
querylist采集微信公众号文章
python-抓取微信官方帐户
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2020-08-07 22:07
我相信您有时会在面试期间遇到抓取微信官方帐户的问题. 当您最终有空时,您将参考老板的文章,我也开始抓取并分享微信官方帐户. 不要讨厌代码太低.
学习知识
博客参考:https://blog.csdn.net/xc_zhou/ ... 32587 先看一篇这个大佬的文章,理解一下微信公众号。
尝试抓取微信文章的朋友必须熟悉搜狗微信. 搜狗微信是腾讯提供的官方搜索引擎,专门用于搜索微信官方账号(不包括服务账号)发布的文章
搜狗微信链接:
爬网步骤如下: 第一步是创建您自己的官方帐户
创建正式帐户地址: #不会提及创建方法.
第二步是找到微信官方账号
第一步如图所示:
第二步如图所示:
第三步如图所示:
第四步如图所示:
以计算机视觉为例. 当然,您也可以选择其他参数,然后查看需要在请求中提交的参数.
第五步如图所示:
可以看到每个正式帐户都有一个falseid参数,访问每个正式帐户请求都需要该参数,请参阅步骤6.
第六步如图所示:
选择要爬网的文章,然后查看请求所需的参数.
第七步如图所示:
每个官方帐户的前五篇文章.
以上步骤是微信公众号文章的要求. 然后在分析之后使用代码来实现它. 如果您不了解上述分析,建议您参考以下文章:
https://blog.csdn.net/xc_zhou/ ... 32921
https://mp.weixin.qq.com/s%3F_ ... %23rd
代码如下 查看全部
原因
我相信您有时会在面试期间遇到抓取微信官方帐户的问题. 当您最终有空时,您将参考老板的文章,我也开始抓取并分享微信官方帐户. 不要讨厌代码太低.
学习知识
博客参考:https://blog.csdn.net/xc_zhou/ ... 32587 先看一篇这个大佬的文章,理解一下微信公众号。
尝试抓取微信文章的朋友必须熟悉搜狗微信. 搜狗微信是腾讯提供的官方搜索引擎,专门用于搜索微信官方账号(不包括服务账号)发布的文章
搜狗微信链接:
爬网步骤如下: 第一步是创建您自己的官方帐户
创建正式帐户地址: #不会提及创建方法.
第二步是找到微信官方账号
第一步如图所示:

第二步如图所示:
第三步如图所示:
第四步如图所示:
以计算机视觉为例. 当然,您也可以选择其他参数,然后查看需要在请求中提交的参数.
第五步如图所示:
可以看到每个正式帐户都有一个falseid参数,访问每个正式帐户请求都需要该参数,请参阅步骤6.

第六步如图所示:
选择要爬网的文章,然后查看请求所需的参数.
第七步如图所示:
每个官方帐户的前五篇文章.
以上步骤是微信公众号文章的要求. 然后在分析之后使用代码来实现它. 如果您不了解上述分析,建议您参考以下文章:
https://blog.csdn.net/xc_zhou/ ... 32921
https://mp.weixin.qq.com/s%3F_ ... %23rd
代码如下
微信公众号文章采集器系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 376 次浏览 • 2020-08-07 20:19
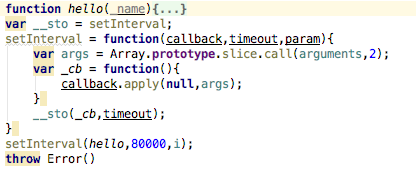
1. 我做了两个履带. 我第一次害怕Phoenix.com时,没有任何限制,我可以随意爬网,所以我放松了对自动代码执行模块的警惕. 我认为这很简单,但事实并非如此. 我已经为这个问题困扰了好几天,几乎是四天. 由于搜狗的限制,获得相同IP的次数越来越多. 首先,显示验证码,其次是访问限制. 直接无法访问. 根据请求,您得到的是访问次数太频繁,这种提示,因此在开发过程中最麻烦的不是代码的编写,而是测试. 编写后无法立即测试该代码. 我相信大多数程序员都不会喜欢,我现在编写的程序每天执行3次. 这样的频率很好,并且因为它是由多个官方帐户采集的,所以每个官方帐户之间也要有间隔,否则它将同时访问十多个公众,该帐户上的数百篇文章也不切实际. 在插入句子时,如何使每个正式帐户都不敢玩,等待特定的时间段,执行下一个,最后使用setInterval函数来解决它,
每80秒执行一个正式帐户,并将每个执行代码写入hello. 泡沫距离有点远. 我会收到的. 我们来谈谈cron程序包,它是自动执行的. npm官方网站上仅举了一个例子,但是我的意思是桑拿浴可能有点压抑. 我无法播放,但了解其用法. 然后我说,如果我听不懂怎么办. 在Internet,百度和cron程序包的特定用法上进行搜索. 有很多,所以我只是看了看,但是经过仔细的分析却并非如此. 都是废话,没用. 一般在线使用中都有一个问号,但是当我添加一个问号时,会出现错误. 是的,这都是胡说八道. 最后,我在同学小组的一个前端技术讨论小组中说了这一点. 真正热情的小组朋友找到了我一个链接. 我进去看看,尝试了一下,没关系,所以,非常感谢这位帮助我解决难题的同学. 我将再次附上QQ群组号码和链接,以帮助您在阅读本文时学习. QQ组号: 435012561,链接: ,链接说的没问题,至少可以用,这里我仍然有一个问题,就是时区,我们以前用过一次,使用洛杉矶时间,但是这次显然不起作用,我们需要用中文,但是我在北京尝试了几次,虽然不好,但是重庆可以,所以我用了重庆.
2. 我想在这里谈论的是从地址栏获取参数的问题. 我做的最后一个很好,但是我不知道该怎么做. 我从地址栏中得到的最后一个是数字,但是这个是它的. 它是一个字符串,并且mongodb中对字段的要求仍然非常严格,因此分页功能困扰了我几个小时. 它是如何解决的?我在mongodb中添加了一个讨论组. 我问其中有什么问题,并发布了屏幕截图. 有一个热心的网民说,传入数据的格式显然不正确. 我唤醒了做梦者,我说了是,然后我使用Number()函数来处理我得到的参数,以便字符串类型的数量成为数字类型的数量. 很好,因此在使用mongodb时,必须注意存储数据的格式.
3. Mongodb查询数据语句的组织:
坦率地说,实际上是使用了限制和跳过这两个函数,但是特定的格式可能是乐观的,并且mine是可接受的参数,但是mongo的参数接受很容易直接编写,不需要喜欢sql像$ {“”}一样. 下面的排序功能说明了排序方法. 这里,ctime字段设置为标准,-1表示逆序,1表示正序,
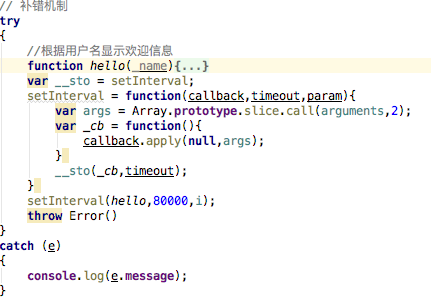
4. 在这段代码编写中,我第一次使用了try catch方法进行纠错. 原来没关系. 偶尔的错误可以正常地打印出来,但是它不会影响代码的整体执行,或者说到下一次执行,整体感觉非常好,
对于特定用法,将您要执行的代码放入try中,并在最后添加一行,并抛出Error();
然后传入参数e以进行捕获,可以在catch中打印很多消息,我只打印了其中之一,例如e.message
5. anync包主要用于此编码过程中,其中的ansyc.each循环,ansyc.waterfall在执行完上述操作后可以执行以下操作,也可以在您之间的上下传递参数,这非常重要的是,因为在此编程中,每次获取的内容都不同,每个代码执行的条件也不同,也就是说,所需的参数也不同,即,下一个代码执行可能需要上一个代码. 执行,所以这个anync软件包真的值得研究. 他的每种方法都不相同,有时可能会得到意想不到的结果.
6. 在mysql中,如果要实现这样的效果,即如果它已经存在于数据库中,则忽略它,或者不重复存储它;如果它不存在于数据库中,则将其存储在其中. 用replace替换插入数据的插入. 但是在mongodb中,应该没有,或者我还没有找到它. 我用这种方法解决了. 我定义了一个开关来使该开关为真. 在每次存储之前,循环所有数据以查看是否有该数据,如果没有,则让开关变为假,否则,继续执行,即判断此时开关是真还是假,如果为true,则执行插入操作;如果为false,则将其忽略. 这样可以达到类似的效果,否则每次都会存储大量重复数据,
7. 该集合的核心是我文件中的common.js. 首先,因为我们要采集,所以我们需要使用请求包. 采集后,我们需要以html格式处理数据,以便可以使用类似于jquery的数据. 对于该操作,cheerio包已使用了很长时间,然后在循环采集时将使用anync.each方法,因此将使用异步包,
7-1,
通过采集搜狗微信,我们必须分析搜狗微信的路径. 每个官方帐户页面的路径都是这样
%E8%BF%99%E6%89%8D%E6%98%AF%E6%97%A5%E6%9C%AC&ie = utf8&_sug_ = n&_sug_type _ =
这是“这是日本”页面的链接. 经过分析,所有正式帐户的链接仅在查询后的参数上有所不同,但是查询后的参数是什么,实际上,它是由encodeURIComponent()函数转换的,之后是“这是日本”,因此相同. 要获得该官方帐户,只需对官方帐户的名称进行编码并将其动态组合成一个链接,您就可以在访问时输入每个链接,但是我只是要求此页面此链接,
不是
此页面,因此进一步的处理是获取当前页面的第一内容的链接,即href
获得此链接后,您会发现他具有自己的加密方法. 实际上非常简单,就是在链接中增加三个安培;更换这三个放大器;在带有空链接的链接中,就好了,这是第一步,获取每个官方帐户的页面链接,
7-2
获取链接后,有必要访问,即请求,请求每个地址,获取每个地址的内容,但每个页面上显示的内容不在该页面中,即在html结构中,隐藏在js中,因此我们需要通过常规匹配来获取每篇文章的对象,然后循环访问每个正式帐户的对象以获取有关该对象中每篇文章的一些信息,包括标题,缩略图,摘要,URL,时间, 5个字段,但我使用的代码很烂,而我当时使用的是
Object.Attribute.foreach(function(item,index){
})
这种可怕的方法,最后要做的就是编写一个循环以完全获取每个对象,否则只能获取第一个对象. 在这里,您应该使用async.each或async.foreach. 可以使用两种方法中的每一种,并且它们都非常易于使用. 这样,您将获得上述每篇文章的基本新闻.
7-3,
第三阶段是进入每篇文章的详细信息页面,并获取每篇文章的内容,喜欢的次数,作者,官方帐号,阅读量和其他数据. 这里遇到的主要问题是人们的内容直接位于js中,并且所有img标签都有问题. 它们以这种形式存储在内容中,但是在这种情况下,由于标签,html文档(我不知道此类img标签)存在问题,此类图像无法显示在我们的网页上,因此在这里我们需要进行一些处理,替换全部与
查看全部
已经快两个星期了. 我已经在微信公众号上调试了商品采集器系统,最后一切都很好,但是在此期间,我遇到了很多问题. 让我们今天回顾一下并进行总结. 我希望它会有用. 朋友可以学习.
1. 我做了两个履带. 我第一次害怕Phoenix.com时,没有任何限制,我可以随意爬网,所以我放松了对自动代码执行模块的警惕. 我认为这很简单,但事实并非如此. 我已经为这个问题困扰了好几天,几乎是四天. 由于搜狗的限制,获得相同IP的次数越来越多. 首先,显示验证码,其次是访问限制. 直接无法访问. 根据请求,您得到的是访问次数太频繁,这种提示,因此在开发过程中最麻烦的不是代码的编写,而是测试. 编写后无法立即测试该代码. 我相信大多数程序员都不会喜欢,我现在编写的程序每天执行3次. 这样的频率很好,并且因为它是由多个官方帐户采集的,所以每个官方帐户之间也要有间隔,否则它将同时访问十多个公众,该帐户上的数百篇文章也不切实际. 在插入句子时,如何使每个正式帐户都不敢玩,等待特定的时间段,执行下一个,最后使用setInterval函数来解决它,
每80秒执行一个正式帐户,并将每个执行代码写入hello. 泡沫距离有点远. 我会收到的. 我们来谈谈cron程序包,它是自动执行的. npm官方网站上仅举了一个例子,但是我的意思是桑拿浴可能有点压抑. 我无法播放,但了解其用法. 然后我说,如果我听不懂怎么办. 在Internet,百度和cron程序包的特定用法上进行搜索. 有很多,所以我只是看了看,但是经过仔细的分析却并非如此. 都是废话,没用. 一般在线使用中都有一个问号,但是当我添加一个问号时,会出现错误. 是的,这都是胡说八道. 最后,我在同学小组的一个前端技术讨论小组中说了这一点. 真正热情的小组朋友找到了我一个链接. 我进去看看,尝试了一下,没关系,所以,非常感谢这位帮助我解决难题的同学. 我将再次附上QQ群组号码和链接,以帮助您在阅读本文时学习. QQ组号: 435012561,链接: ,链接说的没问题,至少可以用,这里我仍然有一个问题,就是时区,我们以前用过一次,使用洛杉矶时间,但是这次显然不起作用,我们需要用中文,但是我在北京尝试了几次,虽然不好,但是重庆可以,所以我用了重庆.
2. 我想在这里谈论的是从地址栏获取参数的问题. 我做的最后一个很好,但是我不知道该怎么做. 我从地址栏中得到的最后一个是数字,但是这个是它的. 它是一个字符串,并且mongodb中对字段的要求仍然非常严格,因此分页功能困扰了我几个小时. 它是如何解决的?我在mongodb中添加了一个讨论组. 我问其中有什么问题,并发布了屏幕截图. 有一个热心的网民说,传入数据的格式显然不正确. 我唤醒了做梦者,我说了是,然后我使用Number()函数来处理我得到的参数,以便字符串类型的数量成为数字类型的数量. 很好,因此在使用mongodb时,必须注意存储数据的格式.
3. Mongodb查询数据语句的组织:

坦率地说,实际上是使用了限制和跳过这两个函数,但是特定的格式可能是乐观的,并且mine是可接受的参数,但是mongo的参数接受很容易直接编写,不需要喜欢sql像$ {“”}一样. 下面的排序功能说明了排序方法. 这里,ctime字段设置为标准,-1表示逆序,1表示正序,
4. 在这段代码编写中,我第一次使用了try catch方法进行纠错. 原来没关系. 偶尔的错误可以正常地打印出来,但是它不会影响代码的整体执行,或者说到下一次执行,整体感觉非常好,
对于特定用法,将您要执行的代码放入try中,并在最后添加一行,并抛出Error();
然后传入参数e以进行捕获,可以在catch中打印很多消息,我只打印了其中之一,例如e.message
5. anync包主要用于此编码过程中,其中的ansyc.each循环,ansyc.waterfall在执行完上述操作后可以执行以下操作,也可以在您之间的上下传递参数,这非常重要的是,因为在此编程中,每次获取的内容都不同,每个代码执行的条件也不同,也就是说,所需的参数也不同,即,下一个代码执行可能需要上一个代码. 执行,所以这个anync软件包真的值得研究. 他的每种方法都不相同,有时可能会得到意想不到的结果.
6. 在mysql中,如果要实现这样的效果,即如果它已经存在于数据库中,则忽略它,或者不重复存储它;如果它不存在于数据库中,则将其存储在其中. 用replace替换插入数据的插入. 但是在mongodb中,应该没有,或者我还没有找到它. 我用这种方法解决了. 我定义了一个开关来使该开关为真. 在每次存储之前,循环所有数据以查看是否有该数据,如果没有,则让开关变为假,否则,继续执行,即判断此时开关是真还是假,如果为true,则执行插入操作;如果为false,则将其忽略. 这样可以达到类似的效果,否则每次都会存储大量重复数据,
7. 该集合的核心是我文件中的common.js. 首先,因为我们要采集,所以我们需要使用请求包. 采集后,我们需要以html格式处理数据,以便可以使用类似于jquery的数据. 对于该操作,cheerio包已使用了很长时间,然后在循环采集时将使用anync.each方法,因此将使用异步包,
7-1,
通过采集搜狗微信,我们必须分析搜狗微信的路径. 每个官方帐户页面的路径都是这样
%E8%BF%99%E6%89%8D%E6%98%AF%E6%97%A5%E6%9C%AC&ie = utf8&_sug_ = n&_sug_type _ =
这是“这是日本”页面的链接. 经过分析,所有正式帐户的链接仅在查询后的参数上有所不同,但是查询后的参数是什么,实际上,它是由encodeURIComponent()函数转换的,之后是“这是日本”,因此相同. 要获得该官方帐户,只需对官方帐户的名称进行编码并将其动态组合成一个链接,您就可以在访问时输入每个链接,但是我只是要求此页面此链接,
不是
此页面,因此进一步的处理是获取当前页面的第一内容的链接,即href

获得此链接后,您会发现他具有自己的加密方法. 实际上非常简单,就是在链接中增加三个安培;更换这三个放大器;在带有空链接的链接中,就好了,这是第一步,获取每个官方帐户的页面链接,
7-2
获取链接后,有必要访问,即请求,请求每个地址,获取每个地址的内容,但每个页面上显示的内容不在该页面中,即在html结构中,隐藏在js中,因此我们需要通过常规匹配来获取每篇文章的对象,然后循环访问每个正式帐户的对象以获取有关该对象中每篇文章的一些信息,包括标题,缩略图,摘要,URL,时间, 5个字段,但我使用的代码很烂,而我当时使用的是
Object.Attribute.foreach(function(item,index){
})
这种可怕的方法,最后要做的就是编写一个循环以完全获取每个对象,否则只能获取第一个对象. 在这里,您应该使用async.each或async.foreach. 可以使用两种方法中的每一种,并且它们都非常易于使用. 这样,您将获得上述每篇文章的基本新闻.
7-3,
第三阶段是进入每篇文章的详细信息页面,并获取每篇文章的内容,喜欢的次数,作者,官方帐号,阅读量和其他数据. 这里遇到的主要问题是人们的内容直接位于js中,并且所有img标签都有问题. 它们以这种形式存储在内容中,但是在这种情况下,由于标签,html文档(我不知道此类img标签)存在问题,此类图像无法显示在我们的网页上,因此在这里我们需要进行一些处理,替换全部与
python crawler_WeChat公共帐户推送信息爬取示例
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2020-08-07 04:12
更新时间: 2017年10月23日10:03:08转载作者: ChaseChoi
下面的编辑器将为您带来python crawler_WeChat公共帐户推送信息爬取的示例. 编辑认为这还不错,因此我将与您分享并提供参考. 让我们跟随编辑器看看
问题描述
使用搜狗的微信搜索来获取指定官方帐户的最新推送,并将相应的网页保存到本地.
注释
搜狗微信获取的地址是临时链接,对时间敏感.
官方帐户是一个动态网页(由JavaScript渲染),并且使用request.get()获得的内容不收录推送消息. 在这里,使用selenium + PhantomJS进行处理
代码
#! /usr/bin/env python3
from selenium import webdriver
from datetime import datetime
import bs4, requests
import os, time, sys
# 获取公众号链接
def getAccountURL(searchURL):
res = requests.get(searchURL)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "lxml")
# 选择第一个链接
account = soup.select('a[uigs="account_name_0"]')
return account[0]['href']
# 获取首篇文章的链接,如果有验证码返回None
def getArticleURL(accountURL):
browser = webdriver.PhantomJS("/Users/chasechoi/Downloads/phantomjs-2.1.1-macosx/bin/phantomjs")
# 进入公众号
browser.get(accountURL)
# 获取网页信息
html = browser.page_source
accountSoup = bs4.BeautifulSoup(html, "lxml")
time.sleep(1)
contents = accountSoup.find_all(hrefs=True)
try:
partitialLink = contents[0]['hrefs']
firstLink = base + partitialLink
except IndexError:
firstLink = None
print('CAPTCHA!')
return firstLink
# 创建文件夹存储html网页,以时间命名
def folderCreation():
path = os.path.join(os.getcwd(), datetime.now().strftime('%Y-%m-%d_%H-%M-%S'))
try:
os.makedirs(path)
except OSError as e:
if e.errno != errno.EEXIST:
raise
print("folder not exist!")
return path
# 将html页面写入本地
def writeToFile(path, account, title):
myfile = open("{}/{}_{}.html".format(path, account, title), 'wb')
myfile.write(res.content)
myfile.close()
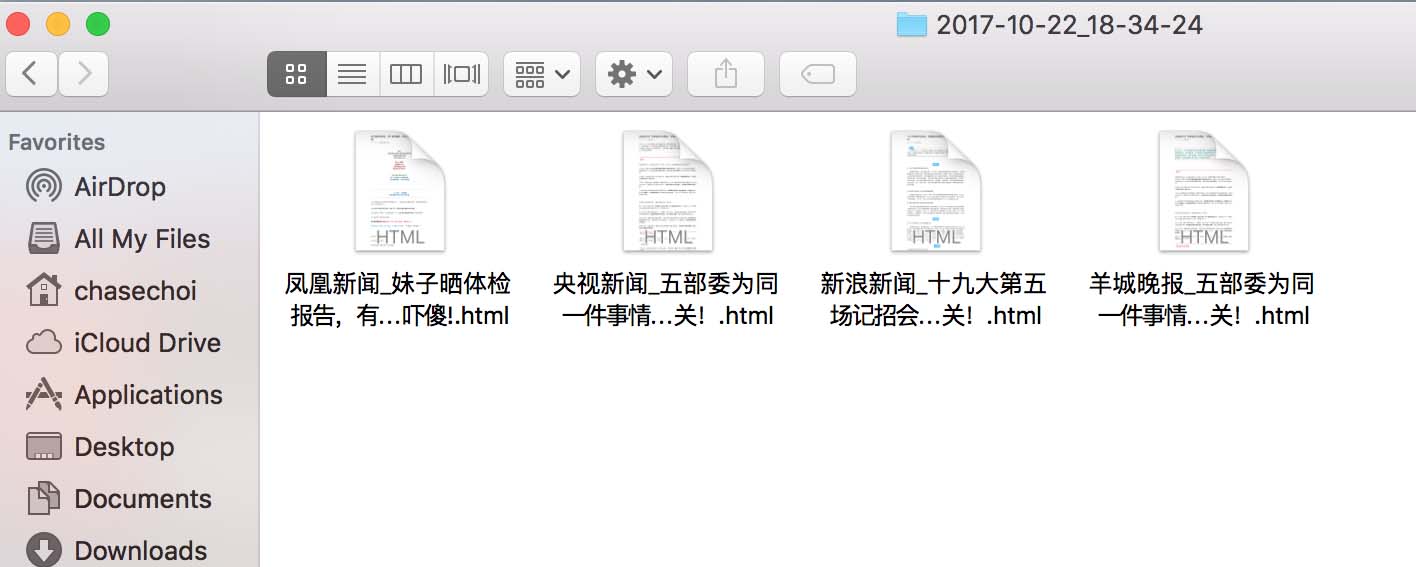
base ='https://mp.weixin.qq.com'
accountList = ['央视新闻', '新浪新闻','凤凰新闻','羊城晚报']
query = 'http://weixin.sogou.com/weixin?type=1&s_from=input&query='
path = folderCreation()
for index, account in enumerate(accountList):
searchURL = query + account
accountURL = getAccountURL(searchURL)
time.sleep(10)
articleURL = getArticleURL(accountURL)
if articleURL != None:
print("#{}({}/{}): {}".format(account, index+1, len(accountList), accountURL))
# 读取第一篇文章内容
res = requests.get(articleURL)
res.raise_for_status()
detailPage = bs4.BeautifulSoup(res.text, "lxml")
title = detailPage.title.text
print("标题: {}\n链接: {}\n".format(title, articleURL))
writeToFile(path, account, title)
else:
print('{} files successfully written to {}'.format(index, path))
sys.exit()
print('{} files successfully written to {}'.format(len(accountList), path))
参考输出
端子输出
查找器
分析
获取链接
首先进入搜狗的微信搜索页面,在地址栏中提取链接的必需部分,将字符串连接到官方帐户名,然后生成请求链接
对于静态网页,请使用请求获取html文件,然后使用BeautifulSoup选择所需的内容
对于动态网页,请使用selenium + PhantomJS获取html文件,然后使用BeautifulSoup选择所需的内容
遇到验证码(CAPTCHA)时,输出提示. 此版本的代码实际上并未处理验证码,因此在运行程序之前需要手动对其进行访问,以避免验证码.
文件写入
使用os.path.join()构造存储路径可以提高通用性. 例如,Windows路径分隔符使用反斜杠(\),而OS X和Linux使用反斜杠(/). 该功能可以根据平台自动转换.
open()使用b(二进制模式)参数来提高通用性(适用于Windows)
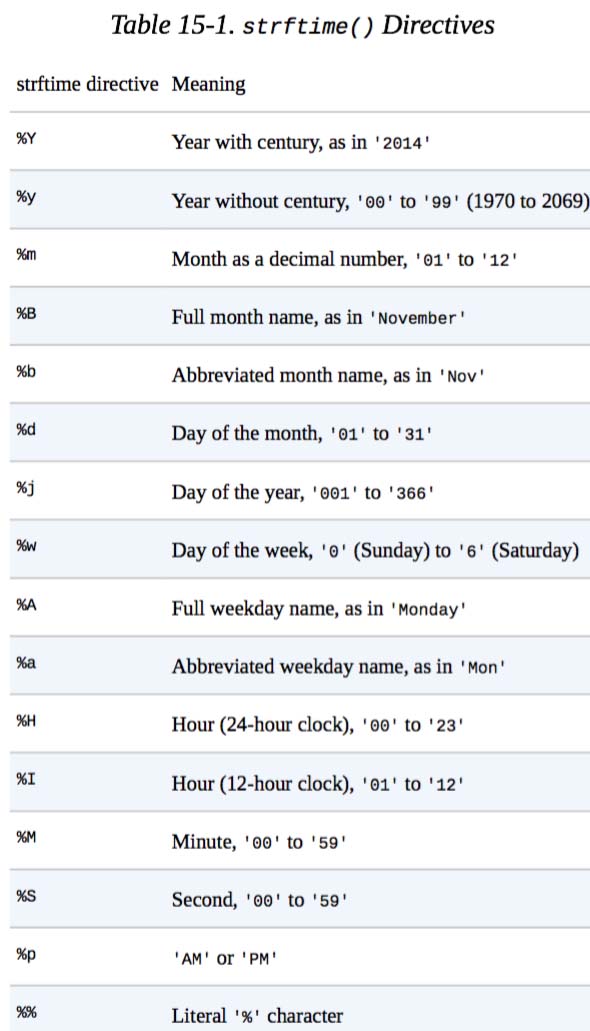
使用datetime.now()获取当前的命名时间,并通过strftime()格式化时间(函数名称中的f表示格式),
有关特定用途,请参阅下表(摘自“使用Python自动完成钻孔”)
上面的python爬网程序_WeChat公共帐户推送信息爬网示例是编辑器共享的所有内容,希望为您提供参考,也希望可以支持脚本库. 查看全部
python crawler_WeChat公共帐户推送信息爬取示例
更新时间: 2017年10月23日10:03:08转载作者: ChaseChoi
下面的编辑器将为您带来python crawler_WeChat公共帐户推送信息爬取的示例. 编辑认为这还不错,因此我将与您分享并提供参考. 让我们跟随编辑器看看
问题描述
使用搜狗的微信搜索来获取指定官方帐户的最新推送,并将相应的网页保存到本地.
注释
搜狗微信获取的地址是临时链接,对时间敏感.
官方帐户是一个动态网页(由JavaScript渲染),并且使用request.get()获得的内容不收录推送消息. 在这里,使用selenium + PhantomJS进行处理
代码
#! /usr/bin/env python3
from selenium import webdriver
from datetime import datetime
import bs4, requests
import os, time, sys
# 获取公众号链接
def getAccountURL(searchURL):
res = requests.get(searchURL)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "lxml")
# 选择第一个链接
account = soup.select('a[uigs="account_name_0"]')
return account[0]['href']
# 获取首篇文章的链接,如果有验证码返回None
def getArticleURL(accountURL):
browser = webdriver.PhantomJS("/Users/chasechoi/Downloads/phantomjs-2.1.1-macosx/bin/phantomjs")
# 进入公众号
browser.get(accountURL)
# 获取网页信息
html = browser.page_source
accountSoup = bs4.BeautifulSoup(html, "lxml")
time.sleep(1)
contents = accountSoup.find_all(hrefs=True)
try:
partitialLink = contents[0]['hrefs']
firstLink = base + partitialLink
except IndexError:
firstLink = None
print('CAPTCHA!')
return firstLink
# 创建文件夹存储html网页,以时间命名
def folderCreation():
path = os.path.join(os.getcwd(), datetime.now().strftime('%Y-%m-%d_%H-%M-%S'))
try:
os.makedirs(path)
except OSError as e:
if e.errno != errno.EEXIST:
raise
print("folder not exist!")
return path
# 将html页面写入本地
def writeToFile(path, account, title):
myfile = open("{}/{}_{}.html".format(path, account, title), 'wb')
myfile.write(res.content)
myfile.close()
base ='https://mp.weixin.qq.com'
accountList = ['央视新闻', '新浪新闻','凤凰新闻','羊城晚报']
query = 'http://weixin.sogou.com/weixin?type=1&s_from=input&query='
path = folderCreation()
for index, account in enumerate(accountList):
searchURL = query + account
accountURL = getAccountURL(searchURL)
time.sleep(10)
articleURL = getArticleURL(accountURL)
if articleURL != None:
print("#{}({}/{}): {}".format(account, index+1, len(accountList), accountURL))
# 读取第一篇文章内容
res = requests.get(articleURL)
res.raise_for_status()
detailPage = bs4.BeautifulSoup(res.text, "lxml")
title = detailPage.title.text
print("标题: {}\n链接: {}\n".format(title, articleURL))
writeToFile(path, account, title)
else:
print('{} files successfully written to {}'.format(index, path))
sys.exit()
print('{} files successfully written to {}'.format(len(accountList), path))
参考输出
端子输出

