
querylist采集微信公众号文章
高蒙2017/02/0613:491.0w浏览0评论
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-08-27 04:04
首页 »PHP 笔记» 如何使用 php采集微信公号文章方法
如何使用php采集微信公号文章
高萌 2017/02/06 13:491.0w 浏览 0 条评论 PHP
最近有采集微信公号文章的需求,所以研究了一下。我发现在刷新搜狗微信公众号文章列表的时候,有一个很恶心的地方就是搜狗会直接屏蔽你的ip并输入验证码。这一步暂时不知道怎么破解。我们只是看php采集微信公号文章内容的方法。至于列表地址的获取,我们后面再研究。在写之前,我搜索了三个用php编写的爬虫:phpQuery、phpspider和QueryList(phpQuery的改进版)。可能不止这些,这就是我发现的。先记录,后研究。下面是我写的一个基本的微信公众号php采集类,是的
最近有采集微信官方号文章的需求,所以研究了一下。我发现在刷新搜狗微信公众号文章列表的时候,有一个很恶心的地方就是搜狗会直接屏蔽你的ip并输入验证码。这一步暂时不知道怎么破解。我们只是看php采集微信公号文章内容的方法。至于list地址的获取,我们以后再研究。
在写之前,我搜索了三个用php编写的爬虫:phpQuery、phpspider和QueryList(phpQuery的改进版本)。可能不止这些,这就是我发现的。先记录,后研究。
以下是我写的一个基本的微信公众号php采集类,有待进一步完善。
/**
* Created by PhpStorm.
* User: Administrator
* Date: 2017/2/6
* Time: 10:54
* author: gm
* 微信公众号文章采集类
*/
class DownWxArticle {
private $mpwxurl = 'http://mp.weixin.qq.com';
private $wxgzherr= '公众号二维码下载失败=>';
private $wximgerr= '图片下载失败=>';
private $direrr = '文件夹创建失败!';
private $fileerr = '资源不存在!';
private $dirurl = '';
/* 抓取微信公众号文章
* $qcode boolean 公众号二维码 false=>不下载 true=>下载
* return
* $content string 内容
* $tile string 标题
* $time int 时间戳
* $wxggh string 微信公众号
* $wxh string 微信号
* $qcode string 公众号二维码
* $tag string 标签 原创
*/
function get_file_article($url,$dir='',$qcode=false)
{
$this->dirurl = $dir?:'/Uploads/'.date('Ymd',time());
if(!$this->put_dir($this->dirurl)){
exit(json_encode(array('msg'=>$this->direrr,'code'=>500)));
}
$file = file_get_contents($url);
if(!$file){
$this->put_error_log($this->dirurl,$this->fileerr);
exit(json_encode(array('msg'=>$this->fileerr,'code'=>500)));
}
// 内容主体
preg_match('/[\s\S]*?/',$file,$content);
// 标题
preg_match('/(.*?)/',$file,$title);
$title = $title?$title[1]:'';
// 时间
preg_match('/(.*?)/',$file,$time);
$time = $time?strtotime($time[1]):'';
// 公众号
preg_match('/(.*?)/',$file,$wxgzh);
$wxgzh = $wxgzh?$wxgzh[1]:'';
// 微信号
preg_match('/([\s\S]*?)/',$file,$wxh);
$wxh = $wxh?$wxh[1]:'';
// 公众号二维码
if($qcode){
preg_match('/window.sg_qr_code="(.*?)";/',$file,$qcode);
$qcodeurl = str_replace('\x26amp;','&',$this->mpwxurl.$qcode[1]);
$qcode = $this->put_file_img($this->dirurl,$qcodeurl);
if(!$qcode){
$this->put_error_log($this->dirurl,$this->wxgzherr.$qcodeurl);
}
}
// 获取标签
preg_match('/(.*?)/',$file,$tag);
$tag = $tag?$tag[1]:'';
// 图片
preg_match_all('//',$content[0],$images);
// 储存原地址和下载后地址
$old = array();
$new = array();
// 去除重复图片地址
$images = array_unique($images[1]);
if($images){
foreach($images as $v){
$filename = $this->put_file_img($this->dirurl,$v);
if($filename){
// 图片保存成功 替换地址
$old[] = $v;
$new[] = $filename;
}else{
// 失败记录日志
$this->put_error_log($this->dirurl,$this->wximgerr.$v);
}
}
$old[] = 'data-src';
$new[] = 'src';
$content = str_replace($old,$new,$content[0]);
}
// 替换音频
$content = str_replace("preview.html","player.html",$content);
// 获取阅读点赞评论等信息
$comment = $this->get_comment_article($url);
$data = array('content'=>$content,'title'=>$title,'time'=>$time,'wxgzh'=>$wxgzh,'wxh'=>$wxh,'qcode'=>$qcode?:'','tag'=>$tag?:'','comment'=>$comment);
return json_encode(array('data'=>$data,'code'=>200,'msg'=>'ok'));
}
/* 抓取保存图片函数
* return
* $filename string 图片地址
*/
function put_file_img($dir='',$image='')
{
// 判断图片的保存类型 截取后四位地址
$exts = array('jpeg','png','jpg');
$filename = $dir.'/'.uniqid().time().rand(10000,99999);
$ext = substr($image,-5);
$ext = explode('=',$ext);
if(in_array($ext[1],$exts) !== false){
$filename .= '.'.$ext[1];
}else{
$filename .= '.gif';
}
$souce = file_get_contents($image);
if(file_put_contents($filename,$souce)){
return $filename;
}else{
return false;
}
}
/* 获取微信公众号文章的【点赞】【阅读】【评论】
* 方法:将地址中的部分参数替换即可。
* 1、s? 替换为 mp/getcomment?
* 2、最后= 替换为 %3D
* return
* read_num 阅读数
* like_num 点赞数
* comment 评论详情
*/
function get_comment_article($url='')
{
$url = substr($url,0,-1);
$url = str_replace('/s','/mp/getcomment',$url).'%3D';
return file_get_contents($url);
}
/* 错误日志记录
* $dir string 文件路径
* $data string 写入内容
*/
function put_error_log($dir,$data)
{
file_put_contents($dir.'/error.log',date('Y-m-d H:i:s',time()).$data.PHP_EOL,FILE_APPEND);
}
/* 创建文件夹
* $dir string 文件夹路径
*/
function put_dir($dir=''){
$bool = true;
if(!is_dir($dir)){
if(!mkdir($dir,777,TRUE)){
$bool = false;
$this->put_error_log($dir,$this->direrr.$dir);
}
}
return $bool;
}
}
使用方法:
$url = '';
$article = new DownWxArticle();
$article->get_file_article($url,'',true); 查看全部
高蒙2017/02/0613:491.0w浏览0评论
首页 »PHP 笔记» 如何使用 php采集微信公号文章方法
如何使用php采集微信公号文章
高萌 2017/02/06 13:491.0w 浏览 0 条评论 PHP
最近有采集微信公号文章的需求,所以研究了一下。我发现在刷新搜狗微信公众号文章列表的时候,有一个很恶心的地方就是搜狗会直接屏蔽你的ip并输入验证码。这一步暂时不知道怎么破解。我们只是看php采集微信公号文章内容的方法。至于列表地址的获取,我们后面再研究。在写之前,我搜索了三个用php编写的爬虫:phpQuery、phpspider和QueryList(phpQuery的改进版)。可能不止这些,这就是我发现的。先记录,后研究。下面是我写的一个基本的微信公众号php采集类,是的
最近有采集微信官方号文章的需求,所以研究了一下。我发现在刷新搜狗微信公众号文章列表的时候,有一个很恶心的地方就是搜狗会直接屏蔽你的ip并输入验证码。这一步暂时不知道怎么破解。我们只是看php采集微信公号文章内容的方法。至于list地址的获取,我们以后再研究。
在写之前,我搜索了三个用php编写的爬虫:phpQuery、phpspider和QueryList(phpQuery的改进版本)。可能不止这些,这就是我发现的。先记录,后研究。
以下是我写的一个基本的微信公众号php采集类,有待进一步完善。
/**
* Created by PhpStorm.
* User: Administrator
* Date: 2017/2/6
* Time: 10:54
* author: gm
* 微信公众号文章采集类
*/
class DownWxArticle {
private $mpwxurl = 'http://mp.weixin.qq.com';
private $wxgzherr= '公众号二维码下载失败=>';
private $wximgerr= '图片下载失败=>';
private $direrr = '文件夹创建失败!';
private $fileerr = '资源不存在!';
private $dirurl = '';
/* 抓取微信公众号文章
* $qcode boolean 公众号二维码 false=>不下载 true=>下载
* return
* $content string 内容
* $tile string 标题
* $time int 时间戳
* $wxggh string 微信公众号
* $wxh string 微信号
* $qcode string 公众号二维码
* $tag string 标签 原创
*/
function get_file_article($url,$dir='',$qcode=false)
{
$this->dirurl = $dir?:'/Uploads/'.date('Ymd',time());
if(!$this->put_dir($this->dirurl)){
exit(json_encode(array('msg'=>$this->direrr,'code'=>500)));
}
$file = file_get_contents($url);
if(!$file){
$this->put_error_log($this->dirurl,$this->fileerr);
exit(json_encode(array('msg'=>$this->fileerr,'code'=>500)));
}
// 内容主体
preg_match('/[\s\S]*?/',$file,$content);
// 标题
preg_match('/(.*?)/',$file,$title);
$title = $title?$title[1]:'';
// 时间
preg_match('/(.*?)/',$file,$time);
$time = $time?strtotime($time[1]):'';
// 公众号
preg_match('/(.*?)/',$file,$wxgzh);
$wxgzh = $wxgzh?$wxgzh[1]:'';
// 微信号
preg_match('/([\s\S]*?)/',$file,$wxh);
$wxh = $wxh?$wxh[1]:'';
// 公众号二维码
if($qcode){
preg_match('/window.sg_qr_code="(.*?)";/',$file,$qcode);
$qcodeurl = str_replace('\x26amp;','&',$this->mpwxurl.$qcode[1]);
$qcode = $this->put_file_img($this->dirurl,$qcodeurl);
if(!$qcode){
$this->put_error_log($this->dirurl,$this->wxgzherr.$qcodeurl);
}
}
// 获取标签
preg_match('/(.*?)/',$file,$tag);
$tag = $tag?$tag[1]:'';
// 图片
preg_match_all('//',$content[0],$images);
// 储存原地址和下载后地址
$old = array();
$new = array();
// 去除重复图片地址
$images = array_unique($images[1]);
if($images){
foreach($images as $v){
$filename = $this->put_file_img($this->dirurl,$v);
if($filename){
// 图片保存成功 替换地址
$old[] = $v;
$new[] = $filename;
}else{
// 失败记录日志
$this->put_error_log($this->dirurl,$this->wximgerr.$v);
}
}
$old[] = 'data-src';
$new[] = 'src';
$content = str_replace($old,$new,$content[0]);
}
// 替换音频
$content = str_replace("preview.html","player.html",$content);
// 获取阅读点赞评论等信息
$comment = $this->get_comment_article($url);
$data = array('content'=>$content,'title'=>$title,'time'=>$time,'wxgzh'=>$wxgzh,'wxh'=>$wxh,'qcode'=>$qcode?:'','tag'=>$tag?:'','comment'=>$comment);
return json_encode(array('data'=>$data,'code'=>200,'msg'=>'ok'));
}
/* 抓取保存图片函数
* return
* $filename string 图片地址
*/
function put_file_img($dir='',$image='')
{
// 判断图片的保存类型 截取后四位地址
$exts = array('jpeg','png','jpg');
$filename = $dir.'/'.uniqid().time().rand(10000,99999);
$ext = substr($image,-5);
$ext = explode('=',$ext);
if(in_array($ext[1],$exts) !== false){
$filename .= '.'.$ext[1];
}else{
$filename .= '.gif';
}
$souce = file_get_contents($image);
if(file_put_contents($filename,$souce)){
return $filename;
}else{
return false;
}
}
/* 获取微信公众号文章的【点赞】【阅读】【评论】
* 方法:将地址中的部分参数替换即可。
* 1、s? 替换为 mp/getcomment?
* 2、最后= 替换为 %3D
* return
* read_num 阅读数
* like_num 点赞数
* comment 评论详情
*/
function get_comment_article($url='')
{
$url = substr($url,0,-1);
$url = str_replace('/s','/mp/getcomment',$url).'%3D';
return file_get_contents($url);
}
/* 错误日志记录
* $dir string 文件路径
* $data string 写入内容
*/
function put_error_log($dir,$data)
{
file_put_contents($dir.'/error.log',date('Y-m-d H:i:s',time()).$data.PHP_EOL,FILE_APPEND);
}
/* 创建文件夹
* $dir string 文件夹路径
*/
function put_dir($dir=''){
$bool = true;
if(!is_dir($dir)){
if(!mkdir($dir,777,TRUE)){
$bool = false;
$this->put_error_log($dir,$this->direrr.$dir);
}
}
return $bool;
}
}
使用方法:
$url = '';
$article = new DownWxArticle();
$article->get_file_article($url,'',true);
微软翻译百度百科微信公众号文章文章内容内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-08-25 19:05
querylist采集微信公众号文章内容
1、文件查看txt文件。
2、输入requesturl地址参数。
3、按回车键。
自己在家做爬虫三个步骤:1.找两篇自己想要的文章,下载文章;2.把下载下来的文章全部request一次,再下载下一篇;3.批量处理所有的图片,并且命名为json参数,当然,其中还有一点机智。
百度,
...
-us/windows/hardware/msie/30.0.2015/scripts/jsdebug.conf
使用微软翻译百度百科微信公众号文章...
留意官方文档:微信公众号网页使用的数据接口都是有文档说明的。
以前用腾讯统计!
实践中,我这边通常是一次性request有几千的图片然后就writecode写入数据库。成功率在80%多。感觉更多还是和熟练程度有关吧。
官方有相关的文档,
微信公众号文章有很多参数组成比如说头图,公众号标题,注册时间,文章列表,是否包含广告字样等。微信公众号推送文章,首先第一步就是获取图片url,然后再查询请求,请求的参数就是公众号名称,文章文章标题,文章内容,原文链接,图片url等。 查看全部
微软翻译百度百科微信公众号文章文章内容内容
querylist采集微信公众号文章内容
1、文件查看txt文件。
2、输入requesturl地址参数。
3、按回车键。
自己在家做爬虫三个步骤:1.找两篇自己想要的文章,下载文章;2.把下载下来的文章全部request一次,再下载下一篇;3.批量处理所有的图片,并且命名为json参数,当然,其中还有一点机智。
百度,
...
-us/windows/hardware/msie/30.0.2015/scripts/jsdebug.conf
使用微软翻译百度百科微信公众号文章...
留意官方文档:微信公众号网页使用的数据接口都是有文档说明的。
以前用腾讯统计!
实践中,我这边通常是一次性request有几千的图片然后就writecode写入数据库。成功率在80%多。感觉更多还是和熟练程度有关吧。
官方有相关的文档,
微信公众号文章有很多参数组成比如说头图,公众号标题,注册时间,文章列表,是否包含广告字样等。微信公众号推送文章,首先第一步就是获取图片url,然后再查询请求,请求的参数就是公众号名称,文章文章标题,文章内容,原文链接,图片url等。
搜狗搜索采集公众号历史消息(图)问题解析
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-08-24 07:37
通过搜狗搜索采集公众号的历史记录存在一些问题:
1、有验证码;
2、历史消息列表只有最近10条群发消息;
3、文章地址有有效期;
4、据说批量采集需要改ip;
通过我之前的文章方法,没有出现这样的问题,虽然采集系统设置不像传统的采集器写规则爬行那么简单。但是batch采集构建一次后的效率还是可以的。而且采集的文章地址是永久有效的,你可以通过采集获取一个公众号的所有历史信息。
先从公众号文章的链接地址说起:
1、微信右上角菜单复制的链接地址:
2、从历史消息列表中获取的地址:
#wechat_redirect
3、完整真实地址:
%3D%3D&devicetype=iOS10.1.1&version=16050120&nettype=WIFI&fontScale=100&pass_ticket=FGRyGfXLPEa4AeOsIZu7KFJo6CiXOZex83Y5YBRglW4%3D&1w_head
以上三个地址是同一篇文章文章的地址,在不同位置获取时得到三个完全不同的结果。
和历史新闻页面一样,微信也有自动添加参数的机制。第一个地址是通过复制链接获得的,看起来像一个变相的代码。其实没用,我们不去想。第二个地址是通过上面文章介绍的方法从json文章历史消息列表中得到的链接地址,我们可以把这个地址保存到数据库中。然后就可以通过这个地址从服务器获取文章的内容了。第三个链接添加参数后,目的是让文章页面中的阅读js获取阅读和点赞的json结果。在我们之前的文章方法中,因为文章页面是由客户端打开显示的,因为有这些参数,文章页面中的js会自动获取阅读量,所以我们可以通过代理服务获取这个文章的阅读量。
本文章的内容是根据本专栏前面文章介绍的方法获得的大量微信文章,我们详细研究了如何获取文章内容和其他一些有用的信息。方法。
(文章list 保存在我的数据库中,一些字段)
1、Get文章源代码:
文章源代码可以通过php函数file_get_content()读入一个变量。因为微信文章的源码可以从浏览器打开,这里就不贴了,以免浪费页面空间。
2、源代码中的有用信息:
1)原创内容:
原创内容收录在一个标签中,通过php代码获取:
<p> 查看全部
搜狗搜索采集公众号历史消息(图)问题解析
通过搜狗搜索采集公众号的历史记录存在一些问题:
1、有验证码;
2、历史消息列表只有最近10条群发消息;
3、文章地址有有效期;
4、据说批量采集需要改ip;
通过我之前的文章方法,没有出现这样的问题,虽然采集系统设置不像传统的采集器写规则爬行那么简单。但是batch采集构建一次后的效率还是可以的。而且采集的文章地址是永久有效的,你可以通过采集获取一个公众号的所有历史信息。
先从公众号文章的链接地址说起:
1、微信右上角菜单复制的链接地址:
2、从历史消息列表中获取的地址:
#wechat_redirect
3、完整真实地址:
%3D%3D&devicetype=iOS10.1.1&version=16050120&nettype=WIFI&fontScale=100&pass_ticket=FGRyGfXLPEa4AeOsIZu7KFJo6CiXOZex83Y5YBRglW4%3D&1w_head
以上三个地址是同一篇文章文章的地址,在不同位置获取时得到三个完全不同的结果。
和历史新闻页面一样,微信也有自动添加参数的机制。第一个地址是通过复制链接获得的,看起来像一个变相的代码。其实没用,我们不去想。第二个地址是通过上面文章介绍的方法从json文章历史消息列表中得到的链接地址,我们可以把这个地址保存到数据库中。然后就可以通过这个地址从服务器获取文章的内容了。第三个链接添加参数后,目的是让文章页面中的阅读js获取阅读和点赞的json结果。在我们之前的文章方法中,因为文章页面是由客户端打开显示的,因为有这些参数,文章页面中的js会自动获取阅读量,所以我们可以通过代理服务获取这个文章的阅读量。
本文章的内容是根据本专栏前面文章介绍的方法获得的大量微信文章,我们详细研究了如何获取文章内容和其他一些有用的信息。方法。

