
php多线程抓取网页
php多线程抓取网页(PHP多线程抓取多个网页及获取数据的通用方法实用第一智慧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-22 02:03
PHP多线程中爬取多个网页并获取数据的通用方法是实用的。第一种是爬取多个网页并通过密集的多线程获取数据的通用方法。这是网站 的管理员为自己的博客和网站 遇到的常见问题。大多数网络相册都提供了便捷的操作来满足用户的需求,但也有一些网络相册不提供便捷的操作。本文从一个例子入手,讨论了使用多线程获取网络相册图片外链地址的一般方法。关键词:环境;多线程;多线程;正则表达式; 网络相册源代码及解释问题在环境中,参考获取相册图片外链的功能,可以实现抓取多个网页。,但这种方法通常是顺序教学中心。当网页数量较少时,这是一种简单有效的方法,但是当需要处理大量网页时,就会带来致命的问题,因为在/环境中执行代码是有时间限制的。这时,多线程获取多个网页成为解决此类问题的最佳选择。处理此类问题的一般过程“检查用户是否已提交数据”,需要多线程处理多个网页的Array。用于读取多个网页数据的多线程处理函数。使用正则表达式从获得的多个网页中提取有用的数据。用户尚未提交数据,则构造一个表单要求用户提供共享数据。相册的页数和相册的总页数。
共享相册的示例是从浏览器的地址中获取的:,例如:://。实际问题是该公司为免费在线相册提供空间。好消息是专辑的总页数在页面的下部。示例:在浏览器中打开上述地址对应的相册,可以在页面底部看到相册允许用户对外链接。以公司的实力,相信能以相册总页数稳定地提供这样的服务,而且用户获取图片地址链接的方法也很简单。但是,一次获取多张图片的外部链接地址几乎是不可能完成的任务。“对网络相册的代码进行简单分析后发现:代码中收录相册图片的外链接地址,只需要使用正则表达式从外代码中提取图片的外链接地址,即可获取相册图片。一个职教中心 接下来的问题出现了:相册的每一页只显示一张图片。如果一个相册有几百张图片,那么至少有几十个网页需要爬取。为了提高效率,需要使用多线程Grab" //关闭资源,释放系统资源。可以在这里添加时间测试代码,记录结束时间,/使用正则表达式提取图片外部链接获取的网络代码// 相册代码的原创部分如下: /// /这里可以添加时间测试代码来记录开始时间。上面代码中收录图片的单独页面的代码中最多有几个这样的代码,所以需要使用函数和正则表达式来获取有用的数据 ////启动更多线程获取网页数据并放入它在数组中 ////创建一个批处理句柄,///设置传输选项?//,/将图片的外链地址输出到浏览器////获取到的信息在文件中以流的形式返回,////可以根据需要改变输出格式添加单独的句柄到批处理会话服务器环境至强测试模式使用两台相同配置相同网络环境的电脑,同时提交数据,测试多个线程获取和使用函数的顺序下面是使用函数顺序的代码获取多个网页数据:,/.
实用第一智慧密集获取相册图片。任丘职教中心的测试执行时间代码在多线程获取网页数据之前添加: ;//获取程序开始执行的时间 Start time:, end time: , Execution time: 用这一行代码来简单地测量代码执行时间。获取相册的图片。考试对象任丘职教中心设有总考组。数据如下:多线程模式相册页面:“提交”/行时间:,终止时间:;.,执行顺序开始时间:,终止时间:.,执行?。:Line time: /『//这里可以添加时间测试代码,记录结束时间开始时间:。,结束时间:多线程获取网页的时间取决于最慢的网页。和网页数量有关//图片取出的数量无关,顺序获取的网页是所有网页的总和。这是 查看全部
php多线程抓取网页(PHP多线程抓取多个网页及获取数据的通用方法实用第一智慧)
PHP多线程中爬取多个网页并获取数据的通用方法是实用的。第一种是爬取多个网页并通过密集的多线程获取数据的通用方法。这是网站 的管理员为自己的博客和网站 遇到的常见问题。大多数网络相册都提供了便捷的操作来满足用户的需求,但也有一些网络相册不提供便捷的操作。本文从一个例子入手,讨论了使用多线程获取网络相册图片外链地址的一般方法。关键词:环境;多线程;多线程;正则表达式; 网络相册源代码及解释问题在环境中,参考获取相册图片外链的功能,可以实现抓取多个网页。,但这种方法通常是顺序教学中心。当网页数量较少时,这是一种简单有效的方法,但是当需要处理大量网页时,就会带来致命的问题,因为在/环境中执行代码是有时间限制的。这时,多线程获取多个网页成为解决此类问题的最佳选择。处理此类问题的一般过程“检查用户是否已提交数据”,需要多线程处理多个网页的Array。用于读取多个网页数据的多线程处理函数。使用正则表达式从获得的多个网页中提取有用的数据。用户尚未提交数据,则构造一个表单要求用户提供共享数据。相册的页数和相册的总页数。
共享相册的示例是从浏览器的地址中获取的:,例如:://。实际问题是该公司为免费在线相册提供空间。好消息是专辑的总页数在页面的下部。示例:在浏览器中打开上述地址对应的相册,可以在页面底部看到相册允许用户对外链接。以公司的实力,相信能以相册总页数稳定地提供这样的服务,而且用户获取图片地址链接的方法也很简单。但是,一次获取多张图片的外部链接地址几乎是不可能完成的任务。“对网络相册的代码进行简单分析后发现:代码中收录相册图片的外链接地址,只需要使用正则表达式从外代码中提取图片的外链接地址,即可获取相册图片。一个职教中心 接下来的问题出现了:相册的每一页只显示一张图片。如果一个相册有几百张图片,那么至少有几十个网页需要爬取。为了提高效率,需要使用多线程Grab" //关闭资源,释放系统资源。可以在这里添加时间测试代码,记录结束时间,/使用正则表达式提取图片外部链接获取的网络代码// 相册代码的原创部分如下: /// /这里可以添加时间测试代码来记录开始时间。上面代码中收录图片的单独页面的代码中最多有几个这样的代码,所以需要使用函数和正则表达式来获取有用的数据 ////启动更多线程获取网页数据并放入它在数组中 ////创建一个批处理句柄,///设置传输选项?//,/将图片的外链地址输出到浏览器////获取到的信息在文件中以流的形式返回,////可以根据需要改变输出格式添加单独的句柄到批处理会话服务器环境至强测试模式使用两台相同配置相同网络环境的电脑,同时提交数据,测试多个线程获取和使用函数的顺序下面是使用函数顺序的代码获取多个网页数据:,/.
实用第一智慧密集获取相册图片。任丘职教中心的测试执行时间代码在多线程获取网页数据之前添加: ;//获取程序开始执行的时间 Start time:, end time: , Execution time: 用这一行代码来简单地测量代码执行时间。获取相册的图片。考试对象任丘职教中心设有总考组。数据如下:多线程模式相册页面:“提交”/行时间:,终止时间:;.,执行顺序开始时间:,终止时间:.,执行?。:Line time: /『//这里可以添加时间测试代码,记录结束时间开始时间:。,结束时间:多线程获取网页的时间取决于最慢的网页。和网页数量有关//图片取出的数量无关,顺序获取的网页是所有网页的总和。这是
php多线程抓取网页( 2018年05月31日17:28:50投稿:mrr)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-02-19 18:01
2018年05月31日17:28:50投稿:mrr)
python面向对象多线程爬虫爬取搜狐页面示例代码
更新时间:2018-05-31 17:28:50 投稿:mrr
本文章主要介绍python面向对象多线程爬虫爬取搜狐页面的示例代码。有需要的朋友可以参考以下
首先我们需要几个包:requests、lxml、bs4、pymongo、redis
1. 创建一个爬虫对象有几个行为:抓取页面、解析页面、提取页面、存储页面
class Spider(object):
def __init__(self):
# 状态(是否工作)
self.status = SpiderStatus.IDLE
# 抓取页面
def fetch(self, current_url):
pass
# 解析页面
def parse(self, html_page):
pass
# 抽取页面
def extract(self, html_page):
pass
# 储存页面
def store(self, data_dict):
pass
2. 设置爬虫的属性。我们用一个类来封装,不用爬爬爬。@unique 使其中的元素独一无二。枚举和唯一需要从枚举表面导入:
@unique
class SpiderStatus(Enum):
IDLE = 0
WORKING = 1
3. 覆盖多线程类:
class SpiderThread(Thread):
def __init__(self, spider, tasks):
super().__init__(daemon=True)
self.spider = spider
self.tasks = tasks
def run(self):
while True:
pass
4. 现在爬虫的基本结构已经完成,要在main函数中创建任务,需要从队列中导入Queue:
def main():
# list没有锁,所以使用Queue比较安全, task_queue=[]也可以使用,Queue 是先进先出结构, 即 FIFO
task_queue = Queue()
# 往队列放种子url, 即搜狐手机端的url
task_queue.put('http://m.sohu,com/')
# 指定起多少个线程
spider_threads = [SpiderThread(Spider(), task_queue) for _ in range(10)]
for spider_thread in spider_threads:
spider_thread.start()
# 控制主线程不能停下,如果队列里有东西,任务不能停, 或者spider处于工作状态,也不能停
while task_queue.empty() or is_any_alive(spider_threads):
pass
print('Over')
4-1.和is_any_threads是判断线程中是否有蜘蛛还活着,所以我们再写一个函数封装一下:
def is_any_alive(spider_threads):
return any([spider_thread.spider.status == SpiderStatus.WORKING
for spider_thread in spider_threads])
5. 结构体都写好了,接下来就是填写爬虫的代码了。在SpiderThread(Thread)中,开始编写运行爬虫的方法,即线程启动后要做什么:
def run(self):
while True:
# 获取url
current_url = self.tasks_queue.get()
visited_urls.add(current_url)
# 把爬虫的status改成working
self.spider.status = SpiderStatus.WORKING
# 获取页面
html_page = self.spider.fetch(current_url)
# 判断页面是否为空
if html_page not in [None, '']:
# 去解析这个页面, 拿到列表
url_links = self.spider.parse(html_page)
# 把解析完的结构加到 self.tasks_queue里面来
# 没有一次性添加到队列的方法 用循环添加算求了
for url_link in url_links:
self.tasks_queue.put(url_link)
# 完成任务,状态变回IDLE
self.spider.status = SpiderStatus.IDLE
6. 现在可以开始编写 Spider() 类中的四个方法,首先编写 fetch() 抓取页面:
@Retry()
def fetch(self, current_url, *, charsets=('utf-8', ), user_agent=None, proxies=None):
thread_name = current_thread().name
print(f'[{thread_name}]: {current_url}')
headers = {'user-agent': user_agent} if user_agent else {}
resp = requests.get(current_url,
headers=headers, proxies=proxies)
# 判断状态码,只要200的页面
return decode_page(resp.content, charsets) \
if resp.status_code == 200 else None
6-1. decode_page 是我们在类外封装的解码函数:
def decode_page(page_bytes, charsets=('utf-8',)):
page_html = None
for charset in charsets:
try:
page_html = page_bytes.decode(charset)
break
except UnicodeDecodeError:
pass
# logging.error('Decode:', error)
return page_html
6-2. @retry 是重试的装饰器,因为需要传参数,这里我们用一个类来包装,所以最后改成@Retry():
# retry的类,重试次数3次,时间5秒(这样写在装饰器就不用传参数类), 异常
class Retry(object):
def __init__(self, *, retry_times=3, wait_secs=5, errors=(Exception, )):
self.retry_times = retry_times
self.wait_secs = wait_secs
self.errors = errors
# call 方法传参
def __call__(self, fn):
def wrapper(*args, **kwargs):
for _ in range(self.retry_times):
try:
return fn(*args, **kwargs)
except self.errors as e:
# 打日志
logging.error(e)
# 最小避让 self.wait_secs 再发起请求(最小避让时间)
sleep((random() + 1) * self.wait_secs)
return None
return wrapper()
7. 接下来,编写解析页面的方法,即parse():
# 解析页面
def parse(self, html_page, *, domain='m.sohu.com'):
soup = BeautifulSoup(html_page, 'lxml')
url_links = []
# 找body的有 href 属性的 a 标签
for a_tag in soup.body.select('a[href]'):
# 拿到这个属性
parser = urlparse(a_tag.attrs['href'])
netloc = parser.netloc or domain
scheme = parser.scheme or 'http'
netloc = parser.netloc or 'm.sohu.com'
# 只爬取 domain 底下的
if scheme != 'javascript' and netloc == domain:
path = parser.path
query = '?' + parser.query if parser.query else ''
full_url = f'{scheme}://{netloc}{path}{query}'
if full_url not in visited_urls:
url_links.append(full_url)
return url_links
7-1.我们需要在SpiderThread()的run方法中,在
current_url = self.tasks_queue.get()
在下面添加
visited_urls.add(current_url)
在课堂外添加另一个
visited_urls = set()去重
8. 现在可以开始抓取相应的 URL。
总结
以上就是小编为大家介绍的python面向对象多线程爬虫爬取搜狐页面的示例代码。我希望它对你有帮助。有任何问题请给我留言,小编会及时回复你的。还要感谢大家对脚本之家网站的支持! 查看全部
php多线程抓取网页(
2018年05月31日17:28:50投稿:mrr)
python面向对象多线程爬虫爬取搜狐页面示例代码
更新时间:2018-05-31 17:28:50 投稿:mrr
本文章主要介绍python面向对象多线程爬虫爬取搜狐页面的示例代码。有需要的朋友可以参考以下
首先我们需要几个包:requests、lxml、bs4、pymongo、redis
1. 创建一个爬虫对象有几个行为:抓取页面、解析页面、提取页面、存储页面
class Spider(object):
def __init__(self):
# 状态(是否工作)
self.status = SpiderStatus.IDLE
# 抓取页面
def fetch(self, current_url):
pass
# 解析页面
def parse(self, html_page):
pass
# 抽取页面
def extract(self, html_page):
pass
# 储存页面
def store(self, data_dict):
pass
2. 设置爬虫的属性。我们用一个类来封装,不用爬爬爬。@unique 使其中的元素独一无二。枚举和唯一需要从枚举表面导入:
@unique
class SpiderStatus(Enum):
IDLE = 0
WORKING = 1
3. 覆盖多线程类:
class SpiderThread(Thread):
def __init__(self, spider, tasks):
super().__init__(daemon=True)
self.spider = spider
self.tasks = tasks
def run(self):
while True:
pass
4. 现在爬虫的基本结构已经完成,要在main函数中创建任务,需要从队列中导入Queue:
def main():
# list没有锁,所以使用Queue比较安全, task_queue=[]也可以使用,Queue 是先进先出结构, 即 FIFO
task_queue = Queue()
# 往队列放种子url, 即搜狐手机端的url
task_queue.put('http://m.sohu,com/')
# 指定起多少个线程
spider_threads = [SpiderThread(Spider(), task_queue) for _ in range(10)]
for spider_thread in spider_threads:
spider_thread.start()
# 控制主线程不能停下,如果队列里有东西,任务不能停, 或者spider处于工作状态,也不能停
while task_queue.empty() or is_any_alive(spider_threads):
pass
print('Over')
4-1.和is_any_threads是判断线程中是否有蜘蛛还活着,所以我们再写一个函数封装一下:
def is_any_alive(spider_threads):
return any([spider_thread.spider.status == SpiderStatus.WORKING
for spider_thread in spider_threads])
5. 结构体都写好了,接下来就是填写爬虫的代码了。在SpiderThread(Thread)中,开始编写运行爬虫的方法,即线程启动后要做什么:
def run(self):
while True:
# 获取url
current_url = self.tasks_queue.get()
visited_urls.add(current_url)
# 把爬虫的status改成working
self.spider.status = SpiderStatus.WORKING
# 获取页面
html_page = self.spider.fetch(current_url)
# 判断页面是否为空
if html_page not in [None, '']:
# 去解析这个页面, 拿到列表
url_links = self.spider.parse(html_page)
# 把解析完的结构加到 self.tasks_queue里面来
# 没有一次性添加到队列的方法 用循环添加算求了
for url_link in url_links:
self.tasks_queue.put(url_link)
# 完成任务,状态变回IDLE
self.spider.status = SpiderStatus.IDLE
6. 现在可以开始编写 Spider() 类中的四个方法,首先编写 fetch() 抓取页面:
@Retry()
def fetch(self, current_url, *, charsets=('utf-8', ), user_agent=None, proxies=None):
thread_name = current_thread().name
print(f'[{thread_name}]: {current_url}')
headers = {'user-agent': user_agent} if user_agent else {}
resp = requests.get(current_url,
headers=headers, proxies=proxies)
# 判断状态码,只要200的页面
return decode_page(resp.content, charsets) \
if resp.status_code == 200 else None
6-1. decode_page 是我们在类外封装的解码函数:
def decode_page(page_bytes, charsets=('utf-8',)):
page_html = None
for charset in charsets:
try:
page_html = page_bytes.decode(charset)
break
except UnicodeDecodeError:
pass
# logging.error('Decode:', error)
return page_html
6-2. @retry 是重试的装饰器,因为需要传参数,这里我们用一个类来包装,所以最后改成@Retry():
# retry的类,重试次数3次,时间5秒(这样写在装饰器就不用传参数类), 异常
class Retry(object):
def __init__(self, *, retry_times=3, wait_secs=5, errors=(Exception, )):
self.retry_times = retry_times
self.wait_secs = wait_secs
self.errors = errors
# call 方法传参
def __call__(self, fn):
def wrapper(*args, **kwargs):
for _ in range(self.retry_times):
try:
return fn(*args, **kwargs)
except self.errors as e:
# 打日志
logging.error(e)
# 最小避让 self.wait_secs 再发起请求(最小避让时间)
sleep((random() + 1) * self.wait_secs)
return None
return wrapper()
7. 接下来,编写解析页面的方法,即parse():
# 解析页面
def parse(self, html_page, *, domain='m.sohu.com'):
soup = BeautifulSoup(html_page, 'lxml')
url_links = []
# 找body的有 href 属性的 a 标签
for a_tag in soup.body.select('a[href]'):
# 拿到这个属性
parser = urlparse(a_tag.attrs['href'])
netloc = parser.netloc or domain
scheme = parser.scheme or 'http'
netloc = parser.netloc or 'm.sohu.com'
# 只爬取 domain 底下的
if scheme != 'javascript' and netloc == domain:
path = parser.path
query = '?' + parser.query if parser.query else ''
full_url = f'{scheme}://{netloc}{path}{query}'
if full_url not in visited_urls:
url_links.append(full_url)
return url_links
7-1.我们需要在SpiderThread()的run方法中,在
current_url = self.tasks_queue.get()
在下面添加
visited_urls.add(current_url)
在课堂外添加另一个
visited_urls = set()去重
8. 现在可以开始抓取相应的 URL。

总结
以上就是小编为大家介绍的python面向对象多线程爬虫爬取搜狐页面的示例代码。我希望它对你有帮助。有任何问题请给我留言,小编会及时回复你的。还要感谢大家对脚本之家网站的支持!
