
php网页抓取乱码
php网页抓取乱码(木庄网络博客:发送给服务器的请求连接的数据不同)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-25 23:12
本文摘自php中文网,作者负一度,侵删。
为什么会这样?细心的童鞋可能会发现我们发送给服务器进行请求连接的数据是不一样的:
第一张图片的信息是{"roomid":98284,"uid":2770}
第二张图片的信息是{"uid":2767,"protoover":2,"roomid":98284}
roomid是真实的房间号,uid是随机生成的一串数字,可以直接复制登录。
相比之下,第二个有更多的“protover”:2个参数。其实第一张图是截取手机客户端的数据包,第二张图是截取电脑网页的数据包。那么是否有这个“protoover”:2个参数可以连接弹幕服务器。
所以我们可以推断,最容易抓取的数据是手机,其次是wap,最后是电脑。
但是很多时候我们抓包数据都是如图2所示的一串乱码,不管用utf8还是gbk编码,都达不到图1所示的效果。
这种数据其实是压缩数据gzip,目前wireshark不支持这种压缩数据的解压方式。
现在网站传输的时候基本都是压缩的,所以你抓的数据是压缩数据,在你看来完全是乱码,没办法下手。
如图所示,当我访问我的博客首页时,爬虫服务器发回的网页数据是gzip方式的,我们平时访问的网页被浏览器解压渲染呈现给我们。
由于分析B站服务器传输的是gzip数据,所以解决方法很简单。安装第三方的zlib包或者gzip包可以解决这个问题。
以上是抓包数据乱码是什么情况?更多详情请关注php中文网文章其他相关话题!
欢迎分享,(木庄网博客交流QQ群:562366239)
转载请注明出处:木庄网博客 » 抓包数据乱码是什么情况? 查看全部
php网页抓取乱码(木庄网络博客:发送给服务器的请求连接的数据不同)
本文摘自php中文网,作者负一度,侵删。
为什么会这样?细心的童鞋可能会发现我们发送给服务器进行请求连接的数据是不一样的:
第一张图片的信息是{"roomid":98284,"uid":2770}
第二张图片的信息是{"uid":2767,"protoover":2,"roomid":98284}
roomid是真实的房间号,uid是随机生成的一串数字,可以直接复制登录。
相比之下,第二个有更多的“protover”:2个参数。其实第一张图是截取手机客户端的数据包,第二张图是截取电脑网页的数据包。那么是否有这个“protoover”:2个参数可以连接弹幕服务器。
所以我们可以推断,最容易抓取的数据是手机,其次是wap,最后是电脑。

但是很多时候我们抓包数据都是如图2所示的一串乱码,不管用utf8还是gbk编码,都达不到图1所示的效果。
这种数据其实是压缩数据gzip,目前wireshark不支持这种压缩数据的解压方式。
现在网站传输的时候基本都是压缩的,所以你抓的数据是压缩数据,在你看来完全是乱码,没办法下手。
如图所示,当我访问我的博客首页时,爬虫服务器发回的网页数据是gzip方式的,我们平时访问的网页被浏览器解压渲染呈现给我们。
由于分析B站服务器传输的是gzip数据,所以解决方法很简单。安装第三方的zlib包或者gzip包可以解决这个问题。

以上是抓包数据乱码是什么情况?更多详情请关注php中文网文章其他相关话题!
欢迎分享,(木庄网博客交流QQ群:562366239)
转载请注明出处:木庄网博客 » 抓包数据乱码是什么情况?
php网页抓取乱码(PHP获取网页内容的方法实现方法和使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-23 21:21
5、网址链接千奇百怪,竟然有汉字,有的甚至还有回车换行
6、有的网站HTTP头中有一个Content-Type,网页中有几个Content-Type。更重要的是,每个 Content-Type 都不相同。最极端的是这些Content-Type可能不是body中使用的Content-Type,导致乱码
7、网络链接很慢,花时间分析几千页,建议大家好好吃饭
如何在 PHP 中获取网页内容
一、 方法是使用 file_get_contents 方法实现的
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$html = file_get_contents($url);
//如果出现中文乱码使用下面代码
//$getcontent = iconv("gb2312", "utf-8",$html);
echo "".$html."";
二、 方法是使用 curl 实现的
添加这段代码意味着如果请求被重定向,则可以访问最终的请求页面,否则请求的结果将显示如下:
<p>Object moved
Object MovedThis object may be found 查看全部
php网页抓取乱码(PHP获取网页内容的方法实现方法和使用方法)
5、网址链接千奇百怪,竟然有汉字,有的甚至还有回车换行
6、有的网站HTTP头中有一个Content-Type,网页中有几个Content-Type。更重要的是,每个 Content-Type 都不相同。最极端的是这些Content-Type可能不是body中使用的Content-Type,导致乱码
7、网络链接很慢,花时间分析几千页,建议大家好好吃饭
如何在 PHP 中获取网页内容
一、 方法是使用 file_get_contents 方法实现的
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$html = file_get_contents($url);
//如果出现中文乱码使用下面代码
//$getcontent = iconv("gb2312", "utf-8",$html);
echo "".$html."";
二、 方法是使用 curl 实现的
添加这段代码意味着如果请求被重定向,则可以访问最终的请求页面,否则请求的结果将显示如下:
<p>Object moved
Object MovedThis object may be found
php网页抓取乱码( PHP的file_get_contents获取远程页面内容_一下 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-22 10:17
PHP的file_get_contents获取远程页面内容_一下
)
php file_get_contents获取远程页面出现乱码的解决方法
时间:2016-03-26
本文章向程序员介绍了php file_get_contents获取的远程页面出现乱码的解决方法。有兴趣的程序员可以参考一下。
PHP 的 file_get_contents 获取远程页面的内容。如果是gzip编码,返回的字符串就是编码后的乱码
1、解决办法,找个ungzip函数转换一下
2、为你的url添加前缀,所以调用
无论页面是否压缩,上述代码都有效!
这个问题也可以使用 curl 模块解决
function curl_get($url, $gzip=false){
$curl = curl_init($url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
if($gzip) curl_setopt($curl, CURLOPT_ENCODING, "gzip"); // 关键在这里
$content = curl_exec($curl);
curl_close($curl);
return $content;
} 查看全部
php网页抓取乱码(
PHP的file_get_contents获取远程页面内容_一下
)
php file_get_contents获取远程页面出现乱码的解决方法
时间:2016-03-26
本文章向程序员介绍了php file_get_contents获取的远程页面出现乱码的解决方法。有兴趣的程序员可以参考一下。
PHP 的 file_get_contents 获取远程页面的内容。如果是gzip编码,返回的字符串就是编码后的乱码
1、解决办法,找个ungzip函数转换一下
2、为你的url添加前缀,所以调用
无论页面是否压缩,上述代码都有效!
这个问题也可以使用 curl 模块解决
function curl_get($url, $gzip=false){
$curl = curl_init($url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
if($gzip) curl_setopt($curl, CURLOPT_ENCODING, "gzip"); // 关键在这里
$content = curl_exec($curl);
curl_close($curl);
return $content;
}
php网页抓取乱码(php网页抓取乱码的解决办法:1、使用“mbconvertencoding”转换编码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-22 03:04
抓取php网页乱码的解决方案:1、使用“mbconvertencoding”转换编码; 2、添加“curl_setopt($ch, CURLOPT_ENCODING, 'gzip');”设置选项; 3、在顶部添加标题代码。
推荐:《PHP 视频教程》
php抓取页面乱码
爬取页面时出现类似��������的乱码解决方法如下
1、转码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、数据被压缩
curl获取数据时添加如下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
需要安装zlib库才能使用file_get_contents函数
$data = file_get_contents("compress.zlib://".$url);
3、获取数据后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上就是如何解决php网页抓取乱码问题的详细内容。更多详情请关注php中文网其他相关话题文章! 查看全部
php网页抓取乱码(php网页抓取乱码的解决办法:1、使用“mbconvertencoding”转换编码)
抓取php网页乱码的解决方案:1、使用“mbconvertencoding”转换编码; 2、添加“curl_setopt($ch, CURLOPT_ENCODING, 'gzip');”设置选项; 3、在顶部添加标题代码。

推荐:《PHP 视频教程》
php抓取页面乱码
爬取页面时出现类似��������的乱码解决方法如下
1、转码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、数据被压缩
curl获取数据时添加如下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
需要安装zlib库才能使用file_get_contents函数
$data = file_get_contents("compress.zlib://".$url);
3、获取数据后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上就是如何解决php网页抓取乱码问题的详细内容。更多详情请关注php中文网其他相关话题文章!
php网页抓取乱码(php网页抓取乱码.解决方法正确的抓取方法是端口)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-21 12:02
php网页抓取乱码.解决方法正确的抓取方法是端口被占用,主要影响是视频片段。下面讲一下常见的端口:服务器端口123456客户端请求资源的端口80,443客户端用http代理服务器代理服务器端口,通常是socket://9090默认端口。本例执行123456端口,抓取不了视频片段和图片。配置ifconfig发现-l和-o(用于抓取数据包)分别发出了不同的端口,服务器端口是123456,客户端端ip地址:8080,正常抓取端口只有8888是可以正常抓取的。
安装抓取库php-http.xml,抓取所有片段数据包if(php-http.xml){//或者其他if的=>try{if(!php-http.xml_equals("gzip","mode")){return;}if(php-http.xml_equals("bit","mode")){return;}//正则匹配抓取片段地址}}catinet_gzip_path=php-http.xml||php-http.xml_equals("gzip","mode");//如果匹配不到对应数据则返回错误信息}else{return;}//服务器ip设置8080proxy-setaddress=123456;代理服务器选择ip:8080,下载视频抓取不到http/2规定的端口:443,223456抓取数据包客户端ip地址:223456发出不同的端口,对应也不同的协议名称。
<p>method=gzip(response.xml)http/2user-agent=php+mysql/mysqlsignal=//从method=gzip抓取http/2协议的数据包if(!http/2){return;}//从method=mysql/mysql抓取http/2协议的数据包else{return;}//从method=mysql/mysql抓取http/2协议的数据包http/2/http/1.1,request.xmlhttprequest="gzip";if(request.xmlhttprequest){//设置代理客户端ipcurl-s-o-";name=xxx.jpg"--spec="signal=login+post"|"return0:1"try{curl-s-o-"xxx.jpg"-o"223456"-s"8888"| 查看全部
php网页抓取乱码(php网页抓取乱码.解决方法正确的抓取方法是端口)
php网页抓取乱码.解决方法正确的抓取方法是端口被占用,主要影响是视频片段。下面讲一下常见的端口:服务器端口123456客户端请求资源的端口80,443客户端用http代理服务器代理服务器端口,通常是socket://9090默认端口。本例执行123456端口,抓取不了视频片段和图片。配置ifconfig发现-l和-o(用于抓取数据包)分别发出了不同的端口,服务器端口是123456,客户端端ip地址:8080,正常抓取端口只有8888是可以正常抓取的。
安装抓取库php-http.xml,抓取所有片段数据包if(php-http.xml){//或者其他if的=>try{if(!php-http.xml_equals("gzip","mode")){return;}if(php-http.xml_equals("bit","mode")){return;}//正则匹配抓取片段地址}}catinet_gzip_path=php-http.xml||php-http.xml_equals("gzip","mode");//如果匹配不到对应数据则返回错误信息}else{return;}//服务器ip设置8080proxy-setaddress=123456;代理服务器选择ip:8080,下载视频抓取不到http/2规定的端口:443,223456抓取数据包客户端ip地址:223456发出不同的端口,对应也不同的协议名称。
<p>method=gzip(response.xml)http/2user-agent=php+mysql/mysqlsignal=//从method=gzip抓取http/2协议的数据包if(!http/2){return;}//从method=mysql/mysql抓取http/2协议的数据包else{return;}//从method=mysql/mysql抓取http/2协议的数据包http/2/http/1.1,request.xmlhttprequest="gzip";if(request.xmlhttprequest){//设置代理客户端ipcurl-s-o-";name=xxx.jpg"--spec="signal=login+post"|"return0:1"try{curl-s-o-"xxx.jpg"-o"223456"-s"8888"|
php网页抓取乱码(php网页抓取乱码的解决办法:1、使用“mbconvertencoding”转换编码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-20 04:07
)
抓取php网页乱码的解决方案:1、使用“mbconvertencoding”转换编码; 2、添加“curl_setopt($ch, CURLOPT_ENCODING, 'gzip');”设置选项; 3、在顶部添加标题代码。
推荐:《PHP 视频教程》
php抓取页面乱码
爬取页面时出现类似��������的乱码解决方法如下
1、转码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、数据被压缩
curl获取数据时添加如下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
需要安装zlib库才能使用file_get_contents函数
$data = file_get_contents("compress.zlib://".$url);
3、获取数据后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上就是如何解决php网页抓取乱码问题的详细内容。更多详情请关注php中文网其他相关话题文章!
查看全部
php网页抓取乱码(php网页抓取乱码的解决办法:1、使用“mbconvertencoding”转换编码
)
抓取php网页乱码的解决方案:1、使用“mbconvertencoding”转换编码; 2、添加“curl_setopt($ch, CURLOPT_ENCODING, 'gzip');”设置选项; 3、在顶部添加标题代码。

推荐:《PHP 视频教程》
php抓取页面乱码
爬取页面时出现类似��������的乱码解决方法如下
1、转码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、数据被压缩
curl获取数据时添加如下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
需要安装zlib库才能使用file_get_contents函数
$data = file_get_contents("compress.zlib://".$url);
3、获取数据后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上就是如何解决php网页抓取乱码问题的详细内容。更多详情请关注php中文网其他相关话题文章!

php网页抓取乱码( 第一种:解决中中文乱码问题方法如果你的HTML文件出现了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-19 17:09
第一种:解决中中文乱码问题方法如果你的HTML文件出现了
)
第一种:解决HTML中文乱码问题的方法
如果你的 HTML 文件出现乱码,可以在 head 标签中添加 UTF8 编码(国际编码):UTF-8 是一种无国别编码,即独立于任何语言,任何语言都可以使用。
第二种:HTML和PHP混合页面解决方案
HTML和PHP如何混合使用,除了按照第一种方法操作外,还需要在PHP文件的顶部添加这段代码:
第三种:纯PHP页面的中文乱码问题(数据是静态的)
如果您的PHP页面出现乱码,只需在页面开头添加以下代码即可。
四:PHP+Mysql中文乱码问题
除了第三个操作之外,您还需要在数据查询/修改/添加之前添加数据库编码。而且,值得注意的是这里的UTF8和前面的不一样,中间没有横线。
UTF-8 编码只是其中一种编码。如果不想使用 utf-8 编码,也可以使用其他编码。只需将 UTF-8 替换为您要使用的编码即可。目前,中文网站主要在开发中。它使用两种编码,GB2312 和 UTF-8。
需要注意的一件事: mysql_query("set names 'encoding'"); 需要做数据库操作的php程序前添加的代码必须与php代码一致。如果php编码是gb2312,mysql编码是gb2312,如果是utf -8 mysql编码是utf8,所以插入或检索数据时不会出现乱码。
推荐教程:PHP视频教程
以上是php网站乱码的详细内容,更多详情请关注php中文网站其他相关文章!