(文章list 保存在我的数据库中,一些字段)
1、Get文章源代码:
文章源代码可以通过php函数file_get_content()读入一个变量。因为微信文章的源码可以从浏览器打开,这里就不贴了,以免浪费页面空间。
2、源代码中的有用信息:
1)原创内容:
原创内容收录在一个标签中,通过php代码获取:
<p>
querylist采集微信公众号文章文章的关键词解析服务参考
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-08-22 21:05
querylist采集微信公众号文章的关键词,并不完全是文章中的关键词,而是“信息流”里的一些包含公众号相关关键词的词。也就是你点开“信息流”,页面里会出现公众号文章的链接(你在输入框里输入关键词时,它并不要求你给文章添加关键词)。在在筛选出的链接页面的右上角,会看到一个蓝色方框的token,即唯一的权威token。
发现querylist的作用,关键词过滤,
querylist是一个文章关键词的数据库,通过文章标题点击querylist查看文章,
querylist提供了你所关注的文章的一些常见的关键词。关键词解析服务一般用于分发效果的衡量。有时可以通过监测关键词的变化情况进行分发的质量和效果的衡量。
分享querylist,供参考
querylist不能理解为链接数量,可以理解为你给这篇文章添加关键词时的“信息流”位置。
在文章详情页面的主图是一个唯一的query地址,在这个query地址下,又会有很多很多的文章在你的浏览过程中展示,每篇文章都是独立,不会共享id。在文章详情页面顶部的显示文章时,展示的query地址不只是显示文章这一个,每一篇文章会有不同的展示位置。而在文章详情页面中是所有显示的文章都要显示。因此,文章详情页只能展示这一篇文章,既可以链接到这一篇文章,也可以分别链接到n篇文章。
所以,当这一篇文章被多篇文章显示之后,说明这一篇没有被多篇文章展示,属于临时状态,过一段时间后,再重新搜索一遍它,再次确认被多篇文章展示过。所以,querylist不是文章数量,而是query地址。不能理解为链接数量。 查看全部
querylist采集微信公众号文章文章的关键词解析服务参考
querylist采集微信公众号文章的关键词,并不完全是文章中的关键词,而是“信息流”里的一些包含公众号相关关键词的词。也就是你点开“信息流”,页面里会出现公众号文章的链接(你在输入框里输入关键词时,它并不要求你给文章添加关键词)。在在筛选出的链接页面的右上角,会看到一个蓝色方框的token,即唯一的权威token。
发现querylist的作用,关键词过滤,
querylist是一个文章关键词的数据库,通过文章标题点击querylist查看文章,
querylist提供了你所关注的文章的一些常见的关键词。关键词解析服务一般用于分发效果的衡量。有时可以通过监测关键词的变化情况进行分发的质量和效果的衡量。
分享querylist,供参考
querylist不能理解为链接数量,可以理解为你给这篇文章添加关键词时的“信息流”位置。
在文章详情页面的主图是一个唯一的query地址,在这个query地址下,又会有很多很多的文章在你的浏览过程中展示,每篇文章都是独立,不会共享id。在文章详情页面顶部的显示文章时,展示的query地址不只是显示文章这一个,每一篇文章会有不同的展示位置。而在文章详情页面中是所有显示的文章都要显示。因此,文章详情页只能展示这一篇文章,既可以链接到这一篇文章,也可以分别链接到n篇文章。
所以,当这一篇文章被多篇文章显示之后,说明这一篇没有被多篇文章展示,属于临时状态,过一段时间后,再重新搜索一遍它,再次确认被多篇文章展示过。所以,querylist不是文章数量,而是query地址。不能理解为链接数量。
微信文章自动化爬取过程中出现的问题及解决办法!
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-08-21 03:30
实现功能
微信账号目前可以获取具体指标:biz、昵称、微信ID、头像、二维码、个人资料、认证、认证信息、账号主题、归属地等
WeChat文章目前可用的具体指标(包括但不限于):阅读数、点赞(浏览)数、评论内容和总评论数、正文内容、图片、视频地址、是否原创、永久链接原文等
实施技术和工具
经过大量长期测试,保证微信客户端采集300公众号每天文章数据稳定运行,不会被封号。如果您频繁访问微信公众号的历史消息页面,将被禁止24小时。
目前比较好的策略:访问文章页面后休眠5秒,访问微信公众号历史消息页面后休眠150秒。
微信购买渠道qq客服:1653925422 60元购买了一个非实名微信账号。购买账号后,不得添加好友,否则将被微信账号永久屏蔽为营销账号。仅用于访问微信。公众号文章不会被封。
详细设计
1、 先准备一批微信公众号biz,爬进redis队列。
数据库设计
两个redis消息队列
1、微信公众号业务队列待抓取
wechat_biz_quene list 先进先出队列
复制代码
2、获取的微信文章detail页面url队列用于遍历获取的历史文章对应的阅读、点赞、评论。
<p>2、在模拟器中打开微信atx框架,模拟点击要运行的第一个公众号拼接的历史消息界面,后续流程和数据流逻辑如下图所示 查看全部
微信文章自动化爬取过程中出现的问题及解决办法!
实现功能
微信账号目前可以获取具体指标:biz、昵称、微信ID、头像、二维码、个人资料、认证、认证信息、账号主题、归属地等
WeChat文章目前可用的具体指标(包括但不限于):阅读数、点赞(浏览)数、评论内容和总评论数、正文内容、图片、视频地址、是否原创、永久链接原文等
实施技术和工具
经过大量长期测试,保证微信客户端采集300公众号每天文章数据稳定运行,不会被封号。如果您频繁访问微信公众号的历史消息页面,将被禁止24小时。
目前比较好的策略:访问文章页面后休眠5秒,访问微信公众号历史消息页面后休眠150秒。
微信购买渠道qq客服:1653925422 60元购买了一个非实名微信账号。购买账号后,不得添加好友,否则将被微信账号永久屏蔽为营销账号。仅用于访问微信。公众号文章不会被封。
详细设计
1、 先准备一批微信公众号biz,爬进redis队列。
数据库设计
两个redis消息队列
1、微信公众号业务队列待抓取
wechat_biz_quene list 先进先出队列
复制代码
2、获取的微信文章detail页面url队列用于遍历获取的历史文章对应的阅读、点赞、评论。
<p>2、在模拟器中打开微信atx框架,模拟点击要运行的第一个公众号拼接的历史消息界面,后续流程和数据流逻辑如下图所示
jsonp对文本的post方式提供支持的querylist集合:xxxpost提交的请求
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-08-20 01:03
querylist采集微信公众号文章信息的querylist集合。请求url“/”返回querylist集合:xxxtitletextcontent\wx:href=''\wx:src=''\wx:msg=''\request'''url这个路径下,有“\\users\\{{username}}"”字段,记录的是用户信息如果请求的url不是users,请使用post方式发送请求,如果没有请求过,就直接返回请求头和文本。
表单域可以请求到文本。msg字段不支持enctype属性。jsonp对文本的post方式提供支持,通过参数可以获取具体内容,如果参数是一个multipart/form-data格式的字段则post传输的数据可以是post、get、head等。请求querylist集合格式url:xxxrequesturl:msg/{{username}}返回的querylist集合:xxxpost提交的请求的querylist集合:xxxmultipart/form-data提交的请求的表单数据格式:[xxx][{{username}}]dataheader限制:post以json格式请求时,请提供dataheader。
提交表单数据时,需要提供binding字段,详见表单提交-materialdesign总结book-home微信公众号图书分类:图书分类querylist集合:{{图书名}}|{{图书书架编号}}+{{isblank}}-{{isblank}}-{{username}}main-endmain-endlocation="/main/"launch-process10微信启动按钮,可以指定定位到相应的位置,注意不要跨域。 查看全部
jsonp对文本的post方式提供支持的querylist集合:xxxpost提交的请求
querylist采集微信公众号文章信息的querylist集合。请求url“/”返回querylist集合:xxxtitletextcontent\wx:href=''\wx:src=''\wx:msg=''\request'''url这个路径下,有“\\users\\{{username}}"”字段,记录的是用户信息如果请求的url不是users,请使用post方式发送请求,如果没有请求过,就直接返回请求头和文本。
表单域可以请求到文本。msg字段不支持enctype属性。jsonp对文本的post方式提供支持,通过参数可以获取具体内容,如果参数是一个multipart/form-data格式的字段则post传输的数据可以是post、get、head等。请求querylist集合格式url:xxxrequesturl:msg/{{username}}返回的querylist集合:xxxpost提交的请求的querylist集合:xxxmultipart/form-data提交的请求的表单数据格式:[xxx][{{username}}]dataheader限制:post以json格式请求时,请提供dataheader。
提交表单数据时,需要提供binding字段,详见表单提交-materialdesign总结book-home微信公众号图书分类:图书分类querylist集合:{{图书名}}|{{图书书架编号}}+{{isblank}}-{{isblank}}-{{username}}main-endmain-endlocation="/main/"launch-process10微信启动按钮,可以指定定位到相应的位置,注意不要跨域。
企业做好网络营销需要六大策略,你做对了吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-08-17 22:03
随着互联网的发展,越来越多的公司从事网络营销。之前也有一篇文章企业如何进行网络营销的文章(欢迎点击《企业做网络营销的六大策略》),但是很多企业都急于进入电商圈,有网络营销中的许多禁忌。网络营销要想成功,必须避免以下八个问题:
1、立即开始,没有任何计划
很多公司一开始对网络营销并没有一个清晰的认识。大多数企业的管理者意识到应该通过报纸、电视等媒体进行网络营销,通过朋友的介绍,或者业务员的鼓动,通过互联网扩大业务和销售。于是我立即安排人员联系制作网站,发布信息,投入线上推广。整个网络营销过程在没有任何计划的情况下展开。一段时间后,不仅没有效果,还失去了继续坚持网络营销的信心和兴趣,出现了公司退出公司宣布退出等悲剧。
众所周知,网络营销是一个“顶级”工程,涉及到很多方面。需要结合自身实际情况,有明确的企业定位。没有定位,就没有营销。然后,分析消费者的需求,制定周密、科学的计划以取得成功。从启动网站建设、企业信息发布,到制定推广预算、选择网络营销方式、安排专职网络营销推广、客服、文案等,一切工作安排到位,持之以恒,使公司的网络营销过程可以顺利进行。只有这样,才能为最终达到理想的网络营销效果打下基础。
2、营销型网站的建设强调设计和轻应用
打造企业网站是开展网络营销非常重要的一环,尤其是打造面向营销的网站。然而,事实上,大多数企业网站并没有在网络营销中发挥应有的作用。这与公司对网站construction的理解分不开。大多数公司认为网站是公司的网上形象,越漂亮越好。美术设计、Flash动画、企业形象成为企业最关注的领域。至于网站是否满足网络营销的需求,是否方便日后的功能添加或调整,暂不考虑。负责网站制作的服务事业部也盲目迎合公司喜好,在表现形式上下功夫,提高网站的建设成本,当然也不负责内部功能和营销应用.
网站construction 是服务于网络营销的需求,这个要明确。 网站施工要设计和应用并重。不仅要注重企业形象展示,还要明确网站的网络营销服务功能和流程,注重产品或服务展示、用户交互、信息检索、客户体验等方面的建设。 ,让网站更实用有效 和谐简单,让网站具有营销力、传播力和转化力。
3、盲目进行垃圾邮件营销、海量信息等
很多企业在面对网络营销时,都不知所措。许多公司选择向各种平台发送垃圾邮件或大量信息,例如 BBS 和博客。虽然短期内企业可以看到一些网络营销效果,比如网站访问量的增加等,但从长远来看,企业遭受的损失远远大于网络营销取得的效果.
一是企业形象受损。垃圾邮件深受网友的厌恶。大多数垃圾邮件都是企业诚信缺失、产品质量差,甚至恶意欺诈和非法产品。企业一旦与垃圾邮件相关联,其在消费者心目中的形象就会大打折扣。
其次,一旦企业习惯了这种低成本、自害的网络营销推广方式,一味追求低报酬、高回报的畸形网络营销产品,对投资回报缺乏正确认识,将难以接受真正健康有益的网络营销服务和产品,错失网络营销和企业发展的良机。企业要结合自身发展情况,有一套适合自己的推广渠道。
4、网络营销产品跟风买
目前,网络营销产品种类繁多,加上销售人员的聪明才智,企业在产品选择上有很多困惑。我们经常会发现,一旦某个行业的几家公司使用了某种网络营销产品,同行业的其他公司就会陆续购买。
很多网络营销服务商已经掌握了公司的购买和比较心理,通过行业客户会议、网络营销产品行业说明会等会议,充分发挥“客户见证”和“推荐”的作用。技能使企业能够削弱自己的判断力,跟随他人的选择,或者盲目竞争和购买。实践证明,适合你的产品才是好产品。跟风购买的网络营销产品往往不仅不是最合适的,而且由于过度使用,网络营销的效果越来越差。创业者要懂得放弃,学会选择。
5、利用搜索引擎竞拍产品,等待兔子
目前,谷歌、雅虎、百度等搜索引擎竞价产品是网络营销的主流产品,越来越多的企业选择搜索引擎竞价产品。大多数企业并不知道在购买了有竞争力的产品后,他们需要定期进行优化和维护,而只是等待客户上门。这种效果只会变得更糟。
搜索引擎竞价的效果是由很多因素组成的。日常消费预算、关键词上词数、报表分析等维护工作的好坏,将直接影响搜索引擎竞价产品的效果。企业在使用竞价产品时,不能坐以待毙,而应定期对其进行维护和优化。如果他们能把握“以用户体验为中心”的原则,努力提升用户的感受,网络营销的效果才能得到提升。 .
6、线上营销和线下营销完全分离
网络营销是整体营销战略的一部分,是实现企业销售和盈利的重要手段。需要线上线下有效结合才能取得显着效果。许多公司认为互联网只是一种媒介。即使他们已经实现了在线营销,他们也可以通过互联网推广他们的公司和产品,提高他们的品牌知名度和企业形象。这是一种不完整的网络营销意识。没有线下参与的网络营销不是真正的网络营销,难以达到“营销”和“销售”的终极目标。
其实,网络营销的作用远不止这些。对于线下体验较多的企业,要抓住线上宣传推广的作用,再线下提升客户体验,从而采集销售线索,挖掘潜在客户,线下与线上相结合,最终达成交易,并为企业创造利润。
7、信息采集方法一劳永逸
采集信息是一种流行的“网络营销方式”。许多网站通过编写程序或使用采集软件从其他网站那里抓取大量需要的网络信息来丰富他们的网站内容。这样,网站的内容快速丰富,搜索引擎收录页面的数量也可以快速增加,可以快速吸引访问者,增加流量。然而事实证明,没有成功的网站来自信息采集,成功的网络营销也没有那么简单。
Information采集可以采集到大量需要的信息,但信息质量参差不齐,大部分是互联网上重复性高的内容,对搜索引擎不起作用。对于用户来说,只是网站的另一个克隆,没有吸引力。对于网站内容的建设,企业还是要脚踏实地,做有自己特色和原创精神的内容,少积累多,用心培养忠实用户,丰富网站一些案例研究。 @的内容逐渐通向成功。
8、Background 数据,重统计多于分析
世界上有没有哪位创业者在进行网络营销时最不注重网络营销的效果?但在现实中,很多企业在对网络营销效果的评价中,大多偏重统计,忽视分析。在网络营销效果方面,网站的访问量和网站的排名是普遍关注的内容。用户回访率、用户来源分析、关键词分析等更深入的网络营销效果分析没有得到重视。
全面的网络营销效果评估应该包括网站访问量、用户粘性、来源分析、搜索引擎关键词效果分析、各种推广产品的应用效果分析。基于对用户信息等方面的分析,可以根据这些分析得出下一步网络营销工作的改进建议和方案。网络营销重统计,轻分析,无助于改善网络营销现状。
以上八家企业在网络营销中应注意的问题。大多数公司都出现了。我相信,如果每个创业者在开展网络营销时都细心、细心、用心,他一定会走向成功。当然,网络营销是一门深不可测的知识领域,更多的还是需要我们主动学习来充实自己的大脑,然后将更多的理论知识应用到实际的生活和工作中。更多网络营销的理论知识和操作技巧,欢迎关注山人资讯,教你如何进行高效的网络营销。
沉阳网站建筑、沉阳网站制作、沉阳微信小程序、沉阳互联网公司开发、沉阳工作网站、沉阳做网站、沉阳制造网站、沉阳网站保护、沉阳网站建筑公司,沉阳制作网页,辽宁网站建筑,辽宁网站设计,企业网站建筑,沉阳,沉阳手机网站,3G网站,手机网站制作,沉阳微信推广,沉阳微信营销,企业微信营销,沉阳微信公众平台营销,沉阳微信开发,沉阳微信公众平台,沉阳微信公众平台开发,沉阳微信自动回复,沉阳微信接入,沉阳微信平台接入,沉阳微信,沉阳Micro网站,沉阳商城开发,沉阳商城建设,沉阳3D打印机,沉阳3D打印服务,沉阳3D打印机 查看全部
企业做好网络营销需要六大策略,你做对了吗?
随着互联网的发展,越来越多的公司从事网络营销。之前也有一篇文章企业如何进行网络营销的文章(欢迎点击《企业做网络营销的六大策略》),但是很多企业都急于进入电商圈,有网络营销中的许多禁忌。网络营销要想成功,必须避免以下八个问题:
1、立即开始,没有任何计划
很多公司一开始对网络营销并没有一个清晰的认识。大多数企业的管理者意识到应该通过报纸、电视等媒体进行网络营销,通过朋友的介绍,或者业务员的鼓动,通过互联网扩大业务和销售。于是我立即安排人员联系制作网站,发布信息,投入线上推广。整个网络营销过程在没有任何计划的情况下展开。一段时间后,不仅没有效果,还失去了继续坚持网络营销的信心和兴趣,出现了公司退出公司宣布退出等悲剧。
众所周知,网络营销是一个“顶级”工程,涉及到很多方面。需要结合自身实际情况,有明确的企业定位。没有定位,就没有营销。然后,分析消费者的需求,制定周密、科学的计划以取得成功。从启动网站建设、企业信息发布,到制定推广预算、选择网络营销方式、安排专职网络营销推广、客服、文案等,一切工作安排到位,持之以恒,使公司的网络营销过程可以顺利进行。只有这样,才能为最终达到理想的网络营销效果打下基础。
2、营销型网站的建设强调设计和轻应用
打造企业网站是开展网络营销非常重要的一环,尤其是打造面向营销的网站。然而,事实上,大多数企业网站并没有在网络营销中发挥应有的作用。这与公司对网站construction的理解分不开。大多数公司认为网站是公司的网上形象,越漂亮越好。美术设计、Flash动画、企业形象成为企业最关注的领域。至于网站是否满足网络营销的需求,是否方便日后的功能添加或调整,暂不考虑。负责网站制作的服务事业部也盲目迎合公司喜好,在表现形式上下功夫,提高网站的建设成本,当然也不负责内部功能和营销应用.
网站construction 是服务于网络营销的需求,这个要明确。 网站施工要设计和应用并重。不仅要注重企业形象展示,还要明确网站的网络营销服务功能和流程,注重产品或服务展示、用户交互、信息检索、客户体验等方面的建设。 ,让网站更实用有效 和谐简单,让网站具有营销力、传播力和转化力。
3、盲目进行垃圾邮件营销、海量信息等
很多企业在面对网络营销时,都不知所措。许多公司选择向各种平台发送垃圾邮件或大量信息,例如 BBS 和博客。虽然短期内企业可以看到一些网络营销效果,比如网站访问量的增加等,但从长远来看,企业遭受的损失远远大于网络营销取得的效果.
一是企业形象受损。垃圾邮件深受网友的厌恶。大多数垃圾邮件都是企业诚信缺失、产品质量差,甚至恶意欺诈和非法产品。企业一旦与垃圾邮件相关联,其在消费者心目中的形象就会大打折扣。
其次,一旦企业习惯了这种低成本、自害的网络营销推广方式,一味追求低报酬、高回报的畸形网络营销产品,对投资回报缺乏正确认识,将难以接受真正健康有益的网络营销服务和产品,错失网络营销和企业发展的良机。企业要结合自身发展情况,有一套适合自己的推广渠道。
4、网络营销产品跟风买
目前,网络营销产品种类繁多,加上销售人员的聪明才智,企业在产品选择上有很多困惑。我们经常会发现,一旦某个行业的几家公司使用了某种网络营销产品,同行业的其他公司就会陆续购买。
很多网络营销服务商已经掌握了公司的购买和比较心理,通过行业客户会议、网络营销产品行业说明会等会议,充分发挥“客户见证”和“推荐”的作用。技能使企业能够削弱自己的判断力,跟随他人的选择,或者盲目竞争和购买。实践证明,适合你的产品才是好产品。跟风购买的网络营销产品往往不仅不是最合适的,而且由于过度使用,网络营销的效果越来越差。创业者要懂得放弃,学会选择。
5、利用搜索引擎竞拍产品,等待兔子
目前,谷歌、雅虎、百度等搜索引擎竞价产品是网络营销的主流产品,越来越多的企业选择搜索引擎竞价产品。大多数企业并不知道在购买了有竞争力的产品后,他们需要定期进行优化和维护,而只是等待客户上门。这种效果只会变得更糟。
搜索引擎竞价的效果是由很多因素组成的。日常消费预算、关键词上词数、报表分析等维护工作的好坏,将直接影响搜索引擎竞价产品的效果。企业在使用竞价产品时,不能坐以待毙,而应定期对其进行维护和优化。如果他们能把握“以用户体验为中心”的原则,努力提升用户的感受,网络营销的效果才能得到提升。 .
6、线上营销和线下营销完全分离
网络营销是整体营销战略的一部分,是实现企业销售和盈利的重要手段。需要线上线下有效结合才能取得显着效果。许多公司认为互联网只是一种媒介。即使他们已经实现了在线营销,他们也可以通过互联网推广他们的公司和产品,提高他们的品牌知名度和企业形象。这是一种不完整的网络营销意识。没有线下参与的网络营销不是真正的网络营销,难以达到“营销”和“销售”的终极目标。
其实,网络营销的作用远不止这些。对于线下体验较多的企业,要抓住线上宣传推广的作用,再线下提升客户体验,从而采集销售线索,挖掘潜在客户,线下与线上相结合,最终达成交易,并为企业创造利润。
7、信息采集方法一劳永逸
采集信息是一种流行的“网络营销方式”。许多网站通过编写程序或使用采集软件从其他网站那里抓取大量需要的网络信息来丰富他们的网站内容。这样,网站的内容快速丰富,搜索引擎收录页面的数量也可以快速增加,可以快速吸引访问者,增加流量。然而事实证明,没有成功的网站来自信息采集,成功的网络营销也没有那么简单。
Information采集可以采集到大量需要的信息,但信息质量参差不齐,大部分是互联网上重复性高的内容,对搜索引擎不起作用。对于用户来说,只是网站的另一个克隆,没有吸引力。对于网站内容的建设,企业还是要脚踏实地,做有自己特色和原创精神的内容,少积累多,用心培养忠实用户,丰富网站一些案例研究。 @的内容逐渐通向成功。
8、Background 数据,重统计多于分析
世界上有没有哪位创业者在进行网络营销时最不注重网络营销的效果?但在现实中,很多企业在对网络营销效果的评价中,大多偏重统计,忽视分析。在网络营销效果方面,网站的访问量和网站的排名是普遍关注的内容。用户回访率、用户来源分析、关键词分析等更深入的网络营销效果分析没有得到重视。
全面的网络营销效果评估应该包括网站访问量、用户粘性、来源分析、搜索引擎关键词效果分析、各种推广产品的应用效果分析。基于对用户信息等方面的分析,可以根据这些分析得出下一步网络营销工作的改进建议和方案。网络营销重统计,轻分析,无助于改善网络营销现状。
以上八家企业在网络营销中应注意的问题。大多数公司都出现了。我相信,如果每个创业者在开展网络营销时都细心、细心、用心,他一定会走向成功。当然,网络营销是一门深不可测的知识领域,更多的还是需要我们主动学习来充实自己的大脑,然后将更多的理论知识应用到实际的生活和工作中。更多网络营销的理论知识和操作技巧,欢迎关注山人资讯,教你如何进行高效的网络营销。
沉阳网站建筑、沉阳网站制作、沉阳微信小程序、沉阳互联网公司开发、沉阳工作网站、沉阳做网站、沉阳制造网站、沉阳网站保护、沉阳网站建筑公司,沉阳制作网页,辽宁网站建筑,辽宁网站设计,企业网站建筑,沉阳,沉阳手机网站,3G网站,手机网站制作,沉阳微信推广,沉阳微信营销,企业微信营销,沉阳微信公众平台营销,沉阳微信开发,沉阳微信公众平台,沉阳微信公众平台开发,沉阳微信自动回复,沉阳微信接入,沉阳微信平台接入,沉阳微信,沉阳Micro网站,沉阳商城开发,沉阳商城建设,沉阳3D打印机,沉阳3D打印服务,沉阳3D打印机
shop_xiaohao001_关注shopx药店_karaoke_社区(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-08-16 04:02
querylist采集微信公众号文章,实现百度、头条等搜索引擎排名和微信搜索的推广。推广效果是电商数据里面永远的痛,只有做好开源节流才能有意想不到的收获。精准推广的本质,在于挖掘目标人群的需求。简单的理解有:做什么产品?买什么东西?购买什么产品?推广还是从人性上挖掘。微信里面,可以通过朋友圈、公众号推送、客服回复等方式,来获取目标人群的公众号信息,然后以公众号为依托,对文章进行推广。
推广效果==人群质量*转化率*精准度基于精准用户人群的分析和优化,达到排名和业绩上的提升。一、筛选目标用户维度包括:用户行为分析,文章发送时间、内容等信息目标用户人群的人物画像,标签,性别、年龄、职业等行为分析包括:用户特征、地域、兴趣爱好等内容,参考一下做的非常不错的文章,从标题到内容都是包装好的,你可以借鉴一下:shop_xiaohao001_关注shopx药店_karaoke_社区_b2c/?itemid=27613055_aw1b0_3ub45464ce7bd1347ee058&utm_source=toutiao-io&utm_medium=toutiao_android&utm_campaign=toutiao_android&utm_term=23&utm_division=zhihu&utm_content=shopx要学会分析用户的行为,用户的行为可以总结成为一些标签比如:停留时间,点赞、转发次数,互动频率...,每个标签通过爬虫抓取,然后组合起来得到最终的人群标签。
文章发送时间决定了有多少人看到你,文章发送时间点需要设置合理,这方面可以采用意图猜测这种方式来推测。根据转发次数,来推测是否有做公众号的推广等。意图猜测是采用用户反馈等第三方服务,比如:活动,促销等等有类似经验的人可以基于你的竞争对手总结出用户使用这个服务时的动机:定向活动推送,用户就会参与,会有转发、关注的动作。
有需求就会参与,有转发、关注、评论等行为才会有下单等一系列动作...分析用户行为,来获取目标人群的特征属性,整理出目标人群的特征集合,例如:男性/女性/地域/...,通过小卡片、二维码或者vip会员邀请码的方式来推送给用户,到点用户自动有收到。优质的内容,不局限于电商类,适合内容营销的有:小黄鸡、悟空问答、360热问、知乎问答等内容整理后再分享出去,简单干脆,有时候文章不吸引用户,可以想想是否是篇章长度的问题,可以从头开始写,随着用户阅读的情况来增加内容的字数,每篇分享的时间点不要超过100字,越简短越有力,时间点过长的文章会加长用户的阅读习惯,不利于用户转化。 查看全部
shop_xiaohao001_关注shopx药店_karaoke_社区(组图)
querylist采集微信公众号文章,实现百度、头条等搜索引擎排名和微信搜索的推广。推广效果是电商数据里面永远的痛,只有做好开源节流才能有意想不到的收获。精准推广的本质,在于挖掘目标人群的需求。简单的理解有:做什么产品?买什么东西?购买什么产品?推广还是从人性上挖掘。微信里面,可以通过朋友圈、公众号推送、客服回复等方式,来获取目标人群的公众号信息,然后以公众号为依托,对文章进行推广。
推广效果==人群质量*转化率*精准度基于精准用户人群的分析和优化,达到排名和业绩上的提升。一、筛选目标用户维度包括:用户行为分析,文章发送时间、内容等信息目标用户人群的人物画像,标签,性别、年龄、职业等行为分析包括:用户特征、地域、兴趣爱好等内容,参考一下做的非常不错的文章,从标题到内容都是包装好的,你可以借鉴一下:shop_xiaohao001_关注shopx药店_karaoke_社区_b2c/?itemid=27613055_aw1b0_3ub45464ce7bd1347ee058&utm_source=toutiao-io&utm_medium=toutiao_android&utm_campaign=toutiao_android&utm_term=23&utm_division=zhihu&utm_content=shopx要学会分析用户的行为,用户的行为可以总结成为一些标签比如:停留时间,点赞、转发次数,互动频率...,每个标签通过爬虫抓取,然后组合起来得到最终的人群标签。
文章发送时间决定了有多少人看到你,文章发送时间点需要设置合理,这方面可以采用意图猜测这种方式来推测。根据转发次数,来推测是否有做公众号的推广等。意图猜测是采用用户反馈等第三方服务,比如:活动,促销等等有类似经验的人可以基于你的竞争对手总结出用户使用这个服务时的动机:定向活动推送,用户就会参与,会有转发、关注的动作。
有需求就会参与,有转发、关注、评论等行为才会有下单等一系列动作...分析用户行为,来获取目标人群的特征属性,整理出目标人群的特征集合,例如:男性/女性/地域/...,通过小卡片、二维码或者vip会员邀请码的方式来推送给用户,到点用户自动有收到。优质的内容,不局限于电商类,适合内容营销的有:小黄鸡、悟空问答、360热问、知乎问答等内容整理后再分享出去,简单干脆,有时候文章不吸引用户,可以想想是否是篇章长度的问题,可以从头开始写,随着用户阅读的情况来增加内容的字数,每篇分享的时间点不要超过100字,越简短越有力,时间点过长的文章会加长用户的阅读习惯,不利于用户转化。
用Python将公众号中文章爬下来获取文章的html信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-08-16 01:21
用Python将公众号中文章爬下来获取文章的html信息
公众号里的文章一定是每一篇文章的必读。
有时候我们关注宝物类公众号,会发现它的历史文章有数百甚至数千篇文章,而作者只索引了他认为更好的几篇。太麻烦了。为了解决这类问题,我决定用Python爬下公众号文章。
基本思路爬取
文章crawling 我们使用公共平台的方式。这个方法虽然简单,但是我们需要有一个公众号。如果我们没有官方账号,我们可以自己注册一个。公众号的注册也比较简单。别说了。
首先登录您的公众号,然后依次进行以下操作
通过上面的操作,我们可以得到cookie等信息,我们先把cookie写入txt文件,实现代码如下:
# 从浏览器中复制出来的 cookie 字符串cookie_str = "自己的 cookie"cookie = {}# 遍历 cookiefor cookies in cookie_str.split("; "): cookie_item = cookies.split("=") cookie[cookie_item[0]] = cookie_item[1]# 将 cookie 写入 txt 文件with open('cookie.txt', "w") as file: file.write(json.dumps(cookie))
接下来我们获取公众号文章列表信息,代码实现如下:
with open("cookie.txt", "r") as file: cookie = file.read()cookies = json.loads(cookie)url = "https://mp.weixin.qq.com"response = requests.get(url, cookies=cookies)# 获取tokentoken = re.findall(r"token=(\d+)", str(response.url))[0]# 请求头信息headers = { "Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B + token + "&lang=zh_CN", "Host": "mp.weixin.qq.com", "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",}# 遍历指定页数的文章for i in range(1, 5, 1): begin = (i - 1) * 5 # 获取文章列表 requestUrl = "https://mp.weixin.qq.com/cgi-b ... 2Bstr(begin)+"&count=5&fakeid=要爬取公众号的fakeid&type=9&query=&token=" + token + "&lang=zh_CN&f=json&ajax=1" search_response = requests.get(requestUrl, cookies=cookies, headers=headers) # 获取 JSON 格式的列表信息 re_text = search_response.json() list = re_text.get("app_msg_list") # 遍历文章列表 for j in list: # 文章链接 url = j["link"] # 文章标题 title = j["title"] print(url) # 等待 8 秒,避免请求过于频繁 time.sleep(8)
保存
通过文章list信息,我们可以得到文章公众号的链接、标题等信息,然后我们可以根据文章使用微信模块获取文章html格式信息关联。模块安装使用pip install wechatsogou就可以了。
这里需要注意的是,我们通过微信模块获取的html信息会存在一些问题。有两个主要问题。一是文章的html信息不全,需要自己补;另一个得到。 html 信息中可能有一些 CSS 样式没有带过来。对于这个问题,我们可以先通过浏览器的开发者工具获取样式,然后手动添加。代码实现如下:
# url:文章链接,title:文章标题def save2html(url, title): # captcha_break_time 为验证码输入错误的重试次数,默认为 1 ws_api = wechatsogou.WechatSogouAPI(captcha_break_time = 3) content_info = ws_api.get_article_content(url) html = f''' {title} {title} {content_info['content_html']} ''' with open(title + '.html', "w", encoding="utf-8") as file: file.write('%s\n'%html)
上面代码中的my.css文件存储了一些没有带过来的CSS样式信息。
用浏览器打开公众号文章的html文件看看效果:
通过上面的显示结果可以看出,我们保存的html文件的显示效果还不错。
参考:
结束
查看全部
用Python将公众号中文章爬下来获取文章的html信息

公众号里的文章一定是每一篇文章的必读。
有时候我们关注宝物类公众号,会发现它的历史文章有数百甚至数千篇文章,而作者只索引了他认为更好的几篇。太麻烦了。为了解决这类问题,我决定用Python爬下公众号文章。
基本思路爬取
文章crawling 我们使用公共平台的方式。这个方法虽然简单,但是我们需要有一个公众号。如果我们没有官方账号,我们可以自己注册一个。公众号的注册也比较简单。别说了。
首先登录您的公众号,然后依次进行以下操作
通过上面的操作,我们可以得到cookie等信息,我们先把cookie写入txt文件,实现代码如下:
# 从浏览器中复制出来的 cookie 字符串cookie_str = "自己的 cookie"cookie = {}# 遍历 cookiefor cookies in cookie_str.split("; "): cookie_item = cookies.split("=") cookie[cookie_item[0]] = cookie_item[1]# 将 cookie 写入 txt 文件with open('cookie.txt', "w") as file: file.write(json.dumps(cookie))
接下来我们获取公众号文章列表信息,代码实现如下:
with open("cookie.txt", "r") as file: cookie = file.read()cookies = json.loads(cookie)url = "https://mp.weixin.qq.com"response = requests.get(url, cookies=cookies)# 获取tokentoken = re.findall(r"token=(\d+)", str(response.url))[0]# 请求头信息headers = { "Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B + token + "&lang=zh_CN", "Host": "mp.weixin.qq.com", "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",}# 遍历指定页数的文章for i in range(1, 5, 1): begin = (i - 1) * 5 # 获取文章列表 requestUrl = "https://mp.weixin.qq.com/cgi-b ... 2Bstr(begin)+"&count=5&fakeid=要爬取公众号的fakeid&type=9&query=&token=" + token + "&lang=zh_CN&f=json&ajax=1" search_response = requests.get(requestUrl, cookies=cookies, headers=headers) # 获取 JSON 格式的列表信息 re_text = search_response.json() list = re_text.get("app_msg_list") # 遍历文章列表 for j in list: # 文章链接 url = j["link"] # 文章标题 title = j["title"] print(url) # 等待 8 秒,避免请求过于频繁 time.sleep(8)
保存
通过文章list信息,我们可以得到文章公众号的链接、标题等信息,然后我们可以根据文章使用微信模块获取文章html格式信息关联。模块安装使用pip install wechatsogou就可以了。
这里需要注意的是,我们通过微信模块获取的html信息会存在一些问题。有两个主要问题。一是文章的html信息不全,需要自己补;另一个得到。 html 信息中可能有一些 CSS 样式没有带过来。对于这个问题,我们可以先通过浏览器的开发者工具获取样式,然后手动添加。代码实现如下:
# url:文章链接,title:文章标题def save2html(url, title): # captcha_break_time 为验证码输入错误的重试次数,默认为 1 ws_api = wechatsogou.WechatSogouAPI(captcha_break_time = 3) content_info = ws_api.get_article_content(url) html = f''' {title} {title} {content_info['content_html']} ''' with open(title + '.html', "w", encoding="utf-8") as file: file.write('%s\n'%html)
上面代码中的my.css文件存储了一些没有带过来的CSS样式信息。
用浏览器打开公众号文章的html文件看看效果:
通过上面的显示结果可以看出,我们保存的html文件的显示效果还不错。
参考:
结束

