
querylist采集微信公众号文章
querylist采集微信公众号文章(垃圾程序员如何采集微信公众号的内容?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-29 00:19
今天,作为一个垃圾程序员的小编,和大家聊聊微信公众号采集的内容?
首先你要明确你的目标:你的采集公众号文章的数据会放在哪里?是在APP上还是在自己的官网上。,
意思是:你用这个微信公众号的内容做什么?
几个小白之前从我这里买过微信公众号采集系统。主要用于采集公众号原创内容,提升网站收录和关键词的内容排名。
问题 1:我可以查看和修改 采集 中的数据吗?
我的回答:采集过来的数据可以在系统上设置:under review,这种情况不会直接采集到你的网站,你可以选择修改文章标题和图片内容,然后发布。
这可以防止搜索引擎发现您在作弊 采集 内容,因为您在后台手动发布它。当然,我们的采集操作系统是原生态开发的,不是市面上的采集软件,所以我们不会在这里hack别人,因为他们开发的系统和软件都比较老,对于搜索引擎。把握一个标准,尤其是百度搜索。
回到正题:如何把采集微信公众号文章放到官网或APP上?
1.公众号抓包是通过微信公众号用户在微信上的登录信息在微信系统中抓包的
2.在微信公众号系统中设置微信公众号登录信息到我们系统
3.使用设置的登录信息进行微信搜索和微信抓包文章
4.将抓到的公众号设置为系统中的普通用户
5. 在系统中编辑、审核并发布捕获的文章,并与对应的用户关联
6.发布的文章和普通用户发布的文章没有区别,可以直接使用之前的管理方式进行管理。
准备公众号获取Token和Cookies的价值
1.用自己的公众号登录
2. 点击“素材管理->新建图文素材”
3.点击图形编辑器工具栏上的“超链接”
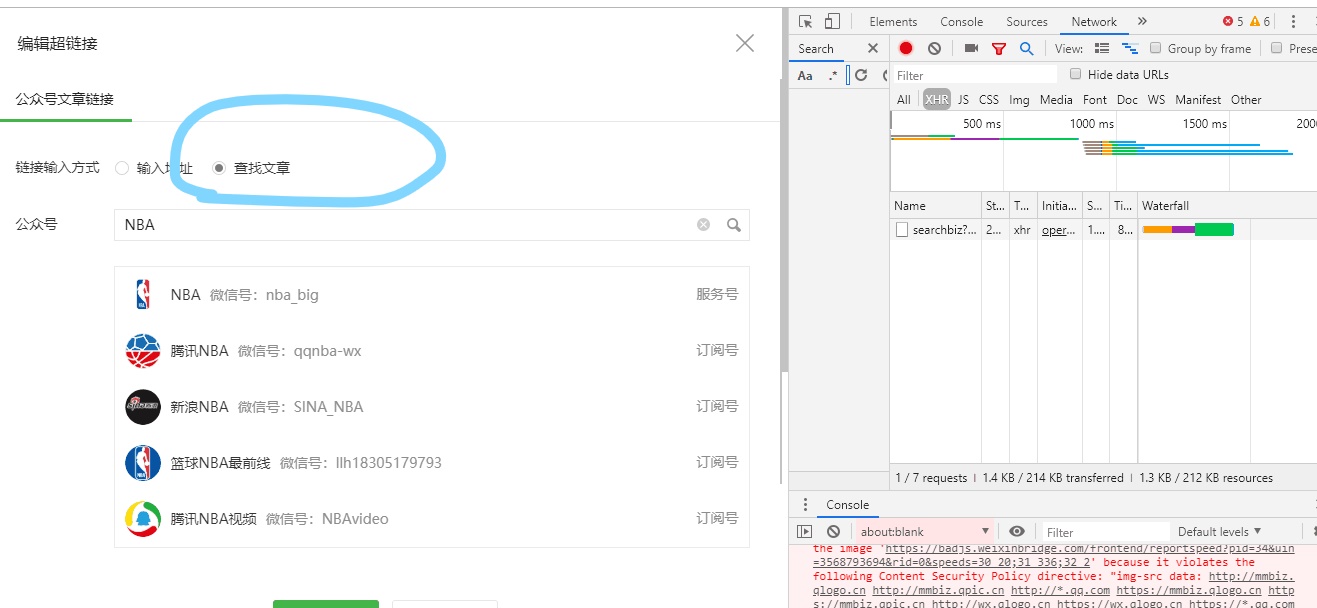
4.在对话框的“链接输入法”中选择“查找文章”
5.采集 使用的接口来自这里
加我微信购买咨询,我的微信是:1124805587 查看全部
querylist采集微信公众号文章(垃圾程序员如何采集微信公众号的内容?(组图))
今天,作为一个垃圾程序员的小编,和大家聊聊微信公众号采集的内容?
首先你要明确你的目标:你的采集公众号文章的数据会放在哪里?是在APP上还是在自己的官网上。,
意思是:你用这个微信公众号的内容做什么?
几个小白之前从我这里买过微信公众号采集系统。主要用于采集公众号原创内容,提升网站收录和关键词的内容排名。
问题 1:我可以查看和修改 采集 中的数据吗?
我的回答:采集过来的数据可以在系统上设置:under review,这种情况不会直接采集到你的网站,你可以选择修改文章标题和图片内容,然后发布。
这可以防止搜索引擎发现您在作弊 采集 内容,因为您在后台手动发布它。当然,我们的采集操作系统是原生态开发的,不是市面上的采集软件,所以我们不会在这里hack别人,因为他们开发的系统和软件都比较老,对于搜索引擎。把握一个标准,尤其是百度搜索。
回到正题:如何把采集微信公众号文章放到官网或APP上?
1.公众号抓包是通过微信公众号用户在微信上的登录信息在微信系统中抓包的
2.在微信公众号系统中设置微信公众号登录信息到我们系统
3.使用设置的登录信息进行微信搜索和微信抓包文章
4.将抓到的公众号设置为系统中的普通用户
5. 在系统中编辑、审核并发布捕获的文章,并与对应的用户关联
6.发布的文章和普通用户发布的文章没有区别,可以直接使用之前的管理方式进行管理。
准备公众号获取Token和Cookies的价值
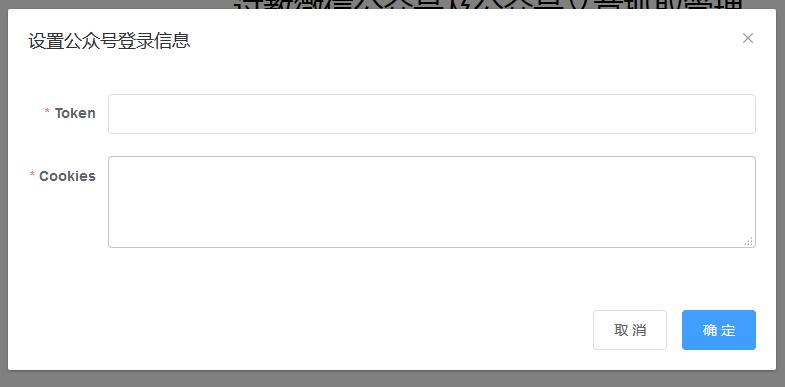
1.用自己的公众号登录
2. 点击“素材管理->新建图文素材”
3.点击图形编辑器工具栏上的“超链接”
4.在对话框的“链接输入法”中选择“查找文章”
5.采集 使用的接口来自这里
加我微信购买咨询,我的微信是:1124805587
querylist采集微信公众号文章(如何采集微信文章?微信啄木鸟助手帮你采集二维码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 328 次浏览 • 2021-10-26 15:26
除了公众号,还提供公众号。此外,可以通过微信公众号采集数据。此外,它还可以采集标题、文章号、原文链接、阅读号、积分、发布时间等数据。具体步骤如下:
1、采集需要采集的公共电话号码列表。
2.将这些公众号添加到清博指数的自定义列表中,
3、每天都会从公众号获取清晰的指数。注:如未查询相关公众号,需进行入库操作。可供微信啄木鸟助手使用,可用于word、PDF等多种格式,采集一种格式。会一直保存在微信公众号里。
微信文章怎么采集?
谢谢
!这个软件就是MicroPort City,一个刚刚开发出来的非常强大的软件。主要通过采集二维码和扫描群码访问。软件结合大数据、爬虫技术和图像分析技术,可以智能识别二维码、检测二维码真伪、智能过滤重复二维码、记忆查询等功能,可以帮助您大大提高群组搜索效率,成功率组进入率和组质量。
通过五个渠道,我们可以采集所有公开的、有效的、真实的、活跃的微信群。这10个二维码中,大约有6-7个是有效的微信群,并且是实时更新的。一天可以采集近万个微信群,上万个微信群,二维码,或特定群。一旦你设置了关键词,你就可以开始采集了。实时采集。软件很强大,行业很广。
如何采集微信文章?
作为新媒体运营的小伙伴,每天需要同步很多文章。发送到微信的文章需要复制到头条、短篇等平台。但是,它不仅容易出现格式错误,而且复制的图像也难以显示。
这是一款可以一键发布文章多平台的浏览器插件,支持同步到今日头条、知乎、简书、掘金、CSDN等9个平台。
使用时只需要安装插件号即可。编辑完文章后,勾选同步平台,系统会自动将文章和图片传送到其他平台,并保存为草稿供您进一步编辑发布。这是非常省时和高效的。
插件也安装好了,添加相关账号即可使用。工作原理与上述插件类似。填写要同步的文章链接,然后选择同步平台。
小曲是第一个常用的。如果你也找到了一个好用的一键同步平台,请分享给我。
①转发本文并关注@fun play
2.私信“一键发布”获取以上插件 查看全部
querylist采集微信公众号文章(如何采集微信文章?微信啄木鸟助手帮你采集二维码)
除了公众号,还提供公众号。此外,可以通过微信公众号采集数据。此外,它还可以采集标题、文章号、原文链接、阅读号、积分、发布时间等数据。具体步骤如下:
1、采集需要采集的公共电话号码列表。
2.将这些公众号添加到清博指数的自定义列表中,
3、每天都会从公众号获取清晰的指数。注:如未查询相关公众号,需进行入库操作。可供微信啄木鸟助手使用,可用于word、PDF等多种格式,采集一种格式。会一直保存在微信公众号里。
微信文章怎么采集?
谢谢
!这个软件就是MicroPort City,一个刚刚开发出来的非常强大的软件。主要通过采集二维码和扫描群码访问。软件结合大数据、爬虫技术和图像分析技术,可以智能识别二维码、检测二维码真伪、智能过滤重复二维码、记忆查询等功能,可以帮助您大大提高群组搜索效率,成功率组进入率和组质量。
通过五个渠道,我们可以采集所有公开的、有效的、真实的、活跃的微信群。这10个二维码中,大约有6-7个是有效的微信群,并且是实时更新的。一天可以采集近万个微信群,上万个微信群,二维码,或特定群。一旦你设置了关键词,你就可以开始采集了。实时采集。软件很强大,行业很广。
如何采集微信文章?
作为新媒体运营的小伙伴,每天需要同步很多文章。发送到微信的文章需要复制到头条、短篇等平台。但是,它不仅容易出现格式错误,而且复制的图像也难以显示。
这是一款可以一键发布文章多平台的浏览器插件,支持同步到今日头条、知乎、简书、掘金、CSDN等9个平台。
使用时只需要安装插件号即可。编辑完文章后,勾选同步平台,系统会自动将文章和图片传送到其他平台,并保存为草稿供您进一步编辑发布。这是非常省时和高效的。
插件也安装好了,添加相关账号即可使用。工作原理与上述插件类似。填写要同步的文章链接,然后选择同步平台。
小曲是第一个常用的。如果你也找到了一个好用的一键同步平台,请分享给我。
①转发本文并关注@fun play
2.私信“一键发布”获取以上插件
querylist采集微信公众号文章( 《千梦ip魔鬼实战训练营》微信公众号文章采集教学)
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-10-24 10:17
《千梦ip魔鬼实战训练营》微信公众号文章采集教学)
一、前言
在上周千梦团队直播的《千梦IP恶魔实战训练营》中,我们推荐了一些比较优秀的同行案例。目前头脑中的许多优秀球员素质都非常高,生产力也很高。内容输出,今天给大家带来微信公众号文章采集教学。
微信公众号采集目前网上有很多方法和软件,有免费的也有付费的,但质量参差不齐,功能也大不相同。下载公众号文章只是最基本的功能,如果能下载peer的所有数据,真的可以帮助我们分析标杆对象。
二、课程实践
1.下载并解压软件
拿到软件后,首先将所有文件解压到桌面文件夹。此版本免费安装,直接启用软件即可。
2.在PC上打开微信
在电脑上下载微信,登录账号同步数据。
3.进入采集对象公众号
进入对应公众号,同时点击历史菜单界面,等待软件**。
4.开始采集
软件采集完成后,建议选择“PDF”格式导出,每个公众号出来后都会变成一个单独的文件夹。
---------------------------------------------
【教程资源介绍】
资源类型:视频+工具
资源大小:136MB
积分兑换:会员150积分兑换(1元=10积分),VIP会员免费下载
【下载说明】
免费注册会员后,使用积分,点击下方“积分兑换”查看百度网盘下载链接。
--------------------------------------------- 查看全部
querylist采集微信公众号文章(
《千梦ip魔鬼实战训练营》微信公众号文章采集教学)

一、前言
在上周千梦团队直播的《千梦IP恶魔实战训练营》中,我们推荐了一些比较优秀的同行案例。目前头脑中的许多优秀球员素质都非常高,生产力也很高。内容输出,今天给大家带来微信公众号文章采集教学。
微信公众号采集目前网上有很多方法和软件,有免费的也有付费的,但质量参差不齐,功能也大不相同。下载公众号文章只是最基本的功能,如果能下载peer的所有数据,真的可以帮助我们分析标杆对象。
二、课程实践
1.下载并解压软件
拿到软件后,首先将所有文件解压到桌面文件夹。此版本免费安装,直接启用软件即可。
2.在PC上打开微信
在电脑上下载微信,登录账号同步数据。
3.进入采集对象公众号
进入对应公众号,同时点击历史菜单界面,等待软件**。
4.开始采集
软件采集完成后,建议选择“PDF”格式导出,每个公众号出来后都会变成一个单独的文件夹。
---------------------------------------------
【教程资源介绍】
资源类型:视频+工具
资源大小:136MB
积分兑换:会员150积分兑换(1元=10积分),VIP会员免费下载
【下载说明】
免费注册会员后,使用积分,点击下方“积分兑换”查看百度网盘下载链接。
---------------------------------------------
querylist采集微信公众号文章( 《千梦ip魔鬼实战训练营》微信公众号文章采集教学)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-10-23 11:09
《千梦ip魔鬼实战训练营》微信公众号文章采集教学)
一、前言
在上周千梦团队直播的《千梦IP恶魔实战训练营》中,我们推荐了一些比较优秀的同行案例。目前头脑中的许多优秀球员素质都非常高,生产力也很高。内容输出,今天给大家带来微信公众号文章采集教学。
微信公众号采集目前网上有很多方法和软件,有免费的也有付费的,但质量参差不齐,功能也大不相同。下载公众号文章只是最基本的功能,如果能下载peer的所有数据,真的可以帮助我们分析标杆对象。
二、课程实践
1.下载并解压软件
拿到软件后,首先将所有文件解压到桌面文件夹。此版本免费安装,直接启用软件即可。
2.在PC上打开微信
在电脑上下载微信,登录账号同步数据。
3.进入采集对象公众号
进入对应公众号,同时点击历史菜单界面,等待软件**。
4.开始采集
软件采集完成后,建议选择“PDF”格式导出,每个公众号出来后都会变成一个单独的文件夹。
---------------------------------------------
【教程资源介绍】
资源类型:视频+工具
资源大小:136MB
积分兑换:会员150积分兑换(1元=10积分),VIP会员免费下载
【下载说明】
免费注册会员后,使用积分,点击下方“积分兑换”查看百度网盘下载链接。
--------------------------------------------- 查看全部
querylist采集微信公众号文章(
《千梦ip魔鬼实战训练营》微信公众号文章采集教学)
一、前言
在上周千梦团队直播的《千梦IP恶魔实战训练营》中,我们推荐了一些比较优秀的同行案例。目前头脑中的许多优秀球员素质都非常高,生产力也很高。内容输出,今天给大家带来微信公众号文章采集教学。
微信公众号采集目前网上有很多方法和软件,有免费的也有付费的,但质量参差不齐,功能也大不相同。下载公众号文章只是最基本的功能,如果能下载peer的所有数据,真的可以帮助我们分析标杆对象。
二、课程实践
1.下载并解压软件
拿到软件后,首先将所有文件解压到桌面文件夹。此版本免费安装,直接启用软件即可。
2.在PC上打开微信
在电脑上下载微信,登录账号同步数据。
3.进入采集对象公众号
进入对应公众号,同时点击历史菜单界面,等待软件**。
4.开始采集
软件采集完成后,建议选择“PDF”格式导出,每个公众号出来后都会变成一个单独的文件夹。
---------------------------------------------
【教程资源介绍】
资源类型:视频+工具
资源大小:136MB
积分兑换:会员150积分兑换(1元=10积分),VIP会员免费下载
【下载说明】
免费注册会员后,使用积分,点击下方“积分兑换”查看百度网盘下载链接。
---------------------------------------------
querylist采集微信公众号文章( UI自动化工具轻松实现微信消息的自动收发和朋友圈爬取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 292 次浏览 • 2021-10-21 06:58
UI自动化工具轻松实现微信消息的自动收发和朋友圈爬取)
大家好,我是小明。昨天,我在《UI自动化工具轻松实现微信消息自动收发和好友动态爬取》一文中演示了三个UIAutomation的使用实例。链接:
由于昨天对UIAutomation的API的理解不够全面,个人代码优化还有很大的空间。今天我们的目标是实现微信PC版联系人信息列表的抓取,这将分别使用PyWinAuto和uiautomation来实现。通过对比,大家就会有更深入的了解。
PyWinAuto 实现
PyWinAuto 官方文档地址:
将 PyWinAuto 连接到桌面程序有两种主要方式:
它们是进程的 pid 和窗口句柄。下面我将演示如何获取微信的进程id和窗口句柄。
根据进程名获取进程ID:
import psutil
def get_pid(proc_name):
for proc in psutil.process_iter(attrs=['pid', 'name']):
if proc.name() == proc_name:
return proc.pid
%time get_pid("WeChat.exe")
Wall time: 224 ms
7268
根据窗口标题和类名查找窗口句柄:
import win32gui
%time hwnd = win32gui.FindWindow("WeChatMainWndForPC", "微信")
hwnd
Wall time: 0 ns
264610
耗时几乎为零,比之前的方法快了100多倍。
于是我用窗口句柄连接微信窗口:
import win32gui
from pywinauto.application import Application
hwnd = win32gui.FindWindow("WeChatMainWndForPC", "微信")
app = Application(backend='uia').connect(handle=hwnd)
app
自动打开通讯录:
import pywinauto
win = app['微信']
txl_btn = win.child_window(title="通讯录", control_type="Button")
txl_btn.draw_outline()
cords = txl_btn.rectangle()
pywinauto.mouse.click(button='left', coords=(
(cords.right+cords.left)//2, (cords.top+cords.bottom)//2))
随机点击好友信息详情后,通过inspect.exe查看节点信息。
然后编写如下代码,根据分析结果运行:
可以看到各种信息提取的很流畅,但是最多需要3.54秒,不一定比手动复制粘贴快。这也是pywinauto的一个缺点,太慢了。
下面我们进行批量爬取。原理大致是每次读取信息面板时,按向下箭头键,发现当前读取的数据与上一次一致。认为爬行已经结束。
由于pywinauto的爬取速度太慢,我手动将好友列表拖到最后,然后运行如下代码:
import pandas as pd
win = app['微信']
contacts = win.child_window(title="联系人", control_type="List")
# 点击第二个可见元素
contacts.children()[1].click_input()
result = []
last = None
num = 0
while 1:
tag = win.Edit2
tmp = tag.parent().parent()
nickname = tag.get_value()
# 跳过两个官方号
if nickname in ["微信团队", "文件传输助手"]:
contacts.type_keys("{DOWN}")
continue
detail = tmp.children()[-1]
whats_up = ""
if hasattr(detail, 'get_value'):
whats_up = detail.get_value()
elif hasattr(detail, 'window_text') and detail.window_text() != "":
# 这种情况说明是企业微信,跳过
contacts.type_keys("{DOWN}")
continue
items = tmp.parent().parent().children()[2].children()
row = {"昵称": nickname, "个性签名": whats_up}
for item in items:
lines = item.children()
k = lines[0].window_text()
v = lines[1].window_text()
row[k.replace(" ", "")] = v
if row == last:
# 与上一条数据一致则说明已经爬取完毕
break
result.append(row)
num += 1
print("\r", num, row,
end=" ")
last = row
contacts.type_keys("{DOWN}")
df = pd.DataFrame(result)
df
最后结果:
可以看出,最后一页11个微信账号的数据抓取耗时45秒。
ui自动化实现
接下来,我们将使用 uiautomation 来实现这种爬取。
获取微信窗口,点击通讯录按钮:
import uiautomation as auto
wechatWindow = auto.WindowControl(searchDepth=1, Name="微信", ClassName='WeChatMainWndForPC')
wechatWindow.SetActive()
txl_btn = wechatWindow.ButtonControl(Name='通讯录')
txl_btn.Click()
然后点击云朵君的好友信息,测试好友信息抽取:
(这个数字,你可以随意添加)
wechatWindow.EditControl(searchDepth=10, foundIndex=2) 表示在10层节点内搜索第二个EditControl类型节点(第一个是搜索框,第二个是朋友的昵称)。
GetParentControl() 和 GetNextSiblingControl() 是昨天没有使用的 API。它们用于获取父节点和下一个兄弟节点。使用这两个 API 来重写昨天的 文章 的代码,将使程序代码变得简单和高效。改进。
然后使用与 PyWinAuto 相同的方式进行批量提取:
还要先测试最后一页的数据:
爬取只用了 11 秒,比 PyWinAuto 快 4 倍。
所以我们可以批量提取所有微信好友的数据。最后,我这边的700多个朋友用了10分钟。虽然速度较慢,但与 PyWinAuto 相比完全可以接受。
代码对比
对于两者,我都试图遵循完全相同的逻辑。
win.Edit2 也得到第二个 EditControl 类型节点,
type_keys 是 PyWinAuto 用来模拟击键的 API,{DOWN} 代表向下的方向键。
PyWinAuto获取父子节点的api都是小写的,没有get,uiautomation获取父子节点的api大写,前缀为Get。
对于 PyWinAuto 中的这行代码:
items = tmp.parent().parent().children()[2].children()
使用 uiautomation:
items = tmp.GetParentControl().GetNextSiblingControl().GetNextSiblingControl().GetChildren()
有一个很大的不同。
这是因为我没有找到PyWinAuto获取兄弟节点的API,所以采用了先获取父节点再获取子节点的方法。
另外,判断是否是企业微信的逻辑不同。PyWinAuto也需要在个性签名为空时处理异常,否则程序会报错退出。具体点需要大家去测试和体验。
其他地方的逻辑几乎相同。
总结
本文还演示了 PyWinAuto 和 uiautomation 读取微信好友列表信息。通过对比,我们可以更深入地了解两者的API用法。作为作者,我在实践中有着深刻的理解。只是文章中的代码并没有体现这些细节,具体的事情需要读者在分析对比的过程中得到答案。仅仅看本文的代码或许可以解决当前的需求,但是很难将本文涉及的技术应用到其他需求上。
童鞋们,让我们通过动手实践来学习吧⁉️学完之后,你会看到任何实现Automation Provider的桌面程序,并且可以爬~ 查看全部
querylist采集微信公众号文章(
UI自动化工具轻松实现微信消息的自动收发和朋友圈爬取)
大家好,我是小明。昨天,我在《UI自动化工具轻松实现微信消息自动收发和好友动态爬取》一文中演示了三个UIAutomation的使用实例。链接:
由于昨天对UIAutomation的API的理解不够全面,个人代码优化还有很大的空间。今天我们的目标是实现微信PC版联系人信息列表的抓取,这将分别使用PyWinAuto和uiautomation来实现。通过对比,大家就会有更深入的了解。
PyWinAuto 实现
PyWinAuto 官方文档地址:
将 PyWinAuto 连接到桌面程序有两种主要方式:
它们是进程的 pid 和窗口句柄。下面我将演示如何获取微信的进程id和窗口句柄。
根据进程名获取进程ID:
import psutil
def get_pid(proc_name):
for proc in psutil.process_iter(attrs=['pid', 'name']):
if proc.name() == proc_name:
return proc.pid
%time get_pid("WeChat.exe")
Wall time: 224 ms
7268
根据窗口标题和类名查找窗口句柄:
import win32gui
%time hwnd = win32gui.FindWindow("WeChatMainWndForPC", "微信")
hwnd
Wall time: 0 ns
264610
耗时几乎为零,比之前的方法快了100多倍。
于是我用窗口句柄连接微信窗口:
import win32gui
from pywinauto.application import Application
hwnd = win32gui.FindWindow("WeChatMainWndForPC", "微信")
app = Application(backend='uia').connect(handle=hwnd)
app
自动打开通讯录:
import pywinauto
win = app['微信']
txl_btn = win.child_window(title="通讯录", control_type="Button")
txl_btn.draw_outline()
cords = txl_btn.rectangle()
pywinauto.mouse.click(button='left', coords=(
(cords.right+cords.left)//2, (cords.top+cords.bottom)//2))
随机点击好友信息详情后,通过inspect.exe查看节点信息。
然后编写如下代码,根据分析结果运行:
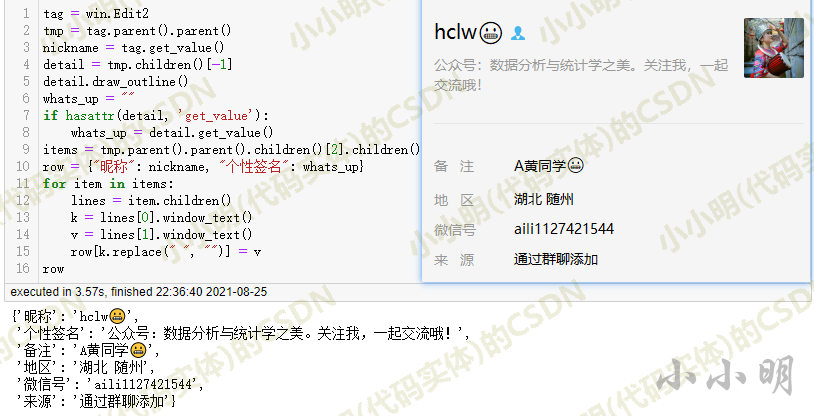
可以看到各种信息提取的很流畅,但是最多需要3.54秒,不一定比手动复制粘贴快。这也是pywinauto的一个缺点,太慢了。
下面我们进行批量爬取。原理大致是每次读取信息面板时,按向下箭头键,发现当前读取的数据与上一次一致。认为爬行已经结束。
由于pywinauto的爬取速度太慢,我手动将好友列表拖到最后,然后运行如下代码:
import pandas as pd
win = app['微信']
contacts = win.child_window(title="联系人", control_type="List")
# 点击第二个可见元素
contacts.children()[1].click_input()
result = []
last = None
num = 0
while 1:
tag = win.Edit2
tmp = tag.parent().parent()
nickname = tag.get_value()
# 跳过两个官方号
if nickname in ["微信团队", "文件传输助手"]:
contacts.type_keys("{DOWN}")
continue
detail = tmp.children()[-1]
whats_up = ""
if hasattr(detail, 'get_value'):
whats_up = detail.get_value()
elif hasattr(detail, 'window_text') and detail.window_text() != "":
# 这种情况说明是企业微信,跳过
contacts.type_keys("{DOWN}")
continue
items = tmp.parent().parent().children()[2].children()
row = {"昵称": nickname, "个性签名": whats_up}
for item in items:
lines = item.children()
k = lines[0].window_text()
v = lines[1].window_text()
row[k.replace(" ", "")] = v
if row == last:
# 与上一条数据一致则说明已经爬取完毕
break
result.append(row)
num += 1
print("\r", num, row,
end=" ")
last = row
contacts.type_keys("{DOWN}")
df = pd.DataFrame(result)
df
最后结果:
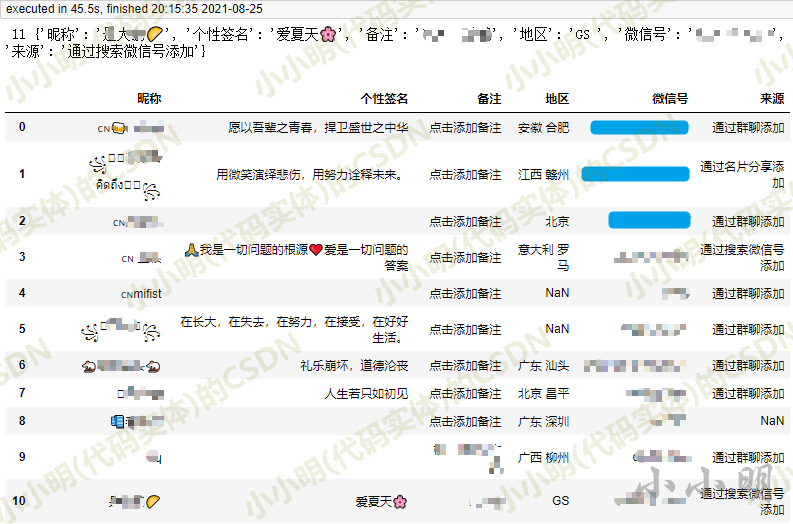
可以看出,最后一页11个微信账号的数据抓取耗时45秒。
ui自动化实现
接下来,我们将使用 uiautomation 来实现这种爬取。
获取微信窗口,点击通讯录按钮:
import uiautomation as auto
wechatWindow = auto.WindowControl(searchDepth=1, Name="微信", ClassName='WeChatMainWndForPC')
wechatWindow.SetActive()
txl_btn = wechatWindow.ButtonControl(Name='通讯录')
txl_btn.Click()
然后点击云朵君的好友信息,测试好友信息抽取:
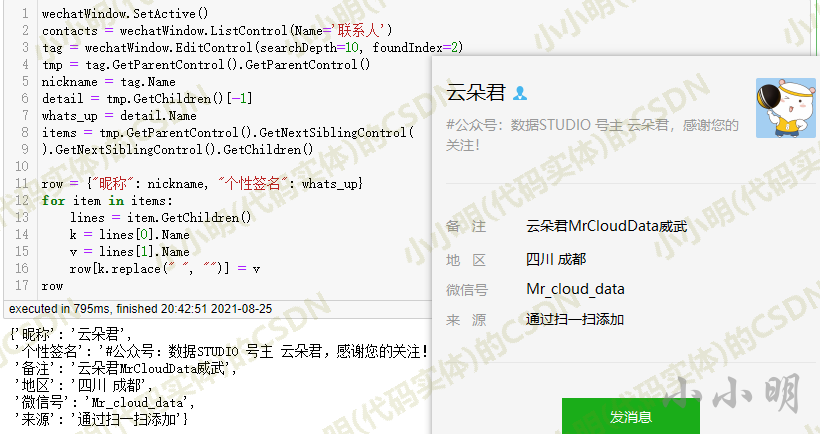
(这个数字,你可以随意添加)
wechatWindow.EditControl(searchDepth=10, foundIndex=2) 表示在10层节点内搜索第二个EditControl类型节点(第一个是搜索框,第二个是朋友的昵称)。
GetParentControl() 和 GetNextSiblingControl() 是昨天没有使用的 API。它们用于获取父节点和下一个兄弟节点。使用这两个 API 来重写昨天的 文章 的代码,将使程序代码变得简单和高效。改进。
然后使用与 PyWinAuto 相同的方式进行批量提取:
还要先测试最后一页的数据:

爬取只用了 11 秒,比 PyWinAuto 快 4 倍。
所以我们可以批量提取所有微信好友的数据。最后,我这边的700多个朋友用了10分钟。虽然速度较慢,但与 PyWinAuto 相比完全可以接受。
代码对比
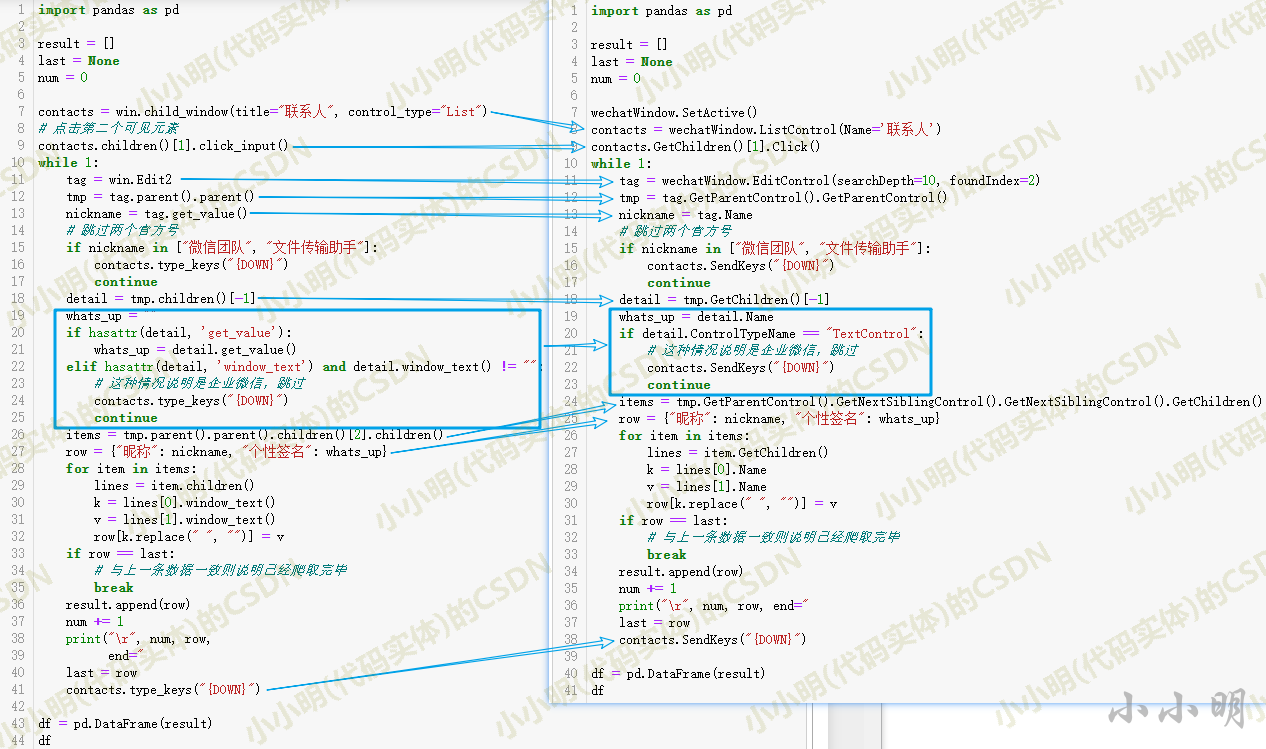
对于两者,我都试图遵循完全相同的逻辑。
win.Edit2 也得到第二个 EditControl 类型节点,
type_keys 是 PyWinAuto 用来模拟击键的 API,{DOWN} 代表向下的方向键。
PyWinAuto获取父子节点的api都是小写的,没有get,uiautomation获取父子节点的api大写,前缀为Get。
对于 PyWinAuto 中的这行代码:
items = tmp.parent().parent().children()[2].children()
使用 uiautomation:
items = tmp.GetParentControl().GetNextSiblingControl().GetNextSiblingControl().GetChildren()
有一个很大的不同。
这是因为我没有找到PyWinAuto获取兄弟节点的API,所以采用了先获取父节点再获取子节点的方法。
另外,判断是否是企业微信的逻辑不同。PyWinAuto也需要在个性签名为空时处理异常,否则程序会报错退出。具体点需要大家去测试和体验。
其他地方的逻辑几乎相同。
总结
本文还演示了 PyWinAuto 和 uiautomation 读取微信好友列表信息。通过对比,我们可以更深入地了解两者的API用法。作为作者,我在实践中有着深刻的理解。只是文章中的代码并没有体现这些细节,具体的事情需要读者在分析对比的过程中得到答案。仅仅看本文的代码或许可以解决当前的需求,但是很难将本文涉及的技术应用到其他需求上。
童鞋们,让我们通过动手实践来学习吧⁉️学完之后,你会看到任何实现Automation Provider的桌面程序,并且可以爬~
querylist采集微信公众号文章(如下如下工具程序利用的是微信公众号 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-19 22:05
)
为了实现爬虫我们需要使用以下工具
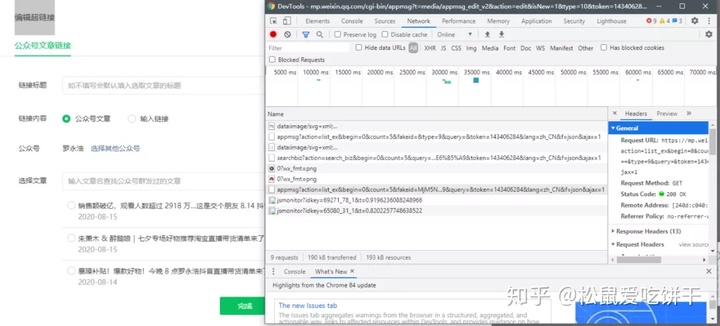
另外,这个爬虫程序使用了微信公众号后台编辑素材接口。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们也需要有一个公众号。
正式开始
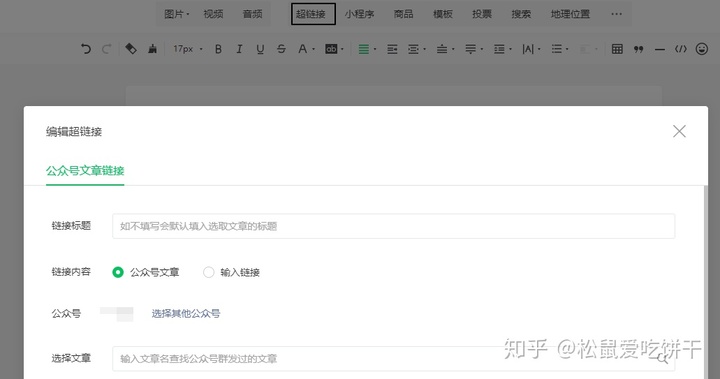
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
接下来,按 F12 打开 Chrome 的开发者工具并选择网络
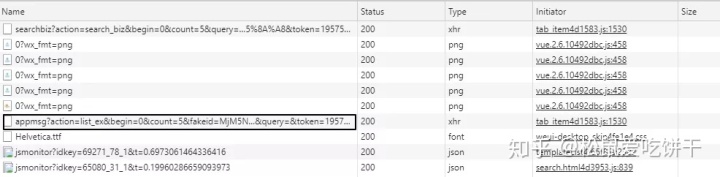
此时,在之前的超链接界面,点击“选择其他公众号”,输入你需要爬取的公众号(例如中国移动)
这时候之前的Network会刷新一些链接,其中以“appmsg”开头的内容就是我们需要分析的
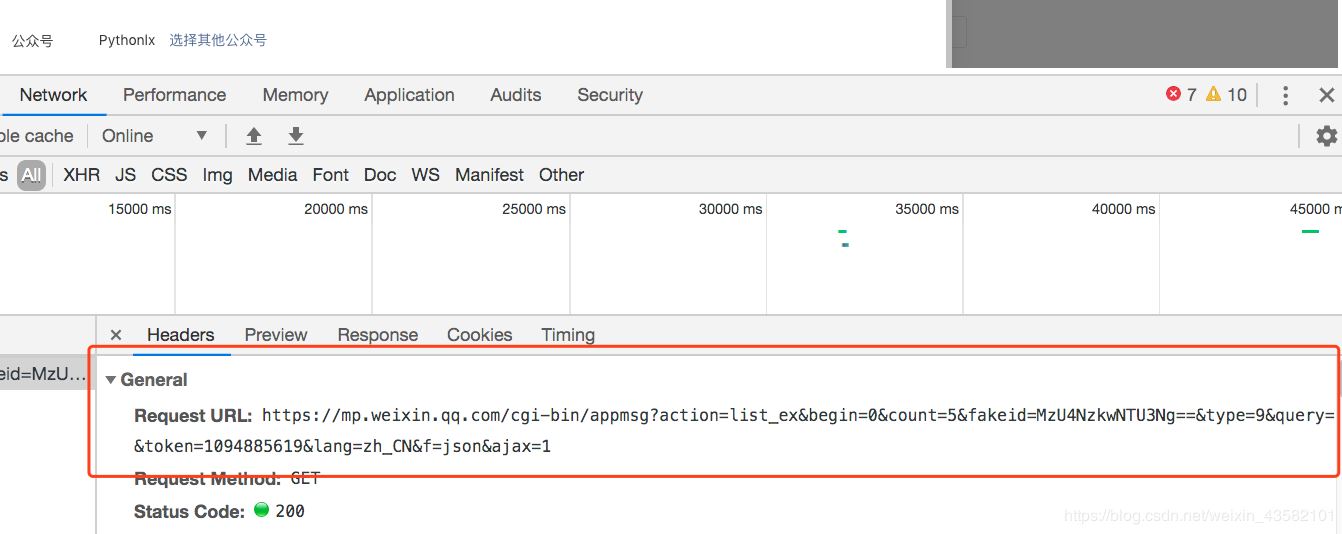
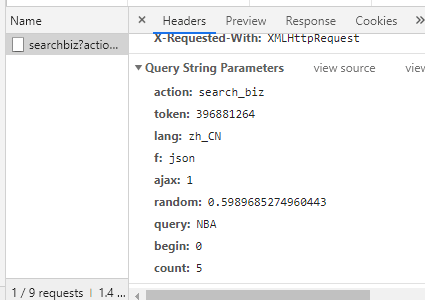
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
它分为三个部分
通过不断浏览下一页,我们发现每次只有begin会改变,每次增加5,这就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码是无法获取资源的
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能在浏览器上获取资源,是因为我们登录了微信公众号后端。而Python没有我们的登录信息,所以请求无效。我们需要在requests中设置headers参数,传入Cookie和User-Agent来模拟登录
由于头信息的内容每次都会变化,我把这些内容放在一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
只需要事后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
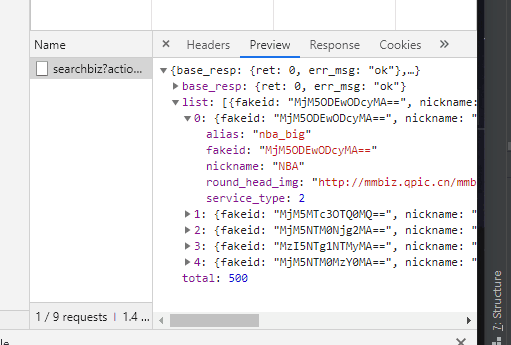
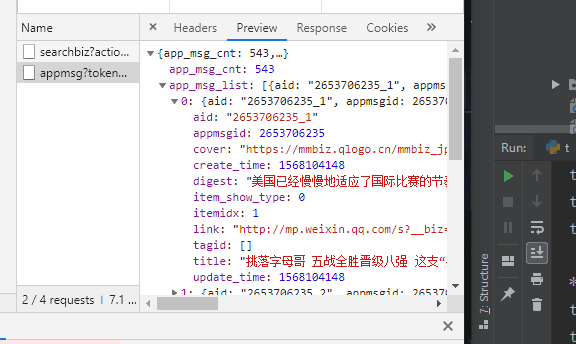
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
appmsgid 是每条推文的唯一标识符,aid 是每条推文的唯一标识符。
其实除了cookies,URL中的token参数也会用来限制爬虫,所以上面代码的输出很可能是{'base_resp': {'ret': 200040,'err_msg':'无效的 csrf 令牌'} }
然后我们写一个循环来获取文章的所有JSON并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
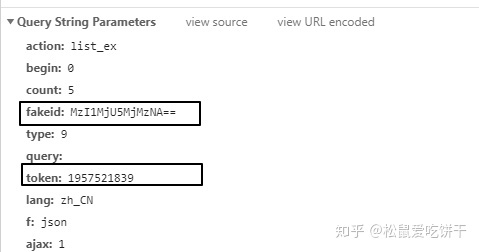
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
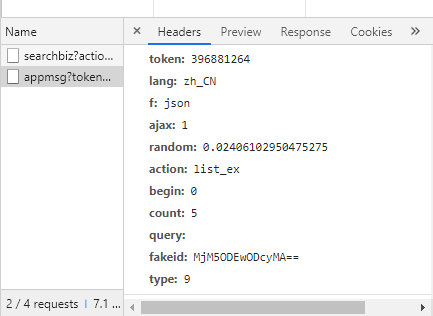
在上面的代码中,我还在“wechat.yaml”文件中存储了fakeid和token。这是因为fakeid是每个公众号的唯一标识,token会经常变化,信息可以通过解析URL获取,也可以从开发者工具查看
爬了一段时间后,会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时,当你尝试在公众号后台插入超链接时,会遇到如下提示
这是公众号的流量限制,一般需要30-60分钟才能继续。为了完美处理这个问题,你可能需要申请多个公众号,可能需要对抗微信公众号登录系统,或者你可能需要设置代理池。
但是我不需要工业级的爬虫,我只想爬取我自己的公众号信息,所以等了一个小时,再次登录公众号,获取cookie和token,运行。我不想用自己的兴趣挑战别人的工作。
最后,将结果保存为 JSON 格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章标识符、标题、URL、发布时间四列,保存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("n".join(info_list)) 查看全部
querylist采集微信公众号文章(如下如下工具程序利用的是微信公众号
)
为了实现爬虫我们需要使用以下工具
另外,这个爬虫程序使用了微信公众号后台编辑素材接口。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们也需要有一个公众号。
正式开始
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
接下来,按 F12 打开 Chrome 的开发者工具并选择网络

此时,在之前的超链接界面,点击“选择其他公众号”,输入你需要爬取的公众号(例如中国移动)

这时候之前的Network会刷新一些链接,其中以“appmsg”开头的内容就是我们需要分析的
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
它分为三个部分
通过不断浏览下一页,我们发现每次只有begin会改变,每次增加5,这就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码是无法获取资源的
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能在浏览器上获取资源,是因为我们登录了微信公众号后端。而Python没有我们的登录信息,所以请求无效。我们需要在requests中设置headers参数,传入Cookie和User-Agent来模拟登录
由于头信息的内容每次都会变化,我把这些内容放在一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
只需要事后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
appmsgid 是每条推文的唯一标识符,aid 是每条推文的唯一标识符。
其实除了cookies,URL中的token参数也会用来限制爬虫,所以上面代码的输出很可能是{'base_resp': {'ret': 200040,'err_msg':'无效的 csrf 令牌'} }
然后我们写一个循环来获取文章的所有JSON并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还在“wechat.yaml”文件中存储了fakeid和token。这是因为fakeid是每个公众号的唯一标识,token会经常变化,信息可以通过解析URL获取,也可以从开发者工具查看
爬了一段时间后,会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时,当你尝试在公众号后台插入超链接时,会遇到如下提示

这是公众号的流量限制,一般需要30-60分钟才能继续。为了完美处理这个问题,你可能需要申请多个公众号,可能需要对抗微信公众号登录系统,或者你可能需要设置代理池。
但是我不需要工业级的爬虫,我只想爬取我自己的公众号信息,所以等了一个小时,再次登录公众号,获取cookie和token,运行。我不想用自己的兴趣挑战别人的工作。
最后,将结果保存为 JSON 格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章标识符、标题、URL、发布时间四列,保存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("n".join(info_list))
querylist采集微信公众号文章(如何处理微信的防盗链?突破难点一操作拥有微信)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-19 22:03
突破难关一操作
拥有一个带有登录和注册链接的微信个人订阅帐户。微信公众平台:
未注册的童鞋可以通过微信公众号进行注册。这个过程非常简单。
登录后,点击左侧菜单栏的“管理”-“物料管理”。然后点击右侧的“新建图形材质”
会弹出一个新标签页,在上方工具栏中找到“超链接”,点击
弹出小窗口,选择“查找文章”,输入需要搜索的公众号,以“宅基地”公众号为例
点击后可以弹出公众号的所有历史记录文章
搜索可以获取所有相关公众号信息,但我只取第一个进行测试,其他所有感兴趣的人也可以获得。
详细信息请参考崔大神的文章,#rd
根据个人公众号界面抓取
根据搜狗微信界面抓取
# -*- coding:utf-8 -*-
import requests,os,time,re
from urllib.parse import quote
from pyquery import PyQuery as pq
from selenium.webdriver import Chrome
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support.wait import WebDriverWait
# 这三行代码是防止在python2上面编码错误的,在python3上面不要要这样设置
# import sys
# reload(sys)
# sys.setdefaultencoding('utf-8')
# 搜索入口地址,以公众为关键字搜索该公众号
def get_search_result_by_keywords(sogou_search_url):
# 爬虫伪装头部设置
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
# 设置操作超时时长
timeout = 5
# 爬虫模拟在一个request.session中完成
s = requests.Session()
log(u'搜索地址为:%s' % sogou_search_url)
return s.get(sogou_search_url, headers=headers, timeout=timeout).content
# 获得公众号主页地址
def get_wx_url_by_sougou_search_html(sougou_search_html):
doc = pq(sougou_search_html)
return doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
# browser = webdriver.PhantomJS(executable_path=r'D:\Python2.7\Scripts\phantomjs.exe')
options = Options()
options.add_argument('-headless') # 无头参数
driver = Chrome(executable_path='chromedriver', chrome_options=options)
wait = WebDriverWait(driver, timeout=10)
driver.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = driver.execute_script("return document.documentElement.outerHTML")
driver.close()
return html
# 获取公众号文章内容
def parse_wx_articles_by_html(selenium_html):
doc = pq(selenium_html)
return doc('div[class="weui_media_box appmsg"]')
# 将获取到的文章转换为字典
def switch_arctiles_to_list(articles):
# 定义存贮变量
articles_list = []
i = 1
# 遍历找到的文章,解析里面的内容
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
###log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 返回字典数据
return {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic
}
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 自定义log函数,主要是加上时间
def log(msg):
print(u'%s: %s' % (time.strftime('%Y-%m-%d_%H-%M-%S'), msg))
# 验证函数
def need_verify(selenium_html):
' 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 '
return pq(selenium_html)('#verify_change').text() != ''
# 创建公众号命名的文件夹
def create_dir(keywords):
if not os.path.exists(keywords):
os.makedirs(keywords)
def run(keywords):
' 爬虫入口函数 '
# Step 0 : 创建公众号命名的文件夹
create_dir(keywords)
# 搜狐微信搜索链接入口
sogou_search_url = 'http://weixin.sogou.com/weixin ... 39%3B % quote(keywords)
# Step 1:GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
log(u'开始获取,微信公众号英文名为:%s' % keywords)
log(u'开始调用sougou搜索引擎')
sougou_search_html = get_search_result_by_keywords(sogou_search_url)
# Step 2:从搜索结果页中解析出公众号主页链接
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
wx_url = get_wx_url_by_sougou_search_html(sougou_search_html)
log(u'获取wx_url成功,%s' % wx_url)
# Step 3:Selenium+PhantomJs获取js异步加载渲染后的html
log(u'开始调用selenium渲染html')
selenium_html = get_selenium_js_html(wx_url)
# Step 4: 检测目标网站是否进行了封锁
if need_verify(selenium_html):
log(u'爬虫被目标网站封锁,请稍后再试')
else:
# Step 5: 使用PyQuery,从Step 3获取的html中解析出公众号文章列表的数据
log(u'调用selenium渲染html完成,开始解析公众号文章')
articles = parse_wx_articles_by_html(selenium_html)
log(u'抓取到微信文章%d篇' % len(articles))
# Step 6: 把微信文章数据封装成字典的list
log(u'开始整合微信文章数据为字典')
articles_list = switch_arctiles_to_list(articles)
return [content['title'] for content in articles_list]
if __name__ == '__main__':
gongzhonghao = input(u'input weixin gongzhonghao:')
if not gongzhonghao:
gongzhonghao = 'spider'
text = " ".join(run(gongzhonghao))
print(text)
直接运行main方法,在控制台输入你要爬的公众号的英文名。中文可能不止一个。精确搜索在这里完成,只找到一个。查看英文公众号,点击手机即可。公众号然后查看公众号信息
防水蛭
微信公众号已经对文章中的图片做了防盗链处理,所以如果图片在公众号、小程序、PC浏览器以外的地方无法显示,建议您阅读这篇文章< @文章学习如何应对微信的反水蛭。
参考: 查看全部
querylist采集微信公众号文章(如何处理微信的防盗链?突破难点一操作拥有微信)
突破难关一操作
拥有一个带有登录和注册链接的微信个人订阅帐户。微信公众平台:
未注册的童鞋可以通过微信公众号进行注册。这个过程非常简单。
登录后,点击左侧菜单栏的“管理”-“物料管理”。然后点击右侧的“新建图形材质”
会弹出一个新标签页,在上方工具栏中找到“超链接”,点击
弹出小窗口,选择“查找文章”,输入需要搜索的公众号,以“宅基地”公众号为例
点击后可以弹出公众号的所有历史记录文章
搜索可以获取所有相关公众号信息,但我只取第一个进行测试,其他所有感兴趣的人也可以获得。
详细信息请参考崔大神的文章,#rd
根据个人公众号界面抓取
根据搜狗微信界面抓取
# -*- coding:utf-8 -*-
import requests,os,time,re
from urllib.parse import quote
from pyquery import PyQuery as pq
from selenium.webdriver import Chrome
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support.wait import WebDriverWait
# 这三行代码是防止在python2上面编码错误的,在python3上面不要要这样设置
# import sys
# reload(sys)
# sys.setdefaultencoding('utf-8')
# 搜索入口地址,以公众为关键字搜索该公众号
def get_search_result_by_keywords(sogou_search_url):
# 爬虫伪装头部设置
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
# 设置操作超时时长
timeout = 5
# 爬虫模拟在一个request.session中完成
s = requests.Session()
log(u'搜索地址为:%s' % sogou_search_url)
return s.get(sogou_search_url, headers=headers, timeout=timeout).content
# 获得公众号主页地址
def get_wx_url_by_sougou_search_html(sougou_search_html):
doc = pq(sougou_search_html)
return doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
# browser = webdriver.PhantomJS(executable_path=r'D:\Python2.7\Scripts\phantomjs.exe')
options = Options()
options.add_argument('-headless') # 无头参数
driver = Chrome(executable_path='chromedriver', chrome_options=options)
wait = WebDriverWait(driver, timeout=10)
driver.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = driver.execute_script("return document.documentElement.outerHTML")
driver.close()
return html
# 获取公众号文章内容
def parse_wx_articles_by_html(selenium_html):
doc = pq(selenium_html)
return doc('div[class="weui_media_box appmsg"]')
# 将获取到的文章转换为字典
def switch_arctiles_to_list(articles):
# 定义存贮变量
articles_list = []
i = 1
# 遍历找到的文章,解析里面的内容
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
###log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 返回字典数据
return {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic
}
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 自定义log函数,主要是加上时间
def log(msg):
print(u'%s: %s' % (time.strftime('%Y-%m-%d_%H-%M-%S'), msg))
# 验证函数
def need_verify(selenium_html):
' 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 '
return pq(selenium_html)('#verify_change').text() != ''
# 创建公众号命名的文件夹
def create_dir(keywords):
if not os.path.exists(keywords):
os.makedirs(keywords)
def run(keywords):
' 爬虫入口函数 '
# Step 0 : 创建公众号命名的文件夹
create_dir(keywords)
# 搜狐微信搜索链接入口
sogou_search_url = 'http://weixin.sogou.com/weixin ... 39%3B % quote(keywords)
# Step 1:GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
log(u'开始获取,微信公众号英文名为:%s' % keywords)
log(u'开始调用sougou搜索引擎')
sougou_search_html = get_search_result_by_keywords(sogou_search_url)
# Step 2:从搜索结果页中解析出公众号主页链接
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
wx_url = get_wx_url_by_sougou_search_html(sougou_search_html)
log(u'获取wx_url成功,%s' % wx_url)
# Step 3:Selenium+PhantomJs获取js异步加载渲染后的html
log(u'开始调用selenium渲染html')
selenium_html = get_selenium_js_html(wx_url)
# Step 4: 检测目标网站是否进行了封锁
if need_verify(selenium_html):
log(u'爬虫被目标网站封锁,请稍后再试')
else:
# Step 5: 使用PyQuery,从Step 3获取的html中解析出公众号文章列表的数据
log(u'调用selenium渲染html完成,开始解析公众号文章')
articles = parse_wx_articles_by_html(selenium_html)
log(u'抓取到微信文章%d篇' % len(articles))
# Step 6: 把微信文章数据封装成字典的list
log(u'开始整合微信文章数据为字典')
articles_list = switch_arctiles_to_list(articles)
return [content['title'] for content in articles_list]
if __name__ == '__main__':
gongzhonghao = input(u'input weixin gongzhonghao:')
if not gongzhonghao:
gongzhonghao = 'spider'
text = " ".join(run(gongzhonghao))
print(text)
直接运行main方法,在控制台输入你要爬的公众号的英文名。中文可能不止一个。精确搜索在这里完成,只找到一个。查看英文公众号,点击手机即可。公众号然后查看公众号信息
防水蛭
微信公众号已经对文章中的图片做了防盗链处理,所以如果图片在公众号、小程序、PC浏览器以外的地方无法显示,建议您阅读这篇文章< @文章学习如何应对微信的反水蛭。
参考:
querylist采集微信公众号文章(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-10-19 15:01
querylist采集微信公众号文章分类的网页数据,不用爬虫(tornado,python等),golang,支持一些可视化的交互设计,nodejs等(同时,这篇文章是代码,需要预先安装nodejs)网页端爬取,使用tornado,同时有网页的分析api,类似spyder,不过它是web平台。微信公众号文章分类采集接入tornado中要说到http的请求,并不需要注册帐号,必须在浏览器上输入网址然后才能操作,先从网页抓取开始,可以通过http请求->》响应网页->》点击分类查看我们通过tornado抓取了taro_spider.js这个页面,采集到包含60个微信公众号文章类别的网页数据,需要编写如下代码:httprequest->connect("")->从浏览器中提交到encoder.py中,接着就有了以下代码:1.post和get请求发送请求发送post请求,soeasy!//connectmesocute,${touchable}httprequest->connect(""),meme!//connectmeme!//get请求发送get请求,同样发送到taro.py中,并且发送后端!//connectmeme!//post请求中accept:json,post:['accept-encoding','gzip,deflate','bytes0xffff']httprequest->connect("")->在taro.py中taro_spider.js与http相关的代码应该在anacondauseragent中,在我实际项目中,taro_spider.js相当于python的pipinstalllxml;forlxmlinenumerate(${lxml}):printlxml.load(lxml)所以,post请求发送的是数据接收者,taro_spider.js等同于lxml。
接着,我们要操作taro_spider.js,进行http请求、响应处理,然后接着我们要运行指定路径下的.py程序并运行这个程序,最后我们采用自己的服务器自己的httpserver去请求就可以。2.请求体处理使用get发送请求,如果不加上#!/usr/bin/envpython#-*-coding:utf-8-*-importjsonimportthreadingimportstructdefpost(url):"""post请求发送到to_header=':'name='to_name'accept='gzip,deflate'content-type='application/x-www-form-urlencoded'"""returnjson.loads(url.replace('/','').text)returnthreading.thread(target=struct.pool,policy=struct.pool)defconnect(host):"""调用一下connect(),然后post请求一下"""host=threading.pool()host.setdefaulthost('。 查看全部
querylist采集微信公众号文章(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
querylist采集微信公众号文章分类的网页数据,不用爬虫(tornado,python等),golang,支持一些可视化的交互设计,nodejs等(同时,这篇文章是代码,需要预先安装nodejs)网页端爬取,使用tornado,同时有网页的分析api,类似spyder,不过它是web平台。微信公众号文章分类采集接入tornado中要说到http的请求,并不需要注册帐号,必须在浏览器上输入网址然后才能操作,先从网页抓取开始,可以通过http请求->》响应网页->》点击分类查看我们通过tornado抓取了taro_spider.js这个页面,采集到包含60个微信公众号文章类别的网页数据,需要编写如下代码:httprequest->connect("")->从浏览器中提交到encoder.py中,接着就有了以下代码:1.post和get请求发送请求发送post请求,soeasy!//connectmesocute,${touchable}httprequest->connect(""),meme!//connectmeme!//get请求发送get请求,同样发送到taro.py中,并且发送后端!//connectmeme!//post请求中accept:json,post:['accept-encoding','gzip,deflate','bytes0xffff']httprequest->connect("")->在taro.py中taro_spider.js与http相关的代码应该在anacondauseragent中,在我实际项目中,taro_spider.js相当于python的pipinstalllxml;forlxmlinenumerate(${lxml}):printlxml.load(lxml)所以,post请求发送的是数据接收者,taro_spider.js等同于lxml。
接着,我们要操作taro_spider.js,进行http请求、响应处理,然后接着我们要运行指定路径下的.py程序并运行这个程序,最后我们采用自己的服务器自己的httpserver去请求就可以。2.请求体处理使用get发送请求,如果不加上#!/usr/bin/envpython#-*-coding:utf-8-*-importjsonimportthreadingimportstructdefpost(url):"""post请求发送到to_header=':'name='to_name'accept='gzip,deflate'content-type='application/x-www-form-urlencoded'"""returnjson.loads(url.replace('/','').text)returnthreading.thread(target=struct.pool,policy=struct.pool)defconnect(host):"""调用一下connect(),然后post请求一下"""host=threading.pool()host.setdefaulthost('。
querylist采集微信公众号文章( 微信读书App已经上线优质公众号推荐模块(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-10-19 10:25
微信读书App已经上线优质公众号推荐模块(图))
微信阅读App上线优质公众号推荐模块。
钛媒体编辑今天点击微信阅读App主界面左下角的书店,弹出了“优质公众号”模块。
在“查看全部”内容列表中,钛媒体发现该模块分为8个子模块:“全部”、“轻松搞笑”、“影评”、“文学杂志”、“互联网”、“知识教育” ”、“商业金融”和“其他”。而在每个子模块中,都有来自微信公众平台文章的各个自媒体账号的收录。
另外,通过微信阅读App搜索栏,可以直接搜索相关公众号和内容。
事实上,今年4月,微信阅读2.4.0就已经加入了一个新功能:引入优质公众号。
而马化腾去年在朋友圈与kol的对话中也透露,微信正在内部测试公众号的付费订阅功能。此后,一直没有消息表明该功能何时正式发布。
微信阅读App的自然付费阅读模式与微信公众号付费阅读自然匹配。不过,微信阅读App中的优质公众号模块依然可以免费阅读。
钛媒体发现,这并不是微信阅读和微信公众号的第一次结合。早在去年9月2.2.0版本上线时,就已经出现了“支持看书”公众号文章”的提示。
关于新功能,钛媒体小编采访了几家公众号运营商,发现微信阅读没有事先就授权和版权问题与运营商沟通。
本次我们将直接抓取微信公众号中的文章,作为独立版块使用。以后会不会涉及版权问题?
从目前的功能来看,微信阅读App看起来是一个完美的“接现成孩子”的过程。同时在搜索一些不知名的公众号时,发现系统并没有收录。可以看出,“优质公众号”是在微信阅读相关数据库筛选后导入的。
据了解,微信阅读App于2015年8月27日正式上线,目前华为应用商店下载量超过1亿。庞大的流量平台未来将如何与微信公众号运营商分享收益?值得期待。(本文首发于钛媒体,作者/桑明强,编辑/丛聪) 查看全部
querylist采集微信公众号文章(
微信读书App已经上线优质公众号推荐模块(图))
微信阅读App上线优质公众号推荐模块。
钛媒体编辑今天点击微信阅读App主界面左下角的书店,弹出了“优质公众号”模块。
在“查看全部”内容列表中,钛媒体发现该模块分为8个子模块:“全部”、“轻松搞笑”、“影评”、“文学杂志”、“互联网”、“知识教育” ”、“商业金融”和“其他”。而在每个子模块中,都有来自微信公众平台文章的各个自媒体账号的收录。
另外,通过微信阅读App搜索栏,可以直接搜索相关公众号和内容。
事实上,今年4月,微信阅读2.4.0就已经加入了一个新功能:引入优质公众号。
而马化腾去年在朋友圈与kol的对话中也透露,微信正在内部测试公众号的付费订阅功能。此后,一直没有消息表明该功能何时正式发布。
微信阅读App的自然付费阅读模式与微信公众号付费阅读自然匹配。不过,微信阅读App中的优质公众号模块依然可以免费阅读。
钛媒体发现,这并不是微信阅读和微信公众号的第一次结合。早在去年9月2.2.0版本上线时,就已经出现了“支持看书”公众号文章”的提示。
关于新功能,钛媒体小编采访了几家公众号运营商,发现微信阅读没有事先就授权和版权问题与运营商沟通。
本次我们将直接抓取微信公众号中的文章,作为独立版块使用。以后会不会涉及版权问题?
从目前的功能来看,微信阅读App看起来是一个完美的“接现成孩子”的过程。同时在搜索一些不知名的公众号时,发现系统并没有收录。可以看出,“优质公众号”是在微信阅读相关数据库筛选后导入的。
据了解,微信阅读App于2015年8月27日正式上线,目前华为应用商店下载量超过1亿。庞大的流量平台未来将如何与微信公众号运营商分享收益?值得期待。(本文首发于钛媒体,作者/桑明强,编辑/丛聪)
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-10-19 02:02
Python微信公众号文章抓取
一.思考
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二. 接口分析
微信公众号获取界面:
范围:
行动=search_biz
开始=0
计数=5
query=官方账号名
token=每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
所以在这个界面,我们只需要获取token,查询就是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取对应公众号文章的界面:
范围:
动作=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。通过模拟用户,输入对应的账号密码,点击登录,就会出现扫码验证,用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求对应的公众号接口,得到我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取到的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
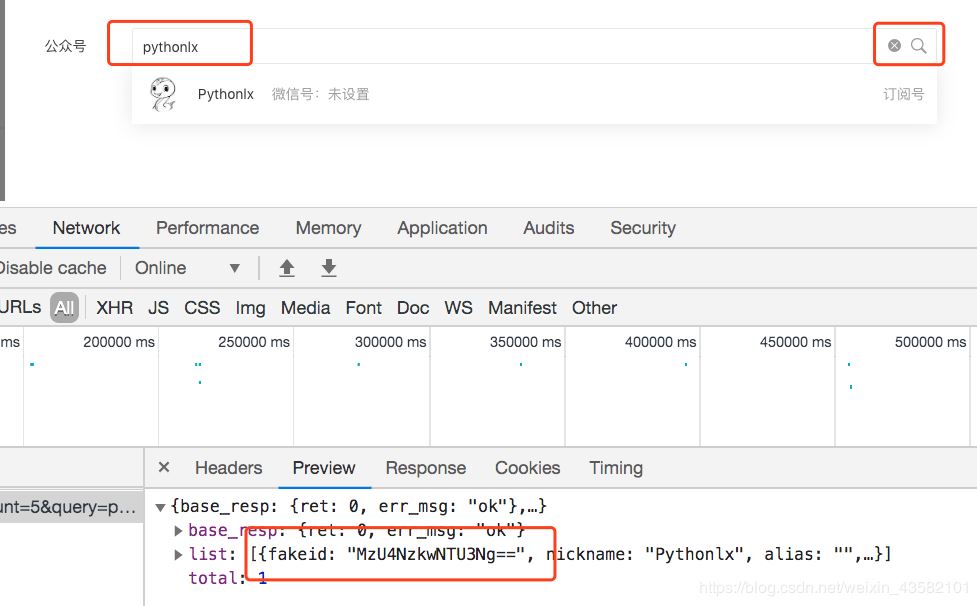
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的数据文章
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了微信公众号文章的抓取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置一个延迟时间,否则账号很容易被封,获取不到返回的数据。 查看全部
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
Python微信公众号文章抓取
一.思考
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面


从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二. 接口分析
微信公众号获取界面:
范围:
行动=search_biz
开始=0
计数=5
query=官方账号名
token=每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
所以在这个界面,我们只需要获取token,查询就是你需要搜索的公众号,登录后可以通过网页链接获取token。

获取对应公众号文章的界面:
范围:
动作=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。

三.实现第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。通过模拟用户,输入对应的账号密码,点击登录,就会出现扫码验证,用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求对应的公众号接口,得到我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取到的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的数据文章
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了微信公众号文章的抓取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置一个延迟时间,否则账号很容易被封,获取不到返回的数据。
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-10-18 08:08
Python微信公众号文章抓取
一.思考
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二. 接口分析
微信公众号获取界面:
范围:
行动=search_biz
开始=0
计数=5
query=官方账号名
token=每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
所以在这个界面,我们只需要获取token,查询就是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取对应公众号文章的界面:
范围:
动作=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。通过模拟用户,输入对应的账号密码,点击登录,就会出现扫码验证,只需用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求对应的公众号接口,得到我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取到的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的数据文章
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了微信公众号文章的抓取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置一个延迟时间,否则账号很容易被封,获取不到返回的数据。 查看全部
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
Python微信公众号文章抓取
一.思考
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二. 接口分析
微信公众号获取界面:
范围:
行动=search_biz
开始=0
计数=5
query=官方账号名
token=每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
所以在这个界面,我们只需要获取token,查询就是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取对应公众号文章的界面:
范围:
动作=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。通过模拟用户,输入对应的账号密码,点击登录,就会出现扫码验证,只需用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求对应的公众号接口,得到我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取到的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的数据文章
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了微信公众号文章的抓取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置一个延迟时间,否则账号很容易被封,获取不到返回的数据。
querylist采集微信公众号文章( 小编来一起获取微信公众号文章的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-10-10 09:18
小编来一起获取微信公众号文章的方法)
微信公众平台获取公众号文章示例
更新时间:2019年12月25日09:45:38 作者:考古学家lx
本文文章主要介绍如何通过微信公众平台获取公众号文章的例子。文章中介绍的示例代码非常详细,对大家的学习或工作有一定的参考学习价值。小伙伴们和小编一起学习吧
之前一直自己维护一个公众号,但是因为个人关系好久没有更新,今天才上来想起来,却偶然发现了微信公众号文章的获取方式。
之前获取的方式很多,通过搜狗、清博、web、客户端等都可以,这个可能不太好,但是操作简单易懂。
所以,首先你需要在微信公众平台上有一个账号
微信公众平台:
登录后,进入首页,点击新建群发。
选择自创图形:
好像是公众号操作教学
进入编辑页面后,点击超链接
弹出一个选择框,我们在框中输入对应的公众号名称,就会出现对应的文章列表
你惊喜吗?您可以打开控制台并检查请求的界面
打开回复,里面有我们需要的文章链接
确认数据后,我们需要对这个界面进行分析。
感觉非常简单。GET 请求携带一些参数。
Fakeid是公众号的唯一ID,所以如果想直接通过名字获取文章列表,还需要先获取fakeid。
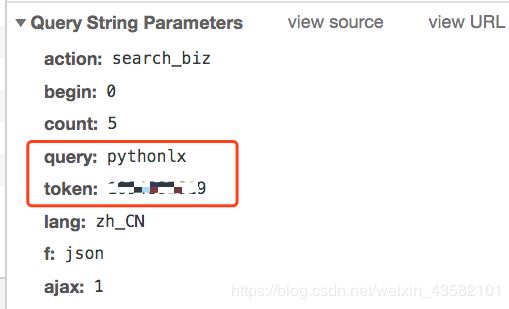
当我们输入官方账号名称时,点击搜索。可以看到搜索界面被触发,返回fakeid。
这个接口需要的参数不多。
接下来我们就可以用代码来模拟上面的操作了。
但是您还需要使用现有的 cookie 来避免登录。
目前,我还没有测试过cookie的有效期。可能需要及时更新 cookie。
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样就可以得到最新的10个文章。如果想获取更多历史记录文章,可以修改数据中的“begin”参数,0为第一页,5为第二页,10为第三页(以此类推)
但是如果你想大规模爬行:
请自己安排一个稳定的代理,降低爬虫速度,准备多个账号,减少被封的可能性。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。 查看全部
querylist采集微信公众号文章(
小编来一起获取微信公众号文章的方法)
微信公众平台获取公众号文章示例
更新时间:2019年12月25日09:45:38 作者:考古学家lx
本文文章主要介绍如何通过微信公众平台获取公众号文章的例子。文章中介绍的示例代码非常详细,对大家的学习或工作有一定的参考学习价值。小伙伴们和小编一起学习吧
之前一直自己维护一个公众号,但是因为个人关系好久没有更新,今天才上来想起来,却偶然发现了微信公众号文章的获取方式。
之前获取的方式很多,通过搜狗、清博、web、客户端等都可以,这个可能不太好,但是操作简单易懂。
所以,首先你需要在微信公众平台上有一个账号
微信公众平台:
登录后,进入首页,点击新建群发。
选择自创图形:
好像是公众号操作教学
进入编辑页面后,点击超链接
弹出一个选择框,我们在框中输入对应的公众号名称,就会出现对应的文章列表
你惊喜吗?您可以打开控制台并检查请求的界面
打开回复,里面有我们需要的文章链接

