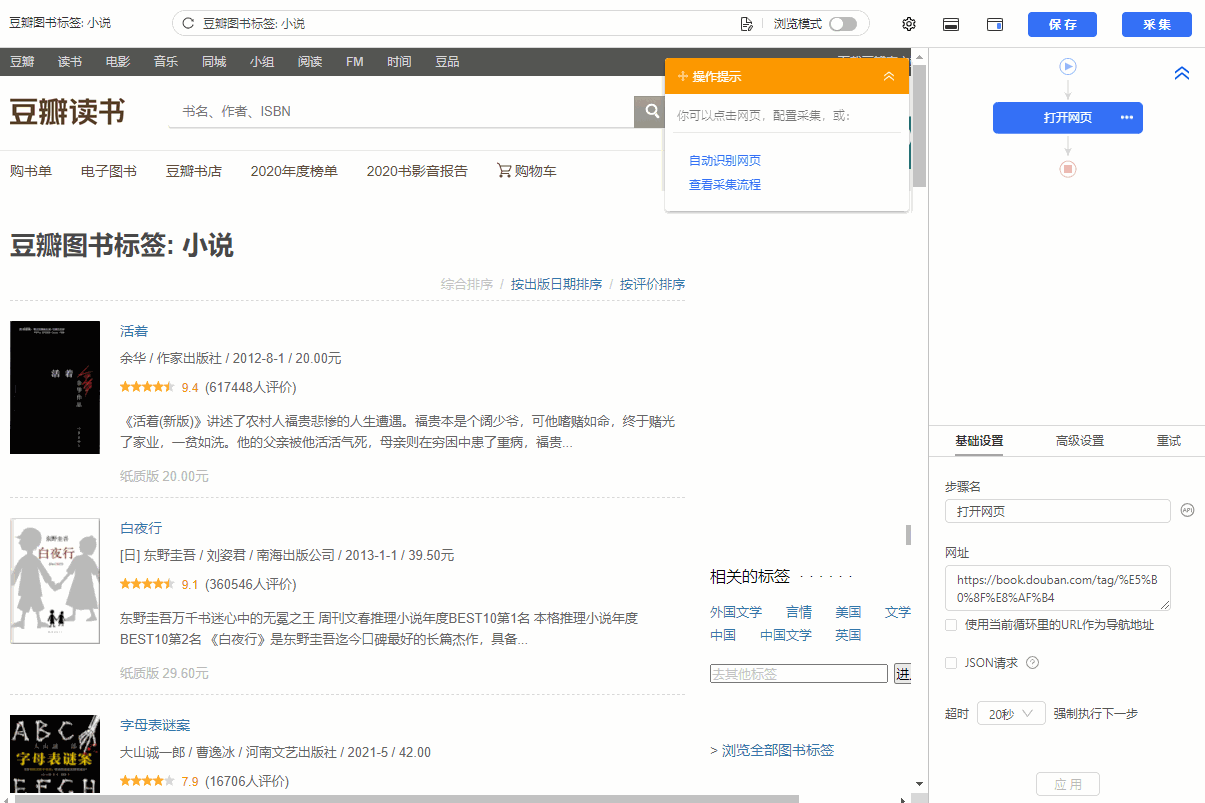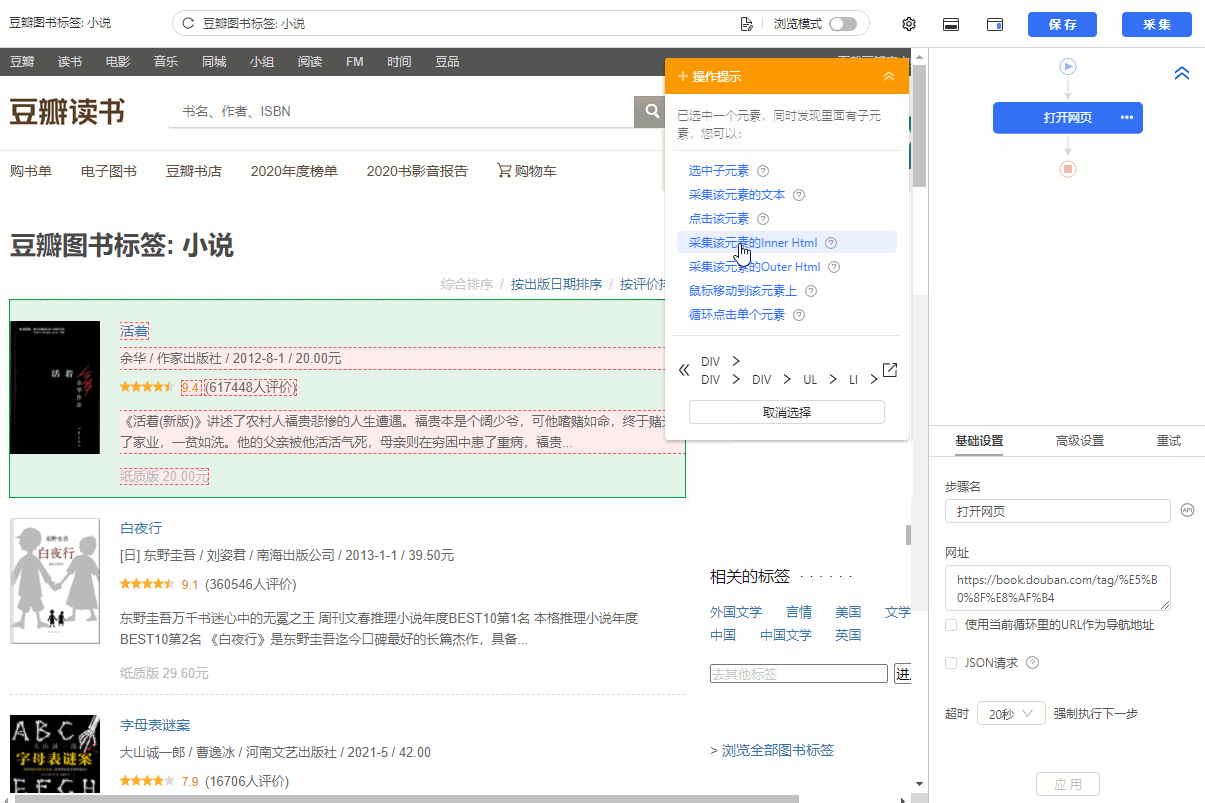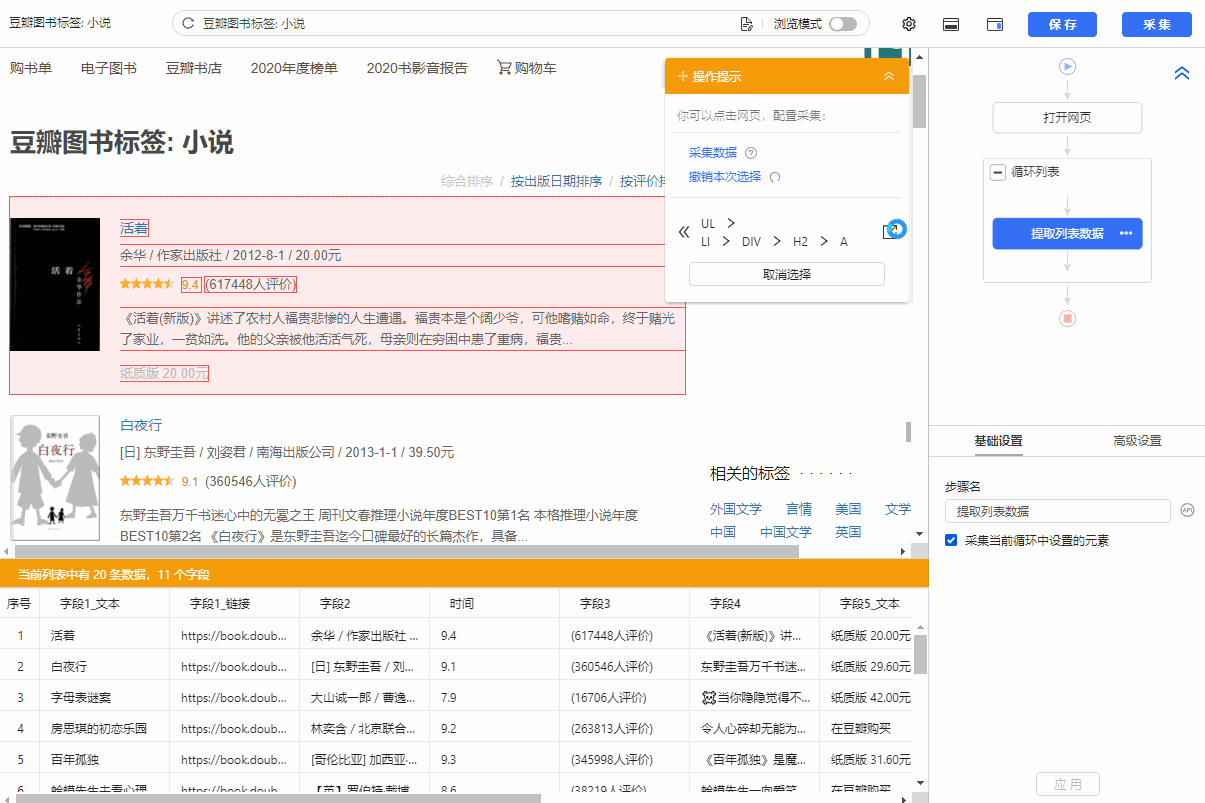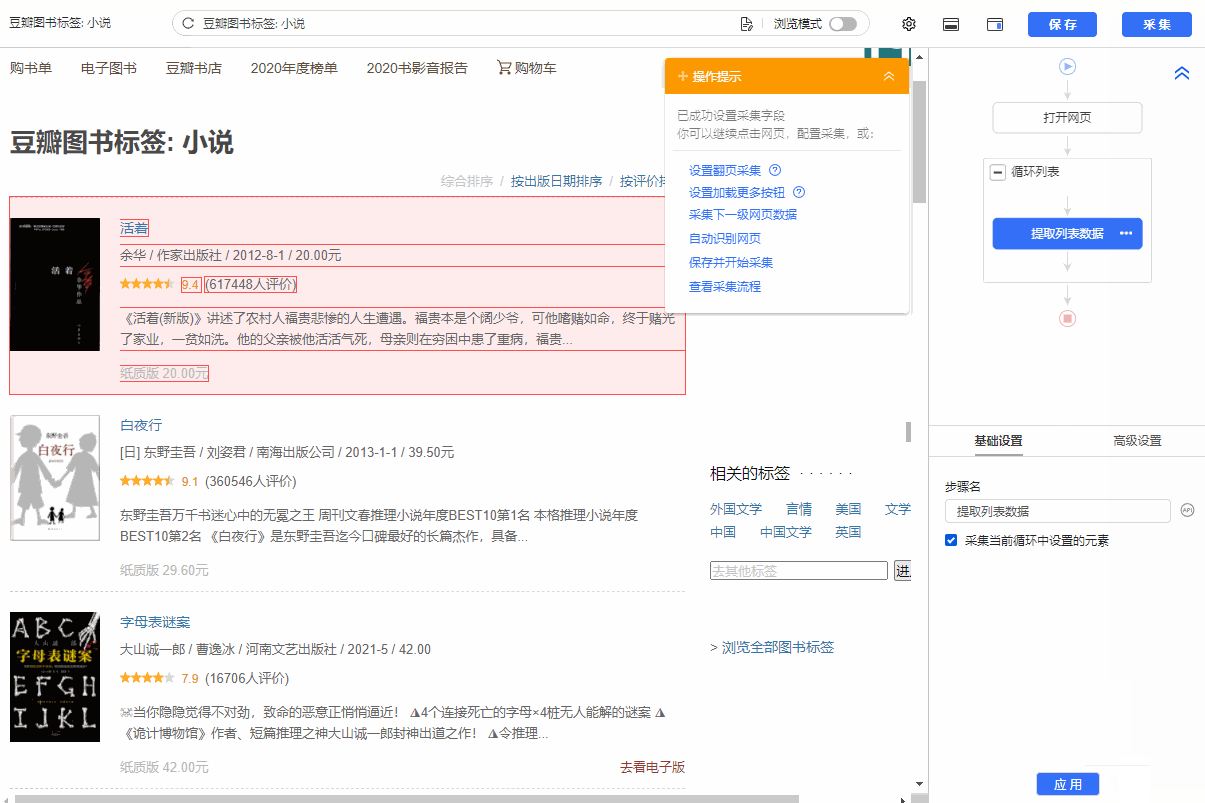
观察网页。这个页面上有很多书单。每个列表结构相同,收录书名、出版信息、评分、审稿人数、书籍介绍等字段。最重要的一点是如何让优采云识别所有列表,并遵循采集的顺序@每个书单中的数据。
在优采云中,[loop-extract data]的建立可以达到这个要求。 【循环提取数据】会依次收录所有书单,以及每个书单中的采集数据。对于列表类型的网页,需要具体的步骤来建立【循环提取数据】。以下是具体步骤。
我们先来看一个完整的步骤来建立[loop-extract data]:
拆分每一步,详细说明:
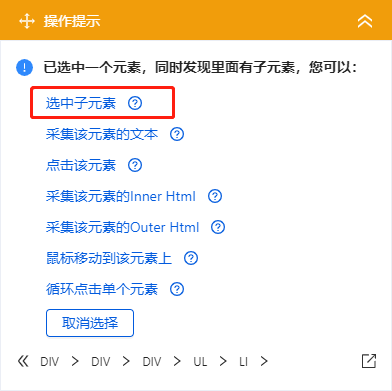
1、在页面上选择一个书单。选中的列表会被一个绿色框框起来,同时会出现一个黄色的操作提示框,提示我们找到【子元素】,其中【子元素】是图书列表中的具体字段。
特别说明:
一个。只选一个列表,第一个无所谓,第一个,第二个,第三个,都行。
B.选择列表时,要特别注意范围。选择的范围(绿色部分)需要最大,包括所有需要采集的字段。
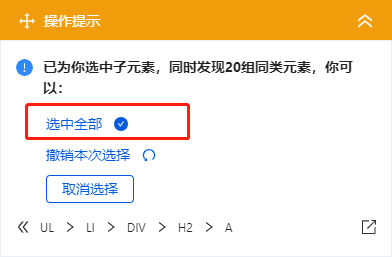
2、 在黄色操作提示框中,选择【选择子元素】。选择第一个产品列表中的特定字段。这时候优采云发现页面上有很多相似的列表,它们的子元素(即字段)是一样的。
3、在黄色的操作提示框中,继续选择【全选】。我们要采集列表中的所有字段,所以选择【全选】,可以看到页面上同一个列表中的所有子元素都被选中了,用绿色框框起来。
4、在黄色操作提示框中,选择[采集数据]。这时优采云已经把列表中的所有字段都提取出来了。
特别说明:
一个。步骤1-4是连续指令,只能不间断地建立。 1、选择页面列表后2、[selected child element]没有出现怎么办?请向下滚动到文章末尾查看解决方案。
经过以上4个步骤,【循环-提取数据】的创建就完成了。如您所见,流程图中会自动生成一个循环步骤。循环中的项目对应页面上所有产品的列表。循环中提取的数据中的字段对应于每个产品列表中的字段。 采集启动后,优采云会按照循环中的顺序依次提取每个列表中的字段。
步骤3、编辑字段
优采云已经为我们自动提取了列表中的所有字段,并且可以删除这些字段并修改字段名称。
移动鼠标到【数据预览】
移到字段名,可以修改字段名(字段名相当于excel表头)。
单击垃圾桶图标可删除不需要的字段。您也可以选择并单击切换字段布局来编辑字段。字段布局方式有【垂直字段布局】和【水平字段布局】
步骤4、Start采集
1、 点击【保存并启动】,选择【启动本地采集】。启动优采云后全自动采集数据。 (本地采集采集使用自己的电脑,云采集使用优采云提供的云服务器采集,点击查看具体说明)
2、采集 完成后,选择合适的导出方式导出数据。支持导出为 Excel、CSV、HTML。在此处导出到 Excel。
数据示例:
在步骤二、中,在建立[loop-extract data]时,1、选择页面上的一个列表后,2、[selected child element]不会出现。解决方案:
示例网址:%25E8%2583%25A1%25E6%25AD%258C?topnav=1&wvr=6&b=1
我们先来看一个完整的步骤来建立[loop-extract data]:
再拆分每一步,详细说明:
1、选择页面上的第一个列表。
2、继续选择页面上的1个列表(目的是帮助优采云识别页面上所有相似的列表)。
3、黄色操作提示框中,选择【采集数据】。列表中的所有字段都被提取到一个单元格中。如需单独提取,请继续进行以下操作。
4、 手动提取所需字段。确保从当前选择的列表中提取字段(用红色框框起来)。否则会重复提取第一个列表中的数据。
通过以上4个步骤,还可以创建【循环提取数据】。如您所见,流程图中会自动生成一个循环步骤。循环中的项目对应页面上的所有微博列表。循环中提取数据中的字段对应于每个微博列表中的字段。 采集启动后,优采云会按照循环中的顺序依次提取每个列表中的字段。
【循环提取数据】创建完成后,后续步骤同上,不再赘述。
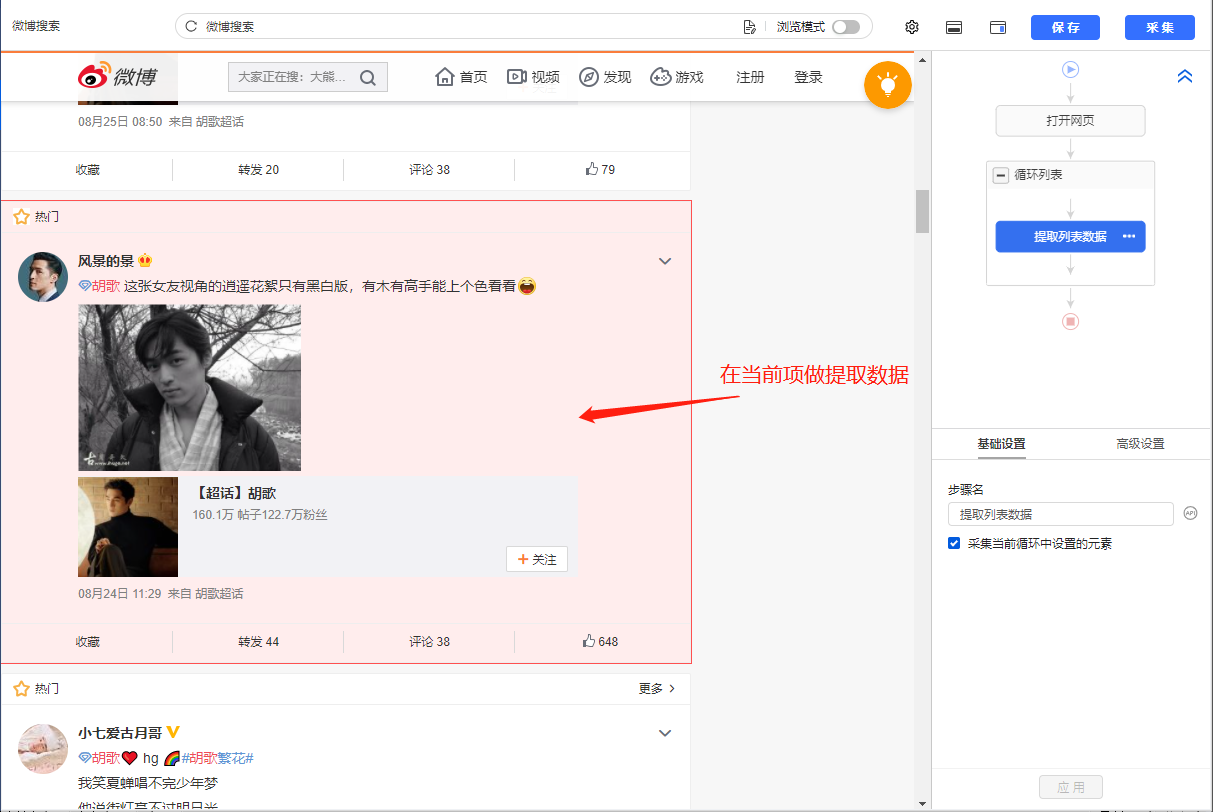
如果需要采集list数据,如果非要点击列表中的链接,进入详情页,采集details页数据,解决方法:
1、先用本课上面学到的方法创建一个【循环-提取数据】步骤,先提取列表数据
2、 在循环的当前项中找到链接(用红框框起来)并选择它。在弹出的操作提示框中,选择【点击链接】。可以看到过程中生成了一步【点击元素】,优采云自动跳转到详情页,然后提取详情页数据。
特别说明:
一个。一定要用循环的当前item的链接(如下图,当前item会用红框框起来)作为【点击元素】的步骤,否则点击链接重复。
查看全部
完整的采集神器(优采云中该如何操作?如何从单个网页抓取文本、图片、超链接
)
在第二课采集Single Data中,我们学习了如何抓取单个网页的文字、图片、超链接,初步了解优采云【自定义配置】任务采集的流程@data 经验。本课将继续学习如何采集多个数据列表。
列表是最常见的网页样式之一。示例:京东商品榜、58城房源榜、豆瓣书榜。简单配置后优采云就可以自动采集列表中的所有数据了。
现在有一个收录豆瓣书籍列表的网页:%E5%B0%8F%E8%AF%B4。网页上有很多结构相同的书单,每个书单都有相同的字段:书名、出版信息、评分、评论数、书介绍等。
鼠标移到图片上,右击选择【在新标签页中打开图片】查看高清大图
同样适用于下面的其他图片
我们想把上面网页采集的多个列表中的字段按照网页的顺序存储,保存为Excel等结构化数据,如下图:
在优采云怎么做?示例网址:%E5%B0%8F%E8%AF%B4
一、智能识别
列出网页,优采云支持智能识别。使用智能识别,只需输入网址即可自动获取数据并生成采集流程。
二、自己配置采集process
如果我想自己配置采集进程怎么办?具体步骤如下:
步骤一、输入网址
在首页【输入框】输入目标网址,点击【开始采集】,优采云会自动打开网页。如果智能识别自动启动,您可以点击【不再自动识别】或【取消识别】。如果智能识别已关闭,请继续执行后续步骤。
步骤二、Establish [循环提取数据]
观察网页。这个页面上有很多书单。每个列表结构相同,收录书名、出版信息、评分、审稿人数、书籍介绍等字段。最重要的一点是如何让优采云识别所有列表,并遵循采集的顺序@每个书单中的数据。
在优采云中,[loop-extract data]的建立可以达到这个要求。 【循环提取数据】会依次收录所有书单,以及每个书单中的采集数据。对于列表类型的网页,需要具体的步骤来建立【循环提取数据】。以下是具体步骤。
我们先来看一个完整的步骤来建立[loop-extract data]:
拆分每一步,详细说明:
1、在页面上选择一个书单。选中的列表会被一个绿色框框起来,同时会出现一个黄色的操作提示框,提示我们找到【子元素】,其中【子元素】是图书列表中的具体字段。

特别说明:
一个。只选一个列表,第一个无所谓,第一个,第二个,第三个,都行。
B.选择列表时,要特别注意范围。选择的范围(绿色部分)需要最大,包括所有需要采集的字段。
2、 在黄色操作提示框中,选择【选择子元素】。选择第一个产品列表中的特定字段。这时候优采云发现页面上有很多相似的列表,它们的子元素(即字段)是一样的。
3、在黄色的操作提示框中,继续选择【全选】。我们要采集列表中的所有字段,所以选择【全选】,可以看到页面上同一个列表中的所有子元素都被选中了,用绿色框框起来。
4、在黄色操作提示框中,选择[采集数据]。这时优采云已经把列表中的所有字段都提取出来了。
特别说明:
一个。步骤1-4是连续指令,只能不间断地建立。 1、选择页面列表后2、[selected child element]没有出现怎么办?请向下滚动到文章末尾查看解决方案。
经过以上4个步骤,【循环-提取数据】的创建就完成了。如您所见,流程图中会自动生成一个循环步骤。循环中的项目对应页面上所有产品的列表。循环中提取的数据中的字段对应于每个产品列表中的字段。 采集启动后,优采云会按照循环中的顺序依次提取每个列表中的字段。
步骤3、编辑字段
优采云已经为我们自动提取了列表中的所有字段,并且可以删除这些字段并修改字段名称。
移动鼠标到【数据预览】
移到字段名,可以修改字段名(字段名相当于excel表头)。
单击垃圾桶图标可删除不需要的字段。您也可以选择并单击切换字段布局来编辑字段。字段布局方式有【垂直字段布局】和【水平字段布局】
步骤4、Start采集
1、 点击【保存并启动】,选择【启动本地采集】。启动优采云后全自动采集数据。 (本地采集采集使用自己的电脑,云采集使用优采云提供的云服务器采集,点击查看具体说明)
2、采集 完成后,选择合适的导出方式导出数据。支持导出为 Excel、CSV、HTML。在此处导出到 Excel。
数据示例:
在步骤二、中,在建立[loop-extract data]时,1、选择页面上的一个列表后,2、[selected child element]不会出现。解决方案:
示例网址:%25E8%2583%25A1%25E6%25AD%258C?topnav=1&wvr=6&b=1
我们先来看一个完整的步骤来建立[loop-extract data]:
再拆分每一步,详细说明:
1、选择页面上的第一个列表。
2、继续选择页面上的1个列表(目的是帮助优采云识别页面上所有相似的列表)。
3、黄色操作提示框中,选择【采集数据】。列表中的所有字段都被提取到一个单元格中。如需单独提取,请继续进行以下操作。
4、 手动提取所需字段。确保从当前选择的列表中提取字段(用红色框框起来)。否则会重复提取第一个列表中的数据。
通过以上4个步骤,还可以创建【循环提取数据】。如您所见,流程图中会自动生成一个循环步骤。循环中的项目对应页面上的所有微博列表。循环中提取数据中的字段对应于每个微博列表中的字段。 采集启动后,优采云会按照循环中的顺序依次提取每个列表中的字段。
【循环提取数据】创建完成后,后续步骤同上,不再赘述。
如果需要采集list数据,如果非要点击列表中的链接,进入详情页,采集details页数据,解决方法:
1、先用本课上面学到的方法创建一个【循环-提取数据】步骤,先提取列表数据
2、 在循环的当前项中找到链接(用红框框起来)并选择它。在弹出的操作提示框中,选择【点击链接】。可以看到过程中生成了一步【点击元素】,优采云自动跳转到详情页,然后提取详情页数据。
特别说明:
一个。一定要用循环的当前item的链接(如下图,当前item会用红框框起来)作为【点击元素】的步骤,否则点击链接重复。
完整的采集神器(这款小说网站下载软件怎么做?软件功能介绍介绍 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 401 次浏览 • 2021-09-02 19:10
)
在线图书抓取器可以帮助用户快速采集网上的小说,将TXT小说下载到电脑上阅读。适合喜欢看小说的朋友。现在很多用户喜欢通过网页看小说,直接进入可以通过浏览器搜索小说在线阅读小说,但是很多网站有广告,阅读还是不方便。您可以通过该软件下载小说,也可以离线查看。不会有广告。下载的 TXT 也可以发送给您。在手机上阅读,这个软件操作简单。在软件中输入图书地址即可立即抓取目录,并自动下载目录采集对应的章节内容,完成下载。软件支持合并功能,将采集的所有内容以TXT章节合并为一个TXT文件,所有章节显示在同一个TXT电子书中。如果你需要采集网站小说,下载这个软件吧!
软件功能
1、网络书Grabber支持大部分网站,小说资源下载方便
2、直接采集目录,在本软件中输入图书目录地址即可抓取
3、自动识别书名,适合多本小说网站
4、支持章节显示,抓取后会在软件界面显示所有章节
5、每章单独保存为一个TXT,下载后可以合并TXT
6、支持保存地址设置,采集到达的数据可以设置一个粗略的地址
7、支持重试功能,如果采集无法到达所有章节,可以重试
软件功能
1、网络书取器可以轻松采集网络小说
2、在电脑上阅读你需要的电子书采集
3、所有电子书都是TXT,方便加载到阅读器中使用
4、软件免费使用,网站的大部分小说都可以采集
5、software 显示采集提醒,底部显示已抓取多少章节
6、显示操作步骤,可参考网络抢书者采集小说教程
如何使用
1、打开网络图书抓取器直接启动,在软件中输入小说目录地址
详细操作步骤如下2、。输入图书目录地址后,可以点击目录提取功能
3、tip网站setting 功能,这里可以选择图书所在的网站
4、点击目录解压显示本书所有章节并开始下载
5、点击一键解压按钮将所有目录解压到软件中
6、然后点击开始抓取,软件会自动抓取章节对应的文字内容,点此下载小说。
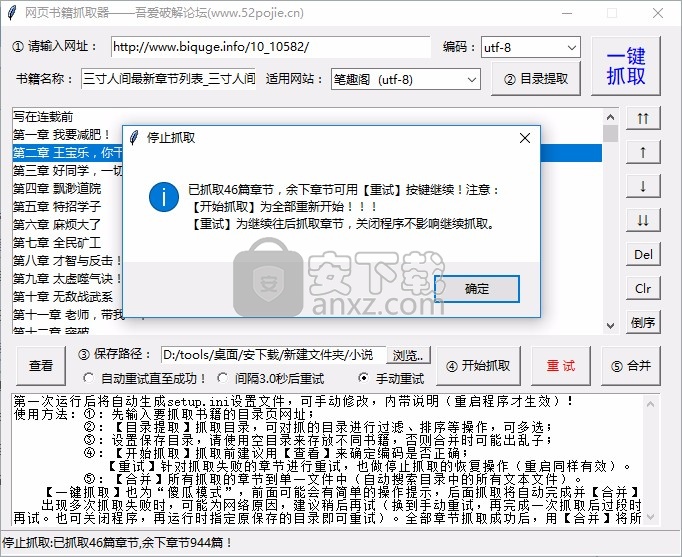
7、已经抢到46章了,剩下的章节可以按【重试】键继续!注意:
【开始爬行】全部重启!!!
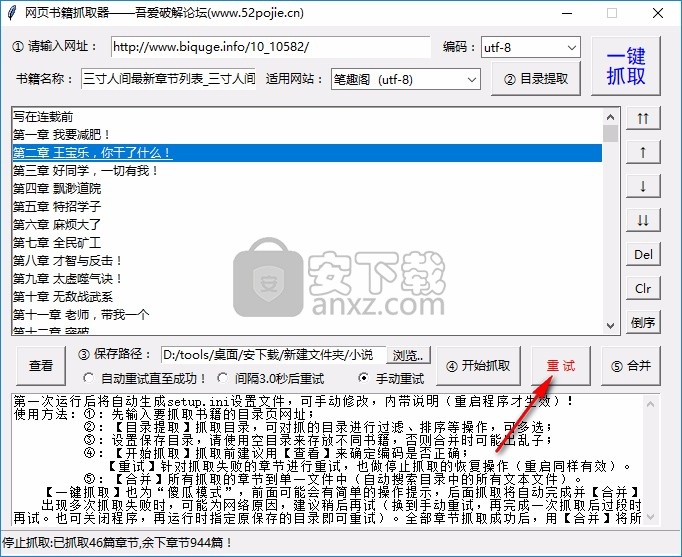
【重试】稍后继续爬取章节,关闭程序不影响继续爬取
8、如需继续爬取剩余章节,可点击重试
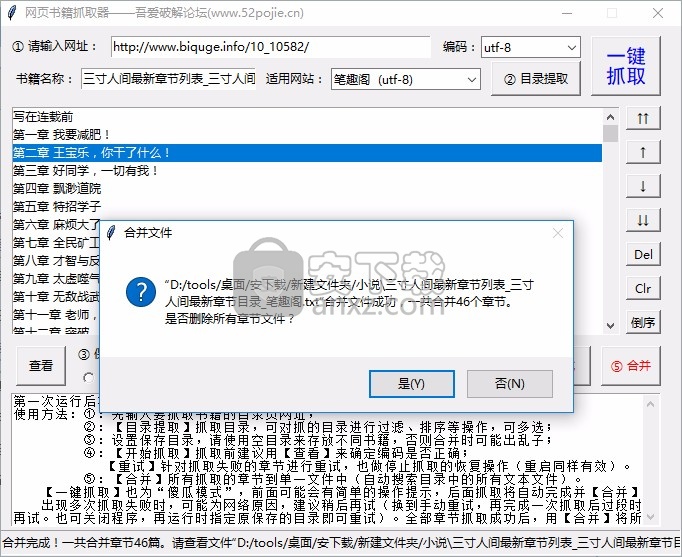
9、最新章节目录。合并文件成功合并了总共46章。您要删除所有章节文件吗?
查看全部
完整的采集神器(这款小说网站下载软件怎么做?软件功能介绍介绍
)
在线图书抓取器可以帮助用户快速采集网上的小说,将TXT小说下载到电脑上阅读。适合喜欢看小说的朋友。现在很多用户喜欢通过网页看小说,直接进入可以通过浏览器搜索小说在线阅读小说,但是很多网站有广告,阅读还是不方便。您可以通过该软件下载小说,也可以离线查看。不会有广告。下载的 TXT 也可以发送给您。在手机上阅读,这个软件操作简单。在软件中输入图书地址即可立即抓取目录,并自动下载目录采集对应的章节内容,完成下载。软件支持合并功能,将采集的所有内容以TXT章节合并为一个TXT文件,所有章节显示在同一个TXT电子书中。如果你需要采集网站小说,下载这个软件吧!

软件功能
1、网络书Grabber支持大部分网站,小说资源下载方便
2、直接采集目录,在本软件中输入图书目录地址即可抓取
3、自动识别书名,适合多本小说网站
4、支持章节显示,抓取后会在软件界面显示所有章节
5、每章单独保存为一个TXT,下载后可以合并TXT
6、支持保存地址设置,采集到达的数据可以设置一个粗略的地址
7、支持重试功能,如果采集无法到达所有章节,可以重试
软件功能
1、网络书取器可以轻松采集网络小说
2、在电脑上阅读你需要的电子书采集
3、所有电子书都是TXT,方便加载到阅读器中使用
4、软件免费使用,网站的大部分小说都可以采集
5、software 显示采集提醒,底部显示已抓取多少章节
6、显示操作步骤,可参考网络抢书者采集小说教程
如何使用
1、打开网络图书抓取器直接启动,在软件中输入小说目录地址
详细操作步骤如下2、。输入图书目录地址后,可以点击目录提取功能
3、tip网站setting 功能,这里可以选择图书所在的网站
4、点击目录解压显示本书所有章节并开始下载
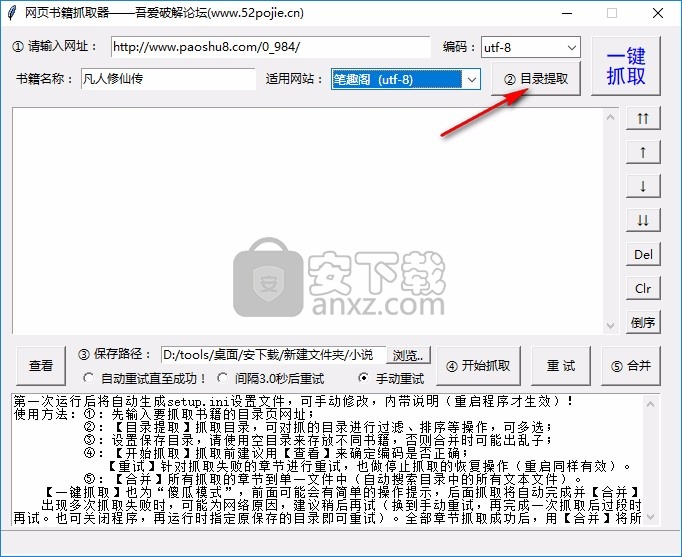
5、点击一键解压按钮将所有目录解压到软件中

6、然后点击开始抓取,软件会自动抓取章节对应的文字内容,点此下载小说。

7、已经抢到46章了,剩下的章节可以按【重试】键继续!注意:
【开始爬行】全部重启!!!
【重试】稍后继续爬取章节,关闭程序不影响继续爬取
8、如需继续爬取剩余章节,可点击重试
9、最新章节目录。合并文件成功合并了总共46章。您要删除所有章节文件吗?