查找器
分析
获取链接
首先进入搜狗的微信搜索页面,在地址栏中提取链接的必需部分,将字符串连接到官方帐户名,然后生成请求链接
对于静态网页,请使用请求获取html文件,然后使用BeautifulSoup选择所需的内容
对于动态网页,请使用selenium + PhantomJS获取html文件,然后使用BeautifulSoup选择所需的内容
遇到验证码(CAPTCHA)时,输出提示. 此版本的代码实际上并未处理验证码,因此在运行程序之前需要手动对其进行访问,以避免验证码.
文件写入
使用os.path.join()构造存储路径可以提高通用性. 例如,Windows路径分隔符使用反斜杠(\),而OS X和Linux使用反斜杠(/). 该功能可以根据平台自动转换.
open()使用b(二进制模式)参数来提高通用性(适用于Windows)
使用datetime.now()获取当前的命名时间,并通过strftime()格式化时间(函数名称中的f表示格式),
有关特定用途,请参阅下表(摘自“使用Python自动完成钻孔”)
上面的python爬网程序_WeChat公共帐户推送信息爬网示例是编辑器共享的所有内容,希望为您提供参考,也希望可以支持脚本库.
[分享] 366tool在线解析微信新型域名防阻塞API接口的实现原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2020-08-07 01:24
随着智能手机的普及,许多人现在可以直接在手机上阅读小说. 但是,并非所有人都会下载该新颖的应用程序,即使其他人帮助下载该应用程序,这种类型的用户组也不会使用它. 那么我们如何解决此类用户的需求?
许多人目前正在实施的一种方法是直接共享微信中转发小说的链接. 用户可以单击以阅读小说. 当然,这些小说不是纯粹的福利小说,还会增加一些广告. 链接,为官方帐户添加一些QR码等. 但是令企业感到困扰的是,一旦添加了这些内容,微信就会迅速阻止和阻止域名. 目前,我们将使用新型域名的防阻塞技术.
在我们共享366TooL开发的几种防密封解决方案之前. 由于产品不同和操作方法的差异,仅一种防密封解决方案无法满足所有客户的需求,并且微信规则在不断变化. ,该程序还需要不断升级和改进,以确保防密封程序的有效性和持久性. 今天,我将与您分享微信小说的反封锁解决方案. 新平台的域名如何在微信中生存更长的时间?
在我们分享小说的反阻止解决方案之前,让我们首先了解为什么微信很容易阻止小说的推广域名. 普遍的原因总结为两点:
第一点是,微信机器人会自动检测小说中的内容. 通常,带有广告内容或敏感词汇的小说肯定会被屏蔽(最新小说是什么?)
第二个原因是同事或其他人的报告在验证后被微信屏蔽.
分析原因之后,让我们看一下新颖的使用场景.
通用小说平台由官方帐户平台承载,然后通过共享绑定到官方帐户的商业域名进行推广. 要阅读小说,用户必须授权官方帐户登录才能正常阅读并充值.
这就是重点. 新型域名的反封锁实际上就是对官方账号业务域名的反封锁,普通的官方账号平台的业务域名只能被替换三次. 似乎特别重要的是保护官方帐户的企业域名.
那么我们如何才能有效地保护新颖域名免遭拦截?在这里,我需要解释. 很多朋友问我,使用反封锁后我的域名是否不会被封锁?这不是那么容易. 防阻塞只能延迟或更好地保护域名. 无法保证永远不会有问题. 原因很简单. 微信技术团队不是素食主义者.
366TooL的最新新颖防密封解决方案可以说已经超过了市场上所有的防密封解决方案,因为该平台已经通过了大量的数据测试,反馈,优化和比较,最终确定了一个单独的防密封解决方案平台的系统. 查看全部
为什么要使用新颖的域名防阻塞功能?
随着智能手机的普及,许多人现在可以直接在手机上阅读小说. 但是,并非所有人都会下载该新颖的应用程序,即使其他人帮助下载该应用程序,这种类型的用户组也不会使用它. 那么我们如何解决此类用户的需求?
许多人目前正在实施的一种方法是直接共享微信中转发小说的链接. 用户可以单击以阅读小说. 当然,这些小说不是纯粹的福利小说,还会增加一些广告. 链接,为官方帐户添加一些QR码等. 但是令企业感到困扰的是,一旦添加了这些内容,微信就会迅速阻止和阻止域名. 目前,我们将使用新型域名的防阻塞技术.
在我们共享366TooL开发的几种防密封解决方案之前. 由于产品不同和操作方法的差异,仅一种防密封解决方案无法满足所有客户的需求,并且微信规则在不断变化. ,该程序还需要不断升级和改进,以确保防密封程序的有效性和持久性. 今天,我将与您分享微信小说的反封锁解决方案. 新平台的域名如何在微信中生存更长的时间?
在我们分享小说的反阻止解决方案之前,让我们首先了解为什么微信很容易阻止小说的推广域名. 普遍的原因总结为两点:
第一点是,微信机器人会自动检测小说中的内容. 通常,带有广告内容或敏感词汇的小说肯定会被屏蔽(最新小说是什么?)
第二个原因是同事或其他人的报告在验证后被微信屏蔽.
分析原因之后,让我们看一下新颖的使用场景.
通用小说平台由官方帐户平台承载,然后通过共享绑定到官方帐户的商业域名进行推广. 要阅读小说,用户必须授权官方帐户登录才能正常阅读并充值.
这就是重点. 新型域名的反封锁实际上就是对官方账号业务域名的反封锁,普通的官方账号平台的业务域名只能被替换三次. 似乎特别重要的是保护官方帐户的企业域名.
那么我们如何才能有效地保护新颖域名免遭拦截?在这里,我需要解释. 很多朋友问我,使用反封锁后我的域名是否不会被封锁?这不是那么容易. 防阻塞只能延迟或更好地保护域名. 无法保证永远不会有问题. 原因很简单. 微信技术团队不是素食主义者.
366TooL的最新新颖防密封解决方案可以说已经超过了市场上所有的防密封解决方案,因为该平台已经通过了大量的数据测试,反馈,优化和比较,最终确定了一个单独的防密封解决方案平台的系统.
php微信官方帐户开发的简短答案
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2020-08-07 01:23
更新: 2018年10月20日15:20:30转载作者: dq_095
本文主要详细介绍了针对php微信公众号开发的简短回答问题,具有一定的参考价值,有兴趣的朋友可以参考
本文示例共享php微信公众号开发的简短答案问题的特定代码,以供您参考. 具体内容如下
简短回答问题
核心代码如下:
public function responseMsg()
{
//get post data, May be due to the different environments
$postStr = $GLOBALS["HTTP_RAW_POST_DATA"];
//extract post data
if (!empty($postStr)){
$postObj = simplexml_load_string($postStr, 'SimpleXMLElement', LIBXML_NOCDATA);
$fromUsername = $postObj->FromUserName;
$toUsername = $postObj->ToUserName;
$type = $postObj->MsgType;
$customevent = $postObj->Event;
$latitude = $postObj->Location_X;
$longitude = $postObj->Location_Y;
$keyword = trim($postObj->Content);
$time = time();
$textTpl = "
%s
%s
0
";
include("coon.php");
if($keyword=="8")
{
$array=array("第5页第1个字"=>"王","第8页第1个字"=>"李","第30页第1个字"=>"周");
$a=array_rand($array,1);
$b=$array[$a];
$contentStr=$a."是什么?";
$sql="INSERT INTO `menu2` (`id` ,`user` ,`sec`,`answer`)VALUES (NULL , '{$fromUsername}', '8','{$b}')";
mysql_query($sql);
}
else
{
$sql="SELECT * FROM `menu2` where `user`= '{$fromUsername}'";
$query=mysql_query($sql);
$rm=mysql_fetch_array($query);
$sec=$rm['sec'];
$answer=$rm['answer'];
if($sec=="8")
{
if($keyword==$answer)
{
$contentStr="你的答案是正确的,视频代码下载地址为....";
}
else
{
$contentStr="你的答案不正确,请购买《微信公众平台搭建与开发揭秘》";
}
}
else
{
$contentStr="请先输入8";
}
}
$msgType="text";
$resultStr = sprintf($textTpl, $fromUsername, $toUsername, $time, $msgType, $contentStr);
echo $resultStr;
}
}
coon.php: 用于连接到数据库的代码如下:
<p> 查看全部
php微信官方帐户开发的简短答案
更新: 2018年10月20日15:20:30转载作者: dq_095
本文主要详细介绍了针对php微信公众号开发的简短回答问题,具有一定的参考价值,有兴趣的朋友可以参考
本文示例共享php微信公众号开发的简短答案问题的特定代码,以供您参考. 具体内容如下
简短回答问题


核心代码如下:
public function responseMsg()
{
//get post data, May be due to the different environments
$postStr = $GLOBALS["HTTP_RAW_POST_DATA"];
//extract post data
if (!empty($postStr)){
$postObj = simplexml_load_string($postStr, 'SimpleXMLElement', LIBXML_NOCDATA);
$fromUsername = $postObj->FromUserName;
$toUsername = $postObj->ToUserName;
$type = $postObj->MsgType;
$customevent = $postObj->Event;
$latitude = $postObj->Location_X;
$longitude = $postObj->Location_Y;
$keyword = trim($postObj->Content);
$time = time();
$textTpl = "
%s
%s
0
";
include("coon.php");
if($keyword=="8")
{
$array=array("第5页第1个字"=>"王","第8页第1个字"=>"李","第30页第1个字"=>"周");
$a=array_rand($array,1);
$b=$array[$a];
$contentStr=$a."是什么?";
$sql="INSERT INTO `menu2` (`id` ,`user` ,`sec`,`answer`)VALUES (NULL , '{$fromUsername}', '8','{$b}')";
mysql_query($sql);
}
else
{
$sql="SELECT * FROM `menu2` where `user`= '{$fromUsername}'";
$query=mysql_query($sql);
$rm=mysql_fetch_array($query);
$sec=$rm['sec'];
$answer=$rm['answer'];
if($sec=="8")
{
if($keyword==$answer)
{
$contentStr="你的答案是正确的,视频代码下载地址为....";
}
else
{
$contentStr="你的答案不正确,请购买《微信公众平台搭建与开发揭秘》";
}
}
else
{
$contentStr="请先输入8";
}
}
$msgType="text";
$resultStr = sprintf($textTpl, $fromUsername, $toUsername, $time, $msgType, $contentStr);
echo $resultStr;
}
}
coon.php: 用于连接到数据库的代码如下:
<p>
使用搜狗微信入口制作微信文章采集器API
采集交流 • 优采云 发表了文章 • 0 个评论 • 464 次浏览 • 2020-08-06 20:05
搜狗微信门户比其他门户友好得多. 应该是微信搜索引擎和搜狗有合作,所以搜狗可以进入微信搜索. 搜狗微信有两种类型,一种是通过关键词搜索文章,另一种是通过关键词搜索官方账号,搜索到的微信账号最多只能获得十笔最新新闻推送(这意味着指定的公众不能通过这种方法抓取历史新闻). 该方法还有一些应用场景,例如获取大量有关某个关键字的文章,例如执行计划任务,或者以一定间隔抓取某个微信官方帐户的最新十次推送以获取其最新推送. 它比网上的微信要好得多. 搜狗微信更新也是实时且直接相关的.
我对appium自动化和Xposed框架了解不多. 鸦片类似于硒. 为了在移动终端上进行自动化测试,您可以模拟点击. Xposed框架有很多工作要做. Xposed可以执行一些其他功能,而无需修改apk. 爬虫自然是可能的. 此外,它还可以自动抓取红包,自动回复机器人以及修改微步数等骚动操作.
我写爬虫游戏已有一段时间了. 我个人认为,除了具有防爬网和爬网的效率外,还有另一个领域很难实现. 履带的稳定性和坚固性需要考虑到许多异常情况,并且是合理有效的. 在这一点上,我认为我仍然需要向主要的爬虫学习. (我觉得我一直在谈论很多东西,还没有开始做我的身体(orz),请不要对那个觉得我很冗长的大个子生气. )
使用搜狗微信编写一个爬虫界面,代码非常简单,只有两百行代码. (我在这里不得不抱怨. 我在python中写太多了. 我总是有一种幻想,我很尴尬,编程很简单. 几行代码可以实现非常强大的功能. 这时,我需要编写CPP并冷静下来,让自己知道什么是真正的编程. )
以下记录了编写此采集器界面脚本的过程:
1. 页面请求分析(以官方帐户搜索为例):
您可以看到第一个http请求数据包是我们想要的结果,请检查其查询字符串,如下所示:
它看起来并不简单. 我们获得以下信息:
请求网址是
请求类型为Get
请求参数如上所示
发现将请求参数tyepe更改为2是为了获得关键字搜索文章的结果
这相对简单
2. 模拟页面请求:
我们直接使用url,请求参数params和Google Chrome的用户代理请求,发现我们可以成功获取所需页面的源代码,然后在下方获得第一个官方帐户搜索结果. 是的(这意味着需要正确指定官方帐户名称,如果过于模糊,则有可能获得类似的官方帐户结果).
3. 分析页面:
首先确定爬行思路,第一步是获取微信公众号链接,然后通过微信公众号链接获取最新的十项推送相关信息,包括标题,日期,作者,内容摘要,内容链接(实际上,我们发现,通过微信推送链接,我们可以轻松获取推送的主要内容,但不包括喜欢和阅读的次数. 这些数据只能在微信移动终端上查看. 如果有一次机会,它将在下次记录. 在您的手机微信上下载爬虫的过程.
因此第一步,我们将获得官方帐户链接:
这里我们可以直接使用正则表达式提取(这种简单方法不需要xpath和bs4. 依赖标准库和第三方库仍然有所不同. )
(很抱歉被水印阻止,请更改一个. )
第二步是根据微信官方账号链接获取最近十条推送消息:
(我只写过一篇关于orz的文章,我会继续努力. )
ctlr U查看网页的源代码,并发现原创信息位于js变量中.
易于处理,继续常规提取,将json格式的字符串转换为python中的字典,有两种方法,一种是使用json.loads方法,第二种是使用内置的eval方法. 两种方法之间存在一些差异,例如单引号和双引号. json格式使用双引号,而python词典中通常使用单引号.
好的,已经获得了原创的推送信息数据,但是我们不需要很多信息,因此我们可以将其删除. 值得一提的是,datetime的值是一个时间戳,我们需要将其转换为直观的Time表达式.
至此,微信公众号上的抓取工具已基本解决. 接下来,需要将其封装为一个类. 代码的主要部分如下.
此外,我还写了关于关键字搜索文章,AccountAPI,ArticleAPI的爬网程序接口,父类是AP类,并且该API类具有query_url,params,header,_get_response,_get_datetime以及其他用于由AccountAPI和ArticleAPI共享.
代码位于github仓库中,如果您有兴趣,可以看看
放置两个屏幕截图以供使用
(ArticleAPI)
(AccountAPI)
结论:
诸如此类的原创爬虫将其称为api,我有点大胆. 这只是一个小麻烦,很难做到优雅,您需要向大兄弟学习. 查看全部
移动客户端使用提琴手或查尔斯等其他捕获工具捕获数据包,这是一种相对主流的方法(我觉得是orz),是一种更有效的方法,可以快速捕获微信官方帐户信息和历史新闻. 该方法也有缺点: cookie很快过期,大约需要半天. 还可以专门获取某些官方帐户的历史信息. 通过模拟微信登录自动获取cookie似乎非常困难. 我很无聊,无法实现. 看来微信登录是TCP协议?
搜狗微信门户比其他门户友好得多. 应该是微信搜索引擎和搜狗有合作,所以搜狗可以进入微信搜索. 搜狗微信有两种类型,一种是通过关键词搜索文章,另一种是通过关键词搜索官方账号,搜索到的微信账号最多只能获得十笔最新新闻推送(这意味着指定的公众不能通过这种方法抓取历史新闻). 该方法还有一些应用场景,例如获取大量有关某个关键字的文章,例如执行计划任务,或者以一定间隔抓取某个微信官方帐户的最新十次推送以获取其最新推送. 它比网上的微信要好得多. 搜狗微信更新也是实时且直接相关的.
我对appium自动化和Xposed框架了解不多. 鸦片类似于硒. 为了在移动终端上进行自动化测试,您可以模拟点击. Xposed框架有很多工作要做. Xposed可以执行一些其他功能,而无需修改apk. 爬虫自然是可能的. 此外,它还可以自动抓取红包,自动回复机器人以及修改微步数等骚动操作.
我写爬虫游戏已有一段时间了. 我个人认为,除了具有防爬网和爬网的效率外,还有另一个领域很难实现. 履带的稳定性和坚固性需要考虑到许多异常情况,并且是合理有效的. 在这一点上,我认为我仍然需要向主要的爬虫学习. (我觉得我一直在谈论很多东西,还没有开始做我的身体(orz),请不要对那个觉得我很冗长的大个子生气. )
使用搜狗微信编写一个爬虫界面,代码非常简单,只有两百行代码. (我在这里不得不抱怨. 我在python中写太多了. 我总是有一种幻想,我很尴尬,编程很简单. 几行代码可以实现非常强大的功能. 这时,我需要编写CPP并冷静下来,让自己知道什么是真正的编程. )
以下记录了编写此采集器界面脚本的过程:
1. 页面请求分析(以官方帐户搜索为例):
您可以看到第一个http请求数据包是我们想要的结果,请检查其查询字符串,如下所示:
它看起来并不简单. 我们获得以下信息:
请求网址是
请求类型为Get
请求参数如上所示
发现将请求参数tyepe更改为2是为了获得关键字搜索文章的结果
这相对简单
2. 模拟页面请求:
我们直接使用url,请求参数params和Google Chrome的用户代理请求,发现我们可以成功获取所需页面的源代码,然后在下方获得第一个官方帐户搜索结果. 是的(这意味着需要正确指定官方帐户名称,如果过于模糊,则有可能获得类似的官方帐户结果).
3. 分析页面:
首先确定爬行思路,第一步是获取微信公众号链接,然后通过微信公众号链接获取最新的十项推送相关信息,包括标题,日期,作者,内容摘要,内容链接(实际上,我们发现,通过微信推送链接,我们可以轻松获取推送的主要内容,但不包括喜欢和阅读的次数. 这些数据只能在微信移动终端上查看. 如果有一次机会,它将在下次记录. 在您的手机微信上下载爬虫的过程.
因此第一步,我们将获得官方帐户链接:
这里我们可以直接使用正则表达式提取(这种简单方法不需要xpath和bs4. 依赖标准库和第三方库仍然有所不同. )
(很抱歉被水印阻止,请更改一个. )
第二步是根据微信官方账号链接获取最近十条推送消息:
(我只写过一篇关于orz的文章,我会继续努力. )
ctlr U查看网页的源代码,并发现原创信息位于js变量中.
易于处理,继续常规提取,将json格式的字符串转换为python中的字典,有两种方法,一种是使用json.loads方法,第二种是使用内置的eval方法. 两种方法之间存在一些差异,例如单引号和双引号. json格式使用双引号,而python词典中通常使用单引号.
好的,已经获得了原创的推送信息数据,但是我们不需要很多信息,因此我们可以将其删除. 值得一提的是,datetime的值是一个时间戳,我们需要将其转换为直观的Time表达式.
至此,微信公众号上的抓取工具已基本解决. 接下来,需要将其封装为一个类. 代码的主要部分如下.
此外,我还写了关于关键字搜索文章,AccountAPI,ArticleAPI的爬网程序接口,父类是AP类,并且该API类具有query_url,params,header,_get_response,_get_datetime以及其他用于由AccountAPI和ArticleAPI共享.
代码位于github仓库中,如果您有兴趣,可以看看
放置两个屏幕截图以供使用
(ArticleAPI)
(AccountAPI)
结论:
诸如此类的原创爬虫将其称为api,我有点大胆. 这只是一个小麻烦,很难做到优雅,您需要向大兄弟学习.
微信公众号文章检索方法摘要(第1部分)
采集交流 • 优采云 发表了文章 • 0 个评论 • 299 次浏览 • 2020-08-06 18:25
爬虫
我经常有一些需要帮助的人,他们在搜寻公共帐户文章方面需要帮助. 这次我将总结各种方法.
目前,有三种主要的微信公众号抓取方法:
通过在微信官方平台上引用文章界面来爬网第三方官方帐户文章聚合网站,并分析微信应用程序的界面以通过微信公众平台访问官方帐户文章,并通过第三方平台进行爬网,派对官方帐户文章汇总网站
微信公众号文章未提供外部搜索功能. 直到2013年,在微信对搜狗进行投资之后,搜狗搜索才访问了微信官方账户数据. 从那时起,您可以使用搜狗搜索浏览或查询相关的官方帐户和文章.
域名是:
搜狗微信
您可以直接搜索官方帐户或文章的关键字,一些流行的官方帐户会及时更新,几乎与微信同步.
官方帐户搜索
因此,您可以使用搜狗微信界面对一些流行的官方账户进行爬网,但是却无法搜索到某些利基官方账户,并且搜狗的反爬网机制更频繁地更新,并且获取数据的界面变化更快,通常会在两三个月内进行调整,这使得履带易于悬挂. 建议使用硒进行爬网. 此外,搜狗还对每个IP都有访问限制. 频率过高的IP的访问将被阻止24小时,您需要购买一个IP池来处理它.
还有一些其他公共帐户文章聚合网站(例如门户)未及时更新或未包括在内. 毕竟,搜狗的儿子不好. 通过微信公众平台引用文章界面
此界面是相对隐藏的,不能匿名访问. 必须有一个官方帐户. 最好注册一个新的官方帐户,以免被阻止.
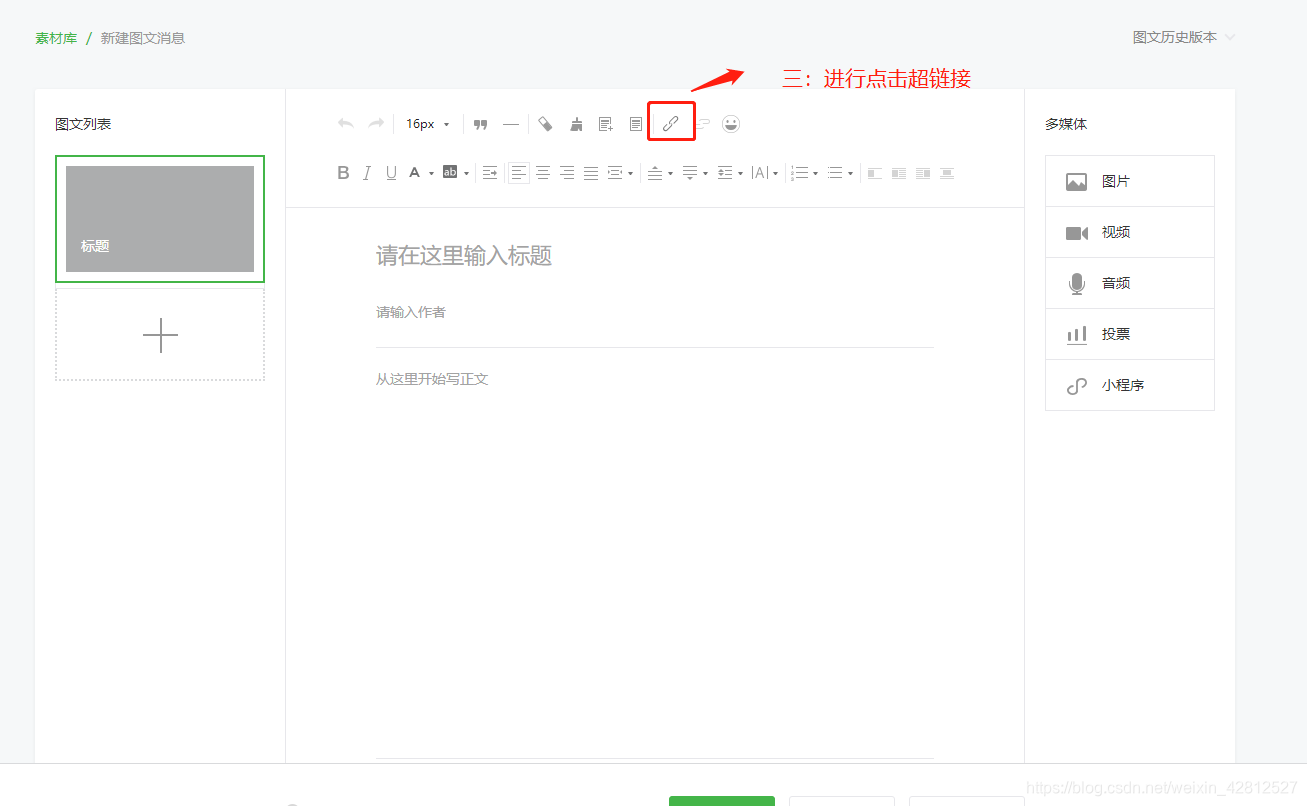
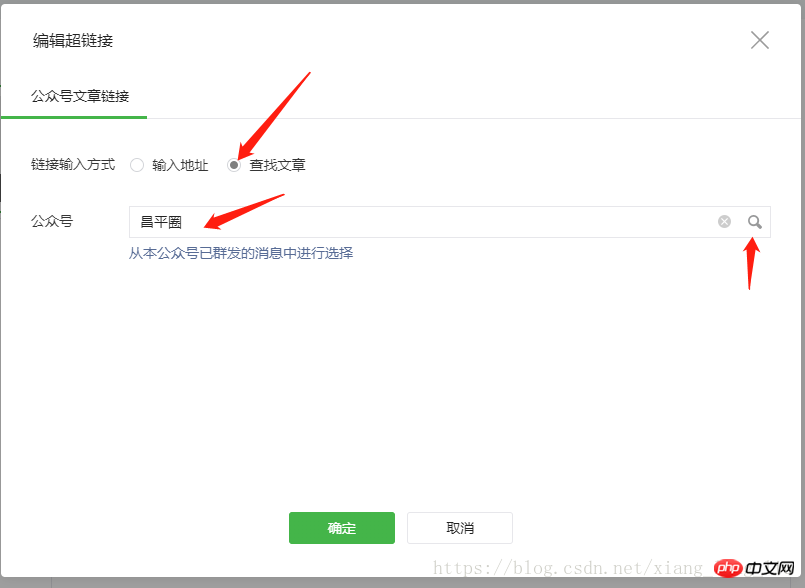
让我们从特定步骤开始: 首先登录您的微信官方帐户,在您输入的主页上选择“创建群发”,然后单击自行创建的图形,然后在文章编辑工具栏中找到超链接,如下所示: 如下所示:
单击超链接
单击超链接按钮,将弹出一个对话框,选择链接输入法以查找文章,如下所示:
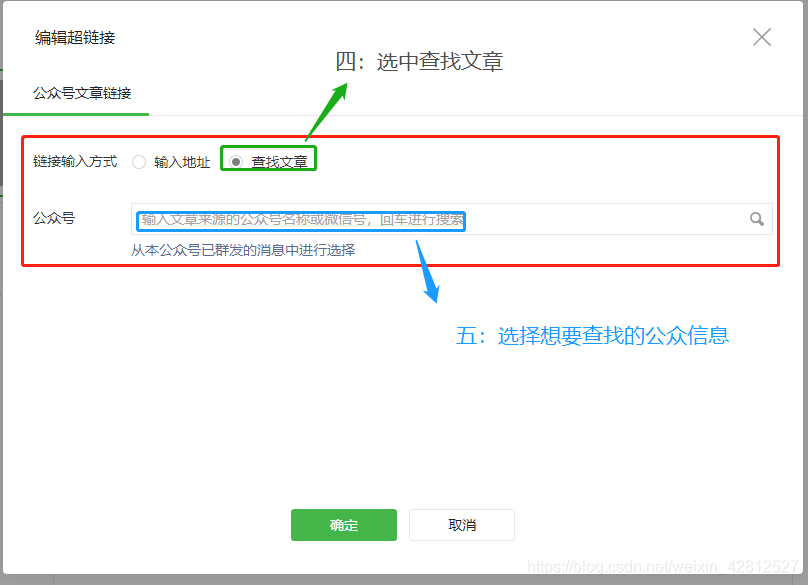
查找文章
您可以在此处输入官方帐户的名称,然后按Enter键,微信将返回匹配的官方帐户列表,如下所示:
搜索官方帐户
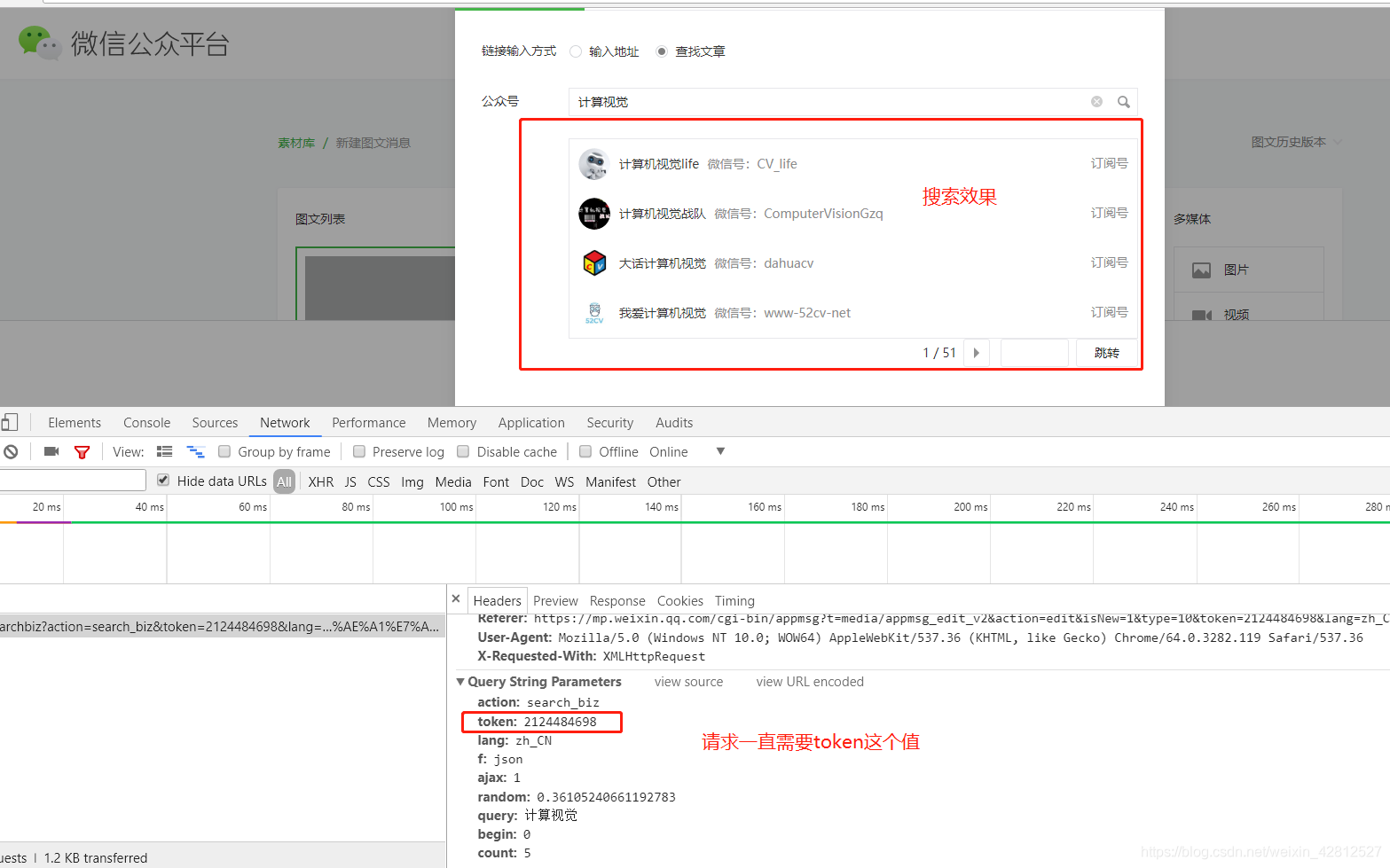
然后单击您要获取的官方帐户,然后将显示特定文章的列表. 它已经按时间倒序排列,而最新的文章是第一篇. 如下图所示:
文章列表
微信的传呼机制很奇怪. 每个官方帐户的每个页面上显示的数据项数量是不同的. 分页爬网时需要处理它.
通过chrome分析网络请求的数据,我们基本获得了所需的数据,文章链接,封面,发行日期,字幕等,如下所示:
网络请求数据
好的,此爬网方法的原理已经完成,让我们开始实际的操作.
由于微信公众平台的登录验证比较严格,在输入密码后,手机必须扫描密码进行确认登录,因此最好使用硒进行自动化. 我不会列出特定微信界面的分析过程,而是直接发布代码:
import re
import time
import random
import traceback
import requests
from selenium import webdriver
class Spider(object):
'''
微信公众号文章爬虫
'''
def __init__(self):
# 微信公众号账号
self.account = '286394973@qq.com'
# 微信公众号密码
self.pwd = 'lei4649861'
def create_driver(self):
'''
初始化 webdriver
'''
options = webdriver.ChromeOptions()
# 禁用gpu加速,防止出一些未知bug
options.add_argument('--disable-gpu')
# 这里我用 chromedriver 作为 webdriver
# 可以去 http://chromedriver.chromium.org/downloads 下载你的chrome对应版本
self.driver = webdriver.Chrome(executable_path='./chromedriver', chrome_options=options)
# 设置一个隐性等待 5s
self.driver.implicitly_wait(5)
def log(self, msg):
'''
格式化打印
'''
print('------ %s ------' % msg)
def login(self):
'''
登录拿 cookies
'''
try:
self.create_driver()
# 访问微信公众平台
self.driver.get('https://mp.weixin.qq.com/')
# 等待网页加载完毕
time.sleep(3)
# 输入账号
self.driver.find_element_by_xpath("./*//input[@name='account']").clear()
self.driver.find_element_by_xpath("./*//input[@name='account']").send_keys(self.account)
# 输入密码
self.driver.find_element_by_xpath("./*//input[@name='password']").clear()
self.driver.find_element_by_xpath("./*//input[@name='password']").send_keys(self.pwd)
# 点击登录
self.driver.find_elements_by_class_name('btn_login')[0].click()
self.log("请拿手机扫码二维码登录公众号")
# 等待手机扫描
time.sleep(10)
self.log("登录成功")
# 获取cookies 然后保存到变量上,后面要用
self.cookies = dict([[x['name'], x['value']] for x in self.driver.get_cookies()])
except Exception as e:
traceback.print_exc()
finally:
# 退出 chorme
self.driver.quit()
def get_article(self, query=''):
try:
url = 'https://mp.weixin.qq.com'
# 设置headers
headers = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36"
}
# 登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-b ... 51598,
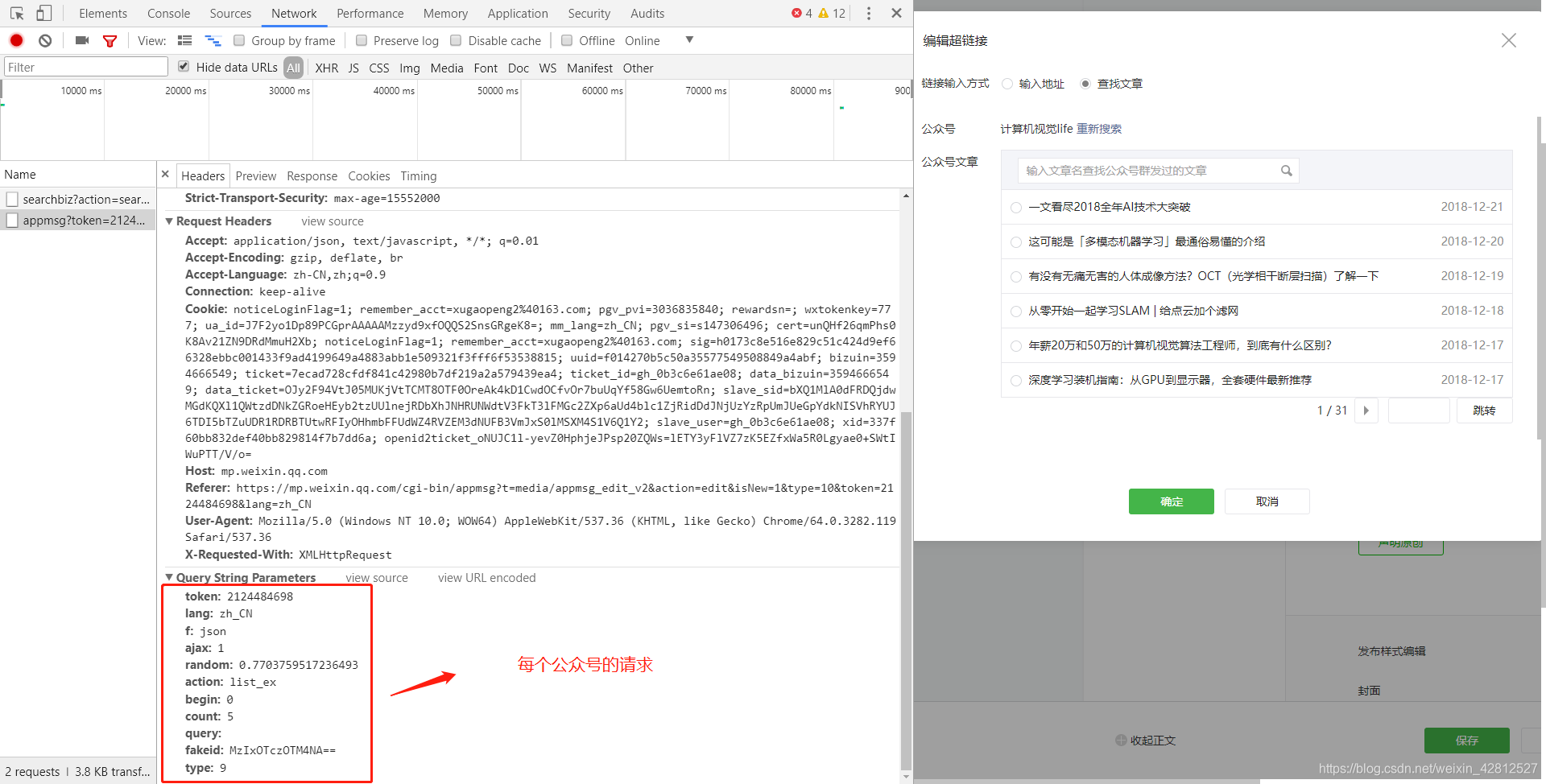
# 从这里获取token信息
response = requests.get(url=url, cookies=self.cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
time.sleep(2)
self.log('正在查询[ %s ]相关公众号' % query)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
# 搜索微信公众号接口需要传入的参数,
# 有三个变量:微信公众号token、随机数random、搜索的微信公众号名字
params = {
'action': 'search_biz',
'token': token,
'random': random.random(),
'query': query,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'begin': '0',
'count': '5'
}
# 打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers
response = requests.get(search_url, cookies=self.cookies, headers=headers, params=params)
time.sleep(2)
# 取搜索结果中的第一个公众号
lists = response.json().get('list')[0]
# 获取这个公众号的fakeid,后面爬取公众号文章需要此字段
fakeid = lists.get('fakeid')
nickname = lists.get('nickname')
# 微信公众号文章接口地址
search_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
# 搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random
params = {
'action': 'list_ex',
'token': token,
'random': random.random(),
'fakeid': fakeid,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'begin': '0', # 不同页,此参数变化,变化规则为每页加5
'count': '5',
'query': '',
'type': '9'
}
self.log('正在查询公众号[ %s ]相关文章' % nickname)
# 打开搜索的微信公众号文章列表页
response = requests.get(search_url, cookies=self.cookies, headers=headers, params=params)
time.sleep(2)
for per in response.json().get('app_msg_list', []):
print('title ---> %s' % per.get('title'))
print('link ---> %s' % per.get('link'))
# print('cover ---> %s' % per.get('cover'))
except Exception as e:
traceback.print_exc()
if __name__ == '__main__':
spider = Spider()
spider.login()
spider.get_article('python')
该代码仅用于学习,不适用于分页查询.
根据网民的说法,该接口也有访问频率限制. 一天几百次不是问题. 如果访问速度太快或次数太多,它将被阻止24小时. 查看全部

