
php网页抓取乱码
php网页抓取乱码(Linuxhtml页面里中文乱码怎么解决1/7/202115 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-13 16:07
)
相关主题
如何解决乱码网页
2/2/202118:06:09
本文运行环境:windows10系统,360安全浏览器12.2.1607.0、Acer S40-51解决方法:打开网页,都是如果看不懂文字,这是乱码。右键单击网页以弹出菜单。在弹出菜单中找到编辑
解决ssh连接CentOS后中文显示乱码
2/2/202117:29:24
ssh远程终端乱码如果SSH终端还是乱码,那么我们还需要设置终端软件的编码。 Xshell:如果终端还是中文乱码怎么办?设置SSH软件,选择支持中文的字体。 Linux
html页面出现中文乱码如何解决
1/7/202115:16:18
中文乱码的解决方法:1、在HTML文档的head部分,使用“”语句设置编码方式; 2、使用网页编辑器打开HTML文档,设置编码统一文件和代码的编码格式。本教程的运行环境:windows7系统
PHP下载中文乱码解决方案
10/7/202015:04:07
php下载中文乱码的解决方法:先打开相关代码文件;然后使用"iconv()"函数解决乱码,具体语法为"$file_name=iconv("utf-8","gb2312",$file_name);"。 php下载解决中文乱码
如何处理乱码的css网页
17/11/202012:04:56
CSS页面乱码解决方法:1、设置CSS字符编码与页面字符编码一致,设置编码语句如“@charset”utf-8“;”;2、当写css时加强注释; 3、 使用字体别名。推荐:《css视频教程》解决方案
centos in ssh,telnet终端中文显示乱码的解决办法
21/1/202106:13:03
在ssh中,telnet终端中文显示乱码解决办法#vim/etc/sysconfig/i18n 将原来的内容:LANG="en_US.UTF-8"SYSFONT="latarcyrheb-sun16"修改为:LANG="zh_CN.GB18030" LANGUAGE="zh_CN.GB
如何确定网页首屏的高度?
17/4/2012 16:27:00
一个有经验的网页设计师在做网页原型设计或者视觉效果图的时候,首先要做的就是清楚地标出网站第一屏的高度线,以便直观的看到网站@ > 首屏高度,首屏可以显示的元素。那么,我们如何标记网页的首屏线呢?
响应式网页设计和 SEO
2013 年 6 月 20 日 14:47:00
所谓的“响应式网页设计(Responsive Web Design)”也是自适应的,即可以自动识别屏幕宽度并做出相应调整的网页设计。目前这种设计出现在越来越多的国内网站中,谷歌已经明确表示鼓励响应式网页设计。
简化您的网页设计
19/2/2013 14:55:00
随着网站构建技术的发展,在网页中实现复杂的功能不再是难事。网页中的功能越来越多。因此,既要兼顾用户的浏览体验,又要兼顾网页设计的美感。平衡点非常重要。
宝安网页设计从SEO角度谈网页设计标准
17/6/202015:30:19
深圳宝安网页设计从SEO角度谈网页设计标准。在任何时候,网站访问者都处于以下阶段之一: 1. 注意; 2、利息; 3.欲望; 4. 行动; 5.满足。每个阶段的访客都不一样
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
DBeaver链接Oracle数据库中文显示乱码
4/3/201801:09:50
1.后台DBeaver是一款不错的开源数据库客户端,基本的增删改查就够了。但是在链接Oracle的时候,由于字符编码的问题,很容易产生乱码。德鲁伊可以用来解决这个问题。可以参考使用Druid解决OracleThin驱动中的中文乱码。下面是详细配置。 (P.S.不光是DBeaver和Oracle,其他客户端和数据库都有乱码问题。
mysql命令行显示中文乱码怎么办
27/10/202015:03:56
mysql命令行显示中文乱码的解决方法:1、出现乱码的原因是登录时使用了lastin码,所以需要重新注销再使用该码清楚地登录; 2、重新查询中文表; 3、登录密码必须和安装数据库时使用的一致
phpimagestring出现中文乱码怎么办
19/8/202012:03:34
phpimagestring出现中文乱码是GD2库本身没有中文字体造成的。解决方法是指定字体来显示输出字符串。推荐:《PHP视频教程》imagestring函数显示中文乱码1.问题描述
如何解决php网页抓取的乱码问题
4/9/202012:03:36
爬取乱码php网页的解决方案:1、使用“mbconvertencoding”转换编码; 2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” option;3、在顶部添加标题代码。推荐
查看全部
php网页抓取乱码(Linuxhtml页面里中文乱码怎么解决1/7/202115
)
相关主题
如何解决乱码网页
2/2/202118:06:09
本文运行环境:windows10系统,360安全浏览器12.2.1607.0、Acer S40-51解决方法:打开网页,都是如果看不懂文字,这是乱码。右键单击网页以弹出菜单。在弹出菜单中找到编辑

解决ssh连接CentOS后中文显示乱码
2/2/202117:29:24
ssh远程终端乱码如果SSH终端还是乱码,那么我们还需要设置终端软件的编码。 Xshell:如果终端还是中文乱码怎么办?设置SSH软件,选择支持中文的字体。 Linux
html页面出现中文乱码如何解决
1/7/202115:16:18
中文乱码的解决方法:1、在HTML文档的head部分,使用“”语句设置编码方式; 2、使用网页编辑器打开HTML文档,设置编码统一文件和代码的编码格式。本教程的运行环境:windows7系统
PHP下载中文乱码解决方案
10/7/202015:04:07
php下载中文乱码的解决方法:先打开相关代码文件;然后使用"iconv()"函数解决乱码,具体语法为"$file_name=iconv("utf-8","gb2312",$file_name);"。 php下载解决中文乱码
如何处理乱码的css网页
17/11/202012:04:56
CSS页面乱码解决方法:1、设置CSS字符编码与页面字符编码一致,设置编码语句如“@charset”utf-8“;”;2、当写css时加强注释; 3、 使用字体别名。推荐:《css视频教程》解决方案
centos in ssh,telnet终端中文显示乱码的解决办法
21/1/202106:13:03
在ssh中,telnet终端中文显示乱码解决办法#vim/etc/sysconfig/i18n 将原来的内容:LANG="en_US.UTF-8"SYSFONT="latarcyrheb-sun16"修改为:LANG="zh_CN.GB18030" LANGUAGE="zh_CN.GB
如何确定网页首屏的高度?
17/4/2012 16:27:00
一个有经验的网页设计师在做网页原型设计或者视觉效果图的时候,首先要做的就是清楚地标出网站第一屏的高度线,以便直观的看到网站@ > 首屏高度,首屏可以显示的元素。那么,我们如何标记网页的首屏线呢?
响应式网页设计和 SEO
2013 年 6 月 20 日 14:47:00
所谓的“响应式网页设计(Responsive Web Design)”也是自适应的,即可以自动识别屏幕宽度并做出相应调整的网页设计。目前这种设计出现在越来越多的国内网站中,谷歌已经明确表示鼓励响应式网页设计。
简化您的网页设计
19/2/2013 14:55:00
随着网站构建技术的发展,在网页中实现复杂的功能不再是难事。网页中的功能越来越多。因此,既要兼顾用户的浏览体验,又要兼顾网页设计的美感。平衡点非常重要。
宝安网页设计从SEO角度谈网页设计标准
17/6/202015:30:19
深圳宝安网页设计从SEO角度谈网页设计标准。在任何时候,网站访问者都处于以下阶段之一: 1. 注意; 2、利息; 3.欲望; 4. 行动; 5.满足。每个阶段的访客都不一样
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
DBeaver链接Oracle数据库中文显示乱码
4/3/201801:09:50
1.后台DBeaver是一款不错的开源数据库客户端,基本的增删改查就够了。但是在链接Oracle的时候,由于字符编码的问题,很容易产生乱码。德鲁伊可以用来解决这个问题。可以参考使用Druid解决OracleThin驱动中的中文乱码。下面是详细配置。 (P.S.不光是DBeaver和Oracle,其他客户端和数据库都有乱码问题。
mysql命令行显示中文乱码怎么办
27/10/202015:03:56
mysql命令行显示中文乱码的解决方法:1、出现乱码的原因是登录时使用了lastin码,所以需要重新注销再使用该码清楚地登录; 2、重新查询中文表; 3、登录密码必须和安装数据库时使用的一致
phpimagestring出现中文乱码怎么办
19/8/202012:03:34
phpimagestring出现中文乱码是GD2库本身没有中文字体造成的。解决方法是指定字体来显示输出字符串。推荐:《PHP视频教程》imagestring函数显示中文乱码1.问题描述
如何解决php网页抓取的乱码问题
4/9/202012:03:36
爬取乱码php网页的解决方案:1、使用“mbconvertencoding”转换编码; 2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” option;3、在顶部添加标题代码。推荐
php网页抓取乱码( PHP与Mysql的数据交互(一)_PHP网页的编码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-09 14:26
PHP与Mysql的数据交互(一)_PHP网页的编码
)
配置phpstudy,访问页面出现中文乱码,解决方法如下。
一、PHP网页的编码
1、 php文件本身的编码要和网页的编码匹配
一种。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; charset=gb2312"),添加一个静态页面,所有文件的编码格式都是ANSI,可以是用记事本打开并保存为选择编码为ANSI以覆盖源文件。
湾。如果要使用utf-8编码,那么php应该输出header:header("Content-Type: text/html; charset=utf-8"),添加静态页面,所有文件的编码格式都是utf- 8.
保存为 utf-8 可能有点麻烦。一般utf-8文件开头都会有BOM。如果使用session,就会出现问题。你可以使用editplus来保存。在editplus中,tools->parameter selection->file->UTF-8 Signature,选择Always delete,然后save去掉BOM信息。
2、php 本身不是 Unicode
substr等所有函数都必须改成mb_substr(需要安装mbstring扩展),或者使用iconv转码。
二、PHP与Mysql的数据交互
1、PHP和数据库的编码要一致
修改mysql配置文件my.ini或f,mysql最好用utf8编码。
2、在需要做数据库操作的php程序前加上mysql_query("set names 'encoding'")
编码与PHP编码一致。如果 PHP 编码为 gb2312,则 MySQL 编码为 gb2312。如果是utf-8,则MySQL编码为utf8,这样插入或检索数据时不会出现乱码。
三、PHP 依赖于操作系统
Windows 和 Linux 的编码是不同的。在Windows环境下,如果调用PHP函数时参数是utf-8编码的,会出现错误,如move_uploaded_file()、filesize()、readfile()等,这些函数是处理上传的。, 下载时经常使用,调用时可能会出错。
虽然在Linux环境下gb2312编码不会出现这些错误,但是保存后的文件名是乱码,无法读取文件。此时,参数可以转换为操作系统识别的编码。编码转换可以是mb_convert_encoding(string, New encoding, original encoding)或者iconv(original encoding, new encoding, string),这样处理后保存的文件名不会出现乱码,可以正常读取文件,可实现中文名称文件的上传下载。
其实还有更好的方案,完全脱离系统,不需要考虑系统编码什么。您可以生成一个只有字母和数字的序列作为文件名,并将原来的中文名称保存在数据库中,这样调用move_uploaded_file()就不会出现问题。下载的时候把文件名改成原来的中文名即可。实现下载的代码如下:
最后,其实就是修改一个php页面,添加一个输出头。
推荐教程:PHP视频教程
以上就是php网页乱码的详细内容。更多详情请关注php中文网文章其他相关话题!
查看全部
php网页抓取乱码(
PHP与Mysql的数据交互(一)_PHP网页的编码
)

配置phpstudy,访问页面出现中文乱码,解决方法如下。
一、PHP网页的编码
1、 php文件本身的编码要和网页的编码匹配
一种。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; charset=gb2312"),添加一个静态页面,所有文件的编码格式都是ANSI,可以是用记事本打开并保存为选择编码为ANSI以覆盖源文件。
湾。如果要使用utf-8编码,那么php应该输出header:header("Content-Type: text/html; charset=utf-8"),添加静态页面,所有文件的编码格式都是utf- 8.
保存为 utf-8 可能有点麻烦。一般utf-8文件开头都会有BOM。如果使用session,就会出现问题。你可以使用editplus来保存。在editplus中,tools->parameter selection->file->UTF-8 Signature,选择Always delete,然后save去掉BOM信息。
2、php 本身不是 Unicode
substr等所有函数都必须改成mb_substr(需要安装mbstring扩展),或者使用iconv转码。
二、PHP与Mysql的数据交互
1、PHP和数据库的编码要一致
修改mysql配置文件my.ini或f,mysql最好用utf8编码。
2、在需要做数据库操作的php程序前加上mysql_query("set names 'encoding'")
编码与PHP编码一致。如果 PHP 编码为 gb2312,则 MySQL 编码为 gb2312。如果是utf-8,则MySQL编码为utf8,这样插入或检索数据时不会出现乱码。
三、PHP 依赖于操作系统
Windows 和 Linux 的编码是不同的。在Windows环境下,如果调用PHP函数时参数是utf-8编码的,会出现错误,如move_uploaded_file()、filesize()、readfile()等,这些函数是处理上传的。, 下载时经常使用,调用时可能会出错。
虽然在Linux环境下gb2312编码不会出现这些错误,但是保存后的文件名是乱码,无法读取文件。此时,参数可以转换为操作系统识别的编码。编码转换可以是mb_convert_encoding(string, New encoding, original encoding)或者iconv(original encoding, new encoding, string),这样处理后保存的文件名不会出现乱码,可以正常读取文件,可实现中文名称文件的上传下载。
其实还有更好的方案,完全脱离系统,不需要考虑系统编码什么。您可以生成一个只有字母和数字的序列作为文件名,并将原来的中文名称保存在数据库中,这样调用move_uploaded_file()就不会出现问题。下载的时候把文件名改成原来的中文名即可。实现下载的代码如下:
最后,其实就是修改一个php页面,添加一个输出头。
推荐教程:PHP视频教程
以上就是php网页乱码的详细内容。更多详情请关注php中文网文章其他相关话题!