querylist采集微信公众号文章信息,关键字采集文章标题和文章大纲
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-08-15 23:10
querylist采集微信公众号文章信息,关键字采集公众号文章标题和文章大纲,再采集公众号用户数据,回流至redis,进行用户浏览记录存储,再与公众号以及用户数据进行相应匹配得到用户画像。
建议先去公众号关注一下,然后给公众号发送“查询”功能,就可以查到公众号标签下全部微信文章的标题、发布时间、阅读数、分享数、历史阅读量和转发量。
我在开发公众号的时候参考了一些文章中描述的,比如如果查询公众号里的某篇文章阅读次数,或者是历史消息数(微信的功能实现中,和历史消息之间的一定距离,微信会给出一个标记),或者是文章分享量等等。原理大致就是公众号要有一个redis服务端与公众号相对应(如果你的目的是简单查询公众号里内容的一个收藏功能,可以换成redisconnect),所以先解决你redis服务端如何与公众号服务端连接,然后再用服务端接口与session相互传递数据即可。
你可以先在公众号发布文章时,用代码获取到该公众号的用户,发送给redis去存储。至于以后使用,可以直接通过session去相互传递用户信息就可以了。
这位大神的文章!微信公众号公众号的数据存储机制是如何的?
公众号推送文章的时候,会在数据库中随机选取一条数据进行缓存,并且设置一个时间间隔来判断当前数据库的数据来源,缓存到数据库中的数据是定时更新的, 查看全部
querylist采集微信公众号文章信息,关键字采集文章标题和文章大纲
querylist采集微信公众号文章信息,关键字采集公众号文章标题和文章大纲,再采集公众号用户数据,回流至redis,进行用户浏览记录存储,再与公众号以及用户数据进行相应匹配得到用户画像。
建议先去公众号关注一下,然后给公众号发送“查询”功能,就可以查到公众号标签下全部微信文章的标题、发布时间、阅读数、分享数、历史阅读量和转发量。
我在开发公众号的时候参考了一些文章中描述的,比如如果查询公众号里的某篇文章阅读次数,或者是历史消息数(微信的功能实现中,和历史消息之间的一定距离,微信会给出一个标记),或者是文章分享量等等。原理大致就是公众号要有一个redis服务端与公众号相对应(如果你的目的是简单查询公众号里内容的一个收藏功能,可以换成redisconnect),所以先解决你redis服务端如何与公众号服务端连接,然后再用服务端接口与session相互传递数据即可。
你可以先在公众号发布文章时,用代码获取到该公众号的用户,发送给redis去存储。至于以后使用,可以直接通过session去相互传递用户信息就可以了。
这位大神的文章!微信公众号公众号的数据存储机制是如何的?
公众号推送文章的时候,会在数据库中随机选取一条数据进行缓存,并且设置一个时间间隔来判断当前数据库的数据来源,缓存到数据库中的数据是定时更新的,
一个好的公众号爬虫将内容抓取保存下来慢慢赏析
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-08-15 19:09
有时候我们会遇到一个很好的公众号,里面的每一篇文章都值得反复阅读。这时候我们就可以使用公众号爬虫抓取并保存内容,慢慢欣赏。
安装 Fiddler
Fiddler的下载地址为:安装完成后,确保手机和电脑的网络是同一个局域网。
Finder 配置
点击工具>>选项>>连接面板,参考下图配置,Fiddler的默认端口是8888,如果8888端口被占用,可以修改为其他端口。
点击工具>>选项>>HTTPS面板,参考下图进行配置
安卓手机配置
进入WLAN设置,选择当前局域网的WIFI设置,代理设置为手动,代理服务器主机名为Finder,右上角点击在线,端口号为8888。
在手机浏览器中访问配置的地址:8888,显示Fiddler Echo Service时,手机配置成功。
为了让 Finddler 拦截 HTTPS 请求,必须在手机中安装 CA 证书。在 :8888 中,单击 FiddlerRoot 证书下载并安装证书。至此配置工作完成。
微信历史页面
以【腾旭大神网】为例,点击【上海新闻】菜单的二级菜单【历史新闻】。
观察 Fiddler 的变化。此时,左侧窗口中会陆续出现多个URL连接地址。这是 Fiddler 截获的 Android 请求。
Result:服务器的响应结果 Protocol:请求协议,微信协议都是HTTPS,所以需要在手机和PC端安装证书。 HOST: 主机名 URL: URL 地址
以 .com/mp/profile_ext?action=home... 开头的 URL 之一正是我们所需要的。点击右侧的Inspectors面板,然后点击下方的Headers和WebView面板,会出现如下图案
标题面板
Request Headers:请求行,收录请求方法、请求地址、等待Client的请求协议、Cookies:请求头
WebView 面板
WebView面板显示服务器返回的HTML代码的渲染结果,Textview面板显示服务器返回的HTML源代码
获取历史页面
在上一节中,公众号消息历史页面已经可以在 Fiddler 的 WebView 面板中显示。本节使用Python抓取历史页面。创建一个名为wxcrawler.py的脚本,我们需要URL地址和HEADER请求头来抓取页面,直接从Finder中复制
将标头转换为 Json
# coding:utf-8
import requests
class WxCrawler(object):
# 复制出来的 Headers,注意这个 x-wechat-key,有时间限制,会过期。当返回的内容出现 验证 的情况,就需要换 x-wechat-key 了
headers = """Connection: keep-alive
x-wechat-uin: MTY4MTI3NDIxNg%3D%3D
x-wechat-key: 5ab2dd82e79bc5343ac5fb7fd20d72509db0ee1772b1043c894b24d441af288ae942feb4cfb4d234f00a4a5ab88c5b625d415b83df4b536d99befc096448d80cfd5a7fcd33380341aa592d070b1399a1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Linux; Android 10; GM1900 Build/QKQ1.190716.003; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/67.0.3396.87 XWEB/992 MMWEBSDK/191102 Mobile Safari/537.36 MMWEBID/7220 MicroMessenger/7.0.9.1560(0x27000933) Process/toolsmp NetType/WIFI Language/zh_CN ABI/arm64
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/wxpic,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,en-US;q=0.9
Cookie: wxuin=1681274216; devicetype=android-29; version=27000933; lang=zh_CN; pass_ticket=JvAJfzySl6uLWYdYwzyQ+4OqrqiZ2zfaI4F2OCVR7omYOmTjYNKalCFbr75X+T6K; rewardsn=; wxtokenkey=777; wap_sid2=COjq2KEGElxBTmotQWtVY2Iwb3BZRkIzd0Y0SnpaUG1HNTQ0SDA4UGJOZi1kaFdFbkl1MHUyYkRKX2xiWFU5VVhDNXBkQlY0U0pRXzlCZW9qZ29oYW9DWmZYOTdmQTBFQUFBfjD+hInvBTgNQJVO
X-Requested-With: com.tencent.mm"""
url = "https://mp.weixin.qq .com/mp/profile_ext?action=home&__biz=MjEwNDI4NTA2MQ==&scene=123&devicetype=android-29&version=27000933&lang=zh_CN&nettype=WIFI&a8scene=7&session_us=wxid_2574365742721&pass_ticket=JvAJfzySl6uLWYdYwzyQ%2B4OqrqiZ2zfaI4F2OCVR7omYOmTjYNKalCFbr75X%2BT6K&wx_header=1"
# 将 Headers 转换为 字典
def header_to_dict(self):
headers = self.headers.split("\n")
headers_dict = dict()
for h in headers:
k,v = h.split(":")
headers_dict[k.strip()] = v.strip()
return headers_dict;
def run(self):
headers = self.header_to_dict()
response = requests.get(self.url, headers=headers, verify=False)
print(response.text)
if __name__ == "__main__":
wx = WxCrawler()
wx.run()
下图是控制台打印的内容,其中JavaScript中变量msgList的值就是需要的内容
下一步是提取msgList的内容,使用正则表达式提取内容,返回一个文章list
import re
import html
import json
def article_list(self, context):
rex = "msgList = '({.*?})'"
pattern = re.compile(pattern=rex, flags=re.S)
match = pattern.search(context)
if match:
data = match.group(1)
data = html.unescape(data)
data = json.loads(data)
articles = data.get("list")
return articles
以下是解析msgList的结果
title:文章title content_url:文章link source_url:原链接,可能为空 摘要:摘要封面:封面图片 datetime:推送时间
其他内容存储在 multi_app_msg_item_list 中
{'comm_msg_info':
{
'id': 1000033457,
'type': 49,
'datetime': 1575101627,
'fakeid': '2104285061',
'status': 2,
'content': ''
},
'app_msg_ext_info':
{
'title': '快查手机!5000多张人脸照正被贱卖,数据曝光令人触目惊心!',
'digest': '谁有权收集人脸信息?',
'content': '',
'fileid': 0,
'content_url': 'http:\\/\\/mp.weixin.qq.com\\/s?__biz=MjEwNDI4NTA2MQ==&mid=2651824634&idx=1&sn=3e4c8eb35abb1b09a4077064ba0c44c8&chksm=4ea8211079dfa8065435409f4d3d3538ad28ddc197063a7e1820dafb9ee23beefca59c3b32d4&scene=27#wechat_redirect',
'source_url': '',
'cover': 'http:\\/\\/mmbiz.qpic.cn\\/mmbiz_jpg\\/G8vkERUJibkstwkIvXB960sMOyQdYF2x2qibTxAIq2eUljRbB6zqBq6ziaiaVqm8GtEWticE6zAYGUYqKJ3SMuvv1EQ\\/0?wx_fmt=jpeg',
'subtype': 9,
'is_multi': 1,
'multi_app_msg_item_list':
[{
'title': '先有鸡还是先有蛋?6.1亿年前的胚胎化石揭晓了',
'digest': '解决了困扰大申君20多年的问题',
'content': '',
'fileid': 0,
'content_url': 'http:\\/\\/mp.weixin.qq.com\\/s?__biz=MjEwNDI4NTA2MQ==&mid=2651824634&idx=2&sn=07b95d31efa9f56d460a16bca817f30d&chksm=4ea8211079dfa8068f42bf0e5df076a95ee3c24cab71294632fe587bcc9238c1a7fb7cd9629b&scene=27#wechat_redirect',
'source_url': '',
'cover': 'http:\\/\\/mmbiz.qpic.cn\\/mmbiz_jpg\\/yl6JkZAE3S92BESibpZgTPE1BcBhSLiaGOgpgVicaLdkIXGExe3mYdyVkE2SDXL1x2lFxldeXu8qXQYwtnx9vibibzQ\\/0?wx_fmt=jpeg',
'author': '',
'copyright_stat': 100,
'del_flag': 1,
'item_show_type': 0,
'audio_fileid': 0,
'duration': 0,
'play_url': '',
'malicious_title_reason_id': 0,
'malicious_content_type': 0
},
{
'title': '外交部惊现“李佳琦”!网友直呼:“OMG被种草了!”',
'digest': '种草了!',
'content': '', ...}
...]
获取单个页面
在上一节中,我们可以得到app_msg_ext_info中的content_url地址,需要从comm_msg_info的不规则Json中获取。这是使用demjson模块完成不规则的comm_msg_info。
安装 demjson 模块
pip3 install demjson
import demjson
# 获取单个文章的URL
content_url_array = []
def content_url(self, articles):
content_url = []
for a in articles:
a = str(a).replace("\/", "/")
a = demjson.decode(a)
content_url_array.append(a['app_msg_ext_info']["content_url"])
# 取更多的
for multi in a['app_msg_ext_info']["multi_app_msg_item_list"]:
self.content_url_array.append(multi['content_url'])
return content_url
获取单个文章的地址后,使用requests.get()函数获取HTML页面并解析
# 解析单个文章
def parse_article(self, headers, content_url):
for i in content_url:
content_response = requests.get(i, headers=headers, verify=False)
with open("wx.html", "wb") as f:
f.write(content_response.content)
html = open("wx.html", encoding="utf-8").read()
soup_body = BeautifulSoup(html, "html.parser")
context = soup_body.find('div', id = 'js_content').text.strip()
print(context)
所有历史文章
当你向下滑动历史消息时,出现Loading...这是公众号正在翻页的历史消息。查Fiddler,公众号请求的地址是.com/mp/profile_ext? action=getmsg&__biz...
翻页请求地址返回结果,一般可以分析。
ret:是否成功,0代表成功msg_count:每页的条目数 can_msg_continue:是否继续翻页,1代表继续翻页general_msg_list:数据,包括标题、文章地址等信息
def page(self, headers):
response = requests.get(self.page_url, headers=headers, verify=False)
result = response.json()
if result.get("ret") == 0:
msg_list = result.get("general_msg_list")
msg_list = demjson.decode(msg_list)
self.content_url(msg_list["list"])
#递归
self.page(headers)
else:
print("无法获取内容")
总结
这里已经爬取了公众号的内容,但尚未爬取单个文章的阅读和查看数量。想想看,如何抓取这些内容变化?
示例代码:
PS:公众号内回复:Python,可以进入Python新手学习交流群,一起
-END- 查看全部
一个好的公众号爬虫将内容抓取保存下来慢慢赏析
有时候我们会遇到一个很好的公众号,里面的每一篇文章都值得反复阅读。这时候我们就可以使用公众号爬虫抓取并保存内容,慢慢欣赏。
安装 Fiddler
Fiddler的下载地址为:安装完成后,确保手机和电脑的网络是同一个局域网。
Finder 配置
点击工具>>选项>>连接面板,参考下图配置,Fiddler的默认端口是8888,如果8888端口被占用,可以修改为其他端口。
点击工具>>选项>>HTTPS面板,参考下图进行配置
安卓手机配置
进入WLAN设置,选择当前局域网的WIFI设置,代理设置为手动,代理服务器主机名为Finder,右上角点击在线,端口号为8888。
在手机浏览器中访问配置的地址:8888,显示Fiddler Echo Service时,手机配置成功。
为了让 Finddler 拦截 HTTPS 请求,必须在手机中安装 CA 证书。在 :8888 中,单击 FiddlerRoot 证书下载并安装证书。至此配置工作完成。
微信历史页面
以【腾旭大神网】为例,点击【上海新闻】菜单的二级菜单【历史新闻】。
观察 Fiddler 的变化。此时,左侧窗口中会陆续出现多个URL连接地址。这是 Fiddler 截获的 Android 请求。
Result:服务器的响应结果 Protocol:请求协议,微信协议都是HTTPS,所以需要在手机和PC端安装证书。 HOST: 主机名 URL: URL 地址
以 .com/mp/profile_ext?action=home... 开头的 URL 之一正是我们所需要的。点击右侧的Inspectors面板,然后点击下方的Headers和WebView面板,会出现如下图案
标题面板
Request Headers:请求行,收录请求方法、请求地址、等待Client的请求协议、Cookies:请求头
WebView 面板
WebView面板显示服务器返回的HTML代码的渲染结果,Textview面板显示服务器返回的HTML源代码
获取历史页面
在上一节中,公众号消息历史页面已经可以在 Fiddler 的 WebView 面板中显示。本节使用Python抓取历史页面。创建一个名为wxcrawler.py的脚本,我们需要URL地址和HEADER请求头来抓取页面,直接从Finder中复制
将标头转换为 Json
# coding:utf-8
import requests
class WxCrawler(object):
# 复制出来的 Headers,注意这个 x-wechat-key,有时间限制,会过期。当返回的内容出现 验证 的情况,就需要换 x-wechat-key 了
headers = """Connection: keep-alive
x-wechat-uin: MTY4MTI3NDIxNg%3D%3D
x-wechat-key: 5ab2dd82e79bc5343ac5fb7fd20d72509db0ee1772b1043c894b24d441af288ae942feb4cfb4d234f00a4a5ab88c5b625d415b83df4b536d99befc096448d80cfd5a7fcd33380341aa592d070b1399a1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Linux; Android 10; GM1900 Build/QKQ1.190716.003; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/67.0.3396.87 XWEB/992 MMWEBSDK/191102 Mobile Safari/537.36 MMWEBID/7220 MicroMessenger/7.0.9.1560(0x27000933) Process/toolsmp NetType/WIFI Language/zh_CN ABI/arm64
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/wxpic,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,en-US;q=0.9
Cookie: wxuin=1681274216; devicetype=android-29; version=27000933; lang=zh_CN; pass_ticket=JvAJfzySl6uLWYdYwzyQ+4OqrqiZ2zfaI4F2OCVR7omYOmTjYNKalCFbr75X+T6K; rewardsn=; wxtokenkey=777; wap_sid2=COjq2KEGElxBTmotQWtVY2Iwb3BZRkIzd0Y0SnpaUG1HNTQ0SDA4UGJOZi1kaFdFbkl1MHUyYkRKX2xiWFU5VVhDNXBkQlY0U0pRXzlCZW9qZ29oYW9DWmZYOTdmQTBFQUFBfjD+hInvBTgNQJVO
X-Requested-With: com.tencent.mm"""
url = "https://mp.weixin.qq .com/mp/profile_ext?action=home&__biz=MjEwNDI4NTA2MQ==&scene=123&devicetype=android-29&version=27000933&lang=zh_CN&nettype=WIFI&a8scene=7&session_us=wxid_2574365742721&pass_ticket=JvAJfzySl6uLWYdYwzyQ%2B4OqrqiZ2zfaI4F2OCVR7omYOmTjYNKalCFbr75X%2BT6K&wx_header=1"
# 将 Headers 转换为 字典
def header_to_dict(self):
headers = self.headers.split("\n")
headers_dict = dict()
for h in headers:
k,v = h.split(":")
headers_dict[k.strip()] = v.strip()
return headers_dict;
def run(self):
headers = self.header_to_dict()
response = requests.get(self.url, headers=headers, verify=False)
print(response.text)
if __name__ == "__main__":
wx = WxCrawler()
wx.run()
下图是控制台打印的内容,其中JavaScript中变量msgList的值就是需要的内容
下一步是提取msgList的内容,使用正则表达式提取内容,返回一个文章list
import re
import html
import json
def article_list(self, context):
rex = "msgList = '({.*?})'"
pattern = re.compile(pattern=rex, flags=re.S)
match = pattern.search(context)
if match:
data = match.group(1)
data = html.unescape(data)
data = json.loads(data)
articles = data.get("list")
return articles
以下是解析msgList的结果
title:文章title content_url:文章link source_url:原链接,可能为空 摘要:摘要封面:封面图片 datetime:推送时间
其他内容存储在 multi_app_msg_item_list 中
{'comm_msg_info':
{
'id': 1000033457,
'type': 49,
'datetime': 1575101627,
'fakeid': '2104285061',
'status': 2,
'content': ''
},
'app_msg_ext_info':
{
'title': '快查手机!5000多张人脸照正被贱卖,数据曝光令人触目惊心!',
'digest': '谁有权收集人脸信息?',
'content': '',
'fileid': 0,
'content_url': 'http:\\/\\/mp.weixin.qq.com\\/s?__biz=MjEwNDI4NTA2MQ==&mid=2651824634&idx=1&sn=3e4c8eb35abb1b09a4077064ba0c44c8&chksm=4ea8211079dfa8065435409f4d3d3538ad28ddc197063a7e1820dafb9ee23beefca59c3b32d4&scene=27#wechat_redirect',
'source_url': '',
'cover': 'http:\\/\\/mmbiz.qpic.cn\\/mmbiz_jpg\\/G8vkERUJibkstwkIvXB960sMOyQdYF2x2qibTxAIq2eUljRbB6zqBq6ziaiaVqm8GtEWticE6zAYGUYqKJ3SMuvv1EQ\\/0?wx_fmt=jpeg',
'subtype': 9,
'is_multi': 1,
'multi_app_msg_item_list':
[{
'title': '先有鸡还是先有蛋?6.1亿年前的胚胎化石揭晓了',
'digest': '解决了困扰大申君20多年的问题',
'content': '',
'fileid': 0,
'content_url': 'http:\\/\\/mp.weixin.qq.com\\/s?__biz=MjEwNDI4NTA2MQ==&mid=2651824634&idx=2&sn=07b95d31efa9f56d460a16bca817f30d&chksm=4ea8211079dfa8068f42bf0e5df076a95ee3c24cab71294632fe587bcc9238c1a7fb7cd9629b&scene=27#wechat_redirect',
'source_url': '',
'cover': 'http:\\/\\/mmbiz.qpic.cn\\/mmbiz_jpg\\/yl6JkZAE3S92BESibpZgTPE1BcBhSLiaGOgpgVicaLdkIXGExe3mYdyVkE2SDXL1x2lFxldeXu8qXQYwtnx9vibibzQ\\/0?wx_fmt=jpeg',
'author': '',
'copyright_stat': 100,
'del_flag': 1,
'item_show_type': 0,
'audio_fileid': 0,
'duration': 0,
'play_url': '',
'malicious_title_reason_id': 0,
'malicious_content_type': 0
},
{
'title': '外交部惊现“李佳琦”!网友直呼:“OMG被种草了!”',
'digest': '种草了!',
'content': '', ...}
...]
获取单个页面
在上一节中,我们可以得到app_msg_ext_info中的content_url地址,需要从comm_msg_info的不规则Json中获取。这是使用demjson模块完成不规则的comm_msg_info。
安装 demjson 模块
pip3 install demjson
import demjson
# 获取单个文章的URL
content_url_array = []
def content_url(self, articles):
content_url = []
for a in articles:
a = str(a).replace("\/", "/")
a = demjson.decode(a)
content_url_array.append(a['app_msg_ext_info']["content_url"])
# 取更多的
for multi in a['app_msg_ext_info']["multi_app_msg_item_list"]:
self.content_url_array.append(multi['content_url'])
return content_url
获取单个文章的地址后,使用requests.get()函数获取HTML页面并解析
# 解析单个文章
def parse_article(self, headers, content_url):
for i in content_url:
content_response = requests.get(i, headers=headers, verify=False)
with open("wx.html", "wb") as f:
f.write(content_response.content)
html = open("wx.html", encoding="utf-8").read()
soup_body = BeautifulSoup(html, "html.parser")
context = soup_body.find('div', id = 'js_content').text.strip()
print(context)
所有历史文章
当你向下滑动历史消息时,出现Loading...这是公众号正在翻页的历史消息。查Fiddler,公众号请求的地址是.com/mp/profile_ext? action=getmsg&__biz...
翻页请求地址返回结果,一般可以分析。
ret:是否成功,0代表成功msg_count:每页的条目数 can_msg_continue:是否继续翻页,1代表继续翻页general_msg_list:数据,包括标题、文章地址等信息
def page(self, headers):
response = requests.get(self.page_url, headers=headers, verify=False)
result = response.json()
if result.get("ret") == 0:
msg_list = result.get("general_msg_list")
msg_list = demjson.decode(msg_list)
self.content_url(msg_list["list"])
#递归
self.page(headers)
else:
print("无法获取内容")
总结
这里已经爬取了公众号的内容,但尚未爬取单个文章的阅读和查看数量。想想看,如何抓取这些内容变化?
示例代码:
PS:公众号内回复:Python,可以进入Python新手学习交流群,一起
-END-
querylist采集微信公众号文章数据,其他对齐参数对店铺的处理思路
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-08-14 19:05
querylist采集微信公众号文章数据,其他对齐参数对店铺的公众号一样。2.重定向的处理思路是用jwttokenhttp/1.1,get/post的cookieheader分别替换成2.0\2.1\2.2的cookie,所以店铺公众号不用对齐参数直接对接会成功,要是客户端修改了店铺公众号的cookie则难通过querylist进行对齐;实际应用中要怎么操作对齐参数得根据实际需求而定。
支付宝和商户开放平台可以互通,要么通过浏览器,要么通过querylistapi;阿里云方案可能有问题(感觉没通过审核),最简单的就是通过collection,在api后面加参数querylist:[2.1]就是2.1的公众号端格式啊,
只能用querylist,不能用cookie,除非你写cookie主动对接。上alifixion通过客户端post获取cookie发送给公众号。前端通过网页版发送数据,要通过cookie统计,目前支付宝的e-cookie抓取控制还不够完善,有些数据抓取不到。所以只能用querylist。
看alibaba需求来,比如天猫要完全对接联盟,是要来回一个个查,如果只是对接个联盟,那么不需要做对齐。如果双方协议不一样,你想最终相互对齐,那么就要再配置一遍querylist。
从alib申请连接,按照常规请求都可以,顺便补充一下:querylist的数据结构是什么, 查看全部
querylist采集微信公众号文章数据,其他对齐参数对店铺的处理思路
querylist采集微信公众号文章数据,其他对齐参数对店铺的公众号一样。2.重定向的处理思路是用jwttokenhttp/1.1,get/post的cookieheader分别替换成2.0\2.1\2.2的cookie,所以店铺公众号不用对齐参数直接对接会成功,要是客户端修改了店铺公众号的cookie则难通过querylist进行对齐;实际应用中要怎么操作对齐参数得根据实际需求而定。
支付宝和商户开放平台可以互通,要么通过浏览器,要么通过querylistapi;阿里云方案可能有问题(感觉没通过审核),最简单的就是通过collection,在api后面加参数querylist:[2.1]就是2.1的公众号端格式啊,
只能用querylist,不能用cookie,除非你写cookie主动对接。上alifixion通过客户端post获取cookie发送给公众号。前端通过网页版发送数据,要通过cookie统计,目前支付宝的e-cookie抓取控制还不够完善,有些数据抓取不到。所以只能用querylist。
看alibaba需求来,比如天猫要完全对接联盟,是要来回一个个查,如果只是对接个联盟,那么不需要做对齐。如果双方协议不一样,你想最终相互对齐,那么就要再配置一遍querylist。
从alib申请连接,按照常规请求都可以,顺便补充一下:querylist的数据结构是什么,
一下如何使用Python构建一个个人微信公众号的电影搜索功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2021-08-11 06:02
今天介绍一下如何使用Python为个人微信公众号搭建电影搜索功能。本文文章将涉及:
要练习文章本文的所有内容,您需要拥有以下资源:
如果不使用注册的域名和个人微信公众号,可以申请微信官方平台测试号使用。流程类似,申请地址为:
现在我们开始输入文本。
1. 创建和部署 Django 应用程序
在这个个人公众号电影搜索器中,一个可靠的网络服务是连接电影资源数据和对接微信公众号的关键。电影资源爬取采集后,需要存入数据库。接收和回复还取决于 Web 应用程序提供的服务。所以我们首先需要创建一个 Web 应用程序。 Python中有许多Web框架。这里我们选择Django1.10,功能齐全,功能强大。没有安装Django的同学使用pip命令安装Django模块:
pip install django==1.10
1.1 创建 Django 项目
我们服务器上的当前目录如下所示:
使用Django的django-admin在这个目录下创建一个Django项目:
django-admin startproject wxmovie
这样我们的文件夹目录下多了一个叫wxmovie的文件夹,里面有一个manage.py文件和一个wxmovie文件夹:
1.2 创建 Django 应用程序
Django项目创建完成后,我们进入项目路径,使用其manage.py文件继续创建Django应用:
python3 manage.py startapp movie
此时wxmovie项目下多了一个名为movie的文件夹,里面收录了电影应用的所有文件:
1.3 配置 Django 项目
Django 项目-wxmovie 和它的应用影片创建完成后,让我们对这个项目做一些基本的配置。打开/wxmovie/wxmovie/目录下的settings.py文件。
将应用影片添加到 wxmovie 项目中:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'movie',
]
在项目根路径下创建一个名为template的文件夹作为django模板目录,并将此路径添加到TEMPLATES中:
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [
os.path.join(os.path.split(os.path.dirname(__file__))[0],'template'),
],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
修改项目的数据库配置为MySQL:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': '****',
'USER': '****',
'PASSWORD': '***',
'HOST': '',
'PORT': '3306',
}
}
修改项目时区的语言配置:
LANGUAGE_CODE = 'zh-hans'
TIME_ZONE = 'Asia/Shanghai'
因为我们使用的是Python3,所以需要在/wxmovie/wxmovie/目录下的\__init__.py文件中加入如下代码,这样我们才能在项目中使用MySQL(需要先安装pymysql模块): 查看全部
一下如何使用Python构建一个个人微信公众号的电影搜索功能
今天介绍一下如何使用Python为个人微信公众号搭建电影搜索功能。本文文章将涉及:
要练习文章本文的所有内容,您需要拥有以下资源:
如果不使用注册的域名和个人微信公众号,可以申请微信官方平台测试号使用。流程类似,申请地址为:
现在我们开始输入文本。
1. 创建和部署 Django 应用程序
在这个个人公众号电影搜索器中,一个可靠的网络服务是连接电影资源数据和对接微信公众号的关键。电影资源爬取采集后,需要存入数据库。接收和回复还取决于 Web 应用程序提供的服务。所以我们首先需要创建一个 Web 应用程序。 Python中有许多Web框架。这里我们选择Django1.10,功能齐全,功能强大。没有安装Django的同学使用pip命令安装Django模块:
pip install django==1.10
1.1 创建 Django 项目
我们服务器上的当前目录如下所示:

使用Django的django-admin在这个目录下创建一个Django项目:
django-admin startproject wxmovie

这样我们的文件夹目录下多了一个叫wxmovie的文件夹,里面有一个manage.py文件和一个wxmovie文件夹:

1.2 创建 Django 应用程序
Django项目创建完成后,我们进入项目路径,使用其manage.py文件继续创建Django应用:
python3 manage.py startapp movie

此时wxmovie项目下多了一个名为movie的文件夹,里面收录了电影应用的所有文件:

1.3 配置 Django 项目
Django 项目-wxmovie 和它的应用影片创建完成后,让我们对这个项目做一些基本的配置。打开/wxmovie/wxmovie/目录下的settings.py文件。
将应用影片添加到 wxmovie 项目中:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'movie',
]
在项目根路径下创建一个名为template的文件夹作为django模板目录,并将此路径添加到TEMPLATES中:
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [
os.path.join(os.path.split(os.path.dirname(__file__))[0],'template'),
],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
修改项目的数据库配置为MySQL:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': '****',
'USER': '****',
'PASSWORD': '***',
'HOST': '',
'PORT': '3306',
}
}
修改项目时区的语言配置:
LANGUAGE_CODE = 'zh-hans'
TIME_ZONE = 'Asia/Shanghai'
因为我们使用的是Python3,所以需要在/wxmovie/wxmovie/目录下的\__init__.py文件中加入如下代码,这样我们才能在项目中使用MySQL(需要先安装pymysql模块):
Q&;A(.39)模拟用户
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-08-09 03:29
一.Idea
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面图文
超链接
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.接口分析
微信公众号访问:
参数:
action=search_biz
开始=0
计数=5
query=官方账号
token=每个账户对应的token值
lang=zh_CN
f=json
ajax=1
请求方法:
获取
所以在这个界面我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。
微信公众号
获取公众号对应的文章界面:
参数:
action=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
type=9
查询=
令牌=557131216
lang=zh_CN
f=json
ajax=1
请求方法:
获取
我们需要在这个接口中获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
微信公众号
三.实现
第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
浏览器 = webdriver.Chrome()
browser.get('#39;)
睡觉(3)
browser.delete_all_cookies()
睡觉(2)
#点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
睡觉(2)
#模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(密码)
睡觉(2)
#点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
睡觉(2)
#微信登录验证
print('请扫描二维码')
睡觉(20)
#刷新当前网页
browser.get('#39;)
睡觉(5)
#获取当前网页链接
url = browser.current_url
#获取当前cookie
cookies = browser.get_cookies()
对于 cookie 中的项目:
post[item['name']] = item['value']
#转成字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt','w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie 在本地保存成功')
#对当前网页链接进行切片,获取token
paramList = url.strip().split('?')[1].split('&')
#定义一个字典来存储数据
paramdict = {}
对于 paramList 中的项目:
paramdict[item.split('=')[0]] = item.split('=')[1]
#返回令牌
返回参数['token']
定义一个登录方法,里面的参数是登录账号和密码,然后定义一个字典来存储cookie的值。模拟用户,输入对应的账号密码,点击登录,会出现扫码验证,用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:
1.请求获取对应的公众号接口,获取我们需要的fakeid
url ='#39;
标题 = {
'HOST':'',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86. 0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt','r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url ='#39;
参数 = {
'action':'search_biz',
'开始':'0',
'计数':'5',
'query':'搜索公众号',
'token':令牌,
'lang':'zh_CN',
'f':'json',
'阿贾克斯':'1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
1
通过上面的代码可以得到对应的公众号数据
fakeid = list.get('fakeid')
1
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的文章data
appmsg_url ='#39;
params_data = {
'action':'list_ex',
'开始':'0',
'计数':'5',
'fakeid':fakeid,
'type': '9',
'查询':'',
'token':令牌,
'lang':'zh_CN',
'f':'json',
'阿贾克斯':'1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了微信公众号文章的抓取。
四.Summary
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置一个延迟时间,否则账号很容易被封,获取不到返回的数据。 查看全部
Q&;A(.39)模拟用户
一.Idea
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面图文

超链接
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.接口分析
微信公众号访问:
参数:
action=search_biz
开始=0
计数=5
query=官方账号
token=每个账户对应的token值
lang=zh_CN
f=json
ajax=1
请求方法:
获取
所以在这个界面我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。

微信公众号
获取公众号对应的文章界面:
参数:
action=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
type=9
查询=
令牌=557131216
lang=zh_CN
f=json
ajax=1
请求方法:
获取
我们需要在这个接口中获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。

微信公众号
三.实现
第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
浏览器 = webdriver.Chrome()
browser.get('#39;)
睡觉(3)
browser.delete_all_cookies()
睡觉(2)
#点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
睡觉(2)
#模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(密码)
睡觉(2)
#点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
睡觉(2)
#微信登录验证
print('请扫描二维码')
睡觉(20)
#刷新当前网页
browser.get('#39;)
睡觉(5)
#获取当前网页链接
url = browser.current_url
#获取当前cookie
cookies = browser.get_cookies()
对于 cookie 中的项目:
post[item['name']] = item['value']
#转成字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt','w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie 在本地保存成功')
#对当前网页链接进行切片,获取token
paramList = url.strip().split('?')[1].split('&')
#定义一个字典来存储数据
paramdict = {}
对于 paramList 中的项目:
paramdict[item.split('=')[0]] = item.split('=')[1]
#返回令牌
返回参数['token']
定义一个登录方法,里面的参数是登录账号和密码,然后定义一个字典来存储cookie的值。模拟用户,输入对应的账号密码,点击登录,会出现扫码验证,用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:
1.请求获取对应的公众号接口,获取我们需要的fakeid
url ='#39;
标题 = {
'HOST':'',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86. 0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt','r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url ='#39;
参数 = {
'action':'search_biz',
'开始':'0',
'计数':'5',
'query':'搜索公众号',
'token':令牌,
'lang':'zh_CN',
'f':'json',
'阿贾克斯':'1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
1
通过上面的代码可以得到对应的公众号数据
fakeid = list.get('fakeid')
1
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的文章data
appmsg_url ='#39;
params_data = {
'action':'list_ex',
'开始':'0',
'计数':'5',
'fakeid':fakeid,
'type': '9',
'查询':'',
'token':令牌,
'lang':'zh_CN',
'f':'json',
'阿贾克斯':'1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了微信公众号文章的抓取。
四.Summary
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置一个延迟时间,否则账号很容易被封,获取不到返回的数据。
苏南大叔讲述一下一款国人出品的php库,叫做querylist
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-08-07 00:28
本文开头,苏南大叔讲了一个中国人出品的PHP库,叫querylist,可以用来抓取网络数据。这个查询列表类似于python下的scrapy。当然,在之前的文章中,苏南大叔介绍了scrapy crawling。有兴趣的可以通过文末的链接了解更多。
如何安装和使用 QueryList,一个 php 数据捕获库? (图5-1)
另外,这个查询列表是基于开源库phpquery的。如果你用过phpquery,在接下来的学习中你会看到一些类似的阴影。如果你没用过phpquery,那你还是可以对比一下jquery,思路都差不多。好了,介绍这么多。如果您有兴趣,欢迎查看下一个查询列表系列文章。
苏南大叔实验时的composer版本是:1.6.5,php版本是7.2.1。
官方网站和安装要求
Querylist是中国人的作品,其官方网站是:
querylist要求的php版本至少为7.0,可以通过以下命令查看本地php版本号:
php -v
如何安装和使用 QueryList,一个 php 数据捕获库? (图5-2)
安装第一步是安装composer
安装composer就不描述太多了。 querylist的使用,理论上与composer密切相关。与composer的使用相关的文章请参考文末链接。如果你已经安装了composer,可以跳过这一步。
下面介绍的是mac下使用命令行语句安装composer的例子:
curl -o composer.phar 'https://getcomposer.org/composer.phar'
mv composer.phar /usr/local/bin/composer
chmod 777 /usr/local/bin/composer
相关链接:
第二步是设置全局加速composer的repo库
这一步不是必须的。如果安装querylist时没有响应,可以执行该语句。声明的目的是为了把composer改成快速的国内源码,类似于node下的cnpm。
composer config -g repo.packagist composer https://packagist.phpcomposer.com
第三步,安装querylist
在空白文件夹下,首先初始化composer项目。
composer init
然后使用composer安装jaeger/querylist。
composer require jaeger/querylist
如何安装和使用 QueryList,一个 php 数据捕获库? (图5-3)
安装成功,查看版本号
截至发稿,使用以下命令查看最新版本的querylist版本号4.0.3。
composer show -i jaeger/querylist
如何安装和使用 QueryList,一个 php 数据捕获库? (图5-4)
介绍示例demo
下面这句话是官方给出的最简单的配置。在此,限于篇幅,苏南叔不做过多解释。
require './vendor/autoload.php';
use QL\QueryList;
$html = array('.two>img:eq(1)','src'),
//采集span标签中的HTML内容
'other' => array('span','html')
);
$data = QueryList::html($html)
->rules($rules)
->query()
->getData();
print_r($data->all());
使用
是key中的key点。新手经常被卡在这里。还有autoload.php,这是composer项目的标准配置。剩下的就是querylist的相关功能了,下面苏南叔叔会详细介绍。敬请关注。
require './vendor/autoload.php';
use QL\QueryList;
如何安装和使用 QueryList,一个 php 数据捕获库? (图5-5)
相关链接汇总
本文中苏南大叔介绍的querylist与scrapy类似。但是querylist是基于php的,对php的忠实用户更具吸引力。
不过,苏南叔还是给你一个建议,那就是多尝试python。在目前的环境下,看来python系列还是很有前途的。而且在爬取方面,scrapy 还是比 querylist 有优势。好的,仅此而已。请继续关注苏南叔的后续文字,谢谢阅读。
[苹果]
[添加群组]
【源码】本文中的代码片段及相关软件,请点击此处获取
【绝密】秘籍文章入口,只教给有缘人
查询列表 phpquery 查看全部
苏南大叔讲述一下一款国人出品的php库,叫做querylist
本文开头,苏南大叔讲了一个中国人出品的PHP库,叫querylist,可以用来抓取网络数据。这个查询列表类似于python下的scrapy。当然,在之前的文章中,苏南大叔介绍了scrapy crawling。有兴趣的可以通过文末的链接了解更多。

如何安装和使用 QueryList,一个 php 数据捕获库? (图5-1)
另外,这个查询列表是基于开源库phpquery的。如果你用过phpquery,在接下来的学习中你会看到一些类似的阴影。如果你没用过phpquery,那你还是可以对比一下jquery,思路都差不多。好了,介绍这么多。如果您有兴趣,欢迎查看下一个查询列表系列文章。
苏南大叔实验时的composer版本是:1.6.5,php版本是7.2.1。
官方网站和安装要求
Querylist是中国人的作品,其官方网站是:
querylist要求的php版本至少为7.0,可以通过以下命令查看本地php版本号:
php -v

如何安装和使用 QueryList,一个 php 数据捕获库? (图5-2)
安装第一步是安装composer
安装composer就不描述太多了。 querylist的使用,理论上与composer密切相关。与composer的使用相关的文章请参考文末链接。如果你已经安装了composer,可以跳过这一步。
下面介绍的是mac下使用命令行语句安装composer的例子:
curl -o composer.phar 'https://getcomposer.org/composer.phar'
mv composer.phar /usr/local/bin/composer
chmod 777 /usr/local/bin/composer
相关链接:
第二步是设置全局加速composer的repo库
这一步不是必须的。如果安装querylist时没有响应,可以执行该语句。声明的目的是为了把composer改成快速的国内源码,类似于node下的cnpm。
composer config -g repo.packagist composer https://packagist.phpcomposer.com
第三步,安装querylist
在空白文件夹下,首先初始化composer项目。
composer init
然后使用composer安装jaeger/querylist。
composer require jaeger/querylist

如何安装和使用 QueryList,一个 php 数据捕获库? (图5-3)
安装成功,查看版本号
截至发稿,使用以下命令查看最新版本的querylist版本号4.0.3。
composer show -i jaeger/querylist

如何安装和使用 QueryList,一个 php 数据捕获库? (图5-4)
介绍示例demo
下面这句话是官方给出的最简单的配置。在此,限于篇幅,苏南叔不做过多解释。
require './vendor/autoload.php';
use QL\QueryList;
$html = array('.two>img:eq(1)','src'),
//采集span标签中的HTML内容
'other' => array('span','html')
);
$data = QueryList::html($html)
->rules($rules)
->query()
->getData();
print_r($data->all());
使用
是key中的key点。新手经常被卡在这里。还有autoload.php,这是composer项目的标准配置。剩下的就是querylist的相关功能了,下面苏南叔叔会详细介绍。敬请关注。
require './vendor/autoload.php';
use QL\QueryList;

如何安装和使用 QueryList,一个 php 数据捕获库? (图5-5)
相关链接汇总
本文中苏南大叔介绍的querylist与scrapy类似。但是querylist是基于php的,对php的忠实用户更具吸引力。
不过,苏南叔还是给你一个建议,那就是多尝试python。在目前的环境下,看来python系列还是很有前途的。而且在爬取方面,scrapy 还是比 querylist 有优势。好的,仅此而已。请继续关注苏南叔的后续文字,谢谢阅读。
[苹果]
[添加群组]
【源码】本文中的代码片段及相关软件,请点击此处获取

【绝密】秘籍文章入口,只教给有缘人
查询列表 phpquery
几天的总条数的话这样写的,真是太神奇了
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-08-04 03:32
这几天一直在做一些python项目的开发。我使用了 python 的 ORM 框架 sqlAlchemy。因为对python和sqlAlchemy不熟悉,所以积累了一些小知识点分享给大家。
获取文章总数
一般情况下,如果我们想知道表的总条目数,sql是这样写的:
select count(id) from user
这样我们就可以得到表中项目的总数
如果我想在sqlAlchemy中获取项目总数应该怎么做?
这种用途,func需要被引用
from sqlalchemy import func
count =session.query(func.count(user.id)).scalar()
如上,我们可以得到数据的数量。
相关链接
截图
按页面搜索
比较简单,直接粘贴代码
我的错误
查询总条目数时不使用Func.count()
我是这样写的
userlist=session.query(user).order_by(user.id.desc())
count=len(list(userlist))
userlist = userlist.limit(pageSize).offset(
(pageIndex-1)*pageSize)
这样也可以得到数据的个数。如果数据量很小,你可能没有什么感觉。数据量大的时候,你会发现查询数据真的很慢
相当于查询数据库两次,然后重新计算内存中的条目数和分页。
这在大量数据的情况下效率极低 查看全部
几天的总条数的话这样写的,真是太神奇了
这几天一直在做一些python项目的开发。我使用了 python 的 ORM 框架 sqlAlchemy。因为对python和sqlAlchemy不熟悉,所以积累了一些小知识点分享给大家。
获取文章总数
一般情况下,如果我们想知道表的总条目数,sql是这样写的:
select count(id) from user
这样我们就可以得到表中项目的总数
如果我想在sqlAlchemy中获取项目总数应该怎么做?
这种用途,func需要被引用
from sqlalchemy import func
count =session.query(func.count(user.id)).scalar()
如上,我们可以得到数据的数量。
相关链接
截图

