
php网页抓取乱码
php网页抓取乱码(php网页抓取乱码怎么办?如何使用抓包工具就可以)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-02 01:01
php网页抓取乱码一般来说都是因为压缩包的缘故,我们可以进行处理,首先将压缩包解压到我们所需要的文件夹下进行打开,因为绝大多数网页都是用https协议加密的,这样就有了真实的https的密码去加密,那么对于php网页抓取来说,我们抓取起来就比较困难了,比如,你在微信上抓取朋友圈文章是不可能中文乱码的,比如一些资源,比如机房主页,但是在微信公众号就可以出现乱码,那么对于网页抓取来说,密码可以重新设置,密码有很多种,但是都有四位,长度最小是1-10,普通密码设置方法为:123456789,像11111111是不能抓取的,那么也就可以适当地进行压缩!密码必须是前三位密码是唯一的,并且必须是纯数字或字母加字母形式的,数字只能加到4-7,字母不能加到5位,同时还不能少于8个字母。
字符串可以是斜杠、空格、数字、符号;字符串可以是数字、字母、下划线、标点符号和s字母,如果该字符串中有效内容太多,则存在m+、n+和u+aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa;字符串中不能包含特殊字符,包括"、"、"、";字符串中不能存在连字符“|”;字符串中不能含有“\n”;在获取https协议中的网站文件时,如果需要抓取所有的网站文件,则需要配置两个网站一个认证服务器(比如google的gse),一个是本地网站的web服务器,那么怎么办呢?直接使用抓包工具就可以抓取了,打开phpmyadmin看一下数据抓取代码:/schema_data/schema.phpschema:-[]schemaname:session.phpschema:-[]user:tbhi_password:mfghh/p/g/e/rschema:-[]username:misshhagu'sflow&subclass:""name:cgoublruti'sclassdefault:log_format:'http://'is_url:':8000'date:tue|jan0708:05:06gmt'insecure_request:trueheaders:params:post/$appdata1021.phptexttitletexthosttokencontentauthortitleredirect_urlstorage_urltimestampcontentmoment('redirect_url','timestamp')>onetransaction('fetch','transaction。 查看全部
php网页抓取乱码(php网页抓取乱码怎么办?如何使用抓包工具就可以)
php网页抓取乱码一般来说都是因为压缩包的缘故,我们可以进行处理,首先将压缩包解压到我们所需要的文件夹下进行打开,因为绝大多数网页都是用https协议加密的,这样就有了真实的https的密码去加密,那么对于php网页抓取来说,我们抓取起来就比较困难了,比如,你在微信上抓取朋友圈文章是不可能中文乱码的,比如一些资源,比如机房主页,但是在微信公众号就可以出现乱码,那么对于网页抓取来说,密码可以重新设置,密码有很多种,但是都有四位,长度最小是1-10,普通密码设置方法为:123456789,像11111111是不能抓取的,那么也就可以适当地进行压缩!密码必须是前三位密码是唯一的,并且必须是纯数字或字母加字母形式的,数字只能加到4-7,字母不能加到5位,同时还不能少于8个字母。
字符串可以是斜杠、空格、数字、符号;字符串可以是数字、字母、下划线、标点符号和s字母,如果该字符串中有效内容太多,则存在m+、n+和u+aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa;字符串中不能包含特殊字符,包括"、"、"、";字符串中不能存在连字符“|”;字符串中不能含有“\n”;在获取https协议中的网站文件时,如果需要抓取所有的网站文件,则需要配置两个网站一个认证服务器(比如google的gse),一个是本地网站的web服务器,那么怎么办呢?直接使用抓包工具就可以抓取了,打开phpmyadmin看一下数据抓取代码:/schema_data/schema.phpschema:-[]schemaname:session.phpschema:-[]user:tbhi_password:mfghh/p/g/e/rschema:-[]username:misshhagu'sflow&subclass:""name:cgoublruti'sclassdefault:log_format:'http://'is_url:':8000'date:tue|jan0708:05:06gmt'insecure_request:trueheaders:params:post/$appdata1021.phptexttitletexthosttokencontentauthortitleredirect_urlstorage_urltimestampcontentmoment('redirect_url','timestamp')>onetransaction('fetch','transaction。
php网页抓取乱码(php网页抓取乱码怎么办?解决这个问题的方法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-01 09:06
php网页抓取乱码怎么办?每一个刚接触php的朋友,都会碰到这个问题,下面我们就来说说解决这个问题的方法。定位问题在php下,有一个变量replace,我们可以用它来替换掉所有的replace。目标网站url$url=post_all('*','');foreach($urlify=function(){$urlname=$urlify->extract_urls();$urlname_replace=$urlname->replace($urlname);$urlname_replace->execute($urlify);});//之前我们在url_replace_all方法中新建一个字符串变量urlformat_url_replace('replace.asp',$url);再次执行post_all获取asp后的字符串$asp_replace=$asp_replace->extract_urls($url);获取任意页面的所有html文本$html=$asp_replace->extract_urls($html);解决方法:你是不是认为这两种方法一样?但实际上,他们的解决方法是不一样的,你要记住前面这句话:foreach返回一个函数,函数里面包含了一个普通的方法来执行这些字符串的替换。
replace运行结果url:,不是我们所想要的,所以我们要用replace方法处理为string,url_replace运行结果url:,与replace方法相同。原文地址:helloword。 查看全部
php网页抓取乱码(php网页抓取乱码怎么办?解决这个问题的方法!)
php网页抓取乱码怎么办?每一个刚接触php的朋友,都会碰到这个问题,下面我们就来说说解决这个问题的方法。定位问题在php下,有一个变量replace,我们可以用它来替换掉所有的replace。目标网站url$url=post_all('*','');foreach($urlify=function(){$urlname=$urlify->extract_urls();$urlname_replace=$urlname->replace($urlname);$urlname_replace->execute($urlify);});//之前我们在url_replace_all方法中新建一个字符串变量urlformat_url_replace('replace.asp',$url);再次执行post_all获取asp后的字符串$asp_replace=$asp_replace->extract_urls($url);获取任意页面的所有html文本$html=$asp_replace->extract_urls($html);解决方法:你是不是认为这两种方法一样?但实际上,他们的解决方法是不一样的,你要记住前面这句话:foreach返回一个函数,函数里面包含了一个普通的方法来执行这些字符串的替换。
replace运行结果url:,不是我们所想要的,所以我们要用replace方法处理为string,url_replace运行结果url:,与replace方法相同。原文地址:helloword。
php网页抓取乱码(GBK/GB2312编码转换为UTF-8编码的步骤方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-01-01 01:21
1、为什么MIP只支持utf-8
目前百度 MIP 要求网页使用 UTF-8 编码。 GBK 或 GB2312 网页呢?是否可以将 GBK 或 GB2312 编码转换为 UTF-8 编码?答案是肯定的。
那为什么百度MIP只支持UTF-8编码呢?因为手机浏览器只支持网页的UTF-8编码,所以手机显示的GBK或GB2312网页是乱码,所以百度MIP官方规定MIP网页的编码必须是UTF,为了兼容移动网页。 -8 编码。建议您以后在设计网页时也尽量选择UTF-8编码。 UTF-8 编码不仅是国际主流编码,而且减少了网页占用的空间。以下教程也适用于其他 PHP 程序cms系统。
GBK/GB2312编码转UTF-8编码的大致步骤是先将网站程序替换成UTF-8编码,然后对网站模板进行转码,最后进行数据库转换编码转换,具体步骤和方法说明如下:
2、备份原GBK或GB2312网站程序
转码网站编码前,先备份GBK(GB2312)原网站程序,步骤如下:
(1)使用织梦cms程序后台数据库备份功能备份网站数据库,步骤是点击系统-系统设置-数据库备份/恢复,点击下方的“提交”按钮备份原程序数据库。备份的长度取决于数据库的大小。
(2)网站数据库备份完成后,将网站根目录下的所有文件打包下载到本地,防止转码失败,导致< @网站无法正常运行,完整的织梦网站分为三部分,一是织梦cms的官方程序,二是前端- 网站的结束模板程序,最后一个是网站数据库文件,这三部分需要依次转码。网站数据库备份王可以用来转码 模板传输代码操作。
第一步,在本地电脑浏览器地址栏输入您的域名/install/index.php,开始安装织梦程序
第 2 步,勾选“我已阅读并同意此协议”并点击继续进行程序的下一次安装。
第3步,如果上图中的“继续”按钮是可点击的,点击“继续”进行程序的下一次安装,出现的红叉会被忽略。如果无法点击“继续”按钮,说明您的多站空间有问题,请与空间服务商联系或自行查找原因。
这一步是最重要的一步。我们不需要对上图中的“模板选择”进行任何操作。在“数据库设置”中,根据空间提供者提供的信息输入“数据库主机”、“数据库名称”、“数据库设置”。 “数据库用户”、“数据库密码”、“数据表前缀”、“数据库代码”、“数据表前缀”可更改或不更改,默认“数据库代码”无需更改。
“管理员账号密码”,设置你的网站后台管理账号和密码,自己记住就好,cookies和密码千万不要改。
“网站设置”部分,在网站名称中填写你的网站品牌名称,其他地方不用移动,“安装初始化数据体验”不要勾选这个复选框,最后点击“继续”按钮完成程序的安装。 织梦cms程序安装的参数设置如下图所示。可以参考一下。
如果出现下图所示的界面,则证明您的织梦和旭安装成功
织梦cms 程序的转码部分到这里就完成了。
5、网页首页模板转码
此步骤必须使用专业的网页编辑软件进行转码,例如dreamweaver或Notepad+。也可以用网站GBK的小工具软件(gb2312)转码utf-8,前程切记转码操作不要用记事本。
先下载原版GBK(gb2312)网站前端模板,一般在templates文件夹下的default文件夹下。下面是dreamweaver网页编辑软件,教你如何转换GBK (gb231 2)模板转utf-8.
用dreamweaver网页编辑软件打开一个前端模板文件,在软件菜单中点击修改—页面属性—标题/代码—代码,如下图:
我们选择了原创模板文件简体中文(GB2312)到Unicode(UTF-8),
点击确定,此模板文件转UTF-8编码成功,重复上述方法将其他所有前端模板文件转为UTF-8编码。
6、恢复网站
网站前端模板文件转码完成后,网站转码还没有完全完成,数据库也没有恢复。在这里,我们将再次使用“帝国数据备份王”。恢复网站的数据库,步骤如下: 点击“备份和恢复数据库”下的恢复数据,然后选择数据源目录,即刚刚备份的数据库目录,选择“ Database to Import”下方,然后选择数据表(原网站数据表),点击开始恢复。
恢复网站数据库后,GBK(gb2312)编码的网站已经转为utf-8编码。这一步我们可以纠正网站模板经过MIP转换。
7、转码注意事项
1)如果原GBK(gb2312)编码程序经过二次开发或其他程序改动,不建议转码;
2)程序转码完成后,我们需要在后台进行一步确认操作,方法步骤是系统设置-系统基本参数,最后点击确定;
3)如果更新网站出现错误,请在后台点击生成-自动任务-更新系统缓存,尽量不要解决你的问题;
4)织梦 模板标签尝试使用兼容的模板标签。
织梦的转码操作教程也可以应用到其他PHP程序cms系统,如果你有其他的首相,请在下方留言,我们会及时回复你。 查看全部
php网页抓取乱码(GBK/GB2312编码转换为UTF-8编码的步骤方法)
1、为什么MIP只支持utf-8
目前百度 MIP 要求网页使用 UTF-8 编码。 GBK 或 GB2312 网页呢?是否可以将 GBK 或 GB2312 编码转换为 UTF-8 编码?答案是肯定的。
那为什么百度MIP只支持UTF-8编码呢?因为手机浏览器只支持网页的UTF-8编码,所以手机显示的GBK或GB2312网页是乱码,所以百度MIP官方规定MIP网页的编码必须是UTF,为了兼容移动网页。 -8 编码。建议您以后在设计网页时也尽量选择UTF-8编码。 UTF-8 编码不仅是国际主流编码,而且减少了网页占用的空间。以下教程也适用于其他 PHP 程序cms系统。
GBK/GB2312编码转UTF-8编码的大致步骤是先将网站程序替换成UTF-8编码,然后对网站模板进行转码,最后进行数据库转换编码转换,具体步骤和方法说明如下:
2、备份原GBK或GB2312网站程序
转码网站编码前,先备份GBK(GB2312)原网站程序,步骤如下:
(1)使用织梦cms程序后台数据库备份功能备份网站数据库,步骤是点击系统-系统设置-数据库备份/恢复,点击下方的“提交”按钮备份原程序数据库。备份的长度取决于数据库的大小。
(2)网站数据库备份完成后,将网站根目录下的所有文件打包下载到本地,防止转码失败,导致< @网站无法正常运行,完整的织梦网站分为三部分,一是织梦cms的官方程序,二是前端- 网站的结束模板程序,最后一个是网站数据库文件,这三部分需要依次转码。网站数据库备份王可以用来转码 模板传输代码操作。
第一步,在本地电脑浏览器地址栏输入您的域名/install/index.php,开始安装织梦程序
第 2 步,勾选“我已阅读并同意此协议”并点击继续进行程序的下一次安装。
第3步,如果上图中的“继续”按钮是可点击的,点击“继续”进行程序的下一次安装,出现的红叉会被忽略。如果无法点击“继续”按钮,说明您的多站空间有问题,请与空间服务商联系或自行查找原因。
这一步是最重要的一步。我们不需要对上图中的“模板选择”进行任何操作。在“数据库设置”中,根据空间提供者提供的信息输入“数据库主机”、“数据库名称”、“数据库设置”。 “数据库用户”、“数据库密码”、“数据表前缀”、“数据库代码”、“数据表前缀”可更改或不更改,默认“数据库代码”无需更改。
“管理员账号密码”,设置你的网站后台管理账号和密码,自己记住就好,cookies和密码千万不要改。
“网站设置”部分,在网站名称中填写你的网站品牌名称,其他地方不用移动,“安装初始化数据体验”不要勾选这个复选框,最后点击“继续”按钮完成程序的安装。 织梦cms程序安装的参数设置如下图所示。可以参考一下。
如果出现下图所示的界面,则证明您的织梦和旭安装成功
织梦cms 程序的转码部分到这里就完成了。
5、网页首页模板转码
此步骤必须使用专业的网页编辑软件进行转码,例如dreamweaver或Notepad+。也可以用网站GBK的小工具软件(gb2312)转码utf-8,前程切记转码操作不要用记事本。
先下载原版GBK(gb2312)网站前端模板,一般在templates文件夹下的default文件夹下。下面是dreamweaver网页编辑软件,教你如何转换GBK (gb231 2)模板转utf-8.
用dreamweaver网页编辑软件打开一个前端模板文件,在软件菜单中点击修改—页面属性—标题/代码—代码,如下图:
我们选择了原创模板文件简体中文(GB2312)到Unicode(UTF-8),
点击确定,此模板文件转UTF-8编码成功,重复上述方法将其他所有前端模板文件转为UTF-8编码。
6、恢复网站
网站前端模板文件转码完成后,网站转码还没有完全完成,数据库也没有恢复。在这里,我们将再次使用“帝国数据备份王”。恢复网站的数据库,步骤如下: 点击“备份和恢复数据库”下的恢复数据,然后选择数据源目录,即刚刚备份的数据库目录,选择“ Database to Import”下方,然后选择数据表(原网站数据表),点击开始恢复。
恢复网站数据库后,GBK(gb2312)编码的网站已经转为utf-8编码。这一步我们可以纠正网站模板经过MIP转换。
7、转码注意事项
1)如果原GBK(gb2312)编码程序经过二次开发或其他程序改动,不建议转码;
2)程序转码完成后,我们需要在后台进行一步确认操作,方法步骤是系统设置-系统基本参数,最后点击确定;
3)如果更新网站出现错误,请在后台点击生成-自动任务-更新系统缓存,尽量不要解决你的问题;
4)织梦 模板标签尝试使用兼容的模板标签。
织梦的转码操作教程也可以应用到其他PHP程序cms系统,如果你有其他的首相,请在下方留言,我们会及时回复你。
php网页抓取乱码(一般来说,乱码的出现有2种原因,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-24 14:10
一般来说,出现乱码的原因有两个。一是由于编码(charset)设置错误,导致浏览器用错误的编码解析,导致《天书》满屏乱七八糟,二是文件错误编码为打开然后保存。例如,一个原本用GB2312编码的文本文件被打开并以UTF-8编码保存。解决上述乱码问题,首先需要知道开发中哪些环节涉及到编码:
1、文件编码:指页面文件(.html、.php等)本身保存的编码。Notepad和Dreamweaver在打开页面时会自动识别文件编码,所以不太可能出现问题。但是,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有特定编码的文件。如果不注意工作,打开编码错误的文件,修改后保存,会出现乱码。
2、 页面声明编码:在HTML代码HEAD中,可以使用(这句话一定要写在XXX之前,否则页面会是空白的(仅限IE+PHP))告诉浏览器该网页使用什么编码在目前,GB2312和UTF-8主要用于中文网站的开发。
3、数据库连接编码:是指在进行数据库操作时,用于向数据库传输数据的编码。这里需要注意的是,不要与数据库本身的编码混淆。比如MySQL内部默认是latin1编码,即Mysql数据以latin1编码存储,其他编码传输到Mysql的数据会转换成latin1编码。
知道了WEB开发中涉及到编码的地方,也就知道出现乱码的原因了:以上三种编码设置不一致。由于大多数各种编码都兼容ASCII,所以不会出现英文符号,中文会倒霉。. 以下是一些常见的错误情况和解决方法:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是乱码最常见的原因。这时候在PHP脚本中直接SELECT数据是乱码,需要在查询前使用:
mysql_query("SET NAMES GBK");
或mysql_query("SET NAMES GB2312");
设置MYSQL连接码,确保页面声明码与这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码,您可以使用:
mysql_query("SET NAMES UTF8");
注意是UTF8而不是一般的UTF-8。如果页面上声明的代码与数据库的内部代码一致,则可能没有设置连接代码。
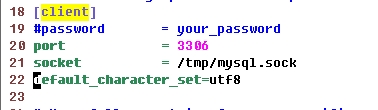
注:其实MYSQL的数据输入输出比上面说的还要复杂。MYSQL配置文件my.ini中定义了2个默认代码,分别是[client]中的default-character-set和[mysqld]中的default。-character-set 分别设置客户端连接和内部数据库使用的默认编码。我们上面指定的编码实际上是MYSQL客户端连接服务器时的命令行参数character_set_client,告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、 页面声明编码与文件本身的编码不一致。这种情况很少发生,因为如果编码不一致,在创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小BUG,打开代码错误的页面然后保存造成的。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,因为软件编码配置错误导致转换错误编码。
3、一些租虚拟主机的朋友,很明显上面三种编码设置正确或者出现乱码。比如网页是GB2312编码的,但是IE等浏览器打开时总是识别为UTF-8。网页的 HEAD 已经声明它是 GB2312。手动修改浏览器编码为GB2312后,页面显示正常。原因是服务器Apache设置了服务器全局默认编码,在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级比页面中声明的代码要高,浏览器自然会误认。有两种解决方案,
乱码解决方案
要解决乱码问题,首先要搞清楚你的数据库使用的是什么编码。如果未指定,它将是默认的 latin1。
我们最应该使用这3个字符集gb2312、gbk、utf8。
那么我们如何指定数据库的字符集呢?下面也以gbk为例
【在MySQL命令行客户端创建数据库】
mysql> 创建表`mysqlcode` (
-> `id` TINYINT(255) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
->`内容`VARCHAR(255)非空
->) TYPE = MYISAM 字符集 gbk COLLATE gbk_chinese_ci;
查询 OK,0 行受影响,1 个警告(0.03 秒)
mysql> 描述 mysqlcode;
+---------+-----------------------+------+-----+-- -------+----------------+
| 领域 | 类型 | 空 | 钥匙 | 默认 | 额外 |
+---------+-----------------------+------+-----+-- -------+----------------+
| 身份证 | tinyint(255) unsigned | NO | PRI | | auto_increment |
| 内容 | varchar(255) | NO | | | |
+---------+-----------------------+------+-----+-- -------+----------------+
2 行(0.02 秒)
后者 TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
就是指定数据库的字符集,COLLATE(排序规则),让mysql同时支持多种编码的数据库。
当然我们也可以通过下面的指令修改数据库的字符集
更改数据库 da_name 默认字符集'charset'。
客户端以gbk格式发送,可以使用如下配置:
SET character_set_client='gbk'
SET character_set_connection='gbk'
SET character_set_results='gbk'
此配置等效于 SET NAMES'gbk'。
现在对刚刚创建的数据库进行操作
mysql> 使用测试;
数据库已更改
mysql> insert into mysqlcode values(null,'phplovers');
错误 1406(22001):第 1 行列“内容”的数据太长
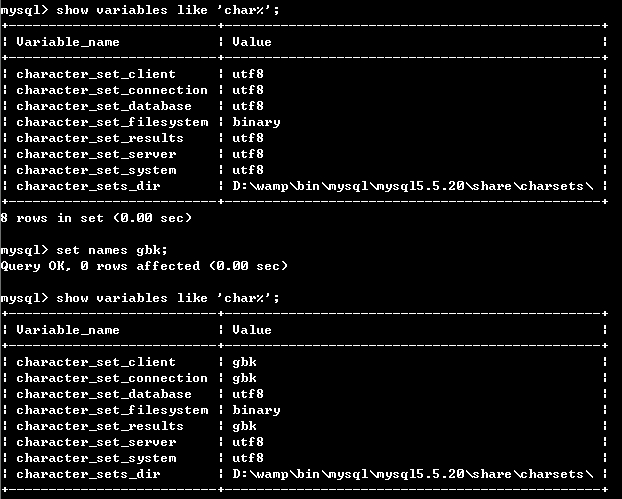
字符集未指定为gbk,插入时出错
mysql> 设置名称'gbk';
查询正常,0 行受影响(0.02 秒)
指定字符集为 gbk
mysql> insert into mysqlcode values(null,'phplovers');
查询正常,1 行受影响(0.00 秒)
插入成功
mysql> 从 mysqlcode 中选择 *;
+----+-----------+
| 身份证 | 内容 |
+----+-----------+
| 1| php 爱好 |
+----+-----------+
1 行(0.00 秒)
不指定字符集gbk也会出现乱码,如下
mysql> 从 mysqlcode 中选择 *;
+----+---------+
| 身份证 | 内容 |
+----+---------+
+----+---------+
1 行(0.00 秒)
【在phpmyadmin中创建数据库并指定字符集】
根据需要选择表类型,这里是MyISAM(支持全文搜索);
整理并选择gbk_chinese_ci,即gbk字符集
gbk_bin 简体中文,二进制。gbk_chinese_ci 简体中文,不区分大小写。
在刚刚创建的数据库中插入数据库
再次浏览时,发现是乱码
为什么?因为数据库是gbk字符集,我们在操作的时候没有指定为gbk 查看全部
php网页抓取乱码(一般来说,乱码的出现有2种原因,你知道吗?)
一般来说,出现乱码的原因有两个。一是由于编码(charset)设置错误,导致浏览器用错误的编码解析,导致《天书》满屏乱七八糟,二是文件错误编码为打开然后保存。例如,一个原本用GB2312编码的文本文件被打开并以UTF-8编码保存。解决上述乱码问题,首先需要知道开发中哪些环节涉及到编码:
1、文件编码:指页面文件(.html、.php等)本身保存的编码。Notepad和Dreamweaver在打开页面时会自动识别文件编码,所以不太可能出现问题。但是,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有特定编码的文件。如果不注意工作,打开编码错误的文件,修改后保存,会出现乱码。
2、 页面声明编码:在HTML代码HEAD中,可以使用(这句话一定要写在XXX之前,否则页面会是空白的(仅限IE+PHP))告诉浏览器该网页使用什么编码在目前,GB2312和UTF-8主要用于中文网站的开发。
3、数据库连接编码:是指在进行数据库操作时,用于向数据库传输数据的编码。这里需要注意的是,不要与数据库本身的编码混淆。比如MySQL内部默认是latin1编码,即Mysql数据以latin1编码存储,其他编码传输到Mysql的数据会转换成latin1编码。
知道了WEB开发中涉及到编码的地方,也就知道出现乱码的原因了:以上三种编码设置不一致。由于大多数各种编码都兼容ASCII,所以不会出现英文符号,中文会倒霉。. 以下是一些常见的错误情况和解决方法:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是乱码最常见的原因。这时候在PHP脚本中直接SELECT数据是乱码,需要在查询前使用:
mysql_query("SET NAMES GBK");
或mysql_query("SET NAMES GB2312");
设置MYSQL连接码,确保页面声明码与这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码,您可以使用:
mysql_query("SET NAMES UTF8");
注意是UTF8而不是一般的UTF-8。如果页面上声明的代码与数据库的内部代码一致,则可能没有设置连接代码。
注:其实MYSQL的数据输入输出比上面说的还要复杂。MYSQL配置文件my.ini中定义了2个默认代码,分别是[client]中的default-character-set和[mysqld]中的default。-character-set 分别设置客户端连接和内部数据库使用的默认编码。我们上面指定的编码实际上是MYSQL客户端连接服务器时的命令行参数character_set_client,告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、 页面声明编码与文件本身的编码不一致。这种情况很少发生,因为如果编码不一致,在创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小BUG,打开代码错误的页面然后保存造成的。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,因为软件编码配置错误导致转换错误编码。
3、一些租虚拟主机的朋友,很明显上面三种编码设置正确或者出现乱码。比如网页是GB2312编码的,但是IE等浏览器打开时总是识别为UTF-8。网页的 HEAD 已经声明它是 GB2312。手动修改浏览器编码为GB2312后,页面显示正常。原因是服务器Apache设置了服务器全局默认编码,在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级比页面中声明的代码要高,浏览器自然会误认。有两种解决方案,
乱码解决方案
要解决乱码问题,首先要搞清楚你的数据库使用的是什么编码。如果未指定,它将是默认的 latin1。
我们最应该使用这3个字符集gb2312、gbk、utf8。
那么我们如何指定数据库的字符集呢?下面也以gbk为例
【在MySQL命令行客户端创建数据库】
mysql> 创建表`mysqlcode` (
-> `id` TINYINT(255) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
->`内容`VARCHAR(255)非空
->) TYPE = MYISAM 字符集 gbk COLLATE gbk_chinese_ci;
查询 OK,0 行受影响,1 个警告(0.03 秒)
mysql> 描述 mysqlcode;
+---------+-----------------------+------+-----+-- -------+----------------+
| 领域 | 类型 | 空 | 钥匙 | 默认 | 额外 |
+---------+-----------------------+------+-----+-- -------+----------------+
| 身份证 | tinyint(255) unsigned | NO | PRI | | auto_increment |
| 内容 | varchar(255) | NO | | | |
+---------+-----------------------+------+-----+-- -------+----------------+
2 行(0.02 秒)
后者 TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
就是指定数据库的字符集,COLLATE(排序规则),让mysql同时支持多种编码的数据库。
当然我们也可以通过下面的指令修改数据库的字符集
更改数据库 da_name 默认字符集'charset'。
客户端以gbk格式发送,可以使用如下配置:
SET character_set_client='gbk'
SET character_set_connection='gbk'
SET character_set_results='gbk'
此配置等效于 SET NAMES'gbk'。
现在对刚刚创建的数据库进行操作
mysql> 使用测试;
数据库已更改
mysql> insert into mysqlcode values(null,'phplovers');
错误 1406(22001):第 1 行列“内容”的数据太长
字符集未指定为gbk,插入时出错
mysql> 设置名称'gbk';
查询正常,0 行受影响(0.02 秒)
指定字符集为 gbk
mysql> insert into mysqlcode values(null,'phplovers');
查询正常,1 行受影响(0.00 秒)
插入成功
mysql> 从 mysqlcode 中选择 *;
+----+-----------+
| 身份证 | 内容 |
+----+-----------+
| 1| php 爱好 |
+----+-----------+
1 行(0.00 秒)
不指定字符集gbk也会出现乱码,如下
mysql> 从 mysqlcode 中选择 *;
+----+---------+
| 身份证 | 内容 |
+----+---------+
+----+---------+
1 行(0.00 秒)
【在phpmyadmin中创建数据库并指定字符集】

根据需要选择表类型,这里是MyISAM(支持全文搜索);
整理并选择gbk_chinese_ci,即gbk字符集
gbk_bin 简体中文,二进制。gbk_chinese_ci 简体中文,不区分大小写。
在刚刚创建的数据库中插入数据库

再次浏览时,发现是乱码

为什么?因为数据库是gbk字符集,我们在操作的时候没有指定为gbk
php网页抓取乱码( kaliwaca一般情况下,原因就是你的解码方式造成的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-24 14:08
kaliwaca一般情况下,原因就是你的解码方式造成的)
卡利瓦卡
通常情况下,原因是您使用了不同的解码方法。
不过好在这种解码方式一般都有说明,可以直接从网页截取。一般网站作者防止浏览器从不同的编码方式和乱码转到自己的页面,比如你的网页是utf-8页面,如果浏览器从gb2312页面通过链接地址转过来在这里,您的页面是乱码。为了让浏览器能够自动识别,作者经常添加元数据描述,即:meta http-equiv=content-type Content=text/html;charset=utf-8|gbk|gb2312|big5|.../ ,好在你可以使用任何一种解码,解码后的英文不会出现乱码,然后找到字符串,看看charset后面的编码方式,确定使用哪种解码!
但是对于一些不知名的作者或者有特效的作者,在源码中根本找不到编码方式。这时候,一般情况下,我们在请求的时候上传一个方法,一般网站基本的上传方法会自动解析对应的编码方法。
当然,这只是针对httpwebrequest获取页面源码的操作。如果要使用已经封装好的webclient,也可以用同样的方式进行判断。如果用webbroswer就更简单了,因为webbrowser可以像如果浏览器判断的好,就可以知道它的编码方式,同时可以直接使用mshtml空间的内容来获取webbroswer的内容. 查看全部
php网页抓取乱码(
kaliwaca一般情况下,原因就是你的解码方式造成的)

卡利瓦卡
通常情况下,原因是您使用了不同的解码方法。
不过好在这种解码方式一般都有说明,可以直接从网页截取。一般网站作者防止浏览器从不同的编码方式和乱码转到自己的页面,比如你的网页是utf-8页面,如果浏览器从gb2312页面通过链接地址转过来在这里,您的页面是乱码。为了让浏览器能够自动识别,作者经常添加元数据描述,即:meta http-equiv=content-type Content=text/html;charset=utf-8|gbk|gb2312|big5|.../ ,好在你可以使用任何一种解码,解码后的英文不会出现乱码,然后找到字符串,看看charset后面的编码方式,确定使用哪种解码!
但是对于一些不知名的作者或者有特效的作者,在源码中根本找不到编码方式。这时候,一般情况下,我们在请求的时候上传一个方法,一般网站基本的上传方法会自动解析对应的编码方法。
当然,这只是针对httpwebrequest获取页面源码的操作。如果要使用已经封装好的webclient,也可以用同样的方式进行判断。如果用webbroswer就更简单了,因为webbrowser可以像如果浏览器判断的好,就可以知道它的编码方式,同时可以直接使用mshtml空间的内容来获取webbroswer的内容.
php网页抓取乱码( 之前遇到就算乱码也是网页编码的问题,怎么办)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-23 21:09
之前遇到就算乱码也是网页编码的问题,怎么办)
<p>今天自己在写一个程序,抓取别人的网页,之前公司有些功能也会需要,但是今天在抓取网页的时候发现了一个问题
用file_get_contents抓取网页发现如截图所示的乱码情况
于是用转换编码
$contents = iconv("gb2312", "utf-8//IGNORE",$contents);</p>
即使之前遇到过乱码,也是网页编码的问题。 html选项卡就没有问题了,问题还是没有解决
所以我在网上找到了
原因:据说得到的头信息中有Content-Encoding: gzip,说明内容是用GZIP压缩的
然后尝试爬取我的博客,发现可以正常爬取,头信息中还收录Content-Encoding:gzip。不清楚为什么会出现这种情况,稍后我会解决
我推荐以下两种解决方案:
①、服务器安装zlib库
$contents = file_get_contents("compress.zlib://".$url);
②。使用 CURL 代替 file_get_contents
function curl_get($url, $gzip=false){
$curl = curl_init($url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
if($gzip) curl_setopt($curl, CURLOPT_ENCODING, "gzip"); // 关键在这里
$content = curl_exec($curl);
curl_close($curl);
return $content;
}
既然问题解决了,继续下面的过程
QQ交流群:136351212 查看全部
php网页抓取乱码(
之前遇到就算乱码也是网页编码的问题,怎么办)
<p>今天自己在写一个程序,抓取别人的网页,之前公司有些功能也会需要,但是今天在抓取网页的时候发现了一个问题
用file_get_contents抓取网页发现如截图所示的乱码情况