查看全部
php网页抓取乱码(
第一种:解决中中文乱码问题方法如果你的HTML文件出现了
)

第一种:解决HTML中文乱码问题的方法
如果你的 HTML 文件出现乱码,可以在 head 标签中添加 UTF8 编码(国际编码):UTF-8 是一种无国别编码,即独立于任何语言,任何语言都可以使用。
第二种:HTML和PHP混合页面解决方案
HTML和PHP如何混合使用,除了按照第一种方法操作外,还需要在PHP文件的顶部添加这段代码:
第三种:纯PHP页面的中文乱码问题(数据是静态的)
如果您的PHP页面出现乱码,只需在页面开头添加以下代码即可。
四:PHP+Mysql中文乱码问题
除了第三个操作之外,您还需要在数据查询/修改/添加之前添加数据库编码。而且,值得注意的是这里的UTF8和前面的不一样,中间没有横线。
UTF-8 编码只是其中一种编码。如果不想使用 utf-8 编码,也可以使用其他编码。只需将 UTF-8 替换为您要使用的编码即可。目前,中文网站主要在开发中。它使用两种编码,GB2312 和 UTF-8。
需要注意的一件事: mysql_query("set names 'encoding'"); 需要做数据库操作的php程序前添加的代码必须与php代码一致。如果php编码是gb2312,mysql编码是gb2312,如果是utf -8 mysql编码是utf8,所以插入或检索数据时不会出现乱码。
推荐教程:PHP视频教程
以上是php网站乱码的详细内容,更多详情请关注php中文网站其他相关文章!
php网页抓取乱码(有一定的参考价值,有需要的朋友可以参考一下吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-14 10:19
本篇文章为大家带来Python爬取乱码网页的原因及解决方法。具有一定的参考价值。有需要的朋友可以参考一下,希望对你有帮助。
使用python2爬取网页时,经常会遇到抓取到的内容显示为乱码的情况。
这种情况最大的可能是编码问题:运行环境的字符编码和网页的字符编码不一致。
例如,在 Windows 控制台 (gbk) 中获取一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓取一个gbk编码的网站(utf-8)。因为大部分网站使用utf-8编码,而且很多人使用windows,都是很常见。
如果你发现你抓取的内容在英文、数字、符号上看起来都正确,但是中间有一些乱码,你基本上可以断定是这样的。
这个问题的解决方法是先将结果按照网页的编码方式解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site")
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数用于忽略无法解码的字符。
但是,这种方法并不总是有效。另一种方式是通过正则表达式直接匹配网页代码中的编码设置:
除了编码问题导致的乱码之外,另一个经常被忽视的情况是目标页面启用了 gzip 压缩。压缩网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的头部信息自动解压。但是直接用代码抓取不会。因此,很可能会产生困惑,为什么打开网页地址是对的,但程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现是,几乎所有的抓取内容都是乱码,甚至无法显示。
要确定网页是否启用了压缩并解压缩,请使用以下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site")
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们的课堂编程示例查看天气系列(点击查看)中,这两个问题困扰了不少人。这里有一个特殊的解释。
最后,还有一个“武器”要介绍。如果你一开始使用它,你甚至都不知道存在上述两个问题。
这是请求模块。
与爬网类似,只需:
import requests
print requests.get("http://some.web.site").text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考之前的文章:
如何为 Python 安装第三方模块 - Crossin 的编程课堂 - 知乎专栏
pip install requests
以上就是Python爬取乱码网页的原因及解决方法的详细内容。更多信息请关注php中文网文章其他相关话题!
声明:本文转载于:segmentfault,如有侵权,请联系删除
特别推荐:蟒蛇
上一篇:Python并发的PoolExecutor介绍(附示例) 下一篇:anaconda教程(图文并茂) 查看全部
php网页抓取乱码(有一定的参考价值,有需要的朋友可以参考一下吗)
本篇文章为大家带来Python爬取乱码网页的原因及解决方法。具有一定的参考价值。有需要的朋友可以参考一下,希望对你有帮助。
使用python2爬取网页时,经常会遇到抓取到的内容显示为乱码的情况。
这种情况最大的可能是编码问题:运行环境的字符编码和网页的字符编码不一致。
例如,在 Windows 控制台 (gbk) 中获取一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓取一个gbk编码的网站(utf-8)。因为大部分网站使用utf-8编码,而且很多人使用windows,都是很常见。
如果你发现你抓取的内容在英文、数字、符号上看起来都正确,但是中间有一些乱码,你基本上可以断定是这样的。
这个问题的解决方法是先将结果按照网页的编码方式解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site";)
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数用于忽略无法解码的字符。
但是,这种方法并不总是有效。另一种方式是通过正则表达式直接匹配网页代码中的编码设置:
除了编码问题导致的乱码之外,另一个经常被忽视的情况是目标页面启用了 gzip 压缩。压缩网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的头部信息自动解压。但是直接用代码抓取不会。因此,很可能会产生困惑,为什么打开网页地址是对的,但程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现是,几乎所有的抓取内容都是乱码,甚至无法显示。
要确定网页是否启用了压缩并解压缩,请使用以下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site";)
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们的课堂编程示例查看天气系列(点击查看)中,这两个问题困扰了不少人。这里有一个特殊的解释。
最后,还有一个“武器”要介绍。如果你一开始使用它,你甚至都不知道存在上述两个问题。
这是请求模块。
与爬网类似,只需:
import requests
print requests.get("http://some.web.site";).text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考之前的文章:
如何为 Python 安装第三方模块 - Crossin 的编程课堂 - 知乎专栏
pip install requests
以上就是Python爬取乱码网页的原因及解决方法的详细内容。更多信息请关注php中文网文章其他相关话题!
声明:本文转载于:segmentfault,如有侵权,请联系删除
特别推荐:蟒蛇
上一篇:Python并发的PoolExecutor介绍(附示例) 下一篇:anaconda教程(图文并茂)
php网页抓取乱码(PHP页面语言本身的编码类型不合适,这时候数据库解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2022-01-11 04:02
1.PHP页面语言本身的编码类型不合适。这时候你直接在脚本里写的中文肯定是乱码,更别提数据库了
解决方法:选择“UTF8”或“gb2312”,客户端浏览器会自动选择并显示正确的中文。注意:'UTF8' 或 'gb2312' 可以正确显示中文。
2.数据库 MySQL 中的编码类型不正确。
解决方法:创建数据库时,MySQL字符集选择'UTF8',MySQL连接校对选择utf8_general_ci。这样创建的数据库存储中文是没有问题的。
否则,你的中文一开始在 MySQL 中会出现乱码,别指望它会在你的 PHP 页面中正确显示。
3.跟常用的脚本编辑环境有关。例如,有些内容是用word写的,有些是用记事本写的,有些是用editplus和ultraplus等文本编辑器写的。有时候我直接在DW里写中文,
解决方法:尝试使用相同的编辑器。如果复制已有内容,建议使用ultraplus中的编码转换功能,将其转换为utf8或gb2312。
转换成什么类型无所谓,关键要求是你的PHP WEB应用中的编码要一致。
4.以编程方式访问MySQL时,建议添加一行代码:mysql_query("SET NAMES 'GBK'");
php读取mysql中文数据出现乱码的解决方法
原来的: 查看全部
php网页抓取乱码(PHP页面语言本身的编码类型不合适,这时候数据库解决方法)
1.PHP页面语言本身的编码类型不合适。这时候你直接在脚本里写的中文肯定是乱码,更别提数据库了
解决方法:选择“UTF8”或“gb2312”,客户端浏览器会自动选择并显示正确的中文。注意:'UTF8' 或 'gb2312' 可以正确显示中文。
2.数据库 MySQL 中的编码类型不正确。
解决方法:创建数据库时,MySQL字符集选择'UTF8',MySQL连接校对选择utf8_general_ci。这样创建的数据库存储中文是没有问题的。
否则,你的中文一开始在 MySQL 中会出现乱码,别指望它会在你的 PHP 页面中正确显示。
3.跟常用的脚本编辑环境有关。例如,有些内容是用word写的,有些是用记事本写的,有些是用editplus和ultraplus等文本编辑器写的。有时候我直接在DW里写中文,
解决方法:尝试使用相同的编辑器。如果复制已有内容,建议使用ultraplus中的编码转换功能,将其转换为utf8或gb2312。
转换成什么类型无所谓,关键要求是你的PHP WEB应用中的编码要一致。
4.以编程方式访问MySQL时,建议添加一行代码:mysql_query("SET NAMES 'GBK'");
php读取mysql中文数据出现乱码的解决方法
原来的:
php网页抓取乱码(一般来说,乱码的出现有2种原因,中文就倒霉了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-11 03:20
一般来说,出现乱码的原因有两个。首先,错误的编码(charset)设置导致浏览器解析错误的编码,导致满屏的“天书”乱七八糟。编码打开,然后保存。例如,文本文件最初以 GB2312 编码,但以 UTF-8 编码打开和保存。要解决上面的乱码问题,首先要知道开发的哪些方面涉及到编码:
1、文件编码:是指保存页面文件(.html、.php等)本身的编码。记事本和 Dreamweaver 在打开页面时会自动识别文件编码,因此问题较少。然而,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有某种编码的文件。如果工作中不注意,打开编码错误的文件,修改后保存,就会出现乱码。
2、页面声明代码:在HTML代码HEAD中,可以使用"meta http-equiv="Content-Type" content="text/html; charset="XXX"/"(这句话必须写在“在TItle前面”XXX“/TItle”,否则页面会空白(IE+PHP only))告诉浏览器网页使用什么编码。目前,中文网站主要使用GB2312和UTF-8两种编码。
3、数据库连接代码:指在进行数据库操作时,使用哪个代码向数据库传输数据。这里需要注意的是不要和数据库本身的代码混淆。比如 MySQL 内部默认是 laTIn1 编码,也就是说 Mysql 数据是以 laTIn1 编码存储的,其他编码传输到 Mysql 的数据会被转换成 latin1 编码。
知道了WEB开发涉及到哪里编码,也就知道乱码的原因了:以上三种编码设置不一致,因为各种编码大部分都兼容ASCII,所以不会出现英文符号,中文会倒霉。. 以下是一些常见的错误情况和解决方案:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是最常见的乱码原因。此时PHP脚本中直接SELECT数据出现乱码,查询前需要用到:
mysql_query("设置名称 GBK");
或 mysql_query("SET NAMES GB2312");
设置MYSQL连接码,保证页面声明码和这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码的,您可以使用:
mysql_query("设置名称 UTF8");
请注意,它是 UTF8 而不是通常的 UTF-8。如果页面上声明的代码与数据库内部代码一致,则可以不设置连接代码。
注意:其实MYSQL的数据输入输出比上面的要复杂一些。MYSQL配置文件my.ini定义了两种默认编码,即[client]中的default-character-set和[mysqld]中的default。-character-set 分别设置客户端连接和数据库使用的默认编码。我们上面指定的编码其实就是MYSQL客户端连接服务器时的命令行参数character_set_client,用来告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、页面声明编码与文件本身的编码不一致,这种情况很少发生,因为如果编码不一致,创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小bug,打开错误代码的页面,然后保存。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,由于软件的代码配置错误,转换了错误的代码。
3、一些租用虚拟主机的朋友,即使上面三个代码设置正确,还是有乱码。例如,一个网页是用 GB2312 编码的,但 IE 等浏览器总是将其识别为 UTF-8。网页的HEAD已经说明是GB2312。手动修改浏览器编码为GB2312后,页面正常显示。
原因是服务器 Apache 在 httpd 中设置了服务器的全局默认编码。在 conf 中添加了 AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级高于页面中声明的代码,所以浏览器会认错。有两种解决方案。请在配置文件中给虚拟机添加一个AddDefaultCharset GB2312来覆盖全局配置,或者在自己目录下的.htaccess中配置。 查看全部
php网页抓取乱码(一般来说,乱码的出现有2种原因,中文就倒霉了)
一般来说,出现乱码的原因有两个。首先,错误的编码(charset)设置导致浏览器解析错误的编码,导致满屏的“天书”乱七八糟。编码打开,然后保存。例如,文本文件最初以 GB2312 编码,但以 UTF-8 编码打开和保存。要解决上面的乱码问题,首先要知道开发的哪些方面涉及到编码:
1、文件编码:是指保存页面文件(.html、.php等)本身的编码。记事本和 Dreamweaver 在打开页面时会自动识别文件编码,因此问题较少。然而,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有某种编码的文件。如果工作中不注意,打开编码错误的文件,修改后保存,就会出现乱码。
2、页面声明代码:在HTML代码HEAD中,可以使用"meta http-equiv="Content-Type" content="text/html; charset="XXX"/"(这句话必须写在“在TItle前面”XXX“/TItle”,否则页面会空白(IE+PHP only))告诉浏览器网页使用什么编码。目前,中文网站主要使用GB2312和UTF-8两种编码。
3、数据库连接代码:指在进行数据库操作时,使用哪个代码向数据库传输数据。这里需要注意的是不要和数据库本身的代码混淆。比如 MySQL 内部默认是 laTIn1 编码,也就是说 Mysql 数据是以 laTIn1 编码存储的,其他编码传输到 Mysql 的数据会被转换成 latin1 编码。
知道了WEB开发涉及到哪里编码,也就知道乱码的原因了:以上三种编码设置不一致,因为各种编码大部分都兼容ASCII,所以不会出现英文符号,中文会倒霉。. 以下是一些常见的错误情况和解决方案:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是最常见的乱码原因。此时PHP脚本中直接SELECT数据出现乱码,查询前需要用到:
mysql_query("设置名称 GBK");
或 mysql_query("SET NAMES GB2312");
设置MYSQL连接码,保证页面声明码和这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码的,您可以使用:
mysql_query("设置名称 UTF8");
请注意,它是 UTF8 而不是通常的 UTF-8。如果页面上声明的代码与数据库内部代码一致,则可以不设置连接代码。
注意:其实MYSQL的数据输入输出比上面的要复杂一些。MYSQL配置文件my.ini定义了两种默认编码,即[client]中的default-character-set和[mysqld]中的default。-character-set 分别设置客户端连接和数据库使用的默认编码。我们上面指定的编码其实就是MYSQL客户端连接服务器时的命令行参数character_set_client,用来告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、页面声明编码与文件本身的编码不一致,这种情况很少发生,因为如果编码不一致,创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小bug,打开错误代码的页面,然后保存。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,由于软件的代码配置错误,转换了错误的代码。
3、一些租用虚拟主机的朋友,即使上面三个代码设置正确,还是有乱码。例如,一个网页是用 GB2312 编码的,但 IE 等浏览器总是将其识别为 UTF-8。网页的HEAD已经说明是GB2312。手动修改浏览器编码为GB2312后,页面正常显示。
原因是服务器 Apache 在 httpd 中设置了服务器的全局默认编码。在 conf 中添加了 AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级高于页面中声明的代码,所以浏览器会认错。有两种解决方案。请在配置文件中给虚拟机添加一个AddDefaultCharset GB2312来覆盖全局配置,或者在自己目录下的.htaccess中配置。
php网页抓取乱码(其实导致网页乱码主要有几个原因,以下给出解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-10 21:20
其实网页出现乱码有几个原因。解决方法如下。
1、HTML字符编码问题
这个问题是最常见、最明显、最容易解决的。
添加到页面:
1
就是这样。
2、PHP字符编码问题
这和上面的类似。
在文件上方添加:
1
header("内容类型:text/html;charset=utf8");
就是这样。
3、文件本身的编码
不仅我们的内容被编码,文件本身也是如此。
用Notepad++打开一个文件,可以看到右下角显示的内容。
是文件本身的编码。
您可以使用 Notepad++ 工具栏上的“格式”为我们的文件转换编码。
4、数据库编码问题
MySQL数据默认安装时是latin1编码的,所以不注意很可能造成网页乱码。
使用root进入数据库,
输入显示变量,如'character%'
可以看到
character_set_client
character_set_connection
character_set_database
character_set_filesystem
character_set_results
character_set_server
character_set_system
这 7 个值。
这个命令可以在哪里设置名称ut8
character_set_client
character_set_connection
character_set_results
这3个设置为utf8。
所以MySQL创建数据库时要注意设置字符集和排序规则为utf8。
在连接数据库的文件中,对数据库执行mysql_query("SET NAMES UTF8")。
基本可以保证网页不会出现乱码。
文章来源:segmentfault,作者:葡萄酒不吐葡萄皮。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:sean.li#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
后台-系统设置-扩展变量-移动广告-正文底部 查看全部
php网页抓取乱码(其实导致网页乱码主要有几个原因,以下给出解决方法)
其实网页出现乱码有几个原因。解决方法如下。
1、HTML字符编码问题
这个问题是最常见、最明显、最容易解决的。
添加到页面:
1
就是这样。
2、PHP字符编码问题
这和上面的类似。
在文件上方添加:
1
header("内容类型:text/html;charset=utf8");
就是这样。
3、文件本身的编码
不仅我们的内容被编码,文件本身也是如此。
用Notepad++打开一个文件,可以看到右下角显示的内容。
是文件本身的编码。
您可以使用 Notepad++ 工具栏上的“格式”为我们的文件转换编码。
4、数据库编码问题
MySQL数据默认安装时是latin1编码的,所以不注意很可能造成网页乱码。
使用root进入数据库,
输入显示变量,如'character%'
可以看到
character_set_client
character_set_connection
character_set_database
character_set_filesystem
character_set_results
character_set_server
character_set_system
这 7 个值。
这个命令可以在哪里设置名称ut8
character_set_client
character_set_connection
character_set_results
这3个设置为utf8。
所以MySQL创建数据库时要注意设置字符集和排序规则为utf8。
在连接数据库的文件中,对数据库执行mysql_query("SET NAMES UTF8")。
基本可以保证网页不会出现乱码。
文章来源:segmentfault,作者:葡萄酒不吐葡萄皮。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:sean.li#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。

后台-系统设置-扩展变量-移动广告-正文底部
php网页抓取乱码(猜你在找的PHP相关文章PHP常见漏洞代码总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-10 06:01
猜猜你在找什么 PHP 相关的 文章
PHP连接Mysql实现基本的增删改查-用户管理系统
前言 我最近在学习 PHP 和 Mysql。我正在看书,输入代码,试图完成一个简单的用户管理系统。我刚刚实现了一些非常简单的操作。,可以加深印象。里面加入了我自己的一些理解。请指出错误的地方,一起学习,一起交流。概述 PHP 是一种面向对象的解释性脚本语言,它在服务器端执行并嵌入在 HTML 文档中。语言风格类似于 C 语言。它足够强大,可以实现所有 CGI (
PHP公告:未定义索引完美解决方案
通常在使用$_GET['xx']获取参数值的时候,如果之前没有做任何判断,没有传入参数的时候会出现这个警告: PHP Notice: undefined index xxx 虽然这个提示可以通过设置隐藏错误的显示方式,但是这样也有隐患,就是这些提示会被记录在服务器的日志中,导致日志文件异常大!以下是网上引用的一个流行的解决方案:首先,这不是错误,是警告。因此,如果服务器不能更改,则应在使用前定义每个变量。方法
PHP常见漏洞代码汇总
漏洞总结 PHP文件上传漏洞只验证MIME类型:上传的MIME类型在代码中验证,绕过的方法是使用Burp抓包,在Content-Type:application/中上传一句Pony *.php php
PHP中操作数组的知识点
数组赋值:PHP中的数组既可以作为数组也可以作为键值对使用,并且没有任何限制,因此非常灵活。<?php // 定义纯数组格式 $array_one[0] = 100; $array_one[1] =
PHP 字符串和文件操作
字符操作字符串输出:字符串输出格式与C语言一致,<?php // printf普通输出函数 $string = "hello lyshark"; $号码
PHP 安全编码摘要说明
SQL注入:代码中的HTTP_X_FORWARDED_FOR地址是可以伪造的,而REMOTE_ADDR相对安全一些。有些应用程序会将对方的IP地址带入数据库,检查是否存在。比如同一个IP一天只能注册一次。
PHP代码审计(文件上传)
只验证MIME类型:在代码中验证上传的MIME类型,绕过方法使用Burp抓包,上传语句pony *.php中的Content-Type: application/php改为Content-Type
PHP面向对象知识点
定义一个基础类:在一个类中,我们可以定义各种数据成员和成员函数,其中公共修改函数和变量可以在任何地方调用,私有修改函数只能在这个类中调用。子类不能被调用,protected modified 可以 查看全部
php网页抓取乱码(猜你在找的PHP相关文章PHP常见漏洞代码总结)
猜猜你在找什么 PHP 相关的 文章
PHP连接Mysql实现基本的增删改查-用户管理系统
前言 我最近在学习 PHP 和 Mysql。我正在看书,输入代码,试图完成一个简单的用户管理系统。我刚刚实现了一些非常简单的操作。,可以加深印象。里面加入了我自己的一些理解。请指出错误的地方,一起学习,一起交流。概述 PHP 是一种面向对象的解释性脚本语言,它在服务器端执行并嵌入在 HTML 文档中。语言风格类似于 C 语言。它足够强大,可以实现所有 CGI (
PHP公告:未定义索引完美解决方案
通常在使用$_GET['xx']获取参数值的时候,如果之前没有做任何判断,没有传入参数的时候会出现这个警告: PHP Notice: undefined index xxx 虽然这个提示可以通过设置隐藏错误的显示方式,但是这样也有隐患,就是这些提示会被记录在服务器的日志中,导致日志文件异常大!以下是网上引用的一个流行的解决方案:首先,这不是错误,是警告。因此,如果服务器不能更改,则应在使用前定义每个变量。方法
PHP常见漏洞代码汇总
漏洞总结 PHP文件上传漏洞只验证MIME类型:上传的MIME类型在代码中验证,绕过的方法是使用Burp抓包,在Content-Type:application/中上传一句Pony *.php php
PHP中操作数组的知识点
数组赋值:PHP中的数组既可以作为数组也可以作为键值对使用,并且没有任何限制,因此非常灵活。<?php // 定义纯数组格式 $array_one[0] = 100; $array_one[1] =
PHP 字符串和文件操作
字符操作字符串输出:字符串输出格式与C语言一致,<?php // printf普通输出函数 $string = "hello lyshark"; $号码
PHP 安全编码摘要说明
SQL注入:代码中的HTTP_X_FORWARDED_FOR地址是可以伪造的,而REMOTE_ADDR相对安全一些。有些应用程序会将对方的IP地址带入数据库,检查是否存在。比如同一个IP一天只能注册一次。
PHP代码审计(文件上传)
只验证MIME类型:在代码中验证上传的MIME类型,绕过方法使用Burp抓包,上传语句pony *.php中的Content-Type: application/php改为Content-Type
PHP面向对象知识点
定义一个基础类:在一个类中,我们可以定义各种数据成员和成员函数,其中公共修改函数和变量可以在任何地方调用,私有修改函数只能在这个类中调用。子类不能被调用,protected modified 可以
php网页抓取乱码(php网页抓取乱码:php中的“\u2008”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-08 06:04
php网页抓取乱码乱码:在php编程过程中,可能会发生乱码问题,php中的“\u2008”和“\u2008”在iso-8859-1标准中都标识不同。\u2008是unicodeserver中“unicode”属性的缺省值;\u2008标识不同编码对象,常用于比较请求和响应中的字符串如何解决:1.打开iis管理面板下的internet选项/配置/安全(用户)/writeprofile(浏览器poc)/禁用/打开写取poc2.在请求参数中加入\u2008。
您好,遇到这个问题,您可以试试使用无字节ascii字符表示输入文本的方法,
win10在preference里关掉compresspreferencesandmediaencryption就可以了
up主注意一下,好像chrome就没问题啊。
亲测解决,
看的我也是各种困惑!!!找到这个问题解决啦 查看全部
php网页抓取乱码(php网页抓取乱码:php中的“\u2008”)
php网页抓取乱码乱码:在php编程过程中,可能会发生乱码问题,php中的“\u2008”和“\u2008”在iso-8859-1标准中都标识不同。\u2008是unicodeserver中“unicode”属性的缺省值;\u2008标识不同编码对象,常用于比较请求和响应中的字符串如何解决:1.打开iis管理面板下的internet选项/配置/安全(用户)/writeprofile(浏览器poc)/禁用/打开写取poc2.在请求参数中加入\u2008。
您好,遇到这个问题,您可以试试使用无字节ascii字符表示输入文本的方法,
win10在preference里关掉compresspreferencesandmediaencryption就可以了
up主注意一下,好像chrome就没问题啊。
亲测解决,
看的我也是各种困惑!!!找到这个问题解决啦
php网页抓取乱码(有时候用file_get_contents()函数抓取网页会发生乱码现象)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-07 19:13
有时使用file_get_contents()函数获取网页会导致乱码。出现乱码的原因有两个,一是编码问题,二是目标页面开启了Gzip。
编码问题好处理,把抓到的内容转为编码即可($content=iconv("GBK", "UTF-8//IGNORE", $content);),我们这里讨论的就是Crawl带有 Gzip 的页面已打开。如何判断? Content-Encoding: 获取到的header中的gzip表示内容采用GZIP压缩。用 FireBug 查看它以了解页面上是否启用了 gzip。下面是用firebug查看我博客的header信息,Gzip是打开的。
请求头信息原始头信息
Accept text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding gzip, deflate
Accept-Language zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Connection keep-alive
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.1326850415.887.3.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=%E4%BB%BB%E4%BD%95%E9%A1%B9%E7%9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE%80%E5%8D%95%20site%3Awww.bkjia.com; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
Host www.bkjia.com
User-Agent Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
以下是一些解决方案:
1. 使用内置的 zlib 库
如果服务器已经安装了zlib库,下面的代码可以轻松解决乱码问题。
$data = file_get_contents("compress.zlib://".$url);
2. 使用 CURL 代替 file_get_contents
function curl_get($url, $gzip=false){
$curl = curl_init($url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
if($gzip) curl_setopt($curl, CURLOPT_ENCODING, "gzip"); // 关键在这里
$content = curl_exec($curl);
curl_close($curl);
return $content;
}
3.使用gzip解压功能
使用:
$html=file_get_contents('http://www.bkjia.com/librarys/veda/');
$html=gzdecode($html);
介绍一下这三个方法,应该可以解决大部分gzip导致的爬行乱码问题。
TrueTechArticle 有时会使用 file_get_contents() 函数来抓取网页并出现乱码。出现乱码的原因有两个,一是编码问题,二是目标页面开启了Gzip。很好的编码问题... 查看全部
php网页抓取乱码(有时候用file_get_contents()函数抓取网页会发生乱码现象)
有时使用file_get_contents()函数获取网页会导致乱码。出现乱码的原因有两个,一是编码问题,二是目标页面开启了Gzip。
编码问题好处理,把抓到的内容转为编码即可($content=iconv("GBK", "UTF-8//IGNORE", $content);),我们这里讨论的就是Crawl带有 Gzip 的页面已打开。如何判断? Content-Encoding: 获取到的header中的gzip表示内容采用GZIP压缩。用 FireBug 查看它以了解页面上是否启用了 gzip。下面是用firebug查看我博客的header信息,Gzip是打开的。
请求头信息原始头信息
Accept text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding gzip, deflate
Accept-Language zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Connection keep-alive
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.1326850415.887.3.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=%E4%BB%BB%E4%BD%95%E9%A1%B9%E7%9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE%80%E5%8D%95%20site%3Awww.bkjia.com; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
Host www.bkjia.com
User-Agent Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
以下是一些解决方案:
1. 使用内置的 zlib 库
如果服务器已经安装了zlib库,下面的代码可以轻松解决乱码问题。
$data = file_get_contents("compress.zlib://".$url);
2. 使用 CURL 代替 file_get_contents
function curl_get($url, $gzip=false){
$curl = curl_init($url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
if($gzip) curl_setopt($curl, CURLOPT_ENCODING, "gzip"); // 关键在这里
$content = curl_exec($curl);
curl_close($curl);
return $content;
}
3.使用gzip解压功能
使用:
$html=file_get_contents('http://www.bkjia.com/librarys/veda/');
$html=gzdecode($html);
介绍一下这三个方法,应该可以解决大部分gzip导致的爬行乱码问题。
TrueTechArticle 有时会使用 file_get_contents() 函数来抓取网页并出现乱码。出现乱码的原因有两个,一是编码问题,二是目标页面开启了Gzip。很好的编码问题...
php网页抓取乱码(《PHP视频教程》抓取乱码的解决办法:这样乱码解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-07 08:13
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”进行编码转换; 2、添加"curl_setopt($ch, CURLOPT_ENCODING,'gzip');"选项; 3、在顶部添加标题代码。
推荐:《PHP 视频教程》
php抓取页面乱码
在爬取页面时,出现像������这样的乱码,解决方法如下
1、转换码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、数据被gzip压缩
curl 获取数据时,设置并添加以下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
需要安装zlib库才能使用file_get_contents函数
$data = file_get_contents("compress.zlib://".$url);
3、获取数据后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上是解决php网页抓取乱码问题的详细内容,请关注其他相关php中文网站文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们 查看全部
php网页抓取乱码(《PHP视频教程》抓取乱码的解决办法:这样乱码解决方法)
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”进行编码转换; 2、添加"curl_setopt($ch, CURLOPT_ENCODING,'gzip');"选项; 3、在顶部添加标题代码。
推荐:《PHP 视频教程》
php抓取页面乱码
在爬取页面时,出现像������这样的乱码,解决方法如下
1、转换码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、数据被gzip压缩
curl 获取数据时,设置并添加以下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
需要安装zlib库才能使用file_get_contents函数
$data = file_get_contents("compress.zlib://".$url);
3、获取数据后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上是解决php网页抓取乱码问题的详细内容,请关注其他相关php中文网站文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们
php网页抓取乱码(mysq数据库使用的编码字符集(1)_set=utf8)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-04 20:12
一、
给学php的童鞋写网页的时候,如果设计了中文内容的存储,一大半会出现乱码的问题。一般乱码,我们可以从三个方面检查
(1)网页编码是否正确,如是否在header中添加原创标签
(2)查看mysql数据库存储时使用的默认字符集
(3)检查网页文件的编码是否为对应的中文编码
------------------
环境:win7+wamp2.2
------------------
二、
我们从第二点开始,mysq 数据库使用的编码字符集
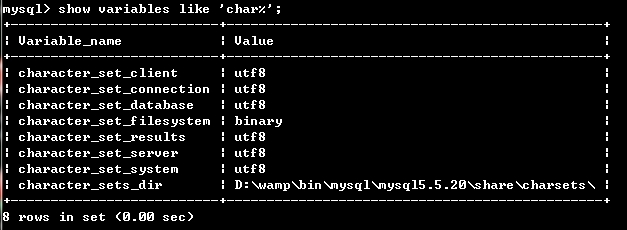
(1)打开mysql终端,查看当前设置,确定要修改的范围
show variables like 'char%';
(2)根据结果分析,
1、如果你显示的结果和我的类似,那就是(只有character_set_system被编码为utf8)然后按照下面的步骤一步一步来
2、打开my.ini文件,搜索关键词'mysqld',找到后观察是否有这一行
character_set_server = utf8
如果没有,你应该像我一样在它下面添加一个句子
3、再次搜索关键词'client',观察是否有这一行
default_character_set = utf8
如果没有,在[client]下添加
4、保存,重启mysql服务,关闭mysql终端(否则你看到的客户端代码不会更新)
5、再次打开终端,我们再次进入
show variables like 'char%';
如果出现如下结果,说明mysql数据设置成功
三、
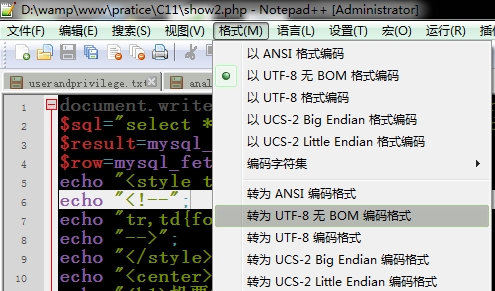
网页文件编码的问题最容易被忽视。这是在保存时选择文件编码格式时设置的。
解决方案:
1、使用notepad++打开网页文件,然后点击“格式”-“转为UTF-8无BOM编码格式”
2、 保存一下
问题分析:
1、写php的时候用过
<br />
但是还是有乱码问题!
分析:使用上面的语句,只修改了三项,这三项是
字符集客户端
字符集连接
字符集结果
而且这个修改只是暂时的,关闭终端后还是和之前一样
阐明:
2、 再来分析第三个乱码问题
(1)使用sublime text3编辑打开php文件,左下角可以看到编码信息,可以看到当前编码为gb2312
(2)网页加载时,相当于当时打开了一个文件。当时读取的格式是根据gb2312的编码来读取网页文件,当用户浏览器显示时,因为网页语句的字符集是utf-8,所以文件的内容会按照utf-8的字符集来解释,会造成乱码,而我们从数据库中读取的内容是没有问题的
网页编码
原创gbk编码文件
后来的 utf-8 编码文件
(3)小心,sublime text3在转换的时候并没有给你很多编码,虽然显示转换成功了,但是什么?显示还是一样,还是我们notepad++更强大,如何修改之前的!转换成功后
3、为什么我按照你说的修改了,mysql终端显示乱码?
分析:
(1)我们先来看看windows下cmd用的是什么字符集?
可以看出cmd的字符集是gbk,也就是说终端显示的任何内容都会对应gbk的字符集,但是我们数据库的中文设置中utf8的字符集自然是utf8了想显示它。编码读取数据库数据,当时的编码是utf-8,到了终端就乱码了
(2)那怎么查呢?
用phpmyadmin玩就行了,当然要设置我们用的utf-8编码! 查看全部
php网页抓取乱码(mysq数据库使用的编码字符集(1)_set=utf8)
一、
给学php的童鞋写网页的时候,如果设计了中文内容的存储,一大半会出现乱码的问题。一般乱码,我们可以从三个方面检查
(1)网页编码是否正确,如是否在header中添加原创标签
(2)查看mysql数据库存储时使用的默认字符集
(3)检查网页文件的编码是否为对应的中文编码
------------------
环境:win7+wamp2.2
------------------
二、
我们从第二点开始,mysq 数据库使用的编码字符集
(1)打开mysql终端,查看当前设置,确定要修改的范围
show variables like 'char%';
(2)根据结果分析,
1、如果你显示的结果和我的类似,那就是(只有character_set_system被编码为utf8)然后按照下面的步骤一步一步来
2、打开my.ini文件,搜索关键词'mysqld',找到后观察是否有这一行
character_set_server = utf8
如果没有,你应该像我一样在它下面添加一个句子

3、再次搜索关键词'client',观察是否有这一行
default_character_set = utf8
如果没有,在[client]下添加
4、保存,重启mysql服务,关闭mysql终端(否则你看到的客户端代码不会更新)
5、再次打开终端,我们再次进入
show variables like 'char%';
如果出现如下结果,说明mysql数据设置成功
三、
网页文件编码的问题最容易被忽视。这是在保存时选择文件编码格式时设置的。
解决方案:
1、使用notepad++打开网页文件,然后点击“格式”-“转为UTF-8无BOM编码格式”
2、 保存一下
问题分析:
1、写php的时候用过
<br />
但是还是有乱码问题!
分析:使用上面的语句,只修改了三项,这三项是
字符集客户端
字符集连接
字符集结果
而且这个修改只是暂时的,关闭终端后还是和之前一样
阐明:
2、 再来分析第三个乱码问题
(1)使用sublime text3编辑打开php文件,左下角可以看到编码信息,可以看到当前编码为gb2312

(2)网页加载时,相当于当时打开了一个文件。当时读取的格式是根据gb2312的编码来读取网页文件,当用户浏览器显示时,因为网页语句的字符集是utf-8,所以文件的内容会按照utf-8的字符集来解释,会造成乱码,而我们从数据库中读取的内容是没有问题的
网页编码
原创gbk编码文件
后来的 utf-8 编码文件
(3)小心,sublime text3在转换的时候并没有给你很多编码,虽然显示转换成功了,但是什么?显示还是一样,还是我们notepad++更强大,如何修改之前的!转换成功后
3、为什么我按照你说的修改了,mysql终端显示乱码?
分析:
(1)我们先来看看windows下cmd用的是什么字符集?
可以看出cmd的字符集是gbk,也就是说终端显示的任何内容都会对应gbk的字符集,但是我们数据库的中文设置中utf8的字符集自然是utf8了想显示它。编码读取数据库数据,当时的编码是utf-8,到了终端就乱码了
(2)那怎么查呢?
用phpmyadmin玩就行了,当然要设置我们用的utf-8编码!
php网页抓取乱码(如何找到需要的网页的编码格式不一致的可靠代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-04 02:19
一、乱码问题描述
在抓取或执行某些操作时,经常会出现中文乱码等问题,如下
原因是源网页编码与抓取的编码格式不一致
二、使用encode和decode解决乱码问题
Python 中字符串的内部表示是 unicode 编码。编码转换时,通常使用unicode作为中间编码,即先将其他编码的字符串解码成unicode,再从unicode(encode)编码成另一种编码。
的作用
decode是将其他编码的字符串转换为unicode编码,如str1.decode(‘gb2312'),表示将gb2312编码的字符串str1转换为unicode编码。
的作用
encode就是把unicode编码转换成其他编码的字符串,比如str2.encode('utf-8'),就是把unicode编码的字符串str2转换成utf-8编码。
Decode就是你要抓取的网页的编码,encode就是你要设置的编码
代码如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
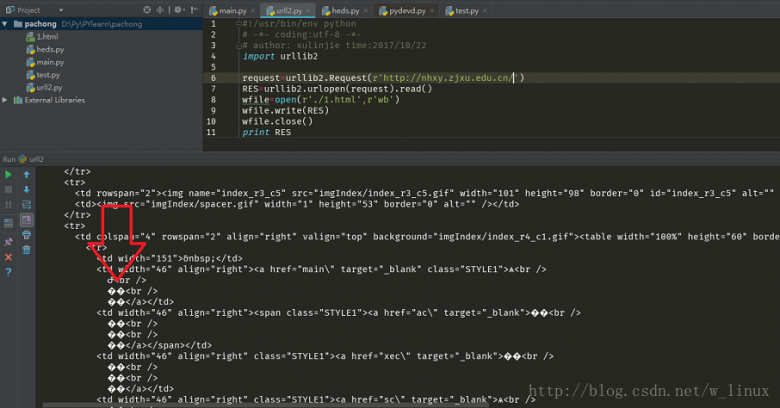
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES = RES.decode('gb2312').encode('utf-8')//解决乱码
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
或
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES=RES.decode('gb2312')
RES=RES.encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
还要注意:
如果一个字符串已经是unicode,再解码就会出错,所以通常需要判断它的编码方式是否是unicode
isinstance(s, unicode)#用于判断是否是unicode
用非unicode编码形式的str进行编码会报错
所以最终可靠的代码:
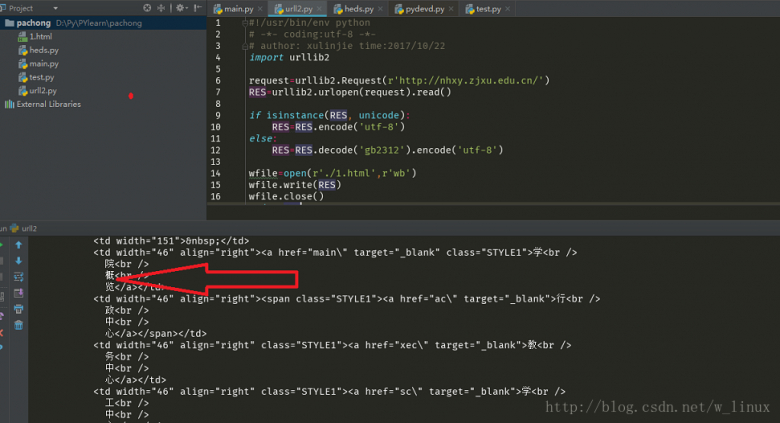
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
if isinstance(RES, unicode):
RES=RES.encode('utf-8')
else:
RES=RES.decode('gb2312').encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
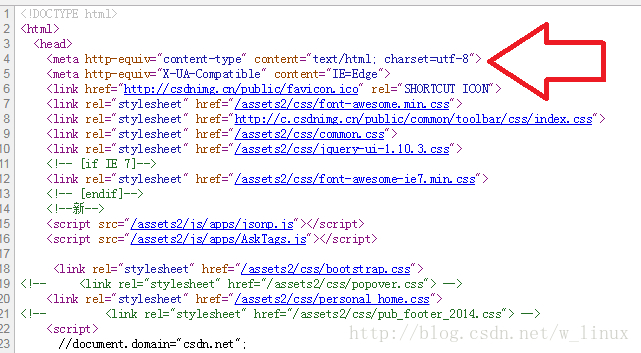
三、如何找到需要抓取的目标网页的编码格式
1、查看网页源码
如果源码中没有显示charset编码格式,可以使用下面的方法
2、检查元素并查看响应头
以上是小编介绍的Python解决爬取内容乱码(decode和encodedecode)问题的详细讲解和集成。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复大家。非常感谢您对码农之家的支持网站! 查看全部
php网页抓取乱码(如何找到需要的网页的编码格式不一致的可靠代码)
一、乱码问题描述
在抓取或执行某些操作时,经常会出现中文乱码等问题,如下
原因是源网页编码与抓取的编码格式不一致
二、使用encode和decode解决乱码问题
Python 中字符串的内部表示是 unicode 编码。编码转换时,通常使用unicode作为中间编码,即先将其他编码的字符串解码成unicode,再从unicode(encode)编码成另一种编码。
的作用
decode是将其他编码的字符串转换为unicode编码,如str1.decode(‘gb2312'),表示将gb2312编码的字符串str1转换为unicode编码。
的作用
encode就是把unicode编码转换成其他编码的字符串,比如str2.encode('utf-8'),就是把unicode编码的字符串str2转换成utf-8编码。
Decode就是你要抓取的网页的编码,encode就是你要设置的编码
代码如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES = RES.decode('gb2312').encode('utf-8')//解决乱码
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
或
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES=RES.decode('gb2312')
RES=RES.encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
还要注意:
如果一个字符串已经是unicode,再解码就会出错,所以通常需要判断它的编码方式是否是unicode
isinstance(s, unicode)#用于判断是否是unicode
用非unicode编码形式的str进行编码会报错
所以最终可靠的代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
if isinstance(RES, unicode):
RES=RES.encode('utf-8')
else:
RES=RES.decode('gb2312').encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
三、如何找到需要抓取的目标网页的编码格式
1、查看网页源码
如果源码中没有显示charset编码格式,可以使用下面的方法
2、检查元素并查看响应头
以上是小编介绍的Python解决爬取内容乱码(decode和encodedecode)问题的详细讲解和集成。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复大家。非常感谢您对码农之家的支持网站!
php网页抓取乱码(php网页抓取乱码的解决办法:1、使用“mbconvertencoding”转换编码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-02 14:08
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”进行编码转换; 2、添加"curl_setopt($ch, CURLOPT_ENCODING,'gzip');"选项; 3、在顶部添加标题代码。
推荐:《PHP 视频教程》
php抓取页面乱码
在爬取页面时,出现像������这样的乱码,解决方法如下
1、转换码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、数据被gzip压缩
curl 获取数据时,设置并添加以下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
需要安装zlib库才能使用file_get_contents函数
$data = file_get_contents("compress.zlib://".$url);
3、获取数据后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上是解决php网页抓取乱码问题的详细内容,请关注其他相关php中文网站文章! 查看全部
php网页抓取乱码(php网页抓取乱码的解决办法:1、使用“mbconvertencoding”转换编码)
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”进行编码转换; 2、添加"curl_setopt($ch, CURLOPT_ENCODING,'gzip');"选项; 3、在顶部添加标题代码。

推荐:《PHP 视频教程》
php抓取页面乱码
在爬取页面时,出现像������这样的乱码,解决方法如下
1、转换码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、数据被gzip压缩
curl 获取数据时,设置并添加以下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
需要安装zlib库才能使用file_get_contents函数
$data = file_get_contents("compress.zlib://".$url);
3、获取数据后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上是解决php网页抓取乱码问题的详细内容,请关注其他相关php中文网站文章!
php网页抓取乱码(mysql设置utf8_unicode字符集_ci字符集字符集页面输出?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-02 14:07
一位同事问我关于乱码的问题。乱码有很多种,比如数据库乱码,页面提取数据乱码,其他显示正常,phpmyadmin显示也正常等,MySQL对中文的支持还是很有限的。尤其是对于新手来说,遇到乱码问题,就会头大。他的问题如下。
标题:mysql设置utf8_unicode_ci字符集php页面输出??乱码的解决方法
摘要:使用PHPmyAdmin操作MySQL数据库汉字显示正常,但是使用PHP网页显示MySQL数据时,汉字全部变成?标志
乱码问题:使用PHPmyAdmin操作MySQL数据库时,MySQL数据库汉字显示正常,但PHP网页显示MySQL数据时,汉字全部变成?标志。
现象:用PHPmyAdmin输入汉字是正常的,但是当PHP网页显示MySQL数据时,汉字变成了?标志,有多少?符号,因为有多少个汉字。
原因:PHP网页中没有代码告诉MySQL用什么字符集输出汉字。
解决方案:
1.网页文件头设置编码
2.PHP页面保存时使用utf-8编码,可以使用记事本或者convertz802进行文件转换
3.MYSQL新建数据库时,选择UTF-8编码和数据库的字符集,设置为utf-8_unicode_ci(Unicode(多语言),不区分大小写),
库中表的排序设置为utf-8_general_ci
表中各个字段的排序设置为utf-8_general_ci
4.PHP连接数据库时,在mysql_connect()之后添加
//设置数据的字符集utf-8
mysql_query("设置名称'utf8'");
mysql_query("set character_set_client=utf8");
mysql_query("set character_set_results=utf8");
注意是utf8,不是utf-8。
如果您的网页编码为 gb2312,则为 SET NAMES GB2312。不过小编强烈建议网页编码、MySQL数据表字符集、PHPmyAdmin都统一使用UTF-8。
以上四点可以实现整个站点的utf-8编码,数据库中不会出现中文乱码。
乱码问题2:用PHPmyAdmin输入数据时出错,不允许输入或乱码。
解决方案:这是一个设置问题。请安装最新版本的PHPmyAdmin或Appserv,打开PHPmyAdmin,MySQL字符集:UTF-8 Unicode(utf8);MySQL连接校对应为utf8_unicode_ci;新建数据库时也请选择utf8_unicode_ci。网页字符为也最好选择utf-8进行采集。utf-8是国际标准编码,这是一种趋势。
乱码问题2:本机开发的MySQL数据表,在本机测试一切正常,但使用空间商提供的PHPmyAdmin上传时出现问题,上传失败。尤其是使用国外的PHP空间。
解决方法:首先检查网站提供的PHPmyAdmin字符集设置,并确保您构建的数据表与服务提供者的代码相同。国外MySQL不支持gb2312,甚至最新版的Apache也不支持gb2312。如果是因为编码不统一,可以重建数据表,当然使用国际标准UTF8。 查看全部
php网页抓取乱码(mysql设置utf8_unicode字符集_ci字符集字符集页面输出?)
