
php网页抓取乱码
php网页抓取乱码(mysq数据库使用的编码字符集(1)_set=utf8)
网站优化 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2022-04-19 16:39
一、
学php的童鞋在写网页的时候,如果设计了中文内容的存储,大部分都会出现乱码的问题。对于一般的乱码,我们可以从三个方面进行检查
(1)网页的编码是否正确,例如是否在header中添加原创标签
(2)检查mysql数据库存储时使用的默认字符集
(3)查看网页文件的编码,是否是对应的中文编码
------------------
环境:win7+wamp2.2
------------------
二、
先从第二点说起,mysq数据库使用的编码字符集
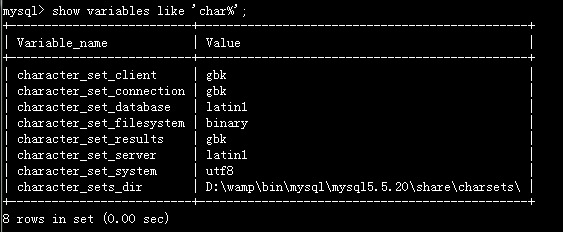
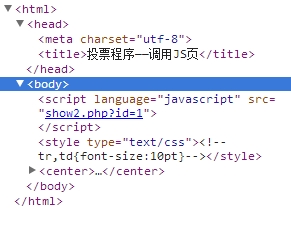
(1)打开mysql终端,查看当前设置,确定要修改的范围
show variables like ‘char%‘;
(2)根据结果分析,
1、如果你显示的结果和我的差不多,也就是(只有character_set_system编码为utf8)那么按照下面的步骤一步步来
2、打开my.ini文件,搜索关键词'mysqld',找到后观察是否有这一行
character_set_server=utf8
如果没有,你应该像我一样在它下面添加一个句子
3、再搜索关键词'client'看看有没有这行
default_character_set=utf8
如果没有,请在 [client] 下添加
4、保存,重启mysql服务,关闭mysql终端(不然你看到的客户端代码不会更新)
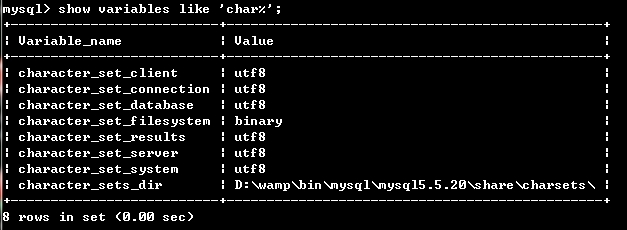
5、再次打开终端,我们再次进入
show variables like ‘char%‘;
如果出现如下结果,即mysql数据设置成功
三、
网页文件编码的问题是最容易被忽略的。保存时选择保存文件编码的格式时设置。
解决方案:
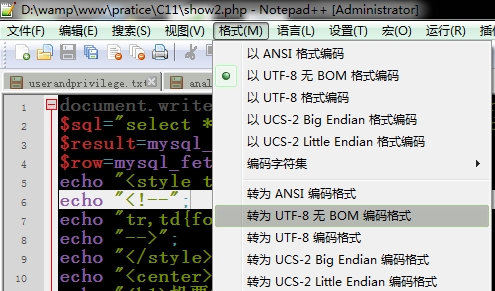
1、使用notepad++打开网页文件,然后在“格式”--“转为UTF-8无BOM编码格式”
2、保存就行
问题分析:
1、写php的时候用过
<br />
但是还是有乱码的问题!
分析:使用上面的语句,只修改了三项,三项是
character_set_client
字符集连接
字符集结果
而且这个修改只是暂时的,关闭终端后还是一样。
阐明:
2、我们来分析第三个乱码问题
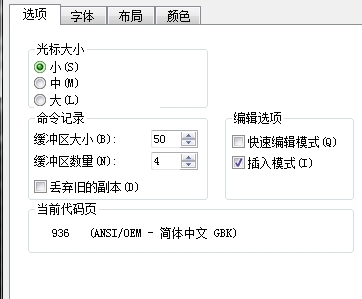
(1)使用sublime text3编辑打开php文件,左下角可以看到编码信息,可以看到当前编码为gb2312
(2)网页加载的时候,相当于打开了一个文件,那个时候读取的格式是按照gb2312的编码读取网页文件的,当是显示在用户的浏览器中,因为网页声明的字符集是utf-8,所以获取到的文件内容会按照utf-8字符集进行解释,会导致乱码,但是没有问题我们从数据库中读取的内容。
网络编码
原创gbk编码文件
后来的 utf-8 编码文件
(3)注意,sublime text3没有给你转换编码,虽然显示转换成功,但是什么?显示还是一样,还是我们notepad++功能更强大,如何修改上一个! 转换成功后
3、为什么我按照你说的修改了,在mysql终端下显示,还是乱码?
分析:
(1)我们先来看看windows下cmd使用的是什么字符集?
可以看出cmd的字符集是gbk,也就是说终端显示的任何内容都会对应gbk的字符集,但是我们数据库的中文设置的utf8字符集,当我们想要显示出来,自然会使用 utf8 编码读取数据库数据,当编码为 utf-8 时,到了终端就乱了
(2)怎么查?
用phpmyadmin就行了,当然我们要设置我们使用的utf-8编码!
本文来自“Do it and enjoy it”博客,请务必保留此出处 查看全部
php网页抓取乱码(mysq数据库使用的编码字符集(1)_set=utf8)
一、
学php的童鞋在写网页的时候,如果设计了中文内容的存储,大部分都会出现乱码的问题。对于一般的乱码,我们可以从三个方面进行检查
(1)网页的编码是否正确,例如是否在header中添加原创标签
(2)检查mysql数据库存储时使用的默认字符集
(3)查看网页文件的编码,是否是对应的中文编码
------------------
环境:win7+wamp2.2
------------------
二、
先从第二点说起,mysq数据库使用的编码字符集
(1)打开mysql终端,查看当前设置,确定要修改的范围
show variables like ‘char%‘;
(2)根据结果分析,
1、如果你显示的结果和我的差不多,也就是(只有character_set_system编码为utf8)那么按照下面的步骤一步步来
2、打开my.ini文件,搜索关键词'mysqld',找到后观察是否有这一行
character_set_server=utf8
如果没有,你应该像我一样在它下面添加一个句子

3、再搜索关键词'client'看看有没有这行
default_character_set=utf8
如果没有,请在 [client] 下添加
4、保存,重启mysql服务,关闭mysql终端(不然你看到的客户端代码不会更新)
5、再次打开终端,我们再次进入
show variables like ‘char%‘;
如果出现如下结果,即mysql数据设置成功
三、
网页文件编码的问题是最容易被忽略的。保存时选择保存文件编码的格式时设置。
解决方案:
1、使用notepad++打开网页文件,然后在“格式”--“转为UTF-8无BOM编码格式”
2、保存就行
问题分析:
1、写php的时候用过
<br />
但是还是有乱码的问题!
分析:使用上面的语句,只修改了三项,三项是
character_set_client
字符集连接
字符集结果
而且这个修改只是暂时的,关闭终端后还是一样。
阐明:
2、我们来分析第三个乱码问题
(1)使用sublime text3编辑打开php文件,左下角可以看到编码信息,可以看到当前编码为gb2312

(2)网页加载的时候,相当于打开了一个文件,那个时候读取的格式是按照gb2312的编码读取网页文件的,当是显示在用户的浏览器中,因为网页声明的字符集是utf-8,所以获取到的文件内容会按照utf-8字符集进行解释,会导致乱码,但是没有问题我们从数据库中读取的内容。
网络编码
原创gbk编码文件
后来的 utf-8 编码文件
(3)注意,sublime text3没有给你转换编码,虽然显示转换成功,但是什么?显示还是一样,还是我们notepad++功能更强大,如何修改上一个! 转换成功后
3、为什么我按照你说的修改了,在mysql终端下显示,还是乱码?
分析:
(1)我们先来看看windows下cmd使用的是什么字符集?
可以看出cmd的字符集是gbk,也就是说终端显示的任何内容都会对应gbk的字符集,但是我们数据库的中文设置的utf8字符集,当我们想要显示出来,自然会使用 utf8 编码读取数据库数据,当编码为 utf-8 时,到了终端就乱了
(2)怎么查?
用phpmyadmin就行了,当然我们要设置我们使用的utf-8编码!
本文来自“Do it and enjoy it”博客,请务必保留此出处
php网页抓取乱码(php网页抓取乱码、失败抓取的原因及解决方法。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-17 09:56
php网页抓取乱码、失败抓取的原因及解决方法。从三个方面入手进行分析,网页中乱码原因和抓取失败原因,并给出解决方案。根据不同网站抓取方法不同。有时候是网站蜘蛛抓取存在问题,有时候是抓取时设置有问题,在网页中正常代码,但是还是会出现乱码等问题,
1、不同于自动编码格式乱码,网页中经常会出现特殊字符。举个例子,当网页中乱码表示中文和带有颜色的png,那么抓取的时候就会出现乱码,请不要纠结一串位数的问题,或者一个大小写问题。
2、所需要爬取的网页链接,有很多下拉框中会出现相同的词语,那么在爬取时会出现定位问题,导致抓取失败。
原因分析针对第一种原因,
1、网页中user-agent或者spider网络请求错误,爬取代码错误或带有post请求码等。
2、这个就涉及到比较专业的爬虫分析类工具,爬虫分析类工具在编程之初就应该开始设置代理ip,然后配置爬虫代理池,spider只接受带有ip验证码的请求。
针对第二种原因,再编写抓取代码之前应该先判断是不是网页正常,是正常就把定位post请求请求码对应的user-agent或者spider等代理ip,
1、迅雷代理ip(每天自动抢红包,满1000就抢,
2、游客代理ip(游客只能访问自己局域网,
3、xx服务器代理(每日任务从中收取月租)我们常用这几种代理,由于xx服务器代理是各个代理都有,所以数量会很多,我们把它写在脚本里面。数据抓取抓取有两种网页内容形式,一种是动态,一种是静态,这里只分析静态内容。
动态内容抓取请抓取下面该图片的网页内容获取来源,
1、判断该图片网页是静态网页还是动态网页,再判断请求参数,不同的请求参数获取的图片不同,3个不同请求参数,
2、将图片字幕放到循环里面。设置代理池图片参数:每张图片会获取n次,将最后一次获取的图片的统计就是字幕大小不同的频率,然后对比字幕大小即可。图片大小一般为{50:100:1000}这样的方式。获取字幕地址参数xxxx对应mp4,对应xxxx是代理ip地址,再download就可以下载。
解决方案:有时候网页中乱码问题不能得到解决,像经常在微信表情包内容中出现这样的乱码,对此很头疼,
1、请求参数用的是动态请求
2、程序构架设计的bug,这种情况常见于处理网页关键url而不是其他关键组件,这样只需要针对缓存问题处理即可。 查看全部
php网页抓取乱码(php网页抓取乱码、失败抓取的原因及解决方法。)
php网页抓取乱码、失败抓取的原因及解决方法。从三个方面入手进行分析,网页中乱码原因和抓取失败原因,并给出解决方案。根据不同网站抓取方法不同。有时候是网站蜘蛛抓取存在问题,有时候是抓取时设置有问题,在网页中正常代码,但是还是会出现乱码等问题,
1、不同于自动编码格式乱码,网页中经常会出现特殊字符。举个例子,当网页中乱码表示中文和带有颜色的png,那么抓取的时候就会出现乱码,请不要纠结一串位数的问题,或者一个大小写问题。
2、所需要爬取的网页链接,有很多下拉框中会出现相同的词语,那么在爬取时会出现定位问题,导致抓取失败。
原因分析针对第一种原因,
1、网页中user-agent或者spider网络请求错误,爬取代码错误或带有post请求码等。
2、这个就涉及到比较专业的爬虫分析类工具,爬虫分析类工具在编程之初就应该开始设置代理ip,然后配置爬虫代理池,spider只接受带有ip验证码的请求。
针对第二种原因,再编写抓取代码之前应该先判断是不是网页正常,是正常就把定位post请求请求码对应的user-agent或者spider等代理ip,
1、迅雷代理ip(每天自动抢红包,满1000就抢,
2、游客代理ip(游客只能访问自己局域网,
3、xx服务器代理(每日任务从中收取月租)我们常用这几种代理,由于xx服务器代理是各个代理都有,所以数量会很多,我们把它写在脚本里面。数据抓取抓取有两种网页内容形式,一种是动态,一种是静态,这里只分析静态内容。
动态内容抓取请抓取下面该图片的网页内容获取来源,
1、判断该图片网页是静态网页还是动态网页,再判断请求参数,不同的请求参数获取的图片不同,3个不同请求参数,
2、将图片字幕放到循环里面。设置代理池图片参数:每张图片会获取n次,将最后一次获取的图片的统计就是字幕大小不同的频率,然后对比字幕大小即可。图片大小一般为{50:100:1000}这样的方式。获取字幕地址参数xxxx对应mp4,对应xxxx是代理ip地址,再download就可以下载。
解决方案:有时候网页中乱码问题不能得到解决,像经常在微信表情包内容中出现这样的乱码,对此很头疼,
1、请求参数用的是动态请求
2、程序构架设计的bug,这种情况常见于处理网页关键url而不是其他关键组件,这样只需要针对缓存问题处理即可。
php网页抓取乱码(从前端页面到后端数据库我一共用到了三个文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-17 08:20
从前端页面到后端数据库,我共享了三个文件:index.html、script.js、index.php。三个文件的统一编码格式是GB2312,但是当inde.html页面的数据通过$.post()提交给index.php时,中文字符会出现乱码。通过查资料得知,在使用ajax post时,浏览器默认使用utf-8编码,页面编码统一为utf-8。也就是说我的gb2312页面提交给php的汉字是转成utf-8格式的,所以需要在php中再次转码。
script.js 中代码的 $.post() 部分:
$.post('index.php?a=insert',submitData,
function(data) {
if(data==1){
$(".black").show();
}
if(data==2) {
alert("请重新提交!")
}
},
"json")
将接收到的数据转换成index.php中的编码格式:
通过转码,不会出现乱码。以上只是我遇到的问题的一种解决方法,还有一些其他的方法供大家参考。
参考: 查看全部
php网页抓取乱码(从前端页面到后端数据库我一共用到了三个文件)
从前端页面到后端数据库,我共享了三个文件:index.html、script.js、index.php。三个文件的统一编码格式是GB2312,但是当inde.html页面的数据通过$.post()提交给index.php时,中文字符会出现乱码。通过查资料得知,在使用ajax post时,浏览器默认使用utf-8编码,页面编码统一为utf-8。也就是说我的gb2312页面提交给php的汉字是转成utf-8格式的,所以需要在php中再次转码。
script.js 中代码的 $.post() 部分:
$.post('index.php?a=insert',submitData,
function(data) {
if(data==1){
$(".black").show();
}
if(data==2) {
alert("请重新提交!")
}
},
"json")
将接收到的数据转换成index.php中的编码格式:
通过转码,不会出现乱码。以上只是我遇到的问题的一种解决方法,还有一些其他的方法供大家参考。
参考:
php网页抓取乱码(php网页抓取乱码、cookie混乱、php下存数据、include路径乱码中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-04-16 09:03
php网页抓取乱码、cookie混乱、php下存数据、include路径乱码中,随着php框架的不断的升级,这些问题也越来越明显。但是php框架向来是先开源,然后不断的被自己的用户购买,源码分析。中间这样说就是怕大家反过来把源码买下来,然后重写一个开源的php框架来完善自己。apache+nginx作为服务器,你又使用动态语言php来和nginx,反向代理apache相交互。
既然有apache/nginx那个就存在进程/线程间的依赖,这些依赖就是线程之间的关系:<p>.php</p>这样一种依赖关系,然后为了保证并发性就是使用了集合。
.php从一定程度上保证了for循环,遍历遍历之类的问题。而
.nginx则是一个单机,或者是负载均衡,线程池之类的,线程安全是个问题。而且任何一个框架的不断升级,例如ror框架,服务器端都开始不断进行系统升级,无法得到完善的进程/线程关系。使用分布式,分布式请求模块等等机制来解决这个问题。</p>
因为php是纯净的命令行语言,没有pythonphp这些复杂的框架与apachenginx这些容器区别,
php确实如楼上说的,内嵌在apache中,但是,php其实是一种特殊的语言,他的源代码是httpd(nginx)代码,所以, 查看全部
php网页抓取乱码(php网页抓取乱码、cookie混乱、php下存数据、include路径乱码中)
php网页抓取乱码、cookie混乱、php下存数据、include路径乱码中,随着php框架的不断的升级,这些问题也越来越明显。但是php框架向来是先开源,然后不断的被自己的用户购买,源码分析。中间这样说就是怕大家反过来把源码买下来,然后重写一个开源的php框架来完善自己。apache+nginx作为服务器,你又使用动态语言php来和nginx,反向代理apache相交互。
既然有apache/nginx那个就存在进程/线程间的依赖,这些依赖就是线程之间的关系:<p>.php</p>这样一种依赖关系,然后为了保证并发性就是使用了集合。
.php从一定程度上保证了for循环,遍历遍历之类的问题。而
.nginx则是一个单机,或者是负载均衡,线程池之类的,线程安全是个问题。而且任何一个框架的不断升级,例如ror框架,服务器端都开始不断进行系统升级,无法得到完善的进程/线程关系。使用分布式,分布式请求模块等等机制来解决这个问题。</p>
因为php是纯净的命令行语言,没有pythonphp这些复杂的框架与apachenginx这些容器区别,
php确实如楼上说的,内嵌在apache中,但是,php其实是一种特殊的语言,他的源代码是httpd(nginx)代码,所以,
php网页抓取乱码(Linux程序不会乱码的根源是什么?如何使程序初始化乱码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-04-09 13:30
乱码的来源:将源代码文件(源字符集)编译/链接生成可执行文件(执行字符集),最后程序在实际环境中运行(运行环境编码)。在此过程中,如果出现字符集不匹配的情况,最终无法显示预期的文本信息,甚至会产生乱码。
综上所述,为了让程序不乱码,必须满足:
代码相关
一般为了在程序中支持国际化,在程序初始化时,将locale设置为系统配置的Native ANSI字符集,即执行:setlocale(LC_ALL, "")。
可以查看文件编码格式:
:file main.cc
main.cc: C++ source text, UTF-8 Unicode text
GCC的源字符集和执行字符集默认都是UTF-8编码的,也就是说GCC默认按照UTF-8解析源代码,编译后的执行字符集也是UTF-8。当然 GCC 也提供了编译选项来改变默认值:
-finput-charset=charset 用于指定源码字符集
-fexec-charset=charset 用于指定执行字符集
另一个参数是:
默认情况下,在 Windows 平台的 gcc 下,宽字符串常量的每个字符都是 16 位 UTF-16 类型。在 Linux 平台上,宽字符串常量的每个字符都是 32 位 UTF-32 类型。-fwide-exec-charset=charset 这个参数可以改变宽字符串常量的类型。比如在x86机器环境下,在Linux操作系统下,要将诸如L“汉字”编译保存为UTF-16字符串,可以使用-fwide-exec-charset=UTF-16LE。
控制台查看代码:
:locale
LANG="zh_CN.UTF-8"
LC_COLLATE="zh_CN.UTF-8"
LC_CTYPE="zh_CN.UTF-8"
LC_MESSAGES="zh_CN.UTF-8"
LC_MONETARY="zh_CN.UTF-8"
LC_NUMERIC="zh_CN.UTF-8"
LC_TIME="zh_CN.UTF-8"
LC_ALL=
参考 查看全部
php网页抓取乱码(Linux程序不会乱码的根源是什么?如何使程序初始化乱码)
乱码的来源:将源代码文件(源字符集)编译/链接生成可执行文件(执行字符集),最后程序在实际环境中运行(运行环境编码)。在此过程中,如果出现字符集不匹配的情况,最终无法显示预期的文本信息,甚至会产生乱码。
综上所述,为了让程序不乱码,必须满足:
代码相关
一般为了在程序中支持国际化,在程序初始化时,将locale设置为系统配置的Native ANSI字符集,即执行:setlocale(LC_ALL, "")。
可以查看文件编码格式:
:file main.cc
main.cc: C++ source text, UTF-8 Unicode text
GCC的源字符集和执行字符集默认都是UTF-8编码的,也就是说GCC默认按照UTF-8解析源代码,编译后的执行字符集也是UTF-8。当然 GCC 也提供了编译选项来改变默认值:
-finput-charset=charset 用于指定源码字符集
-fexec-charset=charset 用于指定执行字符集
另一个参数是:
默认情况下,在 Windows 平台的 gcc 下,宽字符串常量的每个字符都是 16 位 UTF-16 类型。在 Linux 平台上,宽字符串常量的每个字符都是 32 位 UTF-32 类型。-fwide-exec-charset=charset 这个参数可以改变宽字符串常量的类型。比如在x86机器环境下,在Linux操作系统下,要将诸如L“汉字”编译保存为UTF-16字符串,可以使用-fwide-exec-charset=UTF-16LE。
控制台查看代码:
:locale
LANG="zh_CN.UTF-8"
LC_COLLATE="zh_CN.UTF-8"
LC_CTYPE="zh_CN.UTF-8"
LC_MESSAGES="zh_CN.UTF-8"
LC_MONETARY="zh_CN.UTF-8"
LC_NUMERIC="zh_CN.UTF-8"
LC_TIME="zh_CN.UTF-8"
LC_ALL=
参考
php网页抓取乱码(php网页抓取乱码问题解决方法技术限制,内测pep2056)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-04-09 13:04
php网页抓取乱码问题解决方法技术限制,对于一些新标准没有及时更新,例如php5,php7开始就有了pep2052,现在正在内测pep2056。官方文档讲的是使用cookie实现的网页抓取,使用客户端脚本包进行操作cookie存储目标网页的locale(php中,可以为none,也可以为php_parse_cookie,实际上cookie还有很多,包括php_base64等等),当网页抓取完成之后,使用nginx完成forward,从cookie中读取locale值,返回给网页抓取者。
网页抓取过程中,由于客户端脚本在客户端执行,客户端当前所能接收到的cookie为当前的php网页版本和cookienamecookiename也可以为php_url_locale。在抓取过程中如果发生cookie值传递错误,可以通过指定cookiename的方式进行传递。项目原理,由于目前phpsdk依然未实现对php_parse_cookie的支持,我们只能通过extensionname的方式进行抓取,如果客户端不支持,只能使用chromesafari开发者工具抓取。
项目源码可以从公众号下载:-2csr3joaucsbrd6wdg提取码:lpr9php网页抓取乱码问题解决方法php中使用了cookie存储目标网页的locale信息。假如一个网页已经包含locale属性,则服务器对于该locale的读取逻辑是这样的:首先获取目标网页所有的locale的值,我们简称为extended,将extended存入extended_cookie_blocked_tags中,即表示这个网页加载时这个extended的内容是被存储在这个blocked_tag中的。
为了去除这些内容,我们需要把extended_cookie_blocked_tags取出来,作为cookie解析的输入,其中extended_cookie_blocked_tags是写入在php内置数据结构中,即{"extended":"false","cookie_length":null,"cache_write_first":null,"cls_check":true,"flags":[]}。
解析nginx进程返回的locale值,并且更新extended_cookie_blocked_tags中的locale值。这些需要通过上面提到的脚本来执行。相对于c\c++\java等编程语言,php的php_parse_cookie可以很好地处理这些问题。php内置数据结构有多种实现,这里我们使用自定义的flags数组的方式。
整个流程如下:整体思路的思维导图php优点php优点是解决了以下2个问题:一个cookie要存到locale中。二是cookie可以有多份。如果一个cookie被多次请求,可以提高代码可扩展性,但也需要对locale层设计有所约束。简单地说,php对于你选择不对请求作出任何更改。再往深一点,如果你执行ajax请求时有多次加载要继续加载token值是一个常见的需求。也就。 查看全部
php网页抓取乱码(php网页抓取乱码问题解决方法技术限制,内测pep2056)
php网页抓取乱码问题解决方法技术限制,对于一些新标准没有及时更新,例如php5,php7开始就有了pep2052,现在正在内测pep2056。官方文档讲的是使用cookie实现的网页抓取,使用客户端脚本包进行操作cookie存储目标网页的locale(php中,可以为none,也可以为php_parse_cookie,实际上cookie还有很多,包括php_base64等等),当网页抓取完成之后,使用nginx完成forward,从cookie中读取locale值,返回给网页抓取者。
网页抓取过程中,由于客户端脚本在客户端执行,客户端当前所能接收到的cookie为当前的php网页版本和cookienamecookiename也可以为php_url_locale。在抓取过程中如果发生cookie值传递错误,可以通过指定cookiename的方式进行传递。项目原理,由于目前phpsdk依然未实现对php_parse_cookie的支持,我们只能通过extensionname的方式进行抓取,如果客户端不支持,只能使用chromesafari开发者工具抓取。
项目源码可以从公众号下载:-2csr3joaucsbrd6wdg提取码:lpr9php网页抓取乱码问题解决方法php中使用了cookie存储目标网页的locale信息。假如一个网页已经包含locale属性,则服务器对于该locale的读取逻辑是这样的:首先获取目标网页所有的locale的值,我们简称为extended,将extended存入extended_cookie_blocked_tags中,即表示这个网页加载时这个extended的内容是被存储在这个blocked_tag中的。
为了去除这些内容,我们需要把extended_cookie_blocked_tags取出来,作为cookie解析的输入,其中extended_cookie_blocked_tags是写入在php内置数据结构中,即{"extended":"false","cookie_length":null,"cache_write_first":null,"cls_check":true,"flags":[]}。
解析nginx进程返回的locale值,并且更新extended_cookie_blocked_tags中的locale值。这些需要通过上面提到的脚本来执行。相对于c\c++\java等编程语言,php的php_parse_cookie可以很好地处理这些问题。php内置数据结构有多种实现,这里我们使用自定义的flags数组的方式。
整个流程如下:整体思路的思维导图php优点php优点是解决了以下2个问题:一个cookie要存到locale中。二是cookie可以有多份。如果一个cookie被多次请求,可以提高代码可扩展性,但也需要对locale层设计有所约束。简单地说,php对于你选择不对请求作出任何更改。再往深一点,如果你执行ajax请求时有多次加载要继续加载token值是一个常见的需求。也就。
php网页抓取乱码(关于从数据库中查询出的字符串显示在网页上是乱码的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-08 02:18
关于从数据库中查询到的字符串在网页上显示为乱码的问题
MYSQL数据库,从里面查到的数据用echo输出到网页时出现乱码,奇怪的是只有一处乱码,其他地方显示正常。
$sql="从 pw_members 中选择用户名,其中 uid=?";
$result=$handler->exeSql($sql,array($winduid),"select");
如果($结果){
回声'
'.$result["username"].'
'}别的{
回声'
未知的用户名
';
}
这是代码,然后页面以
数据库信息为:
服务器字符集:utf8
数据库字符集:utf8
客户端字符集:utf8
连接字符集:utf8
字段信息:
字段:用户名
类型:varchar(18)
不是所有文字都乱码,只有这个地方乱码,请解释~~
- - - 解决方案 - - - - - - - - - -
未知用户名相信你可以看到这不是乱码
你的数据库是 utf-8 存储的,但是前端显示的 HTML 是用 GBK 编码的。当然,有些部分总是乱码。
您可以将 $result["username"] 转码为 GBK。
$result["username"] = iconv('UTF-8', 'GBK', $result["username"]);
或将您的 .php 或 .html 文件另存为 utf-8
- - - 解决方案 - - - - - - - - - -
数据库编码全部为 UTF-8。您可以将页面编码和文件编码设置为UTF-8,以节省麻烦。为什么需要来回走动?
另外,在获取数据库数据之前指定数据编码
SET NAMES('UTF8');//gbk 查看全部
php网页抓取乱码(关于从数据库中查询出的字符串显示在网页上是乱码的问题)
关于从数据库中查询到的字符串在网页上显示为乱码的问题
MYSQL数据库,从里面查到的数据用echo输出到网页时出现乱码,奇怪的是只有一处乱码,其他地方显示正常。
$sql="从 pw_members 中选择用户名,其中 uid=?";
$result=$handler->exeSql($sql,array($winduid),"select");
如果($结果){
回声'
'.$result["username"].'
'}别的{
回声'
未知的用户名
';
}
这是代码,然后页面以
数据库信息为:
服务器字符集:utf8
数据库字符集:utf8
客户端字符集:utf8
连接字符集:utf8
字段信息:
字段:用户名
类型:varchar(18)
不是所有文字都乱码,只有这个地方乱码,请解释~~
- - - 解决方案 - - - - - - - - - -
未知用户名相信你可以看到这不是乱码
你的数据库是 utf-8 存储的,但是前端显示的 HTML 是用 GBK 编码的。当然,有些部分总是乱码。
您可以将 $result["username"] 转码为 GBK。
$result["username"] = iconv('UTF-8', 'GBK', $result["username"]);
或将您的 .php 或 .html 文件另存为 utf-8
- - - 解决方案 - - - - - - - - - -
数据库编码全部为 UTF-8。您可以将页面编码和文件编码设置为UTF-8,以节省麻烦。为什么需要来回走动?
另外,在获取数据库数据之前指定数据编码
SET NAMES('UTF8');//gbk
php网页抓取乱码(七牛云抓取乱码工具_金柚子php网页抓取查杀工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-07 12:06
php网页抓取乱码查杀工具php网页抓取乱码查杀工具_phpspider工具_金柚子php网页抓取乱码查杀工具_phpspider工具_金柚子使用地址:
可以尝试下七牛云
web网页抓取没有必要学习爬虫,可以从scrapy入手,
还在用比较老的scrapy
七牛云,超级大牛开发的,
吾爱破解,
网页解析工具阿里云的webspider.
phpspy,专门针对php的网页解析,并且免费,而且在国内来说,下载量还很高,谁用谁知道。
低阶版本超级好用。
目前抓取率最高的nodejs抓包工具,是src3145开发的,支持数百种浏览器,src3145github:src3145/node-spider。yzc/node-spider。yzc。js如果要用c++的话,推荐grep-input或者org。apache。ibatis。io。production。php。request。
tp
找个人上传工具,
如果是用phper一定要买一个seaagephpcoderapp会提供很好的服务。十分便宜,用了好几年。不会有任何延迟。
易语言,感觉超爽,
国内有光明日报的,国外比较不知道。
七牛云
推荐一个interface100
链家网可以抓,不过是和链家网合作的。
我们是想爬那边的数据。 查看全部
php网页抓取乱码(七牛云抓取乱码工具_金柚子php网页抓取查杀工具)
php网页抓取乱码查杀工具php网页抓取乱码查杀工具_phpspider工具_金柚子php网页抓取乱码查杀工具_phpspider工具_金柚子使用地址:
可以尝试下七牛云
web网页抓取没有必要学习爬虫,可以从scrapy入手,
还在用比较老的scrapy
七牛云,超级大牛开发的,
吾爱破解,
网页解析工具阿里云的webspider.
phpspy,专门针对php的网页解析,并且免费,而且在国内来说,下载量还很高,谁用谁知道。
低阶版本超级好用。
目前抓取率最高的nodejs抓包工具,是src3145开发的,支持数百种浏览器,src3145github:src3145/node-spider。yzc/node-spider。yzc。js如果要用c++的话,推荐grep-input或者org。apache。ibatis。io。production。php。request。
tp
找个人上传工具,
如果是用phper一定要买一个seaagephpcoderapp会提供很好的服务。十分便宜,用了好几年。不会有任何延迟。
易语言,感觉超爽,
国内有光明日报的,国外比较不知道。
七牛云
推荐一个interface100
链家网可以抓,不过是和链家网合作的。
我们是想爬那边的数据。
php网页抓取乱码(PHP中文乱码现像发生在网页本身的有些产生在于MYSQL)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-04-06 08:03
前言
PHP中的中文乱码是PHP开发中常见的问题之一。中文乱码有时出现在网页本身,有的出现在MYSQL交互过程中,有时与操作系统有关。以下是一个总结。
一、 PHP 网页的编码
最好最快的解决方案是使页面上声明的代码与数据库内部的代码保持一致。如果页面申请的代码与数据库内部的代码不一致,设置连接代码。Mysql_query("设置名称***").
1、 php文件本身的编码应该和网页的编码相匹配。如果你想使用gb2312编码,那么php应该输出header
header("内容类型:text/html;charset=gb2312")
添加静态页面
, 所有文件的编码格式都是ANSI,可以用记事本打开,另存为选择的编码为ANSI,覆盖源文件。
2、 如果你想使用uft-8编码,那么php应该输出header
header("内容类型: text/html; charset=utf-8"),
添加静态页面
, 所有文件的编码格式都是utf-8. 保存为utf-8可能有点麻烦。一般utf-8开头会有BOM。如果使用Session,会有问题,可以使用editplus软件保存。在本软件中,选择Tools→Preferences→File→UTF-8 Signature,选择Always Delete,然后保存即可删除BOM信息。
3、PHP本身不是Unicode,substr等所有函数都必须改成mb_substr(需要安装mbstring扩展);或使用 iconv 进行转码。
在需要做数据库操作的PHP程序前加上mysql_query("set names encoding"),编码和PHP编码一样,如果PHP编码是gb2312,那么mysql编码是gb2312,如果是uft-8 ,那么mysql就是utf8.这样改后就不会出现乱码了。 查看全部
php网页抓取乱码(PHP中文乱码现像发生在网页本身的有些产生在于MYSQL)
前言
PHP中的中文乱码是PHP开发中常见的问题之一。中文乱码有时出现在网页本身,有的出现在MYSQL交互过程中,有时与操作系统有关。以下是一个总结。
一、 PHP 网页的编码
最好最快的解决方案是使页面上声明的代码与数据库内部的代码保持一致。如果页面申请的代码与数据库内部的代码不一致,设置连接代码。Mysql_query("设置名称***").
1、 php文件本身的编码应该和网页的编码相匹配。如果你想使用gb2312编码,那么php应该输出header
header("内容类型:text/html;charset=gb2312")
添加静态页面
, 所有文件的编码格式都是ANSI,可以用记事本打开,另存为选择的编码为ANSI,覆盖源文件。
2、 如果你想使用uft-8编码,那么php应该输出header
header("内容类型: text/html; charset=utf-8"),
添加静态页面
, 所有文件的编码格式都是utf-8. 保存为utf-8可能有点麻烦。一般utf-8开头会有BOM。如果使用Session,会有问题,可以使用editplus软件保存。在本软件中,选择Tools→Preferences→File→UTF-8 Signature,选择Always Delete,然后保存即可删除BOM信息。
3、PHP本身不是Unicode,substr等所有函数都必须改成mb_substr(需要安装mbstring扩展);或使用 iconv 进行转码。
在需要做数据库操作的PHP程序前加上mysql_query("set names encoding"),编码和PHP编码一样,如果PHP编码是gb2312,那么mysql编码是gb2312,如果是uft-8 ,那么mysql就是utf8.这样改后就不会出现乱码了。
php网页抓取乱码(php虚拟主机乱码的解决办法因素有哪些?如何解决乱码问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-06 07:28
html代码乱码的解决方法:1、定义网页的显示代码,如“”;2、设置网页存储码为utf8。
本文运行环境:Windows7系统,HTML5版本,戴尔G3电脑。
如何解决HTML页面中出现乱码的中文显示
第一:定义网页显示代码。如果没有定义网页代码,那么当我们浏览网页时,IE会自动识别网页代码,可能会导致中文显示乱码。所以我们在做网页的时候,会用“”来定义网页代码。(我们常见的 Unicode 编码是 utf-8)
将文件保存为utf-8编码,模仿上面的位置,在页面中添加中间行代码,如果还有乱码,把utf-8改成gbk
二:网页存储编码。这个问题经常被忽视。让我使用 Dreamweaver,这是构建网站的常用工具。当我们使用 DW 创建一个新的默认编码并保存时,它会以两种编码 uft8 格式或 gbk 格式保存。这可以在 Dreamweaver->Edit->Preferences->New Document 中设置。如果设置了默认的utf8格式,那么网页存储码就是utf8,使用的网页显示码也是utf8,如果不一致会导致乱码。我是这样解释的,我不知道它是否解释了问题。
也就是说,当我们遇到乱码问题时,是由于编码不一致造成的。这是对html页面乱码情况的总结。我们从一个例子中得出推论。当我们在使用php虚拟主机建站时遇到乱码问题,也需要考虑三个因素来解决问题。我总结的三个因素:网页显示编码、网页存储编码、数据库编码网站当汉字显示乱码时,请先从这三个方向考虑并解决问题,会得到双倍的结果事半功倍。
【推荐学习:html视频教程】
以上就是如何处理乱码html代码的详细内容。更多详情请关注php中文网文章其他相关话题! 查看全部
php网页抓取乱码(php虚拟主机乱码的解决办法因素有哪些?如何解决乱码问题)
html代码乱码的解决方法:1、定义网页的显示代码,如“”;2、设置网页存储码为utf8。