按页面搜索
比较简单,直接粘贴代码
我的错误
查询总条目数时不使用Func.count()
我是这样写的
userlist=session.query(user).order_by(user.id.desc())
count=len(list(userlist))
userlist = userlist.limit(pageSize).offset(
(pageIndex-1)*pageSize)
这样也可以得到数据的个数。如果数据量很小,你可能没有什么感觉。数据量大的时候,你会发现查询数据真的很慢
相当于查询数据库两次,然后重新计算内存中的条目数和分页。
这在大量数据的情况下效率极低
与token的代码与上篇文章衔接起来代码的流程
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-08-04 00:37
获取网址
在我们解决cookie和token之前,那我们只需要把这两个参数放到请求头中就可以得到我们想要的
首先搜索公司账号名称
这里打开素材管理,点击新建图形素材
点击超链接。转到此页面
在此处提取url、headers和参数并找出更改的参数
random参数是0-1之间的随机浮点数,query是搜索内容,前面提取token
接下来我们看看获取文章的请求和接口
我们对页面的分析完成了,接下来我们开始编写代码,这次的代码是和上一篇文章的代码连接起来的
import time
import json
import random
import csv
from selenium import webdriver
from lxml import html
import requests
import re
# 获取cookies和token
class C_ookie:
# 初始化
def __init__(self):
self.html = ''
# 获取cookie
def get_cookie(self):
cooki = {}
url = 'https://mp.weixin.qq.com'
Browner = webdriver.Chrome()
Browner.get(url)
# 获取账号输入框
ID = Browner.find_element_by_name('account')
# 获取密码输入框
PW = Browner.find_element_by_name('password')
# 输入账号
#输入账号
id =
#输入密码
pw =
# id = input('请输入账号:')
# pw = input('请输入密码:')
ID.send_keys(id)
PW.send_keys(pw)
# 获取登录button,点击登录
Browner.find_element_by_class_name('btn_login').click()
# 等待扫二维码
time.sleep(10)
cks = Browner.get_cookies()
for ck in cks:
cooki[ck['name']] = ck['value']
ck1 = json.dumps(cooki)
print(ck1)
with open('ck.txt','w') as f :
f.write(ck1)
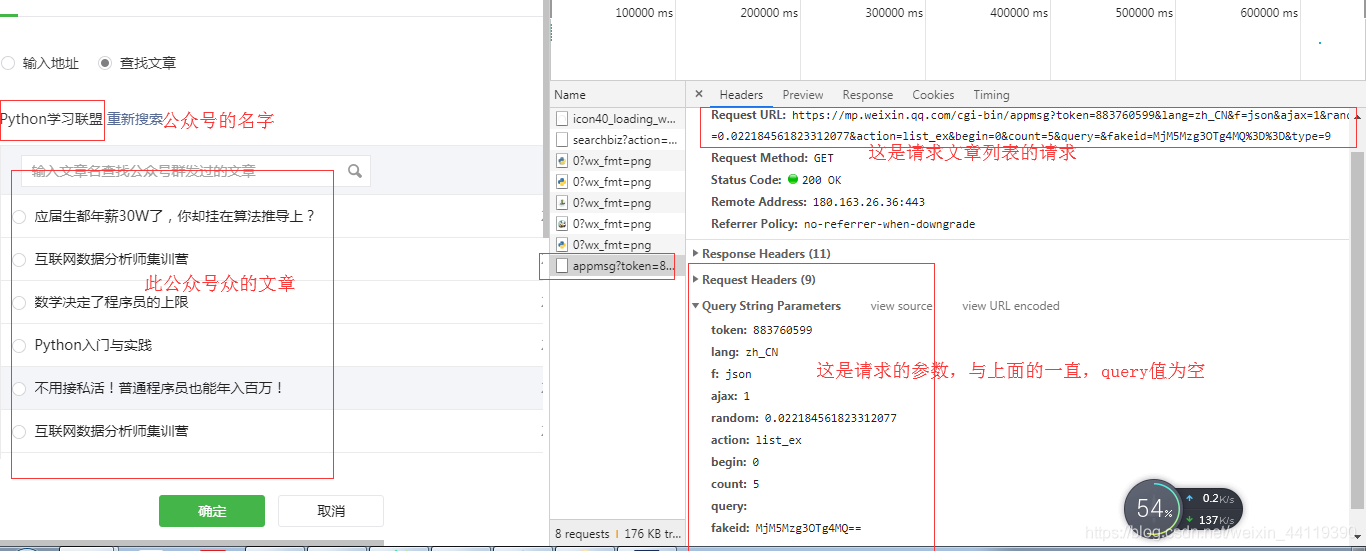
f.close()
self.html = Browner.page_source
# 获取文章
class getEssay:
def __init__(self):
# 获取cookies
with open('ck.txt','r') as f :
cookie = f.read()
f.close()
self.cookie = json.loads(cookie)
# 获取token
self.header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": 'Mozilla / 5.0(WindowsNT6.1;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 74.0.3729.131Safari / 537.36'
}
m_url = 'https://mp.weixin.qq.com'
response = requests.get(url=m_url, cookies=self.cookie)
self.token = re.findall(r'token=(\d+)', str(response.url))[0]
# fakeid与name
self.fakeid = []
# 获取公众号信息
def getGname(self):
# 请求头
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'mp.weixin.qq.com',
'Referer': 'https://mp.weixin.qq.com/cgi-b ... 25int(self.token),
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
# 地址
url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
# query = input('请输入要搜索的公众号关键字:')
# begin = int(input('请输入开始的页数:'))
query = 'python'
begin = 0
begin *= 5
# 请求参数
data = {
'action': 'search_biz',
'token': self.token,
'lang': 'zh_CN',
'f': 'json',
'ajax':' 1',
'random': random.random(),
'query': query,
'begin': begin,
'count': '5'
}
# 请求页面,获取数据
res = requests.get(url=url, cookies=self.cookie, headers=headers, params=data)
name_js = res.text
name_js = json.loads(name_js)
list = name_js['list']
for i in list:
time.sleep(1)
fakeid = i['fakeid']
nickname =i['nickname']
print(nickname,fakeid)
self.fakeid.append((nickname,fakeid))
# 获取文章url
def getEurl(self):
url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'mp.weixin.qq.com',
'Referer': 'https://mp.weixin.qq.com/cgi-b ... 25int(self.token),
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
# 遍历fakeid,访问获取文章链接
for i in self.fakeid:
time.sleep(1)
fake = i[1]
data = {
'token': self.token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': 0,
'count': 5,
'fakeid': fake,
'type': 9
}
res = requests.get(url, cookies=self.cookie, headers=headers, params=data)
js = res.text
link_l = json.loads(js)
self.parJson(link_l)
# 解析提取url
def parJson(self,link_l):
l = link_l['app_msg_list']
for i in l:
link = i['link']
name = i['digest']
self.saveData(name,link)
# 保存数据进csv中
def saveData(self,name,link):
with open('link.csv' ,'a',encoding='utf8') as f:
w = csv.writer(f)
w.writerow((name,link))
print('ok')
C = C_ookie()
C.get_cookie()
G = getEssay()
G.getGname()
G.getEurl()
整个爬取过程就到这里,希望能帮到你 查看全部
与token的代码与上篇文章衔接起来代码的流程
获取网址
在我们解决cookie和token之前,那我们只需要把这两个参数放到请求头中就可以得到我们想要的
首先搜索公司账号名称
这里打开素材管理,点击新建图形素材
点击超链接。转到此页面
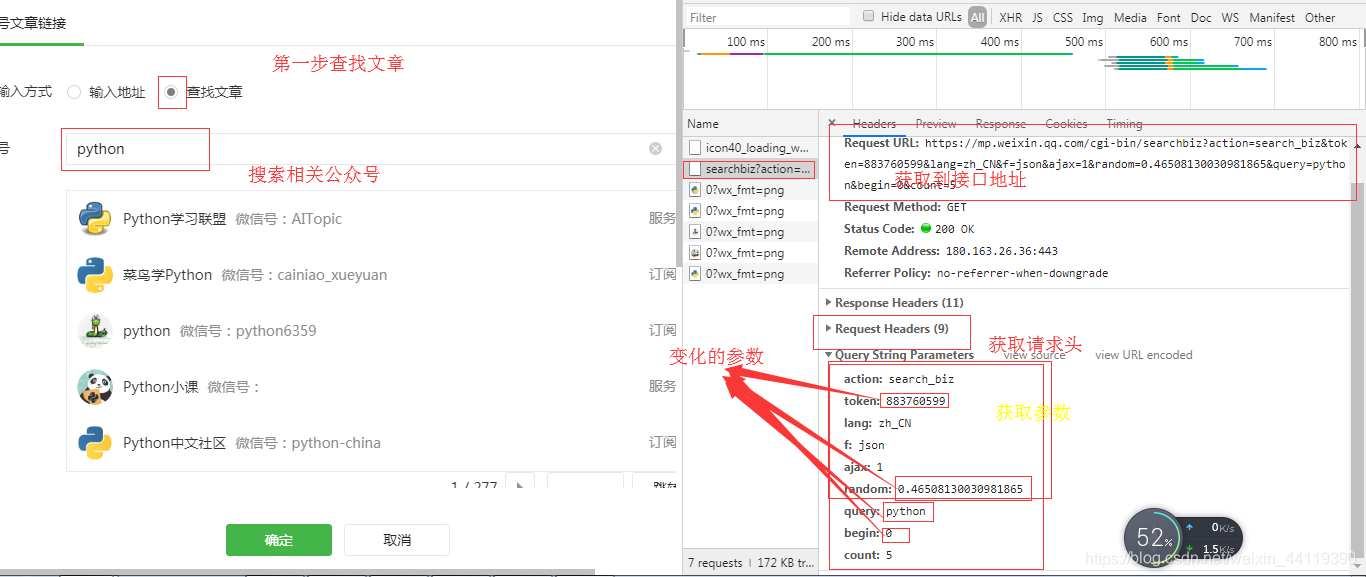
在此处提取url、headers和参数并找出更改的参数
random参数是0-1之间的随机浮点数,query是搜索内容,前面提取token
接下来我们看看获取文章的请求和接口
我们对页面的分析完成了,接下来我们开始编写代码,这次的代码是和上一篇文章的代码连接起来的
import time
import json
import random
import csv
from selenium import webdriver
from lxml import html
import requests
import re
# 获取cookies和token
class C_ookie:
# 初始化
def __init__(self):
self.html = ''
# 获取cookie
def get_cookie(self):
cooki = {}
url = 'https://mp.weixin.qq.com'
Browner = webdriver.Chrome()
Browner.get(url)
# 获取账号输入框
ID = Browner.find_element_by_name('account')
# 获取密码输入框
PW = Browner.find_element_by_name('password')
# 输入账号
#输入账号
id =
#输入密码
pw =
# id = input('请输入账号:')
# pw = input('请输入密码:')
ID.send_keys(id)
PW.send_keys(pw)
# 获取登录button,点击登录
Browner.find_element_by_class_name('btn_login').click()
# 等待扫二维码
time.sleep(10)
cks = Browner.get_cookies()
for ck in cks:
cooki[ck['name']] = ck['value']
ck1 = json.dumps(cooki)
print(ck1)
with open('ck.txt','w') as f :
f.write(ck1)
f.close()
self.html = Browner.page_source
# 获取文章
class getEssay:
def __init__(self):
# 获取cookies
with open('ck.txt','r') as f :
cookie = f.read()
f.close()
self.cookie = json.loads(cookie)
# 获取token
self.header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": 'Mozilla / 5.0(WindowsNT6.1;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 74.0.3729.131Safari / 537.36'
}
m_url = 'https://mp.weixin.qq.com'
response = requests.get(url=m_url, cookies=self.cookie)
self.token = re.findall(r'token=(\d+)', str(response.url))[0]
# fakeid与name
self.fakeid = []
# 获取公众号信息
def getGname(self):
# 请求头
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'mp.weixin.qq.com',
'Referer': 'https://mp.weixin.qq.com/cgi-b ... 25int(self.token),
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
# 地址
url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
# query = input('请输入要搜索的公众号关键字:')
# begin = int(input('请输入开始的页数:'))
query = 'python'
begin = 0
begin *= 5
# 请求参数
data = {
'action': 'search_biz',
'token': self.token,
'lang': 'zh_CN',
'f': 'json',
'ajax':' 1',
'random': random.random(),
'query': query,
'begin': begin,
'count': '5'
}
# 请求页面,获取数据
res = requests.get(url=url, cookies=self.cookie, headers=headers, params=data)
name_js = res.text
name_js = json.loads(name_js)
list = name_js['list']
for i in list:
time.sleep(1)
fakeid = i['fakeid']
nickname =i['nickname']
print(nickname,fakeid)
self.fakeid.append((nickname,fakeid))
# 获取文章url
def getEurl(self):
url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'mp.weixin.qq.com',
'Referer': 'https://mp.weixin.qq.com/cgi-b ... 25int(self.token),
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
# 遍历fakeid,访问获取文章链接
for i in self.fakeid:
time.sleep(1)
fake = i[1]
data = {
'token': self.token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': 0,
'count': 5,
'fakeid': fake,
'type': 9
}
res = requests.get(url, cookies=self.cookie, headers=headers, params=data)
js = res.text
link_l = json.loads(js)
self.parJson(link_l)
# 解析提取url
def parJson(self,link_l):
l = link_l['app_msg_list']
for i in l:
link = i['link']
name = i['digest']
self.saveData(name,link)
# 保存数据进csv中
def saveData(self,name,link):
with open('link.csv' ,'a',encoding='utf8') as f:
w = csv.writer(f)
w.writerow((name,link))
print('ok')
C = C_ookie()
C.get_cookie()
G = getEssay()
G.getGname()
G.getEurl()
整个爬取过程就到这里,希望能帮到你
上面这种是支持微信、短信通知的吗?(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-08-02 05:10
上面这种是支持微信、短信通知的吗?(图)
\Phpcmf\Service::M('member')->notice($uid, $type, $note, $url = '')
$uid 会员id
$type 类型:1系统 2用户 3内容 4应用 5交易 6订单
$note 通知内容
$url 相关链接
以上类型是否支持微信和短信通知?不需要设置通知模板? ?
----------------------------------------------- ------
使用系统通知,不知道如何携带URL参数。如果你想在小程序或者APP中传递一个URL参数! !
\Phpcmf\Service::L('Notice')->send_notice('news', $userlist);
最新任务《{$title}》,时间:{dr_date($sys_time)}
{
"id": "98",
"type": "1",
"uid": "1",
"isnew": "0",
"content": "完成调查任务",
"url": "",
"inputtime": "1575019067"
}, 查看全部
上面这种是支持微信、短信通知的吗?(图)
\Phpcmf\Service::M('member')->notice($uid, $type, $note, $url = '')
$uid 会员id
$type 类型:1系统 2用户 3内容 4应用 5交易 6订单
$note 通知内容
$url 相关链接
以上类型是否支持微信和短信通知?不需要设置通知模板? ?
----------------------------------------------- ------
使用系统通知,不知道如何携带URL参数。如果你想在小程序或者APP中传递一个URL参数! !
\Phpcmf\Service::L('Notice')->send_notice('news', $userlist);
最新任务《{$title}》,时间:{dr_date($sys_time)}
{
"id": "98",
"type": "1",
"uid": "1",
"isnew": "0",
"content": "完成调查任务",
"url": "",
"inputtime": "1575019067"
},
微信小程序订阅消息升级,以前的消息模板不适合使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-08-01 22:09
微信小程序订阅消息更新,之前的消息模板不适合使用
官方文档微信官方文档
要求
使用小程序开启直播讲座,学生可以预约,已经预约的学生会在直播开始前发送提醒和直播开始提醒
整体流程
1、模板由产品在微信小程序中设计,模板id和内容给前后端
2、前端在小程序页面发起消息订阅授权。用户同意授权后,微信返回的templateIds传递给后端
3、后端保存templateIds并组装相应的内容,保存到数据库中
4、使用定时器查询要发送的数据并发送给用户(广播前提醒)
5、用户广播,发送启动提醒
后端关键设计及代码
定义模板
public interface ConstantTemplate {
/**
* 提前提醒
*/
String CLOUD_PREACH_TEMPLATE_ID = "xxxxxxxxxxxxxx";
String CLOUD_PREACH_TEMPLATE_DATA = "{\"time1\":{\"value\":\"%s\"},\"thing2\":{\"value\":\"%s\"},\"thing3\":{\"value\":\"%s\"}}";
/**
* 开播提醒
*/
String INTERVIEW_NOTICE_TEMPLATE_ID = "xxxxxxxxxxxxxxxx";
String INTERVIEW_NOTICE_TEMPLATE_DATA ="{\"thing1\":{\"value\":\"%s\"},\"thing2\":{\"value\":\"%s\"},\time3\":{\"value\":\"%s\"},\"thing4\":{\"value\":\"%s\"},\"thing5\":{\"value\":\"%s\"}}";
}
@Getter
public enum WxMiniMsgTemplateEnum {
/**
* 微信小程序消息模板
*/
CLOUD_PREACH_TEMPLATE(CLOUD_PREACH_TEMPLATE_ID, CLOUD_PREACH_TEMPLATE_DATA),
INTERVIEW_NOTICE_TEMPLATE(INTERVIEW_NOTICE_TEMPLATE_ID, INTERVIEW_NOTICE_TEMPLATE_DATA);
private final String id;
private final String data;
WxMiniMsgTemplateEnum(String id, String data) {
this.id = id;
this.data = data;
}
public static String getDataById(String id) {
return Arrays.stream(WxMiniMsgTemplateEnum.values()).filter(r -> r.getId().equals(id)).findFirst().map(WxMiniMsgTemplateEnum::getData).orElse(null);
}
}
保存消息
for (String templateId : dto.getTemplateIds()) {
//发送小程序订阅消息
XyWxMiniMsgDTO wxMsgDTO = new XyWxMiniMsgDTO();
wxMsgDTO.setPage(dto.getPage());
wxMsgDTO.setEndpoint(com.xyedu.sims.common.enums.SourceTypeEnum.STUDENT_MINI.getCode());
wxMsgDTO.setLang("zh_CN");
wxMsgDTO.setMiniprogramState(ConstantUtil.MiniprogramState);
wxMsgDTO.setTouser(social.getOpenId());
LocalDateTime sendTime = topicInfo.getStartTime();
LocalDateTime pastTime = topicInfo.getEndTime();
//提前20分钟发送通知
wxMsgDTO.setSendTime(sendTime.minusMinutes(20));
wxMsgDTO.setPastTime(pastTime);
String date = DateUtil.getDefaultFormatDate(DateUtil.localDateTimeToDate(topicInfo.getStartTime()));
//组装模板数据
String data = WxMiniMsgTemplateEnum.getDataById(templateId);
if (ToolUtil.isNotEmpty(data)) {
data = String.format(data, date, StrUtil.subWithLength(topicInfo.getTitle(), 0, 20), userCache.getRealName() + "同学,云宣讲即将开始~");
wxMsgDTO.setData(JSONUtil.toJsonStr(data));
}
wxMsgDTO.setTemplateId(templateId);
XyWxMiniMsg miniMsg = BeanUtil.copy(wxMsgDTO, XyWxMiniMsg.class);
//保存至数据库
remoteXyWxMiniMsgService.add(miniMsg);
}
包裹发送工具
@Slf4j
public class WxMiniMsgUtil {
//官方文档: https://developers.weixin.qq.c ... .html
private static final String WX_MINI_MSG_URL = "https://api.weixin.qq.com/cgi- ... 3B%3B
public static Object send(String accessToken, XyWxMiniMsgDTO dto) {
String url = WX_MINI_MSG_URL + accessToken;
Map reqBody = new HashMap();
reqBody.put("touser", dto.getTouser());
reqBody.put("template_id", dto.getTemplateId());
reqBody.put("miniprogram_state", dto.getMiniprogramState());
reqBody.put("lang", dto.getLang());
reqBody.put("page", dto.getPage());
reqBody.put("data", JSONUtil.parseObj(dto.getData()));
try {
return HttpRequest.post(url)
.body(JSONUtil.toJsonStr(reqBody))
.timeout(5000)
.execute()
.body();
} catch (Exception e) {
log.error("send wx mini msg occur an exception,e={}", e.getMessage());
return null;
}
}
}
使用定时器发送,定时器每3分钟执行一次查询,查询未发送或发送失败的消息。如果超过时间,发送状态将设置为过期
@Getter
public enum WxMiniMsgSendStatusEnum {
/**
*
*/
SENDING(0, "未发送"),
SEND_SUCCESS(1, "发送成功"),
SEND_FAIL(2, "发送失败"),
OVERDUE(3,"过期");
private Integer code;
private String msg;
WxMiniMsgSendStatusEnum(Integer code, String msg) {
this.code = code;
this.msg = msg;
}
public static String getMsg(Object code) {
if (code == null) {
return null;
}
return Arrays.stream(values()).filter(e -> e.getCode().equals(code)).findFirst().map(e -> e.getMsg()).orElse("");
}
}
@Override
public ReturnT execute(String param) throws Exception {
log.debug("[send wx mini msg]-start");
XyWxMiniMsgQueryDTO dto = new XyWxMiniMsgQueryDTO();
dto.setEndpoint(SourceTypeEnum.STUDENT_MINI.getCode());
//从数据库中获取应发送的数据列表
List list = remoteXyWxMiniMsgService.list(dto);
if (CollectionUtil.isNotEmpty(list)) {
log.debug("[send wx mini msg]-query list,list.size={}", list.size());
final WxMaService wxService = WxMaConfiguration.getMaService();
String accessToken = wxService.getAccessToken();
for (XyWxMiniMsg msg : list) {
XyWxMiniMsgDTO msgDTO = BeanUtil.copy(msg, XyWxMiniMsgDTO.class);
//通知微信发送订阅消息
Object response = WxMiniMsgUtil.send(accessToken, msgDTO);
if (ToolUtil.isNotEmpty(response)) {
msg.setResponse(response.toString());
JSONObject object = JSONUtil.parseObj(response);
//处理微信响应信息
if (object.containsKey("errcode")
&& NumberUtil.isNumber(object.get("errcode").toString())
&& Integer.valueOf(object.get("errcode").toString()) == 0) {
msg.setSendStatus(WxMiniMsgSendStatusEnum.SEND_SUCCESS.getCode());
} else if (object.containsKey("errcode")
&& NumberUtil.isNumber(object.get("errcode").toString())
&& Integer.valueOf(object.get("errcode").toString()) == 42001) {
log.error("[send wx mini msg]-response fail,refresh accessToken={}", response);
msg.setSendStatus(WxMiniMsgSendStatusEnum.SEND_FAIL.getCode());
WxMaConfiguration.getMaService().getAccessToken(true);
} else {
msg.setSendStatus(WxMiniMsgSendStatusEnum.SEND_FAIL.getCode());
log.error("[send wx mini msg]-response fail,response={}", response);
}
} else {
msg.setSendStatus(WxMiniMsgSendStatusEnum.SEND_FAIL.getCode());
log.error("[send wx mini msg]-response empty,may be catch exception,params[accessToken={}\n,msgDTO={}]", accessToken, msgDTO);
}
}
remoteXyWxMiniMsgService.updateBatch(list);
}
log.debug("[send wx mini msg]-finish");
return ReturnT.SUCCESS;
}
要求点 5 尚未完成。思路大概是在组装提前提醒模板的时候把开机提醒消息保存到数据库中,用templateId+演示的id作为唯一标识,在数据库中查询广播开始时要发送的消息,最后直接通过工具类发送 查看全部
微信小程序订阅消息升级,以前的消息模板不适合使用
微信小程序订阅消息更新,之前的消息模板不适合使用
官方文档微信官方文档
要求
使用小程序开启直播讲座,学生可以预约,已经预约的学生会在直播开始前发送提醒和直播开始提醒
整体流程
1、模板由产品在微信小程序中设计,模板id和内容给前后端
2、前端在小程序页面发起消息订阅授权。用户同意授权后,微信返回的templateIds传递给后端
3、后端保存templateIds并组装相应的内容,保存到数据库中
4、使用定时器查询要发送的数据并发送给用户(广播前提醒)
5、用户广播,发送启动提醒
后端关键设计及代码
定义模板
public interface ConstantTemplate {
/**
* 提前提醒
*/
String CLOUD_PREACH_TEMPLATE_ID = "xxxxxxxxxxxxxx";
String CLOUD_PREACH_TEMPLATE_DATA = "{\"time1\":{\"value\":\"%s\"},\"thing2\":{\"value\":\"%s\"},\"thing3\":{\"value\":\"%s\"}}";
/**
* 开播提醒
*/
String INTERVIEW_NOTICE_TEMPLATE_ID = "xxxxxxxxxxxxxxxx";
String INTERVIEW_NOTICE_TEMPLATE_DATA ="{\"thing1\":{\"value\":\"%s\"},\"thing2\":{\"value\":\"%s\"},\time3\":{\"value\":\"%s\"},\"thing4\":{\"value\":\"%s\"},\"thing5\":{\"value\":\"%s\"}}";
}
@Getter
public enum WxMiniMsgTemplateEnum {
/**
* 微信小程序消息模板
*/
CLOUD_PREACH_TEMPLATE(CLOUD_PREACH_TEMPLATE_ID, CLOUD_PREACH_TEMPLATE_DATA),
INTERVIEW_NOTICE_TEMPLATE(INTERVIEW_NOTICE_TEMPLATE_ID, INTERVIEW_NOTICE_TEMPLATE_DATA);
private final String id;
private final String data;
WxMiniMsgTemplateEnum(String id, String data) {
this.id = id;
this.data = data;
}
public static String getDataById(String id) {
return Arrays.stream(WxMiniMsgTemplateEnum.values()).filter(r -> r.getId().equals(id)).findFirst().map(WxMiniMsgTemplateEnum::getData).orElse(null);
}
}
保存消息
for (String templateId : dto.getTemplateIds()) {
//发送小程序订阅消息
XyWxMiniMsgDTO wxMsgDTO = new XyWxMiniMsgDTO();
wxMsgDTO.setPage(dto.getPage());
wxMsgDTO.setEndpoint(com.xyedu.sims.common.enums.SourceTypeEnum.STUDENT_MINI.getCode());
wxMsgDTO.setLang("zh_CN");
wxMsgDTO.setMiniprogramState(ConstantUtil.MiniprogramState);
wxMsgDTO.setTouser(social.getOpenId());
LocalDateTime sendTime = topicInfo.getStartTime();
LocalDateTime pastTime = topicInfo.getEndTime();
//提前20分钟发送通知
wxMsgDTO.setSendTime(sendTime.minusMinutes(20));
wxMsgDTO.setPastTime(pastTime);
String date = DateUtil.getDefaultFormatDate(DateUtil.localDateTimeToDate(topicInfo.getStartTime()));
//组装模板数据
String data = WxMiniMsgTemplateEnum.getDataById(templateId);
if (ToolUtil.isNotEmpty(data)) {
data = String.format(data, date, StrUtil.subWithLength(topicInfo.getTitle(), 0, 20), userCache.getRealName() + "同学,云宣讲即将开始~");
wxMsgDTO.setData(JSONUtil.toJsonStr(data));
}
wxMsgDTO.setTemplateId(templateId);
XyWxMiniMsg miniMsg = BeanUtil.copy(wxMsgDTO, XyWxMiniMsg.class);
//保存至数据库
remoteXyWxMiniMsgService.add(miniMsg);
}
包裹发送工具
@Slf4j
public class WxMiniMsgUtil {
//官方文档: https://developers.weixin.qq.c ... .html
private static final String WX_MINI_MSG_URL = "https://api.weixin.qq.com/cgi- ... 3B%3B
public static Object send(String accessToken, XyWxMiniMsgDTO dto) {
String url = WX_MINI_MSG_URL + accessToken;
Map reqBody = new HashMap();
reqBody.put("touser", dto.getTouser());
reqBody.put("template_id", dto.getTemplateId());
reqBody.put("miniprogram_state", dto.getMiniprogramState());
reqBody.put("lang", dto.getLang());
reqBody.put("page", dto.getPage());
reqBody.put("data", JSONUtil.parseObj(dto.getData()));
try {
return HttpRequest.post(url)
.body(JSONUtil.toJsonStr(reqBody))
.timeout(5000)
.execute()
.body();
} catch (Exception e) {
log.error("send wx mini msg occur an exception,e={}", e.getMessage());
return null;
}
}
}
使用定时器发送,定时器每3分钟执行一次查询,查询未发送或发送失败的消息。如果超过时间,发送状态将设置为过期
@Getter
public enum WxMiniMsgSendStatusEnum {
/**
*
*/
SENDING(0, "未发送"),
SEND_SUCCESS(1, "发送成功"),
SEND_FAIL(2, "发送失败"),
OVERDUE(3,"过期");
private Integer code;
private String msg;
WxMiniMsgSendStatusEnum(Integer code, String msg) {
this.code = code;
this.msg = msg;
}
public static String getMsg(Object code) {
if (code == null) {
return null;
}
return Arrays.stream(values()).filter(e -> e.getCode().equals(code)).findFirst().map(e -> e.getMsg()).orElse("");
}
}
@Override
public ReturnT execute(String param) throws Exception {
log.debug("[send wx mini msg]-start");
XyWxMiniMsgQueryDTO dto = new XyWxMiniMsgQueryDTO();
dto.setEndpoint(SourceTypeEnum.STUDENT_MINI.getCode());
//从数据库中获取应发送的数据列表
List list = remoteXyWxMiniMsgService.list(dto);
if (CollectionUtil.isNotEmpty(list)) {
log.debug("[send wx mini msg]-query list,list.size={}", list.size());
final WxMaService wxService = WxMaConfiguration.getMaService();
String accessToken = wxService.getAccessToken();
for (XyWxMiniMsg msg : list) {
XyWxMiniMsgDTO msgDTO = BeanUtil.copy(msg, XyWxMiniMsgDTO.class);
//通知微信发送订阅消息
Object response = WxMiniMsgUtil.send(accessToken, msgDTO);
if (ToolUtil.isNotEmpty(response)) {
msg.setResponse(response.toString());
JSONObject object = JSONUtil.parseObj(response);
//处理微信响应信息
if (object.containsKey("errcode")
&& NumberUtil.isNumber(object.get("errcode").toString())
&& Integer.valueOf(object.get("errcode").toString()) == 0) {
msg.setSendStatus(WxMiniMsgSendStatusEnum.SEND_SUCCESS.getCode());
} else if (object.containsKey("errcode")
&& NumberUtil.isNumber(object.get("errcode").toString())
&& Integer.valueOf(object.get("errcode").toString()) == 42001) {
log.error("[send wx mini msg]-response fail,refresh accessToken={}", response);
msg.setSendStatus(WxMiniMsgSendStatusEnum.SEND_FAIL.getCode());
WxMaConfiguration.getMaService().getAccessToken(true);
} else {
msg.setSendStatus(WxMiniMsgSendStatusEnum.SEND_FAIL.getCode());
log.error("[send wx mini msg]-response fail,response={}", response);
}
} else {
msg.setSendStatus(WxMiniMsgSendStatusEnum.SEND_FAIL.getCode());
log.error("[send wx mini msg]-response empty,may be catch exception,params[accessToken={}\n,msgDTO={}]", accessToken, msgDTO);
}
}
remoteXyWxMiniMsgService.updateBatch(list);
}
log.debug("[send wx mini msg]-finish");
return ReturnT.SUCCESS;
}
要求点 5 尚未完成。思路大概是在组装提前提醒模板的时候把开机提醒消息保存到数据库中,用templateId+演示的id作为唯一标识,在数据库中查询广播开始时要发送的消息,最后直接通过工具类发送
基于PHP的服务端开源项目之phpQuery采集文章(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-08-01 07:04
phpQuery 是一个基于 PHP 的服务器端开源项目,它可以让 PHP 开发者轻松处理 DOM 文档的内容,例如获取新闻的头条新闻网站。更有趣的是它使用了jQuery的思想。你可以像使用jQuery一样处理页面内容,获取你想要的页面信息。
采集头条
先看个例子,现在我要的是采集国内新闻的标题,代码如下:
复制代码代码如下:
收录'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('');
echo pq(".blkTop h1:eq(0)")->html();
简单的三行代码,即可获取标题内容。首先在程序中收录phpQuery.php核心程序,然后调用读取目标网页,最后输出对应标签下的内容。
