
querylist采集微信公众号文章
选选择择自自建建图图文文文章章的方方法法示示例例
采集交流 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-07-17 01:36
我通过微信公众号微信公众平台获取公众号公众号document文章章的一个例子。我自己维护了一个公众号,但是因为个人关系,时间久了。没有更新。今天上来缅怀,却偶然发现了微信公众号文章的获取方式。之前获取的方式很多,通过搜狗、清博、web、客户端等都可以,这个可能不太好,但是操作简单易懂。所以。首先,您需要在微信公众平台上拥有一个帐户。微信公众平台:/登录后,进入首页点击新建新建群发。 选择选择自建图文::好像是公众号操作教学进入编辑页面后,点击超链接弹出选择框,我们在框中输入输入对应的公众号号码名称,会出现对应的文章列表。是不是很意外?您可以打开控制台并检查是否打开了请求的接口。回复,里面是我们需要的文字文章章链链接 确认数据后,我们需要对这个界面进行分析分析。感觉非常简单。 GET 请求携带一些参数。 Fakeid是公众号的唯一ID,所以如果想直接通过名字获取文章列表,还需要先获取fakeid。当我们输入官方账号名称时,点击搜索。
可以看到搜索界面被触发,返回fakeid。这个接口需要的参数不多。接下来我们就可以用代码来模拟上面的操作了。但是,仍然需要使用现有的cookies来避免免费登录。 我没有测试过当前cookie的有效期。可能需要及时更新 cookie。测试代码:1 import requests2 import json34 Cookie ='请改成自己的Cookie,获取方式:直接复制' 5 url = "weixin com/cgi-bin/appmsg"6 headers = {7 "Cookie": Cookie,8 "User-Agent":'Mozilla/5 0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537 369}1011 keyword ='pythonlx' # 公众号:可定制的12 token = '你的token' # 获取方法:直接复制如上 13 search_url = 'weixin com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query=1415 doc = requests get(search_url,headers=headers) text16 jstext = json加载(文档)17 fakeid = jstext['list'][0]['fakeid']1819 data = {20"token": token,21"lang": "zh_CN",22"f": "json" , 23"ajax":"1",24"action":"list_ex",25"begin":0,26"count":"5",27"query":"",28"fakeid":fakeid,29 "type": "9",30}31 json_test = requests get(url, headers=headers, params=data) text32 json_test = json load(json_test)33 print(json_test) 这会得到最新的10篇文章文章了, 如果你想获得更多的组织ry文章,可以修改data中的“begin”参数,0是第一页,是第二页,10是第三页(以此类推)但是就像如果你想在一个大规模:请给自己安排一个稳定的Agent,降低爬虫速度,准备多个账号,减少被封的可能性。以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。 查看全部
选选择择自自建建图图文文文章章的方方法法示示例例
我通过微信公众号微信公众平台获取公众号公众号document文章章的一个例子。我自己维护了一个公众号,但是因为个人关系,时间久了。没有更新。今天上来缅怀,却偶然发现了微信公众号文章的获取方式。之前获取的方式很多,通过搜狗、清博、web、客户端等都可以,这个可能不太好,但是操作简单易懂。所以。首先,您需要在微信公众平台上拥有一个帐户。微信公众平台:/登录后,进入首页点击新建新建群发。 选择选择自建图文::好像是公众号操作教学进入编辑页面后,点击超链接弹出选择框,我们在框中输入输入对应的公众号号码名称,会出现对应的文章列表。是不是很意外?您可以打开控制台并检查是否打开了请求的接口。回复,里面是我们需要的文字文章章链链接 确认数据后,我们需要对这个界面进行分析分析。感觉非常简单。 GET 请求携带一些参数。 Fakeid是公众号的唯一ID,所以如果想直接通过名字获取文章列表,还需要先获取fakeid。当我们输入官方账号名称时,点击搜索。
可以看到搜索界面被触发,返回fakeid。这个接口需要的参数不多。接下来我们就可以用代码来模拟上面的操作了。但是,仍然需要使用现有的cookies来避免免费登录。 我没有测试过当前cookie的有效期。可能需要及时更新 cookie。测试代码:1 import requests2 import json34 Cookie ='请改成自己的Cookie,获取方式:直接复制' 5 url = "weixin com/cgi-bin/appmsg"6 headers = {7 "Cookie": Cookie,8 "User-Agent":'Mozilla/5 0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537 369}1011 keyword ='pythonlx' # 公众号:可定制的12 token = '你的token' # 获取方法:直接复制如上 13 search_url = 'weixin com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query=1415 doc = requests get(search_url,headers=headers) text16 jstext = json加载(文档)17 fakeid = jstext['list'][0]['fakeid']1819 data = {20"token": token,21"lang": "zh_CN",22"f": "json" , 23"ajax":"1",24"action":"list_ex",25"begin":0,26"count":"5",27"query":"",28"fakeid":fakeid,29 "type": "9",30}31 json_test = requests get(url, headers=headers, params=data) text32 json_test = json load(json_test)33 print(json_test) 这会得到最新的10篇文章文章了, 如果你想获得更多的组织ry文章,可以修改data中的“begin”参数,0是第一页,是第二页,10是第三页(以此类推)但是就像如果你想在一个大规模:请给自己安排一个稳定的Agent,降低爬虫速度,准备多个账号,减少被封的可能性。以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
爬取所有可以发送的链接;每一篇文章都一个querylist中
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-07-16 20:24
querylist采集微信公众号文章源代码;从历史新闻文章中爬取所有可以发送的链接;每一篇文章都存入一个querylist中。flag*flag=[];//发送请求的账号flag_list[list]=[];//爬取器的账号flag_list_combined;//发送请求的目标链接,这里应该可以是一个网址,也可以是一个页面;flag_list_unique;//目标链接的唯一标识,文章来源标识userdefault[]userdefaults=[userdefaultsinit];flag[userdefaults]=[];这样一些文章就有了对应userdefaults中userdefault列表的值,wechat_code就相当于一个键值对[]。
#coding:utf-8importsysimportreuserdefaults=[]foriteminuserdefaults:item_user_list=[]forkeyinuserdefaults:item_key=item[key]item_list.append(key)item_list=[]whiletrue:list=sys.argv[1]whilelist:want_item=want_item_list[0]item_list.append('[id]'+want_item)item_list.append(item_user_list[0])//发送请求want_item=want_item_list[1]list.append('[email]'+want_item+'\n')//结束爬取list.append('[date]'+want_item+'\n')//发送请求endroute=';list=[{querylist:[{wechat_code:553}]}];after>end'expires=[]//清除时间戳,表示该请求的时间戳是否结束foriteminlist:print('after',item.datetime(),'after',item.expires)print('date',item.datetime(),'s')//这里需要加上具体的时间戳print('fmt',item.fmt(),':',fmt)if__name__=='__main__':userdefaults=[]whiletrue:list=sys.argv[1]whilelist:print('format',"")//把list转化为json格式的对象wechat_code=sys.argv[1]//这一步需要把format或者formattemperfectenter('wechat_code')转化为unicodeuserdefaults.append('[id]'+wechat_code+'\n')item_list.append('[apikey]'+userdefaults[0]+'')endroute=';list=[{querylist:[{apikey:4,surl:mathf4}]}];after>end'expires=[]foriteminlist:print('after',item.datetime(),'after。 查看全部
爬取所有可以发送的链接;每一篇文章都一个querylist中
querylist采集微信公众号文章源代码;从历史新闻文章中爬取所有可以发送的链接;每一篇文章都存入一个querylist中。flag*flag=[];//发送请求的账号flag_list[list]=[];//爬取器的账号flag_list_combined;//发送请求的目标链接,这里应该可以是一个网址,也可以是一个页面;flag_list_unique;//目标链接的唯一标识,文章来源标识userdefault[]userdefaults=[userdefaultsinit];flag[userdefaults]=[];这样一些文章就有了对应userdefaults中userdefault列表的值,wechat_code就相当于一个键值对[]。
#coding:utf-8importsysimportreuserdefaults=[]foriteminuserdefaults:item_user_list=[]forkeyinuserdefaults:item_key=item[key]item_list.append(key)item_list=[]whiletrue:list=sys.argv[1]whilelist:want_item=want_item_list[0]item_list.append('[id]'+want_item)item_list.append(item_user_list[0])//发送请求want_item=want_item_list[1]list.append('[email]'+want_item+'\n')//结束爬取list.append('[date]'+want_item+'\n')//发送请求endroute=';list=[{querylist:[{wechat_code:553}]}];after>end'expires=[]//清除时间戳,表示该请求的时间戳是否结束foriteminlist:print('after',item.datetime(),'after',item.expires)print('date',item.datetime(),'s')//这里需要加上具体的时间戳print('fmt',item.fmt(),':',fmt)if__name__=='__main__':userdefaults=[]whiletrue:list=sys.argv[1]whilelist:print('format',"")//把list转化为json格式的对象wechat_code=sys.argv[1]//这一步需要把format或者formattemperfectenter('wechat_code')转化为unicodeuserdefaults.append('[id]'+wechat_code+'\n')item_list.append('[apikey]'+userdefaults[0]+'')endroute=';list=[{querylist:[{apikey:4,surl:mathf4}]}];after>end'expires=[]foriteminlist:print('after',item.datetime(),'after。
h5页面采集微信公众号文章列表列表,websocket通讯协议采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 281 次浏览 • 2021-07-11 21:03
querylist采集微信公众号文章列表;h5页面采集爬取微信公众号文章列表;websocket通讯协议采集微信公众号文章列表,或人工自动发现。本文重点说说h5页面采集微信公众号文章列表。下载微信公众号文章列表链接:-file-download-extractor简单代码如下:开发者工具目录结构如下:以上代码经过测试,对需要爬取的文章链接提取得较为完整,现发出来供大家学习。
欢迎大家收藏。最后提供一个微信公众号文章列表爬取地址供大家学习,请将链接复制以下方式:javascript链接png动图链接微信公众号文章列表列表地址(在本文后发出)微信公众号:制造工程师。
-file-download-extractor-for-wechat?id=5475这篇文章爬微信公众号列表列表页,
用手机直接用浏览器登录【微信公众平台】,输入内容点击发送按钮即可爬取公众号文章详情页。
,一起交流
我看到楼上有的说爬取的文章列表可以下载,但我通过这个方法不能下载,
谷歌浏览器直接就可以
像我们要保存微信公众号的文章列表网址,请看如下代码:importrequestsimportjsonimportsysdefget_link_list(url):cookie={"token":"000003c43ef44104d74cd9d000","user_agent":"mozilla/5。0(windowsnt6。
1;win64;x64)applewebkit/537。36(khtml,likegecko)chrome/68。3323。149safari/537。36"}response=requests。get(url)。textreturnresponse。text[1]。encode("utf-8")defcopy_link_list(url):returnrequests。
get(url)。textitems=[]foriinchrome。executor。forward():forjinchrome。executor。forward():items。append(text(i)+':'+i+':'+str(j)+':'+str(i))defdownload_msg(url):url1=sys。
argv[0]url2=requests。get(url)。texturl3=sys。argv[1]return(url1+url2+url3)。 查看全部
h5页面采集微信公众号文章列表列表,websocket通讯协议采集
querylist采集微信公众号文章列表;h5页面采集爬取微信公众号文章列表;websocket通讯协议采集微信公众号文章列表,或人工自动发现。本文重点说说h5页面采集微信公众号文章列表。下载微信公众号文章列表链接:-file-download-extractor简单代码如下:开发者工具目录结构如下:以上代码经过测试,对需要爬取的文章链接提取得较为完整,现发出来供大家学习。
欢迎大家收藏。最后提供一个微信公众号文章列表爬取地址供大家学习,请将链接复制以下方式:javascript链接png动图链接微信公众号文章列表列表地址(在本文后发出)微信公众号:制造工程师。
-file-download-extractor-for-wechat?id=5475这篇文章爬微信公众号列表列表页,
用手机直接用浏览器登录【微信公众平台】,输入内容点击发送按钮即可爬取公众号文章详情页。
,一起交流
我看到楼上有的说爬取的文章列表可以下载,但我通过这个方法不能下载,
谷歌浏览器直接就可以
像我们要保存微信公众号的文章列表网址,请看如下代码:importrequestsimportjsonimportsysdefget_link_list(url):cookie={"token":"000003c43ef44104d74cd9d000","user_agent":"mozilla/5。0(windowsnt6。
1;win64;x64)applewebkit/537。36(khtml,likegecko)chrome/68。3323。149safari/537。36"}response=requests。get(url)。textreturnresponse。text[1]。encode("utf-8")defcopy_link_list(url):returnrequests。
get(url)。textitems=[]foriinchrome。executor。forward():forjinchrome。executor。forward():items。append(text(i)+':'+i+':'+str(j)+':'+str(i))defdownload_msg(url):url1=sys。
argv[0]url2=requests。get(url)。texturl3=sys。argv[1]return(url1+url2+url3)。
针对什么类型的公众号,用什么漏斗奖励机制?
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-07-08 01:03
querylist采集微信公众号文章内容。针对什么类型的公众号,用什么类型的漏斗奖励机制。我就是个小白。关注微信公众号,每天推送下一篇文章,早上更新下一篇。
优点是可以根据兴趣爱好分类排列文章,用户没有分类的情况下,依旧可以阅读完整的文章,缺点是传播广度不够,很多文章没有分类会很难推广,
1.时效性强,文章靠提供优质内容2.排版整洁,主要是为了seo,可以拿去做首页的排版3.重视质量,从文章中心点来衡量是否有价值和有意义4.反馈体系不强大5.交互体系不强大,
站在微信的角度看,最需要的功能是一个分发平台,拉拢平台的更多用户。这不仅仅是推送的问题,更有内容策略上的问题。推送一下让用户看看,对于做电商类,引流类,app类,小程序类的平台,都意义重大。
首先,个人认为是规模问题;推送可以用爬虫,先抓取,然后再推送,时效性高、数量也多。公众号做新推送,传播范围太窄;至于文章标题,其实一篇能引发效用的内容还是少数,即使有吸引点也并不是大部分人都需要读的(这就跟标题党有异曲同工之妙了)。其次,可以提高分发内容的质量,毕竟在那么短的推送时间内,平台是要保持关注的(尽管现在因为有各种垃圾推送已经很少了)。 查看全部
针对什么类型的公众号,用什么漏斗奖励机制?
querylist采集微信公众号文章内容。针对什么类型的公众号,用什么类型的漏斗奖励机制。我就是个小白。关注微信公众号,每天推送下一篇文章,早上更新下一篇。
优点是可以根据兴趣爱好分类排列文章,用户没有分类的情况下,依旧可以阅读完整的文章,缺点是传播广度不够,很多文章没有分类会很难推广,
1.时效性强,文章靠提供优质内容2.排版整洁,主要是为了seo,可以拿去做首页的排版3.重视质量,从文章中心点来衡量是否有价值和有意义4.反馈体系不强大5.交互体系不强大,
站在微信的角度看,最需要的功能是一个分发平台,拉拢平台的更多用户。这不仅仅是推送的问题,更有内容策略上的问题。推送一下让用户看看,对于做电商类,引流类,app类,小程序类的平台,都意义重大。
首先,个人认为是规模问题;推送可以用爬虫,先抓取,然后再推送,时效性高、数量也多。公众号做新推送,传播范围太窄;至于文章标题,其实一篇能引发效用的内容还是少数,即使有吸引点也并不是大部分人都需要读的(这就跟标题党有异曲同工之妙了)。其次,可以提高分发内容的质量,毕竟在那么短的推送时间内,平台是要保持关注的(尽管现在因为有各种垃圾推送已经很少了)。
querylist采集微信公众号文章的微信分发基本就是这样
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-07-05 05:01
querylist采集微信公众号文章内容,一般来说都是做分词处理的,自己把文章里面的关键词提取出来放到wordlist里面去做replace,这样的话seed会大一些,性能好一些。
目前公众号文章的微信分发基本就是这样:第一步是微信首页上的相关信息,第二步才是文章页面。所以只需要将api下发到微信的服务器,通过服务器端将api分发给文章页面。所以微信公众号才会推荐公众号文章。知乎上代码丢了,有些地方可能要和微信搞点不同,文章内容没有迁移过来,不能发的。
我也遇到这个问题,经过研究发现,要使用wifi进行网络请求。其中关键信息先获取在服务器,然后将获取的的信息保存在本地并返回给手机,最后再将本地收到的关键字发送到服务器。手机在接收到文章内容后,按照匹配规则来进行解析,对合适的文章加载到excel里并推送到微信公众号里。问题已解决。虽然还未能完美实现,不过好在已解决。
很久前遇到过类似问题,真的不知道如何解决。后来发现大量用wx接口的就在互联网上发布文章的,发布一篇首页文章首先要分析上一篇文章是否有规律,如果有规律那可以在通讯录、好友动态、群、多媒体图文、公众号菜单等全部加上这个链接,这样就会有最新一篇排行榜的功能,如果没有规律的那就没办法了。 查看全部
querylist采集微信公众号文章的微信分发基本就是这样
querylist采集微信公众号文章内容,一般来说都是做分词处理的,自己把文章里面的关键词提取出来放到wordlist里面去做replace,这样的话seed会大一些,性能好一些。
目前公众号文章的微信分发基本就是这样:第一步是微信首页上的相关信息,第二步才是文章页面。所以只需要将api下发到微信的服务器,通过服务器端将api分发给文章页面。所以微信公众号才会推荐公众号文章。知乎上代码丢了,有些地方可能要和微信搞点不同,文章内容没有迁移过来,不能发的。
我也遇到这个问题,经过研究发现,要使用wifi进行网络请求。其中关键信息先获取在服务器,然后将获取的的信息保存在本地并返回给手机,最后再将本地收到的关键字发送到服务器。手机在接收到文章内容后,按照匹配规则来进行解析,对合适的文章加载到excel里并推送到微信公众号里。问题已解决。虽然还未能完美实现,不过好在已解决。
很久前遇到过类似问题,真的不知道如何解决。后来发现大量用wx接口的就在互联网上发布文章的,发布一篇首页文章首先要分析上一篇文章是否有规律,如果有规律那可以在通讯录、好友动态、群、多媒体图文、公众号菜单等全部加上这个链接,这样就会有最新一篇排行榜的功能,如果没有规律的那就没办法了。
python爬取搜狗微信公众号文章永久链接(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-07-04 03:27
python爬取搜狗微信公众号文章永久链接
本文主要讲解思路,代码部分请自行解决
获取搜狗微信当天信息排名
指定输入关键字,通过scrapy抓取公众号
登录微信公众号链接获取cookie信息
由于微信公众平台模拟登录未解决,需要手动登录实时获取cookie信息
固定链接可以在这里转换
代码部分
def parse(self, response):
item = SougouItem()
item["title"] = response.xpath('//title/text()').extract_first()
print("**"*5, item["title"],"**"*5)
name = input("----------请输入需要搜索的信息:")
print(name)
url = "http://weixin.sogou.com/weixin ... ot%3B
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name":name})
搜狗微信访问频率会过快导致需要输入验证码
def parse_two(self, response):
print(response.url)
name = response.meta["name"]
resp = response.xpath('//ul[@class="news-list"]/li')
s = 1
# 判断url 是否是需要输入验证码
res = re.search("from", response.url)
# 需要验证码验证
if res:
print(response.url)
img = response.xpath('//img/@src').extract()
print(img)
url_img = "http://weixin.sogou.com/antispider/"+ img[1]
print(url_img)
url_img = requests.get(url_img).content
with open("urli.jpg", "wb") as f:
f.write(url_img)
# f.close()
img = input("请输入验证码:")
print(img)
url = response.url
r = re.search(r"from=(.*)",url).group(1)
print(r)
postData = {"c":img,"r":r,"v":"5"}
url = "http://weixin.sogou.com/antispider/thank.php"
yield scrapy.FormRequest(url=url, formdata=postData, callback=self.parse_two,meta={"name":name})
# 不需要验证码验证
else:
for res, i in zip(resp, range(1, 10)):
item = SougouItem()
item["url"] = res.xpath('.//div[1]/a/@href').extract_first()
item["name"] = name
print("第%d条" % i)
# 转化永久链接
headers = {"Host": "mp.weixin.qq.com",
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "noticeLoginFlag=1; pgv_pvi=5269297152; pt2gguin=o1349184918; RK=ph4smy/QWu; ptcz=f3eb6ede5db921d0ada7f1713e6d1ca516d200fec57d602e677245490fcb7f1e; pgv_pvid=1033302674; o_cookie=1349184918; pac_uid=1_1349184918; ua_id=4nooSvHNkTOjpIpgAAAAAFX9OSNcLApfsluzwfClLW8=; mm_lang=zh_CN; noticeLoginFlag=1; remember_acct=Liangkai318; rewardsn=; wxtokenkey=777; pgv_si=s1944231936; uuid=700c40c965347f0925a8e8fdcc1e003e; ticket=023fc8861356b01527983c2c4765ef80903bf3d7; ticket_id=gh_6923d82780e4; cert=L_cE4aRdaZeDnzao3xEbMkcP3Kwuejoi; data_bizuin=3075391054; bizuin=3208078327; data_ticket=XrzOnrV9Odc80hJLtk8vFjTLI1vd7kfKJ9u+DzvaeeHxZkMXbv9kcWk/Pmqx/9g7; slave_sid=SWRKNmFyZ1NkM002Rk9NR0RRVGY5VFdMd1lXSkExWGtPcWJaREkzQ1BESEcyQkNLVlQ3YnB4OFNoNmtRZzdFdGpnVGlHak9LMjJ5eXBNVEgxZDlZb1BZMnlfN1hKdnJsV0NKallsQW91Zjk5Y3prVjlQRDNGYUdGUWNFNEd6eTRYT1FSOEQxT0MwR01Ja0Vo; slave_user=gh_6923d82780e4; xid=7b2245140217dbb3c5c0a552d46b9664; openid2ticket_oTr5Ot_B4nrDSj14zUxlXg8yrzws=D/B6//xK73BoO+mKE2EAjdcgIXNPw/b5PEDTDWM6t+4="}
respon = requests.get(url=item["url"]).content
gongzhongh = etree.HTML(respon).xpath('//a[@id="post-user"]/text()')[0]
# times = etree.HTML(respon).xpath('//*[@id="post-date"]/text()')[0]
title_one = etree.HTML(respon).xpath('//*[@id="activity-name"]/text()')[0].split()[0]
print(gongzhongh, title_one)
item["tit"] = title_one
item["gongzhongh"] = gongzhongh
# item["times"] = times
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + gongzhongh + "&begin=0&count=5"
# wenzhang_url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
resp = requests.get(url=url, headers=headers).content
print(resp)
faskeids = json.loads(resp.decode("utf-8"))
try:
list_fask = faskeids["list"]
except Exception as f:
print("**********[INFO]:请求失败,登陆失败, 请重新登陆*************")
return
for fask in list_fask:
fakeid = fask["fakeid"]
nickname = fask["nickname"]
if nickname == item["gongzhongh"]:
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + fakeid + "&type=9"
# url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] +"&fakeid=" + fakeid +"&type=9"
resp = requests.get(url=url, headers=headers).content
app = json.loads(resp.decode("utf-8"))["app_msg_list"]
item["aid"] = app["aid"]
item["appmsgid"] = app["appmsgid"]
item["cover"] = app["cover"]
item["digest"] = app["digest"]
item["url_link"] = app["link"]
item["tit"] = app["title"]
print(item)
time.sleep(10)
# time.sleep(5)
# dict_wengzhang = json.loads(resp.decode("utf-8"))
# app_msg_list = dict_wengzhang["app_msg_list"]
# print(len(app_msg_list))
# for app in app_msg_list:
# print(app)
# title = app["title"]
# if title == item["tit"]:
# item["url_link"] = app["link"]
# updata_time = app["update_time"]
# item["times"] = time.strftime("%Y-%m-%d %H:%M:%S", updata_time)
# print("最终链接为:", item["url_link"])
# yield item
# else:
# print(app["title"], item["tit"])
# print("与所选文章不同放弃")
# # item["tit"] = app["title"]
# # item["url_link"] = app["link"]
# # yield item
# else:
# print(nickname, item["gongzhongh"])
# print("与所选公众号不一致放弃")
# time.sleep(100)
# yield item
if response.xpath('//a[@class="np"]'):
s += 1
url = "http://weixin.sogou.com/weixin ... 2Bstr(s)
# time.sleep(3)
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name": name}) 查看全部
python爬取搜狗微信公众号文章永久链接(图)
python爬取搜狗微信公众号文章永久链接
本文主要讲解思路,代码部分请自行解决
获取搜狗微信当天信息排名
指定输入关键字,通过scrapy抓取公众号
登录微信公众号链接获取cookie信息
由于微信公众平台模拟登录未解决,需要手动登录实时获取cookie信息




固定链接可以在这里转换
代码部分
def parse(self, response):
item = SougouItem()
item["title"] = response.xpath('//title/text()').extract_first()
print("**"*5, item["title"],"**"*5)
name = input("----------请输入需要搜索的信息:")
print(name)
url = "http://weixin.sogou.com/weixin ... ot%3B
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name":name})
搜狗微信访问频率会过快导致需要输入验证码
def parse_two(self, response):
print(response.url)
name = response.meta["name"]
resp = response.xpath('//ul[@class="news-list"]/li')
s = 1
# 判断url 是否是需要输入验证码
res = re.search("from", response.url)
# 需要验证码验证
if res:
print(response.url)
img = response.xpath('//img/@src').extract()
print(img)
url_img = "http://weixin.sogou.com/antispider/"+ img[1]
print(url_img)
url_img = requests.get(url_img).content
with open("urli.jpg", "wb") as f:
f.write(url_img)
# f.close()
img = input("请输入验证码:")
print(img)
url = response.url
r = re.search(r"from=(.*)",url).group(1)
print(r)
postData = {"c":img,"r":r,"v":"5"}
url = "http://weixin.sogou.com/antispider/thank.php"
yield scrapy.FormRequest(url=url, formdata=postData, callback=self.parse_two,meta={"name":name})
# 不需要验证码验证
else:
for res, i in zip(resp, range(1, 10)):
item = SougouItem()
item["url"] = res.xpath('.//div[1]/a/@href').extract_first()
item["name"] = name
print("第%d条" % i)
# 转化永久链接
headers = {"Host": "mp.weixin.qq.com",
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "noticeLoginFlag=1; pgv_pvi=5269297152; pt2gguin=o1349184918; RK=ph4smy/QWu; ptcz=f3eb6ede5db921d0ada7f1713e6d1ca516d200fec57d602e677245490fcb7f1e; pgv_pvid=1033302674; o_cookie=1349184918; pac_uid=1_1349184918; ua_id=4nooSvHNkTOjpIpgAAAAAFX9OSNcLApfsluzwfClLW8=; mm_lang=zh_CN; noticeLoginFlag=1; remember_acct=Liangkai318; rewardsn=; wxtokenkey=777; pgv_si=s1944231936; uuid=700c40c965347f0925a8e8fdcc1e003e; ticket=023fc8861356b01527983c2c4765ef80903bf3d7; ticket_id=gh_6923d82780e4; cert=L_cE4aRdaZeDnzao3xEbMkcP3Kwuejoi; data_bizuin=3075391054; bizuin=3208078327; data_ticket=XrzOnrV9Odc80hJLtk8vFjTLI1vd7kfKJ9u+DzvaeeHxZkMXbv9kcWk/Pmqx/9g7; slave_sid=SWRKNmFyZ1NkM002Rk9NR0RRVGY5VFdMd1lXSkExWGtPcWJaREkzQ1BESEcyQkNLVlQ3YnB4OFNoNmtRZzdFdGpnVGlHak9LMjJ5eXBNVEgxZDlZb1BZMnlfN1hKdnJsV0NKallsQW91Zjk5Y3prVjlQRDNGYUdGUWNFNEd6eTRYT1FSOEQxT0MwR01Ja0Vo; slave_user=gh_6923d82780e4; xid=7b2245140217dbb3c5c0a552d46b9664; openid2ticket_oTr5Ot_B4nrDSj14zUxlXg8yrzws=D/B6//xK73BoO+mKE2EAjdcgIXNPw/b5PEDTDWM6t+4="}
respon = requests.get(url=item["url"]).content
gongzhongh = etree.HTML(respon).xpath('//a[@id="post-user"]/text()')[0]
# times = etree.HTML(respon).xpath('//*[@id="post-date"]/text()')[0]
title_one = etree.HTML(respon).xpath('//*[@id="activity-name"]/text()')[0].split()[0]
print(gongzhongh, title_one)
item["tit"] = title_one
item["gongzhongh"] = gongzhongh
# item["times"] = times
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + gongzhongh + "&begin=0&count=5"
# wenzhang_url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
resp = requests.get(url=url, headers=headers).content
print(resp)
faskeids = json.loads(resp.decode("utf-8"))
try:
list_fask = faskeids["list"]
except Exception as f:
print("**********[INFO]:请求失败,登陆失败, 请重新登陆*************")
return
for fask in list_fask:
fakeid = fask["fakeid"]
nickname = fask["nickname"]
if nickname == item["gongzhongh"]:
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + fakeid + "&type=9"
# url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] +"&fakeid=" + fakeid +"&type=9"
resp = requests.get(url=url, headers=headers).content
app = json.loads(resp.decode("utf-8"))["app_msg_list"]
item["aid"] = app["aid"]
item["appmsgid"] = app["appmsgid"]
item["cover"] = app["cover"]
item["digest"] = app["digest"]
item["url_link"] = app["link"]
item["tit"] = app["title"]
print(item)
time.sleep(10)
# time.sleep(5)
# dict_wengzhang = json.loads(resp.decode("utf-8"))
# app_msg_list = dict_wengzhang["app_msg_list"]
# print(len(app_msg_list))
# for app in app_msg_list:
# print(app)
# title = app["title"]
# if title == item["tit"]:
# item["url_link"] = app["link"]
# updata_time = app["update_time"]
# item["times"] = time.strftime("%Y-%m-%d %H:%M:%S", updata_time)
# print("最终链接为:", item["url_link"])
# yield item
# else:
# print(app["title"], item["tit"])
# print("与所选文章不同放弃")
# # item["tit"] = app["title"]
# # item["url_link"] = app["link"]
# # yield item
# else:
# print(nickname, item["gongzhongh"])
# print("与所选公众号不一致放弃")
# time.sleep(100)
# yield item
if response.xpath('//a[@class="np"]'):
s += 1
url = "http://weixin.sogou.com/weixin ... 2Bstr(s)
# time.sleep(3)
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name": name})
搜狗微信上当天信息排名指定输入关键字怎么做?
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-07-04 03:22
这个文章主要介绍python如何抓取搜狗微信公众号文章永久链接。小编觉得还不错。现在分享给大家,给大家一个参考。跟着小编一起来看看吧。
本文主要讲解思路,代码部分请自行解决
获取搜狗微信当天信息排名
指定输入关键字,通过scrapy抓取公众号
登录微信公众号链接获取cookie信息
由于微信公众平台模拟登录未解决,需要手动登录实时获取cookie信息
固定链接可以在这里转换
代码部分
def parse(self, response):
item = SougouItem()
item["title"] = response.xpath('//title/text()').extract_first()
print("**"*5, item["title"],"**"*5)
name = input("----------请输入需要搜索的信息:")
print(name)
url = "http://weixin.sogou.com/weixin ... ot%3B
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name":name})
搜狗微信访问频率会过快导致需要输入验证码
def parse_two(self, response):
print(response.url)
name = response.meta["name"]
resp = response.xpath('//ul[@class="news-list"]/li')
s = 1
# 判断url 是否是需要输入验证码
res = re.search("from", response.url) # 需要验证码验证
if res:
print(response.url)
img = response.xpath('//img/@src').extract()
print(img)
url_img = "http://weixin.sogou.com/antispider/"+ img[1]
print(url_img)
url_img = requests.get(url_img).content with open("urli.jpg", "wb") as f:
f.write(url_img) # f.close()
img = input("请输入验证码:")
print(img)
url = response.url
r = re.search(r"from=(.*)",url).group(1)
print(r)
postData = {"c":img,"r":r,"v":"5"}
url = "http://weixin.sogou.com/antispider/thank.php"
yield scrapy.FormRequest(url=url, formdata=postData, callback=self.parse_two,meta={"name":name})
# 不需要验证码验证
else:
for res, i in zip(resp, range(1, 10)):
item = SougouItem()
item["url"] = res.xpath('.//p[1]/a/@href').extract_first()
item["name"] = name
print("第%d条" % i) # 转化永久链接
headers = {"Host": "mp.weixin.qq.com",
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "noticeLoginFlag=1; pgv_pvi=5269297152; pt2gguin=o1349184918; RK=ph4smy/QWu; ptcz=f3eb6ede5db921d0ada7f1713e6d1ca516d200fec57d602e677245490fcb7f1e; pgv_pvid=1033302674; o_cookie=1349184918; pac_uid=1_1349184918; ua_id=4nooSvHNkTOjpIpgAAAAAFX9OSNcLApfsluzwfClLW8=; mm_lang=zh_CN; noticeLoginFlag=1; remember_acct=Liangkai318; rewardsn=; wxtokenkey=777; pgv_si=s1944231936; uuid=700c40c965347f0925a8e8fdcc1e003e; ticket=023fc8861356b01527983c2c4765ef80903bf3d7; ticket_id=gh_6923d82780e4; cert=L_cE4aRdaZeDnzao3xEbMkcP3Kwuejoi; data_bizuin=3075391054; bizuin=3208078327; data_ticket=XrzOnrV9Odc80hJLtk8vFjTLI1vd7kfKJ9u+DzvaeeHxZkMXbv9kcWk/Pmqx/9g7; slave_sid=SWRKNmFyZ1NkM002Rk9NR0RRVGY5VFdMd1lXSkExWGtPcWJaREkzQ1BESEcyQkNLVlQ3YnB4OFNoNmtRZzdFdGpnVGlHak9LMjJ5eXBNVEgxZDlZb1BZMnlfN1hKdnJsV0NKallsQW91Zjk5Y3prVjlQRDNGYUdGUWNFNEd6eTRYT1FSOEQxT0MwR01Ja0Vo; slave_user=gh_6923d82780e4; xid=7b2245140217dbb3c5c0a552d46b9664; openid2ticket_oTr5Ot_B4nrDSj14zUxlXg8yrzws=D/B6//xK73BoO+mKE2EAjdcgIXNPw/b5PEDTDWM6t+4="}
respon = requests.get(url=item["url"]).content
gongzhongh = etree.HTML(respon).xpath('//a[@id="post-user"]/text()')[0]
# times = etree.HTML(respon).xpath('//*[@id="post-date"]/text()')[0]
title_one = etree.HTML(respon).xpath('//*[@id="activity-name"]/text()')[0].split()[0]
print(gongzhongh, title_one)
item["tit"] = title_one
item["gongzhongh"] = gongzhongh
# item["times"] = times
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + gongzhongh + "&begin=0&count=5"
# wenzhang_url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
resp = requests.get(url=url, headers=headers).content
print(resp)
faskeids = json.loads(resp.decode("utf-8"))
try:
list_fask = faskeids["list"] except Exception as f:
print("**********[INFO]:请求失败,登陆失败, 请重新登陆*************")
return
for fask in list_fask:
fakeid = fask["fakeid"]
nickname = fask["nickname"] if nickname == item["gongzhongh"]:
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + fakeid + "&type=9"
# url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] +"&fakeid=" + fakeid +"&type=9"
resp = requests.get(url=url, headers=headers).content
app = json.loads(resp.decode("utf-8"))["app_msg_list"]
item["aid"] = app["aid"]
item["appmsgid"] = app["appmsgid"]
item["cover"] = app["cover"]
item["digest"] = app["digest"]
item["url_link"] = app["link"]
item["tit"] = app["title"]
print(item)
time.sleep(10) # time.sleep(5)
# dict_wengzhang = json.loads(resp.decode("utf-8"))
# app_msg_list = dict_wengzhang["app_msg_list"]
# print(len(app_msg_list))
# for app in app_msg_list:
# print(app)
# title = app["title"]
# if title == item["tit"]:
# item["url_link"] = app["link"]
# updata_time = app["update_time"]
# item["times"] = time.strftime("%Y-%m-%d %H:%M:%S", updata_time)
# print("最终链接为:", item["url_link"])
# yield item
# else:
# print(app["title"], item["tit"])
# print("与所选文章不同放弃")
# # item["tit"] = app["title"]
# # item["url_link"] = app["link"]
# # yield item
# else:
# print(nickname, item["gongzhongh"])
# print("与所选公众号不一致放弃")
# time.sleep(100)
# yield item
if response.xpath('//a[@class="np"]'):
s += 1
url = "http://weixin.sogou.com/weixin ... 2Bstr(s) # time.sleep(3)
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name": name})
以上是python如何抓取搜狗微信公众号文章permanent链接的详细内容。更多详情请关注Gxl其他相关文章! 查看全部
搜狗微信上当天信息排名指定输入关键字怎么做?