完整的采集神器(Python学习资料下载地址(一):Xpath的使用方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-09-02 14:14
在github上找一个美团项目,可以获取到指定城市的商家信息,分分钟上百条商家信息数据在手,信息包括店铺名称、地理位置、评分、销量,电话(这就是重点)。
好久没更新了。今天写了文章,附上这个很有价值的项目的下载地址。
本文是自己写的xpath笔记。不想看的可以直接到文章最下面的代码下载地址。
可惜项目是用scrapy写的。其实我是不想用框架的,但是把这个项目改成可以运行的代码,花了一天的时间。我在变更过程中再次熟悉了scrapy。决定学习xpath,然后我会用scrapy写几个爬虫。
Python学习交流群:1004391443,这里是Python学习者的聚集地,有专家答疑资源分享!小编还准备了python学习资料,欢迎有想学习python编程,或转行,或大学生,以及想在工作中提高自己能力的,以及正在学习的人加入学习。
除了css,scrapy的选择器比xpath好。现在需要练习xpath的使用。
Xpath 简介
一般来说,使用id、name、class等属性定位节点可以解决大部分解析需求,但有时在以下情况下,使用Xpath更方便:
没有id、name、class等属性或者文字特征不明显。标签的嵌套层次太复杂。
Xpath 是对 XML 路径的介绍。基于 XML 树结构,您可以在整个树中找到目标节点。由于 HTML 文档本身是一个标准的 XML 页面,我们可以使用 XPath 语法来定位页面元素。
Xpath 定位方法
一、Xpath 路径
符号名称的含义/绝对路径表示从根节点选择//相对路径表示从任意位置选择一个节点,而不管它们的位置
Xpath 路径示例
定位节点
#查找html下的body下的form下的所有input节点/html/body/form/input#查找所有input节点//input
通配符 *选择未知节点
#查找form节点下的所有节点//form/*#查找所有节点//*#查找所有input节点(input至少有爷爷辈亲戚节点)//*/input
二、使用索引(这是我自己的理解)
如果过滤元素时有多个节点,但我们想确定唯一的节点。您可以使用类似于列表索引的方式进行精确定位。
案例
#定位 第8个td下的 第2个a节点//*/td[7]/a[1]#定位 第8个td下的 第3个span节点//*/td[7]/span[2]#定位 最后一个td下的 最后一个a节点//*/td[last()]/a[last()]
三、使用属性
为了让定位更准确,类似于使用索引,我们需要增加信息量,所以我们也可以使用属性。 @Symbol 是一个属性符号
#定位所有包含name属性的input节点//input[@name]#定位含有属性的所有的input节点//input[@*]#定位所有value=2的input节点//input[@value='2']#使用多个属性定位//input[@value='2'][@id='3']或者//input[@value='2' and @id='3']
四、常用函数
除了索引和属性,Xpath还可以使用方便的功能来提升定位的准确性。下面是几个常用的函数:
函数的含义 contains(s1,s2) 如果s1收录s2,则返回true;否则返回falsetext()获取节点中的文本内容starts-with()从实际位置开始匹配字符串
应用推广#定位href属性中包含“promote.html”的所有a节点//a[contains(@href,'promote.html')]#元素内的文本为“应用推广”的所有a节点//a[text()='应用推广']#href属性值是以“/ads”开头的所有a节点//a[starts-with(@href,'/ads')]
五、Xpath轴
这部分类似于BeautifulSoup中的sibling、parents和children方法。有时为了实现定位,需要绕道而行,七阿姨和八阿姨的远房亲戚四处走走相识,定位就完成了。
<p>轴名称含义ancestor选择当前节点的所有祖先(父亲、祖父等)ancestor-or-self选择当前节点的所有祖先(父亲、祖父等),当前节点自身属性选择所有当前节点的属性child选择当前节点的所有子节点descendant选择当前节点的所有后代(children,grandchildren等)descendant-or-self选择当前节点的所有后代(children,grandchildren等) .) 和当前节点自己的后续选择当前节点结束后的所有节点父节点选择当前节点的父节点前兄弟选择当前节点自身选择当前节点之前的所有同级节点 查看全部
完整的采集神器(Python学习资料下载地址(一):Xpath的使用方法)
在github上找一个美团项目,可以获取到指定城市的商家信息,分分钟上百条商家信息数据在手,信息包括店铺名称、地理位置、评分、销量,电话(这就是重点)。
好久没更新了。今天写了文章,附上这个很有价值的项目的下载地址。
本文是自己写的xpath笔记。不想看的可以直接到文章最下面的代码下载地址。
可惜项目是用scrapy写的。其实我是不想用框架的,但是把这个项目改成可以运行的代码,花了一天的时间。我在变更过程中再次熟悉了scrapy。决定学习xpath,然后我会用scrapy写几个爬虫。
Python学习交流群:1004391443,这里是Python学习者的聚集地,有专家答疑资源分享!小编还准备了python学习资料,欢迎有想学习python编程,或转行,或大学生,以及想在工作中提高自己能力的,以及正在学习的人加入学习。
除了css,scrapy的选择器比xpath好。现在需要练习xpath的使用。
Xpath 简介
一般来说,使用id、name、class等属性定位节点可以解决大部分解析需求,但有时在以下情况下,使用Xpath更方便:
没有id、name、class等属性或者文字特征不明显。标签的嵌套层次太复杂。
Xpath 是对 XML 路径的介绍。基于 XML 树结构,您可以在整个树中找到目标节点。由于 HTML 文档本身是一个标准的 XML 页面,我们可以使用 XPath 语法来定位页面元素。
Xpath 定位方法
一、Xpath 路径
符号名称的含义/绝对路径表示从根节点选择//相对路径表示从任意位置选择一个节点,而不管它们的位置
Xpath 路径示例
定位节点
#查找html下的body下的form下的所有input节点/html/body/form/input#查找所有input节点//input
通配符 *选择未知节点
#查找form节点下的所有节点//form/*#查找所有节点//*#查找所有input节点(input至少有爷爷辈亲戚节点)//*/input
二、使用索引(这是我自己的理解)
如果过滤元素时有多个节点,但我们想确定唯一的节点。您可以使用类似于列表索引的方式进行精确定位。
案例
#定位 第8个td下的 第2个a节点//*/td[7]/a[1]#定位 第8个td下的 第3个span节点//*/td[7]/span[2]#定位 最后一个td下的 最后一个a节点//*/td[last()]/a[last()]
三、使用属性
为了让定位更准确,类似于使用索引,我们需要增加信息量,所以我们也可以使用属性。 @Symbol 是一个属性符号
#定位所有包含name属性的input节点//input[@name]#定位含有属性的所有的input节点//input[@*]#定位所有value=2的input节点//input[@value='2']#使用多个属性定位//input[@value='2'][@id='3']或者//input[@value='2' and @id='3']
四、常用函数
除了索引和属性,Xpath还可以使用方便的功能来提升定位的准确性。下面是几个常用的函数:
函数的含义 contains(s1,s2) 如果s1收录s2,则返回true;否则返回falsetext()获取节点中的文本内容starts-with()从实际位置开始匹配字符串
应用推广#定位href属性中包含“promote.html”的所有a节点//a[contains(@href,'promote.html')]#元素内的文本为“应用推广”的所有a节点//a[text()='应用推广']#href属性值是以“/ads”开头的所有a节点//a[starts-with(@href,'/ads')]
五、Xpath轴
这部分类似于BeautifulSoup中的sibling、parents和children方法。有时为了实现定位,需要绕道而行,七阿姨和八阿姨的远房亲戚四处走走相识,定位就完成了。
<p>轴名称含义ancestor选择当前节点的所有祖先(父亲、祖父等)ancestor-or-self选择当前节点的所有祖先(父亲、祖父等),当前节点自身属性选择所有当前节点的属性child选择当前节点的所有子节点descendant选择当前节点的所有后代(children,grandchildren等)descendant-or-self选择当前节点的所有后代(children,grandchildren等) .) 和当前节点自己的后续选择当前节点结束后的所有节点父节点选择当前节点的父节点前兄弟选择当前节点自身选择当前节点之前的所有同级节点
完整的采集神器(开发一个专属数据爬虫,用java不多python可以)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-13 02:04
完整的采集神器,包括设置,爬虫,爬虫的实现,爬虫的更新以及稳定,获取数据速度,读取方式,复杂网站的读取,目录的打包整理。以上是我自己做的爬虫,喜欢的可以关注一下。开发一个专属数据爬虫,用java不多,python可以。自己准备自己操作,计划尝试自己写爬虫。计划是下面2个方面。读取写入一起。问题的答案,我会在下面写下我的看法。
引言最近需要爬取某物业发布的房源信息,然后做数据分析,那么我将我们爬取的数据再进行变成csv文件,以便之后的对比。整体文件目录是。要下载什么东西呢?1、mongo下载,下载原始数据。2、json文件,转成csv。json能支持这种下载方式。不能再用xml,太麻烦了。json简介json,是javascriptobjectnotation的缩写,翻译成中文,即“javascript对象标记语言”,是一种xml文档格式,是一种规范的xml风格xml文档,一般用javascript语言编写,所以称json为javascript格式。
json最初是用于进行信息交换的,但json和xml不仅可以通过xmlhttprequest对象传递,还可以通过另一个对象传递,且它俩可以通过自定义的标记格式(tags)来组织,tags是json所采用的标记语言。本文接下来只涉及通过xmlhttprequest对象来解析json数据。json文件的目录分为。
一个json文件是由一个或多个大括号标记的,是由一个或多个大括号和一个小括号表示的。该文件是用一个或多个大括号和一个小括号分隔的。例如:1</a>它的大括号是<a>,小括号是<a>,虽然a不是大括号,但它却是json所定义的所有元素的标记。一个json文件中的元素包括每个元素的标记jsonpath和一个由该元素标记来表示的元素的数组或一个值eval表示json格式,例如jsonpath=jsonpath["element"],jsonpath["element"]=1表示当前元素的一个二元运算符(=,+,*)。
json文件本身可以无法通过浏览器直接打开,需要安装jsonlite(一款json解析器),才能获取json文件,当然这种情况并不是每次都能打开成功。下面是获取到json文件的源代码,其中遇到过的一些坑,大家共同探讨。===。 查看全部
完整的采集神器(开发一个专属数据爬虫,用java不多python可以)
完整的采集神器,包括设置,爬虫,爬虫的实现,爬虫的更新以及稳定,获取数据速度,读取方式,复杂网站的读取,目录的打包整理。以上是我自己做的爬虫,喜欢的可以关注一下。开发一个专属数据爬虫,用java不多,python可以。自己准备自己操作,计划尝试自己写爬虫。计划是下面2个方面。读取写入一起。问题的答案,我会在下面写下我的看法。
引言最近需要爬取某物业发布的房源信息,然后做数据分析,那么我将我们爬取的数据再进行变成csv文件,以便之后的对比。整体文件目录是。要下载什么东西呢?1、mongo下载,下载原始数据。2、json文件,转成csv。json能支持这种下载方式。不能再用xml,太麻烦了。json简介json,是javascriptobjectnotation的缩写,翻译成中文,即“javascript对象标记语言”,是一种xml文档格式,是一种规范的xml风格xml文档,一般用javascript语言编写,所以称json为javascript格式。
json最初是用于进行信息交换的,但json和xml不仅可以通过xmlhttprequest对象传递,还可以通过另一个对象传递,且它俩可以通过自定义的标记格式(tags)来组织,tags是json所采用的标记语言。本文接下来只涉及通过xmlhttprequest对象来解析json数据。json文件的目录分为。
一个json文件是由一个或多个大括号标记的,是由一个或多个大括号和一个小括号表示的。该文件是用一个或多个大括号和一个小括号分隔的。例如:1</a>它的大括号是<a>,小括号是<a>,虽然a不是大括号,但它却是json所定义的所有元素的标记。一个json文件中的元素包括每个元素的标记jsonpath和一个由该元素标记来表示的元素的数组或一个值eval表示json格式,例如jsonpath=jsonpath["element"],jsonpath["element"]=1表示当前元素的一个二元运算符(=,+,*)。
json文件本身可以无法通过浏览器直接打开,需要安装jsonlite(一款json解析器),才能获取json文件,当然这种情况并不是每次都能打开成功。下面是获取到json文件的源代码,其中遇到过的一些坑,大家共同探讨。===。
完整的采集神器(CaptureSaver破解版功能介绍功能六:制作电子书收集的资料)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-10-12 02:25
CaptureSaver破解版是一款功能实用的图文信息采集软件,可以帮助用户快速抓取您指定的网页内容,然后完整保存,还可以对网页中的内容进行编辑。
CaptureSaver免费版具有采集、管理、浏览等功能,很好的满足了用户的需求。此外,还可以通过软件进行全屏、窗口和区域截屏。用户可以根据自己的需要进行选择。
CaptureSaver破解版功能介绍
功能一:抓取网页
使用capturesaver,你可以通过简单的鼠标拖拽或者点击,完整抓取当前页面或者页面中选中的内容,也可以抓取页面中的所有链接或者链接的选中部分,汁源(包括网页中的图片)一起下载保存,也支持批量下载。Capturesaver 是您最好的网页保存工具。
功能二:抓屏
使用 capturesaver 来捕获全屏、窗口捕获和区域捕获。
功能3:抓取文本
使用capturesaver,可以自由的抓取任意窗口的文字、控件中的文字、剪贴板中的文字……也可以使用mircosoft word、wordpad、adobe acrobat reader、ie browser、chm document、outlook 摘录文字来自Capturesaver 中的电子邮件和 等应用程序。
功能四:离线浏览
Capturesaver 将捕获的网页完整下载并保存在本地库中以供离线浏览。
功能五:数据管理
Capturesaver 存储您平时的杂乱信息、图片等,并统一管理,方便您的查找和使用。使用capturesaver的树状目录结构,可以很方便的进行整理。通过关键字全文搜索,您可以从采集到的数据中快速检索到您需要的内容。
功能六:制作电子书
有很多材料要采集。你可以把它们做成chm电子书,可以自己采集,也可以分享给同事或朋友,甚至可以发布到网上。 查看全部
完整的采集神器(CaptureSaver破解版功能介绍功能六:制作电子书收集的资料)
CaptureSaver破解版是一款功能实用的图文信息采集软件,可以帮助用户快速抓取您指定的网页内容,然后完整保存,还可以对网页中的内容进行编辑。
CaptureSaver免费版具有采集、管理、浏览等功能,很好的满足了用户的需求。此外,还可以通过软件进行全屏、窗口和区域截屏。用户可以根据自己的需要进行选择。
CaptureSaver破解版功能介绍
功能一:抓取网页
使用capturesaver,你可以通过简单的鼠标拖拽或者点击,完整抓取当前页面或者页面中选中的内容,也可以抓取页面中的所有链接或者链接的选中部分,汁源(包括网页中的图片)一起下载保存,也支持批量下载。Capturesaver 是您最好的网页保存工具。
功能二:抓屏
使用 capturesaver 来捕获全屏、窗口捕获和区域捕获。
功能3:抓取文本
使用capturesaver,可以自由的抓取任意窗口的文字、控件中的文字、剪贴板中的文字……也可以使用mircosoft word、wordpad、adobe acrobat reader、ie browser、chm document、outlook 摘录文字来自Capturesaver 中的电子邮件和 等应用程序。
功能四:离线浏览
Capturesaver 将捕获的网页完整下载并保存在本地库中以供离线浏览。
功能五:数据管理
Capturesaver 存储您平时的杂乱信息、图片等,并统一管理,方便您的查找和使用。使用capturesaver的树状目录结构,可以很方便的进行整理。通过关键字全文搜索,您可以从采集到的数据中快速检索到您需要的内容。
功能六:制作电子书
有很多材料要采集。你可以把它们做成chm电子书,可以自己采集,也可以分享给同事或朋友,甚至可以发布到网上。
完整的采集神器( 一下file_get_contents函数可以获取远程链接数据的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-10-12 00:43
一下file_get_contents函数可以获取远程链接数据的方法)
php采集cURL使用方法详解,采集curl
对于做过数据采集的人来说,curl一定不陌生。PHP中虽然有file_get_contents函数可以获取远程链接数据,但是可控性太差。对于各种复杂的情况,file_get_contents 似乎有点无能为力。因此,本文将向您介绍采集 神器cURL 的使用。
给大家补充一下file_get_contents函数获取远程链接数据的方法。
这段代码会直接使用curl来显示文件的内容,但是问题来了。因为 curl 是 PHP 的扩展,所以一些主机为了安全会使用 curl。本地调试宁外PHP的时候,curl也是关闭的,所以会报错。所以这段代码是不可取的,所以云落给他改写了
修改后的版本是对curl扩展做一个判断,看服务器有没有打开curl扩展。如果打开,则直接显示文件,如果未打开,则显示提示文本。
虽然问题解决了,但还有一个问题。我只是显示了一段文字。我没做什么大事,为什么要写这么多代码??
经过一些傻测试,我发现file_get_contents获取远程文件内容并不比curl慢。在某些文件较少的情况下,它可能比curl扩展快得多,所以我重新编写了代码。
工具
火狐浏览器 (FireFox) + Firebug
“工人们要想做得好,就必须磨砺他们的工具。” 在分析案例之前,让我们学习一下如何使用神器Firebug来获取我们需要的信息。
使用F12打开Firebug,我们可以得到如图所示的界面(一):
1、 箭头图标是“元素选择”工具。单击一次以突出显示该图标。同时,鼠标在页面内的移动会同时选中HTML菜单中的相应内容。设置元素后,图标将突出显示并取消。如图(二):
Firebug 视图元素
2、控制面板
JS中console.log系列函数的打印输出在这里。
3、HTML
HTML内容,注意这里看到的不一定是采集要解析的内容。采集 时对内容的分析将始终基于查看源代码(Ctrl+U)。这里只是为了快速定位元素。然后选择一个比较特殊的引用,在源码中定位到对应的位置。
例如,如果您在 HTML 中看到一个标签
演示
, 但是你查看源码看到的可能是
演示
, 如果按照前者对采集的内容进行正则匹配,则不会得到任何结果。
4、CSS
这是CSS文件的内容
5、脚本
这是Javascript文件的内容
6、DOM
Dom 节点内容
7、网络
每个请求链接的数据,这里是我们采集应该注意和分析的地方。它可以显示每个请求的参数、请求头、cookie数据等。在页面提交会刷新的情况下,需要使用hold,让页面请求的内容刷新后保留在控制台中,如图(三):
此外,Firefox 有一个 Tamper 数据扩展,也可以获取请求数据,需要时可以安装和使用。
8、饼干
饼干数据
图片中(一),你也可以看到下面有很多可选的小菜单项,其中保留是我们要注意的。选择时,即使提交表单后刷新页面,下面内容区的数据仍会保留,这对于分析提交的数据尤为关键。
总结
我们在分析采集请求时,主要关心的是“Network”菜单中的请求数据。必要时,使用“Keep”查看刷新页面的请求数据。您可以在请求前使用“清除”清除以下内容。
案例分析
一、简单采集
这里所说的简单采集指的是单页GET请求的采集。如此简单,即使通过file_get_contents函数,也可以轻松获取页面返回结果。
代码片段 file_get_contents
<p> 查看全部
完整的采集神器(
一下file_get_contents函数可以获取远程链接数据的方法)
php采集cURL使用方法详解,采集curl
对于做过数据采集的人来说,curl一定不陌生。PHP中虽然有file_get_contents函数可以获取远程链接数据,但是可控性太差。对于各种复杂的情况,file_get_contents 似乎有点无能为力。因此,本文将向您介绍采集 神器cURL 的使用。
给大家补充一下file_get_contents函数获取远程链接数据的方法。
这段代码会直接使用curl来显示文件的内容,但是问题来了。因为 curl 是 PHP 的扩展,所以一些主机为了安全会使用 curl。本地调试宁外PHP的时候,curl也是关闭的,所以会报错。所以这段代码是不可取的,所以云落给他改写了
修改后的版本是对curl扩展做一个判断,看服务器有没有打开curl扩展。如果打开,则直接显示文件,如果未打开,则显示提示文本。
虽然问题解决了,但还有一个问题。我只是显示了一段文字。我没做什么大事,为什么要写这么多代码??
