
querylist采集微信公众号文章
微信公众号文章的接口分析及应用方法(二)
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-05-26 23:12
微信公众号文章的接口分析及应用方法(二)
Python微信公共帐户文章爬行
一.想法
我们通过微信公众平台网络版图形消息中的超链接获得所需的界面
从界面中,我们可以获得相应的微信公众号和所有相应的微信公众号文章。
二.界面分析
访问微信公众号:
参数:
action = search_biz
开始= 0
count = 5
query =官方帐户名
token =每个帐户对应的令牌值
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
因此在此界面中,我们只需要获取令牌,并且查询是您需要搜索的官方帐户,并且可以在登录后通过Web链接获取令牌。
获取与官方帐户对应的文章界面:
参数:
action = list_ex
开始= 0
count = 5
fakeid = MjM5NDAwMTA2MA ==
type = 9
query =
token = 557131216
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
我们需要在该接口中获取的值是上一步中的令牌和伪标识,并且可以在第一个接口中获取该伪标识。这样我们就可以获得微信公众号文章的数据。
三.要实现的第一步:
首先我们需要模拟通过硒的登录,然后获取cookie和相应的令牌
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义一个登录方法,其中的参数是登录帐户和密码,然后定义一个字典来存储cookie的值。通过模拟用户,输入相应的帐户密码,然后单击“登录”,然后将出现扫描代码验证,只需使用登录微信扫描代码即可。
刷新当前网页后,获取当前的cookie和令牌,然后返回。
第2步:1.请求相应的官方帐户界面,并获取我们需要的伪造物
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获得的令牌和cookie,然后通过request.get请求获取返回的微信官方帐户的json数据
lists = search_resp.json().get('list')[0]
可以通过上面的代码获取相应的官方账户数据
fakeid = lists.get('fakeid')
可以通过上面的代码获得相应的伪造物
2.请求获取微信公众号文章界面,并获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入了fakeid和token,然后调用requests.get请求接口以获取返回的json数据。
我们已经实现了对微信官方帐户文章的抓取。
四.摘要
通过抓取微信公众号文章,您需要掌握硒和请求的用法,以及如何获取请求接口。但是需要注意的是,当我们循环获得文章时,必须设置一个延迟时间,否则该帐户将很容易被阻塞,并且将无法获得返回的数据。 查看全部
微信公众号文章的接口分析及应用方法(二)
Python微信公共帐户文章爬行
一.想法
我们通过微信公众平台网络版图形消息中的超链接获得所需的界面


从界面中,我们可以获得相应的微信公众号和所有相应的微信公众号文章。
二.界面分析
访问微信公众号:
参数:
action = search_biz
开始= 0
count = 5
query =官方帐户名
token =每个帐户对应的令牌值
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
因此在此界面中,我们只需要获取令牌,并且查询是您需要搜索的官方帐户,并且可以在登录后通过Web链接获取令牌。

获取与官方帐户对应的文章界面:
参数:
action = list_ex
开始= 0
count = 5
fakeid = MjM5NDAwMTA2MA ==
type = 9
query =
token = 557131216
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
我们需要在该接口中获取的值是上一步中的令牌和伪标识,并且可以在第一个接口中获取该伪标识。这样我们就可以获得微信公众号文章的数据。

三.要实现的第一步:
首先我们需要模拟通过硒的登录,然后获取cookie和相应的令牌
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义一个登录方法,其中的参数是登录帐户和密码,然后定义一个字典来存储cookie的值。通过模拟用户,输入相应的帐户密码,然后单击“登录”,然后将出现扫描代码验证,只需使用登录微信扫描代码即可。
刷新当前网页后,获取当前的cookie和令牌,然后返回。
第2步:1.请求相应的官方帐户界面,并获取我们需要的伪造物
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获得的令牌和cookie,然后通过request.get请求获取返回的微信官方帐户的json数据
lists = search_resp.json().get('list')[0]
可以通过上面的代码获取相应的官方账户数据
fakeid = lists.get('fakeid')
可以通过上面的代码获得相应的伪造物
2.请求获取微信公众号文章界面,并获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入了fakeid和token,然后调用requests.get请求接口以获取返回的json数据。
我们已经实现了对微信官方帐户文章的抓取。
四.摘要
通过抓取微信公众号文章,您需要掌握硒和请求的用法,以及如何获取请求接口。但是需要注意的是,当我们循环获得文章时,必须设置一个延迟时间,否则该帐户将很容易被阻塞,并且将无法获得返回的数据。
可以看看这些:移动应用实时高质量微信公众号文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-05-23 20:01
querylist采集微信公众号文章。
可以看看这些:移动应用实时抓取高质量微信公众号文章数据
电商的话可以试试支付宝的“店小蜜”。其他领域么,我觉得网易、豆瓣、大鱼是可以考虑的。
可以试试七麦数据
有很多:知乎专栏--七麦网商业价值分析系列top50,用得好,不止是个数据砖头。
想看文章的热度、阅读数、评论数的话,
本人一般用趣头条抓小说的。
推荐平台-七麦数据,抓取近70万公众号文章,可放在你的站点搜索引擎seo查询,通过百度、google、360等搜索引擎查询公众号内容进行过滤
无论是博客、公众号还是新闻,都已经成为我们不可缺少的工具之一。python可以抓取公众号的文章内容,不过很多一些数据在公众号或博客中已经有了,你只需要把这些内容与文章链接发到你的邮箱,然后下载文章就可以了。目前市面上不少抓取工具,
1)发布公众号/博客文章到豆瓣阅读可以对公众号发布的文章进行抓取,相比来说豆瓣阅读和公众号相关性较强,当然如果想知道是哪个公众号文章最多,其实可以关注以下公众号。
2)twitter等社交平台twitter的文章会有链接,但是效果就不是很好了,好的方法就是前面介绍的软件,但是对于普通人来说,还是有点复杂。
3)爬虫工具如果你不想付费用python抓取你想要的网站,可以用爬虫工具,比如:google的beautifulsoup,比如网易云课堂:python爬虫轻松爬取知乎70万精品课程等等,支持自动抓取,这个工具使用也比较方便,当然如果你做站点整站抓取的话,还是要花些时间来收集这些数据。
4)公众号自动回复抓取可以通过微信公众号自动回复抓取其文章,通过公众号的自动回复内容就可以抓取公众号的文章。关注微信公众号:小蚂蚁和小蜜蜂,发送:“福利”可以领取, 查看全部
可以看看这些:移动应用实时高质量微信公众号文章
querylist采集微信公众号文章。
可以看看这些:移动应用实时抓取高质量微信公众号文章数据
电商的话可以试试支付宝的“店小蜜”。其他领域么,我觉得网易、豆瓣、大鱼是可以考虑的。
可以试试七麦数据
有很多:知乎专栏--七麦网商业价值分析系列top50,用得好,不止是个数据砖头。
想看文章的热度、阅读数、评论数的话,
本人一般用趣头条抓小说的。
推荐平台-七麦数据,抓取近70万公众号文章,可放在你的站点搜索引擎seo查询,通过百度、google、360等搜索引擎查询公众号内容进行过滤
无论是博客、公众号还是新闻,都已经成为我们不可缺少的工具之一。python可以抓取公众号的文章内容,不过很多一些数据在公众号或博客中已经有了,你只需要把这些内容与文章链接发到你的邮箱,然后下载文章就可以了。目前市面上不少抓取工具,
1)发布公众号/博客文章到豆瓣阅读可以对公众号发布的文章进行抓取,相比来说豆瓣阅读和公众号相关性较强,当然如果想知道是哪个公众号文章最多,其实可以关注以下公众号。
2)twitter等社交平台twitter的文章会有链接,但是效果就不是很好了,好的方法就是前面介绍的软件,但是对于普通人来说,还是有点复杂。
3)爬虫工具如果你不想付费用python抓取你想要的网站,可以用爬虫工具,比如:google的beautifulsoup,比如网易云课堂:python爬虫轻松爬取知乎70万精品课程等等,支持自动抓取,这个工具使用也比较方便,当然如果你做站点整站抓取的话,还是要花些时间来收集这些数据。
4)公众号自动回复抓取可以通过微信公众号自动回复抓取其文章,通过公众号的自动回复内容就可以抓取公众号的文章。关注微信公众号:小蚂蚁和小蜜蜂,发送:“福利”可以领取,
通过微信公众平台的查找文章接口抓取我们需要的相关文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-05-20 20:06
阅读:4743
通过微信公众平台的搜索文章界面,获取我们需要的相关文章
1.首先,让我们看一下,正常登录我们的微信官方帐户,然后使用文章搜索功能搜索我们需要查找的相关文章。
打开
登录到官方帐户,打开物料管理,然后单击“新建”以共享图形
打开文章搜索界面
输入要搜索的内容后,您可以搜索相关文章的标题,它来自哪个官方帐户以及其他信息。
2.实施思路
这里有一个问题。打开微信公众号的主页,输入帐号密码,然后使用托管的微信帐号扫描代码进行确认,最终可以成功登录微信公众号。该如何解决?
首次登录时,我们可以按照正常过程输入帐户密码,扫描代码进行登录,获取cookie并保存,以便我们稍后调用cookie来验证登录信息当然,Cookie有有效期,但我正在测试,看来它在3-4小时后仍然可以使用,足以完成很多事情。
基本思路:1.通过硒驱动的浏览器打开登录页面,输入帐号密码登录,登录后获取cookie,并保存待调用的cookie; 2.获取cookie后,进入主页并直接跳转以登录。进入个人主页,打开文章搜索框并找到一些需要的信息; 3.获取有用的信息后,构造一个数据包,模拟发布请求,然后返回数据。获取数据后,解析出我们需要的数据。
3.获取Cookie,不要说太多,发布代码
#!/ usr / bin / env python
#_ * _编码:utf-8 _ * _
从硒导入网络驱动程序
导入时间
导入json
driver = webdriver.Chrome()#需要使用Google云端硬盘chromedriver.exe,以支持您当前版本的Google Chrome浏览器
driver.get('#39;)#发起获取请求以打开微信公众号平台登录页面,然后输入帐号密码登录微信公众号
driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [1] / div [1] / div / span / input')。clear ()#找到帐户输入框,清除其中的内容
driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [1] / div [1] / div / span / input')。send_keys (“在此处输入您的帐户”)#找到帐户输入框,输入帐户
time.sleep(3)#等待3秒钟,然后执行下一个操作,以避免网络延迟和浏览器加载输入框的时间,这可能导致以下操作失败
driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [1] / div [2] / div / span / input')。clear ()#找到密码输入框,清除里面的内容
driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [1] / div [2] / div / span / input')。send_keys (“在此处输入密码”)#找到密码输入框,输入密码
time.sleep(3)#原因与上面相同
driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [3] / label')。click()#单击以记住密码
time.sleep(3)#原因与上面相同
<p>driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [4] / a')。click()#click登录 查看全部
通过微信公众平台的查找文章接口抓取我们需要的相关文章
阅读:4743
通过微信公众平台的搜索文章界面,获取我们需要的相关文章
1.首先,让我们看一下,正常登录我们的微信官方帐户,然后使用文章搜索功能搜索我们需要查找的相关文章。
打开
登录到官方帐户,打开物料管理,然后单击“新建”以共享图形
打开文章搜索界面
输入要搜索的内容后,您可以搜索相关文章的标题,它来自哪个官方帐户以及其他信息。
2.实施思路
这里有一个问题。打开微信公众号的主页,输入帐号密码,然后使用托管的微信帐号扫描代码进行确认,最终可以成功登录微信公众号。该如何解决?
首次登录时,我们可以按照正常过程输入帐户密码,扫描代码进行登录,获取cookie并保存,以便我们稍后调用cookie来验证登录信息当然,Cookie有有效期,但我正在测试,看来它在3-4小时后仍然可以使用,足以完成很多事情。
基本思路:1.通过硒驱动的浏览器打开登录页面,输入帐号密码登录,登录后获取cookie,并保存待调用的cookie; 2.获取cookie后,进入主页并直接跳转以登录。进入个人主页,打开文章搜索框并找到一些需要的信息; 3.获取有用的信息后,构造一个数据包,模拟发布请求,然后返回数据。获取数据后,解析出我们需要的数据。
3.获取Cookie,不要说太多,发布代码
#!/ usr / bin / env python
#_ * _编码:utf-8 _ * _
从硒导入网络驱动程序
导入时间
导入json
driver = webdriver.Chrome()#需要使用Google云端硬盘chromedriver.exe,以支持您当前版本的Google Chrome浏览器
driver.get('#39;)#发起获取请求以打开微信公众号平台登录页面,然后输入帐号密码登录微信公众号
driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [1] / div [1] / div / span / input')。clear ()#找到帐户输入框,清除其中的内容
driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [1] / div [1] / div / span / input')。send_keys (“在此处输入您的帐户”)#找到帐户输入框,输入帐户
time.sleep(3)#等待3秒钟,然后执行下一个操作,以避免网络延迟和浏览器加载输入框的时间,这可能导致以下操作失败
driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [1] / div [2] / div / span / input')。clear ()#找到密码输入框,清除里面的内容
driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [1] / div [2] / div / span / input')。send_keys (“在此处输入密码”)#找到密码输入框,输入密码
time.sleep(3)#原因与上面相同
driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [3] / label')。click()#单击以记住密码
time.sleep(3)#原因与上面相同
<p>driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [4] / a')。click()#click登录
querylist采集微信公众号文章源数据方案-python爬取
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2021-05-17 00:02
querylist采集微信公众号文章源数据方案-python爬取微信公众号文章源数据。不论是自动转码还是模拟登录都比较麻烦,因此找了个人就做了下工作。之前不知道有个friendship模块可以直接用。使用方法是直接把写死的方法codepen上面公布。有了io完整的语法经验,代码就好写了。但是有个坏处就是使用的是array,而不是dict。
希望好事成双。当然如果不是全局约束要注意每个注册的ipip可能泄露。关键看submit时间段如何设置。如果长时间内有多次submit不能成功可以尝试让更短的生效时间改为第二天。安装tushare_更多tushare信息-更多数据信息服务tusharecrepot对比微信公众号文章源数据抓取。
-token/getting-started/querylist.csv
是这样的:1。第一步将token生成2。第二步解码解码过程中需要用到微信api然后微信id就是这么的:(hypertexttransferprotocol)client_id='"1234567890"'client_secret="gzh"3。signal_read随着时间的流逝queryset中的数据会持续加载(超时后就不显示数据了,并且直到关闭为止),所以你需要先随机生成一个token再解码获取数据。
网页上的token一定要在编码前用urllib.parse.urlencode方法先处理成二进制,然后传入datetime.datetimeprotocol。这样存储可以用对应的datetime库,datetime包括datetime.fromential(parseint,ansi_parse_utf。
8)和datetime.datetime,可以获取datetime对象,
8),eval(utf8_parse_utf
8)然后还需要解码, 查看全部
querylist采集微信公众号文章源数据方案-python爬取
querylist采集微信公众号文章源数据方案-python爬取微信公众号文章源数据。不论是自动转码还是模拟登录都比较麻烦,因此找了个人就做了下工作。之前不知道有个friendship模块可以直接用。使用方法是直接把写死的方法codepen上面公布。有了io完整的语法经验,代码就好写了。但是有个坏处就是使用的是array,而不是dict。
希望好事成双。当然如果不是全局约束要注意每个注册的ipip可能泄露。关键看submit时间段如何设置。如果长时间内有多次submit不能成功可以尝试让更短的生效时间改为第二天。安装tushare_更多tushare信息-更多数据信息服务tusharecrepot对比微信公众号文章源数据抓取。
-token/getting-started/querylist.csv
是这样的:1。第一步将token生成2。第二步解码解码过程中需要用到微信api然后微信id就是这么的:(hypertexttransferprotocol)client_id='"1234567890"'client_secret="gzh"3。signal_read随着时间的流逝queryset中的数据会持续加载(超时后就不显示数据了,并且直到关闭为止),所以你需要先随机生成一个token再解码获取数据。
网页上的token一定要在编码前用urllib.parse.urlencode方法先处理成二进制,然后传入datetime.datetimeprotocol。这样存储可以用对应的datetime库,datetime包括datetime.fromential(parseint,ansi_parse_utf。
8)和datetime.datetime,可以获取datetime对象,
8),eval(utf8_parse_utf
8)然后还需要解码,
querylist采集微信公众号文章内容提取在做字符串处理之前
采集交流 • 优采云 发表了文章 • 0 个评论 • 218 次浏览 • 2021-05-16 03:03
querylist采集微信公众号文章内容提取在做字符串处理之前,需要先使用lucene库提取文章内容,首先你需要学会使用lucene。下面分享一个lucene解析微信公众号文章的代码。#加载数据wx.loadassocialize('.weixin')#按页读取微信公众号数据wx.loaditemissions('.weixin')#总共有5页wx.loadpages('.weixin')#总共10页wx.loadcurrentpages('.weixin')#总共10页wx.getdatabase('.weixin')#按页读取微信公众号内容wx.setdatabase('.weixin')#微信公众号内容数据lucene读取我们已经准备好的数据,并且读取weixin的数据到excel文件中。
这里我用到了excel数据导入工具,最常用的有excelxl,在介绍如何使用工具之前,先简单了解一下工具:excelxl导入数据导入数据最容易出现的错误之一,就是使用nullpointerexception,这个excel中会有默认的过滤格式,使用户利用这个默认格式没有办法进行读取等操作。这时候可以使用xlwings转换数据格式为windowsdow格式的markdown文件excelxl:xlwings:advancedxmldocumentformattowindowsapplications,andthedefault.#准备环境tomcat:9.0#es选择在windows下面,在python中安装对应版本的es到本地(python2.7)tomcat:windows10#es最好windows下面安装。
使用exists后可以找到原数据xlsxxtest.xlsxexcelxl#读取nullword部分的excelxlxlsxxprint'typetest.xlsx.'console.log('typetest.xlsx.')print'typetest.excelxl.'outputtest.xlsx.test.xlsx.txtxlsxtomcat运行输出结果如下图:要把tomcat读取的excelxl文件转化为workbook格式(xlsxx,然后save使用),需要执行以下命令:wx.startactivity()wx.startactivity()pages=wx.getparams('.weixin')ifwx.isdir(pages):pages=wx.getparams('.weixin')ifwx.isdir(pages):pages=wx.getparams('.weixin')wx.close()整个流程如下图:最后,我们先返回微信公众号文章的数据,并解析它然后导入excelxl文件即可得到数据最后还有一种方法,就是直接把excelxl导入linux中(linux下,xlwings可以直接生成windowsuserdata)。 查看全部
querylist采集微信公众号文章内容提取在做字符串处理之前
querylist采集微信公众号文章内容提取在做字符串处理之前,需要先使用lucene库提取文章内容,首先你需要学会使用lucene。下面分享一个lucene解析微信公众号文章的代码。#加载数据wx.loadassocialize('.weixin')#按页读取微信公众号数据wx.loaditemissions('.weixin')#总共有5页wx.loadpages('.weixin')#总共10页wx.loadcurrentpages('.weixin')#总共10页wx.getdatabase('.weixin')#按页读取微信公众号内容wx.setdatabase('.weixin')#微信公众号内容数据lucene读取我们已经准备好的数据,并且读取weixin的数据到excel文件中。
这里我用到了excel数据导入工具,最常用的有excelxl,在介绍如何使用工具之前,先简单了解一下工具:excelxl导入数据导入数据最容易出现的错误之一,就是使用nullpointerexception,这个excel中会有默认的过滤格式,使用户利用这个默认格式没有办法进行读取等操作。这时候可以使用xlwings转换数据格式为windowsdow格式的markdown文件excelxl:xlwings:advancedxmldocumentformattowindowsapplications,andthedefault.#准备环境tomcat:9.0#es选择在windows下面,在python中安装对应版本的es到本地(python2.7)tomcat:windows10#es最好windows下面安装。
使用exists后可以找到原数据xlsxxtest.xlsxexcelxl#读取nullword部分的excelxlxlsxxprint'typetest.xlsx.'console.log('typetest.xlsx.')print'typetest.excelxl.'outputtest.xlsx.test.xlsx.txtxlsxtomcat运行输出结果如下图:要把tomcat读取的excelxl文件转化为workbook格式(xlsxx,然后save使用),需要执行以下命令:wx.startactivity()wx.startactivity()pages=wx.getparams('.weixin')ifwx.isdir(pages):pages=wx.getparams('.weixin')ifwx.isdir(pages):pages=wx.getparams('.weixin')wx.close()整个流程如下图:最后,我们先返回微信公众号文章的数据,并解析它然后导入excelxl文件即可得到数据最后还有一种方法,就是直接把excelxl导入linux中(linux下,xlwings可以直接生成windowsuserdata)。
2019年录制了一个YouTube视频来具体讲解操作步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-05-13 22:34
2019年10月28日更新:
录制了YouTube视频,详细说明了操作步骤:
youtu.be
原创============
自2014年以来,我一直在批量处理微信官方帐户内容采集。最初的目的是创建html5垃圾邮件内容网站。那时,垃圾站采集到达的微信公众号的内容很容易在公众号中传播。当时,采集批处理特别容易,采集的入口是官方帐户的历史新闻页面。现在这个入口是一样的,但是越来越难了采集。 采集的方法也已更新为许多版本。后来,在2015年,html5垃圾站没有这样做,而是转向采集来定位本地新闻和信息公共帐户,并将前端显示制作为应用程序。因此,形成了可以自动采集官方帐户内容的新闻应用程序。我曾经担心微信技术升级后的一天,采集的内容将不可用,我的新闻应用程序将失败。但是随着微信技术的不断升级,采集方法也得到了升级,这使我越来越有信心。只要存在官方帐户历史记录消息页面,就可以将采集批处理到内容。因此,今天我决定整理一下后记下采集方法。我的方法来自许多同事的共享精神,因此我将继续这种精神并分享我的结果。
这篇文章文章将继续更新,并且您所看到的将保证在您看到时可用。
首先,让我们看一下微信官方帐户历史记录消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=更新于2017年1月11日=
现在根据不同的微信个人帐户,将有两个不同的历史消息页面地址。下面是另一个历史消息页面的地址。第一种地址类型的链接将显示302在anyproxy中的跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据当前信息,这两种页面格式在不同的微信账户中不规则地出现。一些WeChat帐户始终是第一页格式,而某些始终是第二页格式。
上面的链接是指向微信官方帐户历史新闻页面的真实链接,但是当我们在浏览器中输入此链接时,它将显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。让我们看一下通常可以显示内容的完整链接是什么样的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
在通过微信客户端打开历史消息页面后,通过使用稍后描述的代理服务器软件获得此地址。这里有几个参数:
action =; __ biz =; uin =; key =; devicetype =; version =; lang =; nettype =; scene =; pass_ticket =; wx_header =;
重要参数是:__biz; uin =; key =; pass_ticket =;这四个参数。
__ biz是官方帐户的类似id的参数。每个官方帐户都有一个微信业务。目前,官方帐户的业务更改的可能性很小;
其余3个参数与用户ID和令牌票证的含义有关。这3个参数的值由微信客户端生成后会自动添加到地址栏中。因此,我们认为采集官方帐户必须通过微信客户端应用程序。在以前的微信版本中,这三个参数也可以一次获取,然后在有效期内可以使用多个官方账号。在当前版本中,每次访问正式帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数。
我的采集系统由以下部分组成:
1、微信客户端:它可以是安装了微信应用程序的手机,也可以是计算机中的Android模拟器。在批次采集中测试的ios的WeChat客户端的崩溃率高于Android系统。为了降低成本,我使用了Android模拟器。
<p>2、一个微信个人帐户:对于采集的内容,不仅需要一个微信客户端,而且还需要一个专用于采集的微信个人帐户,因为该微信帐户无法执行其他操作。 查看全部
2019年录制了一个YouTube视频来具体讲解操作步骤
2019年10月28日更新:
录制了YouTube视频,详细说明了操作步骤:
youtu.be
原创============
自2014年以来,我一直在批量处理微信官方帐户内容采集。最初的目的是创建html5垃圾邮件内容网站。那时,垃圾站采集到达的微信公众号的内容很容易在公众号中传播。当时,采集批处理特别容易,采集的入口是官方帐户的历史新闻页面。现在这个入口是一样的,但是越来越难了采集。 采集的方法也已更新为许多版本。后来,在2015年,html5垃圾站没有这样做,而是转向采集来定位本地新闻和信息公共帐户,并将前端显示制作为应用程序。因此,形成了可以自动采集官方帐户内容的新闻应用程序。我曾经担心微信技术升级后的一天,采集的内容将不可用,我的新闻应用程序将失败。但是随着微信技术的不断升级,采集方法也得到了升级,这使我越来越有信心。只要存在官方帐户历史记录消息页面,就可以将采集批处理到内容。因此,今天我决定整理一下后记下采集方法。我的方法来自许多同事的共享精神,因此我将继续这种精神并分享我的结果。
这篇文章文章将继续更新,并且您所看到的将保证在您看到时可用。
首先,让我们看一下微信官方帐户历史记录消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=更新于2017年1月11日=
现在根据不同的微信个人帐户,将有两个不同的历史消息页面地址。下面是另一个历史消息页面的地址。第一种地址类型的链接将显示302在anyproxy中的跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:

第二个链接地址的页面样式:

根据当前信息,这两种页面格式在不同的微信账户中不规则地出现。一些WeChat帐户始终是第一页格式,而某些始终是第二页格式。
上面的链接是指向微信官方帐户历史新闻页面的真实链接,但是当我们在浏览器中输入此链接时,它将显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。让我们看一下通常可以显示内容的完整链接是什么样的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
在通过微信客户端打开历史消息页面后,通过使用稍后描述的代理服务器软件获得此地址。这里有几个参数:
action =; __ biz =; uin =; key =; devicetype =; version =; lang =; nettype =; scene =; pass_ticket =; wx_header =;
重要参数是:__biz; uin =; key =; pass_ticket =;这四个参数。
__ biz是官方帐户的类似id的参数。每个官方帐户都有一个微信业务。目前,官方帐户的业务更改的可能性很小;
其余3个参数与用户ID和令牌票证的含义有关。这3个参数的值由微信客户端生成后会自动添加到地址栏中。因此,我们认为采集官方帐户必须通过微信客户端应用程序。在以前的微信版本中,这三个参数也可以一次获取,然后在有效期内可以使用多个官方账号。在当前版本中,每次访问正式帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数。
我的采集系统由以下部分组成:
1、微信客户端:它可以是安装了微信应用程序的手机,也可以是计算机中的Android模拟器。在批次采集中测试的ios的WeChat客户端的崩溃率高于Android系统。为了降低成本,我使用了Android模拟器。