php网页抓取乱码(PHPwebService服务器本地语言的Get方法获取参数时获取到的参数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-09 12:16
最近在做PHP webService服务器,发现使用Get方法获取参数时获取的参数是乱码。经过一番折腾,发现浏览器本地语言的问题。首先,我们来看一下简单的测试代码:
header("内容类型:text/html;charset=UTF-8");
$name=['name'];
var_dump($name);
测试结果如下:
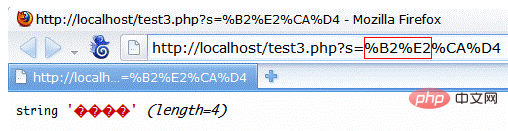
代码声明响应内容的编码为utf-8,显示的内容确实是乱码。这里请注意var_dump输出的变量长度只有4。显然,utf-8编码下两个汉字的长度必须大于4字节,接下来我们看一下火狐访问这个的url页
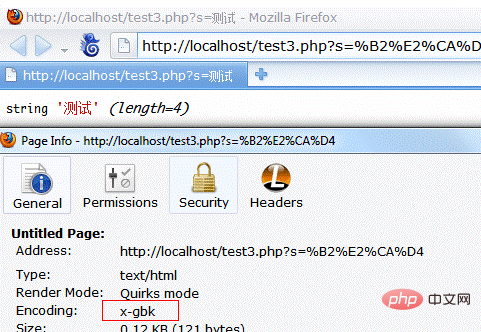
FireFox会自动对中文url进行编码,所以我们可以看到测试变成了%B2%E2%CA%D4。显然,这里的一个词是两个字节,是 gb2313、gbk 等中文编码格式,而不是 utf-8 编码。如果我们将页面的编码切换为gbk,中文参数会正常显示,见下图
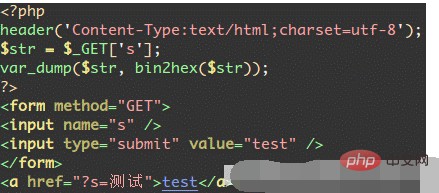
接下来我们再做一个测试,代码如下:
header("内容类型:text/html;charset=UTF-8");
$name=['name'];
var_dump($name);
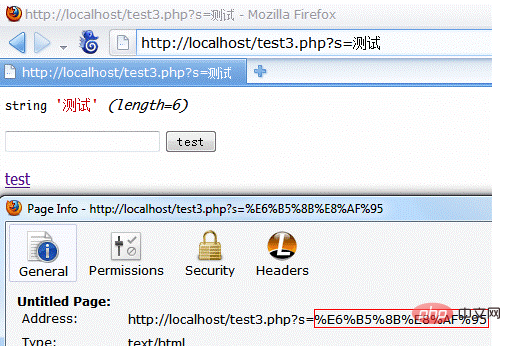
测试结果,正常显示:
那么,是什么导致了这个问题呢?
答案是浏览器的默认编码有问题。我们都使用中文系统,浏览器的默认编码自然会设置为本地化。比如我自己电脑上IE和FireFox的默认编码都是gb系列。
当浏览器请求用户输入的url时,会以默认编码格式而不是页面默认编码格式发送url中的中文,这就是为什么页面中带有中文的链接是正常的,链接我们手动输入
乱码的原因。同样,如果我们将浏览器的默认编码调整为utf-8,那么输入url中的中文就会按照utf-8进行编码。
除上述情况外,还会在以下情况下发生这种情况:
如果gbk编码页面生成的地址链接到utf-8页面,gbk页面的中文以gbk格式编码传输到下一页,那么utf-8后面肯定会出现乱码收到编码。
IIS的url重写模块,重写的中文编码也是gbk,如果你的页面是utf-8编码,那么重写参数会失效。在这些情况下,我们需要使用php内置的转码功能来处理编码问题:
计划一:
$name"gbk","utf-8",$name);
场景二:
$name,"utf-8","gbk");
PS:实测IE浏览器默认GET编码方式采用占用空间最小的方式,即使用GBK码,在php页面中加入这个转换功能即可正常使用。Firefox 和 Chrom 默认为 UTF-8,没有此转换功能。 查看全部
php网页抓取乱码(PHPwebService服务器本地语言的Get方法获取参数时获取到的参数)
最近在做PHP webService服务器,发现使用Get方法获取参数时获取的参数是乱码。经过一番折腾,发现浏览器本地语言的问题。首先,我们来看一下简单的测试代码:
header("内容类型:text/html;charset=UTF-8");
$name=['name'];
var_dump($name);
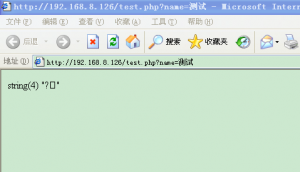
测试结果如下:
代码声明响应内容的编码为utf-8,显示的内容确实是乱码。这里请注意var_dump输出的变量长度只有4。显然,utf-8编码下两个汉字的长度必须大于4字节,接下来我们看一下火狐访问这个的url页
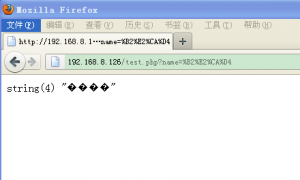
FireFox会自动对中文url进行编码,所以我们可以看到测试变成了%B2%E2%CA%D4。显然,这里的一个词是两个字节,是 gb2313、gbk 等中文编码格式,而不是 utf-8 编码。如果我们将页面的编码切换为gbk,中文参数会正常显示,见下图
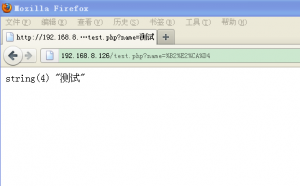
接下来我们再做一个测试,代码如下:
header("内容类型:text/html;charset=UTF-8");
$name=['name'];
var_dump($name);
测试结果,正常显示:
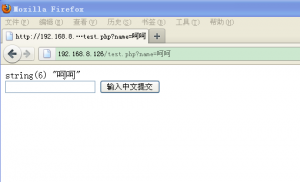
那么,是什么导致了这个问题呢?
答案是浏览器的默认编码有问题。我们都使用中文系统,浏览器的默认编码自然会设置为本地化。比如我自己电脑上IE和FireFox的默认编码都是gb系列。
当浏览器请求用户输入的url时,会以默认编码格式而不是页面默认编码格式发送url中的中文,这就是为什么页面中带有中文的链接是正常的,链接我们手动输入
乱码的原因。同样,如果我们将浏览器的默认编码调整为utf-8,那么输入url中的中文就会按照utf-8进行编码。
除上述情况外,还会在以下情况下发生这种情况:
如果gbk编码页面生成的地址链接到utf-8页面,gbk页面的中文以gbk格式编码传输到下一页,那么utf-8后面肯定会出现乱码收到编码。
IIS的url重写模块,重写的中文编码也是gbk,如果你的页面是utf-8编码,那么重写参数会失效。在这些情况下,我们需要使用php内置的转码功能来处理编码问题:
计划一:
$name"gbk","utf-8",$name);
场景二:
$name,"utf-8","gbk");
PS:实测IE浏览器默认GET编码方式采用占用空间最小的方式,即使用GBK码,在php页面中加入这个转换功能即可正常使用。Firefox 和 Chrom 默认为 UTF-8,没有此转换功能。
php网页抓取乱码(PHP中文乱码有时发生在网页本身产生在于MySQL交互)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-02-27 17:04
PHP中文乱码有时出现在网页本身,有的出现在与MySQL交互的过程中,有时与操作系统有关。下面给出一个摘要。
一。首先是PHP网页的编码
最好最快的解决方案是页面声明的代码与数据库的内部代码保持一致。如果页面应用的页码与数据库内部代码不一致,设置连接代码。
代码显示如下
mysql_query("设置名称 XXX");
XXX 是连接代码。它必须能够解决乱码问题。
1. php文件本身的编码和网页的编码要匹配a。如果你想使用 gb2312 编码,那么 php 应该输出 header:
代码显示如下
header("内容类型: text/html; charset=gb2312"),
添加静态页面
代码显示如下
,
所有文件的编码格式都是ANSI,可以用记事本打开,另存为ANSI,覆盖源文件。湾。如果你想使用 utf-8 编码,那么 php 应该输出 header:
代码显示如下
header("内容类型: text/html; charset=utf-8"),
添加静态页面
代码显示如下
,
所有文件都以 utf-8 编码。保存为 utf-8 可能有点麻烦。一般情况下,一个 utf-8 文件的开头都会有一个 BOM。如果使用会话,就会出现问题。您可以使用editplus来保存它。在editplus中,tools->parameter selection->file->UTF-8 Signature,选择Always delete,然后save去掉BOM信息。
2. php本身不是Unicode,substr等所有函数都必须改成mb_substr(需要安装mbstring扩展);或使用 iconv 进行转码。
二。PHP与Mysql的数据交互
PHP和数据库的编码要一致
1.修改mysql配置文件my.ini或者f,mysql最好用utf8编码
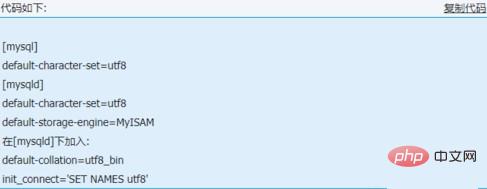
代码显示如下
[mysql] 默认字符集=utf8 [mysqld] 默认字符集=utf8 默认存储引擎=MyISAM
在 [mysqld] 下添加:
代码显示如下
default-collation=utf8_bin init_connect='SET NAMES utf8'
2. 添加mysql_query("设置名称'编码'"); 之前需要做数据库操作的php程序,编码和php编码一样,如果php编码是gb2312,那么mysql编码就是gb2312,如果是utf-8,那么mysql编码就是utf8,所以插入或检索数据时不会出现乱码
三。PHP 和操作系统相关的 Windows 和 Linux 的编码是不同的。在windows环境下,如果调用php函数时参数为utf-8编码,会出现错误,如move_uploaded_file()、filesize()、readfile()等,这些函数在处理上传下载时经常用到,而调用时可能会出现以下错误: 警告:move_uploaded_file()[function.move-uploaded-file]:failed to open stream: Invalid argument in ... 警告: move_uploaded_file()[function.move-uploaded-file]:Unable将 '' 移动到 '' in ... 警告:filesize() [function.filesize]: stat failed for ... in ... 警告:readfile() [function.readfile]:打开流失败:参数无效在..虽然在Linux环境下用gb2312编码不会出现这些错误,保存后文件名乱码,无法读取文件。参数被转换成操作系统识别的编码。编码转换可以是mb_convert_encoding(string,new encoding, original encoding)或者iconv(original encoding,new encoding,string),这样处理后保存的文件名不会出现乱码,也可以正常读取文件,并且可以实现中文名称文件的上传和下载。其实还有更好的方案,完全脱离系统,不需要考虑系统编码什么。您可以生成一个只有字母和数字的序列作为文件名,并将原来的中文名称保存在数据库中,这样调用move_uploaded_file()就不会出现问题。下载时,
实现下载的代码如下
代码显示如下
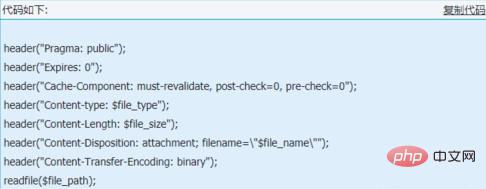
header("Pragma: public");
header("过期时间:0");
header("Cache-Component: must-revalidate, post-check=0, pre-check=0");
header("内容类型:$file_type");
header("内容长度:$file_size");
header("内容配置:附件;文件名="$file_name"");
header("内容传输编码:二进制"); 读取文件($file_path);
$file_type 是文件的类型,$file_name 是原创名称,$file_path 是存储在服务上的文件的地址。
四。下面总结一下为什么乱码一般都是乱码。出现乱码的原因有两个。首先是错误的编码(charset)设置,导致浏览器解析错误的编码,导致满屏都是“天上掉下来的书”,其次是用错误的编码打开文件然后保存。例如,最初以 GB2312 编码的文本文件以 UTF-8 编码打开并保存。要解决上面的乱码问题,首先要知道开发的哪些方面涉及到编码:
1、文件编码:是指保存页面文件(.html、.php等)本身的编码。记事本和 Dreamweaver 在打开页面时会自动识别文件编码,因此问题较少。然而,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有某种编码的文件。如果工作时不注意,打开编码错误的文件,修改后保存,就会出现乱码(感觉很深)。
2、页面声明代码:在HTML代码HEAD中,可以使用
代码显示如下
为了告诉浏览器网页使用什么编码,目前中文网站XXX主要使用GB2312和UTF-8两种编码。3、数据库连接代码:指在数据库操作过程中,使用哪个代码向数据库传输数据。这里需要注意的是不要和数据库本身的代码混淆。例如MySQL内部默认为latin1编码,即Mysql数据以latin1编码存储,其他编码传输到Mysql的数据会转成latin1编码。知道了WEB开发涉及到哪里编码,也就知道乱码的原因了:以上3种编码设置不一致,因为各种编码大部分都兼容ASCII,所以不会出现英文符号,中文会倒霉。.
五号。Showdown一些常见的错误情况和解决方法:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是最常见的乱码原因。此时PHP脚本中直接SELECT数据出现乱码,查询前需要用到:
代码显示如下
mysql_query("设置名称 GBK");
设置MYSQL连接码,保证页面声明码和这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码的,您可以使用:
代码显示如下
mysql_query("设置名称 UTF8");
请注意,它是 UTF8 而不是通常的 UTF-8。如果页面上声明的代码与数据库内部代码一致,则可以不设置连接代码。注意:其实MYSQL的数据输入输出比上面的要复杂一些。MYSQL 配置文件 my.ini 定义了两种默认编码,即 [client] 中的 default-character-set 和 [mysqld] 中的 default -character-set 分别设置用于客户端连接和数据库内部的默认编码。我们上面指定的编码其实就是MYSQL客户端连接服务器时的命令行参数character_set_client,用来告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、页面声明编码与文件本身的编码不一致,这种情况很少发生,因为如果编码不一致,创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小bug,打开错误代码的页面,然后保存。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,由于软件的代码配置错误,转换了错误的代码。3、一些租用虚拟主机的朋友,即使上面三个代码设置正确,还是有乱码的。比如网页是用GB2312编码的,但是IE等浏览器总是把它识别为UTF-8。网页的HEAD已经说明是GB2312。手动修改浏览器编码为GB2312后,页面正常显示。原因是服务器Apache设置了服务器的全局默认编码,并在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级高于页面中声明的代码,所以浏览器会认错。有两种解决方案。请在配置文件的虚拟机中添加一个AddDefaultCharset GB2312来覆盖全局配置,或者在自己目录的.htaccess中进行配置。总结:一句话,解决PHP中文乱码最多的最快的办法就是让页面上声明的代码与数据库内部代码保持一致。
代码显示如下
mysql_query("设置名称 XXX");
XXX 是连接代码。它必须能够解决乱码问题。 查看全部
php网页抓取乱码(PHP中文乱码有时发生在网页本身产生在于MySQL交互)
PHP中文乱码有时出现在网页本身,有的出现在与MySQL交互的过程中,有时与操作系统有关。下面给出一个摘要。
一。首先是PHP网页的编码
最好最快的解决方案是页面声明的代码与数据库的内部代码保持一致。如果页面应用的页码与数据库内部代码不一致,设置连接代码。
代码显示如下
mysql_query("设置名称 XXX");
XXX 是连接代码。它必须能够解决乱码问题。
1. php文件本身的编码和网页的编码要匹配a。如果你想使用 gb2312 编码,那么 php 应该输出 header:
代码显示如下
header("内容类型: text/html; charset=gb2312"),
添加静态页面
代码显示如下
,
所有文件的编码格式都是ANSI,可以用记事本打开,另存为ANSI,覆盖源文件。湾。如果你想使用 utf-8 编码,那么 php 应该输出 header:
代码显示如下
header("内容类型: text/html; charset=utf-8"),
添加静态页面
代码显示如下
,
所有文件都以 utf-8 编码。保存为 utf-8 可能有点麻烦。一般情况下,一个 utf-8 文件的开头都会有一个 BOM。如果使用会话,就会出现问题。您可以使用editplus来保存它。在editplus中,tools->parameter selection->file->UTF-8 Signature,选择Always delete,然后save去掉BOM信息。
2. php本身不是Unicode,substr等所有函数都必须改成mb_substr(需要安装mbstring扩展);或使用 iconv 进行转码。
二。PHP与Mysql的数据交互
PHP和数据库的编码要一致
1.修改mysql配置文件my.ini或者f,mysql最好用utf8编码
代码显示如下
[mysql] 默认字符集=utf8 [mysqld] 默认字符集=utf8 默认存储引擎=MyISAM
在 [mysqld] 下添加:
代码显示如下
default-collation=utf8_bin init_connect='SET NAMES utf8'
2. 添加mysql_query("设置名称'编码'"); 之前需要做数据库操作的php程序,编码和php编码一样,如果php编码是gb2312,那么mysql编码就是gb2312,如果是utf-8,那么mysql编码就是utf8,所以插入或检索数据时不会出现乱码
三。PHP 和操作系统相关的 Windows 和 Linux 的编码是不同的。在windows环境下,如果调用php函数时参数为utf-8编码,会出现错误,如move_uploaded_file()、filesize()、readfile()等,这些函数在处理上传下载时经常用到,而调用时可能会出现以下错误: 警告:move_uploaded_file()[function.move-uploaded-file]:failed to open stream: Invalid argument in ... 警告: move_uploaded_file()[function.move-uploaded-file]:Unable将 '' 移动到 '' in ... 警告:filesize() [function.filesize]: stat failed for ... in ... 警告:readfile() [function.readfile]:打开流失败:参数无效在..虽然在Linux环境下用gb2312编码不会出现这些错误,保存后文件名乱码,无法读取文件。参数被转换成操作系统识别的编码。编码转换可以是mb_convert_encoding(string,new encoding, original encoding)或者iconv(original encoding,new encoding,string),这样处理后保存的文件名不会出现乱码,也可以正常读取文件,并且可以实现中文名称文件的上传和下载。其实还有更好的方案,完全脱离系统,不需要考虑系统编码什么。您可以生成一个只有字母和数字的序列作为文件名,并将原来的中文名称保存在数据库中,这样调用move_uploaded_file()就不会出现问题。下载时,
实现下载的代码如下
代码显示如下
header("Pragma: public");
header("过期时间:0");
header("Cache-Component: must-revalidate, post-check=0, pre-check=0");
header("内容类型:$file_type");
header("内容长度:$file_size");
header("内容配置:附件;文件名="$file_name"");
header("内容传输编码:二进制"); 读取文件($file_path);
$file_type 是文件的类型,$file_name 是原创名称,$file_path 是存储在服务上的文件的地址。
四。下面总结一下为什么乱码一般都是乱码。出现乱码的原因有两个。首先是错误的编码(charset)设置,导致浏览器解析错误的编码,导致满屏都是“天上掉下来的书”,其次是用错误的编码打开文件然后保存。例如,最初以 GB2312 编码的文本文件以 UTF-8 编码打开并保存。要解决上面的乱码问题,首先要知道开发的哪些方面涉及到编码:
1、文件编码:是指保存页面文件(.html、.php等)本身的编码。记事本和 Dreamweaver 在打开页面时会自动识别文件编码,因此问题较少。然而,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有某种编码的文件。如果工作时不注意,打开编码错误的文件,修改后保存,就会出现乱码(感觉很深)。
2、页面声明代码:在HTML代码HEAD中,可以使用
代码显示如下
为了告诉浏览器网页使用什么编码,目前中文网站XXX主要使用GB2312和UTF-8两种编码。3、数据库连接代码:指在数据库操作过程中,使用哪个代码向数据库传输数据。这里需要注意的是不要和数据库本身的代码混淆。例如MySQL内部默认为latin1编码,即Mysql数据以latin1编码存储,其他编码传输到Mysql的数据会转成latin1编码。知道了WEB开发涉及到哪里编码,也就知道乱码的原因了:以上3种编码设置不一致,因为各种编码大部分都兼容ASCII,所以不会出现英文符号,中文会倒霉。.
五号。Showdown一些常见的错误情况和解决方法:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是最常见的乱码原因。此时PHP脚本中直接SELECT数据出现乱码,查询前需要用到:
代码显示如下
mysql_query("设置名称 GBK");
设置MYSQL连接码,保证页面声明码和这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码的,您可以使用:
代码显示如下
mysql_query("设置名称 UTF8");
请注意,它是 UTF8 而不是通常的 UTF-8。如果页面上声明的代码与数据库内部代码一致,则可以不设置连接代码。注意:其实MYSQL的数据输入输出比上面的要复杂一些。MYSQL 配置文件 my.ini 定义了两种默认编码,即 [client] 中的 default-character-set 和 [mysqld] 中的 default -character-set 分别设置用于客户端连接和数据库内部的默认编码。我们上面指定的编码其实就是MYSQL客户端连接服务器时的命令行参数character_set_client,用来告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、页面声明编码与文件本身的编码不一致,这种情况很少发生,因为如果编码不一致,创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小bug,打开错误代码的页面,然后保存。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,由于软件的代码配置错误,转换了错误的代码。3、一些租用虚拟主机的朋友,即使上面三个代码设置正确,还是有乱码的。比如网页是用GB2312编码的,但是IE等浏览器总是把它识别为UTF-8。网页的HEAD已经说明是GB2312。手动修改浏览器编码为GB2312后,页面正常显示。原因是服务器Apache设置了服务器的全局默认编码,并在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级高于页面中声明的代码,所以浏览器会认错。有两种解决方案。请在配置文件的虚拟机中添加一个AddDefaultCharset GB2312来覆盖全局配置,或者在自己目录的.htaccess中进行配置。总结:一句话,解决PHP中文乱码最多的最快的办法就是让页面上声明的代码与数据库内部代码保持一致。
代码显示如下
mysql_query("设置名称 XXX");
XXX 是连接代码。它必须能够解决乱码问题。
php网页抓取乱码(1.为什么会出现乱码?乱码问题的原因是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-02-27 16:15
1.为什么会出现乱码?
出现乱码的原因一般是页面中汉字的编码格式与浏览器的编码格式不匹配。这时候我们需要调整页面的编码格式。让我们来看看如何处理这种问题:
2.页面乱码解决方法
一般我们会使用在PHP页面上声明编码的方法来处理中文乱码的问题,主要是使用header和meta的方法来解决。我们来看看两者的区别
2.1元页面代码
使用标签设置页面编码
这个标签的作用是声明客户端的浏览器使用什么字符集编码来显示页面,xxx可以是GB2312、GBK、UTF-8(不同于MySQL,MySQL是UTF8)等等。因此,大多数页面这个方法可以用来告诉浏览器在显示这个页面时使用什么编码,以免造成编码错误和乱码。也就是说,浏览器总是使用一种编码,我稍后会谈到。
请注意,它属于html信息,它只是一个声明,它的作用是表明服务器已将HTML信息传递给浏览器。
2.2头函数
这个函数header()的作用是将括号中的信息发送到http头。如果括号中的内容如文中所述,那么功能与标签基本相同。你可以比较第一个,发现字符相似。但不同的是,如果有这个功能,浏览器会一直使用你需要的xxx编码,永远不会不听话,所以这个功能非常好用。为什么会这样?那么我们就不得不说一下HTTPS头和HTML信息的区别了:HTTPS头是服务器在使用HTTP协议向浏览器发送HTML信息之前发送的字符串。
因为meta标签属于html信息,所以header()发送的内容首先到达浏览器。通俗点就是header()的优先级比meta高(不知道能不能这么说)。添加一个php页面同时有header("content-type:text/html; charset=xxx"),浏览器只识别之前的http header而不识别meta。当然这个功能只能在一个php页面中使用。
推荐大家使用,灵活灵活。 查看全部
php网页抓取乱码(1.为什么会出现乱码?乱码问题的原因是什么)
1.为什么会出现乱码?
出现乱码的原因一般是页面中汉字的编码格式与浏览器的编码格式不匹配。这时候我们需要调整页面的编码格式。让我们来看看如何处理这种问题:
2.页面乱码解决方法
一般我们会使用在PHP页面上声明编码的方法来处理中文乱码的问题,主要是使用header和meta的方法来解决。我们来看看两者的区别
2.1元页面代码
使用标签设置页面编码
这个标签的作用是声明客户端的浏览器使用什么字符集编码来显示页面,xxx可以是GB2312、GBK、UTF-8(不同于MySQL,MySQL是UTF8)等等。因此,大多数页面这个方法可以用来告诉浏览器在显示这个页面时使用什么编码,以免造成编码错误和乱码。也就是说,浏览器总是使用一种编码,我稍后会谈到。
请注意,它属于html信息,它只是一个声明,它的作用是表明服务器已将HTML信息传递给浏览器。
2.2头函数
这个函数header()的作用是将括号中的信息发送到http头。如果括号中的内容如文中所述,那么功能与标签基本相同。你可以比较第一个,发现字符相似。但不同的是,如果有这个功能,浏览器会一直使用你需要的xxx编码,永远不会不听话,所以这个功能非常好用。为什么会这样?那么我们就不得不说一下HTTPS头和HTML信息的区别了:HTTPS头是服务器在使用HTTP协议向浏览器发送HTML信息之前发送的字符串。
因为meta标签属于html信息,所以header()发送的内容首先到达浏览器。通俗点就是header()的优先级比meta高(不知道能不能这么说)。添加一个php页面同时有header("content-type:text/html; charset=xxx"),浏览器只识别之前的http header而不识别meta。当然这个功能只能在一个php页面中使用。
推荐大家使用,灵活灵活。
php网页抓取乱码(你的php网页乱码了吗一、学习php的童鞋)
网站优化 • 优采云 发表了文章 • 0 个评论 • 354 次浏览 • 2022-02-27 07:12
你的php页面是乱码吗?
一、
学习php童鞋写网页的时候,如果设计中文内容的存储,大部分都会出现乱码的问题。对于一般的乱码,我们可以从三个方面进行检查
(1)网页的编码是否正确,例如是否在header中添加原创标签
元字符集="UTF-8">
(2)查看mysql数据库存储时默认使用的字符集
(3)检查网页文件的编码,是否是对应的中文编码
------------------
环境:win7+wamp2.2
------------------
二、
先从第二点说起,mysq数据库使用的编码字符集
(1)打开mysql终端,查看当前设置,确定要修改的范围
显示像 'char%' 这样的变量;
(2)根据结果分析,
1、如果你显示的结果和我的差不多,也就是(只有character_set_system编码为utf8)那么按照下面的步骤一步步来
2、打开my.ini文件,搜索关键词'mysqld',找到后观察是否有这一行
character_set_server=utf8
如果没有,你应该像我一样在它下面添加一个句子
3、再次搜索关键词'client'看看有没有这行
default_character_set=utf8
如果没有,请在 [client] 下添加
4、保存,重启mysql服务,关闭mysql终端(不然你看到的客户端代码不会更新)
5、再次打开终端,我们再次进入
显示像 'char%' 这样的变量;
如果出现如下结果,即mysql数据设置成功
三、
网页文件编码的问题是最容易被忽略的。保存时选择保存文件编码的格式时设置。
解决方案:
1、使用notepad++打开网页文件,然后在“格式”--“转为UTF-8无BOM编码格式”
2、保存即可
问题分析:
1、写php的时候用过
"font-size:18px;">'设置名称 utf8'); ?>
但是还是有乱码的问题!
分析:使用上面的语句,只修改了三项,三项是
character_set_client
字符集连接
字符集结果
而且这个修改只是暂时的,关闭终端后还是一样。
阐明:
2、我们来分析第三个乱码问题
(1)使用sublime text3编辑打开php文件,左下角可以看到编码信息,可以看到当前编码为gb2312
(2)网页加载的时候,相当于打开了一个文件,那个时候读取的格式是按照gb2312的编码读取网页文件的,当是显示在用户的浏览器中,因为网页声明的字符集是utf-8,所以获取到的文件内容会按照utf-8字符集进行解释,会导致乱码,但是没有问题我们从数据库中读取的内容。
网络编码
原创gbk编码文件
后来的 utf-8 编码文件
(3)注意,sublime text3没有给你转换代码,虽然显示转换成功,但是什么?显示还是一样,还是我们notepad++更强大,前面怎么修改!
3、为什么我按照你说的修改了,在mysql终端下显示,还是乱码?
分析:
(1)我们先来看看windows下cmd使用的是什么字符集?
可以看出cmd的字符集是gbk,也就是说终端显示的任何内容都会对应gbk的字符集,但是我们数据库的中文设置的utf8字符集,当我们想要显示出来,自然会使用 utf8 编码读取数据库数据,当编码为 utf-8 时,到了终端就乱了
(2)怎么查?
用phpmyadmin就行了,当然我们要设置我们使用的utf-8编码!
注:更多精彩教程请关注帮客家图文教程频道,
trueTechArticle 你的php网页是乱码吗?一、 学php的童鞋在写网页的时候,如果是专门用来存储中文内容的,大部分问题都会是乱码。一般的废话... 查看全部
php网页抓取乱码(你的php网页乱码了吗一、学习php的童鞋)
你的php页面是乱码吗?
一、
学习php童鞋写网页的时候,如果设计中文内容的存储,大部分都会出现乱码的问题。对于一般的乱码,我们可以从三个方面进行检查
(1)网页的编码是否正确,例如是否在header中添加原创标签
元字符集="UTF-8">
(2)查看mysql数据库存储时默认使用的字符集
(3)检查网页文件的编码,是否是对应的中文编码
------------------
环境:win7+wamp2.2
------------------
二、
先从第二点说起,mysq数据库使用的编码字符集
(1)打开mysql终端,查看当前设置,确定要修改的范围
显示像 'char%' 这样的变量;
(2)根据结果分析,
1、如果你显示的结果和我的差不多,也就是(只有character_set_system编码为utf8)那么按照下面的步骤一步步来

2、打开my.ini文件,搜索关键词'mysqld',找到后观察是否有这一行
character_set_server=utf8
如果没有,你应该像我一样在它下面添加一个句子

3、再次搜索关键词'client'看看有没有这行
default_character_set=utf8
如果没有,请在 [client] 下添加

4、保存,重启mysql服务,关闭mysql终端(不然你看到的客户端代码不会更新)
5、再次打开终端,我们再次进入
显示像 'char%' 这样的变量;
如果出现如下结果,即mysql数据设置成功

三、
网页文件编码的问题是最容易被忽略的。保存时选择保存文件编码的格式时设置。
解决方案:
1、使用notepad++打开网页文件,然后在“格式”--“转为UTF-8无BOM编码格式”

2、保存即可
问题分析:
1、写php的时候用过
"font-size:18px;">'设置名称 utf8'); ?>
但是还是有乱码的问题!
分析:使用上面的语句,只修改了三项,三项是
character_set_client
字符集连接
字符集结果
而且这个修改只是暂时的,关闭终端后还是一样。
阐明:

2、我们来分析第三个乱码问题
(1)使用sublime text3编辑打开php文件,左下角可以看到编码信息,可以看到当前编码为gb2312

(2)网页加载的时候,相当于打开了一个文件,那个时候读取的格式是按照gb2312的编码读取网页文件的,当是显示在用户的浏览器中,因为网页声明的字符集是utf-8,所以获取到的文件内容会按照utf-8字符集进行解释,会导致乱码,但是没有问题我们从数据库中读取的内容。
网络编码

原创gbk编码文件

后来的 utf-8 编码文件

(3)注意,sublime text3没有给你转换代码,虽然显示转换成功,但是什么?显示还是一样,还是我们notepad++更强大,前面怎么修改!

3、为什么我按照你说的修改了,在mysql终端下显示,还是乱码?
分析:
(1)我们先来看看windows下cmd使用的是什么字符集?

可以看出cmd的字符集是gbk,也就是说终端显示的任何内容都会对应gbk的字符集,但是我们数据库的中文设置的utf8字符集,当我们想要显示出来,自然会使用 utf8 编码读取数据库数据,当编码为 utf-8 时,到了终端就乱了
(2)怎么查?
用phpmyadmin就行了,当然我们要设置我们使用的utf-8编码!
注:更多精彩教程请关注帮客家图文教程频道,
trueTechArticle 你的php网页是乱码吗?一、 学php的童鞋在写网页的时候,如果是专门用来存储中文内容的,大部分问题都会是乱码。一般的废话...
php网页抓取乱码(PHP中文乱码现像发生在网页本身的有些产生在于MYSQL)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-27 07:11
前言
PHP中的中文乱码是PHP开发中常见的问题之一。中文乱码有时出现在网页本身,有的出现在MYSQL交互过程中,有时与操作系统有关。以下是一个总结。
一、 PHP 网页的编码
最好最快的解决方案是使页面上声明的代码与数据库内部的代码保持一致。如果页面申请的代码与数据库内部的代码不一致,设置连接代码。Mysql_query("设置名称***").
1、 php文件本身的编码应该和网页的编码相匹配。如果你想使用gb2312编码,那么php应该输出header
header("内容类型:text/html;charset=gb2312")
添加静态页面
, 所有文件的编码格式都是ANSI,可以用记事本打开,另存为选择的编码为ANSI,覆盖源文件。
2、 如果你想使用uft-8编码,那么php应该输出header
header("内容类型: text/html; charset=utf-8"),
添加静态页面
, 所有文件的编码格式都是utf-8. 保存为utf-8可能有点麻烦。一般utf-8开头会有BOM。如果使用Session,会有问题,可以使用editplus软件保存。在本软件中,选择Tools→Preferences→File→UTF-8 Signature,选择Always Delete,然后保存即可删除BOM信息。
3、PHP本身不是Unicode,substr等所有函数都必须改成mb_substr(需要安装mbstring扩展);或使用 iconv 进行转码。
在需要做数据库操作的PHP程序前加上mysql_query("set names encoding"),编码和PHP编码一样,如果PHP编码是gb2312,那么mysql编码是gb2312,如果是uft-8 ,那么mysql就是utf8.这样改后就不会出现乱码了。 查看全部
php网页抓取乱码(PHP中文乱码现像发生在网页本身的有些产生在于MYSQL)
前言
PHP中的中文乱码是PHP开发中常见的问题之一。中文乱码有时出现在网页本身,有的出现在MYSQL交互过程中,有时与操作系统有关。以下是一个总结。
一、 PHP 网页的编码
最好最快的解决方案是使页面上声明的代码与数据库内部的代码保持一致。如果页面申请的代码与数据库内部的代码不一致,设置连接代码。Mysql_query("设置名称***").
1、 php文件本身的编码应该和网页的编码相匹配。如果你想使用gb2312编码,那么php应该输出header
header("内容类型:text/html;charset=gb2312")
添加静态页面
, 所有文件的编码格式都是ANSI,可以用记事本打开,另存为选择的编码为ANSI,覆盖源文件。
2、 如果你想使用uft-8编码,那么php应该输出header
header("内容类型: text/html; charset=utf-8"),
添加静态页面
, 所有文件的编码格式都是utf-8. 保存为utf-8可能有点麻烦。一般utf-8开头会有BOM。如果使用Session,会有问题,可以使用editplus软件保存。在本软件中,选择Tools→Preferences→File→UTF-8 Signature,选择Always Delete,然后保存即可删除BOM信息。
3、PHP本身不是Unicode,substr等所有函数都必须改成mb_substr(需要安装mbstring扩展);或使用 iconv 进行转码。
在需要做数据库操作的PHP程序前加上mysql_query("set names encoding"),编码和PHP编码一样,如果PHP编码是gb2312,那么mysql编码是gb2312,如果是uft-8 ,那么mysql就是utf8.这样改后就不会出现乱码了。
php网页抓取乱码(,如下:file_get_contents函数(,.))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-24 22:23
本文章主要介绍PHP中使用file_get_contents抓取网页中文乱码问题的解决方法。可以通过使用 curl 配置 gzip 选项来解决。有一定的参考价值。有需要的朋友可以参考以下
本文的例子介绍了如何使用PHP中的file_get_contents来抓取网页的中文乱码问题。分享给大家,供大家参考。具体方法如下:
file_get_contents 函数原本是一个很好的php原生和远程文件操作函数。它让我们可以毫不费力地直接下载远程数据,但是当我用它来阅读网页时,我会遇到一些问题。页面乱码,这里给大家总结一下具体的解决办法。
根据网上朋友的说法,原因可能是服务器开启了GZIP压缩。下面是用firebug查看我的网站的头信息,启用Gzip,请求头信息的原创头信息如下:
复制代码代码如下:
接受 text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
接受编码 gzip,放气
接受-语言 zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
连接保持活动
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.132685041傻瓜式887.3.utmcsr=google|utmccn=(有机)|utmcmd=有机|utmctr=%E4%BB%BB%E4% BD%95%E9%A1%B9%E7% 9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE% 80%E5%8D%95%20现场%3A; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
主机
用户代理 Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
从头信息可以看出Content-Encoding项是Gzip。
解决方法比较简单,就是用curl代替file_get_contents来获取,然后在curl配置参数中加一个,代码如下:
复制代码代码如下:
curl_setopt($ch, CURLOPT_ENCODING, "gzip");
今天用file_get_contents抓图的时候,一开始没发现这个问题,费了好大劲才找到。
使用内置的 zlib 库。如果服务器已经安装了zlib库,可以通过以下代码轻松解决乱码问题。代码如下:
复制代码代码如下:
$data = file_get_contents("compress.zlib://".$url);
希望本文对您的 PHP 编程有所帮助。 查看全部
php网页抓取乱码(,如下:file_get_contents函数(,.))
本文章主要介绍PHP中使用file_get_contents抓取网页中文乱码问题的解决方法。可以通过使用 curl 配置 gzip 选项来解决。有一定的参考价值。有需要的朋友可以参考以下
本文的例子介绍了如何使用PHP中的file_get_contents来抓取网页的中文乱码问题。分享给大家,供大家参考。具体方法如下:
file_get_contents 函数原本是一个很好的php原生和远程文件操作函数。它让我们可以毫不费力地直接下载远程数据,但是当我用它来阅读网页时,我会遇到一些问题。页面乱码,这里给大家总结一下具体的解决办法。
根据网上朋友的说法,原因可能是服务器开启了GZIP压缩。下面是用firebug查看我的网站的头信息,启用Gzip,请求头信息的原创头信息如下:
复制代码代码如下:
接受 text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
接受编码 gzip,放气
接受-语言 zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
连接保持活动
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.132685041傻瓜式887.3.utmcsr=google|utmccn=(有机)|utmcmd=有机|utmctr=%E4%BB%BB%E4% BD%95%E9%A1%B9%E7% 9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE% 80%E5%8D%95%20现场%3A; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
主机
用户代理 Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
从头信息可以看出Content-Encoding项是Gzip。
解决方法比较简单,就是用curl代替file_get_contents来获取,然后在curl配置参数中加一个,代码如下:
复制代码代码如下:
curl_setopt($ch, CURLOPT_ENCODING, "gzip");
今天用file_get_contents抓图的时候,一开始没发现这个问题,费了好大劲才找到。
使用内置的 zlib 库。如果服务器已经安装了zlib库,可以通过以下代码轻松解决乱码问题。代码如下:
复制代码代码如下:
$data = file_get_contents("compress.zlib://".$url);
希望本文对您的 PHP 编程有所帮助。
php网页抓取乱码(不是白忙乎了吗?????)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-24 16:12
网上的解决方案说抓取后使用iconv()转码。看了之后觉得不对:一个是iconv库不一定是编译出来的,更大的问题是编码和流转换有关(如果用iconv,php实际上是把代码转换了两次:stream -> UTF-8 -> GB2312):这不是浪费时间吗?
仔细阅读php文档(不知道大家是怎么写代码的,但是文档很清楚),上面提到了关于fopen()和file_get_contents()“默认是UTF-8,但是用户可以使用stream_default_encoding。 () 或用户定义的上下文属性来更改编码”(如果启用了 unicode 语义,则读取数据的默认编码为 UTF-8. 您可以通过创建自定义上下文或更改默认使用 stream_default_encoding()。)。所以使用 stream_default_encoding('gb2312'); 测试:但问题是这个函数不存在?!似乎只有 php 6 支持它。但是没有出路,还有“用户定义的上下文属性”可以使用。
再仔细看了下文档,终于解决了问题:
复制代码代码如下:
//设置流的编码格式,这里是文件流(file),如果是网络访问,把文件改成http
$opts = array('file' => array('encoding' => 'gb2312'));
$ctxt = stream_context_create($opts);
file_get_contents(文件名, FILE_TEXT, $ctxt); 查看全部
php网页抓取乱码(不是白忙乎了吗?????)
网上的解决方案说抓取后使用iconv()转码。看了之后觉得不对:一个是iconv库不一定是编译出来的,更大的问题是编码和流转换有关(如果用iconv,php实际上是把代码转换了两次:stream -> UTF-8 -> GB2312):这不是浪费时间吗?
仔细阅读php文档(不知道大家是怎么写代码的,但是文档很清楚),上面提到了关于fopen()和file_get_contents()“默认是UTF-8,但是用户可以使用stream_default_encoding。 () 或用户定义的上下文属性来更改编码”(如果启用了 unicode 语义,则读取数据的默认编码为 UTF-8. 您可以通过创建自定义上下文或更改默认使用 stream_default_encoding()。)。所以使用 stream_default_encoding('gb2312'); 测试:但问题是这个函数不存在?!似乎只有 php 6 支持它。但是没有出路,还有“用户定义的上下文属性”可以使用。
再仔细看了下文档,终于解决了问题:
复制代码代码如下:
//设置流的编码格式,这里是文件流(file),如果是网络访问,把文件改成http
$opts = array('file' => array('encoding' => 'gb2312'));
$ctxt = stream_context_create($opts);
file_get_contents(文件名, FILE_TEXT, $ctxt);
php网页抓取乱码(什么是这是的编码?的方式解决乱码问题? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-20 07:13
)
2、如果上面的方法不行,页面还是乱码;或者在head标签下找不到charset属性;或者我们要采集很多网页信息,而这些网页的编码方式不一样,我们不可能一一查看head标签,所以可以使用以下方法解决乱码问题。
(1)python 的 chardet 库
可以使用以下方法解决乱码问题
result = chardet.detect(response.content)
print(result)
data = response.content.decode(chardet.detect(response.content)['encoding'])
{'confidence': 0.99, 'language': '', 'encoding': 'utf-8'}
从输出结果可以看出,这是一种“猜测”编码。猜测的方法是先采集各种编码的特征字符,根据特征字符,有很大概率“猜对”。
这种方法的效率非常低。如果采集的网页很大,你只能猜测其中一段的源码,即
result = chardet.detect(response.content[:1000])
(2)响应编码
您还可以使用另一种方法,即响应自己的 encoding 和 visible_encoding 变量。
response.encoding一般来自response.headers中content-type字段中charset的值,其他情况我不太了解。
response.apparent_encoding 一般使用上面提到的python chardet库方法。
因此,乱码问题可以通过以下方式解决
data = response.content.decode(response.apparent_encoding)
3、总的来说,以上两种方法可以解决乱码问题。但是,如果以上两种方法都不能解决,则可能是网页压缩造成的。这个问题通过以下方式解决。
检查你写的头信息是否收录Accept-Encoding字段。如果是,请删除该字段,乱码问题将得到解决。
headers = {
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221
Safari/537.36 SE 2.X MetaSr 1.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Connection': 'keep-alive',
} 查看全部
php网页抓取乱码(什么是这是的编码?的方式解决乱码问题?
)
2、如果上面的方法不行,页面还是乱码;或者在head标签下找不到charset属性;或者我们要采集很多网页信息,而这些网页的编码方式不一样,我们不可能一一查看head标签,所以可以使用以下方法解决乱码问题。
(1)python 的 chardet 库
可以使用以下方法解决乱码问题
result = chardet.detect(response.content)
print(result)
data = response.content.decode(chardet.detect(response.content)['encoding'])
{'confidence': 0.99, 'language': '', 'encoding': 'utf-8'}
从输出结果可以看出,这是一种“猜测”编码。猜测的方法是先采集各种编码的特征字符,根据特征字符,有很大概率“猜对”。
这种方法的效率非常低。如果采集的网页很大,你只能猜测其中一段的源码,即
result = chardet.detect(response.content[:1000])
(2)响应编码
您还可以使用另一种方法,即响应自己的 encoding 和 visible_encoding 变量。
response.encoding一般来自response.headers中content-type字段中charset的值,其他情况我不太了解。
response.apparent_encoding 一般使用上面提到的python chardet库方法。
因此,乱码问题可以通过以下方式解决
data = response.content.decode(response.apparent_encoding)
3、总的来说,以上两种方法可以解决乱码问题。但是,如果以上两种方法都不能解决,则可能是网页压缩造成的。这个问题通过以下方式解决。
检查你写的头信息是否收录Accept-Encoding字段。如果是,请删除该字段,乱码问题将得到解决。
headers = {
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221
Safari/537.36 SE 2.X MetaSr 1.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Connection': 'keep-alive',
}
php网页抓取乱码(PHP接收get中文参数乱码的解决办法:中文标签乱码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-19 19:17
php获取get参数乱码的解决方法:1、通过"$str=iconv("gb2312", "utf-8", $str);"处理编码;2、 通过 "mb_convert_encoding($str,"utf-8", "gb2312");" 方法。
本文运行环境:Windows7系统,PHP7.1、Dell G3电脑。
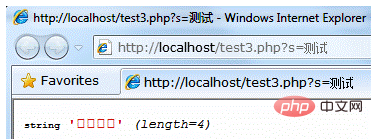
PHP接收GET中文参数乱码的深入研究
相信很多PHPer都会遇到这样的问题:在utf-8页面下,如果直接访问带有test.php?s=test等中文参数的地址,输出参数的值会出现乱码,可以在搜索引擎上查询 看了相关资料后,只给出了一些解决方案,但没有人研究过这个问题的原因。今天,我将通过这篇文章来深入探讨这个问题的原因:
首先我们演示一下这个问题,测试代码和运行结果如下。
代码:
测试结果:
代码声明响应内容的编码为utf-8,显示的内容确实是乱码。
这里请注意,var_dump输出的变量长度只有4。显然,在utf-8编码下,两个汉字的长度必须大于4字节。
那么我们来看看火狐对这个页面url的访问
FireFox会自动对中文url进行编码,所以我们可以看到测试变成了%B2%E2%CA%D4。显然,这里的一个词是两个字节,是 gb2313、gbk 等中文编码格式,而不是 utf-8 编码。(推荐:《PHP 视频教程》)
如果我们将页面的编码切换为gbk,中文参数会正常显示,见下图
这时候就诞生了一个有趣的问题:为什么emlog的中文标签等参数没有乱码?
经过多次测试,我发现了一个小区别:
页面生成emlog中文参数的链接,上面测试直接在地址栏手动输入,
如果我们直接输入原创等链接,程序也会提示找不到标签
测试代码如下:
测试结果,正常显示:
请注意上图中红框内标注的url编码。这次测试中的两个字由6个字节组成,而不是之前的2个字节,所以说明中文参数已经被正确编码为utf-8。
那么,是什么导致了这个问题呢?
答案是浏览器的默认编码有问题。我们都使用中文系统。浏览器的默认编码也将设置为本地化。比如我电脑上IE的FireFox默认编码是gb系列,请参考下图:
IE的默认设置:
Firefox 的默认设置:
因为这个设置,浏览器在请求用户输入的url时,会以默认编码格式而不是页面默认编码格式发送url中的中文,这就是为什么页面中带有中文的链接是正常的,我们手动输入的链接是乱码的原因。同样,如果我们将浏览器的默认编码调整为utf-8,那么输入url中的中文就会按照utf-8进行编码。
除上述情况外,还会在以下情况下发生这种情况:
如果gbk编码页面生成的地址链接到utf-8页面,gbk页面的中文以gbk格式编码传输到下一页,那么utf-8后面肯定会出现乱码收到编码。
IIS的url重写模块,重写的中文编码也是gbk,如果你的页面是utf-8编码,那么重写参数会失效。
在这些情况下,我们需要使用php内置的转码功能来处理编码问题:
计划一:
$str =iconv("gb2312","utf-8",$str);
场景二:
mb_convert_encoding($str,"utf-8", "gb2312");
希望这篇文章能帮助那些在编码问题上摸不着头脑的 PHPer :) 查看全部
php网页抓取乱码(PHP接收get中文参数乱码的解决办法:中文标签乱码)
php获取get参数乱码的解决方法:1、通过"$str=iconv("gb2312", "utf-8", $str);"处理编码;2、 通过 "mb_convert_encoding($str,"utf-8", "gb2312");" 方法。

