
完整的采集神器
完整的采集神器推荐一个人在家傻瓜式地采集网页视频的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 469 次浏览 • 2021-05-25 19:01
完整的采集神器推荐一个人在家傻瓜式地采集网页视频的方法,教程干货满满,
一)正确获取视频地址
1、百度网盘搜索“视频采集神器”,首页不是很好找,
2、会跳转到下载页面,直接点击视频下载即可。
3、下载后为网页视频;
4、如果是高清视频,可以通过视频链接再跳转到视频页面,
二)快速获取网页视频地址
1、打开快速采集工具,
2、复制视频网址,页面左上角有一个视频列表的窗口,可以一键采集。
3、按照下图来切换你要采集的视频页面和范围,
二)采集视频地址有时候因为链接有问题,大家可以尝试利用电脑的剪切板或者浏览器的剪贴板一键采集,
三)提取视频封面
2、在左侧设置框中,选择封面提取方式,大家可以通过将文件放入iphone手机或者电脑中进行提取,
3、将提取的链接复制在浏览器中即可,这样我们就能查看了。
我为什么要说这个呢?因为我不禁要吐槽一下了,我希望大家能点个赞?我不想你们被我牵着鼻子走了。首先,你要有一个合适的网站。真正去实施,理论上你要进行交互,比如打开google,并且成功登录。方法不同,效果也不同。这是我学习的不多,欢迎拍砖,理论上是你要有一个合适的网站。一般说来,互联网上比较有名气的很多免费公共资源如:爱问共享资料,中国知网,万方数据库都可以,但是贵。
除此之外,谷歌、百度,再不济你用360,腾讯微信,它们都能检索出来。第二,要有高质量的视频资源,你看看你的youtube是不是也有很多挺不错的好东西?eqingwu出品的《tableau总览报告》,没什么说的,全是tableau的经典报告。这些内容我都收藏了,如果大家感兴趣的话,或者想要微信课程资源,可以联系我。
第三,要有分层路径。比如你要采集二三本高校的课程视频,你要分成课程名字、课程名字、课程名字、课程名字,这样才能更全面的进行查找。举个例子,我要查“周鸿祎管理学三个案例”,那么,我就要分为周鸿祎、管理学、案例三个部分;如果我要查“陈安之的演讲视频”,也可以有类似的功能,是不是很方便。第四,还是你要有一个合适的关键词或者网站,很多人容易犯两个错误,一个是关键词没有分好,另一个是关键词用的不对。比如我想了解一下好像人大经济学院的公开课比较多,那么就搜“人大经济学。 查看全部
完整的采集神器推荐一个人在家傻瓜式地采集网页视频的方法
完整的采集神器推荐一个人在家傻瓜式地采集网页视频的方法,教程干货满满,
一)正确获取视频地址
1、百度网盘搜索“视频采集神器”,首页不是很好找,
2、会跳转到下载页面,直接点击视频下载即可。
3、下载后为网页视频;
4、如果是高清视频,可以通过视频链接再跳转到视频页面,
二)快速获取网页视频地址
1、打开快速采集工具,
2、复制视频网址,页面左上角有一个视频列表的窗口,可以一键采集。
3、按照下图来切换你要采集的视频页面和范围,
二)采集视频地址有时候因为链接有问题,大家可以尝试利用电脑的剪切板或者浏览器的剪贴板一键采集,
三)提取视频封面
2、在左侧设置框中,选择封面提取方式,大家可以通过将文件放入iphone手机或者电脑中进行提取,
3、将提取的链接复制在浏览器中即可,这样我们就能查看了。
我为什么要说这个呢?因为我不禁要吐槽一下了,我希望大家能点个赞?我不想你们被我牵着鼻子走了。首先,你要有一个合适的网站。真正去实施,理论上你要进行交互,比如打开google,并且成功登录。方法不同,效果也不同。这是我学习的不多,欢迎拍砖,理论上是你要有一个合适的网站。一般说来,互联网上比较有名气的很多免费公共资源如:爱问共享资料,中国知网,万方数据库都可以,但是贵。
除此之外,谷歌、百度,再不济你用360,腾讯微信,它们都能检索出来。第二,要有高质量的视频资源,你看看你的youtube是不是也有很多挺不错的好东西?eqingwu出品的《tableau总览报告》,没什么说的,全是tableau的经典报告。这些内容我都收藏了,如果大家感兴趣的话,或者想要微信课程资源,可以联系我。
第三,要有分层路径。比如你要采集二三本高校的课程视频,你要分成课程名字、课程名字、课程名字、课程名字,这样才能更全面的进行查找。举个例子,我要查“周鸿祎管理学三个案例”,那么,我就要分为周鸿祎、管理学、案例三个部分;如果我要查“陈安之的演讲视频”,也可以有类似的功能,是不是很方便。第四,还是你要有一个合适的关键词或者网站,很多人容易犯两个错误,一个是关键词没有分好,另一个是关键词用的不对。比如我想了解一下好像人大经济学院的公开课比较多,那么就搜“人大经济学。
完整的采集神器第1弹:各种采集工具,常用的神器使用新方法(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2021-05-21 02:03
完整的采集神器第1弹:各种采集工具,常用的神器使用新方法(一)几个采集工具的使用,讲几个我常用的几个采集工具:简道云采集市场数据一共七个用户版,通过简道云管理多行业数据可以很快速,方便的实现复杂的数据处理。第二季有个强大的神器、你来收集,通过强大的数据收集功能,完美收集你的数据!第三季的强大,用户版采集数据可以自动导出excel表格,还不能导出xlsx格式。
第四季就目前为止还可以,其他没用过。采集市场的采集工具大部分都不带视频。第三季神器,专业视频的学习使用,通过视频对平常用的很多工具有了全面的讲解。整个采集市场关于采集工具的基础知识讲解,都可以学习到。以下附上相关图片。个人认为好用的几个采集工具:我个人经常用到的采集工具一些采集工具截图。常用的几个采集工具的使用。
目前大部分采集工具可以直接免费用,部分产品收费。再次提醒:没有足够的采集数据经验的还是别折腾了,真不怎么样。现在各大招聘网站发布招聘信息,看网站的同时,也会采集一些岗位信息。例如拉勾网招聘,可以看看其他企业都需要哪些职位,多关注一下。后面还有几个采集类产品要出免费版,预计今年年底发布。提醒:提前准备数据和采集岗位信息,不然试用版很快就用完了。
推荐一个采集神器,采集钉钉视频,腾讯视频播放器,优酷视频,爱奇艺视频,爱奇艺电视剧,火星小说等常用软件的视频。免费版只能抓取被采集网站的视频,收费版能抓取多家网站视频。可以采集的网站有下面几个:采集素材助手,收费版。可以采集简历,采集聊天截图,采集微信通讯录,多个企业网站的资源截图等图片。无法抓取视频,不过可以抓取文本,收费版付费。
需要采集素材的只能用免费版。采集大象视频,为企业站建站需要采集素材。采集各大视频站相关的视频就可以一次采集,提供采集模板、采集工具等。具体视频:采集大象,快手,b站视频采集神器-采集大象后台提供的模板、采集工具等采集,网页端,主流视频站点素材,比如:新浪视频,搜狐视频,腾讯视频,爱奇艺视频。有些原来没用过的网站也可以采集。希望大家能采集到满意的素材。 查看全部
完整的采集神器第1弹:各种采集工具,常用的神器使用新方法(一)
完整的采集神器第1弹:各种采集工具,常用的神器使用新方法(一)几个采集工具的使用,讲几个我常用的几个采集工具:简道云采集市场数据一共七个用户版,通过简道云管理多行业数据可以很快速,方便的实现复杂的数据处理。第二季有个强大的神器、你来收集,通过强大的数据收集功能,完美收集你的数据!第三季的强大,用户版采集数据可以自动导出excel表格,还不能导出xlsx格式。
第四季就目前为止还可以,其他没用过。采集市场的采集工具大部分都不带视频。第三季神器,专业视频的学习使用,通过视频对平常用的很多工具有了全面的讲解。整个采集市场关于采集工具的基础知识讲解,都可以学习到。以下附上相关图片。个人认为好用的几个采集工具:我个人经常用到的采集工具一些采集工具截图。常用的几个采集工具的使用。
目前大部分采集工具可以直接免费用,部分产品收费。再次提醒:没有足够的采集数据经验的还是别折腾了,真不怎么样。现在各大招聘网站发布招聘信息,看网站的同时,也会采集一些岗位信息。例如拉勾网招聘,可以看看其他企业都需要哪些职位,多关注一下。后面还有几个采集类产品要出免费版,预计今年年底发布。提醒:提前准备数据和采集岗位信息,不然试用版很快就用完了。
推荐一个采集神器,采集钉钉视频,腾讯视频播放器,优酷视频,爱奇艺视频,爱奇艺电视剧,火星小说等常用软件的视频。免费版只能抓取被采集网站的视频,收费版能抓取多家网站视频。可以采集的网站有下面几个:采集素材助手,收费版。可以采集简历,采集聊天截图,采集微信通讯录,多个企业网站的资源截图等图片。无法抓取视频,不过可以抓取文本,收费版付费。
需要采集素材的只能用免费版。采集大象视频,为企业站建站需要采集素材。采集各大视频站相关的视频就可以一次采集,提供采集模板、采集工具等。具体视频:采集大象,快手,b站视频采集神器-采集大象后台提供的模板、采集工具等采集,网页端,主流视频站点素材,比如:新浪视频,搜狐视频,腾讯视频,爱奇艺视频。有些原来没用过的网站也可以采集。希望大家能采集到满意的素材。
完整的采集神器,那就是优采网,全部是免费的
采集交流 • 优采云 发表了文章 • 0 个评论 • 442 次浏览 • 2021-05-18 18:07
完整的采集神器,那就是优采网,全部是免费的。
别说四五千,就算拿百万人民币,找个正规的网站服务商,过采过滤,过滤代码之后,网站都不一定能打开。毕竟你是中文网站,很多标准,已经固定。
建议你还是自己采吧,反正付费成本有限,但是要付出一定的技术含量和一定的时间成本,但是收益也有限,至于找代采或者找外贸培训机构,结果可能也会是一样,很难找到合适的。不过其实对于大多数中小型外贸公司来说,找几个销售同时给你采买几百条样品成本可能不到千元,尤其针对每个国家的采购政策不同,代采公司更是不可能给你找几百条样品来做展示,所以其实你可以专注大客户,小客户的采买有平台代替,但是付费前你也要把合同和采购政策先好好看看,要先有一个初步的了解,如果能拿到其中一些合适的订单就足够了,毕竟大多数公司没有专门的采购业务员来采买产品。
标准还是要学习,过程还是要时间,结果还是不好评判,主要是看你要做什么样的外贸公司。外贸易这一块要看市场发展如何,毕竟大家都知道,大趋势是外贸的特点是客户需求大于供给。供需关系会越来越不平衡,但是大的市场是外贸会越来越好做。外贸人要有眼光,要能看到变化趋势,这样才能从中获利。有独特品牌和产品的外贸企业才是真正有市场前景的外贸企业。 查看全部
完整的采集神器,那就是优采网,全部是免费的
完整的采集神器,那就是优采网,全部是免费的。
别说四五千,就算拿百万人民币,找个正规的网站服务商,过采过滤,过滤代码之后,网站都不一定能打开。毕竟你是中文网站,很多标准,已经固定。
建议你还是自己采吧,反正付费成本有限,但是要付出一定的技术含量和一定的时间成本,但是收益也有限,至于找代采或者找外贸培训机构,结果可能也会是一样,很难找到合适的。不过其实对于大多数中小型外贸公司来说,找几个销售同时给你采买几百条样品成本可能不到千元,尤其针对每个国家的采购政策不同,代采公司更是不可能给你找几百条样品来做展示,所以其实你可以专注大客户,小客户的采买有平台代替,但是付费前你也要把合同和采购政策先好好看看,要先有一个初步的了解,如果能拿到其中一些合适的订单就足够了,毕竟大多数公司没有专门的采购业务员来采买产品。
标准还是要学习,过程还是要时间,结果还是不好评判,主要是看你要做什么样的外贸公司。外贸易这一块要看市场发展如何,毕竟大家都知道,大趋势是外贸的特点是客户需求大于供给。供需关系会越来越不平衡,但是大的市场是外贸会越来越好做。外贸人要有眼光,要能看到变化趋势,这样才能从中获利。有独特品牌和产品的外贸企业才是真正有市场前景的外贸企业。
完整的采集神器 不喜欢多线程爬虫的老板,用这个就ok!
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-05-18 02:01
完整的采集神器,给你最佳的采集体验。不喜欢多线程爬虫的老板,用这个就ok!作者:天下好策略机构,预测3月后会有大的资金流入,是很多大公司开始需要的样子,适合中小企业。相比较于其他的小爬虫,它更稳定,速度也有保障。采集特色:1.多线程爬虫2.国内最大的采集软件工具体系,可实现整站采集3.可实现全球文章、信息的自动识别采集4.支持多选中的多线程,线程数可扩展5.支持内容包索引编辑器的增量采集功能6.支持一键导出本地数据-只要简单设置就能用!!!这就是他最突出的优势。
好处就是你不用懂sql语句,不用有人帮你复制黏贴,更不用懂有splash!!!还有就是可以爬到国内外的信息,数据的精准性对中小企业而言非常重要,目前实现121篇国内外文章,4篇音频,11篇视频,67篇文章的全网检索。采集手工录入信息的时代要过去了,用这个最方便,百度贴吧都有网址,企业资料也有,所以采集是大势所趋。
当然他的收益也还不错,中小企业做个单,利润已经是够你活很久的了,你要是能有一定资金投入,那恭喜你,你赚到了,中小企业本来投入就少,如果这样做,那就更是省钱啦。
我有些本地文件用浏览器自带的baiduspider等,要的话就点, 查看全部
完整的采集神器 不喜欢多线程爬虫的老板,用这个就ok!
完整的采集神器,给你最佳的采集体验。不喜欢多线程爬虫的老板,用这个就ok!作者:天下好策略机构,预测3月后会有大的资金流入,是很多大公司开始需要的样子,适合中小企业。相比较于其他的小爬虫,它更稳定,速度也有保障。采集特色:1.多线程爬虫2.国内最大的采集软件工具体系,可实现整站采集3.可实现全球文章、信息的自动识别采集4.支持多选中的多线程,线程数可扩展5.支持内容包索引编辑器的增量采集功能6.支持一键导出本地数据-只要简单设置就能用!!!这就是他最突出的优势。
好处就是你不用懂sql语句,不用有人帮你复制黏贴,更不用懂有splash!!!还有就是可以爬到国内外的信息,数据的精准性对中小企业而言非常重要,目前实现121篇国内外文章,4篇音频,11篇视频,67篇文章的全网检索。采集手工录入信息的时代要过去了,用这个最方便,百度贴吧都有网址,企业资料也有,所以采集是大势所趋。
当然他的收益也还不错,中小企业做个单,利润已经是够你活很久的了,你要是能有一定资金投入,那恭喜你,你赚到了,中小企业本来投入就少,如果这样做,那就更是省钱啦。
我有些本地文件用浏览器自带的baiduspider等,要的话就点,
公众号商品回复“采集”可以获取小程序的下载链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 349 次浏览 • 2021-05-12 05:04
完整的采集神器更可以直接下载京东的商品,视频,小程序等可以直接采集,适合个人和团队使用,去重复采集,一键去重,支持多个平台的下载,可以当做爬虫,可以对接非常多的商品。
公众号商品回复“采集”可以获取小程序的下载链接如何实现微信公众号商品回复“采集”获取小程序下载链接
可以下载天猫的商品
微信公众号商品回复“采集”,就可以获取小程序的下载链接,并且可以配上小程序的讲解图文,图文链接也可以用js引入。小程序商品回复“采集”后链接可以被采集。
我们做得定制化微商城的中文版,是国内首家运用最新深度学习技术处理图片真人描述并生成文本摘要的。同时还可以根据不同的用户群体和内容策略,结合视频等图文方式进行自由搭配运营。你可以看看这些产品的介绍联系我们吧:深度学习+机器学习+图片描述+自然语言生成,
别走远就是这样,我看看你真人头像。
微信商品回复“采集”
我的天,这我我也发现来,不过我也是自己挖掘着,可以在微信公众号和商品回复“采集”,
问题是“天猫”,那么我觉得最直接的方法,就是使用商品传送门,点进去之后点击底下的“采集数据”,然后点击“下载商品”即可。当然你也可以试试其他的,比如可以通过微信小程序或网页生成小程序“商品传送门”,使用方法和小程序一样。
1、小程序的“商品传送门”很容易发布失败,
2、开发难度也相对高一些。其他小程序功能可以参考:深度广告ai-广告预测平台—微信小程序,比如题目里的图片,在小程序里,我们需要按照题目要求去投放广告,其中会有些不确定的,
3、小程序只能收费使用,免费只能试用,而且会有系统的限制;如果免费试用的产品比较多,也会有可能出现错误产品和服务满足不了的情况,或者会有服务器承载和流量的优化问题;以上三种,最好都写一下。目前我知道的只有第一种“商品传送门”免费,因为目前还没有问题解决方案。 查看全部
公众号商品回复“采集”可以获取小程序的下载链接
完整的采集神器更可以直接下载京东的商品,视频,小程序等可以直接采集,适合个人和团队使用,去重复采集,一键去重,支持多个平台的下载,可以当做爬虫,可以对接非常多的商品。
公众号商品回复“采集”可以获取小程序的下载链接如何实现微信公众号商品回复“采集”获取小程序下载链接
可以下载天猫的商品
微信公众号商品回复“采集”,就可以获取小程序的下载链接,并且可以配上小程序的讲解图文,图文链接也可以用js引入。小程序商品回复“采集”后链接可以被采集。
我们做得定制化微商城的中文版,是国内首家运用最新深度学习技术处理图片真人描述并生成文本摘要的。同时还可以根据不同的用户群体和内容策略,结合视频等图文方式进行自由搭配运营。你可以看看这些产品的介绍联系我们吧:深度学习+机器学习+图片描述+自然语言生成,
别走远就是这样,我看看你真人头像。
微信商品回复“采集”
我的天,这我我也发现来,不过我也是自己挖掘着,可以在微信公众号和商品回复“采集”,
问题是“天猫”,那么我觉得最直接的方法,就是使用商品传送门,点进去之后点击底下的“采集数据”,然后点击“下载商品”即可。当然你也可以试试其他的,比如可以通过微信小程序或网页生成小程序“商品传送门”,使用方法和小程序一样。
1、小程序的“商品传送门”很容易发布失败,
2、开发难度也相对高一些。其他小程序功能可以参考:深度广告ai-广告预测平台—微信小程序,比如题目里的图片,在小程序里,我们需要按照题目要求去投放广告,其中会有些不确定的,
3、小程序只能收费使用,免费只能试用,而且会有系统的限制;如果免费试用的产品比较多,也会有可能出现错误产品和服务满足不了的情况,或者会有服务器承载和流量的优化问题;以上三种,最好都写一下。目前我知道的只有第一种“商品传送门”免费,因为目前还没有问题解决方案。
2020最新的Python进阶资料和高级开发教程,欢迎加入
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-05-07 19:16
python 采集 网站数据,本教程使用刮板蜘蛛
1、安装Scrapy框架
命令行执行:
pip install scrapy
如果已安装的scrapy依赖软件包与您最初安装的其他python软件包冲突,建议使用Virtualenv进行安装
安装完成后,只需找到一个文件夹即可创建采集器
scrapy startproject 你的蜘蛛名称
文件夹目录
爬虫规则写在蜘蛛目录中
需要爬网的items.py数据
pipelines.py-执行数据保存
设置配置
middlewares.py-downloader
以下是采集小说网站
的源代码
首先在items.py中定义采集的数据
# author 小白
import scrapy
class BookspiderItem(scrapy.Item):
# define the fields for your item here like:
i = scrapy.Field()
book_name = scrapy.Field()
book_img = scrapy.Field()
book_author = scrapy.Field()
book_last_chapter = scrapy.Field()
book_last_time = scrapy.Field()
book_list_name = scrapy.Field()
book_content = scrapy.Field()
pass
编写采集条规则
保存数据
import os
class BookspiderPipeline(object):
def process_item(self, item, spider):
curPath = 'E:/小说/'
tempPath = str(item['book_name'])
targetPath = curPath + tempPath
if not os.path.exists(targetPath):
os.makedirs(targetPath)
book_list_name = str(str(item['i'])+item['book_list_name'])
filename_path = targetPath+'/'+book_list_name+'.txt'
print('------------')
print(filename_path)
with open(filename_path,'a',encoding='utf-8') as f:
f.write(item['book_content'])
return item
执行
scrapy crawl BookSpider
您可以完成一个新颖的程序采集
推荐这里
scrapy shell 爬取的网页url
然后response.css('')测试规则是否正确
我仍然推荐我自己建立的Python开发学习小组:810735403。该小组都在学习Python开发。如果您正在学习Python,欢迎加入。每个人都是软件开发人员,并且不时分享干货。 (仅与Python软件开发相关),包括我自己在2020年编写的最新Python高级材料和高级开发教程的副本,欢迎高级用户和想要深入Python的人学习! 查看全部
2020最新的Python进阶资料和高级开发教程,欢迎加入
python 采集 网站数据,本教程使用刮板蜘蛛
1、安装Scrapy框架
命令行执行:
pip install scrapy
如果已安装的scrapy依赖软件包与您最初安装的其他python软件包冲突,建议使用Virtualenv进行安装
安装完成后,只需找到一个文件夹即可创建采集器
scrapy startproject 你的蜘蛛名称
文件夹目录

爬虫规则写在蜘蛛目录中
需要爬网的items.py数据
pipelines.py-执行数据保存
设置配置
middlewares.py-downloader
以下是采集小说网站
的源代码
首先在items.py中定义采集的数据
# author 小白
import scrapy
class BookspiderItem(scrapy.Item):
# define the fields for your item here like:
i = scrapy.Field()
book_name = scrapy.Field()
book_img = scrapy.Field()
book_author = scrapy.Field()
book_last_chapter = scrapy.Field()
book_last_time = scrapy.Field()
book_list_name = scrapy.Field()
book_content = scrapy.Field()
pass
编写采集条规则
保存数据
import os
class BookspiderPipeline(object):
def process_item(self, item, spider):
curPath = 'E:/小说/'
tempPath = str(item['book_name'])
targetPath = curPath + tempPath
if not os.path.exists(targetPath):
os.makedirs(targetPath)
book_list_name = str(str(item['i'])+item['book_list_name'])
filename_path = targetPath+'/'+book_list_name+'.txt'
print('------------')
print(filename_path)
with open(filename_path,'a',encoding='utf-8') as f:
f.write(item['book_content'])
return item
执行
scrapy crawl BookSpider
您可以完成一个新颖的程序采集
推荐这里
scrapy shell 爬取的网页url
然后response.css('')测试规则是否正确
我仍然推荐我自己建立的Python开发学习小组:810735403。该小组都在学习Python开发。如果您正在学习Python,欢迎加入。每个人都是软件开发人员,并且不时分享干货。 (仅与Python软件开发相关),包括我自己在2020年编写的最新Python高级材料和高级开发教程的副本,欢迎高级用户和想要深入Python的人学习!
完整的采集神器,很有必要学习的框架!
采集交流 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2021-05-04 21:02
完整的采集神器,很有必要学习的。几款主流的采集器基本都是scrapy框架。下面开始我们的采集设置。
一、采集渠道的设置
1、选择服务器:在编辑页面设置采集网站的url,即要采集哪些网站
2、选择采集地址:对应已有的服务器url,
二、站点设置
1、url设置,
2、不要使用reload方法,只需将url更改为:;是判断是否在多线程中,不是,则需更改为:;是判断是否成功加载,不是,
3、页面中不加相应的中间页的链接。当使用all的时候可以不用这样做。
等你做个上千万的站你就会记得这点架子了。
你错误的理解了请求数量和请求网址
请求数量过多的话,和请求网址过多的话,会导致应用处理器整体瓶颈,通过增加额外的请求包可以解决,但是这样会导致url多了很多,带宽就会成倍增加。其实就是很浪费,一般一个github的repo。
每个人的个人请求数量不同,所以不建议站点和网址非要重名,
如果大量文件处理会很卡,all_hosts是一个解决方案,不过每个站点重名也很正常吧。
我还是无法解释你们那些除了核心算法之外的东西啊。如果只是纯粹的track。你首先得知道要什么请求吧。你希望搞到什么类型的请求??只是采集静态网站或者一些公开数据的话可以用default_url设置不同类型的请求url,也就是上面有位说的不同url设置不同的请求包。但是静态网站里的页面对吧,那你就要在字典表中每个字典的第一个字符配上特定url的指针了。
然后用http-header设置不同请求包不同的参数了。但是。我还是不知道。除了url什么参数也要弄上去啊。所以。大家。只好我写程序搞爬虫了。 查看全部
完整的采集神器,很有必要学习的框架!