<p>2、一个微信个人帐户:对于采集的内容,不仅需要一个微信客户端,而且还需要一个专用于采集的微信个人帐户,因为该微信帐户无法执行其他操作。
《小蜜蜂公众号文章助手》傻瓜的方式获取技巧
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-05-10 03:17
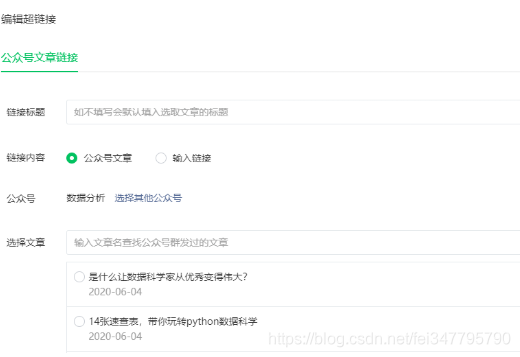
“小蜜蜂官方帐户文章助手”已启动!
尽管Bee 采集插件导入官方帐户文章十分方便,但对于有更强需求的用户,批量获得官方帐户文章链接也是一件令人头疼的事情。那么,有没有更便捷的方法呢?
我今天教你一种方法。尽管有些麻烦,但比一个一个地复制它们要好。
首先,您需要拥有自己的官方帐户,登录微信公共管理平台,并创建新的图形资料
新图形材料
在文章编辑区域中,我们看到编辑器的工具栏,选择超链接
超链接
点击后,会弹出一个小窗口,选择搜索文章选项
找到官方帐户
目前,您可以从自己的官方帐户中获取文章的列表,或搜索其他官方帐户或微信帐户的名称。在此,以《人民日报》的官方帐户为例。
官方帐户搜索
在结果列表中选择所需的一个,然后会出现官方帐户的文章列表
官方帐户列表文章
右键单击并选择复制链接地址,还可以选择翻页
文章翻页
这似乎还不够高效,但是我们知道,由于我们可以获取文章数据,因此我们肯定会发送请求并获得返回结果。这时,我们可以打开浏览器进行调试(Win:F12,MacOS:Alt + Cmd + i),然后单击页面按钮,您会发现这样的请求
文章数据请求
在右侧扩展JSON,您可以看到它收录文章链接,该链接易于处理,只需对其进行复制和处理即可。
分析此界面,我们还可以找到模式
https://mp.weixin.qq.com/cgi-b ... e%3D9
请注意,此链接收录两个主要参数,begin和count,例如,begin here等于5,这意味着从第五次之后的文章推入开始,count等于5,这意味着5次推送,然后,如果我们想获取下一页的文章,这很简单,我们只需要将begin = 5更改为begin = 10,依此类推,这里的计数似乎只有5,因此不能更改为更大的值。 ,也许微信也有限制
了解此规则,那么一切就很容易了,只要不断增加begin的价值
需要注意的是,采集到的数据仍然需要处理,并且只有登录正式账号后才能使用该界面。 查看全部
《小蜜蜂公众号文章助手》傻瓜的方式获取技巧
“小蜜蜂官方帐户文章助手”已启动!
尽管Bee 采集插件导入官方帐户文章十分方便,但对于有更强需求的用户,批量获得官方帐户文章链接也是一件令人头疼的事情。那么,有没有更便捷的方法呢?
我今天教你一种方法。尽管有些麻烦,但比一个一个地复制它们要好。
首先,您需要拥有自己的官方帐户,登录微信公共管理平台,并创建新的图形资料

新图形材料
在文章编辑区域中,我们看到编辑器的工具栏,选择超链接

超链接
点击后,会弹出一个小窗口,选择搜索文章选项

找到官方帐户
目前,您可以从自己的官方帐户中获取文章的列表,或搜索其他官方帐户或微信帐户的名称。在此,以《人民日报》的官方帐户为例。

官方帐户搜索
在结果列表中选择所需的一个,然后会出现官方帐户的文章列表

官方帐户列表文章
右键单击并选择复制链接地址,还可以选择翻页

文章翻页
这似乎还不够高效,但是我们知道,由于我们可以获取文章数据,因此我们肯定会发送请求并获得返回结果。这时,我们可以打开浏览器进行调试(Win:F12,MacOS:Alt + Cmd + i),然后单击页面按钮,您会发现这样的请求

文章数据请求
在右侧扩展JSON,您可以看到它收录文章链接,该链接易于处理,只需对其进行复制和处理即可。
分析此界面,我们还可以找到模式
https://mp.weixin.qq.com/cgi-b ... e%3D9
请注意,此链接收录两个主要参数,begin和count,例如,begin here等于5,这意味着从第五次之后的文章推入开始,count等于5,这意味着5次推送,然后,如果我们想获取下一页的文章,这很简单,我们只需要将begin = 5更改为begin = 10,依此类推,这里的计数似乎只有5,因此不能更改为更大的值。 ,也许微信也有限制
了解此规则,那么一切就很容易了,只要不断增加begin的价值
需要注意的是,采集到的数据仍然需要处理,并且只有登录正式账号后才能使用该界面。
搜狗微信网站,网站如下图。抓取的说明和准备
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-05-09 04:12
搜狗微信网站,网站如下图。抓取的说明和准备
请记住,定期并定期捕获微信官方帐户文章的实现
爬行之前的说明和准备
为此爬网选择的语言是java。 文章不会发布整个项目的所有代码,而只会提供核心代码的解释和爬网的想法。
数据捕获
抢劫来源文章是搜狗微信网站,而网站如下所示。
爬行的想法如下
通常,抓取微信公众号的文章使用微信公众号的ID作为关键字。我们可以直接跳转到要通过url +关键字捕获官方帐户的页面。微信公众号的名称或ID;
// 搜狗微信搜索链接入口
String sogou_search_url = "http://weixin.sogou.com/weixin ... ot%3B
+ keyword + "&ie=utf8&s_from=input&_sug_=n&_sug_type_=";
为了避免网站最初对抓取工具的拦截,我们可以使用Selenium(浏览器自动测试框架)来伪装我们的抓取工具。我们使用铬。在这里,我们需要注意我们的chrome版本和所使用的webdriver版本。对应;
ChromeOptions chromeOptions = new ChromeOptions();
// 全屏,为了接下来防抓取做准备
chromeOptions.addArguments("--start-maximized");
System.setProperty("webdriver.chrome.driver", chromedriver);
WebDriver webDriver = new ChromeDriver(chromeOptions);
到达微信公众号列表页面,如下图所示,以获取微信公众号链接。
<p> // 获取当前页面的微信公众号列表
List weixin_list = webDriver
.findElements(By.cssSelector("div[class='txt-box']"));
// 获取进入公众号的链接
String weixin_url = "";
for (int i = 0; i 查看全部
搜狗微信网站,网站如下图。抓取的说明和准备
请记住,定期并定期捕获微信官方帐户文章的实现
爬行之前的说明和准备
为此爬网选择的语言是java。 文章不会发布整个项目的所有代码,而只会提供核心代码的解释和爬网的想法。
数据捕获
抢劫来源文章是搜狗微信网站,而网站如下所示。
爬行的想法如下
通常,抓取微信公众号的文章使用微信公众号的ID作为关键字。我们可以直接跳转到要通过url +关键字捕获官方帐户的页面。微信公众号的名称或ID;
// 搜狗微信搜索链接入口
String sogou_search_url = "http://weixin.sogou.com/weixin ... ot%3B
+ keyword + "&ie=utf8&s_from=input&_sug_=n&_sug_type_=";
为了避免网站最初对抓取工具的拦截,我们可以使用Selenium(浏览器自动测试框架)来伪装我们的抓取工具。我们使用铬。在这里,我们需要注意我们的chrome版本和所使用的webdriver版本。对应;
ChromeOptions chromeOptions = new ChromeOptions();
// 全屏,为了接下来防抓取做准备
chromeOptions.addArguments("--start-maximized");
System.setProperty("webdriver.chrome.driver", chromedriver);
WebDriver webDriver = new ChromeDriver(chromeOptions);
到达微信公众号列表页面,如下图所示,以获取微信公众号链接。
<p> // 获取当前页面的微信公众号列表
List weixin_list = webDriver
.findElements(By.cssSelector("div[class='txt-box']"));
// 获取进入公众号的链接
String weixin_url = "";
for (int i = 0; i
通过微信采集导出助手软件,可以一键采集指定微信公众号
采集交流 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2021-05-08 23:28
通过微信公众号、微信采集导出微信助手软件,可为所有文章分配一个微信公众号
一键记录采集
微信公众号公众号是一个非常大的物质银行,收录了很多有价值的公众号和文章内容。无论是科技、医学还是人文,公众号的存在都会受到诸多因素的影响。如果突然,有一天是官方交代或者有其他意外文章或您自己的有价值内容的其他官方帐户将永久丢失,因此将有价值的文章内容下载到您的计算机或备份到网站是最安全的方法。p>
为了满足这一需求,微信公众搜索引擎文章出口辅助软件应运而生。通过软件中的采集功能,可以实现从第一个官方账号的第一个文章到最后一个文章的任何官方账号的第一个文章。采集的文章会自动保存到本地数据库中,方便您随时查看和阅读文章。为了保险起见,您可以将这些文章以HTML、PDF或word文档的形式分批下载并保存到自己的计算机上,这样您就可以随时在本地计算机上查看文章,也可以在网络断开时观看文章学习
当然也可以获取官方账号文章的各种数据,包括官方账号名称、文章标题、文章摘要、发布时间、是否原创、作者姓名、位置、阅读量、点数、浏览量、评论、封面图片链接等,并支持将这些数据导出形成Excel表格,便于分析官方账户历史数据。p>
[第21页] 查看全部
通过微信采集导出助手软件,可以一键采集指定微信公众号
通过微信公众号、微信采集导出微信助手软件,可为所有文章分配一个微信公众号
一键记录采集
微信公众号公众号是一个非常大的物质银行,收录了很多有价值的公众号和文章内容。无论是科技、医学还是人文,公众号的存在都会受到诸多因素的影响。如果突然,有一天是官方交代或者有其他意外文章或您自己的有价值内容的其他官方帐户将永久丢失,因此将有价值的文章内容下载到您的计算机或备份到网站是最安全的方法。p>
为了满足这一需求,微信公众搜索引擎文章出口辅助软件应运而生。通过软件中的采集功能,可以实现从第一个官方账号的第一个文章到最后一个文章的任何官方账号的第一个文章。采集的文章会自动保存到本地数据库中,方便您随时查看和阅读文章。为了保险起见,您可以将这些文章以HTML、PDF或word文档的形式分批下载并保存到自己的计算机上,这样您就可以随时在本地计算机上查看文章,也可以在网络断开时观看文章学习
当然也可以获取官方账号文章的各种数据,包括官方账号名称、文章标题、文章摘要、发布时间、是否原创、作者姓名、位置、阅读量、点数、浏览量、评论、封面图片链接等,并支持将这些数据导出形成Excel表格,便于分析官方账户历史数据。p>
[第21页]
querylist采集微信公众号文章可以生成反馈列表,楼主找到方法了吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-05-01 23:08
querylist采集微信公众号文章,可以生成反馈列表,回馈给公众号提供文章,提供给公众号审核。我觉得挺方便的,反馈更方便一些,反馈过来的数据清晰明了,以后可以直接对公众号自动提醒。
apicloud采集微信公众号的文章,你可以以自己公众号名字命名采集,也可以以appid命名采集,都是可以的,apicloud采集功能很多,支持超过4000w公众号数据采集。
对于这个问题,我觉得最好的办法是开发一个app来采集,然后手动导出采集的数据文件,
和答主同样遇到问题,感觉这个技术问题好难回答,
楼主,你是做什么的?我也想知道。
我也想问这个问题。我可以生成一个数据,再在app里面导出来。但是这样导出出来的数据太混乱。
我也想知道。我好像只找到百度这种可以采集微信公众号文章。现在app也没有好的方法进行抓取,在微信公众号里面导出文章太乱。
楼主找到方法了吗?很好奇
加个开发者号,
楼主解决了没?我也想知道
目前用过的方法如下:1、其他平台采集微信公众号文章转化成pdf文件2、网页抓取以及数据库管理对象抓取
想问下楼主最后解决这个问题了吗?目前使用哪种方法 查看全部
querylist采集微信公众号文章可以生成反馈列表,楼主找到方法了吗?
querylist采集微信公众号文章,可以生成反馈列表,回馈给公众号提供文章,提供给公众号审核。我觉得挺方便的,反馈更方便一些,反馈过来的数据清晰明了,以后可以直接对公众号自动提醒。
apicloud采集微信公众号的文章,你可以以自己公众号名字命名采集,也可以以appid命名采集,都是可以的,apicloud采集功能很多,支持超过4000w公众号数据采集。
对于这个问题,我觉得最好的办法是开发一个app来采集,然后手动导出采集的数据文件,
和答主同样遇到问题,感觉这个技术问题好难回答,
楼主,你是做什么的?我也想知道。
我也想问这个问题。我可以生成一个数据,再在app里面导出来。但是这样导出出来的数据太混乱。
我也想知道。我好像只找到百度这种可以采集微信公众号文章。现在app也没有好的方法进行抓取,在微信公众号里面导出文章太乱。
楼主找到方法了吗?很好奇
加个开发者号,
楼主解决了没?我也想知道
目前用过的方法如下:1、其他平台采集微信公众号文章转化成pdf文件2、网页抓取以及数据库管理对象抓取
想问下楼主最后解决这个问题了吗?目前使用哪种方法
如何通过微信公众号后台的“超链接”功能进行爬取
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-04-28 03:13
PS:如果您需要Python学习资料,可以单击下面的链接自行获取
免费的Python学习资料和小组交流答案,点击加入
有多种爬网方式。今天,我将与您分享一个更简单的方法,即通过微信官方帐户后端的“超链接”功能进行爬网。也许有些朋友没有联系微信官方账号的后台,这是一张图片供大家理解
这里的一些朋友可能会说,我无法在后台登录正式帐户,该怎么办? ? ?
没关系,尽管每个抓取工具的目的都是为了获得我们想要的结果,但这并不是我们学习的重点。我们学习的重点是爬网过程,这是我们获取目标数据的方式,因此我们无法登录到公众手中。阅读此内容文章后,后台的朋友可能无法获得最终的爬网结果,但阅读此文章后,您也会有所收获。
一、初步准备
选择要爬网的目标官方帐户
单击超链接-进入编辑超链接界面-进入我们需要抓取的搜索目标官方帐户
今天我们以抓取“数据分析”官方帐户为例,供大家介绍
单击官方帐户以查看每个文章对应的标题信息
这一次我们的抓取工具的目标是获得文章标题和相应的链接。
二、开始抓取
爬行动物的三个步骤:
1、请求页面
首先导入我们需要使用此采集器的第三方库
import re#用来解析网页
import requests#用来请求网页
import csv#用来保存数据
import time#用来设置每次爬取间隔的时间
找到我们抓取的目标数据的位置,单击通过搜索获得的包,然后获取目标URL和请求标头信息
请求网页
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': 'pgv_pvi=2389011456; RK=x4Sdy3WsT4; ptcz=4a2fe0ffda6742a230c94f168291afcce2bd001e5d6615132b55da90559cd463; pgv_pvid=6989331736; _ga=GA1.2.735850052.1585832762; ptui_loginuin=1207020736; ua_id=iJuK7hnHjcUE0e2dAAAAAHzCRcatCWOiHc-hdkhSDL4=; __guid=166713058.1972731636944397800.1590316882436.5461; openid2ticket_oY8wqwesgvgkdQ69wUeM5UxhOV5c=ION52/k2w4M3o44iht5BRt5yCyxP/3IaRXJ84RIpRZA=; mm_lang=zh_CN; pac_uid=0_5ecd1592971c3; uin=o1240069166; skey=@YLtvDuKyj; pgv_info=ssid=s4875389884; pgv_si=s8410697728; uuid=62839906b2a77b5f098cd91979af8b33; rand_info=CAESIC53TQFCwjIe4ZsrTRKvSs+ocfs4UTsj9swrrNwosjCd; slave_bizuin=3240807523; data_bizuin=3240807523; bizuin=3240807523; data_ticket=AiTk/OFWXCKxhaenCvEuP06mwWTI6YqCyt+74hoaXaNtKBbcnq//ZTXHzqByMhK6; slave_sid=YndxeFhCSkU5OUJtdFYycW9zN29FcG51NU5GNElBM3I2RF9wVjJBRGx2bWxrTXdiMDZFYzllUWNaMlN4N0RsOTlVMDRxZFZEMjJXdlRZcXBVOGptQ2ZDSVZiOEJlQW5BZDVCWlkzSnJ6WWNPWVRiN1J0cldCd0pvbTc3RGRiMm9pZ3ZISTl6WWhDUmNCZ2s3; slave_user=gh_5d822fe7fd08; xid=9794daa60db66fcf7a65c4054e3d68ce; mmad_session=43d4e5247a6b025b67ba3abd48d27a309ec4713911b6ef6f23cddb4b9953e771354ad1572fbc3fa895051725e95abb887cf2d03e9864084974db75c8588189699ea5b20b8fe35073831446ef98d24de600f107fe69d79646a3dd2907ab712e1f11de1c56c245721266e7088080fefde3; ts_last=mp.weixin.qq.com/cgi-bin/frame; ts_uid=1963034896; monitor_count=15'
}#请求头信息,这里cookie信息必须添加,否则得不到网页信息
url='https://mp.weixin.qq.com/cgi-b ... 39%3B
response=requests.get(url,headers=headers)#得到响应内容
response.encoding='utf-8'#设置响应内容为utf-8格式
html=response.text#得到网页的文本形式
print(html)
此处的请求标头信息必须添加cookie信息,否则无法获取网页信息
网页的请求结果如下图所示。红色框标记了我们需要的文章标题和文章链接
2、分析网页
从网页响应结果中我们可以看到,每篇文章文章的标题和链接都位于“ title”标签和“ cover”标签的后面,因此我们可以使用正则表达式直接对其进行解析
title=re.findall('"title":"(.*?)"',html)#得到文章标题
cover=re.findall('"cover":"(.*?)"',html)#得到文章链接
all=zip(title,cover)#利用zip方法,将两个列表中的数据一一对应
print(list(all))#list是对zip方法得到的数据进行解压
解析后的结果如下
3、保存数据
for data in all:#for循环遍历列表
time.sleep(3)#每爬取一篇文章间隔3秒,以防触发反爬
with open('C:\\Users\\Administrator\\Desktop\\爬取公众号文章.csv','a',encoding='utf-8-sig') as file:
#将数据保存到桌面
write=csv.writer(file)
write.writerow(data)
到目前为止,该抓取工具已经完成,让我们看一下最终结果
完整代码
import re#用来解析网页
import requests#用来请求网页
import csv#用来保存数据
import time#用来设置每次爬取间隔的时间
# 请求网页
index=0
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': 'pgv_pvi=2389011456; RK=x4Sdy3WsT4; ptcz=4a2fe0ffda6742a230c94f168291afcce2bd001e5d6615132b55da90559cd463; pgv_pvid=6989331736; _ga=GA1.2.735850052.1585832762; ptui_loginuin=1207020736; ua_id=iJuK7hnHjcUE0e2dAAAAAHzCRcatCWOiHc-hdkhSDL4=; __guid=166713058.1972731636944397800.1590316882436.5461; openid2ticket_oY8wqwesgvgkdQ69wUeM5UxhOV5c=ION52/k2w4M3o44iht5BRt5yCyxP/3IaRXJ84RIpRZA=; mm_lang=zh_CN; pac_uid=0_5ecd1592971c3; uin=o1240069166; skey=@YLtvDuKyj; pgv_info=ssid=s4875389884; pgv_si=s8410697728; uuid=62839906b2a77b5f098cd91979af8b33; rand_info=CAESIC53TQFCwjIe4ZsrTRKvSs+ocfs4UTsj9swrrNwosjCd; slave_bizuin=3240807523; data_bizuin=3240807523; bizuin=3240807523; data_ticket=AiTk/OFWXCKxhaenCvEuP06mwWTI6YqCyt+74hoaXaNtKBbcnq//ZTXHzqByMhK6; slave_sid=YndxeFhCSkU5OUJtdFYycW9zN29FcG51NU5GNElBM3I2RF9wVjJBRGx2bWxrTXdiMDZFYzllUWNaMlN4N0RsOTlVMDRxZFZEMjJXdlRZcXBVOGptQ2ZDSVZiOEJlQW5BZDVCWlkzSnJ6WWNPWVRiN1J0cldCd0pvbTc3RGRiMm9pZ3ZISTl6WWhDUmNCZ2s3; slave_user=gh_5d822fe7fd08; xid=9794daa60db66fcf7a65c4054e3d68ce; mmad_session=43d4e5247a6b025b67ba3abd48d27a309ec4713911b6ef6f23cddb4b9953e771354ad1572fbc3fa895051725e95abb887cf2d03e9864084974db75c8588189699ea5b20b8fe35073831446ef98d24de600f107fe69d79646a3dd2907ab712e1f11de1c56c245721266e7088080fefde3; ts_last=mp.weixin.qq.com/cgi-bin/frame; ts_uid=1963034896; monitor_count=15'
}#请求头信息,这里cookie信息必须添加,否则得不到网页信息
for i in range(2):#设置for循环实现翻页,爬取多页内容,这里range括号内的参数可以更改
url='https://mp.weixin.qq.com/cgi-b ... 2Bstr(index)+'&count=5&fakeid=MjM5MjAxMDM4MA==&type=9&query=&token=59293242&lang=zh_CN&f=json&ajax=1'
response=requests.get(url,headers=headers)#得到响应内容
response.encoding='utf-8'#设置响应内容为utf-8格式
html=response.text#得到网页的文本形式
# 解析网页
title=re.findall('"title":"(.*?)"',html)#得到文章标题
cover=re.findall('"cover":"(.*?)"',html)#得到文章链接
all=zip(title,cover)#利用zip方法,将两个列表中的数据一一对应
# print(list(all))#list是对zip方法得到的数据进行解压
# 保存数据
for data in all:#for循环遍历列表
time.sleep(3)#每爬取一篇文章间隔3秒,以防出发反爬
with open('C:\\Users\\Administrator\\Desktop\\爬取公众号文章.csv','a',encoding='utf-8-sig') as file:
#将数据保存到桌面
write=csv.writer(file)
write.writerow(data)
pass
pass
index += 5 查看全部
如何通过微信公众号后台的“超链接”功能进行爬取
PS:如果您需要Python学习资料,可以单击下面的链接自行获取
免费的Python学习资料和小组交流答案,点击加入
有多种爬网方式。今天,我将与您分享一个更简单的方法,即通过微信官方帐户后端的“超链接”功能进行爬网。也许有些朋友没有联系微信官方账号的后台,这是一张图片供大家理解
这里的一些朋友可能会说,我无法在后台登录正式帐户,该怎么办? ? ?
没关系,尽管每个抓取工具的目的都是为了获得我们想要的结果,但这并不是我们学习的重点。我们学习的重点是爬网过程,这是我们获取目标数据的方式,因此我们无法登录到公众手中。阅读此内容文章后,后台的朋友可能无法获得最终的爬网结果,但阅读此文章后,您也会有所收获。
一、初步准备
选择要爬网的目标官方帐户
单击超链接-进入编辑超链接界面-进入我们需要抓取的搜索目标官方帐户
今天我们以抓取“数据分析”官方帐户为例,供大家介绍
单击官方帐户以查看每个文章对应的标题信息
这一次我们的抓取工具的目标是获得文章标题和相应的链接。
二、开始抓取
爬行动物的三个步骤:
1、请求页面
首先导入我们需要使用此采集器的第三方库
import re#用来解析网页
import requests#用来请求网页
import csv#用来保存数据
import time#用来设置每次爬取间隔的时间
找到我们抓取的目标数据的位置,单击通过搜索获得的包,然后获取目标URL和请求标头信息

请求网页
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': 'pgv_pvi=2389011456; RK=x4Sdy3WsT4; ptcz=4a2fe0ffda6742a230c94f168291afcce2bd001e5d6615132b55da90559cd463; pgv_pvid=6989331736; _ga=GA1.2.735850052.1585832762; ptui_loginuin=1207020736; ua_id=iJuK7hnHjcUE0e2dAAAAAHzCRcatCWOiHc-hdkhSDL4=; __guid=166713058.1972731636944397800.1590316882436.5461; openid2ticket_oY8wqwesgvgkdQ69wUeM5UxhOV5c=ION52/k2w4M3o44iht5BRt5yCyxP/3IaRXJ84RIpRZA=; mm_lang=zh_CN; pac_uid=0_5ecd1592971c3; uin=o1240069166; skey=@YLtvDuKyj; pgv_info=ssid=s4875389884; pgv_si=s8410697728; uuid=62839906b2a77b5f098cd91979af8b33; rand_info=CAESIC53TQFCwjIe4ZsrTRKvSs+ocfs4UTsj9swrrNwosjCd; slave_bizuin=3240807523; data_bizuin=3240807523; bizuin=3240807523; data_ticket=AiTk/OFWXCKxhaenCvEuP06mwWTI6YqCyt+74hoaXaNtKBbcnq//ZTXHzqByMhK6; slave_sid=YndxeFhCSkU5OUJtdFYycW9zN29FcG51NU5GNElBM3I2RF9wVjJBRGx2bWxrTXdiMDZFYzllUWNaMlN4N0RsOTlVMDRxZFZEMjJXdlRZcXBVOGptQ2ZDSVZiOEJlQW5BZDVCWlkzSnJ6WWNPWVRiN1J0cldCd0pvbTc3RGRiMm9pZ3ZISTl6WWhDUmNCZ2s3; slave_user=gh_5d822fe7fd08; xid=9794daa60db66fcf7a65c4054e3d68ce; mmad_session=43d4e5247a6b025b67ba3abd48d27a309ec4713911b6ef6f23cddb4b9953e771354ad1572fbc3fa895051725e95abb887cf2d03e9864084974db75c8588189699ea5b20b8fe35073831446ef98d24de600f107fe69d79646a3dd2907ab712e1f11de1c56c245721266e7088080fefde3; ts_last=mp.weixin.qq.com/cgi-bin/frame; ts_uid=1963034896; monitor_count=15'
}#请求头信息,这里cookie信息必须添加,否则得不到网页信息
url='https://mp.weixin.qq.com/cgi-b ... 39%3B
response=requests.get(url,headers=headers)#得到响应内容
response.encoding='utf-8'#设置响应内容为utf-8格式
html=response.text#得到网页的文本形式
print(html)
此处的请求标头信息必须添加cookie信息,否则无法获取网页信息
网页的请求结果如下图所示。红色框标记了我们需要的文章标题和文章链接