本文运行环境:Windows7系统,PHP7.1、Dell G3电脑。
PHP接收GET中文参数乱码的深入研究
相信很多PHPer都会遇到这样的问题:在utf-8页面下,如果直接访问带有test.php?s=test等中文参数的地址,输出参数的值会出现乱码,可以在搜索引擎上查询 看了相关资料后,只给出了一些解决方案,但没有人研究过这个问题的原因。今天,我将通过这篇文章来深入探讨这个问题的原因:
首先我们演示一下这个问题,测试代码和运行结果如下。
代码:

测试结果:

代码声明响应内容的编码为utf-8,显示的内容确实是乱码。
这里请注意,var_dump输出的变量长度只有4。显然,在utf-8编码下,两个汉字的长度必须大于4字节。
那么我们来看看火狐对这个页面url的访问

FireFox会自动对中文url进行编码,所以我们可以看到测试变成了%B2%E2%CA%D4。显然,这里的一个词是两个字节,是 gb2313、gbk 等中文编码格式,而不是 utf-8 编码。(推荐:《PHP 视频教程》)
如果我们将页面的编码切换为gbk,中文参数会正常显示,见下图

这时候就诞生了一个有趣的问题:为什么emlog的中文标签等参数没有乱码?
经过多次测试,我发现了一个小区别:
页面生成emlog中文参数的链接,上面测试直接在地址栏手动输入,
如果我们直接输入原创等链接,程序也会提示找不到标签
测试代码如下:

测试结果,正常显示:

请注意上图中红框内标注的url编码。这次测试中的两个字由6个字节组成,而不是之前的2个字节,所以说明中文参数已经被正确编码为utf-8。
那么,是什么导致了这个问题呢?
答案是浏览器的默认编码有问题。我们都使用中文系统。浏览器的默认编码也将设置为本地化。比如我电脑上IE的FireFox默认编码是gb系列,请参考下图:
IE的默认设置:

Firefox 的默认设置:

因为这个设置,浏览器在请求用户输入的url时,会以默认编码格式而不是页面默认编码格式发送url中的中文,这就是为什么页面中带有中文的链接是正常的,我们手动输入的链接是乱码的原因。同样,如果我们将浏览器的默认编码调整为utf-8,那么输入url中的中文就会按照utf-8进行编码。
除上述情况外,还会在以下情况下发生这种情况:
如果gbk编码页面生成的地址链接到utf-8页面,gbk页面的中文以gbk格式编码传输到下一页,那么utf-8后面肯定会出现乱码收到编码。
IIS的url重写模块,重写的中文编码也是gbk,如果你的页面是utf-8编码,那么重写参数会失效。
在这些情况下,我们需要使用php内置的转码功能来处理编码问题:
计划一:
$str =iconv("gb2312","utf-8",$str);
场景二:
mb_convert_encoding($str,"utf-8", "gb2312");
希望这篇文章能帮助那些在编码问题上摸不着头脑的 PHPer :)
php网页抓取乱码(1.源码文件开头使用__importunicode_literals_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-12 21:21
2021-10-10
虫子有时会破坏你的心情,阻碍你留在现在的状态。但是,我很清楚,那是一种激励,是注定要被你踩到的垫脚石!
python2.7中最头疼的可能就是编码问题了,尤其是window环境下,有时候会莫名其妙的出现问题,有时候昨天还好好的,今天突然就这样了。. . 遇到这种问题,真是一肚子火。. . 他妈的!
首先,我们在写python代码的时候,一定要注意一些编码规范。
1.源文件使用#-*-coding:utf-8-*-指定编码,保存文件为utf-8格式
2.在文件开头使用 from __future__ import unicode_literals 避免在中文前面加 u 以允许迁移到 python3。
3.python内部存储为unicode,所有输入必须先解码成unicode,输入时encode变成想要的编码。常用的window环境有utf-8、gbk、gb2312、gb18030等。
4.通用网站基本都是utf-8或者gb2312。您可以尝试解码然后编码当前输出环境的编码格式。系统默认的编码格式是通过sys.getfilesystemencoding()传递的。说到文件路径,需要转换成系统默认编码。
5.unicode 字符串在写入文件时必须转换为某种字符编码。
在爬取网页的时候,我们可以先看网页的字符编码,可以在html代码或者f12看网中看到:
当您打印网页的源代码时,您必须小心。你可能会得到 UnicodeEncodeError!
你可以这样做:
1 type = sys.getfilesystemencoding()
2 #utf-8为网页编码,可能为gbk等
3 html = html.decode('utf-8').encode(type)
另一种通用的方法是使用 chardet 包来确定网页编码。刚试了一下,速度很慢。. . 需要安装chardet包,地址可以通过pip install chardet或者easy_install chardet安装。使用如下代码:
1 htmlCharsetGuess = chardet.detect(pageCode)
2 htmlCharsetEncoding = htmlCharsetGuess["encoding"]
3 htmlCode_decode = pageCode.decode(htmlCharsetEncoding)
4 type = sys.getfilesystemencoding()
5 htmlCode_encode = htmlCode_decode.encode(type)
6 print htmlCode_encode
还有一种可能是你得到的网站内容已经被gzip压缩了,这个时候我们需要解压。大多数服务器都支持gzip压缩,我改了HttpClient.py。默认情况下,我们去gzip方法访问网站,获取压缩后的内容再进行处理,这样抓包速度更快,我们看一下HttpClient.py的Get方法:
1 import zlib
2 def Get(self, url, refer=None):
3 try:
4 req = urllib2.Request(url)
5 req.add_header('Accept-encoding', 'gzip')#默认以gzip压缩的方式得到网页内容
6 if not (refer is None):
7 req.add_header('Referer', refer)
8 response = urllib2.urlopen(req, timeout=120)
9 html = response.read()
10 gzipped = response.headers.get('Content-Encoding')#查看是否服务器是否支持gzip
11 if gzipped:
12 html = zlib.decompress(html, 16+zlib.MAX_WBITS)#解压缩,得到网页源码
13 return html
14 except urllib2.HTTPError, e:
15 return e.read()
16 except socket.timeout, e:
17 return ''
18 except socket.error, e:
19 return ''
写了这么多,发现没有写出思路,经验少。但是,字符编码之类的东西需要经验。一句话总结,如果出现UnicodeEncodeError错误,说明字符编码有问题。python解释器也是一个工具。你需要让他明白,所以他需要解码,然后他需要编码让你明白。为了万无一失,建议使用chardet包!
分类:
技术要点:
相关文章: 查看全部
php网页抓取乱码(1.源码文件开头使用__importunicode_literals_)
2021-10-10
虫子有时会破坏你的心情,阻碍你留在现在的状态。但是,我很清楚,那是一种激励,是注定要被你踩到的垫脚石!
python2.7中最头疼的可能就是编码问题了,尤其是window环境下,有时候会莫名其妙的出现问题,有时候昨天还好好的,今天突然就这样了。. . 遇到这种问题,真是一肚子火。. . 他妈的!
首先,我们在写python代码的时候,一定要注意一些编码规范。
1.源文件使用#-*-coding:utf-8-*-指定编码,保存文件为utf-8格式
2.在文件开头使用 from __future__ import unicode_literals 避免在中文前面加 u 以允许迁移到 python3。
3.python内部存储为unicode,所有输入必须先解码成unicode,输入时encode变成想要的编码。常用的window环境有utf-8、gbk、gb2312、gb18030等。
4.通用网站基本都是utf-8或者gb2312。您可以尝试解码然后编码当前输出环境的编码格式。系统默认的编码格式是通过sys.getfilesystemencoding()传递的。说到文件路径,需要转换成系统默认编码。
5.unicode 字符串在写入文件时必须转换为某种字符编码。
在爬取网页的时候,我们可以先看网页的字符编码,可以在html代码或者f12看网中看到:
当您打印网页的源代码时,您必须小心。你可能会得到 UnicodeEncodeError!
你可以这样做:
1 type = sys.getfilesystemencoding()
2 #utf-8为网页编码,可能为gbk等
3 html = html.decode('utf-8').encode(type)
另一种通用的方法是使用 chardet 包来确定网页编码。刚试了一下,速度很慢。. . 需要安装chardet包,地址可以通过pip install chardet或者easy_install chardet安装。使用如下代码:
1 htmlCharsetGuess = chardet.detect(pageCode)
2 htmlCharsetEncoding = htmlCharsetGuess["encoding"]
3 htmlCode_decode = pageCode.decode(htmlCharsetEncoding)
4 type = sys.getfilesystemencoding()
5 htmlCode_encode = htmlCode_decode.encode(type)
6 print htmlCode_encode
还有一种可能是你得到的网站内容已经被gzip压缩了,这个时候我们需要解压。大多数服务器都支持gzip压缩,我改了HttpClient.py。默认情况下,我们去gzip方法访问网站,获取压缩后的内容再进行处理,这样抓包速度更快,我们看一下HttpClient.py的Get方法:
1 import zlib
2 def Get(self, url, refer=None):
3 try:
4 req = urllib2.Request(url)
5 req.add_header('Accept-encoding', 'gzip')#默认以gzip压缩的方式得到网页内容
6 if not (refer is None):
7 req.add_header('Referer', refer)
8 response = urllib2.urlopen(req, timeout=120)
9 html = response.read()
10 gzipped = response.headers.get('Content-Encoding')#查看是否服务器是否支持gzip
11 if gzipped:
12 html = zlib.decompress(html, 16+zlib.MAX_WBITS)#解压缩,得到网页源码
13 return html
14 except urllib2.HTTPError, e:
15 return e.read()
16 except socket.timeout, e:
17 return ''
18 except socket.error, e:
19 return ''
写了这么多,发现没有写出思路,经验少。但是,字符编码之类的东西需要经验。一句话总结,如果出现UnicodeEncodeError错误,说明字符编码有问题。python解释器也是一个工具。你需要让他明白,所以他需要解码,然后他需要编码让你明白。为了万无一失,建议使用chardet包!
分类:
技术要点:
相关文章:
php网页抓取乱码(1.PHP解决中文乱码问题(一)_原油期货开发)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-10 22:21
1.PHP解决中文乱码问题
很多情况下程序出现中文输出时,页面会显示乱码
一般有两个原因
编码(charset)设置错误,导致浏览器解析错误的编码,导致乱码文件以错误的编码打开保存,如GBK编码的文件,以UTF-8编码格式打开,然后在UTF-8格式保存,会有乱码问题
对乱码进行分类,针对性解决
1.1 解决HTML页面中文乱码问题
如果你的HTML文本文件有芯片问题,那么可以在head标签中加入UTF-8编码(国际编码):UTF-8是一种没有国家的编码,也就是一种独立的语言,任何语言都可以使用的。
1.2 HTML和PHP混合页面解决方案
如果混合使用 HTML 和 PHP,除了第一种方法中描述的操作外,还需要在 PHP 文件的顶部添加这段代码:
1.3 纯PHP页面中文乱码问题(数据是静态的)
如果PHP页面有芯片,在页面开头添加如下代码即可
1.4 PHP+MySQL中文乱码问题
除了第三个操作,数据库代码必须在数据查询/修改/添加之前添加。
而且需要注意的是这里的UTF8和前面的不一样,中间没有横线
如果数据库版本大于4.1,可以在链接数据库操作后设置字符编码,如下
$conn = mysqli_connect('localhost','root','root','db_name');
mysqli_set_charset($conn,'utf8');
UTF-8 编码只是其中一种编码。如果不想使用utf-8编码,也可以使用其他编码,需要进行编码转换
需要注意的一点是,它是在需要进行数据库操作的php程序之前添加的
mysql_query("set names encoding");
编码必须与 PHP 编码一致。如果 PHP 编码为 gb2312,则 MySQL 编码为 gb2312。如果 PHP 页面编码为 utf-8,则 MySQL 编码为 utf-8。这样可以使数据与页面编码保持一致,插入或检索数据时的芯片更少 查看全部
php网页抓取乱码(1.PHP解决中文乱码问题(一)_原油期货开发)
1.PHP解决中文乱码问题
很多情况下程序出现中文输出时,页面会显示乱码
一般有两个原因
编码(charset)设置错误,导致浏览器解析错误的编码,导致乱码文件以错误的编码打开保存,如GBK编码的文件,以UTF-8编码格式打开,然后在UTF-8格式保存,会有乱码问题
对乱码进行分类,针对性解决
1.1 解决HTML页面中文乱码问题
如果你的HTML文本文件有芯片问题,那么可以在head标签中加入UTF-8编码(国际编码):UTF-8是一种没有国家的编码,也就是一种独立的语言,任何语言都可以使用的。
1.2 HTML和PHP混合页面解决方案
如果混合使用 HTML 和 PHP,除了第一种方法中描述的操作外,还需要在 PHP 文件的顶部添加这段代码:
1.3 纯PHP页面中文乱码问题(数据是静态的)
如果PHP页面有芯片,在页面开头添加如下代码即可
1.4 PHP+MySQL中文乱码问题
除了第三个操作,数据库代码必须在数据查询/修改/添加之前添加。
而且需要注意的是这里的UTF8和前面的不一样,中间没有横线
如果数据库版本大于4.1,可以在链接数据库操作后设置字符编码,如下
$conn = mysqli_connect('localhost','root','root','db_name');
mysqli_set_charset($conn,'utf8');
UTF-8 编码只是其中一种编码。如果不想使用utf-8编码,也可以使用其他编码,需要进行编码转换
需要注意的一点是,它是在需要进行数据库操作的php程序之前添加的
mysql_query("set names encoding");
编码必须与 PHP 编码一致。如果 PHP 编码为 gb2312,则 MySQL 编码为 gb2312。如果 PHP 页面编码为 utf-8,则 MySQL 编码为 utf-8。这样可以使数据与页面编码保持一致,插入或检索数据时的芯片更少
php网页抓取乱码(,乱码的原因及及解决方法解决方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-10 21:12
乱码对于初学者来说一直是个很大的问题。现在总结一下出现乱码的原因和解决方法,主要是mysql数据库和php页面出现乱码。下面详细分析其中的原因。帮助。
一、HTML 页面编码:meta http-equiv=content-type content=text/html; charset=utf-8 这里的编码和数据库教程编码一样,和连接数据库编码一样
二、文件在存储编码中:例如文件inde.php教程,将其存储编码更改为所需的编码。只需使用EditPlus等文本编辑软件将文件另存为,在编码中选择正确的编码(这个被很多人忽略了)
三、数据库编码:比如使用phpmyadmin,选择数据库后,选择操作选项,有排序,也应该设置为统一编码。
四、表格编码:操作与第三点类似,此处不再赘述。
五、字段代码:在建表的字段时,有一个排列。如果内容中收录汉字,必须改为统一编码
六、连接数据库的时候,加一句mysql_query(set names utf8)
在 _select_db() 之后。
七、(刚遇到)网站本地测试成功后,如果上传到网上会出现乱码。可能是本地导出数据时没有选择正确的编码,所以导入网页后会出现乱码。 查看全部
php网页抓取乱码(,乱码的原因及及解决方法解决方案)
乱码对于初学者来说一直是个很大的问题。现在总结一下出现乱码的原因和解决方法,主要是mysql数据库和php页面出现乱码。下面详细分析其中的原因。帮助。
一、HTML 页面编码:meta http-equiv=content-type content=text/html; charset=utf-8 这里的编码和数据库教程编码一样,和连接数据库编码一样
二、文件在存储编码中:例如文件inde.php教程,将其存储编码更改为所需的编码。只需使用EditPlus等文本编辑软件将文件另存为,在编码中选择正确的编码(这个被很多人忽略了)
三、数据库编码:比如使用phpmyadmin,选择数据库后,选择操作选项,有排序,也应该设置为统一编码。
四、表格编码:操作与第三点类似,此处不再赘述。
五、字段代码:在建表的字段时,有一个排列。如果内容中收录汉字,必须改为统一编码
六、连接数据库的时候,加一句mysql_query(set names utf8)
在 _select_db() 之后。
七、(刚遇到)网站本地测试成功后,如果上传到网上会出现乱码。可能是本地导出数据时没有选择正确的编码,所以导入网页后会出现乱码。
php网页抓取乱码( 板Python学习教程--Python基础知识-关注小编头条号 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-10 21:09
板Python学习教程--Python基础知识-关注小编头条号
)
想学Python。关注小编头条号,私信【学习资料】即可免费领取全套系统板Python学习教程!
使用python2爬取网页时,经常会遇到抓取到的内容显示为乱码的情况。
这种情况最大的可能是编码问题:运行环境的字符编码和网页的字符编码不一致。
例如,在 Windows 控制台 (gbk) 中获取一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓一个gbk编码的网站(utf-8)。因为大部分网站使用utf-8编码,而且很多人使用windows,都是很常见。
如果你发现你抓取的内容在英文、数字、符号上看起来都正确,但是中间有一些乱码,你基本上可以断定是这样的。
这个问题的解决方法是先将结果按照网页的编码方式解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllibreq = urllib.urlopen("http://some.web.site")info = req.info()charset = info.getparam('charset')content = req.read()print content.decode(charset, 'ignore')
'ignore' 参数用于忽略无法解码的字符。
但是,这种方法并不总是有效。另一种方式是通过正则表达式直接匹配网页代码中的编码设置:
除了编码问题导致的乱码之外,另一个经常被忽视的情况是目标页面启用了 gzip 压缩。压缩网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的头部信息自动解压。但是直接用代码抓取不会。因此,很可能会产生困惑,为什么打开网页地址是对的,但程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现是,几乎所有的抓取内容都是乱码,甚至无法显示。
要确定网页是否启用了压缩并解压缩,请使用以下代码:
import urllibimport gzipfrom StringIO import StringIOreq = urllib.urlopen("http://some.web.site")info = req.info()encoding = info.getheader('Content-Encoding')content = req.read()if encoding == 'gzip': buf = StringIO(content) gf = gzip.GzipFile(fileobj=buf) content = gf.read()print content
在我们的课堂编程示例查看天气系列(点击查看)中,这两个问题困扰了不少人。这里有一个特殊的解释。
最后,还有一个“武器”要介绍。如果你一开始使用它,你甚至都不知道存在上述两个问题。
这是请求模块。
与爬网类似,只需:
import requestsprint requests.get("http://some.web.site").text
没有编码问题,没有压缩问题。注意
查看全部
php网页抓取乱码(
板Python学习教程--Python基础知识-关注小编头条号
)

想学Python。关注小编头条号,私信【学习资料】即可免费领取全套系统板Python学习教程!
使用python2爬取网页时,经常会遇到抓取到的内容显示为乱码的情况。
这种情况最大的可能是编码问题:运行环境的字符编码和网页的字符编码不一致。
例如,在 Windows 控制台 (gbk) 中获取一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓一个gbk编码的网站(utf-8)。因为大部分网站使用utf-8编码,而且很多人使用windows,都是很常见。
如果你发现你抓取的内容在英文、数字、符号上看起来都正确,但是中间有一些乱码,你基本上可以断定是这样的。

