完整的采集神器(优采云中该如何操作?如何从单个网页抓取文本、图片、超链接 )
优采云 发布时间: 2021-09-04 02:08完整的采集神器(优采云中该如何操作?如何从单个网页抓取文本、图片、超链接
)
在第二课采集Single Data中,我们学习了如何抓取单个网页的文字、图片、超链接,初步了解优采云【自定义配置】任务采集的流程@data 经验。本课将继续学习如何采集多个数据列表。
列表是最常见的网页样式之一。示例:京东商品榜、58城房源榜、豆瓣书榜。简单配置后优采云就可以自动采集列表中的所有数据了。
现在有一个收录豆瓣书籍列表的网页:%E5%B0%8F%E8%AF%B4。网页上有很多结构相同的书单,每个书单都有相同的字段:书名、出版信息、评分、评论数、书介绍等。
鼠标移到图片上,右击选择【在新标签页中打开图片】查看高清大图
同样适用于下面的其他图片
我们想把上面网页采集的多个列表中的字段按照网页的顺序存储,保存为Excel等结构化数据,如下图:
在优采云怎么做?示例网址:%E5%B0%8F%E8%AF%B4
一、智能识别
列出网页,优采云支持智能识别。使用智能识别,只需输入网址即可自动获取数据并生成采集流程。
二、自己配置采集process
如果我想自己配置采集进程怎么办?具体步骤如下:
步骤一、输入网址
在首页【输入框】输入目标网址,点击【开始采集】,优采云会自动打开网页。如果智能识别自动启动,您可以点击【不再自动识别】或【取消识别】。如果智能识别已关闭,请继续执行后续步骤。
步骤二、Establish [循环提取数据]
观察网页。这个页面上有很多书单。每个列表结构相同,收录书名、出版信息、评分、审稿人数、书籍介绍等字段。最重要的一点是如何让优采云识别所有列表,并遵循采集的顺序@每个书单中的数据。
在优采云中,[loop-extract data]的建立可以达到这个要求。 【循环提取数据】会依次收录所有书单,以及每个书单中的采集数据。对于列表类型的网页,需要具体的步骤来建立【循环提取数据】。以下是具体步骤。
我们先来看一个完整的步骤来建立[loop-extract data]:
拆分每一步,详细说明:
1、在页面上选择一个书单。选中的列表会被一个绿色框框起来,同时会出现一个*敏*感*词*的操作提示框,提示我们找到【子元素】,其中【子元素】是图书列表中的具体字段。
特别说明:
一个。只选一个列表,第一个无所谓,第一个,第二个,第三个,都行。
B.选择列表时,要特别注意范围。选择的范围(绿色部分)需要最大,包括所有需要采集的字段。
2、 在*敏*感*词*操作提示框中,选择【选择子元素】。选择第一个产品列表中的特定字段。这时候优采云发现页面上有很多相似的列表,它们的子元素(即字段)是一样的。
3、在*敏*感*词*的操作提示框中,继续选择【全选】。我们要采集列表中的所有字段,所以选择【全选】,可以看到页面上同一个列表中的所有子元素都被选中了,用绿色框框起来。
4、在*敏*感*词*操作提示框中,选择[采集数据]。这时优采云已经把列表中的所有字段都提取出来了。
特别说明:
一个。步骤1-4是连续指令,只能不间断地建立。 1、选择页面列表后2、[selected child element]没有出现怎么办?请向下滚动到文章末尾查看解决方案。
经过以上4个步骤,【循环-提取数据】的创建就完成了。如您所见,流程图中会自动生成一个循环步骤。循环中的项目对应页面上所有产品的列表。循环中提取的数据中的字段对应于每个产品列表中的字段。 采集启动后,优采云会按照循环中的顺序依次提取每个列表中的字段。
步骤3、编辑字段
优采云已经为我们自动提取了列表中的所有字段,并且可以删除这些字段并修改字段名称。
移动鼠标到【数据预览】
移到字段名,可以修改字段名(字段名相当于excel表头)。
单击垃圾桶图标可删除不需要的字段。您也可以选择并单击切换字段布局来编辑字段。字段布局方式有【垂直字段布局】和【水平字段布局】
步骤4、Start采集
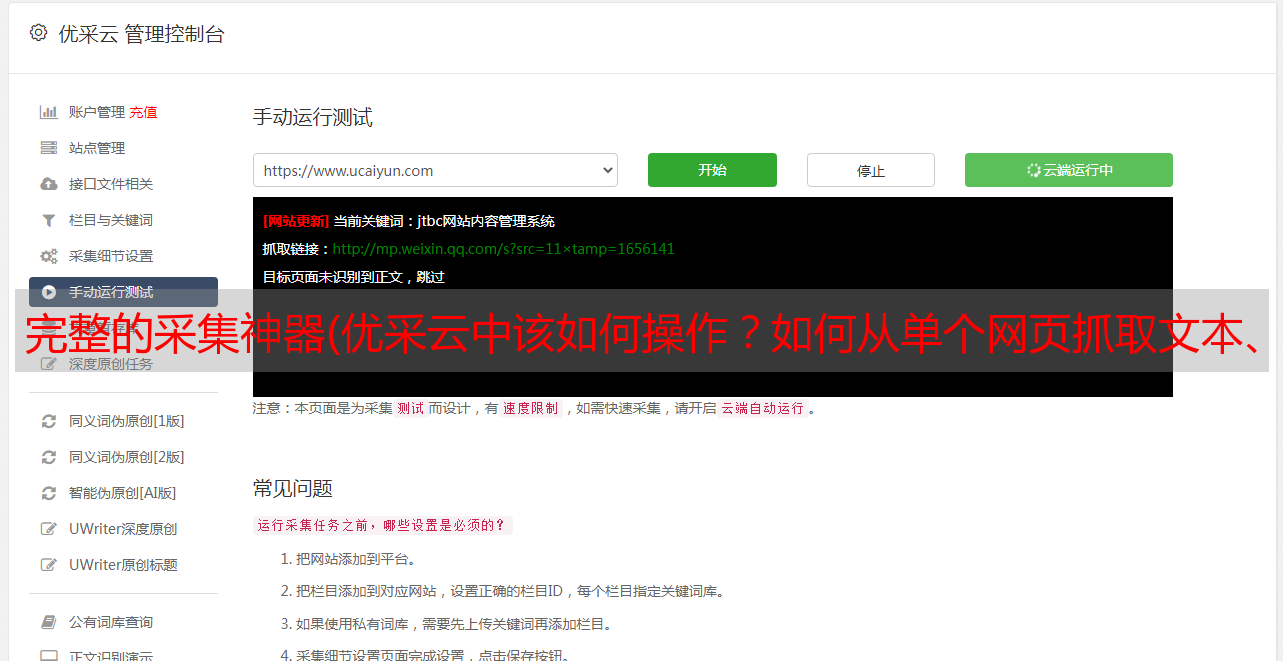
1、 点击【保存并启动】,选择【启动本地采集】。启动优采云后全自动采集数据。 (本地采集采集使用自己的电脑,云采集使用优采云提供的云服务器采集,点击查看具体说明)
2、采集 完成后,选择合适的导出方式导出数据。支持导出为 Excel、CSV、HTML。在此处导出到 Excel。
数据示例:
在步骤二、中,在建立[loop-extract data]时,1、选择页面上的一个列表后,2、[selected child element]不会出现。解决方案:
示例网址:%25E8%2583%25A1%25E6%25AD%258C?topnav=1&wvr=6&b=1
我们先来看一个完整的步骤来建立[loop-extract data]:
再拆分每一步,详细说明:
1、选择页面上的第一个列表。
2、继续选择页面上的1个列表(目的是帮助优采云识别页面上所有相似的列表)。
3、*敏*感*词*操作提示框中,选择【采集数据】。列表中的所有字段都被提取到一个单元格中。如需单独提取,请继续进行以下操作。
4、 手动提取所需字段。确保从当前选择的列表中提取字段(用红色框框起来)。否则会重复提取第一个列表中的数据。
通过以上4个步骤,还可以创建【循环提取数据】。如您所见,流程图中会自动生成一个循环步骤。循环中的项目对应页面上的所有微博列表。循环中提取数据中的字段对应于每个微博列表中的字段。 采集启动后,优采云会按照循环中的顺序依次提取每个列表中的字段。
【循环提取数据】创建完成后,后续步骤同上,不再赘述。
如果需要采集list数据,如果非要点击列表中的链接,进入详情页,采集details页数据,解决方法:
1、先用本课上面学到的方法创建一个【循环-提取数据】步骤,先提取列表数据
2、 在循环的当前项中找到链接(用红框框起来)并选择它。在弹出的操作提示框中,选择【点击链接】。可以看到过程中生成了一步【点击元素】,优采云自动跳转到详情页,然后提取详情页数据。
特别说明:
一个。一定要用循环的当前item的链接(如下图,当前item会用红框框起来)作为【点击元素】的步骤,否则点击链接重复。

