
完整的采集神器
汇总:Prometheus监控神器-服务发现篇(二)
采集交流 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2020-09-07 11:27
本章介绍了服务发现和重新标记的机制和示例。
通过服务发现,我们可以动态发现需要监视的目标实例信息,而无需重新启动Prometheus服务。
如上图所示,对于在线环境,我们可以分为不同的集群:dev,stage和prod。每个群集运行多个主机节点,每个服务器节点运行一个节点导出器实例。 Node Exporter实例会自动在Consul中注册,Prometheus会根据Consul返回的Node Exporter实例信息动态维护Target列表,并轮询这些目标以监视数据。
但是,如果我们仍然需要:
面对这些情况下的要求,我们实际上希望Prometheus Server可以根据某些规则(例如,标记)监视数据从服务发现注册表返回的目标实例中选择性地采集某些Exporter实例。
接下来,我们将尝试如何通过Prometheus强大的Relabel机制实现这些特定目标。
普罗米修斯的重新标记机制
Prometheus的所有Target实例都收录一些默认的元数据标记信息。您可以在Prometheus UI的“目标”页面中查看这些实例的元数据标签的内容:
默认情况下,当Prometheus加载Target实例时,这些Target将收录一些默认标记:
以上标记将告诉Prometheus如何从Target实例获取监视数据。除了这些默认标签之外,我们还可以为目标添加自定义标签。例如,在“基于文件的服务发现”部分的示例中,我们通过JSON配置文件将自定义标签env添加到Target实例。如下所示,标签最终将保存在此实例采集的示例数据中:
node_cpu{cpu="cpu0",env="prod",instance="localhost:9100",job="node",mode="idle"}
通常,系统内部使用以__作为Target前面的标签,因此不会将这些标签写入示例数据。但是,也有一些例外。例如,我们将发现通过Prometheus 采集传递的所有样本数据都将收录一个名为instance的标签,其内容对应于Target实例的__address__。这实际上是一个标签重写过程。
这种重写目标实例标签的机制是在采集样本数据在Prometheus中称为“重新标记”之前发生的。
Prometheus允许用户通过采集任务设置中的relabel_configs添加自定义的重新标记过程。
使用replace / labelmap重写标签
重新标记的最基本的应用场景是基于Target实例中收录的元数据标签动态添加或覆盖标签。例如,通过Consul动态发现的服务实例还将收录以下元数据标签信息:
默认情况下,来自Node Exporter实例采集的示例数据如下:
node_cpu{cpu="cpu0",instance="localhost:9100",job="node",mode="idle"} 93970.8203125
我们希望有一个附加标签dc,它可以指示样本所属的数据中心:
node_cpu{cpu="cpu0",instance="localhost:9100",job="node",mode="idle", dc="dc1"} 93970.8203125
可以将多个relabel_config配置添加到每个采集任务的配置中。最简单的重新标记配置如下:
scrape_configs:
- job_name: node_exporter
consul_sd_configs:
- server: localhost:8500
services:
- node_exporter
relabel_configs:
- source_labels: ["__meta_consul_dc"]
target_label: "dc"
此采集任务通过Consul作为采集的监视目标来动态发现Node Exporter实例信息。在上一节中,我们知道通过Consul动态发现的监视目标将收录一些其他元数据标签,例如__meta_consul_dc标签,指示当前实例所在的Consul数据中心,因此我们希望从这些实例进行监视采集该示例还可以收录这样的标签,例如:
node_cpu{cpu="cpu0",dc="dc1",instance="172.21.0.6:9100",job="consul_sd",mode="guest"}
通过这种方式,可以方便地根据dc标签的值对不同数据中心的数据进行汇总和分析。
在此示例中,通过从Target实例获取__meta_consul_dc的值,并重写从该实例获得的所有样本。
完整的relabel_config配置如下:
# The source labels select values from existing labels. Their content is concatenated
# using the configured separator and matched against the configured regular expression
# for the replace, keep, and drop actions.
[ source_labels: '[' [, ...] ']' ]
# Separator placed between concatenated source label values.
[ separator: | default = ; ]
# Label to which the resulting value is written in a replace action.
# It is mandatory for replace actions. Regex capture groups are available.
[ target_label: ]
# Regular expression against which the extracted value is matched.
[ regex: | default = (.*) ]
# Modulus to take of the hash of the source label values.
[ modulus: ]
# Replacement value against which a regex replace is performed if the
# regular expression matches. Regex capture groups are available.
[ replacement: | default = $1 ]
# Action to perform based on regex matching.
[ action: | default = replace ]
动作定义了元数据标签的当前relabel_config处理方法,默认动作行为是replace。替换行为将根据regex配置匹配source_labels标签的值(多个source_label的值将根据分隔符进行拼接),并将匹配的值写入target_label。如果有多个匹配组,则可以使用$ {1},$ {2}确定要写入的内容。如果没有匹配项,则不会重置target_label。
通过repalce操作,用户可以根据Target的Metadata标签重写或编写新的标签键值对。在多环境的情况下,它可以帮助用户添加与环境相关的特征尺寸,从而更好地执行数据聚合。
除了使用replace之外,还可以将操作配置定义为labelmap。与replace不同,labelmap将根据正则表达式的定义匹配Target实例的所有标签的名称,并使用匹配的内容作为新标签名称,并将其值用作新标签的值。
例如,当监视Kubernetes下的所有主机节点时,要将在这些节点上定义的标签写到样本中,可以使用以下relabel_config配置:
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
使用labelkeep或labeldrop过滤目标标签,并仅保留符合过滤条件的标签,例如:
relabel_configs:
- regex: label_should_drop_(.+)
action: labeldrop
此配置将使用正则表达式来匹配当前Target实例的所有标签,并从Target实例中删除符合regex规则的标签。 labelkeep相反,它将删除所有不匹配正则表达式定义的标签。
使用保留/删除过滤目标实例
在上一部分中,我们介绍了Prometheus的重新标记机制,并使用replace / labelmap / labelkeep / labeldrop来管理标签。在本节的开头提到了第二个问题。使用集中式服务发现注册表时,环境中的所有导出器实例都将在服务发现注册表中注册。具有不同功能(开发,测试,操作和维护)的人员可能只关心某些监视数据。他们可以部署自己的Prometheus Server来监视他们关心的指标数据。如果将这些Prometheus Server 采集放在所有环境中,显然,所有Exporter数据都将浪费大量资源。如何使这些不同的Prometheus Server 采集各自引起关注?答案是重新标记。除默认替换外,relabel_config的操作还支持保留/删除行为。例如,如果只需要采集数据中心dc1中的Node Exporter实例的样本数据,则可以使用以下配置:
scrape_configs:
- job_name: node_exporter
consul_sd_configs:
- server: localhost:8500
services:
- node_exporter
relabel_configs:
- source_labels: ["__meta_consul_dc"]
regex: "dc1"
action: keep
将动作设置为保持时,Prometheus将丢弃与source_labels的值中的正则表达式正则表达式的内容不匹配的Target实例,并且在将动作设置为drop时,它将丢弃与正则表达式正则表达式。内容的Target实例。可以简单地理解为保留以供选择,丢弃以排除。
使用hashmod计算source_labels的哈希值
当relabel_config设置为hashmod时,Prometheus将使用模量值作为系数来计算source_labels值的哈希值。例如:
scrape_configs
- job_name: 'file_ds'
relabel_configs:
- source_labels: [__address__]
modulus: 4
target_label: tmp_hash
action: hashmod
file_sd_configs:
- files:
- targets.json
根据当前Target实例__address__的值,使用4作为系数,以便每个Target实例将收录一个新标签tmp_hash,其值范围在1〜4之间。查看目标实例的标签信息。看到以下结果,每个Target实例都收录一个新的tmp_hash值:
使用Hashmod的功能在目标实例级别实现采集任务的功能分区:
scrape_configs:
- job_name: some_job
relabel_configs:
- source_labels: [__address__]
modulus: 4
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^1$
action: keep
此处应注意,如果重新标记操作仅是为了生成临时变量作为下一个重新标记操作的输入,则可以使用__tmp作为标签名称的前缀,并且该前缀定义的标签将不写到目标的标签或样本的采集。 查看全部
Prometheus监控工件服务发现(二)
本章介绍了服务发现和重新标记的机制和示例。
通过服务发现,我们可以动态发现需要监视的目标实例信息,而无需重新启动Prometheus服务。

如上图所示,对于在线环境,我们可以分为不同的集群:dev,stage和prod。每个群集运行多个主机节点,每个服务器节点运行一个节点导出器实例。 Node Exporter实例会自动在Consul中注册,Prometheus会根据Consul返回的Node Exporter实例信息动态维护Target列表,并轮询这些目标以监视数据。
但是,如果我们仍然需要:
面对这些情况下的要求,我们实际上希望Prometheus Server可以根据某些规则(例如,标记)监视数据从服务发现注册表返回的目标实例中选择性地采集某些Exporter实例。
接下来,我们将尝试如何通过Prometheus强大的Relabel机制实现这些特定目标。
普罗米修斯的重新标记机制
Prometheus的所有Target实例都收录一些默认的元数据标记信息。您可以在Prometheus UI的“目标”页面中查看这些实例的元数据标签的内容:

默认情况下,当Prometheus加载Target实例时,这些Target将收录一些默认标记:
以上标记将告诉Prometheus如何从Target实例获取监视数据。除了这些默认标签之外,我们还可以为目标添加自定义标签。例如,在“基于文件的服务发现”部分的示例中,我们通过JSON配置文件将自定义标签env添加到Target实例。如下所示,标签最终将保存在此实例采集的示例数据中:
node_cpu{cpu="cpu0",env="prod",instance="localhost:9100",job="node",mode="idle"}
通常,系统内部使用以__作为Target前面的标签,因此不会将这些标签写入示例数据。但是,也有一些例外。例如,我们将发现通过Prometheus 采集传递的所有样本数据都将收录一个名为instance的标签,其内容对应于Target实例的__address__。这实际上是一个标签重写过程。
这种重写目标实例标签的机制是在采集样本数据在Prometheus中称为“重新标记”之前发生的。

Prometheus允许用户通过采集任务设置中的relabel_configs添加自定义的重新标记过程。
使用replace / labelmap重写标签
重新标记的最基本的应用场景是基于Target实例中收录的元数据标签动态添加或覆盖标签。例如,通过Consul动态发现的服务实例还将收录以下元数据标签信息:
默认情况下,来自Node Exporter实例采集的示例数据如下:
node_cpu{cpu="cpu0",instance="localhost:9100",job="node",mode="idle"} 93970.8203125
我们希望有一个附加标签dc,它可以指示样本所属的数据中心:
node_cpu{cpu="cpu0",instance="localhost:9100",job="node",mode="idle", dc="dc1"} 93970.8203125
可以将多个relabel_config配置添加到每个采集任务的配置中。最简单的重新标记配置如下:
scrape_configs:
- job_name: node_exporter
consul_sd_configs:
- server: localhost:8500
services:
- node_exporter
relabel_configs:
- source_labels: ["__meta_consul_dc"]
target_label: "dc"
此采集任务通过Consul作为采集的监视目标来动态发现Node Exporter实例信息。在上一节中,我们知道通过Consul动态发现的监视目标将收录一些其他元数据标签,例如__meta_consul_dc标签,指示当前实例所在的Consul数据中心,因此我们希望从这些实例进行监视采集该示例还可以收录这样的标签,例如:
node_cpu{cpu="cpu0",dc="dc1",instance="172.21.0.6:9100",job="consul_sd",mode="guest"}
通过这种方式,可以方便地根据dc标签的值对不同数据中心的数据进行汇总和分析。
在此示例中,通过从Target实例获取__meta_consul_dc的值,并重写从该实例获得的所有样本。
完整的relabel_config配置如下:
# The source labels select values from existing labels. Their content is concatenated
# using the configured separator and matched against the configured regular expression
# for the replace, keep, and drop actions.
[ source_labels: '[' [, ...] ']' ]
# Separator placed between concatenated source label values.
[ separator: | default = ; ]
# Label to which the resulting value is written in a replace action.
# It is mandatory for replace actions. Regex capture groups are available.
[ target_label: ]
# Regular expression against which the extracted value is matched.
[ regex: | default = (.*) ]
# Modulus to take of the hash of the source label values.
[ modulus: ]
# Replacement value against which a regex replace is performed if the
# regular expression matches. Regex capture groups are available.
[ replacement: | default = $1 ]
# Action to perform based on regex matching.
[ action: | default = replace ]
动作定义了元数据标签的当前relabel_config处理方法,默认动作行为是replace。替换行为将根据regex配置匹配source_labels标签的值(多个source_label的值将根据分隔符进行拼接),并将匹配的值写入target_label。如果有多个匹配组,则可以使用$ {1},$ {2}确定要写入的内容。如果没有匹配项,则不会重置target_label。
通过repalce操作,用户可以根据Target的Metadata标签重写或编写新的标签键值对。在多环境的情况下,它可以帮助用户添加与环境相关的特征尺寸,从而更好地执行数据聚合。
除了使用replace之外,还可以将操作配置定义为labelmap。与replace不同,labelmap将根据正则表达式的定义匹配Target实例的所有标签的名称,并使用匹配的内容作为新标签名称,并将其值用作新标签的值。
例如,当监视Kubernetes下的所有主机节点时,要将在这些节点上定义的标签写到样本中,可以使用以下relabel_config配置:
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
使用labelkeep或labeldrop过滤目标标签,并仅保留符合过滤条件的标签,例如:
relabel_configs:
- regex: label_should_drop_(.+)
action: labeldrop
此配置将使用正则表达式来匹配当前Target实例的所有标签,并从Target实例中删除符合regex规则的标签。 labelkeep相反,它将删除所有不匹配正则表达式定义的标签。
使用保留/删除过滤目标实例
在上一部分中,我们介绍了Prometheus的重新标记机制,并使用replace / labelmap / labelkeep / labeldrop来管理标签。在本节的开头提到了第二个问题。使用集中式服务发现注册表时,环境中的所有导出器实例都将在服务发现注册表中注册。具有不同功能(开发,测试,操作和维护)的人员可能只关心某些监视数据。他们可以部署自己的Prometheus Server来监视他们关心的指标数据。如果将这些Prometheus Server 采集放在所有环境中,显然,所有Exporter数据都将浪费大量资源。如何使这些不同的Prometheus Server 采集各自引起关注?答案是重新标记。除默认替换外,relabel_config的操作还支持保留/删除行为。例如,如果只需要采集数据中心dc1中的Node Exporter实例的样本数据,则可以使用以下配置:
scrape_configs:
- job_name: node_exporter
consul_sd_configs:
- server: localhost:8500
services:
- node_exporter
relabel_configs:
- source_labels: ["__meta_consul_dc"]
regex: "dc1"
action: keep
将动作设置为保持时,Prometheus将丢弃与source_labels的值中的正则表达式正则表达式的内容不匹配的Target实例,并且在将动作设置为drop时,它将丢弃与正则表达式正则表达式。内容的Target实例。可以简单地理解为保留以供选择,丢弃以排除。
使用hashmod计算source_labels的哈希值
当relabel_config设置为hashmod时,Prometheus将使用模量值作为系数来计算source_labels值的哈希值。例如:
scrape_configs
- job_name: 'file_ds'
relabel_configs:
- source_labels: [__address__]
modulus: 4
target_label: tmp_hash
action: hashmod
file_sd_configs:
- files:
- targets.json
根据当前Target实例__address__的值,使用4作为系数,以便每个Target实例将收录一个新标签tmp_hash,其值范围在1〜4之间。查看目标实例的标签信息。看到以下结果,每个Target实例都收录一个新的tmp_hash值:
使用Hashmod的功能在目标实例级别实现采集任务的功能分区:
scrape_configs:
- job_name: some_job
relabel_configs:
- source_labels: [__address__]
modulus: 4
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^1$
action: keep
此处应注意,如果重新标记操作仅是为了生成临时变量作为下一个重新标记操作的输入,则可以使用__tmp作为标签名称的前缀,并且该前缀定义的标签将不写到目标的标签或样本的采集。
二手房销售员竟然还有这些“神器”相助采集房源和意向顾客?
采集交流 • 优采云 发表了文章 • 0 个评论 • 292 次浏览 • 2020-08-28 02:50
二手房销售员竟然还有这些“神器”相助采集房源和意向顾客? 在过去一年以来,二手房市场仍然存在两个“难”:“难购房”和“难买房”。 除了相关的政府新政之外,问题的诱因也包括卖方的需求和买方的供应没有确切对接。而这些对接起初主要是借助二手房经纪人为主导的中介机构。 一个成功的二手房销售必然是靠无数的求购信息和售房信息堆积下来。 无论您是进行二手房在线销售还是传统销售,积极获取这“求购”和“售房”这三者数据至关重要,而且获取那些数据信息的过程并不比销售过程容易多少。 你须要搜集数据并建立专用数据库,以便进行剖析,跟进和筛选顾客。 互联网时代,最大的数据量其实是存在于各类网路平台中中,例如 58 同城等平台,以及在各类二手房交易网站上发布的转让和求购信息。 然而,采集数据和各区域房源信息同样是一件比较冗长的事情,一条一条自动复制粘贴费时并且容易出错。毕竟,销售人员更应当把宝贵的时间放到顾客沟通和业务洽谈上。 高质量的搜集工具可以帮助二手房销售人员从行业信息平台上快速获得需求数据和供应数据。 许多公司会选择爬行工具在线抓取数据,但对于这些普遍缺少 IT 背景的销售人员,我建议尝试操作简单易上手的博为小帮软件机器人来采集数据。 博为小帮软件机器人可以代替自动和重复的计算机操作,包括从目标网站采集您须要的顾客数据数组,如顾客姓名,电话号码,地址等,卖家的价钱、地段、户型特点等。使用上去十分简单便捷。 真正的零代码是一个很大的特性。 它不需要 IT 背景。 只要您了解简单的计算机操作,就可以轻松配置它并将其替换为自动复制和粘贴以搜集顾客数据。 拥有自己的顾客和库存数据库以及基于数据的剖析。 这意味着您的业务一旦启动都会更具针对性。 工作效率和成功率也得到保证。 查看全部
二手房销售员竟然还有这些“神器”相助采集房源和意向顾客?
二手房销售员竟然还有这些“神器”相助采集房源和意向顾客? 在过去一年以来,二手房市场仍然存在两个“难”:“难购房”和“难买房”。 除了相关的政府新政之外,问题的诱因也包括卖方的需求和买方的供应没有确切对接。而这些对接起初主要是借助二手房经纪人为主导的中介机构。 一个成功的二手房销售必然是靠无数的求购信息和售房信息堆积下来。 无论您是进行二手房在线销售还是传统销售,积极获取这“求购”和“售房”这三者数据至关重要,而且获取那些数据信息的过程并不比销售过程容易多少。 你须要搜集数据并建立专用数据库,以便进行剖析,跟进和筛选顾客。 互联网时代,最大的数据量其实是存在于各类网路平台中中,例如 58 同城等平台,以及在各类二手房交易网站上发布的转让和求购信息。 然而,采集数据和各区域房源信息同样是一件比较冗长的事情,一条一条自动复制粘贴费时并且容易出错。毕竟,销售人员更应当把宝贵的时间放到顾客沟通和业务洽谈上。 高质量的搜集工具可以帮助二手房销售人员从行业信息平台上快速获得需求数据和供应数据。 许多公司会选择爬行工具在线抓取数据,但对于这些普遍缺少 IT 背景的销售人员,我建议尝试操作简单易上手的博为小帮软件机器人来采集数据。 博为小帮软件机器人可以代替自动和重复的计算机操作,包括从目标网站采集您须要的顾客数据数组,如顾客姓名,电话号码,地址等,卖家的价钱、地段、户型特点等。使用上去十分简单便捷。 真正的零代码是一个很大的特性。 它不需要 IT 背景。 只要您了解简单的计算机操作,就可以轻松配置它并将其替换为自动复制和粘贴以搜集顾客数据。 拥有自己的顾客和库存数据库以及基于数据的剖析。 这意味着您的业务一旦启动都会更具针对性。 工作效率和成功率也得到保证。
优采云采集器 v8.0.16免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 442 次浏览 • 2020-08-25 20:58
优采云采集器是一款十分强悍的数据采集神器,拥有自主的数据估算系统,可以使你快速从网上抓取各类须要的数据信息,支持从网站和网页上获取有用的、十分规范的数据,采用手动采集的形式轻松采集任何网页或网站的数据信息,不需要懂得任何的专业的知识,让一个菜鸟用户都可以快速学会使用,毫无任何方法,软件拥有可视化的操作,让操作更简单高效,简化操作流程,让采集工作更快速完成。而且完全手动采集,不需要人工操作,能够模拟用户的思维进行操作,帮助你从指定网页上精准采集对于你有用的数据资料,不需要去自己找寻,支持抓取的内容十分的多,可以用于搜集信息,商品宝贝的价钱,销量,各种行业的资讯,数据报表等等,收录的内容十分的全面,网页和网站上的内容基本都可以采集。也可以支持社交网站的信息抓取,比如博客,论坛等等,在博客上会有很多的有用的知识,信息,可以通过这款软件进行快速采集,还支持定时操作,可以设定采集数据的时间,可以说是数据抓取采集的不二选择。
安装教程1、下载并解压,运行EXE程序,选择软件的安装目录,点击安装。
2、安装完成,点击完成退出安装界面。
功能特色操作简单,完全可视化图形操作,无需专业IT人员,任何会使用笔记本上网的人都可以轻松把握。
云采集
采集任务手动分配到云端多台服务器同时执行,提高采集效率,可以挺短的时间内 获取成千上万条信息。
拖拽式采集流程
模拟人的操作思维模式,可以登录,输入数据,点击链接,按钮等,还能对不同情况采取不同的采集流程。
图文辨识
内置可扩充的OCR插口,支持解析图片中的文字,可将图片上的文字提取下来。
定时手动采集
采集任务手动运行,可以根据指定的周期手动采集,并且还支持最快一分钟一次的实时采集。
2分钟快速入门
内置从入门到精通所须要的视频教程,2分钟才能上手使用,另外还有文档,论坛,qq群等。
免费使用
它是免费的,并且免费版本没有任何功能限制,你如今就可以试一试,立即下载安装。软件功能单来讲,使用优采云可以十分容易的从任何网页精确采集你须要的数据,生成自定义的、规整的数据格式。优采云数据采集系统能做的包括但并不局限于以下内容:
1. 金融数据,如年报,年报,财务报告, 包括每日最新净值手动采集;
2. 各大新闻门户网站实时监控,自动更新及上传最新发布的新闻;
3. 监控竞争对手最新信息,包括商品价钱及库存; 查看全部
优采云采集器 v8.0.16免费版
优采云采集器是一款十分强悍的数据采集神器,拥有自主的数据估算系统,可以使你快速从网上抓取各类须要的数据信息,支持从网站和网页上获取有用的、十分规范的数据,采用手动采集的形式轻松采集任何网页或网站的数据信息,不需要懂得任何的专业的知识,让一个菜鸟用户都可以快速学会使用,毫无任何方法,软件拥有可视化的操作,让操作更简单高效,简化操作流程,让采集工作更快速完成。而且完全手动采集,不需要人工操作,能够模拟用户的思维进行操作,帮助你从指定网页上精准采集对于你有用的数据资料,不需要去自己找寻,支持抓取的内容十分的多,可以用于搜集信息,商品宝贝的价钱,销量,各种行业的资讯,数据报表等等,收录的内容十分的全面,网页和网站上的内容基本都可以采集。也可以支持社交网站的信息抓取,比如博客,论坛等等,在博客上会有很多的有用的知识,信息,可以通过这款软件进行快速采集,还支持定时操作,可以设定采集数据的时间,可以说是数据抓取采集的不二选择。

