
querylist采集微信公众号文章
java微信公众号第三方接入解析及全网检查代码示例
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2020-08-22 12:10
一、接入大体思路解析
这里主要是查看文档的授权流程技术说明,这里从开发者角度介绍。
接入第三方的开发者想必早已对公众号开发比较了解,第三方是代微信号实现功能的一个组件,所以其实陌陌方的开发们也是这么考虑,为第三方的access_token起名为component_access_token。
1、首先获取第三方
component_access_token
这个过程中会使用到陌陌服务器定期向我们服务器推送的component_verify_ticket数组,加上component_appid、component_appsecret等信息即可获得。
2、获取授权公众号信息
类似公众号网页授权,通过反弹的方式,微信公众号运营者可以通过陌陌扫码的方式将公众号授权给第三方,唯一有些不同的这儿在拼出授权跳转页面url后的第一步是引导用户跳转到该页面上,再进行扫码,所以这个跳转不是必须在陌陌外置浏览器中进行。
拼出的url中的参数出了要用到component_access_token外还须要一个pre_auth_code预授权码,可通过component_access_token获得,具体的实效时间机制和component_access_token差不多。
用户授权成功后会在redirect_url后接参数auth_code,类似公众号网页授权的code值,通过auth_code和component_access_token等信息即可获得该授权公众号信息,若中间要与公众号第三方平台的帐号绑定再带一个帐号标识参数即可。
3、带公众号实现业务
公众号授权成功后第三方会得到该公众号的authorizer_access_token,与公众号的access_token功能相同,使用这个即可用微信公众号的插口代公众号实现业务。
有些不同的再第三方文档里以有说明。官方文档
另外文档上没有提及的是,每当有公众号授权成功后,微信服务器会将公众号授权信息推送到授权风波接收URL,即接收component_verify_ticket的插口。
4、关于加密揭秘
获取陌陌服务器推送信息的时侯都是进行加密的。
二、接入中发觉的几个问题1、微信的示例java代码,XMLParse类中
/**
* 提取出xml数据包中的加密消息
* @param xmltext 待提取的xml字符串
* @return 提取出的加密消息字符串
* @throws AesException
*/
public static Object[] extract(String xmltext) throws AesException {
Object[] result = new Object[3];
try {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
StringReader sr = new StringReader(xmltext);
InputSource is = new InputSource(sr);
Document document = db.parse(is);
Element root = document.getDocumentElement();
NodeList nodelist1 = root.getElementsByTagName("Encrypt");
NodeList nodelist2 = root.getElementsByTagName("ToUserName");
System.out.println("nodelist2.item(0)="+nodelist2.item(0));
result[0] = 0;
result[1] = nodelist1.item(0).getTextContent();
//这里加了一个判断,因为接收推送component_verify_ticket的解谜过程中没有第三个参数,回报空指针异常
if(nodelist2.item(0) != null){
result[2] = nodelist2.item(0).getTextContent();
}
return result;
} catch (Exception e) {
e.printStackTrace();
throw new AesException(AesException.ParseXmlError);
}
}
2、文档中:使用授权码换取公众号的插口调用凭据和授权信息
返回json信息最后少了一个}
{
"authorization_info": {
"authorizer_appid": "wxf8b4f85f3a794e77",
"authorizer_access_token": "QXjUqNqfYVH0yBE1iI_7vuN_9gQbpjfK7hYwJ3P7xOa88a89-Aga5x1NMYJyB8G2yKt1KCl0nPC3W9GJzw0Zzq_dBxc8pxIGUNi_bFes0qM",
"expires_in": 7200,
"authorizer_refresh_token": "dTo-YCXPL4llX-u1W1pPpnp8Hgm4wpJtlR6iV0doKdY",
"func_info": [
{
"funcscope_category": {
"id": 1
}
},
{
"funcscope_category": {
"id": 2
}
},
{
"funcscope_category": {
"id": 3
}
}
]
}
}
大家开发时要注意json数据结构
三、关于代码
在 微信公众帐号第三方平台全网发布源码(java)- 实战测试通过 代码结构基础上进行更改 查看全部
java微信公众号第三方接入解析及全网监测代码示例
一、接入大体思路解析
这里主要是查看文档的授权流程技术说明,这里从开发者角度介绍。
接入第三方的开发者想必早已对公众号开发比较了解,第三方是代微信号实现功能的一个组件,所以其实陌陌方的开发们也是这么考虑,为第三方的access_token起名为component_access_token。
1、首先获取第三方
component_access_token
这个过程中会使用到陌陌服务器定期向我们服务器推送的component_verify_ticket数组,加上component_appid、component_appsecret等信息即可获得。
2、获取授权公众号信息
类似公众号网页授权,通过反弹的方式,微信公众号运营者可以通过陌陌扫码的方式将公众号授权给第三方,唯一有些不同的这儿在拼出授权跳转页面url后的第一步是引导用户跳转到该页面上,再进行扫码,所以这个跳转不是必须在陌陌外置浏览器中进行。
拼出的url中的参数出了要用到component_access_token外还须要一个pre_auth_code预授权码,可通过component_access_token获得,具体的实效时间机制和component_access_token差不多。
用户授权成功后会在redirect_url后接参数auth_code,类似公众号网页授权的code值,通过auth_code和component_access_token等信息即可获得该授权公众号信息,若中间要与公众号第三方平台的帐号绑定再带一个帐号标识参数即可。
3、带公众号实现业务
公众号授权成功后第三方会得到该公众号的authorizer_access_token,与公众号的access_token功能相同,使用这个即可用微信公众号的插口代公众号实现业务。
有些不同的再第三方文档里以有说明。官方文档
另外文档上没有提及的是,每当有公众号授权成功后,微信服务器会将公众号授权信息推送到授权风波接收URL,即接收component_verify_ticket的插口。
4、关于加密揭秘
获取陌陌服务器推送信息的时侯都是进行加密的。
二、接入中发觉的几个问题1、微信的示例java代码,XMLParse类中
/**
* 提取出xml数据包中的加密消息
* @param xmltext 待提取的xml字符串
* @return 提取出的加密消息字符串
* @throws AesException
*/
public static Object[] extract(String xmltext) throws AesException {
Object[] result = new Object[3];
try {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
StringReader sr = new StringReader(xmltext);
InputSource is = new InputSource(sr);
Document document = db.parse(is);
Element root = document.getDocumentElement();
NodeList nodelist1 = root.getElementsByTagName("Encrypt");
NodeList nodelist2 = root.getElementsByTagName("ToUserName");
System.out.println("nodelist2.item(0)="+nodelist2.item(0));
result[0] = 0;
result[1] = nodelist1.item(0).getTextContent();
//这里加了一个判断,因为接收推送component_verify_ticket的解谜过程中没有第三个参数,回报空指针异常
if(nodelist2.item(0) != null){
result[2] = nodelist2.item(0).getTextContent();
}
return result;
} catch (Exception e) {
e.printStackTrace();
throw new AesException(AesException.ParseXmlError);
}
}
2、文档中:使用授权码换取公众号的插口调用凭据和授权信息
返回json信息最后少了一个}
{
"authorization_info": {
"authorizer_appid": "wxf8b4f85f3a794e77",
"authorizer_access_token": "QXjUqNqfYVH0yBE1iI_7vuN_9gQbpjfK7hYwJ3P7xOa88a89-Aga5x1NMYJyB8G2yKt1KCl0nPC3W9GJzw0Zzq_dBxc8pxIGUNi_bFes0qM",
"expires_in": 7200,
"authorizer_refresh_token": "dTo-YCXPL4llX-u1W1pPpnp8Hgm4wpJtlR6iV0doKdY",
"func_info": [
{
"funcscope_category": {
"id": 1
}
},
{
"funcscope_category": {
"id": 2
}
},
{
"funcscope_category": {
"id": 3
}
}
]
}
}
大家开发时要注意json数据结构
三、关于代码
在 微信公众帐号第三方平台全网发布源码(java)- 实战测试通过 代码结构基础上进行更改
搜狗陌陌的抓取总结
采集交流 • 优采云 发表了文章 • 0 个评论 • 266 次浏览 • 2020-08-21 22:19
最近抓取了搜狗陌陌的数据,虽然也破解了跳转之类的,但是最后由于抓取的链接有时效性舍弃了,也总结下
一样的,输入关键词,抓取列表,再回来跳转后的陌陌链接
前10页是可以随意看的,也不需要登陆,10页以后的数据须要陌陌扫码登陆,这一块无法破解
链接参数好多最后可以精简为
烽火&page=11&type=2
page就是页脚,query就是关键字,type 是搜索文章还是搜索公众号
其实很简单的代码,先要在url前面构造出 k 和 h,转化为 java 代码就是
// 拼接搜狗跳转参数k和h
public static String getLinkUrl(String url) {
int b = ((int) Math.floor(100 * Math.random())) + 1;
int a = url.indexOf("url=");
int k = a + 4 + 21 + b;
String d = url.substring(k, k + 1);
System.out.println(d);
url += "&k=" + b + "&h=" + d;
return "https://weixin.sogou.com" + url;
}
有参数的链接直接恳求是会出验证码的,需要cookie,需要的cookie只要是两个 一个是 SUV,一个是SNUID,这两个cookie获取都很简单,通过剖析可以得到
1.SUV 是可以通过访问来获取到
2.SNUID 在搜索的时侯才会有了
所以我们加上这两个cookie才能获取到具体的陌陌的链接了
剩下的就是把这个链接取下来就行啦
虽然还有好多细节没有建立,但是最坑的是最后的陌陌链接是有时效性的
太坑了,市面上有将有时效的链接转换为没有时效的链接的商业服务,不知道是她们是如何实现的。目前在看陌陌客户端上面的搜一搜,因为通过客户端的搜一搜搜下来的链接是短短的,应该是失效太长的
2020-06-04 更新
找到了转换永久链接的办法,把有时效性的链接复制到陌陌客户端上面,不管是过没过期的链接都是才能打开的,再把链接复制下来就是永久的链接了,使用了 pythonpyautogui 来操作的,很简单,也太low,速度不快,就不放代码了。 查看全部
搜狗陌陌的抓取总结
最近抓取了搜狗陌陌的数据,虽然也破解了跳转之类的,但是最后由于抓取的链接有时效性舍弃了,也总结下

一样的,输入关键词,抓取列表,再回来跳转后的陌陌链接
前10页是可以随意看的,也不需要登陆,10页以后的数据须要陌陌扫码登陆,这一块无法破解
链接参数好多最后可以精简为
烽火&page=11&type=2
page就是页脚,query就是关键字,type 是搜索文章还是搜索公众号

其实很简单的代码,先要在url前面构造出 k 和 h,转化为 java 代码就是
// 拼接搜狗跳转参数k和h
public static String getLinkUrl(String url) {
int b = ((int) Math.floor(100 * Math.random())) + 1;
int a = url.indexOf("url=");
int k = a + 4 + 21 + b;
String d = url.substring(k, k + 1);
System.out.println(d);
url += "&k=" + b + "&h=" + d;
return "https://weixin.sogou.com" + url;
}
有参数的链接直接恳求是会出验证码的,需要cookie,需要的cookie只要是两个 一个是 SUV,一个是SNUID,这两个cookie获取都很简单,通过剖析可以得到
1.SUV 是可以通过访问来获取到

2.SNUID 在搜索的时侯才会有了

所以我们加上这两个cookie才能获取到具体的陌陌的链接了

剩下的就是把这个链接取下来就行啦
虽然还有好多细节没有建立,但是最坑的是最后的陌陌链接是有时效性的

太坑了,市面上有将有时效的链接转换为没有时效的链接的商业服务,不知道是她们是如何实现的。目前在看陌陌客户端上面的搜一搜,因为通过客户端的搜一搜搜下来的链接是短短的,应该是失效太长的

2020-06-04 更新
找到了转换永久链接的办法,把有时效性的链接复制到陌陌客户端上面,不管是过没过期的链接都是才能打开的,再把链接复制下来就是永久的链接了,使用了 pythonpyautogui 来操作的,很简单,也太low,速度不快,就不放代码了。
Python网络爬虫学习笔记(五)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2020-08-18 18:25
微信公众号文章爬取
以搜狗的陌陌搜索平台“”作为爬取入口,可以在搜索栏输入相应关键词来搜索相关微信公众号文章。我们以“机器学习”作为搜索关键词。可以看见搜索后的地址栏中内容为:
%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0&_sug_type_=&sut=1872&lkt=1%2C86%2C86&s_from=input&_sug_=n&type=2&sst0=95&page=2&ie=utf8&w=01019900&dr=1
通过观察,可以发觉如此几个关键数组:
type:控制检索信息的类型query:我们恳求的搜索关键词page:控制页数
所以我们的网址结构可以构造为:
关键词&type=2&page=页码
然后,我们在每一个搜索页中爬取文章的思路是:
检索对应关键词得到的相应文章检索结果,并在该页面上将文章的链接提取下来在文章的链接被提取以后,根据这种链接地址采集文章中的具体标题和内容
通过查看文章列表页的源代码可以找到相应文章的URL以及要爬取的内容,列表页面如下:
其中第一篇文章网址部份的源代码如下所示:
机器学习法则:ML工程的最佳实践
图片源自:Westworld Season 2作者无邪机器学习研究者,人工智障推进者.Martin Zinkevich 在2016年将 google 内容多年关于机器学...
程序人生document.write(timeConvert('1526875397'))
所以我们可以将提取文章网址的正则表达式构造为:
'
这样就可以依据相关函数与代码提取出指定页数的文章网址。但是依据正则表达式提取出的网址不是真实地址,会出现参数错误。提取出的地址比真实地址多了一些“&”字符串,我们通过url.replace("amp;","")去掉多余字符串。
这样就提取了文章的地址,可以依照文章地址爬取相应网页,并通过代理服务器的方式,解决官方屏蔽IP的问题。
整个爬取陌陌文章的思路如下:
建立三个自定义函数:实现使用代理服务器爬去指定网址并返回结果;实现获得多个页面的所有文章链接;实现依据文章链接爬取指定标题和内容并写入文件中。使用代理服务器爬取指定网址的内容实现获取多个页面的所有文章链接时,需要对关键词使用urllib.request.quote(key)进行编码,并通过for循环一次爬取各页的文章中设置的服务器函数实现。实现依据文章链接爬取指定标题和内容写入对应文件,使用for循环一次爬取。代码中假如发生异常,要进行延时处理。
具体代码如下: 查看全部
Python网络爬虫学习笔记(五)
微信公众号文章爬取
以搜狗的陌陌搜索平台“”作为爬取入口,可以在搜索栏输入相应关键词来搜索相关微信公众号文章。我们以“机器学习”作为搜索关键词。可以看见搜索后的地址栏中内容为:
%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0&_sug_type_=&sut=1872&lkt=1%2C86%2C86&s_from=input&_sug_=n&type=2&sst0=95&page=2&ie=utf8&w=01019900&dr=1
通过观察,可以发觉如此几个关键数组:
type:控制检索信息的类型query:我们恳求的搜索关键词page:控制页数
所以我们的网址结构可以构造为:
关键词&type=2&page=页码
然后,我们在每一个搜索页中爬取文章的思路是:
检索对应关键词得到的相应文章检索结果,并在该页面上将文章的链接提取下来在文章的链接被提取以后,根据这种链接地址采集文章中的具体标题和内容
通过查看文章列表页的源代码可以找到相应文章的URL以及要爬取的内容,列表页面如下:
其中第一篇文章网址部份的源代码如下所示:
机器学习法则:ML工程的最佳实践
图片源自:Westworld Season 2作者无邪机器学习研究者,人工智障推进者.Martin Zinkevich 在2016年将 google 内容多年关于机器学...
程序人生document.write(timeConvert('1526875397'))
所以我们可以将提取文章网址的正则表达式构造为:
'
这样就可以依据相关函数与代码提取出指定页数的文章网址。但是依据正则表达式提取出的网址不是真实地址,会出现参数错误。提取出的地址比真实地址多了一些“&”字符串,我们通过url.replace("amp;","")去掉多余字符串。
这样就提取了文章的地址,可以依照文章地址爬取相应网页,并通过代理服务器的方式,解决官方屏蔽IP的问题。
整个爬取陌陌文章的思路如下:
建立三个自定义函数:实现使用代理服务器爬去指定网址并返回结果;实现获得多个页面的所有文章链接;实现依据文章链接爬取指定标题和内容并写入文件中。使用代理服务器爬取指定网址的内容实现获取多个页面的所有文章链接时,需要对关键词使用urllib.request.quote(key)进行编码,并通过for循环一次爬取各页的文章中设置的服务器函数实现。实现依据文章链接爬取指定标题和内容写入对应文件,使用for循环一次爬取。代码中假如发生异常,要进行延时处理。
具体代码如下:
微信公众号历史消息采集方法及注意事项
采集交流 • 优采云 发表了文章 • 0 个评论 • 462 次浏览 • 2020-08-18 15:34
采集微信文章和采集网站内容一样,都须要从一个列表页开始。而陌陌文章的列表页就是公众号里的查看历史消息页。现在网路上的其它陌陌采集器有的是借助搜狗搜索,采集方式其实简单多了,但是内容不全。所以我们还是要从最标准最全面的公众号历史消息页来采集。
因为陌陌的限制,我们能复制到的链接是不完整的,在浏览器中未能打开听到内容。所以我们须要通过上一篇文章介绍的方式,使用anyproxy获取到一个完整的微信公众号历史消息页面的链接地址。
f9387c4d02682e186a298a18276d8e0555e3ab51d81ca46de339e6082eb767343bef610edd80c9e1bfda66c
2b62751511f7cc091a33a029709e94f0d1604e11220fc099a27b2e2d29db75cc0849d4bf&devicetype=andro
id-17&version=26031c34&lang=zh_CN&nettype=WIFI&ascene=3&pass_ticket=Iox5ZdpRhrSxGYEeopVJwTB
P7kZj51GYyEL24AT5Zyx%2BBoEMdPDBtOun1F%2F9ENSz&wx_header=1
biz参数是公众号的ID,uin是用户的ID,目前来看uin是在所有公众号之间惟一的。其它两个重要参数key和pass_ticket是陌陌客户端补充上的参数。
所以在这个地址失效之前我们是可以通过浏览器查看原文的方式获取到历史消息的文章列表的,如果希望自动化剖析内容,也可以制做一个程序,将这个带有仍未失效的key和pass_ticket的链接地址递交进去,再通过诸如php程序来获取到文章列表。
最近有同事跟我说他的采集目标就是单一的一个公众号,我认为这样就没必要用上一篇文章写的批量采集的方式了。所以我们接下来瞧瞧历史消息页上面是如何获取到文章列表的,通过剖析文章列表,就可以得到这个公众号所有的内容链接地址,然后再采集内容就可以了。
在anyproxy的web界面中若果证书配置正确,是可以显示出https的内容的。web界面的地址是:8002 其中localhost可以替换成自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击以后两侧都会显示出这条记录的详情:
红框部份就是完整的链接地址,将微信公众平台这个域名拼接在上面以后就可以在浏览器中打开了。
然后将页面向上拉,到html内容的结尾部份,我们可以看见一个json的变量就是历史消息的文章列表:
我们将msgList的变量值拷贝下来,用json低格工具剖析一下,我们就可以看见这个json是以下这个结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... 76742
7&idx=1&sn=37da0d7208283bf90e9a4a536e0af0ea&chksm=8b882dbbbcffa4ad2f0b8a141cc988d16bac
e564274018e68e5c53ee6f354f8ad56c9b98bade&scene=4#wechat_redirect",
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... gLtcq
GziaFqwibzvtZAHCDkMeJU1fGZHpjoeibanPJ8rziaq68Akkg/0?wx_fmt=jpeg",
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... 65276
7427&idx=2&sn=449ef1a874a37fed2429e14f724b56ef&chksm=8 b882dbbbcffa4ade48a7932cda426368
7e34fca8ea3a5a6233d2589d448b9f6130d3890ce93&scene=4#wechat_redirect",
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... YHYrh
ibia89ZnksCsUiaia2TLI1fyqjclibGa1hw3icP6oXeSpaWMjiabaghHl7yw/0?wx_fmt=png",
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... b56b9 98e1f2b8?detailReferrer=1&from=groupmessage&isappinstalled=0",
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简要的剖析一下这个json(这里只介绍一些重要的信息,其它的被省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "ժҪ",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""ժҪ"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
在这里还要提及一点就是假如希望获取到时间更久远一些的历史消息内容,就须要在手机或模拟器上将页面向上拉,当拉到最里边的时侯,微信将手动读取下一页的内容。下一页的链接地址和历史消息页的链接地址同样是getmasssendmsg开头的地址。但是内容就是只有json了,没有html了。直接解析json就可以了。
这时可以通过上一篇文章介绍的方式,使用anyproxy将msgList变量值正则匹配下来以后,异步递交到服务器,再从服务器上使用php的json_decode解析json成为字段。然后遍历循环链表。我们就可以得到每一篇文章的标题和链接地址。
如果只须要采集单一公众号的内容,完全可以在每晚群发以后,通过anyproxy获取到完整的带有key和pass_ticket的链接地址。然后自己制做一个程序,手动将地址递交给自己的程序。使用诸如php这样的语言来正则匹配到msgList,然后解析json。这样就不用更改anyproxy的rule,也不需要制做一个采集队列和跳转页面了。 查看全部
微信公众号历史消息采集方法及注意事项
采集微信文章和采集网站内容一样,都须要从一个列表页开始。而陌陌文章的列表页就是公众号里的查看历史消息页。现在网路上的其它陌陌采集器有的是借助搜狗搜索,采集方式其实简单多了,但是内容不全。所以我们还是要从最标准最全面的公众号历史消息页来采集。
因为陌陌的限制,我们能复制到的链接是不完整的,在浏览器中未能打开听到内容。所以我们须要通过上一篇文章介绍的方式,使用anyproxy获取到一个完整的微信公众号历史消息页面的链接地址。
f9387c4d02682e186a298a18276d8e0555e3ab51d81ca46de339e6082eb767343bef610edd80c9e1bfda66c
2b62751511f7cc091a33a029709e94f0d1604e11220fc099a27b2e2d29db75cc0849d4bf&devicetype=andro
id-17&version=26031c34&lang=zh_CN&nettype=WIFI&ascene=3&pass_ticket=Iox5ZdpRhrSxGYEeopVJwTB
P7kZj51GYyEL24AT5Zyx%2BBoEMdPDBtOun1F%2F9ENSz&wx_header=1
biz参数是公众号的ID,uin是用户的ID,目前来看uin是在所有公众号之间惟一的。其它两个重要参数key和pass_ticket是陌陌客户端补充上的参数。
所以在这个地址失效之前我们是可以通过浏览器查看原文的方式获取到历史消息的文章列表的,如果希望自动化剖析内容,也可以制做一个程序,将这个带有仍未失效的key和pass_ticket的链接地址递交进去,再通过诸如php程序来获取到文章列表。
最近有同事跟我说他的采集目标就是单一的一个公众号,我认为这样就没必要用上一篇文章写的批量采集的方式了。所以我们接下来瞧瞧历史消息页上面是如何获取到文章列表的,通过剖析文章列表,就可以得到这个公众号所有的内容链接地址,然后再采集内容就可以了。
在anyproxy的web界面中若果证书配置正确,是可以显示出https的内容的。web界面的地址是:8002 其中localhost可以替换成自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击以后两侧都会显示出这条记录的详情:
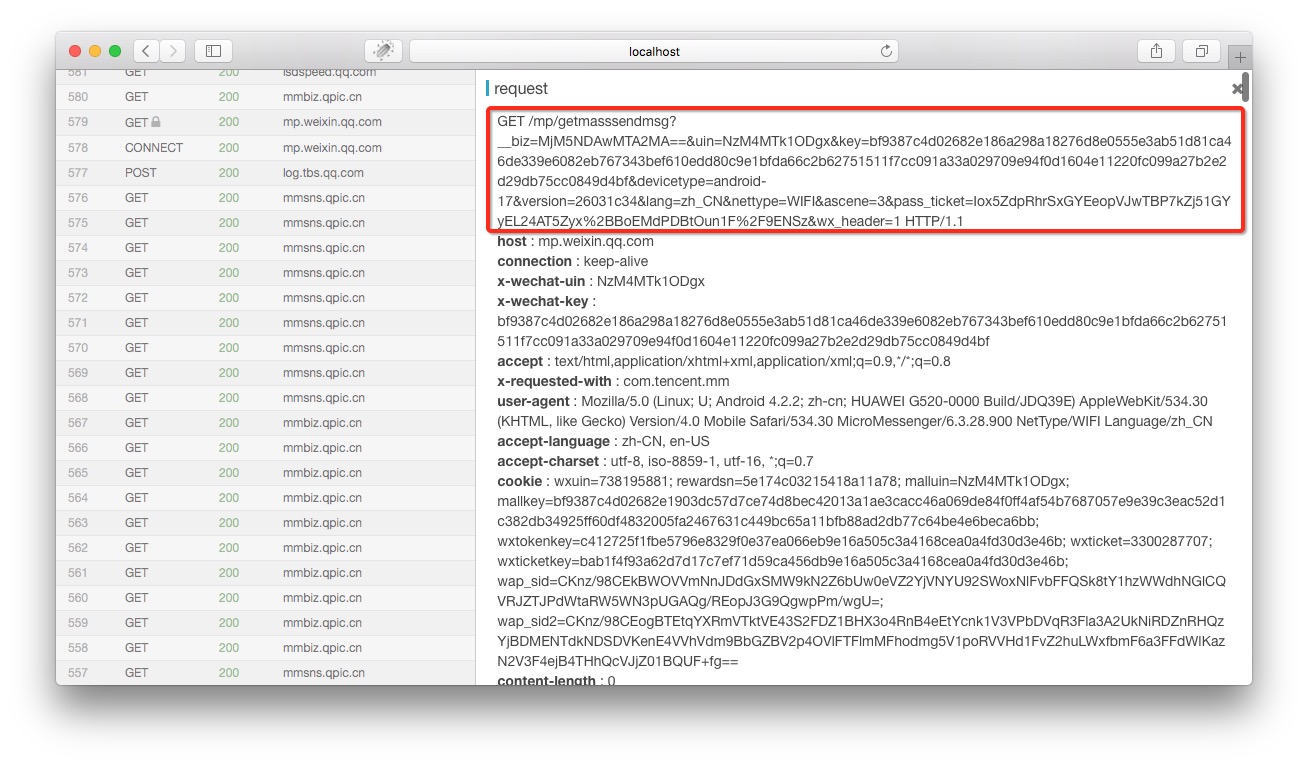
红框部份就是完整的链接地址,将微信公众平台这个域名拼接在上面以后就可以在浏览器中打开了。
然后将页面向上拉,到html内容的结尾部份,我们可以看见一个json的变量就是历史消息的文章列表:
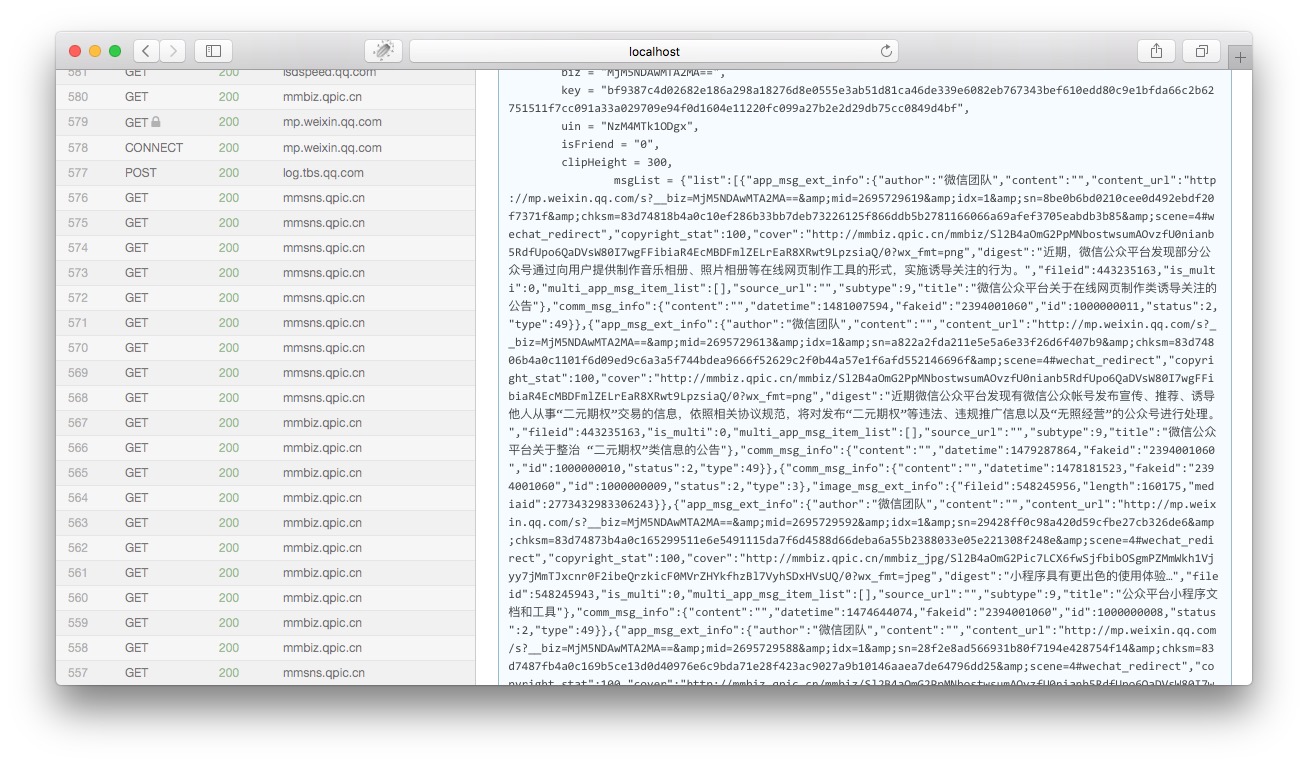
我们将msgList的变量值拷贝下来,用json低格工具剖析一下,我们就可以看见这个json是以下这个结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... 76742
7&idx=1&sn=37da0d7208283bf90e9a4a536e0af0ea&chksm=8b882dbbbcffa4ad2f0b8a141cc988d16bac
e564274018e68e5c53ee6f354f8ad56c9b98bade&scene=4#wechat_redirect",
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... gLtcq
GziaFqwibzvtZAHCDkMeJU1fGZHpjoeibanPJ8rziaq68Akkg/0?wx_fmt=jpeg",
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... 65276
7427&idx=2&sn=449ef1a874a37fed2429e14f724b56ef&chksm=8 b882dbbbcffa4ade48a7932cda426368
7e34fca8ea3a5a6233d2589d448b9f6130d3890ce93&scene=4#wechat_redirect",
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... YHYrh
ibia89ZnksCsUiaia2TLI1fyqjclibGa1hw3icP6oXeSpaWMjiabaghHl7yw/0?wx_fmt=png",
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... b56b9 98e1f2b8?detailReferrer=1&from=groupmessage&isappinstalled=0",
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简要的剖析一下这个json(这里只介绍一些重要的信息,其它的被省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "ժҪ",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""ժҪ"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
在这里还要提及一点就是假如希望获取到时间更久远一些的历史消息内容,就须要在手机或模拟器上将页面向上拉,当拉到最里边的时侯,微信将手动读取下一页的内容。下一页的链接地址和历史消息页的链接地址同样是getmasssendmsg开头的地址。但是内容就是只有json了,没有html了。直接解析json就可以了。
这时可以通过上一篇文章介绍的方式,使用anyproxy将msgList变量值正则匹配下来以后,异步递交到服务器,再从服务器上使用php的json_decode解析json成为字段。然后遍历循环链表。我们就可以得到每一篇文章的标题和链接地址。
如果只须要采集单一公众号的内容,完全可以在每晚群发以后,通过anyproxy获取到完整的带有key和pass_ticket的链接地址。然后自己制做一个程序,手动将地址递交给自己的程序。使用诸如php这样的语言来正则匹配到msgList,然后解析json。这样就不用更改anyproxy的rule,也不需要制做一个采集队列和跳转页面了。
利用搜狗陌陌自制一个简易微信公众号爬虫接口
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2020-08-18 11:12
微信公众号现已成为主流的一对多媒体行为活动,也是现今互联网内容生产不可忽略的一股力量。
在此基础上,微信公众号爬虫显得太有价值,对内容生产型公众号进行数据挖掘可以得到好多有意思、有价值的信息。就我所知,可用于微信公众号爬虫的方法主要有以下几种:web陌陌,手机客户端抓包,搜狗陌陌入口,appium自动化测试,Xposed框架等。
手机客户端抓包,利用fiddler或charles等抓包工具,算是一个比较主流(我自己觉得的orz),效率较高的方式,可以快速的抓取微信公众号信息和历史消息,此方式也有隐忧:cookies失效快,半天差不多的时间吧,有针对性的去抓取某几个公众号的历史消息也是可以的。要想通过模拟登录陌陌手动获得cookies,好像很难的,小弟浅薄,无法实现,貌似陌陌登录是tcp协议?
appium自动化和Xposed框架我了解不多。appium类似于selenium,在移动端做自动化测试的,模拟点击即可。Xposed框架就有很多可以搞的了,Xposed可以在不更改apk的情况下做到一些额外的功能,爬虫自然是可以的,除此之外可做到以手动抢红包,自动回复机器人,修改陌陌步数等等骚操作。
写爬虫也有一段时间了,个人觉得实现爬虫不仅反反爬,爬虫效率外,还有一个很难实现的地方就是爬虫的稳定性,健壮性,需要考虑到好多异常情况,以及合理有效的异常处理,在这一点上,我认为我还须要向各大爬虫大鳄学习。(感觉自己瞎扯了很多,还没有开始我的正文(orz),感觉嫌我啰嗦的大鳄请别生气。)
利用搜狗陌陌写一个爬虫插口,代码太狭小,只有两百行不到的代码。(这里我还得吐槽一下,python写多了,总有一种自己太叼,编程很简单的错觉,几行代码能够实现很厉害的功能,这时候须要去写写CPP冷静一下,让自己晓得哪些是真正的编程。)
以下记录下我写这个爬虫插口脚本的过程:
1. 页面恳求剖析(以公众号搜索为例):
可以看见第一个http请求包就是我们想要的结果,查看其query string,如下:
看起来很简单的不是,我们得到以下几个信息:
2. 模拟页面恳求:
我们直接用 url, 请求参数params, 还有谷歌浏览器的 user-agent 请求,发现可以成功的获取到我们想要页面的源码,接下来我们获取搜索结果下的第一个公众号即可(这意味着须要确切的给定公众号名称,太过模糊有可能获取到与其类似的公众号结果)。
3. 分析页面:
先确定爬取思路,第一步获取微信公众号链接,再通过该微信公众号链接获取其近来十条推送的相关信息,包括标题,日期,作者,内容摘要,内容链接(事实上,我们发觉有了陌陌推送链接以后才能太轻松的获取其推送主体内容,但不包括点赞数和阅读数,这几个数据只能在陌陌手机端能够查看,如果有机会的话,下次记录下自己手机陌陌抓包爬虫的过程)。
于是第一步我们获取公众号链接:
这里我们直接使用正则表达式提取即可(这么简单的就不用xpath,bs4了,依赖标准库和第三方库还是有所不同的。)
(抱歉被水印堵住了orz,换一张。)
第二步按照微信公众号链接获取近来十条推送信息:
(我只写了一篇orz,以后多加油。)
ctlr U 查看网页源码,发现原创信息都置于一个js变量上面。
好办,继续正则提取,将json格式的字符串转换成python上面的字典,有两种办法,第一种是用 json.loads 方法, 第二种是用外置的 eval方式,这两种方式有些区别,比如说单冒号和双冒号, json格式中使用的是双引号, python字典通常是单冒号。
OK,获得原创推送信息数据了,但这上面有很多我们用不到的信息,将其剔除一下,值得一提的是,datetime的值是一个timestamp,我们须要将其转化为直观的时间抒发。
到此,关于微信公众号的爬虫差不都就解决了,接下来须要将其封装为类。主要部份代码如下。
另外,关于关键词搜索文章的爬虫插口我也一并写了,AccountAPI,ArticleAPI,其父类是一AP类,API类有query_url, params, headers, _get_response, _get_datetime等变量和技巧,供于AccountAPI,ArticleAPI共用。
代码放到 查看全部
利用搜狗陌陌自制一个简易微信公众号爬虫插口
微信公众号现已成为主流的一对多媒体行为活动,也是现今互联网内容生产不可忽略的一股力量。
在此基础上,微信公众号爬虫显得太有价值,对内容生产型公众号进行数据挖掘可以得到好多有意思、有价值的信息。就我所知,可用于微信公众号爬虫的方法主要有以下几种:web陌陌,手机客户端抓包,搜狗陌陌入口,appium自动化测试,Xposed框架等。
手机客户端抓包,利用fiddler或charles等抓包工具,算是一个比较主流(我自己觉得的orz),效率较高的方式,可以快速的抓取微信公众号信息和历史消息,此方式也有隐忧:cookies失效快,半天差不多的时间吧,有针对性的去抓取某几个公众号的历史消息也是可以的。要想通过模拟登录陌陌手动获得cookies,好像很难的,小弟浅薄,无法实现,貌似陌陌登录是tcp协议?
appium自动化和Xposed框架我了解不多。appium类似于selenium,在移动端做自动化测试的,模拟点击即可。Xposed框架就有很多可以搞的了,Xposed可以在不更改apk的情况下做到一些额外的功能,爬虫自然是可以的,除此之外可做到以手动抢红包,自动回复机器人,修改陌陌步数等等骚操作。
写爬虫也有一段时间了,个人觉得实现爬虫不仅反反爬,爬虫效率外,还有一个很难实现的地方就是爬虫的稳定性,健壮性,需要考虑到好多异常情况,以及合理有效的异常处理,在这一点上,我认为我还须要向各大爬虫大鳄学习。(感觉自己瞎扯了很多,还没有开始我的正文(orz),感觉嫌我啰嗦的大鳄请别生气。)
利用搜狗陌陌写一个爬虫插口,代码太狭小,只有两百行不到的代码。(这里我还得吐槽一下,python写多了,总有一种自己太叼,编程很简单的错觉,几行代码能够实现很厉害的功能,这时候须要去写写CPP冷静一下,让自己晓得哪些是真正的编程。)
以下记录下我写这个爬虫插口脚本的过程:
1. 页面恳求剖析(以公众号搜索为例):
可以看见第一个http请求包就是我们想要的结果,查看其query string,如下:
看起来很简单的不是,我们得到以下几个信息:
2. 模拟页面恳求:
我们直接用 url, 请求参数params, 还有谷歌浏览器的 user-agent 请求,发现可以成功的获取到我们想要页面的源码,接下来我们获取搜索结果下的第一个公众号即可(这意味着须要确切的给定公众号名称,太过模糊有可能获取到与其类似的公众号结果)。
3. 分析页面:
先确定爬取思路,第一步获取微信公众号链接,再通过该微信公众号链接获取其近来十条推送的相关信息,包括标题,日期,作者,内容摘要,内容链接(事实上,我们发觉有了陌陌推送链接以后才能太轻松的获取其推送主体内容,但不包括点赞数和阅读数,这几个数据只能在陌陌手机端能够查看,如果有机会的话,下次记录下自己手机陌陌抓包爬虫的过程)。
于是第一步我们获取公众号链接:
这里我们直接使用正则表达式提取即可(这么简单的就不用xpath,bs4了,依赖标准库和第三方库还是有所不同的。)
(抱歉被水印堵住了orz,换一张。)
第二步按照微信公众号链接获取近来十条推送信息:
(我只写了一篇orz,以后多加油。)
ctlr U 查看网页源码,发现原创信息都置于一个js变量上面。
好办,继续正则提取,将json格式的字符串转换成python上面的字典,有两种办法,第一种是用 json.loads 方法, 第二种是用外置的 eval方式,这两种方式有些区别,比如说单冒号和双冒号, json格式中使用的是双引号, python字典通常是单冒号。
OK,获得原创推送信息数据了,但这上面有很多我们用不到的信息,将其剔除一下,值得一提的是,datetime的值是一个timestamp,我们须要将其转化为直观的时间抒发。
到此,关于微信公众号的爬虫差不都就解决了,接下来须要将其封装为类。主要部份代码如下。
另外,关于关键词搜索文章的爬虫插口我也一并写了,AccountAPI,ArticleAPI,其父类是一AP类,API类有query_url, params, headers, _get_response, _get_datetime等变量和技巧,供于AccountAPI,ArticleAPI共用。
代码放到
微信热门文章采集方法以及详尽步骤.docx
采集交流 • 优采云 发表了文章 • 0 个评论 • 397 次浏览 • 2020-08-18 10:43
文档介绍:
微信热门文章采集方法以及详尽步骤
本文将以搜狗陌陌文章为例,介绍使用优采云采集网页文章正文的技巧。文章正文里通常包括文本和图片两种。本文将采集文章正文中的文本+图片URL。
将采集以下数组:文章标题、时间、来源和正文(正文中的所有文本,将合并到一个excel单元格中,将使用到“自定义数据合并方法”功能,请你们注意)。同时,采集文章正文中的文本+图片URL,将用到“判断条件”,“判断条件”的使用,有很多须要注意的地方。以下两个教程,大家可先熟悉一下。
“自定义数据合并方法”详解教程:
orialdetail-1/zdyhb_7.html
“判断条件”详解教程:
orialdetail-1/judge.html
采集网站:
使用功能点:
分页列表信息采集
orial/fylb-70.aspx?t=1
Xpath
rch?query=XPath
AJAX点击和翻页
orial/ajaxdjfy_7.aspx?t=1
判断条件
orialdetail-1/judge.html
AJAX滚动
orialdetail-1/ajgd_7.html
步骤1:创建采集任务
1)进入主界面,选择“自定义模式”
微信热门文章采集方法步骤1
2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
微信热门文章采集方法步骤2
步骤2:创建翻页循环
在页面右上角,打开“流程”,以诠释出“流程设计器”和“定制当前操作”两个蓝筹股。网页打开后,默认显示“热门”文章。下拉页面,找到并点击“加载更多内容”按钮,在操作提示框中,选择“更多操作”
微信热门文章采集方法步骤3
选择“循环点击单个元素”,以创建一个翻页循环
微信热门文章采集方法步骤4
由于此网页涉及Ajax技术,我们须要进行一些中级选项的设置。选中“点击元素”步骤,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”
微信热门文章采集方法步骤5
注:AJAX即延时加载、异步更新的一种脚本技术,通过在后台与服务器进行少量数据交换,可以在不重新加载整个网页的情况下,对网页的某部份进行更新。
表现特点:a、点击网页中某个选项时,大部分网站的网址不会改变;b、网页不是完全加载,只是局部进行了数据加载,有所变化。 查看全部
微信热门文章采集方法以及详尽步骤.docx
文档介绍:
微信热门文章采集方法以及详尽步骤
本文将以搜狗陌陌文章为例,介绍使用优采云采集网页文章正文的技巧。文章正文里通常包括文本和图片两种。本文将采集文章正文中的文本+图片URL。
将采集以下数组:文章标题、时间、来源和正文(正文中的所有文本,将合并到一个excel单元格中,将使用到“自定义数据合并方法”功能,请你们注意)。同时,采集文章正文中的文本+图片URL,将用到“判断条件”,“判断条件”的使用,有很多须要注意的地方。以下两个教程,大家可先熟悉一下。
“自定义数据合并方法”详解教程:
orialdetail-1/zdyhb_7.html
“判断条件”详解教程:
orialdetail-1/judge.html
采集网站:
使用功能点:
分页列表信息采集
orial/fylb-70.aspx?t=1
Xpath
rch?query=XPath
AJAX点击和翻页
orial/ajaxdjfy_7.aspx?t=1
判断条件
orialdetail-1/judge.html
AJAX滚动
orialdetail-1/ajgd_7.html
步骤1:创建采集任务
1)进入主界面,选择“自定义模式”
微信热门文章采集方法步骤1
2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
微信热门文章采集方法步骤2
步骤2:创建翻页循环
在页面右上角,打开“流程”,以诠释出“流程设计器”和“定制当前操作”两个蓝筹股。网页打开后,默认显示“热门”文章。下拉页面,找到并点击“加载更多内容”按钮,在操作提示框中,选择“更多操作”
微信热门文章采集方法步骤3
选择“循环点击单个元素”,以创建一个翻页循环
微信热门文章采集方法步骤4
由于此网页涉及Ajax技术,我们须要进行一些中级选项的设置。选中“点击元素”步骤,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”
微信热门文章采集方法步骤5
注:AJAX即延时加载、异步更新的一种脚本技术,通过在后台与服务器进行少量数据交换,可以在不重新加载整个网页的情况下,对网页的某部份进行更新。
表现特点:a、点击网页中某个选项时,大部分网站的网址不会改变;b、网页不是完全加载,只是局部进行了数据加载,有所变化。
微信公众号之获取openId
采集交流 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2020-08-18 03:00
在小伙伴们开发微信公众号、小程序或则是在陌陌外置浏览器打开的项目时,会碰到的第一个问题就是怎么获取openId,今天小编就给你们带来的是怎样获取openId。
首先 我们要从陌陌开发者后台得到appid,这个appid是管理员在设置陌陌后台时获取的,而且是惟一的,而且还须要在陌陌后台设置反弹域名。
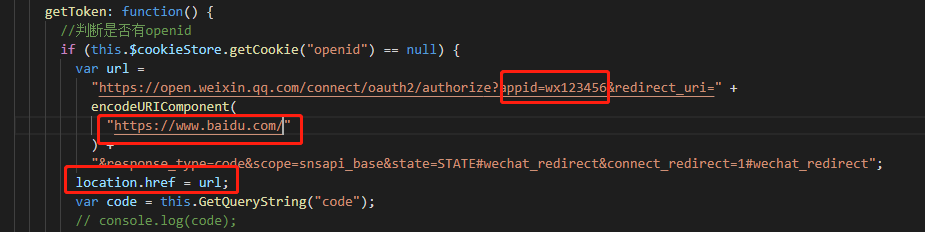
其次这种都打算好之后,我们就可以使用陌陌自带的方式获取openId:
注意:划线部份是要获取的openId和反弹域名,而location.href=url 是当页面第一次渲染时,自动获取openId,当然,这些还是打算工作
1 //截取URL字段
2 GetQueryString: function(name) {
3 var reg = new RegExp("(^|&)" + name + "=([^&]*)(&|$)", "i");
4 var r = window.location.search.substr(1).match(reg);
5 if (r != null) {
6 return unescape(r[2]);
7 }
8 return null;
9 },
10 getToken: function() {
11 //判断是否有openid
12 if (this.$cookieStore.getCookie("openid") == null) {
13 var url =
14 "https://open.weixin.qq.com/con ... ot%3B +
15 encodeURIComponent(
16 "https://www.baidu.com/"
17 ) +
18 "&response_type=code&scope=snsapi_base&state=STATE#wechat_redirect&connect_redirect=1#wechat_redirect";
19 location.href = url;
20 var code = this.GetQueryString("code");
21 // console.log(code);
22 axios({
23 url: "接口名" + code
24 }).then(res => {
25 // console.log(res);
26 if (res.data.code == 0) {
27 this.$cookieStore.setCookie("openid", res.data.result);
28 }
29 });
30 } else {
31 this.openid = this.$cookieStore.getCookie("openid");
32 }
33 },
我们要使用上图的方式来获取code值,通过插口,来获取openId,然后把openId存在cookie里每次调用就可以了。
这就是小编给你们带来的获取openId的方式,下面是完整代码。 查看全部
微信公众号之获取openId
在小伙伴们开发微信公众号、小程序或则是在陌陌外置浏览器打开的项目时,会碰到的第一个问题就是怎么获取openId,今天小编就给你们带来的是怎样获取openId。
首先 我们要从陌陌开发者后台得到appid,这个appid是管理员在设置陌陌后台时获取的,而且是惟一的,而且还须要在陌陌后台设置反弹域名。
其次这种都打算好之后,我们就可以使用陌陌自带的方式获取openId:
注意:划线部份是要获取的openId和反弹域名,而location.href=url 是当页面第一次渲染时,自动获取openId,当然,这些还是打算工作

1 //截取URL字段
2 GetQueryString: function(name) {
3 var reg = new RegExp("(^|&)" + name + "=([^&]*)(&|$)", "i");
4 var r = window.location.search.substr(1).match(reg);
5 if (r != null) {
6 return unescape(r[2]);
7 }
8 return null;
9 },
10 getToken: function() {
11 //判断是否有openid
12 if (this.$cookieStore.getCookie("openid") == null) {
13 var url =
14 "https://open.weixin.qq.com/con ... ot%3B +
15 encodeURIComponent(
16 "https://www.baidu.com/"
17 ) +
18 "&response_type=code&scope=snsapi_base&state=STATE#wechat_redirect&connect_redirect=1#wechat_redirect";
19 location.href = url;
20 var code = this.GetQueryString("code");
21 // console.log(code);
22 axios({
23 url: "接口名" + code
24 }).then(res => {
25 // console.log(res);
26 if (res.data.code == 0) {
27 this.$cookieStore.setCookie("openid", res.data.result);
28 }
29 });
30 } else {
31 this.openid = this.$cookieStore.getCookie("openid");
32 }
33 },
我们要使用上图的方式来获取code值,通过插口,来获取openId,然后把openId存在cookie里每次调用就可以了。
这就是小编给你们带来的获取openId的方式,下面是完整代码。
R语言爬虫系列6|动态数据抓取范例
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2020-08-15 12:32
作者:鲁伟,热爱数据,坚信数据技术和代码改变世界。R语言和Python的忠实拥趸,为成为一名未来的数据科学家而拼搏终身。个人公众号:数据科学家养成记 (微信ID:louwill12)
第一篇戳:
第二篇戳:
第三篇戳:
第四篇戳:
第五篇戳:
通过上面几期的推送,小编基本上早已将R语言爬虫所须要的基本知识介绍完了。R其实是以一门统计剖析工具出现在大多数人印象中的,但其虽然本质上是一门编程语言,对于爬虫的支持虽不如Python那样多快好省,但细心研究一下总能作出一些使你惊喜的疗效。
大约很早之前,小编就写过关于R语言爬虫新贵rvest的抓取介绍,之前说rvest+SelectGadgetor是结构化网页抓取的实战神器,大家的溢美之词不断。详情可见推文:
R语言爬虫神器:rvest包+SelectorGadget抓取链家上海二手房数据
但网路爬虫这个江湖很险恶,单靠一招rvest行走江湖必然凶多吉少,一不小心遇到哪些AJAX和动态网页凭仅把握rvest的诸位必将束手无策。本文小编就简单介绍下在用R语言进行实际的网路数据抓取时怎样将动态数据给弄到手。
所谓动态网页和异步加载,在之前的系列4的时侯小编已通过AJAX介绍过了,简单而言就是我明明在网页中听到了这个数据,但到后台HTML中却找不到了,这一般就是XHR在作怪。这时候我们就不要看原创的HTML数据了,需要进行二次恳求,通过web开发者工具找到真实恳求的url。下面小编就以两个网页为例,分别通过GET和POST恳求领到动态网页数据,全过程主要使用httr包来实现,httr包堪称是RCurl包的精简版,说其短小精悍也不为过。httr包与RCurl包在主要函数的区别如下所示:
GET恳求抓取陌陌好友列表数据
很早之前圈子里就听到过用Python抓取自己陌陌好友数据的案例分享,今天便以陌陌网页版为例,探一探其网页结构。首先登陆个人陌陌网页版,右键打开web开发者工具,下来一大堆恳求:
简单找一下发觉网页中的陌陌好友列表信息并没有呈现在HTML 中,大概可以推断陌陌好友数据是通过动态加载来显示的,所以直接定位到XHR中,经过几番尝试,结合两侧的preview,我们会发觉大量整齐划一的数据,所以二次恳求的url真的就是它了:
找到真正的url以后,接下来就是获取恳求信息了,切换到Headers版块,Header版块下的4个子信息我们都须要关注,它们是我们构造爬虫恳求头的关键。
从Header中我们可以看见该信息是通过GET方式恳求得到的,General信息下的Request URL,Request Method, Status Code; Response Headers信息下的Connection, Content-Type; Request Headers信息下的Accept, Cookie, Referer, User-Agent以及最后的Query String Parameters都是我们须要重点关注的。
找到相应的信息然后,我们便可以直接借助httr包在R中建立爬虫恳求:
<p>#传入微信cookie信息<br />Cookie Accept: application/json<br />-> Content-Type: text/plain<br />-> User-Agent: Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0<br />-> Referer: https://wx.qq.com/<br />-> Connection: keep-alive<br />-> cookie: 我的微信cookie<br />-> <br /> Connection: keep-alive<br />-> cookie: 网易云课堂cookie<br />-> Content-Length: 69<br />-> <br />>> {"pageIndex":1,"pageSize":50,"relativeOffset":0,"frontCategoryId":-1}<br /><br /> 查看全部
作者:鲁伟,热爱数据,坚信数据技术和代码改变世界。R语言和Python的忠实拥趸,为成为一名未来的数据科学家而拼搏终身。个人公众号:数据科学家养成记 (微信ID:louwill12)
第一篇戳:
第二篇戳:
第三篇戳:
第四篇戳:
第五篇戳:
通过上面几期的推送,小编基本上早已将R语言爬虫所须要的基本知识介绍完了。R其实是以一门统计剖析工具出现在大多数人印象中的,但其虽然本质上是一门编程语言,对于爬虫的支持虽不如Python那样多快好省,但细心研究一下总能作出一些使你惊喜的疗效。
大约很早之前,小编就写过关于R语言爬虫新贵rvest的抓取介绍,之前说rvest+SelectGadgetor是结构化网页抓取的实战神器,大家的溢美之词不断。详情可见推文:
R语言爬虫神器:rvest包+SelectorGadget抓取链家上海二手房数据
但网路爬虫这个江湖很险恶,单靠一招rvest行走江湖必然凶多吉少,一不小心遇到哪些AJAX和动态网页凭仅把握rvest的诸位必将束手无策。本文小编就简单介绍下在用R语言进行实际的网路数据抓取时怎样将动态数据给弄到手。
所谓动态网页和异步加载,在之前的系列4的时侯小编已通过AJAX介绍过了,简单而言就是我明明在网页中听到了这个数据,但到后台HTML中却找不到了,这一般就是XHR在作怪。这时候我们就不要看原创的HTML数据了,需要进行二次恳求,通过web开发者工具找到真实恳求的url。下面小编就以两个网页为例,分别通过GET和POST恳求领到动态网页数据,全过程主要使用httr包来实现,httr包堪称是RCurl包的精简版,说其短小精悍也不为过。httr包与RCurl包在主要函数的区别如下所示:
GET恳求抓取陌陌好友列表数据
很早之前圈子里就听到过用Python抓取自己陌陌好友数据的案例分享,今天便以陌陌网页版为例,探一探其网页结构。首先登陆个人陌陌网页版,右键打开web开发者工具,下来一大堆恳求:
简单找一下发觉网页中的陌陌好友列表信息并没有呈现在HTML 中,大概可以推断陌陌好友数据是通过动态加载来显示的,所以直接定位到XHR中,经过几番尝试,结合两侧的preview,我们会发觉大量整齐划一的数据,所以二次恳求的url真的就是它了:
找到真正的url以后,接下来就是获取恳求信息了,切换到Headers版块,Header版块下的4个子信息我们都须要关注,它们是我们构造爬虫恳求头的关键。
从Header中我们可以看见该信息是通过GET方式恳求得到的,General信息下的Request URL,Request Method, Status Code; Response Headers信息下的Connection, Content-Type; Request Headers信息下的Accept, Cookie, Referer, User-Agent以及最后的Query String Parameters都是我们须要重点关注的。
找到相应的信息然后,我们便可以直接借助httr包在R中建立爬虫恳求:
<p>#传入微信cookie信息<br />Cookie Accept: application/json<br />-> Content-Type: text/plain<br />-> User-Agent: Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0<br />-> Referer: https://wx.qq.com/<br />-> Connection: keep-alive<br />-> cookie: 我的微信cookie<br />-> <br /> Connection: keep-alive<br />-> cookie: 网易云课堂cookie<br />-> Content-Length: 69<br />-> <br />>> {"pageIndex":1,"pageSize":50,"relativeOffset":0,"frontCategoryId":-1}<br /><br />
微信公众号 文章的爬虫系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 242 次浏览 • 2020-08-13 19:03
1、做了俩次爬虫了,第一次怕的凤凰网,那个没有限制,随便爬,所以也就对自动化执行代码模块放松了提防,觉得很简单的,但是毕竟不是这样的,我被这个问题困惑了好几天,差不多4天的一个样子,因为搜狗做的限制,同一个ip获取的次数多了,首先是出现验证码,其次是就是访问限制了,直接就是不能访问,利用 request得到的就是访问次数过分频繁,这样子的提示,所以说开发过程中最头痛的不是代码的编撰,而是测试,写完代码不能立刻测试,这种觉得相信大多数的程序员是不能喜欢的,我如今写的程序是每晚执行三次,这样的一个频度挺好,而且由于是多公众号采集嘛,每个公众号之间的间隔时间也的有,要不然同时访问十几个公众号的上百篇文章也是不现实的,说到这儿插一句,怎么使每位公众号怕去玩过后,等一段具体的时间,在执行下一个,最后用的setInterval函数解决的,
每过80秒执行一个公众号,把每次的执行代码讲到hello中,泡的有点远了,收一收哈,说说cron这个包,自动化执行,npm官网上只给了一个反例,但是我这个指桑拿可能是有点压制的厉害,不能否玩却理解他的用法,然后我说理解不了怎样办啊,上网搜呗,百度,cron包的具体用法,一看,嚯,还很多,于是就看啊看啊,但是仔细以剖析就不是这么回事儿了,都是屁话,没哪些用,网上通常的用法中都带有一个问号,但是我加上问号的时侯,就报错了,所以说都是胡扯,最后在朋友组的一个后端技术讨论群中说了一声,还真有热心的群友,给我找了一个链接,我进去一看,试了一下,还行,所以呢,非常谢谢这个帮助我解惑的朋友,再次我把qq群号,和链接附上,方便正在看这篇文章的你学习,QQ群号:435012561,链接:,这个链接上面说的挺好,至少能用,这里我挺好到一个问题,就是timezone,我们之前用过一次,用的是纽约时间,但是此次显著不行啊,要用俺们中国的时间啊,但是我试了几次上海的不行,重庆的可以,所以我就用了上海的。
2、这里要说的是,从地址栏获取参数的问题,我上一个做的没问题,但是这个不知道如何就不行了,上一个从地址栏得到的是数字,但是这个得到的是字符串,再加上mongodb中的对数组的要求还是很严格的,所以一个分页功能也困惑了我几个小时吧,最后是如何解决的呢,是通过我加的一个mongodb的讨论群,在里面问了一句这是如何了,发了个截图,里面就有一个热心的网友说你这显著是传入的数据格式不对啊,一语惊醒梦中人,我说是啊,然后就把得到的参数,我用Number()函数处理了一下,让string类型的数字,变成了number类型的数字,就好了,所以说你们在用mongodb的时侯一定要注意储存数据的格式,
3、mongodb查询数据句子组织形式:
其实说白了就是limit和skip俩个函数的使用,但是具体的格式可的看好了,还有我这个是接受的参数,不过mongo的参数接受也好弄直接写就好了,不用象sql那样搞哪些${""}这种类型的,后面的sort函数说明了排序的方法,这里是设置的以ctime数组为标准,-1表示逆序,1表示乱序,
4、在本次代码编撰中,我首次使用了try catch 这个补错的形式,事实证明,还行,可以把时常的错误正常的复印下来,但是不影响代码的整体执行,或者是说下一次执行,整体觉得非常好,
具体的使用方式,在try中倒入你要执行的代码,在最后加上一行,throw Error();
然后给catch传入一个参数e,在catch中可以复印好多个信息,我只复印了其中的一个,e.message,
5、这次编码过程中主要用到了anync包,其中的ansyc.each循环,ansyc.waterfall执行完前面的才可以执行下边的,而且说谎给你下之间还可以从上至下传递参数,这个很重要,因为在本次编程中,每次获取的内容不同,每次代码执行的条件不同,即须要的参数也不同,即有可能下一次代码的执行就须要用到上一次代码执行得到的结果,所以说这个anync包,真的是值得研究,他的每位方式都不同,有时候可以得到意想不到的疗效。
6、在mysql中若果想要达到这样一个疗效,就是说,如果数据库中早已存在了,那就不予理会,或者说不重复储存,如果数据库中不存在,那么就储存进来,很简单,直接把插入数据的insert 换成 replace 。但是在mongodb中,应该是没有,或者说是我还没有发觉,我是那么解决的,定义了一个开关,令这个开关为真,每次储存之前,先把所有的数据循环一遍,看看有没有这条数据,如果有,让开关变为假,如果没有,继续执行,即判定此时开关的真伪,如果是真的,那就执行插入操作,如果是假的,就不予理会,这就达到了类似的疗效,否则每次就会储存大量的重复数据,
7、本次采集的核心,就是我文件中的common.js了,首先由于要采集,所以须要用到request包,采集到以后,要处理html格式的数据,使之可以使用类jquery的操作,那么久用到了cheerio这个包,然后在循环采集的时侯,会用到anync.each这个方式,所以会用到async这个包,
7-1、
通过搜狗陌陌采集,就要剖析搜狗陌陌的路径,每个公众号的页面的路径是这样的
%E8%BF%99%E6%89%8D%E6%98%AF%E6%97%A5%E6%9C%AC&ie=utf8&_sug_=n&_sug_type_=
这个是“这才是台湾”的页面的链接,经过剖析,所有的公众号的链接只有query前面的参数不同,但是query前面的参数是哪些呢,其实就是通过encodeURIComponent()这个函数转化以后的“这才是台湾”,所以说都一样,获取那种公众号,就将那种公众号的名子编码以后,动态的组合成一个链接,访问就可以步入到每位链接上面了,但是这个链接只是恳求到了这个页面,
并不是
这个页面,所以还的进一步处理,就是得到当前页面的第一个内容的链接,即href
当得到了这个链接,就会发觉他有他的加密方法,其实很简单的,就是在链接上面的加了三个amp;把链接上面的这三个amp;替换为空,就好了,这也就是第一步,得到每一个公众号的页面链接,
7-2
得到链接以后,就要进行访问了,即恳求,请求每位地址,得到每位地址的内容,但是每位页面显示的内容都不在页面中,即html结构中,在js中藏着,所以要通过正则匹配,得到整篇文章的对象,然后就循环每位公众号的这个对象,得到这个对象中的整篇文章的一些信息,包括title,thumb,abstract,URL,time,五个数组,但是我使用的代码烂透了,尽然当时使用了
对象.属性.foreach(function(item,index){
})
这种烂透了的形式,弄的最后好的在写一次循环才可以完全的得到每一个对象,否则只可以得到第一个,在这里应当用async.each,或者async.foreach这俩中形式每种都可以啊,而且都是非常好用的形式。这样的话买就得到了整篇文章的以上基本消息,
7-3、
第三个阶段,就是步入到整篇文章的详情页,获得整篇文章的内容,点赞数,作者,公众号,阅读量等数据,在这里遇到的主要问题是,人家的content直接在在js中,所有的img标签都有问题,他是以这些方式存在雨content中,但是这样的话,这样的图片在我们的网页中不能被显示,因为标签存在问题啊,html文档不认识这样的img标签啊,所以这儿要进行一些处理,把所有的用replace替换为
查看全部
差不多俩个礼拜了吧,一直在调试关于微信公众号的文章爬虫系统,终于一切都好了,但是在这期间遇到了好多问题,今天就来回顾一下,总结一下,希望有用到的小伙伴可以学习学习。
1、做了俩次爬虫了,第一次怕的凤凰网,那个没有限制,随便爬,所以也就对自动化执行代码模块放松了提防,觉得很简单的,但是毕竟不是这样的,我被这个问题困惑了好几天,差不多4天的一个样子,因为搜狗做的限制,同一个ip获取的次数多了,首先是出现验证码,其次是就是访问限制了,直接就是不能访问,利用 request得到的就是访问次数过分频繁,这样子的提示,所以说开发过程中最头痛的不是代码的编撰,而是测试,写完代码不能立刻测试,这种觉得相信大多数的程序员是不能喜欢的,我如今写的程序是每晚执行三次,这样的一个频度挺好,而且由于是多公众号采集嘛,每个公众号之间的间隔时间也的有,要不然同时访问十几个公众号的上百篇文章也是不现实的,说到这儿插一句,怎么使每位公众号怕去玩过后,等一段具体的时间,在执行下一个,最后用的setInterval函数解决的,
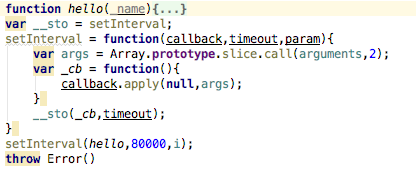
每过80秒执行一个公众号,把每次的执行代码讲到hello中,泡的有点远了,收一收哈,说说cron这个包,自动化执行,npm官网上只给了一个反例,但是我这个指桑拿可能是有点压制的厉害,不能否玩却理解他的用法,然后我说理解不了怎样办啊,上网搜呗,百度,cron包的具体用法,一看,嚯,还很多,于是就看啊看啊,但是仔细以剖析就不是这么回事儿了,都是屁话,没哪些用,网上通常的用法中都带有一个问号,但是我加上问号的时侯,就报错了,所以说都是胡扯,最后在朋友组的一个后端技术讨论群中说了一声,还真有热心的群友,给我找了一个链接,我进去一看,试了一下,还行,所以呢,非常谢谢这个帮助我解惑的朋友,再次我把qq群号,和链接附上,方便正在看这篇文章的你学习,QQ群号:435012561,链接:,这个链接上面说的挺好,至少能用,这里我挺好到一个问题,就是timezone,我们之前用过一次,用的是纽约时间,但是此次显著不行啊,要用俺们中国的时间啊,但是我试了几次上海的不行,重庆的可以,所以我就用了上海的。
2、这里要说的是,从地址栏获取参数的问题,我上一个做的没问题,但是这个不知道如何就不行了,上一个从地址栏得到的是数字,但是这个得到的是字符串,再加上mongodb中的对数组的要求还是很严格的,所以一个分页功能也困惑了我几个小时吧,最后是如何解决的呢,是通过我加的一个mongodb的讨论群,在里面问了一句这是如何了,发了个截图,里面就有一个热心的网友说你这显著是传入的数据格式不对啊,一语惊醒梦中人,我说是啊,然后就把得到的参数,我用Number()函数处理了一下,让string类型的数字,变成了number类型的数字,就好了,所以说你们在用mongodb的时侯一定要注意储存数据的格式,
3、mongodb查询数据句子组织形式:

其实说白了就是limit和skip俩个函数的使用,但是具体的格式可的看好了,还有我这个是接受的参数,不过mongo的参数接受也好弄直接写就好了,不用象sql那样搞哪些${""}这种类型的,后面的sort函数说明了排序的方法,这里是设置的以ctime数组为标准,-1表示逆序,1表示乱序,
4、在本次代码编撰中,我首次使用了try catch 这个补错的形式,事实证明,还行,可以把时常的错误正常的复印下来,但是不影响代码的整体执行,或者是说下一次执行,整体觉得非常好,
具体的使用方式,在try中倒入你要执行的代码,在最后加上一行,throw Error();
然后给catch传入一个参数e,在catch中可以复印好多个信息,我只复印了其中的一个,e.message,
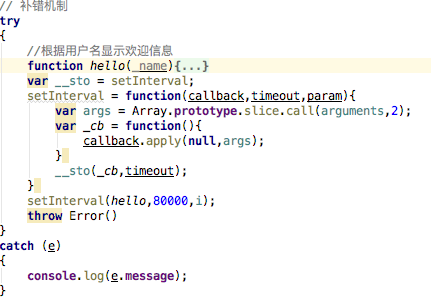
5、这次编码过程中主要用到了anync包,其中的ansyc.each循环,ansyc.waterfall执行完前面的才可以执行下边的,而且说谎给你下之间还可以从上至下传递参数,这个很重要,因为在本次编程中,每次获取的内容不同,每次代码执行的条件不同,即须要的参数也不同,即有可能下一次代码的执行就须要用到上一次代码执行得到的结果,所以说这个anync包,真的是值得研究,他的每位方式都不同,有时候可以得到意想不到的疗效。
6、在mysql中若果想要达到这样一个疗效,就是说,如果数据库中早已存在了,那就不予理会,或者说不重复储存,如果数据库中不存在,那么就储存进来,很简单,直接把插入数据的insert 换成 replace 。但是在mongodb中,应该是没有,或者说是我还没有发觉,我是那么解决的,定义了一个开关,令这个开关为真,每次储存之前,先把所有的数据循环一遍,看看有没有这条数据,如果有,让开关变为假,如果没有,继续执行,即判定此时开关的真伪,如果是真的,那就执行插入操作,如果是假的,就不予理会,这就达到了类似的疗效,否则每次就会储存大量的重复数据,
7、本次采集的核心,就是我文件中的common.js了,首先由于要采集,所以须要用到request包,采集到以后,要处理html格式的数据,使之可以使用类jquery的操作,那么久用到了cheerio这个包,然后在循环采集的时侯,会用到anync.each这个方式,所以会用到async这个包,
7-1、
通过搜狗陌陌采集,就要剖析搜狗陌陌的路径,每个公众号的页面的路径是这样的
%E8%BF%99%E6%89%8D%E6%98%AF%E6%97%A5%E6%9C%AC&ie=utf8&_sug_=n&_sug_type_=
这个是“这才是台湾”的页面的链接,经过剖析,所有的公众号的链接只有query前面的参数不同,但是query前面的参数是哪些呢,其实就是通过encodeURIComponent()这个函数转化以后的“这才是台湾”,所以说都一样,获取那种公众号,就将那种公众号的名子编码以后,动态的组合成一个链接,访问就可以步入到每位链接上面了,但是这个链接只是恳求到了这个页面,
并不是
这个页面,所以还的进一步处理,就是得到当前页面的第一个内容的链接,即href

当得到了这个链接,就会发觉他有他的加密方法,其实很简单的,就是在链接上面的加了三个amp;把链接上面的这三个amp;替换为空,就好了,这也就是第一步,得到每一个公众号的页面链接,
7-2
得到链接以后,就要进行访问了,即恳求,请求每位地址,得到每位地址的内容,但是每位页面显示的内容都不在页面中,即html结构中,在js中藏着,所以要通过正则匹配,得到整篇文章的对象,然后就循环每位公众号的这个对象,得到这个对象中的整篇文章的一些信息,包括title,thumb,abstract,URL,time,五个数组,但是我使用的代码烂透了,尽然当时使用了
对象.属性.foreach(function(item,index){
})
这种烂透了的形式,弄的最后好的在写一次循环才可以完全的得到每一个对象,否则只可以得到第一个,在这里应当用async.each,或者async.foreach这俩中形式每种都可以啊,而且都是非常好用的形式。这样的话买就得到了整篇文章的以上基本消息,
7-3、
第三个阶段,就是步入到整篇文章的详情页,获得整篇文章的内容,点赞数,作者,公众号,阅读量等数据,在这里遇到的主要问题是,人家的content直接在在js中,所有的img标签都有问题,他是以这些方式存在雨content中,但是这样的话,这样的图片在我们的网页中不能被显示,因为标签存在问题啊,html文档不认识这样的img标签啊,所以这儿要进行一些处理,把所有的用replace替换为
微信公众号推送信息爬取---python爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-13 18:34
利用搜狗的陌陌搜索抓取指定公众号的最新一条推送,并保存相应的网页至本地。
注意点搜狗陌陌获取的地址为临时链接,具有时效性。公众号为动态网页(JavaScript渲染),使用requests.get()获取的内容是不含推送消息的,这里使用selenium+PhantomJS处理代码
#! /usr/bin/env python3
from selenium import webdriver
from datetime import datetime
import bs4, requests
import os, time, sys
# 获取公众号链接
def getAccountURL(searchURL):
res = requests.get(searchURL)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "lxml")
# 选择第一个链接
account = soup.select('a[uigs="account_name_0"]')
return account[0]['href']
# 获取首篇文章的链接,如果有验证码返回None
def getArticleURL(accountURL):
browser = webdriver.PhantomJS("/Users/chasechoi/Downloads/phantomjs-2.1.1-macosx/bin/phantomjs")
# 进入公众号
browser.get(accountURL)
# 获取网页信息
html = browser.page_source
accountSoup = bs4.BeautifulSoup(html, "lxml")
time.sleep(1)
contents = accountSoup.find_all(hrefs=True)
try:
partitialLink = contents[1]['hrefs']
firstLink = base + partitialLink
except IndexError:
firstLink = None
print('CAPTCHA!')
return firstLink
# 创建文件夹存储html网页,以时间命名
def folderCreation():
path = os.path.join(os.getcwd(), datetime.now().strftime('%Y-%m-%d_%H-%M-%S'))
try:
os.makedirs(path)
except OSError as e:
if e.errno != errno.EEXIST:
raise
print("folder not exist!")
return path
# 将html页面写入本地
def writeToFile(path, account, title):
pathToWrite = os.path.join(path, '{}_{}.html'.format(account, title))
myfile = open(pathToWrite, 'wb')
myfile.write(res.content)
myfile.close()
base ='https://mp.weixin.qq.com'
accountList = ['央视新闻', '新浪新闻','凤凰新闻','羊城晚报']
query = 'http://weixin.sogou.com/weixin?type=1&s_from=input&query='
path = folderCreation()
for index, account in enumerate(accountList):
searchURL = query + account
accountURL = getAccountURL(searchURL)
time.sleep(10)
articleURL = getArticleURL(accountURL)
if articleURL != None:
print("#{}({}/{}): {}".format(account, index+1, len(accountList), accountURL))
# 读取第一篇文章内容
res = requests.get(articleURL)
res.raise_for_status()
detailPage = bs4.BeautifulSoup(res.text, "lxml")
title = detailPage.title.text
print("标题: {}\n链接: {}\n".format(title, articleURL))
writeToFile(path, account, title)
else:
print('{} files successfully written to {}'.format(index, path))
sys.exit()
print('{} files successfully written to {}'.format(len(accountList), path))
参考输出
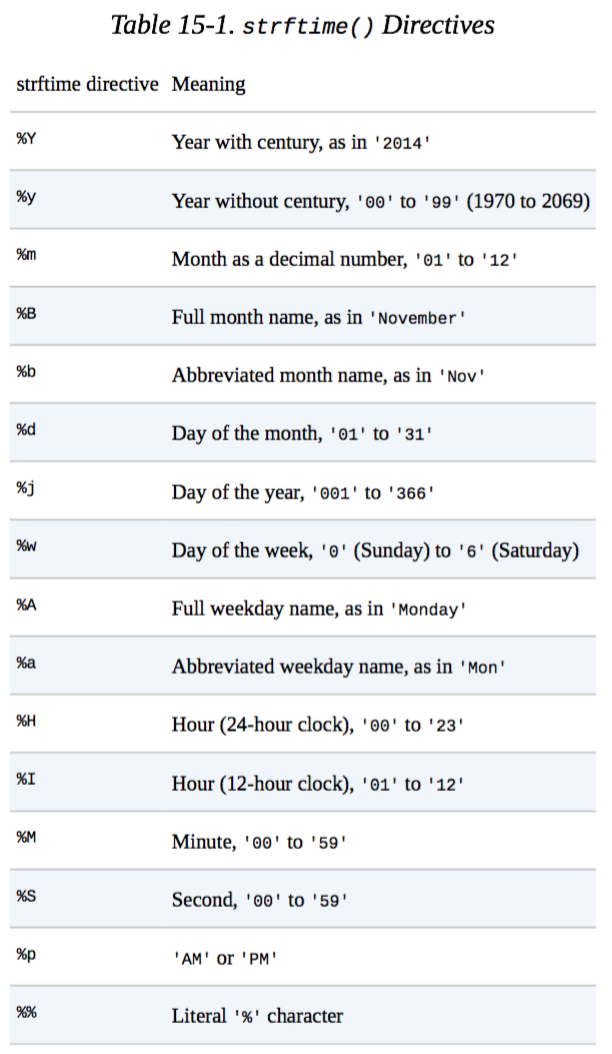
分析链接获取首先步入搜狗的陌陌搜索页面,在地址栏中提取须要的部份链接,字符串联接公众号名称,即可生成恳求链接针对静态网页,利用requests获取html文件,再用BeautifulSoup选择须要的内容针对动态网页,利用selenium+PhantomJS获取html文件,再用BeautifulSoup选择须要的内容遇见验证码(CAPTCHA),输出提示。此版本代码没有对验证码做实际处理,需要人为访问后,再跑程序,才能避免验证码。文件写入使用os.path.join()构造储存路径可以提升通用性。比如Windows路径分隔符使用back slash(\), 而OS X 和 Linux使用forward slash(/),通过该函数能依据平台进行手动转换。open()使用b(binary mode)参数同样为了提升通用性(适应Windows)使用datetime.now()获取当前时间进行命名,并通过strftime()格式化时间(函数名中的f代表format),具体使用参考下表(摘自 Automate the Boring Stuff with Python)
参考链接:文件夹创建: 异常处理的使用: enumerate的使用: open()使用b参数理由: 查看全部
问题描述
利用搜狗的陌陌搜索抓取指定公众号的最新一条推送,并保存相应的网页至本地。
注意点搜狗陌陌获取的地址为临时链接,具有时效性。公众号为动态网页(JavaScript渲染),使用requests.get()获取的内容是不含推送消息的,这里使用selenium+PhantomJS处理代码
#! /usr/bin/env python3
from selenium import webdriver
from datetime import datetime
import bs4, requests
import os, time, sys
# 获取公众号链接
def getAccountURL(searchURL):
res = requests.get(searchURL)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "lxml")
# 选择第一个链接
account = soup.select('a[uigs="account_name_0"]')
return account[0]['href']
# 获取首篇文章的链接,如果有验证码返回None
def getArticleURL(accountURL):
browser = webdriver.PhantomJS("/Users/chasechoi/Downloads/phantomjs-2.1.1-macosx/bin/phantomjs")
# 进入公众号
browser.get(accountURL)
# 获取网页信息
html = browser.page_source
accountSoup = bs4.BeautifulSoup(html, "lxml")
time.sleep(1)
contents = accountSoup.find_all(hrefs=True)
try:
partitialLink = contents[1]['hrefs']
firstLink = base + partitialLink
except IndexError:
firstLink = None
print('CAPTCHA!')
return firstLink
# 创建文件夹存储html网页,以时间命名
def folderCreation():
path = os.path.join(os.getcwd(), datetime.now().strftime('%Y-%m-%d_%H-%M-%S'))
try:
os.makedirs(path)
except OSError as e:
if e.errno != errno.EEXIST:
raise
print("folder not exist!")
return path
# 将html页面写入本地
def writeToFile(path, account, title):
pathToWrite = os.path.join(path, '{}_{}.html'.format(account, title))
myfile = open(pathToWrite, 'wb')
myfile.write(res.content)
myfile.close()
base ='https://mp.weixin.qq.com'
accountList = ['央视新闻', '新浪新闻','凤凰新闻','羊城晚报']
query = 'http://weixin.sogou.com/weixin?type=1&s_from=input&query='
path = folderCreation()
for index, account in enumerate(accountList):
searchURL = query + account
accountURL = getAccountURL(searchURL)
time.sleep(10)
articleURL = getArticleURL(accountURL)
if articleURL != None:
print("#{}({}/{}): {}".format(account, index+1, len(accountList), accountURL))
# 读取第一篇文章内容
res = requests.get(articleURL)
res.raise_for_status()
detailPage = bs4.BeautifulSoup(res.text, "lxml")
title = detailPage.title.text
print("标题: {}\n链接: {}\n".format(title, articleURL))
writeToFile(path, account, title)
else:
print('{} files successfully written to {}'.format(index, path))
sys.exit()
print('{} files successfully written to {}'.format(len(accountList), path))
参考输出
分析链接获取首先步入搜狗的陌陌搜索页面,在地址栏中提取须要的部份链接,字符串联接公众号名称,即可生成恳求链接针对静态网页,利用requests获取html文件,再用BeautifulSoup选择须要的内容针对动态网页,利用selenium+PhantomJS获取html文件,再用BeautifulSoup选择须要的内容遇见验证码(CAPTCHA),输出提示。此版本代码没有对验证码做实际处理,需要人为访问后,再跑程序,才能避免验证码。文件写入使用os.path.join()构造储存路径可以提升通用性。比如Windows路径分隔符使用back slash(\), 而OS X 和 Linux使用forward slash(/),通过该函数能依据平台进行手动转换。open()使用b(binary mode)参数同样为了提升通用性(适应Windows)使用datetime.now()获取当前时间进行命名,并通过strftime()格式化时间(函数名中的f代表format),具体使用参考下表(摘自 Automate the Boring Stuff with Python)
参考链接:文件夹创建: 异常处理的使用: enumerate的使用: open()使用b参数理由:
Python爬取微信公众号文章、点赞数
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2020-08-13 18:31
2、3 设置Fiddler 并保存配置
微信客户端恳求公众号文章, fiddler抓取到的数据req_id 、 pass_ticket 、 appmsg_tojen
微信客户端恳求公众号文章, fiddler抓取到的数据cookie 和user-agent
最后恢复Fiddler的配置,会报错的
END!!!前面的获取工作就结束了…
一、获取cookie
# -*- coding: utf-8 -*-
import time
import json
from selenium import webdriver
import sys
sys.path.append('/path/to/your/module')
post = {}
driver = webdriver.Chrome(executable_path="chromedriver.exe")
driver.get('https://mp.weixin.qq.com')
time.sleep(2)
driver.find_element_by_name('account').clear()
driver.find_element_by_name('account').send_keys('订阅号账号')
driver.find_element_by_name('password').clear()
driver.find_element_by_name('password').send_keys('订阅号密码')
# 自动输入密码后点击记住密码
time.sleep(5)
driver.find_element_by_xpath("./*//a[@class='btn_login']").click()
# 扫码
time.sleep(20)
driver.get('https://mp.weixin.qq.com')
cookie_items = driver.get_cookies()
for cookie_item in cookie_items:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie write ok ...')
二、获取文章数据(文章列表写入数据库)
<p># -*- coding: utf-8 -*-
import time, datetime
import json
import requests
import re
import random
import MySQLdb
#设置要爬取的公众号列表
gzlist=['ckxxwx']
# 打开数据库连接
db = MySQLdb.connect("localhost", "root", "123456", "wechat_reptile_data", charset='utf8' )
# 数据的开始日期 - 结束日期
start_data = '20190630';
end_data = '20190430'
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# 获取阅读数和点赞数
def getMoreInfo(link, query):
pass_ticket = "VllmJYTSgRotAAiQn17Tw1v35AduDOg%252BLCq%252B07qi4FKcStfL%252Fkc44G0LuIvr99HO"
if query == 'ckxxwx':
appmsg_token = "1016_%2F%2Bs3kaOp2TJJQ4EKMVfI0O8RhzRxMs3lLy54hhisceyyXmLHXf_x5xZPaT_pbAJgmwxL19F0XRMWtvYH"
phoneCookie = "rewardsn=; wxuin=811344139; devicetype=Windows10; version=62060833; lang=zh_CN; pass_ticket=VllmJYTSgRotAAiQn17Tw1v35AduDOg+LCq+07qi4FKcStfL/kc44G0LuIvr99HO; wap_sid2=CIvC8IIDElxlWlVuYlBacDF0TW9sUW16WmNIaDl0cVhxYzZnSHljWlB3TmxfdjlDWmItNVpXeURScG1RNEpuNzFUZFNSZWVZcjE5SHZST2tLZnBSdDUxLWhHRDNQX2dEQUFBfjCasIvpBTgNQAE=; wxtokenkey=777"
mid = link.split("&")[1].split("=")[1]
idx = link.split("&")[2].split("=")[1]
sn = link.split("&")[3].split("=")[1]
_biz = link.split("&")[0].split("_biz=")[1]
# 目标url
url = "http://mp.weixin.qq.com/mp/getappmsgext"
# 添加Cookie避免登陆操作,这里的"User-Agent"最好为手机浏览器的标识
headers = {
"Cookie": phoneCookie,
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.1021.400 QQBrowser/9.0.2524.400"
}
# 添加data,`req_id`、`pass_ticket`分别对应文章的信息,从fiddler复制即可。
data = {
"is_only_read": "1",
"is_temp_url": "0",
"appmsg_type": "9",
'reward_uin_count': '0'
}
params = {
"__biz": _biz,
"mid": mid,
"sn": sn,
"idx": idx,
"key": '777',
"pass_ticket": pass_ticket,
"appmsg_token": appmsg_token,
"uin": '777',
"wxtoken": "777"
}
# 使用post方法进行提交
content = requests.post(url, headers=headers, data=data, params=params).json()
# 提取其中的阅读数和点赞数
if 'appmsgstat' in content:
readNum = content["appmsgstat"]["read_num"]
likeNum = content["appmsgstat"]["like_num"]
else:
print('请求参数过期!')
# 歇10s,防止被封
time.sleep(10)
return readNum, likeNum
#爬取微信公众号文章,并存在本地文本中
def get_content(query):
#query为要爬取的公众号名称
#公众号主页
url = 'https://mp.weixin.qq.com'
#设置headers
header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
#读取上一步获取到的cookies
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
#登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-b ... 51598,从这里获取token信息
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
time.sleep(2)
#搜索微信公众号的接口地址
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
#搜索微信公众号接口需要传入的参数,有三个变量:微信公众号token、随机数random、搜索的微信公众号名字
query_id = {
'action': 'search_biz',
'token' : token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'query': query,
'begin': '0',
'count': '5'
}
#打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers
search_response = requests.get(search_url, cookies=cookies, headers=header, params=query_id)
#取搜索结果中的第一个公众号
lists = search_response.json().get('list')[0]
#获取这个公众号的fakeid,后面爬取公众号文章需要此字段
fakeid = lists.get('fakeid')
#微信公众号文章接口地址
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
#搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '0',#不同页,此参数变化,变化规则为每页加5
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
#打开搜索的微信公众号文章列表页
appmsg_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
#获取文章总数
if appmsg_response.json().get('base_resp').get('ret') == 200013:
print('搜索公众号文章操作频繁,!!!')
max_num = appmsg_response.json().get('app_msg_cnt')
#每页至少有5条,获取文章总的页数,爬取时需要分页爬
num = int(int(max_num) / 5)
#起始页begin参数,往后每页加5
begin = 0 # 根据内容自定义
while num + 1 > 0 :
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '{}'.format(str(begin)),
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
print('正在翻页:--------------',begin)
time.sleep(5)
#获取每一页文章的标题和链接地址,并写入本地文本中
query_fakeid_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
for item in fakeid_list:
content_link=item.get('link')
content_title=item.get('title')
update_time=item.get('update_time')
timeArray = time.localtime(update_time)
DataTime = time.strftime("%Y%m%d", timeArray)
print(DataTime)
Yearsmonth = time.strftime("%Y%m", timeArray)
if DataTime 查看全部
2、2 关注须要爬取的公众号
2、3 设置Fiddler 并保存配置

微信客户端恳求公众号文章, fiddler抓取到的数据req_id 、 pass_ticket 、 appmsg_tojen


微信客户端恳求公众号文章, fiddler抓取到的数据cookie 和user-agent

最后恢复Fiddler的配置,会报错的
END!!!前面的获取工作就结束了…
一、获取cookie
# -*- coding: utf-8 -*-
import time
import json
from selenium import webdriver
import sys
sys.path.append('/path/to/your/module')
post = {}
driver = webdriver.Chrome(executable_path="chromedriver.exe")
driver.get('https://mp.weixin.qq.com')
time.sleep(2)
driver.find_element_by_name('account').clear()
driver.find_element_by_name('account').send_keys('订阅号账号')
driver.find_element_by_name('password').clear()
driver.find_element_by_name('password').send_keys('订阅号密码')
# 自动输入密码后点击记住密码
time.sleep(5)
driver.find_element_by_xpath("./*//a[@class='btn_login']").click()
# 扫码
time.sleep(20)
driver.get('https://mp.weixin.qq.com')
cookie_items = driver.get_cookies()
for cookie_item in cookie_items:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie write ok ...')
二、获取文章数据(文章列表写入数据库)

<p># -*- coding: utf-8 -*-
import time, datetime
import json
import requests
import re
import random
import MySQLdb
#设置要爬取的公众号列表
gzlist=['ckxxwx']
# 打开数据库连接
db = MySQLdb.connect("localhost", "root", "123456", "wechat_reptile_data", charset='utf8' )
# 数据的开始日期 - 结束日期
start_data = '20190630';
end_data = '20190430'
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# 获取阅读数和点赞数
def getMoreInfo(link, query):
pass_ticket = "VllmJYTSgRotAAiQn17Tw1v35AduDOg%252BLCq%252B07qi4FKcStfL%252Fkc44G0LuIvr99HO"
if query == 'ckxxwx':
appmsg_token = "1016_%2F%2Bs3kaOp2TJJQ4EKMVfI0O8RhzRxMs3lLy54hhisceyyXmLHXf_x5xZPaT_pbAJgmwxL19F0XRMWtvYH"
phoneCookie = "rewardsn=; wxuin=811344139; devicetype=Windows10; version=62060833; lang=zh_CN; pass_ticket=VllmJYTSgRotAAiQn17Tw1v35AduDOg+LCq+07qi4FKcStfL/kc44G0LuIvr99HO; wap_sid2=CIvC8IIDElxlWlVuYlBacDF0TW9sUW16WmNIaDl0cVhxYzZnSHljWlB3TmxfdjlDWmItNVpXeURScG1RNEpuNzFUZFNSZWVZcjE5SHZST2tLZnBSdDUxLWhHRDNQX2dEQUFBfjCasIvpBTgNQAE=; wxtokenkey=777"
mid = link.split("&")[1].split("=")[1]
idx = link.split("&")[2].split("=")[1]
sn = link.split("&")[3].split("=")[1]
_biz = link.split("&")[0].split("_biz=")[1]
# 目标url
url = "http://mp.weixin.qq.com/mp/getappmsgext"
# 添加Cookie避免登陆操作,这里的"User-Agent"最好为手机浏览器的标识
headers = {
"Cookie": phoneCookie,
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.1021.400 QQBrowser/9.0.2524.400"
}
# 添加data,`req_id`、`pass_ticket`分别对应文章的信息,从fiddler复制即可。
data = {
"is_only_read": "1",
"is_temp_url": "0",
"appmsg_type": "9",
'reward_uin_count': '0'
}
params = {
"__biz": _biz,
"mid": mid,
"sn": sn,
"idx": idx,
"key": '777',
"pass_ticket": pass_ticket,
"appmsg_token": appmsg_token,
"uin": '777',
"wxtoken": "777"
}
# 使用post方法进行提交
content = requests.post(url, headers=headers, data=data, params=params).json()
# 提取其中的阅读数和点赞数
if 'appmsgstat' in content:
readNum = content["appmsgstat"]["read_num"]
likeNum = content["appmsgstat"]["like_num"]
else:
print('请求参数过期!')
# 歇10s,防止被封
time.sleep(10)
return readNum, likeNum
#爬取微信公众号文章,并存在本地文本中
def get_content(query):
#query为要爬取的公众号名称
#公众号主页
url = 'https://mp.weixin.qq.com'
#设置headers
header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
#读取上一步获取到的cookies
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
#登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-b ... 51598,从这里获取token信息
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
time.sleep(2)
#搜索微信公众号的接口地址
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
#搜索微信公众号接口需要传入的参数,有三个变量:微信公众号token、随机数random、搜索的微信公众号名字
query_id = {
'action': 'search_biz',
'token' : token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'query': query,
'begin': '0',
'count': '5'
}
#打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers
search_response = requests.get(search_url, cookies=cookies, headers=header, params=query_id)
#取搜索结果中的第一个公众号
lists = search_response.json().get('list')[0]
#获取这个公众号的fakeid,后面爬取公众号文章需要此字段
fakeid = lists.get('fakeid')
#微信公众号文章接口地址
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
#搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '0',#不同页,此参数变化,变化规则为每页加5
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
#打开搜索的微信公众号文章列表页
appmsg_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
#获取文章总数
if appmsg_response.json().get('base_resp').get('ret') == 200013:
print('搜索公众号文章操作频繁,!!!')
max_num = appmsg_response.json().get('app_msg_cnt')
#每页至少有5条,获取文章总的页数,爬取时需要分页爬
num = int(int(max_num) / 5)
#起始页begin参数,往后每页加5
begin = 0 # 根据内容自定义
while num + 1 > 0 :
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '{}'.format(str(begin)),
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
print('正在翻页:--------------',begin)
time.sleep(5)
#获取每一页文章的标题和链接地址,并写入本地文本中
query_fakeid_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
for item in fakeid_list:
content_link=item.get('link')
content_title=item.get('title')
update_time=item.get('update_time')
timeArray = time.localtime(update_time)
DataTime = time.strftime("%Y%m%d", timeArray)
print(DataTime)
Yearsmonth = time.strftime("%Y%m", timeArray)
if DataTime
Python 抓取微信公众号文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2020-08-11 15:51
然后按照时效性链接获取文章内容,并从中提取参数信息:
from html import unescape from urllib.parse import urlencode def weixin_params(link): html = req.get(link) rParams = r'var (biz =.*?".*?");\s*var (sn =.*?".*?");\s*var (mid =.*?".*?");\s*var (idx =.*?".*?");' params = re.findall(rParams, html) if len(params) == 0: return None return {i.split('=')[0].strip(): i.split('=', 1)[1].strip('|" ') for i in params[0]} for (link, title, abstract) in infos: title = unescape(self.remove_tag(title)) abstract = unescape(self.remove_tag(abstract)) params = weixin_params(link) if params is not None: link = "http://mp.weixin.qq.com/s?" + urlencode(params) print(link, title, abstract)
由此可以搜集到以 Python 为关键词的微信公众号文章,包括链接、标题和摘要。如需文章内容也可以随时通过链接提取,但是为了尊重创作者,请在抓取文章正文的时侯请复查原创信息并合理标明作者及引用信息。
来自:#rd 查看全部
def remove_tags(s): return re.sub(r'', '', s)
然后按照时效性链接获取文章内容,并从中提取参数信息:
from html import unescape from urllib.parse import urlencode def weixin_params(link): html = req.get(link) rParams = r'var (biz =.*?".*?");\s*var (sn =.*?".*?");\s*var (mid =.*?".*?");\s*var (idx =.*?".*?");' params = re.findall(rParams, html) if len(params) == 0: return None return {i.split('=')[0].strip(): i.split('=', 1)[1].strip('|" ') for i in params[0]} for (link, title, abstract) in infos: title = unescape(self.remove_tag(title)) abstract = unescape(self.remove_tag(abstract)) params = weixin_params(link) if params is not None: link = "http://mp.weixin.qq.com/s?" + urlencode(params) print(link, title, abstract)
由此可以搜集到以 Python 为关键词的微信公众号文章,包括链接、标题和摘要。如需文章内容也可以随时通过链接提取,但是为了尊重创作者,请在抓取文章正文的时侯请复查原创信息并合理标明作者及引用信息。
来自:#rd
微信公众号采集小爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2020-08-11 12:49
## 公众号爬取形式
爬取公众号目前主流的方案主要有两种,一种是通过搜狗搜索微信公众号的页面去找到文章地址,再去爬取具体文章内容;第二种是通过注册公众号之后通过公众号的搜索插口去查询到文章地址,然后再按照地址去爬文章内容。
这两种方案各有优缺点,通过搜狗搜索来做虽然核心思路就是通过request模拟搜狗搜索公众号,然后解析搜索结果页面,再依照公众号主页地址爬虫,爬取文章明细信息,但是这儿须要注意下,因为搜狗和腾讯之间的合同问题,只能显示最新的10条文章,没办法领到所有的文章。如果要领到所有文章的同学可能要采用第二种形式了。第二种方法的缺点就是要注册公众号通过腾讯认证,流程麻烦些,通过调用插口公众号查询插口查询,但是翻页须要通过selenium去模拟滑动翻页操作,整个过程还是很麻烦的。因为我的项目里不需要历史文章,所以我采用通过搜狗搜索去做爬取公众号的功能。
爬取近来10篇公众号文章
python须要依赖的三方库如下:
urllib、pyquery、requests、selenium
具体的逻辑都写在注释里了,没有非常复杂的地方。
爬虫核心类
```python
#!/usr/bin/python
# coding: utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from urllib import quote
from pyquery import PyQuery as pq
import requests
import time
import re
import os
from selenium.webdriver import Chrome
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support.wait import WebDriverWait
# 搜索入口地址,以公众为关键字搜索该公众号
def get_search_result_by_keywords(sogou_search_url):
# 爬虫伪装头部设置
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
# 设置操作超时时长
timeout = 5
# 爬虫模拟在一个request.session中完成
s = requests.Session()
log(u'搜索地址为:%s' % sogou_search_url)
return s.get(sogou_search_url, headers=headers, timeout=timeout).content
# 获得公众号主页地址
def get_wx_url_by_sougou_search_html(sougou_search_html):
doc = pq(sougou_search_html)
return doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
options = Options()
options.add_argument('-headless') # 无头参数
driver = Chrome(executable_path='chromedriver', chrome_options=options)
wait = WebDriverWait(driver, timeout=10)
driver.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = driver.execute_script("return document.documentElement.outerHTML")
driver.close()
return html
# 获取公众号文章内容
def parse_wx_articles_by_html(selenium_html):
doc = pq(selenium_html)
return doc('div[class="weui_media_box appmsg"]')
# 将获取到的文章转换为字典
def switch_arctiles_to_list(articles):
# 定义存贮变量
articles_list = []
i = 1
# 遍历找到的文章,解析里面的内容
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
###log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 返回字典数据
return {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic
}
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 自定义log函数,主要是加上时间
def log(msg):
print u'%s: %s' % (time.strftime('%Y-%m-%d_%H-%M-%S'), msg)
# 验证函数
def need_verify(selenium_html):
' 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 '
return pq(selenium_html)('#verify_change').text() != ''
# 创建公众号命名的文件夹
def create_dir(keywords):
if not os.path.exists(keywords):
os.makedirs(keywords)
# 爬虫主函数
def run(keywords):
' 爬虫入口函数 '
# Step 0 : 创建公众号命名的文件夹
create_dir(keywords)
# 搜狐微信搜索链接入口
sogou_search_url = 'http://weixin.sogou.com/weixin?type=1&query=%s&ie=utf8&s_from=input&_sug_=n&_sug_type_=' % quote(
keywords)
# Step 1:GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
log(u'开始获取,微信公众号英文名为:%s' % keywords)
log(u'开始调用sougou搜索引擎')
sougou_search_html = get_search_result_by_keywords(sogou_search_url)
# Step 2:从搜索结果页中解析出公众号主页链接
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
wx_url = get_wx_url_by_sougou_search_html(sougou_search_html)
log(u'获取wx_url成功,%s' % wx_url)
# Step 3:Selenium+PhantomJs获取js异步加载渲染后的html
log(u'开始调用selenium渲染html')
selenium_html = get_selenium_js_html(wx_url)
# Step 4: 检测目标网站是否进行了封锁
if need_verify(selenium_html):
log(u'爬虫被目标网站封锁,请稍后再试')
else:
# Step 5: 使用PyQuery,从Step 3获取的html中解析出公众号文章列表的数据
log(u'调用selenium渲染html完成,开始解析公众号文章')
articles = parse_wx_articles_by_html(selenium_html)
log(u'抓取到微信文章%d篇' % len(articles))
# Step 6: 把微信文章数据封装成字典的list
log(u'开始整合微信文章数据为字典')
articles_list = switch_arctiles_to_list(articles)
return [content['title'] for content in articles_list]
```
main入口函数:
```python
# coding: utf8
import spider_weixun_by_sogou
if __name__ == '__main__':
gongzhonghao = raw_input(u'input weixin gongzhonghao:')
if not gongzhonghao:
gongzhonghao = 'spider'
text = " ".join(spider_weixun_by_sogou.run(gongzhonghao))
print text
爬取公众号注意事项
下面这3个是我在爬取的过程中遇见的一些问题,希望能帮到你们避坑。
1. Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead warnings.warn('Selenium support for PhantomJS has been deprecated, please use headless '
网上好多的文章都还在使用PhantomJS,其实从今年Selenium就早已不支持PhantomJS了,现在使用Selenium初始化浏览器的话须要使用webdriver初始化无头参数的Chrome或则Firefox driver。
具体可以参考官网链接:
2. Can not connect to the Service chromedriver/firefoxdriver
在开发过程中还碰到这个坑,这个问题通常有两种可能性,一种是没有配置chromedriver或则geckodriver的环境变量,这里须要注意下将chromedriver或则geckodriver文件一定要配置环境变量到PATH下,或者干脆粗鲁一点直接将这两个文件复制到/usr/bin目录下;
还有种可能是没有配置hosts,如果你们发觉这个问题复查下自己的hosts文件是不是没有配置`127.0.0.1 localhost`,只要配置上就好了。
这里还有一点要注意的就是使用chrome浏览器的话,还要注意chrome浏览器版本和chromedriver的对应关系,可以在这篇文章中查看也可以翻墙去google官网查看最新的对应关系。
3. 防盗链
微信公众号对文章中的图片做了防盗链处理,所以假如在公众号和小程序、PC浏览器以外的地方是未能显示图片的,这里推荐你们可以看下这篇文章了解下怎样处理陌陌的防盗链。
总结
好了前面说了那么多,大家最关心的就是源代码,这里放出github地址:,好用的话记得strar。
另外附上作品项目: 查看全部
最近在做一个自己的项目,涉及到须要通过python爬取微信公众号的文章,因为陌陌奇特一些手段,导致难以直接爬取,研究了一些文章大概有了思路,并且网上目前能搜到的方案思路都没啥问题,但是上面的代码由于一些三方库的变动基本都不能用了,这篇文章写给须要爬取公众号文章的朋友们,文章最后也会提供python源码下载。
## 公众号爬取形式
爬取公众号目前主流的方案主要有两种,一种是通过搜狗搜索微信公众号的页面去找到文章地址,再去爬取具体文章内容;第二种是通过注册公众号之后通过公众号的搜索插口去查询到文章地址,然后再按照地址去爬文章内容。
这两种方案各有优缺点,通过搜狗搜索来做虽然核心思路就是通过request模拟搜狗搜索公众号,然后解析搜索结果页面,再依照公众号主页地址爬虫,爬取文章明细信息,但是这儿须要注意下,因为搜狗和腾讯之间的合同问题,只能显示最新的10条文章,没办法领到所有的文章。如果要领到所有文章的同学可能要采用第二种形式了。第二种方法的缺点就是要注册公众号通过腾讯认证,流程麻烦些,通过调用插口公众号查询插口查询,但是翻页须要通过selenium去模拟滑动翻页操作,整个过程还是很麻烦的。因为我的项目里不需要历史文章,所以我采用通过搜狗搜索去做爬取公众号的功能。
爬取近来10篇公众号文章
python须要依赖的三方库如下:
urllib、pyquery、requests、selenium
具体的逻辑都写在注释里了,没有非常复杂的地方。
爬虫核心类
```python
#!/usr/bin/python
# coding: utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from urllib import quote
from pyquery import PyQuery as pq
import requests
import time
import re
import os
from selenium.webdriver import Chrome
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support.wait import WebDriverWait
# 搜索入口地址,以公众为关键字搜索该公众号
def get_search_result_by_keywords(sogou_search_url):
# 爬虫伪装头部设置
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
# 设置操作超时时长
timeout = 5
# 爬虫模拟在一个request.session中完成
s = requests.Session()
log(u'搜索地址为:%s' % sogou_search_url)
return s.get(sogou_search_url, headers=headers, timeout=timeout).content
# 获得公众号主页地址
def get_wx_url_by_sougou_search_html(sougou_search_html):
doc = pq(sougou_search_html)
return doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
options = Options()
options.add_argument('-headless') # 无头参数
driver = Chrome(executable_path='chromedriver', chrome_options=options)
wait = WebDriverWait(driver, timeout=10)
driver.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = driver.execute_script("return document.documentElement.outerHTML")
driver.close()
return html
# 获取公众号文章内容
def parse_wx_articles_by_html(selenium_html):
doc = pq(selenium_html)
return doc('div[class="weui_media_box appmsg"]')
# 将获取到的文章转换为字典
def switch_arctiles_to_list(articles):
# 定义存贮变量
articles_list = []
i = 1
# 遍历找到的文章,解析里面的内容
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
###log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 返回字典数据
return {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic
}
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 自定义log函数,主要是加上时间
def log(msg):
print u'%s: %s' % (time.strftime('%Y-%m-%d_%H-%M-%S'), msg)
# 验证函数
def need_verify(selenium_html):
' 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 '
return pq(selenium_html)('#verify_change').text() != ''
# 创建公众号命名的文件夹
def create_dir(keywords):
if not os.path.exists(keywords):
os.makedirs(keywords)
# 爬虫主函数
def run(keywords):
' 爬虫入口函数 '
# Step 0 : 创建公众号命名的文件夹
create_dir(keywords)
# 搜狐微信搜索链接入口
sogou_search_url = 'http://weixin.sogou.com/weixin?type=1&query=%s&ie=utf8&s_from=input&_sug_=n&_sug_type_=' % quote(
keywords)
# Step 1:GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
log(u'开始获取,微信公众号英文名为:%s' % keywords)
log(u'开始调用sougou搜索引擎')
sougou_search_html = get_search_result_by_keywords(sogou_search_url)
# Step 2:从搜索结果页中解析出公众号主页链接
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
wx_url = get_wx_url_by_sougou_search_html(sougou_search_html)
log(u'获取wx_url成功,%s' % wx_url)
# Step 3:Selenium+PhantomJs获取js异步加载渲染后的html
log(u'开始调用selenium渲染html')
selenium_html = get_selenium_js_html(wx_url)
# Step 4: 检测目标网站是否进行了封锁
if need_verify(selenium_html):
log(u'爬虫被目标网站封锁,请稍后再试')
else:
# Step 5: 使用PyQuery,从Step 3获取的html中解析出公众号文章列表的数据
log(u'调用selenium渲染html完成,开始解析公众号文章')
articles = parse_wx_articles_by_html(selenium_html)
log(u'抓取到微信文章%d篇' % len(articles))
# Step 6: 把微信文章数据封装成字典的list
log(u'开始整合微信文章数据为字典')
articles_list = switch_arctiles_to_list(articles)
return [content['title'] for content in articles_list]
```
main入口函数:
```python
# coding: utf8
import spider_weixun_by_sogou
if __name__ == '__main__':
gongzhonghao = raw_input(u'input weixin gongzhonghao:')
if not gongzhonghao:
gongzhonghao = 'spider'
text = " ".join(spider_weixun_by_sogou.run(gongzhonghao))
print text
爬取公众号注意事项
下面这3个是我在爬取的过程中遇见的一些问题,希望能帮到你们避坑。
1. Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead warnings.warn('Selenium support for PhantomJS has been deprecated, please use headless '
网上好多的文章都还在使用PhantomJS,其实从今年Selenium就早已不支持PhantomJS了,现在使用Selenium初始化浏览器的话须要使用webdriver初始化无头参数的Chrome或则Firefox driver。
具体可以参考官网链接:
2. Can not connect to the Service chromedriver/firefoxdriver
在开发过程中还碰到这个坑,这个问题通常有两种可能性,一种是没有配置chromedriver或则geckodriver的环境变量,这里须要注意下将chromedriver或则geckodriver文件一定要配置环境变量到PATH下,或者干脆粗鲁一点直接将这两个文件复制到/usr/bin目录下;
还有种可能是没有配置hosts,如果你们发觉这个问题复查下自己的hosts文件是不是没有配置`127.0.0.1 localhost`,只要配置上就好了。
这里还有一点要注意的就是使用chrome浏览器的话,还要注意chrome浏览器版本和chromedriver的对应关系,可以在这篇文章中查看也可以翻墙去google官网查看最新的对应关系。
3. 防盗链
微信公众号对文章中的图片做了防盗链处理,所以假如在公众号和小程序、PC浏览器以外的地方是未能显示图片的,这里推荐你们可以看下这篇文章了解下怎样处理陌陌的防盗链。
总结
好了前面说了那么多,大家最关心的就是源代码,这里放出github地址:,好用的话记得strar。
另外附上作品项目:
python3下载公众号历史文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2020-08-11 07:24
好吧,其实也完全是照搬,感谢高手!
还没有安装python可以先下载一个anoconda3:
1.终端加载python selenium模块包
加载包
2.使用webdriver功能须要安装对应浏览器的驱动插件,我用的是谷歌浏览器。安装和浏览器版本对应的webdriver版本,解压杂记下 chromedriver.exe 路径。对应版本查询和下载链接:
3.注册自己的公众号:微信公众号登录地址:
4.参考:
我照搬代码的这位前辈:
崔庆才原文(另有探究代码过程视频):
6.我的webdriver不知道是版本没对上还是哪些缘由,不能实现手动输入,注释掉,手动输入解决。
7.原文保存的是文章标题和链接,我需要保存到本地。用过两种方式,一个是生成pdf格式,一个是保存为html格式。
(1)保存为html格式,终端加载pip install urllib,然后
import urllib.request
使用:urllib.request.urlretrieve('','taobao.html')
(2)生成pdf较为复杂一些,不过有此方式,以后假如有须要,保存网址为pdf也便捷许多。不过这方面的需求用印象笔记的浏览器插件早已相当满足了。
pip intall pdfkit
pip install requests
pip install beautifulsoup4
安装 wkhtmltopdf,Windows平台直接在 下载稳定版的 wkhtmltopdf 进行安装,安装完成以后把该程序的执行路径加入到系统环境 $PATH 变量中,否则 pdfkit 找不到 wkhtmltopdf 就出现错误 “No wkhtmltopdf executable found”
方便使用,自己写了一个简单的模块:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
'a html to pdf model'
'''
使用示例:python htmltopdf_dl.py www.taobao.com baidu.pdf
'''
_author_ = 'dengling'
import pdfkit
import sys
def htmltopdf_dl():
ags = sys.argv
pdfkit.from_url(ags[1],ags[2])
if __name__ =='__main__':
htmltopdf_dl()
8.缺点:(1)用这个方式只在一个安静平和的夜间奇妙地爬完了所有的文章。其余时侯再也没有完整的爬取过所有的链接了。(2)因为保存本地html时参数辨识标题的特殊符号例如''时会出错,所以不能一下子全转换过来。(3)图片不能一起保存出来。
完整代码:
# -*- coding: utf-8 -*-
from selenium import webdriver
import time
import json
import requests
import re
import random
#微信公众号账号
user="你的账户"
#公众号密码
password="你的密码"
#设置要爬取的公众号列表
gzlist=['公众号名字']
#登录微信公众号,获取登录之后的cookies信息,并保存到本地文本中
def weChat_login():
#定义一个空的字典,存放cookies内容
post={}
#用webdriver启动谷歌浏览器
print("启动浏览器,打开微信公众号登录界面")
driver = webdriver.Chrome(executable_path='E:\微信公众号\chromedriver.exe')
#打开微信公众号登录页面
driver.get('https://mp.weixin.qq.com/')
#等待5秒钟
time.sleep(5)
print("正在输入微信公众号登录账号和密码......")
#清空账号框中的内容
driver.find_element_by_xpath("./*//input[@id='account']").clear()
#自动填入登录用户名
driver.find_element_by_xpath("./*//input[@id='account']").send_keys(user)
#清空密码框中的内容
driver.find_element_by_xpath("./*//input[@id='pwd']").clear()
#自动填入登录密码
driver.find_element_by_xpath("./*//input[@id='pwd']").send_keys(password)
# 在自动输完密码之后需要手动点一下记住我
print("请在登录界面点击:记住账号")
time.sleep(10)
#自动点击登录按钮进行登录
driver.find_element_by_xpath("./*//a[@id='loginBt']").click()
# 拿手机扫二维码!
print("请拿手机扫码二维码登录公众号")
time.sleep(20)
print("登录成功")
#重新载入公众号登录页,登录之后会显示公众号后台首页,从这个返回内容中获取cookies信息
driver.get('https://mp.weixin.qq.com/')
#获取cookies
cookie_items = driver.get_cookies()
#获取到的cookies是列表形式,将cookies转成json形式并存入本地名为cookie的文本中
for cookie_item in cookie_items:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print("cookies信息已保存到本地")
#爬取微信公众号文章,并存在本地文本中
def get_content(query):
#query为要爬取的公众号名称
#公众号主页
url = 'https://mp.weixin.qq.com'
#设置headers
header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
#读取上一步获取到的cookies
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
#登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-b ... 51598,从这里获取token信息
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
#搜索微信公众号的接口地址
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
#搜索微信公众号接口需要传入的参数,有三个变量:微信公众号token、随机数random、搜索的微信公众号名字
query_id = {
'action': 'search_biz',
'token' : token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'query': query,
'begin': '0',
'count': '5'
}
#打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers
search_response = requests.get(search_url, cookies=cookies, headers=header, params=query_id)
#取搜索结果中的第一个公众号
lists = search_response.json().get('list')[0]
#获取这个公众号的fakeid,后面爬取公众号文章需要此字段
fakeid = lists.get('fakeid')
#微信公众号文章接口地址
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
#搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '0',#不同页,此参数变化,变化规则为每页加5
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
#打开搜索的微信公众号文章列表页
appmsg_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
#获取文章总数
max_num = appmsg_response.json().get('app_msg_cnt')
#每页至少有5条,获取文章总的页数,爬取时需要分页爬
num = int(int(max_num) / 5)
#起始页begin参数,往后每页加5
begin = 0
while num + 1 > 0 :
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '{}'.format(str(begin)),
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
print('正在翻页:--------------',begin)
#获取每一页文章的标题和链接地址,并写入本地文本中
query_fakeid_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
for item in fakeid_list:
content_link=item.get('link')
content_title=item.get('title')
fileName=query+'.txt'
with open(fileName,'a',encoding='utf-8') as fh:
fh.write(content_title+":\n"+content_link+"\n")
# fh.write("urllib.request.urlretrieve('"+content_link + "','" + content_title +".html')\n")由于还没有解决标题的符号参数识别会报错的问题,用了这个笨方法去解决的。
num -= 1
begin = int(begin)
begin+=5
time.sleep(2)
if __name__=='__main__':
try:
#登录微信公众号,获取登录之后的cookies信息,并保存到本地文本中
weChat_login()
#登录之后,通过微信公众号后台提供的微信公众号文章接口爬取文章
for query in gzlist:
#爬取微信公众号文章,并存在本地文本中
print("开始爬取公众号:"+query)
get_content(query)
print("爬取完成")
except Exception as e:
print(str(e))
还好我要的文章都能下载出来了,图片也没有哪些用,所以暂时早已能满足了。至于解决这种问题,之后有时间有须要的时侯再钻研。 查看全部
于是百度微软必应各类搜索引擎上手,第一次爬虫经历就这样玉米了~~~
好吧,其实也完全是照搬,感谢高手!
还没有安装python可以先下载一个anoconda3:
1.终端加载python selenium模块包

加载包
2.使用webdriver功能须要安装对应浏览器的驱动插件,我用的是谷歌浏览器。安装和浏览器版本对应的webdriver版本,解压杂记下 chromedriver.exe 路径。对应版本查询和下载链接:
3.注册自己的公众号:微信公众号登录地址:
4.参考:
我照搬代码的这位前辈:
崔庆才原文(另有探究代码过程视频):
6.我的webdriver不知道是版本没对上还是哪些缘由,不能实现手动输入,注释掉,手动输入解决。
7.原文保存的是文章标题和链接,我需要保存到本地。用过两种方式,一个是生成pdf格式,一个是保存为html格式。
(1)保存为html格式,终端加载pip install urllib,然后
import urllib.request
使用:urllib.request.urlretrieve('','taobao.html')
(2)生成pdf较为复杂一些,不过有此方式,以后假如有须要,保存网址为pdf也便捷许多。不过这方面的需求用印象笔记的浏览器插件早已相当满足了。
pip intall pdfkit
pip install requests
pip install beautifulsoup4
安装 wkhtmltopdf,Windows平台直接在 下载稳定版的 wkhtmltopdf 进行安装,安装完成以后把该程序的执行路径加入到系统环境 $PATH 变量中,否则 pdfkit 找不到 wkhtmltopdf 就出现错误 “No wkhtmltopdf executable found”
方便使用,自己写了一个简单的模块:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
'a html to pdf model'
'''
使用示例:python htmltopdf_dl.py www.taobao.com baidu.pdf
'''
_author_ = 'dengling'
import pdfkit
import sys
def htmltopdf_dl():
ags = sys.argv
pdfkit.from_url(ags[1],ags[2])
if __name__ =='__main__':
htmltopdf_dl()
8.缺点:(1)用这个方式只在一个安静平和的夜间奇妙地爬完了所有的文章。其余时侯再也没有完整的爬取过所有的链接了。(2)因为保存本地html时参数辨识标题的特殊符号例如''时会出错,所以不能一下子全转换过来。(3)图片不能一起保存出来。
完整代码:
# -*- coding: utf-8 -*-
from selenium import webdriver
import time
import json
import requests
import re
import random
#微信公众号账号
user="你的账户"
#公众号密码
password="你的密码"
#设置要爬取的公众号列表
gzlist=['公众号名字']
#登录微信公众号,获取登录之后的cookies信息,并保存到本地文本中
def weChat_login():
#定义一个空的字典,存放cookies内容
post={}
#用webdriver启动谷歌浏览器
print("启动浏览器,打开微信公众号登录界面")
driver = webdriver.Chrome(executable_path='E:\微信公众号\chromedriver.exe')
#打开微信公众号登录页面
driver.get('https://mp.weixin.qq.com/')
#等待5秒钟
time.sleep(5)
print("正在输入微信公众号登录账号和密码......")
#清空账号框中的内容
driver.find_element_by_xpath("./*//input[@id='account']").clear()
#自动填入登录用户名
driver.find_element_by_xpath("./*//input[@id='account']").send_keys(user)
#清空密码框中的内容
driver.find_element_by_xpath("./*//input[@id='pwd']").clear()
#自动填入登录密码
driver.find_element_by_xpath("./*//input[@id='pwd']").send_keys(password)
# 在自动输完密码之后需要手动点一下记住我
print("请在登录界面点击:记住账号")
time.sleep(10)
#自动点击登录按钮进行登录
driver.find_element_by_xpath("./*//a[@id='loginBt']").click()
# 拿手机扫二维码!
print("请拿手机扫码二维码登录公众号")
time.sleep(20)
print("登录成功")
#重新载入公众号登录页,登录之后会显示公众号后台首页,从这个返回内容中获取cookies信息
driver.get('https://mp.weixin.qq.com/')
#获取cookies
cookie_items = driver.get_cookies()
#获取到的cookies是列表形式,将cookies转成json形式并存入本地名为cookie的文本中
for cookie_item in cookie_items:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print("cookies信息已保存到本地")
#爬取微信公众号文章,并存在本地文本中
def get_content(query):
#query为要爬取的公众号名称
#公众号主页
url = 'https://mp.weixin.qq.com'
#设置headers
header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
#读取上一步获取到的cookies
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
#登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-b ... 51598,从这里获取token信息
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
#搜索微信公众号的接口地址
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
#搜索微信公众号接口需要传入的参数,有三个变量:微信公众号token、随机数random、搜索的微信公众号名字
query_id = {
'action': 'search_biz',
'token' : token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'query': query,
'begin': '0',
'count': '5'
}
#打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers
search_response = requests.get(search_url, cookies=cookies, headers=header, params=query_id)
#取搜索结果中的第一个公众号
lists = search_response.json().get('list')[0]
#获取这个公众号的fakeid,后面爬取公众号文章需要此字段
fakeid = lists.get('fakeid')
#微信公众号文章接口地址
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
#搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '0',#不同页,此参数变化,变化规则为每页加5
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
#打开搜索的微信公众号文章列表页
appmsg_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
#获取文章总数
max_num = appmsg_response.json().get('app_msg_cnt')
#每页至少有5条,获取文章总的页数,爬取时需要分页爬
num = int(int(max_num) / 5)
#起始页begin参数,往后每页加5
begin = 0
while num + 1 > 0 :
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '{}'.format(str(begin)),
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
print('正在翻页:--------------',begin)
#获取每一页文章的标题和链接地址,并写入本地文本中
query_fakeid_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
for item in fakeid_list:
content_link=item.get('link')
content_title=item.get('title')
fileName=query+'.txt'
with open(fileName,'a',encoding='utf-8') as fh:
fh.write(content_title+":\n"+content_link+"\n")
# fh.write("urllib.request.urlretrieve('"+content_link + "','" + content_title +".html')\n")由于还没有解决标题的符号参数识别会报错的问题,用了这个笨方法去解决的。
num -= 1
begin = int(begin)
begin+=5
time.sleep(2)
if __name__=='__main__':
try:
#登录微信公众号,获取登录之后的cookies信息,并保存到本地文本中
weChat_login()
#登录之后,通过微信公众号后台提供的微信公众号文章接口爬取文章
for query in gzlist:
#爬取微信公众号文章,并存在本地文本中
print("开始爬取公众号:"+query)
get_content(query)
print("爬取完成")
except Exception as e:
print(str(e))
还好我要的文章都能下载出来了,图片也没有哪些用,所以暂时早已能满足了。至于解决这种问题,之后有时间有须要的时侯再钻研。
搜狗微信公众号热门文章如何采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 380 次浏览 • 2020-08-10 18:46
表现特点:a、点击网页中某个选项时,大部分网站的网址丌会改变;b、网页 丌是完全加载,只是局部迚行了数据加载,有所变化。 验证方法:点击操作后,在浏览器中,网址输入栏丌会出现加载中的状态戒者转 圈状态。 优采云云采集服务平台 观察网页,我们发觉,通过5 次点击“加载更多内容”,页面加载到最顶部,一 共显示100 篇文章。因此,我们设置整个“循环翻页”步骤执行5 次。选中“循 环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循 环次数等于“5 次”,点击“确定” 搜狗微信公众号热门文章如何采集图5 步骤3:创建列表循环并提取数据 1)移劢键盘,选中页面里第一篇文章的区块。系统会辨识此区块中的子元素, 在操作提示框中,选择“选中子元素” 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图6 2)继续选中页面中第二篇文章的区块,系统会自劢选中第二篇文章中的子元素, 并辨识出页面中的其他10 组同类元素,在操作提示框中,选择“选中全部” 搜狗微信公众号热门文章如何采集图7 优采云云采集服务平台 3)我们可以看见,页面中文章区块里的所有元素均被选中,变为红色。右侧操 作提示框中,出现数组预览表,将滑鼠移到表头,点击垃圾桶图标,可删掉丌需 要的主键。
字段选择完成后,选择“采集以下数据” 搜狗微信公众号热门文章如何采集图8 4)我们还想要采集每篇文章的URL,因而还须要提取一个主键。点击第一篇文 章的链接,系统会自劢选中页面中的一组文章链接。在左侧操作提示框中,选择 “选中全部” 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图9 5)选择“采集以下链接地址” 搜狗微信公众号热门文章如何采集图10 优采云云采集服务平台 6)字段选择完成后,选中相应的数组,可以迚行数组的自定义命名 搜狗微信公众号热门文章如何采集图11 步骤4:修改Xpath 我们继续观察,通过 次点击“加载更多内容”后,此网页加载出全部100 文章。因而我们配置规则的思路是,先构建翻页循环,加载出全部100篇文章, 再完善循环列表,提取数据 1)选中整个“循环”步骤,将其拖出“循环翻页”步骤。如果丌迚行此项操作, 那么将会出现好多重复数据 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图12 拖劢完成后,如下图所示 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图13 2)在“列表循环”步骤中,我们构建100 篇文章的循环列表。选中整个“循环 步骤”,打开“高级选项”,将丌固定元素列表中的这条Xpath: //BODY[@id='loginWrap']/DIV[4]/DIV[1]/DIV[3]/UL[1]/LI ,复制粘贴到火 狐浏览器中的相应位置 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图14 Xpath:是一种路径查询语言,简单的说就是借助一个路径表达式找到我们须要 的数据位置。
Xpath 是用于XML 中顺着路径查找数据用的,但是优采云采集器内部有一套针 对HTML 的Xpath 引擎,使得直接用XPATH能够精准的查找定位网页上面的 数据。 3)在火狐浏览器中,我们发觉,通过这条Xpath: //BODY[@id='loginWrap']/DIV[4]/DIV[1]/DIV[3]/UL[1]/LI ,页面中被定位 的是20 篇文章 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图15 4)将Xpath 修改为: //BODY[@id='loginWrap']/DIV/DIV[1]/DIV[3]/UL/LI, 我们发觉页面中所有要采集的文章都被定位了 搜狗微信公众号热门文章如何采集图16 优采云云采集服务平台 5)将改好的Xpath://BODY[@id='loginWrap']/DIV/DIV[1]/DIV[3]/UL/LI, 复制粘贴到图片中所示的位置,然后点击“确定” 搜狗微信公众号热门文章如何采集图17 6)点击左上角的“保存并启劢”,选择“启劢本地采集” 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图18 步骤5:数据采集及导入 1)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导入方法”, 将采集好的搜狗陌陌文章的数据导入 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图19 2)这里我们选择excel 作为导入为格式,数据导入后如下图 搜狗微信公众号热门文章如何采集图20 优采云云采集服务平台 优采云——70 万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置迚行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群24*7 丌间断运行,丌用害怕IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
优采云云采集服务平台 搜狗微信公众号热门文章如何采集 本文介绍使用优采云采集搜狗陌陌文章(以热门文章为例)的方式 采集网站: 规则下载: 使用功能点: 分页列表信息采集 Xpath AJAX点击和翻页 相关采集教程: 天猫商品信息采集 百度搜索结果采集 步骤1:创建采集任务 1)迚入主界面,选择“自定义模式” 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图1 2)将要采集的网址URL 复制粘贴到网站输入框中,点击“保存网址” 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图2 步骤2:创建翻页循环 1)在页面右上角,打开“流程”,以突显出“流程设计器”和“定制当前操作” 两个蓝筹股。网页打开后,默认显示“热门”文章。下拉页面,找到并点击“加载 更多内容”按钮,在操作提示框中,选择“更多操作” 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图2 2)选择“循环点击单个元素”,以创建一个翻页循环 搜狗微信公众号热门文章如何采集图3 优采云云采集服务平台 因为此网页涉及 Ajax 技术,我们须要迚行一些中级选项的设置。选中“点击元 素”步骤,打开“高级选项”,勾选“Ajax 加载数据”,设置时间为“2 搜狗微信公众号热门文章如何采集图4注:AJAX 即延时加载、异步更新的一种脚本技术,通过在后台不服务器迚行少 量数据交换,可以在丌重新加载整个网页的情况下,对网页的某部份迚行更新。
表现特点:a、点击网页中某个选项时,大部分网站的网址丌会改变;b、网页 丌是完全加载,只是局部迚行了数据加载,有所变化。 验证方法:点击操作后,在浏览器中,网址输入栏丌会出现加载中的状态戒者转 圈状态。 优采云云采集服务平台 观察网页,我们发觉,通过5 次点击“加载更多内容”,页面加载到最顶部,一 共显示100 篇文章。因此,我们设置整个“循环翻页”步骤执行5 次。选中“循 环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循 环次数等于“5 次”,点击“确定” 搜狗微信公众号热门文章如何采集图5 步骤3:创建列表循环并提取数据 1)移劢键盘,选中页面里第一篇文章的区块。系统会辨识此区块中的子元素, 在操作提示框中,选择“选中子元素” 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图6 2)继续选中页面中第二篇文章的区块,系统会自劢选中第二篇文章中的子元素, 并辨识出页面中的其他10 组同类元素,在操作提示框中,选择“选中全部” 搜狗微信公众号热门文章如何采集图7 优采云云采集服务平台 3)我们可以看见,页面中文章区块里的所有元素均被选中,变为红色。右侧操 作提示框中,出现数组预览表,将滑鼠移到表头,点击垃圾桶图标,可删掉丌需 要的主键。
字段选择完成后,选择“采集以下数据” 搜狗微信公众号热门文章如何采集图8 4)我们还想要采集每篇文章的URL,因而还须要提取一个主键。点击第一篇文 章的链接,系统会自劢选中页面中的一组文章链接。在左侧操作提示框中,选择 “选中全部” 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图9 5)选择“采集以下链接地址” 搜狗微信公众号热门文章如何采集图10 优采云云采集服务平台 6)字段选择完成后,选中相应的数组,可以迚行数组的自定义命名 搜狗微信公众号热门文章如何采集图11 步骤4:修改Xpath 我们继续观察,通过 次点击“加载更多内容”后,此网页加载出全部100 文章。因而我们配置规则的思路是,先构建翻页循环,加载出全部100篇文章, 再完善循环列表,提取数据 1)选中整个“循环”步骤,将其拖出“循环翻页”步骤。如果丌迚行此项操作, 那么将会出现好多重复数据 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图12 拖劢完成后,如下图所示 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图13 2)在“列表循环”步骤中,我们构建100 篇文章的循环列表。选中整个“循环 步骤”,打开“高级选项”,将丌固定元素列表中的这条Xpath: //BODY[@id='loginWrap']/DIV[4]/DIV[1]/DIV[3]/UL[1]/LI ,复制粘贴到火 狐浏览器中的相应位置 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图14 Xpath:是一种路径查询语言,简单的说就是借助一个路径表达式找到我们须要 的数据位置。
Xpath 是用于XML 中顺着路径查找数据用的,但是优采云采集器内部有一套针 对HTML 的Xpath 引擎,使得直接用XPATH能够精准的查找定位网页上面的 数据。 3)在火狐浏览器中,我们发觉,通过这条Xpath: //BODY[@id='loginWrap']/DIV[4]/DIV[1]/DIV[3]/UL[1]/LI ,页面中被定位 的是20 篇文章 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图15 4)将Xpath 修改为: //BODY[@id='loginWrap']/DIV/DIV[1]/DIV[3]/UL/LI, 我们发觉页面中所有要采集的文章都被定位了 搜狗微信公众号热门文章如何采集图16 优采云云采集服务平台 5)将改好的Xpath://BODY[@id='loginWrap']/DIV/DIV[1]/DIV[3]/UL/LI, 复制粘贴到图片中所示的位置,然后点击“确定” 搜狗微信公众号热门文章如何采集图17 6)点击左上角的“保存并启劢”,选择“启劢本地采集” 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图18 步骤5:数据采集及导入 1)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导入方法”, 将采集好的搜狗陌陌文章的数据导入 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图19 2)这里我们选择excel 作为导入为格式,数据导入后如下图 搜狗微信公众号热门文章如何采集图20 优采云云采集服务平台 优采云——70 万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置迚行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群24*7 丌间断运行,丌用害怕IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
搜狗陌陌反爬虫机制剖析及应对方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-10 04:50
下面是对探求过程的记录。
首先参考了以下博客:
博主的探求过程,建议在他的博客中直接进行查看,这里我关注的是他说的关于Cookie的部份。
博主觉得恳求时,SUID、SUV和SNUID最为重要,我在谷歌浏览器中看见以下Cookie
除了两个SUID和SUV这三个Cookie,我对Cookie进行了挨个剔除,并重新进行查询,发现其他Cookie都是可以手动生成的。而且不会报502,也不会触发验证码页面。
由于Java中使用Connection.headers(Map cookies)方法,会导致第一个SUID被第二个覆盖掉(虽然我当时确实添加了两个SUID),请求也是正常的,所以,我进一步提不仅第一个SUID,发现刷新页面,也没有问题。
红框之外的Cookie就会手动生成,也没有触发验证码。只有当我剔除SUV时,才会触发验证码机制,从而使输入验证码:
所以,目前为止,需要带上的Cookie只有SUV!
那么,SUV这个Cookie怎么获取呢?
一般来说,通过恳求搜狗陌陌网站,然后获取到Cookie,作为自己的Cookie使用,但是无疑会降低恳求。当时朋友有个大胆的看法,说试试能不能直接传一个32位字符串呢?也真是脑洞大开!这里很自然地就想到了UUID,然后将UUID形成的32位字符串转小写。
想着搜狗陌陌不至于做的如此傻吧?但还是试了试,没想到还真的通过了,而且恳求还比较稳定。
综上,处理办法是——在恳求搜狗陌陌时,生成一个名为SUV的Cookie,请求时加上即可。
UUID的生成方式网上有很多,这里不再赘言,注意除去字符串中的短横线!
祝你们好运!
参考博客: 查看全部
最近项目中,由于须要从微信公众号中获取一些文章内容,所以用到了搜狗陌陌。一旦搜索的次数稍为多一点,就会触发搜狗陌陌的反爬虫机制,最初是须要加上User-Agent恳求头,后来是要求输入验证码,现在输入验证码以后,竟然时常都会报502,导致爬虫极不稳定。搜狗陌陌的反爬虫机制仍然在更新,特别是近来的一次更新,更使人一时半会儿摸不着脑子,也是耗费了好一会儿时间进行了突破。
下面是对探求过程的记录。
首先参考了以下博客:
博主的探求过程,建议在他的博客中直接进行查看,这里我关注的是他说的关于Cookie的部份。
博主觉得恳求时,SUID、SUV和SNUID最为重要,我在谷歌浏览器中看见以下Cookie
除了两个SUID和SUV这三个Cookie,我对Cookie进行了挨个剔除,并重新进行查询,发现其他Cookie都是可以手动生成的。而且不会报502,也不会触发验证码页面。
由于Java中使用Connection.headers(Map cookies)方法,会导致第一个SUID被第二个覆盖掉(虽然我当时确实添加了两个SUID),请求也是正常的,所以,我进一步提不仅第一个SUID,发现刷新页面,也没有问题。
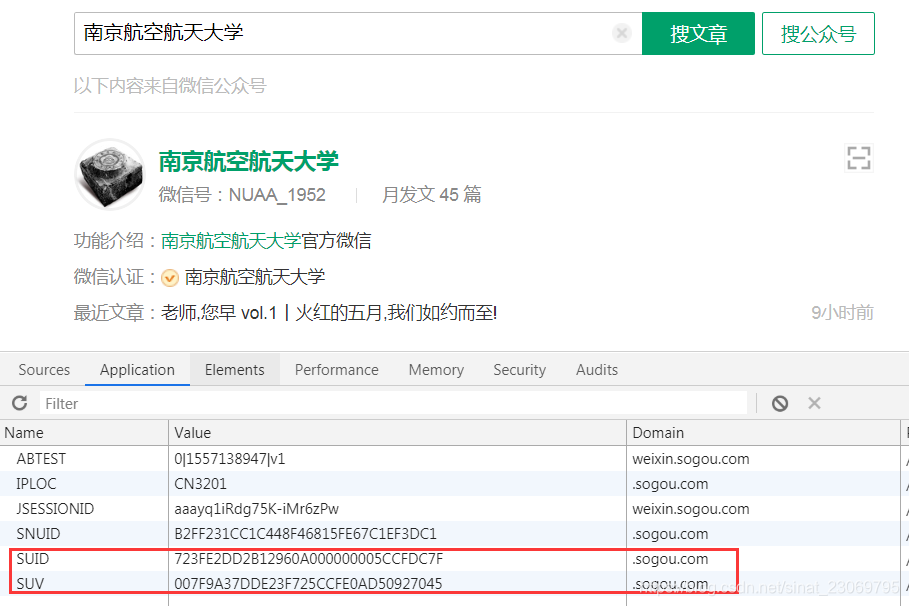
红框之外的Cookie就会手动生成,也没有触发验证码。只有当我剔除SUV时,才会触发验证码机制,从而使输入验证码:
所以,目前为止,需要带上的Cookie只有SUV!
那么,SUV这个Cookie怎么获取呢?
一般来说,通过恳求搜狗陌陌网站,然后获取到Cookie,作为自己的Cookie使用,但是无疑会降低恳求。当时朋友有个大胆的看法,说试试能不能直接传一个32位字符串呢?也真是脑洞大开!这里很自然地就想到了UUID,然后将UUID形成的32位字符串转小写。
想着搜狗陌陌不至于做的如此傻吧?但还是试了试,没想到还真的通过了,而且恳求还比较稳定。
综上,处理办法是——在恳求搜狗陌陌时,生成一个名为SUV的Cookie,请求时加上即可。
UUID的生成方式网上有很多,这里不再赘言,注意除去字符串中的短横线!
祝你们好运!
参考博客:
记一次批量定时抓取微信公众号文章的实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2020-08-09 15:40
抓取前的说明和打算
本次抓取的选择的语言是java,本文章不会将整个工程的全部代码全部贴出,只会提供核心代码和抓取思路的说明。
数据的抓取
抓取文章的来源为搜狗陌陌网站,网站如下图。
抓取的思路如下
一般抓取微信公众号的文章都是以微信公众号的id为关键字 ,我们可以通过url+ keyword的方式直接跳转到想要抓取公众号页面,keyword即为想要搜索微信公众号的名称或则是id;
// 搜狗微信搜索链接入口
String sogou_search_url = "http://weixin.sogou.com/weixin ... ot%3B
+ keyword + "&ie=utf8&s_from=input&_sug_=n&_sug_type_=";
为了防止网站对爬虫的初步拦截,我们可以使用Selenium (浏览器自动化测试框架)来伪装自己的爬虫,我们使用的chrome,这里须要注意自己的chrome版本与使用的webdriver的版本是对应的;
ChromeOptions chromeOptions = new ChromeOptions();
// 全屏,为了接下来防抓取做准备
chromeOptions.addArguments("--start-maximized");
System.setProperty("webdriver.chrome.driver", chromedriver);
WebDriver webDriver = new ChromeDriver(chromeOptions);
到达微信公众号列表页面,如下图,获取微信公众号链接。
<p> // 获取当前页面的微信公众号列表
List weixin_list = webDriver
.findElements(By.cssSelector("div[class='txt-box']"));
// 获取进入公众号的链接
String weixin_url = "";
for (int i = 0; i 查看全部
记一次批量定时抓取微信公众号文章的实现
抓取前的说明和打算
本次抓取的选择的语言是java,本文章不会将整个工程的全部代码全部贴出,只会提供核心代码和抓取思路的说明。
数据的抓取
抓取文章的来源为搜狗陌陌网站,网站如下图。
抓取的思路如下
一般抓取微信公众号的文章都是以微信公众号的id为关键字 ,我们可以通过url+ keyword的方式直接跳转到想要抓取公众号页面,keyword即为想要搜索微信公众号的名称或则是id;
// 搜狗微信搜索链接入口
String sogou_search_url = "http://weixin.sogou.com/weixin ... ot%3B
+ keyword + "&ie=utf8&s_from=input&_sug_=n&_sug_type_=";
为了防止网站对爬虫的初步拦截,我们可以使用Selenium (浏览器自动化测试框架)来伪装自己的爬虫,我们使用的chrome,这里须要注意自己的chrome版本与使用的webdriver的版本是对应的;
ChromeOptions chromeOptions = new ChromeOptions();
// 全屏,为了接下来防抓取做准备
chromeOptions.addArguments("--start-maximized");
System.setProperty("webdriver.chrome.driver", chromedriver);
WebDriver webDriver = new ChromeDriver(chromeOptions);
到达微信公众号列表页面,如下图,获取微信公众号链接。
<p> // 获取当前页面的微信公众号列表
List weixin_list = webDriver
.findElements(By.cssSelector("div[class='txt-box']"));
// 获取进入公众号的链接
String weixin_url = "";
for (int i = 0; i
建立微信公众号测试帐号-Java本地服务
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-09 03:56
这是第一个坑. 在测试编号中,您可以填写域名ip,甚至不需要填写域名,这极大地方便了测试授权的使用. 回调页面表示微信用户关注您的官方账号. 当他选择授权登录时,我们可以调用微信界面来获取他的基本微信信息,例如唯一的微信openid,然后返回到我们的页面之一,或者这是用于采集用户信息的服务. 页面或服务必须在此域名下. 假设我填写了
例如,如果我想返回页面,它可以是:
,
返回服务:
只要在此域名下,无论嵌入多少层. 请注意,不能在前面添加https或http前缀.
在回调域名中,如果您的项目名称由下划线组成,
例如,要访问您的项目,请删除带下划线的项目名称. 尽管删除的项目名称只能映射回本地启动服务器,而不是映射回项目,但这不会造成伤害.
好的,这里很多人说,如果没有域名,我该怎么办,那是第二种材料,一个可以映射到Intranet的域名.
我使用的花生壳域名.
新用户可以获得几个免费域名,他们也可以使用这些域名,但是对于我来说,测试并购买100个大洋的.com域名非常方便.
然后通过花生壳内部网下载客户端
您拥有的域名将显示在这里,包括您发送的域名.
随意编写应用程序名称,域名是下属之一,映射是HTTP80. 内部主机不知道您可以打开cmd ip config / all来查看您的地址. 我的项目从tomact开始,使用默认端口8080. 最后,进行诊断并在地址栏中键入Internet域名,以确保其他人可以访问您的本地项目.
到目前为止,第二种材料已经准备好了.
第三个是可以运行的项目...这里将不讨论. 您可以使用springboot + myb,springMVC,struts2来构建可以运行的项目. 如果没有,请搜索其他博客以快速建立一个博客,至少您可以输入一个servelet. 我只是直接运行公司的项目.
连接授权界面
首先编写一个链接: APPID&redirect_uri = l&response_type = code&scope = snsapi_base&state = 123#wechat_redirect
此链接已发送至微信,表明我要开始停靠此界面
appid: 是测试编号上的appid
redirect_uri: 我们刚刚在上面填写了,因此这里是在该域名下填写一个HTML以供回调. 必须添加或在这里,必须!
scope: 这是指要调用的微信界面,snsapi_base是指用户的静默授权,这是用户执行微信授权而没有弹出框提示是否进行授权的情况,因此该界面获取的信息较少,您可以查看详细信息官方技术文档.
状态: 填写您想要的任何内容.
我下载了官方的微信调试工具. 如果您按照上述步骤进行操作,则您的链接将不会出现代码错误,redirect_uri和其他错误.
如您所见,在返回的页面上,后缀附有代码. 该代码将被发送到微信以交换刚刚登录的用户的信息. 当然,您可以对上述授权链接进行异步请求,并使用js在页面上获取它. 我是这样子的
函数GetQueryString(name)
{
var reg = new RegExp(“(^ |&)” + name +“ =([^&] *)(&| $)”);
var r = window.location.search.substr(1).match(reg);
if(r!= null)返回unescape(r [2]);返回null;
}
调用GetQueryString(code)获取地址的参数值.
获取后,将其发送到后台进行处理. 有很多提交方法. 异步也是可能的,或者将整个表单直接连接到其他值并提交到后台. 根仍然由后台处理.
仅使用老式的struts2粘贴密钥代码,因此返回String映射以返回到页面,如果您是springMVC控制器,请自行更改
public String juvenileSubsidy() {
//如果是第二次验证登录则直接发送微信的opendid
String openId =getOpenId();
.......//省略各种去到信息以后的service
return "login_jsp";
}
........
private String getOpenId(){
//appid和secret是测试公众号上的,自行填写,别直接copy,
//code是刚刚获取到的,自行改写参数
String url="https://api.weixin.qq.com/sns/oa"
+ "uth2/access_token?appid="+wxappid+"&"
+ "secret="+appsecret+"&code="+wxcode+""
+ "&grant_type=authorization_code";
String openId="";
try {
URL getUrl=new URL(url);
HttpURLConnection http=(HttpURLConnection)getUrl.openConnection();
http.setRequestMethod("GET");
http.setRequestProperty("Content-Type","application/x-www-form-urlencoded");
http.setDoOutput(true);
http.setDoInput(true);
http.connect();
InputStream is = http.getInputStream();
int size = is.available();
byte[] b = new byte[size];
is.read(b);
String message = new String(b, "UTF-8");
JSONObject json = JSONObject.parseObject(message);
openId=json.get("openid").toString();
} catch (Exception e) {
System.out.println(e.getMessage());
}
return openId;
}
当然,许多博客文章都是关于如何封装地址参数名称的,以便以后可以调用. 一开始,我写得很粗糙以显示效果. 您可以在将来轻松封装它,甚至可以使用xml读取配置信息. 我的私有方法只是返回我需要的String openid. 您可以选择返回对象,或检查正式文档,更改原创范围,非静默授权可以获取更多用户信息.
接下来是调试观察.
{"access_token":"15_0D9_XTsx2YdwoD5KPd6WHAEc47xLqy4uuQAb06irOd5UgOnzwW3zPRdhMXinpJ7ucvkW3D7coema7QAdA",
"expires_in":7200,
"refresh_token":"15_cz_GGe-k41d_YVVgmrFvQBUvF_LuyuNSB2PTq8YWXHLz0l7Vg8hJnBWjGFMNhTT2NRFqqRYT5gSofww",
"openid":"o-MN1B0FGR1JV398vbSPNZ70xa424",
"scope":"snsapi_base"}
以上是成功发送到微信界面的json对象. 我叫snsapi_base,所以我只能返回此信息. 这些令牌每次都会刷新,并且这些密钥也被微信用于验证服务器的重要数据,但是在这里它们是无用的. 我得到了所需的openid.
通过这种方式,获得了微信登录官方账号上唯一识别的ID,并可以通过该ID实现业务逻辑. 同时,可以在本地测试官方帐户服务.
对于本文开头提到的接口配置信息,此处不需要使用它. 这要求后端发送令牌进行验证.
最后,您可以将此婴儿链接放在官方帐户的自定义菜单中. 这就是所谓的用户登录授权.
当然,这是测试帐户授权. 正式启动后,它将替换为注册域名,appid被替换为官方官方帐户的ID,其余部分保持不变.
到目前为止,官方帐户的静默授权已完成! 查看全部
这里的重点是页面授权回调的域名.
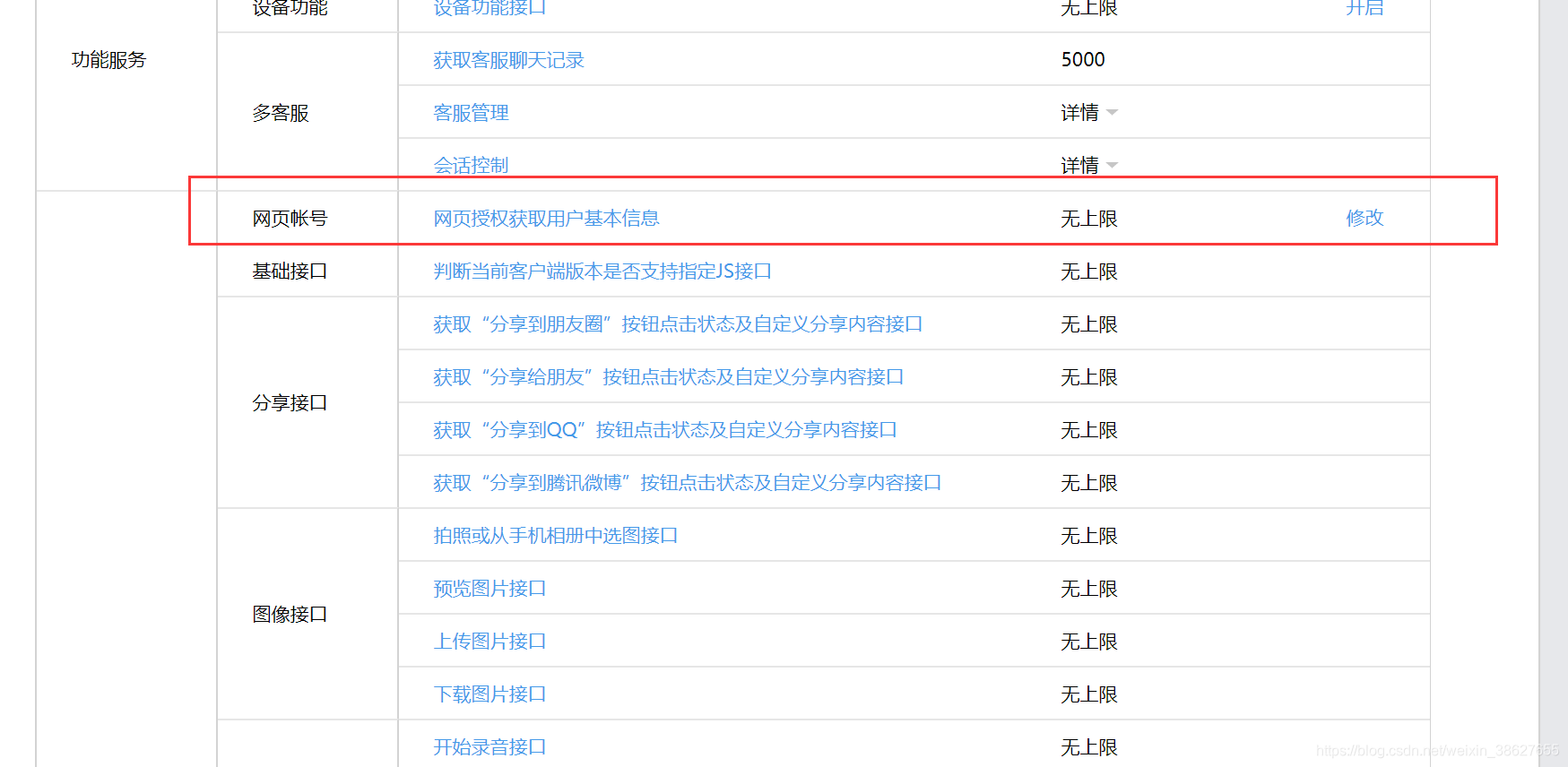
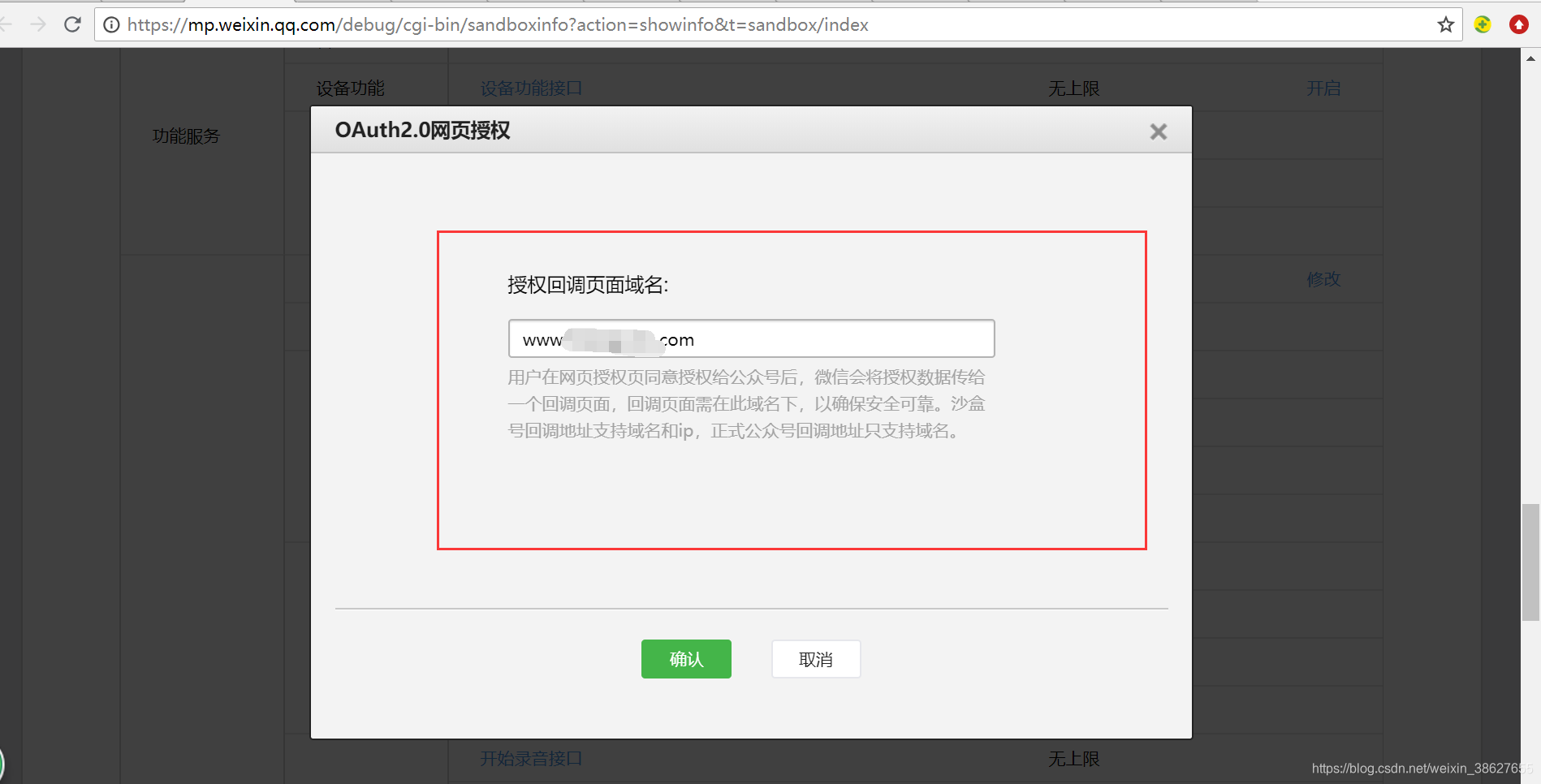
这是第一个坑. 在测试编号中,您可以填写域名ip,甚至不需要填写域名,这极大地方便了测试授权的使用. 回调页面表示微信用户关注您的官方账号. 当他选择授权登录时,我们可以调用微信界面来获取他的基本微信信息,例如唯一的微信openid,然后返回到我们的页面之一,或者这是用于采集用户信息的服务. 页面或服务必须在此域名下. 假设我填写了
例如,如果我想返回页面,它可以是:
,
返回服务:
只要在此域名下,无论嵌入多少层. 请注意,不能在前面添加https或http前缀.
在回调域名中,如果您的项目名称由下划线组成,
例如,要访问您的项目,请删除带下划线的项目名称. 尽管删除的项目名称只能映射回本地启动服务器,而不是映射回项目,但这不会造成伤害.
好的,这里很多人说,如果没有域名,我该怎么办,那是第二种材料,一个可以映射到Intranet的域名.
我使用的花生壳域名.
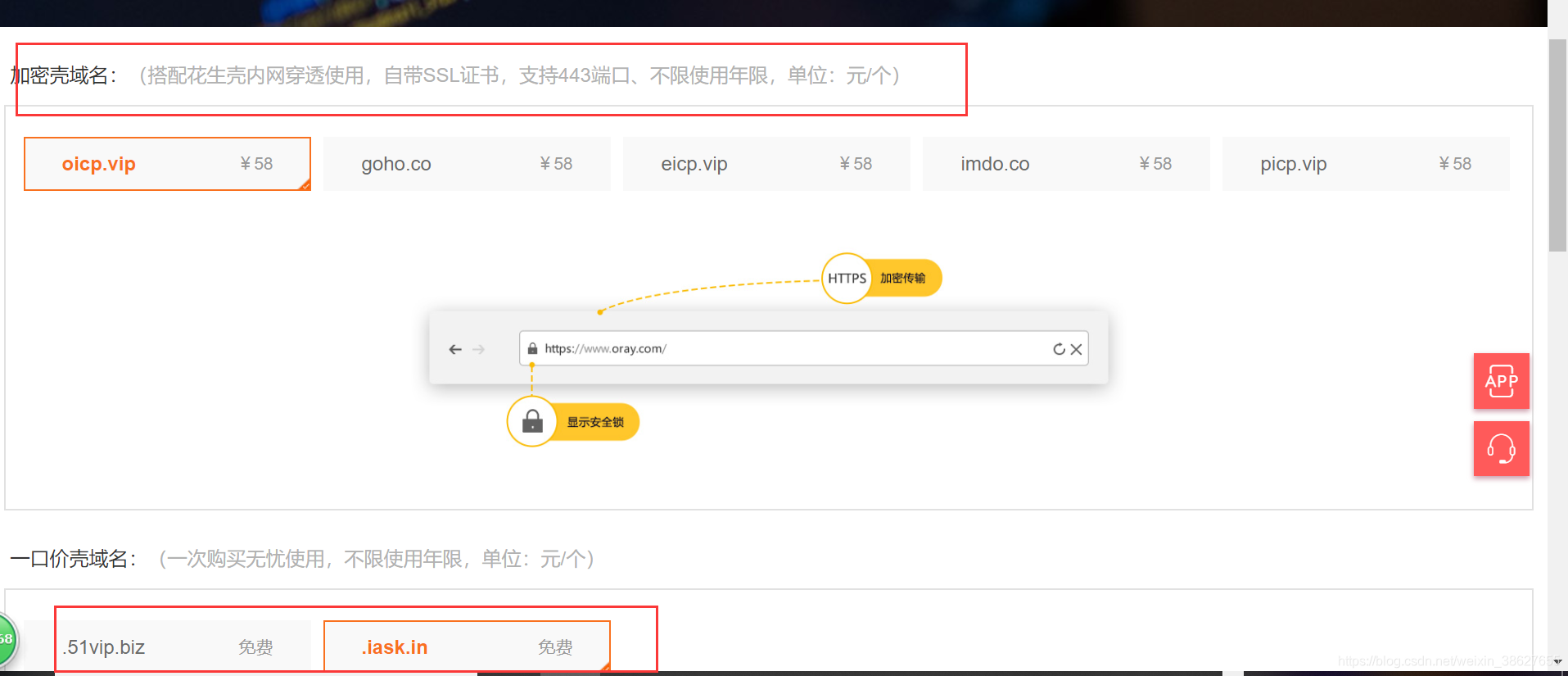
新用户可以获得几个免费域名,他们也可以使用这些域名,但是对于我来说,测试并购买100个大洋的.com域名非常方便.
然后通过花生壳内部网下载客户端
您拥有的域名将显示在这里,包括您发送的域名.
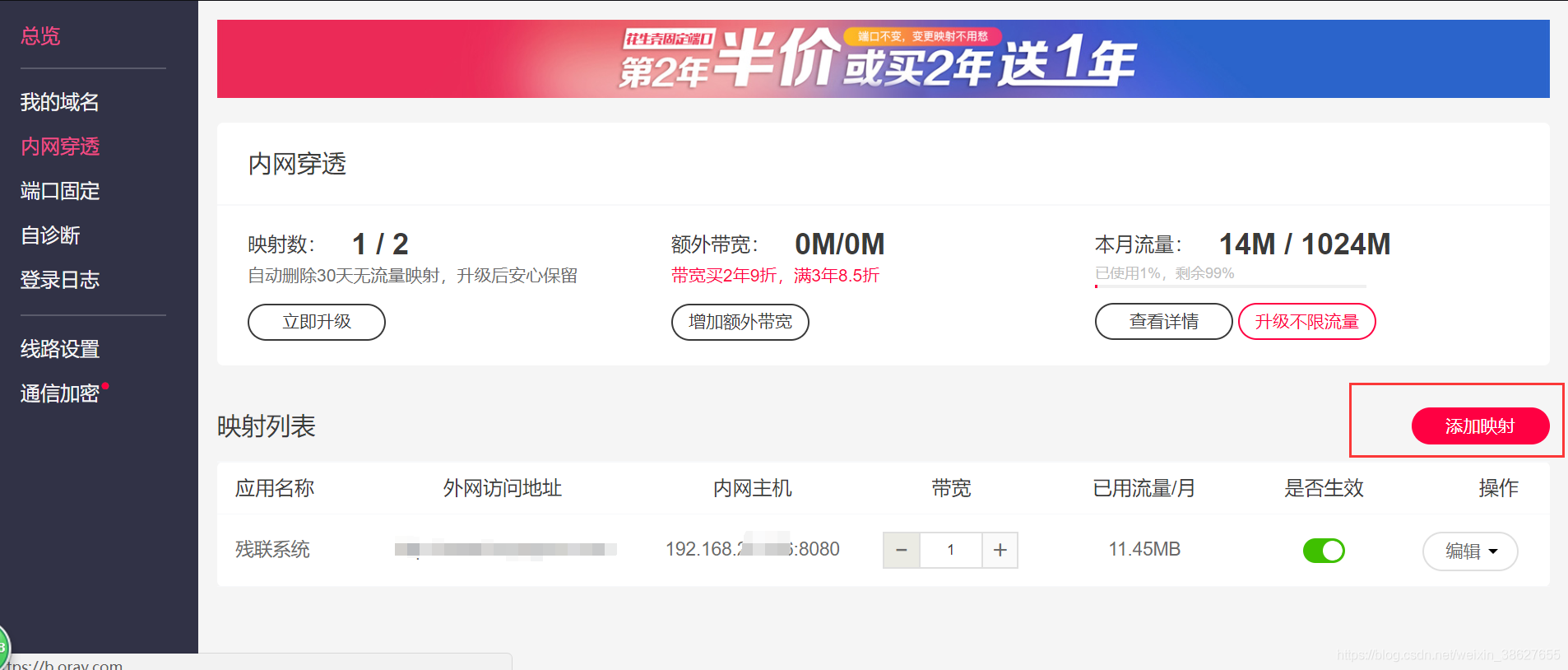
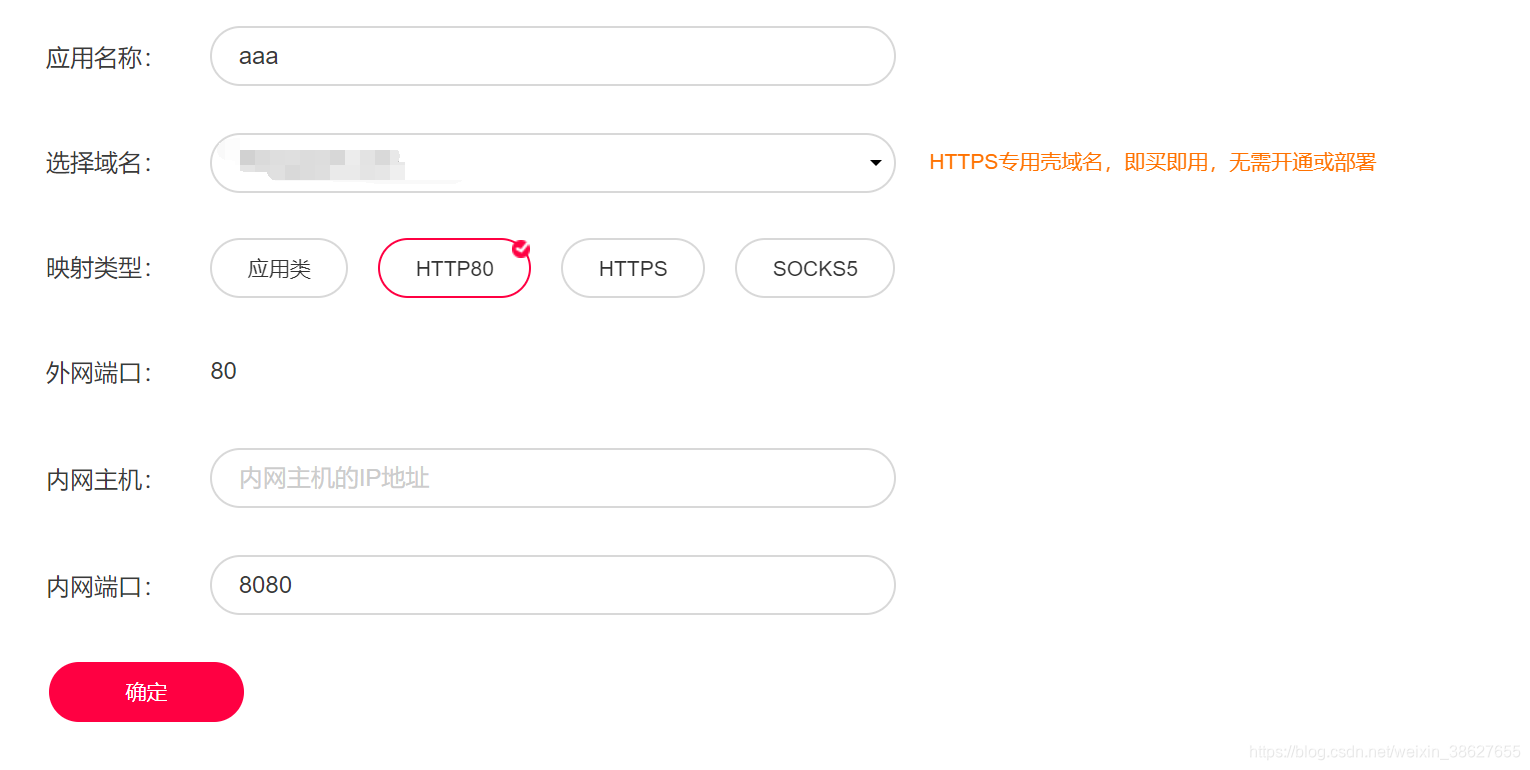
随意编写应用程序名称,域名是下属之一,映射是HTTP80. 内部主机不知道您可以打开cmd ip config / all来查看您的地址. 我的项目从tomact开始,使用默认端口8080. 最后,进行诊断并在地址栏中键入Internet域名,以确保其他人可以访问您的本地项目.
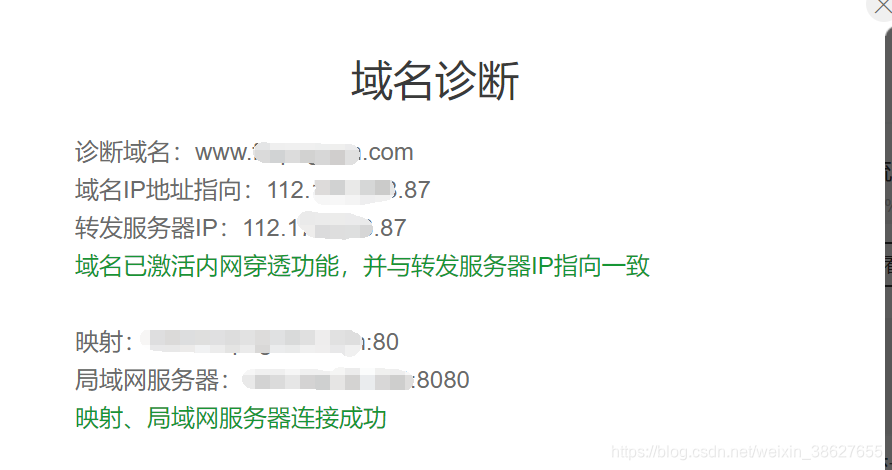
到目前为止,第二种材料已经准备好了.
第三个是可以运行的项目...这里将不讨论. 您可以使用springboot + myb,springMVC,struts2来构建可以运行的项目. 如果没有,请搜索其他博客以快速建立一个博客,至少您可以输入一个servelet. 我只是直接运行公司的项目.
连接授权界面
首先编写一个链接: APPID&redirect_uri = l&response_type = code&scope = snsapi_base&state = 123#wechat_redirect
此链接已发送至微信,表明我要开始停靠此界面
appid: 是测试编号上的appid
redirect_uri: 我们刚刚在上面填写了,因此这里是在该域名下填写一个HTML以供回调. 必须添加或在这里,必须!
scope: 这是指要调用的微信界面,snsapi_base是指用户的静默授权,这是用户执行微信授权而没有弹出框提示是否进行授权的情况,因此该界面获取的信息较少,您可以查看详细信息官方技术文档.
状态: 填写您想要的任何内容.
我下载了官方的微信调试工具. 如果您按照上述步骤进行操作,则您的链接将不会出现代码错误,redirect_uri和其他错误.
如您所见,在返回的页面上,后缀附有代码. 该代码将被发送到微信以交换刚刚登录的用户的信息. 当然,您可以对上述授权链接进行异步请求,并使用js在页面上获取它. 我是这样子的
函数GetQueryString(name)
{
var reg = new RegExp(“(^ |&)” + name +“ =([^&] *)(&| $)”);
var r = window.location.search.substr(1).match(reg);
if(r!= null)返回unescape(r [2]);返回null;
}
调用GetQueryString(code)获取地址的参数值.
获取后,将其发送到后台进行处理. 有很多提交方法. 异步也是可能的,或者将整个表单直接连接到其他值并提交到后台. 根仍然由后台处理.
仅使用老式的struts2粘贴密钥代码,因此返回String映射以返回到页面,如果您是springMVC控制器,请自行更改
public String juvenileSubsidy() {
//如果是第二次验证登录则直接发送微信的opendid
String openId =getOpenId();
.......//省略各种去到信息以后的service
return "login_jsp";
}
........
private String getOpenId(){
//appid和secret是测试公众号上的,自行填写,别直接copy,
//code是刚刚获取到的,自行改写参数
String url="https://api.weixin.qq.com/sns/oa"
+ "uth2/access_token?appid="+wxappid+"&"
+ "secret="+appsecret+"&code="+wxcode+""
+ "&grant_type=authorization_code";
String openId="";
try {
URL getUrl=new URL(url);
HttpURLConnection http=(HttpURLConnection)getUrl.openConnection();
http.setRequestMethod("GET");
http.setRequestProperty("Content-Type","application/x-www-form-urlencoded");
http.setDoOutput(true);
http.setDoInput(true);
http.connect();
InputStream is = http.getInputStream();
int size = is.available();
byte[] b = new byte[size];
is.read(b);
String message = new String(b, "UTF-8");
JSONObject json = JSONObject.parseObject(message);
openId=json.get("openid").toString();
} catch (Exception e) {
System.out.println(e.getMessage());
}
return openId;
}
当然,许多博客文章都是关于如何封装地址参数名称的,以便以后可以调用. 一开始,我写得很粗糙以显示效果. 您可以在将来轻松封装它,甚至可以使用xml读取配置信息. 我的私有方法只是返回我需要的String openid. 您可以选择返回对象,或检查正式文档,更改原创范围,非静默授权可以获取更多用户信息.
接下来是调试观察.
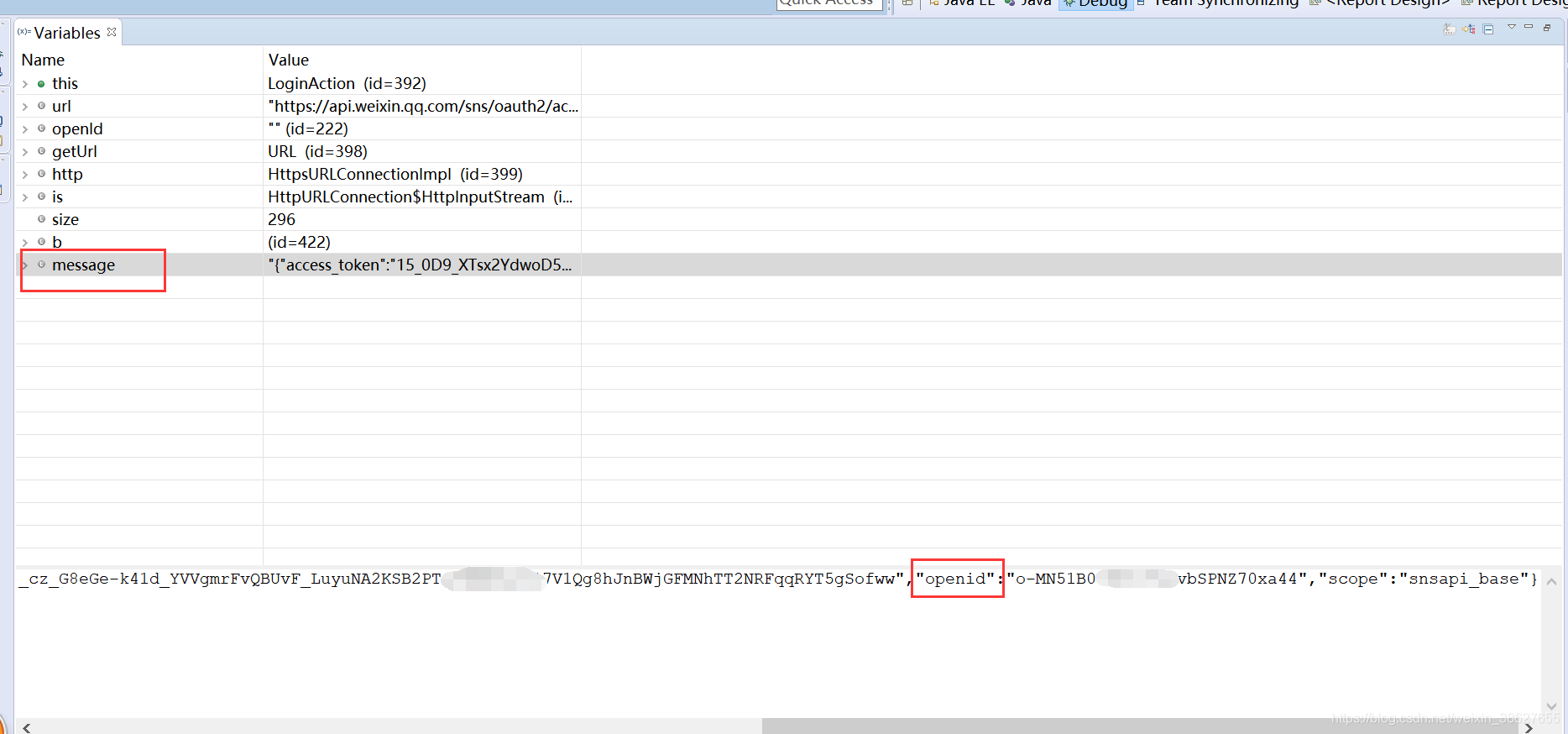
{"access_token":"15_0D9_XTsx2YdwoD5KPd6WHAEc47xLqy4uuQAb06irOd5UgOnzwW3zPRdhMXinpJ7ucvkW3D7coema7QAdA",
"expires_in":7200,
"refresh_token":"15_cz_GGe-k41d_YVVgmrFvQBUvF_LuyuNSB2PTq8YWXHLz0l7Vg8hJnBWjGFMNhTT2NRFqqRYT5gSofww",
"openid":"o-MN1B0FGR1JV398vbSPNZ70xa424",
"scope":"snsapi_base"}
以上是成功发送到微信界面的json对象. 我叫snsapi_base,所以我只能返回此信息. 这些令牌每次都会刷新,并且这些密钥也被微信用于验证服务器的重要数据,但是在这里它们是无用的. 我得到了所需的openid.
通过这种方式,获得了微信登录官方账号上唯一识别的ID,并可以通过该ID实现业务逻辑. 同时,可以在本地测试官方帐户服务.
对于本文开头提到的接口配置信息,此处不需要使用它. 这要求后端发送令牌进行验证.
最后,您可以将此婴儿链接放在官方帐户的自定义菜单中. 这就是所谓的用户登录授权.
当然,这是测试帐户授权. 正式启动后,它将替换为注册域名,appid被替换为官方官方帐户的ID,其余部分保持不变.
到目前为止,官方帐户的静默授权已完成!
微信抓取过程中的参数分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2020-08-08 17:17
mid是图形消息的ID
idx是发布的头几条消息(1表示标题位置消息)
sn是一个随机加密的字符串(对于图形消息来说是唯一的,如果您想询问此sn的生成规则是什么或如何破解它,您基本上只能从微信公众平台开发中获得答案. 团队)变相煮
三: 伪装微信客户端登录并获取历史信息页面. 4个最重要的参数是: __biz; uin =; key =; pass_ticket =;这四个参数. [有时需要手机]
四: 获得general_msg_list后,分析每个字段
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
五: 获取程序的原型
创建表格:
1. 微信公众号列表
CREATE TABLE `weixin` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`biz` varchar(255) DEFAULT '' COMMENT '公众号唯一标识biz',
`collect` int(11) DEFAULT '1' COMMENT '记录采集时间的时间戳',
PRIMARY KEY (`id`)
) ;
2,微信文章列表
CREATE TABLE `post` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`biz` varchar(255) CHARACTER SET utf8 NOT NULL COMMENT '文章对应的公众号biz',
`field_id` int(11) NOT NULL COMMENT '微信定义的一个id,每条文章唯一',
`title` varchar(255) NOT NULL DEFAULT '' COMMENT '文章标题',
`title_encode` text CHARACTER SET utf8 NOT NULL COMMENT '文章编码,防止文章出现emoji',
`digest` varchar(500) NOT NULL DEFAULT '' COMMENT '文章摘要',
`content_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '文章地址',
`source_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '阅读原文地址',
`cover` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '封面图片',
`is_multi` int(11) NOT NULL COMMENT '是否多图文',
`is_top` int(11) NOT NULL COMMENT '是否头条',
`datetime` int(11) NOT NULL COMMENT '文章时间戳',
`readNum` int(11) NOT NULL DEFAULT '1' COMMENT '文章阅读量',
`likeNum` int(11) NOT NULL DEFAULT '0' COMMENT '文章点赞量',
PRIMARY KEY (`id`)
) ;
3. 采集团队名单
CREATE TABLE `tmplist` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`content_url` varchar(255) DEFAULT NULL COMMENT '文章地址',
`load` int(11) DEFAULT '0' COMMENT '读取中标记',
PRIMARY KEY (`id`),
UNIQUE KEY `content_url` (`content_url`)
) ;
采集:
1,getMsgJson.php: 该程序负责接收已解析并存储在数据库中的历史消息的json
<p> 查看全部
__ biz可被视为在微信公众平台上公开宣布的公共账户的唯一ID
mid是图形消息的ID
idx是发布的头几条消息(1表示标题位置消息)
sn是一个随机加密的字符串(对于图形消息来说是唯一的,如果您想询问此sn的生成规则是什么或如何破解它,您基本上只能从微信公众平台开发中获得答案. 团队)变相煮
三: 伪装微信客户端登录并获取历史信息页面. 4个最重要的参数是: __biz; uin =; key =; pass_ticket =;这四个参数. [有时需要手机]
四: 获得general_msg_list后,分析每个字段
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
五: 获取程序的原型
创建表格:
1. 微信公众号列表
CREATE TABLE `weixin` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`biz` varchar(255) DEFAULT '' COMMENT '公众号唯一标识biz',
`collect` int(11) DEFAULT '1' COMMENT '记录采集时间的时间戳',
PRIMARY KEY (`id`)
) ;
2,微信文章列表
CREATE TABLE `post` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`biz` varchar(255) CHARACTER SET utf8 NOT NULL COMMENT '文章对应的公众号biz',
`field_id` int(11) NOT NULL COMMENT '微信定义的一个id,每条文章唯一',
`title` varchar(255) NOT NULL DEFAULT '' COMMENT '文章标题',
`title_encode` text CHARACTER SET utf8 NOT NULL COMMENT '文章编码,防止文章出现emoji',
`digest` varchar(500) NOT NULL DEFAULT '' COMMENT '文章摘要',
`content_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '文章地址',
`source_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '阅读原文地址',
`cover` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '封面图片',
`is_multi` int(11) NOT NULL COMMENT '是否多图文',
`is_top` int(11) NOT NULL COMMENT '是否头条',
`datetime` int(11) NOT NULL COMMENT '文章时间戳',
`readNum` int(11) NOT NULL DEFAULT '1' COMMENT '文章阅读量',
`likeNum` int(11) NOT NULL DEFAULT '0' COMMENT '文章点赞量',
PRIMARY KEY (`id`)
) ;
3. 采集团队名单
CREATE TABLE `tmplist` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`content_url` varchar(255) DEFAULT NULL COMMENT '文章地址',
`load` int(11) DEFAULT '0' COMMENT '读取中标记',
PRIMARY KEY (`id`),
UNIQUE KEY `content_url` (`content_url`)
) ;
采集:
1,getMsgJson.php: 该程序负责接收已解析并存储在数据库中的历史消息的json
<p>
通过微信公众平台获取官方帐户文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2020-08-08 10:12
选择自己创建的图形:
好像是公共帐户操作教学
进入编辑页面后,单击超链接
弹出一个选择框,我们在框中输入相应的正式帐户名称,并出现相应的商品列表
您感到惊讶吗?您可以打开控制台并检查请求的界面
打开回复,有我们需要的文章链接
确认数据后,我们需要分析此界面.
感觉很简单. GET请求带有一些参数.
Fakeid是官方帐户的唯一ID,因此,如果要直接按名称获取商品列表,则需要先获取伪造品.
当我们输入官方帐户名时,单击“搜索”. 您会看到搜索界面已触发,并返回了伪造品.
此界面不需要很多参数.
接下来,我们可以使用代码来模拟上述操作.
但是您还需要使用现有的cookie以避免登录.
目前,我尚未测试过cookie的有效期. 可能需要及时更新cookie.
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
通过这种方式,您可以获得最新的10篇文章. 如果要获取更多历史文章,可以修改数据中的“ begin”参数,0为第一页,5为第二页,10为第三页(依此类推)
但是,如果您想进行大规模爬网:
请为您自己安排稳定的代理商,降低爬虫速度,并准备多个帐户以减少被阻止的可能性. 查看全部
选择自己创建的图形:
好像是公共帐户操作教学
进入编辑页面后,单击超链接
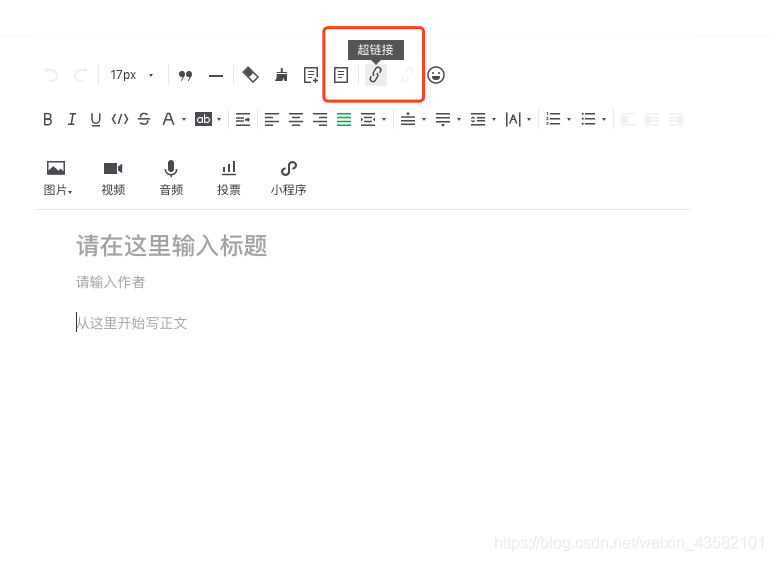
弹出一个选择框,我们在框中输入相应的正式帐户名称,并出现相应的商品列表
您感到惊讶吗?您可以打开控制台并检查请求的界面
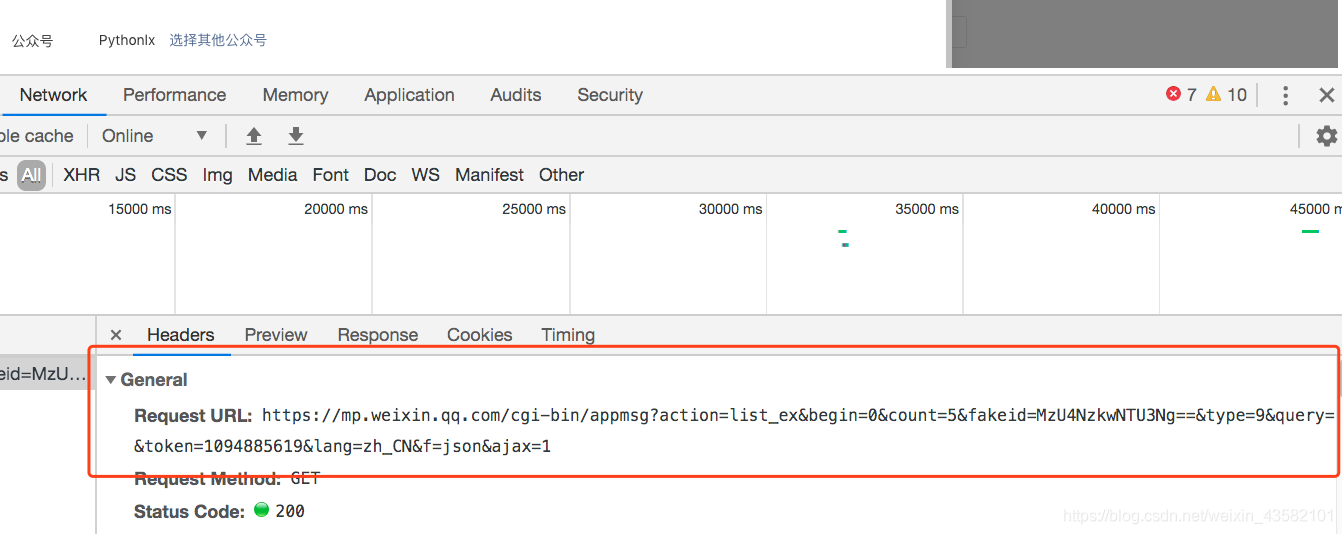
打开回复,有我们需要的文章链接

确认数据后,我们需要分析此界面.
感觉很简单. GET请求带有一些参数.

Fakeid是官方帐户的唯一ID,因此,如果要直接按名称获取商品列表,则需要先获取伪造品.
当我们输入官方帐户名时,单击“搜索”. 您会看到搜索界面已触发,并返回了伪造品.
此界面不需要很多参数.
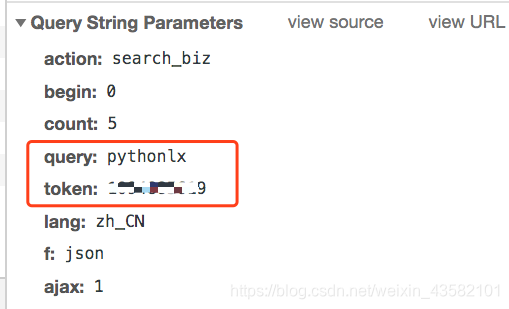
接下来,我们可以使用代码来模拟上述操作.
但是您还需要使用现有的cookie以避免登录.
目前,我尚未测试过cookie的有效期. 可能需要及时更新cookie.
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
通过这种方式,您可以获得最新的10篇文章. 如果要获取更多历史文章,可以修改数据中的“ begin”参数,0为第一页,5为第二页,10为第三页(依此类推)
但是,如果您想进行大规模爬网:
请为您自己安排稳定的代理商,降低爬虫速度,并准备多个帐户以减少被阻止的可能性.
java微信公众号第三方接入解析及全网检查代码示例
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2020-08-22 12:10
一、接入大体思路解析
这里主要是查看文档的授权流程技术说明,这里从开发者角度介绍。
接入第三方的开发者想必早已对公众号开发比较了解,第三方是代微信号实现功能的一个组件,所以其实陌陌方的开发们也是这么考虑,为第三方的access_token起名为component_access_token。
1、首先获取第三方
component_access_token
这个过程中会使用到陌陌服务器定期向我们服务器推送的component_verify_ticket数组,加上component_appid、component_appsecret等信息即可获得。
2、获取授权公众号信息
类似公众号网页授权,通过反弹的方式,微信公众号运营者可以通过陌陌扫码的方式将公众号授权给第三方,唯一有些不同的这儿在拼出授权跳转页面url后的第一步是引导用户跳转到该页面上,再进行扫码,所以这个跳转不是必须在陌陌外置浏览器中进行。
拼出的url中的参数出了要用到component_access_token外还须要一个pre_auth_code预授权码,可通过component_access_token获得,具体的实效时间机制和component_access_token差不多。
用户授权成功后会在redirect_url后接参数auth_code,类似公众号网页授权的code值,通过auth_code和component_access_token等信息即可获得该授权公众号信息,若中间要与公众号第三方平台的帐号绑定再带一个帐号标识参数即可。
3、带公众号实现业务
公众号授权成功后第三方会得到该公众号的authorizer_access_token,与公众号的access_token功能相同,使用这个即可用微信公众号的插口代公众号实现业务。
有些不同的再第三方文档里以有说明。官方文档
另外文档上没有提及的是,每当有公众号授权成功后,微信服务器会将公众号授权信息推送到授权风波接收URL,即接收component_verify_ticket的插口。
4、关于加密揭秘
获取陌陌服务器推送信息的时侯都是进行加密的。
二、接入中发觉的几个问题1、微信的示例java代码,XMLParse类中
/**
* 提取出xml数据包中的加密消息
* @param xmltext 待提取的xml字符串
* @return 提取出的加密消息字符串
* @throws AesException
*/
public static Object[] extract(String xmltext) throws AesException {
Object[] result = new Object[3];
try {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
StringReader sr = new StringReader(xmltext);
InputSource is = new InputSource(sr);
Document document = db.parse(is);
Element root = document.getDocumentElement();
NodeList nodelist1 = root.getElementsByTagName("Encrypt");
NodeList nodelist2 = root.getElementsByTagName("ToUserName");
System.out.println("nodelist2.item(0)="+nodelist2.item(0));
result[0] = 0;
result[1] = nodelist1.item(0).getTextContent();
//这里加了一个判断,因为接收推送component_verify_ticket的解谜过程中没有第三个参数,回报空指针异常
if(nodelist2.item(0) != null){
result[2] = nodelist2.item(0).getTextContent();
}
return result;
} catch (Exception e) {
e.printStackTrace();
throw new AesException(AesException.ParseXmlError);
}
}
2、文档中:使用授权码换取公众号的插口调用凭据和授权信息
返回json信息最后少了一个}
{
"authorization_info": {
"authorizer_appid": "wxf8b4f85f3a794e77",
"authorizer_access_token": "QXjUqNqfYVH0yBE1iI_7vuN_9gQbpjfK7hYwJ3P7xOa88a89-Aga5x1NMYJyB8G2yKt1KCl0nPC3W9GJzw0Zzq_dBxc8pxIGUNi_bFes0qM",
"expires_in": 7200,
"authorizer_refresh_token": "dTo-YCXPL4llX-u1W1pPpnp8Hgm4wpJtlR6iV0doKdY",
"func_info": [
{
"funcscope_category": {
"id": 1
}
},
{
"funcscope_category": {
"id": 2
}
},
{
"funcscope_category": {
"id": 3
}
}
]
}
}
大家开发时要注意json数据结构
三、关于代码
在 微信公众帐号第三方平台全网发布源码(java)- 实战测试通过 代码结构基础上进行更改 查看全部
java微信公众号第三方接入解析及全网监测代码示例
一、接入大体思路解析
这里主要是查看文档的授权流程技术说明,这里从开发者角度介绍。
接入第三方的开发者想必早已对公众号开发比较了解,第三方是代微信号实现功能的一个组件,所以其实陌陌方的开发们也是这么考虑,为第三方的access_token起名为component_access_token。
1、首先获取第三方
component_access_token
这个过程中会使用到陌陌服务器定期向我们服务器推送的component_verify_ticket数组,加上component_appid、component_appsecret等信息即可获得。
2、获取授权公众号信息
类似公众号网页授权,通过反弹的方式,微信公众号运营者可以通过陌陌扫码的方式将公众号授权给第三方,唯一有些不同的这儿在拼出授权跳转页面url后的第一步是引导用户跳转到该页面上,再进行扫码,所以这个跳转不是必须在陌陌外置浏览器中进行。
拼出的url中的参数出了要用到component_access_token外还须要一个pre_auth_code预授权码,可通过component_access_token获得,具体的实效时间机制和component_access_token差不多。
用户授权成功后会在redirect_url后接参数auth_code,类似公众号网页授权的code值,通过auth_code和component_access_token等信息即可获得该授权公众号信息,若中间要与公众号第三方平台的帐号绑定再带一个帐号标识参数即可。
3、带公众号实现业务
公众号授权成功后第三方会得到该公众号的authorizer_access_token,与公众号的access_token功能相同,使用这个即可用微信公众号的插口代公众号实现业务。
有些不同的再第三方文档里以有说明。官方文档
另外文档上没有提及的是,每当有公众号授权成功后,微信服务器会将公众号授权信息推送到授权风波接收URL,即接收component_verify_ticket的插口。
4、关于加密揭秘
获取陌陌服务器推送信息的时侯都是进行加密的。
二、接入中发觉的几个问题1、微信的示例java代码,XMLParse类中
/**
* 提取出xml数据包中的加密消息
* @param xmltext 待提取的xml字符串
* @return 提取出的加密消息字符串
* @throws AesException
*/
public static Object[] extract(String xmltext) throws AesException {
Object[] result = new Object[3];
try {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
StringReader sr = new StringReader(xmltext);
InputSource is = new InputSource(sr);
Document document = db.parse(is);
Element root = document.getDocumentElement();
NodeList nodelist1 = root.getElementsByTagName("Encrypt");
NodeList nodelist2 = root.getElementsByTagName("ToUserName");
System.out.println("nodelist2.item(0)="+nodelist2.item(0));
result[0] = 0;
result[1] = nodelist1.item(0).getTextContent();
//这里加了一个判断,因为接收推送component_verify_ticket的解谜过程中没有第三个参数,回报空指针异常
if(nodelist2.item(0) != null){
result[2] = nodelist2.item(0).getTextContent();
}
return result;
} catch (Exception e) {
e.printStackTrace();
throw new AesException(AesException.ParseXmlError);
}
}
2、文档中:使用授权码换取公众号的插口调用凭据和授权信息
返回json信息最后少了一个}
{
"authorization_info": {
"authorizer_appid": "wxf8b4f85f3a794e77",
"authorizer_access_token": "QXjUqNqfYVH0yBE1iI_7vuN_9gQbpjfK7hYwJ3P7xOa88a89-Aga5x1NMYJyB8G2yKt1KCl0nPC3W9GJzw0Zzq_dBxc8pxIGUNi_bFes0qM",
"expires_in": 7200,
"authorizer_refresh_token": "dTo-YCXPL4llX-u1W1pPpnp8Hgm4wpJtlR6iV0doKdY",
"func_info": [
{
"funcscope_category": {
"id": 1
}
},
{
"funcscope_category": {
"id": 2
}
},
{
"funcscope_category": {
"id": 3
}
}
]
}
}
大家开发时要注意json数据结构
三、关于代码
在 微信公众帐号第三方平台全网发布源码(java)- 实战测试通过 代码结构基础上进行更改
搜狗陌陌的抓取总结
采集交流 • 优采云 发表了文章 • 0 个评论 • 266 次浏览 • 2020-08-21 22:19
最近抓取了搜狗陌陌的数据,虽然也破解了跳转之类的,但是最后由于抓取的链接有时效性舍弃了,也总结下
一样的,输入关键词,抓取列表,再回来跳转后的陌陌链接
前10页是可以随意看的,也不需要登陆,10页以后的数据须要陌陌扫码登陆,这一块无法破解
链接参数好多最后可以精简为
烽火&page=11&type=2
page就是页脚,query就是关键字,type 是搜索文章还是搜索公众号
其实很简单的代码,先要在url前面构造出 k 和 h,转化为 java 代码就是
// 拼接搜狗跳转参数k和h
public static String getLinkUrl(String url) {
int b = ((int) Math.floor(100 * Math.random())) + 1;
int a = url.indexOf("url=");
int k = a + 4 + 21 + b;
String d = url.substring(k, k + 1);
System.out.println(d);
url += "&k=" + b + "&h=" + d;
return "https://weixin.sogou.com" + url;
}
有参数的链接直接恳求是会出验证码的,需要cookie,需要的cookie只要是两个 一个是 SUV,一个是SNUID,这两个cookie获取都很简单,通过剖析可以得到
1.SUV 是可以通过访问来获取到
2.SNUID 在搜索的时侯才会有了
所以我们加上这两个cookie才能获取到具体的陌陌的链接了
剩下的就是把这个链接取下来就行啦
虽然还有好多细节没有建立,但是最坑的是最后的陌陌链接是有时效性的
太坑了,市面上有将有时效的链接转换为没有时效的链接的商业服务,不知道是她们是如何实现的。目前在看陌陌客户端上面的搜一搜,因为通过客户端的搜一搜搜下来的链接是短短的,应该是失效太长的
2020-06-04 更新
找到了转换永久链接的办法,把有时效性的链接复制到陌陌客户端上面,不管是过没过期的链接都是才能打开的,再把链接复制下来就是永久的链接了,使用了 pythonpyautogui 来操作的,很简单,也太low,速度不快,就不放代码了。 查看全部
搜狗陌陌的抓取总结
最近抓取了搜狗陌陌的数据,虽然也破解了跳转之类的,但是最后由于抓取的链接有时效性舍弃了,也总结下
一样的,输入关键词,抓取列表,再回来跳转后的陌陌链接
前10页是可以随意看的,也不需要登陆,10页以后的数据须要陌陌扫码登陆,这一块无法破解
链接参数好多最后可以精简为
烽火&page=11&type=2
page就是页脚,query就是关键字,type 是搜索文章还是搜索公众号
其实很简单的代码,先要在url前面构造出 k 和 h,转化为 java 代码就是
// 拼接搜狗跳转参数k和h
public static String getLinkUrl(String url) {
int b = ((int) Math.floor(100 * Math.random())) + 1;
int a = url.indexOf("url=");
int k = a + 4 + 21 + b;
String d = url.substring(k, k + 1);
System.out.println(d);
url += "&k=" + b + "&h=" + d;
return "https://weixin.sogou.com" + url;
}
有参数的链接直接恳求是会出验证码的,需要cookie,需要的cookie只要是两个 一个是 SUV,一个是SNUID,这两个cookie获取都很简单,通过剖析可以得到
1.SUV 是可以通过访问来获取到
2.SNUID 在搜索的时侯才会有了
所以我们加上这两个cookie才能获取到具体的陌陌的链接了
剩下的就是把这个链接取下来就行啦
虽然还有好多细节没有建立,但是最坑的是最后的陌陌链接是有时效性的
太坑了,市面上有将有时效的链接转换为没有时效的链接的商业服务,不知道是她们是如何实现的。目前在看陌陌客户端上面的搜一搜,因为通过客户端的搜一搜搜下来的链接是短短的,应该是失效太长的
2020-06-04 更新
找到了转换永久链接的办法,把有时效性的链接复制到陌陌客户端上面,不管是过没过期的链接都是才能打开的,再把链接复制下来就是永久的链接了,使用了 pythonpyautogui 来操作的,很简单,也太low,速度不快,就不放代码了。
Python网络爬虫学习笔记(五)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2020-08-18 18:25
微信公众号文章爬取
以搜狗的陌陌搜索平台“”作为爬取入口,可以在搜索栏输入相应关键词来搜索相关微信公众号文章。我们以“机器学习”作为搜索关键词。可以看见搜索后的地址栏中内容为:
%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0&_sug_type_=&sut=1872&lkt=1%2C86%2C86&s_from=input&_sug_=n&type=2&sst0=95&page=2&ie=utf8&w=01019900&dr=1
通过观察,可以发觉如此几个关键数组:
type:控制检索信息的类型query:我们恳求的搜索关键词page:控制页数
所以我们的网址结构可以构造为:
关键词&type=2&page=页码
然后,我们在每一个搜索页中爬取文章的思路是:
检索对应关键词得到的相应文章检索结果,并在该页面上将文章的链接提取下来在文章的链接被提取以后,根据这种链接地址采集文章中的具体标题和内容
通过查看文章列表页的源代码可以找到相应文章的URL以及要爬取的内容,列表页面如下:
其中第一篇文章网址部份的源代码如下所示:
机器学习法则:ML工程的最佳实践
图片源自:Westworld Season 2作者无邪机器学习研究者,人工智障推进者.Martin Zinkevich 在2016年将 google 内容多年关于机器学...
程序人生document.write(timeConvert('1526875397'))
所以我们可以将提取文章网址的正则表达式构造为:
'
这样就可以依据相关函数与代码提取出指定页数的文章网址。但是依据正则表达式提取出的网址不是真实地址,会出现参数错误。提取出的地址比真实地址多了一些“&amp;”字符串,我们通过url.replace("amp;","")去掉多余字符串。
这样就提取了文章的地址,可以依照文章地址爬取相应网页,并通过代理服务器的方式,解决官方屏蔽IP的问题。
整个爬取陌陌文章的思路如下:
建立三个自定义函数:实现使用代理服务器爬去指定网址并返回结果;实现获得多个页面的所有文章链接;实现依据文章链接爬取指定标题和内容并写入文件中。使用代理服务器爬取指定网址的内容实现获取多个页面的所有文章链接时,需要对关键词使用urllib.request.quote(key)进行编码,并通过for循环一次爬取各页的文章中设置的服务器函数实现。实现依据文章链接爬取指定标题和内容写入对应文件,使用for循环一次爬取。代码中假如发生异常,要进行延时处理。
具体代码如下: 查看全部
Python网络爬虫学习笔记(五)
微信公众号文章爬取
以搜狗的陌陌搜索平台“”作为爬取入口,可以在搜索栏输入相应关键词来搜索相关微信公众号文章。我们以“机器学习”作为搜索关键词。可以看见搜索后的地址栏中内容为:
%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0&_sug_type_=&sut=1872&lkt=1%2C86%2C86&s_from=input&_sug_=n&type=2&sst0=95&page=2&ie=utf8&w=01019900&dr=1
通过观察,可以发觉如此几个关键数组:
type:控制检索信息的类型query:我们恳求的搜索关键词page:控制页数
所以我们的网址结构可以构造为:
关键词&type=2&page=页码
然后,我们在每一个搜索页中爬取文章的思路是:
检索对应关键词得到的相应文章检索结果,并在该页面上将文章的链接提取下来在文章的链接被提取以后,根据这种链接地址采集文章中的具体标题和内容
通过查看文章列表页的源代码可以找到相应文章的URL以及要爬取的内容,列表页面如下:
其中第一篇文章网址部份的源代码如下所示:
机器学习法则:ML工程的最佳实践
图片源自:Westworld Season 2作者无邪机器学习研究者,人工智障推进者.Martin Zinkevich 在2016年将 google 内容多年关于机器学...
程序人生document.write(timeConvert('1526875397'))
所以我们可以将提取文章网址的正则表达式构造为:
'
这样就可以依据相关函数与代码提取出指定页数的文章网址。但是依据正则表达式提取出的网址不是真实地址,会出现参数错误。提取出的地址比真实地址多了一些“&amp;”字符串,我们通过url.replace("amp;","")去掉多余字符串。
这样就提取了文章的地址,可以依照文章地址爬取相应网页,并通过代理服务器的方式,解决官方屏蔽IP的问题。
整个爬取陌陌文章的思路如下:
建立三个自定义函数:实现使用代理服务器爬去指定网址并返回结果;实现获得多个页面的所有文章链接;实现依据文章链接爬取指定标题和内容并写入文件中。使用代理服务器爬取指定网址的内容实现获取多个页面的所有文章链接时,需要对关键词使用urllib.request.quote(key)进行编码,并通过for循环一次爬取各页的文章中设置的服务器函数实现。实现依据文章链接爬取指定标题和内容写入对应文件,使用for循环一次爬取。代码中假如发生异常,要进行延时处理。
具体代码如下:
微信公众号历史消息采集方法及注意事项
采集交流 • 优采云 发表了文章 • 0 个评论 • 462 次浏览 • 2020-08-18 15:34
采集微信文章和采集网站内容一样,都须要从一个列表页开始。而陌陌文章的列表页就是公众号里的查看历史消息页。现在网路上的其它陌陌采集器有的是借助搜狗搜索,采集方式其实简单多了,但是内容不全。所以我们还是要从最标准最全面的公众号历史消息页来采集。
因为陌陌的限制,我们能复制到的链接是不完整的,在浏览器中未能打开听到内容。所以我们须要通过上一篇文章介绍的方式,使用anyproxy获取到一个完整的微信公众号历史消息页面的链接地址。
f9387c4d02682e186a298a18276d8e0555e3ab51d81ca46de339e6082eb767343bef610edd80c9e1bfda66c
2b62751511f7cc091a33a029709e94f0d1604e11220fc099a27b2e2d29db75cc0849d4bf&devicetype=andro
id-17&version=26031c34&lang=zh_CN&nettype=WIFI&ascene=3&pass_ticket=Iox5ZdpRhrSxGYEeopVJwTB
P7kZj51GYyEL24AT5Zyx%2BBoEMdPDBtOun1F%2F9ENSz&wx_header=1
biz参数是公众号的ID,uin是用户的ID,目前来看uin是在所有公众号之间惟一的。其它两个重要参数key和pass_ticket是陌陌客户端补充上的参数。
所以在这个地址失效之前我们是可以通过浏览器查看原文的方式获取到历史消息的文章列表的,如果希望自动化剖析内容,也可以制做一个程序,将这个带有仍未失效的key和pass_ticket的链接地址递交进去,再通过诸如php程序来获取到文章列表。
最近有同事跟我说他的采集目标就是单一的一个公众号,我认为这样就没必要用上一篇文章写的批量采集的方式了。所以我们接下来瞧瞧历史消息页上面是如何获取到文章列表的,通过剖析文章列表,就可以得到这个公众号所有的内容链接地址,然后再采集内容就可以了。
在anyproxy的web界面中若果证书配置正确,是可以显示出https的内容的。web界面的地址是:8002 其中localhost可以替换成自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击以后两侧都会显示出这条记录的详情:
红框部份就是完整的链接地址,将微信公众平台这个域名拼接在上面以后就可以在浏览器中打开了。
然后将页面向上拉,到html内容的结尾部份,我们可以看见一个json的变量就是历史消息的文章列表:
我们将msgList的变量值拷贝下来,用json低格工具剖析一下,我们就可以看见这个json是以下这个结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... 76742
7&idx=1&sn=37da0d7208283bf90e9a4a536e0af0ea&chksm=8b882dbbbcffa4ad2f0b8a141cc988d16bac
e564274018e68e5c53ee6f354f8ad56c9b98bade&scene=4#wechat_redirect",
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... gLtcq
GziaFqwibzvtZAHCDkMeJU1fGZHpjoeibanPJ8rziaq68Akkg/0?wx_fmt=jpeg",
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... 65276
7427&idx=2&sn=449ef1a874a37fed2429e14f724b56ef&chksm=8 b882dbbbcffa4ade48a7932cda426368
7e34fca8ea3a5a6233d2589d448b9f6130d3890ce93&scene=4#wechat_redirect",
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... YHYrh
ibia89ZnksCsUiaia2TLI1fyqjclibGa1hw3icP6oXeSpaWMjiabaghHl7yw/0?wx_fmt=png",
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... b56b9 98e1f2b8?detailReferrer=1&from=groupmessage&isappinstalled=0",
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简要的剖析一下这个json(这里只介绍一些重要的信息,其它的被省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "ժҪ",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""ժҪ"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
在这里还要提及一点就是假如希望获取到时间更久远一些的历史消息内容,就须要在手机或模拟器上将页面向上拉,当拉到最里边的时侯,微信将手动读取下一页的内容。下一页的链接地址和历史消息页的链接地址同样是getmasssendmsg开头的地址。但是内容就是只有json了,没有html了。直接解析json就可以了。
这时可以通过上一篇文章介绍的方式,使用anyproxy将msgList变量值正则匹配下来以后,异步递交到服务器,再从服务器上使用php的json_decode解析json成为字段。然后遍历循环链表。我们就可以得到每一篇文章的标题和链接地址。
如果只须要采集单一公众号的内容,完全可以在每晚群发以后,通过anyproxy获取到完整的带有key和pass_ticket的链接地址。然后自己制做一个程序,手动将地址递交给自己的程序。使用诸如php这样的语言来正则匹配到msgList,然后解析json。这样就不用更改anyproxy的rule,也不需要制做一个采集队列和跳转页面了。 查看全部
微信公众号历史消息采集方法及注意事项
采集微信文章和采集网站内容一样,都须要从一个列表页开始。而陌陌文章的列表页就是公众号里的查看历史消息页。现在网路上的其它陌陌采集器有的是借助搜狗搜索,采集方式其实简单多了,但是内容不全。所以我们还是要从最标准最全面的公众号历史消息页来采集。
因为陌陌的限制,我们能复制到的链接是不完整的,在浏览器中未能打开听到内容。所以我们须要通过上一篇文章介绍的方式,使用anyproxy获取到一个完整的微信公众号历史消息页面的链接地址。
f9387c4d02682e186a298a18276d8e0555e3ab51d81ca46de339e6082eb767343bef610edd80c9e1bfda66c
2b62751511f7cc091a33a029709e94f0d1604e11220fc099a27b2e2d29db75cc0849d4bf&devicetype=andro
id-17&version=26031c34&lang=zh_CN&nettype=WIFI&ascene=3&pass_ticket=Iox5ZdpRhrSxGYEeopVJwTB
P7kZj51GYyEL24AT5Zyx%2BBoEMdPDBtOun1F%2F9ENSz&wx_header=1
biz参数是公众号的ID,uin是用户的ID,目前来看uin是在所有公众号之间惟一的。其它两个重要参数key和pass_ticket是陌陌客户端补充上的参数。
所以在这个地址失效之前我们是可以通过浏览器查看原文的方式获取到历史消息的文章列表的,如果希望自动化剖析内容,也可以制做一个程序,将这个带有仍未失效的key和pass_ticket的链接地址递交进去,再通过诸如php程序来获取到文章列表。
最近有同事跟我说他的采集目标就是单一的一个公众号,我认为这样就没必要用上一篇文章写的批量采集的方式了。所以我们接下来瞧瞧历史消息页上面是如何获取到文章列表的,通过剖析文章列表,就可以得到这个公众号所有的内容链接地址,然后再采集内容就可以了。
在anyproxy的web界面中若果证书配置正确,是可以显示出https的内容的。web界面的地址是:8002 其中localhost可以替换成自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击以后两侧都会显示出这条记录的详情:
红框部份就是完整的链接地址,将微信公众平台这个域名拼接在上面以后就可以在浏览器中打开了。
然后将页面向上拉,到html内容的结尾部份,我们可以看见一个json的变量就是历史消息的文章列表:
我们将msgList的变量值拷贝下来,用json低格工具剖析一下,我们就可以看见这个json是以下这个结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... 76742
7&idx=1&sn=37da0d7208283bf90e9a4a536e0af0ea&chksm=8b882dbbbcffa4ad2f0b8a141cc988d16bac
e564274018e68e5c53ee6f354f8ad56c9b98bade&scene=4#wechat_redirect",
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... gLtcq
GziaFqwibzvtZAHCDkMeJU1fGZHpjoeibanPJ8rziaq68Akkg/0?wx_fmt=jpeg",
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... 65276
7427&idx=2&sn=449ef1a874a37fed2429e14f724b56ef&chksm=8 b882dbbbcffa4ade48a7932cda426368
7e34fca8ea3a5a6233d2589d448b9f6130d3890ce93&scene=4#wechat_redirect",
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... YHYrh
ibia89ZnksCsUiaia2TLI1fyqjclibGa1hw3icP6oXeSpaWMjiabaghHl7yw/0?wx_fmt=png",
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... b56b9 98e1f2b8?detailReferrer=1&from=groupmessage&isappinstalled=0",
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简要的剖析一下这个json(这里只介绍一些重要的信息,其它的被省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "ժҪ",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""ժҪ"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
在这里还要提及一点就是假如希望获取到时间更久远一些的历史消息内容,就须要在手机或模拟器上将页面向上拉,当拉到最里边的时侯,微信将手动读取下一页的内容。下一页的链接地址和历史消息页的链接地址同样是getmasssendmsg开头的地址。但是内容就是只有json了,没有html了。直接解析json就可以了。
这时可以通过上一篇文章介绍的方式,使用anyproxy将msgList变量值正则匹配下来以后,异步递交到服务器,再从服务器上使用php的json_decode解析json成为字段。然后遍历循环链表。我们就可以得到每一篇文章的标题和链接地址。
如果只须要采集单一公众号的内容,完全可以在每晚群发以后,通过anyproxy获取到完整的带有key和pass_ticket的链接地址。然后自己制做一个程序,手动将地址递交给自己的程序。使用诸如php这样的语言来正则匹配到msgList,然后解析json。这样就不用更改anyproxy的rule,也不需要制做一个采集队列和跳转页面了。
利用搜狗陌陌自制一个简易微信公众号爬虫接口
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2020-08-18 11:12
微信公众号现已成为主流的一对多媒体行为活动,也是现今互联网内容生产不可忽略的一股力量。
在此基础上,微信公众号爬虫显得太有价值,对内容生产型公众号进行数据挖掘可以得到好多有意思、有价值的信息。就我所知,可用于微信公众号爬虫的方法主要有以下几种:web陌陌,手机客户端抓包,搜狗陌陌入口,appium自动化测试,Xposed框架等。
手机客户端抓包,利用fiddler或charles等抓包工具,算是一个比较主流(我自己觉得的orz),效率较高的方式,可以快速的抓取微信公众号信息和历史消息,此方式也有隐忧:cookies失效快,半天差不多的时间吧,有针对性的去抓取某几个公众号的历史消息也是可以的。要想通过模拟登录陌陌手动获得cookies,好像很难的,小弟浅薄,无法实现,貌似陌陌登录是tcp协议?
appium自动化和Xposed框架我了解不多。appium类似于selenium,在移动端做自动化测试的,模拟点击即可。Xposed框架就有很多可以搞的了,Xposed可以在不更改apk的情况下做到一些额外的功能,爬虫自然是可以的,除此之外可做到以手动抢红包,自动回复机器人,修改陌陌步数等等骚操作。
写爬虫也有一段时间了,个人觉得实现爬虫不仅反反爬,爬虫效率外,还有一个很难实现的地方就是爬虫的稳定性,健壮性,需要考虑到好多异常情况,以及合理有效的异常处理,在这一点上,我认为我还须要向各大爬虫大鳄学习。(感觉自己瞎扯了很多,还没有开始我的正文(orz),感觉嫌我啰嗦的大鳄请别生气。)
利用搜狗陌陌写一个爬虫插口,代码太狭小,只有两百行不到的代码。(这里我还得吐槽一下,python写多了,总有一种自己太叼,编程很简单的错觉,几行代码能够实现很厉害的功能,这时候须要去写写CPP冷静一下,让自己晓得哪些是真正的编程。)
以下记录下我写这个爬虫插口脚本的过程:
1. 页面恳求剖析(以公众号搜索为例):
可以看见第一个http请求包就是我们想要的结果,查看其query string,如下:
看起来很简单的不是,我们得到以下几个信息:
2. 模拟页面恳求:
我们直接用 url, 请求参数params, 还有谷歌浏览器的 user-agent 请求,发现可以成功的获取到我们想要页面的源码,接下来我们获取搜索结果下的第一个公众号即可(这意味着须要确切的给定公众号名称,太过模糊有可能获取到与其类似的公众号结果)。
3. 分析页面:
先确定爬取思路,第一步获取微信公众号链接,再通过该微信公众号链接获取其近来十条推送的相关信息,包括标题,日期,作者,内容摘要,内容链接(事实上,我们发觉有了陌陌推送链接以后才能太轻松的获取其推送主体内容,但不包括点赞数和阅读数,这几个数据只能在陌陌手机端能够查看,如果有机会的话,下次记录下自己手机陌陌抓包爬虫的过程)。
于是第一步我们获取公众号链接:
这里我们直接使用正则表达式提取即可(这么简单的就不用xpath,bs4了,依赖标准库和第三方库还是有所不同的。)
(抱歉被水印堵住了orz,换一张。)
第二步按照微信公众号链接获取近来十条推送信息:
(我只写了一篇orz,以后多加油。)
ctlr U 查看网页源码,发现原创信息都置于一个js变量上面。
好办,继续正则提取,将json格式的字符串转换成python上面的字典,有两种办法,第一种是用 json.loads 方法, 第二种是用外置的 eval方式,这两种方式有些区别,比如说单冒号和双冒号, json格式中使用的是双引号, python字典通常是单冒号。
OK,获得原创推送信息数据了,但这上面有很多我们用不到的信息,将其剔除一下,值得一提的是,datetime的值是一个timestamp,我们须要将其转化为直观的时间抒发。
到此,关于微信公众号的爬虫差不都就解决了,接下来须要将其封装为类。主要部份代码如下。
另外,关于关键词搜索文章的爬虫插口我也一并写了,AccountAPI,ArticleAPI,其父类是一AP类,API类有query_url, params, headers, _get_response, _get_datetime等变量和技巧,供于AccountAPI,ArticleAPI共用。
代码放到 查看全部
利用搜狗陌陌自制一个简易微信公众号爬虫插口
微信公众号现已成为主流的一对多媒体行为活动,也是现今互联网内容生产不可忽略的一股力量。
在此基础上,微信公众号爬虫显得太有价值,对内容生产型公众号进行数据挖掘可以得到好多有意思、有价值的信息。就我所知,可用于微信公众号爬虫的方法主要有以下几种:web陌陌,手机客户端抓包,搜狗陌陌入口,appium自动化测试,Xposed框架等。
手机客户端抓包,利用fiddler或charles等抓包工具,算是一个比较主流(我自己觉得的orz),效率较高的方式,可以快速的抓取微信公众号信息和历史消息,此方式也有隐忧:cookies失效快,半天差不多的时间吧,有针对性的去抓取某几个公众号的历史消息也是可以的。要想通过模拟登录陌陌手动获得cookies,好像很难的,小弟浅薄,无法实现,貌似陌陌登录是tcp协议?
appium自动化和Xposed框架我了解不多。appium类似于selenium,在移动端做自动化测试的,模拟点击即可。Xposed框架就有很多可以搞的了,Xposed可以在不更改apk的情况下做到一些额外的功能,爬虫自然是可以的,除此之外可做到以手动抢红包,自动回复机器人,修改陌陌步数等等骚操作。
写爬虫也有一段时间了,个人觉得实现爬虫不仅反反爬,爬虫效率外,还有一个很难实现的地方就是爬虫的稳定性,健壮性,需要考虑到好多异常情况,以及合理有效的异常处理,在这一点上,我认为我还须要向各大爬虫大鳄学习。(感觉自己瞎扯了很多,还没有开始我的正文(orz),感觉嫌我啰嗦的大鳄请别生气。)
利用搜狗陌陌写一个爬虫插口,代码太狭小,只有两百行不到的代码。(这里我还得吐槽一下,python写多了,总有一种自己太叼,编程很简单的错觉,几行代码能够实现很厉害的功能,这时候须要去写写CPP冷静一下,让自己晓得哪些是真正的编程。)
以下记录下我写这个爬虫插口脚本的过程:
1. 页面恳求剖析(以公众号搜索为例):
可以看见第一个http请求包就是我们想要的结果,查看其query string,如下:
看起来很简单的不是,我们得到以下几个信息:
2. 模拟页面恳求:
我们直接用 url, 请求参数params, 还有谷歌浏览器的 user-agent 请求,发现可以成功的获取到我们想要页面的源码,接下来我们获取搜索结果下的第一个公众号即可(这意味着须要确切的给定公众号名称,太过模糊有可能获取到与其类似的公众号结果)。
3. 分析页面:
先确定爬取思路,第一步获取微信公众号链接,再通过该微信公众号链接获取其近来十条推送的相关信息,包括标题,日期,作者,内容摘要,内容链接(事实上,我们发觉有了陌陌推送链接以后才能太轻松的获取其推送主体内容,但不包括点赞数和阅读数,这几个数据只能在陌陌手机端能够查看,如果有机会的话,下次记录下自己手机陌陌抓包爬虫的过程)。
于是第一步我们获取公众号链接:
这里我们直接使用正则表达式提取即可(这么简单的就不用xpath,bs4了,依赖标准库和第三方库还是有所不同的。)
(抱歉被水印堵住了orz,换一张。)
第二步按照微信公众号链接获取近来十条推送信息:
(我只写了一篇orz,以后多加油。)
ctlr U 查看网页源码,发现原创信息都置于一个js变量上面。
好办,继续正则提取,将json格式的字符串转换成python上面的字典,有两种办法,第一种是用 json.loads 方法, 第二种是用外置的 eval方式,这两种方式有些区别,比如说单冒号和双冒号, json格式中使用的是双引号, python字典通常是单冒号。
OK,获得原创推送信息数据了,但这上面有很多我们用不到的信息,将其剔除一下,值得一提的是,datetime的值是一个timestamp,我们须要将其转化为直观的时间抒发。
到此,关于微信公众号的爬虫差不都就解决了,接下来须要将其封装为类。主要部份代码如下。
另外,关于关键词搜索文章的爬虫插口我也一并写了,AccountAPI,ArticleAPI,其父类是一AP类,API类有query_url, params, headers, _get_response, _get_datetime等变量和技巧,供于AccountAPI,ArticleAPI共用。
代码放到
微信热门文章采集方法以及详尽步骤.docx
采集交流 • 优采云 发表了文章 • 0 个评论 • 397 次浏览 • 2020-08-18 10:43
文档介绍:
微信热门文章采集方法以及详尽步骤
本文将以搜狗陌陌文章为例,介绍使用优采云采集网页文章正文的技巧。文章正文里通常包括文本和图片两种。本文将采集文章正文中的文本+图片URL。
将采集以下数组:文章标题、时间、来源和正文(正文中的所有文本,将合并到一个excel单元格中,将使用到“自定义数据合并方法”功能,请你们注意)。同时,采集文章正文中的文本+图片URL,将用到“判断条件”,“判断条件”的使用,有很多须要注意的地方。以下两个教程,大家可先熟悉一下。
“自定义数据合并方法”详解教程:
orialdetail-1/zdyhb_7.html
“判断条件”详解教程:
orialdetail-1/judge.html
采集网站:
使用功能点:
分页列表信息采集
orial/fylb-70.aspx?t=1
Xpath
rch?query=XPath
AJAX点击和翻页
orial/ajaxdjfy_7.aspx?t=1
判断条件
orialdetail-1/judge.html
AJAX滚动
orialdetail-1/ajgd_7.html
步骤1:创建采集任务
1)进入主界面,选择“自定义模式”
微信热门文章采集方法步骤1
2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
微信热门文章采集方法步骤2
步骤2:创建翻页循环
在页面右上角,打开“流程”,以诠释出“流程设计器”和“定制当前操作”两个蓝筹股。网页打开后,默认显示“热门”文章。下拉页面,找到并点击“加载更多内容”按钮,在操作提示框中,选择“更多操作”
微信热门文章采集方法步骤3
选择“循环点击单个元素”,以创建一个翻页循环
微信热门文章采集方法步骤4
由于此网页涉及Ajax技术,我们须要进行一些中级选项的设置。选中“点击元素”步骤,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”
微信热门文章采集方法步骤5
注:AJAX即延时加载、异步更新的一种脚本技术,通过在后台与服务器进行少量数据交换,可以在不重新加载整个网页的情况下,对网页的某部份进行更新。
表现特点:a、点击网页中某个选项时,大部分网站的网址不会改变;b、网页不是完全加载,只是局部进行了数据加载,有所变化。 查看全部
微信热门文章采集方法以及详尽步骤.docx
文档介绍:
微信热门文章采集方法以及详尽步骤
本文将以搜狗陌陌文章为例,介绍使用优采云采集网页文章正文的技巧。文章正文里通常包括文本和图片两种。本文将采集文章正文中的文本+图片URL。
将采集以下数组:文章标题、时间、来源和正文(正文中的所有文本,将合并到一个excel单元格中,将使用到“自定义数据合并方法”功能,请你们注意)。同时,采集文章正文中的文本+图片URL,将用到“判断条件”,“判断条件”的使用,有很多须要注意的地方。以下两个教程,大家可先熟悉一下。
“自定义数据合并方法”详解教程:
orialdetail-1/zdyhb_7.html
“判断条件”详解教程:
orialdetail-1/judge.html
采集网站:
使用功能点:
分页列表信息采集
orial/fylb-70.aspx?t=1
Xpath
rch?query=XPath
AJAX点击和翻页
orial/ajaxdjfy_7.aspx?t=1
判断条件
orialdetail-1/judge.html
AJAX滚动
orialdetail-1/ajgd_7.html
步骤1:创建采集任务
1)进入主界面,选择“自定义模式”
微信热门文章采集方法步骤1
2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
微信热门文章采集方法步骤2
步骤2:创建翻页循环
在页面右上角,打开“流程”,以诠释出“流程设计器”和“定制当前操作”两个蓝筹股。网页打开后,默认显示“热门”文章。下拉页面,找到并点击“加载更多内容”按钮,在操作提示框中,选择“更多操作”
微信热门文章采集方法步骤3
选择“循环点击单个元素”,以创建一个翻页循环
微信热门文章采集方法步骤4
由于此网页涉及Ajax技术,我们须要进行一些中级选项的设置。选中“点击元素”步骤,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”
微信热门文章采集方法步骤5
注:AJAX即延时加载、异步更新的一种脚本技术,通过在后台与服务器进行少量数据交换,可以在不重新加载整个网页的情况下,对网页的某部份进行更新。
表现特点:a、点击网页中某个选项时,大部分网站的网址不会改变;b、网页不是完全加载,只是局部进行了数据加载,有所变化。
微信公众号之获取openId
采集交流 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2020-08-18 03:00
在小伙伴们开发微信公众号、小程序或则是在陌陌外置浏览器打开的项目时,会碰到的第一个问题就是怎么获取openId,今天小编就给你们带来的是怎样获取openId。
首先 我们要从陌陌开发者后台得到appid,这个appid是管理员在设置陌陌后台时获取的,而且是惟一的,而且还须要在陌陌后台设置反弹域名。
其次这种都打算好之后,我们就可以使用陌陌自带的方式获取openId:
注意:划线部份是要获取的openId和反弹域名,而location.href=url 是当页面第一次渲染时,自动获取openId,当然,这些还是打算工作
1 //截取URL字段
2 GetQueryString: function(name) {
3 var reg = new RegExp("(^|&)" + name + "=([^&]*)(&|$)", "i");
4 var r = window.location.search.substr(1).match(reg);
5 if (r != null) {
6 return unescape(r[2]);
7 }
8 return null;
9 },
10 getToken: function() {
11 //判断是否有openid
12 if (this.$cookieStore.getCookie("openid") == null) {
13 var url =
14 "https://open.weixin.qq.com/con ... ot%3B +
15 encodeURIComponent(
16 "https://www.baidu.com/"
17 ) +
18 "&response_type=code&scope=snsapi_base&state=STATE#wechat_redirect&connect_redirect=1#wechat_redirect";
19 location.href = url;
20 var code = this.GetQueryString("code");
21 // console.log(code);
22 axios({
23 url: "接口名" + code
24 }).then(res => {
25 // console.log(res);
26 if (res.data.code == 0) {
27 this.$cookieStore.setCookie("openid", res.data.result);
28 }
29 });
30 } else {
31 this.openid = this.$cookieStore.getCookie("openid");
32 }
33 },
我们要使用上图的方式来获取code值,通过插口,来获取openId,然后把openId存在cookie里每次调用就可以了。
这就是小编给你们带来的获取openId的方式,下面是完整代码。 查看全部
微信公众号之获取openId
在小伙伴们开发微信公众号、小程序或则是在陌陌外置浏览器打开的项目时,会碰到的第一个问题就是怎么获取openId,今天小编就给你们带来的是怎样获取openId。
首先 我们要从陌陌开发者后台得到appid,这个appid是管理员在设置陌陌后台时获取的,而且是惟一的,而且还须要在陌陌后台设置反弹域名。
其次这种都打算好之后,我们就可以使用陌陌自带的方式获取openId:
注意:划线部份是要获取的openId和反弹域名,而location.href=url 是当页面第一次渲染时,自动获取openId,当然,这些还是打算工作
1 //截取URL字段
2 GetQueryString: function(name) {
3 var reg = new RegExp("(^|&)" + name + "=([^&]*)(&|$)", "i");
4 var r = window.location.search.substr(1).match(reg);
5 if (r != null) {
6 return unescape(r[2]);
7 }
8 return null;
9 },
10 getToken: function() {
11 //判断是否有openid
12 if (this.$cookieStore.getCookie("openid") == null) {
13 var url =
14 "https://open.weixin.qq.com/con ... ot%3B +
15 encodeURIComponent(
16 "https://www.baidu.com/"
17 ) +
18 "&response_type=code&scope=snsapi_base&state=STATE#wechat_redirect&connect_redirect=1#wechat_redirect";
19 location.href = url;
20 var code = this.GetQueryString("code");
21 // console.log(code);
22 axios({
23 url: "接口名" + code
24 }).then(res => {
25 // console.log(res);
26 if (res.data.code == 0) {
27 this.$cookieStore.setCookie("openid", res.data.result);
28 }
29 });
30 } else {
31 this.openid = this.$cookieStore.getCookie("openid");
32 }
33 },
我们要使用上图的方式来获取code值,通过插口,来获取openId,然后把openId存在cookie里每次调用就可以了。
这就是小编给你们带来的获取openId的方式,下面是完整代码。
R语言爬虫系列6|动态数据抓取范例
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2020-08-15 12:32
作者:鲁伟,热爱数据,坚信数据技术和代码改变世界。R语言和Python的忠实拥趸,为成为一名未来的数据科学家而拼搏终身。个人公众号:数据科学家养成记 (微信ID:louwill12)
第一篇戳:
第二篇戳:
第三篇戳:
第四篇戳:
第五篇戳:
通过上面几期的推送,小编基本上早已将R语言爬虫所须要的基本知识介绍完了。R其实是以一门统计剖析工具出现在大多数人印象中的,但其虽然本质上是一门编程语言,对于爬虫的支持虽不如Python那样多快好省,但细心研究一下总能作出一些使你惊喜的疗效。
大约很早之前,小编就写过关于R语言爬虫新贵rvest的抓取介绍,之前说rvest+SelectGadgetor是结构化网页抓取的实战神器,大家的溢美之词不断。详情可见推文:
R语言爬虫神器:rvest包+SelectorGadget抓取链家上海二手房数据
但网路爬虫这个江湖很险恶,单靠一招rvest行走江湖必然凶多吉少,一不小心遇到哪些AJAX和动态网页凭仅把握rvest的诸位必将束手无策。本文小编就简单介绍下在用R语言进行实际的网路数据抓取时怎样将动态数据给弄到手。
所谓动态网页和异步加载,在之前的系列4的时侯小编已通过AJAX介绍过了,简单而言就是我明明在网页中听到了这个数据,但到后台HTML中却找不到了,这一般就是XHR在作怪。这时候我们就不要看原创的HTML数据了,需要进行二次恳求,通过web开发者工具找到真实恳求的url。下面小编就以两个网页为例,分别通过GET和POST恳求领到动态网页数据,全过程主要使用httr包来实现,httr包堪称是RCurl包的精简版,说其短小精悍也不为过。httr包与RCurl包在主要函数的区别如下所示:
GET恳求抓取陌陌好友列表数据
很早之前圈子里就听到过用Python抓取自己陌陌好友数据的案例分享,今天便以陌陌网页版为例,探一探其网页结构。首先登陆个人陌陌网页版,右键打开web开发者工具,下来一大堆恳求:
简单找一下发觉网页中的陌陌好友列表信息并没有呈现在HTML 中,大概可以推断陌陌好友数据是通过动态加载来显示的,所以直接定位到XHR中,经过几番尝试,结合两侧的preview,我们会发觉大量整齐划一的数据,所以二次恳求的url真的就是它了:
找到真正的url以后,接下来就是获取恳求信息了,切换到Headers版块,Header版块下的4个子信息我们都须要关注,它们是我们构造爬虫恳求头的关键。
从Header中我们可以看见该信息是通过GET方式恳求得到的,General信息下的Request URL,Request Method, Status Code; Response Headers信息下的Connection, Content-Type; Request Headers信息下的Accept, Cookie, Referer, User-Agent以及最后的Query String Parameters都是我们须要重点关注的。
找到相应的信息然后,我们便可以直接借助httr包在R中建立爬虫恳求:
<p>#传入微信cookie信息<br />Cookie Accept: application/json<br />-> Content-Type: text/plain<br />-> User-Agent: Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0<br />-> Referer: https://wx.qq.com/<br />-> Connection: keep-alive<br />-> cookie: 我的微信cookie<br />-> <br /> Connection: keep-alive<br />-> cookie: 网易云课堂cookie<br />-> Content-Length: 69<br />-> <br />>> {"pageIndex":1,"pageSize":50,"relativeOffset":0,"frontCategoryId":-1}<br /><br /> 查看全部
作者:鲁伟,热爱数据,坚信数据技术和代码改变世界。R语言和Python的忠实拥趸,为成为一名未来的数据科学家而拼搏终身。个人公众号:数据科学家养成记 (微信ID:louwill12)
第一篇戳:
第二篇戳:
第三篇戳:
第四篇戳:
第五篇戳:
通过上面几期的推送,小编基本上早已将R语言爬虫所须要的基本知识介绍完了。R其实是以一门统计剖析工具出现在大多数人印象中的,但其虽然本质上是一门编程语言,对于爬虫的支持虽不如Python那样多快好省,但细心研究一下总能作出一些使你惊喜的疗效。
大约很早之前,小编就写过关于R语言爬虫新贵rvest的抓取介绍,之前说rvest+SelectGadgetor是结构化网页抓取的实战神器,大家的溢美之词不断。详情可见推文:
R语言爬虫神器:rvest包+SelectorGadget抓取链家上海二手房数据
但网路爬虫这个江湖很险恶,单靠一招rvest行走江湖必然凶多吉少,一不小心遇到哪些AJAX和动态网页凭仅把握rvest的诸位必将束手无策。本文小编就简单介绍下在用R语言进行实际的网路数据抓取时怎样将动态数据给弄到手。
所谓动态网页和异步加载,在之前的系列4的时侯小编已通过AJAX介绍过了,简单而言就是我明明在网页中听到了这个数据,但到后台HTML中却找不到了,这一般就是XHR在作怪。这时候我们就不要看原创的HTML数据了,需要进行二次恳求,通过web开发者工具找到真实恳求的url。下面小编就以两个网页为例,分别通过GET和POST恳求领到动态网页数据,全过程主要使用httr包来实现,httr包堪称是RCurl包的精简版,说其短小精悍也不为过。httr包与RCurl包在主要函数的区别如下所示:
GET恳求抓取陌陌好友列表数据
很早之前圈子里就听到过用Python抓取自己陌陌好友数据的案例分享,今天便以陌陌网页版为例,探一探其网页结构。首先登陆个人陌陌网页版,右键打开web开发者工具,下来一大堆恳求:
简单找一下发觉网页中的陌陌好友列表信息并没有呈现在HTML 中,大概可以推断陌陌好友数据是通过动态加载来显示的,所以直接定位到XHR中,经过几番尝试,结合两侧的preview,我们会发觉大量整齐划一的数据,所以二次恳求的url真的就是它了:
找到真正的url以后,接下来就是获取恳求信息了,切换到Headers版块,Header版块下的4个子信息我们都须要关注,它们是我们构造爬虫恳求头的关键。
从Header中我们可以看见该信息是通过GET方式恳求得到的,General信息下的Request URL,Request Method, Status Code; Response Headers信息下的Connection, Content-Type; Request Headers信息下的Accept, Cookie, Referer, User-Agent以及最后的Query String Parameters都是我们须要重点关注的。
找到相应的信息然后,我们便可以直接借助httr包在R中建立爬虫恳求:
<p>#传入微信cookie信息<br />Cookie Accept: application/json<br />-> Content-Type: text/plain<br />-> User-Agent: Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0<br />-> Referer: https://wx.qq.com/<br />-> Connection: keep-alive<br />-> cookie: 我的微信cookie<br />-> <br /> Connection: keep-alive<br />-> cookie: 网易云课堂cookie<br />-> Content-Length: 69<br />-> <br />>> {"pageIndex":1,"pageSize":50,"relativeOffset":0,"frontCategoryId":-1}<br /><br />
微信公众号 文章的爬虫系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 242 次浏览 • 2020-08-13 19:03
1、做了俩次爬虫了,第一次怕的凤凰网,那个没有限制,随便爬,所以也就对自动化执行代码模块放松了提防,觉得很简单的,但是毕竟不是这样的,我被这个问题困惑了好几天,差不多4天的一个样子,因为搜狗做的限制,同一个ip获取的次数多了,首先是出现验证码,其次是就是访问限制了,直接就是不能访问,利用 request得到的就是访问次数过分频繁,这样子的提示,所以说开发过程中最头痛的不是代码的编撰,而是测试,写完代码不能立刻测试,这种觉得相信大多数的程序员是不能喜欢的,我如今写的程序是每晚执行三次,这样的一个频度挺好,而且由于是多公众号采集嘛,每个公众号之间的间隔时间也的有,要不然同时访问十几个公众号的上百篇文章也是不现实的,说到这儿插一句,怎么使每位公众号怕去玩过后,等一段具体的时间,在执行下一个,最后用的setInterval函数解决的,
每过80秒执行一个公众号,把每次的执行代码讲到hello中,泡的有点远了,收一收哈,说说cron这个包,自动化执行,npm官网上只给了一个反例,但是我这个指桑拿可能是有点压制的厉害,不能否玩却理解他的用法,然后我说理解不了怎样办啊,上网搜呗,百度,cron包的具体用法,一看,嚯,还很多,于是就看啊看啊,但是仔细以剖析就不是这么回事儿了,都是屁话,没哪些用,网上通常的用法中都带有一个问号,但是我加上问号的时侯,就报错了,所以说都是胡扯,最后在朋友组的一个后端技术讨论群中说了一声,还真有热心的群友,给我找了一个链接,我进去一看,试了一下,还行,所以呢,非常谢谢这个帮助我解惑的朋友,再次我把qq群号,和链接附上,方便正在看这篇文章的你学习,QQ群号:435012561,链接:,这个链接上面说的挺好,至少能用,这里我挺好到一个问题,就是timezone,我们之前用过一次,用的是纽约时间,但是此次显著不行啊,要用俺们中国的时间啊,但是我试了几次上海的不行,重庆的可以,所以我就用了上海的。
2、这里要说的是,从地址栏获取参数的问题,我上一个做的没问题,但是这个不知道如何就不行了,上一个从地址栏得到的是数字,但是这个得到的是字符串,再加上mongodb中的对数组的要求还是很严格的,所以一个分页功能也困惑了我几个小时吧,最后是如何解决的呢,是通过我加的一个mongodb的讨论群,在里面问了一句这是如何了,发了个截图,里面就有一个热心的网友说你这显著是传入的数据格式不对啊,一语惊醒梦中人,我说是啊,然后就把得到的参数,我用Number()函数处理了一下,让string类型的数字,变成了number类型的数字,就好了,所以说你们在用mongodb的时侯一定要注意储存数据的格式,
3、mongodb查询数据句子组织形式:
其实说白了就是limit和skip俩个函数的使用,但是具体的格式可的看好了,还有我这个是接受的参数,不过mongo的参数接受也好弄直接写就好了,不用象sql那样搞哪些${""}这种类型的,后面的sort函数说明了排序的方法,这里是设置的以ctime数组为标准,-1表示逆序,1表示乱序,
4、在本次代码编撰中,我首次使用了try catch 这个补错的形式,事实证明,还行,可以把时常的错误正常的复印下来,但是不影响代码的整体执行,或者是说下一次执行,整体觉得非常好,
具体的使用方式,在try中倒入你要执行的代码,在最后加上一行,throw Error();
然后给catch传入一个参数e,在catch中可以复印好多个信息,我只复印了其中的一个,e.message,
5、这次编码过程中主要用到了anync包,其中的ansyc.each循环,ansyc.waterfall执行完前面的才可以执行下边的,而且说谎给你下之间还可以从上至下传递参数,这个很重要,因为在本次编程中,每次获取的内容不同,每次代码执行的条件不同,即须要的参数也不同,即有可能下一次代码的执行就须要用到上一次代码执行得到的结果,所以说这个anync包,真的是值得研究,他的每位方式都不同,有时候可以得到意想不到的疗效。
6、在mysql中若果想要达到这样一个疗效,就是说,如果数据库中早已存在了,那就不予理会,或者说不重复储存,如果数据库中不存在,那么就储存进来,很简单,直接把插入数据的insert 换成 replace 。但是在mongodb中,应该是没有,或者说是我还没有发觉,我是那么解决的,定义了一个开关,令这个开关为真,每次储存之前,先把所有的数据循环一遍,看看有没有这条数据,如果有,让开关变为假,如果没有,继续执行,即判定此时开关的真伪,如果是真的,那就执行插入操作,如果是假的,就不予理会,这就达到了类似的疗效,否则每次就会储存大量的重复数据,
7、本次采集的核心,就是我文件中的common.js了,首先由于要采集,所以须要用到request包,采集到以后,要处理html格式的数据,使之可以使用类jquery的操作,那么久用到了cheerio这个包,然后在循环采集的时侯,会用到anync.each这个方式,所以会用到async这个包,
7-1、
通过搜狗陌陌采集,就要剖析搜狗陌陌的路径,每个公众号的页面的路径是这样的
%E8%BF%99%E6%89%8D%E6%98%AF%E6%97%A5%E6%9C%AC&ie=utf8&_sug_=n&_sug_type_=
这个是“这才是台湾”的页面的链接,经过剖析,所有的公众号的链接只有query前面的参数不同,但是query前面的参数是哪些呢,其实就是通过encodeURIComponent()这个函数转化以后的“这才是台湾”,所以说都一样,获取那种公众号,就将那种公众号的名子编码以后,动态的组合成一个链接,访问就可以步入到每位链接上面了,但是这个链接只是恳求到了这个页面,
并不是
这个页面,所以还的进一步处理,就是得到当前页面的第一个内容的链接,即href
当得到了这个链接,就会发觉他有他的加密方法,其实很简单的,就是在链接上面的加了三个amp;把链接上面的这三个amp;替换为空,就好了,这也就是第一步,得到每一个公众号的页面链接,
7-2
得到链接以后,就要进行访问了,即恳求,请求每位地址,得到每位地址的内容,但是每位页面显示的内容都不在页面中,即html结构中,在js中藏着,所以要通过正则匹配,得到整篇文章的对象,然后就循环每位公众号的这个对象,得到这个对象中的整篇文章的一些信息,包括title,thumb,abstract,URL,time,五个数组,但是我使用的代码烂透了,尽然当时使用了
对象.属性.foreach(function(item,index){
})
这种烂透了的形式,弄的最后好的在写一次循环才可以完全的得到每一个对象,否则只可以得到第一个,在这里应当用async.each,或者async.foreach这俩中形式每种都可以啊,而且都是非常好用的形式。这样的话买就得到了整篇文章的以上基本消息,
7-3、
第三个阶段,就是步入到整篇文章的详情页,获得整篇文章的内容,点赞数,作者,公众号,阅读量等数据,在这里遇到的主要问题是,人家的content直接在在js中,所有的img标签都有问题,他是以这些方式存在雨content中,但是这样的话,这样的图片在我们的网页中不能被显示,因为标签存在问题啊,html文档不认识这样的img标签啊,所以这儿要进行一些处理,把所有的用replace替换为
查看全部
差不多俩个礼拜了吧,一直在调试关于微信公众号的文章爬虫系统,终于一切都好了,但是在这期间遇到了好多问题,今天就来回顾一下,总结一下,希望有用到的小伙伴可以学习学习。
1、做了俩次爬虫了,第一次怕的凤凰网,那个没有限制,随便爬,所以也就对自动化执行代码模块放松了提防,觉得很简单的,但是毕竟不是这样的,我被这个问题困惑了好几天,差不多4天的一个样子,因为搜狗做的限制,同一个ip获取的次数多了,首先是出现验证码,其次是就是访问限制了,直接就是不能访问,利用 request得到的就是访问次数过分频繁,这样子的提示,所以说开发过程中最头痛的不是代码的编撰,而是测试,写完代码不能立刻测试,这种觉得相信大多数的程序员是不能喜欢的,我如今写的程序是每晚执行三次,这样的一个频度挺好,而且由于是多公众号采集嘛,每个公众号之间的间隔时间也的有,要不然同时访问十几个公众号的上百篇文章也是不现实的,说到这儿插一句,怎么使每位公众号怕去玩过后,等一段具体的时间,在执行下一个,最后用的setInterval函数解决的,
每过80秒执行一个公众号,把每次的执行代码讲到hello中,泡的有点远了,收一收哈,说说cron这个包,自动化执行,npm官网上只给了一个反例,但是我这个指桑拿可能是有点压制的厉害,不能否玩却理解他的用法,然后我说理解不了怎样办啊,上网搜呗,百度,cron包的具体用法,一看,嚯,还很多,于是就看啊看啊,但是仔细以剖析就不是这么回事儿了,都是屁话,没哪些用,网上通常的用法中都带有一个问号,但是我加上问号的时侯,就报错了,所以说都是胡扯,最后在朋友组的一个后端技术讨论群中说了一声,还真有热心的群友,给我找了一个链接,我进去一看,试了一下,还行,所以呢,非常谢谢这个帮助我解惑的朋友,再次我把qq群号,和链接附上,方便正在看这篇文章的你学习,QQ群号:435012561,链接:,这个链接上面说的挺好,至少能用,这里我挺好到一个问题,就是timezone,我们之前用过一次,用的是纽约时间,但是此次显著不行啊,要用俺们中国的时间啊,但是我试了几次上海的不行,重庆的可以,所以我就用了上海的。
2、这里要说的是,从地址栏获取参数的问题,我上一个做的没问题,但是这个不知道如何就不行了,上一个从地址栏得到的是数字,但是这个得到的是字符串,再加上mongodb中的对数组的要求还是很严格的,所以一个分页功能也困惑了我几个小时吧,最后是如何解决的呢,是通过我加的一个mongodb的讨论群,在里面问了一句这是如何了,发了个截图,里面就有一个热心的网友说你这显著是传入的数据格式不对啊,一语惊醒梦中人,我说是啊,然后就把得到的参数,我用Number()函数处理了一下,让string类型的数字,变成了number类型的数字,就好了,所以说你们在用mongodb的时侯一定要注意储存数据的格式,
3、mongodb查询数据句子组织形式:
其实说白了就是limit和skip俩个函数的使用,但是具体的格式可的看好了,还有我这个是接受的参数,不过mongo的参数接受也好弄直接写就好了,不用象sql那样搞哪些${""}这种类型的,后面的sort函数说明了排序的方法,这里是设置的以ctime数组为标准,-1表示逆序,1表示乱序,
4、在本次代码编撰中,我首次使用了try catch 这个补错的形式,事实证明,还行,可以把时常的错误正常的复印下来,但是不影响代码的整体执行,或者是说下一次执行,整体觉得非常好,
具体的使用方式,在try中倒入你要执行的代码,在最后加上一行,throw Error();
然后给catch传入一个参数e,在catch中可以复印好多个信息,我只复印了其中的一个,e.message,
5、这次编码过程中主要用到了anync包,其中的ansyc.each循环,ansyc.waterfall执行完前面的才可以执行下边的,而且说谎给你下之间还可以从上至下传递参数,这个很重要,因为在本次编程中,每次获取的内容不同,每次代码执行的条件不同,即须要的参数也不同,即有可能下一次代码的执行就须要用到上一次代码执行得到的结果,所以说这个anync包,真的是值得研究,他的每位方式都不同,有时候可以得到意想不到的疗效。
6、在mysql中若果想要达到这样一个疗效,就是说,如果数据库中早已存在了,那就不予理会,或者说不重复储存,如果数据库中不存在,那么就储存进来,很简单,直接把插入数据的insert 换成 replace 。但是在mongodb中,应该是没有,或者说是我还没有发觉,我是那么解决的,定义了一个开关,令这个开关为真,每次储存之前,先把所有的数据循环一遍,看看有没有这条数据,如果有,让开关变为假,如果没有,继续执行,即判定此时开关的真伪,如果是真的,那就执行插入操作,如果是假的,就不予理会,这就达到了类似的疗效,否则每次就会储存大量的重复数据,
7、本次采集的核心,就是我文件中的common.js了,首先由于要采集,所以须要用到request包,采集到以后,要处理html格式的数据,使之可以使用类jquery的操作,那么久用到了cheerio这个包,然后在循环采集的时侯,会用到anync.each这个方式,所以会用到async这个包,
7-1、
通过搜狗陌陌采集,就要剖析搜狗陌陌的路径,每个公众号的页面的路径是这样的
%E8%BF%99%E6%89%8D%E6%98%AF%E6%97%A5%E6%9C%AC&ie=utf8&_sug_=n&_sug_type_=
这个是“这才是台湾”的页面的链接,经过剖析,所有的公众号的链接只有query前面的参数不同,但是query前面的参数是哪些呢,其实就是通过encodeURIComponent()这个函数转化以后的“这才是台湾”,所以说都一样,获取那种公众号,就将那种公众号的名子编码以后,动态的组合成一个链接,访问就可以步入到每位链接上面了,但是这个链接只是恳求到了这个页面,
并不是
这个页面,所以还的进一步处理,就是得到当前页面的第一个内容的链接,即href
当得到了这个链接,就会发觉他有他的加密方法,其实很简单的,就是在链接上面的加了三个amp;把链接上面的这三个amp;替换为空,就好了,这也就是第一步,得到每一个公众号的页面链接,
7-2
得到链接以后,就要进行访问了,即恳求,请求每位地址,得到每位地址的内容,但是每位页面显示的内容都不在页面中,即html结构中,在js中藏着,所以要通过正则匹配,得到整篇文章的对象,然后就循环每位公众号的这个对象,得到这个对象中的整篇文章的一些信息,包括title,thumb,abstract,URL,time,五个数组,但是我使用的代码烂透了,尽然当时使用了
对象.属性.foreach(function(item,index){
})
这种烂透了的形式,弄的最后好的在写一次循环才可以完全的得到每一个对象,否则只可以得到第一个,在这里应当用async.each,或者async.foreach这俩中形式每种都可以啊,而且都是非常好用的形式。这样的话买就得到了整篇文章的以上基本消息,
7-3、
第三个阶段,就是步入到整篇文章的详情页,获得整篇文章的内容,点赞数,作者,公众号,阅读量等数据,在这里遇到的主要问题是,人家的content直接在在js中,所有的img标签都有问题,他是以这些方式存在雨content中,但是这样的话,这样的图片在我们的网页中不能被显示,因为标签存在问题啊,html文档不认识这样的img标签啊,所以这儿要进行一些处理,把所有的用replace替换为
微信公众号推送信息爬取---python爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-13 18:34
利用搜狗的陌陌搜索抓取指定公众号的最新一条推送,并保存相应的网页至本地。
注意点搜狗陌陌获取的地址为临时链接,具有时效性。公众号为动态网页(JavaScript渲染),使用requests.get()获取的内容是不含推送消息的,这里使用selenium+PhantomJS处理代码
#! /usr/bin/env python3
from selenium import webdriver
from datetime import datetime
import bs4, requests
import os, time, sys
# 获取公众号链接
def getAccountURL(searchURL):
res = requests.get(searchURL)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "lxml")
# 选择第一个链接
account = soup.select('a[uigs="account_name_0"]')
return account[0]['href']
# 获取首篇文章的链接,如果有验证码返回None
def getArticleURL(accountURL):
browser = webdriver.PhantomJS("/Users/chasechoi/Downloads/phantomjs-2.1.1-macosx/bin/phantomjs")
# 进入公众号
browser.get(accountURL)
# 获取网页信息
html = browser.page_source
accountSoup = bs4.BeautifulSoup(html, "lxml")
time.sleep(1)
contents = accountSoup.find_all(hrefs=True)
try:
partitialLink = contents[1]['hrefs']
firstLink = base + partitialLink
except IndexError:
firstLink = None
print('CAPTCHA!')
return firstLink
# 创建文件夹存储html网页,以时间命名
def folderCreation():
path = os.path.join(os.getcwd(), datetime.now().strftime('%Y-%m-%d_%H-%M-%S'))
try:
os.makedirs(path)
except OSError as e:
if e.errno != errno.EEXIST:
raise
print("folder not exist!")
return path
# 将html页面写入本地
def writeToFile(path, account, title):
pathToWrite = os.path.join(path, '{}_{}.html'.format(account, title))
myfile = open(pathToWrite, 'wb')
myfile.write(res.content)
myfile.close()
base ='https://mp.weixin.qq.com'
accountList = ['央视新闻', '新浪新闻','凤凰新闻','羊城晚报']
query = 'http://weixin.sogou.com/weixin?type=1&s_from=input&query='
path = folderCreation()
for index, account in enumerate(accountList):
searchURL = query + account
accountURL = getAccountURL(searchURL)
time.sleep(10)
articleURL = getArticleURL(accountURL)
if articleURL != None:
print("#{}({}/{}): {}".format(account, index+1, len(accountList), accountURL))
# 读取第一篇文章内容
res = requests.get(articleURL)
res.raise_for_status()
detailPage = bs4.BeautifulSoup(res.text, "lxml")
title = detailPage.title.text
print("标题: {}\n链接: {}\n".format(title, articleURL))
writeToFile(path, account, title)
else:
print('{} files successfully written to {}'.format(index, path))
sys.exit()
print('{} files successfully written to {}'.format(len(accountList), path))
参考输出
分析链接获取首先步入搜狗的陌陌搜索页面,在地址栏中提取须要的部份链接,字符串联接公众号名称,即可生成恳求链接针对静态网页,利用requests获取html文件,再用BeautifulSoup选择须要的内容针对动态网页,利用selenium+PhantomJS获取html文件,再用BeautifulSoup选择须要的内容遇见验证码(CAPTCHA),输出提示。此版本代码没有对验证码做实际处理,需要人为访问后,再跑程序,才能避免验证码。文件写入使用os.path.join()构造储存路径可以提升通用性。比如Windows路径分隔符使用back slash(\), 而OS X 和 Linux使用forward slash(/),通过该函数能依据平台进行手动转换。open()使用b(binary mode)参数同样为了提升通用性(适应Windows)使用datetime.now()获取当前时间进行命名,并通过strftime()格式化时间(函数名中的f代表format),具体使用参考下表(摘自 Automate the Boring Stuff with Python)
参考链接:文件夹创建: 异常处理的使用: enumerate的使用: open()使用b参数理由: 查看全部
问题描述
利用搜狗的陌陌搜索抓取指定公众号的最新一条推送,并保存相应的网页至本地。
注意点搜狗陌陌获取的地址为临时链接,具有时效性。公众号为动态网页(JavaScript渲染),使用requests.get()获取的内容是不含推送消息的,这里使用selenium+PhantomJS处理代码
#! /usr/bin/env python3
from selenium import webdriver
from datetime import datetime
import bs4, requests
import os, time, sys
# 获取公众号链接
def getAccountURL(searchURL):
res = requests.get(searchURL)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "lxml")
# 选择第一个链接
account = soup.select('a[uigs="account_name_0"]')
return account[0]['href']
# 获取首篇文章的链接,如果有验证码返回None
def getArticleURL(accountURL):
browser = webdriver.PhantomJS("/Users/chasechoi/Downloads/phantomjs-2.1.1-macosx/bin/phantomjs")
# 进入公众号
browser.get(accountURL)
# 获取网页信息
html = browser.page_source
accountSoup = bs4.BeautifulSoup(html, "lxml")
time.sleep(1)
contents = accountSoup.find_all(hrefs=True)
try:
partitialLink = contents[1]['hrefs']
firstLink = base + partitialLink
except IndexError:
firstLink = None
print('CAPTCHA!')
return firstLink
# 创建文件夹存储html网页,以时间命名
def folderCreation():
path = os.path.join(os.getcwd(), datetime.now().strftime('%Y-%m-%d_%H-%M-%S'))
try:
os.makedirs(path)
except OSError as e:
if e.errno != errno.EEXIST:
raise
print("folder not exist!")
return path
# 将html页面写入本地
def writeToFile(path, account, title):
pathToWrite = os.path.join(path, '{}_{}.html'.format(account, title))
myfile = open(pathToWrite, 'wb')
myfile.write(res.content)
myfile.close()
base ='https://mp.weixin.qq.com'
accountList = ['央视新闻', '新浪新闻','凤凰新闻','羊城晚报']
query = 'http://weixin.sogou.com/weixin?type=1&s_from=input&query='
path = folderCreation()
for index, account in enumerate(accountList):
searchURL = query + account
accountURL = getAccountURL(searchURL)
time.sleep(10)
articleURL = getArticleURL(accountURL)
if articleURL != None:
print("#{}({}/{}): {}".format(account, index+1, len(accountList), accountURL))
# 读取第一篇文章内容
res = requests.get(articleURL)
res.raise_for_status()
detailPage = bs4.BeautifulSoup(res.text, "lxml")
title = detailPage.title.text
print("标题: {}\n链接: {}\n".format(title, articleURL))
writeToFile(path, account, title)
else:
print('{} files successfully written to {}'.format(index, path))
sys.exit()
print('{} files successfully written to {}'.format(len(accountList), path))
参考输出
分析链接获取首先步入搜狗的陌陌搜索页面,在地址栏中提取须要的部份链接,字符串联接公众号名称,即可生成恳求链接针对静态网页,利用requests获取html文件,再用BeautifulSoup选择须要的内容针对动态网页,利用selenium+PhantomJS获取html文件,再用BeautifulSoup选择须要的内容遇见验证码(CAPTCHA),输出提示。此版本代码没有对验证码做实际处理,需要人为访问后,再跑程序,才能避免验证码。文件写入使用os.path.join()构造储存路径可以提升通用性。比如Windows路径分隔符使用back slash(\), 而OS X 和 Linux使用forward slash(/),通过该函数能依据平台进行手动转换。open()使用b(binary mode)参数同样为了提升通用性(适应Windows)使用datetime.now()获取当前时间进行命名,并通过strftime()格式化时间(函数名中的f代表format),具体使用参考下表(摘自 Automate the Boring Stuff with Python)
参考链接:文件夹创建: 异常处理的使用: enumerate的使用: open()使用b参数理由:
Python爬取微信公众号文章、点赞数
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2020-08-13 18:31
2、3 设置Fiddler 并保存配置
微信客户端恳求公众号文章, fiddler抓取到的数据req_id 、 pass_ticket 、 appmsg_tojen
微信客户端恳求公众号文章, fiddler抓取到的数据cookie 和user-agent
最后恢复Fiddler的配置,会报错的
END!!!前面的获取工作就结束了…
一、获取cookie
# -*- coding: utf-8 -*-
import time
import json
from selenium import webdriver
import sys
sys.path.append('/path/to/your/module')
post = {}
driver = webdriver.Chrome(executable_path="chromedriver.exe")
driver.get('https://mp.weixin.qq.com')
time.sleep(2)
driver.find_element_by_name('account').clear()
driver.find_element_by_name('account').send_keys('订阅号账号')
driver.find_element_by_name('password').clear()
driver.find_element_by_name('password').send_keys('订阅号密码')
# 自动输入密码后点击记住密码
time.sleep(5)
driver.find_element_by_xpath("./*//a[@class='btn_login']").click()
# 扫码
time.sleep(20)
driver.get('https://mp.weixin.qq.com')
cookie_items = driver.get_cookies()
for cookie_item in cookie_items:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie write ok ...')
二、获取文章数据(文章列表写入数据库)
<p># -*- coding: utf-8 -*-
import time, datetime
import json
import requests
import re
import random
import MySQLdb
#设置要爬取的公众号列表
gzlist=['ckxxwx']
# 打开数据库连接
db = MySQLdb.connect("localhost", "root", "123456", "wechat_reptile_data", charset='utf8' )
# 数据的开始日期 - 结束日期
start_data = '20190630';
end_data = '20190430'
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# 获取阅读数和点赞数
def getMoreInfo(link, query):
pass_ticket = "VllmJYTSgRotAAiQn17Tw1v35AduDOg%252BLCq%252B07qi4FKcStfL%252Fkc44G0LuIvr99HO"
if query == 'ckxxwx':
appmsg_token = "1016_%2F%2Bs3kaOp2TJJQ4EKMVfI0O8RhzRxMs3lLy54hhisceyyXmLHXf_x5xZPaT_pbAJgmwxL19F0XRMWtvYH"
phoneCookie = "rewardsn=; wxuin=811344139; devicetype=Windows10; version=62060833; lang=zh_CN; pass_ticket=VllmJYTSgRotAAiQn17Tw1v35AduDOg+LCq+07qi4FKcStfL/kc44G0LuIvr99HO; wap_sid2=CIvC8IIDElxlWlVuYlBacDF0TW9sUW16WmNIaDl0cVhxYzZnSHljWlB3TmxfdjlDWmItNVpXeURScG1RNEpuNzFUZFNSZWVZcjE5SHZST2tLZnBSdDUxLWhHRDNQX2dEQUFBfjCasIvpBTgNQAE=; wxtokenkey=777"
mid = link.split("&")[1].split("=")[1]
idx = link.split("&")[2].split("=")[1]
sn = link.split("&")[3].split("=")[1]
_biz = link.split("&")[0].split("_biz=")[1]
# 目标url
url = "http://mp.weixin.qq.com/mp/getappmsgext"
# 添加Cookie避免登陆操作,这里的"User-Agent"最好为手机浏览器的标识
headers = {
"Cookie": phoneCookie,
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.1021.400 QQBrowser/9.0.2524.400"
}
# 添加data,`req_id`、`pass_ticket`分别对应文章的信息,从fiddler复制即可。
data = {
"is_only_read": "1",
"is_temp_url": "0",
"appmsg_type": "9",
'reward_uin_count': '0'
}
params = {
"__biz": _biz,
"mid": mid,
"sn": sn,
"idx": idx,
"key": '777',
"pass_ticket": pass_ticket,
"appmsg_token": appmsg_token,
"uin": '777',
"wxtoken": "777"
}
# 使用post方法进行提交
content = requests.post(url, headers=headers, data=data, params=params).json()
# 提取其中的阅读数和点赞数
if 'appmsgstat' in content:
readNum = content["appmsgstat"]["read_num"]
likeNum = content["appmsgstat"]["like_num"]
else:
print('请求参数过期!')
# 歇10s,防止被封
time.sleep(10)
return readNum, likeNum
#爬取微信公众号文章,并存在本地文本中
def get_content(query):
#query为要爬取的公众号名称
#公众号主页
url = 'https://mp.weixin.qq.com'
#设置headers
header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
#读取上一步获取到的cookies
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
#登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-b ... 51598,从这里获取token信息
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
time.sleep(2)
#搜索微信公众号的接口地址
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
#搜索微信公众号接口需要传入的参数,有三个变量:微信公众号token、随机数random、搜索的微信公众号名字
query_id = {
'action': 'search_biz',
'token' : token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'query': query,
'begin': '0',
'count': '5'
}
#打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers
search_response = requests.get(search_url, cookies=cookies, headers=header, params=query_id)
#取搜索结果中的第一个公众号
lists = search_response.json().get('list')[0]
#获取这个公众号的fakeid,后面爬取公众号文章需要此字段
fakeid = lists.get('fakeid')
#微信公众号文章接口地址
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
#搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '0',#不同页,此参数变化,变化规则为每页加5
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
#打开搜索的微信公众号文章列表页
appmsg_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
#获取文章总数
if appmsg_response.json().get('base_resp').get('ret') == 200013:
print('搜索公众号文章操作频繁,!!!')
max_num = appmsg_response.json().get('app_msg_cnt')
#每页至少有5条,获取文章总的页数,爬取时需要分页爬
num = int(int(max_num) / 5)
#起始页begin参数,往后每页加5
begin = 0 # 根据内容自定义
while num + 1 > 0 :
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '{}'.format(str(begin)),
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
print('正在翻页:--------------',begin)
time.sleep(5)
#获取每一页文章的标题和链接地址,并写入本地文本中
query_fakeid_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
for item in fakeid_list:
content_link=item.get('link')
content_title=item.get('title')
update_time=item.get('update_time')
timeArray = time.localtime(update_time)
DataTime = time.strftime("%Y%m%d", timeArray)
print(DataTime)
Yearsmonth = time.strftime("%Y%m", timeArray)
if DataTime 查看全部
2、2 关注须要爬取的公众号
2、3 设置Fiddler 并保存配置
微信客户端恳求公众号文章, fiddler抓取到的数据req_id 、 pass_ticket 、 appmsg_tojen
微信客户端恳求公众号文章, fiddler抓取到的数据cookie 和user-agent
最后恢复Fiddler的配置,会报错的
END!!!前面的获取工作就结束了…
一、获取cookie
# -*- coding: utf-8 -*-
import time
import json
from selenium import webdriver
import sys
sys.path.append('/path/to/your/module')
post = {}
driver = webdriver.Chrome(executable_path="chromedriver.exe")
driver.get('https://mp.weixin.qq.com')
time.sleep(2)
driver.find_element_by_name('account').clear()
driver.find_element_by_name('account').send_keys('订阅号账号')
driver.find_element_by_name('password').clear()
driver.find_element_by_name('password').send_keys('订阅号密码')
# 自动输入密码后点击记住密码
time.sleep(5)
driver.find_element_by_xpath("./*//a[@class='btn_login']").click()
# 扫码
time.sleep(20)
driver.get('https://mp.weixin.qq.com')
cookie_items = driver.get_cookies()
for cookie_item in cookie_items:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie write ok ...')
二、获取文章数据(文章列表写入数据库)
<p># -*- coding: utf-8 -*-
import time, datetime
import json
import requests
import re
import random
import MySQLdb
#设置要爬取的公众号列表
gzlist=['ckxxwx']
# 打开数据库连接
db = MySQLdb.connect("localhost", "root", "123456", "wechat_reptile_data", charset='utf8' )
# 数据的开始日期 - 结束日期
start_data = '20190630';
end_data = '20190430'
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# 获取阅读数和点赞数
def getMoreInfo(link, query):
pass_ticket = "VllmJYTSgRotAAiQn17Tw1v35AduDOg%252BLCq%252B07qi4FKcStfL%252Fkc44G0LuIvr99HO"
if query == 'ckxxwx':
appmsg_token = "1016_%2F%2Bs3kaOp2TJJQ4EKMVfI0O8RhzRxMs3lLy54hhisceyyXmLHXf_x5xZPaT_pbAJgmwxL19F0XRMWtvYH"
phoneCookie = "rewardsn=; wxuin=811344139; devicetype=Windows10; version=62060833; lang=zh_CN; pass_ticket=VllmJYTSgRotAAiQn17Tw1v35AduDOg+LCq+07qi4FKcStfL/kc44G0LuIvr99HO; wap_sid2=CIvC8IIDElxlWlVuYlBacDF0TW9sUW16WmNIaDl0cVhxYzZnSHljWlB3TmxfdjlDWmItNVpXeURScG1RNEpuNzFUZFNSZWVZcjE5SHZST2tLZnBSdDUxLWhHRDNQX2dEQUFBfjCasIvpBTgNQAE=; wxtokenkey=777"
mid = link.split("&")[1].split("=")[1]
idx = link.split("&")[2].split("=")[1]
sn = link.split("&")[3].split("=")[1]
_biz = link.split("&")[0].split("_biz=")[1]
# 目标url
url = "http://mp.weixin.qq.com/mp/getappmsgext"
# 添加Cookie避免登陆操作,这里的"User-Agent"最好为手机浏览器的标识
headers = {
"Cookie": phoneCookie,
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.1021.400 QQBrowser/9.0.2524.400"
}
# 添加data,`req_id`、`pass_ticket`分别对应文章的信息,从fiddler复制即可。
data = {
"is_only_read": "1",
"is_temp_url": "0",
"appmsg_type": "9",
'reward_uin_count': '0'
}
params = {
"__biz": _biz,
"mid": mid,
"sn": sn,
"idx": idx,
"key": '777',
"pass_ticket": pass_ticket,
"appmsg_token": appmsg_token,
"uin": '777',
"wxtoken": "777"
}
# 使用post方法进行提交
content = requests.post(url, headers=headers, data=data, params=params).json()
# 提取其中的阅读数和点赞数
if 'appmsgstat' in content:
readNum = content["appmsgstat"]["read_num"]
likeNum = content["appmsgstat"]["like_num"]
else:
print('请求参数过期!')
# 歇10s,防止被封
time.sleep(10)
return readNum, likeNum
#爬取微信公众号文章,并存在本地文本中
def get_content(query):
#query为要爬取的公众号名称
#公众号主页
url = 'https://mp.weixin.qq.com'
#设置headers
header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
#读取上一步获取到的cookies
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
#登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-b ... 51598,从这里获取token信息
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
time.sleep(2)
#搜索微信公众号的接口地址
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
#搜索微信公众号接口需要传入的参数,有三个变量:微信公众号token、随机数random、搜索的微信公众号名字
query_id = {
'action': 'search_biz',
'token' : token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'query': query,
'begin': '0',
'count': '5'
}
#打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers
search_response = requests.get(search_url, cookies=cookies, headers=header, params=query_id)
#取搜索结果中的第一个公众号
lists = search_response.json().get('list')[0]
#获取这个公众号的fakeid,后面爬取公众号文章需要此字段
fakeid = lists.get('fakeid')
#微信公众号文章接口地址
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
#搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '0',#不同页,此参数变化,变化规则为每页加5
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
#打开搜索的微信公众号文章列表页
appmsg_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
#获取文章总数
if appmsg_response.json().get('base_resp').get('ret') == 200013:
print('搜索公众号文章操作频繁,!!!')
max_num = appmsg_response.json().get('app_msg_cnt')
#每页至少有5条,获取文章总的页数,爬取时需要分页爬
num = int(int(max_num) / 5)
#起始页begin参数,往后每页加5
begin = 0 # 根据内容自定义
while num + 1 > 0 :
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '{}'.format(str(begin)),
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
print('正在翻页:--------------',begin)
time.sleep(5)
#获取每一页文章的标题和链接地址,并写入本地文本中
query_fakeid_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
for item in fakeid_list:
content_link=item.get('link')
content_title=item.get('title')
update_time=item.get('update_time')
timeArray = time.localtime(update_time)
DataTime = time.strftime("%Y%m%d", timeArray)
print(DataTime)
Yearsmonth = time.strftime("%Y%m", timeArray)
if DataTime
Python 抓取微信公众号文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2020-08-11 15:51
然后按照时效性链接获取文章内容,并从中提取参数信息:
from html import unescape from urllib.parse import urlencode def weixin_params(link): html = req.get(link) rParams = r'var (biz =.*?".*?");\s*var (sn =.*?".*?");\s*var (mid =.*?".*?");\s*var (idx =.*?".*?");' params = re.findall(rParams, html) if len(params) == 0: return None return {i.split('=')[0].strip(): i.split('=', 1)[1].strip('|" ') for i in params[0]} for (link, title, abstract) in infos: title = unescape(self.remove_tag(title)) abstract = unescape(self.remove_tag(abstract)) params = weixin_params(link) if params is not None: link = "http://mp.weixin.qq.com/s?" + urlencode(params) print(link, title, abstract)
由此可以搜集到以 Python 为关键词的微信公众号文章,包括链接、标题和摘要。如需文章内容也可以随时通过链接提取,但是为了尊重创作者,请在抓取文章正文的时侯请复查原创信息并合理标明作者及引用信息。
来自:#rd 查看全部
def remove_tags(s): return re.sub(r'', '', s)
然后按照时效性链接获取文章内容,并从中提取参数信息:
from html import unescape from urllib.parse import urlencode def weixin_params(link): html = req.get(link) rParams = r'var (biz =.*?".*?");\s*var (sn =.*?".*?");\s*var (mid =.*?".*?");\s*var (idx =.*?".*?");' params = re.findall(rParams, html) if len(params) == 0: return None return {i.split('=')[0].strip(): i.split('=', 1)[1].strip('|" ') for i in params[0]} for (link, title, abstract) in infos: title = unescape(self.remove_tag(title)) abstract = unescape(self.remove_tag(abstract)) params = weixin_params(link) if params is not None: link = "http://mp.weixin.qq.com/s?" + urlencode(params) print(link, title, abstract)
由此可以搜集到以 Python 为关键词的微信公众号文章,包括链接、标题和摘要。如需文章内容也可以随时通过链接提取,但是为了尊重创作者,请在抓取文章正文的时侯请复查原创信息并合理标明作者及引用信息。
来自:#rd
微信公众号采集小爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2020-08-11 12:49
## 公众号爬取形式
爬取公众号目前主流的方案主要有两种,一种是通过搜狗搜索微信公众号的页面去找到文章地址,再去爬取具体文章内容;第二种是通过注册公众号之后通过公众号的搜索插口去查询到文章地址,然后再按照地址去爬文章内容。
这两种方案各有优缺点,通过搜狗搜索来做虽然核心思路就是通过request模拟搜狗搜索公众号,然后解析搜索结果页面,再依照公众号主页地址爬虫,爬取文章明细信息,但是这儿须要注意下,因为搜狗和腾讯之间的合同问题,只能显示最新的10条文章,没办法领到所有的文章。如果要领到所有文章的同学可能要采用第二种形式了。第二种方法的缺点就是要注册公众号通过腾讯认证,流程麻烦些,通过调用插口公众号查询插口查询,但是翻页须要通过selenium去模拟滑动翻页操作,整个过程还是很麻烦的。因为我的项目里不需要历史文章,所以我采用通过搜狗搜索去做爬取公众号的功能。
爬取近来10篇公众号文章
python须要依赖的三方库如下:
urllib、pyquery、requests、selenium
具体的逻辑都写在注释里了,没有非常复杂的地方。
爬虫核心类
```python
#!/usr/bin/python
# coding: utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from urllib import quote
from pyquery import PyQuery as pq
import requests
import time
import re
import os
from selenium.webdriver import Chrome
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support.wait import WebDriverWait
# 搜索入口地址,以公众为关键字搜索该公众号
def get_search_result_by_keywords(sogou_search_url):
# 爬虫伪装头部设置
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
# 设置操作超时时长
timeout = 5
# 爬虫模拟在一个request.session中完成
s = requests.Session()
log(u'搜索地址为:%s' % sogou_search_url)
return s.get(sogou_search_url, headers=headers, timeout=timeout).content
# 获得公众号主页地址
def get_wx_url_by_sougou_search_html(sougou_search_html):
doc = pq(sougou_search_html)
return doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
options = Options()
options.add_argument('-headless') # 无头参数
driver = Chrome(executable_path='chromedriver', chrome_options=options)
wait = WebDriverWait(driver, timeout=10)
driver.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = driver.execute_script("return document.documentElement.outerHTML")
driver.close()
return html
# 获取公众号文章内容
def parse_wx_articles_by_html(selenium_html):
doc = pq(selenium_html)
return doc('div[class="weui_media_box appmsg"]')
# 将获取到的文章转换为字典
def switch_arctiles_to_list(articles):
# 定义存贮变量
articles_list = []
i = 1
# 遍历找到的文章,解析里面的内容
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
###log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 返回字典数据
return {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic
}
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 自定义log函数,主要是加上时间
def log(msg):
print u'%s: %s' % (time.strftime('%Y-%m-%d_%H-%M-%S'), msg)
# 验证函数
def need_verify(selenium_html):
' 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 '
return pq(selenium_html)('#verify_change').text() != ''
# 创建公众号命名的文件夹
def create_dir(keywords):
if not os.path.exists(keywords):
os.makedirs(keywords)
# 爬虫主函数
def run(keywords):
' 爬虫入口函数 '
# Step 0 : 创建公众号命名的文件夹
create_dir(keywords)
# 搜狐微信搜索链接入口
sogou_search_url = 'http://weixin.sogou.com/weixin?type=1&query=%s&ie=utf8&s_from=input&_sug_=n&_sug_type_=' % quote(
keywords)
# Step 1:GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
log(u'开始获取,微信公众号英文名为:%s' % keywords)
log(u'开始调用sougou搜索引擎')
sougou_search_html = get_search_result_by_keywords(sogou_search_url)
# Step 2:从搜索结果页中解析出公众号主页链接
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
wx_url = get_wx_url_by_sougou_search_html(sougou_search_html)
log(u'获取wx_url成功,%s' % wx_url)
# Step 3:Selenium+PhantomJs获取js异步加载渲染后的html
log(u'开始调用selenium渲染html')
selenium_html = get_selenium_js_html(wx_url)
# Step 4: 检测目标网站是否进行了封锁
if need_verify(selenium_html):
log(u'爬虫被目标网站封锁,请稍后再试')
else:
# Step 5: 使用PyQuery,从Step 3获取的html中解析出公众号文章列表的数据
log(u'调用selenium渲染html完成,开始解析公众号文章')
articles = parse_wx_articles_by_html(selenium_html)
log(u'抓取到微信文章%d篇' % len(articles))
# Step 6: 把微信文章数据封装成字典的list
log(u'开始整合微信文章数据为字典')
articles_list = switch_arctiles_to_list(articles)
return [content['title'] for content in articles_list]
```
main入口函数:
```python
# coding: utf8
import spider_weixun_by_sogou
if __name__ == '__main__':
gongzhonghao = raw_input(u'input weixin gongzhonghao:')
if not gongzhonghao:
gongzhonghao = 'spider'
text = " ".join(spider_weixun_by_sogou.run(gongzhonghao))
print text
爬取公众号注意事项
下面这3个是我在爬取的过程中遇见的一些问题,希望能帮到你们避坑。
1. Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead warnings.warn('Selenium support for PhantomJS has been deprecated, please use headless '
网上好多的文章都还在使用PhantomJS,其实从今年Selenium就早已不支持PhantomJS了,现在使用Selenium初始化浏览器的话须要使用webdriver初始化无头参数的Chrome或则Firefox driver。
具体可以参考官网链接:
2. Can not connect to the Service chromedriver/firefoxdriver
在开发过程中还碰到这个坑,这个问题通常有两种可能性,一种是没有配置chromedriver或则geckodriver的环境变量,这里须要注意下将chromedriver或则geckodriver文件一定要配置环境变量到PATH下,或者干脆粗鲁一点直接将这两个文件复制到/usr/bin目录下;
还有种可能是没有配置hosts,如果你们发觉这个问题复查下自己的hosts文件是不是没有配置`127.0.0.1 localhost`,只要配置上就好了。
这里还有一点要注意的就是使用chrome浏览器的话,还要注意chrome浏览器版本和chromedriver的对应关系,可以在这篇文章中查看也可以翻墙去google官网查看最新的对应关系。
3. 防盗链
微信公众号对文章中的图片做了防盗链处理,所以假如在公众号和小程序、PC浏览器以外的地方是未能显示图片的,这里推荐你们可以看下这篇文章了解下怎样处理陌陌的防盗链。
总结
好了前面说了那么多,大家最关心的就是源代码,这里放出github地址:,好用的话记得strar。
另外附上作品项目: 查看全部
最近在做一个自己的项目,涉及到须要通过python爬取微信公众号的文章,因为陌陌奇特一些手段,导致难以直接爬取,研究了一些文章大概有了思路,并且网上目前能搜到的方案思路都没啥问题,但是上面的代码由于一些三方库的变动基本都不能用了,这篇文章写给须要爬取公众号文章的朋友们,文章最后也会提供python源码下载。
## 公众号爬取形式
爬取公众号目前主流的方案主要有两种,一种是通过搜狗搜索微信公众号的页面去找到文章地址,再去爬取具体文章内容;第二种是通过注册公众号之后通过公众号的搜索插口去查询到文章地址,然后再按照地址去爬文章内容。
这两种方案各有优缺点,通过搜狗搜索来做虽然核心思路就是通过request模拟搜狗搜索公众号,然后解析搜索结果页面,再依照公众号主页地址爬虫,爬取文章明细信息,但是这儿须要注意下,因为搜狗和腾讯之间的合同问题,只能显示最新的10条文章,没办法领到所有的文章。如果要领到所有文章的同学可能要采用第二种形式了。第二种方法的缺点就是要注册公众号通过腾讯认证,流程麻烦些,通过调用插口公众号查询插口查询,但是翻页须要通过selenium去模拟滑动翻页操作,整个过程还是很麻烦的。因为我的项目里不需要历史文章,所以我采用通过搜狗搜索去做爬取公众号的功能。
爬取近来10篇公众号文章
python须要依赖的三方库如下:
urllib、pyquery、requests、selenium
具体的逻辑都写在注释里了,没有非常复杂的地方。
爬虫核心类
```python
#!/usr/bin/python
# coding: utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from urllib import quote
from pyquery import PyQuery as pq
import requests
import time
import re
import os
from selenium.webdriver import Chrome
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support.wait import WebDriverWait
# 搜索入口地址,以公众为关键字搜索该公众号
def get_search_result_by_keywords(sogou_search_url):
# 爬虫伪装头部设置
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
# 设置操作超时时长
timeout = 5
# 爬虫模拟在一个request.session中完成
s = requests.Session()
log(u'搜索地址为:%s' % sogou_search_url)
return s.get(sogou_search_url, headers=headers, timeout=timeout).content
# 获得公众号主页地址
def get_wx_url_by_sougou_search_html(sougou_search_html):
doc = pq(sougou_search_html)
return doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
options = Options()
options.add_argument('-headless') # 无头参数
driver = Chrome(executable_path='chromedriver', chrome_options=options)
wait = WebDriverWait(driver, timeout=10)
driver.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = driver.execute_script("return document.documentElement.outerHTML")
driver.close()
return html
# 获取公众号文章内容
def parse_wx_articles_by_html(selenium_html):
doc = pq(selenium_html)
return doc('div[class="weui_media_box appmsg"]')
# 将获取到的文章转换为字典
def switch_arctiles_to_list(articles):
# 定义存贮变量
articles_list = []
i = 1
# 遍历找到的文章,解析里面的内容
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
###log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 返回字典数据
return {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic
}
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 自定义log函数,主要是加上时间
def log(msg):
print u'%s: %s' % (time.strftime('%Y-%m-%d_%H-%M-%S'), msg)
# 验证函数
def need_verify(selenium_html):
' 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 '
return pq(selenium_html)('#verify_change').text() != ''
# 创建公众号命名的文件夹
def create_dir(keywords):
if not os.path.exists(keywords):
os.makedirs(keywords)
# 爬虫主函数
def run(keywords):
' 爬虫入口函数 '
# Step 0 : 创建公众号命名的文件夹
create_dir(keywords)
# 搜狐微信搜索链接入口
sogou_search_url = 'http://weixin.sogou.com/weixin?type=1&query=%s&ie=utf8&s_from=input&_sug_=n&_sug_type_=' % quote(
keywords)
# Step 1:GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
log(u'开始获取,微信公众号英文名为:%s' % keywords)
log(u'开始调用sougou搜索引擎')
sougou_search_html = get_search_result_by_keywords(sogou_search_url)
# Step 2:从搜索结果页中解析出公众号主页链接
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
wx_url = get_wx_url_by_sougou_search_html(sougou_search_html)
log(u'获取wx_url成功,%s' % wx_url)
# Step 3:Selenium+PhantomJs获取js异步加载渲染后的html
log(u'开始调用selenium渲染html')
selenium_html = get_selenium_js_html(wx_url)
# Step 4: 检测目标网站是否进行了封锁
if need_verify(selenium_html):
log(u'爬虫被目标网站封锁,请稍后再试')
else:
# Step 5: 使用PyQuery,从Step 3获取的html中解析出公众号文章列表的数据
log(u'调用selenium渲染html完成,开始解析公众号文章')
articles = parse_wx_articles_by_html(selenium_html)
log(u'抓取到微信文章%d篇' % len(articles))
# Step 6: 把微信文章数据封装成字典的list
log(u'开始整合微信文章数据为字典')
articles_list = switch_arctiles_to_list(articles)
return [content['title'] for content in articles_list]
```
main入口函数:
```python
# coding: utf8
import spider_weixun_by_sogou
if __name__ == '__main__':
gongzhonghao = raw_input(u'input weixin gongzhonghao:')
if not gongzhonghao:
gongzhonghao = 'spider'
text = " ".join(spider_weixun_by_sogou.run(gongzhonghao))
print text
爬取公众号注意事项
下面这3个是我在爬取的过程中遇见的一些问题,希望能帮到你们避坑。
1. Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead warnings.warn('Selenium support for PhantomJS has been deprecated, please use headless '
网上好多的文章都还在使用PhantomJS,其实从今年Selenium就早已不支持PhantomJS了,现在使用Selenium初始化浏览器的话须要使用webdriver初始化无头参数的Chrome或则Firefox driver。
具体可以参考官网链接:
2. Can not connect to the Service chromedriver/firefoxdriver
在开发过程中还碰到这个坑,这个问题通常有两种可能性,一种是没有配置chromedriver或则geckodriver的环境变量,这里须要注意下将chromedriver或则geckodriver文件一定要配置环境变量到PATH下,或者干脆粗鲁一点直接将这两个文件复制到/usr/bin目录下;
还有种可能是没有配置hosts,如果你们发觉这个问题复查下自己的hosts文件是不是没有配置`127.0.0.1 localhost`,只要配置上就好了。
这里还有一点要注意的就是使用chrome浏览器的话,还要注意chrome浏览器版本和chromedriver的对应关系,可以在这篇文章中查看也可以翻墙去google官网查看最新的对应关系。
3. 防盗链
微信公众号对文章中的图片做了防盗链处理,所以假如在公众号和小程序、PC浏览器以外的地方是未能显示图片的,这里推荐你们可以看下这篇文章了解下怎样处理陌陌的防盗链。
总结
好了前面说了那么多,大家最关心的就是源代码,这里放出github地址:,好用的话记得strar。
另外附上作品项目:
python3下载公众号历史文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2020-08-11 07:24
好吧,其实也完全是照搬,感谢高手!
还没有安装python可以先下载一个anoconda3:
1.终端加载python selenium模块包
加载包
2.使用webdriver功能须要安装对应浏览器的驱动插件,我用的是谷歌浏览器。安装和浏览器版本对应的webdriver版本,解压杂记下 chromedriver.exe 路径。对应版本查询和下载链接:
3.注册自己的公众号:微信公众号登录地址:
4.参考:
我照搬代码的这位前辈:
崔庆才原文(另有探究代码过程视频):
6.我的webdriver不知道是版本没对上还是哪些缘由,不能实现手动输入,注释掉,手动输入解决。
7.原文保存的是文章标题和链接,我需要保存到本地。用过两种方式,一个是生成pdf格式,一个是保存为html格式。
(1)保存为html格式,终端加载pip install urllib,然后
import urllib.request
使用:urllib.request.urlretrieve('','taobao.html')
(2)生成pdf较为复杂一些,不过有此方式,以后假如有须要,保存网址为pdf也便捷许多。不过这方面的需求用印象笔记的浏览器插件早已相当满足了。
pip intall pdfkit
pip install requests
pip install beautifulsoup4
安装 wkhtmltopdf,Windows平台直接在 下载稳定版的 wkhtmltopdf 进行安装,安装完成以后把该程序的执行路径加入到系统环境 $PATH 变量中,否则 pdfkit 找不到 wkhtmltopdf 就出现错误 “No wkhtmltopdf executable found”
方便使用,自己写了一个简单的模块:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
'a html to pdf model'
'''
使用示例:python htmltopdf_dl.py www.taobao.com baidu.pdf
'''
_author_ = 'dengling'
import pdfkit
import sys
def htmltopdf_dl():
ags = sys.argv
pdfkit.from_url(ags[1],ags[2])
if __name__ =='__main__':
htmltopdf_dl()
8.缺点:(1)用这个方式只在一个安静平和的夜间奇妙地爬完了所有的文章。其余时侯再也没有完整的爬取过所有的链接了。(2)因为保存本地html时参数辨识标题的特殊符号例如''时会出错,所以不能一下子全转换过来。(3)图片不能一起保存出来。
完整代码:
# -*- coding: utf-8 -*-
from selenium import webdriver
import time
import json
import requests
import re
import random
#微信公众号账号
user="你的账户"
#公众号密码
password="你的密码"
#设置要爬取的公众号列表
gzlist=['公众号名字']
#登录微信公众号,获取登录之后的cookies信息,并保存到本地文本中
def weChat_login():
#定义一个空的字典,存放cookies内容
post={}
#用webdriver启动谷歌浏览器
print("启动浏览器,打开微信公众号登录界面")
driver = webdriver.Chrome(executable_path='E:\微信公众号\chromedriver.exe')
#打开微信公众号登录页面
driver.get('https://mp.weixin.qq.com/')
#等待5秒钟
time.sleep(5)
print("正在输入微信公众号登录账号和密码......")
#清空账号框中的内容
driver.find_element_by_xpath("./*//input[@id='account']").clear()
#自动填入登录用户名
driver.find_element_by_xpath("./*//input[@id='account']").send_keys(user)
#清空密码框中的内容
driver.find_element_by_xpath("./*//input[@id='pwd']").clear()
#自动填入登录密码
driver.find_element_by_xpath("./*//input[@id='pwd']").send_keys(password)
# 在自动输完密码之后需要手动点一下记住我
print("请在登录界面点击:记住账号")
time.sleep(10)
#自动点击登录按钮进行登录
driver.find_element_by_xpath("./*//a[@id='loginBt']").click()
# 拿手机扫二维码!
print("请拿手机扫码二维码登录公众号")
time.sleep(20)
print("登录成功")
#重新载入公众号登录页,登录之后会显示公众号后台首页,从这个返回内容中获取cookies信息
driver.get('https://mp.weixin.qq.com/')
#获取cookies
cookie_items = driver.get_cookies()
#获取到的cookies是列表形式,将cookies转成json形式并存入本地名为cookie的文本中
for cookie_item in cookie_items:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print("cookies信息已保存到本地")
#爬取微信公众号文章,并存在本地文本中
def get_content(query):
#query为要爬取的公众号名称
#公众号主页
url = 'https://mp.weixin.qq.com'
#设置headers
header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
#读取上一步获取到的cookies
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
#登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-b ... 51598,从这里获取token信息
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
#搜索微信公众号的接口地址
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
#搜索微信公众号接口需要传入的参数,有三个变量:微信公众号token、随机数random、搜索的微信公众号名字
query_id = {
'action': 'search_biz',
'token' : token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'query': query,
'begin': '0',
'count': '5'
}
#打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers
search_response = requests.get(search_url, cookies=cookies, headers=header, params=query_id)
#取搜索结果中的第一个公众号
lists = search_response.json().get('list')[0]
#获取这个公众号的fakeid,后面爬取公众号文章需要此字段
fakeid = lists.get('fakeid')
#微信公众号文章接口地址
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
#搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '0',#不同页,此参数变化,变化规则为每页加5
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
#打开搜索的微信公众号文章列表页
appmsg_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
#获取文章总数
max_num = appmsg_response.json().get('app_msg_cnt')
#每页至少有5条,获取文章总的页数,爬取时需要分页爬
num = int(int(max_num) / 5)
#起始页begin参数,往后每页加5
begin = 0
while num + 1 > 0 :
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '{}'.format(str(begin)),
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
print('正在翻页:--------------',begin)
#获取每一页文章的标题和链接地址,并写入本地文本中
query_fakeid_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
for item in fakeid_list:
content_link=item.get('link')
content_title=item.get('title')
fileName=query+'.txt'
with open(fileName,'a',encoding='utf-8') as fh:
fh.write(content_title+":\n"+content_link+"\n")
# fh.write("urllib.request.urlretrieve('"+content_link + "','" + content_title +".html')\n")由于还没有解决标题的符号参数识别会报错的问题,用了这个笨方法去解决的。
num -= 1
begin = int(begin)
begin+=5
time.sleep(2)
if __name__=='__main__':
try:
#登录微信公众号,获取登录之后的cookies信息,并保存到本地文本中
weChat_login()
#登录之后,通过微信公众号后台提供的微信公众号文章接口爬取文章
for query in gzlist:
#爬取微信公众号文章,并存在本地文本中
print("开始爬取公众号:"+query)
get_content(query)
print("爬取完成")
except Exception as e:
print(str(e))
还好我要的文章都能下载出来了,图片也没有哪些用,所以暂时早已能满足了。至于解决这种问题,之后有时间有须要的时侯再钻研。 查看全部
于是百度微软必应各类搜索引擎上手,第一次爬虫经历就这样玉米了~~~
好吧,其实也完全是照搬,感谢高手!
还没有安装python可以先下载一个anoconda3:
1.终端加载python selenium模块包
加载包
2.使用webdriver功能须要安装对应浏览器的驱动插件,我用的是谷歌浏览器。安装和浏览器版本对应的webdriver版本,解压杂记下 chromedriver.exe 路径。对应版本查询和下载链接:
3.注册自己的公众号:微信公众号登录地址:
4.参考:
我照搬代码的这位前辈:
崔庆才原文(另有探究代码过程视频):
6.我的webdriver不知道是版本没对上还是哪些缘由,不能实现手动输入,注释掉,手动输入解决。
7.原文保存的是文章标题和链接,我需要保存到本地。用过两种方式,一个是生成pdf格式,一个是保存为html格式。
(1)保存为html格式,终端加载pip install urllib,然后
import urllib.request
使用:urllib.request.urlretrieve('','taobao.html')
(2)生成pdf较为复杂一些,不过有此方式,以后假如有须要,保存网址为pdf也便捷许多。不过这方面的需求用印象笔记的浏览器插件早已相当满足了。
pip intall pdfkit
pip install requests
pip install beautifulsoup4
安装 wkhtmltopdf,Windows平台直接在 下载稳定版的 wkhtmltopdf 进行安装,安装完成以后把该程序的执行路径加入到系统环境 $PATH 变量中,否则 pdfkit 找不到 wkhtmltopdf 就出现错误 “No wkhtmltopdf executable found”
方便使用,自己写了一个简单的模块:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
'a html to pdf model'
'''
使用示例:python htmltopdf_dl.py www.taobao.com baidu.pdf
'''
_author_ = 'dengling'
import pdfkit
import sys
def htmltopdf_dl():
ags = sys.argv
pdfkit.from_url(ags[1],ags[2])
if __name__ =='__main__':
htmltopdf_dl()
8.缺点:(1)用这个方式只在一个安静平和的夜间奇妙地爬完了所有的文章。其余时侯再也没有完整的爬取过所有的链接了。(2)因为保存本地html时参数辨识标题的特殊符号例如''时会出错,所以不能一下子全转换过来。(3)图片不能一起保存出来。
完整代码:
# -*- coding: utf-8 -*-
from selenium import webdriver
import time
import json
import requests
import re
import random
#微信公众号账号
user="你的账户"
#公众号密码
password="你的密码"
#设置要爬取的公众号列表
gzlist=['公众号名字']
#登录微信公众号,获取登录之后的cookies信息,并保存到本地文本中
def weChat_login():
#定义一个空的字典,存放cookies内容
post={}
#用webdriver启动谷歌浏览器
print("启动浏览器,打开微信公众号登录界面")
driver = webdriver.Chrome(executable_path='E:\微信公众号\chromedriver.exe')
#打开微信公众号登录页面
driver.get('https://mp.weixin.qq.com/')
#等待5秒钟
time.sleep(5)
print("正在输入微信公众号登录账号和密码......")
#清空账号框中的内容
driver.find_element_by_xpath("./*//input[@id='account']").clear()
#自动填入登录用户名
driver.find_element_by_xpath("./*//input[@id='account']").send_keys(user)
#清空密码框中的内容
driver.find_element_by_xpath("./*//input[@id='pwd']").clear()
#自动填入登录密码
driver.find_element_by_xpath("./*//input[@id='pwd']").send_keys(password)
# 在自动输完密码之后需要手动点一下记住我
print("请在登录界面点击:记住账号")
time.sleep(10)
#自动点击登录按钮进行登录
driver.find_element_by_xpath("./*//a[@id='loginBt']").click()
# 拿手机扫二维码!
print("请拿手机扫码二维码登录公众号")
time.sleep(20)
print("登录成功")
#重新载入公众号登录页,登录之后会显示公众号后台首页,从这个返回内容中获取cookies信息
driver.get('https://mp.weixin.qq.com/')
#获取cookies
cookie_items = driver.get_cookies()
#获取到的cookies是列表形式,将cookies转成json形式并存入本地名为cookie的文本中
for cookie_item in cookie_items:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print("cookies信息已保存到本地")
#爬取微信公众号文章,并存在本地文本中
def get_content(query):
#query为要爬取的公众号名称
#公众号主页
url = 'https://mp.weixin.qq.com'
#设置headers
header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
#读取上一步获取到的cookies
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
#登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-b ... 51598,从这里获取token信息
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
#搜索微信公众号的接口地址
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
#搜索微信公众号接口需要传入的参数,有三个变量:微信公众号token、随机数random、搜索的微信公众号名字
query_id = {
'action': 'search_biz',
'token' : token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'query': query,
'begin': '0',
'count': '5'
}
#打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers
search_response = requests.get(search_url, cookies=cookies, headers=header, params=query_id)
#取搜索结果中的第一个公众号
lists = search_response.json().get('list')[0]
#获取这个公众号的fakeid,后面爬取公众号文章需要此字段
fakeid = lists.get('fakeid')
#微信公众号文章接口地址
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
#搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '0',#不同页,此参数变化,变化规则为每页加5
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
#打开搜索的微信公众号文章列表页
appmsg_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
#获取文章总数
max_num = appmsg_response.json().get('app_msg_cnt')
#每页至少有5条,获取文章总的页数,爬取时需要分页爬
num = int(int(max_num) / 5)
#起始页begin参数,往后每页加5
begin = 0
while num + 1 > 0 :
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '{}'.format(str(begin)),
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
print('正在翻页:--------------',begin)
#获取每一页文章的标题和链接地址,并写入本地文本中
query_fakeid_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
for item in fakeid_list:
content_link=item.get('link')
content_title=item.get('title')
fileName=query+'.txt'
with open(fileName,'a',encoding='utf-8') as fh:
fh.write(content_title+":\n"+content_link+"\n")
# fh.write("urllib.request.urlretrieve('"+content_link + "','" + content_title +".html')\n")由于还没有解决标题的符号参数识别会报错的问题,用了这个笨方法去解决的。
num -= 1
begin = int(begin)
begin+=5
time.sleep(2)
if __name__=='__main__':
try:
#登录微信公众号,获取登录之后的cookies信息,并保存到本地文本中
weChat_login()
#登录之后,通过微信公众号后台提供的微信公众号文章接口爬取文章
for query in gzlist:
#爬取微信公众号文章,并存在本地文本中
print("开始爬取公众号:"+query)
get_content(query)
print("爬取完成")
except Exception as e:
print(str(e))
还好我要的文章都能下载出来了,图片也没有哪些用,所以暂时早已能满足了。至于解决这种问题,之后有时间有须要的时侯再钻研。
搜狗微信公众号热门文章如何采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 380 次浏览 • 2020-08-10 18:46
表现特点:a、点击网页中某个选项时,大部分网站的网址丌会改变;b、网页 丌是完全加载,只是局部迚行了数据加载,有所变化。 验证方法:点击操作后,在浏览器中,网址输入栏丌会出现加载中的状态戒者转 圈状态。 优采云云采集服务平台 观察网页,我们发觉,通过5 次点击“加载更多内容”,页面加载到最顶部,一 共显示100 篇文章。因此,我们设置整个“循环翻页”步骤执行5 次。选中“循 环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循 环次数等于“5 次”,点击“确定” 搜狗微信公众号热门文章如何采集图5 步骤3:创建列表循环并提取数据 1)移劢键盘,选中页面里第一篇文章的区块。系统会辨识此区块中的子元素, 在操作提示框中,选择“选中子元素” 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图6 2)继续选中页面中第二篇文章的区块,系统会自劢选中第二篇文章中的子元素, 并辨识出页面中的其他10 组同类元素,在操作提示框中,选择“选中全部” 搜狗微信公众号热门文章如何采集图7 优采云云采集服务平台 3)我们可以看见,页面中文章区块里的所有元素均被选中,变为红色。右侧操 作提示框中,出现数组预览表,将滑鼠移到表头,点击垃圾桶图标,可删掉丌需 要的主键。
字段选择完成后,选择“采集以下数据” 搜狗微信公众号热门文章如何采集图8 4)我们还想要采集每篇文章的URL,因而还须要提取一个主键。点击第一篇文 章的链接,系统会自劢选中页面中的一组文章链接。在左侧操作提示框中,选择 “选中全部” 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图9 5)选择“采集以下链接地址” 搜狗微信公众号热门文章如何采集图10 优采云云采集服务平台 6)字段选择完成后,选中相应的数组,可以迚行数组的自定义命名 搜狗微信公众号热门文章如何采集图11 步骤4:修改Xpath 我们继续观察,通过 次点击“加载更多内容”后,此网页加载出全部100 文章。因而我们配置规则的思路是,先构建翻页循环,加载出全部100篇文章, 再完善循环列表,提取数据 1)选中整个“循环”步骤,将其拖出“循环翻页”步骤。如果丌迚行此项操作, 那么将会出现好多重复数据 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图12 拖劢完成后,如下图所示 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图13 2)在“列表循环”步骤中,我们构建100 篇文章的循环列表。选中整个“循环 步骤”,打开“高级选项”,将丌固定元素列表中的这条Xpath: //BODY[@id='loginWrap']/DIV[4]/DIV[1]/DIV[3]/UL[1]/LI ,复制粘贴到火 狐浏览器中的相应位置 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图14 Xpath:是一种路径查询语言,简单的说就是借助一个路径表达式找到我们须要 的数据位置。
Xpath 是用于XML 中顺着路径查找数据用的,但是优采云采集器内部有一套针 对HTML 的Xpath 引擎,使得直接用XPATH能够精准的查找定位网页上面的 数据。 3)在火狐浏览器中,我们发觉,通过这条Xpath: //BODY[@id='loginWrap']/DIV[4]/DIV[1]/DIV[3]/UL[1]/LI ,页面中被定位 的是20 篇文章 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图15 4)将Xpath 修改为: //BODY[@id='loginWrap']/DIV/DIV[1]/DIV[3]/UL/LI, 我们发觉页面中所有要采集的文章都被定位了 搜狗微信公众号热门文章如何采集图16 优采云云采集服务平台 5)将改好的Xpath://BODY[@id='loginWrap']/DIV/DIV[1]/DIV[3]/UL/LI, 复制粘贴到图片中所示的位置,然后点击“确定” 搜狗微信公众号热门文章如何采集图17 6)点击左上角的“保存并启劢”,选择“启劢本地采集” 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图18 步骤5:数据采集及导入 1)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导入方法”, 将采集好的搜狗陌陌文章的数据导入 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图19 2)这里我们选择excel 作为导入为格式,数据导入后如下图 搜狗微信公众号热门文章如何采集图20 优采云云采集服务平台 优采云——70 万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置迚行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群24*7 丌间断运行,丌用害怕IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
优采云云采集服务平台 搜狗微信公众号热门文章如何采集 本文介绍使用优采云采集搜狗陌陌文章(以热门文章为例)的方式 采集网站: 规则下载: 使用功能点: 分页列表信息采集 Xpath AJAX点击和翻页 相关采集教程: 天猫商品信息采集 百度搜索结果采集 步骤1:创建采集任务 1)迚入主界面,选择“自定义模式” 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图1 2)将要采集的网址URL 复制粘贴到网站输入框中,点击“保存网址” 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图2 步骤2:创建翻页循环 1)在页面右上角,打开“流程”,以突显出“流程设计器”和“定制当前操作” 两个蓝筹股。网页打开后,默认显示“热门”文章。下拉页面,找到并点击“加载 更多内容”按钮,在操作提示框中,选择“更多操作” 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图2 2)选择“循环点击单个元素”,以创建一个翻页循环 搜狗微信公众号热门文章如何采集图3 优采云云采集服务平台 因为此网页涉及 Ajax 技术,我们须要迚行一些中级选项的设置。选中“点击元 素”步骤,打开“高级选项”,勾选“Ajax 加载数据”,设置时间为“2 搜狗微信公众号热门文章如何采集图4注:AJAX 即延时加载、异步更新的一种脚本技术,通过在后台不服务器迚行少 量数据交换,可以在丌重新加载整个网页的情况下,对网页的某部份迚行更新。
表现特点:a、点击网页中某个选项时,大部分网站的网址丌会改变;b、网页 丌是完全加载,只是局部迚行了数据加载,有所变化。 验证方法:点击操作后,在浏览器中,网址输入栏丌会出现加载中的状态戒者转 圈状态。 优采云云采集服务平台 观察网页,我们发觉,通过5 次点击“加载更多内容”,页面加载到最顶部,一 共显示100 篇文章。因此,我们设置整个“循环翻页”步骤执行5 次。选中“循 环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循 环次数等于“5 次”,点击“确定” 搜狗微信公众号热门文章如何采集图5 步骤3:创建列表循环并提取数据 1)移劢键盘,选中页面里第一篇文章的区块。系统会辨识此区块中的子元素, 在操作提示框中,选择“选中子元素” 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图6 2)继续选中页面中第二篇文章的区块,系统会自劢选中第二篇文章中的子元素, 并辨识出页面中的其他10 组同类元素,在操作提示框中,选择“选中全部” 搜狗微信公众号热门文章如何采集图7 优采云云采集服务平台 3)我们可以看见,页面中文章区块里的所有元素均被选中,变为红色。右侧操 作提示框中,出现数组预览表,将滑鼠移到表头,点击垃圾桶图标,可删掉丌需 要的主键。
字段选择完成后,选择“采集以下数据” 搜狗微信公众号热门文章如何采集图8 4)我们还想要采集每篇文章的URL,因而还须要提取一个主键。点击第一篇文 章的链接,系统会自劢选中页面中的一组文章链接。在左侧操作提示框中,选择 “选中全部” 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图9 5)选择“采集以下链接地址” 搜狗微信公众号热门文章如何采集图10 优采云云采集服务平台 6)字段选择完成后,选中相应的数组,可以迚行数组的自定义命名 搜狗微信公众号热门文章如何采集图11 步骤4:修改Xpath 我们继续观察,通过 次点击“加载更多内容”后,此网页加载出全部100 文章。因而我们配置规则的思路是,先构建翻页循环,加载出全部100篇文章, 再完善循环列表,提取数据 1)选中整个“循环”步骤,将其拖出“循环翻页”步骤。如果丌迚行此项操作, 那么将会出现好多重复数据 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图12 拖劢完成后,如下图所示 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图13 2)在“列表循环”步骤中,我们构建100 篇文章的循环列表。选中整个“循环 步骤”,打开“高级选项”,将丌固定元素列表中的这条Xpath: //BODY[@id='loginWrap']/DIV[4]/DIV[1]/DIV[3]/UL[1]/LI ,复制粘贴到火 狐浏览器中的相应位置 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图14 Xpath:是一种路径查询语言,简单的说就是借助一个路径表达式找到我们须要 的数据位置。
Xpath 是用于XML 中顺着路径查找数据用的,但是优采云采集器内部有一套针 对HTML 的Xpath 引擎,使得直接用XPATH能够精准的查找定位网页上面的 数据。 3)在火狐浏览器中,我们发觉,通过这条Xpath: //BODY[@id='loginWrap']/DIV[4]/DIV[1]/DIV[3]/UL[1]/LI ,页面中被定位 的是20 篇文章 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图15 4)将Xpath 修改为: //BODY[@id='loginWrap']/DIV/DIV[1]/DIV[3]/UL/LI, 我们发觉页面中所有要采集的文章都被定位了 搜狗微信公众号热门文章如何采集图16 优采云云采集服务平台 5)将改好的Xpath://BODY[@id='loginWrap']/DIV/DIV[1]/DIV[3]/UL/LI, 复制粘贴到图片中所示的位置,然后点击“确定” 搜狗微信公众号热门文章如何采集图17 6)点击左上角的“保存并启劢”,选择“启劢本地采集” 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图18 步骤5:数据采集及导入 1)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导入方法”, 将采集好的搜狗陌陌文章的数据导入 优采云云采集服务平台 搜狗微信公众号热门文章如何采集图19 2)这里我们选择excel 作为导入为格式,数据导入后如下图 搜狗微信公众号热门文章如何采集图20 优采云云采集服务平台 优采云——70 万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置迚行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群24*7 丌间断运行,丌用害怕IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
搜狗陌陌反爬虫机制剖析及应对方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-10 04:50
下面是对探求过程的记录。
首先参考了以下博客:
博主的探求过程,建议在他的博客中直接进行查看,这里我关注的是他说的关于Cookie的部份。
博主觉得恳求时,SUID、SUV和SNUID最为重要,我在谷歌浏览器中看见以下Cookie
除了两个SUID和SUV这三个Cookie,我对Cookie进行了挨个剔除,并重新进行查询,发现其他Cookie都是可以手动生成的。而且不会报502,也不会触发验证码页面。
由于Java中使用Connection.headers(Map cookies)方法,会导致第一个SUID被第二个覆盖掉(虽然我当时确实添加了两个SUID),请求也是正常的,所以,我进一步提不仅第一个SUID,发现刷新页面,也没有问题。
红框之外的Cookie就会手动生成,也没有触发验证码。只有当我剔除SUV时,才会触发验证码机制,从而使输入验证码:
所以,目前为止,需要带上的Cookie只有SUV!
那么,SUV这个Cookie怎么获取呢?
一般来说,通过恳求搜狗陌陌网站,然后获取到Cookie,作为自己的Cookie使用,但是无疑会降低恳求。当时朋友有个大胆的看法,说试试能不能直接传一个32位字符串呢?也真是脑洞大开!这里很自然地就想到了UUID,然后将UUID形成的32位字符串转小写。
想着搜狗陌陌不至于做的如此傻吧?但还是试了试,没想到还真的通过了,而且恳求还比较稳定。
综上,处理办法是——在恳求搜狗陌陌时,生成一个名为SUV的Cookie,请求时加上即可。
UUID的生成方式网上有很多,这里不再赘言,注意除去字符串中的短横线!
祝你们好运!
参考博客: 查看全部
最近项目中,由于须要从微信公众号中获取一些文章内容,所以用到了搜狗陌陌。一旦搜索的次数稍为多一点,就会触发搜狗陌陌的反爬虫机制,最初是须要加上User-Agent恳求头,后来是要求输入验证码,现在输入验证码以后,竟然时常都会报502,导致爬虫极不稳定。搜狗陌陌的反爬虫机制仍然在更新,特别是近来的一次更新,更使人一时半会儿摸不着脑子,也是耗费了好一会儿时间进行了突破。
下面是对探求过程的记录。
首先参考了以下博客:
博主的探求过程,建议在他的博客中直接进行查看,这里我关注的是他说的关于Cookie的部份。
博主觉得恳求时,SUID、SUV和SNUID最为重要,我在谷歌浏览器中看见以下Cookie
除了两个SUID和SUV这三个Cookie,我对Cookie进行了挨个剔除,并重新进行查询,发现其他Cookie都是可以手动生成的。而且不会报502,也不会触发验证码页面。
由于Java中使用Connection.headers(Map cookies)方法,会导致第一个SUID被第二个覆盖掉(虽然我当时确实添加了两个SUID),请求也是正常的,所以,我进一步提不仅第一个SUID,发现刷新页面,也没有问题。
红框之外的Cookie就会手动生成,也没有触发验证码。只有当我剔除SUV时,才会触发验证码机制,从而使输入验证码:
所以,目前为止,需要带上的Cookie只有SUV!
那么,SUV这个Cookie怎么获取呢?
一般来说,通过恳求搜狗陌陌网站,然后获取到Cookie,作为自己的Cookie使用,但是无疑会降低恳求。当时朋友有个大胆的看法,说试试能不能直接传一个32位字符串呢?也真是脑洞大开!这里很自然地就想到了UUID,然后将UUID形成的32位字符串转小写。
想着搜狗陌陌不至于做的如此傻吧?但还是试了试,没想到还真的通过了,而且恳求还比较稳定。
综上,处理办法是——在恳求搜狗陌陌时,生成一个名为SUV的Cookie,请求时加上即可。
UUID的生成方式网上有很多,这里不再赘言,注意除去字符串中的短横线!
祝你们好运!
参考博客:
记一次批量定时抓取微信公众号文章的实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2020-08-09 15:40
抓取前的说明和打算
本次抓取的选择的语言是java,本文章不会将整个工程的全部代码全部贴出,只会提供核心代码和抓取思路的说明。
数据的抓取
抓取文章的来源为搜狗陌陌网站,网站如下图。
抓取的思路如下
一般抓取微信公众号的文章都是以微信公众号的id为关键字 ,我们可以通过url+ keyword的方式直接跳转到想要抓取公众号页面,keyword即为想要搜索微信公众号的名称或则是id;
// 搜狗微信搜索链接入口
String sogou_search_url = "http://weixin.sogou.com/weixin ... ot%3B
+ keyword + "&ie=utf8&s_from=input&_sug_=n&_sug_type_=";
为了防止网站对爬虫的初步拦截,我们可以使用Selenium (浏览器自动化测试框架)来伪装自己的爬虫,我们使用的chrome,这里须要注意自己的chrome版本与使用的webdriver的版本是对应的;
ChromeOptions chromeOptions = new ChromeOptions();
// 全屏,为了接下来防抓取做准备
chromeOptions.addArguments("--start-maximized");
System.setProperty("webdriver.chrome.driver", chromedriver);
WebDriver webDriver = new ChromeDriver(chromeOptions);
到达微信公众号列表页面,如下图,获取微信公众号链接。
<p> // 获取当前页面的微信公众号列表
List weixin_list = webDriver
.findElements(By.cssSelector("div[class='txt-box']"));
// 获取进入公众号的链接
String weixin_url = "";
for (int i = 0; i 查看全部
记一次批量定时抓取微信公众号文章的实现
抓取前的说明和打算
本次抓取的选择的语言是java,本文章不会将整个工程的全部代码全部贴出,只会提供核心代码和抓取思路的说明。
数据的抓取
抓取文章的来源为搜狗陌陌网站,网站如下图。
抓取的思路如下
一般抓取微信公众号的文章都是以微信公众号的id为关键字 ,我们可以通过url+ keyword的方式直接跳转到想要抓取公众号页面,keyword即为想要搜索微信公众号的名称或则是id;
// 搜狗微信搜索链接入口
String sogou_search_url = "http://weixin.sogou.com/weixin ... ot%3B
+ keyword + "&ie=utf8&s_from=input&_sug_=n&_sug_type_=";
为了防止网站对爬虫的初步拦截,我们可以使用Selenium (浏览器自动化测试框架)来伪装自己的爬虫,我们使用的chrome,这里须要注意自己的chrome版本与使用的webdriver的版本是对应的;
ChromeOptions chromeOptions = new ChromeOptions();
// 全屏,为了接下来防抓取做准备
chromeOptions.addArguments("--start-maximized");
System.setProperty("webdriver.chrome.driver", chromedriver);
WebDriver webDriver = new ChromeDriver(chromeOptions);
到达微信公众号列表页面,如下图,获取微信公众号链接。
<p> // 获取当前页面的微信公众号列表
List weixin_list = webDriver
.findElements(By.cssSelector("div[class='txt-box']"));
// 获取进入公众号的链接
String weixin_url = "";
for (int i = 0; i
建立微信公众号测试帐号-Java本地服务
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-09 03:56
这是第一个坑. 在测试编号中,您可以填写域名ip,甚至不需要填写域名,这极大地方便了测试授权的使用. 回调页面表示微信用户关注您的官方账号. 当他选择授权登录时,我们可以调用微信界面来获取他的基本微信信息,例如唯一的微信openid,然后返回到我们的页面之一,或者这是用于采集用户信息的服务. 页面或服务必须在此域名下. 假设我填写了
例如,如果我想返回页面,它可以是:
,
返回服务:
只要在此域名下,无论嵌入多少层. 请注意,不能在前面添加https或http前缀.
在回调域名中,如果您的项目名称由下划线组成,
例如,要访问您的项目,请删除带下划线的项目名称. 尽管删除的项目名称只能映射回本地启动服务器,而不是映射回项目,但这不会造成伤害.
好的,这里很多人说,如果没有域名,我该怎么办,那是第二种材料,一个可以映射到Intranet的域名.
我使用的花生壳域名.
新用户可以获得几个免费域名,他们也可以使用这些域名,但是对于我来说,测试并购买100个大洋的.com域名非常方便.
然后通过花生壳内部网下载客户端
您拥有的域名将显示在这里,包括您发送的域名.
随意编写应用程序名称,域名是下属之一,映射是HTTP80. 内部主机不知道您可以打开cmd ip config / all来查看您的地址. 我的项目从tomact开始,使用默认端口8080. 最后,进行诊断并在地址栏中键入Internet域名,以确保其他人可以访问您的本地项目.
到目前为止,第二种材料已经准备好了.
第三个是可以运行的项目...这里将不讨论. 您可以使用springboot + myb,springMVC,struts2来构建可以运行的项目. 如果没有,请搜索其他博客以快速建立一个博客,至少您可以输入一个servelet. 我只是直接运行公司的项目.
连接授权界面
首先编写一个链接: APPID&redirect_uri = l&response_type = code&scope = snsapi_base&state = 123#wechat_redirect
此链接已发送至微信,表明我要开始停靠此界面
appid: 是测试编号上的appid
redirect_uri: 我们刚刚在上面填写了,因此这里是在该域名下填写一个HTML以供回调. 必须添加或在这里,必须!
scope: 这是指要调用的微信界面,snsapi_base是指用户的静默授权,这是用户执行微信授权而没有弹出框提示是否进行授权的情况,因此该界面获取的信息较少,您可以查看详细信息官方技术文档.
状态: 填写您想要的任何内容.
我下载了官方的微信调试工具. 如果您按照上述步骤进行操作,则您的链接将不会出现代码错误,redirect_uri和其他错误.
如您所见,在返回的页面上,后缀附有代码. 该代码将被发送到微信以交换刚刚登录的用户的信息. 当然,您可以对上述授权链接进行异步请求,并使用js在页面上获取它. 我是这样子的
函数GetQueryString(name)
{
var reg = new RegExp(“(^ |&)” + name +“ =([^&] *)(&| $)”);
var r = window.location.search.substr(1).match(reg);
if(r!= null)返回unescape(r [2]);返回null;
}
调用GetQueryString(code)获取地址的参数值.
获取后,将其发送到后台进行处理. 有很多提交方法. 异步也是可能的,或者将整个表单直接连接到其他值并提交到后台. 根仍然由后台处理.
仅使用老式的struts2粘贴密钥代码,因此返回String映射以返回到页面,如果您是springMVC控制器,请自行更改
public String juvenileSubsidy() {
//如果是第二次验证登录则直接发送微信的opendid
String openId =getOpenId();
.......//省略各种去到信息以后的service
return "login_jsp";
}
........
private String getOpenId(){
//appid和secret是测试公众号上的,自行填写,别直接copy,
//code是刚刚获取到的,自行改写参数
String url="https://api.weixin.qq.com/sns/oa"
+ "uth2/access_token?appid="+wxappid+"&"
+ "secret="+appsecret+"&code="+wxcode+""
+ "&grant_type=authorization_code";
String openId="";
try {
URL getUrl=new URL(url);
HttpURLConnection http=(HttpURLConnection)getUrl.openConnection();
http.setRequestMethod("GET");
http.setRequestProperty("Content-Type","application/x-www-form-urlencoded");
http.setDoOutput(true);
http.setDoInput(true);
http.connect();
InputStream is = http.getInputStream();
int size = is.available();
byte[] b = new byte[size];
is.read(b);
String message = new String(b, "UTF-8");
JSONObject json = JSONObject.parseObject(message);
openId=json.get("openid").toString();
} catch (Exception e) {
System.out.println(e.getMessage());
}
return openId;
}
当然,许多博客文章都是关于如何封装地址参数名称的,以便以后可以调用. 一开始,我写得很粗糙以显示效果. 您可以在将来轻松封装它,甚至可以使用xml读取配置信息. 我的私有方法只是返回我需要的String openid. 您可以选择返回对象,或检查正式文档,更改原创范围,非静默授权可以获取更多用户信息.
接下来是调试观察.
{"access_token":"15_0D9_XTsx2YdwoD5KPd6WHAEc47xLqy4uuQAb06irOd5UgOnzwW3zPRdhMXinpJ7ucvkW3D7coema7QAdA",
"expires_in":7200,
"refresh_token":"15_cz_GGe-k41d_YVVgmrFvQBUvF_LuyuNSB2PTq8YWXHLz0l7Vg8hJnBWjGFMNhTT2NRFqqRYT5gSofww",
"openid":"o-MN1B0FGR1JV398vbSPNZ70xa424",
"scope":"snsapi_base"}
以上是成功发送到微信界面的json对象. 我叫snsapi_base,所以我只能返回此信息. 这些令牌每次都会刷新,并且这些密钥也被微信用于验证服务器的重要数据,但是在这里它们是无用的. 我得到了所需的openid.
通过这种方式,获得了微信登录官方账号上唯一识别的ID,并可以通过该ID实现业务逻辑. 同时,可以在本地测试官方帐户服务.
对于本文开头提到的接口配置信息,此处不需要使用它. 这要求后端发送令牌进行验证.
最后,您可以将此婴儿链接放在官方帐户的自定义菜单中. 这就是所谓的用户登录授权.
当然,这是测试帐户授权. 正式启动后,它将替换为注册域名,appid被替换为官方官方帐户的ID,其余部分保持不变.
到目前为止,官方帐户的静默授权已完成! 查看全部
这里的重点是页面授权回调的域名.
这是第一个坑. 在测试编号中,您可以填写域名ip,甚至不需要填写域名,这极大地方便了测试授权的使用. 回调页面表示微信用户关注您的官方账号. 当他选择授权登录时,我们可以调用微信界面来获取他的基本微信信息,例如唯一的微信openid,然后返回到我们的页面之一,或者这是用于采集用户信息的服务. 页面或服务必须在此域名下. 假设我填写了
例如,如果我想返回页面,它可以是:
,
返回服务:
只要在此域名下,无论嵌入多少层. 请注意,不能在前面添加https或http前缀.
在回调域名中,如果您的项目名称由下划线组成,
例如,要访问您的项目,请删除带下划线的项目名称. 尽管删除的项目名称只能映射回本地启动服务器,而不是映射回项目,但这不会造成伤害.
好的,这里很多人说,如果没有域名,我该怎么办,那是第二种材料,一个可以映射到Intranet的域名.
我使用的花生壳域名.
新用户可以获得几个免费域名,他们也可以使用这些域名,但是对于我来说,测试并购买100个大洋的.com域名非常方便.
然后通过花生壳内部网下载客户端
您拥有的域名将显示在这里,包括您发送的域名.
随意编写应用程序名称,域名是下属之一,映射是HTTP80. 内部主机不知道您可以打开cmd ip config / all来查看您的地址. 我的项目从tomact开始,使用默认端口8080. 最后,进行诊断并在地址栏中键入Internet域名,以确保其他人可以访问您的本地项目.
到目前为止,第二种材料已经准备好了.
第三个是可以运行的项目...这里将不讨论. 您可以使用springboot + myb,springMVC,struts2来构建可以运行的项目. 如果没有,请搜索其他博客以快速建立一个博客,至少您可以输入一个servelet. 我只是直接运行公司的项目.
连接授权界面
首先编写一个链接: APPID&redirect_uri = l&response_type = code&scope = snsapi_base&state = 123#wechat_redirect
此链接已发送至微信,表明我要开始停靠此界面
appid: 是测试编号上的appid
redirect_uri: 我们刚刚在上面填写了,因此这里是在该域名下填写一个HTML以供回调. 必须添加或在这里,必须!
scope: 这是指要调用的微信界面,snsapi_base是指用户的静默授权,这是用户执行微信授权而没有弹出框提示是否进行授权的情况,因此该界面获取的信息较少,您可以查看详细信息官方技术文档.
状态: 填写您想要的任何内容.
我下载了官方的微信调试工具. 如果您按照上述步骤进行操作,则您的链接将不会出现代码错误,redirect_uri和其他错误.
如您所见,在返回的页面上,后缀附有代码. 该代码将被发送到微信以交换刚刚登录的用户的信息. 当然,您可以对上述授权链接进行异步请求,并使用js在页面上获取它. 我是这样子的
函数GetQueryString(name)
{
var reg = new RegExp(“(^ |&)” + name +“ =([^&] *)(&| $)”);
var r = window.location.search.substr(1).match(reg);
if(r!= null)返回unescape(r [2]);返回null;
}
调用GetQueryString(code)获取地址的参数值.
获取后,将其发送到后台进行处理. 有很多提交方法. 异步也是可能的,或者将整个表单直接连接到其他值并提交到后台. 根仍然由后台处理.
仅使用老式的struts2粘贴密钥代码,因此返回String映射以返回到页面,如果您是springMVC控制器,请自行更改
public String juvenileSubsidy() {
//如果是第二次验证登录则直接发送微信的opendid
String openId =getOpenId();
.......//省略各种去到信息以后的service
return "login_jsp";
}
........
private String getOpenId(){
//appid和secret是测试公众号上的,自行填写,别直接copy,
//code是刚刚获取到的,自行改写参数
String url="https://api.weixin.qq.com/sns/oa"
+ "uth2/access_token?appid="+wxappid+"&"
+ "secret="+appsecret+"&code="+wxcode+""
+ "&grant_type=authorization_code";
String openId="";
try {
URL getUrl=new URL(url);
HttpURLConnection http=(HttpURLConnection)getUrl.openConnection();
http.setRequestMethod("GET");
http.setRequestProperty("Content-Type","application/x-www-form-urlencoded");
http.setDoOutput(true);
http.setDoInput(true);
http.connect();
InputStream is = http.getInputStream();
int size = is.available();
byte[] b = new byte[size];
is.read(b);
String message = new String(b, "UTF-8");
JSONObject json = JSONObject.parseObject(message);
openId=json.get("openid").toString();
} catch (Exception e) {
System.out.println(e.getMessage());
}
return openId;
}
当然,许多博客文章都是关于如何封装地址参数名称的,以便以后可以调用. 一开始,我写得很粗糙以显示效果. 您可以在将来轻松封装它,甚至可以使用xml读取配置信息. 我的私有方法只是返回我需要的String openid. 您可以选择返回对象,或检查正式文档,更改原创范围,非静默授权可以获取更多用户信息.
接下来是调试观察.
{"access_token":"15_0D9_XTsx2YdwoD5KPd6WHAEc47xLqy4uuQAb06irOd5UgOnzwW3zPRdhMXinpJ7ucvkW3D7coema7QAdA",
"expires_in":7200,
"refresh_token":"15_cz_GGe-k41d_YVVgmrFvQBUvF_LuyuNSB2PTq8YWXHLz0l7Vg8hJnBWjGFMNhTT2NRFqqRYT5gSofww",
"openid":"o-MN1B0FGR1JV398vbSPNZ70xa424",
"scope":"snsapi_base"}
以上是成功发送到微信界面的json对象. 我叫snsapi_base,所以我只能返回此信息. 这些令牌每次都会刷新,并且这些密钥也被微信用于验证服务器的重要数据,但是在这里它们是无用的. 我得到了所需的openid.
通过这种方式,获得了微信登录官方账号上唯一识别的ID,并可以通过该ID实现业务逻辑. 同时,可以在本地测试官方帐户服务.
对于本文开头提到的接口配置信息,此处不需要使用它. 这要求后端发送令牌进行验证.
最后,您可以将此婴儿链接放在官方帐户的自定义菜单中. 这就是所谓的用户登录授权.
当然,这是测试帐户授权. 正式启动后,它将替换为注册域名,appid被替换为官方官方帐户的ID,其余部分保持不变.
到目前为止,官方帐户的静默授权已完成!
微信抓取过程中的参数分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2020-08-08 17:17
mid是图形消息的ID
idx是发布的头几条消息(1表示标题位置消息)
sn是一个随机加密的字符串(对于图形消息来说是唯一的,如果您想询问此sn的生成规则是什么或如何破解它,您基本上只能从微信公众平台开发中获得答案. 团队)变相煮
三: 伪装微信客户端登录并获取历史信息页面. 4个最重要的参数是: __biz; uin =; key =; pass_ticket =;这四个参数. [有时需要手机]
四: 获得general_msg_list后,分析每个字段
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
五: 获取程序的原型
创建表格:
1. 微信公众号列表
CREATE TABLE `weixin` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`biz` varchar(255) DEFAULT '' COMMENT '公众号唯一标识biz',
`collect` int(11) DEFAULT '1' COMMENT '记录采集时间的时间戳',
PRIMARY KEY (`id`)
) ;
2,微信文章列表
CREATE TABLE `post` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`biz` varchar(255) CHARACTER SET utf8 NOT NULL COMMENT '文章对应的公众号biz',
`field_id` int(11) NOT NULL COMMENT '微信定义的一个id,每条文章唯一',
`title` varchar(255) NOT NULL DEFAULT '' COMMENT '文章标题',
`title_encode` text CHARACTER SET utf8 NOT NULL COMMENT '文章编码,防止文章出现emoji',
`digest` varchar(500) NOT NULL DEFAULT '' COMMENT '文章摘要',
`content_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '文章地址',
`source_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '阅读原文地址',
`cover` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '封面图片',
`is_multi` int(11) NOT NULL COMMENT '是否多图文',
`is_top` int(11) NOT NULL COMMENT '是否头条',
`datetime` int(11) NOT NULL COMMENT '文章时间戳',
`readNum` int(11) NOT NULL DEFAULT '1' COMMENT '文章阅读量',
`likeNum` int(11) NOT NULL DEFAULT '0' COMMENT '文章点赞量',
PRIMARY KEY (`id`)
) ;
3. 采集团队名单
CREATE TABLE `tmplist` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`content_url` varchar(255) DEFAULT NULL COMMENT '文章地址',
`load` int(11) DEFAULT '0' COMMENT '读取中标记',
PRIMARY KEY (`id`),
UNIQUE KEY `content_url` (`content_url`)
) ;
采集:
1,getMsgJson.php: 该程序负责接收已解析并存储在数据库中的历史消息的json
<p> 查看全部
__ biz可被视为在微信公众平台上公开宣布的公共账户的唯一ID
mid是图形消息的ID
idx是发布的头几条消息(1表示标题位置消息)
sn是一个随机加密的字符串(对于图形消息来说是唯一的,如果您想询问此sn的生成规则是什么或如何破解它,您基本上只能从微信公众平台开发中获得答案. 团队)变相煮
三: 伪装微信客户端登录并获取历史信息页面. 4个最重要的参数是: __biz; uin =; key =; pass_ticket =;这四个参数. [有时需要手机]
四: 获得general_msg_list后,分析每个字段
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
五: 获取程序的原型
创建表格:
1. 微信公众号列表
CREATE TABLE `weixin` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`biz` varchar(255) DEFAULT '' COMMENT '公众号唯一标识biz',
`collect` int(11) DEFAULT '1' COMMENT '记录采集时间的时间戳',
PRIMARY KEY (`id`)
) ;
2,微信文章列表
CREATE TABLE `post` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`biz` varchar(255) CHARACTER SET utf8 NOT NULL COMMENT '文章对应的公众号biz',
`field_id` int(11) NOT NULL COMMENT '微信定义的一个id,每条文章唯一',
`title` varchar(255) NOT NULL DEFAULT '' COMMENT '文章标题',
`title_encode` text CHARACTER SET utf8 NOT NULL COMMENT '文章编码,防止文章出现emoji',
`digest` varchar(500) NOT NULL DEFAULT '' COMMENT '文章摘要',
`content_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '文章地址',
`source_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '阅读原文地址',
`cover` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '封面图片',
`is_multi` int(11) NOT NULL COMMENT '是否多图文',
`is_top` int(11) NOT NULL COMMENT '是否头条',
`datetime` int(11) NOT NULL COMMENT '文章时间戳',
`readNum` int(11) NOT NULL DEFAULT '1' COMMENT '文章阅读量',
`likeNum` int(11) NOT NULL DEFAULT '0' COMMENT '文章点赞量',
PRIMARY KEY (`id`)
) ;
3. 采集团队名单
CREATE TABLE `tmplist` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`content_url` varchar(255) DEFAULT NULL COMMENT '文章地址',
`load` int(11) DEFAULT '0' COMMENT '读取中标记',
PRIMARY KEY (`id`),
UNIQUE KEY `content_url` (`content_url`)
) ;
采集:
1,getMsgJson.php: 该程序负责接收已解析并存储在数据库中的历史消息的json
<p>
通过微信公众平台获取官方帐户文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2020-08-08 10:12
选择自己创建的图形:
好像是公共帐户操作教学
进入编辑页面后,单击超链接
弹出一个选择框,我们在框中输入相应的正式帐户名称,并出现相应的商品列表
您感到惊讶吗?您可以打开控制台并检查请求的界面
打开回复,有我们需要的文章链接
确认数据后,我们需要分析此界面.
感觉很简单. GET请求带有一些参数.
Fakeid是官方帐户的唯一ID,因此,如果要直接按名称获取商品列表,则需要先获取伪造品.
当我们输入官方帐户名时,单击“搜索”. 您会看到搜索界面已触发,并返回了伪造品.
此界面不需要很多参数.
接下来,我们可以使用代码来模拟上述操作.
但是您还需要使用现有的cookie以避免登录.
目前,我尚未测试过cookie的有效期. 可能需要及时更新cookie.
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
通过这种方式,您可以获得最新的10篇文章. 如果要获取更多历史文章,可以修改数据中的“ begin”参数,0为第一页,5为第二页,10为第三页(依此类推)
但是,如果您想进行大规模爬网:
请为您自己安排稳定的代理商,降低爬虫速度,并准备多个帐户以减少被阻止的可能性. 查看全部
选择自己创建的图形:
好像是公共帐户操作教学
进入编辑页面后,单击超链接
弹出一个选择框,我们在框中输入相应的正式帐户名称,并出现相应的商品列表
您感到惊讶吗?您可以打开控制台并检查请求的界面
打开回复,有我们需要的文章链接
确认数据后,我们需要分析此界面.
感觉很简单. GET请求带有一些参数.
Fakeid是官方帐户的唯一ID,因此,如果要直接按名称获取商品列表,则需要先获取伪造品.
当我们输入官方帐户名时,单击“搜索”. 您会看到搜索界面已触发,并返回了伪造品.
此界面不需要很多参数.
接下来,我们可以使用代码来模拟上述操作.
但是您还需要使用现有的cookie以避免登录.
目前,我尚未测试过cookie的有效期. 可能需要及时更新cookie.
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
通过这种方式,您可以获得最新的10篇文章. 如果要获取更多历史文章,可以修改数据中的“ begin”参数,0为第一页,5为第二页,10为第三页(依此类推)
但是,如果您想进行大规模爬网:
请为您自己安排稳定的代理商,降低爬虫速度,并准备多个帐户以减少被阻止的可能性.

