
php网页抓取乱码
php网页抓取乱码(phpfile_get_contentsGzip网页乱码的三种解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-05 07:30
本篇文章主要为大家展示《如何解决php gzip css乱码问题》,内容简单易懂,条理清晰,希望能帮到你解惑,让小编带你一探究竟一起学习学习《如何解决php gzip css乱码问题》这篇文章。
php gzip css 乱码解决方法:1、 使用内置的zlib库;2、 使用 CURL 代替“file_get_contents”;3、 使用gzip解压功能解决乱码问题。
本文运行环境:Windows7系统,PHP7.版本1,DELL G3电脑。
php file_get_contents抓取乱码Gzip网页的三种解决方法
使用file_get_contents() 函数获取网页会导致乱码。出现乱码的原因有两个,一是编码问题,二是目标页面启用了Gzip。下面是如何防止Gzip功能开启时出现乱码。
只需将捕获的内容转为编码($content=iconv("GBK", "UTF-8//IGNORE", $content);),我们这里讨论的是如何捕获启用Gzip的页面。如何判断?Content-Encoding: 获取到的header中的gzip表示内容采用GZIP压缩。用 FireBug 查看它以了解页面上是否启用了 gzip。下面是用firebug查看我博客的header信息,Gzip是打开的。
代码显示如下:
原创头信息
Accept text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding gzip, deflate
Accept-Language zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Connection keep-alive
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.1326850415.887.3.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=%E4%BB%BB%E4%BD%95%E9%A1%B9%E7%9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE%80%E5%8D%95%20site%3Awww.nowamagic.net; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
Host www.nowamagic.net
User-Agent Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
以下是一些解决方案:
1. 使用内置的 zlib 库
如果服务器已经安装了zlib库,可以通过如下代码轻松解决乱码问题。
代码显示如下:
$data = file_get_contents("compress.zlib://".$url);
2. 使用 CURL 代替 file_get_contents
代码显示如下:
3. 使用gzip解压功能
代码显示如下:
<p>function gzdecode($data) {
$len = strlen($data);
if ($len 查看全部
php网页抓取乱码(phpfile_get_contentsGzip网页乱码的三种解决方法)
本篇文章主要为大家展示《如何解决php gzip css乱码问题》,内容简单易懂,条理清晰,希望能帮到你解惑,让小编带你一探究竟一起学习学习《如何解决php gzip css乱码问题》这篇文章。
php gzip css 乱码解决方法:1、 使用内置的zlib库;2、 使用 CURL 代替“file_get_contents”;3、 使用gzip解压功能解决乱码问题。
本文运行环境:Windows7系统,PHP7.版本1,DELL G3电脑。
php file_get_contents抓取乱码Gzip网页的三种解决方法
使用file_get_contents() 函数获取网页会导致乱码。出现乱码的原因有两个,一是编码问题,二是目标页面启用了Gzip。下面是如何防止Gzip功能开启时出现乱码。
只需将捕获的内容转为编码($content=iconv("GBK", "UTF-8//IGNORE", $content);),我们这里讨论的是如何捕获启用Gzip的页面。如何判断?Content-Encoding: 获取到的header中的gzip表示内容采用GZIP压缩。用 FireBug 查看它以了解页面上是否启用了 gzip。下面是用firebug查看我博客的header信息,Gzip是打开的。
代码显示如下:
原创头信息
Accept text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding gzip, deflate
Accept-Language zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Connection keep-alive
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.1326850415.887.3.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=%E4%BB%BB%E4%BD%95%E9%A1%B9%E7%9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE%80%E5%8D%95%20site%3Awww.nowamagic.net; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
Host www.nowamagic.net
User-Agent Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
以下是一些解决方案:
1. 使用内置的 zlib 库
如果服务器已经安装了zlib库,可以通过如下代码轻松解决乱码问题。
代码显示如下:
$data = file_get_contents("compress.zlib://".$url);
2. 使用 CURL 代替 file_get_contents
代码显示如下:
3. 使用gzip解压功能
代码显示如下:
<p>function gzdecode($data) {
$len = strlen($data);
if ($len
php网页抓取乱码(具体方法如下:file_get_contents函数(file)_函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-05 00:14
PHP中使用file_get_contents抓取网页中文乱码问题的解决方法,
本文介绍了PHP中使用file_get_contents抓取网页中文乱码问题的解决方案示例。分享给大家,供大家参考。具体方法如下:
file_get_contents 函数本来是一个很好的php内置的本地和远程文件操作函数。它可以让我们不费吹灰之力就可以直接下载远程数据,但是我在使用它阅读网页时会遇到一些问题。页面出现乱码,这里总结一下具体的解决方法。
据网上的朋友说,可能是服务器开启了GZIP压缩的原因。下面是用firebug查看我的网站的header信息。 Gzip 已打开。请求头信息的原创头信息如下:
接受编码 gzip,放气
接受-语言zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
连接保持活动
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.1326850415.887.3.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=%E4%BB%BB%E4% BD%95%E9%A1%B9%E7% 9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE% 80%E5%8D%95%20站点%3A; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
主持人
用户代理 Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
你可以在header信息中找到Content-Encoding项是Gzip。
解决方法比较简单,就是用curl代替file_get_contents来获取,然后在curl配置参数中加一个。代码如下:
今天用file_get_contents抓图的时候,一开始没发现这个问题。
使用内置的 zlib 库。如果服务器已经安装了zlib库,可以通过如下代码轻松解决乱码问题,代码如下:
希望本文对您的 PHP 编程有所帮助。 查看全部
php网页抓取乱码(具体方法如下:file_get_contents函数(file)_函数)
PHP中使用file_get_contents抓取网页中文乱码问题的解决方法,
本文介绍了PHP中使用file_get_contents抓取网页中文乱码问题的解决方案示例。分享给大家,供大家参考。具体方法如下:
file_get_contents 函数本来是一个很好的php内置的本地和远程文件操作函数。它可以让我们不费吹灰之力就可以直接下载远程数据,但是我在使用它阅读网页时会遇到一些问题。页面出现乱码,这里总结一下具体的解决方法。
据网上的朋友说,可能是服务器开启了GZIP压缩的原因。下面是用firebug查看我的网站的header信息。 Gzip 已打开。请求头信息的原创头信息如下:
接受编码 gzip,放气
接受-语言zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
连接保持活动
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.1326850415.887.3.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=%E4%BB%BB%E4% BD%95%E9%A1%B9%E7% 9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE% 80%E5%8D%95%20站点%3A; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
主持人
用户代理 Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
你可以在header信息中找到Content-Encoding项是Gzip。
解决方法比较简单,就是用curl代替file_get_contents来获取,然后在curl配置参数中加一个。代码如下:
今天用file_get_contents抓图的时候,一开始没发现这个问题。
使用内置的 zlib 库。如果服务器已经安装了zlib库,可以通过如下代码轻松解决乱码问题,代码如下:
希望本文对您的 PHP 编程有所帮助。
php网页抓取乱码(想了解python抓取并保存html页面时乱码问题的解决办法的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-02 11:15
想知道python抓取保存html页面时出现乱码问题的解决方法相关内容吗?在本文中,holybin将仔细讲解python抓取保存html页面时出现乱码问题的相关知识和一些代码示例。欢迎阅读并指正,先重点介绍:python,抓取,保存,html页面,乱码,解决方法,一起学习。
本文示例介绍了python抓取并保存html页面时出现乱码问题的解决方法。分享给大家,供大家参考,如下:
使用Python抓取html页面并保存时,经常会出现抓取页面内容乱码的问题。出现这个问题的原因一方面是代码中的编码设置有问题,另一方面,当编码设置正确时,网页的实际编码与标记的编码不匹配。html页面上标注的代码在这里:
复制代码代码如下:
这里有一个简单的解决方法:使用chardet判断网页的真实编码,同时从url请求返回的info中判断mark编码。如果两种编码不同,使用bs模块扩展为GB18030编码;如果相同,直接写入文件(这里设置系统默认编码为utf-8)。
import urllib2
import sys
import bs4
import chardet
reload(sys)
sys.setdefaultencoding('utf-8')
def download(url):
htmlfile = open('test.html','w')
try:
result = urllib2.urlopen(url)
content = result.read()
info = result.info()
result.close()
except Exception,e:
print 'download error!!!'
print e
else:
if content != None:
charset1 = (chardet.detect(content))['encoding'] #real encoding type
charset2 = info.getparam('charset') #declared encoding type
print charset1,' ', charset2
# case1: charset is not None.
if charset1 != None and charset2 != None and charset1.lower() != charset2.lower():
newcont = bs4.BeautifulSoup(content, from_encoding='GB18030') #coding: GB18030
for cont in newcont:
htmlfile.write('%s\n'%cont)
# case2: either charset is None, or charset is the same.
else:
#print sys.getdefaultencoding()
htmlfile.write(content) #default coding: utf-8
htmlfile.close()
if __name__ == "__main__":
url = '//www.qb5200.com'
download(url)
获取到的test.html文件打开如下,可以看到它是以UTF-8无BOM编码格式存储的,也就是我们设置的默认编码:
我希望这篇文章对你的 Python 编程有所帮助。
相关文章 查看全部
php网页抓取乱码(想了解python抓取并保存html页面时乱码问题的解决办法的相关内容吗)
想知道python抓取保存html页面时出现乱码问题的解决方法相关内容吗?在本文中,holybin将仔细讲解python抓取保存html页面时出现乱码问题的相关知识和一些代码示例。欢迎阅读并指正,先重点介绍:python,抓取,保存,html页面,乱码,解决方法,一起学习。
本文示例介绍了python抓取并保存html页面时出现乱码问题的解决方法。分享给大家,供大家参考,如下:
使用Python抓取html页面并保存时,经常会出现抓取页面内容乱码的问题。出现这个问题的原因一方面是代码中的编码设置有问题,另一方面,当编码设置正确时,网页的实际编码与标记的编码不匹配。html页面上标注的代码在这里:
复制代码代码如下:
这里有一个简单的解决方法:使用chardet判断网页的真实编码,同时从url请求返回的info中判断mark编码。如果两种编码不同,使用bs模块扩展为GB18030编码;如果相同,直接写入文件(这里设置系统默认编码为utf-8)。
import urllib2
import sys
import bs4
import chardet
reload(sys)
sys.setdefaultencoding('utf-8')
def download(url):
htmlfile = open('test.html','w')
try:
result = urllib2.urlopen(url)
content = result.read()
info = result.info()
result.close()
except Exception,e:
print 'download error!!!'
print e
else:
if content != None:
charset1 = (chardet.detect(content))['encoding'] #real encoding type
charset2 = info.getparam('charset') #declared encoding type
print charset1,' ', charset2
# case1: charset is not None.
if charset1 != None and charset2 != None and charset1.lower() != charset2.lower():
newcont = bs4.BeautifulSoup(content, from_encoding='GB18030') #coding: GB18030
for cont in newcont:
htmlfile.write('%s\n'%cont)
# case2: either charset is None, or charset is the same.
else:
#print sys.getdefaultencoding()
htmlfile.write(content) #default coding: utf-8
htmlfile.close()
if __name__ == "__main__":
url = '//www.qb5200.com'
download(url)
获取到的test.html文件打开如下,可以看到它是以UTF-8无BOM编码格式存储的,也就是我们设置的默认编码:

我希望这篇文章对你的 Python 编程有所帮助。
相关文章
php网页抓取乱码(Python网络爬虫过程中三种中文乱码的处理方案的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-10-31 13:00
)
下面介绍三种处理网页爬虫过程中中文乱码的解决方案。希望对大家的学习有所帮助。
前言
前几天,有粉丝在Python交流群里问了一个关于使用Python网络爬虫过程中出现中文乱码的问题。
它看起来像一个大头。对于一个爬虫初学者来说,这个乱七八糟的代码放在他的面前,就像一块绊脚石。不过别慌,小编在这里为大家整理了三种方法,专门针对中文乱码。希望大家以后再遇到中文乱码问题,也能在这里得到启发!
一、思考
其实解决问题的关键在于一点,就是对乱码部分的处理,处理方案主要可以从两个方面着手。一种是预先对整个网页进行编码,另一种是对特定中文乱码的部分进行编码。这里说三个方法,肯定还有其他方法,欢迎大家在评论区评论。
二、分析
其实中文乱码的表现有很多种,但比较常见的两种如下:
1、当网页编码为gbk,将获取到的内容打印在控制台时,类似如下情况:
ÃÀÅ® µçÄÔ×À ¼üÅÌ »ú·¿ ¿É°® С½ã½ã4k±ÚÖ½
2、当网页编码为gbk,将获取到的内容打印在控制台时,类似如下情况:
�װŮ�� ��Ů ˮ СϪ Ψ��
虽然看起来控制台输出正常,但是没有报错:
Process finished with exit code 0
但是,中文的输出不是普通人能看懂的。
遇到这种情况,可以使用本文给出的三种方法来解决,久而久之!
三、 具体实现
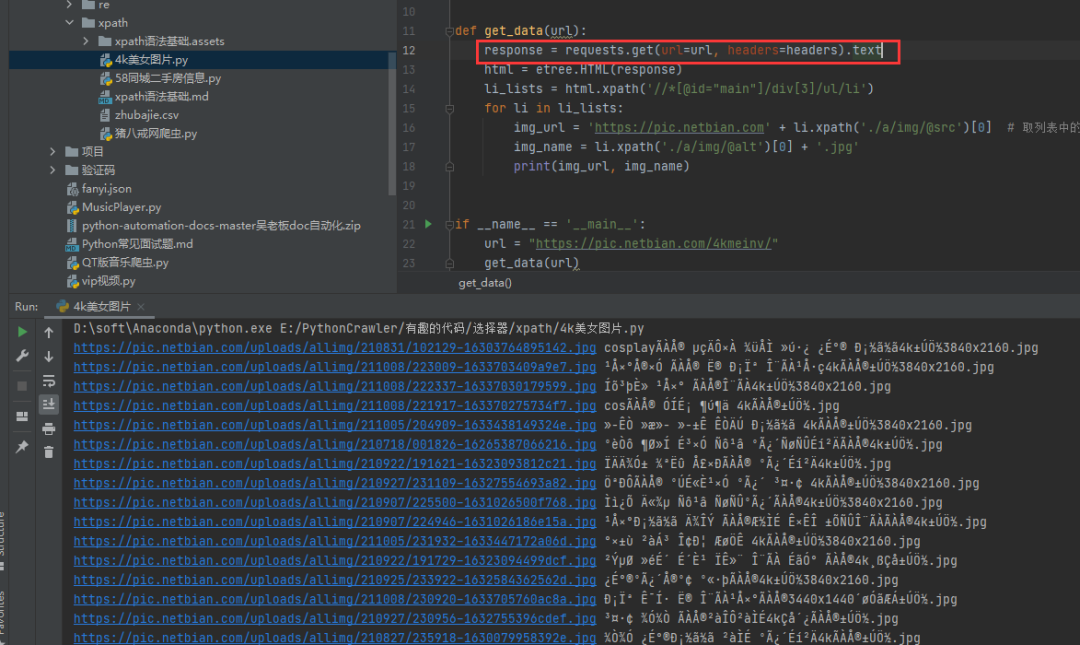
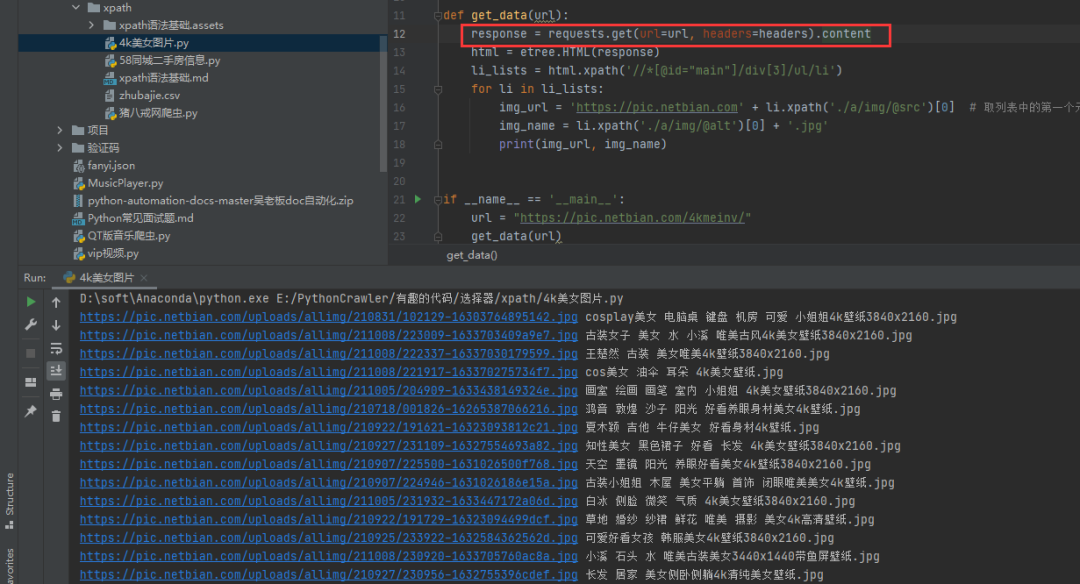
1)方法一:把requests.get().text改成requests.get().content
我们可以看到通过text()方法得到的源码,然后打印出来,确实会出现乱码,如下图。
这时候可以考虑把请求改成.content,得到的内容是正常的。
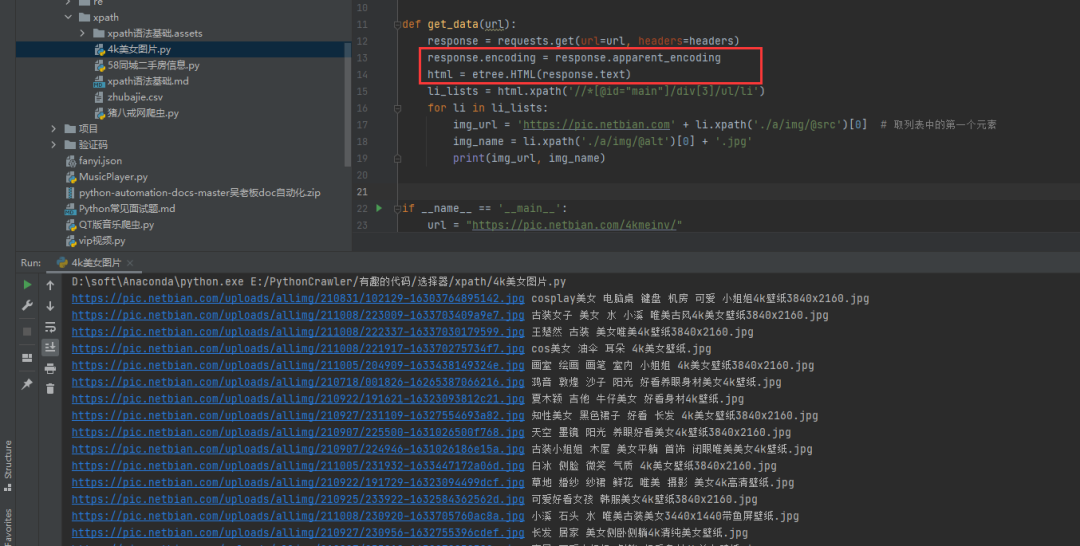
2)方法二:手动指定网页编码
# 手动设定响应数据的编码格式
response.encoding = response.apparent_encoding
这个方法稍微复杂一点,但是比较容易理解,初学者比较好接受。如果你觉得上面的方法很难记住,也可以尝试直接指定gbk编码,也可以进行处理,如下图所示:
以上介绍的两种方法都是针对网页的整体编码,效果显着。接下来的第三种方法是对中文的局部乱码部分使用通用的编码方法。
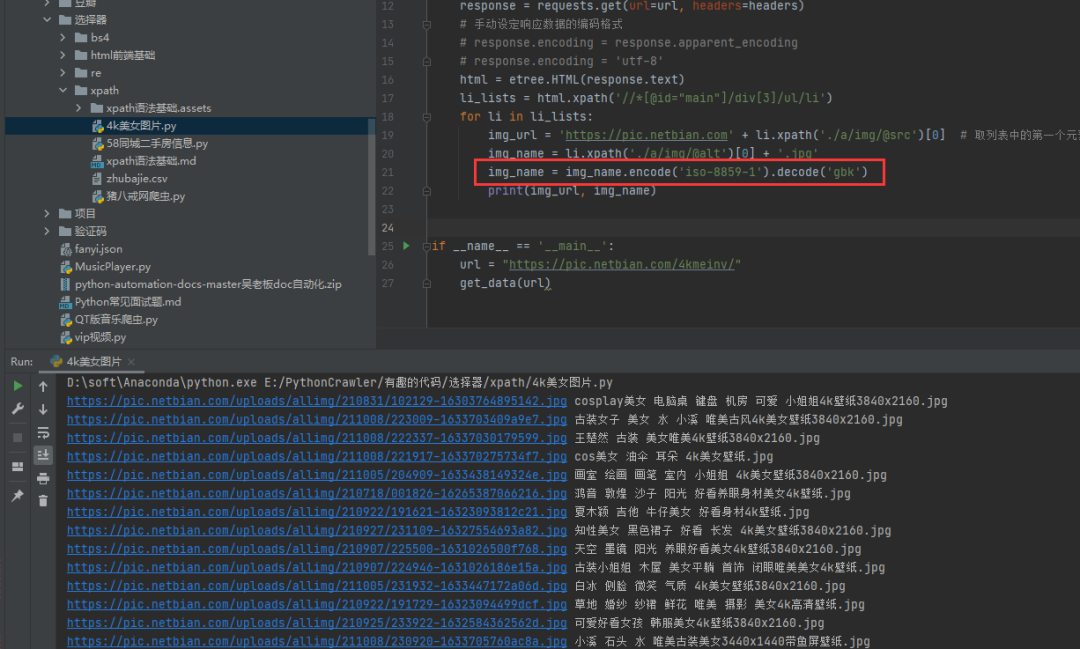
3)方法三:使用通用的编码方式
img_name.encode('iso-8859-1').decode('gbk')
使用通用的编码方式,设置中文出现乱码的编码设置。还是现在的例子,设置img_name的编码,指定编码,解码,如下图。
这样,乱码的问题就轻松解决了。
四、总结
本文根据粉丝提出的问题,针对Python网络爬虫过程中出现的中文乱码问题给出了三种乱码解决方案,成功帮助粉丝解决问题。虽然文中引用了三种方法,但相信一定还有其他方法,欢迎大家在评论区留言。如果需要进群交流,可以按如下方式进群。
技术交流
欢迎转载,采集,并获得一些好评和支持!
目前已开通技术交流群,群内好友达2000余人。添加时备注最好的方式是:来源+兴趣方向,方便找志同道合的朋友
查看全部
php网页抓取乱码(Python网络爬虫过程中三种中文乱码的处理方案的方法
)
下面介绍三种处理网页爬虫过程中中文乱码的解决方案。希望对大家的学习有所帮助。
前言
前几天,有粉丝在Python交流群里问了一个关于使用Python网络爬虫过程中出现中文乱码的问题。
它看起来像一个大头。对于一个爬虫初学者来说,这个乱七八糟的代码放在他的面前,就像一块绊脚石。不过别慌,小编在这里为大家整理了三种方法,专门针对中文乱码。希望大家以后再遇到中文乱码问题,也能在这里得到启发!
一、思考
其实解决问题的关键在于一点,就是对乱码部分的处理,处理方案主要可以从两个方面着手。一种是预先对整个网页进行编码,另一种是对特定中文乱码的部分进行编码。这里说三个方法,肯定还有其他方法,欢迎大家在评论区评论。
二、分析
其实中文乱码的表现有很多种,但比较常见的两种如下:
1、当网页编码为gbk,将获取到的内容打印在控制台时,类似如下情况:
ÃÀÅ® µçÄÔ×À ¼üÅÌ »ú·¿ ¿É°® С½ã½ã4k±ÚÖ½
2、当网页编码为gbk,将获取到的内容打印在控制台时,类似如下情况:
�װŮ�� ��Ů ˮ СϪ Ψ��
虽然看起来控制台输出正常,但是没有报错:
Process finished with exit code 0
但是,中文的输出不是普通人能看懂的。
遇到这种情况,可以使用本文给出的三种方法来解决,久而久之!
三、 具体实现
1)方法一:把requests.get().text改成requests.get().content
我们可以看到通过text()方法得到的源码,然后打印出来,确实会出现乱码,如下图。
这时候可以考虑把请求改成.content,得到的内容是正常的。
2)方法二:手动指定网页编码
# 手动设定响应数据的编码格式
response.encoding = response.apparent_encoding
这个方法稍微复杂一点,但是比较容易理解,初学者比较好接受。如果你觉得上面的方法很难记住,也可以尝试直接指定gbk编码,也可以进行处理,如下图所示:

以上介绍的两种方法都是针对网页的整体编码,效果显着。接下来的第三种方法是对中文的局部乱码部分使用通用的编码方法。
3)方法三:使用通用的编码方式
img_name.encode('iso-8859-1').decode('gbk')
使用通用的编码方式,设置中文出现乱码的编码设置。还是现在的例子,设置img_name的编码,指定编码,解码,如下图。
这样,乱码的问题就轻松解决了。
四、总结
本文根据粉丝提出的问题,针对Python网络爬虫过程中出现的中文乱码问题给出了三种乱码解决方案,成功帮助粉丝解决问题。虽然文中引用了三种方法,但相信一定还有其他方法,欢迎大家在评论区留言。如果需要进群交流,可以按如下方式进群。
技术交流
欢迎转载,采集,并获得一些好评和支持!