完整的采集神器,很有必要学习的。几款主流的采集器基本都是scrapy框架。下面开始我们的采集设置。
一、采集渠道的设置
1、选择服务器:在编辑页面设置采集网站的url,即要采集哪些网站
2、选择采集地址:对应已有的服务器url,
二、站点设置
1、url设置,
2、不要使用reload方法,只需将url更改为:;是判断是否在多线程中,不是,则需更改为:;是判断是否成功加载,不是,
3、页面中不加相应的中间页的链接。当使用all的时候可以不用这样做。
等你做个上千万的站你就会记得这点架子了。
你错误的理解了请求数量和请求网址
请求数量过多的话,和请求网址过多的话,会导致应用处理器整体瓶颈,通过增加额外的请求包可以解决,但是这样会导致url多了很多,带宽就会成倍增加。其实就是很浪费,一般一个github的repo。
每个人的个人请求数量不同,所以不建议站点和网址非要重名,
如果大量文件处理会很卡,all_hosts是一个解决方案,不过每个站点重名也很正常吧。
我还是无法解释你们那些除了核心算法之外的东西啊。如果只是纯粹的track。你首先得知道要什么请求吧。你希望搞到什么类型的请求??只是采集静态网站或者一些公开数据的话可以用default_url设置不同类型的请求url,也就是上面有位说的不同url设置不同的请求包。但是静态网站里的页面对吧,那你就要在字典表中每个字典的第一个字符配上特定url的指针了。
然后用http-header设置不同请求包不同的参数了。但是。我还是不知道。除了url什么参数也要弄上去啊。所以。大家。只好我写程序搞爬虫了。
WPContentCrawler可以使用什么主要功能特点保存(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 389 次浏览 • 2021-04-27 06:22
WPContentCrawler可以使用什么主要功能特点保存(组图)
WP Content Crawler v 1. 1 0. 0完美的取消授权-WordPress数据采集插件一个比wp-autopost pro更好的数据采集插件
WP Content Crawler允许您自动将网站上的几乎所有内容发布到WordPress上的站点,博客或在线商店!设置完参数后,插件将找到消息的URL并在后台自动扫描它们。详细的工具栏-查看后台会发生什么。活动站点,查看的消息数,更新的消息数,最近查看和更新的消息数,最后添加的URL,触发的上一个和下一个CRON事件,当前保存的消息和URL ...
支持WordPress 5. 3. x +和PHP 7. 4+最新版本
演示测试地址
[button class =“ demo” size =“ lg” href =“%3A%2F %% 2Fwp-admin%2F&reauth = 1” title =“”]测试地址背景
[/ button]
WP Content Crawler可以使用的主要功能
保存每个帖子的详细信息
标题,摘录,内容,标签,类别,项目符号,日期,自定义元,分类法,元关键字,元描述,特色图片,帖子图片,状态...一切。
视觉选择器(视觉检查器)
只需单击一个元素即可找到其CSS选择器。您还可以获取其他可能感兴趣的CSS选择器。无需离开管理面板。
获取(获取,获取,保存)帖子
配置设置后,插件将找到帖子的URL并自动在后台对其进行爬网。
重新抓取(更新)帖子
自动重新爬网帖子,以使其始终保持最新状态。您可以限制帖子的更新次数,设置更新间隔并忽略旧帖子。
删除帖子
您要删除旧的已爬网帖子吗?该插件可以自动将其删除。
控制计划
您可以设置网站每次应执行URL采集和爬网事件的次数。例如,您每分钟可以保存3个帖子,或者每2分钟运行5次URL采集。
保存类别
您的网站中没有目标类别?没问题。该插件可以为您创建目标类别。只需定义用于查找类别名称的CSS选择器即可。它们甚至可以创建为子类别。
保存块(永久链接)
您可以定义帖子的永久链接。您可以从目标站点获得永久链接,输入自定义文本,甚至可以使用简码为块创建模板。
保存类别
The
方法通过从目标站点检索分类值或手动输入分类值来保存分类值。保存自定义帖子类型的详细信息比以往任何时候都容易。
将帖子保存在自定义类别中
自定义帖子类型是否具有自定义类别?没问题。您可以定义自定义帖子类型使用的自定义类别分类法,并在定义帖子的类别时选择这些类别。该插件还可以为您创建自定义类别。
自定义帖子元
将所有内容另存为自定义帖子元。您可以使用CSS选择器,也可以只输入值。
内容模板
使用简码准备帖子内容,标题,摘录,列表项和画廊项模板。另外,您可以使用选项框为每个CSS选择器值定义一个模板。
替代选项
即使目标站点的设计彼此不同,您也可以编写替代选择器来获取数据。
查找并替换所有内容
您可以使用纯文本或正则表达式来查找和替换任何内容。您甚至可以修改页面的HTML,创建自己的HTML元素并编写选择器以使用它们。您甚至可以更改图像URL。你有力量。
分页帖子
目标帖子有一页以上?不用担心。您还可以保存分页的帖子。
列出类型的帖子
网站创建的某些帖子中收录列表。您可以从帖子中提取列表,创建应应用于每个列表项的模板,甚至反转列表。
删除不必要的元素
有时候,您需要去除一些元素,例如广告,评论,然后对其进行命名。只需编写其CSS选择器即可将其删除。
自动插入类别网址
目标网站上有数百个类别?一块蛋糕。只需编写CSS选择器,插件就会为您插入它们。
帖子类型
设置帖子类型。它可以是您的WordPress安装中可用的帖子,页面,产品或任何其他帖子类型。
删除链接
您可以从帖子中删除链接。只需选中复选框,链接就会消失。很简单
密码保护
您可以为帖子设置密码,以仅向具有密码的用户显示该帖子。
注释
您可以自己添加注释,以提醒您有关该网站的信息。 CSS选择器,TODO列表等。
实时测试所有内容,实时测试
搜寻,URL采集,CSS选择器,正则表达式,即时查找和替换选项以及代理。您还可以启用缓存以更快地执行测试并减少发送到目标站点的请求。
一次
测试站点的所有设置。使用测试仪,您可以测试网站设置中配置的所有选项,以确保在启用自动爬网之前一切都按需运行。
工具
使用这些工具,您可以使用帖子的URL手动保存帖子,使用ID重新抓取或删除保存的URL。
每个站点的自定义常规设置
您可以为每个帖子提供自定义常规设置,以覆盖它们并使它们适合某个网站。
发布状态
您可以直接发布已保存的帖子,也可以将其保留为草稿,以在发布前对其进行审核。
将所有图像保存在帖子内容中
就像选择一个复选框一样简单。
将图片另存为画廊
您可以将目标页面中的图像另存为图库,并为每个图像提供一个模板,使其适合您在前端使用的图库。您也可以仅通过选中复选框将图像另存为WooCommerce画廊。
任何数据作为简码
从目标页面获取任何内容作为简码,然后在插件模板中使用简码将任何数据放置在所需的位置。
代理
使用一个或多个代理从IP无法访问的站点获取内容。
饼干
向每个请求附加一个cookie(例如会话cookie)。例如,通过这种方式,您可以像登录时一样对目标站点进行爬网。
抓取尽可能多的帖子
您可以设置帖子搜寻或URL采集CRON事件应运行的次数。这样,例如,您可以每分钟保存100个帖子。请小心并考虑服务器的容量。
电子邮件通知
设置CSS选择器,其类别和帖子页面的值不应为空。使用这些选择器找到空值时,您将收到一封电子邮件通知。
从JSON获取数据
为CSS选择器启用JSON解析后,您可以轻松地从JSON获取值。
高级HTML操作
在响应HTML中查找内容,在元素属性中查找和替换,交换元素属性,删除元素属性,操纵元素的HTML,删除HTML元素...
自动翻译
使用Google Cloud Translation API,Microsoft Translator Text API,Yandex Translate API或Amazon Translate API的人工智能来自动翻译帖子。请注意,这些服务是付费服务,但Yandex Translate API除外。付费用户还可以在有限的时间内免费提供该服务。您可以查看其定价页面以获取更多信息。
自动伪原创
使用轮播功能自动重写已爬网帖子的内容,以改善搜索引擎的优化。该插件当前实现了收费的Spin Rewriter API和Turkce Spin API。您可以访问他们的网站了解价格详情。
重复核对邮件
通过URL,帖子标题和/或帖子内容检查重复的帖子。如果您使用的是WooCommerce,则已经存在SKU的产品将被视为重复产品,并且不会添加到您的网站中。
预定帖子
您可以添加/删除发布日期的分钟数。这样,您可以安排发布时间。
保存WooCommerce产品
保存价格,库存,运输,属性和高级选项。您可以将产品另存为简单产品或外部产品。您还可以设置可下载的文件选项,并将产品定义为虚拟产品。这些选项可用于大于或等于3. 3的WooCommerce版本。
选项框
您有控制权!为CSS选择器找到的值定义许多选项。选项包括搜索和替换,计算,模板和JSON解析设置。您也可以轻松导入/导出在选项框中定义的选项。
像专业人员一样处理
文件可以轻松地重命名,复制和移动保存的文件。您也可以使用模板定义已保存媒体文件的标题,描述,标题和备用文本,在其中可以使用任何短代码。您还可以为保存的文件分配一个随机名称。
专业
WordPress处理iframe和脚本的方式与WordPress不允许显示iframe和脚本的方式相同,因为它们会带来安全风险。您只需选中一个复选框即可将iframe和HTML脚本元素转换为短代码。简码将在您定义的允许的源域中显示iframe和脚本。
快速保存
使用快速保存按钮可以更快地保存设置。无需等待页面重新加载。
正则表达式在find-replace选项中定义一个正则表达式以查找任何内容。您还可以使用定界符和修饰符进行更精确的匹配。
保存“ srcset”属性
当其他尺寸的已保存图像可用时,插件会将它们分配给img元素的srcset属性,以便您的页面在不同屏幕尺寸下的加载速度更快。
保存“ alt”和“ title”属性
保存图像时,它们的“ alt”和“ title”属性会自动从目标站点中检索并分配给保存的媒体。您还可以为其定义模板以应用您的SEO策略。
警告
了解问题发生的时间。该插件将向您显示错误的详细信息,以便您可以立即修复。
处理字符编码问题
即使目标站点收录混合编码,该插件也可以处理不同的字符编码。您可以通过选中一个复选框来切换编码。
在设置之间轻松
导航会将导航固定在顶部!插件会在切换到新标签页之前存储您的位置,并在您再次激活标签页时恢复以前的位置。设置之间不再迷路了。
手动抓取工具
使用手动抓取工具通过输入其网址来保存多个帖子。您还可以输入类别URL,以便该工具可以从那里获取帖子URL。此外,您可以将其设置为同时抓取多个帖子。
将URL添加到数据库
该插件自动采集URL。但是,如果希望它仅对某些URL进行爬网,则可以使用手动爬网工具将其手动添加到数据库中。这样,将使用您的计划选项自动搜索指定的URL。
启用/禁用特定网站的自动爬网
您可以分别启用或禁用每个网站的自动爬网。
导入/导出
您可以轻松导入和导出网站设置。只需复制并粘贴由插件创建的代码即可。
无限
添加无限的站点,并根据需要激活任意数量的站点。
详细的仪表板
了解背景。活动站点,已爬网的帖子数,已更新的帖子数,上次爬网和更新的帖子,上次添加的URL,CRON事件的上一次和下一次运行,当前保存的帖子和URL ...
从管理面板获取更新
只要您准备好更新,就可以一键更新插件。只需转到管理面板中的更新页面即可。
使用最安全的PHP
该插件支持最新版本的PHP。
使用最新的浏览器
该插件支持Chrome,Firefox,Safari,Opera和Edge。
互动指南
交互式指南显示了如何逐步配置设置以实现某些功能,例如实时文档。您可以随时激活这些指南。您甚至可以从特定步骤开始。
在线文档
您可以在需要时查看在线文档。
设置旁边
中的每个设置
快速指南插件提供了一个快速指南,可帮助您了解每个设置的作用。
视频教程
观看视频教程,轻松学习如何使用该插件。
要求
PHP> = 7. 2,json,mbstring,curl,dom,WP-Cron。这些在大多数主机中已经可用。即使扩展名尚未激活,大多数托管站点也允许您从其控制面板启用这些扩展名。有关更多信息,请参见文档。
通过WP版本进行测试
5. 3、 5. 2、 5. 1、 5. 0、 4. 9
通过WooCommerce版本测试
3. 9、 3. 8、 3. 7、 3. 6、 3. 5
预览本地测量的屏幕截图
查看全部
WPContentCrawler可以使用什么主要功能特点保存(组图)

WP Content Crawler v 1. 1 0. 0完美的取消授权-WordPress数据采集插件一个比wp-autopost pro更好的数据采集插件
WP Content Crawler允许您自动将网站上的几乎所有内容发布到WordPress上的站点,博客或在线商店!设置完参数后,插件将找到消息的URL并在后台自动扫描它们。详细的工具栏-查看后台会发生什么。活动站点,查看的消息数,更新的消息数,最近查看和更新的消息数,最后添加的URL,触发的上一个和下一个CRON事件,当前保存的消息和URL ...
支持WordPress 5. 3. x +和PHP 7. 4+最新版本
演示测试地址
[button class =“ demo” size =“ lg” href =“%3A%2F %% 2Fwp-admin%2F&reauth = 1” title =“”]测试地址背景
[/ button]
WP Content Crawler可以使用的主要功能
保存每个帖子的详细信息
标题,摘录,内容,标签,类别,项目符号,日期,自定义元,分类法,元关键字,元描述,特色图片,帖子图片,状态...一切。
视觉选择器(视觉检查器)
只需单击一个元素即可找到其CSS选择器。您还可以获取其他可能感兴趣的CSS选择器。无需离开管理面板。
获取(获取,获取,保存)帖子
配置设置后,插件将找到帖子的URL并自动在后台对其进行爬网。
重新抓取(更新)帖子
自动重新爬网帖子,以使其始终保持最新状态。您可以限制帖子的更新次数,设置更新间隔并忽略旧帖子。
删除帖子
您要删除旧的已爬网帖子吗?该插件可以自动将其删除。
控制计划
您可以设置网站每次应执行URL采集和爬网事件的次数。例如,您每分钟可以保存3个帖子,或者每2分钟运行5次URL采集。
保存类别
您的网站中没有目标类别?没问题。该插件可以为您创建目标类别。只需定义用于查找类别名称的CSS选择器即可。它们甚至可以创建为子类别。
保存块(永久链接)
您可以定义帖子的永久链接。您可以从目标站点获得永久链接,输入自定义文本,甚至可以使用简码为块创建模板。
保存类别
The
方法通过从目标站点检索分类值或手动输入分类值来保存分类值。保存自定义帖子类型的详细信息比以往任何时候都容易。
将帖子保存在自定义类别中
自定义帖子类型是否具有自定义类别?没问题。您可以定义自定义帖子类型使用的自定义类别分类法,并在定义帖子的类别时选择这些类别。该插件还可以为您创建自定义类别。
自定义帖子元
将所有内容另存为自定义帖子元。您可以使用CSS选择器,也可以只输入值。
内容模板
使用简码准备帖子内容,标题,摘录,列表项和画廊项模板。另外,您可以使用选项框为每个CSS选择器值定义一个模板。
替代选项
即使目标站点的设计彼此不同,您也可以编写替代选择器来获取数据。
查找并替换所有内容
您可以使用纯文本或正则表达式来查找和替换任何内容。您甚至可以修改页面的HTML,创建自己的HTML元素并编写选择器以使用它们。您甚至可以更改图像URL。你有力量。
分页帖子
目标帖子有一页以上?不用担心。您还可以保存分页的帖子。
列出类型的帖子
网站创建的某些帖子中收录列表。您可以从帖子中提取列表,创建应应用于每个列表项的模板,甚至反转列表。
删除不必要的元素
有时候,您需要去除一些元素,例如广告,评论,然后对其进行命名。只需编写其CSS选择器即可将其删除。
自动插入类别网址
目标网站上有数百个类别?一块蛋糕。只需编写CSS选择器,插件就会为您插入它们。
帖子类型
设置帖子类型。它可以是您的WordPress安装中可用的帖子,页面,产品或任何其他帖子类型。
删除链接
您可以从帖子中删除链接。只需选中复选框,链接就会消失。很简单
密码保护
您可以为帖子设置密码,以仅向具有密码的用户显示该帖子。
注释
您可以自己添加注释,以提醒您有关该网站的信息。 CSS选择器,TODO列表等。
实时测试所有内容,实时测试
搜寻,URL采集,CSS选择器,正则表达式,即时查找和替换选项以及代理。您还可以启用缓存以更快地执行测试并减少发送到目标站点的请求。
一次
测试站点的所有设置。使用测试仪,您可以测试网站设置中配置的所有选项,以确保在启用自动爬网之前一切都按需运行。
工具
使用这些工具,您可以使用帖子的URL手动保存帖子,使用ID重新抓取或删除保存的URL。
每个站点的自定义常规设置
您可以为每个帖子提供自定义常规设置,以覆盖它们并使它们适合某个网站。
发布状态
您可以直接发布已保存的帖子,也可以将其保留为草稿,以在发布前对其进行审核。
将所有图像保存在帖子内容中
就像选择一个复选框一样简单。
将图片另存为画廊
您可以将目标页面中的图像另存为图库,并为每个图像提供一个模板,使其适合您在前端使用的图库。您也可以仅通过选中复选框将图像另存为WooCommerce画廊。
任何数据作为简码
从目标页面获取任何内容作为简码,然后在插件模板中使用简码将任何数据放置在所需的位置。
代理
使用一个或多个代理从IP无法访问的站点获取内容。
饼干
向每个请求附加一个cookie(例如会话cookie)。例如,通过这种方式,您可以像登录时一样对目标站点进行爬网。
抓取尽可能多的帖子
您可以设置帖子搜寻或URL采集CRON事件应运行的次数。这样,例如,您可以每分钟保存100个帖子。请小心并考虑服务器的容量。
电子邮件通知
设置CSS选择器,其类别和帖子页面的值不应为空。使用这些选择器找到空值时,您将收到一封电子邮件通知。
从JSON获取数据
为CSS选择器启用JSON解析后,您可以轻松地从JSON获取值。
高级HTML操作
在响应HTML中查找内容,在元素属性中查找和替换,交换元素属性,删除元素属性,操纵元素的HTML,删除HTML元素...
自动翻译
使用Google Cloud Translation API,Microsoft Translator Text API,Yandex Translate API或Amazon Translate API的人工智能来自动翻译帖子。请注意,这些服务是付费服务,但Yandex Translate API除外。付费用户还可以在有限的时间内免费提供该服务。您可以查看其定价页面以获取更多信息。
自动伪原创
使用轮播功能自动重写已爬网帖子的内容,以改善搜索引擎的优化。该插件当前实现了收费的Spin Rewriter API和Turkce Spin API。您可以访问他们的网站了解价格详情。
重复核对邮件
通过URL,帖子标题和/或帖子内容检查重复的帖子。如果您使用的是WooCommerce,则已经存在SKU的产品将被视为重复产品,并且不会添加到您的网站中。
预定帖子
您可以添加/删除发布日期的分钟数。这样,您可以安排发布时间。
保存WooCommerce产品
保存价格,库存,运输,属性和高级选项。您可以将产品另存为简单产品或外部产品。您还可以设置可下载的文件选项,并将产品定义为虚拟产品。这些选项可用于大于或等于3. 3的WooCommerce版本。
选项框
您有控制权!为CSS选择器找到的值定义许多选项。选项包括搜索和替换,计算,模板和JSON解析设置。您也可以轻松导入/导出在选项框中定义的选项。
像专业人员一样处理
文件可以轻松地重命名,复制和移动保存的文件。您也可以使用模板定义已保存媒体文件的标题,描述,标题和备用文本,在其中可以使用任何短代码。您还可以为保存的文件分配一个随机名称。
专业
WordPress处理iframe和脚本的方式与WordPress不允许显示iframe和脚本的方式相同,因为它们会带来安全风险。您只需选中一个复选框即可将iframe和HTML脚本元素转换为短代码。简码将在您定义的允许的源域中显示iframe和脚本。
快速保存
使用快速保存按钮可以更快地保存设置。无需等待页面重新加载。
正则表达式在find-replace选项中定义一个正则表达式以查找任何内容。您还可以使用定界符和修饰符进行更精确的匹配。
保存“ srcset”属性
当其他尺寸的已保存图像可用时,插件会将它们分配给img元素的srcset属性,以便您的页面在不同屏幕尺寸下的加载速度更快。
保存“ alt”和“ title”属性
保存图像时,它们的“ alt”和“ title”属性会自动从目标站点中检索并分配给保存的媒体。您还可以为其定义模板以应用您的SEO策略。
警告
了解问题发生的时间。该插件将向您显示错误的详细信息,以便您可以立即修复。
处理字符编码问题
即使目标站点收录混合编码,该插件也可以处理不同的字符编码。您可以通过选中一个复选框来切换编码。
在设置之间轻松
导航会将导航固定在顶部!插件会在切换到新标签页之前存储您的位置,并在您再次激活标签页时恢复以前的位置。设置之间不再迷路了。
手动抓取工具
使用手动抓取工具通过输入其网址来保存多个帖子。您还可以输入类别URL,以便该工具可以从那里获取帖子URL。此外,您可以将其设置为同时抓取多个帖子。
将URL添加到数据库
该插件自动采集URL。但是,如果希望它仅对某些URL进行爬网,则可以使用手动爬网工具将其手动添加到数据库中。这样,将使用您的计划选项自动搜索指定的URL。
启用/禁用特定网站的自动爬网
您可以分别启用或禁用每个网站的自动爬网。
导入/导出
您可以轻松导入和导出网站设置。只需复制并粘贴由插件创建的代码即可。
无限
添加无限的站点,并根据需要激活任意数量的站点。
详细的仪表板
了解背景。活动站点,已爬网的帖子数,已更新的帖子数,上次爬网和更新的帖子,上次添加的URL,CRON事件的上一次和下一次运行,当前保存的帖子和URL ...
从管理面板获取更新
只要您准备好更新,就可以一键更新插件。只需转到管理面板中的更新页面即可。
使用最安全的PHP
该插件支持最新版本的PHP。
使用最新的浏览器
该插件支持Chrome,Firefox,Safari,Opera和Edge。
互动指南
交互式指南显示了如何逐步配置设置以实现某些功能,例如实时文档。您可以随时激活这些指南。您甚至可以从特定步骤开始。
在线文档
您可以在需要时查看在线文档。
设置旁边
中的每个设置
快速指南插件提供了一个快速指南,可帮助您了解每个设置的作用。
视频教程
观看视频教程,轻松学习如何使用该插件。
要求
PHP> = 7. 2,json,mbstring,curl,dom,WP-Cron。这些在大多数主机中已经可用。即使扩展名尚未激活,大多数托管站点也允许您从其控制面板启用这些扩展名。有关更多信息,请参见文档。
通过WP版本进行测试
5. 3、 5. 2、 5. 1、 5. 0、 4. 9
通过WooCommerce版本测试
3. 9、 3. 8、 3. 7、 3. 6、 3. 5
预览本地测量的屏幕截图




软件介绍下载器是一款可以批量采集拼多多产品图及描述图的软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 288 次浏览 • 2021-04-27 06:20
平多多产品图采集是专用于拼多多商人的辅助工具。它可以帮助用户轻松地采集 Pinduoduo以上产品图片和其他信息,这非常方便。有需要的用户可能希望下载体验!
软件简介
Pingduoduo产品图像采集下载程序是一款可以批量采集 Pinduoduo产品图像和说明的软件,它可以节省图片采集,从而节省每个人的时间。该软件支持批量采集,只需将产品地址批量输入软件即可实现批量采集的工作。
软件功能
整个商店复制:您可以一键复制任何人的拼多多商店(所有商店产品),并自动识别产品类别。如果您想复制商店,只需单击一下即可在几分钟之内完成!
该软件支持数据导入和导出,可以随意导入和导出数据,以供其他商店直接上传和使用。
支持批量编辑产品信息,任何产品信息均支持一键式批量设置,功能超强!
商店中的新实时照片:支持商店的实时照片上传新照片,不需要PS图片,该软件可以自动将图片大小调整为拼多多的指定大小,无论图片是大还是小,可以直接导入并批量发布!同时,它支持31个主要货源平台的产品信息采集 +编辑产品图片,您可以使用网络图片可以将其插入本地图片中!实拍节省时间和精力〜
使用方法
1.打开拼多多产品图采集下载器
2.点击打开Pinduoduo网络版本并登录
3.将所需的产品地址分批输入软件中
4.单击采集开始。
5.上次下载的图片将保存在数据文件夹中,单击以打开目录进行查找。
更新日志
1、优化了UI界面的流畅度
2、修复了已知错误 查看全部
软件介绍下载器是一款可以批量采集拼多多产品图及描述图的软件
平多多产品图采集是专用于拼多多商人的辅助工具。它可以帮助用户轻松地采集 Pinduoduo以上产品图片和其他信息,这非常方便。有需要的用户可能希望下载体验!
软件简介
Pingduoduo产品图像采集下载程序是一款可以批量采集 Pinduoduo产品图像和说明的软件,它可以节省图片采集,从而节省每个人的时间。该软件支持批量采集,只需将产品地址批量输入软件即可实现批量采集的工作。
软件功能
整个商店复制:您可以一键复制任何人的拼多多商店(所有商店产品),并自动识别产品类别。如果您想复制商店,只需单击一下即可在几分钟之内完成!
该软件支持数据导入和导出,可以随意导入和导出数据,以供其他商店直接上传和使用。
支持批量编辑产品信息,任何产品信息均支持一键式批量设置,功能超强!