确认数据后,我们需要对这个界面进行分析。
感觉非常简单。GET 请求携带一些参数。

Fakeid是公众号的唯一ID,所以如果想直接通过名字获取文章列表,还需要先获取fakeid。
当我们输入官方账号名称时,点击搜索。可以看到搜索界面被触发,返回fakeid。
这个接口需要的参数不多。
接下来我们就可以用代码来模拟上面的操作了。
但是您还需要使用现有的 cookie 来避免登录。
目前,我还没有测试过cookie的有效期。可能需要及时更新 cookie。
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样就可以得到最新的10个文章。如果想获取更多历史记录文章,可以修改数据中的“begin”参数,0为第一页,5为第二页,10为第三页(以此类推)
但是如果你想大规模爬行:
请自己安排一个稳定的代理,降低爬虫速度,准备多个账号,减少被封的可能性。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
querylist采集微信公众号文章(微信公众号后台编辑素材界面的程序利用程序 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-10-07 16:19
)
准备阶段
为了实现爬虫我们需要使用以下工具
另外,这个爬虫程序使用了微信公众号后台编辑素材接口。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们还需要有一个公众号。
图1正式开始
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
图2
接下来,按 F12 打开 Chrome 的开发者工具并选择网络
图3
此时,在之前的超链接界面,点击“选择其他公众号”,输入你需要爬取的公众号(例如中国移动)
图4
这时候之前的Network会刷新一些链接,其中以“appmsg”开头的内容就是我们需要分析的
图5
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
它分为三个部分
通过不断浏览下一页,我们发现每次只有begin会改变,每次增加5,这就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码是无法获取资源的
import requestsurl = "https://mp.weixin.qq.com/cgi-b ... s.get(url).json() # {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能在浏览器上获取资源,是因为我们登录了微信公众号后端。而Python没有我们的登录信息,所以请求无效。我们需要在requests中设置headers参数,传入Cookie和User-Agent来模拟登录
由于头信息的内容每次都会变化,我把这些内容放在一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...user_agent: Mozilla/5.0...
只需要事后阅读
# 读取cookie和user_agentimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
❝
appmsgid 是每条推文的唯一标识符,aid 是每条推文的唯一标识符。
❞
图 6 ❝
其实除了cookies,URL中的token参数也会用来限制爬虫,所以上面代码的输出很可能是{'base_resp': {'ret': 200040,'err_msg':'无效的 csrf 令牌'} }
❞
然后我们写一个循环来获取文章的所有JSON并保存。
import jsonimport requestsimport timeimport randomimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }# 请求参数url = "https://mp.weixin.qq.com/cgi-bin/appmsg"begin = "0"params = { "action": "list_ex", "begin": begin, "count": "5", "fakeid": config['fakeid'], "type": "9", "token": config['token'], "lang": "zh_CN", "f": "json", "ajax": "1"}# 存放结果app_msg_list = []# 在不知道公众号有多少文章的情况下,使用while语句# 也方便重新运行时设置页数i = 0while True: begin = i * 5 params["begin"] = str(begin) # 随机暂停几秒,避免过快的请求导致过快的被查到 time.sleep(random.randint(1,10)) resp = requests.get(url, headers=headers, params = params, verify=False) # 微信流量控制, 退出 if resp.json()['base_resp']['ret'] == 200013: print("frequencey control, stop at {}".format(str(begin))) break # 如果返回的内容中为空则结束 if len(resp.json()['app_msg_list']) == 0: print("all ariticle parsed") break app_msg_list.append(resp.json()) # 翻页 i += 1
在上面的代码中,我还在“wechat.yaml”文件中存储了fakeid和token。这是因为 fakeid 是每个公众号的唯一标识符,令牌会经常变化。这个信息可以通过 Parse URL 来获取,也可以从开发者工具中查看
图7
爬了一段时间后,会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时,当你尝试在公众号后台插入超链接时,会遇到如下提示
图8
这是公众号的流量限制,一般需要30-60分钟才能继续。为了完美处理这个问题,你可能需要申请多个公众号,可能需要对抗微信公众号登录系统,或者你可能需要设置代理池。
但是我不需要工业级的爬虫,我只想爬取自己的公众号信息,所以等了一个小时,再次登录公众号,获取cookie和token,运行。我不想用自己的兴趣挑战别人的工作。
最后,将结果保存为 JSON 格式。
# 保存结果为JSONjson_name = "mp_data_{}.json".format(str(begin))with open(json_name, "w") as file: file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章标识符、标题、URL、发布时间四列,保存为CSV。
info_list = []for msg in app_msg_list: if "app_msg_list" in msg: for item in msg["app_msg_list"]: info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time'])) info_list.append(info)# save as csvwith open("app_msg_list.csv", "w") as file: file.writelines("\n".join(info_list)) 查看全部
querylist采集微信公众号文章(微信公众号后台编辑素材界面的程序利用程序
)
准备阶段
为了实现爬虫我们需要使用以下工具
另外,这个爬虫程序使用了微信公众号后台编辑素材接口。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们还需要有一个公众号。
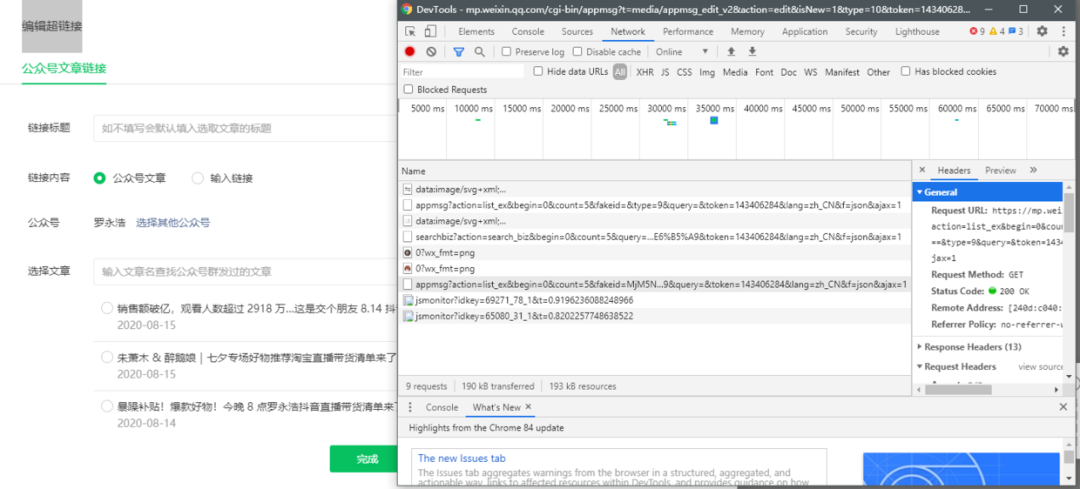
图1正式开始
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
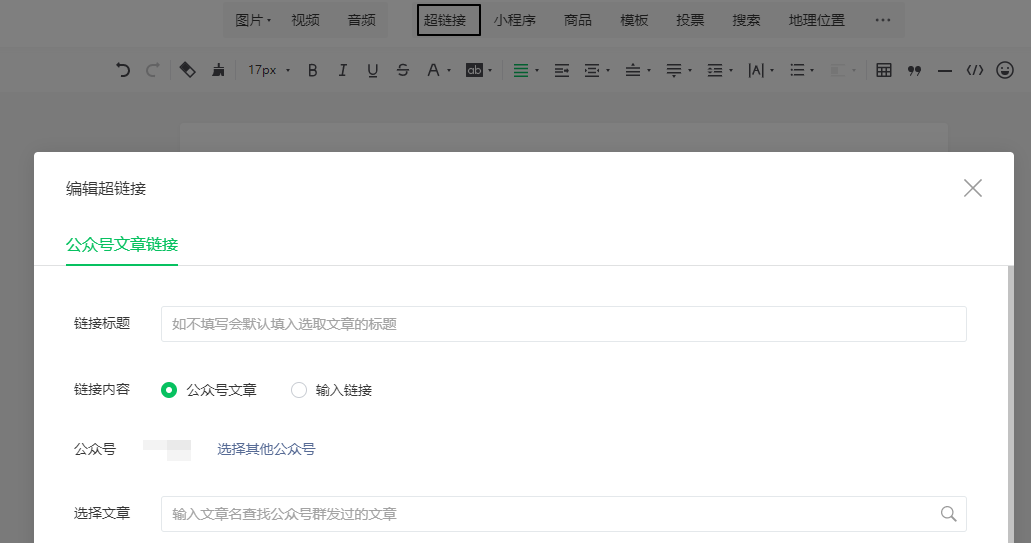
图2
接下来,按 F12 打开 Chrome 的开发者工具并选择网络
图3
此时,在之前的超链接界面,点击“选择其他公众号”,输入你需要爬取的公众号(例如中国移动)
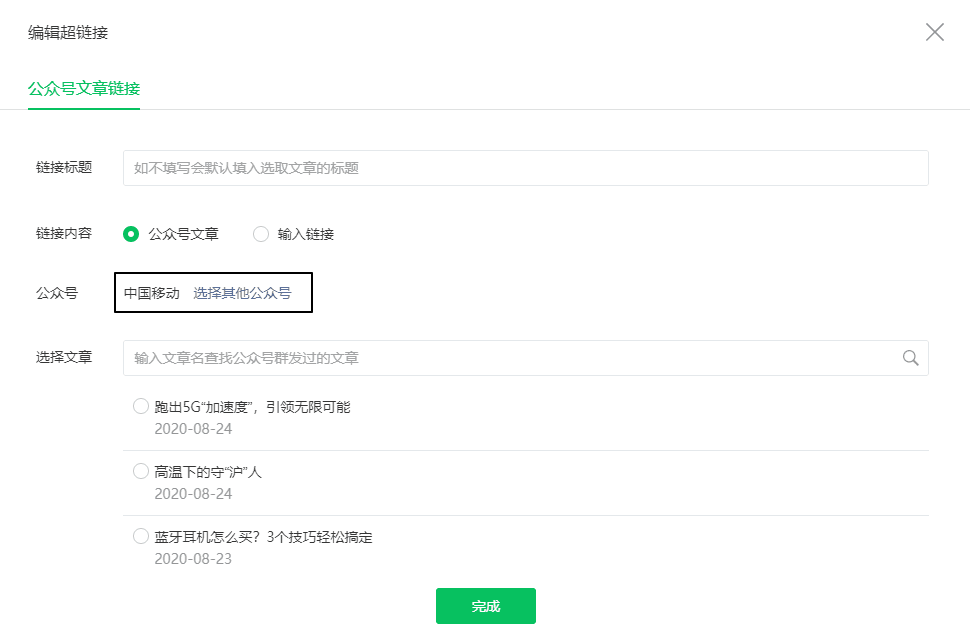
图4
这时候之前的Network会刷新一些链接,其中以“appmsg”开头的内容就是我们需要分析的
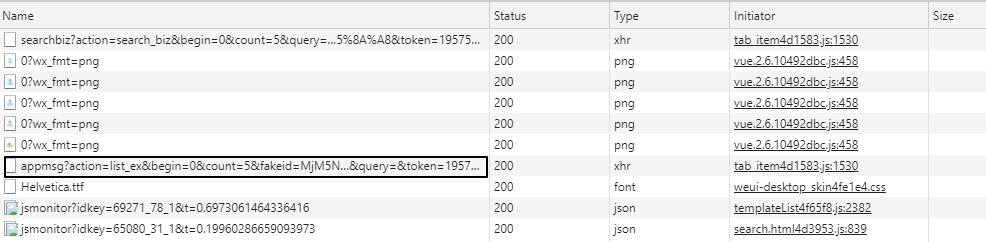
图5
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
它分为三个部分
通过不断浏览下一页,我们发现每次只有begin会改变,每次增加5,这就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码是无法获取资源的
import requestsurl = "https://mp.weixin.qq.com/cgi-b ... s.get(url).json() # {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能在浏览器上获取资源,是因为我们登录了微信公众号后端。而Python没有我们的登录信息,所以请求无效。我们需要在requests中设置headers参数,传入Cookie和User-Agent来模拟登录
由于头信息的内容每次都会变化,我把这些内容放在一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...user_agent: Mozilla/5.0...
只需要事后阅读
# 读取cookie和user_agentimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
❝
appmsgid 是每条推文的唯一标识符,aid 是每条推文的唯一标识符。
❞
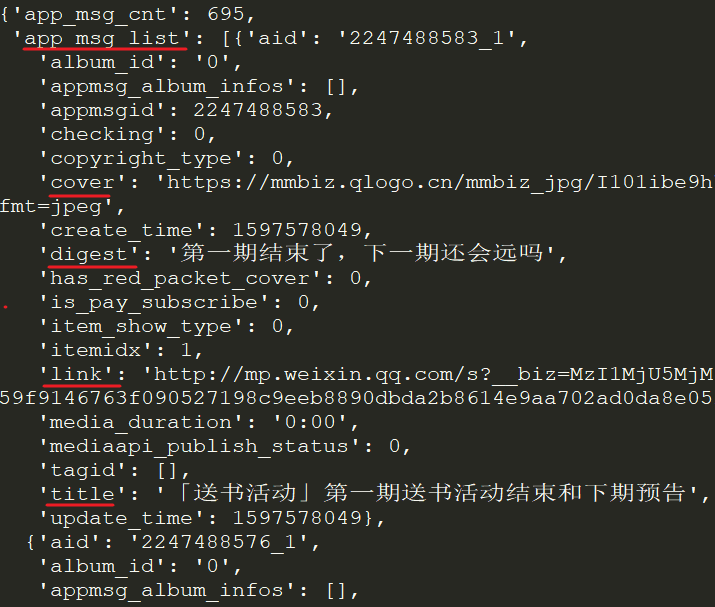
图 6 ❝
其实除了cookies,URL中的token参数也会用来限制爬虫,所以上面代码的输出很可能是{'base_resp': {'ret': 200040,'err_msg':'无效的 csrf 令牌'} }
❞
然后我们写一个循环来获取文章的所有JSON并保存。
import jsonimport requestsimport timeimport randomimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }# 请求参数url = "https://mp.weixin.qq.com/cgi-bin/appmsg"begin = "0"params = { "action": "list_ex", "begin": begin, "count": "5", "fakeid": config['fakeid'], "type": "9", "token": config['token'], "lang": "zh_CN", "f": "json", "ajax": "1"}# 存放结果app_msg_list = []# 在不知道公众号有多少文章的情况下,使用while语句# 也方便重新运行时设置页数i = 0while True: begin = i * 5 params["begin"] = str(begin) # 随机暂停几秒,避免过快的请求导致过快的被查到 time.sleep(random.randint(1,10)) resp = requests.get(url, headers=headers, params = params, verify=False) # 微信流量控制, 退出 if resp.json()['base_resp']['ret'] == 200013: print("frequencey control, stop at {}".format(str(begin))) break # 如果返回的内容中为空则结束 if len(resp.json()['app_msg_list']) == 0: print("all ariticle parsed") break app_msg_list.append(resp.json()) # 翻页 i += 1
在上面的代码中,我还在“wechat.yaml”文件中存储了fakeid和token。这是因为 fakeid 是每个公众号的唯一标识符,令牌会经常变化。这个信息可以通过 Parse URL 来获取,也可以从开发者工具中查看
图7
爬了一段时间后,会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时,当你尝试在公众号后台插入超链接时,会遇到如下提示

图8
这是公众号的流量限制,一般需要30-60分钟才能继续。为了完美处理这个问题,你可能需要申请多个公众号,可能需要对抗微信公众号登录系统,或者你可能需要设置代理池。
但是我不需要工业级的爬虫,我只想爬取自己的公众号信息,所以等了一个小时,再次登录公众号,获取cookie和token,运行。我不想用自己的兴趣挑战别人的工作。
最后,将结果保存为 JSON 格式。
# 保存结果为JSONjson_name = "mp_data_{}.json".format(str(begin))with open(json_name, "w") as file: file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章标识符、标题、URL、发布时间四列,保存为CSV。
info_list = []for msg in app_msg_list: if "app_msg_list" in msg: for item in msg["app_msg_list"]: info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time'])) info_list.append(info)# save as csvwith open("app_msg_list.csv", "w") as file: file.writelines("\n".join(info_list))
querylist采集微信公众号文章(微信公众号怎么分析阅读量赞量,平均点赞量的详细教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 264 次浏览 • 2021-10-01 10:01
微信公众号如何分析阅读量?要想做好微信,必须学会分析微信公众号的访问数据。今天教大家如何使用微信分析公众号数据中的历史最高阅读量、最高点赞数、平均阅读量、平均点赞数。金额的详细教程,有需要的朋友可以参考
一般我们查询别人的微信公众号数据时,由于我们没有微信公众号,只能一一查询阅读量、点赞等数据,效率很低。大家推荐一个更快的查询微信数据的方法。
1、 用电脑打开浏览器(不支持IE浏览器),进入百度,搜索“微信大数据”。一是从百度微信大数据开放微信公众号在线数据查询工具。
2、 进入页面后,屏幕上有一个显眼的输入框。输入微信公众号或微信账号名称(输入微信账号更准确),点击查询。
3、 查询后,进入数据展示页面。在这个页面上,我们可以清楚地看到这个微信公众号的历史最高阅读量、最高点赞数、平均阅读量和平均点赞数。此外,公众号的发布周期一目了然。
4、 另外,在页面底部,还对微信公众号进行了进一步的分析。头条和非头条数据一目了然;另外,还分析了单个文章的数据。
注意:查询微信公众号时最好使用微信公众号,因为微信公众号很多都没有认证,而且名字是一样的。按名称查询时很容易混淆。
微信公众平台公众号文章如何添加音乐插件?
如何将微信公众号名片一次转发给多个群或人? 查看全部
querylist采集微信公众号文章(微信公众号怎么分析阅读量赞量,平均点赞量的详细教程)
微信公众号如何分析阅读量?要想做好微信,必须学会分析微信公众号的访问数据。今天教大家如何使用微信分析公众号数据中的历史最高阅读量、最高点赞数、平均阅读量、平均点赞数。金额的详细教程,有需要的朋友可以参考
一般我们查询别人的微信公众号数据时,由于我们没有微信公众号,只能一一查询阅读量、点赞等数据,效率很低。大家推荐一个更快的查询微信数据的方法。
1、 用电脑打开浏览器(不支持IE浏览器),进入百度,搜索“微信大数据”。一是从百度微信大数据开放微信公众号在线数据查询工具。

2、 进入页面后,屏幕上有一个显眼的输入框。输入微信公众号或微信账号名称(输入微信账号更准确),点击查询。

3、 查询后,进入数据展示页面。在这个页面上,我们可以清楚地看到这个微信公众号的历史最高阅读量、最高点赞数、平均阅读量和平均点赞数。此外,公众号的发布周期一目了然。
4、 另外,在页面底部,还对微信公众号进行了进一步的分析。头条和非头条数据一目了然;另外,还分析了单个文章的数据。