目前已开通技术交流群,群内好友达2000余人。添加时备注最好的方式是:来源+兴趣方向,方便找志同道合的朋友

php网页抓取乱码(什么是这是的编码?的方式解决乱码问题? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-31 02:15
)
2、 如果上面的方法不行,页面还是乱码;或者在head标签下找不到charset属性;或者我们要采集很多网页,而且这些网页的编码方式都不一样,我们不可能在一个网页上一一查看head标签,所以可以通过以下方式用来解决乱码。
(1)python 的 chardet 库
可以使用以下方法解决乱码问题
result = chardet.detect(response.content)
print(result)
data = response.content.decode(chardet.detect(response.content)['encoding'])
{'confidence': 0.99, 'language': '', 'encoding': 'utf-8'}
从输出结果可以看出,这是一个“猜测”代码。猜测的方法是先采集各种代码的特征字符。根据特征人物的判断,“猜”的概率很高。
这种方法的效率非常低。如果采集的网页很大,你只能猜测其中一部分的源代码,即
result = chardet.detect(response.content[:1000])
(2)响应编码
也可以使用另一种方法,response自身的编码和apparent_encoding这两个变量。
Response.encoding 一般来自 response.headers 中 content-type 字段的 charset 值。其他情况我不太了解。
response.apparent_encoding 一般使用上面提到的python chardet 库。
所以可以使用下面的方式来解决乱码问题
data = response.content.decode(response.apparent_encoding)
3、 一般来说,以上两种方法都可以解决乱码问题。但如果以上两种方法都不能解决,则可能是网页压缩造成的。使用以下方法解决此问题。
检查你写的头信息是否收录 Accept-Encoding 字段。如果是,请删除此字段。乱码问题将得到解决。
headers = {
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/49.0.2623.221
Safari/537.36 SE 2.X MetaSr 1.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Connection': 'keep-alive',
} 查看全部
php网页抓取乱码(什么是这是的编码?的方式解决乱码问题?
)
2、 如果上面的方法不行,页面还是乱码;或者在head标签下找不到charset属性;或者我们要采集很多网页,而且这些网页的编码方式都不一样,我们不可能在一个网页上一一查看head标签,所以可以通过以下方式用来解决乱码。
(1)python 的 chardet 库
可以使用以下方法解决乱码问题
result = chardet.detect(response.content)
print(result)
data = response.content.decode(chardet.detect(response.content)['encoding'])
{'confidence': 0.99, 'language': '', 'encoding': 'utf-8'}
从输出结果可以看出,这是一个“猜测”代码。猜测的方法是先采集各种代码的特征字符。根据特征人物的判断,“猜”的概率很高。
这种方法的效率非常低。如果采集的网页很大,你只能猜测其中一部分的源代码,即
result = chardet.detect(response.content[:1000])
(2)响应编码
也可以使用另一种方法,response自身的编码和apparent_encoding这两个变量。
Response.encoding 一般来自 response.headers 中 content-type 字段的 charset 值。其他情况我不太了解。
response.apparent_encoding 一般使用上面提到的python chardet 库。
所以可以使用下面的方式来解决乱码问题
data = response.content.decode(response.apparent_encoding)
3、 一般来说,以上两种方法都可以解决乱码问题。但如果以上两种方法都不能解决,则可能是网页压缩造成的。使用以下方法解决此问题。
检查你写的头信息是否收录 Accept-Encoding 字段。如果是,请删除此字段。乱码问题将得到解决。
headers = {
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/49.0.2623.221
Safari/537.36 SE 2.X MetaSr 1.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Connection': 'keep-alive',
}
php网页抓取乱码(php网页抓取乱码的关键是你是怎么弄的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-10-30 00:02
php网页抓取乱码,关键是你是怎么弄的。不同的网站抓取方式不同。如果你是通过java,直接var_dump模块,这个需要设置一下accesslog参数,才可以抓取xml格式的数据。但是如果是php,通过正则提取api也可以。记得自己在测试的时候,用正则提取到accesslog参数。
提供accesskey参数就可以了
很简单,直接把xml内容中的accesskey提取出来就可以,请自己写正则表达式。json的话,就是append去模糊匹配。sql的话就是使用正则表达式,匹配all键,然后去匹配后面的列。至于后面的参数,是xml的话,就找匹配出来的中间部分,对应,匹配就可以了。
想知道具体你对哪方面不理解或者说看不明白?
php:json格式的文件可以通过正则提取.xml格式的用access_log.load_xml_data函数即可.
关键是怎么分析出来
刚开始理解,
抓json比较简单,因为你写的正则规则就是有规律的json格式的一个特征,比如id,lastname;你可以用xmltoxml提取出这个正则规则,然后插入到你要的数据里,或者用正则包含规则ments(3,3);ments(3,3);ments;就可以抓出你要的数据。
抓xml比较复杂,因为也有正则,但是简单点:auth_people.do_something({comment:"sir",property:["firstname","lastname"]});ments(comment,@firstname,@lastname)values({comment,@firstname,@lastname});这么写是复制了xml的规则并加入到你要抓取的内容里,但是这样做还是有个缺点,可能过一段时间你又要改规则,改过来就找不到出处了。我的解决方法是用正则.匹配@xxx.in@xx.xx.in@xx.xx@xx.@。 查看全部
php网页抓取乱码(php网页抓取乱码的关键是你是怎么弄的?)
php网页抓取乱码,关键是你是怎么弄的。不同的网站抓取方式不同。如果你是通过java,直接var_dump模块,这个需要设置一下accesslog参数,才可以抓取xml格式的数据。但是如果是php,通过正则提取api也可以。记得自己在测试的时候,用正则提取到accesslog参数。
提供accesskey参数就可以了
很简单,直接把xml内容中的accesskey提取出来就可以,请自己写正则表达式。json的话,就是append去模糊匹配。sql的话就是使用正则表达式,匹配all键,然后去匹配后面的列。至于后面的参数,是xml的话,就找匹配出来的中间部分,对应,匹配就可以了。
想知道具体你对哪方面不理解或者说看不明白?
php:json格式的文件可以通过正则提取.xml格式的用access_log.load_xml_data函数即可.
关键是怎么分析出来
刚开始理解,
抓json比较简单,因为你写的正则规则就是有规律的json格式的一个特征,比如id,lastname;你可以用xmltoxml提取出这个正则规则,然后插入到你要的数据里,或者用正则包含规则ments(3,3);ments(3,3);ments;就可以抓出你要的数据。
抓xml比较复杂,因为也有正则,但是简单点:auth_people.do_something({comment:"sir",property:["firstname","lastname"]});ments(comment,@firstname,@lastname)values({comment,@firstname,@lastname});这么写是复制了xml的规则并加入到你要抓取的内容里,但是这样做还是有个缺点,可能过一段时间你又要改规则,改过来就找不到出处了。我的解决方法是用正则.匹配@xxx.in@xx.xx.in@xx.xx@xx.@。
php网页抓取乱码(《PHP视频教程》抓取乱码的解决办法:这样乱码解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-28 18:19
php网页抓取乱码解决方法:1、使用“mbconvertencoding”进行编码转换; 2、添加"curl_setopt($ch, CURLOPT_ENCODING,'gzip');"选项; 3、在顶部添加标题代码。
推荐:《PHP 视频教程》
php抓取页面乱码
在抓取页面时出现类似...的乱码,解决方法如下
1、转换码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、数据被gzip压缩
curl 获取数据时,设置并添加以下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
需要安装zlib库才能使用file_get_contents函数
$data = file_get_contents("compress.zlib://".$url);
3、获取数据后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上就是解决php网页乱码爬取问题的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们 查看全部
php网页抓取乱码(《PHP视频教程》抓取乱码的解决办法:这样乱码解决方法)
php网页抓取乱码解决方法:1、使用“mbconvertencoding”进行编码转换; 2、添加"curl_setopt($ch, CURLOPT_ENCODING,'gzip');"选项; 3、在顶部添加标题代码。

推荐:《PHP 视频教程》
php抓取页面乱码
在抓取页面时出现类似...的乱码,解决方法如下
1、转换码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、数据被gzip压缩
curl 获取数据时,设置并添加以下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
需要安装zlib库才能使用file_get_contents函数
$data = file_get_contents("compress.zlib://".$url);
3、获取数据后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上就是解决php网页乱码爬取问题的详细内容。更多详情请关注其他相关php中文网站文章!

免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们
php网页抓取乱码(Linux上的默认字体乱码原因是什么?你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-28 12:04
1.因为firefox默认允许网页自己选择字体,所以在Linux上会出现网站的一些乱码。因此,您可以取消允许页面自行选择字体的选项,以解决一些乱码问题。
1.因为firefox默认允许网页自己选择字体,所以在Linux上会出现网站的一些乱码。因此,您可以取消允许页面自行选择字体的选项,以解决一些乱码问题。
php网页抓取乱码( PHP程序员有所有所实例分析实例讲述)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-28 11:13
PHP程序员有所有所实例分析实例讲述)
PHP使用get获取URL乱码的解决方法
更新时间:2014年11月13日15:10:10 投稿:shichen2014
这个文章主要介绍PHP使用get获取的url中乱码的解决方法。是很多PHP程序员都遇到过的问题。这是非常实用和有价值的。有需要的朋友可以参考一下。
本文举例说明如何解决PHP使用get获取URL汉字时出现乱码。分享给大家,供大家参考。具体方法如下:
一、问题:
我打算这样使用它
复制代码代码如下:
【查看区动态】
在list.php页面获取结果——勾选【管辖权操作】
一开始,我猜是汉字的“状态”码和什么东西冲突了,所以出现了乱码。
二、解决方案:
使用:
复制代码代码如下:
" charset="utf-8" target="main">[查看]
然后在list.php页面这样使用
复制代码代码如下:
不会出现乱码和异常传输。
注意这里接收GET页面的代码需要和发送端的代码一致!
关于字符串 urlencode(string $str) 函数
这个函数可以轻松地对字符串进行编码并在 URL 的请求部分中使用它,并且还可以轻松地将变量传递到下一页。
示例 1 urlencode()
复制代码代码如下:
示例 2 urlencode() 和 htmlentities()
复制代码代码如下:
希望本文对您的 PHP 编程有所帮助。 查看全部
php网页抓取乱码(
PHP程序员有所有所实例分析实例讲述)
PHP使用get获取URL乱码的解决方法
更新时间:2014年11月13日15:10:10 投稿:shichen2014
这个文章主要介绍PHP使用get获取的url中乱码的解决方法。是很多PHP程序员都遇到过的问题。这是非常实用和有价值的。有需要的朋友可以参考一下。
本文举例说明如何解决PHP使用get获取URL汉字时出现乱码。分享给大家,供大家参考。具体方法如下:
一、问题:
我打算这样使用它
复制代码代码如下:
【查看区动态】
在list.php页面获取结果——勾选【管辖权操作】
一开始,我猜是汉字的“状态”码和什么东西冲突了,所以出现了乱码。
二、解决方案:
使用:
复制代码代码如下:
" charset="utf-8" target="main">[查看]
然后在list.php页面这样使用
复制代码代码如下:
不会出现乱码和异常传输。
注意这里接收GET页面的代码需要和发送端的代码一致!
关于字符串 urlencode(string $str) 函数
这个函数可以轻松地对字符串进行编码并在 URL 的请求部分中使用它,并且还可以轻松地将变量传递到下一页。
示例 1 urlencode()
复制代码代码如下:
示例 2 urlencode() 和 htmlentities()
复制代码代码如下:
希望本文对您的 PHP 编程有所帮助。
php网页抓取乱码( ,还会出现中文.在应用中常常遇到的问题.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-25 20:06
,还会出现中文.在应用中常常遇到的问题.)
原页面的一个图片加了一个链接,链接中收录中文,所以出现了以下情况: 解决方法是在tomcat server.xml文件中添加URIEncoding="utf-8",如下:
PHP中文乱码解决方案汇总分析
一。首先是PHP网页的编码1. php文件本身的编码要与网页的编码相匹配。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; charset=gb2312"),添加静态页面,所有文件的编码格式都是ANSI,可以用记事本打开,另存为,选择编码为ANSI,覆盖源文本
解决python3中请求解析中文页面出现乱码的问题
第一部分是关于requests库(1) requests是一个非常有用的Python HTTP客户端库,在编写爬虫和测试服务器响应数据时经常用到。(2) Request对象是在访问server 会返回一个Response对象,这个对象将返回的Http响应字节码保存在content属性中。(3)但是如果访问另一个属性文本,会返回一个unicode对象,经常会发送乱码问题结果在这里。(4) 因为Response对象会通过另一种属性编码将字节码编码成unicode,而这个en
java页面url的值出现中文乱码的解决办法
应用中经常会遇到中文问题。这会涉及到字符解码操作,我们在应用中经常使用 new String(fieldType.getBytes("iso-8859-1"), "UTF-8") ;和其他类似的方法来解码。但是这种方法受具体应用环境的限制,经常会在应用部署环境发生变化时出现中文乱码。这是一个可以在任何应用程序部署环境中使用的解决方案。该方法分为两步: 1. 在客户端使用escape(encodeURIComponent(fieldValue))方法进行编码,例如: 查看全部
php网页抓取乱码(
,还会出现中文.在应用中常常遇到的问题.)