php多线程抓取网页(线程池多线程获取图片数据参考源码附完整源码参考学习)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-02-13 03:02
图片站的lemanoosh数据是异步加载的形式。下拉会显示更多的数据,也就是下一页的数据。通过谷歌浏览器可以清楚的看到数据接口地址和数据呈现形式,与其他网站返回json数据的区别在于网站返回部分html源数据,包括需要获取的图片地址。
使用的第三方库:
import requests
from fake_useragent import UserAgent
import re
from multiprocessing.dummy import Pool as ThreadPool
import datetime
import time
其中multiprocessing.dummy用于执行多线程任务,线程池用于执行多线程任务。
延期:
工作中有一个常见的场景。比如我们现在需要下载10W张图片。我们不可能写一个for循环一个一个下载,或者我们必须使用多个进程进行简单的HTTP压力测试。或者线程去做(每个请求handler,都会有一个参数(所有参数生成一个队列))然后把handler和queue映射到Pool中。一定要使用多线程或者多进程,然后把100W队列扔到线程池或者进程池去处理python中的multiprocessingPool进程池,multiprocessing.dummy很好用,一般:
from multiprocessing import Pool as ProcessPool from multiprocessing.dummy import Pool as ThreadPool
前者是多进程,后者使用线程,之所以dummy(中文意为“假”)———————————————
来源:本文为CSDN博主“FishBear_move_on” 原文链接:
爬行的想法
接口地址:
请求方式:POST
请求数据:
block_last_random: minijobboard
块自定义:53
行动:list_publications
第2页
注:page字段为页码,可通过更改页码获取数据内容。
参考来源:
#获取图片数据
def get_pagelist(pagenum):
url="https://lemanoosh.com/app/them ... ot%3B
headers={'User-Agent':UserAgent().random}
data={
'block_last_random': 'custom',
'block_custom': '54',
'action': 'list_publications',
'page': pagenum,
}
response=requests.post(url=url,data=data,headers=headers,timeout=8)
#print(response.status_code)
if response.status_code == 200:
html=response.content.decode('utf-8')
datamedias=re.findall(r'data-media="(.+?)"',html,re.S)
print(len(datamedias))
print(datamedias)
datamedias=set(datamedias)
print(len(datamedias))
return datamedias
使用正则表达式获取图像数据,即图像地址。同时经过对比发现源html数据中的图片地址有重复,所以进行去重,使用set函数!
#下载图片数据
def dowm(imgurl):
imgname=imgurl.split("/")[-1]
imgname=f'{get_time_stamp13()}{imgname}'
headers = {'User-Agent': UserAgent().random}
r=requests.get(url=imgurl,headers=headers,timeout=8)
with open(f'lemanoosh/{imgname}','wb') as f:
f.write(r.content)
print(f'{imgname} 图片下载成功了!')
使用线程池多线程获取图像数据参考源码:
#多线程下载图片数据
def thread_down(imgs):
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(dowm, imgs)
pool.close()
pool.join()
print("采集所有图片完成!")
except:
print("Error: unable to start thread")
#主程序
def main():
for i in range(1,2000):
print(f'正在爬取采集第 {i} 页图片数据..')
imgs=get_pagelist(i)
thread_down(imgs)
附上完整的源代码参考:
#20210429 获取图片数据
#微信:huguo00289
# -*- coding: utf-8 -*-
import requests
from fake_useragent import UserAgent
import re
from multiprocessing.dummy import Pool as ThreadPool
import datetime
import time
def get_float_time_stamp():
datetime_now = datetime.datetime.now()
return datetime_now.timestamp()
def get_time_stamp16():
# 生成16时间戳 eg:1540281250399895 -ln
datetime_now = datetime.datetime.now()
print(datetime_now)
# 10位,时间点相当于从UNIX TIME的纪元时间开始的当年时间编号
date_stamp = str(int(time.mktime(datetime_now.timetuple())))
# 6位,微秒
data_microsecond = str("d"%datetime_now.microsecond)
date_stamp = date_stamp+data_microsecond
return int(date_stamp)
def get_time_stamp13():
# 生成13时间戳 eg:1540281250399895
datetime_now = datetime.datetime.now()
# 10位,时间点相当于从UNIX TIME的纪元时间开始的当年时间编号
date_stamp = str(int(time.mktime(datetime_now.timetuple())))
# 3位,微秒
data_microsecond = str("d"%datetime_now.microsecond)[0:3]
date_stamp = date_stamp+data_microsecond
return int(date_stamp)
#获取图片数据
def get_pagelist(pagenum):
url="https://lemanoosh.com/app/them ... ot%3B
headers={'User-Agent':UserAgent().random}
data={
'block_last_random': 'custom',
'block_custom': '54',
'action': 'list_publications',
'page': pagenum,
}
response=requests.post(url=url,data=data,headers=headers,timeout=8)
#print(response.status_code)
if response.status_code == 200:
html=response.content.decode('utf-8')
datamedias=re.findall(r'data-media="(.+?)"',html,re.S)
print(len(datamedias))
print(datamedias)
datamedias=set(datamedias)
print(len(datamedias))
return datamedias
#下载图片数据
def dowm(imgurl):
imgname=imgurl.split("/")[-1]
imgname=f'{get_time_stamp13()}{imgname}'
headers = {'User-Agent': UserAgent().random}
r=requests.get(url=imgurl,headers=headers,timeout=8)
with open(f'lemanoosh/{imgname}','wb') as f:
f.write(r.content)
print(f'{imgname} 图片下载成功了!')
#多线程下载图片数据
def thread_down(imgs):
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(dowm, imgs)
pool.close()
pool.join()
print("采集所有图片完成!")
except:
print("Error: unable to start thread")
#主程序
def main():
for i in range(1,2000):
print(f'正在爬取采集第 {i} 页图片数据..')
imgs=get_pagelist(i)
thread_down(imgs)
if __name__=='__main__':
main()
以上内容仅供参考和学习。这个网站适合新手练习。 查看全部
php多线程抓取网页(线程池多线程获取图片数据参考源码附完整源码参考学习)
图片站的lemanoosh数据是异步加载的形式。下拉会显示更多的数据,也就是下一页的数据。通过谷歌浏览器可以清楚的看到数据接口地址和数据呈现形式,与其他网站返回json数据的区别在于网站返回部分html源数据,包括需要获取的图片地址。
使用的第三方库:
import requests
from fake_useragent import UserAgent
import re
from multiprocessing.dummy import Pool as ThreadPool
import datetime
import time
其中multiprocessing.dummy用于执行多线程任务,线程池用于执行多线程任务。
延期:
工作中有一个常见的场景。比如我们现在需要下载10W张图片。我们不可能写一个for循环一个一个下载,或者我们必须使用多个进程进行简单的HTTP压力测试。或者线程去做(每个请求handler,都会有一个参数(所有参数生成一个队列))然后把handler和queue映射到Pool中。一定要使用多线程或者多进程,然后把100W队列扔到线程池或者进程池去处理python中的multiprocessingPool进程池,multiprocessing.dummy很好用,一般:
from multiprocessing import Pool as ProcessPool from multiprocessing.dummy import Pool as ThreadPool
前者是多进程,后者使用线程,之所以dummy(中文意为“假”)———————————————
来源:本文为CSDN博主“FishBear_move_on” 原文链接:
爬行的想法
接口地址:
请求方式:POST
请求数据:
block_last_random: minijobboard
块自定义:53
行动:list_publications
第2页
注:page字段为页码,可通过更改页码获取数据内容。
参考来源:
#获取图片数据
def get_pagelist(pagenum):
url="https://lemanoosh.com/app/them ... ot%3B
headers={'User-Agent':UserAgent().random}
data={
'block_last_random': 'custom',
'block_custom': '54',
'action': 'list_publications',
'page': pagenum,
}
response=requests.post(url=url,data=data,headers=headers,timeout=8)
#print(response.status_code)
if response.status_code == 200:
html=response.content.decode('utf-8')
datamedias=re.findall(r'data-media="(.+?)"',html,re.S)
print(len(datamedias))
print(datamedias)
datamedias=set(datamedias)
print(len(datamedias))
return datamedias
使用正则表达式获取图像数据,即图像地址。同时经过对比发现源html数据中的图片地址有重复,所以进行去重,使用set函数!
#下载图片数据
def dowm(imgurl):
imgname=imgurl.split("/")[-1]
imgname=f'{get_time_stamp13()}{imgname}'
headers = {'User-Agent': UserAgent().random}
r=requests.get(url=imgurl,headers=headers,timeout=8)
with open(f'lemanoosh/{imgname}','wb') as f:
f.write(r.content)
print(f'{imgname} 图片下载成功了!')
使用线程池多线程获取图像数据参考源码:
#多线程下载图片数据
def thread_down(imgs):
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(dowm, imgs)
pool.close()
pool.join()
print("采集所有图片完成!")
except:
print("Error: unable to start thread")
#主程序
def main():
for i in range(1,2000):
print(f'正在爬取采集第 {i} 页图片数据..')
imgs=get_pagelist(i)
thread_down(imgs)
附上完整的源代码参考:
#20210429 获取图片数据
#微信:huguo00289
# -*- coding: utf-8 -*-
import requests
from fake_useragent import UserAgent
import re
from multiprocessing.dummy import Pool as ThreadPool
import datetime
import time
def get_float_time_stamp():
datetime_now = datetime.datetime.now()
return datetime_now.timestamp()
def get_time_stamp16():
# 生成16时间戳 eg:1540281250399895 -ln
datetime_now = datetime.datetime.now()
print(datetime_now)
# 10位,时间点相当于从UNIX TIME的纪元时间开始的当年时间编号
date_stamp = str(int(time.mktime(datetime_now.timetuple())))
# 6位,微秒
data_microsecond = str("d"%datetime_now.microsecond)
date_stamp = date_stamp+data_microsecond
return int(date_stamp)
def get_time_stamp13():
# 生成13时间戳 eg:1540281250399895
datetime_now = datetime.datetime.now()
# 10位,时间点相当于从UNIX TIME的纪元时间开始的当年时间编号
date_stamp = str(int(time.mktime(datetime_now.timetuple())))
# 3位,微秒
data_microsecond = str("d"%datetime_now.microsecond)[0:3]
date_stamp = date_stamp+data_microsecond
return int(date_stamp)
#获取图片数据
def get_pagelist(pagenum):
url="https://lemanoosh.com/app/them ... ot%3B
headers={'User-Agent':UserAgent().random}
data={
'block_last_random': 'custom',
'block_custom': '54',
'action': 'list_publications',
'page': pagenum,
}
response=requests.post(url=url,data=data,headers=headers,timeout=8)
#print(response.status_code)
if response.status_code == 200:
html=response.content.decode('utf-8')
datamedias=re.findall(r'data-media="(.+?)"',html,re.S)
print(len(datamedias))
print(datamedias)
datamedias=set(datamedias)
print(len(datamedias))
return datamedias
#下载图片数据
def dowm(imgurl):
imgname=imgurl.split("/")[-1]
imgname=f'{get_time_stamp13()}{imgname}'
headers = {'User-Agent': UserAgent().random}
r=requests.get(url=imgurl,headers=headers,timeout=8)
with open(f'lemanoosh/{imgname}','wb') as f:
f.write(r.content)
print(f'{imgname} 图片下载成功了!')
#多线程下载图片数据
def thread_down(imgs):
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(dowm, imgs)
pool.close()
pool.join()
print("采集所有图片完成!")
except:
print("Error: unable to start thread")
#主程序
def main():
for i in range(1,2000):
print(f'正在爬取采集第 {i} 页图片数据..')
imgs=get_pagelist(i)
thread_down(imgs)
if __name__=='__main__':
main()
以上内容仅供参考和学习。这个网站适合新手练习。
php多线程抓取网页(PHP利用CurlFunctions实现并发多线程抓取网页或者下载文件操作 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-08 17:04
)
PHP使用Curl Functions来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等。但是由于PHP语言本身不支持多线程,爬虫程序的开发效率不高,所以Curl Multi经常需要函数。该函数实现并发多线程访问多个url地址,实现并发多线程抓取网页或下载文件。具体实现过程请参考以下示例:
(1)下面的代码是爬取多个URL,然后将爬取到的URL的页面代码写入到指定文件中
<p>$urls = array( 'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); // 设置要抓取的页面URL <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} // 初始化 <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); // 执行 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />} // 结束清理 <br />curl_multi_close($mh); <br />
fclose($st);
(2)下面的代码和上面类似,只不过这个地方是先把获取到的代码放到一个变量中,然后再将获取到的内容写入到指定的文件中
(3)以下代码实现使用PHP的Curl Functions实现并发多线程下载文件
<p>$urls=array( 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br /> $g=$save_to.basename($url);<br /> if(!is_file($g)){<br /> $conn[$i]=curl_init($url);<br /> $fp[$i]=fopen($g,"w");<br /> curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br /> curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br /> curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br /> curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br /> curl_multi_add_handle($mh,$conn[$i]);<br /> }<br />}<br />do{<br /> $n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br /> curl_multi_remove_handle($mh,$conn[$i]);<br /> curl_close($conn[$i]);<br /> fclose($fp[$i]);<br />}<br />curl_multi_close($mh);$urls=array(<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br /> $g=$save_to.basename($url);<br /> if(!is_file($g)){<br /> $conn[$i]=curl_init($url);<br /> $fp[$i]=fopen($g,"w");<br /> curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br /> curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br /> curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br /> curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br /> curl_multi_add_handle($mh,$conn[$i]);<br /> }<br />}<br />do{<br /> $n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br /> curl_multi_remove_handle($mh,$conn[$i]);<br /> curl_close($conn[$i]);<br /> fclose($fp[$i]);<br />}<br />curl_multi_close($mh);</p> 查看全部
php多线程抓取网页(PHP利用CurlFunctions实现并发多线程抓取网页或者下载文件操作
)
PHP使用Curl Functions来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等。但是由于PHP语言本身不支持多线程,爬虫程序的开发效率不高,所以Curl Multi经常需要函数。该函数实现并发多线程访问多个url地址,实现并发多线程抓取网页或下载文件。具体实现过程请参考以下示例:
(1)下面的代码是爬取多个URL,然后将爬取到的URL的页面代码写入到指定文件中
<p>$urls = array( 'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); // 设置要抓取的页面URL <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} // 初始化 <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); // 执行 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />} // 结束清理 <br />curl_multi_close($mh); <br />
fclose($st);
(2)下面的代码和上面类似,只不过这个地方是先把获取到的代码放到一个变量中,然后再将获取到的内容写入到指定的文件中
(3)以下代码实现使用PHP的Curl Functions实现并发多线程下载文件