爬虫
我经常有一些需要帮助的人,他们在搜寻公共帐户文章方面需要帮助. 这次我将总结各种方法.
目前,有三种主要的微信公众号抓取方法:
通过在微信官方平台上引用文章界面来爬网第三方官方帐户文章聚合网站,并分析微信应用程序的界面以通过微信公众平台访问官方帐户文章,并通过第三方平台进行爬网,派对官方帐户文章汇总网站
微信公众号文章未提供外部搜索功能. 直到2013年,在微信对搜狗进行投资之后,搜狗搜索才访问了微信官方账户数据. 从那时起,您可以使用搜狗搜索浏览或查询相关的官方帐户和文章.
域名是:

搜狗微信
您可以直接搜索官方帐户或文章的关键字,一些流行的官方帐户会及时更新,几乎与微信同步.

官方帐户搜索
因此,您可以使用搜狗微信界面对一些流行的官方账户进行爬网,但是却无法搜索到某些利基官方账户,并且搜狗的反爬网机制更频繁地更新,并且获取数据的界面变化更快,通常会在两三个月内进行调整,这使得履带易于悬挂. 建议使用硒进行爬网. 此外,搜狗还对每个IP都有访问限制. 频率过高的IP的访问将被阻止24小时,您需要购买一个IP池来处理它.
还有一些其他公共帐户文章聚合网站(例如门户)未及时更新或未包括在内. 毕竟,搜狗的儿子不好. 通过微信公众平台引用文章界面
此界面是相对隐藏的,不能匿名访问. 必须有一个官方帐户. 最好注册一个新的官方帐户,以免被阻止.
让我们从特定步骤开始: 首先登录您的微信官方帐户,在您输入的主页上选择“创建群发”,然后单击自行创建的图形,然后在文章编辑工具栏中找到超链接,如下所示: 如下所示:

单击超链接
单击超链接按钮,将弹出一个对话框,选择链接输入法以查找文章,如下所示:

查找文章
您可以在此处输入官方帐户的名称,然后按Enter键,微信将返回匹配的官方帐户列表,如下所示:

搜索官方帐户
然后单击您要获取的官方帐户,然后将显示特定文章的列表. 它已经按时间倒序排列,而最新的文章是第一篇. 如下图所示:

文章列表
微信的传呼机制很奇怪. 每个官方帐户的每个页面上显示的数据项数量是不同的. 分页爬网时需要处理它.
通过chrome分析网络请求的数据,我们基本获得了所需的数据,文章链接,封面,发行日期,字幕等,如下所示:

网络请求数据
好的,此爬网方法的原理已经完成,让我们开始实际的操作.
由于微信公众平台的登录验证比较严格,在输入密码后,手机必须扫描密码进行确认登录,因此最好使用硒进行自动化. 我不会列出特定微信界面的分析过程,而是直接发布代码:
import re
import time
import random
import traceback
import requests
from selenium import webdriver
class Spider(object):
'''
微信公众号文章爬虫
'''
def __init__(self):
# 微信公众号账号
self.account = '286394973@qq.com'
# 微信公众号密码
self.pwd = 'lei4649861'
def create_driver(self):
'''
初始化 webdriver
'''
options = webdriver.ChromeOptions()
# 禁用gpu加速,防止出一些未知bug
options.add_argument('--disable-gpu')
# 这里我用 chromedriver 作为 webdriver
# 可以去 http://chromedriver.chromium.org/downloads 下载你的chrome对应版本
self.driver = webdriver.Chrome(executable_path='./chromedriver', chrome_options=options)
# 设置一个隐性等待 5s
self.driver.implicitly_wait(5)
def log(self, msg):
'''
格式化打印
'''
print('------ %s ------' % msg)
def login(self):
'''
登录拿 cookies
'''
try:
self.create_driver()
# 访问微信公众平台
self.driver.get('https://mp.weixin.qq.com/')
# 等待网页加载完毕
time.sleep(3)
# 输入账号
self.driver.find_element_by_xpath("./*//input[@name='account']").clear()
self.driver.find_element_by_xpath("./*//input[@name='account']").send_keys(self.account)
# 输入密码
self.driver.find_element_by_xpath("./*//input[@name='password']").clear()
self.driver.find_element_by_xpath("./*//input[@name='password']").send_keys(self.pwd)
# 点击登录
self.driver.find_elements_by_class_name('btn_login')[0].click()
self.log("请拿手机扫码二维码登录公众号")
# 等待手机扫描
time.sleep(10)
self.log("登录成功")
# 获取cookies 然后保存到变量上,后面要用
self.cookies = dict([[x['name'], x['value']] for x in self.driver.get_cookies()])
except Exception as e:
traceback.print_exc()
finally:
# 退出 chorme
self.driver.quit()
def get_article(self, query=''):
try:
url = 'https://mp.weixin.qq.com'
# 设置headers
headers = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36"
}
# 登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-b ... 51598,
# 从这里获取token信息
response = requests.get(url=url, cookies=self.cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
time.sleep(2)
self.log('正在查询[ %s ]相关公众号' % query)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
# 搜索微信公众号接口需要传入的参数,
# 有三个变量:微信公众号token、随机数random、搜索的微信公众号名字
params = {
'action': 'search_biz',
'token': token,
'random': random.random(),
'query': query,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'begin': '0',
'count': '5'
}
# 打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers
response = requests.get(search_url, cookies=self.cookies, headers=headers, params=params)
time.sleep(2)
# 取搜索结果中的第一个公众号
lists = response.json().get('list')[0]
# 获取这个公众号的fakeid,后面爬取公众号文章需要此字段
fakeid = lists.get('fakeid')
nickname = lists.get('nickname')
# 微信公众号文章接口地址
search_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
# 搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random
params = {
'action': 'list_ex',
'token': token,
'random': random.random(),
'fakeid': fakeid,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'begin': '0', # 不同页,此参数变化,变化规则为每页加5
'count': '5',
'query': '',
'type': '9'
}
self.log('正在查询公众号[ %s ]相关文章' % nickname)
# 打开搜索的微信公众号文章列表页
response = requests.get(search_url, cookies=self.cookies, headers=headers, params=params)
time.sleep(2)
for per in response.json().get('app_msg_list', []):
print('title ---> %s' % per.get('title'))
print('link ---> %s' % per.get('link'))
# print('cover ---> %s' % per.get('cover'))
except Exception as e:
traceback.print_exc()
if __name__ == '__main__':
spider = Spider()
spider.login()
spider.get_article('python')
该代码仅用于学习,不适用于分页查询.
根据网民的说法,该接口也有访问频率限制. 一天几百次不是问题. 如果访问速度太快或次数太多,它将被阻止24小时.
微信公众号内容采集教程. docx29页
采集交流 • 优采云 发表了文章 • 0 个评论 • 365 次浏览 • 2020-08-06 14:14
打开网页后,默认显示“热门”文章. 向下滚动页面,找到并单击“加载更多内容”按钮,在操作提示框中选择“更多操作”,微信公众号文章正文采集步骤3,选择“循环点击单个元素”,创建页面翻转循环微信公众号文章文本采集步骤4由于此网页涉及Ajax技术,因此我们需要设置一些高级选项. 选择“单击元素”步骤,打开“高级选项”,选中“ Ajax加载数据”,将时间设置为“ 2秒”,微信公众号文章正文采集步骤5注意: AJAX是延迟加载和异步更新的脚本通过在后台与服务器进行少量数据交换的技术,可以在不重新加载整个网页的情况下更新网页的特定部分. 性能特点: 当您单击网页中的一个选项时,大多数网站的URL不会更改. b. 该网页未完全加载,仅部分加载了数据并进行了更改. 验证方法: 单击该操作后,URL输入栏将不会在浏览器的加载状态或转弯状态下显示. 观察该网页,我们发现单击“加载更多内容” 5次后,页面将加载到底部,总共显示100条文章. 因此,我们将整个“循环旋转”步骤设置为执行5次. 选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,将循环数设置为“ 5”,单击“确定”,微信公众号文章正文采集步骤6第3步: 创建一个列表循环并提取数据HYPERLINK“ / article / javascript :;”移动鼠标,然后选择页面上的第一个文章链接.
系统将自动识别相似的链接. 在操作提示框中,选择“全选”微信公众号文章正文采集步骤7,选择“单击每个链接”,微信公众号文章正文采集步骤8,系统将自动进入文章明细页面. 单击要采集的字段(在此处单击文章标题),然后在操作提示框中选择“采集此元素的文本”. 文章发布时间和文章来源字段的采集方法与微信公众号文章正文采集步骤9相同. 接下来,将采集文章正文. 首先点击文章正文的第一段,系统会自动识别页面中的相似元素,选择“全选”微信公众号文章正文采集步骤105),可以看到所有正文段落均被选中并转绿色. 选择“采集以下元素文本”微信公众号文章正文采集步骤11注意: 在字段表中,您可以自定义字段以修改微信公众号文章正文采集步骤126)上述操作之后,正文将全部采集的(默认是文本的每个段落都是一个单元格). 一般来说,我们希望将采集的文本合并到同一单元格中. 单击“自定义数据字段”按钮,选择“自定义数据合并方法”,选中“多次提取并将同一字段合并到一行,即,追加到同一字段,例如文本页面合并”,然后单击“确定”,微信公众号文章正文采集步骤13,“自定义数据字段”按钮选择“自定义数据合并方法”,微信公众号文章正文采集步骤14,微信公众号文章正文采集步骤如图15所示. : 修改Xpath1)选择整个“循环步骤”,打开“高级选项”,可以看到由彩云生成的默认值是固定元素列表,该列表定位了前20条微信公众号文章正文采集步骤162的链接)在Firefox中打开采集网页并观察源代码.
我们发现通过此Xpath: // DIV [@ class ='main-left'] / DIV [3] / UL / LI / DIV [2] / H3 [1] / A,在页面All中需要微信公众号文章正文采集步骤中有100条微信公众号文章,在步骤173)将修改后的Xpath复制并粘贴到优采云中显示的位置,然后单击“确定”,微信公众号文章正文采集步骤18步骤5 : 我们将继续观察流程图结构的修改. 5次单击“加载更多内容”后,此页面将加载所有100条文章. 因此,我们的配置规则的思想是首先建立一个翻页周期,加载全部100条文章,然后创建一个周期列表并提取数据1)选择整个``循环''步骤并将其拖出``循环''页面翻页”步骤. 如果您不执行此操作,将会有很多重复的数据. 微信公众号文章正文采集步骤19拖动完成后,如下图所示,微信公众号文章正文采集步骤20步骤6: 数据采集和导出1)单击左上角单击角上的“保存”,然后点击“开始采集”,选择“开始本地采集”,微信公众号文本采集步骤21. 采集完成后,弹出提示,选择“导出数据”,选择“适当的导出方式”,将采集的数据导出到微信公众号文章正文采集步骤223)这里我们选择excel作为导出格式. 数据导出后,如下图所示,微信公众号文章正文采集步骤23如上图所示,部分文章的正文未采集.
这是因为系统自动生成了文章正文的循环列表的Xpath: // [@ id =“ js_content”] / P,因此无法找到本文的正文. 将Xpath修改为: // [@@ =“ =” js_content“] // P,所有文章正文都可以位于微信公众号文章正文采集步骤23微信公众号文章正文采集步骤24说明: 本文的方法是仅适合采集搜狗微信文章正文内容. 无法在文本中采集图片. 如果需要采集图片,则需要在此过程中添加判断条件. 相关集合教程: 京东商品信息集合豆瓣电影简短评论集合58全市信息集合优采云-一个由70万用户选择的网络数据采集器. 1.操作简单,任何人都可以使用: 不需要技术背景,可以通过浏览Internet进行采集. 完全可视化该过程,单击鼠标以完成操作,您可以在2分钟内快速上手. 2.强大的功能,可以在任何网站上采集: 单击,登录,翻页,识别验证码,瀑布流,Ajax脚本异步加载数据页,所有这些都可以通过简单的设置进行采集. 3.云采集,也可以关闭. 配置采集任务后,可以将其关闭,并可以在云中执行该任务. 庞大的云采集集群不间断运行24 * 7,因此无需担心IP被阻塞和网络中断. 4.免费功能+增值服务,可以按需选择. 免费版具有所有功能,可以满足用户的基本采集需求. 同时,建立了一些增值服务(例如私有云)以满足高端付费企业用户的需求. 查看全部
优采云·云采集服务平台微信公众号文章文本采集教程很多时候,我们需要采集网页文章的文本. 本文以搜狗微信文章为例,介绍利用优采云采集网页正文的方法. 文章的正文通常包括文本和图片. 本文仅演示了在正文中采集文本的方法,图像采集将在另一个教程中进行讨论. 本文将采集以下字段: 文章标题,时间,来源和正文(正文中的所有文本都将合并到excel单元格中,并且将使用“自定义数据合并方法”功能,请注意). 以下是“自定义数据合并方法”的详细教程,您可以首先学习: /tutorialdetail-1/zdyhb_7.html集合网站: /使用功能点: 分页列表信息集合“ HYPERLINK” /tutorial/fylb-70.aspx ?t = 1“ /tutorial/fylb-70.aspx?t=1Xpath HYPERLINK” / search?query = XPath“ / search?query = XPathAJAX点击并翻页HYPERLINK” /tutorialdetail-1/ajaxdjfy_7.html“ / tutorialdetail- 1 / ajaxdjfy_7.html步骤1: 创建采集任务1)进入主界面,选择“自定义模式”微信公众号文章正文采集步骤12)复制要采集的URL并粘贴到网站输入框中,单击“保存”. URL”微信公众号2文本采集步骤2 HYPERLINK” / article / javascript :;”步骤2: 创建翻页循环在页面的右上角,打开“ Process”以显示“ Process Designer”和“ Customize Current Operation”的两个部分.
打开网页后,默认显示“热门”文章. 向下滚动页面,找到并单击“加载更多内容”按钮,在操作提示框中选择“更多操作”,微信公众号文章正文采集步骤3,选择“循环点击单个元素”,创建页面翻转循环微信公众号文章文本采集步骤4由于此网页涉及Ajax技术,因此我们需要设置一些高级选项. 选择“单击元素”步骤,打开“高级选项”,选中“ Ajax加载数据”,将时间设置为“ 2秒”,微信公众号文章正文采集步骤5注意: AJAX是延迟加载和异步更新的脚本通过在后台与服务器进行少量数据交换的技术,可以在不重新加载整个网页的情况下更新网页的特定部分. 性能特点: 当您单击网页中的一个选项时,大多数网站的URL不会更改. b. 该网页未完全加载,仅部分加载了数据并进行了更改. 验证方法: 单击该操作后,URL输入栏将不会在浏览器的加载状态或转弯状态下显示. 观察该网页,我们发现单击“加载更多内容” 5次后,页面将加载到底部,总共显示100条文章. 因此,我们将整个“循环旋转”步骤设置为执行5次. 选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,将循环数设置为“ 5”,单击“确定”,微信公众号文章正文采集步骤6第3步: 创建一个列表循环并提取数据HYPERLINK“ / article / javascript :;”移动鼠标,然后选择页面上的第一个文章链接.
系统将自动识别相似的链接. 在操作提示框中,选择“全选”微信公众号文章正文采集步骤7,选择“单击每个链接”,微信公众号文章正文采集步骤8,系统将自动进入文章明细页面. 单击要采集的字段(在此处单击文章标题),然后在操作提示框中选择“采集此元素的文本”. 文章发布时间和文章来源字段的采集方法与微信公众号文章正文采集步骤9相同. 接下来,将采集文章正文. 首先点击文章正文的第一段,系统会自动识别页面中的相似元素,选择“全选”微信公众号文章正文采集步骤105),可以看到所有正文段落均被选中并转绿色. 选择“采集以下元素文本”微信公众号文章正文采集步骤11注意: 在字段表中,您可以自定义字段以修改微信公众号文章正文采集步骤126)上述操作之后,正文将全部采集的(默认是文本的每个段落都是一个单元格). 一般来说,我们希望将采集的文本合并到同一单元格中. 单击“自定义数据字段”按钮,选择“自定义数据合并方法”,选中“多次提取并将同一字段合并到一行,即,追加到同一字段,例如文本页面合并”,然后单击“确定”,微信公众号文章正文采集步骤13,“自定义数据字段”按钮选择“自定义数据合并方法”,微信公众号文章正文采集步骤14,微信公众号文章正文采集步骤如图15所示. : 修改Xpath1)选择整个“循环步骤”,打开“高级选项”,可以看到由彩云生成的默认值是固定元素列表,该列表定位了前20条微信公众号文章正文采集步骤162的链接)在Firefox中打开采集网页并观察源代码.
我们发现通过此Xpath: // DIV [@ class ='main-left'] / DIV [3] / UL / LI / DIV [2] / H3 [1] / A,在页面All中需要微信公众号文章正文采集步骤中有100条微信公众号文章,在步骤173)将修改后的Xpath复制并粘贴到优采云中显示的位置,然后单击“确定”,微信公众号文章正文采集步骤18步骤5 : 我们将继续观察流程图结构的修改. 5次单击“加载更多内容”后,此页面将加载所有100条文章. 因此,我们的配置规则的思想是首先建立一个翻页周期,加载全部100条文章,然后创建一个周期列表并提取数据1)选择整个``循环''步骤并将其拖出``循环''页面翻页”步骤. 如果您不执行此操作,将会有很多重复的数据. 微信公众号文章正文采集步骤19拖动完成后,如下图所示,微信公众号文章正文采集步骤20步骤6: 数据采集和导出1)单击左上角单击角上的“保存”,然后点击“开始采集”,选择“开始本地采集”,微信公众号文本采集步骤21. 采集完成后,弹出提示,选择“导出数据”,选择“适当的导出方式”,将采集的数据导出到微信公众号文章正文采集步骤223)这里我们选择excel作为导出格式. 数据导出后,如下图所示,微信公众号文章正文采集步骤23如上图所示,部分文章的正文未采集.
这是因为系统自动生成了文章正文的循环列表的Xpath: // [@ id =“ js_content”] / P,因此无法找到本文的正文. 将Xpath修改为: // [@@ =“ =” js_content“] // P,所有文章正文都可以位于微信公众号文章正文采集步骤23微信公众号文章正文采集步骤24说明: 本文的方法是仅适合采集搜狗微信文章正文内容. 无法在文本中采集图片. 如果需要采集图片,则需要在此过程中添加判断条件. 相关集合教程: 京东商品信息集合豆瓣电影简短评论集合58全市信息集合优采云-一个由70万用户选择的网络数据采集器. 1.操作简单,任何人都可以使用: 不需要技术背景,可以通过浏览Internet进行采集. 完全可视化该过程,单击鼠标以完成操作,您可以在2分钟内快速上手. 2.强大的功能,可以在任何网站上采集: 单击,登录,翻页,识别验证码,瀑布流,Ajax脚本异步加载数据页,所有这些都可以通过简单的设置进行采集. 3.云采集,也可以关闭. 配置采集任务后,可以将其关闭,并可以在云中执行该任务. 庞大的云采集集群不间断运行24 * 7,因此无需担心IP被阻塞和网络中断. 4.免费功能+增值服务,可以按需选择. 免费版具有所有功能,可以满足用户的基本采集需求. 同时,建立了一些增值服务(例如私有云)以满足高端付费企业用户的需求.
欢迎老朋友开发php微信公众号
采集交流 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2020-08-06 06:06
更新: 2018年10月20日09:38:44转载作者: dq_095
本文主要详细介绍php微信公众号的开发,欢迎老朋友,它具有一定的参考价值,有兴趣的朋友可以参考
本文中的示例共享了由php微信公众号开发的欢迎老朋友的特定代码,供您参考. 具体内容如下
数据库简介
关键代码如下:
$postObj = simplexml_load_string($postStr, 'SimpleXMLElement', LIBXML_NOCDATA);
$fromUsername = $postObj->FromUserName;
$toUsername = $postObj->ToUserName;
$keyword = trim($postObj->Content);
$time = time();
$textTpl = "
%s
0
";
if(!empty( $keyword ))
{
//用 户 名 : $user
//密 码 : $pwd
//主库域名 : $host
//从库域名 : SAE_MYSQL_HOST_S
//端 口 : $port
//数据库名 : $dbname
$dbname = "app_dq095";
$host = "w.rdc.sae.sina.com.cn";
$port = "3306";
$user = "4k514n103z";
$pwd = "2402314li2j1i5im1xy2xizj5y332w2x41k2z203";
/*接着调用mysql_connect()连接服务器*/
// 连主库
$db = mysql_connect($host,$user,$pwd);
if(!$db){
die("Connect Server Failed: " . mysql_error($db));
}
/*连接成功后立即调用mysql_select_db()选中需要连接的数据库*/
if (!mysql_select_db($dbname)) {
die("Select Database Failed: " . mysql_error($db));
}
mysql_query("set names utf-8",$db);
/*至此连接已完全建立,就可对当前数据库进行相应的操作了*/
/*!!!注意,无法再通过本次连接调用mysql_select_db来切换到其它数据库了!!!*/
/* 需要再连接其它数据库,请再使用mysql_connect+mysql_select_db启动另一个连接*/
/**
* 接下来就可以使用其它标准php mysql函数操作进行数据库操作
*/
$sql="SELECT * FROM `welcome`WHERE `user`= '" . iconv("UTF-8","GBK",$fromUsername) . "'";
$query=mysql_query($sql);
$rs=mysql_fetch_array($query);
$b= $rs['user'];
$c=iconv("GBK","UTF-8",$b);
$msgType = "text";
if ($c==$fromUsername)
{
$contentStr = "欢迎老朋友!";
}else{
$sql="INSERT INTO `welcome`(`id`,`user`) VALUES (NULL,'{$fromUsername}')";
mysql_query($sql);
$contentStr = "欢迎新朋友!";
}
$resultStr = sprintf($textTpl, $fromUsername, $toUsername, $time, $msgType, $contentStr);
echo $resultStr;
mysql_close($db);
}else{
echo "Input something...";
}
index.php代码如下 查看全部
欢迎老朋友开发php微信公众号
更新: 2018年10月20日09:38:44转载作者: dq_095
本文主要详细介绍php微信公众号的开发,欢迎老朋友,它具有一定的参考价值,有兴趣的朋友可以参考
本文中的示例共享了由php微信公众号开发的欢迎老朋友的特定代码,供您参考. 具体内容如下
数据库简介