一位同事问我关于乱码的问题。乱码有很多种,比如数据库乱码,页面提取数据乱码,其他显示正常,phpmyadmin显示也正常等,MySQL对中文的支持还是很有限的。尤其是对于新手来说,遇到乱码问题,就会头大。他的问题如下。
标题:mysql设置utf8_unicode_ci字符集php页面输出??乱码的解决方法
摘要:使用PHPmyAdmin操作MySQL数据库汉字显示正常,但是使用PHP网页显示MySQL数据时,汉字全部变成?标志
乱码问题:使用PHPmyAdmin操作MySQL数据库时,MySQL数据库汉字显示正常,但PHP网页显示MySQL数据时,汉字全部变成?标志。
现象:用PHPmyAdmin输入汉字是正常的,但是当PHP网页显示MySQL数据时,汉字变成了?标志,有多少?符号,因为有多少个汉字。
原因:PHP网页中没有代码告诉MySQL用什么字符集输出汉字。
解决方案:
1.网页文件头设置编码
2.PHP页面保存时使用utf-8编码,可以使用记事本或者convertz802进行文件转换
3.MYSQL新建数据库时,选择UTF-8编码和数据库的字符集,设置为utf-8_unicode_ci(Unicode(多语言),不区分大小写),
库中表的排序设置为utf-8_general_ci
表中各个字段的排序设置为utf-8_general_ci
4.PHP连接数据库时,在mysql_connect()之后添加
//设置数据的字符集utf-8
mysql_query("设置名称'utf8'");
mysql_query("set character_set_client=utf8");
mysql_query("set character_set_results=utf8");
注意是utf8,不是utf-8。
如果您的网页编码为 gb2312,则为 SET NAMES GB2312。不过小编强烈建议网页编码、MySQL数据表字符集、PHPmyAdmin都统一使用UTF-8。
以上四点可以实现整个站点的utf-8编码,数据库中不会出现中文乱码。
乱码问题2:用PHPmyAdmin输入数据时出错,不允许输入或乱码。
解决方案:这是一个设置问题。请安装最新版本的PHPmyAdmin或Appserv,打开PHPmyAdmin,MySQL字符集:UTF-8 Unicode(utf8);MySQL连接校对应为utf8_unicode_ci;新建数据库时也请选择utf8_unicode_ci。网页字符为也最好选择utf-8进行采集。utf-8是国际标准编码,这是一种趋势。
乱码问题2:本机开发的MySQL数据表,在本机测试一切正常,但使用空间商提供的PHPmyAdmin上传时出现问题,上传失败。尤其是使用国外的PHP空间。
解决方法:首先检查网站提供的PHPmyAdmin字符集设置,并确保您构建的数据表与服务提供者的代码相同。国外MySQL不支持gb2312,甚至最新版的Apache也不支持gb2312。如果是因为编码不统一,可以重建数据表,当然使用国际标准UTF8。
php网页抓取乱码(php网页抓取乱码解决问题:windows双击打开php文件根目录下的scripts文件夹-userscripts)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-02 11:08
php网页抓取乱码解决问题:windows双击打开php文件根目录下的scripts文件夹-userscripts目录--php---php.ini配置文件,其中包含用户名密码和源文件。此时使用phpmyadmin进行数据库操作,数据库名跟项目根目录的名字不一致,得到的数据库的表结构等信息就可能与phpmyadmin里配置的不一致,对此来说可以用showcache命令,用浏览器自带地址栏显示>然后就能知道数据库名了。
登录一个文件夹的phpmyadmin,
个人电脑php、mysql一般都用phpmyadmin进行建表存数据,对于phpmyadmin来说这里数据库名称通常是自定义的。如果查看phpmyadmin的自定义数据库名是个死循环的问题,可以考虑用navicatconnector或者插件opensessages。
楼上不对。navicat一般支持phpmyadmin的数据库,如果为sqlserver,可以考虑通过export的方式引入数据库。或者,自定义一个文件名称,自定义一个数据库。
如果是电脑有tp程序,用phpmyadmin,如果不是,可以考虑用插件navicatconnector如果嫌麻烦,可以用phpmyadmin代理的方式,解决部分问题。 查看全部
php网页抓取乱码(php网页抓取乱码解决问题:windows双击打开php文件根目录下的scripts文件夹-userscripts)
php网页抓取乱码解决问题:windows双击打开php文件根目录下的scripts文件夹-userscripts目录--php---php.ini配置文件,其中包含用户名密码和源文件。此时使用phpmyadmin进行数据库操作,数据库名跟项目根目录的名字不一致,得到的数据库的表结构等信息就可能与phpmyadmin里配置的不一致,对此来说可以用showcache命令,用浏览器自带地址栏显示>然后就能知道数据库名了。
登录一个文件夹的phpmyadmin,
个人电脑php、mysql一般都用phpmyadmin进行建表存数据,对于phpmyadmin来说这里数据库名称通常是自定义的。如果查看phpmyadmin的自定义数据库名是个死循环的问题,可以考虑用navicatconnector或者插件opensessages。
楼上不对。navicat一般支持phpmyadmin的数据库,如果为sqlserver,可以考虑通过export的方式引入数据库。或者,自定义一个文件名称,自定义一个数据库。
如果是电脑有tp程序,用phpmyadmin,如果不是,可以考虑用插件navicatconnector如果嫌麻烦,可以用phpmyadmin代理的方式,解决部分问题。
php网页抓取乱码(木庄网络博客:发送给服务器的请求连接的数据不同)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-25 23:12
本文摘自php中文网,作者负一度,侵删。
为什么会这样?细心的童鞋可能会发现我们发送给服务器进行请求连接的数据是不一样的:
第一张图片的信息是{"roomid":98284,"uid":2770}
第二张图片的信息是{"uid":2767,"protoover":2,"roomid":98284}
roomid是真实的房间号,uid是随机生成的一串数字,可以直接复制登录。
相比之下,第二个有更多的“protover”:2个参数。其实第一张图是截取手机客户端的数据包,第二张图是截取电脑网页的数据包。那么是否有这个“protoover”:2个参数可以连接弹幕服务器。
所以我们可以推断,最容易抓取的数据是手机,其次是wap,最后是电脑。
但是很多时候我们抓包数据都是如图2所示的一串乱码,不管用utf8还是gbk编码,都达不到图1所示的效果。
这种数据其实是压缩数据gzip,目前wireshark不支持这种压缩数据的解压方式。
现在网站传输的时候基本都是压缩的,所以你抓的数据是压缩数据,在你看来完全是乱码,没办法下手。
如图所示,当我访问我的博客首页时,爬虫服务器发回的网页数据是gzip方式的,我们平时访问的网页被浏览器解压渲染呈现给我们。
由于分析B站服务器传输的是gzip数据,所以解决方法很简单。安装第三方的zlib包或者gzip包可以解决这个问题。
以上是抓包数据乱码是什么情况?更多详情请关注php中文网文章其他相关话题!
欢迎分享,(木庄网博客交流QQ群:562366239)
转载请注明出处:木庄网博客 » 抓包数据乱码是什么情况? 查看全部
php网页抓取乱码(木庄网络博客:发送给服务器的请求连接的数据不同)
本文摘自php中文网,作者负一度,侵删。
为什么会这样?细心的童鞋可能会发现我们发送给服务器进行请求连接的数据是不一样的:
第一张图片的信息是{"roomid":98284,"uid":2770}
第二张图片的信息是{"uid":2767,"protoover":2,"roomid":98284}
roomid是真实的房间号,uid是随机生成的一串数字,可以直接复制登录。
相比之下,第二个有更多的“protover”:2个参数。其实第一张图是截取手机客户端的数据包,第二张图是截取电脑网页的数据包。那么是否有这个“protoover”:2个参数可以连接弹幕服务器。
所以我们可以推断,最容易抓取的数据是手机,其次是wap,最后是电脑。
但是很多时候我们抓包数据都是如图2所示的一串乱码,不管用utf8还是gbk编码,都达不到图1所示的效果。
这种数据其实是压缩数据gzip,目前wireshark不支持这种压缩数据的解压方式。
现在网站传输的时候基本都是压缩的,所以你抓的数据是压缩数据,在你看来完全是乱码,没办法下手。
如图所示,当我访问我的博客首页时,爬虫服务器发回的网页数据是gzip方式的,我们平时访问的网页被浏览器解压渲染呈现给我们。
由于分析B站服务器传输的是gzip数据,所以解决方法很简单。安装第三方的zlib包或者gzip包可以解决这个问题。
以上是抓包数据乱码是什么情况?更多详情请关注php中文网文章其他相关话题!
欢迎分享,(木庄网博客交流QQ群:562366239)
转载请注明出处:木庄网博客 » 抓包数据乱码是什么情况?
php网页抓取乱码(PHP获取网页内容的方法实现方法和使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-23 21:21
5、网址链接千奇百怪,竟然有汉字,有的甚至还有回车换行
6、有的网站HTTP头中有一个Content-Type,网页中有几个Content-Type。更重要的是,每个 Content-Type 都不相同。最极端的是这些Content-Type可能不是body中使用的Content-Type,导致乱码
7、网络链接很慢,花时间分析几千页,建议大家好好吃饭
如何在 PHP 中获取网页内容
一、 方法是使用 file_get_contents 方法实现的
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$html = file_get_contents($url);
//如果出现中文乱码使用下面代码
//$getcontent = iconv("gb2312", "utf-8",$html);
echo "".$html."";
二、 方法是使用 curl 实现的
添加这段代码意味着如果请求被重定向,则可以访问最终的请求页面,否则请求的结果将显示如下:
<p>Object moved
Object MovedThis object may be found 查看全部
php网页抓取乱码(PHP获取网页内容的方法实现方法和使用方法)
5、网址链接千奇百怪,竟然有汉字,有的甚至还有回车换行
6、有的网站HTTP头中有一个Content-Type,网页中有几个Content-Type。更重要的是,每个 Content-Type 都不相同。最极端的是这些Content-Type可能不是body中使用的Content-Type,导致乱码
7、网络链接很慢,花时间分析几千页,建议大家好好吃饭
如何在 PHP 中获取网页内容
一、 方法是使用 file_get_contents 方法实现的
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$html = file_get_contents($url);
//如果出现中文乱码使用下面代码
//$getcontent = iconv("gb2312", "utf-8",$html);
echo "".$html."";
二、 方法是使用 curl 实现的
添加这段代码意味着如果请求被重定向,则可以访问最终的请求页面,否则请求的结果将显示如下:
<p>Object moved
Object MovedThis object may be found
php网页抓取乱码( PHP的file_get_contents获取远程页面内容_一下 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-22 10:17
PHP的file_get_contents获取远程页面内容_一下
)
php file_get_contents获取远程页面出现乱码的解决方法
时间:2016-03-26
本文章向程序员介绍了php file_get_contents获取的远程页面出现乱码的解决方法。有兴趣的程序员可以参考一下。
PHP 的 file_get_contents 获取远程页面的内容。如果是gzip编码,返回的字符串就是编码后的乱码
1、解决办法,找个ungzip函数转换一下
2、为你的url添加前缀,所以调用
无论页面是否压缩,上述代码都有效!
这个问题也可以使用 curl 模块解决
function curl_get($url, $gzip=false){
$curl = curl_init($url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
if($gzip) curl_setopt($curl, CURLOPT_ENCODING, "gzip"); // 关键在这里
$content = curl_exec($curl);
curl_close($curl);
return $content;
} 查看全部
php网页抓取乱码(
PHP的file_get_contents获取远程页面内容_一下
)
php file_get_contents获取远程页面出现乱码的解决方法
时间:2016-03-26
本文章向程序员介绍了php file_get_contents获取的远程页面出现乱码的解决方法。有兴趣的程序员可以参考一下。
PHP 的 file_get_contents 获取远程页面的内容。如果是gzip编码,返回的字符串就是编码后的乱码
1、解决办法,找个ungzip函数转换一下
2、为你的url添加前缀,所以调用
无论页面是否压缩,上述代码都有效!
这个问题也可以使用 curl 模块解决
function curl_get($url, $gzip=false){
$curl = curl_init($url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
if($gzip) curl_setopt($curl, CURLOPT_ENCODING, "gzip"); // 关键在这里
$content = curl_exec($curl);
curl_close($curl);
return $content;
}
php网页抓取乱码(php网页抓取乱码的解决办法:1、使用“mbconvertencoding”转换编码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-22 03:04
抓取php网页乱码的解决方案:1、使用“mbconvertencoding”转换编码; 2、添加“curl_setopt($ch, CURLOPT_ENCODING, 'gzip');”设置选项; 3、在顶部添加标题代码。
推荐:《PHP 视频教程》
php抓取页面乱码
爬取页面时出现类似��������的乱码解决方法如下
1、转码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、数据被压缩
curl获取数据时添加如下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
需要安装zlib库才能使用file_get_contents函数
$data = file_get_contents("compress.zlib://".$url);
3、获取数据后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上就是如何解决php网页抓取乱码问题的详细内容。更多详情请关注php中文网其他相关话题文章! 查看全部
php网页抓取乱码(php网页抓取乱码的解决办法:1、使用“mbconvertencoding”转换编码)
抓取php网页乱码的解决方案:1、使用“mbconvertencoding”转换编码; 2、添加“curl_setopt($ch, CURLOPT_ENCODING, 'gzip');”设置选项; 3、在顶部添加标题代码。
推荐:《PHP 视频教程》
php抓取页面乱码
爬取页面时出现类似��������的乱码解决方法如下
1、转码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、数据被压缩
curl获取数据时添加如下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
需要安装zlib库才能使用file_get_contents函数
$data = file_get_contents("compress.zlib://".$url);
3、获取数据后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上就是如何解决php网页抓取乱码问题的详细内容。更多详情请关注php中文网其他相关话题文章!
php网页抓取乱码(php网页抓取乱码.解决方法正确的抓取方法是端口)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-21 12:02
php网页抓取乱码.解决方法正确的抓取方法是端口被占用,主要影响是视频片段。下面讲一下常见的端口:服务器端口123456客户端请求资源的端口80,443客户端用http代理服务器代理服务器端口,通常是socket://9090默认端口。本例执行123456端口,抓取不了视频片段和图片。配置ifconfig发现-l和-o(用于抓取数据包)分别发出了不同的端口,服务器端口是123456,客户端端ip地址:8080,正常抓取端口只有8888是可以正常抓取的。
安装抓取库php-http.xml,抓取所有片段数据包if(php-http.xml){//或者其他if的=>try{if(!php-http.xml_equals("gzip","mode")){return;}if(php-http.xml_equals("bit","mode")){return;}//正则匹配抓取片段地址}}catinet_gzip_path=php-http.xml||php-http.xml_equals("gzip","mode");//如果匹配不到对应数据则返回错误信息}else{return;}//服务器ip设置8080proxy-setaddress=123456;代理服务器选择ip:8080,下载视频抓取不到http/2规定的端口:443,223456抓取数据包客户端ip地址:223456发出不同的端口,对应也不同的协议名称。
<p>method=gzip(response.xml)http/2user-agent=php+mysql/mysqlsignal=//从method=gzip抓取http/2协议的数据包if(!http/2){return;}//从method=mysql/mysql抓取http/2协议的数据包else{return;}//从method=mysql/mysql抓取http/2协议的数据包http/2/http/1.1,request.xmlhttprequest="gzip";if(request.xmlhttprequest){//设置代理客户端ipcurl-s-o-";name=xxx.jpg"--spec="signal=login+post"|"return0:1"try{curl-s-o-"xxx.jpg"-o"223456"-s"8888"| 查看全部
php网页抓取乱码(php网页抓取乱码.解决方法正确的抓取方法是端口)
php网页抓取乱码.解决方法正确的抓取方法是端口被占用,主要影响是视频片段。下面讲一下常见的端口:服务器端口123456客户端请求资源的端口80,443客户端用http代理服务器代理服务器端口,通常是socket://9090默认端口。本例执行123456端口,抓取不了视频片段和图片。配置ifconfig发现-l和-o(用于抓取数据包)分别发出了不同的端口,服务器端口是123456,客户端端ip地址:8080,正常抓取端口只有8888是可以正常抓取的。
安装抓取库php-http.xml,抓取所有片段数据包if(php-http.xml){//或者其他if的=>try{if(!php-http.xml_equals("gzip","mode")){return;}if(php-http.xml_equals("bit","mode")){return;}//正则匹配抓取片段地址}}catinet_gzip_path=php-http.xml||php-http.xml_equals("gzip","mode");//如果匹配不到对应数据则返回错误信息}else{return;}//服务器ip设置8080proxy-setaddress=123456;代理服务器选择ip:8080,下载视频抓取不到http/2规定的端口:443,223456抓取数据包客户端ip地址:223456发出不同的端口,对应也不同的协议名称。
<p>method=gzip(response.xml)http/2user-agent=php+mysql/mysqlsignal=//从method=gzip抓取http/2协议的数据包if(!http/2){return;}//从method=mysql/mysql抓取http/2协议的数据包else{return;}//从method=mysql/mysql抓取http/2协议的数据包http/2/http/1.1,request.xmlhttprequest="gzip";if(request.xmlhttprequest){//设置代理客户端ipcurl-s-o-";name=xxx.jpg"--spec="signal=login+post"|"return0:1"try{curl-s-o-"xxx.jpg"-o"223456"-s"8888"|
php网页抓取乱码(php网页抓取乱码的解决办法:1、使用“mbconvertencoding”转换编码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-20 04:07
)
抓取php网页乱码的解决方案:1、使用“mbconvertencoding”转换编码; 2、添加“curl_setopt($ch, CURLOPT_ENCODING, 'gzip');”设置选项; 3、在顶部添加标题代码。
推荐:《PHP 视频教程》
php抓取页面乱码
爬取页面时出现类似��������的乱码解决方法如下
1、转码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、数据被压缩
curl获取数据时添加如下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
需要安装zlib库才能使用file_get_contents函数
$data = file_get_contents("compress.zlib://".$url);
3、获取数据后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上就是如何解决php网页抓取乱码问题的详细内容。更多详情请关注php中文网其他相关话题文章!
查看全部
php网页抓取乱码(php网页抓取乱码的解决办法:1、使用“mbconvertencoding”转换编码
)
抓取php网页乱码的解决方案:1、使用“mbconvertencoding”转换编码; 2、添加“curl_setopt($ch, CURLOPT_ENCODING, 'gzip');”设置选项; 3、在顶部添加标题代码。
推荐:《PHP 视频教程》
php抓取页面乱码
爬取页面时出现类似��������的乱码解决方法如下
1、转码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、数据被压缩
curl获取数据时添加如下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
需要安装zlib库才能使用file_get_contents函数
$data = file_get_contents("compress.zlib://".$url);
3、获取数据后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上就是如何解决php网页抓取乱码问题的详细内容。更多详情请关注php中文网其他相关话题文章!
php网页抓取乱码( 第一种:解决中中文乱码问题方法如果你的HTML文件出现了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-19 17:09
第一种:解决中中文乱码问题方法如果你的HTML文件出现了
)
第一种:解决HTML中文乱码问题的方法
如果你的 HTML 文件出现乱码,可以在 head 标签中添加 UTF8 编码(国际编码):UTF-8 是一种无国别编码,即独立于任何语言,任何语言都可以使用。
第二种:HTML和PHP混合页面解决方案
HTML和PHP如何混合使用,除了按照第一种方法操作外,还需要在PHP文件的顶部添加这段代码:
第三种:纯PHP页面的中文乱码问题(数据是静态的)
如果您的PHP页面出现乱码,只需在页面开头添加以下代码即可。
四:PHP+Mysql中文乱码问题
除了第三个操作之外,您还需要在数据查询/修改/添加之前添加数据库编码。而且,值得注意的是这里的UTF8和前面的不一样,中间没有横线。
UTF-8 编码只是其中一种编码。如果不想使用 utf-8 编码,也可以使用其他编码。只需将 UTF-8 替换为您要使用的编码即可。目前,中文网站主要在开发中。它使用两种编码,GB2312 和 UTF-8。
需要注意的一件事: mysql_query("set names 'encoding'"); 需要做数据库操作的php程序前添加的代码必须与php代码一致。如果php编码是gb2312,mysql编码是gb2312,如果是utf -8 mysql编码是utf8,所以插入或检索数据时不会出现乱码。
推荐教程:PHP视频教程
以上是php网站乱码的详细内容,更多详情请关注php中文网站其他相关文章!