原页面的一个图片加了一个链接,链接中收录中文,所以出现了以下情况: 解决方法是在tomcat server.xml文件中添加URIEncoding="utf-8",如下:
PHP中文乱码解决方案汇总分析
一。首先是PHP网页的编码1. php文件本身的编码要与网页的编码相匹配。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; charset=gb2312"),添加静态页面,所有文件的编码格式都是ANSI,可以用记事本打开,另存为,选择编码为ANSI,覆盖源文本
解决python3中请求解析中文页面出现乱码的问题
第一部分是关于requests库(1) requests是一个非常有用的Python HTTP客户端库,在编写爬虫和测试服务器响应数据时经常用到。(2) Request对象是在访问server 会返回一个Response对象,这个对象将返回的Http响应字节码保存在content属性中。(3)但是如果访问另一个属性文本,会返回一个unicode对象,经常会发送乱码问题结果在这里。(4) 因为Response对象会通过另一种属性编码将字节码编码成unicode,而这个en
java页面url的值出现中文乱码的解决办法
应用中经常会遇到中文问题。这会涉及到字符解码操作,我们在应用中经常使用 new String(fieldType.getBytes("iso-8859-1"), "UTF-8") ;和其他类似的方法来解码。但是这种方法受具体应用环境的限制,经常会在应用部署环境发生变化时出现中文乱码。这是一个可以在任何应用程序部署环境中使用的解决方案。该方法分为两步: 1. 在客户端使用escape(encodeURIComponent(fieldValue))方法进行编码,例如:
php网页抓取乱码(出现乱码的原因分析及解决方法有哪些呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-24 00:04
一、乱码原因分析
1.保存文件时,文件有自己的文件编码,是汉字还是其他语言,用什么编码来存储
2.输出时,指定内容的编码,如以网页形式输入时
3.从数据库中取数据时,不确定数据库和字符集
4、以汉字为例。汉字也被编码。一个汉字 gbk 需要两个字符,而 utf8 需要三个字符。
可能导致乱码的潜在原因上面已经说了,我现在就整理一下。
第一种情况,保存的文件和显示代码不一致
如果保存文件时使用utf8编码,输出网页时设置了gbk编码,所以会出现乱码。
第二种情况,保存的文件和数据库中存储的字符不一致
假设,当保存的文件的编码与网页显示的编码相同时,仍然出现乱码。例如,当您保存文件时,您使用 utf8 编码,而您的数据库使用 gb2312 字符集来存储数据。
第三种情况,代码乱码,你还觉得没有
当你发现乱码的时候,当你改变保存文件的编码时,utf8的情况就好了。改成gbk会乱码,但是你觉得还好。这也是出现乱码的原因。这种情况会经常发生。
第四种情况,数据库天生乱码
数据的字符集,保存文件的编码,网页显示的编码都是一样的,但是出现乱码。大多数情况下,当数据进入数据库时,会出现乱码。这种情况比较麻烦。
其次,我的解决乱码的方法不尽人意。
我把这个方法命名为泡顶解牛法。哈哈。数据库,保存文件编码,显示时编码必须一致,以数据库为准
第一种,数据库和保存文件的编码为utf8,网页显示为gb2312。这时,我们将更改显示编码。
第二种是utf8,用于数据库和网页显示,gb2312用于保存文件。这时候就要注意一个。无法直接更改已保存文件的编码。在更改编码之前,请先更改文件的内容。COPY,改编码后,把COPY的内容贴回去,就OK了。
第三种是数据库使用的utf8。保存文件和显示的编码是gb2312。这时候就可以利用程序的功能,对从数据库中检索到的数据进行转码,将utf8转为gb2312,这样就不用改了。文件本身的编码已更改,并且已显示编码。以php为例,mb_convert_encoding($string,"gb2312","utf8");
第四种,数据库中的乱码,是在数据录入时,数据本身与数据库的存储码不同造成的。例如:数据库的存储代码是utf8,当数据存储在数据库中时,添加一个mysql_query("set names utf8;");
三、乱码表现的情况
乱码的表现,我遇到过两个,
1)是字体中出现的乱码,变成了奇怪的字符
2) 直接是空白页。检查源代码,什么都没有。在这种情况下,有时,我认为它是由乱码引起的。页面右击,查看属性,修改代码就知道是不是乱码导致的空白页。 查看全部
php网页抓取乱码(出现乱码的原因分析及解决方法有哪些呢?(图))
一、乱码原因分析
1.保存文件时,文件有自己的文件编码,是汉字还是其他语言,用什么编码来存储
2.输出时,指定内容的编码,如以网页形式输入时
3.从数据库中取数据时,不确定数据库和字符集
4、以汉字为例。汉字也被编码。一个汉字 gbk 需要两个字符,而 utf8 需要三个字符。
可能导致乱码的潜在原因上面已经说了,我现在就整理一下。
第一种情况,保存的文件和显示代码不一致
如果保存文件时使用utf8编码,输出网页时设置了gbk编码,所以会出现乱码。
第二种情况,保存的文件和数据库中存储的字符不一致
假设,当保存的文件的编码与网页显示的编码相同时,仍然出现乱码。例如,当您保存文件时,您使用 utf8 编码,而您的数据库使用 gb2312 字符集来存储数据。
第三种情况,代码乱码,你还觉得没有
当你发现乱码的时候,当你改变保存文件的编码时,utf8的情况就好了。改成gbk会乱码,但是你觉得还好。这也是出现乱码的原因。这种情况会经常发生。
第四种情况,数据库天生乱码
数据的字符集,保存文件的编码,网页显示的编码都是一样的,但是出现乱码。大多数情况下,当数据进入数据库时,会出现乱码。这种情况比较麻烦。
其次,我的解决乱码的方法不尽人意。
我把这个方法命名为泡顶解牛法。哈哈。数据库,保存文件编码,显示时编码必须一致,以数据库为准
第一种,数据库和保存文件的编码为utf8,网页显示为gb2312。这时,我们将更改显示编码。
第二种是utf8,用于数据库和网页显示,gb2312用于保存文件。这时候就要注意一个。无法直接更改已保存文件的编码。在更改编码之前,请先更改文件的内容。COPY,改编码后,把COPY的内容贴回去,就OK了。
第三种是数据库使用的utf8。保存文件和显示的编码是gb2312。这时候就可以利用程序的功能,对从数据库中检索到的数据进行转码,将utf8转为gb2312,这样就不用改了。文件本身的编码已更改,并且已显示编码。以php为例,mb_convert_encoding($string,"gb2312","utf8");
第四种,数据库中的乱码,是在数据录入时,数据本身与数据库的存储码不同造成的。例如:数据库的存储代码是utf8,当数据存储在数据库中时,添加一个mysql_query("set names utf8;");
三、乱码表现的情况
乱码的表现,我遇到过两个,
1)是字体中出现的乱码,变成了奇怪的字符
2) 直接是空白页。检查源代码,什么都没有。在这种情况下,有时,我认为它是由乱码引起的。页面右击,查看属性,修改代码就知道是不是乱码导致的空白页。
php网页抓取乱码(php+mysql是制作网站一般常用的开发语言吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-22 00:00
php+mysql是制作网站的常用开发语言。由于其开源和可扩展性,受到了很多开发者的喜爱,但是在使用的过程中,我们经常会发现php+mysql如果操作不当,很容易出现乱码。说一下我平时遇到的一些情况。
1、数据库和网页编码不一致
因为php开发,我们基本都是用mysql数据库。这是很容易出现的一个现象,就是我们网页的编码和我们数据库的编码有什么不同,很容易出现乱码。修改的方法肯定是将两个代码统一起来,普通程序员稍加注意就可以避免。
2、数据库中的表编码可能不一致
我们在设置数据库的时候,选择默认的编码,一般是utf-8。但是我们经常在表中没有足够数量的字段或表。我们有时可能会为了增加数据库的字段或表。这时候还要注意编码的统一。
3、 用户提交的页面编码与显示数据页面的编码不一致,肯定会导致PHP页面出现乱码。
4、 如果用户输入数据的页面是big5代码,但是显示用户输入的页面是gb2312,这个100%会导致PHP页面乱码。
5、 PHP 连接 MySQL 数据库语句中指定的编码不正确。
6、 如果本地mysql布局与服务器端不一致,我们在导入数据时使用phpmyadmin很容易出现这种现象。
其实使用MySQL+PHP产生乱码的原因和解决方法有很多。当然,主要原因还是在于程序员经验的积累。希望以上内容对大家有所帮助。
北京网站建筑北京网页设计网站制作() 查看全部
php网页抓取乱码(php+mysql是制作网站一般常用的开发语言吗?)
php+mysql是制作网站的常用开发语言。由于其开源和可扩展性,受到了很多开发者的喜爱,但是在使用的过程中,我们经常会发现php+mysql如果操作不当,很容易出现乱码。说一下我平时遇到的一些情况。
1、数据库和网页编码不一致
因为php开发,我们基本都是用mysql数据库。这是很容易出现的一个现象,就是我们网页的编码和我们数据库的编码有什么不同,很容易出现乱码。修改的方法肯定是将两个代码统一起来,普通程序员稍加注意就可以避免。
2、数据库中的表编码可能不一致
我们在设置数据库的时候,选择默认的编码,一般是utf-8。但是我们经常在表中没有足够数量的字段或表。我们有时可能会为了增加数据库的字段或表。这时候还要注意编码的统一。
3、 用户提交的页面编码与显示数据页面的编码不一致,肯定会导致PHP页面出现乱码。
4、 如果用户输入数据的页面是big5代码,但是显示用户输入的页面是gb2312,这个100%会导致PHP页面乱码。
5、 PHP 连接 MySQL 数据库语句中指定的编码不正确。
6、 如果本地mysql布局与服务器端不一致,我们在导入数据时使用phpmyadmin很容易出现这种现象。
其实使用MySQL+PHP产生乱码的原因和解决方法有很多。当然,主要原因还是在于程序员经验的积累。希望以上内容对大家有所帮助。
北京网站建筑北京网页设计网站制作()
php网页抓取乱码( PHP页面中文乱码出现的原因及乱码大部分有什么区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-20 04:10
PHP页面中文乱码出现的原因及乱码大部分有什么区别)
PHP页面中文乱码分析
更新时间:2013年10月29日15:58:04 作者:
php出现乱码的原因:页面文件的编码方式(.html、.php等)、html.head中指定的浏览器编码方式、MySql数据库传输的编码方式、Apache字符集.
PHP页面出现中文乱码的原因有几个,一是页面编码没有统计,二是数据库没有设置编码,三是apache编码有问题。让我向您介绍两种解决方案。一般来说,它是页面。编码不统一。
大部分乱码都是由于编码方式不一致造成的。有四种主要的不一致可能导致这种可能性:
1、 页面文件的编码方式(.html、.php等)
2、html.head中指定的浏览器编码方式
3、MySql数据库传输的编码方式
4、Apache 字符集
在只有PHP代码的页面中,在做JS弹窗时,如果弹窗内容收录中文,可能会出现乱码。
解决方法,一行代码:
中文乱码
复制代码代码如下:
header("Content-Type: text/html; charset=utf-8");
数据库乱码
复制代码代码如下:
.
注意:
1、此代码必须放在文件的顶部,' 查看全部
php网页抓取乱码(
PHP页面中文乱码出现的原因及乱码大部分有什么区别)
PHP页面中文乱码分析
更新时间:2013年10月29日15:58:04 作者:
php出现乱码的原因:页面文件的编码方式(.html、.php等)、html.head中指定的浏览器编码方式、MySql数据库传输的编码方式、Apache字符集.
PHP页面出现中文乱码的原因有几个,一是页面编码没有统计,二是数据库没有设置编码,三是apache编码有问题。让我向您介绍两种解决方案。一般来说,它是页面。编码不统一。
大部分乱码都是由于编码方式不一致造成的。有四种主要的不一致可能导致这种可能性:
1、 页面文件的编码方式(.html、.php等)
2、html.head中指定的浏览器编码方式
3、MySql数据库传输的编码方式
4、Apache 字符集
在只有PHP代码的页面中,在做JS弹窗时,如果弹窗内容收录中文,可能会出现乱码。
解决方法,一行代码:
中文乱码
复制代码代码如下:
header("Content-Type: text/html; charset=utf-8");
数据库乱码
复制代码代码如下:
.
注意:
1、此代码必须放在文件的顶部,'
php网页抓取乱码(有关的乱码问题有哪些方式解决?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-16 14:07
本文文章将详细讲解python爬取乱码网页的解决方法。小编觉得很实用,分享给大家作为参考。我希望每个人都可以阅读这篇文章。得到一些东西。
在使用python爬取网页时,经常会遇到乱码。一旦遇到乱码,就很难得到有用的信息。遇到乱码,我通常有以下几种方法:
1、查看网页源码中的head标签,找到编码方式,例如:
上图中可以看到charset='utf-8',说明这个网页很有可能使用的是'UTF-8'编码(很有可能,但不是100%),可以试试这个编码方法:
result = response.content.decode('utf-8')
这样得到的内容基本没有乱码。
2、 如果上面的方法不行,页面还是乱码;或者在head标签下找不到charset属性;或者我们要采集很多网页,而且这些网页的编码方式都不一样,我们不可能在一个网页上一一查看head标签,所以下面的方法可以用于解决乱码。
(1)python 的 chardet 库
可以使用以下方法解决乱码问题
result = chardet.detect(response.content)
print(result)
data = response.content.decode(chardet.detect(response.content)['encoding'])
{'confidence': 0.99, 'language': '', 'encoding': 'utf-8'}
从输出结果可以看出,这是一个“猜测”代码。猜测的方法是先采集各种代码的特征字符。根据特征人物的判断,“猜”的概率很高。
这种方法的效率非常低。如果采集的网页很大,你只能猜测其中一部分的源代码,即
result = chardet.detect(response.content[:1000])
(2)响应编码
也可以使用另一种方法,response自身的编码和apparent_encoding这两个变量。
Response.encoding 一般来自 response.headers 中 content-type 字段的 charset 值。其他情况我不太了解。
response.apparent_encoding 一般使用上面提到的python chardet 库。
所以可以使用下面的方式来解决乱码问题
data = response.content.decode(response.apparent_encoding)
3、 一般来说,以上两种方法都可以解决乱码问题。但如果以上两种方法都不能解决,则可能是网页压缩造成的。使用以下方法解决此问题。
检查你写的头信息是否收录 Accept-Encoding 字段。如果是,请删除此字段。乱码问题将得到解决。
headers = {
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/49.0.2623.221
Safari/537.36 SE 2.X MetaSr 1.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Connection': 'keep-alive',
}
python抓取网页乱码的解决方法分享到这里。希望以上内容对您有所帮助,让您了解更多。如果你觉得文章不错,可以分享给更多人看。 查看全部
php网页抓取乱码(有关的乱码问题有哪些方式解决?(图))
本文文章将详细讲解python爬取乱码网页的解决方法。小编觉得很实用,分享给大家作为参考。我希望每个人都可以阅读这篇文章。得到一些东西。
在使用python爬取网页时,经常会遇到乱码。一旦遇到乱码,就很难得到有用的信息。遇到乱码,我通常有以下几种方法:
1、查看网页源码中的head标签,找到编码方式,例如:
上图中可以看到charset='utf-8',说明这个网页很有可能使用的是'UTF-8'编码(很有可能,但不是100%),可以试试这个编码方法:
result = response.content.decode('utf-8')
这样得到的内容基本没有乱码。
2、 如果上面的方法不行,页面还是乱码;或者在head标签下找不到charset属性;或者我们要采集很多网页,而且这些网页的编码方式都不一样,我们不可能在一个网页上一一查看head标签,所以下面的方法可以用于解决乱码。
(1)python 的 chardet 库
可以使用以下方法解决乱码问题
result = chardet.detect(response.content)
print(result)
data = response.content.decode(chardet.detect(response.content)['encoding'])
{'confidence': 0.99, 'language': '', 'encoding': 'utf-8'}
从输出结果可以看出,这是一个“猜测”代码。猜测的方法是先采集各种代码的特征字符。根据特征人物的判断,“猜”的概率很高。
这种方法的效率非常低。如果采集的网页很大,你只能猜测其中一部分的源代码,即
result = chardet.detect(response.content[:1000])
(2)响应编码
也可以使用另一种方法,response自身的编码和apparent_encoding这两个变量。
Response.encoding 一般来自 response.headers 中 content-type 字段的 charset 值。其他情况我不太了解。
response.apparent_encoding 一般使用上面提到的python chardet 库。
所以可以使用下面的方式来解决乱码问题
data = response.content.decode(response.apparent_encoding)
3、 一般来说,以上两种方法都可以解决乱码问题。但如果以上两种方法都不能解决,则可能是网页压缩造成的。使用以下方法解决此问题。
检查你写的头信息是否收录 Accept-Encoding 字段。如果是,请删除此字段。乱码问题将得到解决。
headers = {
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/49.0.2623.221
Safari/537.36 SE 2.X MetaSr 1.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Connection': 'keep-alive',
}
python抓取网页乱码的解决方法分享到这里。希望以上内容对您有所帮助,让您了解更多。如果你觉得文章不错,可以分享给更多人看。
php网页抓取乱码(wktmltopdf工具是使用Webkit引擎来将HTML网页转换为PDF文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-10-10 08:22
wktmltopdf 工具使用 Webkit 引擎将 HTML 网页转换为 PDF 文件。wkhtmltopdf工具的相关信息请参考:
/p/wkhtmltop...
…
在使用过程中,部分网页出现中文乱码,部分网页中文显示正常。在通过搜索引擎搜索答案的时候,发现有的人遇到中午一片空白,没有显示。
在开源项目的问答中,有一些作者的回复:
/p/wkhtmltop...
/p/wkhtmltop...
这些问题主要是Linux环境下没有安装中文字体造成的,我遇到的问题是可以显示中文,但是乱码,所以针对这个问题做了几个测试:
1.中文字体问题
2.网页编码
3.文件编码
测试一:(百度首页的charset=utf-8)
图片
[图片上传失败...(image-3a4c23-74)]
可以看出中文是正常的。
测试二(51cto博客网页的charset=gb2312):
图片
图片
可以看出网页内容的编码格式为:gb2312无法显示中文。
测试三:
检查网页中使用的字体:
图片
通过与本地电脑的字体对比,排除了这种可能性。其实转换后的PDF文件是可以显示中文的,虽然是乱码,但是字体问题也可以排除。
测试四:
考虑到wkhtmltopdf使用的是webkit引擎,第二次测试遇到了网页内容编码格式:gb2312,导致中文无法显示,所以使用程序抓取网页进行转换。
@Test
public void test2() throws IOException {
URL url = new URL("http://aiilive.blog.51cto.com/1925756/1332579");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
conn.connect();
if (conn.getResponseCode() == HttpURLConnection.HTTP_OK) {
BufferedInputStream bi = new BufferedInputStream(
conn.getInputStream());
BufferedOutputStream bo = new BufferedOutputStream(
new FileOutputStream(new File("D:\\1332579.html")));
byte[] bts = new byte[1024];
int len = bi.read(bts);
while (len != -1) {
bo.write(bts, 0, len);
len = bi.read(bts);
}
bi.close();
bo.close();
System.out.println("create ok");
}
}
通过本地转换,使页面内容:charset=utf-8,然后再转换,这是因为由于使用了webkit引擎,charset=utf-8是给浏览器的,所以使用。
图像.png
上面的测试还是失败了。!!!
官方指南中说明可以指定编码格式:--encoding encoding format; 经过测试,它不起作用。网上很多人都遇到过这个问题,也有很多人没有遇到过,但是网页正常传输成功。大多数情况下,编码中使用 UTF-8 只是巧合。
测试五:
处理获取的网页文件:
1.文件编码utf-8;字符集=utf-8;结果:中文正常
2.文件编码utf-8;字符集=gb2312;结果:中文正常
3.文件编码ansi;字符集=gb2312;结果:中文乱码
图片
实验做了这个,我们可以看出问题,wkhtmltopdf在转换html文件的时候,html文件的来源可能是一个url,也可能是一个本地的文本文件。从测试一看,百度主页显示中文正常,测试二是51cto博客中文不能正常显示,从测试五可以看出,wkhtmltopdf工作时,--encoding参数实际上是指文件存储。
因此,当无法确定服务器通过URL请求的网页编码文件格式时,会以文件内容编码格式输出,因此得出通过URL请求charset=utf8和charset=gb2312的结论。前者可以用中文显示,后者不能。
PS:Jsp页面编码说明:
1.pageEncoding="UTF-8"是指保存JSP页面时使用的编码方式,即JSP文件保存在硬盘上时使用的编码方式。2.charset="UTF-8" 指的是用于JSP页面输入输出的编码方式。当找不到 pageEncoding 时,许多服务器使用字符集而不是 pageEncoding。
我自己测试的时候网站没有遇到wkhtmltopdf中文乱码的问题。我们的JSP页面格式和内容输出编码格式是统一的,都是UTF-8。 查看全部
php网页抓取乱码(wktmltopdf工具是使用Webkit引擎来将HTML网页转换为PDF文件)
wktmltopdf 工具使用 Webkit 引擎将 HTML 网页转换为 PDF 文件。wkhtmltopdf工具的相关信息请参考:
/p/wkhtmltop...
…
在使用过程中,部分网页出现中文乱码,部分网页中文显示正常。在通过搜索引擎搜索答案的时候,发现有的人遇到中午一片空白,没有显示。
在开源项目的问答中,有一些作者的回复:
/p/wkhtmltop...
/p/wkhtmltop...
这些问题主要是Linux环境下没有安装中文字体造成的,我遇到的问题是可以显示中文,但是乱码,所以针对这个问题做了几个测试:
1.中文字体问题
2.网页编码
3.文件编码
测试一:(百度首页的charset=utf-8)

图片
[图片上传失败...(image-3a4c23-74)]
可以看出中文是正常的。
测试二(51cto博客网页的charset=gb2312):
图片
图片
可以看出网页内容的编码格式为:gb2312无法显示中文。
测试三:
检查网页中使用的字体:
图片
通过与本地电脑的字体对比,排除了这种可能性。其实转换后的PDF文件是可以显示中文的,虽然是乱码,但是字体问题也可以排除。
测试四:
考虑到wkhtmltopdf使用的是webkit引擎,第二次测试遇到了网页内容编码格式:gb2312,导致中文无法显示,所以使用程序抓取网页进行转换。
@Test
public void test2() throws IOException {
URL url = new URL("http://aiilive.blog.51cto.com/1925756/1332579";);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
conn.connect();
if (conn.getResponseCode() == HttpURLConnection.HTTP_OK) {
BufferedInputStream bi = new BufferedInputStream(
conn.getInputStream());
BufferedOutputStream bo = new BufferedOutputStream(
new FileOutputStream(new File("D:\\1332579.html")));
byte[] bts = new byte[1024];
int len = bi.read(bts);
while (len != -1) {
bo.write(bts, 0, len);
len = bi.read(bts);
}
bi.close();
bo.close();
System.out.println("create ok");
}
}
通过本地转换,使页面内容:charset=utf-8,然后再转换,这是因为由于使用了webkit引擎,charset=utf-8是给浏览器的,所以使用。
图像.png
上面的测试还是失败了。!!!
官方指南中说明可以指定编码格式:--encoding encoding format; 经过测试,它不起作用。网上很多人都遇到过这个问题,也有很多人没有遇到过,但是网页正常传输成功。大多数情况下,编码中使用 UTF-8 只是巧合。
测试五:
处理获取的网页文件:
1.文件编码utf-8;字符集=utf-8;结果:中文正常
2.文件编码utf-8;字符集=gb2312;结果:中文正常
3.文件编码ansi;字符集=gb2312;结果:中文乱码
图片
实验做了这个,我们可以看出问题,wkhtmltopdf在转换html文件的时候,html文件的来源可能是一个url,也可能是一个本地的文本文件。从测试一看,百度主页显示中文正常,测试二是51cto博客中文不能正常显示,从测试五可以看出,wkhtmltopdf工作时,--encoding参数实际上是指文件存储。
因此,当无法确定服务器通过URL请求的网页编码文件格式时,会以文件内容编码格式输出,因此得出通过URL请求charset=utf8和charset=gb2312的结论。前者可以用中文显示,后者不能。
PS:Jsp页面编码说明:
1.pageEncoding="UTF-8"是指保存JSP页面时使用的编码方式,即JSP文件保存在硬盘上时使用的编码方式。2.charset="UTF-8" 指的是用于JSP页面输入输出的编码方式。当找不到 pageEncoding 时,许多服务器使用字符集而不是 pageEncoding。
我自己测试的时候网站没有遇到wkhtmltopdf中文乱码的问题。我们的JSP页面格式和内容输出编码格式是统一的,都是UTF-8。
php网页抓取乱码( 网页乱码是最让人气恼的一件事,是否会感觉特别慌乱,有么有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-07 08:23
网页乱码是最让人气恼的一件事,是否会感觉特别慌乱,有么有
)
网页上的乱码是最烦人的。
修改好页面后,发现所有字符都是乱码。你有没有特别心慌?有没有!
接下来,我们将永远分析解决网页乱码问题,再也不用担心乱码了。
在此之前,有必要强调一点:首先我想强调一点,如果你修改网页的时候不小心改了乱码,千万不要保存!
如果点击保存,一定不要关闭编辑器,一定要撤销(常用的快捷键是Ctrl+Z),
除此以外:
既然有时间恢复那些蝌蚪,何不买彩票呢?
进入正题:任何乱码无非就是这五种情况之一:1:Head Meta属性;
2:网页文件编码;
3:数据库内容;
4:数据库结构;
5:连接数据库时的编码方式;
首先,确定自己网页的编码。一般大部分中文网页都是UTF-8或者GB2312也有Unicode的(以下都是以UTF-8为例)
不管你用的是三剑客的Dreamweaver还是Editplus,打开文件,查看->编码->选择“UTF-8”,看看乱码现象是否解决,
1): 解决,修复header Meta属性,请在页面添加这句话统一编码
浏览该属性的页面时,点击Ctrl+U查看源码,header中应该有这个Meta属性
添加 header("Content-type: text/html; charset=utf-8"); PHP动态页面中同样的效果
2):无解,修改文件编码,请使用EditPlus或DW打开修改页面编码。DW 中的页面属性具有编码选项。EditPlus:文档 -> 文件编码 -> 更改文件编码 -> "UTF-8"
可以解决非数据库内容乱码的问题
没解决的会继续往下看。第3点主要是消除乱码和数据库内容的可解析性;
由于上面的Meta和文件编码更正无法解决,只好专注于数据库,
第一步是检查数据是否不可修复。
使用PHPMYADMIN或者直接使用shell命令查看数据内容,看是否乱七八糟。有必要解释一个残酷的事实。如果数据库内存是“蝌蚪文本”,无论怎么转换都是“蝌蚪文本”,无法修复。的。这也是我强调不要保存顶部静态乱码的原因,因为乱码可能是显示器造成的。保存后,完整的数据变得无法识别。
数据库结构,数据库编码必须与网页编码一致,检查数据库的编码格式,如果不一致请修改:
更改my.ini文件中的配置值(该文件在mysql安装目录下)。有两个地方要改,修改成需要的编码格式,然后把之前创建的表删除,然后重新创建,然后插入诸如汉字格式的字段,就不再提示错误信息了。如果有PHPMYADMIN,那就方便多了。通过可视化的数据库管理界面,您可以直接在结构中修改编码属性。
关于改变数据库编码,这里有必要强调一下:编码不是一个地方,而是三个地方!
数据库编码、表格编码、字段编码为最佳策略;字段编码细节,int类型boolean类型timestamp类型等不需要改动,主要是修改varchar、text等数据类型字段的编码。
有人说安装mysql后,在配置MySql Server时,如果修改默认编码格式,将默认latin1改为gb2312或者utf8,然后创建数据库表,中文就可以正常存储和显示了。听说这是对付中国人的常用方式
数据库编码不方便更改。我该怎么办?如果不改,需要转码 iconv("UTF-8","gb2312",$str); 事情,数据库内容量大时的权衡。
您是否发现像手掌一样对数据库进行编码是关键?您需要知道您的数据库默认采用哪种编码。
连接数据库时的编码方式,以PHP为例,检查连接数据库的地方是否有这句话,如果没有请添加
添加 mysql_query("SET NAMES'UTF8'");
这句话很重要,绝对可以解决数据库数据的乱码现象。
还有一个非技术性的解决方法:如果打开网页出现乱码,请尝试修改浏览器的页面编码,如GB2312或UTF-8;可能页面不乱吧~
查看全部
php网页抓取乱码(
网页乱码是最让人气恼的一件事,是否会感觉特别慌乱,有么有
)

网页上的乱码是最烦人的。
修改好页面后,发现所有字符都是乱码。你有没有特别心慌?有没有!
接下来,我们将永远分析解决网页乱码问题,再也不用担心乱码了。
在此之前,有必要强调一点:首先我想强调一点,如果你修改网页的时候不小心改了乱码,千万不要保存!
如果点击保存,一定不要关闭编辑器,一定要撤销(常用的快捷键是Ctrl+Z),
除此以外:
既然有时间恢复那些蝌蚪,何不买彩票呢?
进入正题:任何乱码无非就是这五种情况之一:1:Head Meta属性;
2:网页文件编码;
3:数据库内容;
4:数据库结构;
5:连接数据库时的编码方式;
首先,确定自己网页的编码。一般大部分中文网页都是UTF-8或者GB2312也有Unicode的(以下都是以UTF-8为例)
不管你用的是三剑客的Dreamweaver还是Editplus,打开文件,查看->编码->选择“UTF-8”,看看乱码现象是否解决,
1): 解决,修复header Meta属性,请在页面添加这句话统一编码
浏览该属性的页面时,点击Ctrl+U查看源码,header中应该有这个Meta属性
添加 header("Content-type: text/html; charset=utf-8"); PHP动态页面中同样的效果
2):无解,修改文件编码,请使用EditPlus或DW打开修改页面编码。DW 中的页面属性具有编码选项。EditPlus:文档 -> 文件编码 -> 更改文件编码 -> "UTF-8"
可以解决非数据库内容乱码的问题
没解决的会继续往下看。第3点主要是消除乱码和数据库内容的可解析性;
由于上面的Meta和文件编码更正无法解决,只好专注于数据库,
第一步是检查数据是否不可修复。
使用PHPMYADMIN或者直接使用shell命令查看数据内容,看是否乱七八糟。有必要解释一个残酷的事实。如果数据库内存是“蝌蚪文本”,无论怎么转换都是“蝌蚪文本”,无法修复。的。这也是我强调不要保存顶部静态乱码的原因,因为乱码可能是显示器造成的。保存后,完整的数据变得无法识别。
数据库结构,数据库编码必须与网页编码一致,检查数据库的编码格式,如果不一致请修改:
更改my.ini文件中的配置值(该文件在mysql安装目录下)。有两个地方要改,修改成需要的编码格式,然后把之前创建的表删除,然后重新创建,然后插入诸如汉字格式的字段,就不再提示错误信息了。如果有PHPMYADMIN,那就方便多了。通过可视化的数据库管理界面,您可以直接在结构中修改编码属性。
关于改变数据库编码,这里有必要强调一下:编码不是一个地方,而是三个地方!
数据库编码、表格编码、字段编码为最佳策略;字段编码细节,int类型boolean类型timestamp类型等不需要改动,主要是修改varchar、text等数据类型字段的编码。
有人说安装mysql后,在配置MySql Server时,如果修改默认编码格式,将默认latin1改为gb2312或者utf8,然后创建数据库表,中文就可以正常存储和显示了。听说这是对付中国人的常用方式
数据库编码不方便更改。我该怎么办?如果不改,需要转码 iconv("UTF-8","gb2312",$str); 事情,数据库内容量大时的权衡。
您是否发现像手掌一样对数据库进行编码是关键?您需要知道您的数据库默认采用哪种编码。
连接数据库时的编码方式,以PHP为例,检查连接数据库的地方是否有这句话,如果没有请添加
添加 mysql_query("SET NAMES'UTF8'");
这句话很重要,绝对可以解决数据库数据的乱码现象。
还有一个非技术性的解决方法:如果打开网页出现乱码,请尝试修改浏览器的页面编码,如GB2312或UTF-8;可能页面不乱吧~