本文运行环境:Windows7系统,HTML5版本,戴尔G3电脑。
如何解决HTML页面中出现乱码的中文显示
第一:定义网页显示代码。如果没有定义网页代码,那么当我们浏览网页时,IE会自动识别网页代码,可能会导致中文显示乱码。所以我们在做网页的时候,会用“”来定义网页代码。(我们常见的 Unicode 编码是 utf-8)
将文件保存为utf-8编码,模仿上面的位置,在页面中添加中间行代码,如果还有乱码,把utf-8改成gbk
二:网页存储编码。这个问题经常被忽视。让我使用 Dreamweaver,这是构建网站的常用工具。当我们使用 DW 创建一个新的默认编码并保存时,它会以两种编码 uft8 格式或 gbk 格式保存。这可以在 Dreamweaver->Edit->Preferences->New Document 中设置。如果设置了默认的utf8格式,那么网页存储码就是utf8,使用的网页显示码也是utf8,如果不一致会导致乱码。我是这样解释的,我不知道它是否解释了问题。
也就是说,当我们遇到乱码问题时,是由于编码不一致造成的。这是对html页面乱码情况的总结。我们从一个例子中得出推论。当我们在使用php虚拟主机建站时遇到乱码问题,也需要考虑三个因素来解决问题。我总结的三个因素:网页显示编码、网页存储编码、数据库编码网站当汉字显示乱码时,请先从这三个方向考虑并解决问题,会得到双倍的结果事半功倍。
【推荐学习:html视频教程】
以上就是如何处理乱码html代码的详细内容。更多详情请关注php中文网文章其他相关话题!
php网页抓取乱码(python2抓取网页的内容显示出来是怎么回事?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-04-03 16:01
)
使用python2爬取网页时,经常会遇到抓取到的内容显示为乱码的情况。
这种情况最大的可能是编码问题:运行环境的字符编码和网页的字符编码不一致。
例如,在 Windows 控制台 (gbk) 中获取一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓取一个gbk编码的网站(utf-8)。因为大部分网站使用utf-8编码,而且很多人使用windows,都是很常见。
如果你发现你抓取的内容在英文、数字、符号上看起来都正确,但是中间有一些乱码,你基本上可以断定是这样的。
这个问题的解决方法是先将结果按照网页的编码方式解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site")
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数用于忽略无法解码的字符。
但是,这种方法并不总是有效。另一种方式是通过正则表达式直接匹配网页代码中的编码设置:
除了编码问题导致的乱码之外,另一个经常被忽视的情况是目标页面启用了 gzip 压缩。压缩网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的头部信息自动解压。但是直接用代码抓取不会。因此,很可能会产生困惑,为什么打开网页地址是对的,但程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现是,几乎所有的抓取内容都是乱码,甚至无法显示。
要确定网页是否启用了压缩并解压缩,请使用以下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site")
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们的课堂编程示例查看天气系列(点击查看)中,这两个问题困扰了不少人。这里有一个特殊的解释。
最后,还有一个“武器”要介绍。如果你一开始使用它,你甚至都不知道存在上述两个问题。
这是请求模块。
与爬网类似,只需:
import requests
print requests.get("http://some.web.site").text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考之前的文章:
如何为 Python 安装第三方模块 - Crossin 的编程课堂 - 知乎专栏
pip install requests
其他 文章 和答案:
你是如何自学 Python 的?- 克罗辛的回答
学习编程的过程中可能会走哪些弯路,有哪些经验可以参考?- 克罗辛的回答
初学者如何使用搜索引擎 - Crossin 的 文章 - 知乎 专栏
如何直观的了解程序的运行过程?- Crossin 的 文章 - 知乎 专栏
如何在一台电脑上使用 Python 2 和 Python 3 - Crossin 的编程课堂 - 知乎专栏
Crossin 的编程教室
微信ID:crossincode
论坛:Crossin 的编程教室
QQ群:498545096
查看全部
php网页抓取乱码(python2抓取网页的内容显示出来是怎么回事?(图)
)
使用python2爬取网页时,经常会遇到抓取到的内容显示为乱码的情况。
这种情况最大的可能是编码问题:运行环境的字符编码和网页的字符编码不一致。
例如,在 Windows 控制台 (gbk) 中获取一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓取一个gbk编码的网站(utf-8)。因为大部分网站使用utf-8编码,而且很多人使用windows,都是很常见。
如果你发现你抓取的内容在英文、数字、符号上看起来都正确,但是中间有一些乱码,你基本上可以断定是这样的。

这个问题的解决方法是先将结果按照网页的编码方式解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site";)
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数用于忽略无法解码的字符。
但是,这种方法并不总是有效。另一种方式是通过正则表达式直接匹配网页代码中的编码设置:
除了编码问题导致的乱码之外,另一个经常被忽视的情况是目标页面启用了 gzip 压缩。压缩网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的头部信息自动解压。但是直接用代码抓取不会。因此,很可能会产生困惑,为什么打开网页地址是对的,但程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现是,几乎所有的抓取内容都是乱码,甚至无法显示。
要确定网页是否启用了压缩并解压缩,请使用以下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site";)
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们的课堂编程示例查看天气系列(点击查看)中,这两个问题困扰了不少人。这里有一个特殊的解释。
最后,还有一个“武器”要介绍。如果你一开始使用它,你甚至都不知道存在上述两个问题。
这是请求模块。
与爬网类似,只需:
import requests
print requests.get("http://some.web.site";).text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考之前的文章:
如何为 Python 安装第三方模块 - Crossin 的编程课堂 - 知乎专栏
pip install requests
其他 文章 和答案:
你是如何自学 Python 的?- 克罗辛的回答
学习编程的过程中可能会走哪些弯路,有哪些经验可以参考?- 克罗辛的回答
初学者如何使用搜索引擎 - Crossin 的 文章 - 知乎 专栏
如何直观的了解程序的运行过程?- Crossin 的 文章 - 知乎 专栏
如何在一台电脑上使用 Python 2 和 Python 3 - Crossin 的编程课堂 - 知乎专栏
Crossin 的编程教室
微信ID:crossincode
论坛:Crossin 的编程教室
QQ群:498545096

php网页抓取乱码(php网页抓取乱码原因:curl是丧心病狂之源)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-04-01 17:08
php网页抓取乱码原因:
1、curl是万恶之源
2、你配置非常不合理
3、curl是丧心病狂之源php正则表达式5个坑:
1、正则表达式是加拿大全国牛逼大学非常关注的课程,
2、学会正则表达式可以走遍天下不怕文盲;
3、只要你不是在做需要过多的网页的时候,
4、正则表达式内部可以转义,从而让你看不懂其他的回车,或者replace,
5、学会正则表达式,
1)什么是正则表达式?正则表达式(regularexpression),或称为正则,是通过匹配字符串中的某些特定部分获得字符串所指示的数据的一种表达式。它作为一种广泛使用的文本编辑语言的程序设计语言,正则表达式能够帮助程序员进行文本处理。
2)正则表达式中的注释符号:'[/]';以及'^/'表示字符串中包含了子字符串或者括号之中使用逗号分隔。
3)正则表达式的主要语法结构:符号、表达式及字符串等;表达式即一个预定义的语法规则;正则表达式由大括号{}(或者s代表各种可以包含正则表达式元素的内置程序结构,如?、$、)等标识符定义;正则表达式由小括号表示非数字字符和预定义的空白字符;正则表达式使用正则表达式作为算术表达式,正则表达式同c语言和其他一些机器语言一样,没有指定的编译标志码,编译器随意将正则表达式转换为英文原始字符串。(。
4)正则表达式三个基本算术表达式:匹配模式(bestmatchingmode),有效性(effectiveness)和最大个数(maximumnumberofsequences)匹配模式匹配模式正则表达式是用来寻找目标字符串中某些特定部分的一种表达式。而每个字符串可以有不同的匹配模式,即匹配模式的数量等于该字符串个数的一半。
正则表达式的有效性正则表达式的有效性是字符串中出现字符数量和\r\n换行符等内容的匹配。javascript中正则表达式的有效性:加上换行符换行符\r\n等。(。
5)正则表达式的小括号内一般只有两个正则表达式:(l)(e),两个小括号。(l)代表匹配未知字符,代表“可能”的字符;(e)代表匹配某个字符,代表已知字符。
6)匹配“0-9”中的任意一个可以通过代码,然后发现的“10-99”中的任意一个结果,可以通过验证"\d0-9"isanentiresentencethatisnotentirelynamedanameorspecifiedthelengthofabody。因此应尽量匹配未知字符:(l)。(e)(g)(h)(i)(j),并且一定要匹配没有被escape过的字符串(。
7)匹配空格要 查看全部
php网页抓取乱码(php网页抓取乱码原因:curl是丧心病狂之源)
php网页抓取乱码原因:
1、curl是万恶之源
2、你配置非常不合理
3、curl是丧心病狂之源php正则表达式5个坑:
1、正则表达式是加拿大全国牛逼大学非常关注的课程,
2、学会正则表达式可以走遍天下不怕文盲;
3、只要你不是在做需要过多的网页的时候,
4、正则表达式内部可以转义,从而让你看不懂其他的回车,或者replace,
5、学会正则表达式,
1)什么是正则表达式?正则表达式(regularexpression),或称为正则,是通过匹配字符串中的某些特定部分获得字符串所指示的数据的一种表达式。它作为一种广泛使用的文本编辑语言的程序设计语言,正则表达式能够帮助程序员进行文本处理。
2)正则表达式中的注释符号:'[/]';以及'^/'表示字符串中包含了子字符串或者括号之中使用逗号分隔。
3)正则表达式的主要语法结构:符号、表达式及字符串等;表达式即一个预定义的语法规则;正则表达式由大括号{}(或者s代表各种可以包含正则表达式元素的内置程序结构,如?、$、)等标识符定义;正则表达式由小括号表示非数字字符和预定义的空白字符;正则表达式使用正则表达式作为算术表达式,正则表达式同c语言和其他一些机器语言一样,没有指定的编译标志码,编译器随意将正则表达式转换为英文原始字符串。(。
4)正则表达式三个基本算术表达式:匹配模式(bestmatchingmode),有效性(effectiveness)和最大个数(maximumnumberofsequences)匹配模式匹配模式正则表达式是用来寻找目标字符串中某些特定部分的一种表达式。而每个字符串可以有不同的匹配模式,即匹配模式的数量等于该字符串个数的一半。
正则表达式的有效性正则表达式的有效性是字符串中出现字符数量和\r\n换行符等内容的匹配。javascript中正则表达式的有效性:加上换行符换行符\r\n等。(。
5)正则表达式的小括号内一般只有两个正则表达式:(l)(e),两个小括号。(l)代表匹配未知字符,代表“可能”的字符;(e)代表匹配某个字符,代表已知字符。
6)匹配“0-9”中的任意一个可以通过代码,然后发现的“10-99”中的任意一个结果,可以通过验证"\d0-9"isanentiresentencethatisnotentirelynamedanameorspecifiedthelengthofabody。因此应尽量匹配未知字符:(l)。(e)(g)(h)(i)(j),并且一定要匹配没有被escape过的字符串(。
7)匹配空格要
php网页抓取乱码(一般来说,乱码的出现有2种原因,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-31 17:11
一般来说,出现乱码的原因有两个。首先,错误的编码(charset)设置导致浏览器解析错误的编码,导致满屏的“天书”乱七八糟。编码打开,然后保存。例如,文本文件最初以 GB2312 编码,但以 UTF-8 编码打开和保存。要解决上面的乱码问题,首先要知道开发的哪些方面涉及到编码:
1、文件编码:是指保存页面文件(.html、.php等)本身的编码。记事本和 Dreamweaver 在打开页面时会自动识别文件编码,因此问题较少。然而,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有某种编码的文件。如果工作时不注意,打开编码错误的文件。修改后保存,会出现乱码。
2、页面声明代码:在HTML代码HEAD中,可以使用(这句话一定要写在XXX前面,否则页面会空白(IE+PHP only))告诉浏览器网页是什么代码用途,目前中文网站主要用于GB2312和UTF-8两种编码的开发。
3、数据库连接代码:是指在进行数据库操作时,使用哪个代码向数据库传输数据。这里需要注意的是不要和数据库本身的代码混淆。例如MySQL内部默认为latin1编码,即Mysql数据以latin1编码存储,其他编码传输到Mysql的数据会转成latin1编码。
知道了WEB开发涉及到哪里编码,也就知道乱码的原因了:以上3种编码设置不一致,因为各种编码大部分都兼容ASCII,所以不会出现英文符号,中文会倒霉。. 以下是一些常见的错误情况和解决方案:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是最常见的乱码原因。此时PHP脚本中直接SELECT数据出现乱码,查询前需要用到:
mysql_query("SET NAMES GBK");
或mysql_query("SET NAMES GB2312");
设置MYSQL连接码,保证页面声明码和这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码的,您可以使用:
mysql_query("SET NAMES UTF8");
请注意,它是 UTF8 而不是通常的 UTF-8。如果页面上声明的代码与数据库内部代码一致,则可以不设置连接代码。
注意:其实MYSQL的数据输入输出比上面的要复杂一些。MYSQL配置文件my.ini定义了两种默认编码,即[client]中的default-character-set和[mysqld]中的default。-character-set 分别设置客户端连接和数据库使用的默认编码。我们上面指定的编码其实就是MYSQL客户端连接服务器时的命令行参数character_set_client,用来告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、页面声明编码与文件本身的编码不一致,这种情况很少发生,因为如果编码不一致,创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小bug,打开错误代码的页面,然后保存。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,由于软件的代码配置错误,转换了错误的代码。
3、一些租用虚拟主机的朋友,即使上面三个代码设置正确,还是有乱码。比如网页是用GB2312编码的,但是IE等浏览器总是把它识别为UTF-8。网页的HEAD已经说明是GB2312。手动修改浏览器编码为GB2312后,页面正常显示。原因是服务器Apache设置了服务器的全局默认编码,并在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级高于页面中声明的代码,所以浏览器会认错。有两种解决方案。请在配置文件的虚拟机中添加一个AddDefaultCharset GB2312来覆盖全局配置,
乱码解决方案
要解决乱码问题,首先要弄清楚你的数据库使用的是什么编码。如果未指定,它将是默认的 latin1。
我们应该最多使用gb2312、gbk、utf8这三个字符集。
那么我们如何指定数据库的字符集呢?下面也是gbk的一个例子
[在 MySQL 命令行客户端中创建数据库]
mysql> 创建表`mysqlcode` (
-> `id` TINYINT(255) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> `content` VARCHAR( 255 ) NOT NULL
-> ) TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
查询正常,0 行受影响,1 个警告(0.03 秒)
mysql> desc mysqlcode;
+---------+----------+------+-----+-- -------+----------------+
| 领域 | 类型 | 空 | 钥匙 | 默认 | 额外 |
+---------+----------+------+-----+-- -------+----------------+
| 编号 | tinyint(255) 无符号 | NO | PRI | | auto_increment |
| 内容 | varchar(255) | 否 | | | |
+---------+----------+------+-----+-- -------+----------------+
2 行(0.02 秒)
后者 TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
就是指定数据库的字符集,COLLATE(排序规则),让mysql同时支持多种编码的数据库。
当然我们也可以通过以下命令修改数据库的字符集
更改数据库 da_name 默认字符集 'charset'。
客户端以gbk格式发送,可配置如下:
SET character_set_client='gbk'
SET character_set_connection='gbk'
SET character_set_results='gbk'
此配置等效于 SET NAMES 'gbk'。
现在对刚刚创建的数据库进行操作
mysql> 使用测试;
数据库已更改
mysql> 插入 mysqlcode 值(null,'php 爱好者');
错误 1406(22001):第 1 行的列“内容”的数据太长
字符集未指定为 gbk,插入时出错
mysql> 设置名称 'gbk';
查询正常,0 行受影响(0.02 秒)
指定字符集为 gbk
mysql> 插入 mysqlcode 值(null,'php 爱好者');
查询正常,1 行受影响(0.00 秒)
插入成功
mysql> 从 mysqlcode 中选择 *;
+----+------------+
| 编号 | 内容 |
+----+------------+
| 1| php 爱 |
+----+------------+
一组中的 1 行 (0.00 秒)
不指定字符集gbk时,也会出现乱码,如下
mysql> 从 mysqlcode 中选择 *;
+----+----------+
| 编号 | 内容 |
+----+----------+
+----+----------+
一组中的 1 行 (0.00 秒)
【在phpmyadmin中创建数据库并指定字符集】
根据自己的需要选择表格类型,这里选择MyISAM(支持全文搜索);
整理并选择gbk_chinese_ci即gbk字符集
gbk_bin 简体中文,二进制。gbk_chinese_ci 简体中文,不区分大小写。
将数据库插入到刚刚创建的数据库中
再次浏览时出现乱码
为什么?因为数据库是gbk字符集,我们在操作的时候没有指定为gbk 查看全部
php网页抓取乱码(一般来说,乱码的出现有2种原因,你知道吗?)
一般来说,出现乱码的原因有两个。首先,错误的编码(charset)设置导致浏览器解析错误的编码,导致满屏的“天书”乱七八糟。编码打开,然后保存。例如,文本文件最初以 GB2312 编码,但以 UTF-8 编码打开和保存。要解决上面的乱码问题,首先要知道开发的哪些方面涉及到编码:
1、文件编码:是指保存页面文件(.html、.php等)本身的编码。记事本和 Dreamweaver 在打开页面时会自动识别文件编码,因此问题较少。然而,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有某种编码的文件。如果工作时不注意,打开编码错误的文件。修改后保存,会出现乱码。
2、页面声明代码:在HTML代码HEAD中,可以使用(这句话一定要写在XXX前面,否则页面会空白(IE+PHP only))告诉浏览器网页是什么代码用途,目前中文网站主要用于GB2312和UTF-8两种编码的开发。
3、数据库连接代码:是指在进行数据库操作时,使用哪个代码向数据库传输数据。这里需要注意的是不要和数据库本身的代码混淆。例如MySQL内部默认为latin1编码,即Mysql数据以latin1编码存储,其他编码传输到Mysql的数据会转成latin1编码。
知道了WEB开发涉及到哪里编码,也就知道乱码的原因了:以上3种编码设置不一致,因为各种编码大部分都兼容ASCII,所以不会出现英文符号,中文会倒霉。. 以下是一些常见的错误情况和解决方案:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是最常见的乱码原因。此时PHP脚本中直接SELECT数据出现乱码,查询前需要用到:
mysql_query("SET NAMES GBK");
或mysql_query("SET NAMES GB2312");
设置MYSQL连接码,保证页面声明码和这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码的,您可以使用:
mysql_query("SET NAMES UTF8");
请注意,它是 UTF8 而不是通常的 UTF-8。如果页面上声明的代码与数据库内部代码一致,则可以不设置连接代码。
注意:其实MYSQL的数据输入输出比上面的要复杂一些。MYSQL配置文件my.ini定义了两种默认编码,即[client]中的default-character-set和[mysqld]中的default。-character-set 分别设置客户端连接和数据库使用的默认编码。我们上面指定的编码其实就是MYSQL客户端连接服务器时的命令行参数character_set_client,用来告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、页面声明编码与文件本身的编码不一致,这种情况很少发生,因为如果编码不一致,创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小bug,打开错误代码的页面,然后保存。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,由于软件的代码配置错误,转换了错误的代码。
3、一些租用虚拟主机的朋友,即使上面三个代码设置正确,还是有乱码。比如网页是用GB2312编码的,但是IE等浏览器总是把它识别为UTF-8。网页的HEAD已经说明是GB2312。手动修改浏览器编码为GB2312后,页面正常显示。原因是服务器Apache设置了服务器的全局默认编码,并在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级高于页面中声明的代码,所以浏览器会认错。有两种解决方案。请在配置文件的虚拟机中添加一个AddDefaultCharset GB2312来覆盖全局配置,
乱码解决方案
要解决乱码问题,首先要弄清楚你的数据库使用的是什么编码。如果未指定,它将是默认的 latin1。
我们应该最多使用gb2312、gbk、utf8这三个字符集。
那么我们如何指定数据库的字符集呢?下面也是gbk的一个例子
[在 MySQL 命令行客户端中创建数据库]
mysql> 创建表`mysqlcode` (
-> `id` TINYINT(255) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> `content` VARCHAR( 255 ) NOT NULL
-> ) TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
查询正常,0 行受影响,1 个警告(0.03 秒)
mysql> desc mysqlcode;
+---------+----------+------+-----+-- -------+----------------+
| 领域 | 类型 | 空 | 钥匙 | 默认 | 额外 |
+---------+----------+------+-----+-- -------+----------------+
| 编号 | tinyint(255) 无符号 | NO | PRI | | auto_increment |
| 内容 | varchar(255) | 否 | | | |
+---------+----------+------+-----+-- -------+----------------+
2 行(0.02 秒)
后者 TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
就是指定数据库的字符集,COLLATE(排序规则),让mysql同时支持多种编码的数据库。
当然我们也可以通过以下命令修改数据库的字符集
更改数据库 da_name 默认字符集 'charset'。
客户端以gbk格式发送,可配置如下:
SET character_set_client='gbk'
SET character_set_connection='gbk'
SET character_set_results='gbk'
此配置等效于 SET NAMES 'gbk'。
现在对刚刚创建的数据库进行操作
mysql> 使用测试;
数据库已更改
mysql> 插入 mysqlcode 值(null,'php 爱好者');
错误 1406(22001):第 1 行的列“内容”的数据太长
字符集未指定为 gbk,插入时出错
mysql> 设置名称 'gbk';
查询正常,0 行受影响(0.02 秒)
指定字符集为 gbk
mysql> 插入 mysqlcode 值(null,'php 爱好者');
查询正常,1 行受影响(0.00 秒)
插入成功
mysql> 从 mysqlcode 中选择 *;
+----+------------+
| 编号 | 内容 |
+----+------------+
| 1| php 爱 |
+----+------------+
一组中的 1 行 (0.00 秒)
不指定字符集gbk时,也会出现乱码,如下
mysql> 从 mysqlcode 中选择 *;
+----+----------+
| 编号 | 内容 |
+----+----------+
+----+----------+
一组中的 1 行 (0.00 秒)
【在phpmyadmin中创建数据库并指定字符集】

根据自己的需要选择表格类型,这里选择MyISAM(支持全文搜索);
整理并选择gbk_chinese_ci即gbk字符集
gbk_bin 简体中文,二进制。gbk_chinese_ci 简体中文,不区分大小写。
将数据库插入到刚刚创建的数据库中

再次浏览时出现乱码

为什么?因为数据库是gbk字符集,我们在操作的时候没有指定为gbk
php网页抓取乱码(php网页抓取乱码解决办法这种情况下可以用google翻译)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-30 00:06
php网页抓取乱码解决办法这种情况下可以用google翻译来进行语言翻译,同时也可以根据关键词检索到相应的文献。1.不打扰手机好友2.不影响好友私信数量3.不被关注者感到一本正经4.不影响相关内容被浏览次数想知道更多的技术,看我的专栏:android高级开发架构android高级开发架构-poweredbyadvancedcrafted-知乎专栏。
我发现我的是可以查看到包含大于多少比特的。一个一个查。不会搜索到文献不过有一个好的方法,你自己去试试打开浏览器,在开发者工具中打开代码。找到[language],就可以知道正在输入的文字用多少比特。
lingdigital-advanced-performance.htmllanguage(version2.0):charles
yy。
我在研究zotero,发现能检测到文章中的比特,检测错误的话,不会被认定为是垃圾邮件,也就是所谓的不能标记垃圾邮件。但是你用zotero自带的javascript监控代码,
因为p2p共享的文件都是不能标记垃圾邮件的,因为垃圾邮件是目标制定,最好标记他所在的目标,所以你才没法收到所有的垃圾邮件。p2p共享文件就不存在这个问题,zotero因为是自己搭建的网站,所以可以检测到所有的垃圾邮件。方法是只要在zotero的edit中提交proposal,提交成功后服务器会自动抓取这些proposal,这些proposal的id,zotero就可以根据这些数据自动对文件进行分析。
比如让zotero找到你正在检测的邮件的id,然后再找到另外一段可能是广告文章的邮件的id,这就容易了。其他解决方法可以参考我之前写的文章/。 查看全部
php网页抓取乱码(php网页抓取乱码解决办法这种情况下可以用google翻译)
php网页抓取乱码解决办法这种情况下可以用google翻译来进行语言翻译,同时也可以根据关键词检索到相应的文献。1.不打扰手机好友2.不影响好友私信数量3.不被关注者感到一本正经4.不影响相关内容被浏览次数想知道更多的技术,看我的专栏:android高级开发架构android高级开发架构-poweredbyadvancedcrafted-知乎专栏。
我发现我的是可以查看到包含大于多少比特的。一个一个查。不会搜索到文献不过有一个好的方法,你自己去试试打开浏览器,在开发者工具中打开代码。找到[language],就可以知道正在输入的文字用多少比特。
lingdigital-advanced-performance.htmllanguage(version2.0):charles
yy。
我在研究zotero,发现能检测到文章中的比特,检测错误的话,不会被认定为是垃圾邮件,也就是所谓的不能标记垃圾邮件。但是你用zotero自带的javascript监控代码,
因为p2p共享的文件都是不能标记垃圾邮件的,因为垃圾邮件是目标制定,最好标记他所在的目标,所以你才没法收到所有的垃圾邮件。p2p共享文件就不存在这个问题,zotero因为是自己搭建的网站,所以可以检测到所有的垃圾邮件。方法是只要在zotero的edit中提交proposal,提交成功后服务器会自动抓取这些proposal,这些proposal的id,zotero就可以根据这些数据自动对文件进行分析。
比如让zotero找到你正在检测的邮件的id,然后再找到另外一段可能是广告文章的邮件的id,这就容易了。其他解决方法可以参考我之前写的文章/。
php网页抓取乱码(要说用什么显示网页,要说有什么不同(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-03-19 10:10
统一页面编码
MySQL 数据库编码、HTML 页面编码、PHP 或 HTML 文件编码必须一致。
1、MySQL数据库代码:创建数据库时指定代码(如gbk_chinese_ci)。创建数据表、创建字段、插入数据时不要指定代码,会自动继承数据库的代码。
连接数据库时,还有一个编码。连接数据库后,执行mysql_query('SET NAMES gbk');//把gbk换成你的编码,比如utf8。
2、html页面的编码参考这一行的设置:
复制代码代码如下:
3、php或者html文件本身的编码:用editplus打开php文件或者html文件,保存的时候选择编码,如果数据库和页面编码都是gbk,这里的编码就是ansi;如果数据库和页面编码都是utf-8,那么这里也选择utf-8。
4、在 Javascript 或 Flash 中传递的数据是 utf-8 编码的:
还有一点需要注意的是,Javascript或者Flash传入的数据是utf-8编码的,如果数据库和页面编码是gbk,需要转码后写入数据库。
复制代码代码如下:
iconv('utf-8', 'gbk', $content);
5、在PHP程序中,可以添加一行来指定PHP源程序的编码:
复制代码代码如下:
header('内容类型: text/html; charset=gbk');
php页面编码
1.在文件头设置编码
复制代码代码如下:
@header('内容类型: text/html;charset=UTF-8');
2.header和meta的区别
使用@header('Content-type: text/html; charset=gbk'); 的区别 和
它们都告诉浏览器使用什么编码来显示网页。有什么区别?header 是发送原创的 HTTP 头,网页中什么都不留下,而 meta 是写在网页中的。
一方面,如果页面中没有元数据,则发送 HTTP 标头有效。
其次,使用 header() 函数发送可以收录更多内容的原创 HTTP 标头,设置编码只是其中之一。
第三,有时不需要在网页上显示什么内容,而是告知浏览器后续动作使用什么编码。
时间:2015-04-06 查看全部
php网页抓取乱码(要说用什么显示网页,要说有什么不同(图))
统一页面编码
MySQL 数据库编码、HTML 页面编码、PHP 或 HTML 文件编码必须一致。
1、MySQL数据库代码:创建数据库时指定代码(如gbk_chinese_ci)。创建数据表、创建字段、插入数据时不要指定代码,会自动继承数据库的代码。
连接数据库时,还有一个编码。连接数据库后,执行mysql_query('SET NAMES gbk');//把gbk换成你的编码,比如utf8。
2、html页面的编码参考这一行的设置:
复制代码代码如下:
3、php或者html文件本身的编码:用editplus打开php文件或者html文件,保存的时候选择编码,如果数据库和页面编码都是gbk,这里的编码就是ansi;如果数据库和页面编码都是utf-8,那么这里也选择utf-8。
4、在 Javascript 或 Flash 中传递的数据是 utf-8 编码的:
还有一点需要注意的是,Javascript或者Flash传入的数据是utf-8编码的,如果数据库和页面编码是gbk,需要转码后写入数据库。
复制代码代码如下:
iconv('utf-8', 'gbk', $content);
5、在PHP程序中,可以添加一行来指定PHP源程序的编码:
复制代码代码如下:
header('内容类型: text/html; charset=gbk');
php页面编码
1.在文件头设置编码
复制代码代码如下:
@header('内容类型: text/html;charset=UTF-8');
2.header和meta的区别
使用@header('Content-type: text/html; charset=gbk'); 的区别 和
它们都告诉浏览器使用什么编码来显示网页。有什么区别?header 是发送原创的 HTTP 头,网页中什么都不留下,而 meta 是写在网页中的。
一方面,如果页面中没有元数据,则发送 HTTP 标头有效。
其次,使用 header() 函数发送可以收录更多内容的原创 HTTP 标头,设置编码只是其中之一。
第三,有时不需要在网页上显示什么内容,而是告知浏览器后续动作使用什么编码。
时间:2015-04-06
php网页抓取乱码(php和Mysql出现的中文乱码问题怎么办?见)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-19 10:09
最近一直在写网页,用的是php和Mysql,但是出现了各种问题。说明在Mysql下输入sql语句时,如果sql语句中有中文,则可能不会执行sql语句。解决方法见:解决Mysql server 5.1无法识别中文
解决此问题后,使用php向数据库写入数据时,sql语句无法再次执行。这个问题我也解决了。解决方法见:解决PHP连接Mysql但无法向数据库插入数据的问题。
昨天出现的中文乱码问题,经过一夜的努力,终于解决了。现在PHP和Mysql都可以识别中文,可以正常执行SQL语句了。
解决方法就是在这里写个总结(应该同时解决以上三个问题):
首先是修改Mysql的编码方式。这是一篇写得很详细的帖子。结合我第一个问题的解决方法,完全可以修改Mysql的编码方式。帖子地址:MySql修改数据库编码为UTF8。
接下来是php连接数据库时选择的编码方式。首先,我建议你把所有的编码方式都改成'utf-8',这样写网页或者使用数据库会方便很多。 php在写网页时,添加 则可以使用sql语句访问数据库,添加mysql_query("set names utf8");记住这里是utf8不是utf-8,不是我不小心忘了加横线,而是utf8。 查看全部
php网页抓取乱码(php和Mysql出现的中文乱码问题怎么办?见)
最近一直在写网页,用的是php和Mysql,但是出现了各种问题。说明在Mysql下输入sql语句时,如果sql语句中有中文,则可能不会执行sql语句。解决方法见:解决Mysql server 5.1无法识别中文
解决此问题后,使用php向数据库写入数据时,sql语句无法再次执行。这个问题我也解决了。解决方法见:解决PHP连接Mysql但无法向数据库插入数据的问题。
昨天出现的中文乱码问题,经过一夜的努力,终于解决了。现在PHP和Mysql都可以识别中文,可以正常执行SQL语句了。
解决方法就是在这里写个总结(应该同时解决以上三个问题):
首先是修改Mysql的编码方式。这是一篇写得很详细的帖子。结合我第一个问题的解决方法,完全可以修改Mysql的编码方式。帖子地址:MySql修改数据库编码为UTF8。
接下来是php连接数据库时选择的编码方式。首先,我建议你把所有的编码方式都改成'utf-8',这样写网页或者使用数据库会方便很多。 php在写网页时,添加 则可以使用sql语句访问数据库,添加mysql_query("set names utf8");记住这里是utf8不是utf-8,不是我不小心忘了加横线,而是utf8。
php网页抓取乱码(mysq数据库使用的编码字符集(1)_set=utf8)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-18 15:21
一、
学php的童鞋在写网页的时候,如果设计了中文内容的存储,大部分都会出现乱码的问题。对于一般的乱码,我们可以从三个方面进行检查
(1)网页的编码是否正确,例如是否在header中添加原创标签
(2)检查mysql数据库存储时使用的默认字符集
(3)查看网页文件的编码,是否是对应的中文编码
------------------
环境:win7+wamp2.2
------------------
二、
先从第二点说起,mysq数据库使用的编码字符集
(1)打开mysql终端,查看当前设置,确定要修改的范围
show variables like 'char%';
(2)根据结果分析,
1、如果你显示的结果和我的差不多,也就是(只有character_set_system编码为utf8)那么按照下面的步骤一步步来
2、打开my.ini文件,搜索关键词'mysqld',找到后观察是否有这一行
character_set_server=utf8
如果没有,你应该像我一样在它下面添加一个句子
3、再搜索关键词'client'看看有没有这行
default_character_set=utf8
如果没有,请在 [client] 下添加
4、保存,重启mysql服务,关闭mysql终端(不然你看到的客户端代码不会更新)
5、再次打开终端,我们再次进入
show variables like 'char%';
如果出现如下结果,即mysql数据设置成功
三、
网页文件编码的问题是最容易被忽略的。保存时选择保存文件编码的格式时设置。
解决方案:
1、使用notepad++打开网页文件,然后在“格式”--“转为UTF-8无BOM编码格式”
2、保存就行
问题分析:
1、写php的时候用过
<br />
但是还是有乱码的问题!
分析:使用上面的语句,只修改了三项,三项是
character_set_client
字符集连接
字符集结果
而且这个修改只是暂时的,关闭终端后还是一样。
阐明:
2、我们来分析第三个乱码问题
(1)使用sublime text3编辑打开php文件,左下角可以看到编码信息,可以看到当前编码为gb2312
(2)网页加载的时候,相当于打开了当时的一个文件。那个时候读取的格式按照gb2312的编码读取网页文件,当是显示在用户的浏览器中,因为网页声明的字符集是utf-8,所以获取到的文件内容会按照utf-8字符集进行解释,会导致乱码,但是没有问题我们从数据库中读取的内容。
网络编码
原创gbk编码文件
后来的 utf-8 编码文件
(3)注意,sublime text3没有给你转换编码,虽然显示转换成功,但是什么?显示还是一样,还是我们notepad++功能更强大,如何修改上一个! 转换成功后
3、为什么我按照你说的修改了,在mysql终端下显示,还是乱码?
分析:
(1)我们先来看看windows下cmd使用的是什么字符集?
可以看出cmd的字符集是gbk,也就是说终端显示的任何内容都会对应gbk的字符集,但是我们数据库的中文设置的utf8字符集,当我们想要显示出来,自然会使用 utf8 编码读取数据库数据,当编码为 utf-8 时,到了终端就乱了
(2)怎么查?
用phpmyadmin就行了,当然我们要设置我们使用的utf-8编码! 查看全部
php网页抓取乱码(mysq数据库使用的编码字符集(1)_set=utf8)
一、
学php的童鞋在写网页的时候,如果设计了中文内容的存储,大部分都会出现乱码的问题。对于一般的乱码,我们可以从三个方面进行检查
(1)网页的编码是否正确,例如是否在header中添加原创标签
(2)检查mysql数据库存储时使用的默认字符集
(3)查看网页文件的编码,是否是对应的中文编码
------------------
环境:win7+wamp2.2
------------------
二、
先从第二点说起,mysq数据库使用的编码字符集
(1)打开mysql终端,查看当前设置,确定要修改的范围
show variables like 'char%';
(2)根据结果分析,
1、如果你显示的结果和我的差不多,也就是(只有character_set_system编码为utf8)那么按照下面的步骤一步步来

2、打开my.ini文件,搜索关键词'mysqld',找到后观察是否有这一行
character_set_server=utf8
如果没有,你应该像我一样在它下面添加一个句子

3、再搜索关键词'client'看看有没有这行
default_character_set=utf8
如果没有,请在 [client] 下添加

4、保存,重启mysql服务,关闭mysql终端(不然你看到的客户端代码不会更新)
5、再次打开终端,我们再次进入
show variables like 'char%';
如果出现如下结果,即mysql数据设置成功

三、
网页文件编码的问题是最容易被忽略的。保存时选择保存文件编码的格式时设置。
解决方案:
1、使用notepad++打开网页文件,然后在“格式”--“转为UTF-8无BOM编码格式”

2、保存就行
问题分析:
1、写php的时候用过
<br />
但是还是有乱码的问题!
分析:使用上面的语句,只修改了三项,三项是
character_set_client
字符集连接
字符集结果
而且这个修改只是暂时的,关闭终端后还是一样。
阐明:

2、我们来分析第三个乱码问题
(1)使用sublime text3编辑打开php文件,左下角可以看到编码信息,可以看到当前编码为gb2312

(2)网页加载的时候,相当于打开了当时的一个文件。那个时候读取的格式按照gb2312的编码读取网页文件,当是显示在用户的浏览器中,因为网页声明的字符集是utf-8,所以获取到的文件内容会按照utf-8字符集进行解释,会导致乱码,但是没有问题我们从数据库中读取的内容。
网络编码

原创gbk编码文件

后来的 utf-8 编码文件

(3)注意,sublime text3没有给你转换编码,虽然显示转换成功,但是什么?显示还是一样,还是我们notepad++功能更强大,如何修改上一个! 转换成功后

3、为什么我按照你说的修改了,在mysql终端下显示,还是乱码?
分析:
(1)我们先来看看windows下cmd使用的是什么字符集?

可以看出cmd的字符集是gbk,也就是说终端显示的任何内容都会对应gbk的字符集,但是我们数据库的中文设置的utf8字符集,当我们想要显示出来,自然会使用 utf8 编码读取数据库数据,当编码为 utf-8 时,到了终端就乱了
(2)怎么查?
用phpmyadmin就行了,当然我们要设置我们使用的utf-8编码!
php网页抓取乱码(做了个网络爬虫抓取网页,最后居然搞出来了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-14 19:09
我做了一个网络爬虫来爬取网页,但是如果网页是gbk/gb2312编码的,就会出现乱码,如下:
得到文本后,直接打印,输出结果str如下:
¹óÖÝÈËÊ¿ ¼ÊÔÐÅÏ¢Íø_¹óÖÝÈËÊÂ¿Ê ¼ÊÔÍø_¹óÖݹ«ÎñÔ±¿¿ ¼ÊÔÍø_¹óÖÝÖй«
这个问题困扰了我很久,百度、google都没有找到完全可行的方法,继续折腾,终于出来了!代码转换来回转换,依然无法解决。把问题具体总结一下,分享给大家,互相学习!(有时候问题并不复杂,容易解决。如果问题没有突破,那么解决问题的路是很长的。)总之,遇到问题,选择几种方法去尝试,就有了总是有办法解决它。的。
1.更改网页源代码的编码格式(强调)
# -*- coding:utf8 -*-
import urllib2
req = urllib2.Request("http://www.baidu.com/")
res = urllib2.urlopen(req)
html = res.read()
res.close()
html = unicode(html, "gb2312").encode("utf8") #gb2312--->utf-8
print html
2.python爬取网页时字符集转换问题处理解决方案
有时我们 采集 网页,将字符串保存到文件或在处理后将它们写入数据库。这时,我们需要制定字符串的编码。如果采集网页的编码是gb2312,而我们的数据库是utf-8,不做任何处理直接插入数据库可能会出现乱码(未测试,不知道数据库会不会自动转码),我们需要手动将gb2312转为utf-8。
首先我们知道python中的字符默认是ascii码。当然,英语没有问题。遇到中国人,立马下跪。
不知道大家还记得没有,python中打印汉字的时候,需要在字符串前面加上u:
print u "来基地吗?"
这样就可以显示中文了。u这里的作用是将下面的字符串转换成unicode码,这样才能正确显示中文。
这里有一个与之相关的unicode()函数,使用如下
str="来搞基"
str=unicode(str,"utf-8")
print str
与u的区别在于unicode用于将str转为unicode编码,需要正确指定第二个参数。这里的utf-8是我的test.py脚本本身的文件字符集,默认的可能是ansi。
unicode 是键,下面继续
我们开始爬取百度主页。注意,访问者访问百度主页查看网页源代码时,其charset=gb2312。
import urllib2
def main():
f=urllib2.urlopen("http://www.baidu.com")
str=f.read()
str=unicode(str,"gb2312")
fp=open("baidu.html","w")
fp.write(str.encode("utf-8"))
fp.close()
if name == 'main' :
main()
解释:
我们先用urllib2.urlopen()方法抓取百度主页,f为句柄,使用str=f.read()将所有源码读入str
明确str是我们抓取的html源代码。由于网页默认的字符集是gb2312,如果我们直接保存到文件中,文件编码会是ansi。
对于大部分人来说,这其实已经足够了,但是有时候我只想把gb2312转成utf-8,怎么办呢?
第一的:
str=unicode(str,"gb2312")#这里的gb2312是str的实际字符集,我们现在将其转换为unicode
然后:
str=str.encode("utf-8")#将unicode字符串重新编码为utf-8
最后:
将str写入文件,打开文件查看编码属性,发现是utf-8,把
总结:
我们回顾一下,如果需要按照指定的字符集保存字符串,有以下步骤:
1:使用unicode(str, "original encoding") 将str解码成unicode字符串
2:使用str.encode("specified character set")将unicode字符串str转换成你指定的字符集
3:将str保存到文件,或写入数据库。当然,你已经指定了编码,对吧?
3.用 lxml 解析 html
使用lxml.etree作为网络爬虫来爬取网页,但是如果网页是gbk/gb2312编码的,会出现乱码,如下:
获取文本后,直接打印,输出结果v如下:
¹óÖÝÈËÊ¿ ¼ÊÔÐÅÏ¢Íø¹óÖÝÈËÊÂ¿Ê ¼ÊÔÍø¹óÖݹ«ÎñÔ±¿¿ ¼ÊÔÍø_¹óÖÝÖй
这个 v 的类型又是
response.encoding = 'utf-8'
page = etree.HTML(response.content)
nodes_title = page.xpath("//title//text()")
这样打印出来的nodes_title[0]是正常中文显示的。
特别注意的是response.text容易出现编码问题,所以以后使用response.content。 查看全部
php网页抓取乱码(做了个网络爬虫抓取网页,最后居然搞出来了)
我做了一个网络爬虫来爬取网页,但是如果网页是gbk/gb2312编码的,就会出现乱码,如下:
得到文本后,直接打印,输出结果str如下:
¹óÖÝÈËÊ¿ ¼ÊÔÐÅÏ¢Íø_¹óÖÝÈËÊÂ¿Ê ¼ÊÔÍø_¹óÖݹ«ÎñÔ±¿¿ ¼ÊÔÍø_¹óÖÝÖй«
这个问题困扰了我很久,百度、google都没有找到完全可行的方法,继续折腾,终于出来了!代码转换来回转换,依然无法解决。把问题具体总结一下,分享给大家,互相学习!(有时候问题并不复杂,容易解决。如果问题没有突破,那么解决问题的路是很长的。)总之,遇到问题,选择几种方法去尝试,就有了总是有办法解决它。的。
1.更改网页源代码的编码格式(强调)
# -*- coding:utf8 -*-
import urllib2
req = urllib2.Request("http://www.baidu.com/";)
res = urllib2.urlopen(req)
html = res.read()
res.close()
html = unicode(html, "gb2312").encode("utf8") #gb2312--->utf-8
print html
2.python爬取网页时字符集转换问题处理解决方案
有时我们 采集 网页,将字符串保存到文件或在处理后将它们写入数据库。这时,我们需要制定字符串的编码。如果采集网页的编码是gb2312,而我们的数据库是utf-8,不做任何处理直接插入数据库可能会出现乱码(未测试,不知道数据库会不会自动转码),我们需要手动将gb2312转为utf-8。
首先我们知道python中的字符默认是ascii码。当然,英语没有问题。遇到中国人,立马下跪。
不知道大家还记得没有,python中打印汉字的时候,需要在字符串前面加上u:
print u "来基地吗?"
这样就可以显示中文了。u这里的作用是将下面的字符串转换成unicode码,这样才能正确显示中文。
这里有一个与之相关的unicode()函数,使用如下
str="来搞基"
str=unicode(str,"utf-8")
print str
与u的区别在于unicode用于将str转为unicode编码,需要正确指定第二个参数。这里的utf-8是我的test.py脚本本身的文件字符集,默认的可能是ansi。
unicode 是键,下面继续
我们开始爬取百度主页。注意,访问者访问百度主页查看网页源代码时,其charset=gb2312。
import urllib2
def main():
f=urllib2.urlopen("http://www.baidu.com";)
str=f.read()
str=unicode(str,"gb2312")
fp=open("baidu.html","w")
fp.write(str.encode("utf-8"))
fp.close()
if name == 'main' :
main()
解释:
我们先用urllib2.urlopen()方法抓取百度主页,f为句柄,使用str=f.read()将所有源码读入str
明确str是我们抓取的html源代码。由于网页默认的字符集是gb2312,如果我们直接保存到文件中,文件编码会是ansi。
对于大部分人来说,这其实已经足够了,但是有时候我只想把gb2312转成utf-8,怎么办呢?
第一的:
str=unicode(str,"gb2312")#这里的gb2312是str的实际字符集,我们现在将其转换为unicode
然后:
str=str.encode("utf-8")#将unicode字符串重新编码为utf-8
最后:
将str写入文件,打开文件查看编码属性,发现是utf-8,把
总结:
我们回顾一下,如果需要按照指定的字符集保存字符串,有以下步骤:
1:使用unicode(str, "original encoding") 将str解码成unicode字符串
2:使用str.encode("specified character set")将unicode字符串str转换成你指定的字符集
3:将str保存到文件,或写入数据库。当然,你已经指定了编码,对吧?
3.用 lxml 解析 html
使用lxml.etree作为网络爬虫来爬取网页,但是如果网页是gbk/gb2312编码的,会出现乱码,如下:
获取文本后,直接打印,输出结果v如下:
¹óÖÝÈËÊ¿ ¼ÊÔÐÅÏ¢Íø¹óÖÝÈËÊÂ¿Ê ¼ÊÔÍø¹óÖݹ«ÎñÔ±¿¿ ¼ÊÔÍø_¹óÖÝÖй
这个 v 的类型又是
response.encoding = 'utf-8'
page = etree.HTML(response.content)
nodes_title = page.xpath("//title//text()")
这样打印出来的nodes_title[0]是正常中文显示的。
特别注意的是response.text容易出现编码问题,所以以后使用response.content。
php网页抓取乱码( 如何解决php抓取乱码问题php网页抓取乱码的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-14 19:07
如何解决php抓取乱码问题php网页抓取乱码的)
如何解决php网页抓取出现乱码问题
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”转换编码;2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” 选项; 3、在顶部添加标题代码。推荐
如何解决php传页面参数乱码问题
php传页参数乱码的解决方法:1、打开对应的php代码文件;2、通过“if($tag===iconv('UTF-8',$c,iconv($c ,'UTF-8',$tag))){...} 的方法来解决乱码问题
如何解决乱码网页
本文运行环境:windows10系统,360安全浏览器 1 文本,这个是乱码。右键单击网页以弹出菜单。在弹出菜单中找到编辑
php乱码原因分析
PHP中的中文乱码是PHP开发中常见的问题之一。PHP中文乱码有时出现在网页本身,有的出现在与MySQL交互的过程中,有时与操作系统有关。下面给出一个摘要。一。首先,PHP网页编码最好最快的方案是页面声明的编码与数据库内部编码一致。如果页面应用的页码与数据库内部编码不一致,设置连接编码,mysql_query(\"SETNAMESXXX\");XXX为连接编码。一定能解决乱七八糟的
如何处理乱码的css网页
css网页乱码的解决方法:1、设置CSS字符编码与页面字符编码一致,设置“@charset”utf-8“;”等编码语句;2、写css评论时加强;3、 采用字体的别名。推荐:《css视频教程》解决方案
响应式网页设计和 SEO
所谓“响应式网页设计(Responsive Web Design)”也是自适应的,是一种能够自动识别屏幕宽度并做出相应调整的网页设计。目前这种设计已经出现在越来越多的国内网站中,谷歌已经明确表示鼓励响应式网页设计。
简化您的网页设计
随着网站构建技术的发展,在网页中实现复杂的功能已经不再困难。网页中的功能越来越多。因此,需要在用户的浏览体验和网页设计的美感之间取得平衡。显得非常重要。
宝安网页设计从SEO角度谈网页设计标准
深圳宝安网页设计从SEO角度谈网页设计标准。在任何时候,网站访问者都处于以下阶段之一: 1. 注意;2、利息;3.欲望;4. 行动;5.满足。在每个阶段,参观者都是不同的
什么是优化网页设计?
由于不同的搜索引擎对网页的支持存在差异,所以在设计网页时,不要只关注外观。许多网页设计中常用的元素都会给搜索引擎带来问题。■框架结构(FrameSets) 有些搜索引擎(如FAST)不支持框架结构,其蜘蛛程序无法读取此类网页。■图像块(我
网页设计对网站推广效果的影响
网页设计是一门深奥的课程,它对网站的推广和营销的影响是毋庸置疑的。无论是网页的布局,网页下载的速度,导航系统的便利性,还是用户的浏览效果,都会直接影响到用户的浏览效果,进而影响状态和形象用户心目中的网站,即网页设计的效果直接影响网站的品牌形象和推广营销效果。下
什么是标签页?如何优化标签页?
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
网页登录成功后php如何实现网页跳转?
网页登录成功后php实现网页跳转的方法:首先打开php编辑器,新建一个php文件;然后在[index.php]中输入代码[header('Location:index.php');];最后浏览服务器运行[login.
php下载中文乱码的解决办法
php下载中文乱码的解决方法:先打开相关代码文件;然后使用“iconv()”函数解决乱码,具体语法为“$file_name=iconv("utf-8","gb2312",$file_name);"。php下载解决中文乱码
网站制作和网页设计/区别/描述/\"
/网页设计:就是让美工做设计的所有页面的界面渲染网站,就像建房子之前,会请一位著名的设计师来设计房子的外观。你用什么软件做网页设计?DreamweaverCS6、烟花、Photoshop等
网页登录成功后如何在php中实现网页跳转
网页登录成功后php实现网页跳转的方法:首先打开编辑器,新建一个php文件;然后输入代码“header('Location:index.php');” 在php文件中;最后在浏览器中运行它,这将跳转到索引时 查看全部
php网页抓取乱码(
如何解决php抓取乱码问题php网页抓取乱码的)

如何解决php网页抓取出现乱码问题
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”转换编码;2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” 选项; 3、在顶部添加标题代码。推荐
如何解决php传页面参数乱码问题
php传页参数乱码的解决方法:1、打开对应的php代码文件;2、通过“if($tag===iconv('UTF-8',$c,iconv($c ,'UTF-8',$tag))){...} 的方法来解决乱码问题
如何解决乱码网页
本文运行环境:windows10系统,360安全浏览器 1 文本,这个是乱码。右键单击网页以弹出菜单。在弹出菜单中找到编辑
php乱码原因分析
PHP中的中文乱码是PHP开发中常见的问题之一。PHP中文乱码有时出现在网页本身,有的出现在与MySQL交互的过程中,有时与操作系统有关。下面给出一个摘要。一。首先,PHP网页编码最好最快的方案是页面声明的编码与数据库内部编码一致。如果页面应用的页码与数据库内部编码不一致,设置连接编码,mysql_query(\"SETNAMESXXX\");XXX为连接编码。一定能解决乱七八糟的
如何处理乱码的css网页
css网页乱码的解决方法:1、设置CSS字符编码与页面字符编码一致,设置“@charset”utf-8“;”等编码语句;2、写css评论时加强;3、 采用字体的别名。推荐:《css视频教程》解决方案
响应式网页设计和 SEO
所谓“响应式网页设计(Responsive Web Design)”也是自适应的,是一种能够自动识别屏幕宽度并做出相应调整的网页设计。目前这种设计已经出现在越来越多的国内网站中,谷歌已经明确表示鼓励响应式网页设计。
简化您的网页设计
随着网站构建技术的发展,在网页中实现复杂的功能已经不再困难。网页中的功能越来越多。因此,需要在用户的浏览体验和网页设计的美感之间取得平衡。显得非常重要。
宝安网页设计从SEO角度谈网页设计标准
深圳宝安网页设计从SEO角度谈网页设计标准。在任何时候,网站访问者都处于以下阶段之一: 1. 注意;2、利息;3.欲望;4. 行动;5.满足。在每个阶段,参观者都是不同的
什么是优化网页设计?
由于不同的搜索引擎对网页的支持存在差异,所以在设计网页时,不要只关注外观。许多网页设计中常用的元素都会给搜索引擎带来问题。■框架结构(FrameSets) 有些搜索引擎(如FAST)不支持框架结构,其蜘蛛程序无法读取此类网页。■图像块(我
网页设计对网站推广效果的影响
网页设计是一门深奥的课程,它对网站的推广和营销的影响是毋庸置疑的。无论是网页的布局,网页下载的速度,导航系统的便利性,还是用户的浏览效果,都会直接影响到用户的浏览效果,进而影响状态和形象用户心目中的网站,即网页设计的效果直接影响网站的品牌形象和推广营销效果。下
什么是标签页?如何优化标签页?
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
网页登录成功后php如何实现网页跳转?
网页登录成功后php实现网页跳转的方法:首先打开php编辑器,新建一个php文件;然后在[index.php]中输入代码[header('Location:index.php');];最后浏览服务器运行[login.
php下载中文乱码的解决办法
php下载中文乱码的解决方法:先打开相关代码文件;然后使用“iconv()”函数解决乱码,具体语法为“$file_name=iconv("utf-8","gb2312",$file_name);"。php下载解决中文乱码
网站制作和网页设计/区别/描述/\"
/网页设计:就是让美工做设计的所有页面的界面渲染网站,就像建房子之前,会请一位著名的设计师来设计房子的外观。你用什么软件做网页设计?DreamweaverCS6、烟花、Photoshop等
网页登录成功后如何在php中实现网页跳转
网页登录成功后php实现网页跳转的方法:首先打开编辑器,新建一个php文件;然后输入代码“header('Location:index.php');” 在php文件中;最后在浏览器中运行它,这将跳转到索引时
php网页抓取乱码(怎么自动获取网页的编码格式?的urlopen方法返回一个 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-14 19:02
)
在对爬虫获取的网页进行处理之前,我们需要知道被爬取的网页的编码格式,然后才能正确解码,编码成目标格式保存或者进行后续的文本处理。尤其是在多语言环境中,获取正确的网页编码格式尤为重要。
我们可以手动查看网页源码中meta标签下的content属性,其中charset代表网页的编码格式。所谓爬虫,本质上是一个自动化程序,那么如何自动获取网页的编码格式呢?python的urlopen方法返回一个响应对象,响应的info方法可以返回与url相关的元信息,包括内容格式、长度等信息。如下所示:
貌似只要使用getparam('charset')就可以成功获取到网页编码格式,可惜服务器返回的元信息并不是都收录charset,info中的信息依赖于爬取的url服务器上的爬虫。另外,即使你确定你的爬虫爬取的部分服务器会返回charset信息,也不能保证网页的编码格式一定要和charset一致。因此,最安全的做法是直接探测服务器返回的文本的编码格式。我在这里使用 python 中的 chardet 包。chardet的detect方法可以检测传入字符串的编码格式并给出检测精度。
import urllib2
import chardet
import time
response = urllib2.urlopen('http://www.simmerchan.me/')
content = response.read()
t = time.time()
charset_info = chardet.detect(content)
print charset_info
print charset_info['encoding']
print time.time()-t
{'confidence': 0.99, 'encoding': 'utf-8'}
utf-8
0.468999862671
当获取的网页内容比较大时,使用上述方法检测编码是相当耗时的。一种可能的方法是检测内容片段。
import urllib2
import chardet
import time
response = urllib2.urlopen('http://www.simmerchan.me/')
content = response.read()
t = time.time()
charset_info = chardet.detect(content[:70000])
print charset_info
print charset_info['encoding']
print time.time()-t
{'confidence': 0.99, 'encoding': 'utf-8'}
utf-8
0.114000082016
分片的大小取决于具体的应用场景。在我自己的爬虫项目中,400可以处理大部分的登陆页面。我这里取7000是因为我的网页源码中之前的大部分内容都不收录中文。如果我取 6000,它会被检测为 ascii 码。我也想过取中间段的可能性,比如6000到7000,9000到10000,前者结果是utf-8,准确率是0.99,后者是ISO-8859-2,准确率0.82,事实证明这种方法无效,随机性太大。
获取网页编码格式后,我们可以对网页内容进行解码,然后编码成统一的格式进行处理。
import urllib2
import chardet
import time
response = urllib2.urlopen('http://www.simmerchan.me/')
content = response.read()
t = time.time()
charset = chardet.detect(content[:400])['encoding']
content = content.decode(charset, 'ignore').encode('utf-8')
ignore 参数是忽略那些无法解码成 unicode 的字符。如果不加这个参数,可能会出现类似如下的错误
UnicodeDecodeError: 'gb2312' codec can't decode bytes in position 61399-61400: illegal multibyte sequence 查看全部
php网页抓取乱码(怎么自动获取网页的编码格式?的urlopen方法返回一个
)
在对爬虫获取的网页进行处理之前,我们需要知道被爬取的网页的编码格式,然后才能正确解码,编码成目标格式保存或者进行后续的文本处理。尤其是在多语言环境中,获取正确的网页编码格式尤为重要。
我们可以手动查看网页源码中meta标签下的content属性,其中charset代表网页的编码格式。所谓爬虫,本质上是一个自动化程序,那么如何自动获取网页的编码格式呢?python的urlopen方法返回一个响应对象,响应的info方法可以返回与url相关的元信息,包括内容格式、长度等信息。如下所示:

貌似只要使用getparam('charset')就可以成功获取到网页编码格式,可惜服务器返回的元信息并不是都收录charset,info中的信息依赖于爬取的url服务器上的爬虫。另外,即使你确定你的爬虫爬取的部分服务器会返回charset信息,也不能保证网页的编码格式一定要和charset一致。因此,最安全的做法是直接探测服务器返回的文本的编码格式。我在这里使用 python 中的 chardet 包。chardet的detect方法可以检测传入字符串的编码格式并给出检测精度。
import urllib2
import chardet
import time
response = urllib2.urlopen('http://www.simmerchan.me/')
content = response.read()
t = time.time()
charset_info = chardet.detect(content)
print charset_info
print charset_info['encoding']
print time.time()-t
{'confidence': 0.99, 'encoding': 'utf-8'}
utf-8
0.468999862671
当获取的网页内容比较大时,使用上述方法检测编码是相当耗时的。一种可能的方法是检测内容片段。
import urllib2
import chardet
import time
response = urllib2.urlopen('http://www.simmerchan.me/')
content = response.read()
t = time.time()
charset_info = chardet.detect(content[:70000])
print charset_info
print charset_info['encoding']
print time.time()-t
{'confidence': 0.99, 'encoding': 'utf-8'}
utf-8
0.114000082016
分片的大小取决于具体的应用场景。在我自己的爬虫项目中,400可以处理大部分的登陆页面。我这里取7000是因为我的网页源码中之前的大部分内容都不收录中文。如果我取 6000,它会被检测为 ascii 码。我也想过取中间段的可能性,比如6000到7000,9000到10000,前者结果是utf-8,准确率是0.99,后者是ISO-8859-2,准确率0.82,事实证明这种方法无效,随机性太大。
获取网页编码格式后,我们可以对网页内容进行解码,然后编码成统一的格式进行处理。
import urllib2
import chardet
import time
response = urllib2.urlopen('http://www.simmerchan.me/')
content = response.read()
t = time.time()
charset = chardet.detect(content[:400])['encoding']
content = content.decode(charset, 'ignore').encode('utf-8')
ignore 参数是忽略那些无法解码成 unicode 的字符。如果不加这个参数,可能会出现类似如下的错误
UnicodeDecodeError: 'gb2312' codec can't decode bytes in position 61399-61400: illegal multibyte sequence
php网页抓取乱码(mysq数据库使用的编码字符集(1)_set=utf8)
网站优化 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2022-04-19 16:39
一、
学php的童鞋在写网页的时候,如果设计了中文内容的存储,大部分都会出现乱码的问题。对于一般的乱码,我们可以从三个方面进行检查
(1)网页的编码是否正确,例如是否在header中添加原创标签
(2)检查mysql数据库存储时使用的默认字符集
(3)查看网页文件的编码,是否是对应的中文编码
------------------
环境:win7+wamp2.2
------------------
二、
先从第二点说起,mysq数据库使用的编码字符集
(1)打开mysql终端,查看当前设置,确定要修改的范围
show variables like ‘char%‘;
(2)根据结果分析,
1、如果你显示的结果和我的差不多,也就是(只有character_set_system编码为utf8)那么按照下面的步骤一步步来
2、打开my.ini文件,搜索关键词'mysqld',找到后观察是否有这一行
character_set_server=utf8
如果没有,你应该像我一样在它下面添加一个句子
3、再搜索关键词'client'看看有没有这行
default_character_set=utf8
如果没有,请在 [client] 下添加
4、保存,重启mysql服务,关闭mysql终端(不然你看到的客户端代码不会更新)
5、再次打开终端,我们再次进入
show variables like ‘char%‘;
如果出现如下结果,即mysql数据设置成功
三、
网页文件编码的问题是最容易被忽略的。保存时选择保存文件编码的格式时设置。
解决方案:
1、使用notepad++打开网页文件,然后在“格式”--“转为UTF-8无BOM编码格式”
2、保存就行
问题分析:
1、写php的时候用过
<br />
但是还是有乱码的问题!
分析:使用上面的语句,只修改了三项,三项是
character_set_client
字符集连接
字符集结果
而且这个修改只是暂时的,关闭终端后还是一样。
阐明:
2、我们来分析第三个乱码问题
(1)使用sublime text3编辑打开php文件,左下角可以看到编码信息,可以看到当前编码为gb2312
(2)网页加载的时候,相当于打开了一个文件,那个时候读取的格式是按照gb2312的编码读取网页文件的,当是显示在用户的浏览器中,因为网页声明的字符集是utf-8,所以获取到的文件内容会按照utf-8字符集进行解释,会导致乱码,但是没有问题我们从数据库中读取的内容。
网络编码
原创gbk编码文件
后来的 utf-8 编码文件
(3)注意,sublime text3没有给你转换编码,虽然显示转换成功,但是什么?显示还是一样,还是我们notepad++功能更强大,如何修改上一个! 转换成功后
3、为什么我按照你说的修改了,在mysql终端下显示,还是乱码?
分析:
(1)我们先来看看windows下cmd使用的是什么字符集?
可以看出cmd的字符集是gbk,也就是说终端显示的任何内容都会对应gbk的字符集,但是我们数据库的中文设置的utf8字符集,当我们想要显示出来,自然会使用 utf8 编码读取数据库数据,当编码为 utf-8 时,到了终端就乱了
(2)怎么查?
用phpmyadmin就行了,当然我们要设置我们使用的utf-8编码!
本文来自“Do it and enjoy it”博客,请务必保留此出处 查看全部
php网页抓取乱码(mysq数据库使用的编码字符集(1)_set=utf8)
一、
学php的童鞋在写网页的时候,如果设计了中文内容的存储,大部分都会出现乱码的问题。对于一般的乱码,我们可以从三个方面进行检查
(1)网页的编码是否正确,例如是否在header中添加原创标签
(2)检查mysql数据库存储时使用的默认字符集
(3)查看网页文件的编码,是否是对应的中文编码
------------------
环境:win7+wamp2.2
------------------
二、
先从第二点说起,mysq数据库使用的编码字符集
(1)打开mysql终端,查看当前设置,确定要修改的范围
show variables like ‘char%‘;
(2)根据结果分析,
1、如果你显示的结果和我的差不多,也就是(只有character_set_system编码为utf8)那么按照下面的步骤一步步来
2、打开my.ini文件,搜索关键词'mysqld',找到后观察是否有这一行
character_set_server=utf8
如果没有,你应该像我一样在它下面添加一个句子
3、再搜索关键词'client'看看有没有这行
default_character_set=utf8
如果没有,请在 [client] 下添加
4、保存,重启mysql服务,关闭mysql终端(不然你看到的客户端代码不会更新)
5、再次打开终端,我们再次进入
show variables like ‘char%‘;
如果出现如下结果,即mysql数据设置成功
三、
网页文件编码的问题是最容易被忽略的。保存时选择保存文件编码的格式时设置。
解决方案:
1、使用notepad++打开网页文件,然后在“格式”--“转为UTF-8无BOM编码格式”
2、保存就行
问题分析:
1、写php的时候用过
<br />
但是还是有乱码的问题!
分析:使用上面的语句,只修改了三项,三项是
character_set_client
字符集连接
字符集结果
而且这个修改只是暂时的,关闭终端后还是一样。
阐明:
2、我们来分析第三个乱码问题
(1)使用sublime text3编辑打开php文件,左下角可以看到编码信息,可以看到当前编码为gb2312
(2)网页加载的时候,相当于打开了一个文件,那个时候读取的格式是按照gb2312的编码读取网页文件的,当是显示在用户的浏览器中,因为网页声明的字符集是utf-8,所以获取到的文件内容会按照utf-8字符集进行解释,会导致乱码,但是没有问题我们从数据库中读取的内容。
网络编码
原创gbk编码文件
后来的 utf-8 编码文件
(3)注意,sublime text3没有给你转换编码,虽然显示转换成功,但是什么?显示还是一样,还是我们notepad++功能更强大,如何修改上一个! 转换成功后
3、为什么我按照你说的修改了,在mysql终端下显示,还是乱码?
分析:
(1)我们先来看看windows下cmd使用的是什么字符集?
可以看出cmd的字符集是gbk,也就是说终端显示的任何内容都会对应gbk的字符集,但是我们数据库的中文设置的utf8字符集,当我们想要显示出来,自然会使用 utf8 编码读取数据库数据,当编码为 utf-8 时,到了终端就乱了
(2)怎么查?
用phpmyadmin就行了,当然我们要设置我们使用的utf-8编码!
本文来自“Do it and enjoy it”博客,请务必保留此出处
php网页抓取乱码(php网页抓取乱码、失败抓取的原因及解决方法。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-17 09:56
php网页抓取乱码、失败抓取的原因及解决方法。从三个方面入手进行分析,网页中乱码原因和抓取失败原因,并给出解决方案。根据不同网站抓取方法不同。有时候是网站蜘蛛抓取存在问题,有时候是抓取时设置有问题,在网页中正常代码,但是还是会出现乱码等问题,
1、不同于自动编码格式乱码,网页中经常会出现特殊字符。举个例子,当网页中乱码表示中文和带有颜色的png,那么抓取的时候就会出现乱码,请不要纠结一串位数的问题,或者一个大小写问题。
2、所需要爬取的网页链接,有很多下拉框中会出现相同的词语,那么在爬取时会出现定位问题,导致抓取失败。
原因分析针对第一种原因,
1、网页中user-agent或者spider网络请求错误,爬取代码错误或带有post请求码等。
2、这个就涉及到比较专业的爬虫分析类工具,爬虫分析类工具在编程之初就应该开始设置代理ip,然后配置爬虫代理池,spider只接受带有ip验证码的请求。
针对第二种原因,再编写抓取代码之前应该先判断是不是网页正常,是正常就把定位post请求请求码对应的user-agent或者spider等代理ip,
1、迅雷代理ip(每天自动抢红包,满1000就抢,
2、游客代理ip(游客只能访问自己局域网,
3、xx服务器代理(每日任务从中收取月租)我们常用这几种代理,由于xx服务器代理是各个代理都有,所以数量会很多,我们把它写在脚本里面。数据抓取抓取有两种网页内容形式,一种是动态,一种是静态,这里只分析静态内容。
动态内容抓取请抓取下面该图片的网页内容获取来源,
1、判断该图片网页是静态网页还是动态网页,再判断请求参数,不同的请求参数获取的图片不同,3个不同请求参数,
2、将图片字幕放到循环里面。设置代理池图片参数:每张图片会获取n次,将最后一次获取的图片的统计就是字幕大小不同的频率,然后对比字幕大小即可。图片大小一般为{50:100:1000}这样的方式。获取字幕地址参数xxxx对应mp4,对应xxxx是代理ip地址,再download就可以下载。
解决方案:有时候网页中乱码问题不能得到解决,像经常在微信表情包内容中出现这样的乱码,对此很头疼,
1、请求参数用的是动态请求
2、程序构架设计的bug,这种情况常见于处理网页关键url而不是其他关键组件,这样只需要针对缓存问题处理即可。 查看全部
php网页抓取乱码(php网页抓取乱码、失败抓取的原因及解决方法。)
php网页抓取乱码、失败抓取的原因及解决方法。从三个方面入手进行分析,网页中乱码原因和抓取失败原因,并给出解决方案。根据不同网站抓取方法不同。有时候是网站蜘蛛抓取存在问题,有时候是抓取时设置有问题,在网页中正常代码,但是还是会出现乱码等问题,
1、不同于自动编码格式乱码,网页中经常会出现特殊字符。举个例子,当网页中乱码表示中文和带有颜色的png,那么抓取的时候就会出现乱码,请不要纠结一串位数的问题,或者一个大小写问题。
2、所需要爬取的网页链接,有很多下拉框中会出现相同的词语,那么在爬取时会出现定位问题,导致抓取失败。
原因分析针对第一种原因,
1、网页中user-agent或者spider网络请求错误,爬取代码错误或带有post请求码等。
2、这个就涉及到比较专业的爬虫分析类工具,爬虫分析类工具在编程之初就应该开始设置代理ip,然后配置爬虫代理池,spider只接受带有ip验证码的请求。
针对第二种原因,再编写抓取代码之前应该先判断是不是网页正常,是正常就把定位post请求请求码对应的user-agent或者spider等代理ip,
1、迅雷代理ip(每天自动抢红包,满1000就抢,
2、游客代理ip(游客只能访问自己局域网,
3、xx服务器代理(每日任务从中收取月租)我们常用这几种代理,由于xx服务器代理是各个代理都有,所以数量会很多,我们把它写在脚本里面。数据抓取抓取有两种网页内容形式,一种是动态,一种是静态,这里只分析静态内容。
动态内容抓取请抓取下面该图片的网页内容获取来源,
1、判断该图片网页是静态网页还是动态网页,再判断请求参数,不同的请求参数获取的图片不同,3个不同请求参数,
2、将图片字幕放到循环里面。设置代理池图片参数:每张图片会获取n次,将最后一次获取的图片的统计就是字幕大小不同的频率,然后对比字幕大小即可。图片大小一般为{50:100:1000}这样的方式。获取字幕地址参数xxxx对应mp4,对应xxxx是代理ip地址,再download就可以下载。
解决方案:有时候网页中乱码问题不能得到解决,像经常在微信表情包内容中出现这样的乱码,对此很头疼,
1、请求参数用的是动态请求
2、程序构架设计的bug,这种情况常见于处理网页关键url而不是其他关键组件,这样只需要针对缓存问题处理即可。
php网页抓取乱码(从前端页面到后端数据库我一共用到了三个文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-17 08:20
从前端页面到后端数据库,我共享了三个文件:index.html、script.js、index.php。三个文件的统一编码格式是GB2312,但是当inde.html页面的数据通过$.post()提交给index.php时,中文字符会出现乱码。通过查资料得知,在使用ajax post时,浏览器默认使用utf-8编码,页面编码统一为utf-8。也就是说我的gb2312页面提交给php的汉字是转成utf-8格式的,所以需要在php中再次转码。
script.js 中代码的 $.post() 部分:
$.post('index.php?a=insert',submitData,
function(data) {
if(data==1){
$(".black").show();
}
if(data==2) {
alert("请重新提交!")
}
},
"json")
将接收到的数据转换成index.php中的编码格式:
通过转码,不会出现乱码。以上只是我遇到的问题的一种解决方法,还有一些其他的方法供大家参考。
参考: 查看全部
php网页抓取乱码(从前端页面到后端数据库我一共用到了三个文件)
从前端页面到后端数据库,我共享了三个文件:index.html、script.js、index.php。三个文件的统一编码格式是GB2312,但是当inde.html页面的数据通过$.post()提交给index.php时,中文字符会出现乱码。通过查资料得知,在使用ajax post时,浏览器默认使用utf-8编码,页面编码统一为utf-8。也就是说我的gb2312页面提交给php的汉字是转成utf-8格式的,所以需要在php中再次转码。
script.js 中代码的 $.post() 部分:
$.post('index.php?a=insert',submitData,
function(data) {
if(data==1){
$(".black").show();
}
if(data==2) {
alert("请重新提交!")
}
},
"json")
将接收到的数据转换成index.php中的编码格式:
通过转码,不会出现乱码。以上只是我遇到的问题的一种解决方法,还有一些其他的方法供大家参考。
参考:
php网页抓取乱码(php网页抓取乱码、cookie混乱、php下存数据、include路径乱码中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-04-16 09:03
php网页抓取乱码、cookie混乱、php下存数据、include路径乱码中,随着php框架的不断的升级,这些问题也越来越明显。但是php框架向来是先开源,然后不断的被自己的用户购买,源码分析。中间这样说就是怕大家反过来把源码买下来,然后重写一个开源的php框架来完善自己。apache+nginx作为服务器,你又使用动态语言php来和nginx,反向代理apache相交互。
既然有apache/nginx那个就存在进程/线程间的依赖,这些依赖就是线程之间的关系:<p>.php</p>这样一种依赖关系,然后为了保证并发性就是使用了集合。
.php从一定程度上保证了for循环,遍历遍历之类的问题。而
.nginx则是一个单机,或者是负载均衡,线程池之类的,线程安全是个问题。而且任何一个框架的不断升级,例如ror框架,服务器端都开始不断进行系统升级,无法得到完善的进程/线程关系。使用分布式,分布式请求模块等等机制来解决这个问题。</p>
因为php是纯净的命令行语言,没有pythonphp这些复杂的框架与apachenginx这些容器区别,
php确实如楼上说的,内嵌在apache中,但是,php其实是一种特殊的语言,他的源代码是httpd(nginx)代码,所以, 查看全部
php网页抓取乱码(php网页抓取乱码、cookie混乱、php下存数据、include路径乱码中)
php网页抓取乱码、cookie混乱、php下存数据、include路径乱码中,随着php框架的不断的升级,这些问题也越来越明显。但是php框架向来是先开源,然后不断的被自己的用户购买,源码分析。中间这样说就是怕大家反过来把源码买下来,然后重写一个开源的php框架来完善自己。apache+nginx作为服务器,你又使用动态语言php来和nginx,反向代理apache相交互。
既然有apache/nginx那个就存在进程/线程间的依赖,这些依赖就是线程之间的关系:<p>.php</p>这样一种依赖关系,然后为了保证并发性就是使用了集合。
.php从一定程度上保证了for循环,遍历遍历之类的问题。而
.nginx则是一个单机,或者是负载均衡,线程池之类的,线程安全是个问题。而且任何一个框架的不断升级,例如ror框架,服务器端都开始不断进行系统升级,无法得到完善的进程/线程关系。使用分布式,分布式请求模块等等机制来解决这个问题。</p>
因为php是纯净的命令行语言,没有pythonphp这些复杂的框架与apachenginx这些容器区别,
php确实如楼上说的,内嵌在apache中,但是,php其实是一种特殊的语言,他的源代码是httpd(nginx)代码,所以,
php网页抓取乱码(Linux程序不会乱码的根源是什么?如何使程序初始化乱码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-04-09 13:30
乱码的来源:将源代码文件(源字符集)编译/链接生成可执行文件(执行字符集),最后程序在实际环境中运行(运行环境编码)。在此过程中,如果出现字符集不匹配的情况,最终无法显示预期的文本信息,甚至会产生乱码。
综上所述,为了让程序不乱码,必须满足:
代码相关
一般为了在程序中支持国际化,在程序初始化时,将locale设置为系统配置的Native ANSI字符集,即执行:setlocale(LC_ALL, "")。
可以查看文件编码格式:
:file main.cc
main.cc: C++ source text, UTF-8 Unicode text
GCC的源字符集和执行字符集默认都是UTF-8编码的,也就是说GCC默认按照UTF-8解析源代码,编译后的执行字符集也是UTF-8。当然 GCC 也提供了编译选项来改变默认值:
-finput-charset=charset 用于指定源码字符集
-fexec-charset=charset 用于指定执行字符集
另一个参数是:
默认情况下,在 Windows 平台的 gcc 下,宽字符串常量的每个字符都是 16 位 UTF-16 类型。在 Linux 平台上,宽字符串常量的每个字符都是 32 位 UTF-32 类型。-fwide-exec-charset=charset 这个参数可以改变宽字符串常量的类型。比如在x86机器环境下,在Linux操作系统下,要将诸如L“汉字”编译保存为UTF-16字符串,可以使用-fwide-exec-charset=UTF-16LE。
控制台查看代码:
:locale
LANG="zh_CN.UTF-8"
LC_COLLATE="zh_CN.UTF-8"
LC_CTYPE="zh_CN.UTF-8"
LC_MESSAGES="zh_CN.UTF-8"
LC_MONETARY="zh_CN.UTF-8"
LC_NUMERIC="zh_CN.UTF-8"
LC_TIME="zh_CN.UTF-8"
LC_ALL=
参考 查看全部
php网页抓取乱码(Linux程序不会乱码的根源是什么?如何使程序初始化乱码)
乱码的来源:将源代码文件(源字符集)编译/链接生成可执行文件(执行字符集),最后程序在实际环境中运行(运行环境编码)。在此过程中,如果出现字符集不匹配的情况,最终无法显示预期的文本信息,甚至会产生乱码。
综上所述,为了让程序不乱码,必须满足:
代码相关
一般为了在程序中支持国际化,在程序初始化时,将locale设置为系统配置的Native ANSI字符集,即执行:setlocale(LC_ALL, "")。
可以查看文件编码格式:
:file main.cc
main.cc: C++ source text, UTF-8 Unicode text
GCC的源字符集和执行字符集默认都是UTF-8编码的,也就是说GCC默认按照UTF-8解析源代码,编译后的执行字符集也是UTF-8。当然 GCC 也提供了编译选项来改变默认值:
-finput-charset=charset 用于指定源码字符集
-fexec-charset=charset 用于指定执行字符集
另一个参数是:
默认情况下,在 Windows 平台的 gcc 下,宽字符串常量的每个字符都是 16 位 UTF-16 类型。在 Linux 平台上,宽字符串常量的每个字符都是 32 位 UTF-32 类型。-fwide-exec-charset=charset 这个参数可以改变宽字符串常量的类型。比如在x86机器环境下,在Linux操作系统下,要将诸如L“汉字”编译保存为UTF-16字符串,可以使用-fwide-exec-charset=UTF-16LE。
控制台查看代码:
:locale
LANG="zh_CN.UTF-8"
LC_COLLATE="zh_CN.UTF-8"
LC_CTYPE="zh_CN.UTF-8"
LC_MESSAGES="zh_CN.UTF-8"
LC_MONETARY="zh_CN.UTF-8"
LC_NUMERIC="zh_CN.UTF-8"
LC_TIME="zh_CN.UTF-8"
LC_ALL=
参考
php网页抓取乱码(php网页抓取乱码问题解决方法技术限制,内测pep2056)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-04-09 13:04
php网页抓取乱码问题解决方法技术限制,对于一些新标准没有及时更新,例如php5,php7开始就有了pep2052,现在正在内测pep2056。官方文档讲的是使用cookie实现的网页抓取,使用客户端脚本包进行操作cookie存储目标网页的locale(php中,可以为none,也可以为php_parse_cookie,实际上cookie还有很多,包括php_base64等等),当网页抓取完成之后,使用nginx完成forward,从cookie中读取locale值,返回给网页抓取者。
网页抓取过程中,由于客户端脚本在客户端执行,客户端当前所能接收到的cookie为当前的php网页版本和cookienamecookiename也可以为php_url_locale。在抓取过程中如果发生cookie值传递错误,可以通过指定cookiename的方式进行传递。项目原理,由于目前phpsdk依然未实现对php_parse_cookie的支持,我们只能通过extensionname的方式进行抓取,如果客户端不支持,只能使用chromesafari开发者工具抓取。
项目源码可以从公众号下载:-2csr3joaucsbrd6wdg提取码:lpr9php网页抓取乱码问题解决方法php中使用了cookie存储目标网页的locale信息。假如一个网页已经包含locale属性,则服务器对于该locale的读取逻辑是这样的:首先获取目标网页所有的locale的值,我们简称为extended,将extended存入extended_cookie_blocked_tags中,即表示这个网页加载时这个extended的内容是被存储在这个blocked_tag中的。
为了去除这些内容,我们需要把extended_cookie_blocked_tags取出来,作为cookie解析的输入,其中extended_cookie_blocked_tags是写入在php内置数据结构中,即{"extended":"false","cookie_length":null,"cache_write_first":null,"cls_check":true,"flags":[]}。
解析nginx进程返回的locale值,并且更新extended_cookie_blocked_tags中的locale值。这些需要通过上面提到的脚本来执行。相对于c\c++\java等编程语言,php的php_parse_cookie可以很好地处理这些问题。php内置数据结构有多种实现,这里我们使用自定义的flags数组的方式。
整个流程如下:整体思路的思维导图php优点php优点是解决了以下2个问题:一个cookie要存到locale中。二是cookie可以有多份。如果一个cookie被多次请求,可以提高代码可扩展性,但也需要对locale层设计有所约束。简单地说,php对于你选择不对请求作出任何更改。再往深一点,如果你执行ajax请求时有多次加载要继续加载token值是一个常见的需求。也就。 查看全部
php网页抓取乱码(php网页抓取乱码问题解决方法技术限制,内测pep2056)
php网页抓取乱码问题解决方法技术限制,对于一些新标准没有及时更新,例如php5,php7开始就有了pep2052,现在正在内测pep2056。官方文档讲的是使用cookie实现的网页抓取,使用客户端脚本包进行操作cookie存储目标网页的locale(php中,可以为none,也可以为php_parse_cookie,实际上cookie还有很多,包括php_base64等等),当网页抓取完成之后,使用nginx完成forward,从cookie中读取locale值,返回给网页抓取者。
网页抓取过程中,由于客户端脚本在客户端执行,客户端当前所能接收到的cookie为当前的php网页版本和cookienamecookiename也可以为php_url_locale。在抓取过程中如果发生cookie值传递错误,可以通过指定cookiename的方式进行传递。项目原理,由于目前phpsdk依然未实现对php_parse_cookie的支持,我们只能通过extensionname的方式进行抓取,如果客户端不支持,只能使用chromesafari开发者工具抓取。
项目源码可以从公众号下载:-2csr3joaucsbrd6wdg提取码:lpr9php网页抓取乱码问题解决方法php中使用了cookie存储目标网页的locale信息。假如一个网页已经包含locale属性,则服务器对于该locale的读取逻辑是这样的:首先获取目标网页所有的locale的值,我们简称为extended,将extended存入extended_cookie_blocked_tags中,即表示这个网页加载时这个extended的内容是被存储在这个blocked_tag中的。
为了去除这些内容,我们需要把extended_cookie_blocked_tags取出来,作为cookie解析的输入,其中extended_cookie_blocked_tags是写入在php内置数据结构中,即{"extended":"false","cookie_length":null,"cache_write_first":null,"cls_check":true,"flags":[]}。
解析nginx进程返回的locale值,并且更新extended_cookie_blocked_tags中的locale值。这些需要通过上面提到的脚本来执行。相对于c\c++\java等编程语言,php的php_parse_cookie可以很好地处理这些问题。php内置数据结构有多种实现,这里我们使用自定义的flags数组的方式。
整个流程如下:整体思路的思维导图php优点php优点是解决了以下2个问题:一个cookie要存到locale中。二是cookie可以有多份。如果一个cookie被多次请求,可以提高代码可扩展性,但也需要对locale层设计有所约束。简单地说,php对于你选择不对请求作出任何更改。再往深一点,如果你执行ajax请求时有多次加载要继续加载token值是一个常见的需求。也就。
php网页抓取乱码(关于从数据库中查询出的字符串显示在网页上是乱码的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-08 02:18
关于从数据库中查询到的字符串在网页上显示为乱码的问题
MYSQL数据库,从里面查到的数据用echo输出到网页时出现乱码,奇怪的是只有一处乱码,其他地方显示正常。
$sql="从 pw_members 中选择用户名,其中 uid=?";
$result=$handler->exeSql($sql,array($winduid),"select");
如果($结果){
回声'
'.$result["username"].'
'}别的{
回声'
未知的用户名
';
}
这是代码,然后页面以
数据库信息为:
服务器字符集:utf8
数据库字符集:utf8
客户端字符集:utf8
连接字符集:utf8
字段信息:
字段:用户名
类型:varchar(18)
不是所有文字都乱码,只有这个地方乱码,请解释~~
- - - 解决方案 - - - - - - - - - -
未知用户名相信你可以看到这不是乱码
你的数据库是 utf-8 存储的,但是前端显示的 HTML 是用 GBK 编码的。当然,有些部分总是乱码。
您可以将 $result["username"] 转码为 GBK。
$result["username"] = iconv('UTF-8', 'GBK', $result["username"]);
或将您的 .php 或 .html 文件另存为 utf-8
- - - 解决方案 - - - - - - - - - -
数据库编码全部为 UTF-8。您可以将页面编码和文件编码设置为UTF-8,以节省麻烦。为什么需要来回走动?
另外,在获取数据库数据之前指定数据编码
SET NAMES('UTF8');//gbk 查看全部
php网页抓取乱码(关于从数据库中查询出的字符串显示在网页上是乱码的问题)
关于从数据库中查询到的字符串在网页上显示为乱码的问题
MYSQL数据库,从里面查到的数据用echo输出到网页时出现乱码,奇怪的是只有一处乱码,其他地方显示正常。
$sql="从 pw_members 中选择用户名,其中 uid=?";
$result=$handler->exeSql($sql,array($winduid),"select");
如果($结果){
回声'
'.$result["username"].'
'}别的{
回声'
未知的用户名
';
}
这是代码,然后页面以
数据库信息为:
服务器字符集:utf8
数据库字符集:utf8
客户端字符集:utf8
连接字符集:utf8
字段信息:
字段:用户名
类型:varchar(18)
不是所有文字都乱码,只有这个地方乱码,请解释~~
- - - 解决方案 - - - - - - - - - -
未知用户名相信你可以看到这不是乱码
你的数据库是 utf-8 存储的,但是前端显示的 HTML 是用 GBK 编码的。当然,有些部分总是乱码。
您可以将 $result["username"] 转码为 GBK。
$result["username"] = iconv('UTF-8', 'GBK', $result["username"]);
或将您的 .php 或 .html 文件另存为 utf-8
- - - 解决方案 - - - - - - - - - -
数据库编码全部为 UTF-8。您可以将页面编码和文件编码设置为UTF-8,以节省麻烦。为什么需要来回走动?
另外,在获取数据库数据之前指定数据编码
SET NAMES('UTF8');//gbk
php网页抓取乱码(七牛云抓取乱码工具_金柚子php网页抓取查杀工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-07 12:06
php网页抓取乱码查杀工具php网页抓取乱码查杀工具_phpspider工具_金柚子php网页抓取乱码查杀工具_phpspider工具_金柚子使用地址:
可以尝试下七牛云
web网页抓取没有必要学习爬虫,可以从scrapy入手,
还在用比较老的scrapy
七牛云,超级大牛开发的,
吾爱破解,
网页解析工具阿里云的webspider.
phpspy,专门针对php的网页解析,并且免费,而且在国内来说,下载量还很高,谁用谁知道。
低阶版本超级好用。
目前抓取率最高的nodejs抓包工具,是src3145开发的,支持数百种浏览器,src3145github:src3145/node-spider。yzc/node-spider。yzc。js如果要用c++的话,推荐grep-input或者org。apache。ibatis。io。production。php。request。
tp
找个人上传工具,
如果是用phper一定要买一个seaagephpcoderapp会提供很好的服务。十分便宜,用了好几年。不会有任何延迟。
易语言,感觉超爽,
国内有光明日报的,国外比较不知道。
七牛云
推荐一个interface100
链家网可以抓,不过是和链家网合作的。
我们是想爬那边的数据。 查看全部
php网页抓取乱码(七牛云抓取乱码工具_金柚子php网页抓取查杀工具)
php网页抓取乱码查杀工具php网页抓取乱码查杀工具_phpspider工具_金柚子php网页抓取乱码查杀工具_phpspider工具_金柚子使用地址:
可以尝试下七牛云
web网页抓取没有必要学习爬虫,可以从scrapy入手,
还在用比较老的scrapy
七牛云,超级大牛开发的,
吾爱破解,
网页解析工具阿里云的webspider.
phpspy,专门针对php的网页解析,并且免费,而且在国内来说,下载量还很高,谁用谁知道。
低阶版本超级好用。
目前抓取率最高的nodejs抓包工具,是src3145开发的,支持数百种浏览器,src3145github:src3145/node-spider。yzc/node-spider。yzc。js如果要用c++的话,推荐grep-input或者org。apache。ibatis。io。production。php。request。
tp
找个人上传工具,
如果是用phper一定要买一个seaagephpcoderapp会提供很好的服务。十分便宜,用了好几年。不会有任何延迟。
易语言,感觉超爽,
国内有光明日报的,国外比较不知道。
七牛云
推荐一个interface100
链家网可以抓,不过是和链家网合作的。
我们是想爬那边的数据。
php网页抓取乱码(PHP中文乱码现像发生在网页本身的有些产生在于MYSQL)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-04-06 08:03
前言
PHP中的中文乱码是PHP开发中常见的问题之一。中文乱码有时出现在网页本身,有的出现在MYSQL交互过程中,有时与操作系统有关。以下是一个总结。
一、 PHP 网页的编码
最好最快的解决方案是使页面上声明的代码与数据库内部的代码保持一致。如果页面申请的代码与数据库内部的代码不一致,设置连接代码。Mysql_query("设置名称***").
1、 php文件本身的编码应该和网页的编码相匹配。如果你想使用gb2312编码,那么php应该输出header
header("内容类型:text/html;charset=gb2312")
添加静态页面
, 所有文件的编码格式都是ANSI,可以用记事本打开,另存为选择的编码为ANSI,覆盖源文件。
2、 如果你想使用uft-8编码,那么php应该输出header
header("内容类型: text/html; charset=utf-8"),
添加静态页面
, 所有文件的编码格式都是utf-8. 保存为utf-8可能有点麻烦。一般utf-8开头会有BOM。如果使用Session,会有问题,可以使用editplus软件保存。在本软件中,选择Tools→Preferences→File→UTF-8 Signature,选择Always Delete,然后保存即可删除BOM信息。
3、PHP本身不是Unicode,substr等所有函数都必须改成mb_substr(需要安装mbstring扩展);或使用 iconv 进行转码。
在需要做数据库操作的PHP程序前加上mysql_query("set names encoding"),编码和PHP编码一样,如果PHP编码是gb2312,那么mysql编码是gb2312,如果是uft-8 ,那么mysql就是utf8.这样改后就不会出现乱码了。 查看全部
php网页抓取乱码(PHP中文乱码现像发生在网页本身的有些产生在于MYSQL)
前言
PHP中的中文乱码是PHP开发中常见的问题之一。中文乱码有时出现在网页本身,有的出现在MYSQL交互过程中,有时与操作系统有关。以下是一个总结。
一、 PHP 网页的编码
最好最快的解决方案是使页面上声明的代码与数据库内部的代码保持一致。如果页面申请的代码与数据库内部的代码不一致,设置连接代码。Mysql_query("设置名称***").
1、 php文件本身的编码应该和网页的编码相匹配。如果你想使用gb2312编码,那么php应该输出header
header("内容类型:text/html;charset=gb2312")
添加静态页面
, 所有文件的编码格式都是ANSI,可以用记事本打开,另存为选择的编码为ANSI,覆盖源文件。
2、 如果你想使用uft-8编码,那么php应该输出header
header("内容类型: text/html; charset=utf-8"),
添加静态页面
, 所有文件的编码格式都是utf-8. 保存为utf-8可能有点麻烦。一般utf-8开头会有BOM。如果使用Session,会有问题,可以使用editplus软件保存。在本软件中,选择Tools→Preferences→File→UTF-8 Signature,选择Always Delete,然后保存即可删除BOM信息。
3、PHP本身不是Unicode,substr等所有函数都必须改成mb_substr(需要安装mbstring扩展);或使用 iconv 进行转码。
在需要做数据库操作的PHP程序前加上mysql_query("set names encoding"),编码和PHP编码一样,如果PHP编码是gb2312,那么mysql编码是gb2312,如果是uft-8 ,那么mysql就是utf8.这样改后就不会出现乱码了。
php网页抓取乱码(php虚拟主机乱码的解决办法因素有哪些?如何解决乱码问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-06 07:28
html代码乱码的解决方法:1、定义网页的显示代码,如“”;2、设置网页存储码为utf8。
本文运行环境:Windows7系统,HTML5版本,戴尔G3电脑。
如何解决HTML页面中出现乱码的中文显示
第一:定义网页显示代码。如果没有定义网页代码,那么当我们浏览网页时,IE会自动识别网页代码,可能会导致中文显示乱码。所以我们在做网页的时候,会用“”来定义网页代码。(我们常见的 Unicode 编码是 utf-8)
将文件保存为utf-8编码,模仿上面的位置,在页面中添加中间行代码,如果还有乱码,把utf-8改成gbk
二:网页存储编码。这个问题经常被忽视。让我使用 Dreamweaver,这是构建网站的常用工具。当我们使用 DW 创建一个新的默认编码并保存时,它会以两种编码 uft8 格式或 gbk 格式保存。这可以在 Dreamweaver->Edit->Preferences->New Document 中设置。如果设置了默认的utf8格式,那么网页存储码就是utf8,使用的网页显示码也是utf8,如果不一致会导致乱码。我是这样解释的,我不知道它是否解释了问题。
也就是说,当我们遇到乱码问题时,是由于编码不一致造成的。这是对html页面乱码情况的总结。我们从一个例子中得出推论。当我们在使用php虚拟主机建站时遇到乱码问题,也需要考虑三个因素来解决问题。我总结的三个因素:网页显示编码、网页存储编码、数据库编码网站当汉字显示乱码时,请先从这三个方向考虑并解决问题,会得到双倍的结果事半功倍。
【推荐学习:html视频教程】
以上就是如何处理乱码html代码的详细内容。更多详情请关注php中文网文章其他相关话题! 查看全部
php网页抓取乱码(php虚拟主机乱码的解决办法因素有哪些?如何解决乱码问题)
html代码乱码的解决方法:1、定义网页的显示代码,如“”;2、设置网页存储码为utf8。
本文运行环境:Windows7系统,HTML5版本,戴尔G3电脑。
如何解决HTML页面中出现乱码的中文显示
第一:定义网页显示代码。如果没有定义网页代码,那么当我们浏览网页时,IE会自动识别网页代码,可能会导致中文显示乱码。所以我们在做网页的时候,会用“”来定义网页代码。(我们常见的 Unicode 编码是 utf-8)
将文件保存为utf-8编码,模仿上面的位置,在页面中添加中间行代码,如果还有乱码,把utf-8改成gbk
二:网页存储编码。这个问题经常被忽视。让我使用 Dreamweaver,这是构建网站的常用工具。当我们使用 DW 创建一个新的默认编码并保存时,它会以两种编码 uft8 格式或 gbk 格式保存。这可以在 Dreamweaver->Edit->Preferences->New Document 中设置。如果设置了默认的utf8格式,那么网页存储码就是utf8,使用的网页显示码也是utf8,如果不一致会导致乱码。我是这样解释的,我不知道它是否解释了问题。
也就是说,当我们遇到乱码问题时,是由于编码不一致造成的。这是对html页面乱码情况的总结。我们从一个例子中得出推论。当我们在使用php虚拟主机建站时遇到乱码问题,也需要考虑三个因素来解决问题。我总结的三个因素:网页显示编码、网页存储编码、数据库编码网站当汉字显示乱码时,请先从这三个方向考虑并解决问题,会得到双倍的结果事半功倍。
【推荐学习:html视频教程】
以上就是如何处理乱码html代码的详细内容。更多详情请关注php中文网文章其他相关话题!
php网页抓取乱码(python2抓取网页的内容显示出来是怎么回事?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-04-03 16:01
)
使用python2爬取网页时,经常会遇到抓取到的内容显示为乱码的情况。
这种情况最大的可能是编码问题:运行环境的字符编码和网页的字符编码不一致。
例如,在 Windows 控制台 (gbk) 中获取一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓取一个gbk编码的网站(utf-8)。因为大部分网站使用utf-8编码,而且很多人使用windows,都是很常见。
如果你发现你抓取的内容在英文、数字、符号上看起来都正确,但是中间有一些乱码,你基本上可以断定是这样的。
这个问题的解决方法是先将结果按照网页的编码方式解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site")
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数用于忽略无法解码的字符。
但是,这种方法并不总是有效。另一种方式是通过正则表达式直接匹配网页代码中的编码设置:
除了编码问题导致的乱码之外,另一个经常被忽视的情况是目标页面启用了 gzip 压缩。压缩网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的头部信息自动解压。但是直接用代码抓取不会。因此,很可能会产生困惑,为什么打开网页地址是对的,但程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现是,几乎所有的抓取内容都是乱码,甚至无法显示。
要确定网页是否启用了压缩并解压缩,请使用以下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site")
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们的课堂编程示例查看天气系列(点击查看)中,这两个问题困扰了不少人。这里有一个特殊的解释。
最后,还有一个“武器”要介绍。如果你一开始使用它,你甚至都不知道存在上述两个问题。
这是请求模块。
与爬网类似,只需:
import requests
print requests.get("http://some.web.site").text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考之前的文章:
如何为 Python 安装第三方模块 - Crossin 的编程课堂 - 知乎专栏
pip install requests
其他 文章 和答案:
你是如何自学 Python 的?- 克罗辛的回答
学习编程的过程中可能会走哪些弯路,有哪些经验可以参考?- 克罗辛的回答
初学者如何使用搜索引擎 - Crossin 的 文章 - 知乎 专栏
如何直观的了解程序的运行过程?- Crossin 的 文章 - 知乎 专栏
如何在一台电脑上使用 Python 2 和 Python 3 - Crossin 的编程课堂 - 知乎专栏
Crossin 的编程教室
微信ID:crossincode
论坛:Crossin 的编程教室
QQ群:498545096
查看全部
php网页抓取乱码(python2抓取网页的内容显示出来是怎么回事?(图)
)
使用python2爬取网页时,经常会遇到抓取到的内容显示为乱码的情况。
这种情况最大的可能是编码问题:运行环境的字符编码和网页的字符编码不一致。
例如,在 Windows 控制台 (gbk) 中获取一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓取一个gbk编码的网站(utf-8)。因为大部分网站使用utf-8编码,而且很多人使用windows,都是很常见。
如果你发现你抓取的内容在英文、数字、符号上看起来都正确,但是中间有一些乱码,你基本上可以断定是这样的。
这个问题的解决方法是先将结果按照网页的编码方式解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site";)
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数用于忽略无法解码的字符。
但是,这种方法并不总是有效。另一种方式是通过正则表达式直接匹配网页代码中的编码设置:
除了编码问题导致的乱码之外,另一个经常被忽视的情况是目标页面启用了 gzip 压缩。压缩网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的头部信息自动解压。但是直接用代码抓取不会。因此,很可能会产生困惑,为什么打开网页地址是对的,但程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现是,几乎所有的抓取内容都是乱码,甚至无法显示。
要确定网页是否启用了压缩并解压缩,请使用以下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site";)
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们的课堂编程示例查看天气系列(点击查看)中,这两个问题困扰了不少人。这里有一个特殊的解释。
最后,还有一个“武器”要介绍。如果你一开始使用它,你甚至都不知道存在上述两个问题。
这是请求模块。
与爬网类似,只需:
import requests
print requests.get("http://some.web.site";).text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考之前的文章:
如何为 Python 安装第三方模块 - Crossin 的编程课堂 - 知乎专栏
pip install requests
其他 文章 和答案:
你是如何自学 Python 的?- 克罗辛的回答
学习编程的过程中可能会走哪些弯路,有哪些经验可以参考?- 克罗辛的回答
初学者如何使用搜索引擎 - Crossin 的 文章 - 知乎 专栏
如何直观的了解程序的运行过程?- Crossin 的 文章 - 知乎 专栏
如何在一台电脑上使用 Python 2 和 Python 3 - Crossin 的编程课堂 - 知乎专栏
Crossin 的编程教室
微信ID:crossincode
论坛:Crossin 的编程教室
QQ群:498545096
php网页抓取乱码(php网页抓取乱码原因:curl是丧心病狂之源)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-04-01 17:08
php网页抓取乱码原因:
1、curl是万恶之源
2、你配置非常不合理
3、curl是丧心病狂之源php正则表达式5个坑:
1、正则表达式是加拿大全国牛逼大学非常关注的课程,
2、学会正则表达式可以走遍天下不怕文盲;
3、只要你不是在做需要过多的网页的时候,
4、正则表达式内部可以转义,从而让你看不懂其他的回车,或者replace,
5、学会正则表达式,
1)什么是正则表达式?正则表达式(regularexpression),或称为正则,是通过匹配字符串中的某些特定部分获得字符串所指示的数据的一种表达式。它作为一种广泛使用的文本编辑语言的程序设计语言,正则表达式能够帮助程序员进行文本处理。
2)正则表达式中的注释符号:'[/]';以及'^/'表示字符串中包含了子字符串或者括号之中使用逗号分隔。
3)正则表达式的主要语法结构:符号、表达式及字符串等;表达式即一个预定义的语法规则;正则表达式由大括号{}(或者s代表各种可以包含正则表达式元素的内置程序结构,如?、$、)等标识符定义;正则表达式由小括号表示非数字字符和预定义的空白字符;正则表达式使用正则表达式作为算术表达式,正则表达式同c语言和其他一些机器语言一样,没有指定的编译标志码,编译器随意将正则表达式转换为英文原始字符串。(。
4)正则表达式三个基本算术表达式:匹配模式(bestmatchingmode),有效性(effectiveness)和最大个数(maximumnumberofsequences)匹配模式匹配模式正则表达式是用来寻找目标字符串中某些特定部分的一种表达式。而每个字符串可以有不同的匹配模式,即匹配模式的数量等于该字符串个数的一半。
正则表达式的有效性正则表达式的有效性是字符串中出现字符数量和\r\n换行符等内容的匹配。javascript中正则表达式的有效性:加上换行符换行符\r\n等。(。
5)正则表达式的小括号内一般只有两个正则表达式:(l)(e),两个小括号。(l)代表匹配未知字符,代表“可能”的字符;(e)代表匹配某个字符,代表已知字符。
6)匹配“0-9”中的任意一个可以通过代码,然后发现的“10-99”中的任意一个结果,可以通过验证"\d0-9"isanentiresentencethatisnotentirelynamedanameorspecifiedthelengthofabody。因此应尽量匹配未知字符:(l)。(e)(g)(h)(i)(j),并且一定要匹配没有被escape过的字符串(。
7)匹配空格要 查看全部
php网页抓取乱码(php网页抓取乱码原因:curl是丧心病狂之源)
php网页抓取乱码原因:
1、curl是万恶之源
2、你配置非常不合理
3、curl是丧心病狂之源php正则表达式5个坑:
1、正则表达式是加拿大全国牛逼大学非常关注的课程,
2、学会正则表达式可以走遍天下不怕文盲;
3、只要你不是在做需要过多的网页的时候,
4、正则表达式内部可以转义,从而让你看不懂其他的回车,或者replace,
5、学会正则表达式,
1)什么是正则表达式?正则表达式(regularexpression),或称为正则,是通过匹配字符串中的某些特定部分获得字符串所指示的数据的一种表达式。它作为一种广泛使用的文本编辑语言的程序设计语言,正则表达式能够帮助程序员进行文本处理。
2)正则表达式中的注释符号:'[/]';以及'^/'表示字符串中包含了子字符串或者括号之中使用逗号分隔。
3)正则表达式的主要语法结构:符号、表达式及字符串等;表达式即一个预定义的语法规则;正则表达式由大括号{}(或者s代表各种可以包含正则表达式元素的内置程序结构,如?、$、)等标识符定义;正则表达式由小括号表示非数字字符和预定义的空白字符;正则表达式使用正则表达式作为算术表达式,正则表达式同c语言和其他一些机器语言一样,没有指定的编译标志码,编译器随意将正则表达式转换为英文原始字符串。(。
4)正则表达式三个基本算术表达式:匹配模式(bestmatchingmode),有效性(effectiveness)和最大个数(maximumnumberofsequences)匹配模式匹配模式正则表达式是用来寻找目标字符串中某些特定部分的一种表达式。而每个字符串可以有不同的匹配模式,即匹配模式的数量等于该字符串个数的一半。
正则表达式的有效性正则表达式的有效性是字符串中出现字符数量和\r\n换行符等内容的匹配。javascript中正则表达式的有效性:加上换行符换行符\r\n等。(。
5)正则表达式的小括号内一般只有两个正则表达式:(l)(e),两个小括号。(l)代表匹配未知字符,代表“可能”的字符;(e)代表匹配某个字符,代表已知字符。
6)匹配“0-9”中的任意一个可以通过代码,然后发现的“10-99”中的任意一个结果,可以通过验证"\d0-9"isanentiresentencethatisnotentirelynamedanameorspecifiedthelengthofabody。因此应尽量匹配未知字符:(l)。(e)(g)(h)(i)(j),并且一定要匹配没有被escape过的字符串(。
7)匹配空格要
php网页抓取乱码(一般来说,乱码的出现有2种原因,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-31 17:11
一般来说,出现乱码的原因有两个。首先,错误的编码(charset)设置导致浏览器解析错误的编码,导致满屏的“天书”乱七八糟。编码打开,然后保存。例如,文本文件最初以 GB2312 编码,但以 UTF-8 编码打开和保存。要解决上面的乱码问题,首先要知道开发的哪些方面涉及到编码:
1、文件编码:是指保存页面文件(.html、.php等)本身的编码。记事本和 Dreamweaver 在打开页面时会自动识别文件编码,因此问题较少。然而,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有某种编码的文件。如果工作时不注意,打开编码错误的文件。修改后保存,会出现乱码。
2、页面声明代码:在HTML代码HEAD中,可以使用(这句话一定要写在XXX前面,否则页面会空白(IE+PHP only))告诉浏览器网页是什么代码用途,目前中文网站主要用于GB2312和UTF-8两种编码的开发。
3、数据库连接代码:是指在进行数据库操作时,使用哪个代码向数据库传输数据。这里需要注意的是不要和数据库本身的代码混淆。例如MySQL内部默认为latin1编码,即Mysql数据以latin1编码存储,其他编码传输到Mysql的数据会转成latin1编码。
知道了WEB开发涉及到哪里编码,也就知道乱码的原因了:以上3种编码设置不一致,因为各种编码大部分都兼容ASCII,所以不会出现英文符号,中文会倒霉。. 以下是一些常见的错误情况和解决方案:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是最常见的乱码原因。此时PHP脚本中直接SELECT数据出现乱码,查询前需要用到:
mysql_query("SET NAMES GBK");
或mysql_query("SET NAMES GB2312");
设置MYSQL连接码,保证页面声明码和这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码的,您可以使用:
mysql_query("SET NAMES UTF8");
请注意,它是 UTF8 而不是通常的 UTF-8。如果页面上声明的代码与数据库内部代码一致,则可以不设置连接代码。
注意:其实MYSQL的数据输入输出比上面的要复杂一些。MYSQL配置文件my.ini定义了两种默认编码,即[client]中的default-character-set和[mysqld]中的default。-character-set 分别设置客户端连接和数据库使用的默认编码。我们上面指定的编码其实就是MYSQL客户端连接服务器时的命令行参数character_set_client,用来告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、页面声明编码与文件本身的编码不一致,这种情况很少发生,因为如果编码不一致,创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小bug,打开错误代码的页面,然后保存。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,由于软件的代码配置错误,转换了错误的代码。
3、一些租用虚拟主机的朋友,即使上面三个代码设置正确,还是有乱码。比如网页是用GB2312编码的,但是IE等浏览器总是把它识别为UTF-8。网页的HEAD已经说明是GB2312。手动修改浏览器编码为GB2312后,页面正常显示。原因是服务器Apache设置了服务器的全局默认编码,并在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级高于页面中声明的代码,所以浏览器会认错。有两种解决方案。请在配置文件的虚拟机中添加一个AddDefaultCharset GB2312来覆盖全局配置,
乱码解决方案
要解决乱码问题,首先要弄清楚你的数据库使用的是什么编码。如果未指定,它将是默认的 latin1。
我们应该最多使用gb2312、gbk、utf8这三个字符集。
那么我们如何指定数据库的字符集呢?下面也是gbk的一个例子
[在 MySQL 命令行客户端中创建数据库]
mysql> 创建表`mysqlcode` (
-> `id` TINYINT(255) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> `content` VARCHAR( 255 ) NOT NULL
-> ) TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
查询正常,0 行受影响,1 个警告(0.03 秒)
mysql> desc mysqlcode;
+---------+----------+------+-----+-- -------+----------------+
| 领域 | 类型 | 空 | 钥匙 | 默认 | 额外 |
+---------+----------+------+-----+-- -------+----------------+
| 编号 | tinyint(255) 无符号 | NO | PRI | | auto_increment |
| 内容 | varchar(255) | 否 | | | |
+---------+----------+------+-----+-- -------+----------------+
2 行(0.02 秒)
后者 TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
就是指定数据库的字符集,COLLATE(排序规则),让mysql同时支持多种编码的数据库。
当然我们也可以通过以下命令修改数据库的字符集
更改数据库 da_name 默认字符集 'charset'。
客户端以gbk格式发送,可配置如下:
SET character_set_client='gbk'
SET character_set_connection='gbk'
SET character_set_results='gbk'
此配置等效于 SET NAMES 'gbk'。
现在对刚刚创建的数据库进行操作
mysql> 使用测试;
数据库已更改
mysql> 插入 mysqlcode 值(null,'php 爱好者');
错误 1406(22001):第 1 行的列“内容”的数据太长
字符集未指定为 gbk,插入时出错
mysql> 设置名称 'gbk';
查询正常,0 行受影响(0.02 秒)
指定字符集为 gbk
mysql> 插入 mysqlcode 值(null,'php 爱好者');
查询正常,1 行受影响(0.00 秒)
插入成功
mysql> 从 mysqlcode 中选择 *;
+----+------------+
| 编号 | 内容 |
+----+------------+
| 1| php 爱 |
+----+------------+
一组中的 1 行 (0.00 秒)
不指定字符集gbk时,也会出现乱码,如下
mysql> 从 mysqlcode 中选择 *;
+----+----------+
| 编号 | 内容 |
+----+----------+
+----+----------+
一组中的 1 行 (0.00 秒)
【在phpmyadmin中创建数据库并指定字符集】
根据自己的需要选择表格类型,这里选择MyISAM(支持全文搜索);
整理并选择gbk_chinese_ci即gbk字符集
gbk_bin 简体中文,二进制。gbk_chinese_ci 简体中文,不区分大小写。
将数据库插入到刚刚创建的数据库中
再次浏览时出现乱码
为什么?因为数据库是gbk字符集,我们在操作的时候没有指定为gbk 查看全部
php网页抓取乱码(一般来说,乱码的出现有2种原因,你知道吗?)
一般来说,出现乱码的原因有两个。首先,错误的编码(charset)设置导致浏览器解析错误的编码,导致满屏的“天书”乱七八糟。编码打开,然后保存。例如,文本文件最初以 GB2312 编码,但以 UTF-8 编码打开和保存。要解决上面的乱码问题,首先要知道开发的哪些方面涉及到编码:
1、文件编码:是指保存页面文件(.html、.php等)本身的编码。记事本和 Dreamweaver 在打开页面时会自动识别文件编码,因此问题较少。然而,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有某种编码的文件。如果工作时不注意,打开编码错误的文件。修改后保存,会出现乱码。
2、页面声明代码:在HTML代码HEAD中,可以使用(这句话一定要写在XXX前面,否则页面会空白(IE+PHP only))告诉浏览器网页是什么代码用途,目前中文网站主要用于GB2312和UTF-8两种编码的开发。
3、数据库连接代码:是指在进行数据库操作时,使用哪个代码向数据库传输数据。这里需要注意的是不要和数据库本身的代码混淆。例如MySQL内部默认为latin1编码,即Mysql数据以latin1编码存储,其他编码传输到Mysql的数据会转成latin1编码。
知道了WEB开发涉及到哪里编码,也就知道乱码的原因了:以上3种编码设置不一致,因为各种编码大部分都兼容ASCII,所以不会出现英文符号,中文会倒霉。. 以下是一些常见的错误情况和解决方案:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是最常见的乱码原因。此时PHP脚本中直接SELECT数据出现乱码,查询前需要用到:
mysql_query("SET NAMES GBK");
或mysql_query("SET NAMES GB2312");
设置MYSQL连接码,保证页面声明码和这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码的,您可以使用:
mysql_query("SET NAMES UTF8");
请注意,它是 UTF8 而不是通常的 UTF-8。如果页面上声明的代码与数据库内部代码一致,则可以不设置连接代码。
注意:其实MYSQL的数据输入输出比上面的要复杂一些。MYSQL配置文件my.ini定义了两种默认编码,即[client]中的default-character-set和[mysqld]中的default。-character-set 分别设置客户端连接和数据库使用的默认编码。我们上面指定的编码其实就是MYSQL客户端连接服务器时的命令行参数character_set_client,用来告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、页面声明编码与文件本身的编码不一致,这种情况很少发生,因为如果编码不一致,创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小bug,打开错误代码的页面,然后保存。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,由于软件的代码配置错误,转换了错误的代码。
3、一些租用虚拟主机的朋友,即使上面三个代码设置正确,还是有乱码。比如网页是用GB2312编码的,但是IE等浏览器总是把它识别为UTF-8。网页的HEAD已经说明是GB2312。手动修改浏览器编码为GB2312后,页面正常显示。原因是服务器Apache设置了服务器的全局默认编码,并在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级高于页面中声明的代码,所以浏览器会认错。有两种解决方案。请在配置文件的虚拟机中添加一个AddDefaultCharset GB2312来覆盖全局配置,
乱码解决方案
要解决乱码问题,首先要弄清楚你的数据库使用的是什么编码。如果未指定,它将是默认的 latin1。
我们应该最多使用gb2312、gbk、utf8这三个字符集。
那么我们如何指定数据库的字符集呢?下面也是gbk的一个例子
[在 MySQL 命令行客户端中创建数据库]
mysql> 创建表`mysqlcode` (
-> `id` TINYINT(255) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> `content` VARCHAR( 255 ) NOT NULL
-> ) TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
查询正常,0 行受影响,1 个警告(0.03 秒)
mysql> desc mysqlcode;
+---------+----------+------+-----+-- -------+----------------+
| 领域 | 类型 | 空 | 钥匙 | 默认 | 额外 |
+---------+----------+------+-----+-- -------+----------------+
| 编号 | tinyint(255) 无符号 | NO | PRI | | auto_increment |
| 内容 | varchar(255) | 否 | | | |
+---------+----------+------+-----+-- -------+----------------+
2 行(0.02 秒)
后者 TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
就是指定数据库的字符集,COLLATE(排序规则),让mysql同时支持多种编码的数据库。
当然我们也可以通过以下命令修改数据库的字符集
更改数据库 da_name 默认字符集 'charset'。
客户端以gbk格式发送,可配置如下:
SET character_set_client='gbk'
SET character_set_connection='gbk'
SET character_set_results='gbk'
此配置等效于 SET NAMES 'gbk'。
现在对刚刚创建的数据库进行操作
mysql> 使用测试;
数据库已更改
mysql> 插入 mysqlcode 值(null,'php 爱好者');
错误 1406(22001):第 1 行的列“内容”的数据太长
字符集未指定为 gbk,插入时出错
mysql> 设置名称 'gbk';
查询正常,0 行受影响(0.02 秒)
指定字符集为 gbk
mysql> 插入 mysqlcode 值(null,'php 爱好者');
查询正常,1 行受影响(0.00 秒)
插入成功
mysql> 从 mysqlcode 中选择 *;
+----+------------+
| 编号 | 内容 |
+----+------------+
| 1| php 爱 |
+----+------------+
一组中的 1 行 (0.00 秒)
不指定字符集gbk时,也会出现乱码,如下
mysql> 从 mysqlcode 中选择 *;
+----+----------+
| 编号 | 内容 |
+----+----------+
+----+----------+
一组中的 1 行 (0.00 秒)
【在phpmyadmin中创建数据库并指定字符集】
根据自己的需要选择表格类型,这里选择MyISAM(支持全文搜索);
整理并选择gbk_chinese_ci即gbk字符集
gbk_bin 简体中文,二进制。gbk_chinese_ci 简体中文,不区分大小写。
将数据库插入到刚刚创建的数据库中
再次浏览时出现乱码
为什么?因为数据库是gbk字符集,我们在操作的时候没有指定为gbk
php网页抓取乱码(php网页抓取乱码解决办法这种情况下可以用google翻译)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-30 00:06
php网页抓取乱码解决办法这种情况下可以用google翻译来进行语言翻译,同时也可以根据关键词检索到相应的文献。1.不打扰手机好友2.不影响好友私信数量3.不被关注者感到一本正经4.不影响相关内容被浏览次数想知道更多的技术,看我的专栏:android高级开发架构android高级开发架构-poweredbyadvancedcrafted-知乎专栏。
我发现我的是可以查看到包含大于多少比特的。一个一个查。不会搜索到文献不过有一个好的方法,你自己去试试打开浏览器,在开发者工具中打开代码。找到[language],就可以知道正在输入的文字用多少比特。
lingdigital-advanced-performance.htmllanguage(version2.0):charles
yy。
我在研究zotero,发现能检测到文章中的比特,检测错误的话,不会被认定为是垃圾邮件,也就是所谓的不能标记垃圾邮件。但是你用zotero自带的javascript监控代码,
因为p2p共享的文件都是不能标记垃圾邮件的,因为垃圾邮件是目标制定,最好标记他所在的目标,所以你才没法收到所有的垃圾邮件。p2p共享文件就不存在这个问题,zotero因为是自己搭建的网站,所以可以检测到所有的垃圾邮件。方法是只要在zotero的edit中提交proposal,提交成功后服务器会自动抓取这些proposal,这些proposal的id,zotero就可以根据这些数据自动对文件进行分析。
比如让zotero找到你正在检测的邮件的id,然后再找到另外一段可能是广告文章的邮件的id,这就容易了。其他解决方法可以参考我之前写的文章/。 查看全部
php网页抓取乱码(php网页抓取乱码解决办法这种情况下可以用google翻译)
php网页抓取乱码解决办法这种情况下可以用google翻译来进行语言翻译,同时也可以根据关键词检索到相应的文献。1.不打扰手机好友2.不影响好友私信数量3.不被关注者感到一本正经4.不影响相关内容被浏览次数想知道更多的技术,看我的专栏:android高级开发架构android高级开发架构-poweredbyadvancedcrafted-知乎专栏。
我发现我的是可以查看到包含大于多少比特的。一个一个查。不会搜索到文献不过有一个好的方法,你自己去试试打开浏览器,在开发者工具中打开代码。找到[language],就可以知道正在输入的文字用多少比特。
lingdigital-advanced-performance.htmllanguage(version2.0):charles
yy。
我在研究zotero,发现能检测到文章中的比特,检测错误的话,不会被认定为是垃圾邮件,也就是所谓的不能标记垃圾邮件。但是你用zotero自带的javascript监控代码,
因为p2p共享的文件都是不能标记垃圾邮件的,因为垃圾邮件是目标制定,最好标记他所在的目标,所以你才没法收到所有的垃圾邮件。p2p共享文件就不存在这个问题,zotero因为是自己搭建的网站,所以可以检测到所有的垃圾邮件。方法是只要在zotero的edit中提交proposal,提交成功后服务器会自动抓取这些proposal,这些proposal的id,zotero就可以根据这些数据自动对文件进行分析。
比如让zotero找到你正在检测的邮件的id,然后再找到另外一段可能是广告文章的邮件的id,这就容易了。其他解决方法可以参考我之前写的文章/。
php网页抓取乱码(要说用什么显示网页,要说有什么不同(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-03-19 10:10
统一页面编码
MySQL 数据库编码、HTML 页面编码、PHP 或 HTML 文件编码必须一致。
1、MySQL数据库代码:创建数据库时指定代码(如gbk_chinese_ci)。创建数据表、创建字段、插入数据时不要指定代码,会自动继承数据库的代码。
连接数据库时,还有一个编码。连接数据库后,执行mysql_query('SET NAMES gbk');//把gbk换成你的编码,比如utf8。
2、html页面的编码参考这一行的设置:
复制代码代码如下:
3、php或者html文件本身的编码:用editplus打开php文件或者html文件,保存的时候选择编码,如果数据库和页面编码都是gbk,这里的编码就是ansi;如果数据库和页面编码都是utf-8,那么这里也选择utf-8。
4、在 Javascript 或 Flash 中传递的数据是 utf-8 编码的:
还有一点需要注意的是,Javascript或者Flash传入的数据是utf-8编码的,如果数据库和页面编码是gbk,需要转码后写入数据库。
复制代码代码如下:
iconv('utf-8', 'gbk', $content);
5、在PHP程序中,可以添加一行来指定PHP源程序的编码:
复制代码代码如下:
header('内容类型: text/html; charset=gbk');
php页面编码
1.在文件头设置编码
复制代码代码如下:
@header('内容类型: text/html;charset=UTF-8');
2.header和meta的区别
使用@header('Content-type: text/html; charset=gbk'); 的区别 和
它们都告诉浏览器使用什么编码来显示网页。有什么区别?header 是发送原创的 HTTP 头,网页中什么都不留下,而 meta 是写在网页中的。
一方面,如果页面中没有元数据,则发送 HTTP 标头有效。
其次,使用 header() 函数发送可以收录更多内容的原创 HTTP 标头,设置编码只是其中之一。
第三,有时不需要在网页上显示什么内容,而是告知浏览器后续动作使用什么编码。
时间:2015-04-06 查看全部
php网页抓取乱码(要说用什么显示网页,要说有什么不同(图))
统一页面编码
MySQL 数据库编码、HTML 页面编码、PHP 或 HTML 文件编码必须一致。
1、MySQL数据库代码:创建数据库时指定代码(如gbk_chinese_ci)。创建数据表、创建字段、插入数据时不要指定代码,会自动继承数据库的代码。
连接数据库时,还有一个编码。连接数据库后,执行mysql_query('SET NAMES gbk');//把gbk换成你的编码,比如utf8。
2、html页面的编码参考这一行的设置:
复制代码代码如下:
3、php或者html文件本身的编码:用editplus打开php文件或者html文件,保存的时候选择编码,如果数据库和页面编码都是gbk,这里的编码就是ansi;如果数据库和页面编码都是utf-8,那么这里也选择utf-8。
4、在 Javascript 或 Flash 中传递的数据是 utf-8 编码的:
还有一点需要注意的是,Javascript或者Flash传入的数据是utf-8编码的,如果数据库和页面编码是gbk,需要转码后写入数据库。
复制代码代码如下:
iconv('utf-8', 'gbk', $content);
5、在PHP程序中,可以添加一行来指定PHP源程序的编码:
复制代码代码如下:
header('内容类型: text/html; charset=gbk');
php页面编码
1.在文件头设置编码
复制代码代码如下:
@header('内容类型: text/html;charset=UTF-8');
2.header和meta的区别
使用@header('Content-type: text/html; charset=gbk'); 的区别 和
它们都告诉浏览器使用什么编码来显示网页。有什么区别?header 是发送原创的 HTTP 头,网页中什么都不留下,而 meta 是写在网页中的。
一方面,如果页面中没有元数据,则发送 HTTP 标头有效。
其次,使用 header() 函数发送可以收录更多内容的原创 HTTP 标头,设置编码只是其中之一。
第三,有时不需要在网页上显示什么内容,而是告知浏览器后续动作使用什么编码。
时间:2015-04-06
php网页抓取乱码(php和Mysql出现的中文乱码问题怎么办?见)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-19 10:09
最近一直在写网页,用的是php和Mysql,但是出现了各种问题。说明在Mysql下输入sql语句时,如果sql语句中有中文,则可能不会执行sql语句。解决方法见:解决Mysql server 5.1无法识别中文
解决此问题后,使用php向数据库写入数据时,sql语句无法再次执行。这个问题我也解决了。解决方法见:解决PHP连接Mysql但无法向数据库插入数据的问题。
昨天出现的中文乱码问题,经过一夜的努力,终于解决了。现在PHP和Mysql都可以识别中文,可以正常执行SQL语句了。
解决方法就是在这里写个总结(应该同时解决以上三个问题):
首先是修改Mysql的编码方式。这是一篇写得很详细的帖子。结合我第一个问题的解决方法,完全可以修改Mysql的编码方式。帖子地址:MySql修改数据库编码为UTF8。
接下来是php连接数据库时选择的编码方式。首先,我建议你把所有的编码方式都改成'utf-8',这样写网页或者使用数据库会方便很多。 php在写网页时,添加 则可以使用sql语句访问数据库,添加mysql_query("set names utf8");记住这里是utf8不是utf-8,不是我不小心忘了加横线,而是utf8。 查看全部
php网页抓取乱码(php和Mysql出现的中文乱码问题怎么办?见)
最近一直在写网页,用的是php和Mysql,但是出现了各种问题。说明在Mysql下输入sql语句时,如果sql语句中有中文,则可能不会执行sql语句。解决方法见:解决Mysql server 5.1无法识别中文
解决此问题后,使用php向数据库写入数据时,sql语句无法再次执行。这个问题我也解决了。解决方法见:解决PHP连接Mysql但无法向数据库插入数据的问题。
昨天出现的中文乱码问题,经过一夜的努力,终于解决了。现在PHP和Mysql都可以识别中文,可以正常执行SQL语句了。
解决方法就是在这里写个总结(应该同时解决以上三个问题):
首先是修改Mysql的编码方式。这是一篇写得很详细的帖子。结合我第一个问题的解决方法,完全可以修改Mysql的编码方式。帖子地址:MySql修改数据库编码为UTF8。
接下来是php连接数据库时选择的编码方式。首先,我建议你把所有的编码方式都改成'utf-8',这样写网页或者使用数据库会方便很多。 php在写网页时,添加 则可以使用sql语句访问数据库,添加mysql_query("set names utf8");记住这里是utf8不是utf-8,不是我不小心忘了加横线,而是utf8。
php网页抓取乱码(mysq数据库使用的编码字符集(1)_set=utf8)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-18 15:21
一、
学php的童鞋在写网页的时候,如果设计了中文内容的存储,大部分都会出现乱码的问题。对于一般的乱码,我们可以从三个方面进行检查
(1)网页的编码是否正确,例如是否在header中添加原创标签
(2)检查mysql数据库存储时使用的默认字符集
(3)查看网页文件的编码,是否是对应的中文编码
------------------
环境:win7+wamp2.2
------------------
二、
先从第二点说起,mysq数据库使用的编码字符集
(1)打开mysql终端,查看当前设置,确定要修改的范围
show variables like 'char%';
(2)根据结果分析,
1、如果你显示的结果和我的差不多,也就是(只有character_set_system编码为utf8)那么按照下面的步骤一步步来
2、打开my.ini文件,搜索关键词'mysqld',找到后观察是否有这一行
character_set_server=utf8
如果没有,你应该像我一样在它下面添加一个句子
3、再搜索关键词'client'看看有没有这行
default_character_set=utf8
如果没有,请在 [client] 下添加
4、保存,重启mysql服务,关闭mysql终端(不然你看到的客户端代码不会更新)
5、再次打开终端,我们再次进入
show variables like 'char%';
如果出现如下结果,即mysql数据设置成功
三、
网页文件编码的问题是最容易被忽略的。保存时选择保存文件编码的格式时设置。
解决方案:
1、使用notepad++打开网页文件,然后在“格式”--“转为UTF-8无BOM编码格式”
2、保存就行
问题分析:
1、写php的时候用过
<br />
但是还是有乱码的问题!
分析:使用上面的语句,只修改了三项,三项是
character_set_client
字符集连接
字符集结果
而且这个修改只是暂时的,关闭终端后还是一样。
阐明:
2、我们来分析第三个乱码问题
(1)使用sublime text3编辑打开php文件,左下角可以看到编码信息,可以看到当前编码为gb2312
(2)网页加载的时候,相当于打开了当时的一个文件。那个时候读取的格式按照gb2312的编码读取网页文件,当是显示在用户的浏览器中,因为网页声明的字符集是utf-8,所以获取到的文件内容会按照utf-8字符集进行解释,会导致乱码,但是没有问题我们从数据库中读取的内容。
网络编码
原创gbk编码文件
后来的 utf-8 编码文件
(3)注意,sublime text3没有给你转换编码,虽然显示转换成功,但是什么?显示还是一样,还是我们notepad++功能更强大,如何修改上一个! 转换成功后
3、为什么我按照你说的修改了,在mysql终端下显示,还是乱码?
分析:
(1)我们先来看看windows下cmd使用的是什么字符集?
可以看出cmd的字符集是gbk,也就是说终端显示的任何内容都会对应gbk的字符集,但是我们数据库的中文设置的utf8字符集,当我们想要显示出来,自然会使用 utf8 编码读取数据库数据,当编码为 utf-8 时,到了终端就乱了
(2)怎么查?
用phpmyadmin就行了,当然我们要设置我们使用的utf-8编码! 查看全部
php网页抓取乱码(mysq数据库使用的编码字符集(1)_set=utf8)
一、
学php的童鞋在写网页的时候,如果设计了中文内容的存储,大部分都会出现乱码的问题。对于一般的乱码,我们可以从三个方面进行检查
(1)网页的编码是否正确,例如是否在header中添加原创标签
(2)检查mysql数据库存储时使用的默认字符集
(3)查看网页文件的编码,是否是对应的中文编码
------------------
环境:win7+wamp2.2
------------------
二、
先从第二点说起,mysq数据库使用的编码字符集
(1)打开mysql终端,查看当前设置,确定要修改的范围
show variables like 'char%';
(2)根据结果分析,
1、如果你显示的结果和我的差不多,也就是(只有character_set_system编码为utf8)那么按照下面的步骤一步步来
2、打开my.ini文件,搜索关键词'mysqld',找到后观察是否有这一行
character_set_server=utf8
如果没有,你应该像我一样在它下面添加一个句子
3、再搜索关键词'client'看看有没有这行
default_character_set=utf8
如果没有,请在 [client] 下添加
4、保存,重启mysql服务,关闭mysql终端(不然你看到的客户端代码不会更新)
5、再次打开终端,我们再次进入
show variables like 'char%';
如果出现如下结果,即mysql数据设置成功
三、
网页文件编码的问题是最容易被忽略的。保存时选择保存文件编码的格式时设置。
解决方案:
1、使用notepad++打开网页文件,然后在“格式”--“转为UTF-8无BOM编码格式”
2、保存就行
问题分析:
1、写php的时候用过
<br />
但是还是有乱码的问题!
分析:使用上面的语句,只修改了三项,三项是
character_set_client
字符集连接
字符集结果
而且这个修改只是暂时的,关闭终端后还是一样。
阐明:
2、我们来分析第三个乱码问题
(1)使用sublime text3编辑打开php文件,左下角可以看到编码信息,可以看到当前编码为gb2312
(2)网页加载的时候,相当于打开了当时的一个文件。那个时候读取的格式按照gb2312的编码读取网页文件,当是显示在用户的浏览器中,因为网页声明的字符集是utf-8,所以获取到的文件内容会按照utf-8字符集进行解释,会导致乱码,但是没有问题我们从数据库中读取的内容。
网络编码
原创gbk编码文件
后来的 utf-8 编码文件
(3)注意,sublime text3没有给你转换编码,虽然显示转换成功,但是什么?显示还是一样,还是我们notepad++功能更强大,如何修改上一个! 转换成功后
3、为什么我按照你说的修改了,在mysql终端下显示,还是乱码?
分析:
(1)我们先来看看windows下cmd使用的是什么字符集?
可以看出cmd的字符集是gbk,也就是说终端显示的任何内容都会对应gbk的字符集,但是我们数据库的中文设置的utf8字符集,当我们想要显示出来,自然会使用 utf8 编码读取数据库数据,当编码为 utf-8 时,到了终端就乱了
(2)怎么查?
用phpmyadmin就行了,当然我们要设置我们使用的utf-8编码!
php网页抓取乱码(做了个网络爬虫抓取网页,最后居然搞出来了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-14 19:09
我做了一个网络爬虫来爬取网页,但是如果网页是gbk/gb2312编码的,就会出现乱码,如下:
得到文本后,直接打印,输出结果str如下:
¹óÖÝÈËÊ¿ ¼ÊÔÐÅÏ¢Íø_¹óÖÝÈËÊÂ¿Ê ¼ÊÔÍø_¹óÖݹ«ÎñÔ±¿¿ ¼ÊÔÍø_¹óÖÝÖй«
这个问题困扰了我很久,百度、google都没有找到完全可行的方法,继续折腾,终于出来了!代码转换来回转换,依然无法解决。把问题具体总结一下,分享给大家,互相学习!(有时候问题并不复杂,容易解决。如果问题没有突破,那么解决问题的路是很长的。)总之,遇到问题,选择几种方法去尝试,就有了总是有办法解决它。的。
1.更改网页源代码的编码格式(强调)
# -*- coding:utf8 -*-
import urllib2
req = urllib2.Request("http://www.baidu.com/")
res = urllib2.urlopen(req)
html = res.read()
res.close()
html = unicode(html, "gb2312").encode("utf8") #gb2312--->utf-8
print html
2.python爬取网页时字符集转换问题处理解决方案
有时我们 采集 网页,将字符串保存到文件或在处理后将它们写入数据库。这时,我们需要制定字符串的编码。如果采集网页的编码是gb2312,而我们的数据库是utf-8,不做任何处理直接插入数据库可能会出现乱码(未测试,不知道数据库会不会自动转码),我们需要手动将gb2312转为utf-8。
首先我们知道python中的字符默认是ascii码。当然,英语没有问题。遇到中国人,立马下跪。
不知道大家还记得没有,python中打印汉字的时候,需要在字符串前面加上u:
print u "来基地吗?"
这样就可以显示中文了。u这里的作用是将下面的字符串转换成unicode码,这样才能正确显示中文。
这里有一个与之相关的unicode()函数,使用如下
str="来搞基"
str=unicode(str,"utf-8")
print str
与u的区别在于unicode用于将str转为unicode编码,需要正确指定第二个参数。这里的utf-8是我的test.py脚本本身的文件字符集,默认的可能是ansi。
unicode 是键,下面继续
我们开始爬取百度主页。注意,访问者访问百度主页查看网页源代码时,其charset=gb2312。
import urllib2
def main():
f=urllib2.urlopen("http://www.baidu.com")
str=f.read()
str=unicode(str,"gb2312")
fp=open("baidu.html","w")
fp.write(str.encode("utf-8"))
fp.close()
if name == 'main' :
main()
解释:
我们先用urllib2.urlopen()方法抓取百度主页,f为句柄,使用str=f.read()将所有源码读入str
明确str是我们抓取的html源代码。由于网页默认的字符集是gb2312,如果我们直接保存到文件中,文件编码会是ansi。
对于大部分人来说,这其实已经足够了,但是有时候我只想把gb2312转成utf-8,怎么办呢?
第一的:
str=unicode(str,"gb2312")#这里的gb2312是str的实际字符集,我们现在将其转换为unicode
然后:
str=str.encode("utf-8")#将unicode字符串重新编码为utf-8
最后:
将str写入文件,打开文件查看编码属性,发现是utf-8,把
总结:
我们回顾一下,如果需要按照指定的字符集保存字符串,有以下步骤:
1:使用unicode(str, "original encoding") 将str解码成unicode字符串
2:使用str.encode("specified character set")将unicode字符串str转换成你指定的字符集
3:将str保存到文件,或写入数据库。当然,你已经指定了编码,对吧?
3.用 lxml 解析 html
使用lxml.etree作为网络爬虫来爬取网页,但是如果网页是gbk/gb2312编码的,会出现乱码,如下:
获取文本后,直接打印,输出结果v如下:
¹óÖÝÈËÊ¿ ¼ÊÔÐÅÏ¢Íø¹óÖÝÈËÊÂ¿Ê ¼ÊÔÍø¹óÖݹ«ÎñÔ±¿¿ ¼ÊÔÍø_¹óÖÝÖй
这个 v 的类型又是
response.encoding = 'utf-8'
page = etree.HTML(response.content)
nodes_title = page.xpath("//title//text()")
这样打印出来的nodes_title[0]是正常中文显示的。
特别注意的是response.text容易出现编码问题,所以以后使用response.content。 查看全部
php网页抓取乱码(做了个网络爬虫抓取网页,最后居然搞出来了)
我做了一个网络爬虫来爬取网页,但是如果网页是gbk/gb2312编码的,就会出现乱码,如下:
得到文本后,直接打印,输出结果str如下:
¹óÖÝÈËÊ¿ ¼ÊÔÐÅÏ¢Íø_¹óÖÝÈËÊÂ¿Ê ¼ÊÔÍø_¹óÖݹ«ÎñÔ±¿¿ ¼ÊÔÍø_¹óÖÝÖй«
这个问题困扰了我很久,百度、google都没有找到完全可行的方法,继续折腾,终于出来了!代码转换来回转换,依然无法解决。把问题具体总结一下,分享给大家,互相学习!(有时候问题并不复杂,容易解决。如果问题没有突破,那么解决问题的路是很长的。)总之,遇到问题,选择几种方法去尝试,就有了总是有办法解决它。的。
1.更改网页源代码的编码格式(强调)
# -*- coding:utf8 -*-
import urllib2
req = urllib2.Request("http://www.baidu.com/";)
res = urllib2.urlopen(req)
html = res.read()
res.close()
html = unicode(html, "gb2312").encode("utf8") #gb2312--->utf-8
print html
2.python爬取网页时字符集转换问题处理解决方案
有时我们 采集 网页,将字符串保存到文件或在处理后将它们写入数据库。这时,我们需要制定字符串的编码。如果采集网页的编码是gb2312,而我们的数据库是utf-8,不做任何处理直接插入数据库可能会出现乱码(未测试,不知道数据库会不会自动转码),我们需要手动将gb2312转为utf-8。
首先我们知道python中的字符默认是ascii码。当然,英语没有问题。遇到中国人,立马下跪。
不知道大家还记得没有,python中打印汉字的时候,需要在字符串前面加上u:
print u "来基地吗?"
这样就可以显示中文了。u这里的作用是将下面的字符串转换成unicode码,这样才能正确显示中文。
这里有一个与之相关的unicode()函数,使用如下
str="来搞基"
str=unicode(str,"utf-8")
print str
与u的区别在于unicode用于将str转为unicode编码,需要正确指定第二个参数。这里的utf-8是我的test.py脚本本身的文件字符集,默认的可能是ansi。
unicode 是键,下面继续
我们开始爬取百度主页。注意,访问者访问百度主页查看网页源代码时,其charset=gb2312。
import urllib2
def main():
f=urllib2.urlopen("http://www.baidu.com";)
str=f.read()
str=unicode(str,"gb2312")
fp=open("baidu.html","w")
fp.write(str.encode("utf-8"))
fp.close()
if name == 'main' :
main()
解释:
我们先用urllib2.urlopen()方法抓取百度主页,f为句柄,使用str=f.read()将所有源码读入str
明确str是我们抓取的html源代码。由于网页默认的字符集是gb2312,如果我们直接保存到文件中,文件编码会是ansi。
对于大部分人来说,这其实已经足够了,但是有时候我只想把gb2312转成utf-8,怎么办呢?
第一的:
str=unicode(str,"gb2312")#这里的gb2312是str的实际字符集,我们现在将其转换为unicode
然后:
str=str.encode("utf-8")#将unicode字符串重新编码为utf-8
最后:
将str写入文件,打开文件查看编码属性,发现是utf-8,把
总结:
我们回顾一下,如果需要按照指定的字符集保存字符串,有以下步骤:
1:使用unicode(str, "original encoding") 将str解码成unicode字符串
2:使用str.encode("specified character set")将unicode字符串str转换成你指定的字符集
3:将str保存到文件,或写入数据库。当然,你已经指定了编码,对吧?
3.用 lxml 解析 html
使用lxml.etree作为网络爬虫来爬取网页,但是如果网页是gbk/gb2312编码的,会出现乱码,如下:
获取文本后,直接打印,输出结果v如下:
¹óÖÝÈËÊ¿ ¼ÊÔÐÅÏ¢Íø¹óÖÝÈËÊÂ¿Ê ¼ÊÔÍø¹óÖݹ«ÎñÔ±¿¿ ¼ÊÔÍø_¹óÖÝÖй
这个 v 的类型又是
response.encoding = 'utf-8'
page = etree.HTML(response.content)
nodes_title = page.xpath("//title//text()")
这样打印出来的nodes_title[0]是正常中文显示的。
特别注意的是response.text容易出现编码问题,所以以后使用response.content。
php网页抓取乱码( 如何解决php抓取乱码问题php网页抓取乱码的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-14 19:07
如何解决php抓取乱码问题php网页抓取乱码的)
如何解决php网页抓取出现乱码问题
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”转换编码;2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” 选项; 3、在顶部添加标题代码。推荐
如何解决php传页面参数乱码问题
php传页参数乱码的解决方法:1、打开对应的php代码文件;2、通过“if($tag===iconv('UTF-8',$c,iconv($c ,'UTF-8',$tag))){...} 的方法来解决乱码问题
如何解决乱码网页
本文运行环境:windows10系统,360安全浏览器 1 文本,这个是乱码。右键单击网页以弹出菜单。在弹出菜单中找到编辑
php乱码原因分析
PHP中的中文乱码是PHP开发中常见的问题之一。PHP中文乱码有时出现在网页本身,有的出现在与MySQL交互的过程中,有时与操作系统有关。下面给出一个摘要。一。首先,PHP网页编码最好最快的方案是页面声明的编码与数据库内部编码一致。如果页面应用的页码与数据库内部编码不一致,设置连接编码,mysql_query(\"SETNAMESXXX\");XXX为连接编码。一定能解决乱七八糟的
如何处理乱码的css网页
css网页乱码的解决方法:1、设置CSS字符编码与页面字符编码一致,设置“@charset”utf-8“;”等编码语句;2、写css评论时加强;3、 采用字体的别名。推荐:《css视频教程》解决方案
响应式网页设计和 SEO
所谓“响应式网页设计(Responsive Web Design)”也是自适应的,是一种能够自动识别屏幕宽度并做出相应调整的网页设计。目前这种设计已经出现在越来越多的国内网站中,谷歌已经明确表示鼓励响应式网页设计。
简化您的网页设计
随着网站构建技术的发展,在网页中实现复杂的功能已经不再困难。网页中的功能越来越多。因此,需要在用户的浏览体验和网页设计的美感之间取得平衡。显得非常重要。
宝安网页设计从SEO角度谈网页设计标准
深圳宝安网页设计从SEO角度谈网页设计标准。在任何时候,网站访问者都处于以下阶段之一: 1. 注意;2、利息;3.欲望;4. 行动;5.满足。在每个阶段,参观者都是不同的
什么是优化网页设计?
由于不同的搜索引擎对网页的支持存在差异,所以在设计网页时,不要只关注外观。许多网页设计中常用的元素都会给搜索引擎带来问题。■框架结构(FrameSets) 有些搜索引擎(如FAST)不支持框架结构,其蜘蛛程序无法读取此类网页。■图像块(我
网页设计对网站推广效果的影响
网页设计是一门深奥的课程,它对网站的推广和营销的影响是毋庸置疑的。无论是网页的布局,网页下载的速度,导航系统的便利性,还是用户的浏览效果,都会直接影响到用户的浏览效果,进而影响状态和形象用户心目中的网站,即网页设计的效果直接影响网站的品牌形象和推广营销效果。下
什么是标签页?如何优化标签页?
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
网页登录成功后php如何实现网页跳转?
网页登录成功后php实现网页跳转的方法:首先打开php编辑器,新建一个php文件;然后在[index.php]中输入代码[header('Location:index.php');];最后浏览服务器运行[login.
php下载中文乱码的解决办法
php下载中文乱码的解决方法:先打开相关代码文件;然后使用“iconv()”函数解决乱码,具体语法为“$file_name=iconv("utf-8","gb2312",$file_name);"。php下载解决中文乱码
网站制作和网页设计/区别/描述/\"
/网页设计:就是让美工做设计的所有页面的界面渲染网站,就像建房子之前,会请一位著名的设计师来设计房子的外观。你用什么软件做网页设计?DreamweaverCS6、烟花、Photoshop等
网页登录成功后如何在php中实现网页跳转
网页登录成功后php实现网页跳转的方法:首先打开编辑器,新建一个php文件;然后输入代码“header('Location:index.php');” 在php文件中;最后在浏览器中运行它,这将跳转到索引时 查看全部
php网页抓取乱码(
如何解决php抓取乱码问题php网页抓取乱码的)
如何解决php网页抓取出现乱码问题
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”转换编码;2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” 选项; 3、在顶部添加标题代码。推荐
如何解决php传页面参数乱码问题
php传页参数乱码的解决方法:1、打开对应的php代码文件;2、通过“if($tag===iconv('UTF-8',$c,iconv($c ,'UTF-8',$tag))){...} 的方法来解决乱码问题
如何解决乱码网页
本文运行环境:windows10系统,360安全浏览器 1 文本,这个是乱码。右键单击网页以弹出菜单。在弹出菜单中找到编辑
php乱码原因分析
PHP中的中文乱码是PHP开发中常见的问题之一。PHP中文乱码有时出现在网页本身,有的出现在与MySQL交互的过程中,有时与操作系统有关。下面给出一个摘要。一。首先,PHP网页编码最好最快的方案是页面声明的编码与数据库内部编码一致。如果页面应用的页码与数据库内部编码不一致,设置连接编码,mysql_query(\"SETNAMESXXX\");XXX为连接编码。一定能解决乱七八糟的
如何处理乱码的css网页
css网页乱码的解决方法:1、设置CSS字符编码与页面字符编码一致,设置“@charset”utf-8“;”等编码语句;2、写css评论时加强;3、 采用字体的别名。推荐:《css视频教程》解决方案
响应式网页设计和 SEO
所谓“响应式网页设计(Responsive Web Design)”也是自适应的,是一种能够自动识别屏幕宽度并做出相应调整的网页设计。目前这种设计已经出现在越来越多的国内网站中,谷歌已经明确表示鼓励响应式网页设计。
简化您的网页设计
随着网站构建技术的发展,在网页中实现复杂的功能已经不再困难。网页中的功能越来越多。因此,需要在用户的浏览体验和网页设计的美感之间取得平衡。显得非常重要。
宝安网页设计从SEO角度谈网页设计标准
深圳宝安网页设计从SEO角度谈网页设计标准。在任何时候,网站访问者都处于以下阶段之一: 1. 注意;2、利息;3.欲望;4. 行动;5.满足。在每个阶段,参观者都是不同的
什么是优化网页设计?
由于不同的搜索引擎对网页的支持存在差异,所以在设计网页时,不要只关注外观。许多网页设计中常用的元素都会给搜索引擎带来问题。■框架结构(FrameSets) 有些搜索引擎(如FAST)不支持框架结构,其蜘蛛程序无法读取此类网页。■图像块(我
网页设计对网站推广效果的影响
网页设计是一门深奥的课程,它对网站的推广和营销的影响是毋庸置疑的。无论是网页的布局,网页下载的速度,导航系统的便利性,还是用户的浏览效果,都会直接影响到用户的浏览效果,进而影响状态和形象用户心目中的网站,即网页设计的效果直接影响网站的品牌形象和推广营销效果。下
什么是标签页?如何优化标签页?
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
网页登录成功后php如何实现网页跳转?
网页登录成功后php实现网页跳转的方法:首先打开php编辑器,新建一个php文件;然后在[index.php]中输入代码[header('Location:index.php');];最后浏览服务器运行[login.
php下载中文乱码的解决办法
php下载中文乱码的解决方法:先打开相关代码文件;然后使用“iconv()”函数解决乱码,具体语法为“$file_name=iconv("utf-8","gb2312",$file_name);"。php下载解决中文乱码
网站制作和网页设计/区别/描述/\"
/网页设计:就是让美工做设计的所有页面的界面渲染网站,就像建房子之前,会请一位著名的设计师来设计房子的外观。你用什么软件做网页设计?DreamweaverCS6、烟花、Photoshop等
网页登录成功后如何在php中实现网页跳转
网页登录成功后php实现网页跳转的方法:首先打开编辑器,新建一个php文件;然后输入代码“header('Location:index.php');” 在php文件中;最后在浏览器中运行它,这将跳转到索引时
php网页抓取乱码(怎么自动获取网页的编码格式?的urlopen方法返回一个 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-14 19:02
)
在对爬虫获取的网页进行处理之前,我们需要知道被爬取的网页的编码格式,然后才能正确解码,编码成目标格式保存或者进行后续的文本处理。尤其是在多语言环境中,获取正确的网页编码格式尤为重要。
我们可以手动查看网页源码中meta标签下的content属性,其中charset代表网页的编码格式。所谓爬虫,本质上是一个自动化程序,那么如何自动获取网页的编码格式呢?python的urlopen方法返回一个响应对象,响应的info方法可以返回与url相关的元信息,包括内容格式、长度等信息。如下所示:
貌似只要使用getparam('charset')就可以成功获取到网页编码格式,可惜服务器返回的元信息并不是都收录charset,info中的信息依赖于爬取的url服务器上的爬虫。另外,即使你确定你的爬虫爬取的部分服务器会返回charset信息,也不能保证网页的编码格式一定要和charset一致。因此,最安全的做法是直接探测服务器返回的文本的编码格式。我在这里使用 python 中的 chardet 包。chardet的detect方法可以检测传入字符串的编码格式并给出检测精度。
import urllib2
import chardet
import time
response = urllib2.urlopen('http://www.simmerchan.me/')
content = response.read()
t = time.time()
charset_info = chardet.detect(content)
print charset_info
print charset_info['encoding']
print time.time()-t
{'confidence': 0.99, 'encoding': 'utf-8'}
utf-8
0.468999862671
当获取的网页内容比较大时,使用上述方法检测编码是相当耗时的。一种可能的方法是检测内容片段。
import urllib2
import chardet
import time
response = urllib2.urlopen('http://www.simmerchan.me/')
content = response.read()
t = time.time()
charset_info = chardet.detect(content[:70000])
print charset_info
print charset_info['encoding']
print time.time()-t
{'confidence': 0.99, 'encoding': 'utf-8'}
utf-8
0.114000082016
分片的大小取决于具体的应用场景。在我自己的爬虫项目中,400可以处理大部分的登陆页面。我这里取7000是因为我的网页源码中之前的大部分内容都不收录中文。如果我取 6000,它会被检测为 ascii 码。我也想过取中间段的可能性,比如6000到7000,9000到10000,前者结果是utf-8,准确率是0.99,后者是ISO-8859-2,准确率0.82,事实证明这种方法无效,随机性太大。
获取网页编码格式后,我们可以对网页内容进行解码,然后编码成统一的格式进行处理。
import urllib2
import chardet
import time
response = urllib2.urlopen('http://www.simmerchan.me/')
content = response.read()
t = time.time()
charset = chardet.detect(content[:400])['encoding']
content = content.decode(charset, 'ignore').encode('utf-8')
ignore 参数是忽略那些无法解码成 unicode 的字符。如果不加这个参数,可能会出现类似如下的错误
UnicodeDecodeError: 'gb2312' codec can't decode bytes in position 61399-61400: illegal multibyte sequence 查看全部
php网页抓取乱码(怎么自动获取网页的编码格式?的urlopen方法返回一个
)
在对爬虫获取的网页进行处理之前,我们需要知道被爬取的网页的编码格式,然后才能正确解码,编码成目标格式保存或者进行后续的文本处理。尤其是在多语言环境中,获取正确的网页编码格式尤为重要。
我们可以手动查看网页源码中meta标签下的content属性,其中charset代表网页的编码格式。所谓爬虫,本质上是一个自动化程序,那么如何自动获取网页的编码格式呢?python的urlopen方法返回一个响应对象,响应的info方法可以返回与url相关的元信息,包括内容格式、长度等信息。如下所示:
貌似只要使用getparam('charset')就可以成功获取到网页编码格式,可惜服务器返回的元信息并不是都收录charset,info中的信息依赖于爬取的url服务器上的爬虫。另外,即使你确定你的爬虫爬取的部分服务器会返回charset信息,也不能保证网页的编码格式一定要和charset一致。因此,最安全的做法是直接探测服务器返回的文本的编码格式。我在这里使用 python 中的 chardet 包。chardet的detect方法可以检测传入字符串的编码格式并给出检测精度。
import urllib2
import chardet
import time
response = urllib2.urlopen('http://www.simmerchan.me/')
content = response.read()
t = time.time()
charset_info = chardet.detect(content)
print charset_info
print charset_info['encoding']
print time.time()-t
{'confidence': 0.99, 'encoding': 'utf-8'}
utf-8
0.468999862671
当获取的网页内容比较大时,使用上述方法检测编码是相当耗时的。一种可能的方法是检测内容片段。
import urllib2
import chardet
import time
response = urllib2.urlopen('http://www.simmerchan.me/')
content = response.read()
t = time.time()
charset_info = chardet.detect(content[:70000])
print charset_info
print charset_info['encoding']
print time.time()-t
{'confidence': 0.99, 'encoding': 'utf-8'}
utf-8
0.114000082016
分片的大小取决于具体的应用场景。在我自己的爬虫项目中,400可以处理大部分的登陆页面。我这里取7000是因为我的网页源码中之前的大部分内容都不收录中文。如果我取 6000,它会被检测为 ascii 码。我也想过取中间段的可能性,比如6000到7000,9000到10000,前者结果是utf-8,准确率是0.99,后者是ISO-8859-2,准确率0.82,事实证明这种方法无效,随机性太大。
获取网页编码格式后,我们可以对网页内容进行解码,然后编码成统一的格式进行处理。
import urllib2
import chardet
import time
response = urllib2.urlopen('http://www.simmerchan.me/')
content = response.read()
t = time.time()
charset = chardet.detect(content[:400])['encoding']
content = content.decode(charset, 'ignore').encode('utf-8')
ignore 参数是忽略那些无法解码成 unicode 的字符。如果不加这个参数,可能会出现类似如下的错误
UnicodeDecodeError: 'gb2312' codec can't decode bytes in position 61399-61400: illegal multibyte sequence