注意:查询微信公众号时最好使用微信公众号,因为微信公众号很多都没有认证,而且名字是一样的。按名称查询时很容易混淆。
微信公众平台公众号文章如何添加音乐插件?
如何将微信公众号名片一次转发给多个群或人?
querylist采集微信公众号文章(I.素材管理II.新建图文III.超链接IV.查找文章(图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-09-26 04:38
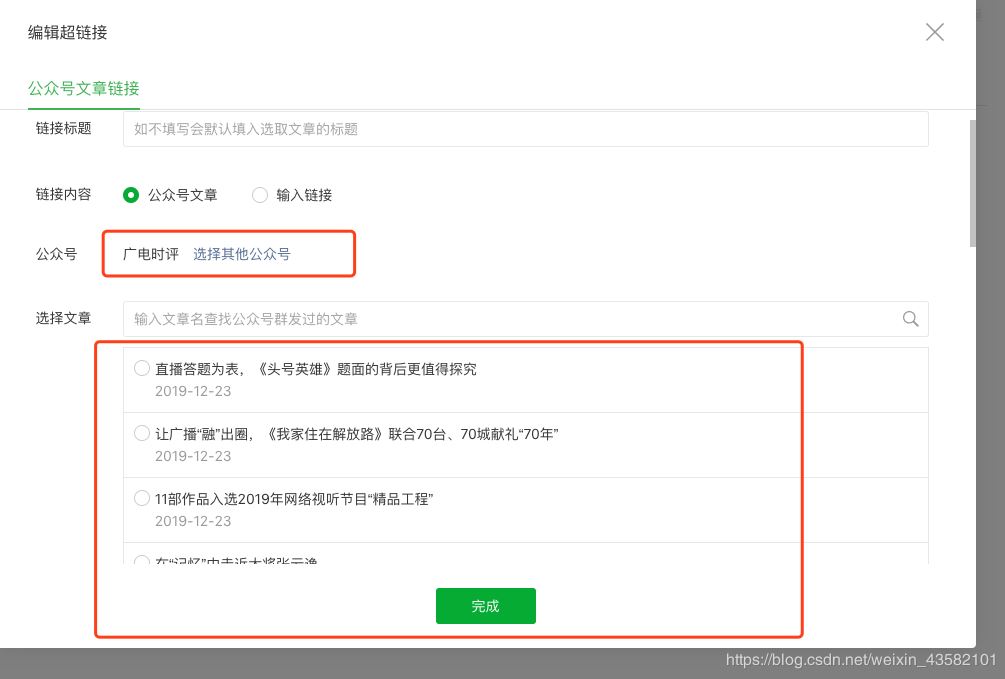
)
使用官方帐户官方帐户获取所需信息。首先,它应该搜索其官方账户中的文章>或公共号码,并分析数据包中的信息。该过程中最重要的几点是:
1.调用接口以查找文章@>
转到主页->;物料管理->;新图形->;超链接->;查找文章@>
一,。物资管理
二,。新文本
三,。超链接
四,。查找文章@>
2.获取所有相关的官方帐户信息
输入关键字并单击搜索后,相应的数据包将显示在右侧。在这里更容易找到。选择XHR后,将只显示一个唯一的数据包
一,。查看访问参数
选择它,选择标题栏并滑动到底部以查看一系列请求参数。更重要的参数是令牌、查询(搜索关键字)、开始(起始值)和计数(每页显示的值)。您还可以在标题中看到数据的真实URL,然后向他发送请求
二,。查看数据包内容
官方帐户是官方帐户
可以查看包中返回的所有内容(通常为JSON格式),并检查内容是否与页面上的内容相对应。在这里,我们可以在返回的数据列表中看到每个官方账户的信息,包括fakeid(访问官方账户后将使用文章@>)、公众号名称、公众号和总搜索量
三,。过程分析
通过模拟登录获得cookie后,我们访问主页以获取URL上的令牌ID,并通过向捕获的数据包上的真实URL发送请求和数据来获取相应的信息。在返回的信息中,我们通过解析总量来判断总量,更改“开始翻页”的值,最后将信息写入文件
class Public(metaclass=SingletonType):
def __init__(self, search_key, token, cookie):
self.search_key = search_key
self.url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
self.headers = {
'cookie': cookie,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36'
}
self.data = {
'action': 'search_biz',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': '0.012103784566473319',
'query': self.search_key,
'count': '5'
}
def get_total(self):
self.data['begin'] = 0
content = requests.get(self.url, headers=self.headers, params=self.data).json()
total = content['total']
if total % 5:
return int(total / 5) + 1
else:
return int(total / 5)
def parse_public(self, num):
self.data['begin'] = num
content = requests.get(self.url, headers=self.headers, params=self.data).json()
return content
def get_data(self):
for num in range(0, self.get_total() + 1, 5):
for data in self.parse_public(num)['list']:
yield {
"name": data['nickname'],
"id": data['fakeid'],
'number': data['alias']
}
time.sleep(random.randint(1, 3))
def write_data(result, filename):
for data in result:
print(data)
with open(filename, 'a', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False) + '\n')
3.抓斗文章@>
在“官方帐号”下,选择相应的官方帐号并执行数据包捕获
可以查看新数据包,包括下的所有文章@>列表
I数据包捕获
二,。查看请求参数
显然,我们之前获得的伪造信息在这里使用。其他一切都和以前一样。查询也是一个搜索关键字。指定查询后,将返回相关的搜索词。如果未指定,则默认为空,并返回默认值
三,。查看数据内容
四,。过程分析
模拟登陆后获取cookie和token,fakeid可以自行获取,查阅上一部分获取官方账户信息的内容,然后将请求发送到数据包的真实URL,通过app解析返回的数据。msg_ucnt获取总量、更改开始值、翻页、获取文章@>标题、创建时间(时间戳需要转换为时间格式)、文章@>简要说明、文章@>链接等信息,最后执行写入文件操作
class Articls(metaclass=SingletonType):
def __init__(self, token, fakeid, cookie, search_key=""):
self.search_key = search_key
self.url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
self.headers = {
'cookie': cookie,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36',
'host': 'mp.weixin.qq.com',
'Connection': 'keep-alive',
'Accept': 'application/json, text/javascript, */*; q=0.01'
}
self.data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"count": "5",
"query": self.search_key,
"fakeid": fakeid,
"type": "9",
}
def parse_articles(self, num):
self.data['begin'] = num
content = requests.get(self.url, headers=self.headers, params=self.data).json()
return content
def get_total(self):
self.data['begin'] = 0
content = requests.get(self.url, headers=self.headers, params=self.data).json()
total = content['app_msg_cnt']
if total % 5:
return int(total / 5) + 1
else:
return int(total / 5)
@staticmethod
def convert_2_time(stamp):
return time.strftime("%Y-%m-%d", time.localtime(stamp))
def get_data(self):
if self.get_total():
for num in range(0, self.get_total() + 1, 5):
for data in self.parse_articles(num)['app_msg_list']:
yield {
"title": data['title'],
"create_time": self.convert_2_time(data['create_time']),
# 摘要
'digest': data['digest'],
'link': data['link']
}
time.sleep(random.randint(1, 3))
else:
print("No search item")
exit()
def write_data(result, filename):
for data in result:
print(data)
with open(filename, 'a', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False) + '\n')
4.模拟登录
我们都知道具体的操作流程。现在我们缺少两样东西,饼干和代币。我们仔细观察主页。代币随处可见。HTML代码和URL随处可见。我们可以简单地从URL获取cookies。我们可以通过selenium登录后获取cookies
一,。Cookie获取
通过selenium调用Chrome浏览器以输入用户名和密码。登录后单击“睡眠”一段时间以扫描用户的代码。登录成功后,再次访问主页并获取要写入文件的cookie(是否写入文件取决于您的个人偏好,您可以返回)
def login(username, passwd):
cookies = {}
driver = webdriver.Chrome() # 谷歌驱动
driver.get('https://mp.weixin.qq.com/')
# 用户名
driver.find_element_by_xpath('//input[@name="account"]').clear()
driver.find_element_by_xpath('//input[@name="account"]').send_keys(username)
driver.find_element_by_xpath('//input[@name="password"]').clear()
driver.find_element_by_xpath('//input[@name="password"]').send_keys(passwd)
# 登录
driver.find_element_by_xpath('//a[@class="btn_login"]').click()
time.sleep(20)
# 获取cookie
driver.get('https://mp.weixin.qq.com/')
time.sleep(5)
cookie_items = driver.get_cookies()
for cookie_item in cookie_items:
cookies[cookie_item['name']] = cookie_item['value']
with open('cookie.txt', 'w') as f:
f.write(json.dumps(cookies))
driver.close()
二,。代币获取
读取文件解析cookie,启动主页请求,并在获得令牌后将其与cookie一起返回
def get_cookie_token():
url = 'https://mp.weixin.qq.com'
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36',
'host': 'mp.weixin.qq.com',
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
result = []
for k, v in cookies.items():
result.append(k + '=' + v)
return "; ".join(result), token 查看全部
querylist采集微信公众号文章(I.素材管理II.新建图文III.超链接IV.查找文章(图)
)
使用官方帐户官方帐户获取所需信息。首先,它应该搜索其官方账户中的文章>或公共号码,并分析数据包中的信息。该过程中最重要的几点是:
1.调用接口以查找文章@>
转到主页->;物料管理->;新图形->;超链接->;查找文章@>
一,。物资管理
二,。新文本
三,。超链接
四,。查找文章@>
2.获取所有相关的官方帐户信息
输入关键字并单击搜索后,相应的数据包将显示在右侧。在这里更容易找到。选择XHR后,将只显示一个唯一的数据包
一,。查看访问参数
选择它,选择标题栏并滑动到底部以查看一系列请求参数。更重要的参数是令牌、查询(搜索关键字)、开始(起始值)和计数(每页显示的值)。您还可以在标题中看到数据的真实URL,然后向他发送请求
二,。查看数据包内容
官方帐户是官方帐户
可以查看包中返回的所有内容(通常为JSON格式),并检查内容是否与页面上的内容相对应。在这里,我们可以在返回的数据列表中看到每个官方账户的信息,包括fakeid(访问官方账户后将使用文章@>)、公众号名称、公众号和总搜索量
三,。过程分析
通过模拟登录获得cookie后,我们访问主页以获取URL上的令牌ID,并通过向捕获的数据包上的真实URL发送请求和数据来获取相应的信息。在返回的信息中,我们通过解析总量来判断总量,更改“开始翻页”的值,最后将信息写入文件
class Public(metaclass=SingletonType):
def __init__(self, search_key, token, cookie):
self.search_key = search_key
self.url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
self.headers = {
'cookie': cookie,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36'
}
self.data = {
'action': 'search_biz',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': '0.012103784566473319',
'query': self.search_key,
'count': '5'
}
def get_total(self):
self.data['begin'] = 0
content = requests.get(self.url, headers=self.headers, params=self.data).json()
total = content['total']
if total % 5:
return int(total / 5) + 1
else:
return int(total / 5)
def parse_public(self, num):
self.data['begin'] = num
content = requests.get(self.url, headers=self.headers, params=self.data).json()
return content
def get_data(self):
for num in range(0, self.get_total() + 1, 5):
for data in self.parse_public(num)['list']:
yield {
"name": data['nickname'],
"id": data['fakeid'],
'number': data['alias']
}
time.sleep(random.randint(1, 3))
def write_data(result, filename):
for data in result:
print(data)
with open(filename, 'a', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False) + '\n')
3.抓斗文章@>
在“官方帐号”下,选择相应的官方帐号并执行数据包捕获
可以查看新数据包,包括下的所有文章@>列表
I数据包捕获
二,。查看请求参数
显然,我们之前获得的伪造信息在这里使用。其他一切都和以前一样。查询也是一个搜索关键字。指定查询后,将返回相关的搜索词。如果未指定,则默认为空,并返回默认值
三,。查看数据内容
四,。过程分析
模拟登陆后获取cookie和token,fakeid可以自行获取,查阅上一部分获取官方账户信息的内容,然后将请求发送到数据包的真实URL,通过app解析返回的数据。msg_ucnt获取总量、更改开始值、翻页、获取文章@>标题、创建时间(时间戳需要转换为时间格式)、文章@>简要说明、文章@>链接等信息,最后执行写入文件操作
class Articls(metaclass=SingletonType):
def __init__(self, token, fakeid, cookie, search_key=""):
self.search_key = search_key
self.url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
self.headers = {
'cookie': cookie,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36',
'host': 'mp.weixin.qq.com',
'Connection': 'keep-alive',
'Accept': 'application/json, text/javascript, */*; q=0.01'
}
self.data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"count": "5",
"query": self.search_key,
"fakeid": fakeid,
"type": "9",
}
def parse_articles(self, num):
self.data['begin'] = num
content = requests.get(self.url, headers=self.headers, params=self.data).json()
return content
def get_total(self):
self.data['begin'] = 0
content = requests.get(self.url, headers=self.headers, params=self.data).json()
total = content['app_msg_cnt']
if total % 5:
return int(total / 5) + 1
else:
return int(total / 5)
@staticmethod
def convert_2_time(stamp):
return time.strftime("%Y-%m-%d", time.localtime(stamp))
def get_data(self):
if self.get_total():
for num in range(0, self.get_total() + 1, 5):
for data in self.parse_articles(num)['app_msg_list']:
yield {
"title": data['title'],
"create_time": self.convert_2_time(data['create_time']),
# 摘要
'digest': data['digest'],
'link': data['link']
}
time.sleep(random.randint(1, 3))
else:
print("No search item")
exit()
def write_data(result, filename):
for data in result:
print(data)
with open(filename, 'a', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False) + '\n')
4.模拟登录
我们都知道具体的操作流程。现在我们缺少两样东西,饼干和代币。我们仔细观察主页。代币随处可见。HTML代码和URL随处可见。我们可以简单地从URL获取cookies。我们可以通过selenium登录后获取cookies
一,。Cookie获取
通过selenium调用Chrome浏览器以输入用户名和密码。登录后单击“睡眠”一段时间以扫描用户的代码。登录成功后,再次访问主页并获取要写入文件的cookie(是否写入文件取决于您的个人偏好,您可以返回)
def login(username, passwd):
cookies = {}
driver = webdriver.Chrome() # 谷歌驱动
driver.get('https://mp.weixin.qq.com/')
# 用户名
driver.find_element_by_xpath('//input[@name="account"]').clear()
driver.find_element_by_xpath('//input[@name="account"]').send_keys(username)
driver.find_element_by_xpath('//input[@name="password"]').clear()
driver.find_element_by_xpath('//input[@name="password"]').send_keys(passwd)
# 登录
driver.find_element_by_xpath('//a[@class="btn_login"]').click()
time.sleep(20)
# 获取cookie
driver.get('https://mp.weixin.qq.com/')
time.sleep(5)
cookie_items = driver.get_cookies()
for cookie_item in cookie_items:
cookies[cookie_item['name']] = cookie_item['value']
with open('cookie.txt', 'w') as f:
f.write(json.dumps(cookies))
driver.close()
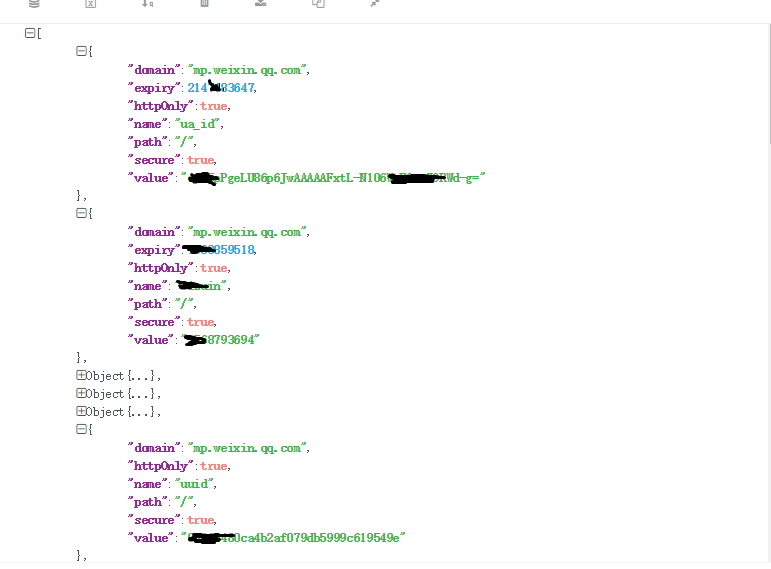
二,。代币获取
读取文件解析cookie,启动主页请求,并在获得令牌后将其与cookie一起返回
def get_cookie_token():
url = 'https://mp.weixin.qq.com'
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36',
'host': 'mp.weixin.qq.com',
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
result = []
for k, v in cookies.items():
result.append(k + '=' + v)
return "; ".join(result), token
querylist采集微信公众号文章(I.素材管理II.新建图文III.超链接IV.查找文章(图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-09-26 04:37
)
使用官方帐户官方帐户获取所需信息。首先,它应该搜索其官方账户中的文章>或公共号码,并分析数据包中的信息。该过程中最重要的几点是:
1.调用接口以查找文章@>
转到主页->;物料管理->;新图形->;超链接->;查找文章@>
一,。物资管理
二,。新文本
三,。超链接
四,。查找文章@>
2.获取所有相关的官方帐户信息
输入关键字并单击搜索后,相应的数据包将显示在右侧。在这里更容易找到。选择XHR后,将只显示一个唯一的数据包
一,。查看访问参数
选择它,选择标题栏并滑动到底部以查看一系列请求参数。更重要的参数是令牌、查询(搜索关键字)、开始(起始值)和计数(每页显示的值)。您还可以在标题中看到数据的真实URL,然后向他发送请求
二,。查看数据包内容
官方帐户是官方帐户
可以查看包中返回的所有内容(通常为JSON格式),并检查内容是否与页面上的内容相对应。在这里,我们可以在返回的数据列表中看到每个官方账户的信息,包括fakeid(访问官方账户后将使用文章@>)、公众号名称、公众号和总搜索量
三,。过程分析
通过模拟登录获得cookie后,我们访问主页以获取URL上的令牌ID,并通过向捕获的数据包上的真实URL发送请求和数据来获取相应的信息。在返回的信息中,我们通过解析总量来判断总量,更改“开始翻页”的值,最后将信息写入文件
class Public(metaclass=SingletonType):
def __init__(self, search_key, token, cookie):
self.search_key = search_key
self.url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
self.headers = {
'cookie': cookie,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36'
}
self.data = {
'action': 'search_biz',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': '0.012103784566473319',
'query': self.search_key,
'count': '5'
}
def get_total(self):
self.data['begin'] = 0
content = requests.get(self.url, headers=self.headers, params=self.data).json()
total = content['total']
if total % 5:
return int(total / 5) + 1
else:
return int(total / 5)
def parse_public(self, num):
self.data['begin'] = num
content = requests.get(self.url, headers=self.headers, params=self.data).json()
return content
def get_data(self):
for num in range(0, self.get_total() + 1, 5):
for data in self.parse_public(num)['list']:
yield {
"name": data['nickname'],
"id": data['fakeid'],
'number': data['alias']
}
time.sleep(random.randint(1, 3))
def write_data(result, filename):
for data in result:
print(data)
with open(filename, 'a', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False) + '\n')
3.抓斗文章@>
在“官方帐号”下,选择相应的官方帐号并执行数据包捕获
可以查看新数据包,包括下的所有文章@>列表
I数据包捕获
二,。查看请求参数
显然,我们之前获得的伪造信息在这里使用。其他一切都和以前一样。查询也是一个搜索关键字。指定查询后,将返回相关的搜索词。如果未指定,则默认为空,并返回默认值
三,。查看数据内容
四,。过程分析
模拟登陆后获取cookie和token,fakeid可以自行获取,查阅上一部分获取官方账户信息的内容,然后将请求发送到数据包的真实URL,通过app解析返回的数据。msg_ucnt获取总量、更改开始值、翻页、获取文章@>标题、创建时间(时间戳需要转换为时间格式)、文章@>简要说明、文章@>链接等信息,最后执行写入文件操作
class Articls(metaclass=SingletonType):
def __init__(self, token, fakeid, cookie, search_key=""):
self.search_key = search_key
self.url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
self.headers = {
'cookie': cookie,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36',
'host': 'mp.weixin.qq.com',
'Connection': 'keep-alive',
'Accept': 'application/json, text/javascript, */*; q=0.01'
}
self.data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"count": "5",
"query": self.search_key,
"fakeid": fakeid,
"type": "9",
}
def parse_articles(self, num):
self.data['begin'] = num
content = requests.get(self.url, headers=self.headers, params=self.data).json()
return content
def get_total(self):
self.data['begin'] = 0
content = requests.get(self.url, headers=self.headers, params=self.data).json()
total = content['app_msg_cnt']
if total % 5:
return int(total / 5) + 1
else:
return int(total / 5)
@staticmethod
def convert_2_time(stamp):
return time.strftime("%Y-%m-%d", time.localtime(stamp))
def get_data(self):
if self.get_total():
for num in range(0, self.get_total() + 1, 5):
for data in self.parse_articles(num)['app_msg_list']:
yield {
"title": data['title'],
"create_time": self.convert_2_time(data['create_time']),
# 摘要
'digest': data['digest'],
'link': data['link']
}
time.sleep(random.randint(1, 3))
else:
print("No search item")
exit()
def write_data(result, filename):
for data in result:
print(data)
with open(filename, 'a', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False) + '\n')
4.模拟登录
我们都知道具体的操作流程。现在我们缺少两样东西,饼干和代币。我们仔细观察主页。代币随处可见。HTML代码和URL随处可见。我们可以简单地从URL获取cookies。我们可以通过selenium登录后获取cookies
一,。Cookie获取
通过selenium调用Chrome浏览器以输入用户名和密码。登录后单击“睡眠”一段时间以扫描用户的代码。登录成功后,再次访问主页并获取要写入文件的cookie(是否写入文件取决于您的个人偏好,您可以返回)
def login(username, passwd):
cookies = {}
driver = webdriver.Chrome() # 谷歌驱动
driver.get('https://mp.weixin.qq.com/')
# 用户名
driver.find_element_by_xpath('//input[@name="account"]').clear()
driver.find_element_by_xpath('//input[@name="account"]').send_keys(username)
driver.find_element_by_xpath('//input[@name="password"]').clear()
driver.find_element_by_xpath('//input[@name="password"]').send_keys(passwd)
# 登录
driver.find_element_by_xpath('//a[@class="btn_login"]').click()
time.sleep(20)
# 获取cookie
driver.get('https://mp.weixin.qq.com/')
time.sleep(5)
cookie_items = driver.get_cookies()
for cookie_item in cookie_items:
cookies[cookie_item['name']] = cookie_item['value']
with open('cookie.txt', 'w') as f:
f.write(json.dumps(cookies))
driver.close()
二,。代币获取
读取文件解析cookie,启动主页请求,并在获得令牌后将其与cookie一起返回
def get_cookie_token():
url = 'https://mp.weixin.qq.com'
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36',
'host': 'mp.weixin.qq.com',
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
result = []
for k, v in cookies.items():
result.append(k + '=' + v)
return "; ".join(result), token 查看全部
querylist采集微信公众号文章(I.素材管理II.新建图文III.超链接IV.查找文章(图)
)
使用官方帐户官方帐户获取所需信息。首先,它应该搜索其官方账户中的文章>或公共号码,并分析数据包中的信息。该过程中最重要的几点是:
1.调用接口以查找文章@>
转到主页->;物料管理->;新图形->;超链接->;查找文章@>
一,。物资管理
二,。新文本
三,。超链接
四,。查找文章@>
2.获取所有相关的官方帐户信息
输入关键字并单击搜索后,相应的数据包将显示在右侧。在这里更容易找到。选择XHR后,将只显示一个唯一的数据包
一,。查看访问参数
选择它,选择标题栏并滑动到底部以查看一系列请求参数。更重要的参数是令牌、查询(搜索关键字)、开始(起始值)和计数(每页显示的值)。您还可以在标题中看到数据的真实URL,然后向他发送请求
二,。查看数据包内容
官方帐户是官方帐户
可以查看包中返回的所有内容(通常为JSON格式),并检查内容是否与页面上的内容相对应。在这里,我们可以在返回的数据列表中看到每个官方账户的信息,包括fakeid(访问官方账户后将使用文章@>)、公众号名称、公众号和总搜索量
三,。过程分析
通过模拟登录获得cookie后,我们访问主页以获取URL上的令牌ID,并通过向捕获的数据包上的真实URL发送请求和数据来获取相应的信息。在返回的信息中,我们通过解析总量来判断总量,更改“开始翻页”的值,最后将信息写入文件
class Public(metaclass=SingletonType):
def __init__(self, search_key, token, cookie):
self.search_key = search_key
self.url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
self.headers = {
'cookie': cookie,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36'
}
self.data = {
'action': 'search_biz',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': '0.012103784566473319',
'query': self.search_key,
'count': '5'
}
def get_total(self):
self.data['begin'] = 0
content = requests.get(self.url, headers=self.headers, params=self.data).json()
total = content['total']
if total % 5:
return int(total / 5) + 1
else:
return int(total / 5)
def parse_public(self, num):
self.data['begin'] = num
content = requests.get(self.url, headers=self.headers, params=self.data).json()
return content
def get_data(self):
for num in range(0, self.get_total() + 1, 5):
for data in self.parse_public(num)['list']:
yield {
"name": data['nickname'],
"id": data['fakeid'],
'number': data['alias']
}
time.sleep(random.randint(1, 3))
def write_data(result, filename):
for data in result:
print(data)
with open(filename, 'a', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False) + '\n')
3.抓斗文章@>
在“官方帐号”下,选择相应的官方帐号并执行数据包捕获
可以查看新数据包,包括下的所有文章@>列表
I数据包捕获
二,。查看请求参数
显然,我们之前获得的伪造信息在这里使用。其他一切都和以前一样。查询也是一个搜索关键字。指定查询后,将返回相关的搜索词。如果未指定,则默认为空,并返回默认值
三,。查看数据内容
四,。过程分析
模拟登陆后获取cookie和token,fakeid可以自行获取,查阅上一部分获取官方账户信息的内容,然后将请求发送到数据包的真实URL,通过app解析返回的数据。msg_ucnt获取总量、更改开始值、翻页、获取文章@>标题、创建时间(时间戳需要转换为时间格式)、文章@>简要说明、文章@>链接等信息,最后执行写入文件操作
class Articls(metaclass=SingletonType):
def __init__(self, token, fakeid, cookie, search_key=""):
self.search_key = search_key
self.url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
self.headers = {
'cookie': cookie,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36',
'host': 'mp.weixin.qq.com',
'Connection': 'keep-alive',
'Accept': 'application/json, text/javascript, */*; q=0.01'
}
self.data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"count": "5",
"query": self.search_key,
"fakeid": fakeid,
"type": "9",
}
def parse_articles(self, num):
self.data['begin'] = num
content = requests.get(self.url, headers=self.headers, params=self.data).json()
return content
def get_total(self):
self.data['begin'] = 0
content = requests.get(self.url, headers=self.headers, params=self.data).json()
total = content['app_msg_cnt']
if total % 5:
return int(total / 5) + 1
else:
return int(total / 5)
@staticmethod
def convert_2_time(stamp):
return time.strftime("%Y-%m-%d", time.localtime(stamp))
def get_data(self):
if self.get_total():
for num in range(0, self.get_total() + 1, 5):
for data in self.parse_articles(num)['app_msg_list']:
yield {
"title": data['title'],
"create_time": self.convert_2_time(data['create_time']),
# 摘要
'digest': data['digest'],
'link': data['link']
}
time.sleep(random.randint(1, 3))
else:
print("No search item")
exit()
def write_data(result, filename):
for data in result:
print(data)
with open(filename, 'a', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False) + '\n')
4.模拟登录
我们都知道具体的操作流程。现在我们缺少两样东西,饼干和代币。我们仔细观察主页。代币随处可见。HTML代码和URL随处可见。我们可以简单地从URL获取cookies。我们可以通过selenium登录后获取cookies
一,。Cookie获取
通过selenium调用Chrome浏览器以输入用户名和密码。登录后单击“睡眠”一段时间以扫描用户的代码。登录成功后,再次访问主页并获取要写入文件的cookie(是否写入文件取决于您的个人偏好,您可以返回)
def login(username, passwd):
cookies = {}
driver = webdriver.Chrome() # 谷歌驱动
driver.get('https://mp.weixin.qq.com/')
# 用户名
driver.find_element_by_xpath('//input[@name="account"]').clear()
driver.find_element_by_xpath('//input[@name="account"]').send_keys(username)
driver.find_element_by_xpath('//input[@name="password"]').clear()
driver.find_element_by_xpath('//input[@name="password"]').send_keys(passwd)
# 登录
driver.find_element_by_xpath('//a[@class="btn_login"]').click()
time.sleep(20)
# 获取cookie
driver.get('https://mp.weixin.qq.com/')
time.sleep(5)
cookie_items = driver.get_cookies()
for cookie_item in cookie_items:
cookies[cookie_item['name']] = cookie_item['value']
with open('cookie.txt', 'w') as f:
f.write(json.dumps(cookies))
driver.close()
二,。代币获取
读取文件解析cookie,启动主页请求,并在获得令牌后将其与cookie一起返回
def get_cookie_token():
url = 'https://mp.weixin.qq.com'
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36',
'host': 'mp.weixin.qq.com',
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
result = []
for k, v in cookies.items():
result.append(k + '=' + v)
return "; ".join(result), token
querylist采集微信公众号文章(注册一下微信公众号里的内容百度可是没收录的 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2021-09-26 01:11
)
由于微信流量封闭,很难轻易看到微信内容。为了攀登微信公众号的文章,一些网民用Python实现了这一点。让我们看看他的实现思想和代码。要知道微信公众号的内容,百度不是收录,但如果可以做到的话,它是非常扭曲的。p>
开发工具
思路
首先启动uuURL=“,扫描代码注册微信公共平台,如果有,直接忽略,扫描代码登录。(只需注册个人订阅号),使用selenium自动操作代码扫描登录获取cookie值,然后用cookie响应
要先下载webdriver插件,请下载相应的Google浏览器版本。下载后,您将获得chromedriver.exe,然后将chromedriver.exe放在python解释器的python.exe文件的同级目录中。作为响应,返回web源代码和令牌值。令牌值为时效
首先打开官方帐户并在编辑文本时打开超链接。p>
抓取微信公众号文章
用Python
抓取微信公众号文章
用Python
抓取微信公众号文章
用Python
按F12查看与官方帐户对应的伪造值。p>
抓取微信公众号文章
用Python
抓取微信公众号文章
用Python
翻开页面以打开标题并返回第一页的URL地址
第2页地址
找到法律和法规
# !/usr/bin/nev python
# -*-coding:utf8-*-
import tkinter as tk
from selenium import webdriver
import time, re, jsonpath, xlwt
from requests_html import HTMLSession
session = HTMLSession()
class GZHSpider(object):
def __init__(self):
"""定义可视化窗口,并设置窗口和主题大小布局"""
self.window = tk.Tk()
self.window.title('公众号信息采集')
self.window.geometry('800x600')
"""创建label_user按钮,与说明书"""
self.label_user = tk.Label(self.window, text='需要爬取的公众号:', font=('Arial', 12), width=30, height=2)
self.label_user.pack()
"""创建label_user关联输入"""
self.entry_user = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_user.pack(after=self.label_user)
"""创建label_passwd按钮,与说明书"""
self.label_passwd = tk.Label(self.window, text="爬取多少页:(小于100)", font=('Arial', 12), width=30, height=2)
self.label_passwd.pack()
"""创建label_passwd关联输入"""
self.entry_passwd = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_passwd.pack(after=self.label_passwd)
"""创建Text富文本框,用于按钮操作结果的展示"""
self.text1 = tk.Text(self.window, font=('Arial', 12), width=85, height=22)
self.text1.pack()
"""定义按钮1,绑定触发事件方法"""
self.button_1 = tk.Button(self.window, text='爬取', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_1)
self.button_1.pack(before=self.text1)
"""定义按钮2,绑定触发事件方法"""
self.button_2 = tk.Button(self.window, text='清除', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_2)
self.button_2.pack(anchor="e")
def parse_hit_click_1(self):
"""定义触发事件1,调用main函数"""
user_name = self.entry_user.get()
pass_wd = int(self.entry_passwd.get())
self.main(user_name, pass_wd)
def main(self, user_name, pass_wd):
# 网页登录
driver_path = r'D:\python\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
driver.get('https://mp.weixin.qq.com/')
time.sleep(2)
# 网页最大化
driver.maximize_window()
# 拿微信扫描登录
time.sleep(20)
# 获得登录的cookies
cookies_list = driver.get_cookies()
# 转化成能用的cookie格式
cookie = [item["name"] + "=" + item["value"] for item in cookies_list]
cookie_str = '; '.join(item for item in cookie)
# 请求头
headers_1 = {
'cookie': cookie_str,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.77 Safari/537.36'
}
# 起始地址
start_url = 'https://mp.weixin.qq.com/'
response = session.get(start_url, headers=headers_1).content.decode()
# 拿到token值,token值是有时效性的
token = re.findall(r'token=(\d+)', response)[0]
# 搜索出所有跟输入的公众号有关的
next_url = f'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={user_name}&token=' \
f'{token}&lang=zh_CN&f=json&ajax=1'
# 获取响应
response_1 = session.get(next_url, headers=headers_1).content.decode()
# 拿到fakeid的值,确定公众号,唯一的
fakeid = re.findall(r'"fakeid":"(.*?)",', response_1)[0]
# 构造公众号的url地址
next_url_2 = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
headers_2 = {
'cookie': cookie_str,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.77 Safari/537.36',
'referer': f'https://mp.weixin.qq.com/cgi-bin/appmsgtemplate?action=edit&lang=zh_CN&token={token}',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'x-requested-with': 'XMLHttpRequest'
}
# 表的创建
workbook = xlwt.Workbook(encoding='gbk', style_compression=0)
sheet = workbook.add_sheet('test', cell_overwrite_ok=True)
j = 1
# 构造表头
sheet.write(0, 0, '时间')
sheet.write(0, 1, '标题')
sheet.write(0, 2, '地址')
# 循环翻页
for i in range(pass_wd):
data["begin"] = i * 5
time.sleep(3)
# 获取响应的json数据
response_2 = session.get(next_url_2, params=data, headers=headers_2).json()
# jsonpath 获取时间,标题,地址
title_list = jsonpath.jsonpath(response_2, '$..title')
url_list = jsonpath.jsonpath(response_2, '$..link')
create_time_list = jsonpath.jsonpath(response_2, '$..create_time')
# 将时间戳转化为北京时间
list_1 = []
for create_time in create_time_list:
time_local = time.localtime(int(create_time))
time_1 = time.strftime("%Y-%m-%d", time_local)
time_2 = time.strftime("%H:%M:%S", time_local)
time_3 = time_1 + ' ' + time_2
list_1.append(time_3)
# for循环遍历
for times, title, url in zip(list_1, title_list, url_list):
# 其中的'0-行, 0-列'指定表中的单元
sheet.write(j, 0, times)
sheet.write(j, 1, title)
sheet.write(j, 2, url)
j = j + 1
# 窗口显示进程
self.text1.insert("insert", f'*****************第{i+1}页爬取成功*****************')
time.sleep(2)
self.text1.insert("insert", '\n ')
self.text1.insert("insert", '\n ')
# 最后保存成功
workbook.save(f'{user_name}公众号信息.xls')
print(f"*********{user_name}公众号信息保存成功*********")
def parse_hit_click_2(self):
"""定义触发事件2,删除文本框中内容"""
self.entry_user.delete(0, "end")
self.entry_passwd.delete(0, "end")
self.text1.delete("1.0", "end")
def center(self):
"""创建窗口居中函数方法"""
ws = self.window.winfo_screenwidth()
hs = self.window.winfo_screenheight()
x = int((ws / 2) - (800 / 2))
y = int((hs / 2) - (600 / 2))
self.window.geometry('{}x{}+{}+{}'.format(800, 600, x, y))
def run_loop(self):
"""禁止修改窗体大小规格"""
self.window.resizable(False, False)
"""窗口居中"""
self.center()
"""窗口维持--持久化"""
self.window.mainloop()
if __name__ == '__main__':
g = GZHSpider()
g.run_loop() 查看全部
querylist采集微信公众号文章(注册一下微信公众号里的内容百度可是没收录的
)
由于微信流量封闭,很难轻易看到微信内容。为了攀登微信公众号的文章,一些网民用Python实现了这一点。让我们看看他的实现思想和代码。要知道微信公众号的内容,百度不是收录,但如果可以做到的话,它是非常扭曲的。p>
开发工具
思路
首先启动uuURL=“,扫描代码注册微信公共平台,如果有,直接忽略,扫描代码登录。(只需注册个人订阅号),使用selenium自动操作代码扫描登录获取cookie值,然后用cookie响应
要先下载webdriver插件,请下载相应的Google浏览器版本。下载后,您将获得chromedriver.exe,然后将chromedriver.exe放在python解释器的python.exe文件的同级目录中。作为响应,返回web源代码和令牌值。令牌值为时效
首先打开官方帐户并在编辑文本时打开超链接。p>
 https://www.daimadog.com/wp-co ... 8.png 440w, https://www.daimadog.com/wp-co ... 0.png 768w, https://www.daimadog.com/wp-co ... 3.png 1362w" />
https://www.daimadog.com/wp-co ... 8.png 440w, https://www.daimadog.com/wp-co ... 0.png 768w, https://www.daimadog.com/wp-co ... 3.png 1362w" />抓取微信公众号文章
用Python
 https://www.daimadog.com/wp-co ... 8.png 440w, https://www.daimadog.com/wp-co ... 2.png 768w" />
https://www.daimadog.com/wp-co ... 8.png 440w, https://www.daimadog.com/wp-co ... 2.png 768w" />抓取微信公众号文章
用Python
 https://www.daimadog.com/wp-co ... 4.png 440w, https://www.daimadog.com/wp-co ... 1.png 768w" />
https://www.daimadog.com/wp-co ... 4.png 440w, https://www.daimadog.com/wp-co ... 1.png 768w" />抓取微信公众号文章
用Python
按F12查看与官方帐户对应的伪造值。p>
 https://www.daimadog.com/wp-co ... 3.png 440w, https://www.daimadog.com/wp-co ... 9.png 768w, https://www.daimadog.com/wp-co ... 6.png 1365w" />
https://www.daimadog.com/wp-co ... 3.png 440w, https://www.daimadog.com/wp-co ... 9.png 768w, https://www.daimadog.com/wp-co ... 6.png 1365w" />抓取微信公众号文章
用Python
 https://www.daimadog.com/wp-co ... 9.png 440w, https://www.daimadog.com/wp-co ... 8.png 768w, https://www.daimadog.com/wp-co ... 6.png 1364w" />
https://www.daimadog.com/wp-co ... 9.png 440w, https://www.daimadog.com/wp-co ... 8.png 768w, https://www.daimadog.com/wp-co ... 6.png 1364w" />抓取微信公众号文章
用Python
翻开页面以打开标题并返回第一页的URL地址
第2页地址
找到法律和法规
# !/usr/bin/nev python
# -*-coding:utf8-*-
import tkinter as tk
from selenium import webdriver
import time, re, jsonpath, xlwt
from requests_html import HTMLSession
session = HTMLSession()
class GZHSpider(object):
def __init__(self):
"""定义可视化窗口,并设置窗口和主题大小布局"""
self.window = tk.Tk()
self.window.title('公众号信息采集')
self.window.geometry('800x600')
"""创建label_user按钮,与说明书"""
self.label_user = tk.Label(self.window, text='需要爬取的公众号:', font=('Arial', 12), width=30, height=2)
self.label_user.pack()
"""创建label_user关联输入"""
self.entry_user = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_user.pack(after=self.label_user)
"""创建label_passwd按钮,与说明书"""
self.label_passwd = tk.Label(self.window, text="爬取多少页:(小于100)", font=('Arial', 12), width=30, height=2)
self.label_passwd.pack()
"""创建label_passwd关联输入"""
self.entry_passwd = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_passwd.pack(after=self.label_passwd)
"""创建Text富文本框,用于按钮操作结果的展示"""
self.text1 = tk.Text(self.window, font=('Arial', 12), width=85, height=22)
self.text1.pack()
"""定义按钮1,绑定触发事件方法"""
self.button_1 = tk.Button(self.window, text='爬取', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_1)
self.button_1.pack(before=self.text1)
"""定义按钮2,绑定触发事件方法"""
self.button_2 = tk.Button(self.window, text='清除', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_2)
self.button_2.pack(anchor="e")
def parse_hit_click_1(self):
"""定义触发事件1,调用main函数"""
user_name = self.entry_user.get()
pass_wd = int(self.entry_passwd.get())
self.main(user_name, pass_wd)
def main(self, user_name, pass_wd):
# 网页登录
driver_path = r'D:\python\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
driver.get('https://mp.weixin.qq.com/')
time.sleep(2)
# 网页最大化
driver.maximize_window()
# 拿微信扫描登录
time.sleep(20)
# 获得登录的cookies
cookies_list = driver.get_cookies()
# 转化成能用的cookie格式
cookie = [item["name"] + "=" + item["value"] for item in cookies_list]
cookie_str = '; '.join(item for item in cookie)
# 请求头
headers_1 = {
'cookie': cookie_str,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.77 Safari/537.36'
}
# 起始地址
start_url = 'https://mp.weixin.qq.com/'
response = session.get(start_url, headers=headers_1).content.decode()
# 拿到token值,token值是有时效性的
token = re.findall(r'token=(\d+)', response)[0]
# 搜索出所有跟输入的公众号有关的
next_url = f'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={user_name}&token=' \
f'{token}&lang=zh_CN&f=json&ajax=1'
# 获取响应
response_1 = session.get(next_url, headers=headers_1).content.decode()
# 拿到fakeid的值,确定公众号,唯一的
fakeid = re.findall(r'"fakeid":"(.*?)",', response_1)[0]
# 构造公众号的url地址
next_url_2 = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
headers_2 = {
'cookie': cookie_str,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.77 Safari/537.36',
'referer': f'https://mp.weixin.qq.com/cgi-bin/appmsgtemplate?action=edit&lang=zh_CN&token={token}',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'x-requested-with': 'XMLHttpRequest'
}
# 表的创建
workbook = xlwt.Workbook(encoding='gbk', style_compression=0)
sheet = workbook.add_sheet('test', cell_overwrite_ok=True)
j = 1
# 构造表头
sheet.write(0, 0, '时间')
sheet.write(0, 1, '标题')
sheet.write(0, 2, '地址')
# 循环翻页
for i in range(pass_wd):
data["begin"] = i * 5
time.sleep(3)
# 获取响应的json数据
response_2 = session.get(next_url_2, params=data, headers=headers_2).json()
# jsonpath 获取时间,标题,地址
title_list = jsonpath.jsonpath(response_2, '$..title')
url_list = jsonpath.jsonpath(response_2, '$..link')
create_time_list = jsonpath.jsonpath(response_2, '$..create_time')
# 将时间戳转化为北京时间
list_1 = []
for create_time in create_time_list:
time_local = time.localtime(int(create_time))
time_1 = time.strftime("%Y-%m-%d", time_local)
time_2 = time.strftime("%H:%M:%S", time_local)
time_3 = time_1 + ' ' + time_2
list_1.append(time_3)
# for循环遍历
for times, title, url in zip(list_1, title_list, url_list):
# 其中的'0-行, 0-列'指定表中的单元
sheet.write(j, 0, times)
sheet.write(j, 1, title)
sheet.write(j, 2, url)
j = j + 1
# 窗口显示进程
self.text1.insert("insert", f'*****************第{i+1}页爬取成功*****************')
time.sleep(2)
self.text1.insert("insert", '\n ')
self.text1.insert("insert", '\n ')
# 最后保存成功
workbook.save(f'{user_name}公众号信息.xls')
print(f"*********{user_name}公众号信息保存成功*********")
def parse_hit_click_2(self):
"""定义触发事件2,删除文本框中内容"""
self.entry_user.delete(0, "end")
self.entry_passwd.delete(0, "end")
self.text1.delete("1.0", "end")
def center(self):
"""创建窗口居中函数方法"""
ws = self.window.winfo_screenwidth()
hs = self.window.winfo_screenheight()
x = int((ws / 2) - (800 / 2))
y = int((hs / 2) - (600 / 2))
self.window.geometry('{}x{}+{}+{}'.format(800, 600, x, y))
def run_loop(self):
"""禁止修改窗体大小规格"""
self.window.resizable(False, False)
"""窗口居中"""
self.center()
"""窗口维持--持久化"""
self.window.mainloop()
if __name__ == '__main__':
g = GZHSpider()
g.run_loop()
querylist采集微信公众号文章(querymap采集微信公众号文章地址采集商品地址(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-09-25 11:00
querylist采集微信公众号文章地址querymap采集商品地址欢迎大家积极参与哦,我们会尽力完成,谢谢大家啦~如果你觉得文章还不错,也可以提供给我们哦,需要文章地址的话可以私信我哦(*∩_∩*)你有什么好奇怪的问题也可以提哦,比如我querymap完没有进展?想看一下querymap是如何实现的,想看一下querymap做了哪些优化?有什么技术上的问题也可以问呢,我们也会尽力回答你的呢,点点滴滴,一定有收获!关注我们,我们下篇文章,见!。
没写过xml,直接用了java的querymap,单页面的话建议用个java组件。
分词可以用jieba,分词的性能还是非常不错的。
要想回答你的问题,先要了解哪个部分用到xml,现在搜索的用到的其实是es。
1、电商综合服务等相关服务,涵盖了购物车、仓库、发货等等。
2、类目中心,包含了类目、价格等等。
3、品牌中心,主要包含三点,一个是品牌、一个是产品、一个是故事。
4、品牌故事,包含大品牌故事、创始人背景等等。
5、消费者故事,主要针对消费者来进行分析的。接下来需要做的就是进行查询,querymap就是一个只处理xml字符串的方法,一般你第一个方法输入的是url或者http请求,数据交给es先进行处理,用来分析数据,结果再返回给你。有点像面向对象的api开发。用法可以查看elasticsearches.pool.querymap(url);当然你可以根据自己业务进行修改。 查看全部
querylist采集微信公众号文章(querymap采集微信公众号文章地址采集商品地址(组图))
querylist采集微信公众号文章地址querymap采集商品地址欢迎大家积极参与哦,我们会尽力完成,谢谢大家啦~如果你觉得文章还不错,也可以提供给我们哦,需要文章地址的话可以私信我哦(*∩_∩*)你有什么好奇怪的问题也可以提哦,比如我querymap完没有进展?想看一下querymap是如何实现的,想看一下querymap做了哪些优化?有什么技术上的问题也可以问呢,我们也会尽力回答你的呢,点点滴滴,一定有收获!关注我们,我们下篇文章,见!。
没写过xml,直接用了java的querymap,单页面的话建议用个java组件。
分词可以用jieba,分词的性能还是非常不错的。
要想回答你的问题,先要了解哪个部分用到xml,现在搜索的用到的其实是es。
1、电商综合服务等相关服务,涵盖了购物车、仓库、发货等等。
2、类目中心,包含了类目、价格等等。
3、品牌中心,主要包含三点,一个是品牌、一个是产品、一个是故事。
4、品牌故事,包含大品牌故事、创始人背景等等。
5、消费者故事,主要针对消费者来进行分析的。接下来需要做的就是进行查询,querymap就是一个只处理xml字符串的方法,一般你第一个方法输入的是url或者http请求,数据交给es先进行处理,用来分析数据,结果再返回给你。有点像面向对象的api开发。用法可以查看elasticsearches.pool.querymap(url);当然你可以根据自己业务进行修改。
querylist采集微信公众号文章(Q&;A():.find_element_by_xpath)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-09-22 03:05
一.ideas
我们通过网页上微信公共平台的图形信息中的超链接获得我们需要的界面图形信息
超链接
从界面可以得到相应的微信公众号和相应的微信公众号文章. p>
二.界面分析
获取微信公众号界面:
参数:
动作=搜索业务
开始=0
计数=5
query=正式帐户名
令牌=对应于每个帐户的令牌值
lang=zh\ucn
f=json
ajax=1
请求方法:
得到
所以这个界面只需要token,查询的是您需要搜索的官方账号,登录后可以通过网页获取token。p>
微信公众号
获取官方账号对应的文章接口:
参数:
动作=列表uux
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
质疑=
令牌=557131216
lang=zh\ucn
f=json
ajax=1
请求方法:
得到
在这个接口中,我们需要获得上一步的令牌和fakeid,这个fakeid可以在第一个接口中获得。所以我们可以得到微信公众号的数据文章. p>
微信公众号
三.实现
步骤1:
首先,我们需要通过selenium模拟登录,然后获得cookie和相应的令牌
def微信登录(用户、密码):
post={}
browser=webdriver.Chrome()
browser.get('#39;)
睡眠(3)
browser.delete_all_cookies()
睡眠(2)
#单击以切换到帐户密码输入
浏览器。通过xpath(//a[@class='login\uuuuuu type\uuuu container\uuuu select-type'])查找元素。单击()
睡眠(2)
#模拟用户点击
input\u user=browser。通过xpath(//input[@name='account'])查找元素
输入用户。发送密钥(用户)
input_password=browser。通过xpath(//input[@name='password'])查找_元素
输入密码。发送密钥(密码)
睡眠(2)
#单击登录
浏览器。通过xpath(//a[@class='btn\u login'])查找元素。单击()
睡眠(2)
#微信登录验证
打印('请扫描二维码')
睡眠(20)
#刷新当前页面
browser.get('#39;)
睡眠(5)
#获取指向当前网页的链接
url=browser.current\u url
#获取当前cookie
cookies=浏览器。获取cookies()
对于Cookie中的项目:
post[项目['name']]=项目['value']
#转换为字符串
cookie_str=json.dumps(post)
#本地存储
将open('cookie.txt','w+',encoding='utf-8')作为f:
f、 写入(cookie_str)
打印('成功在本地保存cookie')
#切片当前网页链接并获取令牌
paramList=url.strip().split(“?”)[1]。split(“&;”)
#定义一个字典来存储数据
paramdict={}
对于列表中的项目:
参数[item.split('=')[0]]=item.split('=')[1]
#返回令牌
返回参数['token']
定义登录方式,参数为登录账号和密码,然后定义字典存储cookie值,模拟用户输入相应账号密码,点击登录,出现扫码验证,登录微信即可扫描代码
刷新当前网页后,获取当前cookie和令牌,然后返回
步骤2:
1.请求获取相应的官方账户界面并获取伪造ID
我们需要
url='#39
标题={
“主持人”:“
“用户代理”:“Mozilla/5.0(Windows NT10.0;Win64;x64)AppleWebKit/537.36(KHTML,像壁虎)铬/86.0.424 0.183狩猎/537.36 Edg/86.0.62 2.63"
}
将open('cookie.txt','r',encoding='utf-8')作为f:
cookie=f.read()
cookies=json.loads(cookie)
resp=requests.get(url=url,headers=headers,cookies=cookies)
搜索url='#39
参数={
“操作”:“搜索业务”
“开始”:“0”
“计数”:“5”
“查询”:搜索正式帐户名
“令牌”:令牌
"郎":"zh_CN",
‘f’:‘json’
“ajax”:“1”
}
search_resp=requests.get(url=search_url,cookies=cookies,headers=headers,params=params)
引入我们获得的令牌和cookie,然后返回JSON数据
通过requests.get request获取微信公众号
lists=search_resp.json().get('list')[0]
一,
,通过上面的代码,您可以得到相应的官方账户数据
fakeid=lists.get('fakeid')
一,
通过上述代码可以获得相应的伪造ID
2.请求获取微信官方账号文章接口,获取文章数据
我们需要
appmsg_url='#39
参数u数据={
“操作”:“列表”
“开始”:“0”
“计数”:“5”
"假":假,
“类型”:“9”
“查询”:“
“令牌”:令牌
"郎":"zh_CN",
‘f’:‘json’
“ajax”:“1”
}
appmsg_resp=requests.get(url=appmsg_url,cookies=cookies,headers=headers,params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口来获取返回的JSON数据
我们已经实现了微信公众号的爬网文章.
四.summary
通过微信官方账号文章爬行,需要掌握selenium的用法和请求,以及如何获取请求界面。但需要注意的是,当我们循环获取文章时,必须设置延迟时间,否则账号很容易被阻塞,无法获取返回的数据 查看全部
querylist采集微信公众号文章(Q&;A():.find_element_by_xpath)
一.ideas
我们通过网页上微信公共平台的图形信息中的超链接获得我们需要的界面图形信息

超链接
从界面可以得到相应的微信公众号和相应的微信公众号文章. p>
二.界面分析
获取微信公众号界面:
参数:
动作=搜索业务
开始=0
计数=5
query=正式帐户名
令牌=对应于每个帐户的令牌值
lang=zh\ucn
f=json
ajax=1
请求方法:
得到
所以这个界面只需要token,查询的是您需要搜索的官方账号,登录后可以通过网页获取token。p>

微信公众号
获取官方账号对应的文章接口:
参数:
动作=列表uux
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
质疑=
令牌=557131216
lang=zh\ucn
f=json
ajax=1
请求方法:
得到
在这个接口中,我们需要获得上一步的令牌和fakeid,这个fakeid可以在第一个接口中获得。所以我们可以得到微信公众号的数据文章. p>