pq() 是一个强大的方法,就像jQuery的$()一样,jQuery的选择器基本可以用在phpQuery上,只要把“.”改一下就行了。到“->”。如上例, pq(".blkTop h1:eq(0)") 抓取class属性为blkTop的DIV元素,找到DIV里面的第一个h1标签,然后使用html()方法获取h1 标签中的内容(带html标签)就是我们要获取的标题信息,如果使用text()方法,只会获取到标题的文本内容,当然一定要用好phpQuery,关键是在文档Node中找到对应的内容。
采集文章List
下面再看一个例子,获取网站的博客列表,请看代码:
复制代码代码如下:
收录'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('');
$artlist = pq(".blog_li");
foreach($artlist as $li){
echo pq($li)->find('h2')->html()."";
}
找到文章 标题并通过循环遍历列表中的 DIV 将其输出就是这么简单。
解析 XML 文档
假设有一个像这样的 test.xml 文档:
复制代码代码如下:
张三
22
王舞
18
现在想获取联系人张三的年龄,代码如下:
复制代码代码如下:
收录'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('test.xml');
echo pq('contact> age:eq(0)');
结果输出:22
和jQuery一样,它就像准确找到文档节点,输出节点下的内容,解析一个XML文档一样简单。现在您不必为采集网站 内容使用繁琐的代码,例如头痛的常规算法和内容替换。有了 phpQuery,一切都变得简单了。
phpquery项目官网地址: 查看全部
基于PHP的服务端开源项目之phpQuery采集文章(一)
phpQuery 是一个基于 PHP 的服务器端开源项目,它可以让 PHP 开发者轻松处理 DOM 文档的内容,例如获取新闻的头条新闻网站。更有趣的是它使用了jQuery的思想。你可以像使用jQuery一样处理页面内容,获取你想要的页面信息。
采集头条
先看个例子,现在我要的是采集国内新闻的标题,代码如下:
复制代码代码如下:
收录'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('');
echo pq(".blkTop h1:eq(0)")->html();
简单的三行代码,即可获取标题内容。首先在程序中收录phpQuery.php核心程序,然后调用读取目标网页,最后输出对应标签下的内容。
pq() 是一个强大的方法,就像jQuery的$()一样,jQuery的选择器基本可以用在phpQuery上,只要把“.”改一下就行了。到“->”。如上例, pq(".blkTop h1:eq(0)") 抓取class属性为blkTop的DIV元素,找到DIV里面的第一个h1标签,然后使用html()方法获取h1 标签中的内容(带html标签)就是我们要获取的标题信息,如果使用text()方法,只会获取到标题的文本内容,当然一定要用好phpQuery,关键是在文档Node中找到对应的内容。
采集文章List
下面再看一个例子,获取网站的博客列表,请看代码:
复制代码代码如下:
收录'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('');
$artlist = pq(".blog_li");
foreach($artlist as $li){
echo pq($li)->find('h2')->html()."";
}
找到文章 标题并通过循环遍历列表中的 DIV 将其输出就是这么简单。
解析 XML 文档
假设有一个像这样的 test.xml 文档:
复制代码代码如下:
张三
22
王舞
18
现在想获取联系人张三的年龄,代码如下:
复制代码代码如下:
收录'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('test.xml');
echo pq('contact> age:eq(0)');
结果输出:22
和jQuery一样,它就像准确找到文档节点,输出节点下的内容,解析一个XML文档一样简单。现在您不必为采集网站 内容使用繁琐的代码,例如头痛的常规算法和内容替换。有了 phpQuery,一切都变得简单了。
phpquery项目官网地址:
高蒙2017/02/0613:491.0w浏览0评论
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-08-27 04:04
首页 »PHP 笔记» 如何使用 php采集微信公号文章方法
如何使用php采集微信公号文章
高萌 2017/02/06 13:491.0w 浏览 0 条评论 PHP
最近有采集微信公号文章的需求,所以研究了一下。我发现在刷新搜狗微信公众号文章列表的时候,有一个很恶心的地方就是搜狗会直接屏蔽你的ip并输入验证码。这一步暂时不知道怎么破解。我们只是看php采集微信公号文章内容的方法。至于列表地址的获取,我们后面再研究。在写之前,我搜索了三个用php编写的爬虫:phpQuery、phpspider和QueryList(phpQuery的改进版)。可能不止这些,这就是我发现的。先记录,后研究。下面是我写的一个基本的微信公众号php采集类,是的
最近有采集微信官方号文章的需求,所以研究了一下。我发现在刷新搜狗微信公众号文章列表的时候,有一个很恶心的地方就是搜狗会直接屏蔽你的ip并输入验证码。这一步暂时不知道怎么破解。我们只是看php采集微信公号文章内容的方法。至于list地址的获取,我们以后再研究。
在写之前,我搜索了三个用php编写的爬虫:phpQuery、phpspider和QueryList(phpQuery的改进版本)。可能不止这些,这就是我发现的。先记录,后研究。
以下是我写的一个基本的微信公众号php采集类,有待进一步完善。
/**
* Created by PhpStorm.
* User: Administrator
* Date: 2017/2/6
* Time: 10:54
* author: gm
* 微信公众号文章采集类
*/
class DownWxArticle {
private $mpwxurl = 'http://mp.weixin.qq.com';
private $wxgzherr= '公众号二维码下载失败=>';
private $wximgerr= '图片下载失败=>';
private $direrr = '文件夹创建失败!';
private $fileerr = '资源不存在!';
private $dirurl = '';
/* 抓取微信公众号文章
* $qcode boolean 公众号二维码 false=>不下载 true=>下载
* return
* $content string 内容
* $tile string 标题
* $time int 时间戳
* $wxggh string 微信公众号
* $wxh string 微信号
* $qcode string 公众号二维码
* $tag string 标签 原创
*/
function get_file_article($url,$dir='',$qcode=false)
{
$this->dirurl = $dir?:'/Uploads/'.date('Ymd',time());
if(!$this->put_dir($this->dirurl)){
exit(json_encode(array('msg'=>$this->direrr,'code'=>500)));
}
$file = file_get_contents($url);
if(!$file){
$this->put_error_log($this->dirurl,$this->fileerr);
exit(json_encode(array('msg'=>$this->fileerr,'code'=>500)));
}
// 内容主体
preg_match('/[\s\S]*?/',$file,$content);
// 标题
preg_match('/(.*?)/',$file,$title);
$title = $title?$title[1]:'';
// 时间
preg_match('/(.*?)/',$file,$time);
$time = $time?strtotime($time[1]):'';
// 公众号
preg_match('/(.*?)/',$file,$wxgzh);
$wxgzh = $wxgzh?$wxgzh[1]:'';
// 微信号
preg_match('/([\s\S]*?)/',$file,$wxh);
$wxh = $wxh?$wxh[1]:'';
// 公众号二维码
if($qcode){
preg_match('/window.sg_qr_code="(.*?)";/',$file,$qcode);
$qcodeurl = str_replace('\x26amp;','&',$this->mpwxurl.$qcode[1]);
$qcode = $this->put_file_img($this->dirurl,$qcodeurl);
if(!$qcode){
$this->put_error_log($this->dirurl,$this->wxgzherr.$qcodeurl);
}
}
// 获取标签
preg_match('/(.*?)/',$file,$tag);
$tag = $tag?$tag[1]:'';
// 图片
preg_match_all('//',$content[0],$images);
// 储存原地址和下载后地址
$old = array();
$new = array();
// 去除重复图片地址
$images = array_unique($images[1]);
if($images){
foreach($images as $v){
$filename = $this->put_file_img($this->dirurl,$v);
if($filename){
// 图片保存成功 替换地址
$old[] = $v;
$new[] = $filename;
}else{
// 失败记录日志
$this->put_error_log($this->dirurl,$this->wximgerr.$v);
}
}
$old[] = 'data-src';
$new[] = 'src';
$content = str_replace($old,$new,$content[0]);
}
// 替换音频
$content = str_replace("preview.html","player.html",$content);
// 获取阅读点赞评论等信息
$comment = $this->get_comment_article($url);
$data = array('content'=>$content,'title'=>$title,'time'=>$time,'wxgzh'=>$wxgzh,'wxh'=>$wxh,'qcode'=>$qcode?:'','tag'=>$tag?:'','comment'=>$comment);
return json_encode(array('data'=>$data,'code'=>200,'msg'=>'ok'));
}
/* 抓取保存图片函数
* return
* $filename string 图片地址
*/
function put_file_img($dir='',$image='')
{
// 判断图片的保存类型 截取后四位地址
$exts = array('jpeg','png','jpg');
$filename = $dir.'/'.uniqid().time().rand(10000,99999);
$ext = substr($image,-5);
$ext = explode('=',$ext);
if(in_array($ext[1],$exts) !== false){
$filename .= '.'.$ext[1];
}else{
$filename .= '.gif';
}
$souce = file_get_contents($image);
if(file_put_contents($filename,$souce)){
return $filename;
}else{
return false;
}
}
/* 获取微信公众号文章的【点赞】【阅读】【评论】
* 方法:将地址中的部分参数替换即可。
* 1、s? 替换为 mp/getcomment?
* 2、最后= 替换为 %3D
* return
* read_num 阅读数
* like_num 点赞数
* comment 评论详情
*/
function get_comment_article($url='')
{
$url = substr($url,0,-1);
$url = str_replace('/s','/mp/getcomment',$url).'%3D';
return file_get_contents($url);
}
/* 错误日志记录
* $dir string 文件路径
* $data string 写入内容
*/
function put_error_log($dir,$data)
{
file_put_contents($dir.'/error.log',date('Y-m-d H:i:s',time()).$data.PHP_EOL,FILE_APPEND);
}
/* 创建文件夹
* $dir string 文件夹路径
*/
function put_dir($dir=''){
$bool = true;
if(!is_dir($dir)){
if(!mkdir($dir,777,TRUE)){
$bool = false;
$this->put_error_log($dir,$this->direrr.$dir);
}
}
return $bool;
}
}
使用方法:
$url = '';
$article = new DownWxArticle();
$article->get_file_article($url,'',true); 查看全部
高蒙2017/02/0613:491.0w浏览0评论
首页 »PHP 笔记» 如何使用 php采集微信公号文章方法
如何使用php采集微信公号文章
高萌 2017/02/06 13:491.0w 浏览 0 条评论 PHP
最近有采集微信公号文章的需求,所以研究了一下。我发现在刷新搜狗微信公众号文章列表的时候,有一个很恶心的地方就是搜狗会直接屏蔽你的ip并输入验证码。这一步暂时不知道怎么破解。我们只是看php采集微信公号文章内容的方法。至于列表地址的获取,我们后面再研究。在写之前,我搜索了三个用php编写的爬虫:phpQuery、phpspider和QueryList(phpQuery的改进版)。可能不止这些,这就是我发现的。先记录,后研究。下面是我写的一个基本的微信公众号php采集类,是的
最近有采集微信官方号文章的需求,所以研究了一下。我发现在刷新搜狗微信公众号文章列表的时候,有一个很恶心的地方就是搜狗会直接屏蔽你的ip并输入验证码。这一步暂时不知道怎么破解。我们只是看php采集微信公号文章内容的方法。至于list地址的获取,我们以后再研究。
在写之前,我搜索了三个用php编写的爬虫:phpQuery、phpspider和QueryList(phpQuery的改进版本)。可能不止这些,这就是我发现的。先记录,后研究。
以下是我写的一个基本的微信公众号php采集类,有待进一步完善。
/**
* Created by PhpStorm.
* User: Administrator
* Date: 2017/2/6
* Time: 10:54
* author: gm
* 微信公众号文章采集类
*/
class DownWxArticle {
private $mpwxurl = 'http://mp.weixin.qq.com';
private $wxgzherr= '公众号二维码下载失败=>';
private $wximgerr= '图片下载失败=>';
private $direrr = '文件夹创建失败!';
private $fileerr = '资源不存在!';
private $dirurl = '';
/* 抓取微信公众号文章
* $qcode boolean 公众号二维码 false=>不下载 true=>下载
* return
* $content string 内容
* $tile string 标题
* $time int 时间戳
* $wxggh string 微信公众号
* $wxh string 微信号
* $qcode string 公众号二维码
* $tag string 标签 原创
*/
function get_file_article($url,$dir='',$qcode=false)
{
$this->dirurl = $dir?:'/Uploads/'.date('Ymd',time());
if(!$this->put_dir($this->dirurl)){
exit(json_encode(array('msg'=>$this->direrr,'code'=>500)));
}
$file = file_get_contents($url);
if(!$file){
$this->put_error_log($this->dirurl,$this->fileerr);
exit(json_encode(array('msg'=>$this->fileerr,'code'=>500)));
}
// 内容主体
preg_match('/[\s\S]*?/',$file,$content);
// 标题
preg_match('/(.*?)/',$file,$title);
$title = $title?$title[1]:'';
// 时间
preg_match('/(.*?)/',$file,$time);
$time = $time?strtotime($time[1]):'';
// 公众号
preg_match('/(.*?)/',$file,$wxgzh);
$wxgzh = $wxgzh?$wxgzh[1]:'';
// 微信号
preg_match('/([\s\S]*?)/',$file,$wxh);
$wxh = $wxh?$wxh[1]:'';
// 公众号二维码
if($qcode){
preg_match('/window.sg_qr_code="(.*?)";/',$file,$qcode);
$qcodeurl = str_replace('\x26amp;','&',$this->mpwxurl.$qcode[1]);
$qcode = $this->put_file_img($this->dirurl,$qcodeurl);
if(!$qcode){
$this->put_error_log($this->dirurl,$this->wxgzherr.$qcodeurl);
}
}
// 获取标签
preg_match('/(.*?)/',$file,$tag);
$tag = $tag?$tag[1]:'';
// 图片
preg_match_all('//',$content[0],$images);
// 储存原地址和下载后地址
$old = array();
$new = array();
// 去除重复图片地址
$images = array_unique($images[1]);
if($images){
foreach($images as $v){
$filename = $this->put_file_img($this->dirurl,$v);
if($filename){
// 图片保存成功 替换地址
$old[] = $v;
$new[] = $filename;
}else{
// 失败记录日志
$this->put_error_log($this->dirurl,$this->wximgerr.$v);
}
}
$old[] = 'data-src';
$new[] = 'src';
$content = str_replace($old,$new,$content[0]);
}
// 替换音频
$content = str_replace("preview.html","player.html",$content);
// 获取阅读点赞评论等信息
$comment = $this->get_comment_article($url);
$data = array('content'=>$content,'title'=>$title,'time'=>$time,'wxgzh'=>$wxgzh,'wxh'=>$wxh,'qcode'=>$qcode?:'','tag'=>$tag?:'','comment'=>$comment);
return json_encode(array('data'=>$data,'code'=>200,'msg'=>'ok'));
}
/* 抓取保存图片函数
* return
* $filename string 图片地址
*/
function put_file_img($dir='',$image='')
{
// 判断图片的保存类型 截取后四位地址
$exts = array('jpeg','png','jpg');
$filename = $dir.'/'.uniqid().time().rand(10000,99999);
$ext = substr($image,-5);
$ext = explode('=',$ext);
if(in_array($ext[1],$exts) !== false){
$filename .= '.'.$ext[1];
}else{
$filename .= '.gif';
}
$souce = file_get_contents($image);
if(file_put_contents($filename,$souce)){
return $filename;
}else{
return false;
}
}
/* 获取微信公众号文章的【点赞】【阅读】【评论】
* 方法:将地址中的部分参数替换即可。
* 1、s? 替换为 mp/getcomment?
* 2、最后= 替换为 %3D
* return
* read_num 阅读数
* like_num 点赞数
* comment 评论详情
*/
function get_comment_article($url='')
{
$url = substr($url,0,-1);
$url = str_replace('/s','/mp/getcomment',$url).'%3D';
return file_get_contents($url);
}
/* 错误日志记录
* $dir string 文件路径
* $data string 写入内容
*/
function put_error_log($dir,$data)
{
file_put_contents($dir.'/error.log',date('Y-m-d H:i:s',time()).$data.PHP_EOL,FILE_APPEND);
}
/* 创建文件夹
* $dir string 文件夹路径
*/
function put_dir($dir=''){
$bool = true;
if(!is_dir($dir)){
if(!mkdir($dir,777,TRUE)){
$bool = false;
$this->put_error_log($dir,$this->direrr.$dir);
}
}
return $bool;
}
}
使用方法:
$url = '';
$article = new DownWxArticle();
$article->get_file_article($url,'',true);
微软翻译百度百科微信公众号文章文章内容内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-08-25 19:05
querylist采集微信公众号文章内容
1、文件查看txt文件。
2、输入requesturl地址参数。
3、按回车键。
自己在家做爬虫三个步骤:1.找两篇自己想要的文章,下载文章;2.把下载下来的文章全部request一次,再下载下一篇;3.批量处理所有的图片,并且命名为json参数,当然,其中还有一点机智。
百度,
...
-us/windows/hardware/msie/30.0.2015/scripts/jsdebug.conf
使用微软翻译百度百科微信公众号文章...
留意官方文档:微信公众号网页使用的数据接口都是有文档说明的。
以前用腾讯统计!
实践中,我这边通常是一次性request有几千的图片然后就writecode写入数据库。成功率在80%多。感觉更多还是和熟练程度有关吧。
官方有相关的文档,
微信公众号文章有很多参数组成比如说头图,公众号标题,注册时间,文章列表,是否包含广告字样等。微信公众号推送文章,首先第一步就是获取图片url,然后再查询请求,请求的参数就是公众号名称,文章文章标题,文章内容,原文链接,图片url等。 查看全部
微软翻译百度百科微信公众号文章文章内容内容
querylist采集微信公众号文章内容
1、文件查看txt文件。
2、输入requesturl地址参数。
3、按回车键。
自己在家做爬虫三个步骤:1.找两篇自己想要的文章,下载文章;2.把下载下来的文章全部request一次,再下载下一篇;3.批量处理所有的图片,并且命名为json参数,当然,其中还有一点机智。
百度,
...
-us/windows/hardware/msie/30.0.2015/scripts/jsdebug.conf
使用微软翻译百度百科微信公众号文章...
留意官方文档:微信公众号网页使用的数据接口都是有文档说明的。
以前用腾讯统计!
实践中,我这边通常是一次性request有几千的图片然后就writecode写入数据库。成功率在80%多。感觉更多还是和熟练程度有关吧。
官方有相关的文档,
微信公众号文章有很多参数组成比如说头图,公众号标题,注册时间,文章列表,是否包含广告字样等。微信公众号推送文章,首先第一步就是获取图片url,然后再查询请求,请求的参数就是公众号名称,文章文章标题,文章内容,原文链接,图片url等。
搜狗搜索采集公众号历史消息(图)问题解析
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-08-24 07:37
通过搜狗搜索采集公众号的历史记录存在一些问题:
1、有验证码;
2、历史消息列表只有最近10条群发消息;
3、文章地址有有效期;
4、据说批量采集需要改ip;
通过我之前的文章方法,没有出现这样的问题,虽然采集系统设置不像传统的采集器写规则爬行那么简单。但是batch采集构建一次后的效率还是可以的。而且采集的文章地址是永久有效的,你可以通过采集获取一个公众号的所有历史信息。
先从公众号文章的链接地址说起:
1、微信右上角菜单复制的链接地址:
2、从历史消息列表中获取的地址:
#wechat_redirect
3、完整真实地址:
%3D%3D&devicetype=iOS10.1.1&version=16050120&nettype=WIFI&fontScale=100&pass_ticket=FGRyGfXLPEa4AeOsIZu7KFJo6CiXOZex83Y5YBRglW4%3D&1w_head
以上三个地址是同一篇文章文章的地址,在不同位置获取时得到三个完全不同的结果。
和历史新闻页面一样,微信也有自动添加参数的机制。第一个地址是通过复制链接获得的,看起来像一个变相的代码。其实没用,我们不去想。第二个地址是通过上面文章介绍的方法从json文章历史消息列表中得到的链接地址,我们可以把这个地址保存到数据库中。然后就可以通过这个地址从服务器获取文章的内容了。第三个链接添加参数后,目的是让文章页面中的阅读js获取阅读和点赞的json结果。在我们之前的文章方法中,因为文章页面是由客户端打开显示的,因为有这些参数,文章页面中的js会自动获取阅读量,所以我们可以通过代理服务获取这个文章的阅读量。
本文章的内容是根据本专栏前面文章介绍的方法获得的大量微信文章,我们详细研究了如何获取文章内容和其他一些有用的信息。方法。
(文章list 保存在我的数据库中,一些字段)
1、Get文章源代码:
文章源代码可以通过php函数file_get_content()读入一个变量。因为微信文章的源码可以从浏览器打开,这里就不贴了,以免浪费页面空间。
2、源代码中的有用信息:
1)原创内容:
原创内容收录在一个标签中,通过php代码获取:
<p> 查看全部
搜狗搜索采集公众号历史消息(图)问题解析
通过搜狗搜索采集公众号的历史记录存在一些问题:
1、有验证码;
2、历史消息列表只有最近10条群发消息;
3、文章地址有有效期;
4、据说批量采集需要改ip;
通过我之前的文章方法,没有出现这样的问题,虽然采集系统设置不像传统的采集器写规则爬行那么简单。但是batch采集构建一次后的效率还是可以的。而且采集的文章地址是永久有效的,你可以通过采集获取一个公众号的所有历史信息。
先从公众号文章的链接地址说起:
1、微信右上角菜单复制的链接地址:
2、从历史消息列表中获取的地址:
#wechat_redirect
3、完整真实地址:
%3D%3D&devicetype=iOS10.1.1&version=16050120&nettype=WIFI&fontScale=100&pass_ticket=FGRyGfXLPEa4AeOsIZu7KFJo6CiXOZex83Y5YBRglW4%3D&1w_head
以上三个地址是同一篇文章文章的地址,在不同位置获取时得到三个完全不同的结果。
和历史新闻页面一样,微信也有自动添加参数的机制。第一个地址是通过复制链接获得的,看起来像一个变相的代码。其实没用,我们不去想。第二个地址是通过上面文章介绍的方法从json文章历史消息列表中得到的链接地址,我们可以把这个地址保存到数据库中。然后就可以通过这个地址从服务器获取文章的内容了。第三个链接添加参数后,目的是让文章页面中的阅读js获取阅读和点赞的json结果。在我们之前的文章方法中,因为文章页面是由客户端打开显示的,因为有这些参数,文章页面中的js会自动获取阅读量,所以我们可以通过代理服务获取这个文章的阅读量。
本文章的内容是根据本专栏前面文章介绍的方法获得的大量微信文章,我们详细研究了如何获取文章内容和其他一些有用的信息。方法。
(文章list 保存在我的数据库中,一些字段)
1、Get文章源代码:
文章源代码可以通过php函数file_get_content()读入一个变量。因为微信文章的源码可以从浏览器打开,这里就不贴了,以免浪费页面空间。
2、源代码中的有用信息:
1)原创内容:
原创内容收录在一个标签中,通过php代码获取:
<p>
querylist采集微信公众号文章文章的关键词解析服务参考
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-08-22 21:05
querylist采集微信公众号文章的关键词,并不完全是文章中的关键词,而是“信息流”里的一些包含公众号相关关键词的词。也就是你点开“信息流”,页面里会出现公众号文章的链接(你在输入框里输入关键词时,它并不要求你给文章添加关键词)。在在筛选出的链接页面的右上角,会看到一个蓝色方框的token,即唯一的权威token。
发现querylist的作用,关键词过滤,
querylist是一个文章关键词的数据库,通过文章标题点击querylist查看文章,
querylist提供了你所关注的文章的一些常见的关键词。关键词解析服务一般用于分发效果的衡量。有时可以通过监测关键词的变化情况进行分发的质量和效果的衡量。
分享querylist,供参考
querylist不能理解为链接数量,可以理解为你给这篇文章添加关键词时的“信息流”位置。
在文章详情页面的主图是一个唯一的query地址,在这个query地址下,又会有很多很多的文章在你的浏览过程中展示,每篇文章都是独立,不会共享id。在文章详情页面顶部的显示文章时,展示的query地址不只是显示文章这一个,每一篇文章会有不同的展示位置。而在文章详情页面中是所有显示的文章都要显示。因此,文章详情页只能展示这一篇文章,既可以链接到这一篇文章,也可以分别链接到n篇文章。
所以,当这一篇文章被多篇文章显示之后,说明这一篇没有被多篇文章展示,属于临时状态,过一段时间后,再重新搜索一遍它,再次确认被多篇文章展示过。所以,querylist不是文章数量,而是query地址。不能理解为链接数量。 查看全部
querylist采集微信公众号文章文章的关键词解析服务参考
querylist采集微信公众号文章的关键词,并不完全是文章中的关键词,而是“信息流”里的一些包含公众号相关关键词的词。也就是你点开“信息流”,页面里会出现公众号文章的链接(你在输入框里输入关键词时,它并不要求你给文章添加关键词)。在在筛选出的链接页面的右上角,会看到一个蓝色方框的token,即唯一的权威token。
发现querylist的作用,关键词过滤,
querylist是一个文章关键词的数据库,通过文章标题点击querylist查看文章,
querylist提供了你所关注的文章的一些常见的关键词。关键词解析服务一般用于分发效果的衡量。有时可以通过监测关键词的变化情况进行分发的质量和效果的衡量。
分享querylist,供参考
querylist不能理解为链接数量,可以理解为你给这篇文章添加关键词时的“信息流”位置。
在文章详情页面的主图是一个唯一的query地址,在这个query地址下,又会有很多很多的文章在你的浏览过程中展示,每篇文章都是独立,不会共享id。在文章详情页面顶部的显示文章时,展示的query地址不只是显示文章这一个,每一篇文章会有不同的展示位置。而在文章详情页面中是所有显示的文章都要显示。因此,文章详情页只能展示这一篇文章,既可以链接到这一篇文章,也可以分别链接到n篇文章。
所以,当这一篇文章被多篇文章显示之后,说明这一篇没有被多篇文章展示,属于临时状态,过一段时间后,再重新搜索一遍它,再次确认被多篇文章展示过。所以,querylist不是文章数量,而是query地址。不能理解为链接数量。
微信文章自动化爬取过程中出现的问题及解决办法!
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-08-21 03:30
实现功能
微信账号目前可以获取具体指标:biz、昵称、微信ID、头像、二维码、个人资料、认证、认证信息、账号主题、归属地等
WeChat文章目前可用的具体指标(包括但不限于):阅读数、点赞(浏览)数、评论内容和总评论数、正文内容、图片、视频地址、是否原创、永久链接原文等
实施技术和工具
经过大量长期测试,保证微信客户端采集300公众号每天文章数据稳定运行,不会被封号。如果您频繁访问微信公众号的历史消息页面,将被禁止24小时。
目前比较好的策略:访问文章页面后休眠5秒,访问微信公众号历史消息页面后休眠150秒。
微信购买渠道qq客服:1653925422 60元购买了一个非实名微信账号。购买账号后,不得添加好友,否则将被微信账号永久屏蔽为营销账号。仅用于访问微信。公众号文章不会被封。
详细设计
1、 先准备一批微信公众号biz,爬进redis队列。
数据库设计
两个redis消息队列
1、微信公众号业务队列待抓取
wechat_biz_quene list 先进先出队列
复制代码
2、获取的微信文章detail页面url队列用于遍历获取的历史文章对应的阅读、点赞、评论。
<p>2、在模拟器中打开微信atx框架,模拟点击要运行的第一个公众号拼接的历史消息界面,后续流程和数据流逻辑如下图所示 查看全部
微信文章自动化爬取过程中出现的问题及解决办法!
实现功能
微信账号目前可以获取具体指标:biz、昵称、微信ID、头像、二维码、个人资料、认证、认证信息、账号主题、归属地等
WeChat文章目前可用的具体指标(包括但不限于):阅读数、点赞(浏览)数、评论内容和总评论数、正文内容、图片、视频地址、是否原创、永久链接原文等
实施技术和工具
经过大量长期测试,保证微信客户端采集300公众号每天文章数据稳定运行,不会被封号。如果您频繁访问微信公众号的历史消息页面,将被禁止24小时。
目前比较好的策略:访问文章页面后休眠5秒,访问微信公众号历史消息页面后休眠150秒。
微信购买渠道qq客服:1653925422 60元购买了一个非实名微信账号。购买账号后,不得添加好友,否则将被微信账号永久屏蔽为营销账号。仅用于访问微信。公众号文章不会被封。
详细设计
1、 先准备一批微信公众号biz,爬进redis队列。
数据库设计
两个redis消息队列
1、微信公众号业务队列待抓取
wechat_biz_quene list 先进先出队列
复制代码
2、获取的微信文章detail页面url队列用于遍历获取的历史文章对应的阅读、点赞、评论。
<p>2、在模拟器中打开微信atx框架,模拟点击要运行的第一个公众号拼接的历史消息界面,后续流程和数据流逻辑如下图所示
jsonp对文本的post方式提供支持的querylist集合:xxxpost提交的请求
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-08-20 01:03
querylist采集微信公众号文章信息的querylist集合。请求url“/”返回querylist集合:xxxtitletextcontent\wx:href=''\wx:src=''\wx:msg=''\request'''url这个路径下,有“\\users\\{{username}}"”字段,记录的是用户信息如果请求的url不是users,请使用post方式发送请求,如果没有请求过,就直接返回请求头和文本。
表单域可以请求到文本。msg字段不支持enctype属性。jsonp对文本的post方式提供支持,通过参数可以获取具体内容,如果参数是一个multipart/form-data格式的字段则post传输的数据可以是post、get、head等。请求querylist集合格式url:xxxrequesturl:msg/{{username}}返回的querylist集合:xxxpost提交的请求的querylist集合:xxxmultipart/form-data提交的请求的表单数据格式:[xxx][{{username}}]dataheader限制:post以json格式请求时,请提供dataheader。
提交表单数据时,需要提供binding字段,详见表单提交-materialdesign总结book-home微信公众号图书分类:图书分类querylist集合:{{图书名}}|{{图书书架编号}}+{{isblank}}-{{isblank}}-{{username}}main-endmain-endlocation="/main/"launch-process10微信启动按钮,可以指定定位到相应的位置,注意不要跨域。 查看全部
jsonp对文本的post方式提供支持的querylist集合:xxxpost提交的请求
querylist采集微信公众号文章信息的querylist集合。请求url“/”返回querylist集合:xxxtitletextcontent\wx:href=''\wx:src=''\wx:msg=''\request'''url这个路径下,有“\\users\\{{username}}"”字段,记录的是用户信息如果请求的url不是users,请使用post方式发送请求,如果没有请求过,就直接返回请求头和文本。
表单域可以请求到文本。msg字段不支持enctype属性。jsonp对文本的post方式提供支持,通过参数可以获取具体内容,如果参数是一个multipart/form-data格式的字段则post传输的数据可以是post、get、head等。请求querylist集合格式url:xxxrequesturl:msg/{{username}}返回的querylist集合:xxxpost提交的请求的querylist集合:xxxmultipart/form-data提交的请求的表单数据格式:[xxx][{{username}}]dataheader限制:post以json格式请求时,请提供dataheader。
提交表单数据时,需要提供binding字段,详见表单提交-materialdesign总结book-home微信公众号图书分类:图书分类querylist集合:{{图书名}}|{{图书书架编号}}+{{isblank}}-{{isblank}}-{{username}}main-endmain-endlocation="/main/"launch-process10微信启动按钮,可以指定定位到相应的位置,注意不要跨域。
企业做好网络营销需要六大策略,你做对了吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-08-17 22:03
随着互联网的发展,越来越多的公司从事网络营销。之前也有一篇文章企业如何进行网络营销的文章(欢迎点击《企业做网络营销的六大策略》),但是很多企业都急于进入电商圈,有网络营销中的许多禁忌。网络营销要想成功,必须避免以下八个问题:
1、立即开始,没有任何计划
很多公司一开始对网络营销并没有一个清晰的认识。大多数企业的管理者意识到应该通过报纸、电视等媒体进行网络营销,通过朋友的介绍,或者业务员的鼓动,通过互联网扩大业务和销售。于是我立即安排人员联系制作网站,发布信息,投入线上推广。整个网络营销过程在没有任何计划的情况下展开。一段时间后,不仅没有效果,还失去了继续坚持网络营销的信心和兴趣,出现了公司退出公司宣布退出等悲剧。
众所周知,网络营销是一个“顶级”工程,涉及到很多方面。需要结合自身实际情况,有明确的企业定位。没有定位,就没有营销。然后,分析消费者的需求,制定周密、科学的计划以取得成功。从启动网站建设、企业信息发布,到制定推广预算、选择网络营销方式、安排专职网络营销推广、客服、文案等,一切工作安排到位,持之以恒,使公司的网络营销过程可以顺利进行。只有这样,才能为最终达到理想的网络营销效果打下基础。
2、营销型网站的建设强调设计和轻应用
打造企业网站是开展网络营销非常重要的一环,尤其是打造面向营销的网站。然而,事实上,大多数企业网站并没有在网络营销中发挥应有的作用。这与公司对网站construction的理解分不开。大多数公司认为网站是公司的网上形象,越漂亮越好。美术设计、Flash动画、企业形象成为企业最关注的领域。至于网站是否满足网络营销的需求,是否方便日后的功能添加或调整,暂不考虑。负责网站制作的服务事业部也盲目迎合公司喜好,在表现形式上下功夫,提高网站的建设成本,当然也不负责内部功能和营销应用.
网站construction 是服务于网络营销的需求,这个要明确。 网站施工要设计和应用并重。不仅要注重企业形象展示,还要明确网站的网络营销服务功能和流程,注重产品或服务展示、用户交互、信息检索、客户体验等方面的建设。 ,让网站更实用有效 和谐简单,让网站具有营销力、传播力和转化力。
3、盲目进行垃圾邮件营销、海量信息等
很多企业在面对网络营销时,都不知所措。许多公司选择向各种平台发送垃圾邮件或大量信息,例如 BBS 和博客。虽然短期内企业可以看到一些网络营销效果,比如网站访问量的增加等,但从长远来看,企业遭受的损失远远大于网络营销取得的效果.
一是企业形象受损。垃圾邮件深受网友的厌恶。大多数垃圾邮件都是企业诚信缺失、产品质量差,甚至恶意欺诈和非法产品。企业一旦与垃圾邮件相关联,其在消费者心目中的形象就会大打折扣。
其次,一旦企业习惯了这种低成本、自害的网络营销推广方式,一味追求低报酬、高回报的畸形网络营销产品,对投资回报缺乏正确认识,将难以接受真正健康有益的网络营销服务和产品,错失网络营销和企业发展的良机。企业要结合自身发展情况,有一套适合自己的推广渠道。
4、网络营销产品跟风买
目前,网络营销产品种类繁多,加上销售人员的聪明才智,企业在产品选择上有很多困惑。我们经常会发现,一旦某个行业的几家公司使用了某种网络营销产品,同行业的其他公司就会陆续购买。
很多网络营销服务商已经掌握了公司的购买和比较心理,通过行业客户会议、网络营销产品行业说明会等会议,充分发挥“客户见证”和“推荐”的作用。技能使企业能够削弱自己的判断力,跟随他人的选择,或者盲目竞争和购买。实践证明,适合你的产品才是好产品。跟风购买的网络营销产品往往不仅不是最合适的,而且由于过度使用,网络营销的效果越来越差。创业者要懂得放弃,学会选择。
5、利用搜索引擎竞拍产品,等待兔子
目前,谷歌、雅虎、百度等搜索引擎竞价产品是网络营销的主流产品,越来越多的企业选择搜索引擎竞价产品。大多数企业并不知道在购买了有竞争力的产品后,他们需要定期进行优化和维护,而只是等待客户上门。这种效果只会变得更糟。
搜索引擎竞价的效果是由很多因素组成的。日常消费预算、关键词上词数、报表分析等维护工作的好坏,将直接影响搜索引擎竞价产品的效果。企业在使用竞价产品时,不能坐以待毙,而应定期对其进行维护和优化。如果他们能把握“以用户体验为中心”的原则,努力提升用户的感受,网络营销的效果才能得到提升。 .
6、线上营销和线下营销完全分离
网络营销是整体营销战略的一部分,是实现企业销售和盈利的重要手段。需要线上线下有效结合才能取得显着效果。许多公司认为互联网只是一种媒介。即使他们已经实现了在线营销,他们也可以通过互联网推广他们的公司和产品,提高他们的品牌知名度和企业形象。这是一种不完整的网络营销意识。没有线下参与的网络营销不是真正的网络营销,难以达到“营销”和“销售”的终极目标。
其实,网络营销的作用远不止这些。对于线下体验较多的企业,要抓住线上宣传推广的作用,再线下提升客户体验,从而采集销售线索,挖掘潜在客户,线下与线上相结合,最终达成交易,并为企业创造利润。
7、信息采集方法一劳永逸
采集信息是一种流行的“网络营销方式”。许多网站通过编写程序或使用采集软件从其他网站那里抓取大量需要的网络信息来丰富他们的网站内容。这样,网站的内容快速丰富,搜索引擎收录页面的数量也可以快速增加,可以快速吸引访问者,增加流量。然而事实证明,没有成功的网站来自信息采集,成功的网络营销也没有那么简单。
Information采集可以采集到大量需要的信息,但信息质量参差不齐,大部分是互联网上重复性高的内容,对搜索引擎不起作用。对于用户来说,只是网站的另一个克隆,没有吸引力。对于网站内容的建设,企业还是要脚踏实地,做有自己特色和原创精神的内容,少积累多,用心培养忠实用户,丰富网站一些案例研究。 @的内容逐渐通向成功。
8、Background 数据,重统计多于分析
世界上有没有哪位创业者在进行网络营销时最不注重网络营销的效果?但在现实中,很多企业在对网络营销效果的评价中,大多偏重统计,忽视分析。在网络营销效果方面,网站的访问量和网站的排名是普遍关注的内容。用户回访率、用户来源分析、关键词分析等更深入的网络营销效果分析没有得到重视。