这个问题的解决方法是先将结果按照网页的编码方式解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllibreq = urllib.urlopen("http://some.web.site";)info = req.info()charset = info.getparam('charset')content = req.read()print content.decode(charset, 'ignore')
'ignore' 参数用于忽略无法解码的字符。
但是,这种方法并不总是有效。另一种方式是通过正则表达式直接匹配网页代码中的编码设置:
除了编码问题导致的乱码之外,另一个经常被忽视的情况是目标页面启用了 gzip 压缩。压缩网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的头部信息自动解压。但是直接用代码抓取不会。因此,很可能会产生困惑,为什么打开网页地址是对的,但程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现是,几乎所有的抓取内容都是乱码,甚至无法显示。
要确定网页是否启用了压缩并解压缩,请使用以下代码:
import urllibimport gzipfrom StringIO import StringIOreq = urllib.urlopen("http://some.web.site";)info = req.info()encoding = info.getheader('Content-Encoding')content = req.read()if encoding == 'gzip': buf = StringIO(content) gf = gzip.GzipFile(fileobj=buf) content = gf.read()print content
在我们的课堂编程示例查看天气系列(点击查看)中,这两个问题困扰了不少人。这里有一个特殊的解释。
最后,还有一个“武器”要介绍。如果你一开始使用它,你甚至都不知道存在上述两个问题。
这是请求模块。
与爬网类似,只需:
import requestsprint requests.get("http://some.web.site";).text
没有编码问题,没有压缩问题。注意

php网页抓取乱码(php和Mysql出现的中文乱码问题怎么办?见)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-08 01:12
最近一直在写网页,用的是php和Mysql,但是出现了各种问题。说明在Mysql下输入sql语句时,如果sql语句中有中文,则可能不会执行sql语句。解决方法见:解决Mysql server 5.1无法识别中文
解决此问题后,使用php向数据库写入数据时,sql语句无法再次执行。这个问题我也解决了。解决方法见:解决PHP连接Mysql但无法向数据库插入数据。
昨天出现的中文乱码问题,经过一夜的努力,终于解决了。现在PHP和Mysql都可以识别中文,可以正常执行SQL语句了。
解决方法就是在这里写个总结(应该同时解决以上三个问题):
首先是修改Mysql的编码方式。这是一篇写得很详细的帖子。结合我第一个问题的解决方法,完全可以修改Mysql的编码方式。帖子地址:MySql修改数据库编码为UTF8。
接下来是php连接数据库时选择的编码方式。首先,我建议你把所有的编码方式都改成'utf-8',这样写网页或者使用数据库都方便很多。 php写网页时,添加 则可以使用sql语句访问数据库,添加mysql_query("set names utf8");记住这里是utf8不是utf-8,不是我不小心忘了加横线,而是utf8。 查看全部
php网页抓取乱码(php和Mysql出现的中文乱码问题怎么办?见)
最近一直在写网页,用的是php和Mysql,但是出现了各种问题。说明在Mysql下输入sql语句时,如果sql语句中有中文,则可能不会执行sql语句。解决方法见:解决Mysql server 5.1无法识别中文
解决此问题后,使用php向数据库写入数据时,sql语句无法再次执行。这个问题我也解决了。解决方法见:解决PHP连接Mysql但无法向数据库插入数据。
昨天出现的中文乱码问题,经过一夜的努力,终于解决了。现在PHP和Mysql都可以识别中文,可以正常执行SQL语句了。
解决方法就是在这里写个总结(应该同时解决以上三个问题):
首先是修改Mysql的编码方式。这是一篇写得很详细的帖子。结合我第一个问题的解决方法,完全可以修改Mysql的编码方式。帖子地址:MySql修改数据库编码为UTF8。
接下来是php连接数据库时选择的编码方式。首先,我建议你把所有的编码方式都改成'utf-8',这样写网页或者使用数据库都方便很多。 php写网页时,添加 则可以使用sql语句访问数据库,添加mysql_query("set names utf8");记住这里是utf8不是utf-8,不是我不小心忘了加横线,而是utf8。
php网页抓取乱码(用file_get_contents()函数抓取网页会发生乱码现象)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-07 18:19
使用 file_get_contents() 函数抓取网页会导致乱码。出现乱码的原因有两个,一是编码问题,二是目标页面开启了Gzip。下面是如何开启Gzip功能避免乱码
对抓取的内容进行编码($content=iconv("GBK", "UTF-8//IGNORE", $content);),我们这里讨论的是如何抓取和打开Gzip页面。如何判断?获取到的header中收录Content-Encoding:gzip,表示内容是GZIP压缩的。使用 FireBug 查看页面是否启用了 gzip。以下是我用firebug查看的博客的头信息,启用了Gzip。
请求头信息原创头信息
Accept text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding gzip, deflate
Accept-Language zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Connection keep-alive
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.1326850415.887.3.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=%E4%BB%BB%E4%BD%95%E9%A1%B9%E7%9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE%80%E5%8D%95%20site%3Awww.nowamagic.net; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
Host www.nowamagic.net
User-Agent Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
这里有一些解决方案:
1.使用内置的zlib库
如果服务器已经安装了zlib库,下面的代码可以轻松解决乱码问题。
$data = file_get_contents("compress.zlib://".$url);
2. 使用 CURL 代替 file_get_contents
function curl_get($url, $gzip=false){
$curl = curl_init($url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
if($gzip) curl_setopt($curl, CURLOPT_ENCODING, "gzip"); // 关键在这里
$content = curl_exec($curl);
curl_close($curl);
return $content;
}
3.使用gzip解压功能
function gzdecode($data) {
$len = strlen($data);
if ($len < 18 || strcmp(substr($data,0,2),"\x1f\x8b")) {
return null; // Not GZIP format (See RFC 1952)
}
$method = ord(substr($data,2,1)); // Compression method
$flags = ord(substr($data,3,1)); // Flags
if ($flags & 31 != $flags) {
// Reserved bits are set -- NOT ALLOWED by RFC 1952
return null;
}
// NOTE: $mtime may be negative (PHP integer limitations)
$mtime = unpack("V", substr($data,4,4));
$mtime = $mtime[1];
$xfl = substr($data,8,1);
$os = substr($data,8,1);
$headerlen = 10;
$extralen = 0;
$extra = "";
if ($flags & 4) {
// 2-byte length prefixed EXTRA data in header
if ($len - $headerlen - 2 < 8) {
return false; // Invalid format
}
$extralen = unpack("v",substr($data,8,2));
$extralen = $extralen[1];
if ($len - $headerlen - 2 - $extralen < 8) {
return false; // Invalid format
}
$extra = substr($data,10,$extralen);
$headerlen += 2 + $extralen;
}
$filenamelen = 0;
$filename = "";
if ($flags & 8) {
// C-style string file NAME data in header
if ($len - $headerlen - 1 < 8) {
return false; // Invalid format
}
$filenamelen = strpos(substr($data,8+$extralen),chr(0));
if ($filenamelen === false || $len - $headerlen - $filenamelen - 1 < 8) {
return false; // Invalid format
}
$filename = substr($data,$headerlen,$filenamelen);
$headerlen += $filenamelen + 1;
}
$commentlen = 0;
$comment = "";
if ($flags & 16) {
// C-style string COMMENT data in header
if ($len - $headerlen - 1 < 8) {
return false; // Invalid format
}
$commentlen = strpos(substr($data,8+$extralen+$filenamelen),chr(0));
if ($commentlen === false || $len - $headerlen - $commentlen - 1 < 8) {
return false; // Invalid header format
}
$comment = substr($data,$headerlen,$commentlen);
$headerlen += $commentlen + 1;
}
$headercrc = "";
if ($flags & 1) {
// 2-bytes (lowest order) of CRC32 on header present
if ($len - $headerlen - 2 < 8) {
return false; // Invalid format
}
$calccrc = crc32(substr($data,0,$headerlen)) & 0xffff;
$headercrc = unpack("v", substr($data,$headerlen,2));
$headercrc = $headercrc[1];
if ($headercrc != $calccrc) {
return false; // Bad header CRC
}
$headerlen += 2;
}
// GZIP FOOTER - These be negative due to PHP's limitations
$datacrc = unpack("V",substr($data,-8,4));
$datacrc = $datacrc[1];
$isize = unpack("V",substr($data,-4));
$isize = $isize[1];
// Perform the decompression:
$bodylen = $len-$headerlen-8;
if ($bodylen < 1) {
// This should never happen - IMPLEMENTATION BUG!
return null;
}
$body = substr($data,$headerlen,$bodylen);
$data = "";
if ($bodylen > 0) {
switch ($method) {
case 8:
// Currently the only supported compression method:
$data = gzinflate($body);
break;
default:
// Unknown compression method
return false;
}
} else {
// I'm not sure if zero-byte body content is allowed.
// Allow it for now... Do nothing...
}
// Verifiy decompressed size and CRC32:
// NOTE: This may fail with large data sizes depending on how
// PHP's integer limitations affect strlen() since $isize
// may be negative for large sizes.
if ($isize != strlen($data) || crc32($data) != $datacrc) {
// Bad format! Length or CRC doesn't match!
return false;
}
return $data;
}
用途:
$html=file_get_contents('http://www.gxlcms.com/');
$html=gzdecode($html);
介绍这三种方法,应该可以解决gzip引起的大部分乱码问题。 查看全部
php网页抓取乱码(用file_get_contents()函数抓取网页会发生乱码现象)
使用 file_get_contents() 函数抓取网页会导致乱码。出现乱码的原因有两个,一是编码问题,二是目标页面开启了Gzip。下面是如何开启Gzip功能避免乱码
对抓取的内容进行编码($content=iconv("GBK", "UTF-8//IGNORE", $content);),我们这里讨论的是如何抓取和打开Gzip页面。如何判断?获取到的header中收录Content-Encoding:gzip,表示内容是GZIP压缩的。使用 FireBug 查看页面是否启用了 gzip。以下是我用firebug查看的博客的头信息,启用了Gzip。
请求头信息原创头信息
Accept text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding gzip, deflate
Accept-Language zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Connection keep-alive
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.1326850415.887.3.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=%E4%BB%BB%E4%BD%95%E9%A1%B9%E7%9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE%80%E5%8D%95%20site%3Awww.nowamagic.net; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
Host www.nowamagic.net
User-Agent Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
这里有一些解决方案:
1.使用内置的zlib库
如果服务器已经安装了zlib库,下面的代码可以轻松解决乱码问题。
$data = file_get_contents("compress.zlib://".$url);
2. 使用 CURL 代替 file_get_contents
function curl_get($url, $gzip=false){
$curl = curl_init($url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
if($gzip) curl_setopt($curl, CURLOPT_ENCODING, "gzip"); // 关键在这里
$content = curl_exec($curl);
curl_close($curl);
return $content;
}
3.使用gzip解压功能
function gzdecode($data) {
$len = strlen($data);
if ($len < 18 || strcmp(substr($data,0,2),"\x1f\x8b")) {
return null; // Not GZIP format (See RFC 1952)
}
$method = ord(substr($data,2,1)); // Compression method
$flags = ord(substr($data,3,1)); // Flags
if ($flags & 31 != $flags) {
// Reserved bits are set -- NOT ALLOWED by RFC 1952
return null;
}
// NOTE: $mtime may be negative (PHP integer limitations)
$mtime = unpack("V", substr($data,4,4));
$mtime = $mtime[1];
$xfl = substr($data,8,1);
$os = substr($data,8,1);
$headerlen = 10;
$extralen = 0;
$extra = "";
if ($flags & 4) {
// 2-byte length prefixed EXTRA data in header
if ($len - $headerlen - 2 < 8) {
return false; // Invalid format
}
$extralen = unpack("v",substr($data,8,2));
$extralen = $extralen[1];
if ($len - $headerlen - 2 - $extralen < 8) {
return false; // Invalid format
}
$extra = substr($data,10,$extralen);
$headerlen += 2 + $extralen;
}
$filenamelen = 0;
$filename = "";
if ($flags & 8) {
// C-style string file NAME data in header
if ($len - $headerlen - 1 < 8) {
return false; // Invalid format
}
$filenamelen = strpos(substr($data,8+$extralen),chr(0));
if ($filenamelen === false || $len - $headerlen - $filenamelen - 1 < 8) {
return false; // Invalid format
}
$filename = substr($data,$headerlen,$filenamelen);
$headerlen += $filenamelen + 1;
}
$commentlen = 0;
$comment = "";
if ($flags & 16) {
// C-style string COMMENT data in header
if ($len - $headerlen - 1 < 8) {
return false; // Invalid format
}
$commentlen = strpos(substr($data,8+$extralen+$filenamelen),chr(0));
if ($commentlen === false || $len - $headerlen - $commentlen - 1 < 8) {
return false; // Invalid header format
}
$comment = substr($data,$headerlen,$commentlen);
$headerlen += $commentlen + 1;
}
$headercrc = "";
if ($flags & 1) {
// 2-bytes (lowest order) of CRC32 on header present
if ($len - $headerlen - 2 < 8) {
return false; // Invalid format
}
$calccrc = crc32(substr($data,0,$headerlen)) & 0xffff;
$headercrc = unpack("v", substr($data,$headerlen,2));
$headercrc = $headercrc[1];
if ($headercrc != $calccrc) {
return false; // Bad header CRC
}
$headerlen += 2;
}
// GZIP FOOTER - These be negative due to PHP's limitations
$datacrc = unpack("V",substr($data,-8,4));
$datacrc = $datacrc[1];
$isize = unpack("V",substr($data,-4));
$isize = $isize[1];
// Perform the decompression:
$bodylen = $len-$headerlen-8;
if ($bodylen < 1) {
// This should never happen - IMPLEMENTATION BUG!
return null;
}
$body = substr($data,$headerlen,$bodylen);
$data = "";
if ($bodylen > 0) {
switch ($method) {
case 8:
// Currently the only supported compression method:
$data = gzinflate($body);
break;
default:
// Unknown compression method
return false;
}
} else {
// I'm not sure if zero-byte body content is allowed.
// Allow it for now... Do nothing...
}
// Verifiy decompressed size and CRC32:
// NOTE: This may fail with large data sizes depending on how
// PHP's integer limitations affect strlen() since $isize
// may be negative for large sizes.
if ($isize != strlen($data) || crc32($data) != $datacrc) {
// Bad format! Length or CRC doesn't match!
return false;
}
return $data;
}
用途:
$html=file_get_contents('http://www.gxlcms.com/');
$html=gzdecode($html);
介绍这三种方法,应该可以解决gzip引起的大部分乱码问题。
php网页抓取乱码(python2抓取网页的内容显示出来是怎么回事?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-05 23:15
)
使用python2爬取网页时,经常会遇到抓取到的内容显示为乱码的情况。
这种情况最大的可能是编码问题:运行环境的字符编码和网页的字符编码不一致。
例如,在 Windows 控制台 (gbk) 中获取一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓取一个gbk编码的网站(utf-8)。因为大部分网站使用utf-8编码,而且很多人使用windows,都是很常见。
如果你发现你抓取的内容在英文、数字、符号上看起来都正确,但是中间有一些乱码,你基本上可以断定是这样的。
这个问题的解决方法是先将结果按照网页的编码方式解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site")
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
复制代码
'ignore' 参数用于忽略无法解码的字符。
但是,这种方法并不总是有效。另一种方式是通过正则表达式直接匹配网页代码中的编码设置:
复制代码
除了编码问题导致的乱码之外,另一个经常被忽视的情况是目标页面启用了 gzip 压缩。压缩网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的头部信息自动解压。但是直接用代码抓取不会。因此,很可能会产生困惑,为什么打开网页地址是对的,但程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现是,几乎所有的抓取内容都是乱码,甚至无法显示。
要确定网页是否启用了压缩并解压缩,请使用以下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site")
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
复制代码
在我们的课堂编程示例查看天气系列(点击查看)中,这两个问题困扰了不少人。这里有一个特殊的解释。
最后,还有一个“武器”要介绍。如果你一开始使用它,你甚至都不知道存在上述两个问题。
这是请求模块。
与爬网类似,只需:
import requests
print requests.get("http://some.web.site").text
复制代码
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考之前的文章:
如何为 Python 安装第三方模块 - Crossin 的编程课堂 - 知乎专栏
pip install requests
复制代码
其他 文章 和答案:
查看全部
php网页抓取乱码(python2抓取网页的内容显示出来是怎么回事?(图)
)
使用python2爬取网页时,经常会遇到抓取到的内容显示为乱码的情况。
这种情况最大的可能是编码问题:运行环境的字符编码和网页的字符编码不一致。
例如,在 Windows 控制台 (gbk) 中获取一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓取一个gbk编码的网站(utf-8)。因为大部分网站使用utf-8编码,而且很多人使用windows,都是很常见。
如果你发现你抓取的内容在英文、数字、符号上看起来都正确,但是中间有一些乱码,你基本上可以断定是这样的。

这个问题的解决方法是先将结果按照网页的编码方式解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site";)
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
复制代码
'ignore' 参数用于忽略无法解码的字符。
但是,这种方法并不总是有效。另一种方式是通过正则表达式直接匹配网页代码中的编码设置:
复制代码
除了编码问题导致的乱码之外,另一个经常被忽视的情况是目标页面启用了 gzip 压缩。压缩网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的头部信息自动解压。但是直接用代码抓取不会。因此,很可能会产生困惑,为什么打开网页地址是对的,但程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现是,几乎所有的抓取内容都是乱码,甚至无法显示。
要确定网页是否启用了压缩并解压缩,请使用以下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site";)
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
复制代码
在我们的课堂编程示例查看天气系列(点击查看)中,这两个问题困扰了不少人。这里有一个特殊的解释。
最后,还有一个“武器”要介绍。如果你一开始使用它,你甚至都不知道存在上述两个问题。
这是请求模块。
与爬网类似,只需:
import requests
print requests.get("http://some.web.site";).text
复制代码
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考之前的文章:
如何为 Python 安装第三方模块 - Crossin 的编程课堂 - 知乎专栏
pip install requests
复制代码
其他 文章 和答案:

php网页抓取乱码(一下爬虫乱码的解决方法有哪些?时出现了问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-29 11:14
现在越来越多的人在学习爬虫程序,难免会在学习中遇到问题,比如爬取时出现乱码等。跟大家分享一下爬虫乱码的解决方法。
网络爬虫有两种选择,一种是nutch、hetriex,一种是自编译爬虫。处理乱码的时候,原理是一样的,但是处理乱码的时候,前者只能在理解后修改源代码,所以要浪费一些精力;后者更加自由方便,可以在编码过程中处理。这也是很多人在用框架写爬虫的时候没有开始的原因。比如比较成熟的nutch在处理乱码方面比较简单,所以还是会出现乱码,所以需要二次开发才能真正解决乱码问题。
1、网络爬虫出现乱码的原因
源页面的编码与爬取后的编码转换不一致。如果源网页是gbk编码的字节流,程序爬取后直接用utf-8编码输出到存储文件,难免会造成乱码,即源网页编码时程序爬取编码一致时不会出现乱码,统一字符编码后不会出现乱码。注意区分源网络代码A、程序直接使用的代码B、统一转换字符的代码c。
A. 是网页的服务端编码
B. 抓取的数据最初是一个字节数组,由A编码。只有B=A时才能没有乱码,否则在字符集不兼容的情况下总会出现乱码。此步骤通常用于测试。
C、统一转码是指得到网页的原码A后进行统一编码,主要是将各个网页的数据统一为一种编码,通常选择字符集较大的utf-8比较合适。
每个网页都有自己的编码,比如gbk、utf-8、iso8859-1,还有日系jp系统编码,西欧、俄文等编码都不一样,爬的时候总会展开出各种编码,有的爬虫对网页进行简单的编码识别,然后进行统一编码,有的不判断源页面,直接按照utf-8处理,显然会造成乱码。
2、乱码的解决方法
(1)程序通过编码B恢复源网页数据
很明显,这里的B等于A。在java中,如果得到的源网页的字节数组是source_byte_array,那么就转换为String str=new String(source_byte_array, B); 也就是内存中的这些字节数组对应的字符被正确编码并可以显示,此时的打印输出是正常的。这一步通常用于调试或控制台输出进行测试。
(2)确定源网页的编码A
代码A通常位于网页中的三个位置,http头的内容,网页的元字符集,以及网页头中的Document定义。在获取源网页的代码时,依次判断这三部分数据就足够了,而且从前到后优先级也是一样的。
这个理论上是对的,但是国内有的网站确实是很不合规的,比如gbk,其实是utf-8,有的是utf-8,其实是gbk,当然这个很A小批量 网站,但它确实存在。因此,在确定网页代码时,应针对特殊情况进行特殊处理,如中文校验、默认代码等策略。
还有一种情况是以上三种都没有编码信息,一般使用第三方网页编码智能识别工具如cpdetector来做。准确率,但我实际上发现准确率仍然非常有限。
不过结合以上三种编码确认方式后,中文乱码问题几乎可以完全解决。在我基于nutch1.6二次开发的网络爬虫系统中,据统计正确编码可以达到99.的99%,这也证明了上述方法策略的可行性。
(3) 统一转码
网络爬虫系统的数据来源很多,当无法使用数据时,就会将其转换成它的原创数据,即使这样做是非常没用的。所以一般的爬虫系统应该对抓取到的结果进行统一编码,这样就可以统一对外使用,方便使用。这时候在(2)的基础上,可以做一个统一的编码转换。java中的实现如下
源网页的字节数组是source_byte_array
转换成普通字符串:String normal_source_str=new String(source_byte_array, C),可以直接用java api存储,但很多时候不直接写字符串,因为一般爬虫存储是存储多源web pages 合并到一个文件中,所以需要记录字节偏移量,所以下一步。
然后将得到的str转换成统一编码C格式的字节数组,然后byte[] new_byte_array=normal_source_str.getBytes©,然后可以使用java io api将数组写入文件并记录对应的字节数组Offset等。实际使用时,可以直接通过io读取。
以上方案可以解决爬取时出现乱码的问题。爬取信息不仅会出现乱码,还有网站爬取涉及法律、IP封禁、IP限制等,如何避免IP封杀?为了防止ip被屏蔽,我们需要使用代理ip软件。一直在用**可变ip**,全国城市ip,自动去重,百万优质动态ip每天可使用,支持http/https/socks5三大协议! 查看全部
php网页抓取乱码(一下爬虫乱码的解决方法有哪些?时出现了问题)
现在越来越多的人在学习爬虫程序,难免会在学习中遇到问题,比如爬取时出现乱码等。跟大家分享一下爬虫乱码的解决方法。
网络爬虫有两种选择,一种是nutch、hetriex,一种是自编译爬虫。处理乱码的时候,原理是一样的,但是处理乱码的时候,前者只能在理解后修改源代码,所以要浪费一些精力;后者更加自由方便,可以在编码过程中处理。这也是很多人在用框架写爬虫的时候没有开始的原因。比如比较成熟的nutch在处理乱码方面比较简单,所以还是会出现乱码,所以需要二次开发才能真正解决乱码问题。
1、网络爬虫出现乱码的原因
源页面的编码与爬取后的编码转换不一致。如果源网页是gbk编码的字节流,程序爬取后直接用utf-8编码输出到存储文件,难免会造成乱码,即源网页编码时程序爬取编码一致时不会出现乱码,统一字符编码后不会出现乱码。注意区分源网络代码A、程序直接使用的代码B、统一转换字符的代码c。
A. 是网页的服务端编码
B. 抓取的数据最初是一个字节数组,由A编码。只有B=A时才能没有乱码,否则在字符集不兼容的情况下总会出现乱码。此步骤通常用于测试。
C、统一转码是指得到网页的原码A后进行统一编码,主要是将各个网页的数据统一为一种编码,通常选择字符集较大的utf-8比较合适。
每个网页都有自己的编码,比如gbk、utf-8、iso8859-1,还有日系jp系统编码,西欧、俄文等编码都不一样,爬的时候总会展开出各种编码,有的爬虫对网页进行简单的编码识别,然后进行统一编码,有的不判断源页面,直接按照utf-8处理,显然会造成乱码。
2、乱码的解决方法
(1)程序通过编码B恢复源网页数据
很明显,这里的B等于A。在java中,如果得到的源网页的字节数组是source_byte_array,那么就转换为String str=new String(source_byte_array, B); 也就是内存中的这些字节数组对应的字符被正确编码并可以显示,此时的打印输出是正常的。这一步通常用于调试或控制台输出进行测试。
(2)确定源网页的编码A
代码A通常位于网页中的三个位置,http头的内容,网页的元字符集,以及网页头中的Document定义。在获取源网页的代码时,依次判断这三部分数据就足够了,而且从前到后优先级也是一样的。
这个理论上是对的,但是国内有的网站确实是很不合规的,比如gbk,其实是utf-8,有的是utf-8,其实是gbk,当然这个很A小批量 网站,但它确实存在。因此,在确定网页代码时,应针对特殊情况进行特殊处理,如中文校验、默认代码等策略。
还有一种情况是以上三种都没有编码信息,一般使用第三方网页编码智能识别工具如cpdetector来做。准确率,但我实际上发现准确率仍然非常有限。
不过结合以上三种编码确认方式后,中文乱码问题几乎可以完全解决。在我基于nutch1.6二次开发的网络爬虫系统中,据统计正确编码可以达到99.的99%,这也证明了上述方法策略的可行性。
(3) 统一转码
网络爬虫系统的数据来源很多,当无法使用数据时,就会将其转换成它的原创数据,即使这样做是非常没用的。所以一般的爬虫系统应该对抓取到的结果进行统一编码,这样就可以统一对外使用,方便使用。这时候在(2)的基础上,可以做一个统一的编码转换。java中的实现如下
源网页的字节数组是source_byte_array
转换成普通字符串:String normal_source_str=new String(source_byte_array, C),可以直接用java api存储,但很多时候不直接写字符串,因为一般爬虫存储是存储多源web pages 合并到一个文件中,所以需要记录字节偏移量,所以下一步。
然后将得到的str转换成统一编码C格式的字节数组,然后byte[] new_byte_array=normal_source_str.getBytes©,然后可以使用java io api将数组写入文件并记录对应的字节数组Offset等。实际使用时,可以直接通过io读取。
以上方案可以解决爬取时出现乱码的问题。爬取信息不仅会出现乱码,还有网站爬取涉及法律、IP封禁、IP限制等,如何避免IP封杀?为了防止ip被屏蔽,我们需要使用代理ip软件。一直在用**可变ip**,全国城市ip,自动去重,百万优质动态ip每天可使用,支持http/https/socks5三大协议!
php网页抓取乱码(利用encode与decode解决乱码问题的解决方法有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-26 08:25
一、乱码问题描述
经常在爬虫或者一些操作中,经常会出现中文乱码等问题,如下
原因是源网页的编码与爬取后的编码格式不一致。
二、使用encode和decode解决乱码问题
Python 中字符串的内部表示是 unicode 编码。在进行编码转换时,通常需要使用unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再将unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符串转成unicode编码,如str1.decode('gb2312'),意思是将gb2312编码的字符串str1转换成u source gaodai#ma#com *generation#代码net nicode 编码。
encode的作用是将unicode编码转换为其他编码字符串,如str2.encode('utf-8'),意思是将unicode编码的字符串str2转换为utf-8编码。
decode里面写的是你要抓取的网页的code,encode是你要设置的code
代码显示如下
#!/usr/bin/env python # -*- coding:utf-8 -*- # author: xulinjie time:2017/10/22 import urllib2 request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/') RES=urllib2.urlopen(request).read() RES = RES.decode('gb2312').encode('utf-8')//解决乱码 wfile=open(r'./1.html',r'wb') wfile.write(RES) wfile.close() print RES
或者
#!/usr/bin/env python # -*- coding:utf-8 -*- # author: xulinjie time:2017/10/22 import urllib2 request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/') RES=urllib2.urlopen(request).read() RES=RES.decode('gb2312') RES=RES.encode('utf-8') wfile=open(r'./1.html',r'wb') wfile.write(RES) wfile.close() print RES
但还要注意:
如果一个字符串已经是unicode,那么解码就会出错,所以通常需要判断编码方式是否是unicode
isinstance(s, unicode)#用于判断是否为unicode
用非unicode编码的str编码会报错
所以最终可靠的代码:
#!/usr/bin/env python # -*- coding:utf-8 -*- # author: xulinjie time:2017/10/22 import urllib2 request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/') RES=urllib2.urlopen(request).read() if isinstance(RES, unicode): RES=RES.encode('utf-8') else: RES=RES.decode('gb2312').encode('utf-8') wfile=open(r'./1.html',r'wb') wfile.write(RES) wfile.close() print RES
三、如何找到需要爬取的着陆页的编码格式
1、查看网页源代码
如果源码中没有charset编码格式显示,可以使用下面的方法
2、检查元素,查看响应标头 查看全部
php网页抓取乱码(利用encode与decode解决乱码问题的解决方法有哪些?)
一、乱码问题描述
经常在爬虫或者一些操作中,经常会出现中文乱码等问题,如下
原因是源网页的编码与爬取后的编码格式不一致。
二、使用encode和decode解决乱码问题
Python 中字符串的内部表示是 unicode 编码。在进行编码转换时,通常需要使用unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再将unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符串转成unicode编码,如str1.decode('gb2312'),意思是将gb2312编码的字符串str1转换成u source gaodai#ma#com *generation#代码net nicode 编码。
encode的作用是将unicode编码转换为其他编码字符串,如str2.encode('utf-8'),意思是将unicode编码的字符串str2转换为utf-8编码。
decode里面写的是你要抓取的网页的code,encode是你要设置的code
代码显示如下
#!/usr/bin/env python # -*- coding:utf-8 -*- # author: xulinjie time:2017/10/22 import urllib2 request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/') RES=urllib2.urlopen(request).read() RES = RES.decode('gb2312').encode('utf-8')//解决乱码 wfile=open(r'./1.html',r'wb') wfile.write(RES) wfile.close() print RES
或者
#!/usr/bin/env python # -*- coding:utf-8 -*- # author: xulinjie time:2017/10/22 import urllib2 request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/') RES=urllib2.urlopen(request).read() RES=RES.decode('gb2312') RES=RES.encode('utf-8') wfile=open(r'./1.html',r'wb') wfile.write(RES) wfile.close() print RES
但还要注意:
如果一个字符串已经是unicode,那么解码就会出错,所以通常需要判断编码方式是否是unicode
isinstance(s, unicode)#用于判断是否为unicode
用非unicode编码的str编码会报错
所以最终可靠的代码:
#!/usr/bin/env python # -*- coding:utf-8 -*- # author: xulinjie time:2017/10/22 import urllib2 request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/') RES=urllib2.urlopen(request).read() if isinstance(RES, unicode): RES=RES.encode('utf-8') else: RES=RES.decode('gb2312').encode('utf-8') wfile=open(r'./1.html',r'wb') wfile.write(RES) wfile.close() print RES
三、如何找到需要爬取的着陆页的编码格式
1、查看网页源代码
如果源码中没有charset编码格式显示,可以使用下面的方法
2、检查元素,查看响应标头
php网页抓取乱码(Linuxhtml页面里中文乱码怎么解决1/7/202115 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-13 16:07
)
相关主题
如何解决乱码网页
2/2/202118:06:09
本文运行环境:windows10系统,360安全浏览器12.2.1607.0、Acer S40-51解决方法:打开网页,都是如果看不懂文字,这是乱码。右键单击网页以弹出菜单。在弹出菜单中找到编辑
解决ssh连接CentOS后中文显示乱码
2/2/202117:29:24
ssh远程终端乱码如果SSH终端还是乱码,那么我们还需要设置终端软件的编码。 Xshell:如果终端还是中文乱码怎么办?设置SSH软件,选择支持中文的字体。 Linux
html页面出现中文乱码如何解决
1/7/202115:16:18
中文乱码的解决方法:1、在HTML文档的head部分,使用“”语句设置编码方式; 2、使用网页编辑器打开HTML文档,设置编码统一文件和代码的编码格式。本教程的运行环境:windows7系统
PHP下载中文乱码解决方案
10/7/202015:04:07
php下载中文乱码的解决方法:先打开相关代码文件;然后使用"iconv()"函数解决乱码,具体语法为"$file_name=iconv("utf-8","gb2312",$file_name);"。 php下载解决中文乱码
如何处理乱码的css网页
17/11/202012:04:56
CSS页面乱码解决方法:1、设置CSS字符编码与页面字符编码一致,设置编码语句如“@charset”utf-8“;”;2、当写css时加强注释; 3、 使用字体别名。推荐:《css视频教程》解决方案
centos in ssh,telnet终端中文显示乱码的解决办法
21/1/202106:13:03
在ssh中,telnet终端中文显示乱码解决办法#vim/etc/sysconfig/i18n 将原来的内容:LANG="en_US.UTF-8"SYSFONT="latarcyrheb-sun16"修改为:LANG="zh_CN.GB18030" LANGUAGE="zh_CN.GB
如何确定网页首屏的高度?
17/4/2012 16:27:00
一个有经验的网页设计师在做网页原型设计或者视觉效果图的时候,首先要做的就是清楚地标出网站第一屏的高度线,以便直观的看到网站@ > 首屏高度,首屏可以显示的元素。那么,我们如何标记网页的首屏线呢?
响应式网页设计和 SEO
2013 年 6 月 20 日 14:47:00
所谓的“响应式网页设计(Responsive Web Design)”也是自适应的,即可以自动识别屏幕宽度并做出相应调整的网页设计。目前这种设计出现在越来越多的国内网站中,谷歌已经明确表示鼓励响应式网页设计。
简化您的网页设计
19/2/2013 14:55:00
随着网站构建技术的发展,在网页中实现复杂的功能不再是难事。网页中的功能越来越多。因此,既要兼顾用户的浏览体验,又要兼顾网页设计的美感。平衡点非常重要。
宝安网页设计从SEO角度谈网页设计标准
17/6/202015:30:19
深圳宝安网页设计从SEO角度谈网页设计标准。在任何时候,网站访问者都处于以下阶段之一: 1. 注意; 2、利息; 3.欲望; 4. 行动; 5.满足。每个阶段的访客都不一样
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
DBeaver链接Oracle数据库中文显示乱码
4/3/201801:09:50
1.后台DBeaver是一款不错的开源数据库客户端,基本的增删改查就够了。但是在链接Oracle的时候,由于字符编码的问题,很容易产生乱码。德鲁伊可以用来解决这个问题。可以参考使用Druid解决OracleThin驱动中的中文乱码。下面是详细配置。 (P.S.不光是DBeaver和Oracle,其他客户端和数据库都有乱码问题。
mysql命令行显示中文乱码怎么办
27/10/202015:03:56
mysql命令行显示中文乱码的解决方法:1、出现乱码的原因是登录时使用了lastin码,所以需要重新注销再使用该码清楚地登录; 2、重新查询中文表; 3、登录密码必须和安装数据库时使用的一致
phpimagestring出现中文乱码怎么办
19/8/202012:03:34
phpimagestring出现中文乱码是GD2库本身没有中文字体造成的。解决方法是指定字体来显示输出字符串。推荐:《PHP视频教程》imagestring函数显示中文乱码1.问题描述
如何解决php网页抓取的乱码问题
4/9/202012:03:36
爬取乱码php网页的解决方案:1、使用“mbconvertencoding”转换编码; 2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” option;3、在顶部添加标题代码。推荐
查看全部
php网页抓取乱码(Linuxhtml页面里中文乱码怎么解决1/7/202115
)
相关主题
如何解决乱码网页
2/2/202118:06:09
本文运行环境:windows10系统,360安全浏览器12.2.1607.0、Acer S40-51解决方法:打开网页,都是如果看不懂文字,这是乱码。右键单击网页以弹出菜单。在弹出菜单中找到编辑
解决ssh连接CentOS后中文显示乱码
2/2/202117:29:24
ssh远程终端乱码如果SSH终端还是乱码,那么我们还需要设置终端软件的编码。 Xshell:如果终端还是中文乱码怎么办?设置SSH软件,选择支持中文的字体。 Linux
html页面出现中文乱码如何解决
1/7/202115:16:18
中文乱码的解决方法:1、在HTML文档的head部分,使用“”语句设置编码方式; 2、使用网页编辑器打开HTML文档,设置编码统一文件和代码的编码格式。本教程的运行环境:windows7系统
PHP下载中文乱码解决方案
10/7/202015:04:07
php下载中文乱码的解决方法:先打开相关代码文件;然后使用"iconv()"函数解决乱码,具体语法为"$file_name=iconv("utf-8","gb2312",$file_name);"。 php下载解决中文乱码
如何处理乱码的css网页
17/11/202012:04:56
CSS页面乱码解决方法:1、设置CSS字符编码与页面字符编码一致,设置编码语句如“@charset”utf-8“;”;2、当写css时加强注释; 3、 使用字体别名。推荐:《css视频教程》解决方案
centos in ssh,telnet终端中文显示乱码的解决办法
21/1/202106:13:03
在ssh中,telnet终端中文显示乱码解决办法#vim/etc/sysconfig/i18n 将原来的内容:LANG="en_US.UTF-8"SYSFONT="latarcyrheb-sun16"修改为:LANG="zh_CN.GB18030" LANGUAGE="zh_CN.GB
如何确定网页首屏的高度?
17/4/2012 16:27:00
一个有经验的网页设计师在做网页原型设计或者视觉效果图的时候,首先要做的就是清楚地标出网站第一屏的高度线,以便直观的看到网站@ > 首屏高度,首屏可以显示的元素。那么,我们如何标记网页的首屏线呢?
响应式网页设计和 SEO
2013 年 6 月 20 日 14:47:00
所谓的“响应式网页设计(Responsive Web Design)”也是自适应的,即可以自动识别屏幕宽度并做出相应调整的网页设计。目前这种设计出现在越来越多的国内网站中,谷歌已经明确表示鼓励响应式网页设计。
简化您的网页设计
19/2/2013 14:55:00
随着网站构建技术的发展,在网页中实现复杂的功能不再是难事。网页中的功能越来越多。因此,既要兼顾用户的浏览体验,又要兼顾网页设计的美感。平衡点非常重要。
宝安网页设计从SEO角度谈网页设计标准
17/6/202015:30:19
深圳宝安网页设计从SEO角度谈网页设计标准。在任何时候,网站访问者都处于以下阶段之一: 1. 注意; 2、利息; 3.欲望; 4. 行动; 5.满足。每个阶段的访客都不一样
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
DBeaver链接Oracle数据库中文显示乱码
4/3/201801:09:50
1.后台DBeaver是一款不错的开源数据库客户端,基本的增删改查就够了。但是在链接Oracle的时候,由于字符编码的问题,很容易产生乱码。德鲁伊可以用来解决这个问题。可以参考使用Druid解决OracleThin驱动中的中文乱码。下面是详细配置。 (P.S.不光是DBeaver和Oracle,其他客户端和数据库都有乱码问题。
mysql命令行显示中文乱码怎么办
27/10/202015:03:56
mysql命令行显示中文乱码的解决方法:1、出现乱码的原因是登录时使用了lastin码,所以需要重新注销再使用该码清楚地登录; 2、重新查询中文表; 3、登录密码必须和安装数据库时使用的一致
phpimagestring出现中文乱码怎么办
19/8/202012:03:34
phpimagestring出现中文乱码是GD2库本身没有中文字体造成的。解决方法是指定字体来显示输出字符串。推荐:《PHP视频教程》imagestring函数显示中文乱码1.问题描述
如何解决php网页抓取的乱码问题
4/9/202012:03:36
爬取乱码php网页的解决方案:1、使用“mbconvertencoding”转换编码; 2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” option;3、在顶部添加标题代码。推荐
php网页抓取乱码( PHP与Mysql的数据交互(一)_PHP网页的编码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-09 14:26
PHP与Mysql的数据交互(一)_PHP网页的编码
)
配置phpstudy,访问页面出现中文乱码,解决方法如下。
一、PHP网页的编码
1、 php文件本身的编码要和网页的编码匹配
一种。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; charset=gb2312"),添加一个静态页面,所有文件的编码格式都是ANSI,可以是用记事本打开并保存为选择编码为ANSI以覆盖源文件。
湾。如果要使用utf-8编码,那么php应该输出header:header("Content-Type: text/html; charset=utf-8"),添加静态页面,所有文件的编码格式都是utf- 8.
保存为 utf-8 可能有点麻烦。一般utf-8文件开头都会有BOM。如果使用session,就会出现问题。你可以使用editplus来保存。在editplus中,tools->parameter selection->file->UTF-8 Signature,选择Always delete,然后save去掉BOM信息。
2、php 本身不是 Unicode
substr等所有函数都必须改成mb_substr(需要安装mbstring扩展),或者使用iconv转码。
二、PHP与Mysql的数据交互
1、PHP和数据库的编码要一致
修改mysql配置文件my.ini或f,mysql最好用utf8编码。
2、在需要做数据库操作的php程序前加上mysql_query("set names 'encoding'")
编码与PHP编码一致。如果 PHP 编码为 gb2312,则 MySQL 编码为 gb2312。如果是utf-8,则MySQL编码为utf8,这样插入或检索数据时不会出现乱码。
三、PHP 依赖于操作系统
Windows 和 Linux 的编码是不同的。在Windows环境下,如果调用PHP函数时参数是utf-8编码的,会出现错误,如move_uploaded_file()、filesize()、readfile()等,这些函数是处理上传的。, 下载时经常使用,调用时可能会出错。
虽然在Linux环境下gb2312编码不会出现这些错误,但是保存后的文件名是乱码,无法读取文件。此时,参数可以转换为操作系统识别的编码。编码转换可以是mb_convert_encoding(string, New encoding, original encoding)或者iconv(original encoding, new encoding, string),这样处理后保存的文件名不会出现乱码,可以正常读取文件,可实现中文名称文件的上传下载。
其实还有更好的方案,完全脱离系统,不需要考虑系统编码什么。您可以生成一个只有字母和数字的序列作为文件名,并将原来的中文名称保存在数据库中,这样调用move_uploaded_file()就不会出现问题。下载的时候把文件名改成原来的中文名即可。实现下载的代码如下:
最后,其实就是修改一个php页面,添加一个输出头。
推荐教程:PHP视频教程
以上就是php网页乱码的详细内容。更多详情请关注php中文网文章其他相关话题!
查看全部
php网页抓取乱码(
PHP与Mysql的数据交互(一)_PHP网页的编码
)
配置phpstudy,访问页面出现中文乱码,解决方法如下。
一、PHP网页的编码
1、 php文件本身的编码要和网页的编码匹配
一种。如果要使用gb2312编码,那么php应该输出header:header("Content-Type: text/html; charset=gb2312"),添加一个静态页面,所有文件的编码格式都是ANSI,可以是用记事本打开并保存为选择编码为ANSI以覆盖源文件。
湾。如果要使用utf-8编码,那么php应该输出header:header("Content-Type: text/html; charset=utf-8"),添加静态页面,所有文件的编码格式都是utf- 8.
保存为 utf-8 可能有点麻烦。一般utf-8文件开头都会有BOM。如果使用session,就会出现问题。你可以使用editplus来保存。在editplus中,tools->parameter selection->file->UTF-8 Signature,选择Always delete,然后save去掉BOM信息。
2、php 本身不是 Unicode
substr等所有函数都必须改成mb_substr(需要安装mbstring扩展),或者使用iconv转码。
二、PHP与Mysql的数据交互
1、PHP和数据库的编码要一致
修改mysql配置文件my.ini或f,mysql最好用utf8编码。
2、在需要做数据库操作的php程序前加上mysql_query("set names 'encoding'")
编码与PHP编码一致。如果 PHP 编码为 gb2312,则 MySQL 编码为 gb2312。如果是utf-8,则MySQL编码为utf8,这样插入或检索数据时不会出现乱码。
三、PHP 依赖于操作系统
Windows 和 Linux 的编码是不同的。在Windows环境下,如果调用PHP函数时参数是utf-8编码的,会出现错误,如move_uploaded_file()、filesize()、readfile()等,这些函数是处理上传的。, 下载时经常使用,调用时可能会出错。
虽然在Linux环境下gb2312编码不会出现这些错误,但是保存后的文件名是乱码,无法读取文件。此时,参数可以转换为操作系统识别的编码。编码转换可以是mb_convert_encoding(string, New encoding, original encoding)或者iconv(original encoding, new encoding, string),这样处理后保存的文件名不会出现乱码,可以正常读取文件,可实现中文名称文件的上传下载。
其实还有更好的方案,完全脱离系统,不需要考虑系统编码什么。您可以生成一个只有字母和数字的序列作为文件名,并将原来的中文名称保存在数据库中,这样调用move_uploaded_file()就不会出现问题。下载的时候把文件名改成原来的中文名即可。实现下载的代码如下:
最后,其实就是修改一个php页面,添加一个输出头。
推荐教程:PHP视频教程
以上就是php网页乱码的详细内容。更多详情请关注php中文网文章其他相关话题!
php网页抓取乱码(PHPwebService服务器本地语言的Get方法获取参数时获取到的参数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-09 12:16
最近在做PHP webService服务器,发现使用Get方法获取参数时获取的参数是乱码。经过一番折腾,发现浏览器本地语言的问题。首先,我们来看一下简单的测试代码:
header("内容类型:text/html;charset=UTF-8");
$name=['name'];
var_dump($name);
测试结果如下:
代码声明响应内容的编码为utf-8,显示的内容确实是乱码。这里请注意var_dump输出的变量长度只有4。显然,utf-8编码下两个汉字的长度必须大于4字节,接下来我们看一下火狐访问这个的url页
FireFox会自动对中文url进行编码,所以我们可以看到测试变成了%B2%E2%CA%D4。显然,这里的一个词是两个字节,是 gb2313、gbk 等中文编码格式,而不是 utf-8 编码。如果我们将页面的编码切换为gbk,中文参数会正常显示,见下图
接下来我们再做一个测试,代码如下:
header("内容类型:text/html;charset=UTF-8");
$name=['name'];
var_dump($name);
测试结果,正常显示:
那么,是什么导致了这个问题呢?
答案是浏览器的默认编码有问题。我们都使用中文系统,浏览器的默认编码自然会设置为本地化。比如我自己电脑上IE和FireFox的默认编码都是gb系列。
当浏览器请求用户输入的url时,会以默认编码格式而不是页面默认编码格式发送url中的中文,这就是为什么页面中带有中文的链接是正常的,链接我们手动输入
乱码的原因。同样,如果我们将浏览器的默认编码调整为utf-8,那么输入url中的中文就会按照utf-8进行编码。
除上述情况外,还会在以下情况下发生这种情况:
如果gbk编码页面生成的地址链接到utf-8页面,gbk页面的中文以gbk格式编码传输到下一页,那么utf-8后面肯定会出现乱码收到编码。
IIS的url重写模块,重写的中文编码也是gbk,如果你的页面是utf-8编码,那么重写参数会失效。在这些情况下,我们需要使用php内置的转码功能来处理编码问题:
计划一:
$name"gbk","utf-8",$name);
场景二:
$name,"utf-8","gbk");
PS:实测IE浏览器默认GET编码方式采用占用空间最小的方式,即使用GBK码,在php页面中加入这个转换功能即可正常使用。Firefox 和 Chrom 默认为 UTF-8,没有此转换功能。 查看全部
php网页抓取乱码(PHPwebService服务器本地语言的Get方法获取参数时获取到的参数)
最近在做PHP webService服务器,发现使用Get方法获取参数时获取的参数是乱码。经过一番折腾,发现浏览器本地语言的问题。首先,我们来看一下简单的测试代码:
header("内容类型:text/html;charset=UTF-8");
$name=['name'];
var_dump($name);
测试结果如下:
代码声明响应内容的编码为utf-8,显示的内容确实是乱码。这里请注意var_dump输出的变量长度只有4。显然,utf-8编码下两个汉字的长度必须大于4字节,接下来我们看一下火狐访问这个的url页
FireFox会自动对中文url进行编码,所以我们可以看到测试变成了%B2%E2%CA%D4。显然,这里的一个词是两个字节,是 gb2313、gbk 等中文编码格式,而不是 utf-8 编码。如果我们将页面的编码切换为gbk,中文参数会正常显示,见下图
接下来我们再做一个测试,代码如下:
header("内容类型:text/html;charset=UTF-8");
$name=['name'];
var_dump($name);
测试结果,正常显示:
那么,是什么导致了这个问题呢?
答案是浏览器的默认编码有问题。我们都使用中文系统,浏览器的默认编码自然会设置为本地化。比如我自己电脑上IE和FireFox的默认编码都是gb系列。
当浏览器请求用户输入的url时,会以默认编码格式而不是页面默认编码格式发送url中的中文,这就是为什么页面中带有中文的链接是正常的,链接我们手动输入
乱码的原因。同样,如果我们将浏览器的默认编码调整为utf-8,那么输入url中的中文就会按照utf-8进行编码。
除上述情况外,还会在以下情况下发生这种情况:
如果gbk编码页面生成的地址链接到utf-8页面,gbk页面的中文以gbk格式编码传输到下一页,那么utf-8后面肯定会出现乱码收到编码。
IIS的url重写模块,重写的中文编码也是gbk,如果你的页面是utf-8编码,那么重写参数会失效。在这些情况下,我们需要使用php内置的转码功能来处理编码问题:
计划一:
$name"gbk","utf-8",$name);
场景二:
$name,"utf-8","gbk");
PS:实测IE浏览器默认GET编码方式采用占用空间最小的方式,即使用GBK码,在php页面中加入这个转换功能即可正常使用。Firefox 和 Chrom 默认为 UTF-8,没有此转换功能。
php网页抓取乱码(PHP中文乱码有时发生在网页本身产生在于MySQL交互)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-02-27 17:04
PHP中文乱码有时出现在网页本身,有的出现在与MySQL交互的过程中,有时与操作系统有关。下面给出一个摘要。
一。首先是PHP网页的编码
最好最快的解决方案是页面声明的代码与数据库的内部代码保持一致。如果页面应用的页码与数据库内部代码不一致,设置连接代码。
代码显示如下
mysql_query("设置名称 XXX");
XXX 是连接代码。它必须能够解决乱码问题。
1. php文件本身的编码和网页的编码要匹配a。如果你想使用 gb2312 编码,那么 php 应该输出 header:
代码显示如下
header("内容类型: text/html; charset=gb2312"),
添加静态页面
代码显示如下
,
所有文件的编码格式都是ANSI,可以用记事本打开,另存为ANSI,覆盖源文件。湾。如果你想使用 utf-8 编码,那么 php 应该输出 header:
代码显示如下
header("内容类型: text/html; charset=utf-8"),
添加静态页面
代码显示如下
,
所有文件都以 utf-8 编码。保存为 utf-8 可能有点麻烦。一般情况下,一个 utf-8 文件的开头都会有一个 BOM。如果使用会话,就会出现问题。您可以使用editplus来保存它。在editplus中,tools->parameter selection->file->UTF-8 Signature,选择Always delete,然后save去掉BOM信息。
2. php本身不是Unicode,substr等所有函数都必须改成mb_substr(需要安装mbstring扩展);或使用 iconv 进行转码。
二。PHP与Mysql的数据交互
PHP和数据库的编码要一致