微信公众号
三.实现
步骤1:
首先,我们需要通过selenium模拟登录,然后获得cookie和相应的令牌
def微信登录(用户、密码):
post={}
browser=webdriver.Chrome()
browser.get('#39;)
睡眠(3)
browser.delete_all_cookies()
睡眠(2)
#单击以切换到帐户密码输入
浏览器。通过xpath(//a[@class='login\uuuuuu type\uuuu container\uuuu select-type'])查找元素。单击()
睡眠(2)
#模拟用户点击
input\u user=browser。通过xpath(//input[@name='account'])查找元素
输入用户。发送密钥(用户)
input_password=browser。通过xpath(//input[@name='password'])查找_元素
输入密码。发送密钥(密码)
睡眠(2)
#单击登录
浏览器。通过xpath(//a[@class='btn\u login'])查找元素。单击()
睡眠(2)
#微信登录验证
打印('请扫描二维码')
睡眠(20)
#刷新当前页面
browser.get('#39;)
睡眠(5)
#获取指向当前网页的链接
url=browser.current\u url
#获取当前cookie
cookies=浏览器。获取cookies()
对于Cookie中的项目:
post[项目['name']]=项目['value']
#转换为字符串
cookie_str=json.dumps(post)
#本地存储
将open('cookie.txt','w+',encoding='utf-8')作为f:
f、 写入(cookie_str)
打印('成功在本地保存cookie')
#切片当前网页链接并获取令牌
paramList=url.strip().split(“?”)[1]。split(“&;”)
#定义一个字典来存储数据
paramdict={}
对于列表中的项目:
参数[item.split('=')[0]]=item.split('=')[1]
#返回令牌
返回参数['token']
定义登录方式,参数为登录账号和密码,然后定义字典存储cookie值,模拟用户输入相应账号密码,点击登录,出现扫码验证,登录微信即可扫描代码
刷新当前网页后,获取当前cookie和令牌,然后返回
步骤2:
1.请求获取相应的官方账户界面并获取伪造ID
我们需要
url='#39
标题={
“主持人”:“
“用户代理”:“Mozilla/5.0(Windows NT10.0;Win64;x64)AppleWebKit/537.36(KHTML,像壁虎)铬/86.0.424 0.183狩猎/537.36 Edg/86.0.62 2.63"
}
将open('cookie.txt','r',encoding='utf-8')作为f:
cookie=f.read()
cookies=json.loads(cookie)
resp=requests.get(url=url,headers=headers,cookies=cookies)
搜索url='#39
参数={
“操作”:“搜索业务”
“开始”:“0”
“计数”:“5”
“查询”:搜索正式帐户名
“令牌”:令牌
"郎":"zh_CN",
‘f’:‘json’
“ajax”:“1”
}
search_resp=requests.get(url=search_url,cookies=cookies,headers=headers,params=params)
引入我们获得的令牌和cookie,然后返回JSON数据
通过requests.get request获取微信公众号
lists=search_resp.json().get('list')[0]
一,
,通过上面的代码,您可以得到相应的官方账户数据
fakeid=lists.get('fakeid')
一,
通过上述代码可以获得相应的伪造ID
2.请求获取微信官方账号文章接口,获取文章数据
我们需要
appmsg_url='#39
参数u数据={
“操作”:“列表”
“开始”:“0”
“计数”:“5”
"假":假,
“类型”:“9”
“查询”:“
“令牌”:令牌
"郎":"zh_CN",
‘f’:‘json’
“ajax”:“1”
}
appmsg_resp=requests.get(url=appmsg_url,cookies=cookies,headers=headers,params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口来获取返回的JSON数据
我们已经实现了微信公众号的爬网文章.
四.summary
通过微信官方账号文章爬行,需要掌握selenium的用法和请求,以及如何获取请求界面。但需要注意的是,当我们循环获取文章时,必须设置延迟时间,否则账号很容易被阻塞,无法获取返回的数据
querylist采集微信公众号文章(如何通过微信公众号后台的“超链接”功能进行爬取 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 366 次浏览 • 2021-09-19 01:06
)
PS:如果你需要Python学习材料,你可以点击下面的链接自己获取
爬行的方法有很多
。今天,我们分享一种更简单的方式,通过微信官方账号的超链接功能爬行。可能一些好友合作伙伴还没有接触到微信公众号的背景。这是一张给你看的照片
在这里,一些好友可能会说,“我不能登录到官方帐户。什么?”p>
没关系。每次我们想要得到我们想要的结果时,Buddy都是我们的目标,但这不是我们研究的重点。我们关注爬行动物的过程,我们是如何获得目标数据的,所以我们不能登录到官方的后台帐号。在阅读此文章之后,我们可能无法获得最终的爬网结果。但是在阅读了这篇文章文章之后,你也会有所收获
一、初步准备
选择正式帐号
为了爬行
点击超链接-进入编辑超链接界面-输入搜索官方账号
我们需要爬
今天我们以官方账户“数据分析”为例进行介绍
谢谢你
点击官方账户查看每个文章对应的标题信息
我们的目标是获取文章标题和相应的链接
二、开始爬行
爬虫三部曲:
1、请求网页
首先,导入此爬虫程序所需的第三方库
import re#用来解析网页
import requests#用来请求网页
import csv#用来保存数据
import time#用来设置每次爬取间隔的时间
找到我们抓取的目标数据的位置,点击搜索得到的包,得到目标网站和请求头信息
请求网页
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': 'pgv_pvi=2389011456; RK=x4Sdy3WsT4; ptcz=4a2fe0ffda6742a230c94f168291afcce2bd001e5d6615132b55da90559cd463; pgv_pvid=6989331736; _ga=GA1.2.735850052.1585832762; ptui_loginuin=1207020736; ua_id=iJuK7hnHjcUE0e2dAAAAAHzCRcatCWOiHc-hdkhSDL4=; __guid=166713058.1972731636944397800.1590316882436.5461; openid2ticket_oY8wqwesgvgkdQ69wUeM5UxhOV5c=ION52/k2w4M3o44iht5BRt5yCyxP/3IaRXJ84RIpRZA=; mm_lang=zh_CN; pac_uid=0_5ecd1592971c3; uin=o1240069166; [email protected]; pgv_info=ssid=s4875389884; pgv_si=s8410697728; uuid=62839906b2a77b5f098cd91979af8b33; rand_info=CAESIC53TQFCwjIe4ZsrTRKvSs+ocfs4UTsj9swrrNwosjCd; slave_bizuin=3240807523; data_bizuin=3240807523; bizuin=3240807523; data_ticket=AiTk/OFWXCKxhaenCvEuP06mwWTI6YqCyt+74hoaXaNtKBbcnq//ZTXHzqByMhK6; slave_sid=YndxeFhCSkU5OUJtdFYycW9zN29FcG51NU5GNElBM3I2RF9wVjJBRGx2bWxrTXdiMDZFYzllUWNaMlN4N0RsOTlVMDRxZFZEMjJXdlRZcXBVOGptQ2ZDSVZiOEJlQW5BZDVCWlkzSnJ6WWNPWVRiN1J0cldCd0pvbTc3RGRiMm9pZ3ZISTl6WWhDUmNCZ2s3; slave_user=gh_5d822fe7fd08; xid=9794daa60db66fcf7a65c4054e3d68ce; mmad_session=43d4e5247a6b025b67ba3abd48d27a309ec4713911b6ef6f23cddb4b9953e771354ad1572fbc3fa895051725e95abb887cf2d03e9864084974db75c8588189699ea5b20b8fe35073831446ef98d24de600f107fe69d79646a3dd2907ab712e1f11de1c56c245721266e7088080fefde3; ts_last=mp.weixin.qq.com/cgi-bin/frame; ts_uid=1963034896; monitor_count=15'
}#请求头信息,这里cookie信息必须添加,否则得不到网页信息
url='https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=0&count=5&fakeid=MjM5MjAxMDM4MA==&type=9&query=&token=59293242&lang=zh_CN&f=json&ajax=1'
response=requests.get(url,headers=headers)#得到响应内容
response.encoding='utf-8'#设置响应内容为utf-8格式
html=response.text#得到网页的文本形式
print(html)
此处的请求标头信息必须与cookie信息一起添加,否则无法获取网页信息
该网页的请求结果如下图所示。红色框表示我们需要的文章标题和文章链接
2、parse网页
从网页响应结果可以看出,每个文章文章的标题和链接分别位于“title”标记和“cover”标记后面,因此我们可以使用正则表达式直接解析它们
title=re.findall('"title":"(.*?)"',html)#得到文章标题
cover=re.findall('"cover":"(.*?)"',html)#得到文章链接
all=zip(title,cover)#利用zip方法,将两个列表中的数据一一对应
print(list(all))#list是对zip方法得到的数据进行解压
分析结果如下
3、保存数据
for data in all:#for循环遍历列表
time.sleep(3)#每爬取一篇文章间隔3秒,以防触发反爬
with open('C:\\Users\\Administrator\\Desktop\\爬取公众号文章.csv','a',encoding='utf-8-sig') as file:
#将数据保存到桌面
write=csv.writer(file)
write.writerow(data)
到目前为止,爬虫程序已经完成。让我们看一下最终结果
完整代码
import re#用来解析网页
import requests#用来请求网页
import csv#用来保存数据
import time#用来设置每次爬取间隔的时间
# 请求网页
index=0
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': 'pgv_pvi=2389011456; RK=x4Sdy3WsT4; ptcz=4a2fe0ffda6742a230c94f168291afcce2bd001e5d6615132b55da90559cd463; pgv_pvid=6989331736; _ga=GA1.2.735850052.1585832762; ptui_loginuin=1207020736; ua_id=iJuK7hnHjcUE0e2dAAAAAHzCRcatCWOiHc-hdkhSDL4=; __guid=166713058.1972731636944397800.1590316882436.5461; openid2ticket_oY8wqwesgvgkdQ69wUeM5UxhOV5c=ION52/k2w4M3o44iht5BRt5yCyxP/3IaRXJ84RIpRZA=; mm_lang=zh_CN; pac_uid=0_5ecd1592971c3; uin=o1240069166; [email protected]; pgv_info=ssid=s4875389884; pgv_si=s8410697728; uuid=62839906b2a77b5f098cd91979af8b33; rand_info=CAESIC53TQFCwjIe4ZsrTRKvSs+ocfs4UTsj9swrrNwosjCd; slave_bizuin=3240807523; data_bizuin=3240807523; bizuin=3240807523; data_ticket=AiTk/OFWXCKxhaenCvEuP06mwWTI6YqCyt+74hoaXaNtKBbcnq//ZTXHzqByMhK6; slave_sid=YndxeFhCSkU5OUJtdFYycW9zN29FcG51NU5GNElBM3I2RF9wVjJBRGx2bWxrTXdiMDZFYzllUWNaMlN4N0RsOTlVMDRxZFZEMjJXdlRZcXBVOGptQ2ZDSVZiOEJlQW5BZDVCWlkzSnJ6WWNPWVRiN1J0cldCd0pvbTc3RGRiMm9pZ3ZISTl6WWhDUmNCZ2s3; slave_user=gh_5d822fe7fd08; xid=9794daa60db66fcf7a65c4054e3d68ce; mmad_session=43d4e5247a6b025b67ba3abd48d27a309ec4713911b6ef6f23cddb4b9953e771354ad1572fbc3fa895051725e95abb887cf2d03e9864084974db75c8588189699ea5b20b8fe35073831446ef98d24de600f107fe69d79646a3dd2907ab712e1f11de1c56c245721266e7088080fefde3; ts_last=mp.weixin.qq.com/cgi-bin/frame; ts_uid=1963034896; monitor_count=15'
}#请求头信息,这里cookie信息必须添加,否则得不到网页信息
for i in range(2):#设置for循环实现翻页,爬取多页内容,这里range括号内的参数可以更改
url='https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin='+str(index)+'&count=5&fakeid=MjM5MjAxMDM4MA==&type=9&query=&token=59293242&lang=zh_CN&f=json&ajax=1'
response=requests.get(url,headers=headers)#得到响应内容
response.encoding='utf-8'#设置响应内容为utf-8格式
html=response.text#得到网页的文本形式
# 解析网页
title=re.findall('"title":"(.*?)"',html)#得到文章标题
cover=re.findall('"cover":"(.*?)"',html)#得到文章链接
all=zip(title,cover)#利用zip方法,将两个列表中的数据一一对应
# print(list(all))#list是对zip方法得到的数据进行解压
# 保存数据
for data in all:#for循环遍历列表
time.sleep(3)#每爬取一篇文章间隔3秒,以防出发反爬
with open('C:\\Users\\Administrator\\Desktop\\爬取公众号文章.csv','a',encoding='utf-8-sig') as file:
#将数据保存到桌面
write=csv.writer(file)
write.writerow(data)
pass
pass
index += 5 查看全部
querylist采集微信公众号文章(如何通过微信公众号后台的“超链接”功能进行爬取
)
PS:如果你需要Python学习材料,你可以点击下面的链接自己获取
爬行的方法有很多
。今天,我们分享一种更简单的方式,通过微信官方账号的超链接功能爬行。可能一些好友合作伙伴还没有接触到微信公众号的背景。这是一张给你看的照片

在这里,一些好友可能会说,“我不能登录到官方帐户。什么?”p>
没关系。每次我们想要得到我们想要的结果时,Buddy都是我们的目标,但这不是我们研究的重点。我们关注爬行动物的过程,我们是如何获得目标数据的,所以我们不能登录到官方的后台帐号。在阅读此文章之后,我们可能无法获得最终的爬网结果。但是在阅读了这篇文章文章之后,你也会有所收获
一、初步准备
选择正式帐号
为了爬行
点击超链接-进入编辑超链接界面-输入搜索官方账号
我们需要爬
今天我们以官方账户“数据分析”为例进行介绍
谢谢你

点击官方账户查看每个文章对应的标题信息

我们的目标是获取文章标题和相应的链接
二、开始爬行
爬虫三部曲:
1、请求网页
首先,导入此爬虫程序所需的第三方库
import re#用来解析网页
import requests#用来请求网页
import csv#用来保存数据
import time#用来设置每次爬取间隔的时间
找到我们抓取的目标数据的位置,点击搜索得到的包,得到目标网站和请求头信息

请求网页
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': 'pgv_pvi=2389011456; RK=x4Sdy3WsT4; ptcz=4a2fe0ffda6742a230c94f168291afcce2bd001e5d6615132b55da90559cd463; pgv_pvid=6989331736; _ga=GA1.2.735850052.1585832762; ptui_loginuin=1207020736; ua_id=iJuK7hnHjcUE0e2dAAAAAHzCRcatCWOiHc-hdkhSDL4=; __guid=166713058.1972731636944397800.1590316882436.5461; openid2ticket_oY8wqwesgvgkdQ69wUeM5UxhOV5c=ION52/k2w4M3o44iht5BRt5yCyxP/3IaRXJ84RIpRZA=; mm_lang=zh_CN; pac_uid=0_5ecd1592971c3; uin=o1240069166; [email protected]; pgv_info=ssid=s4875389884; pgv_si=s8410697728; uuid=62839906b2a77b5f098cd91979af8b33; rand_info=CAESIC53TQFCwjIe4ZsrTRKvSs+ocfs4UTsj9swrrNwosjCd; slave_bizuin=3240807523; data_bizuin=3240807523; bizuin=3240807523; data_ticket=AiTk/OFWXCKxhaenCvEuP06mwWTI6YqCyt+74hoaXaNtKBbcnq//ZTXHzqByMhK6; slave_sid=YndxeFhCSkU5OUJtdFYycW9zN29FcG51NU5GNElBM3I2RF9wVjJBRGx2bWxrTXdiMDZFYzllUWNaMlN4N0RsOTlVMDRxZFZEMjJXdlRZcXBVOGptQ2ZDSVZiOEJlQW5BZDVCWlkzSnJ6WWNPWVRiN1J0cldCd0pvbTc3RGRiMm9pZ3ZISTl6WWhDUmNCZ2s3; slave_user=gh_5d822fe7fd08; xid=9794daa60db66fcf7a65c4054e3d68ce; mmad_session=43d4e5247a6b025b67ba3abd48d27a309ec4713911b6ef6f23cddb4b9953e771354ad1572fbc3fa895051725e95abb887cf2d03e9864084974db75c8588189699ea5b20b8fe35073831446ef98d24de600f107fe69d79646a3dd2907ab712e1f11de1c56c245721266e7088080fefde3; ts_last=mp.weixin.qq.com/cgi-bin/frame; ts_uid=1963034896; monitor_count=15'
}#请求头信息,这里cookie信息必须添加,否则得不到网页信息
url='https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=0&count=5&fakeid=MjM5MjAxMDM4MA==&type=9&query=&token=59293242&lang=zh_CN&f=json&ajax=1'
response=requests.get(url,headers=headers)#得到响应内容
response.encoding='utf-8'#设置响应内容为utf-8格式
html=response.text#得到网页的文本形式
print(html)
此处的请求标头信息必须与cookie信息一起添加,否则无法获取网页信息
该网页的请求结果如下图所示。红色框表示我们需要的文章标题和文章链接
2、parse网页
从网页响应结果可以看出,每个文章文章的标题和链接分别位于“title”标记和“cover”标记后面,因此我们可以使用正则表达式直接解析它们
title=re.findall('"title":"(.*?)"',html)#得到文章标题
cover=re.findall('"cover":"(.*?)"',html)#得到文章链接
all=zip(title,cover)#利用zip方法,将两个列表中的数据一一对应
print(list(all))#list是对zip方法得到的数据进行解压
分析结果如下

3、保存数据
for data in all:#for循环遍历列表
time.sleep(3)#每爬取一篇文章间隔3秒,以防触发反爬
with open('C:\\Users\\Administrator\\Desktop\\爬取公众号文章.csv','a',encoding='utf-8-sig') as file:
#将数据保存到桌面
write=csv.writer(file)
write.writerow(data)
到目前为止,爬虫程序已经完成。让我们看一下最终结果