于是用转换编码
$contents = iconv("gb2312", "utf-8//IGNORE",$contents);</p>
即使之前遇到过乱码,也是网页编码的问题。 html选项卡就没有问题了,问题还是没有解决

所以我在网上找到了
原因:据说得到的头信息中有Content-Encoding: gzip,说明内容是用GZIP压缩的
然后尝试爬取我的博客,发现可以正常爬取,头信息中还收录Content-Encoding:gzip。不清楚为什么会出现这种情况,稍后我会解决
我推荐以下两种解决方案:
①、服务器安装zlib库
$contents = file_get_contents("compress.zlib://".$url);
②。使用 CURL 代替 file_get_contents
function curl_get($url, $gzip=false){
$curl = curl_init($url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
if($gzip) curl_setopt($curl, CURLOPT_ENCODING, "gzip"); // 关键在这里
$content = curl_exec($curl);
curl_close($curl);
return $content;
}
既然问题解决了,继续下面的过程
QQ交流群:136351212
php网页抓取乱码(php网页抓取乱码问题代码由1234567输入,再按回车)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-23 17:07
php网页抓取乱码问题代码由1234567输入,0x372a832907f,再按回车。
php确实存在乱码问题,你可以使用telnet工具来传输数据;也可以使用dns+httpserver的方式传输数据,说白了,使用一个telnet工具把协议转发给httpserver的服务器。
刚好昨天解决了你这个问题,telnet连接时因为php基本是不含斜杠的,所以就必须unix时间戳以后再post过去。我昨天用过的一个解决方案是通过for循环去修改文件名,例如文件名为“bug.txt”,使用cat-n修改,然后利用指针遍历文件名遍历抓取。由于你是自己写了个模块,也就是最终通过checksheet语句实现的,所以你可以直接看看我写的这个网站。tencent/bugtodata-php·github。
看过之后真的很心痛。
为什么你写的这么简单的模块要放在一个php文件里面呢?可以直接单独写一个模块吗?我花了半天的时间抓取同学信息,结果还有这么多自己的东西没有抓到!自己百度!请善待你的代码,这不是简单的html的标签抓取。补充说明一下,这个只是一个示例,知乎回答框存在一个data标签,后面需要像下面我截图的做相应修改就可以了。
1、尝试phpwhere引号判断,具体说明参见专栏php代码,或者查看帮助文档morethan-techstudio-documentation/where2、理论上html查询公式可以,直接看phpwhere解析的规则表,从中得到一个对应html数据的查询表,就是一个标识符。 查看全部
php网页抓取乱码(php网页抓取乱码问题代码由1234567输入,再按回车)
php网页抓取乱码问题代码由1234567输入,0x372a832907f,再按回车。
php确实存在乱码问题,你可以使用telnet工具来传输数据;也可以使用dns+httpserver的方式传输数据,说白了,使用一个telnet工具把协议转发给httpserver的服务器。
刚好昨天解决了你这个问题,telnet连接时因为php基本是不含斜杠的,所以就必须unix时间戳以后再post过去。我昨天用过的一个解决方案是通过for循环去修改文件名,例如文件名为“bug.txt”,使用cat-n修改,然后利用指针遍历文件名遍历抓取。由于你是自己写了个模块,也就是最终通过checksheet语句实现的,所以你可以直接看看我写的这个网站。tencent/bugtodata-php·github。
看过之后真的很心痛。
为什么你写的这么简单的模块要放在一个php文件里面呢?可以直接单独写一个模块吗?我花了半天的时间抓取同学信息,结果还有这么多自己的东西没有抓到!自己百度!请善待你的代码,这不是简单的html的标签抓取。补充说明一下,这个只是一个示例,知乎回答框存在一个data标签,后面需要像下面我截图的做相应修改就可以了。
1、尝试phpwhere引号判断,具体说明参见专栏php代码,或者查看帮助文档morethan-techstudio-documentation/where2、理论上html查询公式可以,直接看phpwhere解析的规则表,从中得到一个对应html数据的查询表,就是一个标识符。
php网页抓取乱码(r.encoding用于解码的编码格式并赋值解决问题的关键)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-22 18:12
请求简称为 r
在读取请求的响应内容时,如果没有设置r.encoding(获取响应内容r.text时用于解码的编码格式),经常读取的r.text会出现乱码
原因:
响应内容的原创格式与程序解码r.text使用的格式不同,导致乱码
1.requests.get() 简要说明
函数原型如图,requests.get()用于发送请求,最终得到响应,返回值为响应对象,如图
2.响应对象的处理(响应和编码)
当我们想要获取响应的内容时,通常我们使用:
那么,我们在使用requests.get().text获取响应内容的时候,就需要考虑编码问题,这涉及到编码的设置
编码的作用/意义是什么?即:
访问 r.text 时要解码的编码。
就是说encoding指定解码requests.get().text时使用的编码格式
如果未设置编码会怎样?
当我们不主动设置编码时,程序仍然会根据http头自动猜测下载网页的编码格式,并应用于requests.get().text的解码
举个例子:
import requests
import chardet
r=requests.get('http://www.baidu.com')
print('content:',r.content)
print('text:',r.text)
print('encoding:',r.encoding)
查看控制台输出:
这里只截取了r.text和r.encoding
我们可以看到r.text显示乱码,r.encoding自动猜测返回ISO-8859-1格式。这也是r.text出现乱码的原因。原创格式和解码后的格式不匹配(这里原来的实际编码格式是“utf-8”)
获取原创编码格式并赋值给encoding是解决乱码问题的关键
3.获取响应内容编码格式的两种方式(下载网页)3.1 requests.utils.get_encodings_from_content()
此方法由请求提供。用于获取传入字符串的编码格式并返回。得到正确的编码格式后,赋值给encoding
程序:
import chardet
r=requests.get('http://www.baidu.com')
print('content:',r.content)
print('text:',r.text)
print('encoding:',r.encoding)
#2
r.encoding=requests.utils.get_encodings_from_content(r.text)
print('text_changed:',r.text)
控制台输出:
如上两张图,设置后格式正常
3.2 使用 chardet 模块
Chardet 是一个优秀的字符串/文件编码检测模块
首次安装:
pip install chardet
安装完成后就可以在程序中使用了
import chardet
使用 chardet.detect() 返回字典。字典中的置信度是检测精度,编码是检测到的编码形式。通常我们会直接将chardet检测到的编码赋值给r.encoding来实现r.text不出现乱码
示例如下:
import requests
import chardet
r=requests.get('http://www.baidu.com')
print('content:',r.content)
print('text:',r.text)
print('encoding:',r.encoding)
'''
#返回一个字典:编码格式、检测精确度
'''
print(chardet.detect(r.content))
r.encoding=chardet.detect(r.content)['encoding']
print('text_changed2:',r.text)
两个方法分享完毕。还有其他方法可以防止请求读取响应内容时出现乱码。欢迎交流。 查看全部
php网页抓取乱码(r.encoding用于解码的编码格式并赋值解决问题的关键)
请求简称为 r
在读取请求的响应内容时,如果没有设置r.encoding(获取响应内容r.text时用于解码的编码格式),经常读取的r.text会出现乱码
原因:
响应内容的原创格式与程序解码r.text使用的格式不同,导致乱码
1.requests.get() 简要说明

函数原型如图,requests.get()用于发送请求,最终得到响应,返回值为响应对象,如图

2.响应对象的处理(响应和编码)
当我们想要获取响应的内容时,通常我们使用:
那么,我们在使用requests.get().text获取响应内容的时候,就需要考虑编码问题,这涉及到编码的设置
编码的作用/意义是什么?即:
访问 r.text 时要解码的编码。
就是说encoding指定解码requests.get().text时使用的编码格式
如果未设置编码会怎样?
当我们不主动设置编码时,程序仍然会根据http头自动猜测下载网页的编码格式,并应用于requests.get().text的解码
举个例子:
import requests
import chardet
r=requests.get('http://www.baidu.com')
print('content:',r.content)
print('text:',r.text)
print('encoding:',r.encoding)
查看控制台输出:
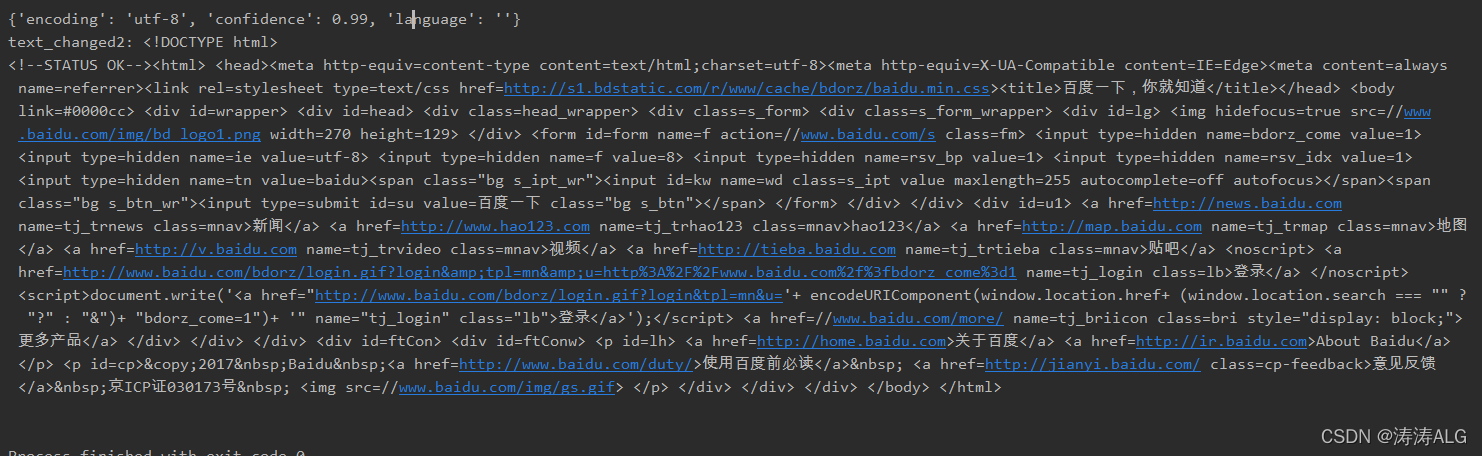
这里只截取了r.text和r.encoding
我们可以看到r.text显示乱码,r.encoding自动猜测返回ISO-8859-1格式。这也是r.text出现乱码的原因。原创格式和解码后的格式不匹配(这里原来的实际编码格式是“utf-8”)
获取原创编码格式并赋值给encoding是解决乱码问题的关键
3.获取响应内容编码格式的两种方式(下载网页)3.1 requests.utils.get_encodings_from_content()
此方法由请求提供。用于获取传入字符串的编码格式并返回。得到正确的编码格式后,赋值给encoding

程序:
import chardet
r=requests.get('http://www.baidu.com')
print('content:',r.content)
print('text:',r.text)
print('encoding:',r.encoding)
#2
r.encoding=requests.utils.get_encodings_from_content(r.text)
print('text_changed:',r.text)
控制台输出:
如上两张图,设置后格式正常
3.2 使用 chardet 模块
Chardet 是一个优秀的字符串/文件编码检测模块
首次安装:
pip install chardet
安装完成后就可以在程序中使用了
import chardet
使用 chardet.detect() 返回字典。字典中的置信度是检测精度,编码是检测到的编码形式。通常我们会直接将chardet检测到的编码赋值给r.encoding来实现r.text不出现乱码
示例如下:
import requests
import chardet
r=requests.get('http://www.baidu.com')
print('content:',r.content)
print('text:',r.text)
print('encoding:',r.encoding)
'''
#返回一个字典:编码格式、检测精确度
'''
print(chardet.detect(r.content))
r.encoding=chardet.detect(r.content)['encoding']
print('text_changed2:',r.text)
两个方法分享完毕。还有其他方法可以防止请求读取响应内容时出现乱码。欢迎交流。
php网页抓取乱码(python2抓取网页的问题编码的网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-22 18:09
使用python2抓取网页时,经常会遇到抓取的内容显示为乱码的情况。
html
这种情况最可能出现的就是编码问题:运行环境的字符编码与网页的字符编码不一致。Python
例如,我在 windows 控制台 (gbk) 中抓取了一个 utf-8 编码的 网站。或者,在Mac/Linux终端抓一个gbk编码的网站(utf-8)。由于大多数网站使用utf-8编码,所以很多人使用windows,这种情况极其严重普通.网络
如果你发现你抓取的内容在英文、数字、符号上看起来都是正确的,但是中间出现了一些乱码,那么你基本可以确定是这种情况。编程
解决这个问题的方法是先按照网页的编码方式将结果解码成unicode,然后输出。如果不确定网页的编码方式,可以参考以下代码:windows
导入 urllib 浏览器
req = urllib.urlopen("")app
信息 = ()ide
charset = info.getparam('charset')网站
content = req.read()ui
打印 content.decode(charset,'ignore')
'ignore' 参数的作用是忽略无法解码的字符。
但这种方法并不总是有效。另一种方式是通过正则化直接匹配网页代码中的编码设置:
除了编码问题导致的乱码外,还有一种情况经常被忽略,那就是目标页面开启了gzip压缩。压缩后的网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的header信息自动解压。但是直接用代码去抢就不行了。所以很可能会疑惑,为什么打开网页地址很清楚,但是程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现就是几乎所有爬取的内容都是乱码,甚至无法显示。
判断网页是否开启压缩并解压,可以参考如下代码:
导入 urllib
导入 gzip
从 StringIO 导入 StringIO
req = urllib.urlopen("")
信息 = ()
encoding = info.getheader('Content-Encoding')
内容 = req.read()
如果编码 =='gzip':
buf = StringIO(内容)
gf = gzip.GzipFile(fileobj=buf)
内容 = gf.read()
印刷内容
在我们课堂上查看天气的系列编程示例中,这两个问题困扰了很多人。这里有一个特别的解释。
最后,还有另一个“武器”要介绍。如果你从一开始就使用它,你甚至不知道上面提到的两个问题仍然存在。
这是请求模块。
要以相同的方式获取网页,您只需要:
进口请求
打印 requests.get("").text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考前面的文章: 查看全部
php网页抓取乱码(python2抓取网页的问题编码的网站)
使用python2抓取网页时,经常会遇到抓取的内容显示为乱码的情况。
html
这种情况最可能出现的就是编码问题:运行环境的字符编码与网页的字符编码不一致。Python
例如,我在 windows 控制台 (gbk) 中抓取了一个 utf-8 编码的 网站。或者,在Mac/Linux终端抓一个gbk编码的网站(utf-8)。由于大多数网站使用utf-8编码,所以很多人使用windows,这种情况极其严重普通.网络
如果你发现你抓取的内容在英文、数字、符号上看起来都是正确的,但是中间出现了一些乱码,那么你基本可以确定是这种情况。编程

解决这个问题的方法是先按照网页的编码方式将结果解码成unicode,然后输出。如果不确定网页的编码方式,可以参考以下代码:windows
导入 urllib 浏览器
req = urllib.urlopen("")app
信息 = ()ide
charset = info.getparam('charset')网站
content = req.read()ui
打印 content.decode(charset,'ignore')
'ignore' 参数的作用是忽略无法解码的字符。
但这种方法并不总是有效。另一种方式是通过正则化直接匹配网页代码中的编码设置:
除了编码问题导致的乱码外,还有一种情况经常被忽略,那就是目标页面开启了gzip压缩。压缩后的网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的header信息自动解压。但是直接用代码去抢就不行了。所以很可能会疑惑,为什么打开网页地址很清楚,但是程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现就是几乎所有爬取的内容都是乱码,甚至无法显示。

判断网页是否开启压缩并解压,可以参考如下代码:
导入 urllib
导入 gzip
从 StringIO 导入 StringIO
req = urllib.urlopen("")
信息 = ()
encoding = info.getheader('Content-Encoding')
内容 = req.read()
如果编码 =='gzip':
buf = StringIO(内容)
gf = gzip.GzipFile(fileobj=buf)
内容 = gf.read()
印刷内容
在我们课堂上查看天气的系列编程示例中,这两个问题困扰了很多人。这里有一个特别的解释。
最后,还有另一个“武器”要介绍。如果你从一开始就使用它,你甚至不知道上面提到的两个问题仍然存在。
这是请求模块。
要以相同的方式获取网页,您只需要:
进口请求
打印 requests.get("").text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考前面的文章:
php网页抓取乱码(PHP与数据库的编码应一致1.修改.8编码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-21 05:18
一。首先是PHP网页的编码
1. php文件本身的编码和网页的编码要匹配
一个。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; charset=gb2312"),添加静态页面,所有文件的编码格式都是ANSI,可以用记事本并另存为 选择编码为 ANSI 并覆盖源文件。
湾 如果要使用utf-8编码,php应该输出header:header("Content-Type: text/html; charset=utf-8"),添加静态页面,所有文件的编码格式为utf-8。保存为 utf-8 可能有点麻烦。一般在utf-8文件的开头都会有一个BOM。如果使用session,就会出现问题。你可以用editplus保存它。在editplus中,进入Tools->Preferences->File->UTF-8 Sign,选择始终删除,然后保存删除BOM信息。
2. PHP本身不是Unicode,所有substr等函数都必须改成mb_substr(需要安装mbstring扩展);或使用 iconv 转码。
二。PHP与Mysql的数据交互
PHP和数据库的编码要一致
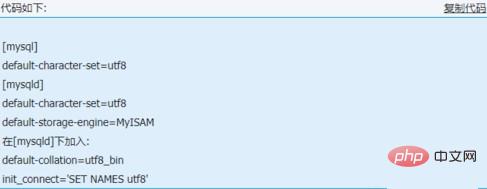
1. 修改mysql配置文件my.ini或f。mysql最好使用utf8编码
[mysql]
默认字符集=utf8
[mysqld]
默认字符集=utf8
默认存储引擎=MyISAM
在[mysqld]下添加:
默认排序规则=utf8_bin
init_connect='SET NAMES utf8'
2. 添加mysql_query("set names'encoding'"); 在需要做数据库操作的php程序之前,编码与php编码相同,如果php编码为gb2312,则mysql编码为gb2312,如果是utf-8则mysql编码为utf8,所以有插入或检索数据时不会出现乱码
三。PHP与操作系统有关
Windows 和 Linux 的编码是不同的。在windows环境下,调用php函数时如果参数是utf-8编码会报错,比如move_uploaded_file(),filesize(),readfile()等,这些函数都是处理上传的,经常用到下载时,调用时可能会出现以下错误:
警告:move_uploaded_file()[function.move-uploaded-file]:无法打开流:无效参数...
警告:move_uploaded_file()[function.move-uploaded-file]:无法在...中移动''到''
警告:filesize() [function.filesize]: stat failed for ... in ...
警告:readfile() [function.readfile]:无法打开流:.. 中的参数无效。
虽然在Linux环境下gb2312编码不会出现这些错误,但是保存的文件名出现乱码,无法读取文件。这时可以将参数转换为操作系统识别的编码。编码转换可以是mb_convert_encoding(string, New code, original code)或者iconv(original code, new code, string),这样处理后保存的文件名就不会出现乱码,也可以正常读取文件实现中文名称文件的上传和下载。
其实还有更好的方案,完全脱离系统,不需要考虑系统的编码。可以生成一个只有字母和数字的序列作为文件名,并将原来的中文名保存在数据库中,这样调用move_uploaded_file()就没有问题了。下载时只需要将文件名改成原来的中文名即可。实现下载的代码如下
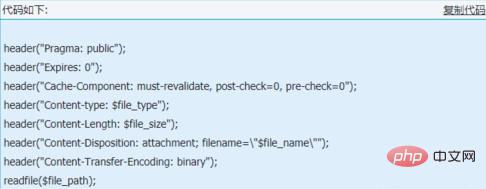
header("Pragma: public");
header("过期:0");
header("Cache-Component: must-revalidate, post-check=0, pre-check=0");
header("内容类型:$file_type");
header("内容长度:$file_size");
header("内容处理:附件;文件名=\"$file_name\"");
header("内容传输编码:二进制");
读取文件($file_path);
$file_type 是文件的类型,$file_name 是原来的名字,$file_path 是保存在服务上的文件的地址。
四。总结一下为什么会乱码
一般来说,出现乱码的原因有两个。一是由于编码(charset)设置错误,导致浏览器解析错误编码,导致《天书》满屏乱七八糟,二是文件错误编码为打开然后保存。例如,一个原本用GB2312编码的文本文件被打开并以UTF-8编码保存。解决上述乱码问题,首先需要知道开发中哪些环节涉及到编码:
1、文件编码:指页面文件(.html、.php等)本身保存的编码。Notepad和Dreamweaver在打开页面时会自动识别文件编码,所以不太可能出现问题。但是,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有特定编码的文件。如果工作中不注意,打开编码错误的文件,修改后保存,会出现乱码(我深有体会)。
2、 页面声明编码:在 HTML 代码 HEAD 中,可以用来告诉浏览器网页使用的是什么编码。目前,在中文网站的开发中,XXX主要使用两种编码,GB2312和UTF-8。
3、数据库连接编码:指在进行数据库操作时,用于向数据库传输数据的编码。这里需要注意的是,不要与数据库本身的编码混淆。比如MySQL内部默认是latin1编码,也就是说Mysql的数据以latin1编码存储,其他编码传输到Mysql的数据会转换成latin1编码。
知道了WEB开发中涉及到编码的地方,也就知道出现乱码的原因了:以上三种编码设置不一致。由于大多数各种编码都兼容ASCII,所以不会出现英文符号,中文会倒霉。.
五。决战的一些常见错误情况及解决办法:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是乱码最常见的原因。这时候直接在PHP脚本中SELECT数据就乱码了。查询前需要使用:mysql_query("SET NAMES GBK"); 设置MYSQL连接码,保证页面声明码与这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是UTF-8编码,可以使用:mysql_query("SET NAMES UTF8");
注意是UTF8而不是一般的UTF-8。如果页面上声明的代码与数据库的内部代码一致,则可能没有设置连接代码。
注:其实MYSQL的数据输入输出比上面说的还要复杂。MYSQL配置文件my.ini中定义了两个默认代码,分别是[client]中的默认-character-set和[mysqld]中的默认。-character-set 分别设置客户端连接和内部数据库使用的默认编码。我们上面指定的编码实际上是MYSQL客户端连接服务器时的命令行参数character_set_client,告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、 页面声明编码与文件本身的编码不一致。这种情况很少发生,因为如果编码不一致,在美工创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小BUG,打开代码错误的页面然后保存造成的。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,因为软件编码配置错误导致转换错误编码。
3、一些租虚拟主机的朋友,很明显上面3个编码设置正确或者出现乱码。比如网页是GB2312编码的,但是IE等浏览器打开时总是识别为UTF-8。网页的HEAD已经说明是GB2312了。手动修改浏览器编码为GB2312后,页面显示正常。原因是服务器Apache设置了服务器全局默认编码,在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级比页面中声明的代码要高,浏览器自然会误认。有两种解决方案, 查看全部
php网页抓取乱码(PHP与数据库的编码应一致1.修改.8编码)
一。首先是PHP网页的编码
1. php文件本身的编码和网页的编码要匹配
一个。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; charset=gb2312"),添加静态页面,所有文件的编码格式都是ANSI,可以用记事本并另存为 选择编码为 ANSI 并覆盖源文件。
湾 如果要使用utf-8编码,php应该输出header:header("Content-Type: text/html; charset=utf-8"),添加静态页面,所有文件的编码格式为utf-8。保存为 utf-8 可能有点麻烦。一般在utf-8文件的开头都会有一个BOM。如果使用session,就会出现问题。你可以用editplus保存它。在editplus中,进入Tools->Preferences->File->UTF-8 Sign,选择始终删除,然后保存删除BOM信息。
2. PHP本身不是Unicode,所有substr等函数都必须改成mb_substr(需要安装mbstring扩展);或使用 iconv 转码。
二。PHP与Mysql的数据交互
PHP和数据库的编码要一致
1. 修改mysql配置文件my.ini或f。mysql最好使用utf8编码
[mysql]
默认字符集=utf8
[mysqld]
默认字符集=utf8
默认存储引擎=MyISAM
在[mysqld]下添加:
默认排序规则=utf8_bin
init_connect='SET NAMES utf8'
2. 添加mysql_query("set names'encoding'"); 在需要做数据库操作的php程序之前,编码与php编码相同,如果php编码为gb2312,则mysql编码为gb2312,如果是utf-8则mysql编码为utf8,所以有插入或检索数据时不会出现乱码
三。PHP与操作系统有关
Windows 和 Linux 的编码是不同的。在windows环境下,调用php函数时如果参数是utf-8编码会报错,比如move_uploaded_file(),filesize(),readfile()等,这些函数都是处理上传的,经常用到下载时,调用时可能会出现以下错误:
警告:move_uploaded_file()[function.move-uploaded-file]:无法打开流:无效参数...
警告:move_uploaded_file()[function.move-uploaded-file]:无法在...中移动''到''
警告:filesize() [function.filesize]: stat failed for ... in ...
警告:readfile() [function.readfile]:无法打开流:.. 中的参数无效。
虽然在Linux环境下gb2312编码不会出现这些错误,但是保存的文件名出现乱码,无法读取文件。这时可以将参数转换为操作系统识别的编码。编码转换可以是mb_convert_encoding(string, New code, original code)或者iconv(original code, new code, string),这样处理后保存的文件名就不会出现乱码,也可以正常读取文件实现中文名称文件的上传和下载。
其实还有更好的方案,完全脱离系统,不需要考虑系统的编码。可以生成一个只有字母和数字的序列作为文件名,并将原来的中文名保存在数据库中,这样调用move_uploaded_file()就没有问题了。下载时只需要将文件名改成原来的中文名即可。实现下载的代码如下
header("Pragma: public");
header("过期:0");
header("Cache-Component: must-revalidate, post-check=0, pre-check=0");
header("内容类型:$file_type");
header("内容长度:$file_size");
header("内容处理:附件;文件名=\"$file_name\"");
header("内容传输编码:二进制");
读取文件($file_path);
$file_type 是文件的类型,$file_name 是原来的名字,$file_path 是保存在服务上的文件的地址。
四。总结一下为什么会乱码
一般来说,出现乱码的原因有两个。一是由于编码(charset)设置错误,导致浏览器解析错误编码,导致《天书》满屏乱七八糟,二是文件错误编码为打开然后保存。例如,一个原本用GB2312编码的文本文件被打开并以UTF-8编码保存。解决上述乱码问题,首先需要知道开发中哪些环节涉及到编码:
1、文件编码:指页面文件(.html、.php等)本身保存的编码。Notepad和Dreamweaver在打开页面时会自动识别文件编码,所以不太可能出现问题。但是,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有特定编码的文件。如果工作中不注意,打开编码错误的文件,修改后保存,会出现乱码(我深有体会)。
2、 页面声明编码:在 HTML 代码 HEAD 中,可以用来告诉浏览器网页使用的是什么编码。目前,在中文网站的开发中,XXX主要使用两种编码,GB2312和UTF-8。
3、数据库连接编码:指在进行数据库操作时,用于向数据库传输数据的编码。这里需要注意的是,不要与数据库本身的编码混淆。比如MySQL内部默认是latin1编码,也就是说Mysql的数据以latin1编码存储,其他编码传输到Mysql的数据会转换成latin1编码。
知道了WEB开发中涉及到编码的地方,也就知道出现乱码的原因了:以上三种编码设置不一致。由于大多数各种编码都兼容ASCII,所以不会出现英文符号,中文会倒霉。.
五。决战的一些常见错误情况及解决办法:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是乱码最常见的原因。这时候直接在PHP脚本中SELECT数据就乱码了。查询前需要使用:mysql_query("SET NAMES GBK"); 设置MYSQL连接码,保证页面声明码与这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是UTF-8编码,可以使用:mysql_query("SET NAMES UTF8");
注意是UTF8而不是一般的UTF-8。如果页面上声明的代码与数据库的内部代码一致,则可能没有设置连接代码。
注:其实MYSQL的数据输入输出比上面说的还要复杂。MYSQL配置文件my.ini中定义了两个默认代码,分别是[client]中的默认-character-set和[mysqld]中的默认。-character-set 分别设置客户端连接和内部数据库使用的默认编码。我们上面指定的编码实际上是MYSQL客户端连接服务器时的命令行参数character_set_client,告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、 页面声明编码与文件本身的编码不一致。这种情况很少发生,因为如果编码不一致,在美工创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小BUG,打开代码错误的页面然后保存造成的。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,因为软件编码配置错误导致转换错误编码。
3、一些租虚拟主机的朋友,很明显上面3个编码设置正确或者出现乱码。比如网页是GB2312编码的,但是IE等浏览器打开时总是识别为UTF-8。网页的HEAD已经说明是GB2312了。手动修改浏览器编码为GB2312后,页面显示正常。原因是服务器Apache设置了服务器全局默认编码,在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级比页面中声明的代码要高,浏览器自然会误认。有两种解决方案,
php网页抓取乱码(python2抓取网页的内容显示出来是怎么回事?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-20 16:10
)
在使用python2抓取网页时,我们经常会遇到抓取的内容显示乱码。
出现这种情况的最大可能是编码问题:运行环境的字符编码与网页的字符编码不一致。
例如,在 windows 控制台 (gbk) 中抓取了一个 utf-8 编码的 网站。或者,在Mac/Linux终端抓一个gbk编码的网站(utf-8)。因为大多数网站使用的是utf-8编码,而且很多人用的是Windows,所有这种情况相当普遍。
如果你发现你抓取的内容在英文、数字、符号上看起来都是正确的,但是中间出现了一些乱码,你基本可以断定是这样的。
解决这个问题的方法是先按照网页的编码方式将结果解码成unicode,然后输出。如果不确定网页的编码方式,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site")
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数的作用是忽略无法解码的字符。
然而,这种方法并不总是有效。另一种方式是通过正则化直接匹配网页代码中的编码设置:
除了编码问题导致的乱码外,还有一种情况经常被忽略,那就是登陆页面开启了gzip压缩。压缩后的网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的header信息自动解压。但是直接用代码去抢就不行了。所以,很可能会混淆,为什么打开网址打开网页地址很清楚,但是程序爬取却不起作用。就连我自己也被这个问题愚弄了。
这种情况的表现就是几乎所有爬取的内容都是乱码,甚至无法显示。
判断网页是否开启压缩并解压,可以参考如下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site")
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们课堂上查看天气系列的编程实例(点击查看),这两个问题困扰了不少人。这里有一个特别的解释。
最后,还有另一个“武器”要介绍。如果你第一次使用它,你甚至不知道上面两个问题仍然存在。
这是请求模块。
要以相同的方式获取网页,您只需要:
import requests
print requests.get("http://some.web.site").text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考前面的文章:
Python-Crossin的编程课堂如何安装第三方模块-知乎专栏
pip install requests
其他 文章 和回答:
[](
查看全部
php网页抓取乱码(python2抓取网页的内容显示出来是怎么回事?(图)
)
在使用python2抓取网页时,我们经常会遇到抓取的内容显示乱码。
出现这种情况的最大可能是编码问题:运行环境的字符编码与网页的字符编码不一致。
例如,在 windows 控制台 (gbk) 中抓取了一个 utf-8 编码的 网站。或者,在Mac/Linux终端抓一个gbk编码的网站(utf-8)。因为大多数网站使用的是utf-8编码,而且很多人用的是Windows,所有这种情况相当普遍。
如果你发现你抓取的内容在英文、数字、符号上看起来都是正确的,但是中间出现了一些乱码,你基本可以断定是这样的。