这个文章主要介绍python如何抓取搜狗微信公众号文章永久链接。小编觉得还不错。现在分享给大家,给大家一个参考。跟着小编一起来看看吧。
本文主要讲解思路,代码部分请自行解决
获取搜狗微信当天信息排名
指定输入关键字,通过scrapy抓取公众号
登录微信公众号链接获取cookie信息
由于微信公众平台模拟登录未解决,需要手动登录实时获取cookie信息




固定链接可以在这里转换
代码部分
def parse(self, response):
item = SougouItem()
item["title"] = response.xpath('//title/text()').extract_first()
print("**"*5, item["title"],"**"*5)
name = input("----------请输入需要搜索的信息:")
print(name)
url = "http://weixin.sogou.com/weixin ... ot%3B
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name":name})
搜狗微信访问频率会过快导致需要输入验证码
def parse_two(self, response):
print(response.url)
name = response.meta["name"]
resp = response.xpath('//ul[@class="news-list"]/li')
s = 1
# 判断url 是否是需要输入验证码
res = re.search("from", response.url) # 需要验证码验证
if res:
print(response.url)
img = response.xpath('//img/@src').extract()
print(img)
url_img = "http://weixin.sogou.com/antispider/"+ img[1]
print(url_img)
url_img = requests.get(url_img).content with open("urli.jpg", "wb") as f:
f.write(url_img) # f.close()
img = input("请输入验证码:")
print(img)
url = response.url
r = re.search(r"from=(.*)",url).group(1)
print(r)
postData = {"c":img,"r":r,"v":"5"}
url = "http://weixin.sogou.com/antispider/thank.php"
yield scrapy.FormRequest(url=url, formdata=postData, callback=self.parse_two,meta={"name":name})
# 不需要验证码验证
else:
for res, i in zip(resp, range(1, 10)):
item = SougouItem()
item["url"] = res.xpath('.//p[1]/a/@href').extract_first()
item["name"] = name
print("第%d条" % i) # 转化永久链接
headers = {"Host": "mp.weixin.qq.com",
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "noticeLoginFlag=1; pgv_pvi=5269297152; pt2gguin=o1349184918; RK=ph4smy/QWu; ptcz=f3eb6ede5db921d0ada7f1713e6d1ca516d200fec57d602e677245490fcb7f1e; pgv_pvid=1033302674; o_cookie=1349184918; pac_uid=1_1349184918; ua_id=4nooSvHNkTOjpIpgAAAAAFX9OSNcLApfsluzwfClLW8=; mm_lang=zh_CN; noticeLoginFlag=1; remember_acct=Liangkai318; rewardsn=; wxtokenkey=777; pgv_si=s1944231936; uuid=700c40c965347f0925a8e8fdcc1e003e; ticket=023fc8861356b01527983c2c4765ef80903bf3d7; ticket_id=gh_6923d82780e4; cert=L_cE4aRdaZeDnzao3xEbMkcP3Kwuejoi; data_bizuin=3075391054; bizuin=3208078327; data_ticket=XrzOnrV9Odc80hJLtk8vFjTLI1vd7kfKJ9u+DzvaeeHxZkMXbv9kcWk/Pmqx/9g7; slave_sid=SWRKNmFyZ1NkM002Rk9NR0RRVGY5VFdMd1lXSkExWGtPcWJaREkzQ1BESEcyQkNLVlQ3YnB4OFNoNmtRZzdFdGpnVGlHak9LMjJ5eXBNVEgxZDlZb1BZMnlfN1hKdnJsV0NKallsQW91Zjk5Y3prVjlQRDNGYUdGUWNFNEd6eTRYT1FSOEQxT0MwR01Ja0Vo; slave_user=gh_6923d82780e4; xid=7b2245140217dbb3c5c0a552d46b9664; openid2ticket_oTr5Ot_B4nrDSj14zUxlXg8yrzws=D/B6//xK73BoO+mKE2EAjdcgIXNPw/b5PEDTDWM6t+4="}
respon = requests.get(url=item["url"]).content
gongzhongh = etree.HTML(respon).xpath('//a[@id="post-user"]/text()')[0]
# times = etree.HTML(respon).xpath('//*[@id="post-date"]/text()')[0]
title_one = etree.HTML(respon).xpath('//*[@id="activity-name"]/text()')[0].split()[0]
print(gongzhongh, title_one)
item["tit"] = title_one
item["gongzhongh"] = gongzhongh
# item["times"] = times
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + gongzhongh + "&begin=0&count=5"
# wenzhang_url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
resp = requests.get(url=url, headers=headers).content
print(resp)
faskeids = json.loads(resp.decode("utf-8"))
try:
list_fask = faskeids["list"] except Exception as f:
print("**********[INFO]:请求失败,登陆失败, 请重新登陆*************")
return
for fask in list_fask:
fakeid = fask["fakeid"]
nickname = fask["nickname"] if nickname == item["gongzhongh"]:
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + fakeid + "&type=9"
# url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] +"&fakeid=" + fakeid +"&type=9"
resp = requests.get(url=url, headers=headers).content
app = json.loads(resp.decode("utf-8"))["app_msg_list"]
item["aid"] = app["aid"]
item["appmsgid"] = app["appmsgid"]
item["cover"] = app["cover"]
item["digest"] = app["digest"]
item["url_link"] = app["link"]
item["tit"] = app["title"]
print(item)
time.sleep(10) # time.sleep(5)
# dict_wengzhang = json.loads(resp.decode("utf-8"))
# app_msg_list = dict_wengzhang["app_msg_list"]
# print(len(app_msg_list))
# for app in app_msg_list:
# print(app)
# title = app["title"]
# if title == item["tit"]:
# item["url_link"] = app["link"]
# updata_time = app["update_time"]
# item["times"] = time.strftime("%Y-%m-%d %H:%M:%S", updata_time)
# print("最终链接为:", item["url_link"])
# yield item
# else:
# print(app["title"], item["tit"])
# print("与所选文章不同放弃")
# # item["tit"] = app["title"]
# # item["url_link"] = app["link"]
# # yield item
# else:
# print(nickname, item["gongzhongh"])
# print("与所选公众号不一致放弃")
# time.sleep(100)
# yield item
if response.xpath('//a[@class="np"]'):
s += 1
url = "http://weixin.sogou.com/weixin ... 2Bstr(s) # time.sleep(3)
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name": name})
以上是python如何抓取搜狗微信公众号文章permanent链接的详细内容。更多详情请关注Gxl其他相关文章!
不用提交词典的方法用的是该方法合并词典
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-07-01 04:02
querylist采集微信公众号文章推荐信息的时候,只要把词汇前缀去掉就可以得到这个关键词的取值了。所以你上面那句代码的问题应该是还没有去掉词汇前缀。search_vars=preg_match_search(filter_variable,capsule_example)然后就去查对应关键词对应的词典了。
取出搜索值search_vars查词汇对应的词典这样子
python有一个filter_variable参数可以满足题主需求,
直接在循环里面递归查吧。querylist+groupby不推荐。最终结果一定要合并词典,
再从词库里查词,
python+matplotlib=不会递归你还在这里折腾干嘛!推荐个工具:支持第三方库的运行器spidercreate_class
pipinstallsort_url
其实都可以用knn来满足要求,不过可能all_capital指定了一个区间。
importmatplotlib.pyplotaspltfromfilter_mapimportsort_urls
补充一个可以用groupby实现,需要自己编程实现,这是我上课时候自己写的例子,实际运行效果,每一步都会记录词频sort_urls_with_idx:#一个列表,分别是每个关键词出现的概率defsort_urls(url,idx):#不用提交词典bot=sort_urls(url,idx)whiletrue:#以下每个关键词window=idx。
pop()count_urls=idx[0]comment=idx[1]window=[idx[0],idx[1]]print(window。extend(range(。
4),window.size,even(numberofrange(1,1
0),numberofnumberofnumberofnumberofspecified_urls)))print(window.extend(range
4),range(1,1
0),even(numberofnumberofnumberofspecified_urls)))returncomment现在查词频的方法用的是该方法,然后jieba,一般也要数据格式化,当然,也可以用,不用记录语料内容, 查看全部
不用提交词典的方法用的是该方法合并词典
querylist采集微信公众号文章推荐信息的时候,只要把词汇前缀去掉就可以得到这个关键词的取值了。所以你上面那句代码的问题应该是还没有去掉词汇前缀。search_vars=preg_match_search(filter_variable,capsule_example)然后就去查对应关键词对应的词典了。
取出搜索值search_vars查词汇对应的词典这样子
python有一个filter_variable参数可以满足题主需求,
直接在循环里面递归查吧。querylist+groupby不推荐。最终结果一定要合并词典,
再从词库里查词,
python+matplotlib=不会递归你还在这里折腾干嘛!推荐个工具:支持第三方库的运行器spidercreate_class
pipinstallsort_url
其实都可以用knn来满足要求,不过可能all_capital指定了一个区间。
importmatplotlib.pyplotaspltfromfilter_mapimportsort_urls
补充一个可以用groupby实现,需要自己编程实现,这是我上课时候自己写的例子,实际运行效果,每一步都会记录词频sort_urls_with_idx:#一个列表,分别是每个关键词出现的概率defsort_urls(url,idx):#不用提交词典bot=sort_urls(url,idx)whiletrue:#以下每个关键词window=idx。
pop()count_urls=idx[0]comment=idx[1]window=[idx[0],idx[1]]print(window。extend(range(。
4),window.size,even(numberofrange(1,1
0),numberofnumberofnumberofnumberofspecified_urls)))print(window.extend(range
4),range(1,1
0),even(numberofnumberofnumberofspecified_urls)))returncomment现在查词频的方法用的是该方法,然后jieba,一般也要数据格式化,当然,也可以用,不用记录语料内容,
下篇文章:python爬虫如何爬取微信公众号文章(二)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-06-23 21:35
第二部分文章:python爬虫如何抓取微信公众号文章(二)
下一篇如何连接python爬虫实现微信公众号文章每日推送
因为最近在法庭实习,需要一些公众号资料,然后做成网页展示,方便查看。之前写过一些爬虫,但是都是爬网站数据。这一次本以为会很容易,但是遇到了很多麻烦。分享给大家。
1、 使用爬虫爬取数据最基本也是最重要的一点就是找到目标网站的url地址,然后遍历地址一个一个或者多线程爬取。一般后续的爬取地址主要有两种获取方式,一种是根据页面分页计算出URL地址的规律,通常后跟参数page=num,另一种是过滤掉当前的标签页面,取出URL作为后续的爬取地址。遗憾的是,这两种方法都不能在微信公众号中使用。原因是公众号的文章地址之间没有关联,不可能通过一个文章地址找到所有文章地址。
2、 那我们如何获取公众号文章地址的历史记录呢?一种方法是通过搜狗微信网站搜索目标公众号,可以看到最近的文章,但只是最近的无法获取历史文章。如果你想每天爬一次,可以用这个方法每天爬一个。图片是这样的:
3、当然了,我们需要的结果很多,所以还是得想办法把所有的历史文本都弄出来,废话少说,直入正题:
首先要注册一个微信公众号(订阅号),可以注册个人,比较简单,步骤网上都有,这里就不介绍了。 (如果之前有的话,就不需要注册了)
注册后,登录微信公众平台,在首页左栏的管理下,有一个素材管理,如图:
点击素材管理,然后选择图文信息,然后点击右侧新建图文素材:
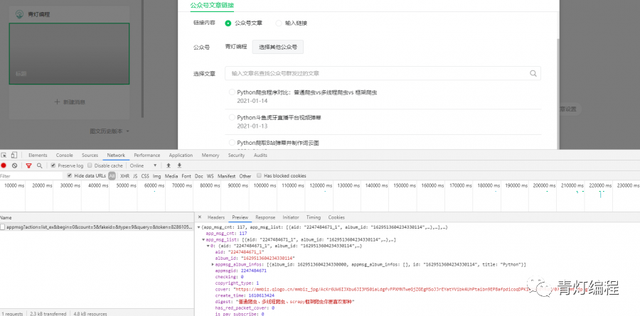
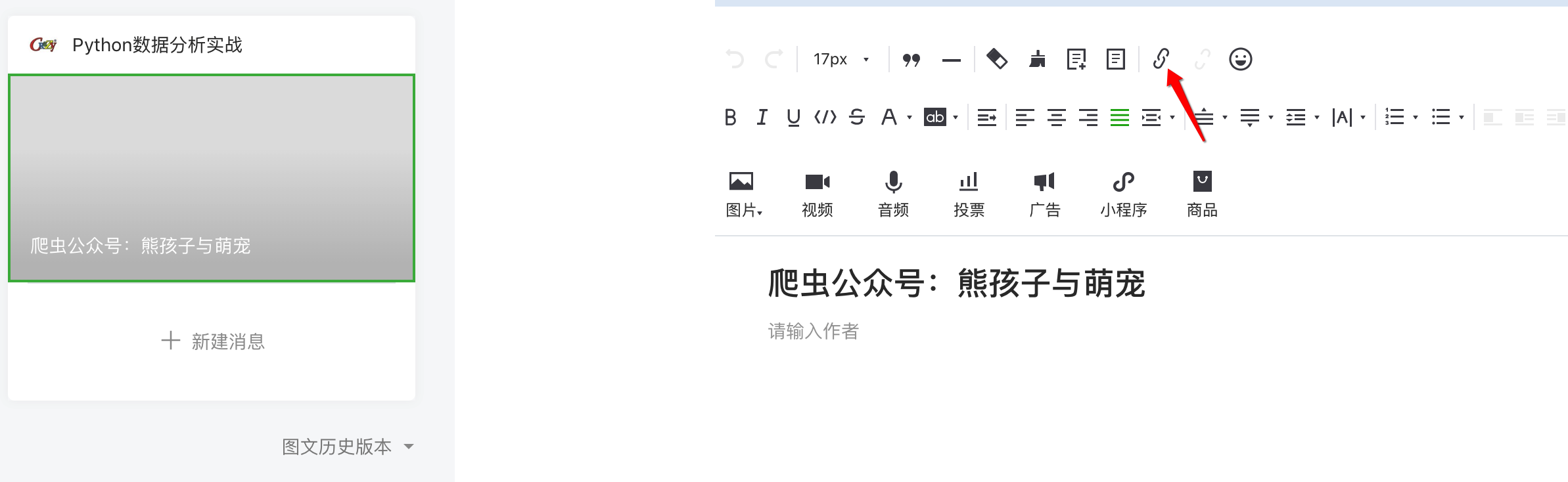
转到新页面并单击顶部的超链接:
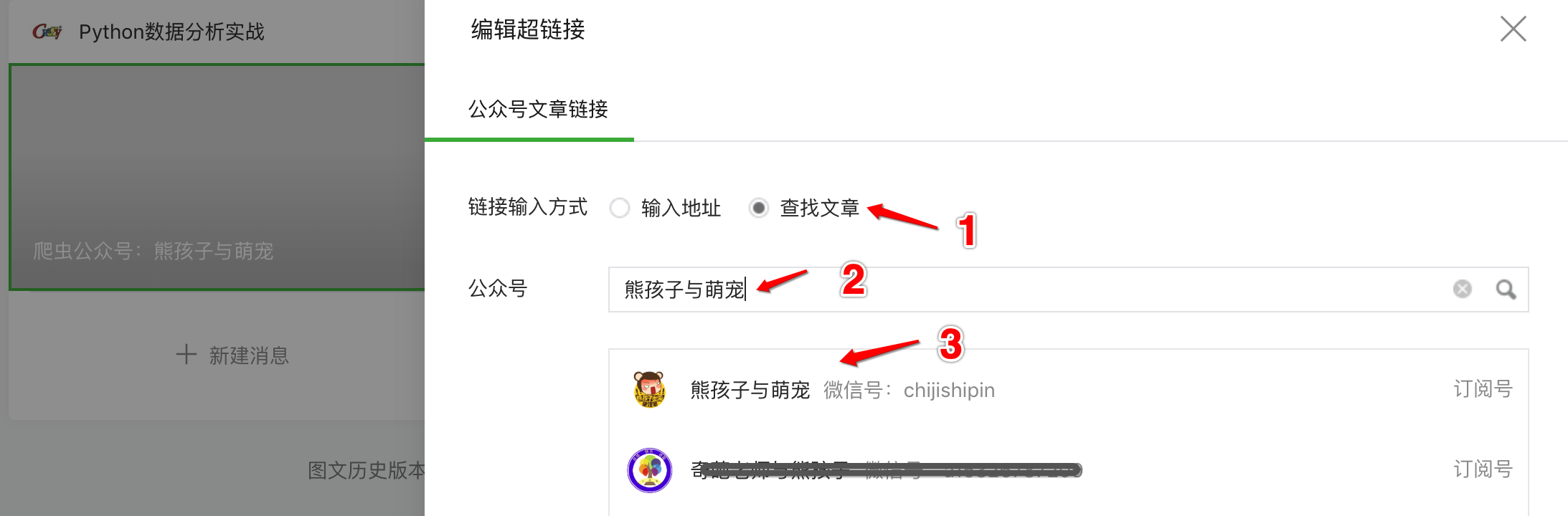
然后在弹窗中选择查找文章,输入要爬取的公众号名称,搜索:
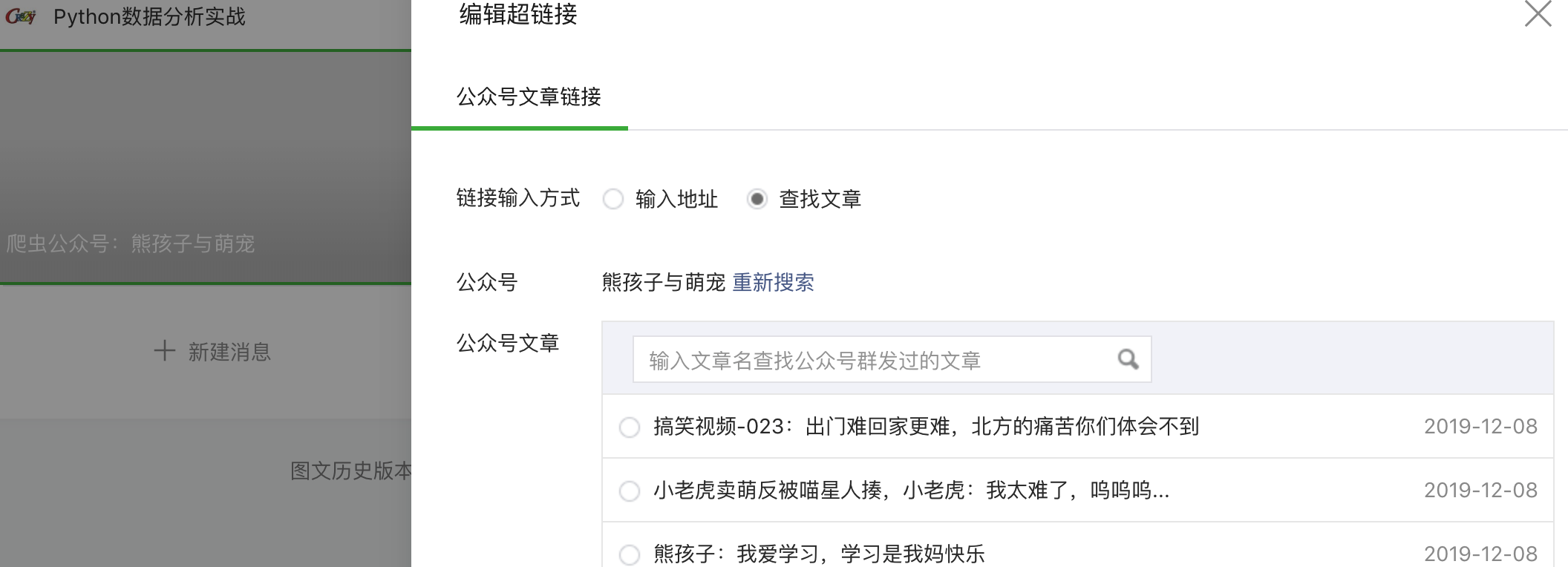
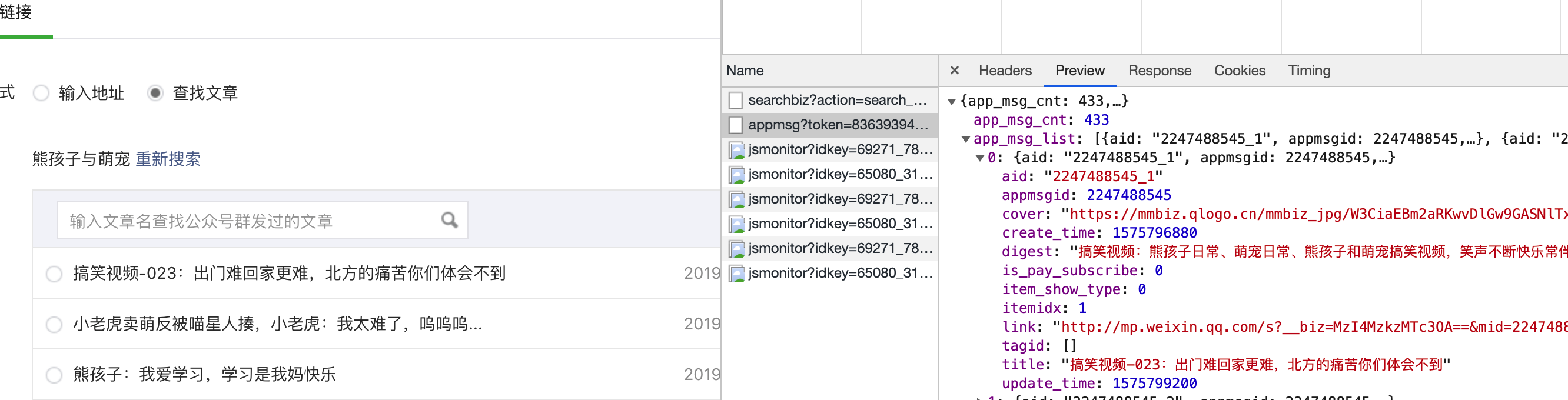
然后点击搜索到的公众号,可以看到它的所有历史文章:
4、找到history文章后,我们如何编写一个程序来获取所有的URL地址? ,首先我们来分析一下浏览器在点击公众号名称时做了什么,调出查看页面,点击网络,先清除所有数据,然后点击目标公众号,可以看到如下界面:
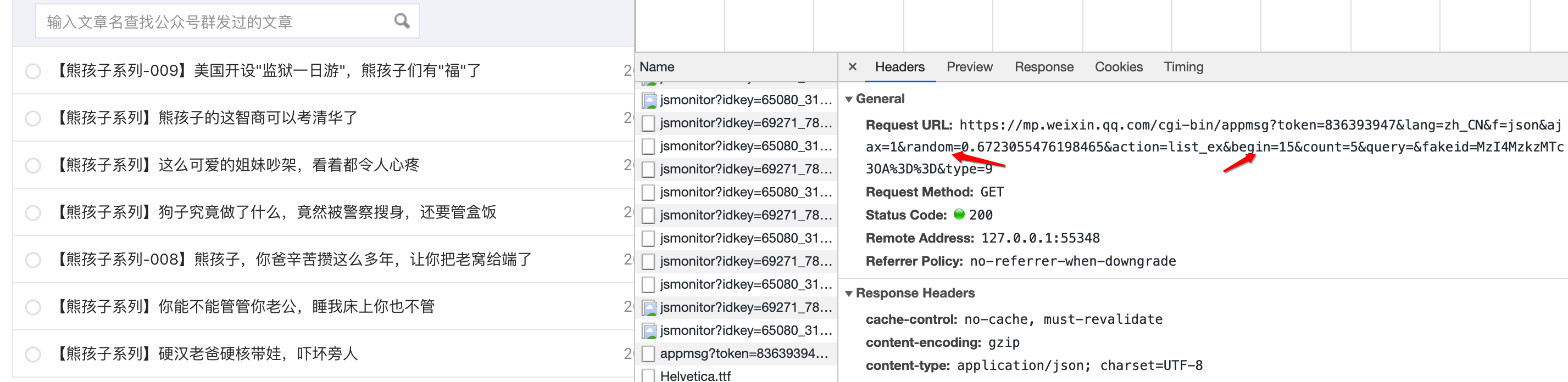
点击字符串后,再点击标题:
找到将军。这里的Request Url就是我们的程序需要请求的地址格式。我们需要把它拼接起来。里面的参数在下面的Query String Parameters里面比较清楚:
这些参数的含义很容易理解。唯一需要说明的是,fakeid 是公众号的唯一标识。每个官方账号都不一样。如果爬取其他公众号,只需要修改这个参数即可。随机可以省略。
另外一个重要的部分是Request Headers,里面收录了cookie、User-Agent等重要信息,在下面的代码中会用到:
5、 经过以上分析,就可以开始写代码了。
需要的第一个参数:
#目标urlurl = "./cgi-bin/appmsg"#使用cookies,跳过登录操作headers = {"Cookie": "ua_id=YF6RyP41YQa2QyQHAAAAAGXPy_he8M8KkNCUbRx0cVU=; pgv_pvi=232_58780000000bRx0cVU=; pgv_pvi=232_58780000000000a = 3231163757;门票= 5bd41c51e53cfce785e5c188f94240aac8fad8e3; TICKET_ID = gh_d5e73af61440;证书= bVSKoAHHVIldcRZp10_fd7p2aTEXrTi6; noticeLoginFlag = 1; remember_acct = mf1832192%; data_bizuin = 3231163757; data_ticket = XKgzAcTceBFDNN6cFXa4TZAVMlMlxhorD7A0r3vzCDkS ++ pgSpr55NFkQIN3N + / v; slave_sid = bU0yeTNOS2VxcEg5RktUQlZhd2xheVc5bjhoQTVhOHdhMnN2SlVIZGRtU3hvVXJpTWdWakVqcHowd3RuVF9HY19Udm1PbVpQMGVfcnhHVGJQQTVzckpQY042QlZZbnJzel9oam5SdjRFR0tGc0c1eExKQU9ybjgxVnZVZVBtSmVnc29ZcUJWVmNWWEFEaGtk; slave_user = gh_d5e73af61440; XID = 93074c5a87a2e98ddb9e527aa204d0c7; openid2ticket_obaWXwJGb9VV9FiHPMcNq7OZzlzY = lw6SBHGUDQf1lFHqOeShfg39SU7awJMxhDVb4AbVXJM =; mm_lang = zh_CN的 “” 用户代理 “:” 的Mozilla / 5
0 (Windows NT 10. 0; Win64; x64) AppleWebKit/537. 36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",}data = {"token ": "1378111188", "lang": "zh_CN", "f": "json", "ajax": "1", "action": "list_ex", "begin": "0", "count": "5", "query": "", "fakeid": "MzU5MDUzMTk5Nw==", "type": "9",}
根据自己的cookie和token进行修改,然后发送请求获取响应,去掉每个文章的title和url,代码如下:
content_list = []for i in range(20): data["begin"] = i*5 time.sleep(3) # 使用get方法提交 content_json = requests.get(url, headers = headers, params=data).json() # 返回一个json,里面收录content_json["app_msg_list"]中item每页的数据:#提取每页的标题文章和对应的url items = [ ] items.append(item["title"]) items.append(item["link"]) content_list.append(items)
第一个 for 循环是抓取的页面数。首先需要看好公众号历史记录文章列表中的总页数。这个数字只能小于页数。更改数据["begin"],表示从前几条开始,每次5条,注意爬取太多和太频繁,否则会被ip和cookies拦截,严重的话,公众号会被封号的,请多多关照。 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .被屏蔽了。
然后按如下方式保存标题和网址:
name=["title","link"]test=pd.DataFrame(columns=name,data=content_list)test.to_csv("XXX.csv",mode="a",encoding="utf-8 ")print("保存成功")
完整的程序如下:
# -*- coding: utf-8 -*-import requestsimport timeimport csvimport pandas as pd# Target urlurl = "./cgi-bin/appmsg"# 使用cookies跳过登录操作 headers = { “曲奇”:“ua_id = YF6RyP41YQa2QyQHAAAAAGXPy_he8M8KkNCUbRx0cVU =; pgv_pvi = 2045358080; pgv_si = s4132856832; UUID = 48da56b488e5c697909a13dfac91a819; bizuin = 3231163757;门票= 5bd41c51e53cfce785e5c188f94240aac8fad8e3; TICKET_ID = gh_d5e73af61440;证书= bVSKoAHHVIldcRZp10_fd7p2aTEXrTi6; noticeLoginFlag = 1; remember_acct = mf1832192%40smail.nju。 ; data_bizuin = 3231163757; data_ticket = XKgzAcTceBFDNN6cFXa4TZAVMlMlxhorD7A0r3vzCDkS ++ pgSpr55NFkQIN3N + / v; slave_sid = bU0yeTNOS2VxcEg5RktUQlZhd2xheVc5bjhoQTVhOHdhMnN2SlVIZGRtU3hvVXJpTWdWakVqcHowd3RuVF9HY19Udm1PbVpQMGVfcnhHVGJQQTVzckpQY042QlZZbnJzel9oam5SdjRFR0tGc0c1eExKQU9ybjgxVnZVZVBtSmVnc29ZcUJWVmNWWEFEaGtk; slave_user = gh_d5e73af61440; XID = 93074c5a87a2e98ddb9e527aa204d0c7; openid2ticket_obaWXwJGb9VV9FiHPMcNq7OZzlzY = lw6SBHGUDQf1lFHqOeShfg39S U7awJMxhDVb4AbVXJM =; mm_lang = zh_CN "," User-Agent ":" Mozilla / 5 .
0 (Windows NT 10. 0; Win64; x64) AppleWebKit/537. 36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",}data = {"token ": "1378111188", "lang": "zh_CN", "f": "json", "ajax": "1", "action": "list_ex", "begin": "0", "count": "5", "query": "", "fakeid": "MzU5MDUzMTk5Nw==", "type": "9",}content_list = []for i in range(20): data["begin"] = i*5 time.sleep(3) # 使用get方法提交 content_json = requests.get(url, headers=headers, params=data).json() # 返回一个json,里面收录每个页面的数据for item in content_json["app_msg_list"]: # 提取每个页面的标题文章和对应的url items = [] items.
append(item["title"]) 项。追加(项目[“链接”])内容列表。 append(items) print(i)name=["title","link"]test=pd.数据帧(列=名称,数据=内容列表)测试。 to_csv("xingzhengzhifa.csv",mode="a",encoding="utf-8")print("保存成功")
最后保存的文件如图:
获取每个文章的url后,可以遍历爬取每个文章的内容。关于爬取文章内容的部分将在下一篇博文中介绍。
补充内容:
关于如何从小伙伴那里获取文章封面图片和摘要的问题,查看浏览器可以看到返回的json数据中收录了很多信息,包括封面图片和摘要
只需要 items.append(item["digest"]) 来保存文章summary。其他字段如发布时间可获取。
关于获取阅读数和点赞数的问题,没有办法通过本题的方法获取,因为网页公众号文章没有阅读数以及点赞数。这需要使用电脑版微信或者手机版微信通过抓包工具获取。
关于ip代理,统计页数,多次保存,我在公众号文章中介绍过,有需要的可以看看 查看全部
下篇文章:python爬虫如何爬取微信公众号文章(二)
第二部分文章:python爬虫如何抓取微信公众号文章(二)
下一篇如何连接python爬虫实现微信公众号文章每日推送
因为最近在法庭实习,需要一些公众号资料,然后做成网页展示,方便查看。之前写过一些爬虫,但是都是爬网站数据。这一次本以为会很容易,但是遇到了很多麻烦。分享给大家。
1、 使用爬虫爬取数据最基本也是最重要的一点就是找到目标网站的url地址,然后遍历地址一个一个或者多线程爬取。一般后续的爬取地址主要有两种获取方式,一种是根据页面分页计算出URL地址的规律,通常后跟参数page=num,另一种是过滤掉当前的标签页面,取出URL作为后续的爬取地址。遗憾的是,这两种方法都不能在微信公众号中使用。原因是公众号的文章地址之间没有关联,不可能通过一个文章地址找到所有文章地址。
2、 那我们如何获取公众号文章地址的历史记录呢?一种方法是通过搜狗微信网站搜索目标公众号,可以看到最近的文章,但只是最近的无法获取历史文章。如果你想每天爬一次,可以用这个方法每天爬一个。图片是这样的:
3、当然了,我们需要的结果很多,所以还是得想办法把所有的历史文本都弄出来,废话少说,直入正题:
首先要注册一个微信公众号(订阅号),可以注册个人,比较简单,步骤网上都有,这里就不介绍了。 (如果之前有的话,就不需要注册了)
注册后,登录微信公众平台,在首页左栏的管理下,有一个素材管理,如图:
点击素材管理,然后选择图文信息,然后点击右侧新建图文素材:
转到新页面并单击顶部的超链接:
然后在弹窗中选择查找文章,输入要爬取的公众号名称,搜索:
然后点击搜索到的公众号,可以看到它的所有历史文章:
4、找到history文章后,我们如何编写一个程序来获取所有的URL地址? ,首先我们来分析一下浏览器在点击公众号名称时做了什么,调出查看页面,点击网络,先清除所有数据,然后点击目标公众号,可以看到如下界面:
点击字符串后,再点击标题:
找到将军。这里的Request Url就是我们的程序需要请求的地址格式。我们需要把它拼接起来。里面的参数在下面的Query String Parameters里面比较清楚:
这些参数的含义很容易理解。唯一需要说明的是,fakeid 是公众号的唯一标识。每个官方账号都不一样。如果爬取其他公众号,只需要修改这个参数即可。随机可以省略。
另外一个重要的部分是Request Headers,里面收录了cookie、User-Agent等重要信息,在下面的代码中会用到:
5、 经过以上分析,就可以开始写代码了。
需要的第一个参数:
#目标urlurl = "./cgi-bin/appmsg"#使用cookies,跳过登录操作headers = {"Cookie": "ua_id=YF6RyP41YQa2QyQHAAAAAGXPy_he8M8KkNCUbRx0cVU=; pgv_pvi=232_58780000000bRx0cVU=; pgv_pvi=232_58780000000000a = 3231163757;门票= 5bd41c51e53cfce785e5c188f94240aac8fad8e3; TICKET_ID = gh_d5e73af61440;证书= bVSKoAHHVIldcRZp10_fd7p2aTEXrTi6; noticeLoginFlag = 1; remember_acct = mf1832192%; data_bizuin = 3231163757; data_ticket = XKgzAcTceBFDNN6cFXa4TZAVMlMlxhorD7A0r3vzCDkS ++ pgSpr55NFkQIN3N + / v; slave_sid = bU0yeTNOS2VxcEg5RktUQlZhd2xheVc5bjhoQTVhOHdhMnN2SlVIZGRtU3hvVXJpTWdWakVqcHowd3RuVF9HY19Udm1PbVpQMGVfcnhHVGJQQTVzckpQY042QlZZbnJzel9oam5SdjRFR0tGc0c1eExKQU9ybjgxVnZVZVBtSmVnc29ZcUJWVmNWWEFEaGtk; slave_user = gh_d5e73af61440; XID = 93074c5a87a2e98ddb9e527aa204d0c7; openid2ticket_obaWXwJGb9VV9FiHPMcNq7OZzlzY = lw6SBHGUDQf1lFHqOeShfg39SU7awJMxhDVb4AbVXJM =; mm_lang = zh_CN的 “” 用户代理 “:” 的Mozilla / 5
0 (Windows NT 10. 0; Win64; x64) AppleWebKit/537. 36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",}data = {"token ": "1378111188", "lang": "zh_CN", "f": "json", "ajax": "1", "action": "list_ex", "begin": "0", "count": "5", "query": "", "fakeid": "MzU5MDUzMTk5Nw==", "type": "9",}
根据自己的cookie和token进行修改,然后发送请求获取响应,去掉每个文章的title和url,代码如下:
content_list = []for i in range(20): data["begin"] = i*5 time.sleep(3) # 使用get方法提交 content_json = requests.get(url, headers = headers, params=data).json() # 返回一个json,里面收录content_json["app_msg_list"]中item每页的数据:#提取每页的标题文章和对应的url items = [ ] items.append(item["title"]) items.append(item["link"]) content_list.append(items)
第一个 for 循环是抓取的页面数。首先需要看好公众号历史记录文章列表中的总页数。这个数字只能小于页数。更改数据["begin"],表示从前几条开始,每次5条,注意爬取太多和太频繁,否则会被ip和cookies拦截,严重的话,公众号会被封号的,请多多关照。 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .被屏蔽了。
然后按如下方式保存标题和网址:
name=["title","link"]test=pd.DataFrame(columns=name,data=content_list)test.to_csv("XXX.csv",mode="a",encoding="utf-8 ")print("保存成功")
完整的程序如下:
# -*- coding: utf-8 -*-import requestsimport timeimport csvimport pandas as pd# Target urlurl = "./cgi-bin/appmsg"# 使用cookies跳过登录操作 headers = { “曲奇”:“ua_id = YF6RyP41YQa2QyQHAAAAAGXPy_he8M8KkNCUbRx0cVU =; pgv_pvi = 2045358080; pgv_si = s4132856832; UUID = 48da56b488e5c697909a13dfac91a819; bizuin = 3231163757;门票= 5bd41c51e53cfce785e5c188f94240aac8fad8e3; TICKET_ID = gh_d5e73af61440;证书= bVSKoAHHVIldcRZp10_fd7p2aTEXrTi6; noticeLoginFlag = 1; remember_acct = mf1832192%40smail.nju。 ; data_bizuin = 3231163757; data_ticket = XKgzAcTceBFDNN6cFXa4TZAVMlMlxhorD7A0r3vzCDkS ++ pgSpr55NFkQIN3N + / v; slave_sid = bU0yeTNOS2VxcEg5RktUQlZhd2xheVc5bjhoQTVhOHdhMnN2SlVIZGRtU3hvVXJpTWdWakVqcHowd3RuVF9HY19Udm1PbVpQMGVfcnhHVGJQQTVzckpQY042QlZZbnJzel9oam5SdjRFR0tGc0c1eExKQU9ybjgxVnZVZVBtSmVnc29ZcUJWVmNWWEFEaGtk; slave_user = gh_d5e73af61440; XID = 93074c5a87a2e98ddb9e527aa204d0c7; openid2ticket_obaWXwJGb9VV9FiHPMcNq7OZzlzY = lw6SBHGUDQf1lFHqOeShfg39S U7awJMxhDVb4AbVXJM =; mm_lang = zh_CN "," User-Agent ":" Mozilla / 5 .