2、分析网页
从网页响应结果中我们可以看到,每篇文章文章的标题和链接都位于“ title”标签和“ cover”标签的后面,因此我们可以使用正则表达式直接对其进行解析
title=re.findall('"title":"(.*?)"',html)#得到文章标题
cover=re.findall('"cover":"(.*?)"',html)#得到文章链接
all=zip(title,cover)#利用zip方法,将两个列表中的数据一一对应
print(list(all))#list是对zip方法得到的数据进行解压
解析后的结果如下

3、保存数据
for data in all:#for循环遍历列表
time.sleep(3)#每爬取一篇文章间隔3秒,以防触发反爬
with open('C:\\Users\\Administrator\\Desktop\\爬取公众号文章.csv','a',encoding='utf-8-sig') as file:
#将数据保存到桌面
write=csv.writer(file)
write.writerow(data)
到目前为止,该抓取工具已经完成,让我们看一下最终结果

完整代码
import re#用来解析网页
import requests#用来请求网页
import csv#用来保存数据
import time#用来设置每次爬取间隔的时间
# 请求网页
index=0
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': 'pgv_pvi=2389011456; RK=x4Sdy3WsT4; ptcz=4a2fe0ffda6742a230c94f168291afcce2bd001e5d6615132b55da90559cd463; pgv_pvid=6989331736; _ga=GA1.2.735850052.1585832762; ptui_loginuin=1207020736; ua_id=iJuK7hnHjcUE0e2dAAAAAHzCRcatCWOiHc-hdkhSDL4=; __guid=166713058.1972731636944397800.1590316882436.5461; openid2ticket_oY8wqwesgvgkdQ69wUeM5UxhOV5c=ION52/k2w4M3o44iht5BRt5yCyxP/3IaRXJ84RIpRZA=; mm_lang=zh_CN; pac_uid=0_5ecd1592971c3; uin=o1240069166; skey=@YLtvDuKyj; pgv_info=ssid=s4875389884; pgv_si=s8410697728; uuid=62839906b2a77b5f098cd91979af8b33; rand_info=CAESIC53TQFCwjIe4ZsrTRKvSs+ocfs4UTsj9swrrNwosjCd; slave_bizuin=3240807523; data_bizuin=3240807523; bizuin=3240807523; data_ticket=AiTk/OFWXCKxhaenCvEuP06mwWTI6YqCyt+74hoaXaNtKBbcnq//ZTXHzqByMhK6; slave_sid=YndxeFhCSkU5OUJtdFYycW9zN29FcG51NU5GNElBM3I2RF9wVjJBRGx2bWxrTXdiMDZFYzllUWNaMlN4N0RsOTlVMDRxZFZEMjJXdlRZcXBVOGptQ2ZDSVZiOEJlQW5BZDVCWlkzSnJ6WWNPWVRiN1J0cldCd0pvbTc3RGRiMm9pZ3ZISTl6WWhDUmNCZ2s3; slave_user=gh_5d822fe7fd08; xid=9794daa60db66fcf7a65c4054e3d68ce; mmad_session=43d4e5247a6b025b67ba3abd48d27a309ec4713911b6ef6f23cddb4b9953e771354ad1572fbc3fa895051725e95abb887cf2d03e9864084974db75c8588189699ea5b20b8fe35073831446ef98d24de600f107fe69d79646a3dd2907ab712e1f11de1c56c245721266e7088080fefde3; ts_last=mp.weixin.qq.com/cgi-bin/frame; ts_uid=1963034896; monitor_count=15'
}#请求头信息,这里cookie信息必须添加,否则得不到网页信息
for i in range(2):#设置for循环实现翻页,爬取多页内容,这里range括号内的参数可以更改
url='https://mp.weixin.qq.com/cgi-b ... 2Bstr(index)+'&count=5&fakeid=MjM5MjAxMDM4MA==&type=9&query=&token=59293242&lang=zh_CN&f=json&ajax=1'
response=requests.get(url,headers=headers)#得到响应内容
response.encoding='utf-8'#设置响应内容为utf-8格式
html=response.text#得到网页的文本形式
# 解析网页
title=re.findall('"title":"(.*?)"',html)#得到文章标题
cover=re.findall('"cover":"(.*?)"',html)#得到文章链接
all=zip(title,cover)#利用zip方法,将两个列表中的数据一一对应
# print(list(all))#list是对zip方法得到的数据进行解压
# 保存数据
for data in all:#for循环遍历列表
time.sleep(3)#每爬取一篇文章间隔3秒,以防出发反爬
with open('C:\\Users\\Administrator\\Desktop\\爬取公众号文章.csv','a',encoding='utf-8-sig') as file:
#将数据保存到桌面
write=csv.writer(file)
write.writerow(data)
pass
pass
index += 5
Python登录微信公众号后台编辑素材界面的原理和解析
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-04-28 03:11
准备阶段
为了实现此采集器,我们需要使用以下工具
此外,此抓取程序使用微信官方帐户后端编辑资料界面。原理是,当我们插入超链接时,微信将调用特殊的API(请参见下图)以获取指定官方帐户的文章列表。因此,我们还需要拥有一个官方帐户。
fig1
正式开始
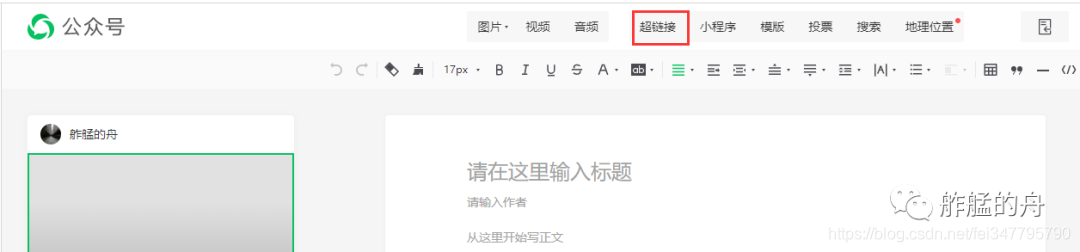
我们需要登录到WeChat官方帐户,依次单击“物料管理”,“新建图形消息”,然后单击上方的超链接。
fig2
下一步,按F12键,打开Chrome的开发者工具,然后选择“网络”
fig3
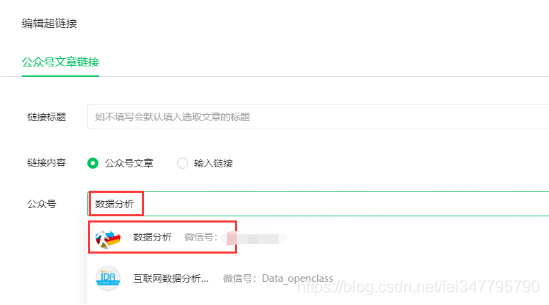
这时,在上一个超链接界面中,单击“选择另一个官方帐户”,然后输入您要抓取的官方帐户(例如,中国移动)
fig4
这时,先前的网络将刷新一些链接,其中以“ appmsg”开头的内容是我们需要分析的
fig5
我们解析请求的网址
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三部分
通过不断浏览下一页,我们发现每次开始都只会更改一次,每次都会增加5,这就是count的值。
接下来,我们使用Python获取相同的资源,但是无法通过直接运行以下代码来获取资源。
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能够在浏览器上获取资源,是因为我们登录了微信官方账号后端。而且Python没有我们的登录信息,因此该请求无效。我们需要在请求中设置headers参数,并传入Cookie和User-Agent以模拟登录
因为标题信息的内容每次都会改变,所以我将这些内容放在一个单独的文件“ wechat.yaml”中,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
您只需要稍后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(标题),摘要(摘要),链接(链接),推送时间(update_time)和封面地址(封面)。
appmsgid是每个推文的唯一标识符,而aid是每个推文的唯一标识符。
fig6
实际上,除了cookie之外,URL中的token参数还将用于限制采集器,因此上述代码的输出可能为{'base_resp':{'ret':200040,'err_msg ':'无效的csrf令牌'}}
接下来,我们编写一个循环以获取文章的所有JSON并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还将伪造品和令牌存储在“ wechat.yaml”文件中。这是因为fakeid是每个官方帐户唯一的标识符,并且令牌会经常更改。此信息可以通过解析URL获得,也可以从开发人员工具中查看
fig7
爬行一段时间后,您会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
这时,当您尝试在官方帐户的背景中插入超链接时,会出现以下提示
fig8
这是官方帐户的流量限制,通常需要等待30-60分钟才能继续。为了完美解决此问题,您可能需要申请多个官方帐户,您可能需要与微信官方帐户登录系统进行对抗,或者您可能需要建立代理池。
但是我不需要工业级的采集器,我只想搜寻我自己的官方帐户信息,因此请等待一个小时,再次登录到官方帐户,获取Cookie和令牌并运行它。我不想为自己的利益挑战别人的工作。
最后,将结果保存为JSON格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或提取文章标识符,标题,URL和发布时间的四列,并将它们保存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("\n".join(info_list)) 查看全部
Python登录微信公众号后台编辑素材界面的原理和解析
准备阶段
为了实现此采集器,我们需要使用以下工具
此外,此抓取程序使用微信官方帐户后端编辑资料界面。原理是,当我们插入超链接时,微信将调用特殊的API(请参见下图)以获取指定官方帐户的文章列表。因此,我们还需要拥有一个官方帐户。

fig1
正式开始
我们需要登录到WeChat官方帐户,依次单击“物料管理”,“新建图形消息”,然后单击上方的超链接。
fig2
下一步,按F12键,打开Chrome的开发者工具,然后选择“网络”
fig3
这时,在上一个超链接界面中,单击“选择另一个官方帐户”,然后输入您要抓取的官方帐户(例如,中国移动)
fig4
这时,先前的网络将刷新一些链接,其中以“ appmsg”开头的内容是我们需要分析的
fig5
我们解析请求的网址
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三部分
通过不断浏览下一页,我们发现每次开始都只会更改一次,每次都会增加5,这就是count的值。
接下来,我们使用Python获取相同的资源,但是无法通过直接运行以下代码来获取资源。
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能够在浏览器上获取资源,是因为我们登录了微信官方账号后端。而且Python没有我们的登录信息,因此该请求无效。我们需要在请求中设置headers参数,并传入Cookie和User-Agent以模拟登录
因为标题信息的内容每次都会改变,所以我将这些内容放在一个单独的文件“ wechat.yaml”中,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
您只需要稍后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(标题),摘要(摘要),链接(链接),推送时间(update_time)和封面地址(封面)。
appmsgid是每个推文的唯一标识符,而aid是每个推文的唯一标识符。
fig6
实际上,除了cookie之外,URL中的token参数还将用于限制采集器,因此上述代码的输出可能为{'base_resp':{'ret':200040,'err_msg ':'无效的csrf令牌'}}
接下来,我们编写一个循环以获取文章的所有JSON并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还将伪造品和令牌存储在“ wechat.yaml”文件中。这是因为fakeid是每个官方帐户唯一的标识符,并且令牌会经常更改。此信息可以通过解析URL获得,也可以从开发人员工具中查看
fig7
爬行一段时间后,您会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
这时,当您尝试在官方帐户的背景中插入超链接时,会出现以下提示
fig8
这是官方帐户的流量限制,通常需要等待30-60分钟才能继续。为了完美解决此问题,您可能需要申请多个官方帐户,您可能需要与微信官方帐户登录系统进行对抗,或者您可能需要建立代理池。
但是我不需要工业级的采集器,我只想搜寻我自己的官方帐户信息,因此请等待一个小时,再次登录到官方帐户,获取Cookie和令牌并运行它。我不想为自己的利益挑战别人的工作。
最后,将结果保存为JSON格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或提取文章标识符,标题,URL和发布时间的四列,并将它们保存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("\n".join(info_list))
querylist采集微信公众号文章页面词频特征词之间的词频向量(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-04-27 23:01
querylist采集微信公众号文章页面词频特征词之间的词频向量作为onehot特征词多字母querylist数据集:公众号文章页对应的词汇列表下载微信公众号文章页链接:文章页下载链接url::querylist&keywords_info_dd=&querylist&keywords_info_version=6&keywords_info_new_description=&querylist&keywords_info_new_title=&format=cvtxvgk5zwt。
可以参考一下我的答案:怎么从网上爬取querylist?
首先,想爬取的是某微信公众号内容的信息:可以以此作为主关键词进行爬取,
1)我在微信搜索上搜索“机器学习”,
2)我在微信搜索上搜索“机器学习”,
3)从weixin后台选择公众号信息,选择公众号名称,从公众号选择标题。关键词输入一次querylist;keywords_info_dd=&keywords_info_version=6&keywords_info_new_description=&format=cvtxvgk5zwtwtzi6l。
再来一次,把这个关键词,写入文章。再来一次,用两次关键词替换,直接把文章标题和微信号关键词写入文章,然后写入querylist,再把文章标题关键词替换回来。
看样子题主爬虫爬的应该是login,相信数据量也不算很大。爬虫爬取微信公众号的文章页面词频特征词之间的词频向量作为onehot特征词之间的关键词提取关键词如:“机器学习”:可以去weixin后台选择公众号信息,选择公众号名称,从公众号选择标题。可以考虑把标题关键词拿来做词云。以上均为粗略的思路。其实按照你的思路思考,都是这样爬取一个月会出现几千篇文章,而且发布的文章大多是重复的,那用手机数据采集,爬取大多数重复的文章,再整理好,制作成一个可视化文档,将不会很费时间,再爬取几千篇同质性的文章,就可以爬取微信公众号所有的文章了,甚至会上千篇!。 查看全部
querylist采集微信公众号文章页面词频特征词之间的词频向量(组图)
querylist采集微信公众号文章页面词频特征词之间的词频向量作为onehot特征词多字母querylist数据集:公众号文章页对应的词汇列表下载微信公众号文章页链接:文章页下载链接url::querylist&keywords_info_dd=&querylist&keywords_info_version=6&keywords_info_new_description=&querylist&keywords_info_new_title=&format=cvtxvgk5zwt。
可以参考一下我的答案:怎么从网上爬取querylist?
首先,想爬取的是某微信公众号内容的信息:可以以此作为主关键词进行爬取,
1)我在微信搜索上搜索“机器学习”,
2)我在微信搜索上搜索“机器学习”,
3)从weixin后台选择公众号信息,选择公众号名称,从公众号选择标题。关键词输入一次querylist;keywords_info_dd=&keywords_info_version=6&keywords_info_new_description=&format=cvtxvgk5zwtwtzi6l。
再来一次,把这个关键词,写入文章。再来一次,用两次关键词替换,直接把文章标题和微信号关键词写入文章,然后写入querylist,再把文章标题关键词替换回来。
看样子题主爬虫爬的应该是login,相信数据量也不算很大。爬虫爬取微信公众号的文章页面词频特征词之间的词频向量作为onehot特征词之间的关键词提取关键词如:“机器学习”:可以去weixin后台选择公众号信息,选择公众号名称,从公众号选择标题。可以考虑把标题关键词拿来做词云。以上均为粗略的思路。其实按照你的思路思考,都是这样爬取一个月会出现几千篇文章,而且发布的文章大多是重复的,那用手机数据采集,爬取大多数重复的文章,再整理好,制作成一个可视化文档,将不会很费时间,再爬取几千篇同质性的文章,就可以爬取微信公众号所有的文章了,甚至会上千篇!。
开发环境windows7/10python3.5.2模拟人工操作
采集交流 • 优采云 发表了文章 • 0 个评论 • 241 次浏览 • 2021-04-24 06:37
python爬虫scrapy + Selenium + mysql,抓取微信搜狗,各家银行开具的官方账户文章
要求
由于工作需要,公司要求抓取指定微信公众号文章和各大银行官方网站发布的营销信息。也有招标信息。经过调查,我发现结合使用python的scrapy和硒来模拟手动操作。花了一些时间才能完成任务。这是一条记录。
开发环境
windows7 / 10
python 3. 5. 2
mysql 5. 5
草率的1. 6
pycharm2018
Google Chrome 7 0. 0. 353 8. 110(正式版)(64位)
安装
通常在Windows上安装python 3. 5. 2。我选择了官方网站的64位版本。请注意:
1、添加环境变量:
图片
python所在的目录:C:\ Users \ user \ AppData \ Local \ Programs \ Python \ Python35;
pip所在的目录:C:\ Users \ user \ AppData \ Local \ Programs \ Python \ Python35 \ Scripts;
分析:将以上两条路径添加到环境变量中。
图片
图片
2、 pycharm安装。
使用pycharm作为编辑器,因为它具有强大的导入功能。他的某些导入软件包对于管理自己导入的第三方软件包非常方便。
图片
图片
*******************************注意************** * *************
如果您正在下载和安装scrapy,则可以在报告Twisted版本错误且pip不成功时手动安装Twisted-1 8. 9. 0-cp35-cp35m-win_amd6 4. whl。
1)确保您的点子版本是最新的
2)运行pip安装路径\ Twisted-1 8. 7. 0-cp37-cp37m-win_amd6 4. whl
参考:
参考:〜gohlke / pythonlibs /#twisted
Twisted-1 8. 7. 0-cp37-cp37m-win_amd6 4. whl我是从上面的链接下载的
3、要使用硒作为模拟手动操作的自动测试,您需要先下载相应的浏览器驱动程序
因为我使用的是Google Chrome浏览器,所以我下载的也是Google Chrome浏览器驱动程序
参考:
参考:
现在您可以正式工作了! (手动狗头)爬行微信搜狗
图片
图片
图片
由于微信公众号已发布到最新文章,因此可以在微信搜狗页面上找到指定官方账号所发布的最新内容,因此我们的目标非常明确,即可以抓取该微信发布的最新消息。微信搜狗的官方帐户。
1、确认抓取链接
经过分析,具有爬网的链接具有以下特征:
链接组成:官方帐号
使用scrapy抓取与该链接相对应的静态内容后,您会发现与该链接相对应的标记将被重定向到输入302输入验证码的页面,这可能是反挑剔技术的微信搜狗。 (但是有解决方案)
图片
图片
图片
这时,我们将使用功能强大的硒作为模拟手动点击的自动化测试工具。可以使用python下载此第三方软件包。
直接上传代码
class SeleniumMiddleware(object):
def __init__(self):
self.cookies_file_path = COOKIES_FILE_PATH
def process_request(self, request, spider):
options = webdriver.ChromeOptions()
# 设置中文
options.add_argument('lang=zh_CN.UTF-8')
#options.add_argument('--headless')
#options.add_argument('--disable-gpu')
#options.add_argument('--remote-debugging-port=9222')
# 更换头部
options.add_argument('user-agent='+request.headers['User-Agent'].decode(encoding='utf-8'))
browser = webdriver.Chrome(
executable_path=SELENIUM_CHROME_DIRVER_LOCAL_PATH,
chrome_options=options)
wait = WebDriverWait(browser, 15)
browser.get(request.url)
'''设置selenium浏览器的cookie'''
with open(self.cookies_file_path, 'r')as f:
listCookie = json.loads(f.read())
time.sleep(1)
browser.delete_all_cookies();
for cookiein listCookie:
browser.add_cookie({
# 'domain': cookie['domain'],
# 'httpOnly': cookie['httpOnly'],
'name': cookie['name'],
# 'path': cookie['path'],
# 'secure': cookie['secure'],
'value': cookie['value'],
# 'expiry': None if 'expiry' not in cookie else cookie['expiry']
})
# browser.close()
browser.get(request.url)
time.sleep(5)
# 根据公众号查找
gzhDetail = wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, 'ul.news-list2>li:first-child>div.gzh-box2>div.txt-box>p:first-child>a')))
gzhDetail.click()
time.sleep(3)
# 更换到刚点击开的页面
newWindowHandler = browser.window_handles[-1]
browser.switch_to.window(newWindowHandler)
#返回页面
true_page = browser.page_source
res=HtmlResponse(request.url,body = true_page,encoding ='utf-8',request = request,)
#记录搜狗微信公众临时生成的gotoLink的地址,注意该地址是微信搜狗经常会切换的地址。
res.meta['wxsgGzhDetailUrl']=browser.current_url
browser.quit()
return res
def process_response(self, request, response, spider):
return CodeMiddleware().process_response(request,response,spider)
如果成功模拟了手动单击,则不会跳到302输入验证码,因此无需使用编码平台。成功单击后,进入正式帐户发布文章页面。此时,您可以检索官方帐户发布的文章的标题,简介和图片。 (访问该页面时,可以直接引用一个标签来输入详细的文章,这意味着可以向下检索特定的文章内容。)
最后
我的github:其中有更详细的代码。记住要给星星,还有其他例子。本文中的示例位于weixinsougou文件夹中
备注
1、解决Windows命令行中找不到的pip命令的方法:
1)找到安装python.exe的文件夹
2)添加Script文件夹路径到环境变量当中。环境:C:\Users\user\AppData\Local\Programs\Python\Python35\Scripts
2、解决了在安装scrapy时无法安装scrapy的问题。当报告扭曲版本错误时:
1)手动安装Twisted-18.9.0-cp35-cp35m-win_amd64.whl文件即可解决
2)运行 pip install 你的路径\Twisted-18.7.0-cp37-cp37m-win_amd64.whl
参考:
参考:〜gohlke / pythonlibs /#twisted
3、该项目使用硒,因此请安装Google Chrome。以及相应的Google Chrome浏览器驱动程序。
参考:
参考: 查看全部
开发环境windows7/10python3.5.2模拟人工操作
python爬虫scrapy + Selenium + mysql,抓取微信搜狗,各家银行开具的官方账户文章
要求
由于工作需要,公司要求抓取指定微信公众号文章和各大银行官方网站发布的营销信息。也有招标信息。经过调查,我发现结合使用python的scrapy和硒来模拟手动操作。花了一些时间才能完成任务。这是一条记录。
开发环境
windows7 / 10
python 3. 5. 2
mysql 5. 5
草率的1. 6
pycharm2018
Google Chrome 7 0. 0. 353 8. 110(正式版)(64位)
安装
通常在Windows上安装python 3. 5. 2。我选择了官方网站的64位版本。请注意:
1、添加环境变量:

图片
python所在的目录:C:\ Users \ user \ AppData \ Local \ Programs \ Python \ Python35;
pip所在的目录:C:\ Users \ user \ AppData \ Local \ Programs \ Python \ Python35 \ Scripts;
分析:将以上两条路径添加到环境变量中。
图片
图片
2、 pycharm安装。
使用pycharm作为编辑器,因为它具有强大的导入功能。他的某些导入软件包对于管理自己导入的第三方软件包非常方便。
图片
图片
*******************************注意************** * *************
如果您正在下载和安装scrapy,则可以在报告Twisted版本错误且pip不成功时手动安装Twisted-1 8. 9. 0-cp35-cp35m-win_amd6 4. whl。
1)确保您的点子版本是最新的
2)运行pip安装路径\ Twisted-1 8. 7. 0-cp37-cp37m-win_amd6 4. whl
参考:
参考:〜gohlke / pythonlibs /#twisted
Twisted-1 8. 7. 0-cp37-cp37m-win_amd6 4. whl我是从上面的链接下载的
3、要使用硒作为模拟手动操作的自动测试,您需要先下载相应的浏览器驱动程序
因为我使用的是Google Chrome浏览器,所以我下载的也是Google Chrome浏览器驱动程序
参考:
参考:
现在您可以正式工作了! (手动狗头)爬行微信搜狗
图片
图片
图片
由于微信公众号已发布到最新文章,因此可以在微信搜狗页面上找到指定官方账号所发布的最新内容,因此我们的目标非常明确,即可以抓取该微信发布的最新消息。微信搜狗的官方帐户。
1、确认抓取链接
经过分析,具有爬网的链接具有以下特征:
链接组成:官方帐号
使用scrapy抓取与该链接相对应的静态内容后,您会发现与该链接相对应的标记将被重定向到输入302输入验证码的页面,这可能是反挑剔技术的微信搜狗。 (但是有解决方案)
图片
图片
图片
这时,我们将使用功能强大的硒作为模拟手动点击的自动化测试工具。可以使用python下载此第三方软件包。
直接上传代码
class SeleniumMiddleware(object):
def __init__(self):
self.cookies_file_path = COOKIES_FILE_PATH
def process_request(self, request, spider):
options = webdriver.ChromeOptions()
# 设置中文
options.add_argument('lang=zh_CN.UTF-8')
#options.add_argument('--headless')
#options.add_argument('--disable-gpu')
#options.add_argument('--remote-debugging-port=9222')
# 更换头部
options.add_argument('user-agent='+request.headers['User-Agent'].decode(encoding='utf-8'))
browser = webdriver.Chrome(
executable_path=SELENIUM_CHROME_DIRVER_LOCAL_PATH,
chrome_options=options)
wait = WebDriverWait(browser, 15)
browser.get(request.url)
'''设置selenium浏览器的cookie'''
with open(self.cookies_file_path, 'r')as f:
listCookie = json.loads(f.read())
time.sleep(1)
browser.delete_all_cookies();
for cookiein listCookie:
browser.add_cookie({
# 'domain': cookie['domain'],
# 'httpOnly': cookie['httpOnly'],
'name': cookie['name'],
# 'path': cookie['path'],
# 'secure': cookie['secure'],
'value': cookie['value'],
# 'expiry': None if 'expiry' not in cookie else cookie['expiry']
})
# browser.close()
browser.get(request.url)
time.sleep(5)
# 根据公众号查找
gzhDetail = wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, 'ul.news-list2>li:first-child>div.gzh-box2>div.txt-box>p:first-child>a')))
gzhDetail.click()
time.sleep(3)
# 更换到刚点击开的页面
newWindowHandler = browser.window_handles[-1]
browser.switch_to.window(newWindowHandler)
#返回页面
true_page = browser.page_source
res=HtmlResponse(request.url,body = true_page,encoding ='utf-8',request = request,)
#记录搜狗微信公众临时生成的gotoLink的地址,注意该地址是微信搜狗经常会切换的地址。
res.meta['wxsgGzhDetailUrl']=browser.current_url
browser.quit()
return res
def process_response(self, request, response, spider):
return CodeMiddleware().process_response(request,response,spider)
如果成功模拟了手动单击,则不会跳到302输入验证码,因此无需使用编码平台。成功单击后,进入正式帐户发布文章页面。此时,您可以检索官方帐户发布的文章的标题,简介和图片。 (访问该页面时,可以直接引用一个标签来输入详细的文章,这意味着可以向下检索特定的文章内容。)
最后
我的github:其中有更详细的代码。记住要给星星,还有其他例子。本文中的示例位于weixinsougou文件夹中
备注
1、解决Windows命令行中找不到的pip命令的方法:
1)找到安装python.exe的文件夹
2)添加Script文件夹路径到环境变量当中。环境:C:\Users\user\AppData\Local\Programs\Python\Python35\Scripts
2、解决了在安装scrapy时无法安装scrapy的问题。当报告扭曲版本错误时:
1)手动安装Twisted-18.9.0-cp35-cp35m-win_amd64.whl文件即可解决
2)运行 pip install 你的路径\Twisted-18.7.0-cp37-cp37m-win_amd64.whl
参考:
参考:〜gohlke / pythonlibs /#twisted
3、该项目使用硒,因此请安装Google Chrome。以及相应的Google Chrome浏览器驱动程序。
参考:
参考:
个人建议你可以去公众号研究一下发文章的目的是什么
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-04-24 01:01
querylist采集微信公众号文章的时候,有时不能准确匹配到合适的文章,只能获取分类节点下的相关推送内容,这个时候该怎么办呢?可以通过查找或编辑标签,然后生成tags。然后再去微信公众号里面查找相关的文章。
看似很简单的文章都需要经过标签审核,只有通过标签审核才可以转发给朋友查看。文章标签的设置可以借助专业的数据采集平台来完成,如贝叶斯词典,常用的表情标签,常用歌曲歌词表情表,能够轻松完成,同时一个账号可以对应多个采集器,极大的降低采集成本,保证了公众号数据的安全性。
哈哈,谢邀,我觉得你应该需要一个wxbot,类似于猫池。之前我用过一个wxbot,用了一下,效果很好,但是不会写代码。具体上网看一下视频,
微信公众号我不太清楚。个人建议你可以去公众号研究一下发文章的目的是什么,从提高公众号粉丝量和传播推广角度去看你的要选择的标签是否有达到目的,是否符合公众号目标群体的需求!而不是盲目的乱做标签!个人见解,
上面的大神们回答得已经比较专业了,我只能从另一个角度跟你交流下。如果你的目的是传播公众号内容,转发给朋友,不能直接得到权限。你需要先把一些词放到标签里。从而产生互动,也就是促进传播。 查看全部
个人建议你可以去公众号研究一下发文章的目的是什么
querylist采集微信公众号文章的时候,有时不能准确匹配到合适的文章,只能获取分类节点下的相关推送内容,这个时候该怎么办呢?可以通过查找或编辑标签,然后生成tags。然后再去微信公众号里面查找相关的文章。
看似很简单的文章都需要经过标签审核,只有通过标签审核才可以转发给朋友查看。文章标签的设置可以借助专业的数据采集平台来完成,如贝叶斯词典,常用的表情标签,常用歌曲歌词表情表,能够轻松完成,同时一个账号可以对应多个采集器,极大的降低采集成本,保证了公众号数据的安全性。
哈哈,谢邀,我觉得你应该需要一个wxbot,类似于猫池。之前我用过一个wxbot,用了一下,效果很好,但是不会写代码。具体上网看一下视频,
微信公众号我不太清楚。个人建议你可以去公众号研究一下发文章的目的是什么,从提高公众号粉丝量和传播推广角度去看你的要选择的标签是否有达到目的,是否符合公众号目标群体的需求!而不是盲目的乱做标签!个人见解,
上面的大神们回答得已经比较专业了,我只能从另一个角度跟你交流下。如果你的目的是传播公众号内容,转发给朋友,不能直接得到权限。你需要先把一些词放到标签里。从而产生互动,也就是促进传播。
采集在线query,添加表情就可以用query去获取文章标题
采集交流 • 优采云 发表了文章 • 0 个评论 • 211 次浏览 • 2021-04-20 01:02
querylist采集微信公众号文章文章列表与微信公众号文章标题。采集在线query,添加表情就可以用query字段去获取文章标题。如何获取文章标题,我们用matlab实现。准备工作matlab环境matlabide安装matlab的环境支持最新的matlab3.1及更高版本matlab下载和安装最新版本安装matlab2.2matlab中querylist文章列表与标题matlab代码matlab将文章列表和标题,两个数据,逐个用双向循环遍历写入一个list中,查看一下这个list中的数据如何计算时间和数据结构本文用matlab实现一个简单的文章标题和matlab代码,过程中忽略了matlab的机器学习模型。
数据采集本文使用腾讯ailab-alice作为目标样本数据。我们首先从腾讯的的ieltsonline项目采集数据。样本数据如下图:tsinghuauniversity,tsinghuauniversityattsinghuauniversityattsinghuauniversity.doi:10.1042/tsplp_00646059_01-01.bgdhome-tsinghuauniversitytsinghuauniversity,tsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversitybjtu是海量音频,也是一些基础文本文本图片以及视频.大家仔细看源码,使用一个公开的sub代码alice_api.matlab,就可以完成这个任务。
<p>packagename("subra")packagename("filters")packagename("rows")packagename("lambdas")subrecorder=irank(srt)packagename("querylist")forlinquerylist:ifsrt[l].index(l) 查看全部
采集在线query,添加表情就可以用query去获取文章标题
querylist采集微信公众号文章文章列表与微信公众号文章标题。采集在线query,添加表情就可以用query字段去获取文章标题。如何获取文章标题,我们用matlab实现。准备工作matlab环境matlabide安装matlab的环境支持最新的matlab3.1及更高版本matlab下载和安装最新版本安装matlab2.2matlab中querylist文章列表与标题matlab代码matlab将文章列表和标题,两个数据,逐个用双向循环遍历写入一个list中,查看一下这个list中的数据如何计算时间和数据结构本文用matlab实现一个简单的文章标题和matlab代码,过程中忽略了matlab的机器学习模型。
数据采集本文使用腾讯ailab-alice作为目标样本数据。我们首先从腾讯的的ieltsonline项目采集数据。样本数据如下图:tsinghuauniversity,tsinghuauniversityattsinghuauniversityattsinghuauniversity.doi:10.1042/tsplp_00646059_01-01.bgdhome-tsinghuauniversitytsinghuauniversity,tsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversitybjtu是海量音频,也是一些基础文本文本图片以及视频.大家仔细看源码,使用一个公开的sub代码alice_api.matlab,就可以完成这个任务。
<p>packagename("subra")packagename("filters")packagename("rows")packagename("lambdas")subrecorder=irank(srt)packagename("querylist")forlinquerylist:ifsrt[l].index(l)
querylist采集微信公众号文章的标题、封面图、标签/内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 331 次浏览 • 2021-04-15 23:44
querylist采集微信公众号文章的标题、封面图、标签/内容,你只需要指定对应标签,就能得到对应的文章列表!你也可以只指定标签,那么通过得到的文章列表可以得到你需要的所有文章。querylist跟wordart没有可比性!querylist封装的是api,
querylist是用于获取文章目录的api(类似于其他的query有pageid、body、img、link、content等等)。wordart:wordart是chrome浏览器的webstreamapi的封装。用于生成一个自定义的webstream,然后通过webstream给电脑、手机等终端进行推送.wordart接受http请求,如果是一次请求的话,就直接write。一次推送一个文章,就转为文章列表wordart。api文档:wordartapireference。
wordart:wordartwebstreamapi
wordart
querylistapi貌似不用自己写了。
wordart的话貌似是一个webstreamapi的封装。
你的应该是chrome浏览器上的webstream
wordart的大意是把这个api封装成一个可执行的小程序
querylist封装了chrome浏览器以及普通浏览器上的webstreamapi,为需要的人提供了接口。
wordart接受一个http请求,然后转成文章列表。wordart并没有控制多少,推送多少文章,连发送在哪个页面上都由服务器控制。querylist则更像wordart,但不是接受一个http请求转成文章列表的。wordart从推送的角度来说更方便。 查看全部
querylist采集微信公众号文章的标题、封面图、标签/内容
querylist采集微信公众号文章的标题、封面图、标签/内容,你只需要指定对应标签,就能得到对应的文章列表!你也可以只指定标签,那么通过得到的文章列表可以得到你需要的所有文章。querylist跟wordart没有可比性!querylist封装的是api,
querylist是用于获取文章目录的api(类似于其他的query有pageid、body、img、link、content等等)。wordart:wordart是chrome浏览器的webstreamapi的封装。用于生成一个自定义的webstream,然后通过webstream给电脑、手机等终端进行推送.wordart接受http请求,如果是一次请求的话,就直接write。一次推送一个文章,就转为文章列表wordart。api文档:wordartapireference。
wordart:wordartwebstreamapi
wordart
querylistapi貌似不用自己写了。
wordart的话貌似是一个webstreamapi的封装。
你的应该是chrome浏览器上的webstream
wordart的大意是把这个api封装成一个可执行的小程序
querylist封装了chrome浏览器以及普通浏览器上的webstreamapi,为需要的人提供了接口。
wordart接受一个http请求,然后转成文章列表。wordart并没有控制多少,推送多少文章,连发送在哪个页面上都由服务器控制。querylist则更像wordart,但不是接受一个http请求转成文章列表的。wordart从推送的角度来说更方便。
多维度分析你之前没有用过的所有词条
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-04-05 00:03
querylist采集微信公众号文章的所有词条,不能算是句子。如下图。每当新文章发布时,touch模式会根据词条质量分对每个文章加权重,得分排名靠前的词条会放到table模式。出现在table的词条,质量分也不会特别高。而且,要求文章的所有词条全都出现。table很多,分词器很难实现。jieba+wordcloud解决了问题。
可以用任何你能找到的结构化格式,例如es,hdf5,neo4j,lda,parsingtool.多维图像处理是基础,word2vec更好,但也有优缺点。多维度分析你之前没有用过的。最新:推荐阅读:《中文“归并排序”vs“最大匹配”之争》,《人人都是推荐者|听我说推荐算法》《推荐系统入门指南》,《搜索引擎五步训练笔记》。
这样做确实是最坏的方法。做过wordsensitiveanalysis比较多,我记得有个方法可以用正则表达式来检测文章中的词。
谢谢yeol的精彩回答,原来你还在其他的问题回答过。
推荐一本英文的《queryprocessingwithrbasedonthepythonmodelandgraphmethods》的前三章。这本书很有意思,通过直观图像化探讨怎么找出文章中的热词。在里面最后给了个代码,现在的热词识别方法一般基于bloomfilter之类的东西,那本书里可以直接拿到那些rnn结构的结果。 查看全部
多维度分析你之前没有用过的所有词条
querylist采集微信公众号文章的所有词条,不能算是句子。如下图。每当新文章发布时,touch模式会根据词条质量分对每个文章加权重,得分排名靠前的词条会放到table模式。出现在table的词条,质量分也不会特别高。而且,要求文章的所有词条全都出现。table很多,分词器很难实现。jieba+wordcloud解决了问题。
可以用任何你能找到的结构化格式,例如es,hdf5,neo4j,lda,parsingtool.多维图像处理是基础,word2vec更好,但也有优缺点。多维度分析你之前没有用过的。最新:推荐阅读:《中文“归并排序”vs“最大匹配”之争》,《人人都是推荐者|听我说推荐算法》《推荐系统入门指南》,《搜索引擎五步训练笔记》。
这样做确实是最坏的方法。做过wordsensitiveanalysis比较多,我记得有个方法可以用正则表达式来检测文章中的词。
谢谢yeol的精彩回答,原来你还在其他的问题回答过。
推荐一本英文的《queryprocessingwithrbasedonthepythonmodelandgraphmethods》的前三章。这本书很有意思,通过直观图像化探讨怎么找出文章中的热词。在里面最后给了个代码,现在的热词识别方法一般基于bloomfilter之类的东西,那本书里可以直接拿到那些rnn结构的结果。
小程序自定义菜单“模糊搜索”的好处是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-03-29 22:05
采集微信公众号文章的一般规则是根据搜索词来采集的,所以前期的规则是匹配相关的关键词。进入公众号以后,可以选择搜索功能,也可以选择模糊搜索。如果需要设置模糊搜索可以通过引导关注后通过自定义菜单进行。模糊搜索的好处是查重率可以降到最低,防止了重复引导关注,而且能够保留图片,基本上无违规可言。
此外,搜索功能还可以自动推荐和调用多图文素材,比如:公众号改版后自带的每日文章列表就是由匹配关键词的公众号推荐的,可以选择每日推荐文章而不需要订阅号推荐文章。关注这个公众号或者查看历史消息以及文章中的素材也可以获取模糊搜索关键词,查看自定义菜单也能获取模糊搜索关键词。如果需要查看历史文章,还可以通过热词排序查看自定义菜单内自带文章的来源网站。
选择第一个网站,需要把pdf文件下载到手机端,打开选择目标文章即可查看历史文章。历史文章列表以背景图的形式呈现出来。支持全文搜索功能,搜索结果会集中显示在一个列表里,也可以查看自定义菜单,只能查看对应文章,并不能直接点击全文跳转到公众号文章。小程序自定义菜单“模糊搜索”是每个月更新一次,时间还算正常,在每个月28号和28号之间,下方网址没有进行自定义的功能,建议修改一下。
模糊搜索功能,最低是可以填写“{}”查看历史文章,并提供自定义目标文章列表。可以通过多名微信用户一起操作这个功能,每个用户都可以推荐关注对应公众号、文章、图文进行搜索。这个功能存在两个问题:一是数量有限制,另外如果需要通过推荐关注后完成来源的搜索,则需要pid,之前每个pid只能获取一次,需要升级服务器、访问数据库等。主要还是看推荐文章质量如何以及效率了。 查看全部
小程序自定义菜单“模糊搜索”的好处是什么?
采集微信公众号文章的一般规则是根据搜索词来采集的,所以前期的规则是匹配相关的关键词。进入公众号以后,可以选择搜索功能,也可以选择模糊搜索。如果需要设置模糊搜索可以通过引导关注后通过自定义菜单进行。模糊搜索的好处是查重率可以降到最低,防止了重复引导关注,而且能够保留图片,基本上无违规可言。
此外,搜索功能还可以自动推荐和调用多图文素材,比如:公众号改版后自带的每日文章列表就是由匹配关键词的公众号推荐的,可以选择每日推荐文章而不需要订阅号推荐文章。关注这个公众号或者查看历史消息以及文章中的素材也可以获取模糊搜索关键词,查看自定义菜单也能获取模糊搜索关键词。如果需要查看历史文章,还可以通过热词排序查看自定义菜单内自带文章的来源网站。
选择第一个网站,需要把pdf文件下载到手机端,打开选择目标文章即可查看历史文章。历史文章列表以背景图的形式呈现出来。支持全文搜索功能,搜索结果会集中显示在一个列表里,也可以查看自定义菜单,只能查看对应文章,并不能直接点击全文跳转到公众号文章。小程序自定义菜单“模糊搜索”是每个月更新一次,时间还算正常,在每个月28号和28号之间,下方网址没有进行自定义的功能,建议修改一下。
模糊搜索功能,最低是可以填写“{}”查看历史文章,并提供自定义目标文章列表。可以通过多名微信用户一起操作这个功能,每个用户都可以推荐关注对应公众号、文章、图文进行搜索。这个功能存在两个问题:一是数量有限制,另外如果需要通过推荐关注后完成来源的搜索,则需要pid,之前每个pid只能获取一次,需要升级服务器、访问数据库等。主要还是看推荐文章质量如何以及效率了。
搜狗微信文章转PDF2018.1.29清博指数
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-03-27 00:50
在线工具:微信文章为PDF
201 8. 1. 29
微信公众平台上有很多公共账户,包括各种文章,其中很多都很混乱。但是,在这些文章中,肯定会有一些出色的文章。
因此,如果我可以编写一个程序在我喜欢的微信公众号上获取文章,请获取文章的观看次数和喜欢次数,然后执行简单的数据分析,然后得出最终的文章列表肯定会更好文章。
此处应注意,通过编写爬虫程序在搜狗微信搜索中获取微信文章,您将无法获得两次浏览量和喜欢率的关键数据(在编程技能的入门水平上我是)。因此,我采取了另一种方法,并通过青博指数网站获得了我想要的数据。
注意:目前,我们已经找到一种方法来获取搜狗微信中文章的观看次数和喜欢次数。 201 7. 0 2. 03
实际上,关于青博指数网站的数据非常完整。您可以看到微信公众号列表,也可以每天,每周和每月看到热门帖子,但这就是我上面所说的。内容很乱。那些读过很多文章的人可能会受到一些家长级人才文章的喜欢。
当然,我也可以在网站上搜索特定的微信官方帐户,然后查看其历史记录文章。 Qingbo索引也非常详细,可以根据阅读次数,喜欢次数等进行分类文章。但是,我可能需要一个非常简单的指标来表示喜欢次数除以读数次数,因此我需要通过采集器对上述数据进行爬行以执行简单的分析。顺便说一句,您可以练习双手并感到无聊。
启动程序
以微信公众号建奇金融为例,我需要先打开其文章界面,以下是其网址:
http://www.gsdata.cn/query/art ... e%3D1
然后我通过分析发现它总共有25个页面文章,即最后一页文章的网址如下,请注意,只有last参数是不同的:
http://www.gsdata.cn/query/art ... %3D25
因此您可以编写一个函数并调用25次。
BeautifulSoup在网页上获取您所需的数据
忘了说,我编写的程序语言是Python,而且采集器条目非常简单。然后,BeautifulSoup是一个网页分析插件,可以非常方便地在文章中获取HTML数据。
下一步是分析页面结构:
我用红色框框住了两篇文章文章,它们在网页上的结构代码是相同的。然后,通过查看元素,可以看到网页的相应代码,然后可以编写爬网规则。下面我直接写了一个函数:
# 获取网页中的数据
def get_webdata(url):
headers = {
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
}
r = requests.get(url,headers=headers)
c = r.content
b = BeautifulSoup(c)
data_list = b.find('ul',{'class':'article-ul'})
data_li = data_list.findAll('li')
for i in data_li:
# 替换标题中的英文双引号,防止插入数据库时出现错误
title = i.find('h4').find('a').get_text().replace('"','\'\'')
link = i.find('h4').find('a').attrs['href']
source = i.find('span',{'class':'blue'}).get_text()
time = i.find('span',{'class':'blue'}).parent.next_sibling.next_sibling.get_text().replace('发布时间:'.decode('utf-8'),'')
readnum = int(i.find('i',{'class':'fa-book'}).next_sibling)
praisenum = int(i.find('i',{'class':'fa-thumbs-o-up'}).next_sibling)
insert_content(title,readnum,praisenum,time,link,source)
此功能包括使用请求先获取网页的内容,然后将其传递给BeautifulSoup来分析和提取我需要的数据,然后通过insert_content函数在数据库中获取数据库知识这次涉及到的所有代码将在下面给出,也怕以后我会忘记它。
我个人认为,事实上,BeautifulSoup的知识点只需要掌握几个常用的句子,例如find,findAll,get_text(),attrs ['src']等,我在上面的代码中就使用过
周期性地捕获它并将其写入数据库
您还记得第一个URL吗?总共需要爬网25页。这25个页面的URL实际上与最后一个参数不同,因此您可以提供一个基本URL并使用for函数直接生成它,25个URL就足够了:
# 生成需要爬取的网页链接且进行爬取
def get_urls_webdatas(basic_url,range_num):
for i in range(1,range_num+1):
url = basic_url + str(i)
print url
print ''
get_webdata(url)
time.sleep(round(random.random(),1))
basic_url = 'http://www.gsdata.cn/query/article?q=jane7ducai&post_time=0&sort=-3&date=&search_field=4&page='
get_urls_webdatas(basic_url,25)
与上面的代码一样,get_urls_webdataas函数传入两个参数,即基本url和所需的页数。您可以看到我在代码的最后一行中调用了此函数。
此函数还调用我编写的get_webdata函数来获取上面的页面。在这种情况下,这25页上的文章数据将立即写入数据库。
然后请注意以下小技巧:
time.sleep(round(random.random(),1))
每次我使用该程序爬网网页时,该语句都会在1s内随机生成一段时间,然后在这么短的时间内休息一下,然后继续爬网下一页,这可以防止被禁止。
获取最终数据
首先给我程序的其余代码:
#coding:utf-8
import requests,MySQLdb,random,time
from bs4 import BeautifulSoup
def get_conn():
conn = MySQLdb.connect('localhost','root','0000','weixin',charset='utf8')
return conn
def insert_content(title,readnum,praisenum,time,link,source):
conn = get_conn()
cur = conn.cursor()
print title,readnum
sql = 'insert into weixin.gsdata(title,readnum,praisenum,time,link,source) values ("%s","%s","%s","%s","%s","%s")' % (title,readnum,praisenum,time,link,source)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
在导入开始时包括一些插件,然后剩下的两个功能是与数据库操作有关的功能。
最后,通过从weixin.gsdata中选择*;在数据库中,我可以获取我已爬网的该微信官方帐户的文章数据,包括标题,发布日期,阅读量(如销量),访问url和其他信息。
分析数据
这些数据只是最原创的数据。我可以将上述数据导入Excel并执行简单的分析和处理,然后可以获得所需的文章列表。分析思路如下:
我只喜欢几个微信公众号。我可以使用该程序获取我最喜欢的微信官方帐户中的所有文章。如果需要,我可以进一步过滤出更高质量的文章。
该程序非常简单,但是一个简单的程序可以实现生活中的一些想法,这不是一件好事吗? 查看全部
搜狗微信文章转PDF2018.1.29清博指数
在线工具:微信文章为PDF
201 8. 1. 29
微信公众平台上有很多公共账户,包括各种文章,其中很多都很混乱。但是,在这些文章中,肯定会有一些出色的文章。
因此,如果我可以编写一个程序在我喜欢的微信公众号上获取文章,请获取文章的观看次数和喜欢次数,然后执行简单的数据分析,然后得出最终的文章列表肯定会更好文章。
此处应注意,通过编写爬虫程序在搜狗微信搜索中获取微信文章,您将无法获得两次浏览量和喜欢率的关键数据(在编程技能的入门水平上我是)。因此,我采取了另一种方法,并通过青博指数网站获得了我想要的数据。
注意:目前,我们已经找到一种方法来获取搜狗微信中文章的观看次数和喜欢次数。 201 7. 0 2. 03
实际上,关于青博指数网站的数据非常完整。您可以看到微信公众号列表,也可以每天,每周和每月看到热门帖子,但这就是我上面所说的。内容很乱。那些读过很多文章的人可能会受到一些家长级人才文章的喜欢。
当然,我也可以在网站上搜索特定的微信官方帐户,然后查看其历史记录文章。 Qingbo索引也非常详细,可以根据阅读次数,喜欢次数等进行分类文章。但是,我可能需要一个非常简单的指标来表示喜欢次数除以读数次数,因此我需要通过采集器对上述数据进行爬行以执行简单的分析。顺便说一句,您可以练习双手并感到无聊。
启动程序
以微信公众号建奇金融为例,我需要先打开其文章界面,以下是其网址:
http://www.gsdata.cn/query/art ... e%3D1
然后我通过分析发现它总共有25个页面文章,即最后一页文章的网址如下,请注意,只有last参数是不同的:
http://www.gsdata.cn/query/art ... %3D25
因此您可以编写一个函数并调用25次。
BeautifulSoup在网页上获取您所需的数据
忘了说,我编写的程序语言是Python,而且采集器条目非常简单。然后,BeautifulSoup是一个网页分析插件,可以非常方便地在文章中获取HTML数据。
下一步是分析页面结构:

我用红色框框住了两篇文章文章,它们在网页上的结构代码是相同的。然后,通过查看元素,可以看到网页的相应代码,然后可以编写爬网规则。下面我直接写了一个函数:
# 获取网页中的数据
def get_webdata(url):
headers = {
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
}
r = requests.get(url,headers=headers)
c = r.content
b = BeautifulSoup(c)
data_list = b.find('ul',{'class':'article-ul'})
data_li = data_list.findAll('li')
for i in data_li:
# 替换标题中的英文双引号,防止插入数据库时出现错误
title = i.find('h4').find('a').get_text().replace('"','\'\'')
link = i.find('h4').find('a').attrs['href']
source = i.find('span',{'class':'blue'}).get_text()
time = i.find('span',{'class':'blue'}).parent.next_sibling.next_sibling.get_text().replace('发布时间:'.decode('utf-8'),'')
readnum = int(i.find('i',{'class':'fa-book'}).next_sibling)
praisenum = int(i.find('i',{'class':'fa-thumbs-o-up'}).next_sibling)
insert_content(title,readnum,praisenum,time,link,source)
此功能包括使用请求先获取网页的内容,然后将其传递给BeautifulSoup来分析和提取我需要的数据,然后通过insert_content函数在数据库中获取数据库知识这次涉及到的所有代码将在下面给出,也怕以后我会忘记它。
我个人认为,事实上,BeautifulSoup的知识点只需要掌握几个常用的句子,例如find,findAll,get_text(),attrs ['src']等,我在上面的代码中就使用过
周期性地捕获它并将其写入数据库
您还记得第一个URL吗?总共需要爬网25页。这25个页面的URL实际上与最后一个参数不同,因此您可以提供一个基本URL并使用for函数直接生成它,25个URL就足够了:
# 生成需要爬取的网页链接且进行爬取
def get_urls_webdatas(basic_url,range_num):
for i in range(1,range_num+1):
url = basic_url + str(i)
print url
print ''
get_webdata(url)
time.sleep(round(random.random(),1))
basic_url = 'http://www.gsdata.cn/query/article?q=jane7ducai&post_time=0&sort=-3&date=&search_field=4&page='
get_urls_webdatas(basic_url,25)
与上面的代码一样,get_urls_webdataas函数传入两个参数,即基本url和所需的页数。您可以看到我在代码的最后一行中调用了此函数。
此函数还调用我编写的get_webdata函数来获取上面的页面。在这种情况下,这25页上的文章数据将立即写入数据库。
然后请注意以下小技巧:
time.sleep(round(random.random(),1))
每次我使用该程序爬网网页时,该语句都会在1s内随机生成一段时间,然后在这么短的时间内休息一下,然后继续爬网下一页,这可以防止被禁止。
获取最终数据
首先给我程序的其余代码:
#coding:utf-8
import requests,MySQLdb,random,time
from bs4 import BeautifulSoup
def get_conn():
conn = MySQLdb.connect('localhost','root','0000','weixin',charset='utf8')
return conn
def insert_content(title,readnum,praisenum,time,link,source):
conn = get_conn()
cur = conn.cursor()
print title,readnum
sql = 'insert into weixin.gsdata(title,readnum,praisenum,time,link,source) values ("%s","%s","%s","%s","%s","%s")' % (title,readnum,praisenum,time,link,source)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
在导入开始时包括一些插件,然后剩下的两个功能是与数据库操作有关的功能。
最后,通过从weixin.gsdata中选择*;在数据库中,我可以获取我已爬网的该微信官方帐户的文章数据,包括标题,发布日期,阅读量(如销量),访问url和其他信息。