1.修改mysql配置文件my.ini或者f,mysql最好用utf8编码
代码显示如下
[mysql] 默认字符集=utf8 [mysqld] 默认字符集=utf8 默认存储引擎=MyISAM
在 [mysqld] 下添加:
代码显示如下
default-collation=utf8_bin init_connect='SET NAMES utf8'
2. 添加mysql_query("设置名称'编码'"); 之前需要做数据库操作的php程序,编码和php编码一样,如果php编码是gb2312,那么mysql编码就是gb2312,如果是utf-8,那么mysql编码就是utf8,所以插入或检索数据时不会出现乱码
三。PHP 和操作系统相关的 Windows 和 Linux 的编码是不同的。在windows环境下,如果调用php函数时参数为utf-8编码,会出现错误,如move_uploaded_file()、filesize()、readfile()等,这些函数在处理上传下载时经常用到,而调用时可能会出现以下错误: 警告:move_uploaded_file()[function.move-uploaded-file]:failed to open stream: Invalid argument in ... 警告: move_uploaded_file()[function.move-uploaded-file]:Unable将 '' 移动到 '' in ... 警告:filesize() [function.filesize]: stat failed for ... in ... 警告:readfile() [function.readfile]:打开流失败:参数无效在..虽然在Linux环境下用gb2312编码不会出现这些错误,保存后文件名乱码,无法读取文件。参数被转换成操作系统识别的编码。编码转换可以是mb_convert_encoding(string,new encoding, original encoding)或者iconv(original encoding,new encoding,string),这样处理后保存的文件名不会出现乱码,也可以正常读取文件,并且可以实现中文名称文件的上传和下载。其实还有更好的方案,完全脱离系统,不需要考虑系统编码什么。您可以生成一个只有字母和数字的序列作为文件名,并将原来的中文名称保存在数据库中,这样调用move_uploaded_file()就不会出现问题。下载时,
实现下载的代码如下
代码显示如下
header("Pragma: public");
header("过期时间:0");
header("Cache-Component: must-revalidate, post-check=0, pre-check=0");
header("内容类型:$file_type");
header("内容长度:$file_size");
header("内容配置:附件;文件名="$file_name"");
header("内容传输编码:二进制"); 读取文件($file_path);
$file_type 是文件的类型,$file_name 是原创名称,$file_path 是存储在服务上的文件的地址。
四。下面总结一下为什么乱码一般都是乱码。出现乱码的原因有两个。首先是错误的编码(charset)设置,导致浏览器解析错误的编码,导致满屏都是“天上掉下来的书”,其次是用错误的编码打开文件然后保存。例如,最初以 GB2312 编码的文本文件以 UTF-8 编码打开并保存。要解决上面的乱码问题,首先要知道开发的哪些方面涉及到编码:
1、文件编码:是指保存页面文件(.html、.php等)本身的编码。记事本和 Dreamweaver 在打开页面时会自动识别文件编码,因此问题较少。然而,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有某种编码的文件。如果工作时不注意,打开编码错误的文件,修改后保存,就会出现乱码(感觉很深)。
2、页面声明代码:在HTML代码HEAD中,可以使用
代码显示如下
为了告诉浏览器网页使用什么编码,目前中文网站XXX主要使用GB2312和UTF-8两种编码。3、数据库连接代码:指在数据库操作过程中,使用哪个代码向数据库传输数据。这里需要注意的是不要和数据库本身的代码混淆。例如MySQL内部默认为latin1编码,即Mysql数据以latin1编码存储,其他编码传输到Mysql的数据会转成latin1编码。知道了WEB开发涉及到哪里编码,也就知道乱码的原因了:以上3种编码设置不一致,因为各种编码大部分都兼容ASCII,所以不会出现英文符号,中文会倒霉。.
五号。Showdown一些常见的错误情况和解决方法:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是最常见的乱码原因。此时PHP脚本中直接SELECT数据出现乱码,查询前需要用到:
代码显示如下
mysql_query("设置名称 GBK");
设置MYSQL连接码,保证页面声明码和这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码的,您可以使用:
代码显示如下
mysql_query("设置名称 UTF8");
请注意,它是 UTF8 而不是通常的 UTF-8。如果页面上声明的代码与数据库内部代码一致,则可以不设置连接代码。注意:其实MYSQL的数据输入输出比上面的要复杂一些。MYSQL 配置文件 my.ini 定义了两种默认编码,即 [client] 中的 default-character-set 和 [mysqld] 中的 default -character-set 分别设置用于客户端连接和数据库内部的默认编码。我们上面指定的编码其实就是MYSQL客户端连接服务器时的命令行参数character_set_client,用来告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、页面声明编码与文件本身的编码不一致,这种情况很少发生,因为如果编码不一致,创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小bug,打开错误代码的页面,然后保存。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,由于软件的代码配置错误,转换了错误的代码。3、一些租用虚拟主机的朋友,即使上面三个代码设置正确,还是有乱码的。比如网页是用GB2312编码的,但是IE等浏览器总是把它识别为UTF-8。网页的HEAD已经说明是GB2312。手动修改浏览器编码为GB2312后,页面正常显示。原因是服务器Apache设置了服务器的全局默认编码,并在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级高于页面中声明的代码,所以浏览器会认错。有两种解决方案。请在配置文件的虚拟机中添加一个AddDefaultCharset GB2312来覆盖全局配置,或者在自己目录的.htaccess中进行配置。总结:一句话,解决PHP中文乱码最多的最快的办法就是让页面上声明的代码与数据库内部代码保持一致。
代码显示如下
mysql_query("设置名称 XXX");
XXX 是连接代码。它必须能够解决乱码问题。 查看全部
php网页抓取乱码(PHP中文乱码有时发生在网页本身产生在于MySQL交互)
PHP中文乱码有时出现在网页本身,有的出现在与MySQL交互的过程中,有时与操作系统有关。下面给出一个摘要。
一。首先是PHP网页的编码
最好最快的解决方案是页面声明的代码与数据库的内部代码保持一致。如果页面应用的页码与数据库内部代码不一致,设置连接代码。
代码显示如下
mysql_query("设置名称 XXX");
XXX 是连接代码。它必须能够解决乱码问题。
1. php文件本身的编码和网页的编码要匹配a。如果你想使用 gb2312 编码,那么 php 应该输出 header:
代码显示如下
header("内容类型: text/html; charset=gb2312"),
添加静态页面
代码显示如下
,
所有文件的编码格式都是ANSI,可以用记事本打开,另存为ANSI,覆盖源文件。湾。如果你想使用 utf-8 编码,那么 php 应该输出 header:
代码显示如下
header("内容类型: text/html; charset=utf-8"),
添加静态页面
代码显示如下
,
所有文件都以 utf-8 编码。保存为 utf-8 可能有点麻烦。一般情况下,一个 utf-8 文件的开头都会有一个 BOM。如果使用会话,就会出现问题。您可以使用editplus来保存它。在editplus中,tools->parameter selection->file->UTF-8 Signature,选择Always delete,然后save去掉BOM信息。
2. php本身不是Unicode,substr等所有函数都必须改成mb_substr(需要安装mbstring扩展);或使用 iconv 进行转码。
二。PHP与Mysql的数据交互
PHP和数据库的编码要一致
1.修改mysql配置文件my.ini或者f,mysql最好用utf8编码
代码显示如下
[mysql] 默认字符集=utf8 [mysqld] 默认字符集=utf8 默认存储引擎=MyISAM
在 [mysqld] 下添加:
代码显示如下
default-collation=utf8_bin init_connect='SET NAMES utf8'
2. 添加mysql_query("设置名称'编码'"); 之前需要做数据库操作的php程序,编码和php编码一样,如果php编码是gb2312,那么mysql编码就是gb2312,如果是utf-8,那么mysql编码就是utf8,所以插入或检索数据时不会出现乱码
三。PHP 和操作系统相关的 Windows 和 Linux 的编码是不同的。在windows环境下,如果调用php函数时参数为utf-8编码,会出现错误,如move_uploaded_file()、filesize()、readfile()等,这些函数在处理上传下载时经常用到,而调用时可能会出现以下错误: 警告:move_uploaded_file()[function.move-uploaded-file]:failed to open stream: Invalid argument in ... 警告: move_uploaded_file()[function.move-uploaded-file]:Unable将 '' 移动到 '' in ... 警告:filesize() [function.filesize]: stat failed for ... in ... 警告:readfile() [function.readfile]:打开流失败:参数无效在..虽然在Linux环境下用gb2312编码不会出现这些错误,保存后文件名乱码,无法读取文件。参数被转换成操作系统识别的编码。编码转换可以是mb_convert_encoding(string,new encoding, original encoding)或者iconv(original encoding,new encoding,string),这样处理后保存的文件名不会出现乱码,也可以正常读取文件,并且可以实现中文名称文件的上传和下载。其实还有更好的方案,完全脱离系统,不需要考虑系统编码什么。您可以生成一个只有字母和数字的序列作为文件名,并将原来的中文名称保存在数据库中,这样调用move_uploaded_file()就不会出现问题。下载时,
实现下载的代码如下
代码显示如下
header("Pragma: public");
header("过期时间:0");
header("Cache-Component: must-revalidate, post-check=0, pre-check=0");
header("内容类型:$file_type");
header("内容长度:$file_size");
header("内容配置:附件;文件名="$file_name"");
header("内容传输编码:二进制"); 读取文件($file_path);
$file_type 是文件的类型,$file_name 是原创名称,$file_path 是存储在服务上的文件的地址。
四。下面总结一下为什么乱码一般都是乱码。出现乱码的原因有两个。首先是错误的编码(charset)设置,导致浏览器解析错误的编码,导致满屏都是“天上掉下来的书”,其次是用错误的编码打开文件然后保存。例如,最初以 GB2312 编码的文本文件以 UTF-8 编码打开并保存。要解决上面的乱码问题,首先要知道开发的哪些方面涉及到编码:
1、文件编码:是指保存页面文件(.html、.php等)本身的编码。记事本和 Dreamweaver 在打开页面时会自动识别文件编码,因此问题较少。然而,ZendStudio 不会自动识别编码。它只会根据首选项的配置打开具有某种编码的文件。如果工作时不注意,打开编码错误的文件,修改后保存,就会出现乱码(感觉很深)。
2、页面声明代码:在HTML代码HEAD中,可以使用
代码显示如下
为了告诉浏览器网页使用什么编码,目前中文网站XXX主要使用GB2312和UTF-8两种编码。3、数据库连接代码:指在数据库操作过程中,使用哪个代码向数据库传输数据。这里需要注意的是不要和数据库本身的代码混淆。例如MySQL内部默认为latin1编码,即Mysql数据以latin1编码存储,其他编码传输到Mysql的数据会转成latin1编码。知道了WEB开发涉及到哪里编码,也就知道乱码的原因了:以上3种编码设置不一致,因为各种编码大部分都兼容ASCII,所以不会出现英文符号,中文会倒霉。.
五号。Showdown一些常见的错误情况和解决方法:
1、数据库使用UTF8编码,页面声明编码为GB2312,这是最常见的乱码原因。此时PHP脚本中直接SELECT数据出现乱码,查询前需要用到:
代码显示如下
mysql_query("设置名称 GBK");
设置MYSQL连接码,保证页面声明码和这里设置的连接码一致(GBK是GB2312的扩展)。如果页面是 UTF-8 编码的,您可以使用:
代码显示如下
mysql_query("设置名称 UTF8");
请注意,它是 UTF8 而不是通常的 UTF-8。如果页面上声明的代码与数据库内部代码一致,则可以不设置连接代码。注意:其实MYSQL的数据输入输出比上面的要复杂一些。MYSQL 配置文件 my.ini 定义了两种默认编码,即 [client] 中的 default-character-set 和 [mysqld] 中的 default -character-set 分别设置用于客户端连接和数据库内部的默认编码。我们上面指定的编码其实就是MYSQL客户端连接服务器时的命令行参数character_set_client,用来告诉MYSQL服务器接收到的客户端数据是什么编码,而不是使用默认的编码。
2、页面声明编码与文件本身的编码不一致,这种情况很少发生,因为如果编码不一致,创建页面时浏览器会看到乱码。更多的时候是发布后修改了一些小bug,打开错误代码的页面,然后保存。或者使用一些FTP软件直接在线修改文件,比如CuteFTP,由于软件的代码配置错误,转换了错误的代码。3、一些租用虚拟主机的朋友,即使上面三个代码设置正确,还是有乱码的。比如网页是用GB2312编码的,但是IE等浏览器总是把它识别为UTF-8。网页的HEAD已经说明是GB2312。手动修改浏览器编码为GB2312后,页面正常显示。原因是服务器Apache设置了服务器的全局默认编码,并在httpd.conf中添加了AddDefaultCharset UTF-8。这时候服务器会先把HTTP头发送给浏览器,它的优先级高于页面中声明的代码,所以浏览器会认错。有两种解决方案。请在配置文件的虚拟机中添加一个AddDefaultCharset GB2312来覆盖全局配置,或者在自己目录的.htaccess中进行配置。总结:一句话,解决PHP中文乱码最多的最快的办法就是让页面上声明的代码与数据库内部代码保持一致。
代码显示如下
mysql_query("设置名称 XXX");
XXX 是连接代码。它必须能够解决乱码问题。
php网页抓取乱码(1.为什么会出现乱码?乱码问题的原因是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-02-27 16:15
1.为什么会出现乱码?
出现乱码的原因一般是页面中汉字的编码格式与浏览器的编码格式不匹配。这时候我们需要调整页面的编码格式。让我们来看看如何处理这种问题:
2.页面乱码解决方法
一般我们会使用在PHP页面上声明编码的方法来处理中文乱码的问题,主要是使用header和meta的方法来解决。我们来看看两者的区别
2.1元页面代码
使用标签设置页面编码
这个标签的作用是声明客户端的浏览器使用什么字符集编码来显示页面,xxx可以是GB2312、GBK、UTF-8(不同于MySQL,MySQL是UTF8)等等。因此,大多数页面这个方法可以用来告诉浏览器在显示这个页面时使用什么编码,以免造成编码错误和乱码。也就是说,浏览器总是使用一种编码,我稍后会谈到。
请注意,它属于html信息,它只是一个声明,它的作用是表明服务器已将HTML信息传递给浏览器。
2.2头函数
这个函数header()的作用是将括号中的信息发送到http头。如果括号中的内容如文中所述,那么功能与标签基本相同。你可以比较第一个,发现字符相似。但不同的是,如果有这个功能,浏览器会一直使用你需要的xxx编码,永远不会不听话,所以这个功能非常好用。为什么会这样?那么我们就不得不说一下HTTPS头和HTML信息的区别了:HTTPS头是服务器在使用HTTP协议向浏览器发送HTML信息之前发送的字符串。
因为meta标签属于html信息,所以header()发送的内容首先到达浏览器。通俗点就是header()的优先级比meta高(不知道能不能这么说)。添加一个php页面同时有header("content-type:text/html; charset=xxx"),浏览器只识别之前的http header而不识别meta。当然这个功能只能在一个php页面中使用。
推荐大家使用,灵活灵活。 查看全部
php网页抓取乱码(1.为什么会出现乱码?乱码问题的原因是什么)
1.为什么会出现乱码?
出现乱码的原因一般是页面中汉字的编码格式与浏览器的编码格式不匹配。这时候我们需要调整页面的编码格式。让我们来看看如何处理这种问题:
2.页面乱码解决方法
一般我们会使用在PHP页面上声明编码的方法来处理中文乱码的问题,主要是使用header和meta的方法来解决。我们来看看两者的区别
2.1元页面代码
使用标签设置页面编码
这个标签的作用是声明客户端的浏览器使用什么字符集编码来显示页面,xxx可以是GB2312、GBK、UTF-8(不同于MySQL,MySQL是UTF8)等等。因此,大多数页面这个方法可以用来告诉浏览器在显示这个页面时使用什么编码,以免造成编码错误和乱码。也就是说,浏览器总是使用一种编码,我稍后会谈到。
请注意,它属于html信息,它只是一个声明,它的作用是表明服务器已将HTML信息传递给浏览器。
2.2头函数
这个函数header()的作用是将括号中的信息发送到http头。如果括号中的内容如文中所述,那么功能与标签基本相同。你可以比较第一个,发现字符相似。但不同的是,如果有这个功能,浏览器会一直使用你需要的xxx编码,永远不会不听话,所以这个功能非常好用。为什么会这样?那么我们就不得不说一下HTTPS头和HTML信息的区别了:HTTPS头是服务器在使用HTTP协议向浏览器发送HTML信息之前发送的字符串。
因为meta标签属于html信息,所以header()发送的内容首先到达浏览器。通俗点就是header()的优先级比meta高(不知道能不能这么说)。添加一个php页面同时有header("content-type:text/html; charset=xxx"),浏览器只识别之前的http header而不识别meta。当然这个功能只能在一个php页面中使用。
推荐大家使用,灵活灵活。
php网页抓取乱码(你的php网页乱码了吗一、学习php的童鞋)
网站优化 • 优采云 发表了文章 • 0 个评论 • 354 次浏览 • 2022-02-27 07:12
你的php页面是乱码吗?
一、
学习php童鞋写网页的时候,如果设计中文内容的存储,大部分都会出现乱码的问题。对于一般的乱码,我们可以从三个方面进行检查
(1)网页的编码是否正确,例如是否在header中添加原创标签
元字符集="UTF-8">
(2)查看mysql数据库存储时默认使用的字符集
(3)检查网页文件的编码,是否是对应的中文编码
------------------
环境:win7+wamp2.2
------------------
二、
先从第二点说起,mysq数据库使用的编码字符集
(1)打开mysql终端,查看当前设置,确定要修改的范围
显示像 'char%' 这样的变量;
(2)根据结果分析,
1、如果你显示的结果和我的差不多,也就是(只有character_set_system编码为utf8)那么按照下面的步骤一步步来
2、打开my.ini文件,搜索关键词'mysqld',找到后观察是否有这一行
character_set_server=utf8
如果没有,你应该像我一样在它下面添加一个句子
3、再次搜索关键词'client'看看有没有这行
default_character_set=utf8
如果没有,请在 [client] 下添加
4、保存,重启mysql服务,关闭mysql终端(不然你看到的客户端代码不会更新)
5、再次打开终端,我们再次进入
显示像 'char%' 这样的变量;
如果出现如下结果,即mysql数据设置成功
三、
网页文件编码的问题是最容易被忽略的。保存时选择保存文件编码的格式时设置。
解决方案:
1、使用notepad++打开网页文件,然后在“格式”--“转为UTF-8无BOM编码格式”
2、保存即可
问题分析:
1、写php的时候用过
"font-size:18px;">'设置名称 utf8'); ?>
但是还是有乱码的问题!
分析:使用上面的语句,只修改了三项,三项是
character_set_client
字符集连接
字符集结果
而且这个修改只是暂时的,关闭终端后还是一样。
阐明:
2、我们来分析第三个乱码问题
(1)使用sublime text3编辑打开php文件,左下角可以看到编码信息,可以看到当前编码为gb2312
(2)网页加载的时候,相当于打开了一个文件,那个时候读取的格式是按照gb2312的编码读取网页文件的,当是显示在用户的浏览器中,因为网页声明的字符集是utf-8,所以获取到的文件内容会按照utf-8字符集进行解释,会导致乱码,但是没有问题我们从数据库中读取的内容。
网络编码
原创gbk编码文件
后来的 utf-8 编码文件
(3)注意,sublime text3没有给你转换代码,虽然显示转换成功,但是什么?显示还是一样,还是我们notepad++更强大,前面怎么修改!
3、为什么我按照你说的修改了,在mysql终端下显示,还是乱码?
分析:
(1)我们先来看看windows下cmd使用的是什么字符集?
可以看出cmd的字符集是gbk,也就是说终端显示的任何内容都会对应gbk的字符集,但是我们数据库的中文设置的utf8字符集,当我们想要显示出来,自然会使用 utf8 编码读取数据库数据,当编码为 utf-8 时,到了终端就乱了
(2)怎么查?
用phpmyadmin就行了,当然我们要设置我们使用的utf-8编码!
注:更多精彩教程请关注帮客家图文教程频道,
trueTechArticle 你的php网页是乱码吗?一、 学php的童鞋在写网页的时候,如果是专门用来存储中文内容的,大部分问题都会是乱码。一般的废话... 查看全部
php网页抓取乱码(你的php网页乱码了吗一、学习php的童鞋)
你的php页面是乱码吗?
一、
学习php童鞋写网页的时候,如果设计中文内容的存储,大部分都会出现乱码的问题。对于一般的乱码,我们可以从三个方面进行检查
(1)网页的编码是否正确,例如是否在header中添加原创标签
元字符集="UTF-8">
(2)查看mysql数据库存储时默认使用的字符集
(3)检查网页文件的编码,是否是对应的中文编码
------------------
环境:win7+wamp2.2
------------------
二、
先从第二点说起,mysq数据库使用的编码字符集
(1)打开mysql终端,查看当前设置,确定要修改的范围
显示像 'char%' 这样的变量;
(2)根据结果分析,
1、如果你显示的结果和我的差不多,也就是(只有character_set_system编码为utf8)那么按照下面的步骤一步步来
2、打开my.ini文件,搜索关键词'mysqld',找到后观察是否有这一行
character_set_server=utf8
如果没有,你应该像我一样在它下面添加一个句子
3、再次搜索关键词'client'看看有没有这行
default_character_set=utf8
如果没有,请在 [client] 下添加
4、保存,重启mysql服务,关闭mysql终端(不然你看到的客户端代码不会更新)
5、再次打开终端,我们再次进入
显示像 'char%' 这样的变量;
如果出现如下结果,即mysql数据设置成功
三、
网页文件编码的问题是最容易被忽略的。保存时选择保存文件编码的格式时设置。
解决方案:
1、使用notepad++打开网页文件,然后在“格式”--“转为UTF-8无BOM编码格式”
2、保存即可
问题分析:
1、写php的时候用过
"font-size:18px;">'设置名称 utf8'); ?>
但是还是有乱码的问题!
分析:使用上面的语句,只修改了三项,三项是
character_set_client
字符集连接
字符集结果
而且这个修改只是暂时的,关闭终端后还是一样。
阐明:
2、我们来分析第三个乱码问题
(1)使用sublime text3编辑打开php文件,左下角可以看到编码信息,可以看到当前编码为gb2312
(2)网页加载的时候,相当于打开了一个文件,那个时候读取的格式是按照gb2312的编码读取网页文件的,当是显示在用户的浏览器中,因为网页声明的字符集是utf-8,所以获取到的文件内容会按照utf-8字符集进行解释,会导致乱码,但是没有问题我们从数据库中读取的内容。
网络编码
原创gbk编码文件
后来的 utf-8 编码文件
(3)注意,sublime text3没有给你转换代码,虽然显示转换成功,但是什么?显示还是一样,还是我们notepad++更强大,前面怎么修改!
3、为什么我按照你说的修改了,在mysql终端下显示,还是乱码?
分析:
(1)我们先来看看windows下cmd使用的是什么字符集?
可以看出cmd的字符集是gbk,也就是说终端显示的任何内容都会对应gbk的字符集,但是我们数据库的中文设置的utf8字符集,当我们想要显示出来,自然会使用 utf8 编码读取数据库数据,当编码为 utf-8 时,到了终端就乱了
(2)怎么查?
用phpmyadmin就行了,当然我们要设置我们使用的utf-8编码!
注:更多精彩教程请关注帮客家图文教程频道,
trueTechArticle 你的php网页是乱码吗?一、 学php的童鞋在写网页的时候,如果是专门用来存储中文内容的,大部分问题都会是乱码。一般的废话...
php网页抓取乱码(PHP中文乱码现像发生在网页本身的有些产生在于MYSQL)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-27 07:11
前言
PHP中的中文乱码是PHP开发中常见的问题之一。中文乱码有时出现在网页本身,有的出现在MYSQL交互过程中,有时与操作系统有关。以下是一个总结。
一、 PHP 网页的编码
最好最快的解决方案是使页面上声明的代码与数据库内部的代码保持一致。如果页面申请的代码与数据库内部的代码不一致,设置连接代码。Mysql_query("设置名称***").
1、 php文件本身的编码应该和网页的编码相匹配。如果你想使用gb2312编码,那么php应该输出header
header("内容类型:text/html;charset=gb2312")
添加静态页面
, 所有文件的编码格式都是ANSI,可以用记事本打开,另存为选择的编码为ANSI,覆盖源文件。
2、 如果你想使用uft-8编码,那么php应该输出header
header("内容类型: text/html; charset=utf-8"),
添加静态页面
, 所有文件的编码格式都是utf-8. 保存为utf-8可能有点麻烦。一般utf-8开头会有BOM。如果使用Session,会有问题,可以使用editplus软件保存。在本软件中,选择Tools→Preferences→File→UTF-8 Signature,选择Always Delete,然后保存即可删除BOM信息。
3、PHP本身不是Unicode,substr等所有函数都必须改成mb_substr(需要安装mbstring扩展);或使用 iconv 进行转码。
在需要做数据库操作的PHP程序前加上mysql_query("set names encoding"),编码和PHP编码一样,如果PHP编码是gb2312,那么mysql编码是gb2312,如果是uft-8 ,那么mysql就是utf8.这样改后就不会出现乱码了。 查看全部
php网页抓取乱码(PHP中文乱码现像发生在网页本身的有些产生在于MYSQL)
前言
PHP中的中文乱码是PHP开发中常见的问题之一。中文乱码有时出现在网页本身,有的出现在MYSQL交互过程中,有时与操作系统有关。以下是一个总结。
一、 PHP 网页的编码
最好最快的解决方案是使页面上声明的代码与数据库内部的代码保持一致。如果页面申请的代码与数据库内部的代码不一致,设置连接代码。Mysql_query("设置名称***").
1、 php文件本身的编码应该和网页的编码相匹配。如果你想使用gb2312编码,那么php应该输出header
header("内容类型:text/html;charset=gb2312")
添加静态页面
, 所有文件的编码格式都是ANSI,可以用记事本打开,另存为选择的编码为ANSI,覆盖源文件。
2、 如果你想使用uft-8编码,那么php应该输出header
header("内容类型: text/html; charset=utf-8"),
添加静态页面
, 所有文件的编码格式都是utf-8. 保存为utf-8可能有点麻烦。一般utf-8开头会有BOM。如果使用Session,会有问题,可以使用editplus软件保存。在本软件中,选择Tools→Preferences→File→UTF-8 Signature,选择Always Delete,然后保存即可删除BOM信息。
3、PHP本身不是Unicode,substr等所有函数都必须改成mb_substr(需要安装mbstring扩展);或使用 iconv 进行转码。
在需要做数据库操作的PHP程序前加上mysql_query("set names encoding"),编码和PHP编码一样,如果PHP编码是gb2312,那么mysql编码是gb2312,如果是uft-8 ,那么mysql就是utf8.这样改后就不会出现乱码了。
php网页抓取乱码(,如下:file_get_contents函数(,.))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-24 22:23
本文章主要介绍PHP中使用file_get_contents抓取网页中文乱码问题的解决方法。可以通过使用 curl 配置 gzip 选项来解决。有一定的参考价值。有需要的朋友可以参考以下
本文的例子介绍了如何使用PHP中的file_get_contents来抓取网页的中文乱码问题。分享给大家,供大家参考。具体方法如下:
file_get_contents 函数原本是一个很好的php原生和远程文件操作函数。它让我们可以毫不费力地直接下载远程数据,但是当我用它来阅读网页时,我会遇到一些问题。页面乱码,这里给大家总结一下具体的解决办法。
根据网上朋友的说法,原因可能是服务器开启了GZIP压缩。下面是用firebug查看我的网站的头信息,启用Gzip,请求头信息的原创头信息如下:
复制代码代码如下:
接受 text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
接受编码 gzip,放气
接受-语言 zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
连接保持活动
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.132685041傻瓜式887.3.utmcsr=google|utmccn=(有机)|utmcmd=有机|utmctr=%E4%BB%BB%E4% BD%95%E9%A1%B9%E7% 9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE% 80%E5%8D%95%20现场%3A; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
主机
用户代理 Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
从头信息可以看出Content-Encoding项是Gzip。
解决方法比较简单,就是用curl代替file_get_contents来获取,然后在curl配置参数中加一个,代码如下:
复制代码代码如下:
curl_setopt($ch, CURLOPT_ENCODING, "gzip");
今天用file_get_contents抓图的时候,一开始没发现这个问题,费了好大劲才找到。
使用内置的 zlib 库。如果服务器已经安装了zlib库,可以通过以下代码轻松解决乱码问题。代码如下:
复制代码代码如下:
$data = file_get_contents("compress.zlib://".$url);
希望本文对您的 PHP 编程有所帮助。 查看全部
php网页抓取乱码(,如下:file_get_contents函数(,.))
本文章主要介绍PHP中使用file_get_contents抓取网页中文乱码问题的解决方法。可以通过使用 curl 配置 gzip 选项来解决。有一定的参考价值。有需要的朋友可以参考以下
本文的例子介绍了如何使用PHP中的file_get_contents来抓取网页的中文乱码问题。分享给大家,供大家参考。具体方法如下:
file_get_contents 函数原本是一个很好的php原生和远程文件操作函数。它让我们可以毫不费力地直接下载远程数据,但是当我用它来阅读网页时,我会遇到一些问题。页面乱码,这里给大家总结一下具体的解决办法。
根据网上朋友的说法,原因可能是服务器开启了GZIP压缩。下面是用firebug查看我的网站的头信息,启用Gzip,请求头信息的原创头信息如下:
复制代码代码如下:
接受 text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
接受编码 gzip,放气
接受-语言 zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
连接保持活动
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.132685041傻瓜式887.3.utmcsr=google|utmccn=(有机)|utmcmd=有机|utmctr=%E4%BB%BB%E4% BD%95%E9%A1%B9%E7% 9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE% 80%E5%8D%95%20现场%3A; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
主机
用户代理 Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
从头信息可以看出Content-Encoding项是Gzip。
解决方法比较简单,就是用curl代替file_get_contents来获取,然后在curl配置参数中加一个,代码如下:
复制代码代码如下:
curl_setopt($ch, CURLOPT_ENCODING, "gzip");
今天用file_get_contents抓图的时候,一开始没发现这个问题,费了好大劲才找到。
使用内置的 zlib 库。如果服务器已经安装了zlib库,可以通过以下代码轻松解决乱码问题。代码如下:
复制代码代码如下:
$data = file_get_contents("compress.zlib://".$url);
希望本文对您的 PHP 编程有所帮助。
php网页抓取乱码(不是白忙乎了吗?????)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-24 16:12
网上的解决方案说抓取后使用iconv()转码。看了之后觉得不对:一个是iconv库不一定是编译出来的,更大的问题是编码和流转换有关(如果用iconv,php实际上是把代码转换了两次:stream -> UTF-8 -> GB2312):这不是浪费时间吗?
仔细阅读php文档(不知道大家是怎么写代码的,但是文档很清楚),上面提到了关于fopen()和file_get_contents()“默认是UTF-8,但是用户可以使用stream_default_encoding。 () 或用户定义的上下文属性来更改编码”(如果启用了 unicode 语义,则读取数据的默认编码为 UTF-8. 您可以通过创建自定义上下文或更改默认使用 stream_default_encoding()。)。所以使用 stream_default_encoding('gb2312'); 测试:但问题是这个函数不存在?!似乎只有 php 6 支持它。但是没有出路,还有“用户定义的上下文属性”可以使用。
再仔细看了下文档,终于解决了问题:
复制代码代码如下:
//设置流的编码格式,这里是文件流(file),如果是网络访问,把文件改成http
$opts = array('file' => array('encoding' => 'gb2312'));
$ctxt = stream_context_create($opts);
file_get_contents(文件名, FILE_TEXT, $ctxt); 查看全部
php网页抓取乱码(不是白忙乎了吗?????)
网上的解决方案说抓取后使用iconv()转码。看了之后觉得不对:一个是iconv库不一定是编译出来的,更大的问题是编码和流转换有关(如果用iconv,php实际上是把代码转换了两次:stream -> UTF-8 -> GB2312):这不是浪费时间吗?
仔细阅读php文档(不知道大家是怎么写代码的,但是文档很清楚),上面提到了关于fopen()和file_get_contents()“默认是UTF-8,但是用户可以使用stream_default_encoding。 () 或用户定义的上下文属性来更改编码”(如果启用了 unicode 语义,则读取数据的默认编码为 UTF-8. 您可以通过创建自定义上下文或更改默认使用 stream_default_encoding()。)。所以使用 stream_default_encoding('gb2312'); 测试:但问题是这个函数不存在?!似乎只有 php 6 支持它。但是没有出路,还有“用户定义的上下文属性”可以使用。
再仔细看了下文档,终于解决了问题:
复制代码代码如下:
//设置流的编码格式,这里是文件流(file),如果是网络访问,把文件改成http
$opts = array('file' => array('encoding' => 'gb2312'));
$ctxt = stream_context_create($opts);
file_get_contents(文件名, FILE_TEXT, $ctxt);
php网页抓取乱码(什么是这是的编码?的方式解决乱码问题? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-20 07:13