php网页抓取乱码(黑客行为称为“乱码黑客”行为的操作效果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-10-06 19:08
本指南专门针对将收录大量关键字的乱码网页添加到您的 网站 中的黑客行为。我们称这种黑客为“乱码黑客”。我们专门为 (cms) 用户推出了本指南;但即使您没有使用内容管理系统,本指南也会对您有所帮助。
注意:不确定您的 网站 是否已被入侵?请阅读我们的指南,了解如何首先检查您的 网站 是否已被入侵。
我们希望确保本指南对您真的有帮助。请提供反馈以帮助我们改进!识别此类黑客的目录
乱码黑客会自动在你的网站上创建许多网页,上面堆满了关键字的无意义句子。这些页面不是由您创建的,但它们的 URL 可能会吸引用户点击。黑客的目的是让被黑的网页出现在谷歌搜索结果中。然后,如果用户尝试访问这些页面,他们将被重定向到不相关的页面(例如色情网站)。当用户访问这些不相关的网页时,黑客就会获得收益。以下是一些您可能会在 网站 上看到的受乱码黑客影响的文件类型示例:
有时,这些页面所在文件夹的名称由随机字符组成,并且使用不同的语言:
首先,请检查 Search Console 中的安全问题工具,看看 Google 是否在您的 网站 上发现了上述任何被黑页面。有时,您也可以通过打开 Google 搜索窗口并输入 site:your site url(使用您的 网站 根级 URL)来找到此类网页。搜索结果页将显示 Google 为您的 网站 编入索引的网页,包括被黑的网页。您可以翻阅几页搜索结果,看看是否可以找到任何不寻常的 URL。如果您在 Google 搜索结果中没有看到任何被黑内容,请使用其他搜索引擎搜索相同的搜索词。此操作的效果如下例所示。
请注意,上面的搜索结果收录许多不是由 网站 的所有者创建的页面。如果您仔细查看描述,您将看到此 hack 创建的乱码示例。
通常,当您点击被黑网页的链接时,您要么被重定向到其他网站,要么看到一个充满乱码内容的网页。但是,您可能还会看到该页面不存在的消息(例如 404 错误)。不要被愚弄!当网页仍然被黑客入侵时,黑客会试图说服您该网页已消失或已修复。为此,他们将隐藏真实内容。您可以在谷歌爬虫中输入您的网站 URL,查看是否存在隐藏真实内容的问题。Google 抓取工具可让您查看可能隐藏的内容。
如果您看到上述问题,则说明您的网站可能受到了此类黑客攻击。
解决黑客问题
在开始之前,请为要删除的任何文件创建一个脱机副本,以防将来需要恢复它们。在开始清理过程之前,最好备份整个 网站。为此,您可以离线保存服务器上的所有文件,或搜索最适合您的特定内容管理系统的备份选项。
检查 .htaccess 文件(共 2 步)
乱码黑客将使用 .htaccess 文件重定向您的 网站 访问者。
第1步
在 网站 上找到您的 .htaccess 文件。如果您不确定在哪里可以找到此文件,并且您使用的是 WordPress、Joomla 或 Drupal 等内容管理系统,请在搜索中搜索“.htaccess 文件的位置”和您的内容管理系统的名称引擎。您可能会看到多个 .htaccess 文件,具体取决于您的 网站。然后,列出所有 .htaccess 文件的位置。
注意:.htaccess 通常是一个“隐藏文件”。请确保在搜索此类文件时启用显示隐藏文件选项。
第2步
将所有 .htaccess 文件替换为相应 .htaccess 文件的未破解版本或默认版本。您通常可以通过搜索“默认 .htaccess 文件”和内容管理系统的名称来找到 .htaccess 文件的默认版本。对于带有多个 .htaccess 文件的 网站,请找到每个文件的未破解版本并替换它。
如果没有默认的 .htaccess 文件,并且您从未在 网站 上配置过任何 .htaccess 文件,那么您在 网站 上找到的 .htaccess 文件可能是恶意文件。为安全起见,请离线保存 .htaccess 文件的副本,然后从 网站 中删除相应的 .htaccess 文件。
查找并删除其他恶意文件(共 5 个步骤)
识别恶意文件可能很棘手,可能需要几个小时才能完成。检查文件时请不要担心。如果您还没有备份 网站 上的文件,这是个好时机。您可以在 Google 搜索中搜索“备份网站”和您的内容管理系统的名称,以查找有关如何备份 网站 的说明。
第1步
如果您使用内容管理系统,请重新安装该内容管理系统默认分发中收录的所有核心(默认)文件,以及您可能添加的任何内容(例如主题、模块、插件)。这有助于确保这些文件不收录被黑内容。您可以在 Google 搜索中搜索“重新安装”和您的内容管理系统的名称,以查找有关重新安装过程的说明。如果您有任何插件、模块、扩展或主题,请确保您也重新安装它们。
重新安装这些核心文件可能会导致您所做的任何自定义丢失。确保在重新安装之前创建数据库和所有文件的备份。
第2步
现在,您需要查找剩余的任何其他恶意或受损文件。这是此过程中最困难和最耗时的部分,但在您完成此部分后,您马上就完成了!
这种黑客通常会留下两种类型的文件:.txt 文件和 .php 文件。.txt 文件充当模板文件,而 .php 文件决定了您的 网站 上加载了什么样的无意义内容。首先,查找 .txt 文件。根据您连接到 网站 的方式,您应该会看到某种文件搜索功能。搜索“.txt”以查找所有扩展名为 .txt 的文件。这些文件中的大多数是合法的文本文件,例如许可协议、自述文件等。您要查找的是一组特定的 .txt 文件,其中收录用于创建垃圾邮件模板的 HTML 代码。以下是您可能会在这些恶意 .txt 文件中找到的不同代码的代码片段。
黑客使用关键字替换方法来创建垃圾邮件页面。您很可能会在整个被黑文件中看到一些可以替换的常用词。
{keyword}
此外,这些文件中的大多数都收录某种代码,可以将垃圾邮件链接和垃圾邮件文本置于可见网页之外。
Cheap prescription drugs
请删除这些 .txt 文件。如果这些文件在同一个文件夹中,您可以删除整个文件夹。
第 3 步
查找恶意 PHP 文件会稍微困难一些。您的 网站 上可能存在一个或多个恶意 PHP 文件。这些文件可能收录在同一个子目录中,也可能分布在整个 网站 中。
不要因为您认为需要打开和查看每个 PHP 文件而感到压力太大。首先,创建您要调查的可疑 PHP 文件列表。以下方法可用于确定哪些 PHP 文件可疑:
第四步
创建可疑 PHP 文件列表后,您可以检查这些文件是正常文件还是恶意文件。如果你不熟悉PHP文件,这个过程会消耗更多的时间,所以你不妨查阅一些PHP文件。但即使您不熟悉编码,您仍然可以通过一些基本模式找到恶意文件。
首先,扫描您发现的可疑文件,找到收录看似凌乱的字母和数字组合的大块文本。大文本块的前面通常是PHP函数的组合(例如base64_decode、rot13、eval、strrev、gzinflate)。以下是此类代码块的示例。有时,所有这些代码都被填充到一长串文本中,使其看起来比实际大小要小。
base64_decode(strrev("hMXZpRXaslmYhJXZuxWd2BSZ0l2cgknbhByZul2czVmckRWYgknYgM3ajFGd0FGIlJXd0VnZgk
nbhBSbvJnZgUGdpNHIyV3b5BSZyV3YlNHIvRHI0V2Zy9mZgQ3Ju9GRg4SZ0l2cgIXdvlHI4lmZg4WYjBSdvlHIsU2chVmcnBydv
JGblBiZvBCdpJGIhBCZuFGIl1Wa0BCa0l2dgQXdCBiLkJXYoBSZiBibhNGIlR2bjBycphGdgcmbpRXYjNXdmJ2blRGI5xWZ0Fmb
1RncvZmbVBiLn5WauVGcwFGagM3J0FGa3BCZuFGdzJXZk5Wdg8GdgU3b5BicvZGI0xWdjlmZmlGZgQXagU2ah1GIvRHIzlGa0B
SZrlGbgUGZvNGIlRWaoByb0BSZrlGbgMnclt2YhhEIuUGZvNGIlxmYhRWYlJnb1BychByZulGZhJXZ1F3ch1GIlR2bjBCZlRXY
jNXdmJ2bgMXdvl2YpxWYtBiZvBSZjVWawBSYgMXagMXaoRFIskGS"));
有时,这种类型的代码并不凌乱,看起来像一个普通的脚本。如果您不确定代码是否恶意,请访问我们的;在这个论坛里,一群有经验的网站站长可以帮你查看相关文件。
第 5 步
现在您知道哪些文件是可疑的,您可以通过将它们保存在您的计算机上来创建备份或创建本地副本,使它们不是恶意文件,然后删除这些可疑文件。
检查您的 网站 是否已被清理
删除被黑的文件后,请检查您的努力是否得到了回报。还记得你之前发现的那些乱码吗?使用“Google 抓取工具”再次检查这些页面,看看它们是否仍然存在。如果他们在“Google crawler”中的结果是“not found”,那么您的 网站 可能处于良好状态!
您也可以按照“被黑网站”疑难解答工具中的步骤检查网站上是否还有被黑内容。
如何防止再次入侵?
修复网站上的漏洞是修复网站的最后一个关键步骤。最近的一项研究发现,20% 的被黑 网站 会在 1 天内再次被黑。了解 网站 是如何被黑的非常有用。请参阅我们的指南,了解垃圾邮件发送者使用的最常见的 网站 黑客方法,以开始调查问题。但是,如果您无法查明 网站 是如何被入侵的,您可以按照下面的清单来减少 网站 上的漏洞数量。
其他资源
如果您仍然无法修复 网站,还有一些其他资源可以帮助您。
这些工具可以扫描您的网站,可能会发现有问题的内容。除 VirusTotal 外,Google 不会运行或支持其他工具。
Virus Total、Sucuri Site Check、Quttera:这些工具(以及许多其他工具)可能能够扫描您的 网站 以找出有问题的内容。但请注意,这些扫描工具并不能保证能找到所有类型的问题内容。
以下是 Google 提供的其他可以帮助您的资源:
没有找到您认为可能有用的工具?请留下反馈并告诉我们。 查看全部
php网页抓取乱码(黑客行为称为“乱码黑客”行为的操作效果)
本指南专门针对将收录大量关键字的乱码网页添加到您的 网站 中的黑客行为。我们称这种黑客为“乱码黑客”。我们专门为 (cms) 用户推出了本指南;但即使您没有使用内容管理系统,本指南也会对您有所帮助。
注意:不确定您的 网站 是否已被入侵?请阅读我们的指南,了解如何首先检查您的 网站 是否已被入侵。
我们希望确保本指南对您真的有帮助。请提供反馈以帮助我们改进!识别此类黑客的目录
乱码黑客会自动在你的网站上创建许多网页,上面堆满了关键字的无意义句子。这些页面不是由您创建的,但它们的 URL 可能会吸引用户点击。黑客的目的是让被黑的网页出现在谷歌搜索结果中。然后,如果用户尝试访问这些页面,他们将被重定向到不相关的页面(例如色情网站)。当用户访问这些不相关的网页时,黑客就会获得收益。以下是一些您可能会在 网站 上看到的受乱码黑客影响的文件类型示例:
有时,这些页面所在文件夹的名称由随机字符组成,并且使用不同的语言:
首先,请检查 Search Console 中的安全问题工具,看看 Google 是否在您的 网站 上发现了上述任何被黑页面。有时,您也可以通过打开 Google 搜索窗口并输入 site:your site url(使用您的 网站 根级 URL)来找到此类网页。搜索结果页将显示 Google 为您的 网站 编入索引的网页,包括被黑的网页。您可以翻阅几页搜索结果,看看是否可以找到任何不寻常的 URL。如果您在 Google 搜索结果中没有看到任何被黑内容,请使用其他搜索引擎搜索相同的搜索词。此操作的效果如下例所示。

请注意,上面的搜索结果收录许多不是由 网站 的所有者创建的页面。如果您仔细查看描述,您将看到此 hack 创建的乱码示例。
通常,当您点击被黑网页的链接时,您要么被重定向到其他网站,要么看到一个充满乱码内容的网页。但是,您可能还会看到该页面不存在的消息(例如 404 错误)。不要被愚弄!当网页仍然被黑客入侵时,黑客会试图说服您该网页已消失或已修复。为此,他们将隐藏真实内容。您可以在谷歌爬虫中输入您的网站 URL,查看是否存在隐藏真实内容的问题。Google 抓取工具可让您查看可能隐藏的内容。
如果您看到上述问题,则说明您的网站可能受到了此类黑客攻击。
解决黑客问题
在开始之前,请为要删除的任何文件创建一个脱机副本,以防将来需要恢复它们。在开始清理过程之前,最好备份整个 网站。为此,您可以离线保存服务器上的所有文件,或搜索最适合您的特定内容管理系统的备份选项。
检查 .htaccess 文件(共 2 步)
乱码黑客将使用 .htaccess 文件重定向您的 网站 访问者。
第1步
在 网站 上找到您的 .htaccess 文件。如果您不确定在哪里可以找到此文件,并且您使用的是 WordPress、Joomla 或 Drupal 等内容管理系统,请在搜索中搜索“.htaccess 文件的位置”和您的内容管理系统的名称引擎。您可能会看到多个 .htaccess 文件,具体取决于您的 网站。然后,列出所有 .htaccess 文件的位置。
注意:.htaccess 通常是一个“隐藏文件”。请确保在搜索此类文件时启用显示隐藏文件选项。
第2步
将所有 .htaccess 文件替换为相应 .htaccess 文件的未破解版本或默认版本。您通常可以通过搜索“默认 .htaccess 文件”和内容管理系统的名称来找到 .htaccess 文件的默认版本。对于带有多个 .htaccess 文件的 网站,请找到每个文件的未破解版本并替换它。
如果没有默认的 .htaccess 文件,并且您从未在 网站 上配置过任何 .htaccess 文件,那么您在 网站 上找到的 .htaccess 文件可能是恶意文件。为安全起见,请离线保存 .htaccess 文件的副本,然后从 网站 中删除相应的 .htaccess 文件。
查找并删除其他恶意文件(共 5 个步骤)
识别恶意文件可能很棘手,可能需要几个小时才能完成。检查文件时请不要担心。如果您还没有备份 网站 上的文件,这是个好时机。您可以在 Google 搜索中搜索“备份网站”和您的内容管理系统的名称,以查找有关如何备份 网站 的说明。
第1步
如果您使用内容管理系统,请重新安装该内容管理系统默认分发中收录的所有核心(默认)文件,以及您可能添加的任何内容(例如主题、模块、插件)。这有助于确保这些文件不收录被黑内容。您可以在 Google 搜索中搜索“重新安装”和您的内容管理系统的名称,以查找有关重新安装过程的说明。如果您有任何插件、模块、扩展或主题,请确保您也重新安装它们。
重新安装这些核心文件可能会导致您所做的任何自定义丢失。确保在重新安装之前创建数据库和所有文件的备份。
第2步
现在,您需要查找剩余的任何其他恶意或受损文件。这是此过程中最困难和最耗时的部分,但在您完成此部分后,您马上就完成了!
这种黑客通常会留下两种类型的文件:.txt 文件和 .php 文件。.txt 文件充当模板文件,而 .php 文件决定了您的 网站 上加载了什么样的无意义内容。首先,查找 .txt 文件。根据您连接到 网站 的方式,您应该会看到某种文件搜索功能。搜索“.txt”以查找所有扩展名为 .txt 的文件。这些文件中的大多数是合法的文本文件,例如许可协议、自述文件等。您要查找的是一组特定的 .txt 文件,其中收录用于创建垃圾邮件模板的 HTML 代码。以下是您可能会在这些恶意 .txt 文件中找到的不同代码的代码片段。
黑客使用关键字替换方法来创建垃圾邮件页面。您很可能会在整个被黑文件中看到一些可以替换的常用词。
{keyword}
此外,这些文件中的大多数都收录某种代码,可以将垃圾邮件链接和垃圾邮件文本置于可见网页之外。
Cheap prescription drugs
请删除这些 .txt 文件。如果这些文件在同一个文件夹中,您可以删除整个文件夹。
第 3 步
查找恶意 PHP 文件会稍微困难一些。您的 网站 上可能存在一个或多个恶意 PHP 文件。这些文件可能收录在同一个子目录中,也可能分布在整个 网站 中。
不要因为您认为需要打开和查看每个 PHP 文件而感到压力太大。首先,创建您要调查的可疑 PHP 文件列表。以下方法可用于确定哪些 PHP 文件可疑:
第四步
创建可疑 PHP 文件列表后,您可以检查这些文件是正常文件还是恶意文件。如果你不熟悉PHP文件,这个过程会消耗更多的时间,所以你不妨查阅一些PHP文件。但即使您不熟悉编码,您仍然可以通过一些基本模式找到恶意文件。
首先,扫描您发现的可疑文件,找到收录看似凌乱的字母和数字组合的大块文本。大文本块的前面通常是PHP函数的组合(例如base64_decode、rot13、eval、strrev、gzinflate)。以下是此类代码块的示例。有时,所有这些代码都被填充到一长串文本中,使其看起来比实际大小要小。
base64_decode(strrev("hMXZpRXaslmYhJXZuxWd2BSZ0l2cgknbhByZul2czVmckRWYgknYgM3ajFGd0FGIlJXd0VnZgk
nbhBSbvJnZgUGdpNHIyV3b5BSZyV3YlNHIvRHI0V2Zy9mZgQ3Ju9GRg4SZ0l2cgIXdvlHI4lmZg4WYjBSdvlHIsU2chVmcnBydv
JGblBiZvBCdpJGIhBCZuFGIl1Wa0BCa0l2dgQXdCBiLkJXYoBSZiBibhNGIlR2bjBycphGdgcmbpRXYjNXdmJ2blRGI5xWZ0Fmb
1RncvZmbVBiLn5WauVGcwFGagM3J0FGa3BCZuFGdzJXZk5Wdg8GdgU3b5BicvZGI0xWdjlmZmlGZgQXagU2ah1GIvRHIzlGa0B
SZrlGbgUGZvNGIlRWaoByb0BSZrlGbgMnclt2YhhEIuUGZvNGIlxmYhRWYlJnb1BychByZulGZhJXZ1F3ch1GIlR2bjBCZlRXY
jNXdmJ2bgMXdvl2YpxWYtBiZvBSZjVWawBSYgMXagMXaoRFIskGS"));
有时,这种类型的代码并不凌乱,看起来像一个普通的脚本。如果您不确定代码是否恶意,请访问我们的;在这个论坛里,一群有经验的网站站长可以帮你查看相关文件。
第 5 步
现在您知道哪些文件是可疑的,您可以通过将它们保存在您的计算机上来创建备份或创建本地副本,使它们不是恶意文件,然后删除这些可疑文件。
检查您的 网站 是否已被清理
删除被黑的文件后,请检查您的努力是否得到了回报。还记得你之前发现的那些乱码吗?使用“Google 抓取工具”再次检查这些页面,看看它们是否仍然存在。如果他们在“Google crawler”中的结果是“not found”,那么您的 网站 可能处于良好状态!
您也可以按照“被黑网站”疑难解答工具中的步骤检查网站上是否还有被黑内容。
如何防止再次入侵?
修复网站上的漏洞是修复网站的最后一个关键步骤。最近的一项研究发现,20% 的被黑 网站 会在 1 天内再次被黑。了解 网站 是如何被黑的非常有用。请参阅我们的指南,了解垃圾邮件发送者使用的最常见的 网站 黑客方法,以开始调查问题。但是,如果您无法查明 网站 是如何被入侵的,您可以按照下面的清单来减少 网站 上的漏洞数量。
其他资源
如果您仍然无法修复 网站,还有一些其他资源可以帮助您。
这些工具可以扫描您的网站,可能会发现有问题的内容。除 VirusTotal 外,Google 不会运行或支持其他工具。
Virus Total、Sucuri Site Check、Quttera:这些工具(以及许多其他工具)可能能够扫描您的 网站 以找出有问题的内容。但请注意,这些扫描工具并不能保证能找到所有类型的问题内容。
以下是 Google 提供的其他可以帮助您的资源:
没有找到您认为可能有用的工具?请留下反馈并告诉我们。
php网页抓取乱码(一个需求需要用cheerio抓取一个网页js脚本插入末尾)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-06 16:02
最近有开发需求,使用cheerio抓取一个网页,然后在标签的末尾插入一个js脚本。然后确保浏览器正常运行。现将遇到的问题记录下来。
这里有一个问题:
Node.js 默认不支持 utf-8 编码,所以在抓取非 utf-8 中文网页时会出现乱码。比如网易的首页代码是gb2312,爬取就会出现乱码。百度大佬都用icon-lite转码(有兴趣的可以百度cheerio中文乱码)。(只是他们说的和我说的不一样。我需要将网页返回给浏览器)。然后我开始尝试。思路大概是这样:获取代理层将请求返回的html请求头的header中的content-type,来确定这个网页的编码方式。然后使用 iconv.decode 进行相应的转码,然后进行 js 替换。但是这种情况有一个漏洞,如下图
有些网站开发不够规范,甚至在content-type中没有声明网页的编码方式。因此,这条路是行不通的,只能通过抓取标签来确定网页的相应编码,然后进行转码。
var newDataStr = '';
var charset="utf-8";
var arr=responseDetail.response.body.toString().match(/]*?)>/g);
if(arr){
arr.forEach(function(val){
var match=val.match(/charset\s*=\s*(.+)\"/);
if(match && match[1]){
if(match[1].substr(0,1)=='"')match[1]=match[1].substr(1);
charset=match[1].trim();
return false;
}
})
}
var html = iconv.decode(responseDetail.response.body, charset);
// var html = responseDetail.response.body.toString();
var $ = cheerio.load(html);
responseDetail.response.body = newDataStr;
return {response: responseDetail.response}
试了下,大部分网页中文编码问题都解决了,但是还是有一些地方出现中文乱码
这个问题主要是因为节点转码成gbk后我没有将新插入的页面转码到初始状态。浏览器下载后,浏览器无法识别部分js xhr代码,导致出现部分代码。所以
newDataStr=iconv.encode($.html(), charset); 只需将其恢复为原创编码方式 查看全部
php网页抓取乱码(一个需求需要用cheerio抓取一个网页js脚本插入末尾)
最近有开发需求,使用cheerio抓取一个网页,然后在标签的末尾插入一个js脚本。然后确保浏览器正常运行。现将遇到的问题记录下来。
这里有一个问题:
Node.js 默认不支持 utf-8 编码,所以在抓取非 utf-8 中文网页时会出现乱码。比如网易的首页代码是gb2312,爬取就会出现乱码。百度大佬都用icon-lite转码(有兴趣的可以百度cheerio中文乱码)。(只是他们说的和我说的不一样。我需要将网页返回给浏览器)。然后我开始尝试。思路大概是这样:获取代理层将请求返回的html请求头的header中的content-type,来确定这个网页的编码方式。然后使用 iconv.decode 进行相应的转码,然后进行 js 替换。但是这种情况有一个漏洞,如下图

有些网站开发不够规范,甚至在content-type中没有声明网页的编码方式。因此,这条路是行不通的,只能通过抓取标签来确定网页的相应编码,然后进行转码。
var newDataStr = '';
var charset="utf-8";
var arr=responseDetail.response.body.toString().match(/]*?)>/g);
if(arr){
arr.forEach(function(val){
var match=val.match(/charset\s*=\s*(.+)\"/);
if(match && match[1]){
if(match[1].substr(0,1)=='"')match[1]=match[1].substr(1);
charset=match[1].trim();
return false;
}
})
}
var html = iconv.decode(responseDetail.response.body, charset);
// var html = responseDetail.response.body.toString();
var $ = cheerio.load(html);
responseDetail.response.body = newDataStr;
return {response: responseDetail.response}
试了下,大部分网页中文编码问题都解决了,但是还是有一些地方出现中文乱码