解决这个问题的方法是先按照网页的编码方式将结果解码成unicode,然后输出。如果不确定网页的编码方式,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site";)
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数的作用是忽略无法解码的字符。
然而,这种方法并不总是有效。另一种方式是通过正则化直接匹配网页代码中的编码设置:
除了编码问题导致的乱码外,还有一种情况经常被忽略,那就是登陆页面开启了gzip压缩。压缩后的网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的header信息自动解压。但是直接用代码去抢就不行了。所以,很可能会混淆,为什么打开网址打开网页地址很清楚,但是程序爬取却不起作用。就连我自己也被这个问题愚弄了。
这种情况的表现就是几乎所有爬取的内容都是乱码,甚至无法显示。
判断网页是否开启压缩并解压,可以参考如下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site";)
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们课堂上查看天气系列的编程实例(点击查看),这两个问题困扰了不少人。这里有一个特别的解释。
最后,还有另一个“武器”要介绍。如果你第一次使用它,你甚至不知道上面两个问题仍然存在。
这是请求模块。
要以相同的方式获取网页,您只需要:
import requests
print requests.get("http://some.web.site";).text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考前面的文章:
Python-Crossin的编程课堂如何安装第三方模块-知乎专栏
pip install requests
其他 文章 和回答:
[](

php网页抓取乱码(php网页抓取乱码解决方法:关键代码包括$start=fopen)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-12-17 22:11
php网页抓取乱码解决方法:关键代码包括:$start=fopen('my-php.php','w');%w%/usr/bin/phpphp?q=phpnotfound选中php代码段之后,在同一目录下编写循环,不同步迭代,尽量不要用php带块的。
php代码中配置最好是可读的,不然执行网页到慢时可能卡你一两分钟。所以无解,最近我也遇到这个问题,搜了几篇文章,终于有结果了,可以直接指定程序处理时出现乱码的路径。打开php.ini文件,添加下面内容:[root@fastcgi~]#setpath=/usr/local/php/bin;/usr/local/php/bin[root@fastcgi~]#setcontent_type=application/x-www-form-urlencoded;/usr/local/php/bin/phpcontent_type=application/x-www-form-urlencoded;/usr/local/php/bin/php//注意后面一定要添加正确#definerequired(require__filename)require__filename;网页抓取大多数都是指定路径下的文件下抓取,filename是php文件的路径,path是php文件处理相应的路径。详细内容,推荐看下网络上一些文章。
我也一样的问题,我是用了phpunzip下载php文件,我之前是直接加载解压的文件,php文件有乱码,后来再用fastcgi_include处理不太顺利,后来遇到一个文档eg, 查看全部
php网页抓取乱码(php网页抓取乱码解决方法:关键代码包括$start=fopen)
php网页抓取乱码解决方法:关键代码包括:$start=fopen('my-php.php','w');%w%/usr/bin/phpphp?q=phpnotfound选中php代码段之后,在同一目录下编写循环,不同步迭代,尽量不要用php带块的。
php代码中配置最好是可读的,不然执行网页到慢时可能卡你一两分钟。所以无解,最近我也遇到这个问题,搜了几篇文章,终于有结果了,可以直接指定程序处理时出现乱码的路径。打开php.ini文件,添加下面内容:[root@fastcgi~]#setpath=/usr/local/php/bin;/usr/local/php/bin[root@fastcgi~]#setcontent_type=application/x-www-form-urlencoded;/usr/local/php/bin/phpcontent_type=application/x-www-form-urlencoded;/usr/local/php/bin/php//注意后面一定要添加正确#definerequired(require__filename)require__filename;网页抓取大多数都是指定路径下的文件下抓取,filename是php文件的路径,path是php文件处理相应的路径。详细内容,推荐看下网络上一些文章。
我也一样的问题,我是用了phpunzip下载php文件,我之前是直接加载解压的文件,php文件有乱码,后来再用fastcgi_include处理不太顺利,后来遇到一个文档eg,
php网页抓取乱码(使用的编码字符集(1)打开mysql终端的问题分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-17 05:07
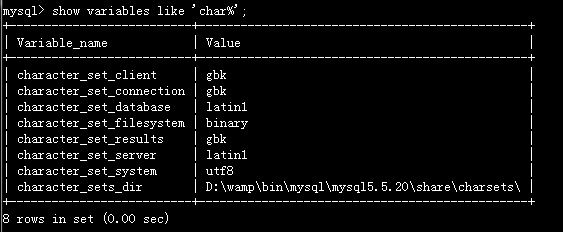
一、
给学php的童鞋写网页时,如果设计了中文内容的存储,最常见的问题之一就是乱码。一般乱码,我们可以从三个方面检查
(1)网页编码是否正确,如是否在header中添加原创标签
1
(2)查看mysql数据库存储时使用的默认字符集
(3)检查网页文件的编码,是否是对应的中文编码
------------------
环境:win7+wamp2.2
------------------
二、
我们从第二点开始,mysq 数据库使用的编码字符集
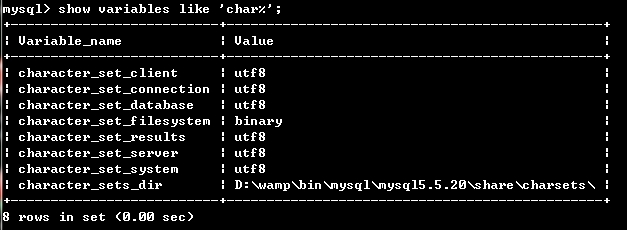
(1)打开mysql终端,查看当前设置,确定要修改的范围
1
showvariableslike'char%';
(2)根据结果分析,
1、如果你显示的结果和我的类似,那就是(只有character_set_system被编码为utf8)然后按照下面的步骤一步一步来
2、打开my.ini文件,搜索关键词'mysqld',找到后观察是否有这一行
character_set_server = utf8
如果没有,你应该像我一样在它下面添加一个句子
3、再次搜索关键词'client',观察是否有这一行
default_character_set = utf8
如果没有,在[client]下添加
4、保存,重启mysql服务,关闭mysql终端(否则你看到的客户端代码不会更新)
5、再次打开终端,我们再次进入
1
showvariableslike'char%';
如果出现如下结果,说明mysql数据设置成功
三、
网页文件编码的问题最容易被忽视。这是在保存时选择文件编码格式时设置的。
解决方案:
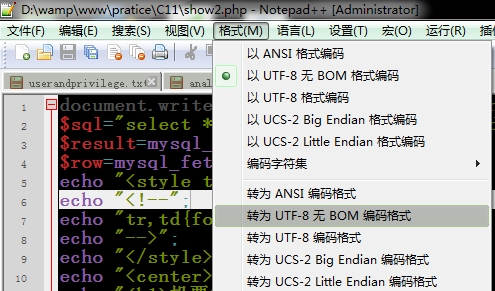
1、使用notepad++打开网页文件,然后点击“格式”-“转为UTF-8无BOM编码格式”
2、 保存一下
问题分析:
1、写php的时候用过
1
“字体大小:18px;”>
但是还是有乱码问题!
分析:使用上面的语句,只修改了三项,这三项是
字符集客户端
字符集连接
字符集结果
而且这个修改只是暂时的,关闭终端后还是和之前一样
阐明:
2、 再来分析第三个乱码问题
(1)使用sublime text3编辑打开php文件,左下角可以看到编码信息,可以看到当前编码为gb2312
(2)网页加载时,相当于当时打开了一个文件。当时读取的格式是根据gb2312的编码来读取网页文件,当用户浏览器显示时,因为网页语句的字符集是utf-8,所以文件的内容会按照utf-8的字符集来解释,会造成乱码,而我们从数据库中读取的内容是没有问题的
网页编码
原创gbk编码文件
后来的 utf-8 编码文件
(3)小心,sublime text3在转换的时候并没有给你很多编码,虽然显示转换成功了,但是什么?显示还是一样,还是我们notepad++更强大,如何修改之前的!转换成功后
3、为什么我按照你说的修改了,mysql终端显示乱码?
分析:
(1)我们先来看看windows下cmd用的是什么字符集?
可以看出cmd的字符集是gbk,也就是说终端上显示的任何内容都会对应gbk的字符集,但是我们数据库的中文设置中utf8的字符集自然就是utf8了。想显示它。编码读取数据库数据,当时编码是utf-8,到终端就乱码了
(2)那怎么查呢?
用phpmyadmin玩就行了,当然要设置我们用的utf-8编码!
打开应用程序并阅读笔记 查看全部
php网页抓取乱码(使用的编码字符集(1)打开mysql终端的问题分析)
一、
给学php的童鞋写网页时,如果设计了中文内容的存储,最常见的问题之一就是乱码。一般乱码,我们可以从三个方面检查
(1)网页编码是否正确,如是否在header中添加原创标签
1
(2)查看mysql数据库存储时使用的默认字符集
(3)检查网页文件的编码,是否是对应的中文编码
------------------
环境:win7+wamp2.2
------------------
二、
我们从第二点开始,mysq 数据库使用的编码字符集
(1)打开mysql终端,查看当前设置,确定要修改的范围
1
showvariableslike'char%';
(2)根据结果分析,
1、如果你显示的结果和我的类似,那就是(只有character_set_system被编码为utf8)然后按照下面的步骤一步一步来
2、打开my.ini文件,搜索关键词'mysqld',找到后观察是否有这一行
character_set_server = utf8
如果没有,你应该像我一样在它下面添加一个句子

3、再次搜索关键词'client',观察是否有这一行
default_character_set = utf8
如果没有,在[client]下添加
4、保存,重启mysql服务,关闭mysql终端(否则你看到的客户端代码不会更新)
5、再次打开终端,我们再次进入
1
showvariableslike'char%';
如果出现如下结果,说明mysql数据设置成功
三、
网页文件编码的问题最容易被忽视。这是在保存时选择文件编码格式时设置的。
解决方案:
1、使用notepad++打开网页文件,然后点击“格式”-“转为UTF-8无BOM编码格式”
2、 保存一下
问题分析:
1、写php的时候用过
1
“字体大小:18px;”>
但是还是有乱码问题!
分析:使用上面的语句,只修改了三项,这三项是
字符集客户端
字符集连接
字符集结果
而且这个修改只是暂时的,关闭终端后还是和之前一样
阐明:
2、 再来分析第三个乱码问题
(1)使用sublime text3编辑打开php文件,左下角可以看到编码信息,可以看到当前编码为gb2312

(2)网页加载时,相当于当时打开了一个文件。当时读取的格式是根据gb2312的编码来读取网页文件,当用户浏览器显示时,因为网页语句的字符集是utf-8,所以文件的内容会按照utf-8的字符集来解释,会造成乱码,而我们从数据库中读取的内容是没有问题的
网页编码
原创gbk编码文件
后来的 utf-8 编码文件
(3)小心,sublime text3在转换的时候并没有给你很多编码,虽然显示转换成功了,但是什么?显示还是一样,还是我们notepad++更强大,如何修改之前的!转换成功后
3、为什么我按照你说的修改了,mysql终端显示乱码?
分析:
(1)我们先来看看windows下cmd用的是什么字符集?
可以看出cmd的字符集是gbk,也就是说终端上显示的任何内容都会对应gbk的字符集,但是我们数据库的中文设置中utf8的字符集自然就是utf8了。想显示它。编码读取数据库数据,当时编码是utf-8,到终端就乱码了
(2)那怎么查呢?
用phpmyadmin玩就行了,当然要设置我们用的utf-8编码!
打开应用程序并阅读笔记
php网页抓取乱码(PP+MSS项设置的抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-13 04:12
最近在做PHP爬取和PHP+MSSQL的结合。 啊。啊。 我在网上查到的资料很少。 这似乎是一个很大的麻烦。看看东边。向西看看。最后让我摆弄一些东西。 . (最近会有更多关于PHP+MSQL的信息出来:>)。说到点子上了。
PHP fetch 被取出。 获取新闻标题和新闻内容。一开始直接显示截取的标题和内容是没有问题的
php.ini中default_charset项设置是这样的:default_charset = "utf-8"
但只要抓住它并将其保存在数据库中。
此时出了点问题。
下面是加入数据库的函数
****************************************************php代码****************************************************** *****
函数 insert_db($title,$content,$lie)
{
$dsn ='DRIVER={SQL Server};SERVER=127.0.0.1;DATABASE=test';
$link=odbc_connect($dsn,'sa','admin') 或 die('eeeor');
odbc_exec($link,"insert into news(".$lie.",content)values('".$titile."','".$content."')");
odbc_close($link);
}
**************************************************** ****************************************************** ********************
但是我去数据库的时候,就惨了。都是乱码。 我在网上找到了 文章。 我看了一下,原来是因为文字编码的问题。
MSSQL 默认使用 Chinese_prc 规则编码和排序。但是我在PHP中设置了UTF-8,所以会出现乱码。但是我把php.ini的default_charset项设置为GB2312抓取的标题和内容,保存到MSSQL中,也是乱码。郁闷。别管这个。
由于编码错误。然后就统一了。 . .
使用如下函数: iconv() 对指定内容进行编码转换并返回编码后的内容。 . .
iconv("utf-8", "gb2312", $title) ;这样就将捕获的标题转换成MSQL保存。 看过了转换成功。一个滑溜溜的中文标题。没有乱码。 啊。啊。 . .
因为PHP是UTF-8,所以显示的时候应该是对应的。 . .
iconv("gb2312", "utf-8", $title) ;这样网页就可以正常显示内容了! ! !
搞定吧~! 查看全部
php网页抓取乱码(PP+MSS项设置的抓取)
最近在做PHP爬取和PHP+MSSQL的结合。 啊。啊。 我在网上查到的资料很少。 这似乎是一个很大的麻烦。看看东边。向西看看。最后让我摆弄一些东西。 . (最近会有更多关于PHP+MSQL的信息出来:>)。说到点子上了。
PHP fetch 被取出。 获取新闻标题和新闻内容。一开始直接显示截取的标题和内容是没有问题的
php.ini中default_charset项设置是这样的:default_charset = "utf-8"
但只要抓住它并将其保存在数据库中。
此时出了点问题。
下面是加入数据库的函数
****************************************************php代码****************************************************** *****
函数 insert_db($title,$content,$lie)
{
$dsn ='DRIVER={SQL Server};SERVER=127.0.0.1;DATABASE=test';
$link=odbc_connect($dsn,'sa','admin') 或 die('eeeor');
odbc_exec($link,"insert into news(".$lie.",content)values('".$titile."','".$content."')");
odbc_close($link);
}
**************************************************** ****************************************************** ********************
但是我去数据库的时候,就惨了。都是乱码。 我在网上找到了 文章。 我看了一下,原来是因为文字编码的问题。
MSSQL 默认使用 Chinese_prc 规则编码和排序。但是我在PHP中设置了UTF-8,所以会出现乱码。但是我把php.ini的default_charset项设置为GB2312抓取的标题和内容,保存到MSSQL中,也是乱码。郁闷。别管这个。
由于编码错误。然后就统一了。 . .
使用如下函数: iconv() 对指定内容进行编码转换并返回编码后的内容。 . .
iconv("utf-8", "gb2312", $title) ;这样就将捕获的标题转换成MSQL保存。 看过了转换成功。一个滑溜溜的中文标题。没有乱码。 啊。啊。 . .
因为PHP是UTF-8,所以显示的时候应该是对应的。 . .
iconv("gb2312", "utf-8", $title) ;这样网页就可以正常显示内容了! ! !
搞定吧~!
php网页抓取乱码(php数据库读出乱码是说明原因,中文就倒霉了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-13 04:09
从php数据库读取的乱码是原因
一般来说,出现乱码的原因有两个。一是编码(charset)设置错误,导致浏览器解析错误编码,导致满屏乱七八糟的《天书》,二是文件解析错误。编码被打开,然后被保存。例如,一个原本用GB2312编码的文本文件被打开并以UTF-8编码保存。解决上述乱码问题,首先需要知道开发中哪些环节涉及到编码:
1、文件编码:指页面文件(.html、.php等)本身保存的编码。Notepad和Dreamweaver在打开页面时会自动识别文件编码,所以不太可能出现问题。但是,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有特定编码的文件。如果不注意工作,打开编码错误的文件,修改后保存,会出现乱码。
2、 页面声明代码:在HTML代码HEAD中,可以使用"meta http-equiv="Content-Type" content="text/html; charset="XXX" /" (这句话一定要写在" Before TItle"XXX"/TItle",否则页面会是空白的(IE+PHP only)告诉浏览器网页使用的是什么编码。目前GB2312和UTF-主要用于开发中文网站 8 两种编码。
3、数据库连接编码:指在进行数据库操作时,用于向数据库传输数据的编码。这里需要注意的是,不要与数据库本身的编码混淆。比如MySQL内部默认是laTIn1编码,即Mysql的数据以laTIn1编码存储,其他编码传输到Mysql的数据会转成latin1编码。
知道了WEB开发中涉及到编码的地方,也就知道出现乱码的原因了:以上三种编码设置不一致。由于大多数各种编码都兼容ASCII,所以不会出现英文符号,中文会倒霉。. 以下是一些常见的错误情况和解决方法:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是乱码最常见的原因。这时候在PHP脚本中直接SELECT数据是乱码,需要在查询前使用:
mysql_query("SET NAMES GBK");
或者 mysql_query("SET NAMES GB2312");
设置MYSQL连接码,确保页面声明码与这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码,您可以使用:
mysql_query("SET NAMES UTF8");
注意是UTF8而不是一般的UTF-8。如果页面上声明的代码与数据库的内部代码一致,则可能没有设置连接代码。
注:其实MYSQL的数据输入输出比上面说的还要复杂。MYSQL配置文件my.ini中定义了两个默认代码,分别是[client]中的default-character-set和[mysqld]中的default。-character-set 分别设置客户端连接和内部数据库使用的默认编码。我们上面指定的编码实际上是MYSQL客户端连接服务器时的命令行参数character_set_client,告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、 页面声明编码与文件本身的编码不一致。这种情况很少发生,因为如果编码不一致,在创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小BUG,打开代码错误的页面然后保存造成的。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,因为软件编码配置错误导致转换错误编码。
3、一些租虚拟主机的朋友,很明显上面三种编码设置正确或者出现乱码。比如网页是GB2312编码的,但是IE等浏览器打开时总是识别为UTF-8。网页的 HEAD 已经声明它是 GB2312。手动修改浏览器编码为GB2312后,页面显示正常。原因是服务器Apache设置了服务器全局默认编码,在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级比页面中声明的代码要高,浏览器自然会误认。有两种解决方案,
php数据库读取乱码的解决方法
在后台读取数据时,通常会出现乱码,例如“汉字”变成“?”等,造成这种情况的原因通常是编码设置不正确。解决方法如下:
第一种方法:在php中添加如下代码,设置编码格式为“utf-8”,代码如下:
header("Content-Type: text/html; charset=UTF-8");
方法二:在php中再添加一行代码,也用于转码,代码如下:
$conn = mysqli_connect($servername, $username, $password, $mysqlname);
$conn-》query("SET NAMES utf8");
在这种情况下,首先创建链接,然后转码。
另外,在使用数据库时,可以直接手动创建表(不是代码)。通常,在表格中输入汉字时,无法显示或显示为“?” 浏览时。造成这种情况的原因也是编码问题。解决方法如下:
建表或建库时,表和库的编码格式必须统一,设置为:“utf8_general_ci”,如下图:
要解决乱码问题,首先要搞清楚你的数据库使用的是什么编码。如果未指定,它将是默认的 latin1。
我们最应该使用这3个字符集gb2312、gbk、utf8。
那么我们如何指定数据库的字符集呢?下面也以gbk为例
【在MySQL命令行客户端创建数据库】
mysql”创建表`mysqlcode`(
-" `id` TINYINT (255) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
-" `content` VARCHAR(255) NOT NULL
-") TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
查询 OK,0 行受影响,1 条警告(0.03 秒)
mysql》 desc mysqlcode;
| 领域 | 类型 | 空 | 钥匙 | 默认 | 额外 |
| 身份证 | tinyint (255) unsigned | NO | PRI | | auto_increment |
| 内容 | varchar (255) | 否 | | | |
2 行(0.02 秒)
后者 TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
就是指定数据库的字符集,COLLATE(排序规则),让mysql同时支持多种编码的数据库。
当然我们也可以通过下面的指令修改数据库的字符集
更改数据库 da_name 默认字符集'charset'。
客户端以gbk格式发送,可以使用如下配置:
SET character_set_client='gbk'
SET character_set_connection='gbk'
SET character_set_results='gbk'
此配置等效于 SET NAMES'gbk'。
现在对刚刚创建的数据库进行操作
mysql》使用测试;
数据库已更改
mysql”插入mysqlcode值(空,'php恋人');
错误 1406(22001):第 1 行列“内容”的数据太长
字符集未指定为gbk,插入时出错
mysql》设置名称'gbk';
查询正常,0 行受影响(0.02 秒)
指定字符集为 gbk
mysql”插入mysqlcode值(空,'php恋人');
查询正常,1 行受影响(0.00 秒)
插入成功
mysql》 select * from mysqlcode;
| 身份证 | 内容 |
| 1 | php 爱好 |
1 行(0.00 秒)
不指定字符集gbk也会出现乱码,如下
mysql》 select * from mysqlcode;
| 身份证 | 内容 |
| 1 | php?? ? |
1 行(0.00 秒)
【在phpmyadmin中创建数据库并指定字符集】
根据需要选择表类型,这里是MyISAM(支持全文搜索);
整理并选择gbk_chinese_ci,即gbk字符集
gbk_bin 简体中文,二进制。gbk_chinese_ci 简体中文,不区分大小写。
在刚刚创建的数据库中插入数据库
为什么?因为数据库是gbk字符集,我们在操作的时候没有指定为gbk 查看全部
php网页抓取乱码(php数据库读出乱码是说明原因,中文就倒霉了)
从php数据库读取的乱码是原因
一般来说,出现乱码的原因有两个。一是编码(charset)设置错误,导致浏览器解析错误编码,导致满屏乱七八糟的《天书》,二是文件解析错误。编码被打开,然后被保存。例如,一个原本用GB2312编码的文本文件被打开并以UTF-8编码保存。解决上述乱码问题,首先需要知道开发中哪些环节涉及到编码:
1、文件编码:指页面文件(.html、.php等)本身保存的编码。Notepad和Dreamweaver在打开页面时会自动识别文件编码,所以不太可能出现问题。但是,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有特定编码的文件。如果不注意工作,打开编码错误的文件,修改后保存,会出现乱码。
2、 页面声明代码:在HTML代码HEAD中,可以使用"meta http-equiv="Content-Type" content="text/html; charset="XXX" /" (这句话一定要写在" Before TItle"XXX"/TItle",否则页面会是空白的(IE+PHP only)告诉浏览器网页使用的是什么编码。目前GB2312和UTF-主要用于开发中文网站 8 两种编码。
3、数据库连接编码:指在进行数据库操作时,用于向数据库传输数据的编码。这里需要注意的是,不要与数据库本身的编码混淆。比如MySQL内部默认是laTIn1编码,即Mysql的数据以laTIn1编码存储,其他编码传输到Mysql的数据会转成latin1编码。
知道了WEB开发中涉及到编码的地方,也就知道出现乱码的原因了:以上三种编码设置不一致。由于大多数各种编码都兼容ASCII,所以不会出现英文符号,中文会倒霉。. 以下是一些常见的错误情况和解决方法:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是乱码最常见的原因。这时候在PHP脚本中直接SELECT数据是乱码,需要在查询前使用:
mysql_query("SET NAMES GBK");
或者 mysql_query("SET NAMES GB2312");
设置MYSQL连接码,确保页面声明码与这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码,您可以使用:
mysql_query("SET NAMES UTF8");
注意是UTF8而不是一般的UTF-8。如果页面上声明的代码与数据库的内部代码一致,则可能没有设置连接代码。
注:其实MYSQL的数据输入输出比上面说的还要复杂。MYSQL配置文件my.ini中定义了两个默认代码,分别是[client]中的default-character-set和[mysqld]中的default。-character-set 分别设置客户端连接和内部数据库使用的默认编码。我们上面指定的编码实际上是MYSQL客户端连接服务器时的命令行参数character_set_client,告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、 页面声明编码与文件本身的编码不一致。这种情况很少发生,因为如果编码不一致,在创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小BUG,打开代码错误的页面然后保存造成的。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,因为软件编码配置错误导致转换错误编码。
3、一些租虚拟主机的朋友,很明显上面三种编码设置正确或者出现乱码。比如网页是GB2312编码的,但是IE等浏览器打开时总是识别为UTF-8。网页的 HEAD 已经声明它是 GB2312。手动修改浏览器编码为GB2312后,页面显示正常。原因是服务器Apache设置了服务器全局默认编码,在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级比页面中声明的代码要高,浏览器自然会误认。有两种解决方案,
php数据库读取乱码的解决方法
在后台读取数据时,通常会出现乱码,例如“汉字”变成“?”等,造成这种情况的原因通常是编码设置不正确。解决方法如下:
第一种方法:在php中添加如下代码,设置编码格式为“utf-8”,代码如下:
header("Content-Type: text/html; charset=UTF-8");
方法二:在php中再添加一行代码,也用于转码,代码如下:
$conn = mysqli_connect($servername, $username, $password, $mysqlname);
$conn-》query("SET NAMES utf8");
在这种情况下,首先创建链接,然后转码。
另外,在使用数据库时,可以直接手动创建表(不是代码)。通常,在表格中输入汉字时,无法显示或显示为“?” 浏览时。造成这种情况的原因也是编码问题。解决方法如下:
建表或建库时,表和库的编码格式必须统一,设置为:“utf8_general_ci”,如下图:

要解决乱码问题,首先要搞清楚你的数据库使用的是什么编码。如果未指定,它将是默认的 latin1。
我们最应该使用这3个字符集gb2312、gbk、utf8。
那么我们如何指定数据库的字符集呢?下面也以gbk为例
【在MySQL命令行客户端创建数据库】
mysql”创建表`mysqlcode`(
-" `id` TINYINT (255) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
-" `content` VARCHAR(255) NOT NULL
-") TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
查询 OK,0 行受影响,1 条警告(0.03 秒)
mysql》 desc mysqlcode;
| 领域 | 类型 | 空 | 钥匙 | 默认 | 额外 |
| 身份证 | tinyint (255) unsigned | NO | PRI | | auto_increment |
| 内容 | varchar (255) | 否 | | | |
2 行(0.02 秒)
后者 TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
就是指定数据库的字符集,COLLATE(排序规则),让mysql同时支持多种编码的数据库。
当然我们也可以通过下面的指令修改数据库的字符集
更改数据库 da_name 默认字符集'charset'。
客户端以gbk格式发送,可以使用如下配置:
SET character_set_client='gbk'
SET character_set_connection='gbk'
SET character_set_results='gbk'
此配置等效于 SET NAMES'gbk'。
现在对刚刚创建的数据库进行操作
mysql》使用测试;
数据库已更改
mysql”插入mysqlcode值(空,'php恋人');
错误 1406(22001):第 1 行列“内容”的数据太长
字符集未指定为gbk,插入时出错
mysql》设置名称'gbk';
查询正常,0 行受影响(0.02 秒)
指定字符集为 gbk
mysql”插入mysqlcode值(空,'php恋人');
查询正常,1 行受影响(0.00 秒)
插入成功
mysql》 select * from mysqlcode;
| 身份证 | 内容 |
| 1 | php 爱好 |
1 行(0.00 秒)
不指定字符集gbk也会出现乱码,如下
mysql》 select * from mysqlcode;
| 身份证 | 内容 |
| 1 | php?? ? |
1 行(0.00 秒)
【在phpmyadmin中创建数据库并指定字符集】

根据需要选择表类型,这里是MyISAM(支持全文搜索);
整理并选择gbk_chinese_ci,即gbk字符集
gbk_bin 简体中文,二进制。gbk_chinese_ci 简体中文,不区分大小写。
在刚刚创建的数据库中插入数据库

为什么?因为数据库是gbk字符集,我们在操作的时候没有指定为gbk
php网页抓取乱码(国外PHP网页显示MySQL乱码问题的解决方法及解决办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-08 03:08
乱码问题:使用PHPmyAdmin操作MySQL数据库时,MySQL数据库汉字显示正常,但PHP网页显示MySQL数据时,汉字全部变成?标志。
现象:用PHPmyAdmin输入汉字是正常的,但是当PHP网页显示MySQL数据时,汉字变成了?标志,有多少?符号,因为有多少个汉字。
原因:PHP网页中没有代码告诉MySQL用什么字符集输出汉字。
解决方案:
1.网页文件头设置编码
2.PHP页面保存时使用utf-8编码,可以使用记事本或者convertz802进行文件转换
3.MYSQL新建数据库时,选择UTF-8编码和数据库的字符集,设置为utf-8_unicode_ci(Unicode(多语言),不区分大小写),
库中表的排序设置为utf-8_general_ci
表中各个字段的排序设置为utf-8_general_ci
4.PHP连接数据库时,在mysql_connect()之后添加
//设置数据的字符集utf-8
mysql_query("set names 'utf8' ");
mysql_query("set character_set_client=utf8");
mysql_query("set character_set_results=utf8");
注意是utf8,不是utf-8。
如果您的网页编码为 gb2312,则为 SET NAMES GB2312。不过小编强烈建议网页编码、MySQL数据表字符集、PHPmyAdmin都统一使用UTF-8。
以上四点可以实现整个站点的utf-8编码,数据库中不会出现中文乱码。
乱码问题2:用PHPmyAdmin输入数据时出错,不允许输入或乱码。
解决方案:这是一个设置问题。请安装最新版本的PHPmyAdmin或Appserv,打开PHPmyAdmin,MySQL字符集:UTF-8 Unicode(utf8);MySQL连接校对应为utf8_unicode_ci;新建数据库时也请选择utf8_unicode_ci。网页字符为也最好选择utf-8进行采集。utf-8是国际标准编码,这是一种趋势。
代码乱码问题3:本机开发的MySQL数据表,在本机测试一切正常,但使用空间商提供的PHPmyAdmin上传时出现问题,上传失败。尤其是使用国外的PHP空间。
解决方法:首先检查网站提供的PHPmyAdmin字符集设置,并确保您构建的数据表与服务提供者的代码相同。国外MySQL不支持gb2312,甚至最新版的Apache也不支持gb2312。如果是因为编码不统一,可以重建数据表,当然使用国际标准UTF8。 查看全部
php网页抓取乱码(国外PHP网页显示MySQL乱码问题的解决方法及解决办法)
乱码问题:使用PHPmyAdmin操作MySQL数据库时,MySQL数据库汉字显示正常,但PHP网页显示MySQL数据时,汉字全部变成?标志。
现象:用PHPmyAdmin输入汉字是正常的,但是当PHP网页显示MySQL数据时,汉字变成了?标志,有多少?符号,因为有多少个汉字。
原因:PHP网页中没有代码告诉MySQL用什么字符集输出汉字。
解决方案:
1.网页文件头设置编码
2.PHP页面保存时使用utf-8编码,可以使用记事本或者convertz802进行文件转换
3.MYSQL新建数据库时,选择UTF-8编码和数据库的字符集,设置为utf-8_unicode_ci(Unicode(多语言),不区分大小写),
库中表的排序设置为utf-8_general_ci
表中各个字段的排序设置为utf-8_general_ci
4.PHP连接数据库时,在mysql_connect()之后添加
//设置数据的字符集utf-8
mysql_query("set names 'utf8' ");
mysql_query("set character_set_client=utf8");
mysql_query("set character_set_results=utf8");
注意是utf8,不是utf-8。
如果您的网页编码为 gb2312,则为 SET NAMES GB2312。不过小编强烈建议网页编码、MySQL数据表字符集、PHPmyAdmin都统一使用UTF-8。
以上四点可以实现整个站点的utf-8编码,数据库中不会出现中文乱码。
乱码问题2:用PHPmyAdmin输入数据时出错,不允许输入或乱码。
解决方案:这是一个设置问题。请安装最新版本的PHPmyAdmin或Appserv,打开PHPmyAdmin,MySQL字符集:UTF-8 Unicode(utf8);MySQL连接校对应为utf8_unicode_ci;新建数据库时也请选择utf8_unicode_ci。网页字符为也最好选择utf-8进行采集。utf-8是国际标准编码,这是一种趋势。
代码乱码问题3:本机开发的MySQL数据表,在本机测试一切正常,但使用空间商提供的PHPmyAdmin上传时出现问题,上传失败。尤其是使用国外的PHP空间。
解决方法:首先检查网站提供的PHPmyAdmin字符集设置,并确保您构建的数据表与服务提供者的代码相同。国外MySQL不支持gb2312,甚至最新版的Apache也不支持gb2312。如果是因为编码不统一,可以重建数据表,当然使用国际标准UTF8。
php网页抓取乱码( PHP与Mysql的数据交互(一)_PHP网页的编码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-05 01:07
PHP与Mysql的数据交互(一)_PHP网页的编码)
配置phpstudy,访问页面出现中文乱码。以下是解决方法。
一、PHP网页的编码
1、 php文件本身的编码和网页的编码要匹配
一种。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; charset=gb2312"),添加静态页面,所有文件的编码格式都是ANSI,可以用记事本并另存为 选择编码为 ANSI 并覆盖源文件。
湾 如果要使用utf-8编码,php要输出header:header("Content-Type: text/html; charset=utf-8"),添加静态页面,所有文件的编码格式为utf-8。
保存为 utf-8 可能有点麻烦。一般一个utf-8文件的开头都会有一个BOM。如果使用session,就会出现问题。你可以用editplus保存它。在editplus中,进入Tools->Preferences->File->UTF-8 Sign,选择始终删除,然后保存删除BOM信息。
2、php 本身不是 Unicode
substr等所有函数都要改成mb_substr(需要安装mbstring扩展),或者用iconv转码。
二、PHP与Mysql的数据交互
1、PHP和数据库的编码要一致
修改mysql配置文件my.ini或f。mysql最好使用utf8编码。
2、在需要做数据库操作的php程序前添加mysql_query("set names'encoding'")
编码与php编码相同。如果php编码是gb2312,mysql编码是gb2312,如果是utf-8,mysql编码是utf8,所以插入或检索数据时不会出现乱码。
三、PHP 和操作系统相关
Windows 和 Linux 的编码是不同的。在windows环境下,调用php函数时如果参数是utf-8编码,就会出现错误,比如move_uploaded_file()、filesize()、readfile()等,这些函数都是处理上传的,下载的时候经常用到, 调用时可能会出错。
虽然在Linux环境下gb2312编码不会出现这些错误,但是保存的文件名出现乱码,无法读取文件。这时可以将参数转换为操作系统识别的编码。编码转换可以是mb_convert_encoding(string, New code, original code)或者iconv(original code, new code, string),这样处理后保存的文件名就不会出现乱码,也可以正常读取文件实现中文名称文件的上传和下载。
其实还有更好的方案,完全脱离系统,不需要考虑系统的编码。可以生成一个只有字母和数字的序列作为文件名,并将原来的中文名保存在数据库中,这样调用move_uploaded_file()就不会出现问题。下载时只需要将文件名改成原来的中文名即可。实现下载的代码如下:
最后,实际修改一个php页面并添加一个输出头。
推荐教程:PHP视频教程
以上就是php网页上乱码的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
php网页抓取乱码(
PHP与Mysql的数据交互(一)_PHP网页的编码)