全面的网络营销效果评估应该包括网站访问量、用户粘性、来源分析、搜索引擎关键词效果分析、各种推广产品的应用效果分析。基于对用户信息等方面的分析,可以根据这些分析得出下一步网络营销工作的改进建议和方案。网络营销重统计,轻分析,无助于改善网络营销现状。
以上八家企业在网络营销中应注意的问题。大多数公司都出现了。我相信,如果每个创业者在开展网络营销时都细心、细心、用心,他一定会走向成功。当然,网络营销是一门深不可测的知识领域,更多的还是需要我们主动学习来充实自己的大脑,然后将更多的理论知识应用到实际的生活和工作中。更多网络营销的理论知识和操作技巧,欢迎关注山人资讯,教你如何进行高效的网络营销。
沉阳网站建筑、沉阳网站制作、沉阳微信小程序、沉阳互联网公司开发、沉阳工作网站、沉阳做网站、沉阳制造网站、沉阳网站保护、沉阳网站建筑公司,沉阳制作网页,辽宁网站建筑,辽宁网站设计,企业网站建筑,沉阳,沉阳手机网站,3G网站,手机网站制作,沉阳微信推广,沉阳微信营销,企业微信营销,沉阳微信公众平台营销,沉阳微信开发,沉阳微信公众平台,沉阳微信公众平台开发,沉阳微信自动回复,沉阳微信接入,沉阳微信平台接入,沉阳微信,沉阳Micro网站,沉阳商城开发,沉阳商城建设,沉阳3D打印机,沉阳3D打印服务,沉阳3D打印机 查看全部
企业做好网络营销需要六大策略,你做对了吗?
随着互联网的发展,越来越多的公司从事网络营销。之前也有一篇文章企业如何进行网络营销的文章(欢迎点击《企业做网络营销的六大策略》),但是很多企业都急于进入电商圈,有网络营销中的许多禁忌。网络营销要想成功,必须避免以下八个问题:
1、立即开始,没有任何计划
很多公司一开始对网络营销并没有一个清晰的认识。大多数企业的管理者意识到应该通过报纸、电视等媒体进行网络营销,通过朋友的介绍,或者业务员的鼓动,通过互联网扩大业务和销售。于是我立即安排人员联系制作网站,发布信息,投入线上推广。整个网络营销过程在没有任何计划的情况下展开。一段时间后,不仅没有效果,还失去了继续坚持网络营销的信心和兴趣,出现了公司退出公司宣布退出等悲剧。
众所周知,网络营销是一个“顶级”工程,涉及到很多方面。需要结合自身实际情况,有明确的企业定位。没有定位,就没有营销。然后,分析消费者的需求,制定周密、科学的计划以取得成功。从启动网站建设、企业信息发布,到制定推广预算、选择网络营销方式、安排专职网络营销推广、客服、文案等,一切工作安排到位,持之以恒,使公司的网络营销过程可以顺利进行。只有这样,才能为最终达到理想的网络营销效果打下基础。
2、营销型网站的建设强调设计和轻应用
打造企业网站是开展网络营销非常重要的一环,尤其是打造面向营销的网站。然而,事实上,大多数企业网站并没有在网络营销中发挥应有的作用。这与公司对网站construction的理解分不开。大多数公司认为网站是公司的网上形象,越漂亮越好。美术设计、Flash动画、企业形象成为企业最关注的领域。至于网站是否满足网络营销的需求,是否方便日后的功能添加或调整,暂不考虑。负责网站制作的服务事业部也盲目迎合公司喜好,在表现形式上下功夫,提高网站的建设成本,当然也不负责内部功能和营销应用.
网站construction 是服务于网络营销的需求,这个要明确。 网站施工要设计和应用并重。不仅要注重企业形象展示,还要明确网站的网络营销服务功能和流程,注重产品或服务展示、用户交互、信息检索、客户体验等方面的建设。 ,让网站更实用有效 和谐简单,让网站具有营销力、传播力和转化力。
3、盲目进行垃圾邮件营销、海量信息等
很多企业在面对网络营销时,都不知所措。许多公司选择向各种平台发送垃圾邮件或大量信息,例如 BBS 和博客。虽然短期内企业可以看到一些网络营销效果,比如网站访问量的增加等,但从长远来看,企业遭受的损失远远大于网络营销取得的效果.
一是企业形象受损。垃圾邮件深受网友的厌恶。大多数垃圾邮件都是企业诚信缺失、产品质量差,甚至恶意欺诈和非法产品。企业一旦与垃圾邮件相关联,其在消费者心目中的形象就会大打折扣。
其次,一旦企业习惯了这种低成本、自害的网络营销推广方式,一味追求低报酬、高回报的畸形网络营销产品,对投资回报缺乏正确认识,将难以接受真正健康有益的网络营销服务和产品,错失网络营销和企业发展的良机。企业要结合自身发展情况,有一套适合自己的推广渠道。
4、网络营销产品跟风买
目前,网络营销产品种类繁多,加上销售人员的聪明才智,企业在产品选择上有很多困惑。我们经常会发现,一旦某个行业的几家公司使用了某种网络营销产品,同行业的其他公司就会陆续购买。
很多网络营销服务商已经掌握了公司的购买和比较心理,通过行业客户会议、网络营销产品行业说明会等会议,充分发挥“客户见证”和“推荐”的作用。技能使企业能够削弱自己的判断力,跟随他人的选择,或者盲目竞争和购买。实践证明,适合你的产品才是好产品。跟风购买的网络营销产品往往不仅不是最合适的,而且由于过度使用,网络营销的效果越来越差。创业者要懂得放弃,学会选择。
5、利用搜索引擎竞拍产品,等待兔子
目前,谷歌、雅虎、百度等搜索引擎竞价产品是网络营销的主流产品,越来越多的企业选择搜索引擎竞价产品。大多数企业并不知道在购买了有竞争力的产品后,他们需要定期进行优化和维护,而只是等待客户上门。这种效果只会变得更糟。
搜索引擎竞价的效果是由很多因素组成的。日常消费预算、关键词上词数、报表分析等维护工作的好坏,将直接影响搜索引擎竞价产品的效果。企业在使用竞价产品时,不能坐以待毙,而应定期对其进行维护和优化。如果他们能把握“以用户体验为中心”的原则,努力提升用户的感受,网络营销的效果才能得到提升。 .
6、线上营销和线下营销完全分离
网络营销是整体营销战略的一部分,是实现企业销售和盈利的重要手段。需要线上线下有效结合才能取得显着效果。许多公司认为互联网只是一种媒介。即使他们已经实现了在线营销,他们也可以通过互联网推广他们的公司和产品,提高他们的品牌知名度和企业形象。这是一种不完整的网络营销意识。没有线下参与的网络营销不是真正的网络营销,难以达到“营销”和“销售”的终极目标。
其实,网络营销的作用远不止这些。对于线下体验较多的企业,要抓住线上宣传推广的作用,再线下提升客户体验,从而采集销售线索,挖掘潜在客户,线下与线上相结合,最终达成交易,并为企业创造利润。
7、信息采集方法一劳永逸
采集信息是一种流行的“网络营销方式”。许多网站通过编写程序或使用采集软件从其他网站那里抓取大量需要的网络信息来丰富他们的网站内容。这样,网站的内容快速丰富,搜索引擎收录页面的数量也可以快速增加,可以快速吸引访问者,增加流量。然而事实证明,没有成功的网站来自信息采集,成功的网络营销也没有那么简单。
Information采集可以采集到大量需要的信息,但信息质量参差不齐,大部分是互联网上重复性高的内容,对搜索引擎不起作用。对于用户来说,只是网站的另一个克隆,没有吸引力。对于网站内容的建设,企业还是要脚踏实地,做有自己特色和原创精神的内容,少积累多,用心培养忠实用户,丰富网站一些案例研究。 @的内容逐渐通向成功。
8、Background 数据,重统计多于分析
世界上有没有哪位创业者在进行网络营销时最不注重网络营销的效果?但在现实中,很多企业在对网络营销效果的评价中,大多偏重统计,忽视分析。在网络营销效果方面,网站的访问量和网站的排名是普遍关注的内容。用户回访率、用户来源分析、关键词分析等更深入的网络营销效果分析没有得到重视。
全面的网络营销效果评估应该包括网站访问量、用户粘性、来源分析、搜索引擎关键词效果分析、各种推广产品的应用效果分析。基于对用户信息等方面的分析,可以根据这些分析得出下一步网络营销工作的改进建议和方案。网络营销重统计,轻分析,无助于改善网络营销现状。
以上八家企业在网络营销中应注意的问题。大多数公司都出现了。我相信,如果每个创业者在开展网络营销时都细心、细心、用心,他一定会走向成功。当然,网络营销是一门深不可测的知识领域,更多的还是需要我们主动学习来充实自己的大脑,然后将更多的理论知识应用到实际的生活和工作中。更多网络营销的理论知识和操作技巧,欢迎关注山人资讯,教你如何进行高效的网络营销。
沉阳网站建筑、沉阳网站制作、沉阳微信小程序、沉阳互联网公司开发、沉阳工作网站、沉阳做网站、沉阳制造网站、沉阳网站保护、沉阳网站建筑公司,沉阳制作网页,辽宁网站建筑,辽宁网站设计,企业网站建筑,沉阳,沉阳手机网站,3G网站,手机网站制作,沉阳微信推广,沉阳微信营销,企业微信营销,沉阳微信公众平台营销,沉阳微信开发,沉阳微信公众平台,沉阳微信公众平台开发,沉阳微信自动回复,沉阳微信接入,沉阳微信平台接入,沉阳微信,沉阳Micro网站,沉阳商城开发,沉阳商城建设,沉阳3D打印机,沉阳3D打印服务,沉阳3D打印机
shop_xiaohao001_关注shopx药店_karaoke_社区(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-08-16 04:02
querylist采集微信公众号文章,实现百度、头条等搜索引擎排名和微信搜索的推广。推广效果是电商数据里面永远的痛,只有做好开源节流才能有意想不到的收获。精准推广的本质,在于挖掘目标人群的需求。简单的理解有:做什么产品?买什么东西?购买什么产品?推广还是从人性上挖掘。微信里面,可以通过朋友圈、公众号推送、客服回复等方式,来获取目标人群的公众号信息,然后以公众号为依托,对文章进行推广。
推广效果==人群质量*转化率*精准度基于精准用户人群的分析和优化,达到排名和业绩上的提升。一、筛选目标用户维度包括:用户行为分析,文章发送时间、内容等信息目标用户人群的人物画像,标签,性别、年龄、职业等行为分析包括:用户特征、地域、兴趣爱好等内容,参考一下做的非常不错的文章,从标题到内容都是包装好的,你可以借鉴一下:shop_xiaohao001_关注shopx药店_karaoke_社区_b2c/?itemid=27613055_aw1b0_3ub45464ce7bd1347ee058&utm_source=toutiao-io&utm_medium=toutiao_android&utm_campaign=toutiao_android&utm_term=23&utm_division=zhihu&utm_content=shopx要学会分析用户的行为,用户的行为可以总结成为一些标签比如:停留时间,点赞、转发次数,互动频率...,每个标签通过爬虫抓取,然后组合起来得到最终的人群标签。
文章发送时间决定了有多少人看到你,文章发送时间点需要设置合理,这方面可以采用意图猜测这种方式来推测。根据转发次数,来推测是否有做公众号的推广等。意图猜测是采用用户反馈等第三方服务,比如:活动,促销等等有类似经验的人可以基于你的竞争对手总结出用户使用这个服务时的动机:定向活动推送,用户就会参与,会有转发、关注的动作。
有需求就会参与,有转发、关注、评论等行为才会有下单等一系列动作...分析用户行为,来获取目标人群的特征属性,整理出目标人群的特征集合,例如:男性/女性/地域/...,通过小卡片、二维码或者vip会员邀请码的方式来推送给用户,到点用户自动有收到。优质的内容,不局限于电商类,适合内容营销的有:小黄鸡、悟空问答、360热问、知乎问答等内容整理后再分享出去,简单干脆,有时候文章不吸引用户,可以想想是否是篇章长度的问题,可以从头开始写,随着用户阅读的情况来增加内容的字数,每篇分享的时间点不要超过100字,越简短越有力,时间点过长的文章会加长用户的阅读习惯,不利于用户转化。 查看全部
shop_xiaohao001_关注shopx药店_karaoke_社区(组图)
querylist采集微信公众号文章,实现百度、头条等搜索引擎排名和微信搜索的推广。推广效果是电商数据里面永远的痛,只有做好开源节流才能有意想不到的收获。精准推广的本质,在于挖掘目标人群的需求。简单的理解有:做什么产品?买什么东西?购买什么产品?推广还是从人性上挖掘。微信里面,可以通过朋友圈、公众号推送、客服回复等方式,来获取目标人群的公众号信息,然后以公众号为依托,对文章进行推广。
推广效果==人群质量*转化率*精准度基于精准用户人群的分析和优化,达到排名和业绩上的提升。一、筛选目标用户维度包括:用户行为分析,文章发送时间、内容等信息目标用户人群的人物画像,标签,性别、年龄、职业等行为分析包括:用户特征、地域、兴趣爱好等内容,参考一下做的非常不错的文章,从标题到内容都是包装好的,你可以借鉴一下:shop_xiaohao001_关注shopx药店_karaoke_社区_b2c/?itemid=27613055_aw1b0_3ub45464ce7bd1347ee058&utm_source=toutiao-io&utm_medium=toutiao_android&utm_campaign=toutiao_android&utm_term=23&utm_division=zhihu&utm_content=shopx要学会分析用户的行为,用户的行为可以总结成为一些标签比如:停留时间,点赞、转发次数,互动频率...,每个标签通过爬虫抓取,然后组合起来得到最终的人群标签。
文章发送时间决定了有多少人看到你,文章发送时间点需要设置合理,这方面可以采用意图猜测这种方式来推测。根据转发次数,来推测是否有做公众号的推广等。意图猜测是采用用户反馈等第三方服务,比如:活动,促销等等有类似经验的人可以基于你的竞争对手总结出用户使用这个服务时的动机:定向活动推送,用户就会参与,会有转发、关注的动作。
有需求就会参与,有转发、关注、评论等行为才会有下单等一系列动作...分析用户行为,来获取目标人群的特征属性,整理出目标人群的特征集合,例如:男性/女性/地域/...,通过小卡片、二维码或者vip会员邀请码的方式来推送给用户,到点用户自动有收到。优质的内容,不局限于电商类,适合内容营销的有:小黄鸡、悟空问答、360热问、知乎问答等内容整理后再分享出去,简单干脆,有时候文章不吸引用户,可以想想是否是篇章长度的问题,可以从头开始写,随着用户阅读的情况来增加内容的字数,每篇分享的时间点不要超过100字,越简短越有力,时间点过长的文章会加长用户的阅读习惯,不利于用户转化。
用Python将公众号中文章爬下来获取文章的html信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-08-16 01:21
用Python将公众号中文章爬下来获取文章的html信息
公众号里的文章一定是每一篇文章的必读。
有时候我们关注宝物类公众号,会发现它的历史文章有数百甚至数千篇文章,而作者只索引了他认为更好的几篇。太麻烦了。为了解决这类问题,我决定用Python爬下公众号文章。
基本思路爬取
文章crawling 我们使用公共平台的方式。这个方法虽然简单,但是我们需要有一个公众号。如果我们没有官方账号,我们可以自己注册一个。公众号的注册也比较简单。别说了。
首先登录您的公众号,然后依次进行以下操作
通过上面的操作,我们可以得到cookie等信息,我们先把cookie写入txt文件,实现代码如下:
# 从浏览器中复制出来的 cookie 字符串cookie_str = "自己的 cookie"cookie = {}# 遍历 cookiefor cookies in cookie_str.split("; "): cookie_item = cookies.split("=") cookie[cookie_item[0]] = cookie_item[1]# 将 cookie 写入 txt 文件with open('cookie.txt', "w") as file: file.write(json.dumps(cookie))
接下来我们获取公众号文章列表信息,代码实现如下:
with open("cookie.txt", "r") as file: cookie = file.read()cookies = json.loads(cookie)url = "https://mp.weixin.qq.com"response = requests.get(url, cookies=cookies)# 获取tokentoken = re.findall(r"token=(\d+)", str(response.url))[0]# 请求头信息headers = { "Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B + token + "&lang=zh_CN", "Host": "mp.weixin.qq.com", "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",}# 遍历指定页数的文章for i in range(1, 5, 1): begin = (i - 1) * 5 # 获取文章列表 requestUrl = "https://mp.weixin.qq.com/cgi-b ... 2Bstr(begin)+"&count=5&fakeid=要爬取公众号的fakeid&type=9&query=&token=" + token + "&lang=zh_CN&f=json&ajax=1" search_response = requests.get(requestUrl, cookies=cookies, headers=headers) # 获取 JSON 格式的列表信息 re_text = search_response.json() list = re_text.get("app_msg_list") # 遍历文章列表 for j in list: # 文章链接 url = j["link"] # 文章标题 title = j["title"] print(url) # 等待 8 秒,避免请求过于频繁 time.sleep(8)
保存
通过文章list信息,我们可以得到文章公众号的链接、标题等信息,然后我们可以根据文章使用微信模块获取文章html格式信息关联。模块安装使用pip install wechatsogou就可以了。
这里需要注意的是,我们通过微信模块获取的html信息会存在一些问题。有两个主要问题。一是文章的html信息不全,需要自己补;另一个得到。 html 信息中可能有一些 CSS 样式没有带过来。对于这个问题,我们可以先通过浏览器的开发者工具获取样式,然后手动添加。代码实现如下:
# url:文章链接,title:文章标题def save2html(url, title): # captcha_break_time 为验证码输入错误的重试次数,默认为 1 ws_api = wechatsogou.WechatSogouAPI(captcha_break_time = 3) content_info = ws_api.get_article_content(url) html = f''' {title} {title} {content_info['content_html']} ''' with open(title + '.html', "w", encoding="utf-8") as file: file.write('%s\n'%html)
上面代码中的my.css文件存储了一些没有带过来的CSS样式信息。
用浏览器打开公众号文章的html文件看看效果:
通过上面的显示结果可以看出,我们保存的html文件的显示效果还不错。
参考:
结束
查看全部
用Python将公众号中文章爬下来获取文章的html信息
公众号里的文章一定是每一篇文章的必读。
有时候我们关注宝物类公众号,会发现它的历史文章有数百甚至数千篇文章,而作者只索引了他认为更好的几篇。太麻烦了。为了解决这类问题,我决定用Python爬下公众号文章。
基本思路爬取
文章crawling 我们使用公共平台的方式。这个方法虽然简单,但是我们需要有一个公众号。如果我们没有官方账号,我们可以自己注册一个。公众号的注册也比较简单。别说了。
首先登录您的公众号,然后依次进行以下操作
通过上面的操作,我们可以得到cookie等信息,我们先把cookie写入txt文件,实现代码如下:
# 从浏览器中复制出来的 cookie 字符串cookie_str = "自己的 cookie"cookie = {}# 遍历 cookiefor cookies in cookie_str.split("; "): cookie_item = cookies.split("=") cookie[cookie_item[0]] = cookie_item[1]# 将 cookie 写入 txt 文件with open('cookie.txt', "w") as file: file.write(json.dumps(cookie))
接下来我们获取公众号文章列表信息,代码实现如下:
with open("cookie.txt", "r") as file: cookie = file.read()cookies = json.loads(cookie)url = "https://mp.weixin.qq.com"response = requests.get(url, cookies=cookies)# 获取tokentoken = re.findall(r"token=(\d+)", str(response.url))[0]# 请求头信息headers = { "Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B + token + "&lang=zh_CN", "Host": "mp.weixin.qq.com", "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",}# 遍历指定页数的文章for i in range(1, 5, 1): begin = (i - 1) * 5 # 获取文章列表 requestUrl = "https://mp.weixin.qq.com/cgi-b ... 2Bstr(begin)+"&count=5&fakeid=要爬取公众号的fakeid&type=9&query=&token=" + token + "&lang=zh_CN&f=json&ajax=1" search_response = requests.get(requestUrl, cookies=cookies, headers=headers) # 获取 JSON 格式的列表信息 re_text = search_response.json() list = re_text.get("app_msg_list") # 遍历文章列表 for j in list: # 文章链接 url = j["link"] # 文章标题 title = j["title"] print(url) # 等待 8 秒,避免请求过于频繁 time.sleep(8)
保存
通过文章list信息,我们可以得到文章公众号的链接、标题等信息,然后我们可以根据文章使用微信模块获取文章html格式信息关联。模块安装使用pip install wechatsogou就可以了。
这里需要注意的是,我们通过微信模块获取的html信息会存在一些问题。有两个主要问题。一是文章的html信息不全,需要自己补;另一个得到。 html 信息中可能有一些 CSS 样式没有带过来。对于这个问题,我们可以先通过浏览器的开发者工具获取样式,然后手动添加。代码实现如下:
# url:文章链接,title:文章标题def save2html(url, title): # captcha_break_time 为验证码输入错误的重试次数,默认为 1 ws_api = wechatsogou.WechatSogouAPI(captcha_break_time = 3) content_info = ws_api.get_article_content(url) html = f''' {title} {title} {content_info['content_html']} ''' with open(title + '.html', "w", encoding="utf-8") as file: file.write('%s\n'%html)
上面代码中的my.css文件存储了一些没有带过来的CSS样式信息。
用浏览器打开公众号文章的html文件看看效果:
通过上面的显示结果可以看出,我们保存的html文件的显示效果还不错。
参考:
结束
querylist采集微信公众号文章信息,关键字采集文章标题和文章大纲
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-08-15 23:10
querylist采集微信公众号文章信息,关键字采集公众号文章标题和文章大纲,再采集公众号用户数据,回流至redis,进行用户浏览记录存储,再与公众号以及用户数据进行相应匹配得到用户画像。
建议先去公众号关注一下,然后给公众号发送“查询”功能,就可以查到公众号标签下全部微信文章的标题、发布时间、阅读数、分享数、历史阅读量和转发量。
我在开发公众号的时候参考了一些文章中描述的,比如如果查询公众号里的某篇文章阅读次数,或者是历史消息数(微信的功能实现中,和历史消息之间的一定距离,微信会给出一个标记),或者是文章分享量等等。原理大致就是公众号要有一个redis服务端与公众号相对应(如果你的目的是简单查询公众号里内容的一个收藏功能,可以换成redisconnect),所以先解决你redis服务端如何与公众号服务端连接,然后再用服务端接口与session相互传递数据即可。
你可以先在公众号发布文章时,用代码获取到该公众号的用户,发送给redis去存储。至于以后使用,可以直接通过session去相互传递用户信息就可以了。
这位大神的文章!微信公众号公众号的数据存储机制是如何的?
公众号推送文章的时候,会在数据库中随机选取一条数据进行缓存,并且设置一个时间间隔来判断当前数据库的数据来源,缓存到数据库中的数据是定时更新的, 查看全部
querylist采集微信公众号文章信息,关键字采集文章标题和文章大纲
querylist采集微信公众号文章信息,关键字采集公众号文章标题和文章大纲,再采集公众号用户数据,回流至redis,进行用户浏览记录存储,再与公众号以及用户数据进行相应匹配得到用户画像。
建议先去公众号关注一下,然后给公众号发送“查询”功能,就可以查到公众号标签下全部微信文章的标题、发布时间、阅读数、分享数、历史阅读量和转发量。
我在开发公众号的时候参考了一些文章中描述的,比如如果查询公众号里的某篇文章阅读次数,或者是历史消息数(微信的功能实现中,和历史消息之间的一定距离,微信会给出一个标记),或者是文章分享量等等。原理大致就是公众号要有一个redis服务端与公众号相对应(如果你的目的是简单查询公众号里内容的一个收藏功能,可以换成redisconnect),所以先解决你redis服务端如何与公众号服务端连接,然后再用服务端接口与session相互传递数据即可。
你可以先在公众号发布文章时,用代码获取到该公众号的用户,发送给redis去存储。至于以后使用,可以直接通过session去相互传递用户信息就可以了。
这位大神的文章!微信公众号公众号的数据存储机制是如何的?
公众号推送文章的时候,会在数据库中随机选取一条数据进行缓存,并且设置一个时间间隔来判断当前数据库的数据来源,缓存到数据库中的数据是定时更新的,
一个好的公众号爬虫将内容抓取保存下来慢慢赏析
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-08-15 19:09
有时候我们会遇到一个很好的公众号,里面的每一篇文章都值得反复阅读。这时候我们就可以使用公众号爬虫抓取并保存内容,慢慢欣赏。
安装 Fiddler
Fiddler的下载地址为:安装完成后,确保手机和电脑的网络是同一个局域网。
Finder 配置
点击工具>>选项>>连接面板,参考下图配置,Fiddler的默认端口是8888,如果8888端口被占用,可以修改为其他端口。
点击工具>>选项>>HTTPS面板,参考下图进行配置
安卓手机配置
进入WLAN设置,选择当前局域网的WIFI设置,代理设置为手动,代理服务器主机名为Finder,右上角点击在线,端口号为8888。
在手机浏览器中访问配置的地址:8888,显示Fiddler Echo Service时,手机配置成功。
为了让 Finddler 拦截 HTTPS 请求,必须在手机中安装 CA 证书。在 :8888 中,单击 FiddlerRoot 证书下载并安装证书。至此配置工作完成。
微信历史页面
以【腾旭大神网】为例,点击【上海新闻】菜单的二级菜单【历史新闻】。
观察 Fiddler 的变化。此时,左侧窗口中会陆续出现多个URL连接地址。这是 Fiddler 截获的 Android 请求。
Result:服务器的响应结果 Protocol:请求协议,微信协议都是HTTPS,所以需要在手机和PC端安装证书。 HOST: 主机名 URL: URL 地址
以 .com/mp/profile_ext?action=home... 开头的 URL 之一正是我们所需要的。点击右侧的Inspectors面板,然后点击下方的Headers和WebView面板,会出现如下图案
标题面板
Request Headers:请求行,收录请求方法、请求地址、等待Client的请求协议、Cookies:请求头
WebView 面板
WebView面板显示服务器返回的HTML代码的渲染结果,Textview面板显示服务器返回的HTML源代码
获取历史页面
在上一节中,公众号消息历史页面已经可以在 Fiddler 的 WebView 面板中显示。本节使用Python抓取历史页面。创建一个名为wxcrawler.py的脚本,我们需要URL地址和HEADER请求头来抓取页面,直接从Finder中复制
将标头转换为 Json
# coding:utf-8
import requests
class WxCrawler(object):
# 复制出来的 Headers,注意这个 x-wechat-key,有时间限制,会过期。当返回的内容出现 验证 的情况,就需要换 x-wechat-key 了
headers = """Connection: keep-alive
x-wechat-uin: MTY4MTI3NDIxNg%3D%3D
x-wechat-key: 5ab2dd82e79bc5343ac5fb7fd20d72509db0ee1772b1043c894b24d441af288ae942feb4cfb4d234f00a4a5ab88c5b625d415b83df4b536d99befc096448d80cfd5a7fcd33380341aa592d070b1399a1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Linux; Android 10; GM1900 Build/QKQ1.190716.003; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/67.0.3396.87 XWEB/992 MMWEBSDK/191102 Mobile Safari/537.36 MMWEBID/7220 MicroMessenger/7.0.9.1560(0x27000933) Process/toolsmp NetType/WIFI Language/zh_CN ABI/arm64
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/wxpic,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,en-US;q=0.9
Cookie: wxuin=1681274216; devicetype=android-29; version=27000933; lang=zh_CN; pass_ticket=JvAJfzySl6uLWYdYwzyQ+4OqrqiZ2zfaI4F2OCVR7omYOmTjYNKalCFbr75X+T6K; rewardsn=; wxtokenkey=777; wap_sid2=COjq2KEGElxBTmotQWtVY2Iwb3BZRkIzd0Y0SnpaUG1HNTQ0SDA4UGJOZi1kaFdFbkl1MHUyYkRKX2xiWFU5VVhDNXBkQlY0U0pRXzlCZW9qZ29oYW9DWmZYOTdmQTBFQUFBfjD+hInvBTgNQJVO
X-Requested-With: com.tencent.mm"""
url = "https://mp.weixin.qq .com/mp/profile_ext?action=home&__biz=MjEwNDI4NTA2MQ==&scene=123&devicetype=android-29&version=27000933&lang=zh_CN&nettype=WIFI&a8scene=7&session_us=wxid_2574365742721&pass_ticket=JvAJfzySl6uLWYdYwzyQ%2B4OqrqiZ2zfaI4F2OCVR7omYOmTjYNKalCFbr75X%2BT6K&wx_header=1"
# 将 Headers 转换为 字典
def header_to_dict(self):
headers = self.headers.split("\n")
headers_dict = dict()
for h in headers:
k,v = h.split(":")
headers_dict[k.strip()] = v.strip()
return headers_dict;
def run(self):
headers = self.header_to_dict()
response = requests.get(self.url, headers=headers, verify=False)
print(response.text)
if __name__ == "__main__":
wx = WxCrawler()
wx.run()
下图是控制台打印的内容,其中JavaScript中变量msgList的值就是需要的内容
下一步是提取msgList的内容,使用正则表达式提取内容,返回一个文章list
import re
import html
import json
def article_list(self, context):
rex = "msgList = '({.*?})'"
pattern = re.compile(pattern=rex, flags=re.S)
match = pattern.search(context)
if match:
data = match.group(1)
data = html.unescape(data)
data = json.loads(data)
articles = data.get("list")
return articles
以下是解析msgList的结果
title:文章title content_url:文章link source_url:原链接,可能为空 摘要:摘要封面:封面图片 datetime:推送时间
其他内容存储在 multi_app_msg_item_list 中
{'comm_msg_info':
{
'id': 1000033457,
'type': 49,
'datetime': 1575101627,
'fakeid': '2104285061',
'status': 2,
'content': ''
},
'app_msg_ext_info':
{
'title': '快查手机!5000多张人脸照正被贱卖,数据曝光令人触目惊心!',
'digest': '谁有权收集人脸信息?',
'content': '',
'fileid': 0,
'content_url': 'http:\\/\\/mp.weixin.qq.com\\/s?__biz=MjEwNDI4NTA2MQ==&mid=2651824634&idx=1&sn=3e4c8eb35abb1b09a4077064ba0c44c8&chksm=4ea8211079dfa8065435409f4d3d3538ad28ddc197063a7e1820dafb9ee23beefca59c3b32d4&scene=27#wechat_redirect',
'source_url': '',
'cover': 'http:\\/\\/mmbiz.qpic.cn\\/mmbiz_jpg\\/G8vkERUJibkstwkIvXB960sMOyQdYF2x2qibTxAIq2eUljRbB6zqBq6ziaiaVqm8GtEWticE6zAYGUYqKJ3SMuvv1EQ\\/0?wx_fmt=jpeg',
'subtype': 9,
'is_multi': 1,
'multi_app_msg_item_list':
[{
'title': '先有鸡还是先有蛋?6.1亿年前的胚胎化石揭晓了',
'digest': '解决了困扰大申君20多年的问题',
'content': '',
'fileid': 0,
'content_url': 'http:\\/\\/mp.weixin.qq.com\\/s?__biz=MjEwNDI4NTA2MQ==&mid=2651824634&idx=2&sn=07b95d31efa9f56d460a16bca817f30d&chksm=4ea8211079dfa8068f42bf0e5df076a95ee3c24cab71294632fe587bcc9238c1a7fb7cd9629b&scene=27#wechat_redirect',
'source_url': '',
'cover': 'http:\\/\\/mmbiz.qpic.cn\\/mmbiz_jpg\\/yl6JkZAE3S92BESibpZgTPE1BcBhSLiaGOgpgVicaLdkIXGExe3mYdyVkE2SDXL1x2lFxldeXu8qXQYwtnx9vibibzQ\\/0?wx_fmt=jpeg',
'author': '',
'copyright_stat': 100,
'del_flag': 1,
'item_show_type': 0,
'audio_fileid': 0,
'duration': 0,
'play_url': '',
'malicious_title_reason_id': 0,
'malicious_content_type': 0
},
{
'title': '外交部惊现“李佳琦”!网友直呼:“OMG被种草了!”',
'digest': '种草了!',
'content': '', ...}
...]
获取单个页面
在上一节中,我们可以得到app_msg_ext_info中的content_url地址,需要从comm_msg_info的不规则Json中获取。这是使用demjson模块完成不规则的comm_msg_info。
安装 demjson 模块
pip3 install demjson
import demjson
# 获取单个文章的URL
content_url_array = []
def content_url(self, articles):
content_url = []
for a in articles:
a = str(a).replace("\/", "/")
a = demjson.decode(a)
content_url_array.append(a['app_msg_ext_info']["content_url"])
# 取更多的
for multi in a['app_msg_ext_info']["multi_app_msg_item_list"]:
self.content_url_array.append(multi['content_url'])
return content_url
获取单个文章的地址后,使用requests.get()函数获取HTML页面并解析
# 解析单个文章
def parse_article(self, headers, content_url):
for i in content_url:
content_response = requests.get(i, headers=headers, verify=False)
with open("wx.html", "wb") as f:
f.write(content_response.content)
html = open("wx.html", encoding="utf-8").read()
soup_body = BeautifulSoup(html, "html.parser")
context = soup_body.find('div', id = 'js_content').text.strip()
print(context)
所有历史文章
当你向下滑动历史消息时,出现Loading...这是公众号正在翻页的历史消息。查Fiddler,公众号请求的地址是.com/mp/profile_ext? action=getmsg&__biz...
翻页请求地址返回结果,一般可以分析。
ret:是否成功,0代表成功msg_count:每页的条目数 can_msg_continue:是否继续翻页,1代表继续翻页general_msg_list:数据,包括标题、文章地址等信息
def page(self, headers):
response = requests.get(self.page_url, headers=headers, verify=False)
result = response.json()
if result.get("ret") == 0:
msg_list = result.get("general_msg_list")
msg_list = demjson.decode(msg_list)
self.content_url(msg_list["list"])
#递归
self.page(headers)
else:
print("无法获取内容")
总结
这里已经爬取了公众号的内容,但尚未爬取单个文章的阅读和查看数量。想想看,如何抓取这些内容变化?
示例代码:
PS:公众号内回复:Python,可以进入Python新手学习交流群,一起
-END- 查看全部
一个好的公众号爬虫将内容抓取保存下来慢慢赏析
有时候我们会遇到一个很好的公众号,里面的每一篇文章都值得反复阅读。这时候我们就可以使用公众号爬虫抓取并保存内容,慢慢欣赏。
安装 Fiddler
Fiddler的下载地址为:安装完成后,确保手机和电脑的网络是同一个局域网。
Finder 配置
点击工具>>选项>>连接面板,参考下图配置,Fiddler的默认端口是8888,如果8888端口被占用,可以修改为其他端口。
点击工具>>选项>>HTTPS面板,参考下图进行配置
安卓手机配置
进入WLAN设置,选择当前局域网的WIFI设置,代理设置为手动,代理服务器主机名为Finder,右上角点击在线,端口号为8888。
在手机浏览器中访问配置的地址:8888,显示Fiddler Echo Service时,手机配置成功。
为了让 Finddler 拦截 HTTPS 请求,必须在手机中安装 CA 证书。在 :8888 中,单击 FiddlerRoot 证书下载并安装证书。至此配置工作完成。
微信历史页面
以【腾旭大神网】为例,点击【上海新闻】菜单的二级菜单【历史新闻】。
观察 Fiddler 的变化。此时,左侧窗口中会陆续出现多个URL连接地址。这是 Fiddler 截获的 Android 请求。
Result:服务器的响应结果 Protocol:请求协议,微信协议都是HTTPS,所以需要在手机和PC端安装证书。 HOST: 主机名 URL: URL 地址
以 .com/mp/profile_ext?action=home... 开头的 URL 之一正是我们所需要的。点击右侧的Inspectors面板,然后点击下方的Headers和WebView面板,会出现如下图案
标题面板
Request Headers:请求行,收录请求方法、请求地址、等待Client的请求协议、Cookies:请求头
WebView 面板
WebView面板显示服务器返回的HTML代码的渲染结果,Textview面板显示服务器返回的HTML源代码
获取历史页面
在上一节中,公众号消息历史页面已经可以在 Fiddler 的 WebView 面板中显示。本节使用Python抓取历史页面。创建一个名为wxcrawler.py的脚本,我们需要URL地址和HEADER请求头来抓取页面,直接从Finder中复制
将标头转换为 Json
# coding:utf-8
import requests
class WxCrawler(object):
# 复制出来的 Headers,注意这个 x-wechat-key,有时间限制,会过期。当返回的内容出现 验证 的情况,就需要换 x-wechat-key 了
headers = """Connection: keep-alive
x-wechat-uin: MTY4MTI3NDIxNg%3D%3D
x-wechat-key: 5ab2dd82e79bc5343ac5fb7fd20d72509db0ee1772b1043c894b24d441af288ae942feb4cfb4d234f00a4a5ab88c5b625d415b83df4b536d99befc096448d80cfd5a7fcd33380341aa592d070b1399a1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Linux; Android 10; GM1900 Build/QKQ1.190716.003; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/67.0.3396.87 XWEB/992 MMWEBSDK/191102 Mobile Safari/537.36 MMWEBID/7220 MicroMessenger/7.0.9.1560(0x27000933) Process/toolsmp NetType/WIFI Language/zh_CN ABI/arm64
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/wxpic,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,en-US;q=0.9