查看全部
php网页抓取乱码(
第一种:解决中中文乱码问题方法如果你的HTML文件出现了
)
第一种:解决HTML中文乱码问题的方法
如果你的 HTML 文件出现乱码,可以在 head 标签中添加 UTF8 编码(国际编码):UTF-8 是一种无国别编码,即独立于任何语言,任何语言都可以使用。
第二种:HTML和PHP混合页面解决方案
HTML和PHP如何混合使用,除了按照第一种方法操作外,还需要在PHP文件的顶部添加这段代码:
第三种:纯PHP页面的中文乱码问题(数据是静态的)
如果您的PHP页面出现乱码,只需在页面开头添加以下代码即可。
四:PHP+Mysql中文乱码问题
除了第三个操作之外,您还需要在数据查询/修改/添加之前添加数据库编码。而且,值得注意的是这里的UTF8和前面的不一样,中间没有横线。
UTF-8 编码只是其中一种编码。如果不想使用 utf-8 编码,也可以使用其他编码。只需将 UTF-8 替换为您要使用的编码即可。目前,中文网站主要在开发中。它使用两种编码,GB2312 和 UTF-8。
需要注意的一件事: mysql_query("set names 'encoding'"); 需要做数据库操作的php程序前添加的代码必须与php代码一致。如果php编码是gb2312,mysql编码是gb2312,如果是utf -8 mysql编码是utf8,所以插入或检索数据时不会出现乱码。
推荐教程:PHP视频教程
以上是php网站乱码的详细内容,更多详情请关注php中文网站其他相关文章!
php网页抓取乱码(有一定的参考价值,有需要的朋友可以参考一下吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-14 10:19
本篇文章为大家带来Python爬取乱码网页的原因及解决方法。具有一定的参考价值。有需要的朋友可以参考一下,希望对你有帮助。
使用python2爬取网页时,经常会遇到抓取到的内容显示为乱码的情况。
这种情况最大的可能是编码问题:运行环境的字符编码和网页的字符编码不一致。
例如,在 Windows 控制台 (gbk) 中获取一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓取一个gbk编码的网站(utf-8)。因为大部分网站使用utf-8编码,而且很多人使用windows,都是很常见。
如果你发现你抓取的内容在英文、数字、符号上看起来都正确,但是中间有一些乱码,你基本上可以断定是这样的。
这个问题的解决方法是先将结果按照网页的编码方式解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site")
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数用于忽略无法解码的字符。
但是,这种方法并不总是有效。另一种方式是通过正则表达式直接匹配网页代码中的编码设置:
除了编码问题导致的乱码之外,另一个经常被忽视的情况是目标页面启用了 gzip 压缩。压缩网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的头部信息自动解压。但是直接用代码抓取不会。因此,很可能会产生困惑,为什么打开网页地址是对的,但程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现是,几乎所有的抓取内容都是乱码,甚至无法显示。
要确定网页是否启用了压缩并解压缩,请使用以下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site")
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们的课堂编程示例查看天气系列(点击查看)中,这两个问题困扰了不少人。这里有一个特殊的解释。
最后,还有一个“武器”要介绍。如果你一开始使用它,你甚至都不知道存在上述两个问题。
这是请求模块。
与爬网类似,只需:
import requests
print requests.get("http://some.web.site").text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考之前的文章:
如何为 Python 安装第三方模块 - Crossin 的编程课堂 - 知乎专栏
pip install requests
以上就是Python爬取乱码网页的原因及解决方法的详细内容。更多信息请关注php中文网文章其他相关话题!
声明:本文转载于:segmentfault,如有侵权,请联系删除
特别推荐:蟒蛇
上一篇:Python并发的PoolExecutor介绍(附示例) 下一篇:anaconda教程(图文并茂) 查看全部
php网页抓取乱码(有一定的参考价值,有需要的朋友可以参考一下吗)
本篇文章为大家带来Python爬取乱码网页的原因及解决方法。具有一定的参考价值。有需要的朋友可以参考一下,希望对你有帮助。
使用python2爬取网页时,经常会遇到抓取到的内容显示为乱码的情况。
这种情况最大的可能是编码问题:运行环境的字符编码和网页的字符编码不一致。
例如,在 Windows 控制台 (gbk) 中获取一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓取一个gbk编码的网站(utf-8)。因为大部分网站使用utf-8编码,而且很多人使用windows,都是很常见。
如果你发现你抓取的内容在英文、数字、符号上看起来都正确,但是中间有一些乱码,你基本上可以断定是这样的。
这个问题的解决方法是先将结果按照网页的编码方式解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site";)
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数用于忽略无法解码的字符。
但是,这种方法并不总是有效。另一种方式是通过正则表达式直接匹配网页代码中的编码设置:
除了编码问题导致的乱码之外,另一个经常被忽视的情况是目标页面启用了 gzip 压缩。压缩网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的头部信息自动解压。但是直接用代码抓取不会。因此,很可能会产生困惑,为什么打开网页地址是对的,但程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现是,几乎所有的抓取内容都是乱码,甚至无法显示。
要确定网页是否启用了压缩并解压缩,请使用以下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site";)
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们的课堂编程示例查看天气系列(点击查看)中,这两个问题困扰了不少人。这里有一个特殊的解释。
最后,还有一个“武器”要介绍。如果你一开始使用它,你甚至都不知道存在上述两个问题。
这是请求模块。
与爬网类似,只需:
import requests
print requests.get("http://some.web.site";).text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考之前的文章:
如何为 Python 安装第三方模块 - Crossin 的编程课堂 - 知乎专栏
pip install requests
以上就是Python爬取乱码网页的原因及解决方法的详细内容。更多信息请关注php中文网文章其他相关话题!
声明:本文转载于:segmentfault,如有侵权,请联系删除
特别推荐:蟒蛇
上一篇:Python并发的PoolExecutor介绍(附示例) 下一篇:anaconda教程(图文并茂)
php网页抓取乱码(PHP页面语言本身的编码类型不合适,这时候数据库解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2022-01-11 04:02
1.PHP页面语言本身的编码类型不合适。这时候你直接在脚本里写的中文肯定是乱码,更别提数据库了
解决方法:选择“UTF8”或“gb2312”,客户端浏览器会自动选择并显示正确的中文。注意:'UTF8' 或 'gb2312' 可以正确显示中文。
2.数据库 MySQL 中的编码类型不正确。
解决方法:创建数据库时,MySQL字符集选择'UTF8',MySQL连接校对选择utf8_general_ci。这样创建的数据库存储中文是没有问题的。
否则,你的中文一开始在 MySQL 中会出现乱码,别指望它会在你的 PHP 页面中正确显示。
3.跟常用的脚本编辑环境有关。例如,有些内容是用word写的,有些是用记事本写的,有些是用editplus和ultraplus等文本编辑器写的。有时候我直接在DW里写中文,
解决方法:尝试使用相同的编辑器。如果复制已有内容,建议使用ultraplus中的编码转换功能,将其转换为utf8或gb2312。
转换成什么类型无所谓,关键要求是你的PHP WEB应用中的编码要一致。
4.以编程方式访问MySQL时,建议添加一行代码:mysql_query("SET NAMES 'GBK'");
php读取mysql中文数据出现乱码的解决方法
原来的: 查看全部
php网页抓取乱码(PHP页面语言本身的编码类型不合适,这时候数据库解决方法)
1.PHP页面语言本身的编码类型不合适。这时候你直接在脚本里写的中文肯定是乱码,更别提数据库了
解决方法:选择“UTF8”或“gb2312”,客户端浏览器会自动选择并显示正确的中文。注意:'UTF8' 或 'gb2312' 可以正确显示中文。
2.数据库 MySQL 中的编码类型不正确。
解决方法:创建数据库时,MySQL字符集选择'UTF8',MySQL连接校对选择utf8_general_ci。这样创建的数据库存储中文是没有问题的。
否则,你的中文一开始在 MySQL 中会出现乱码,别指望它会在你的 PHP 页面中正确显示。
3.跟常用的脚本编辑环境有关。例如,有些内容是用word写的,有些是用记事本写的,有些是用editplus和ultraplus等文本编辑器写的。有时候我直接在DW里写中文,
解决方法:尝试使用相同的编辑器。如果复制已有内容,建议使用ultraplus中的编码转换功能,将其转换为utf8或gb2312。
转换成什么类型无所谓,关键要求是你的PHP WEB应用中的编码要一致。
4.以编程方式访问MySQL时,建议添加一行代码:mysql_query("SET NAMES 'GBK'");
php读取mysql中文数据出现乱码的解决方法
原来的:
php网页抓取乱码(一般来说,乱码的出现有2种原因,中文就倒霉了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-11 03:20
一般来说,出现乱码的原因有两个。首先,错误的编码(charset)设置导致浏览器解析错误的编码,导致满屏的“天书”乱七八糟。编码打开,然后保存。例如,文本文件最初以 GB2312 编码,但以 UTF-8 编码打开和保存。要解决上面的乱码问题,首先要知道开发的哪些方面涉及到编码:
1、文件编码:是指保存页面文件(.html、.php等)本身的编码。记事本和 Dreamweaver 在打开页面时会自动识别文件编码,因此问题较少。然而,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有某种编码的文件。如果工作中不注意,打开编码错误的文件,修改后保存,就会出现乱码。
2、页面声明代码:在HTML代码HEAD中,可以使用"meta http-equiv="Content-Type" content="text/html; charset="XXX"/"(这句话必须写在“在TItle前面”XXX“/TItle”,否则页面会空白(IE+PHP only))告诉浏览器网页使用什么编码。目前,中文网站主要使用GB2312和UTF-8两种编码。
3、数据库连接代码:指在进行数据库操作时,使用哪个代码向数据库传输数据。这里需要注意的是不要和数据库本身的代码混淆。比如 MySQL 内部默认是 laTIn1 编码,也就是说 Mysql 数据是以 laTIn1 编码存储的,其他编码传输到 Mysql 的数据会被转换成 latin1 编码。
知道了WEB开发涉及到哪里编码,也就知道乱码的原因了:以上三种编码设置不一致,因为各种编码大部分都兼容ASCII,所以不会出现英文符号,中文会倒霉。. 以下是一些常见的错误情况和解决方案:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是最常见的乱码原因。此时PHP脚本中直接SELECT数据出现乱码,查询前需要用到:
mysql_query("设置名称 GBK");
或 mysql_query("SET NAMES GB2312");
设置MYSQL连接码,保证页面声明码和这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码的,您可以使用:
mysql_query("设置名称 UTF8");
请注意,它是 UTF8 而不是通常的 UTF-8。如果页面上声明的代码与数据库内部代码一致,则可以不设置连接代码。
注意:其实MYSQL的数据输入输出比上面的要复杂一些。MYSQL配置文件my.ini定义了两种默认编码,即[client]中的default-character-set和[mysqld]中的default。-character-set 分别设置客户端连接和数据库使用的默认编码。我们上面指定的编码其实就是MYSQL客户端连接服务器时的命令行参数character_set_client,用来告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、页面声明编码与文件本身的编码不一致,这种情况很少发生,因为如果编码不一致,创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小bug,打开错误代码的页面,然后保存。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,由于软件的代码配置错误,转换了错误的代码。
3、一些租用虚拟主机的朋友,即使上面三个代码设置正确,还是有乱码。例如,一个网页是用 GB2312 编码的,但 IE 等浏览器总是将其识别为 UTF-8。网页的HEAD已经说明是GB2312。手动修改浏览器编码为GB2312后,页面正常显示。
原因是服务器 Apache 在 httpd 中设置了服务器的全局默认编码。在 conf 中添加了 AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级高于页面中声明的代码,所以浏览器会认错。有两种解决方案。请在配置文件中给虚拟机添加一个AddDefaultCharset GB2312来覆盖全局配置,或者在自己目录下的.htaccess中配置。 查看全部
php网页抓取乱码(一般来说,乱码的出现有2种原因,中文就倒霉了)
一般来说,出现乱码的原因有两个。首先,错误的编码(charset)设置导致浏览器解析错误的编码,导致满屏的“天书”乱七八糟。编码打开,然后保存。例如,文本文件最初以 GB2312 编码,但以 UTF-8 编码打开和保存。要解决上面的乱码问题,首先要知道开发的哪些方面涉及到编码:
1、文件编码:是指保存页面文件(.html、.php等)本身的编码。记事本和 Dreamweaver 在打开页面时会自动识别文件编码,因此问题较少。然而,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有某种编码的文件。如果工作中不注意,打开编码错误的文件,修改后保存,就会出现乱码。
2、页面声明代码:在HTML代码HEAD中,可以使用"meta http-equiv="Content-Type" content="text/html; charset="XXX"/"(这句话必须写在“在TItle前面”XXX“/TItle”,否则页面会空白(IE+PHP only))告诉浏览器网页使用什么编码。目前,中文网站主要使用GB2312和UTF-8两种编码。
3、数据库连接代码:指在进行数据库操作时,使用哪个代码向数据库传输数据。这里需要注意的是不要和数据库本身的代码混淆。比如 MySQL 内部默认是 laTIn1 编码,也就是说 Mysql 数据是以 laTIn1 编码存储的,其他编码传输到 Mysql 的数据会被转换成 latin1 编码。
知道了WEB开发涉及到哪里编码,也就知道乱码的原因了:以上三种编码设置不一致,因为各种编码大部分都兼容ASCII,所以不会出现英文符号,中文会倒霉。. 以下是一些常见的错误情况和解决方案:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是最常见的乱码原因。此时PHP脚本中直接SELECT数据出现乱码,查询前需要用到:
mysql_query("设置名称 GBK");
或 mysql_query("SET NAMES GB2312");
设置MYSQL连接码,保证页面声明码和这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码的,您可以使用:
mysql_query("设置名称 UTF8");
请注意,它是 UTF8 而不是通常的 UTF-8。如果页面上声明的代码与数据库内部代码一致,则可以不设置连接代码。
注意:其实MYSQL的数据输入输出比上面的要复杂一些。MYSQL配置文件my.ini定义了两种默认编码,即[client]中的default-character-set和[mysqld]中的default。-character-set 分别设置客户端连接和数据库使用的默认编码。我们上面指定的编码其实就是MYSQL客户端连接服务器时的命令行参数character_set_client,用来告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、页面声明编码与文件本身的编码不一致,这种情况很少发生,因为如果编码不一致,创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小bug,打开错误代码的页面,然后保存。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,由于软件的代码配置错误,转换了错误的代码。
3、一些租用虚拟主机的朋友,即使上面三个代码设置正确,还是有乱码。例如,一个网页是用 GB2312 编码的,但 IE 等浏览器总是将其识别为 UTF-8。网页的HEAD已经说明是GB2312。手动修改浏览器编码为GB2312后,页面正常显示。
原因是服务器 Apache 在 httpd 中设置了服务器的全局默认编码。在 conf 中添加了 AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级高于页面中声明的代码,所以浏览器会认错。有两种解决方案。请在配置文件中给虚拟机添加一个AddDefaultCharset GB2312来覆盖全局配置,或者在自己目录下的.htaccess中配置。
php网页抓取乱码(其实导致网页乱码主要有几个原因,以下给出解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-10 21:20
其实网页出现乱码有几个原因。解决方法如下。
1、HTML字符编码问题
这个问题是最常见、最明显、最容易解决的。
添加到页面:
1
就是这样。
2、PHP字符编码问题
这和上面的类似。
在文件上方添加:
1
header("内容类型:text/html;charset=utf8");
就是这样。
3、文件本身的编码
不仅我们的内容被编码,文件本身也是如此。
用Notepad++打开一个文件,可以看到右下角显示的内容。
是文件本身的编码。
您可以使用 Notepad++ 工具栏上的“格式”为我们的文件转换编码。
4、数据库编码问题
MySQL数据默认安装时是latin1编码的,所以不注意很可能造成网页乱码。
使用root进入数据库,
输入显示变量,如'character%'
可以看到
character_set_client
character_set_connection
character_set_database
character_set_filesystem
character_set_results
character_set_server
character_set_system
这 7 个值。
这个命令可以在哪里设置名称ut8
character_set_client
character_set_connection
character_set_results
这3个设置为utf8。
所以MySQL创建数据库时要注意设置字符集和排序规则为utf8。
在连接数据库的文件中,对数据库执行mysql_query("SET NAMES UTF8")。
基本可以保证网页不会出现乱码。
文章来源:segmentfault,作者:葡萄酒不吐葡萄皮。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:sean.li#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
后台-系统设置-扩展变量-移动广告-正文底部 查看全部
php网页抓取乱码(其实导致网页乱码主要有几个原因,以下给出解决方法)
其实网页出现乱码有几个原因。解决方法如下。
1、HTML字符编码问题
这个问题是最常见、最明显、最容易解决的。
添加到页面:
1
就是这样。
2、PHP字符编码问题
这和上面的类似。
在文件上方添加:
1
header("内容类型:text/html;charset=utf8");
就是这样。
3、文件本身的编码
不仅我们的内容被编码,文件本身也是如此。