安装教程1、下载并解压,运行EXE程序,选择软件的安装目录,点击安装。

2、安装完成,点击完成退出安装界面。

功能特色操作简单,完全可视化图形操作,无需专业IT人员,任何会使用笔记本上网的人都可以轻松把握。
云采集
采集任务手动分配到云端多台服务器同时执行,提高采集效率,可以挺短的时间内 获取成千上万条信息。
拖拽式采集流程
模拟人的操作思维模式,可以登录,输入数据,点击链接,按钮等,还能对不同情况采取不同的采集流程。
图文辨识
内置可扩充的OCR插口,支持解析图片中的文字,可将图片上的文字提取下来。
定时手动采集
采集任务手动运行,可以根据指定的周期手动采集,并且还支持最快一分钟一次的实时采集。
2分钟快速入门
内置从入门到精通所须要的视频教程,2分钟才能上手使用,另外还有文档,论坛,qq群等。
免费使用
它是免费的,并且免费版本没有任何功能限制,你如今就可以试一试,立即下载安装。软件功能单来讲,使用优采云可以十分容易的从任何网页精确采集你须要的数据,生成自定义的、规整的数据格式。优采云数据采集系统能做的包括但并不局限于以下内容:
1. 金融数据,如年报,年报,财务报告, 包括每日最新净值手动采集;
2. 各大新闻门户网站实时监控,自动更新及上传最新发布的新闻;
3. 监控竞争对手最新信息,包括商品价钱及库存;
观远数据发布表单利器GuanForm,一站式智能数据剖析平台再升级
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2020-08-11 21:49
在观远平台上,企业如需统一采集数据和督查需求,无需利用第三方表单工具,可以直接通过GuanForm设置表单填写信息,填写后搜集的数据才能通过SQL直接提取,快速导出观远数据的BI剖析平台进行后续可视化剖析,从而实现数据口径更统一,数据采集与剖析更实时高效。
对于还在用Excel搜集数据或则没有任何相关工具的企业来说,GuanForm能支持在线整合并递交数据,让职工从繁杂的合并Excel操作中解放下来,有更多时间去做创造性的工作。
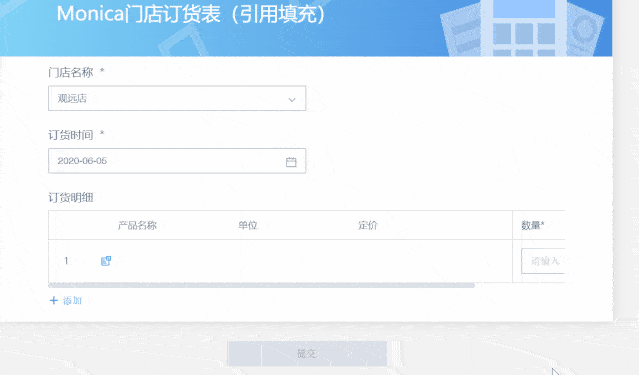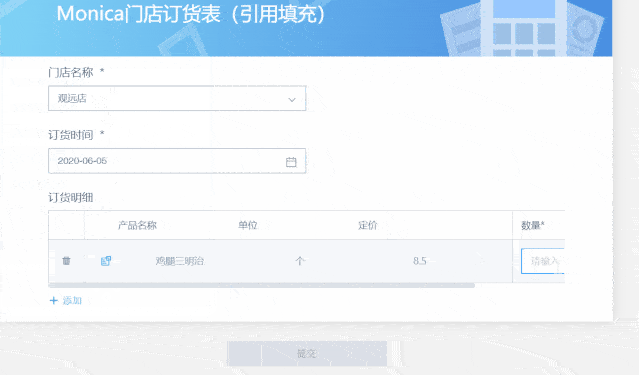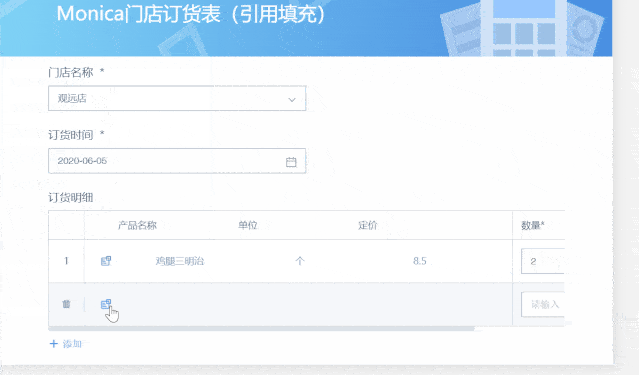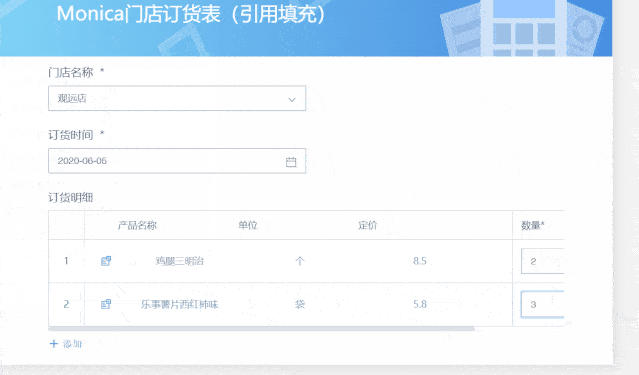
前期搜集的数据质量难以保证,导致后续剖析结果不确切,这也是数据剖析过程中的难点。通过GuanForm的“引用填充”功能,能够在源头规范主数据填写质量,此外,还可以结合单选、多选、数字格式等控件引导数据提交者在第一步就确切输入。
例如,在零售行业的店面订货场景,在填写订货明细的时侯,需要逐行填写产品名称、单位、定价和订货数目等数据,而其中前两者的信息是相对固定的主数据,必须和商品表中的信息一致就能保证数据口径统一,这些信息就可以通过“引用填充”的功能只能从商品主数据中引用过来填充到当前表单,省时省力又保证了数据的正确性。
表单的数据安全与权限管理是企业关注的另一要点,GuanForm从用户管理、表单管理、数据管理多方面进行把控,防止搜集信息泄露的同时,做到使不同的人拥有不同的操作权限和数据权限。
那么,如此强悍的数据采集“神器”要怎么使用呢?
下面将从设计表单、设置表单权限、表单数据搜集3个步骤为你们逐一介绍:
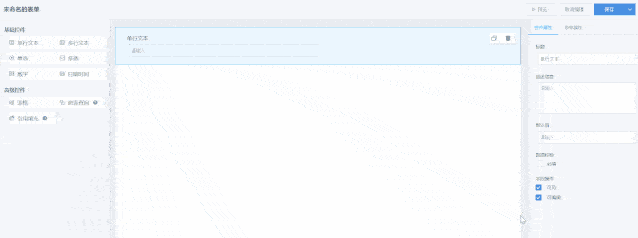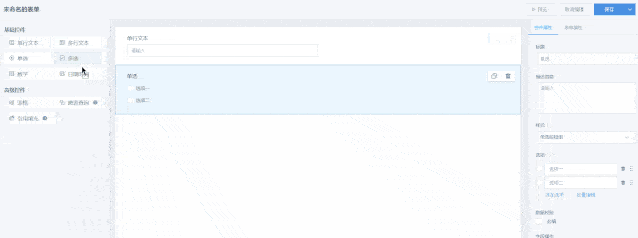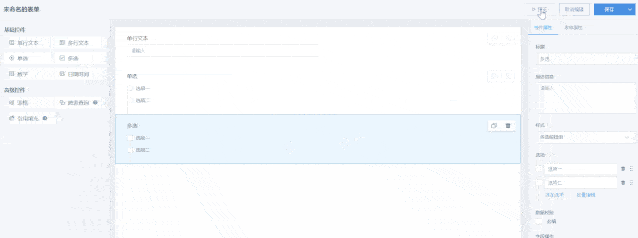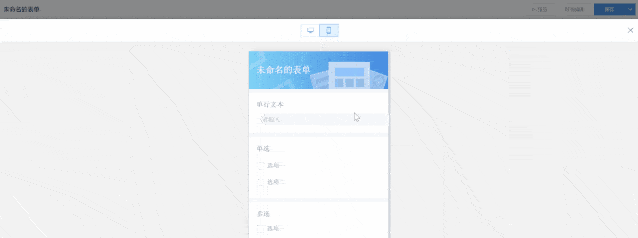
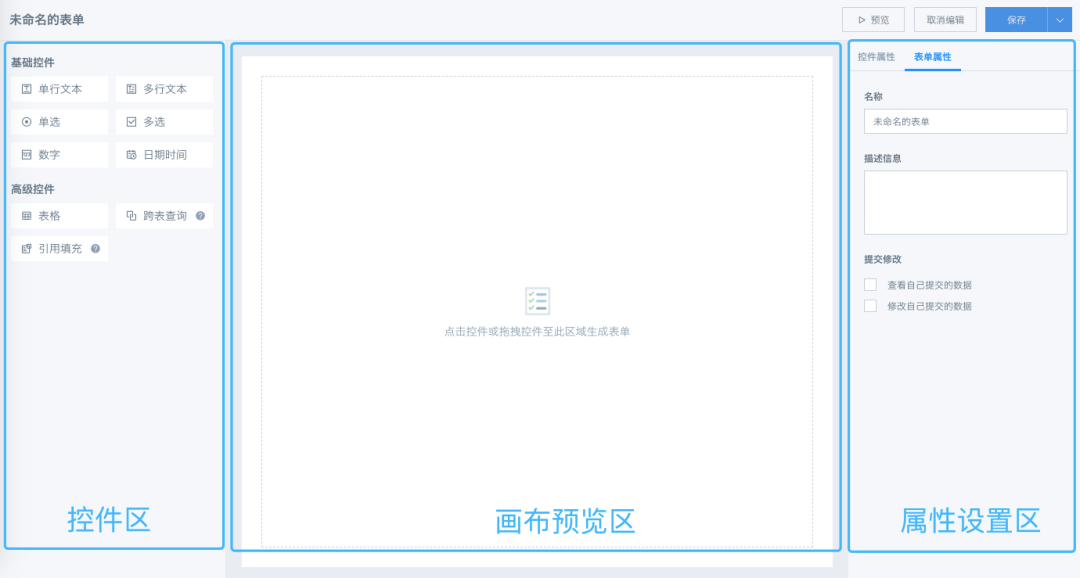
01.表单设计
登录表单系统后,点击右上角的“新建表单”来到表单编辑页面,观远表单通过控件的拖拉拽生成,灵活易用,使用门槛低。
设计页面由3部份组成:控件县、画布预览县和属性设置县。
表单数组由控件组成,在画布县可自由拖放排版,同时也可以点击页面上方的“预览”查看表单最终疗效。目前提供以下常用控件:
02.设置表单权限
表单的权限分为所有者和提交者,只有成为表单的所有者,才可以对表单进行更改维护;只有成为表单的提交者,才准许录入数据,这样可以有效避免表单信息的泄漏,防止非目标用户的脏数据混杂进来。
对于搜集上来的表单数据,默认只有所有者可以查看和管理。同时也开放设置项,允许提交者查看和更改自己递交的数据,但未能查看其他人的数据,从而确保数据的安全性。
03.表单数据搜集
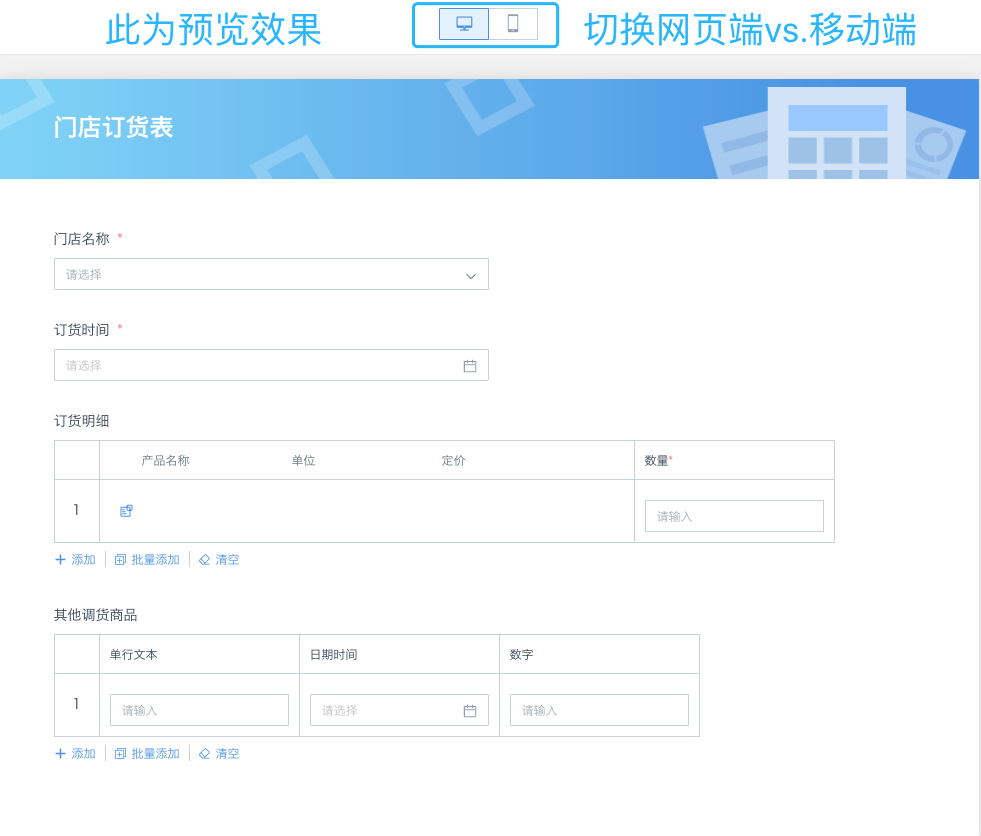
GuanForm支持网页端和移动端多渠道的数据采集,支持无缝内嵌到钉钉、企业陌陌、企业自研APP等多种客户端。
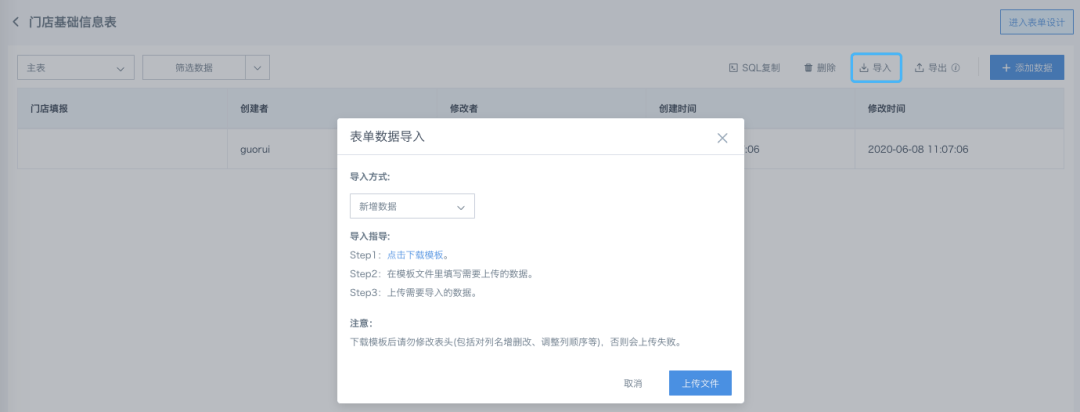
除了单条数据的逐一录入,GuanForm还提供了批量导出的功能,点击右上角“导入”,按照提示下载模板,在模板里填写须要上传的数据后,点击“上传文件”即可。
总结一下,GuanForm是由观远提供的灵活易用的表单搭建和表单数据管理工具,具有表单制做灵活简便、权限管理简约建立的优点;网页端移动端分发双管齐下,且表单数据支持快速对接观远BI平台,助力企业零散数据电子化。
观远数据()成立于2016年,以“AI+BI 让决策更智能”为使命,深耕零售、消费以及互联网领域,致力于为顾客提供新一代智能数据剖析平台以及零售消费行业的最佳数据剖析实践。目前服务联合利华、沃尔玛、全家、来伊份、生鲜传奇、lily男装、红豆、小红书、蜜芽宝贝等著名企业。公司总部坐落广州,并在广州、上海、深圳等地设有办事处。
声明:该文观点仅代表作者本人,搜狐号系信息发布平台,搜狐仅提供信息储存空间服务。 查看全部
只需一个负责人完成创建表单——发送表单——采集信息——管理数据——导入观远BI平台的全流程,真正做到数据采集和数据剖析平台一体化。
在观远平台上,企业如需统一采集数据和督查需求,无需利用第三方表单工具,可以直接通过GuanForm设置表单填写信息,填写后搜集的数据才能通过SQL直接提取,快速导出观远数据的BI剖析平台进行后续可视化剖析,从而实现数据口径更统一,数据采集与剖析更实时高效。
对于还在用Excel搜集数据或则没有任何相关工具的企业来说,GuanForm能支持在线整合并递交数据,让职工从繁杂的合并Excel操作中解放下来,有更多时间去做创造性的工作。
前期搜集的数据质量难以保证,导致后续剖析结果不确切,这也是数据剖析过程中的难点。通过GuanForm的“引用填充”功能,能够在源头规范主数据填写质量,此外,还可以结合单选、多选、数字格式等控件引导数据提交者在第一步就确切输入。
例如,在零售行业的店面订货场景,在填写订货明细的时侯,需要逐行填写产品名称、单位、定价和订货数目等数据,而其中前两者的信息是相对固定的主数据,必须和商品表中的信息一致就能保证数据口径统一,这些信息就可以通过“引用填充”的功能只能从商品主数据中引用过来填充到当前表单,省时省力又保证了数据的正确性。
表单的数据安全与权限管理是企业关注的另一要点,GuanForm从用户管理、表单管理、数据管理多方面进行把控,防止搜集信息泄露的同时,做到使不同的人拥有不同的操作权限和数据权限。
那么,如此强悍的数据采集“神器”要怎么使用呢?
下面将从设计表单、设置表单权限、表单数据搜集3个步骤为你们逐一介绍:
01.表单设计
登录表单系统后,点击右上角的“新建表单”来到表单编辑页面,观远表单通过控件的拖拉拽生成,灵活易用,使用门槛低。
设计页面由3部份组成:控件县、画布预览县和属性设置县。
表单数组由控件组成,在画布县可自由拖放排版,同时也可以点击页面上方的“预览”查看表单最终疗效。目前提供以下常用控件:
02.设置表单权限
表单的权限分为所有者和提交者,只有成为表单的所有者,才可以对表单进行更改维护;只有成为表单的提交者,才准许录入数据,这样可以有效避免表单信息的泄漏,防止非目标用户的脏数据混杂进来。
对于搜集上来的表单数据,默认只有所有者可以查看和管理。同时也开放设置项,允许提交者查看和更改自己递交的数据,但未能查看其他人的数据,从而确保数据的安全性。
03.表单数据搜集
GuanForm支持网页端和移动端多渠道的数据采集,支持无缝内嵌到钉钉、企业陌陌、企业自研APP等多种客户端。
除了单条数据的逐一录入,GuanForm还提供了批量导出的功能,点击右上角“导入”,按照提示下载模板,在模板里填写须要上传的数据后,点击“上传文件”即可。
总结一下,GuanForm是由观远提供的灵活易用的表单搭建和表单数据管理工具,具有表单制做灵活简便、权限管理简约建立的优点;网页端移动端分发双管齐下,且表单数据支持快速对接观远BI平台,助力企业零散数据电子化。
观远数据()成立于2016年,以“AI+BI 让决策更智能”为使命,深耕零售、消费以及互联网领域,致力于为顾客提供新一代智能数据剖析平台以及零售消费行业的最佳数据剖析实践。目前服务联合利华、沃尔玛、全家、来伊份、生鲜传奇、lily男装、红豆、小红书、蜜芽宝贝等著名企业。公司总部坐落广州,并在广州、上海、深圳等地设有办事处。
声明:该文观点仅代表作者本人,搜狐号系信息发布平台,搜狐仅提供信息储存空间服务。
一个导航替你搜集了全网最酷最高效的工具利器,悄悄采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2020-08-09 17:43
一、网站体验测评1.网站设计
首先从官网设计上来看吧,点开网站进去,整体觉得太简约,框架清晰,比通常的导航网站更加开朗和前卫一些。交互设计上也是十分简单,点击站点即可跳转到对方网站。相比我之前使用的一些导航可能出于seo优化考虑,还会有一个跳转页面,对于用户体验虽然不是太友好。
2.网站内容
再来看内容里面,第一大块就是推荐各类站点,主要有办公、设计、开发、品牌、营销...等几大块,里面推荐的80%产品本身都是特别用心优秀的,比如logo在线智能生成设计,有些可能会太冷门并且当我使用了以后,都进了我的采集夹,遗憾为何没有早点发觉,互联网信息差很严重了吧!我恨!在站点选择这块,我认为是这个站做的最好的地方了,发现这些被埋没的好工具好网站,让价值传递出去被更多人听到。在文章后面都会给你们推荐几个一定要试试都利器工具,这里先继续说它的第二块内容。
一个单一的导航可能难以明晰一个产品的调性,它这儿添加了一个文章内容蓝筹股,里面的文章主要内容是,具体介绍这些优秀的产品工具以及帮你们评测各类产品、或者一些资源和技能分享。我觉得这块的主要作用就是,能够使用户的逗留时间更长一些,以及降低这个导航的附加价值,就像6套ppt模板,这种整理好可以直接下载的资源就很实用了。
二、神器推荐
在前面和你们分享了我自己对这个导航网站的一些体验体会,如果是非常的话,我认为可以打八分左右吧,在一些站点分类里面我认为做得还不是挺好希望见到它继续进步。接下来,我想和大家分享一些,我通过这个创业利器导航发觉的几个非常棒的产品工具(没有收广告费)
1.搜图利器
写文章的时侯,配图是刚需,目前不管是平台也好还是个人对于图片版权意识越来越重视,不敢象原先那样随意用了。我之前仍然使用的是美国那几个免版权的图库,比如unsplash、pixbay这种,不太便捷的是加载速率会比较慢,并且不支持英文搜索。
搜图利器这个工具,最大的亮点是聚合了这几家商用免版权图库,一键英文搜索,需要工作场景的图片直接输入”工作“就可以,会出现各大图库的图片,直接下载就完事了。重点是完全免费的!
2.甜蒜填图
这也是我近来才发觉的一个小工具,做设计的朋友肯定都晓得,设计稿中须要各类图片占位,首先须要下载好图片,然后一个个位置做填充,超麻烦der,其实我认为这些机械复制性的工作早就该被工具取代了呀。甜蒜填图就是这样的一款工具,对接了免费版权图库,支持打标签一键填充所有图片,大大提升了工作效率,设计师们用上去~
3.MIXKIT
纸质媒体时代过去了以后迎来了数字媒体时代,现在动态视频比文字更有吸引力,不管是企业宣传还是个人品牌,都希望通过短视频来传播影响力。最近我也在尝试做一些视频出来玩,比较难的是很难找到那个炫目的素材,国内基本上都是收费且有版权限制的。在利器导航上发觉了这个网站之后,点进去一看,免版权可商用!爱了!并且呢,整个网站设计的也太棒啊,当然关键是上面的素材内容十分丰富,阔以直接下载用到自己视频上面,做片头或则特效都可以~
不知不觉写了那么长,感觉好玩的产品真的推荐不完诶,累了累了!想知道更多有趣、有价值、好用的工具就去创业利器导航发觉叭~ 查看全部
一、网站体验测评1.网站设计
首先从官网设计上来看吧,点开网站进去,整体觉得太简约,框架清晰,比通常的导航网站更加开朗和前卫一些。交互设计上也是十分简单,点击站点即可跳转到对方网站。相比我之前使用的一些导航可能出于seo优化考虑,还会有一个跳转页面,对于用户体验虽然不是太友好。
2.网站内容
再来看内容里面,第一大块就是推荐各类站点,主要有办公、设计、开发、品牌、营销...等几大块,里面推荐的80%产品本身都是特别用心优秀的,比如logo在线智能生成设计,有些可能会太冷门并且当我使用了以后,都进了我的采集夹,遗憾为何没有早点发觉,互联网信息差很严重了吧!我恨!在站点选择这块,我认为是这个站做的最好的地方了,发现这些被埋没的好工具好网站,让价值传递出去被更多人听到。在文章后面都会给你们推荐几个一定要试试都利器工具,这里先继续说它的第二块内容。
一个单一的导航可能难以明晰一个产品的调性,它这儿添加了一个文章内容蓝筹股,里面的文章主要内容是,具体介绍这些优秀的产品工具以及帮你们评测各类产品、或者一些资源和技能分享。我觉得这块的主要作用就是,能够使用户的逗留时间更长一些,以及降低这个导航的附加价值,就像6套ppt模板,这种整理好可以直接下载的资源就很实用了。