Cookie: wxuin=1681274216; devicetype=android-29; version=27000933; lang=zh_CN; pass_ticket=JvAJfzySl6uLWYdYwzyQ+4OqrqiZ2zfaI4F2OCVR7omYOmTjYNKalCFbr75X+T6K; rewardsn=; wxtokenkey=777; wap_sid2=COjq2KEGElxBTmotQWtVY2Iwb3BZRkIzd0Y0SnpaUG1HNTQ0SDA4UGJOZi1kaFdFbkl1MHUyYkRKX2xiWFU5VVhDNXBkQlY0U0pRXzlCZW9qZ29oYW9DWmZYOTdmQTBFQUFBfjD+hInvBTgNQJVO
X-Requested-With: com.tencent.mm"""
url = "https://mp.weixin.qq .com/mp/profile_ext?action=home&__biz=MjEwNDI4NTA2MQ==&scene=123&devicetype=android-29&version=27000933&lang=zh_CN&nettype=WIFI&a8scene=7&session_us=wxid_2574365742721&pass_ticket=JvAJfzySl6uLWYdYwzyQ%2B4OqrqiZ2zfaI4F2OCVR7omYOmTjYNKalCFbr75X%2BT6K&wx_header=1"
# 将 Headers 转换为 字典
def header_to_dict(self):
headers = self.headers.split("\n")
headers_dict = dict()
for h in headers:
k,v = h.split(":")
headers_dict[k.strip()] = v.strip()
return headers_dict;
def run(self):
headers = self.header_to_dict()
response = requests.get(self.url, headers=headers, verify=False)
print(response.text)
if __name__ == "__main__":
wx = WxCrawler()
wx.run()
下图是控制台打印的内容,其中JavaScript中变量msgList的值就是需要的内容
下一步是提取msgList的内容,使用正则表达式提取内容,返回一个文章list
import re
import html
import json
def article_list(self, context):
rex = "msgList = '({.*?})'"
pattern = re.compile(pattern=rex, flags=re.S)
match = pattern.search(context)
if match:
data = match.group(1)
data = html.unescape(data)
data = json.loads(data)
articles = data.get("list")
return articles
以下是解析msgList的结果
title:文章title content_url:文章link source_url:原链接,可能为空 摘要:摘要封面:封面图片 datetime:推送时间
其他内容存储在 multi_app_msg_item_list 中
{'comm_msg_info':
{
'id': 1000033457,
'type': 49,
'datetime': 1575101627,
'fakeid': '2104285061',
'status': 2,
'content': ''
},
'app_msg_ext_info':
{
'title': '快查手机!5000多张人脸照正被贱卖,数据曝光令人触目惊心!',
'digest': '谁有权收集人脸信息?',
'content': '',
'fileid': 0,
'content_url': 'http:\\/\\/mp.weixin.qq.com\\/s?__biz=MjEwNDI4NTA2MQ==&mid=2651824634&idx=1&sn=3e4c8eb35abb1b09a4077064ba0c44c8&chksm=4ea8211079dfa8065435409f4d3d3538ad28ddc197063a7e1820dafb9ee23beefca59c3b32d4&scene=27#wechat_redirect',
'source_url': '',
'cover': 'http:\\/\\/mmbiz.qpic.cn\\/mmbiz_jpg\\/G8vkERUJibkstwkIvXB960sMOyQdYF2x2qibTxAIq2eUljRbB6zqBq6ziaiaVqm8GtEWticE6zAYGUYqKJ3SMuvv1EQ\\/0?wx_fmt=jpeg',
'subtype': 9,
'is_multi': 1,
'multi_app_msg_item_list':
[{
'title': '先有鸡还是先有蛋?6.1亿年前的胚胎化石揭晓了',
'digest': '解决了困扰大申君20多年的问题',
'content': '',
'fileid': 0,
'content_url': 'http:\\/\\/mp.weixin.qq.com\\/s?__biz=MjEwNDI4NTA2MQ==&mid=2651824634&idx=2&sn=07b95d31efa9f56d460a16bca817f30d&chksm=4ea8211079dfa8068f42bf0e5df076a95ee3c24cab71294632fe587bcc9238c1a7fb7cd9629b&scene=27#wechat_redirect',
'source_url': '',
'cover': 'http:\\/\\/mmbiz.qpic.cn\\/mmbiz_jpg\\/yl6JkZAE3S92BESibpZgTPE1BcBhSLiaGOgpgVicaLdkIXGExe3mYdyVkE2SDXL1x2lFxldeXu8qXQYwtnx9vibibzQ\\/0?wx_fmt=jpeg',
'author': '',
'copyright_stat': 100,
'del_flag': 1,
'item_show_type': 0,
'audio_fileid': 0,
'duration': 0,
'play_url': '',
'malicious_title_reason_id': 0,
'malicious_content_type': 0
},
{
'title': '外交部惊现“李佳琦”!网友直呼:“OMG被种草了!”',
'digest': '种草了!',
'content': '', ...}
...]
获取单个页面
在上一节中,我们可以得到app_msg_ext_info中的content_url地址,需要从comm_msg_info的不规则Json中获取。这是使用demjson模块完成不规则的comm_msg_info。
安装 demjson 模块
pip3 install demjson
import demjson
# 获取单个文章的URL
content_url_array = []
def content_url(self, articles):
content_url = []
for a in articles:
a = str(a).replace("\/", "/")
a = demjson.decode(a)
content_url_array.append(a['app_msg_ext_info']["content_url"])
# 取更多的
for multi in a['app_msg_ext_info']["multi_app_msg_item_list"]:
self.content_url_array.append(multi['content_url'])
return content_url
获取单个文章的地址后,使用requests.get()函数获取HTML页面并解析
# 解析单个文章
def parse_article(self, headers, content_url):
for i in content_url:
content_response = requests.get(i, headers=headers, verify=False)
with open("wx.html", "wb") as f:
f.write(content_response.content)
html = open("wx.html", encoding="utf-8").read()
soup_body = BeautifulSoup(html, "html.parser")
context = soup_body.find('div', id = 'js_content').text.strip()
print(context)
所有历史文章
当你向下滑动历史消息时,出现Loading...这是公众号正在翻页的历史消息。查Fiddler,公众号请求的地址是.com/mp/profile_ext? action=getmsg&__biz...
翻页请求地址返回结果,一般可以分析。
ret:是否成功,0代表成功msg_count:每页的条目数 can_msg_continue:是否继续翻页,1代表继续翻页general_msg_list:数据,包括标题、文章地址等信息
def page(self, headers):
response = requests.get(self.page_url, headers=headers, verify=False)
result = response.json()
if result.get("ret") == 0:
msg_list = result.get("general_msg_list")
msg_list = demjson.decode(msg_list)
self.content_url(msg_list["list"])
#递归
self.page(headers)
else:
print("无法获取内容")
总结
这里已经爬取了公众号的内容,但尚未爬取单个文章的阅读和查看数量。想想看,如何抓取这些内容变化?
示例代码:
PS:公众号内回复:Python,可以进入Python新手学习交流群,一起
-END-
querylist采集微信公众号文章数据,其他对齐参数对店铺的处理思路
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-08-14 19:05
querylist采集微信公众号文章数据,其他对齐参数对店铺的公众号一样。2.重定向的处理思路是用jwttokenhttp/1.1,get/post的cookieheader分别替换成2.0\2.1\2.2的cookie,所以店铺公众号不用对齐参数直接对接会成功,要是客户端修改了店铺公众号的cookie则难通过querylist进行对齐;实际应用中要怎么操作对齐参数得根据实际需求而定。
支付宝和商户开放平台可以互通,要么通过浏览器,要么通过querylistapi;阿里云方案可能有问题(感觉没通过审核),最简单的就是通过collection,在api后面加参数querylist:[2.1]就是2.1的公众号端格式啊,
只能用querylist,不能用cookie,除非你写cookie主动对接。上alifixion通过客户端post获取cookie发送给公众号。前端通过网页版发送数据,要通过cookie统计,目前支付宝的e-cookie抓取控制还不够完善,有些数据抓取不到。所以只能用querylist。
看alibaba需求来,比如天猫要完全对接联盟,是要来回一个个查,如果只是对接个联盟,那么不需要做对齐。如果双方协议不一样,你想最终相互对齐,那么就要再配置一遍querylist。
从alib申请连接,按照常规请求都可以,顺便补充一下:querylist的数据结构是什么, 查看全部
querylist采集微信公众号文章数据,其他对齐参数对店铺的处理思路
querylist采集微信公众号文章数据,其他对齐参数对店铺的公众号一样。2.重定向的处理思路是用jwttokenhttp/1.1,get/post的cookieheader分别替换成2.0\2.1\2.2的cookie,所以店铺公众号不用对齐参数直接对接会成功,要是客户端修改了店铺公众号的cookie则难通过querylist进行对齐;实际应用中要怎么操作对齐参数得根据实际需求而定。
支付宝和商户开放平台可以互通,要么通过浏览器,要么通过querylistapi;阿里云方案可能有问题(感觉没通过审核),最简单的就是通过collection,在api后面加参数querylist:[2.1]就是2.1的公众号端格式啊,
只能用querylist,不能用cookie,除非你写cookie主动对接。上alifixion通过客户端post获取cookie发送给公众号。前端通过网页版发送数据,要通过cookie统计,目前支付宝的e-cookie抓取控制还不够完善,有些数据抓取不到。所以只能用querylist。
看alibaba需求来,比如天猫要完全对接联盟,是要来回一个个查,如果只是对接个联盟,那么不需要做对齐。如果双方协议不一样,你想最终相互对齐,那么就要再配置一遍querylist。
从alib申请连接,按照常规请求都可以,顺便补充一下:querylist的数据结构是什么,
一下如何使用Python构建一个个人微信公众号的电影搜索功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2021-08-11 06:02
今天介绍一下如何使用Python为个人微信公众号搭建电影搜索功能。本文文章将涉及:
要练习文章本文的所有内容,您需要拥有以下资源:
如果不使用注册的域名和个人微信公众号,可以申请微信官方平台测试号使用。流程类似,申请地址为:
现在我们开始输入文本。
1. 创建和部署 Django 应用程序
在这个个人公众号电影搜索器中,一个可靠的网络服务是连接电影资源数据和对接微信公众号的关键。电影资源爬取采集后,需要存入数据库。接收和回复还取决于 Web 应用程序提供的服务。所以我们首先需要创建一个 Web 应用程序。 Python中有许多Web框架。这里我们选择Django1.10,功能齐全,功能强大。没有安装Django的同学使用pip命令安装Django模块:
pip install django==1.10
1.1 创建 Django 项目
我们服务器上的当前目录如下所示:
使用Django的django-admin在这个目录下创建一个Django项目:
django-admin startproject wxmovie
这样我们的文件夹目录下多了一个叫wxmovie的文件夹,里面有一个manage.py文件和一个wxmovie文件夹:
1.2 创建 Django 应用程序
Django项目创建完成后,我们进入项目路径,使用其manage.py文件继续创建Django应用:
python3 manage.py startapp movie
此时wxmovie项目下多了一个名为movie的文件夹,里面收录了电影应用的所有文件:
1.3 配置 Django 项目
Django 项目-wxmovie 和它的应用影片创建完成后,让我们对这个项目做一些基本的配置。打开/wxmovie/wxmovie/目录下的settings.py文件。
将应用影片添加到 wxmovie 项目中:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'movie',
]
在项目根路径下创建一个名为template的文件夹作为django模板目录,并将此路径添加到TEMPLATES中:
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [
os.path.join(os.path.split(os.path.dirname(__file__))[0],'template'),
],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
修改项目的数据库配置为MySQL:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': '****',
'USER': '****',
'PASSWORD': '***',
'HOST': '',
'PORT': '3306',
}
}
修改项目时区的语言配置:
LANGUAGE_CODE = 'zh-hans'
TIME_ZONE = 'Asia/Shanghai'
因为我们使用的是Python3,所以需要在/wxmovie/wxmovie/目录下的\__init__.py文件中加入如下代码,这样我们才能在项目中使用MySQL(需要先安装pymysql模块): 查看全部
一下如何使用Python构建一个个人微信公众号的电影搜索功能
今天介绍一下如何使用Python为个人微信公众号搭建电影搜索功能。本文文章将涉及:
要练习文章本文的所有内容,您需要拥有以下资源:
如果不使用注册的域名和个人微信公众号,可以申请微信官方平台测试号使用。流程类似,申请地址为:
现在我们开始输入文本。
1. 创建和部署 Django 应用程序
在这个个人公众号电影搜索器中,一个可靠的网络服务是连接电影资源数据和对接微信公众号的关键。电影资源爬取采集后,需要存入数据库。接收和回复还取决于 Web 应用程序提供的服务。所以我们首先需要创建一个 Web 应用程序。 Python中有许多Web框架。这里我们选择Django1.10,功能齐全,功能强大。没有安装Django的同学使用pip命令安装Django模块:
pip install django==1.10
1.1 创建 Django 项目
我们服务器上的当前目录如下所示:
使用Django的django-admin在这个目录下创建一个Django项目:
django-admin startproject wxmovie
这样我们的文件夹目录下多了一个叫wxmovie的文件夹,里面有一个manage.py文件和一个wxmovie文件夹:
1.2 创建 Django 应用程序
Django项目创建完成后,我们进入项目路径,使用其manage.py文件继续创建Django应用:
python3 manage.py startapp movie
此时wxmovie项目下多了一个名为movie的文件夹,里面收录了电影应用的所有文件:
1.3 配置 Django 项目
Django 项目-wxmovie 和它的应用影片创建完成后,让我们对这个项目做一些基本的配置。打开/wxmovie/wxmovie/目录下的settings.py文件。
将应用影片添加到 wxmovie 项目中:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'movie',
]
在项目根路径下创建一个名为template的文件夹作为django模板目录,并将此路径添加到TEMPLATES中:
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [
os.path.join(os.path.split(os.path.dirname(__file__))[0],'template'),
],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
修改项目的数据库配置为MySQL:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': '****',
'USER': '****',
'PASSWORD': '***',
'HOST': '',
'PORT': '3306',
}
}
修改项目时区的语言配置:
LANGUAGE_CODE = 'zh-hans'
TIME_ZONE = 'Asia/Shanghai'
因为我们使用的是Python3,所以需要在/wxmovie/wxmovie/目录下的\__init__.py文件中加入如下代码,这样我们才能在项目中使用MySQL(需要先安装pymysql模块):
Q&;A(.39)模拟用户
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-08-09 03:29
一.Idea
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面图文
超链接
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.接口分析
微信公众号访问:
参数:
action=search_biz
开始=0
计数=5
query=官方账号
token=每个账户对应的token值
lang=zh_CN
f=json
ajax=1
请求方法:
获取
所以在这个界面我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。
微信公众号
获取公众号对应的文章界面:
参数:
action=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
type=9
查询=
令牌=557131216
lang=zh_CN
f=json
ajax=1
请求方法:
获取
我们需要在这个接口中获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
微信公众号
三.实现
第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
浏览器 = webdriver.Chrome()
browser.get('#39;)
睡觉(3)
browser.delete_all_cookies()
睡觉(2)
#点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
睡觉(2)
#模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(密码)
睡觉(2)
#点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
睡觉(2)
#微信登录验证
print('请扫描二维码')
睡觉(20)
#刷新当前网页
browser.get('#39;)
睡觉(5)
#获取当前网页链接
url = browser.current_url
#获取当前cookie
cookies = browser.get_cookies()
对于 cookie 中的项目:
post[item['name']] = item['value']
#转成字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt','w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie 在本地保存成功')
#对当前网页链接进行切片,获取token
paramList = url.strip().split('?')[1].split('&')
#定义一个字典来存储数据
paramdict = {}
对于 paramList 中的项目:
paramdict[item.split('=')[0]] = item.split('=')[1]
#返回令牌
返回参数['token']
定义一个登录方法,里面的参数是登录账号和密码,然后定义一个字典来存储cookie的值。模拟用户,输入对应的账号密码,点击登录,会出现扫码验证,用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:
1.请求获取对应的公众号接口,获取我们需要的fakeid
url ='#39;
标题 = {
'HOST':'',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86. 0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt','r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url ='#39;
参数 = {
'action':'search_biz',
'开始':'0',
'计数':'5',
'query':'搜索公众号',
'token':令牌,
'lang':'zh_CN',
'f':'json',
'阿贾克斯':'1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
1
通过上面的代码可以得到对应的公众号数据
fakeid = list.get('fakeid')
1
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的文章data
appmsg_url ='#39;
params_data = {
'action':'list_ex',
'开始':'0',
'计数':'5',
'fakeid':fakeid,
'type': '9',
'查询':'',
'token':令牌,
'lang':'zh_CN',
'f':'json',
'阿贾克斯':'1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了微信公众号文章的抓取。
四.Summary
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置一个延迟时间,否则账号很容易被封,获取不到返回的数据。 查看全部
Q&;A(.39)模拟用户
一.Idea
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面图文
超链接
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.接口分析
微信公众号访问:
参数:
action=search_biz
开始=0
计数=5
query=官方账号
token=每个账户对应的token值
lang=zh_CN
f=json
ajax=1
请求方法:
获取
所以在这个界面我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。
微信公众号
获取公众号对应的文章界面:
参数:
action=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
type=9
查询=
令牌=557131216
lang=zh_CN
f=json
ajax=1
请求方法:
获取
我们需要在这个接口中获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
微信公众号
三.实现
第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
浏览器 = webdriver.Chrome()
browser.get('#39;)
睡觉(3)
browser.delete_all_cookies()
睡觉(2)
#点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
睡觉(2)
#模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(密码)
睡觉(2)
#点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
睡觉(2)
#微信登录验证
print('请扫描二维码')
睡觉(20)
#刷新当前网页
browser.get('#39;)
睡觉(5)
#获取当前网页链接
url = browser.current_url
#获取当前cookie
cookies = browser.get_cookies()
对于 cookie 中的项目:
post[item['name']] = item['value']
#转成字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt','w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie 在本地保存成功')
#对当前网页链接进行切片,获取token
paramList = url.strip().split('?')[1].split('&')
#定义一个字典来存储数据
paramdict = {}
对于 paramList 中的项目:
paramdict[item.split('=')[0]] = item.split('=')[1]
#返回令牌
返回参数['token']
定义一个登录方法,里面的参数是登录账号和密码,然后定义一个字典来存储cookie的值。模拟用户,输入对应的账号密码,点击登录,会出现扫码验证,用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:
1.请求获取对应的公众号接口,获取我们需要的fakeid
url ='#39;
标题 = {
'HOST':'',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86. 0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt','r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url ='#39;
参数 = {
'action':'search_biz',
'开始':'0',
'计数':'5',
'query':'搜索公众号',
'token':令牌,
'lang':'zh_CN',
'f':'json',
'阿贾克斯':'1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
1
通过上面的代码可以得到对应的公众号数据
fakeid = list.get('fakeid')
1
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的文章data
appmsg_url ='#39;
params_data = {
'action':'list_ex',
'开始':'0',
'计数':'5',
'fakeid':fakeid,
'type': '9',
'查询':'',
'token':令牌,
'lang':'zh_CN',
'f':'json',
'阿贾克斯':'1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了微信公众号文章的抓取。
四.Summary
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置一个延迟时间,否则账号很容易被封,获取不到返回的数据。
苏南大叔讲述一下一款国人出品的php库,叫做querylist
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-08-07 00:28
本文开头,苏南大叔讲了一个中国人出品的PHP库,叫querylist,可以用来抓取网络数据。这个查询列表类似于python下的scrapy。当然,在之前的文章中,苏南大叔介绍了scrapy crawling。有兴趣的可以通过文末的链接了解更多。
如何安装和使用 QueryList,一个 php 数据捕获库? (图5-1)
另外,这个查询列表是基于开源库phpquery的。如果你用过phpquery,在接下来的学习中你会看到一些类似的阴影。如果你没用过phpquery,那你还是可以对比一下jquery,思路都差不多。好了,介绍这么多。如果您有兴趣,欢迎查看下一个查询列表系列文章。
苏南大叔实验时的composer版本是:1.6.5,php版本是7.2.1。
官方网站和安装要求
Querylist是中国人的作品,其官方网站是:
querylist要求的php版本至少为7.0,可以通过以下命令查看本地php版本号:
php -v
如何安装和使用 QueryList,一个 php 数据捕获库? (图5-2)
安装第一步是安装composer
安装composer就不描述太多了。 querylist的使用,理论上与composer密切相关。与composer的使用相关的文章请参考文末链接。如果你已经安装了composer,可以跳过这一步。
下面介绍的是mac下使用命令行语句安装composer的例子:
curl -o composer.phar 'https://getcomposer.org/composer.phar'
mv composer.phar /usr/local/bin/composer
chmod 777 /usr/local/bin/composer
相关链接:
第二步是设置全局加速composer的repo库
这一步不是必须的。如果安装querylist时没有响应,可以执行该语句。声明的目的是为了把composer改成快速的国内源码,类似于node下的cnpm。
composer config -g repo.packagist composer https://packagist.phpcomposer.com
第三步,安装querylist
在空白文件夹下,首先初始化composer项目。
composer init
然后使用composer安装jaeger/querylist。
composer require jaeger/querylist
如何安装和使用 QueryList,一个 php 数据捕获库? (图5-3)
安装成功,查看版本号
截至发稿,使用以下命令查看最新版本的querylist版本号4.0.3。
composer show -i jaeger/querylist
如何安装和使用 QueryList,一个 php 数据捕获库? (图5-4)
介绍示例demo
下面这句话是官方给出的最简单的配置。在此,限于篇幅,苏南叔不做过多解释。
require './vendor/autoload.php';
use QL\QueryList;
$html = array('.two>img:eq(1)','src'),
//采集span标签中的HTML内容
'other' => array('span','html')
);
$data = QueryList::html($html)
->rules($rules)
->query()
->getData();
print_r($data->all());
使用
是key中的key点。新手经常被卡在这里。还有autoload.php,这是composer项目的标准配置。剩下的就是querylist的相关功能了,下面苏南叔叔会详细介绍。敬请关注。
require './vendor/autoload.php';
use QL\QueryList;
如何安装和使用 QueryList,一个 php 数据捕获库? (图5-5)
相关链接汇总
本文中苏南大叔介绍的querylist与scrapy类似。但是querylist是基于php的,对php的忠实用户更具吸引力。
不过,苏南叔还是给你一个建议,那就是多尝试python。在目前的环境下,看来python系列还是很有前途的。而且在爬取方面,scrapy 还是比 querylist 有优势。好的,仅此而已。请继续关注苏南叔的后续文字,谢谢阅读。
[苹果]
[添加群组]
【源码】本文中的代码片段及相关软件,请点击此处获取
【绝密】秘籍文章入口,只教给有缘人
查询列表 phpquery 查看全部
苏南大叔讲述一下一款国人出品的php库,叫做querylist
本文开头,苏南大叔讲了一个中国人出品的PHP库,叫querylist,可以用来抓取网络数据。这个查询列表类似于python下的scrapy。当然,在之前的文章中,苏南大叔介绍了scrapy crawling。有兴趣的可以通过文末的链接了解更多。
如何安装和使用 QueryList,一个 php 数据捕获库? (图5-1)
另外,这个查询列表是基于开源库phpquery的。如果你用过phpquery,在接下来的学习中你会看到一些类似的阴影。如果你没用过phpquery,那你还是可以对比一下jquery,思路都差不多。好了,介绍这么多。如果您有兴趣,欢迎查看下一个查询列表系列文章。
苏南大叔实验时的composer版本是:1.6.5,php版本是7.2.1。
官方网站和安装要求
Querylist是中国人的作品,其官方网站是:
querylist要求的php版本至少为7.0,可以通过以下命令查看本地php版本号:
php -v
如何安装和使用 QueryList,一个 php 数据捕获库? (图5-2)
安装第一步是安装composer
安装composer就不描述太多了。 querylist的使用,理论上与composer密切相关。与composer的使用相关的文章请参考文末链接。如果你已经安装了composer,可以跳过这一步。
下面介绍的是mac下使用命令行语句安装composer的例子:
curl -o composer.phar 'https://getcomposer.org/composer.phar'
mv composer.phar /usr/local/bin/composer
chmod 777 /usr/local/bin/composer
相关链接:
第二步是设置全局加速composer的repo库
这一步不是必须的。如果安装querylist时没有响应,可以执行该语句。声明的目的是为了把composer改成快速的国内源码,类似于node下的cnpm。
composer config -g repo.packagist composer https://packagist.phpcomposer.com
第三步,安装querylist
在空白文件夹下,首先初始化composer项目。
composer init
然后使用composer安装jaeger/querylist。
composer require jaeger/querylist
如何安装和使用 QueryList,一个 php 数据捕获库? (图5-3)
安装成功,查看版本号
截至发稿,使用以下命令查看最新版本的querylist版本号4.0.3。
composer show -i jaeger/querylist
如何安装和使用 QueryList,一个 php 数据捕获库? (图5-4)
介绍示例demo
下面这句话是官方给出的最简单的配置。在此,限于篇幅,苏南叔不做过多解释。
require './vendor/autoload.php';
use QL\QueryList;
$html = array('.two>img:eq(1)','src'),
//采集span标签中的HTML内容
'other' => array('span','html')
);
$data = QueryList::html($html)
->rules($rules)
->query()
->getData();
print_r($data->all());
使用
是key中的key点。新手经常被卡在这里。还有autoload.php,这是composer项目的标准配置。剩下的就是querylist的相关功能了,下面苏南叔叔会详细介绍。敬请关注。
require './vendor/autoload.php';
use QL\QueryList;
如何安装和使用 QueryList,一个 php 数据捕获库? (图5-5)
相关链接汇总
本文中苏南大叔介绍的querylist与scrapy类似。但是querylist是基于php的,对php的忠实用户更具吸引力。
不过,苏南叔还是给你一个建议,那就是多尝试python。在目前的环境下,看来python系列还是很有前途的。而且在爬取方面,scrapy 还是比 querylist 有优势。好的,仅此而已。请继续关注苏南叔的后续文字,谢谢阅读。
[苹果]
[添加群组]
【源码】本文中的代码片段及相关软件,请点击此处获取
【绝密】秘籍文章入口,只教给有缘人
查询列表 phpquery
几天的总条数的话这样写的,真是太神奇了
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-08-04 03:32
这几天一直在做一些python项目的开发。我使用了 python 的 ORM 框架 sqlAlchemy。因为对python和sqlAlchemy不熟悉,所以积累了一些小知识点分享给大家。
获取文章总数
一般情况下,如果我们想知道表的总条目数,sql是这样写的:
select count(id) from user
这样我们就可以得到表中项目的总数
如果我想在sqlAlchemy中获取项目总数应该怎么做?
这种用途,func需要被引用
from sqlalchemy import func
count =session.query(func.count(user.id)).scalar()
如上,我们可以得到数据的数量。
相关链接
截图
按页面搜索
比较简单,直接粘贴代码
我的错误
查询总条目数时不使用Func.count()
我是这样写的
userlist=session.query(user).order_by(user.id.desc())
count=len(list(userlist))
userlist = userlist.limit(pageSize).offset(
(pageIndex-1)*pageSize)
这样也可以得到数据的个数。如果数据量很小,你可能没有什么感觉。数据量大的时候,你会发现查询数据真的很慢
相当于查询数据库两次,然后重新计算内存中的条目数和分页。
这在大量数据的情况下效率极低 查看全部
几天的总条数的话这样写的,真是太神奇了
这几天一直在做一些python项目的开发。我使用了 python 的 ORM 框架 sqlAlchemy。因为对python和sqlAlchemy不熟悉,所以积累了一些小知识点分享给大家。
获取文章总数
一般情况下,如果我们想知道表的总条目数,sql是这样写的:
select count(id) from user
这样我们就可以得到表中项目的总数
如果我想在sqlAlchemy中获取项目总数应该怎么做?
这种用途,func需要被引用
from sqlalchemy import func
count =session.query(func.count(user.id)).scalar()
如上,我们可以得到数据的数量。
相关链接
截图
按页面搜索
比较简单,直接粘贴代码
我的错误
查询总条目数时不使用Func.count()
我是这样写的
userlist=session.query(user).order_by(user.id.desc())
count=len(list(userlist))
userlist = userlist.limit(pageSize).offset(
(pageIndex-1)*pageSize)
这样也可以得到数据的个数。如果数据量很小,你可能没有什么感觉。数据量大的时候,你会发现查询数据真的很慢
相当于查询数据库两次,然后重新计算内存中的条目数和分页。
这在大量数据的情况下效率极低
与token的代码与上篇文章衔接起来代码的流程
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-08-04 00:37
获取网址
在我们解决cookie和token之前,那我们只需要把这两个参数放到请求头中就可以得到我们想要的
首先搜索公司账号名称
这里打开素材管理,点击新建图形素材
点击超链接。转到此页面
在此处提取url、headers和参数并找出更改的参数
random参数是0-1之间的随机浮点数,query是搜索内容,前面提取token
接下来我们看看获取文章的请求和接口
我们对页面的分析完成了,接下来我们开始编写代码,这次的代码是和上一篇文章的代码连接起来的
import time
import json
import random
import csv
from selenium import webdriver
from lxml import html
import requests
import re
# 获取cookies和token
class C_ookie:
# 初始化
def __init__(self):
self.html = ''
# 获取cookie
def get_cookie(self):
cooki = {}
url = 'https://mp.weixin.qq.com'
Browner = webdriver.Chrome()
Browner.get(url)
# 获取账号输入框
ID = Browner.find_element_by_name('account')
# 获取密码输入框
PW = Browner.find_element_by_name('password')
# 输入账号
#输入账号
id =
#输入密码
pw =
# id = input('请输入账号:')
# pw = input('请输入密码:')
ID.send_keys(id)
PW.send_keys(pw)
# 获取登录button,点击登录
Browner.find_element_by_class_name('btn_login').click()
# 等待扫二维码
time.sleep(10)
cks = Browner.get_cookies()
for ck in cks:
cooki[ck['name']] = ck['value']
ck1 = json.dumps(cooki)
print(ck1)
with open('ck.txt','w') as f :
f.write(ck1)
f.close()
self.html = Browner.page_source
# 获取文章
class getEssay:
def __init__(self):
# 获取cookies
with open('ck.txt','r') as f :
cookie = f.read()
f.close()
self.cookie = json.loads(cookie)
# 获取token
self.header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": 'Mozilla / 5.0(WindowsNT6.1;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 74.0.3729.131Safari / 537.36'