用Notepad++打开一个文件,可以看到右下角显示的内容。
是文件本身的编码。
您可以使用 Notepad++ 工具栏上的“格式”为我们的文件转换编码。
4、数据库编码问题
MySQL数据默认安装时是latin1编码的,所以不注意很可能造成网页乱码。
使用root进入数据库,
输入显示变量,如'character%'
可以看到
character_set_client
character_set_connection
character_set_database
character_set_filesystem
character_set_results
character_set_server
character_set_system
这 7 个值。
这个命令可以在哪里设置名称ut8
character_set_client
character_set_connection
character_set_results
这3个设置为utf8。
所以MySQL创建数据库时要注意设置字符集和排序规则为utf8。
在连接数据库的文件中,对数据库执行mysql_query("SET NAMES UTF8")。
基本可以保证网页不会出现乱码。
文章来源:segmentfault,作者:葡萄酒不吐葡萄皮。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:sean.li#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
后台-系统设置-扩展变量-移动广告-正文底部
php网页抓取乱码(猜你在找的PHP相关文章PHP常见漏洞代码总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-10 06:01
猜猜你在找什么 PHP 相关的 文章
PHP连接Mysql实现基本的增删改查-用户管理系统
前言 我最近在学习 PHP 和 Mysql。我正在看书,输入代码,试图完成一个简单的用户管理系统。我刚刚实现了一些非常简单的操作。,可以加深印象。里面加入了我自己的一些理解。请指出错误的地方,一起学习,一起交流。概述 PHP 是一种面向对象的解释性脚本语言,它在服务器端执行并嵌入在 HTML 文档中。语言风格类似于 C 语言。它足够强大,可以实现所有 CGI (
PHP公告:未定义索引完美解决方案
通常在使用$_GET['xx']获取参数值的时候,如果之前没有做任何判断,没有传入参数的时候会出现这个警告: PHP Notice: undefined index xxx 虽然这个提示可以通过设置隐藏错误的显示方式,但是这样也有隐患,就是这些提示会被记录在服务器的日志中,导致日志文件异常大!以下是网上引用的一个流行的解决方案:首先,这不是错误,是警告。因此,如果服务器不能更改,则应在使用前定义每个变量。方法
PHP常见漏洞代码汇总
漏洞总结 PHP文件上传漏洞只验证MIME类型:上传的MIME类型在代码中验证,绕过的方法是使用Burp抓包,在Content-Type:application/中上传一句Pony *.php php
PHP中操作数组的知识点
数组赋值:PHP中的数组既可以作为数组也可以作为键值对使用,并且没有任何限制,因此非常灵活。<?php // 定义纯数组格式 $array_one[0] = 100; $array_one[1] =
PHP 字符串和文件操作
字符操作字符串输出:字符串输出格式与C语言一致,<?php // printf普通输出函数 $string = "hello lyshark"; $号码
PHP 安全编码摘要说明
SQL注入:代码中的HTTP_X_FORWARDED_FOR地址是可以伪造的,而REMOTE_ADDR相对安全一些。有些应用程序会将对方的IP地址带入数据库,检查是否存在。比如同一个IP一天只能注册一次。
PHP代码审计(文件上传)
只验证MIME类型:在代码中验证上传的MIME类型,绕过方法使用Burp抓包,上传语句pony *.php中的Content-Type: application/php改为Content-Type
PHP面向对象知识点
定义一个基础类:在一个类中,我们可以定义各种数据成员和成员函数,其中公共修改函数和变量可以在任何地方调用,私有修改函数只能在这个类中调用。子类不能被调用,protected modified 可以 查看全部
php网页抓取乱码(猜你在找的PHP相关文章PHP常见漏洞代码总结)
猜猜你在找什么 PHP 相关的 文章
PHP连接Mysql实现基本的增删改查-用户管理系统
前言 我最近在学习 PHP 和 Mysql。我正在看书,输入代码,试图完成一个简单的用户管理系统。我刚刚实现了一些非常简单的操作。,可以加深印象。里面加入了我自己的一些理解。请指出错误的地方,一起学习,一起交流。概述 PHP 是一种面向对象的解释性脚本语言,它在服务器端执行并嵌入在 HTML 文档中。语言风格类似于 C 语言。它足够强大,可以实现所有 CGI (
PHP公告:未定义索引完美解决方案
通常在使用$_GET['xx']获取参数值的时候,如果之前没有做任何判断,没有传入参数的时候会出现这个警告: PHP Notice: undefined index xxx 虽然这个提示可以通过设置隐藏错误的显示方式,但是这样也有隐患,就是这些提示会被记录在服务器的日志中,导致日志文件异常大!以下是网上引用的一个流行的解决方案:首先,这不是错误,是警告。因此,如果服务器不能更改,则应在使用前定义每个变量。方法
PHP常见漏洞代码汇总
漏洞总结 PHP文件上传漏洞只验证MIME类型:上传的MIME类型在代码中验证,绕过的方法是使用Burp抓包,在Content-Type:application/中上传一句Pony *.php php
PHP中操作数组的知识点
数组赋值:PHP中的数组既可以作为数组也可以作为键值对使用,并且没有任何限制,因此非常灵活。<?php // 定义纯数组格式 $array_one[0] = 100; $array_one[1] =
PHP 字符串和文件操作
字符操作字符串输出:字符串输出格式与C语言一致,<?php // printf普通输出函数 $string = "hello lyshark"; $号码
PHP 安全编码摘要说明
SQL注入:代码中的HTTP_X_FORWARDED_FOR地址是可以伪造的,而REMOTE_ADDR相对安全一些。有些应用程序会将对方的IP地址带入数据库,检查是否存在。比如同一个IP一天只能注册一次。
PHP代码审计(文件上传)
只验证MIME类型:在代码中验证上传的MIME类型,绕过方法使用Burp抓包,上传语句pony *.php中的Content-Type: application/php改为Content-Type
PHP面向对象知识点
定义一个基础类:在一个类中,我们可以定义各种数据成员和成员函数,其中公共修改函数和变量可以在任何地方调用,私有修改函数只能在这个类中调用。子类不能被调用,protected modified 可以
php网页抓取乱码(php网页抓取乱码:php中的“\u2008”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-08 06:04
php网页抓取乱码乱码:在php编程过程中,可能会发生乱码问题,php中的“\u2008”和“\u2008”在iso-8859-1标准中都标识不同。\u2008是unicodeserver中“unicode”属性的缺省值;\u2008标识不同编码对象,常用于比较请求和响应中的字符串如何解决:1.打开iis管理面板下的internet选项/配置/安全(用户)/writeprofile(浏览器poc)/禁用/打开写取poc2.在请求参数中加入\u2008。
您好,遇到这个问题,您可以试试使用无字节ascii字符表示输入文本的方法,
win10在preference里关掉compresspreferencesandmediaencryption就可以了
up主注意一下,好像chrome就没问题啊。
亲测解决,
看的我也是各种困惑!!!找到这个问题解决啦 查看全部
php网页抓取乱码(php网页抓取乱码:php中的“\u2008”)
php网页抓取乱码乱码:在php编程过程中,可能会发生乱码问题,php中的“\u2008”和“\u2008”在iso-8859-1标准中都标识不同。\u2008是unicodeserver中“unicode”属性的缺省值;\u2008标识不同编码对象,常用于比较请求和响应中的字符串如何解决:1.打开iis管理面板下的internet选项/配置/安全(用户)/writeprofile(浏览器poc)/禁用/打开写取poc2.在请求参数中加入\u2008。
您好,遇到这个问题,您可以试试使用无字节ascii字符表示输入文本的方法,
win10在preference里关掉compresspreferencesandmediaencryption就可以了
up主注意一下,好像chrome就没问题啊。
亲测解决,
看的我也是各种困惑!!!找到这个问题解决啦
php网页抓取乱码(有时候用file_get_contents()函数抓取网页会发生乱码现象)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-07 19:13
有时使用file_get_contents()函数获取网页会导致乱码。出现乱码的原因有两个,一是编码问题,二是目标页面开启了Gzip。
编码问题好处理,把抓到的内容转为编码即可($content=iconv("GBK", "UTF-8//IGNORE", $content);),我们这里讨论的就是Crawl带有 Gzip 的页面已打开。如何判断? Content-Encoding: 获取到的header中的gzip表示内容采用GZIP压缩。用 FireBug 查看它以了解页面上是否启用了 gzip。下面是用firebug查看我博客的header信息,Gzip是打开的。
请求头信息原始头信息
Accept text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding gzip, deflate
Accept-Language zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Connection keep-alive
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.1326850415.887.3.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=%E4%BB%BB%E4%BD%95%E9%A1%B9%E7%9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE%80%E5%8D%95%20site%3Awww.bkjia.com; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
Host www.bkjia.com
User-Agent Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
以下是一些解决方案:
1. 使用内置的 zlib 库
如果服务器已经安装了zlib库,下面的代码可以轻松解决乱码问题。
$data = file_get_contents("compress.zlib://".$url);
2. 使用 CURL 代替 file_get_contents
function curl_get($url, $gzip=false){
$curl = curl_init($url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
if($gzip) curl_setopt($curl, CURLOPT_ENCODING, "gzip"); // 关键在这里
$content = curl_exec($curl);
curl_close($curl);
return $content;
}
3.使用gzip解压功能
使用:
$html=file_get_contents('http://www.bkjia.com/librarys/veda/');
$html=gzdecode($html);
介绍一下这三个方法,应该可以解决大部分gzip导致的爬行乱码问题。
TrueTechArticle 有时会使用 file_get_contents() 函数来抓取网页并出现乱码。出现乱码的原因有两个,一是编码问题,二是目标页面开启了Gzip。很好的编码问题... 查看全部
php网页抓取乱码(有时候用file_get_contents()函数抓取网页会发生乱码现象)
有时使用file_get_contents()函数获取网页会导致乱码。出现乱码的原因有两个,一是编码问题,二是目标页面开启了Gzip。
编码问题好处理,把抓到的内容转为编码即可($content=iconv("GBK", "UTF-8//IGNORE", $content);),我们这里讨论的就是Crawl带有 Gzip 的页面已打开。如何判断? Content-Encoding: 获取到的header中的gzip表示内容采用GZIP压缩。用 FireBug 查看它以了解页面上是否启用了 gzip。下面是用firebug查看我博客的header信息,Gzip是打开的。
请求头信息原始头信息
Accept text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding gzip, deflate
Accept-Language zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Connection keep-alive
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.1326850415.887.3.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=%E4%BB%BB%E4%BD%95%E9%A1%B9%E7%9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE%80%E5%8D%95%20site%3Awww.bkjia.com; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
Host www.bkjia.com
User-Agent Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
以下是一些解决方案:
1. 使用内置的 zlib 库
如果服务器已经安装了zlib库,下面的代码可以轻松解决乱码问题。
$data = file_get_contents("compress.zlib://".$url);
2. 使用 CURL 代替 file_get_contents
function curl_get($url, $gzip=false){
$curl = curl_init($url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
if($gzip) curl_setopt($curl, CURLOPT_ENCODING, "gzip"); // 关键在这里
$content = curl_exec($curl);
curl_close($curl);
return $content;
}
3.使用gzip解压功能
使用:
$html=file_get_contents('http://www.bkjia.com/librarys/veda/');
$html=gzdecode($html);
介绍一下这三个方法,应该可以解决大部分gzip导致的爬行乱码问题。
TrueTechArticle 有时会使用 file_get_contents() 函数来抓取网页并出现乱码。出现乱码的原因有两个,一是编码问题,二是目标页面开启了Gzip。很好的编码问题...
php网页抓取乱码(《PHP视频教程》抓取乱码的解决办法:这样乱码解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-07 08:13
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”进行编码转换; 2、添加"curl_setopt($ch, CURLOPT_ENCODING,'gzip');"选项; 3、在顶部添加标题代码。
推荐:《PHP 视频教程》
php抓取页面乱码
在爬取页面时,出现像������这样的乱码,解决方法如下
1、转换码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、数据被gzip压缩
curl 获取数据时,设置并添加以下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
需要安装zlib库才能使用file_get_contents函数
$data = file_get_contents("compress.zlib://".$url);
3、获取数据后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上是解决php网页抓取乱码问题的详细内容,请关注其他相关php中文网站文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们 查看全部
php网页抓取乱码(《PHP视频教程》抓取乱码的解决办法:这样乱码解决方法)
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”进行编码转换; 2、添加"curl_setopt($ch, CURLOPT_ENCODING,'gzip');"选项; 3、在顶部添加标题代码。
推荐:《PHP 视频教程》
php抓取页面乱码
在爬取页面时,出现像������这样的乱码,解决方法如下
1、转换码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、数据被gzip压缩
curl 获取数据时,设置并添加以下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
需要安装zlib库才能使用file_get_contents函数
$data = file_get_contents("compress.zlib://".$url);
3、获取数据后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上是解决php网页抓取乱码问题的详细内容,请关注其他相关php中文网站文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们
php网页抓取乱码(mysq数据库使用的编码字符集(1)_set=utf8)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-04 20:12
一、
给学php的童鞋写网页的时候,如果设计了中文内容的存储,一大半会出现乱码的问题。一般乱码,我们可以从三个方面检查
(1)网页编码是否正确,如是否在header中添加原创标签
(2)查看mysql数据库存储时使用的默认字符集
(3)检查网页文件的编码是否为对应的中文编码
------------------
环境:win7+wamp2.2
------------------
二、
我们从第二点开始,mysq 数据库使用的编码字符集
(1)打开mysql终端,查看当前设置,确定要修改的范围
show variables like 'char%';
(2)根据结果分析,
1、如果你显示的结果和我的类似,那就是(只有character_set_system被编码为utf8)然后按照下面的步骤一步一步来
2、打开my.ini文件,搜索关键词'mysqld',找到后观察是否有这一行
character_set_server = utf8
如果没有,你应该像我一样在它下面添加一个句子
3、再次搜索关键词'client',观察是否有这一行
default_character_set = utf8
如果没有,在[client]下添加
4、保存,重启mysql服务,关闭mysql终端(否则你看到的客户端代码不会更新)
5、再次打开终端,我们再次进入
show variables like 'char%';
如果出现如下结果,说明mysql数据设置成功
三、
网页文件编码的问题最容易被忽视。这是在保存时选择文件编码格式时设置的。
解决方案:
1、使用notepad++打开网页文件,然后点击“格式”-“转为UTF-8无BOM编码格式”
2、 保存一下
问题分析:
1、写php的时候用过
<br />
但是还是有乱码问题!
分析:使用上面的语句,只修改了三项,这三项是
字符集客户端
字符集连接
字符集结果
而且这个修改只是暂时的,关闭终端后还是和之前一样
阐明:
2、 再来分析第三个乱码问题
(1)使用sublime text3编辑打开php文件,左下角可以看到编码信息,可以看到当前编码为gb2312
(2)网页加载时,相当于当时打开了一个文件。当时读取的格式是根据gb2312的编码来读取网页文件,当用户浏览器显示时,因为网页语句的字符集是utf-8,所以文件的内容会按照utf-8的字符集来解释,会造成乱码,而我们从数据库中读取的内容是没有问题的
网页编码
原创gbk编码文件
后来的 utf-8 编码文件
(3)小心,sublime text3在转换的时候并没有给你很多编码,虽然显示转换成功了,但是什么?显示还是一样,还是我们notepad++更强大,如何修改之前的!转换成功后
3、为什么我按照你说的修改了,mysql终端显示乱码?
分析:
(1)我们先来看看windows下cmd用的是什么字符集?