二、神器推荐
在前面和你们分享了我自己对这个导航网站的一些体验体会,如果是非常的话,我认为可以打八分左右吧,在一些站点分类里面我认为做得还不是挺好希望见到它继续进步。接下来,我想和大家分享一些,我通过这个创业利器导航发觉的几个非常棒的产品工具(没有收广告费)
1.搜图利器

写文章的时侯,配图是刚需,目前不管是平台也好还是个人对于图片版权意识越来越重视,不敢象原先那样随意用了。我之前仍然使用的是美国那几个免版权的图库,比如unsplash、pixbay这种,不太便捷的是加载速率会比较慢,并且不支持英文搜索。
搜图利器这个工具,最大的亮点是聚合了这几家商用免版权图库,一键英文搜索,需要工作场景的图片直接输入”工作“就可以,会出现各大图库的图片,直接下载就完事了。重点是完全免费的!
2.甜蒜填图
这也是我近来才发觉的一个小工具,做设计的朋友肯定都晓得,设计稿中须要各类图片占位,首先须要下载好图片,然后一个个位置做填充,超麻烦der,其实我认为这些机械复制性的工作早就该被工具取代了呀。甜蒜填图就是这样的一款工具,对接了免费版权图库,支持打标签一键填充所有图片,大大提升了工作效率,设计师们用上去~
3.MIXKIT

纸质媒体时代过去了以后迎来了数字媒体时代,现在动态视频比文字更有吸引力,不管是企业宣传还是个人品牌,都希望通过短视频来传播影响力。最近我也在尝试做一些视频出来玩,比较难的是很难找到那个炫目的素材,国内基本上都是收费且有版权限制的。在利器导航上发觉了这个网站之后,点进去一看,免版权可商用!爱了!并且呢,整个网站设计的也太棒啊,当然关键是上面的素材内容十分丰富,阔以直接下载用到自己视频上面,做片头或则特效都可以~
不知不觉写了那么长,感觉好玩的产品真的推荐不完诶,累了累了!想知道更多有趣、有价值、好用的工具就去创业利器导航发觉叭~
【】神器!小白也能用的免费网路爬虫软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-09 11:55
……
是不是特别有趣?
更厉害的是!官网提供了大量的实战教程(文字版+视频版),也可以进行教程的搜索,对于小白选手来说,真是很棒了!
优采云采集器()
下面,我们就以抓取马蜂窝上所有日本自由行的信息为例,实际操作一下:
1、下载软件安装注册登入后,复制马蜂窝日本自由行旅行功略的网页。
2、新建智能模式采集任务
也可以在软件上直接新建采集任务,也可以通过导出规则来创建任务。
3、设置提取数据字段
智能模式下,输入网址后软件即可手动辨识出页面上的数据并生成采集结果,每一类数据对应一个采集字段,可以右击更改数组名称、增减数组、处理数据等。
比如须要采集攻略的功略标题、攻略链接、阅读量、体验人数以及封面图等信息,设置疗效如下
4、提取详情页数据
列表页上有日本自由行功略的部份信息,我们须要功略的具体内容,右击功略链接使用“深入采集”功能,跳转到详情页进行采集。
在详情页面可以看见功略的详尽内容、评论数等信息,还可以见到特别多的图片,如果一 一设置数组,会特别多,而且整篇的图片位置不同,所以可以添加一个特殊数组,“页面PDF”。
5、设置采集任务
点击“设置”按钮,可以进行运行设置和防屏蔽设置,这里我们勾选“跳过继续采集”,设置“5”秒恳求等待时间,勾选“不加载网页图片”,防屏蔽设置默认设置,点击保存。
6、开始采集
点击“保存并启动”按钮,弹出一些中级设置,直接点击“启动”运行工具。
7、提取数据
任务启动以后开始手动采集数据,可以直观的看见程序运行过程和采集结果,采集结束以后有提醒。
8、导出数据
数据采集完成后,可以查看和导入数据,软件支持多种导入方法和导入文件的格式(EXCEL、CSV、HTML和TXT),选择自己须要方法和文件类型,点击“确认导入”。
好了,上面是一个简单的反例。看完以后,是不是发觉,原来爬虫爬取数据也可以如此简单!有兴趣的小伙伴快去试试吧。
这里就不放下载地址了,感兴趣的可以去官网下载,非常贴心的提供了三个版本。
查看全部


……
是不是特别有趣?
更厉害的是!官网提供了大量的实战教程(文字版+视频版),也可以进行教程的搜索,对于小白选手来说,真是很棒了!

优采云采集器()
下面,我们就以抓取马蜂窝上所有日本自由行的信息为例,实际操作一下:
1、下载软件安装注册登入后,复制马蜂窝日本自由行旅行功略的网页。

2、新建智能模式采集任务
也可以在软件上直接新建采集任务,也可以通过导出规则来创建任务。

3、设置提取数据字段
智能模式下,输入网址后软件即可手动辨识出页面上的数据并生成采集结果,每一类数据对应一个采集字段,可以右击更改数组名称、增减数组、处理数据等。

比如须要采集攻略的功略标题、攻略链接、阅读量、体验人数以及封面图等信息,设置疗效如下

4、提取详情页数据
列表页上有日本自由行功略的部份信息,我们须要功略的具体内容,右击功略链接使用“深入采集”功能,跳转到详情页进行采集。

在详情页面可以看见功略的详尽内容、评论数等信息,还可以见到特别多的图片,如果一 一设置数组,会特别多,而且整篇的图片位置不同,所以可以添加一个特殊数组,“页面PDF”。

5、设置采集任务
点击“设置”按钮,可以进行运行设置和防屏蔽设置,这里我们勾选“跳过继续采集”,设置“5”秒恳求等待时间,勾选“不加载网页图片”,防屏蔽设置默认设置,点击保存。

6、开始采集
点击“保存并启动”按钮,弹出一些中级设置,直接点击“启动”运行工具。

7、提取数据
任务启动以后开始手动采集数据,可以直观的看见程序运行过程和采集结果,采集结束以后有提醒。

8、导出数据
数据采集完成后,可以查看和导入数据,软件支持多种导入方法和导入文件的格式(EXCEL、CSV、HTML和TXT),选择自己须要方法和文件类型,点击“确认导入”。

好了,上面是一个简单的反例。看完以后,是不是发觉,原来爬虫爬取数据也可以如此简单!有兴趣的小伙伴快去试试吧。
这里就不放下载地址了,感兴趣的可以去官网下载,非常贴心的提供了三个版本。

设计干货| Wall Crack-Eagle推荐的设计师灵感和材料库工件
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2020-08-08 22:47
许多工具非常简单易用,可以在垂直方向上提高我们的生产效率. 但是,使用所有工具是不现实的. 根据您的当前情况进行选择是不可避免的选择,并且并非不可替代. 因此,我没有动力共享这些工具,因为它的需求不强.
这次我要介绍的是唯一给我印象深刻的新设计工具-鹰.
一个,Eagle有什么用
简而言之,它是设计器的资源管理器.
管理设计采集的灵感图纸,材料文件,屏幕截图和Sketch控件.
1. 灵感图管理
通常,我们习惯于使用花瓣,本地文件夹和Pinterest来采集在Internet上看到的精美图片. Eagle使我们能够快速导入这些平台的内容.
认识我的人应该知道我采集的花瓣很多,但是大多数公司和咖啡馆的网络都很差,很难访问他们的采集. Pinterest更加糟糕,因为它依赖于推翻墙. ,因此我首先将所有在线图片移至Eagle. 如果您不习惯采集并且想快速建立自己的灵感库,则可以直接在花瓣中找到绘图板并将其导入,也可以直接使用我的采集集:
酸梅超人的花瓣首页
从花瓣导入的设置
导入画板后
所有图片导入后,我们可以根据文件夹对它们进行分类. 当前,文件夹仅支持两个级别的文件夹深度. 您也可以在文件夹中添加标签,也可以单独选择图片以添加标签,这很方便,尽管我很少使用它,但我们会很快找到它.
用于简历的灵感分类文件夹
为图片添加标签
然后,我们可以在上面的工具栏中对采集的图片进行排序和过滤. 颜色过滤功能非常实用. 当您要查找特定色彩系统的参考时,可以快速将其滤除.
使用滤色器功能后的结果
这样,Eagle可以快速过滤和预览我采集的成千上万张参考图片,这远远优于网页的效率.
图片缩放预览
2. 网页采集插件
更方便的事情是Eagle具有浏览器捕获插件. 我们可以使用此插件快速捕获整个网页或其中的某个区域. 最方便的方法是右键单击所需的图片,然后选择“将图像保存到Eagle”,图片将自动下载到本地未分类的文件夹中,请等到以后再处理.
Safari上的鹰插件
3. 物料管理
您还记得我以前做过的材料分享吗?我们还可以将材料导入Eagle并快速找到它. 如果使用Mac,您可能会认为这与保存自己的文件夹没有什么不同,但是关键是Eagle也支持Windows平台,这对于像我们这样的多平台用户来说非常重要.
Windows平台无法像Mac一样快地预览AI和PSD文件,因此通常的做法是在源文件旁边放置JPG,这似乎真的很累!尽管Adobe Bridge也可以做到,但是其实际体验并不理想. 但是Eagle也可以在Windows下快速预览PSD和AI文件.
图标材料的采集
4,草图组件
这可以看作是UI设计人员的武器. 过去,当我们处理UI KIT集合时,我们主要将相同类型的组件和项目粘贴到画布中,并在需要使用它们时将它们复制.
我的一个项目的组件库
Eagle允许我们从Sketch复制元素. 只要将元素复制到Sketch中并粘贴到Eagle中,您就可以看到相应的组件缩略图,并且在左上角可以看到代表Sketch的图标. 调用项目时,它的速度非常快,无需打开上一个项目的设计文件.
草图组件的集合
第二,Eagle的备份
如果您确实将Eagle作为主要灵感和资料库,那么高级应用程序将无法绕过该工具来同步云服务.
首先,Eagle将数据保存在本地硬盘上,并且不会通过自己的服务器进行备份(估计将来会启用此服务),那么您需要一种固定的备份方法来确保您的数据安全性(悲剧不断重复),以确保长时间整理的内容不会由于硬盘损坏或丢失而在整夜解放之前返回.
因此,同步云服务是最可靠的解决方案. 如果我们将本地Eagle文件夹设置为云同步,则每次添加图片和资料时,它们都会实时更新到服务器,以确保数据的安全性. . 另外,使用云服务使我们能够在其他计算机上读取这些数据并进行编辑,以确保我们的房屋和公司的内容同步.
我自己的私有云同步服务
关于同步云,目前阻止了外部服务,例如Google Drive,Dropbox等,因此建议您首先使用Apple的iCloud Drive. 创建和加载资源库时,我们将直接在此文件夹中进行操作. 它可以达到我们备份和同步数据的目的. 目前,Windows平台还提供了iCloud Drive软件,这也使我们可以跨平台使用此应用程序.
创建资源库的过程
MAC上的iCloud文件夹
Windows上的iCloud面板
当然,如果团队需要它,则类似于Dropbox的同步磁盘可以由多个人共享. 您可以创建一个新的资源库,并一起维护项目中使用的材料和组件!目前还不太实用,期待官方网站的更新和完善!
三个. 购买Eagle
Eagle不是免费的,但是好的软件仍然鼓励每个人都购买它(给别人一点支持,给彼此一个机会,个性保证并不宽泛!),让他们更积极地更新产品.
官方网站上的默认价格为30美元,10个人可以节省20%的订单. 想要购买的学生可以加入一个小组,小组号: 5537969.
预览: 已经下载了数十个G的样机资源尚未整理,应该在下周一和周二进行更新,敬请关注. =! 查看全部
近年来,与设计相关的轻量级工具太多了,例如Affinity系列,QC Studio,Vectr,Pixate等.
许多工具非常简单易用,可以在垂直方向上提高我们的生产效率. 但是,使用所有工具是不现实的. 根据您的当前情况进行选择是不可避免的选择,并且并非不可替代. 因此,我没有动力共享这些工具,因为它的需求不强.
这次我要介绍的是唯一给我印象深刻的新设计工具-鹰.

一个,Eagle有什么用
简而言之,它是设计器的资源管理器.
管理设计采集的灵感图纸,材料文件,屏幕截图和Sketch控件.
1. 灵感图管理
通常,我们习惯于使用花瓣,本地文件夹和Pinterest来采集在Internet上看到的精美图片. Eagle使我们能够快速导入这些平台的内容.
认识我的人应该知道我采集的花瓣很多,但是大多数公司和咖啡馆的网络都很差,很难访问他们的采集. Pinterest更加糟糕,因为它依赖于推翻墙. ,因此我首先将所有在线图片移至Eagle. 如果您不习惯采集并且想快速建立自己的灵感库,则可以直接在花瓣中找到绘图板并将其导入,也可以直接使用我的采集集:
酸梅超人的花瓣首页
从花瓣导入的设置
导入画板后
所有图片导入后,我们可以根据文件夹对它们进行分类. 当前,文件夹仅支持两个级别的文件夹深度. 您也可以在文件夹中添加标签,也可以单独选择图片以添加标签,这很方便,尽管我很少使用它,但我们会很快找到它.
用于简历的灵感分类文件夹
为图片添加标签
然后,我们可以在上面的工具栏中对采集的图片进行排序和过滤. 颜色过滤功能非常实用. 当您要查找特定色彩系统的参考时,可以快速将其滤除.
使用滤色器功能后的结果
这样,Eagle可以快速过滤和预览我采集的成千上万张参考图片,这远远优于网页的效率.
图片缩放预览
2. 网页采集插件
更方便的事情是Eagle具有浏览器捕获插件. 我们可以使用此插件快速捕获整个网页或其中的某个区域. 最方便的方法是右键单击所需的图片,然后选择“将图像保存到Eagle”,图片将自动下载到本地未分类的文件夹中,请等到以后再处理.
Safari上的鹰插件
3. 物料管理
您还记得我以前做过的材料分享吗?我们还可以将材料导入Eagle并快速找到它. 如果使用Mac,您可能会认为这与保存自己的文件夹没有什么不同,但是关键是Eagle也支持Windows平台,这对于像我们这样的多平台用户来说非常重要.
Windows平台无法像Mac一样快地预览AI和PSD文件,因此通常的做法是在源文件旁边放置JPG,这似乎真的很累!尽管Adobe Bridge也可以做到,但是其实际体验并不理想. 但是Eagle也可以在Windows下快速预览PSD和AI文件.
图标材料的采集
4,草图组件
这可以看作是UI设计人员的武器. 过去,当我们处理UI KIT集合时,我们主要将相同类型的组件和项目粘贴到画布中,并在需要使用它们时将它们复制.
我的一个项目的组件库
Eagle允许我们从Sketch复制元素. 只要将元素复制到Sketch中并粘贴到Eagle中,您就可以看到相应的组件缩略图,并且在左上角可以看到代表Sketch的图标. 调用项目时,它的速度非常快,无需打开上一个项目的设计文件.
草图组件的集合
第二,Eagle的备份
如果您确实将Eagle作为主要灵感和资料库,那么高级应用程序将无法绕过该工具来同步云服务.
首先,Eagle将数据保存在本地硬盘上,并且不会通过自己的服务器进行备份(估计将来会启用此服务),那么您需要一种固定的备份方法来确保您的数据安全性(悲剧不断重复),以确保长时间整理的内容不会由于硬盘损坏或丢失而在整夜解放之前返回.
因此,同步云服务是最可靠的解决方案. 如果我们将本地Eagle文件夹设置为云同步,则每次添加图片和资料时,它们都会实时更新到服务器,以确保数据的安全性. . 另外,使用云服务使我们能够在其他计算机上读取这些数据并进行编辑,以确保我们的房屋和公司的内容同步.
我自己的私有云同步服务
关于同步云,目前阻止了外部服务,例如Google Drive,Dropbox等,因此建议您首先使用Apple的iCloud Drive. 创建和加载资源库时,我们将直接在此文件夹中进行操作. 它可以达到我们备份和同步数据的目的. 目前,Windows平台还提供了iCloud Drive软件,这也使我们可以跨平台使用此应用程序.
创建资源库的过程
MAC上的iCloud文件夹
Windows上的iCloud面板
当然,如果团队需要它,则类似于Dropbox的同步磁盘可以由多个人共享. 您可以创建一个新的资源库,并一起维护项目中使用的材料和组件!目前还不太实用,期待官方网站的更新和完善!
三个. 购买Eagle
Eagle不是免费的,但是好的软件仍然鼓励每个人都购买它(给别人一点支持,给彼此一个机会,个性保证并不宽泛!),让他们更积极地更新产品.
官方网站上的默认价格为30美元,10个人可以节省20%的订单. 想要购买的学生可以加入一个小组,小组号: 5537969.
预览: 已经下载了数十个G的样机资源尚未整理,应该在下周一和周二进行更新,敬请关注. =!
一波易于使用的工件!
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2020-08-08 19:41
易于使用神器打击!互相给予一切,欢迎大家交流和学习. 1.外文文献搜索网站
/index.html
2. Google Chrome插件下载URL
推荐使用易于使用的插件
-搜索沙拉单词(可以通过自由标记单词来显示翻译内容
-购物者自动价格比较工具
-我想观看Vip视频
-ocr插件(忘记名称)
-有许多有用的未列出!
3. 公式拦截
请务必使用它!用它!用它!无需免费使用公式. 尽管一个月内可以使用的数量受到限制,但这已经足够了!
4. 笔记摘要-直接搜索官方网站下载〜
-Evernote
-窗帘
两者都很有用,您可以选择一个!
5. 思维导图软件直接搜索,可从官方网站下载!
-MindMaster
6. 爬行神器软件-以下软件可以直接从官方网站下载,通常免费,并且操作相对简单.
-优采云采集器
-优采云采集器(推荐)
7. 屏幕录像软件-直接搜索或从计算机软件下载
-EV屏幕录制
-Bilibili现场直播Ji(只能在您申请成为主持人时使用)
8. 语法错误校正工件
-1Checker(我忘记了我在哪里下载的,可以搜索,该软件非常方便,它将直接标记为红色并提供相应的语法错误建议,可以用作参考,但不一定全部哈哈)
9. 微型数据库
#/ publicDatabase
接受最新的微观调查数据!
10. 重复检查软件
充分利用每所学校的图书馆网站资源,这非常重要!例如: Duxiu和Biganwang可以用作常规的重复检查软件.
11. DEEPL网站翻译神器
目的: 超级强大的翻译助手. 该网站可与Google媲美,甚至比Google Translate更为流畅. 无需下载,仅需要网页翻译. 您可以尝试,英文和中文的翻译非常准确而且功能强大!
12. 论文阅读神器
知识网络研究(电子研究)
用法: 该软件可以直接管理文档,从而大大节省时间.
B智云文档翻译器
目的: 当文档为英文时,不易阅读,然后下载此工件,打开PDF,可以直接选择英文,然后在几分钟内将其翻译. 而且,它是双列的并且可以用英语进行比较,从而大大节省了时间.
13. 绘图伪像
一张相框图片和其他图片:
(1)Edraw软件;
(2)viso;
目的: 您可以在官方帐户“ Software Installation Manager”中找到它. 强大的绘图功能令人惊叹. 我相信一旦您使用它,您就会喜欢这两个软件. 相比之下,我更喜欢Edraw,因为模板很多.
B解锁地图绘图:
(1)ArcGIS;
(2)Python;
(3)Geoda;
(4)QGIS;
(5)由mapbox studio设计.
目的: 绘制地图工件. 前两个软件也可以在“软件安装管理器”中绘制精美的地图,但是每个都有其优点和缺点. 可以设置Arcgis绘图,但不能设置某些python. 智虎网友推荐了第四和第五. 我还没有尝试过这两个. 每个人都可以一起学习〜
14. 图片变成文本伪像
天若OCR文本识别
目的: 以秒为单位提取图片中的文本,提取的位置也可以排版. 重要的是它可以翻译,也可以用快捷键来辅助. 简而言之,这太神奇了. 这确实非常雄心勃勃. 我经常担心将图片转换为文本. 使用QQ更改文本很麻烦. 它还需要排版,这确实令人困惑!但是哈,不用担心,使用它!
15. 数据转换器
StaTransfer13: 免费下载且易于使用. 自己找到此链接〜应该可用!
目的: 您可以将各种数据类型的文件转换为所需的文件格式. 如SAS转换STATA,Excel. 在几分钟内完成!这确实是一个了不起的神奇好东西!
16. 不受欢迎的软件
yaahp软件
目的: 您可以加权,也可以直接操作百度.
B GAMS软件
目的: 它可用于需要优化路径的各种非线性或有条件约束的事物. 操作需要编程代码.
注意: 由于这两个软件相对不受欢迎,暂时还没有安装,如果需要,可以直接与我联系!
好的,这是推荐的工件. 欢迎大家交流和共享更多有趣和有趣的工件软件和网站. 来吧! 查看全部