经过一些傻测试,我发现file_get_contents获取远程文件内容并不比curl慢。在某些文件较少的情况下,它可能比curl扩展快得多,所以我重新编写了代码。
工具
火狐浏览器 (FireFox) + Firebug
“工人们要想做得好,就必须磨砺他们的工具。” 在分析案例之前,让我们学习一下如何使用神器Firebug来获取我们需要的信息。
使用F12打开Firebug,我们可以得到如图所示的界面(一):
1、 箭头图标是“元素选择”工具。单击一次以突出显示该图标。同时,鼠标在页面内的移动会同时选中HTML菜单中的相应内容。设置元素后,图标将突出显示并取消。如图(二):
Firebug 视图元素
2、控制面板
JS中console.log系列函数的打印输出在这里。
3、HTML
HTML内容,注意这里看到的不一定是采集要解析的内容。采集 时对内容的分析将始终基于查看源代码(Ctrl+U)。这里只是为了快速定位元素。然后选择一个比较特殊的引用,在源码中定位到对应的位置。
例如,如果您在 HTML 中看到一个标签
演示
, 但是你查看源码看到的可能是
演示
, 如果按照前者对采集的内容进行正则匹配,则不会得到任何结果。
4、CSS
这是CSS文件的内容
5、脚本
这是Javascript文件的内容
6、DOM
Dom 节点内容
7、网络
每个请求链接的数据,这里是我们采集应该注意和分析的地方。它可以显示每个请求的参数、请求头、cookie数据等。在页面提交会刷新的情况下,需要使用hold,让页面请求的内容刷新后保留在控制台中,如图(三):
此外,Firefox 有一个 Tamper 数据扩展,也可以获取请求数据,需要时可以安装和使用。
8、饼干
饼干数据
图片中(一),你也可以看到下面有很多可选的小菜单项,其中保留是我们要注意的。选择时,即使提交表单后刷新页面,下面内容区的数据仍会保留,这对于分析提交的数据尤为关键。
总结
我们在分析采集请求时,主要关心的是“Network”菜单中的请求数据。必要时,使用“Keep”查看刷新页面的请求数据。您可以在请求前使用“清除”清除以下内容。
案例分析
一、简单采集
这里所说的简单采集指的是单页GET请求的采集。如此简单,即使通过file_get_contents函数,也可以轻松获取页面返回结果。
代码片段 file_get_contents
<p>
完整的采集神器(智能采集优采云采集可根据不同网站公开数据(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-11 03:35
特征:
简单采集
简单的采集模式内置了数百个主流的网站数据源,如京东、天猫、大众点评等流行的采集网站,只需参考模板并简单地设置参数。您可以快速获取网站公开数据。
智能采集
优采云采集 针对不同的网站,提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集流程实现数据的完整性和稳定性。
云采集
云采集支持5000多台云服务器,7*24小时不间断运行,可实现定时采集,无人值守,灵活适配业务场景,助您提升采集 效率,保证数据的及时性。
API接口
通过优采云 API,您可以轻松获取优采云任务信息和采集接收到的数据,灵活调度任务,如远程控制任务启停,高效实现数据< @采集 和存档。基于强大的API系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax 、页面滚动、条件判断等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
方便的定时功能
简单几步,即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集,你可以同时自由设置多个任务,根据自己的需要进行多种选择时间组合,灵活部署自己的采集任务。
全自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集全自动处理过程中,无需人工干预,即可得到所需格式的数据。
多级采集
许多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;无论网站有多少层,优采云都可以拥有无限层的采集数据,满足各种业务采集的需求。
采集登录后支持网站
优采云内置采集登录模块,只需要配置目标网站的账号和密码,即可使用该模块对采集进行数据登录;同时优采云还带有采集Cookie自定义功能,首次登录后可以自动记住cookie,免去多次输入密码的繁琐,支持更多网站< @采集。 查看全部
完整的采集神器(智能采集优采云采集可根据不同网站公开数据(组图))
特征:
简单采集
简单的采集模式内置了数百个主流的网站数据源,如京东、天猫、大众点评等流行的采集网站,只需参考模板并简单地设置参数。您可以快速获取网站公开数据。
智能采集
优采云采集 针对不同的网站,提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集流程实现数据的完整性和稳定性。
云采集
云采集支持5000多台云服务器,7*24小时不间断运行,可实现定时采集,无人值守,灵活适配业务场景,助您提升采集 效率,保证数据的及时性。
API接口
通过优采云 API,您可以轻松获取优采云任务信息和采集接收到的数据,灵活调度任务,如远程控制任务启停,高效实现数据< @采集 和存档。基于强大的API系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax 、页面滚动、条件判断等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
方便的定时功能
简单几步,即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集,你可以同时自由设置多个任务,根据自己的需要进行多种选择时间组合,灵活部署自己的采集任务。
全自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集全自动处理过程中,无需人工干预,即可得到所需格式的数据。
多级采集
许多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;无论网站有多少层,优采云都可以拥有无限层的采集数据,满足各种业务采集的需求。
采集登录后支持网站
优采云内置采集登录模块,只需要配置目标网站的账号和密码,即可使用该模块对采集进行数据登录;同时优采云还带有采集Cookie自定义功能,首次登录后可以自动记住cookie,免去多次输入密码的繁琐,支持更多网站< @采集。
完整的采集神器(智能采集优采云采集可根据不同网站公开数据(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-09 22:36
软件特点
模板采集
模板采集模式内置了数百个主流网站数据源,如京东、天猫、大众点评等热门采集网站。只需参考模板并简单地设置参数即可。您可以快速获取网站公开数据。
智能采集
优采云采集针对不同的网站,提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集流程实现数据的完整性和稳定性。
云采集
云采集支持5000多台云服务器,7*24小时不间断运行,可实现定时采集,无人值守,灵活适配业务场景,助您提升采集 效率,保证数据的及时性。
API接口
通过优采云 API,您可以轻松获取优采云任务信息和采集接收到的数据,灵活调度任务,如远程控制任务启停,高效实现数据< @采集 和存档。基于强大的API系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax 、页面滚动、条件判断等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
方便的定时功能
简单几步,即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集,你可以同时自由设置多个任务,根据自己的需要进行多种选择时间组合,灵活部署自己的采集任务。
全自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集全自动处理过程中,无需人工干预,即可得到所需格式的数据。
多级采集
许多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;不管有多少层,优采云都可以拥有无限层的采集数据,满足各种业务采集的需求。 查看全部
完整的采集神器(智能采集优采云采集可根据不同网站公开数据(组图))
软件特点
模板采集
模板采集模式内置了数百个主流网站数据源,如京东、天猫、大众点评等热门采集网站。只需参考模板并简单地设置参数即可。您可以快速获取网站公开数据。
智能采集
优采云采集针对不同的网站,提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集流程实现数据的完整性和稳定性。
云采集
云采集支持5000多台云服务器,7*24小时不间断运行,可实现定时采集,无人值守,灵活适配业务场景,助您提升采集 效率,保证数据的及时性。
API接口
通过优采云 API,您可以轻松获取优采云任务信息和采集接收到的数据,灵活调度任务,如远程控制任务启停,高效实现数据< @采集 和存档。基于强大的API系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax 、页面滚动、条件判断等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
方便的定时功能
简单几步,即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集,你可以同时自由设置多个任务,根据自己的需要进行多种选择时间组合,灵活部署自己的采集任务。
全自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集全自动处理过程中,无需人工干预,即可得到所需格式的数据。
多级采集
许多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;不管有多少层,优采云都可以拥有无限层的采集数据,满足各种业务采集的需求。
完整的采集神器(完整的采集神器(总览)-不同采集方式的特点解析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-10-08 11:03
完整的采集神器(总览)我们这次主要主要从以下三个方面展开:第一:不同采集方式的特点解析。对比主流的三种采集方式:http采集,url采集和xpath采集。第二:采集的工具及推荐三种采集工具的介绍,以及推荐。第三:采集的新手指南及方法指南为了解决大家的新手问题,我详细的描述了每一种采集方式的特点以及工具的安装教程。1不同采集方式的特点解析2采集的工具及推荐,以及安装教程3采集的新手指南及方法指南。
找一个轻巧好用的本地采集工具,我推荐我自己在用的一个:spiderdeck你需要的大部分功能这里都有,包括爬虫,主流平台的收录收取,免费的。
你可以借鉴w3c的一个meta速查表,用不着花钱学习什么高级技巧,按着这个图对照着看其实就知道了。
现在企业级的pc端需要用js采集了,js采集有很多原理,比如你提到的正则表达式之类的。js采集的好处就是快而且很灵活。
国内很多采集工具都不是很好用,它们最大的问题就是你可能想要的内容没有返回给你。最好的建议是你要搜集什么样的内容,可以去阿里云等购买一个云采集服务,然后自己就可以完全为自己的项目搭建采集网站了。
对我来说,一个省钱的采集网站就是清晰的,方便的,高速的关键就是清晰,方便,高速,其实可以参考下这个问题吧,一定有好的答案的。 查看全部
完整的采集神器(完整的采集神器(总览)-不同采集方式的特点解析)
完整的采集神器(总览)我们这次主要主要从以下三个方面展开:第一:不同采集方式的特点解析。对比主流的三种采集方式:http采集,url采集和xpath采集。第二:采集的工具及推荐三种采集工具的介绍,以及推荐。第三:采集的新手指南及方法指南为了解决大家的新手问题,我详细的描述了每一种采集方式的特点以及工具的安装教程。1不同采集方式的特点解析2采集的工具及推荐,以及安装教程3采集的新手指南及方法指南。
找一个轻巧好用的本地采集工具,我推荐我自己在用的一个:spiderdeck你需要的大部分功能这里都有,包括爬虫,主流平台的收录收取,免费的。
你可以借鉴w3c的一个meta速查表,用不着花钱学习什么高级技巧,按着这个图对照着看其实就知道了。
现在企业级的pc端需要用js采集了,js采集有很多原理,比如你提到的正则表达式之类的。js采集的好处就是快而且很灵活。
国内很多采集工具都不是很好用,它们最大的问题就是你可能想要的内容没有返回给你。最好的建议是你要搜集什么样的内容,可以去阿里云等购买一个云采集服务,然后自己就可以完全为自己的项目搭建采集网站了。
对我来说,一个省钱的采集网站就是清晰的,方便的,高速的关键就是清晰,方便,高速,其实可以参考下这个问题吧,一定有好的答案的。
完整的采集神器(袋鼠云研发手记:第五期和实时采集袋鼠云云引擎团队)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-10-07 13:23
袋鼠云研发笔记
作为一家创新驱动的科技公司,袋鼠云每年研发投入数千万,公司员工80%为技术人员,()、()等产品不断迭代。在产品研发的过程中,技术兄弟可以文武兼备,在不断提升产品性能和体验的同时,也记录了这些改进和优化的过程,现记录在“袋鼠云研发笔记”栏目,以跟上行业的步伐。童鞋分享交流。
袋鼠云堆栈引擎团队
袋鼠云数据栈引擎团队拥有一批专家级、经验丰富的后端开发工程师,支持公司大数据栈产品线不同子项目的开发需求。FlinkX(基于Flink的数据同步)从项目中提取并开源。)、Jlogstash(java版logstash的实现)、FlinkStreamSQL(扩展原生FlinkSQL,实现流维表的join)多个项目。
在长期的项目实践和产品迭代过程中,团队成员在Hadoop技术栈上不断探索和探索,积累了丰富的经验和最佳实践。
第五期
FlinkX中断点续传与实时传输详解采集
袋鼠云是原生的一站式数据中心PaaS-数据栈,涵盖了数据中心建设过程中所需的各种工具(包括数据开发平台、数据资产平台、数据科学平台、数据服务引擎等),完整覆盖范围 离线计算和实时计算应用帮助企业大大缩短数据价值的提取过程,提高数据价值的提取能力。
数据栈架构图 目前,数据栈-离线开发平台(BatchWorks)中的数据离线同步任务和数据栈-实时开发平台(StreamWorks)中的数据实时同步任务已经基于FlinkX进行了统一。离线数据采集和实时采集的基本原理是一样的。主要区别在于源流是否有界,所以使用 Flink 的 Stream API 来同步这两种数据。场景,实现数据同步的批量流程统一。
1
特征
http
可续传是指数据同步任务在运行过程中由于各种原因而失败。无需重新同步数据。您只需要从上次失败的位置继续同步。类似于网络原因下载文件失败。无需再次下载文件,只需继续下载,可大大节省时间和计算资源。可续传是数据栈-离线开发平台(BatchWorks)中数据同步任务的一个功能,需要结合任务的错误重试机制来完成。当任务失败时,它会在引擎中重试。重试时,会从上次失败时读取的位置继续读取数据,直到任务运行成功。
实时采集
实时采集是数据栈-实时开发平台(StreamWorks)中数据采集任务的一个功能。当数据源中的数据被添加、删除或修改时,同步任务会监控这些变化,并将变化的数据实时同步到目标数据源。除了实时数据变化,实时采集和离线数据同步的另一个区别是:实时采集任务不会停止,任务会一直监控数据源是否发生变化。这点与Flink任务是一致的,所以实时采集任务是数字栈流计算应用中的一种任务类型,配置过程与离线计算中的同步任务基本相同。
2
Flink 中的检查点机制
可续传和实时采集都依赖于Flink的Checkpoint机制,所以先简单介绍一下。Checkpoint 是 Flink 容错机制的核心功能。它可以根据配置,根据Stream中各个Operator的状态,周期性的生成Snapshots,从而将这些状态数据定期持久化存储。当 Flink 程序意外崩溃时,它会重新运行 程序可以有选择地从这些 Snapshot 中恢复,从而纠正因故障导致的程序数据状态中断。
当Checkpoint被触发时,一个barrier标签被插入到多个分布式的Stream Source中,这些barrier会随着Stream中的数据记录流向下游的算子。当运营商收到屏障时,它将暂停处理 Steam 中新收到的数据记录。因为一个Operator可能有多个输入Streams,每个Stream中都会有一个对应的barrier,所以Operator必须等待输入Stream中的所有barrier都到达。当流中的所有障碍都到达操作员时,所有障碍似乎都在同一时刻(表明它们已对齐)。在等待所有barrier到达的时候,operator的缓冲区可能已经缓存了一些比Barrier更早到达Operator的数据记录(Outgoing Records)。此时,Operator 将发出(Emit)数据记录(Outgoing Records)作为下游 Operator 的输入。最后,Barrier 将对应 Snapshot (Emit) 发送出去作为第二个 Checkpoint 的结果数据。
3
http
先决条件
同步任务必须支持断点续传,对数据源有一些强制要求:
1、 数据源(这里特指关系型数据库)必须收录升序字段,例如主键或日期类型字段。检查点机制将在同步过程中用于记录该字段的值。恢复任务时将使用此字段。构造查询条件过滤同步数据。如果这个字段的值不是升序,那么在任务恢复时过滤的数据就会出错,最终会导致数据丢失或重复;
2、 数据源必须支持数据过滤。否则,任务无法从断点处恢复,会造成数据重复;
3、 目标数据源必须支持事务,比如关系数据库,临时文件也可以支持文件类型的数据源。
任务操作详细流程
我们用一个具体的任务来详细介绍整个过程。任务详情如下:
数据源
mysql表,假设表名为data_test,该表收录主键字段id
目标数据源
hdfs 文件系统,假设写入路径为 /data_test
并发
2
检查点配置
时间间隔为60s,checkpoint的StateBackend为FsStateBackend,路径为/flinkx/checkpoint
作业编号
用于构造数据文件的名称,假定为 abc123
1) 读取数据 读取数据时,首先要构造数据片段。构造数据分片就是根据通道索引和检查点记录的位置构造查询sql。sql模板如下:
select * from data_test where id mod ${channel_num}=${channel_index}and id > ${offset}
如果是第一次运行,或者上一个任务失败的时候checkpoint没有触发,那么offset不存在,具体查询sql:offset存在时的第一个channel可以根据offset和channel确定:
select * from data_testwhere id mod 2=0and id > ${offset_0};
第二个频道:
select * from data_testwhere id mod 2=1and id > ${offset_1};
不存在偏移时的第一个通道:
select * from data_testwhere id mod 2=0;
第二个频道:
select * from data_testwhere id mod 2=1;
数据分片构建完成后,每个通道根据自己的数据分片来读取数据。2) 写数据前写数据:检查/data_test目录是否存在,如果目录不存在,则创建此目录,如果目录存在,执行2次操作;判断是否以覆盖方式写入数据,如果是,删除/data_test目录,然后创建目录,如果不是,执行3次操作;检查/data_test/.data目录是否存在,如果存在则先将其删除,然后再创建,确保没有其他任务因异常失败留下脏数据文件;写入hdfs的数据是单片写入的,不支持批量写入。数据会先写入/data_test/.data/目录,数据文件的命名格式为:channelIndex.jobId.fileIndex 收录三个部分:通道索引、jobId 和文件索引。3) 当checkpoint被触发时,FlinkX中的“status”代表的是标识字段id的值。我们假设触发检查点时两个通道的读写情况如图:
检查点触发后,两个阅读器首先生成一个Snapshot记录阅读状态,通道0的状态为id=12,通道1的状态为id=11。快照生成后,会在数据流中插入一个barrier,这个barrier会和数据一起流向Writer。以 Writer_0 为例。Writer_0 接收 Reader_0 和 Reader_1 发送的数据。假设先收到了Reader_0的barrier,那么Writer_0就停止向HDFS写入数据,先把收到的数据放入InputBuffer,等待Reader_1的barrier到达。然后写出Buffer中的所有数据,然后生成Writer的Snapshot。整个checkpoint结束后,记录的任务状态为:Reader_0:id=12Reader_1:id=11Writer_0:id=无法确定Writer_1:id=无法确定任务状态会记录在配置的HDFS目录/flinkx/checkpoint/abc123中。因为每个Writer接收两个Reader的数据,每个通道的数据读写速率可能不同,所以Writer接收数据的顺序是不确定的,但这不影响数据的准确性,因为数据是read 这个时候只能用Reader记录的状态来构造查询sql,我们只需要确保数据真的写入HDFS即可。
Writer 在生成快照之前,会做一系列的操作来保证所有接收到的数据都写入到 HDFS: a.关闭写入 HDFS 文件的数据流,此时会在 / data_test/.data 目录:/data_test/.data/0.abc123.0/data_test/.data/1.abc123.0b。将生成的两个数据文件移动到/data_test目录下;C、更新文件名模板为:channelIndex.abc123.1; 快照生成后,任务继续读写数据。如果在生成快照的过程中出现异常,任务会直接失败,所以不会生成这个快照,任务恢复时会从上次成功的快照恢复任务。4) 任务正常结束。
select * from data_testwhere id mod 2=0and id > 12;
第二个频道:
select * from data_testwhere id mod 2=1and id > 11;
这样就可以从上次失败的位置继续读取数据。
支持可续传的插件
理论上,只要支持过滤数据的数据源和支持事务的数据源能够支持续传功能,FlinkX目前支持的插件如下:
读者
作家
mysql等关系数据读取插件
HDFS、FTP、mysql等关系型数据库编写插件
4
实时采集
目前 FlinkX 支持实时采集 插件,包括 KafKa 和 binlog 插件。binlog插件是专门为实时采集 mysql数据库设计的。如果要支持其他数据源,只需要将数据输入到Kafka,然后使用FlinkX的Kafka插件来消费数据。比如oracle,你只需要使用oracle的ogg将数据发送到Kafka即可。这里专门讲解mysql的实时采集插件binlog。
二进制日志