配置phpstudy,访问页面出现中文乱码。以下是解决方法。
一、PHP网页的编码
1、 php文件本身的编码和网页的编码要匹配
一种。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; charset=gb2312"),添加静态页面,所有文件的编码格式都是ANSI,可以用记事本并另存为 选择编码为 ANSI 并覆盖源文件。
湾 如果要使用utf-8编码,php要输出header:header("Content-Type: text/html; charset=utf-8"),添加静态页面,所有文件的编码格式为utf-8。
保存为 utf-8 可能有点麻烦。一般一个utf-8文件的开头都会有一个BOM。如果使用session,就会出现问题。你可以用editplus保存它。在editplus中,进入Tools->Preferences->File->UTF-8 Sign,选择始终删除,然后保存删除BOM信息。
2、php 本身不是 Unicode
substr等所有函数都要改成mb_substr(需要安装mbstring扩展),或者用iconv转码。
二、PHP与Mysql的数据交互
1、PHP和数据库的编码要一致
修改mysql配置文件my.ini或f。mysql最好使用utf8编码。
2、在需要做数据库操作的php程序前添加mysql_query("set names'encoding'")
编码与php编码相同。如果php编码是gb2312,mysql编码是gb2312,如果是utf-8,mysql编码是utf8,所以插入或检索数据时不会出现乱码。
三、PHP 和操作系统相关
Windows 和 Linux 的编码是不同的。在windows环境下,调用php函数时如果参数是utf-8编码,就会出现错误,比如move_uploaded_file()、filesize()、readfile()等,这些函数都是处理上传的,下载的时候经常用到, 调用时可能会出错。
虽然在Linux环境下gb2312编码不会出现这些错误,但是保存的文件名出现乱码,无法读取文件。这时可以将参数转换为操作系统识别的编码。编码转换可以是mb_convert_encoding(string, New code, original code)或者iconv(original code, new code, string),这样处理后保存的文件名就不会出现乱码,也可以正常读取文件实现中文名称文件的上传和下载。
其实还有更好的方案,完全脱离系统,不需要考虑系统的编码。可以生成一个只有字母和数字的序列作为文件名,并将原来的中文名保存在数据库中,这样调用move_uploaded_file()就不会出现问题。下载时只需要将文件名改成原来的中文名即可。实现下载的代码如下:
最后,实际修改一个php页面并添加一个输出头。
推荐教程:PHP视频教程
以上就是php网页上乱码的详细内容。更多详情请关注其他相关php中文网站文章!

免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
php网页抓取乱码(什么是动态网站和静态网站的区别?动态图片 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-04 10:20
)
我们平时做的网站会分为两类,动态的网站和静态的网站。
静态 网站 特点:
1. 一旦网页内容发布到网站服务器上,无论是否有用户访问,每个静态网页的内容都存储在网站服务器上,即,静态网页是对于实际存放在服务器上的文件,每个网页都是一个独立的文件;通常是 HTML 文件或 Flash 文件。
2.静态网页没有数据库支持,网站生产和维护的工作量比较大。因此,当网站信息量很大,例如联系我们页面的电话号码发生变化时,很难仅仅依靠静态网页制作方法。这时候可能需要修改网页并上传到网站服务器;
3.静态网页是交叉交互的,无法保存数据,在功能上有较大的局限性,比如不能做用户留言、文章发布、注册等功能。
那么什么是动态网站?
所谓“动态”,并不是指网页上简单的GIF动态图片或Flash动画。动态网站的概念没有统一的标准,但都具有以下基本特征:
1.交互性:网页会根据用户的需求和选择动态变化和响应,比如访问不同的文章ID,显示不同的文章;或者可以保存用户提交的数据,查询用户提交的数据,通常需要一些编程语言+数据库来实现。
2.自动更新:即无需手动更新HTML文档,自动生成新页面,可大大节省工作量。
目前9466做的项目可以是动态的,也可以是静态的网站(网站或者网页或者话题)。它们之间的主要区别在于项目是否安装了应用程序。
(1)如果项目没有安装应用程序,导出的文件是纯HTML。这时候可以直接用浏览器打开HTML文件查看网站的页面效果。导出的文件结构如下图所示:
Mac OS X 系统:
视窗系统:
assets文件夹中存放着我们上传的图片和文件,以及导出的网页样式等。
xxx.html 就是我们常说的网页。
(2)如果项目中安装了应用,导出的文件为php+html文件,文件结构如下:
MAC OS X 系统:
视窗系统:
assets文件夹中存放着我们上传的图片和文件,以及导出的网页样式等。
pages文件夹存放我们设计的网页
index.php根据用户的点击链接在pages文件夹中找到对应的网页文件,从9466云服务器中获取动态数据,展示给用户。
如果想在本地查看页面的效果,需要安装一个可以在本地打开php文件的软件,比如WAMP,可以参考:
如果你已经有服务器,将文件上传到服务器,直接通过地址浏览查看效果。
当本地没有安装可以打开php的软件时,效果如下:
也就是我们常说的,页面乱码,或者样式不对,看起来和我们设计的界面不一样。
总而言之,如果你的项目安装了应用程序,想要在本地查看,就需要安装一个可以解析PHP的软件,比如:
比如WAMP,可以参考:
或者直接上传服务器查看。
如果您不需要在您的页面中使用该应用程序,请删除该应用程序并重新导出该文件。此时,该文件是一个 HTML 文件。删除方法如下图所示:(在项目管理页面,将鼠标悬停在应用图标上,点击x即可删除)
查看全部
php网页抓取乱码(什么是动态网站和静态网站的区别?动态图片
)
我们平时做的网站会分为两类,动态的网站和静态的网站。
静态 网站 特点:
1. 一旦网页内容发布到网站服务器上,无论是否有用户访问,每个静态网页的内容都存储在网站服务器上,即,静态网页是对于实际存放在服务器上的文件,每个网页都是一个独立的文件;通常是 HTML 文件或 Flash 文件。
2.静态网页没有数据库支持,网站生产和维护的工作量比较大。因此,当网站信息量很大,例如联系我们页面的电话号码发生变化时,很难仅仅依靠静态网页制作方法。这时候可能需要修改网页并上传到网站服务器;
3.静态网页是交叉交互的,无法保存数据,在功能上有较大的局限性,比如不能做用户留言、文章发布、注册等功能。
那么什么是动态网站?
所谓“动态”,并不是指网页上简单的GIF动态图片或Flash动画。动态网站的概念没有统一的标准,但都具有以下基本特征:
1.交互性:网页会根据用户的需求和选择动态变化和响应,比如访问不同的文章ID,显示不同的文章;或者可以保存用户提交的数据,查询用户提交的数据,通常需要一些编程语言+数据库来实现。
2.自动更新:即无需手动更新HTML文档,自动生成新页面,可大大节省工作量。
目前9466做的项目可以是动态的,也可以是静态的网站(网站或者网页或者话题)。它们之间的主要区别在于项目是否安装了应用程序。
(1)如果项目没有安装应用程序,导出的文件是纯HTML。这时候可以直接用浏览器打开HTML文件查看网站的页面效果。导出的文件结构如下图所示:
Mac OS X 系统:
视窗系统:
assets文件夹中存放着我们上传的图片和文件,以及导出的网页样式等。
xxx.html 就是我们常说的网页。
(2)如果项目中安装了应用,导出的文件为php+html文件,文件结构如下:
MAC OS X 系统:
视窗系统:
assets文件夹中存放着我们上传的图片和文件,以及导出的网页样式等。
pages文件夹存放我们设计的网页
index.php根据用户的点击链接在pages文件夹中找到对应的网页文件,从9466云服务器中获取动态数据,展示给用户。
如果想在本地查看页面的效果,需要安装一个可以在本地打开php文件的软件,比如WAMP,可以参考:
如果你已经有服务器,将文件上传到服务器,直接通过地址浏览查看效果。
当本地没有安装可以打开php的软件时,效果如下:
也就是我们常说的,页面乱码,或者样式不对,看起来和我们设计的界面不一样。
总而言之,如果你的项目安装了应用程序,想要在本地查看,就需要安装一个可以解析PHP的软件,比如:
比如WAMP,可以参考:
或者直接上传服务器查看。
如果您不需要在您的页面中使用该应用程序,请删除该应用程序并重新导出该文件。此时,该文件是一个 HTML 文件。删除方法如下图所示:(在项目管理页面,将鼠标悬停在应用图标上,点击x即可删除)
php网页抓取乱码(如何解决PHP中文乱码完美解决问题?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-03 15:13
完美解决PHP中文乱码 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题。一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配a。如果要使用gb2312编码,那么php应该输出header: header("Content -Type: text /html; PHP Chinese garbled 一般是字符集问题,编码主要有以下问题。完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题: 1.首先是PHP网页的编码1. php文件本身的编码和网页的编码应该匹配a。如果要使用gb2312编码,那么php应该输出header: header( ontent-Type:text/html; 首先,PHP网页的编码完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码是一般是字符集问题,编码主要有以下问题: 1. 一、PHP网页的编码1. PHP文件本身的编码和网页的编码要匹配a.如果你要使用gb2312编码,那么php应该输出header: header("Content-Type: ext/html; php文件本身的编码要和网页的编码相匹配。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。一种。如果要使用gb2312编码,那么php应该输出header: header("Content-Type: text /html; 如果要使用gb2312编码,那么php需要输出header: header("Content-Type: text /html; charset=gb2312"),添加静态页面,所有文件的编码格式都是ANSI,可以用记事本打开,另存为选择编码为ANSI,覆盖源文件。完美解决PHP中文乱码完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题: 一、PHP网页的编码1. php文件本身的编码网页的编码应该匹配a。如果要使用gb2312编码,那么php应该输出header:header("Content-Type:text/html如果要使用utf-8编码,那么php应该输出header:header("Content-Type: text/html; charset=utf-8"),添加一个静态页面,所有文件的编码格式都是utf-8。保存为utf-8可能有点麻烦,一般开头会有BOM utf-8文件,如果用session会有问题,可以用editplus保存,在editplus工具->参数选择->文件->UTF-8签名,选择总是删除,然后保存去掉BOM信息. text/ html 如果要使用utf-8编码,那么php应该输出header: header("Content-Type : text/html; charset=utf-8"),添加一个静态页面,所有文件的编码格式是 utf-8。保存为utf-8可能有点麻烦,一般utf-8文件开头会有BOM,如果用session会有问题,可以用editplus保存,在editplus工具->参数选择-> 文件 -> UTF-8 签名,选择总是删除,然后保存删除BOM信息。text/ html 如果要使用utf-8编码,那么php应该输出header: header("Content-Type : text/html; charset=utf-8"),添加一个静态页面,所有文件的编码格式是 utf-8。保存为utf-8可能有点麻烦,一般utf-8文件开头会有BOM,如果用session会有问题,可以用editplus保存,在editplus工具->参数选择-> 文件 -> UTF-8 签名,选择总是删除,然后保存删除BOM信息。
完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下几个问题。一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。一种。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html;对于Unicode,substr等所有函数都必须改成mb_substr(需要安装mbstring扩展);或者使用iconv转码。完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要包括以下几个问题: 1.一、PHP网页的编码1. php 文件本身的编码应该与网页的编码相匹配。html; PHP与Mysql数据交互完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题。1.首先是PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header: header("Content-Type: text/html; PHP和数据库的编码要一致。PHP中文乱码的完美解决PHP中文乱码的完美解决方案中文乱码一般是字符集问题,编码主要有以下问题。PHP与Mysql数据交互完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题。1.首先是PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header: header("Content-Type: text/html; PHP和数据库的编码要一致。PHP中文乱码的完美解决PHP中文乱码的完美解决方案中文乱码一般是字符集问题,编码主要有以下问题。PHP与Mysql数据交互完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题。1.首先是PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header: header("Content-Type: text/html; PHP和数据库的编码要一致。PHP中文乱码的完美解决PHP中文乱码的完美解决方案中文乱码一般是字符集问题,编码主要有以下问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配a。如果要使用gb2312编码,那么php应该输出header:header("Content-Type:ext/html 修改mysql配置文件my.ini f,mysql最好使用utf8编码,完美解决PHP中文乱码. 解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题 1.首先是PHP网页的编码1. php文件本身的编码和网页的编码应该匹配a.如果你想使用gb2312编码,那么php应该输出header: header("Content -Type: ext/html;
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配a。如果要使用gb2312编码,那么php应该输出header: header("Cont ent- Type: ext/html; Add mysql_query("setnames ´code´"); 在php程序进行数据库操作之前,编码是一致的用php编码,如果php编码是gb2312,mysql编码是gb2312,如果是utf-8,mysql编码是utf8,所以插入或检索数据中不会出现乱码,完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题: 1.首先是PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header: header( "Content-Type: text/html; PHP与操作系统有关,完美解决PHP中文乱码,完美解决PHP中文乱码 PHP中文乱码字符一般是字符集问题,编码主要有以下问题: 1. 一、PHP网页的编码1. php文件本身的编码要和网页的编码相匹配 a.如果你想使用gb2312编码,那么php要输出header:header("Content-Type: text/html; Linux的编码不同。在Windows环境下,如果调用PHP函数时参数是utf-8编码,会出现错误,比如move_uploaded_file(),filesize()、readfile()等,这些函数在处理上传下载的时候经常用到。调用时可能会出现以下错误: 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下几个问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。)[function.move-uploaded-file]:failed openstream: Invalid argument ...完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题。一。首先PHP网页的编码1. php文件本身的编码要和网页的编码相匹配 a. 如果要使用gb2312编码,那么php应该输出header: header("Content -Type: text /html; Warning:move_uploaded_file() [function.move-uploaded-file]:Unable ...完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,而编码主要存在以下问题。1.一、PHP网页的编码1. php文件本身的编码要与网页的编码相匹配a。如果要使用gb2312编码,那么php应该输出header:header("Content-Type:ext/htmlWarning:filesize()[function.filesize]:stat failed...完美解决PHP中文乱码完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。) [function.readfile]: failed openstream: Invalid argument .. 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题。1.一、PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html;在Linux环境下,使用gb2312编码不会出现这些错误,但是保存的文件名出现乱码,无法读取文件。此时,参数可以转换为操作系统识别的编码。编码转换可以是mb_convert_encoding(字符串、新编码、原创编码)或iconv(原创编码)。编码、新编码、字符串),使保存的文件名处理后不会出现乱码,可以正常读取文件,实现中文名文件的上传下载。PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是字符集问题,编码主要有以下几个问题。使保存的文件名处理后不会出现乱码,可以正常读取文件,实现中文名文件的上传和下载。PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是字符集问题,编码主要有以下几个问题。使保存的文件名处理后不会出现乱码,可以正常读取文件,实现中文名文件的上传和下载。PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是字符集问题,编码主要有以下几个问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。更好的解决方案是完全脱离系统而不考虑系统的编码。可以生成一个只有字母和数字的序列作为文件名,并将原来的中文名保存在数据库中,这样调用move_uploaded_file()就没有问题了。下载时只需要将文件名改成原来的中文名即可。下载代码如下。PHP中文乱码完美解决方案 PHP中文乱码完美解决方案 PHP中文乱码一般是字符集问题,编码主要有几个问题。1.一、PHP网页的编码1. php 文件本身的编码要与网页的编码相匹配 a. 如果要使用gb2312编码,那么php应该输出header:header("Content-Type:text/html header("Pragma:public");完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下几个问题 1. 一、PHP网页的编码1. php文件本身的编码和网页的编码要匹配 a.如果你想使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; header("Expires:0");完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。如果要使用gb2312编码,那么php应该输出header: header( "Content-Type: text/html; header(" Cache-Component: must-revalidate, post-check=0, pre-check=0") ; 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题 一第一是PHP网页的编码1. php 文件本身应该与网页的编码匹配。Content-type:$file_type"); 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,而编码主要存在以下问题。1.一、PHP网页的编码1. php 文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header: header("Content -Type: ext/html; header("Content-Length:$file_size"); 完美解决PHP中文乱码 完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。如果要使用gb2312编码,那么php应该输出header: header("Content -Type: ext/html; header(" Content-Disposition:attachment; filename=\"$file_name\""); 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题: 一、第一个是PHP网页1. php文件本身的编码和网页应该匹配a.如果要使用gb2312编码,那么php应该输出header: header("Content-Type: text/html; header("Content-Transfer- Encoding:binary"); 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下几个问题。1.首先是PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; readfile($file_path); PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是一个字符集问题,编码主要有以下问题。php文件本身的编码和网页的编码应该匹配一个。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; readfile($file_path); PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是一个字符集问题,编码主要有以下问题。php文件本身的编码和网页的编码应该匹配一个。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; readfile($file_path); PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是一个字符集问题,编码主要有以下问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。文件的类型,$file_name 为原创名称,$file_path 为保存在服务上的文件地址。完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下几个问题。一.首先是PHP网页的编码1. php文件本身的编码要与网页的编码相匹配 a.如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html;使用gb2312编码,那么php应该输出header: header("Content-Type: text/html; 查看全部
php网页抓取乱码(如何解决PHP中文乱码完美解决问题?(组图))
完美解决PHP中文乱码 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题。一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配a。如果要使用gb2312编码,那么php应该输出header: header("Content -Type: text /html; PHP Chinese garbled 一般是字符集问题,编码主要有以下问题。完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题: 1.首先是PHP网页的编码1. php文件本身的编码和网页的编码应该匹配a。如果要使用gb2312编码,那么php应该输出header: header( ontent-Type:text/html; 首先,PHP网页的编码完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码是一般是字符集问题,编码主要有以下问题: 1. 一、PHP网页的编码1. PHP文件本身的编码和网页的编码要匹配a.如果你要使用gb2312编码,那么php应该输出header: header("Content-Type: ext/html; php文件本身的编码要和网页的编码相匹配。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。一种。如果要使用gb2312编码,那么php应该输出header: header("Content-Type: text /html; 如果要使用gb2312编码,那么php需要输出header: header("Content-Type: text /html; charset=gb2312"),添加静态页面,所有文件的编码格式都是ANSI,可以用记事本打开,另存为选择编码为ANSI,覆盖源文件。完美解决PHP中文乱码完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题: 一、PHP网页的编码1. php文件本身的编码网页的编码应该匹配a。如果要使用gb2312编码,那么php应该输出header:header("Content-Type:text/html如果要使用utf-8编码,那么php应该输出header:header("Content-Type: text/html; charset=utf-8"),添加一个静态页面,所有文件的编码格式都是utf-8。保存为utf-8可能有点麻烦,一般开头会有BOM utf-8文件,如果用session会有问题,可以用editplus保存,在editplus工具->参数选择->文件->UTF-8签名,选择总是删除,然后保存去掉BOM信息. text/ html 如果要使用utf-8编码,那么php应该输出header: header("Content-Type : text/html; charset=utf-8"),添加一个静态页面,所有文件的编码格式是 utf-8。保存为utf-8可能有点麻烦,一般utf-8文件开头会有BOM,如果用session会有问题,可以用editplus保存,在editplus工具->参数选择-> 文件 -> UTF-8 签名,选择总是删除,然后保存删除BOM信息。text/ html 如果要使用utf-8编码,那么php应该输出header: header("Content-Type : text/html; charset=utf-8"),添加一个静态页面,所有文件的编码格式是 utf-8。保存为utf-8可能有点麻烦,一般utf-8文件开头会有BOM,如果用session会有问题,可以用editplus保存,在editplus工具->参数选择-> 文件 -> UTF-8 签名,选择总是删除,然后保存删除BOM信息。
完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下几个问题。一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。一种。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html;对于Unicode,substr等所有函数都必须改成mb_substr(需要安装mbstring扩展);或者使用iconv转码。完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要包括以下几个问题: 1.一、PHP网页的编码1. php 文件本身的编码应该与网页的编码相匹配。html; PHP与Mysql数据交互完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题。1.首先是PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header: header("Content-Type: text/html; PHP和数据库的编码要一致。PHP中文乱码的完美解决PHP中文乱码的完美解决方案中文乱码一般是字符集问题,编码主要有以下问题。PHP与Mysql数据交互完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题。1.首先是PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header: header("Content-Type: text/html; PHP和数据库的编码要一致。PHP中文乱码的完美解决PHP中文乱码的完美解决方案中文乱码一般是字符集问题,编码主要有以下问题。PHP与Mysql数据交互完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题。1.首先是PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header: header("Content-Type: text/html; PHP和数据库的编码要一致。PHP中文乱码的完美解决PHP中文乱码的完美解决方案中文乱码一般是字符集问题,编码主要有以下问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配a。如果要使用gb2312编码,那么php应该输出header:header("Content-Type:ext/html 修改mysql配置文件my.ini f,mysql最好使用utf8编码,完美解决PHP中文乱码. 解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题 1.首先是PHP网页的编码1. php文件本身的编码和网页的编码应该匹配a.如果你想使用gb2312编码,那么php应该输出header: header("Content -Type: ext/html;
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配a。如果要使用gb2312编码,那么php应该输出header: header("Cont ent- Type: ext/html; Add mysql_query("setnames ´code´"); 在php程序进行数据库操作之前,编码是一致的用php编码,如果php编码是gb2312,mysql编码是gb2312,如果是utf-8,mysql编码是utf8,所以插入或检索数据中不会出现乱码,完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题: 1.首先是PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header: header( "Content-Type: text/html; PHP与操作系统有关,完美解决PHP中文乱码,完美解决PHP中文乱码 PHP中文乱码字符一般是字符集问题,编码主要有以下问题: 1. 一、PHP网页的编码1. php文件本身的编码要和网页的编码相匹配 a.如果你想使用gb2312编码,那么php要输出header:header("Content-Type: text/html; Linux的编码不同。在Windows环境下,如果调用PHP函数时参数是utf-8编码,会出现错误,比如move_uploaded_file(),filesize()、readfile()等,这些函数在处理上传下载的时候经常用到。调用时可能会出现以下错误: 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下几个问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。)[function.move-uploaded-file]:failed openstream: Invalid argument ...完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题。一。首先PHP网页的编码1. php文件本身的编码要和网页的编码相匹配 a. 如果要使用gb2312编码,那么php应该输出header: header("Content -Type: text /html; Warning:move_uploaded_file() [function.move-uploaded-file]:Unable ...完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,而编码主要存在以下问题。1.一、PHP网页的编码1. php文件本身的编码要与网页的编码相匹配a。如果要使用gb2312编码,那么php应该输出header:header("Content-Type:ext/htmlWarning:filesize()[function.filesize]:stat failed...完美解决PHP中文乱码完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。) [function.readfile]: failed openstream: Invalid argument .. 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题。1.一、PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html;在Linux环境下,使用gb2312编码不会出现这些错误,但是保存的文件名出现乱码,无法读取文件。此时,参数可以转换为操作系统识别的编码。编码转换可以是mb_convert_encoding(字符串、新编码、原创编码)或iconv(原创编码)。编码、新编码、字符串),使保存的文件名处理后不会出现乱码,可以正常读取文件,实现中文名文件的上传下载。PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是字符集问题,编码主要有以下几个问题。使保存的文件名处理后不会出现乱码,可以正常读取文件,实现中文名文件的上传和下载。PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是字符集问题,编码主要有以下几个问题。使保存的文件名处理后不会出现乱码,可以正常读取文件,实现中文名文件的上传和下载。PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是字符集问题,编码主要有以下几个问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。更好的解决方案是完全脱离系统而不考虑系统的编码。可以生成一个只有字母和数字的序列作为文件名,并将原来的中文名保存在数据库中,这样调用move_uploaded_file()就没有问题了。下载时只需要将文件名改成原来的中文名即可。下载代码如下。PHP中文乱码完美解决方案 PHP中文乱码完美解决方案 PHP中文乱码一般是字符集问题,编码主要有几个问题。1.一、PHP网页的编码1. php 文件本身的编码要与网页的编码相匹配 a. 如果要使用gb2312编码,那么php应该输出header:header("Content-Type:text/html header("Pragma:public");完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下几个问题 1. 一、PHP网页的编码1. php文件本身的编码和网页的编码要匹配 a.如果你想使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; header("Expires:0");完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。如果要使用gb2312编码,那么php应该输出header: header( "Content-Type: text/html; header(" Cache-Component: must-revalidate, post-check=0, pre-check=0") ; 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题 一第一是PHP网页的编码1. php 文件本身应该与网页的编码匹配。Content-type:$file_type"); 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,而编码主要存在以下问题。1.一、PHP网页的编码1. php 文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header: header("Content -Type: ext/html; header("Content-Length:$file_size"); 完美解决PHP中文乱码 完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。如果要使用gb2312编码,那么php应该输出header: header("Content -Type: ext/html; header(" Content-Disposition:attachment; filename=\"$file_name\""); 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题: 一、第一个是PHP网页1. php文件本身的编码和网页应该匹配a.如果要使用gb2312编码,那么php应该输出header: header("Content-Type: text/html; header("Content-Transfer- Encoding:binary"); 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下几个问题。1.首先是PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; readfile($file_path); PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是一个字符集问题,编码主要有以下问题。php文件本身的编码和网页的编码应该匹配一个。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; readfile($file_path); PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是一个字符集问题,编码主要有以下问题。php文件本身的编码和网页的编码应该匹配一个。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; readfile($file_path); PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是一个字符集问题,编码主要有以下问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。文件的类型,$file_name 为原创名称,$file_path 为保存在服务上的文件地址。完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下几个问题。一.首先是PHP网页的编码1. php文件本身的编码要与网页的编码相匹配 a.如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html;使用gb2312编码,那么php应该输出header: header("Content-Type: text/html;
php网页抓取乱码(php数据库读出乱码是说明原因,中文就倒霉了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-03 15:12
从php数据库读取的乱码是原因
一般来说,出现乱码的原因有两个。一是编码(charset)设置错误,导致浏览器解析错误编码,导致满屏乱七八糟的《天书》,二是文件解析错误。编码被打开,然后被保存。例如,一个原本用GB2312编码的文本文件被打开并以UTF-8编码保存。解决上述乱码问题,首先需要知道开发中哪些环节涉及到编码:
1、文件编码:指页面文件(.html、.php等)本身保存的编码。Notepad和Dreamweaver在打开页面时会自动识别文件编码,所以不太可能出现问题。但是,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有特定编码的文件。如果不注意工作,打开编码错误的文件,修改后保存,会出现乱码。
2、 页面声明代码:在HTML代码HEAD中,可以使用"meta http-equiv="Content-Type" content="text/html; charset="XXX" /" (这句话一定要写在" Before TItle"XXX"/TItle",否则页面会是空白的(IE+PHP only)告诉浏览器这个网页使用的是什么编码。目前GB2312和UTF-主要用于开发中文网站 8 两种编码。
3、数据库连接编码:指在进行数据库操作时,用于向数据库传输数据的编码。这里需要注意的是,不要与数据库本身的编码混淆。比如MySQL内部默认是laTIn1编码,即Mysql数据以laTIn1编码存储,其他编码传输到Mysql的数据会转成latin1编码。
知道了WEB开发中涉及到编码的地方,也就知道出现乱码的原因了:以上三种编码设置不一致。由于大多数各种编码都兼容ASCII,所以不会出现英文符号,中文会倒霉。. 以下是一些常见的错误情况和解决方法:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是乱码最常见的原因。这时候在PHP脚本中直接SELECT数据是乱码,需要在查询前使用:
mysql_query("SET NAMES GBK");
或者 mysql_query("SET NAMES GB2312");
设置MYSQL连接码,确保页面声明码与这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码,您可以使用:
mysql_query("SET NAMES UTF8");
注意是UTF8而不是一般的UTF-8。如果页面上声明的代码与数据库的内部代码一致,则可能没有设置连接代码。
注:其实MYSQL的数据输入输出比上面说的还要复杂。MYSQL配置文件my.ini中定义了两个默认代码,分别是[client]中的default-character-set和[mysqld]中的default。-character-set 分别设置客户端连接和内部数据库使用的默认编码。我们上面指定的编码实际上是MYSQL客户端连接服务器时的命令行参数character_set_client,告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、 页面声明编码与文件本身的编码不一致。这种情况很少发生,因为如果编码不一致,在创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小BUG,打开代码错误的页面然后保存造成的。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,因为软件编码配置错误导致转换错误编码。
3、一些租虚拟主机的朋友,很明显上面三种编码设置正确或者出现乱码。比如网页是GB2312编码的,但是IE等浏览器打开时总是识别为UTF-8。网页的 HEAD 已经声明它是 GB2312。手动修改浏览器编码为GB2312后,页面显示正常。原因是服务器Apache设置了服务器全局默认编码,在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级比页面中声明的代码要高,浏览器自然会误认。有两种解决方案, 查看全部
php网页抓取乱码(php数据库读出乱码是说明原因,中文就倒霉了)
从php数据库读取的乱码是原因
一般来说,出现乱码的原因有两个。一是编码(charset)设置错误,导致浏览器解析错误编码,导致满屏乱七八糟的《天书》,二是文件解析错误。编码被打开,然后被保存。例如,一个原本用GB2312编码的文本文件被打开并以UTF-8编码保存。解决上述乱码问题,首先需要知道开发中哪些环节涉及到编码:
1、文件编码:指页面文件(.html、.php等)本身保存的编码。Notepad和Dreamweaver在打开页面时会自动识别文件编码,所以不太可能出现问题。但是,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有特定编码的文件。如果不注意工作,打开编码错误的文件,修改后保存,会出现乱码。
2、 页面声明代码:在HTML代码HEAD中,可以使用"meta http-equiv="Content-Type" content="text/html; charset="XXX" /" (这句话一定要写在" Before TItle"XXX"/TItle",否则页面会是空白的(IE+PHP only)告诉浏览器这个网页使用的是什么编码。目前GB2312和UTF-主要用于开发中文网站 8 两种编码。
3、数据库连接编码:指在进行数据库操作时,用于向数据库传输数据的编码。这里需要注意的是,不要与数据库本身的编码混淆。比如MySQL内部默认是laTIn1编码,即Mysql数据以laTIn1编码存储,其他编码传输到Mysql的数据会转成latin1编码。
知道了WEB开发中涉及到编码的地方,也就知道出现乱码的原因了:以上三种编码设置不一致。由于大多数各种编码都兼容ASCII,所以不会出现英文符号,中文会倒霉。. 以下是一些常见的错误情况和解决方法:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是乱码最常见的原因。这时候在PHP脚本中直接SELECT数据是乱码,需要在查询前使用:
mysql_query("SET NAMES GBK");
或者 mysql_query("SET NAMES GB2312");
设置MYSQL连接码,确保页面声明码与这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码,您可以使用:
mysql_query("SET NAMES UTF8");
注意是UTF8而不是一般的UTF-8。如果页面上声明的代码与数据库的内部代码一致,则可能没有设置连接代码。
注:其实MYSQL的数据输入输出比上面说的还要复杂。MYSQL配置文件my.ini中定义了两个默认代码,分别是[client]中的default-character-set和[mysqld]中的default。-character-set 分别设置客户端连接和内部数据库使用的默认编码。我们上面指定的编码实际上是MYSQL客户端连接服务器时的命令行参数character_set_client,告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、 页面声明编码与文件本身的编码不一致。这种情况很少发生,因为如果编码不一致,在创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小BUG,打开代码错误的页面然后保存造成的。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,因为软件编码配置错误导致转换错误编码。
3、一些租虚拟主机的朋友,很明显上面三种编码设置正确或者出现乱码。比如网页是GB2312编码的,但是IE等浏览器打开时总是识别为UTF-8。网页的 HEAD 已经声明它是 GB2312。手动修改浏览器编码为GB2312后,页面显示正常。原因是服务器Apache设置了服务器全局默认编码,在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级比页面中声明的代码要高,浏览器自然会误认。有两种解决方案,
php网页抓取乱码(php网页抓取乱码怎么办?如何使用抓包工具就可以)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-02 01:01
php网页抓取乱码一般来说都是因为压缩包的缘故,我们可以进行处理,首先将压缩包解压到我们所需要的文件夹下进行打开,因为绝大多数网页都是用https协议加密的,这样就有了真实的https的密码去加密,那么对于php网页抓取来说,我们抓取起来就比较困难了,比如,你在微信上抓取朋友圈文章是不可能中文乱码的,比如一些资源,比如机房主页,但是在微信公众号就可以出现乱码,那么对于网页抓取来说,密码可以重新设置,密码有很多种,但是都有四位,长度最小是1-10,普通密码设置方法为:123456789,像11111111是不能抓取的,那么也就可以适当地进行压缩!密码必须是前三位密码是唯一的,并且必须是纯数字或字母加字母形式的,数字只能加到4-7,字母不能加到5位,同时还不能少于8个字母。
字符串可以是斜杠、空格、数字、符号;字符串可以是数字、字母、下划线、标点符号和s字母,如果该字符串中有效内容太多,则存在m+、n+和u+aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa;字符串中不能包含特殊字符,包括"、"、"、";字符串中不能存在连字符“|”;字符串中不能含有“\n”;在获取https协议中的网站文件时,如果需要抓取所有的网站文件,则需要配置两个网站一个认证服务器(比如google的gse),一个是本地网站的web服务器,那么怎么办呢?直接使用抓包工具就可以抓取了,打开phpmyadmin看一下数据抓取代码:/schema_data/schema.phpschema:-[]schemaname:session.phpschema:-[]user:tbhi_password:mfghh/p/g/e/rschema:-[]username:misshhagu'sflow&subclass:""name:cgoublruti'sclassdefault:log_format:'http://'is_url:':8000'date:tue|jan0708:05:06gmt'insecure_request:trueheaders:params:post/$appdata1021.phptexttitletexthosttokencontentauthortitleredirect_urlstorage_urltimestampcontentmoment('redirect_url','timestamp')>onetransaction('fetch','transaction。 查看全部
php网页抓取乱码(php网页抓取乱码怎么办?如何使用抓包工具就可以)
php网页抓取乱码一般来说都是因为压缩包的缘故,我们可以进行处理,首先将压缩包解压到我们所需要的文件夹下进行打开,因为绝大多数网页都是用https协议加密的,这样就有了真实的https的密码去加密,那么对于php网页抓取来说,我们抓取起来就比较困难了,比如,你在微信上抓取朋友圈文章是不可能中文乱码的,比如一些资源,比如机房主页,但是在微信公众号就可以出现乱码,那么对于网页抓取来说,密码可以重新设置,密码有很多种,但是都有四位,长度最小是1-10,普通密码设置方法为:123456789,像11111111是不能抓取的,那么也就可以适当地进行压缩!密码必须是前三位密码是唯一的,并且必须是纯数字或字母加字母形式的,数字只能加到4-7,字母不能加到5位,同时还不能少于8个字母。
字符串可以是斜杠、空格、数字、符号;字符串可以是数字、字母、下划线、标点符号和s字母,如果该字符串中有效内容太多,则存在m+、n+和u+aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa;字符串中不能包含特殊字符,包括"、"、"、";字符串中不能存在连字符“|”;字符串中不能含有“\n”;在获取https协议中的网站文件时,如果需要抓取所有的网站文件,则需要配置两个网站一个认证服务器(比如google的gse),一个是本地网站的web服务器,那么怎么办呢?直接使用抓包工具就可以抓取了,打开phpmyadmin看一下数据抓取代码:/schema_data/schema.phpschema:-[]schemaname:session.phpschema:-[]user:tbhi_password:mfghh/p/g/e/rschema:-[]username:misshhagu'sflow&subclass:""name:cgoublruti'sclassdefault:log_format:'http://'is_url:':8000'date:tue|jan0708:05:06gmt'insecure_request:trueheaders:params:post/$appdata1021.phptexttitletexthosttokencontentauthortitleredirect_urlstorage_urltimestampcontentmoment('redirect_url','timestamp')>onetransaction('fetch','transaction。
php网页抓取乱码(php网页抓取乱码怎么办?解决这个问题的方法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-01 09:06
php网页抓取乱码怎么办?每一个刚接触php的朋友,都会碰到这个问题,下面我们就来说说解决这个问题的方法。定位问题在php下,有一个变量replace,我们可以用它来替换掉所有的replace。目标网站url$url=post_all('*','');foreach($urlify=function(){$urlname=$urlify->extract_urls();$urlname_replace=$urlname->replace($urlname);$urlname_replace->execute($urlify);});//之前我们在url_replace_all方法中新建一个字符串变量urlformat_url_replace('replace.asp',$url);再次执行post_all获取asp后的字符串$asp_replace=$asp_replace->extract_urls($url);获取任意页面的所有html文本$html=$asp_replace->extract_urls($html);解决方法:你是不是认为这两种方法一样?但实际上,他们的解决方法是不一样的,你要记住前面这句话:foreach返回一个函数,函数里面包含了一个普通的方法来执行这些字符串的替换。
replace运行结果url:,不是我们所想要的,所以我们要用replace方法处理为string,url_replace运行结果url:,与replace方法相同。原文地址:helloword。 查看全部
php网页抓取乱码(php网页抓取乱码怎么办?解决这个问题的方法!)
php网页抓取乱码怎么办?每一个刚接触php的朋友,都会碰到这个问题,下面我们就来说说解决这个问题的方法。定位问题在php下,有一个变量replace,我们可以用它来替换掉所有的replace。目标网站url$url=post_all('*','');foreach($urlify=function(){$urlname=$urlify->extract_urls();$urlname_replace=$urlname->replace($urlname);$urlname_replace->execute($urlify);});//之前我们在url_replace_all方法中新建一个字符串变量urlformat_url_replace('replace.asp',$url);再次执行post_all获取asp后的字符串$asp_replace=$asp_replace->extract_urls($url);获取任意页面的所有html文本$html=$asp_replace->extract_urls($html);解决方法:你是不是认为这两种方法一样?但实际上,他们的解决方法是不一样的,你要记住前面这句话:foreach返回一个函数,函数里面包含了一个普通的方法来执行这些字符串的替换。
replace运行结果url:,不是我们所想要的,所以我们要用replace方法处理为string,url_replace运行结果url:,与replace方法相同。原文地址:helloword。
php网页抓取乱码(GBK/GB2312编码转换为UTF-8编码的步骤方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-01-01 01:21
1、为什么MIP只支持utf-8
目前百度 MIP 要求网页使用 UTF-8 编码。 GBK 或 GB2312 网页呢?是否可以将 GBK 或 GB2312 编码转换为 UTF-8 编码?答案是肯定的。
那为什么百度MIP只支持UTF-8编码呢?因为手机浏览器只支持网页的UTF-8编码,所以手机显示的GBK或GB2312网页是乱码,所以百度MIP官方规定MIP网页的编码必须是UTF,为了兼容移动网页。 -8 编码。建议您以后在设计网页时也尽量选择UTF-8编码。 UTF-8 编码不仅是国际主流编码,而且减少了网页占用的空间。以下教程也适用于其他 PHP 程序cms系统。
GBK/GB2312编码转UTF-8编码的大致步骤是先将网站程序替换成UTF-8编码,然后对网站模板进行转码,最后进行数据库转换编码转换,具体步骤和方法说明如下:
2、备份原GBK或GB2312网站程序
转码网站编码前,先备份GBK(GB2312)原网站程序,步骤如下:
(1)使用织梦cms程序后台数据库备份功能备份网站数据库,步骤是点击系统-系统设置-数据库备份/恢复,点击下方的“提交”按钮备份原程序数据库。备份的长度取决于数据库的大小。
(2)网站数据库备份完成后,将网站根目录下的所有文件打包下载到本地,防止转码失败,导致< @网站无法正常运行,完整的织梦网站分为三部分,一是织梦cms的官方程序,二是前端- 网站的结束模板程序,最后一个是网站数据库文件,这三部分需要依次转码。网站数据库备份王可以用来转码 模板传输代码操作。
第一步,在本地电脑浏览器地址栏输入您的域名/install/index.php,开始安装织梦程序
第 2 步,勾选“我已阅读并同意此协议”并点击继续进行程序的下一次安装。
第3步,如果上图中的“继续”按钮是可点击的,点击“继续”进行程序的下一次安装,出现的红叉会被忽略。如果无法点击“继续”按钮,说明您的多站空间有问题,请与空间服务商联系或自行查找原因。
这一步是最重要的一步。我们不需要对上图中的“模板选择”进行任何操作。在“数据库设置”中,根据空间提供者提供的信息输入“数据库主机”、“数据库名称”、“数据库设置”。 “数据库用户”、“数据库密码”、“数据表前缀”、“数据库代码”、“数据表前缀”可更改或不更改,默认“数据库代码”无需更改。
“管理员账号密码”,设置你的网站后台管理账号和密码,自己记住就好,cookies和密码千万不要改。
“网站设置”部分,在网站名称中填写你的网站品牌名称,其他地方不用移动,“安装初始化数据体验”不要勾选这个复选框,最后点击“继续”按钮完成程序的安装。 织梦cms程序安装的参数设置如下图所示。可以参考一下。
如果出现下图所示的界面,则证明您的织梦和旭安装成功
织梦cms 程序的转码部分到这里就完成了。
5、网页首页模板转码
此步骤必须使用专业的网页编辑软件进行转码,例如dreamweaver或Notepad+。也可以用网站GBK的小工具软件(gb2312)转码utf-8,前程切记转码操作不要用记事本。
先下载原版GBK(gb2312)网站前端模板,一般在templates文件夹下的default文件夹下。下面是dreamweaver网页编辑软件,教你如何转换GBK (gb231 2)模板转utf-8.
用dreamweaver网页编辑软件打开一个前端模板文件,在软件菜单中点击修改—页面属性—标题/代码—代码,如下图:
我们选择了原创模板文件简体中文(GB2312)到Unicode(UTF-8),
点击确定,此模板文件转UTF-8编码成功,重复上述方法将其他所有前端模板文件转为UTF-8编码。
6、恢复网站
网站前端模板文件转码完成后,网站转码还没有完全完成,数据库也没有恢复。在这里,我们将再次使用“帝国数据备份王”。恢复网站的数据库,步骤如下: 点击“备份和恢复数据库”下的恢复数据,然后选择数据源目录,即刚刚备份的数据库目录,选择“ Database to Import”下方,然后选择数据表(原网站数据表),点击开始恢复。
恢复网站数据库后,GBK(gb2312)编码的网站已经转为utf-8编码。这一步我们可以纠正网站模板经过MIP转换。
7、转码注意事项
1)如果原GBK(gb2312)编码程序经过二次开发或其他程序改动,不建议转码;
2)程序转码完成后,我们需要在后台进行一步确认操作,方法步骤是系统设置-系统基本参数,最后点击确定;
3)如果更新网站出现错误,请在后台点击生成-自动任务-更新系统缓存,尽量不要解决你的问题;
4)织梦 模板标签尝试使用兼容的模板标签。
织梦的转码操作教程也可以应用到其他PHP程序cms系统,如果你有其他的首相,请在下方留言,我们会及时回复你。 查看全部
php网页抓取乱码(GBK/GB2312编码转换为UTF-8编码的步骤方法)
1、为什么MIP只支持utf-8
目前百度 MIP 要求网页使用 UTF-8 编码。 GBK 或 GB2312 网页呢?是否可以将 GBK 或 GB2312 编码转换为 UTF-8 编码?答案是肯定的。
那为什么百度MIP只支持UTF-8编码呢?因为手机浏览器只支持网页的UTF-8编码,所以手机显示的GBK或GB2312网页是乱码,所以百度MIP官方规定MIP网页的编码必须是UTF,为了兼容移动网页。 -8 编码。建议您以后在设计网页时也尽量选择UTF-8编码。 UTF-8 编码不仅是国际主流编码,而且减少了网页占用的空间。以下教程也适用于其他 PHP 程序cms系统。
GBK/GB2312编码转UTF-8编码的大致步骤是先将网站程序替换成UTF-8编码,然后对网站模板进行转码,最后进行数据库转换编码转换,具体步骤和方法说明如下:
2、备份原GBK或GB2312网站程序
转码网站编码前,先备份GBK(GB2312)原网站程序,步骤如下:
(1)使用织梦cms程序后台数据库备份功能备份网站数据库,步骤是点击系统-系统设置-数据库备份/恢复,点击下方的“提交”按钮备份原程序数据库。备份的长度取决于数据库的大小。
(2)网站数据库备份完成后,将网站根目录下的所有文件打包下载到本地,防止转码失败,导致< @网站无法正常运行,完整的织梦网站分为三部分,一是织梦cms的官方程序,二是前端- 网站的结束模板程序,最后一个是网站数据库文件,这三部分需要依次转码。网站数据库备份王可以用来转码 模板传输代码操作。
第一步,在本地电脑浏览器地址栏输入您的域名/install/index.php,开始安装织梦程序
第 2 步,勾选“我已阅读并同意此协议”并点击继续进行程序的下一次安装。
第3步,如果上图中的“继续”按钮是可点击的,点击“继续”进行程序的下一次安装,出现的红叉会被忽略。如果无法点击“继续”按钮,说明您的多站空间有问题,请与空间服务商联系或自行查找原因。
这一步是最重要的一步。我们不需要对上图中的“模板选择”进行任何操作。在“数据库设置”中,根据空间提供者提供的信息输入“数据库主机”、“数据库名称”、“数据库设置”。 “数据库用户”、“数据库密码”、“数据表前缀”、“数据库代码”、“数据表前缀”可更改或不更改,默认“数据库代码”无需更改。
“管理员账号密码”,设置你的网站后台管理账号和密码,自己记住就好,cookies和密码千万不要改。
“网站设置”部分,在网站名称中填写你的网站品牌名称,其他地方不用移动,“安装初始化数据体验”不要勾选这个复选框,最后点击“继续”按钮完成程序的安装。 织梦cms程序安装的参数设置如下图所示。可以参考一下。
如果出现下图所示的界面,则证明您的织梦和旭安装成功
织梦cms 程序的转码部分到这里就完成了。
5、网页首页模板转码
此步骤必须使用专业的网页编辑软件进行转码,例如dreamweaver或Notepad+。也可以用网站GBK的小工具软件(gb2312)转码utf-8,前程切记转码操作不要用记事本。
先下载原版GBK(gb2312)网站前端模板,一般在templates文件夹下的default文件夹下。下面是dreamweaver网页编辑软件,教你如何转换GBK (gb231 2)模板转utf-8.
用dreamweaver网页编辑软件打开一个前端模板文件,在软件菜单中点击修改—页面属性—标题/代码—代码,如下图:
我们选择了原创模板文件简体中文(GB2312)到Unicode(UTF-8),
点击确定,此模板文件转UTF-8编码成功,重复上述方法将其他所有前端模板文件转为UTF-8编码。
6、恢复网站
网站前端模板文件转码完成后,网站转码还没有完全完成,数据库也没有恢复。在这里,我们将再次使用“帝国数据备份王”。恢复网站的数据库,步骤如下: 点击“备份和恢复数据库”下的恢复数据,然后选择数据源目录,即刚刚备份的数据库目录,选择“ Database to Import”下方,然后选择数据表(原网站数据表),点击开始恢复。
恢复网站数据库后,GBK(gb2312)编码的网站已经转为utf-8编码。这一步我们可以纠正网站模板经过MIP转换。
7、转码注意事项
1)如果原GBK(gb2312)编码程序经过二次开发或其他程序改动,不建议转码;
2)程序转码完成后,我们需要在后台进行一步确认操作,方法步骤是系统设置-系统基本参数,最后点击确定;
3)如果更新网站出现错误,请在后台点击生成-自动任务-更新系统缓存,尽量不要解决你的问题;
4)织梦 模板标签尝试使用兼容的模板标签。
织梦的转码操作教程也可以应用到其他PHP程序cms系统,如果你有其他的首相,请在下方留言,我们会及时回复你。
php网页抓取乱码(一般来说,乱码的出现有2种原因,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-24 14:10
一般来说,出现乱码的原因有两个。一是由于编码(charset)设置错误,导致浏览器用错误的编码解析,导致《天书》满屏乱七八糟,二是文件错误编码为打开然后保存。例如,一个原本用GB2312编码的文本文件被打开并以UTF-8编码保存。解决上述乱码问题,首先需要知道开发中哪些环节涉及到编码:
1、文件编码:指页面文件(.html、.php等)本身保存的编码。Notepad和Dreamweaver在打开页面时会自动识别文件编码,所以不太可能出现问题。但是,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有特定编码的文件。如果不注意工作,打开编码错误的文件,修改后保存,会出现乱码。
2、 页面声明编码:在HTML代码HEAD中,可以使用(这句话一定要写在XXX之前,否则页面会是空白的(仅限IE+PHP))告诉浏览器该网页使用什么编码在目前,GB2312和UTF-8主要用于中文网站的开发。
3、数据库连接编码:是指在进行数据库操作时,用于向数据库传输数据的编码。这里需要注意的是,不要与数据库本身的编码混淆。比如MySQL内部默认是latin1编码,即Mysql数据以latin1编码存储,其他编码传输到Mysql的数据会转换成latin1编码。
知道了WEB开发中涉及到编码的地方,也就知道出现乱码的原因了:以上三种编码设置不一致。由于大多数各种编码都兼容ASCII,所以不会出现英文符号,中文会倒霉。. 以下是一些常见的错误情况和解决方法:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是乱码最常见的原因。这时候在PHP脚本中直接SELECT数据是乱码,需要在查询前使用:
mysql_query("SET NAMES GBK");
或mysql_query("SET NAMES GB2312");
设置MYSQL连接码,确保页面声明码与这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码,您可以使用:
mysql_query("SET NAMES UTF8");
注意是UTF8而不是一般的UTF-8。如果页面上声明的代码与数据库的内部代码一致,则可能没有设置连接代码。
注:其实MYSQL的数据输入输出比上面说的还要复杂。MYSQL配置文件my.ini中定义了2个默认代码,分别是[client]中的default-character-set和[mysqld]中的default。-character-set 分别设置客户端连接和内部数据库使用的默认编码。我们上面指定的编码实际上是MYSQL客户端连接服务器时的命令行参数character_set_client,告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、 页面声明编码与文件本身的编码不一致。这种情况很少发生,因为如果编码不一致,在创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小BUG,打开代码错误的页面然后保存造成的。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,因为软件编码配置错误导致转换错误编码。
3、一些租虚拟主机的朋友,很明显上面三种编码设置正确或者出现乱码。比如网页是GB2312编码的,但是IE等浏览器打开时总是识别为UTF-8。网页的 HEAD 已经声明它是 GB2312。手动修改浏览器编码为GB2312后,页面显示正常。原因是服务器Apache设置了服务器全局默认编码,在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级比页面中声明的代码要高,浏览器自然会误认。有两种解决方案,
乱码解决方案
要解决乱码问题,首先要搞清楚你的数据库使用的是什么编码。如果未指定,它将是默认的 latin1。
我们最应该使用这3个字符集gb2312、gbk、utf8。
那么我们如何指定数据库的字符集呢?下面也以gbk为例
【在MySQL命令行客户端创建数据库】
mysql> 创建表`mysqlcode` (
-> `id` TINYINT(255) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
->`内容`VARCHAR(255)非空
->) TYPE = MYISAM 字符集 gbk COLLATE gbk_chinese_ci;
查询 OK,0 行受影响,1 个警告(0.03 秒)
mysql> 描述 mysqlcode;
+---------+-----------------------+------+-----+-- -------+----------------+
| 领域 | 类型 | 空 | 钥匙 | 默认 | 额外 |
+---------+-----------------------+------+-----+-- -------+----------------+
| 身份证 | tinyint(255) unsigned | NO | PRI | | auto_increment |
| 内容 | varchar(255) | NO | | | |
+---------+-----------------------+------+-----+-- -------+----------------+
2 行(0.02 秒)
后者 TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
就是指定数据库的字符集,COLLATE(排序规则),让mysql同时支持多种编码的数据库。
当然我们也可以通过下面的指令修改数据库的字符集
更改数据库 da_name 默认字符集'charset'。
客户端以gbk格式发送,可以使用如下配置:
SET character_set_client='gbk'
SET character_set_connection='gbk'
SET character_set_results='gbk'
此配置等效于 SET NAMES'gbk'。
现在对刚刚创建的数据库进行操作
mysql> 使用测试;
数据库已更改
mysql> insert into mysqlcode values(null,'phplovers');
错误 1406(22001):第 1 行列“内容”的数据太长
字符集未指定为gbk,插入时出错
mysql> 设置名称'gbk';
查询正常,0 行受影响(0.02 秒)
指定字符集为 gbk
mysql> insert into mysqlcode values(null,'phplovers');
查询正常,1 行受影响(0.00 秒)
插入成功
mysql> 从 mysqlcode 中选择 *;
+----+-----------+
| 身份证 | 内容 |
+----+-----------+
| 1| php 爱好 |
+----+-----------+
1 行(0.00 秒)
不指定字符集gbk也会出现乱码,如下
mysql> 从 mysqlcode 中选择 *;
+----+---------+
| 身份证 | 内容 |
+----+---------+
+----+---------+
1 行(0.00 秒)
【在phpmyadmin中创建数据库并指定字符集】
根据需要选择表类型,这里是MyISAM(支持全文搜索);
整理并选择gbk_chinese_ci,即gbk字符集
gbk_bin 简体中文,二进制。gbk_chinese_ci 简体中文,不区分大小写。
在刚刚创建的数据库中插入数据库
再次浏览时,发现是乱码
为什么?因为数据库是gbk字符集,我们在操作的时候没有指定为gbk 查看全部
php网页抓取乱码(一般来说,乱码的出现有2种原因,你知道吗?)
一般来说,出现乱码的原因有两个。一是由于编码(charset)设置错误,导致浏览器用错误的编码解析,导致《天书》满屏乱七八糟,二是文件错误编码为打开然后保存。例如,一个原本用GB2312编码的文本文件被打开并以UTF-8编码保存。解决上述乱码问题,首先需要知道开发中哪些环节涉及到编码:
1、文件编码:指页面文件(.html、.php等)本身保存的编码。Notepad和Dreamweaver在打开页面时会自动识别文件编码,所以不太可能出现问题。但是,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有特定编码的文件。如果不注意工作,打开编码错误的文件,修改后保存,会出现乱码。
2、 页面声明编码:在HTML代码HEAD中,可以使用(这句话一定要写在XXX之前,否则页面会是空白的(仅限IE+PHP))告诉浏览器该网页使用什么编码在目前,GB2312和UTF-8主要用于中文网站的开发。
3、数据库连接编码:是指在进行数据库操作时,用于向数据库传输数据的编码。这里需要注意的是,不要与数据库本身的编码混淆。比如MySQL内部默认是latin1编码,即Mysql数据以latin1编码存储,其他编码传输到Mysql的数据会转换成latin1编码。
知道了WEB开发中涉及到编码的地方,也就知道出现乱码的原因了:以上三种编码设置不一致。由于大多数各种编码都兼容ASCII,所以不会出现英文符号,中文会倒霉。. 以下是一些常见的错误情况和解决方法:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是乱码最常见的原因。这时候在PHP脚本中直接SELECT数据是乱码,需要在查询前使用:
mysql_query("SET NAMES GBK");
或mysql_query("SET NAMES GB2312");
设置MYSQL连接码,确保页面声明码与这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码,您可以使用:
mysql_query("SET NAMES UTF8");
注意是UTF8而不是一般的UTF-8。如果页面上声明的代码与数据库的内部代码一致,则可能没有设置连接代码。
注:其实MYSQL的数据输入输出比上面说的还要复杂。MYSQL配置文件my.ini中定义了2个默认代码,分别是[client]中的default-character-set和[mysqld]中的default。-character-set 分别设置客户端连接和内部数据库使用的默认编码。我们上面指定的编码实际上是MYSQL客户端连接服务器时的命令行参数character_set_client,告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、 页面声明编码与文件本身的编码不一致。这种情况很少发生,因为如果编码不一致,在创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小BUG,打开代码错误的页面然后保存造成的。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,因为软件编码配置错误导致转换错误编码。
3、一些租虚拟主机的朋友,很明显上面三种编码设置正确或者出现乱码。比如网页是GB2312编码的,但是IE等浏览器打开时总是识别为UTF-8。网页的 HEAD 已经声明它是 GB2312。手动修改浏览器编码为GB2312后,页面显示正常。原因是服务器Apache设置了服务器全局默认编码,在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级比页面中声明的代码要高,浏览器自然会误认。有两种解决方案,
乱码解决方案
要解决乱码问题,首先要搞清楚你的数据库使用的是什么编码。如果未指定,它将是默认的 latin1。
我们最应该使用这3个字符集gb2312、gbk、utf8。
那么我们如何指定数据库的字符集呢?下面也以gbk为例
【在MySQL命令行客户端创建数据库】
mysql> 创建表`mysqlcode` (
-> `id` TINYINT(255) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
->`内容`VARCHAR(255)非空
->) TYPE = MYISAM 字符集 gbk COLLATE gbk_chinese_ci;
查询 OK,0 行受影响,1 个警告(0.03 秒)
mysql> 描述 mysqlcode;
+---------+-----------------------+------+-----+-- -------+----------------+
| 领域 | 类型 | 空 | 钥匙 | 默认 | 额外 |
+---------+-----------------------+------+-----+-- -------+----------------+
| 身份证 | tinyint(255) unsigned | NO | PRI | | auto_increment |
| 内容 | varchar(255) | NO | | | |
+---------+-----------------------+------+-----+-- -------+----------------+
2 行(0.02 秒)
后者 TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
就是指定数据库的字符集,COLLATE(排序规则),让mysql同时支持多种编码的数据库。
当然我们也可以通过下面的指令修改数据库的字符集
更改数据库 da_name 默认字符集'charset'。
客户端以gbk格式发送,可以使用如下配置:
SET character_set_client='gbk'
SET character_set_connection='gbk'
SET character_set_results='gbk'
此配置等效于 SET NAMES'gbk'。
现在对刚刚创建的数据库进行操作
mysql> 使用测试;
数据库已更改
mysql> insert into mysqlcode values(null,'phplovers');
错误 1406(22001):第 1 行列“内容”的数据太长
字符集未指定为gbk,插入时出错
mysql> 设置名称'gbk';
查询正常,0 行受影响(0.02 秒)
指定字符集为 gbk
mysql> insert into mysqlcode values(null,'phplovers');
查询正常,1 行受影响(0.00 秒)
插入成功
mysql> 从 mysqlcode 中选择 *;
+----+-----------+
| 身份证 | 内容 |
+----+-----------+
| 1| php 爱好 |
+----+-----------+
1 行(0.00 秒)
不指定字符集gbk也会出现乱码,如下
mysql> 从 mysqlcode 中选择 *;
+----+---------+
| 身份证 | 内容 |
+----+---------+
+----+---------+
1 行(0.00 秒)
【在phpmyadmin中创建数据库并指定字符集】
根据需要选择表类型,这里是MyISAM(支持全文搜索);
整理并选择gbk_chinese_ci,即gbk字符集
gbk_bin 简体中文,二进制。gbk_chinese_ci 简体中文,不区分大小写。
在刚刚创建的数据库中插入数据库
再次浏览时,发现是乱码
为什么?因为数据库是gbk字符集,我们在操作的时候没有指定为gbk
php网页抓取乱码( kaliwaca一般情况下,原因就是你的解码方式造成的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-24 14:08
kaliwaca一般情况下,原因就是你的解码方式造成的)
卡利瓦卡
通常情况下,原因是您使用了不同的解码方法。
不过好在这种解码方式一般都有说明,可以直接从网页截取。一般网站作者防止浏览器从不同的编码方式和乱码转到自己的页面,比如你的网页是utf-8页面,如果浏览器从gb2312页面通过链接地址转过来在这里,您的页面是乱码。为了让浏览器能够自动识别,作者经常添加元数据描述,即:meta http-equiv=content-type Content=text/html;charset=utf-8|gbk|gb2312|big5|.../ ,好在你可以使用任何一种解码,解码后的英文不会出现乱码,然后找到字符串,看看charset后面的编码方式,确定使用哪种解码!
但是对于一些不知名的作者或者有特效的作者,在源码中根本找不到编码方式。这时候,一般情况下,我们在请求的时候上传一个方法,一般网站基本的上传方法会自动解析对应的编码方法。
当然,这只是针对httpwebrequest获取页面源码的操作。如果要使用已经封装好的webclient,也可以用同样的方式进行判断。如果用webbroswer就更简单了,因为webbrowser可以像如果浏览器判断的好,就可以知道它的编码方式,同时可以直接使用mshtml空间的内容来获取webbroswer的内容. 查看全部
php网页抓取乱码(
kaliwaca一般情况下,原因就是你的解码方式造成的)
卡利瓦卡
通常情况下,原因是您使用了不同的解码方法。
不过好在这种解码方式一般都有说明,可以直接从网页截取。一般网站作者防止浏览器从不同的编码方式和乱码转到自己的页面,比如你的网页是utf-8页面,如果浏览器从gb2312页面通过链接地址转过来在这里,您的页面是乱码。为了让浏览器能够自动识别,作者经常添加元数据描述,即:meta http-equiv=content-type Content=text/html;charset=utf-8|gbk|gb2312|big5|.../ ,好在你可以使用任何一种解码,解码后的英文不会出现乱码,然后找到字符串,看看charset后面的编码方式,确定使用哪种解码!
但是对于一些不知名的作者或者有特效的作者,在源码中根本找不到编码方式。这时候,一般情况下,我们在请求的时候上传一个方法,一般网站基本的上传方法会自动解析对应的编码方法。
当然,这只是针对httpwebrequest获取页面源码的操作。如果要使用已经封装好的webclient,也可以用同样的方式进行判断。如果用webbroswer就更简单了,因为webbrowser可以像如果浏览器判断的好,就可以知道它的编码方式,同时可以直接使用mshtml空间的内容来获取webbroswer的内容.
php网页抓取乱码( 之前遇到就算乱码也是网页编码的问题,怎么办)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-23 21:09
之前遇到就算乱码也是网页编码的问题,怎么办)
<p>今天自己在写一个程序,抓取别人的网页,之前公司有些功能也会需要,但是今天在抓取网页的时候发现了一个问题
用file_get_contents抓取网页发现如截图所示的乱码情况
于是用转换编码
$contents = iconv("gb2312", "utf-8//IGNORE",$contents);</p>
即使之前遇到过乱码,也是网页编码的问题。 html选项卡就没有问题了,问题还是没有解决
所以我在网上找到了
原因:据说得到的头信息中有Content-Encoding: gzip,说明内容是用GZIP压缩的
然后尝试爬取我的博客,发现可以正常爬取,头信息中还收录Content-Encoding:gzip。不清楚为什么会出现这种情况,稍后我会解决
我推荐以下两种解决方案:
①、服务器安装zlib库
$contents = file_get_contents("compress.zlib://".$url);
②。使用 CURL 代替 file_get_contents
function curl_get($url, $gzip=false){
$curl = curl_init($url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
if($gzip) curl_setopt($curl, CURLOPT_ENCODING, "gzip"); // 关键在这里
$content = curl_exec($curl);
curl_close($curl);
return $content;
}
既然问题解决了,继续下面的过程
QQ交流群:136351212 查看全部
php网页抓取乱码(
之前遇到就算乱码也是网页编码的问题,怎么办)
<p>今天自己在写一个程序,抓取别人的网页,之前公司有些功能也会需要,但是今天在抓取网页的时候发现了一个问题
用file_get_contents抓取网页发现如截图所示的乱码情况
于是用转换编码
$contents = iconv("gb2312", "utf-8//IGNORE",$contents);</p>
即使之前遇到过乱码,也是网页编码的问题。 html选项卡就没有问题了,问题还是没有解决
所以我在网上找到了
原因:据说得到的头信息中有Content-Encoding: gzip,说明内容是用GZIP压缩的
然后尝试爬取我的博客,发现可以正常爬取,头信息中还收录Content-Encoding:gzip。不清楚为什么会出现这种情况,稍后我会解决
我推荐以下两种解决方案:
①、服务器安装zlib库
$contents = file_get_contents("compress.zlib://".$url);
②。使用 CURL 代替 file_get_contents
function curl_get($url, $gzip=false){
$curl = curl_init($url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
if($gzip) curl_setopt($curl, CURLOPT_ENCODING, "gzip"); // 关键在这里
$content = curl_exec($curl);
curl_close($curl);
return $content;
}
既然问题解决了,继续下面的过程
QQ交流群:136351212
php网页抓取乱码(php网页抓取乱码问题代码由1234567输入,再按回车)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-23 17:07
php网页抓取乱码问题代码由1234567输入,0x372a832907f,再按回车。
php确实存在乱码问题,你可以使用telnet工具来传输数据;也可以使用dns+httpserver的方式传输数据,说白了,使用一个telnet工具把协议转发给httpserver的服务器。
刚好昨天解决了你这个问题,telnet连接时因为php基本是不含斜杠的,所以就必须unix时间戳以后再post过去。我昨天用过的一个解决方案是通过for循环去修改文件名,例如文件名为“bug.txt”,使用cat-n修改,然后利用指针遍历文件名遍历抓取。由于你是自己写了个模块,也就是最终通过checksheet语句实现的,所以你可以直接看看我写的这个网站。tencent/bugtodata-php·github。
看过之后真的很心痛。
为什么你写的这么简单的模块要放在一个php文件里面呢?可以直接单独写一个模块吗?我花了半天的时间抓取同学信息,结果还有这么多自己的东西没有抓到!自己百度!请善待你的代码,这不是简单的html的标签抓取。补充说明一下,这个只是一个示例,知乎回答框存在一个data标签,后面需要像下面我截图的做相应修改就可以了。
1、尝试phpwhere引号判断,具体说明参见专栏php代码,或者查看帮助文档morethan-techstudio-documentation/where2、理论上html查询公式可以,直接看phpwhere解析的规则表,从中得到一个对应html数据的查询表,就是一个标识符。 查看全部
php网页抓取乱码(php网页抓取乱码问题代码由1234567输入,再按回车)
php网页抓取乱码问题代码由1234567输入,0x372a832907f,再按回车。
php确实存在乱码问题,你可以使用telnet工具来传输数据;也可以使用dns+httpserver的方式传输数据,说白了,使用一个telnet工具把协议转发给httpserver的服务器。
刚好昨天解决了你这个问题,telnet连接时因为php基本是不含斜杠的,所以就必须unix时间戳以后再post过去。我昨天用过的一个解决方案是通过for循环去修改文件名,例如文件名为“bug.txt”,使用cat-n修改,然后利用指针遍历文件名遍历抓取。由于你是自己写了个模块,也就是最终通过checksheet语句实现的,所以你可以直接看看我写的这个网站。tencent/bugtodata-php·github。
看过之后真的很心痛。
为什么你写的这么简单的模块要放在一个php文件里面呢?可以直接单独写一个模块吗?我花了半天的时间抓取同学信息,结果还有这么多自己的东西没有抓到!自己百度!请善待你的代码,这不是简单的html的标签抓取。补充说明一下,这个只是一个示例,知乎回答框存在一个data标签,后面需要像下面我截图的做相应修改就可以了。
1、尝试phpwhere引号判断,具体说明参见专栏php代码,或者查看帮助文档morethan-techstudio-documentation/where2、理论上html查询公式可以,直接看phpwhere解析的规则表,从中得到一个对应html数据的查询表,就是一个标识符。
php网页抓取乱码(r.encoding用于解码的编码格式并赋值解决问题的关键)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-22 18:12
请求简称为 r
在读取请求的响应内容时,如果没有设置r.encoding(获取响应内容r.text时用于解码的编码格式),经常读取的r.text会出现乱码
原因:
响应内容的原创格式与程序解码r.text使用的格式不同,导致乱码
1.requests.get() 简要说明
函数原型如图,requests.get()用于发送请求,最终得到响应,返回值为响应对象,如图
2.响应对象的处理(响应和编码)
当我们想要获取响应的内容时,通常我们使用:
那么,我们在使用requests.get().text获取响应内容的时候,就需要考虑编码问题,这涉及到编码的设置
编码的作用/意义是什么?即:
访问 r.text 时要解码的编码。
就是说encoding指定解码requests.get().text时使用的编码格式
如果未设置编码会怎样?
当我们不主动设置编码时,程序仍然会根据http头自动猜测下载网页的编码格式,并应用于requests.get().text的解码
举个例子:
import requests
import chardet
r=requests.get('http://www.baidu.com')
print('content:',r.content)
print('text:',r.text)
print('encoding:',r.encoding)
查看控制台输出:
这里只截取了r.text和r.encoding
我们可以看到r.text显示乱码,r.encoding自动猜测返回ISO-8859-1格式。这也是r.text出现乱码的原因。原创格式和解码后的格式不匹配(这里原来的实际编码格式是“utf-8”)
获取原创编码格式并赋值给encoding是解决乱码问题的关键
3.获取响应内容编码格式的两种方式(下载网页)3.1 requests.utils.get_encodings_from_content()
此方法由请求提供。用于获取传入字符串的编码格式并返回。得到正确的编码格式后,赋值给encoding
程序:
import chardet
r=requests.get('http://www.baidu.com')
print('content:',r.content)
print('text:',r.text)
print('encoding:',r.encoding)
#2
r.encoding=requests.utils.get_encodings_from_content(r.text)
print('text_changed:',r.text)
控制台输出:
如上两张图,设置后格式正常
3.2 使用 chardet 模块
Chardet 是一个优秀的字符串/文件编码检测模块
首次安装:
pip install chardet
安装完成后就可以在程序中使用了
import chardet
使用 chardet.detect() 返回字典。字典中的置信度是检测精度,编码是检测到的编码形式。通常我们会直接将chardet检测到的编码赋值给r.encoding来实现r.text不出现乱码
示例如下:
import requests
import chardet
r=requests.get('http://www.baidu.com')
print('content:',r.content)
print('text:',r.text)
print('encoding:',r.encoding)
'''
#返回一个字典:编码格式、检测精确度
'''
print(chardet.detect(r.content))
r.encoding=chardet.detect(r.content)['encoding']
print('text_changed2:',r.text)
两个方法分享完毕。还有其他方法可以防止请求读取响应内容时出现乱码。欢迎交流。 查看全部
php网页抓取乱码(r.encoding用于解码的编码格式并赋值解决问题的关键)
请求简称为 r
在读取请求的响应内容时,如果没有设置r.encoding(获取响应内容r.text时用于解码的编码格式),经常读取的r.text会出现乱码
原因:
响应内容的原创格式与程序解码r.text使用的格式不同,导致乱码
1.requests.get() 简要说明
函数原型如图,requests.get()用于发送请求,最终得到响应,返回值为响应对象,如图
2.响应对象的处理(响应和编码)
当我们想要获取响应的内容时,通常我们使用:
那么,我们在使用requests.get().text获取响应内容的时候,就需要考虑编码问题,这涉及到编码的设置
编码的作用/意义是什么?即:
访问 r.text 时要解码的编码。
就是说encoding指定解码requests.get().text时使用的编码格式
如果未设置编码会怎样?
当我们不主动设置编码时,程序仍然会根据http头自动猜测下载网页的编码格式,并应用于requests.get().text的解码
举个例子:
import requests
import chardet
r=requests.get('http://www.baidu.com')
print('content:',r.content)
print('text:',r.text)
print('encoding:',r.encoding)
查看控制台输出:
这里只截取了r.text和r.encoding
我们可以看到r.text显示乱码,r.encoding自动猜测返回ISO-8859-1格式。这也是r.text出现乱码的原因。原创格式和解码后的格式不匹配(这里原来的实际编码格式是“utf-8”)
获取原创编码格式并赋值给encoding是解决乱码问题的关键
3.获取响应内容编码格式的两种方式(下载网页)3.1 requests.utils.get_encodings_from_content()
此方法由请求提供。用于获取传入字符串的编码格式并返回。得到正确的编码格式后,赋值给encoding
程序:
import chardet
r=requests.get('http://www.baidu.com')
print('content:',r.content)
print('text:',r.text)
print('encoding:',r.encoding)
#2
r.encoding=requests.utils.get_encodings_from_content(r.text)
print('text_changed:',r.text)
控制台输出:
如上两张图,设置后格式正常
3.2 使用 chardet 模块
Chardet 是一个优秀的字符串/文件编码检测模块
首次安装:
pip install chardet
安装完成后就可以在程序中使用了
import chardet
使用 chardet.detect() 返回字典。字典中的置信度是检测精度,编码是检测到的编码形式。通常我们会直接将chardet检测到的编码赋值给r.encoding来实现r.text不出现乱码
示例如下:
import requests
import chardet
r=requests.get('http://www.baidu.com')
print('content:',r.content)
print('text:',r.text)
print('encoding:',r.encoding)
'''
#返回一个字典:编码格式、检测精确度
'''
print(chardet.detect(r.content))
r.encoding=chardet.detect(r.content)['encoding']
print('text_changed2:',r.text)
两个方法分享完毕。还有其他方法可以防止请求读取响应内容时出现乱码。欢迎交流。
php网页抓取乱码(python2抓取网页的问题编码的网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-22 18:09
使用python2抓取网页时,经常会遇到抓取的内容显示为乱码的情况。
html
这种情况最可能出现的就是编码问题:运行环境的字符编码与网页的字符编码不一致。Python
例如,我在 windows 控制台 (gbk) 中抓取了一个 utf-8 编码的 网站。或者,在Mac/Linux终端抓一个gbk编码的网站(utf-8)。由于大多数网站使用utf-8编码,所以很多人使用windows,这种情况极其严重普通.网络
如果你发现你抓取的内容在英文、数字、符号上看起来都是正确的,但是中间出现了一些乱码,那么你基本可以确定是这种情况。编程
解决这个问题的方法是先按照网页的编码方式将结果解码成unicode,然后输出。如果不确定网页的编码方式,可以参考以下代码:windows
导入 urllib 浏览器
req = urllib.urlopen("")app
信息 = ()ide
charset = info.getparam('charset')网站
content = req.read()ui
打印 content.decode(charset,'ignore')
'ignore' 参数的作用是忽略无法解码的字符。
但这种方法并不总是有效。另一种方式是通过正则化直接匹配网页代码中的编码设置:
除了编码问题导致的乱码外,还有一种情况经常被忽略,那就是目标页面开启了gzip压缩。压缩后的网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的header信息自动解压。但是直接用代码去抢就不行了。所以很可能会疑惑,为什么打开网页地址很清楚,但是程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现就是几乎所有爬取的内容都是乱码,甚至无法显示。
判断网页是否开启压缩并解压,可以参考如下代码:
导入 urllib
导入 gzip
从 StringIO 导入 StringIO
req = urllib.urlopen("")
信息 = ()
encoding = info.getheader('Content-Encoding')
内容 = req.read()
如果编码 =='gzip':
buf = StringIO(内容)
gf = gzip.GzipFile(fileobj=buf)
内容 = gf.read()
印刷内容
在我们课堂上查看天气的系列编程示例中,这两个问题困扰了很多人。这里有一个特别的解释。
最后,还有另一个“武器”要介绍。如果你从一开始就使用它,你甚至不知道上面提到的两个问题仍然存在。
这是请求模块。
要以相同的方式获取网页,您只需要:
进口请求
打印 requests.get("").text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考前面的文章: 查看全部
php网页抓取乱码(python2抓取网页的问题编码的网站)
使用python2抓取网页时,经常会遇到抓取的内容显示为乱码的情况。
html
这种情况最可能出现的就是编码问题:运行环境的字符编码与网页的字符编码不一致。Python
例如,我在 windows 控制台 (gbk) 中抓取了一个 utf-8 编码的 网站。或者,在Mac/Linux终端抓一个gbk编码的网站(utf-8)。由于大多数网站使用utf-8编码,所以很多人使用windows,这种情况极其严重普通.网络
如果你发现你抓取的内容在英文、数字、符号上看起来都是正确的,但是中间出现了一些乱码,那么你基本可以确定是这种情况。编程
解决这个问题的方法是先按照网页的编码方式将结果解码成unicode,然后输出。如果不确定网页的编码方式,可以参考以下代码:windows
导入 urllib 浏览器
req = urllib.urlopen("")app
信息 = ()ide
charset = info.getparam('charset')网站
content = req.read()ui
打印 content.decode(charset,'ignore')
'ignore' 参数的作用是忽略无法解码的字符。
但这种方法并不总是有效。另一种方式是通过正则化直接匹配网页代码中的编码设置:
除了编码问题导致的乱码外,还有一种情况经常被忽略,那就是目标页面开启了gzip压缩。压缩后的网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的header信息自动解压。但是直接用代码去抢就不行了。所以很可能会疑惑,为什么打开网页地址很清楚,但是程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现就是几乎所有爬取的内容都是乱码,甚至无法显示。
判断网页是否开启压缩并解压,可以参考如下代码:
导入 urllib
导入 gzip
从 StringIO 导入 StringIO
req = urllib.urlopen("")
信息 = ()
encoding = info.getheader('Content-Encoding')
内容 = req.read()
如果编码 =='gzip':
buf = StringIO(内容)
gf = gzip.GzipFile(fileobj=buf)
内容 = gf.read()
印刷内容
在我们课堂上查看天气的系列编程示例中,这两个问题困扰了很多人。这里有一个特别的解释。
最后,还有另一个“武器”要介绍。如果你从一开始就使用它,你甚至不知道上面提到的两个问题仍然存在。
这是请求模块。
要以相同的方式获取网页,您只需要:
进口请求
打印 requests.get("").text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考前面的文章:
php网页抓取乱码(PHP与数据库的编码应一致1.修改.8编码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-21 05:18
一。首先是PHP网页的编码
1. php文件本身的编码和网页的编码要匹配
一个。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; charset=gb2312"),添加静态页面,所有文件的编码格式都是ANSI,可以用记事本并另存为 选择编码为 ANSI 并覆盖源文件。
湾 如果要使用utf-8编码,php应该输出header:header("Content-Type: text/html; charset=utf-8"),添加静态页面,所有文件的编码格式为utf-8。保存为 utf-8 可能有点麻烦。一般在utf-8文件的开头都会有一个BOM。如果使用session,就会出现问题。你可以用editplus保存它。在editplus中,进入Tools->Preferences->File->UTF-8 Sign,选择始终删除,然后保存删除BOM信息。
2. PHP本身不是Unicode,所有substr等函数都必须改成mb_substr(需要安装mbstring扩展);或使用 iconv 转码。
二。PHP与Mysql的数据交互
PHP和数据库的编码要一致
1. 修改mysql配置文件my.ini或f。mysql最好使用utf8编码
[mysql]
默认字符集=utf8
[mysqld]
默认字符集=utf8
默认存储引擎=MyISAM
在[mysqld]下添加:
默认排序规则=utf8_bin
init_connect='SET NAMES utf8'
2. 添加mysql_query("set names'encoding'"); 在需要做数据库操作的php程序之前,编码与php编码相同,如果php编码为gb2312,则mysql编码为gb2312,如果是utf-8则mysql编码为utf8,所以有插入或检索数据时不会出现乱码
三。PHP与操作系统有关
Windows 和 Linux 的编码是不同的。在windows环境下,调用php函数时如果参数是utf-8编码会报错,比如move_uploaded_file(),filesize(),readfile()等,这些函数都是处理上传的,经常用到下载时,调用时可能会出现以下错误:
警告:move_uploaded_file()[function.move-uploaded-file]:无法打开流:无效参数...
警告:move_uploaded_file()[function.move-uploaded-file]:无法在...中移动''到''
警告:filesize() [function.filesize]: stat failed for ... in ...
警告:readfile() [function.readfile]:无法打开流:.. 中的参数无效。
虽然在Linux环境下gb2312编码不会出现这些错误,但是保存的文件名出现乱码,无法读取文件。这时可以将参数转换为操作系统识别的编码。编码转换可以是mb_convert_encoding(string, New code, original code)或者iconv(original code, new code, string),这样处理后保存的文件名就不会出现乱码,也可以正常读取文件实现中文名称文件的上传和下载。
其实还有更好的方案,完全脱离系统,不需要考虑系统的编码。可以生成一个只有字母和数字的序列作为文件名,并将原来的中文名保存在数据库中,这样调用move_uploaded_file()就没有问题了。下载时只需要将文件名改成原来的中文名即可。实现下载的代码如下
header("Pragma: public");
header("过期:0");
header("Cache-Component: must-revalidate, post-check=0, pre-check=0");
header("内容类型:$file_type");
header("内容长度:$file_size");
header("内容处理:附件;文件名=\"$file_name\"");