)
2、如果上面的方法不行,页面还是乱码;或者在head标签下找不到charset属性;或者我们要采集很多网页信息,而这些网页的编码方式不一样,我们不可能一一查看head标签,所以可以使用以下方法解决乱码问题。
(1)python 的 chardet 库
可以使用以下方法解决乱码问题
result = chardet.detect(response.content)
print(result)
data = response.content.decode(chardet.detect(response.content)['encoding'])
{'confidence': 0.99, 'language': '', 'encoding': 'utf-8'}
从输出结果可以看出,这是一种“猜测”编码。猜测的方法是先采集各种编码的特征字符,根据特征字符,有很大概率“猜对”。
这种方法的效率非常低。如果采集的网页很大,你只能猜测其中一段的源码,即
result = chardet.detect(response.content[:1000])
(2)响应编码
您还可以使用另一种方法,即响应自己的 encoding 和 visible_encoding 变量。
response.encoding一般来自response.headers中content-type字段中charset的值,其他情况我不太了解。
response.apparent_encoding 一般使用上面提到的python chardet库方法。
因此,乱码问题可以通过以下方式解决
data = response.content.decode(response.apparent_encoding)
3、总的来说,以上两种方法可以解决乱码问题。但是,如果以上两种方法都不能解决,则可能是网页压缩造成的。这个问题通过以下方式解决。
检查你写的头信息是否收录Accept-Encoding字段。如果是,请删除该字段,乱码问题将得到解决。
headers = {
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221
Safari/537.36 SE 2.X MetaSr 1.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Connection': 'keep-alive',
} 查看全部
php网页抓取乱码(什么是这是的编码?的方式解决乱码问题?
)
2、如果上面的方法不行,页面还是乱码;或者在head标签下找不到charset属性;或者我们要采集很多网页信息,而这些网页的编码方式不一样,我们不可能一一查看head标签,所以可以使用以下方法解决乱码问题。
(1)python 的 chardet 库
可以使用以下方法解决乱码问题
result = chardet.detect(response.content)
print(result)
data = response.content.decode(chardet.detect(response.content)['encoding'])
{'confidence': 0.99, 'language': '', 'encoding': 'utf-8'}
从输出结果可以看出,这是一种“猜测”编码。猜测的方法是先采集各种编码的特征字符,根据特征字符,有很大概率“猜对”。
这种方法的效率非常低。如果采集的网页很大,你只能猜测其中一段的源码,即
result = chardet.detect(response.content[:1000])
(2)响应编码
您还可以使用另一种方法,即响应自己的 encoding 和 visible_encoding 变量。
response.encoding一般来自response.headers中content-type字段中charset的值,其他情况我不太了解。
response.apparent_encoding 一般使用上面提到的python chardet库方法。
因此,乱码问题可以通过以下方式解决
data = response.content.decode(response.apparent_encoding)
3、总的来说,以上两种方法可以解决乱码问题。但是,如果以上两种方法都不能解决,则可能是网页压缩造成的。这个问题通过以下方式解决。
检查你写的头信息是否收录Accept-Encoding字段。如果是,请删除该字段,乱码问题将得到解决。
headers = {
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221
Safari/537.36 SE 2.X MetaSr 1.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Connection': 'keep-alive',
}
php网页抓取乱码(PHP接收get中文参数乱码的解决办法:中文标签乱码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-19 19:17
php获取get参数乱码的解决方法:1、通过"$str=iconv("gb2312", "utf-8", $str);"处理编码;2、 通过 "mb_convert_encoding($str,"utf-8", "gb2312");" 方法。
本文运行环境:Windows7系统,PHP7.1、Dell G3电脑。
PHP接收GET中文参数乱码的深入研究
相信很多PHPer都会遇到这样的问题:在utf-8页面下,如果直接访问带有test.php?s=test等中文参数的地址,输出参数的值会出现乱码,可以在搜索引擎上查询 看了相关资料后,只给出了一些解决方案,但没有人研究过这个问题的原因。今天,我将通过这篇文章来深入探讨这个问题的原因:
首先我们演示一下这个问题,测试代码和运行结果如下。
代码:
测试结果:
代码声明响应内容的编码为utf-8,显示的内容确实是乱码。
这里请注意,var_dump输出的变量长度只有4。显然,在utf-8编码下,两个汉字的长度必须大于4字节。
那么我们来看看火狐对这个页面url的访问
FireFox会自动对中文url进行编码,所以我们可以看到测试变成了%B2%E2%CA%D4。显然,这里的一个词是两个字节,是 gb2313、gbk 等中文编码格式,而不是 utf-8 编码。(推荐:《PHP 视频教程》)
如果我们将页面的编码切换为gbk,中文参数会正常显示,见下图
这时候就诞生了一个有趣的问题:为什么emlog的中文标签等参数没有乱码?
经过多次测试,我发现了一个小区别:
页面生成emlog中文参数的链接,上面测试直接在地址栏手动输入,
如果我们直接输入原创等链接,程序也会提示找不到标签
测试代码如下:
测试结果,正常显示:
请注意上图中红框内标注的url编码。这次测试中的两个字由6个字节组成,而不是之前的2个字节,所以说明中文参数已经被正确编码为utf-8。
那么,是什么导致了这个问题呢?
答案是浏览器的默认编码有问题。我们都使用中文系统。浏览器的默认编码也将设置为本地化。比如我电脑上IE的FireFox默认编码是gb系列,请参考下图:
IE的默认设置:
Firefox 的默认设置:
因为这个设置,浏览器在请求用户输入的url时,会以默认编码格式而不是页面默认编码格式发送url中的中文,这就是为什么页面中带有中文的链接是正常的,我们手动输入的链接是乱码的原因。同样,如果我们将浏览器的默认编码调整为utf-8,那么输入url中的中文就会按照utf-8进行编码。
除上述情况外,还会在以下情况下发生这种情况:
如果gbk编码页面生成的地址链接到utf-8页面,gbk页面的中文以gbk格式编码传输到下一页,那么utf-8后面肯定会出现乱码收到编码。
IIS的url重写模块,重写的中文编码也是gbk,如果你的页面是utf-8编码,那么重写参数会失效。
在这些情况下,我们需要使用php内置的转码功能来处理编码问题:
计划一:
$str =iconv("gb2312","utf-8",$str);
场景二:
mb_convert_encoding($str,"utf-8", "gb2312");
希望这篇文章能帮助那些在编码问题上摸不着头脑的 PHPer :) 查看全部
php网页抓取乱码(PHP接收get中文参数乱码的解决办法:中文标签乱码)
php获取get参数乱码的解决方法:1、通过"$str=iconv("gb2312", "utf-8", $str);"处理编码;2、 通过 "mb_convert_encoding($str,"utf-8", "gb2312");" 方法。
本文运行环境:Windows7系统,PHP7.1、Dell G3电脑。
PHP接收GET中文参数乱码的深入研究
相信很多PHPer都会遇到这样的问题:在utf-8页面下,如果直接访问带有test.php?s=test等中文参数的地址,输出参数的值会出现乱码,可以在搜索引擎上查询 看了相关资料后,只给出了一些解决方案,但没有人研究过这个问题的原因。今天,我将通过这篇文章来深入探讨这个问题的原因:
首先我们演示一下这个问题,测试代码和运行结果如下。
代码:
测试结果:
代码声明响应内容的编码为utf-8,显示的内容确实是乱码。
这里请注意,var_dump输出的变量长度只有4。显然,在utf-8编码下,两个汉字的长度必须大于4字节。
那么我们来看看火狐对这个页面url的访问
FireFox会自动对中文url进行编码,所以我们可以看到测试变成了%B2%E2%CA%D4。显然,这里的一个词是两个字节,是 gb2313、gbk 等中文编码格式,而不是 utf-8 编码。(推荐:《PHP 视频教程》)
如果我们将页面的编码切换为gbk,中文参数会正常显示,见下图
这时候就诞生了一个有趣的问题:为什么emlog的中文标签等参数没有乱码?
经过多次测试,我发现了一个小区别:
页面生成emlog中文参数的链接,上面测试直接在地址栏手动输入,
如果我们直接输入原创等链接,程序也会提示找不到标签
测试代码如下:
测试结果,正常显示:
请注意上图中红框内标注的url编码。这次测试中的两个字由6个字节组成,而不是之前的2个字节,所以说明中文参数已经被正确编码为utf-8。
那么,是什么导致了这个问题呢?
答案是浏览器的默认编码有问题。我们都使用中文系统。浏览器的默认编码也将设置为本地化。比如我电脑上IE的FireFox默认编码是gb系列,请参考下图:
IE的默认设置:
Firefox 的默认设置:
因为这个设置,浏览器在请求用户输入的url时,会以默认编码格式而不是页面默认编码格式发送url中的中文,这就是为什么页面中带有中文的链接是正常的,我们手动输入的链接是乱码的原因。同样,如果我们将浏览器的默认编码调整为utf-8,那么输入url中的中文就会按照utf-8进行编码。
除上述情况外,还会在以下情况下发生这种情况:
如果gbk编码页面生成的地址链接到utf-8页面,gbk页面的中文以gbk格式编码传输到下一页,那么utf-8后面肯定会出现乱码收到编码。
IIS的url重写模块,重写的中文编码也是gbk,如果你的页面是utf-8编码,那么重写参数会失效。
在这些情况下,我们需要使用php内置的转码功能来处理编码问题:
计划一:
$str =iconv("gb2312","utf-8",$str);
场景二:
mb_convert_encoding($str,"utf-8", "gb2312");
希望这篇文章能帮助那些在编码问题上摸不着头脑的 PHPer :)
php网页抓取乱码(1.源码文件开头使用__importunicode_literals_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-12 21:21
2021-10-10
虫子有时会破坏你的心情,阻碍你留在现在的状态。但是,我很清楚,那是一种激励,是注定要被你踩到的垫脚石!
python2.7中最头疼的可能就是编码问题了,尤其是window环境下,有时候会莫名其妙的出现问题,有时候昨天还好好的,今天突然就这样了。. . 遇到这种问题,真是一肚子火。. . 他妈的!
首先,我们在写python代码的时候,一定要注意一些编码规范。
1.源文件使用#-*-coding:utf-8-*-指定编码,保存文件为utf-8格式
2.在文件开头使用 from __future__ import unicode_literals 避免在中文前面加 u 以允许迁移到 python3。
3.python内部存储为unicode,所有输入必须先解码成unicode,输入时encode变成想要的编码。常用的window环境有utf-8、gbk、gb2312、gb18030等。
4.通用网站基本都是utf-8或者gb2312。您可以尝试解码然后编码当前输出环境的编码格式。系统默认的编码格式是通过sys.getfilesystemencoding()传递的。说到文件路径,需要转换成系统默认编码。
5.unicode 字符串在写入文件时必须转换为某种字符编码。
在爬取网页的时候,我们可以先看网页的字符编码,可以在html代码或者f12看网中看到:
当您打印网页的源代码时,您必须小心。你可能会得到 UnicodeEncodeError!
你可以这样做:
1 type = sys.getfilesystemencoding()
2 #utf-8为网页编码,可能为gbk等
3 html = html.decode('utf-8').encode(type)
另一种通用的方法是使用 chardet 包来确定网页编码。刚试了一下,速度很慢。. . 需要安装chardet包,地址可以通过pip install chardet或者easy_install chardet安装。使用如下代码:
1 htmlCharsetGuess = chardet.detect(pageCode)
2 htmlCharsetEncoding = htmlCharsetGuess["encoding"]
3 htmlCode_decode = pageCode.decode(htmlCharsetEncoding)
4 type = sys.getfilesystemencoding()
5 htmlCode_encode = htmlCode_decode.encode(type)
6 print htmlCode_encode
还有一种可能是你得到的网站内容已经被gzip压缩了,这个时候我们需要解压。大多数服务器都支持gzip压缩,我改了HttpClient.py。默认情况下,我们去gzip方法访问网站,获取压缩后的内容再进行处理,这样抓包速度更快,我们看一下HttpClient.py的Get方法:
1 import zlib
2 def Get(self, url, refer=None):
3 try:
4 req = urllib2.Request(url)
5 req.add_header('Accept-encoding', 'gzip')#默认以gzip压缩的方式得到网页内容
6 if not (refer is None):
7 req.add_header('Referer', refer)
8 response = urllib2.urlopen(req, timeout=120)
9 html = response.read()
10 gzipped = response.headers.get('Content-Encoding')#查看是否服务器是否支持gzip
11 if gzipped:
12 html = zlib.decompress(html, 16+zlib.MAX_WBITS)#解压缩,得到网页源码
13 return html
14 except urllib2.HTTPError, e:
15 return e.read()
16 except socket.timeout, e:
17 return ''
18 except socket.error, e:
19 return ''
写了这么多,发现没有写出思路,经验少。但是,字符编码之类的东西需要经验。一句话总结,如果出现UnicodeEncodeError错误,说明字符编码有问题。python解释器也是一个工具。你需要让他明白,所以他需要解码,然后他需要编码让你明白。为了万无一失,建议使用chardet包!
分类:
技术要点:
相关文章: 查看全部
php网页抓取乱码(1.源码文件开头使用__importunicode_literals_)
2021-10-10
虫子有时会破坏你的心情,阻碍你留在现在的状态。但是,我很清楚,那是一种激励,是注定要被你踩到的垫脚石!
python2.7中最头疼的可能就是编码问题了,尤其是window环境下,有时候会莫名其妙的出现问题,有时候昨天还好好的,今天突然就这样了。. . 遇到这种问题,真是一肚子火。. . 他妈的!
首先,我们在写python代码的时候,一定要注意一些编码规范。
1.源文件使用#-*-coding:utf-8-*-指定编码,保存文件为utf-8格式
2.在文件开头使用 from __future__ import unicode_literals 避免在中文前面加 u 以允许迁移到 python3。
3.python内部存储为unicode,所有输入必须先解码成unicode,输入时encode变成想要的编码。常用的window环境有utf-8、gbk、gb2312、gb18030等。
4.通用网站基本都是utf-8或者gb2312。您可以尝试解码然后编码当前输出环境的编码格式。系统默认的编码格式是通过sys.getfilesystemencoding()传递的。说到文件路径,需要转换成系统默认编码。
5.unicode 字符串在写入文件时必须转换为某种字符编码。
在爬取网页的时候,我们可以先看网页的字符编码,可以在html代码或者f12看网中看到:
当您打印网页的源代码时,您必须小心。你可能会得到 UnicodeEncodeError!
你可以这样做:
1 type = sys.getfilesystemencoding()
2 #utf-8为网页编码,可能为gbk等
3 html = html.decode('utf-8').encode(type)
另一种通用的方法是使用 chardet 包来确定网页编码。刚试了一下,速度很慢。. . 需要安装chardet包,地址可以通过pip install chardet或者easy_install chardet安装。使用如下代码:
1 htmlCharsetGuess = chardet.detect(pageCode)
2 htmlCharsetEncoding = htmlCharsetGuess["encoding"]
3 htmlCode_decode = pageCode.decode(htmlCharsetEncoding)
4 type = sys.getfilesystemencoding()
5 htmlCode_encode = htmlCode_decode.encode(type)
6 print htmlCode_encode
还有一种可能是你得到的网站内容已经被gzip压缩了,这个时候我们需要解压。大多数服务器都支持gzip压缩,我改了HttpClient.py。默认情况下,我们去gzip方法访问网站,获取压缩后的内容再进行处理,这样抓包速度更快,我们看一下HttpClient.py的Get方法:
1 import zlib
2 def Get(self, url, refer=None):
3 try:
4 req = urllib2.Request(url)
5 req.add_header('Accept-encoding', 'gzip')#默认以gzip压缩的方式得到网页内容
6 if not (refer is None):
7 req.add_header('Referer', refer)
8 response = urllib2.urlopen(req, timeout=120)
9 html = response.read()
10 gzipped = response.headers.get('Content-Encoding')#查看是否服务器是否支持gzip
11 if gzipped:
12 html = zlib.decompress(html, 16+zlib.MAX_WBITS)#解压缩,得到网页源码
13 return html
14 except urllib2.HTTPError, e:
15 return e.read()
16 except socket.timeout, e:
17 return ''
18 except socket.error, e:
19 return ''
写了这么多,发现没有写出思路,经验少。但是,字符编码之类的东西需要经验。一句话总结,如果出现UnicodeEncodeError错误,说明字符编码有问题。python解释器也是一个工具。你需要让他明白,所以他需要解码,然后他需要编码让你明白。为了万无一失,建议使用chardet包!
分类:
技术要点:
相关文章:
php网页抓取乱码(1.PHP解决中文乱码问题(一)_原油期货开发)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-10 22:21
1.PHP解决中文乱码问题
很多情况下程序出现中文输出时,页面会显示乱码
一般有两个原因
编码(charset)设置错误,导致浏览器解析错误的编码,导致乱码文件以错误的编码打开保存,如GBK编码的文件,以UTF-8编码格式打开,然后在UTF-8格式保存,会有乱码问题
对乱码进行分类,针对性解决
1.1 解决HTML页面中文乱码问题
如果你的HTML文本文件有芯片问题,那么可以在head标签中加入UTF-8编码(国际编码):UTF-8是一种没有国家的编码,也就是一种独立的语言,任何语言都可以使用的。
1.2 HTML和PHP混合页面解决方案
如果混合使用 HTML 和 PHP,除了第一种方法中描述的操作外,还需要在 PHP 文件的顶部添加这段代码:
1.3 纯PHP页面中文乱码问题(数据是静态的)
如果PHP页面有芯片,在页面开头添加如下代码即可
1.4 PHP+MySQL中文乱码问题
除了第三个操作,数据库代码必须在数据查询/修改/添加之前添加。
而且需要注意的是这里的UTF8和前面的不一样,中间没有横线
如果数据库版本大于4.1,可以在链接数据库操作后设置字符编码,如下
$conn = mysqli_connect('localhost','root','root','db_name');
mysqli_set_charset($conn,'utf8');
UTF-8 编码只是其中一种编码。如果不想使用utf-8编码,也可以使用其他编码,需要进行编码转换
需要注意的一点是,它是在需要进行数据库操作的php程序之前添加的
mysql_query("set names encoding");
编码必须与 PHP 编码一致。如果 PHP 编码为 gb2312,则 MySQL 编码为 gb2312。如果 PHP 页面编码为 utf-8,则 MySQL 编码为 utf-8。这样可以使数据与页面编码保持一致,插入或检索数据时的芯片更少 查看全部
php网页抓取乱码(1.PHP解决中文乱码问题(一)_原油期货开发)
1.PHP解决中文乱码问题
很多情况下程序出现中文输出时,页面会显示乱码
一般有两个原因
编码(charset)设置错误,导致浏览器解析错误的编码,导致乱码文件以错误的编码打开保存,如GBK编码的文件,以UTF-8编码格式打开,然后在UTF-8格式保存,会有乱码问题
对乱码进行分类,针对性解决
1.1 解决HTML页面中文乱码问题
如果你的HTML文本文件有芯片问题,那么可以在head标签中加入UTF-8编码(国际编码):UTF-8是一种没有国家的编码,也就是一种独立的语言,任何语言都可以使用的。
1.2 HTML和PHP混合页面解决方案
如果混合使用 HTML 和 PHP,除了第一种方法中描述的操作外,还需要在 PHP 文件的顶部添加这段代码:
1.3 纯PHP页面中文乱码问题(数据是静态的)
如果PHP页面有芯片,在页面开头添加如下代码即可
1.4 PHP+MySQL中文乱码问题
除了第三个操作,数据库代码必须在数据查询/修改/添加之前添加。
而且需要注意的是这里的UTF8和前面的不一样,中间没有横线
如果数据库版本大于4.1,可以在链接数据库操作后设置字符编码,如下
$conn = mysqli_connect('localhost','root','root','db_name');
mysqli_set_charset($conn,'utf8');
UTF-8 编码只是其中一种编码。如果不想使用utf-8编码,也可以使用其他编码,需要进行编码转换
需要注意的一点是,它是在需要进行数据库操作的php程序之前添加的
mysql_query("set names encoding");
编码必须与 PHP 编码一致。如果 PHP 编码为 gb2312,则 MySQL 编码为 gb2312。如果 PHP 页面编码为 utf-8,则 MySQL 编码为 utf-8。这样可以使数据与页面编码保持一致,插入或检索数据时的芯片更少
php网页抓取乱码(,乱码的原因及及解决方法解决方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-10 21:12
乱码对于初学者来说一直是个很大的问题。现在总结一下出现乱码的原因和解决方法,主要是mysql数据库和php页面出现乱码。下面详细分析其中的原因。帮助。
一、HTML 页面编码:meta http-equiv=content-type content=text/html; charset=utf-8 这里的编码和数据库教程编码一样,和连接数据库编码一样
二、文件在存储编码中:例如文件inde.php教程,将其存储编码更改为所需的编码。只需使用EditPlus等文本编辑软件将文件另存为,在编码中选择正确的编码(这个被很多人忽略了)
三、数据库编码:比如使用phpmyadmin,选择数据库后,选择操作选项,有排序,也应该设置为统一编码。
四、表格编码:操作与第三点类似,此处不再赘述。
五、字段代码:在建表的字段时,有一个排列。如果内容中收录汉字,必须改为统一编码
六、连接数据库的时候,加一句mysql_query(set names utf8)
在 _select_db() 之后。
七、(刚遇到)网站本地测试成功后,如果上传到网上会出现乱码。可能是本地导出数据时没有选择正确的编码,所以导入网页后会出现乱码。 查看全部
php网页抓取乱码(,乱码的原因及及解决方法解决方案)
乱码对于初学者来说一直是个很大的问题。现在总结一下出现乱码的原因和解决方法,主要是mysql数据库和php页面出现乱码。下面详细分析其中的原因。帮助。
一、HTML 页面编码:meta http-equiv=content-type content=text/html; charset=utf-8 这里的编码和数据库教程编码一样,和连接数据库编码一样
二、文件在存储编码中:例如文件inde.php教程,将其存储编码更改为所需的编码。只需使用EditPlus等文本编辑软件将文件另存为,在编码中选择正确的编码(这个被很多人忽略了)
三、数据库编码:比如使用phpmyadmin,选择数据库后,选择操作选项,有排序,也应该设置为统一编码。
四、表格编码:操作与第三点类似,此处不再赘述。
五、字段代码:在建表的字段时,有一个排列。如果内容中收录汉字,必须改为统一编码
六、连接数据库的时候,加一句mysql_query(set names utf8)
在 _select_db() 之后。
七、(刚遇到)网站本地测试成功后,如果上传到网上会出现乱码。可能是本地导出数据时没有选择正确的编码,所以导入网页后会出现乱码。
php网页抓取乱码( 板Python学习教程--Python基础知识-关注小编头条号 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-10 21:09
板Python学习教程--Python基础知识-关注小编头条号
)
想学Python。关注小编头条号,私信【学习资料】即可免费领取全套系统板Python学习教程!
使用python2爬取网页时,经常会遇到抓取到的内容显示为乱码的情况。
这种情况最大的可能是编码问题:运行环境的字符编码和网页的字符编码不一致。
例如,在 Windows 控制台 (gbk) 中获取一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓一个gbk编码的网站(utf-8)。因为大部分网站使用utf-8编码,而且很多人使用windows,都是很常见。
如果你发现你抓取的内容在英文、数字、符号上看起来都正确,但是中间有一些乱码,你基本上可以断定是这样的。
这个问题的解决方法是先将结果按照网页的编码方式解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllibreq = urllib.urlopen("http://some.web.site")info = req.info()charset = info.getparam('charset')content = req.read()print content.decode(charset, 'ignore')
'ignore' 参数用于忽略无法解码的字符。
但是,这种方法并不总是有效。另一种方式是通过正则表达式直接匹配网页代码中的编码设置:
除了编码问题导致的乱码之外,另一个经常被忽视的情况是目标页面启用了 gzip 压缩。压缩网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的头部信息自动解压。但是直接用代码抓取不会。因此,很可能会产生困惑,为什么打开网页地址是对的,但程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现是,几乎所有的抓取内容都是乱码,甚至无法显示。
要确定网页是否启用了压缩并解压缩,请使用以下代码:
import urllibimport gzipfrom StringIO import StringIOreq = urllib.urlopen("http://some.web.site")info = req.info()encoding = info.getheader('Content-Encoding')content = req.read()if encoding == 'gzip': buf = StringIO(content) gf = gzip.GzipFile(fileobj=buf) content = gf.read()print content
在我们的课堂编程示例查看天气系列(点击查看)中,这两个问题困扰了不少人。这里有一个特殊的解释。
最后,还有一个“武器”要介绍。如果你一开始使用它,你甚至都不知道存在上述两个问题。
这是请求模块。
与爬网类似,只需:
import requestsprint requests.get("http://some.web.site").text
没有编码问题,没有压缩问题。注意
查看全部
php网页抓取乱码(
板Python学习教程--Python基础知识-关注小编头条号
)
想学Python。关注小编头条号,私信【学习资料】即可免费领取全套系统板Python学习教程!
使用python2爬取网页时,经常会遇到抓取到的内容显示为乱码的情况。
这种情况最大的可能是编码问题:运行环境的字符编码和网页的字符编码不一致。
例如,在 Windows 控制台 (gbk) 中获取一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓一个gbk编码的网站(utf-8)。因为大部分网站使用utf-8编码,而且很多人使用windows,都是很常见。
如果你发现你抓取的内容在英文、数字、符号上看起来都正确,但是中间有一些乱码,你基本上可以断定是这样的。
这个问题的解决方法是先将结果按照网页的编码方式解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllibreq = urllib.urlopen("http://some.web.site";)info = req.info()charset = info.getparam('charset')content = req.read()print content.decode(charset, 'ignore')
'ignore' 参数用于忽略无法解码的字符。
但是,这种方法并不总是有效。另一种方式是通过正则表达式直接匹配网页代码中的编码设置:
除了编码问题导致的乱码之外,另一个经常被忽视的情况是目标页面启用了 gzip 压缩。压缩网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的头部信息自动解压。但是直接用代码抓取不会。因此,很可能会产生困惑,为什么打开网页地址是对的,但程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现是,几乎所有的抓取内容都是乱码,甚至无法显示。
要确定网页是否启用了压缩并解压缩,请使用以下代码:
import urllibimport gzipfrom StringIO import StringIOreq = urllib.urlopen("http://some.web.site";)info = req.info()encoding = info.getheader('Content-Encoding')content = req.read()if encoding == 'gzip': buf = StringIO(content) gf = gzip.GzipFile(fileobj=buf) content = gf.read()print content
在我们的课堂编程示例查看天气系列(点击查看)中,这两个问题困扰了不少人。这里有一个特殊的解释。
最后,还有一个“武器”要介绍。如果你一开始使用它,你甚至都不知道存在上述两个问题。
这是请求模块。
与爬网类似,只需:
import requestsprint requests.get("http://some.web.site";).text
没有编码问题,没有压缩问题。注意
php网页抓取乱码(php和Mysql出现的中文乱码问题怎么办?见)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-08 01:12
最近一直在写网页,用的是php和Mysql,但是出现了各种问题。说明在Mysql下输入sql语句时,如果sql语句中有中文,则可能不会执行sql语句。解决方法见:解决Mysql server 5.1无法识别中文
解决此问题后,使用php向数据库写入数据时,sql语句无法再次执行。这个问题我也解决了。解决方法见:解决PHP连接Mysql但无法向数据库插入数据。
昨天出现的中文乱码问题,经过一夜的努力,终于解决了。现在PHP和Mysql都可以识别中文,可以正常执行SQL语句了。
解决方法就是在这里写个总结(应该同时解决以上三个问题):
首先是修改Mysql的编码方式。这是一篇写得很详细的帖子。结合我第一个问题的解决方法,完全可以修改Mysql的编码方式。帖子地址:MySql修改数据库编码为UTF8。
接下来是php连接数据库时选择的编码方式。首先,我建议你把所有的编码方式都改成'utf-8',这样写网页或者使用数据库都方便很多。 php写网页时,添加 则可以使用sql语句访问数据库,添加mysql_query("set names utf8");记住这里是utf8不是utf-8,不是我不小心忘了加横线,而是utf8。 查看全部
php网页抓取乱码(php和Mysql出现的中文乱码问题怎么办?见)
最近一直在写网页,用的是php和Mysql,但是出现了各种问题。说明在Mysql下输入sql语句时,如果sql语句中有中文,则可能不会执行sql语句。解决方法见:解决Mysql server 5.1无法识别中文
解决此问题后,使用php向数据库写入数据时,sql语句无法再次执行。这个问题我也解决了。解决方法见:解决PHP连接Mysql但无法向数据库插入数据。
昨天出现的中文乱码问题,经过一夜的努力,终于解决了。现在PHP和Mysql都可以识别中文,可以正常执行SQL语句了。
解决方法就是在这里写个总结(应该同时解决以上三个问题):
首先是修改Mysql的编码方式。这是一篇写得很详细的帖子。结合我第一个问题的解决方法,完全可以修改Mysql的编码方式。帖子地址:MySql修改数据库编码为UTF8。
接下来是php连接数据库时选择的编码方式。首先,我建议你把所有的编码方式都改成'utf-8',这样写网页或者使用数据库都方便很多。 php写网页时,添加 则可以使用sql语句访问数据库,添加mysql_query("set names utf8");记住这里是utf8不是utf-8,不是我不小心忘了加横线,而是utf8。
php网页抓取乱码(用file_get_contents()函数抓取网页会发生乱码现象)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-07 18:19
使用 file_get_contents() 函数抓取网页会导致乱码。出现乱码的原因有两个,一是编码问题,二是目标页面开启了Gzip。下面是如何开启Gzip功能避免乱码
对抓取的内容进行编码($content=iconv("GBK", "UTF-8//IGNORE", $content);),我们这里讨论的是如何抓取和打开Gzip页面。如何判断?获取到的header中收录Content-Encoding:gzip,表示内容是GZIP压缩的。使用 FireBug 查看页面是否启用了 gzip。以下是我用firebug查看的博客的头信息,启用了Gzip。
请求头信息原创头信息
Accept text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding gzip, deflate
Accept-Language zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Connection keep-alive
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.1326850415.887.3.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=%E4%BB%BB%E4%BD%95%E9%A1%B9%E7%9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE%80%E5%8D%95%20site%3Awww.nowamagic.net; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
Host www.nowamagic.net
User-Agent Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
这里有一些解决方案:
1.使用内置的zlib库
如果服务器已经安装了zlib库,下面的代码可以轻松解决乱码问题。
$data = file_get_contents("compress.zlib://".$url);
2. 使用 CURL 代替 file_get_contents
function curl_get($url, $gzip=false){
$curl = curl_init($url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
if($gzip) curl_setopt($curl, CURLOPT_ENCODING, "gzip"); // 关键在这里
$content = curl_exec($curl);
curl_close($curl);
return $content;
}
3.使用gzip解压功能
function gzdecode($data) {