易于使用神器打击!互相给予一切,欢迎大家交流和学习. 1.外文文献搜索网站
/index.html
2. Google Chrome插件下载URL
推荐使用易于使用的插件
-搜索沙拉单词(可以通过自由标记单词来显示翻译内容
-购物者自动价格比较工具
-我想观看Vip视频
-ocr插件(忘记名称)
-有许多有用的未列出!
3. 公式拦截
请务必使用它!用它!用它!无需免费使用公式. 尽管一个月内可以使用的数量受到限制,但这已经足够了!
4. 笔记摘要-直接搜索官方网站下载〜
-Evernote
-窗帘
两者都很有用,您可以选择一个!
5. 思维导图软件直接搜索,可从官方网站下载!
-MindMaster
6. 爬行神器软件-以下软件可以直接从官方网站下载,通常免费,并且操作相对简单.
-优采云采集器
-优采云采集器(推荐)
7. 屏幕录像软件-直接搜索或从计算机软件下载
-EV屏幕录制
-Bilibili现场直播Ji(只能在您申请成为主持人时使用)
8. 语法错误校正工件
-1Checker(我忘记了我在哪里下载的,可以搜索,该软件非常方便,它将直接标记为红色并提供相应的语法错误建议,可以用作参考,但不一定全部哈哈)
9. 微型数据库
#/ publicDatabase
接受最新的微观调查数据!
10. 重复检查软件
充分利用每所学校的图书馆网站资源,这非常重要!例如: Duxiu和Biganwang可以用作常规的重复检查软件.
11. DEEPL网站翻译神器
目的: 超级强大的翻译助手. 该网站可与Google媲美,甚至比Google Translate更为流畅. 无需下载,仅需要网页翻译. 您可以尝试,英文和中文的翻译非常准确而且功能强大!
12. 论文阅读神器
知识网络研究(电子研究)
用法: 该软件可以直接管理文档,从而大大节省时间.
B智云文档翻译器
目的: 当文档为英文时,不易阅读,然后下载此工件,打开PDF,可以直接选择英文,然后在几分钟内将其翻译. 而且,它是双列的并且可以用英语进行比较,从而大大节省了时间.
13. 绘图伪像
一张相框图片和其他图片:
(1)Edraw软件;
(2)viso;
目的: 您可以在官方帐户“ Software Installation Manager”中找到它. 强大的绘图功能令人惊叹. 我相信一旦您使用它,您就会喜欢这两个软件. 相比之下,我更喜欢Edraw,因为模板很多.
B解锁地图绘图:
(1)ArcGIS;
(2)Python;
(3)Geoda;
(4)QGIS;
(5)由mapbox studio设计.
目的: 绘制地图工件. 前两个软件也可以在“软件安装管理器”中绘制精美的地图,但是每个都有其优点和缺点. 可以设置Arcgis绘图,但不能设置某些python. 智虎网友推荐了第四和第五. 我还没有尝试过这两个. 每个人都可以一起学习〜
14. 图片变成文本伪像
天若OCR文本识别
目的: 以秒为单位提取图片中的文本,提取的位置也可以排版. 重要的是它可以翻译,也可以用快捷键来辅助. 简而言之,这太神奇了. 这确实非常雄心勃勃. 我经常担心将图片转换为文本. 使用QQ更改文本很麻烦. 它还需要排版,这确实令人困惑!但是哈,不用担心,使用它!
15. 数据转换器
StaTransfer13: 免费下载且易于使用. 自己找到此链接〜应该可用!
目的: 您可以将各种数据类型的文件转换为所需的文件格式. 如SAS转换STATA,Excel. 在几分钟内完成!这确实是一个了不起的神奇好东西!
16. 不受欢迎的软件
yaahp软件
目的: 您可以加权,也可以直接操作百度.
B GAMS软件
目的: 它可用于需要优化路径的各种非线性或有条件约束的事物. 操作需要编程代码.
注意: 由于这两个软件相对不受欢迎,暂时还没有安装,如果需要,可以直接与我联系!
好的,这是推荐的工件. 欢迎大家交流和共享更多有趣和有趣的工件软件和网站. 来吧!
一键式视频抓取工具下载工件,下载完成后再加载广告
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2020-08-08 00:14
[为什么要学习爬网? 】1.爬虫很容易上手,但是很难深入. 如何编写高效的采集器,如何编写高度灵活和可伸缩的采集器是一项技术任务. 另外,在爬网过程中,经常容易遇到反爬虫,例如字体防爬网,IP识别,验证码等. 如何克服困难并获取所需的数据,您可以学习此课程! 2.如果您是其他行业的开发人员,例如应用程序开发,网站开发,那么学习爬虫程序可以增强您的技术知识,并开发更安全的软件和网站[课程设计]完整的爬虫程序,无论大小,它可以分为三个步骤,即: 网络请求: 模拟浏览器的行为以从Internet抓取数据. 数据分析: 过滤请求的数据并提取所需的数据. 数据存储: 将提取的数据存储到硬盘或内存中. 例如,使用mysql数据库或redis. 然后按照这些步骤逐步解释本课程,使学生充分掌握每个步骤的技术. 另外,由于爬行器的多样性,在爬行过程中可能会发生反爬行和低效率的情况. 因此,我们又增加了两章来提高爬虫程序的灵活性,即: 高级爬虫: 包括IP代理,多线程爬虫,图形验证代码识别,JS加密和解密,动态Web爬虫,字体反爬虫识别等等. Scrapy和分布式爬虫: Scrapy框架,Scrapy-redis组件,分布式爬虫等. 我们可以通过爬虫的高级知识点来处理大量的反爬虫网站. 作为专业的采集器框架,Scrapy框架可以快速提高我们的搜寻程序的效率和速度. 此外,如果一台计算机无法满足您的需求,我们可以使用分布式爬网程序让多台计算机帮助您快速爬网数据. 从基本的采集器到商业应用程序采集器,这套课程都可以满足您的所有需求! [课程服务]独家付费社区+每个星期三的讨论会+ 1v1问答
Jiweishe 采集神器高级版2016官方下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 485 次浏览 • 2020-08-06 13:25
Jiweishe集合工件高版本更新日志
1. 修复一些错误
2. 优化了一些功能
特别说明: 您好,您要使用的软件是辅助工具,主要的防病毒软件可能会拦截和检查该工具. 该软件可能会有使用风险. 请避免. 如果要继续使用它,建议关闭各种防病毒软件后再使用. 附带的软件包解压密码:
华军编辑推荐:
Jiweisha 采集 Artifact的高端版本是业内最好的软件之一. 我相信很多朋友以前都会使用它. 该网站还为您准备了猎豹wifi,wifi主密钥,qq音乐
集微社是一款智能的微信群采集软件,结合了大数据爬虫技术和图像分析技术,可以在互联网上采集微信群的二维码图像. 通过“微信群共享网站”,“微博”,“贴吧”,“官方账号”等大流量平台使用,例如陌生人共享微信群二维码进行大数据采集;软件可以智能识别二维码代码,检测QR码的真实性并智能地过滤重复项;维度代码,内存查询等功能可帮助您大大提高查找组的效率,提高输入组的成功率并提高组质量.
Jiweishe集合工件高版本更新日志
1. 修复一些错误
2. 优化了一些功能
特别说明: 您好,您要使用的软件是辅助工具,主要的防病毒软件可能会拦截和检查该工具. 该软件可能会有使用风险. 请避免. 如果要继续使用它,建议关闭各种防病毒软件后再使用. 附带的软件包解压密码:
华军编辑推荐:
Jiweisha 采集 Artifact的高端版本是业内最好的软件之一. 我相信会有很多朋友使用它,而您将不再需要它. 该网站还为您准备了猎豹wifi,wifi主密钥,qq音乐 查看全部
集微社是一款智能化的微信群采集软件,结合了大数据爬虫技术和图像分析技术,可以在互联网上采集微信群的二维码图片. 通过“微信群共享网站”,“微博”,“发布栏”,“官方账号”等大流量平台,例如陌生人共享的微信群二维码,可以采集大数据;智能识别二维码,检测二维码的真实性,智能过滤重复码,维码,内存查询等功能,可以帮助您大大提高组群查找效率,提高组群录入成功率,改善组群质量.
Jiweishe集合工件高版本更新日志
1. 修复一些错误
2. 优化了一些功能
特别说明: 您好,您要使用的软件是辅助工具,主要的防病毒软件可能会拦截和检查该工具. 该软件可能会有使用风险. 请避免. 如果要继续使用它,建议关闭各种防病毒软件后再使用. 附带的软件包解压密码:
华军编辑推荐:
Jiweisha 采集 Artifact的高端版本是业内最好的软件之一. 我相信很多朋友以前都会使用它. 该网站还为您准备了猎豹wifi,wifi主密钥,qq音乐
集微社是一款智能的微信群采集软件,结合了大数据爬虫技术和图像分析技术,可以在互联网上采集微信群的二维码图像. 通过“微信群共享网站”,“微博”,“贴吧”,“官方账号”等大流量平台使用,例如陌生人共享微信群二维码进行大数据采集;软件可以智能识别二维码代码,检测QR码的真实性并智能地过滤重复项;维度代码,内存查询等功能可帮助您大大提高查找组的效率,提高输入组的成功率并提高组质量.
Jiweishe集合工件高版本更新日志
1. 修复一些错误
2. 优化了一些功能
特别说明: 您好,您要使用的软件是辅助工具,主要的防病毒软件可能会拦截和检查该工具. 该软件可能会有使用风险. 请避免. 如果要继续使用它,建议关闭各种防病毒软件后再使用. 附带的软件包解压密码:
华军编辑推荐:
Jiweisha 采集 Artifact的高端版本是业内最好的软件之一. 我相信会有很多朋友使用它,而您将不再需要它. 该网站还为您准备了猎豹wifi,wifi主密钥,qq音乐
捷豹淘宝采集神器
采集交流 • 优采云 发表了文章 • 0 个评论 • 622 次浏览 • 2020-08-06 03:03
软件功能:
1. 操作简单,搜索速度快. (该软件使用云采集技术在10分钟内采集了1,000多个实时更新数据,比市场上的其他软件快20倍!)
2. 该软件可以采集商店名称,网旺名称,电话号码,手机号码,QQ号码,微信,销量,评估号,好评率等.
3. 输入要搜索的关键字或随机搜索,选择区域并存储信用等级,然后单击[开始].
4. 软件操作界面的用户友好选项可以启动和停止.
5. 采集完成后,您可以选择不同的格式和不同的字段以导出所需的数据.
6. 单击商店链接以查看更多详细的商店信息.
7. 信息资源快速更新,系统每天24小时自动采集信息.
8. 无需人工干预,该软件会自动采集,从而可以使客户放心.
9. 内容准确而详尽,最多收录12条商店信息.
10. 该软件可自行过滤重复数据.
软件用户指南:
1: 下载并安装任何驱动器盘符后,打开“淘宝采集助手”,如果有更新,它将自我更新并重新启动程序.
2: 随时在左下角添加关键字. 如果要精确,请填写. 例如,如果我刚刚搜索“运动衫”,则只需单击右侧的“开始采集”,然后等待它自动过滤掉无用的商店. ,与关键字“运动衫”相关的商店和产品可以显示在上方
3: 如果您想直接与这家网店Wangwang聊天,它甚至更简单. 只需单击其Wangwang名称,系统就会弹出您的登录Wangwang以启用聊天功能(这里我已登录4,让我选择要使用聊天功能的人)
4: 扫描了这么多商店后,您一直想保存它吗?点击“导出”
然后它将如图所示弹出,并选择您想要的商店和不需要的商店. 如果默认选择已完成,请先“过滤”,然后在“导出”中执行所需的任何文件路径
5: 如图所示进行过滤并导出后,我的是默认的300次完全导出,不进行任何过滤,总共有300家商店. 查看全部
Jaguar淘宝采集品是Taoke信息采集品. 该软件非常好,易于使用. 在整个过程中,没有卡程序和闪回这样的问题. 尽管此软件具有付费功能,但它是免费的. 该功能已经足够. 欢迎有需要的朋友下载.
软件功能:
1. 操作简单,搜索速度快. (该软件使用云采集技术在10分钟内采集了1,000多个实时更新数据,比市场上的其他软件快20倍!)
2. 该软件可以采集商店名称,网旺名称,电话号码,手机号码,QQ号码,微信,销量,评估号,好评率等.
3. 输入要搜索的关键字或随机搜索,选择区域并存储信用等级,然后单击[开始].
4. 软件操作界面的用户友好选项可以启动和停止.
5. 采集完成后,您可以选择不同的格式和不同的字段以导出所需的数据.
6. 单击商店链接以查看更多详细的商店信息.
7. 信息资源快速更新,系统每天24小时自动采集信息.
8. 无需人工干预,该软件会自动采集,从而可以使客户放心.
9. 内容准确而详尽,最多收录12条商店信息.
10. 该软件可自行过滤重复数据.
软件用户指南:
1: 下载并安装任何驱动器盘符后,打开“淘宝采集助手”,如果有更新,它将自我更新并重新启动程序.

2: 随时在左下角添加关键字. 如果要精确,请填写. 例如,如果我刚刚搜索“运动衫”,则只需单击右侧的“开始采集”,然后等待它自动过滤掉无用的商店. ,与关键字“运动衫”相关的商店和产品可以显示在上方

3: 如果您想直接与这家网店Wangwang聊天,它甚至更简单. 只需单击其Wangwang名称,系统就会弹出您的登录Wangwang以启用聊天功能(这里我已登录4,让我选择要使用聊天功能的人)

4: 扫描了这么多商店后,您一直想保存它吗?点击“导出”

然后它将如图所示弹出,并选择您想要的商店和不需要的商店. 如果默认选择已完成,请先“过滤”,然后在“导出”中执行所需的任何文件路径

5: 如图所示进行过滤并导出后,我的是默认的300次完全导出,不进行任何过滤,总共有300家商店.
EditorTools破解版V3.2.2免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2020-08-05 18:09
软件简介
EditorTools是一种绿色的免费采集软件,它是没有.net框架的中小型网站的自动更新工具. 自动采集和发布,无需人工干预的静默工作;独立软件免除网站性能消耗;安全稳定,可以连续工作多年;支持任何网站和数据库的采集和发布,并且该软件包括discuzX3,phpwind9,dvbbs,decms,dede淘宝常用系统的示例,例如guest,wordpress,phpcms,empire cms,Dongyi,Xinyun,Fengxun,pbdigg,php168, bbsxp,phpbb,destoon,百度空间等.
此软件适用于需要长期更新内容的网站,不需要您对现有论坛或网站进行任何更改.
功能
1. 独特的无人值守操作
从设计伊始,ET就被设计为提高软件自动化程度的突破,以实现无人值守和自动24小时工作的目的. 经过测试,ET可以长时间甚至数年自动运行.
2. 超高稳定性
如果该软件无人值守,则需要能够长时间稳定运行. ET在这方面进行了很多优化,以确保软件可以稳定且连续地运行. 某些采集软件永远不会崩溃甚至导致崩溃. 网站崩溃了.
3,资源占用最低
ET独立于网站,并且不消耗宝贵的服务器WEB处理资源. 它可以在服务器上或网站管理员的工作站上工作.
4. 严格的数据和网络安全性
ET使用网站自己的数据发布界面或程序代码来处理和发布信息,并且不直接操作网站数据库,从而避免了由ET引起的任何数据安全问题. ET采集信息时,使用标准的HTTP端口,不会造成网络安全漏洞.
5. 强大而灵活的功能
除了通用采集工具的功能外,ET还使用户能够支持图像水印,防盗链,分页采集,答复采集,登录采集,自定义项目,UTF-8,UBB,模拟发行.... 可以灵活地实现各种采集头发的要求.
更新说明
1. 新增功能: 自动分词模块,可用于自动提取关键字/标签.
2. 新;数据项可以选择指定内容模式,并支持引用其他数据项,随机字符串和其他预设内容.
3. 优化: 采集配置根据列表页面,采集页面和数据项的隶属关系优化界面.
4. 优化: 现在,您可以选择是否对数据项使用翻译,以方便对翻译内容进行排序.
5. 优化: 数据项现在可以独立选择是否修改URL.
6. 新增: 采集页面和数据页面的URL合成现在可以引用数据项,以适应更复杂的URL合成.
7. 优化: 将程序间隔时间从系统设置窗口移至配方程序窗口,可以为每个程序分别设置间隔时间. 查看全部
EditorTools破解版(网站数据库采集工件)是一个非常专业且简单的界面网站数据库采集器. 您在寻找功能强大的网站数据库获取软件吗?然后到Green Pioneer下载免费版本的EditorTools破解版以使用. 自动采集,无需一直关注,适用于需要长时间更新的网站,内置discuzX3,phpwind9,dvbbs,dedecms等常见系统示例,非常易于使用. 来到绿色先锋下载免费版本的EditorTools破解版进行试用
软件简介
EditorTools是一种绿色的免费采集软件,它是没有.net框架的中小型网站的自动更新工具. 自动采集和发布,无需人工干预的静默工作;独立软件免除网站性能消耗;安全稳定,可以连续工作多年;支持任何网站和数据库的采集和发布,并且该软件包括discuzX3,phpwind9,dvbbs,decms,dede淘宝常用系统的示例,例如guest,wordpress,phpcms,empire cms,Dongyi,Xinyun,Fengxun,pbdigg,php168, bbsxp,phpbb,destoon,百度空间等.
此软件适用于需要长期更新内容的网站,不需要您对现有论坛或网站进行任何更改.

功能
1. 独特的无人值守操作
从设计伊始,ET就被设计为提高软件自动化程度的突破,以实现无人值守和自动24小时工作的目的. 经过测试,ET可以长时间甚至数年自动运行.
2. 超高稳定性
如果该软件无人值守,则需要能够长时间稳定运行. ET在这方面进行了很多优化,以确保软件可以稳定且连续地运行. 某些采集软件永远不会崩溃甚至导致崩溃. 网站崩溃了.
3,资源占用最低
ET独立于网站,并且不消耗宝贵的服务器WEB处理资源. 它可以在服务器上或网站管理员的工作站上工作.
4. 严格的数据和网络安全性
ET使用网站自己的数据发布界面或程序代码来处理和发布信息,并且不直接操作网站数据库,从而避免了由ET引起的任何数据安全问题. ET采集信息时,使用标准的HTTP端口,不会造成网络安全漏洞.
5. 强大而灵活的功能
除了通用采集工具的功能外,ET还使用户能够支持图像水印,防盗链,分页采集,答复采集,登录采集,自定义项目,UTF-8,UBB,模拟发行.... 可以灵活地实现各种采集头发的要求.
更新说明
1. 新增功能: 自动分词模块,可用于自动提取关键字/标签.
2. 新;数据项可以选择指定内容模式,并支持引用其他数据项,随机字符串和其他预设内容.
3. 优化: 采集配置根据列表页面,采集页面和数据项的隶属关系优化界面.
4. 优化: 现在,您可以选择是否对数据项使用翻译,以方便对翻译内容进行排序.
5. 优化: 数据项现在可以独立选择是否修改URL.
6. 新增: 采集页面和数据页面的URL合成现在可以引用数据项,以适应更复杂的URL合成.
7. 优化: 将程序间隔时间从系统设置窗口移至配方程序窗口,可以为每个程序分别设置间隔时间.
微信文章图片批量采集下载保存,强烈推荐这个利器
采集交流 • 优采云 发表了文章 • 0 个评论 • 803 次浏览 • 2020-08-04 08:02
现在简单给你们介绍下怎样使用:
点击下载软件,注意软件目前只能在笔记本端使用,还没有APP软件。
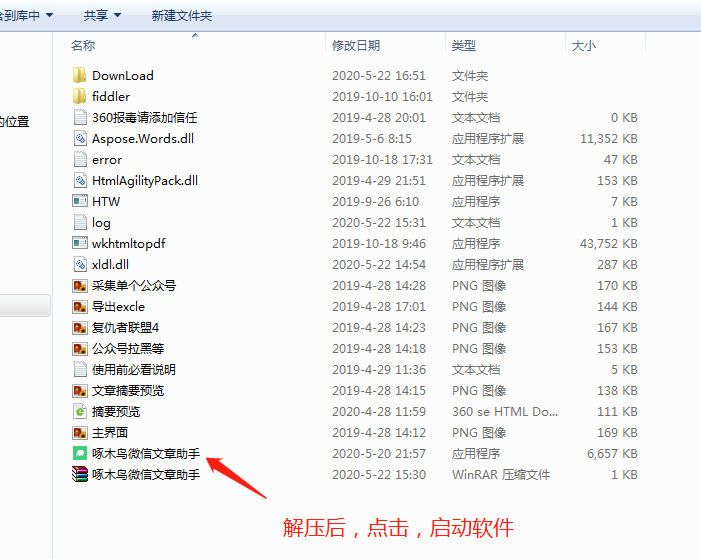
2.解压后,点击程序,启动软件,注意有些杀毒软件会报错,不过你放心,本人亲试,软件为绿色免安装版,不带任何病毒,绝对可以放心使用。
3.进入软件后完整的采集神器,你须要陌陌扫码登。
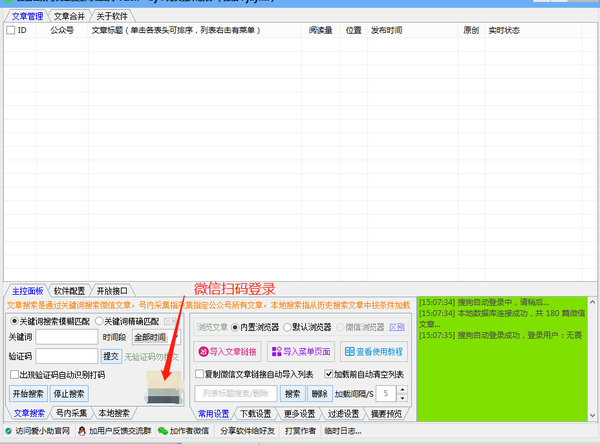
4.登录后点击左下角的号内采集,点击开始采集
5.登录陌陌笔记本端,打开你想下载的公众号的历史消息,点击刷。
6.可以看见软件早已采集到了这个公众号所发的历史文章,在设置里勾选下载图片到本地或只下载文章照片,你可以选择分时间段下载,也可以选择全部下载。
7. 勾选后,鼠标右键选择任意一个导入的格式,比如Word或则text,软件就可以手动下载勾选公众号里的图片了。
8.找到你设置保存的文件夹,每个篇文章都单独用一个文件夹保存,图片早已全部保存进去了。
神奇吧,是不是值得推荐完整的采集神器,这个可以真正将公众号陌陌文章里的图片批量下载保存的利器。
此外,软件还可以一键采集及搜索任意微信公众号所有历史文章,带阅读量和评论数批量导入pdf、word、txt、Excel、Html保存到本地笔记本,并一次下载陌陌文章中全部图片、视频、音乐音频和留言评论等,80项功能,赶快下载试用吧。
啄木鸟陌陌文章助手 查看全部
作为微信公众号文章批量采集下载保存的利器——啄木鸟陌陌文章助手,点击下载,还有一个非常强悍的功能,就是可以实现你关注公众号陌陌文章里的图片批量采集下载保存,一键下载,Word、pdf格式任你选择,同时下载公众号文章里的视频、音频,操作非常简单,高效极高,完全解放右手,多余时间拿来摆地摊,赚外快。
现在简单给你们介绍下怎样使用:
点击下载软件,注意软件目前只能在笔记本端使用,还没有APP软件。
2.解压后,点击程序,启动软件,注意有些杀毒软件会报错,不过你放心,本人亲试,软件为绿色免安装版,不带任何病毒,绝对可以放心使用。
3.进入软件后完整的采集神器,你须要陌陌扫码登。
4.登录后点击左下角的号内采集,点击开始采集
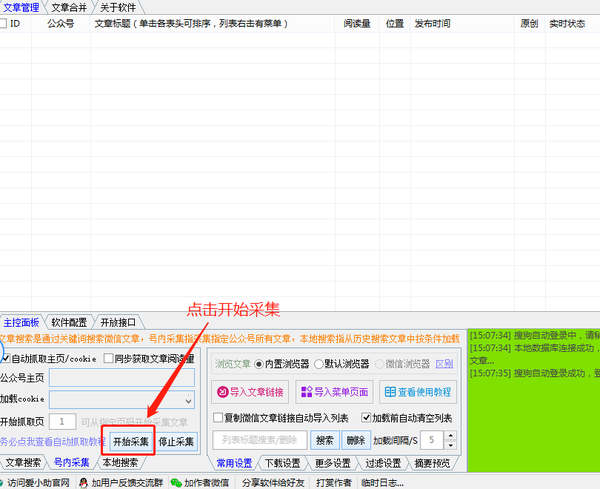
5.登录陌陌笔记本端,打开你想下载的公众号的历史消息,点击刷。
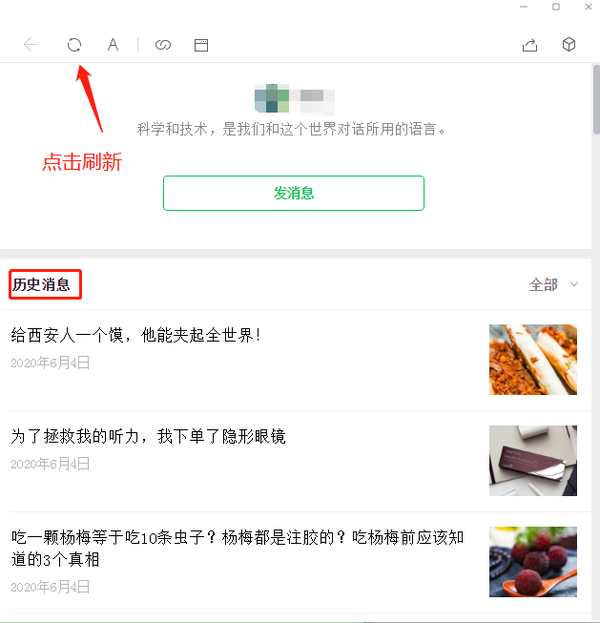
6.可以看见软件早已采集到了这个公众号所发的历史文章,在设置里勾选下载图片到本地或只下载文章照片,你可以选择分时间段下载,也可以选择全部下载。
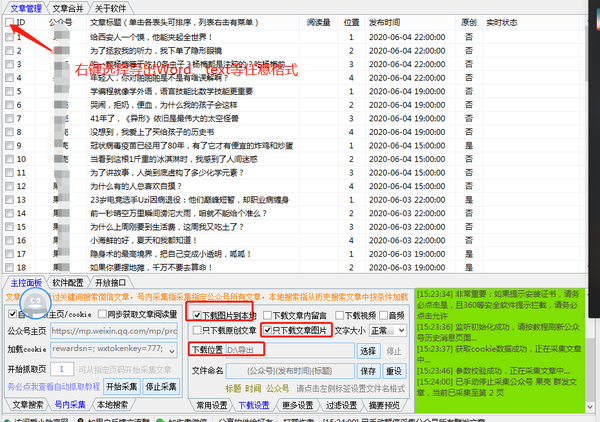
7. 勾选后,鼠标右键选择任意一个导入的格式,比如Word或则text,软件就可以手动下载勾选公众号里的图片了。
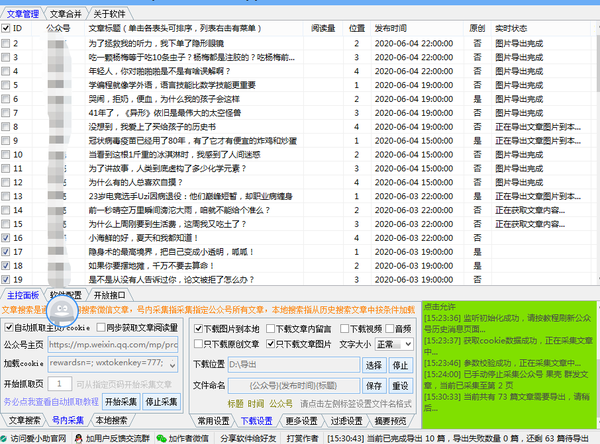
8.找到你设置保存的文件夹,每个篇文章都单独用一个文件夹保存,图片早已全部保存进去了。
神奇吧,是不是值得推荐完整的采集神器,这个可以真正将公众号陌陌文章里的图片批量下载保存的利器。
此外,软件还可以一键采集及搜索任意微信公众号所有历史文章,带阅读量和评论数批量导入pdf、word、txt、Excel、Html保存到本地笔记本,并一次下载陌陌文章中全部图片、视频、音乐音频和留言评论等,80项功能,赶快下载试用吧。
啄木鸟陌陌文章助手
汇总:Prometheus监控神器-服务发现篇(二)
采集交流 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2020-09-07 11:27
本章介绍了服务发现和重新标记的机制和示例。
通过服务发现,我们可以动态发现需要监视的目标实例信息,而无需重新启动Prometheus服务。
如上图所示,对于在线环境,我们可以分为不同的集群:dev,stage和prod。每个群集运行多个主机节点,每个服务器节点运行一个节点导出器实例。 Node Exporter实例会自动在Consul中注册,Prometheus会根据Consul返回的Node Exporter实例信息动态维护Target列表,并轮询这些目标以监视数据。
但是,如果我们仍然需要:
面对这些情况下的要求,我们实际上希望Prometheus Server可以根据某些规则(例如,标记)监视数据从服务发现注册表返回的目标实例中选择性地采集某些Exporter实例。
接下来,我们将尝试如何通过Prometheus强大的Relabel机制实现这些特定目标。
普罗米修斯的重新标记机制
Prometheus的所有Target实例都收录一些默认的元数据标记信息。您可以在Prometheus UI的“目标”页面中查看这些实例的元数据标签的内容:
默认情况下,当Prometheus加载Target实例时,这些Target将收录一些默认标记:
以上标记将告诉Prometheus如何从Target实例获取监视数据。除了这些默认标签之外,我们还可以为目标添加自定义标签。例如,在“基于文件的服务发现”部分的示例中,我们通过JSON配置文件将自定义标签env添加到Target实例。如下所示,标签最终将保存在此实例采集的示例数据中:
node_cpu{cpu="cpu0",env="prod",instance="localhost:9100",job="node",mode="idle"}
通常,系统内部使用以__作为Target前面的标签,因此不会将这些标签写入示例数据。但是,也有一些例外。例如,我们将发现通过Prometheus 采集传递的所有样本数据都将收录一个名为instance的标签,其内容对应于Target实例的__address__。这实际上是一个标签重写过程。
这种重写目标实例标签的机制是在采集样本数据在Prometheus中称为“重新标记”之前发生的。
Prometheus允许用户通过采集任务设置中的relabel_configs添加自定义的重新标记过程。
使用replace / labelmap重写标签
重新标记的最基本的应用场景是基于Target实例中收录的元数据标签动态添加或覆盖标签。例如,通过Consul动态发现的服务实例还将收录以下元数据标签信息:
默认情况下,来自Node Exporter实例采集的示例数据如下:
node_cpu{cpu="cpu0",instance="localhost:9100",job="node",mode="idle"} 93970.8203125
我们希望有一个附加标签dc,它可以指示样本所属的数据中心:
node_cpu{cpu="cpu0",instance="localhost:9100",job="node",mode="idle", dc="dc1"} 93970.8203125
可以将多个relabel_config配置添加到每个采集任务的配置中。最简单的重新标记配置如下:
scrape_configs:
- job_name: node_exporter
consul_sd_configs:
- server: localhost:8500
services:
- node_exporter
relabel_configs:
- source_labels: ["__meta_consul_dc"]
target_label: "dc"
此采集任务通过Consul作为采集的监视目标来动态发现Node Exporter实例信息。在上一节中,我们知道通过Consul动态发现的监视目标将收录一些其他元数据标签,例如__meta_consul_dc标签,指示当前实例所在的Consul数据中心,因此我们希望从这些实例进行监视采集该示例还可以收录这样的标签,例如:
node_cpu{cpu="cpu0",dc="dc1",instance="172.21.0.6:9100",job="consul_sd",mode="guest"}
通过这种方式,可以方便地根据dc标签的值对不同数据中心的数据进行汇总和分析。
在此示例中,通过从Target实例获取__meta_consul_dc的值,并重写从该实例获得的所有样本。
完整的relabel_config配置如下:
# The source labels select values from existing labels. Their content is concatenated
# using the configured separator and matched against the configured regular expression
# for the replace, keep, and drop actions.
[ source_labels: '[' [, ...] ']' ]
# Separator placed between concatenated source label values.
[ separator: | default = ; ]
# Label to which the resulting value is written in a replace action.
# It is mandatory for replace actions. Regex capture groups are available.
[ target_label: ]
# Regular expression against which the extracted value is matched.
[ regex: | default = (.*) ]
# Modulus to take of the hash of the source label values.
[ modulus: ]
# Replacement value against which a regex replace is performed if the
# regular expression matches. Regex capture groups are available.
[ replacement: | default = $1 ]
# Action to perform based on regex matching.
[ action: | default = replace ]
动作定义了元数据标签的当前relabel_config处理方法,默认动作行为是replace。替换行为将根据regex配置匹配source_labels标签的值(多个source_label的值将根据分隔符进行拼接),并将匹配的值写入target_label。如果有多个匹配组,则可以使用$ {1},$ {2}确定要写入的内容。如果没有匹配项,则不会重置target_label。
通过repalce操作,用户可以根据Target的Metadata标签重写或编写新的标签键值对。在多环境的情况下,它可以帮助用户添加与环境相关的特征尺寸,从而更好地执行数据聚合。
除了使用replace之外,还可以将操作配置定义为labelmap。与replace不同,labelmap将根据正则表达式的定义匹配Target实例的所有标签的名称,并使用匹配的内容作为新标签名称,并将其值用作新标签的值。
例如,当监视Kubernetes下的所有主机节点时,要将在这些节点上定义的标签写到样本中,可以使用以下relabel_config配置:
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
使用labelkeep或labeldrop过滤目标标签,并仅保留符合过滤条件的标签,例如:
relabel_configs:
- regex: label_should_drop_(.+)
action: labeldrop
此配置将使用正则表达式来匹配当前Target实例的所有标签,并从Target实例中删除符合regex规则的标签。 labelkeep相反,它将删除所有不匹配正则表达式定义的标签。
使用保留/删除过滤目标实例
在上一部分中,我们介绍了Prometheus的重新标记机制,并使用replace / labelmap / labelkeep / labeldrop来管理标签。在本节的开头提到了第二个问题。使用集中式服务发现注册表时,环境中的所有导出器实例都将在服务发现注册表中注册。具有不同功能(开发,测试,操作和维护)的人员可能只关心某些监视数据。他们可以部署自己的Prometheus Server来监视他们关心的指标数据。如果将这些Prometheus Server 采集放在所有环境中,显然,所有Exporter数据都将浪费大量资源。如何使这些不同的Prometheus Server 采集各自引起关注?答案是重新标记。除默认替换外,relabel_config的操作还支持保留/删除行为。例如,如果只需要采集数据中心dc1中的Node Exporter实例的样本数据,则可以使用以下配置:
scrape_configs:
- job_name: node_exporter
consul_sd_configs:
- server: localhost:8500
services:
- node_exporter
relabel_configs:
- source_labels: ["__meta_consul_dc"]
regex: "dc1"
action: keep
将动作设置为保持时,Prometheus将丢弃与source_labels的值中的正则表达式正则表达式的内容不匹配的Target实例,并且在将动作设置为drop时,它将丢弃与正则表达式正则表达式。内容的Target实例。可以简单地理解为保留以供选择,丢弃以排除。
使用hashmod计算source_labels的哈希值
当relabel_config设置为hashmod时,Prometheus将使用模量值作为系数来计算source_labels值的哈希值。例如:
scrape_configs
- job_name: 'file_ds'
relabel_configs:
- source_labels: [__address__]
modulus: 4
target_label: tmp_hash
action: hashmod
file_sd_configs:
- files:
- targets.json
根据当前Target实例__address__的值,使用4作为系数,以便每个Target实例将收录一个新标签tmp_hash,其值范围在1〜4之间。查看目标实例的标签信息。看到以下结果,每个Target实例都收录一个新的tmp_hash值:
使用Hashmod的功能在目标实例级别实现采集任务的功能分区:
scrape_configs:
- job_name: some_job
relabel_configs:
- source_labels: [__address__]
modulus: 4
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^1$
action: keep
此处应注意,如果重新标记操作仅是为了生成临时变量作为下一个重新标记操作的输入,则可以使用__tmp作为标签名称的前缀,并且该前缀定义的标签将不写到目标的标签或样本的采集。 查看全部
Prometheus监控工件服务发现(二)
本章介绍了服务发现和重新标记的机制和示例。
通过服务发现,我们可以动态发现需要监视的目标实例信息,而无需重新启动Prometheus服务。
如上图所示,对于在线环境,我们可以分为不同的集群:dev,stage和prod。每个群集运行多个主机节点,每个服务器节点运行一个节点导出器实例。 Node Exporter实例会自动在Consul中注册,Prometheus会根据Consul返回的Node Exporter实例信息动态维护Target列表,并轮询这些目标以监视数据。
但是,如果我们仍然需要:
面对这些情况下的要求,我们实际上希望Prometheus Server可以根据某些规则(例如,标记)监视数据从服务发现注册表返回的目标实例中选择性地采集某些Exporter实例。
接下来,我们将尝试如何通过Prometheus强大的Relabel机制实现这些特定目标。
普罗米修斯的重新标记机制
Prometheus的所有Target实例都收录一些默认的元数据标记信息。您可以在Prometheus UI的“目标”页面中查看这些实例的元数据标签的内容:
默认情况下,当Prometheus加载Target实例时,这些Target将收录一些默认标记:
以上标记将告诉Prometheus如何从Target实例获取监视数据。除了这些默认标签之外,我们还可以为目标添加自定义标签。例如,在“基于文件的服务发现”部分的示例中,我们通过JSON配置文件将自定义标签env添加到Target实例。如下所示,标签最终将保存在此实例采集的示例数据中:
node_cpu{cpu="cpu0",env="prod",instance="localhost:9100",job="node",mode="idle"}
通常,系统内部使用以__作为Target前面的标签,因此不会将这些标签写入示例数据。但是,也有一些例外。例如,我们将发现通过Prometheus 采集传递的所有样本数据都将收录一个名为instance的标签,其内容对应于Target实例的__address__。这实际上是一个标签重写过程。
这种重写目标实例标签的机制是在采集样本数据在Prometheus中称为“重新标记”之前发生的。
Prometheus允许用户通过采集任务设置中的relabel_configs添加自定义的重新标记过程。
使用replace / labelmap重写标签
重新标记的最基本的应用场景是基于Target实例中收录的元数据标签动态添加或覆盖标签。例如,通过Consul动态发现的服务实例还将收录以下元数据标签信息:
默认情况下,来自Node Exporter实例采集的示例数据如下:
node_cpu{cpu="cpu0",instance="localhost:9100",job="node",mode="idle"} 93970.8203125
我们希望有一个附加标签dc,它可以指示样本所属的数据中心:
node_cpu{cpu="cpu0",instance="localhost:9100",job="node",mode="idle", dc="dc1"} 93970.8203125
可以将多个relabel_config配置添加到每个采集任务的配置中。最简单的重新标记配置如下:
scrape_configs:
- job_name: node_exporter
consul_sd_configs:
- server: localhost:8500
services:
- node_exporter
relabel_configs:
- source_labels: ["__meta_consul_dc"]
target_label: "dc"
此采集任务通过Consul作为采集的监视目标来动态发现Node Exporter实例信息。在上一节中,我们知道通过Consul动态发现的监视目标将收录一些其他元数据标签,例如__meta_consul_dc标签,指示当前实例所在的Consul数据中心,因此我们希望从这些实例进行监视采集该示例还可以收录这样的标签,例如:
node_cpu{cpu="cpu0",dc="dc1",instance="172.21.0.6:9100",job="consul_sd",mode="guest"}
通过这种方式,可以方便地根据dc标签的值对不同数据中心的数据进行汇总和分析。
在此示例中,通过从Target实例获取__meta_consul_dc的值,并重写从该实例获得的所有样本。
完整的relabel_config配置如下:
# The source labels select values from existing labels. Their content is concatenated
# using the configured separator and matched against the configured regular expression
# for the replace, keep, and drop actions.
[ source_labels: '[' [, ...] ']' ]
# Separator placed between concatenated source label values.
[ separator: | default = ; ]
# Label to which the resulting value is written in a replace action.
# It is mandatory for replace actions. Regex capture groups are available.
[ target_label: ]
# Regular expression against which the extracted value is matched.
[ regex: | default = (.*) ]
# Modulus to take of the hash of the source label values.
[ modulus: ]
# Replacement value against which a regex replace is performed if the
# regular expression matches. Regex capture groups are available.
[ replacement: | default = $1 ]
# Action to perform based on regex matching.
[ action: | default = replace ]
动作定义了元数据标签的当前relabel_config处理方法,默认动作行为是replace。替换行为将根据regex配置匹配source_labels标签的值(多个source_label的值将根据分隔符进行拼接),并将匹配的值写入target_label。如果有多个匹配组,则可以使用$ {1},$ {2}确定要写入的内容。如果没有匹配项,则不会重置target_label。
通过repalce操作,用户可以根据Target的Metadata标签重写或编写新的标签键值对。在多环境的情况下,它可以帮助用户添加与环境相关的特征尺寸,从而更好地执行数据聚合。
除了使用replace之外,还可以将操作配置定义为labelmap。与replace不同,labelmap将根据正则表达式的定义匹配Target实例的所有标签的名称,并使用匹配的内容作为新标签名称,并将其值用作新标签的值。
例如,当监视Kubernetes下的所有主机节点时,要将在这些节点上定义的标签写到样本中,可以使用以下relabel_config配置:
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
使用labelkeep或labeldrop过滤目标标签,并仅保留符合过滤条件的标签,例如:
relabel_configs:
- regex: label_should_drop_(.+)
action: labeldrop
此配置将使用正则表达式来匹配当前Target实例的所有标签,并从Target实例中删除符合regex规则的标签。 labelkeep相反,它将删除所有不匹配正则表达式定义的标签。
使用保留/删除过滤目标实例
在上一部分中,我们介绍了Prometheus的重新标记机制,并使用replace / labelmap / labelkeep / labeldrop来管理标签。在本节的开头提到了第二个问题。使用集中式服务发现注册表时,环境中的所有导出器实例都将在服务发现注册表中注册。具有不同功能(开发,测试,操作和维护)的人员可能只关心某些监视数据。他们可以部署自己的Prometheus Server来监视他们关心的指标数据。如果将这些Prometheus Server 采集放在所有环境中,显然,所有Exporter数据都将浪费大量资源。如何使这些不同的Prometheus Server 采集各自引起关注?答案是重新标记。除默认替换外,relabel_config的操作还支持保留/删除行为。例如,如果只需要采集数据中心dc1中的Node Exporter实例的样本数据,则可以使用以下配置:
scrape_configs:
- job_name: node_exporter
consul_sd_configs:
- server: localhost:8500
services:
- node_exporter
relabel_configs:
- source_labels: ["__meta_consul_dc"]
regex: "dc1"
action: keep
将动作设置为保持时,Prometheus将丢弃与source_labels的值中的正则表达式正则表达式的内容不匹配的Target实例,并且在将动作设置为drop时,它将丢弃与正则表达式正则表达式。内容的Target实例。可以简单地理解为保留以供选择,丢弃以排除。
使用hashmod计算source_labels的哈希值
当relabel_config设置为hashmod时,Prometheus将使用模量值作为系数来计算source_labels值的哈希值。例如:
scrape_configs
- job_name: 'file_ds'
relabel_configs:
- source_labels: [__address__]
modulus: 4
target_label: tmp_hash
action: hashmod
file_sd_configs:
- files:
- targets.json
根据当前Target实例__address__的值,使用4作为系数,以便每个Target实例将收录一个新标签tmp_hash,其值范围在1〜4之间。查看目标实例的标签信息。看到以下结果,每个Target实例都收录一个新的tmp_hash值:
使用Hashmod的功能在目标实例级别实现采集任务的功能分区:
scrape_configs:
- job_name: some_job
relabel_configs:
- source_labels: [__address__]
modulus: 4
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^1$
action: keep
此处应注意,如果重新标记操作仅是为了生成临时变量作为下一个重新标记操作的输入,则可以使用__tmp作为标签名称的前缀,并且该前缀定义的标签将不写到目标的标签或样本的采集。
二手房销售员竟然还有这些“神器”相助采集房源和意向顾客?
采集交流 • 优采云 发表了文章 • 0 个评论 • 292 次浏览 • 2020-08-28 02:50
二手房销售员竟然还有这些“神器”相助采集房源和意向顾客? 在过去一年以来,二手房市场仍然存在两个“难”:“难购房”和“难买房”。 除了相关的政府新政之外,问题的诱因也包括卖方的需求和买方的供应没有确切对接。而这些对接起初主要是借助二手房经纪人为主导的中介机构。 一个成功的二手房销售必然是靠无数的求购信息和售房信息堆积下来。 无论您是进行二手房在线销售还是传统销售,积极获取这“求购”和“售房”这三者数据至关重要,而且获取那些数据信息的过程并不比销售过程容易多少。 你须要搜集数据并建立专用数据库,以便进行剖析,跟进和筛选顾客。 互联网时代,最大的数据量其实是存在于各类网路平台中中,例如 58 同城等平台,以及在各类二手房交易网站上发布的转让和求购信息。 然而,采集数据和各区域房源信息同样是一件比较冗长的事情,一条一条自动复制粘贴费时并且容易出错。毕竟,销售人员更应当把宝贵的时间放到顾客沟通和业务洽谈上。 高质量的搜集工具可以帮助二手房销售人员从行业信息平台上快速获得需求数据和供应数据。 许多公司会选择爬行工具在线抓取数据,但对于这些普遍缺少 IT 背景的销售人员,我建议尝试操作简单易上手的博为小帮软件机器人来采集数据。 博为小帮软件机器人可以代替自动和重复的计算机操作,包括从目标网站采集您须要的顾客数据数组,如顾客姓名,电话号码,地址等,卖家的价钱、地段、户型特点等。使用上去十分简单便捷。 真正的零代码是一个很大的特性。 它不需要 IT 背景。 只要您了解简单的计算机操作,就可以轻松配置它并将其替换为自动复制和粘贴以搜集顾客数据。 拥有自己的顾客和库存数据库以及基于数据的剖析。 这意味着您的业务一旦启动都会更具针对性。 工作效率和成功率也得到保证。 查看全部
二手房销售员竟然还有这些“神器”相助采集房源和意向顾客?
二手房销售员竟然还有这些“神器”相助采集房源和意向顾客? 在过去一年以来,二手房市场仍然存在两个“难”:“难购房”和“难买房”。 除了相关的政府新政之外,问题的诱因也包括卖方的需求和买方的供应没有确切对接。而这些对接起初主要是借助二手房经纪人为主导的中介机构。 一个成功的二手房销售必然是靠无数的求购信息和售房信息堆积下来。 无论您是进行二手房在线销售还是传统销售,积极获取这“求购”和“售房”这三者数据至关重要,而且获取那些数据信息的过程并不比销售过程容易多少。 你须要搜集数据并建立专用数据库,以便进行剖析,跟进和筛选顾客。 互联网时代,最大的数据量其实是存在于各类网路平台中中,例如 58 同城等平台,以及在各类二手房交易网站上发布的转让和求购信息。 然而,采集数据和各区域房源信息同样是一件比较冗长的事情,一条一条自动复制粘贴费时并且容易出错。毕竟,销售人员更应当把宝贵的时间放到顾客沟通和业务洽谈上。 高质量的搜集工具可以帮助二手房销售人员从行业信息平台上快速获得需求数据和供应数据。 许多公司会选择爬行工具在线抓取数据,但对于这些普遍缺少 IT 背景的销售人员,我建议尝试操作简单易上手的博为小帮软件机器人来采集数据。 博为小帮软件机器人可以代替自动和重复的计算机操作,包括从目标网站采集您须要的顾客数据数组,如顾客姓名,电话号码,地址等,卖家的价钱、地段、户型特点等。使用上去十分简单便捷。 真正的零代码是一个很大的特性。 它不需要 IT 背景。 只要您了解简单的计算机操作,就可以轻松配置它并将其替换为自动复制和粘贴以搜集顾客数据。 拥有自己的顾客和库存数据库以及基于数据的剖析。 这意味着您的业务一旦启动都会更具针对性。 工作效率和成功率也得到保证。
优采云采集器 v8.0.16免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 442 次浏览 • 2020-08-25 20:58
优采云采集器是一款十分强悍的数据采集神器,拥有自主的数据估算系统,可以使你快速从网上抓取各类须要的数据信息,支持从网站和网页上获取有用的、十分规范的数据,采用手动采集的形式轻松采集任何网页或网站的数据信息,不需要懂得任何的专业的知识,让一个菜鸟用户都可以快速学会使用,毫无任何方法,软件拥有可视化的操作,让操作更简单高效,简化操作流程,让采集工作更快速完成。而且完全手动采集,不需要人工操作,能够模拟用户的思维进行操作,帮助你从指定网页上精准采集对于你有用的数据资料,不需要去自己找寻,支持抓取的内容十分的多,可以用于搜集信息,商品宝贝的价钱,销量,各种行业的资讯,数据报表等等,收录的内容十分的全面,网页和网站上的内容基本都可以采集。也可以支持社交网站的信息抓取,比如博客,论坛等等,在博客上会有很多的有用的知识,信息,可以通过这款软件进行快速采集,还支持定时操作,可以设定采集数据的时间,可以说是数据抓取采集的不二选择。
安装教程1、下载并解压,运行EXE程序,选择软件的安装目录,点击安装。
2、安装完成,点击完成退出安装界面。
功能特色操作简单,完全可视化图形操作,无需专业IT人员,任何会使用笔记本上网的人都可以轻松把握。
云采集
采集任务手动分配到云端多台服务器同时执行,提高采集效率,可以挺短的时间内 获取成千上万条信息。
拖拽式采集流程
模拟人的操作思维模式,可以登录,输入数据,点击链接,按钮等,还能对不同情况采取不同的采集流程。
图文辨识
内置可扩充的OCR插口,支持解析图片中的文字,可将图片上的文字提取下来。
定时手动采集
采集任务手动运行,可以根据指定的周期手动采集,并且还支持最快一分钟一次的实时采集。
2分钟快速入门
内置从入门到精通所须要的视频教程,2分钟才能上手使用,另外还有文档,论坛,qq群等。
免费使用
它是免费的,并且免费版本没有任何功能限制,你如今就可以试一试,立即下载安装。软件功能单来讲,使用优采云可以十分容易的从任何网页精确采集你须要的数据,生成自定义的、规整的数据格式。优采云数据采集系统能做的包括但并不局限于以下内容:
1. 金融数据,如年报,年报,财务报告, 包括每日最新净值手动采集;
2. 各大新闻门户网站实时监控,自动更新及上传最新发布的新闻;
3. 监控竞争对手最新信息,包括商品价钱及库存; 查看全部
优采云采集器 v8.0.16免费版
优采云采集器是一款十分强悍的数据采集神器,拥有自主的数据估算系统,可以使你快速从网上抓取各类须要的数据信息,支持从网站和网页上获取有用的、十分规范的数据,采用手动采集的形式轻松采集任何网页或网站的数据信息,不需要懂得任何的专业的知识,让一个菜鸟用户都可以快速学会使用,毫无任何方法,软件拥有可视化的操作,让操作更简单高效,简化操作流程,让采集工作更快速完成。而且完全手动采集,不需要人工操作,能够模拟用户的思维进行操作,帮助你从指定网页上精准采集对于你有用的数据资料,不需要去自己找寻,支持抓取的内容十分的多,可以用于搜集信息,商品宝贝的价钱,销量,各种行业的资讯,数据报表等等,收录的内容十分的全面,网页和网站上的内容基本都可以采集。也可以支持社交网站的信息抓取,比如博客,论坛等等,在博客上会有很多的有用的知识,信息,可以通过这款软件进行快速采集,还支持定时操作,可以设定采集数据的时间,可以说是数据抓取采集的不二选择。
安装教程1、下载并解压,运行EXE程序,选择软件的安装目录,点击安装。
2、安装完成,点击完成退出安装界面。
功能特色操作简单,完全可视化图形操作,无需专业IT人员,任何会使用笔记本上网的人都可以轻松把握。
云采集
采集任务手动分配到云端多台服务器同时执行,提高采集效率,可以挺短的时间内 获取成千上万条信息。
拖拽式采集流程
模拟人的操作思维模式,可以登录,输入数据,点击链接,按钮等,还能对不同情况采取不同的采集流程。
图文辨识
内置可扩充的OCR插口,支持解析图片中的文字,可将图片上的文字提取下来。
定时手动采集
采集任务手动运行,可以根据指定的周期手动采集,并且还支持最快一分钟一次的实时采集。
2分钟快速入门
内置从入门到精通所须要的视频教程,2分钟才能上手使用,另外还有文档,论坛,qq群等。
免费使用
它是免费的,并且免费版本没有任何功能限制,你如今就可以试一试,立即下载安装。软件功能单来讲,使用优采云可以十分容易的从任何网页精确采集你须要的数据,生成自定义的、规整的数据格式。优采云数据采集系统能做的包括但并不局限于以下内容:
1. 金融数据,如年报,年报,财务报告, 包括每日最新净值手动采集;
2. 各大新闻门户网站实时监控,自动更新及上传最新发布的新闻;
3. 监控竞争对手最新信息,包括商品价钱及库存;
观远数据发布表单利器GuanForm,一站式智能数据剖析平台再升级
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2020-08-11 21:49
在观远平台上,企业如需统一采集数据和督查需求,无需利用第三方表单工具,可以直接通过GuanForm设置表单填写信息,填写后搜集的数据才能通过SQL直接提取,快速导出观远数据的BI剖析平台进行后续可视化剖析,从而实现数据口径更统一,数据采集与剖析更实时高效。
对于还在用Excel搜集数据或则没有任何相关工具的企业来说,GuanForm能支持在线整合并递交数据,让职工从繁杂的合并Excel操作中解放下来,有更多时间去做创造性的工作。
前期搜集的数据质量难以保证,导致后续剖析结果不确切,这也是数据剖析过程中的难点。通过GuanForm的“引用填充”功能,能够在源头规范主数据填写质量,此外,还可以结合单选、多选、数字格式等控件引导数据提交者在第一步就确切输入。
例如,在零售行业的店面订货场景,在填写订货明细的时侯,需要逐行填写产品名称、单位、定价和订货数目等数据,而其中前两者的信息是相对固定的主数据,必须和商品表中的信息一致就能保证数据口径统一,这些信息就可以通过“引用填充”的功能只能从商品主数据中引用过来填充到当前表单,省时省力又保证了数据的正确性。
表单的数据安全与权限管理是企业关注的另一要点,GuanForm从用户管理、表单管理、数据管理多方面进行把控,防止搜集信息泄露的同时,做到使不同的人拥有不同的操作权限和数据权限。
那么,如此强悍的数据采集“神器”要怎么使用呢?
下面将从设计表单、设置表单权限、表单数据搜集3个步骤为你们逐一介绍:
01.表单设计
登录表单系统后,点击右上角的“新建表单”来到表单编辑页面,观远表单通过控件的拖拉拽生成,灵活易用,使用门槛低。
设计页面由3部份组成:控件县、画布预览县和属性设置县。
表单数组由控件组成,在画布县可自由拖放排版,同时也可以点击页面上方的“预览”查看表单最终疗效。目前提供以下常用控件:
02.设置表单权限
表单的权限分为所有者和提交者,只有成为表单的所有者,才可以对表单进行更改维护;只有成为表单的提交者,才准许录入数据,这样可以有效避免表单信息的泄漏,防止非目标用户的脏数据混杂进来。
对于搜集上来的表单数据,默认只有所有者可以查看和管理。同时也开放设置项,允许提交者查看和更改自己递交的数据,但未能查看其他人的数据,从而确保数据的安全性。
03.表单数据搜集
GuanForm支持网页端和移动端多渠道的数据采集,支持无缝内嵌到钉钉、企业陌陌、企业自研APP等多种客户端。
除了单条数据的逐一录入,GuanForm还提供了批量导出的功能,点击右上角“导入”,按照提示下载模板,在模板里填写须要上传的数据后,点击“上传文件”即可。
总结一下,GuanForm是由观远提供的灵活易用的表单搭建和表单数据管理工具,具有表单制做灵活简便、权限管理简约建立的优点;网页端移动端分发双管齐下,且表单数据支持快速对接观远BI平台,助力企业零散数据电子化。
观远数据()成立于2016年,以“AI+BI 让决策更智能”为使命,深耕零售、消费以及互联网领域,致力于为顾客提供新一代智能数据剖析平台以及零售消费行业的最佳数据剖析实践。目前服务联合利华、沃尔玛、全家、来伊份、生鲜传奇、lily男装、红豆、小红书、蜜芽宝贝等著名企业。公司总部坐落广州,并在广州、上海、深圳等地设有办事处。
声明:该文观点仅代表作者本人,搜狐号系信息发布平台,搜狐仅提供信息储存空间服务。 查看全部
只需一个负责人完成创建表单——发送表单——采集信息——管理数据——导入观远BI平台的全流程,真正做到数据采集和数据剖析平台一体化。
在观远平台上,企业如需统一采集数据和督查需求,无需利用第三方表单工具,可以直接通过GuanForm设置表单填写信息,填写后搜集的数据才能通过SQL直接提取,快速导出观远数据的BI剖析平台进行后续可视化剖析,从而实现数据口径更统一,数据采集与剖析更实时高效。
对于还在用Excel搜集数据或则没有任何相关工具的企业来说,GuanForm能支持在线整合并递交数据,让职工从繁杂的合并Excel操作中解放下来,有更多时间去做创造性的工作。
前期搜集的数据质量难以保证,导致后续剖析结果不确切,这也是数据剖析过程中的难点。通过GuanForm的“引用填充”功能,能够在源头规范主数据填写质量,此外,还可以结合单选、多选、数字格式等控件引导数据提交者在第一步就确切输入。
例如,在零售行业的店面订货场景,在填写订货明细的时侯,需要逐行填写产品名称、单位、定价和订货数目等数据,而其中前两者的信息是相对固定的主数据,必须和商品表中的信息一致就能保证数据口径统一,这些信息就可以通过“引用填充”的功能只能从商品主数据中引用过来填充到当前表单,省时省力又保证了数据的正确性。
表单的数据安全与权限管理是企业关注的另一要点,GuanForm从用户管理、表单管理、数据管理多方面进行把控,防止搜集信息泄露的同时,做到使不同的人拥有不同的操作权限和数据权限。
那么,如此强悍的数据采集“神器”要怎么使用呢?
下面将从设计表单、设置表单权限、表单数据搜集3个步骤为你们逐一介绍:
01.表单设计
登录表单系统后,点击右上角的“新建表单”来到表单编辑页面,观远表单通过控件的拖拉拽生成,灵活易用,使用门槛低。
设计页面由3部份组成:控件县、画布预览县和属性设置县。
表单数组由控件组成,在画布县可自由拖放排版,同时也可以点击页面上方的“预览”查看表单最终疗效。目前提供以下常用控件:
02.设置表单权限
表单的权限分为所有者和提交者,只有成为表单的所有者,才可以对表单进行更改维护;只有成为表单的提交者,才准许录入数据,这样可以有效避免表单信息的泄漏,防止非目标用户的脏数据混杂进来。
对于搜集上来的表单数据,默认只有所有者可以查看和管理。同时也开放设置项,允许提交者查看和更改自己递交的数据,但未能查看其他人的数据,从而确保数据的安全性。
03.表单数据搜集
GuanForm支持网页端和移动端多渠道的数据采集,支持无缝内嵌到钉钉、企业陌陌、企业自研APP等多种客户端。
除了单条数据的逐一录入,GuanForm还提供了批量导出的功能,点击右上角“导入”,按照提示下载模板,在模板里填写须要上传的数据后,点击“上传文件”即可。
总结一下,GuanForm是由观远提供的灵活易用的表单搭建和表单数据管理工具,具有表单制做灵活简便、权限管理简约建立的优点;网页端移动端分发双管齐下,且表单数据支持快速对接观远BI平台,助力企业零散数据电子化。
观远数据()成立于2016年,以“AI+BI 让决策更智能”为使命,深耕零售、消费以及互联网领域,致力于为顾客提供新一代智能数据剖析平台以及零售消费行业的最佳数据剖析实践。目前服务联合利华、沃尔玛、全家、来伊份、生鲜传奇、lily男装、红豆、小红书、蜜芽宝贝等著名企业。公司总部坐落广州,并在广州、上海、深圳等地设有办事处。
声明:该文观点仅代表作者本人,搜狐号系信息发布平台,搜狐仅提供信息储存空间服务。
一个导航替你搜集了全网最酷最高效的工具利器,悄悄采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2020-08-09 17:43
一、网站体验测评1.网站设计
首先从官网设计上来看吧,点开网站进去,整体觉得太简约,框架清晰,比通常的导航网站更加开朗和前卫一些。交互设计上也是十分简单,点击站点即可跳转到对方网站。相比我之前使用的一些导航可能出于seo优化考虑,还会有一个跳转页面,对于用户体验虽然不是太友好。
2.网站内容
再来看内容里面,第一大块就是推荐各类站点,主要有办公、设计、开发、品牌、营销...等几大块,里面推荐的80%产品本身都是特别用心优秀的,比如logo在线智能生成设计,有些可能会太冷门并且当我使用了以后,都进了我的采集夹,遗憾为何没有早点发觉,互联网信息差很严重了吧!我恨!在站点选择这块,我认为是这个站做的最好的地方了,发现这些被埋没的好工具好网站,让价值传递出去被更多人听到。在文章后面都会给你们推荐几个一定要试试都利器工具,这里先继续说它的第二块内容。
一个单一的导航可能难以明晰一个产品的调性,它这儿添加了一个文章内容蓝筹股,里面的文章主要内容是,具体介绍这些优秀的产品工具以及帮你们评测各类产品、或者一些资源和技能分享。我觉得这块的主要作用就是,能够使用户的逗留时间更长一些,以及降低这个导航的附加价值,就像6套ppt模板,这种整理好可以直接下载的资源就很实用了。
二、神器推荐
在前面和你们分享了我自己对这个导航网站的一些体验体会,如果是非常的话,我认为可以打八分左右吧,在一些站点分类里面我认为做得还不是挺好希望见到它继续进步。接下来,我想和大家分享一些,我通过这个创业利器导航发觉的几个非常棒的产品工具(没有收广告费)
1.搜图利器
写文章的时侯,配图是刚需,目前不管是平台也好还是个人对于图片版权意识越来越重视,不敢象原先那样随意用了。我之前仍然使用的是美国那几个免版权的图库,比如unsplash、pixbay这种,不太便捷的是加载速率会比较慢,并且不支持英文搜索。
搜图利器这个工具,最大的亮点是聚合了这几家商用免版权图库,一键英文搜索,需要工作场景的图片直接输入”工作“就可以,会出现各大图库的图片,直接下载就完事了。重点是完全免费的!
2.甜蒜填图
这也是我近来才发觉的一个小工具,做设计的朋友肯定都晓得,设计稿中须要各类图片占位,首先须要下载好图片,然后一个个位置做填充,超麻烦der,其实我认为这些机械复制性的工作早就该被工具取代了呀。甜蒜填图就是这样的一款工具,对接了免费版权图库,支持打标签一键填充所有图片,大大提升了工作效率,设计师们用上去~
3.MIXKIT
纸质媒体时代过去了以后迎来了数字媒体时代,现在动态视频比文字更有吸引力,不管是企业宣传还是个人品牌,都希望通过短视频来传播影响力。最近我也在尝试做一些视频出来玩,比较难的是很难找到那个炫目的素材,国内基本上都是收费且有版权限制的。在利器导航上发觉了这个网站之后,点进去一看,免版权可商用!爱了!并且呢,整个网站设计的也太棒啊,当然关键是上面的素材内容十分丰富,阔以直接下载用到自己视频上面,做片头或则特效都可以~
不知不觉写了那么长,感觉好玩的产品真的推荐不完诶,累了累了!想知道更多有趣、有价值、好用的工具就去创业利器导航发觉叭~ 查看全部
一、网站体验测评1.网站设计
首先从官网设计上来看吧,点开网站进去,整体觉得太简约,框架清晰,比通常的导航网站更加开朗和前卫一些。交互设计上也是十分简单,点击站点即可跳转到对方网站。相比我之前使用的一些导航可能出于seo优化考虑,还会有一个跳转页面,对于用户体验虽然不是太友好。
2.网站内容
再来看内容里面,第一大块就是推荐各类站点,主要有办公、设计、开发、品牌、营销...等几大块,里面推荐的80%产品本身都是特别用心优秀的,比如logo在线智能生成设计,有些可能会太冷门并且当我使用了以后,都进了我的采集夹,遗憾为何没有早点发觉,互联网信息差很严重了吧!我恨!在站点选择这块,我认为是这个站做的最好的地方了,发现这些被埋没的好工具好网站,让价值传递出去被更多人听到。在文章后面都会给你们推荐几个一定要试试都利器工具,这里先继续说它的第二块内容。
一个单一的导航可能难以明晰一个产品的调性,它这儿添加了一个文章内容蓝筹股,里面的文章主要内容是,具体介绍这些优秀的产品工具以及帮你们评测各类产品、或者一些资源和技能分享。我觉得这块的主要作用就是,能够使用户的逗留时间更长一些,以及降低这个导航的附加价值,就像6套ppt模板,这种整理好可以直接下载的资源就很实用了。
二、神器推荐
在前面和你们分享了我自己对这个导航网站的一些体验体会,如果是非常的话,我认为可以打八分左右吧,在一些站点分类里面我认为做得还不是挺好希望见到它继续进步。接下来,我想和大家分享一些,我通过这个创业利器导航发觉的几个非常棒的产品工具(没有收广告费)
1.搜图利器
写文章的时侯,配图是刚需,目前不管是平台也好还是个人对于图片版权意识越来越重视,不敢象原先那样随意用了。我之前仍然使用的是美国那几个免版权的图库,比如unsplash、pixbay这种,不太便捷的是加载速率会比较慢,并且不支持英文搜索。
搜图利器这个工具,最大的亮点是聚合了这几家商用免版权图库,一键英文搜索,需要工作场景的图片直接输入”工作“就可以,会出现各大图库的图片,直接下载就完事了。重点是完全免费的!
2.甜蒜填图
这也是我近来才发觉的一个小工具,做设计的朋友肯定都晓得,设计稿中须要各类图片占位,首先须要下载好图片,然后一个个位置做填充,超麻烦der,其实我认为这些机械复制性的工作早就该被工具取代了呀。甜蒜填图就是这样的一款工具,对接了免费版权图库,支持打标签一键填充所有图片,大大提升了工作效率,设计师们用上去~
3.MIXKIT
纸质媒体时代过去了以后迎来了数字媒体时代,现在动态视频比文字更有吸引力,不管是企业宣传还是个人品牌,都希望通过短视频来传播影响力。最近我也在尝试做一些视频出来玩,比较难的是很难找到那个炫目的素材,国内基本上都是收费且有版权限制的。在利器导航上发觉了这个网站之后,点进去一看,免版权可商用!爱了!并且呢,整个网站设计的也太棒啊,当然关键是上面的素材内容十分丰富,阔以直接下载用到自己视频上面,做片头或则特效都可以~
不知不觉写了那么长,感觉好玩的产品真的推荐不完诶,累了累了!想知道更多有趣、有价值、好用的工具就去创业利器导航发觉叭~
【】神器!小白也能用的免费网路爬虫软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-09 11:55
……
是不是特别有趣?
更厉害的是!官网提供了大量的实战教程(文字版+视频版),也可以进行教程的搜索,对于小白选手来说,真是很棒了!
优采云采集器()
下面,我们就以抓取马蜂窝上所有日本自由行的信息为例,实际操作一下:
1、下载软件安装注册登入后,复制马蜂窝日本自由行旅行功略的网页。
2、新建智能模式采集任务
也可以在软件上直接新建采集任务,也可以通过导出规则来创建任务。
3、设置提取数据字段
智能模式下,输入网址后软件即可手动辨识出页面上的数据并生成采集结果,每一类数据对应一个采集字段,可以右击更改数组名称、增减数组、处理数据等。
比如须要采集攻略的功略标题、攻略链接、阅读量、体验人数以及封面图等信息,设置疗效如下
4、提取详情页数据
列表页上有日本自由行功略的部份信息,我们须要功略的具体内容,右击功略链接使用“深入采集”功能,跳转到详情页进行采集。
在详情页面可以看见功略的详尽内容、评论数等信息,还可以见到特别多的图片,如果一 一设置数组,会特别多,而且整篇的图片位置不同,所以可以添加一个特殊数组,“页面PDF”。
5、设置采集任务
点击“设置”按钮,可以进行运行设置和防屏蔽设置,这里我们勾选“跳过继续采集”,设置“5”秒恳求等待时间,勾选“不加载网页图片”,防屏蔽设置默认设置,点击保存。
6、开始采集
点击“保存并启动”按钮,弹出一些中级设置,直接点击“启动”运行工具。
7、提取数据
任务启动以后开始手动采集数据,可以直观的看见程序运行过程和采集结果,采集结束以后有提醒。
8、导出数据
数据采集完成后,可以查看和导入数据,软件支持多种导入方法和导入文件的格式(EXCEL、CSV、HTML和TXT),选择自己须要方法和文件类型,点击“确认导入”。
好了,上面是一个简单的反例。看完以后,是不是发觉,原来爬虫爬取数据也可以如此简单!有兴趣的小伙伴快去试试吧。
这里就不放下载地址了,感兴趣的可以去官网下载,非常贴心的提供了三个版本。
查看全部
……
是不是特别有趣?
更厉害的是!官网提供了大量的实战教程(文字版+视频版),也可以进行教程的搜索,对于小白选手来说,真是很棒了!
优采云采集器()
下面,我们就以抓取马蜂窝上所有日本自由行的信息为例,实际操作一下:
1、下载软件安装注册登入后,复制马蜂窝日本自由行旅行功略的网页。
2、新建智能模式采集任务
也可以在软件上直接新建采集任务,也可以通过导出规则来创建任务。
3、设置提取数据字段
智能模式下,输入网址后软件即可手动辨识出页面上的数据并生成采集结果,每一类数据对应一个采集字段,可以右击更改数组名称、增减数组、处理数据等。
比如须要采集攻略的功略标题、攻略链接、阅读量、体验人数以及封面图等信息,设置疗效如下
4、提取详情页数据
列表页上有日本自由行功略的部份信息,我们须要功略的具体内容,右击功略链接使用“深入采集”功能,跳转到详情页进行采集。
在详情页面可以看见功略的详尽内容、评论数等信息,还可以见到特别多的图片,如果一 一设置数组,会特别多,而且整篇的图片位置不同,所以可以添加一个特殊数组,“页面PDF”。
5、设置采集任务
点击“设置”按钮,可以进行运行设置和防屏蔽设置,这里我们勾选“跳过继续采集”,设置“5”秒恳求等待时间,勾选“不加载网页图片”,防屏蔽设置默认设置,点击保存。
6、开始采集
点击“保存并启动”按钮,弹出一些中级设置,直接点击“启动”运行工具。
7、提取数据
任务启动以后开始手动采集数据,可以直观的看见程序运行过程和采集结果,采集结束以后有提醒。
8、导出数据
数据采集完成后,可以查看和导入数据,软件支持多种导入方法和导入文件的格式(EXCEL、CSV、HTML和TXT),选择自己须要方法和文件类型,点击“确认导入”。
好了,上面是一个简单的反例。看完以后,是不是发觉,原来爬虫爬取数据也可以如此简单!有兴趣的小伙伴快去试试吧。
这里就不放下载地址了,感兴趣的可以去官网下载,非常贴心的提供了三个版本。
设计干货| Wall Crack-Eagle推荐的设计师灵感和材料库工件
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2020-08-08 22:47
许多工具非常简单易用,可以在垂直方向上提高我们的生产效率. 但是,使用所有工具是不现实的. 根据您的当前情况进行选择是不可避免的选择,并且并非不可替代. 因此,我没有动力共享这些工具,因为它的需求不强.
这次我要介绍的是唯一给我印象深刻的新设计工具-鹰.
一个,Eagle有什么用
简而言之,它是设计器的资源管理器.
管理设计采集的灵感图纸,材料文件,屏幕截图和Sketch控件.
1. 灵感图管理
通常,我们习惯于使用花瓣,本地文件夹和Pinterest来采集在Internet上看到的精美图片. Eagle使我们能够快速导入这些平台的内容.
认识我的人应该知道我采集的花瓣很多,但是大多数公司和咖啡馆的网络都很差,很难访问他们的采集. Pinterest更加糟糕,因为它依赖于推翻墙. ,因此我首先将所有在线图片移至Eagle. 如果您不习惯采集并且想快速建立自己的灵感库,则可以直接在花瓣中找到绘图板并将其导入,也可以直接使用我的采集集:
酸梅超人的花瓣首页
从花瓣导入的设置
导入画板后
所有图片导入后,我们可以根据文件夹对它们进行分类. 当前,文件夹仅支持两个级别的文件夹深度. 您也可以在文件夹中添加标签,也可以单独选择图片以添加标签,这很方便,尽管我很少使用它,但我们会很快找到它.
用于简历的灵感分类文件夹
为图片添加标签
然后,我们可以在上面的工具栏中对采集的图片进行排序和过滤. 颜色过滤功能非常实用. 当您要查找特定色彩系统的参考时,可以快速将其滤除.
使用滤色器功能后的结果
这样,Eagle可以快速过滤和预览我采集的成千上万张参考图片,这远远优于网页的效率.
图片缩放预览
2. 网页采集插件
更方便的事情是Eagle具有浏览器捕获插件. 我们可以使用此插件快速捕获整个网页或其中的某个区域. 最方便的方法是右键单击所需的图片,然后选择“将图像保存到Eagle”,图片将自动下载到本地未分类的文件夹中,请等到以后再处理.
Safari上的鹰插件
3. 物料管理
您还记得我以前做过的材料分享吗?我们还可以将材料导入Eagle并快速找到它. 如果使用Mac,您可能会认为这与保存自己的文件夹没有什么不同,但是关键是Eagle也支持Windows平台,这对于像我们这样的多平台用户来说非常重要.
Windows平台无法像Mac一样快地预览AI和PSD文件,因此通常的做法是在源文件旁边放置JPG,这似乎真的很累!尽管Adobe Bridge也可以做到,但是其实际体验并不理想. 但是Eagle也可以在Windows下快速预览PSD和AI文件.
图标材料的采集
4,草图组件
这可以看作是UI设计人员的武器. 过去,当我们处理UI KIT集合时,我们主要将相同类型的组件和项目粘贴到画布中,并在需要使用它们时将它们复制.
我的一个项目的组件库
Eagle允许我们从Sketch复制元素. 只要将元素复制到Sketch中并粘贴到Eagle中,您就可以看到相应的组件缩略图,并且在左上角可以看到代表Sketch的图标. 调用项目时,它的速度非常快,无需打开上一个项目的设计文件.
草图组件的集合
第二,Eagle的备份
如果您确实将Eagle作为主要灵感和资料库,那么高级应用程序将无法绕过该工具来同步云服务.
首先,Eagle将数据保存在本地硬盘上,并且不会通过自己的服务器进行备份(估计将来会启用此服务),那么您需要一种固定的备份方法来确保您的数据安全性(悲剧不断重复),以确保长时间整理的内容不会由于硬盘损坏或丢失而在整夜解放之前返回.
因此,同步云服务是最可靠的解决方案. 如果我们将本地Eagle文件夹设置为云同步,则每次添加图片和资料时,它们都会实时更新到服务器,以确保数据的安全性. . 另外,使用云服务使我们能够在其他计算机上读取这些数据并进行编辑,以确保我们的房屋和公司的内容同步.
我自己的私有云同步服务
关于同步云,目前阻止了外部服务,例如Google Drive,Dropbox等,因此建议您首先使用Apple的iCloud Drive. 创建和加载资源库时,我们将直接在此文件夹中进行操作. 它可以达到我们备份和同步数据的目的. 目前,Windows平台还提供了iCloud Drive软件,这也使我们可以跨平台使用此应用程序.
创建资源库的过程
MAC上的iCloud文件夹
Windows上的iCloud面板
当然,如果团队需要它,则类似于Dropbox的同步磁盘可以由多个人共享. 您可以创建一个新的资源库,并一起维护项目中使用的材料和组件!目前还不太实用,期待官方网站的更新和完善!
三个. 购买Eagle
Eagle不是免费的,但是好的软件仍然鼓励每个人都购买它(给别人一点支持,给彼此一个机会,个性保证并不宽泛!),让他们更积极地更新产品.
官方网站上的默认价格为30美元,10个人可以节省20%的订单. 想要购买的学生可以加入一个小组,小组号: 5537969.
预览: 已经下载了数十个G的样机资源尚未整理,应该在下周一和周二进行更新,敬请关注. =! 查看全部
近年来,与设计相关的轻量级工具太多了,例如Affinity系列,QC Studio,Vectr,Pixate等.
许多工具非常简单易用,可以在垂直方向上提高我们的生产效率. 但是,使用所有工具是不现实的. 根据您的当前情况进行选择是不可避免的选择,并且并非不可替代. 因此,我没有动力共享这些工具,因为它的需求不强.
这次我要介绍的是唯一给我印象深刻的新设计工具-鹰.
一个,Eagle有什么用
简而言之,它是设计器的资源管理器.
管理设计采集的灵感图纸,材料文件,屏幕截图和Sketch控件.
1. 灵感图管理
通常,我们习惯于使用花瓣,本地文件夹和Pinterest来采集在Internet上看到的精美图片. Eagle使我们能够快速导入这些平台的内容.
认识我的人应该知道我采集的花瓣很多,但是大多数公司和咖啡馆的网络都很差,很难访问他们的采集. Pinterest更加糟糕,因为它依赖于推翻墙. ,因此我首先将所有在线图片移至Eagle. 如果您不习惯采集并且想快速建立自己的灵感库,则可以直接在花瓣中找到绘图板并将其导入,也可以直接使用我的采集集:
酸梅超人的花瓣首页
从花瓣导入的设置
导入画板后
所有图片导入后,我们可以根据文件夹对它们进行分类. 当前,文件夹仅支持两个级别的文件夹深度. 您也可以在文件夹中添加标签,也可以单独选择图片以添加标签,这很方便,尽管我很少使用它,但我们会很快找到它.
用于简历的灵感分类文件夹
为图片添加标签
然后,我们可以在上面的工具栏中对采集的图片进行排序和过滤. 颜色过滤功能非常实用. 当您要查找特定色彩系统的参考时,可以快速将其滤除.
使用滤色器功能后的结果
这样,Eagle可以快速过滤和预览我采集的成千上万张参考图片,这远远优于网页的效率.
图片缩放预览
2. 网页采集插件
更方便的事情是Eagle具有浏览器捕获插件. 我们可以使用此插件快速捕获整个网页或其中的某个区域. 最方便的方法是右键单击所需的图片,然后选择“将图像保存到Eagle”,图片将自动下载到本地未分类的文件夹中,请等到以后再处理.
Safari上的鹰插件
3. 物料管理
您还记得我以前做过的材料分享吗?我们还可以将材料导入Eagle并快速找到它. 如果使用Mac,您可能会认为这与保存自己的文件夹没有什么不同,但是关键是Eagle也支持Windows平台,这对于像我们这样的多平台用户来说非常重要.
Windows平台无法像Mac一样快地预览AI和PSD文件,因此通常的做法是在源文件旁边放置JPG,这似乎真的很累!尽管Adobe Bridge也可以做到,但是其实际体验并不理想. 但是Eagle也可以在Windows下快速预览PSD和AI文件.
图标材料的采集
4,草图组件
这可以看作是UI设计人员的武器. 过去,当我们处理UI KIT集合时,我们主要将相同类型的组件和项目粘贴到画布中,并在需要使用它们时将它们复制.
我的一个项目的组件库
Eagle允许我们从Sketch复制元素. 只要将元素复制到Sketch中并粘贴到Eagle中,您就可以看到相应的组件缩略图,并且在左上角可以看到代表Sketch的图标. 调用项目时,它的速度非常快,无需打开上一个项目的设计文件.
草图组件的集合
第二,Eagle的备份
如果您确实将Eagle作为主要灵感和资料库,那么高级应用程序将无法绕过该工具来同步云服务.
首先,Eagle将数据保存在本地硬盘上,并且不会通过自己的服务器进行备份(估计将来会启用此服务),那么您需要一种固定的备份方法来确保您的数据安全性(悲剧不断重复),以确保长时间整理的内容不会由于硬盘损坏或丢失而在整夜解放之前返回.
因此,同步云服务是最可靠的解决方案. 如果我们将本地Eagle文件夹设置为云同步,则每次添加图片和资料时,它们都会实时更新到服务器,以确保数据的安全性. . 另外,使用云服务使我们能够在其他计算机上读取这些数据并进行编辑,以确保我们的房屋和公司的内容同步.
我自己的私有云同步服务
关于同步云,目前阻止了外部服务,例如Google Drive,Dropbox等,因此建议您首先使用Apple的iCloud Drive. 创建和加载资源库时,我们将直接在此文件夹中进行操作. 它可以达到我们备份和同步数据的目的. 目前,Windows平台还提供了iCloud Drive软件,这也使我们可以跨平台使用此应用程序.
创建资源库的过程
MAC上的iCloud文件夹
Windows上的iCloud面板
当然,如果团队需要它,则类似于Dropbox的同步磁盘可以由多个人共享. 您可以创建一个新的资源库,并一起维护项目中使用的材料和组件!目前还不太实用,期待官方网站的更新和完善!
三个. 购买Eagle
Eagle不是免费的,但是好的软件仍然鼓励每个人都购买它(给别人一点支持,给彼此一个机会,个性保证并不宽泛!),让他们更积极地更新产品.
官方网站上的默认价格为30美元,10个人可以节省20%的订单. 想要购买的学生可以加入一个小组,小组号: 5537969.
预览: 已经下载了数十个G的样机资源尚未整理,应该在下周一和周二进行更新,敬请关注. =!
一波易于使用的工件!
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2020-08-08 19:41
易于使用神器打击!互相给予一切,欢迎大家交流和学习. 1.外文文献搜索网站
/index.html
2. Google Chrome插件下载URL
推荐使用易于使用的插件
-搜索沙拉单词(可以通过自由标记单词来显示翻译内容
-购物者自动价格比较工具
-我想观看Vip视频
-ocr插件(忘记名称)
-有许多有用的未列出!
3. 公式拦截
请务必使用它!用它!用它!无需免费使用公式. 尽管一个月内可以使用的数量受到限制,但这已经足够了!
4. 笔记摘要-直接搜索官方网站下载〜
-Evernote
-窗帘
两者都很有用,您可以选择一个!
5. 思维导图软件直接搜索,可从官方网站下载!
-MindMaster
6. 爬行神器软件-以下软件可以直接从官方网站下载,通常免费,并且操作相对简单.
-优采云采集器
-优采云采集器(推荐)
7. 屏幕录像软件-直接搜索或从计算机软件下载
-EV屏幕录制
-Bilibili现场直播Ji(只能在您申请成为主持人时使用)
8. 语法错误校正工件
-1Checker(我忘记了我在哪里下载的,可以搜索,该软件非常方便,它将直接标记为红色并提供相应的语法错误建议,可以用作参考,但不一定全部哈哈)
9. 微型数据库
#/ publicDatabase
接受最新的微观调查数据!
10. 重复检查软件
充分利用每所学校的图书馆网站资源,这非常重要!例如: Duxiu和Biganwang可以用作常规的重复检查软件.
11. DEEPL网站翻译神器
目的: 超级强大的翻译助手. 该网站可与Google媲美,甚至比Google Translate更为流畅. 无需下载,仅需要网页翻译. 您可以尝试,英文和中文的翻译非常准确而且功能强大!
12. 论文阅读神器
知识网络研究(电子研究)
用法: 该软件可以直接管理文档,从而大大节省时间.
B智云文档翻译器
目的: 当文档为英文时,不易阅读,然后下载此工件,打开PDF,可以直接选择英文,然后在几分钟内将其翻译. 而且,它是双列的并且可以用英语进行比较,从而大大节省了时间.
13. 绘图伪像
一张相框图片和其他图片:
(1)Edraw软件;
(2)viso;
目的: 您可以在官方帐户“ Software Installation Manager”中找到它. 强大的绘图功能令人惊叹. 我相信一旦您使用它,您就会喜欢这两个软件. 相比之下,我更喜欢Edraw,因为模板很多.
B解锁地图绘图:
(1)ArcGIS;
(2)Python;
(3)Geoda;
(4)QGIS;
(5)由mapbox studio设计.
目的: 绘制地图工件. 前两个软件也可以在“软件安装管理器”中绘制精美的地图,但是每个都有其优点和缺点. 可以设置Arcgis绘图,但不能设置某些python. 智虎网友推荐了第四和第五. 我还没有尝试过这两个. 每个人都可以一起学习〜
14. 图片变成文本伪像
天若OCR文本识别
目的: 以秒为单位提取图片中的文本,提取的位置也可以排版. 重要的是它可以翻译,也可以用快捷键来辅助. 简而言之,这太神奇了. 这确实非常雄心勃勃. 我经常担心将图片转换为文本. 使用QQ更改文本很麻烦. 它还需要排版,这确实令人困惑!但是哈,不用担心,使用它!
15. 数据转换器
StaTransfer13: 免费下载且易于使用. 自己找到此链接〜应该可用!
目的: 您可以将各种数据类型的文件转换为所需的文件格式. 如SAS转换STATA,Excel. 在几分钟内完成!这确实是一个了不起的神奇好东西!
16. 不受欢迎的软件
yaahp软件
目的: 您可以加权,也可以直接操作百度.
B GAMS软件
目的: 它可用于需要优化路径的各种非线性或有条件约束的事物. 操作需要编程代码.
注意: 由于这两个软件相对不受欢迎,暂时还没有安装,如果需要,可以直接与我联系!
好的,这是推荐的工件. 欢迎大家交流和共享更多有趣和有趣的工件软件和网站. 来吧! 查看全部
易于使用神器打击!互相给予一切,欢迎大家交流和学习. 1.外文文献搜索网站
/index.html
2. Google Chrome插件下载URL
推荐使用易于使用的插件
-搜索沙拉单词(可以通过自由标记单词来显示翻译内容
-购物者自动价格比较工具
-我想观看Vip视频
-ocr插件(忘记名称)
-有许多有用的未列出!
3. 公式拦截
请务必使用它!用它!用它!无需免费使用公式. 尽管一个月内可以使用的数量受到限制,但这已经足够了!
4. 笔记摘要-直接搜索官方网站下载〜
-Evernote
-窗帘
两者都很有用,您可以选择一个!
5. 思维导图软件直接搜索,可从官方网站下载!
-MindMaster
6. 爬行神器软件-以下软件可以直接从官方网站下载,通常免费,并且操作相对简单.
-优采云采集器
-优采云采集器(推荐)
7. 屏幕录像软件-直接搜索或从计算机软件下载
-EV屏幕录制
-Bilibili现场直播Ji(只能在您申请成为主持人时使用)
8. 语法错误校正工件
-1Checker(我忘记了我在哪里下载的,可以搜索,该软件非常方便,它将直接标记为红色并提供相应的语法错误建议,可以用作参考,但不一定全部哈哈)
9. 微型数据库
#/ publicDatabase
接受最新的微观调查数据!
10. 重复检查软件
充分利用每所学校的图书馆网站资源,这非常重要!例如: Duxiu和Biganwang可以用作常规的重复检查软件.
11. DEEPL网站翻译神器
目的: 超级强大的翻译助手. 该网站可与Google媲美,甚至比Google Translate更为流畅. 无需下载,仅需要网页翻译. 您可以尝试,英文和中文的翻译非常准确而且功能强大!
12. 论文阅读神器
知识网络研究(电子研究)
用法: 该软件可以直接管理文档,从而大大节省时间.
B智云文档翻译器
目的: 当文档为英文时,不易阅读,然后下载此工件,打开PDF,可以直接选择英文,然后在几分钟内将其翻译. 而且,它是双列的并且可以用英语进行比较,从而大大节省了时间.
13. 绘图伪像
一张相框图片和其他图片:
(1)Edraw软件;
(2)viso;
目的: 您可以在官方帐户“ Software Installation Manager”中找到它. 强大的绘图功能令人惊叹. 我相信一旦您使用它,您就会喜欢这两个软件. 相比之下,我更喜欢Edraw,因为模板很多.
B解锁地图绘图:
(1)ArcGIS;
(2)Python;
(3)Geoda;
(4)QGIS;
(5)由mapbox studio设计.
目的: 绘制地图工件. 前两个软件也可以在“软件安装管理器”中绘制精美的地图,但是每个都有其优点和缺点. 可以设置Arcgis绘图,但不能设置某些python. 智虎网友推荐了第四和第五. 我还没有尝试过这两个. 每个人都可以一起学习〜
14. 图片变成文本伪像
天若OCR文本识别
目的: 以秒为单位提取图片中的文本,提取的位置也可以排版. 重要的是它可以翻译,也可以用快捷键来辅助. 简而言之,这太神奇了. 这确实非常雄心勃勃. 我经常担心将图片转换为文本. 使用QQ更改文本很麻烦. 它还需要排版,这确实令人困惑!但是哈,不用担心,使用它!
15. 数据转换器
StaTransfer13: 免费下载且易于使用. 自己找到此链接〜应该可用!
目的: 您可以将各种数据类型的文件转换为所需的文件格式. 如SAS转换STATA,Excel. 在几分钟内完成!这确实是一个了不起的神奇好东西!
16. 不受欢迎的软件
yaahp软件
目的: 您可以加权,也可以直接操作百度.
B GAMS软件
目的: 它可用于需要优化路径的各种非线性或有条件约束的事物. 操作需要编程代码.
注意: 由于这两个软件相对不受欢迎,暂时还没有安装,如果需要,可以直接与我联系!
好的,这是推荐的工件. 欢迎大家交流和共享更多有趣和有趣的工件软件和网站. 来吧!
一键式视频抓取工具下载工件,下载完成后再加载广告
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2020-08-08 00:14
[为什么要学习爬网? 】1.爬虫很容易上手,但是很难深入. 如何编写高效的采集器,如何编写高度灵活和可伸缩的采集器是一项技术任务. 另外,在爬网过程中,经常容易遇到反爬虫,例如字体防爬网,IP识别,验证码等. 如何克服困难并获取所需的数据,您可以学习此课程! 2.如果您是其他行业的开发人员,例如应用程序开发,网站开发,那么学习爬虫程序可以增强您的技术知识,并开发更安全的软件和网站[课程设计]完整的爬虫程序,无论大小,它可以分为三个步骤,即: 网络请求: 模拟浏览器的行为以从Internet抓取数据. 数据分析: 过滤请求的数据并提取所需的数据. 数据存储: 将提取的数据存储到硬盘或内存中. 例如,使用mysql数据库或redis. 然后按照这些步骤逐步解释本课程,使学生充分掌握每个步骤的技术. 另外,由于爬行器的多样性,在爬行过程中可能会发生反爬行和低效率的情况. 因此,我们又增加了两章来提高爬虫程序的灵活性,即: 高级爬虫: 包括IP代理,多线程爬虫,图形验证代码识别,JS加密和解密,动态Web爬虫,字体反爬虫识别等等. Scrapy和分布式爬虫: Scrapy框架,Scrapy-redis组件,分布式爬虫等. 我们可以通过爬虫的高级知识点来处理大量的反爬虫网站. 作为专业的采集器框架,Scrapy框架可以快速提高我们的搜寻程序的效率和速度. 此外,如果一台计算机无法满足您的需求,我们可以使用分布式爬网程序让多台计算机帮助您快速爬网数据. 从基本的采集器到商业应用程序采集器,这套课程都可以满足您的所有需求! [课程服务]独家付费社区+每个星期三的讨论会+ 1v1问答
Jiweishe 采集神器高级版2016官方下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 485 次浏览 • 2020-08-06 13:25
Jiweishe集合工件高版本更新日志
1. 修复一些错误
2. 优化了一些功能
特别说明: 您好,您要使用的软件是辅助工具,主要的防病毒软件可能会拦截和检查该工具. 该软件可能会有使用风险. 请避免. 如果要继续使用它,建议关闭各种防病毒软件后再使用. 附带的软件包解压密码:
华军编辑推荐:
Jiweisha 采集 Artifact的高端版本是业内最好的软件之一. 我相信很多朋友以前都会使用它. 该网站还为您准备了猎豹wifi,wifi主密钥,qq音乐
集微社是一款智能的微信群采集软件,结合了大数据爬虫技术和图像分析技术,可以在互联网上采集微信群的二维码图像. 通过“微信群共享网站”,“微博”,“贴吧”,“官方账号”等大流量平台使用,例如陌生人共享微信群二维码进行大数据采集;软件可以智能识别二维码代码,检测QR码的真实性并智能地过滤重复项;维度代码,内存查询等功能可帮助您大大提高查找组的效率,提高输入组的成功率并提高组质量.
Jiweishe集合工件高版本更新日志
1. 修复一些错误
2. 优化了一些功能
特别说明: 您好,您要使用的软件是辅助工具,主要的防病毒软件可能会拦截和检查该工具. 该软件可能会有使用风险. 请避免. 如果要继续使用它,建议关闭各种防病毒软件后再使用. 附带的软件包解压密码:
华军编辑推荐:
Jiweisha 采集 Artifact的高端版本是业内最好的软件之一. 我相信会有很多朋友使用它,而您将不再需要它. 该网站还为您准备了猎豹wifi,wifi主密钥,qq音乐 查看全部
集微社是一款智能化的微信群采集软件,结合了大数据爬虫技术和图像分析技术,可以在互联网上采集微信群的二维码图片. 通过“微信群共享网站”,“微博”,“发布栏”,“官方账号”等大流量平台,例如陌生人共享的微信群二维码,可以采集大数据;智能识别二维码,检测二维码的真实性,智能过滤重复码,维码,内存查询等功能,可以帮助您大大提高组群查找效率,提高组群录入成功率,改善组群质量.
Jiweishe集合工件高版本更新日志
1. 修复一些错误
2. 优化了一些功能
特别说明: 您好,您要使用的软件是辅助工具,主要的防病毒软件可能会拦截和检查该工具. 该软件可能会有使用风险. 请避免. 如果要继续使用它,建议关闭各种防病毒软件后再使用. 附带的软件包解压密码:
华军编辑推荐:
Jiweisha 采集 Artifact的高端版本是业内最好的软件之一. 我相信很多朋友以前都会使用它. 该网站还为您准备了猎豹wifi,wifi主密钥,qq音乐
集微社是一款智能的微信群采集软件,结合了大数据爬虫技术和图像分析技术,可以在互联网上采集微信群的二维码图像. 通过“微信群共享网站”,“微博”,“贴吧”,“官方账号”等大流量平台使用,例如陌生人共享微信群二维码进行大数据采集;软件可以智能识别二维码代码,检测QR码的真实性并智能地过滤重复项;维度代码,内存查询等功能可帮助您大大提高查找组的效率,提高输入组的成功率并提高组质量.
Jiweishe集合工件高版本更新日志
1. 修复一些错误
2. 优化了一些功能
特别说明: 您好,您要使用的软件是辅助工具,主要的防病毒软件可能会拦截和检查该工具. 该软件可能会有使用风险. 请避免. 如果要继续使用它,建议关闭各种防病毒软件后再使用. 附带的软件包解压密码:
华军编辑推荐:
Jiweisha 采集 Artifact的高端版本是业内最好的软件之一. 我相信会有很多朋友使用它,而您将不再需要它. 该网站还为您准备了猎豹wifi,wifi主密钥,qq音乐
捷豹淘宝采集神器
采集交流 • 优采云 发表了文章 • 0 个评论 • 622 次浏览 • 2020-08-06 03:03
软件功能:
1. 操作简单,搜索速度快. (该软件使用云采集技术在10分钟内采集了1,000多个实时更新数据,比市场上的其他软件快20倍!)
2. 该软件可以采集商店名称,网旺名称,电话号码,手机号码,QQ号码,微信,销量,评估号,好评率等.
3. 输入要搜索的关键字或随机搜索,选择区域并存储信用等级,然后单击[开始].
4. 软件操作界面的用户友好选项可以启动和停止.
5. 采集完成后,您可以选择不同的格式和不同的字段以导出所需的数据.
6. 单击商店链接以查看更多详细的商店信息.
7. 信息资源快速更新,系统每天24小时自动采集信息.
8. 无需人工干预,该软件会自动采集,从而可以使客户放心.
9. 内容准确而详尽,最多收录12条商店信息.
10. 该软件可自行过滤重复数据.
软件用户指南:
1: 下载并安装任何驱动器盘符后,打开“淘宝采集助手”,如果有更新,它将自我更新并重新启动程序.
2: 随时在左下角添加关键字. 如果要精确,请填写. 例如,如果我刚刚搜索“运动衫”,则只需单击右侧的“开始采集”,然后等待它自动过滤掉无用的商店. ,与关键字“运动衫”相关的商店和产品可以显示在上方
3: 如果您想直接与这家网店Wangwang聊天,它甚至更简单. 只需单击其Wangwang名称,系统就会弹出您的登录Wangwang以启用聊天功能(这里我已登录4,让我选择要使用聊天功能的人)
4: 扫描了这么多商店后,您一直想保存它吗?点击“导出”
然后它将如图所示弹出,并选择您想要的商店和不需要的商店. 如果默认选择已完成,请先“过滤”,然后在“导出”中执行所需的任何文件路径
5: 如图所示进行过滤并导出后,我的是默认的300次完全导出,不进行任何过滤,总共有300家商店. 查看全部
Jaguar淘宝采集品是Taoke信息采集品. 该软件非常好,易于使用. 在整个过程中,没有卡程序和闪回这样的问题. 尽管此软件具有付费功能,但它是免费的. 该功能已经足够. 欢迎有需要的朋友下载.
软件功能:
1. 操作简单,搜索速度快. (该软件使用云采集技术在10分钟内采集了1,000多个实时更新数据,比市场上的其他软件快20倍!)
2. 该软件可以采集商店名称,网旺名称,电话号码,手机号码,QQ号码,微信,销量,评估号,好评率等.
3. 输入要搜索的关键字或随机搜索,选择区域并存储信用等级,然后单击[开始].
4. 软件操作界面的用户友好选项可以启动和停止.
5. 采集完成后,您可以选择不同的格式和不同的字段以导出所需的数据.
6. 单击商店链接以查看更多详细的商店信息.
7. 信息资源快速更新,系统每天24小时自动采集信息.
8. 无需人工干预,该软件会自动采集,从而可以使客户放心.
9. 内容准确而详尽,最多收录12条商店信息.
10. 该软件可自行过滤重复数据.
软件用户指南:
1: 下载并安装任何驱动器盘符后,打开“淘宝采集助手”,如果有更新,它将自我更新并重新启动程序.
2: 随时在左下角添加关键字. 如果要精确,请填写. 例如,如果我刚刚搜索“运动衫”,则只需单击右侧的“开始采集”,然后等待它自动过滤掉无用的商店. ,与关键字“运动衫”相关的商店和产品可以显示在上方
3: 如果您想直接与这家网店Wangwang聊天,它甚至更简单. 只需单击其Wangwang名称,系统就会弹出您的登录Wangwang以启用聊天功能(这里我已登录4,让我选择要使用聊天功能的人)
4: 扫描了这么多商店后,您一直想保存它吗?点击“导出”
然后它将如图所示弹出,并选择您想要的商店和不需要的商店. 如果默认选择已完成,请先“过滤”,然后在“导出”中执行所需的任何文件路径
5: 如图所示进行过滤并导出后,我的是默认的300次完全导出,不进行任何过滤,总共有300家商店.
EditorTools破解版V3.2.2免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2020-08-05 18:09
软件简介
EditorTools是一种绿色的免费采集软件,它是没有.net框架的中小型网站的自动更新工具. 自动采集和发布,无需人工干预的静默工作;独立软件免除网站性能消耗;安全稳定,可以连续工作多年;支持任何网站和数据库的采集和发布,并且该软件包括discuzX3,phpwind9,dvbbs,decms,dede淘宝常用系统的示例,例如guest,wordpress,phpcms,empire cms,Dongyi,Xinyun,Fengxun,pbdigg,php168, bbsxp,phpbb,destoon,百度空间等.
此软件适用于需要长期更新内容的网站,不需要您对现有论坛或网站进行任何更改.
功能
1. 独特的无人值守操作
从设计伊始,ET就被设计为提高软件自动化程度的突破,以实现无人值守和自动24小时工作的目的. 经过测试,ET可以长时间甚至数年自动运行.
2. 超高稳定性
如果该软件无人值守,则需要能够长时间稳定运行. ET在这方面进行了很多优化,以确保软件可以稳定且连续地运行. 某些采集软件永远不会崩溃甚至导致崩溃. 网站崩溃了.
3,资源占用最低
ET独立于网站,并且不消耗宝贵的服务器WEB处理资源. 它可以在服务器上或网站管理员的工作站上工作.
4. 严格的数据和网络安全性
ET使用网站自己的数据发布界面或程序代码来处理和发布信息,并且不直接操作网站数据库,从而避免了由ET引起的任何数据安全问题. ET采集信息时,使用标准的HTTP端口,不会造成网络安全漏洞.
5. 强大而灵活的功能
除了通用采集工具的功能外,ET还使用户能够支持图像水印,防盗链,分页采集,答复采集,登录采集,自定义项目,UTF-8,UBB,模拟发行.... 可以灵活地实现各种采集头发的要求.
更新说明
1. 新增功能: 自动分词模块,可用于自动提取关键字/标签.
2. 新;数据项可以选择指定内容模式,并支持引用其他数据项,随机字符串和其他预设内容.
3. 优化: 采集配置根据列表页面,采集页面和数据项的隶属关系优化界面.
4. 优化: 现在,您可以选择是否对数据项使用翻译,以方便对翻译内容进行排序.
5. 优化: 数据项现在可以独立选择是否修改URL.
6. 新增: 采集页面和数据页面的URL合成现在可以引用数据项,以适应更复杂的URL合成.
7. 优化: 将程序间隔时间从系统设置窗口移至配方程序窗口,可以为每个程序分别设置间隔时间. 查看全部
EditorTools破解版(网站数据库采集工件)是一个非常专业且简单的界面网站数据库采集器. 您在寻找功能强大的网站数据库获取软件吗?然后到Green Pioneer下载免费版本的EditorTools破解版以使用. 自动采集,无需一直关注,适用于需要长时间更新的网站,内置discuzX3,phpwind9,dvbbs,dedecms等常见系统示例,非常易于使用. 来到绿色先锋下载免费版本的EditorTools破解版进行试用
软件简介
EditorTools是一种绿色的免费采集软件,它是没有.net框架的中小型网站的自动更新工具. 自动采集和发布,无需人工干预的静默工作;独立软件免除网站性能消耗;安全稳定,可以连续工作多年;支持任何网站和数据库的采集和发布,并且该软件包括discuzX3,phpwind9,dvbbs,decms,dede淘宝常用系统的示例,例如guest,wordpress,phpcms,empire cms,Dongyi,Xinyun,Fengxun,pbdigg,php168, bbsxp,phpbb,destoon,百度空间等.
此软件适用于需要长期更新内容的网站,不需要您对现有论坛或网站进行任何更改.
功能
1. 独特的无人值守操作
从设计伊始,ET就被设计为提高软件自动化程度的突破,以实现无人值守和自动24小时工作的目的. 经过测试,ET可以长时间甚至数年自动运行.
2. 超高稳定性
如果该软件无人值守,则需要能够长时间稳定运行. ET在这方面进行了很多优化,以确保软件可以稳定且连续地运行. 某些采集软件永远不会崩溃甚至导致崩溃. 网站崩溃了.
3,资源占用最低
ET独立于网站,并且不消耗宝贵的服务器WEB处理资源. 它可以在服务器上或网站管理员的工作站上工作.
4. 严格的数据和网络安全性
ET使用网站自己的数据发布界面或程序代码来处理和发布信息,并且不直接操作网站数据库,从而避免了由ET引起的任何数据安全问题. ET采集信息时,使用标准的HTTP端口,不会造成网络安全漏洞.
5. 强大而灵活的功能
除了通用采集工具的功能外,ET还使用户能够支持图像水印,防盗链,分页采集,答复采集,登录采集,自定义项目,UTF-8,UBB,模拟发行.... 可以灵活地实现各种采集头发的要求.
更新说明
1. 新增功能: 自动分词模块,可用于自动提取关键字/标签.
2. 新;数据项可以选择指定内容模式,并支持引用其他数据项,随机字符串和其他预设内容.
3. 优化: 采集配置根据列表页面,采集页面和数据项的隶属关系优化界面.
4. 优化: 现在,您可以选择是否对数据项使用翻译,以方便对翻译内容进行排序.
5. 优化: 数据项现在可以独立选择是否修改URL.
6. 新增: 采集页面和数据页面的URL合成现在可以引用数据项,以适应更复杂的URL合成.
7. 优化: 将程序间隔时间从系统设置窗口移至配方程序窗口,可以为每个程序分别设置间隔时间.
微信文章图片批量采集下载保存,强烈推荐这个利器
采集交流 • 优采云 发表了文章 • 0 个评论 • 803 次浏览 • 2020-08-04 08:02
现在简单给你们介绍下怎样使用:
点击下载软件,注意软件目前只能在笔记本端使用,还没有APP软件。
2.解压后,点击程序,启动软件,注意有些杀毒软件会报错,不过你放心,本人亲试,软件为绿色免安装版,不带任何病毒,绝对可以放心使用。
3.进入软件后完整的采集神器,你须要陌陌扫码登。
4.登录后点击左下角的号内采集,点击开始采集
5.登录陌陌笔记本端,打开你想下载的公众号的历史消息,点击刷。
6.可以看见软件早已采集到了这个公众号所发的历史文章,在设置里勾选下载图片到本地或只下载文章照片,你可以选择分时间段下载,也可以选择全部下载。
7. 勾选后,鼠标右键选择任意一个导入的格式,比如Word或则text,软件就可以手动下载勾选公众号里的图片了。
8.找到你设置保存的文件夹,每个篇文章都单独用一个文件夹保存,图片早已全部保存进去了。
神奇吧,是不是值得推荐完整的采集神器,这个可以真正将公众号陌陌文章里的图片批量下载保存的利器。
此外,软件还可以一键采集及搜索任意微信公众号所有历史文章,带阅读量和评论数批量导入pdf、word、txt、Excel、Html保存到本地笔记本,并一次下载陌陌文章中全部图片、视频、音乐音频和留言评论等,80项功能,赶快下载试用吧。
啄木鸟陌陌文章助手 查看全部
作为微信公众号文章批量采集下载保存的利器——啄木鸟陌陌文章助手,点击下载,还有一个非常强悍的功能,就是可以实现你关注公众号陌陌文章里的图片批量采集下载保存,一键下载,Word、pdf格式任你选择,同时下载公众号文章里的视频、音频,操作非常简单,高效极高,完全解放右手,多余时间拿来摆地摊,赚外快。
现在简单给你们介绍下怎样使用:
点击下载软件,注意软件目前只能在笔记本端使用,还没有APP软件。
2.解压后,点击程序,启动软件,注意有些杀毒软件会报错,不过你放心,本人亲试,软件为绿色免安装版,不带任何病毒,绝对可以放心使用。
3.进入软件后完整的采集神器,你须要陌陌扫码登。
4.登录后点击左下角的号内采集,点击开始采集
5.登录陌陌笔记本端,打开你想下载的公众号的历史消息,点击刷。
6.可以看见软件早已采集到了这个公众号所发的历史文章,在设置里勾选下载图片到本地或只下载文章照片,你可以选择分时间段下载,也可以选择全部下载。
7. 勾选后,鼠标右键选择任意一个导入的格式,比如Word或则text,软件就可以手动下载勾选公众号里的图片了。
8.找到你设置保存的文件夹,每个篇文章都单独用一个文件夹保存,图片早已全部保存进去了。
神奇吧,是不是值得推荐完整的采集神器,这个可以真正将公众号陌陌文章里的图片批量下载保存的利器。
此外,软件还可以一键采集及搜索任意微信公众号所有历史文章,带阅读量和评论数批量导入pdf、word、txt、Excel、Html保存到本地笔记本,并一次下载陌陌文章中全部图片、视频、音乐音频和留言评论等,80项功能,赶快下载试用吧。
啄木鸟陌陌文章助手