<p>$urls=array( 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br /> $g=$save_to.basename($url);<br /> if(!is_file($g)){<br /> $conn[$i]=curl_init($url);<br /> $fp[$i]=fopen($g,"w");<br /> curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br /> curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br /> curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br /> curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br /> curl_multi_add_handle($mh,$conn[$i]);<br /> }<br />}<br />do{<br /> $n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br /> curl_multi_remove_handle($mh,$conn[$i]);<br /> curl_close($conn[$i]);<br /> fclose($fp[$i]);<br />}<br />curl_multi_close($mh);$urls=array(<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br /> $g=$save_to.basename($url);<br /> if(!is_file($g)){<br /> $conn[$i]=curl_init($url);<br /> $fp[$i]=fopen($g,"w");<br /> curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br /> curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br /> curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br /> curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br /> curl_multi_add_handle($mh,$conn[$i]);<br /> }<br />}<br />do{<br /> $n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br /> curl_multi_remove_handle($mh,$conn[$i]);<br /> curl_close($conn[$i]);<br /> fclose($fp[$i]);<br />}<br />curl_multi_close($mh);</p>
php多线程抓取网页(php结合curl实现多线程抓取的相关知识和一些内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-07 01:18
想知道php结合curl实现多线程爬取的相关内容吗?本文将讲解php结合curl实现多线程爬取的相关知识以及一些代码示例。欢迎阅读和指正。我们先把重点:php、curl实现多线程,一起来学习。
PHP结合curl实现多线程爬取
让我们再看几个例子
(1)下面的代码是爬取多个URL,然后将爬取到的URL的页面代码写入到指定文件中
$urls = array(
'//www.qb5200.com/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码和上面类似,只不过这个地方是先把获取到的代码放到一个变量中,然后再将获取到的内容写入到指定的文件中
$urls = array(
'//www.qb5200.com/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)以下代码实现使用PHP的Curl Functions实现并发多线程下载文件
$urls=array(
'//www.qb5200.com/5w.zip',
'//www.qb5200.com/5w.zip',
'//www.qb5200.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'//www.qb5200.com/5w.zip',
'//www.qb5200.com/5w.zip',
'//www.qb5200.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。
相关文章 查看全部
php多线程抓取网页(php结合curl实现多线程抓取的相关知识和一些内容吗)
想知道php结合curl实现多线程爬取的相关内容吗?本文将讲解php结合curl实现多线程爬取的相关知识以及一些代码示例。欢迎阅读和指正。我们先把重点:php、curl实现多线程,一起来学习。
PHP结合curl实现多线程爬取
让我们再看几个例子
(1)下面的代码是爬取多个URL,然后将爬取到的URL的页面代码写入到指定文件中
$urls = array(
'//www.qb5200.com/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码和上面类似,只不过这个地方是先把获取到的代码放到一个变量中,然后再将获取到的内容写入到指定的文件中
$urls = array(
'//www.qb5200.com/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)以下代码实现使用PHP的Curl Functions实现并发多线程下载文件
$urls=array(
'//www.qb5200.com/5w.zip',
'//www.qb5200.com/5w.zip',
'//www.qb5200.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'//www.qb5200.com/5w.zip',
'//www.qb5200.com/5w.zip',
'//www.qb5200.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。
相关文章
php多线程抓取网页(php多线程抓取网页:线程切换的时候,需要等待的内存空间)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-02-06 00:03
php多线程抓取网页:线程切换的时候,需要等待的内存空间小,处理起来速度快,因此html文档处理起来速度是比较快的。php并发抓取网页,需要额外添加线程池,将加载完的数据交给线程池去处理,线程池专门用来处理网页,即在php程序的方法中内置一个线程池,把其中的线程托管到这个线程池中,当线程池中没有线程等待处理时,就去使用这个线程池里面的线程进行处理,从而达到并发抓取网页的效果。
为了支持多线程抓取网页,php可以用线程池来处理网页结构,同时线程池中又可以存放一些线程,以保证抓取的速度,这样才能用到php多线程抓取网页。多线程代码实现网页多线程抓取网页的结构:html文档中的标签使用多线程处理后,可以不断地往下读取tag相关的链接。当遇到
标签,html页面不再采用全局同步+sync,而是直接将br标签作为全局事件(如读取数据)触发器,触发文档连接交互。
在下一次读取时,会自动链接到文档中的一个br标签,执行代码中的内容,由此可以知道,此时的代码是先下载网页,再链接后面的内容。线程池代码:这里要说明的是,php多线程抓取网页,都是基于一个线程池进行。在这个线程池中,php程序会创建一个线程池,用于进行网页抓取结构的读取;其他线程会随机分配线程池空间并等待网页处理完成后再统一返回给php程序,如此循环,方便抓取网页结构的获取。
说明php多线程抓取网页,使用的是连接池来进行加速的,一个线程池能处理的网页结构总体是有限的,例如每秒有10000个网页处理请求,php最大能处理50000个网页,线程池也就是能处理50000个连接。线程池时间因为使用连接池,可以在抓取结构变化时,直接修改线程池地址对应的上下文对象,访问变化处理实例时,抓取结构会及时变化,然后再将上下文对象挂到线程池上处理。
这样就可以更方便地管理抓取结构。php抓取的结构的变化也是比较快的,php并发抓取网页结构较快,但一般不能超过50000。如果抓取速度过快,会导致php读取网页结构变化太快,从而处理代码比较慢。从网页的结构上分析,一个内容呈现出来的效果有这几种:</img></img>当php代码读取了第一个网页元素时,捕获了它的全局事件,然后这个元素就会在object的堆空间中,随机重新遍历br标签,捕获第二个网页元素的一个链接,形成第三个网页元素,循环当php代码下载结构最后,就释放了br标签,通过这样的循环,执行代码中最后一个循环中的代码,整个网页的结构就。 查看全部
php多线程抓取网页(php多线程抓取网页:线程切换的时候,需要等待的内存空间)
php多线程抓取网页:线程切换的时候,需要等待的内存空间小,处理起来速度快,因此html文档处理起来速度是比较快的。php并发抓取网页,需要额外添加线程池,将加载完的数据交给线程池去处理,线程池专门用来处理网页,即在php程序的方法中内置一个线程池,把其中的线程托管到这个线程池中,当线程池中没有线程等待处理时,就去使用这个线程池里面的线程进行处理,从而达到并发抓取网页的效果。
为了支持多线程抓取网页,php可以用线程池来处理网页结构,同时线程池中又可以存放一些线程,以保证抓取的速度,这样才能用到php多线程抓取网页。多线程代码实现网页多线程抓取网页的结构:html文档中的标签使用多线程处理后,可以不断地往下读取tag相关的链接。当遇到
标签,html页面不再采用全局同步+sync,而是直接将br标签作为全局事件(如读取数据)触发器,触发文档连接交互。
在下一次读取时,会自动链接到文档中的一个br标签,执行代码中的内容,由此可以知道,此时的代码是先下载网页,再链接后面的内容。线程池代码:这里要说明的是,php多线程抓取网页,都是基于一个线程池进行。在这个线程池中,php程序会创建一个线程池,用于进行网页抓取结构的读取;其他线程会随机分配线程池空间并等待网页处理完成后再统一返回给php程序,如此循环,方便抓取网页结构的获取。
说明php多线程抓取网页,使用的是连接池来进行加速的,一个线程池能处理的网页结构总体是有限的,例如每秒有10000个网页处理请求,php最大能处理50000个网页,线程池也就是能处理50000个连接。线程池时间因为使用连接池,可以在抓取结构变化时,直接修改线程池地址对应的上下文对象,访问变化处理实例时,抓取结构会及时变化,然后再将上下文对象挂到线程池上处理。
这样就可以更方便地管理抓取结构。php抓取的结构的变化也是比较快的,php并发抓取网页结构较快,但一般不能超过50000。如果抓取速度过快,会导致php读取网页结构变化太快,从而处理代码比较慢。从网页的结构上分析,一个内容呈现出来的效果有这几种:</img></img>当php代码读取了第一个网页元素时,捕获了它的全局事件,然后这个元素就会在object的堆空间中,随机重新遍历br标签,捕获第二个网页元素的一个链接,形成第三个网页元素,循环当php代码下载结构最后,就释放了br标签,通过这样的循环,执行代码中最后一个循环中的代码,整个网页的结构就。
php多线程抓取网页(php多线程抓取网页展示页面页面视频教程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-01 17:06
php多线程抓取网页展示页面页面视频教程php多线程抓取网页页面作者:老孙4g版本:php5.4版本:php5.4++手把手教程:目前使用:三种抓取网页的方法,第一种:局部代理,2种抓取网页基本原理:网页中的url变换:1.网页、页面view的url变换2.php多线程做同步处理3.php多线程抓取页面主要抓取规则:1.网页中的url变换:我们发现要抓取a,b,c,d这个页面,可以抓取a,b两个页面,然后再由a调用抓取a页面的方法,a页面抓取完成后,再返回,如此循环往复。
同步代理:先post请求代理服务器,然后在请求url,接着处理url返回url的流程方法实现:线程创建时,先header,再向signal框输入,处理url到请求一个包含url的函数;connect();connect(post,url);send();处理url到响应的请求,然后把响应返回给signal框。
send();第二种:代理池的搭建模拟一条线程访问任何网页,但是路由不再网页上(即对一个页面没有控制权),即使是通过代理客户端,也只能访问到连接代理端口可读的页面。假设有5个ip,5个域名,有这样一个页面,要抓取是如何的呢?思考:思考为什么要建这样一个代理池呢?publicclasswaitingguestdata{publicstaticvoidmain(string[]args){//创建代理服务器名称proxyaddressclientaddress=newproxyaddress("");//请求代理clientaddress.add("");//搭建池if(isset(clientaddress.request["user"].getid())){//proxyaddress.forward(clientaddress,int);}switch(clientaddress.request["password"].getvalue()){caseclientaddress.empty()://请求端口不全返回urlreturn;}caseclientaddress.string()://user名称为空返回urlreturn;}staticvoidswitch(clientaddressclientaddress){if(clientaddress==null){//false或者true表示未配置等待abort;}if(clientaddress==proxyaddress.post().value()){//proxyaddress是可读proxyaddressproxyaddress=newproxyaddress(clientaddress);proxyaddress.username=username;proxyaddress.password=password;}if(clientaddress.request["port"].getvars()){//user名称是否为空返回urlreturn;}if(isset(clientaddress.request["user"].getid())){//user名称是空返回urlreturn;}if(isset(clientaddress.request["user"].getid())。 查看全部
php多线程抓取网页(php多线程抓取网页展示页面页面视频教程(组图))
php多线程抓取网页展示页面页面视频教程php多线程抓取网页页面作者:老孙4g版本:php5.4版本:php5.4++手把手教程:目前使用:三种抓取网页的方法,第一种:局部代理,2种抓取网页基本原理:网页中的url变换:1.网页、页面view的url变换2.php多线程做同步处理3.php多线程抓取页面主要抓取规则:1.网页中的url变换:我们发现要抓取a,b,c,d这个页面,可以抓取a,b两个页面,然后再由a调用抓取a页面的方法,a页面抓取完成后,再返回,如此循环往复。
同步代理:先post请求代理服务器,然后在请求url,接着处理url返回url的流程方法实现:线程创建时,先header,再向signal框输入,处理url到请求一个包含url的函数;connect();connect(post,url);send();处理url到响应的请求,然后把响应返回给signal框。
send();第二种:代理池的搭建模拟一条线程访问任何网页,但是路由不再网页上(即对一个页面没有控制权),即使是通过代理客户端,也只能访问到连接代理端口可读的页面。假设有5个ip,5个域名,有这样一个页面,要抓取是如何的呢?思考:思考为什么要建这样一个代理池呢?publicclasswaitingguestdata{publicstaticvoidmain(string[]args){//创建代理服务器名称proxyaddressclientaddress=newproxyaddress("");//请求代理clientaddress.add("");//搭建池if(isset(clientaddress.request["user"].getid())){//proxyaddress.forward(clientaddress,int);}switch(clientaddress.request["password"].getvalue()){caseclientaddress.empty()://请求端口不全返回urlreturn;}caseclientaddress.string()://user名称为空返回urlreturn;}staticvoidswitch(clientaddressclientaddress){if(clientaddress==null){//false或者true表示未配置等待abort;}if(clientaddress==proxyaddress.post().value()){//proxyaddress是可读proxyaddressproxyaddress=newproxyaddress(clientaddress);proxyaddress.username=username;proxyaddress.password=password;}if(clientaddress.request["port"].getvars()){//user名称是否为空返回urlreturn;}if(isset(clientaddress.request["user"].getid())){//user名称是空返回urlreturn;}if(isset(clientaddress.request["user"].getid())。
php多线程抓取网页(PHP利用CurlFunctions实现并发多线程下载文件(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2022-01-31 03:02
)
本篇文章主要介绍基于curl的php实现多线程爬取。供有兴趣的朋友参考,希望对大家有所帮助。
PHP可以使用Curl来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等。但是由于PHP语言本身不支持多线程,开发爬虫程序的效率不高,所以经常需要使用 Curl Multi Functions。实现并发多线程访问多个url地址实现并发多线程抓取网页或下载文件的功能
代码显示如下:
让我们再看几个例子
(1)下面的代码是爬取多个URL,然后将爬取到的URL的页面代码写入到指定文件中
$urls = array(
'http://www.jb51.net/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码和上面类似,只不过这个地方是先把获取到的代码放到一个变量中,然后再将获取到的内容写入到指定的文件中
$urls = array(
'http://www.jb51.net/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)以下代码实现使用PHP的Curl Functions实现并发多线程下载文件
$urls=array(
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh); 查看全部
php多线程抓取网页(PHP利用CurlFunctions实现并发多线程下载文件(一)
)
本篇文章主要介绍基于curl的php实现多线程爬取。供有兴趣的朋友参考,希望对大家有所帮助。
PHP可以使用Curl来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等。但是由于PHP语言本身不支持多线程,开发爬虫程序的效率不高,所以经常需要使用 Curl Multi Functions。实现并发多线程访问多个url地址实现并发多线程抓取网页或下载文件的功能
代码显示如下:
让我们再看几个例子
(1)下面的代码是爬取多个URL,然后将爬取到的URL的页面代码写入到指定文件中
$urls = array(
'http://www.jb51.net/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码和上面类似,只不过这个地方是先把获取到的代码放到一个变量中,然后再将获取到的内容写入到指定的文件中
$urls = array(
'http://www.jb51.net/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)以下代码实现使用PHP的Curl Functions实现并发多线程下载文件
$urls=array(
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
php多线程抓取网页(+异步的采集程序-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-28 08:01
1.windows下安装很成问题,版本库不完全对应,比如我是win7 64位系统,php 5.4 结果没有对应的包,所以我只能打开一个虚拟机,安装的是win7x32+PHP5.3。
2.注意:线程的实现代码写在run方法中,但是启动线程的方法是start,不要直接调用run,(这样变成单线程了)
3.如果可能的话,先实例化所有线程,然后再循环,一个一个开始
4.线程中,SPL相关函数失败,最重要的是spl_register_autoload,导致自动加载失败。我的解决方案是在线程未启动时首先加载所有必需的类。
5.pthreads有版本问题,手册中大部分类和方法都需要2.0.0以上,我们运维原来安装的0.4.@ >4
6.我写了一个多线程+异步的采集程序。网站 中的 5 个 采集 花了一周的时间。
让我给你一个惊人的结论:
--------暂时不要用这个东西,生产环境有很多问题
1. 频繁的内存泄漏
2.遇到一个奇怪的问题:在线程中创建一个对象,在构造的时候给对象的属性赋值,然后回去取回,值就没了~~~,这个问题不不可避免(与时间无关,与代码有关),我特地写了一个测试示例,没有错误。
3.一开始我用纯多线程写采集(不使用async),效率不高。然后我改变了组合方法。
4.下周的工作,我要摆脱线程部分,它太不稳定了。采集只使用异步。
吐槽:有些程序员分不清异步和并发。
补充:
经过调试,上述问题2已经解决,是由于框架中另一个位置的隐藏bug造成的。
它在虚拟机上运行良好,但尚未在服务器上运行。 查看全部
php多线程抓取网页(+异步的采集程序-上海怡健医学)
1.windows下安装很成问题,版本库不完全对应,比如我是win7 64位系统,php 5.4 结果没有对应的包,所以我只能打开一个虚拟机,安装的是win7x32+PHP5.3。
2.注意:线程的实现代码写在run方法中,但是启动线程的方法是start,不要直接调用run,(这样变成单线程了)
3.如果可能的话,先实例化所有线程,然后再循环,一个一个开始
4.线程中,SPL相关函数失败,最重要的是spl_register_autoload,导致自动加载失败。我的解决方案是在线程未启动时首先加载所有必需的类。
5.pthreads有版本问题,手册中大部分类和方法都需要2.0.0以上,我们运维原来安装的0.4.@ >4
6.我写了一个多线程+异步的采集程序。网站 中的 5 个 采集 花了一周的时间。
让我给你一个惊人的结论:
--------暂时不要用这个东西,生产环境有很多问题
1. 频繁的内存泄漏
2.遇到一个奇怪的问题:在线程中创建一个对象,在构造的时候给对象的属性赋值,然后回去取回,值就没了~~~,这个问题不不可避免(与时间无关,与代码有关),我特地写了一个测试示例,没有错误。
3.一开始我用纯多线程写采集(不使用async),效率不高。然后我改变了组合方法。
4.下周的工作,我要摆脱线程部分,它太不稳定了。采集只使用异步。
吐槽:有些程序员分不清异步和并发。
补充:
经过调试,上述问题2已经解决,是由于框架中另一个位置的隐藏bug造成的。
它在虚拟机上运行良好,但尚未在服务器上运行。
php多线程抓取网页(如何搭建PHP开发环境搭建只有两步:第一目标系统获取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-25 03:05
可以看出,很多PHP新手常年在各个技术群里问关于PHP的问题,很多时候都会被别人说:何不去搜索引擎寻找更远的地方?
我也觉得新人在学习的时候不能只问问题,容易产生惰性。但是,国内相对不乐观的情况,让很多新手在没有良好基础的情况下选择上手PHP。此外,围绕 PHP 的圈子往往是浮躁的。即使他们选择了搜索引擎,如果没有良好的基础,也很难选择哪种教程可靠。作为PHP入门必备的PHP开发环境的建立,这个问题就更加明显了。
无数的文章把本来很简单的PHP开发环境弄的极其复杂,而文章过分强调PHP语言的Web特性,强行绑架了PHP和Apache、Nginx、IIS不是的第三方应用部分PHP入门开发环节会导致很多PHPer新手误入歧途,忽略了PHP作为脚本语言的本质,从而忽略了学习更多基础知识的重要性,导致很多PHPer倾向于认为自己可以搭建一个网站只知道PHP的心态。
以上是吐槽。
如何搭建PHP开发环境
搭建PHP开发环境只需两步:
下载PHP二进制包(或源码包),解压到指定目录(源码包编译安装到指定目录);将解压缩(或安装)目录添加到环境变量中。
这篇文章就结束了。
只是在开玩笑。我的 文章 风格不仅仅是关于步骤,什么都没有。
估计很多看过很多环境搭建文章的PHPer都会说,怎么会有这样的事情发生呢?这也令人不解,一个开发环境怎么会对其他人如此复杂?到底是一个PHP开发环境,还是一整套HTTP服务?
不知道什么是 HTTP 服务?那么你需要 Apache、Nginx 和 IIS 来做什么?当然,目标不是学PHP,而是想用PHP快速创建一个网站,所以没说。另外,从 PHP 5.4 开始,PHP 自带了一个简单的 HTTP 服务器,对于常规开发来说基本足够了。
以下是正文:
第一个目标:根据目标系统获取PHP本身在Linux系统下通过包管理器获取PHP
常见的 Linux 发行版都自带包管理器,这些工具可以方便的获取打包好的 PHP 及其依赖的组件。由于发行版数量众多,这里仅以Ubuntu和CentOS为例,其他发行版操作类似。
Ubuntu:
sudo apt-get -y 安装 php
中央操作系统:
须藤百胜安装 -y php
需要注意的是,在不同的系统下,其包管理器自动安装的PHP版本可能不同,甚至有些系统的包管理器能提供的PHP版本更低。但是,大多数包管理器可以为已发布的软件指定存储库(源),并且一些组织提供收录更新版本的包管理器的存储库(源)。您还可以选择通过从源代码编译和安装来获取最新的 PHP。
OSX/macOS系统下通过包管理器(Homebrew)获取PHP
OSX/macOS下默认没有包管理器(有些Linux/Unix系统也没有包管理器),但是这个系统下有一个非常有名的包管理器Homebrew(),它的官网提供了一个方法安装自制软件。本文不再重复该过程。
安装 Homebrew 后,您可以使用以下命令安装 PHP:
冲泡安装php
如果要安装 PHP 7.0 的版本,可以使用以下命令安装:
冲泡安装php70
Linux/Unix系统下获取源码安装PHP
通过获取源代码,然后编译安装,可以轻松获取最新版本的 PHP 及其扩展,生成的 PHP 环境也是高度可定制的。
编译安装还是很简单的,但是相比于分发包的方式,编译安装最大的麻烦就是它的依赖组件包。根据你的配置项,在整个编译过程中会需要很多依赖。
处理依赖问题超出了本文的范围。依赖包也可以通过包管理器安装,也可以通过编译安装每个依赖包。显然,后者的(重复)工作量会非常大,所以大部分选择编译安装 PHP 及其依赖往往是通过脚本的方式完成的。
获取PHP源代码主要有两种方式:
下载并获取源代码的压缩文件,解压后解压源代码,在源代码目录执行如下命令编译安装:
$ ./configure
$ make
$ sudo make install
./configure是一个用来生成Makefile的脚本,里面收录了很多编译选项,比如设置最终编译的程序安装目录(即PHP安装目录),设置编译到核心的扩展,设置配置文件目录等。使用:./configure --help 以获得更多编译选项。
许多人害怕编译和安装。事实上,在当前环境下编译和安装都非常简单。所有的编译配置都很容易以统一的形式设置(即通过configure),设置完成后直接编译即可。很多人害怕的原因是配置选项太多,但这些也是套路。如果你的英文稍微好一点,通过查看各个编译选项的介绍,就可以一目了然地了解是否应该添加它们。此外,它确实不起作用,您可以使用其他常用的编译选项。
Windows下获取PHP
在 Windows 上安装 PHP 最简单的方法是先访问它,选择你需要的 PHP 版本,下载它,然后解压到你要安装的目录。
除了下载页面上的PHP版本,除了系统位选项,每个版本下还有两个选项:线程安全(Thread Safe)和非线程安全(Non Thread Safe),一般我们会选择非线程安全的threading Safe,这是因为 IIS 的 FastCGI 用于 Windows 上的主流情况,它使用多进程模型而不是早期的 ISAPI 多线程模型。在多进程模型下,线程安全非常鸡肋,性能很差。非线程安全可以换取更高的性能。
第二个目标:环境变量
什么是环境变量?简单来说,当你在控制台下执行 php 时,Windows 系统会在设置的名为 PATH 的环境变量中提供的(很多)路径中寻找 php.exe、php.bat 等的存在。 system 执行文件,Linux/Unix 系统也在名为PATH 的环境变量下设置的路径中搜索可执行目标文件。
如果你在Windows系统上,如果你的PHP安装在D:\Environment\php70,如果你当前的工作目录在D:\Development\Project,你需要在这个目录下运行一个PHP脚本(名为foo.php ),如果环境变量中没有添加 D:\Environment\php70,那么你必须输入命令来运行这个脚本:
D:\环境\php70\php.exe foo.php
如果将 PHP 安装目录添加到环境变量中,可以这样做:
php foo.php
在 Linux/Unix 下也是如此。比如你在/usr/local/php/70下编译安装PHP,工作目录是/home/developer/project,下面有一个文件foo.php。要执行 PHP,必须输入 PHP /usr/local/php/70/bin/php 的完整路径。
所以这里环境变量的作用就是提供一个全局路径,不管你的工作目录在哪里,都可以访问环境变量定义的目录下的可执行文件,比如PHP解释器在目录下环境变量,你可以随时随地调用PHP解释器来执行你的PHP脚本文件。既然可以随时随地执行PHP脚本,那不是说PHP开发环境没有问题吗?
这时候有人会疑惑,PHP不就是网站吗?可以看到这里,相信一般不会问这个问题吧?如果你真的有这个问题,那么我建议你老老实实从 PHP 官方文档开始阅读。
【结尾】
本作品采用《CC协议》,转载须注明作者及本文链接 查看全部
php多线程抓取网页(如何搭建PHP开发环境搭建只有两步:第一目标系统获取)
可以看出,很多PHP新手常年在各个技术群里问关于PHP的问题,很多时候都会被别人说:何不去搜索引擎寻找更远的地方?
我也觉得新人在学习的时候不能只问问题,容易产生惰性。但是,国内相对不乐观的情况,让很多新手在没有良好基础的情况下选择上手PHP。此外,围绕 PHP 的圈子往往是浮躁的。即使他们选择了搜索引擎,如果没有良好的基础,也很难选择哪种教程可靠。作为PHP入门必备的PHP开发环境的建立,这个问题就更加明显了。
无数的文章把本来很简单的PHP开发环境弄的极其复杂,而文章过分强调PHP语言的Web特性,强行绑架了PHP和Apache、Nginx、IIS不是的第三方应用部分PHP入门开发环节会导致很多PHPer新手误入歧途,忽略了PHP作为脚本语言的本质,从而忽略了学习更多基础知识的重要性,导致很多PHPer倾向于认为自己可以搭建一个网站只知道PHP的心态。
以上是吐槽。
如何搭建PHP开发环境
搭建PHP开发环境只需两步:
下载PHP二进制包(或源码包),解压到指定目录(源码包编译安装到指定目录);将解压缩(或安装)目录添加到环境变量中。
这篇文章就结束了。
只是在开玩笑。我的 文章 风格不仅仅是关于步骤,什么都没有。
估计很多看过很多环境搭建文章的PHPer都会说,怎么会有这样的事情发生呢?这也令人不解,一个开发环境怎么会对其他人如此复杂?到底是一个PHP开发环境,还是一整套HTTP服务?
不知道什么是 HTTP 服务?那么你需要 Apache、Nginx 和 IIS 来做什么?当然,目标不是学PHP,而是想用PHP快速创建一个网站,所以没说。另外,从 PHP 5.4 开始,PHP 自带了一个简单的 HTTP 服务器,对于常规开发来说基本足够了。
以下是正文:
第一个目标:根据目标系统获取PHP本身在Linux系统下通过包管理器获取PHP
常见的 Linux 发行版都自带包管理器,这些工具可以方便的获取打包好的 PHP 及其依赖的组件。由于发行版数量众多,这里仅以Ubuntu和CentOS为例,其他发行版操作类似。
Ubuntu:
sudo apt-get -y 安装 php
中央操作系统:
须藤百胜安装 -y php
需要注意的是,在不同的系统下,其包管理器自动安装的PHP版本可能不同,甚至有些系统的包管理器能提供的PHP版本更低。但是,大多数包管理器可以为已发布的软件指定存储库(源),并且一些组织提供收录更新版本的包管理器的存储库(源)。您还可以选择通过从源代码编译和安装来获取最新的 PHP。
OSX/macOS系统下通过包管理器(Homebrew)获取PHP
OSX/macOS下默认没有包管理器(有些Linux/Unix系统也没有包管理器),但是这个系统下有一个非常有名的包管理器Homebrew(),它的官网提供了一个方法安装自制软件。本文不再重复该过程。
安装 Homebrew 后,您可以使用以下命令安装 PHP:
冲泡安装php
如果要安装 PHP 7.0 的版本,可以使用以下命令安装:
冲泡安装php70
Linux/Unix系统下获取源码安装PHP
通过获取源代码,然后编译安装,可以轻松获取最新版本的 PHP 及其扩展,生成的 PHP 环境也是高度可定制的。
编译安装还是很简单的,但是相比于分发包的方式,编译安装最大的麻烦就是它的依赖组件包。根据你的配置项,在整个编译过程中会需要很多依赖。
处理依赖问题超出了本文的范围。依赖包也可以通过包管理器安装,也可以通过编译安装每个依赖包。显然,后者的(重复)工作量会非常大,所以大部分选择编译安装 PHP 及其依赖往往是通过脚本的方式完成的。
获取PHP源代码主要有两种方式:
下载并获取源代码的压缩文件,解压后解压源代码,在源代码目录执行如下命令编译安装:
$ ./configure
$ make
$ sudo make install
./configure是一个用来生成Makefile的脚本,里面收录了很多编译选项,比如设置最终编译的程序安装目录(即PHP安装目录),设置编译到核心的扩展,设置配置文件目录等。使用:./configure --help 以获得更多编译选项。
许多人害怕编译和安装。事实上,在当前环境下编译和安装都非常简单。所有的编译配置都很容易以统一的形式设置(即通过configure),设置完成后直接编译即可。很多人害怕的原因是配置选项太多,但这些也是套路。如果你的英文稍微好一点,通过查看各个编译选项的介绍,就可以一目了然地了解是否应该添加它们。此外,它确实不起作用,您可以使用其他常用的编译选项。
Windows下获取PHP
在 Windows 上安装 PHP 最简单的方法是先访问它,选择你需要的 PHP 版本,下载它,然后解压到你要安装的目录。
除了下载页面上的PHP版本,除了系统位选项,每个版本下还有两个选项:线程安全(Thread Safe)和非线程安全(Non Thread Safe),一般我们会选择非线程安全的threading Safe,这是因为 IIS 的 FastCGI 用于 Windows 上的主流情况,它使用多进程模型而不是早期的 ISAPI 多线程模型。在多进程模型下,线程安全非常鸡肋,性能很差。非线程安全可以换取更高的性能。
第二个目标:环境变量
什么是环境变量?简单来说,当你在控制台下执行 php 时,Windows 系统会在设置的名为 PATH 的环境变量中提供的(很多)路径中寻找 php.exe、php.bat 等的存在。 system 执行文件,Linux/Unix 系统也在名为PATH 的环境变量下设置的路径中搜索可执行目标文件。
如果你在Windows系统上,如果你的PHP安装在D:\Environment\php70,如果你当前的工作目录在D:\Development\Project,你需要在这个目录下运行一个PHP脚本(名为foo.php ),如果环境变量中没有添加 D:\Environment\php70,那么你必须输入命令来运行这个脚本:
D:\环境\php70\php.exe foo.php
如果将 PHP 安装目录添加到环境变量中,可以这样做:
php foo.php
在 Linux/Unix 下也是如此。比如你在/usr/local/php/70下编译安装PHP,工作目录是/home/developer/project,下面有一个文件foo.php。要执行 PHP,必须输入 PHP /usr/local/php/70/bin/php 的完整路径。
所以这里环境变量的作用就是提供一个全局路径,不管你的工作目录在哪里,都可以访问环境变量定义的目录下的可执行文件,比如PHP解释器在目录下环境变量,你可以随时随地调用PHP解释器来执行你的PHP脚本文件。既然可以随时随地执行PHP脚本,那不是说PHP开发环境没有问题吗?
这时候有人会疑惑,PHP不就是网站吗?可以看到这里,相信一般不会问这个问题吧?如果你真的有这个问题,那么我建议你老老实实从 PHP 官方文档开始阅读。
【结尾】
本作品采用《CC协议》,转载须注明作者及本文链接
php多线程抓取网页(什么是虚拟机?“语言级虚拟机”可能是不一样的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-17 17:03
来源:
什么是虚拟机?
“虚拟机”是一个很大的概念。从字面上看,“虚拟机”的意思是“虚拟计算机”。我们在学习服务器端编程的时候,相信大部分同学都接触过虚拟机。有这样一个场景,因为我们日常使用的电脑大部分都是Windows操作系统,而服务器软件大多运行在Linux系统上。如果我们在 Windows 上编程,我们不能直接在 Windows 上进行编程。测试非常不方便。基于这个场景,有一个虚拟机。它的作用是在windows系统的基础上运行Linux系统,然后我们可以很方便的在windows系统上测试Linux系统的程序。这个Linux操作系统是通过一些技术手段虚拟化的,
今天要讲的虚拟机和上面提到的虚拟机略有不同,但是它们解决的问题是一样的。上面提到的虚拟机虚拟化了一个完整的操作系统,我称之为“操作系统级虚拟机”。我们今天要讲的虚拟机是针对编程语言的。它可以达到的效果是相同的代码在不同的操作系统上运行,输出相同的结果。它可以编写一次,到处运行。我称之为“语言级虚拟机”。我们非常熟悉的编程语言,比如Java、PHP、Python等,其实都是基于虚拟机的语言,它们都是跨平台的。我们只需要编写一次代码,就可以在不同的操作系统上运行,
学过系统编程的同学应该都知道,不同的操作系统为同一个功能提供的“系统API”可能是不同的。例如,Windows 和 Linux 系统都提供了用于网络监控的 API,但它们对应的 SOCKET API 不同。假设我们使用的是平台相关的编程语言(如C、C++),我们在编程的时候一定要注意这个区别。并且针对不同的操作系统做相应的兼容性处理,否则程序在Linux系统上可以正常运行,但是Windows会报错。类似的区别还有很多,具体细节只能从相应的系统编程手册中了解。有些系统API完全不同,而有些只是个别参数不同,并且方法名称完全相同。程序员在写代码的时候需要时刻注意这些,这样才能写出健壮的跨平台代码,这对于新手来说是非常困难的。,而这样一来,程序员就需要将很大一部分精力花在兼容性问题上,而不是专注于实际功能的开发。
有了虚拟机,上面的问题就不存在了。虚拟机的角色只是一个中介代理。例如,我们是大城市的新手,想租房子。北京、上海、广州等大城市的房东那么多,如果没有房产中介(虚拟机),需要连接N个房东,然后才能租到合适的房子;有了房产中介(虚拟机),我们只需要告诉房产中介(虚拟机)我们要租什么样的房子,房产中介(虚拟机)会协调各个房东,我们就可以租到合适的房子,过程不同,结果是一样的。同理,以Socket API调用为例,我们把写好的代码交给虚拟机,然后虚拟机负责调用系统API,相当于在中间加了一层中介代理,虚拟机会根据操作系统选择正确的。Soekct API,帮助我们完成最终的功能。这样做的好处是程序员不再需要关注底层 API 的细节,可以专注于真实函数的编写。虚拟机帮助我们屏蔽了底层系统API的细节,编程的门槛也大大降低,代码的健壮性也大大提高。帮助我们完成最终的功能。这样做的好处是程序员不再需要关注底层 API 的细节,可以专注于真实函数的编写。虚拟机帮助我们屏蔽了底层系统API的细节,编程的门槛也大大降低,代码的健壮性也大大提高。帮助我们完成最终的功能。这样做的好处是程序员不再需要关注底层 API 的细节,可以专注于真实函数的编写。虚拟机帮助我们屏蔽了底层系统API的细节,编程的门槛也大大降低,代码的健壮性也大大提高。
PHP执行流程 PHP解释执行流程
了解PHP的同学都知道PHP是一种解释型语言,也称为脚本语言。它的特点是重量轻,使用方便。传统的编程语言需要经过编译链接后才能执行并输出结果。脚本语言(PHP)省略了这个过程,可以直接通过shell命令执行并输出相应的结果,非常轻量级、直观、易用。说实话,我进坑编程的时候也学过Java。为什么我终于进了PHP的坑?也许这些特点吸引了我。
刚才我们只讲了PHP的优点,但大多数时候,有得有失。我认为编程语言也是如此。PHP非常轻量级和好用,所以一定是以牺牲一些优势为代价的,否则为什么呢?其他编程语言不这样做。接下来说说PHP的执行过程。我想了解PHP的执行过程,然后才能了解PHP语言设计的选择。
以下是启用 Opcache 后 PHP 运行的主要流程。
图1
从图1可以看出,加载PHP代码文件后,首先通过词法分析器(re2c/lex),从代码中提取单词符号(token),再通过语法分析器(yacc/bison) , 从token中找到语法结构后,生成抽象语法树(AST),然后由静态编译器生成Opcode。最后,解释器模拟机器指令来执行每个 Opcode。
另外,当 PHP 打开 Opcache 时,ZendVM 会缓存 Opcode 并缓存在共享内存中。不仅如此,ZendVM 还会优化编译后的 Opcode。编译的优化技术包括方法内联、常量传播和重复代码删除。有了Opcache,不仅可以省去词法分析、语法分析、静态编译等步骤,而且还额外优化了Opcode,程序的执行效率比第一次执行要快。
以上就是PHP解释和执行的过程。虽然解释和执行对程序员非常友好,省略了静态编译这一步,但实际上这个过程并没有省略。它只是由虚拟机为我们完成,以牺牲一些性能为代价。重量轻、易于使用和灵活。其中,词法分析、语法分析、静态编译、解释执行等过程都是在执行过程中完成的。
编译语言执行过程
在了解了解释型语言的执行过程之后,我们再来看看编译型语言的执行过程作为对比,看看它与解释型语言有什么不同。
图 2
从图2可以看出,虚线框内的执行过程包括:词法分析、语法分析、编译。这三个步骤也收录在 PHP 的解释和执行中。唯一不同的是,C/C++的这三个步骤都是在编译过程中由编译器提前完成的,这样在运行时节省了大量的时间和开销。汇编代码生成后,第四步,链接汇编文件,生成可执行文件。这里的可执行文件是指二进制机器码,可以直接由CPU执行,无需额外翻译。这四个步骤统称为静态编译。可以清楚地看出,与解释型语言相比,编译型语言在前期需要做更多的工作,而是换取更高的性能和执行效率。因此,一般在大型项目中,由于性能要求比较高,代码量较大,如果使用解释型语言,执行效率会大大降低。使用静态编译可以达到更好的执行效率,降低服务器采购成本。
什么是 JIT?
JIT可以说是虚拟机中技术含量最高的技术。刚才我们讲了解释型语言和编译型语言的执行过程,分析了各自的优缺点。我们可以思考一下,是否有一种技术,它不仅在解释语言中具有轻量级和易于使用的优点,而且还具有编译语言的高性能。结论是 JIT。下面我们要介绍的是编程语言中的JIT技术。它的全称是“即时编译”。这是什么意思?我们先来看看维基百科对即时编译的定义。
在计算机技术中,即时编译(英文:just-in-time compilation,缩写为JIT;也译作即时编译、实时编译),又称动态翻译或运行时编译,是一种执行计算机代码的方法,其中一种方法涉及在程序执行期间(在运行时)而不是在执行之前进行编译。通常,这涉及将源代码或更常见的字节码转换为机器代码,然后直接执行。实现 JIT 编译器的系统通常会不断分析正在执行的代码,并确定代码的某些部分在哪里编译或重新编译。
正如我们刚才所说,JIT不仅具有解释语言的轻量级易用性,而且具有高性能,那么它是如何实现的呢?以PHP8新增的JIT特性为例,下图描述了PHP开启JIT特性后的执行过程。PHP8-JIT基于对Opcache的优化,在编译前对保存在Opcache中的Opcode进行优化。将Opcode编译成CPU可识别的可执行文件,即二进制文件,相当于C++编译后的可执行文件,但是这个过程不需要在运行前完成,而是在运行时虚拟机启动一个后台线程, 将Opcode转换成二进制文件,二进制文件缓存后,下次执行逻辑时,CPU直接执行即可,无需多说,理论性能与C++相同。这样做的好处是在实现高性能的同时,保留了 PHP 语言的易用性和灵活性。
图 3
JIT的触发条件
JIT实际上是将运行时的一部分代码转换成可执行文件并缓存起来,以加快下一段代码的执行速度。那么程序启动后会触发JIT吗?
程序第一次启动时,JIT 不起作用。可以理解为,PHP/Java代码第一次执行时,依然是以解释的形式运行。程序运行一段时间后需要触发JIT。说到这里,你有没有和我一样的疑问,为什么JIT在程序启动的时候会把所有的代码都转换成可执行文件并缓存起来,就像C++一样,这样不是更高效吗?Java 语言中确实有少量这样的应用,但都不是主流。主要有以下几个原因
全部编译成二进制文件需要很多时间,而且程序启动会很慢,这对于大型项目来说是无法接受的。并不是所有的代码都是性能优化所必需的,大部分代码在实际场景中用的不多。编译成二进制会占用大量容量。提前编译相当于静态编译。与静态编译相比,JIT 编译具有许多不可替代的优势。
JIT的触发条件主要基于“计数器的热点检测”。虚拟机为每个方法(或代码块)建立一个计数器。如果执行次数超过某个阈值,则认为是“热方法”。达到阈值后,虚拟机启动后台线程,将代码块编译成可执行文件,缓存在内存中,加快下一次执行的速度。以上只是对热代码的触发规则的简单说明。实际虚拟机采用的规则会比这个复杂。
JIT和提前编译的优缺点
JIT 编译器是在运行时执行的,我们可以很容易地看出,与提前编译相比,它有几个明显的缺点。首先,JIT 编译需要消耗运行时计算资源。最初,这些资源可用于执行程序。不管JIT编译器怎么优化(比如分层编译),这都是一个无法回避的问题,而最耗费资源的一步就是“过程间分析”,比如分析方法是否永远不能被调用,抽象是否方法只会调用单个版本的结论,这些信息对于生成高质量代码非常有价值,但是要准确获取这些信息必须经过大量耗时的计算,消耗大量的运行时计算资源. 反过来,
说了这么多,JIT编译和提前编译在性能优化上真的没有优势吗?结论是否定的,JIT 编译具有提前编译的许多不可替代的优点。正是因为JIT编译器是在运行时进行的,所以JIT编译器才能获取程序的真实数据。通过在程序运行时不断的采集监控信息,分析数据,JIT编译器可以对程序做一些事情。提前静态编译器无法进行的激进优化。
一是性能分析指导优化。比如JIT编译器在运行的时候,通过程序运行的监控数据,如果发现一些代码块执行的非常频繁,可以重点优化这块代码,例如:分配更好的寄存器、缓存等到此代码。
然后是积极的预测优化。比如有一个接口有3个实现类,但在实际运行过程中,实现类A的运行时间超过95%。通过数据分析,可以从根本上进行预测。每次执行 A。如果多次发现预测错误,可以返回解释状态再次执行,但这只是小概率事件,不影响程序执行结果。
最后是链接时优化。传统的编译步骤是将编译优化和链接分开。这意味着什么?添加一个程序需要用到A、B、C三个库。编译器首先编译这3个类库,并通过各种手段进行优化,转换成汇编代码保存在一个文件中。最后一步是转换这 3 个库。汇编文件链接在一起,最后转换成可执行文件。这里有一个问题。三个库 A、B 和 C 在编译时分别进行优化。不可能假设 A 和 B 中的某些方法被重复执行,或者可以通过方法内联进行优化。但是JIT编译器的不同之处在于它在运行时是动态链接的,可以优化整个程序的调用栈,
总结
写这篇博客的主要目的是总结这段时间学到的虚拟机相关技术。google了一下PHP虚拟机相关的文章,发现可以参考的文章很少。由于Java和PHP的执行原理非常相似,所以我想通过学习Java虚拟机可以理解ZendVM的工作原理。Java虚拟机非常成熟,可以说是虚拟机的鼻祖。有很多关于 JVM 世界的优秀书籍。它给我带来了一个新的世界,让我对虚拟机有了新的认识,JIT技术更让我惊喜。
最后,PHP 是世界上最好的语言!
参考 查看全部
php多线程抓取网页(什么是虚拟机?“语言级虚拟机”可能是不一样的)
来源:
什么是虚拟机?
“虚拟机”是一个很大的概念。从字面上看,“虚拟机”的意思是“虚拟计算机”。我们在学习服务器端编程的时候,相信大部分同学都接触过虚拟机。有这样一个场景,因为我们日常使用的电脑大部分都是Windows操作系统,而服务器软件大多运行在Linux系统上。如果我们在 Windows 上编程,我们不能直接在 Windows 上进行编程。测试非常不方便。基于这个场景,有一个虚拟机。它的作用是在windows系统的基础上运行Linux系统,然后我们可以很方便的在windows系统上测试Linux系统的程序。这个Linux操作系统是通过一些技术手段虚拟化的,
今天要讲的虚拟机和上面提到的虚拟机略有不同,但是它们解决的问题是一样的。上面提到的虚拟机虚拟化了一个完整的操作系统,我称之为“操作系统级虚拟机”。我们今天要讲的虚拟机是针对编程语言的。它可以达到的效果是相同的代码在不同的操作系统上运行,输出相同的结果。它可以编写一次,到处运行。我称之为“语言级虚拟机”。我们非常熟悉的编程语言,比如Java、PHP、Python等,其实都是基于虚拟机的语言,它们都是跨平台的。我们只需要编写一次代码,就可以在不同的操作系统上运行,
学过系统编程的同学应该都知道,不同的操作系统为同一个功能提供的“系统API”可能是不同的。例如,Windows 和 Linux 系统都提供了用于网络监控的 API,但它们对应的 SOCKET API 不同。假设我们使用的是平台相关的编程语言(如C、C++),我们在编程的时候一定要注意这个区别。并且针对不同的操作系统做相应的兼容性处理,否则程序在Linux系统上可以正常运行,但是Windows会报错。类似的区别还有很多,具体细节只能从相应的系统编程手册中了解。有些系统API完全不同,而有些只是个别参数不同,并且方法名称完全相同。程序员在写代码的时候需要时刻注意这些,这样才能写出健壮的跨平台代码,这对于新手来说是非常困难的。,而这样一来,程序员就需要将很大一部分精力花在兼容性问题上,而不是专注于实际功能的开发。
有了虚拟机,上面的问题就不存在了。虚拟机的角色只是一个中介代理。例如,我们是大城市的新手,想租房子。北京、上海、广州等大城市的房东那么多,如果没有房产中介(虚拟机),需要连接N个房东,然后才能租到合适的房子;有了房产中介(虚拟机),我们只需要告诉房产中介(虚拟机)我们要租什么样的房子,房产中介(虚拟机)会协调各个房东,我们就可以租到合适的房子,过程不同,结果是一样的。同理,以Socket API调用为例,我们把写好的代码交给虚拟机,然后虚拟机负责调用系统API,相当于在中间加了一层中介代理,虚拟机会根据操作系统选择正确的。Soekct API,帮助我们完成最终的功能。这样做的好处是程序员不再需要关注底层 API 的细节,可以专注于真实函数的编写。虚拟机帮助我们屏蔽了底层系统API的细节,编程的门槛也大大降低,代码的健壮性也大大提高。帮助我们完成最终的功能。这样做的好处是程序员不再需要关注底层 API 的细节,可以专注于真实函数的编写。虚拟机帮助我们屏蔽了底层系统API的细节,编程的门槛也大大降低,代码的健壮性也大大提高。帮助我们完成最终的功能。这样做的好处是程序员不再需要关注底层 API 的细节,可以专注于真实函数的编写。虚拟机帮助我们屏蔽了底层系统API的细节,编程的门槛也大大降低,代码的健壮性也大大提高。
PHP执行流程 PHP解释执行流程
了解PHP的同学都知道PHP是一种解释型语言,也称为脚本语言。它的特点是重量轻,使用方便。传统的编程语言需要经过编译链接后才能执行并输出结果。脚本语言(PHP)省略了这个过程,可以直接通过shell命令执行并输出相应的结果,非常轻量级、直观、易用。说实话,我进坑编程的时候也学过Java。为什么我终于进了PHP的坑?也许这些特点吸引了我。
刚才我们只讲了PHP的优点,但大多数时候,有得有失。我认为编程语言也是如此。PHP非常轻量级和好用,所以一定是以牺牲一些优势为代价的,否则为什么呢?其他编程语言不这样做。接下来说说PHP的执行过程。我想了解PHP的执行过程,然后才能了解PHP语言设计的选择。
以下是启用 Opcache 后 PHP 运行的主要流程。
图1
从图1可以看出,加载PHP代码文件后,首先通过词法分析器(re2c/lex),从代码中提取单词符号(token),再通过语法分析器(yacc/bison) , 从token中找到语法结构后,生成抽象语法树(AST),然后由静态编译器生成Opcode。最后,解释器模拟机器指令来执行每个 Opcode。
另外,当 PHP 打开 Opcache 时,ZendVM 会缓存 Opcode 并缓存在共享内存中。不仅如此,ZendVM 还会优化编译后的 Opcode。编译的优化技术包括方法内联、常量传播和重复代码删除。有了Opcache,不仅可以省去词法分析、语法分析、静态编译等步骤,而且还额外优化了Opcode,程序的执行效率比第一次执行要快。
以上就是PHP解释和执行的过程。虽然解释和执行对程序员非常友好,省略了静态编译这一步,但实际上这个过程并没有省略。它只是由虚拟机为我们完成,以牺牲一些性能为代价。重量轻、易于使用和灵活。其中,词法分析、语法分析、静态编译、解释执行等过程都是在执行过程中完成的。
编译语言执行过程
在了解了解释型语言的执行过程之后,我们再来看看编译型语言的执行过程作为对比,看看它与解释型语言有什么不同。
图 2
从图2可以看出,虚线框内的执行过程包括:词法分析、语法分析、编译。这三个步骤也收录在 PHP 的解释和执行中。唯一不同的是,C/C++的这三个步骤都是在编译过程中由编译器提前完成的,这样在运行时节省了大量的时间和开销。汇编代码生成后,第四步,链接汇编文件,生成可执行文件。这里的可执行文件是指二进制机器码,可以直接由CPU执行,无需额外翻译。这四个步骤统称为静态编译。可以清楚地看出,与解释型语言相比,编译型语言在前期需要做更多的工作,而是换取更高的性能和执行效率。因此,一般在大型项目中,由于性能要求比较高,代码量较大,如果使用解释型语言,执行效率会大大降低。使用静态编译可以达到更好的执行效率,降低服务器采购成本。
什么是 JIT?
JIT可以说是虚拟机中技术含量最高的技术。刚才我们讲了解释型语言和编译型语言的执行过程,分析了各自的优缺点。我们可以思考一下,是否有一种技术,它不仅在解释语言中具有轻量级和易于使用的优点,而且还具有编译语言的高性能。结论是 JIT。下面我们要介绍的是编程语言中的JIT技术。它的全称是“即时编译”。这是什么意思?我们先来看看维基百科对即时编译的定义。
在计算机技术中,即时编译(英文:just-in-time compilation,缩写为JIT;也译作即时编译、实时编译),又称动态翻译或运行时编译,是一种执行计算机代码的方法,其中一种方法涉及在程序执行期间(在运行时)而不是在执行之前进行编译。通常,这涉及将源代码或更常见的字节码转换为机器代码,然后直接执行。实现 JIT 编译器的系统通常会不断分析正在执行的代码,并确定代码的某些部分在哪里编译或重新编译。
正如我们刚才所说,JIT不仅具有解释语言的轻量级易用性,而且具有高性能,那么它是如何实现的呢?以PHP8新增的JIT特性为例,下图描述了PHP开启JIT特性后的执行过程。PHP8-JIT基于对Opcache的优化,在编译前对保存在Opcache中的Opcode进行优化。将Opcode编译成CPU可识别的可执行文件,即二进制文件,相当于C++编译后的可执行文件,但是这个过程不需要在运行前完成,而是在运行时虚拟机启动一个后台线程, 将Opcode转换成二进制文件,二进制文件缓存后,下次执行逻辑时,CPU直接执行即可,无需多说,理论性能与C++相同。这样做的好处是在实现高性能的同时,保留了 PHP 语言的易用性和灵活性。
图 3
JIT的触发条件
JIT实际上是将运行时的一部分代码转换成可执行文件并缓存起来,以加快下一段代码的执行速度。那么程序启动后会触发JIT吗?
程序第一次启动时,JIT 不起作用。可以理解为,PHP/Java代码第一次执行时,依然是以解释的形式运行。程序运行一段时间后需要触发JIT。说到这里,你有没有和我一样的疑问,为什么JIT在程序启动的时候会把所有的代码都转换成可执行文件并缓存起来,就像C++一样,这样不是更高效吗?Java 语言中确实有少量这样的应用,但都不是主流。主要有以下几个原因
全部编译成二进制文件需要很多时间,而且程序启动会很慢,这对于大型项目来说是无法接受的。并不是所有的代码都是性能优化所必需的,大部分代码在实际场景中用的不多。编译成二进制会占用大量容量。提前编译相当于静态编译。与静态编译相比,JIT 编译具有许多不可替代的优势。
JIT的触发条件主要基于“计数器的热点检测”。虚拟机为每个方法(或代码块)建立一个计数器。如果执行次数超过某个阈值,则认为是“热方法”。达到阈值后,虚拟机启动后台线程,将代码块编译成可执行文件,缓存在内存中,加快下一次执行的速度。以上只是对热代码的触发规则的简单说明。实际虚拟机采用的规则会比这个复杂。
JIT和提前编译的优缺点
JIT 编译器是在运行时执行的,我们可以很容易地看出,与提前编译相比,它有几个明显的缺点。首先,JIT 编译需要消耗运行时计算资源。最初,这些资源可用于执行程序。不管JIT编译器怎么优化(比如分层编译),这都是一个无法回避的问题,而最耗费资源的一步就是“过程间分析”,比如分析方法是否永远不能被调用,抽象是否方法只会调用单个版本的结论,这些信息对于生成高质量代码非常有价值,但是要准确获取这些信息必须经过大量耗时的计算,消耗大量的运行时计算资源. 反过来,
说了这么多,JIT编译和提前编译在性能优化上真的没有优势吗?结论是否定的,JIT 编译具有提前编译的许多不可替代的优点。正是因为JIT编译器是在运行时进行的,所以JIT编译器才能获取程序的真实数据。通过在程序运行时不断的采集监控信息,分析数据,JIT编译器可以对程序做一些事情。提前静态编译器无法进行的激进优化。
一是性能分析指导优化。比如JIT编译器在运行的时候,通过程序运行的监控数据,如果发现一些代码块执行的非常频繁,可以重点优化这块代码,例如:分配更好的寄存器、缓存等到此代码。
然后是积极的预测优化。比如有一个接口有3个实现类,但在实际运行过程中,实现类A的运行时间超过95%。通过数据分析,可以从根本上进行预测。每次执行 A。如果多次发现预测错误,可以返回解释状态再次执行,但这只是小概率事件,不影响程序执行结果。
最后是链接时优化。传统的编译步骤是将编译优化和链接分开。这意味着什么?添加一个程序需要用到A、B、C三个库。编译器首先编译这3个类库,并通过各种手段进行优化,转换成汇编代码保存在一个文件中。最后一步是转换这 3 个库。汇编文件链接在一起,最后转换成可执行文件。这里有一个问题。三个库 A、B 和 C 在编译时分别进行优化。不可能假设 A 和 B 中的某些方法被重复执行,或者可以通过方法内联进行优化。但是JIT编译器的不同之处在于它在运行时是动态链接的,可以优化整个程序的调用栈,
总结
写这篇博客的主要目的是总结这段时间学到的虚拟机相关技术。google了一下PHP虚拟机相关的文章,发现可以参考的文章很少。由于Java和PHP的执行原理非常相似,所以我想通过学习Java虚拟机可以理解ZendVM的工作原理。Java虚拟机非常成熟,可以说是虚拟机的鼻祖。有很多关于 JVM 世界的优秀书籍。它给我带来了一个新的世界,让我对虚拟机有了新的认识,JIT技术更让我惊喜。
最后,PHP 是世界上最好的语言!
参考
php多线程抓取网页(什么是网络爬虫?PHP和Python都写过爬虫和提取程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-14 19:14
什么是网络爬虫?
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
爬行动物有什么用?
很多语言都可以用来编写爬虫,比如Java、PHP、Python等,它们各有优缺点。
PHP 和 Python 都编写了爬虫和文本提取器。
我开始使用PHP,那么我们来谈谈PHP的优点:
1.语言比较简单,PHP是一门很随意的语言。它很容易编写,让您专注于您正在尝试做的事情,而不是各种语法规则等等。
2.各种功能模块齐全,分为两部分:
1.网页下载:curl等扩展库;
2.文档解析:dom、xpath、tidy、各种转码工具,可能和题主的问题不太一样,我的爬虫需要提取文本,所以需要很复杂的文本处理,所以各种方便的文本处理工具是我的最爱。;
总之,很容易上手。
缺点:
1.并发处理能力弱:由于当时PHP没有线程和进程功能,为了实现并发,需要借用多通道消费模型,而PHP使用了select模型。实现起来比较麻烦,可能是因为level的问题,我的程序经常会出现一些错误,导致错过catch。
让我们谈谈Python:
优势:
1.各种爬虫框架,方便高效的下载网页;
2.多线程,成熟稳定的进程模型,爬虫是典型的多任务场景,请求一个页面会有很长的延迟,一般会多等待。多线程或多进程将优化程序效率,提高整个系统的下载和分析能力。
3.GAE的支持,我写爬虫的时候刚好有GAE,而且只支持Python。使用 GAE 创建的爬虫几乎是免费的。最多,我有将近一千个应用程序实例在工作。
缺点:
1. 对非标准HTML的适应性差:比如一个页面同时收录GB18030字符集中文和UTF-8字符集中文,Python处理不像PHP那么简单,需要自己做很多的判断工作。当然,这在提取文本时很麻烦。
Java和C++当时也在研究,比脚本语言更麻烦,所以放弃了。
总之,如果你开发一个小规模的爬虫脚本语言,它是一门各方面都有优势的语言。如果你想开发复杂的爬虫系统,Java可能是一个额外的选择,而C++我觉得写一个模块更合适。对于爬虫系统来说,下载和内容解析只是两个基本功能。一个真正好的系统还包括完整的任务调度、监控、存储、页面数据保存和更新逻辑、重新加载等等。爬虫是一个消耗带宽的应用程序。一个好的设计会节省大量的带宽和服务器资源,好坏差距很大。
全面的
编写爬虫是同时编写和测试。测试但再次更改。这个程序用python写是最方便的。
而python相关的库也是最方便的,比如request、jieba、redis、gevent、NLTK、lxml、pyquery、BeautifulSoup、Pillow。无论是最简单的爬虫还是非常复杂的爬虫,都可以轻松搞定。
如果你从成为python工程师还是新手,可以从“我的专栏”开始学习。 查看全部
php多线程抓取网页(什么是网络爬虫?PHP和Python都写过爬虫和提取程序)
什么是网络爬虫?