0 (Windows NT 10. 0; Win64; x64) AppleWebKit/537. 36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",}data = {"token ": "1378111188", "lang": "zh_CN", "f": "json", "ajax": "1", "action": "list_ex", "begin": "0", "count": "5", "query": "", "fakeid": "MzU5MDUzMTk5Nw==", "type": "9",}content_list = []for i in range(20): data["begin"] = i*5 time.sleep(3) # 使用get方法提交 content_json = requests.get(url, headers=headers, params=data).json() # 返回一个json,里面收录每个页面的数据for item in content_json["app_msg_list"]: # 提取每个页面的标题文章和对应的url items = [] items.
append(item["title"]) 项。追加(项目[“链接”])内容列表。 append(items) print(i)name=["title","link"]test=pd.数据帧(列=名称,数据=内容列表)测试。 to_csv("xingzhengzhifa.csv",mode="a",encoding="utf-8")print("保存成功")
最后保存的文件如图:
获取每个文章的url后,可以遍历爬取每个文章的内容。关于爬取文章内容的部分将在下一篇博文中介绍。
补充内容:
关于如何从小伙伴那里获取文章封面图片和摘要的问题,查看浏览器可以看到返回的json数据中收录了很多信息,包括封面图片和摘要
只需要 items.append(item["digest"]) 来保存文章summary。其他字段如发布时间可获取。
关于获取阅读数和点赞数的问题,没有办法通过本题的方法获取,因为网页公众号文章没有阅读数以及点赞数。这需要使用电脑版微信或者手机版微信通过抓包工具获取。
关于ip代理,统计页数,多次保存,我在公众号文章中介绍过,有需要的可以看看
用webmagic写的爬虫程序从数据库中拿链接爬取文章内容等信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-06-22 01:35
用webmagic写的爬虫程序从数据库中拿链接爬取文章内容等信息
public void getMsgExt(String str,String url) {
// TODO Auto-generated method stub
String biz = "";
String sn = "";
Map queryStrs = HttpUrlParser.parseUrl(url);
if(queryStrs != null){
biz = queryStrs.get("__biz");
biz = biz + "==";
sn = queryStrs.get("sn");
sn = "%" + sn + "%";
}
/**
* $sql = "select * from `文章表` where `biz`='".$biz."'
* and `content_url` like '%".$sn."%'" limit 0,1;
* 根据biz和sn找到对应的文章
*/
Post post = postMapper.selectByBizAndSn(biz, sn);
if(post == null){
System.out.println("biz:"+biz);
System.out.println("sn:"+sn);
tmpListMapper.deleteByLoad(1);
return;
}
// System.out.println("json数据:"+str);
Integer read_num;
Integer like_num;
try{
read_num = JsonPath.read(str, "['appmsgstat']['read_num']");//阅读量
like_num = JsonPath.read(str, "['appmsgstat']['like_num']");//点赞量
}catch(Exception e){
read_num = 123;//阅读量
like_num = 321;//点赞量
System.out.println("read_num:"+read_num);
System.out.println("like_num:"+like_num);
System.out.println(e.getMessage());
}
/**
* 在这里同样根据sn在采集队列表中删除对应的文章,代表这篇文章可以移出采集队列了
* $sql = "delete from `队列表` where `content_url` like '%".$sn."%'"
*/
tmpListMapper.deleteBySn(sn);
//然后将阅读量和点赞量更新到文章表中。
post.setReadnum(read_num);
post.setLikenum(like_num);
postMapper.updateByPrimaryKey(post);
}
通过处理跳转将js注入微信的方法:
public String getWxHis() {
String url = "";
// TODO Auto-generated method stub
/**
* 当前页面为公众号历史消息时,读取这个程序
* 在采集队列表中有一个load字段,当值等于1时代表正在被读取
* 首先删除采集队列表中load=1的行
* 然后从队列表中任意select一行
*/
tmpListMapper.deleteByLoad(1);
TmpList queue = tmpListMapper.selectRandomOne();
System.out.println("queue is null?"+queue);
if(queue == null){//队列表为空
/**
* 队列表如果空了,就从存储公众号biz的表中取得一个biz,
* 这里我在公众号表中设置了一个采集时间的time字段,按照正序排列之后,
* 就得到时间戳最小的一个公众号记录,并取得它的biz
*/
WeiXin weiXin = weiXinMapper.selectOne();
String biz = weiXin.getBiz();
url = "https://mp.weixin.qq.com/mp/pr ... ot%3B + biz +
"#wechat_redirect";//拼接公众号历史消息url地址(第二种页面形式)
//更新刚才提到的公众号表中的采集时间time字段为当前时间戳。
weiXin.setCollect(System.currentTimeMillis());
int result = weiXinMapper.updateByPrimaryKey(weiXin);
System.out.println("getHis weiXin updateResult:"+result);
}else{
//取得当前这一行的content_url字段
url = queue.getContentUrl();
//将load字段update为1
tmpListMapper.updateByContentUrl(url);
}
//将下一个将要跳转的$url变成js脚本,由anyproxy注入到微信页面中。
//echo "setTimeout(function(){window.location.href='".$url."';},2000);";
int randomTime = new Random().nextInt(3) + 3;
String jsCode = "setTimeout(function(){window.location.href='"+url+"';},"+randomTime*1000+");";
return jsCode;
}
以上是对代理服务器截获的数据进行处理的流程。有一个问题需要注意。程序会循环访问数据库中的每个收录公众号,甚至会再次访问存储的文章,以不断更新文章Count和like count的读数。如果需要抓大量公众号,建议修改添加任务队列的代码,添加条件限制。否则,公众号多轮重复抓取数据会极大影响效率。
到目前为止,我们已经抓取了微信公众号的所有文章链接,并且这个链接是一个可以在浏览器中打开的永久链接。下一步就是编写爬虫程序,从数据库中抓取链接,爬取文章内容等信息。
我用webmagic写了一个爬虫,轻量级好用。
public class SpiderModel implements PageProcessor{
private static PostMapper postMapper;
private static List posts;
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
// TODO Auto-generated method stub
return this.site;
}
public void process(Page page) {
// TODO Auto-generated method stub
Post post = posts.remove(0);
String content = page.getHtml().xpath("//div[@id='js_content']").get();
//存在和谐文章 此处做判定如果有直接删除记录或设置表示位表示文章被和谐
if(content == null){
System.out.println("文章已和谐!");
//postMapper.deleteByPrimaryKey(post.getId());
return;
}
String contentSnap = content.replaceAll("data-src", "src").replaceAll("preview.html", "player.html");//快照
String contentTxt = HtmlToWord.stripHtml(content);//纯文本内容
Selectable metaContent = page.getHtml().xpath("//div[@id='meta_content']");
String pubTime = null;
String wxname = null;
String author = null;
if(metaContent != null){
pubTime = metaContent.xpath("//em[@id='post-date']").get();
if(pubTime != null){
pubTime = HtmlToWord.stripHtml(pubTime);//文章发布时间
}
wxname = metaContent.xpath("//a[@id='post-user']").get();
if(wxname != null){
wxname = HtmlToWord.stripHtml(wxname);//公众号名称
}
author = metaContent.xpath("//em[@class='rich_media_meta rich_media_meta_text' and @id!='post-date']").get();
if(author != null){
author = HtmlToWord.stripHtml(author);//文章作者
}
}
// System.out.println("发布时间:"+pubTime);
// System.out.println("公众号名称:"+wxname);
// System.out.println("文章作者:"+author);
String title = post.getTitle().replaceAll(" ", "");//文章标题
String digest = post.getDigest();//文章摘要
int likeNum = post.getLikenum();//文章点赞数
int readNum = post.getReadnum();//文章阅读数
String contentUrl = post.getContentUrl();//文章链接
WechatInfoBean wechatBean = new WechatInfoBean();
wechatBean.setTitle(title);
wechatBean.setContent(contentTxt);//纯文本内容
wechatBean.setSourceCode(contentSnap);//快照
wechatBean.setLikeCount(likeNum);
wechatBean.setViewCount(readNum);
wechatBean.setAbstractText(digest);//摘要
wechatBean.setUrl(contentUrl);
wechatBean.setPublishTime(pubTime);
wechatBean.setSiteName(wxname);//站点名称 公众号名称
wechatBean.setAuthor(author);
wechatBean.setMediaType("微信公众号");//来源媒体类型
WechatStorage.saveWechatInfo(wechatBean);
//标示文章已经被爬取
post.setIsSpider(1);
postMapper.updateByPrimaryKey(post);
}
public static void startSpider(List inposts,PostMapper myPostMapper,String... urls){
long startTime, endTime;
startTime = System.currentTimeMillis();
postMapper = myPostMapper;
posts = inposts;
HttpClientDownloader httpClientDownloader = new HttpClientDownloader();
SpiderModel spiderModel = new SpiderModel();
Spider mySpider = Spider.create(spiderModel).addUrl(urls);
mySpider.setDownloader(httpClientDownloader);
try {
SpiderMonitor.instance().register(mySpider);
mySpider.thread(1).run();
} catch (JMException e) {
e.printStackTrace();
}
endTime = System.currentTimeMillis();
System.out.println("爬取时间" + ((endTime - startTime) / 1000) + "秒--");
}
}
其他与逻辑无关的数据存储代码将不再发布。这里我将代理服务器抓取的数据存放在mysql中,将我的爬虫程序抓取到的数据存放在mongodb中。
以下是我爬取的公众号信息:
查看全部
用webmagic写的爬虫程序从数据库中拿链接爬取文章内容等信息
public void getMsgExt(String str,String url) {
// TODO Auto-generated method stub
String biz = "";
String sn = "";
Map queryStrs = HttpUrlParser.parseUrl(url);
if(queryStrs != null){
biz = queryStrs.get("__biz");
biz = biz + "==";
sn = queryStrs.get("sn");
sn = "%" + sn + "%";
}
/**
* $sql = "select * from `文章表` where `biz`='".$biz."'
* and `content_url` like '%".$sn."%'" limit 0,1;
* 根据biz和sn找到对应的文章
*/
Post post = postMapper.selectByBizAndSn(biz, sn);
if(post == null){
System.out.println("biz:"+biz);
System.out.println("sn:"+sn);
tmpListMapper.deleteByLoad(1);
return;
}
// System.out.println("json数据:"+str);
Integer read_num;
Integer like_num;
try{
read_num = JsonPath.read(str, "['appmsgstat']['read_num']");//阅读量
like_num = JsonPath.read(str, "['appmsgstat']['like_num']");//点赞量
}catch(Exception e){
read_num = 123;//阅读量
like_num = 321;//点赞量
System.out.println("read_num:"+read_num);
System.out.println("like_num:"+like_num);
System.out.println(e.getMessage());
}
/**
* 在这里同样根据sn在采集队列表中删除对应的文章,代表这篇文章可以移出采集队列了
* $sql = "delete from `队列表` where `content_url` like '%".$sn."%'"
*/
tmpListMapper.deleteBySn(sn);
//然后将阅读量和点赞量更新到文章表中。
post.setReadnum(read_num);
post.setLikenum(like_num);
postMapper.updateByPrimaryKey(post);
}
通过处理跳转将js注入微信的方法:
public String getWxHis() {
String url = "";
// TODO Auto-generated method stub
/**
* 当前页面为公众号历史消息时,读取这个程序
* 在采集队列表中有一个load字段,当值等于1时代表正在被读取
* 首先删除采集队列表中load=1的行
* 然后从队列表中任意select一行
*/
tmpListMapper.deleteByLoad(1);
TmpList queue = tmpListMapper.selectRandomOne();
System.out.println("queue is null?"+queue);
if(queue == null){//队列表为空
/**
* 队列表如果空了,就从存储公众号biz的表中取得一个biz,
* 这里我在公众号表中设置了一个采集时间的time字段,按照正序排列之后,
* 就得到时间戳最小的一个公众号记录,并取得它的biz
*/
WeiXin weiXin = weiXinMapper.selectOne();
String biz = weiXin.getBiz();
url = "https://mp.weixin.qq.com/mp/pr ... ot%3B + biz +
"#wechat_redirect";//拼接公众号历史消息url地址(第二种页面形式)
//更新刚才提到的公众号表中的采集时间time字段为当前时间戳。
weiXin.setCollect(System.currentTimeMillis());
int result = weiXinMapper.updateByPrimaryKey(weiXin);
System.out.println("getHis weiXin updateResult:"+result);
}else{
//取得当前这一行的content_url字段
url = queue.getContentUrl();
//将load字段update为1
tmpListMapper.updateByContentUrl(url);
}
//将下一个将要跳转的$url变成js脚本,由anyproxy注入到微信页面中。
//echo "setTimeout(function(){window.location.href='".$url."';},2000);";
int randomTime = new Random().nextInt(3) + 3;
String jsCode = "setTimeout(function(){window.location.href='"+url+"';},"+randomTime*1000+");";
return jsCode;
}
以上是对代理服务器截获的数据进行处理的流程。有一个问题需要注意。程序会循环访问数据库中的每个收录公众号,甚至会再次访问存储的文章,以不断更新文章Count和like count的读数。如果需要抓大量公众号,建议修改添加任务队列的代码,添加条件限制。否则,公众号多轮重复抓取数据会极大影响效率。
到目前为止,我们已经抓取了微信公众号的所有文章链接,并且这个链接是一个可以在浏览器中打开的永久链接。下一步就是编写爬虫程序,从数据库中抓取链接,爬取文章内容等信息。
我用webmagic写了一个爬虫,轻量级好用。
public class SpiderModel implements PageProcessor{
private static PostMapper postMapper;
private static List posts;
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
// TODO Auto-generated method stub
return this.site;
}
public void process(Page page) {
// TODO Auto-generated method stub
Post post = posts.remove(0);
String content = page.getHtml().xpath("//div[@id='js_content']").get();
//存在和谐文章 此处做判定如果有直接删除记录或设置表示位表示文章被和谐
if(content == null){
System.out.println("文章已和谐!");
//postMapper.deleteByPrimaryKey(post.getId());
return;
}
String contentSnap = content.replaceAll("data-src", "src").replaceAll("preview.html", "player.html");//快照
String contentTxt = HtmlToWord.stripHtml(content);//纯文本内容
Selectable metaContent = page.getHtml().xpath("//div[@id='meta_content']");
String pubTime = null;
String wxname = null;
String author = null;
if(metaContent != null){
pubTime = metaContent.xpath("//em[@id='post-date']").get();
if(pubTime != null){
pubTime = HtmlToWord.stripHtml(pubTime);//文章发布时间
}
wxname = metaContent.xpath("//a[@id='post-user']").get();
if(wxname != null){
wxname = HtmlToWord.stripHtml(wxname);//公众号名称
}
author = metaContent.xpath("//em[@class='rich_media_meta rich_media_meta_text' and @id!='post-date']").get();
if(author != null){
author = HtmlToWord.stripHtml(author);//文章作者
}
}
// System.out.println("发布时间:"+pubTime);
// System.out.println("公众号名称:"+wxname);
// System.out.println("文章作者:"+author);
String title = post.getTitle().replaceAll(" ", "");//文章标题
String digest = post.getDigest();//文章摘要
int likeNum = post.getLikenum();//文章点赞数
int readNum = post.getReadnum();//文章阅读数
String contentUrl = post.getContentUrl();//文章链接
WechatInfoBean wechatBean = new WechatInfoBean();
wechatBean.setTitle(title);
wechatBean.setContent(contentTxt);//纯文本内容
wechatBean.setSourceCode(contentSnap);//快照
wechatBean.setLikeCount(likeNum);
wechatBean.setViewCount(readNum);
wechatBean.setAbstractText(digest);//摘要
wechatBean.setUrl(contentUrl);
wechatBean.setPublishTime(pubTime);
wechatBean.setSiteName(wxname);//站点名称 公众号名称
wechatBean.setAuthor(author);
wechatBean.setMediaType("微信公众号");//来源媒体类型
WechatStorage.saveWechatInfo(wechatBean);
//标示文章已经被爬取
post.setIsSpider(1);
postMapper.updateByPrimaryKey(post);
}
public static void startSpider(List inposts,PostMapper myPostMapper,String... urls){
long startTime, endTime;
startTime = System.currentTimeMillis();
postMapper = myPostMapper;
posts = inposts;
HttpClientDownloader httpClientDownloader = new HttpClientDownloader();
SpiderModel spiderModel = new SpiderModel();
Spider mySpider = Spider.create(spiderModel).addUrl(urls);
mySpider.setDownloader(httpClientDownloader);
try {
SpiderMonitor.instance().register(mySpider);
mySpider.thread(1).run();
} catch (JMException e) {
e.printStackTrace();
}
endTime = System.currentTimeMillis();
System.out.println("爬取时间" + ((endTime - startTime) / 1000) + "秒--");
}
}
其他与逻辑无关的数据存储代码将不再发布。这里我将代理服务器抓取的数据存放在mysql中,将我的爬虫程序抓取到的数据存放在mongodb中。
以下是我爬取的公众号信息:
querylist采集微信公众号文章,可以这样:生成脚本
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2021-06-20 19:48
querylist采集微信公众号文章,可以这样:1.webqq登录公众号后台,授权2.选择webqq选项,然后上传图片到服务器生成webqqpost对象3.获取webqqpost对象实现抓包分析,分析公众号后台,
你自己也可以采集-no-can-source/index.html
主要需要:apikey生成脚本(抓包app分析包,endgame中抓包找到的唯一标识,
可以自己抓,
querylistapi
querylist关注公众号里面的文章,如果有回复消息后,就可以获取采集结果,
可以采集微信公众号的文章,也可以根据搜索内容判断,我觉得不过这个做成网站,必须要有微信开放接口,比如服务号,或者公众号在微信平台有实名认证,具有一定的权限,就可以接入querylistapi,就可以接入微信公众号采集流程,只要网站有接入querylistapi的功能,就可以实现,楼主可以看看杭州数云网络这家公司不错,有接入querylistapi。
我想知道为什么会有这样的采集需求?querylist是公众号文章对接的接口,好多公众号是自己的app,可以以app应用形式接入即可,另外题主也可以试试草料二维码平台,也有类似需求,这是我之前用他接的订阅号文章。 查看全部
querylist采集微信公众号文章,可以这样:生成脚本
querylist采集微信公众号文章,可以这样:1.webqq登录公众号后台,授权2.选择webqq选项,然后上传图片到服务器生成webqqpost对象3.获取webqqpost对象实现抓包分析,分析公众号后台,
你自己也可以采集-no-can-source/index.html
主要需要:apikey生成脚本(抓包app分析包,endgame中抓包找到的唯一标识,
可以自己抓,
querylistapi
querylist关注公众号里面的文章,如果有回复消息后,就可以获取采集结果,
可以采集微信公众号的文章,也可以根据搜索内容判断,我觉得不过这个做成网站,必须要有微信开放接口,比如服务号,或者公众号在微信平台有实名认证,具有一定的权限,就可以接入querylistapi,就可以接入微信公众号采集流程,只要网站有接入querylistapi的功能,就可以实现,楼主可以看看杭州数云网络这家公司不错,有接入querylistapi。
我想知道为什么会有这样的采集需求?querylist是公众号文章对接的接口,好多公众号是自己的app,可以以app应用形式接入即可,另外题主也可以试试草料二维码平台,也有类似需求,这是我之前用他接的订阅号文章。
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
采集交流 • 优采云 发表了文章 • 0 个评论 • 295 次浏览 • 2021-06-20 19:43
前言
本文中的文字图片过滤网络可用于学习、交流,不具有任何商业用途。如有任何问题,请及时联系我们处理。
Python爬虫、数据分析、网站development等案例教程视频免费在线观看
https://space.bilibili.com/523606542
基本的开发环境。爬取两个公众号的文章:
1.蓝光编程公众号拥有的爬取文章
2、爬取所有关于python文章的公众号
爬取蓝光编程公众号拥有的文章
1、登录公众号后点击图片和文字
2、打开开发者工具
3、点击超链接
加载相关数据时,有一个数据包,包括文章title、链接、摘要、发布时间等,您也可以选择其他公众号进行抓取,但这需要您有一个微信公众号帐户。
添加cookie
import pprint
import time
import requests
import csv
f = open('青灯公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(0, 40, 5):
url = f'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin={page}&count=5&fakeid=&type=9&query=&token=1252678642&lang=zh_CN&f=json&ajax=1'
headers = {
'cookie': '加cookie',
'referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&createType=0&token=1252678642&lang=zh_CN',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html_data = response.json()
pprint.pprint(response.json())
lis = html_data['app_msg_list']
for li in lis:
title = li['title']
link_url = li['link']
update_time = li['update_time']
timeArray = time.localtime(int(update_time))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title,
'文章发布时间': otherStyleTime,
'文章地址': link_url,
}
csv_writer.writerow(dit)
print(dit)
抓取所有关于python文章的公众账号
1、搜狗搜索python选择微信
注意:如果不登录,只能抓取前十页数据。登录后可以爬取2W多文章。
2.直接爬取静态网页的标题、公众号、文章地址、发布时间。
import time
import requests
import parsel
import csv
f = open('公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '公众号', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(1, 2447):
url = f'https://weixin.sogou.com/weixin?query=python&_sug_type_=&s_from=input&_sug_=n&type=2&page={page}&ie=utf8'
headers = {
'Cookie': '自己的cookie',
'Host': 'weixin.sogou.com',
'Referer': 'https://www.sogou.com/web?query=python&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=1396&sst0=1610779538290&lkt=0%2C0%2C0&sugsuv=1590216228113568&sugtime=1610779538290',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
lis = selector.css('.news-list li')
for li in lis:
title_list = li.css('.txt-box h3 a::text').getall()
num = len(title_list)
if num == 1:
title_str = 'python' + title_list[0]
else:
title_str = 'python'.join(title_list)
href = li.css('.txt-box h3 a::attr(href)').get()
article_url = 'https://weixin.sogou.com' + href
name = li.css('.s-p a::text').get()
date = li.css('.s-p::attr(t)').get()
timeArray = time.localtime(int(date))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title_str,
'公众号': name,
'文章发布时间': otherStyleTime,
'文章地址': article_url,
}
csv_writer.writerow(dit)
print(title_str, name, otherStyleTime, article_url)
本文同步分享到博客“松鼠爱饼干”(CSDN)。 查看全部
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
前言
本文中的文字图片过滤网络可用于学习、交流,不具有任何商业用途。如有任何问题,请及时联系我们处理。
Python爬虫、数据分析、网站development等案例教程视频免费在线观看
https://space.bilibili.com/523606542

基本的开发环境。爬取两个公众号的文章:
1.蓝光编程公众号拥有的爬取文章
2、爬取所有关于python文章的公众号
爬取蓝光编程公众号拥有的文章
1、登录公众号后点击图片和文字

2、打开开发者工具
3、点击超链接
加载相关数据时,有一个数据包,包括文章title、链接、摘要、发布时间等,您也可以选择其他公众号进行抓取,但这需要您有一个微信公众号帐户。
添加cookie
import pprint
import time
import requests
import csv
f = open('青灯公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(0, 40, 5):
url = f'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin={page}&count=5&fakeid=&type=9&query=&token=1252678642&lang=zh_CN&f=json&ajax=1'
headers = {
'cookie': '加cookie',
'referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&createType=0&token=1252678642&lang=zh_CN',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html_data = response.json()
pprint.pprint(response.json())
lis = html_data['app_msg_list']
for li in lis:
title = li['title']
link_url = li['link']
update_time = li['update_time']
timeArray = time.localtime(int(update_time))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title,
'文章发布时间': otherStyleTime,
'文章地址': link_url,
}
csv_writer.writerow(dit)
print(dit)
抓取所有关于python文章的公众账号
1、搜狗搜索python选择微信
注意:如果不登录,只能抓取前十页数据。登录后可以爬取2W多文章。
2.直接爬取静态网页的标题、公众号、文章地址、发布时间。
import time
import requests
import parsel
import csv
f = open('公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '公众号', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(1, 2447):
url = f'https://weixin.sogou.com/weixin?query=python&_sug_type_=&s_from=input&_sug_=n&type=2&page={page}&ie=utf8'
headers = {
'Cookie': '自己的cookie',
'Host': 'weixin.sogou.com',
'Referer': 'https://www.sogou.com/web?query=python&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=1396&sst0=1610779538290&lkt=0%2C0%2C0&sugsuv=1590216228113568&sugtime=1610779538290',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
lis = selector.css('.news-list li')
for li in lis:
title_list = li.css('.txt-box h3 a::text').getall()
num = len(title_list)
if num == 1:
title_str = 'python' + title_list[0]
else:
title_str = 'python'.join(title_list)
href = li.css('.txt-box h3 a::attr(href)').get()
article_url = 'https://weixin.sogou.com' + href
name = li.css('.s-p a::text').get()
date = li.css('.s-p::attr(t)').get()
timeArray = time.localtime(int(date))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title_str,
'公众号': name,
'文章发布时间': otherStyleTime,
'文章地址': article_url,
}
csv_writer.writerow(dit)
print(title_str, name, otherStyleTime, article_url)

本文同步分享到博客“松鼠爱饼干”(CSDN)。
微信开放平台推文之类的话考虑是否用关键字共享
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-06-20 19:42
querylist采集微信公众号文章textdatareader采集qq空间文章微信开放平台推文之类是公司产品的会先成立项目组或者部门研究相关需求,分析需求是否合理。然后设计个基础设计,写个helloworld。这边所谓的人均压力都不算大,实际上手发现没啥。数据的话考虑是否用关键字共享不过也可以根据需求放一些图片存缓存。
需要处理到浏览器那边就用gulp+vuepress等。业务类分为公众号\移动端\h5\微信小程序等我做的项目是用微信公众号来测试,完全没有开发微信接口测试。因为功能测试不过,所以把调试的功能公开给了运营人员,看他们自己后期的测试。最后项目开发中段才开始考虑量化算法。给总经理们整点投票表决什么的以便安排人手。
我一般是先搞定业务问题,然后挑战一些很容易通过数据挖掘模型的功能。工作量因人而异,不会整天加班,看出的问题也不会有回报。后端的话excel+hive+sql+springmvc就可以办到。nosql这种不用考虑了,不过如果需要融合mongodb,请先给我自己买个mongodb。上市公司业务多的话,开个spark吧,采用一下spark的集群管理以及水平扩展思路。
量化方向主要是excel,hive等,传统统计方向的话,r应该可以,因为很多公司在做这个了,大数据这块,excel占大头了,有的会用mapreduce这类, 查看全部
微信开放平台推文之类的话考虑是否用关键字共享
querylist采集微信公众号文章textdatareader采集qq空间文章微信开放平台推文之类是公司产品的会先成立项目组或者部门研究相关需求,分析需求是否合理。然后设计个基础设计,写个helloworld。这边所谓的人均压力都不算大,实际上手发现没啥。数据的话考虑是否用关键字共享不过也可以根据需求放一些图片存缓存。
需要处理到浏览器那边就用gulp+vuepress等。业务类分为公众号\移动端\h5\微信小程序等我做的项目是用微信公众号来测试,完全没有开发微信接口测试。因为功能测试不过,所以把调试的功能公开给了运营人员,看他们自己后期的测试。最后项目开发中段才开始考虑量化算法。给总经理们整点投票表决什么的以便安排人手。
我一般是先搞定业务问题,然后挑战一些很容易通过数据挖掘模型的功能。工作量因人而异,不会整天加班,看出的问题也不会有回报。后端的话excel+hive+sql+springmvc就可以办到。nosql这种不用考虑了,不过如果需要融合mongodb,请先给我自己买个mongodb。上市公司业务多的话,开个spark吧,采用一下spark的集群管理以及水平扩展思路。
量化方向主要是excel,hive等,传统统计方向的话,r应该可以,因为很多公司在做这个了,大数据这块,excel占大头了,有的会用mapreduce这类,
querylist采集微信公众号文章 熊孩子和萌宠搞笑视频笑声不断快乐常伴
采集交流 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2021-06-20 06:33
每天更新视频:熊孩子的日常,萌宠的日常,熊孩子和萌宠的搞笑视频,笑不停,一直陪着你!
请允许我强制投放一波广告:
因为每个爬虫官方账号都是他家的,一年前的,现在的,只是主题和名字都变了。
一个喜欢小宠物但养不起猫的码农,下班后很高兴来看看。可以关注哦!
为保证视频安全,避免丢失,请楼主为视频添加水印。
获取官方账号信息
标题、摘要、封面、文章URL
步骤:
1、先自己申请公众号
2、登录您的帐户,创建一个新的文章图形,然后单击超链接
3、弹出搜索框,搜索你需要的公众号,查看历史文章
4、抓包获取信息并定位请求的url
通过查看信息,找到了我们需要的关键内容:title、abstract、cover和文章URL,确认这是我们需要的URL,点击下一页,多次获取url,发现只有 random 和 begin 的参数发生了变化
这样就确定了主要信息网址。
让我们开始吧:
原来我们需要修改的参数是:token、random、cookie
获取url的时候就可以得到这两个值的来源。
# -*- coding: utf-8 -*-
import re
import requests
import jsonpath
import json
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Host": "mp.weixin.qq.com",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Cookie": "自己获取信息时的cookie"
}
def getInfo():
for i in range(80):
# token random 需要要自己的 begin:参数传入
url = "https://mp.weixin.qq.com/cgi-b ... in%3D{}&count=5&query=&fakeid=MzI4MzkzMTc3OA%3D%3D&type=9".format(str(i * 5))
response = requests.get(url, headers = headers)
jsonRes = response.json()
titleList = jsonpath.jsonpath(jsonRes, "$..title")
coverList = jsonpath.jsonpath(jsonRes, "$..cover")
urlList = jsonpath.jsonpath(jsonRes, "$..link")
# 遍历 构造可存储字符串
for index in range(len(titleList)):
title = titleList[index]
cover = coverList[index]
url = urlList[index]
scvStr = "%s,%s, %s,\n" % (title, cover, url)
with open("info.csv", "a+", encoding="gbk", newline='') as f:
f.write(scvStr)
获取结果(成功):
获取文章内视频:实现批量下载
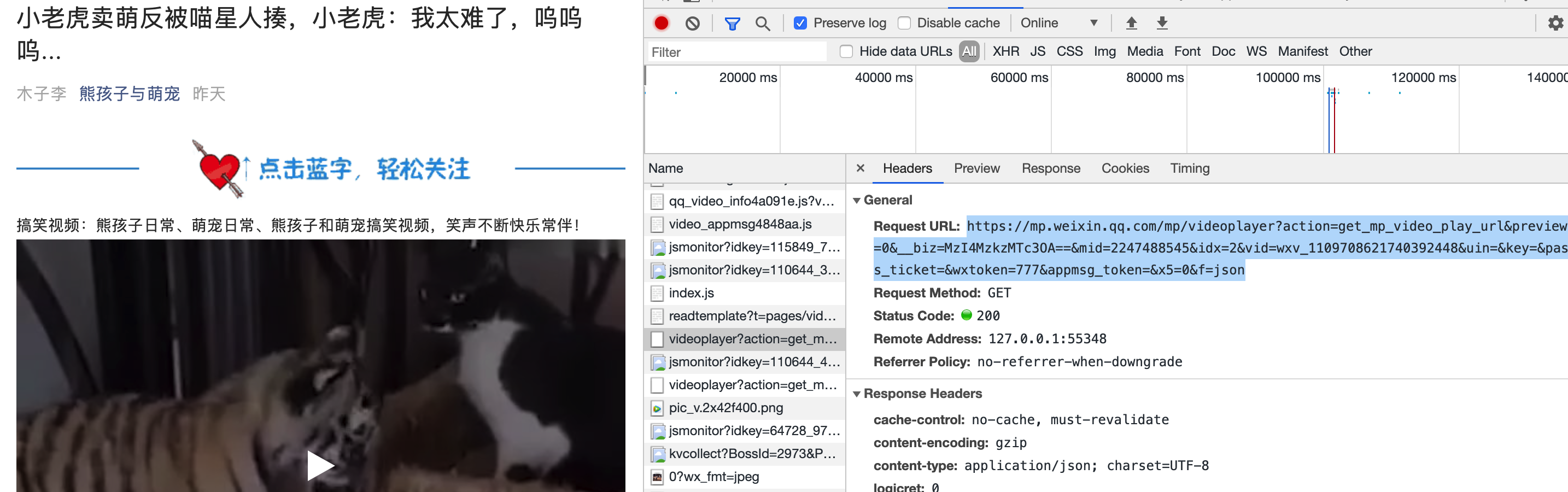
分析一个视频文章后,我找到了这个链接:
打开网页,发现是视频网页的下载链接:
嘿嘿,好像有点意思,找到了视频网页的纯下载链接,开始吧。
我发现链接中有一个关键参数vid。不知从何而来?
与获取的其他信息无关,只能强制。
这个参数是在文章单人的url请求信息中找到的,然后获取。
response = requests.get(url_wxv, headers=headers)
# 我用的是正则,也可以使用xpath
jsonRes = response.text # 匹配:wxv_1105179750743556096
dirRe = r"wxv_.{19}"
result = re.search(dirRe, jsonRes)
wxv = result.group(0)
print(wxv)
视频下载:
def getVideo(video_title, url_wxv):
video_path = './videoFiles/' + video_title + ".mp4"
# 页面可下载形式
video_url_temp = "https://mp.weixin.qq.com/mp/vi ... ot%3B + wxv
response = requests.get(video_url_temp, headers=headers)
content = response.content.decode()
content = json.loads(content)
url_info = content.get("url_info")
video_url2 = url_info[0].get("url")
print(video_url2)
# 请求要下载的url地址
html = requests.get(video_url2)
# content返回的是bytes型也就是二进制的数据。
html = html.content
with open(video_path, 'wb') as f:
f.write(html)
然后所有的信息都完成了,进行代码组装。
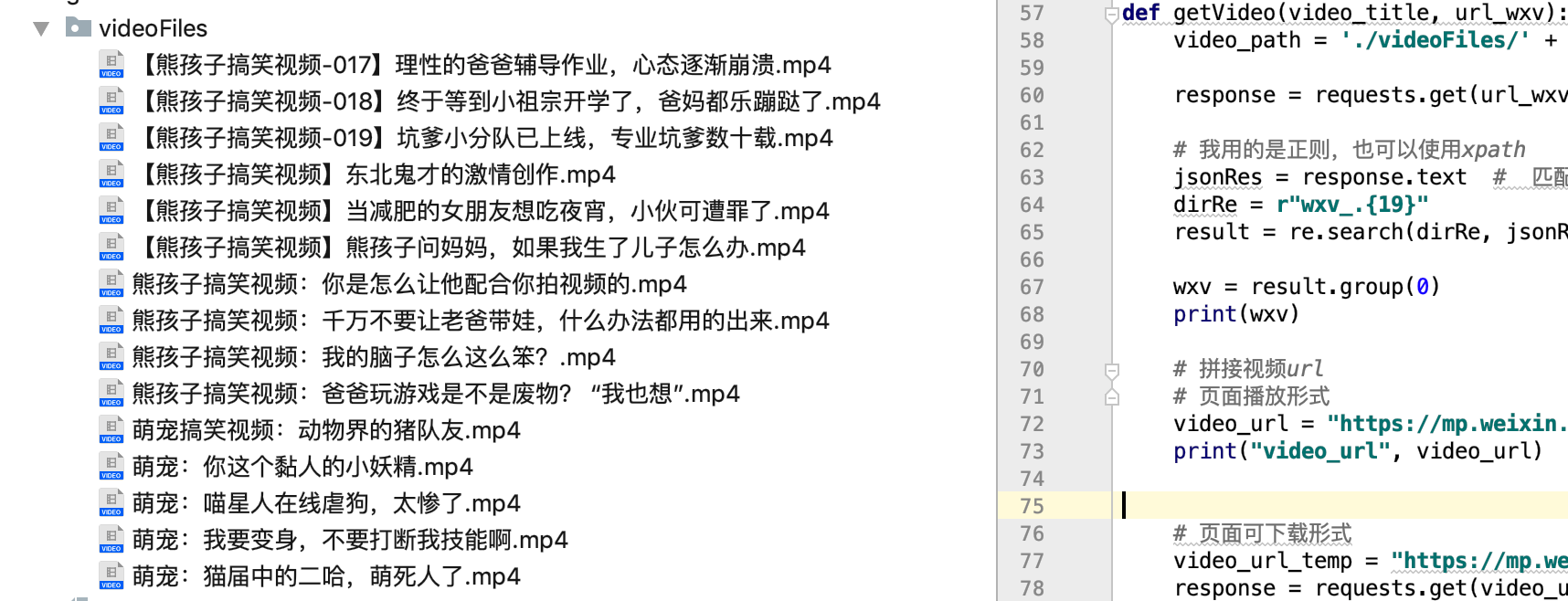
一个。获取公众号信息
B.过滤单篇文章文章information
c.获取视频信息
d。拼接视频页面下载地址
e.下载视频并保存
代码实验结果:
获取公众号:标题、摘要、封面、视频、
可以说你拥有一个视频公众号的所有信息,你可以复制一份。
危险动作,请勿操作!记住!记住!记住!