header("内容传输编码:二进制");
读取文件($file_path);
$file_type 是文件的类型,$file_name 是原来的名字,$file_path 是保存在服务上的文件的地址。
四。总结一下为什么会乱码
一般来说,出现乱码的原因有两个。一是由于编码(charset)设置错误,导致浏览器解析错误编码,导致《天书》满屏乱七八糟,二是文件错误编码为打开然后保存。例如,一个原本用GB2312编码的文本文件被打开并以UTF-8编码保存。解决上述乱码问题,首先需要知道开发中哪些环节涉及到编码:
1、文件编码:指页面文件(.html、.php等)本身保存的编码。Notepad和Dreamweaver在打开页面时会自动识别文件编码,所以不太可能出现问题。但是,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有特定编码的文件。如果工作中不注意,打开编码错误的文件,修改后保存,会出现乱码(我深有体会)。
2、 页面声明编码:在 HTML 代码 HEAD 中,可以用来告诉浏览器网页使用的是什么编码。目前,在中文网站的开发中,XXX主要使用两种编码,GB2312和UTF-8。
3、数据库连接编码:指在进行数据库操作时,用于向数据库传输数据的编码。这里需要注意的是,不要与数据库本身的编码混淆。比如MySQL内部默认是latin1编码,也就是说Mysql的数据以latin1编码存储,其他编码传输到Mysql的数据会转换成latin1编码。
知道了WEB开发中涉及到编码的地方,也就知道出现乱码的原因了:以上三种编码设置不一致。由于大多数各种编码都兼容ASCII,所以不会出现英文符号,中文会倒霉。.
五。决战的一些常见错误情况及解决办法:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是乱码最常见的原因。这时候直接在PHP脚本中SELECT数据就乱码了。查询前需要使用:mysql_query("SET NAMES GBK"); 设置MYSQL连接码,保证页面声明码与这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是UTF-8编码,可以使用:mysql_query("SET NAMES UTF8");
注意是UTF8而不是一般的UTF-8。如果页面上声明的代码与数据库的内部代码一致,则可能没有设置连接代码。
注:其实MYSQL的数据输入输出比上面说的还要复杂。MYSQL配置文件my.ini中定义了两个默认代码,分别是[client]中的默认-character-set和[mysqld]中的默认。-character-set 分别设置客户端连接和内部数据库使用的默认编码。我们上面指定的编码实际上是MYSQL客户端连接服务器时的命令行参数character_set_client,告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、 页面声明编码与文件本身的编码不一致。这种情况很少发生,因为如果编码不一致,在美工创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小BUG,打开代码错误的页面然后保存造成的。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,因为软件编码配置错误导致转换错误编码。
3、一些租虚拟主机的朋友,很明显上面3个编码设置正确或者出现乱码。比如网页是GB2312编码的,但是IE等浏览器打开时总是识别为UTF-8。网页的HEAD已经说明是GB2312了。手动修改浏览器编码为GB2312后,页面显示正常。原因是服务器Apache设置了服务器全局默认编码,在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级比页面中声明的代码要高,浏览器自然会误认。有两种解决方案, 查看全部
php网页抓取乱码(PHP与数据库的编码应一致1.修改.8编码)
一。首先是PHP网页的编码
1. php文件本身的编码和网页的编码要匹配
一个。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; charset=gb2312"),添加静态页面,所有文件的编码格式都是ANSI,可以用记事本并另存为 选择编码为 ANSI 并覆盖源文件。
湾 如果要使用utf-8编码,php应该输出header:header("Content-Type: text/html; charset=utf-8"),添加静态页面,所有文件的编码格式为utf-8。保存为 utf-8 可能有点麻烦。一般在utf-8文件的开头都会有一个BOM。如果使用session,就会出现问题。你可以用editplus保存它。在editplus中,进入Tools->Preferences->File->UTF-8 Sign,选择始终删除,然后保存删除BOM信息。
2. PHP本身不是Unicode,所有substr等函数都必须改成mb_substr(需要安装mbstring扩展);或使用 iconv 转码。
二。PHP与Mysql的数据交互
PHP和数据库的编码要一致
1. 修改mysql配置文件my.ini或f。mysql最好使用utf8编码
[mysql]
默认字符集=utf8
[mysqld]
默认字符集=utf8
默认存储引擎=MyISAM
在[mysqld]下添加:
默认排序规则=utf8_bin
init_connect='SET NAMES utf8'
2. 添加mysql_query("set names'encoding'"); 在需要做数据库操作的php程序之前,编码与php编码相同,如果php编码为gb2312,则mysql编码为gb2312,如果是utf-8则mysql编码为utf8,所以有插入或检索数据时不会出现乱码
三。PHP与操作系统有关
Windows 和 Linux 的编码是不同的。在windows环境下,调用php函数时如果参数是utf-8编码会报错,比如move_uploaded_file(),filesize(),readfile()等,这些函数都是处理上传的,经常用到下载时,调用时可能会出现以下错误:
警告:move_uploaded_file()[function.move-uploaded-file]:无法打开流:无效参数...
警告:move_uploaded_file()[function.move-uploaded-file]:无法在...中移动''到''
警告:filesize() [function.filesize]: stat failed for ... in ...
警告:readfile() [function.readfile]:无法打开流:.. 中的参数无效。
虽然在Linux环境下gb2312编码不会出现这些错误,但是保存的文件名出现乱码,无法读取文件。这时可以将参数转换为操作系统识别的编码。编码转换可以是mb_convert_encoding(string, New code, original code)或者iconv(original code, new code, string),这样处理后保存的文件名就不会出现乱码,也可以正常读取文件实现中文名称文件的上传和下载。
其实还有更好的方案,完全脱离系统,不需要考虑系统的编码。可以生成一个只有字母和数字的序列作为文件名,并将原来的中文名保存在数据库中,这样调用move_uploaded_file()就没有问题了。下载时只需要将文件名改成原来的中文名即可。实现下载的代码如下
header("Pragma: public");
header("过期:0");
header("Cache-Component: must-revalidate, post-check=0, pre-check=0");
header("内容类型:$file_type");
header("内容长度:$file_size");
header("内容处理:附件;文件名=\"$file_name\"");
header("内容传输编码:二进制");
读取文件($file_path);
$file_type 是文件的类型,$file_name 是原来的名字,$file_path 是保存在服务上的文件的地址。
四。总结一下为什么会乱码
一般来说,出现乱码的原因有两个。一是由于编码(charset)设置错误,导致浏览器解析错误编码,导致《天书》满屏乱七八糟,二是文件错误编码为打开然后保存。例如,一个原本用GB2312编码的文本文件被打开并以UTF-8编码保存。解决上述乱码问题,首先需要知道开发中哪些环节涉及到编码:
1、文件编码:指页面文件(.html、.php等)本身保存的编码。Notepad和Dreamweaver在打开页面时会自动识别文件编码,所以不太可能出现问题。但是,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有特定编码的文件。如果工作中不注意,打开编码错误的文件,修改后保存,会出现乱码(我深有体会)。
2、 页面声明编码:在 HTML 代码 HEAD 中,可以用来告诉浏览器网页使用的是什么编码。目前,在中文网站的开发中,XXX主要使用两种编码,GB2312和UTF-8。
3、数据库连接编码:指在进行数据库操作时,用于向数据库传输数据的编码。这里需要注意的是,不要与数据库本身的编码混淆。比如MySQL内部默认是latin1编码,也就是说Mysql的数据以latin1编码存储,其他编码传输到Mysql的数据会转换成latin1编码。
知道了WEB开发中涉及到编码的地方,也就知道出现乱码的原因了:以上三种编码设置不一致。由于大多数各种编码都兼容ASCII,所以不会出现英文符号,中文会倒霉。.
五。决战的一些常见错误情况及解决办法:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是乱码最常见的原因。这时候直接在PHP脚本中SELECT数据就乱码了。查询前需要使用:mysql_query("SET NAMES GBK"); 设置MYSQL连接码,保证页面声明码与这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是UTF-8编码,可以使用:mysql_query("SET NAMES UTF8");
注意是UTF8而不是一般的UTF-8。如果页面上声明的代码与数据库的内部代码一致,则可能没有设置连接代码。
注:其实MYSQL的数据输入输出比上面说的还要复杂。MYSQL配置文件my.ini中定义了两个默认代码,分别是[client]中的默认-character-set和[mysqld]中的默认。-character-set 分别设置客户端连接和内部数据库使用的默认编码。我们上面指定的编码实际上是MYSQL客户端连接服务器时的命令行参数character_set_client,告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、 页面声明编码与文件本身的编码不一致。这种情况很少发生,因为如果编码不一致,在美工创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小BUG,打开代码错误的页面然后保存造成的。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,因为软件编码配置错误导致转换错误编码。
3、一些租虚拟主机的朋友,很明显上面3个编码设置正确或者出现乱码。比如网页是GB2312编码的,但是IE等浏览器打开时总是识别为UTF-8。网页的HEAD已经说明是GB2312了。手动修改浏览器编码为GB2312后,页面显示正常。原因是服务器Apache设置了服务器全局默认编码,在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级比页面中声明的代码要高,浏览器自然会误认。有两种解决方案,
php网页抓取乱码(python2抓取网页的内容显示出来是怎么回事?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-20 16:10
)
在使用python2抓取网页时,我们经常会遇到抓取的内容显示乱码。
出现这种情况的最大可能是编码问题:运行环境的字符编码与网页的字符编码不一致。
例如,在 windows 控制台 (gbk) 中抓取了一个 utf-8 编码的 网站。或者,在Mac/Linux终端抓一个gbk编码的网站(utf-8)。因为大多数网站使用的是utf-8编码,而且很多人用的是Windows,所有这种情况相当普遍。
如果你发现你抓取的内容在英文、数字、符号上看起来都是正确的,但是中间出现了一些乱码,你基本可以断定是这样的。
解决这个问题的方法是先按照网页的编码方式将结果解码成unicode,然后输出。如果不确定网页的编码方式,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site")
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数的作用是忽略无法解码的字符。
然而,这种方法并不总是有效。另一种方式是通过正则化直接匹配网页代码中的编码设置:
除了编码问题导致的乱码外,还有一种情况经常被忽略,那就是登陆页面开启了gzip压缩。压缩后的网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的header信息自动解压。但是直接用代码去抢就不行了。所以,很可能会混淆,为什么打开网址打开网页地址很清楚,但是程序爬取却不起作用。就连我自己也被这个问题愚弄了。
这种情况的表现就是几乎所有爬取的内容都是乱码,甚至无法显示。
判断网页是否开启压缩并解压,可以参考如下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site")
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们课堂上查看天气系列的编程实例(点击查看),这两个问题困扰了不少人。这里有一个特别的解释。
最后,还有另一个“武器”要介绍。如果你第一次使用它,你甚至不知道上面两个问题仍然存在。
这是请求模块。
要以相同的方式获取网页,您只需要:
import requests
print requests.get("http://some.web.site").text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考前面的文章:
Python-Crossin的编程课堂如何安装第三方模块-知乎专栏
pip install requests
其他 文章 和回答:
[](
查看全部
php网页抓取乱码(python2抓取网页的内容显示出来是怎么回事?(图)
)
在使用python2抓取网页时,我们经常会遇到抓取的内容显示乱码。
出现这种情况的最大可能是编码问题:运行环境的字符编码与网页的字符编码不一致。
例如,在 windows 控制台 (gbk) 中抓取了一个 utf-8 编码的 网站。或者,在Mac/Linux终端抓一个gbk编码的网站(utf-8)。因为大多数网站使用的是utf-8编码,而且很多人用的是Windows,所有这种情况相当普遍。
如果你发现你抓取的内容在英文、数字、符号上看起来都是正确的,但是中间出现了一些乱码,你基本可以断定是这样的。
解决这个问题的方法是先按照网页的编码方式将结果解码成unicode,然后输出。如果不确定网页的编码方式,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site";)
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数的作用是忽略无法解码的字符。
然而,这种方法并不总是有效。另一种方式是通过正则化直接匹配网页代码中的编码设置:
除了编码问题导致的乱码外,还有一种情况经常被忽略,那就是登陆页面开启了gzip压缩。压缩后的网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的header信息自动解压。但是直接用代码去抢就不行了。所以,很可能会混淆,为什么打开网址打开网页地址很清楚,但是程序爬取却不起作用。就连我自己也被这个问题愚弄了。
这种情况的表现就是几乎所有爬取的内容都是乱码,甚至无法显示。
判断网页是否开启压缩并解压,可以参考如下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site";)
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们课堂上查看天气系列的编程实例(点击查看),这两个问题困扰了不少人。这里有一个特别的解释。
最后,还有另一个“武器”要介绍。如果你第一次使用它,你甚至不知道上面两个问题仍然存在。
这是请求模块。
要以相同的方式获取网页,您只需要:
import requests
print requests.get("http://some.web.site";).text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考前面的文章:
Python-Crossin的编程课堂如何安装第三方模块-知乎专栏
pip install requests
其他 文章 和回答:
[](
php网页抓取乱码(php网页抓取乱码解决方法:关键代码包括$start=fopen)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-12-17 22:11
php网页抓取乱码解决方法:关键代码包括:$start=fopen('my-php.php','w');%w%/usr/bin/phpphp?q=phpnotfound选中php代码段之后,在同一目录下编写循环,不同步迭代,尽量不要用php带块的。
php代码中配置最好是可读的,不然执行网页到慢时可能卡你一两分钟。所以无解,最近我也遇到这个问题,搜了几篇文章,终于有结果了,可以直接指定程序处理时出现乱码的路径。打开php.ini文件,添加下面内容:[root@fastcgi~]#setpath=/usr/local/php/bin;/usr/local/php/bin[root@fastcgi~]#setcontent_type=application/x-www-form-urlencoded;/usr/local/php/bin/phpcontent_type=application/x-www-form-urlencoded;/usr/local/php/bin/php//注意后面一定要添加正确#definerequired(require__filename)require__filename;网页抓取大多数都是指定路径下的文件下抓取,filename是php文件的路径,path是php文件处理相应的路径。详细内容,推荐看下网络上一些文章。
我也一样的问题,我是用了phpunzip下载php文件,我之前是直接加载解压的文件,php文件有乱码,后来再用fastcgi_include处理不太顺利,后来遇到一个文档eg, 查看全部
php网页抓取乱码(php网页抓取乱码解决方法:关键代码包括$start=fopen)
php网页抓取乱码解决方法:关键代码包括:$start=fopen('my-php.php','w');%w%/usr/bin/phpphp?q=phpnotfound选中php代码段之后,在同一目录下编写循环,不同步迭代,尽量不要用php带块的。
php代码中配置最好是可读的,不然执行网页到慢时可能卡你一两分钟。所以无解,最近我也遇到这个问题,搜了几篇文章,终于有结果了,可以直接指定程序处理时出现乱码的路径。打开php.ini文件,添加下面内容:[root@fastcgi~]#setpath=/usr/local/php/bin;/usr/local/php/bin[root@fastcgi~]#setcontent_type=application/x-www-form-urlencoded;/usr/local/php/bin/phpcontent_type=application/x-www-form-urlencoded;/usr/local/php/bin/php//注意后面一定要添加正确#definerequired(require__filename)require__filename;网页抓取大多数都是指定路径下的文件下抓取,filename是php文件的路径,path是php文件处理相应的路径。详细内容,推荐看下网络上一些文章。
我也一样的问题,我是用了phpunzip下载php文件,我之前是直接加载解压的文件,php文件有乱码,后来再用fastcgi_include处理不太顺利,后来遇到一个文档eg,
php网页抓取乱码(使用的编码字符集(1)打开mysql终端的问题分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-17 05:07
一、
给学php的童鞋写网页时,如果设计了中文内容的存储,最常见的问题之一就是乱码。一般乱码,我们可以从三个方面检查
(1)网页编码是否正确,如是否在header中添加原创标签
1
(2)查看mysql数据库存储时使用的默认字符集
(3)检查网页文件的编码,是否是对应的中文编码
------------------
环境:win7+wamp2.2
------------------
二、
我们从第二点开始,mysq 数据库使用的编码字符集
(1)打开mysql终端,查看当前设置,确定要修改的范围
1
showvariableslike'char%';
(2)根据结果分析,
1、如果你显示的结果和我的类似,那就是(只有character_set_system被编码为utf8)然后按照下面的步骤一步一步来
2、打开my.ini文件,搜索关键词'mysqld',找到后观察是否有这一行
character_set_server = utf8
如果没有,你应该像我一样在它下面添加一个句子
3、再次搜索关键词'client',观察是否有这一行
default_character_set = utf8
如果没有,在[client]下添加
4、保存,重启mysql服务,关闭mysql终端(否则你看到的客户端代码不会更新)
5、再次打开终端,我们再次进入
1
showvariableslike'char%';
如果出现如下结果,说明mysql数据设置成功
三、
网页文件编码的问题最容易被忽视。这是在保存时选择文件编码格式时设置的。
解决方案:
1、使用notepad++打开网页文件,然后点击“格式”-“转为UTF-8无BOM编码格式”
2、 保存一下
问题分析:
1、写php的时候用过
1
“字体大小:18px;”>
但是还是有乱码问题!
分析:使用上面的语句,只修改了三项,这三项是
字符集客户端
字符集连接
字符集结果
而且这个修改只是暂时的,关闭终端后还是和之前一样
阐明:
2、 再来分析第三个乱码问题
(1)使用sublime text3编辑打开php文件,左下角可以看到编码信息,可以看到当前编码为gb2312
(2)网页加载时,相当于当时打开了一个文件。当时读取的格式是根据gb2312的编码来读取网页文件,当用户浏览器显示时,因为网页语句的字符集是utf-8,所以文件的内容会按照utf-8的字符集来解释,会造成乱码,而我们从数据库中读取的内容是没有问题的
网页编码
原创gbk编码文件
后来的 utf-8 编码文件
(3)小心,sublime text3在转换的时候并没有给你很多编码,虽然显示转换成功了,但是什么?显示还是一样,还是我们notepad++更强大,如何修改之前的!转换成功后
3、为什么我按照你说的修改了,mysql终端显示乱码?
分析:
(1)我们先来看看windows下cmd用的是什么字符集?
可以看出cmd的字符集是gbk,也就是说终端上显示的任何内容都会对应gbk的字符集,但是我们数据库的中文设置中utf8的字符集自然就是utf8了。想显示它。编码读取数据库数据,当时编码是utf-8,到终端就乱码了
(2)那怎么查呢?
用phpmyadmin玩就行了,当然要设置我们用的utf-8编码!
打开应用程序并阅读笔记 查看全部
php网页抓取乱码(使用的编码字符集(1)打开mysql终端的问题分析)
一、
给学php的童鞋写网页时,如果设计了中文内容的存储,最常见的问题之一就是乱码。一般乱码,我们可以从三个方面检查
(1)网页编码是否正确,如是否在header中添加原创标签
1
(2)查看mysql数据库存储时使用的默认字符集
(3)检查网页文件的编码,是否是对应的中文编码
------------------
环境:win7+wamp2.2
------------------
二、
我们从第二点开始,mysq 数据库使用的编码字符集
(1)打开mysql终端,查看当前设置,确定要修改的范围
1
showvariableslike'char%';
(2)根据结果分析,
1、如果你显示的结果和我的类似,那就是(只有character_set_system被编码为utf8)然后按照下面的步骤一步一步来
2、打开my.ini文件,搜索关键词'mysqld',找到后观察是否有这一行
character_set_server = utf8
如果没有,你应该像我一样在它下面添加一个句子
3、再次搜索关键词'client',观察是否有这一行
default_character_set = utf8
如果没有,在[client]下添加
4、保存,重启mysql服务,关闭mysql终端(否则你看到的客户端代码不会更新)
5、再次打开终端,我们再次进入
1
showvariableslike'char%';
如果出现如下结果,说明mysql数据设置成功
三、
网页文件编码的问题最容易被忽视。这是在保存时选择文件编码格式时设置的。
解决方案:
1、使用notepad++打开网页文件,然后点击“格式”-“转为UTF-8无BOM编码格式”
2、 保存一下
问题分析:
1、写php的时候用过
1
“字体大小:18px;”>
但是还是有乱码问题!
分析:使用上面的语句,只修改了三项,这三项是
字符集客户端
字符集连接
字符集结果
而且这个修改只是暂时的,关闭终端后还是和之前一样
阐明:
2、 再来分析第三个乱码问题
(1)使用sublime text3编辑打开php文件,左下角可以看到编码信息,可以看到当前编码为gb2312
(2)网页加载时,相当于当时打开了一个文件。当时读取的格式是根据gb2312的编码来读取网页文件,当用户浏览器显示时,因为网页语句的字符集是utf-8,所以文件的内容会按照utf-8的字符集来解释,会造成乱码,而我们从数据库中读取的内容是没有问题的
网页编码
原创gbk编码文件
后来的 utf-8 编码文件
(3)小心,sublime text3在转换的时候并没有给你很多编码,虽然显示转换成功了,但是什么?显示还是一样,还是我们notepad++更强大,如何修改之前的!转换成功后
3、为什么我按照你说的修改了,mysql终端显示乱码?
分析:
(1)我们先来看看windows下cmd用的是什么字符集?
可以看出cmd的字符集是gbk,也就是说终端上显示的任何内容都会对应gbk的字符集,但是我们数据库的中文设置中utf8的字符集自然就是utf8了。想显示它。编码读取数据库数据,当时编码是utf-8,到终端就乱码了
(2)那怎么查呢?
用phpmyadmin玩就行了,当然要设置我们用的utf-8编码!
打开应用程序并阅读笔记
php网页抓取乱码(PP+MSS项设置的抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-13 04:12
最近在做PHP爬取和PHP+MSSQL的结合。 啊。啊。 我在网上查到的资料很少。 这似乎是一个很大的麻烦。看看东边。向西看看。最后让我摆弄一些东西。 . (最近会有更多关于PHP+MSQL的信息出来:>)。说到点子上了。
PHP fetch 被取出。 获取新闻标题和新闻内容。一开始直接显示截取的标题和内容是没有问题的
php.ini中default_charset项设置是这样的:default_charset = "utf-8"
但只要抓住它并将其保存在数据库中。
此时出了点问题。
下面是加入数据库的函数
****************************************************php代码****************************************************** *****
函数 insert_db($title,$content,$lie)
{
$dsn ='DRIVER={SQL Server};SERVER=127.0.0.1;DATABASE=test';
$link=odbc_connect($dsn,'sa','admin') 或 die('eeeor');
odbc_exec($link,"insert into news(".$lie.",content)values('".$titile."','".$content."')");
odbc_close($link);
}
**************************************************** ****************************************************** ********************
但是我去数据库的时候,就惨了。都是乱码。 我在网上找到了 文章。 我看了一下,原来是因为文字编码的问题。
MSSQL 默认使用 Chinese_prc 规则编码和排序。但是我在PHP中设置了UTF-8,所以会出现乱码。但是我把php.ini的default_charset项设置为GB2312抓取的标题和内容,保存到MSSQL中,也是乱码。郁闷。别管这个。
由于编码错误。然后就统一了。 . .
使用如下函数: iconv() 对指定内容进行编码转换并返回编码后的内容。 . .
iconv("utf-8", "gb2312", $title) ;这样就将捕获的标题转换成MSQL保存。 看过了转换成功。一个滑溜溜的中文标题。没有乱码。 啊。啊。 . .
因为PHP是UTF-8,所以显示的时候应该是对应的。 . .
iconv("gb2312", "utf-8", $title) ;这样网页就可以正常显示内容了! ! !
搞定吧~! 查看全部
php网页抓取乱码(PP+MSS项设置的抓取)
最近在做PHP爬取和PHP+MSSQL的结合。 啊。啊。 我在网上查到的资料很少。 这似乎是一个很大的麻烦。看看东边。向西看看。最后让我摆弄一些东西。 . (最近会有更多关于PHP+MSQL的信息出来:>)。说到点子上了。
PHP fetch 被取出。 获取新闻标题和新闻内容。一开始直接显示截取的标题和内容是没有问题的
php.ini中default_charset项设置是这样的:default_charset = "utf-8"
但只要抓住它并将其保存在数据库中。
此时出了点问题。
下面是加入数据库的函数
****************************************************php代码****************************************************** *****
函数 insert_db($title,$content,$lie)
{
$dsn ='DRIVER={SQL Server};SERVER=127.0.0.1;DATABASE=test';
$link=odbc_connect($dsn,'sa','admin') 或 die('eeeor');
odbc_exec($link,"insert into news(".$lie.",content)values('".$titile."','".$content."')");
odbc_close($link);
}
**************************************************** ****************************************************** ********************
但是我去数据库的时候,就惨了。都是乱码。 我在网上找到了 文章。 我看了一下,原来是因为文字编码的问题。
MSSQL 默认使用 Chinese_prc 规则编码和排序。但是我在PHP中设置了UTF-8,所以会出现乱码。但是我把php.ini的default_charset项设置为GB2312抓取的标题和内容,保存到MSSQL中,也是乱码。郁闷。别管这个。
由于编码错误。然后就统一了。 . .
使用如下函数: iconv() 对指定内容进行编码转换并返回编码后的内容。 . .
iconv("utf-8", "gb2312", $title) ;这样就将捕获的标题转换成MSQL保存。 看过了转换成功。一个滑溜溜的中文标题。没有乱码。 啊。啊。 . .
因为PHP是UTF-8,所以显示的时候应该是对应的。 . .
iconv("gb2312", "utf-8", $title) ;这样网页就可以正常显示内容了! ! !
搞定吧~!
php网页抓取乱码(php数据库读出乱码是说明原因,中文就倒霉了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-13 04:09
从php数据库读取的乱码是原因
一般来说,出现乱码的原因有两个。一是编码(charset)设置错误,导致浏览器解析错误编码,导致满屏乱七八糟的《天书》,二是文件解析错误。编码被打开,然后被保存。例如,一个原本用GB2312编码的文本文件被打开并以UTF-8编码保存。解决上述乱码问题,首先需要知道开发中哪些环节涉及到编码:
1、文件编码:指页面文件(.html、.php等)本身保存的编码。Notepad和Dreamweaver在打开页面时会自动识别文件编码,所以不太可能出现问题。但是,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有特定编码的文件。如果不注意工作,打开编码错误的文件,修改后保存,会出现乱码。
2、 页面声明代码:在HTML代码HEAD中,可以使用"meta http-equiv="Content-Type" content="text/html; charset="XXX" /" (这句话一定要写在" Before TItle"XXX"/TItle",否则页面会是空白的(IE+PHP only)告诉浏览器网页使用的是什么编码。目前GB2312和UTF-主要用于开发中文网站 8 两种编码。
3、数据库连接编码:指在进行数据库操作时,用于向数据库传输数据的编码。这里需要注意的是,不要与数据库本身的编码混淆。比如MySQL内部默认是laTIn1编码,即Mysql的数据以laTIn1编码存储,其他编码传输到Mysql的数据会转成latin1编码。
知道了WEB开发中涉及到编码的地方,也就知道出现乱码的原因了:以上三种编码设置不一致。由于大多数各种编码都兼容ASCII,所以不会出现英文符号,中文会倒霉。. 以下是一些常见的错误情况和解决方法:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是乱码最常见的原因。这时候在PHP脚本中直接SELECT数据是乱码,需要在查询前使用:
mysql_query("SET NAMES GBK");
或者 mysql_query("SET NAMES GB2312");
设置MYSQL连接码,确保页面声明码与这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码,您可以使用:
mysql_query("SET NAMES UTF8");
注意是UTF8而不是一般的UTF-8。如果页面上声明的代码与数据库的内部代码一致,则可能没有设置连接代码。
注:其实MYSQL的数据输入输出比上面说的还要复杂。MYSQL配置文件my.ini中定义了两个默认代码,分别是[client]中的default-character-set和[mysqld]中的default。-character-set 分别设置客户端连接和内部数据库使用的默认编码。我们上面指定的编码实际上是MYSQL客户端连接服务器时的命令行参数character_set_client,告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、 页面声明编码与文件本身的编码不一致。这种情况很少发生,因为如果编码不一致,在创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小BUG,打开代码错误的页面然后保存造成的。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,因为软件编码配置错误导致转换错误编码。
3、一些租虚拟主机的朋友,很明显上面三种编码设置正确或者出现乱码。比如网页是GB2312编码的,但是IE等浏览器打开时总是识别为UTF-8。网页的 HEAD 已经声明它是 GB2312。手动修改浏览器编码为GB2312后,页面显示正常。原因是服务器Apache设置了服务器全局默认编码,在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级比页面中声明的代码要高,浏览器自然会误认。有两种解决方案,
php数据库读取乱码的解决方法
在后台读取数据时,通常会出现乱码,例如“汉字”变成“?”等,造成这种情况的原因通常是编码设置不正确。解决方法如下:
第一种方法:在php中添加如下代码,设置编码格式为“utf-8”,代码如下:
header("Content-Type: text/html; charset=UTF-8");
方法二:在php中再添加一行代码,也用于转码,代码如下:
$conn = mysqli_connect($servername, $username, $password, $mysqlname);
$conn-》query("SET NAMES utf8");
在这种情况下,首先创建链接,然后转码。
另外,在使用数据库时,可以直接手动创建表(不是代码)。通常,在表格中输入汉字时,无法显示或显示为“?” 浏览时。造成这种情况的原因也是编码问题。解决方法如下:
建表或建库时,表和库的编码格式必须统一,设置为:“utf8_general_ci”,如下图:
要解决乱码问题,首先要搞清楚你的数据库使用的是什么编码。如果未指定,它将是默认的 latin1。
我们最应该使用这3个字符集gb2312、gbk、utf8。
那么我们如何指定数据库的字符集呢?下面也以gbk为例
【在MySQL命令行客户端创建数据库】
mysql”创建表`mysqlcode`(
-" `id` TINYINT (255) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
-" `content` VARCHAR(255) NOT NULL
-") TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
查询 OK,0 行受影响,1 条警告(0.03 秒)
mysql》 desc mysqlcode;
| 领域 | 类型 | 空 | 钥匙 | 默认 | 额外 |
| 身份证 | tinyint (255) unsigned | NO | PRI | | auto_increment |
| 内容 | varchar (255) | 否 | | | |
2 行(0.02 秒)
后者 TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
就是指定数据库的字符集,COLLATE(排序规则),让mysql同时支持多种编码的数据库。
当然我们也可以通过下面的指令修改数据库的字符集
更改数据库 da_name 默认字符集'charset'。
客户端以gbk格式发送,可以使用如下配置:
SET character_set_client='gbk'
SET character_set_connection='gbk'
SET character_set_results='gbk'
此配置等效于 SET NAMES'gbk'。
现在对刚刚创建的数据库进行操作
mysql》使用测试;
数据库已更改
mysql”插入mysqlcode值(空,'php恋人');
错误 1406(22001):第 1 行列“内容”的数据太长
字符集未指定为gbk,插入时出错
mysql》设置名称'gbk';
查询正常,0 行受影响(0.02 秒)
指定字符集为 gbk
mysql”插入mysqlcode值(空,'php恋人');
查询正常,1 行受影响(0.00 秒)
插入成功
mysql》 select * from mysqlcode;
| 身份证 | 内容 |
| 1 | php 爱好 |
1 行(0.00 秒)
不指定字符集gbk也会出现乱码,如下
mysql》 select * from mysqlcode;
| 身份证 | 内容 |
| 1 | php?? ? |
1 行(0.00 秒)
【在phpmyadmin中创建数据库并指定字符集】
根据需要选择表类型,这里是MyISAM(支持全文搜索);
整理并选择gbk_chinese_ci,即gbk字符集
gbk_bin 简体中文,二进制。gbk_chinese_ci 简体中文,不区分大小写。
在刚刚创建的数据库中插入数据库
为什么?因为数据库是gbk字符集,我们在操作的时候没有指定为gbk 查看全部
php网页抓取乱码(php数据库读出乱码是说明原因,中文就倒霉了)
从php数据库读取的乱码是原因
一般来说,出现乱码的原因有两个。一是编码(charset)设置错误,导致浏览器解析错误编码,导致满屏乱七八糟的《天书》,二是文件解析错误。编码被打开,然后被保存。例如,一个原本用GB2312编码的文本文件被打开并以UTF-8编码保存。解决上述乱码问题,首先需要知道开发中哪些环节涉及到编码:
1、文件编码:指页面文件(.html、.php等)本身保存的编码。Notepad和Dreamweaver在打开页面时会自动识别文件编码,所以不太可能出现问题。但是,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有特定编码的文件。如果不注意工作,打开编码错误的文件,修改后保存,会出现乱码。
2、 页面声明代码:在HTML代码HEAD中,可以使用"meta http-equiv="Content-Type" content="text/html; charset="XXX" /" (这句话一定要写在" Before TItle"XXX"/TItle",否则页面会是空白的(IE+PHP only)告诉浏览器网页使用的是什么编码。目前GB2312和UTF-主要用于开发中文网站 8 两种编码。
3、数据库连接编码:指在进行数据库操作时,用于向数据库传输数据的编码。这里需要注意的是,不要与数据库本身的编码混淆。比如MySQL内部默认是laTIn1编码,即Mysql的数据以laTIn1编码存储,其他编码传输到Mysql的数据会转成latin1编码。
知道了WEB开发中涉及到编码的地方,也就知道出现乱码的原因了:以上三种编码设置不一致。由于大多数各种编码都兼容ASCII,所以不会出现英文符号,中文会倒霉。. 以下是一些常见的错误情况和解决方法:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是乱码最常见的原因。这时候在PHP脚本中直接SELECT数据是乱码,需要在查询前使用:
mysql_query("SET NAMES GBK");
或者 mysql_query("SET NAMES GB2312");
设置MYSQL连接码,确保页面声明码与这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码,您可以使用:
mysql_query("SET NAMES UTF8");
注意是UTF8而不是一般的UTF-8。如果页面上声明的代码与数据库的内部代码一致,则可能没有设置连接代码。
注:其实MYSQL的数据输入输出比上面说的还要复杂。MYSQL配置文件my.ini中定义了两个默认代码,分别是[client]中的default-character-set和[mysqld]中的default。-character-set 分别设置客户端连接和内部数据库使用的默认编码。我们上面指定的编码实际上是MYSQL客户端连接服务器时的命令行参数character_set_client,告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、 页面声明编码与文件本身的编码不一致。这种情况很少发生,因为如果编码不一致,在创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小BUG,打开代码错误的页面然后保存造成的。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,因为软件编码配置错误导致转换错误编码。
3、一些租虚拟主机的朋友,很明显上面三种编码设置正确或者出现乱码。比如网页是GB2312编码的,但是IE等浏览器打开时总是识别为UTF-8。网页的 HEAD 已经声明它是 GB2312。手动修改浏览器编码为GB2312后,页面显示正常。原因是服务器Apache设置了服务器全局默认编码,在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级比页面中声明的代码要高,浏览器自然会误认。有两种解决方案,
php数据库读取乱码的解决方法
在后台读取数据时,通常会出现乱码,例如“汉字”变成“?”等,造成这种情况的原因通常是编码设置不正确。解决方法如下:
第一种方法:在php中添加如下代码,设置编码格式为“utf-8”,代码如下:
header("Content-Type: text/html; charset=UTF-8");
方法二:在php中再添加一行代码,也用于转码,代码如下:
$conn = mysqli_connect($servername, $username, $password, $mysqlname);
$conn-》query("SET NAMES utf8");
在这种情况下,首先创建链接,然后转码。
另外,在使用数据库时,可以直接手动创建表(不是代码)。通常,在表格中输入汉字时,无法显示或显示为“?” 浏览时。造成这种情况的原因也是编码问题。解决方法如下:
建表或建库时,表和库的编码格式必须统一,设置为:“utf8_general_ci”,如下图:
要解决乱码问题,首先要搞清楚你的数据库使用的是什么编码。如果未指定,它将是默认的 latin1。
我们最应该使用这3个字符集gb2312、gbk、utf8。
那么我们如何指定数据库的字符集呢?下面也以gbk为例
【在MySQL命令行客户端创建数据库】
mysql”创建表`mysqlcode`(
-" `id` TINYINT (255) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
-" `content` VARCHAR(255) NOT NULL
-") TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
查询 OK,0 行受影响,1 条警告(0.03 秒)
mysql》 desc mysqlcode;
| 领域 | 类型 | 空 | 钥匙 | 默认 | 额外 |
| 身份证 | tinyint (255) unsigned | NO | PRI | | auto_increment |
| 内容 | varchar (255) | 否 | | | |
2 行(0.02 秒)
后者 TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
就是指定数据库的字符集,COLLATE(排序规则),让mysql同时支持多种编码的数据库。
当然我们也可以通过下面的指令修改数据库的字符集
更改数据库 da_name 默认字符集'charset'。
客户端以gbk格式发送,可以使用如下配置:
SET character_set_client='gbk'
SET character_set_connection='gbk'
SET character_set_results='gbk'
此配置等效于 SET NAMES'gbk'。
现在对刚刚创建的数据库进行操作
mysql》使用测试;
数据库已更改
mysql”插入mysqlcode值(空,'php恋人');
错误 1406(22001):第 1 行列“内容”的数据太长
字符集未指定为gbk,插入时出错
mysql》设置名称'gbk';
查询正常,0 行受影响(0.02 秒)
指定字符集为 gbk
mysql”插入mysqlcode值(空,'php恋人');
查询正常,1 行受影响(0.00 秒)
插入成功
mysql》 select * from mysqlcode;
| 身份证 | 内容 |
| 1 | php 爱好 |
1 行(0.00 秒)
不指定字符集gbk也会出现乱码,如下
mysql》 select * from mysqlcode;
| 身份证 | 内容 |
| 1 | php?? ? |
1 行(0.00 秒)
【在phpmyadmin中创建数据库并指定字符集】
根据需要选择表类型,这里是MyISAM(支持全文搜索);
整理并选择gbk_chinese_ci,即gbk字符集
gbk_bin 简体中文,二进制。gbk_chinese_ci 简体中文,不区分大小写。
在刚刚创建的数据库中插入数据库
为什么?因为数据库是gbk字符集,我们在操作的时候没有指定为gbk
php网页抓取乱码(国外PHP网页显示MySQL乱码问题的解决方法及解决办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-08 03:08
乱码问题:使用PHPmyAdmin操作MySQL数据库时,MySQL数据库汉字显示正常,但PHP网页显示MySQL数据时,汉字全部变成?标志。
现象:用PHPmyAdmin输入汉字是正常的,但是当PHP网页显示MySQL数据时,汉字变成了?标志,有多少?符号,因为有多少个汉字。
原因:PHP网页中没有代码告诉MySQL用什么字符集输出汉字。
解决方案:
1.网页文件头设置编码
2.PHP页面保存时使用utf-8编码,可以使用记事本或者convertz802进行文件转换
3.MYSQL新建数据库时,选择UTF-8编码和数据库的字符集,设置为utf-8_unicode_ci(Unicode(多语言),不区分大小写),
库中表的排序设置为utf-8_general_ci
表中各个字段的排序设置为utf-8_general_ci
4.PHP连接数据库时,在mysql_connect()之后添加
//设置数据的字符集utf-8
mysql_query("set names 'utf8' ");
mysql_query("set character_set_client=utf8");
mysql_query("set character_set_results=utf8");
注意是utf8,不是utf-8。
如果您的网页编码为 gb2312,则为 SET NAMES GB2312。不过小编强烈建议网页编码、MySQL数据表字符集、PHPmyAdmin都统一使用UTF-8。
以上四点可以实现整个站点的utf-8编码,数据库中不会出现中文乱码。
乱码问题2:用PHPmyAdmin输入数据时出错,不允许输入或乱码。
解决方案:这是一个设置问题。请安装最新版本的PHPmyAdmin或Appserv,打开PHPmyAdmin,MySQL字符集:UTF-8 Unicode(utf8);MySQL连接校对应为utf8_unicode_ci;新建数据库时也请选择utf8_unicode_ci。网页字符为也最好选择utf-8进行采集。utf-8是国际标准编码,这是一种趋势。
代码乱码问题3:本机开发的MySQL数据表,在本机测试一切正常,但使用空间商提供的PHPmyAdmin上传时出现问题,上传失败。尤其是使用国外的PHP空间。
解决方法:首先检查网站提供的PHPmyAdmin字符集设置,并确保您构建的数据表与服务提供者的代码相同。国外MySQL不支持gb2312,甚至最新版的Apache也不支持gb2312。如果是因为编码不统一,可以重建数据表,当然使用国际标准UTF8。 查看全部
php网页抓取乱码(国外PHP网页显示MySQL乱码问题的解决方法及解决办法)
乱码问题:使用PHPmyAdmin操作MySQL数据库时,MySQL数据库汉字显示正常,但PHP网页显示MySQL数据时,汉字全部变成?标志。
现象:用PHPmyAdmin输入汉字是正常的,但是当PHP网页显示MySQL数据时,汉字变成了?标志,有多少?符号,因为有多少个汉字。
原因:PHP网页中没有代码告诉MySQL用什么字符集输出汉字。
解决方案:
1.网页文件头设置编码
2.PHP页面保存时使用utf-8编码,可以使用记事本或者convertz802进行文件转换
3.MYSQL新建数据库时,选择UTF-8编码和数据库的字符集,设置为utf-8_unicode_ci(Unicode(多语言),不区分大小写),
库中表的排序设置为utf-8_general_ci
表中各个字段的排序设置为utf-8_general_ci
4.PHP连接数据库时,在mysql_connect()之后添加
//设置数据的字符集utf-8
mysql_query("set names 'utf8' ");
mysql_query("set character_set_client=utf8");
mysql_query("set character_set_results=utf8");
注意是utf8,不是utf-8。
如果您的网页编码为 gb2312,则为 SET NAMES GB2312。不过小编强烈建议网页编码、MySQL数据表字符集、PHPmyAdmin都统一使用UTF-8。
以上四点可以实现整个站点的utf-8编码,数据库中不会出现中文乱码。
乱码问题2:用PHPmyAdmin输入数据时出错,不允许输入或乱码。
解决方案:这是一个设置问题。请安装最新版本的PHPmyAdmin或Appserv,打开PHPmyAdmin,MySQL字符集:UTF-8 Unicode(utf8);MySQL连接校对应为utf8_unicode_ci;新建数据库时也请选择utf8_unicode_ci。网页字符为也最好选择utf-8进行采集。utf-8是国际标准编码,这是一种趋势。
代码乱码问题3:本机开发的MySQL数据表,在本机测试一切正常,但使用空间商提供的PHPmyAdmin上传时出现问题,上传失败。尤其是使用国外的PHP空间。
解决方法:首先检查网站提供的PHPmyAdmin字符集设置,并确保您构建的数据表与服务提供者的代码相同。国外MySQL不支持gb2312,甚至最新版的Apache也不支持gb2312。如果是因为编码不统一,可以重建数据表,当然使用国际标准UTF8。