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
爬行动物有什么用?
很多语言都可以用来编写爬虫,比如Java、PHP、Python等,它们各有优缺点。
PHP 和 Python 都编写了爬虫和文本提取器。
我开始使用PHP,那么我们来谈谈PHP的优点:
1.语言比较简单,PHP是一门很随意的语言。它很容易编写,让您专注于您正在尝试做的事情,而不是各种语法规则等等。
2.各种功能模块齐全,分为两部分:
1.网页下载:curl等扩展库;
2.文档解析:dom、xpath、tidy、各种转码工具,可能和题主的问题不太一样,我的爬虫需要提取文本,所以需要很复杂的文本处理,所以各种方便的文本处理工具是我的最爱。;
总之,很容易上手。
缺点:
1.并发处理能力弱:由于当时PHP没有线程和进程功能,为了实现并发,需要借用多通道消费模型,而PHP使用了select模型。实现起来比较麻烦,可能是因为level的问题,我的程序经常会出现一些错误,导致错过catch。
让我们谈谈Python:
优势:
1.各种爬虫框架,方便高效的下载网页;
2.多线程,成熟稳定的进程模型,爬虫是典型的多任务场景,请求一个页面会有很长的延迟,一般会多等待。多线程或多进程将优化程序效率,提高整个系统的下载和分析能力。
3.GAE的支持,我写爬虫的时候刚好有GAE,而且只支持Python。使用 GAE 创建的爬虫几乎是免费的。最多,我有将近一千个应用程序实例在工作。
缺点:
1. 对非标准HTML的适应性差:比如一个页面同时收录GB18030字符集中文和UTF-8字符集中文,Python处理不像PHP那么简单,需要自己做很多的判断工作。当然,这在提取文本时很麻烦。
Java和C++当时也在研究,比脚本语言更麻烦,所以放弃了。
总之,如果你开发一个小规模的爬虫脚本语言,它是一门各方面都有优势的语言。如果你想开发复杂的爬虫系统,Java可能是一个额外的选择,而C++我觉得写一个模块更合适。对于爬虫系统来说,下载和内容解析只是两个基本功能。一个真正好的系统还包括完整的任务调度、监控、存储、页面数据保存和更新逻辑、重新加载等等。爬虫是一个消耗带宽的应用程序。一个好的设计会节省大量的带宽和服务器资源,好坏差距很大。
全面的
编写爬虫是同时编写和测试。测试但再次更改。这个程序用python写是最方便的。
而python相关的库也是最方便的,比如request、jieba、redis、gevent、NLTK、lxml、pyquery、BeautifulSoup、Pillow。无论是最简单的爬虫还是非常复杂的爬虫,都可以轻松搞定。
如果你从成为python工程师还是新手,可以从“我的专栏”开始学习。
php多线程抓取网页(php里提供了一个函数curl_multi_init(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-14 08:10
curl_init() 以单线程模式处理事物。如果需要使用多线程模式进行事务处理,那么PHP为我们提供了一个函数curl_multi_init(),就是多线程模式处理事务的函数。
curl_multi_init() 多线程可以提高网页的处理速度吗?今天我将通过一个实验来验证这个问题。
我今天的测试很简单,就是抓取网页的内容,需要连续抓取5次,使用curl_init()和curl_multi_init()函数完成,记录两次耗时,并比较得出结论。
首先,使用 curl_init() 单线程连续抓取网页内容 5 次。
然后,使用 curl_multi_init() 多线程连续抓取网页内容 5 次。
为了避免随机性,我测试了5次(通过CTRL+F5强制刷新),数据如下:
curl_init():
第一次
第二次
第三次
第四次
第五次
平均
时间(毫秒)
3724
3615
2540
1957年
2794
2926
curl_multi_init():
第一次
第二次
第三次
第四次
第五次
平均
时间(毫秒)
4275
2912
3691
4198
3891
3793
从测试结果来看,我们发现两种方式的耗时相差不大,只有700多毫秒。很多人原本以为多线程会比单线程花更少的时间,但事实并非如此。从数据上看,多线程比单线程花费的时间要多一点。但是对于一些事务来说,多线程处理不一定是追求速度,需要注意。
关于 curl_multi_init()
一般来说,考虑使用curl_multi_init()的时候,目的是同时请求多个url,而不是一个一个,否则需要curl_init()。
但是在使用curl_multi的时候,可能会遇到cpu消耗高、网页假死等现象。可以阅读《PHP使用curl_multi_select解决curl_multi网页假死问题》
curl_multi的使用步骤总结如下:
各功能作用说明:
curl_multi_init()
初始化 curl 批处理句柄资源。
curl_multi_add_handle()
将单独的 curl 句柄资源添加到 curl 批处理会话。curl_multi_add_handle()函数有两个参数,第一个参数代表一个curl批量句柄资源,第二个参数代表单个curl句柄资源。
curl_multi_exec()
解析一个curl批处理句柄,curl_multi_exec()函数有两个参数,第一个参数代表一个批处理句柄资源,第二个参数是一个引用值参数,表示剩余的单个curl句柄资源需要处理的数量。
curl_multi_remove_handle()
curl_multi_remove_handle()函数有两个参数,第一个参数代表一个curl批处理句柄资源,第二个参数代表一个单独的curl句柄资源。
curl_multi_close()
关闭批处理资源。
curl_multi_getcontent()
如果设置了 CURLOPT_RETURNTRANSFER,则返回获取的输出的文本流。
curl_multi_info_read()
获取当前解析的 curl 的相关传输信息。
原文链接: 查看全部
php多线程抓取网页(php里提供了一个函数curl_multi_init(组图))
curl_init() 以单线程模式处理事物。如果需要使用多线程模式进行事务处理,那么PHP为我们提供了一个函数curl_multi_init(),就是多线程模式处理事务的函数。
curl_multi_init() 多线程可以提高网页的处理速度吗?今天我将通过一个实验来验证这个问题。
我今天的测试很简单,就是抓取网页的内容,需要连续抓取5次,使用curl_init()和curl_multi_init()函数完成,记录两次耗时,并比较得出结论。
首先,使用 curl_init() 单线程连续抓取网页内容 5 次。
然后,使用 curl_multi_init() 多线程连续抓取网页内容 5 次。
为了避免随机性,我测试了5次(通过CTRL+F5强制刷新),数据如下:
curl_init():
第一次
第二次
第三次
第四次
第五次
平均
时间(毫秒)
3724
3615
2540
1957年
2794
2926
curl_multi_init():
第一次
第二次
第三次
第四次
第五次
平均
时间(毫秒)
4275
2912
3691
4198
3891
3793
从测试结果来看,我们发现两种方式的耗时相差不大,只有700多毫秒。很多人原本以为多线程会比单线程花更少的时间,但事实并非如此。从数据上看,多线程比单线程花费的时间要多一点。但是对于一些事务来说,多线程处理不一定是追求速度,需要注意。
关于 curl_multi_init()
一般来说,考虑使用curl_multi_init()的时候,目的是同时请求多个url,而不是一个一个,否则需要curl_init()。
但是在使用curl_multi的时候,可能会遇到cpu消耗高、网页假死等现象。可以阅读《PHP使用curl_multi_select解决curl_multi网页假死问题》
curl_multi的使用步骤总结如下:
各功能作用说明:
curl_multi_init()
初始化 curl 批处理句柄资源。
curl_multi_add_handle()
将单独的 curl 句柄资源添加到 curl 批处理会话。curl_multi_add_handle()函数有两个参数,第一个参数代表一个curl批量句柄资源,第二个参数代表单个curl句柄资源。
curl_multi_exec()
解析一个curl批处理句柄,curl_multi_exec()函数有两个参数,第一个参数代表一个批处理句柄资源,第二个参数是一个引用值参数,表示剩余的单个curl句柄资源需要处理的数量。
curl_multi_remove_handle()
curl_multi_remove_handle()函数有两个参数,第一个参数代表一个curl批处理句柄资源,第二个参数代表一个单独的curl句柄资源。
curl_multi_close()
关闭批处理资源。
curl_multi_getcontent()
如果设置了 CURLOPT_RETURNTRANSFER,则返回获取的输出的文本流。
curl_multi_info_read()
获取当前解析的 curl 的相关传输信息。
原文链接:
php多线程抓取网页(一下如何使用缓存(Redis)实现分布式锁(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-11 17:04
分布式锁是指在分布式部署环境中,多个客户端可以通过锁机制互斥访问共享资源。
目前比较常见的分布式锁实现方案有以下几种:
下面介绍如何使用缓存(Redis)实现分布式锁。
使用 Redis 实现分布式锁的最简单方法是使用命令 SETNX。SETNX(SET if Not eXist)的用法是:SETNX键值。只有当key key 不存在时,key key 的value 才设置为value。如果 key key 存在,SETNX 什么也不做。SETNX 设置成功返回,设置失败返回0。当你想获取锁时,直接使用SETNX获取锁。当要解除锁定时,使用 DEL 命令删除对应的键键。
上述方案有一个致命的问题,就是线程由于一些异常因素(如宕机)而获得锁后,无法正常进行解锁操作,锁永远不会被释放。为此,我们可以为此锁添加超时。第一次我们会想到Redis的EXPIRE命令(EXPIRE键秒)。但是这里我们不能使用EXPIRE来实现分布式锁,因为它是和SETNX一起的两个操作,这两个操作之间可能会出现异常,所以还是达不到预期的效果。示例如下:
// STEP 1<br style="-webkit-tap-highlight-color: transparent;">SETNX key value<br style="-webkit-tap-highlight-color: transparent;">// 若在这里(STEP1和STEP2之间)程序突然崩溃,则无法设置过期时间,将有可能无法释放锁<br style="-webkit-tap-highlight-color: transparent;">// STEP 2<br style="-webkit-tap-highlight-color: transparent;">EXPIRE key expireTime<br style="-webkit-tap-highlight-color: transparent;">
正确的手势是使用命令“SET key value [EX seconds] [PX milliseconds] [NX|XX]”。
从 Redis 2.6.12 开始,可以通过一系列参数来修改 SET 命令的行为:
比如我们需要创建一个分布式锁,并将过期时间设置为10s,那么我们可以执行如下命令:
SET lockKey lockValue EX 10 NX<br style="-webkit-tap-highlight-color: transparent;">或者<br style="-webkit-tap-highlight-color: transparent;">SET lockKey lockValue PX 10000 NX<br style="-webkit-tap-highlight-color: transparent;">
注意EX和PX不能同时使用,否则会报错:ERR syntax error。
解锁时,使用 DEL 命令解锁。
修改后的方案看起来很完美,但实际上还是有问题。想象一下,线程A获取了一个锁,设置过期时间为10s,然后执行业务逻辑需要15s。此时线程A获取的锁已经被Redis的过期机制自动释放了。线程A获取锁后10s后,锁可能已经被其他线程获取。当线程 A 执行完业务逻辑并准备解锁时(DEL 键),就可以删除其他线程已经获得的锁。
所以最好的办法就是在开锁的时候判断锁是不是你自己的。我们可以在设置key的时候将value设置为唯一值uniqueValue(可以是随机值,UUID,也可以是机器号+线程号,签名等的组合)。解锁时,即删除key时,首先判断key对应的值是否与之前设置的值相等。如果相等,则可以删除密钥。伪代码示例如下:
if uniqueKey == GET(key) {<br style="-webkit-tap-highlight-color: transparent;"> DEL key<br style="-webkit-tap-highlight-color: transparent;">}<br style="-webkit-tap-highlight-color: transparent;">
这里我们一眼就能看出问题所在:GET和DEL是两个独立的操作,在GET执行之后和DEL执行之前的间隙中可能会出现异常。如果我们只是确保解锁代码是原子的,我们就可以解决问题。这里我们介绍一种新的方式,即Lua脚本,示例如下:
if redis.call("get",KEYS[1]) == ARGV[1] then<br style="-webkit-tap-highlight-color: transparent;"> return redis.call("del",KEYS[1])<br style="-webkit-tap-highlight-color: transparent;">else<br style="-webkit-tap-highlight-color: transparent;"> return 0<br style="-webkit-tap-highlight-color: transparent;">end<br style="-webkit-tap-highlight-color: transparent;">
其中 ARGV[1] 表示设置密钥时指定的唯一值。
由于 Lua 脚本的原子性,当 Redis 执行脚本时,其他客户端的命令需要等待 Lua 脚本执行后才能执行。
下面用Jedis来演示获取锁和解锁的实现,如下:
public boolean lock(String lockKey, String uniqueValue, int seconds){<br style="-webkit-tap-highlight-color: transparent;"> SetParams params = new SetParams();<br style="-webkit-tap-highlight-color: transparent;"> params.nx().ex(seconds);<br style="-webkit-tap-highlight-color: transparent;"> String result = jedis.set(lockKey, uniqueValue, params);<br style="-webkit-tap-highlight-color: transparent;"> if ("OK".equals(result)) {<br style="-webkit-tap-highlight-color: transparent;"> return true;<br style="-webkit-tap-highlight-color: transparent;"> }<br style="-webkit-tap-highlight-color: transparent;"> return false;<br style="-webkit-tap-highlight-color: transparent;">}<br style="-webkit-tap-highlight-color: transparent;">public boolean unlock(String lockKey, String uniqueValue){<br style="-webkit-tap-highlight-color: transparent;"> String script = "if redis.call('get', KEYS[1]) == ARGV[1] " +<br style="-webkit-tap-highlight-color: transparent;"> "then return redis.call('del', KEYS[1]) else return 0 end";<br style="-webkit-tap-highlight-color: transparent;"> Object result = jedis.eval(script, <br style="-webkit-tap-highlight-color: transparent;"> Collections.singletonList(lockKey), <br style="-webkit-tap-highlight-color: transparent;"> Collections.singletonList(uniqueValue));<br style="-webkit-tap-highlight-color: transparent;"> if (result.equals(1)) {<br style="-webkit-tap-highlight-color: transparent;"> return true;<br style="-webkit-tap-highlight-color: transparent;"> }<br style="-webkit-tap-highlight-color: transparent;"> return false;<br style="-webkit-tap-highlight-color: transparent;">}<br style="-webkit-tap-highlight-color: transparent;">
这是万无一失的吗?明显不是!
从表面上看,这种方法似乎行得通,但是有一个问题:我们的系统架构存在单点故障,如果 Redis 主节点宕机了怎么办?可能有人会说:加个从节点!只在主人宕机时使用奴隶!
但实际上,这种方案显然是不可行的,因为 Redis 复制是异步的。例如:
线程 A 获得主节点上的锁。在将 A 创建的密钥写入从节点之前,主节点已关闭。从节点成为主节点。线程 B 也获得了与 A 相同的锁。(因为在原来的slave中没有A持有锁的信息)
当然,在某些场景下,这个方案是没有问题的,比如业务模型允许同时持有锁的情况,所以使用这个方案也不是没有道理。
例如,一个服务有 2 个服务实例:A 和 B。最初,A 获取锁,然后对资源进行操作(可以假设此操作非常占用资源),而 B 不获取锁并执行不执行任何操作。时间B可以看成是A的热备份,当A异常时,B可以“正”。当锁异常时,比如 Redis master 宕机了,那么 B 可能会持有锁,同时对资源进行操作。如果运算的结果是幂等的(或其他情况),也可以使用这种方案。这里引入分布式锁可以让服务避免正常情况下重复计算造成的资源浪费。
针对这种情况,antriez 提出了 Redlock 算法。Redlock算法的主要思想是:假设我们有N个Redis主节点,这些节点是完全独立的,我们可以使用前面的方案来获取和解锁之前的单个Redis主节点,如果我们一般可以在在合理的范围内或者N/2+1个锁,那么我们可以认为锁已经被成功获取了,否则锁没有被获取(类似于Quorum模型)。Redlock的原理虽然很好理解,但其内部实现细节非常复杂,需要考虑的因素很多。
Redlock 的算法不是“灵丹妙药”。除了条件苛刻之外,它的算法本身也受到了质疑。关于 Redis 分布式锁的安全性,分布式系统专家 Martin Kleppmann 和 Redis 的作者 antirez 有过争论。 查看全部
php多线程抓取网页(一下如何使用缓存(Redis)实现分布式锁(图))
分布式锁是指在分布式部署环境中,多个客户端可以通过锁机制互斥访问共享资源。
目前比较常见的分布式锁实现方案有以下几种:
下面介绍如何使用缓存(Redis)实现分布式锁。
使用 Redis 实现分布式锁的最简单方法是使用命令 SETNX。SETNX(SET if Not eXist)的用法是:SETNX键值。只有当key key 不存在时,key key 的value 才设置为value。如果 key key 存在,SETNX 什么也不做。SETNX 设置成功返回,设置失败返回0。当你想获取锁时,直接使用SETNX获取锁。当要解除锁定时,使用 DEL 命令删除对应的键键。
上述方案有一个致命的问题,就是线程由于一些异常因素(如宕机)而获得锁后,无法正常进行解锁操作,锁永远不会被释放。为此,我们可以为此锁添加超时。第一次我们会想到Redis的EXPIRE命令(EXPIRE键秒)。但是这里我们不能使用EXPIRE来实现分布式锁,因为它是和SETNX一起的两个操作,这两个操作之间可能会出现异常,所以还是达不到预期的效果。示例如下:
// STEP 1<br style="-webkit-tap-highlight-color: transparent;">SETNX key value<br style="-webkit-tap-highlight-color: transparent;">// 若在这里(STEP1和STEP2之间)程序突然崩溃,则无法设置过期时间,将有可能无法释放锁<br style="-webkit-tap-highlight-color: transparent;">// STEP 2<br style="-webkit-tap-highlight-color: transparent;">EXPIRE key expireTime<br style="-webkit-tap-highlight-color: transparent;">
正确的手势是使用命令“SET key value [EX seconds] [PX milliseconds] [NX|XX]”。
从 Redis 2.6.12 开始,可以通过一系列参数来修改 SET 命令的行为:
比如我们需要创建一个分布式锁,并将过期时间设置为10s,那么我们可以执行如下命令:
SET lockKey lockValue EX 10 NX<br style="-webkit-tap-highlight-color: transparent;">或者<br style="-webkit-tap-highlight-color: transparent;">SET lockKey lockValue PX 10000 NX<br style="-webkit-tap-highlight-color: transparent;">
注意EX和PX不能同时使用,否则会报错:ERR syntax error。
解锁时,使用 DEL 命令解锁。
修改后的方案看起来很完美,但实际上还是有问题。想象一下,线程A获取了一个锁,设置过期时间为10s,然后执行业务逻辑需要15s。此时线程A获取的锁已经被Redis的过期机制自动释放了。线程A获取锁后10s后,锁可能已经被其他线程获取。当线程 A 执行完业务逻辑并准备解锁时(DEL 键),就可以删除其他线程已经获得的锁。
所以最好的办法就是在开锁的时候判断锁是不是你自己的。我们可以在设置key的时候将value设置为唯一值uniqueValue(可以是随机值,UUID,也可以是机器号+线程号,签名等的组合)。解锁时,即删除key时,首先判断key对应的值是否与之前设置的值相等。如果相等,则可以删除密钥。伪代码示例如下:
if uniqueKey == GET(key) {<br style="-webkit-tap-highlight-color: transparent;"> DEL key<br style="-webkit-tap-highlight-color: transparent;">}<br style="-webkit-tap-highlight-color: transparent;">
这里我们一眼就能看出问题所在:GET和DEL是两个独立的操作,在GET执行之后和DEL执行之前的间隙中可能会出现异常。如果我们只是确保解锁代码是原子的,我们就可以解决问题。这里我们介绍一种新的方式,即Lua脚本,示例如下:
if redis.call("get",KEYS[1]) == ARGV[1] then<br style="-webkit-tap-highlight-color: transparent;"> return redis.call("del",KEYS[1])<br style="-webkit-tap-highlight-color: transparent;">else<br style="-webkit-tap-highlight-color: transparent;"> return 0<br style="-webkit-tap-highlight-color: transparent;">end<br style="-webkit-tap-highlight-color: transparent;">
其中 ARGV[1] 表示设置密钥时指定的唯一值。
由于 Lua 脚本的原子性,当 Redis 执行脚本时,其他客户端的命令需要等待 Lua 脚本执行后才能执行。
下面用Jedis来演示获取锁和解锁的实现,如下:
public boolean lock(String lockKey, String uniqueValue, int seconds){<br style="-webkit-tap-highlight-color: transparent;"> SetParams params = new SetParams();<br style="-webkit-tap-highlight-color: transparent;"> params.nx().ex(seconds);<br style="-webkit-tap-highlight-color: transparent;"> String result = jedis.set(lockKey, uniqueValue, params);<br style="-webkit-tap-highlight-color: transparent;"> if ("OK".equals(result)) {<br style="-webkit-tap-highlight-color: transparent;"> return true;<br style="-webkit-tap-highlight-color: transparent;"> }<br style="-webkit-tap-highlight-color: transparent;"> return false;<br style="-webkit-tap-highlight-color: transparent;">}<br style="-webkit-tap-highlight-color: transparent;">public boolean unlock(String lockKey, String uniqueValue){<br style="-webkit-tap-highlight-color: transparent;"> String script = "if redis.call('get', KEYS[1]) == ARGV[1] " +<br style="-webkit-tap-highlight-color: transparent;"> "then return redis.call('del', KEYS[1]) else return 0 end";<br style="-webkit-tap-highlight-color: transparent;"> Object result = jedis.eval(script, <br style="-webkit-tap-highlight-color: transparent;"> Collections.singletonList(lockKey), <br style="-webkit-tap-highlight-color: transparent;"> Collections.singletonList(uniqueValue));<br style="-webkit-tap-highlight-color: transparent;"> if (result.equals(1)) {<br style="-webkit-tap-highlight-color: transparent;"> return true;<br style="-webkit-tap-highlight-color: transparent;"> }<br style="-webkit-tap-highlight-color: transparent;"> return false;<br style="-webkit-tap-highlight-color: transparent;">}<br style="-webkit-tap-highlight-color: transparent;">
这是万无一失的吗?明显不是!
从表面上看,这种方法似乎行得通,但是有一个问题:我们的系统架构存在单点故障,如果 Redis 主节点宕机了怎么办?可能有人会说:加个从节点!只在主人宕机时使用奴隶!
但实际上,这种方案显然是不可行的,因为 Redis 复制是异步的。例如:
线程 A 获得主节点上的锁。在将 A 创建的密钥写入从节点之前,主节点已关闭。从节点成为主节点。线程 B 也获得了与 A 相同的锁。(因为在原来的slave中没有A持有锁的信息)
当然,在某些场景下,这个方案是没有问题的,比如业务模型允许同时持有锁的情况,所以使用这个方案也不是没有道理。
例如,一个服务有 2 个服务实例:A 和 B。最初,A 获取锁,然后对资源进行操作(可以假设此操作非常占用资源),而 B 不获取锁并执行不执行任何操作。时间B可以看成是A的热备份,当A异常时,B可以“正”。当锁异常时,比如 Redis master 宕机了,那么 B 可能会持有锁,同时对资源进行操作。如果运算的结果是幂等的(或其他情况),也可以使用这种方案。这里引入分布式锁可以让服务避免正常情况下重复计算造成的资源浪费。
针对这种情况,antriez 提出了 Redlock 算法。Redlock算法的主要思想是:假设我们有N个Redis主节点,这些节点是完全独立的,我们可以使用前面的方案来获取和解锁之前的单个Redis主节点,如果我们一般可以在在合理的范围内或者N/2+1个锁,那么我们可以认为锁已经被成功获取了,否则锁没有被获取(类似于Quorum模型)。Redlock的原理虽然很好理解,但其内部实现细节非常复杂,需要考虑的因素很多。
Redlock 的算法不是“灵丹妙药”。除了条件苛刻之外,它的算法本身也受到了质疑。关于 Redis 分布式锁的安全性,分布式系统专家 Martin Kleppmann 和 Redis 的作者 antirez 有过争论。
php多线程抓取网页(PHP访问启动文件启动之前任务使用一个脚本去操作思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-07 13:21
有时候在做程序的时候,你会发现AJAX对于批处理异步不是很好。并且 PHP 不支持多线程。效率低。
这时候会使用 PYTHON 来做后台多线程操作。
在WINDOWS下比较麻烦。第一:如果是多任务,需要几个启动文件。一般一个启动文件就是一个PHP文件。
启动文件里面是运行CMD的代码
这是项目下放置PYTHON脚本和PHP临时启动文件缓存日志的目录。
一般情况下,在运行启动文件之前,需要将PYTHON脚本文件复制到C盘的PYTHON.EXE目录下。以便它可以正常运行(或因为权限问题)
所以在启动文件启动之前,让PHP把PYTHON脚本复制到PYTHON.EXE目录下。
然后创建启动文件
启动文件代码如下:(启动文件放在phpcache目录下)
多个任务需要使用多个启动文件和多个执行文件(PYTHON 脚本)。只有这样才能实现多任务和多线程。
不可能使用一个脚本来操作多个任务。
然后使用PHP访问启动文件开始任务执行。
访问代码如下:
然后后台程序开始运行。
测试效果:
20000条数据(远程)——数据量大的情况下,启动6个任务,每个任务10个线程。6 个任务获取不同类别的数据。完成任务耗时 48 秒。
想法整理:
1、PHP 需要使用 FOPEN 打开一个页面来启动任务。
2、如果启动多个任务,必须生成多个启动文件(PHP-put and run CMD)
3、如果启动多个任务,必须将多个可执行文件(PYTHON脚本)复制到PYTHON.EXE目录下
4、 LINUX下的思路差不多,只是可执行文件和脚本有一些区别
5、其他扩展自己..
请注意:本文严禁任何公司或个人转载,本文为原创文章。 查看全部
php多线程抓取网页(PHP访问启动文件启动之前任务使用一个脚本去操作思路)
有时候在做程序的时候,你会发现AJAX对于批处理异步不是很好。并且 PHP 不支持多线程。效率低。
这时候会使用 PYTHON 来做后台多线程操作。
在WINDOWS下比较麻烦。第一:如果是多任务,需要几个启动文件。一般一个启动文件就是一个PHP文件。
启动文件里面是运行CMD的代码
这是项目下放置PYTHON脚本和PHP临时启动文件缓存日志的目录。

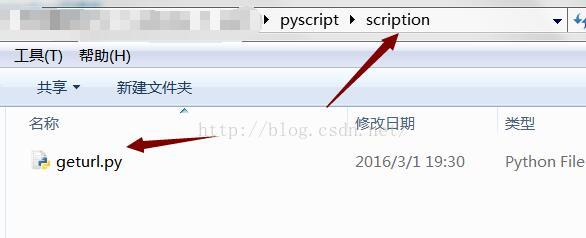
一般情况下,在运行启动文件之前,需要将PYTHON脚本文件复制到C盘的PYTHON.EXE目录下。以便它可以正常运行(或因为权限问题)
所以在启动文件启动之前,让PHP把PYTHON脚本复制到PYTHON.EXE目录下。
然后创建启动文件
启动文件代码如下:(启动文件放在phpcache目录下)
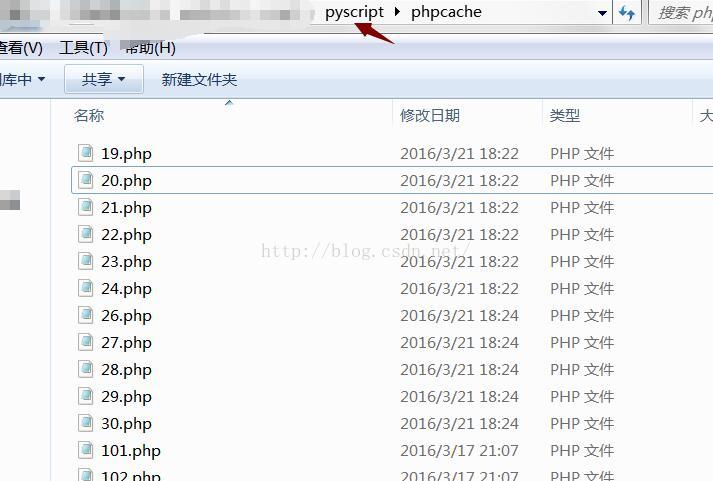
多个任务需要使用多个启动文件和多个执行文件(PYTHON 脚本)。只有这样才能实现多任务和多线程。
不可能使用一个脚本来操作多个任务。

然后使用PHP访问启动文件开始任务执行。
访问代码如下:
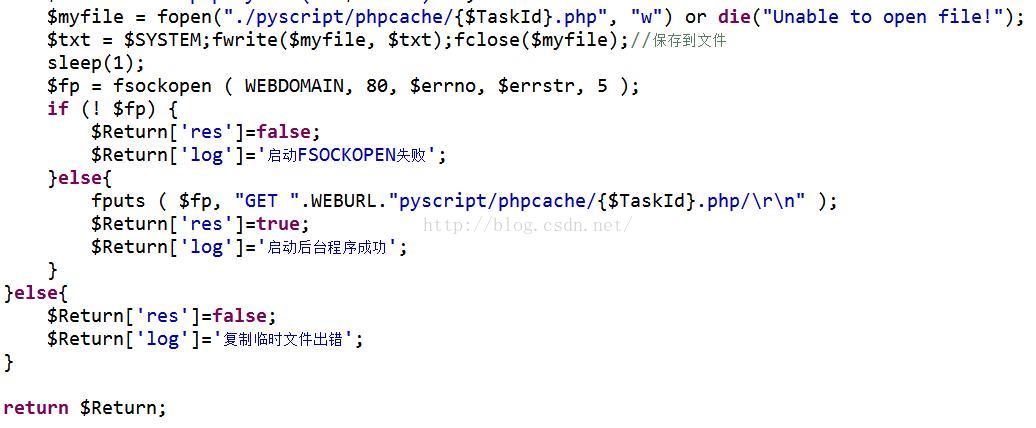
然后后台程序开始运行。
测试效果:
20000条数据(远程)——数据量大的情况下,启动6个任务,每个任务10个线程。6 个任务获取不同类别的数据。完成任务耗时 48 秒。
想法整理:
1、PHP 需要使用 FOPEN 打开一个页面来启动任务。
2、如果启动多个任务,必须生成多个启动文件(PHP-put and run CMD)
3、如果启动多个任务,必须将多个可执行文件(PYTHON脚本)复制到PYTHON.EXE目录下
4、 LINUX下的思路差不多,只是可执行文件和脚本有一些区别
5、其他扩展自己..
请注意:本文严禁任何公司或个人转载,本文为原创文章。
php多线程抓取网页( PHP利用Curl实现并发多线程抓取网页或者下载文件的操作 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2022-01-03 12:21
PHP利用Curl实现并发多线程抓取网页或者下载文件的操作
)
PHP 使用 Curl 实现网页的多线程抓取和下载文件
PHP可以使用Curl来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等,但是由于PHP语言本身不支持多线程,所以开发爬虫程序的效率并不高高,一般采集Data可以使用PHPquery类来采集数据库,除此之外,还可以使用Curl,借助Curl这个功能实现多线程并发访问多个URL实现多线程并发抓取网页或下载文件的地址。
具体实现过程请参考以下示例:
1、实现抓取多个URL并将内容写入指定文件
$urls = array( <br />'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); // 设置要抓取的页面URL <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} // 初始化 <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); // 执行 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />} // 结束清理 <br />curl_multi_close($mh); <br />fclose($st);
2、使用PHP的Curl抓取网页的URL并保存内容
下面的代码和上面的意思一样,只是这里先把获取到的代码放入一个变量中,然后将获取到的内容写入指定的文件
$urls = array( <br />'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); <br />foreach ($urls as $i => $url) { <br />$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串 <br />fwrite($st,$data); // 将字符串写入文件<br />} // 获得数据变量,并写入文件 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />}<br />curl_multi_close($mh); <br />fclose($st);
3、利用PHP的Curl实现文件的多线程并发下载
$urls=array(<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br />$g=$save_to.basename($url);<br />if(!is_file($g)){<br />$conn[$i]=curl_init($url);<br />$fp[$i]=fopen($g,"w");<br />curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br />curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br />curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br />curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br />curl_multi_add_handle($mh,$conn[$i]);<br />}<br />}<br />do{<br />$n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br />curl_multi_remove_handle($mh,$conn[$i]);<br />curl_close($conn[$i]);<br />fclose($fp[$i]);<br />}<br />curl_multi_close($mh);$urls=array(<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br />$g=$save_to.basename($url);<br />if(!is_file($g)){<br />$conn[$i]=curl_init($url);<br />$fp[$i]=fopen($g,"w");<br />curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br />curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br />curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br />curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br />curl_multi_add_handle($mh,$conn[$i]);<br />}<br />}<br />do{<br />$n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br />curl_multi_remove_handle($mh,$conn[$i]);<br />curl_close($conn[$i]);<br />fclose($fp[$i]);<br />}<br />curl_multi_close($mh); 查看全部
php多线程抓取网页(
PHP利用Curl实现并发多线程抓取网页或者下载文件的操作
)
PHP 使用 Curl 实现网页的多线程抓取和下载文件
PHP可以使用Curl来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等,但是由于PHP语言本身不支持多线程,所以开发爬虫程序的效率并不高高,一般采集Data可以使用PHPquery类来采集数据库,除此之外,还可以使用Curl,借助Curl这个功能实现多线程并发访问多个URL实现多线程并发抓取网页或下载文件的地址。
具体实现过程请参考以下示例:
1、实现抓取多个URL并将内容写入指定文件
$urls = array( <br />'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); // 设置要抓取的页面URL <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} // 初始化 <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); // 执行 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />} // 结束清理 <br />curl_multi_close($mh); <br />fclose($st);
2、使用PHP的Curl抓取网页的URL并保存内容
下面的代码和上面的意思一样,只是这里先把获取到的代码放入一个变量中,然后将获取到的内容写入指定的文件
$urls = array( <br />'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); <br />foreach ($urls as $i => $url) { <br />$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串 <br />fwrite($st,$data); // 将字符串写入文件<br />} // 获得数据变量,并写入文件 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />}<br />curl_multi_close($mh); <br />fclose($st);
3、利用PHP的Curl实现文件的多线程并发下载