binlog 是由 Mysql 服务器层维护的二进制日志。它与innodb引擎中的redo/undo log是完全不同的日志;它主要用于记录更新或潜在更新mysql数据的SQL语句,并使用“事务”。表格保存在磁盘上。binlog的主要功能有:
Replication:MySQL Replication在Master端打开binlog,Master将自己的binlog传递给slave并重放,达到主从数据一致性的目的;
数据恢复:通过mysqlbinlog工具恢复数据;
增量备份。
MySQL 主备复制
有记录数据变化的binlog日志是不够的。我们还需要用到MySQL的主从复制功能:主从复制是指一台服务器作为主数据库服务器,另一台或多台服务器作为从数据库服务器。数据自动复制到从服务器。
主从复制的过程:MySQL主将数据变化写入二进制日志(二进制日志,这里的记录称为二进制日志事件,可以通过show binlog events查看);MySQL slave 将 master 的二进制日志事件复制到它的 Relay 日志;MySQL slave 重放中继日志中的事件,并将数据更改反映到自己的数据中。
写入 Hive
binlog插件可以监控多张表的数据变化。解析的数据收录表名信息。读取的数据可以写入目标数据库中的某个表,也可以根据数据中收录的表名信息进行写入。对于不同的表,目前只有 Hive 插件支持该功能。Hive插件目前只有一个写插件,功能是基于HDFS写插件实现的,也就是说从binlog读到hive写也支持故障恢复功能。
写入Hive的过程:从数据中解析出MySQL表名,然后根据表名映射规则转换成对应的Hive表名;检查Hive表是否存在,如果不存在,则创建Hive表;查询Hive表的相关信息,构造HdfsOutputFormat;调用 HdfsOutputFormat 将数据写入 HDFS。
欢迎了解袋鼠云数栈 查看全部
完整的采集神器(袋鼠云研发手记:第五期和实时采集袋鼠云云引擎团队)
袋鼠云研发笔记
作为一家创新驱动的科技公司,袋鼠云每年研发投入数千万,公司员工80%为技术人员,()、()等产品不断迭代。在产品研发的过程中,技术兄弟可以文武兼备,在不断提升产品性能和体验的同时,也记录了这些改进和优化的过程,现记录在“袋鼠云研发笔记”栏目,以跟上行业的步伐。童鞋分享交流。
袋鼠云堆栈引擎团队
袋鼠云数据栈引擎团队拥有一批专家级、经验丰富的后端开发工程师,支持公司大数据栈产品线不同子项目的开发需求。FlinkX(基于Flink的数据同步)从项目中提取并开源。)、Jlogstash(java版logstash的实现)、FlinkStreamSQL(扩展原生FlinkSQL,实现流维表的join)多个项目。
在长期的项目实践和产品迭代过程中,团队成员在Hadoop技术栈上不断探索和探索,积累了丰富的经验和最佳实践。
第五期
FlinkX中断点续传与实时传输详解采集
袋鼠云是原生的一站式数据中心PaaS-数据栈,涵盖了数据中心建设过程中所需的各种工具(包括数据开发平台、数据资产平台、数据科学平台、数据服务引擎等),完整覆盖范围 离线计算和实时计算应用帮助企业大大缩短数据价值的提取过程,提高数据价值的提取能力。
数据栈架构图 目前,数据栈-离线开发平台(BatchWorks)中的数据离线同步任务和数据栈-实时开发平台(StreamWorks)中的数据实时同步任务已经基于FlinkX进行了统一。离线数据采集和实时采集的基本原理是一样的。主要区别在于源流是否有界,所以使用 Flink 的 Stream API 来同步这两种数据。场景,实现数据同步的批量流程统一。
1
特征
http
可续传是指数据同步任务在运行过程中由于各种原因而失败。无需重新同步数据。您只需要从上次失败的位置继续同步。类似于网络原因下载文件失败。无需再次下载文件,只需继续下载,可大大节省时间和计算资源。可续传是数据栈-离线开发平台(BatchWorks)中数据同步任务的一个功能,需要结合任务的错误重试机制来完成。当任务失败时,它会在引擎中重试。重试时,会从上次失败时读取的位置继续读取数据,直到任务运行成功。
实时采集
实时采集是数据栈-实时开发平台(StreamWorks)中数据采集任务的一个功能。当数据源中的数据被添加、删除或修改时,同步任务会监控这些变化,并将变化的数据实时同步到目标数据源。除了实时数据变化,实时采集和离线数据同步的另一个区别是:实时采集任务不会停止,任务会一直监控数据源是否发生变化。这点与Flink任务是一致的,所以实时采集任务是数字栈流计算应用中的一种任务类型,配置过程与离线计算中的同步任务基本相同。
2
Flink 中的检查点机制
可续传和实时采集都依赖于Flink的Checkpoint机制,所以先简单介绍一下。Checkpoint 是 Flink 容错机制的核心功能。它可以根据配置,根据Stream中各个Operator的状态,周期性的生成Snapshots,从而将这些状态数据定期持久化存储。当 Flink 程序意外崩溃时,它会重新运行 程序可以有选择地从这些 Snapshot 中恢复,从而纠正因故障导致的程序数据状态中断。
当Checkpoint被触发时,一个barrier标签被插入到多个分布式的Stream Source中,这些barrier会随着Stream中的数据记录流向下游的算子。当运营商收到屏障时,它将暂停处理 Steam 中新收到的数据记录。因为一个Operator可能有多个输入Streams,每个Stream中都会有一个对应的barrier,所以Operator必须等待输入Stream中的所有barrier都到达。当流中的所有障碍都到达操作员时,所有障碍似乎都在同一时刻(表明它们已对齐)。在等待所有barrier到达的时候,operator的缓冲区可能已经缓存了一些比Barrier更早到达Operator的数据记录(Outgoing Records)。此时,Operator 将发出(Emit)数据记录(Outgoing Records)作为下游 Operator 的输入。最后,Barrier 将对应 Snapshot (Emit) 发送出去作为第二个 Checkpoint 的结果数据。
3
http
先决条件
同步任务必须支持断点续传,对数据源有一些强制要求:
1、 数据源(这里特指关系型数据库)必须收录升序字段,例如主键或日期类型字段。检查点机制将在同步过程中用于记录该字段的值。恢复任务时将使用此字段。构造查询条件过滤同步数据。如果这个字段的值不是升序,那么在任务恢复时过滤的数据就会出错,最终会导致数据丢失或重复;
2、 数据源必须支持数据过滤。否则,任务无法从断点处恢复,会造成数据重复;
3、 目标数据源必须支持事务,比如关系数据库,临时文件也可以支持文件类型的数据源。
任务操作详细流程
我们用一个具体的任务来详细介绍整个过程。任务详情如下:
数据源
mysql表,假设表名为data_test,该表收录主键字段id
目标数据源
hdfs 文件系统,假设写入路径为 /data_test
并发
2
检查点配置
时间间隔为60s,checkpoint的StateBackend为FsStateBackend,路径为/flinkx/checkpoint
作业编号
用于构造数据文件的名称,假定为 abc123
1) 读取数据 读取数据时,首先要构造数据片段。构造数据分片就是根据通道索引和检查点记录的位置构造查询sql。sql模板如下:
select * from data_test where id mod ${channel_num}=${channel_index}and id > ${offset}
如果是第一次运行,或者上一个任务失败的时候checkpoint没有触发,那么offset不存在,具体查询sql:offset存在时的第一个channel可以根据offset和channel确定:
select * from data_testwhere id mod 2=0and id > ${offset_0};
第二个频道:
select * from data_testwhere id mod 2=1and id > ${offset_1};
不存在偏移时的第一个通道:
select * from data_testwhere id mod 2=0;
第二个频道:
select * from data_testwhere id mod 2=1;
数据分片构建完成后,每个通道根据自己的数据分片来读取数据。2) 写数据前写数据:检查/data_test目录是否存在,如果目录不存在,则创建此目录,如果目录存在,执行2次操作;判断是否以覆盖方式写入数据,如果是,删除/data_test目录,然后创建目录,如果不是,执行3次操作;检查/data_test/.data目录是否存在,如果存在则先将其删除,然后再创建,确保没有其他任务因异常失败留下脏数据文件;写入hdfs的数据是单片写入的,不支持批量写入。数据会先写入/data_test/.data/目录,数据文件的命名格式为:channelIndex.jobId.fileIndex 收录三个部分:通道索引、jobId 和文件索引。3) 当checkpoint被触发时,FlinkX中的“status”代表的是标识字段id的值。我们假设触发检查点时两个通道的读写情况如图:
检查点触发后,两个阅读器首先生成一个Snapshot记录阅读状态,通道0的状态为id=12,通道1的状态为id=11。快照生成后,会在数据流中插入一个barrier,这个barrier会和数据一起流向Writer。以 Writer_0 为例。Writer_0 接收 Reader_0 和 Reader_1 发送的数据。假设先收到了Reader_0的barrier,那么Writer_0就停止向HDFS写入数据,先把收到的数据放入InputBuffer,等待Reader_1的barrier到达。然后写出Buffer中的所有数据,然后生成Writer的Snapshot。整个checkpoint结束后,记录的任务状态为:Reader_0:id=12Reader_1:id=11Writer_0:id=无法确定Writer_1:id=无法确定任务状态会记录在配置的HDFS目录/flinkx/checkpoint/abc123中。因为每个Writer接收两个Reader的数据,每个通道的数据读写速率可能不同,所以Writer接收数据的顺序是不确定的,但这不影响数据的准确性,因为数据是read 这个时候只能用Reader记录的状态来构造查询sql,我们只需要确保数据真的写入HDFS即可。
Writer 在生成快照之前,会做一系列的操作来保证所有接收到的数据都写入到 HDFS: a.关闭写入 HDFS 文件的数据流,此时会在 / data_test/.data 目录:/data_test/.data/0.abc123.0/data_test/.data/1.abc123.0b。将生成的两个数据文件移动到/data_test目录下;C、更新文件名模板为:channelIndex.abc123.1; 快照生成后,任务继续读写数据。如果在生成快照的过程中出现异常,任务会直接失败,所以不会生成这个快照,任务恢复时会从上次成功的快照恢复任务。4) 任务正常结束。
select * from data_testwhere id mod 2=0and id > 12;
第二个频道:
select * from data_testwhere id mod 2=1and id > 11;
这样就可以从上次失败的位置继续读取数据。
支持可续传的插件
理论上,只要支持过滤数据的数据源和支持事务的数据源能够支持续传功能,FlinkX目前支持的插件如下:
读者
作家
mysql等关系数据读取插件
HDFS、FTP、mysql等关系型数据库编写插件
4
实时采集
目前 FlinkX 支持实时采集 插件,包括 KafKa 和 binlog 插件。binlog插件是专门为实时采集 mysql数据库设计的。如果要支持其他数据源,只需要将数据输入到Kafka,然后使用FlinkX的Kafka插件来消费数据。比如oracle,你只需要使用oracle的ogg将数据发送到Kafka即可。这里专门讲解mysql的实时采集插件binlog。
二进制日志
binlog 是由 Mysql 服务器层维护的二进制日志。它与innodb引擎中的redo/undo log是完全不同的日志;它主要用于记录更新或潜在更新mysql数据的SQL语句,并使用“事务”。表格保存在磁盘上。binlog的主要功能有:
Replication:MySQL Replication在Master端打开binlog,Master将自己的binlog传递给slave并重放,达到主从数据一致性的目的;
数据恢复:通过mysqlbinlog工具恢复数据;
增量备份。
MySQL 主备复制
有记录数据变化的binlog日志是不够的。我们还需要用到MySQL的主从复制功能:主从复制是指一台服务器作为主数据库服务器,另一台或多台服务器作为从数据库服务器。数据自动复制到从服务器。
主从复制的过程:MySQL主将数据变化写入二进制日志(二进制日志,这里的记录称为二进制日志事件,可以通过show binlog events查看);MySQL slave 将 master 的二进制日志事件复制到它的 Relay 日志;MySQL slave 重放中继日志中的事件,并将数据更改反映到自己的数据中。
写入 Hive
binlog插件可以监控多张表的数据变化。解析的数据收录表名信息。读取的数据可以写入目标数据库中的某个表,也可以根据数据中收录的表名信息进行写入。对于不同的表,目前只有 Hive 插件支持该功能。Hive插件目前只有一个写插件,功能是基于HDFS写插件实现的,也就是说从binlog读到hive写也支持故障恢复功能。
写入Hive的过程:从数据中解析出MySQL表名,然后根据表名映射规则转换成对应的Hive表名;检查Hive表是否存在,如果不存在,则创建Hive表;查询Hive表的相关信息,构造HdfsOutputFormat;调用 HdfsOutputFormat 将数据写入 HDFS。
欢迎了解袋鼠云数栈
完整的采集神器(完整的采集神器--网页采集软件(清风网))
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-09-27 15:04
完整的采集神器--网页采集软件-清风网这篇文章不算太老,
前两年天池举办这场比赛的时候,使用的qcva800在demo中已经可以正常采集一些资源,自己一时兴起尝试做了一个,结果这两年差不多这两年已经很少有人用了,一方面应为qcva800采集速度慢,另一方面,采集结果不是get就是post的那种,无法保存。我觉得有点遗憾。因为我感觉对于自己遇到的问题总想用更好的工具处理,开始找了知乎一些比较专业人士,也花了不少功夫才把线路给堵死,现在很后悔当初没有坚持。
但是也已经没有了补救的可能性。最后直接放弃。前不久参加一个国内比赛,比赛的时候用我姐姐的编程语言c++写了一个爬虫,他直接调用,体验一下,结果性能不足,一方面抓取过程出错很多,网速慢得一逼,最终好在是在第三方反爬的魔掌下,抓到了不少,实验结果还不错。后来因为版权问题,暂停了两个月时间。我想说,在说其他方面性能问题之前,先说一下我以前写爬虫的时候遇到的采集问题。
首先,采集请求需要一定的http头信息,这个是模拟或者查看代码获取,另外它是从服务器返回数据,还有分布在多个web框架中处理多个动态url头,像springmvc需要传递参数:post/get/put/delete/out/prompt/upload等等,还有就是selenium支持代理处理来查看这些请求也能有一些经验。
这些使用多线程都能解决,但是一开始没有这些编程思维,性能大大下降。结果就是爬取速度慢。比赛中的下载密码破解都是提前制作的,而且还加入了传输的密码,其实后来也挺蛋疼,因为自己不写,现在都是自己加密码加密转换。而且还需要尝试,我比赛的链接本来就要显示成google后缀,根本没法输入。另外,有时候好不容易爬到的东西,不能保存。
如果想要保存的话,只能手动insert到缓存中,post返回的还不能直接保存。一个url无法正常返回到数据库里。总的来说,做爬虫这两年,找到现在不能成熟的解决方案太多,这是一个无止境的开发工作。想借着这个机会,更细致的总结一下。工具限制在知乎这种公开环境里的话,我相信,大家不会被限制在各种工具中,然后保存在硬盘上。
但是大家应该遇到过,或者自己去实现这样的硬盘找回吧,现在主流都是基于mongodb+redis的方案,然后gossip,hash等做一个字典,然后用html_decode做处理,json.load或者json.stringify等其他文件格式转换。这个只能自己写一下脚本去慢慢实现一下保存,只是一个入门而已。工具的。 查看全部
完整的采集神器(完整的采集神器--网页采集软件(清风网))
完整的采集神器--网页采集软件-清风网这篇文章不算太老,
前两年天池举办这场比赛的时候,使用的qcva800在demo中已经可以正常采集一些资源,自己一时兴起尝试做了一个,结果这两年差不多这两年已经很少有人用了,一方面应为qcva800采集速度慢,另一方面,采集结果不是get就是post的那种,无法保存。我觉得有点遗憾。因为我感觉对于自己遇到的问题总想用更好的工具处理,开始找了知乎一些比较专业人士,也花了不少功夫才把线路给堵死,现在很后悔当初没有坚持。
但是也已经没有了补救的可能性。最后直接放弃。前不久参加一个国内比赛,比赛的时候用我姐姐的编程语言c++写了一个爬虫,他直接调用,体验一下,结果性能不足,一方面抓取过程出错很多,网速慢得一逼,最终好在是在第三方反爬的魔掌下,抓到了不少,实验结果还不错。后来因为版权问题,暂停了两个月时间。我想说,在说其他方面性能问题之前,先说一下我以前写爬虫的时候遇到的采集问题。
首先,采集请求需要一定的http头信息,这个是模拟或者查看代码获取,另外它是从服务器返回数据,还有分布在多个web框架中处理多个动态url头,像springmvc需要传递参数:post/get/put/delete/out/prompt/upload等等,还有就是selenium支持代理处理来查看这些请求也能有一些经验。
这些使用多线程都能解决,但是一开始没有这些编程思维,性能大大下降。结果就是爬取速度慢。比赛中的下载密码破解都是提前制作的,而且还加入了传输的密码,其实后来也挺蛋疼,因为自己不写,现在都是自己加密码加密转换。而且还需要尝试,我比赛的链接本来就要显示成google后缀,根本没法输入。另外,有时候好不容易爬到的东西,不能保存。
如果想要保存的话,只能手动insert到缓存中,post返回的还不能直接保存。一个url无法正常返回到数据库里。总的来说,做爬虫这两年,找到现在不能成熟的解决方案太多,这是一个无止境的开发工作。想借着这个机会,更细致的总结一下。工具限制在知乎这种公开环境里的话,我相信,大家不会被限制在各种工具中,然后保存在硬盘上。
但是大家应该遇到过,或者自己去实现这样的硬盘找回吧,现在主流都是基于mongodb+redis的方案,然后gossip,hash等做一个字典,然后用html_decode做处理,json.load或者json.stringify等其他文件格式转换。这个只能自己写一下脚本去慢慢实现一下保存,只是一个入门而已。工具的。
完整的采集神器(一下file_get_contents函数可以获取远程链接数据的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-09-24 21:23
对于做过数据采集的人来说,curl一定不陌生。PHP中虽然有file_get_contents函数可以获取远程链接数据,但是可控性太差。对于各种复杂的情况,file_get_contents 似乎有点无能为力。因此,本文将向您介绍采集 神器cURL 的使用。
给大家补充一下file_get_contents函数获取远程链接数据的方法。
这段代码会直接使用curl来显示文件的内容,但是问题来了。因为 curl 是 PHP 的扩展,所以一些主机为了安全会使用 curl。本地调试宁外PHP的时候,curl也是关闭的,所以会报错。所以这段代码是不可取的,所以云落给他改写了
修改后的版本是对curl扩展做一个判断,看服务器有没有打开curl扩展。如果打开,则直接显示文件,如果未打开,则显示提示文本。
虽然问题解决了,但还有一个问题。我只是显示了一段文字。我没做什么大事,为什么要写这么多代码??
经过一些傻测试,我发现file_get_contents获取远程文件内容并不比curl慢。在某些文件较少的情况下,它可能比curl扩展快得多,所以我重新编写了代码。
工具
火狐浏览器 (FireFox) + Firebug
“工人们要想做得好,就必须磨砺他们的工具。” 在分析案例之前,让我们学习一下如何使用神器Firebug来获取我们需要的信息。
使用F12打开Firebug,我们可以得到如图所示的界面(一):
1、 箭头图标是“元素选择”工具。单击一次以突出显示该图标。同时,鼠标在页面内的移动会同时选中HTML菜单中的相应内容。设置元素后,图标将突出显示并取消。如图(二):
Firebug 视图元素
2、控制面板
JS中console.log系列函数的打印输出在这里。
3、HTML
HTML内容,注意这里看到的不一定是采集要解析的内容。采集 时对内容的分析将始终基于查看源代码(Ctrl+U)。这里只是为了快速定位元素。然后选择一个比较特殊的引用,在源码中定位到对应的位置。
例如,如果您在 HTML 中看到一个标签
演示
, 但是你查看源码看到的可能是
演示
, 如果按照前者对采集的内容进行正则匹配,则不会得到任何结果。
4、CSS
这是CSS文件的内容
5、脚本
这是Javascript文件的内容
6、DOM
Dom 节点内容
7、网络
每个请求链接的数据,这里是我们采集应该注意和分析的地方。它可以显示每个请求的参数、请求头、cookie数据等。在页面提交会刷新的情况下,需要使用hold,让页面请求的内容刷新后保留在控制台中,如图(三):
此外,Firefox 有一个 Tamper 数据扩展,也可以获取请求数据,需要时可以安装和使用。
8、饼干
饼干数据
在图片中(一),你也可以看到下面有很多可选的小菜单项,其中keep是我们要注意的。当它被选中时,即使页面通过提交刷新表单,下面内容区域的数据仍会保留,这对于分析提交的数据尤为关键。
总结
我们在分析采集请求时,主要关心的是“Network”菜单中的请求数据。必要时,使用“Keep”查看刷新页面的请求数据。您可以在请求前使用“清除”清除以下内容。
案例分析
一、Simple采集这里所说的simple采集是指单页GET请求的采集。如此简单,即使通过file_get_contents函数,也可以轻松获得页面返回结果。
代码片段 file_get_contents
<p> 查看全部
完整的采集神器(一下file_get_contents函数可以获取远程链接数据的方法)
对于做过数据采集的人来说,curl一定不陌生。PHP中虽然有file_get_contents函数可以获取远程链接数据,但是可控性太差。对于各种复杂的情况,file_get_contents 似乎有点无能为力。因此,本文将向您介绍采集 神器cURL 的使用。
给大家补充一下file_get_contents函数获取远程链接数据的方法。
这段代码会直接使用curl来显示文件的内容,但是问题来了。因为 curl 是 PHP 的扩展,所以一些主机为了安全会使用 curl。本地调试宁外PHP的时候,curl也是关闭的,所以会报错。所以这段代码是不可取的,所以云落给他改写了
修改后的版本是对curl扩展做一个判断,看服务器有没有打开curl扩展。如果打开,则直接显示文件,如果未打开,则显示提示文本。
虽然问题解决了,但还有一个问题。我只是显示了一段文字。我没做什么大事,为什么要写这么多代码??
经过一些傻测试,我发现file_get_contents获取远程文件内容并不比curl慢。在某些文件较少的情况下,它可能比curl扩展快得多,所以我重新编写了代码。
工具
火狐浏览器 (FireFox) + Firebug
“工人们要想做得好,就必须磨砺他们的工具。” 在分析案例之前,让我们学习一下如何使用神器Firebug来获取我们需要的信息。
使用F12打开Firebug,我们可以得到如图所示的界面(一):
1、 箭头图标是“元素选择”工具。单击一次以突出显示该图标。同时,鼠标在页面内的移动会同时选中HTML菜单中的相应内容。设置元素后,图标将突出显示并取消。如图(二):
Firebug 视图元素
2、控制面板
JS中console.log系列函数的打印输出在这里。
3、HTML
HTML内容,注意这里看到的不一定是采集要解析的内容。采集 时对内容的分析将始终基于查看源代码(Ctrl+U)。这里只是为了快速定位元素。然后选择一个比较特殊的引用,在源码中定位到对应的位置。
例如,如果您在 HTML 中看到一个标签
演示
, 但是你查看源码看到的可能是
演示
, 如果按照前者对采集的内容进行正则匹配,则不会得到任何结果。
4、CSS
这是CSS文件的内容
5、脚本
这是Javascript文件的内容
6、DOM
Dom 节点内容
7、网络
每个请求链接的数据,这里是我们采集应该注意和分析的地方。它可以显示每个请求的参数、请求头、cookie数据等。在页面提交会刷新的情况下,需要使用hold,让页面请求的内容刷新后保留在控制台中,如图(三):
此外,Firefox 有一个 Tamper 数据扩展,也可以获取请求数据,需要时可以安装和使用。
8、饼干
饼干数据
在图片中(一),你也可以看到下面有很多可选的小菜单项,其中keep是我们要注意的。当它被选中时,即使页面通过提交刷新表单,下面内容区域的数据仍会保留,这对于分析提交的数据尤为关键。
总结
我们在分析采集请求时,主要关心的是“Network”菜单中的请求数据。必要时,使用“Keep”查看刷新页面的请求数据。您可以在请求前使用“清除”清除以下内容。
案例分析
一、Simple采集这里所说的simple采集是指单页GET请求的采集。如此简单,即使通过file_get_contents函数,也可以轻松获得页面返回结果。
代码片段 file_get_contents
<p>
完整的采集神器(完整的采集神器:打开ie浏览器,安装web前端)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-22 15:02
完整的采集神器:.打开ie浏览器,安装web前端挖掘器:进入开发者选项,代理->tcp代理->单输入url->一直下一步,加载成功后,启动fiddler,然后打开某站点的任何页面:(注意浏览器的设置页面里没有那行代码):intra:(或者intra[])[0],intra[][0]的意思是“从ie的默认url路径开始,到真正要请求的站点为止”的任意个数,代表可以扫描的页面数,一般我们需要扫描“本站全部”或者“本站特定页面”。
当然,本身设置url路径的时候就可以启用fiddler,不用这一步时,才扫描本站所有页面,所以这一步是多余的。fiddler设置url可以点菜单中的general->settings,选择firstclickfiddlersettings,在settings填入你的ie默认url。如上图,在工具栏上就会出现“工具”,工具f2里面就有一个“浏览fiddler设置”。
2.浏览器中输入“”,输入需要扫描的网址,点next,浏览器会给出一个断网页的区域,然后我们要做的就是点击这个区域的按钮(点击之后不要关闭浏览器)。这里的意思是显示“next:”后面的页面(如果没有关闭浏览器,浏览器默认不显示)。下图就是正常的页面显示路径。点击按钮后:这时候会跳转到ie或者360,在这里和360浏览器共享同一个数据,所以可以使用上述方法抓取本站内容。
然后在浏览器中输入自己的网址:,输入:点next,浏览器就会给你列出本站所有特定页面了,随便你点开哪一个,然后在页面上右键点击:可以得到“download”,上方的图是所有页面的下载链接。 查看全部
完整的采集神器(完整的采集神器:打开ie浏览器,安装web前端)
完整的采集神器:.打开ie浏览器,安装web前端挖掘器:进入开发者选项,代理->tcp代理->单输入url->一直下一步,加载成功后,启动fiddler,然后打开某站点的任何页面:(注意浏览器的设置页面里没有那行代码):intra:(或者intra[])[0],intra[][0]的意思是“从ie的默认url路径开始,到真正要请求的站点为止”的任意个数,代表可以扫描的页面数,一般我们需要扫描“本站全部”或者“本站特定页面”。
当然,本身设置url路径的时候就可以启用fiddler,不用这一步时,才扫描本站所有页面,所以这一步是多余的。fiddler设置url可以点菜单中的general->settings,选择firstclickfiddlersettings,在settings填入你的ie默认url。如上图,在工具栏上就会出现“工具”,工具f2里面就有一个“浏览fiddler设置”。
2.浏览器中输入“”,输入需要扫描的网址,点next,浏览器会给出一个断网页的区域,然后我们要做的就是点击这个区域的按钮(点击之后不要关闭浏览器)。这里的意思是显示“next:”后面的页面(如果没有关闭浏览器,浏览器默认不显示)。下图就是正常的页面显示路径。点击按钮后:这时候会跳转到ie或者360,在这里和360浏览器共享同一个数据,所以可以使用上述方法抓取本站内容。
然后在浏览器中输入自己的网址:,输入:点next,浏览器就会给你列出本站所有特定页面了,随便你点开哪一个,然后在页面上右键点击:可以得到“download”,上方的图是所有页面的下载链接。
完整的采集神器(优采云采集器——做工完美性能强悍的网页内容采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-09-22 03:19
优采云采集器在前谷歌技术团队强大实力的支持下,基于最流行的人工智能技术构建了创新的新一代web内容采集软件。该软件具有很强的兼容性,可以同时满足windows、MAC和Linux的完整操作系统。因此,该软件几乎可以在所有主要平台上使用。该软件具有完美的工艺和强大的性能。它不仅可以自动化采集的数据,还可以确保数据在采集过程中被清理干净,删除不必要的代码数据,消除他人的痕迹,让采集的内容真正成为自己的成果,并在数据源过滤各种数据内容,为后期内容的填补奠定了坚实的基础。对于各种有需求的用户,其功能支持两种不同的采集模式:智能模式和流程图。多个采集模式更有可能,这可以确保采集达到最完美的内容。在强化软件功能的同时,它也不会忘记优化其运行,这对于大多数产品、运营、金融、新闻、电子商务来说,它是一款为销售和数据分析从业者以及政府机构和学术研究等用户量身定制的热门产品。通过使用优采云采集器,用户可以更悠闲地享受工作时间。在忙碌和效率为王的时代,一个好的软件是非常重要的。用户可以快速准确地获取大量的网页数据,彻底解决了手工数据采集面临的各种问题,降低了获取信息的成本,有需要的用户不妨下载并试用
功能特征
1、可视点击,一键式采集网页数据
完全拖放点击操作,无需开发任何人都可以在不了解技术的情况下使用的web数据采集器
2、采集和出口是免费、无限制和有保证的
所有免费采集软件,无限制数据导出,数据可以导出到本地文件,发布到网站和数据库等
3、可在后台运行并实时显示速度
您可以在不干扰其他前台工作的情况下切换软件的后台操作。悬架窗口可以实时查看采集速度和采集数据
4、full platform,可用于win/MAC/Linux
与其他采集器不同,优采云支持所有操作系统版本更新和功能升级,以同步所有平台
优采云采集器适用场景
1、品牌/价格监控
监控品牌信息和产品评估,跟踪价格趋势,竞争产品分析,SEO监控和优化,舆论监控等
2、行业分析
采集国内外的主要新闻来源、博客、论坛、社交网络和电子商务平台有助于行业分析和商业决策
3、产品开发
自动获取格式化数据,适用于不同终端的产品内容同步。准确获取用户反馈和偏好,提高研发效率
4、precision营销
快速识别潜在客户,全面采集客户需求。提高营销效率,提高销售业绩
5、学术研究
一键访问海量数据,支持大数据分析研究、机器学习训练建模、人工智能学术研究等
使用教程
步骤1:创建采集任务
1、start优采云采集器,进入主界面,点击创建任务按钮创建“向导采集Task”
2、输入百度搜索的URL,包括三种方式
a。手动输入:直接在输入框中输入URL。多个URL需要用换行符分隔
b。单击以读取文件:用户选择一个文件来存储URL。文件中可以有多个URL地址,并且该地址需要用换行符分隔
c。批量添加方式:通过添加和调整地址参数,生成多个常规地址
步骤2:定制采集流程
1、单击“创建”自动打开第一个URL,然后进入自定义设置页面。默认情况下,已创建开始、打开网页和结束的流程块。底部模板区域用于拖动到画布以生成新的流程块;单击“打开的网页”中的“属性”按钮修改打开的网址
2、add input text flow block(添加输入文本流块):将底部模板区域中的输入文本块拖动到打开的网页块背面附近。当阴影区域出现时,可以释放鼠标。此时,它将自动连接并完成添加
3、generate a complete flow chart:按照上面添加输入文本流块的拖放过程添加一个新块,如下图所示:
4、单击开始采集开始采集@
步骤3:数据采集和导出
1、采集正在运行任务
2、采集完成后,选择“导出数据”将所有数据导出到本地文件
3、选择“导出方法”导出采集良好数据。在这里,您可以选择excel作为导出格式
4、采集数据导出已完成
更新日志
优采云采集器v3.5.4更新日志(2021-03)-09)
更新日期:2020年11月2日
增加
导出CSV时支持制表符分隔符
添加用于退出软件的API接口
优化
优化文件下载的各种兼容性问题
修理
修复按组运行的问题
修复已处理链接无法深入采集的错误@ 查看全部
完整的采集神器(优采云采集器——做工完美性能强悍的网页内容采集软件)
优采云采集器在前谷歌技术团队强大实力的支持下,基于最流行的人工智能技术构建了创新的新一代web内容采集软件。该软件具有很强的兼容性,可以同时满足windows、MAC和Linux的完整操作系统。因此,该软件几乎可以在所有主要平台上使用。该软件具有完美的工艺和强大的性能。它不仅可以自动化采集的数据,还可以确保数据在采集过程中被清理干净,删除不必要的代码数据,消除他人的痕迹,让采集的内容真正成为自己的成果,并在数据源过滤各种数据内容,为后期内容的填补奠定了坚实的基础。对于各种有需求的用户,其功能支持两种不同的采集模式:智能模式和流程图。多个采集模式更有可能,这可以确保采集达到最完美的内容。在强化软件功能的同时,它也不会忘记优化其运行,这对于大多数产品、运营、金融、新闻、电子商务来说,它是一款为销售和数据分析从业者以及政府机构和学术研究等用户量身定制的热门产品。通过使用优采云采集器,用户可以更悠闲地享受工作时间。在忙碌和效率为王的时代,一个好的软件是非常重要的。用户可以快速准确地获取大量的网页数据,彻底解决了手工数据采集面临的各种问题,降低了获取信息的成本,有需要的用户不妨下载并试用
https://www.aiweibk.com/wp-con ... 0.jpg 300w" />功能特征
1、可视点击,一键式采集网页数据
完全拖放点击操作,无需开发任何人都可以在不了解技术的情况下使用的web数据采集器
2、采集和出口是免费、无限制和有保证的
所有免费采集软件,无限制数据导出,数据可以导出到本地文件,发布到网站和数据库等
3、可在后台运行并实时显示速度
您可以在不干扰其他前台工作的情况下切换软件的后台操作。悬架窗口可以实时查看采集速度和采集数据
4、full platform,可用于win/MAC/Linux
与其他采集器不同,优采云支持所有操作系统版本更新和功能升级,以同步所有平台
优采云采集器适用场景
1、品牌/价格监控
监控品牌信息和产品评估,跟踪价格趋势,竞争产品分析,SEO监控和优化,舆论监控等
2、行业分析
采集国内外的主要新闻来源、博客、论坛、社交网络和电子商务平台有助于行业分析和商业决策
3、产品开发
自动获取格式化数据,适用于不同终端的产品内容同步。准确获取用户反馈和偏好,提高研发效率
4、precision营销
快速识别潜在客户,全面采集客户需求。提高营销效率,提高销售业绩
5、学术研究
一键访问海量数据,支持大数据分析研究、机器学习训练建模、人工智能学术研究等
使用教程
步骤1:创建采集任务
1、start优采云采集器,进入主界面,点击创建任务按钮创建“向导采集Task”
https://www.aiweibk.com/wp-con ... 1.jpg 300w" />2、输入百度搜索的URL,包括三种方式
a。手动输入:直接在输入框中输入URL。多个URL需要用换行符分隔
b。单击以读取文件:用户选择一个文件来存储URL。文件中可以有多个URL地址,并且该地址需要用换行符分隔
c。批量添加方式:通过添加和调整地址参数,生成多个常规地址
https://www.aiweibk.com/wp-con ... 1.jpg 300w" />步骤2:定制采集流程
1、单击“创建”自动打开第一个URL,然后进入自定义设置页面。默认情况下,已创建开始、打开网页和结束的流程块。底部模板区域用于拖动到画布以生成新的流程块;单击“打开的网页”中的“属性”按钮修改打开的网址
https://www.aiweibk.com/wp-con ... 2.jpg 300w" />2、add input text flow block(添加输入文本流块):将底部模板区域中的输入文本块拖动到打开的网页块背面附近。当阴影区域出现时,可以释放鼠标。此时,它将自动连接并完成添加
https://www.aiweibk.com/wp-con ... 1.jpg 300w" />3、generate a complete flow chart:按照上面添加输入文本流块的拖放过程添加一个新块,如下图所示:
https://www.aiweibk.com/wp-con ... 1.jpg 300w" />4、单击开始采集开始采集@
https://www.aiweibk.com/wp-con ... 0.jpg 300w" />步骤3:数据采集和导出
1、采集正在运行任务
https://www.aiweibk.com/wp-con ... 0.jpg 300w" />2、采集完成后,选择“导出数据”将所有数据导出到本地文件
https://www.aiweibk.com/wp-con ... 1.jpg 300w" />3、选择“导出方法”导出采集良好数据。在这里,您可以选择excel作为导出格式
https://www.aiweibk.com/wp-con ... 9.jpg 300w" />4、采集数据导出已完成
https://www.aiweibk.com/wp-con ... 5.jpg 300w" />更新日志
优采云采集器v3.5.4更新日志(2021-03)-09)
更新日期:2020年11月2日
增加
导出CSV时支持制表符分隔符
添加用于退出软件的API接口
优化
优化文件下载的各种兼容性问题
修理
修复按组运行的问题
修复已处理链接无法深入采集的错误@
完整的采集神器(易撰自媒体采集平台特色五年数据服务:确保数据完整稳定系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-09-20 21:17
一转自媒体采集平台是不久的将来非常流行的办公产品。对于许多公务员来说,每个人都需要大量的材料。您可以通过搜索关键信息找到所需的资源内容,这些信息可以免费使用。你还在等什么?赶快下载轻松编写的自媒体采集平台
易于编写自媒体采集平台教程
1.首先在浏览器上打开易于书写的网站。有两种方法1.直接在浏览器上进入易写的网站网站
2.在搜索引擎上输入“一转”关键词并单击以输入网站。然后,在网站右上角,找到注册部分
2.点击登录,二维码弹出。然后拿出手机,打开微信界面,使用“扫描”功能
3.登录并注册后,进入工具页面开始使用工具。如何使用工具取决于您的个人情况
4.如果您遇到其他问题,您可以单击右侧个人中心的FAQ页面。将会有详细的答案
易于编写自媒体采集平台功能
五年数据服务:确保数据完整性和稳定性
系统模块化开发:按需配置,降低成本
核心算法:成熟算法技术改进
完善的售后服务:每天24小时
多种支持计划:零代理费、零风险
易于编写自媒体采集平台函数
1.此外,标题中的数字将让用户准确把握关键点。以小编的名字为例。如果你扫描过去的数据,这将是显而易见的。您可以看到,这引入了四种标题创建方法。因此,有需要的用户会点击阅读,这反映了数字的清晰度
2.知乎标题让用户感觉这正是我所需要的。然而,它更适合于一些科普帖子或干货文章标题来评价当前的热门话题。最常见的标题创建方法是将问题抛给用户,让用户参与,从而改进推荐
3.使用比较规则选择标题是最好的。比较的冲突是明显的,可以更好地吸引用户的注意力,引起冲突,增强用户的好奇心。比较规则是一种常用的标题技巧。每个人都可以结合内容以比较的形式创建标题
易于编写自媒体采集平台的优点
1、professional information-这里是为您提供的咨询信息。最热门的新闻可以及时为您推送和选择
2、原创materials-有许多原创materials和编辑功能可以让您获得真实的体验,许多内容可以在第一时间获得
3、intelligent search-在这里您可以搜索您感兴趣的内容,及时选择焦点,并在线浏览所有数据 查看全部
完整的采集神器(易撰自媒体采集平台特色五年数据服务:确保数据完整稳定系统)
一转自媒体采集平台是不久的将来非常流行的办公产品。对于许多公务员来说,每个人都需要大量的材料。您可以通过搜索关键信息找到所需的资源内容,这些信息可以免费使用。你还在等什么?赶快下载轻松编写的自媒体采集平台
易于编写自媒体采集平台教程
1.首先在浏览器上打开易于书写的网站。有两种方法1.直接在浏览器上进入易写的网站网站
2.在搜索引擎上输入“一转”关键词并单击以输入网站。然后,在网站右上角,找到注册部分
2.点击登录,二维码弹出。然后拿出手机,打开微信界面,使用“扫描”功能
3.登录并注册后,进入工具页面开始使用工具。如何使用工具取决于您的个人情况
4.如果您遇到其他问题,您可以单击右侧个人中心的FAQ页面。将会有详细的答案
易于编写自媒体采集平台功能
五年数据服务:确保数据完整性和稳定性
系统模块化开发:按需配置,降低成本
核心算法:成熟算法技术改进
完善的售后服务:每天24小时
多种支持计划:零代理费、零风险
易于编写自媒体采集平台函数
1.此外,标题中的数字将让用户准确把握关键点。以小编的名字为例。如果你扫描过去的数据,这将是显而易见的。您可以看到,这引入了四种标题创建方法。因此,有需要的用户会点击阅读,这反映了数字的清晰度
2.知乎标题让用户感觉这正是我所需要的。然而,它更适合于一些科普帖子或干货文章标题来评价当前的热门话题。最常见的标题创建方法是将问题抛给用户,让用户参与,从而改进推荐
3.使用比较规则选择标题是最好的。比较的冲突是明显的,可以更好地吸引用户的注意力,引起冲突,增强用户的好奇心。比较规则是一种常用的标题技巧。每个人都可以结合内容以比较的形式创建标题
易于编写自媒体采集平台的优点
1、professional information-这里是为您提供的咨询信息。最热门的新闻可以及时为您推送和选择
2、原创materials-有许多原创materials和编辑功能可以让您获得真实的体验,许多内容可以在第一时间获得
3、intelligent search-在这里您可以搜索您感兴趣的内容,及时选择焦点,并在线浏览所有数据
完整的采集神器(bilibili视频信息采集工具下载|抖音流行歌曲批量下载器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2021-09-20 21:14
bilibili视频信息采集工具是一个视频信息采集工具,支持采集 K15 采集 K15 采集 K 1 @ 伪原创的的的的的的的的的是的的的的的的的的的的的的的的的的的的的的的形式的的的的的的非毒性!
软件简介
毕ilibili视频下载软件是一家批次下载工具为B站内置,它可以帮助用户下载B站视频,动画,让您浏览直接,并支持视频在线播放,只是简单的操作,通常多次视频也是如此无法缓存下载,但也以大量下载。让我们分享一个Bilibili Live下载软件给您,您可以下载所有视频!