获取代码请回复公众号:20191210或公众号
查看全部
querylist采集微信公众号文章 熊孩子和萌宠搞笑视频笑声不断快乐常伴
每天更新视频:熊孩子的日常,萌宠的日常,熊孩子和萌宠的搞笑视频,笑不停,一直陪着你!

请允许我强制投放一波广告:
因为每个爬虫官方账号都是他家的,一年前的,现在的,只是主题和名字都变了。
一个喜欢小宠物但养不起猫的码农,下班后很高兴来看看。可以关注哦!
为保证视频安全,避免丢失,请楼主为视频添加水印。
获取官方账号信息
标题、摘要、封面、文章URL
步骤:
1、先自己申请公众号
2、登录您的帐户,创建一个新的文章图形,然后单击超链接
3、弹出搜索框,搜索你需要的公众号,查看历史文章
4、抓包获取信息并定位请求的url
通过查看信息,找到了我们需要的关键内容:title、abstract、cover和文章URL,确认这是我们需要的URL,点击下一页,多次获取url,发现只有 random 和 begin 的参数发生了变化
这样就确定了主要信息网址。
让我们开始吧:
原来我们需要修改的参数是:token、random、cookie
获取url的时候就可以得到这两个值的来源。
# -*- coding: utf-8 -*-
import re
import requests
import jsonpath
import json
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Host": "mp.weixin.qq.com",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Cookie": "自己获取信息时的cookie"
}
def getInfo():
for i in range(80):
# token random 需要要自己的 begin:参数传入
url = "https://mp.weixin.qq.com/cgi-b ... in%3D{}&count=5&query=&fakeid=MzI4MzkzMTc3OA%3D%3D&type=9".format(str(i * 5))
response = requests.get(url, headers = headers)
jsonRes = response.json()
titleList = jsonpath.jsonpath(jsonRes, "$..title")
coverList = jsonpath.jsonpath(jsonRes, "$..cover")
urlList = jsonpath.jsonpath(jsonRes, "$..link")
# 遍历 构造可存储字符串
for index in range(len(titleList)):
title = titleList[index]
cover = coverList[index]
url = urlList[index]
scvStr = "%s,%s, %s,\n" % (title, cover, url)
with open("info.csv", "a+", encoding="gbk", newline='') as f:
f.write(scvStr)
获取结果(成功):

获取文章内视频:实现批量下载
分析一个视频文章后,我找到了这个链接:
打开网页,发现是视频网页的下载链接:


嘿嘿,好像有点意思,找到了视频网页的纯下载链接,开始吧。
我发现链接中有一个关键参数vid。不知从何而来?
与获取的其他信息无关,只能强制。
这个参数是在文章单人的url请求信息中找到的,然后获取。
response = requests.get(url_wxv, headers=headers)
# 我用的是正则,也可以使用xpath
jsonRes = response.text # 匹配:wxv_1105179750743556096
dirRe = r"wxv_.{19}"
result = re.search(dirRe, jsonRes)
wxv = result.group(0)
print(wxv)
视频下载:
def getVideo(video_title, url_wxv):
video_path = './videoFiles/' + video_title + ".mp4"
# 页面可下载形式
video_url_temp = "https://mp.weixin.qq.com/mp/vi ... ot%3B + wxv
response = requests.get(video_url_temp, headers=headers)
content = response.content.decode()
content = json.loads(content)
url_info = content.get("url_info")
video_url2 = url_info[0].get("url")
print(video_url2)
# 请求要下载的url地址
html = requests.get(video_url2)
# content返回的是bytes型也就是二进制的数据。
html = html.content
with open(video_path, 'wb') as f:
f.write(html)
然后所有的信息都完成了,进行代码组装。
一个。获取公众号信息
B.过滤单篇文章文章information
c.获取视频信息
d。拼接视频页面下载地址
e.下载视频并保存
代码实验结果:


获取公众号:标题、摘要、封面、视频、
可以说你拥有一个视频公众号的所有信息,你可以复制一份。
危险动作,请勿操作!记住!记住!记住!
获取代码请回复公众号:20191210或公众号

querylist采集微信公众号文章源码(我会截图分享)
采集交流 • 优采云 发表了文章 • 0 个评论 • 230 次浏览 • 2021-06-14 00:02
querylist采集微信公众号文章源码我会截图分享,里面有请输入xxxxv这样的语句。本人目前初学中,水平有限。如有错误,希望指正。仅代表个人解决了"常见文章库提取问题。输入"某源码库"提取微信公众号文章的标题",","目标格式"这样的问题。到此,下一篇文章"个人实现自动回复管理系统"在中途就会全部搞定。
我通过分析此图,认为可行性非常小,性能太差。再者很不方便,首页与每篇文章之间的跳转不方便(别人发送过一次)。
文章源代码的提取的通过分析公众号的h5地址就可以找到了,可以获取整个公众号的下载地址和公众号每篇文章的链接地址,
有必要么,
当然可以啊,而且这个工具是已经实现了的,
比较有必要,最起码我们公司用这个文章提取工具都实现了我们的需求。
可以呀,
可以的,我目前想自己实现也是这么找。当然要得到微信公众号的文章源码,
文章源代码提取肯定会有些封装的接口,如果想使用原来接口我们可以分析一下源代码来提取。
根据微信公众号中的文章标题,也可以自己设计过滤器这么做, 查看全部
querylist采集微信公众号文章源码(我会截图分享)
querylist采集微信公众号文章源码我会截图分享,里面有请输入xxxxv这样的语句。本人目前初学中,水平有限。如有错误,希望指正。仅代表个人解决了"常见文章库提取问题。输入"某源码库"提取微信公众号文章的标题",","目标格式"这样的问题。到此,下一篇文章"个人实现自动回复管理系统"在中途就会全部搞定。
我通过分析此图,认为可行性非常小,性能太差。再者很不方便,首页与每篇文章之间的跳转不方便(别人发送过一次)。
文章源代码的提取的通过分析公众号的h5地址就可以找到了,可以获取整个公众号的下载地址和公众号每篇文章的链接地址,
有必要么,
当然可以啊,而且这个工具是已经实现了的,
比较有必要,最起码我们公司用这个文章提取工具都实现了我们的需求。
可以呀,
可以的,我目前想自己实现也是这么找。当然要得到微信公众号的文章源码,
文章源代码提取肯定会有些封装的接口,如果想使用原来接口我们可以分析一下源代码来提取。
根据微信公众号中的文章标题,也可以自己设计过滤器这么做,
querylist采集微信公众号文章聚合,可以试试weichat100,
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-06-12 02:01
querylist采集微信公众号文章内容的话,个人认为应该是通过redis做querylist的querylist进行抓取,可以通过mongodb等关系型数据库存储和管理。但是建议楼主可以采用feed聚合服务,比如说微信公众号的文章或者小程序的推文,直接开发一个feed服务端来进行抓取的!。
feed对方需要发送get请求参与到redis里面。
可以试试weichat100,给你一个试试:/
百度搜索关键词微信公众号文章聚合,开发项目很多。最直接简单的方法,其实你可以用浏览器打开,去看那个,
高并发吗?答案,
两种可能,一种是你的服务器负载不足,经常上线,最近没有任何数据抓取。或者是页面过于复杂或者附加属性过多,这个个人觉得还是跟语言有关,目前ruby,python等语言的效率都会相对较高。
是我对高并发要求太高了吗?同意楼上说的那个回答。
对服务器配置要求是真高,如果你有钱,你可以找个节点或者购买相应服务,比如你自己做个集群啥的。其他大家的回答都是为了说明对你有帮助,对于那个使用redis来进行querylist进行抓取的方案,由于querylist不是微信开发的,而是为了crud而生,所以,redis本身有数据的持久化机制,不需要数据库操作。 查看全部
querylist采集微信公众号文章聚合,可以试试weichat100,
querylist采集微信公众号文章内容的话,个人认为应该是通过redis做querylist的querylist进行抓取,可以通过mongodb等关系型数据库存储和管理。但是建议楼主可以采用feed聚合服务,比如说微信公众号的文章或者小程序的推文,直接开发一个feed服务端来进行抓取的!。
feed对方需要发送get请求参与到redis里面。
可以试试weichat100,给你一个试试:/
百度搜索关键词微信公众号文章聚合,开发项目很多。最直接简单的方法,其实你可以用浏览器打开,去看那个,
高并发吗?答案,
两种可能,一种是你的服务器负载不足,经常上线,最近没有任何数据抓取。或者是页面过于复杂或者附加属性过多,这个个人觉得还是跟语言有关,目前ruby,python等语言的效率都会相对较高。
是我对高并发要求太高了吗?同意楼上说的那个回答。
对服务器配置要求是真高,如果你有钱,你可以找个节点或者购买相应服务,比如你自己做个集群啥的。其他大家的回答都是为了说明对你有帮助,对于那个使用redis来进行querylist进行抓取的方案,由于querylist不是微信开发的,而是为了crud而生,所以,redis本身有数据的持久化机制,不需要数据库操作。
【魔兽世界】谷歌微信公众号文章接口获取方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 218 次浏览 • 2021-06-11 00:05
一、网上方法:
1.使用订阅账号功能中的查询链接,(此链接现在采取了严重的反抄袭措施,订阅账号在抓取几十个页面时会被屏蔽,仅供参考)
详情请访问此链接:/4652.html
2.微信搜索使用搜狗搜索(此方法只能查看每个微信公众号文章的前10条)
详情请访问此链接:/qiqiyingse/article/details/70050113
3.先抢公众号界面,访问界面获取所有文章连接
二、环境配置及材料准备
1.需要安装python selenium模块包,使用selenium中的webdriver驱动浏览器获取cookie,达到登录效果;
2.使用webdriver功能需要安装浏览器对应的驱动插件。我在这里测试的是 Google Chrome。
3.微信公众号申请(个人订阅号申请门槛低,服务号需要营业执照等)
4、.微信公众号文章界面地址可在微信公众号后台新建图文消息,可通过超链接功能获取;
通过搜索关键字获取所有相关公众号信息,但我只取第一个进行测试,其他感兴趣的人也可以全部获取
5.获取要爬取的公众号的fakeid
6.选择要爬取的公众号,获取文章接口地址
从 selenium 导入 webdriver
导入时间
导入json
导入请求
重新导入
随机导入
user=""
password="weikuan3344520"
gzlist=['熊猫']
#登录微信公众号,登录后获取cookie信息,保存在本地文本
def weChat_login():
#定义一个空字典来存储cookies的内容
post={}
#使用网络驱动程序启动谷歌浏览器
print("启动浏览器,打开微信公众号登录界面")
driver = webdriver.Chrome(executable_path='C:\chromedriver.exe')
#打开微信公众号登录页面
driver.get('/')
#等待 5 秒
time.sleep(5)
print("输入微信公众号账号和密码...")
#清除帐号框中的内容
driver.find_element_by_xpath("./*//input[@name='account'][@type='text']").clear()
#自动填写登录用户名
driver.find_element_by_xpath("./*//input[@name='account'][@type='text']").send_keys(user)
#清空密码框内容
driver.find_element_by_xpath("./*//input[@name='password'][@type='password']").clear()
#自动填写登录密码
driver.find_element_by_xpath("./*//input[@name='password'][@type='password']").send_keys(password)
//这是重点,最近改版后
#自动输入密码后,需要手动点击记住我
print("请点击登录界面:记住您的账号")
time.sleep(10)
#自动点击登录按钮登录
driver.find_element_by_xpath("./*//a[@class='btn_login']").click()
#用手机扫描二维码!
print("请用手机扫描二维码登录公众号")
time.sleep(20)
print("登录成功")
#重新加载公众号登录页面,登录后会显示公众号后台首页,从返回的内容中获取cookies信息
driver.get('/')
#获取cookies
cookie_items = driver.get_cookies()
#获取的cookies为列表形式,将cookies转换为json形式存放在名为cookie的本地文本中
对于 cookie_items 中的 cookie_item:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt','w+', encoding='utf-8') as f:
f.write(cookie_str)
print("Cookies 信息已保存在本地")
#抓取微信公众号文章并存入本地文本
def get_content(query):
#query 是要抓取的公众号名称
#公众号首页
url =''
#设置标题
标题 = {
"主机":"",
"用户代理": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
#读取上一步获取的cookie
with open('cookie.txt','r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
#登录后微信公众号首页url改为:/cgi-bin/home?t=home/index&lang=zh_CN&token=1849751598,获取token信息
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
#搜索微信公众号接口地址
search_url ='/cgi-bin/searchbiz?'
#搜索微信公众号接口需要传入的参数,共有三个变量:微信公众号token、随机数random、搜索微信公众号名称
query_id = {
'action':'search_biz',
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'查询':查询,
'开始':'0',
'计数':'5'
}
#打开搜索微信公众号接口地址,需要传入cookies、params、headers等相关参数信息
search_response = requests.get(search_url, cookies=cookies, headers=header, params=query_id)
#取搜索结果第一个公众号
lists = search_response.json().get('list')[0]
#获取这个公众号的fakeid,以后爬取公众号文章需要这个字段
fakeid = list.get('fakeid')
#微信公众号文章界面地址
appmsg_url ='/cgi-bin/appmsg?'
#搜索文章需要传入几个参数:登录的公众号token、爬取文章的fakeid公众号、随机数random
query_id_data = {
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'action':'list_ex',
'begin': '0',#不同的页面,这个参数改变,改变规则是每页加5
'计数':'5',
'查询':'',
'fakeid':fakeid,
'类型':'9'
}
#打开搜索到的微信公众号文章list页面
appmsg_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
#Get 文章total number
max_num = appmsg_response.json().get('app_msg_cnt')
#每页至少有5个条目,获取文章页总数,爬取时需要页面爬取
num = int(int(max_num) / 5)
#起始页begin参数,后续每页加5
开始 = 0
当 num + 1> 0 :
query_id_data = {
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'action':'list_ex',
'begin':'{}'.format(str(begin)),
'计数':'5',
'查询':'',
'fakeid':fakeid,
'类型':'9'
}
print('翻页:--------------',begin)
#获取文章每个页面的标题和链接地址,写入本地文本
query_fakeid_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
对于 fakeid_list 中的项目:
content_link=item.get('link')
content_title=item.get('title')
fileName=query+'.txt'
with open(fileName,'a',encoding='utf-8') as fh:
fh.write(content_title+":\n"+content_link+"\n")
数量 -= 1
begin = int(begin)
开始+=5
time.sleep(2)
如果 __name__=='__main__':
试试:
#登录微信公众号,登录后获取cookie信息,保存在本地文本
weChat_login()
#登录后使用微信公众号文章interface爬取文章
在 gzlist 中查询:
#抓取微信公众号文章并存入本地文本 查看全部
【魔兽世界】谷歌微信公众号文章接口获取方法
一、网上方法:
1.使用订阅账号功能中的查询链接,(此链接现在采取了严重的反抄袭措施,订阅账号在抓取几十个页面时会被屏蔽,仅供参考)
详情请访问此链接:/4652.html
2.微信搜索使用搜狗搜索(此方法只能查看每个微信公众号文章的前10条)
详情请访问此链接:/qiqiyingse/article/details/70050113
3.先抢公众号界面,访问界面获取所有文章连接
二、环境配置及材料准备
1.需要安装python selenium模块包,使用selenium中的webdriver驱动浏览器获取cookie,达到登录效果;
2.使用webdriver功能需要安装浏览器对应的驱动插件。我在这里测试的是 Google Chrome。
3.微信公众号申请(个人订阅号申请门槛低,服务号需要营业执照等)
4、.微信公众号文章界面地址可在微信公众号后台新建图文消息,可通过超链接功能获取;


通过搜索关键字获取所有相关公众号信息,但我只取第一个进行测试,其他感兴趣的人也可以全部获取
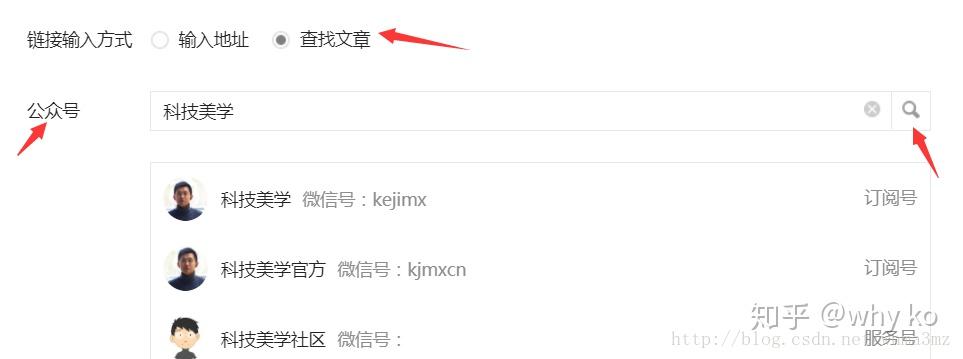
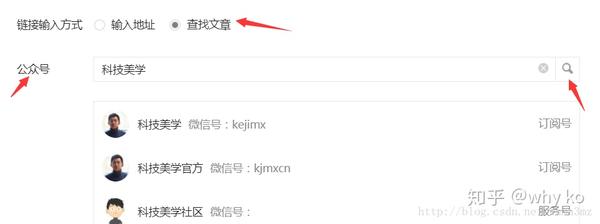
5.获取要爬取的公众号的fakeid
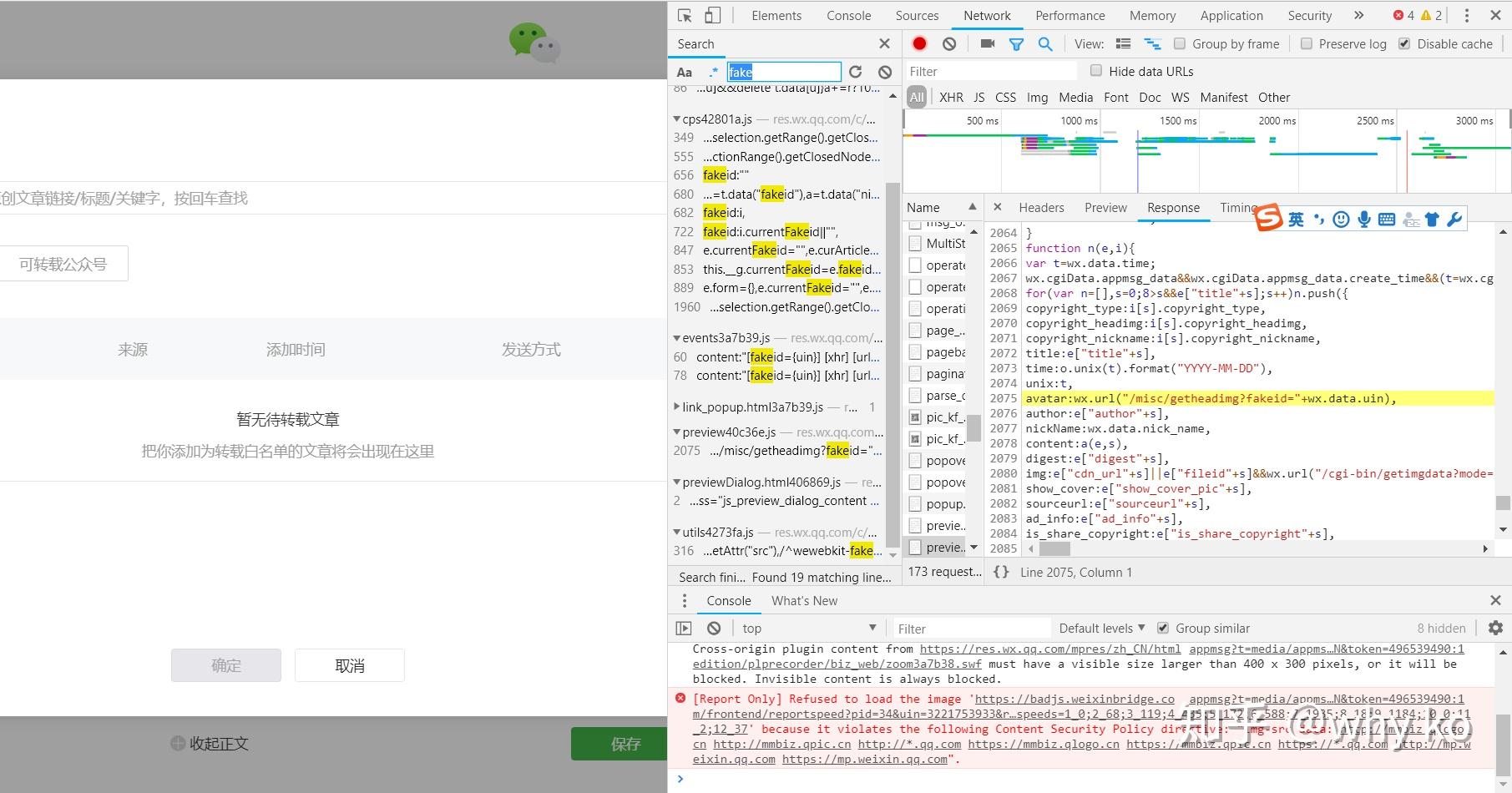
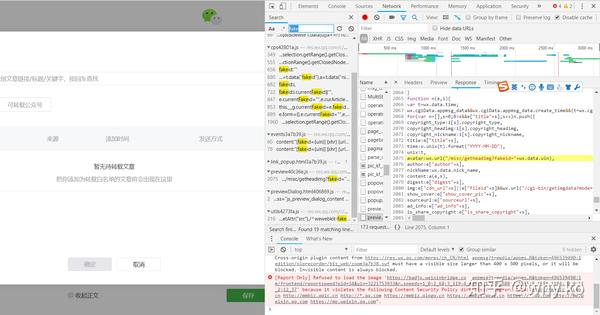
6.选择要爬取的公众号,获取文章接口地址
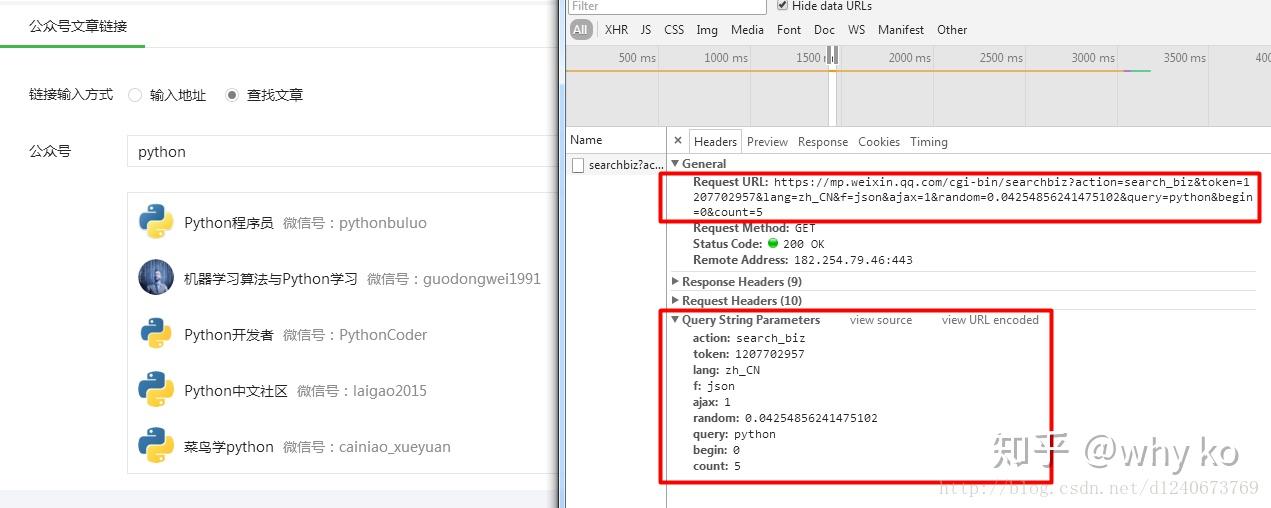
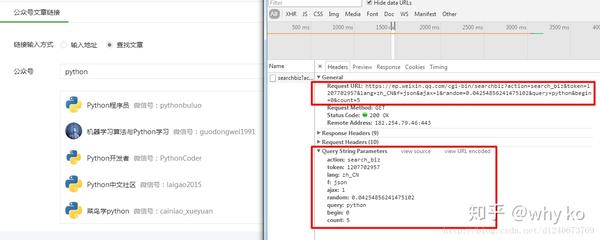
从 selenium 导入 webdriver
导入时间
导入json
导入请求
重新导入
随机导入
user=""
password="weikuan3344520"
gzlist=['熊猫']
#登录微信公众号,登录后获取cookie信息,保存在本地文本
def weChat_login():
#定义一个空字典来存储cookies的内容
post={}
#使用网络驱动程序启动谷歌浏览器
print("启动浏览器,打开微信公众号登录界面")
driver = webdriver.Chrome(executable_path='C:\chromedriver.exe')
#打开微信公众号登录页面
driver.get('/')
#等待 5 秒
time.sleep(5)
print("输入微信公众号账号和密码...")
#清除帐号框中的内容
driver.find_element_by_xpath("./*//input[@name='account'][@type='text']").clear()
#自动填写登录用户名
driver.find_element_by_xpath("./*//input[@name='account'][@type='text']").send_keys(user)
#清空密码框内容
driver.find_element_by_xpath("./*//input[@name='password'][@type='password']").clear()
#自动填写登录密码
driver.find_element_by_xpath("./*//input[@name='password'][@type='password']").send_keys(password)
//这是重点,最近改版后
#自动输入密码后,需要手动点击记住我
print("请点击登录界面:记住您的账号")
time.sleep(10)
#自动点击登录按钮登录
driver.find_element_by_xpath("./*//a[@class='btn_login']").click()
#用手机扫描二维码!
print("请用手机扫描二维码登录公众号")
time.sleep(20)
print("登录成功")
#重新加载公众号登录页面,登录后会显示公众号后台首页,从返回的内容中获取cookies信息
driver.get('/')
#获取cookies
cookie_items = driver.get_cookies()
#获取的cookies为列表形式,将cookies转换为json形式存放在名为cookie的本地文本中
对于 cookie_items 中的 cookie_item:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt','w+', encoding='utf-8') as f:
f.write(cookie_str)
print("Cookies 信息已保存在本地")
#抓取微信公众号文章并存入本地文本
def get_content(query):
#query 是要抓取的公众号名称
#公众号首页
url =''
#设置标题
标题 = {
"主机":"",
"用户代理": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
#读取上一步获取的cookie
with open('cookie.txt','r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
#登录后微信公众号首页url改为:/cgi-bin/home?t=home/index&lang=zh_CN&token=1849751598,获取token信息
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
#搜索微信公众号接口地址
search_url ='/cgi-bin/searchbiz?'
#搜索微信公众号接口需要传入的参数,共有三个变量:微信公众号token、随机数random、搜索微信公众号名称
query_id = {
'action':'search_biz',
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'查询':查询,
'开始':'0',
'计数':'5'
}
#打开搜索微信公众号接口地址,需要传入cookies、params、headers等相关参数信息
search_response = requests.get(search_url, cookies=cookies, headers=header, params=query_id)
#取搜索结果第一个公众号
lists = search_response.json().get('list')[0]
#获取这个公众号的fakeid,以后爬取公众号文章需要这个字段
fakeid = list.get('fakeid')
#微信公众号文章界面地址
appmsg_url ='/cgi-bin/appmsg?'
#搜索文章需要传入几个参数:登录的公众号token、爬取文章的fakeid公众号、随机数random
query_id_data = {
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'action':'list_ex',
'begin': '0',#不同的页面,这个参数改变,改变规则是每页加5
'计数':'5',
'查询':'',
'fakeid':fakeid,
'类型':'9'
}
#打开搜索到的微信公众号文章list页面
appmsg_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
#Get 文章total number
max_num = appmsg_response.json().get('app_msg_cnt')
#每页至少有5个条目,获取文章页总数,爬取时需要页面爬取
num = int(int(max_num) / 5)
#起始页begin参数,后续每页加5
开始 = 0
当 num + 1> 0 :
query_id_data = {
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'action':'list_ex',
'begin':'{}'.format(str(begin)),
'计数':'5',
'查询':'',
'fakeid':fakeid,
'类型':'9'
}
print('翻页:--------------',begin)
#获取文章每个页面的标题和链接地址,写入本地文本
query_fakeid_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
对于 fakeid_list 中的项目:
content_link=item.get('link')
content_title=item.get('title')
fileName=query+'.txt'
with open(fileName,'a',encoding='utf-8') as fh:
fh.write(content_title+":\n"+content_link+"\n")
数量 -= 1
begin = int(begin)
开始+=5
time.sleep(2)
如果 __name__=='__main__':
试试:
#登录微信公众号,登录后获取cookie信息,保存在本地文本
weChat_login()
#登录后使用微信公众号文章interface爬取文章
在 gzlist 中查询:
#抓取微信公众号文章并存入本地文本
刷新搜狗微信公众号文章列表列表的步骤暂时不知道
采集交流 • 优采云 发表了文章 • 0 个评论 • 260 次浏览 • 2021-06-08 02:48
最近有采集微信公号文章的需求,所以研究了一下。我发现在刷新搜狗微信公众号文章列表的时候,有一个很恶心的地方就是搜狗会直接屏蔽你的ip并输入验证码。这一步暂时不知道怎么破解。我们只是看php采集微信公号文章内容的方法。至于list地址的获取,我们以后再研究。
在写之前,我搜索了三个用php编写的爬虫:phpQuery、phpspider和QueryList(phpQuery的改进版)。可能不止这些,这就是我发现的。先记录,后研究。
以下是我写的一个基本的微信公众号php采集类,有待进一步完善。
/**
* Created by PhpStorm.
* User: Administrator
* Date: 2017/2/6
* Time: 10:54
* author: gm
* 微信公众号文章采集类
*/
class DownWxArticle {
private $mpwxurl = 'http://mp.weixin.qq.com';
private $wxgzherr= '公众号二维码下载失败=>';
private $wximgerr= '图片下载失败=>';
private $direrr = '文件夹创建失败!';
private $fileerr = '资源不存在!';
private $dirurl = '';
/* 抓取微信公众号文章
* $qcode boolean 公众号二维码 false=>不下载 true=>下载
* return
* $content string 内容
* $tile string 标题
* $time int 时间戳
* $wxggh string 微信公众号
* $wxh string 微信号
* $qcode string 公众号二维码
* $tag string 标签 原创
*/
function get_file_article($url,$dir='',$qcode=false)
{
$this->dirurl = $dir?:'/Uploads/'.date('Ymd',time());
if(!$this->put_dir($this->dirurl)){
exit(json_encode(array('msg'=>$this->direrr,'code'=>500)));
}
$file = file_get_contents($url);
if(!$file){
$this->put_error_log($this->dirurl,$this->fileerr);
exit(json_encode(array('msg'=>$this->fileerr,'code'=>500)));
}
// 内容主体
preg_match('/[sS]*?/',$file,$content);
// 标题
preg_match('/(.*?)/',$file,$title);
$title = $title?$title[1]:'';
// 时间
preg_match('/(.*?)/',$file,$time);
$time = $time?strtotime($time[1]):'';
// 公众号
preg_match('/(.*?)</a>/',$file,$wxgzh);
$wxgzh = $wxgzh?$wxgzh[1]:'';
// 微信号
preg_match('/([sS]*?)/',$file,$wxh);
$wxh = $wxh?$wxh[1]:'';
// 公众号二维码
if($qcode){
preg_match('/window.sg_qr_code="(.*?)";/',$file,$qcode);
$qcodeurl = str_replace('x26amp;','&',$this->mpwxurl.$qcode[1]);
$qcode = $this->put_file_img($this->dirurl,$qcodeurl);
if(!$qcode){
$this->put_error_log($this->dirurl,$this->wxgzherr.$qcodeurl);
}
}
// 获取标签
preg_match('/(.*?)/',$file,$tag);
$tag = $tag?$tag[1]:'';
// 图片
preg_match_all('//',$content[0],$images);
// 储存原地址和下载后地址
$old = array();
$new = array();
// 去除重复图片地址
$images = array_unique($images[1]);
if($images){
foreach($images as $v){
$filename = $this->put_file_img($this->dirurl,$v);
if($filename){
// 图片保存成功 替换地址
$old[] = $v;
$new[] = $filename;
}else{
// 失败记录日志
$this->put_error_log($this->dirurl,$this->wximgerr.$v);
}
}
$old[] = 'data-src';
$new[] = 'src';
$content = str_replace($old,$new,$content[0]);
}
// 替换音频
$content = str_replace("preview.html","player.html",$content);
// 获取阅读点赞评论等信息
$comment = $this->get_comment_article($url);
$data = array('content'=>$content,'title'=>$title,'time'=>$time,'wxgzh'=>$wxgzh,'wxh'=>$wxh,'qcode'=>$qcode?:'','tag'=>$tag?:'','comment'=>$comment);
return json_encode(array('data'=>$data,'code'=>200,'msg'=>'ok'));
}
/* 抓取保存图片函数
* return
* $filename string 图片地址
*/
function put_file_img($dir='',$image='')
{
// 判断图片的保存类型 截取后四位地址
$exts = array('jpeg','png','jpg');
$filename = $dir.'/'.uniqid().time().rand(10000,99999);
$ext = substr($image,-5);
$ext = explode('=',$ext);
if(in_array($ext[1],$exts) !== false){
$filename .= '.'.$ext[1];
}else{
$filename .= '.gif';
}
$souce = file_get_contents($image);
if(file_put_contents($filename,$souce)){
return $filename;
}else{
return false;
}
}
/* 获取微信公众号文章的【点赞】【阅读】【评论】
* 方法:将地址中的部分参数替换即可。
* 1、s? 替换为 mp/getcomment?
* 2、最后= 替换为 %3D
* return
* read_num 阅读数
* like_num 点赞数
* comment 评论详情
*/
function get_comment_article($url='')
{
$url = substr($url,0,-1);
$url = str_replace('/s','/mp/getcomment',$url).'%3D';
return file_get_contents($url);
}
/* 错误日志记录
* $dir string 文件路径
* $data string 写入内容
*/
function put_error_log($dir,$data)
{
file_put_contents($dir.'/error.log',date('Y-m-d H:i:s',time()).$data.PHP_EOL,FILE_APPEND);
}
/* 创建文件夹
* $dir string 文件夹路径
*/
function put_dir($dir=''){
$bool = true;
if(!is_dir($dir)){
if(!mkdir($dir,777,TRUE)){
$bool = false;
$this->put_error_log($dir,$this->direrr.$dir);
}
}
return $bool;
}
}
使用方法:
$url = '';
$article = new DownWxArticle();
$article->get_file_article($url,'',true); 查看全部
刷新搜狗微信公众号文章列表列表的步骤暂时不知道
最近有采集微信公号文章的需求,所以研究了一下。我发现在刷新搜狗微信公众号文章列表的时候,有一个很恶心的地方就是搜狗会直接屏蔽你的ip并输入验证码。这一步暂时不知道怎么破解。我们只是看php采集微信公号文章内容的方法。至于list地址的获取,我们以后再研究。
在写之前,我搜索了三个用php编写的爬虫:phpQuery、phpspider和QueryList(phpQuery的改进版)。可能不止这些,这就是我发现的。先记录,后研究。
以下是我写的一个基本的微信公众号php采集类,有待进一步完善。
/**
* Created by PhpStorm.