$len = strlen($data);
if ($len < 18 || strcmp(substr($data,0,2),"\x1f\x8b")) {
return null; // Not GZIP format (See RFC 1952)
}
$method = ord(substr($data,2,1)); // Compression method
$flags = ord(substr($data,3,1)); // Flags
if ($flags & 31 != $flags) {
// Reserved bits are set -- NOT ALLOWED by RFC 1952
return null;
}
// NOTE: $mtime may be negative (PHP integer limitations)
$mtime = unpack("V", substr($data,4,4));
$mtime = $mtime[1];
$xfl = substr($data,8,1);
$os = substr($data,8,1);
$headerlen = 10;
$extralen = 0;
$extra = "";
if ($flags & 4) {
// 2-byte length prefixed EXTRA data in header
if ($len - $headerlen - 2 < 8) {
return false; // Invalid format
}
$extralen = unpack("v",substr($data,8,2));
$extralen = $extralen[1];
if ($len - $headerlen - 2 - $extralen < 8) {
return false; // Invalid format
}
$extra = substr($data,10,$extralen);
$headerlen += 2 + $extralen;
}
$filenamelen = 0;
$filename = "";
if ($flags & 8) {
// C-style string file NAME data in header
if ($len - $headerlen - 1 < 8) {
return false; // Invalid format
}
$filenamelen = strpos(substr($data,8+$extralen),chr(0));
if ($filenamelen === false || $len - $headerlen - $filenamelen - 1 < 8) {
return false; // Invalid format
}
$filename = substr($data,$headerlen,$filenamelen);
$headerlen += $filenamelen + 1;
}
$commentlen = 0;
$comment = "";
if ($flags & 16) {
// C-style string COMMENT data in header
if ($len - $headerlen - 1 < 8) {
return false; // Invalid format
}
$commentlen = strpos(substr($data,8+$extralen+$filenamelen),chr(0));
if ($commentlen === false || $len - $headerlen - $commentlen - 1 < 8) {
return false; // Invalid header format
}
$comment = substr($data,$headerlen,$commentlen);
$headerlen += $commentlen + 1;
}
$headercrc = "";
if ($flags & 1) {
// 2-bytes (lowest order) of CRC32 on header present
if ($len - $headerlen - 2 < 8) {
return false; // Invalid format
}
$calccrc = crc32(substr($data,0,$headerlen)) & 0xffff;
$headercrc = unpack("v", substr($data,$headerlen,2));
$headercrc = $headercrc[1];
if ($headercrc != $calccrc) {
return false; // Bad header CRC
}
$headerlen += 2;
}
// GZIP FOOTER - These be negative due to PHP's limitations
$datacrc = unpack("V",substr($data,-8,4));
$datacrc = $datacrc[1];
$isize = unpack("V",substr($data,-4));
$isize = $isize[1];
// Perform the decompression:
$bodylen = $len-$headerlen-8;
if ($bodylen < 1) {
// This should never happen - IMPLEMENTATION BUG!
return null;
}
$body = substr($data,$headerlen,$bodylen);
$data = "";
if ($bodylen > 0) {
switch ($method) {
case 8:
// Currently the only supported compression method:
$data = gzinflate($body);
break;
default:
// Unknown compression method
return false;
}
} else {
// I'm not sure if zero-byte body content is allowed.
// Allow it for now... Do nothing...
}
// Verifiy decompressed size and CRC32:
// NOTE: This may fail with large data sizes depending on how
// PHP's integer limitations affect strlen() since $isize
// may be negative for large sizes.
if ($isize != strlen($data) || crc32($data) != $datacrc) {
// Bad format! Length or CRC doesn't match!
return false;
}
return $data;
}
用途:
$html=file_get_contents('http://www.gxlcms.com/');
$html=gzdecode($html);
介绍这三种方法,应该可以解决gzip引起的大部分乱码问题。 查看全部
php网页抓取乱码(用file_get_contents()函数抓取网页会发生乱码现象)
使用 file_get_contents() 函数抓取网页会导致乱码。出现乱码的原因有两个,一是编码问题,二是目标页面开启了Gzip。下面是如何开启Gzip功能避免乱码
对抓取的内容进行编码($content=iconv("GBK", "UTF-8//IGNORE", $content);),我们这里讨论的是如何抓取和打开Gzip页面。如何判断?获取到的header中收录Content-Encoding:gzip,表示内容是GZIP压缩的。使用 FireBug 查看页面是否启用了 gzip。以下是我用firebug查看的博客的头信息,启用了Gzip。
请求头信息原创头信息
Accept text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding gzip, deflate
Accept-Language zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Connection keep-alive
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.1326850415.887.3.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=%E4%BB%BB%E4%BD%95%E9%A1%B9%E7%9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE%80%E5%8D%95%20site%3Awww.nowamagic.net; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
Host www.nowamagic.net
User-Agent Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
这里有一些解决方案:
1.使用内置的zlib库
如果服务器已经安装了zlib库,下面的代码可以轻松解决乱码问题。
$data = file_get_contents("compress.zlib://".$url);
2. 使用 CURL 代替 file_get_contents
function curl_get($url, $gzip=false){
$curl = curl_init($url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
if($gzip) curl_setopt($curl, CURLOPT_ENCODING, "gzip"); // 关键在这里
$content = curl_exec($curl);
curl_close($curl);
return $content;
}
3.使用gzip解压功能
function gzdecode($data) {
$len = strlen($data);
if ($len < 18 || strcmp(substr($data,0,2),"\x1f\x8b")) {
return null; // Not GZIP format (See RFC 1952)
}
$method = ord(substr($data,2,1)); // Compression method
$flags = ord(substr($data,3,1)); // Flags
if ($flags & 31 != $flags) {
// Reserved bits are set -- NOT ALLOWED by RFC 1952
return null;
}
// NOTE: $mtime may be negative (PHP integer limitations)
$mtime = unpack("V", substr($data,4,4));
$mtime = $mtime[1];
$xfl = substr($data,8,1);
$os = substr($data,8,1);
$headerlen = 10;
$extralen = 0;
$extra = "";
if ($flags & 4) {
// 2-byte length prefixed EXTRA data in header
if ($len - $headerlen - 2 < 8) {
return false; // Invalid format
}
$extralen = unpack("v",substr($data,8,2));
$extralen = $extralen[1];
if ($len - $headerlen - 2 - $extralen < 8) {
return false; // Invalid format
}
$extra = substr($data,10,$extralen);
$headerlen += 2 + $extralen;
}
$filenamelen = 0;
$filename = "";
if ($flags & 8) {
// C-style string file NAME data in header
if ($len - $headerlen - 1 < 8) {
return false; // Invalid format
}
$filenamelen = strpos(substr($data,8+$extralen),chr(0));
if ($filenamelen === false || $len - $headerlen - $filenamelen - 1 < 8) {
return false; // Invalid format
}
$filename = substr($data,$headerlen,$filenamelen);
$headerlen += $filenamelen + 1;
}
$commentlen = 0;
$comment = "";
if ($flags & 16) {
// C-style string COMMENT data in header
if ($len - $headerlen - 1 < 8) {
return false; // Invalid format
}
$commentlen = strpos(substr($data,8+$extralen+$filenamelen),chr(0));
if ($commentlen === false || $len - $headerlen - $commentlen - 1 < 8) {
return false; // Invalid header format
}
$comment = substr($data,$headerlen,$commentlen);
$headerlen += $commentlen + 1;
}
$headercrc = "";
if ($flags & 1) {
// 2-bytes (lowest order) of CRC32 on header present
if ($len - $headerlen - 2 < 8) {
return false; // Invalid format
}
$calccrc = crc32(substr($data,0,$headerlen)) & 0xffff;
$headercrc = unpack("v", substr($data,$headerlen,2));
$headercrc = $headercrc[1];
if ($headercrc != $calccrc) {
return false; // Bad header CRC
}
$headerlen += 2;
}
// GZIP FOOTER - These be negative due to PHP's limitations
$datacrc = unpack("V",substr($data,-8,4));
$datacrc = $datacrc[1];
$isize = unpack("V",substr($data,-4));
$isize = $isize[1];
// Perform the decompression:
$bodylen = $len-$headerlen-8;
if ($bodylen < 1) {
// This should never happen - IMPLEMENTATION BUG!
return null;
}
$body = substr($data,$headerlen,$bodylen);
$data = "";
if ($bodylen > 0) {
switch ($method) {
case 8:
// Currently the only supported compression method:
$data = gzinflate($body);
break;
default:
// Unknown compression method
return false;
}
} else {
// I'm not sure if zero-byte body content is allowed.
// Allow it for now... Do nothing...
}
// Verifiy decompressed size and CRC32:
// NOTE: This may fail with large data sizes depending on how
// PHP's integer limitations affect strlen() since $isize
// may be negative for large sizes.
if ($isize != strlen($data) || crc32($data) != $datacrc) {
// Bad format! Length or CRC doesn't match!
return false;
}
return $data;
}
用途:
$html=file_get_contents('http://www.gxlcms.com/');
$html=gzdecode($html);
介绍这三种方法,应该可以解决gzip引起的大部分乱码问题。
php网页抓取乱码(python2抓取网页的内容显示出来是怎么回事?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-05 23:15
)
使用python2爬取网页时,经常会遇到抓取到的内容显示为乱码的情况。
这种情况最大的可能是编码问题:运行环境的字符编码和网页的字符编码不一致。
例如,在 Windows 控制台 (gbk) 中获取一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓取一个gbk编码的网站(utf-8)。因为大部分网站使用utf-8编码,而且很多人使用windows,都是很常见。
如果你发现你抓取的内容在英文、数字、符号上看起来都正确,但是中间有一些乱码,你基本上可以断定是这样的。
这个问题的解决方法是先将结果按照网页的编码方式解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site")
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
复制代码
'ignore' 参数用于忽略无法解码的字符。
但是,这种方法并不总是有效。另一种方式是通过正则表达式直接匹配网页代码中的编码设置:
复制代码
除了编码问题导致的乱码之外,另一个经常被忽视的情况是目标页面启用了 gzip 压缩。压缩网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的头部信息自动解压。但是直接用代码抓取不会。因此,很可能会产生困惑,为什么打开网页地址是对的,但程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现是,几乎所有的抓取内容都是乱码,甚至无法显示。
要确定网页是否启用了压缩并解压缩,请使用以下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site")
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
复制代码
在我们的课堂编程示例查看天气系列(点击查看)中,这两个问题困扰了不少人。这里有一个特殊的解释。
最后,还有一个“武器”要介绍。如果你一开始使用它,你甚至都不知道存在上述两个问题。
这是请求模块。
与爬网类似,只需:
import requests
print requests.get("http://some.web.site").text
复制代码
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考之前的文章:
如何为 Python 安装第三方模块 - Crossin 的编程课堂 - 知乎专栏
pip install requests
复制代码
其他 文章 和答案:
查看全部
php网页抓取乱码(python2抓取网页的内容显示出来是怎么回事?(图)
)
使用python2爬取网页时,经常会遇到抓取到的内容显示为乱码的情况。
这种情况最大的可能是编码问题:运行环境的字符编码和网页的字符编码不一致。
例如,在 Windows 控制台 (gbk) 中获取一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓取一个gbk编码的网站(utf-8)。因为大部分网站使用utf-8编码,而且很多人使用windows,都是很常见。
如果你发现你抓取的内容在英文、数字、符号上看起来都正确,但是中间有一些乱码,你基本上可以断定是这样的。
这个问题的解决方法是先将结果按照网页的编码方式解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site";)
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
复制代码
'ignore' 参数用于忽略无法解码的字符。
但是,这种方法并不总是有效。另一种方式是通过正则表达式直接匹配网页代码中的编码设置:
复制代码
除了编码问题导致的乱码之外,另一个经常被忽视的情况是目标页面启用了 gzip 压缩。压缩网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的头部信息自动解压。但是直接用代码抓取不会。因此,很可能会产生困惑,为什么打开网页地址是对的,但程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现是,几乎所有的抓取内容都是乱码,甚至无法显示。
要确定网页是否启用了压缩并解压缩,请使用以下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site";)
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
复制代码
在我们的课堂编程示例查看天气系列(点击查看)中,这两个问题困扰了不少人。这里有一个特殊的解释。
最后,还有一个“武器”要介绍。如果你一开始使用它,你甚至都不知道存在上述两个问题。
这是请求模块。
与爬网类似,只需:
import requests
print requests.get("http://some.web.site";).text
复制代码
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考之前的文章:
如何为 Python 安装第三方模块 - Crossin 的编程课堂 - 知乎专栏
pip install requests
复制代码
其他 文章 和答案:
php网页抓取乱码(一下爬虫乱码的解决方法有哪些?时出现了问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-29 11:14
现在越来越多的人在学习爬虫程序,难免会在学习中遇到问题,比如爬取时出现乱码等。跟大家分享一下爬虫乱码的解决方法。
网络爬虫有两种选择,一种是nutch、hetriex,一种是自编译爬虫。处理乱码的时候,原理是一样的,但是处理乱码的时候,前者只能在理解后修改源代码,所以要浪费一些精力;后者更加自由方便,可以在编码过程中处理。这也是很多人在用框架写爬虫的时候没有开始的原因。比如比较成熟的nutch在处理乱码方面比较简单,所以还是会出现乱码,所以需要二次开发才能真正解决乱码问题。
1、网络爬虫出现乱码的原因
源页面的编码与爬取后的编码转换不一致。如果源网页是gbk编码的字节流,程序爬取后直接用utf-8编码输出到存储文件,难免会造成乱码,即源网页编码时程序爬取编码一致时不会出现乱码,统一字符编码后不会出现乱码。注意区分源网络代码A、程序直接使用的代码B、统一转换字符的代码c。
A. 是网页的服务端编码
B. 抓取的数据最初是一个字节数组,由A编码。只有B=A时才能没有乱码,否则在字符集不兼容的情况下总会出现乱码。此步骤通常用于测试。
C、统一转码是指得到网页的原码A后进行统一编码,主要是将各个网页的数据统一为一种编码,通常选择字符集较大的utf-8比较合适。
每个网页都有自己的编码,比如gbk、utf-8、iso8859-1,还有日系jp系统编码,西欧、俄文等编码都不一样,爬的时候总会展开出各种编码,有的爬虫对网页进行简单的编码识别,然后进行统一编码,有的不判断源页面,直接按照utf-8处理,显然会造成乱码。
2、乱码的解决方法
(1)程序通过编码B恢复源网页数据
很明显,这里的B等于A。在java中,如果得到的源网页的字节数组是source_byte_array,那么就转换为String str=new String(source_byte_array, B); 也就是内存中的这些字节数组对应的字符被正确编码并可以显示,此时的打印输出是正常的。这一步通常用于调试或控制台输出进行测试。
(2)确定源网页的编码A
代码A通常位于网页中的三个位置,http头的内容,网页的元字符集,以及网页头中的Document定义。在获取源网页的代码时,依次判断这三部分数据就足够了,而且从前到后优先级也是一样的。
这个理论上是对的,但是国内有的网站确实是很不合规的,比如gbk,其实是utf-8,有的是utf-8,其实是gbk,当然这个很A小批量 网站,但它确实存在。因此,在确定网页代码时,应针对特殊情况进行特殊处理,如中文校验、默认代码等策略。
还有一种情况是以上三种都没有编码信息,一般使用第三方网页编码智能识别工具如cpdetector来做。准确率,但我实际上发现准确率仍然非常有限。
不过结合以上三种编码确认方式后,中文乱码问题几乎可以完全解决。在我基于nutch1.6二次开发的网络爬虫系统中,据统计正确编码可以达到99.的99%,这也证明了上述方法策略的可行性。
(3) 统一转码
网络爬虫系统的数据来源很多,当无法使用数据时,就会将其转换成它的原创数据,即使这样做是非常没用的。所以一般的爬虫系统应该对抓取到的结果进行统一编码,这样就可以统一对外使用,方便使用。这时候在(2)的基础上,可以做一个统一的编码转换。java中的实现如下
源网页的字节数组是source_byte_array
转换成普通字符串:String normal_source_str=new String(source_byte_array, C),可以直接用java api存储,但很多时候不直接写字符串,因为一般爬虫存储是存储多源web pages 合并到一个文件中,所以需要记录字节偏移量,所以下一步。
然后将得到的str转换成统一编码C格式的字节数组,然后byte[] new_byte_array=normal_source_str.getBytes©,然后可以使用java io api将数组写入文件并记录对应的字节数组Offset等。实际使用时,可以直接通过io读取。
以上方案可以解决爬取时出现乱码的问题。爬取信息不仅会出现乱码,还有网站爬取涉及法律、IP封禁、IP限制等,如何避免IP封杀?为了防止ip被屏蔽,我们需要使用代理ip软件。一直在用**可变ip**,全国城市ip,自动去重,百万优质动态ip每天可使用,支持http/https/socks5三大协议! 查看全部
php网页抓取乱码(一下爬虫乱码的解决方法有哪些?时出现了问题)
现在越来越多的人在学习爬虫程序,难免会在学习中遇到问题,比如爬取时出现乱码等。跟大家分享一下爬虫乱码的解决方法。
网络爬虫有两种选择,一种是nutch、hetriex,一种是自编译爬虫。处理乱码的时候,原理是一样的,但是处理乱码的时候,前者只能在理解后修改源代码,所以要浪费一些精力;后者更加自由方便,可以在编码过程中处理。这也是很多人在用框架写爬虫的时候没有开始的原因。比如比较成熟的nutch在处理乱码方面比较简单,所以还是会出现乱码,所以需要二次开发才能真正解决乱码问题。
1、网络爬虫出现乱码的原因
源页面的编码与爬取后的编码转换不一致。如果源网页是gbk编码的字节流,程序爬取后直接用utf-8编码输出到存储文件,难免会造成乱码,即源网页编码时程序爬取编码一致时不会出现乱码,统一字符编码后不会出现乱码。注意区分源网络代码A、程序直接使用的代码B、统一转换字符的代码c。
A. 是网页的服务端编码
B. 抓取的数据最初是一个字节数组,由A编码。只有B=A时才能没有乱码,否则在字符集不兼容的情况下总会出现乱码。此步骤通常用于测试。
C、统一转码是指得到网页的原码A后进行统一编码,主要是将各个网页的数据统一为一种编码,通常选择字符集较大的utf-8比较合适。
每个网页都有自己的编码,比如gbk、utf-8、iso8859-1,还有日系jp系统编码,西欧、俄文等编码都不一样,爬的时候总会展开出各种编码,有的爬虫对网页进行简单的编码识别,然后进行统一编码,有的不判断源页面,直接按照utf-8处理,显然会造成乱码。
2、乱码的解决方法
(1)程序通过编码B恢复源网页数据
很明显,这里的B等于A。在java中,如果得到的源网页的字节数组是source_byte_array,那么就转换为String str=new String(source_byte_array, B); 也就是内存中的这些字节数组对应的字符被正确编码并可以显示,此时的打印输出是正常的。这一步通常用于调试或控制台输出进行测试。
(2)确定源网页的编码A
代码A通常位于网页中的三个位置,http头的内容,网页的元字符集,以及网页头中的Document定义。在获取源网页的代码时,依次判断这三部分数据就足够了,而且从前到后优先级也是一样的。
这个理论上是对的,但是国内有的网站确实是很不合规的,比如gbk,其实是utf-8,有的是utf-8,其实是gbk,当然这个很A小批量 网站,但它确实存在。因此,在确定网页代码时,应针对特殊情况进行特殊处理,如中文校验、默认代码等策略。
还有一种情况是以上三种都没有编码信息,一般使用第三方网页编码智能识别工具如cpdetector来做。准确率,但我实际上发现准确率仍然非常有限。
不过结合以上三种编码确认方式后,中文乱码问题几乎可以完全解决。在我基于nutch1.6二次开发的网络爬虫系统中,据统计正确编码可以达到99.的99%,这也证明了上述方法策略的可行性。
(3) 统一转码
网络爬虫系统的数据来源很多,当无法使用数据时,就会将其转换成它的原创数据,即使这样做是非常没用的。所以一般的爬虫系统应该对抓取到的结果进行统一编码,这样就可以统一对外使用,方便使用。这时候在(2)的基础上,可以做一个统一的编码转换。java中的实现如下
源网页的字节数组是source_byte_array
转换成普通字符串:String normal_source_str=new String(source_byte_array, C),可以直接用java api存储,但很多时候不直接写字符串,因为一般爬虫存储是存储多源web pages 合并到一个文件中,所以需要记录字节偏移量,所以下一步。
然后将得到的str转换成统一编码C格式的字节数组,然后byte[] new_byte_array=normal_source_str.getBytes©,然后可以使用java io api将数组写入文件并记录对应的字节数组Offset等。实际使用时,可以直接通过io读取。
以上方案可以解决爬取时出现乱码的问题。爬取信息不仅会出现乱码,还有网站爬取涉及法律、IP封禁、IP限制等,如何避免IP封杀?为了防止ip被屏蔽,我们需要使用代理ip软件。一直在用**可变ip**,全国城市ip,自动去重,百万优质动态ip每天可使用,支持http/https/socks5三大协议!
php网页抓取乱码(利用encode与decode解决乱码问题的解决方法有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-26 08:25
一、乱码问题描述
经常在爬虫或者一些操作中,经常会出现中文乱码等问题,如下
原因是源网页的编码与爬取后的编码格式不一致。
二、使用encode和decode解决乱码问题
Python 中字符串的内部表示是 unicode 编码。在进行编码转换时,通常需要使用unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再将unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符串转成unicode编码,如str1.decode('gb2312'),意思是将gb2312编码的字符串str1转换成u source gaodai#ma#com *generation#代码net nicode 编码。
encode的作用是将unicode编码转换为其他编码字符串,如str2.encode('utf-8'),意思是将unicode编码的字符串str2转换为utf-8编码。
decode里面写的是你要抓取的网页的code,encode是你要设置的code
代码显示如下
#!/usr/bin/env python # -*- coding:utf-8 -*- # author: xulinjie time:2017/10/22 import urllib2 request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/') RES=urllib2.urlopen(request).read() RES = RES.decode('gb2312').encode('utf-8')//解决乱码 wfile=open(r'./1.html',r'wb') wfile.write(RES) wfile.close() print RES
或者
#!/usr/bin/env python # -*- coding:utf-8 -*- # author: xulinjie time:2017/10/22 import urllib2 request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/') RES=urllib2.urlopen(request).read() RES=RES.decode('gb2312') RES=RES.encode('utf-8') wfile=open(r'./1.html',r'wb') wfile.write(RES) wfile.close() print RES
但还要注意:
如果一个字符串已经是unicode,那么解码就会出错,所以通常需要判断编码方式是否是unicode
isinstance(s, unicode)#用于判断是否为unicode
用非unicode编码的str编码会报错
所以最终可靠的代码:
#!/usr/bin/env python # -*- coding:utf-8 -*- # author: xulinjie time:2017/10/22 import urllib2 request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/') RES=urllib2.urlopen(request).read() if isinstance(RES, unicode): RES=RES.encode('utf-8') else: RES=RES.decode('gb2312').encode('utf-8') wfile=open(r'./1.html',r'wb') wfile.write(RES) wfile.close() print RES
三、如何找到需要爬取的着陆页的编码格式
1、查看网页源代码
如果源码中没有charset编码格式显示,可以使用下面的方法
2、检查元素,查看响应标头 查看全部
php网页抓取乱码(利用encode与decode解决乱码问题的解决方法有哪些?)
一、乱码问题描述
经常在爬虫或者一些操作中,经常会出现中文乱码等问题,如下
原因是源网页的编码与爬取后的编码格式不一致。
二、使用encode和decode解决乱码问题
Python 中字符串的内部表示是 unicode 编码。在进行编码转换时,通常需要使用unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再将unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符串转成unicode编码,如str1.decode('gb2312'),意思是将gb2312编码的字符串str1转换成u source gaodai#ma#com *generation#代码net nicode 编码。
encode的作用是将unicode编码转换为其他编码字符串,如str2.encode('utf-8'),意思是将unicode编码的字符串str2转换为utf-8编码。
decode里面写的是你要抓取的网页的code,encode是你要设置的code
代码显示如下
#!/usr/bin/env python # -*- coding:utf-8 -*- # author: xulinjie time:2017/10/22 import urllib2 request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/') RES=urllib2.urlopen(request).read() RES = RES.decode('gb2312').encode('utf-8')//解决乱码 wfile=open(r'./1.html',r'wb') wfile.write(RES) wfile.close() print RES
或者
#!/usr/bin/env python # -*- coding:utf-8 -*- # author: xulinjie time:2017/10/22 import urllib2 request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/') RES=urllib2.urlopen(request).read() RES=RES.decode('gb2312') RES=RES.encode('utf-8') wfile=open(r'./1.html',r'wb') wfile.write(RES) wfile.close() print RES
但还要注意:
如果一个字符串已经是unicode,那么解码就会出错,所以通常需要判断编码方式是否是unicode
isinstance(s, unicode)#用于判断是否为unicode
用非unicode编码的str编码会报错
所以最终可靠的代码:
#!/usr/bin/env python # -*- coding:utf-8 -*- # author: xulinjie time:2017/10/22 import urllib2 request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/') RES=urllib2.urlopen(request).read() if isinstance(RES, unicode): RES=RES.encode('utf-8') else: RES=RES.decode('gb2312').encode('utf-8') wfile=open(r'./1.html',r'wb') wfile.write(RES) wfile.close() print RES
三、如何找到需要爬取的着陆页的编码格式
1、查看网页源代码
如果源码中没有charset编码格式显示,可以使用下面的方法
2、检查元素,查看响应标头