}
m_url = 'https://mp.weixin.qq.com'
response = requests.get(url=m_url, cookies=self.cookie)
self.token = re.findall(r'token=(\d+)', str(response.url))[0]
# fakeid与name
self.fakeid = []
# 获取公众号信息
def getGname(self):
# 请求头
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'mp.weixin.qq.com',
'Referer': 'https://mp.weixin.qq.com/cgi-b ... 25int(self.token),
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
# 地址
url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
# query = input('请输入要搜索的公众号关键字:')
# begin = int(input('请输入开始的页数:'))
query = 'python'
begin = 0
begin *= 5
# 请求参数
data = {
'action': 'search_biz',
'token': self.token,
'lang': 'zh_CN',
'f': 'json',
'ajax':' 1',
'random': random.random(),
'query': query,
'begin': begin,
'count': '5'
}
# 请求页面,获取数据
res = requests.get(url=url, cookies=self.cookie, headers=headers, params=data)
name_js = res.text
name_js = json.loads(name_js)
list = name_js['list']
for i in list:
time.sleep(1)
fakeid = i['fakeid']
nickname =i['nickname']
print(nickname,fakeid)
self.fakeid.append((nickname,fakeid))
# 获取文章url
def getEurl(self):
url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'mp.weixin.qq.com',
'Referer': 'https://mp.weixin.qq.com/cgi-b ... 25int(self.token),
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
# 遍历fakeid,访问获取文章链接
for i in self.fakeid:
time.sleep(1)
fake = i[1]
data = {
'token': self.token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': 0,
'count': 5,
'fakeid': fake,
'type': 9
}
res = requests.get(url, cookies=self.cookie, headers=headers, params=data)
js = res.text
link_l = json.loads(js)
self.parJson(link_l)
# 解析提取url
def parJson(self,link_l):
l = link_l['app_msg_list']
for i in l:
link = i['link']
name = i['digest']
self.saveData(name,link)
# 保存数据进csv中
def saveData(self,name,link):
with open('link.csv' ,'a',encoding='utf8') as f:
w = csv.writer(f)
w.writerow((name,link))
print('ok')
C = C_ookie()
C.get_cookie()
G = getEssay()
G.getGname()
G.getEurl()
整个爬取过程就到这里,希望能帮到你 查看全部
与token的代码与上篇文章衔接起来代码的流程
获取网址
在我们解决cookie和token之前,那我们只需要把这两个参数放到请求头中就可以得到我们想要的
首先搜索公司账号名称
这里打开素材管理,点击新建图形素材
点击超链接。转到此页面
在此处提取url、headers和参数并找出更改的参数
random参数是0-1之间的随机浮点数,query是搜索内容,前面提取token
接下来我们看看获取文章的请求和接口
我们对页面的分析完成了,接下来我们开始编写代码,这次的代码是和上一篇文章的代码连接起来的
import time
import json
import random
import csv
from selenium import webdriver
from lxml import html
import requests
import re
# 获取cookies和token
class C_ookie:
# 初始化
def __init__(self):
self.html = ''
# 获取cookie
def get_cookie(self):
cooki = {}
url = 'https://mp.weixin.qq.com'
Browner = webdriver.Chrome()
Browner.get(url)
# 获取账号输入框
ID = Browner.find_element_by_name('account')
# 获取密码输入框
PW = Browner.find_element_by_name('password')
# 输入账号
#输入账号
id =
#输入密码
pw =
# id = input('请输入账号:')
# pw = input('请输入密码:')
ID.send_keys(id)
PW.send_keys(pw)
# 获取登录button,点击登录
Browner.find_element_by_class_name('btn_login').click()
# 等待扫二维码
time.sleep(10)
cks = Browner.get_cookies()
for ck in cks:
cooki[ck['name']] = ck['value']
ck1 = json.dumps(cooki)
print(ck1)
with open('ck.txt','w') as f :
f.write(ck1)
f.close()
self.html = Browner.page_source
# 获取文章
class getEssay:
def __init__(self):
# 获取cookies
with open('ck.txt','r') as f :
cookie = f.read()
f.close()
self.cookie = json.loads(cookie)
# 获取token
self.header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": 'Mozilla / 5.0(WindowsNT6.1;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 74.0.3729.131Safari / 537.36'
}
m_url = 'https://mp.weixin.qq.com'
response = requests.get(url=m_url, cookies=self.cookie)
self.token = re.findall(r'token=(\d+)', str(response.url))[0]
# fakeid与name
self.fakeid = []
# 获取公众号信息
def getGname(self):
# 请求头
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'mp.weixin.qq.com',
'Referer': 'https://mp.weixin.qq.com/cgi-b ... 25int(self.token),
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
# 地址
url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
# query = input('请输入要搜索的公众号关键字:')
# begin = int(input('请输入开始的页数:'))
query = 'python'
begin = 0
begin *= 5
# 请求参数
data = {
'action': 'search_biz',
'token': self.token,
'lang': 'zh_CN',
'f': 'json',
'ajax':' 1',
'random': random.random(),
'query': query,
'begin': begin,
'count': '5'
}
# 请求页面,获取数据
res = requests.get(url=url, cookies=self.cookie, headers=headers, params=data)
name_js = res.text
name_js = json.loads(name_js)
list = name_js['list']
for i in list:
time.sleep(1)
fakeid = i['fakeid']
nickname =i['nickname']
print(nickname,fakeid)
self.fakeid.append((nickname,fakeid))
# 获取文章url
def getEurl(self):
url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'mp.weixin.qq.com',
'Referer': 'https://mp.weixin.qq.com/cgi-b ... 25int(self.token),
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
# 遍历fakeid,访问获取文章链接
for i in self.fakeid:
time.sleep(1)
fake = i[1]
data = {
'token': self.token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': 0,
'count': 5,
'fakeid': fake,
'type': 9
}
res = requests.get(url, cookies=self.cookie, headers=headers, params=data)
js = res.text
link_l = json.loads(js)
self.parJson(link_l)
# 解析提取url
def parJson(self,link_l):
l = link_l['app_msg_list']
for i in l:
link = i['link']
name = i['digest']
self.saveData(name,link)
# 保存数据进csv中
def saveData(self,name,link):
with open('link.csv' ,'a',encoding='utf8') as f:
w = csv.writer(f)
w.writerow((name,link))
print('ok')
C = C_ookie()
C.get_cookie()
G = getEssay()
G.getGname()
G.getEurl()
整个爬取过程就到这里,希望能帮到你
上面这种是支持微信、短信通知的吗?(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-08-02 05:10
上面这种是支持微信、短信通知的吗?(图)
\Phpcmf\Service::M('member')->notice($uid, $type, $note, $url = '')
$uid 会员id
$type 类型:1系统 2用户 3内容 4应用 5交易 6订单
$note 通知内容
$url 相关链接
以上类型是否支持微信和短信通知?不需要设置通知模板? ?
----------------------------------------------- ------
使用系统通知,不知道如何携带URL参数。如果你想在小程序或者APP中传递一个URL参数! !
\Phpcmf\Service::L('Notice')->send_notice('news', $userlist);
最新任务《{$title}》,时间:{dr_date($sys_time)}
{
"id": "98",
"type": "1",
"uid": "1",
"isnew": "0",
"content": "完成调查任务",
"url": "",
"inputtime": "1575019067"
}, 查看全部
上面这种是支持微信、短信通知的吗?(图)
\Phpcmf\Service::M('member')->notice($uid, $type, $note, $url = '')
$uid 会员id
$type 类型:1系统 2用户 3内容 4应用 5交易 6订单
$note 通知内容
$url 相关链接
以上类型是否支持微信和短信通知?不需要设置通知模板? ?
----------------------------------------------- ------
使用系统通知,不知道如何携带URL参数。如果你想在小程序或者APP中传递一个URL参数! !
\Phpcmf\Service::L('Notice')->send_notice('news', $userlist);
最新任务《{$title}》,时间:{dr_date($sys_time)}
{
"id": "98",
"type": "1",
"uid": "1",
"isnew": "0",
"content": "完成调查任务",
"url": "",
"inputtime": "1575019067"
},
微信小程序订阅消息升级,以前的消息模板不适合使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-08-01 22:09
微信小程序订阅消息更新,之前的消息模板不适合使用
官方文档微信官方文档
要求
使用小程序开启直播讲座,学生可以预约,已经预约的学生会在直播开始前发送提醒和直播开始提醒
整体流程
1、模板由产品在微信小程序中设计,模板id和内容给前后端
2、前端在小程序页面发起消息订阅授权。用户同意授权后,微信返回的templateIds传递给后端
3、后端保存templateIds并组装相应的内容,保存到数据库中
4、使用定时器查询要发送的数据并发送给用户(广播前提醒)
5、用户广播,发送启动提醒
后端关键设计及代码
定义模板
public interface ConstantTemplate {
/**
* 提前提醒
*/
String CLOUD_PREACH_TEMPLATE_ID = "xxxxxxxxxxxxxx";
String CLOUD_PREACH_TEMPLATE_DATA = "{\"time1\":{\"value\":\"%s\"},\"thing2\":{\"value\":\"%s\"},\"thing3\":{\"value\":\"%s\"}}";
/**
* 开播提醒
*/
String INTERVIEW_NOTICE_TEMPLATE_ID = "xxxxxxxxxxxxxxxx";
String INTERVIEW_NOTICE_TEMPLATE_DATA ="{\"thing1\":{\"value\":\"%s\"},\"thing2\":{\"value\":\"%s\"},\time3\":{\"value\":\"%s\"},\"thing4\":{\"value\":\"%s\"},\"thing5\":{\"value\":\"%s\"}}";
}
@Getter
public enum WxMiniMsgTemplateEnum {
/**
* 微信小程序消息模板
*/
CLOUD_PREACH_TEMPLATE(CLOUD_PREACH_TEMPLATE_ID, CLOUD_PREACH_TEMPLATE_DATA),
INTERVIEW_NOTICE_TEMPLATE(INTERVIEW_NOTICE_TEMPLATE_ID, INTERVIEW_NOTICE_TEMPLATE_DATA);
private final String id;
private final String data;
WxMiniMsgTemplateEnum(String id, String data) {
this.id = id;
this.data = data;
}
public static String getDataById(String id) {
return Arrays.stream(WxMiniMsgTemplateEnum.values()).filter(r -> r.getId().equals(id)).findFirst().map(WxMiniMsgTemplateEnum::getData).orElse(null);
}
}
保存消息
for (String templateId : dto.getTemplateIds()) {
//发送小程序订阅消息
XyWxMiniMsgDTO wxMsgDTO = new XyWxMiniMsgDTO();
wxMsgDTO.setPage(dto.getPage());
wxMsgDTO.setEndpoint(com.xyedu.sims.common.enums.SourceTypeEnum.STUDENT_MINI.getCode());
wxMsgDTO.setLang("zh_CN");
wxMsgDTO.setMiniprogramState(ConstantUtil.MiniprogramState);
wxMsgDTO.setTouser(social.getOpenId());
LocalDateTime sendTime = topicInfo.getStartTime();
LocalDateTime pastTime = topicInfo.getEndTime();
//提前20分钟发送通知
wxMsgDTO.setSendTime(sendTime.minusMinutes(20));
wxMsgDTO.setPastTime(pastTime);
String date = DateUtil.getDefaultFormatDate(DateUtil.localDateTimeToDate(topicInfo.getStartTime()));
//组装模板数据
String data = WxMiniMsgTemplateEnum.getDataById(templateId);
if (ToolUtil.isNotEmpty(data)) {
data = String.format(data, date, StrUtil.subWithLength(topicInfo.getTitle(), 0, 20), userCache.getRealName() + "同学,云宣讲即将开始~");
wxMsgDTO.setData(JSONUtil.toJsonStr(data));
}
wxMsgDTO.setTemplateId(templateId);
XyWxMiniMsg miniMsg = BeanUtil.copy(wxMsgDTO, XyWxMiniMsg.class);
//保存至数据库
remoteXyWxMiniMsgService.add(miniMsg);
}
包裹发送工具
@Slf4j
public class WxMiniMsgUtil {
//官方文档: https://developers.weixin.qq.c ... .html
private static final String WX_MINI_MSG_URL = "https://api.weixin.qq.com/cgi- ... 3B%3B
public static Object send(String accessToken, XyWxMiniMsgDTO dto) {
String url = WX_MINI_MSG_URL + accessToken;
Map reqBody = new HashMap();
reqBody.put("touser", dto.getTouser());
reqBody.put("template_id", dto.getTemplateId());
reqBody.put("miniprogram_state", dto.getMiniprogramState());
reqBody.put("lang", dto.getLang());
reqBody.put("page", dto.getPage());
reqBody.put("data", JSONUtil.parseObj(dto.getData()));
try {
return HttpRequest.post(url)
.body(JSONUtil.toJsonStr(reqBody))
.timeout(5000)
.execute()
.body();
} catch (Exception e) {
log.error("send wx mini msg occur an exception,e={}", e.getMessage());
return null;
}
}
}
使用定时器发送,定时器每3分钟执行一次查询,查询未发送或发送失败的消息。如果超过时间,发送状态将设置为过期
@Getter
public enum WxMiniMsgSendStatusEnum {
/**
*
*/
SENDING(0, "未发送"),
SEND_SUCCESS(1, "发送成功"),
SEND_FAIL(2, "发送失败"),
OVERDUE(3,"过期");
private Integer code;
private String msg;
WxMiniMsgSendStatusEnum(Integer code, String msg) {
this.code = code;
this.msg = msg;
}
public static String getMsg(Object code) {
if (code == null) {
return null;
}
return Arrays.stream(values()).filter(e -> e.getCode().equals(code)).findFirst().map(e -> e.getMsg()).orElse("");
}
}
@Override
public ReturnT execute(String param) throws Exception {
log.debug("[send wx mini msg]-start");
XyWxMiniMsgQueryDTO dto = new XyWxMiniMsgQueryDTO();
dto.setEndpoint(SourceTypeEnum.STUDENT_MINI.getCode());
//从数据库中获取应发送的数据列表
List list = remoteXyWxMiniMsgService.list(dto);
if (CollectionUtil.isNotEmpty(list)) {
log.debug("[send wx mini msg]-query list,list.size={}", list.size());
final WxMaService wxService = WxMaConfiguration.getMaService();
String accessToken = wxService.getAccessToken();
for (XyWxMiniMsg msg : list) {
XyWxMiniMsgDTO msgDTO = BeanUtil.copy(msg, XyWxMiniMsgDTO.class);
//通知微信发送订阅消息
Object response = WxMiniMsgUtil.send(accessToken, msgDTO);
if (ToolUtil.isNotEmpty(response)) {
msg.setResponse(response.toString());
JSONObject object = JSONUtil.parseObj(response);
//处理微信响应信息
if (object.containsKey("errcode")
&& NumberUtil.isNumber(object.get("errcode").toString())
&& Integer.valueOf(object.get("errcode").toString()) == 0) {
msg.setSendStatus(WxMiniMsgSendStatusEnum.SEND_SUCCESS.getCode());
} else if (object.containsKey("errcode")
&& NumberUtil.isNumber(object.get("errcode").toString())
&& Integer.valueOf(object.get("errcode").toString()) == 42001) {
log.error("[send wx mini msg]-response fail,refresh accessToken={}", response);
msg.setSendStatus(WxMiniMsgSendStatusEnum.SEND_FAIL.getCode());
WxMaConfiguration.getMaService().getAccessToken(true);
} else {
msg.setSendStatus(WxMiniMsgSendStatusEnum.SEND_FAIL.getCode());
log.error("[send wx mini msg]-response fail,response={}", response);
}
} else {
msg.setSendStatus(WxMiniMsgSendStatusEnum.SEND_FAIL.getCode());
log.error("[send wx mini msg]-response empty,may be catch exception,params[accessToken={}\n,msgDTO={}]", accessToken, msgDTO);
}
}
remoteXyWxMiniMsgService.updateBatch(list);
}
log.debug("[send wx mini msg]-finish");
return ReturnT.SUCCESS;
}
要求点 5 尚未完成。思路大概是在组装提前提醒模板的时候把开机提醒消息保存到数据库中,用templateId+演示的id作为唯一标识,在数据库中查询广播开始时要发送的消息,最后直接通过工具类发送 查看全部
微信小程序订阅消息升级,以前的消息模板不适合使用
微信小程序订阅消息更新,之前的消息模板不适合使用
官方文档微信官方文档
要求
使用小程序开启直播讲座,学生可以预约,已经预约的学生会在直播开始前发送提醒和直播开始提醒
整体流程
1、模板由产品在微信小程序中设计,模板id和内容给前后端
2、前端在小程序页面发起消息订阅授权。用户同意授权后,微信返回的templateIds传递给后端
3、后端保存templateIds并组装相应的内容,保存到数据库中
4、使用定时器查询要发送的数据并发送给用户(广播前提醒)
5、用户广播,发送启动提醒
后端关键设计及代码
定义模板
public interface ConstantTemplate {
/**
* 提前提醒
*/
String CLOUD_PREACH_TEMPLATE_ID = "xxxxxxxxxxxxxx";
String CLOUD_PREACH_TEMPLATE_DATA = "{\"time1\":{\"value\":\"%s\"},\"thing2\":{\"value\":\"%s\"},\"thing3\":{\"value\":\"%s\"}}";
/**
* 开播提醒
*/
String INTERVIEW_NOTICE_TEMPLATE_ID = "xxxxxxxxxxxxxxxx";
String INTERVIEW_NOTICE_TEMPLATE_DATA ="{\"thing1\":{\"value\":\"%s\"},\"thing2\":{\"value\":\"%s\"},\time3\":{\"value\":\"%s\"},\"thing4\":{\"value\":\"%s\"},\"thing5\":{\"value\":\"%s\"}}";
}
@Getter
public enum WxMiniMsgTemplateEnum {
/**
* 微信小程序消息模板
*/
CLOUD_PREACH_TEMPLATE(CLOUD_PREACH_TEMPLATE_ID, CLOUD_PREACH_TEMPLATE_DATA),
INTERVIEW_NOTICE_TEMPLATE(INTERVIEW_NOTICE_TEMPLATE_ID, INTERVIEW_NOTICE_TEMPLATE_DATA);
private final String id;
private final String data;
WxMiniMsgTemplateEnum(String id, String data) {
this.id = id;
this.data = data;
}
public static String getDataById(String id) {
return Arrays.stream(WxMiniMsgTemplateEnum.values()).filter(r -> r.getId().equals(id)).findFirst().map(WxMiniMsgTemplateEnum::getData).orElse(null);
}
}
保存消息
for (String templateId : dto.getTemplateIds()) {
//发送小程序订阅消息
XyWxMiniMsgDTO wxMsgDTO = new XyWxMiniMsgDTO();
wxMsgDTO.setPage(dto.getPage());
wxMsgDTO.setEndpoint(com.xyedu.sims.common.enums.SourceTypeEnum.STUDENT_MINI.getCode());
wxMsgDTO.setLang("zh_CN");
wxMsgDTO.setMiniprogramState(ConstantUtil.MiniprogramState);
wxMsgDTO.setTouser(social.getOpenId());
LocalDateTime sendTime = topicInfo.getStartTime();
LocalDateTime pastTime = topicInfo.getEndTime();
//提前20分钟发送通知
wxMsgDTO.setSendTime(sendTime.minusMinutes(20));
wxMsgDTO.setPastTime(pastTime);
String date = DateUtil.getDefaultFormatDate(DateUtil.localDateTimeToDate(topicInfo.getStartTime()));
//组装模板数据
String data = WxMiniMsgTemplateEnum.getDataById(templateId);
if (ToolUtil.isNotEmpty(data)) {
data = String.format(data, date, StrUtil.subWithLength(topicInfo.getTitle(), 0, 20), userCache.getRealName() + "同学,云宣讲即将开始~");
wxMsgDTO.setData(JSONUtil.toJsonStr(data));
}
wxMsgDTO.setTemplateId(templateId);
XyWxMiniMsg miniMsg = BeanUtil.copy(wxMsgDTO, XyWxMiniMsg.class);
//保存至数据库
remoteXyWxMiniMsgService.add(miniMsg);
}
包裹发送工具
@Slf4j
public class WxMiniMsgUtil {
//官方文档: https://developers.weixin.qq.c ... .html
private static final String WX_MINI_MSG_URL = "https://api.weixin.qq.com/cgi- ... 3B%3B
public static Object send(String accessToken, XyWxMiniMsgDTO dto) {
String url = WX_MINI_MSG_URL + accessToken;
Map reqBody = new HashMap();
reqBody.put("touser", dto.getTouser());
reqBody.put("template_id", dto.getTemplateId());
reqBody.put("miniprogram_state", dto.getMiniprogramState());
reqBody.put("lang", dto.getLang());
reqBody.put("page", dto.getPage());
reqBody.put("data", JSONUtil.parseObj(dto.getData()));
try {
return HttpRequest.post(url)
.body(JSONUtil.toJsonStr(reqBody))
.timeout(5000)
.execute()
.body();
} catch (Exception e) {
log.error("send wx mini msg occur an exception,e={}", e.getMessage());
return null;
}
}
}
使用定时器发送,定时器每3分钟执行一次查询,查询未发送或发送失败的消息。如果超过时间,发送状态将设置为过期
@Getter
public enum WxMiniMsgSendStatusEnum {
/**
*
*/
SENDING(0, "未发送"),
SEND_SUCCESS(1, "发送成功"),
SEND_FAIL(2, "发送失败"),
OVERDUE(3,"过期");
private Integer code;
private String msg;
WxMiniMsgSendStatusEnum(Integer code, String msg) {
this.code = code;
this.msg = msg;
}
public static String getMsg(Object code) {
if (code == null) {
return null;
}
return Arrays.stream(values()).filter(e -> e.getCode().equals(code)).findFirst().map(e -> e.getMsg()).orElse("");
}
}
@Override
public ReturnT execute(String param) throws Exception {
log.debug("[send wx mini msg]-start");
XyWxMiniMsgQueryDTO dto = new XyWxMiniMsgQueryDTO();
dto.setEndpoint(SourceTypeEnum.STUDENT_MINI.getCode());
//从数据库中获取应发送的数据列表
List list = remoteXyWxMiniMsgService.list(dto);
if (CollectionUtil.isNotEmpty(list)) {
log.debug("[send wx mini msg]-query list,list.size={}", list.size());
final WxMaService wxService = WxMaConfiguration.getMaService();
String accessToken = wxService.getAccessToken();
for (XyWxMiniMsg msg : list) {
XyWxMiniMsgDTO msgDTO = BeanUtil.copy(msg, XyWxMiniMsgDTO.class);
//通知微信发送订阅消息
Object response = WxMiniMsgUtil.send(accessToken, msgDTO);
if (ToolUtil.isNotEmpty(response)) {
msg.setResponse(response.toString());
JSONObject object = JSONUtil.parseObj(response);
//处理微信响应信息
if (object.containsKey("errcode")
&& NumberUtil.isNumber(object.get("errcode").toString())
&& Integer.valueOf(object.get("errcode").toString()) == 0) {
msg.setSendStatus(WxMiniMsgSendStatusEnum.SEND_SUCCESS.getCode());
} else if (object.containsKey("errcode")
&& NumberUtil.isNumber(object.get("errcode").toString())
&& Integer.valueOf(object.get("errcode").toString()) == 42001) {
log.error("[send wx mini msg]-response fail,refresh accessToken={}", response);
msg.setSendStatus(WxMiniMsgSendStatusEnum.SEND_FAIL.getCode());
WxMaConfiguration.getMaService().getAccessToken(true);
} else {
msg.setSendStatus(WxMiniMsgSendStatusEnum.SEND_FAIL.getCode());
log.error("[send wx mini msg]-response fail,response={}", response);
}
} else {
msg.setSendStatus(WxMiniMsgSendStatusEnum.SEND_FAIL.getCode());
log.error("[send wx mini msg]-response empty,may be catch exception,params[accessToken={}\n,msgDTO={}]", accessToken, msgDTO);
}
}
remoteXyWxMiniMsgService.updateBatch(list);
}
log.debug("[send wx mini msg]-finish");
return ReturnT.SUCCESS;
}
要求点 5 尚未完成。思路大概是在组装提前提醒模板的时候把开机提醒消息保存到数据库中,用templateId+演示的id作为唯一标识,在数据库中查询广播开始时要发送的消息,最后直接通过工具类发送
基于PHP的服务端开源项目之phpQuery采集文章(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-08-01 07:04
phpQuery 是一个基于 PHP 的服务器端开源项目,它可以让 PHP 开发者轻松处理 DOM 文档的内容,例如获取新闻的头条新闻网站。更有趣的是它使用了jQuery的思想。你可以像使用jQuery一样处理页面内容,获取你想要的页面信息。
采集头条
先看个例子,现在我要的是采集国内新闻的标题,代码如下:
复制代码代码如下:
收录'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('');
echo pq(".blkTop h1:eq(0)")->html();
简单的三行代码,即可获取标题内容。首先在程序中收录phpQuery.php核心程序,然后调用读取目标网页,最后输出对应标签下的内容。
pq() 是一个强大的方法,就像jQuery的$()一样,jQuery的选择器基本可以用在phpQuery上,只要把“.”改一下就行了。到“->”。如上例, pq(".blkTop h1:eq(0)") 抓取class属性为blkTop的DIV元素,找到DIV里面的第一个h1标签,然后使用html()方法获取h1 标签中的内容(带html标签)就是我们要获取的标题信息,如果使用text()方法,只会获取到标题的文本内容,当然一定要用好phpQuery,关键是在文档Node中找到对应的内容。
采集文章List
下面再看一个例子,获取网站的博客列表,请看代码:
复制代码代码如下:
收录'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('');
$artlist = pq(".blog_li");
foreach($artlist as $li){
echo pq($li)->find('h2')->html()."";
}
找到文章 标题并通过循环遍历列表中的 DIV 将其输出就是这么简单。
解析 XML 文档
假设有一个像这样的 test.xml 文档:
复制代码代码如下:
张三
22
王舞
18
现在想获取联系人张三的年龄,代码如下:
复制代码代码如下:
收录'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('test.xml');
echo pq('contact> age:eq(0)');
结果输出:22
和jQuery一样,它就像准确找到文档节点,输出节点下的内容,解析一个XML文档一样简单。现在您不必为采集网站 内容使用繁琐的代码,例如头痛的常规算法和内容替换。有了 phpQuery,一切都变得简单了。
phpquery项目官网地址: 查看全部
基于PHP的服务端开源项目之phpQuery采集文章(一)
phpQuery 是一个基于 PHP 的服务器端开源项目,它可以让 PHP 开发者轻松处理 DOM 文档的内容,例如获取新闻的头条新闻网站。更有趣的是它使用了jQuery的思想。你可以像使用jQuery一样处理页面内容,获取你想要的页面信息。
采集头条
先看个例子,现在我要的是采集国内新闻的标题,代码如下:
复制代码代码如下:
收录'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('');
echo pq(".blkTop h1:eq(0)")->html();
简单的三行代码,即可获取标题内容。首先在程序中收录phpQuery.php核心程序,然后调用读取目标网页,最后输出对应标签下的内容。
pq() 是一个强大的方法,就像jQuery的$()一样,jQuery的选择器基本可以用在phpQuery上,只要把“.”改一下就行了。到“->”。如上例, pq(".blkTop h1:eq(0)") 抓取class属性为blkTop的DIV元素,找到DIV里面的第一个h1标签,然后使用html()方法获取h1 标签中的内容(带html标签)就是我们要获取的标题信息,如果使用text()方法,只会获取到标题的文本内容,当然一定要用好phpQuery,关键是在文档Node中找到对应的内容。
采集文章List
下面再看一个例子,获取网站的博客列表,请看代码:
复制代码代码如下:
收录'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('');
$artlist = pq(".blog_li");
foreach($artlist as $li){
echo pq($li)->find('h2')->html()."";
}
找到文章 标题并通过循环遍历列表中的 DIV 将其输出就是这么简单。
解析 XML 文档
假设有一个像这样的 test.xml 文档:
复制代码代码如下:
张三
22
王舞
18
现在想获取联系人张三的年龄,代码如下:
复制代码代码如下:
收录'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('test.xml');
echo pq('contact> age:eq(0)');
结果输出:22
和jQuery一样,它就像准确找到文档节点,输出节点下的内容,解析一个XML文档一样简单。现在您不必为采集网站 内容使用繁琐的代码,例如头痛的常规算法和内容替换。有了 phpQuery,一切都变得简单了。
phpquery项目官网地址:

