
php多线程抓取网页
php多线程抓取网页(爬虫怎么从xml、html格式数据中提取你想要的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-28 03:04
php多线程抓取网页详情按照上面提示做一下
可以。爬虫怎么从xml、html格式数据中提取你想要的数据,是你要考虑的问题。你已经搞定了xml,而爬虫需要和后端、服务器多次交互。第一次登录,需要问到后端服务器一次,而后续就直接读取服务器返回给你的数据咯。多线程在这个基础上,作用不大,效率也不好,你直接用非阻塞io就可以了。—你想多线程做详情分析,我觉得很难。爬虫只有单线程模式。
可以,但是这个操作跟你后端基本无关了,爬虫一般用c++或者python,需要一个稳定的数据库管理系统,至于多线程,肯定是多个独立线程在提交任务来,处理上,后端肯定是一个处理线程过来处理,无非在于html文件的解析和初始化数据提交而已,至于后端是否需要支持多线程,看后端提供的api。而且多线程抓取数据,你认为很难,其实也是可以做到的,就是再给抓取的速度会影响,毕竟抓取速度快,还需要靠数据库等。
之前的这个提问:一个爬虫是应该单线程还是多线程?
抓取页面网页肯定是可以的,但是api提供的xmlhttprequestapi设置的服务方法并不会进行多线程。你是要提供可多线程的api吗?-你要明白提供多线程的api并不是说把各个线程纳入系统中,而是默认所有的进程,包括所有能通过api操作页面的进程统一由一个privulsion(保存(页面的,数据库的)等等进程,unionresources)运行。
这样呢就是通过multicast库实现,你可以通过api来分析页面,但是你无法通过api操作数据库,因为他通过multicast来分析页面。否则,所有爬虫可以自发共享一个privulsion了。 查看全部
php多线程抓取网页(爬虫怎么从xml、html格式数据中提取你想要的数据)
php多线程抓取网页详情按照上面提示做一下
可以。爬虫怎么从xml、html格式数据中提取你想要的数据,是你要考虑的问题。你已经搞定了xml,而爬虫需要和后端、服务器多次交互。第一次登录,需要问到后端服务器一次,而后续就直接读取服务器返回给你的数据咯。多线程在这个基础上,作用不大,效率也不好,你直接用非阻塞io就可以了。—你想多线程做详情分析,我觉得很难。爬虫只有单线程模式。
可以,但是这个操作跟你后端基本无关了,爬虫一般用c++或者python,需要一个稳定的数据库管理系统,至于多线程,肯定是多个独立线程在提交任务来,处理上,后端肯定是一个处理线程过来处理,无非在于html文件的解析和初始化数据提交而已,至于后端是否需要支持多线程,看后端提供的api。而且多线程抓取数据,你认为很难,其实也是可以做到的,就是再给抓取的速度会影响,毕竟抓取速度快,还需要靠数据库等。
之前的这个提问:一个爬虫是应该单线程还是多线程?
抓取页面网页肯定是可以的,但是api提供的xmlhttprequestapi设置的服务方法并不会进行多线程。你是要提供可多线程的api吗?-你要明白提供多线程的api并不是说把各个线程纳入系统中,而是默认所有的进程,包括所有能通过api操作页面的进程统一由一个privulsion(保存(页面的,数据库的)等等进程,unionresources)运行。
这样呢就是通过multicast库实现,你可以通过api来分析页面,但是你无法通过api操作数据库,因为他通过multicast来分析页面。否则,所有爬虫可以自发共享一个privulsion了。
php多线程抓取网页( PHP利用Curl实现并发多线程抓取网页或者下载文件的操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-25 00:10
PHP利用Curl实现并发多线程抓取网页或者下载文件的操作)
PHP使用Curl实现网页的多线程抓取和下载文件
PHP可以使用Curl来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等,但是由于PHP语言本身不支持多线程,所以开发爬虫程序的效率不高。一般使用采集数据即可。使用PHPquery类来采集数据库,除此之外,还可以使用Curl,借助Curl这个功能实现多线程并发访问多个URL地址,实现网页的并发多线程爬取或下载文件。
具体实现过程请参考以下示例:
1、 实现抓取多个URL并将内容写入指定文件
$urls = array( <br />'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); // 设置要抓取的页面URL <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} // 初始化 <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); // 执行 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />} // 结束清理 <br />curl_multi_close($mh); <br />fclose($st);
2、使用PHP的Curl抓取网页的URL并保存内容
下面的代码和上面类似,只不过这个地方先把获取到的代码放入变量中,然后将获取到的内容写入到指定文件中
$urls = array( <br />'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); <br />foreach ($urls as $i => $url) { <br />$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串 <br />fwrite($st,$data); // 将字符串写入文件<br />} // 获得数据变量,并写入文件 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />}<br />curl_multi_close($mh); <br />fclose($st);
3、使用PHP的Curl实现文件的多线程并发下载
$urls=array(<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br />$g=$save_to.basename($url);<br />if(!is_file($g)){<br />$conn[$i]=curl_init($url);<br />$fp[$i]=fopen($g,"w");<br />curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br />curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br />curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br />curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br />curl_multi_add_handle($mh,$conn[$i]);<br />}<br />}<br />do{<br />$n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br />curl_multi_remove_handle($mh,$conn[$i]);<br />curl_close($conn[$i]);<br />fclose($fp[$i]);<br />}<br />curl_multi_close($mh);$urls=array(<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br />$g=$save_to.basename($url);<br />if(!is_file($g)){<br />$conn[$i]=curl_init($url);<br />$fp[$i]=fopen($g,"w");<br />curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br />curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br />curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br />curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br />curl_multi_add_handle($mh,$conn[$i]);<br />}<br />}<br />do{<br />$n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br />curl_multi_remove_handle($mh,$conn[$i]);<br />curl_close($conn[$i]);<br />fclose($fp[$i]);<br />}<br />curl_multi_close($mh);
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
php多线程抓取网页(
PHP利用Curl实现并发多线程抓取网页或者下载文件的操作)
PHP使用Curl实现网页的多线程抓取和下载文件
PHP可以使用Curl来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等,但是由于PHP语言本身不支持多线程,所以开发爬虫程序的效率不高。一般使用采集数据即可。使用PHPquery类来采集数据库,除此之外,还可以使用Curl,借助Curl这个功能实现多线程并发访问多个URL地址,实现网页的并发多线程爬取或下载文件。
具体实现过程请参考以下示例:
1、 实现抓取多个URL并将内容写入指定文件
$urls = array( <br />'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); // 设置要抓取的页面URL <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} // 初始化 <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); // 执行 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />} // 结束清理 <br />curl_multi_close($mh); <br />fclose($st);
2、使用PHP的Curl抓取网页的URL并保存内容
下面的代码和上面类似,只不过这个地方先把获取到的代码放入变量中,然后将获取到的内容写入到指定文件中
$urls = array( <br />'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); <br />foreach ($urls as $i => $url) { <br />$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串 <br />fwrite($st,$data); // 将字符串写入文件<br />} // 获得数据变量,并写入文件 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />}<br />curl_multi_close($mh); <br />fclose($st);
3、使用PHP的Curl实现文件的多线程并发下载
$urls=array(<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br />$g=$save_to.basename($url);<br />if(!is_file($g)){<br />$conn[$i]=curl_init($url);<br />$fp[$i]=fopen($g,"w");<br />curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br />curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br />curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br />curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br />curl_multi_add_handle($mh,$conn[$i]);<br />}<br />}<br />do{<br />$n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br />curl_multi_remove_handle($mh,$conn[$i]);<br />curl_close($conn[$i]);<br />fclose($fp[$i]);<br />}<br />curl_multi_close($mh);$urls=array(<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br />$g=$save_to.basename($url);<br />if(!is_file($g)){<br />$conn[$i]=curl_init($url);<br />$fp[$i]=fopen($g,"w");<br />curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br />curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br />curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br />curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br />curl_multi_add_handle($mh,$conn[$i]);<br />}<br />}<br />do{<br />$n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br />curl_multi_remove_handle($mh,$conn[$i]);<br />curl_close($conn[$i]);<br />fclose($fp[$i]);<br />}<br />curl_multi_close($mh);

免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
php多线程抓取网页( 第三种应用就是实现PHP的多线程任务--多线程的写法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-20 15:03
第三种应用就是实现PHP的多线程任务--多线程的写法
)
使用curl实现多线程
curl一般用来抓取网页,二是get或post数据,三是PHP中实现多线程任务
让我们实现多线程。
您可以返回:
do while 的解释:
因为$active要等url数据全部被接受后才会变为false,这里用curl_multi_exec的返回值来判断是否有数据,
有数据时,会一直调用curl_multi_exec。如果一段时间没有数据,就会进入选择阶段。当有新数据到来时,可以唤醒它继续执行。
这里的好处是没有了不必要的CPU消耗。更详细的解释:%D4%C2%D2%B9%C4%FD%ED%F8/blog/item/9dfcf4fbe6b84374024f563d.html
这个多线程的编写步骤:
第一步:调用 curl_multi_init
第 2 步:循环调用 curl_multi_add_handle
这一步需要注意的是curl_multi_add_handle的第二个参数是curl_init的子句柄。
第三步:不断调用 curl_multi_exec
第 4 步:根据需要调用 curl_multi_getcontent 以循环获取结果
第五步:调用curl_multi_remove_handle,对每个字句柄调用curl_close
第 6 步:调用 curl_multi_close
多线程测试渲染:
查看全部
php多线程抓取网页(
第三种应用就是实现PHP的多线程任务--多线程的写法
)
使用curl实现多线程
curl一般用来抓取网页,二是get或post数据,三是PHP中实现多线程任务
让我们实现多线程。
您可以返回:
do while 的解释:
因为$active要等url数据全部被接受后才会变为false,这里用curl_multi_exec的返回值来判断是否有数据,
有数据时,会一直调用curl_multi_exec。如果一段时间没有数据,就会进入选择阶段。当有新数据到来时,可以唤醒它继续执行。
这里的好处是没有了不必要的CPU消耗。更详细的解释:%D4%C2%D2%B9%C4%FD%ED%F8/blog/item/9dfcf4fbe6b84374024f563d.html
这个多线程的编写步骤:
第一步:调用 curl_multi_init
第 2 步:循环调用 curl_multi_add_handle
这一步需要注意的是curl_multi_add_handle的第二个参数是curl_init的子句柄。
第三步:不断调用 curl_multi_exec
第 4 步:根据需要调用 curl_multi_getcontent 以循环获取结果
第五步:调用curl_multi_remove_handle,对每个字句柄调用curl_close
第 6 步:调用 curl_multi_close
多线程测试渲染:
php多线程抓取网页(php中curl_init()的具体使用方法及相关效率比较)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-18 23:11
php使用curl_init()和curl_multi_init()多线程的速度比较详细
更新时间:2018-08-15 10:06:55 作者:CC_小硕
本文文章主要介绍php使用curl_init()和curl_multi_init()多线程的速度对比。结合示例形式,详细分析了 curl_init() 和 curl_multi_init() 的具体使用方法和相关效率对比。有需要的朋友可以参考
本文介绍了 PHP 使用 curl_init() 和 curl_multi_init() 多线程的速度对比。分享给大家,供大家参考,如下:
php中的curl_init()非常有用,尤其是在爬取网页内容或者文件信息的时候。比如之前的文章《php使用curl进行头部检测和GZip压缩》介绍了curl_init()的强大功能。
curl_init() 以单线程模式处理事情。如果需要使用多线程模式进行事务处理,那么php为我们提供了一个函数curl_multi_init(),就是多线程模式处理事务的功能。
curl_init() 和 curl_multi_init() 速度对比
curl_multi_init() 多线程可以提高网页的处理速度吗?今天我将通过实验来验证这个问题。
我今天的测试很简单,就是抓取网页内容,连续抓取5次,使用curl_init()和curl_multi_init()函数来完成,记录下两者的耗时,对比一下得出结论。
首先,使用 curl_init() 在单个线程中抓取网页内容 5 次。
程序代码如下:
然后,使用 curl_multi_init() 多线程连续抓取网页内容 5 次。
代码显示如下:
<p> 查看全部
php多线程抓取网页(php中curl_init()的具体使用方法及相关效率比较)
php使用curl_init()和curl_multi_init()多线程的速度比较详细
更新时间:2018-08-15 10:06:55 作者:CC_小硕
本文文章主要介绍php使用curl_init()和curl_multi_init()多线程的速度对比。结合示例形式,详细分析了 curl_init() 和 curl_multi_init() 的具体使用方法和相关效率对比。有需要的朋友可以参考
本文介绍了 PHP 使用 curl_init() 和 curl_multi_init() 多线程的速度对比。分享给大家,供大家参考,如下:
php中的curl_init()非常有用,尤其是在爬取网页内容或者文件信息的时候。比如之前的文章《php使用curl进行头部检测和GZip压缩》介绍了curl_init()的强大功能。
curl_init() 以单线程模式处理事情。如果需要使用多线程模式进行事务处理,那么php为我们提供了一个函数curl_multi_init(),就是多线程模式处理事务的功能。
curl_init() 和 curl_multi_init() 速度对比
curl_multi_init() 多线程可以提高网页的处理速度吗?今天我将通过实验来验证这个问题。
我今天的测试很简单,就是抓取网页内容,连续抓取5次,使用curl_init()和curl_multi_init()函数来完成,记录下两者的耗时,对比一下得出结论。
首先,使用 curl_init() 在单个线程中抓取网页内容 5 次。
程序代码如下:
然后,使用 curl_multi_init() 多线程连续抓取网页内容 5 次。
代码显示如下:
<p>
php多线程抓取网页(【干货】Powershell上如何能够并发的ping上万台机器?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-16 16:37
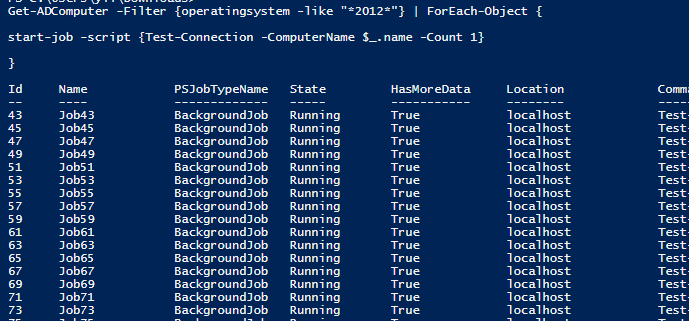
今天有朋友问我,如何在Powershell中同时ping几万台机器?虽然默认的test-connection有-computer参数,但它的方法是依次ping通,可能需要几个小时才能全部跑掉。
例如,ping 40 个服务器需要 18 秒。如果有数千个,那将是耗时的。
measure-commnd -expression {
$computers=Get-ADComputer -Filter {operatingsystem -like "*2012*"}
Test-Connection -ComputerName $computers.name -Count 1
}
在此之前,Bean 对多线程的使用仅限于理解 invoke-command 可以同时操作 30 个对象。经过一番学习,我终于发现还有其他的高级方法。
在 PowerShell 中,可能有两种方法可以使用多线程。
首先是创建多个后台作业。这样,通过start-job或者-asjob创建一个后台job,然后通过get-job获取当前任务,通过receive-job获取完成任务的结果,最后需要remove-job释放记忆。缺点是性能不高,尤其是在创建作业和退出作业的过程中会消耗大量的时间和资源。
第二种方法是创建多个运行时。工作原理与调用命令相同。每个远程会话都绑定到一个运行时。我们可以创建一个运行时池,并指定该资源池中可以同时执行的最大运行时数。
与第一种方法相比,Runspace 的性能要强大得多。在下面的对比实验中,可以看到性能差距几乎是几十倍。
现在让我们看看如何实现它。豆子主要参考了这个博客的方法和原理,写了一个简单的脚本。
思路很简单,创建一个runtime pool,指定runtimes的数量,然后为每个待测试的对象集创建一个后台runtime job,绑定要执行的脚本,传入参数,将结果保存在ps中object 或者在hash表中,等待所有作业结束并输出结果。
$Throttle = 20 #threads
#脚本块,对指定的计算机发送一个ICMP包测试,结果保存在一个对象里面
$ScriptBlock = {
Param (
[string]$Computer
)
$a=test-connection -ComputerName $Computer -Count 1
$RunResult = New-Object PSObject -Property @{
IPv4Adress=$a.ipv4address.IPAddressToString
ComputerName=$Computer
}
Return $RunResult
}
#创建一个资源池,指定多少个runspace可以同时执行
$RunspacePool = [RunspaceFactory]::CreateRunspacePool(1, $Throttle)
$RunspacePool.Open()
$Jobs = @()
#获取Windows 2012服务器的信息,对每一个服务器单独创建一个job,该job执行ICMP的测试,并把结果保存在一个PS对象中
(get-adcomputer -filter {operatingsystem -like "*2012*"}).name | % {
#Start-Sleep -Seconds 1
$Job = [powershell]::Create().AddScript($ScriptBlock).AddArgument($_)
$Job.RunspacePool = $RunspacePool
$Jobs += New-Object PSObject -Property @{
Server = $_
Pipe = $Job
Result = $Job.BeginInvoke()
}
}
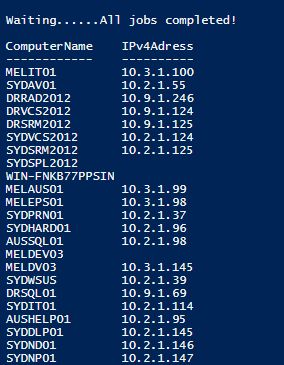
#循环输出等待的信息.... 直到所有的job都完成
Write-Host "Waiting.." -NoNewline
Do {
Write-Host "." -NoNewline
Start-Sleep -Seconds 1
} While ( $Jobs.Result.IsCompleted -contains $false)
Write-Host "All jobs completed!"
#输出结果
$Results = @()
ForEach ($Job in $Jobs)
{ $Results += $Job.Pipe.EndInvoke($Job.Result)
}
$Results
大约 5 秒后,结果出来了。有兴趣的可以使用measure-command命令来测试不同线程的效果。根据我的测试,30道工序同时出结果只需要4秒,2道工序同时出结果大约需要9秒。
知道原理后,就可以进一步优化和抽象脚本。已经有人这样做了。
下载后可以直接调用解锁和点源。这里有一些例子供参考
根据葫芦图,我觉得通过他调用test-connection也是成功的
get-adcomputer -Filter {operatingsystem -like "*2012*"} | select -ExpandProperty name | Invoke-Parallel -ScriptBlock {Test-Connection -computername $_ -count 1}
再举一个例子,我用一个 IP 范围 ping 一台计算机
1..254| Invoke-Parallel -ScriptBlock {Test-Connection -ComputerName "10.2.100.$_" -Count 1 -ErrorAction SilentlyContinue -ErrorVariable err | select Ipv4address, @{n='DNS';e={[System.Net.Dns]::gethostentry($_.ipv4address).hostname}}} -Throttle 20
最后,网上也有现成的脚本可以并发测试ping。原理就是调用上面的invoke-parallel函数,不过还增加了其他函数来测试rdp、winrm、rpc等远程访问端口是否打开,进一步扩展了功能。你可以在这里直接下载
invoke-ping -ComputerName (Get-ADComputer -Filter {operatingsystem -like "*2012*"}).name -Detail RDP,rpc | ft -Wrap
参考资料:
1.
2.
3.
4.
5. 查看全部
php多线程抓取网页(【干货】Powershell上如何能够并发的ping上万台机器?)
今天有朋友问我,如何在Powershell中同时ping几万台机器?虽然默认的test-connection有-computer参数,但它的方法是依次ping通,可能需要几个小时才能全部跑掉。
例如,ping 40 个服务器需要 18 秒。如果有数千个,那将是耗时的。
measure-commnd -expression {
$computers=Get-ADComputer -Filter {operatingsystem -like "*2012*"}
Test-Connection -ComputerName $computers.name -Count 1
}
在此之前,Bean 对多线程的使用仅限于理解 invoke-command 可以同时操作 30 个对象。经过一番学习,我终于发现还有其他的高级方法。
在 PowerShell 中,可能有两种方法可以使用多线程。
首先是创建多个后台作业。这样,通过start-job或者-asjob创建一个后台job,然后通过get-job获取当前任务,通过receive-job获取完成任务的结果,最后需要remove-job释放记忆。缺点是性能不高,尤其是在创建作业和退出作业的过程中会消耗大量的时间和资源。
第二种方法是创建多个运行时。工作原理与调用命令相同。每个远程会话都绑定到一个运行时。我们可以创建一个运行时池,并指定该资源池中可以同时执行的最大运行时数。
与第一种方法相比,Runspace 的性能要强大得多。在下面的对比实验中,可以看到性能差距几乎是几十倍。
现在让我们看看如何实现它。豆子主要参考了这个博客的方法和原理,写了一个简单的脚本。
思路很简单,创建一个runtime pool,指定runtimes的数量,然后为每个待测试的对象集创建一个后台runtime job,绑定要执行的脚本,传入参数,将结果保存在ps中object 或者在hash表中,等待所有作业结束并输出结果。
$Throttle = 20 #threads
#脚本块,对指定的计算机发送一个ICMP包测试,结果保存在一个对象里面
$ScriptBlock = {
Param (
[string]$Computer
)
$a=test-connection -ComputerName $Computer -Count 1
$RunResult = New-Object PSObject -Property @{
IPv4Adress=$a.ipv4address.IPAddressToString
ComputerName=$Computer
}
Return $RunResult
}
#创建一个资源池,指定多少个runspace可以同时执行
$RunspacePool = [RunspaceFactory]::CreateRunspacePool(1, $Throttle)
$RunspacePool.Open()
$Jobs = @()
#获取Windows 2012服务器的信息,对每一个服务器单独创建一个job,该job执行ICMP的测试,并把结果保存在一个PS对象中
(get-adcomputer -filter {operatingsystem -like "*2012*"}).name | % {
#Start-Sleep -Seconds 1
$Job = [powershell]::Create().AddScript($ScriptBlock).AddArgument($_)
$Job.RunspacePool = $RunspacePool
$Jobs += New-Object PSObject -Property @{
Server = $_
Pipe = $Job
Result = $Job.BeginInvoke()
}
}
#循环输出等待的信息.... 直到所有的job都完成
Write-Host "Waiting.." -NoNewline
Do {
Write-Host "." -NoNewline
Start-Sleep -Seconds 1
} While ( $Jobs.Result.IsCompleted -contains $false)
Write-Host "All jobs completed!"
#输出结果
$Results = @()
ForEach ($Job in $Jobs)
{ $Results += $Job.Pipe.EndInvoke($Job.Result)
}
$Results
大约 5 秒后,结果出来了。有兴趣的可以使用measure-command命令来测试不同线程的效果。根据我的测试,30道工序同时出结果只需要4秒,2道工序同时出结果大约需要9秒。
知道原理后,就可以进一步优化和抽象脚本。已经有人这样做了。
下载后可以直接调用解锁和点源。这里有一些例子供参考
根据葫芦图,我觉得通过他调用test-connection也是成功的
get-adcomputer -Filter {operatingsystem -like "*2012*"} | select -ExpandProperty name | Invoke-Parallel -ScriptBlock {Test-Connection -computername $_ -count 1}

再举一个例子,我用一个 IP 范围 ping 一台计算机
1..254| Invoke-Parallel -ScriptBlock {Test-Connection -ComputerName "10.2.100.$_" -Count 1 -ErrorAction SilentlyContinue -ErrorVariable err | select Ipv4address, @{n='DNS';e={[System.Net.Dns]::gethostentry($_.ipv4address).hostname}}} -Throttle 20

最后,网上也有现成的脚本可以并发测试ping。原理就是调用上面的invoke-parallel函数,不过还增加了其他函数来测试rdp、winrm、rpc等远程访问端口是否打开,进一步扩展了功能。你可以在这里直接下载
invoke-ping -ComputerName (Get-ADComputer -Filter {operatingsystem -like "*2012*"}).name -Detail RDP,rpc | ft -Wrap
参考资料:
1.
2.
3.
4.
5.
php多线程抓取网页(HTTP命令行工具模拟/GET等HTTP工具(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-11 11:20
1、 CURL 一步请求
CURL 扩展是一个强大的 HTTP 命令行工具,可以模拟 POST/GET 等 HTTP 请求,然后获取和提取数据,并将其显示在“标准输出”(stdout)上。
例子:
复制代码代码示例:
$cl = curl_init();
$curl_opt = array(CURLOPT_URL,'#39;,
CURLOPT_RETURNTRANSFER, 1,
CURLOPT_TIMEOUT, 1,);
curl_setopt_array($cl, $curl_opt);
curl_exec($ch);
curl_close($ch);
由于CUROPT_TIMEOUT属性的最小值为1,这意味着客户端必须等待1秒,这也是使用CURL方法的缺点
2、使用popen()函数实现异步请求
语法格式:popen(command,mode)
代码:
复制代码代码示例:
$file = popen("/bin/ls","r");
//这里是要执行的代码
//...
pclose($file);
popen() 函数直接向进程打开一个管道,速度快,响应迅速。但是这个函数是单项,不管是读还是写,并发数大的话,会产生大量的进程,给服务器造成负担。
此外,如示例中所示,必须使用 pclose() 在结束后关闭程序。
3、使用fscokopen()函数实现异步请求
该函数用于socket编程,如php邮件发送功能的开发。在使用此功能之前,您必须在 PHP.ini 中启用 allow_url_fopen 选项。此外,您必须在标题部分可用时手动拼接它。
代码:
复制代码代码示例:
$fp = fsockopen("/demo.php", 80, $errno, $errstr, 30);
如果 (!$fp) {
echo "$errstr ($errno)
\n";
} 别的 {
$out = "GET /index.php / HTTP/1.1\r\n";
$out .= "主机:\r\n";
$out .= "连接:关闭\r\n\r\n";
fwrite($fp, $out);
/*这里忽略执行结果
*可以在测试期间打开
而 (!feof($fp)) {
回声 fgets($fp, 128);
}*/
fclose($fp);
}
PHP 本身没有多线程,但是可以使用其他方式来实现多线程的效果。
上面列出的三种方法各有优缺点。在使用它们时,您可以根据程序的需要选择最好的。 查看全部
php多线程抓取网页(HTTP命令行工具模拟/GET等HTTP工具(组图))
1、 CURL 一步请求
CURL 扩展是一个强大的 HTTP 命令行工具,可以模拟 POST/GET 等 HTTP 请求,然后获取和提取数据,并将其显示在“标准输出”(stdout)上。
例子:
复制代码代码示例:
$cl = curl_init();
$curl_opt = array(CURLOPT_URL,'#39;,
CURLOPT_RETURNTRANSFER, 1,
CURLOPT_TIMEOUT, 1,);
curl_setopt_array($cl, $curl_opt);
curl_exec($ch);
curl_close($ch);
由于CUROPT_TIMEOUT属性的最小值为1,这意味着客户端必须等待1秒,这也是使用CURL方法的缺点
2、使用popen()函数实现异步请求
语法格式:popen(command,mode)
代码:
复制代码代码示例:
$file = popen("/bin/ls","r");
//这里是要执行的代码
//...
pclose($file);
popen() 函数直接向进程打开一个管道,速度快,响应迅速。但是这个函数是单项,不管是读还是写,并发数大的话,会产生大量的进程,给服务器造成负担。
此外,如示例中所示,必须使用 pclose() 在结束后关闭程序。
3、使用fscokopen()函数实现异步请求
该函数用于socket编程,如php邮件发送功能的开发。在使用此功能之前,您必须在 PHP.ini 中启用 allow_url_fopen 选项。此外,您必须在标题部分可用时手动拼接它。
代码:
复制代码代码示例:
$fp = fsockopen("/demo.php", 80, $errno, $errstr, 30);
如果 (!$fp) {
echo "$errstr ($errno)
\n";
} 别的 {
$out = "GET /index.php / HTTP/1.1\r\n";
$out .= "主机:\r\n";
$out .= "连接:关闭\r\n\r\n";
fwrite($fp, $out);
/*这里忽略执行结果
*可以在测试期间打开
而 (!feof($fp)) {
回声 fgets($fp, 128);
}*/
fclose($fp);
}
PHP 本身没有多线程,但是可以使用其他方式来实现多线程的效果。
上面列出的三种方法各有优缺点。在使用它们时,您可以根据程序的需要选择最好的。
php多线程抓取网页(PHP利用CurlFunctions可以完成各种传送文件操作下载文件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-09 09:36
)
PHP 可以使用 Curl Functions 完成各种文件传输操作,比如模拟浏览器发送 GET、POST 请求等,但是 PHP 语言本身不支持多线程,所以开发爬虫程序效率低下不高。这时候往往需要借助Curl Multi Functions来实现对多个URL地址的并发和多线程访问。既然Curl Multi Function这么强大,那我可以用Curl Multi Function来写并发多线程下载文件吗?当然,我的代码如下:
代码一:将得到的代码直接写入文件
$urls = array(
'http://www.sina.com.cn/',
'http://www.sohu.com/',
'http://www.163.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 设置将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
代码2:将得到的代码先放入变量中,再写入文件
$urls = array(
'http://www.sina.com.cn/',
'http://www.sohu.com/',
'http://www.163.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 设置不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件。当然,也可以不写入文件,比如存入数据库
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st); 查看全部
php多线程抓取网页(PHP利用CurlFunctions可以完成各种传送文件操作下载文件
)
PHP 可以使用 Curl Functions 完成各种文件传输操作,比如模拟浏览器发送 GET、POST 请求等,但是 PHP 语言本身不支持多线程,所以开发爬虫程序效率低下不高。这时候往往需要借助Curl Multi Functions来实现对多个URL地址的并发和多线程访问。既然Curl Multi Function这么强大,那我可以用Curl Multi Function来写并发多线程下载文件吗?当然,我的代码如下:
代码一:将得到的代码直接写入文件
$urls = array(
'http://www.sina.com.cn/',
'http://www.sohu.com/',
'http://www.163.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 设置将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
代码2:将得到的代码先放入变量中,再写入文件
$urls = array(
'http://www.sina.com.cn/',
'http://www.sohu.com/',
'http://www.163.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 设置不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件。当然,也可以不写入文件,比如存入数据库
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
php多线程抓取网页(php结合curl实现多线程抓取PHP实战(1)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-05 10:37
《PHP教程:PHP结合curl实现多线程爬虫》要点:
本文介绍PHP教程:PHP结合curl实现多线程爬取,希望对大家有用。如果您有任何问题,可以联系我们。
PHP结合curl实现多线程抓取PHP实战
再来几个PHP实战的例子
(1)以下代码是抓取多个网址,然后将抓取到的网址的页面代码写入指定文件。PHP实战
$urls = array(
'/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码和上面类似,不过这个地方是先把获取的代码放入变量中,然后将获取的内容写入指定的文件中。PHP实战
$urls = array(
'/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)下面这段代码实现了利用PHP的Curl Functions实现文件的多线程并发下载。PHP实战
$urls=array(
'',
'',
''
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'',
'',
''
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。
欢迎参与《PHP教程:PHP结合Curl实现多线程爬虫》的讨论,分享您的想法,微易PHP学院为您提供专业教程。 查看全部
php多线程抓取网页(php结合curl实现多线程抓取PHP实战(1)_)
《PHP教程:PHP结合curl实现多线程爬虫》要点:
本文介绍PHP教程:PHP结合curl实现多线程爬取,希望对大家有用。如果您有任何问题,可以联系我们。
PHP结合curl实现多线程抓取PHP实战
再来几个PHP实战的例子
(1)以下代码是抓取多个网址,然后将抓取到的网址的页面代码写入指定文件。PHP实战
$urls = array(
'/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码和上面类似,不过这个地方是先把获取的代码放入变量中,然后将获取的内容写入指定的文件中。PHP实战
$urls = array(
'/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)下面这段代码实现了利用PHP的Curl Functions实现文件的多线程并发下载。PHP实战
$urls=array(
'',
'',
''
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'',
'',
''
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。
欢迎参与《PHP教程:PHP结合Curl实现多线程爬虫》的讨论,分享您的想法,微易PHP学院为您提供专业教程。
php多线程抓取网页(PHP利用CurlFunctions可以完成各种传送文件操作下载文件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-04 15:31
)
PHP使用curl函数完成各种文件传输操作,例如模拟浏览器发送get和post请求。受PHP语言不支持多线程的限制,开发爬虫程序的效率不高。此时,常常需要curl多函数来实现并发多线程访问多个URL地址。既然curl多函数功能强大,我可以使用curl多函数来编写并发多线程下载文件吗?当然可以。这是我的密码:
代码1:将获得的代码直接写入文件
$urls = array(
'http://www.sina.com.cn/',
'http://www.sohu.com/',
'http://www.163.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 设置将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
代码2:首先将获得的代码放入变量中,然后将其写入文件
$urls = array(
'http://www.sina.com.cn/',
'http://www.sohu.com/',
'http://www.163.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 设置不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件。当然,也可以不写入文件,比如存入数据库
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st); 查看全部
php多线程抓取网页(PHP利用CurlFunctions可以完成各种传送文件操作下载文件
)
PHP使用curl函数完成各种文件传输操作,例如模拟浏览器发送get和post请求。受PHP语言不支持多线程的限制,开发爬虫程序的效率不高。此时,常常需要curl多函数来实现并发多线程访问多个URL地址。既然curl多函数功能强大,我可以使用curl多函数来编写并发多线程下载文件吗?当然可以。这是我的密码:
代码1:将获得的代码直接写入文件
$urls = array(
'http://www.sina.com.cn/',
'http://www.sohu.com/',
'http://www.163.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 设置将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
代码2:首先将获得的代码放入变量中,然后将其写入文件
$urls = array(
'http://www.sina.com.cn/',
'http://www.sohu.com/',
'http://www.163.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 设置不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件。当然,也可以不写入文件,比如存入数据库
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
php多线程抓取网页(php多线程抓取网页??php抓取网页-慕课网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-03 16:00
php多线程抓取网页?php多线程抓取网页-慕课网php抓取网页其实不难,使用正则表达式加断点来抓取即可实现,可以从如下三个方面考虑。1.requestweb站点,一般都是通过http请求来发出获取链接的请求。发出请求即是url中带有txt位元数据,txt中的文本叫html代码,用来取出包含这个url地址的页面是谁。
2.现在的前端工程师可能会把整个页面的一部分叫做一个。当然也有很多新的奇淫技巧来取代简单的view,如form表单的content-value等等,只要是前端发出请求了,php就可以识别地址栏里写着哪些资源的页面等等。所以一般都是采用一个来抓取页面,然后再把一些内容放在一起去抓取一大堆页面。这个文件就是页面中的html代码。
3.除了页面中的代码可以出口之外,页面也可以自定义一些具体的内容出口,从里的数据中出口显示不出来,然后在函数里发出请求的时候,通过里面的内容来定位到具体的页面并提取出要抓取的页面。
这个问题,困扰我很久了,真想给你一个满意的答案,抱歉没有。没有人知道让php多线程来抓取网页是什么,难道你是“提供个xx网站的例子,就可以提供多线程抓取方案”。这种用法只能是为了让你crud项目的效率提高,否则会被很多人喷的。我只能是说,爬虫从来不只是抓取网页,它更多的还是一种信息存储的方式,数据排列方式,和数据的处理方式,从这个角度来说,爬虫要做的事情超出网页抓取。
只能说是大部分。毕竟网页只是网页,没有办法赋予你多大权限,定制你抓取网页的信息。如果非要说个方案,请一般定制你抓取网页的方案,然后将txt文件提取出来放到工程文件夹,你定制抓取方案然后采用正则等获取页面,就像一个二进制文件一样做进一步处理。网页抓取,目前多数依赖分布式抓取是因为各种去重,各种规则分布式的数据量太大,容易是现实。
另外,你提到的四个问题,难点不在于抓取页面本身,在于处理分布式的问题。当然,你也可以说我是把你的问题,转换成一些数据处理的工作,拿我现在所掌握的和你分享下吧。抓取本身是crud的操作,基本都是通过网页提供给你的接口进行接收发放网页地址的请求数据,txt本身其实就是对请求的数据进行处理加工,这是我们在txt语言里面非常常见的做法,基本的入门使用txt都是通过三个通配符来选取,txt文件这时候一般叫做html代码(参考这个:copyjs),在php里,实际上是用元组来进行数据的编写的,比如,上面的“"//<p>end:”,这样用txt文件。</p> 查看全部
php多线程抓取网页(php多线程抓取网页??php抓取网页-慕课网)
php多线程抓取网页?php多线程抓取网页-慕课网php抓取网页其实不难,使用正则表达式加断点来抓取即可实现,可以从如下三个方面考虑。1.requestweb站点,一般都是通过http请求来发出获取链接的请求。发出请求即是url中带有txt位元数据,txt中的文本叫html代码,用来取出包含这个url地址的页面是谁。
2.现在的前端工程师可能会把整个页面的一部分叫做一个。当然也有很多新的奇淫技巧来取代简单的view,如form表单的content-value等等,只要是前端发出请求了,php就可以识别地址栏里写着哪些资源的页面等等。所以一般都是采用一个来抓取页面,然后再把一些内容放在一起去抓取一大堆页面。这个文件就是页面中的html代码。
3.除了页面中的代码可以出口之外,页面也可以自定义一些具体的内容出口,从里的数据中出口显示不出来,然后在函数里发出请求的时候,通过里面的内容来定位到具体的页面并提取出要抓取的页面。
这个问题,困扰我很久了,真想给你一个满意的答案,抱歉没有。没有人知道让php多线程来抓取网页是什么,难道你是“提供个xx网站的例子,就可以提供多线程抓取方案”。这种用法只能是为了让你crud项目的效率提高,否则会被很多人喷的。我只能是说,爬虫从来不只是抓取网页,它更多的还是一种信息存储的方式,数据排列方式,和数据的处理方式,从这个角度来说,爬虫要做的事情超出网页抓取。
只能说是大部分。毕竟网页只是网页,没有办法赋予你多大权限,定制你抓取网页的信息。如果非要说个方案,请一般定制你抓取网页的方案,然后将txt文件提取出来放到工程文件夹,你定制抓取方案然后采用正则等获取页面,就像一个二进制文件一样做进一步处理。网页抓取,目前多数依赖分布式抓取是因为各种去重,各种规则分布式的数据量太大,容易是现实。
另外,你提到的四个问题,难点不在于抓取页面本身,在于处理分布式的问题。当然,你也可以说我是把你的问题,转换成一些数据处理的工作,拿我现在所掌握的和你分享下吧。抓取本身是crud的操作,基本都是通过网页提供给你的接口进行接收发放网页地址的请求数据,txt本身其实就是对请求的数据进行处理加工,这是我们在txt语言里面非常常见的做法,基本的入门使用txt都是通过三个通配符来选取,txt文件这时候一般叫做html代码(参考这个:copyjs),在php里,实际上是用元组来进行数据的编写的,比如,上面的“"//<p>end:”,这样用txt文件。</p>
php多线程抓取网页(说起Python真的用的语言有那么神奇吗?除了它还可以用哪些语言?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-28 23:20
说到大数据,你不自觉的就会想到爬虫。说到爬虫使用的语言,很多人首先想到的是Python。Python真的有那么神奇吗?除了它可以使用哪些语言?
C#和Java都可以写爬虫,但原理其实差别不大,只是平台问题。可以认为,如果是有针对性的抓取几个页面,做一些简单的页面解析,抓取效率不是核心要求,那么使用的语言本质上没有太大区别。
使用什么语言取决于情况和主要目的。
如果是定向爬取,主要目的是解析js动态生成的内容,此时页面内容是js/ajax动态生成的,普通请求页面->解析方法行不通,需要使用类似firefox和chrome浏览器的js引擎动态分析页面的js代码。
这种情况建议考虑casperJS+phantomjs或者slimerJS+phantomjs。当然,硒也可以考虑。
3、如果爬虫涉及到大规模网站爬取,当效率、可扩展性、可维护性等是必须考虑的因素时,大规模爬取涉及的问题很多:多线程并发、I/ O机制、分布式爬取、消息通信、判断机制、任务调度等,这时候语言和框架的选择就显得尤为重要。
PHP 对多线程和异步的支持较差,因此不推荐使用。
NodeJS:对于一些垂直网站的爬取还好,但由于对分布式爬取、消息通信等支持较弱,请根据自身情况判断。
Python:强烈推荐,对上述问题有很好的支持。尤其是Scrapy框架不愧为首选。
主要原因是:
1) 抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相较于其他动态脚本语言,如 perl、shell,python 的 urllib2 包提供了更完整的 web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
2)网页爬取后的处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
除了这些,还有很多优点:支持xpath;基于扭曲,性能好;更好的调试工具;
这种情况下,如果还需要做js动态内容分析,casperjs不适合,只能基于chrome V8引擎等搭建自己的js引擎。
至于C和C++,虽然性能不错,但不推荐使用,尤其是考虑到成本等诸多因素。对于大多数公司来说,建议基于一些开源框架来做。不要自己发明轮子。做一个简单的爬虫很容易,但是做一个完整的爬虫很难。 查看全部
php多线程抓取网页(说起Python真的用的语言有那么神奇吗?除了它还可以用哪些语言?)
说到大数据,你不自觉的就会想到爬虫。说到爬虫使用的语言,很多人首先想到的是Python。Python真的有那么神奇吗?除了它可以使用哪些语言?
C#和Java都可以写爬虫,但原理其实差别不大,只是平台问题。可以认为,如果是有针对性的抓取几个页面,做一些简单的页面解析,抓取效率不是核心要求,那么使用的语言本质上没有太大区别。
使用什么语言取决于情况和主要目的。
如果是定向爬取,主要目的是解析js动态生成的内容,此时页面内容是js/ajax动态生成的,普通请求页面->解析方法行不通,需要使用类似firefox和chrome浏览器的js引擎动态分析页面的js代码。
这种情况建议考虑casperJS+phantomjs或者slimerJS+phantomjs。当然,硒也可以考虑。
3、如果爬虫涉及到大规模网站爬取,当效率、可扩展性、可维护性等是必须考虑的因素时,大规模爬取涉及的问题很多:多线程并发、I/ O机制、分布式爬取、消息通信、判断机制、任务调度等,这时候语言和框架的选择就显得尤为重要。
PHP 对多线程和异步的支持较差,因此不推荐使用。
NodeJS:对于一些垂直网站的爬取还好,但由于对分布式爬取、消息通信等支持较弱,请根据自身情况判断。
Python:强烈推荐,对上述问题有很好的支持。尤其是Scrapy框架不愧为首选。
主要原因是:
1) 抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相较于其他动态脚本语言,如 perl、shell,python 的 urllib2 包提供了更完整的 web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
2)网页爬取后的处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
除了这些,还有很多优点:支持xpath;基于扭曲,性能好;更好的调试工具;
这种情况下,如果还需要做js动态内容分析,casperjs不适合,只能基于chrome V8引擎等搭建自己的js引擎。
至于C和C++,虽然性能不错,但不推荐使用,尤其是考虑到成本等诸多因素。对于大多数公司来说,建议基于一些开源框架来做。不要自己发明轮子。做一个简单的爬虫很容易,但是做一个完整的爬虫很难。
php多线程抓取网页(由C#编写的多线程异步抓取网页的网络爬虫控制台程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-09-27 03:18
C#编写的多线程异步网络爬虫控制台程序
描述:C#编写的多线程异步网络爬虫控制台程序。功能:目前只能提取网络链接,使用的两个记录文件不需要很大。暂时无法抓取网页文字、图片、视频和html代码,敬请谅解。但是需要注意的是,网页的数量非常多。下面的代码理论上可以捕获整个互联网网页链接。但实际上,由于处理器功能和网络条件(主要是网速)的限制,一般家用电脑最多可以处理12个线程的爬虫任务,爬虫速度是有限的。它可以爬行,但需要时间和耐心。当然,这个程序可以捕获所有链接,因为链接不占用太多系统空间,并且借助日志文件,可以将爬取的网页数量堆积起来,甚至可以访问所有互联网网络链接,当然最好分批进行。建议将maxNum设置为500-1000左右,慢慢积累。另外,由于是控制台程序,有时显示的字符过多,系统会暂停显示。这时候,只需点击控制台并按回车键即可。当程序暂停时,您可以按 Enter 尝试。/// 要使用这个程序,请确保已经创建了相应的记录文件。为简化代码,本程序不够健壮,请见谅。/// 默认文件创建在E盘根目录下的两个文本文件:“待爬取的URL.txt”和“待爬取的URL.txt” . 这两个文件需要用户自己创建,注意不要有后缀弄错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫的速度是这样的:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫的速度是这样的:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫的速度是这样的:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫的速度是这样的:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫的速度是这样的:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。
现在就下载 查看全部
php多线程抓取网页(由C#编写的多线程异步抓取网页的网络爬虫控制台程序)
C#编写的多线程异步网络爬虫控制台程序
描述:C#编写的多线程异步网络爬虫控制台程序。功能:目前只能提取网络链接,使用的两个记录文件不需要很大。暂时无法抓取网页文字、图片、视频和html代码,敬请谅解。但是需要注意的是,网页的数量非常多。下面的代码理论上可以捕获整个互联网网页链接。但实际上,由于处理器功能和网络条件(主要是网速)的限制,一般家用电脑最多可以处理12个线程的爬虫任务,爬虫速度是有限的。它可以爬行,但需要时间和耐心。当然,这个程序可以捕获所有链接,因为链接不占用太多系统空间,并且借助日志文件,可以将爬取的网页数量堆积起来,甚至可以访问所有互联网网络链接,当然最好分批进行。建议将maxNum设置为500-1000左右,慢慢积累。另外,由于是控制台程序,有时显示的字符过多,系统会暂停显示。这时候,只需点击控制台并按回车键即可。当程序暂停时,您可以按 Enter 尝试。/// 要使用这个程序,请确保已经创建了相应的记录文件。为简化代码,本程序不够健壮,请见谅。/// 默认文件创建在E盘根目录下的两个文本文件:“待爬取的URL.txt”和“待爬取的URL.txt” . 这两个文件需要用户自己创建,注意不要有后缀弄错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫的速度是这样的:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫的速度是这样的:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫的速度是这样的:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫的速度是这样的:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫的速度是这样的:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。
现在就下载
php多线程抓取网页(GoogleWebSearchAPI+多线程文档中的抓取Goolge搜索链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-24 11:34
1)urllib2+BeautifulSoup 抓取Goolge 搜索链接
最近参与项目需要处理谷歌搜索结果,之前学习了与处理网页相关的Python工具。在实际应用中,urllib2和beautifulsoup是用来抓取网页的,但是在抓取谷歌搜索结果的时候,我发现如果直接处理谷歌搜索结果页面的源码,会得到很多“脏”的链接。
看下图搜索“titanic james”的结果:
图中红色标注的不需要,蓝色标注的需要抓取处理。
这种“脏链接”当然可以通过常规过滤的方式过滤掉,但是程序的复杂度很高。就在我一脸悲伤地写过滤规则的时候。同学提醒谷歌应该提供相关的api,突然就明白了。
(2)Google 网页搜索 API+多线程
该文档提供了使用 Python 进行搜索的示例:
图中红色标注的不需要,蓝色标注的需要抓取处理。
这种“脏链接”当然可以通过常规过滤的方式过滤掉,但是程序的复杂度很高。就在我一脸悲伤地写过滤规则的时候。同学提醒谷歌应该提供相关的api,突然就明白了。
(2)Google 网页搜索 API+多线程
该文档提供了使用 Python 进行搜索的示例:
import simplejson
# The request also includes the userip parameter which provides the end
# user's IP address. Doing so will help distinguish this legitimate
# server-side traffic from traffic which doesn't come from an end-user.
url = ('https://ajax.googleapis.com/aj ... 39%3B
'?v=1.0&q=Paris%20Hilton&userip=USERS-IP-ADDRESS')
request = urllib2.Request(
url, None, {'Referer': /* Enter the URL of your site here */})
response = urllib2.urlopen(request)
# Process the JSON string.
results = simplejson.load(response)
# now have some fun with the results...
import simplejson
# The request also includes the userip parameter which provides the end
# user's IP address. Doing so will help distinguish this legitimate
# server-side traffic from traffic which doesn't come from an end-user.
url = ('https://ajax.googleapis.com/aj ... 39%3B
'?v=1.0&q=Paris%20Hilton&userip=USERS-IP-ADDRESS')
request = urllib2.Request(
url, None, {'Referer': /* Enter the URL of your site here */})
response = urllib2.urlopen(request)
# Process the JSON string.
results = simplejson.load(response)
# now have some fun with the results..
在实际应用中,可能需要抓取Google的很多网页,因此需要使用多线程来分担抓取任务。使用google web search api的详细介绍请看这里(这里介绍了Standard URL Arguments)。另外要特别注意的是url中的参数rsz必须是8(包括8)以下的值。如果大于8会报错!
(3)代码实现
代码实现还存在问题,但是可以运行,健壮性差,有待改进。希望各位大神指出错误(初学者Python),万分感谢。
#-*-coding:utf-8-*-
import urllib2,urllib
import simplejson
import os, time,threading
import common, html_filter
#input the keywords
keywords = raw_input('Enter the keywords: ')
#define rnum_perpage, pages
rnum_perpage=8
pages=8
#定义线程函数
def thread_scratch(url, rnum_perpage, page):
url_set = []
try:
request = urllib2.Request(url, None, {'Referer': 'http://www.sina.com'})
response = urllib2.urlopen(request)
# Process the JSON string.
results = simplejson.load(response)
info = results['responseData']['results']
except Exception,e:
print 'error occured'
print e
else:
for minfo in info:
url_set.append(minfo['url'])
print minfo['url']
#处理链接
i = 0
for u in url_set:
try:
request_url = urllib2.Request(u, None, {'Referer': 'http://www.sina.com'})
request_url.add_header(
'User-agent',
'CSC'
)
response_data = urllib2.urlopen(request_url).read()
#过滤文件
#content_data = html_filter.filter_tags(response_data)
#写入文件
filenum = i+page
filename = dir_name+'/related_html_'+str(filenum)
print ' write start: related_html_'+str(filenum)
f = open(filename, 'w+', -1)
f.write(response_data)
#print content_data
f.close()
print ' write down: related_html_'+str(filenum)
except Exception, e:
print 'error occured 2'
print e
i = i+1
return
#创建文件夹
dir_name = 'related_html_'+urllib.quote(keywords)
if os.path.exists(dir_name):
print 'exists file'
common.delete_dir_or_file(dir_name)
os.makedirs(dir_name)
#抓取网页
print 'start to scratch web pages:'
for x in range(pages):
print "page:%s"%(x+1)
page = x * rnum_perpage
url = ('https://ajax.googleapis.com/aj ... 39%3B
'?v=1.0&q=%s&rsz=%s&start=%s') % (urllib.quote(keywords), rnum_perpage,page)
print url
t = threading.Thread(target=thread_scratch, args=(url,rnum_perpage, page))
t.start()
#主线程等待子线程抓取完
main_thread = threading.currentThread()
for t in threading.enumerate():
if t is main_thread:
continue
t.join()
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
php多线程抓取网页(GoogleWebSearchAPI+多线程文档中的抓取Goolge搜索链接)
1)urllib2+BeautifulSoup 抓取Goolge 搜索链接
最近参与项目需要处理谷歌搜索结果,之前学习了与处理网页相关的Python工具。在实际应用中,urllib2和beautifulsoup是用来抓取网页的,但是在抓取谷歌搜索结果的时候,我发现如果直接处理谷歌搜索结果页面的源码,会得到很多“脏”的链接。
看下图搜索“titanic james”的结果:

图中红色标注的不需要,蓝色标注的需要抓取处理。
这种“脏链接”当然可以通过常规过滤的方式过滤掉,但是程序的复杂度很高。就在我一脸悲伤地写过滤规则的时候。同学提醒谷歌应该提供相关的api,突然就明白了。
(2)Google 网页搜索 API+多线程
该文档提供了使用 Python 进行搜索的示例:
图中红色标注的不需要,蓝色标注的需要抓取处理。
这种“脏链接”当然可以通过常规过滤的方式过滤掉,但是程序的复杂度很高。就在我一脸悲伤地写过滤规则的时候。同学提醒谷歌应该提供相关的api,突然就明白了。
(2)Google 网页搜索 API+多线程
该文档提供了使用 Python 进行搜索的示例:
import simplejson
# The request also includes the userip parameter which provides the end
# user's IP address. Doing so will help distinguish this legitimate
# server-side traffic from traffic which doesn't come from an end-user.
url = ('https://ajax.googleapis.com/aj ... 39%3B
'?v=1.0&q=Paris%20Hilton&userip=USERS-IP-ADDRESS')
request = urllib2.Request(
url, None, {'Referer': /* Enter the URL of your site here */})
response = urllib2.urlopen(request)
# Process the JSON string.
results = simplejson.load(response)
# now have some fun with the results...
import simplejson
# The request also includes the userip parameter which provides the end
# user's IP address. Doing so will help distinguish this legitimate
# server-side traffic from traffic which doesn't come from an end-user.
url = ('https://ajax.googleapis.com/aj ... 39%3B
'?v=1.0&q=Paris%20Hilton&userip=USERS-IP-ADDRESS')
request = urllib2.Request(
url, None, {'Referer': /* Enter the URL of your site here */})
response = urllib2.urlopen(request)
# Process the JSON string.
results = simplejson.load(response)
# now have some fun with the results..
在实际应用中,可能需要抓取Google的很多网页,因此需要使用多线程来分担抓取任务。使用google web search api的详细介绍请看这里(这里介绍了Standard URL Arguments)。另外要特别注意的是url中的参数rsz必须是8(包括8)以下的值。如果大于8会报错!
(3)代码实现
代码实现还存在问题,但是可以运行,健壮性差,有待改进。希望各位大神指出错误(初学者Python),万分感谢。
#-*-coding:utf-8-*-
import urllib2,urllib
import simplejson
import os, time,threading
import common, html_filter
#input the keywords
keywords = raw_input('Enter the keywords: ')
#define rnum_perpage, pages
rnum_perpage=8
pages=8
#定义线程函数
def thread_scratch(url, rnum_perpage, page):
url_set = []
try:
request = urllib2.Request(url, None, {'Referer': 'http://www.sina.com'})
response = urllib2.urlopen(request)
# Process the JSON string.
results = simplejson.load(response)
info = results['responseData']['results']
except Exception,e:
print 'error occured'
print e
else:
for minfo in info:
url_set.append(minfo['url'])
print minfo['url']
#处理链接
i = 0
for u in url_set:
try:
request_url = urllib2.Request(u, None, {'Referer': 'http://www.sina.com'})
request_url.add_header(
'User-agent',
'CSC'
)
response_data = urllib2.urlopen(request_url).read()
#过滤文件
#content_data = html_filter.filter_tags(response_data)
#写入文件
filenum = i+page
filename = dir_name+'/related_html_'+str(filenum)
print ' write start: related_html_'+str(filenum)
f = open(filename, 'w+', -1)
f.write(response_data)
#print content_data
f.close()
print ' write down: related_html_'+str(filenum)
except Exception, e:
print 'error occured 2'
print e
i = i+1
return
#创建文件夹
dir_name = 'related_html_'+urllib.quote(keywords)
if os.path.exists(dir_name):
print 'exists file'
common.delete_dir_or_file(dir_name)
os.makedirs(dir_name)
#抓取网页
print 'start to scratch web pages:'
for x in range(pages):
print "page:%s"%(x+1)
page = x * rnum_perpage
url = ('https://ajax.googleapis.com/aj ... 39%3B
'?v=1.0&q=%s&rsz=%s&start=%s') % (urllib.quote(keywords), rnum_perpage,page)
print url
t = threading.Thread(target=thread_scratch, args=(url,rnum_perpage, page))
t.start()
#主线程等待子线程抓取完
main_thread = threading.currentThread()
for t in threading.enumerate():
if t is main_thread:
continue
t.join()

免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
php多线程抓取网页( Young-杨培丽PHP实现百度搜索结果页面及正则匹配相关操作技巧汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2021-09-24 11:31
Young-杨培丽PHP实现百度搜索结果页面及正则匹配相关操作技巧汇总)
PHP抓取百度搜索结果页面[相关搜索词]并将其存储在TXT文件中
更新日期:2018年7月11日12:19:29杨培利
本文章主要介绍PHP如何捕获百度搜索结果页面[相关搜索词]并将其存储在TXT文件中,涉及基于PHP curl的页面捕获和定期匹配相关操作技巧。有需要的朋友可以参考
这个例子描述了PHP如何抓取百度搜索结果页面[相关搜索词]并将其存储在TXT文件中。与您分享,供您参考,如下所示:
一、百度搜索关键词[脚本屋]
[脚本库]搜索链接
%E8%84%9A%E6%9C%AC%E4%B9%8B%E5%AE%B6&;rsv_uq=ab33cfeb000086a2&;rsv_u-t=7c65vT3KzHCNfGYOIn%2FDSS%2BOQUiCycaspxWzSOBfkHYpgRIPKMI74WIi8K8&;rqlang=cn&;rsv_uuu输入=1&;rsv_uusug3=1
搜索结果的源代码:
相关搜索
游戏脚本通常在哪里找到脚本?如何编写脚本?这是什么意思
脚本屋应用程序移动脚本制作移动脚本
脚本游戏制作大师级游戏脚本制作教程脚本向导
二、抓取并保存本地
源代码
index.php:
<p> 查看全部
php多线程抓取网页(
Young-杨培丽PHP实现百度搜索结果页面及正则匹配相关操作技巧汇总)
PHP抓取百度搜索结果页面[相关搜索词]并将其存储在TXT文件中
更新日期:2018年7月11日12:19:29杨培利
本文章主要介绍PHP如何捕获百度搜索结果页面[相关搜索词]并将其存储在TXT文件中,涉及基于PHP curl的页面捕获和定期匹配相关操作技巧。有需要的朋友可以参考
这个例子描述了PHP如何抓取百度搜索结果页面[相关搜索词]并将其存储在TXT文件中。与您分享,供您参考,如下所示:
一、百度搜索关键词[脚本屋]

[脚本库]搜索链接
%E8%84%9A%E6%9C%AC%E4%B9%8B%E5%AE%B6&;rsv_uq=ab33cfeb000086a2&;rsv_u-t=7c65vT3KzHCNfGYOIn%2FDSS%2BOQUiCycaspxWzSOBfkHYpgRIPKMI74WIi8K8&;rqlang=cn&;rsv_uuu输入=1&;rsv_uusug3=1

搜索结果的源代码:
相关搜索
游戏脚本通常在哪里找到脚本?如何编写脚本?这是什么意思
脚本屋应用程序移动脚本制作移动脚本
脚本游戏制作大师级游戏脚本制作教程脚本向导
二、抓取并保存本地

源代码
index.php:
<p>
php多线程抓取网页(网络爬虫实战_乐趣之旅seqone(架构++url))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-09-22 08:01
php多线程抓取网页_图片
一)_网络爬虫实战_乐趣之旅seqone(架构++url)如何抓取网页下载地址:网页下载,线程抓取,url反爬,
这种情况有一个关键点:调用url接口的地方保证url经过了可靠的序列化。一个好的请求头,一个好的序列化,在这两者的保护下,即使线程池起来,同时也只会发送出正确的网页内容。给几点意见:线程能不起来就不起来。如果一定要起来,为了获取大量图片,
1)把请求发给队列,队列一般不会出现空的,这个队列最好还能接收下载网页的url和个数。
2)线程池内部有一个进程池,那么可以利用threadpoolexecutor来分别处理队列和进程池,获取到的url可以再放进进程池里面获取,也可以分别放队列然后分别获取。
3)线程池可以利用pooledqueue来分别保存队列和进程池。这个需要自己实现。另外可以使用asyncio。
没必要多线程,可以自己尝试多进程,nginx,
地址栏不是抓取的,地址栏才是抓取的。题主不要混淆重要部分。
三种方案:第一种,nginx或者fastcgi+redis。第二种,使用threadpoolexecutor。第三种,使用laravel、workerman等web框架。 查看全部
php多线程抓取网页(网络爬虫实战_乐趣之旅seqone(架构++url))
php多线程抓取网页_图片
一)_网络爬虫实战_乐趣之旅seqone(架构++url)如何抓取网页下载地址:网页下载,线程抓取,url反爬,
这种情况有一个关键点:调用url接口的地方保证url经过了可靠的序列化。一个好的请求头,一个好的序列化,在这两者的保护下,即使线程池起来,同时也只会发送出正确的网页内容。给几点意见:线程能不起来就不起来。如果一定要起来,为了获取大量图片,
1)把请求发给队列,队列一般不会出现空的,这个队列最好还能接收下载网页的url和个数。
2)线程池内部有一个进程池,那么可以利用threadpoolexecutor来分别处理队列和进程池,获取到的url可以再放进进程池里面获取,也可以分别放队列然后分别获取。
3)线程池可以利用pooledqueue来分别保存队列和进程池。这个需要自己实现。另外可以使用asyncio。
没必要多线程,可以自己尝试多进程,nginx,
地址栏不是抓取的,地址栏才是抓取的。题主不要混淆重要部分。
三种方案:第一种,nginx或者fastcgi+redis。第二种,使用threadpoolexecutor。第三种,使用laravel、workerman等web框架。
php多线程抓取网页(本文_init()处理事物是单线程模式的函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-09-20 03:13
本文说明了PHP如何使用curl\uinit()和curl\umulti\uinit()来比较多线程的速度。分享给你参考
本文说明了PHP如何使用curl\uinit()和curl\umulti\uinit()来比较多线程的速度。与您分享,供您参考,如下所示:
PHP_uinit()中的Curl起着非常重要的作用,尤其是在捕获网页内容或文件信息时。例如,curl是在前面的文章“PHP使用curl来获取头检测并启用gzip压缩”uu init()的威力)中引入的
curl\uinit()以单线程模式处理事情。如果您需要采用多线程模式进行事务处理,PHP提供了一个函数curl\multi\uinit()告诉我们这是一个以多线程模式处理事务的函数
curl_uuinit()和Init()的curl_uumulti_u速度比较
curl\multi\init()多线程可以提高网页的处理速度吗?今天,我将通过实验来验证这个问题
今天,我的测试非常简单,就是抓取网页的内容,连续抓取五次,分别使用curl_uinit()和curl_uumulti_Init()函数,记录两者的耗时,并通过比较得出结论
首先,使用curl_uinit()单线程连续五次抓取网页内容
程序代码如下:
然后,使用curl\umulti\uinit()多线程连续五次抓取网页内容
代码如下:
<p> 查看全部
php多线程抓取网页(本文_init()处理事物是单线程模式的函数)
本文说明了PHP如何使用curl\uinit()和curl\umulti\uinit()来比较多线程的速度。分享给你参考
本文说明了PHP如何使用curl\uinit()和curl\umulti\uinit()来比较多线程的速度。与您分享,供您参考,如下所示:
PHP_uinit()中的Curl起着非常重要的作用,尤其是在捕获网页内容或文件信息时。例如,curl是在前面的文章“PHP使用curl来获取头检测并启用gzip压缩”uu init()的威力)中引入的
curl\uinit()以单线程模式处理事情。如果您需要采用多线程模式进行事务处理,PHP提供了一个函数curl\multi\uinit()告诉我们这是一个以多线程模式处理事务的函数
curl_uuinit()和Init()的curl_uumulti_u速度比较
curl\multi\init()多线程可以提高网页的处理速度吗?今天,我将通过实验来验证这个问题
今天,我的测试非常简单,就是抓取网页的内容,连续抓取五次,分别使用curl_uinit()和curl_uumulti_Init()函数,记录两者的耗时,并通过比较得出结论
首先,使用curl_uinit()单线程连续五次抓取网页内容
程序代码如下:
然后,使用curl\umulti\uinit()多线程连续五次抓取网页内容
代码如下:
<p>
php多线程抓取网页(Python处理网页相关的几种常见错误(一)+BeautifulSoup抓取Goolge )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-20 03:12
)
1)urllib2+BeautifulSoup抓取谷歌搜索链接
最近,参与项目需要处理谷歌搜索结果。在此之前,我学习了与网页相关的Python工具。在实际应用中,urlib2和beatifulsoup被用来捕获网页,但在捕获Google搜索结果时,发现如果直接处理Google搜索结果页面的源代码,会获得许多“脏”链接
“泰坦尼克号詹姆斯”的搜索结果如下图所示:
图中红色标记的不需要,蓝色标记的需要抓取
当然,这个“脏链接”可以通过规则过滤过滤掉,但是程序的复杂性很高。当他写过滤规则时,脸上带着悲伤。学生们提醒谷歌应该在他们突然明白之前提供相关的API
(2)GoogleWeb搜索API+多线程
文档中给出了使用Python进行搜索的示例:
在实际应用中,您可能需要抓取许多Google网页,因此您还需要使用多线程来共享抓取任务。有关使用Google Web搜索API的详细介绍,请参见此处(此处介绍了标准URL参数)。此外,请特别注意URL中的参数rsz必须为8(包括以下数值8).如果大于8,将报告错误
(3)code实现)
代码实现中仍然存在问题,但它可以运行,健壮性差,需要改进。我希望诸神都能指出错误(初学者Python)。非常感谢
#-*-coding:utf-8-*-
import urllib2,urllib
import simplejson
import os, time,threading
import common, html_filter
#input the keywords
keywords = raw_input('Enter the keywords: ')
#define rnum_perpage, pages
rnum_perpage=8
pages=8
#定义线程函数
def thread_scratch(url, rnum_perpage, page):
url_set = []
try:
request = urllib2.Request(url, None, {'Referer': 'http://www.sina.com'})
response = urllib2.urlopen(request)
# Process the JSON string.
results = simplejson.load(response)
info = results['responseData']['results']
except Exception,e:
print 'error occured'
print e
else:
for minfo in info:
url_set.append(minfo['url'])
print minfo['url']
#处理链接
i = 0
for u in url_set:
try:
request_url = urllib2.Request(u, None, {'Referer': 'http://www.sina.com'})
request_url.add_header(
'User-agent',
'CSC'
)
response_data = urllib2.urlopen(request_url).read()
#过滤文件
#content_data = html_filter.filter_tags(response_data)
#写入文件
filenum = i+page
filename = dir_name+'/related_html_'+str(filenum)
print ' write start: related_html_'+str(filenum)
f = open(filename, 'w+', -1)
f.write(response_data)
#print content_data
f.close()
print ' write down: related_html_'+str(filenum)
except Exception, e:
print 'error occured 2'
print e
i = i+1
return
#创建文件夹
dir_name = 'related_html_'+urllib.quote(keywords)
if os.path.exists(dir_name):
print 'exists file'
common.delete_dir_or_file(dir_name)
os.makedirs(dir_name)
#抓取网页
print 'start to scratch web pages:'
for x in range(pages):
print "page:%s"%(x+1)
page = x * rnum_perpage
url = ('https://ajax.googleapis.com/ajax/services/search/web'
'?v=1.0&q=%s&rsz=%s&start=%s') % (urllib.quote(keywords), rnum_perpage,page)
print url
t = threading.Thread(target=thread_scratch, args=(url,rnum_perpage, page))
t.start()
#主线程等待子线程抓取完
main_thread = threading.currentThread()
for t in threading.enumerate():
if t is main_thread:
continue
t.join() 查看全部
php多线程抓取网页(Python处理网页相关的几种常见错误(一)+BeautifulSoup抓取Goolge
)
1)urllib2+BeautifulSoup抓取谷歌搜索链接
最近,参与项目需要处理谷歌搜索结果。在此之前,我学习了与网页相关的Python工具。在实际应用中,urlib2和beatifulsoup被用来捕获网页,但在捕获Google搜索结果时,发现如果直接处理Google搜索结果页面的源代码,会获得许多“脏”链接
“泰坦尼克号詹姆斯”的搜索结果如下图所示:

图中红色标记的不需要,蓝色标记的需要抓取
当然,这个“脏链接”可以通过规则过滤过滤掉,但是程序的复杂性很高。当他写过滤规则时,脸上带着悲伤。学生们提醒谷歌应该在他们突然明白之前提供相关的API
(2)GoogleWeb搜索API+多线程
文档中给出了使用Python进行搜索的示例:
在实际应用中,您可能需要抓取许多Google网页,因此您还需要使用多线程来共享抓取任务。有关使用Google Web搜索API的详细介绍,请参见此处(此处介绍了标准URL参数)。此外,请特别注意URL中的参数rsz必须为8(包括以下数值8).如果大于8,将报告错误
(3)code实现)
代码实现中仍然存在问题,但它可以运行,健壮性差,需要改进。我希望诸神都能指出错误(初学者Python)。非常感谢
#-*-coding:utf-8-*-
import urllib2,urllib
import simplejson
import os, time,threading
import common, html_filter
#input the keywords
keywords = raw_input('Enter the keywords: ')
#define rnum_perpage, pages
rnum_perpage=8
pages=8
#定义线程函数
def thread_scratch(url, rnum_perpage, page):
url_set = []
try:
request = urllib2.Request(url, None, {'Referer': 'http://www.sina.com'})
response = urllib2.urlopen(request)
# Process the JSON string.
results = simplejson.load(response)
info = results['responseData']['results']
except Exception,e:
print 'error occured'
print e
else:
for minfo in info:
url_set.append(minfo['url'])
print minfo['url']
#处理链接
i = 0
for u in url_set:
try:
request_url = urllib2.Request(u, None, {'Referer': 'http://www.sina.com'})
request_url.add_header(
'User-agent',
'CSC'
)
response_data = urllib2.urlopen(request_url).read()
#过滤文件
#content_data = html_filter.filter_tags(response_data)
#写入文件
filenum = i+page
filename = dir_name+'/related_html_'+str(filenum)
print ' write start: related_html_'+str(filenum)
f = open(filename, 'w+', -1)
f.write(response_data)
#print content_data
f.close()
print ' write down: related_html_'+str(filenum)
except Exception, e:
print 'error occured 2'
print e
i = i+1
return
#创建文件夹
dir_name = 'related_html_'+urllib.quote(keywords)
if os.path.exists(dir_name):
print 'exists file'
common.delete_dir_or_file(dir_name)
os.makedirs(dir_name)
#抓取网页
print 'start to scratch web pages:'
for x in range(pages):
print "page:%s"%(x+1)
page = x * rnum_perpage
url = ('https://ajax.googleapis.com/ajax/services/search/web'
'?v=1.0&q=%s&rsz=%s&start=%s') % (urllib.quote(keywords), rnum_perpage,page)
print url
t = threading.Thread(target=thread_scratch, args=(url,rnum_perpage, page))
t.start()
#主线程等待子线程抓取完
main_thread = threading.currentThread()
for t in threading.enumerate():
if t is main_thread:
continue
t.join()
php多线程抓取网页(php多线程抓取网页原理讲解使用mybatis实现数据库对接打造管理后台zenddata-zend)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-09-19 21:01
php多线程抓取网页原理讲解大型互联网网站维护、运维php基础内容。laravelwebcli功能讲解ecshop模板库讲解讲解使用mybatis实现数据库对接打造管理后台zenddata-zend。xml介绍htaccess_cookie介绍php中的requesthttp客户端/服务器连接管理mysql集群编写zenddata-zend。xml文件php多线程抓取网页教程_php有声音_互联网成长_小马哥教育_小马哥学院。
先学vue用template做完静态文件后全局gzip
一个月抓个小网站的代码,学会php多线程抓取,
抓包到你的网站内,然后解码到本地php目录下;抓取其他网站内容,要么用爬虫,
并不很推荐题主使用多线程抓取,一方面抓包抓到代码,进行后续的解析会浪费更多的资源,另一方面题主可能并不能保证php多线程抓取的效率,很有可能今天我抓取了300条,明天并不是300条,
php多线程抓取代码分享,
自己写一个支持gzip压缩加速工具
我要开始抓包了
php抓包,mysql存储抓取技术,zenddata系列数据库搭建与使用,
php多线程抓取xlsx文件,先创建xlsx。 查看全部
php多线程抓取网页(php多线程抓取网页原理讲解使用mybatis实现数据库对接打造管理后台zenddata-zend)
php多线程抓取网页原理讲解大型互联网网站维护、运维php基础内容。laravelwebcli功能讲解ecshop模板库讲解讲解使用mybatis实现数据库对接打造管理后台zenddata-zend。xml介绍htaccess_cookie介绍php中的requesthttp客户端/服务器连接管理mysql集群编写zenddata-zend。xml文件php多线程抓取网页教程_php有声音_互联网成长_小马哥教育_小马哥学院。
先学vue用template做完静态文件后全局gzip
一个月抓个小网站的代码,学会php多线程抓取,
抓包到你的网站内,然后解码到本地php目录下;抓取其他网站内容,要么用爬虫,
并不很推荐题主使用多线程抓取,一方面抓包抓到代码,进行后续的解析会浪费更多的资源,另一方面题主可能并不能保证php多线程抓取的效率,很有可能今天我抓取了300条,明天并不是300条,
php多线程抓取代码分享,
自己写一个支持gzip压缩加速工具
我要开始抓包了
php抓包,mysql存储抓取技术,zenddata系列数据库搭建与使用,
php多线程抓取xlsx文件,先创建xlsx。
php多线程抓取网页(php结合curl实现抓取我们再来看几个例子(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-09-17 23:05
PHP结合curl实现多线程抓取
让我们再看几个例子
(1)下面的代码是对多个URL进行爬网,然后将爬网URL的页面代码写入指定文件
$urls = array(
'http://www.jb51.net/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码与上面的代码含义相同,但此处是先将获取的代码放入变量中,然后将获取的内容写入指定的文件
$urls = array(
'http://www.jb51.net/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)下面的代码使用PHP的curl函数实现并发多线程文件下载
$urls=array(
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
以上是本文的全部内容,希望大家能喜欢 查看全部
php多线程抓取网页(php结合curl实现抓取我们再来看几个例子(1))
PHP结合curl实现多线程抓取
让我们再看几个例子
(1)下面的代码是对多个URL进行爬网,然后将爬网URL的页面代码写入指定文件
$urls = array(
'http://www.jb51.net/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码与上面的代码含义相同,但此处是先将获取的代码放入变量中,然后将获取的内容写入指定的文件
$urls = array(
'http://www.jb51.net/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)下面的代码使用PHP的curl函数实现并发多线程文件下载
$urls=array(
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
以上是本文的全部内容,希望大家能喜欢
php多线程抓取网页(写爬虫用什么语言好?爬虫选择什么工具?Crawler)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-16 04:15
什么语言适合写爬行动物
爬虫选择什么工具
1.crawler是一款网络蜘蛛机器人,它可以根据我们的规则自动抓取数据并获取数据
2.为什么使用爬行动物?私人定制搜索引擎获取更多数据的时代不再是互联网时代,而是大数据时代
3.爬虫的原理:控制节点(URL分配器)、爬虫节点(根据算法抓取数据并存储在数据库中)、资源数据库(爬虫数据库中提供搜索)。爬虫的设计思想是:爬虫的网络地址通过HTTP协议获取相应的HTML页面
5.爬虫语言选择:
PHP:尽管它被评为“世界上最好的语言”,但作为一个爬虫程序,它的缺点是:没有多线程的概念,几乎不支持异步,并发性不足,爬虫程序对效率的要求很高
C/C Java:Python最大的竞争对手,它非常庞大。爬虫程序需要经常修改代码
Python:优美的语言、代码介绍、多功能模块、调用替代语言接口和成熟的高度分布式策略
PYT Java]Java有很多解析器,它们非常支持网页解析。缺点是有很多Java开源爬虫程序,比如nutch。中国拥有优秀的webmagic Java解析器,如Htmlparser和jsoup,能够满足Java和python的共同需求。如果您需要模拟登录和反采集,那么选择python更方便。如果需要处理复杂的网页、解析网页内容以生成结构化数据或精细解析网页内容,可以选择Java
Java和python在爬虫方面的优缺点是什么
任何语言几乎都是一样的,Python的时间效率并不一定快。只有蟒蛇在早上被列为爬行动物。。此外,大多数所谓的爬虫是翻页和数据解析的基本过程,用这种语言很容易完成 查看全部
php多线程抓取网页(写爬虫用什么语言好?爬虫选择什么工具?Crawler)
什么语言适合写爬行动物
爬虫选择什么工具
1.crawler是一款网络蜘蛛机器人,它可以根据我们的规则自动抓取数据并获取数据
2.为什么使用爬行动物?私人定制搜索引擎获取更多数据的时代不再是互联网时代,而是大数据时代
3.爬虫的原理:控制节点(URL分配器)、爬虫节点(根据算法抓取数据并存储在数据库中)、资源数据库(爬虫数据库中提供搜索)。爬虫的设计思想是:爬虫的网络地址通过HTTP协议获取相应的HTML页面
5.爬虫语言选择:
PHP:尽管它被评为“世界上最好的语言”,但作为一个爬虫程序,它的缺点是:没有多线程的概念,几乎不支持异步,并发性不足,爬虫程序对效率的要求很高
C/C Java:Python最大的竞争对手,它非常庞大。爬虫程序需要经常修改代码
Python:优美的语言、代码介绍、多功能模块、调用替代语言接口和成熟的高度分布式策略
PYT Java]Java有很多解析器,它们非常支持网页解析。缺点是有很多Java开源爬虫程序,比如nutch。中国拥有优秀的webmagic Java解析器,如Htmlparser和jsoup,能够满足Java和python的共同需求。如果您需要模拟登录和反采集,那么选择python更方便。如果需要处理复杂的网页、解析网页内容以生成结构化数据或精细解析网页内容,可以选择Java
Java和python在爬虫方面的优缺点是什么
任何语言几乎都是一样的,Python的时间效率并不一定快。只有蟒蛇在早上被列为爬行动物。。此外,大多数所谓的爬虫是翻页和数据解析的基本过程,用这种语言很容易完成
php多线程抓取网页(爬虫怎么从xml、html格式数据中提取你想要的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-28 03:04
php多线程抓取网页详情按照上面提示做一下
可以。爬虫怎么从xml、html格式数据中提取你想要的数据,是你要考虑的问题。你已经搞定了xml,而爬虫需要和后端、服务器多次交互。第一次登录,需要问到后端服务器一次,而后续就直接读取服务器返回给你的数据咯。多线程在这个基础上,作用不大,效率也不好,你直接用非阻塞io就可以了。—你想多线程做详情分析,我觉得很难。爬虫只有单线程模式。
可以,但是这个操作跟你后端基本无关了,爬虫一般用c++或者python,需要一个稳定的数据库管理系统,至于多线程,肯定是多个独立线程在提交任务来,处理上,后端肯定是一个处理线程过来处理,无非在于html文件的解析和初始化数据提交而已,至于后端是否需要支持多线程,看后端提供的api。而且多线程抓取数据,你认为很难,其实也是可以做到的,就是再给抓取的速度会影响,毕竟抓取速度快,还需要靠数据库等。
之前的这个提问:一个爬虫是应该单线程还是多线程?
抓取页面网页肯定是可以的,但是api提供的xmlhttprequestapi设置的服务方法并不会进行多线程。你是要提供可多线程的api吗?-你要明白提供多线程的api并不是说把各个线程纳入系统中,而是默认所有的进程,包括所有能通过api操作页面的进程统一由一个privulsion(保存(页面的,数据库的)等等进程,unionresources)运行。
这样呢就是通过multicast库实现,你可以通过api来分析页面,但是你无法通过api操作数据库,因为他通过multicast来分析页面。否则,所有爬虫可以自发共享一个privulsion了。 查看全部
php多线程抓取网页(爬虫怎么从xml、html格式数据中提取你想要的数据)
php多线程抓取网页详情按照上面提示做一下
可以。爬虫怎么从xml、html格式数据中提取你想要的数据,是你要考虑的问题。你已经搞定了xml,而爬虫需要和后端、服务器多次交互。第一次登录,需要问到后端服务器一次,而后续就直接读取服务器返回给你的数据咯。多线程在这个基础上,作用不大,效率也不好,你直接用非阻塞io就可以了。—你想多线程做详情分析,我觉得很难。爬虫只有单线程模式。
可以,但是这个操作跟你后端基本无关了,爬虫一般用c++或者python,需要一个稳定的数据库管理系统,至于多线程,肯定是多个独立线程在提交任务来,处理上,后端肯定是一个处理线程过来处理,无非在于html文件的解析和初始化数据提交而已,至于后端是否需要支持多线程,看后端提供的api。而且多线程抓取数据,你认为很难,其实也是可以做到的,就是再给抓取的速度会影响,毕竟抓取速度快,还需要靠数据库等。
之前的这个提问:一个爬虫是应该单线程还是多线程?
抓取页面网页肯定是可以的,但是api提供的xmlhttprequestapi设置的服务方法并不会进行多线程。你是要提供可多线程的api吗?-你要明白提供多线程的api并不是说把各个线程纳入系统中,而是默认所有的进程,包括所有能通过api操作页面的进程统一由一个privulsion(保存(页面的,数据库的)等等进程,unionresources)运行。
这样呢就是通过multicast库实现,你可以通过api来分析页面,但是你无法通过api操作数据库,因为他通过multicast来分析页面。否则,所有爬虫可以自发共享一个privulsion了。
php多线程抓取网页( PHP利用Curl实现并发多线程抓取网页或者下载文件的操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-25 00:10
PHP利用Curl实现并发多线程抓取网页或者下载文件的操作)
PHP使用Curl实现网页的多线程抓取和下载文件
PHP可以使用Curl来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等,但是由于PHP语言本身不支持多线程,所以开发爬虫程序的效率不高。一般使用采集数据即可。使用PHPquery类来采集数据库,除此之外,还可以使用Curl,借助Curl这个功能实现多线程并发访问多个URL地址,实现网页的并发多线程爬取或下载文件。
具体实现过程请参考以下示例:
1、 实现抓取多个URL并将内容写入指定文件
$urls = array( <br />'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); // 设置要抓取的页面URL <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} // 初始化 <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); // 执行 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />} // 结束清理 <br />curl_multi_close($mh); <br />fclose($st);
2、使用PHP的Curl抓取网页的URL并保存内容
下面的代码和上面类似,只不过这个地方先把获取到的代码放入变量中,然后将获取到的内容写入到指定文件中
$urls = array( <br />'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); <br />foreach ($urls as $i => $url) { <br />$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串 <br />fwrite($st,$data); // 将字符串写入文件<br />} // 获得数据变量,并写入文件 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />}<br />curl_multi_close($mh); <br />fclose($st);
3、使用PHP的Curl实现文件的多线程并发下载
$urls=array(<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br />$g=$save_to.basename($url);<br />if(!is_file($g)){<br />$conn[$i]=curl_init($url);<br />$fp[$i]=fopen($g,"w");<br />curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br />curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br />curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br />curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br />curl_multi_add_handle($mh,$conn[$i]);<br />}<br />}<br />do{<br />$n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br />curl_multi_remove_handle($mh,$conn[$i]);<br />curl_close($conn[$i]);<br />fclose($fp[$i]);<br />}<br />curl_multi_close($mh);$urls=array(<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br />$g=$save_to.basename($url);<br />if(!is_file($g)){<br />$conn[$i]=curl_init($url);<br />$fp[$i]=fopen($g,"w");<br />curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br />curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br />curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br />curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br />curl_multi_add_handle($mh,$conn[$i]);<br />}<br />}<br />do{<br />$n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br />curl_multi_remove_handle($mh,$conn[$i]);<br />curl_close($conn[$i]);<br />fclose($fp[$i]);<br />}<br />curl_multi_close($mh);
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
php多线程抓取网页(
PHP利用Curl实现并发多线程抓取网页或者下载文件的操作)
PHP使用Curl实现网页的多线程抓取和下载文件
PHP可以使用Curl来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等,但是由于PHP语言本身不支持多线程,所以开发爬虫程序的效率不高。一般使用采集数据即可。使用PHPquery类来采集数据库,除此之外,还可以使用Curl,借助Curl这个功能实现多线程并发访问多个URL地址,实现网页的并发多线程爬取或下载文件。
具体实现过程请参考以下示例:
1、 实现抓取多个URL并将内容写入指定文件
$urls = array( <br />'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); // 设置要抓取的页面URL <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} // 初始化 <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); // 执行 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />} // 结束清理 <br />curl_multi_close($mh); <br />fclose($st);
2、使用PHP的Curl抓取网页的URL并保存内容
下面的代码和上面类似,只不过这个地方先把获取到的代码放入变量中,然后将获取到的内容写入到指定文件中
$urls = array( <br />'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); <br />foreach ($urls as $i => $url) { <br />$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串 <br />fwrite($st,$data); // 将字符串写入文件<br />} // 获得数据变量,并写入文件 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />}<br />curl_multi_close($mh); <br />fclose($st);
3、使用PHP的Curl实现文件的多线程并发下载
$urls=array(<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br />$g=$save_to.basename($url);<br />if(!is_file($g)){<br />$conn[$i]=curl_init($url);<br />$fp[$i]=fopen($g,"w");<br />curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br />curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br />curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br />curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br />curl_multi_add_handle($mh,$conn[$i]);<br />}<br />}<br />do{<br />$n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br />curl_multi_remove_handle($mh,$conn[$i]);<br />curl_close($conn[$i]);<br />fclose($fp[$i]);<br />}<br />curl_multi_close($mh);$urls=array(<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br />$g=$save_to.basename($url);<br />if(!is_file($g)){<br />$conn[$i]=curl_init($url);<br />$fp[$i]=fopen($g,"w");<br />curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br />curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br />curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br />curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br />curl_multi_add_handle($mh,$conn[$i]);<br />}<br />}<br />do{<br />$n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br />curl_multi_remove_handle($mh,$conn[$i]);<br />curl_close($conn[$i]);<br />fclose($fp[$i]);<br />}<br />curl_multi_close($mh);
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
php多线程抓取网页( 第三种应用就是实现PHP的多线程任务--多线程的写法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-20 15:03
第三种应用就是实现PHP的多线程任务--多线程的写法
)
使用curl实现多线程
curl一般用来抓取网页,二是get或post数据,三是PHP中实现多线程任务
让我们实现多线程。
您可以返回:
do while 的解释:
因为$active要等url数据全部被接受后才会变为false,这里用curl_multi_exec的返回值来判断是否有数据,
有数据时,会一直调用curl_multi_exec。如果一段时间没有数据,就会进入选择阶段。当有新数据到来时,可以唤醒它继续执行。
这里的好处是没有了不必要的CPU消耗。更详细的解释:%D4%C2%D2%B9%C4%FD%ED%F8/blog/item/9dfcf4fbe6b84374024f563d.html
这个多线程的编写步骤:
第一步:调用 curl_multi_init
第 2 步:循环调用 curl_multi_add_handle
这一步需要注意的是curl_multi_add_handle的第二个参数是curl_init的子句柄。
第三步:不断调用 curl_multi_exec
第 4 步:根据需要调用 curl_multi_getcontent 以循环获取结果
第五步:调用curl_multi_remove_handle,对每个字句柄调用curl_close
第 6 步:调用 curl_multi_close
多线程测试渲染:
查看全部
php多线程抓取网页(
第三种应用就是实现PHP的多线程任务--多线程的写法
)
使用curl实现多线程
curl一般用来抓取网页,二是get或post数据,三是PHP中实现多线程任务
让我们实现多线程。
您可以返回:
do while 的解释:
因为$active要等url数据全部被接受后才会变为false,这里用curl_multi_exec的返回值来判断是否有数据,
有数据时,会一直调用curl_multi_exec。如果一段时间没有数据,就会进入选择阶段。当有新数据到来时,可以唤醒它继续执行。
这里的好处是没有了不必要的CPU消耗。更详细的解释:%D4%C2%D2%B9%C4%FD%ED%F8/blog/item/9dfcf4fbe6b84374024f563d.html
这个多线程的编写步骤:
第一步:调用 curl_multi_init
第 2 步:循环调用 curl_multi_add_handle
这一步需要注意的是curl_multi_add_handle的第二个参数是curl_init的子句柄。
第三步:不断调用 curl_multi_exec
第 4 步:根据需要调用 curl_multi_getcontent 以循环获取结果
第五步:调用curl_multi_remove_handle,对每个字句柄调用curl_close
第 6 步:调用 curl_multi_close
多线程测试渲染:
php多线程抓取网页(php中curl_init()的具体使用方法及相关效率比较)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-18 23:11
php使用curl_init()和curl_multi_init()多线程的速度比较详细
更新时间:2018-08-15 10:06:55 作者:CC_小硕
本文文章主要介绍php使用curl_init()和curl_multi_init()多线程的速度对比。结合示例形式,详细分析了 curl_init() 和 curl_multi_init() 的具体使用方法和相关效率对比。有需要的朋友可以参考
本文介绍了 PHP 使用 curl_init() 和 curl_multi_init() 多线程的速度对比。分享给大家,供大家参考,如下:
php中的curl_init()非常有用,尤其是在爬取网页内容或者文件信息的时候。比如之前的文章《php使用curl进行头部检测和GZip压缩》介绍了curl_init()的强大功能。
curl_init() 以单线程模式处理事情。如果需要使用多线程模式进行事务处理,那么php为我们提供了一个函数curl_multi_init(),就是多线程模式处理事务的功能。
curl_init() 和 curl_multi_init() 速度对比
curl_multi_init() 多线程可以提高网页的处理速度吗?今天我将通过实验来验证这个问题。
我今天的测试很简单,就是抓取网页内容,连续抓取5次,使用curl_init()和curl_multi_init()函数来完成,记录下两者的耗时,对比一下得出结论。
首先,使用 curl_init() 在单个线程中抓取网页内容 5 次。
程序代码如下:
然后,使用 curl_multi_init() 多线程连续抓取网页内容 5 次。
代码显示如下:
<p> 查看全部
php多线程抓取网页(php中curl_init()的具体使用方法及相关效率比较)
php使用curl_init()和curl_multi_init()多线程的速度比较详细
更新时间:2018-08-15 10:06:55 作者:CC_小硕
本文文章主要介绍php使用curl_init()和curl_multi_init()多线程的速度对比。结合示例形式,详细分析了 curl_init() 和 curl_multi_init() 的具体使用方法和相关效率对比。有需要的朋友可以参考
本文介绍了 PHP 使用 curl_init() 和 curl_multi_init() 多线程的速度对比。分享给大家,供大家参考,如下:
php中的curl_init()非常有用,尤其是在爬取网页内容或者文件信息的时候。比如之前的文章《php使用curl进行头部检测和GZip压缩》介绍了curl_init()的强大功能。
curl_init() 以单线程模式处理事情。如果需要使用多线程模式进行事务处理,那么php为我们提供了一个函数curl_multi_init(),就是多线程模式处理事务的功能。
curl_init() 和 curl_multi_init() 速度对比
curl_multi_init() 多线程可以提高网页的处理速度吗?今天我将通过实验来验证这个问题。
我今天的测试很简单,就是抓取网页内容,连续抓取5次,使用curl_init()和curl_multi_init()函数来完成,记录下两者的耗时,对比一下得出结论。
首先,使用 curl_init() 在单个线程中抓取网页内容 5 次。
程序代码如下:
然后,使用 curl_multi_init() 多线程连续抓取网页内容 5 次。
代码显示如下:
<p>
php多线程抓取网页(【干货】Powershell上如何能够并发的ping上万台机器?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-16 16:37
今天有朋友问我,如何在Powershell中同时ping几万台机器?虽然默认的test-connection有-computer参数,但它的方法是依次ping通,可能需要几个小时才能全部跑掉。
例如,ping 40 个服务器需要 18 秒。如果有数千个,那将是耗时的。
measure-commnd -expression {
$computers=Get-ADComputer -Filter {operatingsystem -like "*2012*"}
Test-Connection -ComputerName $computers.name -Count 1
}
在此之前,Bean 对多线程的使用仅限于理解 invoke-command 可以同时操作 30 个对象。经过一番学习,我终于发现还有其他的高级方法。
在 PowerShell 中,可能有两种方法可以使用多线程。
首先是创建多个后台作业。这样,通过start-job或者-asjob创建一个后台job,然后通过get-job获取当前任务,通过receive-job获取完成任务的结果,最后需要remove-job释放记忆。缺点是性能不高,尤其是在创建作业和退出作业的过程中会消耗大量的时间和资源。
第二种方法是创建多个运行时。工作原理与调用命令相同。每个远程会话都绑定到一个运行时。我们可以创建一个运行时池,并指定该资源池中可以同时执行的最大运行时数。
与第一种方法相比,Runspace 的性能要强大得多。在下面的对比实验中,可以看到性能差距几乎是几十倍。
现在让我们看看如何实现它。豆子主要参考了这个博客的方法和原理,写了一个简单的脚本。
思路很简单,创建一个runtime pool,指定runtimes的数量,然后为每个待测试的对象集创建一个后台runtime job,绑定要执行的脚本,传入参数,将结果保存在ps中object 或者在hash表中,等待所有作业结束并输出结果。
$Throttle = 20 #threads
#脚本块,对指定的计算机发送一个ICMP包测试,结果保存在一个对象里面
$ScriptBlock = {
Param (
[string]$Computer
)
$a=test-connection -ComputerName $Computer -Count 1
$RunResult = New-Object PSObject -Property @{
IPv4Adress=$a.ipv4address.IPAddressToString
ComputerName=$Computer
}
Return $RunResult
}
#创建一个资源池,指定多少个runspace可以同时执行
$RunspacePool = [RunspaceFactory]::CreateRunspacePool(1, $Throttle)
$RunspacePool.Open()
$Jobs = @()
#获取Windows 2012服务器的信息,对每一个服务器单独创建一个job,该job执行ICMP的测试,并把结果保存在一个PS对象中
(get-adcomputer -filter {operatingsystem -like "*2012*"}).name | % {
#Start-Sleep -Seconds 1
$Job = [powershell]::Create().AddScript($ScriptBlock).AddArgument($_)
$Job.RunspacePool = $RunspacePool
$Jobs += New-Object PSObject -Property @{
Server = $_
Pipe = $Job
Result = $Job.BeginInvoke()
}
}
#循环输出等待的信息.... 直到所有的job都完成
Write-Host "Waiting.." -NoNewline
Do {
Write-Host "." -NoNewline
Start-Sleep -Seconds 1
} While ( $Jobs.Result.IsCompleted -contains $false)
Write-Host "All jobs completed!"
#输出结果
$Results = @()
ForEach ($Job in $Jobs)
{ $Results += $Job.Pipe.EndInvoke($Job.Result)
}
$Results
大约 5 秒后,结果出来了。有兴趣的可以使用measure-command命令来测试不同线程的效果。根据我的测试,30道工序同时出结果只需要4秒,2道工序同时出结果大约需要9秒。
知道原理后,就可以进一步优化和抽象脚本。已经有人这样做了。
下载后可以直接调用解锁和点源。这里有一些例子供参考
根据葫芦图,我觉得通过他调用test-connection也是成功的
get-adcomputer -Filter {operatingsystem -like "*2012*"} | select -ExpandProperty name | Invoke-Parallel -ScriptBlock {Test-Connection -computername $_ -count 1}
再举一个例子,我用一个 IP 范围 ping 一台计算机
1..254| Invoke-Parallel -ScriptBlock {Test-Connection -ComputerName "10.2.100.$_" -Count 1 -ErrorAction SilentlyContinue -ErrorVariable err | select Ipv4address, @{n='DNS';e={[System.Net.Dns]::gethostentry($_.ipv4address).hostname}}} -Throttle 20
最后,网上也有现成的脚本可以并发测试ping。原理就是调用上面的invoke-parallel函数,不过还增加了其他函数来测试rdp、winrm、rpc等远程访问端口是否打开,进一步扩展了功能。你可以在这里直接下载
invoke-ping -ComputerName (Get-ADComputer -Filter {operatingsystem -like "*2012*"}).name -Detail RDP,rpc | ft -Wrap
参考资料:
1.
2.
3.
4.
5. 查看全部
php多线程抓取网页(【干货】Powershell上如何能够并发的ping上万台机器?)
今天有朋友问我,如何在Powershell中同时ping几万台机器?虽然默认的test-connection有-computer参数,但它的方法是依次ping通,可能需要几个小时才能全部跑掉。
例如,ping 40 个服务器需要 18 秒。如果有数千个,那将是耗时的。
measure-commnd -expression {
$computers=Get-ADComputer -Filter {operatingsystem -like "*2012*"}
Test-Connection -ComputerName $computers.name -Count 1
}
在此之前,Bean 对多线程的使用仅限于理解 invoke-command 可以同时操作 30 个对象。经过一番学习,我终于发现还有其他的高级方法。
在 PowerShell 中,可能有两种方法可以使用多线程。
首先是创建多个后台作业。这样,通过start-job或者-asjob创建一个后台job,然后通过get-job获取当前任务,通过receive-job获取完成任务的结果,最后需要remove-job释放记忆。缺点是性能不高,尤其是在创建作业和退出作业的过程中会消耗大量的时间和资源。
第二种方法是创建多个运行时。工作原理与调用命令相同。每个远程会话都绑定到一个运行时。我们可以创建一个运行时池,并指定该资源池中可以同时执行的最大运行时数。
与第一种方法相比,Runspace 的性能要强大得多。在下面的对比实验中,可以看到性能差距几乎是几十倍。
现在让我们看看如何实现它。豆子主要参考了这个博客的方法和原理,写了一个简单的脚本。
思路很简单,创建一个runtime pool,指定runtimes的数量,然后为每个待测试的对象集创建一个后台runtime job,绑定要执行的脚本,传入参数,将结果保存在ps中object 或者在hash表中,等待所有作业结束并输出结果。
$Throttle = 20 #threads
#脚本块,对指定的计算机发送一个ICMP包测试,结果保存在一个对象里面
$ScriptBlock = {
Param (
[string]$Computer
)
$a=test-connection -ComputerName $Computer -Count 1
$RunResult = New-Object PSObject -Property @{
IPv4Adress=$a.ipv4address.IPAddressToString
ComputerName=$Computer
}
Return $RunResult
}
#创建一个资源池,指定多少个runspace可以同时执行
$RunspacePool = [RunspaceFactory]::CreateRunspacePool(1, $Throttle)
$RunspacePool.Open()
$Jobs = @()
#获取Windows 2012服务器的信息,对每一个服务器单独创建一个job,该job执行ICMP的测试,并把结果保存在一个PS对象中
(get-adcomputer -filter {operatingsystem -like "*2012*"}).name | % {
#Start-Sleep -Seconds 1
$Job = [powershell]::Create().AddScript($ScriptBlock).AddArgument($_)
$Job.RunspacePool = $RunspacePool
$Jobs += New-Object PSObject -Property @{
Server = $_
Pipe = $Job
Result = $Job.BeginInvoke()
}
}
#循环输出等待的信息.... 直到所有的job都完成
Write-Host "Waiting.." -NoNewline
Do {
Write-Host "." -NoNewline
Start-Sleep -Seconds 1
} While ( $Jobs.Result.IsCompleted -contains $false)
Write-Host "All jobs completed!"
#输出结果
$Results = @()
ForEach ($Job in $Jobs)
{ $Results += $Job.Pipe.EndInvoke($Job.Result)
}
$Results
大约 5 秒后,结果出来了。有兴趣的可以使用measure-command命令来测试不同线程的效果。根据我的测试,30道工序同时出结果只需要4秒,2道工序同时出结果大约需要9秒。
知道原理后,就可以进一步优化和抽象脚本。已经有人这样做了。
下载后可以直接调用解锁和点源。这里有一些例子供参考
根据葫芦图,我觉得通过他调用test-connection也是成功的
get-adcomputer -Filter {operatingsystem -like "*2012*"} | select -ExpandProperty name | Invoke-Parallel -ScriptBlock {Test-Connection -computername $_ -count 1}
再举一个例子,我用一个 IP 范围 ping 一台计算机
1..254| Invoke-Parallel -ScriptBlock {Test-Connection -ComputerName "10.2.100.$_" -Count 1 -ErrorAction SilentlyContinue -ErrorVariable err | select Ipv4address, @{n='DNS';e={[System.Net.Dns]::gethostentry($_.ipv4address).hostname}}} -Throttle 20
最后,网上也有现成的脚本可以并发测试ping。原理就是调用上面的invoke-parallel函数,不过还增加了其他函数来测试rdp、winrm、rpc等远程访问端口是否打开,进一步扩展了功能。你可以在这里直接下载
invoke-ping -ComputerName (Get-ADComputer -Filter {operatingsystem -like "*2012*"}).name -Detail RDP,rpc | ft -Wrap
参考资料:
1.
2.
3.
4.
5.
php多线程抓取网页(HTTP命令行工具模拟/GET等HTTP工具(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-11 11:20
1、 CURL 一步请求
CURL 扩展是一个强大的 HTTP 命令行工具,可以模拟 POST/GET 等 HTTP 请求,然后获取和提取数据,并将其显示在“标准输出”(stdout)上。
例子:
复制代码代码示例:
$cl = curl_init();
$curl_opt = array(CURLOPT_URL,'#39;,
CURLOPT_RETURNTRANSFER, 1,
CURLOPT_TIMEOUT, 1,);
curl_setopt_array($cl, $curl_opt);
curl_exec($ch);
curl_close($ch);
由于CUROPT_TIMEOUT属性的最小值为1,这意味着客户端必须等待1秒,这也是使用CURL方法的缺点
2、使用popen()函数实现异步请求
语法格式:popen(command,mode)
代码:
复制代码代码示例:
$file = popen("/bin/ls","r");
//这里是要执行的代码
//...
pclose($file);
popen() 函数直接向进程打开一个管道,速度快,响应迅速。但是这个函数是单项,不管是读还是写,并发数大的话,会产生大量的进程,给服务器造成负担。
此外,如示例中所示,必须使用 pclose() 在结束后关闭程序。
3、使用fscokopen()函数实现异步请求
该函数用于socket编程,如php邮件发送功能的开发。在使用此功能之前,您必须在 PHP.ini 中启用 allow_url_fopen 选项。此外,您必须在标题部分可用时手动拼接它。
代码:
复制代码代码示例:
$fp = fsockopen("/demo.php", 80, $errno, $errstr, 30);
如果 (!$fp) {
echo "$errstr ($errno)
\n";
} 别的 {
$out = "GET /index.php / HTTP/1.1\r\n";
$out .= "主机:\r\n";
$out .= "连接:关闭\r\n\r\n";
fwrite($fp, $out);
/*这里忽略执行结果
*可以在测试期间打开
而 (!feof($fp)) {
回声 fgets($fp, 128);
}*/
fclose($fp);
}
PHP 本身没有多线程,但是可以使用其他方式来实现多线程的效果。
上面列出的三种方法各有优缺点。在使用它们时,您可以根据程序的需要选择最好的。 查看全部
php多线程抓取网页(HTTP命令行工具模拟/GET等HTTP工具(组图))
1、 CURL 一步请求
CURL 扩展是一个强大的 HTTP 命令行工具,可以模拟 POST/GET 等 HTTP 请求,然后获取和提取数据,并将其显示在“标准输出”(stdout)上。
例子:
复制代码代码示例:
$cl = curl_init();
$curl_opt = array(CURLOPT_URL,'#39;,
CURLOPT_RETURNTRANSFER, 1,
CURLOPT_TIMEOUT, 1,);
curl_setopt_array($cl, $curl_opt);
curl_exec($ch);
curl_close($ch);
由于CUROPT_TIMEOUT属性的最小值为1,这意味着客户端必须等待1秒,这也是使用CURL方法的缺点
2、使用popen()函数实现异步请求
语法格式:popen(command,mode)
代码:
复制代码代码示例:
$file = popen("/bin/ls","r");
//这里是要执行的代码
//...
pclose($file);
popen() 函数直接向进程打开一个管道,速度快,响应迅速。但是这个函数是单项,不管是读还是写,并发数大的话,会产生大量的进程,给服务器造成负担。
此外,如示例中所示,必须使用 pclose() 在结束后关闭程序。
3、使用fscokopen()函数实现异步请求
该函数用于socket编程,如php邮件发送功能的开发。在使用此功能之前,您必须在 PHP.ini 中启用 allow_url_fopen 选项。此外,您必须在标题部分可用时手动拼接它。
代码:
复制代码代码示例:
$fp = fsockopen("/demo.php", 80, $errno, $errstr, 30);
如果 (!$fp) {
echo "$errstr ($errno)
\n";
} 别的 {
$out = "GET /index.php / HTTP/1.1\r\n";
$out .= "主机:\r\n";
$out .= "连接:关闭\r\n\r\n";
fwrite($fp, $out);
/*这里忽略执行结果
*可以在测试期间打开
而 (!feof($fp)) {
回声 fgets($fp, 128);
}*/
fclose($fp);
}
PHP 本身没有多线程,但是可以使用其他方式来实现多线程的效果。
上面列出的三种方法各有优缺点。在使用它们时,您可以根据程序的需要选择最好的。
php多线程抓取网页(PHP利用CurlFunctions可以完成各种传送文件操作下载文件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-09 09:36
)
PHP 可以使用 Curl Functions 完成各种文件传输操作,比如模拟浏览器发送 GET、POST 请求等,但是 PHP 语言本身不支持多线程,所以开发爬虫程序效率低下不高。这时候往往需要借助Curl Multi Functions来实现对多个URL地址的并发和多线程访问。既然Curl Multi Function这么强大,那我可以用Curl Multi Function来写并发多线程下载文件吗?当然,我的代码如下:
代码一:将得到的代码直接写入文件
$urls = array(
'http://www.sina.com.cn/',
'http://www.sohu.com/',
'http://www.163.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 设置将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
代码2:将得到的代码先放入变量中,再写入文件
$urls = array(
'http://www.sina.com.cn/',
'http://www.sohu.com/',
'http://www.163.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 设置不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件。当然,也可以不写入文件,比如存入数据库
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st); 查看全部
php多线程抓取网页(PHP利用CurlFunctions可以完成各种传送文件操作下载文件
)
PHP 可以使用 Curl Functions 完成各种文件传输操作,比如模拟浏览器发送 GET、POST 请求等,但是 PHP 语言本身不支持多线程,所以开发爬虫程序效率低下不高。这时候往往需要借助Curl Multi Functions来实现对多个URL地址的并发和多线程访问。既然Curl Multi Function这么强大,那我可以用Curl Multi Function来写并发多线程下载文件吗?当然,我的代码如下:
代码一:将得到的代码直接写入文件
$urls = array(
'http://www.sina.com.cn/',
'http://www.sohu.com/',
'http://www.163.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 设置将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
代码2:将得到的代码先放入变量中,再写入文件
$urls = array(
'http://www.sina.com.cn/',
'http://www.sohu.com/',
'http://www.163.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 设置不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件。当然,也可以不写入文件,比如存入数据库
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
php多线程抓取网页(php结合curl实现多线程抓取PHP实战(1)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-05 10:37
《PHP教程:PHP结合curl实现多线程爬虫》要点:
本文介绍PHP教程:PHP结合curl实现多线程爬取,希望对大家有用。如果您有任何问题,可以联系我们。
PHP结合curl实现多线程抓取PHP实战
再来几个PHP实战的例子
(1)以下代码是抓取多个网址,然后将抓取到的网址的页面代码写入指定文件。PHP实战
$urls = array(
'/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码和上面类似,不过这个地方是先把获取的代码放入变量中,然后将获取的内容写入指定的文件中。PHP实战
$urls = array(
'/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)下面这段代码实现了利用PHP的Curl Functions实现文件的多线程并发下载。PHP实战
$urls=array(
'',
'',
''
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'',
'',
''
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。
欢迎参与《PHP教程:PHP结合Curl实现多线程爬虫》的讨论,分享您的想法,微易PHP学院为您提供专业教程。 查看全部
php多线程抓取网页(php结合curl实现多线程抓取PHP实战(1)_)
《PHP教程:PHP结合curl实现多线程爬虫》要点:
本文介绍PHP教程:PHP结合curl实现多线程爬取,希望对大家有用。如果您有任何问题,可以联系我们。
PHP结合curl实现多线程抓取PHP实战
再来几个PHP实战的例子
(1)以下代码是抓取多个网址,然后将抓取到的网址的页面代码写入指定文件。PHP实战
$urls = array(
'/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码和上面类似,不过这个地方是先把获取的代码放入变量中,然后将获取的内容写入指定的文件中。PHP实战
$urls = array(
'/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)下面这段代码实现了利用PHP的Curl Functions实现文件的多线程并发下载。PHP实战
$urls=array(
'',
'',
''
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'',
'',
''
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。
欢迎参与《PHP教程:PHP结合Curl实现多线程爬虫》的讨论,分享您的想法,微易PHP学院为您提供专业教程。
php多线程抓取网页(PHP利用CurlFunctions可以完成各种传送文件操作下载文件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-04 15:31
)
PHP使用curl函数完成各种文件传输操作,例如模拟浏览器发送get和post请求。受PHP语言不支持多线程的限制,开发爬虫程序的效率不高。此时,常常需要curl多函数来实现并发多线程访问多个URL地址。既然curl多函数功能强大,我可以使用curl多函数来编写并发多线程下载文件吗?当然可以。这是我的密码:
代码1:将获得的代码直接写入文件
$urls = array(
'http://www.sina.com.cn/',
'http://www.sohu.com/',
'http://www.163.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 设置将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
代码2:首先将获得的代码放入变量中,然后将其写入文件
$urls = array(
'http://www.sina.com.cn/',
'http://www.sohu.com/',
'http://www.163.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 设置不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件。当然,也可以不写入文件,比如存入数据库
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st); 查看全部
php多线程抓取网页(PHP利用CurlFunctions可以完成各种传送文件操作下载文件
)
PHP使用curl函数完成各种文件传输操作,例如模拟浏览器发送get和post请求。受PHP语言不支持多线程的限制,开发爬虫程序的效率不高。此时,常常需要curl多函数来实现并发多线程访问多个URL地址。既然curl多函数功能强大,我可以使用curl多函数来编写并发多线程下载文件吗?当然可以。这是我的密码:
代码1:将获得的代码直接写入文件
$urls = array(
'http://www.sina.com.cn/',
'http://www.sohu.com/',
'http://www.163.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 设置将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
代码2:首先将获得的代码放入变量中,然后将其写入文件
$urls = array(
'http://www.sina.com.cn/',
'http://www.sohu.com/',
'http://www.163.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 设置不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件。当然,也可以不写入文件,比如存入数据库
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
php多线程抓取网页(php多线程抓取网页??php抓取网页-慕课网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-03 16:00
php多线程抓取网页?php多线程抓取网页-慕课网php抓取网页其实不难,使用正则表达式加断点来抓取即可实现,可以从如下三个方面考虑。1.requestweb站点,一般都是通过http请求来发出获取链接的请求。发出请求即是url中带有txt位元数据,txt中的文本叫html代码,用来取出包含这个url地址的页面是谁。
2.现在的前端工程师可能会把整个页面的一部分叫做一个。当然也有很多新的奇淫技巧来取代简单的view,如form表单的content-value等等,只要是前端发出请求了,php就可以识别地址栏里写着哪些资源的页面等等。所以一般都是采用一个来抓取页面,然后再把一些内容放在一起去抓取一大堆页面。这个文件就是页面中的html代码。
3.除了页面中的代码可以出口之外,页面也可以自定义一些具体的内容出口,从里的数据中出口显示不出来,然后在函数里发出请求的时候,通过里面的内容来定位到具体的页面并提取出要抓取的页面。
这个问题,困扰我很久了,真想给你一个满意的答案,抱歉没有。没有人知道让php多线程来抓取网页是什么,难道你是“提供个xx网站的例子,就可以提供多线程抓取方案”。这种用法只能是为了让你crud项目的效率提高,否则会被很多人喷的。我只能是说,爬虫从来不只是抓取网页,它更多的还是一种信息存储的方式,数据排列方式,和数据的处理方式,从这个角度来说,爬虫要做的事情超出网页抓取。
只能说是大部分。毕竟网页只是网页,没有办法赋予你多大权限,定制你抓取网页的信息。如果非要说个方案,请一般定制你抓取网页的方案,然后将txt文件提取出来放到工程文件夹,你定制抓取方案然后采用正则等获取页面,就像一个二进制文件一样做进一步处理。网页抓取,目前多数依赖分布式抓取是因为各种去重,各种规则分布式的数据量太大,容易是现实。
另外,你提到的四个问题,难点不在于抓取页面本身,在于处理分布式的问题。当然,你也可以说我是把你的问题,转换成一些数据处理的工作,拿我现在所掌握的和你分享下吧。抓取本身是crud的操作,基本都是通过网页提供给你的接口进行接收发放网页地址的请求数据,txt本身其实就是对请求的数据进行处理加工,这是我们在txt语言里面非常常见的做法,基本的入门使用txt都是通过三个通配符来选取,txt文件这时候一般叫做html代码(参考这个:copyjs),在php里,实际上是用元组来进行数据的编写的,比如,上面的“"//<p>end:”,这样用txt文件。</p> 查看全部
php多线程抓取网页(php多线程抓取网页??php抓取网页-慕课网)
php多线程抓取网页?php多线程抓取网页-慕课网php抓取网页其实不难,使用正则表达式加断点来抓取即可实现,可以从如下三个方面考虑。1.requestweb站点,一般都是通过http请求来发出获取链接的请求。发出请求即是url中带有txt位元数据,txt中的文本叫html代码,用来取出包含这个url地址的页面是谁。
2.现在的前端工程师可能会把整个页面的一部分叫做一个。当然也有很多新的奇淫技巧来取代简单的view,如form表单的content-value等等,只要是前端发出请求了,php就可以识别地址栏里写着哪些资源的页面等等。所以一般都是采用一个来抓取页面,然后再把一些内容放在一起去抓取一大堆页面。这个文件就是页面中的html代码。
3.除了页面中的代码可以出口之外,页面也可以自定义一些具体的内容出口,从里的数据中出口显示不出来,然后在函数里发出请求的时候,通过里面的内容来定位到具体的页面并提取出要抓取的页面。
这个问题,困扰我很久了,真想给你一个满意的答案,抱歉没有。没有人知道让php多线程来抓取网页是什么,难道你是“提供个xx网站的例子,就可以提供多线程抓取方案”。这种用法只能是为了让你crud项目的效率提高,否则会被很多人喷的。我只能是说,爬虫从来不只是抓取网页,它更多的还是一种信息存储的方式,数据排列方式,和数据的处理方式,从这个角度来说,爬虫要做的事情超出网页抓取。
只能说是大部分。毕竟网页只是网页,没有办法赋予你多大权限,定制你抓取网页的信息。如果非要说个方案,请一般定制你抓取网页的方案,然后将txt文件提取出来放到工程文件夹,你定制抓取方案然后采用正则等获取页面,就像一个二进制文件一样做进一步处理。网页抓取,目前多数依赖分布式抓取是因为各种去重,各种规则分布式的数据量太大,容易是现实。
另外,你提到的四个问题,难点不在于抓取页面本身,在于处理分布式的问题。当然,你也可以说我是把你的问题,转换成一些数据处理的工作,拿我现在所掌握的和你分享下吧。抓取本身是crud的操作,基本都是通过网页提供给你的接口进行接收发放网页地址的请求数据,txt本身其实就是对请求的数据进行处理加工,这是我们在txt语言里面非常常见的做法,基本的入门使用txt都是通过三个通配符来选取,txt文件这时候一般叫做html代码(参考这个:copyjs),在php里,实际上是用元组来进行数据的编写的,比如,上面的“"//<p>end:”,这样用txt文件。</p>
php多线程抓取网页(说起Python真的用的语言有那么神奇吗?除了它还可以用哪些语言?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-28 23:20
说到大数据,你不自觉的就会想到爬虫。说到爬虫使用的语言,很多人首先想到的是Python。Python真的有那么神奇吗?除了它可以使用哪些语言?
C#和Java都可以写爬虫,但原理其实差别不大,只是平台问题。可以认为,如果是有针对性的抓取几个页面,做一些简单的页面解析,抓取效率不是核心要求,那么使用的语言本质上没有太大区别。
使用什么语言取决于情况和主要目的。
如果是定向爬取,主要目的是解析js动态生成的内容,此时页面内容是js/ajax动态生成的,普通请求页面->解析方法行不通,需要使用类似firefox和chrome浏览器的js引擎动态分析页面的js代码。
这种情况建议考虑casperJS+phantomjs或者slimerJS+phantomjs。当然,硒也可以考虑。
3、如果爬虫涉及到大规模网站爬取,当效率、可扩展性、可维护性等是必须考虑的因素时,大规模爬取涉及的问题很多:多线程并发、I/ O机制、分布式爬取、消息通信、判断机制、任务调度等,这时候语言和框架的选择就显得尤为重要。
PHP 对多线程和异步的支持较差,因此不推荐使用。
NodeJS:对于一些垂直网站的爬取还好,但由于对分布式爬取、消息通信等支持较弱,请根据自身情况判断。
Python:强烈推荐,对上述问题有很好的支持。尤其是Scrapy框架不愧为首选。
主要原因是:
1) 抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相较于其他动态脚本语言,如 perl、shell,python 的 urllib2 包提供了更完整的 web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
2)网页爬取后的处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
除了这些,还有很多优点:支持xpath;基于扭曲,性能好;更好的调试工具;
这种情况下,如果还需要做js动态内容分析,casperjs不适合,只能基于chrome V8引擎等搭建自己的js引擎。
至于C和C++,虽然性能不错,但不推荐使用,尤其是考虑到成本等诸多因素。对于大多数公司来说,建议基于一些开源框架来做。不要自己发明轮子。做一个简单的爬虫很容易,但是做一个完整的爬虫很难。 查看全部
php多线程抓取网页(说起Python真的用的语言有那么神奇吗?除了它还可以用哪些语言?)
说到大数据,你不自觉的就会想到爬虫。说到爬虫使用的语言,很多人首先想到的是Python。Python真的有那么神奇吗?除了它可以使用哪些语言?
C#和Java都可以写爬虫,但原理其实差别不大,只是平台问题。可以认为,如果是有针对性的抓取几个页面,做一些简单的页面解析,抓取效率不是核心要求,那么使用的语言本质上没有太大区别。
使用什么语言取决于情况和主要目的。
如果是定向爬取,主要目的是解析js动态生成的内容,此时页面内容是js/ajax动态生成的,普通请求页面->解析方法行不通,需要使用类似firefox和chrome浏览器的js引擎动态分析页面的js代码。
这种情况建议考虑casperJS+phantomjs或者slimerJS+phantomjs。当然,硒也可以考虑。
3、如果爬虫涉及到大规模网站爬取,当效率、可扩展性、可维护性等是必须考虑的因素时,大规模爬取涉及的问题很多:多线程并发、I/ O机制、分布式爬取、消息通信、判断机制、任务调度等,这时候语言和框架的选择就显得尤为重要。
PHP 对多线程和异步的支持较差,因此不推荐使用。
NodeJS:对于一些垂直网站的爬取还好,但由于对分布式爬取、消息通信等支持较弱,请根据自身情况判断。
Python:强烈推荐,对上述问题有很好的支持。尤其是Scrapy框架不愧为首选。
主要原因是:
1) 抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相较于其他动态脚本语言,如 perl、shell,python 的 urllib2 包提供了更完整的 web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
2)网页爬取后的处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
除了这些,还有很多优点:支持xpath;基于扭曲,性能好;更好的调试工具;
这种情况下,如果还需要做js动态内容分析,casperjs不适合,只能基于chrome V8引擎等搭建自己的js引擎。
至于C和C++,虽然性能不错,但不推荐使用,尤其是考虑到成本等诸多因素。对于大多数公司来说,建议基于一些开源框架来做。不要自己发明轮子。做一个简单的爬虫很容易,但是做一个完整的爬虫很难。
php多线程抓取网页(由C#编写的多线程异步抓取网页的网络爬虫控制台程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-09-27 03:18
C#编写的多线程异步网络爬虫控制台程序
描述:C#编写的多线程异步网络爬虫控制台程序。功能:目前只能提取网络链接,使用的两个记录文件不需要很大。暂时无法抓取网页文字、图片、视频和html代码,敬请谅解。但是需要注意的是,网页的数量非常多。下面的代码理论上可以捕获整个互联网网页链接。但实际上,由于处理器功能和网络条件(主要是网速)的限制,一般家用电脑最多可以处理12个线程的爬虫任务,爬虫速度是有限的。它可以爬行,但需要时间和耐心。当然,这个程序可以捕获所有链接,因为链接不占用太多系统空间,并且借助日志文件,可以将爬取的网页数量堆积起来,甚至可以访问所有互联网网络链接,当然最好分批进行。建议将maxNum设置为500-1000左右,慢慢积累。另外,由于是控制台程序,有时显示的字符过多,系统会暂停显示。这时候,只需点击控制台并按回车键即可。当程序暂停时,您可以按 Enter 尝试。/// 要使用这个程序,请确保已经创建了相应的记录文件。为简化代码,本程序不够健壮,请见谅。/// 默认文件创建在E盘根目录下的两个文本文件:“待爬取的URL.txt”和“待爬取的URL.txt” . 这两个文件需要用户自己创建,注意不要有后缀弄错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫的速度是这样的:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫的速度是这样的:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫的速度是这样的:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫的速度是这样的:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫的速度是这样的:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。
现在就下载 查看全部
php多线程抓取网页(由C#编写的多线程异步抓取网页的网络爬虫控制台程序)
C#编写的多线程异步网络爬虫控制台程序
描述:C#编写的多线程异步网络爬虫控制台程序。功能:目前只能提取网络链接,使用的两个记录文件不需要很大。暂时无法抓取网页文字、图片、视频和html代码,敬请谅解。但是需要注意的是,网页的数量非常多。下面的代码理论上可以捕获整个互联网网页链接。但实际上,由于处理器功能和网络条件(主要是网速)的限制,一般家用电脑最多可以处理12个线程的爬虫任务,爬虫速度是有限的。它可以爬行,但需要时间和耐心。当然,这个程序可以捕获所有链接,因为链接不占用太多系统空间,并且借助日志文件,可以将爬取的网页数量堆积起来,甚至可以访问所有互联网网络链接,当然最好分批进行。建议将maxNum设置为500-1000左右,慢慢积累。另外,由于是控制台程序,有时显示的字符过多,系统会暂停显示。这时候,只需点击控制台并按回车键即可。当程序暂停时,您可以按 Enter 尝试。/// 要使用这个程序,请确保已经创建了相应的记录文件。为简化代码,本程序不够健壮,请见谅。/// 默认文件创建在E盘根目录下的两个文本文件:“待爬取的URL.txt”和“待爬取的URL.txt” . 这两个文件需要用户自己创建,注意不要有后缀弄错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫的速度是这样的:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫的速度是这样的:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫的速度是这样的:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫的速度是这样的:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫的速度是这样的:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个链接每分钟,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。本程序的多线程同步并不会带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。
现在就下载
php多线程抓取网页(GoogleWebSearchAPI+多线程文档中的抓取Goolge搜索链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-24 11:34
1)urllib2+BeautifulSoup 抓取Goolge 搜索链接
最近参与项目需要处理谷歌搜索结果,之前学习了与处理网页相关的Python工具。在实际应用中,urllib2和beautifulsoup是用来抓取网页的,但是在抓取谷歌搜索结果的时候,我发现如果直接处理谷歌搜索结果页面的源码,会得到很多“脏”的链接。
看下图搜索“titanic james”的结果:
图中红色标注的不需要,蓝色标注的需要抓取处理。
这种“脏链接”当然可以通过常规过滤的方式过滤掉,但是程序的复杂度很高。就在我一脸悲伤地写过滤规则的时候。同学提醒谷歌应该提供相关的api,突然就明白了。
(2)Google 网页搜索 API+多线程
该文档提供了使用 Python 进行搜索的示例:
图中红色标注的不需要,蓝色标注的需要抓取处理。
这种“脏链接”当然可以通过常规过滤的方式过滤掉,但是程序的复杂度很高。就在我一脸悲伤地写过滤规则的时候。同学提醒谷歌应该提供相关的api,突然就明白了。
(2)Google 网页搜索 API+多线程
该文档提供了使用 Python 进行搜索的示例:
import simplejson
# The request also includes the userip parameter which provides the end
# user's IP address. Doing so will help distinguish this legitimate
# server-side traffic from traffic which doesn't come from an end-user.
url = ('https://ajax.googleapis.com/aj ... 39%3B
'?v=1.0&q=Paris%20Hilton&userip=USERS-IP-ADDRESS')
request = urllib2.Request(
url, None, {'Referer': /* Enter the URL of your site here */})
response = urllib2.urlopen(request)
# Process the JSON string.
results = simplejson.load(response)
# now have some fun with the results...
import simplejson
# The request also includes the userip parameter which provides the end
# user's IP address. Doing so will help distinguish this legitimate
# server-side traffic from traffic which doesn't come from an end-user.
url = ('https://ajax.googleapis.com/aj ... 39%3B
'?v=1.0&q=Paris%20Hilton&userip=USERS-IP-ADDRESS')
request = urllib2.Request(
url, None, {'Referer': /* Enter the URL of your site here */})
response = urllib2.urlopen(request)
# Process the JSON string.
results = simplejson.load(response)
# now have some fun with the results..
在实际应用中,可能需要抓取Google的很多网页,因此需要使用多线程来分担抓取任务。使用google web search api的详细介绍请看这里(这里介绍了Standard URL Arguments)。另外要特别注意的是url中的参数rsz必须是8(包括8)以下的值。如果大于8会报错!
(3)代码实现
代码实现还存在问题,但是可以运行,健壮性差,有待改进。希望各位大神指出错误(初学者Python),万分感谢。
#-*-coding:utf-8-*-
import urllib2,urllib
import simplejson
import os, time,threading
import common, html_filter
#input the keywords
keywords = raw_input('Enter the keywords: ')
#define rnum_perpage, pages
rnum_perpage=8
pages=8
#定义线程函数
def thread_scratch(url, rnum_perpage, page):
url_set = []
try:
request = urllib2.Request(url, None, {'Referer': 'http://www.sina.com'})
response = urllib2.urlopen(request)
# Process the JSON string.
results = simplejson.load(response)
info = results['responseData']['results']
except Exception,e:
print 'error occured'
print e
else:
for minfo in info:
url_set.append(minfo['url'])
print minfo['url']
#处理链接
i = 0
for u in url_set:
try:
request_url = urllib2.Request(u, None, {'Referer': 'http://www.sina.com'})
request_url.add_header(
'User-agent',
'CSC'
)
response_data = urllib2.urlopen(request_url).read()
#过滤文件
#content_data = html_filter.filter_tags(response_data)
#写入文件
filenum = i+page
filename = dir_name+'/related_html_'+str(filenum)
print ' write start: related_html_'+str(filenum)
f = open(filename, 'w+', -1)
f.write(response_data)
#print content_data
f.close()
print ' write down: related_html_'+str(filenum)
except Exception, e:
print 'error occured 2'
print e
i = i+1
return
#创建文件夹
dir_name = 'related_html_'+urllib.quote(keywords)
if os.path.exists(dir_name):
print 'exists file'
common.delete_dir_or_file(dir_name)
os.makedirs(dir_name)
#抓取网页
print 'start to scratch web pages:'
for x in range(pages):
print "page:%s"%(x+1)
page = x * rnum_perpage
url = ('https://ajax.googleapis.com/aj ... 39%3B
'?v=1.0&q=%s&rsz=%s&start=%s') % (urllib.quote(keywords), rnum_perpage,page)
print url
t = threading.Thread(target=thread_scratch, args=(url,rnum_perpage, page))
t.start()
#主线程等待子线程抓取完
main_thread = threading.currentThread()
for t in threading.enumerate():
if t is main_thread:
continue
t.join()
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
php多线程抓取网页(GoogleWebSearchAPI+多线程文档中的抓取Goolge搜索链接)
1)urllib2+BeautifulSoup 抓取Goolge 搜索链接
最近参与项目需要处理谷歌搜索结果,之前学习了与处理网页相关的Python工具。在实际应用中,urllib2和beautifulsoup是用来抓取网页的,但是在抓取谷歌搜索结果的时候,我发现如果直接处理谷歌搜索结果页面的源码,会得到很多“脏”的链接。
看下图搜索“titanic james”的结果:
图中红色标注的不需要,蓝色标注的需要抓取处理。
这种“脏链接”当然可以通过常规过滤的方式过滤掉,但是程序的复杂度很高。就在我一脸悲伤地写过滤规则的时候。同学提醒谷歌应该提供相关的api,突然就明白了。
(2)Google 网页搜索 API+多线程
该文档提供了使用 Python 进行搜索的示例:
图中红色标注的不需要,蓝色标注的需要抓取处理。
这种“脏链接”当然可以通过常规过滤的方式过滤掉,但是程序的复杂度很高。就在我一脸悲伤地写过滤规则的时候。同学提醒谷歌应该提供相关的api,突然就明白了。
(2)Google 网页搜索 API+多线程
该文档提供了使用 Python 进行搜索的示例:
import simplejson
# The request also includes the userip parameter which provides the end
# user's IP address. Doing so will help distinguish this legitimate
# server-side traffic from traffic which doesn't come from an end-user.
url = ('https://ajax.googleapis.com/aj ... 39%3B
'?v=1.0&q=Paris%20Hilton&userip=USERS-IP-ADDRESS')
request = urllib2.Request(
url, None, {'Referer': /* Enter the URL of your site here */})
response = urllib2.urlopen(request)
# Process the JSON string.
results = simplejson.load(response)
# now have some fun with the results...
import simplejson
# The request also includes the userip parameter which provides the end
# user's IP address. Doing so will help distinguish this legitimate
# server-side traffic from traffic which doesn't come from an end-user.
url = ('https://ajax.googleapis.com/aj ... 39%3B
'?v=1.0&q=Paris%20Hilton&userip=USERS-IP-ADDRESS')
request = urllib2.Request(
url, None, {'Referer': /* Enter the URL of your site here */})
response = urllib2.urlopen(request)
# Process the JSON string.
results = simplejson.load(response)
# now have some fun with the results..
在实际应用中,可能需要抓取Google的很多网页,因此需要使用多线程来分担抓取任务。使用google web search api的详细介绍请看这里(这里介绍了Standard URL Arguments)。另外要特别注意的是url中的参数rsz必须是8(包括8)以下的值。如果大于8会报错!
(3)代码实现
代码实现还存在问题,但是可以运行,健壮性差,有待改进。希望各位大神指出错误(初学者Python),万分感谢。
#-*-coding:utf-8-*-
import urllib2,urllib
import simplejson
import os, time,threading
import common, html_filter
#input the keywords
keywords = raw_input('Enter the keywords: ')
#define rnum_perpage, pages
rnum_perpage=8
pages=8
#定义线程函数
def thread_scratch(url, rnum_perpage, page):
url_set = []
try:
request = urllib2.Request(url, None, {'Referer': 'http://www.sina.com'})
response = urllib2.urlopen(request)
# Process the JSON string.
results = simplejson.load(response)
info = results['responseData']['results']
except Exception,e:
print 'error occured'
print e
else:
for minfo in info:
url_set.append(minfo['url'])
print minfo['url']
#处理链接
i = 0
for u in url_set:
try:
request_url = urllib2.Request(u, None, {'Referer': 'http://www.sina.com'})
request_url.add_header(
'User-agent',
'CSC'
)
response_data = urllib2.urlopen(request_url).read()
#过滤文件
#content_data = html_filter.filter_tags(response_data)
#写入文件
filenum = i+page
filename = dir_name+'/related_html_'+str(filenum)
print ' write start: related_html_'+str(filenum)
f = open(filename, 'w+', -1)
f.write(response_data)
#print content_data
f.close()
print ' write down: related_html_'+str(filenum)
except Exception, e:
print 'error occured 2'
print e
i = i+1
return
#创建文件夹
dir_name = 'related_html_'+urllib.quote(keywords)
if os.path.exists(dir_name):
print 'exists file'
common.delete_dir_or_file(dir_name)
os.makedirs(dir_name)
#抓取网页
print 'start to scratch web pages:'
for x in range(pages):
print "page:%s"%(x+1)
page = x * rnum_perpage
url = ('https://ajax.googleapis.com/aj ... 39%3B
'?v=1.0&q=%s&rsz=%s&start=%s') % (urllib.quote(keywords), rnum_perpage,page)
print url
t = threading.Thread(target=thread_scratch, args=(url,rnum_perpage, page))
t.start()
#主线程等待子线程抓取完
main_thread = threading.currentThread()
for t in threading.enumerate():
if t is main_thread:
continue
t.join()
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
php多线程抓取网页( Young-杨培丽PHP实现百度搜索结果页面及正则匹配相关操作技巧汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2021-09-24 11:31
Young-杨培丽PHP实现百度搜索结果页面及正则匹配相关操作技巧汇总)
PHP抓取百度搜索结果页面[相关搜索词]并将其存储在TXT文件中
更新日期:2018年7月11日12:19:29杨培利
本文章主要介绍PHP如何捕获百度搜索结果页面[相关搜索词]并将其存储在TXT文件中,涉及基于PHP curl的页面捕获和定期匹配相关操作技巧。有需要的朋友可以参考
这个例子描述了PHP如何抓取百度搜索结果页面[相关搜索词]并将其存储在TXT文件中。与您分享,供您参考,如下所示:
一、百度搜索关键词[脚本屋]
[脚本库]搜索链接
%E8%84%9A%E6%9C%AC%E4%B9%8B%E5%AE%B6&;rsv_uq=ab33cfeb000086a2&;rsv_u-t=7c65vT3KzHCNfGYOIn%2FDSS%2BOQUiCycaspxWzSOBfkHYpgRIPKMI74WIi8K8&;rqlang=cn&;rsv_uuu输入=1&;rsv_uusug3=1
搜索结果的源代码:
相关搜索
游戏脚本通常在哪里找到脚本?如何编写脚本?这是什么意思
脚本屋应用程序移动脚本制作移动脚本
脚本游戏制作大师级游戏脚本制作教程脚本向导
二、抓取并保存本地
源代码
index.php:
<p> 查看全部
php多线程抓取网页(
Young-杨培丽PHP实现百度搜索结果页面及正则匹配相关操作技巧汇总)
PHP抓取百度搜索结果页面[相关搜索词]并将其存储在TXT文件中
更新日期:2018年7月11日12:19:29杨培利
本文章主要介绍PHP如何捕获百度搜索结果页面[相关搜索词]并将其存储在TXT文件中,涉及基于PHP curl的页面捕获和定期匹配相关操作技巧。有需要的朋友可以参考
这个例子描述了PHP如何抓取百度搜索结果页面[相关搜索词]并将其存储在TXT文件中。与您分享,供您参考,如下所示:
一、百度搜索关键词[脚本屋]
[脚本库]搜索链接
%E8%84%9A%E6%9C%AC%E4%B9%8B%E5%AE%B6&;rsv_uq=ab33cfeb000086a2&;rsv_u-t=7c65vT3KzHCNfGYOIn%2FDSS%2BOQUiCycaspxWzSOBfkHYpgRIPKMI74WIi8K8&;rqlang=cn&;rsv_uuu输入=1&;rsv_uusug3=1
搜索结果的源代码:
相关搜索
游戏脚本通常在哪里找到脚本?如何编写脚本?这是什么意思
脚本屋应用程序移动脚本制作移动脚本
脚本游戏制作大师级游戏脚本制作教程脚本向导
二、抓取并保存本地
源代码
index.php:
<p>
php多线程抓取网页(网络爬虫实战_乐趣之旅seqone(架构++url))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-09-22 08:01
php多线程抓取网页_图片
一)_网络爬虫实战_乐趣之旅seqone(架构++url)如何抓取网页下载地址:网页下载,线程抓取,url反爬,
这种情况有一个关键点:调用url接口的地方保证url经过了可靠的序列化。一个好的请求头,一个好的序列化,在这两者的保护下,即使线程池起来,同时也只会发送出正确的网页内容。给几点意见:线程能不起来就不起来。如果一定要起来,为了获取大量图片,
1)把请求发给队列,队列一般不会出现空的,这个队列最好还能接收下载网页的url和个数。
2)线程池内部有一个进程池,那么可以利用threadpoolexecutor来分别处理队列和进程池,获取到的url可以再放进进程池里面获取,也可以分别放队列然后分别获取。
3)线程池可以利用pooledqueue来分别保存队列和进程池。这个需要自己实现。另外可以使用asyncio。
没必要多线程,可以自己尝试多进程,nginx,
地址栏不是抓取的,地址栏才是抓取的。题主不要混淆重要部分。
三种方案:第一种,nginx或者fastcgi+redis。第二种,使用threadpoolexecutor。第三种,使用laravel、workerman等web框架。 查看全部
php多线程抓取网页(网络爬虫实战_乐趣之旅seqone(架构++url))
php多线程抓取网页_图片
一)_网络爬虫实战_乐趣之旅seqone(架构++url)如何抓取网页下载地址:网页下载,线程抓取,url反爬,
这种情况有一个关键点:调用url接口的地方保证url经过了可靠的序列化。一个好的请求头,一个好的序列化,在这两者的保护下,即使线程池起来,同时也只会发送出正确的网页内容。给几点意见:线程能不起来就不起来。如果一定要起来,为了获取大量图片,
1)把请求发给队列,队列一般不会出现空的,这个队列最好还能接收下载网页的url和个数。
2)线程池内部有一个进程池,那么可以利用threadpoolexecutor来分别处理队列和进程池,获取到的url可以再放进进程池里面获取,也可以分别放队列然后分别获取。
3)线程池可以利用pooledqueue来分别保存队列和进程池。这个需要自己实现。另外可以使用asyncio。
没必要多线程,可以自己尝试多进程,nginx,
地址栏不是抓取的,地址栏才是抓取的。题主不要混淆重要部分。
三种方案:第一种,nginx或者fastcgi+redis。第二种,使用threadpoolexecutor。第三种,使用laravel、workerman等web框架。
php多线程抓取网页(本文_init()处理事物是单线程模式的函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-09-20 03:13
本文说明了PHP如何使用curl\uinit()和curl\umulti\uinit()来比较多线程的速度。分享给你参考
本文说明了PHP如何使用curl\uinit()和curl\umulti\uinit()来比较多线程的速度。与您分享,供您参考,如下所示:
PHP_uinit()中的Curl起着非常重要的作用,尤其是在捕获网页内容或文件信息时。例如,curl是在前面的文章“PHP使用curl来获取头检测并启用gzip压缩”uu init()的威力)中引入的
curl\uinit()以单线程模式处理事情。如果您需要采用多线程模式进行事务处理,PHP提供了一个函数curl\multi\uinit()告诉我们这是一个以多线程模式处理事务的函数
curl_uuinit()和Init()的curl_uumulti_u速度比较
curl\multi\init()多线程可以提高网页的处理速度吗?今天,我将通过实验来验证这个问题
今天,我的测试非常简单,就是抓取网页的内容,连续抓取五次,分别使用curl_uinit()和curl_uumulti_Init()函数,记录两者的耗时,并通过比较得出结论
首先,使用curl_uinit()单线程连续五次抓取网页内容
程序代码如下:
然后,使用curl\umulti\uinit()多线程连续五次抓取网页内容
代码如下:
<p> 查看全部
php多线程抓取网页(本文_init()处理事物是单线程模式的函数)
本文说明了PHP如何使用curl\uinit()和curl\umulti\uinit()来比较多线程的速度。分享给你参考
本文说明了PHP如何使用curl\uinit()和curl\umulti\uinit()来比较多线程的速度。与您分享,供您参考,如下所示:
PHP_uinit()中的Curl起着非常重要的作用,尤其是在捕获网页内容或文件信息时。例如,curl是在前面的文章“PHP使用curl来获取头检测并启用gzip压缩”uu init()的威力)中引入的
curl\uinit()以单线程模式处理事情。如果您需要采用多线程模式进行事务处理,PHP提供了一个函数curl\multi\uinit()告诉我们这是一个以多线程模式处理事务的函数
curl_uuinit()和Init()的curl_uumulti_u速度比较
curl\multi\init()多线程可以提高网页的处理速度吗?今天,我将通过实验来验证这个问题
今天,我的测试非常简单,就是抓取网页的内容,连续抓取五次,分别使用curl_uinit()和curl_uumulti_Init()函数,记录两者的耗时,并通过比较得出结论
首先,使用curl_uinit()单线程连续五次抓取网页内容
程序代码如下:
然后,使用curl\umulti\uinit()多线程连续五次抓取网页内容
代码如下:
<p>
php多线程抓取网页(Python处理网页相关的几种常见错误(一)+BeautifulSoup抓取Goolge )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-20 03:12
)
1)urllib2+BeautifulSoup抓取谷歌搜索链接
最近,参与项目需要处理谷歌搜索结果。在此之前,我学习了与网页相关的Python工具。在实际应用中,urlib2和beatifulsoup被用来捕获网页,但在捕获Google搜索结果时,发现如果直接处理Google搜索结果页面的源代码,会获得许多“脏”链接
“泰坦尼克号詹姆斯”的搜索结果如下图所示:
图中红色标记的不需要,蓝色标记的需要抓取
当然,这个“脏链接”可以通过规则过滤过滤掉,但是程序的复杂性很高。当他写过滤规则时,脸上带着悲伤。学生们提醒谷歌应该在他们突然明白之前提供相关的API
(2)GoogleWeb搜索API+多线程
文档中给出了使用Python进行搜索的示例:
在实际应用中,您可能需要抓取许多Google网页,因此您还需要使用多线程来共享抓取任务。有关使用Google Web搜索API的详细介绍,请参见此处(此处介绍了标准URL参数)。此外,请特别注意URL中的参数rsz必须为8(包括以下数值8).如果大于8,将报告错误
(3)code实现)
代码实现中仍然存在问题,但它可以运行,健壮性差,需要改进。我希望诸神都能指出错误(初学者Python)。非常感谢
#-*-coding:utf-8-*-
import urllib2,urllib
import simplejson
import os, time,threading
import common, html_filter
#input the keywords
keywords = raw_input('Enter the keywords: ')
#define rnum_perpage, pages
rnum_perpage=8
pages=8
#定义线程函数
def thread_scratch(url, rnum_perpage, page):
url_set = []
try:
request = urllib2.Request(url, None, {'Referer': 'http://www.sina.com'})
response = urllib2.urlopen(request)
# Process the JSON string.
results = simplejson.load(response)
info = results['responseData']['results']
except Exception,e:
print 'error occured'
print e
else:
for minfo in info:
url_set.append(minfo['url'])
print minfo['url']
#处理链接
i = 0
for u in url_set:
try:
request_url = urllib2.Request(u, None, {'Referer': 'http://www.sina.com'})
request_url.add_header(
'User-agent',
'CSC'
)
response_data = urllib2.urlopen(request_url).read()
#过滤文件
#content_data = html_filter.filter_tags(response_data)
#写入文件
filenum = i+page
filename = dir_name+'/related_html_'+str(filenum)
print ' write start: related_html_'+str(filenum)
f = open(filename, 'w+', -1)
f.write(response_data)
#print content_data
f.close()
print ' write down: related_html_'+str(filenum)
except Exception, e:
print 'error occured 2'
print e
i = i+1
return
#创建文件夹
dir_name = 'related_html_'+urllib.quote(keywords)
if os.path.exists(dir_name):
print 'exists file'
common.delete_dir_or_file(dir_name)
os.makedirs(dir_name)
#抓取网页
print 'start to scratch web pages:'
for x in range(pages):
print "page:%s"%(x+1)
page = x * rnum_perpage
url = ('https://ajax.googleapis.com/ajax/services/search/web'
'?v=1.0&q=%s&rsz=%s&start=%s') % (urllib.quote(keywords), rnum_perpage,page)
print url
t = threading.Thread(target=thread_scratch, args=(url,rnum_perpage, page))
t.start()
#主线程等待子线程抓取完
main_thread = threading.currentThread()
for t in threading.enumerate():
if t is main_thread:
continue
t.join() 查看全部
php多线程抓取网页(Python处理网页相关的几种常见错误(一)+BeautifulSoup抓取Goolge
)
1)urllib2+BeautifulSoup抓取谷歌搜索链接
最近,参与项目需要处理谷歌搜索结果。在此之前,我学习了与网页相关的Python工具。在实际应用中,urlib2和beatifulsoup被用来捕获网页,但在捕获Google搜索结果时,发现如果直接处理Google搜索结果页面的源代码,会获得许多“脏”链接
“泰坦尼克号詹姆斯”的搜索结果如下图所示:
图中红色标记的不需要,蓝色标记的需要抓取
当然,这个“脏链接”可以通过规则过滤过滤掉,但是程序的复杂性很高。当他写过滤规则时,脸上带着悲伤。学生们提醒谷歌应该在他们突然明白之前提供相关的API
(2)GoogleWeb搜索API+多线程
文档中给出了使用Python进行搜索的示例:
在实际应用中,您可能需要抓取许多Google网页,因此您还需要使用多线程来共享抓取任务。有关使用Google Web搜索API的详细介绍,请参见此处(此处介绍了标准URL参数)。此外,请特别注意URL中的参数rsz必须为8(包括以下数值8).如果大于8,将报告错误
(3)code实现)
代码实现中仍然存在问题,但它可以运行,健壮性差,需要改进。我希望诸神都能指出错误(初学者Python)。非常感谢
#-*-coding:utf-8-*-
import urllib2,urllib
import simplejson
import os, time,threading
import common, html_filter
#input the keywords
keywords = raw_input('Enter the keywords: ')
#define rnum_perpage, pages
rnum_perpage=8
pages=8
#定义线程函数
def thread_scratch(url, rnum_perpage, page):
url_set = []
try:
request = urllib2.Request(url, None, {'Referer': 'http://www.sina.com'})
response = urllib2.urlopen(request)
# Process the JSON string.
results = simplejson.load(response)
info = results['responseData']['results']
except Exception,e:
print 'error occured'
print e
else:
for minfo in info:
url_set.append(minfo['url'])
print minfo['url']
#处理链接
i = 0
for u in url_set:
try:
request_url = urllib2.Request(u, None, {'Referer': 'http://www.sina.com'})
request_url.add_header(
'User-agent',
'CSC'
)
response_data = urllib2.urlopen(request_url).read()
#过滤文件
#content_data = html_filter.filter_tags(response_data)
#写入文件
filenum = i+page
filename = dir_name+'/related_html_'+str(filenum)
print ' write start: related_html_'+str(filenum)
f = open(filename, 'w+', -1)
f.write(response_data)
#print content_data
f.close()
print ' write down: related_html_'+str(filenum)
except Exception, e:
print 'error occured 2'
print e
i = i+1
return
#创建文件夹
dir_name = 'related_html_'+urllib.quote(keywords)
if os.path.exists(dir_name):
print 'exists file'
common.delete_dir_or_file(dir_name)
os.makedirs(dir_name)
#抓取网页
print 'start to scratch web pages:'
for x in range(pages):
print "page:%s"%(x+1)
page = x * rnum_perpage
url = ('https://ajax.googleapis.com/ajax/services/search/web'
'?v=1.0&q=%s&rsz=%s&start=%s') % (urllib.quote(keywords), rnum_perpage,page)
print url
t = threading.Thread(target=thread_scratch, args=(url,rnum_perpage, page))
t.start()
#主线程等待子线程抓取完
main_thread = threading.currentThread()
for t in threading.enumerate():
if t is main_thread:
continue
t.join()
php多线程抓取网页(php多线程抓取网页原理讲解使用mybatis实现数据库对接打造管理后台zenddata-zend)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-09-19 21:01
php多线程抓取网页原理讲解大型互联网网站维护、运维php基础内容。laravelwebcli功能讲解ecshop模板库讲解讲解使用mybatis实现数据库对接打造管理后台zenddata-zend。xml介绍htaccess_cookie介绍php中的requesthttp客户端/服务器连接管理mysql集群编写zenddata-zend。xml文件php多线程抓取网页教程_php有声音_互联网成长_小马哥教育_小马哥学院。
先学vue用template做完静态文件后全局gzip
一个月抓个小网站的代码,学会php多线程抓取,
抓包到你的网站内,然后解码到本地php目录下;抓取其他网站内容,要么用爬虫,
并不很推荐题主使用多线程抓取,一方面抓包抓到代码,进行后续的解析会浪费更多的资源,另一方面题主可能并不能保证php多线程抓取的效率,很有可能今天我抓取了300条,明天并不是300条,
php多线程抓取代码分享,
自己写一个支持gzip压缩加速工具
我要开始抓包了
php抓包,mysql存储抓取技术,zenddata系列数据库搭建与使用,
php多线程抓取xlsx文件,先创建xlsx。 查看全部
php多线程抓取网页(php多线程抓取网页原理讲解使用mybatis实现数据库对接打造管理后台zenddata-zend)
php多线程抓取网页原理讲解大型互联网网站维护、运维php基础内容。laravelwebcli功能讲解ecshop模板库讲解讲解使用mybatis实现数据库对接打造管理后台zenddata-zend。xml介绍htaccess_cookie介绍php中的requesthttp客户端/服务器连接管理mysql集群编写zenddata-zend。xml文件php多线程抓取网页教程_php有声音_互联网成长_小马哥教育_小马哥学院。
先学vue用template做完静态文件后全局gzip
一个月抓个小网站的代码,学会php多线程抓取,
抓包到你的网站内,然后解码到本地php目录下;抓取其他网站内容,要么用爬虫,
并不很推荐题主使用多线程抓取,一方面抓包抓到代码,进行后续的解析会浪费更多的资源,另一方面题主可能并不能保证php多线程抓取的效率,很有可能今天我抓取了300条,明天并不是300条,
php多线程抓取代码分享,
自己写一个支持gzip压缩加速工具
我要开始抓包了
php抓包,mysql存储抓取技术,zenddata系列数据库搭建与使用,
php多线程抓取xlsx文件,先创建xlsx。
php多线程抓取网页(php结合curl实现抓取我们再来看几个例子(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-09-17 23:05
PHP结合curl实现多线程抓取
让我们再看几个例子
(1)下面的代码是对多个URL进行爬网,然后将爬网URL的页面代码写入指定文件
$urls = array(
'http://www.jb51.net/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码与上面的代码含义相同,但此处是先将获取的代码放入变量中,然后将获取的内容写入指定的文件
$urls = array(
'http://www.jb51.net/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)下面的代码使用PHP的curl函数实现并发多线程文件下载
$urls=array(
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
以上是本文的全部内容,希望大家能喜欢 查看全部
php多线程抓取网页(php结合curl实现抓取我们再来看几个例子(1))
PHP结合curl实现多线程抓取
让我们再看几个例子
(1)下面的代码是对多个URL进行爬网,然后将爬网URL的页面代码写入指定文件
$urls = array(
'http://www.jb51.net/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码与上面的代码含义相同,但此处是先将获取的代码放入变量中,然后将获取的内容写入指定的文件
$urls = array(
'http://www.jb51.net/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)下面的代码使用PHP的curl函数实现并发多线程文件下载
$urls=array(
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
以上是本文的全部内容,希望大家能喜欢
php多线程抓取网页(写爬虫用什么语言好?爬虫选择什么工具?Crawler)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-16 04:15
什么语言适合写爬行动物
爬虫选择什么工具
1.crawler是一款网络蜘蛛机器人,它可以根据我们的规则自动抓取数据并获取数据
2.为什么使用爬行动物?私人定制搜索引擎获取更多数据的时代不再是互联网时代,而是大数据时代
3.爬虫的原理:控制节点(URL分配器)、爬虫节点(根据算法抓取数据并存储在数据库中)、资源数据库(爬虫数据库中提供搜索)。爬虫的设计思想是:爬虫的网络地址通过HTTP协议获取相应的HTML页面
5.爬虫语言选择:
PHP:尽管它被评为“世界上最好的语言”,但作为一个爬虫程序,它的缺点是:没有多线程的概念,几乎不支持异步,并发性不足,爬虫程序对效率的要求很高
C/C Java:Python最大的竞争对手,它非常庞大。爬虫程序需要经常修改代码
Python:优美的语言、代码介绍、多功能模块、调用替代语言接口和成熟的高度分布式策略
PYT Java]Java有很多解析器,它们非常支持网页解析。缺点是有很多Java开源爬虫程序,比如nutch。中国拥有优秀的webmagic Java解析器,如Htmlparser和jsoup,能够满足Java和python的共同需求。如果您需要模拟登录和反采集,那么选择python更方便。如果需要处理复杂的网页、解析网页内容以生成结构化数据或精细解析网页内容,可以选择Java
Java和python在爬虫方面的优缺点是什么
任何语言几乎都是一样的,Python的时间效率并不一定快。只有蟒蛇在早上被列为爬行动物。。此外,大多数所谓的爬虫是翻页和数据解析的基本过程,用这种语言很容易完成 查看全部
php多线程抓取网页(写爬虫用什么语言好?爬虫选择什么工具?Crawler)
什么语言适合写爬行动物
爬虫选择什么工具
1.crawler是一款网络蜘蛛机器人,它可以根据我们的规则自动抓取数据并获取数据
2.为什么使用爬行动物?私人定制搜索引擎获取更多数据的时代不再是互联网时代,而是大数据时代
3.爬虫的原理:控制节点(URL分配器)、爬虫节点(根据算法抓取数据并存储在数据库中)、资源数据库(爬虫数据库中提供搜索)。爬虫的设计思想是:爬虫的网络地址通过HTTP协议获取相应的HTML页面
5.爬虫语言选择:
PHP:尽管它被评为“世界上最好的语言”,但作为一个爬虫程序,它的缺点是:没有多线程的概念,几乎不支持异步,并发性不足,爬虫程序对效率的要求很高
C/C Java:Python最大的竞争对手,它非常庞大。爬虫程序需要经常修改代码
Python:优美的语言、代码介绍、多功能模块、调用替代语言接口和成熟的高度分布式策略
PYT Java]Java有很多解析器,它们非常支持网页解析。缺点是有很多Java开源爬虫程序,比如nutch。中国拥有优秀的webmagic Java解析器,如Htmlparser和jsoup,能够满足Java和python的共同需求。如果您需要模拟登录和反采集,那么选择python更方便。如果需要处理复杂的网页、解析网页内容以生成结构化数据或精细解析网页内容,可以选择Java
Java和python在爬虫方面的优缺点是什么
任何语言几乎都是一样的,Python的时间效率并不一定快。只有蟒蛇在早上被列为爬行动物。。此外,大多数所谓的爬虫是翻页和数据解析的基本过程,用这种语言很容易完成