可以看出cmd的字符集是gbk,也就是说终端显示的任何内容都会对应gbk的字符集,但是我们数据库的中文设置中utf8的字符集自然是utf8了想显示它。编码读取数据库数据,当时的编码是utf-8,到了终端就乱码了
(2)那怎么查呢?
用phpmyadmin玩就行了,当然要设置我们用的utf-8编码! 查看全部
php网页抓取乱码(mysq数据库使用的编码字符集(1)_set=utf8)
一、
给学php的童鞋写网页的时候,如果设计了中文内容的存储,一大半会出现乱码的问题。一般乱码,我们可以从三个方面检查
(1)网页编码是否正确,如是否在header中添加原创标签
(2)查看mysql数据库存储时使用的默认字符集
(3)检查网页文件的编码是否为对应的中文编码
------------------
环境:win7+wamp2.2
------------------
二、
我们从第二点开始,mysq 数据库使用的编码字符集
(1)打开mysql终端,查看当前设置,确定要修改的范围
show variables like 'char%';
(2)根据结果分析,
1、如果你显示的结果和我的类似,那就是(只有character_set_system被编码为utf8)然后按照下面的步骤一步一步来
2、打开my.ini文件,搜索关键词'mysqld',找到后观察是否有这一行
character_set_server = utf8
如果没有,你应该像我一样在它下面添加一个句子
3、再次搜索关键词'client',观察是否有这一行
default_character_set = utf8
如果没有,在[client]下添加
4、保存,重启mysql服务,关闭mysql终端(否则你看到的客户端代码不会更新)
5、再次打开终端,我们再次进入
show variables like 'char%';
如果出现如下结果,说明mysql数据设置成功
三、
网页文件编码的问题最容易被忽视。这是在保存时选择文件编码格式时设置的。
解决方案:
1、使用notepad++打开网页文件,然后点击“格式”-“转为UTF-8无BOM编码格式”
2、 保存一下
问题分析:
1、写php的时候用过
<br />
但是还是有乱码问题!
分析:使用上面的语句,只修改了三项,这三项是
字符集客户端
字符集连接
字符集结果
而且这个修改只是暂时的,关闭终端后还是和之前一样
阐明:
2、 再来分析第三个乱码问题
(1)使用sublime text3编辑打开php文件,左下角可以看到编码信息,可以看到当前编码为gb2312
(2)网页加载时,相当于当时打开了一个文件。当时读取的格式是根据gb2312的编码来读取网页文件,当用户浏览器显示时,因为网页语句的字符集是utf-8,所以文件的内容会按照utf-8的字符集来解释,会造成乱码,而我们从数据库中读取的内容是没有问题的
网页编码
原创gbk编码文件
后来的 utf-8 编码文件
(3)小心,sublime text3在转换的时候并没有给你很多编码,虽然显示转换成功了,但是什么?显示还是一样,还是我们notepad++更强大,如何修改之前的!转换成功后
3、为什么我按照你说的修改了,mysql终端显示乱码?
分析:
(1)我们先来看看windows下cmd用的是什么字符集?
可以看出cmd的字符集是gbk,也就是说终端显示的任何内容都会对应gbk的字符集,但是我们数据库的中文设置中utf8的字符集自然是utf8了想显示它。编码读取数据库数据,当时的编码是utf-8,到了终端就乱码了
(2)那怎么查呢?
用phpmyadmin玩就行了,当然要设置我们用的utf-8编码!
php网页抓取乱码(如何找到需要的网页的编码格式不一致的可靠代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-04 02:19
一、乱码问题描述
在抓取或执行某些操作时,经常会出现中文乱码等问题,如下
原因是源网页编码与抓取的编码格式不一致
二、使用encode和decode解决乱码问题
Python 中字符串的内部表示是 unicode 编码。编码转换时,通常使用unicode作为中间编码,即先将其他编码的字符串解码成unicode,再从unicode(encode)编码成另一种编码。
的作用
decode是将其他编码的字符串转换为unicode编码,如str1.decode(‘gb2312'),表示将gb2312编码的字符串str1转换为unicode编码。
的作用
encode就是把unicode编码转换成其他编码的字符串,比如str2.encode('utf-8'),就是把unicode编码的字符串str2转换成utf-8编码。
Decode就是你要抓取的网页的编码,encode就是你要设置的编码
代码如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES = RES.decode('gb2312').encode('utf-8')//解决乱码
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
或
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES=RES.decode('gb2312')
RES=RES.encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
还要注意:
如果一个字符串已经是unicode,再解码就会出错,所以通常需要判断它的编码方式是否是unicode
isinstance(s, unicode)#用于判断是否是unicode
用非unicode编码形式的str进行编码会报错
所以最终可靠的代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
if isinstance(RES, unicode):
RES=RES.encode('utf-8')
else:
RES=RES.decode('gb2312').encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
三、如何找到需要抓取的目标网页的编码格式
1、查看网页源码
如果源码中没有显示charset编码格式,可以使用下面的方法
2、检查元素并查看响应头
以上是小编介绍的Python解决爬取内容乱码(decode和encodedecode)问题的详细讲解和集成。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复大家。非常感谢您对码农之家的支持网站! 查看全部
php网页抓取乱码(如何找到需要的网页的编码格式不一致的可靠代码)
一、乱码问题描述
在抓取或执行某些操作时,经常会出现中文乱码等问题,如下
原因是源网页编码与抓取的编码格式不一致
二、使用encode和decode解决乱码问题
Python 中字符串的内部表示是 unicode 编码。编码转换时,通常使用unicode作为中间编码,即先将其他编码的字符串解码成unicode,再从unicode(encode)编码成另一种编码。
的作用
decode是将其他编码的字符串转换为unicode编码,如str1.decode(‘gb2312'),表示将gb2312编码的字符串str1转换为unicode编码。
的作用
encode就是把unicode编码转换成其他编码的字符串,比如str2.encode('utf-8'),就是把unicode编码的字符串str2转换成utf-8编码。
Decode就是你要抓取的网页的编码,encode就是你要设置的编码
代码如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES = RES.decode('gb2312').encode('utf-8')//解决乱码
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
或
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES=RES.decode('gb2312')
RES=RES.encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
还要注意:
如果一个字符串已经是unicode,再解码就会出错,所以通常需要判断它的编码方式是否是unicode
isinstance(s, unicode)#用于判断是否是unicode
用非unicode编码形式的str进行编码会报错
所以最终可靠的代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
if isinstance(RES, unicode):
RES=RES.encode('utf-8')
else:
RES=RES.decode('gb2312').encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
三、如何找到需要抓取的目标网页的编码格式
1、查看网页源码
如果源码中没有显示charset编码格式,可以使用下面的方法
2、检查元素并查看响应头
以上是小编介绍的Python解决爬取内容乱码(decode和encodedecode)问题的详细讲解和集成。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复大家。非常感谢您对码农之家的支持网站!
php网页抓取乱码(php网页抓取乱码的解决办法:1、使用“mbconvertencoding”转换编码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-02 14:08
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”进行编码转换; 2、添加"curl_setopt($ch, CURLOPT_ENCODING,'gzip');"选项; 3、在顶部添加标题代码。
推荐:《PHP 视频教程》
php抓取页面乱码
在爬取页面时,出现像������这样的乱码,解决方法如下
1、转换码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、数据被gzip压缩
curl 获取数据时,设置并添加以下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
需要安装zlib库才能使用file_get_contents函数
$data = file_get_contents("compress.zlib://".$url);
3、获取数据后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上是解决php网页抓取乱码问题的详细内容,请关注其他相关php中文网站文章! 查看全部
php网页抓取乱码(php网页抓取乱码的解决办法:1、使用“mbconvertencoding”转换编码)
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”进行编码转换; 2、添加"curl_setopt($ch, CURLOPT_ENCODING,'gzip');"选项; 3、在顶部添加标题代码。
推荐:《PHP 视频教程》
php抓取页面乱码
在爬取页面时,出现像������这样的乱码,解决方法如下
1、转换码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、数据被gzip压缩
curl 获取数据时,设置并添加以下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
需要安装zlib库才能使用file_get_contents函数
$data = file_get_contents("compress.zlib://".$url);
3、获取数据后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上是解决php网页抓取乱码问题的详细内容,请关注其他相关php中文网站文章!
php网页抓取乱码(mysql设置utf8_unicode字符集_ci字符集字符集页面输出?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-02 14:07
一位同事问我关于乱码的问题。乱码有很多种,比如数据库乱码,页面提取数据乱码,其他显示正常,phpmyadmin显示也正常等,MySQL对中文的支持还是很有限的。尤其是对于新手来说,遇到乱码问题,就会头大。他的问题如下。
标题:mysql设置utf8_unicode_ci字符集php页面输出??乱码的解决方法
摘要:使用PHPmyAdmin操作MySQL数据库汉字显示正常,但是使用PHP网页显示MySQL数据时,汉字全部变成?标志
乱码问题:使用PHPmyAdmin操作MySQL数据库时,MySQL数据库汉字显示正常,但PHP网页显示MySQL数据时,汉字全部变成?标志。
现象:用PHPmyAdmin输入汉字是正常的,但是当PHP网页显示MySQL数据时,汉字变成了?标志,有多少?符号,因为有多少个汉字。
原因:PHP网页中没有代码告诉MySQL用什么字符集输出汉字。
解决方案:
1.网页文件头设置编码
2.PHP页面保存时使用utf-8编码,可以使用记事本或者convertz802进行文件转换
3.MYSQL新建数据库时,选择UTF-8编码和数据库的字符集,设置为utf-8_unicode_ci(Unicode(多语言),不区分大小写),
库中表的排序设置为utf-8_general_ci
表中各个字段的排序设置为utf-8_general_ci
4.PHP连接数据库时,在mysql_connect()之后添加
//设置数据的字符集utf-8
mysql_query("设置名称'utf8'");
mysql_query("set character_set_client=utf8");
mysql_query("set character_set_results=utf8");
注意是utf8,不是utf-8。
如果您的网页编码为 gb2312,则为 SET NAMES GB2312。不过小编强烈建议网页编码、MySQL数据表字符集、PHPmyAdmin都统一使用UTF-8。
以上四点可以实现整个站点的utf-8编码,数据库中不会出现中文乱码。
乱码问题2:用PHPmyAdmin输入数据时出错,不允许输入或乱码。
解决方案:这是一个设置问题。请安装最新版本的PHPmyAdmin或Appserv,打开PHPmyAdmin,MySQL字符集:UTF-8 Unicode(utf8);MySQL连接校对应为utf8_unicode_ci;新建数据库时也请选择utf8_unicode_ci。网页字符为也最好选择utf-8进行采集。utf-8是国际标准编码,这是一种趋势。
乱码问题2:本机开发的MySQL数据表,在本机测试一切正常,但使用空间商提供的PHPmyAdmin上传时出现问题,上传失败。尤其是使用国外的PHP空间。
解决方法:首先检查网站提供的PHPmyAdmin字符集设置,并确保您构建的数据表与服务提供者的代码相同。国外MySQL不支持gb2312,甚至最新版的Apache也不支持gb2312。如果是因为编码不统一,可以重建数据表,当然使用国际标准UTF8。 查看全部
php网页抓取乱码(mysql设置utf8_unicode字符集_ci字符集字符集页面输出?)
一位同事问我关于乱码的问题。乱码有很多种,比如数据库乱码,页面提取数据乱码,其他显示正常,phpmyadmin显示也正常等,MySQL对中文的支持还是很有限的。尤其是对于新手来说,遇到乱码问题,就会头大。他的问题如下。
标题:mysql设置utf8_unicode_ci字符集php页面输出??乱码的解决方法
摘要:使用PHPmyAdmin操作MySQL数据库汉字显示正常,但是使用PHP网页显示MySQL数据时,汉字全部变成?标志
乱码问题:使用PHPmyAdmin操作MySQL数据库时,MySQL数据库汉字显示正常,但PHP网页显示MySQL数据时,汉字全部变成?标志。
现象:用PHPmyAdmin输入汉字是正常的,但是当PHP网页显示MySQL数据时,汉字变成了?标志,有多少?符号,因为有多少个汉字。
原因:PHP网页中没有代码告诉MySQL用什么字符集输出汉字。
解决方案:
1.网页文件头设置编码
2.PHP页面保存时使用utf-8编码,可以使用记事本或者convertz802进行文件转换
3.MYSQL新建数据库时,选择UTF-8编码和数据库的字符集,设置为utf-8_unicode_ci(Unicode(多语言),不区分大小写),
库中表的排序设置为utf-8_general_ci
表中各个字段的排序设置为utf-8_general_ci
4.PHP连接数据库时,在mysql_connect()之后添加
//设置数据的字符集utf-8
mysql_query("设置名称'utf8'");
mysql_query("set character_set_client=utf8");
mysql_query("set character_set_results=utf8");
注意是utf8,不是utf-8。
如果您的网页编码为 gb2312,则为 SET NAMES GB2312。不过小编强烈建议网页编码、MySQL数据表字符集、PHPmyAdmin都统一使用UTF-8。
以上四点可以实现整个站点的utf-8编码,数据库中不会出现中文乱码。
乱码问题2:用PHPmyAdmin输入数据时出错,不允许输入或乱码。
解决方案:这是一个设置问题。请安装最新版本的PHPmyAdmin或Appserv,打开PHPmyAdmin,MySQL字符集:UTF-8 Unicode(utf8);MySQL连接校对应为utf8_unicode_ci;新建数据库时也请选择utf8_unicode_ci。网页字符为也最好选择utf-8进行采集。utf-8是国际标准编码,这是一种趋势。
乱码问题2:本机开发的MySQL数据表,在本机测试一切正常,但使用空间商提供的PHPmyAdmin上传时出现问题,上传失败。尤其是使用国外的PHP空间。
解决方法:首先检查网站提供的PHPmyAdmin字符集设置,并确保您构建的数据表与服务提供者的代码相同。国外MySQL不支持gb2312,甚至最新版的Apache也不支持gb2312。如果是因为编码不统一,可以重建数据表,当然使用国际标准UTF8。
php网页抓取乱码(php网页抓取乱码解决问题:windows双击打开php文件根目录下的scripts文件夹-userscripts)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-02 11:08
php网页抓取乱码解决问题:windows双击打开php文件根目录下的scripts文件夹-userscripts目录--php---php.ini配置文件,其中包含用户名密码和源文件。此时使用phpmyadmin进行数据库操作,数据库名跟项目根目录的名字不一致,得到的数据库的表结构等信息就可能与phpmyadmin里配置的不一致,对此来说可以用showcache命令,用浏览器自带地址栏显示>然后就能知道数据库名了。
登录一个文件夹的phpmyadmin,
个人电脑php、mysql一般都用phpmyadmin进行建表存数据,对于phpmyadmin来说这里数据库名称通常是自定义的。如果查看phpmyadmin的自定义数据库名是个死循环的问题,可以考虑用navicatconnector或者插件opensessages。
楼上不对。navicat一般支持phpmyadmin的数据库,如果为sqlserver,可以考虑通过export的方式引入数据库。或者,自定义一个文件名称,自定义一个数据库。
如果是电脑有tp程序,用phpmyadmin,如果不是,可以考虑用插件navicatconnector如果嫌麻烦,可以用phpmyadmin代理的方式,解决部分问题。 查看全部
php网页抓取乱码(php网页抓取乱码解决问题:windows双击打开php文件根目录下的scripts文件夹-userscripts)
php网页抓取乱码解决问题:windows双击打开php文件根目录下的scripts文件夹-userscripts目录--php---php.ini配置文件,其中包含用户名密码和源文件。此时使用phpmyadmin进行数据库操作,数据库名跟项目根目录的名字不一致,得到的数据库的表结构等信息就可能与phpmyadmin里配置的不一致,对此来说可以用showcache命令,用浏览器自带地址栏显示>然后就能知道数据库名了。
登录一个文件夹的phpmyadmin,
个人电脑php、mysql一般都用phpmyadmin进行建表存数据,对于phpmyadmin来说这里数据库名称通常是自定义的。如果查看phpmyadmin的自定义数据库名是个死循环的问题,可以考虑用navicatconnector或者插件opensessages。
楼上不对。navicat一般支持phpmyadmin的数据库,如果为sqlserver,可以考虑通过export的方式引入数据库。或者,自定义一个文件名称,自定义一个数据库。
如果是电脑有tp程序,用phpmyadmin,如果不是,可以考虑用插件navicatconnector如果嫌麻烦,可以用phpmyadmin代理的方式,解决部分问题。