关键代码如下:
$postObj = simplexml_load_string($postStr, 'SimpleXMLElement', LIBXML_NOCDATA);
$fromUsername = $postObj->FromUserName;
$toUsername = $postObj->ToUserName;
$keyword = trim($postObj->Content);
$time = time();
$textTpl = "
%s
0
";
if(!empty( $keyword ))
{
//用 户 名 : $user
//密 码 : $pwd
//主库域名 : $host
//从库域名 : SAE_MYSQL_HOST_S
//端 口 : $port
//数据库名 : $dbname
$dbname = "app_dq095";
$host = "w.rdc.sae.sina.com.cn";
$port = "3306";
$user = "4k514n103z";
$pwd = "2402314li2j1i5im1xy2xizj5y332w2x41k2z203";
/*接着调用mysql_connect()连接服务器*/
// 连主库
$db = mysql_connect($host,$user,$pwd);
if(!$db){
die("Connect Server Failed: " . mysql_error($db));
}
/*连接成功后立即调用mysql_select_db()选中需要连接的数据库*/
if (!mysql_select_db($dbname)) {
die("Select Database Failed: " . mysql_error($db));
}
mysql_query("set names utf-8",$db);
/*至此连接已完全建立,就可对当前数据库进行相应的操作了*/
/*!!!注意,无法再通过本次连接调用mysql_select_db来切换到其它数据库了!!!*/
/* 需要再连接其它数据库,请再使用mysql_connect+mysql_select_db启动另一个连接*/
/**
* 接下来就可以使用其它标准php mysql函数操作进行数据库操作
*/
$sql="SELECT * FROM `welcome`WHERE `user`= '" . iconv("UTF-8","GBK",$fromUsername) . "'";
$query=mysql_query($sql);
$rs=mysql_fetch_array($query);
$b= $rs['user'];
$c=iconv("GBK","UTF-8",$b);
$msgType = "text";
if ($c==$fromUsername)
{
$contentStr = "欢迎老朋友!";
}else{
$sql="INSERT INTO `welcome`(`id`,`user`) VALUES (NULL,'{$fromUsername}')";
mysql_query($sql);
$contentStr = "欢迎新朋友!";
}
$resultStr = sprintf($textTpl, $fromUsername, $toUsername, $time, $msgType, $contentStr);
echo $resultStr;
mysql_close($db);
}else{
echo "Input something...";
}
index.php代码如下
微信公众号文章搜寻器系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2020-08-06 04:04
1. 我做了两个履带. 第一次我害怕Phoenix.com时,没有任何限制,我可以随意爬网,所以我放松了对自动代码执行模块的警惕. 我认为这很简单,但事实并非如此. 我已经为这个问题困扰了好几天,几乎是四天. 由于搜狗的限制,获得相同IP的次数越来越多. 首先,显示验证码,其次是访问限制. 直接无法访问. 根据请求,您得到的是访问次数太频繁,这种提示,因此在开发过程中最麻烦的不是代码的编写,而是测试. 编写后无法立即测试该代码. 我相信大多数程序员都不会喜欢,我现在编写的程序每天执行3次. 这样的频率很好,并且因为它是由多个正式帐户采集的,所以每个正式帐户之间也要有一个间隔,否则它将同时访问十多个公众,该帐户上的数百篇文章也是不现实的. 在插入句子时,如何使每个正式帐户都不敢玩,等待特定的时间段,执行下一个,最后使用setInterval函数来解决它,
每80秒执行一个正式帐户,并将每个执行代码写入hello. 泡沫距离有点远. 我会收到的. 我们来谈谈cron程序包,它是自动执行的. npm官方网站上仅举了一个例子,但是我的意思是桑拿浴可能有点压抑. 我无法播放,但了解其用法. 然后我说,如果我听不懂怎么办. 在Internet,百度和cron程序包的特定用法上进行搜索. 有很多,所以我只是看了看,但是经过仔细的分析却并非如此. 都是废话,没用. 一般在线使用中都有一个问号,但是当我添加一个问号时,会出现错误. 是的,这都是胡说八道. 最后,我在同学小组的一个前端技术讨论小组中说了这一点. 真正热情的小组朋友找到了我一个链接. 我进去看看,尝试了一下,没关系,所以,非常感谢这位帮助我解决难题的同学. 我将再次附上QQ群组号码和链接,以帮助您在阅读本文时学习. QQ组号: 435012561,链接: ,链接说的没问题,至少可以用,这里我仍然有一个问题,就是时区,我们以前用过一次,使用洛杉矶时间,但是这次显然不起作用,我们需要用中文,但是我在北京尝试了几次,虽然不好,但是重庆可以,所以我用了重庆.
2. 我想在这里谈论的是从地址栏获取参数的问题. 我做的最后一个很好,但是我不知道该怎么做. 我从地址栏中得到的最后一个是数字,但是这个是它的. 它是一个字符串,并且mongodb中对字段的要求仍然非常严格,因此分页功能困扰了我几个小时. 它是如何解决的?我在mongodb中添加了一个讨论组. 我问其中有什么问题,并发布了屏幕截图. 有一个热心的网民说,传入数据的格式显然不正确. 我唤醒了做梦者,我说了是,然后我使用Number()函数来处理我得到的参数,以便字符串类型的数量成为数字类型的数量. 很好,因此在使用mongodb时,必须注意存储数据的格式.
3. Mongodb查询数据语句的组织:
坦率地说,实际上是使用了限制和跳过这两个函数,但是特定的格式可能是乐观的,并且mine是可接受的参数,但是mongo的参数接受很容易直接编写,不需要喜欢sql像$ {“”}一样. 下面的排序功能说明了排序方法. 这里,ctime字段设置为标准,-1表示逆序,1表示正序,
4. 在这段代码编写中,我第一次使用了try catch方法进行纠错. 原来没关系. 偶尔的错误可以正常地打印出来,但是它不会影响代码的整体执行,或者说到下一次执行,整体感觉非常好,
对于特定用法,将您要执行的代码放入try中,并在最后添加一行,并抛出Error();
然后传入参数e以进行捕获,可以在catch中打印很多消息,我只打印了其中之一,例如e.message
5. anync包主要用于此编码过程中,其中的ansyc.each循环,ansyc.waterfall在执行完上述操作后可以执行以下操作,也可以在您之间的上下传递参数,这非常重要的是,因为在此编程中,每次获取的内容都不同,每个代码执行的条件也不同,也就是说,所需的参数也不同,即,下一个代码执行可能需要上一个代码. 执行,所以这个anync软件包真的值得研究. 他的每种方法都不相同,有时可能会得到意想不到的结果.
6. 在mysql中,如果要实现这样的效果,即如果它已经存在于数据库中,则忽略它,或者不重复存储它;如果它不存在于数据库中,则将其存储在其中. 用replace替换插入数据的插入. 但是在mongodb中,应该没有,或者我还没有找到它. 我用这种方法解决了. 我定义了一个开关来使该开关为真. 在每次存储之前,循环所有数据以查看是否有该数据,如果没有,则让开关变为假,否则,继续执行,即判断此时开关是真还是假,如果为true,则执行插入操作;如果为false,则将其忽略. 这样可以达到类似的效果,否则每次都会存储大量重复数据,
7. 该集合的核心是我文件中的common.js. 首先,因为我们要采集,所以我们需要使用请求包. 采集后,我们需要以html格式处理数据,以便可以使用类似于jquery的数据. 对于该操作,cheerio包已使用了很长时间,然后在循环采集时将使用anync.each方法,因此将使用异步包,
7-1,
通过采集搜狗微信,我们必须分析搜狗微信的路径. 每个官方帐户页面的路径都是这样
%E8%BF%99%E6%89%8D%E6%98%AF%E6%97%A5%E6%9C%AC&ie = utf8&_sug_ = n&_sug_type _ =
这是“这是日本”页面的链接. 经过分析,所有正式帐户的链接仅在查询后的参数上有所不同,但是查询后的参数是什么,实际上,它是由encodeURIComponent()函数转换的,之后是“这是日本”,因此相同. 要获得该官方帐户,只需对官方帐户的名称进行编码并将其动态组合成一个链接,您就可以在访问时输入每个链接,但是我只是要求此页面此链接,
不是
此页面,因此进一步的处理是获取当前页面的第一内容的链接,即href
获得此链接后,您会发现他具有自己的加密方法. 实际上非常简单,就是在链接中增加三个安培;更换这三个放大器;在带有空链接的链接中,就好了,这是第一步,获取每个官方帐户的页面链接,
7-2
获取链接后,有必要访问,即请求,请求每个地址,获取每个地址的内容,但每个页面上显示的内容不在该页面中,即在html结构中,隐藏在js中,因此我们需要通过常规匹配来获取每篇文章的对象,然后循环访问每个正式帐户的对象以获取有关该对象中每篇文章的一些信息,包括标题,缩略图,摘要,URL,时间, 5个字段,但我使用的代码很烂,而我当时使用的是
Object.Attribute.foreach(function(item,index){
})
这种可怕的方法,最后要做的就是编写一个循环以完全获取每个对象,否则只能获取第一个对象. 在这里,您应该使用async.each或async.foreach. 可以使用两种方法中的每一种,并且它们都非常易于使用. 这样,您将获得上述每篇文章的基本新闻.
7-3,
第三阶段是进入每篇文章的详细信息页面,并获取每篇文章的内容,喜欢的次数,作者,官方帐号,阅读量和其他数据. 这里遇到的主要问题是人们的内容直接位于js中,并且所有img标签都有问题. 它们以这种形式存储在内容中,但是在这种情况下,由于标签,html文档(我不知道此类img标签)存在问题,此类图像无法显示在我们的网页上,因此在这里我们需要进行一些处理,替换全部与
查看全部
已经快两个星期了. 我已经在微信公众号上调试了商品搜寻器系统,最后一切都很好,但是在此期间,我遇到了很多问题. 让我们今天回顾一下并进行总结. 我希望它会有用. 朋友可以学习.
1. 我做了两个履带. 第一次我害怕Phoenix.com时,没有任何限制,我可以随意爬网,所以我放松了对自动代码执行模块的警惕. 我认为这很简单,但事实并非如此. 我已经为这个问题困扰了好几天,几乎是四天. 由于搜狗的限制,获得相同IP的次数越来越多. 首先,显示验证码,其次是访问限制. 直接无法访问. 根据请求,您得到的是访问次数太频繁,这种提示,因此在开发过程中最麻烦的不是代码的编写,而是测试. 编写后无法立即测试该代码. 我相信大多数程序员都不会喜欢,我现在编写的程序每天执行3次. 这样的频率很好,并且因为它是由多个正式帐户采集的,所以每个正式帐户之间也要有一个间隔,否则它将同时访问十多个公众,该帐户上的数百篇文章也是不现实的. 在插入句子时,如何使每个正式帐户都不敢玩,等待特定的时间段,执行下一个,最后使用setInterval函数来解决它,
每80秒执行一个正式帐户,并将每个执行代码写入hello. 泡沫距离有点远. 我会收到的. 我们来谈谈cron程序包,它是自动执行的. npm官方网站上仅举了一个例子,但是我的意思是桑拿浴可能有点压抑. 我无法播放,但了解其用法. 然后我说,如果我听不懂怎么办. 在Internet,百度和cron程序包的特定用法上进行搜索. 有很多,所以我只是看了看,但是经过仔细的分析却并非如此. 都是废话,没用. 一般在线使用中都有一个问号,但是当我添加一个问号时,会出现错误. 是的,这都是胡说八道. 最后,我在同学小组的一个前端技术讨论小组中说了这一点. 真正热情的小组朋友找到了我一个链接. 我进去看看,尝试了一下,没关系,所以,非常感谢这位帮助我解决难题的同学. 我将再次附上QQ群组号码和链接,以帮助您在阅读本文时学习. QQ组号: 435012561,链接: ,链接说的没问题,至少可以用,这里我仍然有一个问题,就是时区,我们以前用过一次,使用洛杉矶时间,但是这次显然不起作用,我们需要用中文,但是我在北京尝试了几次,虽然不好,但是重庆可以,所以我用了重庆.
2. 我想在这里谈论的是从地址栏获取参数的问题. 我做的最后一个很好,但是我不知道该怎么做. 我从地址栏中得到的最后一个是数字,但是这个是它的. 它是一个字符串,并且mongodb中对字段的要求仍然非常严格,因此分页功能困扰了我几个小时. 它是如何解决的?我在mongodb中添加了一个讨论组. 我问其中有什么问题,并发布了屏幕截图. 有一个热心的网民说,传入数据的格式显然不正确. 我唤醒了做梦者,我说了是,然后我使用Number()函数来处理我得到的参数,以便字符串类型的数量成为数字类型的数量. 很好,因此在使用mongodb时,必须注意存储数据的格式.
3. Mongodb查询数据语句的组织:
坦率地说,实际上是使用了限制和跳过这两个函数,但是特定的格式可能是乐观的,并且mine是可接受的参数,但是mongo的参数接受很容易直接编写,不需要喜欢sql像$ {“”}一样. 下面的排序功能说明了排序方法. 这里,ctime字段设置为标准,-1表示逆序,1表示正序,
4. 在这段代码编写中,我第一次使用了try catch方法进行纠错. 原来没关系. 偶尔的错误可以正常地打印出来,但是它不会影响代码的整体执行,或者说到下一次执行,整体感觉非常好,
对于特定用法,将您要执行的代码放入try中,并在最后添加一行,并抛出Error();
然后传入参数e以进行捕获,可以在catch中打印很多消息,我只打印了其中之一,例如e.message
5. anync包主要用于此编码过程中,其中的ansyc.each循环,ansyc.waterfall在执行完上述操作后可以执行以下操作,也可以在您之间的上下传递参数,这非常重要的是,因为在此编程中,每次获取的内容都不同,每个代码执行的条件也不同,也就是说,所需的参数也不同,即,下一个代码执行可能需要上一个代码. 执行,所以这个anync软件包真的值得研究. 他的每种方法都不相同,有时可能会得到意想不到的结果.
6. 在mysql中,如果要实现这样的效果,即如果它已经存在于数据库中,则忽略它,或者不重复存储它;如果它不存在于数据库中,则将其存储在其中. 用replace替换插入数据的插入. 但是在mongodb中,应该没有,或者我还没有找到它. 我用这种方法解决了. 我定义了一个开关来使该开关为真. 在每次存储之前,循环所有数据以查看是否有该数据,如果没有,则让开关变为假,否则,继续执行,即判断此时开关是真还是假,如果为true,则执行插入操作;如果为false,则将其忽略. 这样可以达到类似的效果,否则每次都会存储大量重复数据,
7. 该集合的核心是我文件中的common.js. 首先,因为我们要采集,所以我们需要使用请求包. 采集后,我们需要以html格式处理数据,以便可以使用类似于jquery的数据. 对于该操作,cheerio包已使用了很长时间,然后在循环采集时将使用anync.each方法,因此将使用异步包,
7-1,
通过采集搜狗微信,我们必须分析搜狗微信的路径. 每个官方帐户页面的路径都是这样
%E8%BF%99%E6%89%8D%E6%98%AF%E6%97%A5%E6%9C%AC&ie = utf8&_sug_ = n&_sug_type _ =
这是“这是日本”页面的链接. 经过分析,所有正式帐户的链接仅在查询后的参数上有所不同,但是查询后的参数是什么,实际上,它是由encodeURIComponent()函数转换的,之后是“这是日本”,因此相同. 要获得该官方帐户,只需对官方帐户的名称进行编码并将其动态组合成一个链接,您就可以在访问时输入每个链接,但是我只是要求此页面此链接,
不是
此页面,因此进一步的处理是获取当前页面的第一内容的链接,即href
获得此链接后,您会发现他具有自己的加密方法. 实际上非常简单,就是在链接中增加三个安培;更换这三个放大器;在带有空链接的链接中,就好了,这是第一步,获取每个官方帐户的页面链接,
7-2
获取链接后,有必要访问,即请求,请求每个地址,获取每个地址的内容,但每个页面上显示的内容不在该页面中,即在html结构中,隐藏在js中,因此我们需要通过常规匹配来获取每篇文章的对象,然后循环访问每个正式帐户的对象以获取有关该对象中每篇文章的一些信息,包括标题,缩略图,摘要,URL,时间, 5个字段,但我使用的代码很烂,而我当时使用的是
Object.Attribute.foreach(function(item,index){
})
这种可怕的方法,最后要做的就是编写一个循环以完全获取每个对象,否则只能获取第一个对象. 在这里,您应该使用async.each或async.foreach. 可以使用两种方法中的每一种,并且它们都非常易于使用. 这样,您将获得上述每篇文章的基本新闻.
7-3,
第三阶段是进入每篇文章的详细信息页面,并获取每篇文章的内容,喜欢的次数,作者,官方帐号,阅读量和其他数据. 这里遇到的主要问题是人们的内容直接位于js中,并且所有img标签都有问题. 它们以这种形式存储在内容中,但是在这种情况下,由于标签,html文档(我不知道此类img标签)存在问题,此类图像无法显示在我们的网页上,因此在这里我们需要进行一些处理,替换全部与
如何在搜狗微信公众号上采集热门文章. docx 18页
采集交流 • 优采云 发表了文章 • 0 个评论 • 455 次浏览 • 2020-08-06 00:00
下拉页面,找到并单击“加载更多内容”按钮,在操作提示框中选择“更多操作”搜狗微信公众号热门文章如何采集图2选择“循环单击单个元素”创建一个页面翻阅周期如何在搜狗微信公众号上采集热门文章图3由于此页面涉及Ajax技术,因此我们需要设置一些高级选项. 选择“单击元素”步骤,打开“高级选项”,选中“ Ajax加载数据”,将时间设置为“ 2秒”. 如何在搜狗微信公众号上采集热门文章图4注意: AJAX表示延迟加载和异步更新. 这种脚本技术通过在后台与服务器进行少量数据交换,可以更新网页的特定部分,而无需重新加载整个网页. 性能特点: 当您单击网页中的一个选项时,大多数网站的URL不会更改. b. 该网页未完全加载,仅部分加载了数据并进行了更改. 验证方法: 单击该操作后,URL输入栏将不会在浏览器的加载状态或转弯状态下显示. 观察该网页,我们发现单击“加载更多内容” 5次后,页面将加载到底部,总共显示100条文章. 因此,我们将整个“循环旋转”步骤设置为执行5次. 选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,将循环数设置为等于“ 5次”,然后单击“确定”. 搜狗微信公众号图5步骤3: 创建列表循环并提取数据HYPERLINK“ / article / javascript :;” 1)移动鼠标以选择页面上第一篇文章的框.
系统将识别此块中的子元素. 在操作提示框中,选择“选择子元素”. 如何在搜狗微信公众号上采集热门文章. 图62)继续在页面上选择第二篇文章的块,系统将第二篇文章中的子元素会被自动选择,页面上的其他10组相似元素也会被识别. 在操作提示框中,选择“全选”. 如何在搜狗微信公众号上采集热门文章. 图73)可以看到,页面上文章区域中的所有元素均已选中,并变为绿色. 在右侧的操作提示框中,将显示一个字段预览表. 将鼠标移到表格的顶部,然后单击垃圾箱图标以删除不必要的字段. 字段选择完成后,选择“采集以下数据”. 如何在搜狗微信公众号上采集热门文章. 图84)我们还希望采集每篇文章的URL,因此需要提取一个字段. 单击第一篇文章的链接,系统将自动在页面上选择一组文章链接. 在右侧的操作提示框中,选择“全选”如何在搜狗微信公众号上采集热门文章图95)选择“采集以下链接地址”如何在搜狗微信公众号上采集热门文章图106)选择后在字段中,选择相应的字段,您可以自定义字段的命名. 图11第4步: 修改Xpath让我们继续观察. 5次单击“加载更多内容”后,此页面将加载所有100条文章. 因此,我们的配置规则的思想是首先建立一个翻页周期,加载全部100条文章,然后创建一个周期列表并提取数据1)选择整个``循环''步骤并将其拖出``循环''翻页”步骤.
如果不执行此操作,将有很多重复的数据. 如何在搜狗微信公众号上采集热门文章图12拖动完成后,如下图所示,如何在搜狗微信公众号上采集热门文章图13在“列表循环”中“在此步骤中,循环的100篇文章列表. 选择整个“循环步骤”,打开“高级选项”,元素列表中的Xpath不会被固定: // BODY [@ id ='loginWrap'] / DIV [4] / DIV [1] / DIV [3] / UL [1] / LI,将其复制并粘贴到Firefox浏览器中的相应位置. 如何在搜狗微信公众号上采集热门文章图14 Xpath: 是一种路径查询语言,简而言之,它使用路径表达式来查找我们需要定位的数据,Xpath用于沿XML路径查找数据,但是Ucai云采集器中有一套针对HTML的Xpath引擎,因此您可以直接使用XPATH可以准确地在网页中查找和定位数据3)在Firefox浏览器中,我们通过以下Xpath发现: // BODY [@ id ='loginWrap'] / DIV [4] / DIV [1] / DIV [3] / UL [1] / LI,该页面上的页面有20篇文章,搜狗微信公众号,如何采集热门文章图154)将Xpath修改为: // BODY [@ id ='loginWrap'] / DIV / DIV [1] / DIV [3] / UL / LI,我们发现该页面上要采集的所有文章都位于搜狗微信公众号上. 热门文章如何采集图16中所示的Xpath: // BODY [@ id ='loginWrap'] / DIV / DIV [1] / DIV [3] / UL / LI,复制并粘贴到图片中所示的位置,然后单击“确定”,搜狗微信公众号热门文章如何采集图176)单击左上角的“保存并开始”,选择“开始本地采集”如何在搜狗微信公众号上采集热门文章”图18步骤5: 数据采集和导出采集完成后,将弹出提示,选择“导出数据”,选择“适当的导出方法”,并采集搜狗微信文章数据导出搜狗微信官方账号如何搜集热门文章图19在这里我们选择excel作为导出格式,数据导出后,下图显示了如何采集搜狗微信公众号热门文章: 图20优采云-70万用户选择的Web数据采集器.
1. 该操作很简单,任何人都可以使用: 不需要技术背景,并且可以通过浏览Internet进行采集. 完全可视化该过程,单击鼠标以完成操作,您可以在2分钟内快速上手. 2.强大的功能,可以在任何网站上采集: 单击,登录,翻页,识别验证码,瀑布流,Ajax脚本异步加载数据页,所有这些都可以通过简单的设置进行采集. 3.云采集,也可以关闭. 配置采集任务后,可以将其关闭,并可以在云中执行该任务. 庞大的云采集集群不间断运行24 * 7,因此无需担心IP被阻塞和网络中断. 4.免费功能+增值服务,可以按需选择. 免费版具有所有功能,可以满足用户的基本采集需求. 同时,建立了一些增值服务(例如私有云)以满足高端付费企业用户的需求. 查看全部
优采云·云采集服务平台优采云·云采集服务平台搜狗微信公众号如何采集热门文章本文介绍如何使用优采云来采集搜狗微信文章(以热门文章为例). 规则下载: 使用功能点: 寻呼列表信息采集HYPERLINK“ /tutorial/fylb-70.aspx?t=1” /tutorial/fylb-70.aspx?t=1Xpath HYPERLINK“ / search?query = XPath” / search? query = XPathAJAX单击并翻页HYPERLINK“ /tutorial/ajaxdjfy_7.aspx?t=1” /tutorial/ajaxdjfy_7.aspx?t=1相关的采集教程: 天猫商品信息采集百度搜索结果采集步骤1: 创建采集任务1)进入主界面,选择“自定义模式”如何在搜狗微信公众号上采集热门文章图12)复制要采集的URL到网站输入框中,单击“保存URL”如何在搜狗微信上采集热门文章官方帐户图2 HYPERLINK“ / article / javascript :;”第2步: 创建翻页循环. 在页面的右上角,打开“流程”以显示“流程设计器”和“自定义当前操作”的两个部分. 打开网页后,默认显示“热门”文章.
下拉页面,找到并单击“加载更多内容”按钮,在操作提示框中选择“更多操作”搜狗微信公众号热门文章如何采集图2选择“循环单击单个元素”创建一个页面翻阅周期如何在搜狗微信公众号上采集热门文章图3由于此页面涉及Ajax技术,因此我们需要设置一些高级选项. 选择“单击元素”步骤,打开“高级选项”,选中“ Ajax加载数据”,将时间设置为“ 2秒”. 如何在搜狗微信公众号上采集热门文章图4注意: AJAX表示延迟加载和异步更新. 这种脚本技术通过在后台与服务器进行少量数据交换,可以更新网页的特定部分,而无需重新加载整个网页. 性能特点: 当您单击网页中的一个选项时,大多数网站的URL不会更改. b. 该网页未完全加载,仅部分加载了数据并进行了更改. 验证方法: 单击该操作后,URL输入栏将不会在浏览器的加载状态或转弯状态下显示. 观察该网页,我们发现单击“加载更多内容” 5次后,页面将加载到底部,总共显示100条文章. 因此,我们将整个“循环旋转”步骤设置为执行5次. 选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,将循环数设置为等于“ 5次”,然后单击“确定”. 搜狗微信公众号图5步骤3: 创建列表循环并提取数据HYPERLINK“ / article / javascript :;” 1)移动鼠标以选择页面上第一篇文章的框.
系统将识别此块中的子元素. 在操作提示框中,选择“选择子元素”. 如何在搜狗微信公众号上采集热门文章. 图62)继续在页面上选择第二篇文章的块,系统将第二篇文章中的子元素会被自动选择,页面上的其他10组相似元素也会被识别. 在操作提示框中,选择“全选”. 如何在搜狗微信公众号上采集热门文章. 图73)可以看到,页面上文章区域中的所有元素均已选中,并变为绿色. 在右侧的操作提示框中,将显示一个字段预览表. 将鼠标移到表格的顶部,然后单击垃圾箱图标以删除不必要的字段. 字段选择完成后,选择“采集以下数据”. 如何在搜狗微信公众号上采集热门文章. 图84)我们还希望采集每篇文章的URL,因此需要提取一个字段. 单击第一篇文章的链接,系统将自动在页面上选择一组文章链接. 在右侧的操作提示框中,选择“全选”如何在搜狗微信公众号上采集热门文章图95)选择“采集以下链接地址”如何在搜狗微信公众号上采集热门文章图106)选择后在字段中,选择相应的字段,您可以自定义字段的命名. 图11第4步: 修改Xpath让我们继续观察. 5次单击“加载更多内容”后,此页面将加载所有100条文章. 因此,我们的配置规则的思想是首先建立一个翻页周期,加载全部100条文章,然后创建一个周期列表并提取数据1)选择整个``循环''步骤并将其拖出``循环''翻页”步骤.
如果不执行此操作,将有很多重复的数据. 如何在搜狗微信公众号上采集热门文章图12拖动完成后,如下图所示,如何在搜狗微信公众号上采集热门文章图13在“列表循环”中“在此步骤中,循环的100篇文章列表. 选择整个“循环步骤”,打开“高级选项”,元素列表中的Xpath不会被固定: // BODY [@ id ='loginWrap'] / DIV [4] / DIV [1] / DIV [3] / UL [1] / LI,将其复制并粘贴到Firefox浏览器中的相应位置. 如何在搜狗微信公众号上采集热门文章图14 Xpath: 是一种路径查询语言,简而言之,它使用路径表达式来查找我们需要定位的数据,Xpath用于沿XML路径查找数据,但是Ucai云采集器中有一套针对HTML的Xpath引擎,因此您可以直接使用XPATH可以准确地在网页中查找和定位数据3)在Firefox浏览器中,我们通过以下Xpath发现: // BODY [@ id ='loginWrap'] / DIV [4] / DIV [1] / DIV [3] / UL [1] / LI,该页面上的页面有20篇文章,搜狗微信公众号,如何采集热门文章图154)将Xpath修改为: // BODY [@ id ='loginWrap'] / DIV / DIV [1] / DIV [3] / UL / LI,我们发现该页面上要采集的所有文章都位于搜狗微信公众号上. 热门文章如何采集图16中所示的Xpath: // BODY [@ id ='loginWrap'] / DIV / DIV [1] / DIV [3] / UL / LI,复制并粘贴到图片中所示的位置,然后单击“确定”,搜狗微信公众号热门文章如何采集图176)单击左上角的“保存并开始”,选择“开始本地采集”如何在搜狗微信公众号上采集热门文章”图18步骤5: 数据采集和导出采集完成后,将弹出提示,选择“导出数据”,选择“适当的导出方法”,并采集搜狗微信文章数据导出搜狗微信官方账号如何搜集热门文章图19在这里我们选择excel作为导出格式,数据导出后,下图显示了如何采集搜狗微信公众号热门文章: 图20优采云-70万用户选择的Web数据采集器.
1. 该操作很简单,任何人都可以使用: 不需要技术背景,并且可以通过浏览Internet进行采集. 完全可视化该过程,单击鼠标以完成操作,您可以在2分钟内快速上手. 2.强大的功能,可以在任何网站上采集: 单击,登录,翻页,识别验证码,瀑布流,Ajax脚本异步加载数据页,所有这些都可以通过简单的设置进行采集. 3.云采集,也可以关闭. 配置采集任务后,可以将其关闭,并可以在云中执行该任务. 庞大的云采集集群不间断运行24 * 7,因此无需担心IP被阻塞和网络中断. 4.免费功能+增值服务,可以按需选择. 免费版具有所有功能,可以满足用户的基本采集需求. 同时,建立了一些增值服务(例如私有云)以满足高端付费企业用户的需求.
分析python如何抓取搜狗微信官方账号永久链接的想法
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2020-08-05 21:08
本文主要解释了这些想法,请自行解决代码部分
在搜狗微信上获取当天的信息排名
指定输入关键字并通过scrapy抢夺官方帐户
通过登录微信官方帐户链接获取Cookie信息
由于尚未解决对微信公众平台的模拟登录,因此需要手动登录以实时获取cookie信息
固定链接可以在此处转换
代码部分
def parse(self, response):
item = SougouItem()
item["title"] = response.xpath('//title/text()').extract_first()
print("**"*5, item["title"],"**"*5)
name = input("----------请输入需要搜索的信息:")
print(name)
url = "http://weixin.sogou.com/weixin ... ot%3B
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name":name})
搜狗微信访问频率太快,导致需要输入验证码 查看全部
本文主要介绍关于python如何抓取Sogou微信官方帐户的永久链接的思想分析. 编辑认为这是相当不错的. 现在,我将与您分享并提供参考. 让我们跟随编辑器看一下.
本文主要解释了这些想法,请自行解决代码部分
在搜狗微信上获取当天的信息排名
指定输入关键字并通过scrapy抢夺官方帐户
通过登录微信官方帐户链接获取Cookie信息
由于尚未解决对微信公众平台的模拟登录,因此需要手动登录以实时获取cookie信息