这个问题主要是因为节点转码成gbk后我没有将新插入的页面转码到初始状态。浏览器下载后,浏览器无法识别部分js xhr代码,导致出现部分代码。所以
newDataStr=iconv.encode($.html(), charset); 只需将其恢复为原创编码方式
php网页抓取乱码(不会php网页抓取乱码怎么办。这个其实很简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-30 18:01
php网页抓取乱码怎么办。这个其实很简单,因为php现在已经非常的普及了,不会php也能够根据其他编程语言或者自己开发的程序来编写页面抓取程序。首先用php抓取一个想要抓取的php网页,你会看到网页上面包含很多框架的spanicon,这些icon其实是动态加载出来的一些数据,同时也和网页中的内容相关,这些icon就是我们要用到网页抓取的数据源。
其次,你会看到网页中会有很多的urlencodedjs:document.getelementbyid("imgurl").each().foreach({innerhtml:function(){functioninnertex($h){$h();}});}})..最后你会发现所有的数据都会出现在网页的源代码中,因为你抓取的时候肯定会加载别的源码,所以应该将数据抓取进来!解决方法就是使用request.get("")将数据发送出去。
实战首先你会获取一个链接,比如get/tutorial?test=a2&grid=r-1然后点开链接看到这里的xxx是这个php网页抓取程序抓取的phpicon,$test=request.get("");代码如下:xxxstring$icon;request.get("");当然这里xxx可以是任何字符串。
然后把这个xxx发送到filereader中读取即可。最后基本上就能够读取数据了,$test=request.get("");直接用get方法就可以了。推荐一本我觉得不错的php书籍,翻译过来是php5反序列化。第四章抓取原理讲的不错,值得反复阅读。 查看全部
php网页抓取乱码(不会php网页抓取乱码怎么办。这个其实很简单)
php网页抓取乱码怎么办。这个其实很简单,因为php现在已经非常的普及了,不会php也能够根据其他编程语言或者自己开发的程序来编写页面抓取程序。首先用php抓取一个想要抓取的php网页,你会看到网页上面包含很多框架的spanicon,这些icon其实是动态加载出来的一些数据,同时也和网页中的内容相关,这些icon就是我们要用到网页抓取的数据源。
其次,你会看到网页中会有很多的urlencodedjs:document.getelementbyid("imgurl").each().foreach({innerhtml:function(){functioninnertex($h){$h();}});}})..最后你会发现所有的数据都会出现在网页的源代码中,因为你抓取的时候肯定会加载别的源码,所以应该将数据抓取进来!解决方法就是使用request.get("")将数据发送出去。
实战首先你会获取一个链接,比如get/tutorial?test=a2&grid=r-1然后点开链接看到这里的xxx是这个php网页抓取程序抓取的phpicon,$test=request.get("");代码如下:xxxstring$icon;request.get("");当然这里xxx可以是任何字符串。
然后把这个xxx发送到filereader中读取即可。最后基本上就能够读取数据了,$test=request.get("");直接用get方法就可以了。推荐一本我觉得不错的php书籍,翻译过来是php5反序列化。第四章抓取原理讲的不错,值得反复阅读。
php网页抓取乱码(phpcurl获取乱码的解决办法:首先打开相应的脚本文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-29 10:28
使用PHP curl获取乱码的解决方案:首先打开相应的脚本文件;然后获取网页文本;最后,使用“b_convert_编码($outpagext,'UTF-8','GB2312');”方法将GB2312转换为“UTF-8”
推荐:PHP视频教程
问题:
Curl用于从电影天堂获取电影信息,结果中有乱码,如图所示:
解决方案
官方文件中有一个curlopt,编码选项,尝试过了,实际上是无用的
我们在页面的标题中看到代码GB2312
应该是
//curl 前面的设置不冗述
//执行 curl
$outPageTxt = curl_exec($film); //outPageTxt 是得到的网页文本
curl_close($film);
//文本转码
$outPageTxt = mb_convert_encoding($outPageTxt, 'utf-8','GB2312');
//把 GB2312 转到 UTF-8
echo $outPageTxt;
使用说明
mb_uu转换_uu编码(输出变量、传输到的代码、传输到的代码)
结果
以上是如何解决在PHP curl中获取乱码的问题。欲了解更多信息,请关注其他相关文章
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系 查看全部
php网页抓取乱码(phpcurl获取乱码的解决办法:首先打开相应的脚本文件)
使用PHP curl获取乱码的解决方案:首先打开相应的脚本文件;然后获取网页文本;最后,使用“b_convert_编码($outpagext,'UTF-8','GB2312');”方法将GB2312转换为“UTF-8”

推荐:PHP视频教程
问题:
Curl用于从电影天堂获取电影信息,结果中有乱码,如图所示:

解决方案
官方文件中有一个curlopt,编码选项,尝试过了,实际上是无用的
我们在页面的标题中看到代码GB2312

应该是
//curl 前面的设置不冗述
//执行 curl
$outPageTxt = curl_exec($film); //outPageTxt 是得到的网页文本
curl_close($film);
//文本转码
$outPageTxt = mb_convert_encoding($outPageTxt, 'utf-8','GB2312');
//把 GB2312 转到 UTF-8
echo $outPageTxt;
使用说明
mb_uu转换_uu编码(输出变量、传输到的代码、传输到的代码)
结果