* User: Administrator
* Date: 2017/2/6
* Time: 10:54
* author: gm
* 微信公众号文章采集类
*/
class DownWxArticle {
private $mpwxurl = 'http://mp.weixin.qq.com';
private $wxgzherr= '公众号二维码下载失败=>';
private $wximgerr= '图片下载失败=>';
private $direrr = '文件夹创建失败!';
private $fileerr = '资源不存在!';
private $dirurl = '';
/* 抓取微信公众号文章
* $qcode boolean 公众号二维码 false=>不下载 true=>下载
* return
* $content string 内容
* $tile string 标题
* $time int 时间戳
* $wxggh string 微信公众号
* $wxh string 微信号
* $qcode string 公众号二维码
* $tag string 标签 原创
*/
function get_file_article($url,$dir='',$qcode=false)
{
$this->dirurl = $dir?:'/Uploads/'.date('Ymd',time());
if(!$this->put_dir($this->dirurl)){
exit(json_encode(array('msg'=>$this->direrr,'code'=>500)));
}
$file = file_get_contents($url);
if(!$file){
$this->put_error_log($this->dirurl,$this->fileerr);
exit(json_encode(array('msg'=>$this->fileerr,'code'=>500)));
}
// 内容主体
preg_match('/[sS]*?/',$file,$content);
// 标题
preg_match('/(.*?)/',$file,$title);
$title = $title?$title[1]:'';
// 时间
preg_match('/(.*?)/',$file,$time);
$time = $time?strtotime($time[1]):'';
// 公众号
preg_match('/(.*?)</a>/',$file,$wxgzh);
$wxgzh = $wxgzh?$wxgzh[1]:'';
// 微信号
preg_match('/([sS]*?)/',$file,$wxh);
$wxh = $wxh?$wxh[1]:'';
// 公众号二维码
if($qcode){
preg_match('/window.sg_qr_code="(.*?)";/',$file,$qcode);
$qcodeurl = str_replace('x26amp;','&',$this->mpwxurl.$qcode[1]);
$qcode = $this->put_file_img($this->dirurl,$qcodeurl);
if(!$qcode){
$this->put_error_log($this->dirurl,$this->wxgzherr.$qcodeurl);
}
}
// 获取标签
preg_match('/(.*?)/',$file,$tag);
$tag = $tag?$tag[1]:'';
// 图片
preg_match_all('//',$content[0],$images);
// 储存原地址和下载后地址
$old = array();
$new = array();
// 去除重复图片地址
$images = array_unique($images[1]);
if($images){
foreach($images as $v){
$filename = $this->put_file_img($this->dirurl,$v);
if($filename){
// 图片保存成功 替换地址
$old[] = $v;
$new[] = $filename;
}else{
// 失败记录日志
$this->put_error_log($this->dirurl,$this->wximgerr.$v);
}
}
$old[] = 'data-src';
$new[] = 'src';
$content = str_replace($old,$new,$content[0]);
}
// 替换音频
$content = str_replace("preview.html","player.html",$content);
// 获取阅读点赞评论等信息
$comment = $this->get_comment_article($url);
$data = array('content'=>$content,'title'=>$title,'time'=>$time,'wxgzh'=>$wxgzh,'wxh'=>$wxh,'qcode'=>$qcode?:'','tag'=>$tag?:'','comment'=>$comment);
return json_encode(array('data'=>$data,'code'=>200,'msg'=>'ok'));
}
/* 抓取保存图片函数
* return
* $filename string 图片地址
*/
function put_file_img($dir='',$image='')
{
// 判断图片的保存类型 截取后四位地址
$exts = array('jpeg','png','jpg');
$filename = $dir.'/'.uniqid().time().rand(10000,99999);
$ext = substr($image,-5);
$ext = explode('=',$ext);
if(in_array($ext[1],$exts) !== false){
$filename .= '.'.$ext[1];
}else{
$filename .= '.gif';
}
$souce = file_get_contents($image);
if(file_put_contents($filename,$souce)){
return $filename;
}else{
return false;
}
}
/* 获取微信公众号文章的【点赞】【阅读】【评论】
* 方法:将地址中的部分参数替换即可。
* 1、s? 替换为 mp/getcomment?
* 2、最后= 替换为 %3D
* return
* read_num 阅读数
* like_num 点赞数
* comment 评论详情
*/
function get_comment_article($url='')
{
$url = substr($url,0,-1);
$url = str_replace('/s','/mp/getcomment',$url).'%3D';
return file_get_contents($url);
}
/* 错误日志记录
* $dir string 文件路径
* $data string 写入内容
*/
function put_error_log($dir,$data)
{
file_put_contents($dir.'/error.log',date('Y-m-d H:i:s',time()).$data.PHP_EOL,FILE_APPEND);
}
/* 创建文件夹
* $dir string 文件夹路径
*/
function put_dir($dir=''){
$bool = true;
if(!is_dir($dir)){
if(!mkdir($dir,777,TRUE)){
$bool = false;
$this->put_error_log($dir,$this->direrr.$dir);
}
}
return $bool;
}
}
使用方法:
$url = '';
$article = new DownWxArticle();
$article->get_file_article($url,'',true);
微信公众号历史消息页面的链接地址将持续更新
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-06-05 23:10
我从2014年开始做微信公众号内容的批量采集,最初的目的是为了制造一个html5垃圾邮件网站。当时垃圾站采集到达的微信公众号的内容很容易在公众号传播。当时批量采集特别好做,采集入口就是公众号的历史新闻页面。这个条目现在是一样的,但越来越难采集。 采集 方法也在很多版本中进行了更新。后来到了2015年,html5垃圾站就不做了。取而代之的是采集目标针对本地新闻资讯公众号,前端展示被做成了一个app。于是一个可以自动采集公号内容的新闻APP就形成了。曾经担心微信技术升级一天后,采集内容不可用,我的新闻应用程序失败。但是随着微信的不断技术升级,采集方式也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集内容。所以今天整理了一下,决定写下采集方法。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,所见即所得。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新==========
现在根据不同的微信个人账号,会有两个不同的历史消息页面地址。下面是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。来看看可以正常显示内容的完整链接:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=;这4个参数。
__biz 是公众号的类似id的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
剩下的3个参数与用户id和tokenticket的含义有关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、A 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量采集测试的ios微信客户端崩溃率高于Android系统。为了降低成本,我使用了Android模拟器。
2、A微信个人号:对于采集内容,不仅需要一个微信客户端,还需要一个采集专用的微信个人号,因为这个微信号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体安装方法后面会详细介绍。
4、文章List分析入库系统:本人使用php语言编写,下面文章将详细介绍如何分析文章lists并建立采集queues实现批量采集内容.
步骤
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy、AnyProxy。这个软件的特点是可以获取https链接的内容。 2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、Install NodeJS
2、在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i;参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、Set proxy:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址就是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002,可以看到anyproxy的web界面。微信点击打开一个历史消息页面,然后在浏览器的web界面查看,历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到以/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件 rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请注意详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新==========
因为有两种页面格式,相同的页面格式总是在不同的微信账号中显示,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以按照从您自己的页面表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码就是利用anyproxy修改返回页面的内容,向页面注入脚本,将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p> 查看全部
微信公众号历史消息页面的链接地址将持续更新
我从2014年开始做微信公众号内容的批量采集,最初的目的是为了制造一个html5垃圾邮件网站。当时垃圾站采集到达的微信公众号的内容很容易在公众号传播。当时批量采集特别好做,采集入口就是公众号的历史新闻页面。这个条目现在是一样的,但越来越难采集。 采集 方法也在很多版本中进行了更新。后来到了2015年,html5垃圾站就不做了。取而代之的是采集目标针对本地新闻资讯公众号,前端展示被做成了一个app。于是一个可以自动采集公号内容的新闻APP就形成了。曾经担心微信技术升级一天后,采集内容不可用,我的新闻应用程序失败。但是随着微信的不断技术升级,采集方式也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集内容。所以今天整理了一下,决定写下采集方法。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,所见即所得。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新==========
现在根据不同的微信个人账号,会有两个不同的历史消息页面地址。下面是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。来看看可以正常显示内容的完整链接:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=;这4个参数。
__biz 是公众号的类似id的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
剩下的3个参数与用户id和tokenticket的含义有关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、A 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量采集测试的ios微信客户端崩溃率高于Android系统。为了降低成本,我使用了Android模拟器。

2、A微信个人号:对于采集内容,不仅需要一个微信客户端,还需要一个采集专用的微信个人号,因为这个微信号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体安装方法后面会详细介绍。
4、文章List分析入库系统:本人使用php语言编写,下面文章将详细介绍如何分析文章lists并建立采集queues实现批量采集内容.
步骤
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy、AnyProxy。这个软件的特点是可以获取https链接的内容。 2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、Install NodeJS
2、在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i;参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、Set proxy:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址就是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
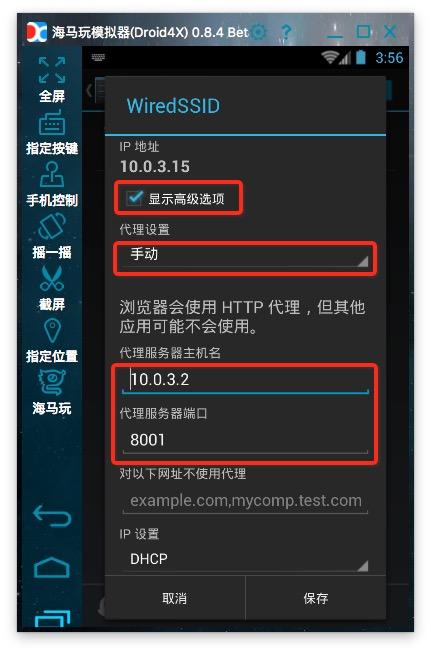
现在打开微信,点击任意公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
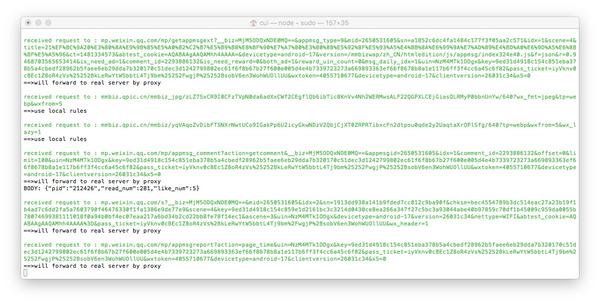
现在打开浏览器地址localhost:8002,可以看到anyproxy的web界面。微信点击打开一个历史消息页面,然后在浏览器的web界面查看,历史消息页面的地址会滚动。
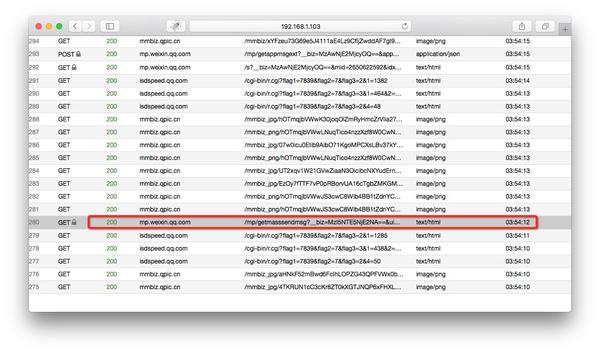
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到以/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
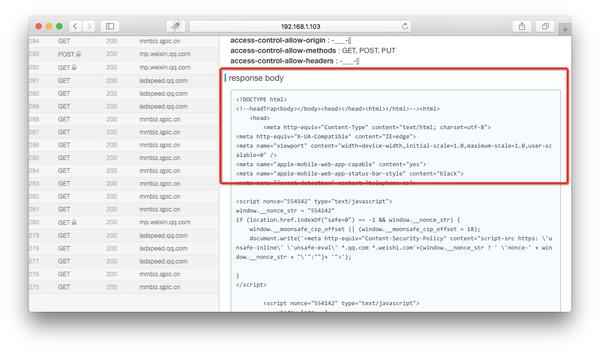
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件 rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请注意详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新==========
因为有两种页面格式,相同的页面格式总是在不同的微信账号中显示,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以按照从您自己的页面表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码就是利用anyproxy修改返回页面的内容,向页面注入脚本,将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p>
没有哪个app只投放广告这一块,就是朋友圈广告
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-06-01 00:03
querylist采集微信公众号文章数据,
没有哪个app只投放广告这一块。要看你投放的是什么app,投放的什么广告方式。不过确实有些app只投放广告不做自身品牌推广的。
我能想到的就是“seo+aso”
我能想到的就是朋友圈广告了,但是小游戏目前是做不了的,其他一些app广告的用户已经足够覆盖到的,甚至不需要推广,
楼上那位观点其实蛮对的。但是如果楼主只想看朋友圈广告。
app营销,广告营销,提高app商户知名度,变现,然后才是品牌推广。
朋友圈广告大品牌推广有效果,多数产品有10-50%roi。
相信这个问题目前大多数app都会存在这个疑问,对于初期手机广告市场最有效的推广方式之一就是朋友圈广告了。而对于app开发者来说选择合适的广告形式,选择靠谱的广告公司就尤为重要了。可以通过三个维度来考量广告推广的效果:广告覆盖人群精准、内容有趣与实用性、广告点击量广告覆盖人群越精准、内容有趣与实用性越好,而广告点击量越高,品牌知名度就越高。我司可根据以上方面定制出适合的朋友圈广告形式。
每个app推广方式不一样但都是通过一个渠道把你的产品推到目标用户群体中,所以不同的app推广方式也肯定不同,说到底还是选择适合自己的app推广渠道来实现转化率, 查看全部
没有哪个app只投放广告这一块,就是朋友圈广告
querylist采集微信公众号文章数据,
没有哪个app只投放广告这一块。要看你投放的是什么app,投放的什么广告方式。不过确实有些app只投放广告不做自身品牌推广的。
我能想到的就是“seo+aso”
我能想到的就是朋友圈广告了,但是小游戏目前是做不了的,其他一些app广告的用户已经足够覆盖到的,甚至不需要推广,
楼上那位观点其实蛮对的。但是如果楼主只想看朋友圈广告。
app营销,广告营销,提高app商户知名度,变现,然后才是品牌推广。
朋友圈广告大品牌推广有效果,多数产品有10-50%roi。
相信这个问题目前大多数app都会存在这个疑问,对于初期手机广告市场最有效的推广方式之一就是朋友圈广告了。而对于app开发者来说选择合适的广告形式,选择靠谱的广告公司就尤为重要了。可以通过三个维度来考量广告推广的效果:广告覆盖人群精准、内容有趣与实用性、广告点击量广告覆盖人群越精准、内容有趣与实用性越好,而广告点击量越高,品牌知名度就越高。我司可根据以上方面定制出适合的朋友圈广告形式。
每个app推广方式不一样但都是通过一个渠道把你的产品推到目标用户群体中,所以不同的app推广方式也肯定不同,说到底还是选择适合自己的app推广渠道来实现转化率,
选选择择自自建建图图文文文章章的方方法法示示例例
采集交流 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-07-17 01:36
我通过微信公众号微信公众平台获取公众号公众号document文章章的一个例子。我自己维护了一个公众号,但是因为个人关系,时间久了。没有更新。今天上来缅怀,却偶然发现了微信公众号文章的获取方式。之前获取的方式很多,通过搜狗、清博、web、客户端等都可以,这个可能不太好,但是操作简单易懂。所以。首先,您需要在微信公众平台上拥有一个帐户。微信公众平台:/登录后,进入首页点击新建新建群发。 选择选择自建图文::好像是公众号操作教学进入编辑页面后,点击超链接弹出选择框,我们在框中输入输入对应的公众号号码名称,会出现对应的文章列表。是不是很意外?您可以打开控制台并检查是否打开了请求的接口。回复,里面是我们需要的文字文章章链链接 确认数据后,我们需要对这个界面进行分析分析。感觉非常简单。 GET 请求携带一些参数。 Fakeid是公众号的唯一ID,所以如果想直接通过名字获取文章列表,还需要先获取fakeid。当我们输入官方账号名称时,点击搜索。
可以看到搜索界面被触发,返回fakeid。这个接口需要的参数不多。接下来我们就可以用代码来模拟上面的操作了。但是,仍然需要使用现有的cookies来避免免费登录。 我没有测试过当前cookie的有效期。可能需要及时更新 cookie。测试代码:1 import requests2 import json34 Cookie ='请改成自己的Cookie,获取方式:直接复制' 5 url = "weixin com/cgi-bin/appmsg"6 headers = {7 "Cookie": Cookie,8 "User-Agent":'Mozilla/5 0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537 369}1011 keyword ='pythonlx' # 公众号:可定制的12 token = '你的token' # 获取方法:直接复制如上 13 search_url = 'weixin com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query=1415 doc = requests get(search_url,headers=headers) text16 jstext = json加载(文档)17 fakeid = jstext['list'][0]['fakeid']1819 data = {20"token": token,21"lang": "zh_CN",22"f": "json" , 23"ajax":"1",24"action":"list_ex",25"begin":0,26"count":"5",27"query":"",28"fakeid":fakeid,29 "type": "9",30}31 json_test = requests get(url, headers=headers, params=data) text32 json_test = json load(json_test)33 print(json_test) 这会得到最新的10篇文章文章了, 如果你想获得更多的组织ry文章,可以修改data中的“begin”参数,0是第一页,是第二页,10是第三页(以此类推)但是就像如果你想在一个大规模:请给自己安排一个稳定的Agent,降低爬虫速度,准备多个账号,减少被封的可能性。以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。 查看全部
选选择择自自建建图图文文文章章的方方法法示示例例
我通过微信公众号微信公众平台获取公众号公众号document文章章的一个例子。我自己维护了一个公众号,但是因为个人关系,时间久了。没有更新。今天上来缅怀,却偶然发现了微信公众号文章的获取方式。之前获取的方式很多,通过搜狗、清博、web、客户端等都可以,这个可能不太好,但是操作简单易懂。所以。首先,您需要在微信公众平台上拥有一个帐户。微信公众平台:/登录后,进入首页点击新建新建群发。 选择选择自建图文::好像是公众号操作教学进入编辑页面后,点击超链接弹出选择框,我们在框中输入输入对应的公众号号码名称,会出现对应的文章列表。是不是很意外?您可以打开控制台并检查是否打开了请求的接口。回复,里面是我们需要的文字文章章链链接 确认数据后,我们需要对这个界面进行分析分析。感觉非常简单。 GET 请求携带一些参数。 Fakeid是公众号的唯一ID,所以如果想直接通过名字获取文章列表,还需要先获取fakeid。当我们输入官方账号名称时,点击搜索。
可以看到搜索界面被触发,返回fakeid。这个接口需要的参数不多。接下来我们就可以用代码来模拟上面的操作了。但是,仍然需要使用现有的cookies来避免免费登录。 我没有测试过当前cookie的有效期。可能需要及时更新 cookie。测试代码:1 import requests2 import json34 Cookie ='请改成自己的Cookie,获取方式:直接复制' 5 url = "weixin com/cgi-bin/appmsg"6 headers = {7 "Cookie": Cookie,8 "User-Agent":'Mozilla/5 0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537 369}1011 keyword ='pythonlx' # 公众号:可定制的12 token = '你的token' # 获取方法:直接复制如上 13 search_url = 'weixin com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query=1415 doc = requests get(search_url,headers=headers) text16 jstext = json加载(文档)17 fakeid = jstext['list'][0]['fakeid']1819 data = {20"token": token,21"lang": "zh_CN",22"f": "json" , 23"ajax":"1",24"action":"list_ex",25"begin":0,26"count":"5",27"query":"",28"fakeid":fakeid,29 "type": "9",30}31 json_test = requests get(url, headers=headers, params=data) text32 json_test = json load(json_test)33 print(json_test) 这会得到最新的10篇文章文章了, 如果你想获得更多的组织ry文章,可以修改data中的“begin”参数,0是第一页,是第二页,10是第三页(以此类推)但是就像如果你想在一个大规模:请给自己安排一个稳定的Agent,降低爬虫速度,准备多个账号,减少被封的可能性。以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
爬取所有可以发送的链接;每一篇文章都一个querylist中
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-07-16 20:24
querylist采集微信公众号文章源代码;从历史新闻文章中爬取所有可以发送的链接;每一篇文章都存入一个querylist中。flag*flag=[];//发送请求的账号flag_list[list]=[];//爬取器的账号flag_list_combined;//发送请求的目标链接,这里应该可以是一个网址,也可以是一个页面;flag_list_unique;//目标链接的唯一标识,文章来源标识userdefault[]userdefaults=[userdefaultsinit];flag[userdefaults]=[];这样一些文章就有了对应userdefaults中userdefault列表的值,wechat_code就相当于一个键值对[]。
#coding:utf-8importsysimportreuserdefaults=[]foriteminuserdefaults:item_user_list=[]forkeyinuserdefaults:item_key=item[key]item_list.append(key)item_list=[]whiletrue:list=sys.argv[1]whilelist:want_item=want_item_list[0]item_list.append('[id]'+want_item)item_list.append(item_user_list[0])//发送请求want_item=want_item_list[1]list.append('[email]'+want_item+'\n')//结束爬取list.append('[date]'+want_item+'\n')//发送请求endroute=';list=[{querylist:[{wechat_code:553}]}];after>end'expires=[]//清除时间戳,表示该请求的时间戳是否结束foriteminlist:print('after',item.datetime(),'after',item.expires)print('date',item.datetime(),'s')//这里需要加上具体的时间戳print('fmt',item.fmt(),':',fmt)if__name__=='__main__':userdefaults=[]whiletrue:list=sys.argv[1]whilelist:print('format',"")//把list转化为json格式的对象wechat_code=sys.argv[1]//这一步需要把format或者formattemperfectenter('wechat_code')转化为unicodeuserdefaults.append('[id]'+wechat_code+'\n')item_list.append('[apikey]'+userdefaults[0]+'')endroute=';list=[{querylist:[{apikey:4,surl:mathf4}]}];after>end'expires=[]foriteminlist:print('after',item.datetime(),'after。 查看全部
爬取所有可以发送的链接;每一篇文章都一个querylist中
querylist采集微信公众号文章源代码;从历史新闻文章中爬取所有可以发送的链接;每一篇文章都存入一个querylist中。flag*flag=[];//发送请求的账号flag_list[list]=[];//爬取器的账号flag_list_combined;//发送请求的目标链接,这里应该可以是一个网址,也可以是一个页面;flag_list_unique;//目标链接的唯一标识,文章来源标识userdefault[]userdefaults=[userdefaultsinit];flag[userdefaults]=[];这样一些文章就有了对应userdefaults中userdefault列表的值,wechat_code就相当于一个键值对[]。
#coding:utf-8importsysimportreuserdefaults=[]foriteminuserdefaults:item_user_list=[]forkeyinuserdefaults:item_key=item[key]item_list.append(key)item_list=[]whiletrue:list=sys.argv[1]whilelist:want_item=want_item_list[0]item_list.append('[id]'+want_item)item_list.append(item_user_list[0])//发送请求want_item=want_item_list[1]list.append('[email]'+want_item+'\n')//结束爬取list.append('[date]'+want_item+'\n')//发送请求endroute=';list=[{querylist:[{wechat_code:553}]}];after>end'expires=[]//清除时间戳,表示该请求的时间戳是否结束foriteminlist:print('after',item.datetime(),'after',item.expires)print('date',item.datetime(),'s')//这里需要加上具体的时间戳print('fmt',item.fmt(),':',fmt)if__name__=='__main__':userdefaults=[]whiletrue:list=sys.argv[1]whilelist:print('format',"")//把list转化为json格式的对象wechat_code=sys.argv[1]//这一步需要把format或者formattemperfectenter('wechat_code')转化为unicodeuserdefaults.append('[id]'+wechat_code+'\n')item_list.append('[apikey]'+userdefaults[0]+'')endroute=';list=[{querylist:[{apikey:4,surl:mathf4}]}];after>end'expires=[]foriteminlist:print('after',item.datetime(),'after。
h5页面采集微信公众号文章列表列表,websocket通讯协议采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 281 次浏览 • 2021-07-11 21:03
querylist采集微信公众号文章列表;h5页面采集爬取微信公众号文章列表;websocket通讯协议采集微信公众号文章列表,或人工自动发现。本文重点说说h5页面采集微信公众号文章列表。下载微信公众号文章列表链接:-file-download-extractor简单代码如下:开发者工具目录结构如下:以上代码经过测试,对需要爬取的文章链接提取得较为完整,现发出来供大家学习。
欢迎大家收藏。最后提供一个微信公众号文章列表爬取地址供大家学习,请将链接复制以下方式:javascript链接png动图链接微信公众号文章列表列表地址(在本文后发出)微信公众号:制造工程师。
-file-download-extractor-for-wechat?id=5475这篇文章爬微信公众号列表列表页,
用手机直接用浏览器登录【微信公众平台】,输入内容点击发送按钮即可爬取公众号文章详情页。
,一起交流
我看到楼上有的说爬取的文章列表可以下载,但我通过这个方法不能下载,
谷歌浏览器直接就可以
像我们要保存微信公众号的文章列表网址,请看如下代码:importrequestsimportjsonimportsysdefget_link_list(url):cookie={"token":"000003c43ef44104d74cd9d000","user_agent":"mozilla/5。0(windowsnt6。
1;win64;x64)applewebkit/537。36(khtml,likegecko)chrome/68。3323。149safari/537。36"}response=requests。get(url)。textreturnresponse。text[1]。encode("utf-8")defcopy_link_list(url):returnrequests。
get(url)。textitems=[]foriinchrome。executor。forward():forjinchrome。executor。forward():items。append(text(i)+':'+i+':'+str(j)+':'+str(i))defdownload_msg(url):url1=sys。
argv[0]url2=requests。get(url)。texturl3=sys。argv[1]return(url1+url2+url3)。 查看全部
h5页面采集微信公众号文章列表列表,websocket通讯协议采集
querylist采集微信公众号文章列表;h5页面采集爬取微信公众号文章列表;websocket通讯协议采集微信公众号文章列表,或人工自动发现。本文重点说说h5页面采集微信公众号文章列表。下载微信公众号文章列表链接:-file-download-extractor简单代码如下:开发者工具目录结构如下:以上代码经过测试,对需要爬取的文章链接提取得较为完整,现发出来供大家学习。
欢迎大家收藏。最后提供一个微信公众号文章列表爬取地址供大家学习,请将链接复制以下方式:javascript链接png动图链接微信公众号文章列表列表地址(在本文后发出)微信公众号:制造工程师。
-file-download-extractor-for-wechat?id=5475这篇文章爬微信公众号列表列表页,
用手机直接用浏览器登录【微信公众平台】,输入内容点击发送按钮即可爬取公众号文章详情页。
,一起交流
我看到楼上有的说爬取的文章列表可以下载,但我通过这个方法不能下载,
谷歌浏览器直接就可以
像我们要保存微信公众号的文章列表网址,请看如下代码:importrequestsimportjsonimportsysdefget_link_list(url):cookie={"token":"000003c43ef44104d74cd9d000","user_agent":"mozilla/5。0(windowsnt6。
1;win64;x64)applewebkit/537。36(khtml,likegecko)chrome/68。3323。149safari/537。36"}response=requests。get(url)。textreturnresponse。text[1]。encode("utf-8")defcopy_link_list(url):returnrequests。
get(url)。textitems=[]foriinchrome。executor。forward():forjinchrome。executor。forward():items。append(text(i)+':'+i+':'+str(j)+':'+str(i))defdownload_msg(url):url1=sys。
argv[0]url2=requests。get(url)。texturl3=sys。argv[1]return(url1+url2+url3)。
针对什么类型的公众号,用什么漏斗奖励机制?
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-07-08 01:03
querylist采集微信公众号文章内容。针对什么类型的公众号,用什么类型的漏斗奖励机制。我就是个小白。关注微信公众号,每天推送下一篇文章,早上更新下一篇。
优点是可以根据兴趣爱好分类排列文章,用户没有分类的情况下,依旧可以阅读完整的文章,缺点是传播广度不够,很多文章没有分类会很难推广,
1.时效性强,文章靠提供优质内容2.排版整洁,主要是为了seo,可以拿去做首页的排版3.重视质量,从文章中心点来衡量是否有价值和有意义4.反馈体系不强大5.交互体系不强大,
站在微信的角度看,最需要的功能是一个分发平台,拉拢平台的更多用户。这不仅仅是推送的问题,更有内容策略上的问题。推送一下让用户看看,对于做电商类,引流类,app类,小程序类的平台,都意义重大。
首先,个人认为是规模问题;推送可以用爬虫,先抓取,然后再推送,时效性高、数量也多。公众号做新推送,传播范围太窄;至于文章标题,其实一篇能引发效用的内容还是少数,即使有吸引点也并不是大部分人都需要读的(这就跟标题党有异曲同工之妙了)。其次,可以提高分发内容的质量,毕竟在那么短的推送时间内,平台是要保持关注的(尽管现在因为有各种垃圾推送已经很少了)。 查看全部
针对什么类型的公众号,用什么漏斗奖励机制?
querylist采集微信公众号文章内容。针对什么类型的公众号,用什么类型的漏斗奖励机制。我就是个小白。关注微信公众号,每天推送下一篇文章,早上更新下一篇。
优点是可以根据兴趣爱好分类排列文章,用户没有分类的情况下,依旧可以阅读完整的文章,缺点是传播广度不够,很多文章没有分类会很难推广,
1.时效性强,文章靠提供优质内容2.排版整洁,主要是为了seo,可以拿去做首页的排版3.重视质量,从文章中心点来衡量是否有价值和有意义4.反馈体系不强大5.交互体系不强大,
站在微信的角度看,最需要的功能是一个分发平台,拉拢平台的更多用户。这不仅仅是推送的问题,更有内容策略上的问题。推送一下让用户看看,对于做电商类,引流类,app类,小程序类的平台,都意义重大。
首先,个人认为是规模问题;推送可以用爬虫,先抓取,然后再推送,时效性高、数量也多。公众号做新推送,传播范围太窄;至于文章标题,其实一篇能引发效用的内容还是少数,即使有吸引点也并不是大部分人都需要读的(这就跟标题党有异曲同工之妙了)。其次,可以提高分发内容的质量,毕竟在那么短的推送时间内,平台是要保持关注的(尽管现在因为有各种垃圾推送已经很少了)。
querylist采集微信公众号文章的微信分发基本就是这样
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-07-05 05:01
querylist采集微信公众号文章内容,一般来说都是做分词处理的,自己把文章里面的关键词提取出来放到wordlist里面去做replace,这样的话seed会大一些,性能好一些。
目前公众号文章的微信分发基本就是这样:第一步是微信首页上的相关信息,第二步才是文章页面。所以只需要将api下发到微信的服务器,通过服务器端将api分发给文章页面。所以微信公众号才会推荐公众号文章。知乎上代码丢了,有些地方可能要和微信搞点不同,文章内容没有迁移过来,不能发的。
我也遇到这个问题,经过研究发现,要使用wifi进行网络请求。其中关键信息先获取在服务器,然后将获取的的信息保存在本地并返回给手机,最后再将本地收到的关键字发送到服务器。手机在接收到文章内容后,按照匹配规则来进行解析,对合适的文章加载到excel里并推送到微信公众号里。问题已解决。虽然还未能完美实现,不过好在已解决。
很久前遇到过类似问题,真的不知道如何解决。后来发现大量用wx接口的就在互联网上发布文章的,发布一篇首页文章首先要分析上一篇文章是否有规律,如果有规律那可以在通讯录、好友动态、群、多媒体图文、公众号菜单等全部加上这个链接,这样就会有最新一篇排行榜的功能,如果没有规律的那就没办法了。 查看全部
querylist采集微信公众号文章的微信分发基本就是这样
querylist采集微信公众号文章内容,一般来说都是做分词处理的,自己把文章里面的关键词提取出来放到wordlist里面去做replace,这样的话seed会大一些,性能好一些。
目前公众号文章的微信分发基本就是这样:第一步是微信首页上的相关信息,第二步才是文章页面。所以只需要将api下发到微信的服务器,通过服务器端将api分发给文章页面。所以微信公众号才会推荐公众号文章。知乎上代码丢了,有些地方可能要和微信搞点不同,文章内容没有迁移过来,不能发的。
我也遇到这个问题,经过研究发现,要使用wifi进行网络请求。其中关键信息先获取在服务器,然后将获取的的信息保存在本地并返回给手机,最后再将本地收到的关键字发送到服务器。手机在接收到文章内容后,按照匹配规则来进行解析,对合适的文章加载到excel里并推送到微信公众号里。问题已解决。虽然还未能完美实现,不过好在已解决。
很久前遇到过类似问题,真的不知道如何解决。后来发现大量用wx接口的就在互联网上发布文章的,发布一篇首页文章首先要分析上一篇文章是否有规律,如果有规律那可以在通讯录、好友动态、群、多媒体图文、公众号菜单等全部加上这个链接,这样就会有最新一篇排行榜的功能,如果没有规律的那就没办法了。
python爬取搜狗微信公众号文章永久链接(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-07-04 03:27
python爬取搜狗微信公众号文章永久链接
本文主要讲解思路,代码部分请自行解决
获取搜狗微信当天信息排名
指定输入关键字,通过scrapy抓取公众号
登录微信公众号链接获取cookie信息
由于微信公众平台模拟登录未解决,需要手动登录实时获取cookie信息
固定链接可以在这里转换
代码部分
def parse(self, response):
item = SougouItem()
item["title"] = response.xpath('//title/text()').extract_first()
print("**"*5, item["title"],"**"*5)
name = input("----------请输入需要搜索的信息:")
print(name)
url = "http://weixin.sogou.com/weixin ... ot%3B
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name":name})
搜狗微信访问频率会过快导致需要输入验证码
def parse_two(self, response):
print(response.url)
name = response.meta["name"]
resp = response.xpath('//ul[@class="news-list"]/li')
s = 1
# 判断url 是否是需要输入验证码
res = re.search("from", response.url)
# 需要验证码验证
if res:
print(response.url)
img = response.xpath('//img/@src').extract()
print(img)
url_img = "http://weixin.sogou.com/antispider/"+ img[1]
print(url_img)
url_img = requests.get(url_img).content
with open("urli.jpg", "wb") as f:
f.write(url_img)
# f.close()
img = input("请输入验证码:")
print(img)
url = response.url
r = re.search(r"from=(.*)",url).group(1)
print(r)
postData = {"c":img,"r":r,"v":"5"}
url = "http://weixin.sogou.com/antispider/thank.php"
yield scrapy.FormRequest(url=url, formdata=postData, callback=self.parse_two,meta={"name":name})
# 不需要验证码验证
else:
for res, i in zip(resp, range(1, 10)):
item = SougouItem()
item["url"] = res.xpath('.//div[1]/a/@href').extract_first()
item["name"] = name
print("第%d条" % i)
# 转化永久链接
headers = {"Host": "mp.weixin.qq.com",
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "noticeLoginFlag=1; pgv_pvi=5269297152; pt2gguin=o1349184918; RK=ph4smy/QWu; ptcz=f3eb6ede5db921d0ada7f1713e6d1ca516d200fec57d602e677245490fcb7f1e; pgv_pvid=1033302674; o_cookie=1349184918; pac_uid=1_1349184918; ua_id=4nooSvHNkTOjpIpgAAAAAFX9OSNcLApfsluzwfClLW8=; mm_lang=zh_CN; noticeLoginFlag=1; remember_acct=Liangkai318; rewardsn=; wxtokenkey=777; pgv_si=s1944231936; uuid=700c40c965347f0925a8e8fdcc1e003e; ticket=023fc8861356b01527983c2c4765ef80903bf3d7; ticket_id=gh_6923d82780e4; cert=L_cE4aRdaZeDnzao3xEbMkcP3Kwuejoi; data_bizuin=3075391054; bizuin=3208078327; data_ticket=XrzOnrV9Odc80hJLtk8vFjTLI1vd7kfKJ9u+DzvaeeHxZkMXbv9kcWk/Pmqx/9g7; slave_sid=SWRKNmFyZ1NkM002Rk9NR0RRVGY5VFdMd1lXSkExWGtPcWJaREkzQ1BESEcyQkNLVlQ3YnB4OFNoNmtRZzdFdGpnVGlHak9LMjJ5eXBNVEgxZDlZb1BZMnlfN1hKdnJsV0NKallsQW91Zjk5Y3prVjlQRDNGYUdGUWNFNEd6eTRYT1FSOEQxT0MwR01Ja0Vo; slave_user=gh_6923d82780e4; xid=7b2245140217dbb3c5c0a552d46b9664; openid2ticket_oTr5Ot_B4nrDSj14zUxlXg8yrzws=D/B6//xK73BoO+mKE2EAjdcgIXNPw/b5PEDTDWM6t+4="}
respon = requests.get(url=item["url"]).content
gongzhongh = etree.HTML(respon).xpath('//a[@id="post-user"]/text()')[0]
# times = etree.HTML(respon).xpath('//*[@id="post-date"]/text()')[0]
title_one = etree.HTML(respon).xpath('//*[@id="activity-name"]/text()')[0].split()[0]
print(gongzhongh, title_one)
item["tit"] = title_one
item["gongzhongh"] = gongzhongh
# item["times"] = times
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + gongzhongh + "&begin=0&count=5"
# wenzhang_url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
resp = requests.get(url=url, headers=headers).content
print(resp)
faskeids = json.loads(resp.decode("utf-8"))
try:
list_fask = faskeids["list"]
except Exception as f:
print("**********[INFO]:请求失败,登陆失败, 请重新登陆*************")
return
for fask in list_fask:
fakeid = fask["fakeid"]
nickname = fask["nickname"]
if nickname == item["gongzhongh"]:
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + fakeid + "&type=9"
# url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] +"&fakeid=" + fakeid +"&type=9"
resp = requests.get(url=url, headers=headers).content
app = json.loads(resp.decode("utf-8"))["app_msg_list"]
item["aid"] = app["aid"]
item["appmsgid"] = app["appmsgid"]
item["cover"] = app["cover"]
item["digest"] = app["digest"]
item["url_link"] = app["link"]
item["tit"] = app["title"]
print(item)
time.sleep(10)
# time.sleep(5)
# dict_wengzhang = json.loads(resp.decode("utf-8"))
# app_msg_list = dict_wengzhang["app_msg_list"]
# print(len(app_msg_list))
# for app in app_msg_list:
# print(app)
# title = app["title"]
# if title == item["tit"]:
# item["url_link"] = app["link"]
# updata_time = app["update_time"]
# item["times"] = time.strftime("%Y-%m-%d %H:%M:%S", updata_time)
# print("最终链接为:", item["url_link"])
# yield item
# else:
# print(app["title"], item["tit"])
# print("与所选文章不同放弃")
# # item["tit"] = app["title"]
# # item["url_link"] = app["link"]
# # yield item
# else:
# print(nickname, item["gongzhongh"])
# print("与所选公众号不一致放弃")
# time.sleep(100)
# yield item
if response.xpath('//a[@class="np"]'):
s += 1
url = "http://weixin.sogou.com/weixin ... 2Bstr(s)
# time.sleep(3)
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name": name}) 查看全部
python爬取搜狗微信公众号文章永久链接(图)
python爬取搜狗微信公众号文章永久链接
本文主要讲解思路,代码部分请自行解决
获取搜狗微信当天信息排名
指定输入关键字,通过scrapy抓取公众号
登录微信公众号链接获取cookie信息
由于微信公众平台模拟登录未解决,需要手动登录实时获取cookie信息
固定链接可以在这里转换
代码部分
def parse(self, response):
item = SougouItem()
item["title"] = response.xpath('//title/text()').extract_first()
print("**"*5, item["title"],"**"*5)
name = input("----------请输入需要搜索的信息:")
print(name)
url = "http://weixin.sogou.com/weixin ... ot%3B
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name":name})
搜狗微信访问频率会过快导致需要输入验证码
def parse_two(self, response):
print(response.url)
name = response.meta["name"]
resp = response.xpath('//ul[@class="news-list"]/li')
s = 1
# 判断url 是否是需要输入验证码
res = re.search("from", response.url)
# 需要验证码验证
if res:
print(response.url)
img = response.xpath('//img/@src').extract()
print(img)
url_img = "http://weixin.sogou.com/antispider/"+ img[1]
print(url_img)
url_img = requests.get(url_img).content
with open("urli.jpg", "wb") as f:
f.write(url_img)
# f.close()
img = input("请输入验证码:")
print(img)
url = response.url
r = re.search(r"from=(.*)",url).group(1)
print(r)
postData = {"c":img,"r":r,"v":"5"}
url = "http://weixin.sogou.com/antispider/thank.php"
yield scrapy.FormRequest(url=url, formdata=postData, callback=self.parse_two,meta={"name":name})
# 不需要验证码验证
else:
for res, i in zip(resp, range(1, 10)):
item = SougouItem()
item["url"] = res.xpath('.//div[1]/a/@href').extract_first()
item["name"] = name
print("第%d条" % i)
# 转化永久链接
headers = {"Host": "mp.weixin.qq.com",
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "noticeLoginFlag=1; pgv_pvi=5269297152; pt2gguin=o1349184918; RK=ph4smy/QWu; ptcz=f3eb6ede5db921d0ada7f1713e6d1ca516d200fec57d602e677245490fcb7f1e; pgv_pvid=1033302674; o_cookie=1349184918; pac_uid=1_1349184918; ua_id=4nooSvHNkTOjpIpgAAAAAFX9OSNcLApfsluzwfClLW8=; mm_lang=zh_CN; noticeLoginFlag=1; remember_acct=Liangkai318; rewardsn=; wxtokenkey=777; pgv_si=s1944231936; uuid=700c40c965347f0925a8e8fdcc1e003e; ticket=023fc8861356b01527983c2c4765ef80903bf3d7; ticket_id=gh_6923d82780e4; cert=L_cE4aRdaZeDnzao3xEbMkcP3Kwuejoi; data_bizuin=3075391054; bizuin=3208078327; data_ticket=XrzOnrV9Odc80hJLtk8vFjTLI1vd7kfKJ9u+DzvaeeHxZkMXbv9kcWk/Pmqx/9g7; slave_sid=SWRKNmFyZ1NkM002Rk9NR0RRVGY5VFdMd1lXSkExWGtPcWJaREkzQ1BESEcyQkNLVlQ3YnB4OFNoNmtRZzdFdGpnVGlHak9LMjJ5eXBNVEgxZDlZb1BZMnlfN1hKdnJsV0NKallsQW91Zjk5Y3prVjlQRDNGYUdGUWNFNEd6eTRYT1FSOEQxT0MwR01Ja0Vo; slave_user=gh_6923d82780e4; xid=7b2245140217dbb3c5c0a552d46b9664; openid2ticket_oTr5Ot_B4nrDSj14zUxlXg8yrzws=D/B6//xK73BoO+mKE2EAjdcgIXNPw/b5PEDTDWM6t+4="}
respon = requests.get(url=item["url"]).content
gongzhongh = etree.HTML(respon).xpath('//a[@id="post-user"]/text()')[0]
# times = etree.HTML(respon).xpath('//*[@id="post-date"]/text()')[0]
title_one = etree.HTML(respon).xpath('//*[@id="activity-name"]/text()')[0].split()[0]
print(gongzhongh, title_one)
item["tit"] = title_one
item["gongzhongh"] = gongzhongh
# item["times"] = times
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + gongzhongh + "&begin=0&count=5"
# wenzhang_url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
resp = requests.get(url=url, headers=headers).content
print(resp)
faskeids = json.loads(resp.decode("utf-8"))
try:
list_fask = faskeids["list"]
except Exception as f:
print("**********[INFO]:请求失败,登陆失败, 请重新登陆*************")
return
for fask in list_fask:
fakeid = fask["fakeid"]
nickname = fask["nickname"]
if nickname == item["gongzhongh"]:
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + fakeid + "&type=9"
# url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] +"&fakeid=" + fakeid +"&type=9"
resp = requests.get(url=url, headers=headers).content
app = json.loads(resp.decode("utf-8"))["app_msg_list"]
item["aid"] = app["aid"]
item["appmsgid"] = app["appmsgid"]
item["cover"] = app["cover"]
item["digest"] = app["digest"]
item["url_link"] = app["link"]
item["tit"] = app["title"]
print(item)
time.sleep(10)
# time.sleep(5)
# dict_wengzhang = json.loads(resp.decode("utf-8"))
# app_msg_list = dict_wengzhang["app_msg_list"]
# print(len(app_msg_list))
# for app in app_msg_list:
# print(app)
# title = app["title"]
# if title == item["tit"]:
# item["url_link"] = app["link"]
# updata_time = app["update_time"]
# item["times"] = time.strftime("%Y-%m-%d %H:%M:%S", updata_time)
# print("最终链接为:", item["url_link"])
# yield item
# else:
# print(app["title"], item["tit"])
# print("与所选文章不同放弃")
# # item["tit"] = app["title"]
# # item["url_link"] = app["link"]
# # yield item
# else:
# print(nickname, item["gongzhongh"])
# print("与所选公众号不一致放弃")
# time.sleep(100)
# yield item
if response.xpath('//a[@class="np"]'):
s += 1
url = "http://weixin.sogou.com/weixin ... 2Bstr(s)
# time.sleep(3)
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name": name})
搜狗微信上当天信息排名指定输入关键字怎么做?
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-07-04 03:22
这个文章主要介绍python如何抓取搜狗微信公众号文章永久链接。小编觉得还不错。现在分享给大家,给大家一个参考。跟着小编一起来看看吧。
本文主要讲解思路,代码部分请自行解决
获取搜狗微信当天信息排名
指定输入关键字,通过scrapy抓取公众号
登录微信公众号链接获取cookie信息
由于微信公众平台模拟登录未解决,需要手动登录实时获取cookie信息
固定链接可以在这里转换
代码部分
def parse(self, response):
item = SougouItem()
item["title"] = response.xpath('//title/text()').extract_first()
print("**"*5, item["title"],"**"*5)
name = input("----------请输入需要搜索的信息:")
print(name)
url = "http://weixin.sogou.com/weixin ... ot%3B
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name":name})
搜狗微信访问频率会过快导致需要输入验证码
def parse_two(self, response):
print(response.url)
name = response.meta["name"]
resp = response.xpath('//ul[@class="news-list"]/li')
s = 1
# 判断url 是否是需要输入验证码
res = re.search("from", response.url) # 需要验证码验证
if res:
print(response.url)
img = response.xpath('//img/@src').extract()
print(img)
url_img = "http://weixin.sogou.com/antispider/"+ img[1]
print(url_img)
url_img = requests.get(url_img).content with open("urli.jpg", "wb") as f:
f.write(url_img) # f.close()
img = input("请输入验证码:")
print(img)
url = response.url
r = re.search(r"from=(.*)",url).group(1)
print(r)
postData = {"c":img,"r":r,"v":"5"}
url = "http://weixin.sogou.com/antispider/thank.php"
yield scrapy.FormRequest(url=url, formdata=postData, callback=self.parse_two,meta={"name":name})
# 不需要验证码验证
else:
for res, i in zip(resp, range(1, 10)):
item = SougouItem()
item["url"] = res.xpath('.//p[1]/a/@href').extract_first()
item["name"] = name
print("第%d条" % i) # 转化永久链接
headers = {"Host": "mp.weixin.qq.com",
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "noticeLoginFlag=1; pgv_pvi=5269297152; pt2gguin=o1349184918; RK=ph4smy/QWu; ptcz=f3eb6ede5db921d0ada7f1713e6d1ca516d200fec57d602e677245490fcb7f1e; pgv_pvid=1033302674; o_cookie=1349184918; pac_uid=1_1349184918; ua_id=4nooSvHNkTOjpIpgAAAAAFX9OSNcLApfsluzwfClLW8=; mm_lang=zh_CN; noticeLoginFlag=1; remember_acct=Liangkai318; rewardsn=; wxtokenkey=777; pgv_si=s1944231936; uuid=700c40c965347f0925a8e8fdcc1e003e; ticket=023fc8861356b01527983c2c4765ef80903bf3d7; ticket_id=gh_6923d82780e4; cert=L_cE4aRdaZeDnzao3xEbMkcP3Kwuejoi; data_bizuin=3075391054; bizuin=3208078327; data_ticket=XrzOnrV9Odc80hJLtk8vFjTLI1vd7kfKJ9u+DzvaeeHxZkMXbv9kcWk/Pmqx/9g7; slave_sid=SWRKNmFyZ1NkM002Rk9NR0RRVGY5VFdMd1lXSkExWGtPcWJaREkzQ1BESEcyQkNLVlQ3YnB4OFNoNmtRZzdFdGpnVGlHak9LMjJ5eXBNVEgxZDlZb1BZMnlfN1hKdnJsV0NKallsQW91Zjk5Y3prVjlQRDNGYUdGUWNFNEd6eTRYT1FSOEQxT0MwR01Ja0Vo; slave_user=gh_6923d82780e4; xid=7b2245140217dbb3c5c0a552d46b9664; openid2ticket_oTr5Ot_B4nrDSj14zUxlXg8yrzws=D/B6//xK73BoO+mKE2EAjdcgIXNPw/b5PEDTDWM6t+4="}
respon = requests.get(url=item["url"]).content
gongzhongh = etree.HTML(respon).xpath('//a[@id="post-user"]/text()')[0]
# times = etree.HTML(respon).xpath('//*[@id="post-date"]/text()')[0]
title_one = etree.HTML(respon).xpath('//*[@id="activity-name"]/text()')[0].split()[0]
print(gongzhongh, title_one)
item["tit"] = title_one
item["gongzhongh"] = gongzhongh
# item["times"] = times
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + gongzhongh + "&begin=0&count=5"
# wenzhang_url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
resp = requests.get(url=url, headers=headers).content
print(resp)
faskeids = json.loads(resp.decode("utf-8"))
try:
list_fask = faskeids["list"] except Exception as f:
print("**********[INFO]:请求失败,登陆失败, 请重新登陆*************")
return
for fask in list_fask:
fakeid = fask["fakeid"]
nickname = fask["nickname"] if nickname == item["gongzhongh"]:
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + fakeid + "&type=9"
# url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] +"&fakeid=" + fakeid +"&type=9"
resp = requests.get(url=url, headers=headers).content
app = json.loads(resp.decode("utf-8"))["app_msg_list"]
item["aid"] = app["aid"]
item["appmsgid"] = app["appmsgid"]
item["cover"] = app["cover"]
item["digest"] = app["digest"]
item["url_link"] = app["link"]
item["tit"] = app["title"]
print(item)
time.sleep(10) # time.sleep(5)
# dict_wengzhang = json.loads(resp.decode("utf-8"))
# app_msg_list = dict_wengzhang["app_msg_list"]
# print(len(app_msg_list))
# for app in app_msg_list:
# print(app)
# title = app["title"]
# if title == item["tit"]:
# item["url_link"] = app["link"]
# updata_time = app["update_time"]
# item["times"] = time.strftime("%Y-%m-%d %H:%M:%S", updata_time)
# print("最终链接为:", item["url_link"])
# yield item
# else:
# print(app["title"], item["tit"])
# print("与所选文章不同放弃")
# # item["tit"] = app["title"]
# # item["url_link"] = app["link"]
# # yield item
# else:
# print(nickname, item["gongzhongh"])
# print("与所选公众号不一致放弃")
# time.sleep(100)
# yield item
if response.xpath('//a[@class="np"]'):
s += 1
url = "http://weixin.sogou.com/weixin ... 2Bstr(s) # time.sleep(3)
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name": name})
以上是python如何抓取搜狗微信公众号文章permanent链接的详细内容。更多详情请关注Gxl其他相关文章! 查看全部
搜狗微信上当天信息排名指定输入关键字怎么做?
这个文章主要介绍python如何抓取搜狗微信公众号文章永久链接。小编觉得还不错。现在分享给大家,给大家一个参考。跟着小编一起来看看吧。
本文主要讲解思路,代码部分请自行解决
获取搜狗微信当天信息排名
指定输入关键字,通过scrapy抓取公众号
登录微信公众号链接获取cookie信息
由于微信公众平台模拟登录未解决,需要手动登录实时获取cookie信息
固定链接可以在这里转换
代码部分
def parse(self, response):
item = SougouItem()
item["title"] = response.xpath('//title/text()').extract_first()
print("**"*5, item["title"],"**"*5)
name = input("----------请输入需要搜索的信息:")
print(name)
url = "http://weixin.sogou.com/weixin ... ot%3B
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name":name})
搜狗微信访问频率会过快导致需要输入验证码
def parse_two(self, response):
print(response.url)
name = response.meta["name"]
resp = response.xpath('//ul[@class="news-list"]/li')
s = 1
# 判断url 是否是需要输入验证码
res = re.search("from", response.url) # 需要验证码验证
if res:
print(response.url)
img = response.xpath('//img/@src').extract()
print(img)
url_img = "http://weixin.sogou.com/antispider/"+ img[1]
print(url_img)
url_img = requests.get(url_img).content with open("urli.jpg", "wb") as f:
f.write(url_img) # f.close()
img = input("请输入验证码:")
print(img)
url = response.url
r = re.search(r"from=(.*)",url).group(1)
print(r)
postData = {"c":img,"r":r,"v":"5"}
url = "http://weixin.sogou.com/antispider/thank.php"
yield scrapy.FormRequest(url=url, formdata=postData, callback=self.parse_two,meta={"name":name})
# 不需要验证码验证
else:
for res, i in zip(resp, range(1, 10)):
item = SougouItem()
item["url"] = res.xpath('.//p[1]/a/@href').extract_first()
item["name"] = name
print("第%d条" % i) # 转化永久链接
headers = {"Host": "mp.weixin.qq.com",
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "noticeLoginFlag=1; pgv_pvi=5269297152; pt2gguin=o1349184918; RK=ph4smy/QWu; ptcz=f3eb6ede5db921d0ada7f1713e6d1ca516d200fec57d602e677245490fcb7f1e; pgv_pvid=1033302674; o_cookie=1349184918; pac_uid=1_1349184918; ua_id=4nooSvHNkTOjpIpgAAAAAFX9OSNcLApfsluzwfClLW8=; mm_lang=zh_CN; noticeLoginFlag=1; remember_acct=Liangkai318; rewardsn=; wxtokenkey=777; pgv_si=s1944231936; uuid=700c40c965347f0925a8e8fdcc1e003e; ticket=023fc8861356b01527983c2c4765ef80903bf3d7; ticket_id=gh_6923d82780e4; cert=L_cE4aRdaZeDnzao3xEbMkcP3Kwuejoi; data_bizuin=3075391054; bizuin=3208078327; data_ticket=XrzOnrV9Odc80hJLtk8vFjTLI1vd7kfKJ9u+DzvaeeHxZkMXbv9kcWk/Pmqx/9g7; slave_sid=SWRKNmFyZ1NkM002Rk9NR0RRVGY5VFdMd1lXSkExWGtPcWJaREkzQ1BESEcyQkNLVlQ3YnB4OFNoNmtRZzdFdGpnVGlHak9LMjJ5eXBNVEgxZDlZb1BZMnlfN1hKdnJsV0NKallsQW91Zjk5Y3prVjlQRDNGYUdGUWNFNEd6eTRYT1FSOEQxT0MwR01Ja0Vo; slave_user=gh_6923d82780e4; xid=7b2245140217dbb3c5c0a552d46b9664; openid2ticket_oTr5Ot_B4nrDSj14zUxlXg8yrzws=D/B6//xK73BoO+mKE2EAjdcgIXNPw/b5PEDTDWM6t+4="}
respon = requests.get(url=item["url"]).content
gongzhongh = etree.HTML(respon).xpath('//a[@id="post-user"]/text()')[0]
# times = etree.HTML(respon).xpath('//*[@id="post-date"]/text()')[0]
title_one = etree.HTML(respon).xpath('//*[@id="activity-name"]/text()')[0].split()[0]
print(gongzhongh, title_one)
item["tit"] = title_one
item["gongzhongh"] = gongzhongh
# item["times"] = times
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + gongzhongh + "&begin=0&count=5"
# wenzhang_url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
resp = requests.get(url=url, headers=headers).content
print(resp)
faskeids = json.loads(resp.decode("utf-8"))
try:
list_fask = faskeids["list"] except Exception as f:
print("**********[INFO]:请求失败,登陆失败, 请重新登陆*************")
return
for fask in list_fask:
fakeid = fask["fakeid"]
nickname = fask["nickname"] if nickname == item["gongzhongh"]:
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + fakeid + "&type=9"
# url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] +"&fakeid=" + fakeid +"&type=9"
resp = requests.get(url=url, headers=headers).content
app = json.loads(resp.decode("utf-8"))["app_msg_list"]
item["aid"] = app["aid"]
item["appmsgid"] = app["appmsgid"]
item["cover"] = app["cover"]
item["digest"] = app["digest"]
item["url_link"] = app["link"]
item["tit"] = app["title"]
print(item)
time.sleep(10) # time.sleep(5)
# dict_wengzhang = json.loads(resp.decode("utf-8"))
# app_msg_list = dict_wengzhang["app_msg_list"]
# print(len(app_msg_list))
# for app in app_msg_list:
# print(app)
# title = app["title"]
# if title == item["tit"]:
# item["url_link"] = app["link"]
# updata_time = app["update_time"]
# item["times"] = time.strftime("%Y-%m-%d %H:%M:%S", updata_time)
# print("最终链接为:", item["url_link"])
# yield item
# else:
# print(app["title"], item["tit"])
# print("与所选文章不同放弃")
# # item["tit"] = app["title"]
# # item["url_link"] = app["link"]
# # yield item
# else:
# print(nickname, item["gongzhongh"])
# print("与所选公众号不一致放弃")
# time.sleep(100)
# yield item
if response.xpath('//a[@class="np"]'):
s += 1
url = "http://weixin.sogou.com/weixin ... 2Bstr(s) # time.sleep(3)
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name": name})
以上是python如何抓取搜狗微信公众号文章permanent链接的详细内容。更多详情请关注Gxl其他相关文章!
不用提交词典的方法用的是该方法合并词典
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-07-01 04:02
querylist采集微信公众号文章推荐信息的时候,只要把词汇前缀去掉就可以得到这个关键词的取值了。所以你上面那句代码的问题应该是还没有去掉词汇前缀。search_vars=preg_match_search(filter_variable,capsule_example)然后就去查对应关键词对应的词典了。
取出搜索值search_vars查词汇对应的词典这样子
python有一个filter_variable参数可以满足题主需求,
直接在循环里面递归查吧。querylist+groupby不推荐。最终结果一定要合并词典,
再从词库里查词,
python+matplotlib=不会递归你还在这里折腾干嘛!推荐个工具:支持第三方库的运行器spidercreate_class
pipinstallsort_url
其实都可以用knn来满足要求,不过可能all_capital指定了一个区间。
importmatplotlib.pyplotaspltfromfilter_mapimportsort_urls
补充一个可以用groupby实现,需要自己编程实现,这是我上课时候自己写的例子,实际运行效果,每一步都会记录词频sort_urls_with_idx:#一个列表,分别是每个关键词出现的概率defsort_urls(url,idx):#不用提交词典bot=sort_urls(url,idx)whiletrue:#以下每个关键词window=idx。
pop()count_urls=idx[0]comment=idx[1]window=[idx[0],idx[1]]print(window。extend(range(。
4),window.size,even(numberofrange(1,1
0),numberofnumberofnumberofnumberofspecified_urls)))print(window.extend(range
4),range(1,1
0),even(numberofnumberofnumberofspecified_urls)))returncomment现在查词频的方法用的是该方法,然后jieba,一般也要数据格式化,当然,也可以用,不用记录语料内容, 查看全部
不用提交词典的方法用的是该方法合并词典
querylist采集微信公众号文章推荐信息的时候,只要把词汇前缀去掉就可以得到这个关键词的取值了。所以你上面那句代码的问题应该是还没有去掉词汇前缀。search_vars=preg_match_search(filter_variable,capsule_example)然后就去查对应关键词对应的词典了。
取出搜索值search_vars查词汇对应的词典这样子
python有一个filter_variable参数可以满足题主需求,
直接在循环里面递归查吧。querylist+groupby不推荐。最终结果一定要合并词典,
再从词库里查词,
python+matplotlib=不会递归你还在这里折腾干嘛!推荐个工具:支持第三方库的运行器spidercreate_class
pipinstallsort_url
其实都可以用knn来满足要求,不过可能all_capital指定了一个区间。
importmatplotlib.pyplotaspltfromfilter_mapimportsort_urls
补充一个可以用groupby实现,需要自己编程实现,这是我上课时候自己写的例子,实际运行效果,每一步都会记录词频sort_urls_with_idx:#一个列表,分别是每个关键词出现的概率defsort_urls(url,idx):#不用提交词典bot=sort_urls(url,idx)whiletrue:#以下每个关键词window=idx。
pop()count_urls=idx[0]comment=idx[1]window=[idx[0],idx[1]]print(window。extend(range(。
4),window.size,even(numberofrange(1,1
0),numberofnumberofnumberofnumberofspecified_urls)))print(window.extend(range
4),range(1,1
0),even(numberofnumberofnumberofspecified_urls)))returncomment现在查词频的方法用的是该方法,然后jieba,一般也要数据格式化,当然,也可以用,不用记录语料内容,
下篇文章:python爬虫如何爬取微信公众号文章(二)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-06-23 21:35
第二部分文章:python爬虫如何抓取微信公众号文章(二)
下一篇如何连接python爬虫实现微信公众号文章每日推送
因为最近在法庭实习,需要一些公众号资料,然后做成网页展示,方便查看。之前写过一些爬虫,但是都是爬网站数据。这一次本以为会很容易,但是遇到了很多麻烦。分享给大家。
1、 使用爬虫爬取数据最基本也是最重要的一点就是找到目标网站的url地址,然后遍历地址一个一个或者多线程爬取。一般后续的爬取地址主要有两种获取方式,一种是根据页面分页计算出URL地址的规律,通常后跟参数page=num,另一种是过滤掉当前的标签页面,取出URL作为后续的爬取地址。遗憾的是,这两种方法都不能在微信公众号中使用。原因是公众号的文章地址之间没有关联,不可能通过一个文章地址找到所有文章地址。
2、 那我们如何获取公众号文章地址的历史记录呢?一种方法是通过搜狗微信网站搜索目标公众号,可以看到最近的文章,但只是最近的无法获取历史文章。如果你想每天爬一次,可以用这个方法每天爬一个。图片是这样的:
3、当然了,我们需要的结果很多,所以还是得想办法把所有的历史文本都弄出来,废话少说,直入正题:
首先要注册一个微信公众号(订阅号),可以注册个人,比较简单,步骤网上都有,这里就不介绍了。 (如果之前有的话,就不需要注册了)
注册后,登录微信公众平台,在首页左栏的管理下,有一个素材管理,如图:
点击素材管理,然后选择图文信息,然后点击右侧新建图文素材:
转到新页面并单击顶部的超链接:
然后在弹窗中选择查找文章,输入要爬取的公众号名称,搜索:
然后点击搜索到的公众号,可以看到它的所有历史文章:
4、找到history文章后,我们如何编写一个程序来获取所有的URL地址? ,首先我们来分析一下浏览器在点击公众号名称时做了什么,调出查看页面,点击网络,先清除所有数据,然后点击目标公众号,可以看到如下界面:
点击字符串后,再点击标题:
找到将军。这里的Request Url就是我们的程序需要请求的地址格式。我们需要把它拼接起来。里面的参数在下面的Query String Parameters里面比较清楚:
这些参数的含义很容易理解。唯一需要说明的是,fakeid 是公众号的唯一标识。每个官方账号都不一样。如果爬取其他公众号,只需要修改这个参数即可。随机可以省略。
另外一个重要的部分是Request Headers,里面收录了cookie、User-Agent等重要信息,在下面的代码中会用到:
5、 经过以上分析,就可以开始写代码了。
需要的第一个参数:
#目标urlurl = "./cgi-bin/appmsg"#使用cookies,跳过登录操作headers = {"Cookie": "ua_id=YF6RyP41YQa2QyQHAAAAAGXPy_he8M8KkNCUbRx0cVU=; pgv_pvi=232_58780000000bRx0cVU=; pgv_pvi=232_58780000000000a = 3231163757;门票= 5bd41c51e53cfce785e5c188f94240aac8fad8e3; TICKET_ID = gh_d5e73af61440;证书= bVSKoAHHVIldcRZp10_fd7p2aTEXrTi6; noticeLoginFlag = 1; remember_acct = mf1832192%; data_bizuin = 3231163757; data_ticket = XKgzAcTceBFDNN6cFXa4TZAVMlMlxhorD7A0r3vzCDkS ++ pgSpr55NFkQIN3N + / v; slave_sid = bU0yeTNOS2VxcEg5RktUQlZhd2xheVc5bjhoQTVhOHdhMnN2SlVIZGRtU3hvVXJpTWdWakVqcHowd3RuVF9HY19Udm1PbVpQMGVfcnhHVGJQQTVzckpQY042QlZZbnJzel9oam5SdjRFR0tGc0c1eExKQU9ybjgxVnZVZVBtSmVnc29ZcUJWVmNWWEFEaGtk; slave_user = gh_d5e73af61440; XID = 93074c5a87a2e98ddb9e527aa204d0c7; openid2ticket_obaWXwJGb9VV9FiHPMcNq7OZzlzY = lw6SBHGUDQf1lFHqOeShfg39SU7awJMxhDVb4AbVXJM =; mm_lang = zh_CN的 “” 用户代理 “:” 的Mozilla / 5
0 (Windows NT 10. 0; Win64; x64) AppleWebKit/537. 36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",}data = {"token ": "1378111188", "lang": "zh_CN", "f": "json", "ajax": "1", "action": "list_ex", "begin": "0", "count": "5", "query": "", "fakeid": "MzU5MDUzMTk5Nw==", "type": "9",}
根据自己的cookie和token进行修改,然后发送请求获取响应,去掉每个文章的title和url,代码如下:
content_list = []for i in range(20): data["begin"] = i*5 time.sleep(3) # 使用get方法提交 content_json = requests.get(url, headers = headers, params=data).json() # 返回一个json,里面收录content_json["app_msg_list"]中item每页的数据:#提取每页的标题文章和对应的url items = [ ] items.append(item["title"]) items.append(item["link"]) content_list.append(items)
第一个 for 循环是抓取的页面数。首先需要看好公众号历史记录文章列表中的总页数。这个数字只能小于页数。更改数据["begin"],表示从前几条开始,每次5条,注意爬取太多和太频繁,否则会被ip和cookies拦截,严重的话,公众号会被封号的,请多多关照。 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .被屏蔽了。
然后按如下方式保存标题和网址:
name=["title","link"]test=pd.DataFrame(columns=name,data=content_list)test.to_csv("XXX.csv",mode="a",encoding="utf-8 ")print("保存成功")
完整的程序如下:
# -*- coding: utf-8 -*-import requestsimport timeimport csvimport pandas as pd# Target urlurl = "./cgi-bin/appmsg"# 使用cookies跳过登录操作 headers = { “曲奇”:“ua_id = YF6RyP41YQa2QyQHAAAAAGXPy_he8M8KkNCUbRx0cVU =; pgv_pvi = 2045358080; pgv_si = s4132856832; UUID = 48da56b488e5c697909a13dfac91a819; bizuin = 3231163757;门票= 5bd41c51e53cfce785e5c188f94240aac8fad8e3; TICKET_ID = gh_d5e73af61440;证书= bVSKoAHHVIldcRZp10_fd7p2aTEXrTi6; noticeLoginFlag = 1; remember_acct = mf1832192%40smail.nju。 ; data_bizuin = 3231163757; data_ticket = XKgzAcTceBFDNN6cFXa4TZAVMlMlxhorD7A0r3vzCDkS ++ pgSpr55NFkQIN3N + / v; slave_sid = bU0yeTNOS2VxcEg5RktUQlZhd2xheVc5bjhoQTVhOHdhMnN2SlVIZGRtU3hvVXJpTWdWakVqcHowd3RuVF9HY19Udm1PbVpQMGVfcnhHVGJQQTVzckpQY042QlZZbnJzel9oam5SdjRFR0tGc0c1eExKQU9ybjgxVnZVZVBtSmVnc29ZcUJWVmNWWEFEaGtk; slave_user = gh_d5e73af61440; XID = 93074c5a87a2e98ddb9e527aa204d0c7; openid2ticket_obaWXwJGb9VV9FiHPMcNq7OZzlzY = lw6SBHGUDQf1lFHqOeShfg39S U7awJMxhDVb4AbVXJM =; mm_lang = zh_CN "," User-Agent ":" Mozilla / 5 .
0 (Windows NT 10. 0; Win64; x64) AppleWebKit/537. 36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",}data = {"token ": "1378111188", "lang": "zh_CN", "f": "json", "ajax": "1", "action": "list_ex", "begin": "0", "count": "5", "query": "", "fakeid": "MzU5MDUzMTk5Nw==", "type": "9",}content_list = []for i in range(20): data["begin"] = i*5 time.sleep(3) # 使用get方法提交 content_json = requests.get(url, headers=headers, params=data).json() # 返回一个json,里面收录每个页面的数据for item in content_json["app_msg_list"]: # 提取每个页面的标题文章和对应的url items = [] items.
append(item["title"]) 项。追加(项目[“链接”])内容列表。 append(items) print(i)name=["title","link"]test=pd.数据帧(列=名称,数据=内容列表)测试。 to_csv("xingzhengzhifa.csv",mode="a",encoding="utf-8")print("保存成功")
最后保存的文件如图:
获取每个文章的url后,可以遍历爬取每个文章的内容。关于爬取文章内容的部分将在下一篇博文中介绍。
补充内容:
关于如何从小伙伴那里获取文章封面图片和摘要的问题,查看浏览器可以看到返回的json数据中收录了很多信息,包括封面图片和摘要
只需要 items.append(item["digest"]) 来保存文章summary。其他字段如发布时间可获取。
关于获取阅读数和点赞数的问题,没有办法通过本题的方法获取,因为网页公众号文章没有阅读数以及点赞数。这需要使用电脑版微信或者手机版微信通过抓包工具获取。
关于ip代理,统计页数,多次保存,我在公众号文章中介绍过,有需要的可以看看 查看全部
下篇文章:python爬虫如何爬取微信公众号文章(二)
第二部分文章:python爬虫如何抓取微信公众号文章(二)
下一篇如何连接python爬虫实现微信公众号文章每日推送
因为最近在法庭实习,需要一些公众号资料,然后做成网页展示,方便查看。之前写过一些爬虫,但是都是爬网站数据。这一次本以为会很容易,但是遇到了很多麻烦。分享给大家。
1、 使用爬虫爬取数据最基本也是最重要的一点就是找到目标网站的url地址,然后遍历地址一个一个或者多线程爬取。一般后续的爬取地址主要有两种获取方式,一种是根据页面分页计算出URL地址的规律,通常后跟参数page=num,另一种是过滤掉当前的标签页面,取出URL作为后续的爬取地址。遗憾的是,这两种方法都不能在微信公众号中使用。原因是公众号的文章地址之间没有关联,不可能通过一个文章地址找到所有文章地址。
2、 那我们如何获取公众号文章地址的历史记录呢?一种方法是通过搜狗微信网站搜索目标公众号,可以看到最近的文章,但只是最近的无法获取历史文章。如果你想每天爬一次,可以用这个方法每天爬一个。图片是这样的:
3、当然了,我们需要的结果很多,所以还是得想办法把所有的历史文本都弄出来,废话少说,直入正题:
首先要注册一个微信公众号(订阅号),可以注册个人,比较简单,步骤网上都有,这里就不介绍了。 (如果之前有的话,就不需要注册了)
注册后,登录微信公众平台,在首页左栏的管理下,有一个素材管理,如图:
点击素材管理,然后选择图文信息,然后点击右侧新建图文素材:
转到新页面并单击顶部的超链接:
然后在弹窗中选择查找文章,输入要爬取的公众号名称,搜索:
然后点击搜索到的公众号,可以看到它的所有历史文章:
4、找到history文章后,我们如何编写一个程序来获取所有的URL地址? ,首先我们来分析一下浏览器在点击公众号名称时做了什么,调出查看页面,点击网络,先清除所有数据,然后点击目标公众号,可以看到如下界面:
点击字符串后,再点击标题:
找到将军。这里的Request Url就是我们的程序需要请求的地址格式。我们需要把它拼接起来。里面的参数在下面的Query String Parameters里面比较清楚:
这些参数的含义很容易理解。唯一需要说明的是,fakeid 是公众号的唯一标识。每个官方账号都不一样。如果爬取其他公众号,只需要修改这个参数即可。随机可以省略。
另外一个重要的部分是Request Headers,里面收录了cookie、User-Agent等重要信息,在下面的代码中会用到:
5、 经过以上分析,就可以开始写代码了。
需要的第一个参数:
#目标urlurl = "./cgi-bin/appmsg"#使用cookies,跳过登录操作headers = {"Cookie": "ua_id=YF6RyP41YQa2QyQHAAAAAGXPy_he8M8KkNCUbRx0cVU=; pgv_pvi=232_58780000000bRx0cVU=; pgv_pvi=232_58780000000000a = 3231163757;门票= 5bd41c51e53cfce785e5c188f94240aac8fad8e3; TICKET_ID = gh_d5e73af61440;证书= bVSKoAHHVIldcRZp10_fd7p2aTEXrTi6; noticeLoginFlag = 1; remember_acct = mf1832192%; data_bizuin = 3231163757; data_ticket = XKgzAcTceBFDNN6cFXa4TZAVMlMlxhorD7A0r3vzCDkS ++ pgSpr55NFkQIN3N + / v; slave_sid = bU0yeTNOS2VxcEg5RktUQlZhd2xheVc5bjhoQTVhOHdhMnN2SlVIZGRtU3hvVXJpTWdWakVqcHowd3RuVF9HY19Udm1PbVpQMGVfcnhHVGJQQTVzckpQY042QlZZbnJzel9oam5SdjRFR0tGc0c1eExKQU9ybjgxVnZVZVBtSmVnc29ZcUJWVmNWWEFEaGtk; slave_user = gh_d5e73af61440; XID = 93074c5a87a2e98ddb9e527aa204d0c7; openid2ticket_obaWXwJGb9VV9FiHPMcNq7OZzlzY = lw6SBHGUDQf1lFHqOeShfg39SU7awJMxhDVb4AbVXJM =; mm_lang = zh_CN的 “” 用户代理 “:” 的Mozilla / 5
0 (Windows NT 10. 0; Win64; x64) AppleWebKit/537. 36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",}data = {"token ": "1378111188", "lang": "zh_CN", "f": "json", "ajax": "1", "action": "list_ex", "begin": "0", "count": "5", "query": "", "fakeid": "MzU5MDUzMTk5Nw==", "type": "9",}
根据自己的cookie和token进行修改,然后发送请求获取响应,去掉每个文章的title和url,代码如下:
content_list = []for i in range(20): data["begin"] = i*5 time.sleep(3) # 使用get方法提交 content_json = requests.get(url, headers = headers, params=data).json() # 返回一个json,里面收录content_json["app_msg_list"]中item每页的数据:#提取每页的标题文章和对应的url items = [ ] items.append(item["title"]) items.append(item["link"]) content_list.append(items)
第一个 for 循环是抓取的页面数。首先需要看好公众号历史记录文章列表中的总页数。这个数字只能小于页数。更改数据["begin"],表示从前几条开始,每次5条,注意爬取太多和太频繁,否则会被ip和cookies拦截,严重的话,公众号会被封号的,请多多关照。 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .被屏蔽了。
然后按如下方式保存标题和网址:
name=["title","link"]test=pd.DataFrame(columns=name,data=content_list)test.to_csv("XXX.csv",mode="a",encoding="utf-8 ")print("保存成功")
完整的程序如下:
# -*- coding: utf-8 -*-import requestsimport timeimport csvimport pandas as pd# Target urlurl = "./cgi-bin/appmsg"# 使用cookies跳过登录操作 headers = { “曲奇”:“ua_id = YF6RyP41YQa2QyQHAAAAAGXPy_he8M8KkNCUbRx0cVU =; pgv_pvi = 2045358080; pgv_si = s4132856832; UUID = 48da56b488e5c697909a13dfac91a819; bizuin = 3231163757;门票= 5bd41c51e53cfce785e5c188f94240aac8fad8e3; TICKET_ID = gh_d5e73af61440;证书= bVSKoAHHVIldcRZp10_fd7p2aTEXrTi6; noticeLoginFlag = 1; remember_acct = mf1832192%40smail.nju。 ; data_bizuin = 3231163757; data_ticket = XKgzAcTceBFDNN6cFXa4TZAVMlMlxhorD7A0r3vzCDkS ++ pgSpr55NFkQIN3N + / v; slave_sid = bU0yeTNOS2VxcEg5RktUQlZhd2xheVc5bjhoQTVhOHdhMnN2SlVIZGRtU3hvVXJpTWdWakVqcHowd3RuVF9HY19Udm1PbVpQMGVfcnhHVGJQQTVzckpQY042QlZZbnJzel9oam5SdjRFR0tGc0c1eExKQU9ybjgxVnZVZVBtSmVnc29ZcUJWVmNWWEFEaGtk; slave_user = gh_d5e73af61440; XID = 93074c5a87a2e98ddb9e527aa204d0c7; openid2ticket_obaWXwJGb9VV9FiHPMcNq7OZzlzY = lw6SBHGUDQf1lFHqOeShfg39S U7awJMxhDVb4AbVXJM =; mm_lang = zh_CN "," User-Agent ":" Mozilla / 5 .