固定链接可以在此处转换
代码部分
def parse(self, response):
item = SougouItem()
item["title"] = response.xpath('//title/text()').extract_first()
print("**"*5, item["title"],"**"*5)
name = input("----------请输入需要搜索的信息:")
print(name)
url = "http://weixin.sogou.com/weixin ... ot%3B
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name":name})
搜狗微信访问频率太快,导致需要输入验证码
python-抓取微信官方帐户
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2020-08-07 22:07
我相信您有时会在面试期间遇到抓取微信官方帐户的问题. 当您最终有空时,您将参考老板的文章,我也开始抓取并分享微信官方帐户. 不要讨厌代码太低.
学习知识
博客参考:https://blog.csdn.net/xc_zhou/ ... 32587 先看一篇这个大佬的文章,理解一下微信公众号。
尝试抓取微信文章的朋友必须熟悉搜狗微信. 搜狗微信是腾讯提供的官方搜索引擎,专门用于搜索微信官方账号(不包括服务账号)发布的文章
搜狗微信链接:
爬网步骤如下: 第一步是创建您自己的官方帐户
创建正式帐户地址: #不会提及创建方法.
第二步是找到微信官方账号
第一步如图所示:
第二步如图所示:
第三步如图所示:
第四步如图所示:
以计算机视觉为例. 当然,您也可以选择其他参数,然后查看需要在请求中提交的参数.
第五步如图所示:
可以看到每个正式帐户都有一个falseid参数,访问每个正式帐户请求都需要该参数,请参阅步骤6.
第六步如图所示:
选择要爬网的文章,然后查看请求所需的参数.
第七步如图所示:
每个官方帐户的前五篇文章.
以上步骤是微信公众号文章的要求. 然后在分析之后使用代码来实现它. 如果您不了解上述分析,建议您参考以下文章:
https://blog.csdn.net/xc_zhou/ ... 32921
https://mp.weixin.qq.com/s%3F_ ... %23rd
代码如下 查看全部
原因
我相信您有时会在面试期间遇到抓取微信官方帐户的问题. 当您最终有空时,您将参考老板的文章,我也开始抓取并分享微信官方帐户. 不要讨厌代码太低.
学习知识
博客参考:https://blog.csdn.net/xc_zhou/ ... 32587 先看一篇这个大佬的文章,理解一下微信公众号。
尝试抓取微信文章的朋友必须熟悉搜狗微信. 搜狗微信是腾讯提供的官方搜索引擎,专门用于搜索微信官方账号(不包括服务账号)发布的文章
搜狗微信链接:
爬网步骤如下: 第一步是创建您自己的官方帐户
创建正式帐户地址: #不会提及创建方法.
第二步是找到微信官方账号
第一步如图所示:
第二步如图所示:
第三步如图所示:
第四步如图所示:
以计算机视觉为例. 当然,您也可以选择其他参数,然后查看需要在请求中提交的参数.
第五步如图所示:
可以看到每个正式帐户都有一个falseid参数,访问每个正式帐户请求都需要该参数,请参阅步骤6.
第六步如图所示:
选择要爬网的文章,然后查看请求所需的参数.
第七步如图所示:
每个官方帐户的前五篇文章.
以上步骤是微信公众号文章的要求. 然后在分析之后使用代码来实现它. 如果您不了解上述分析,建议您参考以下文章:
https://blog.csdn.net/xc_zhou/ ... 32921
https://mp.weixin.qq.com/s%3F_ ... %23rd
代码如下
微信公众号文章采集器系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 376 次浏览 • 2020-08-07 20:19
1. 我做了两个履带. 我第一次害怕Phoenix.com时,没有任何限制,我可以随意爬网,所以我放松了对自动代码执行模块的警惕. 我认为这很简单,但事实并非如此. 我已经为这个问题困扰了好几天,几乎是四天. 由于搜狗的限制,获得相同IP的次数越来越多. 首先,显示验证码,其次是访问限制. 直接无法访问. 根据请求,您得到的是访问次数太频繁,这种提示,因此在开发过程中最麻烦的不是代码的编写,而是测试. 编写后无法立即测试该代码. 我相信大多数程序员都不会喜欢,我现在编写的程序每天执行3次. 这样的频率很好,并且因为它是由多个官方帐户采集的,所以每个官方帐户之间也要有间隔,否则它将同时访问十多个公众,该帐户上的数百篇文章也不切实际. 在插入句子时,如何使每个正式帐户都不敢玩,等待特定的时间段,执行下一个,最后使用setInterval函数来解决它,
每80秒执行一个正式帐户,并将每个执行代码写入hello. 泡沫距离有点远. 我会收到的. 我们来谈谈cron程序包,它是自动执行的. npm官方网站上仅举了一个例子,但是我的意思是桑拿浴可能有点压抑. 我无法播放,但了解其用法. 然后我说,如果我听不懂怎么办. 在Internet,百度和cron程序包的特定用法上进行搜索. 有很多,所以我只是看了看,但是经过仔细的分析却并非如此. 都是废话,没用. 一般在线使用中都有一个问号,但是当我添加一个问号时,会出现错误. 是的,这都是胡说八道. 最后,我在同学小组的一个前端技术讨论小组中说了这一点. 真正热情的小组朋友找到了我一个链接. 我进去看看,尝试了一下,没关系,所以,非常感谢这位帮助我解决难题的同学. 我将再次附上QQ群组号码和链接,以帮助您在阅读本文时学习. QQ组号: 435012561,链接: ,链接说的没问题,至少可以用,这里我仍然有一个问题,就是时区,我们以前用过一次,使用洛杉矶时间,但是这次显然不起作用,我们需要用中文,但是我在北京尝试了几次,虽然不好,但是重庆可以,所以我用了重庆.
2. 我想在这里谈论的是从地址栏获取参数的问题. 我做的最后一个很好,但是我不知道该怎么做. 我从地址栏中得到的最后一个是数字,但是这个是它的. 它是一个字符串,并且mongodb中对字段的要求仍然非常严格,因此分页功能困扰了我几个小时. 它是如何解决的?我在mongodb中添加了一个讨论组. 我问其中有什么问题,并发布了屏幕截图. 有一个热心的网民说,传入数据的格式显然不正确. 我唤醒了做梦者,我说了是,然后我使用Number()函数来处理我得到的参数,以便字符串类型的数量成为数字类型的数量. 很好,因此在使用mongodb时,必须注意存储数据的格式.
3. Mongodb查询数据语句的组织:
坦率地说,实际上是使用了限制和跳过这两个函数,但是特定的格式可能是乐观的,并且mine是可接受的参数,但是mongo的参数接受很容易直接编写,不需要喜欢sql像$ {“”}一样. 下面的排序功能说明了排序方法. 这里,ctime字段设置为标准,-1表示逆序,1表示正序,
4. 在这段代码编写中,我第一次使用了try catch方法进行纠错. 原来没关系. 偶尔的错误可以正常地打印出来,但是它不会影响代码的整体执行,或者说到下一次执行,整体感觉非常好,
对于特定用法,将您要执行的代码放入try中,并在最后添加一行,并抛出Error();
然后传入参数e以进行捕获,可以在catch中打印很多消息,我只打印了其中之一,例如e.message
5. anync包主要用于此编码过程中,其中的ansyc.each循环,ansyc.waterfall在执行完上述操作后可以执行以下操作,也可以在您之间的上下传递参数,这非常重要的是,因为在此编程中,每次获取的内容都不同,每个代码执行的条件也不同,也就是说,所需的参数也不同,即,下一个代码执行可能需要上一个代码. 执行,所以这个anync软件包真的值得研究. 他的每种方法都不相同,有时可能会得到意想不到的结果.
6. 在mysql中,如果要实现这样的效果,即如果它已经存在于数据库中,则忽略它,或者不重复存储它;如果它不存在于数据库中,则将其存储在其中. 用replace替换插入数据的插入. 但是在mongodb中,应该没有,或者我还没有找到它. 我用这种方法解决了. 我定义了一个开关来使该开关为真. 在每次存储之前,循环所有数据以查看是否有该数据,如果没有,则让开关变为假,否则,继续执行,即判断此时开关是真还是假,如果为true,则执行插入操作;如果为false,则将其忽略. 这样可以达到类似的效果,否则每次都会存储大量重复数据,
7. 该集合的核心是我文件中的common.js. 首先,因为我们要采集,所以我们需要使用请求包. 采集后,我们需要以html格式处理数据,以便可以使用类似于jquery的数据. 对于该操作,cheerio包已使用了很长时间,然后在循环采集时将使用anync.each方法,因此将使用异步包,
7-1,
通过采集搜狗微信,我们必须分析搜狗微信的路径. 每个官方帐户页面的路径都是这样
%E8%BF%99%E6%89%8D%E6%98%AF%E6%97%A5%E6%9C%AC&ie = utf8&_sug_ = n&_sug_type _ =
这是“这是日本”页面的链接. 经过分析,所有正式帐户的链接仅在查询后的参数上有所不同,但是查询后的参数是什么,实际上,它是由encodeURIComponent()函数转换的,之后是“这是日本”,因此相同. 要获得该官方帐户,只需对官方帐户的名称进行编码并将其动态组合成一个链接,您就可以在访问时输入每个链接,但是我只是要求此页面此链接,
不是
此页面,因此进一步的处理是获取当前页面的第一内容的链接,即href
获得此链接后,您会发现他具有自己的加密方法. 实际上非常简单,就是在链接中增加三个安培;更换这三个放大器;在带有空链接的链接中,就好了,这是第一步,获取每个官方帐户的页面链接,
7-2
获取链接后,有必要访问,即请求,请求每个地址,获取每个地址的内容,但每个页面上显示的内容不在该页面中,即在html结构中,隐藏在js中,因此我们需要通过常规匹配来获取每篇文章的对象,然后循环访问每个正式帐户的对象以获取有关该对象中每篇文章的一些信息,包括标题,缩略图,摘要,URL,时间, 5个字段,但我使用的代码很烂,而我当时使用的是
Object.Attribute.foreach(function(item,index){
})
这种可怕的方法,最后要做的就是编写一个循环以完全获取每个对象,否则只能获取第一个对象. 在这里,您应该使用async.each或async.foreach. 可以使用两种方法中的每一种,并且它们都非常易于使用. 这样,您将获得上述每篇文章的基本新闻.
7-3,
第三阶段是进入每篇文章的详细信息页面,并获取每篇文章的内容,喜欢的次数,作者,官方帐号,阅读量和其他数据. 这里遇到的主要问题是人们的内容直接位于js中,并且所有img标签都有问题. 它们以这种形式存储在内容中,但是在这种情况下,由于标签,html文档(我不知道此类img标签)存在问题,此类图像无法显示在我们的网页上,因此在这里我们需要进行一些处理,替换全部与
查看全部
已经快两个星期了. 我已经在微信公众号上调试了商品采集器系统,最后一切都很好,但是在此期间,我遇到了很多问题. 让我们今天回顾一下并进行总结. 我希望它会有用. 朋友可以学习.
1. 我做了两个履带. 我第一次害怕Phoenix.com时,没有任何限制,我可以随意爬网,所以我放松了对自动代码执行模块的警惕. 我认为这很简单,但事实并非如此. 我已经为这个问题困扰了好几天,几乎是四天. 由于搜狗的限制,获得相同IP的次数越来越多. 首先,显示验证码,其次是访问限制. 直接无法访问. 根据请求,您得到的是访问次数太频繁,这种提示,因此在开发过程中最麻烦的不是代码的编写,而是测试. 编写后无法立即测试该代码. 我相信大多数程序员都不会喜欢,我现在编写的程序每天执行3次. 这样的频率很好,并且因为它是由多个官方帐户采集的,所以每个官方帐户之间也要有间隔,否则它将同时访问十多个公众,该帐户上的数百篇文章也不切实际. 在插入句子时,如何使每个正式帐户都不敢玩,等待特定的时间段,执行下一个,最后使用setInterval函数来解决它,
每80秒执行一个正式帐户,并将每个执行代码写入hello. 泡沫距离有点远. 我会收到的. 我们来谈谈cron程序包,它是自动执行的. npm官方网站上仅举了一个例子,但是我的意思是桑拿浴可能有点压抑. 我无法播放,但了解其用法. 然后我说,如果我听不懂怎么办. 在Internet,百度和cron程序包的特定用法上进行搜索. 有很多,所以我只是看了看,但是经过仔细的分析却并非如此. 都是废话,没用. 一般在线使用中都有一个问号,但是当我添加一个问号时,会出现错误. 是的,这都是胡说八道. 最后,我在同学小组的一个前端技术讨论小组中说了这一点. 真正热情的小组朋友找到了我一个链接. 我进去看看,尝试了一下,没关系,所以,非常感谢这位帮助我解决难题的同学. 我将再次附上QQ群组号码和链接,以帮助您在阅读本文时学习. QQ组号: 435012561,链接: ,链接说的没问题,至少可以用,这里我仍然有一个问题,就是时区,我们以前用过一次,使用洛杉矶时间,但是这次显然不起作用,我们需要用中文,但是我在北京尝试了几次,虽然不好,但是重庆可以,所以我用了重庆.
2. 我想在这里谈论的是从地址栏获取参数的问题. 我做的最后一个很好,但是我不知道该怎么做. 我从地址栏中得到的最后一个是数字,但是这个是它的. 它是一个字符串,并且mongodb中对字段的要求仍然非常严格,因此分页功能困扰了我几个小时. 它是如何解决的?我在mongodb中添加了一个讨论组. 我问其中有什么问题,并发布了屏幕截图. 有一个热心的网民说,传入数据的格式显然不正确. 我唤醒了做梦者,我说了是,然后我使用Number()函数来处理我得到的参数,以便字符串类型的数量成为数字类型的数量. 很好,因此在使用mongodb时,必须注意存储数据的格式.
3. Mongodb查询数据语句的组织:
坦率地说,实际上是使用了限制和跳过这两个函数,但是特定的格式可能是乐观的,并且mine是可接受的参数,但是mongo的参数接受很容易直接编写,不需要喜欢sql像$ {“”}一样. 下面的排序功能说明了排序方法. 这里,ctime字段设置为标准,-1表示逆序,1表示正序,
4. 在这段代码编写中,我第一次使用了try catch方法进行纠错. 原来没关系. 偶尔的错误可以正常地打印出来,但是它不会影响代码的整体执行,或者说到下一次执行,整体感觉非常好,
对于特定用法,将您要执行的代码放入try中,并在最后添加一行,并抛出Error();
然后传入参数e以进行捕获,可以在catch中打印很多消息,我只打印了其中之一,例如e.message
5. anync包主要用于此编码过程中,其中的ansyc.each循环,ansyc.waterfall在执行完上述操作后可以执行以下操作,也可以在您之间的上下传递参数,这非常重要的是,因为在此编程中,每次获取的内容都不同,每个代码执行的条件也不同,也就是说,所需的参数也不同,即,下一个代码执行可能需要上一个代码. 执行,所以这个anync软件包真的值得研究. 他的每种方法都不相同,有时可能会得到意想不到的结果.
6. 在mysql中,如果要实现这样的效果,即如果它已经存在于数据库中,则忽略它,或者不重复存储它;如果它不存在于数据库中,则将其存储在其中. 用replace替换插入数据的插入. 但是在mongodb中,应该没有,或者我还没有找到它. 我用这种方法解决了. 我定义了一个开关来使该开关为真. 在每次存储之前,循环所有数据以查看是否有该数据,如果没有,则让开关变为假,否则,继续执行,即判断此时开关是真还是假,如果为true,则执行插入操作;如果为false,则将其忽略. 这样可以达到类似的效果,否则每次都会存储大量重复数据,
7. 该集合的核心是我文件中的common.js. 首先,因为我们要采集,所以我们需要使用请求包. 采集后,我们需要以html格式处理数据,以便可以使用类似于jquery的数据. 对于该操作,cheerio包已使用了很长时间,然后在循环采集时将使用anync.each方法,因此将使用异步包,
7-1,
通过采集搜狗微信,我们必须分析搜狗微信的路径. 每个官方帐户页面的路径都是这样
%E8%BF%99%E6%89%8D%E6%98%AF%E6%97%A5%E6%9C%AC&ie = utf8&_sug_ = n&_sug_type _ =
这是“这是日本”页面的链接. 经过分析,所有正式帐户的链接仅在查询后的参数上有所不同,但是查询后的参数是什么,实际上,它是由encodeURIComponent()函数转换的,之后是“这是日本”,因此相同. 要获得该官方帐户,只需对官方帐户的名称进行编码并将其动态组合成一个链接,您就可以在访问时输入每个链接,但是我只是要求此页面此链接,
不是
此页面,因此进一步的处理是获取当前页面的第一内容的链接,即href
获得此链接后,您会发现他具有自己的加密方法. 实际上非常简单,就是在链接中增加三个安培;更换这三个放大器;在带有空链接的链接中,就好了,这是第一步,获取每个官方帐户的页面链接,
7-2
获取链接后,有必要访问,即请求,请求每个地址,获取每个地址的内容,但每个页面上显示的内容不在该页面中,即在html结构中,隐藏在js中,因此我们需要通过常规匹配来获取每篇文章的对象,然后循环访问每个正式帐户的对象以获取有关该对象中每篇文章的一些信息,包括标题,缩略图,摘要,URL,时间, 5个字段,但我使用的代码很烂,而我当时使用的是
Object.Attribute.foreach(function(item,index){
})
这种可怕的方法,最后要做的就是编写一个循环以完全获取每个对象,否则只能获取第一个对象. 在这里,您应该使用async.each或async.foreach. 可以使用两种方法中的每一种,并且它们都非常易于使用. 这样,您将获得上述每篇文章的基本新闻.
7-3,
第三阶段是进入每篇文章的详细信息页面,并获取每篇文章的内容,喜欢的次数,作者,官方帐号,阅读量和其他数据. 这里遇到的主要问题是人们的内容直接位于js中,并且所有img标签都有问题. 它们以这种形式存储在内容中,但是在这种情况下,由于标签,html文档(我不知道此类img标签)存在问题,此类图像无法显示在我们的网页上,因此在这里我们需要进行一些处理,替换全部与
python crawler_WeChat公共帐户推送信息爬取示例
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2020-08-07 04:12
更新时间: 2017年10月23日10:03:08转载作者: ChaseChoi
下面的编辑器将为您带来python crawler_WeChat公共帐户推送信息爬取的示例. 编辑认为这还不错,因此我将与您分享并提供参考. 让我们跟随编辑器看看
问题描述
使用搜狗的微信搜索来获取指定官方帐户的最新推送,并将相应的网页保存到本地.
注释
搜狗微信获取的地址是临时链接,对时间敏感.
官方帐户是一个动态网页(由JavaScript渲染),并且使用request.get()获得的内容不收录推送消息. 在这里,使用selenium + PhantomJS进行处理
代码
#! /usr/bin/env python3
from selenium import webdriver
from datetime import datetime
import bs4, requests
import os, time, sys
# 获取公众号链接
def getAccountURL(searchURL):
res = requests.get(searchURL)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "lxml")
# 选择第一个链接
account = soup.select('a[uigs="account_name_0"]')
return account[0]['href']
# 获取首篇文章的链接,如果有验证码返回None
def getArticleURL(accountURL):
browser = webdriver.PhantomJS("/Users/chasechoi/Downloads/phantomjs-2.1.1-macosx/bin/phantomjs")
# 进入公众号
browser.get(accountURL)
# 获取网页信息
html = browser.page_source
accountSoup = bs4.BeautifulSoup(html, "lxml")
time.sleep(1)
contents = accountSoup.find_all(hrefs=True)
try:
partitialLink = contents[0]['hrefs']
firstLink = base + partitialLink
except IndexError:
firstLink = None
print('CAPTCHA!')
return firstLink
# 创建文件夹存储html网页,以时间命名
def folderCreation():
path = os.path.join(os.getcwd(), datetime.now().strftime('%Y-%m-%d_%H-%M-%S'))
try:
os.makedirs(path)
except OSError as e:
if e.errno != errno.EEXIST:
raise
print("folder not exist!")
return path
# 将html页面写入本地
def writeToFile(path, account, title):
myfile = open("{}/{}_{}.html".format(path, account, title), 'wb')
myfile.write(res.content)
myfile.close()
base ='https://mp.weixin.qq.com'
accountList = ['央视新闻', '新浪新闻','凤凰新闻','羊城晚报']
query = 'http://weixin.sogou.com/weixin?type=1&s_from=input&query='
path = folderCreation()
for index, account in enumerate(accountList):
searchURL = query + account
accountURL = getAccountURL(searchURL)
time.sleep(10)
articleURL = getArticleURL(accountURL)
if articleURL != None:
print("#{}({}/{}): {}".format(account, index+1, len(accountList), accountURL))
# 读取第一篇文章内容
res = requests.get(articleURL)
res.raise_for_status()
detailPage = bs4.BeautifulSoup(res.text, "lxml")
title = detailPage.title.text
print("标题: {}\n链接: {}\n".format(title, articleURL))
writeToFile(path, account, title)
else:
print('{} files successfully written to {}'.format(index, path))
sys.exit()
print('{} files successfully written to {}'.format(len(accountList), path))
参考输出
端子输出
查找器
分析
获取链接
首先进入搜狗的微信搜索页面,在地址栏中提取链接的必需部分,将字符串连接到官方帐户名,然后生成请求链接
对于静态网页,请使用请求获取html文件,然后使用BeautifulSoup选择所需的内容
对于动态网页,请使用selenium + PhantomJS获取html文件,然后使用BeautifulSoup选择所需的内容
遇到验证码(CAPTCHA)时,输出提示. 此版本的代码实际上并未处理验证码,因此在运行程序之前需要手动对其进行访问,以避免验证码.
文件写入
使用os.path.join()构造存储路径可以提高通用性. 例如,Windows路径分隔符使用反斜杠(\),而OS X和Linux使用反斜杠(/). 该功能可以根据平台自动转换.
open()使用b(二进制模式)参数来提高通用性(适用于Windows)
使用datetime.now()获取当前的命名时间,并通过strftime()格式化时间(函数名称中的f表示格式),
有关特定用途,请参阅下表(摘自“使用Python自动完成钻孔”)
上面的python爬网程序_WeChat公共帐户推送信息爬网示例是编辑器共享的所有内容,希望为您提供参考,也希望可以支持脚本库. 查看全部
python crawler_WeChat公共帐户推送信息爬取示例
更新时间: 2017年10月23日10:03:08转载作者: ChaseChoi
下面的编辑器将为您带来python crawler_WeChat公共帐户推送信息爬取的示例. 编辑认为这还不错,因此我将与您分享并提供参考. 让我们跟随编辑器看看
问题描述
使用搜狗的微信搜索来获取指定官方帐户的最新推送,并将相应的网页保存到本地.
注释
搜狗微信获取的地址是临时链接,对时间敏感.
官方帐户是一个动态网页(由JavaScript渲染),并且使用request.get()获得的内容不收录推送消息. 在这里,使用selenium + PhantomJS进行处理
代码
#! /usr/bin/env python3
from selenium import webdriver
from datetime import datetime
import bs4, requests
import os, time, sys
# 获取公众号链接
def getAccountURL(searchURL):
res = requests.get(searchURL)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "lxml")
# 选择第一个链接
account = soup.select('a[uigs="account_name_0"]')
return account[0]['href']
# 获取首篇文章的链接,如果有验证码返回None
def getArticleURL(accountURL):
browser = webdriver.PhantomJS("/Users/chasechoi/Downloads/phantomjs-2.1.1-macosx/bin/phantomjs")
# 进入公众号
browser.get(accountURL)
# 获取网页信息
html = browser.page_source
accountSoup = bs4.BeautifulSoup(html, "lxml")
time.sleep(1)
contents = accountSoup.find_all(hrefs=True)
try:
partitialLink = contents[0]['hrefs']
firstLink = base + partitialLink
except IndexError:
firstLink = None
print('CAPTCHA!')
return firstLink
# 创建文件夹存储html网页,以时间命名
def folderCreation():
path = os.path.join(os.getcwd(), datetime.now().strftime('%Y-%m-%d_%H-%M-%S'))
try:
os.makedirs(path)
except OSError as e:
if e.errno != errno.EEXIST:
raise
print("folder not exist!")
return path
# 将html页面写入本地
def writeToFile(path, account, title):
myfile = open("{}/{}_{}.html".format(path, account, title), 'wb')
myfile.write(res.content)
myfile.close()
base ='https://mp.weixin.qq.com'
accountList = ['央视新闻', '新浪新闻','凤凰新闻','羊城晚报']
query = 'http://weixin.sogou.com/weixin?type=1&s_from=input&query='
path = folderCreation()
for index, account in enumerate(accountList):
searchURL = query + account
accountURL = getAccountURL(searchURL)
time.sleep(10)
articleURL = getArticleURL(accountURL)
if articleURL != None:
print("#{}({}/{}): {}".format(account, index+1, len(accountList), accountURL))
# 读取第一篇文章内容
res = requests.get(articleURL)
res.raise_for_status()
detailPage = bs4.BeautifulSoup(res.text, "lxml")
title = detailPage.title.text
print("标题: {}\n链接: {}\n".format(title, articleURL))
writeToFile(path, account, title)
else:
print('{} files successfully written to {}'.format(index, path))
sys.exit()
print('{} files successfully written to {}'.format(len(accountList), path))
参考输出
端子输出
查找器
分析
获取链接
首先进入搜狗的微信搜索页面,在地址栏中提取链接的必需部分,将字符串连接到官方帐户名,然后生成请求链接
对于静态网页,请使用请求获取html文件,然后使用BeautifulSoup选择所需的内容