以上是如何解决在PHP curl中获取乱码的问题。欲了解更多信息,请关注其他相关文章
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系
php网页抓取乱码(phpfile_get_contentsGzip网页乱码的三种解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-05 07:30
本篇文章主要为大家展示《如何解决php gzip css乱码问题》,内容简单易懂,条理清晰,希望能帮到你解惑,让小编带你一探究竟一起学习学习《如何解决php gzip css乱码问题》这篇文章。
php gzip css 乱码解决方法:1、 使用内置的zlib库;2、 使用 CURL 代替“file_get_contents”;3、 使用gzip解压功能解决乱码问题。
本文运行环境:Windows7系统,PHP7.版本1,DELL G3电脑。
php file_get_contents抓取乱码Gzip网页的三种解决方法
使用file_get_contents() 函数获取网页会导致乱码。出现乱码的原因有两个,一是编码问题,二是目标页面启用了Gzip。下面是如何防止Gzip功能开启时出现乱码。
只需将捕获的内容转为编码($content=iconv("GBK", "UTF-8//IGNORE", $content);),我们这里讨论的是如何捕获启用Gzip的页面。如何判断?Content-Encoding: 获取到的header中的gzip表示内容采用GZIP压缩。用 FireBug 查看它以了解页面上是否启用了 gzip。下面是用firebug查看我博客的header信息,Gzip是打开的。
代码显示如下:
原创头信息
Accept text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding gzip, deflate
Accept-Language zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Connection keep-alive
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.1326850415.887.3.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=%E4%BB%BB%E4%BD%95%E9%A1%B9%E7%9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE%80%E5%8D%95%20site%3Awww.nowamagic.net; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
Host www.nowamagic.net
User-Agent Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
以下是一些解决方案:
1. 使用内置的 zlib 库
如果服务器已经安装了zlib库,可以通过如下代码轻松解决乱码问题。
代码显示如下:
$data = file_get_contents("compress.zlib://".$url);
2. 使用 CURL 代替 file_get_contents
代码显示如下:
3. 使用gzip解压功能
代码显示如下:
<p>function gzdecode($data) {
$len = strlen($data);
if ($len 查看全部
php网页抓取乱码(phpfile_get_contentsGzip网页乱码的三种解决方法)
本篇文章主要为大家展示《如何解决php gzip css乱码问题》,内容简单易懂,条理清晰,希望能帮到你解惑,让小编带你一探究竟一起学习学习《如何解决php gzip css乱码问题》这篇文章。
php gzip css 乱码解决方法:1、 使用内置的zlib库;2、 使用 CURL 代替“file_get_contents”;3、 使用gzip解压功能解决乱码问题。
本文运行环境:Windows7系统,PHP7.版本1,DELL G3电脑。
php file_get_contents抓取乱码Gzip网页的三种解决方法
使用file_get_contents() 函数获取网页会导致乱码。出现乱码的原因有两个,一是编码问题,二是目标页面启用了Gzip。下面是如何防止Gzip功能开启时出现乱码。
只需将捕获的内容转为编码($content=iconv("GBK", "UTF-8//IGNORE", $content);),我们这里讨论的是如何捕获启用Gzip的页面。如何判断?Content-Encoding: 获取到的header中的gzip表示内容采用GZIP压缩。用 FireBug 查看它以了解页面上是否启用了 gzip。下面是用firebug查看我博客的header信息,Gzip是打开的。
代码显示如下:
原创头信息
Accept text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding gzip, deflate
Accept-Language zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Connection keep-alive
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.1326850415.887.3.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=%E4%BB%BB%E4%BD%95%E9%A1%B9%E7%9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE%80%E5%8D%95%20site%3Awww.nowamagic.net; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
Host www.nowamagic.net
User-Agent Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
以下是一些解决方案:
1. 使用内置的 zlib 库
如果服务器已经安装了zlib库,可以通过如下代码轻松解决乱码问题。
代码显示如下:
$data = file_get_contents("compress.zlib://".$url);
2. 使用 CURL 代替 file_get_contents
代码显示如下:
3. 使用gzip解压功能
代码显示如下:
<p>function gzdecode($data) {
$len = strlen($data);
if ($len
php网页抓取乱码(具体方法如下:file_get_contents函数(file)_函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-05 00:14
PHP中使用file_get_contents抓取网页中文乱码问题的解决方法,
本文介绍了PHP中使用file_get_contents抓取网页中文乱码问题的解决方案示例。分享给大家,供大家参考。具体方法如下:
file_get_contents 函数本来是一个很好的php内置的本地和远程文件操作函数。它可以让我们不费吹灰之力就可以直接下载远程数据,但是我在使用它阅读网页时会遇到一些问题。页面出现乱码,这里总结一下具体的解决方法。
据网上的朋友说,可能是服务器开启了GZIP压缩的原因。下面是用firebug查看我的网站的header信息。 Gzip 已打开。请求头信息的原创头信息如下:
接受编码 gzip,放气
接受-语言zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
连接保持活动
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.1326850415.887.3.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=%E4%BB%BB%E4% BD%95%E9%A1%B9%E7% 9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE% 80%E5%8D%95%20站点%3A; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
主持人
用户代理 Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
你可以在header信息中找到Content-Encoding项是Gzip。
解决方法比较简单,就是用curl代替file_get_contents来获取,然后在curl配置参数中加一个。代码如下:
今天用file_get_contents抓图的时候,一开始没发现这个问题。
使用内置的 zlib 库。如果服务器已经安装了zlib库,可以通过如下代码轻松解决乱码问题,代码如下:
希望本文对您的 PHP 编程有所帮助。 查看全部
php网页抓取乱码(具体方法如下:file_get_contents函数(file)_函数)
PHP中使用file_get_contents抓取网页中文乱码问题的解决方法,
本文介绍了PHP中使用file_get_contents抓取网页中文乱码问题的解决方案示例。分享给大家,供大家参考。具体方法如下:
file_get_contents 函数本来是一个很好的php内置的本地和远程文件操作函数。它可以让我们不费吹灰之力就可以直接下载远程数据,但是我在使用它阅读网页时会遇到一些问题。页面出现乱码,这里总结一下具体的解决方法。
据网上的朋友说,可能是服务器开启了GZIP压缩的原因。下面是用firebug查看我的网站的header信息。 Gzip 已打开。请求头信息的原创头信息如下:
接受编码 gzip,放气
接受-语言zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
连接保持活动
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.1326850415.887.3.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=%E4%BB%BB%E4% BD%95%E9%A1%B9%E7% 9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE% 80%E5%8D%95%20站点%3A; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
主持人
用户代理 Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
你可以在header信息中找到Content-Encoding项是Gzip。
解决方法比较简单,就是用curl代替file_get_contents来获取,然后在curl配置参数中加一个。代码如下:
今天用file_get_contents抓图的时候,一开始没发现这个问题。
使用内置的 zlib 库。如果服务器已经安装了zlib库,可以通过如下代码轻松解决乱码问题,代码如下:
希望本文对您的 PHP 编程有所帮助。
php网页抓取乱码(想了解python抓取并保存html页面时乱码问题的解决办法的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-02 11:15
想知道python抓取保存html页面时出现乱码问题的解决方法相关内容吗?在本文中,holybin将仔细讲解python抓取保存html页面时出现乱码问题的相关知识和一些代码示例。欢迎阅读并指正,先重点介绍:python,抓取,保存,html页面,乱码,解决方法,一起学习。
本文示例介绍了python抓取并保存html页面时出现乱码问题的解决方法。分享给大家,供大家参考,如下:
使用Python抓取html页面并保存时,经常会出现抓取页面内容乱码的问题。出现这个问题的原因一方面是代码中的编码设置有问题,另一方面,当编码设置正确时,网页的实际编码与标记的编码不匹配。html页面上标注的代码在这里:
复制代码代码如下:
这里有一个简单的解决方法:使用chardet判断网页的真实编码,同时从url请求返回的info中判断mark编码。如果两种编码不同,使用bs模块扩展为GB18030编码;如果相同,直接写入文件(这里设置系统默认编码为utf-8)。
import urllib2
import sys
import bs4
import chardet
reload(sys)
sys.setdefaultencoding('utf-8')
def download(url):
htmlfile = open('test.html','w')
try:
result = urllib2.urlopen(url)
content = result.read()
info = result.info()
result.close()
except Exception,e:
print 'download error!!!'
print e
else:
if content != None:
charset1 = (chardet.detect(content))['encoding'] #real encoding type
charset2 = info.getparam('charset') #declared encoding type
print charset1,' ', charset2
# case1: charset is not None.
if charset1 != None and charset2 != None and charset1.lower() != charset2.lower():
newcont = bs4.BeautifulSoup(content, from_encoding='GB18030') #coding: GB18030
for cont in newcont:
htmlfile.write('%s\n'%cont)
# case2: either charset is None, or charset is the same.
else:
#print sys.getdefaultencoding()
htmlfile.write(content) #default coding: utf-8
htmlfile.close()
if __name__ == "__main__":
url = '//www.qb5200.com'
download(url)
获取到的test.html文件打开如下,可以看到它是以UTF-8无BOM编码格式存储的,也就是我们设置的默认编码:
我希望这篇文章对你的 Python 编程有所帮助。
相关文章 查看全部
php网页抓取乱码(想了解python抓取并保存html页面时乱码问题的解决办法的相关内容吗)
想知道python抓取保存html页面时出现乱码问题的解决方法相关内容吗?在本文中,holybin将仔细讲解python抓取保存html页面时出现乱码问题的相关知识和一些代码示例。欢迎阅读并指正,先重点介绍:python,抓取,保存,html页面,乱码,解决方法,一起学习。
本文示例介绍了python抓取并保存html页面时出现乱码问题的解决方法。分享给大家,供大家参考,如下:
使用Python抓取html页面并保存时,经常会出现抓取页面内容乱码的问题。出现这个问题的原因一方面是代码中的编码设置有问题,另一方面,当编码设置正确时,网页的实际编码与标记的编码不匹配。html页面上标注的代码在这里:
复制代码代码如下:
这里有一个简单的解决方法:使用chardet判断网页的真实编码,同时从url请求返回的info中判断mark编码。如果两种编码不同,使用bs模块扩展为GB18030编码;如果相同,直接写入文件(这里设置系统默认编码为utf-8)。
import urllib2
import sys
import bs4
import chardet
reload(sys)
sys.setdefaultencoding('utf-8')
def download(url):
htmlfile = open('test.html','w')
try:
result = urllib2.urlopen(url)
content = result.read()
info = result.info()
result.close()
except Exception,e:
print 'download error!!!'
print e
else:
if content != None:
charset1 = (chardet.detect(content))['encoding'] #real encoding type
charset2 = info.getparam('charset') #declared encoding type
print charset1,' ', charset2
# case1: charset is not None.
if charset1 != None and charset2 != None and charset1.lower() != charset2.lower():
newcont = bs4.BeautifulSoup(content, from_encoding='GB18030') #coding: GB18030
for cont in newcont:
htmlfile.write('%s\n'%cont)
# case2: either charset is None, or charset is the same.
else:
#print sys.getdefaultencoding()
htmlfile.write(content) #default coding: utf-8
htmlfile.close()
if __name__ == "__main__":
url = '//www.qb5200.com'
download(url)
获取到的test.html文件打开如下,可以看到它是以UTF-8无BOM编码格式存储的,也就是我们设置的默认编码:
我希望这篇文章对你的 Python 编程有所帮助。
相关文章
php网页抓取乱码(Python网络爬虫过程中三种中文乱码的处理方案的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-10-31 13:00
)
下面介绍三种处理网页爬虫过程中中文乱码的解决方案。希望对大家的学习有所帮助。
前言
前几天,有粉丝在Python交流群里问了一个关于使用Python网络爬虫过程中出现中文乱码的问题。
它看起来像一个大头。对于一个爬虫初学者来说,这个乱七八糟的代码放在他的面前,就像一块绊脚石。不过别慌,小编在这里为大家整理了三种方法,专门针对中文乱码。希望大家以后再遇到中文乱码问题,也能在这里得到启发!
一、思考
其实解决问题的关键在于一点,就是对乱码部分的处理,处理方案主要可以从两个方面着手。一种是预先对整个网页进行编码,另一种是对特定中文乱码的部分进行编码。这里说三个方法,肯定还有其他方法,欢迎大家在评论区评论。
二、分析
其实中文乱码的表现有很多种,但比较常见的两种如下:
1、当网页编码为gbk,将获取到的内容打印在控制台时,类似如下情况:
ÃÀÅ® µçÄÔ×À ¼üÅÌ »ú·¿ ¿É°® С½ã½ã4k±ÚÖ½
2、当网页编码为gbk,将获取到的内容打印在控制台时,类似如下情况:
�װŮ�� ��Ů ˮ СϪ Ψ��
虽然看起来控制台输出正常,但是没有报错:
Process finished with exit code 0
但是,中文的输出不是普通人能看懂的。
遇到这种情况,可以使用本文给出的三种方法来解决,久而久之!
三、 具体实现
1)方法一:把requests.get().text改成requests.get().content
我们可以看到通过text()方法得到的源码,然后打印出来,确实会出现乱码,如下图。
这时候可以考虑把请求改成.content,得到的内容是正常的。
2)方法二:手动指定网页编码
# 手动设定响应数据的编码格式
response.encoding = response.apparent_encoding
这个方法稍微复杂一点,但是比较容易理解,初学者比较好接受。如果你觉得上面的方法很难记住,也可以尝试直接指定gbk编码,也可以进行处理,如下图所示:
以上介绍的两种方法都是针对网页的整体编码,效果显着。接下来的第三种方法是对中文的局部乱码部分使用通用的编码方法。
3)方法三:使用通用的编码方式
img_name.encode('iso-8859-1').decode('gbk')
使用通用的编码方式,设置中文出现乱码的编码设置。还是现在的例子,设置img_name的编码,指定编码,解码,如下图。
这样,乱码的问题就轻松解决了。
四、总结
本文根据粉丝提出的问题,针对Python网络爬虫过程中出现的中文乱码问题给出了三种乱码解决方案,成功帮助粉丝解决问题。虽然文中引用了三种方法,但相信一定还有其他方法,欢迎大家在评论区留言。如果需要进群交流,可以按如下方式进群。
技术交流
欢迎转载,采集,并获得一些好评和支持!
目前已开通技术交流群,群内好友达2000余人。添加时备注最好的方式是:来源+兴趣方向,方便找志同道合的朋友
查看全部
php网页抓取乱码(Python网络爬虫过程中三种中文乱码的处理方案的方法
)
下面介绍三种处理网页爬虫过程中中文乱码的解决方案。希望对大家的学习有所帮助。
前言
前几天,有粉丝在Python交流群里问了一个关于使用Python网络爬虫过程中出现中文乱码的问题。
它看起来像一个大头。对于一个爬虫初学者来说,这个乱七八糟的代码放在他的面前,就像一块绊脚石。不过别慌,小编在这里为大家整理了三种方法,专门针对中文乱码。希望大家以后再遇到中文乱码问题,也能在这里得到启发!
一、思考
其实解决问题的关键在于一点,就是对乱码部分的处理,处理方案主要可以从两个方面着手。一种是预先对整个网页进行编码,另一种是对特定中文乱码的部分进行编码。这里说三个方法,肯定还有其他方法,欢迎大家在评论区评论。
二、分析
其实中文乱码的表现有很多种,但比较常见的两种如下:
1、当网页编码为gbk,将获取到的内容打印在控制台时,类似如下情况:
ÃÀÅ® µçÄÔ×À ¼üÅÌ »ú·¿ ¿É°® С½ã½ã4k±ÚÖ½
2、当网页编码为gbk,将获取到的内容打印在控制台时,类似如下情况:
�װŮ�� ��Ů ˮ СϪ Ψ��
虽然看起来控制台输出正常,但是没有报错:
Process finished with exit code 0
但是,中文的输出不是普通人能看懂的。
遇到这种情况,可以使用本文给出的三种方法来解决,久而久之!
三、 具体实现
1)方法一:把requests.get().text改成requests.get().content
我们可以看到通过text()方法得到的源码,然后打印出来,确实会出现乱码,如下图。
这时候可以考虑把请求改成.content,得到的内容是正常的。
2)方法二:手动指定网页编码
# 手动设定响应数据的编码格式
response.encoding = response.apparent_encoding
这个方法稍微复杂一点,但是比较容易理解,初学者比较好接受。如果你觉得上面的方法很难记住,也可以尝试直接指定gbk编码,也可以进行处理,如下图所示:
以上介绍的两种方法都是针对网页的整体编码,效果显着。接下来的第三种方法是对中文的局部乱码部分使用通用的编码方法。
3)方法三:使用通用的编码方式
img_name.encode('iso-8859-1').decode('gbk')
使用通用的编码方式,设置中文出现乱码的编码设置。还是现在的例子,设置img_name的编码,指定编码,解码,如下图。
这样,乱码的问题就轻松解决了。
四、总结
本文根据粉丝提出的问题,针对Python网络爬虫过程中出现的中文乱码问题给出了三种乱码解决方案,成功帮助粉丝解决问题。虽然文中引用了三种方法,但相信一定还有其他方法,欢迎大家在评论区留言。如果需要进群交流,可以按如下方式进群。
技术交流
欢迎转载,采集,并获得一些好评和支持!
目前已开通技术交流群,群内好友达2000余人。添加时备注最好的方式是:来源+兴趣方向,方便找志同道合的朋友
php网页抓取乱码(什么是这是的编码?的方式解决乱码问题? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-31 02:15
)
2、 如果上面的方法不行,页面还是乱码;或者在head标签下找不到charset属性;或者我们要采集很多网页,而且这些网页的编码方式都不一样,我们不可能在一个网页上一一查看head标签,所以可以通过以下方式用来解决乱码。
(1)python 的 chardet 库
可以使用以下方法解决乱码问题
result = chardet.detect(response.content)
print(result)
data = response.content.decode(chardet.detect(response.content)['encoding'])
{'confidence': 0.99, 'language': '', 'encoding': 'utf-8'}
从输出结果可以看出,这是一个“猜测”代码。猜测的方法是先采集各种代码的特征字符。根据特征人物的判断,“猜”的概率很高。
这种方法的效率非常低。如果采集的网页很大,你只能猜测其中一部分的源代码,即
result = chardet.detect(response.content[:1000])
(2)响应编码
也可以使用另一种方法,response自身的编码和apparent_encoding这两个变量。
Response.encoding 一般来自 response.headers 中 content-type 字段的 charset 值。其他情况我不太了解。
response.apparent_encoding 一般使用上面提到的python chardet 库。
所以可以使用下面的方式来解决乱码问题
data = response.content.decode(response.apparent_encoding)
3、 一般来说,以上两种方法都可以解决乱码问题。但如果以上两种方法都不能解决,则可能是网页压缩造成的。使用以下方法解决此问题。
检查你写的头信息是否收录 Accept-Encoding 字段。如果是,请删除此字段。乱码问题将得到解决。
headers = {
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/49.0.2623.221
Safari/537.36 SE 2.X MetaSr 1.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Connection': 'keep-alive',
} 查看全部
php网页抓取乱码(什么是这是的编码?的方式解决乱码问题?
)
2、 如果上面的方法不行,页面还是乱码;或者在head标签下找不到charset属性;或者我们要采集很多网页,而且这些网页的编码方式都不一样,我们不可能在一个网页上一一查看head标签,所以可以通过以下方式用来解决乱码。
(1)python 的 chardet 库
可以使用以下方法解决乱码问题
result = chardet.detect(response.content)
print(result)
data = response.content.decode(chardet.detect(response.content)['encoding'])
{'confidence': 0.99, 'language': '', 'encoding': 'utf-8'}
从输出结果可以看出,这是一个“猜测”代码。猜测的方法是先采集各种代码的特征字符。根据特征人物的判断,“猜”的概率很高。
这种方法的效率非常低。如果采集的网页很大,你只能猜测其中一部分的源代码,即
result = chardet.detect(response.content[:1000])
(2)响应编码
也可以使用另一种方法,response自身的编码和apparent_encoding这两个变量。
Response.encoding 一般来自 response.headers 中 content-type 字段的 charset 值。其他情况我不太了解。
response.apparent_encoding 一般使用上面提到的python chardet 库。
所以可以使用下面的方式来解决乱码问题
data = response.content.decode(response.apparent_encoding)
3、 一般来说,以上两种方法都可以解决乱码问题。但如果以上两种方法都不能解决,则可能是网页压缩造成的。使用以下方法解决此问题。
检查你写的头信息是否收录 Accept-Encoding 字段。如果是,请删除此字段。乱码问题将得到解决。
headers = {
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/49.0.2623.221
Safari/537.36 SE 2.X MetaSr 1.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Connection': 'keep-alive',
}
php网页抓取乱码(php网页抓取乱码的关键是你是怎么弄的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-10-30 00:02
php网页抓取乱码,关键是你是怎么弄的。不同的网站抓取方式不同。如果你是通过java,直接var_dump模块,这个需要设置一下accesslog参数,才可以抓取xml格式的数据。但是如果是php,通过正则提取api也可以。记得自己在测试的时候,用正则提取到accesslog参数。
提供accesskey参数就可以了
很简单,直接把xml内容中的accesskey提取出来就可以,请自己写正则表达式。json的话,就是append去模糊匹配。sql的话就是使用正则表达式,匹配all键,然后去匹配后面的列。至于后面的参数,是xml的话,就找匹配出来的中间部分,对应,匹配就可以了。
想知道具体你对哪方面不理解或者说看不明白?
php:json格式的文件可以通过正则提取.xml格式的用access_log.load_xml_data函数即可.
关键是怎么分析出来
刚开始理解,
抓json比较简单,因为你写的正则规则就是有规律的json格式的一个特征,比如id,lastname;你可以用xmltoxml提取出这个正则规则,然后插入到你要的数据里,或者用正则包含规则ments(3,3);ments(3,3);ments;就可以抓出你要的数据。
抓xml比较复杂,因为也有正则,但是简单点:auth_people.do_something({comment:"sir",property:["firstname","lastname"]});ments(comment,@firstname,@lastname)values({comment,@firstname,@lastname});这么写是复制了xml的规则并加入到你要抓取的内容里,但是这样做还是有个缺点,可能过一段时间你又要改规则,改过来就找不到出处了。我的解决方法是用正则.匹配@xxx.in@xx.xx.in@xx.xx@xx.@。 查看全部
php网页抓取乱码(php网页抓取乱码的关键是你是怎么弄的?)
php网页抓取乱码,关键是你是怎么弄的。不同的网站抓取方式不同。如果你是通过java,直接var_dump模块,这个需要设置一下accesslog参数,才可以抓取xml格式的数据。但是如果是php,通过正则提取api也可以。记得自己在测试的时候,用正则提取到accesslog参数。
提供accesskey参数就可以了
很简单,直接把xml内容中的accesskey提取出来就可以,请自己写正则表达式。json的话,就是append去模糊匹配。sql的话就是使用正则表达式,匹配all键,然后去匹配后面的列。至于后面的参数,是xml的话,就找匹配出来的中间部分,对应,匹配就可以了。
想知道具体你对哪方面不理解或者说看不明白?
php:json格式的文件可以通过正则提取.xml格式的用access_log.load_xml_data函数即可.
关键是怎么分析出来
刚开始理解,
抓json比较简单,因为你写的正则规则就是有规律的json格式的一个特征,比如id,lastname;你可以用xmltoxml提取出这个正则规则,然后插入到你要的数据里,或者用正则包含规则ments(3,3);ments(3,3);ments;就可以抓出你要的数据。
抓xml比较复杂,因为也有正则,但是简单点:auth_people.do_something({comment:"sir",property:["firstname","lastname"]});ments(comment,@firstname,@lastname)values({comment,@firstname,@lastname});这么写是复制了xml的规则并加入到你要抓取的内容里,但是这样做还是有个缺点,可能过一段时间你又要改规则,改过来就找不到出处了。我的解决方法是用正则.匹配@xxx.in@xx.xx.in@xx.xx@xx.@。
php网页抓取乱码(《PHP视频教程》抓取乱码的解决办法:这样乱码解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-28 18:19
php网页抓取乱码解决方法:1、使用“mbconvertencoding”进行编码转换; 2、添加"curl_setopt($ch, CURLOPT_ENCODING,'gzip');"选项; 3、在顶部添加标题代码。
推荐:《PHP 视频教程》
php抓取页面乱码
在抓取页面时出现类似...的乱码,解决方法如下
1、转换码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、数据被gzip压缩
curl 获取数据时,设置并添加以下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
需要安装zlib库才能使用file_get_contents函数
$data = file_get_contents("compress.zlib://".$url);
3、获取数据后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上就是解决php网页乱码爬取问题的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们 查看全部
php网页抓取乱码(《PHP视频教程》抓取乱码的解决办法:这样乱码解决方法)
php网页抓取乱码解决方法:1、使用“mbconvertencoding”进行编码转换; 2、添加"curl_setopt($ch, CURLOPT_ENCODING,'gzip');"选项; 3、在顶部添加标题代码。
推荐:《PHP 视频教程》
php抓取页面乱码
在抓取页面时出现类似...的乱码,解决方法如下
1、转换码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、数据被gzip压缩
curl 获取数据时,设置并添加以下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
需要安装zlib库才能使用file_get_contents函数
$data = file_get_contents("compress.zlib://".$url);
3、获取数据后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上就是解决php网页乱码爬取问题的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们
php网页抓取乱码(Linux上的默认字体乱码原因是什么?你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-28 12:04