毕ilibili视频下载程序是一个视频下载工具的哩哩视频视频视频,易于使用,下载速度,通过av的b站视频的推出视频,如果找不到av号码,也可以使用AV编号获取功能,下载的视频是MP4格式,易于观看。
指令
如果下载期间下载失败,则可能是时间限制,地址无效,并且可以解决然后下载它。
您可以使用Ctrl和Shift Multiplexing
1、将复制要下载到软件对应位置的视频链接,单击“分辨率”
2、选择该分辨率的视频,单击右键单击以选择“下载视频”或“下载所有视频”
上一个:伪原创6 @热下载下载工具下载下载| 伪原创6 @流行批批下载下载
下一篇:VSO下载视频下载v 5.1.1. 70官方版 查看全部
完整的采集神器(bilibili视频信息采集工具下载|抖音流行歌曲批量下载器)
bilibili视频信息采集工具是一个视频信息采集工具,支持采集 K15 采集 K15 采集 K 1 @ 伪原创的的的的的的的的的是的的的的的的的的的的的的的的的的的的的的的形式的的的的的的非毒性!
软件简介
毕ilibili视频下载软件是一家批次下载工具为B站内置,它可以帮助用户下载B站视频,动画,让您浏览直接,并支持视频在线播放,只是简单的操作,通常多次视频也是如此无法缓存下载,但也以大量下载。让我们分享一个Bilibili Live下载软件给您,您可以下载所有视频!
毕ilibili视频下载程序是一个视频下载工具的哩哩视频视频视频,易于使用,下载速度,通过av的b站视频的推出视频,如果找不到av号码,也可以使用AV编号获取功能,下载的视频是MP4格式,易于观看。
指令
如果下载期间下载失败,则可能是时间限制,地址无效,并且可以解决然后下载它。
您可以使用Ctrl和Shift Multiplexing
1、将复制要下载到软件对应位置的视频链接,单击“分辨率”
2、选择该分辨率的视频,单击右键单击以选择“下载视频”或“下载所有视频”
上一个:伪原创6 @热下载下载工具下载下载| 伪原创6 @流行批批下载下载
下一篇:VSO下载视频下载v 5.1.1. 70官方版
完整的采集神器(完美者()网络标准头像采集工具,增加保存批量速拍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-09-20 21:11
Perfectist()网站基于软件下载,修订版网站扩展了功能板块,以解决用户在使用软件网站过程中遇到的所有问题,增加了“软件百科全书”和“Brocade Wonder technology”等新渠道,能够更好的为用户的软件使用周期提供更专业的服务
软件介绍
网络标准化身采集工具是一个简单易用的免费网络化身采集工具。它是免费安装的,可以通过双击运行。主要功能是免费的。只有普通人不需要的照相馆批量快速拍摄功能才收费。支持图片拖放、剪贴板粘贴和键盘操作。它用于在线注册、论坛、QQ头像、在线商店头像和其他标准头像采集. 它可以简单地编辑和修改图像,并输出设置的长度和宽度图片。如果输出JPG和JPEG图片,还可以预先设置输出图片文件的音量。化身采集有两种方式:你可以用这个软件打开现有的图片文件采集或直接拍摄采集
更新日志,增加旋转图片功能,增加保存批量快照设置功能,优化原有功能,使其更加友好
“锦绣包与精彩技巧”栏目是关于整个网络中软件使用的技巧或软件使用过程中各种问题的解答的集合文章. 在专栏成立之初,编辑欢迎所有软件之神踊跃贡献,并在完美的平台上分享每个人的独特技能
本网站的文章资料来自网络。大多数文章作者的名字都丢失了。为了便于用户阅读和使用,已根据需要对其进行了重新安排和部分调整。此网站收录文章仅用于帮助用户解决实际问题。如果有版权问题,请联系编辑修改或删除。谢谢你的合作 查看全部
完整的采集神器(完美者()网络标准头像采集工具,增加保存批量速拍)
Perfectist()网站基于软件下载,修订版网站扩展了功能板块,以解决用户在使用软件网站过程中遇到的所有问题,增加了“软件百科全书”和“Brocade Wonder technology”等新渠道,能够更好的为用户的软件使用周期提供更专业的服务
软件介绍
网络标准化身采集工具是一个简单易用的免费网络化身采集工具。它是免费安装的,可以通过双击运行。主要功能是免费的。只有普通人不需要的照相馆批量快速拍摄功能才收费。支持图片拖放、剪贴板粘贴和键盘操作。它用于在线注册、论坛、QQ头像、在线商店头像和其他标准头像采集. 它可以简单地编辑和修改图像,并输出设置的长度和宽度图片。如果输出JPG和JPEG图片,还可以预先设置输出图片文件的音量。化身采集有两种方式:你可以用这个软件打开现有的图片文件采集或直接拍摄采集
更新日志,增加旋转图片功能,增加保存批量快照设置功能,优化原有功能,使其更加友好
“锦绣包与精彩技巧”栏目是关于整个网络中软件使用的技巧或软件使用过程中各种问题的解答的集合文章. 在专栏成立之初,编辑欢迎所有软件之神踊跃贡献,并在完美的平台上分享每个人的独特技能
本网站的文章资料来自网络。大多数文章作者的名字都丢失了。为了便于用户阅读和使用,已根据需要对其进行了重新安排和部分调整。此网站收录文章仅用于帮助用户解决实际问题。如果有版权问题,请联系编辑修改或删除。谢谢你的合作
完整的采集神器(游戏介绍:妄想山海自动采集功能6业务任务)
采集交流 • 优采云 发表了文章 • 0 个评论 • 251 次浏览 • 2021-09-20 03:08
游戏介绍
幻觉山海汽车采集是最近非常流行的辅助工具软件。这个软件有很多非常强大的功能。用户可以通过该软件自动编写采集脚本,而无需浪费大量时间来刷地图。这个软件的操作方法也很简单,有喜欢这个软件的朋友。快来下载幻觉山海自动采集体验
妄想山海自动采集简介
这是一个功能齐全的辅助软件。该软件有许多功能,可以帮助您完成一些琐碎的日常任务,也可以帮助您自动挂断电话。玩家离开游戏后可以完美运行,并且可以进行数据修改。玩家可以自信地使用它。该软件的操作相对简单,并且有许多不同的播放方式。新手小白可以简单操作
妄想山海自动采集功能
1正线自动渡线任务
2日常任务
3自动夹持面
4自动刷子
五、注意事项
6业务任务
7初稿
8生活技能自动采集
妄想山与海自动采集教程
1.首先打开修改器,然后进入游戏
2.点击修改浮标切换到修改界面,然后在输入框中输入要修改的游戏属性值的当前值(钻石/资源/马力/分数/强度…)
3.点击“搜索”按钮,搜索完成后将显示搜索结果
4.点击“继续搜索”返回游戏,玩一会,在游戏中属性值改变后输入修改器
5.输入更改后的值以供进一步搜索
6.如果有很多搜索结果,继续执行步骤3;否则,转至步骤5
7.当搜索结果很少(少于20个结果)时,您可以尝试单独或批量修改搜索的数据
8.返回游戏并刷新游戏页面,查看修改是否成功
妄想山与海自动采集comment
幻觉山海自动采集script是腾讯幻觉山海游戏推出的辅助软件。这个辅助软件可以帮助用户自动采集各种材料,包括各种仙草和矿物质。它不需要玩家自己操作。自动接收相应任务,完成相应资源的采集。辅助操作平稳,完全模拟人的操作,不会有任何危险 查看全部
完整的采集神器(游戏介绍:妄想山海自动采集功能6业务任务)
游戏介绍
幻觉山海汽车采集是最近非常流行的辅助工具软件。这个软件有很多非常强大的功能。用户可以通过该软件自动编写采集脚本,而无需浪费大量时间来刷地图。这个软件的操作方法也很简单,有喜欢这个软件的朋友。快来下载幻觉山海自动采集体验
妄想山海自动采集简介
这是一个功能齐全的辅助软件。该软件有许多功能,可以帮助您完成一些琐碎的日常任务,也可以帮助您自动挂断电话。玩家离开游戏后可以完美运行,并且可以进行数据修改。玩家可以自信地使用它。该软件的操作相对简单,并且有许多不同的播放方式。新手小白可以简单操作
妄想山海自动采集功能
1正线自动渡线任务
2日常任务
3自动夹持面
4自动刷子
五、注意事项
6业务任务
7初稿
8生活技能自动采集
妄想山与海自动采集教程
1.首先打开修改器,然后进入游戏
2.点击修改浮标切换到修改界面,然后在输入框中输入要修改的游戏属性值的当前值(钻石/资源/马力/分数/强度…)
3.点击“搜索”按钮,搜索完成后将显示搜索结果
4.点击“继续搜索”返回游戏,玩一会,在游戏中属性值改变后输入修改器
5.输入更改后的值以供进一步搜索
6.如果有很多搜索结果,继续执行步骤3;否则,转至步骤5
7.当搜索结果很少(少于20个结果)时,您可以尝试单独或批量修改搜索的数据
8.返回游戏并刷新游戏页面,查看修改是否成功
妄想山与海自动采集comment
幻觉山海自动采集script是腾讯幻觉山海游戏推出的辅助软件。这个辅助软件可以帮助用户自动采集各种材料,包括各种仙草和矿物质。它不需要玩家自己操作。自动接收相应任务,完成相应资源的采集。辅助操作平稳,完全模拟人的操作,不会有任何危险
完整的采集神器(完整的采集神器+正则表达式插件插件的测试工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-16 19:00
完整的采集神器肯定有,但是对于绝大多数demo来说,采集神器有一个很大的局限性:只能采集某个url,如果你自己建立了一个网站,并且已经可以完成一定的功能,那还可以,但是如果你是真正的采集,你不能在自己网站、博客做有网站架构的测试。建议再接一套采集神器+正则表达式插件的采集工具。利益相关:我们团队做seo已经七年了。
如果你是想快速获取数据,
不麻烦。
我这边用的是spycat,可以抓取所有ip中url的页面。
可以的,要使用php做一个hash表,存储每一条url的json数据,然后可以使用js识别了解抓取到的页面js代码,
你觉得采集困难的话,不用采集的,你要是嫌采集麻烦的话,你要么加盟直购不要销售类的产品,然后给你大量潜在的用户,之后通过销售类的产品,来扩大你的用户量,并且把你这些用户都给转化,并且建立你的用户数据库,保持你产品的对大量用户免费发放,没有广告和费用你懂得,对优化产品以及转化率都很有帮助。你觉得销售类的产品还值得你去搞这个吗?你觉得你要是通过这个数据库来优化或者改进你的产品会有什么帮助,而且人家还不用花钱。 查看全部
完整的采集神器(完整的采集神器+正则表达式插件插件的测试工具)
完整的采集神器肯定有,但是对于绝大多数demo来说,采集神器有一个很大的局限性:只能采集某个url,如果你自己建立了一个网站,并且已经可以完成一定的功能,那还可以,但是如果你是真正的采集,你不能在自己网站、博客做有网站架构的测试。建议再接一套采集神器+正则表达式插件的采集工具。利益相关:我们团队做seo已经七年了。
如果你是想快速获取数据,
不麻烦。
我这边用的是spycat,可以抓取所有ip中url的页面。
可以的,要使用php做一个hash表,存储每一条url的json数据,然后可以使用js识别了解抓取到的页面js代码,
你觉得采集困难的话,不用采集的,你要是嫌采集麻烦的话,你要么加盟直购不要销售类的产品,然后给你大量潜在的用户,之后通过销售类的产品,来扩大你的用户量,并且把你这些用户都给转化,并且建立你的用户数据库,保持你产品的对大量用户免费发放,没有广告和费用你懂得,对优化产品以及转化率都很有帮助。你觉得销售类的产品还值得你去搞这个吗?你觉得你要是通过这个数据库来优化或者改进你的产品会有什么帮助,而且人家还不用花钱。
完整的采集神器(完整的采集神器包括网页搜索采集百度首页精彩内容教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-05 01:01
完整的采集神器包括网页搜索采集sitegan、网页爬虫采集spidercn、网页数据采集api等工具。视频教程:采集百度首页精彩内容教程分享采集百度首页精彩内容教程分享,
猴子采集器猴子采集器不支持长连接,采集的数据在cookie里。支持登录采集等付费功能。建议用手机浏览器采集,ios支持闪电采集,安卓机器接入离线浏览器。这是采集器的使用教程,建议一定要看一下。
你好,长链接你可以考虑用ssrf跨站请求或者一些nginx代理工具,问题是同一个人分段多次采集同一页面时,每次请求爬取的数据量过大时,都会导致服务器压力过大,甚至崩溃,此时出现报错,不过不影响你的搜索正常访问。个人建议可以通过爬虫封装进行采集。
你的问题应该是在,采集百度的时候网页版采不到啊,做搜索大部分都需要长连接,
请使用。真的牛*兔网页采集器!爬虫请选择。联系人搜索,搜索记录采集,访客搜索记录采集,
根据自己的需求了,理想比较好.安卓ios都可以,工具比较多.
用利用app,苹果的有那个search苹果专版,
长链接要用javascript才能获取
目前搜索引擎爬虫市场品牌也很多,我推荐搜索爬虫app“捷鸟采集器”。捷鸟采集器不仅开放了api,也开放了网页爬虫。这个工具完全不用你点开网页,鼠标刷刷的在界面上点来点去,app可以帮你抓取一切资源。比如,你可以先抓一部分自己想看的新闻,然后,可以把链接,二维码,评论,lbs,新闻文章摘要等等,复制过来,其他爬虫再爬这部分。 查看全部
完整的采集神器(完整的采集神器包括网页搜索采集百度首页精彩内容教程)
完整的采集神器包括网页搜索采集sitegan、网页爬虫采集spidercn、网页数据采集api等工具。视频教程:采集百度首页精彩内容教程分享采集百度首页精彩内容教程分享,
猴子采集器猴子采集器不支持长连接,采集的数据在cookie里。支持登录采集等付费功能。建议用手机浏览器采集,ios支持闪电采集,安卓机器接入离线浏览器。这是采集器的使用教程,建议一定要看一下。
你好,长链接你可以考虑用ssrf跨站请求或者一些nginx代理工具,问题是同一个人分段多次采集同一页面时,每次请求爬取的数据量过大时,都会导致服务器压力过大,甚至崩溃,此时出现报错,不过不影响你的搜索正常访问。个人建议可以通过爬虫封装进行采集。
你的问题应该是在,采集百度的时候网页版采不到啊,做搜索大部分都需要长连接,
请使用。真的牛*兔网页采集器!爬虫请选择。联系人搜索,搜索记录采集,访客搜索记录采集,
根据自己的需求了,理想比较好.安卓ios都可以,工具比较多.