php网页抓取乱码( PHP与Mysql的数据交互(一)_PHP网页的编码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-05 01:07
PHP与Mysql的数据交互(一)_PHP网页的编码)
配置phpstudy,访问页面出现中文乱码。以下是解决方法。
一、PHP网页的编码
1、 php文件本身的编码和网页的编码要匹配
一种。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; charset=gb2312"),添加静态页面,所有文件的编码格式都是ANSI,可以用记事本并另存为 选择编码为 ANSI 并覆盖源文件。
湾 如果要使用utf-8编码,php要输出header:header("Content-Type: text/html; charset=utf-8"),添加静态页面,所有文件的编码格式为utf-8。
保存为 utf-8 可能有点麻烦。一般一个utf-8文件的开头都会有一个BOM。如果使用session,就会出现问题。你可以用editplus保存它。在editplus中,进入Tools->Preferences->File->UTF-8 Sign,选择始终删除,然后保存删除BOM信息。
2、php 本身不是 Unicode
substr等所有函数都要改成mb_substr(需要安装mbstring扩展),或者用iconv转码。
二、PHP与Mysql的数据交互
1、PHP和数据库的编码要一致
修改mysql配置文件my.ini或f。mysql最好使用utf8编码。
2、在需要做数据库操作的php程序前添加mysql_query("set names'encoding'")
编码与php编码相同。如果php编码是gb2312,mysql编码是gb2312,如果是utf-8,mysql编码是utf8,所以插入或检索数据时不会出现乱码。
三、PHP 和操作系统相关
Windows 和 Linux 的编码是不同的。在windows环境下,调用php函数时如果参数是utf-8编码,就会出现错误,比如move_uploaded_file()、filesize()、readfile()等,这些函数都是处理上传的,下载的时候经常用到, 调用时可能会出错。
虽然在Linux环境下gb2312编码不会出现这些错误,但是保存的文件名出现乱码,无法读取文件。这时可以将参数转换为操作系统识别的编码。编码转换可以是mb_convert_encoding(string, New code, original code)或者iconv(original code, new code, string),这样处理后保存的文件名就不会出现乱码,也可以正常读取文件实现中文名称文件的上传和下载。
其实还有更好的方案,完全脱离系统,不需要考虑系统的编码。可以生成一个只有字母和数字的序列作为文件名,并将原来的中文名保存在数据库中,这样调用move_uploaded_file()就不会出现问题。下载时只需要将文件名改成原来的中文名即可。实现下载的代码如下:
最后,实际修改一个php页面并添加一个输出头。
推荐教程:PHP视频教程
以上就是php网页上乱码的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
php网页抓取乱码(
PHP与Mysql的数据交互(一)_PHP网页的编码)
配置phpstudy,访问页面出现中文乱码。以下是解决方法。
一、PHP网页的编码
1、 php文件本身的编码和网页的编码要匹配
一种。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; charset=gb2312"),添加静态页面,所有文件的编码格式都是ANSI,可以用记事本并另存为 选择编码为 ANSI 并覆盖源文件。
湾 如果要使用utf-8编码,php要输出header:header("Content-Type: text/html; charset=utf-8"),添加静态页面,所有文件的编码格式为utf-8。
保存为 utf-8 可能有点麻烦。一般一个utf-8文件的开头都会有一个BOM。如果使用session,就会出现问题。你可以用editplus保存它。在editplus中,进入Tools->Preferences->File->UTF-8 Sign,选择始终删除,然后保存删除BOM信息。
2、php 本身不是 Unicode
substr等所有函数都要改成mb_substr(需要安装mbstring扩展),或者用iconv转码。
二、PHP与Mysql的数据交互
1、PHP和数据库的编码要一致
修改mysql配置文件my.ini或f。mysql最好使用utf8编码。
2、在需要做数据库操作的php程序前添加mysql_query("set names'encoding'")
编码与php编码相同。如果php编码是gb2312,mysql编码是gb2312,如果是utf-8,mysql编码是utf8,所以插入或检索数据时不会出现乱码。
三、PHP 和操作系统相关
Windows 和 Linux 的编码是不同的。在windows环境下,调用php函数时如果参数是utf-8编码,就会出现错误,比如move_uploaded_file()、filesize()、readfile()等,这些函数都是处理上传的,下载的时候经常用到, 调用时可能会出错。
虽然在Linux环境下gb2312编码不会出现这些错误,但是保存的文件名出现乱码,无法读取文件。这时可以将参数转换为操作系统识别的编码。编码转换可以是mb_convert_encoding(string, New code, original code)或者iconv(original code, new code, string),这样处理后保存的文件名就不会出现乱码,也可以正常读取文件实现中文名称文件的上传和下载。
其实还有更好的方案,完全脱离系统,不需要考虑系统的编码。可以生成一个只有字母和数字的序列作为文件名,并将原来的中文名保存在数据库中,这样调用move_uploaded_file()就不会出现问题。下载时只需要将文件名改成原来的中文名即可。实现下载的代码如下:
最后,实际修改一个php页面并添加一个输出头。
推荐教程:PHP视频教程
以上就是php网页上乱码的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
php网页抓取乱码(什么是动态网站和静态网站的区别?动态图片 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-04 10:20
)
我们平时做的网站会分为两类,动态的网站和静态的网站。
静态 网站 特点:
1. 一旦网页内容发布到网站服务器上,无论是否有用户访问,每个静态网页的内容都存储在网站服务器上,即,静态网页是对于实际存放在服务器上的文件,每个网页都是一个独立的文件;通常是 HTML 文件或 Flash 文件。
2.静态网页没有数据库支持,网站生产和维护的工作量比较大。因此,当网站信息量很大,例如联系我们页面的电话号码发生变化时,很难仅仅依靠静态网页制作方法。这时候可能需要修改网页并上传到网站服务器;
3.静态网页是交叉交互的,无法保存数据,在功能上有较大的局限性,比如不能做用户留言、文章发布、注册等功能。
那么什么是动态网站?
所谓“动态”,并不是指网页上简单的GIF动态图片或Flash动画。动态网站的概念没有统一的标准,但都具有以下基本特征:
1.交互性:网页会根据用户的需求和选择动态变化和响应,比如访问不同的文章ID,显示不同的文章;或者可以保存用户提交的数据,查询用户提交的数据,通常需要一些编程语言+数据库来实现。
2.自动更新:即无需手动更新HTML文档,自动生成新页面,可大大节省工作量。
目前9466做的项目可以是动态的,也可以是静态的网站(网站或者网页或者话题)。它们之间的主要区别在于项目是否安装了应用程序。
(1)如果项目没有安装应用程序,导出的文件是纯HTML。这时候可以直接用浏览器打开HTML文件查看网站的页面效果。导出的文件结构如下图所示:
Mac OS X 系统:
视窗系统:
assets文件夹中存放着我们上传的图片和文件,以及导出的网页样式等。
xxx.html 就是我们常说的网页。
(2)如果项目中安装了应用,导出的文件为php+html文件,文件结构如下:
MAC OS X 系统:
视窗系统:
assets文件夹中存放着我们上传的图片和文件,以及导出的网页样式等。
pages文件夹存放我们设计的网页
index.php根据用户的点击链接在pages文件夹中找到对应的网页文件,从9466云服务器中获取动态数据,展示给用户。
如果想在本地查看页面的效果,需要安装一个可以在本地打开php文件的软件,比如WAMP,可以参考:
如果你已经有服务器,将文件上传到服务器,直接通过地址浏览查看效果。
当本地没有安装可以打开php的软件时,效果如下:
也就是我们常说的,页面乱码,或者样式不对,看起来和我们设计的界面不一样。
总而言之,如果你的项目安装了应用程序,想要在本地查看,就需要安装一个可以解析PHP的软件,比如:
比如WAMP,可以参考:
或者直接上传服务器查看。
如果您不需要在您的页面中使用该应用程序,请删除该应用程序并重新导出该文件。此时,该文件是一个 HTML 文件。删除方法如下图所示:(在项目管理页面,将鼠标悬停在应用图标上,点击x即可删除)
查看全部
php网页抓取乱码(什么是动态网站和静态网站的区别?动态图片
)
我们平时做的网站会分为两类,动态的网站和静态的网站。
静态 网站 特点:
1. 一旦网页内容发布到网站服务器上,无论是否有用户访问,每个静态网页的内容都存储在网站服务器上,即,静态网页是对于实际存放在服务器上的文件,每个网页都是一个独立的文件;通常是 HTML 文件或 Flash 文件。
2.静态网页没有数据库支持,网站生产和维护的工作量比较大。因此,当网站信息量很大,例如联系我们页面的电话号码发生变化时,很难仅仅依靠静态网页制作方法。这时候可能需要修改网页并上传到网站服务器;
3.静态网页是交叉交互的,无法保存数据,在功能上有较大的局限性,比如不能做用户留言、文章发布、注册等功能。
那么什么是动态网站?
所谓“动态”,并不是指网页上简单的GIF动态图片或Flash动画。动态网站的概念没有统一的标准,但都具有以下基本特征:
1.交互性:网页会根据用户的需求和选择动态变化和响应,比如访问不同的文章ID,显示不同的文章;或者可以保存用户提交的数据,查询用户提交的数据,通常需要一些编程语言+数据库来实现。
2.自动更新:即无需手动更新HTML文档,自动生成新页面,可大大节省工作量。
目前9466做的项目可以是动态的,也可以是静态的网站(网站或者网页或者话题)。它们之间的主要区别在于项目是否安装了应用程序。
(1)如果项目没有安装应用程序,导出的文件是纯HTML。这时候可以直接用浏览器打开HTML文件查看网站的页面效果。导出的文件结构如下图所示:
Mac OS X 系统:
视窗系统:
assets文件夹中存放着我们上传的图片和文件,以及导出的网页样式等。
xxx.html 就是我们常说的网页。
(2)如果项目中安装了应用,导出的文件为php+html文件,文件结构如下:
MAC OS X 系统:
视窗系统:
assets文件夹中存放着我们上传的图片和文件,以及导出的网页样式等。
pages文件夹存放我们设计的网页
index.php根据用户的点击链接在pages文件夹中找到对应的网页文件,从9466云服务器中获取动态数据,展示给用户。
如果想在本地查看页面的效果,需要安装一个可以在本地打开php文件的软件,比如WAMP,可以参考:
如果你已经有服务器,将文件上传到服务器,直接通过地址浏览查看效果。
当本地没有安装可以打开php的软件时,效果如下:
也就是我们常说的,页面乱码,或者样式不对,看起来和我们设计的界面不一样。
总而言之,如果你的项目安装了应用程序,想要在本地查看,就需要安装一个可以解析PHP的软件,比如:
比如WAMP,可以参考:
或者直接上传服务器查看。
如果您不需要在您的页面中使用该应用程序,请删除该应用程序并重新导出该文件。此时,该文件是一个 HTML 文件。删除方法如下图所示:(在项目管理页面,将鼠标悬停在应用图标上,点击x即可删除)
php网页抓取乱码(如何解决PHP中文乱码完美解决问题?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-03 15:13
完美解决PHP中文乱码 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题。一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配a。如果要使用gb2312编码,那么php应该输出header: header("Content -Type: text /html; PHP Chinese garbled 一般是字符集问题,编码主要有以下问题。完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题: 1.首先是PHP网页的编码1. php文件本身的编码和网页的编码应该匹配a。如果要使用gb2312编码,那么php应该输出header: header( ontent-Type:text/html; 首先,PHP网页的编码完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码是一般是字符集问题,编码主要有以下问题: 1. 一、PHP网页的编码1. PHP文件本身的编码和网页的编码要匹配a.如果你要使用gb2312编码,那么php应该输出header: header("Content-Type: ext/html; php文件本身的编码要和网页的编码相匹配。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。一种。如果要使用gb2312编码,那么php应该输出header: header("Content-Type: text /html; 如果要使用gb2312编码,那么php需要输出header: header("Content-Type: text /html; charset=gb2312"),添加静态页面,所有文件的编码格式都是ANSI,可以用记事本打开,另存为选择编码为ANSI,覆盖源文件。完美解决PHP中文乱码完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题: 一、PHP网页的编码1. php文件本身的编码网页的编码应该匹配a。如果要使用gb2312编码,那么php应该输出header:header("Content-Type:text/html如果要使用utf-8编码,那么php应该输出header:header("Content-Type: text/html; charset=utf-8"),添加一个静态页面,所有文件的编码格式都是utf-8。保存为utf-8可能有点麻烦,一般开头会有BOM utf-8文件,如果用session会有问题,可以用editplus保存,在editplus工具->参数选择->文件->UTF-8签名,选择总是删除,然后保存去掉BOM信息. text/ html 如果要使用utf-8编码,那么php应该输出header: header("Content-Type : text/html; charset=utf-8"),添加一个静态页面,所有文件的编码格式是 utf-8。保存为utf-8可能有点麻烦,一般utf-8文件开头会有BOM,如果用session会有问题,可以用editplus保存,在editplus工具->参数选择-> 文件 -> UTF-8 签名,选择总是删除,然后保存删除BOM信息。text/ html 如果要使用utf-8编码,那么php应该输出header: header("Content-Type : text/html; charset=utf-8"),添加一个静态页面,所有文件的编码格式是 utf-8。保存为utf-8可能有点麻烦,一般utf-8文件开头会有BOM,如果用session会有问题,可以用editplus保存,在editplus工具->参数选择-> 文件 -> UTF-8 签名,选择总是删除,然后保存删除BOM信息。
完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下几个问题。一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。一种。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html;对于Unicode,substr等所有函数都必须改成mb_substr(需要安装mbstring扩展);或者使用iconv转码。完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要包括以下几个问题: 1.一、PHP网页的编码1. php 文件本身的编码应该与网页的编码相匹配。html; PHP与Mysql数据交互完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题。1.首先是PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header: header("Content-Type: text/html; PHP和数据库的编码要一致。PHP中文乱码的完美解决PHP中文乱码的完美解决方案中文乱码一般是字符集问题,编码主要有以下问题。PHP与Mysql数据交互完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题。1.首先是PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header: header("Content-Type: text/html; PHP和数据库的编码要一致。PHP中文乱码的完美解决PHP中文乱码的完美解决方案中文乱码一般是字符集问题,编码主要有以下问题。PHP与Mysql数据交互完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题。1.首先是PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header: header("Content-Type: text/html; PHP和数据库的编码要一致。PHP中文乱码的完美解决PHP中文乱码的完美解决方案中文乱码一般是字符集问题,编码主要有以下问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配a。如果要使用gb2312编码,那么php应该输出header:header("Content-Type:ext/html 修改mysql配置文件my.ini f,mysql最好使用utf8编码,完美解决PHP中文乱码. 解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题 1.首先是PHP网页的编码1. php文件本身的编码和网页的编码应该匹配a.如果你想使用gb2312编码,那么php应该输出header: header("Content -Type: ext/html;
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配a。如果要使用gb2312编码,那么php应该输出header: header("Cont ent- Type: ext/html; Add mysql_query("setnames ´code´"); 在php程序进行数据库操作之前,编码是一致的用php编码,如果php编码是gb2312,mysql编码是gb2312,如果是utf-8,mysql编码是utf8,所以插入或检索数据中不会出现乱码,完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题: 1.首先是PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header: header( "Content-Type: text/html; PHP与操作系统有关,完美解决PHP中文乱码,完美解决PHP中文乱码 PHP中文乱码字符一般是字符集问题,编码主要有以下问题: 1. 一、PHP网页的编码1. php文件本身的编码要和网页的编码相匹配 a.如果你想使用gb2312编码,那么php要输出header:header("Content-Type: text/html; Linux的编码不同。在Windows环境下,如果调用PHP函数时参数是utf-8编码,会出现错误,比如move_uploaded_file(),filesize()、readfile()等,这些函数在处理上传下载的时候经常用到。调用时可能会出现以下错误: 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下几个问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。)[function.move-uploaded-file]:failed openstream: Invalid argument ...完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题。一。首先PHP网页的编码1. php文件本身的编码要和网页的编码相匹配 a. 如果要使用gb2312编码,那么php应该输出header: header("Content -Type: text /html; Warning:move_uploaded_file() [function.move-uploaded-file]:Unable ...完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,而编码主要存在以下问题。1.一、PHP网页的编码1. php文件本身的编码要与网页的编码相匹配a。如果要使用gb2312编码,那么php应该输出header:header("Content-Type:ext/htmlWarning:filesize()[function.filesize]:stat failed...完美解决PHP中文乱码完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。) [function.readfile]: failed openstream: Invalid argument .. 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题。1.一、PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html;在Linux环境下,使用gb2312编码不会出现这些错误,但是保存的文件名出现乱码,无法读取文件。此时,参数可以转换为操作系统识别的编码。编码转换可以是mb_convert_encoding(字符串、新编码、原创编码)或iconv(原创编码)。编码、新编码、字符串),使保存的文件名处理后不会出现乱码,可以正常读取文件,实现中文名文件的上传下载。PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是字符集问题,编码主要有以下几个问题。使保存的文件名处理后不会出现乱码,可以正常读取文件,实现中文名文件的上传和下载。PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是字符集问题,编码主要有以下几个问题。使保存的文件名处理后不会出现乱码,可以正常读取文件,实现中文名文件的上传和下载。PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是字符集问题,编码主要有以下几个问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。更好的解决方案是完全脱离系统而不考虑系统的编码。可以生成一个只有字母和数字的序列作为文件名,并将原来的中文名保存在数据库中,这样调用move_uploaded_file()就没有问题了。下载时只需要将文件名改成原来的中文名即可。下载代码如下。PHP中文乱码完美解决方案 PHP中文乱码完美解决方案 PHP中文乱码一般是字符集问题,编码主要有几个问题。1.一、PHP网页的编码1. php 文件本身的编码要与网页的编码相匹配 a. 如果要使用gb2312编码,那么php应该输出header:header("Content-Type:text/html header("Pragma:public");完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下几个问题 1. 一、PHP网页的编码1. php文件本身的编码和网页的编码要匹配 a.如果你想使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; header("Expires:0");完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。如果要使用gb2312编码,那么php应该输出header: header( "Content-Type: text/html; header(" Cache-Component: must-revalidate, post-check=0, pre-check=0") ; 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题 一第一是PHP网页的编码1. php 文件本身应该与网页的编码匹配。Content-type:$file_type"); 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,而编码主要存在以下问题。1.一、PHP网页的编码1. php 文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header: header("Content -Type: ext/html; header("Content-Length:$file_size"); 完美解决PHP中文乱码 完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。如果要使用gb2312编码,那么php应该输出header: header("Content -Type: ext/html; header(" Content-Disposition:attachment; filename=\"$file_name\""); 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题: 一、第一个是PHP网页1. php文件本身的编码和网页应该匹配a.如果要使用gb2312编码,那么php应该输出header: header("Content-Type: text/html; header("Content-Transfer- Encoding:binary"); 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下几个问题。1.首先是PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; readfile($file_path); PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是一个字符集问题,编码主要有以下问题。php文件本身的编码和网页的编码应该匹配一个。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; readfile($file_path); PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是一个字符集问题,编码主要有以下问题。php文件本身的编码和网页的编码应该匹配一个。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; readfile($file_path); PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是一个字符集问题,编码主要有以下问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。文件的类型,$file_name 为原创名称,$file_path 为保存在服务上的文件地址。完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下几个问题。一.首先是PHP网页的编码1. php文件本身的编码要与网页的编码相匹配 a.如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html;使用gb2312编码,那么php应该输出header: header("Content-Type: text/html; 查看全部
php网页抓取乱码(如何解决PHP中文乱码完美解决问题?(组图))
完美解决PHP中文乱码 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题。一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配a。如果要使用gb2312编码,那么php应该输出header: header("Content -Type: text /html; PHP Chinese garbled 一般是字符集问题,编码主要有以下问题。完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题: 1.首先是PHP网页的编码1. php文件本身的编码和网页的编码应该匹配a。如果要使用gb2312编码,那么php应该输出header: header( ontent-Type:text/html; 首先,PHP网页的编码完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码是一般是字符集问题,编码主要有以下问题: 1. 一、PHP网页的编码1. PHP文件本身的编码和网页的编码要匹配a.如果你要使用gb2312编码,那么php应该输出header: header("Content-Type: ext/html; php文件本身的编码要和网页的编码相匹配。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。一种。如果要使用gb2312编码,那么php应该输出header: header("Content-Type: text /html; 如果要使用gb2312编码,那么php需要输出header: header("Content-Type: text /html; charset=gb2312"),添加静态页面,所有文件的编码格式都是ANSI,可以用记事本打开,另存为选择编码为ANSI,覆盖源文件。完美解决PHP中文乱码完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题: 一、PHP网页的编码1. php文件本身的编码网页的编码应该匹配a。如果要使用gb2312编码,那么php应该输出header:header("Content-Type:text/html如果要使用utf-8编码,那么php应该输出header:header("Content-Type: text/html; charset=utf-8"),添加一个静态页面,所有文件的编码格式都是utf-8。保存为utf-8可能有点麻烦,一般开头会有BOM utf-8文件,如果用session会有问题,可以用editplus保存,在editplus工具->参数选择->文件->UTF-8签名,选择总是删除,然后保存去掉BOM信息. text/ html 如果要使用utf-8编码,那么php应该输出header: header("Content-Type : text/html; charset=utf-8"),添加一个静态页面,所有文件的编码格式是 utf-8。保存为utf-8可能有点麻烦,一般utf-8文件开头会有BOM,如果用session会有问题,可以用editplus保存,在editplus工具->参数选择-> 文件 -> UTF-8 签名,选择总是删除,然后保存删除BOM信息。text/ html 如果要使用utf-8编码,那么php应该输出header: header("Content-Type : text/html; charset=utf-8"),添加一个静态页面,所有文件的编码格式是 utf-8。保存为utf-8可能有点麻烦,一般utf-8文件开头会有BOM,如果用session会有问题,可以用editplus保存,在editplus工具->参数选择-> 文件 -> UTF-8 签名,选择总是删除,然后保存删除BOM信息。
完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下几个问题。一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。一种。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html;对于Unicode,substr等所有函数都必须改成mb_substr(需要安装mbstring扩展);或者使用iconv转码。完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要包括以下几个问题: 1.一、PHP网页的编码1. php 文件本身的编码应该与网页的编码相匹配。html; PHP与Mysql数据交互完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题。1.首先是PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header: header("Content-Type: text/html; PHP和数据库的编码要一致。PHP中文乱码的完美解决PHP中文乱码的完美解决方案中文乱码一般是字符集问题,编码主要有以下问题。PHP与Mysql数据交互完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题。1.首先是PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header: header("Content-Type: text/html; PHP和数据库的编码要一致。PHP中文乱码的完美解决PHP中文乱码的完美解决方案中文乱码一般是字符集问题,编码主要有以下问题。PHP与Mysql数据交互完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题。1.首先是PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header: header("Content-Type: text/html; PHP和数据库的编码要一致。PHP中文乱码的完美解决PHP中文乱码的完美解决方案中文乱码一般是字符集问题,编码主要有以下问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配a。如果要使用gb2312编码,那么php应该输出header:header("Content-Type:ext/html 修改mysql配置文件my.ini f,mysql最好使用utf8编码,完美解决PHP中文乱码. 解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题 1.首先是PHP网页的编码1. php文件本身的编码和网页的编码应该匹配a.如果你想使用gb2312编码,那么php应该输出header: header("Content -Type: ext/html;
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配a。如果要使用gb2312编码,那么php应该输出header: header("Cont ent- Type: ext/html; Add mysql_query("setnames ´code´"); 在php程序进行数据库操作之前,编码是一致的用php编码,如果php编码是gb2312,mysql编码是gb2312,如果是utf-8,mysql编码是utf8,所以插入或检索数据中不会出现乱码,完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题: 1.首先是PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header: header( "Content-Type: text/html; PHP与操作系统有关,完美解决PHP中文乱码,完美解决PHP中文乱码 PHP中文乱码字符一般是字符集问题,编码主要有以下问题: 1. 一、PHP网页的编码1. php文件本身的编码要和网页的编码相匹配 a.如果你想使用gb2312编码,那么php要输出header:header("Content-Type: text/html; Linux的编码不同。在Windows环境下,如果调用PHP函数时参数是utf-8编码,会出现错误,比如move_uploaded_file(),filesize()、readfile()等,这些函数在处理上传下载的时候经常用到。调用时可能会出现以下错误: 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下几个问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。)[function.move-uploaded-file]:failed openstream: Invalid argument ...完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题。一。首先PHP网页的编码1. php文件本身的编码要和网页的编码相匹配 a. 如果要使用gb2312编码,那么php应该输出header: header("Content -Type: text /html; Warning:move_uploaded_file() [function.move-uploaded-file]:Unable ...完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,而编码主要存在以下问题。1.一、PHP网页的编码1. php文件本身的编码要与网页的编码相匹配a。如果要使用gb2312编码,那么php应该输出header:header("Content-Type:ext/htmlWarning:filesize()[function.filesize]:stat failed...完美解决PHP中文乱码完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。) [function.readfile]: failed openstream: Invalid argument .. 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题。1.一、PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html;在Linux环境下,使用gb2312编码不会出现这些错误,但是保存的文件名出现乱码,无法读取文件。此时,参数可以转换为操作系统识别的编码。编码转换可以是mb_convert_encoding(字符串、新编码、原创编码)或iconv(原创编码)。编码、新编码、字符串),使保存的文件名处理后不会出现乱码,可以正常读取文件,实现中文名文件的上传下载。PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是字符集问题,编码主要有以下几个问题。使保存的文件名处理后不会出现乱码,可以正常读取文件,实现中文名文件的上传和下载。PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是字符集问题,编码主要有以下几个问题。使保存的文件名处理后不会出现乱码,可以正常读取文件,实现中文名文件的上传和下载。PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是字符集问题,编码主要有以下几个问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。更好的解决方案是完全脱离系统而不考虑系统的编码。可以生成一个只有字母和数字的序列作为文件名,并将原来的中文名保存在数据库中,这样调用move_uploaded_file()就没有问题了。下载时只需要将文件名改成原来的中文名即可。下载代码如下。PHP中文乱码完美解决方案 PHP中文乱码完美解决方案 PHP中文乱码一般是字符集问题,编码主要有几个问题。1.一、PHP网页的编码1. php 文件本身的编码要与网页的编码相匹配 a. 如果要使用gb2312编码,那么php应该输出header:header("Content-Type:text/html header("Pragma:public");完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下几个问题 1. 一、PHP网页的编码1. php文件本身的编码和网页的编码要匹配 a.如果你想使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; header("Expires:0");完美解决PHP中文乱码完美解决PHP中文乱码PHP中文乱码一般是字符集问题,
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。如果要使用gb2312编码,那么php应该输出header: header( "Content-Type: text/html; header(" Cache-Component: must-revalidate, post-check=0, pre-check=0") ; 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题 一第一是PHP网页的编码1. php 文件本身应该与网页的编码匹配。Content-type:$file_type"); 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,而编码主要存在以下问题。1.一、PHP网页的编码1. php 文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header: header("Content -Type: ext/html; header("Content-Length:$file_size"); 完美解决PHP中文乱码 完美解决PHP中文乱码PHP中文乱码一般是字符集问题,编码主要有以下问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。如果要使用gb2312编码,那么php应该输出header: header("Content -Type: ext/html; header(" Content-Disposition:attachment; filename=\"$file_name\""); 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下问题: 一、第一个是PHP网页1. php文件本身的编码和网页应该匹配a.如果要使用gb2312编码,那么php应该输出header: header("Content-Type: text/html; header("Content-Transfer- Encoding:binary"); 完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下几个问题。1.首先是PHP网页的编码1. php文件本身的编码和网页的编码要匹配a。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; readfile($file_path); PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是一个字符集问题,编码主要有以下问题。php文件本身的编码和网页的编码应该匹配一个。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; readfile($file_path); PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是一个字符集问题,编码主要有以下问题。php文件本身的编码和网页的编码应该匹配一个。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; readfile($file_path); PHP中文乱码完美解决PHP中文乱码完美解决PHP中文乱码一般都是一个字符集问题,编码主要有以下问题。
一。首先是PHP网页的编码1. php文件本身的编码要和网页的编码相匹配。文件的类型,$file_name 为原创名称,$file_path 为保存在服务上的文件地址。完美解决PHP中文乱码 完美解决PHP中文乱码 PHP中文乱码一般是字符集问题,编码主要有以下几个问题。一.首先是PHP网页的编码1. php文件本身的编码要与网页的编码相匹配 a.如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html;使用gb2312编码,那么php应该输出header: header("Content-Type: text/html;
php网页抓取乱码(php数据库读出乱码是说明原因,中文就倒霉了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-03 15:12
从php数据库读取的乱码是原因
一般来说,出现乱码的原因有两个。一是编码(charset)设置错误,导致浏览器解析错误编码,导致满屏乱七八糟的《天书》,二是文件解析错误。编码被打开,然后被保存。例如,一个原本用GB2312编码的文本文件被打开并以UTF-8编码保存。解决上述乱码问题,首先需要知道开发中哪些环节涉及到编码:
1、文件编码:指页面文件(.html、.php等)本身保存的编码。Notepad和Dreamweaver在打开页面时会自动识别文件编码,所以不太可能出现问题。但是,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有特定编码的文件。如果不注意工作,打开编码错误的文件,修改后保存,会出现乱码。
2、 页面声明代码:在HTML代码HEAD中,可以使用"meta http-equiv="Content-Type" content="text/html; charset="XXX" /" (这句话一定要写在" Before TItle"XXX"/TItle",否则页面会是空白的(IE+PHP only)告诉浏览器这个网页使用的是什么编码。目前GB2312和UTF-主要用于开发中文网站 8 两种编码。
3、数据库连接编码:指在进行数据库操作时,用于向数据库传输数据的编码。这里需要注意的是,不要与数据库本身的编码混淆。比如MySQL内部默认是laTIn1编码,即Mysql数据以laTIn1编码存储,其他编码传输到Mysql的数据会转成latin1编码。
知道了WEB开发中涉及到编码的地方,也就知道出现乱码的原因了:以上三种编码设置不一致。由于大多数各种编码都兼容ASCII,所以不会出现英文符号,中文会倒霉。. 以下是一些常见的错误情况和解决方法:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是乱码最常见的原因。这时候在PHP脚本中直接SELECT数据是乱码,需要在查询前使用:
mysql_query("SET NAMES GBK");
或者 mysql_query("SET NAMES GB2312");
设置MYSQL连接码,确保页面声明码与这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码,您可以使用:
mysql_query("SET NAMES UTF8");
注意是UTF8而不是一般的UTF-8。如果页面上声明的代码与数据库的内部代码一致,则可能没有设置连接代码。
注:其实MYSQL的数据输入输出比上面说的还要复杂。MYSQL配置文件my.ini中定义了两个默认代码,分别是[client]中的default-character-set和[mysqld]中的default。-character-set 分别设置客户端连接和内部数据库使用的默认编码。我们上面指定的编码实际上是MYSQL客户端连接服务器时的命令行参数character_set_client,告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、 页面声明编码与文件本身的编码不一致。这种情况很少发生,因为如果编码不一致,在创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小BUG,打开代码错误的页面然后保存造成的。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,因为软件编码配置错误导致转换错误编码。
3、一些租虚拟主机的朋友,很明显上面三种编码设置正确或者出现乱码。比如网页是GB2312编码的,但是IE等浏览器打开时总是识别为UTF-8。网页的 HEAD 已经声明它是 GB2312。手动修改浏览器编码为GB2312后,页面显示正常。原因是服务器Apache设置了服务器全局默认编码,在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级比页面中声明的代码要高,浏览器自然会误认。有两种解决方案, 查看全部
php网页抓取乱码(php数据库读出乱码是说明原因,中文就倒霉了)
从php数据库读取的乱码是原因
一般来说,出现乱码的原因有两个。一是编码(charset)设置错误,导致浏览器解析错误编码,导致满屏乱七八糟的《天书》,二是文件解析错误。编码被打开,然后被保存。例如,一个原本用GB2312编码的文本文件被打开并以UTF-8编码保存。解决上述乱码问题,首先需要知道开发中哪些环节涉及到编码:
1、文件编码:指页面文件(.html、.php等)本身保存的编码。Notepad和Dreamweaver在打开页面时会自动识别文件编码,所以不太可能出现问题。但是,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有特定编码的文件。如果不注意工作,打开编码错误的文件,修改后保存,会出现乱码。
2、 页面声明代码:在HTML代码HEAD中,可以使用"meta http-equiv="Content-Type" content="text/html; charset="XXX" /" (这句话一定要写在" Before TItle"XXX"/TItle",否则页面会是空白的(IE+PHP only)告诉浏览器这个网页使用的是什么编码。目前GB2312和UTF-主要用于开发中文网站 8 两种编码。
3、数据库连接编码:指在进行数据库操作时,用于向数据库传输数据的编码。这里需要注意的是,不要与数据库本身的编码混淆。比如MySQL内部默认是laTIn1编码,即Mysql数据以laTIn1编码存储,其他编码传输到Mysql的数据会转成latin1编码。
知道了WEB开发中涉及到编码的地方,也就知道出现乱码的原因了:以上三种编码设置不一致。由于大多数各种编码都兼容ASCII,所以不会出现英文符号,中文会倒霉。. 以下是一些常见的错误情况和解决方法:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是乱码最常见的原因。这时候在PHP脚本中直接SELECT数据是乱码,需要在查询前使用:
mysql_query("SET NAMES GBK");
或者 mysql_query("SET NAMES GB2312");
设置MYSQL连接码,确保页面声明码与这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码,您可以使用:
mysql_query("SET NAMES UTF8");
注意是UTF8而不是一般的UTF-8。如果页面上声明的代码与数据库的内部代码一致,则可能没有设置连接代码。
注:其实MYSQL的数据输入输出比上面说的还要复杂。MYSQL配置文件my.ini中定义了两个默认代码,分别是[client]中的default-character-set和[mysqld]中的default。-character-set 分别设置客户端连接和内部数据库使用的默认编码。我们上面指定的编码实际上是MYSQL客户端连接服务器时的命令行参数character_set_client,告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、 页面声明编码与文件本身的编码不一致。这种情况很少发生,因为如果编码不一致,在创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小BUG,打开代码错误的页面然后保存造成的。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,因为软件编码配置错误导致转换错误编码。
3、一些租虚拟主机的朋友,很明显上面三种编码设置正确或者出现乱码。比如网页是GB2312编码的,但是IE等浏览器打开时总是识别为UTF-8。网页的 HEAD 已经声明它是 GB2312。手动修改浏览器编码为GB2312后,页面显示正常。原因是服务器Apache设置了服务器全局默认编码,在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级比页面中声明的代码要高,浏览器自然会误认。有两种解决方案,