0 (Windows NT 10. 0; Win64; x64) AppleWebKit/537. 36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",}data = {"token ": "1378111188", "lang": "zh_CN", "f": "json", "ajax": "1", "action": "list_ex", "begin": "0", "count": "5", "query": "", "fakeid": "MzU5MDUzMTk5Nw==", "type": "9",}content_list = []for i in range(20): data["begin"] = i*5 time.sleep(3) # 使用get方法提交 content_json = requests.get(url, headers=headers, params=data).json() # 返回一个json,里面收录每个页面的数据for item in content_json["app_msg_list"]: # 提取每个页面的标题文章和对应的url items = [] items.
append(item["title"]) 项。追加(项目[“链接”])内容列表。 append(items) print(i)name=["title","link"]test=pd.数据帧(列=名称,数据=内容列表)测试。 to_csv("xingzhengzhifa.csv",mode="a",encoding="utf-8")print("保存成功")
最后保存的文件如图:
获取每个文章的url后,可以遍历爬取每个文章的内容。关于爬取文章内容的部分将在下一篇博文中介绍。
补充内容:
关于如何从小伙伴那里获取文章封面图片和摘要的问题,查看浏览器可以看到返回的json数据中收录了很多信息,包括封面图片和摘要
只需要 items.append(item["digest"]) 来保存文章summary。其他字段如发布时间可获取。
关于获取阅读数和点赞数的问题,没有办法通过本题的方法获取,因为网页公众号文章没有阅读数以及点赞数。这需要使用电脑版微信或者手机版微信通过抓包工具获取。
关于ip代理,统计页数,多次保存,我在公众号文章中介绍过,有需要的可以看看
用webmagic写的爬虫程序从数据库中拿链接爬取文章内容等信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-06-22 01:35
用webmagic写的爬虫程序从数据库中拿链接爬取文章内容等信息
public void getMsgExt(String str,String url) {
// TODO Auto-generated method stub
String biz = "";
String sn = "";
Map queryStrs = HttpUrlParser.parseUrl(url);
if(queryStrs != null){
biz = queryStrs.get("__biz");
biz = biz + "==";
sn = queryStrs.get("sn");
sn = "%" + sn + "%";
}
/**
* $sql = "select * from `文章表` where `biz`='".$biz."'
* and `content_url` like '%".$sn."%'" limit 0,1;
* 根据biz和sn找到对应的文章
*/
Post post = postMapper.selectByBizAndSn(biz, sn);
if(post == null){
System.out.println("biz:"+biz);
System.out.println("sn:"+sn);
tmpListMapper.deleteByLoad(1);
return;
}
// System.out.println("json数据:"+str);
Integer read_num;
Integer like_num;
try{
read_num = JsonPath.read(str, "['appmsgstat']['read_num']");//阅读量
like_num = JsonPath.read(str, "['appmsgstat']['like_num']");//点赞量
}catch(Exception e){
read_num = 123;//阅读量
like_num = 321;//点赞量
System.out.println("read_num:"+read_num);
System.out.println("like_num:"+like_num);
System.out.println(e.getMessage());
}
/**
* 在这里同样根据sn在采集队列表中删除对应的文章,代表这篇文章可以移出采集队列了
* $sql = "delete from `队列表` where `content_url` like '%".$sn."%'"
*/
tmpListMapper.deleteBySn(sn);
//然后将阅读量和点赞量更新到文章表中。
post.setReadnum(read_num);
post.setLikenum(like_num);
postMapper.updateByPrimaryKey(post);
}
通过处理跳转将js注入微信的方法:
public String getWxHis() {
String url = "";
// TODO Auto-generated method stub
/**
* 当前页面为公众号历史消息时,读取这个程序
* 在采集队列表中有一个load字段,当值等于1时代表正在被读取
* 首先删除采集队列表中load=1的行
* 然后从队列表中任意select一行
*/
tmpListMapper.deleteByLoad(1);
TmpList queue = tmpListMapper.selectRandomOne();
System.out.println("queue is null?"+queue);
if(queue == null){//队列表为空
/**
* 队列表如果空了,就从存储公众号biz的表中取得一个biz,
* 这里我在公众号表中设置了一个采集时间的time字段,按照正序排列之后,
* 就得到时间戳最小的一个公众号记录,并取得它的biz
*/
WeiXin weiXin = weiXinMapper.selectOne();
String biz = weiXin.getBiz();
url = "https://mp.weixin.qq.com/mp/pr ... ot%3B + biz +
"#wechat_redirect";//拼接公众号历史消息url地址(第二种页面形式)
//更新刚才提到的公众号表中的采集时间time字段为当前时间戳。
weiXin.setCollect(System.currentTimeMillis());
int result = weiXinMapper.updateByPrimaryKey(weiXin);
System.out.println("getHis weiXin updateResult:"+result);
}else{
//取得当前这一行的content_url字段
url = queue.getContentUrl();
//将load字段update为1
tmpListMapper.updateByContentUrl(url);
}
//将下一个将要跳转的$url变成js脚本,由anyproxy注入到微信页面中。
//echo "setTimeout(function(){window.location.href='".$url."';},2000);";
int randomTime = new Random().nextInt(3) + 3;
String jsCode = "setTimeout(function(){window.location.href='"+url+"';},"+randomTime*1000+");";
return jsCode;
}
以上是对代理服务器截获的数据进行处理的流程。有一个问题需要注意。程序会循环访问数据库中的每个收录公众号,甚至会再次访问存储的文章,以不断更新文章Count和like count的读数。如果需要抓大量公众号,建议修改添加任务队列的代码,添加条件限制。否则,公众号多轮重复抓取数据会极大影响效率。
到目前为止,我们已经抓取了微信公众号的所有文章链接,并且这个链接是一个可以在浏览器中打开的永久链接。下一步就是编写爬虫程序,从数据库中抓取链接,爬取文章内容等信息。
我用webmagic写了一个爬虫,轻量级好用。
public class SpiderModel implements PageProcessor{
private static PostMapper postMapper;
private static List posts;
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
// TODO Auto-generated method stub
return this.site;
}
public void process(Page page) {
// TODO Auto-generated method stub
Post post = posts.remove(0);
String content = page.getHtml().xpath("//div[@id='js_content']").get();
//存在和谐文章 此处做判定如果有直接删除记录或设置表示位表示文章被和谐
if(content == null){
System.out.println("文章已和谐!");
//postMapper.deleteByPrimaryKey(post.getId());
return;
}
String contentSnap = content.replaceAll("data-src", "src").replaceAll("preview.html", "player.html");//快照
String contentTxt = HtmlToWord.stripHtml(content);//纯文本内容
Selectable metaContent = page.getHtml().xpath("//div[@id='meta_content']");
String pubTime = null;
String wxname = null;
String author = null;
if(metaContent != null){
pubTime = metaContent.xpath("//em[@id='post-date']").get();
if(pubTime != null){
pubTime = HtmlToWord.stripHtml(pubTime);//文章发布时间
}
wxname = metaContent.xpath("//a[@id='post-user']").get();
if(wxname != null){
wxname = HtmlToWord.stripHtml(wxname);//公众号名称
}
author = metaContent.xpath("//em[@class='rich_media_meta rich_media_meta_text' and @id!='post-date']").get();
if(author != null){
author = HtmlToWord.stripHtml(author);//文章作者
}
}
// System.out.println("发布时间:"+pubTime);
// System.out.println("公众号名称:"+wxname);
// System.out.println("文章作者:"+author);
String title = post.getTitle().replaceAll(" ", "");//文章标题
String digest = post.getDigest();//文章摘要
int likeNum = post.getLikenum();//文章点赞数
int readNum = post.getReadnum();//文章阅读数
String contentUrl = post.getContentUrl();//文章链接
WechatInfoBean wechatBean = new WechatInfoBean();
wechatBean.setTitle(title);
wechatBean.setContent(contentTxt);//纯文本内容
wechatBean.setSourceCode(contentSnap);//快照
wechatBean.setLikeCount(likeNum);
wechatBean.setViewCount(readNum);
wechatBean.setAbstractText(digest);//摘要
wechatBean.setUrl(contentUrl);
wechatBean.setPublishTime(pubTime);
wechatBean.setSiteName(wxname);//站点名称 公众号名称
wechatBean.setAuthor(author);
wechatBean.setMediaType("微信公众号");//来源媒体类型
WechatStorage.saveWechatInfo(wechatBean);
//标示文章已经被爬取
post.setIsSpider(1);
postMapper.updateByPrimaryKey(post);
}
public static void startSpider(List inposts,PostMapper myPostMapper,String... urls){
long startTime, endTime;
startTime = System.currentTimeMillis();
postMapper = myPostMapper;
posts = inposts;
HttpClientDownloader httpClientDownloader = new HttpClientDownloader();
SpiderModel spiderModel = new SpiderModel();
Spider mySpider = Spider.create(spiderModel).addUrl(urls);
mySpider.setDownloader(httpClientDownloader);
try {
SpiderMonitor.instance().register(mySpider);
mySpider.thread(1).run();
} catch (JMException e) {
e.printStackTrace();
}
endTime = System.currentTimeMillis();
System.out.println("爬取时间" + ((endTime - startTime) / 1000) + "秒--");
}
}
其他与逻辑无关的数据存储代码将不再发布。这里我将代理服务器抓取的数据存放在mysql中,将我的爬虫程序抓取到的数据存放在mongodb中。
以下是我爬取的公众号信息:
查看全部
用webmagic写的爬虫程序从数据库中拿链接爬取文章内容等信息
public void getMsgExt(String str,String url) {
// TODO Auto-generated method stub
String biz = "";
String sn = "";
Map queryStrs = HttpUrlParser.parseUrl(url);
if(queryStrs != null){
biz = queryStrs.get("__biz");
biz = biz + "==";
sn = queryStrs.get("sn");
sn = "%" + sn + "%";
}
/**
* $sql = "select * from `文章表` where `biz`='".$biz."'
* and `content_url` like '%".$sn."%'" limit 0,1;
* 根据biz和sn找到对应的文章
*/
Post post = postMapper.selectByBizAndSn(biz, sn);
if(post == null){
System.out.println("biz:"+biz);
System.out.println("sn:"+sn);
tmpListMapper.deleteByLoad(1);
return;
}
// System.out.println("json数据:"+str);
Integer read_num;
Integer like_num;
try{
read_num = JsonPath.read(str, "['appmsgstat']['read_num']");//阅读量
like_num = JsonPath.read(str, "['appmsgstat']['like_num']");//点赞量
}catch(Exception e){
read_num = 123;//阅读量
like_num = 321;//点赞量
System.out.println("read_num:"+read_num);
System.out.println("like_num:"+like_num);
System.out.println(e.getMessage());
}
/**
* 在这里同样根据sn在采集队列表中删除对应的文章,代表这篇文章可以移出采集队列了
* $sql = "delete from `队列表` where `content_url` like '%".$sn."%'"
*/
tmpListMapper.deleteBySn(sn);
//然后将阅读量和点赞量更新到文章表中。
post.setReadnum(read_num);
post.setLikenum(like_num);
postMapper.updateByPrimaryKey(post);
}
通过处理跳转将js注入微信的方法:
public String getWxHis() {
String url = "";
// TODO Auto-generated method stub
/**
* 当前页面为公众号历史消息时,读取这个程序
* 在采集队列表中有一个load字段,当值等于1时代表正在被读取
* 首先删除采集队列表中load=1的行
* 然后从队列表中任意select一行
*/
tmpListMapper.deleteByLoad(1);
TmpList queue = tmpListMapper.selectRandomOne();
System.out.println("queue is null?"+queue);
if(queue == null){//队列表为空
/**
* 队列表如果空了,就从存储公众号biz的表中取得一个biz,
* 这里我在公众号表中设置了一个采集时间的time字段,按照正序排列之后,
* 就得到时间戳最小的一个公众号记录,并取得它的biz
*/
WeiXin weiXin = weiXinMapper.selectOne();
String biz = weiXin.getBiz();
url = "https://mp.weixin.qq.com/mp/pr ... ot%3B + biz +
"#wechat_redirect";//拼接公众号历史消息url地址(第二种页面形式)
//更新刚才提到的公众号表中的采集时间time字段为当前时间戳。
weiXin.setCollect(System.currentTimeMillis());
int result = weiXinMapper.updateByPrimaryKey(weiXin);
System.out.println("getHis weiXin updateResult:"+result);
}else{
//取得当前这一行的content_url字段
url = queue.getContentUrl();
//将load字段update为1
tmpListMapper.updateByContentUrl(url);
}
//将下一个将要跳转的$url变成js脚本,由anyproxy注入到微信页面中。
//echo "setTimeout(function(){window.location.href='".$url."';},2000);";
int randomTime = new Random().nextInt(3) + 3;
String jsCode = "setTimeout(function(){window.location.href='"+url+"';},"+randomTime*1000+");";
return jsCode;
}
以上是对代理服务器截获的数据进行处理的流程。有一个问题需要注意。程序会循环访问数据库中的每个收录公众号,甚至会再次访问存储的文章,以不断更新文章Count和like count的读数。如果需要抓大量公众号,建议修改添加任务队列的代码,添加条件限制。否则,公众号多轮重复抓取数据会极大影响效率。
到目前为止,我们已经抓取了微信公众号的所有文章链接,并且这个链接是一个可以在浏览器中打开的永久链接。下一步就是编写爬虫程序,从数据库中抓取链接,爬取文章内容等信息。
我用webmagic写了一个爬虫,轻量级好用。
public class SpiderModel implements PageProcessor{
private static PostMapper postMapper;
private static List posts;
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
// TODO Auto-generated method stub
return this.site;
}
public void process(Page page) {
// TODO Auto-generated method stub
Post post = posts.remove(0);
String content = page.getHtml().xpath("//div[@id='js_content']").get();
//存在和谐文章 此处做判定如果有直接删除记录或设置表示位表示文章被和谐
if(content == null){
System.out.println("文章已和谐!");
//postMapper.deleteByPrimaryKey(post.getId());
return;
}
String contentSnap = content.replaceAll("data-src", "src").replaceAll("preview.html", "player.html");//快照
String contentTxt = HtmlToWord.stripHtml(content);//纯文本内容
Selectable metaContent = page.getHtml().xpath("//div[@id='meta_content']");
String pubTime = null;
String wxname = null;
String author = null;
if(metaContent != null){
pubTime = metaContent.xpath("//em[@id='post-date']").get();
if(pubTime != null){
pubTime = HtmlToWord.stripHtml(pubTime);//文章发布时间
}
wxname = metaContent.xpath("//a[@id='post-user']").get();
if(wxname != null){
wxname = HtmlToWord.stripHtml(wxname);//公众号名称
}
author = metaContent.xpath("//em[@class='rich_media_meta rich_media_meta_text' and @id!='post-date']").get();
if(author != null){
author = HtmlToWord.stripHtml(author);//文章作者
}
}
// System.out.println("发布时间:"+pubTime);
// System.out.println("公众号名称:"+wxname);
// System.out.println("文章作者:"+author);
String title = post.getTitle().replaceAll(" ", "");//文章标题
String digest = post.getDigest();//文章摘要
int likeNum = post.getLikenum();//文章点赞数
int readNum = post.getReadnum();//文章阅读数
String contentUrl = post.getContentUrl();//文章链接
WechatInfoBean wechatBean = new WechatInfoBean();
wechatBean.setTitle(title);
wechatBean.setContent(contentTxt);//纯文本内容
wechatBean.setSourceCode(contentSnap);//快照
wechatBean.setLikeCount(likeNum);
wechatBean.setViewCount(readNum);
wechatBean.setAbstractText(digest);//摘要
wechatBean.setUrl(contentUrl);
wechatBean.setPublishTime(pubTime);
wechatBean.setSiteName(wxname);//站点名称 公众号名称
wechatBean.setAuthor(author);
wechatBean.setMediaType("微信公众号");//来源媒体类型
WechatStorage.saveWechatInfo(wechatBean);
//标示文章已经被爬取
post.setIsSpider(1);
postMapper.updateByPrimaryKey(post);
}
public static void startSpider(List inposts,PostMapper myPostMapper,String... urls){
long startTime, endTime;
startTime = System.currentTimeMillis();
postMapper = myPostMapper;
posts = inposts;
HttpClientDownloader httpClientDownloader = new HttpClientDownloader();
SpiderModel spiderModel = new SpiderModel();
Spider mySpider = Spider.create(spiderModel).addUrl(urls);
mySpider.setDownloader(httpClientDownloader);
try {
SpiderMonitor.instance().register(mySpider);
mySpider.thread(1).run();
} catch (JMException e) {
e.printStackTrace();
}
endTime = System.currentTimeMillis();
System.out.println("爬取时间" + ((endTime - startTime) / 1000) + "秒--");
}
}
其他与逻辑无关的数据存储代码将不再发布。这里我将代理服务器抓取的数据存放在mysql中,将我的爬虫程序抓取到的数据存放在mongodb中。
以下是我爬取的公众号信息:
querylist采集微信公众号文章,可以这样:生成脚本
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2021-06-20 19:48
querylist采集微信公众号文章,可以这样:1.webqq登录公众号后台,授权2.选择webqq选项,然后上传图片到服务器生成webqqpost对象3.获取webqqpost对象实现抓包分析,分析公众号后台,
你自己也可以采集-no-can-source/index.html
主要需要:apikey生成脚本(抓包app分析包,endgame中抓包找到的唯一标识,
可以自己抓,
querylistapi
querylist关注公众号里面的文章,如果有回复消息后,就可以获取采集结果,
可以采集微信公众号的文章,也可以根据搜索内容判断,我觉得不过这个做成网站,必须要有微信开放接口,比如服务号,或者公众号在微信平台有实名认证,具有一定的权限,就可以接入querylistapi,就可以接入微信公众号采集流程,只要网站有接入querylistapi的功能,就可以实现,楼主可以看看杭州数云网络这家公司不错,有接入querylistapi。
我想知道为什么会有这样的采集需求?querylist是公众号文章对接的接口,好多公众号是自己的app,可以以app应用形式接入即可,另外题主也可以试试草料二维码平台,也有类似需求,这是我之前用他接的订阅号文章。 查看全部
querylist采集微信公众号文章,可以这样:生成脚本
querylist采集微信公众号文章,可以这样:1.webqq登录公众号后台,授权2.选择webqq选项,然后上传图片到服务器生成webqqpost对象3.获取webqqpost对象实现抓包分析,分析公众号后台,
你自己也可以采集-no-can-source/index.html
主要需要:apikey生成脚本(抓包app分析包,endgame中抓包找到的唯一标识,
可以自己抓,
querylistapi
querylist关注公众号里面的文章,如果有回复消息后,就可以获取采集结果,
可以采集微信公众号的文章,也可以根据搜索内容判断,我觉得不过这个做成网站,必须要有微信开放接口,比如服务号,或者公众号在微信平台有实名认证,具有一定的权限,就可以接入querylistapi,就可以接入微信公众号采集流程,只要网站有接入querylistapi的功能,就可以实现,楼主可以看看杭州数云网络这家公司不错,有接入querylistapi。
我想知道为什么会有这样的采集需求?querylist是公众号文章对接的接口,好多公众号是自己的app,可以以app应用形式接入即可,另外题主也可以试试草料二维码平台,也有类似需求,这是我之前用他接的订阅号文章。
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
采集交流 • 优采云 发表了文章 • 0 个评论 • 295 次浏览 • 2021-06-20 19:43
前言
本文中的文字图片过滤网络可用于学习、交流,不具有任何商业用途。如有任何问题,请及时联系我们处理。
Python爬虫、数据分析、网站development等案例教程视频免费在线观看
https://space.bilibili.com/523606542
基本的开发环境。爬取两个公众号的文章:
1.蓝光编程公众号拥有的爬取文章
2、爬取所有关于python文章的公众号
爬取蓝光编程公众号拥有的文章
1、登录公众号后点击图片和文字
2、打开开发者工具
3、点击超链接
加载相关数据时,有一个数据包,包括文章title、链接、摘要、发布时间等,您也可以选择其他公众号进行抓取,但这需要您有一个微信公众号帐户。
添加cookie
import pprint
import time
import requests
import csv
f = open('青灯公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(0, 40, 5):
url = f'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin={page}&count=5&fakeid=&type=9&query=&token=1252678642&lang=zh_CN&f=json&ajax=1'
headers = {
'cookie': '加cookie',
'referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&createType=0&token=1252678642&lang=zh_CN',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html_data = response.json()
pprint.pprint(response.json())
lis = html_data['app_msg_list']
for li in lis:
title = li['title']
link_url = li['link']
update_time = li['update_time']
timeArray = time.localtime(int(update_time))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title,
'文章发布时间': otherStyleTime,
'文章地址': link_url,
}
csv_writer.writerow(dit)
print(dit)
抓取所有关于python文章的公众账号
1、搜狗搜索python选择微信
注意:如果不登录,只能抓取前十页数据。登录后可以爬取2W多文章。
2.直接爬取静态网页的标题、公众号、文章地址、发布时间。
import time
import requests
import parsel
import csv
f = open('公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '公众号', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(1, 2447):
url = f'https://weixin.sogou.com/weixin?query=python&_sug_type_=&s_from=input&_sug_=n&type=2&page={page}&ie=utf8'
headers = {
'Cookie': '自己的cookie',
'Host': 'weixin.sogou.com',
'Referer': 'https://www.sogou.com/web?query=python&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=1396&sst0=1610779538290&lkt=0%2C0%2C0&sugsuv=1590216228113568&sugtime=1610779538290',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
lis = selector.css('.news-list li')
for li in lis:
title_list = li.css('.txt-box h3 a::text').getall()
num = len(title_list)
if num == 1:
title_str = 'python' + title_list[0]
else:
title_str = 'python'.join(title_list)
href = li.css('.txt-box h3 a::attr(href)').get()
article_url = 'https://weixin.sogou.com' + href
name = li.css('.s-p a::text').get()
date = li.css('.s-p::attr(t)').get()
timeArray = time.localtime(int(date))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title_str,
'公众号': name,
'文章发布时间': otherStyleTime,
'文章地址': article_url,
}
csv_writer.writerow(dit)
print(title_str, name, otherStyleTime, article_url)
本文同步分享到博客“松鼠爱饼干”(CSDN)。 查看全部
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
前言
本文中的文字图片过滤网络可用于学习、交流,不具有任何商业用途。如有任何问题,请及时联系我们处理。
Python爬虫、数据分析、网站development等案例教程视频免费在线观看
https://space.bilibili.com/523606542
基本的开发环境。爬取两个公众号的文章:
1.蓝光编程公众号拥有的爬取文章
2、爬取所有关于python文章的公众号
爬取蓝光编程公众号拥有的文章
1、登录公众号后点击图片和文字
2、打开开发者工具
3、点击超链接
加载相关数据时,有一个数据包,包括文章title、链接、摘要、发布时间等,您也可以选择其他公众号进行抓取,但这需要您有一个微信公众号帐户。
添加cookie
import pprint
import time
import requests
import csv
f = open('青灯公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(0, 40, 5):
url = f'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin={page}&count=5&fakeid=&type=9&query=&token=1252678642&lang=zh_CN&f=json&ajax=1'
headers = {
'cookie': '加cookie',
'referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&createType=0&token=1252678642&lang=zh_CN',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html_data = response.json()
pprint.pprint(response.json())
lis = html_data['app_msg_list']
for li in lis:
title = li['title']
link_url = li['link']
update_time = li['update_time']
timeArray = time.localtime(int(update_time))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title,
'文章发布时间': otherStyleTime,
'文章地址': link_url,
}
csv_writer.writerow(dit)
print(dit)
抓取所有关于python文章的公众账号
1、搜狗搜索python选择微信
注意:如果不登录,只能抓取前十页数据。登录后可以爬取2W多文章。
2.直接爬取静态网页的标题、公众号、文章地址、发布时间。
import time
import requests
import parsel
import csv
f = open('公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '公众号', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(1, 2447):
url = f'https://weixin.sogou.com/weixin?query=python&_sug_type_=&s_from=input&_sug_=n&type=2&page={page}&ie=utf8'
headers = {
'Cookie': '自己的cookie',
'Host': 'weixin.sogou.com',
'Referer': 'https://www.sogou.com/web?query=python&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=1396&sst0=1610779538290&lkt=0%2C0%2C0&sugsuv=1590216228113568&sugtime=1610779538290',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
lis = selector.css('.news-list li')
for li in lis:
title_list = li.css('.txt-box h3 a::text').getall()
num = len(title_list)
if num == 1:
title_str = 'python' + title_list[0]
else:
title_str = 'python'.join(title_list)
href = li.css('.txt-box h3 a::attr(href)').get()
article_url = 'https://weixin.sogou.com' + href
name = li.css('.s-p a::text').get()
date = li.css('.s-p::attr(t)').get()
timeArray = time.localtime(int(date))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title_str,
'公众号': name,
'文章发布时间': otherStyleTime,
'文章地址': article_url,
}
csv_writer.writerow(dit)
print(title_str, name, otherStyleTime, article_url)
本文同步分享到博客“松鼠爱饼干”(CSDN)。
微信开放平台推文之类的话考虑是否用关键字共享
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-06-20 19:42
querylist采集微信公众号文章textdatareader采集qq空间文章微信开放平台推文之类是公司产品的会先成立项目组或者部门研究相关需求,分析需求是否合理。然后设计个基础设计,写个helloworld。这边所谓的人均压力都不算大,实际上手发现没啥。数据的话考虑是否用关键字共享不过也可以根据需求放一些图片存缓存。
需要处理到浏览器那边就用gulp+vuepress等。业务类分为公众号\移动端\h5\微信小程序等我做的项目是用微信公众号来测试,完全没有开发微信接口测试。因为功能测试不过,所以把调试的功能公开给了运营人员,看他们自己后期的测试。最后项目开发中段才开始考虑量化算法。给总经理们整点投票表决什么的以便安排人手。
我一般是先搞定业务问题,然后挑战一些很容易通过数据挖掘模型的功能。工作量因人而异,不会整天加班,看出的问题也不会有回报。后端的话excel+hive+sql+springmvc就可以办到。nosql这种不用考虑了,不过如果需要融合mongodb,请先给我自己买个mongodb。上市公司业务多的话,开个spark吧,采用一下spark的集群管理以及水平扩展思路。
量化方向主要是excel,hive等,传统统计方向的话,r应该可以,因为很多公司在做这个了,大数据这块,excel占大头了,有的会用mapreduce这类, 查看全部
微信开放平台推文之类的话考虑是否用关键字共享
querylist采集微信公众号文章textdatareader采集qq空间文章微信开放平台推文之类是公司产品的会先成立项目组或者部门研究相关需求,分析需求是否合理。然后设计个基础设计,写个helloworld。这边所谓的人均压力都不算大,实际上手发现没啥。数据的话考虑是否用关键字共享不过也可以根据需求放一些图片存缓存。
需要处理到浏览器那边就用gulp+vuepress等。业务类分为公众号\移动端\h5\微信小程序等我做的项目是用微信公众号来测试,完全没有开发微信接口测试。因为功能测试不过,所以把调试的功能公开给了运营人员,看他们自己后期的测试。最后项目开发中段才开始考虑量化算法。给总经理们整点投票表决什么的以便安排人手。
我一般是先搞定业务问题,然后挑战一些很容易通过数据挖掘模型的功能。工作量因人而异,不会整天加班,看出的问题也不会有回报。后端的话excel+hive+sql+springmvc就可以办到。nosql这种不用考虑了,不过如果需要融合mongodb,请先给我自己买个mongodb。上市公司业务多的话,开个spark吧,采用一下spark的集群管理以及水平扩展思路。
量化方向主要是excel,hive等,传统统计方向的话,r应该可以,因为很多公司在做这个了,大数据这块,excel占大头了,有的会用mapreduce这类,
querylist采集微信公众号文章 熊孩子和萌宠搞笑视频笑声不断快乐常伴
采集交流 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2021-06-20 06:33
每天更新视频:熊孩子的日常,萌宠的日常,熊孩子和萌宠的搞笑视频,笑不停,一直陪着你!
请允许我强制投放一波广告:
因为每个爬虫官方账号都是他家的,一年前的,现在的,只是主题和名字都变了。
一个喜欢小宠物但养不起猫的码农,下班后很高兴来看看。可以关注哦!
为保证视频安全,避免丢失,请楼主为视频添加水印。
获取官方账号信息
标题、摘要、封面、文章URL
步骤:
1、先自己申请公众号
2、登录您的帐户,创建一个新的文章图形,然后单击超链接
3、弹出搜索框,搜索你需要的公众号,查看历史文章
4、抓包获取信息并定位请求的url
通过查看信息,找到了我们需要的关键内容:title、abstract、cover和文章URL,确认这是我们需要的URL,点击下一页,多次获取url,发现只有 random 和 begin 的参数发生了变化
这样就确定了主要信息网址。
让我们开始吧:
原来我们需要修改的参数是:token、random、cookie
获取url的时候就可以得到这两个值的来源。
# -*- coding: utf-8 -*-
import re
import requests
import jsonpath
import json
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Host": "mp.weixin.qq.com",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Cookie": "自己获取信息时的cookie"
}
def getInfo():
for i in range(80):
# token random 需要要自己的 begin:参数传入
url = "https://mp.weixin.qq.com/cgi-b ... in%3D{}&count=5&query=&fakeid=MzI4MzkzMTc3OA%3D%3D&type=9".format(str(i * 5))
response = requests.get(url, headers = headers)
jsonRes = response.json()
titleList = jsonpath.jsonpath(jsonRes, "$..title")
coverList = jsonpath.jsonpath(jsonRes, "$..cover")
urlList = jsonpath.jsonpath(jsonRes, "$..link")
# 遍历 构造可存储字符串
for index in range(len(titleList)):
title = titleList[index]
cover = coverList[index]
url = urlList[index]
scvStr = "%s,%s, %s,\n" % (title, cover, url)
with open("info.csv", "a+", encoding="gbk", newline='') as f:
f.write(scvStr)
获取结果(成功):
获取文章内视频:实现批量下载
分析一个视频文章后,我找到了这个链接:
打开网页,发现是视频网页的下载链接:
嘿嘿,好像有点意思,找到了视频网页的纯下载链接,开始吧。
我发现链接中有一个关键参数vid。不知从何而来?
与获取的其他信息无关,只能强制。
这个参数是在文章单人的url请求信息中找到的,然后获取。
response = requests.get(url_wxv, headers=headers)
# 我用的是正则,也可以使用xpath
jsonRes = response.text # 匹配:wxv_1105179750743556096
dirRe = r"wxv_.{19}"
result = re.search(dirRe, jsonRes)
wxv = result.group(0)
print(wxv)
视频下载:
def getVideo(video_title, url_wxv):
video_path = './videoFiles/' + video_title + ".mp4"
# 页面可下载形式
video_url_temp = "https://mp.weixin.qq.com/mp/vi ... ot%3B + wxv
response = requests.get(video_url_temp, headers=headers)
content = response.content.decode()
content = json.loads(content)
url_info = content.get("url_info")
video_url2 = url_info[0].get("url")
print(video_url2)
# 请求要下载的url地址
html = requests.get(video_url2)
# content返回的是bytes型也就是二进制的数据。
html = html.content
with open(video_path, 'wb') as f:
f.write(html)
然后所有的信息都完成了,进行代码组装。
一个。获取公众号信息
B.过滤单篇文章文章information
c.获取视频信息
d。拼接视频页面下载地址
e.下载视频并保存
代码实验结果:
获取公众号:标题、摘要、封面、视频、
可以说你拥有一个视频公众号的所有信息,你可以复制一份。
危险动作,请勿操作!记住!记住!记住!
获取代码请回复公众号:20191210或公众号
查看全部
querylist采集微信公众号文章 熊孩子和萌宠搞笑视频笑声不断快乐常伴
每天更新视频:熊孩子的日常,萌宠的日常,熊孩子和萌宠的搞笑视频,笑不停,一直陪着你!
请允许我强制投放一波广告:
因为每个爬虫官方账号都是他家的,一年前的,现在的,只是主题和名字都变了。
一个喜欢小宠物但养不起猫的码农,下班后很高兴来看看。可以关注哦!