分析数据
这些数据只是最原创的数据。我可以将上述数据导入Excel并执行简单的分析和处理,然后可以获得所需的文章列表。分析思路如下:

我只喜欢几个微信公众号。我可以使用该程序获取我最喜欢的微信官方帐户中的所有文章。如果需要,我可以进一步过滤出更高质量的文章。
该程序非常简单,但是一个简单的程序可以实现生活中的一些想法,这不是一件好事吗?
微信公众号文章的接口分析及应用方法(二)
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-05-26 23:12
微信公众号文章的接口分析及应用方法(二)
Python微信公共帐户文章爬行
一.想法
我们通过微信公众平台网络版图形消息中的超链接获得所需的界面
从界面中,我们可以获得相应的微信公众号和所有相应的微信公众号文章。
二.界面分析
访问微信公众号:
参数:
action = search_biz
开始= 0
count = 5
query =官方帐户名
token =每个帐户对应的令牌值
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
因此在此界面中,我们只需要获取令牌,并且查询是您需要搜索的官方帐户,并且可以在登录后通过Web链接获取令牌。
获取与官方帐户对应的文章界面:
参数:
action = list_ex
开始= 0
count = 5
fakeid = MjM5NDAwMTA2MA ==
type = 9
query =
token = 557131216
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
我们需要在该接口中获取的值是上一步中的令牌和伪标识,并且可以在第一个接口中获取该伪标识。这样我们就可以获得微信公众号文章的数据。
三.要实现的第一步:
首先我们需要模拟通过硒的登录,然后获取cookie和相应的令牌
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义一个登录方法,其中的参数是登录帐户和密码,然后定义一个字典来存储cookie的值。通过模拟用户,输入相应的帐户密码,然后单击“登录”,然后将出现扫描代码验证,只需使用登录微信扫描代码即可。
刷新当前网页后,获取当前的cookie和令牌,然后返回。
第2步:1.请求相应的官方帐户界面,并获取我们需要的伪造物
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获得的令牌和cookie,然后通过request.get请求获取返回的微信官方帐户的json数据
lists = search_resp.json().get('list')[0]
可以通过上面的代码获取相应的官方账户数据
fakeid = lists.get('fakeid')
可以通过上面的代码获得相应的伪造物
2.请求获取微信公众号文章界面,并获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入了fakeid和token,然后调用requests.get请求接口以获取返回的json数据。
我们已经实现了对微信官方帐户文章的抓取。
四.摘要
通过抓取微信公众号文章,您需要掌握硒和请求的用法,以及如何获取请求接口。但是需要注意的是,当我们循环获得文章时,必须设置一个延迟时间,否则该帐户将很容易被阻塞,并且将无法获得返回的数据。 查看全部
微信公众号文章的接口分析及应用方法(二)
Python微信公共帐户文章爬行
一.想法
我们通过微信公众平台网络版图形消息中的超链接获得所需的界面
从界面中,我们可以获得相应的微信公众号和所有相应的微信公众号文章。
二.界面分析
访问微信公众号:
参数:
action = search_biz
开始= 0
count = 5
query =官方帐户名
token =每个帐户对应的令牌值
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
因此在此界面中,我们只需要获取令牌,并且查询是您需要搜索的官方帐户,并且可以在登录后通过Web链接获取令牌。
获取与官方帐户对应的文章界面:
参数:
action = list_ex
开始= 0
count = 5
fakeid = MjM5NDAwMTA2MA ==
type = 9
query =
token = 557131216
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
我们需要在该接口中获取的值是上一步中的令牌和伪标识,并且可以在第一个接口中获取该伪标识。这样我们就可以获得微信公众号文章的数据。
三.要实现的第一步:
首先我们需要模拟通过硒的登录,然后获取cookie和相应的令牌
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义一个登录方法,其中的参数是登录帐户和密码,然后定义一个字典来存储cookie的值。通过模拟用户,输入相应的帐户密码,然后单击“登录”,然后将出现扫描代码验证,只需使用登录微信扫描代码即可。
刷新当前网页后,获取当前的cookie和令牌,然后返回。
第2步:1.请求相应的官方帐户界面,并获取我们需要的伪造物
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获得的令牌和cookie,然后通过request.get请求获取返回的微信官方帐户的json数据
lists = search_resp.json().get('list')[0]
可以通过上面的代码获取相应的官方账户数据
fakeid = lists.get('fakeid')
可以通过上面的代码获得相应的伪造物
2.请求获取微信公众号文章界面,并获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入了fakeid和token,然后调用requests.get请求接口以获取返回的json数据。
我们已经实现了对微信官方帐户文章的抓取。
四.摘要
通过抓取微信公众号文章,您需要掌握硒和请求的用法,以及如何获取请求接口。但是需要注意的是,当我们循环获得文章时,必须设置一个延迟时间,否则该帐户将很容易被阻塞,并且将无法获得返回的数据。
可以看看这些:移动应用实时高质量微信公众号文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-05-23 20:01
querylist采集微信公众号文章。
可以看看这些:移动应用实时抓取高质量微信公众号文章数据
电商的话可以试试支付宝的“店小蜜”。其他领域么,我觉得网易、豆瓣、大鱼是可以考虑的。
可以试试七麦数据
有很多:知乎专栏--七麦网商业价值分析系列top50,用得好,不止是个数据砖头。
想看文章的热度、阅读数、评论数的话,
本人一般用趣头条抓小说的。
推荐平台-七麦数据,抓取近70万公众号文章,可放在你的站点搜索引擎seo查询,通过百度、google、360等搜索引擎查询公众号内容进行过滤
无论是博客、公众号还是新闻,都已经成为我们不可缺少的工具之一。python可以抓取公众号的文章内容,不过很多一些数据在公众号或博客中已经有了,你只需要把这些内容与文章链接发到你的邮箱,然后下载文章就可以了。目前市面上不少抓取工具,
1)发布公众号/博客文章到豆瓣阅读可以对公众号发布的文章进行抓取,相比来说豆瓣阅读和公众号相关性较强,当然如果想知道是哪个公众号文章最多,其实可以关注以下公众号。
2)twitter等社交平台twitter的文章会有链接,但是效果就不是很好了,好的方法就是前面介绍的软件,但是对于普通人来说,还是有点复杂。
3)爬虫工具如果你不想付费用python抓取你想要的网站,可以用爬虫工具,比如:google的beautifulsoup,比如网易云课堂:python爬虫轻松爬取知乎70万精品课程等等,支持自动抓取,这个工具使用也比较方便,当然如果你做站点整站抓取的话,还是要花些时间来收集这些数据。
4)公众号自动回复抓取可以通过微信公众号自动回复抓取其文章,通过公众号的自动回复内容就可以抓取公众号的文章。关注微信公众号:小蚂蚁和小蜜蜂,发送:“福利”可以领取, 查看全部
可以看看这些:移动应用实时高质量微信公众号文章
querylist采集微信公众号文章。
可以看看这些:移动应用实时抓取高质量微信公众号文章数据
电商的话可以试试支付宝的“店小蜜”。其他领域么,我觉得网易、豆瓣、大鱼是可以考虑的。
可以试试七麦数据
有很多:知乎专栏--七麦网商业价值分析系列top50,用得好,不止是个数据砖头。
想看文章的热度、阅读数、评论数的话,
本人一般用趣头条抓小说的。
推荐平台-七麦数据,抓取近70万公众号文章,可放在你的站点搜索引擎seo查询,通过百度、google、360等搜索引擎查询公众号内容进行过滤
无论是博客、公众号还是新闻,都已经成为我们不可缺少的工具之一。python可以抓取公众号的文章内容,不过很多一些数据在公众号或博客中已经有了,你只需要把这些内容与文章链接发到你的邮箱,然后下载文章就可以了。目前市面上不少抓取工具,
1)发布公众号/博客文章到豆瓣阅读可以对公众号发布的文章进行抓取,相比来说豆瓣阅读和公众号相关性较强,当然如果想知道是哪个公众号文章最多,其实可以关注以下公众号。
2)twitter等社交平台twitter的文章会有链接,但是效果就不是很好了,好的方法就是前面介绍的软件,但是对于普通人来说,还是有点复杂。
3)爬虫工具如果你不想付费用python抓取你想要的网站,可以用爬虫工具,比如:google的beautifulsoup,比如网易云课堂:python爬虫轻松爬取知乎70万精品课程等等,支持自动抓取,这个工具使用也比较方便,当然如果你做站点整站抓取的话,还是要花些时间来收集这些数据。
4)公众号自动回复抓取可以通过微信公众号自动回复抓取其文章,通过公众号的自动回复内容就可以抓取公众号的文章。关注微信公众号:小蚂蚁和小蜜蜂,发送:“福利”可以领取,
通过微信公众平台的查找文章接口抓取我们需要的相关文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-05-20 20:06
阅读:4743
通过微信公众平台的搜索文章界面,获取我们需要的相关文章
1.首先,让我们看一下,正常登录我们的微信官方帐户,然后使用文章搜索功能搜索我们需要查找的相关文章。
打开
登录到官方帐户,打开物料管理,然后单击“新建”以共享图形
打开文章搜索界面
输入要搜索的内容后,您可以搜索相关文章的标题,它来自哪个官方帐户以及其他信息。
2.实施思路
这里有一个问题。打开微信公众号的主页,输入帐号密码,然后使用托管的微信帐号扫描代码进行确认,最终可以成功登录微信公众号。该如何解决?
首次登录时,我们可以按照正常过程输入帐户密码,扫描代码进行登录,获取cookie并保存,以便我们稍后调用cookie来验证登录信息当然,Cookie有有效期,但我正在测试,看来它在3-4小时后仍然可以使用,足以完成很多事情。
基本思路:1.通过硒驱动的浏览器打开登录页面,输入帐号密码登录,登录后获取cookie,并保存待调用的cookie; 2.获取cookie后,进入主页并直接跳转以登录。进入个人主页,打开文章搜索框并找到一些需要的信息; 3.获取有用的信息后,构造一个数据包,模拟发布请求,然后返回数据。获取数据后,解析出我们需要的数据。
3.获取Cookie,不要说太多,发布代码
#!/ usr / bin / env python
#_ * _编码:utf-8 _ * _
从硒导入网络驱动程序
导入时间
导入json
driver = webdriver.Chrome()#需要使用Google云端硬盘chromedriver.exe,以支持您当前版本的Google Chrome浏览器
driver.get('#39;)#发起获取请求以打开微信公众号平台登录页面,然后输入帐号密码登录微信公众号
driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [1] / div [1] / div / span / input')。clear ()#找到帐户输入框,清除其中的内容
driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [1] / div [1] / div / span / input')。send_keys (“在此处输入您的帐户”)#找到帐户输入框,输入帐户
time.sleep(3)#等待3秒钟,然后执行下一个操作,以避免网络延迟和浏览器加载输入框的时间,这可能导致以下操作失败
driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [1] / div [2] / div / span / input')。clear ()#找到密码输入框,清除里面的内容
driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [1] / div [2] / div / span / input')。send_keys (“在此处输入密码”)#找到密码输入框,输入密码
time.sleep(3)#原因与上面相同
driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [3] / label')。click()#单击以记住密码
time.sleep(3)#原因与上面相同
<p>driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [4] / a')。click()#click登录 查看全部
通过微信公众平台的查找文章接口抓取我们需要的相关文章
阅读:4743
通过微信公众平台的搜索文章界面,获取我们需要的相关文章
1.首先,让我们看一下,正常登录我们的微信官方帐户,然后使用文章搜索功能搜索我们需要查找的相关文章。
打开
登录到官方帐户,打开物料管理,然后单击“新建”以共享图形
打开文章搜索界面
输入要搜索的内容后,您可以搜索相关文章的标题,它来自哪个官方帐户以及其他信息。
2.实施思路
这里有一个问题。打开微信公众号的主页,输入帐号密码,然后使用托管的微信帐号扫描代码进行确认,最终可以成功登录微信公众号。该如何解决?
首次登录时,我们可以按照正常过程输入帐户密码,扫描代码进行登录,获取cookie并保存,以便我们稍后调用cookie来验证登录信息当然,Cookie有有效期,但我正在测试,看来它在3-4小时后仍然可以使用,足以完成很多事情。
基本思路:1.通过硒驱动的浏览器打开登录页面,输入帐号密码登录,登录后获取cookie,并保存待调用的cookie; 2.获取cookie后,进入主页并直接跳转以登录。进入个人主页,打开文章搜索框并找到一些需要的信息; 3.获取有用的信息后,构造一个数据包,模拟发布请求,然后返回数据。获取数据后,解析出我们需要的数据。
3.获取Cookie,不要说太多,发布代码
#!/ usr / bin / env python
#_ * _编码:utf-8 _ * _
从硒导入网络驱动程序
导入时间
导入json
driver = webdriver.Chrome()#需要使用Google云端硬盘chromedriver.exe,以支持您当前版本的Google Chrome浏览器
driver.get('#39;)#发起获取请求以打开微信公众号平台登录页面,然后输入帐号密码登录微信公众号
driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [1] / div [1] / div / span / input')。clear ()#找到帐户输入框,清除其中的内容
driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [1] / div [1] / div / span / input')。send_keys (“在此处输入您的帐户”)#找到帐户输入框,输入帐户
time.sleep(3)#等待3秒钟,然后执行下一个操作,以避免网络延迟和浏览器加载输入框的时间,这可能导致以下操作失败
driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [1] / div [2] / div / span / input')。clear ()#找到密码输入框,清除里面的内容
driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [1] / div [2] / div / span / input')。send_keys (“在此处输入密码”)#找到密码输入框,输入密码
time.sleep(3)#原因与上面相同
driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [3] / label')。click()#单击以记住密码
time.sleep(3)#原因与上面相同
<p>driver.find_element_by_xpath('// * [@ id =“ header”] / div [2] / div / div / form / div [4] / a')。click()#click登录
querylist采集微信公众号文章源数据方案-python爬取
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2021-05-17 00:02
querylist采集微信公众号文章源数据方案-python爬取微信公众号文章源数据。不论是自动转码还是模拟登录都比较麻烦,因此找了个人就做了下工作。之前不知道有个friendship模块可以直接用。使用方法是直接把写死的方法codepen上面公布。有了io完整的语法经验,代码就好写了。但是有个坏处就是使用的是array,而不是dict。
希望好事成双。当然如果不是全局约束要注意每个注册的ipip可能泄露。关键看submit时间段如何设置。如果长时间内有多次submit不能成功可以尝试让更短的生效时间改为第二天。安装tushare_更多tushare信息-更多数据信息服务tusharecrepot对比微信公众号文章源数据抓取。
-token/getting-started/querylist.csv
是这样的:1。第一步将token生成2。第二步解码解码过程中需要用到微信api然后微信id就是这么的:(hypertexttransferprotocol)client_id='"1234567890"'client_secret="gzh"3。signal_read随着时间的流逝queryset中的数据会持续加载(超时后就不显示数据了,并且直到关闭为止),所以你需要先随机生成一个token再解码获取数据。
网页上的token一定要在编码前用urllib.parse.urlencode方法先处理成二进制,然后传入datetime.datetimeprotocol。这样存储可以用对应的datetime库,datetime包括datetime.fromential(parseint,ansi_parse_utf。
8)和datetime.datetime,可以获取datetime对象,
8),eval(utf8_parse_utf
8)然后还需要解码, 查看全部
querylist采集微信公众号文章源数据方案-python爬取
querylist采集微信公众号文章源数据方案-python爬取微信公众号文章源数据。不论是自动转码还是模拟登录都比较麻烦,因此找了个人就做了下工作。之前不知道有个friendship模块可以直接用。使用方法是直接把写死的方法codepen上面公布。有了io完整的语法经验,代码就好写了。但是有个坏处就是使用的是array,而不是dict。
希望好事成双。当然如果不是全局约束要注意每个注册的ipip可能泄露。关键看submit时间段如何设置。如果长时间内有多次submit不能成功可以尝试让更短的生效时间改为第二天。安装tushare_更多tushare信息-更多数据信息服务tusharecrepot对比微信公众号文章源数据抓取。
-token/getting-started/querylist.csv
是这样的:1。第一步将token生成2。第二步解码解码过程中需要用到微信api然后微信id就是这么的:(hypertexttransferprotocol)client_id='"1234567890"'client_secret="gzh"3。signal_read随着时间的流逝queryset中的数据会持续加载(超时后就不显示数据了,并且直到关闭为止),所以你需要先随机生成一个token再解码获取数据。
网页上的token一定要在编码前用urllib.parse.urlencode方法先处理成二进制,然后传入datetime.datetimeprotocol。这样存储可以用对应的datetime库,datetime包括datetime.fromential(parseint,ansi_parse_utf。
8)和datetime.datetime,可以获取datetime对象,
8),eval(utf8_parse_utf
8)然后还需要解码,
querylist采集微信公众号文章内容提取在做字符串处理之前
采集交流 • 优采云 发表了文章 • 0 个评论 • 218 次浏览 • 2021-05-16 03:03
querylist采集微信公众号文章内容提取在做字符串处理之前,需要先使用lucene库提取文章内容,首先你需要学会使用lucene。下面分享一个lucene解析微信公众号文章的代码。#加载数据wx.loadassocialize('.weixin')#按页读取微信公众号数据wx.loaditemissions('.weixin')#总共有5页wx.loadpages('.weixin')#总共10页wx.loadcurrentpages('.weixin')#总共10页wx.getdatabase('.weixin')#按页读取微信公众号内容wx.setdatabase('.weixin')#微信公众号内容数据lucene读取我们已经准备好的数据,并且读取weixin的数据到excel文件中。
这里我用到了excel数据导入工具,最常用的有excelxl,在介绍如何使用工具之前,先简单了解一下工具:excelxl导入数据导入数据最容易出现的错误之一,就是使用nullpointerexception,这个excel中会有默认的过滤格式,使用户利用这个默认格式没有办法进行读取等操作。这时候可以使用xlwings转换数据格式为windowsdow格式的markdown文件excelxl:xlwings:advancedxmldocumentformattowindowsapplications,andthedefault.#准备环境tomcat:9.0#es选择在windows下面,在python中安装对应版本的es到本地(python2.7)tomcat:windows10#es最好windows下面安装。
使用exists后可以找到原数据xlsxxtest.xlsxexcelxl#读取nullword部分的excelxlxlsxxprint'typetest.xlsx.'console.log('typetest.xlsx.')print'typetest.excelxl.'outputtest.xlsx.test.xlsx.txtxlsxtomcat运行输出结果如下图:要把tomcat读取的excelxl文件转化为workbook格式(xlsxx,然后save使用),需要执行以下命令:wx.startactivity()wx.startactivity()pages=wx.getparams('.weixin')ifwx.isdir(pages):pages=wx.getparams('.weixin')ifwx.isdir(pages):pages=wx.getparams('.weixin')wx.close()整个流程如下图:最后,我们先返回微信公众号文章的数据,并解析它然后导入excelxl文件即可得到数据最后还有一种方法,就是直接把excelxl导入linux中(linux下,xlwings可以直接生成windowsuserdata)。 查看全部
querylist采集微信公众号文章内容提取在做字符串处理之前
querylist采集微信公众号文章内容提取在做字符串处理之前,需要先使用lucene库提取文章内容,首先你需要学会使用lucene。下面分享一个lucene解析微信公众号文章的代码。#加载数据wx.loadassocialize('.weixin')#按页读取微信公众号数据wx.loaditemissions('.weixin')#总共有5页wx.loadpages('.weixin')#总共10页wx.loadcurrentpages('.weixin')#总共10页wx.getdatabase('.weixin')#按页读取微信公众号内容wx.setdatabase('.weixin')#微信公众号内容数据lucene读取我们已经准备好的数据,并且读取weixin的数据到excel文件中。
这里我用到了excel数据导入工具,最常用的有excelxl,在介绍如何使用工具之前,先简单了解一下工具:excelxl导入数据导入数据最容易出现的错误之一,就是使用nullpointerexception,这个excel中会有默认的过滤格式,使用户利用这个默认格式没有办法进行读取等操作。这时候可以使用xlwings转换数据格式为windowsdow格式的markdown文件excelxl:xlwings:advancedxmldocumentformattowindowsapplications,andthedefault.#准备环境tomcat:9.0#es选择在windows下面,在python中安装对应版本的es到本地(python2.7)tomcat:windows10#es最好windows下面安装。
使用exists后可以找到原数据xlsxxtest.xlsxexcelxl#读取nullword部分的excelxlxlsxxprint'typetest.xlsx.'console.log('typetest.xlsx.')print'typetest.excelxl.'outputtest.xlsx.test.xlsx.txtxlsxtomcat运行输出结果如下图:要把tomcat读取的excelxl文件转化为workbook格式(xlsxx,然后save使用),需要执行以下命令:wx.startactivity()wx.startactivity()pages=wx.getparams('.weixin')ifwx.isdir(pages):pages=wx.getparams('.weixin')ifwx.isdir(pages):pages=wx.getparams('.weixin')wx.close()整个流程如下图:最后,我们先返回微信公众号文章的数据,并解析它然后导入excelxl文件即可得到数据最后还有一种方法,就是直接把excelxl导入linux中(linux下,xlwings可以直接生成windowsuserdata)。
2019年录制了一个YouTube视频来具体讲解操作步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-05-13 22:34
2019年10月28日更新:
录制了YouTube视频,详细说明了操作步骤:
youtu.be
原创============
自2014年以来,我一直在批量处理微信官方帐户内容采集。最初的目的是创建html5垃圾邮件内容网站。那时,垃圾站采集到达的微信公众号的内容很容易在公众号中传播。当时,采集批处理特别容易,采集的入口是官方帐户的历史新闻页面。现在这个入口是一样的,但是越来越难了采集。 采集的方法也已更新为许多版本。后来,在2015年,html5垃圾站没有这样做,而是转向采集来定位本地新闻和信息公共帐户,并将前端显示制作为应用程序。因此,形成了可以自动采集官方帐户内容的新闻应用程序。我曾经担心微信技术升级后的一天,采集的内容将不可用,我的新闻应用程序将失败。但是随着微信技术的不断升级,采集方法也得到了升级,这使我越来越有信心。只要存在官方帐户历史记录消息页面,就可以将采集批处理到内容。因此,今天我决定整理一下后记下采集方法。我的方法来自许多同事的共享精神,因此我将继续这种精神并分享我的结果。
这篇文章文章将继续更新,并且您所看到的将保证在您看到时可用。
首先,让我们看一下微信官方帐户历史记录消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=更新于2017年1月11日=
现在根据不同的微信个人帐户,将有两个不同的历史消息页面地址。下面是另一个历史消息页面的地址。第一种地址类型的链接将显示302在anyproxy中的跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据当前信息,这两种页面格式在不同的微信账户中不规则地出现。一些WeChat帐户始终是第一页格式,而某些始终是第二页格式。
上面的链接是指向微信官方帐户历史新闻页面的真实链接,但是当我们在浏览器中输入此链接时,它将显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。让我们看一下通常可以显示内容的完整链接是什么样的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
在通过微信客户端打开历史消息页面后,通过使用稍后描述的代理服务器软件获得此地址。这里有几个参数:
action =; __ biz =; uin =; key =; devicetype =; version =; lang =; nettype =; scene =; pass_ticket =; wx_header =;
重要参数是:__biz; uin =; key =; pass_ticket =;这四个参数。
__ biz是官方帐户的类似id的参数。每个官方帐户都有一个微信业务。目前,官方帐户的业务更改的可能性很小;
其余3个参数与用户ID和令牌票证的含义有关。这3个参数的值由微信客户端生成后会自动添加到地址栏中。因此,我们认为采集官方帐户必须通过微信客户端应用程序。在以前的微信版本中,这三个参数也可以一次获取,然后在有效期内可以使用多个官方账号。在当前版本中,每次访问正式帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数。
我的采集系统由以下部分组成:
1、微信客户端:它可以是安装了微信应用程序的手机,也可以是计算机中的Android模拟器。在批次采集中测试的ios的WeChat客户端的崩溃率高于Android系统。为了降低成本,我使用了Android模拟器。
<p>2、一个微信个人帐户:对于采集的内容,不仅需要一个微信客户端,而且还需要一个专用于采集的微信个人帐户,因为该微信帐户无法执行其他操作。 查看全部
2019年录制了一个YouTube视频来具体讲解操作步骤
2019年10月28日更新:
录制了YouTube视频,详细说明了操作步骤:
youtu.be
原创============
自2014年以来,我一直在批量处理微信官方帐户内容采集。最初的目的是创建html5垃圾邮件内容网站。那时,垃圾站采集到达的微信公众号的内容很容易在公众号中传播。当时,采集批处理特别容易,采集的入口是官方帐户的历史新闻页面。现在这个入口是一样的,但是越来越难了采集。 采集的方法也已更新为许多版本。后来,在2015年,html5垃圾站没有这样做,而是转向采集来定位本地新闻和信息公共帐户,并将前端显示制作为应用程序。因此,形成了可以自动采集官方帐户内容的新闻应用程序。我曾经担心微信技术升级后的一天,采集的内容将不可用,我的新闻应用程序将失败。但是随着微信技术的不断升级,采集方法也得到了升级,这使我越来越有信心。只要存在官方帐户历史记录消息页面,就可以将采集批处理到内容。因此,今天我决定整理一下后记下采集方法。我的方法来自许多同事的共享精神,因此我将继续这种精神并分享我的结果。
这篇文章文章将继续更新,并且您所看到的将保证在您看到时可用。
首先,让我们看一下微信官方帐户历史记录消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=更新于2017年1月11日=
现在根据不同的微信个人帐户,将有两个不同的历史消息页面地址。下面是另一个历史消息页面的地址。第一种地址类型的链接将显示302在anyproxy中的跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据当前信息,这两种页面格式在不同的微信账户中不规则地出现。一些WeChat帐户始终是第一页格式,而某些始终是第二页格式。
上面的链接是指向微信官方帐户历史新闻页面的真实链接,但是当我们在浏览器中输入此链接时,它将显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。让我们看一下通常可以显示内容的完整链接是什么样的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
在通过微信客户端打开历史消息页面后,通过使用稍后描述的代理服务器软件获得此地址。这里有几个参数:
action =; __ biz =; uin =; key =; devicetype =; version =; lang =; nettype =; scene =; pass_ticket =; wx_header =;
重要参数是:__biz; uin =; key =; pass_ticket =;这四个参数。
__ biz是官方帐户的类似id的参数。每个官方帐户都有一个微信业务。目前,官方帐户的业务更改的可能性很小;
其余3个参数与用户ID和令牌票证的含义有关。这3个参数的值由微信客户端生成后会自动添加到地址栏中。因此,我们认为采集官方帐户必须通过微信客户端应用程序。在以前的微信版本中,这三个参数也可以一次获取,然后在有效期内可以使用多个官方账号。在当前版本中,每次访问正式帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数。
我的采集系统由以下部分组成:
1、微信客户端:它可以是安装了微信应用程序的手机,也可以是计算机中的Android模拟器。在批次采集中测试的ios的WeChat客户端的崩溃率高于Android系统。为了降低成本,我使用了Android模拟器。
<p>2、一个微信个人帐户:对于采集的内容,不仅需要一个微信客户端,而且还需要一个专用于采集的微信个人帐户,因为该微信帐户无法执行其他操作。
《小蜜蜂公众号文章助手》傻瓜的方式获取技巧
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-05-10 03:17
“小蜜蜂官方帐户文章助手”已启动!
尽管Bee 采集插件导入官方帐户文章十分方便,但对于有更强需求的用户,批量获得官方帐户文章链接也是一件令人头疼的事情。那么,有没有更便捷的方法呢?
我今天教你一种方法。尽管有些麻烦,但比一个一个地复制它们要好。
首先,您需要拥有自己的官方帐户,登录微信公共管理平台,并创建新的图形资料
新图形材料
在文章编辑区域中,我们看到编辑器的工具栏,选择超链接
超链接
点击后,会弹出一个小窗口,选择搜索文章选项
找到官方帐户
目前,您可以从自己的官方帐户中获取文章的列表,或搜索其他官方帐户或微信帐户的名称。在此,以《人民日报》的官方帐户为例。
官方帐户搜索
在结果列表中选择所需的一个,然后会出现官方帐户的文章列表
官方帐户列表文章
右键单击并选择复制链接地址,还可以选择翻页
文章翻页
这似乎还不够高效,但是我们知道,由于我们可以获取文章数据,因此我们肯定会发送请求并获得返回结果。这时,我们可以打开浏览器进行调试(Win:F12,MacOS:Alt + Cmd + i),然后单击页面按钮,您会发现这样的请求
文章数据请求
在右侧扩展JSON,您可以看到它收录文章链接,该链接易于处理,只需对其进行复制和处理即可。
分析此界面,我们还可以找到模式
https://mp.weixin.qq.com/cgi-b ... e%3D9
请注意,此链接收录两个主要参数,begin和count,例如,begin here等于5,这意味着从第五次之后的文章推入开始,count等于5,这意味着5次推送,然后,如果我们想获取下一页的文章,这很简单,我们只需要将begin = 5更改为begin = 10,依此类推,这里的计数似乎只有5,因此不能更改为更大的值。 ,也许微信也有限制
了解此规则,那么一切就很容易了,只要不断增加begin的价值
需要注意的是,采集到的数据仍然需要处理,并且只有登录正式账号后才能使用该界面。 查看全部
《小蜜蜂公众号文章助手》傻瓜的方式获取技巧
“小蜜蜂官方帐户文章助手”已启动!
尽管Bee 采集插件导入官方帐户文章十分方便,但对于有更强需求的用户,批量获得官方帐户文章链接也是一件令人头疼的事情。那么,有没有更便捷的方法呢?
我今天教你一种方法。尽管有些麻烦,但比一个一个地复制它们要好。
首先,您需要拥有自己的官方帐户,登录微信公共管理平台,并创建新的图形资料
新图形材料
在文章编辑区域中,我们看到编辑器的工具栏,选择超链接
超链接
点击后,会弹出一个小窗口,选择搜索文章选项
找到官方帐户
目前,您可以从自己的官方帐户中获取文章的列表,或搜索其他官方帐户或微信帐户的名称。在此,以《人民日报》的官方帐户为例。
官方帐户搜索
在结果列表中选择所需的一个,然后会出现官方帐户的文章列表
官方帐户列表文章
右键单击并选择复制链接地址,还可以选择翻页
文章翻页
这似乎还不够高效,但是我们知道,由于我们可以获取文章数据,因此我们肯定会发送请求并获得返回结果。这时,我们可以打开浏览器进行调试(Win:F12,MacOS:Alt + Cmd + i),然后单击页面按钮,您会发现这样的请求
文章数据请求
在右侧扩展JSON,您可以看到它收录文章链接,该链接易于处理,只需对其进行复制和处理即可。
分析此界面,我们还可以找到模式
https://mp.weixin.qq.com/cgi-b ... e%3D9
请注意,此链接收录两个主要参数,begin和count,例如,begin here等于5,这意味着从第五次之后的文章推入开始,count等于5,这意味着5次推送,然后,如果我们想获取下一页的文章,这很简单,我们只需要将begin = 5更改为begin = 10,依此类推,这里的计数似乎只有5,因此不能更改为更大的值。 ,也许微信也有限制
了解此规则,那么一切就很容易了,只要不断增加begin的价值
需要注意的是,采集到的数据仍然需要处理,并且只有登录正式账号后才能使用该界面。
搜狗微信网站,网站如下图。抓取的说明和准备
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-05-09 04:12
搜狗微信网站,网站如下图。抓取的说明和准备
请记住,定期并定期捕获微信官方帐户文章的实现
爬行之前的说明和准备
为此爬网选择的语言是java。 文章不会发布整个项目的所有代码,而只会提供核心代码的解释和爬网的想法。
数据捕获
抢劫来源文章是搜狗微信网站,而网站如下所示。
爬行的想法如下
通常,抓取微信公众号的文章使用微信公众号的ID作为关键字。我们可以直接跳转到要通过url +关键字捕获官方帐户的页面。微信公众号的名称或ID;
// 搜狗微信搜索链接入口
String sogou_search_url = "http://weixin.sogou.com/weixin ... ot%3B
+ keyword + "&ie=utf8&s_from=input&_sug_=n&_sug_type_=";
为了避免网站最初对抓取工具的拦截,我们可以使用Selenium(浏览器自动测试框架)来伪装我们的抓取工具。我们使用铬。在这里,我们需要注意我们的chrome版本和所使用的webdriver版本。对应;
ChromeOptions chromeOptions = new ChromeOptions();
// 全屏,为了接下来防抓取做准备
chromeOptions.addArguments("--start-maximized");
System.setProperty("webdriver.chrome.driver", chromedriver);
WebDriver webDriver = new ChromeDriver(chromeOptions);
到达微信公众号列表页面,如下图所示,以获取微信公众号链接。
<p> // 获取当前页面的微信公众号列表
List weixin_list = webDriver
.findElements(By.cssSelector("div[class='txt-box']"));
// 获取进入公众号的链接
String weixin_url = "";
for (int i = 0; i 查看全部
搜狗微信网站,网站如下图。抓取的说明和准备
请记住,定期并定期捕获微信官方帐户文章的实现
爬行之前的说明和准备
为此爬网选择的语言是java。 文章不会发布整个项目的所有代码,而只会提供核心代码的解释和爬网的想法。
数据捕获
抢劫来源文章是搜狗微信网站,而网站如下所示。
爬行的想法如下
通常,抓取微信公众号的文章使用微信公众号的ID作为关键字。我们可以直接跳转到要通过url +关键字捕获官方帐户的页面。微信公众号的名称或ID;
// 搜狗微信搜索链接入口
String sogou_search_url = "http://weixin.sogou.com/weixin ... ot%3B
+ keyword + "&ie=utf8&s_from=input&_sug_=n&_sug_type_=";
为了避免网站最初对抓取工具的拦截,我们可以使用Selenium(浏览器自动测试框架)来伪装我们的抓取工具。我们使用铬。在这里,我们需要注意我们的chrome版本和所使用的webdriver版本。对应;
ChromeOptions chromeOptions = new ChromeOptions();
// 全屏,为了接下来防抓取做准备
chromeOptions.addArguments("--start-maximized");
System.setProperty("webdriver.chrome.driver", chromedriver);
WebDriver webDriver = new ChromeDriver(chromeOptions);
到达微信公众号列表页面,如下图所示,以获取微信公众号链接。
<p> // 获取当前页面的微信公众号列表
List weixin_list = webDriver
.findElements(By.cssSelector("div[class='txt-box']"));
// 获取进入公众号的链接
String weixin_url = "";
for (int i = 0; i
通过微信采集导出助手软件,可以一键采集指定微信公众号
采集交流 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2021-05-08 23:28
通过微信公众号、微信采集导出微信助手软件,可为所有文章分配一个微信公众号
一键记录采集
微信公众号公众号是一个非常大的物质银行,收录了很多有价值的公众号和文章内容。无论是科技、医学还是人文,公众号的存在都会受到诸多因素的影响。如果突然,有一天是官方交代或者有其他意外文章或您自己的有价值内容的其他官方帐户将永久丢失,因此将有价值的文章内容下载到您的计算机或备份到网站是最安全的方法。p>
为了满足这一需求,微信公众搜索引擎文章出口辅助软件应运而生。通过软件中的采集功能,可以实现从第一个官方账号的第一个文章到最后一个文章的任何官方账号的第一个文章。采集的文章会自动保存到本地数据库中,方便您随时查看和阅读文章。为了保险起见,您可以将这些文章以HTML、PDF或word文档的形式分批下载并保存到自己的计算机上,这样您就可以随时在本地计算机上查看文章,也可以在网络断开时观看文章学习
当然也可以获取官方账号文章的各种数据,包括官方账号名称、文章标题、文章摘要、发布时间、是否原创、作者姓名、位置、阅读量、点数、浏览量、评论、封面图片链接等,并支持将这些数据导出形成Excel表格,便于分析官方账户历史数据。p>
[第21页] 查看全部
通过微信采集导出助手软件,可以一键采集指定微信公众号
通过微信公众号、微信采集导出微信助手软件,可为所有文章分配一个微信公众号
一键记录采集
微信公众号公众号是一个非常大的物质银行,收录了很多有价值的公众号和文章内容。无论是科技、医学还是人文,公众号的存在都会受到诸多因素的影响。如果突然,有一天是官方交代或者有其他意外文章或您自己的有价值内容的其他官方帐户将永久丢失,因此将有价值的文章内容下载到您的计算机或备份到网站是最安全的方法。p>
为了满足这一需求,微信公众搜索引擎文章出口辅助软件应运而生。通过软件中的采集功能,可以实现从第一个官方账号的第一个文章到最后一个文章的任何官方账号的第一个文章。采集的文章会自动保存到本地数据库中,方便您随时查看和阅读文章。为了保险起见,您可以将这些文章以HTML、PDF或word文档的形式分批下载并保存到自己的计算机上,这样您就可以随时在本地计算机上查看文章,也可以在网络断开时观看文章学习
当然也可以获取官方账号文章的各种数据,包括官方账号名称、文章标题、文章摘要、发布时间、是否原创、作者姓名、位置、阅读量、点数、浏览量、评论、封面图片链接等,并支持将这些数据导出形成Excel表格,便于分析官方账户历史数据。p>
[第21页]
querylist采集微信公众号文章可以生成反馈列表,楼主找到方法了吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-05-01 23:08
querylist采集微信公众号文章,可以生成反馈列表,回馈给公众号提供文章,提供给公众号审核。我觉得挺方便的,反馈更方便一些,反馈过来的数据清晰明了,以后可以直接对公众号自动提醒。
apicloud采集微信公众号的文章,你可以以自己公众号名字命名采集,也可以以appid命名采集,都是可以的,apicloud采集功能很多,支持超过4000w公众号数据采集。
对于这个问题,我觉得最好的办法是开发一个app来采集,然后手动导出采集的数据文件,
和答主同样遇到问题,感觉这个技术问题好难回答,
楼主,你是做什么的?我也想知道。
我也想问这个问题。我可以生成一个数据,再在app里面导出来。但是这样导出出来的数据太混乱。
我也想知道。我好像只找到百度这种可以采集微信公众号文章。现在app也没有好的方法进行抓取,在微信公众号里面导出文章太乱。
楼主找到方法了吗?很好奇
加个开发者号,
楼主解决了没?我也想知道
目前用过的方法如下:1、其他平台采集微信公众号文章转化成pdf文件2、网页抓取以及数据库管理对象抓取
想问下楼主最后解决这个问题了吗?目前使用哪种方法 查看全部
querylist采集微信公众号文章可以生成反馈列表,楼主找到方法了吗?
querylist采集微信公众号文章,可以生成反馈列表,回馈给公众号提供文章,提供给公众号审核。我觉得挺方便的,反馈更方便一些,反馈过来的数据清晰明了,以后可以直接对公众号自动提醒。
apicloud采集微信公众号的文章,你可以以自己公众号名字命名采集,也可以以appid命名采集,都是可以的,apicloud采集功能很多,支持超过4000w公众号数据采集。
对于这个问题,我觉得最好的办法是开发一个app来采集,然后手动导出采集的数据文件,
和答主同样遇到问题,感觉这个技术问题好难回答,
楼主,你是做什么的?我也想知道。
我也想问这个问题。我可以生成一个数据,再在app里面导出来。但是这样导出出来的数据太混乱。
我也想知道。我好像只找到百度这种可以采集微信公众号文章。现在app也没有好的方法进行抓取,在微信公众号里面导出文章太乱。
楼主找到方法了吗?很好奇
加个开发者号,
楼主解决了没?我也想知道
目前用过的方法如下:1、其他平台采集微信公众号文章转化成pdf文件2、网页抓取以及数据库管理对象抓取
想问下楼主最后解决这个问题了吗?目前使用哪种方法
如何通过微信公众号后台的“超链接”功能进行爬取
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-04-28 03:13
PS:如果您需要Python学习资料,可以单击下面的链接自行获取
免费的Python学习资料和小组交流答案,点击加入
有多种爬网方式。今天,我将与您分享一个更简单的方法,即通过微信官方帐户后端的“超链接”功能进行爬网。也许有些朋友没有联系微信官方账号的后台,这是一张图片供大家理解
这里的一些朋友可能会说,我无法在后台登录正式帐户,该怎么办? ? ?
没关系,尽管每个抓取工具的目的都是为了获得我们想要的结果,但这并不是我们学习的重点。我们学习的重点是爬网过程,这是我们获取目标数据的方式,因此我们无法登录到公众手中。阅读此内容文章后,后台的朋友可能无法获得最终的爬网结果,但阅读此文章后,您也会有所收获。
一、初步准备
选择要爬网的目标官方帐户
单击超链接-进入编辑超链接界面-进入我们需要抓取的搜索目标官方帐户
今天我们以抓取“数据分析”官方帐户为例,供大家介绍
单击官方帐户以查看每个文章对应的标题信息
这一次我们的抓取工具的目标是获得文章标题和相应的链接。
二、开始抓取
爬行动物的三个步骤:
1、请求页面
首先导入我们需要使用此采集器的第三方库
import re#用来解析网页
import requests#用来请求网页
import csv#用来保存数据
import time#用来设置每次爬取间隔的时间
找到我们抓取的目标数据的位置,单击通过搜索获得的包,然后获取目标URL和请求标头信息
请求网页
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': 'pgv_pvi=2389011456; RK=x4Sdy3WsT4; ptcz=4a2fe0ffda6742a230c94f168291afcce2bd001e5d6615132b55da90559cd463; pgv_pvid=6989331736; _ga=GA1.2.735850052.1585832762; ptui_loginuin=1207020736; ua_id=iJuK7hnHjcUE0e2dAAAAAHzCRcatCWOiHc-hdkhSDL4=; __guid=166713058.1972731636944397800.1590316882436.5461; openid2ticket_oY8wqwesgvgkdQ69wUeM5UxhOV5c=ION52/k2w4M3o44iht5BRt5yCyxP/3IaRXJ84RIpRZA=; mm_lang=zh_CN; pac_uid=0_5ecd1592971c3; uin=o1240069166; skey=@YLtvDuKyj; pgv_info=ssid=s4875389884; pgv_si=s8410697728; uuid=62839906b2a77b5f098cd91979af8b33; rand_info=CAESIC53TQFCwjIe4ZsrTRKvSs+ocfs4UTsj9swrrNwosjCd; slave_bizuin=3240807523; data_bizuin=3240807523; bizuin=3240807523; data_ticket=AiTk/OFWXCKxhaenCvEuP06mwWTI6YqCyt+74hoaXaNtKBbcnq//ZTXHzqByMhK6; slave_sid=YndxeFhCSkU5OUJtdFYycW9zN29FcG51NU5GNElBM3I2RF9wVjJBRGx2bWxrTXdiMDZFYzllUWNaMlN4N0RsOTlVMDRxZFZEMjJXdlRZcXBVOGptQ2ZDSVZiOEJlQW5BZDVCWlkzSnJ6WWNPWVRiN1J0cldCd0pvbTc3RGRiMm9pZ3ZISTl6WWhDUmNCZ2s3; slave_user=gh_5d822fe7fd08; xid=9794daa60db66fcf7a65c4054e3d68ce; mmad_session=43d4e5247a6b025b67ba3abd48d27a309ec4713911b6ef6f23cddb4b9953e771354ad1572fbc3fa895051725e95abb887cf2d03e9864084974db75c8588189699ea5b20b8fe35073831446ef98d24de600f107fe69d79646a3dd2907ab712e1f11de1c56c245721266e7088080fefde3; ts_last=mp.weixin.qq.com/cgi-bin/frame; ts_uid=1963034896; monitor_count=15'
}#请求头信息,这里cookie信息必须添加,否则得不到网页信息
url='https://mp.weixin.qq.com/cgi-b ... 39%3B
response=requests.get(url,headers=headers)#得到响应内容
response.encoding='utf-8'#设置响应内容为utf-8格式
html=response.text#得到网页的文本形式
print(html)
此处的请求标头信息必须添加cookie信息,否则无法获取网页信息
网页的请求结果如下图所示。红色框标记了我们需要的文章标题和文章链接
2、分析网页
从网页响应结果中我们可以看到,每篇文章文章的标题和链接都位于“ title”标签和“ cover”标签的后面,因此我们可以使用正则表达式直接对其进行解析
title=re.findall('"title":"(.*?)"',html)#得到文章标题
cover=re.findall('"cover":"(.*?)"',html)#得到文章链接
all=zip(title,cover)#利用zip方法,将两个列表中的数据一一对应
print(list(all))#list是对zip方法得到的数据进行解压
解析后的结果如下
3、保存数据
for data in all:#for循环遍历列表
time.sleep(3)#每爬取一篇文章间隔3秒,以防触发反爬
with open('C:\\Users\\Administrator\\Desktop\\爬取公众号文章.csv','a',encoding='utf-8-sig') as file:
#将数据保存到桌面
write=csv.writer(file)
write.writerow(data)
到目前为止,该抓取工具已经完成,让我们看一下最终结果
完整代码
import re#用来解析网页
import requests#用来请求网页
import csv#用来保存数据
import time#用来设置每次爬取间隔的时间
# 请求网页
index=0
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': 'pgv_pvi=2389011456; RK=x4Sdy3WsT4; ptcz=4a2fe0ffda6742a230c94f168291afcce2bd001e5d6615132b55da90559cd463; pgv_pvid=6989331736; _ga=GA1.2.735850052.1585832762; ptui_loginuin=1207020736; ua_id=iJuK7hnHjcUE0e2dAAAAAHzCRcatCWOiHc-hdkhSDL4=; __guid=166713058.1972731636944397800.1590316882436.5461; openid2ticket_oY8wqwesgvgkdQ69wUeM5UxhOV5c=ION52/k2w4M3o44iht5BRt5yCyxP/3IaRXJ84RIpRZA=; mm_lang=zh_CN; pac_uid=0_5ecd1592971c3; uin=o1240069166; skey=@YLtvDuKyj; pgv_info=ssid=s4875389884; pgv_si=s8410697728; uuid=62839906b2a77b5f098cd91979af8b33; rand_info=CAESIC53TQFCwjIe4ZsrTRKvSs+ocfs4UTsj9swrrNwosjCd; slave_bizuin=3240807523; data_bizuin=3240807523; bizuin=3240807523; data_ticket=AiTk/OFWXCKxhaenCvEuP06mwWTI6YqCyt+74hoaXaNtKBbcnq//ZTXHzqByMhK6; slave_sid=YndxeFhCSkU5OUJtdFYycW9zN29FcG51NU5GNElBM3I2RF9wVjJBRGx2bWxrTXdiMDZFYzllUWNaMlN4N0RsOTlVMDRxZFZEMjJXdlRZcXBVOGptQ2ZDSVZiOEJlQW5BZDVCWlkzSnJ6WWNPWVRiN1J0cldCd0pvbTc3RGRiMm9pZ3ZISTl6WWhDUmNCZ2s3; slave_user=gh_5d822fe7fd08; xid=9794daa60db66fcf7a65c4054e3d68ce; mmad_session=43d4e5247a6b025b67ba3abd48d27a309ec4713911b6ef6f23cddb4b9953e771354ad1572fbc3fa895051725e95abb887cf2d03e9864084974db75c8588189699ea5b20b8fe35073831446ef98d24de600f107fe69d79646a3dd2907ab712e1f11de1c56c245721266e7088080fefde3; ts_last=mp.weixin.qq.com/cgi-bin/frame; ts_uid=1963034896; monitor_count=15'
}#请求头信息,这里cookie信息必须添加,否则得不到网页信息
for i in range(2):#设置for循环实现翻页,爬取多页内容,这里range括号内的参数可以更改
url='https://mp.weixin.qq.com/cgi-b ... 2Bstr(index)+'&count=5&fakeid=MjM5MjAxMDM4MA==&type=9&query=&token=59293242&lang=zh_CN&f=json&ajax=1'
response=requests.get(url,headers=headers)#得到响应内容
response.encoding='utf-8'#设置响应内容为utf-8格式
html=response.text#得到网页的文本形式
# 解析网页
title=re.findall('"title":"(.*?)"',html)#得到文章标题
cover=re.findall('"cover":"(.*?)"',html)#得到文章链接
all=zip(title,cover)#利用zip方法,将两个列表中的数据一一对应
# print(list(all))#list是对zip方法得到的数据进行解压
# 保存数据
for data in all:#for循环遍历列表
time.sleep(3)#每爬取一篇文章间隔3秒,以防出发反爬
with open('C:\\Users\\Administrator\\Desktop\\爬取公众号文章.csv','a',encoding='utf-8-sig') as file:
#将数据保存到桌面
write=csv.writer(file)
write.writerow(data)
pass
pass
index += 5 查看全部
如何通过微信公众号后台的“超链接”功能进行爬取
PS:如果您需要Python学习资料,可以单击下面的链接自行获取
免费的Python学习资料和小组交流答案,点击加入
有多种爬网方式。今天,我将与您分享一个更简单的方法,即通过微信官方帐户后端的“超链接”功能进行爬网。也许有些朋友没有联系微信官方账号的后台,这是一张图片供大家理解
这里的一些朋友可能会说,我无法在后台登录正式帐户,该怎么办? ? ?
没关系,尽管每个抓取工具的目的都是为了获得我们想要的结果,但这并不是我们学习的重点。我们学习的重点是爬网过程,这是我们获取目标数据的方式,因此我们无法登录到公众手中。阅读此内容文章后,后台的朋友可能无法获得最终的爬网结果,但阅读此文章后,您也会有所收获。
一、初步准备
选择要爬网的目标官方帐户
单击超链接-进入编辑超链接界面-进入我们需要抓取的搜索目标官方帐户
今天我们以抓取“数据分析”官方帐户为例,供大家介绍
单击官方帐户以查看每个文章对应的标题信息
这一次我们的抓取工具的目标是获得文章标题和相应的链接。
二、开始抓取
爬行动物的三个步骤:
1、请求页面
首先导入我们需要使用此采集器的第三方库
import re#用来解析网页
import requests#用来请求网页
import csv#用来保存数据
import time#用来设置每次爬取间隔的时间
找到我们抓取的目标数据的位置,单击通过搜索获得的包,然后获取目标URL和请求标头信息
请求网页
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': 'pgv_pvi=2389011456; RK=x4Sdy3WsT4; ptcz=4a2fe0ffda6742a230c94f168291afcce2bd001e5d6615132b55da90559cd463; pgv_pvid=6989331736; _ga=GA1.2.735850052.1585832762; ptui_loginuin=1207020736; ua_id=iJuK7hnHjcUE0e2dAAAAAHzCRcatCWOiHc-hdkhSDL4=; __guid=166713058.1972731636944397800.1590316882436.5461; openid2ticket_oY8wqwesgvgkdQ69wUeM5UxhOV5c=ION52/k2w4M3o44iht5BRt5yCyxP/3IaRXJ84RIpRZA=; mm_lang=zh_CN; pac_uid=0_5ecd1592971c3; uin=o1240069166; skey=@YLtvDuKyj; pgv_info=ssid=s4875389884; pgv_si=s8410697728; uuid=62839906b2a77b5f098cd91979af8b33; rand_info=CAESIC53TQFCwjIe4ZsrTRKvSs+ocfs4UTsj9swrrNwosjCd; slave_bizuin=3240807523; data_bizuin=3240807523; bizuin=3240807523; data_ticket=AiTk/OFWXCKxhaenCvEuP06mwWTI6YqCyt+74hoaXaNtKBbcnq//ZTXHzqByMhK6; slave_sid=YndxeFhCSkU5OUJtdFYycW9zN29FcG51NU5GNElBM3I2RF9wVjJBRGx2bWxrTXdiMDZFYzllUWNaMlN4N0RsOTlVMDRxZFZEMjJXdlRZcXBVOGptQ2ZDSVZiOEJlQW5BZDVCWlkzSnJ6WWNPWVRiN1J0cldCd0pvbTc3RGRiMm9pZ3ZISTl6WWhDUmNCZ2s3; slave_user=gh_5d822fe7fd08; xid=9794daa60db66fcf7a65c4054e3d68ce; mmad_session=43d4e5247a6b025b67ba3abd48d27a309ec4713911b6ef6f23cddb4b9953e771354ad1572fbc3fa895051725e95abb887cf2d03e9864084974db75c8588189699ea5b20b8fe35073831446ef98d24de600f107fe69d79646a3dd2907ab712e1f11de1c56c245721266e7088080fefde3; ts_last=mp.weixin.qq.com/cgi-bin/frame; ts_uid=1963034896; monitor_count=15'
}#请求头信息,这里cookie信息必须添加,否则得不到网页信息
url='https://mp.weixin.qq.com/cgi-b ... 39%3B
response=requests.get(url,headers=headers)#得到响应内容
response.encoding='utf-8'#设置响应内容为utf-8格式
html=response.text#得到网页的文本形式
print(html)
此处的请求标头信息必须添加cookie信息,否则无法获取网页信息
网页的请求结果如下图所示。红色框标记了我们需要的文章标题和文章链接
2、分析网页
从网页响应结果中我们可以看到,每篇文章文章的标题和链接都位于“ title”标签和“ cover”标签的后面,因此我们可以使用正则表达式直接对其进行解析
title=re.findall('"title":"(.*?)"',html)#得到文章标题
cover=re.findall('"cover":"(.*?)"',html)#得到文章链接
all=zip(title,cover)#利用zip方法,将两个列表中的数据一一对应
print(list(all))#list是对zip方法得到的数据进行解压
解析后的结果如下
3、保存数据
for data in all:#for循环遍历列表
time.sleep(3)#每爬取一篇文章间隔3秒,以防触发反爬
with open('C:\\Users\\Administrator\\Desktop\\爬取公众号文章.csv','a',encoding='utf-8-sig') as file:
#将数据保存到桌面
write=csv.writer(file)
write.writerow(data)
到目前为止,该抓取工具已经完成,让我们看一下最终结果
完整代码
import re#用来解析网页
import requests#用来请求网页
import csv#用来保存数据
import time#用来设置每次爬取间隔的时间
# 请求网页
index=0
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': 'pgv_pvi=2389011456; RK=x4Sdy3WsT4; ptcz=4a2fe0ffda6742a230c94f168291afcce2bd001e5d6615132b55da90559cd463; pgv_pvid=6989331736; _ga=GA1.2.735850052.1585832762; ptui_loginuin=1207020736; ua_id=iJuK7hnHjcUE0e2dAAAAAHzCRcatCWOiHc-hdkhSDL4=; __guid=166713058.1972731636944397800.1590316882436.5461; openid2ticket_oY8wqwesgvgkdQ69wUeM5UxhOV5c=ION52/k2w4M3o44iht5BRt5yCyxP/3IaRXJ84RIpRZA=; mm_lang=zh_CN; pac_uid=0_5ecd1592971c3; uin=o1240069166; skey=@YLtvDuKyj; pgv_info=ssid=s4875389884; pgv_si=s8410697728; uuid=62839906b2a77b5f098cd91979af8b33; rand_info=CAESIC53TQFCwjIe4ZsrTRKvSs+ocfs4UTsj9swrrNwosjCd; slave_bizuin=3240807523; data_bizuin=3240807523; bizuin=3240807523; data_ticket=AiTk/OFWXCKxhaenCvEuP06mwWTI6YqCyt+74hoaXaNtKBbcnq//ZTXHzqByMhK6; slave_sid=YndxeFhCSkU5OUJtdFYycW9zN29FcG51NU5GNElBM3I2RF9wVjJBRGx2bWxrTXdiMDZFYzllUWNaMlN4N0RsOTlVMDRxZFZEMjJXdlRZcXBVOGptQ2ZDSVZiOEJlQW5BZDVCWlkzSnJ6WWNPWVRiN1J0cldCd0pvbTc3RGRiMm9pZ3ZISTl6WWhDUmNCZ2s3; slave_user=gh_5d822fe7fd08; xid=9794daa60db66fcf7a65c4054e3d68ce; mmad_session=43d4e5247a6b025b67ba3abd48d27a309ec4713911b6ef6f23cddb4b9953e771354ad1572fbc3fa895051725e95abb887cf2d03e9864084974db75c8588189699ea5b20b8fe35073831446ef98d24de600f107fe69d79646a3dd2907ab712e1f11de1c56c245721266e7088080fefde3; ts_last=mp.weixin.qq.com/cgi-bin/frame; ts_uid=1963034896; monitor_count=15'
}#请求头信息,这里cookie信息必须添加,否则得不到网页信息
for i in range(2):#设置for循环实现翻页,爬取多页内容,这里range括号内的参数可以更改
url='https://mp.weixin.qq.com/cgi-b ... 2Bstr(index)+'&count=5&fakeid=MjM5MjAxMDM4MA==&type=9&query=&token=59293242&lang=zh_CN&f=json&ajax=1'
response=requests.get(url,headers=headers)#得到响应内容
response.encoding='utf-8'#设置响应内容为utf-8格式
html=response.text#得到网页的文本形式
# 解析网页
title=re.findall('"title":"(.*?)"',html)#得到文章标题
cover=re.findall('"cover":"(.*?)"',html)#得到文章链接
all=zip(title,cover)#利用zip方法,将两个列表中的数据一一对应
# print(list(all))#list是对zip方法得到的数据进行解压
# 保存数据
for data in all:#for循环遍历列表
time.sleep(3)#每爬取一篇文章间隔3秒,以防出发反爬
with open('C:\\Users\\Administrator\\Desktop\\爬取公众号文章.csv','a',encoding='utf-8-sig') as file:
#将数据保存到桌面
write=csv.writer(file)
write.writerow(data)
pass
pass
index += 5
Python登录微信公众号后台编辑素材界面的原理和解析
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-04-28 03:11
准备阶段
为了实现此采集器,我们需要使用以下工具
此外,此抓取程序使用微信官方帐户后端编辑资料界面。原理是,当我们插入超链接时,微信将调用特殊的API(请参见下图)以获取指定官方帐户的文章列表。因此,我们还需要拥有一个官方帐户。
fig1
正式开始
我们需要登录到WeChat官方帐户,依次单击“物料管理”,“新建图形消息”,然后单击上方的超链接。
fig2
下一步,按F12键,打开Chrome的开发者工具,然后选择“网络”
fig3
这时,在上一个超链接界面中,单击“选择另一个官方帐户”,然后输入您要抓取的官方帐户(例如,中国移动)
fig4
这时,先前的网络将刷新一些链接,其中以“ appmsg”开头的内容是我们需要分析的
fig5
我们解析请求的网址
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三部分
通过不断浏览下一页,我们发现每次开始都只会更改一次,每次都会增加5,这就是count的值。
接下来,我们使用Python获取相同的资源,但是无法通过直接运行以下代码来获取资源。
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能够在浏览器上获取资源,是因为我们登录了微信官方账号后端。而且Python没有我们的登录信息,因此该请求无效。我们需要在请求中设置headers参数,并传入Cookie和User-Agent以模拟登录
因为标题信息的内容每次都会改变,所以我将这些内容放在一个单独的文件“ wechat.yaml”中,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
您只需要稍后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(标题),摘要(摘要),链接(链接),推送时间(update_time)和封面地址(封面)。
appmsgid是每个推文的唯一标识符,而aid是每个推文的唯一标识符。
fig6
实际上,除了cookie之外,URL中的token参数还将用于限制采集器,因此上述代码的输出可能为{'base_resp':{'ret':200040,'err_msg ':'无效的csrf令牌'}}
接下来,我们编写一个循环以获取文章的所有JSON并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还将伪造品和令牌存储在“ wechat.yaml”文件中。这是因为fakeid是每个官方帐户唯一的标识符,并且令牌会经常更改。此信息可以通过解析URL获得,也可以从开发人员工具中查看
fig7
爬行一段时间后,您会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
这时,当您尝试在官方帐户的背景中插入超链接时,会出现以下提示
fig8
这是官方帐户的流量限制,通常需要等待30-60分钟才能继续。为了完美解决此问题,您可能需要申请多个官方帐户,您可能需要与微信官方帐户登录系统进行对抗,或者您可能需要建立代理池。
但是我不需要工业级的采集器,我只想搜寻我自己的官方帐户信息,因此请等待一个小时,再次登录到官方帐户,获取Cookie和令牌并运行它。我不想为自己的利益挑战别人的工作。
最后,将结果保存为JSON格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或提取文章标识符,标题,URL和发布时间的四列,并将它们保存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("\n".join(info_list)) 查看全部
Python登录微信公众号后台编辑素材界面的原理和解析
准备阶段
为了实现此采集器,我们需要使用以下工具
此外,此抓取程序使用微信官方帐户后端编辑资料界面。原理是,当我们插入超链接时,微信将调用特殊的API(请参见下图)以获取指定官方帐户的文章列表。因此,我们还需要拥有一个官方帐户。
fig1
正式开始
我们需要登录到WeChat官方帐户,依次单击“物料管理”,“新建图形消息”,然后单击上方的超链接。
fig2
下一步,按F12键,打开Chrome的开发者工具,然后选择“网络”
fig3
这时,在上一个超链接界面中,单击“选择另一个官方帐户”,然后输入您要抓取的官方帐户(例如,中国移动)
fig4
这时,先前的网络将刷新一些链接,其中以“ appmsg”开头的内容是我们需要分析的
fig5
我们解析请求的网址
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三部分
通过不断浏览下一页,我们发现每次开始都只会更改一次,每次都会增加5,这就是count的值。
接下来,我们使用Python获取相同的资源,但是无法通过直接运行以下代码来获取资源。
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能够在浏览器上获取资源,是因为我们登录了微信官方账号后端。而且Python没有我们的登录信息,因此该请求无效。我们需要在请求中设置headers参数,并传入Cookie和User-Agent以模拟登录
因为标题信息的内容每次都会改变,所以我将这些内容放在一个单独的文件“ wechat.yaml”中,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
您只需要稍后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(标题),摘要(摘要),链接(链接),推送时间(update_time)和封面地址(封面)。
appmsgid是每个推文的唯一标识符,而aid是每个推文的唯一标识符。
fig6
实际上,除了cookie之外,URL中的token参数还将用于限制采集器,因此上述代码的输出可能为{'base_resp':{'ret':200040,'err_msg ':'无效的csrf令牌'}}
接下来,我们编写一个循环以获取文章的所有JSON并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还将伪造品和令牌存储在“ wechat.yaml”文件中。这是因为fakeid是每个官方帐户唯一的标识符,并且令牌会经常更改。此信息可以通过解析URL获得,也可以从开发人员工具中查看
fig7
爬行一段时间后,您会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
这时,当您尝试在官方帐户的背景中插入超链接时,会出现以下提示
fig8
这是官方帐户的流量限制,通常需要等待30-60分钟才能继续。为了完美解决此问题,您可能需要申请多个官方帐户,您可能需要与微信官方帐户登录系统进行对抗,或者您可能需要建立代理池。
但是我不需要工业级的采集器,我只想搜寻我自己的官方帐户信息,因此请等待一个小时,再次登录到官方帐户,获取Cookie和令牌并运行它。我不想为自己的利益挑战别人的工作。
最后,将结果保存为JSON格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或提取文章标识符,标题,URL和发布时间的四列,并将它们保存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("\n".join(info_list))
querylist采集微信公众号文章页面词频特征词之间的词频向量(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-04-27 23:01
querylist采集微信公众号文章页面词频特征词之间的词频向量作为onehot特征词多字母querylist数据集:公众号文章页对应的词汇列表下载微信公众号文章页链接:文章页下载链接url::querylist&keywords_info_dd=&querylist&keywords_info_version=6&keywords_info_new_description=&querylist&keywords_info_new_title=&format=cvtxvgk5zwt。
可以参考一下我的答案:怎么从网上爬取querylist?
首先,想爬取的是某微信公众号内容的信息:可以以此作为主关键词进行爬取,
1)我在微信搜索上搜索“机器学习”,
2)我在微信搜索上搜索“机器学习”,
3)从weixin后台选择公众号信息,选择公众号名称,从公众号选择标题。关键词输入一次querylist;keywords_info_dd=&keywords_info_version=6&keywords_info_new_description=&format=cvtxvgk5zwtwtzi6l。
再来一次,把这个关键词,写入文章。再来一次,用两次关键词替换,直接把文章标题和微信号关键词写入文章,然后写入querylist,再把文章标题关键词替换回来。
看样子题主爬虫爬的应该是login,相信数据量也不算很大。爬虫爬取微信公众号的文章页面词频特征词之间的词频向量作为onehot特征词之间的关键词提取关键词如:“机器学习”:可以去weixin后台选择公众号信息,选择公众号名称,从公众号选择标题。可以考虑把标题关键词拿来做词云。以上均为粗略的思路。其实按照你的思路思考,都是这样爬取一个月会出现几千篇文章,而且发布的文章大多是重复的,那用手机数据采集,爬取大多数重复的文章,再整理好,制作成一个可视化文档,将不会很费时间,再爬取几千篇同质性的文章,就可以爬取微信公众号所有的文章了,甚至会上千篇!。 查看全部
querylist采集微信公众号文章页面词频特征词之间的词频向量(组图)
querylist采集微信公众号文章页面词频特征词之间的词频向量作为onehot特征词多字母querylist数据集:公众号文章页对应的词汇列表下载微信公众号文章页链接:文章页下载链接url::querylist&keywords_info_dd=&querylist&keywords_info_version=6&keywords_info_new_description=&querylist&keywords_info_new_title=&format=cvtxvgk5zwt。
可以参考一下我的答案:怎么从网上爬取querylist?
首先,想爬取的是某微信公众号内容的信息:可以以此作为主关键词进行爬取,
1)我在微信搜索上搜索“机器学习”,
2)我在微信搜索上搜索“机器学习”,
3)从weixin后台选择公众号信息,选择公众号名称,从公众号选择标题。关键词输入一次querylist;keywords_info_dd=&keywords_info_version=6&keywords_info_new_description=&format=cvtxvgk5zwtwtzi6l。
再来一次,把这个关键词,写入文章。再来一次,用两次关键词替换,直接把文章标题和微信号关键词写入文章,然后写入querylist,再把文章标题关键词替换回来。
看样子题主爬虫爬的应该是login,相信数据量也不算很大。爬虫爬取微信公众号的文章页面词频特征词之间的词频向量作为onehot特征词之间的关键词提取关键词如:“机器学习”:可以去weixin后台选择公众号信息,选择公众号名称,从公众号选择标题。可以考虑把标题关键词拿来做词云。以上均为粗略的思路。其实按照你的思路思考,都是这样爬取一个月会出现几千篇文章,而且发布的文章大多是重复的,那用手机数据采集,爬取大多数重复的文章,再整理好,制作成一个可视化文档,将不会很费时间,再爬取几千篇同质性的文章,就可以爬取微信公众号所有的文章了,甚至会上千篇!。
开发环境windows7/10python3.5.2模拟人工操作
采集交流 • 优采云 发表了文章 • 0 个评论 • 241 次浏览 • 2021-04-24 06:37
python爬虫scrapy + Selenium + mysql,抓取微信搜狗,各家银行开具的官方账户文章
要求
由于工作需要,公司要求抓取指定微信公众号文章和各大银行官方网站发布的营销信息。也有招标信息。经过调查,我发现结合使用python的scrapy和硒来模拟手动操作。花了一些时间才能完成任务。这是一条记录。
开发环境
windows7 / 10
python 3. 5. 2
mysql 5. 5
草率的1. 6
pycharm2018
Google Chrome 7 0. 0. 353 8. 110(正式版)(64位)
安装
通常在Windows上安装python 3. 5. 2。我选择了官方网站的64位版本。请注意:
1、添加环境变量:
图片
python所在的目录:C:\ Users \ user \ AppData \ Local \ Programs \ Python \ Python35;
pip所在的目录:C:\ Users \ user \ AppData \ Local \ Programs \ Python \ Python35 \ Scripts;
分析:将以上两条路径添加到环境变量中。
图片
图片
2、 pycharm安装。
使用pycharm作为编辑器,因为它具有强大的导入功能。他的某些导入软件包对于管理自己导入的第三方软件包非常方便。
图片
图片
*******************************注意************** * *************
如果您正在下载和安装scrapy,则可以在报告Twisted版本错误且pip不成功时手动安装Twisted-1 8. 9. 0-cp35-cp35m-win_amd6 4. whl。
1)确保您的点子版本是最新的
2)运行pip安装路径\ Twisted-1 8. 7. 0-cp37-cp37m-win_amd6 4. whl
参考:
参考:〜gohlke / pythonlibs /#twisted
Twisted-1 8. 7. 0-cp37-cp37m-win_amd6 4. whl我是从上面的链接下载的
3、要使用硒作为模拟手动操作的自动测试,您需要先下载相应的浏览器驱动程序
因为我使用的是Google Chrome浏览器,所以我下载的也是Google Chrome浏览器驱动程序
参考:
参考:
现在您可以正式工作了! (手动狗头)爬行微信搜狗
图片
图片
图片
由于微信公众号已发布到最新文章,因此可以在微信搜狗页面上找到指定官方账号所发布的最新内容,因此我们的目标非常明确,即可以抓取该微信发布的最新消息。微信搜狗的官方帐户。
1、确认抓取链接
经过分析,具有爬网的链接具有以下特征:
链接组成:官方帐号
使用scrapy抓取与该链接相对应的静态内容后,您会发现与该链接相对应的标记将被重定向到输入302输入验证码的页面,这可能是反挑剔技术的微信搜狗。 (但是有解决方案)
图片
图片
图片
这时,我们将使用功能强大的硒作为模拟手动点击的自动化测试工具。可以使用python下载此第三方软件包。
直接上传代码
class SeleniumMiddleware(object):
def __init__(self):
self.cookies_file_path = COOKIES_FILE_PATH
def process_request(self, request, spider):
options = webdriver.ChromeOptions()
# 设置中文
options.add_argument('lang=zh_CN.UTF-8')
#options.add_argument('--headless')
#options.add_argument('--disable-gpu')
#options.add_argument('--remote-debugging-port=9222')
# 更换头部
options.add_argument('user-agent='+request.headers['User-Agent'].decode(encoding='utf-8'))
browser = webdriver.Chrome(
executable_path=SELENIUM_CHROME_DIRVER_LOCAL_PATH,
chrome_options=options)
wait = WebDriverWait(browser, 15)
browser.get(request.url)
'''设置selenium浏览器的cookie'''
with open(self.cookies_file_path, 'r')as f:
listCookie = json.loads(f.read())
time.sleep(1)
browser.delete_all_cookies();
for cookiein listCookie:
browser.add_cookie({
# 'domain': cookie['domain'],
# 'httpOnly': cookie['httpOnly'],
'name': cookie['name'],
# 'path': cookie['path'],
# 'secure': cookie['secure'],
'value': cookie['value'],
# 'expiry': None if 'expiry' not in cookie else cookie['expiry']
})
# browser.close()
browser.get(request.url)
time.sleep(5)
# 根据公众号查找
gzhDetail = wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, 'ul.news-list2>li:first-child>div.gzh-box2>div.txt-box>p:first-child>a')))
gzhDetail.click()
time.sleep(3)
# 更换到刚点击开的页面
newWindowHandler = browser.window_handles[-1]
browser.switch_to.window(newWindowHandler)
#返回页面
true_page = browser.page_source
res=HtmlResponse(request.url,body = true_page,encoding ='utf-8',request = request,)
#记录搜狗微信公众临时生成的gotoLink的地址,注意该地址是微信搜狗经常会切换的地址。
res.meta['wxsgGzhDetailUrl']=browser.current_url
browser.quit()
return res
def process_response(self, request, response, spider):
return CodeMiddleware().process_response(request,response,spider)
如果成功模拟了手动单击,则不会跳到302输入验证码,因此无需使用编码平台。成功单击后,进入正式帐户发布文章页面。此时,您可以检索官方帐户发布的文章的标题,简介和图片。 (访问该页面时,可以直接引用一个标签来输入详细的文章,这意味着可以向下检索特定的文章内容。)
最后
我的github:其中有更详细的代码。记住要给星星,还有其他例子。本文中的示例位于weixinsougou文件夹中
备注
1、解决Windows命令行中找不到的pip命令的方法:
1)找到安装python.exe的文件夹
2)添加Script文件夹路径到环境变量当中。环境:C:\Users\user\AppData\Local\Programs\Python\Python35\Scripts
2、解决了在安装scrapy时无法安装scrapy的问题。当报告扭曲版本错误时:
1)手动安装Twisted-18.9.0-cp35-cp35m-win_amd64.whl文件即可解决
2)运行 pip install 你的路径\Twisted-18.7.0-cp37-cp37m-win_amd64.whl
参考:
参考:〜gohlke / pythonlibs /#twisted
3、该项目使用硒,因此请安装Google Chrome。以及相应的Google Chrome浏览器驱动程序。
参考:
参考: 查看全部
开发环境windows7/10python3.5.2模拟人工操作
python爬虫scrapy + Selenium + mysql,抓取微信搜狗,各家银行开具的官方账户文章
要求
由于工作需要,公司要求抓取指定微信公众号文章和各大银行官方网站发布的营销信息。也有招标信息。经过调查,我发现结合使用python的scrapy和硒来模拟手动操作。花了一些时间才能完成任务。这是一条记录。
开发环境
windows7 / 10
python 3. 5. 2
mysql 5. 5
草率的1. 6
pycharm2018
Google Chrome 7 0. 0. 353 8. 110(正式版)(64位)
安装
通常在Windows上安装python 3. 5. 2。我选择了官方网站的64位版本。请注意:
1、添加环境变量:
图片
python所在的目录:C:\ Users \ user \ AppData \ Local \ Programs \ Python \ Python35;
pip所在的目录:C:\ Users \ user \ AppData \ Local \ Programs \ Python \ Python35 \ Scripts;
分析:将以上两条路径添加到环境变量中。
图片
图片
2、 pycharm安装。
使用pycharm作为编辑器,因为它具有强大的导入功能。他的某些导入软件包对于管理自己导入的第三方软件包非常方便。
图片
图片
*******************************注意************** * *************
如果您正在下载和安装scrapy,则可以在报告Twisted版本错误且pip不成功时手动安装Twisted-1 8. 9. 0-cp35-cp35m-win_amd6 4. whl。
1)确保您的点子版本是最新的
2)运行pip安装路径\ Twisted-1 8. 7. 0-cp37-cp37m-win_amd6 4. whl
参考:
参考:〜gohlke / pythonlibs /#twisted
Twisted-1 8. 7. 0-cp37-cp37m-win_amd6 4. whl我是从上面的链接下载的
3、要使用硒作为模拟手动操作的自动测试,您需要先下载相应的浏览器驱动程序
因为我使用的是Google Chrome浏览器,所以我下载的也是Google Chrome浏览器驱动程序
参考:
参考:
现在您可以正式工作了! (手动狗头)爬行微信搜狗
图片
图片
图片
由于微信公众号已发布到最新文章,因此可以在微信搜狗页面上找到指定官方账号所发布的最新内容,因此我们的目标非常明确,即可以抓取该微信发布的最新消息。微信搜狗的官方帐户。
1、确认抓取链接
经过分析,具有爬网的链接具有以下特征:
链接组成:官方帐号
使用scrapy抓取与该链接相对应的静态内容后,您会发现与该链接相对应的标记将被重定向到输入302输入验证码的页面,这可能是反挑剔技术的微信搜狗。 (但是有解决方案)
图片
图片
图片
这时,我们将使用功能强大的硒作为模拟手动点击的自动化测试工具。可以使用python下载此第三方软件包。
直接上传代码
class SeleniumMiddleware(object):
def __init__(self):
self.cookies_file_path = COOKIES_FILE_PATH
def process_request(self, request, spider):
options = webdriver.ChromeOptions()
# 设置中文
options.add_argument('lang=zh_CN.UTF-8')
#options.add_argument('--headless')
#options.add_argument('--disable-gpu')
#options.add_argument('--remote-debugging-port=9222')
# 更换头部
options.add_argument('user-agent='+request.headers['User-Agent'].decode(encoding='utf-8'))
browser = webdriver.Chrome(
executable_path=SELENIUM_CHROME_DIRVER_LOCAL_PATH,
chrome_options=options)
wait = WebDriverWait(browser, 15)
browser.get(request.url)
'''设置selenium浏览器的cookie'''
with open(self.cookies_file_path, 'r')as f:
listCookie = json.loads(f.read())
time.sleep(1)
browser.delete_all_cookies();
for cookiein listCookie:
browser.add_cookie({
# 'domain': cookie['domain'],
# 'httpOnly': cookie['httpOnly'],
'name': cookie['name'],
# 'path': cookie['path'],
# 'secure': cookie['secure'],
'value': cookie['value'],
# 'expiry': None if 'expiry' not in cookie else cookie['expiry']
})
# browser.close()
browser.get(request.url)
time.sleep(5)
# 根据公众号查找
gzhDetail = wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, 'ul.news-list2>li:first-child>div.gzh-box2>div.txt-box>p:first-child>a')))
gzhDetail.click()
time.sleep(3)
# 更换到刚点击开的页面
newWindowHandler = browser.window_handles[-1]
browser.switch_to.window(newWindowHandler)
#返回页面
true_page = browser.page_source
res=HtmlResponse(request.url,body = true_page,encoding ='utf-8',request = request,)
#记录搜狗微信公众临时生成的gotoLink的地址,注意该地址是微信搜狗经常会切换的地址。
res.meta['wxsgGzhDetailUrl']=browser.current_url
browser.quit()
return res
def process_response(self, request, response, spider):
return CodeMiddleware().process_response(request,response,spider)
如果成功模拟了手动单击,则不会跳到302输入验证码,因此无需使用编码平台。成功单击后,进入正式帐户发布文章页面。此时,您可以检索官方帐户发布的文章的标题,简介和图片。 (访问该页面时,可以直接引用一个标签来输入详细的文章,这意味着可以向下检索特定的文章内容。)
最后
我的github:其中有更详细的代码。记住要给星星,还有其他例子。本文中的示例位于weixinsougou文件夹中
备注
1、解决Windows命令行中找不到的pip命令的方法:
1)找到安装python.exe的文件夹
2)添加Script文件夹路径到环境变量当中。环境:C:\Users\user\AppData\Local\Programs\Python\Python35\Scripts
2、解决了在安装scrapy时无法安装scrapy的问题。当报告扭曲版本错误时:
1)手动安装Twisted-18.9.0-cp35-cp35m-win_amd64.whl文件即可解决
2)运行 pip install 你的路径\Twisted-18.7.0-cp37-cp37m-win_amd64.whl
参考:
参考:〜gohlke / pythonlibs /#twisted
3、该项目使用硒,因此请安装Google Chrome。以及相应的Google Chrome浏览器驱动程序。
参考:
参考:
个人建议你可以去公众号研究一下发文章的目的是什么
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-04-24 01:01
querylist采集微信公众号文章的时候,有时不能准确匹配到合适的文章,只能获取分类节点下的相关推送内容,这个时候该怎么办呢?可以通过查找或编辑标签,然后生成tags。然后再去微信公众号里面查找相关的文章。
看似很简单的文章都需要经过标签审核,只有通过标签审核才可以转发给朋友查看。文章标签的设置可以借助专业的数据采集平台来完成,如贝叶斯词典,常用的表情标签,常用歌曲歌词表情表,能够轻松完成,同时一个账号可以对应多个采集器,极大的降低采集成本,保证了公众号数据的安全性。
哈哈,谢邀,我觉得你应该需要一个wxbot,类似于猫池。之前我用过一个wxbot,用了一下,效果很好,但是不会写代码。具体上网看一下视频,
微信公众号我不太清楚。个人建议你可以去公众号研究一下发文章的目的是什么,从提高公众号粉丝量和传播推广角度去看你的要选择的标签是否有达到目的,是否符合公众号目标群体的需求!而不是盲目的乱做标签!个人见解,
上面的大神们回答得已经比较专业了,我只能从另一个角度跟你交流下。如果你的目的是传播公众号内容,转发给朋友,不能直接得到权限。你需要先把一些词放到标签里。从而产生互动,也就是促进传播。 查看全部
个人建议你可以去公众号研究一下发文章的目的是什么
querylist采集微信公众号文章的时候,有时不能准确匹配到合适的文章,只能获取分类节点下的相关推送内容,这个时候该怎么办呢?可以通过查找或编辑标签,然后生成tags。然后再去微信公众号里面查找相关的文章。
看似很简单的文章都需要经过标签审核,只有通过标签审核才可以转发给朋友查看。文章标签的设置可以借助专业的数据采集平台来完成,如贝叶斯词典,常用的表情标签,常用歌曲歌词表情表,能够轻松完成,同时一个账号可以对应多个采集器,极大的降低采集成本,保证了公众号数据的安全性。
哈哈,谢邀,我觉得你应该需要一个wxbot,类似于猫池。之前我用过一个wxbot,用了一下,效果很好,但是不会写代码。具体上网看一下视频,
微信公众号我不太清楚。个人建议你可以去公众号研究一下发文章的目的是什么,从提高公众号粉丝量和传播推广角度去看你的要选择的标签是否有达到目的,是否符合公众号目标群体的需求!而不是盲目的乱做标签!个人见解,
上面的大神们回答得已经比较专业了,我只能从另一个角度跟你交流下。如果你的目的是传播公众号内容,转发给朋友,不能直接得到权限。你需要先把一些词放到标签里。从而产生互动,也就是促进传播。
采集在线query,添加表情就可以用query去获取文章标题
采集交流 • 优采云 发表了文章 • 0 个评论 • 211 次浏览 • 2021-04-20 01:02
querylist采集微信公众号文章文章列表与微信公众号文章标题。采集在线query,添加表情就可以用query字段去获取文章标题。如何获取文章标题,我们用matlab实现。准备工作matlab环境matlabide安装matlab的环境支持最新的matlab3.1及更高版本matlab下载和安装最新版本安装matlab2.2matlab中querylist文章列表与标题matlab代码matlab将文章列表和标题,两个数据,逐个用双向循环遍历写入一个list中,查看一下这个list中的数据如何计算时间和数据结构本文用matlab实现一个简单的文章标题和matlab代码,过程中忽略了matlab的机器学习模型。
数据采集本文使用腾讯ailab-alice作为目标样本数据。我们首先从腾讯的的ieltsonline项目采集数据。样本数据如下图:tsinghuauniversity,tsinghuauniversityattsinghuauniversityattsinghuauniversity.doi:10.1042/tsplp_00646059_01-01.bgdhome-tsinghuauniversitytsinghuauniversity,tsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversitybjtu是海量音频,也是一些基础文本文本图片以及视频.大家仔细看源码,使用一个公开的sub代码alice_api.matlab,就可以完成这个任务。
<p>packagename("subra")packagename("filters")packagename("rows")packagename("lambdas")subrecorder=irank(srt)packagename("querylist")forlinquerylist:ifsrt[l].index(l) 查看全部
采集在线query,添加表情就可以用query去获取文章标题
querylist采集微信公众号文章文章列表与微信公众号文章标题。采集在线query,添加表情就可以用query字段去获取文章标题。如何获取文章标题,我们用matlab实现。准备工作matlab环境matlabide安装matlab的环境支持最新的matlab3.1及更高版本matlab下载和安装最新版本安装matlab2.2matlab中querylist文章列表与标题matlab代码matlab将文章列表和标题,两个数据,逐个用双向循环遍历写入一个list中,查看一下这个list中的数据如何计算时间和数据结构本文用matlab实现一个简单的文章标题和matlab代码,过程中忽略了matlab的机器学习模型。
数据采集本文使用腾讯ailab-alice作为目标样本数据。我们首先从腾讯的的ieltsonline项目采集数据。样本数据如下图:tsinghuauniversity,tsinghuauniversityattsinghuauniversityattsinghuauniversity.doi:10.1042/tsplp_00646059_01-01.bgdhome-tsinghuauniversitytsinghuauniversity,tsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversityattsinghuauniversitybjtu是海量音频,也是一些基础文本文本图片以及视频.大家仔细看源码,使用一个公开的sub代码alice_api.matlab,就可以完成这个任务。
<p>packagename("subra")packagename("filters")packagename("rows")packagename("lambdas")subrecorder=irank(srt)packagename("querylist")forlinquerylist:ifsrt[l].index(l)
querylist采集微信公众号文章的标题、封面图、标签/内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 331 次浏览 • 2021-04-15 23:44
querylist采集微信公众号文章的标题、封面图、标签/内容,你只需要指定对应标签,就能得到对应的文章列表!你也可以只指定标签,那么通过得到的文章列表可以得到你需要的所有文章。querylist跟wordart没有可比性!querylist封装的是api,
querylist是用于获取文章目录的api(类似于其他的query有pageid、body、img、link、content等等)。wordart:wordart是chrome浏览器的webstreamapi的封装。用于生成一个自定义的webstream,然后通过webstream给电脑、手机等终端进行推送.wordart接受http请求,如果是一次请求的话,就直接write。一次推送一个文章,就转为文章列表wordart。api文档:wordartapireference。
wordart:wordartwebstreamapi
wordart
querylistapi貌似不用自己写了。
wordart的话貌似是一个webstreamapi的封装。
你的应该是chrome浏览器上的webstream
wordart的大意是把这个api封装成一个可执行的小程序
querylist封装了chrome浏览器以及普通浏览器上的webstreamapi,为需要的人提供了接口。
wordart接受一个http请求,然后转成文章列表。wordart并没有控制多少,推送多少文章,连发送在哪个页面上都由服务器控制。querylist则更像wordart,但不是接受一个http请求转成文章列表的。wordart从推送的角度来说更方便。 查看全部
querylist采集微信公众号文章的标题、封面图、标签/内容
querylist采集微信公众号文章的标题、封面图、标签/内容,你只需要指定对应标签,就能得到对应的文章列表!你也可以只指定标签,那么通过得到的文章列表可以得到你需要的所有文章。querylist跟wordart没有可比性!querylist封装的是api,
querylist是用于获取文章目录的api(类似于其他的query有pageid、body、img、link、content等等)。wordart:wordart是chrome浏览器的webstreamapi的封装。用于生成一个自定义的webstream,然后通过webstream给电脑、手机等终端进行推送.wordart接受http请求,如果是一次请求的话,就直接write。一次推送一个文章,就转为文章列表wordart。api文档:wordartapireference。
wordart:wordartwebstreamapi
wordart
querylistapi貌似不用自己写了。
wordart的话貌似是一个webstreamapi的封装。
你的应该是chrome浏览器上的webstream
wordart的大意是把这个api封装成一个可执行的小程序
querylist封装了chrome浏览器以及普通浏览器上的webstreamapi,为需要的人提供了接口。
wordart接受一个http请求,然后转成文章列表。wordart并没有控制多少,推送多少文章,连发送在哪个页面上都由服务器控制。querylist则更像wordart,但不是接受一个http请求转成文章列表的。wordart从推送的角度来说更方便。
多维度分析你之前没有用过的所有词条
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-04-05 00:03
querylist采集微信公众号文章的所有词条,不能算是句子。如下图。每当新文章发布时,touch模式会根据词条质量分对每个文章加权重,得分排名靠前的词条会放到table模式。出现在table的词条,质量分也不会特别高。而且,要求文章的所有词条全都出现。table很多,分词器很难实现。jieba+wordcloud解决了问题。
可以用任何你能找到的结构化格式,例如es,hdf5,neo4j,lda,parsingtool.多维图像处理是基础,word2vec更好,但也有优缺点。多维度分析你之前没有用过的。最新:推荐阅读:《中文“归并排序”vs“最大匹配”之争》,《人人都是推荐者|听我说推荐算法》《推荐系统入门指南》,《搜索引擎五步训练笔记》。
这样做确实是最坏的方法。做过wordsensitiveanalysis比较多,我记得有个方法可以用正则表达式来检测文章中的词。
谢谢yeol的精彩回答,原来你还在其他的问题回答过。
推荐一本英文的《queryprocessingwithrbasedonthepythonmodelandgraphmethods》的前三章。这本书很有意思,通过直观图像化探讨怎么找出文章中的热词。在里面最后给了个代码,现在的热词识别方法一般基于bloomfilter之类的东西,那本书里可以直接拿到那些rnn结构的结果。 查看全部
多维度分析你之前没有用过的所有词条
querylist采集微信公众号文章的所有词条,不能算是句子。如下图。每当新文章发布时,touch模式会根据词条质量分对每个文章加权重,得分排名靠前的词条会放到table模式。出现在table的词条,质量分也不会特别高。而且,要求文章的所有词条全都出现。table很多,分词器很难实现。jieba+wordcloud解决了问题。
可以用任何你能找到的结构化格式,例如es,hdf5,neo4j,lda,parsingtool.多维图像处理是基础,word2vec更好,但也有优缺点。多维度分析你之前没有用过的。最新:推荐阅读:《中文“归并排序”vs“最大匹配”之争》,《人人都是推荐者|听我说推荐算法》《推荐系统入门指南》,《搜索引擎五步训练笔记》。
这样做确实是最坏的方法。做过wordsensitiveanalysis比较多,我记得有个方法可以用正则表达式来检测文章中的词。
谢谢yeol的精彩回答,原来你还在其他的问题回答过。
推荐一本英文的《queryprocessingwithrbasedonthepythonmodelandgraphmethods》的前三章。这本书很有意思,通过直观图像化探讨怎么找出文章中的热词。在里面最后给了个代码,现在的热词识别方法一般基于bloomfilter之类的东西,那本书里可以直接拿到那些rnn结构的结果。
小程序自定义菜单“模糊搜索”的好处是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-03-29 22:05
采集微信公众号文章的一般规则是根据搜索词来采集的,所以前期的规则是匹配相关的关键词。进入公众号以后,可以选择搜索功能,也可以选择模糊搜索。如果需要设置模糊搜索可以通过引导关注后通过自定义菜单进行。模糊搜索的好处是查重率可以降到最低,防止了重复引导关注,而且能够保留图片,基本上无违规可言。
此外,搜索功能还可以自动推荐和调用多图文素材,比如:公众号改版后自带的每日文章列表就是由匹配关键词的公众号推荐的,可以选择每日推荐文章而不需要订阅号推荐文章。关注这个公众号或者查看历史消息以及文章中的素材也可以获取模糊搜索关键词,查看自定义菜单也能获取模糊搜索关键词。如果需要查看历史文章,还可以通过热词排序查看自定义菜单内自带文章的来源网站。
选择第一个网站,需要把pdf文件下载到手机端,打开选择目标文章即可查看历史文章。历史文章列表以背景图的形式呈现出来。支持全文搜索功能,搜索结果会集中显示在一个列表里,也可以查看自定义菜单,只能查看对应文章,并不能直接点击全文跳转到公众号文章。小程序自定义菜单“模糊搜索”是每个月更新一次,时间还算正常,在每个月28号和28号之间,下方网址没有进行自定义的功能,建议修改一下。
模糊搜索功能,最低是可以填写“{}”查看历史文章,并提供自定义目标文章列表。可以通过多名微信用户一起操作这个功能,每个用户都可以推荐关注对应公众号、文章、图文进行搜索。这个功能存在两个问题:一是数量有限制,另外如果需要通过推荐关注后完成来源的搜索,则需要pid,之前每个pid只能获取一次,需要升级服务器、访问数据库等。主要还是看推荐文章质量如何以及效率了。 查看全部
小程序自定义菜单“模糊搜索”的好处是什么?
采集微信公众号文章的一般规则是根据搜索词来采集的,所以前期的规则是匹配相关的关键词。进入公众号以后,可以选择搜索功能,也可以选择模糊搜索。如果需要设置模糊搜索可以通过引导关注后通过自定义菜单进行。模糊搜索的好处是查重率可以降到最低,防止了重复引导关注,而且能够保留图片,基本上无违规可言。
此外,搜索功能还可以自动推荐和调用多图文素材,比如:公众号改版后自带的每日文章列表就是由匹配关键词的公众号推荐的,可以选择每日推荐文章而不需要订阅号推荐文章。关注这个公众号或者查看历史消息以及文章中的素材也可以获取模糊搜索关键词,查看自定义菜单也能获取模糊搜索关键词。如果需要查看历史文章,还可以通过热词排序查看自定义菜单内自带文章的来源网站。
选择第一个网站,需要把pdf文件下载到手机端,打开选择目标文章即可查看历史文章。历史文章列表以背景图的形式呈现出来。支持全文搜索功能,搜索结果会集中显示在一个列表里,也可以查看自定义菜单,只能查看对应文章,并不能直接点击全文跳转到公众号文章。小程序自定义菜单“模糊搜索”是每个月更新一次,时间还算正常,在每个月28号和28号之间,下方网址没有进行自定义的功能,建议修改一下。
模糊搜索功能,最低是可以填写“{}”查看历史文章,并提供自定义目标文章列表。可以通过多名微信用户一起操作这个功能,每个用户都可以推荐关注对应公众号、文章、图文进行搜索。这个功能存在两个问题:一是数量有限制,另外如果需要通过推荐关注后完成来源的搜索,则需要pid,之前每个pid只能获取一次,需要升级服务器、访问数据库等。主要还是看推荐文章质量如何以及效率了。
搜狗微信文章转PDF2018.1.29清博指数
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-03-27 00:50
在线工具:微信文章为PDF
201 8. 1. 29
微信公众平台上有很多公共账户,包括各种文章,其中很多都很混乱。但是,在这些文章中,肯定会有一些出色的文章。
因此,如果我可以编写一个程序在我喜欢的微信公众号上获取文章,请获取文章的观看次数和喜欢次数,然后执行简单的数据分析,然后得出最终的文章列表肯定会更好文章。
此处应注意,通过编写爬虫程序在搜狗微信搜索中获取微信文章,您将无法获得两次浏览量和喜欢率的关键数据(在编程技能的入门水平上我是)。因此,我采取了另一种方法,并通过青博指数网站获得了我想要的数据。
注意:目前,我们已经找到一种方法来获取搜狗微信中文章的观看次数和喜欢次数。 201 7. 0 2. 03
实际上,关于青博指数网站的数据非常完整。您可以看到微信公众号列表,也可以每天,每周和每月看到热门帖子,但这就是我上面所说的。内容很乱。那些读过很多文章的人可能会受到一些家长级人才文章的喜欢。
当然,我也可以在网站上搜索特定的微信官方帐户,然后查看其历史记录文章。 Qingbo索引也非常详细,可以根据阅读次数,喜欢次数等进行分类文章。但是,我可能需要一个非常简单的指标来表示喜欢次数除以读数次数,因此我需要通过采集器对上述数据进行爬行以执行简单的分析。顺便说一句,您可以练习双手并感到无聊。
启动程序
以微信公众号建奇金融为例,我需要先打开其文章界面,以下是其网址:
http://www.gsdata.cn/query/art ... e%3D1
然后我通过分析发现它总共有25个页面文章,即最后一页文章的网址如下,请注意,只有last参数是不同的:
http://www.gsdata.cn/query/art ... %3D25
因此您可以编写一个函数并调用25次。
BeautifulSoup在网页上获取您所需的数据
忘了说,我编写的程序语言是Python,而且采集器条目非常简单。然后,BeautifulSoup是一个网页分析插件,可以非常方便地在文章中获取HTML数据。
下一步是分析页面结构:
我用红色框框住了两篇文章文章,它们在网页上的结构代码是相同的。然后,通过查看元素,可以看到网页的相应代码,然后可以编写爬网规则。下面我直接写了一个函数:
# 获取网页中的数据
def get_webdata(url):
headers = {
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
}
r = requests.get(url,headers=headers)
c = r.content
b = BeautifulSoup(c)
data_list = b.find('ul',{'class':'article-ul'})
data_li = data_list.findAll('li')
for i in data_li:
# 替换标题中的英文双引号,防止插入数据库时出现错误
title = i.find('h4').find('a').get_text().replace('"','\'\'')
link = i.find('h4').find('a').attrs['href']
source = i.find('span',{'class':'blue'}).get_text()
time = i.find('span',{'class':'blue'}).parent.next_sibling.next_sibling.get_text().replace('发布时间:'.decode('utf-8'),'')
readnum = int(i.find('i',{'class':'fa-book'}).next_sibling)
praisenum = int(i.find('i',{'class':'fa-thumbs-o-up'}).next_sibling)
insert_content(title,readnum,praisenum,time,link,source)
此功能包括使用请求先获取网页的内容,然后将其传递给BeautifulSoup来分析和提取我需要的数据,然后通过insert_content函数在数据库中获取数据库知识这次涉及到的所有代码将在下面给出,也怕以后我会忘记它。
我个人认为,事实上,BeautifulSoup的知识点只需要掌握几个常用的句子,例如find,findAll,get_text(),attrs ['src']等,我在上面的代码中就使用过
周期性地捕获它并将其写入数据库
您还记得第一个URL吗?总共需要爬网25页。这25个页面的URL实际上与最后一个参数不同,因此您可以提供一个基本URL并使用for函数直接生成它,25个URL就足够了:
# 生成需要爬取的网页链接且进行爬取
def get_urls_webdatas(basic_url,range_num):
for i in range(1,range_num+1):
url = basic_url + str(i)
print url
print ''
get_webdata(url)
time.sleep(round(random.random(),1))
basic_url = 'http://www.gsdata.cn/query/article?q=jane7ducai&post_time=0&sort=-3&date=&search_field=4&page='
get_urls_webdatas(basic_url,25)
与上面的代码一样,get_urls_webdataas函数传入两个参数,即基本url和所需的页数。您可以看到我在代码的最后一行中调用了此函数。
此函数还调用我编写的get_webdata函数来获取上面的页面。在这种情况下,这25页上的文章数据将立即写入数据库。
然后请注意以下小技巧:
time.sleep(round(random.random(),1))
每次我使用该程序爬网网页时,该语句都会在1s内随机生成一段时间,然后在这么短的时间内休息一下,然后继续爬网下一页,这可以防止被禁止。
获取最终数据
首先给我程序的其余代码:
#coding:utf-8
import requests,MySQLdb,random,time
from bs4 import BeautifulSoup
def get_conn():
conn = MySQLdb.connect('localhost','root','0000','weixin',charset='utf8')
return conn
def insert_content(title,readnum,praisenum,time,link,source):
conn = get_conn()
cur = conn.cursor()
print title,readnum
sql = 'insert into weixin.gsdata(title,readnum,praisenum,time,link,source) values ("%s","%s","%s","%s","%s","%s")' % (title,readnum,praisenum,time,link,source)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
在导入开始时包括一些插件,然后剩下的两个功能是与数据库操作有关的功能。
最后,通过从weixin.gsdata中选择*;在数据库中,我可以获取我已爬网的该微信官方帐户的文章数据,包括标题,发布日期,阅读量(如销量),访问url和其他信息。
分析数据
这些数据只是最原创的数据。我可以将上述数据导入Excel并执行简单的分析和处理,然后可以获得所需的文章列表。分析思路如下:
我只喜欢几个微信公众号。我可以使用该程序获取我最喜欢的微信官方帐户中的所有文章。如果需要,我可以进一步过滤出更高质量的文章。
该程序非常简单,但是一个简单的程序可以实现生活中的一些想法,这不是一件好事吗? 查看全部
搜狗微信文章转PDF2018.1.29清博指数
在线工具:微信文章为PDF
201 8. 1. 29
微信公众平台上有很多公共账户,包括各种文章,其中很多都很混乱。但是,在这些文章中,肯定会有一些出色的文章。
因此,如果我可以编写一个程序在我喜欢的微信公众号上获取文章,请获取文章的观看次数和喜欢次数,然后执行简单的数据分析,然后得出最终的文章列表肯定会更好文章。
此处应注意,通过编写爬虫程序在搜狗微信搜索中获取微信文章,您将无法获得两次浏览量和喜欢率的关键数据(在编程技能的入门水平上我是)。因此,我采取了另一种方法,并通过青博指数网站获得了我想要的数据。
注意:目前,我们已经找到一种方法来获取搜狗微信中文章的观看次数和喜欢次数。 201 7. 0 2. 03
实际上,关于青博指数网站的数据非常完整。您可以看到微信公众号列表,也可以每天,每周和每月看到热门帖子,但这就是我上面所说的。内容很乱。那些读过很多文章的人可能会受到一些家长级人才文章的喜欢。
当然,我也可以在网站上搜索特定的微信官方帐户,然后查看其历史记录文章。 Qingbo索引也非常详细,可以根据阅读次数,喜欢次数等进行分类文章。但是,我可能需要一个非常简单的指标来表示喜欢次数除以读数次数,因此我需要通过采集器对上述数据进行爬行以执行简单的分析。顺便说一句,您可以练习双手并感到无聊。
启动程序
以微信公众号建奇金融为例,我需要先打开其文章界面,以下是其网址:
http://www.gsdata.cn/query/art ... e%3D1
然后我通过分析发现它总共有25个页面文章,即最后一页文章的网址如下,请注意,只有last参数是不同的:
http://www.gsdata.cn/query/art ... %3D25
因此您可以编写一个函数并调用25次。
BeautifulSoup在网页上获取您所需的数据
忘了说,我编写的程序语言是Python,而且采集器条目非常简单。然后,BeautifulSoup是一个网页分析插件,可以非常方便地在文章中获取HTML数据。
下一步是分析页面结构:
我用红色框框住了两篇文章文章,它们在网页上的结构代码是相同的。然后,通过查看元素,可以看到网页的相应代码,然后可以编写爬网规则。下面我直接写了一个函数:
# 获取网页中的数据
def get_webdata(url):
headers = {
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
}
r = requests.get(url,headers=headers)
c = r.content
b = BeautifulSoup(c)
data_list = b.find('ul',{'class':'article-ul'})
data_li = data_list.findAll('li')
for i in data_li:
# 替换标题中的英文双引号,防止插入数据库时出现错误
title = i.find('h4').find('a').get_text().replace('"','\'\'')
link = i.find('h4').find('a').attrs['href']
source = i.find('span',{'class':'blue'}).get_text()
time = i.find('span',{'class':'blue'}).parent.next_sibling.next_sibling.get_text().replace('发布时间:'.decode('utf-8'),'')
readnum = int(i.find('i',{'class':'fa-book'}).next_sibling)
praisenum = int(i.find('i',{'class':'fa-thumbs-o-up'}).next_sibling)
insert_content(title,readnum,praisenum,time,link,source)
此功能包括使用请求先获取网页的内容,然后将其传递给BeautifulSoup来分析和提取我需要的数据,然后通过insert_content函数在数据库中获取数据库知识这次涉及到的所有代码将在下面给出,也怕以后我会忘记它。
我个人认为,事实上,BeautifulSoup的知识点只需要掌握几个常用的句子,例如find,findAll,get_text(),attrs ['src']等,我在上面的代码中就使用过
周期性地捕获它并将其写入数据库
您还记得第一个URL吗?总共需要爬网25页。这25个页面的URL实际上与最后一个参数不同,因此您可以提供一个基本URL并使用for函数直接生成它,25个URL就足够了:
# 生成需要爬取的网页链接且进行爬取
def get_urls_webdatas(basic_url,range_num):
for i in range(1,range_num+1):
url = basic_url + str(i)
print url
print ''
get_webdata(url)
time.sleep(round(random.random(),1))
basic_url = 'http://www.gsdata.cn/query/article?q=jane7ducai&post_time=0&sort=-3&date=&search_field=4&page='
get_urls_webdatas(basic_url,25)
与上面的代码一样,get_urls_webdataas函数传入两个参数,即基本url和所需的页数。您可以看到我在代码的最后一行中调用了此函数。
此函数还调用我编写的get_webdata函数来获取上面的页面。在这种情况下,这25页上的文章数据将立即写入数据库。
然后请注意以下小技巧:
time.sleep(round(random.random(),1))
每次我使用该程序爬网网页时,该语句都会在1s内随机生成一段时间,然后在这么短的时间内休息一下,然后继续爬网下一页,这可以防止被禁止。
获取最终数据
首先给我程序的其余代码:
#coding:utf-8
import requests,MySQLdb,random,time
from bs4 import BeautifulSoup
def get_conn():
conn = MySQLdb.connect('localhost','root','0000','weixin',charset='utf8')
return conn
def insert_content(title,readnum,praisenum,time,link,source):
conn = get_conn()
cur = conn.cursor()
print title,readnum
sql = 'insert into weixin.gsdata(title,readnum,praisenum,time,link,source) values ("%s","%s","%s","%s","%s","%s")' % (title,readnum,praisenum,time,link,source)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
在导入开始时包括一些插件,然后剩下的两个功能是与数据库操作有关的功能。
最后,通过从weixin.gsdata中选择*;在数据库中,我可以获取我已爬网的该微信官方帐户的文章数据,包括标题,发布日期,阅读量(如销量),访问url和其他信息。
分析数据
这些数据只是最原创的数据。我可以将上述数据导入Excel并执行简单的分析和处理,然后可以获得所需的文章列表。分析思路如下:
我只喜欢几个微信公众号。我可以使用该程序获取我最喜欢的微信官方帐户中的所有文章。如果需要,我可以进一步过滤出更高质量的文章。
该程序非常简单,但是一个简单的程序可以实现生活中的一些想法,这不是一件好事吗?