1.因为firefox默认允许网页自己选择字体,所以在Linux上会出现网站的一些乱码。因此,您可以取消允许页面自行选择字体的选项,以解决一些乱码问题。
1.因为firefox默认允许网页自己选择字体,所以在Linux上会出现网站的一些乱码。因此,您可以取消允许页面自行选择字体的选项,以解决一些乱码问题。
php网页抓取乱码( PHP程序员有所有所实例分析实例讲述)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-28 11:13
PHP程序员有所有所实例分析实例讲述)
PHP使用get获取URL乱码的解决方法
更新时间:2014年11月13日15:10:10 投稿:shichen2014
这个文章主要介绍PHP使用get获取的url中乱码的解决方法。是很多PHP程序员都遇到过的问题。这是非常实用和有价值的。有需要的朋友可以参考一下。
本文举例说明如何解决PHP使用get获取URL汉字时出现乱码。分享给大家,供大家参考。具体方法如下:
一、问题:
我打算这样使用它
复制代码代码如下:
【查看区动态】
在list.php页面获取结果——勾选【管辖权操作】
一开始,我猜是汉字的“状态”码和什么东西冲突了,所以出现了乱码。
二、解决方案:
使用:
复制代码代码如下:
" charset="utf-8" target="main">[查看]
然后在list.php页面这样使用
复制代码代码如下:
不会出现乱码和异常传输。
注意这里接收GET页面的代码需要和发送端的代码一致!
关于字符串 urlencode(string $str) 函数
这个函数可以轻松地对字符串进行编码并在 URL 的请求部分中使用它,并且还可以轻松地将变量传递到下一页。
示例 1 urlencode()
复制代码代码如下:
示例 2 urlencode() 和 htmlentities()
复制代码代码如下:
希望本文对您的 PHP 编程有所帮助。 查看全部
php网页抓取乱码(
PHP程序员有所有所实例分析实例讲述)
PHP使用get获取URL乱码的解决方法
更新时间:2014年11月13日15:10:10 投稿:shichen2014
这个文章主要介绍PHP使用get获取的url中乱码的解决方法。是很多PHP程序员都遇到过的问题。这是非常实用和有价值的。有需要的朋友可以参考一下。
本文举例说明如何解决PHP使用get获取URL汉字时出现乱码。分享给大家,供大家参考。具体方法如下:
一、问题:
我打算这样使用它
复制代码代码如下:
【查看区动态】
在list.php页面获取结果——勾选【管辖权操作】
一开始,我猜是汉字的“状态”码和什么东西冲突了,所以出现了乱码。
二、解决方案:
使用:
复制代码代码如下:
" charset="utf-8" target="main">[查看]
然后在list.php页面这样使用
复制代码代码如下:
不会出现乱码和异常传输。
注意这里接收GET页面的代码需要和发送端的代码一致!
关于字符串 urlencode(string $str) 函数
这个函数可以轻松地对字符串进行编码并在 URL 的请求部分中使用它,并且还可以轻松地将变量传递到下一页。
示例 1 urlencode()
复制代码代码如下:
示例 2 urlencode() 和 htmlentities()
复制代码代码如下:
希望本文对您的 PHP 编程有所帮助。
php网页抓取乱码( ,还会出现中文.在应用中常常遇到的问题.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-25 20:06
,还会出现中文.在应用中常常遇到的问题.)
原页面的一个图片加了一个链接,链接中收录中文,所以出现了以下情况: 解决方法是在tomcat server.xml文件中添加URIEncoding="utf-8",如下:
PHP中文乱码解决方案汇总分析
一。首先是PHP网页的编码1. php文件本身的编码要与网页的编码相匹配。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; charset=gb2312"),添加静态页面,所有文件的编码格式都是ANSI,可以用记事本打开,另存为,选择编码为ANSI,覆盖源文本
解决python3中请求解析中文页面出现乱码的问题
第一部分是关于requests库(1) requests是一个非常有用的Python HTTP客户端库,在编写爬虫和测试服务器响应数据时经常用到。(2) Request对象是在访问server 会返回一个Response对象,这个对象将返回的Http响应字节码保存在content属性中。(3)但是如果访问另一个属性文本,会返回一个unicode对象,经常会发送乱码问题结果在这里。(4) 因为Response对象会通过另一种属性编码将字节码编码成unicode,而这个en
java页面url的值出现中文乱码的解决办法
应用中经常会遇到中文问题。这会涉及到字符解码操作,我们在应用中经常使用 new String(fieldType.getBytes("iso-8859-1"), "UTF-8") ;和其他类似的方法来解码。但是这种方法受具体应用环境的限制,经常会在应用部署环境发生变化时出现中文乱码。这是一个可以在任何应用程序部署环境中使用的解决方案。该方法分为两步: 1. 在客户端使用escape(encodeURIComponent(fieldValue))方法进行编码,例如: 查看全部
php网页抓取乱码(
,还会出现中文.在应用中常常遇到的问题.)
原页面的一个图片加了一个链接,链接中收录中文,所以出现了以下情况: 解决方法是在tomcat server.xml文件中添加URIEncoding="utf-8",如下:
PHP中文乱码解决方案汇总分析
一。首先是PHP网页的编码1. php文件本身的编码要与网页的编码相匹配。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; charset=gb2312"),添加静态页面,所有文件的编码格式都是ANSI,可以用记事本打开,另存为,选择编码为ANSI,覆盖源文本
解决python3中请求解析中文页面出现乱码的问题
第一部分是关于requests库(1) requests是一个非常有用的Python HTTP客户端库,在编写爬虫和测试服务器响应数据时经常用到。(2) Request对象是在访问server 会返回一个Response对象,这个对象将返回的Http响应字节码保存在content属性中。(3)但是如果访问另一个属性文本,会返回一个unicode对象,经常会发送乱码问题结果在这里。(4) 因为Response对象会通过另一种属性编码将字节码编码成unicode,而这个en
java页面url的值出现中文乱码的解决办法
应用中经常会遇到中文问题。这会涉及到字符解码操作,我们在应用中经常使用 new String(fieldType.getBytes("iso-8859-1"), "UTF-8") ;和其他类似的方法来解码。但是这种方法受具体应用环境的限制,经常会在应用部署环境发生变化时出现中文乱码。这是一个可以在任何应用程序部署环境中使用的解决方案。该方法分为两步: 1. 在客户端使用escape(encodeURIComponent(fieldValue))方法进行编码,例如:
php网页抓取乱码(出现乱码的原因分析及解决方法有哪些呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-24 00:04
一、乱码原因分析
1.保存文件时,文件有自己的文件编码,是汉字还是其他语言,用什么编码来存储
2.输出时,指定内容的编码,如以网页形式输入时
3.从数据库中取数据时,不确定数据库和字符集
4、以汉字为例。汉字也被编码。一个汉字 gbk 需要两个字符,而 utf8 需要三个字符。
可能导致乱码的潜在原因上面已经说了,我现在就整理一下。
第一种情况,保存的文件和显示代码不一致
如果保存文件时使用utf8编码,输出网页时设置了gbk编码,所以会出现乱码。
第二种情况,保存的文件和数据库中存储的字符不一致
假设,当保存的文件的编码与网页显示的编码相同时,仍然出现乱码。例如,当您保存文件时,您使用 utf8 编码,而您的数据库使用 gb2312 字符集来存储数据。
第三种情况,代码乱码,你还觉得没有
当你发现乱码的时候,当你改变保存文件的编码时,utf8的情况就好了。改成gbk会乱码,但是你觉得还好。这也是出现乱码的原因。这种情况会经常发生。
第四种情况,数据库天生乱码
数据的字符集,保存文件的编码,网页显示的编码都是一样的,但是出现乱码。大多数情况下,当数据进入数据库时,会出现乱码。这种情况比较麻烦。
其次,我的解决乱码的方法不尽人意。
我把这个方法命名为泡顶解牛法。哈哈。数据库,保存文件编码,显示时编码必须一致,以数据库为准
第一种,数据库和保存文件的编码为utf8,网页显示为gb2312。这时,我们将更改显示编码。
第二种是utf8,用于数据库和网页显示,gb2312用于保存文件。这时候就要注意一个。无法直接更改已保存文件的编码。在更改编码之前,请先更改文件的内容。COPY,改编码后,把COPY的内容贴回去,就OK了。
第三种是数据库使用的utf8。保存文件和显示的编码是gb2312。这时候就可以利用程序的功能,对从数据库中检索到的数据进行转码,将utf8转为gb2312,这样就不用改了。文件本身的编码已更改,并且已显示编码。以php为例,mb_convert_encoding($string,"gb2312","utf8");
第四种,数据库中的乱码,是在数据录入时,数据本身与数据库的存储码不同造成的。例如:数据库的存储代码是utf8,当数据存储在数据库中时,添加一个mysql_query("set names utf8;");
三、乱码表现的情况
乱码的表现,我遇到过两个,
1)是字体中出现的乱码,变成了奇怪的字符
2) 直接是空白页。检查源代码,什么都没有。在这种情况下,有时,我认为它是由乱码引起的。页面右击,查看属性,修改代码就知道是不是乱码导致的空白页。 查看全部
php网页抓取乱码(出现乱码的原因分析及解决方法有哪些呢?(图))
一、乱码原因分析
1.保存文件时,文件有自己的文件编码,是汉字还是其他语言,用什么编码来存储
2.输出时,指定内容的编码,如以网页形式输入时
3.从数据库中取数据时,不确定数据库和字符集
4、以汉字为例。汉字也被编码。一个汉字 gbk 需要两个字符,而 utf8 需要三个字符。
可能导致乱码的潜在原因上面已经说了,我现在就整理一下。
第一种情况,保存的文件和显示代码不一致
如果保存文件时使用utf8编码,输出网页时设置了gbk编码,所以会出现乱码。
第二种情况,保存的文件和数据库中存储的字符不一致
假设,当保存的文件的编码与网页显示的编码相同时,仍然出现乱码。例如,当您保存文件时,您使用 utf8 编码,而您的数据库使用 gb2312 字符集来存储数据。
第三种情况,代码乱码,你还觉得没有
当你发现乱码的时候,当你改变保存文件的编码时,utf8的情况就好了。改成gbk会乱码,但是你觉得还好。这也是出现乱码的原因。这种情况会经常发生。
第四种情况,数据库天生乱码
数据的字符集,保存文件的编码,网页显示的编码都是一样的,但是出现乱码。大多数情况下,当数据进入数据库时,会出现乱码。这种情况比较麻烦。
其次,我的解决乱码的方法不尽人意。
我把这个方法命名为泡顶解牛法。哈哈。数据库,保存文件编码,显示时编码必须一致,以数据库为准
第一种,数据库和保存文件的编码为utf8,网页显示为gb2312。这时,我们将更改显示编码。
第二种是utf8,用于数据库和网页显示,gb2312用于保存文件。这时候就要注意一个。无法直接更改已保存文件的编码。在更改编码之前,请先更改文件的内容。COPY,改编码后,把COPY的内容贴回去,就OK了。
第三种是数据库使用的utf8。保存文件和显示的编码是gb2312。这时候就可以利用程序的功能,对从数据库中检索到的数据进行转码,将utf8转为gb2312,这样就不用改了。文件本身的编码已更改,并且已显示编码。以php为例,mb_convert_encoding($string,"gb2312","utf8");
第四种,数据库中的乱码,是在数据录入时,数据本身与数据库的存储码不同造成的。例如:数据库的存储代码是utf8,当数据存储在数据库中时,添加一个mysql_query("set names utf8;");
三、乱码表现的情况
乱码的表现,我遇到过两个,
1)是字体中出现的乱码,变成了奇怪的字符
2) 直接是空白页。检查源代码,什么都没有。在这种情况下,有时,我认为它是由乱码引起的。页面右击,查看属性,修改代码就知道是不是乱码导致的空白页。
php网页抓取乱码(php+mysql是制作网站一般常用的开发语言吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-22 00:00
php+mysql是制作网站的常用开发语言。由于其开源和可扩展性,受到了很多开发者的喜爱,但是在使用的过程中,我们经常会发现php+mysql如果操作不当,很容易出现乱码。说一下我平时遇到的一些情况。
1、数据库和网页编码不一致
因为php开发,我们基本都是用mysql数据库。这是很容易出现的一个现象,就是我们网页的编码和我们数据库的编码有什么不同,很容易出现乱码。修改的方法肯定是将两个代码统一起来,普通程序员稍加注意就可以避免。
2、数据库中的表编码可能不一致
我们在设置数据库的时候,选择默认的编码,一般是utf-8。但是我们经常在表中没有足够数量的字段或表。我们有时可能会为了增加数据库的字段或表。这时候还要注意编码的统一。
3、 用户提交的页面编码与显示数据页面的编码不一致,肯定会导致PHP页面出现乱码。
4、 如果用户输入数据的页面是big5代码,但是显示用户输入的页面是gb2312,这个100%会导致PHP页面乱码。
5、 PHP 连接 MySQL 数据库语句中指定的编码不正确。
6、 如果本地mysql布局与服务器端不一致,我们在导入数据时使用phpmyadmin很容易出现这种现象。
其实使用MySQL+PHP产生乱码的原因和解决方法有很多。当然,主要原因还是在于程序员经验的积累。希望以上内容对大家有所帮助。
北京网站建筑北京网页设计网站制作() 查看全部
php网页抓取乱码(php+mysql是制作网站一般常用的开发语言吗?)
php+mysql是制作网站的常用开发语言。由于其开源和可扩展性,受到了很多开发者的喜爱,但是在使用的过程中,我们经常会发现php+mysql如果操作不当,很容易出现乱码。说一下我平时遇到的一些情况。
1、数据库和网页编码不一致
因为php开发,我们基本都是用mysql数据库。这是很容易出现的一个现象,就是我们网页的编码和我们数据库的编码有什么不同,很容易出现乱码。修改的方法肯定是将两个代码统一起来,普通程序员稍加注意就可以避免。
2、数据库中的表编码可能不一致
我们在设置数据库的时候,选择默认的编码,一般是utf-8。但是我们经常在表中没有足够数量的字段或表。我们有时可能会为了增加数据库的字段或表。这时候还要注意编码的统一。
3、 用户提交的页面编码与显示数据页面的编码不一致,肯定会导致PHP页面出现乱码。
4、 如果用户输入数据的页面是big5代码,但是显示用户输入的页面是gb2312,这个100%会导致PHP页面乱码。
5、 PHP 连接 MySQL 数据库语句中指定的编码不正确。
6、 如果本地mysql布局与服务器端不一致,我们在导入数据时使用phpmyadmin很容易出现这种现象。
其实使用MySQL+PHP产生乱码的原因和解决方法有很多。当然,主要原因还是在于程序员经验的积累。希望以上内容对大家有所帮助。
北京网站建筑北京网页设计网站制作()
php网页抓取乱码( PHP页面中文乱码出现的原因及乱码大部分有什么区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-20 04:10
PHP页面中文乱码出现的原因及乱码大部分有什么区别)
PHP页面中文乱码分析
更新时间:2013年10月29日15:58:04 作者:
php出现乱码的原因:页面文件的编码方式(.html、.php等)、html.head中指定的浏览器编码方式、MySql数据库传输的编码方式、Apache字符集.
PHP页面出现中文乱码的原因有几个,一是页面编码没有统计,二是数据库没有设置编码,三是apache编码有问题。让我向您介绍两种解决方案。一般来说,它是页面。编码不统一。
大部分乱码都是由于编码方式不一致造成的。有四种主要的不一致可能导致这种可能性:
1、 页面文件的编码方式(.html、.php等)
2、html.head中指定的浏览器编码方式
3、MySql数据库传输的编码方式
4、Apache 字符集
在只有PHP代码的页面中,在做JS弹窗时,如果弹窗内容收录中文,可能会出现乱码。
解决方法,一行代码:
中文乱码
复制代码代码如下:
header("Content-Type: text/html; charset=utf-8");
数据库乱码
复制代码代码如下:
.
注意:
1、此代码必须放在文件的顶部,' 查看全部
php网页抓取乱码(
PHP页面中文乱码出现的原因及乱码大部分有什么区别)
PHP页面中文乱码分析
更新时间:2013年10月29日15:58:04 作者:
php出现乱码的原因:页面文件的编码方式(.html、.php等)、html.head中指定的浏览器编码方式、MySql数据库传输的编码方式、Apache字符集.
PHP页面出现中文乱码的原因有几个,一是页面编码没有统计,二是数据库没有设置编码,三是apache编码有问题。让我向您介绍两种解决方案。一般来说,它是页面。编码不统一。
大部分乱码都是由于编码方式不一致造成的。有四种主要的不一致可能导致这种可能性:
1、 页面文件的编码方式(.html、.php等)
2、html.head中指定的浏览器编码方式
3、MySql数据库传输的编码方式
4、Apache 字符集
在只有PHP代码的页面中,在做JS弹窗时,如果弹窗内容收录中文,可能会出现乱码。
解决方法,一行代码:
中文乱码
复制代码代码如下:
header("Content-Type: text/html; charset=utf-8");
数据库乱码
复制代码代码如下:
.
注意:
1、此代码必须放在文件的顶部,'
php网页抓取乱码(有关的乱码问题有哪些方式解决?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-16 14:07
本文文章将详细讲解python爬取乱码网页的解决方法。小编觉得很实用,分享给大家作为参考。我希望每个人都可以阅读这篇文章。得到一些东西。
在使用python爬取网页时,经常会遇到乱码。一旦遇到乱码,就很难得到有用的信息。遇到乱码,我通常有以下几种方法:
1、查看网页源码中的head标签,找到编码方式,例如:
上图中可以看到charset='utf-8',说明这个网页很有可能使用的是'UTF-8'编码(很有可能,但不是100%),可以试试这个编码方法:
result = response.content.decode('utf-8')
这样得到的内容基本没有乱码。
2、 如果上面的方法不行,页面还是乱码;或者在head标签下找不到charset属性;或者我们要采集很多网页,而且这些网页的编码方式都不一样,我们不可能在一个网页上一一查看head标签,所以下面的方法可以用于解决乱码。
(1)python 的 chardet 库
可以使用以下方法解决乱码问题
result = chardet.detect(response.content)
print(result)
data = response.content.decode(chardet.detect(response.content)['encoding'])
{'confidence': 0.99, 'language': '', 'encoding': 'utf-8'}
从输出结果可以看出,这是一个“猜测”代码。猜测的方法是先采集各种代码的特征字符。根据特征人物的判断,“猜”的概率很高。
这种方法的效率非常低。如果采集的网页很大,你只能猜测其中一部分的源代码,即
result = chardet.detect(response.content[:1000])
(2)响应编码
也可以使用另一种方法,response自身的编码和apparent_encoding这两个变量。
Response.encoding 一般来自 response.headers 中 content-type 字段的 charset 值。其他情况我不太了解。
response.apparent_encoding 一般使用上面提到的python chardet 库。
所以可以使用下面的方式来解决乱码问题
data = response.content.decode(response.apparent_encoding)
3、 一般来说,以上两种方法都可以解决乱码问题。但如果以上两种方法都不能解决,则可能是网页压缩造成的。使用以下方法解决此问题。
检查你写的头信息是否收录 Accept-Encoding 字段。如果是,请删除此字段。乱码问题将得到解决。
headers = {
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/49.0.2623.221
Safari/537.36 SE 2.X MetaSr 1.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Connection': 'keep-alive',
}
python抓取网页乱码的解决方法分享到这里。希望以上内容对您有所帮助,让您了解更多。如果你觉得文章不错,可以分享给更多人看。 查看全部
php网页抓取乱码(有关的乱码问题有哪些方式解决?(图))
本文文章将详细讲解python爬取乱码网页的解决方法。小编觉得很实用,分享给大家作为参考。我希望每个人都可以阅读这篇文章。得到一些东西。
在使用python爬取网页时,经常会遇到乱码。一旦遇到乱码,就很难得到有用的信息。遇到乱码,我通常有以下几种方法:
1、查看网页源码中的head标签,找到编码方式,例如:
上图中可以看到charset='utf-8',说明这个网页很有可能使用的是'UTF-8'编码(很有可能,但不是100%),可以试试这个编码方法:
result = response.content.decode('utf-8')
这样得到的内容基本没有乱码。
2、 如果上面的方法不行,页面还是乱码;或者在head标签下找不到charset属性;或者我们要采集很多网页,而且这些网页的编码方式都不一样,我们不可能在一个网页上一一查看head标签,所以下面的方法可以用于解决乱码。
(1)python 的 chardet 库
可以使用以下方法解决乱码问题
result = chardet.detect(response.content)
print(result)
data = response.content.decode(chardet.detect(response.content)['encoding'])
{'confidence': 0.99, 'language': '', 'encoding': 'utf-8'}
从输出结果可以看出,这是一个“猜测”代码。猜测的方法是先采集各种代码的特征字符。根据特征人物的判断,“猜”的概率很高。
这种方法的效率非常低。如果采集的网页很大,你只能猜测其中一部分的源代码,即
result = chardet.detect(response.content[:1000])
(2)响应编码
也可以使用另一种方法,response自身的编码和apparent_encoding这两个变量。
Response.encoding 一般来自 response.headers 中 content-type 字段的 charset 值。其他情况我不太了解。
response.apparent_encoding 一般使用上面提到的python chardet 库。
所以可以使用下面的方式来解决乱码问题
data = response.content.decode(response.apparent_encoding)
3、 一般来说,以上两种方法都可以解决乱码问题。但如果以上两种方法都不能解决,则可能是网页压缩造成的。使用以下方法解决此问题。
检查你写的头信息是否收录 Accept-Encoding 字段。如果是,请删除此字段。乱码问题将得到解决。
headers = {
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/49.0.2623.221
Safari/537.36 SE 2.X MetaSr 1.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Connection': 'keep-alive',
}
python抓取网页乱码的解决方法分享到这里。希望以上内容对您有所帮助,让您了解更多。如果你觉得文章不错,可以分享给更多人看。
php网页抓取乱码(wktmltopdf工具是使用Webkit引擎来将HTML网页转换为PDF文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-10-10 08:22
wktmltopdf 工具使用 Webkit 引擎将 HTML 网页转换为 PDF 文件。wkhtmltopdf工具的相关信息请参考:
/p/wkhtmltop...
…
在使用过程中,部分网页出现中文乱码,部分网页中文显示正常。在通过搜索引擎搜索答案的时候,发现有的人遇到中午一片空白,没有显示。
在开源项目的问答中,有一些作者的回复:
/p/wkhtmltop...
/p/wkhtmltop...
这些问题主要是Linux环境下没有安装中文字体造成的,我遇到的问题是可以显示中文,但是乱码,所以针对这个问题做了几个测试:
1.中文字体问题
2.网页编码
3.文件编码
测试一:(百度首页的charset=utf-8)
图片
[图片上传失败...(image-3a4c23-74)]
可以看出中文是正常的。
测试二(51cto博客网页的charset=gb2312):
图片
图片
可以看出网页内容的编码格式为:gb2312无法显示中文。
测试三:
检查网页中使用的字体:
图片
通过与本地电脑的字体对比,排除了这种可能性。其实转换后的PDF文件是可以显示中文的,虽然是乱码,但是字体问题也可以排除。
测试四:
考虑到wkhtmltopdf使用的是webkit引擎,第二次测试遇到了网页内容编码格式:gb2312,导致中文无法显示,所以使用程序抓取网页进行转换。
@Test
public void test2() throws IOException {
URL url = new URL("http://aiilive.blog.51cto.com/1925756/1332579");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
conn.connect();
if (conn.getResponseCode() == HttpURLConnection.HTTP_OK) {
BufferedInputStream bi = new BufferedInputStream(
conn.getInputStream());
BufferedOutputStream bo = new BufferedOutputStream(
new FileOutputStream(new File("D:\\1332579.html")));
byte[] bts = new byte[1024];
int len = bi.read(bts);
while (len != -1) {
bo.write(bts, 0, len);
len = bi.read(bts);
}
bi.close();
bo.close();
System.out.println("create ok");
}
}
通过本地转换,使页面内容:charset=utf-8,然后再转换,这是因为由于使用了webkit引擎,charset=utf-8是给浏览器的,所以使用。
图像.png
上面的测试还是失败了。!!!
官方指南中说明可以指定编码格式:--encoding encoding format; 经过测试,它不起作用。网上很多人都遇到过这个问题,也有很多人没有遇到过,但是网页正常传输成功。大多数情况下,编码中使用 UTF-8 只是巧合。
测试五:
处理获取的网页文件:
1.文件编码utf-8;字符集=utf-8;结果:中文正常
2.文件编码utf-8;字符集=gb2312;结果:中文正常
3.文件编码ansi;字符集=gb2312;结果:中文乱码
图片
实验做了这个,我们可以看出问题,wkhtmltopdf在转换html文件的时候,html文件的来源可能是一个url,也可能是一个本地的文本文件。从测试一看,百度主页显示中文正常,测试二是51cto博客中文不能正常显示,从测试五可以看出,wkhtmltopdf工作时,--encoding参数实际上是指文件存储。
因此,当无法确定服务器通过URL请求的网页编码文件格式时,会以文件内容编码格式输出,因此得出通过URL请求charset=utf8和charset=gb2312的结论。前者可以用中文显示,后者不能。
PS:Jsp页面编码说明:
1.pageEncoding="UTF-8"是指保存JSP页面时使用的编码方式,即JSP文件保存在硬盘上时使用的编码方式。2.charset="UTF-8" 指的是用于JSP页面输入输出的编码方式。当找不到 pageEncoding 时,许多服务器使用字符集而不是 pageEncoding。
我自己测试的时候网站没有遇到wkhtmltopdf中文乱码的问题。我们的JSP页面格式和内容输出编码格式是统一的,都是UTF-8。 查看全部
php网页抓取乱码(wktmltopdf工具是使用Webkit引擎来将HTML网页转换为PDF文件)
wktmltopdf 工具使用 Webkit 引擎将 HTML 网页转换为 PDF 文件。wkhtmltopdf工具的相关信息请参考:
/p/wkhtmltop...
…
在使用过程中,部分网页出现中文乱码,部分网页中文显示正常。在通过搜索引擎搜索答案的时候,发现有的人遇到中午一片空白,没有显示。
在开源项目的问答中,有一些作者的回复:
/p/wkhtmltop...
/p/wkhtmltop...
这些问题主要是Linux环境下没有安装中文字体造成的,我遇到的问题是可以显示中文,但是乱码,所以针对这个问题做了几个测试:
1.中文字体问题
2.网页编码
3.文件编码
测试一:(百度首页的charset=utf-8)
图片
[图片上传失败...(image-3a4c23-74)]
可以看出中文是正常的。
测试二(51cto博客网页的charset=gb2312):
图片
图片
可以看出网页内容的编码格式为:gb2312无法显示中文。
测试三:
检查网页中使用的字体:
图片
通过与本地电脑的字体对比,排除了这种可能性。其实转换后的PDF文件是可以显示中文的,虽然是乱码,但是字体问题也可以排除。
测试四:
考虑到wkhtmltopdf使用的是webkit引擎,第二次测试遇到了网页内容编码格式:gb2312,导致中文无法显示,所以使用程序抓取网页进行转换。
@Test
public void test2() throws IOException {
URL url = new URL("http://aiilive.blog.51cto.com/1925756/1332579";);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
conn.connect();
if (conn.getResponseCode() == HttpURLConnection.HTTP_OK) {
BufferedInputStream bi = new BufferedInputStream(
conn.getInputStream());
BufferedOutputStream bo = new BufferedOutputStream(
new FileOutputStream(new File("D:\\1332579.html")));
byte[] bts = new byte[1024];
int len = bi.read(bts);
while (len != -1) {
bo.write(bts, 0, len);
len = bi.read(bts);
}
bi.close();
bo.close();
System.out.println("create ok");
}
}
通过本地转换,使页面内容:charset=utf-8,然后再转换,这是因为由于使用了webkit引擎,charset=utf-8是给浏览器的,所以使用。
图像.png
上面的测试还是失败了。!!!
官方指南中说明可以指定编码格式:--encoding encoding format; 经过测试,它不起作用。网上很多人都遇到过这个问题,也有很多人没有遇到过,但是网页正常传输成功。大多数情况下,编码中使用 UTF-8 只是巧合。
测试五:
处理获取的网页文件:
1.文件编码utf-8;字符集=utf-8;结果:中文正常
2.文件编码utf-8;字符集=gb2312;结果:中文正常
3.文件编码ansi;字符集=gb2312;结果:中文乱码
图片
实验做了这个,我们可以看出问题,wkhtmltopdf在转换html文件的时候,html文件的来源可能是一个url,也可能是一个本地的文本文件。从测试一看,百度主页显示中文正常,测试二是51cto博客中文不能正常显示,从测试五可以看出,wkhtmltopdf工作时,--encoding参数实际上是指文件存储。
因此,当无法确定服务器通过URL请求的网页编码文件格式时,会以文件内容编码格式输出,因此得出通过URL请求charset=utf8和charset=gb2312的结论。前者可以用中文显示,后者不能。
PS:Jsp页面编码说明:
1.pageEncoding="UTF-8"是指保存JSP页面时使用的编码方式,即JSP文件保存在硬盘上时使用的编码方式。2.charset="UTF-8" 指的是用于JSP页面输入输出的编码方式。当找不到 pageEncoding 时,许多服务器使用字符集而不是 pageEncoding。
我自己测试的时候网站没有遇到wkhtmltopdf中文乱码的问题。我们的JSP页面格式和内容输出编码格式是统一的,都是UTF-8。
php网页抓取乱码( 网页乱码是最让人气恼的一件事,是否会感觉特别慌乱,有么有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-07 08:23
网页乱码是最让人气恼的一件事,是否会感觉特别慌乱,有么有
)
网页上的乱码是最烦人的。
修改好页面后,发现所有字符都是乱码。你有没有特别心慌?有没有!
接下来,我们将永远分析解决网页乱码问题,再也不用担心乱码了。
在此之前,有必要强调一点:首先我想强调一点,如果你修改网页的时候不小心改了乱码,千万不要保存!
如果点击保存,一定不要关闭编辑器,一定要撤销(常用的快捷键是Ctrl+Z),
除此以外:
既然有时间恢复那些蝌蚪,何不买彩票呢?
进入正题:任何乱码无非就是这五种情况之一:1:Head Meta属性;
2:网页文件编码;
3:数据库内容;
4:数据库结构;
5:连接数据库时的编码方式;
首先,确定自己网页的编码。一般大部分中文网页都是UTF-8或者GB2312也有Unicode的(以下都是以UTF-8为例)
不管你用的是三剑客的Dreamweaver还是Editplus,打开文件,查看->编码->选择“UTF-8”,看看乱码现象是否解决,
1): 解决,修复header Meta属性,请在页面添加这句话统一编码
浏览该属性的页面时,点击Ctrl+U查看源码,header中应该有这个Meta属性
添加 header("Content-type: text/html; charset=utf-8"); PHP动态页面中同样的效果
2):无解,修改文件编码,请使用EditPlus或DW打开修改页面编码。DW 中的页面属性具有编码选项。EditPlus:文档 -> 文件编码 -> 更改文件编码 -> "UTF-8"
可以解决非数据库内容乱码的问题
没解决的会继续往下看。第3点主要是消除乱码和数据库内容的可解析性;
由于上面的Meta和文件编码更正无法解决,只好专注于数据库,
第一步是检查数据是否不可修复。
使用PHPMYADMIN或者直接使用shell命令查看数据内容,看是否乱七八糟。有必要解释一个残酷的事实。如果数据库内存是“蝌蚪文本”,无论怎么转换都是“蝌蚪文本”,无法修复。的。这也是我强调不要保存顶部静态乱码的原因,因为乱码可能是显示器造成的。保存后,完整的数据变得无法识别。