对于动态网页,请使用selenium + PhantomJS获取html文件,然后使用BeautifulSoup选择所需的内容
遇到验证码(CAPTCHA)时,输出提示. 此版本的代码实际上并未处理验证码,因此在运行程序之前需要手动对其进行访问,以避免验证码.
文件写入
使用os.path.join()构造存储路径可以提高通用性. 例如,Windows路径分隔符使用反斜杠(\),而OS X和Linux使用反斜杠(/). 该功能可以根据平台自动转换.
open()使用b(二进制模式)参数来提高通用性(适用于Windows)
使用datetime.now()获取当前的命名时间,并通过strftime()格式化时间(函数名称中的f表示格式),
有关特定用途,请参阅下表(摘自“使用Python自动完成钻孔”)
上面的python爬网程序_WeChat公共帐户推送信息爬网示例是编辑器共享的所有内容,希望为您提供参考,也希望可以支持脚本库.
[分享] 366tool在线解析微信新型域名防阻塞API接口的实现原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2020-08-07 01:24
随着智能手机的普及,许多人现在可以直接在手机上阅读小说. 但是,并非所有人都会下载该新颖的应用程序,即使其他人帮助下载该应用程序,这种类型的用户组也不会使用它. 那么我们如何解决此类用户的需求?
许多人目前正在实施的一种方法是直接共享微信中转发小说的链接. 用户可以单击以阅读小说. 当然,这些小说不是纯粹的福利小说,还会增加一些广告. 链接,为官方帐户添加一些QR码等. 但是令企业感到困扰的是,一旦添加了这些内容,微信就会迅速阻止和阻止域名. 目前,我们将使用新型域名的防阻塞技术.
在我们共享366TooL开发的几种防密封解决方案之前. 由于产品不同和操作方法的差异,仅一种防密封解决方案无法满足所有客户的需求,并且微信规则在不断变化. ,该程序还需要不断升级和改进,以确保防密封程序的有效性和持久性. 今天,我将与您分享微信小说的反封锁解决方案. 新平台的域名如何在微信中生存更长的时间?
在我们分享小说的反阻止解决方案之前,让我们首先了解为什么微信很容易阻止小说的推广域名. 普遍的原因总结为两点:
第一点是,微信机器人会自动检测小说中的内容. 通常,带有广告内容或敏感词汇的小说肯定会被屏蔽(最新小说是什么?)
第二个原因是同事或其他人的报告在验证后被微信屏蔽.
分析原因之后,让我们看一下新颖的使用场景.
通用小说平台由官方帐户平台承载,然后通过共享绑定到官方帐户的商业域名进行推广. 要阅读小说,用户必须授权官方帐户登录才能正常阅读并充值.
这就是重点. 新型域名的反封锁实际上就是对官方账号业务域名的反封锁,普通的官方账号平台的业务域名只能被替换三次. 似乎特别重要的是保护官方帐户的企业域名.
那么我们如何才能有效地保护新颖域名免遭拦截?在这里,我需要解释. 很多朋友问我,使用反封锁后我的域名是否不会被封锁?这不是那么容易. 防阻塞只能延迟或更好地保护域名. 无法保证永远不会有问题. 原因很简单. 微信技术团队不是素食主义者.
366TooL的最新新颖防密封解决方案可以说已经超过了市场上所有的防密封解决方案,因为该平台已经通过了大量的数据测试,反馈,优化和比较,最终确定了一个单独的防密封解决方案平台的系统. 查看全部
为什么要使用新颖的域名防阻塞功能?
随着智能手机的普及,许多人现在可以直接在手机上阅读小说. 但是,并非所有人都会下载该新颖的应用程序,即使其他人帮助下载该应用程序,这种类型的用户组也不会使用它. 那么我们如何解决此类用户的需求?
许多人目前正在实施的一种方法是直接共享微信中转发小说的链接. 用户可以单击以阅读小说. 当然,这些小说不是纯粹的福利小说,还会增加一些广告. 链接,为官方帐户添加一些QR码等. 但是令企业感到困扰的是,一旦添加了这些内容,微信就会迅速阻止和阻止域名. 目前,我们将使用新型域名的防阻塞技术.
在我们共享366TooL开发的几种防密封解决方案之前. 由于产品不同和操作方法的差异,仅一种防密封解决方案无法满足所有客户的需求,并且微信规则在不断变化. ,该程序还需要不断升级和改进,以确保防密封程序的有效性和持久性. 今天,我将与您分享微信小说的反封锁解决方案. 新平台的域名如何在微信中生存更长的时间?
在我们分享小说的反阻止解决方案之前,让我们首先了解为什么微信很容易阻止小说的推广域名. 普遍的原因总结为两点:
第一点是,微信机器人会自动检测小说中的内容. 通常,带有广告内容或敏感词汇的小说肯定会被屏蔽(最新小说是什么?)
第二个原因是同事或其他人的报告在验证后被微信屏蔽.
分析原因之后,让我们看一下新颖的使用场景.
通用小说平台由官方帐户平台承载,然后通过共享绑定到官方帐户的商业域名进行推广. 要阅读小说,用户必须授权官方帐户登录才能正常阅读并充值.
这就是重点. 新型域名的反封锁实际上就是对官方账号业务域名的反封锁,普通的官方账号平台的业务域名只能被替换三次. 似乎特别重要的是保护官方帐户的企业域名.
那么我们如何才能有效地保护新颖域名免遭拦截?在这里,我需要解释. 很多朋友问我,使用反封锁后我的域名是否不会被封锁?这不是那么容易. 防阻塞只能延迟或更好地保护域名. 无法保证永远不会有问题. 原因很简单. 微信技术团队不是素食主义者.
366TooL的最新新颖防密封解决方案可以说已经超过了市场上所有的防密封解决方案,因为该平台已经通过了大量的数据测试,反馈,优化和比较,最终确定了一个单独的防密封解决方案平台的系统.
php微信官方帐户开发的简短答案
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2020-08-07 01:23
更新: 2018年10月20日15:20:30转载作者: dq_095
本文主要详细介绍了针对php微信公众号开发的简短回答问题,具有一定的参考价值,有兴趣的朋友可以参考
本文示例共享php微信公众号开发的简短答案问题的特定代码,以供您参考. 具体内容如下
简短回答问题
核心代码如下:
public function responseMsg()
{
//get post data, May be due to the different environments
$postStr = $GLOBALS["HTTP_RAW_POST_DATA"];
//extract post data
if (!empty($postStr)){
$postObj = simplexml_load_string($postStr, 'SimpleXMLElement', LIBXML_NOCDATA);
$fromUsername = $postObj->FromUserName;
$toUsername = $postObj->ToUserName;
$type = $postObj->MsgType;
$customevent = $postObj->Event;
$latitude = $postObj->Location_X;
$longitude = $postObj->Location_Y;
$keyword = trim($postObj->Content);
$time = time();
$textTpl = "
%s
%s
0
";
include("coon.php");
if($keyword=="8")
{
$array=array("第5页第1个字"=>"王","第8页第1个字"=>"李","第30页第1个字"=>"周");
$a=array_rand($array,1);
$b=$array[$a];
$contentStr=$a."是什么?";
$sql="INSERT INTO `menu2` (`id` ,`user` ,`sec`,`answer`)VALUES (NULL , '{$fromUsername}', '8','{$b}')";
mysql_query($sql);
}
else
{
$sql="SELECT * FROM `menu2` where `user`= '{$fromUsername}'";
$query=mysql_query($sql);
$rm=mysql_fetch_array($query);
$sec=$rm['sec'];
$answer=$rm['answer'];
if($sec=="8")
{
if($keyword==$answer)
{
$contentStr="你的答案是正确的,视频代码下载地址为....";
}
else
{
$contentStr="你的答案不正确,请购买《微信公众平台搭建与开发揭秘》";
}
}
else
{
$contentStr="请先输入8";
}
}
$msgType="text";
$resultStr = sprintf($textTpl, $fromUsername, $toUsername, $time, $msgType, $contentStr);
echo $resultStr;
}
}
coon.php: 用于连接到数据库的代码如下:
<p> 查看全部
php微信官方帐户开发的简短答案
更新: 2018年10月20日15:20:30转载作者: dq_095
本文主要详细介绍了针对php微信公众号开发的简短回答问题,具有一定的参考价值,有兴趣的朋友可以参考
本文示例共享php微信公众号开发的简短答案问题的特定代码,以供您参考. 具体内容如下
简短回答问题
核心代码如下:
public function responseMsg()
{
//get post data, May be due to the different environments
$postStr = $GLOBALS["HTTP_RAW_POST_DATA"];
//extract post data
if (!empty($postStr)){
$postObj = simplexml_load_string($postStr, 'SimpleXMLElement', LIBXML_NOCDATA);
$fromUsername = $postObj->FromUserName;
$toUsername = $postObj->ToUserName;
$type = $postObj->MsgType;
$customevent = $postObj->Event;
$latitude = $postObj->Location_X;
$longitude = $postObj->Location_Y;
$keyword = trim($postObj->Content);
$time = time();
$textTpl = "
%s
%s
0
";
include("coon.php");
if($keyword=="8")
{
$array=array("第5页第1个字"=>"王","第8页第1个字"=>"李","第30页第1个字"=>"周");
$a=array_rand($array,1);
$b=$array[$a];
$contentStr=$a."是什么?";
$sql="INSERT INTO `menu2` (`id` ,`user` ,`sec`,`answer`)VALUES (NULL , '{$fromUsername}', '8','{$b}')";
mysql_query($sql);
}
else
{
$sql="SELECT * FROM `menu2` where `user`= '{$fromUsername}'";
$query=mysql_query($sql);
$rm=mysql_fetch_array($query);
$sec=$rm['sec'];
$answer=$rm['answer'];
if($sec=="8")
{
if($keyword==$answer)
{
$contentStr="你的答案是正确的,视频代码下载地址为....";
}
else
{
$contentStr="你的答案不正确,请购买《微信公众平台搭建与开发揭秘》";
}
}
else
{
$contentStr="请先输入8";
}
}
$msgType="text";
$resultStr = sprintf($textTpl, $fromUsername, $toUsername, $time, $msgType, $contentStr);
echo $resultStr;
}
}
coon.php: 用于连接到数据库的代码如下:
<p>
使用搜狗微信入口制作微信文章采集器API
采集交流 • 优采云 发表了文章 • 0 个评论 • 464 次浏览 • 2020-08-06 20:05
搜狗微信门户比其他门户友好得多. 应该是微信搜索引擎和搜狗有合作,所以搜狗可以进入微信搜索. 搜狗微信有两种类型,一种是通过关键词搜索文章,另一种是通过关键词搜索官方账号,搜索到的微信账号最多只能获得十笔最新新闻推送(这意味着指定的公众不能通过这种方法抓取历史新闻). 该方法还有一些应用场景,例如获取大量有关某个关键字的文章,例如执行计划任务,或者以一定间隔抓取某个微信官方帐户的最新十次推送以获取其最新推送. 它比网上的微信要好得多. 搜狗微信更新也是实时且直接相关的.
我对appium自动化和Xposed框架了解不多. 鸦片类似于硒. 为了在移动终端上进行自动化测试,您可以模拟点击. Xposed框架有很多工作要做. Xposed可以执行一些其他功能,而无需修改apk. 爬虫自然是可能的. 此外,它还可以自动抓取红包,自动回复机器人以及修改微步数等骚动操作.
我写爬虫游戏已有一段时间了. 我个人认为,除了具有防爬网和爬网的效率外,还有另一个领域很难实现. 履带的稳定性和坚固性需要考虑到许多异常情况,并且是合理有效的. 在这一点上,我认为我仍然需要向主要的爬虫学习. (我觉得我一直在谈论很多东西,还没有开始做我的身体(orz),请不要对那个觉得我很冗长的大个子生气. )
使用搜狗微信编写一个爬虫界面,代码非常简单,只有两百行代码. (我在这里不得不抱怨. 我在python中写太多了. 我总是有一种幻想,我很尴尬,编程很简单. 几行代码可以实现非常强大的功能. 这时,我需要编写CPP并冷静下来,让自己知道什么是真正的编程. )
以下记录了编写此采集器界面脚本的过程:
1. 页面请求分析(以官方帐户搜索为例):
您可以看到第一个http请求数据包是我们想要的结果,请检查其查询字符串,如下所示:
它看起来并不简单. 我们获得以下信息:
请求网址是
请求类型为Get
请求参数如上所示
发现将请求参数tyepe更改为2是为了获得关键字搜索文章的结果
这相对简单
2. 模拟页面请求:
我们直接使用url,请求参数params和Google Chrome的用户代理请求,发现我们可以成功获取所需页面的源代码,然后在下方获得第一个官方帐户搜索结果. 是的(这意味着需要正确指定官方帐户名称,如果过于模糊,则有可能获得类似的官方帐户结果).
3. 分析页面:
首先确定爬行思路,第一步是获取微信公众号链接,然后通过微信公众号链接获取最新的十项推送相关信息,包括标题,日期,作者,内容摘要,内容链接(实际上,我们发现,通过微信推送链接,我们可以轻松获取推送的主要内容,但不包括喜欢和阅读的次数. 这些数据只能在微信移动终端上查看. 如果有一次机会,它将在下次记录. 在您的手机微信上下载爬虫的过程.
因此第一步,我们将获得官方帐户链接:
这里我们可以直接使用正则表达式提取(这种简单方法不需要xpath和bs4. 依赖标准库和第三方库仍然有所不同. )
(很抱歉被水印阻止,请更改一个. )
第二步是根据微信官方账号链接获取最近十条推送消息:
(我只写过一篇关于orz的文章,我会继续努力. )
ctlr U查看网页的源代码,并发现原创信息位于js变量中.
易于处理,继续常规提取,将json格式的字符串转换为python中的字典,有两种方法,一种是使用json.loads方法,第二种是使用内置的eval方法. 两种方法之间存在一些差异,例如单引号和双引号. json格式使用双引号,而python词典中通常使用单引号.
好的,已经获得了原创的推送信息数据,但是我们不需要很多信息,因此我们可以将其删除. 值得一提的是,datetime的值是一个时间戳,我们需要将其转换为直观的Time表达式.
至此,微信公众号上的抓取工具已基本解决. 接下来,需要将其封装为一个类. 代码的主要部分如下.
此外,我还写了关于关键字搜索文章,AccountAPI,ArticleAPI的爬网程序接口,父类是AP类,并且该API类具有query_url,params,header,_get_response,_get_datetime以及其他用于由AccountAPI和ArticleAPI共享.
代码位于github仓库中,如果您有兴趣,可以看看
放置两个屏幕截图以供使用
(ArticleAPI)
(AccountAPI)
结论:
诸如此类的原创爬虫将其称为api,我有点大胆. 这只是一个小麻烦,很难做到优雅,您需要向大兄弟学习. 查看全部
移动客户端使用提琴手或查尔斯等其他捕获工具捕获数据包,这是一种相对主流的方法(我觉得是orz),是一种更有效的方法,可以快速捕获微信官方帐户信息和历史新闻. 该方法也有缺点: cookie很快过期,大约需要半天. 还可以专门获取某些官方帐户的历史信息. 通过模拟微信登录自动获取cookie似乎非常困难. 我很无聊,无法实现. 看来微信登录是TCP协议?
搜狗微信门户比其他门户友好得多. 应该是微信搜索引擎和搜狗有合作,所以搜狗可以进入微信搜索. 搜狗微信有两种类型,一种是通过关键词搜索文章,另一种是通过关键词搜索官方账号,搜索到的微信账号最多只能获得十笔最新新闻推送(这意味着指定的公众不能通过这种方法抓取历史新闻). 该方法还有一些应用场景,例如获取大量有关某个关键字的文章,例如执行计划任务,或者以一定间隔抓取某个微信官方帐户的最新十次推送以获取其最新推送. 它比网上的微信要好得多. 搜狗微信更新也是实时且直接相关的.
我对appium自动化和Xposed框架了解不多. 鸦片类似于硒. 为了在移动终端上进行自动化测试,您可以模拟点击. Xposed框架有很多工作要做. Xposed可以执行一些其他功能,而无需修改apk. 爬虫自然是可能的. 此外,它还可以自动抓取红包,自动回复机器人以及修改微步数等骚动操作.
我写爬虫游戏已有一段时间了. 我个人认为,除了具有防爬网和爬网的效率外,还有另一个领域很难实现. 履带的稳定性和坚固性需要考虑到许多异常情况,并且是合理有效的. 在这一点上,我认为我仍然需要向主要的爬虫学习. (我觉得我一直在谈论很多东西,还没有开始做我的身体(orz),请不要对那个觉得我很冗长的大个子生气. )
使用搜狗微信编写一个爬虫界面,代码非常简单,只有两百行代码. (我在这里不得不抱怨. 我在python中写太多了. 我总是有一种幻想,我很尴尬,编程很简单. 几行代码可以实现非常强大的功能. 这时,我需要编写CPP并冷静下来,让自己知道什么是真正的编程. )
以下记录了编写此采集器界面脚本的过程:
1. 页面请求分析(以官方帐户搜索为例):
您可以看到第一个http请求数据包是我们想要的结果,请检查其查询字符串,如下所示:
它看起来并不简单. 我们获得以下信息:
请求网址是
请求类型为Get
请求参数如上所示
发现将请求参数tyepe更改为2是为了获得关键字搜索文章的结果
这相对简单
2. 模拟页面请求:
我们直接使用url,请求参数params和Google Chrome的用户代理请求,发现我们可以成功获取所需页面的源代码,然后在下方获得第一个官方帐户搜索结果. 是的(这意味着需要正确指定官方帐户名称,如果过于模糊,则有可能获得类似的官方帐户结果).
3. 分析页面:
首先确定爬行思路,第一步是获取微信公众号链接,然后通过微信公众号链接获取最新的十项推送相关信息,包括标题,日期,作者,内容摘要,内容链接(实际上,我们发现,通过微信推送链接,我们可以轻松获取推送的主要内容,但不包括喜欢和阅读的次数. 这些数据只能在微信移动终端上查看. 如果有一次机会,它将在下次记录. 在您的手机微信上下载爬虫的过程.
因此第一步,我们将获得官方帐户链接:
这里我们可以直接使用正则表达式提取(这种简单方法不需要xpath和bs4. 依赖标准库和第三方库仍然有所不同. )
(很抱歉被水印阻止,请更改一个. )
第二步是根据微信官方账号链接获取最近十条推送消息:
(我只写过一篇关于orz的文章,我会继续努力. )
ctlr U查看网页的源代码,并发现原创信息位于js变量中.
易于处理,继续常规提取,将json格式的字符串转换为python中的字典,有两种方法,一种是使用json.loads方法,第二种是使用内置的eval方法. 两种方法之间存在一些差异,例如单引号和双引号. json格式使用双引号,而python词典中通常使用单引号.
好的,已经获得了原创的推送信息数据,但是我们不需要很多信息,因此我们可以将其删除. 值得一提的是,datetime的值是一个时间戳,我们需要将其转换为直观的Time表达式.
至此,微信公众号上的抓取工具已基本解决. 接下来,需要将其封装为一个类. 代码的主要部分如下.
此外,我还写了关于关键字搜索文章,AccountAPI,ArticleAPI的爬网程序接口,父类是AP类,并且该API类具有query_url,params,header,_get_response,_get_datetime以及其他用于由AccountAPI和ArticleAPI共享.
代码位于github仓库中,如果您有兴趣,可以看看
放置两个屏幕截图以供使用
(ArticleAPI)
(AccountAPI)
结论:
诸如此类的原创爬虫将其称为api,我有点大胆. 这只是一个小麻烦,很难做到优雅,您需要向大兄弟学习.
微信公众号文章检索方法摘要(第1部分)
采集交流 • 优采云 发表了文章 • 0 个评论 • 299 次浏览 • 2020-08-06 18:25
爬虫
我经常有一些需要帮助的人,他们在搜寻公共帐户文章方面需要帮助. 这次我将总结各种方法.
目前,有三种主要的微信公众号抓取方法:
通过在微信官方平台上引用文章界面来爬网第三方官方帐户文章聚合网站,并分析微信应用程序的界面以通过微信公众平台访问官方帐户文章,并通过第三方平台进行爬网,派对官方帐户文章汇总网站
微信公众号文章未提供外部搜索功能. 直到2013年,在微信对搜狗进行投资之后,搜狗搜索才访问了微信官方账户数据. 从那时起,您可以使用搜狗搜索浏览或查询相关的官方帐户和文章.
域名是:
搜狗微信
您可以直接搜索官方帐户或文章的关键字,一些流行的官方帐户会及时更新,几乎与微信同步.
官方帐户搜索
因此,您可以使用搜狗微信界面对一些流行的官方账户进行爬网,但是却无法搜索到某些利基官方账户,并且搜狗的反爬网机制更频繁地更新,并且获取数据的界面变化更快,通常会在两三个月内进行调整,这使得履带易于悬挂. 建议使用硒进行爬网. 此外,搜狗还对每个IP都有访问限制. 频率过高的IP的访问将被阻止24小时,您需要购买一个IP池来处理它.
还有一些其他公共帐户文章聚合网站(例如门户)未及时更新或未包括在内. 毕竟,搜狗的儿子不好. 通过微信公众平台引用文章界面
此界面是相对隐藏的,不能匿名访问. 必须有一个官方帐户. 最好注册一个新的官方帐户,以免被阻止.
让我们从特定步骤开始: 首先登录您的微信官方帐户,在您输入的主页上选择“创建群发”,然后单击自行创建的图形,然后在文章编辑工具栏中找到超链接,如下所示: 如下所示:
单击超链接
单击超链接按钮,将弹出一个对话框,选择链接输入法以查找文章,如下所示:
查找文章
您可以在此处输入官方帐户的名称,然后按Enter键,微信将返回匹配的官方帐户列表,如下所示:
搜索官方帐户
然后单击您要获取的官方帐户,然后将显示特定文章的列表. 它已经按时间倒序排列,而最新的文章是第一篇. 如下图所示:
文章列表
微信的传呼机制很奇怪. 每个官方帐户的每个页面上显示的数据项数量是不同的. 分页爬网时需要处理它.
通过chrome分析网络请求的数据,我们基本获得了所需的数据,文章链接,封面,发行日期,字幕等,如下所示:
网络请求数据
好的,此爬网方法的原理已经完成,让我们开始实际的操作.
由于微信公众平台的登录验证比较严格,在输入密码后,手机必须扫描密码进行确认登录,因此最好使用硒进行自动化. 我不会列出特定微信界面的分析过程,而是直接发布代码:
import re
import time
import random
import traceback
import requests
from selenium import webdriver
class Spider(object):
'''
微信公众号文章爬虫
'''
def __init__(self):
# 微信公众号账号
self.account = '286394973@qq.com'
# 微信公众号密码
self.pwd = 'lei4649861'
def create_driver(self):
'''
初始化 webdriver
'''
options = webdriver.ChromeOptions()
# 禁用gpu加速,防止出一些未知bug
options.add_argument('--disable-gpu')
# 这里我用 chromedriver 作为 webdriver
# 可以去 http://chromedriver.chromium.org/downloads 下载你的chrome对应版本
self.driver = webdriver.Chrome(executable_path='./chromedriver', chrome_options=options)
# 设置一个隐性等待 5s
self.driver.implicitly_wait(5)
def log(self, msg):
'''
格式化打印
'''
print('------ %s ------' % msg)
def login(self):
'''
登录拿 cookies
'''
try:
self.create_driver()
# 访问微信公众平台
self.driver.get('https://mp.weixin.qq.com/')
# 等待网页加载完毕
time.sleep(3)
# 输入账号
self.driver.find_element_by_xpath("./*//input[@name='account']").clear()
self.driver.find_element_by_xpath("./*//input[@name='account']").send_keys(self.account)
# 输入密码
self.driver.find_element_by_xpath("./*//input[@name='password']").clear()
self.driver.find_element_by_xpath("./*//input[@name='password']").send_keys(self.pwd)
# 点击登录
self.driver.find_elements_by_class_name('btn_login')[0].click()
self.log("请拿手机扫码二维码登录公众号")
# 等待手机扫描
time.sleep(10)
self.log("登录成功")
# 获取cookies 然后保存到变量上,后面要用
self.cookies = dict([[x['name'], x['value']] for x in self.driver.get_cookies()])
except Exception as e:
traceback.print_exc()
finally:
# 退出 chorme
self.driver.quit()
def get_article(self, query=''):
try:
url = 'https://mp.weixin.qq.com'
# 设置headers
headers = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36"
}
# 登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-b ... 51598,
# 从这里获取token信息
response = requests.get(url=url, cookies=self.cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
time.sleep(2)
self.log('正在查询[ %s ]相关公众号' % query)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
# 搜索微信公众号接口需要传入的参数,
# 有三个变量:微信公众号token、随机数random、搜索的微信公众号名字
params = {
'action': 'search_biz',
'token': token,
'random': random.random(),
'query': query,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'begin': '0',
'count': '5'
}
# 打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers
response = requests.get(search_url, cookies=self.cookies, headers=headers, params=params)
time.sleep(2)
# 取搜索结果中的第一个公众号
lists = response.json().get('list')[0]
# 获取这个公众号的fakeid,后面爬取公众号文章需要此字段
fakeid = lists.get('fakeid')
nickname = lists.get('nickname')
# 微信公众号文章接口地址
search_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
# 搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random
params = {
'action': 'list_ex',
'token': token,
'random': random.random(),
'fakeid': fakeid,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'begin': '0', # 不同页,此参数变化,变化规则为每页加5
'count': '5',
'query': '',
'type': '9'
}
self.log('正在查询公众号[ %s ]相关文章' % nickname)
# 打开搜索的微信公众号文章列表页
response = requests.get(search_url, cookies=self.cookies, headers=headers, params=params)