完整代码
import re#用来解析网页
import requests#用来请求网页
import csv#用来保存数据
import time#用来设置每次爬取间隔的时间
# 请求网页
index=0
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': 'pgv_pvi=2389011456; RK=x4Sdy3WsT4; ptcz=4a2fe0ffda6742a230c94f168291afcce2bd001e5d6615132b55da90559cd463; pgv_pvid=6989331736; _ga=GA1.2.735850052.1585832762; ptui_loginuin=1207020736; ua_id=iJuK7hnHjcUE0e2dAAAAAHzCRcatCWOiHc-hdkhSDL4=; __guid=166713058.1972731636944397800.1590316882436.5461; openid2ticket_oY8wqwesgvgkdQ69wUeM5UxhOV5c=ION52/k2w4M3o44iht5BRt5yCyxP/3IaRXJ84RIpRZA=; mm_lang=zh_CN; pac_uid=0_5ecd1592971c3; uin=o1240069166; [email protected]; pgv_info=ssid=s4875389884; pgv_si=s8410697728; uuid=62839906b2a77b5f098cd91979af8b33; rand_info=CAESIC53TQFCwjIe4ZsrTRKvSs+ocfs4UTsj9swrrNwosjCd; slave_bizuin=3240807523; data_bizuin=3240807523; bizuin=3240807523; data_ticket=AiTk/OFWXCKxhaenCvEuP06mwWTI6YqCyt+74hoaXaNtKBbcnq//ZTXHzqByMhK6; slave_sid=YndxeFhCSkU5OUJtdFYycW9zN29FcG51NU5GNElBM3I2RF9wVjJBRGx2bWxrTXdiMDZFYzllUWNaMlN4N0RsOTlVMDRxZFZEMjJXdlRZcXBVOGptQ2ZDSVZiOEJlQW5BZDVCWlkzSnJ6WWNPWVRiN1J0cldCd0pvbTc3RGRiMm9pZ3ZISTl6WWhDUmNCZ2s3; slave_user=gh_5d822fe7fd08; xid=9794daa60db66fcf7a65c4054e3d68ce; mmad_session=43d4e5247a6b025b67ba3abd48d27a309ec4713911b6ef6f23cddb4b9953e771354ad1572fbc3fa895051725e95abb887cf2d03e9864084974db75c8588189699ea5b20b8fe35073831446ef98d24de600f107fe69d79646a3dd2907ab712e1f11de1c56c245721266e7088080fefde3; ts_last=mp.weixin.qq.com/cgi-bin/frame; ts_uid=1963034896; monitor_count=15'
}#请求头信息,这里cookie信息必须添加,否则得不到网页信息
for i in range(2):#设置for循环实现翻页,爬取多页内容,这里range括号内的参数可以更改
url='https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin='+str(index)+'&count=5&fakeid=MjM5MjAxMDM4MA==&type=9&query=&token=59293242&lang=zh_CN&f=json&ajax=1'
response=requests.get(url,headers=headers)#得到响应内容
response.encoding='utf-8'#设置响应内容为utf-8格式
html=response.text#得到网页的文本形式
# 解析网页
title=re.findall('"title":"(.*?)"',html)#得到文章标题
cover=re.findall('"cover":"(.*?)"',html)#得到文章链接
all=zip(title,cover)#利用zip方法,将两个列表中的数据一一对应
# print(list(all))#list是对zip方法得到的数据进行解压
# 保存数据
for data in all:#for循环遍历列表
time.sleep(3)#每爬取一篇文章间隔3秒,以防出发反爬
with open('C:\\Users\\Administrator\\Desktop\\爬取公众号文章.csv','a',encoding='utf-8-sig') as file:
#将数据保存到桌面
write=csv.writer(file)
write.writerow(data)
pass
pass
index += 5
querylist采集微信公众号文章(垃圾程序员如何采集微信公众号的内容?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-29 00:19
今天,作为一个垃圾程序员的小编,和大家聊聊微信公众号采集的内容?
首先你要明确你的目标:你的采集公众号文章的数据会放在哪里?是在APP上还是在自己的官网上。,
意思是:你用这个微信公众号的内容做什么?
几个小白之前从我这里买过微信公众号采集系统。主要用于采集公众号原创内容,提升网站收录和关键词的内容排名。
问题 1:我可以查看和修改 采集 中的数据吗?
我的回答:采集过来的数据可以在系统上设置:under review,这种情况不会直接采集到你的网站,你可以选择修改文章标题和图片内容,然后发布。
这可以防止搜索引擎发现您在作弊 采集 内容,因为您在后台手动发布它。当然,我们的采集操作系统是原生态开发的,不是市面上的采集软件,所以我们不会在这里hack别人,因为他们开发的系统和软件都比较老,对于搜索引擎。把握一个标准,尤其是百度搜索。
回到正题:如何把采集微信公众号文章放到官网或APP上?
1.公众号抓包是通过微信公众号用户在微信上的登录信息在微信系统中抓包的
2.在微信公众号系统中设置微信公众号登录信息到我们系统
3.使用设置的登录信息进行微信搜索和微信抓包文章
4.将抓到的公众号设置为系统中的普通用户
5. 在系统中编辑、审核并发布捕获的文章,并与对应的用户关联
6.发布的文章和普通用户发布的文章没有区别,可以直接使用之前的管理方式进行管理。
准备公众号获取Token和Cookies的价值
1.用自己的公众号登录
2. 点击“素材管理->新建图文素材”
3.点击图形编辑器工具栏上的“超链接”
4.在对话框的“链接输入法”中选择“查找文章”
5.采集 使用的接口来自这里
加我微信购买咨询,我的微信是:1124805587 查看全部
querylist采集微信公众号文章(垃圾程序员如何采集微信公众号的内容?(组图))
今天,作为一个垃圾程序员的小编,和大家聊聊微信公众号采集的内容?
首先你要明确你的目标:你的采集公众号文章的数据会放在哪里?是在APP上还是在自己的官网上。,
意思是:你用这个微信公众号的内容做什么?
几个小白之前从我这里买过微信公众号采集系统。主要用于采集公众号原创内容,提升网站收录和关键词的内容排名。
问题 1:我可以查看和修改 采集 中的数据吗?
我的回答:采集过来的数据可以在系统上设置:under review,这种情况不会直接采集到你的网站,你可以选择修改文章标题和图片内容,然后发布。
这可以防止搜索引擎发现您在作弊 采集 内容,因为您在后台手动发布它。当然,我们的采集操作系统是原生态开发的,不是市面上的采集软件,所以我们不会在这里hack别人,因为他们开发的系统和软件都比较老,对于搜索引擎。把握一个标准,尤其是百度搜索。
回到正题:如何把采集微信公众号文章放到官网或APP上?
1.公众号抓包是通过微信公众号用户在微信上的登录信息在微信系统中抓包的
2.在微信公众号系统中设置微信公众号登录信息到我们系统
3.使用设置的登录信息进行微信搜索和微信抓包文章
4.将抓到的公众号设置为系统中的普通用户
5. 在系统中编辑、审核并发布捕获的文章,并与对应的用户关联
6.发布的文章和普通用户发布的文章没有区别,可以直接使用之前的管理方式进行管理。
准备公众号获取Token和Cookies的价值
1.用自己的公众号登录
2. 点击“素材管理->新建图文素材”
3.点击图形编辑器工具栏上的“超链接”
4.在对话框的“链接输入法”中选择“查找文章”
5.采集 使用的接口来自这里
加我微信购买咨询,我的微信是:1124805587
querylist采集微信公众号文章(如何采集微信文章?微信啄木鸟助手帮你采集二维码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 328 次浏览 • 2021-10-26 15:26
除了公众号,还提供公众号。此外,可以通过微信公众号采集数据。此外,它还可以采集标题、文章号、原文链接、阅读号、积分、发布时间等数据。具体步骤如下:
1、采集需要采集的公共电话号码列表。
2.将这些公众号添加到清博指数的自定义列表中,
3、每天都会从公众号获取清晰的指数。注:如未查询相关公众号,需进行入库操作。可供微信啄木鸟助手使用,可用于word、PDF等多种格式,采集一种格式。会一直保存在微信公众号里。
微信文章怎么采集?
谢谢
!这个软件就是MicroPort City,一个刚刚开发出来的非常强大的软件。主要通过采集二维码和扫描群码访问。软件结合大数据、爬虫技术和图像分析技术,可以智能识别二维码、检测二维码真伪、智能过滤重复二维码、记忆查询等功能,可以帮助您大大提高群组搜索效率,成功率组进入率和组质量。
通过五个渠道,我们可以采集所有公开的、有效的、真实的、活跃的微信群。这10个二维码中,大约有6-7个是有效的微信群,并且是实时更新的。一天可以采集近万个微信群,上万个微信群,二维码,或特定群。一旦你设置了关键词,你就可以开始采集了。实时采集。软件很强大,行业很广。
如何采集微信文章?
作为新媒体运营的小伙伴,每天需要同步很多文章。发送到微信的文章需要复制到头条、短篇等平台。但是,它不仅容易出现格式错误,而且复制的图像也难以显示。
这是一款可以一键发布文章多平台的浏览器插件,支持同步到今日头条、知乎、简书、掘金、CSDN等9个平台。
使用时只需要安装插件号即可。编辑完文章后,勾选同步平台,系统会自动将文章和图片传送到其他平台,并保存为草稿供您进一步编辑发布。这是非常省时和高效的。
插件也安装好了,添加相关账号即可使用。工作原理与上述插件类似。填写要同步的文章链接,然后选择同步平台。
小曲是第一个常用的。如果你也找到了一个好用的一键同步平台,请分享给我。
①转发本文并关注@fun play
2.私信“一键发布”获取以上插件 查看全部
querylist采集微信公众号文章(如何采集微信文章?微信啄木鸟助手帮你采集二维码)
除了公众号,还提供公众号。此外,可以通过微信公众号采集数据。此外,它还可以采集标题、文章号、原文链接、阅读号、积分、发布时间等数据。具体步骤如下:
1、采集需要采集的公共电话号码列表。
2.将这些公众号添加到清博指数的自定义列表中,
3、每天都会从公众号获取清晰的指数。注:如未查询相关公众号,需进行入库操作。可供微信啄木鸟助手使用,可用于word、PDF等多种格式,采集一种格式。会一直保存在微信公众号里。
微信文章怎么采集?
谢谢
!这个软件就是MicroPort City,一个刚刚开发出来的非常强大的软件。主要通过采集二维码和扫描群码访问。软件结合大数据、爬虫技术和图像分析技术,可以智能识别二维码、检测二维码真伪、智能过滤重复二维码、记忆查询等功能,可以帮助您大大提高群组搜索效率,成功率组进入率和组质量。
通过五个渠道,我们可以采集所有公开的、有效的、真实的、活跃的微信群。这10个二维码中,大约有6-7个是有效的微信群,并且是实时更新的。一天可以采集近万个微信群,上万个微信群,二维码,或特定群。一旦你设置了关键词,你就可以开始采集了。实时采集。软件很强大,行业很广。
如何采集微信文章?
作为新媒体运营的小伙伴,每天需要同步很多文章。发送到微信的文章需要复制到头条、短篇等平台。但是,它不仅容易出现格式错误,而且复制的图像也难以显示。
这是一款可以一键发布文章多平台的浏览器插件,支持同步到今日头条、知乎、简书、掘金、CSDN等9个平台。
使用时只需要安装插件号即可。编辑完文章后,勾选同步平台,系统会自动将文章和图片传送到其他平台,并保存为草稿供您进一步编辑发布。这是非常省时和高效的。
插件也安装好了,添加相关账号即可使用。工作原理与上述插件类似。填写要同步的文章链接,然后选择同步平台。
小曲是第一个常用的。如果你也找到了一个好用的一键同步平台,请分享给我。
①转发本文并关注@fun play
2.私信“一键发布”获取以上插件
querylist采集微信公众号文章( 《千梦ip魔鬼实战训练营》微信公众号文章采集教学)
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-10-24 10:17
《千梦ip魔鬼实战训练营》微信公众号文章采集教学)
一、前言
在上周千梦团队直播的《千梦IP恶魔实战训练营》中,我们推荐了一些比较优秀的同行案例。目前头脑中的许多优秀球员素质都非常高,生产力也很高。内容输出,今天给大家带来微信公众号文章采集教学。
微信公众号采集目前网上有很多方法和软件,有免费的也有付费的,但质量参差不齐,功能也大不相同。下载公众号文章只是最基本的功能,如果能下载peer的所有数据,真的可以帮助我们分析标杆对象。
二、课程实践
1.下载并解压软件
拿到软件后,首先将所有文件解压到桌面文件夹。此版本免费安装,直接启用软件即可。
2.在PC上打开微信
在电脑上下载微信,登录账号同步数据。
3.进入采集对象公众号
进入对应公众号,同时点击历史菜单界面,等待软件**。
4.开始采集
软件采集完成后,建议选择“PDF”格式导出,每个公众号出来后都会变成一个单独的文件夹。
---------------------------------------------
【教程资源介绍】
资源类型:视频+工具
资源大小:136MB
积分兑换:会员150积分兑换(1元=10积分),VIP会员免费下载
【下载说明】
免费注册会员后,使用积分,点击下方“积分兑换”查看百度网盘下载链接。
--------------------------------------------- 查看全部
querylist采集微信公众号文章(
《千梦ip魔鬼实战训练营》微信公众号文章采集教学)
一、前言
在上周千梦团队直播的《千梦IP恶魔实战训练营》中,我们推荐了一些比较优秀的同行案例。目前头脑中的许多优秀球员素质都非常高,生产力也很高。内容输出,今天给大家带来微信公众号文章采集教学。
微信公众号采集目前网上有很多方法和软件,有免费的也有付费的,但质量参差不齐,功能也大不相同。下载公众号文章只是最基本的功能,如果能下载peer的所有数据,真的可以帮助我们分析标杆对象。
二、课程实践
1.下载并解压软件
拿到软件后,首先将所有文件解压到桌面文件夹。此版本免费安装,直接启用软件即可。
2.在PC上打开微信
在电脑上下载微信,登录账号同步数据。
3.进入采集对象公众号
进入对应公众号,同时点击历史菜单界面,等待软件**。
4.开始采集
软件采集完成后,建议选择“PDF”格式导出,每个公众号出来后都会变成一个单独的文件夹。
---------------------------------------------
【教程资源介绍】
资源类型:视频+工具
资源大小:136MB
积分兑换:会员150积分兑换(1元=10积分),VIP会员免费下载
【下载说明】
免费注册会员后,使用积分,点击下方“积分兑换”查看百度网盘下载链接。
---------------------------------------------
querylist采集微信公众号文章( 《千梦ip魔鬼实战训练营》微信公众号文章采集教学)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-10-23 11:09
《千梦ip魔鬼实战训练营》微信公众号文章采集教学)
一、前言
在上周千梦团队直播的《千梦IP恶魔实战训练营》中,我们推荐了一些比较优秀的同行案例。目前头脑中的许多优秀球员素质都非常高,生产力也很高。内容输出,今天给大家带来微信公众号文章采集教学。
微信公众号采集目前网上有很多方法和软件,有免费的也有付费的,但质量参差不齐,功能也大不相同。下载公众号文章只是最基本的功能,如果能下载peer的所有数据,真的可以帮助我们分析标杆对象。
二、课程实践
1.下载并解压软件
拿到软件后,首先将所有文件解压到桌面文件夹。此版本免费安装,直接启用软件即可。
2.在PC上打开微信
在电脑上下载微信,登录账号同步数据。
3.进入采集对象公众号
进入对应公众号,同时点击历史菜单界面,等待软件**。
4.开始采集
软件采集完成后,建议选择“PDF”格式导出,每个公众号出来后都会变成一个单独的文件夹。
---------------------------------------------
【教程资源介绍】
资源类型:视频+工具
资源大小:136MB
积分兑换:会员150积分兑换(1元=10积分),VIP会员免费下载
【下载说明】
免费注册会员后,使用积分,点击下方“积分兑换”查看百度网盘下载链接。
--------------------------------------------- 查看全部
querylist采集微信公众号文章(
《千梦ip魔鬼实战训练营》微信公众号文章采集教学)
一、前言
在上周千梦团队直播的《千梦IP恶魔实战训练营》中,我们推荐了一些比较优秀的同行案例。目前头脑中的许多优秀球员素质都非常高,生产力也很高。内容输出,今天给大家带来微信公众号文章采集教学。
微信公众号采集目前网上有很多方法和软件,有免费的也有付费的,但质量参差不齐,功能也大不相同。下载公众号文章只是最基本的功能,如果能下载peer的所有数据,真的可以帮助我们分析标杆对象。
二、课程实践
1.下载并解压软件
拿到软件后,首先将所有文件解压到桌面文件夹。此版本免费安装,直接启用软件即可。
2.在PC上打开微信
在电脑上下载微信,登录账号同步数据。
3.进入采集对象公众号
进入对应公众号,同时点击历史菜单界面,等待软件**。
4.开始采集
软件采集完成后,建议选择“PDF”格式导出,每个公众号出来后都会变成一个单独的文件夹。
---------------------------------------------
【教程资源介绍】
资源类型:视频+工具
资源大小:136MB
积分兑换:会员150积分兑换(1元=10积分),VIP会员免费下载
【下载说明】
免费注册会员后,使用积分,点击下方“积分兑换”查看百度网盘下载链接。
---------------------------------------------
querylist采集微信公众号文章( UI自动化工具轻松实现微信消息的自动收发和朋友圈爬取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 292 次浏览 • 2021-10-21 06:58
UI自动化工具轻松实现微信消息的自动收发和朋友圈爬取)
大家好,我是小明。昨天,我在《UI自动化工具轻松实现微信消息自动收发和好友动态爬取》一文中演示了三个UIAutomation的使用实例。链接:
由于昨天对UIAutomation的API的理解不够全面,个人代码优化还有很大的空间。今天我们的目标是实现微信PC版联系人信息列表的抓取,这将分别使用PyWinAuto和uiautomation来实现。通过对比,大家就会有更深入的了解。
PyWinAuto 实现
PyWinAuto 官方文档地址:
将 PyWinAuto 连接到桌面程序有两种主要方式:
它们是进程的 pid 和窗口句柄。下面我将演示如何获取微信的进程id和窗口句柄。
根据进程名获取进程ID:
import psutil
def get_pid(proc_name):
for proc in psutil.process_iter(attrs=['pid', 'name']):
if proc.name() == proc_name:
return proc.pid
%time get_pid("WeChat.exe")
Wall time: 224 ms
7268
根据窗口标题和类名查找窗口句柄:
import win32gui
%time hwnd = win32gui.FindWindow("WeChatMainWndForPC", "微信")
hwnd
Wall time: 0 ns
264610
耗时几乎为零,比之前的方法快了100多倍。
于是我用窗口句柄连接微信窗口:
import win32gui
from pywinauto.application import Application
hwnd = win32gui.FindWindow("WeChatMainWndForPC", "微信")
app = Application(backend='uia').connect(handle=hwnd)
app
自动打开通讯录:
import pywinauto
win = app['微信']
txl_btn = win.child_window(title="通讯录", control_type="Button")
txl_btn.draw_outline()
cords = txl_btn.rectangle()
pywinauto.mouse.click(button='left', coords=(
(cords.right+cords.left)//2, (cords.top+cords.bottom)//2))
随机点击好友信息详情后,通过inspect.exe查看节点信息。
然后编写如下代码,根据分析结果运行:
可以看到各种信息提取的很流畅,但是最多需要3.54秒,不一定比手动复制粘贴快。这也是pywinauto的一个缺点,太慢了。
下面我们进行批量爬取。原理大致是每次读取信息面板时,按向下箭头键,发现当前读取的数据与上一次一致。认为爬行已经结束。
由于pywinauto的爬取速度太慢,我手动将好友列表拖到最后,然后运行如下代码:
import pandas as pd
win = app['微信']
contacts = win.child_window(title="联系人", control_type="List")
# 点击第二个可见元素
contacts.children()[1].click_input()
result = []
last = None
num = 0
while 1:
tag = win.Edit2
tmp = tag.parent().parent()
nickname = tag.get_value()
# 跳过两个官方号
if nickname in ["微信团队", "文件传输助手"]:
contacts.type_keys("{DOWN}")
continue
detail = tmp.children()[-1]
whats_up = ""
if hasattr(detail, 'get_value'):
whats_up = detail.get_value()
elif hasattr(detail, 'window_text') and detail.window_text() != "":
# 这种情况说明是企业微信,跳过
contacts.type_keys("{DOWN}")
continue
items = tmp.parent().parent().children()[2].children()
row = {"昵称": nickname, "个性签名": whats_up}
for item in items:
lines = item.children()
k = lines[0].window_text()
v = lines[1].window_text()
row[k.replace(" ", "")] = v
if row == last:
# 与上一条数据一致则说明已经爬取完毕
break
result.append(row)
num += 1
print("\r", num, row,
end=" ")
last = row
contacts.type_keys("{DOWN}")
df = pd.DataFrame(result)
df
最后结果:
可以看出,最后一页11个微信账号的数据抓取耗时45秒。
ui自动化实现
接下来,我们将使用 uiautomation 来实现这种爬取。
获取微信窗口,点击通讯录按钮:
import uiautomation as auto
wechatWindow = auto.WindowControl(searchDepth=1, Name="微信", ClassName='WeChatMainWndForPC')
wechatWindow.SetActive()
txl_btn = wechatWindow.ButtonControl(Name='通讯录')
txl_btn.Click()
然后点击云朵君的好友信息,测试好友信息抽取:
(这个数字,你可以随意添加)
wechatWindow.EditControl(searchDepth=10, foundIndex=2) 表示在10层节点内搜索第二个EditControl类型节点(第一个是搜索框,第二个是朋友的昵称)。
GetParentControl() 和 GetNextSiblingControl() 是昨天没有使用的 API。它们用于获取父节点和下一个兄弟节点。使用这两个 API 来重写昨天的 文章 的代码,将使程序代码变得简单和高效。改进。
然后使用与 PyWinAuto 相同的方式进行批量提取:
还要先测试最后一页的数据:
爬取只用了 11 秒,比 PyWinAuto 快 4 倍。
所以我们可以批量提取所有微信好友的数据。最后,我这边的700多个朋友用了10分钟。虽然速度较慢,但与 PyWinAuto 相比完全可以接受。
代码对比
对于两者,我都试图遵循完全相同的逻辑。
win.Edit2 也得到第二个 EditControl 类型节点,
type_keys 是 PyWinAuto 用来模拟击键的 API,{DOWN} 代表向下的方向键。
PyWinAuto获取父子节点的api都是小写的,没有get,uiautomation获取父子节点的api大写,前缀为Get。
对于 PyWinAuto 中的这行代码:
items = tmp.parent().parent().children()[2].children()
使用 uiautomation:
items = tmp.GetParentControl().GetNextSiblingControl().GetNextSiblingControl().GetChildren()
有一个很大的不同。
这是因为我没有找到PyWinAuto获取兄弟节点的API,所以采用了先获取父节点再获取子节点的方法。
另外,判断是否是企业微信的逻辑不同。PyWinAuto也需要在个性签名为空时处理异常,否则程序会报错退出。具体点需要大家去测试和体验。
其他地方的逻辑几乎相同。
总结
本文还演示了 PyWinAuto 和 uiautomation 读取微信好友列表信息。通过对比,我们可以更深入地了解两者的API用法。作为作者,我在实践中有着深刻的理解。只是文章中的代码并没有体现这些细节,具体的事情需要读者在分析对比的过程中得到答案。仅仅看本文的代码或许可以解决当前的需求,但是很难将本文涉及的技术应用到其他需求上。
童鞋们,让我们通过动手实践来学习吧⁉️学完之后,你会看到任何实现Automation Provider的桌面程序,并且可以爬~ 查看全部
querylist采集微信公众号文章(
UI自动化工具轻松实现微信消息的自动收发和朋友圈爬取)
大家好,我是小明。昨天,我在《UI自动化工具轻松实现微信消息自动收发和好友动态爬取》一文中演示了三个UIAutomation的使用实例。链接:
由于昨天对UIAutomation的API的理解不够全面,个人代码优化还有很大的空间。今天我们的目标是实现微信PC版联系人信息列表的抓取,这将分别使用PyWinAuto和uiautomation来实现。通过对比,大家就会有更深入的了解。
PyWinAuto 实现
PyWinAuto 官方文档地址:
将 PyWinAuto 连接到桌面程序有两种主要方式:
它们是进程的 pid 和窗口句柄。下面我将演示如何获取微信的进程id和窗口句柄。
根据进程名获取进程ID:
import psutil
def get_pid(proc_name):
for proc in psutil.process_iter(attrs=['pid', 'name']):
if proc.name() == proc_name:
return proc.pid
%time get_pid("WeChat.exe")
Wall time: 224 ms
7268
根据窗口标题和类名查找窗口句柄:
import win32gui
%time hwnd = win32gui.FindWindow("WeChatMainWndForPC", "微信")
hwnd
Wall time: 0 ns
264610
耗时几乎为零,比之前的方法快了100多倍。
于是我用窗口句柄连接微信窗口:
import win32gui
from pywinauto.application import Application
hwnd = win32gui.FindWindow("WeChatMainWndForPC", "微信")
app = Application(backend='uia').connect(handle=hwnd)
app
自动打开通讯录:
import pywinauto
win = app['微信']
txl_btn = win.child_window(title="通讯录", control_type="Button")
txl_btn.draw_outline()
cords = txl_btn.rectangle()
pywinauto.mouse.click(button='left', coords=(
(cords.right+cords.left)//2, (cords.top+cords.bottom)//2))
随机点击好友信息详情后,通过inspect.exe查看节点信息。
然后编写如下代码,根据分析结果运行:
可以看到各种信息提取的很流畅,但是最多需要3.54秒,不一定比手动复制粘贴快。这也是pywinauto的一个缺点,太慢了。
下面我们进行批量爬取。原理大致是每次读取信息面板时,按向下箭头键,发现当前读取的数据与上一次一致。认为爬行已经结束。
由于pywinauto的爬取速度太慢,我手动将好友列表拖到最后,然后运行如下代码:
import pandas as pd
win = app['微信']
contacts = win.child_window(title="联系人", control_type="List")
# 点击第二个可见元素
contacts.children()[1].click_input()
result = []
last = None
num = 0
while 1:
tag = win.Edit2
tmp = tag.parent().parent()
nickname = tag.get_value()
# 跳过两个官方号
if nickname in ["微信团队", "文件传输助手"]:
contacts.type_keys("{DOWN}")
continue
detail = tmp.children()[-1]
whats_up = ""
if hasattr(detail, 'get_value'):
whats_up = detail.get_value()
elif hasattr(detail, 'window_text') and detail.window_text() != "":
# 这种情况说明是企业微信,跳过
contacts.type_keys("{DOWN}")
continue
items = tmp.parent().parent().children()[2].children()
row = {"昵称": nickname, "个性签名": whats_up}
for item in items:
lines = item.children()
k = lines[0].window_text()
v = lines[1].window_text()
row[k.replace(" ", "")] = v
if row == last:
# 与上一条数据一致则说明已经爬取完毕
break
result.append(row)
num += 1
print("\r", num, row,
end=" ")
last = row
contacts.type_keys("{DOWN}")
df = pd.DataFrame(result)
df
最后结果:
可以看出,最后一页11个微信账号的数据抓取耗时45秒。
ui自动化实现
接下来,我们将使用 uiautomation 来实现这种爬取。
获取微信窗口,点击通讯录按钮:
import uiautomation as auto
wechatWindow = auto.WindowControl(searchDepth=1, Name="微信", ClassName='WeChatMainWndForPC')
wechatWindow.SetActive()
txl_btn = wechatWindow.ButtonControl(Name='通讯录')
txl_btn.Click()
然后点击云朵君的好友信息,测试好友信息抽取:
(这个数字,你可以随意添加)
wechatWindow.EditControl(searchDepth=10, foundIndex=2) 表示在10层节点内搜索第二个EditControl类型节点(第一个是搜索框,第二个是朋友的昵称)。
GetParentControl() 和 GetNextSiblingControl() 是昨天没有使用的 API。它们用于获取父节点和下一个兄弟节点。使用这两个 API 来重写昨天的 文章 的代码,将使程序代码变得简单和高效。改进。
然后使用与 PyWinAuto 相同的方式进行批量提取:
还要先测试最后一页的数据:
爬取只用了 11 秒,比 PyWinAuto 快 4 倍。
所以我们可以批量提取所有微信好友的数据。最后,我这边的700多个朋友用了10分钟。虽然速度较慢,但与 PyWinAuto 相比完全可以接受。
代码对比
对于两者,我都试图遵循完全相同的逻辑。
win.Edit2 也得到第二个 EditControl 类型节点,
type_keys 是 PyWinAuto 用来模拟击键的 API,{DOWN} 代表向下的方向键。
PyWinAuto获取父子节点的api都是小写的,没有get,uiautomation获取父子节点的api大写,前缀为Get。
对于 PyWinAuto 中的这行代码:
items = tmp.parent().parent().children()[2].children()
使用 uiautomation:
items = tmp.GetParentControl().GetNextSiblingControl().GetNextSiblingControl().GetChildren()
有一个很大的不同。
这是因为我没有找到PyWinAuto获取兄弟节点的API,所以采用了先获取父节点再获取子节点的方法。
另外,判断是否是企业微信的逻辑不同。PyWinAuto也需要在个性签名为空时处理异常,否则程序会报错退出。具体点需要大家去测试和体验。
其他地方的逻辑几乎相同。
总结
本文还演示了 PyWinAuto 和 uiautomation 读取微信好友列表信息。通过对比,我们可以更深入地了解两者的API用法。作为作者,我在实践中有着深刻的理解。只是文章中的代码并没有体现这些细节,具体的事情需要读者在分析对比的过程中得到答案。仅仅看本文的代码或许可以解决当前的需求,但是很难将本文涉及的技术应用到其他需求上。
童鞋们,让我们通过动手实践来学习吧⁉️学完之后,你会看到任何实现Automation Provider的桌面程序,并且可以爬~
querylist采集微信公众号文章(如下如下工具程序利用的是微信公众号 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-19 22:05
)
为了实现爬虫我们需要使用以下工具
另外,这个爬虫程序使用了微信公众号后台编辑素材接口。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们也需要有一个公众号。
正式开始
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
接下来,按 F12 打开 Chrome 的开发者工具并选择网络
此时,在之前的超链接界面,点击“选择其他公众号”,输入你需要爬取的公众号(例如中国移动)
这时候之前的Network会刷新一些链接,其中以“appmsg”开头的内容就是我们需要分析的
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
它分为三个部分
通过不断浏览下一页,我们发现每次只有begin会改变,每次增加5,这就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码是无法获取资源的
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能在浏览器上获取资源,是因为我们登录了微信公众号后端。而Python没有我们的登录信息,所以请求无效。我们需要在requests中设置headers参数,传入Cookie和User-Agent来模拟登录
由于头信息的内容每次都会变化,我把这些内容放在一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
只需要事后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
appmsgid 是每条推文的唯一标识符,aid 是每条推文的唯一标识符。
其实除了cookies,URL中的token参数也会用来限制爬虫,所以上面代码的输出很可能是{'base_resp': {'ret': 200040,'err_msg':'无效的 csrf 令牌'} }
然后我们写一个循环来获取文章的所有JSON并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还在“wechat.yaml”文件中存储了fakeid和token。这是因为fakeid是每个公众号的唯一标识,token会经常变化,信息可以通过解析URL获取,也可以从开发者工具查看
爬了一段时间后,会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时,当你尝试在公众号后台插入超链接时,会遇到如下提示
这是公众号的流量限制,一般需要30-60分钟才能继续。为了完美处理这个问题,你可能需要申请多个公众号,可能需要对抗微信公众号登录系统,或者你可能需要设置代理池。
但是我不需要工业级的爬虫,我只想爬取我自己的公众号信息,所以等了一个小时,再次登录公众号,获取cookie和token,运行。我不想用自己的兴趣挑战别人的工作。
最后,将结果保存为 JSON 格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章标识符、标题、URL、发布时间四列,保存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("n".join(info_list)) 查看全部
querylist采集微信公众号文章(如下如下工具程序利用的是微信公众号
)
为了实现爬虫我们需要使用以下工具
另外,这个爬虫程序使用了微信公众号后台编辑素材接口。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们也需要有一个公众号。
正式开始
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
接下来,按 F12 打开 Chrome 的开发者工具并选择网络
此时,在之前的超链接界面,点击“选择其他公众号”,输入你需要爬取的公众号(例如中国移动)
这时候之前的Network会刷新一些链接,其中以“appmsg”开头的内容就是我们需要分析的
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
它分为三个部分
通过不断浏览下一页,我们发现每次只有begin会改变,每次增加5,这就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码是无法获取资源的
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能在浏览器上获取资源,是因为我们登录了微信公众号后端。而Python没有我们的登录信息,所以请求无效。我们需要在requests中设置headers参数,传入Cookie和User-Agent来模拟登录
由于头信息的内容每次都会变化,我把这些内容放在一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
只需要事后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
appmsgid 是每条推文的唯一标识符,aid 是每条推文的唯一标识符。
其实除了cookies,URL中的token参数也会用来限制爬虫,所以上面代码的输出很可能是{'base_resp': {'ret': 200040,'err_msg':'无效的 csrf 令牌'} }
然后我们写一个循环来获取文章的所有JSON并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还在“wechat.yaml”文件中存储了fakeid和token。这是因为fakeid是每个公众号的唯一标识,token会经常变化,信息可以通过解析URL获取,也可以从开发者工具查看
爬了一段时间后,会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时,当你尝试在公众号后台插入超链接时,会遇到如下提示
这是公众号的流量限制,一般需要30-60分钟才能继续。为了完美处理这个问题,你可能需要申请多个公众号,可能需要对抗微信公众号登录系统,或者你可能需要设置代理池。
但是我不需要工业级的爬虫,我只想爬取我自己的公众号信息,所以等了一个小时,再次登录公众号,获取cookie和token,运行。我不想用自己的兴趣挑战别人的工作。
最后,将结果保存为 JSON 格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章标识符、标题、URL、发布时间四列,保存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("n".join(info_list))
querylist采集微信公众号文章(如何处理微信的防盗链?突破难点一操作拥有微信)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-19 22:03
突破难关一操作
拥有一个带有登录和注册链接的微信个人订阅帐户。微信公众平台:
未注册的童鞋可以通过微信公众号进行注册。这个过程非常简单。
登录后,点击左侧菜单栏的“管理”-“物料管理”。然后点击右侧的“新建图形材质”
会弹出一个新标签页,在上方工具栏中找到“超链接”,点击
弹出小窗口,选择“查找文章”,输入需要搜索的公众号,以“宅基地”公众号为例
点击后可以弹出公众号的所有历史记录文章
搜索可以获取所有相关公众号信息,但我只取第一个进行测试,其他所有感兴趣的人也可以获得。
详细信息请参考崔大神的文章,#rd
根据个人公众号界面抓取
根据搜狗微信界面抓取
# -*- coding:utf-8 -*-
import requests,os,time,re
from urllib.parse import quote
from pyquery import PyQuery as pq
from selenium.webdriver import Chrome
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support.wait import WebDriverWait
# 这三行代码是防止在python2上面编码错误的,在python3上面不要要这样设置
# import sys
# reload(sys)
# sys.setdefaultencoding('utf-8')
# 搜索入口地址,以公众为关键字搜索该公众号
def get_search_result_by_keywords(sogou_search_url):
# 爬虫伪装头部设置
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
# 设置操作超时时长
timeout = 5
# 爬虫模拟在一个request.session中完成
s = requests.Session()
log(u'搜索地址为:%s' % sogou_search_url)
return s.get(sogou_search_url, headers=headers, timeout=timeout).content
# 获得公众号主页地址
def get_wx_url_by_sougou_search_html(sougou_search_html):
doc = pq(sougou_search_html)
return doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
# browser = webdriver.PhantomJS(executable_path=r'D:\Python2.7\Scripts\phantomjs.exe')
options = Options()
options.add_argument('-headless') # 无头参数
driver = Chrome(executable_path='chromedriver', chrome_options=options)
wait = WebDriverWait(driver, timeout=10)
driver.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = driver.execute_script("return document.documentElement.outerHTML")
driver.close()
return html
# 获取公众号文章内容
def parse_wx_articles_by_html(selenium_html):
doc = pq(selenium_html)
return doc('div[class="weui_media_box appmsg"]')
# 将获取到的文章转换为字典
def switch_arctiles_to_list(articles):
# 定义存贮变量
articles_list = []
i = 1
# 遍历找到的文章,解析里面的内容
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
###log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 返回字典数据
return {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic
}
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 自定义log函数,主要是加上时间
def log(msg):
print(u'%s: %s' % (time.strftime('%Y-%m-%d_%H-%M-%S'), msg))
# 验证函数
def need_verify(selenium_html):
' 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 '
return pq(selenium_html)('#verify_change').text() != ''
# 创建公众号命名的文件夹
def create_dir(keywords):
if not os.path.exists(keywords):
os.makedirs(keywords)
def run(keywords):
' 爬虫入口函数 '
# Step 0 : 创建公众号命名的文件夹
create_dir(keywords)
# 搜狐微信搜索链接入口
sogou_search_url = 'http://weixin.sogou.com/weixin ... 39%3B % quote(keywords)
# Step 1:GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
log(u'开始获取,微信公众号英文名为:%s' % keywords)
log(u'开始调用sougou搜索引擎')
sougou_search_html = get_search_result_by_keywords(sogou_search_url)
# Step 2:从搜索结果页中解析出公众号主页链接
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
wx_url = get_wx_url_by_sougou_search_html(sougou_search_html)
log(u'获取wx_url成功,%s' % wx_url)
# Step 3:Selenium+PhantomJs获取js异步加载渲染后的html
log(u'开始调用selenium渲染html')
selenium_html = get_selenium_js_html(wx_url)
# Step 4: 检测目标网站是否进行了封锁
if need_verify(selenium_html):
log(u'爬虫被目标网站封锁,请稍后再试')
else:
# Step 5: 使用PyQuery,从Step 3获取的html中解析出公众号文章列表的数据
log(u'调用selenium渲染html完成,开始解析公众号文章')
articles = parse_wx_articles_by_html(selenium_html)
log(u'抓取到微信文章%d篇' % len(articles))
# Step 6: 把微信文章数据封装成字典的list
log(u'开始整合微信文章数据为字典')
articles_list = switch_arctiles_to_list(articles)
return [content['title'] for content in articles_list]
if __name__ == '__main__':
gongzhonghao = input(u'input weixin gongzhonghao:')
if not gongzhonghao:
gongzhonghao = 'spider'
text = " ".join(run(gongzhonghao))
print(text)
直接运行main方法,在控制台输入你要爬的公众号的英文名。中文可能不止一个。精确搜索在这里完成,只找到一个。查看英文公众号,点击手机即可。公众号然后查看公众号信息
防水蛭
微信公众号已经对文章中的图片做了防盗链处理,所以如果图片在公众号、小程序、PC浏览器以外的地方无法显示,建议您阅读这篇文章< @文章学习如何应对微信的反水蛭。
参考: 查看全部
querylist采集微信公众号文章(如何处理微信的防盗链?突破难点一操作拥有微信)
突破难关一操作
拥有一个带有登录和注册链接的微信个人订阅帐户。微信公众平台:
未注册的童鞋可以通过微信公众号进行注册。这个过程非常简单。
登录后,点击左侧菜单栏的“管理”-“物料管理”。然后点击右侧的“新建图形材质”
会弹出一个新标签页,在上方工具栏中找到“超链接”,点击
弹出小窗口,选择“查找文章”,输入需要搜索的公众号,以“宅基地”公众号为例
点击后可以弹出公众号的所有历史记录文章
搜索可以获取所有相关公众号信息,但我只取第一个进行测试,其他所有感兴趣的人也可以获得。
详细信息请参考崔大神的文章,#rd
根据个人公众号界面抓取
根据搜狗微信界面抓取
# -*- coding:utf-8 -*-
import requests,os,time,re
from urllib.parse import quote
from pyquery import PyQuery as pq
from selenium.webdriver import Chrome
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support.wait import WebDriverWait
# 这三行代码是防止在python2上面编码错误的,在python3上面不要要这样设置
# import sys
# reload(sys)
# sys.setdefaultencoding('utf-8')
# 搜索入口地址,以公众为关键字搜索该公众号
def get_search_result_by_keywords(sogou_search_url):
# 爬虫伪装头部设置
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
# 设置操作超时时长
timeout = 5
# 爬虫模拟在一个request.session中完成
s = requests.Session()
log(u'搜索地址为:%s' % sogou_search_url)
return s.get(sogou_search_url, headers=headers, timeout=timeout).content
# 获得公众号主页地址
def get_wx_url_by_sougou_search_html(sougou_search_html):
doc = pq(sougou_search_html)
return doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
# browser = webdriver.PhantomJS(executable_path=r'D:\Python2.7\Scripts\phantomjs.exe')
options = Options()
options.add_argument('-headless') # 无头参数
driver = Chrome(executable_path='chromedriver', chrome_options=options)
wait = WebDriverWait(driver, timeout=10)
driver.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = driver.execute_script("return document.documentElement.outerHTML")
driver.close()
return html
# 获取公众号文章内容
def parse_wx_articles_by_html(selenium_html):
doc = pq(selenium_html)
return doc('div[class="weui_media_box appmsg"]')
# 将获取到的文章转换为字典
def switch_arctiles_to_list(articles):
# 定义存贮变量
articles_list = []
i = 1
# 遍历找到的文章,解析里面的内容
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
###log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 返回字典数据
return {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic
}
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 自定义log函数,主要是加上时间
def log(msg):
print(u'%s: %s' % (time.strftime('%Y-%m-%d_%H-%M-%S'), msg))
# 验证函数
def need_verify(selenium_html):
' 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 '
return pq(selenium_html)('#verify_change').text() != ''
# 创建公众号命名的文件夹
def create_dir(keywords):
if not os.path.exists(keywords):
os.makedirs(keywords)
def run(keywords):
' 爬虫入口函数 '
# Step 0 : 创建公众号命名的文件夹
create_dir(keywords)
# 搜狐微信搜索链接入口
sogou_search_url = 'http://weixin.sogou.com/weixin ... 39%3B % quote(keywords)
# Step 1:GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
log(u'开始获取,微信公众号英文名为:%s' % keywords)
log(u'开始调用sougou搜索引擎')
sougou_search_html = get_search_result_by_keywords(sogou_search_url)
# Step 2:从搜索结果页中解析出公众号主页链接
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
wx_url = get_wx_url_by_sougou_search_html(sougou_search_html)
log(u'获取wx_url成功,%s' % wx_url)
# Step 3:Selenium+PhantomJs获取js异步加载渲染后的html
log(u'开始调用selenium渲染html')
selenium_html = get_selenium_js_html(wx_url)
# Step 4: 检测目标网站是否进行了封锁
if need_verify(selenium_html):
log(u'爬虫被目标网站封锁,请稍后再试')
else:
# Step 5: 使用PyQuery,从Step 3获取的html中解析出公众号文章列表的数据
log(u'调用selenium渲染html完成,开始解析公众号文章')
articles = parse_wx_articles_by_html(selenium_html)
log(u'抓取到微信文章%d篇' % len(articles))
# Step 6: 把微信文章数据封装成字典的list
log(u'开始整合微信文章数据为字典')
articles_list = switch_arctiles_to_list(articles)
return [content['title'] for content in articles_list]
if __name__ == '__main__':
gongzhonghao = input(u'input weixin gongzhonghao:')
if not gongzhonghao:
gongzhonghao = 'spider'
text = " ".join(run(gongzhonghao))
print(text)
直接运行main方法,在控制台输入你要爬的公众号的英文名。中文可能不止一个。精确搜索在这里完成,只找到一个。查看英文公众号,点击手机即可。公众号然后查看公众号信息
防水蛭
微信公众号已经对文章中的图片做了防盗链处理,所以如果图片在公众号、小程序、PC浏览器以外的地方无法显示,建议您阅读这篇文章< @文章学习如何应对微信的反水蛭。
参考:
querylist采集微信公众号文章(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-10-19 15:01
querylist采集微信公众号文章分类的网页数据,不用爬虫(tornado,python等),golang,支持一些可视化的交互设计,nodejs等(同时,这篇文章是代码,需要预先安装nodejs)网页端爬取,使用tornado,同时有网页的分析api,类似spyder,不过它是web平台。微信公众号文章分类采集接入tornado中要说到http的请求,并不需要注册帐号,必须在浏览器上输入网址然后才能操作,先从网页抓取开始,可以通过http请求->》响应网页->》点击分类查看我们通过tornado抓取了taro_spider.js这个页面,采集到包含60个微信公众号文章类别的网页数据,需要编写如下代码:httprequest->connect("")->从浏览器中提交到encoder.py中,接着就有了以下代码:1.post和get请求发送请求发送post请求,soeasy!//connectmesocute,${touchable}httprequest->connect(""),meme!//connectmeme!//get请求发送get请求,同样发送到taro.py中,并且发送后端!//connectmeme!//post请求中accept:json,post:['accept-encoding','gzip,deflate','bytes0xffff']httprequest->connect("")->在taro.py中taro_spider.js与http相关的代码应该在anacondauseragent中,在我实际项目中,taro_spider.js相当于python的pipinstalllxml;forlxmlinenumerate(${lxml}):printlxml.load(lxml)所以,post请求发送的是数据接收者,taro_spider.js等同于lxml。
接着,我们要操作taro_spider.js,进行http请求、响应处理,然后接着我们要运行指定路径下的.py程序并运行这个程序,最后我们采用自己的服务器自己的httpserver去请求就可以。2.请求体处理使用get发送请求,如果不加上#!/usr/bin/envpython#-*-coding:utf-8-*-importjsonimportthreadingimportstructdefpost(url):"""post请求发送到to_header=':'name='to_name'accept='gzip,deflate'content-type='application/x-www-form-urlencoded'"""returnjson.loads(url.replace('/','').text)returnthreading.thread(target=struct.pool,policy=struct.pool)defconnect(host):"""调用一下connect(),然后post请求一下"""host=threading.pool()host.setdefaulthost('。 查看全部
querylist采集微信公众号文章(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
querylist采集微信公众号文章分类的网页数据,不用爬虫(tornado,python等),golang,支持一些可视化的交互设计,nodejs等(同时,这篇文章是代码,需要预先安装nodejs)网页端爬取,使用tornado,同时有网页的分析api,类似spyder,不过它是web平台。微信公众号文章分类采集接入tornado中要说到http的请求,并不需要注册帐号,必须在浏览器上输入网址然后才能操作,先从网页抓取开始,可以通过http请求->》响应网页->》点击分类查看我们通过tornado抓取了taro_spider.js这个页面,采集到包含60个微信公众号文章类别的网页数据,需要编写如下代码:httprequest->connect("")->从浏览器中提交到encoder.py中,接着就有了以下代码:1.post和get请求发送请求发送post请求,soeasy!//connectmesocute,${touchable}httprequest->connect(""),meme!//connectmeme!//get请求发送get请求,同样发送到taro.py中,并且发送后端!//connectmeme!//post请求中accept:json,post:['accept-encoding','gzip,deflate','bytes0xffff']httprequest->connect("")->在taro.py中taro_spider.js与http相关的代码应该在anacondauseragent中,在我实际项目中,taro_spider.js相当于python的pipinstalllxml;forlxmlinenumerate(${lxml}):printlxml.load(lxml)所以,post请求发送的是数据接收者,taro_spider.js等同于lxml。
接着,我们要操作taro_spider.js,进行http请求、响应处理,然后接着我们要运行指定路径下的.py程序并运行这个程序,最后我们采用自己的服务器自己的httpserver去请求就可以。2.请求体处理使用get发送请求,如果不加上#!/usr/bin/envpython#-*-coding:utf-8-*-importjsonimportthreadingimportstructdefpost(url):"""post请求发送到to_header=':'name='to_name'accept='gzip,deflate'content-type='application/x-www-form-urlencoded'"""returnjson.loads(url.replace('/','').text)returnthreading.thread(target=struct.pool,policy=struct.pool)defconnect(host):"""调用一下connect(),然后post请求一下"""host=threading.pool()host.setdefaulthost('。
querylist采集微信公众号文章( 微信读书App已经上线优质公众号推荐模块(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-10-19 10:25
微信读书App已经上线优质公众号推荐模块(图))
微信阅读App上线优质公众号推荐模块。
钛媒体编辑今天点击微信阅读App主界面左下角的书店,弹出了“优质公众号”模块。
在“查看全部”内容列表中,钛媒体发现该模块分为8个子模块:“全部”、“轻松搞笑”、“影评”、“文学杂志”、“互联网”、“知识教育” ”、“商业金融”和“其他”。而在每个子模块中,都有来自微信公众平台文章的各个自媒体账号的收录。
另外,通过微信阅读App搜索栏,可以直接搜索相关公众号和内容。
事实上,今年4月,微信阅读2.4.0就已经加入了一个新功能:引入优质公众号。
而马化腾去年在朋友圈与kol的对话中也透露,微信正在内部测试公众号的付费订阅功能。此后,一直没有消息表明该功能何时正式发布。
微信阅读App的自然付费阅读模式与微信公众号付费阅读自然匹配。不过,微信阅读App中的优质公众号模块依然可以免费阅读。
钛媒体发现,这并不是微信阅读和微信公众号的第一次结合。早在去年9月2.2.0版本上线时,就已经出现了“支持看书”公众号文章”的提示。
关于新功能,钛媒体小编采访了几家公众号运营商,发现微信阅读没有事先就授权和版权问题与运营商沟通。
本次我们将直接抓取微信公众号中的文章,作为独立版块使用。以后会不会涉及版权问题?
从目前的功能来看,微信阅读App看起来是一个完美的“接现成孩子”的过程。同时在搜索一些不知名的公众号时,发现系统并没有收录。可以看出,“优质公众号”是在微信阅读相关数据库筛选后导入的。
据了解,微信阅读App于2015年8月27日正式上线,目前华为应用商店下载量超过1亿。庞大的流量平台未来将如何与微信公众号运营商分享收益?值得期待。(本文首发于钛媒体,作者/桑明强,编辑/丛聪) 查看全部
querylist采集微信公众号文章(
微信读书App已经上线优质公众号推荐模块(图))
微信阅读App上线优质公众号推荐模块。
钛媒体编辑今天点击微信阅读App主界面左下角的书店,弹出了“优质公众号”模块。
在“查看全部”内容列表中,钛媒体发现该模块分为8个子模块:“全部”、“轻松搞笑”、“影评”、“文学杂志”、“互联网”、“知识教育” ”、“商业金融”和“其他”。而在每个子模块中,都有来自微信公众平台文章的各个自媒体账号的收录。