用利用app,苹果的有那个search苹果专版,
长链接要用javascript才能获取
目前搜索引擎爬虫市场品牌也很多,我推荐搜索爬虫app“捷鸟采集器”。捷鸟采集器不仅开放了api,也开放了网页爬虫。这个工具完全不用你点开网页,鼠标刷刷的在界面上点来点去,app可以帮你抓取一切资源。比如,你可以先抓一部分自己想看的新闻,然后,可以把链接,二维码,评论,lbs,新闻文章摘要等等,复制过来,其他爬虫再爬这部分。
完整的采集神器(优采云中该如何操作?如何从单个网页抓取文本、图片、超链接 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-09-04 02:08
)
在第二课采集Single Data中,我们学习了如何抓取单个网页的文字、图片、超链接,初步了解优采云【自定义配置】任务采集的流程@data 经验。本课将继续学习如何采集多个数据列表。
列表是最常见的网页样式之一。示例:京东商品榜、58城房源榜、豆瓣书榜。简单配置后优采云就可以自动采集列表中的所有数据了。
现在有一个收录豆瓣书籍列表的网页:%E5%B0%8F%E8%AF%B4。网页上有很多结构相同的书单,每个书单都有相同的字段:书名、出版信息、评分、评论数、书介绍等。
鼠标移到图片上,右击选择【在新标签页中打开图片】查看高清大图
同样适用于下面的其他图片
我们想把上面网页采集的多个列表中的字段按照网页的顺序存储,保存为Excel等结构化数据,如下图:
在优采云怎么做?示例网址:%E5%B0%8F%E8%AF%B4
一、智能识别
列出网页,优采云支持智能识别。使用智能识别,只需输入网址即可自动获取数据并生成采集流程。
二、自己配置采集process
如果我想自己配置采集进程怎么办?具体步骤如下:
步骤一、输入网址
在首页【输入框】输入目标网址,点击【开始采集】,优采云会自动打开网页。如果智能识别自动启动,您可以点击【不再自动识别】或【取消识别】。如果智能识别已关闭,请继续执行后续步骤。
步骤二、Establish [循环提取数据]
观察网页。这个页面上有很多书单。每个列表结构相同,收录书名、出版信息、评分、审稿人数、书籍介绍等字段。最重要的一点是如何让优采云识别所有列表,并遵循采集的顺序@每个书单中的数据。
在优采云中,[loop-extract data]的建立可以达到这个要求。 【循环提取数据】会依次收录所有书单,以及每个书单中的采集数据。对于列表类型的网页,需要具体的步骤来建立【循环提取数据】。以下是具体步骤。
我们先来看一个完整的步骤来建立[loop-extract data]:
拆分每一步,详细说明:
1、在页面上选择一个书单。选中的列表会被一个绿色框框起来,同时会出现一个黄色的操作提示框,提示我们找到【子元素】,其中【子元素】是图书列表中的具体字段。
特别说明:
一个。只选一个列表,第一个无所谓,第一个,第二个,第三个,都行。
B.选择列表时,要特别注意范围。选择的范围(绿色部分)需要最大,包括所有需要采集的字段。
2、 在黄色操作提示框中,选择【选择子元素】。选择第一个产品列表中的特定字段。这时候优采云发现页面上有很多相似的列表,它们的子元素(即字段)是一样的。
3、在黄色的操作提示框中,继续选择【全选】。我们要采集列表中的所有字段,所以选择【全选】,可以看到页面上同一个列表中的所有子元素都被选中了,用绿色框框起来。
4、在黄色操作提示框中,选择[采集数据]。这时优采云已经把列表中的所有字段都提取出来了。
特别说明:
一个。步骤1-4是连续指令,只能不间断地建立。 1、选择页面列表后2、[selected child element]没有出现怎么办?请向下滚动到文章末尾查看解决方案。
经过以上4个步骤,【循环-提取数据】的创建就完成了。如您所见,流程图中会自动生成一个循环步骤。循环中的项目对应页面上所有产品的列表。循环中提取的数据中的字段对应于每个产品列表中的字段。 采集启动后,优采云会按照循环中的顺序依次提取每个列表中的字段。
步骤3、编辑字段
优采云已经为我们自动提取了列表中的所有字段,并且可以删除这些字段并修改字段名称。
移动鼠标到【数据预览】
移到字段名,可以修改字段名(字段名相当于excel表头)。
单击垃圾桶图标可删除不需要的字段。您也可以选择并单击切换字段布局来编辑字段。字段布局方式有【垂直字段布局】和【水平字段布局】
步骤4、Start采集
1、 点击【保存并启动】,选择【启动本地采集】。启动优采云后全自动采集数据。 (本地采集采集使用自己的电脑,云采集使用优采云提供的云服务器采集,点击查看具体说明)
2、采集 完成后,选择合适的导出方式导出数据。支持导出为 Excel、CSV、HTML。在此处导出到 Excel。
数据示例:
在步骤二、中,在建立[loop-extract data]时,1、选择页面上的一个列表后,2、[selected child element]不会出现。解决方案:
示例网址:%25E8%2583%25A1%25E6%25AD%258C?topnav=1&wvr=6&b=1
我们先来看一个完整的步骤来建立[loop-extract data]:
再拆分每一步,详细说明:
1、选择页面上的第一个列表。
2、继续选择页面上的1个列表(目的是帮助优采云识别页面上所有相似的列表)。
3、黄色操作提示框中,选择【采集数据】。列表中的所有字段都被提取到一个单元格中。如需单独提取,请继续进行以下操作。
4、 手动提取所需字段。确保从当前选择的列表中提取字段(用红色框框起来)。否则会重复提取第一个列表中的数据。
通过以上4个步骤,还可以创建【循环提取数据】。如您所见,流程图中会自动生成一个循环步骤。循环中的项目对应页面上的所有微博列表。循环中提取数据中的字段对应于每个微博列表中的字段。 采集启动后,优采云会按照循环中的顺序依次提取每个列表中的字段。
【循环提取数据】创建完成后,后续步骤同上,不再赘述。
如果需要采集list数据,如果非要点击列表中的链接,进入详情页,采集details页数据,解决方法:
1、先用本课上面学到的方法创建一个【循环-提取数据】步骤,先提取列表数据
2、 在循环的当前项中找到链接(用红框框起来)并选择它。在弹出的操作提示框中,选择【点击链接】。可以看到过程中生成了一步【点击元素】,优采云自动跳转到详情页,然后提取详情页数据。
特别说明:
一个。一定要用循环的当前item的链接(如下图,当前item会用红框框起来)作为【点击元素】的步骤,否则点击链接重复。
查看全部
完整的采集神器(优采云中该如何操作?如何从单个网页抓取文本、图片、超链接
)
在第二课采集Single Data中,我们学习了如何抓取单个网页的文字、图片、超链接,初步了解优采云【自定义配置】任务采集的流程@data 经验。本课将继续学习如何采集多个数据列表。
列表是最常见的网页样式之一。示例:京东商品榜、58城房源榜、豆瓣书榜。简单配置后优采云就可以自动采集列表中的所有数据了。
现在有一个收录豆瓣书籍列表的网页:%E5%B0%8F%E8%AF%B4。网页上有很多结构相同的书单,每个书单都有相同的字段:书名、出版信息、评分、评论数、书介绍等。
鼠标移到图片上,右击选择【在新标签页中打开图片】查看高清大图
同样适用于下面的其他图片
我们想把上面网页采集的多个列表中的字段按照网页的顺序存储,保存为Excel等结构化数据,如下图:
在优采云怎么做?示例网址:%E5%B0%8F%E8%AF%B4
一、智能识别
列出网页,优采云支持智能识别。使用智能识别,只需输入网址即可自动获取数据并生成采集流程。
二、自己配置采集process
如果我想自己配置采集进程怎么办?具体步骤如下:
步骤一、输入网址
在首页【输入框】输入目标网址,点击【开始采集】,优采云会自动打开网页。如果智能识别自动启动,您可以点击【不再自动识别】或【取消识别】。如果智能识别已关闭,请继续执行后续步骤。
步骤二、Establish [循环提取数据]
观察网页。这个页面上有很多书单。每个列表结构相同,收录书名、出版信息、评分、审稿人数、书籍介绍等字段。最重要的一点是如何让优采云识别所有列表,并遵循采集的顺序@每个书单中的数据。
在优采云中,[loop-extract data]的建立可以达到这个要求。 【循环提取数据】会依次收录所有书单,以及每个书单中的采集数据。对于列表类型的网页,需要具体的步骤来建立【循环提取数据】。以下是具体步骤。
我们先来看一个完整的步骤来建立[loop-extract data]:
拆分每一步,详细说明:
1、在页面上选择一个书单。选中的列表会被一个绿色框框起来,同时会出现一个黄色的操作提示框,提示我们找到【子元素】,其中【子元素】是图书列表中的具体字段。
特别说明:
一个。只选一个列表,第一个无所谓,第一个,第二个,第三个,都行。
B.选择列表时,要特别注意范围。选择的范围(绿色部分)需要最大,包括所有需要采集的字段。
2、 在黄色操作提示框中,选择【选择子元素】。选择第一个产品列表中的特定字段。这时候优采云发现页面上有很多相似的列表,它们的子元素(即字段)是一样的。
3、在黄色的操作提示框中,继续选择【全选】。我们要采集列表中的所有字段,所以选择【全选】,可以看到页面上同一个列表中的所有子元素都被选中了,用绿色框框起来。
4、在黄色操作提示框中,选择[采集数据]。这时优采云已经把列表中的所有字段都提取出来了。
特别说明:
一个。步骤1-4是连续指令,只能不间断地建立。 1、选择页面列表后2、[selected child element]没有出现怎么办?请向下滚动到文章末尾查看解决方案。
经过以上4个步骤,【循环-提取数据】的创建就完成了。如您所见,流程图中会自动生成一个循环步骤。循环中的项目对应页面上所有产品的列表。循环中提取的数据中的字段对应于每个产品列表中的字段。 采集启动后,优采云会按照循环中的顺序依次提取每个列表中的字段。
步骤3、编辑字段
优采云已经为我们自动提取了列表中的所有字段,并且可以删除这些字段并修改字段名称。
移动鼠标到【数据预览】
移到字段名,可以修改字段名(字段名相当于excel表头)。
单击垃圾桶图标可删除不需要的字段。您也可以选择并单击切换字段布局来编辑字段。字段布局方式有【垂直字段布局】和【水平字段布局】
步骤4、Start采集
1、 点击【保存并启动】,选择【启动本地采集】。启动优采云后全自动采集数据。 (本地采集采集使用自己的电脑,云采集使用优采云提供的云服务器采集,点击查看具体说明)
2、采集 完成后,选择合适的导出方式导出数据。支持导出为 Excel、CSV、HTML。在此处导出到 Excel。
数据示例:
在步骤二、中,在建立[loop-extract data]时,1、选择页面上的一个列表后,2、[selected child element]不会出现。解决方案:
示例网址:%25E8%2583%25A1%25E6%25AD%258C?topnav=1&wvr=6&b=1
我们先来看一个完整的步骤来建立[loop-extract data]:
再拆分每一步,详细说明:
1、选择页面上的第一个列表。
2、继续选择页面上的1个列表(目的是帮助优采云识别页面上所有相似的列表)。
3、黄色操作提示框中,选择【采集数据】。列表中的所有字段都被提取到一个单元格中。如需单独提取,请继续进行以下操作。
4、 手动提取所需字段。确保从当前选择的列表中提取字段(用红色框框起来)。否则会重复提取第一个列表中的数据。
通过以上4个步骤,还可以创建【循环提取数据】。如您所见,流程图中会自动生成一个循环步骤。循环中的项目对应页面上的所有微博列表。循环中提取数据中的字段对应于每个微博列表中的字段。 采集启动后,优采云会按照循环中的顺序依次提取每个列表中的字段。
【循环提取数据】创建完成后,后续步骤同上,不再赘述。
如果需要采集list数据,如果非要点击列表中的链接,进入详情页,采集details页数据,解决方法:
1、先用本课上面学到的方法创建一个【循环-提取数据】步骤,先提取列表数据
2、 在循环的当前项中找到链接(用红框框起来)并选择它。在弹出的操作提示框中,选择【点击链接】。可以看到过程中生成了一步【点击元素】,优采云自动跳转到详情页,然后提取详情页数据。
特别说明:
一个。一定要用循环的当前item的链接(如下图,当前item会用红框框起来)作为【点击元素】的步骤,否则点击链接重复。
完整的采集神器(这款小说网站下载软件怎么做?软件功能介绍介绍 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 401 次浏览 • 2021-09-02 19:10
)
在线图书抓取器可以帮助用户快速采集网上的小说,将TXT小说下载到电脑上阅读。适合喜欢看小说的朋友。现在很多用户喜欢通过网页看小说,直接进入可以通过浏览器搜索小说在线阅读小说,但是很多网站有广告,阅读还是不方便。您可以通过该软件下载小说,也可以离线查看。不会有广告。下载的 TXT 也可以发送给您。在手机上阅读,这个软件操作简单。在软件中输入图书地址即可立即抓取目录,并自动下载目录采集对应的章节内容,完成下载。软件支持合并功能,将采集的所有内容以TXT章节合并为一个TXT文件,所有章节显示在同一个TXT电子书中。如果你需要采集网站小说,下载这个软件吧!
软件功能
1、网络书Grabber支持大部分网站,小说资源下载方便
2、直接采集目录,在本软件中输入图书目录地址即可抓取
3、自动识别书名,适合多本小说网站
4、支持章节显示,抓取后会在软件界面显示所有章节
5、每章单独保存为一个TXT,下载后可以合并TXT
6、支持保存地址设置,采集到达的数据可以设置一个粗略的地址
7、支持重试功能,如果采集无法到达所有章节,可以重试
软件功能
1、网络书取器可以轻松采集网络小说
2、在电脑上阅读你需要的电子书采集
3、所有电子书都是TXT,方便加载到阅读器中使用
4、软件免费使用,网站的大部分小说都可以采集
5、software 显示采集提醒,底部显示已抓取多少章节
6、显示操作步骤,可参考网络抢书者采集小说教程
如何使用
1、打开网络图书抓取器直接启动,在软件中输入小说目录地址
详细操作步骤如下2、。输入图书目录地址后,可以点击目录提取功能
3、tip网站setting 功能,这里可以选择图书所在的网站
4、点击目录解压显示本书所有章节并开始下载
5、点击一键解压按钮将所有目录解压到软件中
6、然后点击开始抓取,软件会自动抓取章节对应的文字内容,点此下载小说。
7、已经抢到46章了,剩下的章节可以按【重试】键继续!注意:
【开始爬行】全部重启!!!
【重试】稍后继续爬取章节,关闭程序不影响继续爬取
8、如需继续爬取剩余章节,可点击重试
9、最新章节目录。合并文件成功合并了总共46章。您要删除所有章节文件吗?
查看全部
完整的采集神器(这款小说网站下载软件怎么做?软件功能介绍介绍
)
在线图书抓取器可以帮助用户快速采集网上的小说,将TXT小说下载到电脑上阅读。适合喜欢看小说的朋友。现在很多用户喜欢通过网页看小说,直接进入可以通过浏览器搜索小说在线阅读小说,但是很多网站有广告,阅读还是不方便。您可以通过该软件下载小说,也可以离线查看。不会有广告。下载的 TXT 也可以发送给您。在手机上阅读,这个软件操作简单。在软件中输入图书地址即可立即抓取目录,并自动下载目录采集对应的章节内容,完成下载。软件支持合并功能,将采集的所有内容以TXT章节合并为一个TXT文件,所有章节显示在同一个TXT电子书中。如果你需要采集网站小说,下载这个软件吧!
软件功能
1、网络书Grabber支持大部分网站,小说资源下载方便
2、直接采集目录,在本软件中输入图书目录地址即可抓取
3、自动识别书名,适合多本小说网站
4、支持章节显示,抓取后会在软件界面显示所有章节
5、每章单独保存为一个TXT,下载后可以合并TXT
6、支持保存地址设置,采集到达的数据可以设置一个粗略的地址
7、支持重试功能,如果采集无法到达所有章节,可以重试
软件功能
1、网络书取器可以轻松采集网络小说
2、在电脑上阅读你需要的电子书采集
3、所有电子书都是TXT,方便加载到阅读器中使用
4、软件免费使用,网站的大部分小说都可以采集
5、software 显示采集提醒,底部显示已抓取多少章节
6、显示操作步骤,可参考网络抢书者采集小说教程
如何使用
1、打开网络图书抓取器直接启动,在软件中输入小说目录地址
详细操作步骤如下2、。输入图书目录地址后,可以点击目录提取功能
3、tip网站setting 功能,这里可以选择图书所在的网站
4、点击目录解压显示本书所有章节并开始下载
5、点击一键解压按钮将所有目录解压到软件中
6、然后点击开始抓取,软件会自动抓取章节对应的文字内容,点此下载小说。
7、已经抢到46章了,剩下的章节可以按【重试】键继续!注意:
【开始爬行】全部重启!!!
【重试】稍后继续爬取章节,关闭程序不影响继续爬取
8、如需继续爬取剩余章节,可点击重试
9、最新章节目录。合并文件成功合并了总共46章。您要删除所有章节文件吗?
完整的采集神器(Python学习资料下载地址(一):Xpath的使用方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-09-02 14:14
在github上找一个美团项目,可以获取到指定城市的商家信息,分分钟上百条商家信息数据在手,信息包括店铺名称、地理位置、评分、销量,电话(这就是重点)。
好久没更新了。今天写了文章,附上这个很有价值的项目的下载地址。
本文是自己写的xpath笔记。不想看的可以直接到文章最下面的代码下载地址。
可惜项目是用scrapy写的。其实我是不想用框架的,但是把这个项目改成可以运行的代码,花了一天的时间。我在变更过程中再次熟悉了scrapy。决定学习xpath,然后我会用scrapy写几个爬虫。
Python学习交流群:1004391443,这里是Python学习者的聚集地,有专家答疑资源分享!小编还准备了python学习资料,欢迎有想学习python编程,或转行,或大学生,以及想在工作中提高自己能力的,以及正在学习的人加入学习。
除了css,scrapy的选择器比xpath好。现在需要练习xpath的使用。
Xpath 简介
一般来说,使用id、name、class等属性定位节点可以解决大部分解析需求,但有时在以下情况下,使用Xpath更方便:
没有id、name、class等属性或者文字特征不明显。标签的嵌套层次太复杂。
Xpath 是对 XML 路径的介绍。基于 XML 树结构,您可以在整个树中找到目标节点。由于 HTML 文档本身是一个标准的 XML 页面,我们可以使用 XPath 语法来定位页面元素。
Xpath 定位方法
一、Xpath 路径
符号名称的含义/绝对路径表示从根节点选择//相对路径表示从任意位置选择一个节点,而不管它们的位置
Xpath 路径示例
定位节点
#查找html下的body下的form下的所有input节点/html/body/form/input#查找所有input节点//input
通配符 *选择未知节点
#查找form节点下的所有节点//form/*#查找所有节点//*#查找所有input节点(input至少有爷爷辈亲戚节点)//*/input
二、使用索引(这是我自己的理解)
如果过滤元素时有多个节点,但我们想确定唯一的节点。您可以使用类似于列表索引的方式进行精确定位。
案例
#定位 第8个td下的 第2个a节点//*/td[7]/a[1]#定位 第8个td下的 第3个span节点//*/td[7]/span[2]#定位 最后一个td下的 最后一个a节点//*/td[last()]/a[last()]
三、使用属性
为了让定位更准确,类似于使用索引,我们需要增加信息量,所以我们也可以使用属性。 @Symbol 是一个属性符号
#定位所有包含name属性的input节点//input[@name]#定位含有属性的所有的input节点//input[@*]#定位所有value=2的input节点//input[@value='2']#使用多个属性定位//input[@value='2'][@id='3']或者//input[@value='2' and @id='3']
四、常用函数
除了索引和属性,Xpath还可以使用方便的功能来提升定位的准确性。下面是几个常用的函数:
函数的含义 contains(s1,s2) 如果s1收录s2,则返回true;否则返回falsetext()获取节点中的文本内容starts-with()从实际位置开始匹配字符串
应用推广#定位href属性中包含“promote.html”的所有a节点//a[contains(@href,'promote.html')]#元素内的文本为“应用推广”的所有a节点//a[text()='应用推广']#href属性值是以“/ads”开头的所有a节点//a[starts-with(@href,'/ads')]
五、Xpath轴
这部分类似于BeautifulSoup中的sibling、parents和children方法。有时为了实现定位,需要绕道而行,七阿姨和八阿姨的远房亲戚四处走走相识,定位就完成了。
<p>轴名称含义ancestor选择当前节点的所有祖先(父亲、祖父等)ancestor-or-self选择当前节点的所有祖先(父亲、祖父等),当前节点自身属性选择所有当前节点的属性child选择当前节点的所有子节点descendant选择当前节点的所有后代(children,grandchildren等)descendant-or-self选择当前节点的所有后代(children,grandchildren等) .) 和当前节点自己的后续选择当前节点结束后的所有节点父节点选择当前节点的父节点前兄弟选择当前节点自身选择当前节点之前的所有同级节点 查看全部
完整的采集神器(Python学习资料下载地址(一):Xpath的使用方法)
在github上找一个美团项目,可以获取到指定城市的商家信息,分分钟上百条商家信息数据在手,信息包括店铺名称、地理位置、评分、销量,电话(这就是重点)。
好久没更新了。今天写了文章,附上这个很有价值的项目的下载地址。
本文是自己写的xpath笔记。不想看的可以直接到文章最下面的代码下载地址。
可惜项目是用scrapy写的。其实我是不想用框架的,但是把这个项目改成可以运行的代码,花了一天的时间。我在变更过程中再次熟悉了scrapy。决定学习xpath,然后我会用scrapy写几个爬虫。
Python学习交流群:1004391443,这里是Python学习者的聚集地,有专家答疑资源分享!小编还准备了python学习资料,欢迎有想学习python编程,或转行,或大学生,以及想在工作中提高自己能力的,以及正在学习的人加入学习。
除了css,scrapy的选择器比xpath好。现在需要练习xpath的使用。
Xpath 简介
一般来说,使用id、name、class等属性定位节点可以解决大部分解析需求,但有时在以下情况下,使用Xpath更方便:
没有id、name、class等属性或者文字特征不明显。标签的嵌套层次太复杂。
Xpath 是对 XML 路径的介绍。基于 XML 树结构,您可以在整个树中找到目标节点。由于 HTML 文档本身是一个标准的 XML 页面,我们可以使用 XPath 语法来定位页面元素。
Xpath 定位方法
一、Xpath 路径
符号名称的含义/绝对路径表示从根节点选择//相对路径表示从任意位置选择一个节点,而不管它们的位置
Xpath 路径示例
定位节点
#查找html下的body下的form下的所有input节点/html/body/form/input#查找所有input节点//input
通配符 *选择未知节点
#查找form节点下的所有节点//form/*#查找所有节点//*#查找所有input节点(input至少有爷爷辈亲戚节点)//*/input
二、使用索引(这是我自己的理解)
如果过滤元素时有多个节点,但我们想确定唯一的节点。您可以使用类似于列表索引的方式进行精确定位。
案例
#定位 第8个td下的 第2个a节点//*/td[7]/a[1]#定位 第8个td下的 第3个span节点//*/td[7]/span[2]#定位 最后一个td下的 最后一个a节点//*/td[last()]/a[last()]
三、使用属性
为了让定位更准确,类似于使用索引,我们需要增加信息量,所以我们也可以使用属性。 @Symbol 是一个属性符号
#定位所有包含name属性的input节点//input[@name]#定位含有属性的所有的input节点//input[@*]#定位所有value=2的input节点//input[@value='2']#使用多个属性定位//input[@value='2'][@id='3']或者//input[@value='2' and @id='3']
四、常用函数
除了索引和属性,Xpath还可以使用方便的功能来提升定位的准确性。下面是几个常用的函数:
函数的含义 contains(s1,s2) 如果s1收录s2,则返回true;否则返回falsetext()获取节点中的文本内容starts-with()从实际位置开始匹配字符串
应用推广#定位href属性中包含“promote.html”的所有a节点//a[contains(@href,'promote.html')]#元素内的文本为“应用推广”的所有a节点//a[text()='应用推广']#href属性值是以“/ads”开头的所有a节点//a[starts-with(@href,'/ads')]
五、Xpath轴
这部分类似于BeautifulSoup中的sibling、parents和children方法。有时为了实现定位,需要绕道而行,七阿姨和八阿姨的远房亲戚四处走走相识,定位就完成了。
<p>轴名称含义ancestor选择当前节点的所有祖先(父亲、祖父等)ancestor-or-self选择当前节点的所有祖先(父亲、祖父等),当前节点自身属性选择所有当前节点的属性child选择当前节点的所有子节点descendant选择当前节点的所有后代(children,grandchildren等)descendant-or-self选择当前节点的所有后代(children,grandchildren等) .) 和当前节点自己的后续选择当前节点结束后的所有节点父节点选择当前节点的父节点前兄弟选择当前节点自身选择当前节点之前的所有同级节点