time.sleep(2)
for per in response.json().get('app_msg_list', []):
print('title ---> %s' % per.get('title'))
print('link ---> %s' % per.get('link'))
# print('cover ---> %s' % per.get('cover'))
except Exception as e:
traceback.print_exc()
if __name__ == '__main__':
spider = Spider()
spider.login()
spider.get_article('python')
该代码仅用于学习,不适用于分页查询.
根据网民的说法,该接口也有访问频率限制. 一天几百次不是问题. 如果访问速度太快或次数太多,它将被阻止24小时. 查看全部
爬虫
我经常有一些需要帮助的人,他们在搜寻公共帐户文章方面需要帮助. 这次我将总结各种方法.
目前,有三种主要的微信公众号抓取方法:
通过在微信官方平台上引用文章界面来爬网第三方官方帐户文章聚合网站,并分析微信应用程序的界面以通过微信公众平台访问官方帐户文章,并通过第三方平台进行爬网,派对官方帐户文章汇总网站
微信公众号文章未提供外部搜索功能. 直到2013年,在微信对搜狗进行投资之后,搜狗搜索才访问了微信官方账户数据. 从那时起,您可以使用搜狗搜索浏览或查询相关的官方帐户和文章.
域名是:
搜狗微信
您可以直接搜索官方帐户或文章的关键字,一些流行的官方帐户会及时更新,几乎与微信同步.
官方帐户搜索
因此,您可以使用搜狗微信界面对一些流行的官方账户进行爬网,但是却无法搜索到某些利基官方账户,并且搜狗的反爬网机制更频繁地更新,并且获取数据的界面变化更快,通常会在两三个月内进行调整,这使得履带易于悬挂. 建议使用硒进行爬网. 此外,搜狗还对每个IP都有访问限制. 频率过高的IP的访问将被阻止24小时,您需要购买一个IP池来处理它.
还有一些其他公共帐户文章聚合网站(例如门户)未及时更新或未包括在内. 毕竟,搜狗的儿子不好. 通过微信公众平台引用文章界面
此界面是相对隐藏的,不能匿名访问. 必须有一个官方帐户. 最好注册一个新的官方帐户,以免被阻止.
让我们从特定步骤开始: 首先登录您的微信官方帐户,在您输入的主页上选择“创建群发”,然后单击自行创建的图形,然后在文章编辑工具栏中找到超链接,如下所示: 如下所示:
单击超链接
单击超链接按钮,将弹出一个对话框,选择链接输入法以查找文章,如下所示:
查找文章
您可以在此处输入官方帐户的名称,然后按Enter键,微信将返回匹配的官方帐户列表,如下所示:
搜索官方帐户
然后单击您要获取的官方帐户,然后将显示特定文章的列表. 它已经按时间倒序排列,而最新的文章是第一篇. 如下图所示:
文章列表
微信的传呼机制很奇怪. 每个官方帐户的每个页面上显示的数据项数量是不同的. 分页爬网时需要处理它.
通过chrome分析网络请求的数据,我们基本获得了所需的数据,文章链接,封面,发行日期,字幕等,如下所示:
网络请求数据
好的,此爬网方法的原理已经完成,让我们开始实际的操作.
由于微信公众平台的登录验证比较严格,在输入密码后,手机必须扫描密码进行确认登录,因此最好使用硒进行自动化. 我不会列出特定微信界面的分析过程,而是直接发布代码:
import re
import time
import random
import traceback
import requests
from selenium import webdriver
class Spider(object):
'''
微信公众号文章爬虫
'''
def __init__(self):
# 微信公众号账号
self.account = '286394973@qq.com'
# 微信公众号密码
self.pwd = 'lei4649861'
def create_driver(self):
'''
初始化 webdriver
'''
options = webdriver.ChromeOptions()
# 禁用gpu加速,防止出一些未知bug
options.add_argument('--disable-gpu')
# 这里我用 chromedriver 作为 webdriver
# 可以去 http://chromedriver.chromium.org/downloads 下载你的chrome对应版本
self.driver = webdriver.Chrome(executable_path='./chromedriver', chrome_options=options)
# 设置一个隐性等待 5s
self.driver.implicitly_wait(5)
def log(self, msg):
'''
格式化打印
'''
print('------ %s ------' % msg)
def login(self):
'''
登录拿 cookies
'''
try:
self.create_driver()
# 访问微信公众平台
self.driver.get('https://mp.weixin.qq.com/')
# 等待网页加载完毕
time.sleep(3)
# 输入账号
self.driver.find_element_by_xpath("./*//input[@name='account']").clear()
self.driver.find_element_by_xpath("./*//input[@name='account']").send_keys(self.account)
# 输入密码
self.driver.find_element_by_xpath("./*//input[@name='password']").clear()
self.driver.find_element_by_xpath("./*//input[@name='password']").send_keys(self.pwd)
# 点击登录
self.driver.find_elements_by_class_name('btn_login')[0].click()
self.log("请拿手机扫码二维码登录公众号")
# 等待手机扫描
time.sleep(10)
self.log("登录成功")
# 获取cookies 然后保存到变量上,后面要用
self.cookies = dict([[x['name'], x['value']] for x in self.driver.get_cookies()])
except Exception as e:
traceback.print_exc()
finally:
# 退出 chorme
self.driver.quit()
def get_article(self, query=''):
try:
url = 'https://mp.weixin.qq.com'
# 设置headers
headers = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36"
}
# 登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-b ... 51598,
# 从这里获取token信息
response = requests.get(url=url, cookies=self.cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
time.sleep(2)
self.log('正在查询[ %s ]相关公众号' % query)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
# 搜索微信公众号接口需要传入的参数,
# 有三个变量:微信公众号token、随机数random、搜索的微信公众号名字
params = {
'action': 'search_biz',
'token': token,
'random': random.random(),
'query': query,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'begin': '0',
'count': '5'
}
# 打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers
response = requests.get(search_url, cookies=self.cookies, headers=headers, params=params)
time.sleep(2)
# 取搜索结果中的第一个公众号
lists = response.json().get('list')[0]
# 获取这个公众号的fakeid,后面爬取公众号文章需要此字段
fakeid = lists.get('fakeid')
nickname = lists.get('nickname')
# 微信公众号文章接口地址
search_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
# 搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random
params = {
'action': 'list_ex',
'token': token,
'random': random.random(),
'fakeid': fakeid,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'begin': '0', # 不同页,此参数变化,变化规则为每页加5
'count': '5',
'query': '',
'type': '9'
}
self.log('正在查询公众号[ %s ]相关文章' % nickname)
# 打开搜索的微信公众号文章列表页
response = requests.get(search_url, cookies=self.cookies, headers=headers, params=params)
time.sleep(2)
for per in response.json().get('app_msg_list', []):
print('title ---> %s' % per.get('title'))
print('link ---> %s' % per.get('link'))
# print('cover ---> %s' % per.get('cover'))
except Exception as e:
traceback.print_exc()
if __name__ == '__main__':
spider = Spider()
spider.login()
spider.get_article('python')
该代码仅用于学习,不适用于分页查询.
根据网民的说法,该接口也有访问频率限制. 一天几百次不是问题. 如果访问速度太快或次数太多,它将被阻止24小时.
微信公众号内容采集教程. docx29页
采集交流 • 优采云 发表了文章 • 0 个评论 • 365 次浏览 • 2020-08-06 14:14
打开网页后,默认显示“热门”文章. 向下滚动页面,找到并单击“加载更多内容”按钮,在操作提示框中选择“更多操作”,微信公众号文章正文采集步骤3,选择“循环点击单个元素”,创建页面翻转循环微信公众号文章文本采集步骤4由于此网页涉及Ajax技术,因此我们需要设置一些高级选项. 选择“单击元素”步骤,打开“高级选项”,选中“ Ajax加载数据”,将时间设置为“ 2秒”,微信公众号文章正文采集步骤5注意: AJAX是延迟加载和异步更新的脚本通过在后台与服务器进行少量数据交换的技术,可以在不重新加载整个网页的情况下更新网页的特定部分. 性能特点: 当您单击网页中的一个选项时,大多数网站的URL不会更改. b. 该网页未完全加载,仅部分加载了数据并进行了更改. 验证方法: 单击该操作后,URL输入栏将不会在浏览器的加载状态或转弯状态下显示. 观察该网页,我们发现单击“加载更多内容” 5次后,页面将加载到底部,总共显示100条文章. 因此,我们将整个“循环旋转”步骤设置为执行5次. 选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,将循环数设置为“ 5”,单击“确定”,微信公众号文章正文采集步骤6第3步: 创建一个列表循环并提取数据HYPERLINK“ / article / javascript :;”移动鼠标,然后选择页面上的第一个文章链接.
系统将自动识别相似的链接. 在操作提示框中,选择“全选”微信公众号文章正文采集步骤7,选择“单击每个链接”,微信公众号文章正文采集步骤8,系统将自动进入文章明细页面. 单击要采集的字段(在此处单击文章标题),然后在操作提示框中选择“采集此元素的文本”. 文章发布时间和文章来源字段的采集方法与微信公众号文章正文采集步骤9相同. 接下来,将采集文章正文. 首先点击文章正文的第一段,系统会自动识别页面中的相似元素,选择“全选”微信公众号文章正文采集步骤105),可以看到所有正文段落均被选中并转绿色. 选择“采集以下元素文本”微信公众号文章正文采集步骤11注意: 在字段表中,您可以自定义字段以修改微信公众号文章正文采集步骤126)上述操作之后,正文将全部采集的(默认是文本的每个段落都是一个单元格). 一般来说,我们希望将采集的文本合并到同一单元格中. 单击“自定义数据字段”按钮,选择“自定义数据合并方法”,选中“多次提取并将同一字段合并到一行,即,追加到同一字段,例如文本页面合并”,然后单击“确定”,微信公众号文章正文采集步骤13,“自定义数据字段”按钮选择“自定义数据合并方法”,微信公众号文章正文采集步骤14,微信公众号文章正文采集步骤如图15所示. : 修改Xpath1)选择整个“循环步骤”,打开“高级选项”,可以看到由彩云生成的默认值是固定元素列表,该列表定位了前20条微信公众号文章正文采集步骤162的链接)在Firefox中打开采集网页并观察源代码.
我们发现通过此Xpath: // DIV [@ class ='main-left'] / DIV [3] / UL / LI / DIV [2] / H3 [1] / A,在页面All中需要微信公众号文章正文采集步骤中有100条微信公众号文章,在步骤173)将修改后的Xpath复制并粘贴到优采云中显示的位置,然后单击“确定”,微信公众号文章正文采集步骤18步骤5 : 我们将继续观察流程图结构的修改. 5次单击“加载更多内容”后,此页面将加载所有100条文章. 因此,我们的配置规则的思想是首先建立一个翻页周期,加载全部100条文章,然后创建一个周期列表并提取数据1)选择整个``循环''步骤并将其拖出``循环''页面翻页”步骤. 如果您不执行此操作,将会有很多重复的数据. 微信公众号文章正文采集步骤19拖动完成后,如下图所示,微信公众号文章正文采集步骤20步骤6: 数据采集和导出1)单击左上角单击角上的“保存”,然后点击“开始采集”,选择“开始本地采集”,微信公众号文本采集步骤21. 采集完成后,弹出提示,选择“导出数据”,选择“适当的导出方式”,将采集的数据导出到微信公众号文章正文采集步骤223)这里我们选择excel作为导出格式. 数据导出后,如下图所示,微信公众号文章正文采集步骤23如上图所示,部分文章的正文未采集.
这是因为系统自动生成了文章正文的循环列表的Xpath: // [@ id =“ js_content”] / P,因此无法找到本文的正文. 将Xpath修改为: // [@@ =“ =” js_content“] // P,所有文章正文都可以位于微信公众号文章正文采集步骤23微信公众号文章正文采集步骤24说明: 本文的方法是仅适合采集搜狗微信文章正文内容. 无法在文本中采集图片. 如果需要采集图片,则需要在此过程中添加判断条件. 相关集合教程: 京东商品信息集合豆瓣电影简短评论集合58全市信息集合优采云-一个由70万用户选择的网络数据采集器. 1.操作简单,任何人都可以使用: 不需要技术背景,可以通过浏览Internet进行采集. 完全可视化该过程,单击鼠标以完成操作,您可以在2分钟内快速上手. 2.强大的功能,可以在任何网站上采集: 单击,登录,翻页,识别验证码,瀑布流,Ajax脚本异步加载数据页,所有这些都可以通过简单的设置进行采集. 3.云采集,也可以关闭. 配置采集任务后,可以将其关闭,并可以在云中执行该任务. 庞大的云采集集群不间断运行24 * 7,因此无需担心IP被阻塞和网络中断. 4.免费功能+增值服务,可以按需选择. 免费版具有所有功能,可以满足用户的基本采集需求. 同时,建立了一些增值服务(例如私有云)以满足高端付费企业用户的需求. 查看全部
优采云·云采集服务平台微信公众号文章文本采集教程很多时候,我们需要采集网页文章的文本. 本文以搜狗微信文章为例,介绍利用优采云采集网页正文的方法. 文章的正文通常包括文本和图片. 本文仅演示了在正文中采集文本的方法,图像采集将在另一个教程中进行讨论. 本文将采集以下字段: 文章标题,时间,来源和正文(正文中的所有文本都将合并到excel单元格中,并且将使用“自定义数据合并方法”功能,请注意). 以下是“自定义数据合并方法”的详细教程,您可以首先学习: /tutorialdetail-1/zdyhb_7.html集合网站: /使用功能点: 分页列表信息集合“ HYPERLINK” /tutorial/fylb-70.aspx ?t = 1“ /tutorial/fylb-70.aspx?t=1Xpath HYPERLINK” / search?query = XPath“ / search?query = XPathAJAX点击并翻页HYPERLINK” /tutorialdetail-1/ajaxdjfy_7.html“ / tutorialdetail- 1 / ajaxdjfy_7.html步骤1: 创建采集任务1)进入主界面,选择“自定义模式”微信公众号文章正文采集步骤12)复制要采集的URL并粘贴到网站输入框中,单击“保存”. URL”微信公众号2文本采集步骤2 HYPERLINK” / article / javascript :;”步骤2: 创建翻页循环在页面的右上角,打开“ Process”以显示“ Process Designer”和“ Customize Current Operation”的两个部分.
打开网页后,默认显示“热门”文章. 向下滚动页面,找到并单击“加载更多内容”按钮,在操作提示框中选择“更多操作”,微信公众号文章正文采集步骤3,选择“循环点击单个元素”,创建页面翻转循环微信公众号文章文本采集步骤4由于此网页涉及Ajax技术,因此我们需要设置一些高级选项. 选择“单击元素”步骤,打开“高级选项”,选中“ Ajax加载数据”,将时间设置为“ 2秒”,微信公众号文章正文采集步骤5注意: AJAX是延迟加载和异步更新的脚本通过在后台与服务器进行少量数据交换的技术,可以在不重新加载整个网页的情况下更新网页的特定部分. 性能特点: 当您单击网页中的一个选项时,大多数网站的URL不会更改. b. 该网页未完全加载,仅部分加载了数据并进行了更改. 验证方法: 单击该操作后,URL输入栏将不会在浏览器的加载状态或转弯状态下显示. 观察该网页,我们发现单击“加载更多内容” 5次后,页面将加载到底部,总共显示100条文章. 因此,我们将整个“循环旋转”步骤设置为执行5次. 选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,将循环数设置为“ 5”,单击“确定”,微信公众号文章正文采集步骤6第3步: 创建一个列表循环并提取数据HYPERLINK“ / article / javascript :;”移动鼠标,然后选择页面上的第一个文章链接.
系统将自动识别相似的链接. 在操作提示框中,选择“全选”微信公众号文章正文采集步骤7,选择“单击每个链接”,微信公众号文章正文采集步骤8,系统将自动进入文章明细页面. 单击要采集的字段(在此处单击文章标题),然后在操作提示框中选择“采集此元素的文本”. 文章发布时间和文章来源字段的采集方法与微信公众号文章正文采集步骤9相同. 接下来,将采集文章正文. 首先点击文章正文的第一段,系统会自动识别页面中的相似元素,选择“全选”微信公众号文章正文采集步骤105),可以看到所有正文段落均被选中并转绿色. 选择“采集以下元素文本”微信公众号文章正文采集步骤11注意: 在字段表中,您可以自定义字段以修改微信公众号文章正文采集步骤126)上述操作之后,正文将全部采集的(默认是文本的每个段落都是一个单元格). 一般来说,我们希望将采集的文本合并到同一单元格中. 单击“自定义数据字段”按钮,选择“自定义数据合并方法”,选中“多次提取并将同一字段合并到一行,即,追加到同一字段,例如文本页面合并”,然后单击“确定”,微信公众号文章正文采集步骤13,“自定义数据字段”按钮选择“自定义数据合并方法”,微信公众号文章正文采集步骤14,微信公众号文章正文采集步骤如图15所示. : 修改Xpath1)选择整个“循环步骤”,打开“高级选项”,可以看到由彩云生成的默认值是固定元素列表,该列表定位了前20条微信公众号文章正文采集步骤162的链接)在Firefox中打开采集网页并观察源代码.
我们发现通过此Xpath: // DIV [@ class ='main-left'] / DIV [3] / UL / LI / DIV [2] / H3 [1] / A,在页面All中需要微信公众号文章正文采集步骤中有100条微信公众号文章,在步骤173)将修改后的Xpath复制并粘贴到优采云中显示的位置,然后单击“确定”,微信公众号文章正文采集步骤18步骤5 : 我们将继续观察流程图结构的修改. 5次单击“加载更多内容”后,此页面将加载所有100条文章. 因此,我们的配置规则的思想是首先建立一个翻页周期,加载全部100条文章,然后创建一个周期列表并提取数据1)选择整个``循环''步骤并将其拖出``循环''页面翻页”步骤. 如果您不执行此操作,将会有很多重复的数据. 微信公众号文章正文采集步骤19拖动完成后,如下图所示,微信公众号文章正文采集步骤20步骤6: 数据采集和导出1)单击左上角单击角上的“保存”,然后点击“开始采集”,选择“开始本地采集”,微信公众号文本采集步骤21. 采集完成后,弹出提示,选择“导出数据”,选择“适当的导出方式”,将采集的数据导出到微信公众号文章正文采集步骤223)这里我们选择excel作为导出格式. 数据导出后,如下图所示,微信公众号文章正文采集步骤23如上图所示,部分文章的正文未采集.
这是因为系统自动生成了文章正文的循环列表的Xpath: // [@ id =“ js_content”] / P,因此无法找到本文的正文. 将Xpath修改为: // [@@ =“ =” js_content“] // P,所有文章正文都可以位于微信公众号文章正文采集步骤23微信公众号文章正文采集步骤24说明: 本文的方法是仅适合采集搜狗微信文章正文内容. 无法在文本中采集图片. 如果需要采集图片,则需要在此过程中添加判断条件. 相关集合教程: 京东商品信息集合豆瓣电影简短评论集合58全市信息集合优采云-一个由70万用户选择的网络数据采集器. 1.操作简单,任何人都可以使用: 不需要技术背景,可以通过浏览Internet进行采集. 完全可视化该过程,单击鼠标以完成操作,您可以在2分钟内快速上手. 2.强大的功能,可以在任何网站上采集: 单击,登录,翻页,识别验证码,瀑布流,Ajax脚本异步加载数据页,所有这些都可以通过简单的设置进行采集. 3.云采集,也可以关闭. 配置采集任务后,可以将其关闭,并可以在云中执行该任务. 庞大的云采集集群不间断运行24 * 7,因此无需担心IP被阻塞和网络中断. 4.免费功能+增值服务,可以按需选择. 免费版具有所有功能,可以满足用户的基本采集需求. 同时,建立了一些增值服务(例如私有云)以满足高端付费企业用户的需求.
欢迎老朋友开发php微信公众号
采集交流 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2020-08-06 06:06
更新: 2018年10月20日09:38:44转载作者: dq_095
本文主要详细介绍php微信公众号的开发,欢迎老朋友,它具有一定的参考价值,有兴趣的朋友可以参考
本文中的示例共享了由php微信公众号开发的欢迎老朋友的特定代码,供您参考. 具体内容如下
数据库简介
关键代码如下:
$postObj = simplexml_load_string($postStr, 'SimpleXMLElement', LIBXML_NOCDATA);
$fromUsername = $postObj->FromUserName;
$toUsername = $postObj->ToUserName;
$keyword = trim($postObj->Content);
$time = time();
$textTpl = "
%s
0
";
if(!empty( $keyword ))
{
//用 户 名 : $user
//密 码 : $pwd
//主库域名 : $host
//从库域名 : SAE_MYSQL_HOST_S
//端 口 : $port
//数据库名 : $dbname
$dbname = "app_dq095";
$host = "w.rdc.sae.sina.com.cn";
$port = "3306";
$user = "4k514n103z";
$pwd = "2402314li2j1i5im1xy2xizj5y332w2x41k2z203";
/*接着调用mysql_connect()连接服务器*/
// 连主库
$db = mysql_connect($host,$user,$pwd);
if(!$db){
die("Connect Server Failed: " . mysql_error($db));
}
/*连接成功后立即调用mysql_select_db()选中需要连接的数据库*/
if (!mysql_select_db($dbname)) {
die("Select Database Failed: " . mysql_error($db));
}
mysql_query("set names utf-8",$db);
/*至此连接已完全建立,就可对当前数据库进行相应的操作了*/
/*!!!注意,无法再通过本次连接调用mysql_select_db来切换到其它数据库了!!!*/
/* 需要再连接其它数据库,请再使用mysql_connect+mysql_select_db启动另一个连接*/
/**
* 接下来就可以使用其它标准php mysql函数操作进行数据库操作
*/
$sql="SELECT * FROM `welcome`WHERE `user`= '" . iconv("UTF-8","GBK",$fromUsername) . "'";
$query=mysql_query($sql);
$rs=mysql_fetch_array($query);
$b= $rs['user'];
$c=iconv("GBK","UTF-8",$b);
$msgType = "text";
if ($c==$fromUsername)
{
$contentStr = "欢迎老朋友!";
}else{
$sql="INSERT INTO `welcome`(`id`,`user`) VALUES (NULL,'{$fromUsername}')";
mysql_query($sql);
$contentStr = "欢迎新朋友!";
}
$resultStr = sprintf($textTpl, $fromUsername, $toUsername, $time, $msgType, $contentStr);
echo $resultStr;
mysql_close($db);
}else{
echo "Input something...";
}
index.php代码如下 查看全部
欢迎老朋友开发php微信公众号
更新: 2018年10月20日09:38:44转载作者: dq_095
本文主要详细介绍php微信公众号的开发,欢迎老朋友,它具有一定的参考价值,有兴趣的朋友可以参考
本文中的示例共享了由php微信公众号开发的欢迎老朋友的特定代码,供您参考. 具体内容如下
数据库简介
关键代码如下:
$postObj = simplexml_load_string($postStr, 'SimpleXMLElement', LIBXML_NOCDATA);
$fromUsername = $postObj->FromUserName;
$toUsername = $postObj->ToUserName;
$keyword = trim($postObj->Content);
$time = time();
$textTpl = "
%s
0
";
if(!empty( $keyword ))
{
//用 户 名 : $user
//密 码 : $pwd
//主库域名 : $host
//从库域名 : SAE_MYSQL_HOST_S
//端 口 : $port
//数据库名 : $dbname
$dbname = "app_dq095";
$host = "w.rdc.sae.sina.com.cn";
$port = "3306";
$user = "4k514n103z";
$pwd = "2402314li2j1i5im1xy2xizj5y332w2x41k2z203";
/*接着调用mysql_connect()连接服务器*/
// 连主库
$db = mysql_connect($host,$user,$pwd);
if(!$db){
die("Connect Server Failed: " . mysql_error($db));
}
/*连接成功后立即调用mysql_select_db()选中需要连接的数据库*/
if (!mysql_select_db($dbname)) {
die("Select Database Failed: " . mysql_error($db));
}
mysql_query("set names utf-8",$db);
/*至此连接已完全建立,就可对当前数据库进行相应的操作了*/
/*!!!注意,无法再通过本次连接调用mysql_select_db来切换到其它数据库了!!!*/
/* 需要再连接其它数据库,请再使用mysql_connect+mysql_select_db启动另一个连接*/
/**
* 接下来就可以使用其它标准php mysql函数操作进行数据库操作
*/