另外,通过微信阅读App搜索栏,可以直接搜索相关公众号和内容。
事实上,今年4月,微信阅读2.4.0就已经加入了一个新功能:引入优质公众号。
而马化腾去年在朋友圈与kol的对话中也透露,微信正在内部测试公众号的付费订阅功能。此后,一直没有消息表明该功能何时正式发布。
微信阅读App的自然付费阅读模式与微信公众号付费阅读自然匹配。不过,微信阅读App中的优质公众号模块依然可以免费阅读。
钛媒体发现,这并不是微信阅读和微信公众号的第一次结合。早在去年9月2.2.0版本上线时,就已经出现了“支持看书”公众号文章”的提示。
关于新功能,钛媒体小编采访了几家公众号运营商,发现微信阅读没有事先就授权和版权问题与运营商沟通。
本次我们将直接抓取微信公众号中的文章,作为独立版块使用。以后会不会涉及版权问题?
从目前的功能来看,微信阅读App看起来是一个完美的“接现成孩子”的过程。同时在搜索一些不知名的公众号时,发现系统并没有收录。可以看出,“优质公众号”是在微信阅读相关数据库筛选后导入的。
据了解,微信阅读App于2015年8月27日正式上线,目前华为应用商店下载量超过1亿。庞大的流量平台未来将如何与微信公众号运营商分享收益?值得期待。(本文首发于钛媒体,作者/桑明强,编辑/丛聪)
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-10-19 02:02
Python微信公众号文章抓取
一.思考
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二. 接口分析
微信公众号获取界面:
范围:
行动=search_biz
开始=0
计数=5
query=官方账号名
token=每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
所以在这个界面,我们只需要获取token,查询就是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取对应公众号文章的界面:
范围:
动作=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。通过模拟用户,输入对应的账号密码,点击登录,就会出现扫码验证,用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求对应的公众号接口,得到我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取到的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的数据文章
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了微信公众号文章的抓取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置一个延迟时间,否则账号很容易被封,获取不到返回的数据。 查看全部
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
Python微信公众号文章抓取
一.思考
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二. 接口分析
微信公众号获取界面:
范围:
行动=search_biz
开始=0
计数=5
query=官方账号名
token=每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
所以在这个界面,我们只需要获取token,查询就是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取对应公众号文章的界面:
范围:
动作=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。通过模拟用户,输入对应的账号密码,点击登录,就会出现扫码验证,用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求对应的公众号接口,得到我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取到的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的数据文章
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了微信公众号文章的抓取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置一个延迟时间,否则账号很容易被封,获取不到返回的数据。
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-10-18 08:08
Python微信公众号文章抓取
一.思考
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二. 接口分析
微信公众号获取界面:
范围:
行动=search_biz
开始=0
计数=5
query=官方账号名
token=每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
所以在这个界面,我们只需要获取token,查询就是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取对应公众号文章的界面:
范围:
动作=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。通过模拟用户,输入对应的账号密码,点击登录,就会出现扫码验证,只需用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求对应的公众号接口,得到我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取到的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的数据文章
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了微信公众号文章的抓取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置一个延迟时间,否则账号很容易被封,获取不到返回的数据。 查看全部
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
Python微信公众号文章抓取
一.思考
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二. 接口分析
微信公众号获取界面:
范围:
行动=search_biz
开始=0
计数=5
query=官方账号名
token=每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
所以在这个界面,我们只需要获取token,查询就是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取对应公众号文章的界面:
范围:
动作=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。通过模拟用户,输入对应的账号密码,点击登录,就会出现扫码验证,只需用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求对应的公众号接口,得到我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取到的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的数据文章
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了微信公众号文章的抓取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置一个延迟时间,否则账号很容易被封,获取不到返回的数据。
querylist采集微信公众号文章( 小编来一起获取微信公众号文章的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-10-10 09:18
小编来一起获取微信公众号文章的方法)
微信公众平台获取公众号文章示例
更新时间:2019年12月25日09:45:38 作者:考古学家lx
本文文章主要介绍如何通过微信公众平台获取公众号文章的例子。文章中介绍的示例代码非常详细,对大家的学习或工作有一定的参考学习价值。小伙伴们和小编一起学习吧
之前一直自己维护一个公众号,但是因为个人关系好久没有更新,今天才上来想起来,却偶然发现了微信公众号文章的获取方式。
之前获取的方式很多,通过搜狗、清博、web、客户端等都可以,这个可能不太好,但是操作简单易懂。
所以,首先你需要在微信公众平台上有一个账号
微信公众平台:
登录后,进入首页,点击新建群发。
选择自创图形:
好像是公众号操作教学
进入编辑页面后,点击超链接
弹出一个选择框,我们在框中输入对应的公众号名称,就会出现对应的文章列表
你惊喜吗?您可以打开控制台并检查请求的界面
打开回复,里面有我们需要的文章链接
确认数据后,我们需要对这个界面进行分析。
感觉非常简单。GET 请求携带一些参数。
Fakeid是公众号的唯一ID,所以如果想直接通过名字获取文章列表,还需要先获取fakeid。
当我们输入官方账号名称时,点击搜索。可以看到搜索界面被触发,返回fakeid。
这个接口需要的参数不多。
接下来我们就可以用代码来模拟上面的操作了。
但是您还需要使用现有的 cookie 来避免登录。
目前,我还没有测试过cookie的有效期。可能需要及时更新 cookie。
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样就可以得到最新的10个文章。如果想获取更多历史记录文章,可以修改数据中的“begin”参数,0为第一页,5为第二页,10为第三页(以此类推)
但是如果你想大规模爬行:
请自己安排一个稳定的代理,降低爬虫速度,准备多个账号,减少被封的可能性。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。 查看全部
querylist采集微信公众号文章(
小编来一起获取微信公众号文章的方法)
微信公众平台获取公众号文章示例
更新时间:2019年12月25日09:45:38 作者:考古学家lx
本文文章主要介绍如何通过微信公众平台获取公众号文章的例子。文章中介绍的示例代码非常详细,对大家的学习或工作有一定的参考学习价值。小伙伴们和小编一起学习吧
之前一直自己维护一个公众号,但是因为个人关系好久没有更新,今天才上来想起来,却偶然发现了微信公众号文章的获取方式。
之前获取的方式很多,通过搜狗、清博、web、客户端等都可以,这个可能不太好,但是操作简单易懂。
所以,首先你需要在微信公众平台上有一个账号
微信公众平台:
登录后,进入首页,点击新建群发。
选择自创图形:
好像是公众号操作教学
进入编辑页面后,点击超链接
弹出一个选择框,我们在框中输入对应的公众号名称,就会出现对应的文章列表
你惊喜吗?您可以打开控制台并检查请求的界面
打开回复,里面有我们需要的文章链接
确认数据后,我们需要对这个界面进行分析。
感觉非常简单。GET 请求携带一些参数。
Fakeid是公众号的唯一ID,所以如果想直接通过名字获取文章列表,还需要先获取fakeid。
当我们输入官方账号名称时,点击搜索。可以看到搜索界面被触发,返回fakeid。
这个接口需要的参数不多。
接下来我们就可以用代码来模拟上面的操作了。
但是您还需要使用现有的 cookie 来避免登录。
目前,我还没有测试过cookie的有效期。可能需要及时更新 cookie。
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样就可以得到最新的10个文章。如果想获取更多历史记录文章,可以修改数据中的“begin”参数,0为第一页,5为第二页,10为第三页(以此类推)
但是如果你想大规模爬行:
请自己安排一个稳定的代理,降低爬虫速度,准备多个账号,减少被封的可能性。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
querylist采集微信公众号文章(微信公众号后台编辑素材界面的程序利用程序 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-10-07 16:19
)
准备阶段
为了实现爬虫我们需要使用以下工具
另外,这个爬虫程序使用了微信公众号后台编辑素材接口。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们还需要有一个公众号。
图1正式开始
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
图2
接下来,按 F12 打开 Chrome 的开发者工具并选择网络
图3
此时,在之前的超链接界面,点击“选择其他公众号”,输入你需要爬取的公众号(例如中国移动)
图4
这时候之前的Network会刷新一些链接,其中以“appmsg”开头的内容就是我们需要分析的
图5
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
它分为三个部分
通过不断浏览下一页,我们发现每次只有begin会改变,每次增加5,这就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码是无法获取资源的
import requestsurl = "https://mp.weixin.qq.com/cgi-b ... s.get(url).json() # {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能在浏览器上获取资源,是因为我们登录了微信公众号后端。而Python没有我们的登录信息,所以请求无效。我们需要在requests中设置headers参数,传入Cookie和User-Agent来模拟登录
由于头信息的内容每次都会变化,我把这些内容放在一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...user_agent: Mozilla/5.0...
只需要事后阅读
# 读取cookie和user_agentimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
❝
appmsgid 是每条推文的唯一标识符,aid 是每条推文的唯一标识符。
❞
图 6 ❝
其实除了cookies,URL中的token参数也会用来限制爬虫,所以上面代码的输出很可能是{'base_resp': {'ret': 200040,'err_msg':'无效的 csrf 令牌'} }
❞
然后我们写一个循环来获取文章的所有JSON并保存。
import jsonimport requestsimport timeimport randomimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }# 请求参数url = "https://mp.weixin.qq.com/cgi-bin/appmsg"begin = "0"params = { "action": "list_ex", "begin": begin, "count": "5", "fakeid": config['fakeid'], "type": "9", "token": config['token'], "lang": "zh_CN", "f": "json", "ajax": "1"}# 存放结果app_msg_list = []# 在不知道公众号有多少文章的情况下,使用while语句# 也方便重新运行时设置页数i = 0while True: begin = i * 5 params["begin"] = str(begin) # 随机暂停几秒,避免过快的请求导致过快的被查到 time.sleep(random.randint(1,10)) resp = requests.get(url, headers=headers, params = params, verify=False) # 微信流量控制, 退出 if resp.json()['base_resp']['ret'] == 200013: print("frequencey control, stop at {}".format(str(begin))) break # 如果返回的内容中为空则结束 if len(resp.json()['app_msg_list']) == 0: print("all ariticle parsed") break app_msg_list.append(resp.json()) # 翻页 i += 1
在上面的代码中,我还在“wechat.yaml”文件中存储了fakeid和token。这是因为 fakeid 是每个公众号的唯一标识符,令牌会经常变化。这个信息可以通过 Parse URL 来获取,也可以从开发者工具中查看
图7
爬了一段时间后,会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时,当你尝试在公众号后台插入超链接时,会遇到如下提示
图8
这是公众号的流量限制,一般需要30-60分钟才能继续。为了完美处理这个问题,你可能需要申请多个公众号,可能需要对抗微信公众号登录系统,或者你可能需要设置代理池。
但是我不需要工业级的爬虫,我只想爬取自己的公众号信息,所以等了一个小时,再次登录公众号,获取cookie和token,运行。我不想用自己的兴趣挑战别人的工作。
最后,将结果保存为 JSON 格式。
# 保存结果为JSONjson_name = "mp_data_{}.json".format(str(begin))with open(json_name, "w") as file: file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章标识符、标题、URL、发布时间四列,保存为CSV。
info_list = []for msg in app_msg_list: if "app_msg_list" in msg: for item in msg["app_msg_list"]: info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time'])) info_list.append(info)# save as csvwith open("app_msg_list.csv", "w") as file: file.writelines("\n".join(info_list)) 查看全部
querylist采集微信公众号文章(微信公众号后台编辑素材界面的程序利用程序
)
准备阶段
为了实现爬虫我们需要使用以下工具
另外,这个爬虫程序使用了微信公众号后台编辑素材接口。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们还需要有一个公众号。
图1正式开始
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
图2
接下来,按 F12 打开 Chrome 的开发者工具并选择网络
图3
此时,在之前的超链接界面,点击“选择其他公众号”,输入你需要爬取的公众号(例如中国移动)
图4
这时候之前的Network会刷新一些链接,其中以“appmsg”开头的内容就是我们需要分析的
图5
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
它分为三个部分
通过不断浏览下一页,我们发现每次只有begin会改变,每次增加5,这就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码是无法获取资源的
import requestsurl = "https://mp.weixin.qq.com/cgi-b ... s.get(url).json() # {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能在浏览器上获取资源,是因为我们登录了微信公众号后端。而Python没有我们的登录信息,所以请求无效。我们需要在requests中设置headers参数,传入Cookie和User-Agent来模拟登录
由于头信息的内容每次都会变化,我把这些内容放在一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...user_agent: Mozilla/5.0...
只需要事后阅读
# 读取cookie和user_agentimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
❝
appmsgid 是每条推文的唯一标识符,aid 是每条推文的唯一标识符。
❞
图 6 ❝
其实除了cookies,URL中的token参数也会用来限制爬虫,所以上面代码的输出很可能是{'base_resp': {'ret': 200040,'err_msg':'无效的 csrf 令牌'} }
❞
然后我们写一个循环来获取文章的所有JSON并保存。
import jsonimport requestsimport timeimport randomimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }# 请求参数url = "https://mp.weixin.qq.com/cgi-bin/appmsg"begin = "0"params = { "action": "list_ex", "begin": begin, "count": "5", "fakeid": config['fakeid'], "type": "9", "token": config['token'], "lang": "zh_CN", "f": "json", "ajax": "1"}# 存放结果app_msg_list = []# 在不知道公众号有多少文章的情况下,使用while语句# 也方便重新运行时设置页数i = 0while True: begin = i * 5 params["begin"] = str(begin) # 随机暂停几秒,避免过快的请求导致过快的被查到 time.sleep(random.randint(1,10)) resp = requests.get(url, headers=headers, params = params, verify=False) # 微信流量控制, 退出 if resp.json()['base_resp']['ret'] == 200013: print("frequencey control, stop at {}".format(str(begin))) break # 如果返回的内容中为空则结束 if len(resp.json()['app_msg_list']) == 0: print("all ariticle parsed") break app_msg_list.append(resp.json()) # 翻页 i += 1
在上面的代码中,我还在“wechat.yaml”文件中存储了fakeid和token。这是因为 fakeid 是每个公众号的唯一标识符,令牌会经常变化。这个信息可以通过 Parse URL 来获取,也可以从开发者工具中查看
图7
爬了一段时间后,会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时,当你尝试在公众号后台插入超链接时,会遇到如下提示
图8
这是公众号的流量限制,一般需要30-60分钟才能继续。为了完美处理这个问题,你可能需要申请多个公众号,可能需要对抗微信公众号登录系统,或者你可能需要设置代理池。
但是我不需要工业级的爬虫,我只想爬取自己的公众号信息,所以等了一个小时,再次登录公众号,获取cookie和token,运行。我不想用自己的兴趣挑战别人的工作。
最后,将结果保存为 JSON 格式。
# 保存结果为JSONjson_name = "mp_data_{}.json".format(str(begin))with open(json_name, "w") as file: file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章标识符、标题、URL、发布时间四列,保存为CSV。
info_list = []for msg in app_msg_list: if "app_msg_list" in msg: for item in msg["app_msg_list"]: info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time'])) info_list.append(info)# save as csvwith open("app_msg_list.csv", "w") as file: file.writelines("\n".join(info_list))
querylist采集微信公众号文章(微信公众号怎么分析阅读量赞量,平均点赞量的详细教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 264 次浏览 • 2021-10-01 10:01
微信公众号如何分析阅读量?要想做好微信,必须学会分析微信公众号的访问数据。今天教大家如何使用微信分析公众号数据中的历史最高阅读量、最高点赞数、平均阅读量、平均点赞数。金额的详细教程,有需要的朋友可以参考
一般我们查询别人的微信公众号数据时,由于我们没有微信公众号,只能一一查询阅读量、点赞等数据,效率很低。大家推荐一个更快的查询微信数据的方法。
1、 用电脑打开浏览器(不支持IE浏览器),进入百度,搜索“微信大数据”。一是从百度微信大数据开放微信公众号在线数据查询工具。
2、 进入页面后,屏幕上有一个显眼的输入框。输入微信公众号或微信账号名称(输入微信账号更准确),点击查询。
3、 查询后,进入数据展示页面。在这个页面上,我们可以清楚地看到这个微信公众号的历史最高阅读量、最高点赞数、平均阅读量和平均点赞数。此外,公众号的发布周期一目了然。
4、 另外,在页面底部,还对微信公众号进行了进一步的分析。头条和非头条数据一目了然;另外,还分析了单个文章的数据。
注意:查询微信公众号时最好使用微信公众号,因为微信公众号很多都没有认证,而且名字是一样的。按名称查询时很容易混淆。
微信公众平台公众号文章如何添加音乐插件?
如何将微信公众号名片一次转发给多个群或人? 查看全部
querylist采集微信公众号文章(微信公众号怎么分析阅读量赞量,平均点赞量的详细教程)
微信公众号如何分析阅读量?要想做好微信,必须学会分析微信公众号的访问数据。今天教大家如何使用微信分析公众号数据中的历史最高阅读量、最高点赞数、平均阅读量、平均点赞数。金额的详细教程,有需要的朋友可以参考
一般我们查询别人的微信公众号数据时,由于我们没有微信公众号,只能一一查询阅读量、点赞等数据,效率很低。大家推荐一个更快的查询微信数据的方法。
1、 用电脑打开浏览器(不支持IE浏览器),进入百度,搜索“微信大数据”。一是从百度微信大数据开放微信公众号在线数据查询工具。
2、 进入页面后,屏幕上有一个显眼的输入框。输入微信公众号或微信账号名称(输入微信账号更准确),点击查询。
3、 查询后,进入数据展示页面。在这个页面上,我们可以清楚地看到这个微信公众号的历史最高阅读量、最高点赞数、平均阅读量和平均点赞数。此外,公众号的发布周期一目了然。
4、 另外,在页面底部,还对微信公众号进行了进一步的分析。头条和非头条数据一目了然;另外,还分析了单个文章的数据。
注意:查询微信公众号时最好使用微信公众号,因为微信公众号很多都没有认证,而且名字是一样的。按名称查询时很容易混淆。
微信公众平台公众号文章如何添加音乐插件?
如何将微信公众号名片一次转发给多个群或人?
querylist采集微信公众号文章(I.素材管理II.新建图文III.超链接IV.查找文章(图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-09-26 04:38
)
使用官方帐户官方帐户获取所需信息。首先,它应该搜索其官方账户中的文章>或公共号码,并分析数据包中的信息。该过程中最重要的几点是:
1.调用接口以查找文章@>
转到主页->;物料管理->;新图形->;超链接->;查找文章@>
一,。物资管理
二,。新文本
三,。超链接
四,。查找文章@>
2.获取所有相关的官方帐户信息
输入关键字并单击搜索后,相应的数据包将显示在右侧。在这里更容易找到。选择XHR后,将只显示一个唯一的数据包
一,。查看访问参数
选择它,选择标题栏并滑动到底部以查看一系列请求参数。更重要的参数是令牌、查询(搜索关键字)、开始(起始值)和计数(每页显示的值)。您还可以在标题中看到数据的真实URL,然后向他发送请求
二,。查看数据包内容
官方帐户是官方帐户
可以查看包中返回的所有内容(通常为JSON格式),并检查内容是否与页面上的内容相对应。在这里,我们可以在返回的数据列表中看到每个官方账户的信息,包括fakeid(访问官方账户后将使用文章@>)、公众号名称、公众号和总搜索量
三,。过程分析
通过模拟登录获得cookie后,我们访问主页以获取URL上的令牌ID,并通过向捕获的数据包上的真实URL发送请求和数据来获取相应的信息。在返回的信息中,我们通过解析总量来判断总量,更改“开始翻页”的值,最后将信息写入文件
class Public(metaclass=SingletonType):
def __init__(self, search_key, token, cookie):
self.search_key = search_key
self.url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
self.headers = {
'cookie': cookie,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36'
}
self.data = {
'action': 'search_biz',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': '0.012103784566473319',
'query': self.search_key,
'count': '5'
}
def get_total(self):
self.data['begin'] = 0
content = requests.get(self.url, headers=self.headers, params=self.data).json()
total = content['total']
if total % 5:
return int(total / 5) + 1
else:
return int(total / 5)
def parse_public(self, num):
self.data['begin'] = num
content = requests.get(self.url, headers=self.headers, params=self.data).json()
return content
def get_data(self):
for num in range(0, self.get_total() + 1, 5):
for data in self.parse_public(num)['list']:
yield {
"name": data['nickname'],
"id": data['fakeid'],
'number': data['alias']
}
time.sleep(random.randint(1, 3))
def write_data(result, filename):
for data in result:
print(data)
with open(filename, 'a', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False) + '\n')
3.抓斗文章@>
在“官方帐号”下,选择相应的官方帐号并执行数据包捕获
可以查看新数据包,包括下的所有文章@>列表
I数据包捕获
二,。查看请求参数
显然,我们之前获得的伪造信息在这里使用。其他一切都和以前一样。查询也是一个搜索关键字。指定查询后,将返回相关的搜索词。如果未指定,则默认为空,并返回默认值
三,。查看数据内容
四,。过程分析
模拟登陆后获取cookie和token,fakeid可以自行获取,查阅上一部分获取官方账户信息的内容,然后将请求发送到数据包的真实URL,通过app解析返回的数据。msg_ucnt获取总量、更改开始值、翻页、获取文章@>标题、创建时间(时间戳需要转换为时间格式)、文章@>简要说明、文章@>链接等信息,最后执行写入文件操作
class Articls(metaclass=SingletonType):
def __init__(self, token, fakeid, cookie, search_key=""):
self.search_key = search_key
self.url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
self.headers = {
'cookie': cookie,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36',
'host': 'mp.weixin.qq.com',
'Connection': 'keep-alive',
'Accept': 'application/json, text/javascript, */*; q=0.01'
}
self.data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"count": "5",
"query": self.search_key,
"fakeid": fakeid,
"type": "9",
}
def parse_articles(self, num):
self.data['begin'] = num
content = requests.get(self.url, headers=self.headers, params=self.data).json()
return content
def get_total(self):
self.data['begin'] = 0
content = requests.get(self.url, headers=self.headers, params=self.data).json()
total = content['app_msg_cnt']
if total % 5:
return int(total / 5) + 1
else:
return int(total / 5)
@staticmethod
def convert_2_time(stamp):
return time.strftime("%Y-%m-%d", time.localtime(stamp))
def get_data(self):
if self.get_total():
for num in range(0, self.get_total() + 1, 5):
for data in self.parse_articles(num)['app_msg_list']:
yield {
"title": data['title'],
"create_time": self.convert_2_time(data['create_time']),
# 摘要
'digest': data['digest'],
'link': data['link']
}
time.sleep(random.randint(1, 3))
else:
print("No search item")
exit()
def write_data(result, filename):
for data in result:
print(data)
with open(filename, 'a', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False) + '\n')
4.模拟登录
我们都知道具体的操作流程。现在我们缺少两样东西,饼干和代币。我们仔细观察主页。代币随处可见。HTML代码和URL随处可见。我们可以简单地从URL获取cookies。我们可以通过selenium登录后获取cookies
一,。Cookie获取
通过selenium调用Chrome浏览器以输入用户名和密码。登录后单击“睡眠”一段时间以扫描用户的代码。登录成功后,再次访问主页并获取要写入文件的cookie(是否写入文件取决于您的个人偏好,您可以返回)
def login(username, passwd):
cookies = {}
driver = webdriver.Chrome() # 谷歌驱动
driver.get('https://mp.weixin.qq.com/')
# 用户名
driver.find_element_by_xpath('//input[@name="account"]').clear()
driver.find_element_by_xpath('//input[@name="account"]').send_keys(username)
driver.find_element_by_xpath('//input[@name="password"]').clear()
driver.find_element_by_xpath('//input[@name="password"]').send_keys(passwd)
# 登录
driver.find_element_by_xpath('//a[@class="btn_login"]').click()
time.sleep(20)
# 获取cookie
driver.get('https://mp.weixin.qq.com/')
time.sleep(5)
cookie_items = driver.get_cookies()
for cookie_item in cookie_items:
cookies[cookie_item['name']] = cookie_item['value']
with open('cookie.txt', 'w') as f:
f.write(json.dumps(cookies))
driver.close()
二,。代币获取
读取文件解析cookie,启动主页请求,并在获得令牌后将其与cookie一起返回
def get_cookie_token():
url = 'https://mp.weixin.qq.com'
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36',
'host': 'mp.weixin.qq.com',
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
result = []
for k, v in cookies.items():
result.append(k + '=' + v)
return "; ".join(result), token 查看全部
querylist采集微信公众号文章(I.素材管理II.新建图文III.超链接IV.查找文章(图)
)
使用官方帐户官方帐户获取所需信息。首先,它应该搜索其官方账户中的文章>或公共号码,并分析数据包中的信息。该过程中最重要的几点是:
1.调用接口以查找文章@>
转到主页->;物料管理->;新图形->;超链接->;查找文章@>
一,。物资管理
二,。新文本
三,。超链接
四,。查找文章@>
2.获取所有相关的官方帐户信息
输入关键字并单击搜索后,相应的数据包将显示在右侧。在这里更容易找到。选择XHR后,将只显示一个唯一的数据包
一,。查看访问参数
选择它,选择标题栏并滑动到底部以查看一系列请求参数。更重要的参数是令牌、查询(搜索关键字)、开始(起始值)和计数(每页显示的值)。您还可以在标题中看到数据的真实URL,然后向他发送请求
二,。查看数据包内容
官方帐户是官方帐户
可以查看包中返回的所有内容(通常为JSON格式),并检查内容是否与页面上的内容相对应。在这里,我们可以在返回的数据列表中看到每个官方账户的信息,包括fakeid(访问官方账户后将使用文章@>)、公众号名称、公众号和总搜索量
三,。过程分析
通过模拟登录获得cookie后,我们访问主页以获取URL上的令牌ID,并通过向捕获的数据包上的真实URL发送请求和数据来获取相应的信息。在返回的信息中,我们通过解析总量来判断总量,更改“开始翻页”的值,最后将信息写入文件
class Public(metaclass=SingletonType):
def __init__(self, search_key, token, cookie):
self.search_key = search_key
self.url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
self.headers = {
'cookie': cookie,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36'
}
self.data = {
'action': 'search_biz',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': '0.012103784566473319',
'query': self.search_key,
'count': '5'
}
def get_total(self):
self.data['begin'] = 0
content = requests.get(self.url, headers=self.headers, params=self.data).json()
total = content['total']
if total % 5:
return int(total / 5) + 1
else:
return int(total / 5)
def parse_public(self, num):
self.data['begin'] = num
content = requests.get(self.url, headers=self.headers, params=self.data).json()
return content
def get_data(self):
for num in range(0, self.get_total() + 1, 5):
for data in self.parse_public(num)['list']:
yield {
"name": data['nickname'],
"id": data['fakeid'],
'number': data['alias']
}
time.sleep(random.randint(1, 3))
def write_data(result, filename):
for data in result:
print(data)
with open(filename, 'a', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False) + '\n')
3.抓斗文章@>
在“官方帐号”下,选择相应的官方帐号并执行数据包捕获
可以查看新数据包,包括下的所有文章@>列表
I数据包捕获
二,。查看请求参数
显然,我们之前获得的伪造信息在这里使用。其他一切都和以前一样。查询也是一个搜索关键字。指定查询后,将返回相关的搜索词。如果未指定,则默认为空,并返回默认值
三,。查看数据内容
四,。过程分析
模拟登陆后获取cookie和token,fakeid可以自行获取,查阅上一部分获取官方账户信息的内容,然后将请求发送到数据包的真实URL,通过app解析返回的数据。msg_ucnt获取总量、更改开始值、翻页、获取文章@>标题、创建时间(时间戳需要转换为时间格式)、文章@>简要说明、文章@>链接等信息,最后执行写入文件操作
class Articls(metaclass=SingletonType):
def __init__(self, token, fakeid, cookie, search_key=""):
self.search_key = search_key
self.url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
self.headers = {
'cookie': cookie,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36',
'host': 'mp.weixin.qq.com',
'Connection': 'keep-alive',
'Accept': 'application/json, text/javascript, */*; q=0.01'
}
self.data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"count": "5",
"query": self.search_key,
"fakeid": fakeid,
"type": "9",
}
def parse_articles(self, num):
self.data['begin'] = num
content = requests.get(self.url, headers=self.headers, params=self.data).json()
return content
def get_total(self):
self.data['begin'] = 0
content = requests.get(self.url, headers=self.headers, params=self.data).json()
total = content['app_msg_cnt']
if total % 5:
return int(total / 5) + 1
else:
return int(total / 5)
@staticmethod
def convert_2_time(stamp):
return time.strftime("%Y-%m-%d", time.localtime(stamp))
def get_data(self):
if self.get_total():
for num in range(0, self.get_total() + 1, 5):
for data in self.parse_articles(num)['app_msg_list']:
yield {
"title": data['title'],
"create_time": self.convert_2_time(data['create_time']),
# 摘要
'digest': data['digest'],
'link': data['link']
}
time.sleep(random.randint(1, 3))
else:
print("No search item")
exit()
def write_data(result, filename):
for data in result:
print(data)
with open(filename, 'a', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False) + '\n')
4.模拟登录
我们都知道具体的操作流程。现在我们缺少两样东西,饼干和代币。我们仔细观察主页。代币随处可见。HTML代码和URL随处可见。我们可以简单地从URL获取cookies。我们可以通过selenium登录后获取cookies
一,。Cookie获取
通过selenium调用Chrome浏览器以输入用户名和密码。登录后单击“睡眠”一段时间以扫描用户的代码。登录成功后,再次访问主页并获取要写入文件的cookie(是否写入文件取决于您的个人偏好,您可以返回)
def login(username, passwd):
cookies = {}
driver = webdriver.Chrome() # 谷歌驱动
driver.get('https://mp.weixin.qq.com/')
# 用户名
driver.find_element_by_xpath('//input[@name="account"]').clear()
driver.find_element_by_xpath('//input[@name="account"]').send_keys(username)
driver.find_element_by_xpath('//input[@name="password"]').clear()
driver.find_element_by_xpath('//input[@name="password"]').send_keys(passwd)
# 登录
driver.find_element_by_xpath('//a[@class="btn_login"]').click()
time.sleep(20)
# 获取cookie
driver.get('https://mp.weixin.qq.com/')
time.sleep(5)
cookie_items = driver.get_cookies()
for cookie_item in cookie_items:
cookies[cookie_item['name']] = cookie_item['value']
with open('cookie.txt', 'w') as f:
f.write(json.dumps(cookies))
driver.close()
二,。代币获取
读取文件解析cookie,启动主页请求,并在获得令牌后将其与cookie一起返回
def get_cookie_token():
url = 'https://mp.weixin.qq.com'
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36',
'host': 'mp.weixin.qq.com',
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
result = []
for k, v in cookies.items():
result.append(k + '=' + v)
return "; ".join(result), token
querylist采集微信公众号文章(I.素材管理II.新建图文III.超链接IV.查找文章(图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-09-26 04:37
)
使用官方帐户官方帐户获取所需信息。首先,它应该搜索其官方账户中的文章>或公共号码,并分析数据包中的信息。该过程中最重要的几点是:
1.调用接口以查找文章@>
转到主页->;物料管理->;新图形->;超链接->;查找文章@>
一,。物资管理
二,。新文本
三,。超链接
四,。查找文章@>
2.获取所有相关的官方帐户信息
输入关键字并单击搜索后,相应的数据包将显示在右侧。在这里更容易找到。选择XHR后,将只显示一个唯一的数据包
一,。查看访问参数
选择它,选择标题栏并滑动到底部以查看一系列请求参数。更重要的参数是令牌、查询(搜索关键字)、开始(起始值)和计数(每页显示的值)。您还可以在标题中看到数据的真实URL,然后向他发送请求
二,。查看数据包内容
官方帐户是官方帐户
可以查看包中返回的所有内容(通常为JSON格式),并检查内容是否与页面上的内容相对应。在这里,我们可以在返回的数据列表中看到每个官方账户的信息,包括fakeid(访问官方账户后将使用文章@>)、公众号名称、公众号和总搜索量
三,。过程分析
通过模拟登录获得cookie后,我们访问主页以获取URL上的令牌ID,并通过向捕获的数据包上的真实URL发送请求和数据来获取相应的信息。在返回的信息中,我们通过解析总量来判断总量,更改“开始翻页”的值,最后将信息写入文件
class Public(metaclass=SingletonType):
def __init__(self, search_key, token, cookie):
self.search_key = search_key
self.url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
self.headers = {
'cookie': cookie,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36'
}
self.data = {
'action': 'search_biz',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': '0.012103784566473319',
'query': self.search_key,
'count': '5'
}
def get_total(self):
self.data['begin'] = 0
content = requests.get(self.url, headers=self.headers, params=self.data).json()
total = content['total']
if total % 5:
return int(total / 5) + 1
else:
return int(total / 5)
def parse_public(self, num):
self.data['begin'] = num
content = requests.get(self.url, headers=self.headers, params=self.data).json()
return content
def get_data(self):
for num in range(0, self.get_total() + 1, 5):
for data in self.parse_public(num)['list']:
yield {
"name": data['nickname'],
"id": data['fakeid'],
'number': data['alias']
}
time.sleep(random.randint(1, 3))
def write_data(result, filename):
for data in result:
print(data)
with open(filename, 'a', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False) + '\n')
3.抓斗文章@>
在“官方帐号”下,选择相应的官方帐号并执行数据包捕获
可以查看新数据包,包括下的所有文章@>列表
I数据包捕获
二,。查看请求参数
显然,我们之前获得的伪造信息在这里使用。其他一切都和以前一样。查询也是一个搜索关键字。指定查询后,将返回相关的搜索词。如果未指定,则默认为空,并返回默认值
三,。查看数据内容
四,。过程分析
模拟登陆后获取cookie和token,fakeid可以自行获取,查阅上一部分获取官方账户信息的内容,然后将请求发送到数据包的真实URL,通过app解析返回的数据。msg_ucnt获取总量、更改开始值、翻页、获取文章@>标题、创建时间(时间戳需要转换为时间格式)、文章@>简要说明、文章@>链接等信息,最后执行写入文件操作
class Articls(metaclass=SingletonType):
def __init__(self, token, fakeid, cookie, search_key=""):
self.search_key = search_key
self.url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
self.headers = {
'cookie': cookie,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36',
'host': 'mp.weixin.qq.com',
'Connection': 'keep-alive',
'Accept': 'application/json, text/javascript, */*; q=0.01'
}
self.data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"count": "5",
"query": self.search_key,
"fakeid": fakeid,
"type": "9",
}
def parse_articles(self, num):
self.data['begin'] = num
content = requests.get(self.url, headers=self.headers, params=self.data).json()
return content
def get_total(self):
self.data['begin'] = 0
content = requests.get(self.url, headers=self.headers, params=self.data).json()
total = content['app_msg_cnt']
if total % 5:
return int(total / 5) + 1
else:
return int(total / 5)
@staticmethod
def convert_2_time(stamp):
return time.strftime("%Y-%m-%d", time.localtime(stamp))
def get_data(self):
if self.get_total():
for num in range(0, self.get_total() + 1, 5):
for data in self.parse_articles(num)['app_msg_list']:
yield {
"title": data['title'],
"create_time": self.convert_2_time(data['create_time']),
# 摘要
'digest': data['digest'],
'link': data['link']
}
time.sleep(random.randint(1, 3))
else:
print("No search item")
exit()
def write_data(result, filename):
for data in result:
print(data)
with open(filename, 'a', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False) + '\n')
4.模拟登录
我们都知道具体的操作流程。现在我们缺少两样东西,饼干和代币。我们仔细观察主页。代币随处可见。HTML代码和URL随处可见。我们可以简单地从URL获取cookies。我们可以通过selenium登录后获取cookies
一,。Cookie获取
通过selenium调用Chrome浏览器以输入用户名和密码。登录后单击“睡眠”一段时间以扫描用户的代码。登录成功后,再次访问主页并获取要写入文件的cookie(是否写入文件取决于您的个人偏好,您可以返回)
def login(username, passwd):
cookies = {}
driver = webdriver.Chrome() # 谷歌驱动
driver.get('https://mp.weixin.qq.com/')
# 用户名
driver.find_element_by_xpath('//input[@name="account"]').clear()
driver.find_element_by_xpath('//input[@name="account"]').send_keys(username)
driver.find_element_by_xpath('//input[@name="password"]').clear()
driver.find_element_by_xpath('//input[@name="password"]').send_keys(passwd)
# 登录
driver.find_element_by_xpath('//a[@class="btn_login"]').click()
time.sleep(20)
# 获取cookie
driver.get('https://mp.weixin.qq.com/')
time.sleep(5)
cookie_items = driver.get_cookies()
for cookie_item in cookie_items:
cookies[cookie_item['name']] = cookie_item['value']
with open('cookie.txt', 'w') as f:
f.write(json.dumps(cookies))
driver.close()
二,。代币获取
读取文件解析cookie,启动主页请求,并在获得令牌后将其与cookie一起返回
def get_cookie_token():
url = 'https://mp.weixin.qq.com'
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36',
'host': 'mp.weixin.qq.com',
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
result = []
for k, v in cookies.items():
result.append(k + '=' + v)
return "; ".join(result), token 查看全部
querylist采集微信公众号文章(I.素材管理II.新建图文III.超链接IV.查找文章(图)
)
使用官方帐户官方帐户获取所需信息。首先,它应该搜索其官方账户中的文章>或公共号码,并分析数据包中的信息。该过程中最重要的几点是:
1.调用接口以查找文章@>
转到主页->;物料管理->;新图形->;超链接->;查找文章@>
一,。物资管理
二,。新文本
三,。超链接
四,。查找文章@>
2.获取所有相关的官方帐户信息
输入关键字并单击搜索后,相应的数据包将显示在右侧。在这里更容易找到。选择XHR后,将只显示一个唯一的数据包
一,。查看访问参数
选择它,选择标题栏并滑动到底部以查看一系列请求参数。更重要的参数是令牌、查询(搜索关键字)、开始(起始值)和计数(每页显示的值)。您还可以在标题中看到数据的真实URL,然后向他发送请求
二,。查看数据包内容
官方帐户是官方帐户
可以查看包中返回的所有内容(通常为JSON格式),并检查内容是否与页面上的内容相对应。在这里,我们可以在返回的数据列表中看到每个官方账户的信息,包括fakeid(访问官方账户后将使用文章@>)、公众号名称、公众号和总搜索量
三,。过程分析
通过模拟登录获得cookie后,我们访问主页以获取URL上的令牌ID,并通过向捕获的数据包上的真实URL发送请求和数据来获取相应的信息。在返回的信息中,我们通过解析总量来判断总量,更改“开始翻页”的值,最后将信息写入文件
class Public(metaclass=SingletonType):
def __init__(self, search_key, token, cookie):
self.search_key = search_key
self.url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
self.headers = {
'cookie': cookie,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36'
}
self.data = {
'action': 'search_biz',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': '0.012103784566473319',
'query': self.search_key,
'count': '5'
}
def get_total(self):
self.data['begin'] = 0
content = requests.get(self.url, headers=self.headers, params=self.data).json()
total = content['total']
if total % 5:
return int(total / 5) + 1
else:
return int(total / 5)
def parse_public(self, num):
self.data['begin'] = num
content = requests.get(self.url, headers=self.headers, params=self.data).json()
return content
def get_data(self):
for num in range(0, self.get_total() + 1, 5):
for data in self.parse_public(num)['list']:
yield {
"name": data['nickname'],
"id": data['fakeid'],
'number': data['alias']
}
time.sleep(random.randint(1, 3))
def write_data(result, filename):
for data in result:
print(data)
with open(filename, 'a', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False) + '\n')
3.抓斗文章@>
在“官方帐号”下,选择相应的官方帐号并执行数据包捕获
可以查看新数据包,包括下的所有文章@>列表
I数据包捕获
二,。查看请求参数
显然,我们之前获得的伪造信息在这里使用。其他一切都和以前一样。查询也是一个搜索关键字。指定查询后,将返回相关的搜索词。如果未指定,则默认为空,并返回默认值
三,。查看数据内容
四,。过程分析
模拟登陆后获取cookie和token,fakeid可以自行获取,查阅上一部分获取官方账户信息的内容,然后将请求发送到数据包的真实URL,通过app解析返回的数据。msg_ucnt获取总量、更改开始值、翻页、获取文章@>标题、创建时间(时间戳需要转换为时间格式)、文章@>简要说明、文章@>链接等信息,最后执行写入文件操作
class Articls(metaclass=SingletonType):
def __init__(self, token, fakeid, cookie, search_key=""):
self.search_key = search_key
self.url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
self.headers = {
'cookie': cookie,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36',
'host': 'mp.weixin.qq.com',
'Connection': 'keep-alive',
'Accept': 'application/json, text/javascript, */*; q=0.01'
}
self.data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"count": "5",
"query": self.search_key,
"fakeid": fakeid,
"type": "9",
}
def parse_articles(self, num):
self.data['begin'] = num
content = requests.get(self.url, headers=self.headers, params=self.data).json()
return content
def get_total(self):
self.data['begin'] = 0
content = requests.get(self.url, headers=self.headers, params=self.data).json()
total = content['app_msg_cnt']
if total % 5:
return int(total / 5) + 1
else:
return int(total / 5)
@staticmethod
def convert_2_time(stamp):
return time.strftime("%Y-%m-%d", time.localtime(stamp))
def get_data(self):
if self.get_total():
for num in range(0, self.get_total() + 1, 5):
for data in self.parse_articles(num)['app_msg_list']:
yield {
"title": data['title'],
"create_time": self.convert_2_time(data['create_time']),
# 摘要
'digest': data['digest'],
'link': data['link']
}
time.sleep(random.randint(1, 3))
else:
print("No search item")
exit()
def write_data(result, filename):
for data in result:
print(data)
with open(filename, 'a', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False) + '\n')
4.模拟登录
我们都知道具体的操作流程。现在我们缺少两样东西,饼干和代币。我们仔细观察主页。代币随处可见。HTML代码和URL随处可见。我们可以简单地从URL获取cookies。我们可以通过selenium登录后获取cookies
一,。Cookie获取
通过selenium调用Chrome浏览器以输入用户名和密码。登录后单击“睡眠”一段时间以扫描用户的代码。登录成功后,再次访问主页并获取要写入文件的cookie(是否写入文件取决于您的个人偏好,您可以返回)
def login(username, passwd):
cookies = {}
driver = webdriver.Chrome() # 谷歌驱动
driver.get('https://mp.weixin.qq.com/')
# 用户名
driver.find_element_by_xpath('//input[@name="account"]').clear()
driver.find_element_by_xpath('//input[@name="account"]').send_keys(username)
driver.find_element_by_xpath('//input[@name="password"]').clear()
driver.find_element_by_xpath('//input[@name="password"]').send_keys(passwd)
# 登录
driver.find_element_by_xpath('//a[@class="btn_login"]').click()
time.sleep(20)
# 获取cookie
driver.get('https://mp.weixin.qq.com/')
time.sleep(5)
cookie_items = driver.get_cookies()
for cookie_item in cookie_items:
cookies[cookie_item['name']] = cookie_item['value']
with open('cookie.txt', 'w') as f:
f.write(json.dumps(cookies))
driver.close()
二,。代币获取
读取文件解析cookie,启动主页请求,并在获得令牌后将其与cookie一起返回
def get_cookie_token():
url = 'https://mp.weixin.qq.com'
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/74.0.3729.169 Safari/537.36',
'host': 'mp.weixin.qq.com',
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
result = []
for k, v in cookies.items():
result.append(k + '=' + v)
return "; ".join(result), token
querylist采集微信公众号文章(注册一下微信公众号里的内容百度可是没收录的 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2021-09-26 01:11
)
由于微信流量封闭,很难轻易看到微信内容。为了攀登微信公众号的文章,一些网民用Python实现了这一点。让我们看看他的实现思想和代码。要知道微信公众号的内容,百度不是收录,但如果可以做到的话,它是非常扭曲的。p>
开发工具
思路
首先启动uuURL=“,扫描代码注册微信公共平台,如果有,直接忽略,扫描代码登录。(只需注册个人订阅号),使用selenium自动操作代码扫描登录获取cookie值,然后用cookie响应
要先下载webdriver插件,请下载相应的Google浏览器版本。下载后,您将获得chromedriver.exe,然后将chromedriver.exe放在python解释器的python.exe文件的同级目录中。作为响应,返回web源代码和令牌值。令牌值为时效
首先打开官方帐户并在编辑文本时打开超链接。p>
抓取微信公众号文章
用Python
抓取微信公众号文章
用Python
抓取微信公众号文章
用Python
按F12查看与官方帐户对应的伪造值。p>
抓取微信公众号文章
用Python
抓取微信公众号文章
用Python
翻开页面以打开标题并返回第一页的URL地址
第2页地址
找到法律和法规
# !/usr/bin/nev python
# -*-coding:utf8-*-
import tkinter as tk
from selenium import webdriver
import time, re, jsonpath, xlwt
from requests_html import HTMLSession
session = HTMLSession()
class GZHSpider(object):
def __init__(self):
"""定义可视化窗口,并设置窗口和主题大小布局"""
self.window = tk.Tk()
self.window.title('公众号信息采集')
self.window.geometry('800x600')
"""创建label_user按钮,与说明书"""
self.label_user = tk.Label(self.window, text='需要爬取的公众号:', font=('Arial', 12), width=30, height=2)
self.label_user.pack()
"""创建label_user关联输入"""
self.entry_user = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_user.pack(after=self.label_user)
"""创建label_passwd按钮,与说明书"""
self.label_passwd = tk.Label(self.window, text="爬取多少页:(小于100)", font=('Arial', 12), width=30, height=2)
self.label_passwd.pack()
"""创建label_passwd关联输入"""
self.entry_passwd = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_passwd.pack(after=self.label_passwd)
"""创建Text富文本框,用于按钮操作结果的展示"""
self.text1 = tk.Text(self.window, font=('Arial', 12), width=85, height=22)
self.text1.pack()
"""定义按钮1,绑定触发事件方法"""
self.button_1 = tk.Button(self.window, text='爬取', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_1)
self.button_1.pack(before=self.text1)
"""定义按钮2,绑定触发事件方法"""
self.button_2 = tk.Button(self.window, text='清除', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_2)
self.button_2.pack(anchor="e")
def parse_hit_click_1(self):
"""定义触发事件1,调用main函数"""
user_name = self.entry_user.get()
pass_wd = int(self.entry_passwd.get())
self.main(user_name, pass_wd)
def main(self, user_name, pass_wd):
# 网页登录
driver_path = r'D:\python\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
driver.get('https://mp.weixin.qq.com/')
time.sleep(2)
# 网页最大化
driver.maximize_window()
# 拿微信扫描登录
time.sleep(20)
# 获得登录的cookies
cookies_list = driver.get_cookies()
# 转化成能用的cookie格式
cookie = [item["name"] + "=" + item["value"] for item in cookies_list]
cookie_str = '; '.join(item for item in cookie)
# 请求头
headers_1 = {
'cookie': cookie_str,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.77 Safari/537.36'
}
# 起始地址
start_url = 'https://mp.weixin.qq.com/'
response = session.get(start_url, headers=headers_1).content.decode()
# 拿到token值,token值是有时效性的
token = re.findall(r'token=(\d+)', response)[0]
# 搜索出所有跟输入的公众号有关的
next_url = f'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={user_name}&token=' \
f'{token}&lang=zh_CN&f=json&ajax=1'
# 获取响应
response_1 = session.get(next_url, headers=headers_1).content.decode()
# 拿到fakeid的值,确定公众号,唯一的
fakeid = re.findall(r'"fakeid":"(.*?)",', response_1)[0]
# 构造公众号的url地址
next_url_2 = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
headers_2 = {
'cookie': cookie_str,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.77 Safari/537.36',
'referer': f'https://mp.weixin.qq.com/cgi-bin/appmsgtemplate?action=edit&lang=zh_CN&token={token}',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'x-requested-with': 'XMLHttpRequest'
}
# 表的创建
workbook = xlwt.Workbook(encoding='gbk', style_compression=0)
sheet = workbook.add_sheet('test', cell_overwrite_ok=True)
j = 1
# 构造表头
sheet.write(0, 0, '时间')
sheet.write(0, 1, '标题')
sheet.write(0, 2, '地址')
# 循环翻页
for i in range(pass_wd):
data["begin"] = i * 5
time.sleep(3)
# 获取响应的json数据
response_2 = session.get(next_url_2, params=data, headers=headers_2).json()
# jsonpath 获取时间,标题,地址
title_list = jsonpath.jsonpath(response_2, '$..title')
url_list = jsonpath.jsonpath(response_2, '$..link')
create_time_list = jsonpath.jsonpath(response_2, '$..create_time')
# 将时间戳转化为北京时间
list_1 = []
for create_time in create_time_list:
time_local = time.localtime(int(create_time))
time_1 = time.strftime("%Y-%m-%d", time_local)
time_2 = time.strftime("%H:%M:%S", time_local)
time_3 = time_1 + ' ' + time_2
list_1.append(time_3)
# for循环遍历
for times, title, url in zip(list_1, title_list, url_list):
# 其中的'0-行, 0-列'指定表中的单元
sheet.write(j, 0, times)
sheet.write(j, 1, title)
sheet.write(j, 2, url)
j = j + 1
# 窗口显示进程
self.text1.insert("insert", f'*****************第{i+1}页爬取成功*****************')
time.sleep(2)
self.text1.insert("insert", '\n ')
self.text1.insert("insert", '\n ')
# 最后保存成功
workbook.save(f'{user_name}公众号信息.xls')
print(f"*********{user_name}公众号信息保存成功*********")
def parse_hit_click_2(self):
"""定义触发事件2,删除文本框中内容"""
self.entry_user.delete(0, "end")
self.entry_passwd.delete(0, "end")
self.text1.delete("1.0", "end")
def center(self):
"""创建窗口居中函数方法"""
ws = self.window.winfo_screenwidth()
hs = self.window.winfo_screenheight()
x = int((ws / 2) - (800 / 2))
y = int((hs / 2) - (600 / 2))
self.window.geometry('{}x{}+{}+{}'.format(800, 600, x, y))
def run_loop(self):
"""禁止修改窗体大小规格"""
self.window.resizable(False, False)
"""窗口居中"""
self.center()
"""窗口维持--持久化"""
self.window.mainloop()
if __name__ == '__main__':
g = GZHSpider()
g.run_loop() 查看全部
querylist采集微信公众号文章(注册一下微信公众号里的内容百度可是没收录的
)
由于微信流量封闭,很难轻易看到微信内容。为了攀登微信公众号的文章,一些网民用Python实现了这一点。让我们看看他的实现思想和代码。要知道微信公众号的内容,百度不是收录,但如果可以做到的话,它是非常扭曲的。p>
开发工具
思路
首先启动uuURL=“,扫描代码注册微信公共平台,如果有,直接忽略,扫描代码登录。(只需注册个人订阅号),使用selenium自动操作代码扫描登录获取cookie值,然后用cookie响应
要先下载webdriver插件,请下载相应的Google浏览器版本。下载后,您将获得chromedriver.exe,然后将chromedriver.exe放在python解释器的python.exe文件的同级目录中。作为响应,返回web源代码和令牌值。令牌值为时效
首先打开官方帐户并在编辑文本时打开超链接。p>
https://www.daimadog.com/wp-co ... 8.png 440w, https://www.daimadog.com/wp-co ... 0.png 768w, https://www.daimadog.com/wp-co ... 3.png 1362w" />抓取微信公众号文章
用Python
https://www.daimadog.com/wp-co ... 8.png 440w, https://www.daimadog.com/wp-co ... 2.png 768w" />抓取微信公众号文章
用Python
https://www.daimadog.com/wp-co ... 4.png 440w, https://www.daimadog.com/wp-co ... 1.png 768w" />抓取微信公众号文章
用Python
按F12查看与官方帐户对应的伪造值。p>
https://www.daimadog.com/wp-co ... 3.png 440w, https://www.daimadog.com/wp-co ... 9.png 768w, https://www.daimadog.com/wp-co ... 6.png 1365w" />抓取微信公众号文章
用Python
https://www.daimadog.com/wp-co ... 9.png 440w, https://www.daimadog.com/wp-co ... 8.png 768w, https://www.daimadog.com/wp-co ... 6.png 1364w" />抓取微信公众号文章
用Python
翻开页面以打开标题并返回第一页的URL地址
第2页地址
找到法律和法规
# !/usr/bin/nev python
# -*-coding:utf8-*-
import tkinter as tk
from selenium import webdriver
import time, re, jsonpath, xlwt
from requests_html import HTMLSession
session = HTMLSession()
class GZHSpider(object):
def __init__(self):
"""定义可视化窗口,并设置窗口和主题大小布局"""
self.window = tk.Tk()
self.window.title('公众号信息采集')
self.window.geometry('800x600')
"""创建label_user按钮,与说明书"""
self.label_user = tk.Label(self.window, text='需要爬取的公众号:', font=('Arial', 12), width=30, height=2)
self.label_user.pack()
"""创建label_user关联输入"""
self.entry_user = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_user.pack(after=self.label_user)
"""创建label_passwd按钮,与说明书"""
self.label_passwd = tk.Label(self.window, text="爬取多少页:(小于100)", font=('Arial', 12), width=30, height=2)
self.label_passwd.pack()
"""创建label_passwd关联输入"""
self.entry_passwd = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_passwd.pack(after=self.label_passwd)
"""创建Text富文本框,用于按钮操作结果的展示"""
self.text1 = tk.Text(self.window, font=('Arial', 12), width=85, height=22)
self.text1.pack()
"""定义按钮1,绑定触发事件方法"""
self.button_1 = tk.Button(self.window, text='爬取', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_1)
self.button_1.pack(before=self.text1)
"""定义按钮2,绑定触发事件方法"""
self.button_2 = tk.Button(self.window, text='清除', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_2)
self.button_2.pack(anchor="e")
def parse_hit_click_1(self):
"""定义触发事件1,调用main函数"""
user_name = self.entry_user.get()
pass_wd = int(self.entry_passwd.get())
self.main(user_name, pass_wd)
def main(self, user_name, pass_wd):
# 网页登录
driver_path = r'D:\python\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
driver.get('https://mp.weixin.qq.com/')
time.sleep(2)
# 网页最大化
driver.maximize_window()
# 拿微信扫描登录
time.sleep(20)
# 获得登录的cookies
cookies_list = driver.get_cookies()
# 转化成能用的cookie格式
cookie = [item["name"] + "=" + item["value"] for item in cookies_list]
cookie_str = '; '.join(item for item in cookie)
# 请求头
headers_1 = {
'cookie': cookie_str,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.77 Safari/537.36'
}
# 起始地址
start_url = 'https://mp.weixin.qq.com/'
response = session.get(start_url, headers=headers_1).content.decode()
# 拿到token值,token值是有时效性的
token = re.findall(r'token=(\d+)', response)[0]
# 搜索出所有跟输入的公众号有关的
next_url = f'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={user_name}&token=' \
f'{token}&lang=zh_CN&f=json&ajax=1'
# 获取响应
response_1 = session.get(next_url, headers=headers_1).content.decode()
# 拿到fakeid的值,确定公众号,唯一的
fakeid = re.findall(r'"fakeid":"(.*?)",', response_1)[0]
# 构造公众号的url地址
next_url_2 = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
headers_2 = {
'cookie': cookie_str,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.77 Safari/537.36',
'referer': f'https://mp.weixin.qq.com/cgi-bin/appmsgtemplate?action=edit&lang=zh_CN&token={token}',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'x-requested-with': 'XMLHttpRequest'
}
# 表的创建
workbook = xlwt.Workbook(encoding='gbk', style_compression=0)
sheet = workbook.add_sheet('test', cell_overwrite_ok=True)
j = 1
# 构造表头
sheet.write(0, 0, '时间')
sheet.write(0, 1, '标题')
sheet.write(0, 2, '地址')
# 循环翻页
for i in range(pass_wd):
data["begin"] = i * 5
time.sleep(3)
# 获取响应的json数据
response_2 = session.get(next_url_2, params=data, headers=headers_2).json()
# jsonpath 获取时间,标题,地址
title_list = jsonpath.jsonpath(response_2, '$..title')
url_list = jsonpath.jsonpath(response_2, '$..link')
create_time_list = jsonpath.jsonpath(response_2, '$..create_time')
# 将时间戳转化为北京时间
list_1 = []
for create_time in create_time_list:
time_local = time.localtime(int(create_time))
time_1 = time.strftime("%Y-%m-%d", time_local)
time_2 = time.strftime("%H:%M:%S", time_local)
time_3 = time_1 + ' ' + time_2
list_1.append(time_3)
# for循环遍历
for times, title, url in zip(list_1, title_list, url_list):
# 其中的'0-行, 0-列'指定表中的单元
sheet.write(j, 0, times)
sheet.write(j, 1, title)
sheet.write(j, 2, url)
j = j + 1
# 窗口显示进程
self.text1.insert("insert", f'*****************第{i+1}页爬取成功*****************')
time.sleep(2)
self.text1.insert("insert", '\n ')
self.text1.insert("insert", '\n ')
# 最后保存成功
workbook.save(f'{user_name}公众号信息.xls')
print(f"*********{user_name}公众号信息保存成功*********")
def parse_hit_click_2(self):
"""定义触发事件2,删除文本框中内容"""
self.entry_user.delete(0, "end")
self.entry_passwd.delete(0, "end")
self.text1.delete("1.0", "end")
def center(self):
"""创建窗口居中函数方法"""
ws = self.window.winfo_screenwidth()
hs = self.window.winfo_screenheight()
x = int((ws / 2) - (800 / 2))
y = int((hs / 2) - (600 / 2))
self.window.geometry('{}x{}+{}+{}'.format(800, 600, x, y))
def run_loop(self):
"""禁止修改窗体大小规格"""
self.window.resizable(False, False)
"""窗口居中"""
self.center()
"""窗口维持--持久化"""
self.window.mainloop()
if __name__ == '__main__':
g = GZHSpider()
g.run_loop()
querylist采集微信公众号文章(querymap采集微信公众号文章地址采集商品地址(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-09-25 11:00
querylist采集微信公众号文章地址querymap采集商品地址欢迎大家积极参与哦,我们会尽力完成,谢谢大家啦~如果你觉得文章还不错,也可以提供给我们哦,需要文章地址的话可以私信我哦(*∩_∩*)你有什么好奇怪的问题也可以提哦,比如我querymap完没有进展?想看一下querymap是如何实现的,想看一下querymap做了哪些优化?有什么技术上的问题也可以问呢,我们也会尽力回答你的呢,点点滴滴,一定有收获!关注我们,我们下篇文章,见!。
没写过xml,直接用了java的querymap,单页面的话建议用个java组件。
分词可以用jieba,分词的性能还是非常不错的。
要想回答你的问题,先要了解哪个部分用到xml,现在搜索的用到的其实是es。
1、电商综合服务等相关服务,涵盖了购物车、仓库、发货等等。
2、类目中心,包含了类目、价格等等。
3、品牌中心,主要包含三点,一个是品牌、一个是产品、一个是故事。
4、品牌故事,包含大品牌故事、创始人背景等等。
5、消费者故事,主要针对消费者来进行分析的。接下来需要做的就是进行查询,querymap就是一个只处理xml字符串的方法,一般你第一个方法输入的是url或者http请求,数据交给es先进行处理,用来分析数据,结果再返回给你。有点像面向对象的api开发。用法可以查看elasticsearches.pool.querymap(url);当然你可以根据自己业务进行修改。 查看全部
querylist采集微信公众号文章(querymap采集微信公众号文章地址采集商品地址(组图))
querylist采集微信公众号文章地址querymap采集商品地址欢迎大家积极参与哦,我们会尽力完成,谢谢大家啦~如果你觉得文章还不错,也可以提供给我们哦,需要文章地址的话可以私信我哦(*∩_∩*)你有什么好奇怪的问题也可以提哦,比如我querymap完没有进展?想看一下querymap是如何实现的,想看一下querymap做了哪些优化?有什么技术上的问题也可以问呢,我们也会尽力回答你的呢,点点滴滴,一定有收获!关注我们,我们下篇文章,见!。
没写过xml,直接用了java的querymap,单页面的话建议用个java组件。
分词可以用jieba,分词的性能还是非常不错的。
要想回答你的问题,先要了解哪个部分用到xml,现在搜索的用到的其实是es。
1、电商综合服务等相关服务,涵盖了购物车、仓库、发货等等。
2、类目中心,包含了类目、价格等等。
3、品牌中心,主要包含三点,一个是品牌、一个是产品、一个是故事。
4、品牌故事,包含大品牌故事、创始人背景等等。
5、消费者故事,主要针对消费者来进行分析的。接下来需要做的就是进行查询,querymap就是一个只处理xml字符串的方法,一般你第一个方法输入的是url或者http请求,数据交给es先进行处理,用来分析数据,结果再返回给你。有点像面向对象的api开发。用法可以查看elasticsearches.pool.querymap(url);当然你可以根据自己业务进行修改。
querylist采集微信公众号文章(Q&;A():.find_element_by_xpath)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-09-22 03:05
一.ideas
我们通过网页上微信公共平台的图形信息中的超链接获得我们需要的界面图形信息
超链接
从界面可以得到相应的微信公众号和相应的微信公众号文章. p>
二.界面分析
获取微信公众号界面:
参数:
动作=搜索业务
开始=0
计数=5
query=正式帐户名
令牌=对应于每个帐户的令牌值
lang=zh\ucn
f=json
ajax=1
请求方法:
得到
所以这个界面只需要token,查询的是您需要搜索的官方账号,登录后可以通过网页获取token。p>
微信公众号
获取官方账号对应的文章接口:
参数:
动作=列表uux
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
质疑=
令牌=557131216
lang=zh\ucn
f=json
ajax=1
请求方法:
得到
在这个接口中,我们需要获得上一步的令牌和fakeid,这个fakeid可以在第一个接口中获得。所以我们可以得到微信公众号的数据文章. p>
微信公众号
三.实现
步骤1:
首先,我们需要通过selenium模拟登录,然后获得cookie和相应的令牌
def微信登录(用户、密码):
post={}
browser=webdriver.Chrome()
browser.get('#39;)
睡眠(3)
browser.delete_all_cookies()
睡眠(2)
#单击以切换到帐户密码输入
浏览器。通过xpath(//a[@class='login\uuuuuu type\uuuu container\uuuu select-type'])查找元素。单击()
睡眠(2)
#模拟用户点击
input\u user=browser。通过xpath(//input[@name='account'])查找元素
输入用户。发送密钥(用户)
input_password=browser。通过xpath(//input[@name='password'])查找_元素
输入密码。发送密钥(密码)
睡眠(2)
#单击登录
浏览器。通过xpath(//a[@class='btn\u login'])查找元素。单击()
睡眠(2)
#微信登录验证
打印('请扫描二维码')
睡眠(20)
#刷新当前页面
browser.get('#39;)
睡眠(5)
#获取指向当前网页的链接
url=browser.current\u url
#获取当前cookie
cookies=浏览器。获取cookies()
对于Cookie中的项目:
post[项目['name']]=项目['value']
#转换为字符串
cookie_str=json.dumps(post)
#本地存储
将open('cookie.txt','w+',encoding='utf-8')作为f:
f、 写入(cookie_str)
打印('成功在本地保存cookie')
#切片当前网页链接并获取令牌
paramList=url.strip().split(“?”)[1]。split(“&;”)
#定义一个字典来存储数据
paramdict={}
对于列表中的项目:
参数[item.split('=')[0]]=item.split('=')[1]
#返回令牌
返回参数['token']
定义登录方式,参数为登录账号和密码,然后定义字典存储cookie值,模拟用户输入相应账号密码,点击登录,出现扫码验证,登录微信即可扫描代码
刷新当前网页后,获取当前cookie和令牌,然后返回
步骤2:
1.请求获取相应的官方账户界面并获取伪造ID
我们需要
url='#39
标题={
“主持人”:“
“用户代理”:“Mozilla/5.0(Windows NT10.0;Win64;x64)AppleWebKit/537.36(KHTML,像壁虎)铬/86.0.424 0.183狩猎/537.36 Edg/86.0.62 2.63"
}
将open('cookie.txt','r',encoding='utf-8')作为f:
cookie=f.read()
cookies=json.loads(cookie)
resp=requests.get(url=url,headers=headers,cookies=cookies)
搜索url='#39
参数={
“操作”:“搜索业务”
“开始”:“0”
“计数”:“5”
“查询”:搜索正式帐户名
“令牌”:令牌
"郎":"zh_CN",
‘f’:‘json’
“ajax”:“1”
}
search_resp=requests.get(url=search_url,cookies=cookies,headers=headers,params=params)
引入我们获得的令牌和cookie,然后返回JSON数据
通过requests.get request获取微信公众号
lists=search_resp.json().get('list')[0]
一,
,通过上面的代码,您可以得到相应的官方账户数据
fakeid=lists.get('fakeid')
一,
通过上述代码可以获得相应的伪造ID
2.请求获取微信官方账号文章接口,获取文章数据
我们需要
appmsg_url='#39
参数u数据={
“操作”:“列表”
“开始”:“0”
“计数”:“5”
"假":假,
“类型”:“9”
“查询”:“
“令牌”:令牌
"郎":"zh_CN",
‘f’:‘json’
“ajax”:“1”
}
appmsg_resp=requests.get(url=appmsg_url,cookies=cookies,headers=headers,params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口来获取返回的JSON数据
我们已经实现了微信公众号的爬网文章.
四.summary
通过微信官方账号文章爬行,需要掌握selenium的用法和请求,以及如何获取请求界面。但需要注意的是,当我们循环获取文章时,必须设置延迟时间,否则账号很容易被阻塞,无法获取返回的数据 查看全部
querylist采集微信公众号文章(Q&;A():.find_element_by_xpath)
一.ideas
我们通过网页上微信公共平台的图形信息中的超链接获得我们需要的界面图形信息
超链接
从界面可以得到相应的微信公众号和相应的微信公众号文章. p>
二.界面分析
获取微信公众号界面:
参数:
动作=搜索业务
开始=0
计数=5
query=正式帐户名
令牌=对应于每个帐户的令牌值
lang=zh\ucn
f=json
ajax=1
请求方法:
得到
所以这个界面只需要token,查询的是您需要搜索的官方账号,登录后可以通过网页获取token。p>
微信公众号
获取官方账号对应的文章接口:
参数:
动作=列表uux
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
质疑=
令牌=557131216
lang=zh\ucn
f=json
ajax=1
请求方法:
得到
在这个接口中,我们需要获得上一步的令牌和fakeid,这个fakeid可以在第一个接口中获得。所以我们可以得到微信公众号的数据文章. p>
微信公众号
三.实现
步骤1:
首先,我们需要通过selenium模拟登录,然后获得cookie和相应的令牌
def微信登录(用户、密码):
post={}
browser=webdriver.Chrome()
browser.get('#39;)
睡眠(3)
browser.delete_all_cookies()
睡眠(2)
#单击以切换到帐户密码输入
浏览器。通过xpath(//a[@class='login\uuuuuu type\uuuu container\uuuu select-type'])查找元素。单击()
睡眠(2)
#模拟用户点击
input\u user=browser。通过xpath(//input[@name='account'])查找元素
输入用户。发送密钥(用户)
input_password=browser。通过xpath(//input[@name='password'])查找_元素
输入密码。发送密钥(密码)
睡眠(2)
#单击登录
浏览器。通过xpath(//a[@class='btn\u login'])查找元素。单击()
睡眠(2)
#微信登录验证
打印('请扫描二维码')
睡眠(20)
#刷新当前页面
browser.get('#39;)
睡眠(5)
#获取指向当前网页的链接
url=browser.current\u url
#获取当前cookie
cookies=浏览器。获取cookies()
对于Cookie中的项目:
post[项目['name']]=项目['value']
#转换为字符串
cookie_str=json.dumps(post)
#本地存储
将open('cookie.txt','w+',encoding='utf-8')作为f:
f、 写入(cookie_str)
打印('成功在本地保存cookie')
#切片当前网页链接并获取令牌
paramList=url.strip().split(“?”)[1]。split(“&;”)
#定义一个字典来存储数据
paramdict={}
对于列表中的项目:
参数[item.split('=')[0]]=item.split('=')[1]
#返回令牌
返回参数['token']
定义登录方式,参数为登录账号和密码,然后定义字典存储cookie值,模拟用户输入相应账号密码,点击登录,出现扫码验证,登录微信即可扫描代码
刷新当前网页后,获取当前cookie和令牌,然后返回
步骤2:
1.请求获取相应的官方账户界面并获取伪造ID
我们需要
url='#39
标题={
“主持人”:“
“用户代理”:“Mozilla/5.0(Windows NT10.0;Win64;x64)AppleWebKit/537.36(KHTML,像壁虎)铬/86.0.424 0.183狩猎/537.36 Edg/86.0.62 2.63"
}
将open('cookie.txt','r',encoding='utf-8')作为f:
cookie=f.read()
cookies=json.loads(cookie)
resp=requests.get(url=url,headers=headers,cookies=cookies)
搜索url='#39
参数={
“操作”:“搜索业务”
“开始”:“0”
“计数”:“5”
“查询”:搜索正式帐户名
“令牌”:令牌
"郎":"zh_CN",
‘f’:‘json’
“ajax”:“1”
}
search_resp=requests.get(url=search_url,cookies=cookies,headers=headers,params=params)
引入我们获得的令牌和cookie,然后返回JSON数据
通过requests.get request获取微信公众号
lists=search_resp.json().get('list')[0]
一,
,通过上面的代码,您可以得到相应的官方账户数据
fakeid=lists.get('fakeid')
一,
通过上述代码可以获得相应的伪造ID
2.请求获取微信官方账号文章接口,获取文章数据
我们需要
appmsg_url='#39
参数u数据={
“操作”:“列表”
“开始”:“0”
“计数”:“5”
"假":假,
“类型”:“9”
“查询”:“
“令牌”:令牌
"郎":"zh_CN",
‘f’:‘json’
“ajax”:“1”
}
appmsg_resp=requests.get(url=appmsg_url,cookies=cookies,headers=headers,params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口来获取返回的JSON数据
我们已经实现了微信公众号的爬网文章.
四.summary
通过微信官方账号文章爬行,需要掌握selenium的用法和请求,以及如何获取请求界面。但需要注意的是,当我们循环获取文章时,必须设置延迟时间,否则账号很容易被阻塞,无法获取返回的数据
querylist采集微信公众号文章(如何通过微信公众号后台的“超链接”功能进行爬取 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 366 次浏览 • 2021-09-19 01:06
)
PS:如果你需要Python学习材料,你可以点击下面的链接自己获取
爬行的方法有很多
。今天,我们分享一种更简单的方式,通过微信官方账号的超链接功能爬行。可能一些好友合作伙伴还没有接触到微信公众号的背景。这是一张给你看的照片
在这里,一些好友可能会说,“我不能登录到官方帐户。什么?”p>
没关系。每次我们想要得到我们想要的结果时,Buddy都是我们的目标,但这不是我们研究的重点。我们关注爬行动物的过程,我们是如何获得目标数据的,所以我们不能登录到官方的后台帐号。在阅读此文章之后,我们可能无法获得最终的爬网结果。但是在阅读了这篇文章文章之后,你也会有所收获
一、初步准备
选择正式帐号
为了爬行
点击超链接-进入编辑超链接界面-输入搜索官方账号
我们需要爬
今天我们以官方账户“数据分析”为例进行介绍
谢谢你
点击官方账户查看每个文章对应的标题信息
我们的目标是获取文章标题和相应的链接
二、开始爬行
爬虫三部曲:
1、请求网页
首先,导入此爬虫程序所需的第三方库
import re#用来解析网页
import requests#用来请求网页
import csv#用来保存数据
import time#用来设置每次爬取间隔的时间
找到我们抓取的目标数据的位置,点击搜索得到的包,得到目标网站和请求头信息
请求网页
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': 'pgv_pvi=2389011456; RK=x4Sdy3WsT4; ptcz=4a2fe0ffda6742a230c94f168291afcce2bd001e5d6615132b55da90559cd463; pgv_pvid=6989331736; _ga=GA1.2.735850052.1585832762; ptui_loginuin=1207020736; ua_id=iJuK7hnHjcUE0e2dAAAAAHzCRcatCWOiHc-hdkhSDL4=; __guid=166713058.1972731636944397800.1590316882436.5461; openid2ticket_oY8wqwesgvgkdQ69wUeM5UxhOV5c=ION52/k2w4M3o44iht5BRt5yCyxP/3IaRXJ84RIpRZA=; mm_lang=zh_CN; pac_uid=0_5ecd1592971c3; uin=o1240069166; [email protected]; pgv_info=ssid=s4875389884; pgv_si=s8410697728; uuid=62839906b2a77b5f098cd91979af8b33; rand_info=CAESIC53TQFCwjIe4ZsrTRKvSs+ocfs4UTsj9swrrNwosjCd; slave_bizuin=3240807523; data_bizuin=3240807523; bizuin=3240807523; data_ticket=AiTk/OFWXCKxhaenCvEuP06mwWTI6YqCyt+74hoaXaNtKBbcnq//ZTXHzqByMhK6; slave_sid=YndxeFhCSkU5OUJtdFYycW9zN29FcG51NU5GNElBM3I2RF9wVjJBRGx2bWxrTXdiMDZFYzllUWNaMlN4N0RsOTlVMDRxZFZEMjJXdlRZcXBVOGptQ2ZDSVZiOEJlQW5BZDVCWlkzSnJ6WWNPWVRiN1J0cldCd0pvbTc3RGRiMm9pZ3ZISTl6WWhDUmNCZ2s3; slave_user=gh_5d822fe7fd08; xid=9794daa60db66fcf7a65c4054e3d68ce; mmad_session=43d4e5247a6b025b67ba3abd48d27a309ec4713911b6ef6f23cddb4b9953e771354ad1572fbc3fa895051725e95abb887cf2d03e9864084974db75c8588189699ea5b20b8fe35073831446ef98d24de600f107fe69d79646a3dd2907ab712e1f11de1c56c245721266e7088080fefde3; ts_last=mp.weixin.qq.com/cgi-bin/frame; ts_uid=1963034896; monitor_count=15'
}#请求头信息,这里cookie信息必须添加,否则得不到网页信息
url='https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=0&count=5&fakeid=MjM5MjAxMDM4MA==&type=9&query=&token=59293242&lang=zh_CN&f=json&ajax=1'
response=requests.get(url,headers=headers)#得到响应内容
response.encoding='utf-8'#设置响应内容为utf-8格式
html=response.text#得到网页的文本形式
print(html)
此处的请求标头信息必须与cookie信息一起添加,否则无法获取网页信息
该网页的请求结果如下图所示。红色框表示我们需要的文章标题和文章链接
2、parse网页
从网页响应结果可以看出,每个文章文章的标题和链接分别位于“title”标记和“cover”标记后面,因此我们可以使用正则表达式直接解析它们
title=re.findall('"title":"(.*?)"',html)#得到文章标题
cover=re.findall('"cover":"(.*?)"',html)#得到文章链接
all=zip(title,cover)#利用zip方法,将两个列表中的数据一一对应
print(list(all))#list是对zip方法得到的数据进行解压
分析结果如下
3、保存数据
for data in all:#for循环遍历列表
time.sleep(3)#每爬取一篇文章间隔3秒,以防触发反爬
with open('C:\\Users\\Administrator\\Desktop\\爬取公众号文章.csv','a',encoding='utf-8-sig') as file:
#将数据保存到桌面
write=csv.writer(file)
write.writerow(data)
到目前为止,爬虫程序已经完成。让我们看一下最终结果
完整代码
import re#用来解析网页
import requests#用来请求网页
import csv#用来保存数据
import time#用来设置每次爬取间隔的时间
# 请求网页
index=0
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': 'pgv_pvi=2389011456; RK=x4Sdy3WsT4; ptcz=4a2fe0ffda6742a230c94f168291afcce2bd001e5d6615132b55da90559cd463; pgv_pvid=6989331736; _ga=GA1.2.735850052.1585832762; ptui_loginuin=1207020736; ua_id=iJuK7hnHjcUE0e2dAAAAAHzCRcatCWOiHc-hdkhSDL4=; __guid=166713058.1972731636944397800.1590316882436.5461; openid2ticket_oY8wqwesgvgkdQ69wUeM5UxhOV5c=ION52/k2w4M3o44iht5BRt5yCyxP/3IaRXJ84RIpRZA=; mm_lang=zh_CN; pac_uid=0_5ecd1592971c3; uin=o1240069166; [email protected]; pgv_info=ssid=s4875389884; pgv_si=s8410697728; uuid=62839906b2a77b5f098cd91979af8b33; rand_info=CAESIC53TQFCwjIe4ZsrTRKvSs+ocfs4UTsj9swrrNwosjCd; slave_bizuin=3240807523; data_bizuin=3240807523; bizuin=3240807523; data_ticket=AiTk/OFWXCKxhaenCvEuP06mwWTI6YqCyt+74hoaXaNtKBbcnq//ZTXHzqByMhK6; slave_sid=YndxeFhCSkU5OUJtdFYycW9zN29FcG51NU5GNElBM3I2RF9wVjJBRGx2bWxrTXdiMDZFYzllUWNaMlN4N0RsOTlVMDRxZFZEMjJXdlRZcXBVOGptQ2ZDSVZiOEJlQW5BZDVCWlkzSnJ6WWNPWVRiN1J0cldCd0pvbTc3RGRiMm9pZ3ZISTl6WWhDUmNCZ2s3; slave_user=gh_5d822fe7fd08; xid=9794daa60db66fcf7a65c4054e3d68ce; mmad_session=43d4e5247a6b025b67ba3abd48d27a309ec4713911b6ef6f23cddb4b9953e771354ad1572fbc3fa895051725e95abb887cf2d03e9864084974db75c8588189699ea5b20b8fe35073831446ef98d24de600f107fe69d79646a3dd2907ab712e1f11de1c56c245721266e7088080fefde3; ts_last=mp.weixin.qq.com/cgi-bin/frame; ts_uid=1963034896; monitor_count=15'
}#请求头信息,这里cookie信息必须添加,否则得不到网页信息
for i in range(2):#设置for循环实现翻页,爬取多页内容,这里range括号内的参数可以更改
url='https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin='+str(index)+'&count=5&fakeid=MjM5MjAxMDM4MA==&type=9&query=&token=59293242&lang=zh_CN&f=json&ajax=1'
response=requests.get(url,headers=headers)#得到响应内容
response.encoding='utf-8'#设置响应内容为utf-8格式
html=response.text#得到网页的文本形式
# 解析网页
title=re.findall('"title":"(.*?)"',html)#得到文章标题
cover=re.findall('"cover":"(.*?)"',html)#得到文章链接
all=zip(title,cover)#利用zip方法,将两个列表中的数据一一对应
# print(list(all))#list是对zip方法得到的数据进行解压
# 保存数据
for data in all:#for循环遍历列表
time.sleep(3)#每爬取一篇文章间隔3秒,以防出发反爬
with open('C:\\Users\\Administrator\\Desktop\\爬取公众号文章.csv','a',encoding='utf-8-sig') as file:
#将数据保存到桌面
write=csv.writer(file)
write.writerow(data)
pass
pass
index += 5 查看全部
querylist采集微信公众号文章(如何通过微信公众号后台的“超链接”功能进行爬取
)
PS:如果你需要Python学习材料,你可以点击下面的链接自己获取
爬行的方法有很多
。今天,我们分享一种更简单的方式,通过微信官方账号的超链接功能爬行。可能一些好友合作伙伴还没有接触到微信公众号的背景。这是一张给你看的照片
在这里,一些好友可能会说,“我不能登录到官方帐户。什么?”p>
没关系。每次我们想要得到我们想要的结果时,Buddy都是我们的目标,但这不是我们研究的重点。我们关注爬行动物的过程,我们是如何获得目标数据的,所以我们不能登录到官方的后台帐号。在阅读此文章之后,我们可能无法获得最终的爬网结果。但是在阅读了这篇文章文章之后,你也会有所收获
一、初步准备
选择正式帐号
为了爬行
点击超链接-进入编辑超链接界面-输入搜索官方账号
我们需要爬
今天我们以官方账户“数据分析”为例进行介绍
谢谢你
点击官方账户查看每个文章对应的标题信息
我们的目标是获取文章标题和相应的链接
二、开始爬行
爬虫三部曲:
1、请求网页
首先,导入此爬虫程序所需的第三方库
import re#用来解析网页
import requests#用来请求网页
import csv#用来保存数据
import time#用来设置每次爬取间隔的时间
找到我们抓取的目标数据的位置,点击搜索得到的包,得到目标网站和请求头信息
请求网页
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': 'pgv_pvi=2389011456; RK=x4Sdy3WsT4; ptcz=4a2fe0ffda6742a230c94f168291afcce2bd001e5d6615132b55da90559cd463; pgv_pvid=6989331736; _ga=GA1.2.735850052.1585832762; ptui_loginuin=1207020736; ua_id=iJuK7hnHjcUE0e2dAAAAAHzCRcatCWOiHc-hdkhSDL4=; __guid=166713058.1972731636944397800.1590316882436.5461; openid2ticket_oY8wqwesgvgkdQ69wUeM5UxhOV5c=ION52/k2w4M3o44iht5BRt5yCyxP/3IaRXJ84RIpRZA=; mm_lang=zh_CN; pac_uid=0_5ecd1592971c3; uin=o1240069166; [email protected]; pgv_info=ssid=s4875389884; pgv_si=s8410697728; uuid=62839906b2a77b5f098cd91979af8b33; rand_info=CAESIC53TQFCwjIe4ZsrTRKvSs+ocfs4UTsj9swrrNwosjCd; slave_bizuin=3240807523; data_bizuin=3240807523; bizuin=3240807523; data_ticket=AiTk/OFWXCKxhaenCvEuP06mwWTI6YqCyt+74hoaXaNtKBbcnq//ZTXHzqByMhK6; slave_sid=YndxeFhCSkU5OUJtdFYycW9zN29FcG51NU5GNElBM3I2RF9wVjJBRGx2bWxrTXdiMDZFYzllUWNaMlN4N0RsOTlVMDRxZFZEMjJXdlRZcXBVOGptQ2ZDSVZiOEJlQW5BZDVCWlkzSnJ6WWNPWVRiN1J0cldCd0pvbTc3RGRiMm9pZ3ZISTl6WWhDUmNCZ2s3; slave_user=gh_5d822fe7fd08; xid=9794daa60db66fcf7a65c4054e3d68ce; mmad_session=43d4e5247a6b025b67ba3abd48d27a309ec4713911b6ef6f23cddb4b9953e771354ad1572fbc3fa895051725e95abb887cf2d03e9864084974db75c8588189699ea5b20b8fe35073831446ef98d24de600f107fe69d79646a3dd2907ab712e1f11de1c56c245721266e7088080fefde3; ts_last=mp.weixin.qq.com/cgi-bin/frame; ts_uid=1963034896; monitor_count=15'
}#请求头信息,这里cookie信息必须添加,否则得不到网页信息
url='https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=0&count=5&fakeid=MjM5MjAxMDM4MA==&type=9&query=&token=59293242&lang=zh_CN&f=json&ajax=1'
response=requests.get(url,headers=headers)#得到响应内容
response.encoding='utf-8'#设置响应内容为utf-8格式
html=response.text#得到网页的文本形式
print(html)
此处的请求标头信息必须与cookie信息一起添加,否则无法获取网页信息
该网页的请求结果如下图所示。红色框表示我们需要的文章标题和文章链接
2、parse网页
从网页响应结果可以看出,每个文章文章的标题和链接分别位于“title”标记和“cover”标记后面,因此我们可以使用正则表达式直接解析它们
title=re.findall('"title":"(.*?)"',html)#得到文章标题
cover=re.findall('"cover":"(.*?)"',html)#得到文章链接
all=zip(title,cover)#利用zip方法,将两个列表中的数据一一对应
print(list(all))#list是对zip方法得到的数据进行解压
分析结果如下
3、保存数据
for data in all:#for循环遍历列表
time.sleep(3)#每爬取一篇文章间隔3秒,以防触发反爬
with open('C:\\Users\\Administrator\\Desktop\\爬取公众号文章.csv','a',encoding='utf-8-sig') as file:
#将数据保存到桌面
write=csv.writer(file)
write.writerow(data)
到目前为止,爬虫程序已经完成。让我们看一下最终结果
完整代码
import re#用来解析网页
import requests#用来请求网页
import csv#用来保存数据
import time#用来设置每次爬取间隔的时间
# 请求网页
index=0
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': 'pgv_pvi=2389011456; RK=x4Sdy3WsT4; ptcz=4a2fe0ffda6742a230c94f168291afcce2bd001e5d6615132b55da90559cd463; pgv_pvid=6989331736; _ga=GA1.2.735850052.1585832762; ptui_loginuin=1207020736; ua_id=iJuK7hnHjcUE0e2dAAAAAHzCRcatCWOiHc-hdkhSDL4=; __guid=166713058.1972731636944397800.1590316882436.5461; openid2ticket_oY8wqwesgvgkdQ69wUeM5UxhOV5c=ION52/k2w4M3o44iht5BRt5yCyxP/3IaRXJ84RIpRZA=; mm_lang=zh_CN; pac_uid=0_5ecd1592971c3; uin=o1240069166; [email protected]; pgv_info=ssid=s4875389884; pgv_si=s8410697728; uuid=62839906b2a77b5f098cd91979af8b33; rand_info=CAESIC53TQFCwjIe4ZsrTRKvSs+ocfs4UTsj9swrrNwosjCd; slave_bizuin=3240807523; data_bizuin=3240807523; bizuin=3240807523; data_ticket=AiTk/OFWXCKxhaenCvEuP06mwWTI6YqCyt+74hoaXaNtKBbcnq//ZTXHzqByMhK6; slave_sid=YndxeFhCSkU5OUJtdFYycW9zN29FcG51NU5GNElBM3I2RF9wVjJBRGx2bWxrTXdiMDZFYzllUWNaMlN4N0RsOTlVMDRxZFZEMjJXdlRZcXBVOGptQ2ZDSVZiOEJlQW5BZDVCWlkzSnJ6WWNPWVRiN1J0cldCd0pvbTc3RGRiMm9pZ3ZISTl6WWhDUmNCZ2s3; slave_user=gh_5d822fe7fd08; xid=9794daa60db66fcf7a65c4054e3d68ce; mmad_session=43d4e5247a6b025b67ba3abd48d27a309ec4713911b6ef6f23cddb4b9953e771354ad1572fbc3fa895051725e95abb887cf2d03e9864084974db75c8588189699ea5b20b8fe35073831446ef98d24de600f107fe69d79646a3dd2907ab712e1f11de1c56c245721266e7088080fefde3; ts_last=mp.weixin.qq.com/cgi-bin/frame; ts_uid=1963034896; monitor_count=15'
}#请求头信息,这里cookie信息必须添加,否则得不到网页信息
for i in range(2):#设置for循环实现翻页,爬取多页内容,这里range括号内的参数可以更改
url='https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin='+str(index)+'&count=5&fakeid=MjM5MjAxMDM4MA==&type=9&query=&token=59293242&lang=zh_CN&f=json&ajax=1'
response=requests.get(url,headers=headers)#得到响应内容
response.encoding='utf-8'#设置响应内容为utf-8格式
html=response.text#得到网页的文本形式
# 解析网页
title=re.findall('"title":"(.*?)"',html)#得到文章标题
cover=re.findall('"cover":"(.*?)"',html)#得到文章链接
all=zip(title,cover)#利用zip方法,将两个列表中的数据一一对应
# print(list(all))#list是对zip方法得到的数据进行解压
# 保存数据
for data in all:#for循环遍历列表
time.sleep(3)#每爬取一篇文章间隔3秒,以防出发反爬
with open('C:\\Users\\Administrator\\Desktop\\爬取公众号文章.csv','a',encoding='utf-8-sig') as file:
#将数据保存到桌面
write=csv.writer(file)
write.writerow(data)
pass
pass
index += 5