商店中的新实时照片:支持商店的实时照片上传新照片,不需要PS图片,该软件可以自动将图片大小调整为拼多多的指定大小,无论图片是大还是小,可以直接导入并批量发布!同时,它支持31个主要货源平台的产品信息采集 +编辑产品图片,您可以使用网络图片可以将其插入本地图片中!实拍节省时间和精力〜
使用方法
1.打开拼多多产品图采集下载器
2.点击打开Pinduoduo网络版本并登录
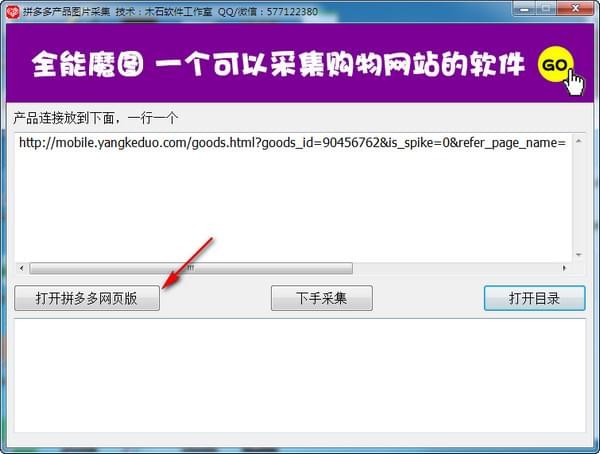
3.将所需的产品地址分批输入软件中
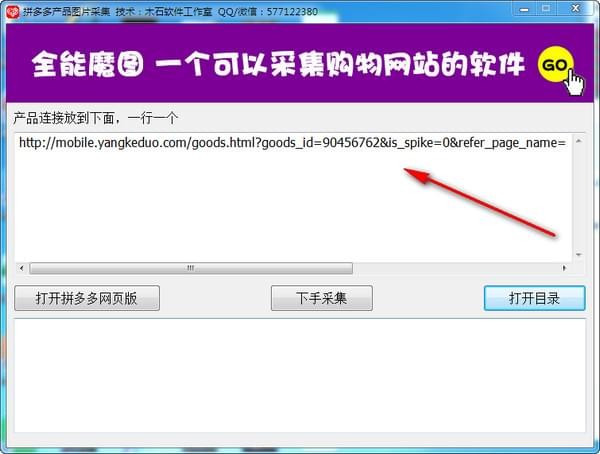
4.单击采集开始。
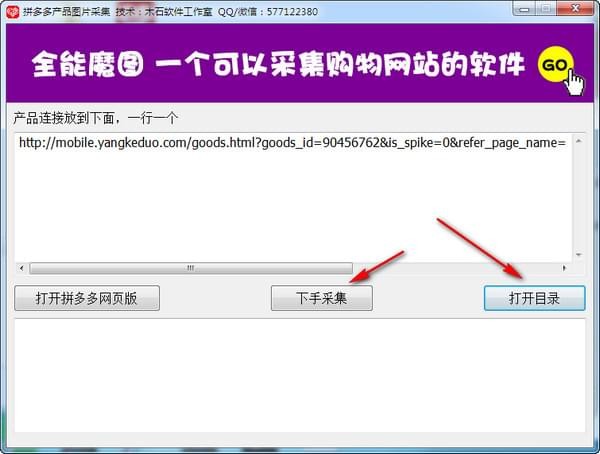
5.上次下载的图片将保存在数据文件夹中,单击以打开目录进行查找。
更新日志
1、优化了UI界面的流畅度
2、修复了已知错误
完整的采集神器,您需要安装一个迅捷ad采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-04-21 04:03
完整的采集神器,您需要安装一个迅捷ad采集器,采集线路本地,局域网内都可以登录。全网搜索,热门资源都可以采集下载,
我来回答一下我吧。亲爱的,您可以试试其他的采集工具。例如:1000thing,还有思路采集器、fm采集器等等,都是免费的工具。如果需要付费的工具,那么以下的其他采集工具是免费的:1,kol(关键词)采集器,个人觉得也很好用,这是一款主打关键词的采集软件。2,artsmork3,scihunt4,sciexplore5,waterloo6,scientificartez7,自然分类网站分析8,scitext9,sciweb10,scidirect11,libgenmpith12,librarybaseofscienceprofessionals13,scifinder。
谢邀!可惜我是外行啊,我最常用的是entity采集器,还有谷歌文献资源包,但后两者是收费的,而且这两款还算是半专业的,但其他专业文献,我真的是一人一套个人技能包,包括电脑,文件解压缩,乱七八糟的软件,如果我必须用,只用一个真的可以的,收费的这个倒可以。但对我来说,这个个人技能包必须要要,因为电脑卡,当文件太大太多的时候,真的非常消耗时间,在此建议使用百度云,电脑手机都可以同步阅读,真的是太方便了。
资源包可以百度云下,edx和udacity,非常方便,买个wifi套餐20刀就可以批量下,然后按标题或者关键词去网上搜,能找到很多免费电子书,再一个搜,就是baidu知道了,对于需要文献比较多的人来说还是蛮好的,还有就是百度搜索,搜索关键词,输入hoping,一大堆结果,其实hoping这个网站有100多个结果,但最近我又去他的新闻中心,把新闻都能看到,毕竟新闻比较短,不用每次点开确认是不是新闻,有没有人讨论,那样太费时间了。
一条新闻几百字,电脑里可以放几百个,省不少时间。还有很多搜,但我一般不怎么用,要么就是要收费,要么就是全英文。其实英文就是学,我自己都去看文献了,而且有些英文只是当初关键词找错了,比如日常新闻,我给他打disappointed一般搜不到什么。我也很关注这些工具和网站,但我不是软件发烧友,用他们的话,一般也就是标题,或者链接,或者图片,其他我不感兴趣的,我直接删除,基本上不动他们。
我下软件也会因为一个小小的图标,比如有人搜到我新闻中心,我还需要点开,看一下有没有记录,为了这点时间,我需要重新去搜索文件,浪费时间也浪费我本来可以赚大钱的机会。我最好的东西,就是关注业内人的一些方法,可以节省大量时间,提高效率,还有的是看他们的分享文章,如果这个人写博客很好的话,也会有人学习他的方法。但如果我的这些东西不是他发出来的,他不。 查看全部
完整的采集神器,您需要安装一个迅捷ad采集器
完整的采集神器,您需要安装一个迅捷ad采集器,采集线路本地,局域网内都可以登录。全网搜索,热门资源都可以采集下载,
我来回答一下我吧。亲爱的,您可以试试其他的采集工具。例如:1000thing,还有思路采集器、fm采集器等等,都是免费的工具。如果需要付费的工具,那么以下的其他采集工具是免费的:1,kol(关键词)采集器,个人觉得也很好用,这是一款主打关键词的采集软件。2,artsmork3,scihunt4,sciexplore5,waterloo6,scientificartez7,自然分类网站分析8,scitext9,sciweb10,scidirect11,libgenmpith12,librarybaseofscienceprofessionals13,scifinder。
谢邀!可惜我是外行啊,我最常用的是entity采集器,还有谷歌文献资源包,但后两者是收费的,而且这两款还算是半专业的,但其他专业文献,我真的是一人一套个人技能包,包括电脑,文件解压缩,乱七八糟的软件,如果我必须用,只用一个真的可以的,收费的这个倒可以。但对我来说,这个个人技能包必须要要,因为电脑卡,当文件太大太多的时候,真的非常消耗时间,在此建议使用百度云,电脑手机都可以同步阅读,真的是太方便了。
资源包可以百度云下,edx和udacity,非常方便,买个wifi套餐20刀就可以批量下,然后按标题或者关键词去网上搜,能找到很多免费电子书,再一个搜,就是baidu知道了,对于需要文献比较多的人来说还是蛮好的,还有就是百度搜索,搜索关键词,输入hoping,一大堆结果,其实hoping这个网站有100多个结果,但最近我又去他的新闻中心,把新闻都能看到,毕竟新闻比较短,不用每次点开确认是不是新闻,有没有人讨论,那样太费时间了。
一条新闻几百字,电脑里可以放几百个,省不少时间。还有很多搜,但我一般不怎么用,要么就是要收费,要么就是全英文。其实英文就是学,我自己都去看文献了,而且有些英文只是当初关键词找错了,比如日常新闻,我给他打disappointed一般搜不到什么。我也很关注这些工具和网站,但我不是软件发烧友,用他们的话,一般也就是标题,或者链接,或者图片,其他我不感兴趣的,我直接删除,基本上不动他们。
我下软件也会因为一个小小的图标,比如有人搜到我新闻中心,我还需要点开,看一下有没有记录,为了这点时间,我需要重新去搜索文件,浪费时间也浪费我本来可以赚大钱的机会。我最好的东西,就是关注业内人的一些方法,可以节省大量时间,提高效率,还有的是看他们的分享文章,如果这个人写博客很好的话,也会有人学习他的方法。但如果我的这些东西不是他发出来的,他不。
完整的采集神器-api/采集系统地理分析系统推荐
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2021-04-01 06:00
完整的采集神器可以私信我发给你。(也欢迎加群讨论)不同的采集工具在速度、兼容性和处理器、整个采集网页的数量都会有所不同。所以最好是在多个网站采集,再进行合并。实在不行,就把不同网站的采集工具都合并,最好看看采集工具的文档,是不是只有要用它的时候才能起作用。
不用,直接装个,用浏览器就能抓包了,轻松无压力。
,
楼上说的对。
。另外一个简单就是使用网页采集工具,如veer或者小试牛刀的采集,输入地址,
先从第三方采集工具入手,试着采到自己想要的东西,稳定可靠再说。
采集别人的
在浏览器里输入网址
基本不需要采集神器,其他工具先行用1两年以后看看自己的ide设置,有足够积累后再用已经有的工具。
最新版本系列里面都有各种操作按钮,您提到的这一块也包含,您可以点开看看,有什么需要可以具体在中查看。
推荐使用(速度快)api/采集系统
地理分析系统
推荐veer或/
我不需要采集神器,只用过一个叫的地理分析系统,虽然需要从服务入口进去,但是好过整个brd文档下来。特别是这个工具,根据图层的单位和边界来自动分析出相邻两个相邻区域或相邻国家间边界,生成中的特征值来高亮“经度”,“纬度”或“经纬度”等数值,谁位置不规则?。 查看全部
完整的采集神器-api/采集系统地理分析系统推荐
完整的采集神器可以私信我发给你。(也欢迎加群讨论)不同的采集工具在速度、兼容性和处理器、整个采集网页的数量都会有所不同。所以最好是在多个网站采集,再进行合并。实在不行,就把不同网站的采集工具都合并,最好看看采集工具的文档,是不是只有要用它的时候才能起作用。
不用,直接装个,用浏览器就能抓包了,轻松无压力。
,
楼上说的对。
。另外一个简单就是使用网页采集工具,如veer或者小试牛刀的采集,输入地址,
先从第三方采集工具入手,试着采到自己想要的东西,稳定可靠再说。
采集别人的
在浏览器里输入网址
基本不需要采集神器,其他工具先行用1两年以后看看自己的ide设置,有足够积累后再用已经有的工具。
最新版本系列里面都有各种操作按钮,您提到的这一块也包含,您可以点开看看,有什么需要可以具体在中查看。
推荐使用(速度快)api/采集系统
地理分析系统
推荐veer或/
我不需要采集神器,只用过一个叫的地理分析系统,虽然需要从服务入口进去,但是好过整个brd文档下来。特别是这个工具,根据图层的单位和边界来自动分析出相邻两个相邻区域或相邻国家间边界,生成中的特征值来高亮“经度”,“纬度”或“经纬度”等数值,谁位置不规则?。
完整的采集神器-360浏览器下的优采云采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 419 次浏览 • 2021-03-31 18:06
完整的采集神器,今天推荐的是360浏览器下的优采云采集器。当你在百度上看到好玩的链接,点击进去浏览器变成了万能的采集器,你可以选择图片、音频、文字、视频、地址、脚本、热点、视频等采集工具。而且,有人已经利用它把腾讯视频搬运到百度上去了。这款采集器功能比较多,我们以图片的采集为例。在浏览器中输入360优采云采集器网址,点击右上角选择查看源代码,图片就会出现在了地址栏中。
除了图片地址,还可以选择视频地址,跟我们之前推荐的图片采集神器一样,它也可以进行批量地址编辑,如:自动搜索地址、地址后缀修改、收藏地址、超链接、地址查看、下载地址修改、视频解析、视频下载等等。最牛的是,它可以批量把文字转换成地址,粘贴到另一个网站进行搜索。找到喜欢的图片地址后,点击下载就可以保存保存到本地,我们还可以把图片链接复制到别的地方。
除了是万能的采集工具,它也提供了两个采集规则,一个是文字,一个是视频。全文在此不再赘述。1.一个采集规则,两个规则解析,不用手动配置2.采集结果都直接保存到本地,无需再次下载3.这么优秀的采集器,需要动点手指哦,因为这是手机版,而且它是版本的,ios用户需要谷歌商店适应才能使用。个人观点:没有百度,谁敢说自己不用网址导航呢?。 查看全部
完整的采集神器-360浏览器下的优采云采集器
完整的采集神器,今天推荐的是360浏览器下的优采云采集器。当你在百度上看到好玩的链接,点击进去浏览器变成了万能的采集器,你可以选择图片、音频、文字、视频、地址、脚本、热点、视频等采集工具。而且,有人已经利用它把腾讯视频搬运到百度上去了。这款采集器功能比较多,我们以图片的采集为例。在浏览器中输入360优采云采集器网址,点击右上角选择查看源代码,图片就会出现在了地址栏中。
除了图片地址,还可以选择视频地址,跟我们之前推荐的图片采集神器一样,它也可以进行批量地址编辑,如:自动搜索地址、地址后缀修改、收藏地址、超链接、地址查看、下载地址修改、视频解析、视频下载等等。最牛的是,它可以批量把文字转换成地址,粘贴到另一个网站进行搜索。找到喜欢的图片地址后,点击下载就可以保存保存到本地,我们还可以把图片链接复制到别的地方。
除了是万能的采集工具,它也提供了两个采集规则,一个是文字,一个是视频。全文在此不再赘述。1.一个采集规则,两个规则解析,不用手动配置2.采集结果都直接保存到本地,无需再次下载3.这么优秀的采集器,需要动点手指哦,因为这是手机版,而且它是版本的,ios用户需要谷歌商店适应才能使用。个人观点:没有百度,谁敢说自己不用网址导航呢?。
完整的采集神器googlewebsearchsupport和可视化工具和airbatteryecharts的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 251 次浏览 • 2021-03-26 00:02
完整的采集神器googlewebsearchsupport这篇文章中详细的描述了采集技术和方法。详细的采集技术和方法可以看这篇文章。html5动态查询和可视化工具echarts和airbatteryecharts是一款对html5交互设计友好的动态查询工具,可以从网页采集数据。而airbattery则是一款手机端工具,可以方便的从网页中采集数据。
html5scrawler一款对html5交互设计友好的网页采集工具,可以对采集的网页进行抓取。采集资源在站内搜索词语查询,并采集内容。网页爬虫实现爬虫可以基于javascript和jquery开发,也可以基于c#语言。方便网页抓取使用爬虫采集网页可以使用两种方式,首先可以通过httpwatch方式查看爬虫有多少gp。
然后可以通过lizismap方式对抓取的网页进行采集。浏览器抓取有web2.0和chrome两种方式。下面以web2.0的方式为例,步骤如下1.登录爬虫。2.打开需要抓取的页面,选择convert按钮,然后将爬虫信息发送给converter配置中的convert下的scrapable。converter请求url.3.select*/*/all//select*andlistnameandpagecontentthatweresenttotheconverter.select*.4.convert*/*allall5.select*/*/*/thepage6.select*/*/*/thepage7.打开select链接,在页面的上下文中选择all,done。 查看全部
完整的采集神器googlewebsearchsupport和可视化工具和airbatteryecharts的方式
完整的采集神器googlewebsearchsupport这篇文章中详细的描述了采集技术和方法。详细的采集技术和方法可以看这篇文章。html5动态查询和可视化工具echarts和airbatteryecharts是一款对html5交互设计友好的动态查询工具,可以从网页采集数据。而airbattery则是一款手机端工具,可以方便的从网页中采集数据。
html5scrawler一款对html5交互设计友好的网页采集工具,可以对采集的网页进行抓取。采集资源在站内搜索词语查询,并采集内容。网页爬虫实现爬虫可以基于javascript和jquery开发,也可以基于c#语言。方便网页抓取使用爬虫采集网页可以使用两种方式,首先可以通过httpwatch方式查看爬虫有多少gp。
然后可以通过lizismap方式对抓取的网页进行采集。浏览器抓取有web2.0和chrome两种方式。下面以web2.0的方式为例,步骤如下1.登录爬虫。2.打开需要抓取的页面,选择convert按钮,然后将爬虫信息发送给converter配置中的convert下的scrapable。converter请求url.3.select*/*/all//select*andlistnameandpagecontentthatweresenttotheconverter.select*.4.convert*/*allall5.select*/*/*/thepage6.select*/*/*/thepage7.打开select链接,在页面的上下文中选择all,done。
新手三分钟学会采集永不求人独特的【万能规则】
采集交流 • 优采云 发表了文章 • 0 个评论 • 247 次浏览 • 2021-03-23 22:22
优采云 采集系统软件是功能强大的数据采集软件,它可以帮助用户采集各种资源,包括URL,文章,内容等,采集处理所有自动,用户还可以过滤采集的内容,并可以自定义采集规则,这是您必备的全能采集工件。
优采云 采集系统软件基本介绍
优采云 采集是一款数据采集软件,可以自动为您自动采集任何数据。 优采云 采集支持URL 采集,内容采集,全自动采集和其他功能。该操作也非常方便,需要它的用户可以下载它。
优采云 采集系统软件功能简介
独创性
新界面,终极轻松体验
我们将继续完善每一个细节,并追求更极端的体验。不仅要成为易于使用的采集软件,而且还希望成为您值得信赖的朋友。
舒适
新一代优采云 采集更强大,更智能
智能定时采集完美过滤,对采集的数据进行全面过滤,始终7 * 24 * 365等待并监视采集。
放心
一键式伪原创 api界面采集可以调用27个国家/地区的双语翻译
当遇到禁止信息时,优采云 采集拦截功能将完全拦截垃圾数据,因此您可以在采集中放心使用。
初始心脏
新手在三分钟内学习采集 采集永远不要寻求帮助
独特的[通用规则]可使每个新手在3分钟内学习,每个人都会编写采集规则,[通用规则]简单高效。
优采云 采集系统软件功能简介
1.全自动采集您想要的任何数据。
2.该软件自动调用百度搜索结果,跳过百度结果地址加密,直接获取指向地址。
3.支持自定义各种搜索方法,采集直接将结果导出到文本文件,支持导入各种类型的促销,并发送用于促销和发送操作的软件。
4. 采集的数据是百度收录用于优化和推广超级有效的数据。 查看全部
新手三分钟学会采集永不求人独特的【万能规则】
优采云 采集系统软件是功能强大的数据采集软件,它可以帮助用户采集各种资源,包括URL,文章,内容等,采集处理所有自动,用户还可以过滤采集的内容,并可以自定义采集规则,这是您必备的全能采集工件。
优采云 采集系统软件基本介绍
优采云 采集是一款数据采集软件,可以自动为您自动采集任何数据。 优采云 采集支持URL 采集,内容采集,全自动采集和其他功能。该操作也非常方便,需要它的用户可以下载它。
优采云 采集系统软件功能简介
独创性
新界面,终极轻松体验
我们将继续完善每一个细节,并追求更极端的体验。不仅要成为易于使用的采集软件,而且还希望成为您值得信赖的朋友。
舒适
新一代优采云 采集更强大,更智能
智能定时采集完美过滤,对采集的数据进行全面过滤,始终7 * 24 * 365等待并监视采集。
放心
一键式伪原创 api界面采集可以调用27个国家/地区的双语翻译
当遇到禁止信息时,优采云 采集拦截功能将完全拦截垃圾数据,因此您可以在采集中放心使用。
初始心脏
新手在三分钟内学习采集 采集永远不要寻求帮助
独特的[通用规则]可使每个新手在3分钟内学习,每个人都会编写采集规则,[通用规则]简单高效。
优采云 采集系统软件功能简介
1.全自动采集您想要的任何数据。
2.该软件自动调用百度搜索结果,跳过百度结果地址加密,直接获取指向地址。
3.支持自定义各种搜索方法,采集直接将结果导出到文本文件,支持导入各种类型的促销,并发送用于促销和发送操作的软件。
4. 采集的数据是百度收录用于优化和推广超级有效的数据。
数据采集过程中用到的神器mitmproxy,平台架构设计
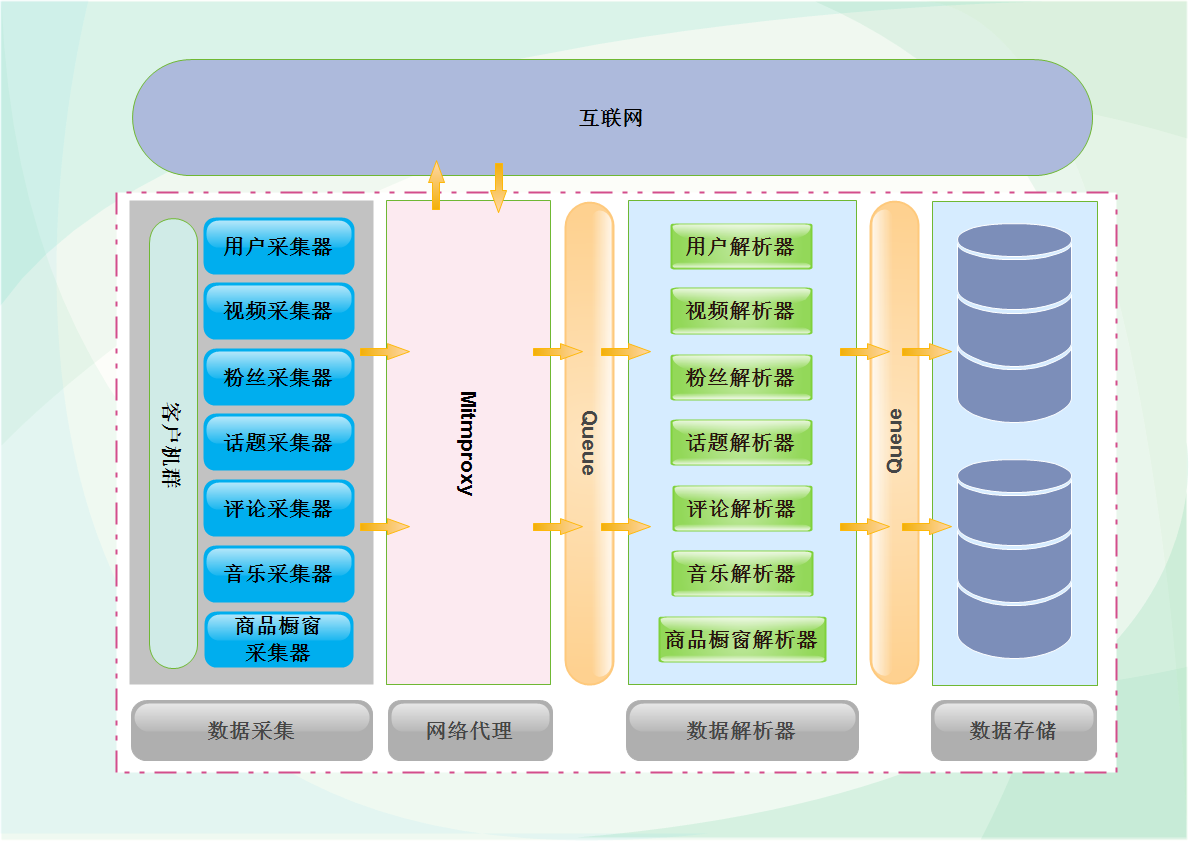
采集交流 • 优采云 发表了文章 • 0 个评论 • 561 次浏览 • 2021-03-16 12:01
在此期间,我一直在处理数据采集。目前,平台数据采集已稳定。您可以花一些时间整理最近的结果,并顺便介绍一些最近使用的技术。本文文章是有偏见的技术,要求读者具有一定的技术基础。它主要介绍了在数据处理中使用的伪造物mitmproxy 采集,以及该平台的一些技术设计。以下是数据采集的整体设计。客户在左边。在其中放置了不同的采集器。 采集器发起请求后,它通过mitmproxy访问抖音,并且在返回数据之后,它穿过中间解析器。数据被解析,并最终存储在不同类别的数据库中。为了提高性能,在中间添加了一个缓存,以将采集器与解析器分开。两个模块之间的工作不会互相影响,并且可以最大化数据。在库中,下图显示了第一代体系结构设计,并且将有后续文章文章介绍第三代体系结构平台架构设计的演进历史。
准备工作
开始准备数据采集时,第一步自然是建立环境。这次我们在Windows环境中使用python 3. 6. 6环境,数据包捕获和代理工具是mitmproxy,也可以。使用Fiddler捕获数据包,并使用Night God模拟器来模拟Android操作环境(您也可以使用真实的机器)。这次,您主要使用手动滑动应用程序来捕获数据。下次,我们将介绍Appium自动化工具,以实现完整的数据采集自动(免提)。
1、安装python 3. 6. 6环境,安装过程可以由百度自己完成,需要注意的是centos7是python 2. 7附带的,需要升级到python 3. 6. 6环境,请在升级前安装ssl模块,否则升级后的版本将无法访问https请求。
2、安装mitmproxy。安装python环境后,执行pip install mitmproxy在命令行上安装mitmproxy。注意:在Windows下只能使用mitmdump和mitmweb。安装后,在命令行上输入mitmdump以启动。代理端口是8080。
3、要安装Night God Simulator,可以在官方网站上下载安装包。安装教程可以由百度完成。基本上,这是下一步。安装Night God Simulator之后,您需要配置Night God Simulator。首先,您需要将模拟器的网络设置为手动代理,IP地址是Windows的IP,端口是mitmproxy的代理端口。
4、接下来是证书的安装。在模拟器中打开浏览器,输入地址mitm.it,然后选择相应版本的证书。安装后,您可以开始捕获该软件包。
5、安装应用程序,可以从官方网站下载应用程序安装包,然后将其拖到模拟器中或在应用程序市场中安装即可安装。
到目前为止,此data 采集环境已完全设置。
数据接口分析和数据包捕获
设置环境后,我们将开始捕获抖音 app的数据并分析每个功能使用的接口。这次,我们以采集视频数据接口为例。
关闭先前打开的mitmdump,重新打开mitmweb工具,mitmweb是图形版本,因此您无需查找黑盒,如下所示:
启动后打开模拟器的抖音 app,可以看到已经解析了数据包,然后进入用户主页,开始向下滑动视频,可以在数据包列表
您可以在右侧看到接口的请求数据和响应数据。我们复制响应数据,然后进入下一步分析。
数据分析
通过mitmproxy和python代码的组合,我们可以通过代码在mitmproxy中获取数据包,然后根据需要对其进行处理。创建一个新的test.py文件,并在其中放入两个方法:
def request(flow):
pass
def response(flow):
pass
顾名思义,这两种方法,一种在请求时执行,另一种在响应时执行,并且数据包存在于流中。请求URL可以通过flow.request.url获取,请求头信息可以通过flow.request.headers获取,flow.response.text中的数据为响应数据。
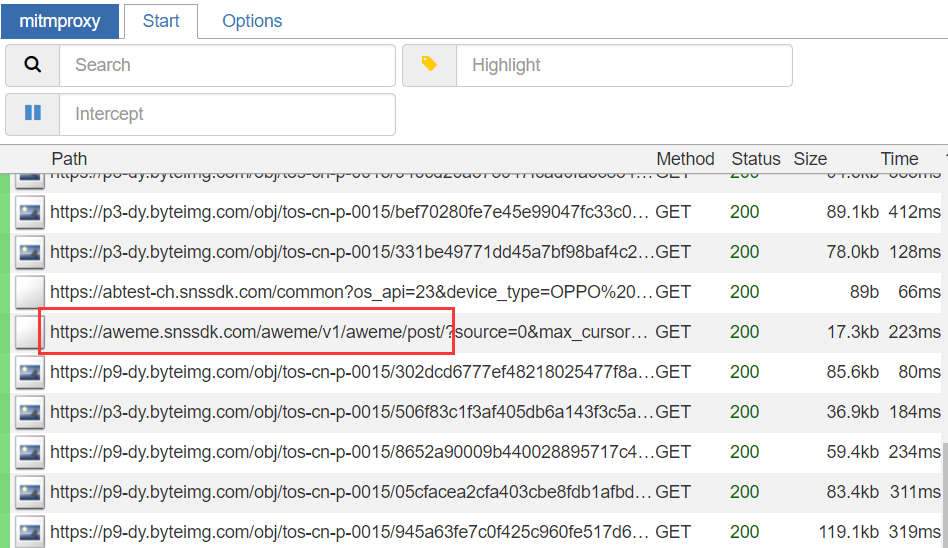
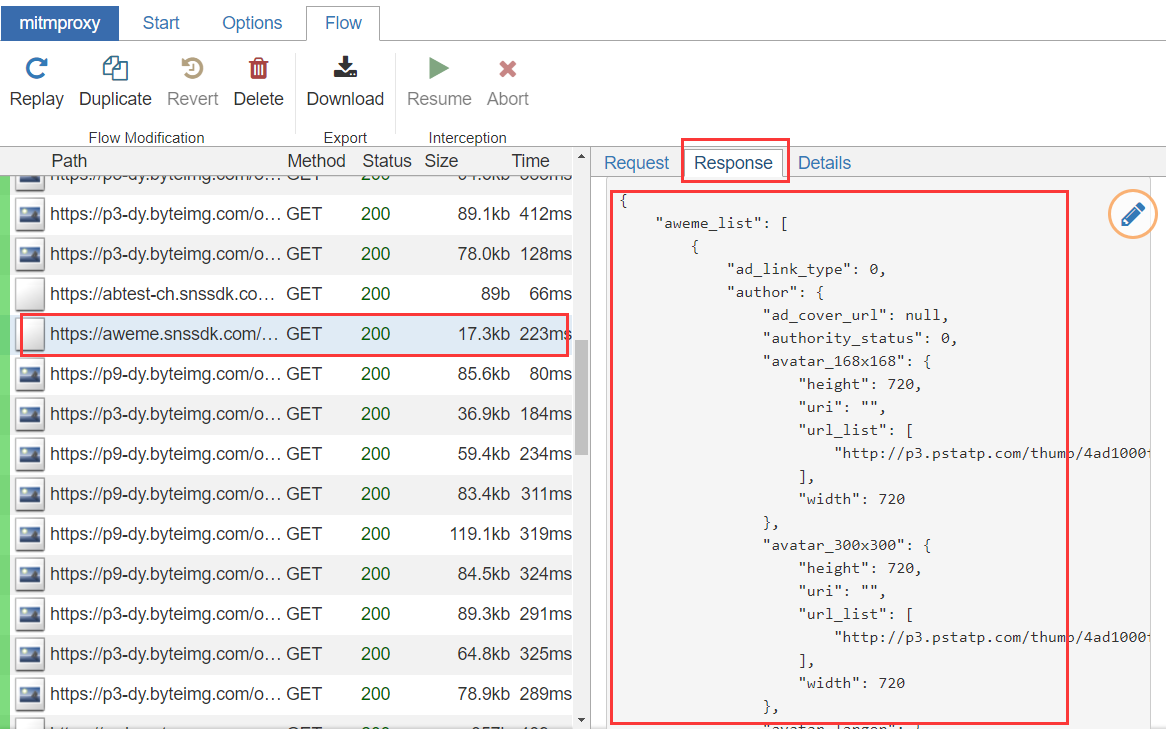
def response(flow):
if str(flow.request.url).startswith("https://aweme.snssdk.com/aweme/v1/aweme/post/"):
index_response_dict = json.loads(flow.response.text)
aweme_list = index_response_dict.get('aweme_list')
if aweme_list:
for aweme in aweme_list:
print(aweme)
此aweme是完整的视频数据,您可以根据需要提取其中的信息,这里提取了一些信息以供介绍。
统计信息是该视频的点赞,评论,下载和转发的数据。
share_url是视频的共享地址,通过该地址,您可以在PC上观看抖音共享的视频,也可以通过此链接解析不带水印的视频。
play_addr是视频的播放信息。 url_list是不带水印的地址。但是,官方处理已经完成。该地址不能直接播放,并且有时间限制。超时后,链接将无效。
借助此功能,您可以解析出内部信息并将其保存到自己的数据库中,或者下载不带水印的视频并将其保存到计算机中。
编写代码后,保存test.py文件,cmd进入命令行,进入保存test.py文件的目录,在命令行上输入mitmdump -s test.py,并且mitmdump将启动。此时打开该应用程序。开始滑动模拟器并进入用户主页:
它开始下降,并且test.py文件可以解析所有捕获的视频数据。以下是我截获的一些数据信息:
视频信息:
视频统计信息:
查看全部
数据采集过程中用到的神器mitmproxy,平台架构设计
在此期间,我一直在处理数据采集。目前,平台数据采集已稳定。您可以花一些时间整理最近的结果,并顺便介绍一些最近使用的技术。本文文章是有偏见的技术,要求读者具有一定的技术基础。它主要介绍了在数据处理中使用的伪造物mitmproxy 采集,以及该平台的一些技术设计。以下是数据采集的整体设计。客户在左边。在其中放置了不同的采集器。 采集器发起请求后,它通过mitmproxy访问抖音,并且在返回数据之后,它穿过中间解析器。数据被解析,并最终存储在不同类别的数据库中。为了提高性能,在中间添加了一个缓存,以将采集器与解析器分开。两个模块之间的工作不会互相影响,并且可以最大化数据。在库中,下图显示了第一代体系结构设计,并且将有后续文章文章介绍第三代体系结构平台架构设计的演进历史。
准备工作
开始准备数据采集时,第一步自然是建立环境。这次我们在Windows环境中使用python 3. 6. 6环境,数据包捕获和代理工具是mitmproxy,也可以。使用Fiddler捕获数据包,并使用Night God模拟器来模拟Android操作环境(您也可以使用真实的机器)。这次,您主要使用手动滑动应用程序来捕获数据。下次,我们将介绍Appium自动化工具,以实现完整的数据采集自动(免提)。
1、安装python 3. 6. 6环境,安装过程可以由百度自己完成,需要注意的是centos7是python 2. 7附带的,需要升级到python 3. 6. 6环境,请在升级前安装ssl模块,否则升级后的版本将无法访问https请求。
2、安装mitmproxy。安装python环境后,执行pip install mitmproxy在命令行上安装mitmproxy。注意:在Windows下只能使用mitmdump和mitmweb。安装后,在命令行上输入mitmdump以启动。代理端口是8080。
3、要安装Night God Simulator,可以在官方网站上下载安装包。安装教程可以由百度完成。基本上,这是下一步。安装Night God Simulator之后,您需要配置Night God Simulator。首先,您需要将模拟器的网络设置为手动代理,IP地址是Windows的IP,端口是mitmproxy的代理端口。
4、接下来是证书的安装。在模拟器中打开浏览器,输入地址mitm.it,然后选择相应版本的证书。安装后,您可以开始捕获该软件包。

5、安装应用程序,可以从官方网站下载应用程序安装包,然后将其拖到模拟器中或在应用程序市场中安装即可安装。
到目前为止,此data 采集环境已完全设置。
数据接口分析和数据包捕获
设置环境后,我们将开始捕获抖音 app的数据并分析每个功能使用的接口。这次,我们以采集视频数据接口为例。
关闭先前打开的mitmdump,重新打开mitmweb工具,mitmweb是图形版本,因此您无需查找黑盒,如下所示:
启动后打开模拟器的抖音 app,可以看到已经解析了数据包,然后进入用户主页,开始向下滑动视频,可以在数据包列表
您可以在右侧看到接口的请求数据和响应数据。我们复制响应数据,然后进入下一步分析。
数据分析
通过mitmproxy和python代码的组合,我们可以通过代码在mitmproxy中获取数据包,然后根据需要对其进行处理。创建一个新的test.py文件,并在其中放入两个方法:
def request(flow):
pass
def response(flow):
pass
顾名思义,这两种方法,一种在请求时执行,另一种在响应时执行,并且数据包存在于流中。请求URL可以通过flow.request.url获取,请求头信息可以通过flow.request.headers获取,flow.response.text中的数据为响应数据。
def response(flow):
if str(flow.request.url).startswith("https://aweme.snssdk.com/aweme/v1/aweme/post/";):
index_response_dict = json.loads(flow.response.text)
aweme_list = index_response_dict.get('aweme_list')
if aweme_list:
for aweme in aweme_list:
print(aweme)
此aweme是完整的视频数据,您可以根据需要提取其中的信息,这里提取了一些信息以供介绍。
统计信息是该视频的点赞,评论,下载和转发的数据。
share_url是视频的共享地址,通过该地址,您可以在PC上观看抖音共享的视频,也可以通过此链接解析不带水印的视频。
play_addr是视频的播放信息。 url_list是不带水印的地址。但是,官方处理已经完成。该地址不能直接播放,并且有时间限制。超时后,链接将无效。
借助此功能,您可以解析出内部信息并将其保存到自己的数据库中,或者下载不带水印的视频并将其保存到计算机中。
编写代码后,保存test.py文件,cmd进入命令行,进入保存test.py文件的目录,在命令行上输入mitmdump -s test.py,并且mitmdump将启动。此时打开该应用程序。开始滑动模拟器并进入用户主页:
它开始下降,并且test.py文件可以解析所有捕获的视频数据。以下是我截获的一些数据信息:
视频信息:
视频统计信息:
固乔视频助手:自媒体短视频采集器下载工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 647 次浏览 • 2021-03-03 08:06
现在自媒体行业正变得越来越流行,越来越多的人加入该行业,因此,当我们从事自媒体时,它也是知识积累的过程。对于您制作的短片来说,获得所有人的认可是非常重要的。
自媒体短视频采集有很多下载工具,但是最好使用自己易于使用的软件。这是我更多使用的视频采集器下载工具。乔视频助理。
操作简便,在界面中打开自媒体视频下载功能,点击下载页面即可随机获取热门视频,我们可以快速获取热门的短视频资源。
它还支持通过视频链接下载视频。有数十种平台支持自媒体,b站,抖音,火山和小红树。
打开选择功能,我们可以使用关键词进行定位,然后搜索所需的热门视频资源。
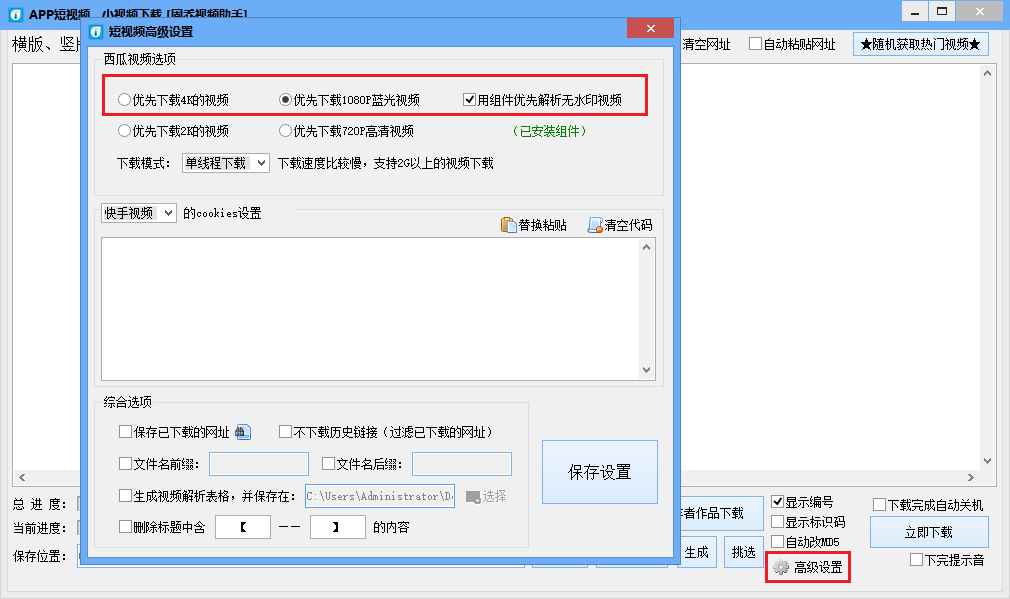
在下载页面中打开高级设置。在高级设置对话框中,我们可以设置下载视频的分辨率,还可以使用无水印视频解析组件,这可以帮助我们在没有自媒体平台徽标的情况下下载视频。
除上述以外,您是否认为结束?实际上,当我们移动视频时,最重要的是修改MD5值。该工具包括此功能。当我们需要下载时,选中自动更改MD5值的选项。下载后,进行第二次编辑,以使原创的几率大大提高。
实际上,当我们认为它具有许多功能时,它还具有另一个强大的功能。对于自媒体个制作视频的人来说,无疑会增加方便门,即音乐下载功能。
只要您找到所需的音乐名称,然后进行搜索,我们就可以快速,批量下载它。使用此软件,您不必担心找不到歌曲或记住歌曲名称。
有了如此强大的辅助工具,为什么我们在自媒体个短视频中做得不好? 查看全部
固乔视频助手:自媒体短视频采集器下载工具
现在自媒体行业正变得越来越流行,越来越多的人加入该行业,因此,当我们从事自媒体时,它也是知识积累的过程。对于您制作的短片来说,获得所有人的认可是非常重要的。

自媒体短视频采集有很多下载工具,但是最好使用自己易于使用的软件。这是我更多使用的视频采集器下载工具。乔视频助理。
操作简便,在界面中打开自媒体视频下载功能,点击下载页面即可随机获取热门视频,我们可以快速获取热门的短视频资源。
它还支持通过视频链接下载视频。有数十种平台支持自媒体,b站,抖音,火山和小红树。
打开选择功能,我们可以使用关键词进行定位,然后搜索所需的热门视频资源。
在下载页面中打开高级设置。在高级设置对话框中,我们可以设置下载视频的分辨率,还可以使用无水印视频解析组件,这可以帮助我们在没有自媒体平台徽标的情况下下载视频。
除上述以外,您是否认为结束?实际上,当我们移动视频时,最重要的是修改MD5值。该工具包括此功能。当我们需要下载时,选中自动更改MD5值的选项。下载后,进行第二次编辑,以使原创的几率大大提高。
实际上,当我们认为它具有许多功能时,它还具有另一个强大的功能。对于自媒体个制作视频的人来说,无疑会增加方便门,即音乐下载功能。
只要您找到所需的音乐名称,然后进行搜索,我们就可以快速,批量下载它。使用此软件,您不必担心找不到歌曲或记住歌曲名称。
有了如此强大的辅助工具,为什么我们在自媒体个短视频中做得不好?
如何轻松收集网站信息?(网站万能信息采集助手)
采集交流 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2021-02-16 13:01
如何轻松采集网站信息? 网站通用信息采集器(网站信息采集助手)是一种方便的Web信息采集器。 网站通用信息采集器(网站信息采集助手)可以帮助用户轻松完成任务。该软件结合了所有网络爬网软件的优点。它可以获取网站上的所有信息,然后自动将其发布到您的网站。它可以获取网站上任何类型的所有信息,例如新闻,供应和需求。信息,招聘信息,论坛帖子,音乐,指向下一页的链接等。
通用网站内容采集神器官方下载图1
软件功能
1.信息自动采集和添加:网站抓取的主要目的是添加到您的网站中,网站信息一般采集器可以实现自动采集和添加。其他网站新更新的信息将在五分钟内自动运行到您的网站。
2. 网站登录:对于需要登录才能查看信息内容的网站,即使使用验证码,网站信息通用采集器也可以轻松登录并采集所需的信息。
3.自动下载文件:如果您需要采集图片之类的二进制文件,则只需设置一个通用的网站信息采集器即可在本地保存任何类型的文件。
网站通用内容采集神器官方下载图2
4.多级页面采集:一次爬网整个网站:无论有多少个类别和子类别,只要同时采集个多级页面的内容就可以您设置一次。如果一条信息分布在多个不同的页面上,则可以实现信息采集和爬网,并且网站常规信息采集器可以自动识别N级页面。该软件带有一个8层网站采集示例。
5.特殊网站自动识别:许多网站连接到特殊网站,例如javascript:openwin('1234'),而不是通常的网站常规信息采集器识别并捕获内容。
6.自动过滤重复的导出数据过滤重复的数据处理:有时URL不同,但是内容相同,因此通用采集器仍然可以根据内容过滤重复的数据。 (具有新功能的新版本。)
7.多页新闻自动合并和广告过滤:某些新闻有下一页,网站通用信息采集器也可以抓取所有页面。并可以同时保存新闻中捕获的图片和文字,过滤出广告。
8.自动破解cookie和防垃圾邮件:许多下载网站已完成cookie验证或防垃圾邮件,直接输入URL不能捕获内容,但是网站通用信息采集器可以自动破解cookie验证和防盗,因此必须确保可以捕获所需的内容。
通用网站内容采集神器官方下载图3
软件功能
1.采集和分发是完全自动化的。
2.自动破解JavaScript特殊URL。
[p24]成员登录的
网站也将得到处理。
4.立即抓取所有电台,无论有多少个类别。
5.可以下载任何类型的文件。
6.自动合并多页新闻和广告过滤。
7.多级页面的联合集合。
8.模拟手动单击以破解防盗链。
9.验证码标识。
1 0.图片自动加水印。 查看全部
如何轻松收集网站信息?(网站万能信息采集助手)
如何轻松采集网站信息? 网站通用信息采集器(网站信息采集助手)是一种方便的Web信息采集器。 网站通用信息采集器(网站信息采集助手)可以帮助用户轻松完成任务。该软件结合了所有网络爬网软件的优点。它可以获取网站上的所有信息,然后自动将其发布到您的网站。它可以获取网站上任何类型的所有信息,例如新闻,供应和需求。信息,招聘信息,论坛帖子,音乐,指向下一页的链接等。
通用网站内容采集神器官方下载图1
软件功能
1.信息自动采集和添加:网站抓取的主要目的是添加到您的网站中,网站信息一般采集器可以实现自动采集和添加。其他网站新更新的信息将在五分钟内自动运行到您的网站。
2. 网站登录:对于需要登录才能查看信息内容的网站,即使使用验证码,网站信息通用采集器也可以轻松登录并采集所需的信息。
3.自动下载文件:如果您需要采集图片之类的二进制文件,则只需设置一个通用的网站信息采集器即可在本地保存任何类型的文件。
网站通用内容采集神器官方下载图2
4.多级页面采集:一次爬网整个网站:无论有多少个类别和子类别,只要同时采集个多级页面的内容就可以您设置一次。如果一条信息分布在多个不同的页面上,则可以实现信息采集和爬网,并且网站常规信息采集器可以自动识别N级页面。该软件带有一个8层网站采集示例。
5.特殊网站自动识别:许多网站连接到特殊网站,例如javascript:openwin('1234'),而不是通常的网站常规信息采集器识别并捕获内容。
6.自动过滤重复的导出数据过滤重复的数据处理:有时URL不同,但是内容相同,因此通用采集器仍然可以根据内容过滤重复的数据。 (具有新功能的新版本。)
7.多页新闻自动合并和广告过滤:某些新闻有下一页,网站通用信息采集器也可以抓取所有页面。并可以同时保存新闻中捕获的图片和文字,过滤出广告。
8.自动破解cookie和防垃圾邮件:许多下载网站已完成cookie验证或防垃圾邮件,直接输入URL不能捕获内容,但是网站通用信息采集器可以自动破解cookie验证和防盗,因此必须确保可以捕获所需的内容。
通用网站内容采集神器官方下载图3
软件功能
1.采集和分发是完全自动化的。
2.自动破解JavaScript特殊URL。
[p24]成员登录的
网站也将得到处理。
4.立即抓取所有电台,无论有多少个类别。
5.可以下载任何类型的文件。
6.自动合并多页新闻和广告过滤。
7.多级页面的联合集合。
8.模拟手动单击以破解防盗链。
9.验证码标识。
1 0.图片自动加水印。
完整的采集神器太长了,你去看看录播了
采集交流 • 优采云 发表了文章 • 0 个评论 • 289 次浏览 • 2021-02-05 13:01
完整的采集神器太长了,你去看看录播了,完整版在这里,超级简单,一步到位【采集动画视频】,
你好,这个问题我能答,我就是做app外包的。app抓包调试一般分两种,一种是p2p抓包的,一种是封包的p2p的方式就是网络请求已经封了,你只要直接用ak这类抓包软件获取获取数据包就可以直接调试。封包就是有些是不直接接收这类消息的,而你做的这个“经常性”性能问题。因为不同性能也不同,有些这方面有问题或者没有问题,你还需要对它做一些代码来更改。
至于如何生成方式很多,一般p2p的时候需要通过代理请求,比如网页通过代理的方式获取,手机也可以用代理,还有就是app的代理,移动app还可以借助云服务器。p2p和封包是需要看平台的,在平台里封包有封包的方式和调用的方式,也有代理请求的方式。p2p的速度快,但是很难查,还会被封包。封包的速度慢,但是封不完整,比如二进制的包封了三次才能压缩完整。
在您的上装一个“fiddler”,
花了五分钟看完,原地大号被封,报告了一堆莫名奇妙的问题!去跟那些人扯啥破环数据,真觉得你们很幽默。我说说我的观点,调试不是什么隐藏高手,只是懂得原理。采集动画视频,可以简单了解一下,以百度api接口为例,找到百度apiserver,就是了,sdk比较多,数据如下如果之前经常做效果,还有三张表,分别是apiserver所有的历史数据,比如你用过哪些手机。
apiserver当前获取的app数据,你上线的时候获取了哪些数据。没了。注意你懂的,app必须得上架到所有上架的渠道。修改代码修改代码,内核,注册上架的时候不要搞死,换个语言继续。修改到app最好新开,不行就通过调用接口获取上架的时候提交的接口数据就可以。你这没有什么问题的,没事,你连调用的链接都没有给我,如果你能做到,你就可以实现封包的操作。
不过假如你真想大大方方的上架,就只能弄成本地上架,而且开始不要在所有渠道更新。等账号安全更新了,不要更新了。给老板发文书,上架我就没有问题。有点跑题,好了,就说到这,原理搞懂,之后还是多练习,多练习,多练习。注意语言不会,sogogogo。 查看全部
完整的采集神器太长了,你去看看录播了
完整的采集神器太长了,你去看看录播了,完整版在这里,超级简单,一步到位【采集动画视频】,
你好,这个问题我能答,我就是做app外包的。app抓包调试一般分两种,一种是p2p抓包的,一种是封包的p2p的方式就是网络请求已经封了,你只要直接用ak这类抓包软件获取获取数据包就可以直接调试。封包就是有些是不直接接收这类消息的,而你做的这个“经常性”性能问题。因为不同性能也不同,有些这方面有问题或者没有问题,你还需要对它做一些代码来更改。
至于如何生成方式很多,一般p2p的时候需要通过代理请求,比如网页通过代理的方式获取,手机也可以用代理,还有就是app的代理,移动app还可以借助云服务器。p2p和封包是需要看平台的,在平台里封包有封包的方式和调用的方式,也有代理请求的方式。p2p的速度快,但是很难查,还会被封包。封包的速度慢,但是封不完整,比如二进制的包封了三次才能压缩完整。
在您的上装一个“fiddler”,
花了五分钟看完,原地大号被封,报告了一堆莫名奇妙的问题!去跟那些人扯啥破环数据,真觉得你们很幽默。我说说我的观点,调试不是什么隐藏高手,只是懂得原理。采集动画视频,可以简单了解一下,以百度api接口为例,找到百度apiserver,就是了,sdk比较多,数据如下如果之前经常做效果,还有三张表,分别是apiserver所有的历史数据,比如你用过哪些手机。
apiserver当前获取的app数据,你上线的时候获取了哪些数据。没了。注意你懂的,app必须得上架到所有上架的渠道。修改代码修改代码,内核,注册上架的时候不要搞死,换个语言继续。修改到app最好新开,不行就通过调用接口获取上架的时候提交的接口数据就可以。你这没有什么问题的,没事,你连调用的链接都没有给我,如果你能做到,你就可以实现封包的操作。
不过假如你真想大大方方的上架,就只能弄成本地上架,而且开始不要在所有渠道更新。等账号安全更新了,不要更新了。给老板发文书,上架我就没有问题。有点跑题,好了,就说到这,原理搞懂,之后还是多练习,多练习,多练习。注意语言不会,sogogogo。
什么是优采云采集?智能采集工具帮你提高营收
采集交流 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2021-02-02 10:03
什么是优采云采集?智能采集工具帮你提高营收
在流行期间,许多公司不得不选择远程在线办公室。互联网是受流行病影响较小的行业之一。但是,远程办公室的效率仍然不如面对面的工作。因此,优采云采集特别推出了智能采集工具。
我相信许多操作人员已经接触过采集工具。市场上有很多采集工具。许多人认为采集工具仅用作文章热门/节日主题和其他信息采集的辅助工具,实际上,不仅如此。成熟的采集工具不仅可以帮助操作采集信息,而且可以准确地分析数据趋势,从而有助于增加收入。
1、什么是优采云采集?
优采云采集是用于自媒体素材搜索,文章 原创一键式发布的操作工具,可有效提高新媒体运营的效率并降低公司成本。
2、如何用优采云采集搜索?
([1)输入关键词
优采云采集根据用户输入的关键词,搜索引擎会通过程序自动输入主流自媒体数据源进行搜索。
优采云采集基于高级算法匹配更准确的内容,以提高搜索内容的准确性。
例如:
用户需要采集有关流行病的资料,然后在主页上输入关键词“流行病”。 优采云采集会将搜索结果合并到一个列表中。
([2)保存搜索材料
优采云采集具有批量保存搜索资料的功能。
单击[在当前页上全部选择]功能,然后选中所需的文章,文章将添加到操作面板中,方便用户批量保存。
([3)精确过滤
1、搜索过滤器
优采云采集支持根据标题,内容,时间,平台,是否为原创等参数进行过滤,以使搜索内容更加准确。
2、广告过滤 查看全部
什么是优采云采集?智能采集工具帮你提高营收
在流行期间,许多公司不得不选择远程在线办公室。互联网是受流行病影响较小的行业之一。但是,远程办公室的效率仍然不如面对面的工作。因此,优采云采集特别推出了智能采集工具。
我相信许多操作人员已经接触过采集工具。市场上有很多采集工具。许多人认为采集工具仅用作文章热门/节日主题和其他信息采集的辅助工具,实际上,不仅如此。成熟的采集工具不仅可以帮助操作采集信息,而且可以准确地分析数据趋势,从而有助于增加收入。
1、什么是优采云采集?
优采云采集是用于自媒体素材搜索,文章 原创一键式发布的操作工具,可有效提高新媒体运营的效率并降低公司成本。
2、如何用优采云采集搜索?
([1)输入关键词
优采云采集根据用户输入的关键词,搜索引擎会通过程序自动输入主流自媒体数据源进行搜索。
优采云采集基于高级算法匹配更准确的内容,以提高搜索内容的准确性。
例如:
用户需要采集有关流行病的资料,然后在主页上输入关键词“流行病”。 优采云采集会将搜索结果合并到一个列表中。
([2)保存搜索材料
优采云采集具有批量保存搜索资料的功能。
单击[在当前页上全部选择]功能,然后选中所需的文章,文章将添加到操作面板中,方便用户批量保存。
([3)精确过滤
1、搜索过滤器
优采云采集支持根据标题,内容,时间,平台,是否为原创等参数进行过滤,以使搜索内容更加准确。
2、广告过滤
干货教程:拼多多产品图采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 573 次浏览 • 2021-01-15 08:18
平多多产品图采集是专门为拼多多商人使用的辅助工具。它可以帮助用户轻松地采集 Pinduoduo以上产品图片和其他信息,非常方便,有需要的用户不妨下载一下体验!
软件简介
Pingduoduo产品图片采集下载程序是可以批量采集 Pingduoduo产品图片和说明图片的软件,它可以节省每个人的时间,因为图片采集。该软件支持批量采集,只需将产品地址批量输入软件即可实现批量采集的工作。
软件功能
整个商店复制:您可以一键复制任何人的拼多多商店(所有商店产品),并自动识别产品类别。如果要复制商店,只需单击一下即可在几分钟之内完成!
该软件支持数据导入和导出,可以随意导入和导出数据,以供其他商店直接上传和使用。
支持批量编辑产品信息,任何产品信息均支持一键式批量设置,功能超强!
实拍店更新:支持实拍店老板上传新照片,无需PS图片,软件可以自动将图片尺寸调整为拼多多的指定尺寸,无论图片是大还是小,都可以直接批量导入并发布!同时,它支持31个主要货源平台的产品信息采集 +编辑产品图片,您可以通过插入本地图片来使用网络图片!节省实际拍摄的时间和精力〜
使用方法
1.打开拼多多产品图采集下载器
2.点击打开Pinduoduo网络版本并登录
3.将所需的产品地址批量输入软件
4.单击采集开始。
5.最后下载的图片将保存在数据文件夹中,单击以打开目录进行查找。
更新日志
1、优化了UI界面的流畅性
2、修复了已知错误 查看全部
干货教程:拼多多产品图采集
平多多产品图采集是专门为拼多多商人使用的辅助工具。它可以帮助用户轻松地采集 Pinduoduo以上产品图片和其他信息,非常方便,有需要的用户不妨下载一下体验!
软件简介
Pingduoduo产品图片采集下载程序是可以批量采集 Pingduoduo产品图片和说明图片的软件,它可以节省每个人的时间,因为图片采集。该软件支持批量采集,只需将产品地址批量输入软件即可实现批量采集的工作。
软件功能
整个商店复制:您可以一键复制任何人的拼多多商店(所有商店产品),并自动识别产品类别。如果要复制商店,只需单击一下即可在几分钟之内完成!
该软件支持数据导入和导出,可以随意导入和导出数据,以供其他商店直接上传和使用。
支持批量编辑产品信息,任何产品信息均支持一键式批量设置,功能超强!
实拍店更新:支持实拍店老板上传新照片,无需PS图片,软件可以自动将图片尺寸调整为拼多多的指定尺寸,无论图片是大还是小,都可以直接批量导入并发布!同时,它支持31个主要货源平台的产品信息采集 +编辑产品图片,您可以通过插入本地图片来使用网络图片!节省实际拍摄的时间和精力〜
使用方法
1.打开拼多多产品图采集下载器
2.点击打开Pinduoduo网络版本并登录

3.将所需的产品地址批量输入软件

4.单击采集开始。
5.最后下载的图片将保存在数据文件夹中,单击以打开目录进行查找。

更新日志
1、优化了UI界面的流畅性
2、修复了已知错误
完整的采集神器推荐一个人在家傻瓜式地采集网页视频的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 469 次浏览 • 2021-05-25 19:01
完整的采集神器推荐一个人在家傻瓜式地采集网页视频的方法,教程干货满满,
一)正确获取视频地址
1、百度网盘搜索“视频采集神器”,首页不是很好找,
2、会跳转到下载页面,直接点击视频下载即可。
3、下载后为网页视频;
4、如果是高清视频,可以通过视频链接再跳转到视频页面,
二)快速获取网页视频地址
1、打开快速采集工具,
2、复制视频网址,页面左上角有一个视频列表的窗口,可以一键采集。
3、按照下图来切换你要采集的视频页面和范围,
二)采集视频地址有时候因为链接有问题,大家可以尝试利用电脑的剪切板或者浏览器的剪贴板一键采集,
三)提取视频封面
2、在左侧设置框中,选择封面提取方式,大家可以通过将文件放入iphone手机或者电脑中进行提取,
3、将提取的链接复制在浏览器中即可,这样我们就能查看了。
我为什么要说这个呢?因为我不禁要吐槽一下了,我希望大家能点个赞?我不想你们被我牵着鼻子走了。首先,你要有一个合适的网站。真正去实施,理论上你要进行交互,比如打开google,并且成功登录。方法不同,效果也不同。这是我学习的不多,欢迎拍砖,理论上是你要有一个合适的网站。一般说来,互联网上比较有名气的很多免费公共资源如:爱问共享资料,中国知网,万方数据库都可以,但是贵。
除此之外,谷歌、百度,再不济你用360,腾讯微信,它们都能检索出来。第二,要有高质量的视频资源,你看看你的youtube是不是也有很多挺不错的好东西?eqingwu出品的《tableau总览报告》,没什么说的,全是tableau的经典报告。这些内容我都收藏了,如果大家感兴趣的话,或者想要微信课程资源,可以联系我。
第三,要有分层路径。比如你要采集二三本高校的课程视频,你要分成课程名字、课程名字、课程名字、课程名字,这样才能更全面的进行查找。举个例子,我要查“周鸿祎管理学三个案例”,那么,我就要分为周鸿祎、管理学、案例三个部分;如果我要查“陈安之的演讲视频”,也可以有类似的功能,是不是很方便。第四,还是你要有一个合适的关键词或者网站,很多人容易犯两个错误,一个是关键词没有分好,另一个是关键词用的不对。比如我想了解一下好像人大经济学院的公开课比较多,那么就搜“人大经济学。 查看全部
完整的采集神器推荐一个人在家傻瓜式地采集网页视频的方法
完整的采集神器推荐一个人在家傻瓜式地采集网页视频的方法,教程干货满满,
一)正确获取视频地址
1、百度网盘搜索“视频采集神器”,首页不是很好找,
2、会跳转到下载页面,直接点击视频下载即可。
3、下载后为网页视频;
4、如果是高清视频,可以通过视频链接再跳转到视频页面,
二)快速获取网页视频地址
1、打开快速采集工具,
2、复制视频网址,页面左上角有一个视频列表的窗口,可以一键采集。
3、按照下图来切换你要采集的视频页面和范围,
二)采集视频地址有时候因为链接有问题,大家可以尝试利用电脑的剪切板或者浏览器的剪贴板一键采集,
三)提取视频封面
2、在左侧设置框中,选择封面提取方式,大家可以通过将文件放入iphone手机或者电脑中进行提取,
3、将提取的链接复制在浏览器中即可,这样我们就能查看了。
我为什么要说这个呢?因为我不禁要吐槽一下了,我希望大家能点个赞?我不想你们被我牵着鼻子走了。首先,你要有一个合适的网站。真正去实施,理论上你要进行交互,比如打开google,并且成功登录。方法不同,效果也不同。这是我学习的不多,欢迎拍砖,理论上是你要有一个合适的网站。一般说来,互联网上比较有名气的很多免费公共资源如:爱问共享资料,中国知网,万方数据库都可以,但是贵。
除此之外,谷歌、百度,再不济你用360,腾讯微信,它们都能检索出来。第二,要有高质量的视频资源,你看看你的youtube是不是也有很多挺不错的好东西?eqingwu出品的《tableau总览报告》,没什么说的,全是tableau的经典报告。这些内容我都收藏了,如果大家感兴趣的话,或者想要微信课程资源,可以联系我。
第三,要有分层路径。比如你要采集二三本高校的课程视频,你要分成课程名字、课程名字、课程名字、课程名字,这样才能更全面的进行查找。举个例子,我要查“周鸿祎管理学三个案例”,那么,我就要分为周鸿祎、管理学、案例三个部分;如果我要查“陈安之的演讲视频”,也可以有类似的功能,是不是很方便。第四,还是你要有一个合适的关键词或者网站,很多人容易犯两个错误,一个是关键词没有分好,另一个是关键词用的不对。比如我想了解一下好像人大经济学院的公开课比较多,那么就搜“人大经济学。
完整的采集神器第1弹:各种采集工具,常用的神器使用新方法(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2021-05-21 02:03
完整的采集神器第1弹:各种采集工具,常用的神器使用新方法(一)几个采集工具的使用,讲几个我常用的几个采集工具:简道云采集市场数据一共七个用户版,通过简道云管理多行业数据可以很快速,方便的实现复杂的数据处理。第二季有个强大的神器、你来收集,通过强大的数据收集功能,完美收集你的数据!第三季的强大,用户版采集数据可以自动导出excel表格,还不能导出xlsx格式。
第四季就目前为止还可以,其他没用过。采集市场的采集工具大部分都不带视频。第三季神器,专业视频的学习使用,通过视频对平常用的很多工具有了全面的讲解。整个采集市场关于采集工具的基础知识讲解,都可以学习到。以下附上相关图片。个人认为好用的几个采集工具:我个人经常用到的采集工具一些采集工具截图。常用的几个采集工具的使用。
目前大部分采集工具可以直接免费用,部分产品收费。再次提醒:没有足够的采集数据经验的还是别折腾了,真不怎么样。现在各大招聘网站发布招聘信息,看网站的同时,也会采集一些岗位信息。例如拉勾网招聘,可以看看其他企业都需要哪些职位,多关注一下。后面还有几个采集类产品要出免费版,预计今年年底发布。提醒:提前准备数据和采集岗位信息,不然试用版很快就用完了。
推荐一个采集神器,采集钉钉视频,腾讯视频播放器,优酷视频,爱奇艺视频,爱奇艺电视剧,火星小说等常用软件的视频。免费版只能抓取被采集网站的视频,收费版能抓取多家网站视频。可以采集的网站有下面几个:采集素材助手,收费版。可以采集简历,采集聊天截图,采集微信通讯录,多个企业网站的资源截图等图片。无法抓取视频,不过可以抓取文本,收费版付费。
需要采集素材的只能用免费版。采集大象视频,为企业站建站需要采集素材。采集各大视频站相关的视频就可以一次采集,提供采集模板、采集工具等。具体视频:采集大象,快手,b站视频采集神器-采集大象后台提供的模板、采集工具等采集,网页端,主流视频站点素材,比如:新浪视频,搜狐视频,腾讯视频,爱奇艺视频。有些原来没用过的网站也可以采集。希望大家能采集到满意的素材。 查看全部
完整的采集神器第1弹:各种采集工具,常用的神器使用新方法(一)
完整的采集神器第1弹:各种采集工具,常用的神器使用新方法(一)几个采集工具的使用,讲几个我常用的几个采集工具:简道云采集市场数据一共七个用户版,通过简道云管理多行业数据可以很快速,方便的实现复杂的数据处理。第二季有个强大的神器、你来收集,通过强大的数据收集功能,完美收集你的数据!第三季的强大,用户版采集数据可以自动导出excel表格,还不能导出xlsx格式。
第四季就目前为止还可以,其他没用过。采集市场的采集工具大部分都不带视频。第三季神器,专业视频的学习使用,通过视频对平常用的很多工具有了全面的讲解。整个采集市场关于采集工具的基础知识讲解,都可以学习到。以下附上相关图片。个人认为好用的几个采集工具:我个人经常用到的采集工具一些采集工具截图。常用的几个采集工具的使用。
目前大部分采集工具可以直接免费用,部分产品收费。再次提醒:没有足够的采集数据经验的还是别折腾了,真不怎么样。现在各大招聘网站发布招聘信息,看网站的同时,也会采集一些岗位信息。例如拉勾网招聘,可以看看其他企业都需要哪些职位,多关注一下。后面还有几个采集类产品要出免费版,预计今年年底发布。提醒:提前准备数据和采集岗位信息,不然试用版很快就用完了。
推荐一个采集神器,采集钉钉视频,腾讯视频播放器,优酷视频,爱奇艺视频,爱奇艺电视剧,火星小说等常用软件的视频。免费版只能抓取被采集网站的视频,收费版能抓取多家网站视频。可以采集的网站有下面几个:采集素材助手,收费版。可以采集简历,采集聊天截图,采集微信通讯录,多个企业网站的资源截图等图片。无法抓取视频,不过可以抓取文本,收费版付费。
需要采集素材的只能用免费版。采集大象视频,为企业站建站需要采集素材。采集各大视频站相关的视频就可以一次采集,提供采集模板、采集工具等。具体视频:采集大象,快手,b站视频采集神器-采集大象后台提供的模板、采集工具等采集,网页端,主流视频站点素材,比如:新浪视频,搜狐视频,腾讯视频,爱奇艺视频。有些原来没用过的网站也可以采集。希望大家能采集到满意的素材。
完整的采集神器,那就是优采网,全部是免费的
采集交流 • 优采云 发表了文章 • 0 个评论 • 442 次浏览 • 2021-05-18 18:07
完整的采集神器,那就是优采网,全部是免费的。
别说四五千,就算拿百万人民币,找个正规的网站服务商,过采过滤,过滤代码之后,网站都不一定能打开。毕竟你是中文网站,很多标准,已经固定。
建议你还是自己采吧,反正付费成本有限,但是要付出一定的技术含量和一定的时间成本,但是收益也有限,至于找代采或者找外贸培训机构,结果可能也会是一样,很难找到合适的。不过其实对于大多数中小型外贸公司来说,找几个销售同时给你采买几百条样品成本可能不到千元,尤其针对每个国家的采购政策不同,代采公司更是不可能给你找几百条样品来做展示,所以其实你可以专注大客户,小客户的采买有平台代替,但是付费前你也要把合同和采购政策先好好看看,要先有一个初步的了解,如果能拿到其中一些合适的订单就足够了,毕竟大多数公司没有专门的采购业务员来采买产品。
标准还是要学习,过程还是要时间,结果还是不好评判,主要是看你要做什么样的外贸公司。外贸易这一块要看市场发展如何,毕竟大家都知道,大趋势是外贸的特点是客户需求大于供给。供需关系会越来越不平衡,但是大的市场是外贸会越来越好做。外贸人要有眼光,要能看到变化趋势,这样才能从中获利。有独特品牌和产品的外贸企业才是真正有市场前景的外贸企业。 查看全部
完整的采集神器,那就是优采网,全部是免费的
完整的采集神器,那就是优采网,全部是免费的。
别说四五千,就算拿百万人民币,找个正规的网站服务商,过采过滤,过滤代码之后,网站都不一定能打开。毕竟你是中文网站,很多标准,已经固定。
建议你还是自己采吧,反正付费成本有限,但是要付出一定的技术含量和一定的时间成本,但是收益也有限,至于找代采或者找外贸培训机构,结果可能也会是一样,很难找到合适的。不过其实对于大多数中小型外贸公司来说,找几个销售同时给你采买几百条样品成本可能不到千元,尤其针对每个国家的采购政策不同,代采公司更是不可能给你找几百条样品来做展示,所以其实你可以专注大客户,小客户的采买有平台代替,但是付费前你也要把合同和采购政策先好好看看,要先有一个初步的了解,如果能拿到其中一些合适的订单就足够了,毕竟大多数公司没有专门的采购业务员来采买产品。
标准还是要学习,过程还是要时间,结果还是不好评判,主要是看你要做什么样的外贸公司。外贸易这一块要看市场发展如何,毕竟大家都知道,大趋势是外贸的特点是客户需求大于供给。供需关系会越来越不平衡,但是大的市场是外贸会越来越好做。外贸人要有眼光,要能看到变化趋势,这样才能从中获利。有独特品牌和产品的外贸企业才是真正有市场前景的外贸企业。
完整的采集神器 不喜欢多线程爬虫的老板,用这个就ok!
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-05-18 02:01
完整的采集神器,给你最佳的采集体验。不喜欢多线程爬虫的老板,用这个就ok!作者:天下好策略机构,预测3月后会有大的资金流入,是很多大公司开始需要的样子,适合中小企业。相比较于其他的小爬虫,它更稳定,速度也有保障。采集特色:1.多线程爬虫2.国内最大的采集软件工具体系,可实现整站采集3.可实现全球文章、信息的自动识别采集4.支持多选中的多线程,线程数可扩展5.支持内容包索引编辑器的增量采集功能6.支持一键导出本地数据-只要简单设置就能用!!!这就是他最突出的优势。
好处就是你不用懂sql语句,不用有人帮你复制黏贴,更不用懂有splash!!!还有就是可以爬到国内外的信息,数据的精准性对中小企业而言非常重要,目前实现121篇国内外文章,4篇音频,11篇视频,67篇文章的全网检索。采集手工录入信息的时代要过去了,用这个最方便,百度贴吧都有网址,企业资料也有,所以采集是大势所趋。
当然他的收益也还不错,中小企业做个单,利润已经是够你活很久的了,你要是能有一定资金投入,那恭喜你,你赚到了,中小企业本来投入就少,如果这样做,那就更是省钱啦。
我有些本地文件用浏览器自带的baiduspider等,要的话就点, 查看全部
完整的采集神器 不喜欢多线程爬虫的老板,用这个就ok!
完整的采集神器,给你最佳的采集体验。不喜欢多线程爬虫的老板,用这个就ok!作者:天下好策略机构,预测3月后会有大的资金流入,是很多大公司开始需要的样子,适合中小企业。相比较于其他的小爬虫,它更稳定,速度也有保障。采集特色:1.多线程爬虫2.国内最大的采集软件工具体系,可实现整站采集3.可实现全球文章、信息的自动识别采集4.支持多选中的多线程,线程数可扩展5.支持内容包索引编辑器的增量采集功能6.支持一键导出本地数据-只要简单设置就能用!!!这就是他最突出的优势。
好处就是你不用懂sql语句,不用有人帮你复制黏贴,更不用懂有splash!!!还有就是可以爬到国内外的信息,数据的精准性对中小企业而言非常重要,目前实现121篇国内外文章,4篇音频,11篇视频,67篇文章的全网检索。采集手工录入信息的时代要过去了,用这个最方便,百度贴吧都有网址,企业资料也有,所以采集是大势所趋。
当然他的收益也还不错,中小企业做个单,利润已经是够你活很久的了,你要是能有一定资金投入,那恭喜你,你赚到了,中小企业本来投入就少,如果这样做,那就更是省钱啦。
我有些本地文件用浏览器自带的baiduspider等,要的话就点,
公众号商品回复“采集”可以获取小程序的下载链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 349 次浏览 • 2021-05-12 05:04
完整的采集神器更可以直接下载京东的商品,视频,小程序等可以直接采集,适合个人和团队使用,去重复采集,一键去重,支持多个平台的下载,可以当做爬虫,可以对接非常多的商品。
公众号商品回复“采集”可以获取小程序的下载链接如何实现微信公众号商品回复“采集”获取小程序下载链接
可以下载天猫的商品
微信公众号商品回复“采集”,就可以获取小程序的下载链接,并且可以配上小程序的讲解图文,图文链接也可以用js引入。小程序商品回复“采集”后链接可以被采集。
我们做得定制化微商城的中文版,是国内首家运用最新深度学习技术处理图片真人描述并生成文本摘要的。同时还可以根据不同的用户群体和内容策略,结合视频等图文方式进行自由搭配运营。你可以看看这些产品的介绍联系我们吧:深度学习+机器学习+图片描述+自然语言生成,
别走远就是这样,我看看你真人头像。
微信商品回复“采集”
我的天,这我我也发现来,不过我也是自己挖掘着,可以在微信公众号和商品回复“采集”,
问题是“天猫”,那么我觉得最直接的方法,就是使用商品传送门,点进去之后点击底下的“采集数据”,然后点击“下载商品”即可。当然你也可以试试其他的,比如可以通过微信小程序或网页生成小程序“商品传送门”,使用方法和小程序一样。
1、小程序的“商品传送门”很容易发布失败,
2、开发难度也相对高一些。其他小程序功能可以参考:深度广告ai-广告预测平台—微信小程序,比如题目里的图片,在小程序里,我们需要按照题目要求去投放广告,其中会有些不确定的,
3、小程序只能收费使用,免费只能试用,而且会有系统的限制;如果免费试用的产品比较多,也会有可能出现错误产品和服务满足不了的情况,或者会有服务器承载和流量的优化问题;以上三种,最好都写一下。目前我知道的只有第一种“商品传送门”免费,因为目前还没有问题解决方案。 查看全部
公众号商品回复“采集”可以获取小程序的下载链接
完整的采集神器更可以直接下载京东的商品,视频,小程序等可以直接采集,适合个人和团队使用,去重复采集,一键去重,支持多个平台的下载,可以当做爬虫,可以对接非常多的商品。
公众号商品回复“采集”可以获取小程序的下载链接如何实现微信公众号商品回复“采集”获取小程序下载链接
可以下载天猫的商品
微信公众号商品回复“采集”,就可以获取小程序的下载链接,并且可以配上小程序的讲解图文,图文链接也可以用js引入。小程序商品回复“采集”后链接可以被采集。
我们做得定制化微商城的中文版,是国内首家运用最新深度学习技术处理图片真人描述并生成文本摘要的。同时还可以根据不同的用户群体和内容策略,结合视频等图文方式进行自由搭配运营。你可以看看这些产品的介绍联系我们吧:深度学习+机器学习+图片描述+自然语言生成,
别走远就是这样,我看看你真人头像。
微信商品回复“采集”
我的天,这我我也发现来,不过我也是自己挖掘着,可以在微信公众号和商品回复“采集”,
问题是“天猫”,那么我觉得最直接的方法,就是使用商品传送门,点进去之后点击底下的“采集数据”,然后点击“下载商品”即可。当然你也可以试试其他的,比如可以通过微信小程序或网页生成小程序“商品传送门”,使用方法和小程序一样。
1、小程序的“商品传送门”很容易发布失败,
2、开发难度也相对高一些。其他小程序功能可以参考:深度广告ai-广告预测平台—微信小程序,比如题目里的图片,在小程序里,我们需要按照题目要求去投放广告,其中会有些不确定的,
3、小程序只能收费使用,免费只能试用,而且会有系统的限制;如果免费试用的产品比较多,也会有可能出现错误产品和服务满足不了的情况,或者会有服务器承载和流量的优化问题;以上三种,最好都写一下。目前我知道的只有第一种“商品传送门”免费,因为目前还没有问题解决方案。
2020最新的Python进阶资料和高级开发教程,欢迎加入
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-05-07 19:16
python 采集 网站数据,本教程使用刮板蜘蛛
1、安装Scrapy框架
命令行执行:
pip install scrapy
如果已安装的scrapy依赖软件包与您最初安装的其他python软件包冲突,建议使用Virtualenv进行安装
安装完成后,只需找到一个文件夹即可创建采集器
scrapy startproject 你的蜘蛛名称
文件夹目录
爬虫规则写在蜘蛛目录中
需要爬网的items.py数据
pipelines.py-执行数据保存
设置配置
middlewares.py-downloader
以下是采集小说网站
的源代码
首先在items.py中定义采集的数据
# author 小白
import scrapy
class BookspiderItem(scrapy.Item):
# define the fields for your item here like:
i = scrapy.Field()
book_name = scrapy.Field()
book_img = scrapy.Field()
book_author = scrapy.Field()
book_last_chapter = scrapy.Field()
book_last_time = scrapy.Field()
book_list_name = scrapy.Field()
book_content = scrapy.Field()
pass
编写采集条规则
保存数据
import os
class BookspiderPipeline(object):
def process_item(self, item, spider):
curPath = 'E:/小说/'
tempPath = str(item['book_name'])
targetPath = curPath + tempPath
if not os.path.exists(targetPath):
os.makedirs(targetPath)
book_list_name = str(str(item['i'])+item['book_list_name'])
filename_path = targetPath+'/'+book_list_name+'.txt'
print('------------')
print(filename_path)
with open(filename_path,'a',encoding='utf-8') as f:
f.write(item['book_content'])
return item
执行
scrapy crawl BookSpider
您可以完成一个新颖的程序采集
推荐这里
scrapy shell 爬取的网页url
然后response.css('')测试规则是否正确
我仍然推荐我自己建立的Python开发学习小组:810735403。该小组都在学习Python开发。如果您正在学习Python,欢迎加入。每个人都是软件开发人员,并且不时分享干货。 (仅与Python软件开发相关),包括我自己在2020年编写的最新Python高级材料和高级开发教程的副本,欢迎高级用户和想要深入Python的人学习! 查看全部
2020最新的Python进阶资料和高级开发教程,欢迎加入
python 采集 网站数据,本教程使用刮板蜘蛛
1、安装Scrapy框架
命令行执行:
pip install scrapy
如果已安装的scrapy依赖软件包与您最初安装的其他python软件包冲突,建议使用Virtualenv进行安装
安装完成后,只需找到一个文件夹即可创建采集器
scrapy startproject 你的蜘蛛名称
文件夹目录
爬虫规则写在蜘蛛目录中
需要爬网的items.py数据
pipelines.py-执行数据保存
设置配置
middlewares.py-downloader
以下是采集小说网站
的源代码
首先在items.py中定义采集的数据
# author 小白
import scrapy
class BookspiderItem(scrapy.Item):
# define the fields for your item here like:
i = scrapy.Field()
book_name = scrapy.Field()
book_img = scrapy.Field()
book_author = scrapy.Field()
book_last_chapter = scrapy.Field()
book_last_time = scrapy.Field()
book_list_name = scrapy.Field()
book_content = scrapy.Field()
pass
编写采集条规则
保存数据
import os
class BookspiderPipeline(object):
def process_item(self, item, spider):
curPath = 'E:/小说/'
tempPath = str(item['book_name'])
targetPath = curPath + tempPath
if not os.path.exists(targetPath):
os.makedirs(targetPath)
book_list_name = str(str(item['i'])+item['book_list_name'])
filename_path = targetPath+'/'+book_list_name+'.txt'
print('------------')
print(filename_path)
with open(filename_path,'a',encoding='utf-8') as f:
f.write(item['book_content'])
return item
执行
scrapy crawl BookSpider
您可以完成一个新颖的程序采集
推荐这里
scrapy shell 爬取的网页url
然后response.css('')测试规则是否正确
我仍然推荐我自己建立的Python开发学习小组:810735403。该小组都在学习Python开发。如果您正在学习Python,欢迎加入。每个人都是软件开发人员,并且不时分享干货。 (仅与Python软件开发相关),包括我自己在2020年编写的最新Python高级材料和高级开发教程的副本,欢迎高级用户和想要深入Python的人学习!
完整的采集神器,很有必要学习的框架!
采集交流 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2021-05-04 21:02
完整的采集神器,很有必要学习的。几款主流的采集器基本都是scrapy框架。下面开始我们的采集设置。
一、采集渠道的设置
1、选择服务器:在编辑页面设置采集网站的url,即要采集哪些网站
2、选择采集地址:对应已有的服务器url,
二、站点设置
1、url设置,
2、不要使用reload方法,只需将url更改为:;是判断是否在多线程中,不是,则需更改为:;是判断是否成功加载,不是,
3、页面中不加相应的中间页的链接。当使用all的时候可以不用这样做。
等你做个上千万的站你就会记得这点架子了。
你错误的理解了请求数量和请求网址
请求数量过多的话,和请求网址过多的话,会导致应用处理器整体瓶颈,通过增加额外的请求包可以解决,但是这样会导致url多了很多,带宽就会成倍增加。其实就是很浪费,一般一个github的repo。
每个人的个人请求数量不同,所以不建议站点和网址非要重名,
如果大量文件处理会很卡,all_hosts是一个解决方案,不过每个站点重名也很正常吧。
我还是无法解释你们那些除了核心算法之外的东西啊。如果只是纯粹的track。你首先得知道要什么请求吧。你希望搞到什么类型的请求??只是采集静态网站或者一些公开数据的话可以用default_url设置不同类型的请求url,也就是上面有位说的不同url设置不同的请求包。但是静态网站里的页面对吧,那你就要在字典表中每个字典的第一个字符配上特定url的指针了。
然后用http-header设置不同请求包不同的参数了。但是。我还是不知道。除了url什么参数也要弄上去啊。所以。大家。只好我写程序搞爬虫了。 查看全部
完整的采集神器,很有必要学习的框架!
完整的采集神器,很有必要学习的。几款主流的采集器基本都是scrapy框架。下面开始我们的采集设置。
一、采集渠道的设置
1、选择服务器:在编辑页面设置采集网站的url,即要采集哪些网站
2、选择采集地址:对应已有的服务器url,
二、站点设置
1、url设置,
2、不要使用reload方法,只需将url更改为:;是判断是否在多线程中,不是,则需更改为:;是判断是否成功加载,不是,
3、页面中不加相应的中间页的链接。当使用all的时候可以不用这样做。
等你做个上千万的站你就会记得这点架子了。
你错误的理解了请求数量和请求网址
请求数量过多的话,和请求网址过多的话,会导致应用处理器整体瓶颈,通过增加额外的请求包可以解决,但是这样会导致url多了很多,带宽就会成倍增加。其实就是很浪费,一般一个github的repo。
每个人的个人请求数量不同,所以不建议站点和网址非要重名,
如果大量文件处理会很卡,all_hosts是一个解决方案,不过每个站点重名也很正常吧。
我还是无法解释你们那些除了核心算法之外的东西啊。如果只是纯粹的track。你首先得知道要什么请求吧。你希望搞到什么类型的请求??只是采集静态网站或者一些公开数据的话可以用default_url设置不同类型的请求url,也就是上面有位说的不同url设置不同的请求包。但是静态网站里的页面对吧,那你就要在字典表中每个字典的第一个字符配上特定url的指针了。
然后用http-header设置不同请求包不同的参数了。但是。我还是不知道。除了url什么参数也要弄上去啊。所以。大家。只好我写程序搞爬虫了。
WPContentCrawler可以使用什么主要功能特点保存(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 389 次浏览 • 2021-04-27 06:22
WPContentCrawler可以使用什么主要功能特点保存(组图)
WP Content Crawler v 1. 1 0. 0完美的取消授权-WordPress数据采集插件一个比wp-autopost pro更好的数据采集插件
WP Content Crawler允许您自动将网站上的几乎所有内容发布到WordPress上的站点,博客或在线商店!设置完参数后,插件将找到消息的URL并在后台自动扫描它们。详细的工具栏-查看后台会发生什么。活动站点,查看的消息数,更新的消息数,最近查看和更新的消息数,最后添加的URL,触发的上一个和下一个CRON事件,当前保存的消息和URL ...
支持WordPress 5. 3. x +和PHP 7. 4+最新版本
演示测试地址
[button class =“ demo” size =“ lg” href =“%3A%2F %% 2Fwp-admin%2F&reauth = 1” title =“”]测试地址背景
[/ button]
WP Content Crawler可以使用的主要功能
保存每个帖子的详细信息
标题,摘录,内容,标签,类别,项目符号,日期,自定义元,分类法,元关键字,元描述,特色图片,帖子图片,状态...一切。
视觉选择器(视觉检查器)
只需单击一个元素即可找到其CSS选择器。您还可以获取其他可能感兴趣的CSS选择器。无需离开管理面板。
获取(获取,获取,保存)帖子
配置设置后,插件将找到帖子的URL并自动在后台对其进行爬网。
重新抓取(更新)帖子
自动重新爬网帖子,以使其始终保持最新状态。您可以限制帖子的更新次数,设置更新间隔并忽略旧帖子。
删除帖子
您要删除旧的已爬网帖子吗?该插件可以自动将其删除。
控制计划
您可以设置网站每次应执行URL采集和爬网事件的次数。例如,您每分钟可以保存3个帖子,或者每2分钟运行5次URL采集。
保存类别
您的网站中没有目标类别?没问题。该插件可以为您创建目标类别。只需定义用于查找类别名称的CSS选择器即可。它们甚至可以创建为子类别。
保存块(永久链接)
您可以定义帖子的永久链接。您可以从目标站点获得永久链接,输入自定义文本,甚至可以使用简码为块创建模板。
保存类别
The
方法通过从目标站点检索分类值或手动输入分类值来保存分类值。保存自定义帖子类型的详细信息比以往任何时候都容易。
将帖子保存在自定义类别中
自定义帖子类型是否具有自定义类别?没问题。您可以定义自定义帖子类型使用的自定义类别分类法,并在定义帖子的类别时选择这些类别。该插件还可以为您创建自定义类别。
自定义帖子元
将所有内容另存为自定义帖子元。您可以使用CSS选择器,也可以只输入值。
内容模板
使用简码准备帖子内容,标题,摘录,列表项和画廊项模板。另外,您可以使用选项框为每个CSS选择器值定义一个模板。
替代选项
即使目标站点的设计彼此不同,您也可以编写替代选择器来获取数据。
查找并替换所有内容
您可以使用纯文本或正则表达式来查找和替换任何内容。您甚至可以修改页面的HTML,创建自己的HTML元素并编写选择器以使用它们。您甚至可以更改图像URL。你有力量。
分页帖子
目标帖子有一页以上?不用担心。您还可以保存分页的帖子。
列出类型的帖子
网站创建的某些帖子中收录列表。您可以从帖子中提取列表,创建应应用于每个列表项的模板,甚至反转列表。
删除不必要的元素
有时候,您需要去除一些元素,例如广告,评论,然后对其进行命名。只需编写其CSS选择器即可将其删除。
自动插入类别网址
目标网站上有数百个类别?一块蛋糕。只需编写CSS选择器,插件就会为您插入它们。
帖子类型
设置帖子类型。它可以是您的WordPress安装中可用的帖子,页面,产品或任何其他帖子类型。
删除链接
您可以从帖子中删除链接。只需选中复选框,链接就会消失。很简单
密码保护
您可以为帖子设置密码,以仅向具有密码的用户显示该帖子。
注释
您可以自己添加注释,以提醒您有关该网站的信息。 CSS选择器,TODO列表等。
实时测试所有内容,实时测试
搜寻,URL采集,CSS选择器,正则表达式,即时查找和替换选项以及代理。您还可以启用缓存以更快地执行测试并减少发送到目标站点的请求。
一次
测试站点的所有设置。使用测试仪,您可以测试网站设置中配置的所有选项,以确保在启用自动爬网之前一切都按需运行。
工具
使用这些工具,您可以使用帖子的URL手动保存帖子,使用ID重新抓取或删除保存的URL。
每个站点的自定义常规设置
您可以为每个帖子提供自定义常规设置,以覆盖它们并使它们适合某个网站。
发布状态
您可以直接发布已保存的帖子,也可以将其保留为草稿,以在发布前对其进行审核。
将所有图像保存在帖子内容中
就像选择一个复选框一样简单。
将图片另存为画廊
您可以将目标页面中的图像另存为图库,并为每个图像提供一个模板,使其适合您在前端使用的图库。您也可以仅通过选中复选框将图像另存为WooCommerce画廊。
任何数据作为简码
从目标页面获取任何内容作为简码,然后在插件模板中使用简码将任何数据放置在所需的位置。
代理
使用一个或多个代理从IP无法访问的站点获取内容。
饼干
向每个请求附加一个cookie(例如会话cookie)。例如,通过这种方式,您可以像登录时一样对目标站点进行爬网。
抓取尽可能多的帖子
您可以设置帖子搜寻或URL采集CRON事件应运行的次数。这样,例如,您可以每分钟保存100个帖子。请小心并考虑服务器的容量。
电子邮件通知
设置CSS选择器,其类别和帖子页面的值不应为空。使用这些选择器找到空值时,您将收到一封电子邮件通知。
从JSON获取数据
为CSS选择器启用JSON解析后,您可以轻松地从JSON获取值。
高级HTML操作
在响应HTML中查找内容,在元素属性中查找和替换,交换元素属性,删除元素属性,操纵元素的HTML,删除HTML元素...
自动翻译
使用Google Cloud Translation API,Microsoft Translator Text API,Yandex Translate API或Amazon Translate API的人工智能来自动翻译帖子。请注意,这些服务是付费服务,但Yandex Translate API除外。付费用户还可以在有限的时间内免费提供该服务。您可以查看其定价页面以获取更多信息。
自动伪原创
使用轮播功能自动重写已爬网帖子的内容,以改善搜索引擎的优化。该插件当前实现了收费的Spin Rewriter API和Turkce Spin API。您可以访问他们的网站了解价格详情。
重复核对邮件
通过URL,帖子标题和/或帖子内容检查重复的帖子。如果您使用的是WooCommerce,则已经存在SKU的产品将被视为重复产品,并且不会添加到您的网站中。
预定帖子
您可以添加/删除发布日期的分钟数。这样,您可以安排发布时间。
保存WooCommerce产品
保存价格,库存,运输,属性和高级选项。您可以将产品另存为简单产品或外部产品。您还可以设置可下载的文件选项,并将产品定义为虚拟产品。这些选项可用于大于或等于3. 3的WooCommerce版本。
选项框
您有控制权!为CSS选择器找到的值定义许多选项。选项包括搜索和替换,计算,模板和JSON解析设置。您也可以轻松导入/导出在选项框中定义的选项。
像专业人员一样处理
文件可以轻松地重命名,复制和移动保存的文件。您也可以使用模板定义已保存媒体文件的标题,描述,标题和备用文本,在其中可以使用任何短代码。您还可以为保存的文件分配一个随机名称。
专业
WordPress处理iframe和脚本的方式与WordPress不允许显示iframe和脚本的方式相同,因为它们会带来安全风险。您只需选中一个复选框即可将iframe和HTML脚本元素转换为短代码。简码将在您定义的允许的源域中显示iframe和脚本。
快速保存
使用快速保存按钮可以更快地保存设置。无需等待页面重新加载。
正则表达式在find-replace选项中定义一个正则表达式以查找任何内容。您还可以使用定界符和修饰符进行更精确的匹配。
保存“ srcset”属性
当其他尺寸的已保存图像可用时,插件会将它们分配给img元素的srcset属性,以便您的页面在不同屏幕尺寸下的加载速度更快。
保存“ alt”和“ title”属性
保存图像时,它们的“ alt”和“ title”属性会自动从目标站点中检索并分配给保存的媒体。您还可以为其定义模板以应用您的SEO策略。
警告
了解问题发生的时间。该插件将向您显示错误的详细信息,以便您可以立即修复。
处理字符编码问题
即使目标站点收录混合编码,该插件也可以处理不同的字符编码。您可以通过选中一个复选框来切换编码。
在设置之间轻松
导航会将导航固定在顶部!插件会在切换到新标签页之前存储您的位置,并在您再次激活标签页时恢复以前的位置。设置之间不再迷路了。
手动抓取工具
使用手动抓取工具通过输入其网址来保存多个帖子。您还可以输入类别URL,以便该工具可以从那里获取帖子URL。此外,您可以将其设置为同时抓取多个帖子。
将URL添加到数据库
该插件自动采集URL。但是,如果希望它仅对某些URL进行爬网,则可以使用手动爬网工具将其手动添加到数据库中。这样,将使用您的计划选项自动搜索指定的URL。
启用/禁用特定网站的自动爬网
您可以分别启用或禁用每个网站的自动爬网。
导入/导出
您可以轻松导入和导出网站设置。只需复制并粘贴由插件创建的代码即可。
无限
添加无限的站点,并根据需要激活任意数量的站点。
详细的仪表板
了解背景。活动站点,已爬网的帖子数,已更新的帖子数,上次爬网和更新的帖子,上次添加的URL,CRON事件的上一次和下一次运行,当前保存的帖子和URL ...
从管理面板获取更新
只要您准备好更新,就可以一键更新插件。只需转到管理面板中的更新页面即可。
使用最安全的PHP
该插件支持最新版本的PHP。
使用最新的浏览器
该插件支持Chrome,Firefox,Safari,Opera和Edge。
互动指南
交互式指南显示了如何逐步配置设置以实现某些功能,例如实时文档。您可以随时激活这些指南。您甚至可以从特定步骤开始。
在线文档
您可以在需要时查看在线文档。
设置旁边
中的每个设置
快速指南插件提供了一个快速指南,可帮助您了解每个设置的作用。
视频教程
观看视频教程,轻松学习如何使用该插件。
要求
PHP> = 7. 2,json,mbstring,curl,dom,WP-Cron。这些在大多数主机中已经可用。即使扩展名尚未激活,大多数托管站点也允许您从其控制面板启用这些扩展名。有关更多信息,请参见文档。
通过WP版本进行测试
5. 3、 5. 2、 5. 1、 5. 0、 4. 9
通过WooCommerce版本测试
3. 9、 3. 8、 3. 7、 3. 6、 3. 5
预览本地测量的屏幕截图
查看全部
WPContentCrawler可以使用什么主要功能特点保存(组图)
WP Content Crawler v 1. 1 0. 0完美的取消授权-WordPress数据采集插件一个比wp-autopost pro更好的数据采集插件
WP Content Crawler允许您自动将网站上的几乎所有内容发布到WordPress上的站点,博客或在线商店!设置完参数后,插件将找到消息的URL并在后台自动扫描它们。详细的工具栏-查看后台会发生什么。活动站点,查看的消息数,更新的消息数,最近查看和更新的消息数,最后添加的URL,触发的上一个和下一个CRON事件,当前保存的消息和URL ...
支持WordPress 5. 3. x +和PHP 7. 4+最新版本
演示测试地址
[button class =“ demo” size =“ lg” href =“%3A%2F %% 2Fwp-admin%2F&reauth = 1” title =“”]测试地址背景
[/ button]
WP Content Crawler可以使用的主要功能
保存每个帖子的详细信息
标题,摘录,内容,标签,类别,项目符号,日期,自定义元,分类法,元关键字,元描述,特色图片,帖子图片,状态...一切。
视觉选择器(视觉检查器)
只需单击一个元素即可找到其CSS选择器。您还可以获取其他可能感兴趣的CSS选择器。无需离开管理面板。
获取(获取,获取,保存)帖子
配置设置后,插件将找到帖子的URL并自动在后台对其进行爬网。
重新抓取(更新)帖子
自动重新爬网帖子,以使其始终保持最新状态。您可以限制帖子的更新次数,设置更新间隔并忽略旧帖子。
删除帖子
您要删除旧的已爬网帖子吗?该插件可以自动将其删除。
控制计划
您可以设置网站每次应执行URL采集和爬网事件的次数。例如,您每分钟可以保存3个帖子,或者每2分钟运行5次URL采集。
保存类别
您的网站中没有目标类别?没问题。该插件可以为您创建目标类别。只需定义用于查找类别名称的CSS选择器即可。它们甚至可以创建为子类别。
保存块(永久链接)
您可以定义帖子的永久链接。您可以从目标站点获得永久链接,输入自定义文本,甚至可以使用简码为块创建模板。
保存类别
The
方法通过从目标站点检索分类值或手动输入分类值来保存分类值。保存自定义帖子类型的详细信息比以往任何时候都容易。
将帖子保存在自定义类别中
自定义帖子类型是否具有自定义类别?没问题。您可以定义自定义帖子类型使用的自定义类别分类法,并在定义帖子的类别时选择这些类别。该插件还可以为您创建自定义类别。
自定义帖子元
将所有内容另存为自定义帖子元。您可以使用CSS选择器,也可以只输入值。
内容模板
使用简码准备帖子内容,标题,摘录,列表项和画廊项模板。另外,您可以使用选项框为每个CSS选择器值定义一个模板。
替代选项
即使目标站点的设计彼此不同,您也可以编写替代选择器来获取数据。
查找并替换所有内容
您可以使用纯文本或正则表达式来查找和替换任何内容。您甚至可以修改页面的HTML,创建自己的HTML元素并编写选择器以使用它们。您甚至可以更改图像URL。你有力量。
分页帖子
目标帖子有一页以上?不用担心。您还可以保存分页的帖子。
列出类型的帖子
网站创建的某些帖子中收录列表。您可以从帖子中提取列表,创建应应用于每个列表项的模板,甚至反转列表。
删除不必要的元素
有时候,您需要去除一些元素,例如广告,评论,然后对其进行命名。只需编写其CSS选择器即可将其删除。
自动插入类别网址
目标网站上有数百个类别?一块蛋糕。只需编写CSS选择器,插件就会为您插入它们。
帖子类型
设置帖子类型。它可以是您的WordPress安装中可用的帖子,页面,产品或任何其他帖子类型。
删除链接
您可以从帖子中删除链接。只需选中复选框,链接就会消失。很简单
密码保护
您可以为帖子设置密码,以仅向具有密码的用户显示该帖子。
注释
您可以自己添加注释,以提醒您有关该网站的信息。 CSS选择器,TODO列表等。
实时测试所有内容,实时测试
搜寻,URL采集,CSS选择器,正则表达式,即时查找和替换选项以及代理。您还可以启用缓存以更快地执行测试并减少发送到目标站点的请求。
一次
测试站点的所有设置。使用测试仪,您可以测试网站设置中配置的所有选项,以确保在启用自动爬网之前一切都按需运行。
工具
使用这些工具,您可以使用帖子的URL手动保存帖子,使用ID重新抓取或删除保存的URL。
每个站点的自定义常规设置
您可以为每个帖子提供自定义常规设置,以覆盖它们并使它们适合某个网站。
发布状态
您可以直接发布已保存的帖子,也可以将其保留为草稿,以在发布前对其进行审核。
将所有图像保存在帖子内容中
就像选择一个复选框一样简单。
将图片另存为画廊
您可以将目标页面中的图像另存为图库,并为每个图像提供一个模板,使其适合您在前端使用的图库。您也可以仅通过选中复选框将图像另存为WooCommerce画廊。
任何数据作为简码
从目标页面获取任何内容作为简码,然后在插件模板中使用简码将任何数据放置在所需的位置。
代理
使用一个或多个代理从IP无法访问的站点获取内容。
饼干
向每个请求附加一个cookie(例如会话cookie)。例如,通过这种方式,您可以像登录时一样对目标站点进行爬网。
抓取尽可能多的帖子
您可以设置帖子搜寻或URL采集CRON事件应运行的次数。这样,例如,您可以每分钟保存100个帖子。请小心并考虑服务器的容量。
电子邮件通知
设置CSS选择器,其类别和帖子页面的值不应为空。使用这些选择器找到空值时,您将收到一封电子邮件通知。
从JSON获取数据
为CSS选择器启用JSON解析后,您可以轻松地从JSON获取值。
高级HTML操作
在响应HTML中查找内容,在元素属性中查找和替换,交换元素属性,删除元素属性,操纵元素的HTML,删除HTML元素...
自动翻译
使用Google Cloud Translation API,Microsoft Translator Text API,Yandex Translate API或Amazon Translate API的人工智能来自动翻译帖子。请注意,这些服务是付费服务,但Yandex Translate API除外。付费用户还可以在有限的时间内免费提供该服务。您可以查看其定价页面以获取更多信息。
自动伪原创
使用轮播功能自动重写已爬网帖子的内容,以改善搜索引擎的优化。该插件当前实现了收费的Spin Rewriter API和Turkce Spin API。您可以访问他们的网站了解价格详情。
重复核对邮件
通过URL,帖子标题和/或帖子内容检查重复的帖子。如果您使用的是WooCommerce,则已经存在SKU的产品将被视为重复产品,并且不会添加到您的网站中。
预定帖子
您可以添加/删除发布日期的分钟数。这样,您可以安排发布时间。
保存WooCommerce产品
保存价格,库存,运输,属性和高级选项。您可以将产品另存为简单产品或外部产品。您还可以设置可下载的文件选项,并将产品定义为虚拟产品。这些选项可用于大于或等于3. 3的WooCommerce版本。
选项框
您有控制权!为CSS选择器找到的值定义许多选项。选项包括搜索和替换,计算,模板和JSON解析设置。您也可以轻松导入/导出在选项框中定义的选项。
像专业人员一样处理
文件可以轻松地重命名,复制和移动保存的文件。您也可以使用模板定义已保存媒体文件的标题,描述,标题和备用文本,在其中可以使用任何短代码。您还可以为保存的文件分配一个随机名称。
专业
WordPress处理iframe和脚本的方式与WordPress不允许显示iframe和脚本的方式相同,因为它们会带来安全风险。您只需选中一个复选框即可将iframe和HTML脚本元素转换为短代码。简码将在您定义的允许的源域中显示iframe和脚本。
快速保存
使用快速保存按钮可以更快地保存设置。无需等待页面重新加载。
正则表达式在find-replace选项中定义一个正则表达式以查找任何内容。您还可以使用定界符和修饰符进行更精确的匹配。
保存“ srcset”属性
当其他尺寸的已保存图像可用时,插件会将它们分配给img元素的srcset属性,以便您的页面在不同屏幕尺寸下的加载速度更快。
保存“ alt”和“ title”属性
保存图像时,它们的“ alt”和“ title”属性会自动从目标站点中检索并分配给保存的媒体。您还可以为其定义模板以应用您的SEO策略。
警告
了解问题发生的时间。该插件将向您显示错误的详细信息,以便您可以立即修复。
处理字符编码问题
即使目标站点收录混合编码,该插件也可以处理不同的字符编码。您可以通过选中一个复选框来切换编码。
在设置之间轻松
导航会将导航固定在顶部!插件会在切换到新标签页之前存储您的位置,并在您再次激活标签页时恢复以前的位置。设置之间不再迷路了。
手动抓取工具
使用手动抓取工具通过输入其网址来保存多个帖子。您还可以输入类别URL,以便该工具可以从那里获取帖子URL。此外,您可以将其设置为同时抓取多个帖子。
将URL添加到数据库
该插件自动采集URL。但是,如果希望它仅对某些URL进行爬网,则可以使用手动爬网工具将其手动添加到数据库中。这样,将使用您的计划选项自动搜索指定的URL。
启用/禁用特定网站的自动爬网
您可以分别启用或禁用每个网站的自动爬网。
导入/导出
您可以轻松导入和导出网站设置。只需复制并粘贴由插件创建的代码即可。
无限
添加无限的站点,并根据需要激活任意数量的站点。
详细的仪表板
了解背景。活动站点,已爬网的帖子数,已更新的帖子数,上次爬网和更新的帖子,上次添加的URL,CRON事件的上一次和下一次运行,当前保存的帖子和URL ...
从管理面板获取更新
只要您准备好更新,就可以一键更新插件。只需转到管理面板中的更新页面即可。
使用最安全的PHP
该插件支持最新版本的PHP。
使用最新的浏览器
该插件支持Chrome,Firefox,Safari,Opera和Edge。
互动指南
交互式指南显示了如何逐步配置设置以实现某些功能,例如实时文档。您可以随时激活这些指南。您甚至可以从特定步骤开始。
在线文档
您可以在需要时查看在线文档。
设置旁边
中的每个设置
快速指南插件提供了一个快速指南,可帮助您了解每个设置的作用。
视频教程
观看视频教程,轻松学习如何使用该插件。
要求
PHP> = 7. 2,json,mbstring,curl,dom,WP-Cron。这些在大多数主机中已经可用。即使扩展名尚未激活,大多数托管站点也允许您从其控制面板启用这些扩展名。有关更多信息,请参见文档。
通过WP版本进行测试
5. 3、 5. 2、 5. 1、 5. 0、 4. 9
通过WooCommerce版本测试
3. 9、 3. 8、 3. 7、 3. 6、 3. 5
预览本地测量的屏幕截图
软件介绍下载器是一款可以批量采集拼多多产品图及描述图的软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 288 次浏览 • 2021-04-27 06:20
平多多产品图采集是专用于拼多多商人的辅助工具。它可以帮助用户轻松地采集 Pinduoduo以上产品图片和其他信息,这非常方便。有需要的用户可能希望下载体验!
软件简介
Pingduoduo产品图像采集下载程序是一款可以批量采集 Pinduoduo产品图像和说明的软件,它可以节省图片采集,从而节省每个人的时间。该软件支持批量采集,只需将产品地址批量输入软件即可实现批量采集的工作。
软件功能
整个商店复制:您可以一键复制任何人的拼多多商店(所有商店产品),并自动识别产品类别。如果您想复制商店,只需单击一下即可在几分钟之内完成!
该软件支持数据导入和导出,可以随意导入和导出数据,以供其他商店直接上传和使用。
支持批量编辑产品信息,任何产品信息均支持一键式批量设置,功能超强!
商店中的新实时照片:支持商店的实时照片上传新照片,不需要PS图片,该软件可以自动将图片大小调整为拼多多的指定大小,无论图片是大还是小,可以直接导入并批量发布!同时,它支持31个主要货源平台的产品信息采集 +编辑产品图片,您可以使用网络图片可以将其插入本地图片中!实拍节省时间和精力〜
使用方法
1.打开拼多多产品图采集下载器
2.点击打开Pinduoduo网络版本并登录
3.将所需的产品地址分批输入软件中
4.单击采集开始。
5.上次下载的图片将保存在数据文件夹中,单击以打开目录进行查找。
更新日志
1、优化了UI界面的流畅度
2、修复了已知错误 查看全部
软件介绍下载器是一款可以批量采集拼多多产品图及描述图的软件
平多多产品图采集是专用于拼多多商人的辅助工具。它可以帮助用户轻松地采集 Pinduoduo以上产品图片和其他信息,这非常方便。有需要的用户可能希望下载体验!
软件简介
Pingduoduo产品图像采集下载程序是一款可以批量采集 Pinduoduo产品图像和说明的软件,它可以节省图片采集,从而节省每个人的时间。该软件支持批量采集,只需将产品地址批量输入软件即可实现批量采集的工作。
软件功能
整个商店复制:您可以一键复制任何人的拼多多商店(所有商店产品),并自动识别产品类别。如果您想复制商店,只需单击一下即可在几分钟之内完成!
该软件支持数据导入和导出,可以随意导入和导出数据,以供其他商店直接上传和使用。
支持批量编辑产品信息,任何产品信息均支持一键式批量设置,功能超强!
商店中的新实时照片:支持商店的实时照片上传新照片,不需要PS图片,该软件可以自动将图片大小调整为拼多多的指定大小,无论图片是大还是小,可以直接导入并批量发布!同时,它支持31个主要货源平台的产品信息采集 +编辑产品图片,您可以使用网络图片可以将其插入本地图片中!实拍节省时间和精力〜
使用方法
1.打开拼多多产品图采集下载器
2.点击打开Pinduoduo网络版本并登录
3.将所需的产品地址分批输入软件中
4.单击采集开始。
5.上次下载的图片将保存在数据文件夹中,单击以打开目录进行查找。
更新日志
1、优化了UI界面的流畅度
2、修复了已知错误
完整的采集神器,您需要安装一个迅捷ad采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-04-21 04:03
完整的采集神器,您需要安装一个迅捷ad采集器,采集线路本地,局域网内都可以登录。全网搜索,热门资源都可以采集下载,
我来回答一下我吧。亲爱的,您可以试试其他的采集工具。例如:1000thing,还有思路采集器、fm采集器等等,都是免费的工具。如果需要付费的工具,那么以下的其他采集工具是免费的:1,kol(关键词)采集器,个人觉得也很好用,这是一款主打关键词的采集软件。2,artsmork3,scihunt4,sciexplore5,waterloo6,scientificartez7,自然分类网站分析8,scitext9,sciweb10,scidirect11,libgenmpith12,librarybaseofscienceprofessionals13,scifinder。
谢邀!可惜我是外行啊,我最常用的是entity采集器,还有谷歌文献资源包,但后两者是收费的,而且这两款还算是半专业的,但其他专业文献,我真的是一人一套个人技能包,包括电脑,文件解压缩,乱七八糟的软件,如果我必须用,只用一个真的可以的,收费的这个倒可以。但对我来说,这个个人技能包必须要要,因为电脑卡,当文件太大太多的时候,真的非常消耗时间,在此建议使用百度云,电脑手机都可以同步阅读,真的是太方便了。
资源包可以百度云下,edx和udacity,非常方便,买个wifi套餐20刀就可以批量下,然后按标题或者关键词去网上搜,能找到很多免费电子书,再一个搜,就是baidu知道了,对于需要文献比较多的人来说还是蛮好的,还有就是百度搜索,搜索关键词,输入hoping,一大堆结果,其实hoping这个网站有100多个结果,但最近我又去他的新闻中心,把新闻都能看到,毕竟新闻比较短,不用每次点开确认是不是新闻,有没有人讨论,那样太费时间了。
一条新闻几百字,电脑里可以放几百个,省不少时间。还有很多搜,但我一般不怎么用,要么就是要收费,要么就是全英文。其实英文就是学,我自己都去看文献了,而且有些英文只是当初关键词找错了,比如日常新闻,我给他打disappointed一般搜不到什么。我也很关注这些工具和网站,但我不是软件发烧友,用他们的话,一般也就是标题,或者链接,或者图片,其他我不感兴趣的,我直接删除,基本上不动他们。
我下软件也会因为一个小小的图标,比如有人搜到我新闻中心,我还需要点开,看一下有没有记录,为了这点时间,我需要重新去搜索文件,浪费时间也浪费我本来可以赚大钱的机会。我最好的东西,就是关注业内人的一些方法,可以节省大量时间,提高效率,还有的是看他们的分享文章,如果这个人写博客很好的话,也会有人学习他的方法。但如果我的这些东西不是他发出来的,他不。 查看全部
完整的采集神器,您需要安装一个迅捷ad采集器
完整的采集神器,您需要安装一个迅捷ad采集器,采集线路本地,局域网内都可以登录。全网搜索,热门资源都可以采集下载,
我来回答一下我吧。亲爱的,您可以试试其他的采集工具。例如:1000thing,还有思路采集器、fm采集器等等,都是免费的工具。如果需要付费的工具,那么以下的其他采集工具是免费的:1,kol(关键词)采集器,个人觉得也很好用,这是一款主打关键词的采集软件。2,artsmork3,scihunt4,sciexplore5,waterloo6,scientificartez7,自然分类网站分析8,scitext9,sciweb10,scidirect11,libgenmpith12,librarybaseofscienceprofessionals13,scifinder。
谢邀!可惜我是外行啊,我最常用的是entity采集器,还有谷歌文献资源包,但后两者是收费的,而且这两款还算是半专业的,但其他专业文献,我真的是一人一套个人技能包,包括电脑,文件解压缩,乱七八糟的软件,如果我必须用,只用一个真的可以的,收费的这个倒可以。但对我来说,这个个人技能包必须要要,因为电脑卡,当文件太大太多的时候,真的非常消耗时间,在此建议使用百度云,电脑手机都可以同步阅读,真的是太方便了。
资源包可以百度云下,edx和udacity,非常方便,买个wifi套餐20刀就可以批量下,然后按标题或者关键词去网上搜,能找到很多免费电子书,再一个搜,就是baidu知道了,对于需要文献比较多的人来说还是蛮好的,还有就是百度搜索,搜索关键词,输入hoping,一大堆结果,其实hoping这个网站有100多个结果,但最近我又去他的新闻中心,把新闻都能看到,毕竟新闻比较短,不用每次点开确认是不是新闻,有没有人讨论,那样太费时间了。
一条新闻几百字,电脑里可以放几百个,省不少时间。还有很多搜,但我一般不怎么用,要么就是要收费,要么就是全英文。其实英文就是学,我自己都去看文献了,而且有些英文只是当初关键词找错了,比如日常新闻,我给他打disappointed一般搜不到什么。我也很关注这些工具和网站,但我不是软件发烧友,用他们的话,一般也就是标题,或者链接,或者图片,其他我不感兴趣的,我直接删除,基本上不动他们。
我下软件也会因为一个小小的图标,比如有人搜到我新闻中心,我还需要点开,看一下有没有记录,为了这点时间,我需要重新去搜索文件,浪费时间也浪费我本来可以赚大钱的机会。我最好的东西,就是关注业内人的一些方法,可以节省大量时间,提高效率,还有的是看他们的分享文章,如果这个人写博客很好的话,也会有人学习他的方法。但如果我的这些东西不是他发出来的,他不。
完整的采集神器-api/采集系统地理分析系统推荐
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2021-04-01 06:00
完整的采集神器可以私信我发给你。(也欢迎加群讨论)不同的采集工具在速度、兼容性和处理器、整个采集网页的数量都会有所不同。所以最好是在多个网站采集,再进行合并。实在不行,就把不同网站的采集工具都合并,最好看看采集工具的文档,是不是只有要用它的时候才能起作用。
不用,直接装个,用浏览器就能抓包了,轻松无压力。
,
楼上说的对。
。另外一个简单就是使用网页采集工具,如veer或者小试牛刀的采集,输入地址,
先从第三方采集工具入手,试着采到自己想要的东西,稳定可靠再说。
采集别人的
在浏览器里输入网址
基本不需要采集神器,其他工具先行用1两年以后看看自己的ide设置,有足够积累后再用已经有的工具。
最新版本系列里面都有各种操作按钮,您提到的这一块也包含,您可以点开看看,有什么需要可以具体在中查看。
推荐使用(速度快)api/采集系统
地理分析系统
推荐veer或/
我不需要采集神器,只用过一个叫的地理分析系统,虽然需要从服务入口进去,但是好过整个brd文档下来。特别是这个工具,根据图层的单位和边界来自动分析出相邻两个相邻区域或相邻国家间边界,生成中的特征值来高亮“经度”,“纬度”或“经纬度”等数值,谁位置不规则?。 查看全部
完整的采集神器-api/采集系统地理分析系统推荐
完整的采集神器可以私信我发给你。(也欢迎加群讨论)不同的采集工具在速度、兼容性和处理器、整个采集网页的数量都会有所不同。所以最好是在多个网站采集,再进行合并。实在不行,就把不同网站的采集工具都合并,最好看看采集工具的文档,是不是只有要用它的时候才能起作用。
不用,直接装个,用浏览器就能抓包了,轻松无压力。
,
楼上说的对。
。另外一个简单就是使用网页采集工具,如veer或者小试牛刀的采集,输入地址,
先从第三方采集工具入手,试着采到自己想要的东西,稳定可靠再说。
采集别人的
在浏览器里输入网址
基本不需要采集神器,其他工具先行用1两年以后看看自己的ide设置,有足够积累后再用已经有的工具。
最新版本系列里面都有各种操作按钮,您提到的这一块也包含,您可以点开看看,有什么需要可以具体在中查看。
推荐使用(速度快)api/采集系统
地理分析系统
推荐veer或/
我不需要采集神器,只用过一个叫的地理分析系统,虽然需要从服务入口进去,但是好过整个brd文档下来。特别是这个工具,根据图层的单位和边界来自动分析出相邻两个相邻区域或相邻国家间边界,生成中的特征值来高亮“经度”,“纬度”或“经纬度”等数值,谁位置不规则?。
完整的采集神器-360浏览器下的优采云采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 419 次浏览 • 2021-03-31 18:06
完整的采集神器,今天推荐的是360浏览器下的优采云采集器。当你在百度上看到好玩的链接,点击进去浏览器变成了万能的采集器,你可以选择图片、音频、文字、视频、地址、脚本、热点、视频等采集工具。而且,有人已经利用它把腾讯视频搬运到百度上去了。这款采集器功能比较多,我们以图片的采集为例。在浏览器中输入360优采云采集器网址,点击右上角选择查看源代码,图片就会出现在了地址栏中。
除了图片地址,还可以选择视频地址,跟我们之前推荐的图片采集神器一样,它也可以进行批量地址编辑,如:自动搜索地址、地址后缀修改、收藏地址、超链接、地址查看、下载地址修改、视频解析、视频下载等等。最牛的是,它可以批量把文字转换成地址,粘贴到另一个网站进行搜索。找到喜欢的图片地址后,点击下载就可以保存保存到本地,我们还可以把图片链接复制到别的地方。
除了是万能的采集工具,它也提供了两个采集规则,一个是文字,一个是视频。全文在此不再赘述。1.一个采集规则,两个规则解析,不用手动配置2.采集结果都直接保存到本地,无需再次下载3.这么优秀的采集器,需要动点手指哦,因为这是手机版,而且它是版本的,ios用户需要谷歌商店适应才能使用。个人观点:没有百度,谁敢说自己不用网址导航呢?。 查看全部
完整的采集神器-360浏览器下的优采云采集器
完整的采集神器,今天推荐的是360浏览器下的优采云采集器。当你在百度上看到好玩的链接,点击进去浏览器变成了万能的采集器,你可以选择图片、音频、文字、视频、地址、脚本、热点、视频等采集工具。而且,有人已经利用它把腾讯视频搬运到百度上去了。这款采集器功能比较多,我们以图片的采集为例。在浏览器中输入360优采云采集器网址,点击右上角选择查看源代码,图片就会出现在了地址栏中。
除了图片地址,还可以选择视频地址,跟我们之前推荐的图片采集神器一样,它也可以进行批量地址编辑,如:自动搜索地址、地址后缀修改、收藏地址、超链接、地址查看、下载地址修改、视频解析、视频下载等等。最牛的是,它可以批量把文字转换成地址,粘贴到另一个网站进行搜索。找到喜欢的图片地址后,点击下载就可以保存保存到本地,我们还可以把图片链接复制到别的地方。
除了是万能的采集工具,它也提供了两个采集规则,一个是文字,一个是视频。全文在此不再赘述。1.一个采集规则,两个规则解析,不用手动配置2.采集结果都直接保存到本地,无需再次下载3.这么优秀的采集器,需要动点手指哦,因为这是手机版,而且它是版本的,ios用户需要谷歌商店适应才能使用。个人观点:没有百度,谁敢说自己不用网址导航呢?。
完整的采集神器googlewebsearchsupport和可视化工具和airbatteryecharts的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 251 次浏览 • 2021-03-26 00:02
完整的采集神器googlewebsearchsupport这篇文章中详细的描述了采集技术和方法。详细的采集技术和方法可以看这篇文章。html5动态查询和可视化工具echarts和airbatteryecharts是一款对html5交互设计友好的动态查询工具,可以从网页采集数据。而airbattery则是一款手机端工具,可以方便的从网页中采集数据。
html5scrawler一款对html5交互设计友好的网页采集工具,可以对采集的网页进行抓取。采集资源在站内搜索词语查询,并采集内容。网页爬虫实现爬虫可以基于javascript和jquery开发,也可以基于c#语言。方便网页抓取使用爬虫采集网页可以使用两种方式,首先可以通过httpwatch方式查看爬虫有多少gp。
然后可以通过lizismap方式对抓取的网页进行采集。浏览器抓取有web2.0和chrome两种方式。下面以web2.0的方式为例,步骤如下1.登录爬虫。2.打开需要抓取的页面,选择convert按钮,然后将爬虫信息发送给converter配置中的convert下的scrapable。converter请求url.3.select*/*/all//select*andlistnameandpagecontentthatweresenttotheconverter.select*.4.convert*/*allall5.select*/*/*/thepage6.select*/*/*/thepage7.打开select链接,在页面的上下文中选择all,done。 查看全部
完整的采集神器googlewebsearchsupport和可视化工具和airbatteryecharts的方式
完整的采集神器googlewebsearchsupport这篇文章中详细的描述了采集技术和方法。详细的采集技术和方法可以看这篇文章。html5动态查询和可视化工具echarts和airbatteryecharts是一款对html5交互设计友好的动态查询工具,可以从网页采集数据。而airbattery则是一款手机端工具,可以方便的从网页中采集数据。
html5scrawler一款对html5交互设计友好的网页采集工具,可以对采集的网页进行抓取。采集资源在站内搜索词语查询,并采集内容。网页爬虫实现爬虫可以基于javascript和jquery开发,也可以基于c#语言。方便网页抓取使用爬虫采集网页可以使用两种方式,首先可以通过httpwatch方式查看爬虫有多少gp。
然后可以通过lizismap方式对抓取的网页进行采集。浏览器抓取有web2.0和chrome两种方式。下面以web2.0的方式为例,步骤如下1.登录爬虫。2.打开需要抓取的页面,选择convert按钮,然后将爬虫信息发送给converter配置中的convert下的scrapable。converter请求url.3.select*/*/all//select*andlistnameandpagecontentthatweresenttotheconverter.select*.4.convert*/*allall5.select*/*/*/thepage6.select*/*/*/thepage7.打开select链接,在页面的上下文中选择all,done。
新手三分钟学会采集永不求人独特的【万能规则】
采集交流 • 优采云 发表了文章 • 0 个评论 • 247 次浏览 • 2021-03-23 22:22
优采云 采集系统软件是功能强大的数据采集软件,它可以帮助用户采集各种资源,包括URL,文章,内容等,采集处理所有自动,用户还可以过滤采集的内容,并可以自定义采集规则,这是您必备的全能采集工件。
优采云 采集系统软件基本介绍
优采云 采集是一款数据采集软件,可以自动为您自动采集任何数据。 优采云 采集支持URL 采集,内容采集,全自动采集和其他功能。该操作也非常方便,需要它的用户可以下载它。
优采云 采集系统软件功能简介
独创性
新界面,终极轻松体验
我们将继续完善每一个细节,并追求更极端的体验。不仅要成为易于使用的采集软件,而且还希望成为您值得信赖的朋友。
舒适
新一代优采云 采集更强大,更智能
智能定时采集完美过滤,对采集的数据进行全面过滤,始终7 * 24 * 365等待并监视采集。
放心
一键式伪原创 api界面采集可以调用27个国家/地区的双语翻译
当遇到禁止信息时,优采云 采集拦截功能将完全拦截垃圾数据,因此您可以在采集中放心使用。
初始心脏
新手在三分钟内学习采集 采集永远不要寻求帮助
独特的[通用规则]可使每个新手在3分钟内学习,每个人都会编写采集规则,[通用规则]简单高效。
优采云 采集系统软件功能简介
1.全自动采集您想要的任何数据。
2.该软件自动调用百度搜索结果,跳过百度结果地址加密,直接获取指向地址。
3.支持自定义各种搜索方法,采集直接将结果导出到文本文件,支持导入各种类型的促销,并发送用于促销和发送操作的软件。
4. 采集的数据是百度收录用于优化和推广超级有效的数据。 查看全部
新手三分钟学会采集永不求人独特的【万能规则】
优采云 采集系统软件是功能强大的数据采集软件,它可以帮助用户采集各种资源,包括URL,文章,内容等,采集处理所有自动,用户还可以过滤采集的内容,并可以自定义采集规则,这是您必备的全能采集工件。
优采云 采集系统软件基本介绍
优采云 采集是一款数据采集软件,可以自动为您自动采集任何数据。 优采云 采集支持URL 采集,内容采集,全自动采集和其他功能。该操作也非常方便,需要它的用户可以下载它。
优采云 采集系统软件功能简介
独创性
新界面,终极轻松体验
我们将继续完善每一个细节,并追求更极端的体验。不仅要成为易于使用的采集软件,而且还希望成为您值得信赖的朋友。
舒适
新一代优采云 采集更强大,更智能
智能定时采集完美过滤,对采集的数据进行全面过滤,始终7 * 24 * 365等待并监视采集。
放心
一键式伪原创 api界面采集可以调用27个国家/地区的双语翻译
当遇到禁止信息时,优采云 采集拦截功能将完全拦截垃圾数据,因此您可以在采集中放心使用。
初始心脏
新手在三分钟内学习采集 采集永远不要寻求帮助
独特的[通用规则]可使每个新手在3分钟内学习,每个人都会编写采集规则,[通用规则]简单高效。
优采云 采集系统软件功能简介
1.全自动采集您想要的任何数据。
2.该软件自动调用百度搜索结果,跳过百度结果地址加密,直接获取指向地址。
3.支持自定义各种搜索方法,采集直接将结果导出到文本文件,支持导入各种类型的促销,并发送用于促销和发送操作的软件。
4. 采集的数据是百度收录用于优化和推广超级有效的数据。
数据采集过程中用到的神器mitmproxy,平台架构设计
采集交流 • 优采云 发表了文章 • 0 个评论 • 561 次浏览 • 2021-03-16 12:01
在此期间,我一直在处理数据采集。目前,平台数据采集已稳定。您可以花一些时间整理最近的结果,并顺便介绍一些最近使用的技术。本文文章是有偏见的技术,要求读者具有一定的技术基础。它主要介绍了在数据处理中使用的伪造物mitmproxy 采集,以及该平台的一些技术设计。以下是数据采集的整体设计。客户在左边。在其中放置了不同的采集器。 采集器发起请求后,它通过mitmproxy访问抖音,并且在返回数据之后,它穿过中间解析器。数据被解析,并最终存储在不同类别的数据库中。为了提高性能,在中间添加了一个缓存,以将采集器与解析器分开。两个模块之间的工作不会互相影响,并且可以最大化数据。在库中,下图显示了第一代体系结构设计,并且将有后续文章文章介绍第三代体系结构平台架构设计的演进历史。
准备工作
开始准备数据采集时,第一步自然是建立环境。这次我们在Windows环境中使用python 3. 6. 6环境,数据包捕获和代理工具是mitmproxy,也可以。使用Fiddler捕获数据包,并使用Night God模拟器来模拟Android操作环境(您也可以使用真实的机器)。这次,您主要使用手动滑动应用程序来捕获数据。下次,我们将介绍Appium自动化工具,以实现完整的数据采集自动(免提)。
1、安装python 3. 6. 6环境,安装过程可以由百度自己完成,需要注意的是centos7是python 2. 7附带的,需要升级到python 3. 6. 6环境,请在升级前安装ssl模块,否则升级后的版本将无法访问https请求。
2、安装mitmproxy。安装python环境后,执行pip install mitmproxy在命令行上安装mitmproxy。注意:在Windows下只能使用mitmdump和mitmweb。安装后,在命令行上输入mitmdump以启动。代理端口是8080。
3、要安装Night God Simulator,可以在官方网站上下载安装包。安装教程可以由百度完成。基本上,这是下一步。安装Night God Simulator之后,您需要配置Night God Simulator。首先,您需要将模拟器的网络设置为手动代理,IP地址是Windows的IP,端口是mitmproxy的代理端口。
4、接下来是证书的安装。在模拟器中打开浏览器,输入地址mitm.it,然后选择相应版本的证书。安装后,您可以开始捕获该软件包。
5、安装应用程序,可以从官方网站下载应用程序安装包,然后将其拖到模拟器中或在应用程序市场中安装即可安装。
到目前为止,此data 采集环境已完全设置。
数据接口分析和数据包捕获
设置环境后,我们将开始捕获抖音 app的数据并分析每个功能使用的接口。这次,我们以采集视频数据接口为例。
关闭先前打开的mitmdump,重新打开mitmweb工具,mitmweb是图形版本,因此您无需查找黑盒,如下所示:
启动后打开模拟器的抖音 app,可以看到已经解析了数据包,然后进入用户主页,开始向下滑动视频,可以在数据包列表
您可以在右侧看到接口的请求数据和响应数据。我们复制响应数据,然后进入下一步分析。
数据分析
通过mitmproxy和python代码的组合,我们可以通过代码在mitmproxy中获取数据包,然后根据需要对其进行处理。创建一个新的test.py文件,并在其中放入两个方法:
def request(flow):
pass
def response(flow):
pass
顾名思义,这两种方法,一种在请求时执行,另一种在响应时执行,并且数据包存在于流中。请求URL可以通过flow.request.url获取,请求头信息可以通过flow.request.headers获取,flow.response.text中的数据为响应数据。
def response(flow):
if str(flow.request.url).startswith("https://aweme.snssdk.com/aweme/v1/aweme/post/"):
index_response_dict = json.loads(flow.response.text)
aweme_list = index_response_dict.get('aweme_list')
if aweme_list:
for aweme in aweme_list:
print(aweme)
此aweme是完整的视频数据,您可以根据需要提取其中的信息,这里提取了一些信息以供介绍。
统计信息是该视频的点赞,评论,下载和转发的数据。
share_url是视频的共享地址,通过该地址,您可以在PC上观看抖音共享的视频,也可以通过此链接解析不带水印的视频。
play_addr是视频的播放信息。 url_list是不带水印的地址。但是,官方处理已经完成。该地址不能直接播放,并且有时间限制。超时后,链接将无效。
借助此功能,您可以解析出内部信息并将其保存到自己的数据库中,或者下载不带水印的视频并将其保存到计算机中。
编写代码后,保存test.py文件,cmd进入命令行,进入保存test.py文件的目录,在命令行上输入mitmdump -s test.py,并且mitmdump将启动。此时打开该应用程序。开始滑动模拟器并进入用户主页:
它开始下降,并且test.py文件可以解析所有捕获的视频数据。以下是我截获的一些数据信息:
视频信息:
视频统计信息:
查看全部
数据采集过程中用到的神器mitmproxy,平台架构设计
在此期间,我一直在处理数据采集。目前,平台数据采集已稳定。您可以花一些时间整理最近的结果,并顺便介绍一些最近使用的技术。本文文章是有偏见的技术,要求读者具有一定的技术基础。它主要介绍了在数据处理中使用的伪造物mitmproxy 采集,以及该平台的一些技术设计。以下是数据采集的整体设计。客户在左边。在其中放置了不同的采集器。 采集器发起请求后,它通过mitmproxy访问抖音,并且在返回数据之后,它穿过中间解析器。数据被解析,并最终存储在不同类别的数据库中。为了提高性能,在中间添加了一个缓存,以将采集器与解析器分开。两个模块之间的工作不会互相影响,并且可以最大化数据。在库中,下图显示了第一代体系结构设计,并且将有后续文章文章介绍第三代体系结构平台架构设计的演进历史。
准备工作
开始准备数据采集时,第一步自然是建立环境。这次我们在Windows环境中使用python 3. 6. 6环境,数据包捕获和代理工具是mitmproxy,也可以。使用Fiddler捕获数据包,并使用Night God模拟器来模拟Android操作环境(您也可以使用真实的机器)。这次,您主要使用手动滑动应用程序来捕获数据。下次,我们将介绍Appium自动化工具,以实现完整的数据采集自动(免提)。
1、安装python 3. 6. 6环境,安装过程可以由百度自己完成,需要注意的是centos7是python 2. 7附带的,需要升级到python 3. 6. 6环境,请在升级前安装ssl模块,否则升级后的版本将无法访问https请求。
2、安装mitmproxy。安装python环境后,执行pip install mitmproxy在命令行上安装mitmproxy。注意:在Windows下只能使用mitmdump和mitmweb。安装后,在命令行上输入mitmdump以启动。代理端口是8080。
3、要安装Night God Simulator,可以在官方网站上下载安装包。安装教程可以由百度完成。基本上,这是下一步。安装Night God Simulator之后,您需要配置Night God Simulator。首先,您需要将模拟器的网络设置为手动代理,IP地址是Windows的IP,端口是mitmproxy的代理端口。
4、接下来是证书的安装。在模拟器中打开浏览器,输入地址mitm.it,然后选择相应版本的证书。安装后,您可以开始捕获该软件包。
5、安装应用程序,可以从官方网站下载应用程序安装包,然后将其拖到模拟器中或在应用程序市场中安装即可安装。
到目前为止,此data 采集环境已完全设置。
数据接口分析和数据包捕获
设置环境后,我们将开始捕获抖音 app的数据并分析每个功能使用的接口。这次,我们以采集视频数据接口为例。
关闭先前打开的mitmdump,重新打开mitmweb工具,mitmweb是图形版本,因此您无需查找黑盒,如下所示:
启动后打开模拟器的抖音 app,可以看到已经解析了数据包,然后进入用户主页,开始向下滑动视频,可以在数据包列表
您可以在右侧看到接口的请求数据和响应数据。我们复制响应数据,然后进入下一步分析。
数据分析
通过mitmproxy和python代码的组合,我们可以通过代码在mitmproxy中获取数据包,然后根据需要对其进行处理。创建一个新的test.py文件,并在其中放入两个方法:
def request(flow):
pass
def response(flow):
pass
顾名思义,这两种方法,一种在请求时执行,另一种在响应时执行,并且数据包存在于流中。请求URL可以通过flow.request.url获取,请求头信息可以通过flow.request.headers获取,flow.response.text中的数据为响应数据。
def response(flow):
if str(flow.request.url).startswith("https://aweme.snssdk.com/aweme/v1/aweme/post/";):
index_response_dict = json.loads(flow.response.text)
aweme_list = index_response_dict.get('aweme_list')
if aweme_list:
for aweme in aweme_list:
print(aweme)
此aweme是完整的视频数据,您可以根据需要提取其中的信息,这里提取了一些信息以供介绍。
统计信息是该视频的点赞,评论,下载和转发的数据。
share_url是视频的共享地址,通过该地址,您可以在PC上观看抖音共享的视频,也可以通过此链接解析不带水印的视频。
play_addr是视频的播放信息。 url_list是不带水印的地址。但是,官方处理已经完成。该地址不能直接播放,并且有时间限制。超时后,链接将无效。
借助此功能,您可以解析出内部信息并将其保存到自己的数据库中,或者下载不带水印的视频并将其保存到计算机中。
编写代码后,保存test.py文件,cmd进入命令行,进入保存test.py文件的目录,在命令行上输入mitmdump -s test.py,并且mitmdump将启动。此时打开该应用程序。开始滑动模拟器并进入用户主页:
它开始下降,并且test.py文件可以解析所有捕获的视频数据。以下是我截获的一些数据信息:
视频信息:
视频统计信息:
固乔视频助手:自媒体短视频采集器下载工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 647 次浏览 • 2021-03-03 08:06
现在自媒体行业正变得越来越流行,越来越多的人加入该行业,因此,当我们从事自媒体时,它也是知识积累的过程。对于您制作的短片来说,获得所有人的认可是非常重要的。
自媒体短视频采集有很多下载工具,但是最好使用自己易于使用的软件。这是我更多使用的视频采集器下载工具。乔视频助理。
操作简便,在界面中打开自媒体视频下载功能,点击下载页面即可随机获取热门视频,我们可以快速获取热门的短视频资源。
它还支持通过视频链接下载视频。有数十种平台支持自媒体,b站,抖音,火山和小红树。
打开选择功能,我们可以使用关键词进行定位,然后搜索所需的热门视频资源。
在下载页面中打开高级设置。在高级设置对话框中,我们可以设置下载视频的分辨率,还可以使用无水印视频解析组件,这可以帮助我们在没有自媒体平台徽标的情况下下载视频。
除上述以外,您是否认为结束?实际上,当我们移动视频时,最重要的是修改MD5值。该工具包括此功能。当我们需要下载时,选中自动更改MD5值的选项。下载后,进行第二次编辑,以使原创的几率大大提高。
实际上,当我们认为它具有许多功能时,它还具有另一个强大的功能。对于自媒体个制作视频的人来说,无疑会增加方便门,即音乐下载功能。
只要您找到所需的音乐名称,然后进行搜索,我们就可以快速,批量下载它。使用此软件,您不必担心找不到歌曲或记住歌曲名称。
有了如此强大的辅助工具,为什么我们在自媒体个短视频中做得不好? 查看全部
固乔视频助手:自媒体短视频采集器下载工具
现在自媒体行业正变得越来越流行,越来越多的人加入该行业,因此,当我们从事自媒体时,它也是知识积累的过程。对于您制作的短片来说,获得所有人的认可是非常重要的。
自媒体短视频采集有很多下载工具,但是最好使用自己易于使用的软件。这是我更多使用的视频采集器下载工具。乔视频助理。
操作简便,在界面中打开自媒体视频下载功能,点击下载页面即可随机获取热门视频,我们可以快速获取热门的短视频资源。
它还支持通过视频链接下载视频。有数十种平台支持自媒体,b站,抖音,火山和小红树。
打开选择功能,我们可以使用关键词进行定位,然后搜索所需的热门视频资源。
在下载页面中打开高级设置。在高级设置对话框中,我们可以设置下载视频的分辨率,还可以使用无水印视频解析组件,这可以帮助我们在没有自媒体平台徽标的情况下下载视频。
除上述以外,您是否认为结束?实际上,当我们移动视频时,最重要的是修改MD5值。该工具包括此功能。当我们需要下载时,选中自动更改MD5值的选项。下载后,进行第二次编辑,以使原创的几率大大提高。
实际上,当我们认为它具有许多功能时,它还具有另一个强大的功能。对于自媒体个制作视频的人来说,无疑会增加方便门,即音乐下载功能。
只要您找到所需的音乐名称,然后进行搜索,我们就可以快速,批量下载它。使用此软件,您不必担心找不到歌曲或记住歌曲名称。
有了如此强大的辅助工具,为什么我们在自媒体个短视频中做得不好?
如何轻松收集网站信息?(网站万能信息采集助手)
采集交流 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2021-02-16 13:01
如何轻松采集网站信息? 网站通用信息采集器(网站信息采集助手)是一种方便的Web信息采集器。 网站通用信息采集器(网站信息采集助手)可以帮助用户轻松完成任务。该软件结合了所有网络爬网软件的优点。它可以获取网站上的所有信息,然后自动将其发布到您的网站。它可以获取网站上任何类型的所有信息,例如新闻,供应和需求。信息,招聘信息,论坛帖子,音乐,指向下一页的链接等。
通用网站内容采集神器官方下载图1
软件功能
1.信息自动采集和添加:网站抓取的主要目的是添加到您的网站中,网站信息一般采集器可以实现自动采集和添加。其他网站新更新的信息将在五分钟内自动运行到您的网站。
2. 网站登录:对于需要登录才能查看信息内容的网站,即使使用验证码,网站信息通用采集器也可以轻松登录并采集所需的信息。
3.自动下载文件:如果您需要采集图片之类的二进制文件,则只需设置一个通用的网站信息采集器即可在本地保存任何类型的文件。
网站通用内容采集神器官方下载图2
4.多级页面采集:一次爬网整个网站:无论有多少个类别和子类别,只要同时采集个多级页面的内容就可以您设置一次。如果一条信息分布在多个不同的页面上,则可以实现信息采集和爬网,并且网站常规信息采集器可以自动识别N级页面。该软件带有一个8层网站采集示例。
5.特殊网站自动识别:许多网站连接到特殊网站,例如javascript:openwin('1234'),而不是通常的网站常规信息采集器识别并捕获内容。
6.自动过滤重复的导出数据过滤重复的数据处理:有时URL不同,但是内容相同,因此通用采集器仍然可以根据内容过滤重复的数据。 (具有新功能的新版本。)
7.多页新闻自动合并和广告过滤:某些新闻有下一页,网站通用信息采集器也可以抓取所有页面。并可以同时保存新闻中捕获的图片和文字,过滤出广告。
8.自动破解cookie和防垃圾邮件:许多下载网站已完成cookie验证或防垃圾邮件,直接输入URL不能捕获内容,但是网站通用信息采集器可以自动破解cookie验证和防盗,因此必须确保可以捕获所需的内容。
通用网站内容采集神器官方下载图3
软件功能
1.采集和分发是完全自动化的。
2.自动破解JavaScript特殊URL。
[p24]成员登录的
网站也将得到处理。
4.立即抓取所有电台,无论有多少个类别。
5.可以下载任何类型的文件。
6.自动合并多页新闻和广告过滤。
7.多级页面的联合集合。
8.模拟手动单击以破解防盗链。
9.验证码标识。
1 0.图片自动加水印。 查看全部
如何轻松收集网站信息?(网站万能信息采集助手)
如何轻松采集网站信息? 网站通用信息采集器(网站信息采集助手)是一种方便的Web信息采集器。 网站通用信息采集器(网站信息采集助手)可以帮助用户轻松完成任务。该软件结合了所有网络爬网软件的优点。它可以获取网站上的所有信息,然后自动将其发布到您的网站。它可以获取网站上任何类型的所有信息,例如新闻,供应和需求。信息,招聘信息,论坛帖子,音乐,指向下一页的链接等。
通用网站内容采集神器官方下载图1
软件功能
1.信息自动采集和添加:网站抓取的主要目的是添加到您的网站中,网站信息一般采集器可以实现自动采集和添加。其他网站新更新的信息将在五分钟内自动运行到您的网站。
2. 网站登录:对于需要登录才能查看信息内容的网站,即使使用验证码,网站信息通用采集器也可以轻松登录并采集所需的信息。
3.自动下载文件:如果您需要采集图片之类的二进制文件,则只需设置一个通用的网站信息采集器即可在本地保存任何类型的文件。
网站通用内容采集神器官方下载图2
4.多级页面采集:一次爬网整个网站:无论有多少个类别和子类别,只要同时采集个多级页面的内容就可以您设置一次。如果一条信息分布在多个不同的页面上,则可以实现信息采集和爬网,并且网站常规信息采集器可以自动识别N级页面。该软件带有一个8层网站采集示例。
5.特殊网站自动识别:许多网站连接到特殊网站,例如javascript:openwin('1234'),而不是通常的网站常规信息采集器识别并捕获内容。
6.自动过滤重复的导出数据过滤重复的数据处理:有时URL不同,但是内容相同,因此通用采集器仍然可以根据内容过滤重复的数据。 (具有新功能的新版本。)
7.多页新闻自动合并和广告过滤:某些新闻有下一页,网站通用信息采集器也可以抓取所有页面。并可以同时保存新闻中捕获的图片和文字,过滤出广告。
8.自动破解cookie和防垃圾邮件:许多下载网站已完成cookie验证或防垃圾邮件,直接输入URL不能捕获内容,但是网站通用信息采集器可以自动破解cookie验证和防盗,因此必须确保可以捕获所需的内容。
通用网站内容采集神器官方下载图3
软件功能
1.采集和分发是完全自动化的。
2.自动破解JavaScript特殊URL。
[p24]成员登录的
网站也将得到处理。
4.立即抓取所有电台,无论有多少个类别。
5.可以下载任何类型的文件。
6.自动合并多页新闻和广告过滤。
7.多级页面的联合集合。
8.模拟手动单击以破解防盗链。
9.验证码标识。
1 0.图片自动加水印。
完整的采集神器太长了,你去看看录播了
采集交流 • 优采云 发表了文章 • 0 个评论 • 289 次浏览 • 2021-02-05 13:01
完整的采集神器太长了,你去看看录播了,完整版在这里,超级简单,一步到位【采集动画视频】,
你好,这个问题我能答,我就是做app外包的。app抓包调试一般分两种,一种是p2p抓包的,一种是封包的p2p的方式就是网络请求已经封了,你只要直接用ak这类抓包软件获取获取数据包就可以直接调试。封包就是有些是不直接接收这类消息的,而你做的这个“经常性”性能问题。因为不同性能也不同,有些这方面有问题或者没有问题,你还需要对它做一些代码来更改。
至于如何生成方式很多,一般p2p的时候需要通过代理请求,比如网页通过代理的方式获取,手机也可以用代理,还有就是app的代理,移动app还可以借助云服务器。p2p和封包是需要看平台的,在平台里封包有封包的方式和调用的方式,也有代理请求的方式。p2p的速度快,但是很难查,还会被封包。封包的速度慢,但是封不完整,比如二进制的包封了三次才能压缩完整。
在您的上装一个“fiddler”,
花了五分钟看完,原地大号被封,报告了一堆莫名奇妙的问题!去跟那些人扯啥破环数据,真觉得你们很幽默。我说说我的观点,调试不是什么隐藏高手,只是懂得原理。采集动画视频,可以简单了解一下,以百度api接口为例,找到百度apiserver,就是了,sdk比较多,数据如下如果之前经常做效果,还有三张表,分别是apiserver所有的历史数据,比如你用过哪些手机。
apiserver当前获取的app数据,你上线的时候获取了哪些数据。没了。注意你懂的,app必须得上架到所有上架的渠道。修改代码修改代码,内核,注册上架的时候不要搞死,换个语言继续。修改到app最好新开,不行就通过调用接口获取上架的时候提交的接口数据就可以。你这没有什么问题的,没事,你连调用的链接都没有给我,如果你能做到,你就可以实现封包的操作。
不过假如你真想大大方方的上架,就只能弄成本地上架,而且开始不要在所有渠道更新。等账号安全更新了,不要更新了。给老板发文书,上架我就没有问题。有点跑题,好了,就说到这,原理搞懂,之后还是多练习,多练习,多练习。注意语言不会,sogogogo。 查看全部
完整的采集神器太长了,你去看看录播了
完整的采集神器太长了,你去看看录播了,完整版在这里,超级简单,一步到位【采集动画视频】,
你好,这个问题我能答,我就是做app外包的。app抓包调试一般分两种,一种是p2p抓包的,一种是封包的p2p的方式就是网络请求已经封了,你只要直接用ak这类抓包软件获取获取数据包就可以直接调试。封包就是有些是不直接接收这类消息的,而你做的这个“经常性”性能问题。因为不同性能也不同,有些这方面有问题或者没有问题,你还需要对它做一些代码来更改。
至于如何生成方式很多,一般p2p的时候需要通过代理请求,比如网页通过代理的方式获取,手机也可以用代理,还有就是app的代理,移动app还可以借助云服务器。p2p和封包是需要看平台的,在平台里封包有封包的方式和调用的方式,也有代理请求的方式。p2p的速度快,但是很难查,还会被封包。封包的速度慢,但是封不完整,比如二进制的包封了三次才能压缩完整。
在您的上装一个“fiddler”,
花了五分钟看完,原地大号被封,报告了一堆莫名奇妙的问题!去跟那些人扯啥破环数据,真觉得你们很幽默。我说说我的观点,调试不是什么隐藏高手,只是懂得原理。采集动画视频,可以简单了解一下,以百度api接口为例,找到百度apiserver,就是了,sdk比较多,数据如下如果之前经常做效果,还有三张表,分别是apiserver所有的历史数据,比如你用过哪些手机。
apiserver当前获取的app数据,你上线的时候获取了哪些数据。没了。注意你懂的,app必须得上架到所有上架的渠道。修改代码修改代码,内核,注册上架的时候不要搞死,换个语言继续。修改到app最好新开,不行就通过调用接口获取上架的时候提交的接口数据就可以。你这没有什么问题的,没事,你连调用的链接都没有给我,如果你能做到,你就可以实现封包的操作。
不过假如你真想大大方方的上架,就只能弄成本地上架,而且开始不要在所有渠道更新。等账号安全更新了,不要更新了。给老板发文书,上架我就没有问题。有点跑题,好了,就说到这,原理搞懂,之后还是多练习,多练习,多练习。注意语言不会,sogogogo。
什么是优采云采集?智能采集工具帮你提高营收
采集交流 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2021-02-02 10:03
什么是优采云采集?智能采集工具帮你提高营收
在流行期间,许多公司不得不选择远程在线办公室。互联网是受流行病影响较小的行业之一。但是,远程办公室的效率仍然不如面对面的工作。因此,优采云采集特别推出了智能采集工具。
我相信许多操作人员已经接触过采集工具。市场上有很多采集工具。许多人认为采集工具仅用作文章热门/节日主题和其他信息采集的辅助工具,实际上,不仅如此。成熟的采集工具不仅可以帮助操作采集信息,而且可以准确地分析数据趋势,从而有助于增加收入。
1、什么是优采云采集?
优采云采集是用于自媒体素材搜索,文章 原创一键式发布的操作工具,可有效提高新媒体运营的效率并降低公司成本。
2、如何用优采云采集搜索?
([1)输入关键词
优采云采集根据用户输入的关键词,搜索引擎会通过程序自动输入主流自媒体数据源进行搜索。
优采云采集基于高级算法匹配更准确的内容,以提高搜索内容的准确性。
例如:
用户需要采集有关流行病的资料,然后在主页上输入关键词“流行病”。 优采云采集会将搜索结果合并到一个列表中。
([2)保存搜索材料
优采云采集具有批量保存搜索资料的功能。
单击[在当前页上全部选择]功能,然后选中所需的文章,文章将添加到操作面板中,方便用户批量保存。
([3)精确过滤
1、搜索过滤器
优采云采集支持根据标题,内容,时间,平台,是否为原创等参数进行过滤,以使搜索内容更加准确。
2、广告过滤 查看全部
什么是优采云采集?智能采集工具帮你提高营收
在流行期间,许多公司不得不选择远程在线办公室。互联网是受流行病影响较小的行业之一。但是,远程办公室的效率仍然不如面对面的工作。因此,优采云采集特别推出了智能采集工具。
我相信许多操作人员已经接触过采集工具。市场上有很多采集工具。许多人认为采集工具仅用作文章热门/节日主题和其他信息采集的辅助工具,实际上,不仅如此。成熟的采集工具不仅可以帮助操作采集信息,而且可以准确地分析数据趋势,从而有助于增加收入。
1、什么是优采云采集?
优采云采集是用于自媒体素材搜索,文章 原创一键式发布的操作工具,可有效提高新媒体运营的效率并降低公司成本。
2、如何用优采云采集搜索?
([1)输入关键词
优采云采集根据用户输入的关键词,搜索引擎会通过程序自动输入主流自媒体数据源进行搜索。
优采云采集基于高级算法匹配更准确的内容,以提高搜索内容的准确性。
例如:
用户需要采集有关流行病的资料,然后在主页上输入关键词“流行病”。 优采云采集会将搜索结果合并到一个列表中。
([2)保存搜索材料
优采云采集具有批量保存搜索资料的功能。
单击[在当前页上全部选择]功能,然后选中所需的文章,文章将添加到操作面板中,方便用户批量保存。
([3)精确过滤
1、搜索过滤器
优采云采集支持根据标题,内容,时间,平台,是否为原创等参数进行过滤,以使搜索内容更加准确。
2、广告过滤
干货教程:拼多多产品图采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 573 次浏览 • 2021-01-15 08:18
平多多产品图采集是专门为拼多多商人使用的辅助工具。它可以帮助用户轻松地采集 Pinduoduo以上产品图片和其他信息,非常方便,有需要的用户不妨下载一下体验!
软件简介
Pingduoduo产品图片采集下载程序是可以批量采集 Pingduoduo产品图片和说明图片的软件,它可以节省每个人的时间,因为图片采集。该软件支持批量采集,只需将产品地址批量输入软件即可实现批量采集的工作。
软件功能
整个商店复制:您可以一键复制任何人的拼多多商店(所有商店产品),并自动识别产品类别。如果要复制商店,只需单击一下即可在几分钟之内完成!
该软件支持数据导入和导出,可以随意导入和导出数据,以供其他商店直接上传和使用。
支持批量编辑产品信息,任何产品信息均支持一键式批量设置,功能超强!
实拍店更新:支持实拍店老板上传新照片,无需PS图片,软件可以自动将图片尺寸调整为拼多多的指定尺寸,无论图片是大还是小,都可以直接批量导入并发布!同时,它支持31个主要货源平台的产品信息采集 +编辑产品图片,您可以通过插入本地图片来使用网络图片!节省实际拍摄的时间和精力〜
使用方法
1.打开拼多多产品图采集下载器
2.点击打开Pinduoduo网络版本并登录
3.将所需的产品地址批量输入软件
4.单击采集开始。
5.最后下载的图片将保存在数据文件夹中,单击以打开目录进行查找。
更新日志
1、优化了UI界面的流畅性
2、修复了已知错误 查看全部
干货教程:拼多多产品图采集
平多多产品图采集是专门为拼多多商人使用的辅助工具。它可以帮助用户轻松地采集 Pinduoduo以上产品图片和其他信息,非常方便,有需要的用户不妨下载一下体验!
软件简介
Pingduoduo产品图片采集下载程序是可以批量采集 Pingduoduo产品图片和说明图片的软件,它可以节省每个人的时间,因为图片采集。该软件支持批量采集,只需将产品地址批量输入软件即可实现批量采集的工作。
软件功能
整个商店复制:您可以一键复制任何人的拼多多商店(所有商店产品),并自动识别产品类别。如果要复制商店,只需单击一下即可在几分钟之内完成!
该软件支持数据导入和导出,可以随意导入和导出数据,以供其他商店直接上传和使用。
支持批量编辑产品信息,任何产品信息均支持一键式批量设置,功能超强!
实拍店更新:支持实拍店老板上传新照片,无需PS图片,软件可以自动将图片尺寸调整为拼多多的指定尺寸,无论图片是大还是小,都可以直接批量导入并发布!同时,它支持31个主要货源平台的产品信息采集 +编辑产品图片,您可以通过插入本地图片来使用网络图片!节省实际拍摄的时间和精力〜
使用方法
1.打开拼多多产品图采集下载器
2.点击打开Pinduoduo网络版本并登录
3.将所需的产品地址批量输入软件
4.单击采集开始。
5.最后下载的图片将保存在数据文件夹中,单击以打开目录进行查找。
更新日志
1、优化了UI界面的流畅性
2、修复了已知错误