$sql="SELECT * FROM `welcome`WHERE `user`= '" . iconv("UTF-8","GBK",$fromUsername) . "'";
$query=mysql_query($sql);
$rs=mysql_fetch_array($query);
$b= $rs['user'];
$c=iconv("GBK","UTF-8",$b);
$msgType = "text";
if ($c==$fromUsername)
{
$contentStr = "欢迎老朋友!";
}else{
$sql="INSERT INTO `welcome`(`id`,`user`) VALUES (NULL,'{$fromUsername}')";
mysql_query($sql);
$contentStr = "欢迎新朋友!";
}
$resultStr = sprintf($textTpl, $fromUsername, $toUsername, $time, $msgType, $contentStr);
echo $resultStr;
mysql_close($db);
}else{
echo "Input something...";
}
index.php代码如下
微信公众号文章搜寻器系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2020-08-06 04:04
1. 我做了两个履带. 第一次我害怕Phoenix.com时,没有任何限制,我可以随意爬网,所以我放松了对自动代码执行模块的警惕. 我认为这很简单,但事实并非如此. 我已经为这个问题困扰了好几天,几乎是四天. 由于搜狗的限制,获得相同IP的次数越来越多. 首先,显示验证码,其次是访问限制. 直接无法访问. 根据请求,您得到的是访问次数太频繁,这种提示,因此在开发过程中最麻烦的不是代码的编写,而是测试. 编写后无法立即测试该代码. 我相信大多数程序员都不会喜欢,我现在编写的程序每天执行3次. 这样的频率很好,并且因为它是由多个正式帐户采集的,所以每个正式帐户之间也要有一个间隔,否则它将同时访问十多个公众,该帐户上的数百篇文章也是不现实的. 在插入句子时,如何使每个正式帐户都不敢玩,等待特定的时间段,执行下一个,最后使用setInterval函数来解决它,
每80秒执行一个正式帐户,并将每个执行代码写入hello. 泡沫距离有点远. 我会收到的. 我们来谈谈cron程序包,它是自动执行的. npm官方网站上仅举了一个例子,但是我的意思是桑拿浴可能有点压抑. 我无法播放,但了解其用法. 然后我说,如果我听不懂怎么办. 在Internet,百度和cron程序包的特定用法上进行搜索. 有很多,所以我只是看了看,但是经过仔细的分析却并非如此. 都是废话,没用. 一般在线使用中都有一个问号,但是当我添加一个问号时,会出现错误. 是的,这都是胡说八道. 最后,我在同学小组的一个前端技术讨论小组中说了这一点. 真正热情的小组朋友找到了我一个链接. 我进去看看,尝试了一下,没关系,所以,非常感谢这位帮助我解决难题的同学. 我将再次附上QQ群组号码和链接,以帮助您在阅读本文时学习. QQ组号: 435012561,链接: ,链接说的没问题,至少可以用,这里我仍然有一个问题,就是时区,我们以前用过一次,使用洛杉矶时间,但是这次显然不起作用,我们需要用中文,但是我在北京尝试了几次,虽然不好,但是重庆可以,所以我用了重庆.
2. 我想在这里谈论的是从地址栏获取参数的问题. 我做的最后一个很好,但是我不知道该怎么做. 我从地址栏中得到的最后一个是数字,但是这个是它的. 它是一个字符串,并且mongodb中对字段的要求仍然非常严格,因此分页功能困扰了我几个小时. 它是如何解决的?我在mongodb中添加了一个讨论组. 我问其中有什么问题,并发布了屏幕截图. 有一个热心的网民说,传入数据的格式显然不正确. 我唤醒了做梦者,我说了是,然后我使用Number()函数来处理我得到的参数,以便字符串类型的数量成为数字类型的数量. 很好,因此在使用mongodb时,必须注意存储数据的格式.
3. Mongodb查询数据语句的组织:
坦率地说,实际上是使用了限制和跳过这两个函数,但是特定的格式可能是乐观的,并且mine是可接受的参数,但是mongo的参数接受很容易直接编写,不需要喜欢sql像$ {“”}一样. 下面的排序功能说明了排序方法. 这里,ctime字段设置为标准,-1表示逆序,1表示正序,
4. 在这段代码编写中,我第一次使用了try catch方法进行纠错. 原来没关系. 偶尔的错误可以正常地打印出来,但是它不会影响代码的整体执行,或者说到下一次执行,整体感觉非常好,
对于特定用法,将您要执行的代码放入try中,并在最后添加一行,并抛出Error();
然后传入参数e以进行捕获,可以在catch中打印很多消息,我只打印了其中之一,例如e.message
5. anync包主要用于此编码过程中,其中的ansyc.each循环,ansyc.waterfall在执行完上述操作后可以执行以下操作,也可以在您之间的上下传递参数,这非常重要的是,因为在此编程中,每次获取的内容都不同,每个代码执行的条件也不同,也就是说,所需的参数也不同,即,下一个代码执行可能需要上一个代码. 执行,所以这个anync软件包真的值得研究. 他的每种方法都不相同,有时可能会得到意想不到的结果.
6. 在mysql中,如果要实现这样的效果,即如果它已经存在于数据库中,则忽略它,或者不重复存储它;如果它不存在于数据库中,则将其存储在其中. 用replace替换插入数据的插入. 但是在mongodb中,应该没有,或者我还没有找到它. 我用这种方法解决了. 我定义了一个开关来使该开关为真. 在每次存储之前,循环所有数据以查看是否有该数据,如果没有,则让开关变为假,否则,继续执行,即判断此时开关是真还是假,如果为true,则执行插入操作;如果为false,则将其忽略. 这样可以达到类似的效果,否则每次都会存储大量重复数据,
7. 该集合的核心是我文件中的common.js. 首先,因为我们要采集,所以我们需要使用请求包. 采集后,我们需要以html格式处理数据,以便可以使用类似于jquery的数据. 对于该操作,cheerio包已使用了很长时间,然后在循环采集时将使用anync.each方法,因此将使用异步包,
7-1,
通过采集搜狗微信,我们必须分析搜狗微信的路径. 每个官方帐户页面的路径都是这样
%E8%BF%99%E6%89%8D%E6%98%AF%E6%97%A5%E6%9C%AC&ie = utf8&_sug_ = n&_sug_type _ =
这是“这是日本”页面的链接. 经过分析,所有正式帐户的链接仅在查询后的参数上有所不同,但是查询后的参数是什么,实际上,它是由encodeURIComponent()函数转换的,之后是“这是日本”,因此相同. 要获得该官方帐户,只需对官方帐户的名称进行编码并将其动态组合成一个链接,您就可以在访问时输入每个链接,但是我只是要求此页面此链接,
不是
此页面,因此进一步的处理是获取当前页面的第一内容的链接,即href
获得此链接后,您会发现他具有自己的加密方法. 实际上非常简单,就是在链接中增加三个安培;更换这三个放大器;在带有空链接的链接中,就好了,这是第一步,获取每个官方帐户的页面链接,
7-2
获取链接后,有必要访问,即请求,请求每个地址,获取每个地址的内容,但每个页面上显示的内容不在该页面中,即在html结构中,隐藏在js中,因此我们需要通过常规匹配来获取每篇文章的对象,然后循环访问每个正式帐户的对象以获取有关该对象中每篇文章的一些信息,包括标题,缩略图,摘要,URL,时间, 5个字段,但我使用的代码很烂,而我当时使用的是
Object.Attribute.foreach(function(item,index){
})
这种可怕的方法,最后要做的就是编写一个循环以完全获取每个对象,否则只能获取第一个对象. 在这里,您应该使用async.each或async.foreach. 可以使用两种方法中的每一种,并且它们都非常易于使用. 这样,您将获得上述每篇文章的基本新闻.
7-3,
第三阶段是进入每篇文章的详细信息页面,并获取每篇文章的内容,喜欢的次数,作者,官方帐号,阅读量和其他数据. 这里遇到的主要问题是人们的内容直接位于js中,并且所有img标签都有问题. 它们以这种形式存储在内容中,但是在这种情况下,由于标签,html文档(我不知道此类img标签)存在问题,此类图像无法显示在我们的网页上,因此在这里我们需要进行一些处理,替换全部与
查看全部
已经快两个星期了. 我已经在微信公众号上调试了商品搜寻器系统,最后一切都很好,但是在此期间,我遇到了很多问题. 让我们今天回顾一下并进行总结. 我希望它会有用. 朋友可以学习.
1. 我做了两个履带. 第一次我害怕Phoenix.com时,没有任何限制,我可以随意爬网,所以我放松了对自动代码执行模块的警惕. 我认为这很简单,但事实并非如此. 我已经为这个问题困扰了好几天,几乎是四天. 由于搜狗的限制,获得相同IP的次数越来越多. 首先,显示验证码,其次是访问限制. 直接无法访问. 根据请求,您得到的是访问次数太频繁,这种提示,因此在开发过程中最麻烦的不是代码的编写,而是测试. 编写后无法立即测试该代码. 我相信大多数程序员都不会喜欢,我现在编写的程序每天执行3次. 这样的频率很好,并且因为它是由多个正式帐户采集的,所以每个正式帐户之间也要有一个间隔,否则它将同时访问十多个公众,该帐户上的数百篇文章也是不现实的. 在插入句子时,如何使每个正式帐户都不敢玩,等待特定的时间段,执行下一个,最后使用setInterval函数来解决它,
每80秒执行一个正式帐户,并将每个执行代码写入hello. 泡沫距离有点远. 我会收到的. 我们来谈谈cron程序包,它是自动执行的. npm官方网站上仅举了一个例子,但是我的意思是桑拿浴可能有点压抑. 我无法播放,但了解其用法. 然后我说,如果我听不懂怎么办. 在Internet,百度和cron程序包的特定用法上进行搜索. 有很多,所以我只是看了看,但是经过仔细的分析却并非如此. 都是废话,没用. 一般在线使用中都有一个问号,但是当我添加一个问号时,会出现错误. 是的,这都是胡说八道. 最后,我在同学小组的一个前端技术讨论小组中说了这一点. 真正热情的小组朋友找到了我一个链接. 我进去看看,尝试了一下,没关系,所以,非常感谢这位帮助我解决难题的同学. 我将再次附上QQ群组号码和链接,以帮助您在阅读本文时学习. QQ组号: 435012561,链接: ,链接说的没问题,至少可以用,这里我仍然有一个问题,就是时区,我们以前用过一次,使用洛杉矶时间,但是这次显然不起作用,我们需要用中文,但是我在北京尝试了几次,虽然不好,但是重庆可以,所以我用了重庆.
2. 我想在这里谈论的是从地址栏获取参数的问题. 我做的最后一个很好,但是我不知道该怎么做. 我从地址栏中得到的最后一个是数字,但是这个是它的. 它是一个字符串,并且mongodb中对字段的要求仍然非常严格,因此分页功能困扰了我几个小时. 它是如何解决的?我在mongodb中添加了一个讨论组. 我问其中有什么问题,并发布了屏幕截图. 有一个热心的网民说,传入数据的格式显然不正确. 我唤醒了做梦者,我说了是,然后我使用Number()函数来处理我得到的参数,以便字符串类型的数量成为数字类型的数量. 很好,因此在使用mongodb时,必须注意存储数据的格式.
3. Mongodb查询数据语句的组织:
坦率地说,实际上是使用了限制和跳过这两个函数,但是特定的格式可能是乐观的,并且mine是可接受的参数,但是mongo的参数接受很容易直接编写,不需要喜欢sql像$ {“”}一样. 下面的排序功能说明了排序方法. 这里,ctime字段设置为标准,-1表示逆序,1表示正序,
4. 在这段代码编写中,我第一次使用了try catch方法进行纠错. 原来没关系. 偶尔的错误可以正常地打印出来,但是它不会影响代码的整体执行,或者说到下一次执行,整体感觉非常好,
对于特定用法,将您要执行的代码放入try中,并在最后添加一行,并抛出Error();
然后传入参数e以进行捕获,可以在catch中打印很多消息,我只打印了其中之一,例如e.message
5. anync包主要用于此编码过程中,其中的ansyc.each循环,ansyc.waterfall在执行完上述操作后可以执行以下操作,也可以在您之间的上下传递参数,这非常重要的是,因为在此编程中,每次获取的内容都不同,每个代码执行的条件也不同,也就是说,所需的参数也不同,即,下一个代码执行可能需要上一个代码. 执行,所以这个anync软件包真的值得研究. 他的每种方法都不相同,有时可能会得到意想不到的结果.
6. 在mysql中,如果要实现这样的效果,即如果它已经存在于数据库中,则忽略它,或者不重复存储它;如果它不存在于数据库中,则将其存储在其中. 用replace替换插入数据的插入. 但是在mongodb中,应该没有,或者我还没有找到它. 我用这种方法解决了. 我定义了一个开关来使该开关为真. 在每次存储之前,循环所有数据以查看是否有该数据,如果没有,则让开关变为假,否则,继续执行,即判断此时开关是真还是假,如果为true,则执行插入操作;如果为false,则将其忽略. 这样可以达到类似的效果,否则每次都会存储大量重复数据,
7. 该集合的核心是我文件中的common.js. 首先,因为我们要采集,所以我们需要使用请求包. 采集后,我们需要以html格式处理数据,以便可以使用类似于jquery的数据. 对于该操作,cheerio包已使用了很长时间,然后在循环采集时将使用anync.each方法,因此将使用异步包,
7-1,
通过采集搜狗微信,我们必须分析搜狗微信的路径. 每个官方帐户页面的路径都是这样
%E8%BF%99%E6%89%8D%E6%98%AF%E6%97%A5%E6%9C%AC&ie = utf8&_sug_ = n&_sug_type _ =
这是“这是日本”页面的链接. 经过分析,所有正式帐户的链接仅在查询后的参数上有所不同,但是查询后的参数是什么,实际上,它是由encodeURIComponent()函数转换的,之后是“这是日本”,因此相同. 要获得该官方帐户,只需对官方帐户的名称进行编码并将其动态组合成一个链接,您就可以在访问时输入每个链接,但是我只是要求此页面此链接,
不是
此页面,因此进一步的处理是获取当前页面的第一内容的链接,即href
获得此链接后,您会发现他具有自己的加密方法. 实际上非常简单,就是在链接中增加三个安培;更换这三个放大器;在带有空链接的链接中,就好了,这是第一步,获取每个官方帐户的页面链接,
7-2
获取链接后,有必要访问,即请求,请求每个地址,获取每个地址的内容,但每个页面上显示的内容不在该页面中,即在html结构中,隐藏在js中,因此我们需要通过常规匹配来获取每篇文章的对象,然后循环访问每个正式帐户的对象以获取有关该对象中每篇文章的一些信息,包括标题,缩略图,摘要,URL,时间, 5个字段,但我使用的代码很烂,而我当时使用的是
Object.Attribute.foreach(function(item,index){
})
这种可怕的方法,最后要做的就是编写一个循环以完全获取每个对象,否则只能获取第一个对象. 在这里,您应该使用async.each或async.foreach. 可以使用两种方法中的每一种,并且它们都非常易于使用. 这样,您将获得上述每篇文章的基本新闻.
7-3,
第三阶段是进入每篇文章的详细信息页面,并获取每篇文章的内容,喜欢的次数,作者,官方帐号,阅读量和其他数据. 这里遇到的主要问题是人们的内容直接位于js中,并且所有img标签都有问题. 它们以这种形式存储在内容中,但是在这种情况下,由于标签,html文档(我不知道此类img标签)存在问题,此类图像无法显示在我们的网页上,因此在这里我们需要进行一些处理,替换全部与
如何在搜狗微信公众号上采集热门文章. docx 18页
采集交流 • 优采云 发表了文章 • 0 个评论 • 455 次浏览 • 2020-08-06 00:00
下拉页面,找到并单击“加载更多内容”按钮,在操作提示框中选择“更多操作”搜狗微信公众号热门文章如何采集图2选择“循环单击单个元素”创建一个页面翻阅周期如何在搜狗微信公众号上采集热门文章图3由于此页面涉及Ajax技术,因此我们需要设置一些高级选项. 选择“单击元素”步骤,打开“高级选项”,选中“ Ajax加载数据”,将时间设置为“ 2秒”. 如何在搜狗微信公众号上采集热门文章图4注意: AJAX表示延迟加载和异步更新. 这种脚本技术通过在后台与服务器进行少量数据交换,可以更新网页的特定部分,而无需重新加载整个网页. 性能特点: 当您单击网页中的一个选项时,大多数网站的URL不会更改. b. 该网页未完全加载,仅部分加载了数据并进行了更改. 验证方法: 单击该操作后,URL输入栏将不会在浏览器的加载状态或转弯状态下显示. 观察该网页,我们发现单击“加载更多内容” 5次后,页面将加载到底部,总共显示100条文章. 因此,我们将整个“循环旋转”步骤设置为执行5次. 选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,将循环数设置为等于“ 5次”,然后单击“确定”. 搜狗微信公众号图5步骤3: 创建列表循环并提取数据HYPERLINK“ / article / javascript :;” 1)移动鼠标以选择页面上第一篇文章的框.
系统将识别此块中的子元素. 在操作提示框中,选择“选择子元素”. 如何在搜狗微信公众号上采集热门文章. 图62)继续在页面上选择第二篇文章的块,系统将第二篇文章中的子元素会被自动选择,页面上的其他10组相似元素也会被识别. 在操作提示框中,选择“全选”. 如何在搜狗微信公众号上采集热门文章. 图73)可以看到,页面上文章区域中的所有元素均已选中,并变为绿色. 在右侧的操作提示框中,将显示一个字段预览表. 将鼠标移到表格的顶部,然后单击垃圾箱图标以删除不必要的字段. 字段选择完成后,选择“采集以下数据”. 如何在搜狗微信公众号上采集热门文章. 图84)我们还希望采集每篇文章的URL,因此需要提取一个字段. 单击第一篇文章的链接,系统将自动在页面上选择一组文章链接. 在右侧的操作提示框中,选择“全选”如何在搜狗微信公众号上采集热门文章图95)选择“采集以下链接地址”如何在搜狗微信公众号上采集热门文章图106)选择后在字段中,选择相应的字段,您可以自定义字段的命名. 图11第4步: 修改Xpath让我们继续观察. 5次单击“加载更多内容”后,此页面将加载所有100条文章. 因此,我们的配置规则的思想是首先建立一个翻页周期,加载全部100条文章,然后创建一个周期列表并提取数据1)选择整个``循环''步骤并将其拖出``循环''翻页”步骤.
如果不执行此操作,将有很多重复的数据. 如何在搜狗微信公众号上采集热门文章图12拖动完成后,如下图所示,如何在搜狗微信公众号上采集热门文章图13在“列表循环”中“在此步骤中,循环的100篇文章列表. 选择整个“循环步骤”,打开“高级选项”,元素列表中的Xpath不会被固定: // BODY [@ id ='loginWrap'] / DIV [4] / DIV [1] / DIV [3] / UL [1] / LI,将其复制并粘贴到Firefox浏览器中的相应位置. 如何在搜狗微信公众号上采集热门文章图14 Xpath: 是一种路径查询语言,简而言之,它使用路径表达式来查找我们需要定位的数据,Xpath用于沿XML路径查找数据,但是Ucai云采集器中有一套针对HTML的Xpath引擎,因此您可以直接使用XPATH可以准确地在网页中查找和定位数据3)在Firefox浏览器中,我们通过以下Xpath发现: // BODY [@ id ='loginWrap'] / DIV [4] / DIV [1] / DIV [3] / UL [1] / LI,该页面上的页面有20篇文章,搜狗微信公众号,如何采集热门文章图154)将Xpath修改为: // BODY [@ id ='loginWrap'] / DIV / DIV [1] / DIV [3] / UL / LI,我们发现该页面上要采集的所有文章都位于搜狗微信公众号上. 热门文章如何采集图16中所示的Xpath: // BODY [@ id ='loginWrap'] / DIV / DIV [1] / DIV [3] / UL / LI,复制并粘贴到图片中所示的位置,然后单击“确定”,搜狗微信公众号热门文章如何采集图176)单击左上角的“保存并开始”,选择“开始本地采集”如何在搜狗微信公众号上采集热门文章”图18步骤5: 数据采集和导出采集完成后,将弹出提示,选择“导出数据”,选择“适当的导出方法”,并采集搜狗微信文章数据导出搜狗微信官方账号如何搜集热门文章图19在这里我们选择excel作为导出格式,数据导出后,下图显示了如何采集搜狗微信公众号热门文章: 图20优采云-70万用户选择的Web数据采集器.
1. 该操作很简单,任何人都可以使用: 不需要技术背景,并且可以通过浏览Internet进行采集. 完全可视化该过程,单击鼠标以完成操作,您可以在2分钟内快速上手. 2.强大的功能,可以在任何网站上采集: 单击,登录,翻页,识别验证码,瀑布流,Ajax脚本异步加载数据页,所有这些都可以通过简单的设置进行采集. 3.云采集,也可以关闭. 配置采集任务后,可以将其关闭,并可以在云中执行该任务. 庞大的云采集集群不间断运行24 * 7,因此无需担心IP被阻塞和网络中断. 4.免费功能+增值服务,可以按需选择. 免费版具有所有功能,可以满足用户的基本采集需求. 同时,建立了一些增值服务(例如私有云)以满足高端付费企业用户的需求. 查看全部
优采云·云采集服务平台优采云·云采集服务平台搜狗微信公众号如何采集热门文章本文介绍如何使用优采云来采集搜狗微信文章(以热门文章为例). 规则下载: 使用功能点: 寻呼列表信息采集HYPERLINK“ /tutorial/fylb-70.aspx?t=1” /tutorial/fylb-70.aspx?t=1Xpath HYPERLINK“ / search?query = XPath” / search? query = XPathAJAX单击并翻页HYPERLINK“ /tutorial/ajaxdjfy_7.aspx?t=1” /tutorial/ajaxdjfy_7.aspx?t=1相关的采集教程: 天猫商品信息采集百度搜索结果采集步骤1: 创建采集任务1)进入主界面,选择“自定义模式”如何在搜狗微信公众号上采集热门文章图12)复制要采集的URL到网站输入框中,单击“保存URL”如何在搜狗微信上采集热门文章官方帐户图2 HYPERLINK“ / article / javascript :;”第2步: 创建翻页循环. 在页面的右上角,打开“流程”以显示“流程设计器”和“自定义当前操作”的两个部分. 打开网页后,默认显示“热门”文章.
下拉页面,找到并单击“加载更多内容”按钮,在操作提示框中选择“更多操作”搜狗微信公众号热门文章如何采集图2选择“循环单击单个元素”创建一个页面翻阅周期如何在搜狗微信公众号上采集热门文章图3由于此页面涉及Ajax技术,因此我们需要设置一些高级选项. 选择“单击元素”步骤,打开“高级选项”,选中“ Ajax加载数据”,将时间设置为“ 2秒”. 如何在搜狗微信公众号上采集热门文章图4注意: AJAX表示延迟加载和异步更新. 这种脚本技术通过在后台与服务器进行少量数据交换,可以更新网页的特定部分,而无需重新加载整个网页. 性能特点: 当您单击网页中的一个选项时,大多数网站的URL不会更改. b. 该网页未完全加载,仅部分加载了数据并进行了更改. 验证方法: 单击该操作后,URL输入栏将不会在浏览器的加载状态或转弯状态下显示. 观察该网页,我们发现单击“加载更多内容” 5次后,页面将加载到底部,总共显示100条文章. 因此,我们将整个“循环旋转”步骤设置为执行5次. 选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,将循环数设置为等于“ 5次”,然后单击“确定”. 搜狗微信公众号图5步骤3: 创建列表循环并提取数据HYPERLINK“ / article / javascript :;” 1)移动鼠标以选择页面上第一篇文章的框.
系统将识别此块中的子元素. 在操作提示框中,选择“选择子元素”. 如何在搜狗微信公众号上采集热门文章. 图62)继续在页面上选择第二篇文章的块,系统将第二篇文章中的子元素会被自动选择,页面上的其他10组相似元素也会被识别. 在操作提示框中,选择“全选”. 如何在搜狗微信公众号上采集热门文章. 图73)可以看到,页面上文章区域中的所有元素均已选中,并变为绿色. 在右侧的操作提示框中,将显示一个字段预览表. 将鼠标移到表格的顶部,然后单击垃圾箱图标以删除不必要的字段. 字段选择完成后,选择“采集以下数据”. 如何在搜狗微信公众号上采集热门文章. 图84)我们还希望采集每篇文章的URL,因此需要提取一个字段. 单击第一篇文章的链接,系统将自动在页面上选择一组文章链接. 在右侧的操作提示框中,选择“全选”如何在搜狗微信公众号上采集热门文章图95)选择“采集以下链接地址”如何在搜狗微信公众号上采集热门文章图106)选择后在字段中,选择相应的字段,您可以自定义字段的命名. 图11第4步: 修改Xpath让我们继续观察. 5次单击“加载更多内容”后,此页面将加载所有100条文章. 因此,我们的配置规则的思想是首先建立一个翻页周期,加载全部100条文章,然后创建一个周期列表并提取数据1)选择整个``循环''步骤并将其拖出``循环''翻页”步骤.
如果不执行此操作,将有很多重复的数据. 如何在搜狗微信公众号上采集热门文章图12拖动完成后,如下图所示,如何在搜狗微信公众号上采集热门文章图13在“列表循环”中“在此步骤中,循环的100篇文章列表. 选择整个“循环步骤”,打开“高级选项”,元素列表中的Xpath不会被固定: // BODY [@ id ='loginWrap'] / DIV [4] / DIV [1] / DIV [3] / UL [1] / LI,将其复制并粘贴到Firefox浏览器中的相应位置. 如何在搜狗微信公众号上采集热门文章图14 Xpath: 是一种路径查询语言,简而言之,它使用路径表达式来查找我们需要定位的数据,Xpath用于沿XML路径查找数据,但是Ucai云采集器中有一套针对HTML的Xpath引擎,因此您可以直接使用XPATH可以准确地在网页中查找和定位数据3)在Firefox浏览器中,我们通过以下Xpath发现: // BODY [@ id ='loginWrap'] / DIV [4] / DIV [1] / DIV [3] / UL [1] / LI,该页面上的页面有20篇文章,搜狗微信公众号,如何采集热门文章图154)将Xpath修改为: // BODY [@ id ='loginWrap'] / DIV / DIV [1] / DIV [3] / UL / LI,我们发现该页面上要采集的所有文章都位于搜狗微信公众号上. 热门文章如何采集图16中所示的Xpath: // BODY [@ id ='loginWrap'] / DIV / DIV [1] / DIV [3] / UL / LI,复制并粘贴到图片中所示的位置,然后单击“确定”,搜狗微信公众号热门文章如何采集图176)单击左上角的“保存并开始”,选择“开始本地采集”如何在搜狗微信公众号上采集热门文章”图18步骤5: 数据采集和导出采集完成后,将弹出提示,选择“导出数据”,选择“适当的导出方法”,并采集搜狗微信文章数据导出搜狗微信官方账号如何搜集热门文章图19在这里我们选择excel作为导出格式,数据导出后,下图显示了如何采集搜狗微信公众号热门文章: 图20优采云-70万用户选择的Web数据采集器.
1. 该操作很简单,任何人都可以使用: 不需要技术背景,并且可以通过浏览Internet进行采集. 完全可视化该过程,单击鼠标以完成操作,您可以在2分钟内快速上手. 2.强大的功能,可以在任何网站上采集: 单击,登录,翻页,识别验证码,瀑布流,Ajax脚本异步加载数据页,所有这些都可以通过简单的设置进行采集. 3.云采集,也可以关闭. 配置采集任务后,可以将其关闭,并可以在云中执行该任务. 庞大的云采集集群不间断运行24 * 7,因此无需担心IP被阻塞和网络中断. 4.免费功能+增值服务,可以按需选择. 免费版具有所有功能,可以满足用户的基本采集需求. 同时,建立了一些增值服务(例如私有云)以满足高端付费企业用户的需求.
分析python如何抓取搜狗微信官方账号永久链接的想法
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2020-08-05 21:08
本文主要解释了这些想法,请自行解决代码部分
在搜狗微信上获取当天的信息排名
指定输入关键字并通过scrapy抢夺官方帐户
通过登录微信官方帐户链接获取Cookie信息
由于尚未解决对微信公众平台的模拟登录,因此需要手动登录以实时获取cookie信息
固定链接可以在此处转换
代码部分
def parse(self, response):
item = SougouItem()
item["title"] = response.xpath('//title/text()').extract_first()
print("**"*5, item["title"],"**"*5)
name = input("----------请输入需要搜索的信息:")
print(name)
url = "http://weixin.sogou.com/weixin ... ot%3B
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name":name})
搜狗微信访问频率太快,导致需要输入验证码 查看全部
本文主要介绍关于python如何抓取Sogou微信官方帐户的永久链接的思想分析. 编辑认为这是相当不错的. 现在,我将与您分享并提供参考. 让我们跟随编辑器看一下.
本文主要解释了这些想法,请自行解决代码部分
在搜狗微信上获取当天的信息排名
指定输入关键字并通过scrapy抢夺官方帐户
通过登录微信官方帐户链接获取Cookie信息
由于尚未解决对微信公众平台的模拟登录,因此需要手动登录以实时获取cookie信息
固定链接可以在此处转换
代码部分
def parse(self, response):
item = SougouItem()
item["title"] = response.xpath('//title/text()').extract_first()
print("**"*5, item["title"],"**"*5)
name = input("----------请输入需要搜索的信息:")
print(name)
url = "http://weixin.sogou.com/weixin ... ot%3B
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name":name})
搜狗微信访问频率太快,导致需要输入验证码