数据库结构,数据库编码必须与网页编码一致,检查数据库的编码格式,如果不一致请修改:
更改my.ini文件中的配置值(该文件在mysql安装目录下)。有两个地方要改,修改成需要的编码格式,然后把之前创建的表删除,然后重新创建,然后插入诸如汉字格式的字段,就不再提示错误信息了。如果有PHPMYADMIN,那就方便多了。通过可视化的数据库管理界面,您可以直接在结构中修改编码属性。
关于改变数据库编码,这里有必要强调一下:编码不是一个地方,而是三个地方!
数据库编码、表格编码、字段编码为最佳策略;字段编码细节,int类型boolean类型timestamp类型等不需要改动,主要是修改varchar、text等数据类型字段的编码。
有人说安装mysql后,在配置MySql Server时,如果修改默认编码格式,将默认latin1改为gb2312或者utf8,然后创建数据库表,中文就可以正常存储和显示了。听说这是对付中国人的常用方式
数据库编码不方便更改。我该怎么办?如果不改,需要转码 iconv("UTF-8","gb2312",$str); 事情,数据库内容量大时的权衡。
您是否发现像手掌一样对数据库进行编码是关键?您需要知道您的数据库默认采用哪种编码。
连接数据库时的编码方式,以PHP为例,检查连接数据库的地方是否有这句话,如果没有请添加
添加 mysql_query("SET NAMES'UTF8'");
这句话很重要,绝对可以解决数据库数据的乱码现象。
还有一个非技术性的解决方法:如果打开网页出现乱码,请尝试修改浏览器的页面编码,如GB2312或UTF-8;可能页面不乱吧~
查看全部
php网页抓取乱码(
网页乱码是最让人气恼的一件事,是否会感觉特别慌乱,有么有
)
网页上的乱码是最烦人的。
修改好页面后,发现所有字符都是乱码。你有没有特别心慌?有没有!
接下来,我们将永远分析解决网页乱码问题,再也不用担心乱码了。
在此之前,有必要强调一点:首先我想强调一点,如果你修改网页的时候不小心改了乱码,千万不要保存!
如果点击保存,一定不要关闭编辑器,一定要撤销(常用的快捷键是Ctrl+Z),
除此以外:
既然有时间恢复那些蝌蚪,何不买彩票呢?
进入正题:任何乱码无非就是这五种情况之一:1:Head Meta属性;
2:网页文件编码;
3:数据库内容;
4:数据库结构;
5:连接数据库时的编码方式;
首先,确定自己网页的编码。一般大部分中文网页都是UTF-8或者GB2312也有Unicode的(以下都是以UTF-8为例)
不管你用的是三剑客的Dreamweaver还是Editplus,打开文件,查看->编码->选择“UTF-8”,看看乱码现象是否解决,
1): 解决,修复header Meta属性,请在页面添加这句话统一编码
浏览该属性的页面时,点击Ctrl+U查看源码,header中应该有这个Meta属性
添加 header("Content-type: text/html; charset=utf-8"); PHP动态页面中同样的效果
2):无解,修改文件编码,请使用EditPlus或DW打开修改页面编码。DW 中的页面属性具有编码选项。EditPlus:文档 -> 文件编码 -> 更改文件编码 -> "UTF-8"
可以解决非数据库内容乱码的问题
没解决的会继续往下看。第3点主要是消除乱码和数据库内容的可解析性;
由于上面的Meta和文件编码更正无法解决,只好专注于数据库,
第一步是检查数据是否不可修复。
使用PHPMYADMIN或者直接使用shell命令查看数据内容,看是否乱七八糟。有必要解释一个残酷的事实。如果数据库内存是“蝌蚪文本”,无论怎么转换都是“蝌蚪文本”,无法修复。的。这也是我强调不要保存顶部静态乱码的原因,因为乱码可能是显示器造成的。保存后,完整的数据变得无法识别。
数据库结构,数据库编码必须与网页编码一致,检查数据库的编码格式,如果不一致请修改:
更改my.ini文件中的配置值(该文件在mysql安装目录下)。有两个地方要改,修改成需要的编码格式,然后把之前创建的表删除,然后重新创建,然后插入诸如汉字格式的字段,就不再提示错误信息了。如果有PHPMYADMIN,那就方便多了。通过可视化的数据库管理界面,您可以直接在结构中修改编码属性。
关于改变数据库编码,这里有必要强调一下:编码不是一个地方,而是三个地方!
数据库编码、表格编码、字段编码为最佳策略;字段编码细节,int类型boolean类型timestamp类型等不需要改动,主要是修改varchar、text等数据类型字段的编码。
有人说安装mysql后,在配置MySql Server时,如果修改默认编码格式,将默认latin1改为gb2312或者utf8,然后创建数据库表,中文就可以正常存储和显示了。听说这是对付中国人的常用方式
数据库编码不方便更改。我该怎么办?如果不改,需要转码 iconv("UTF-8","gb2312",$str); 事情,数据库内容量大时的权衡。
您是否发现像手掌一样对数据库进行编码是关键?您需要知道您的数据库默认采用哪种编码。
连接数据库时的编码方式,以PHP为例,检查连接数据库的地方是否有这句话,如果没有请添加
添加 mysql_query("SET NAMES'UTF8'");
这句话很重要,绝对可以解决数据库数据的乱码现象。
还有一个非技术性的解决方法:如果打开网页出现乱码,请尝试修改浏览器的页面编码,如GB2312或UTF-8;可能页面不乱吧~
php网页抓取乱码(黑客行为称为“乱码黑客”行为的操作效果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-10-06 19:08
本指南专门针对将收录大量关键字的乱码网页添加到您的 网站 中的黑客行为。我们称这种黑客为“乱码黑客”。我们专门为 (cms) 用户推出了本指南;但即使您没有使用内容管理系统,本指南也会对您有所帮助。
注意:不确定您的 网站 是否已被入侵?请阅读我们的指南,了解如何首先检查您的 网站 是否已被入侵。
我们希望确保本指南对您真的有帮助。请提供反馈以帮助我们改进!识别此类黑客的目录
乱码黑客会自动在你的网站上创建许多网页,上面堆满了关键字的无意义句子。这些页面不是由您创建的,但它们的 URL 可能会吸引用户点击。黑客的目的是让被黑的网页出现在谷歌搜索结果中。然后,如果用户尝试访问这些页面,他们将被重定向到不相关的页面(例如色情网站)。当用户访问这些不相关的网页时,黑客就会获得收益。以下是一些您可能会在 网站 上看到的受乱码黑客影响的文件类型示例:
有时,这些页面所在文件夹的名称由随机字符组成,并且使用不同的语言:
首先,请检查 Search Console 中的安全问题工具,看看 Google 是否在您的 网站 上发现了上述任何被黑页面。有时,您也可以通过打开 Google 搜索窗口并输入 site:your site url(使用您的 网站 根级 URL)来找到此类网页。搜索结果页将显示 Google 为您的 网站 编入索引的网页,包括被黑的网页。您可以翻阅几页搜索结果,看看是否可以找到任何不寻常的 URL。如果您在 Google 搜索结果中没有看到任何被黑内容,请使用其他搜索引擎搜索相同的搜索词。此操作的效果如下例所示。
请注意,上面的搜索结果收录许多不是由 网站 的所有者创建的页面。如果您仔细查看描述,您将看到此 hack 创建的乱码示例。
通常,当您点击被黑网页的链接时,您要么被重定向到其他网站,要么看到一个充满乱码内容的网页。但是,您可能还会看到该页面不存在的消息(例如 404 错误)。不要被愚弄!当网页仍然被黑客入侵时,黑客会试图说服您该网页已消失或已修复。为此,他们将隐藏真实内容。您可以在谷歌爬虫中输入您的网站 URL,查看是否存在隐藏真实内容的问题。Google 抓取工具可让您查看可能隐藏的内容。
如果您看到上述问题,则说明您的网站可能受到了此类黑客攻击。
解决黑客问题
在开始之前,请为要删除的任何文件创建一个脱机副本,以防将来需要恢复它们。在开始清理过程之前,最好备份整个 网站。为此,您可以离线保存服务器上的所有文件,或搜索最适合您的特定内容管理系统的备份选项。
检查 .htaccess 文件(共 2 步)
乱码黑客将使用 .htaccess 文件重定向您的 网站 访问者。
第1步
在 网站 上找到您的 .htaccess 文件。如果您不确定在哪里可以找到此文件,并且您使用的是 WordPress、Joomla 或 Drupal 等内容管理系统,请在搜索中搜索“.htaccess 文件的位置”和您的内容管理系统的名称引擎。您可能会看到多个 .htaccess 文件,具体取决于您的 网站。然后,列出所有 .htaccess 文件的位置。
注意:.htaccess 通常是一个“隐藏文件”。请确保在搜索此类文件时启用显示隐藏文件选项。
第2步
将所有 .htaccess 文件替换为相应 .htaccess 文件的未破解版本或默认版本。您通常可以通过搜索“默认 .htaccess 文件”和内容管理系统的名称来找到 .htaccess 文件的默认版本。对于带有多个 .htaccess 文件的 网站,请找到每个文件的未破解版本并替换它。
如果没有默认的 .htaccess 文件,并且您从未在 网站 上配置过任何 .htaccess 文件,那么您在 网站 上找到的 .htaccess 文件可能是恶意文件。为安全起见,请离线保存 .htaccess 文件的副本,然后从 网站 中删除相应的 .htaccess 文件。
查找并删除其他恶意文件(共 5 个步骤)
识别恶意文件可能很棘手,可能需要几个小时才能完成。检查文件时请不要担心。如果您还没有备份 网站 上的文件,这是个好时机。您可以在 Google 搜索中搜索“备份网站”和您的内容管理系统的名称,以查找有关如何备份 网站 的说明。
第1步
如果您使用内容管理系统,请重新安装该内容管理系统默认分发中收录的所有核心(默认)文件,以及您可能添加的任何内容(例如主题、模块、插件)。这有助于确保这些文件不收录被黑内容。您可以在 Google 搜索中搜索“重新安装”和您的内容管理系统的名称,以查找有关重新安装过程的说明。如果您有任何插件、模块、扩展或主题,请确保您也重新安装它们。
重新安装这些核心文件可能会导致您所做的任何自定义丢失。确保在重新安装之前创建数据库和所有文件的备份。
第2步
现在,您需要查找剩余的任何其他恶意或受损文件。这是此过程中最困难和最耗时的部分,但在您完成此部分后,您马上就完成了!
这种黑客通常会留下两种类型的文件:.txt 文件和 .php 文件。.txt 文件充当模板文件,而 .php 文件决定了您的 网站 上加载了什么样的无意义内容。首先,查找 .txt 文件。根据您连接到 网站 的方式,您应该会看到某种文件搜索功能。搜索“.txt”以查找所有扩展名为 .txt 的文件。这些文件中的大多数是合法的文本文件,例如许可协议、自述文件等。您要查找的是一组特定的 .txt 文件,其中收录用于创建垃圾邮件模板的 HTML 代码。以下是您可能会在这些恶意 .txt 文件中找到的不同代码的代码片段。
黑客使用关键字替换方法来创建垃圾邮件页面。您很可能会在整个被黑文件中看到一些可以替换的常用词。
{keyword}
此外,这些文件中的大多数都收录某种代码,可以将垃圾邮件链接和垃圾邮件文本置于可见网页之外。
Cheap prescription drugs
请删除这些 .txt 文件。如果这些文件在同一个文件夹中,您可以删除整个文件夹。
第 3 步
查找恶意 PHP 文件会稍微困难一些。您的 网站 上可能存在一个或多个恶意 PHP 文件。这些文件可能收录在同一个子目录中,也可能分布在整个 网站 中。
不要因为您认为需要打开和查看每个 PHP 文件而感到压力太大。首先,创建您要调查的可疑 PHP 文件列表。以下方法可用于确定哪些 PHP 文件可疑:
第四步
创建可疑 PHP 文件列表后,您可以检查这些文件是正常文件还是恶意文件。如果你不熟悉PHP文件,这个过程会消耗更多的时间,所以你不妨查阅一些PHP文件。但即使您不熟悉编码,您仍然可以通过一些基本模式找到恶意文件。
首先,扫描您发现的可疑文件,找到收录看似凌乱的字母和数字组合的大块文本。大文本块的前面通常是PHP函数的组合(例如base64_decode、rot13、eval、strrev、gzinflate)。以下是此类代码块的示例。有时,所有这些代码都被填充到一长串文本中,使其看起来比实际大小要小。
base64_decode(strrev("hMXZpRXaslmYhJXZuxWd2BSZ0l2cgknbhByZul2czVmckRWYgknYgM3ajFGd0FGIlJXd0VnZgk
nbhBSbvJnZgUGdpNHIyV3b5BSZyV3YlNHIvRHI0V2Zy9mZgQ3Ju9GRg4SZ0l2cgIXdvlHI4lmZg4WYjBSdvlHIsU2chVmcnBydv
JGblBiZvBCdpJGIhBCZuFGIl1Wa0BCa0l2dgQXdCBiLkJXYoBSZiBibhNGIlR2bjBycphGdgcmbpRXYjNXdmJ2blRGI5xWZ0Fmb
1RncvZmbVBiLn5WauVGcwFGagM3J0FGa3BCZuFGdzJXZk5Wdg8GdgU3b5BicvZGI0xWdjlmZmlGZgQXagU2ah1GIvRHIzlGa0B
SZrlGbgUGZvNGIlRWaoByb0BSZrlGbgMnclt2YhhEIuUGZvNGIlxmYhRWYlJnb1BychByZulGZhJXZ1F3ch1GIlR2bjBCZlRXY
jNXdmJ2bgMXdvl2YpxWYtBiZvBSZjVWawBSYgMXagMXaoRFIskGS"));
有时,这种类型的代码并不凌乱,看起来像一个普通的脚本。如果您不确定代码是否恶意,请访问我们的;在这个论坛里,一群有经验的网站站长可以帮你查看相关文件。
第 5 步
现在您知道哪些文件是可疑的,您可以通过将它们保存在您的计算机上来创建备份或创建本地副本,使它们不是恶意文件,然后删除这些可疑文件。
检查您的 网站 是否已被清理
删除被黑的文件后,请检查您的努力是否得到了回报。还记得你之前发现的那些乱码吗?使用“Google 抓取工具”再次检查这些页面,看看它们是否仍然存在。如果他们在“Google crawler”中的结果是“not found”,那么您的 网站 可能处于良好状态!
您也可以按照“被黑网站”疑难解答工具中的步骤检查网站上是否还有被黑内容。
如何防止再次入侵?
修复网站上的漏洞是修复网站的最后一个关键步骤。最近的一项研究发现,20% 的被黑 网站 会在 1 天内再次被黑。了解 网站 是如何被黑的非常有用。请参阅我们的指南,了解垃圾邮件发送者使用的最常见的 网站 黑客方法,以开始调查问题。但是,如果您无法查明 网站 是如何被入侵的,您可以按照下面的清单来减少 网站 上的漏洞数量。
其他资源
如果您仍然无法修复 网站,还有一些其他资源可以帮助您。
这些工具可以扫描您的网站,可能会发现有问题的内容。除 VirusTotal 外,Google 不会运行或支持其他工具。
Virus Total、Sucuri Site Check、Quttera:这些工具(以及许多其他工具)可能能够扫描您的 网站 以找出有问题的内容。但请注意,这些扫描工具并不能保证能找到所有类型的问题内容。
以下是 Google 提供的其他可以帮助您的资源:
没有找到您认为可能有用的工具?请留下反馈并告诉我们。 查看全部
php网页抓取乱码(黑客行为称为“乱码黑客”行为的操作效果)
本指南专门针对将收录大量关键字的乱码网页添加到您的 网站 中的黑客行为。我们称这种黑客为“乱码黑客”。我们专门为 (cms) 用户推出了本指南;但即使您没有使用内容管理系统,本指南也会对您有所帮助。
注意:不确定您的 网站 是否已被入侵?请阅读我们的指南,了解如何首先检查您的 网站 是否已被入侵。
我们希望确保本指南对您真的有帮助。请提供反馈以帮助我们改进!识别此类黑客的目录
乱码黑客会自动在你的网站上创建许多网页,上面堆满了关键字的无意义句子。这些页面不是由您创建的,但它们的 URL 可能会吸引用户点击。黑客的目的是让被黑的网页出现在谷歌搜索结果中。然后,如果用户尝试访问这些页面,他们将被重定向到不相关的页面(例如色情网站)。当用户访问这些不相关的网页时,黑客就会获得收益。以下是一些您可能会在 网站 上看到的受乱码黑客影响的文件类型示例:
有时,这些页面所在文件夹的名称由随机字符组成,并且使用不同的语言:
首先,请检查 Search Console 中的安全问题工具,看看 Google 是否在您的 网站 上发现了上述任何被黑页面。有时,您也可以通过打开 Google 搜索窗口并输入 site:your site url(使用您的 网站 根级 URL)来找到此类网页。搜索结果页将显示 Google 为您的 网站 编入索引的网页,包括被黑的网页。您可以翻阅几页搜索结果,看看是否可以找到任何不寻常的 URL。如果您在 Google 搜索结果中没有看到任何被黑内容,请使用其他搜索引擎搜索相同的搜索词。此操作的效果如下例所示。
请注意,上面的搜索结果收录许多不是由 网站 的所有者创建的页面。如果您仔细查看描述,您将看到此 hack 创建的乱码示例。
通常,当您点击被黑网页的链接时,您要么被重定向到其他网站,要么看到一个充满乱码内容的网页。但是,您可能还会看到该页面不存在的消息(例如 404 错误)。不要被愚弄!当网页仍然被黑客入侵时,黑客会试图说服您该网页已消失或已修复。为此,他们将隐藏真实内容。您可以在谷歌爬虫中输入您的网站 URL,查看是否存在隐藏真实内容的问题。Google 抓取工具可让您查看可能隐藏的内容。
如果您看到上述问题,则说明您的网站可能受到了此类黑客攻击。
解决黑客问题
在开始之前,请为要删除的任何文件创建一个脱机副本,以防将来需要恢复它们。在开始清理过程之前,最好备份整个 网站。为此,您可以离线保存服务器上的所有文件,或搜索最适合您的特定内容管理系统的备份选项。
检查 .htaccess 文件(共 2 步)
乱码黑客将使用 .htaccess 文件重定向您的 网站 访问者。
第1步
在 网站 上找到您的 .htaccess 文件。如果您不确定在哪里可以找到此文件,并且您使用的是 WordPress、Joomla 或 Drupal 等内容管理系统,请在搜索中搜索“.htaccess 文件的位置”和您的内容管理系统的名称引擎。您可能会看到多个 .htaccess 文件,具体取决于您的 网站。然后,列出所有 .htaccess 文件的位置。
注意:.htaccess 通常是一个“隐藏文件”。请确保在搜索此类文件时启用显示隐藏文件选项。
第2步
将所有 .htaccess 文件替换为相应 .htaccess 文件的未破解版本或默认版本。您通常可以通过搜索“默认 .htaccess 文件”和内容管理系统的名称来找到 .htaccess 文件的默认版本。对于带有多个 .htaccess 文件的 网站,请找到每个文件的未破解版本并替换它。
如果没有默认的 .htaccess 文件,并且您从未在 网站 上配置过任何 .htaccess 文件,那么您在 网站 上找到的 .htaccess 文件可能是恶意文件。为安全起见,请离线保存 .htaccess 文件的副本,然后从 网站 中删除相应的 .htaccess 文件。
查找并删除其他恶意文件(共 5 个步骤)
识别恶意文件可能很棘手,可能需要几个小时才能完成。检查文件时请不要担心。如果您还没有备份 网站 上的文件,这是个好时机。您可以在 Google 搜索中搜索“备份网站”和您的内容管理系统的名称,以查找有关如何备份 网站 的说明。
第1步
如果您使用内容管理系统,请重新安装该内容管理系统默认分发中收录的所有核心(默认)文件,以及您可能添加的任何内容(例如主题、模块、插件)。这有助于确保这些文件不收录被黑内容。您可以在 Google 搜索中搜索“重新安装”和您的内容管理系统的名称,以查找有关重新安装过程的说明。如果您有任何插件、模块、扩展或主题,请确保您也重新安装它们。
重新安装这些核心文件可能会导致您所做的任何自定义丢失。确保在重新安装之前创建数据库和所有文件的备份。
第2步
现在,您需要查找剩余的任何其他恶意或受损文件。这是此过程中最困难和最耗时的部分,但在您完成此部分后,您马上就完成了!
这种黑客通常会留下两种类型的文件:.txt 文件和 .php 文件。.txt 文件充当模板文件,而 .php 文件决定了您的 网站 上加载了什么样的无意义内容。首先,查找 .txt 文件。根据您连接到 网站 的方式,您应该会看到某种文件搜索功能。搜索“.txt”以查找所有扩展名为 .txt 的文件。这些文件中的大多数是合法的文本文件,例如许可协议、自述文件等。您要查找的是一组特定的 .txt 文件,其中收录用于创建垃圾邮件模板的 HTML 代码。以下是您可能会在这些恶意 .txt 文件中找到的不同代码的代码片段。
黑客使用关键字替换方法来创建垃圾邮件页面。您很可能会在整个被黑文件中看到一些可以替换的常用词。
{keyword}
此外,这些文件中的大多数都收录某种代码,可以将垃圾邮件链接和垃圾邮件文本置于可见网页之外。
Cheap prescription drugs
请删除这些 .txt 文件。如果这些文件在同一个文件夹中,您可以删除整个文件夹。
第 3 步
查找恶意 PHP 文件会稍微困难一些。您的 网站 上可能存在一个或多个恶意 PHP 文件。这些文件可能收录在同一个子目录中,也可能分布在整个 网站 中。
不要因为您认为需要打开和查看每个 PHP 文件而感到压力太大。首先,创建您要调查的可疑 PHP 文件列表。以下方法可用于确定哪些 PHP 文件可疑:
第四步
创建可疑 PHP 文件列表后,您可以检查这些文件是正常文件还是恶意文件。如果你不熟悉PHP文件,这个过程会消耗更多的时间,所以你不妨查阅一些PHP文件。但即使您不熟悉编码,您仍然可以通过一些基本模式找到恶意文件。
首先,扫描您发现的可疑文件,找到收录看似凌乱的字母和数字组合的大块文本。大文本块的前面通常是PHP函数的组合(例如base64_decode、rot13、eval、strrev、gzinflate)。以下是此类代码块的示例。有时,所有这些代码都被填充到一长串文本中,使其看起来比实际大小要小。
base64_decode(strrev("hMXZpRXaslmYhJXZuxWd2BSZ0l2cgknbhByZul2czVmckRWYgknYgM3ajFGd0FGIlJXd0VnZgk
nbhBSbvJnZgUGdpNHIyV3b5BSZyV3YlNHIvRHI0V2Zy9mZgQ3Ju9GRg4SZ0l2cgIXdvlHI4lmZg4WYjBSdvlHIsU2chVmcnBydv
JGblBiZvBCdpJGIhBCZuFGIl1Wa0BCa0l2dgQXdCBiLkJXYoBSZiBibhNGIlR2bjBycphGdgcmbpRXYjNXdmJ2blRGI5xWZ0Fmb
1RncvZmbVBiLn5WauVGcwFGagM3J0FGa3BCZuFGdzJXZk5Wdg8GdgU3b5BicvZGI0xWdjlmZmlGZgQXagU2ah1GIvRHIzlGa0B
SZrlGbgUGZvNGIlRWaoByb0BSZrlGbgMnclt2YhhEIuUGZvNGIlxmYhRWYlJnb1BychByZulGZhJXZ1F3ch1GIlR2bjBCZlRXY
jNXdmJ2bgMXdvl2YpxWYtBiZvBSZjVWawBSYgMXagMXaoRFIskGS"));
有时,这种类型的代码并不凌乱,看起来像一个普通的脚本。如果您不确定代码是否恶意,请访问我们的;在这个论坛里,一群有经验的网站站长可以帮你查看相关文件。
第 5 步
现在您知道哪些文件是可疑的,您可以通过将它们保存在您的计算机上来创建备份或创建本地副本,使它们不是恶意文件,然后删除这些可疑文件。
检查您的 网站 是否已被清理
删除被黑的文件后,请检查您的努力是否得到了回报。还记得你之前发现的那些乱码吗?使用“Google 抓取工具”再次检查这些页面,看看它们是否仍然存在。如果他们在“Google crawler”中的结果是“not found”,那么您的 网站 可能处于良好状态!
您也可以按照“被黑网站”疑难解答工具中的步骤检查网站上是否还有被黑内容。
如何防止再次入侵?
修复网站上的漏洞是修复网站的最后一个关键步骤。最近的一项研究发现,20% 的被黑 网站 会在 1 天内再次被黑。了解 网站 是如何被黑的非常有用。请参阅我们的指南,了解垃圾邮件发送者使用的最常见的 网站 黑客方法,以开始调查问题。但是,如果您无法查明 网站 是如何被入侵的,您可以按照下面的清单来减少 网站 上的漏洞数量。
其他资源
如果您仍然无法修复 网站,还有一些其他资源可以帮助您。
这些工具可以扫描您的网站,可能会发现有问题的内容。除 VirusTotal 外,Google 不会运行或支持其他工具。
Virus Total、Sucuri Site Check、Quttera:这些工具(以及许多其他工具)可能能够扫描您的 网站 以找出有问题的内容。但请注意,这些扫描工具并不能保证能找到所有类型的问题内容。
以下是 Google 提供的其他可以帮助您的资源:
没有找到您认为可能有用的工具?请留下反馈并告诉我们。
php网页抓取乱码(一个需求需要用cheerio抓取一个网页js脚本插入末尾)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-06 16:02
最近有开发需求,使用cheerio抓取一个网页,然后在标签的末尾插入一个js脚本。然后确保浏览器正常运行。现将遇到的问题记录下来。
这里有一个问题:
Node.js 默认不支持 utf-8 编码,所以在抓取非 utf-8 中文网页时会出现乱码。比如网易的首页代码是gb2312,爬取就会出现乱码。百度大佬都用icon-lite转码(有兴趣的可以百度cheerio中文乱码)。(只是他们说的和我说的不一样。我需要将网页返回给浏览器)。然后我开始尝试。思路大概是这样:获取代理层将请求返回的html请求头的header中的content-type,来确定这个网页的编码方式。然后使用 iconv.decode 进行相应的转码,然后进行 js 替换。但是这种情况有一个漏洞,如下图
有些网站开发不够规范,甚至在content-type中没有声明网页的编码方式。因此,这条路是行不通的,只能通过抓取标签来确定网页的相应编码,然后进行转码。
var newDataStr = '';
var charset="utf-8";
var arr=responseDetail.response.body.toString().match(/]*?)>/g);
if(arr){
arr.forEach(function(val){
var match=val.match(/charset\s*=\s*(.+)\"/);
if(match && match[1]){
if(match[1].substr(0,1)=='"')match[1]=match[1].substr(1);
charset=match[1].trim();
return false;
}
})
}
var html = iconv.decode(responseDetail.response.body, charset);
// var html = responseDetail.response.body.toString();
var $ = cheerio.load(html);
responseDetail.response.body = newDataStr;
return {response: responseDetail.response}
试了下,大部分网页中文编码问题都解决了,但是还是有一些地方出现中文乱码
这个问题主要是因为节点转码成gbk后我没有将新插入的页面转码到初始状态。浏览器下载后,浏览器无法识别部分js xhr代码,导致出现部分代码。所以
newDataStr=iconv.encode($.html(), charset); 只需将其恢复为原创编码方式 查看全部
php网页抓取乱码(一个需求需要用cheerio抓取一个网页js脚本插入末尾)
最近有开发需求,使用cheerio抓取一个网页,然后在标签的末尾插入一个js脚本。然后确保浏览器正常运行。现将遇到的问题记录下来。
这里有一个问题:
Node.js 默认不支持 utf-8 编码,所以在抓取非 utf-8 中文网页时会出现乱码。比如网易的首页代码是gb2312,爬取就会出现乱码。百度大佬都用icon-lite转码(有兴趣的可以百度cheerio中文乱码)。(只是他们说的和我说的不一样。我需要将网页返回给浏览器)。然后我开始尝试。思路大概是这样:获取代理层将请求返回的html请求头的header中的content-type,来确定这个网页的编码方式。然后使用 iconv.decode 进行相应的转码,然后进行 js 替换。但是这种情况有一个漏洞,如下图
有些网站开发不够规范,甚至在content-type中没有声明网页的编码方式。因此,这条路是行不通的,只能通过抓取标签来确定网页的相应编码,然后进行转码。
var newDataStr = '';
var charset="utf-8";
var arr=responseDetail.response.body.toString().match(/]*?)>/g);
if(arr){
arr.forEach(function(val){
var match=val.match(/charset\s*=\s*(.+)\"/);
if(match && match[1]){
if(match[1].substr(0,1)=='"')match[1]=match[1].substr(1);
charset=match[1].trim();
return false;
}
})
}
var html = iconv.decode(responseDetail.response.body, charset);
// var html = responseDetail.response.body.toString();
var $ = cheerio.load(html);
responseDetail.response.body = newDataStr;
return {response: responseDetail.response}
试了下,大部分网页中文编码问题都解决了,但是还是有一些地方出现中文乱码
这个问题主要是因为节点转码成gbk后我没有将新插入的页面转码到初始状态。浏览器下载后,浏览器无法识别部分js xhr代码,导致出现部分代码。所以
newDataStr=iconv.encode($.html(), charset); 只需将其恢复为原创编码方式
php网页抓取乱码(不会php网页抓取乱码怎么办。这个其实很简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-30 18:01
php网页抓取乱码怎么办。这个其实很简单,因为php现在已经非常的普及了,不会php也能够根据其他编程语言或者自己开发的程序来编写页面抓取程序。首先用php抓取一个想要抓取的php网页,你会看到网页上面包含很多框架的spanicon,这些icon其实是动态加载出来的一些数据,同时也和网页中的内容相关,这些icon就是我们要用到网页抓取的数据源。
其次,你会看到网页中会有很多的urlencodedjs:document.getelementbyid("imgurl").each().foreach({innerhtml:function(){functioninnertex($h){$h();}});}})..最后你会发现所有的数据都会出现在网页的源代码中,因为你抓取的时候肯定会加载别的源码,所以应该将数据抓取进来!解决方法就是使用request.get("")将数据发送出去。
实战首先你会获取一个链接,比如get/tutorial?test=a2&grid=r-1然后点开链接看到这里的xxx是这个php网页抓取程序抓取的phpicon,$test=request.get("");代码如下:xxxstring$icon;request.get("");当然这里xxx可以是任何字符串。
然后把这个xxx发送到filereader中读取即可。最后基本上就能够读取数据了,$test=request.get("");直接用get方法就可以了。推荐一本我觉得不错的php书籍,翻译过来是php5反序列化。第四章抓取原理讲的不错,值得反复阅读。 查看全部
php网页抓取乱码(不会php网页抓取乱码怎么办。这个其实很简单)
php网页抓取乱码怎么办。这个其实很简单,因为php现在已经非常的普及了,不会php也能够根据其他编程语言或者自己开发的程序来编写页面抓取程序。首先用php抓取一个想要抓取的php网页,你会看到网页上面包含很多框架的spanicon,这些icon其实是动态加载出来的一些数据,同时也和网页中的内容相关,这些icon就是我们要用到网页抓取的数据源。
其次,你会看到网页中会有很多的urlencodedjs:document.getelementbyid("imgurl").each().foreach({innerhtml:function(){functioninnertex($h){$h();}});}})..最后你会发现所有的数据都会出现在网页的源代码中,因为你抓取的时候肯定会加载别的源码,所以应该将数据抓取进来!解决方法就是使用request.get("")将数据发送出去。
实战首先你会获取一个链接,比如get/tutorial?test=a2&grid=r-1然后点开链接看到这里的xxx是这个php网页抓取程序抓取的phpicon,$test=request.get("");代码如下:xxxstring$icon;request.get("");当然这里xxx可以是任何字符串。
然后把这个xxx发送到filereader中读取即可。最后基本上就能够读取数据了,$test=request.get("");直接用get方法就可以了。推荐一本我觉得不错的php书籍,翻译过来是php5反序列化。第四章抓取原理讲的不错,值得反复阅读。
php网页抓取乱码(phpcurl获取乱码的解决办法:首先打开相应的脚本文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-29 10:28
使用PHP curl获取乱码的解决方案:首先打开相应的脚本文件;然后获取网页文本;最后,使用“b_convert_编码($outpagext,'UTF-8','GB2312');”方法将GB2312转换为“UTF-8”
推荐:PHP视频教程
问题:
Curl用于从电影天堂获取电影信息,结果中有乱码,如图所示:
解决方案
官方文件中有一个curlopt,编码选项,尝试过了,实际上是无用的
我们在页面的标题中看到代码GB2312
应该是
//curl 前面的设置不冗述
//执行 curl
$outPageTxt = curl_exec($film); //outPageTxt 是得到的网页文本
curl_close($film);
//文本转码
$outPageTxt = mb_convert_encoding($outPageTxt, 'utf-8','GB2312');
//把 GB2312 转到 UTF-8
echo $outPageTxt;
使用说明
mb_uu转换_uu编码(输出变量、传输到的代码、传输到的代码)
结果
以上是如何解决在PHP curl中获取乱码的问题。欲了解更多信息,请关注其他相关文章
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系 查看全部
php网页抓取乱码(phpcurl获取乱码的解决办法:首先打开相应的脚本文件)
使用PHP curl获取乱码的解决方案:首先打开相应的脚本文件;然后获取网页文本;最后,使用“b_convert_编码($outpagext,'UTF-8','GB2312');”方法将GB2312转换为“UTF-8”
推荐:PHP视频教程
问题:
Curl用于从电影天堂获取电影信息,结果中有乱码,如图所示:
解决方案
官方文件中有一个curlopt,编码选项,尝试过了,实际上是无用的
我们在页面的标题中看到代码GB2312
应该是
//curl 前面的设置不冗述
//执行 curl
$outPageTxt = curl_exec($film); //outPageTxt 是得到的网页文本
curl_close($film);
//文本转码
$outPageTxt = mb_convert_encoding($outPageTxt, 'utf-8','GB2312');
//把 GB2312 转到 UTF-8
echo $outPageTxt;
使用说明
mb_uu转换_uu编码(输出变量、传输到的代码、传输到的代码)
结果
以上是如何解决在PHP curl中获取乱码的问题。欲了解更多信息,请关注其他相关文章
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系