为保证视频安全,避免丢失,请楼主为视频添加水印。
获取官方账号信息
标题、摘要、封面、文章URL
步骤:
1、先自己申请公众号
2、登录您的帐户,创建一个新的文章图形,然后单击超链接
3、弹出搜索框,搜索你需要的公众号,查看历史文章
4、抓包获取信息并定位请求的url
通过查看信息,找到了我们需要的关键内容:title、abstract、cover和文章URL,确认这是我们需要的URL,点击下一页,多次获取url,发现只有 random 和 begin 的参数发生了变化
这样就确定了主要信息网址。
让我们开始吧:
原来我们需要修改的参数是:token、random、cookie
获取url的时候就可以得到这两个值的来源。
# -*- coding: utf-8 -*-
import re
import requests
import jsonpath
import json
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Host": "mp.weixin.qq.com",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Cookie": "自己获取信息时的cookie"
}
def getInfo():
for i in range(80):
# token random 需要要自己的 begin:参数传入
url = "https://mp.weixin.qq.com/cgi-b ... in%3D{}&count=5&query=&fakeid=MzI4MzkzMTc3OA%3D%3D&type=9".format(str(i * 5))
response = requests.get(url, headers = headers)
jsonRes = response.json()
titleList = jsonpath.jsonpath(jsonRes, "$..title")
coverList = jsonpath.jsonpath(jsonRes, "$..cover")
urlList = jsonpath.jsonpath(jsonRes, "$..link")
# 遍历 构造可存储字符串
for index in range(len(titleList)):
title = titleList[index]
cover = coverList[index]
url = urlList[index]
scvStr = "%s,%s, %s,\n" % (title, cover, url)
with open("info.csv", "a+", encoding="gbk", newline='') as f:
f.write(scvStr)
获取结果(成功):
获取文章内视频:实现批量下载
分析一个视频文章后,我找到了这个链接:
打开网页,发现是视频网页的下载链接:
嘿嘿,好像有点意思,找到了视频网页的纯下载链接,开始吧。
我发现链接中有一个关键参数vid。不知从何而来?
与获取的其他信息无关,只能强制。
这个参数是在文章单人的url请求信息中找到的,然后获取。
response = requests.get(url_wxv, headers=headers)
# 我用的是正则,也可以使用xpath
jsonRes = response.text # 匹配:wxv_1105179750743556096
dirRe = r"wxv_.{19}"
result = re.search(dirRe, jsonRes)
wxv = result.group(0)
print(wxv)
视频下载:
def getVideo(video_title, url_wxv):
video_path = './videoFiles/' + video_title + ".mp4"
# 页面可下载形式
video_url_temp = "https://mp.weixin.qq.com/mp/vi ... ot%3B + wxv
response = requests.get(video_url_temp, headers=headers)
content = response.content.decode()
content = json.loads(content)
url_info = content.get("url_info")
video_url2 = url_info[0].get("url")
print(video_url2)
# 请求要下载的url地址
html = requests.get(video_url2)
# content返回的是bytes型也就是二进制的数据。
html = html.content
with open(video_path, 'wb') as f:
f.write(html)
然后所有的信息都完成了,进行代码组装。
一个。获取公众号信息
B.过滤单篇文章文章information
c.获取视频信息
d。拼接视频页面下载地址
e.下载视频并保存
代码实验结果:
获取公众号:标题、摘要、封面、视频、
可以说你拥有一个视频公众号的所有信息,你可以复制一份。
危险动作,请勿操作!记住!记住!记住!
获取代码请回复公众号:20191210或公众号
querylist采集微信公众号文章源码(我会截图分享)
采集交流 • 优采云 发表了文章 • 0 个评论 • 230 次浏览 • 2021-06-14 00:02
querylist采集微信公众号文章源码我会截图分享,里面有请输入xxxxv这样的语句。本人目前初学中,水平有限。如有错误,希望指正。仅代表个人解决了"常见文章库提取问题。输入"某源码库"提取微信公众号文章的标题",","目标格式"这样的问题。到此,下一篇文章"个人实现自动回复管理系统"在中途就会全部搞定。
我通过分析此图,认为可行性非常小,性能太差。再者很不方便,首页与每篇文章之间的跳转不方便(别人发送过一次)。
文章源代码的提取的通过分析公众号的h5地址就可以找到了,可以获取整个公众号的下载地址和公众号每篇文章的链接地址,
有必要么,
当然可以啊,而且这个工具是已经实现了的,
比较有必要,最起码我们公司用这个文章提取工具都实现了我们的需求。
可以呀,
可以的,我目前想自己实现也是这么找。当然要得到微信公众号的文章源码,
文章源代码提取肯定会有些封装的接口,如果想使用原来接口我们可以分析一下源代码来提取。
根据微信公众号中的文章标题,也可以自己设计过滤器这么做, 查看全部
querylist采集微信公众号文章源码(我会截图分享)
querylist采集微信公众号文章源码我会截图分享,里面有请输入xxxxv这样的语句。本人目前初学中,水平有限。如有错误,希望指正。仅代表个人解决了"常见文章库提取问题。输入"某源码库"提取微信公众号文章的标题",","目标格式"这样的问题。到此,下一篇文章"个人实现自动回复管理系统"在中途就会全部搞定。
我通过分析此图,认为可行性非常小,性能太差。再者很不方便,首页与每篇文章之间的跳转不方便(别人发送过一次)。
文章源代码的提取的通过分析公众号的h5地址就可以找到了,可以获取整个公众号的下载地址和公众号每篇文章的链接地址,
有必要么,
当然可以啊,而且这个工具是已经实现了的,
比较有必要,最起码我们公司用这个文章提取工具都实现了我们的需求。
可以呀,
可以的,我目前想自己实现也是这么找。当然要得到微信公众号的文章源码,
文章源代码提取肯定会有些封装的接口,如果想使用原来接口我们可以分析一下源代码来提取。
根据微信公众号中的文章标题,也可以自己设计过滤器这么做,
querylist采集微信公众号文章聚合,可以试试weichat100,
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-06-12 02:01
querylist采集微信公众号文章内容的话,个人认为应该是通过redis做querylist的querylist进行抓取,可以通过mongodb等关系型数据库存储和管理。但是建议楼主可以采用feed聚合服务,比如说微信公众号的文章或者小程序的推文,直接开发一个feed服务端来进行抓取的!。
feed对方需要发送get请求参与到redis里面。
可以试试weichat100,给你一个试试:/
百度搜索关键词微信公众号文章聚合,开发项目很多。最直接简单的方法,其实你可以用浏览器打开,去看那个,
高并发吗?答案,
两种可能,一种是你的服务器负载不足,经常上线,最近没有任何数据抓取。或者是页面过于复杂或者附加属性过多,这个个人觉得还是跟语言有关,目前ruby,python等语言的效率都会相对较高。
是我对高并发要求太高了吗?同意楼上说的那个回答。
对服务器配置要求是真高,如果你有钱,你可以找个节点或者购买相应服务,比如你自己做个集群啥的。其他大家的回答都是为了说明对你有帮助,对于那个使用redis来进行querylist进行抓取的方案,由于querylist不是微信开发的,而是为了crud而生,所以,redis本身有数据的持久化机制,不需要数据库操作。 查看全部
querylist采集微信公众号文章聚合,可以试试weichat100,
querylist采集微信公众号文章内容的话,个人认为应该是通过redis做querylist的querylist进行抓取,可以通过mongodb等关系型数据库存储和管理。但是建议楼主可以采用feed聚合服务,比如说微信公众号的文章或者小程序的推文,直接开发一个feed服务端来进行抓取的!。
feed对方需要发送get请求参与到redis里面。
可以试试weichat100,给你一个试试:/
百度搜索关键词微信公众号文章聚合,开发项目很多。最直接简单的方法,其实你可以用浏览器打开,去看那个,
高并发吗?答案,
两种可能,一种是你的服务器负载不足,经常上线,最近没有任何数据抓取。或者是页面过于复杂或者附加属性过多,这个个人觉得还是跟语言有关,目前ruby,python等语言的效率都会相对较高。
是我对高并发要求太高了吗?同意楼上说的那个回答。
对服务器配置要求是真高,如果你有钱,你可以找个节点或者购买相应服务,比如你自己做个集群啥的。其他大家的回答都是为了说明对你有帮助,对于那个使用redis来进行querylist进行抓取的方案,由于querylist不是微信开发的,而是为了crud而生,所以,redis本身有数据的持久化机制,不需要数据库操作。
【魔兽世界】谷歌微信公众号文章接口获取方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 218 次浏览 • 2021-06-11 00:05
一、网上方法:
1.使用订阅账号功能中的查询链接,(此链接现在采取了严重的反抄袭措施,订阅账号在抓取几十个页面时会被屏蔽,仅供参考)
详情请访问此链接:/4652.html
2.微信搜索使用搜狗搜索(此方法只能查看每个微信公众号文章的前10条)
详情请访问此链接:/qiqiyingse/article/details/70050113
3.先抢公众号界面,访问界面获取所有文章连接
二、环境配置及材料准备
1.需要安装python selenium模块包,使用selenium中的webdriver驱动浏览器获取cookie,达到登录效果;
2.使用webdriver功能需要安装浏览器对应的驱动插件。我在这里测试的是 Google Chrome。
3.微信公众号申请(个人订阅号申请门槛低,服务号需要营业执照等)
4、.微信公众号文章界面地址可在微信公众号后台新建图文消息,可通过超链接功能获取;
通过搜索关键字获取所有相关公众号信息,但我只取第一个进行测试,其他感兴趣的人也可以全部获取
5.获取要爬取的公众号的fakeid
6.选择要爬取的公众号,获取文章接口地址
从 selenium 导入 webdriver
导入时间
导入json
导入请求
重新导入
随机导入
user=""
password="weikuan3344520"
gzlist=['熊猫']
#登录微信公众号,登录后获取cookie信息,保存在本地文本
def weChat_login():
#定义一个空字典来存储cookies的内容
post={}
#使用网络驱动程序启动谷歌浏览器
print("启动浏览器,打开微信公众号登录界面")
driver = webdriver.Chrome(executable_path='C:\chromedriver.exe')
#打开微信公众号登录页面
driver.get('/')
#等待 5 秒
time.sleep(5)
print("输入微信公众号账号和密码...")
#清除帐号框中的内容
driver.find_element_by_xpath("./*//input[@name='account'][@type='text']").clear()
#自动填写登录用户名
driver.find_element_by_xpath("./*//input[@name='account'][@type='text']").send_keys(user)
#清空密码框内容
driver.find_element_by_xpath("./*//input[@name='password'][@type='password']").clear()
#自动填写登录密码
driver.find_element_by_xpath("./*//input[@name='password'][@type='password']").send_keys(password)
//这是重点,最近改版后
#自动输入密码后,需要手动点击记住我
print("请点击登录界面:记住您的账号")
time.sleep(10)
#自动点击登录按钮登录
driver.find_element_by_xpath("./*//a[@class='btn_login']").click()
#用手机扫描二维码!
print("请用手机扫描二维码登录公众号")
time.sleep(20)
print("登录成功")
#重新加载公众号登录页面,登录后会显示公众号后台首页,从返回的内容中获取cookies信息
driver.get('/')
#获取cookies
cookie_items = driver.get_cookies()
#获取的cookies为列表形式,将cookies转换为json形式存放在名为cookie的本地文本中
对于 cookie_items 中的 cookie_item:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt','w+', encoding='utf-8') as f:
f.write(cookie_str)
print("Cookies 信息已保存在本地")
#抓取微信公众号文章并存入本地文本
def get_content(query):
#query 是要抓取的公众号名称
#公众号首页
url =''
#设置标题
标题 = {
"主机":"",
"用户代理": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
#读取上一步获取的cookie
with open('cookie.txt','r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
#登录后微信公众号首页url改为:/cgi-bin/home?t=home/index&lang=zh_CN&token=1849751598,获取token信息
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
#搜索微信公众号接口地址
search_url ='/cgi-bin/searchbiz?'
#搜索微信公众号接口需要传入的参数,共有三个变量:微信公众号token、随机数random、搜索微信公众号名称
query_id = {
'action':'search_biz',
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'查询':查询,
'开始':'0',
'计数':'5'
}
#打开搜索微信公众号接口地址,需要传入cookies、params、headers等相关参数信息
search_response = requests.get(search_url, cookies=cookies, headers=header, params=query_id)
#取搜索结果第一个公众号
lists = search_response.json().get('list')[0]
#获取这个公众号的fakeid,以后爬取公众号文章需要这个字段
fakeid = list.get('fakeid')
#微信公众号文章界面地址
appmsg_url ='/cgi-bin/appmsg?'
#搜索文章需要传入几个参数:登录的公众号token、爬取文章的fakeid公众号、随机数random
query_id_data = {
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'action':'list_ex',
'begin': '0',#不同的页面,这个参数改变,改变规则是每页加5
'计数':'5',
'查询':'',
'fakeid':fakeid,
'类型':'9'
}
#打开搜索到的微信公众号文章list页面
appmsg_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
#Get 文章total number
max_num = appmsg_response.json().get('app_msg_cnt')
#每页至少有5个条目,获取文章页总数,爬取时需要页面爬取
num = int(int(max_num) / 5)
#起始页begin参数,后续每页加5
开始 = 0
当 num + 1> 0 :
query_id_data = {
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'action':'list_ex',
'begin':'{}'.format(str(begin)),
'计数':'5',
'查询':'',
'fakeid':fakeid,
'类型':'9'
}
print('翻页:--------------',begin)
#获取文章每个页面的标题和链接地址,写入本地文本
query_fakeid_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
对于 fakeid_list 中的项目:
content_link=item.get('link')
content_title=item.get('title')
fileName=query+'.txt'
with open(fileName,'a',encoding='utf-8') as fh:
fh.write(content_title+":\n"+content_link+"\n")
数量 -= 1
begin = int(begin)
开始+=5
time.sleep(2)
如果 __name__=='__main__':
试试:
#登录微信公众号,登录后获取cookie信息,保存在本地文本
weChat_login()
#登录后使用微信公众号文章interface爬取文章
在 gzlist 中查询:
#抓取微信公众号文章并存入本地文本 查看全部
【魔兽世界】谷歌微信公众号文章接口获取方法
一、网上方法:
1.使用订阅账号功能中的查询链接,(此链接现在采取了严重的反抄袭措施,订阅账号在抓取几十个页面时会被屏蔽,仅供参考)
详情请访问此链接:/4652.html
2.微信搜索使用搜狗搜索(此方法只能查看每个微信公众号文章的前10条)
详情请访问此链接:/qiqiyingse/article/details/70050113
3.先抢公众号界面,访问界面获取所有文章连接
二、环境配置及材料准备
1.需要安装python selenium模块包,使用selenium中的webdriver驱动浏览器获取cookie,达到登录效果;
2.使用webdriver功能需要安装浏览器对应的驱动插件。我在这里测试的是 Google Chrome。
3.微信公众号申请(个人订阅号申请门槛低,服务号需要营业执照等)
4、.微信公众号文章界面地址可在微信公众号后台新建图文消息,可通过超链接功能获取;
通过搜索关键字获取所有相关公众号信息,但我只取第一个进行测试,其他感兴趣的人也可以全部获取
5.获取要爬取的公众号的fakeid
6.选择要爬取的公众号,获取文章接口地址
从 selenium 导入 webdriver
导入时间
导入json
导入请求
重新导入
随机导入
user=""
password="weikuan3344520"
gzlist=['熊猫']
#登录微信公众号,登录后获取cookie信息,保存在本地文本
def weChat_login():
#定义一个空字典来存储cookies的内容
post={}
#使用网络驱动程序启动谷歌浏览器
print("启动浏览器,打开微信公众号登录界面")
driver = webdriver.Chrome(executable_path='C:\chromedriver.exe')
#打开微信公众号登录页面
driver.get('/')
#等待 5 秒
time.sleep(5)
print("输入微信公众号账号和密码...")
#清除帐号框中的内容
driver.find_element_by_xpath("./*//input[@name='account'][@type='text']").clear()
#自动填写登录用户名
driver.find_element_by_xpath("./*//input[@name='account'][@type='text']").send_keys(user)
#清空密码框内容
driver.find_element_by_xpath("./*//input[@name='password'][@type='password']").clear()
#自动填写登录密码
driver.find_element_by_xpath("./*//input[@name='password'][@type='password']").send_keys(password)
//这是重点,最近改版后
#自动输入密码后,需要手动点击记住我
print("请点击登录界面:记住您的账号")
time.sleep(10)
#自动点击登录按钮登录
driver.find_element_by_xpath("./*//a[@class='btn_login']").click()
#用手机扫描二维码!
print("请用手机扫描二维码登录公众号")
time.sleep(20)
print("登录成功")
#重新加载公众号登录页面,登录后会显示公众号后台首页,从返回的内容中获取cookies信息
driver.get('/')
#获取cookies
cookie_items = driver.get_cookies()
#获取的cookies为列表形式,将cookies转换为json形式存放在名为cookie的本地文本中
对于 cookie_items 中的 cookie_item:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt','w+', encoding='utf-8') as f:
f.write(cookie_str)
print("Cookies 信息已保存在本地")
#抓取微信公众号文章并存入本地文本
def get_content(query):
#query 是要抓取的公众号名称
#公众号首页
url =''
#设置标题
标题 = {
"主机":"",
"用户代理": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
#读取上一步获取的cookie
with open('cookie.txt','r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
#登录后微信公众号首页url改为:/cgi-bin/home?t=home/index&lang=zh_CN&token=1849751598,获取token信息
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
#搜索微信公众号接口地址
search_url ='/cgi-bin/searchbiz?'
#搜索微信公众号接口需要传入的参数,共有三个变量:微信公众号token、随机数random、搜索微信公众号名称
query_id = {
'action':'search_biz',
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'查询':查询,
'开始':'0',
'计数':'5'
}
#打开搜索微信公众号接口地址,需要传入cookies、params、headers等相关参数信息
search_response = requests.get(search_url, cookies=cookies, headers=header, params=query_id)
#取搜索结果第一个公众号
lists = search_response.json().get('list')[0]
#获取这个公众号的fakeid,以后爬取公众号文章需要这个字段
fakeid = list.get('fakeid')
#微信公众号文章界面地址
appmsg_url ='/cgi-bin/appmsg?'
#搜索文章需要传入几个参数:登录的公众号token、爬取文章的fakeid公众号、随机数random
query_id_data = {
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'action':'list_ex',
'begin': '0',#不同的页面,这个参数改变,改变规则是每页加5
'计数':'5',
'查询':'',
'fakeid':fakeid,
'类型':'9'
}
#打开搜索到的微信公众号文章list页面
appmsg_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
#Get 文章total number
max_num = appmsg_response.json().get('app_msg_cnt')
#每页至少有5个条目,获取文章页总数,爬取时需要页面爬取
num = int(int(max_num) / 5)
#起始页begin参数,后续每页加5
开始 = 0
当 num + 1> 0 :
query_id_data = {
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'action':'list_ex',
'begin':'{}'.format(str(begin)),
'计数':'5',
'查询':'',
'fakeid':fakeid,
'类型':'9'
}
print('翻页:--------------',begin)
#获取文章每个页面的标题和链接地址,写入本地文本
query_fakeid_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
对于 fakeid_list 中的项目:
content_link=item.get('link')
content_title=item.get('title')
fileName=query+'.txt'
with open(fileName,'a',encoding='utf-8') as fh:
fh.write(content_title+":\n"+content_link+"\n")
数量 -= 1
begin = int(begin)
开始+=5
time.sleep(2)
如果 __name__=='__main__':
试试:
#登录微信公众号,登录后获取cookie信息,保存在本地文本
weChat_login()
#登录后使用微信公众号文章interface爬取文章
在 gzlist 中查询:
#抓取微信公众号文章并存入本地文本
刷新搜狗微信公众号文章列表列表的步骤暂时不知道
采集交流 • 优采云 发表了文章 • 0 个评论 • 260 次浏览 • 2021-06-08 02:48
最近有采集微信公号文章的需求,所以研究了一下。我发现在刷新搜狗微信公众号文章列表的时候,有一个很恶心的地方就是搜狗会直接屏蔽你的ip并输入验证码。这一步暂时不知道怎么破解。我们只是看php采集微信公号文章内容的方法。至于list地址的获取,我们以后再研究。
在写之前,我搜索了三个用php编写的爬虫:phpQuery、phpspider和QueryList(phpQuery的改进版)。可能不止这些,这就是我发现的。先记录,后研究。
以下是我写的一个基本的微信公众号php采集类,有待进一步完善。
/**
* Created by PhpStorm.
* User: Administrator
* Date: 2017/2/6
* Time: 10:54
* author: gm
* 微信公众号文章采集类
*/
class DownWxArticle {
private $mpwxurl = 'http://mp.weixin.qq.com';
private $wxgzherr= '公众号二维码下载失败=>';
private $wximgerr= '图片下载失败=>';
private $direrr = '文件夹创建失败!';
private $fileerr = '资源不存在!';
private $dirurl = '';
/* 抓取微信公众号文章
* $qcode boolean 公众号二维码 false=>不下载 true=>下载
* return
* $content string 内容
* $tile string 标题
* $time int 时间戳
* $wxggh string 微信公众号
* $wxh string 微信号
* $qcode string 公众号二维码
* $tag string 标签 原创
*/
function get_file_article($url,$dir='',$qcode=false)
{
$this->dirurl = $dir?:'/Uploads/'.date('Ymd',time());
if(!$this->put_dir($this->dirurl)){
exit(json_encode(array('msg'=>$this->direrr,'code'=>500)));
}
$file = file_get_contents($url);
if(!$file){
$this->put_error_log($this->dirurl,$this->fileerr);
exit(json_encode(array('msg'=>$this->fileerr,'code'=>500)));
}
// 内容主体
preg_match('/[sS]*?/',$file,$content);
// 标题
preg_match('/(.*?)/',$file,$title);
$title = $title?$title[1]:'';
// 时间
preg_match('/(.*?)/',$file,$time);
$time = $time?strtotime($time[1]):'';
// 公众号
preg_match('/(.*?)</a>/',$file,$wxgzh);
$wxgzh = $wxgzh?$wxgzh[1]:'';
// 微信号
preg_match('/([sS]*?)/',$file,$wxh);
$wxh = $wxh?$wxh[1]:'';
// 公众号二维码
if($qcode){
preg_match('/window.sg_qr_code="(.*?)";/',$file,$qcode);
$qcodeurl = str_replace('x26amp;','&',$this->mpwxurl.$qcode[1]);
$qcode = $this->put_file_img($this->dirurl,$qcodeurl);
if(!$qcode){
$this->put_error_log($this->dirurl,$this->wxgzherr.$qcodeurl);
}
}
// 获取标签
preg_match('/(.*?)/',$file,$tag);
$tag = $tag?$tag[1]:'';
// 图片
preg_match_all('//',$content[0],$images);
// 储存原地址和下载后地址
$old = array();
$new = array();
// 去除重复图片地址
$images = array_unique($images[1]);
if($images){
foreach($images as $v){
$filename = $this->put_file_img($this->dirurl,$v);
if($filename){
// 图片保存成功 替换地址
$old[] = $v;
$new[] = $filename;
}else{
// 失败记录日志
$this->put_error_log($this->dirurl,$this->wximgerr.$v);
}
}
$old[] = 'data-src';
$new[] = 'src';
$content = str_replace($old,$new,$content[0]);
}
// 替换音频
$content = str_replace("preview.html","player.html",$content);
// 获取阅读点赞评论等信息
$comment = $this->get_comment_article($url);
$data = array('content'=>$content,'title'=>$title,'time'=>$time,'wxgzh'=>$wxgzh,'wxh'=>$wxh,'qcode'=>$qcode?:'','tag'=>$tag?:'','comment'=>$comment);
return json_encode(array('data'=>$data,'code'=>200,'msg'=>'ok'));
}
/* 抓取保存图片函数
* return
* $filename string 图片地址
*/
function put_file_img($dir='',$image='')
{
// 判断图片的保存类型 截取后四位地址
$exts = array('jpeg','png','jpg');
$filename = $dir.'/'.uniqid().time().rand(10000,99999);
$ext = substr($image,-5);
$ext = explode('=',$ext);
if(in_array($ext[1],$exts) !== false){
$filename .= '.'.$ext[1];
}else{
$filename .= '.gif';
}
$souce = file_get_contents($image);
if(file_put_contents($filename,$souce)){
return $filename;
}else{
return false;
}
}
/* 获取微信公众号文章的【点赞】【阅读】【评论】
* 方法:将地址中的部分参数替换即可。
* 1、s? 替换为 mp/getcomment?
* 2、最后= 替换为 %3D
* return
* read_num 阅读数
* like_num 点赞数
* comment 评论详情
*/
function get_comment_article($url='')
{
$url = substr($url,0,-1);
$url = str_replace('/s','/mp/getcomment',$url).'%3D';
return file_get_contents($url);
}
/* 错误日志记录
* $dir string 文件路径
* $data string 写入内容
*/
function put_error_log($dir,$data)
{
file_put_contents($dir.'/error.log',date('Y-m-d H:i:s',time()).$data.PHP_EOL,FILE_APPEND);
}
/* 创建文件夹
* $dir string 文件夹路径
*/
function put_dir($dir=''){
$bool = true;
if(!is_dir($dir)){
if(!mkdir($dir,777,TRUE)){
$bool = false;
$this->put_error_log($dir,$this->direrr.$dir);
}
}
return $bool;
}
}
使用方法:
$url = '';
$article = new DownWxArticle();
$article->get_file_article($url,'',true); 查看全部
刷新搜狗微信公众号文章列表列表的步骤暂时不知道
最近有采集微信公号文章的需求,所以研究了一下。我发现在刷新搜狗微信公众号文章列表的时候,有一个很恶心的地方就是搜狗会直接屏蔽你的ip并输入验证码。这一步暂时不知道怎么破解。我们只是看php采集微信公号文章内容的方法。至于list地址的获取,我们以后再研究。
在写之前,我搜索了三个用php编写的爬虫:phpQuery、phpspider和QueryList(phpQuery的改进版)。可能不止这些,这就是我发现的。先记录,后研究。
以下是我写的一个基本的微信公众号php采集类,有待进一步完善。
/**
* Created by PhpStorm.
* User: Administrator
* Date: 2017/2/6
* Time: 10:54
* author: gm
* 微信公众号文章采集类
*/
class DownWxArticle {
private $mpwxurl = 'http://mp.weixin.qq.com';
private $wxgzherr= '公众号二维码下载失败=>';
private $wximgerr= '图片下载失败=>';
private $direrr = '文件夹创建失败!';
private $fileerr = '资源不存在!';
private $dirurl = '';
/* 抓取微信公众号文章
* $qcode boolean 公众号二维码 false=>不下载 true=>下载
* return
* $content string 内容
* $tile string 标题
* $time int 时间戳
* $wxggh string 微信公众号
* $wxh string 微信号
* $qcode string 公众号二维码
* $tag string 标签 原创
*/
function get_file_article($url,$dir='',$qcode=false)
{
$this->dirurl = $dir?:'/Uploads/'.date('Ymd',time());
if(!$this->put_dir($this->dirurl)){
exit(json_encode(array('msg'=>$this->direrr,'code'=>500)));
}
$file = file_get_contents($url);
if(!$file){
$this->put_error_log($this->dirurl,$this->fileerr);
exit(json_encode(array('msg'=>$this->fileerr,'code'=>500)));
}
// 内容主体
preg_match('/[sS]*?/',$file,$content);
// 标题
preg_match('/(.*?)/',$file,$title);
$title = $title?$title[1]:'';
// 时间
preg_match('/(.*?)/',$file,$time);
$time = $time?strtotime($time[1]):'';
// 公众号
preg_match('/(.*?)</a>/',$file,$wxgzh);
$wxgzh = $wxgzh?$wxgzh[1]:'';
// 微信号
preg_match('/([sS]*?)/',$file,$wxh);
$wxh = $wxh?$wxh[1]:'';
// 公众号二维码
if($qcode){
preg_match('/window.sg_qr_code="(.*?)";/',$file,$qcode);
$qcodeurl = str_replace('x26amp;','&',$this->mpwxurl.$qcode[1]);
$qcode = $this->put_file_img($this->dirurl,$qcodeurl);
if(!$qcode){
$this->put_error_log($this->dirurl,$this->wxgzherr.$qcodeurl);
}
}
// 获取标签
preg_match('/(.*?)/',$file,$tag);
$tag = $tag?$tag[1]:'';
// 图片
preg_match_all('//',$content[0],$images);
// 储存原地址和下载后地址
$old = array();
$new = array();
// 去除重复图片地址
$images = array_unique($images[1]);
if($images){
foreach($images as $v){
$filename = $this->put_file_img($this->dirurl,$v);
if($filename){
// 图片保存成功 替换地址
$old[] = $v;
$new[] = $filename;
}else{
// 失败记录日志
$this->put_error_log($this->dirurl,$this->wximgerr.$v);
}
}
$old[] = 'data-src';
$new[] = 'src';
$content = str_replace($old,$new,$content[0]);
}
// 替换音频
$content = str_replace("preview.html","player.html",$content);
// 获取阅读点赞评论等信息
$comment = $this->get_comment_article($url);
$data = array('content'=>$content,'title'=>$title,'time'=>$time,'wxgzh'=>$wxgzh,'wxh'=>$wxh,'qcode'=>$qcode?:'','tag'=>$tag?:'','comment'=>$comment);
return json_encode(array('data'=>$data,'code'=>200,'msg'=>'ok'));
}
/* 抓取保存图片函数
* return
* $filename string 图片地址
*/
function put_file_img($dir='',$image='')
{
// 判断图片的保存类型 截取后四位地址
$exts = array('jpeg','png','jpg');
$filename = $dir.'/'.uniqid().time().rand(10000,99999);
$ext = substr($image,-5);
$ext = explode('=',$ext);
if(in_array($ext[1],$exts) !== false){
$filename .= '.'.$ext[1];
}else{
$filename .= '.gif';
}
$souce = file_get_contents($image);
if(file_put_contents($filename,$souce)){
return $filename;
}else{
return false;
}
}
/* 获取微信公众号文章的【点赞】【阅读】【评论】
* 方法:将地址中的部分参数替换即可。
* 1、s? 替换为 mp/getcomment?
* 2、最后= 替换为 %3D
* return
* read_num 阅读数
* like_num 点赞数
* comment 评论详情
*/
function get_comment_article($url='')
{
$url = substr($url,0,-1);
$url = str_replace('/s','/mp/getcomment',$url).'%3D';
return file_get_contents($url);
}
/* 错误日志记录
* $dir string 文件路径
* $data string 写入内容
*/
function put_error_log($dir,$data)
{
file_put_contents($dir.'/error.log',date('Y-m-d H:i:s',time()).$data.PHP_EOL,FILE_APPEND);
}
/* 创建文件夹
* $dir string 文件夹路径
*/
function put_dir($dir=''){
$bool = true;
if(!is_dir($dir)){
if(!mkdir($dir,777,TRUE)){
$bool = false;
$this->put_error_log($dir,$this->direrr.$dir);
}
}
return $bool;
}
}
使用方法:
$url = '';
$article = new DownWxArticle();
$article->get_file_article($url,'',true);
微信公众号历史消息页面的链接地址将持续更新
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-06-05 23:10
我从2014年开始做微信公众号内容的批量采集,最初的目的是为了制造一个html5垃圾邮件网站。当时垃圾站采集到达的微信公众号的内容很容易在公众号传播。当时批量采集特别好做,采集入口就是公众号的历史新闻页面。这个条目现在是一样的,但越来越难采集。 采集 方法也在很多版本中进行了更新。后来到了2015年,html5垃圾站就不做了。取而代之的是采集目标针对本地新闻资讯公众号,前端展示被做成了一个app。于是一个可以自动采集公号内容的新闻APP就形成了。曾经担心微信技术升级一天后,采集内容不可用,我的新闻应用程序失败。但是随着微信的不断技术升级,采集方式也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集内容。所以今天整理了一下,决定写下采集方法。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,所见即所得。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新==========
现在根据不同的微信个人账号,会有两个不同的历史消息页面地址。下面是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。来看看可以正常显示内容的完整链接:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=;这4个参数。
__biz 是公众号的类似id的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
剩下的3个参数与用户id和tokenticket的含义有关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、A 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量采集测试的ios微信客户端崩溃率高于Android系统。为了降低成本,我使用了Android模拟器。
2、A微信个人号:对于采集内容,不仅需要一个微信客户端,还需要一个采集专用的微信个人号,因为这个微信号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体安装方法后面会详细介绍。
4、文章List分析入库系统:本人使用php语言编写,下面文章将详细介绍如何分析文章lists并建立采集queues实现批量采集内容.
步骤
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy、AnyProxy。这个软件的特点是可以获取https链接的内容。 2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、Install NodeJS
2、在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i;参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、Set proxy:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址就是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002,可以看到anyproxy的web界面。微信点击打开一个历史消息页面,然后在浏览器的web界面查看,历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到以/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件 rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请注意详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新==========
因为有两种页面格式,相同的页面格式总是在不同的微信账号中显示,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以按照从您自己的页面表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码就是利用anyproxy修改返回页面的内容,向页面注入脚本,将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p> 查看全部
微信公众号历史消息页面的链接地址将持续更新
我从2014年开始做微信公众号内容的批量采集,最初的目的是为了制造一个html5垃圾邮件网站。当时垃圾站采集到达的微信公众号的内容很容易在公众号传播。当时批量采集特别好做,采集入口就是公众号的历史新闻页面。这个条目现在是一样的,但越来越难采集。 采集 方法也在很多版本中进行了更新。后来到了2015年,html5垃圾站就不做了。取而代之的是采集目标针对本地新闻资讯公众号,前端展示被做成了一个app。于是一个可以自动采集公号内容的新闻APP就形成了。曾经担心微信技术升级一天后,采集内容不可用,我的新闻应用程序失败。但是随着微信的不断技术升级,采集方式也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集内容。所以今天整理了一下,决定写下采集方法。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,所见即所得。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新==========
现在根据不同的微信个人账号,会有两个不同的历史消息页面地址。下面是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。来看看可以正常显示内容的完整链接:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=;这4个参数。
__biz 是公众号的类似id的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
剩下的3个参数与用户id和tokenticket的含义有关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、A 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量采集测试的ios微信客户端崩溃率高于Android系统。为了降低成本,我使用了Android模拟器。
2、A微信个人号:对于采集内容,不仅需要一个微信客户端,还需要一个采集专用的微信个人号,因为这个微信号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体安装方法后面会详细介绍。
4、文章List分析入库系统:本人使用php语言编写,下面文章将详细介绍如何分析文章lists并建立采集queues实现批量采集内容.
步骤
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy、AnyProxy。这个软件的特点是可以获取https链接的内容。 2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、Install NodeJS
2、在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i;参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、Set proxy:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址就是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002,可以看到anyproxy的web界面。微信点击打开一个历史消息页面,然后在浏览器的web界面查看,历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到以/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件 rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请注意详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新==========
因为有两种页面格式,相同的页面格式总是在不同的微信账号中显示,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以按照从您自己的页面表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码就是利用anyproxy修改返回页面的内容,向页面注入脚本,将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p>
没有哪个app只投放广告这一块,就是朋友圈广告
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-06-01 00:03
querylist采集微信公众号文章数据,
没有哪个app只投放广告这一块。要看你投放的是什么app,投放的什么广告方式。不过确实有些app只投放广告不做自身品牌推广的。
我能想到的就是“seo+aso”
我能想到的就是朋友圈广告了,但是小游戏目前是做不了的,其他一些app广告的用户已经足够覆盖到的,甚至不需要推广,
楼上那位观点其实蛮对的。但是如果楼主只想看朋友圈广告。
app营销,广告营销,提高app商户知名度,变现,然后才是品牌推广。
朋友圈广告大品牌推广有效果,多数产品有10-50%roi。
相信这个问题目前大多数app都会存在这个疑问,对于初期手机广告市场最有效的推广方式之一就是朋友圈广告了。而对于app开发者来说选择合适的广告形式,选择靠谱的广告公司就尤为重要了。可以通过三个维度来考量广告推广的效果:广告覆盖人群精准、内容有趣与实用性、广告点击量广告覆盖人群越精准、内容有趣与实用性越好,而广告点击量越高,品牌知名度就越高。我司可根据以上方面定制出适合的朋友圈广告形式。
每个app推广方式不一样但都是通过一个渠道把你的产品推到目标用户群体中,所以不同的app推广方式也肯定不同,说到底还是选择适合自己的app推广渠道来实现转化率, 查看全部
没有哪个app只投放广告这一块,就是朋友圈广告
querylist采集微信公众号文章数据,
没有哪个app只投放广告这一块。要看你投放的是什么app,投放的什么广告方式。不过确实有些app只投放广告不做自身品牌推广的。
我能想到的就是“seo+aso”
我能想到的就是朋友圈广告了,但是小游戏目前是做不了的,其他一些app广告的用户已经足够覆盖到的,甚至不需要推广,
楼上那位观点其实蛮对的。但是如果楼主只想看朋友圈广告。
app营销,广告营销,提高app商户知名度,变现,然后才是品牌推广。
朋友圈广告大品牌推广有效果,多数产品有10-50%roi。
相信这个问题目前大多数app都会存在这个疑问,对于初期手机广告市场最有效的推广方式之一就是朋友圈广告了。而对于app开发者来说选择合适的广告形式,选择靠谱的广告公司就尤为重要了。可以通过三个维度来考量广告推广的效果:广告覆盖人群精准、内容有趣与实用性、广告点击量广告覆盖人群越精准、内容有趣与实用性越好,而广告点击量越高,品牌知名度就越高。我司可根据以上方面定制出适合的朋友圈广告形式。
每个app推广方式不一样但都是通过一个渠道把你的产品推到目标用户群体中,所以不同的app推广方式也肯定不同,说到底还是选择适合自己的app推广渠道来实现转化率,