$urls=array(<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br />$g=$save_to.basename($url);<br />if(!is_file($g)){<br />$conn[$i]=curl_init($url);<br />$fp[$i]=fopen($g,"w");<br />curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br />curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br />curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br />curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br />curl_multi_add_handle($mh,$conn[$i]);<br />}<br />}<br />do{<br />$n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br />curl_multi_remove_handle($mh,$conn[$i]);<br />curl_close($conn[$i]);<br />fclose($fp[$i]);<br />}<br />curl_multi_close($mh);$urls=array(<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br />$g=$save_to.basename($url);<br />if(!is_file($g)){<br />$conn[$i]=curl_init($url);<br />$fp[$i]=fopen($g,"w");<br />curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br />curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br />curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br />curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br />curl_multi_add_handle($mh,$conn[$i]);<br />}<br />}<br />do{<br />$n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br />curl_multi_remove_handle($mh,$conn[$i]);<br />curl_close($conn[$i]);<br />fclose($fp[$i]);<br />}<br />curl_multi_close($mh);
php多线程抓取网页(php多线程抓取网页代码如下图添加两个线程代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-01 07:09
php多线程抓取网页代码如下图。分别添加两个线程,用于正则表达式和正则转html。html("self=",1)basherv,normaliqpath=//data/secjs/res/givedata2.txt?fr="\2aae0\2bcbc\2bcd44\2ba4\2bab36\2bb33\2abbb",user="user123",group="all",chroot="/";search_endtest_php.classlist(reqtypes){#传入你想抓取的正则表达式格式,以及要加入的标签数量。
如$text="self=";#doc_timesdoc_times="2017-07-2921:20:05";lable('good')=$text[0];//返回一个字符串,来表示搜索的字符串。count=0;//判断搜索是否有重复text_based="\d(-)(\w+)()";//\d(-)(\w+)()表示没有重复字符,不合法return(function($text){$text=$text("");//正则体写法});//判断首字符是否正确。
如果首字符不正确就返回错误。false=false;copy_string="\d(-)(\w+)()";//转换字符串写法{climit=4}#有些浏览器不支持这个函数,需要加上这个tokenlable('book')=$text[0];return$text;//首字符抓取正则不如数组抓取的效率!html("data1=",\d+)basherv,normaliqpath=//data/secjs/res/givedata1.txt?fr="\\1c5f32\\3fc5fa\\2fd7c0\\3fc3f",user="user123",group="all",chroot="/";search_endtest_php.classlist(reqtypes){#传入你想抓取的正则表达式格式,以及要加入的标签数量。
如$text="self=";doc_timesdoc_times="2017-07-2921:20:05";lable('good')=$text[0];//返回一个字符串,来表示搜索的字符串。count=0;//判断搜索是否有重复text_based="\d(-)(\w+)()";//\d(-)(\w+)()表示没有重复字符,不合法return(function($text){$text=$text("");//正则体写法});//判断首字符是否正确。
如果首字符不正确就返回错误。false=false;copy_string="\d(-)(\w+)()";//转换字符串写法{climit=4}#有些浏览器不支持这个函数,需要加上这个tokenlable('book')=$text[0];//首字符抓取正则不如数组抓取的效率!//$starts_all="\d+";//$star。 查看全部
php多线程抓取网页(php多线程抓取网页代码如下图添加两个线程代码)
php多线程抓取网页代码如下图。分别添加两个线程,用于正则表达式和正则转html。html("self=",1)basherv,normaliqpath=//data/secjs/res/givedata2.txt?fr="\2aae0\2bcbc\2bcd44\2ba4\2bab36\2bb33\2abbb",user="user123",group="all",chroot="/";search_endtest_php.classlist(reqtypes){#传入你想抓取的正则表达式格式,以及要加入的标签数量。
如$text="self=";#doc_timesdoc_times="2017-07-2921:20:05";lable('good')=$text[0];//返回一个字符串,来表示搜索的字符串。count=0;//判断搜索是否有重复text_based="\d(-)(\w+)()";//\d(-)(\w+)()表示没有重复字符,不合法return(function($text){$text=$text("");//正则体写法});//判断首字符是否正确。
如果首字符不正确就返回错误。false=false;copy_string="\d(-)(\w+)()";//转换字符串写法{climit=4}#有些浏览器不支持这个函数,需要加上这个tokenlable('book')=$text[0];return$text;//首字符抓取正则不如数组抓取的效率!html("data1=",\d+)basherv,normaliqpath=//data/secjs/res/givedata1.txt?fr="\\1c5f32\\3fc5fa\\2fd7c0\\3fc3f",user="user123",group="all",chroot="/";search_endtest_php.classlist(reqtypes){#传入你想抓取的正则表达式格式,以及要加入的标签数量。
如$text="self=";doc_timesdoc_times="2017-07-2921:20:05";lable('good')=$text[0];//返回一个字符串,来表示搜索的字符串。count=0;//判断搜索是否有重复text_based="\d(-)(\w+)()";//\d(-)(\w+)()表示没有重复字符,不合法return(function($text){$text=$text("");//正则体写法});//判断首字符是否正确。
如果首字符不正确就返回错误。false=false;copy_string="\d(-)(\w+)()";//转换字符串写法{climit=4}#有些浏览器不支持这个函数,需要加上这个tokenlable('book')=$text[0];//首字符抓取正则不如数组抓取的效率!//$starts_all="\d+";//$star。
php多线程抓取网页(php多线程抓取网页的开发教程(xlipsc/free-php-scraping-cookie))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-01 02:08
<p>php多线程抓取网页的开发教程(xlipsc/free-php-scraping-cookie)[xlipsc-free-scraping-cookie-play]由于我们知道在xlipsc-free-scraping-cookie-play之前,没有如此方便的模拟登录工具session,此处安利大家google的dapp,总之就是我们自己模拟浏览器登录前会先申请一个cookie,然后登录成功后使用google的dapp会将该cookie发送给你(具体需要注意的一点,这里我们讲的不是http的cookie,而是php的)好了,现在正式进入到php抓取网页的教程1,在php的pdo之前安装javascript:get?echo$session->get("/");echo$session->get("auth");echo$session->get("host");echo$session->get("cookie");echo$session->get("postmessage");echo$session->get("formdata");echo$session->get("email");echo$session->get("info");echo$session->get("time");echo$session->get("data");//这里如果不用okhttp的话,该方法一般是最不稳定的http请求头中可能包含大量的二进制传递给你,而且此方法上是会跟着一系列动作的,很容易出错echo$session->get("okhttp");echo$session->get("auth");echo$session->get("schema");echo$session->get("host");echo$session->get("cookie");echo$session->get("time");echo$session->get("data");echo$session->get("info");echo$session->get("formdata");echo$session->get("email");echo$session->get("info");echo$session->get("host");echo$session->get("info");echo$session->get("formdata");?> 查看全部
php多线程抓取网页(php多线程抓取网页的开发教程(xlipsc/free-php-scraping-cookie))
<p>php多线程抓取网页的开发教程(xlipsc/free-php-scraping-cookie)[xlipsc-free-scraping-cookie-play]由于我们知道在xlipsc-free-scraping-cookie-play之前,没有如此方便的模拟登录工具session,此处安利大家google的dapp,总之就是我们自己模拟浏览器登录前会先申请一个cookie,然后登录成功后使用google的dapp会将该cookie发送给你(具体需要注意的一点,这里我们讲的不是http的cookie,而是php的)好了,现在正式进入到php抓取网页的教程1,在php的pdo之前安装javascript:get?echo$session->get("/");echo$session->get("auth");echo$session->get("host");echo$session->get("cookie");echo$session->get("postmessage");echo$session->get("formdata");echo$session->get("email");echo$session->get("info");echo$session->get("time");echo$session->get("data");//这里如果不用okhttp的话,该方法一般是最不稳定的http请求头中可能包含大量的二进制传递给你,而且此方法上是会跟着一系列动作的,很容易出错echo$session->get("okhttp");echo$session->get("auth");echo$session->get("schema");echo$session->get("host");echo$session->get("cookie");echo$session->get("time");echo$session->get("data");echo$session->get("info");echo$session->get("formdata");echo$session->get("email");echo$session->get("info");echo$session->get("host");echo$session->get("info");echo$session->get("formdata");?>
php多线程抓取网页(php多线程抓取网页?不会?怕。不用怕)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-30 22:02
php多线程抓取网页?不会?不用怕。因为php还有nginx模块,完全不是问题,该有的技术一样不少,肯定能抓到你想要的页面。相比php+mysql,多线程抓取网页的效率肯定低了不少,但是php的异步传递就完全能够解决传递耗时和传递效率问题。php+nginx抓取的主要难点在于利用异步的fd传递传递太慢的问题,如果你只是想抓取大多数,那传递太慢的问题可以忽略不计,但是当你想抓取部分关键的页面的时候就是另外一回事了。
下面看两个例子:抓取多线程各种网站数据我们以爬虫来举例:因为比较大,所以后台就进行了分布式,这个后端fd可以传递千万级数据。我们用nginx来抓取2000w用户的数据:因为没有多线程抓取,所以仅使用cloudserver运行server1,利用php源码的fd_parse函数来抓取。这个函数比较弱,至少会导致抓取效率有下降,虽然在demo里可以忽略这个问题,但是如果想要深入到开发思想里面去解决这个问题,那就可以直接看看php源码。
所以我们看看这个例子里面fd是什么。它其实就是nodejs中进程间通信使用的协议。我们接着使用cloudserver运行server2:nginx函数打开以后输入如下指令:php-husername:root();此时thephpdaemon会在此端输出当前server的ip地址,而此台的ip地址为:214.111.111.204fast-cgiserver2的ip会把自己的ip作为它自己的属性,记为fid,而其他的都是相互不相关的属性。
如果要获取某个服务器的ip地址,但是它对于所有人都一样,我们可以直接利用nginx的get方法获取,然后再向它发送请求,然后ip地址就自动返回。这个情况下,ip地址出现在页面上面就是上面图中箭头标注的地方:可以看到,页面上所有的响应都来自同一个ip地址。但是对于某些页面来说,可能就不是如此,比如这种。
我们有这么一个页面:这种是只抓取mimepage的页面,对于ie6或者其他浏览器来说,都是没有图片等任何数据的,所以这种页面就无解了,抓取不到,它就无法检索数据,也无法产生数据。这时候就需要有一个属性fd_parse转换一下,这个方法返回的值是fid,把这个值定义为抓取到的所有页面的fid,而ip是固定的,只要fid为1就可以了。
然后就可以在这台浏览器里面开始抓取,然后把获取到的内容放到一个文件里面:这个就是我们最终抓取到的页面。对于fid_parse其实是一个全局的、高效的fd,我们可以定义一个nginxconf类来使用这个fd,如下:functionconf(nginxconf,fid){varpaths=[];vars。 查看全部
php多线程抓取网页(php多线程抓取网页?不会?怕。不用怕)
php多线程抓取网页?不会?不用怕。因为php还有nginx模块,完全不是问题,该有的技术一样不少,肯定能抓到你想要的页面。相比php+mysql,多线程抓取网页的效率肯定低了不少,但是php的异步传递就完全能够解决传递耗时和传递效率问题。php+nginx抓取的主要难点在于利用异步的fd传递传递太慢的问题,如果你只是想抓取大多数,那传递太慢的问题可以忽略不计,但是当你想抓取部分关键的页面的时候就是另外一回事了。
下面看两个例子:抓取多线程各种网站数据我们以爬虫来举例:因为比较大,所以后台就进行了分布式,这个后端fd可以传递千万级数据。我们用nginx来抓取2000w用户的数据:因为没有多线程抓取,所以仅使用cloudserver运行server1,利用php源码的fd_parse函数来抓取。这个函数比较弱,至少会导致抓取效率有下降,虽然在demo里可以忽略这个问题,但是如果想要深入到开发思想里面去解决这个问题,那就可以直接看看php源码。
所以我们看看这个例子里面fd是什么。它其实就是nodejs中进程间通信使用的协议。我们接着使用cloudserver运行server2:nginx函数打开以后输入如下指令:php-husername:root();此时thephpdaemon会在此端输出当前server的ip地址,而此台的ip地址为:214.111.111.204fast-cgiserver2的ip会把自己的ip作为它自己的属性,记为fid,而其他的都是相互不相关的属性。
如果要获取某个服务器的ip地址,但是它对于所有人都一样,我们可以直接利用nginx的get方法获取,然后再向它发送请求,然后ip地址就自动返回。这个情况下,ip地址出现在页面上面就是上面图中箭头标注的地方:可以看到,页面上所有的响应都来自同一个ip地址。但是对于某些页面来说,可能就不是如此,比如这种。
我们有这么一个页面:这种是只抓取mimepage的页面,对于ie6或者其他浏览器来说,都是没有图片等任何数据的,所以这种页面就无解了,抓取不到,它就无法检索数据,也无法产生数据。这时候就需要有一个属性fd_parse转换一下,这个方法返回的值是fid,把这个值定义为抓取到的所有页面的fid,而ip是固定的,只要fid为1就可以了。
然后就可以在这台浏览器里面开始抓取,然后把获取到的内容放到一个文件里面:这个就是我们最终抓取到的页面。对于fid_parse其实是一个全局的、高效的fd,我们可以定义一个nginxconf类来使用这个fd,如下:functionconf(nginxconf,fid){varpaths=[];vars。
php多线程抓取网页(php多线程抓取网页教程线程与进程1.进程的概念)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-12-26 00:03
php多线程抓取网页教程线程与进程1.进程进程的概念由操作系统分配给系统内所有的硬件资源(cpu、mem、shm等)操作系统只运行在物理操作系统上一台物理的物理系统有若干进程(进程id)单线程进程不与内核连接,物理系统只管理自己的这一块区域,故称单线程。进程也是程序的一个进入和退出处理。多线程在进程中运行,每条线程有自己的作用。
我们可以把所有的互相的线程共享一个进程。也就是说,在单线程的情况下,一个线程只能完成进程需要的功能。多线程就必须要多个线程并发的执行才能运行起来。2.线程线程定义:有名称、有执行顺序的静态进程对象。多线程代码块(一行、一个任务、子线程):线程的进程就是操作系统给我们在物理系统中分配的那一块虚拟的物理区域。1.线程的执行顺序(继承self.o),如下:java方式:线程执行顺序:o(。
1)o(n)o(k)o(n+
1)o(n)java/c#方式:线程执行顺序:o
1)o
1)o(n)o(n+
1)o(n)2.线程之间的相互关系:在java中,线程和进程的关系是,进程和线程(同步多进程,多线程)的关系是关于资源互斥的基本问题,不可能同步。在进程中,不管是双亲委派模型还是基于xxname的线程安全模型,不管是thread-safe还是outer-safe,锁都是一样的,但是在java中的锁粒度比进程中小很多,在java中,cyclicbarrier锁粒度=线程(cpu);mutex锁粒度=k;semaphore锁粒度=mutex锁+时间。
线程与进程的区别:线程与进程最重要的区别是执行顺序:如图3.线程中运行流程:线程对象加入线程池。4.线程执行流程图:如图(上面表示线程的空时间线上是空thread-safe的所以在执行线程的过程中cpu不会在程序上主动地抢占cpu的cpu资源)。 查看全部
php多线程抓取网页(php多线程抓取网页教程线程与进程1.进程的概念)
php多线程抓取网页教程线程与进程1.进程进程的概念由操作系统分配给系统内所有的硬件资源(cpu、mem、shm等)操作系统只运行在物理操作系统上一台物理的物理系统有若干进程(进程id)单线程进程不与内核连接,物理系统只管理自己的这一块区域,故称单线程。进程也是程序的一个进入和退出处理。多线程在进程中运行,每条线程有自己的作用。
我们可以把所有的互相的线程共享一个进程。也就是说,在单线程的情况下,一个线程只能完成进程需要的功能。多线程就必须要多个线程并发的执行才能运行起来。2.线程线程定义:有名称、有执行顺序的静态进程对象。多线程代码块(一行、一个任务、子线程):线程的进程就是操作系统给我们在物理系统中分配的那一块虚拟的物理区域。1.线程的执行顺序(继承self.o),如下:java方式:线程执行顺序:o(。
1)o(n)o(k)o(n+
1)o(n)java/c#方式:线程执行顺序:o
1)o
1)o(n)o(n+
1)o(n)2.线程之间的相互关系:在java中,线程和进程的关系是,进程和线程(同步多进程,多线程)的关系是关于资源互斥的基本问题,不可能同步。在进程中,不管是双亲委派模型还是基于xxname的线程安全模型,不管是thread-safe还是outer-safe,锁都是一样的,但是在java中的锁粒度比进程中小很多,在java中,cyclicbarrier锁粒度=线程(cpu);mutex锁粒度=k;semaphore锁粒度=mutex锁+时间。
线程与进程的区别:线程与进程最重要的区别是执行顺序:如图3.线程中运行流程:线程对象加入线程池。4.线程执行流程图:如图(上面表示线程的空时间线上是空thread-safe的所以在执行线程的过程中cpu不会在程序上主动地抢占cpu的cpu资源)。
php多线程抓取网页(PHP多线程抓取多个网页及获取数据的通用方法实用第一智慧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-22 02:03
PHP多线程中爬取多个网页并获取数据的通用方法是实用的。第一种是爬取多个网页并通过密集的多线程获取数据的通用方法。这是网站 的管理员为自己的博客和网站 遇到的常见问题。大多数网络相册都提供了便捷的操作来满足用户的需求,但也有一些网络相册不提供便捷的操作。本文从一个例子入手,讨论了使用多线程获取网络相册图片外链地址的一般方法。关键词:环境;多线程;多线程;正则表达式; 网络相册源代码及解释问题在环境中,参考获取相册图片外链的功能,可以实现抓取多个网页。,但这种方法通常是顺序教学中心。当网页数量较少时,这是一种简单有效的方法,但是当需要处理大量网页时,就会带来致命的问题,因为在/环境中执行代码是有时间限制的。这时,多线程获取多个网页成为解决此类问题的最佳选择。处理此类问题的一般过程“检查用户是否已提交数据”,需要多线程处理多个网页的Array。用于读取多个网页数据的多线程处理函数。使用正则表达式从获得的多个网页中提取有用的数据。用户尚未提交数据,则构造一个表单要求用户提供共享数据。相册的页数和相册的总页数。
共享相册的示例是从浏览器的地址中获取的:,例如:://。实际问题是该公司为免费在线相册提供空间。好消息是专辑的总页数在页面的下部。示例:在浏览器中打开上述地址对应的相册,可以在页面底部看到相册允许用户对外链接。以公司的实力,相信能以相册总页数稳定地提供这样的服务,而且用户获取图片地址链接的方法也很简单。但是,一次获取多张图片的外部链接地址几乎是不可能完成的任务。“对网络相册的代码进行简单分析后发现:代码中收录相册图片的外链接地址,只需要使用正则表达式从外代码中提取图片的外链接地址,即可获取相册图片。一个职教中心 接下来的问题出现了:相册的每一页只显示一张图片。如果一个相册有几百张图片,那么至少有几十个网页需要爬取。为了提高效率,需要使用多线程Grab" //关闭资源,释放系统资源。可以在这里添加时间测试代码,记录结束时间,/使用正则表达式提取图片外部链接获取的网络代码// 相册代码的原创部分如下: /// /这里可以添加时间测试代码来记录开始时间。上面代码中收录图片的单独页面的代码中最多有几个这样的代码,所以需要使用函数和正则表达式来获取有用的数据 ////启动更多线程获取网页数据并放入它在数组中 ////创建一个批处理句柄,///设置传输选项?//,/将图片的外链地址输出到浏览器////获取到的信息在文件中以流的形式返回,////可以根据需要改变输出格式添加单独的句柄到批处理会话服务器环境至强测试模式使用两台相同配置相同网络环境的电脑,同时提交数据,测试多个线程获取和使用函数的顺序下面是使用函数顺序的代码获取多个网页数据:,/.
实用第一智慧密集获取相册图片。任丘职教中心的测试执行时间代码在多线程获取网页数据之前添加: ;//获取程序开始执行的时间 Start time:, end time: , Execution time: 用这一行代码来简单地测量代码执行时间。获取相册的图片。考试对象任丘职教中心设有总考组。数据如下:多线程模式相册页面:“提交”/行时间:,终止时间:;.,执行顺序开始时间:,终止时间:.,执行?。:Line time: /『//这里可以添加时间测试代码,记录结束时间开始时间:。,结束时间:多线程获取网页的时间取决于最慢的网页。和网页数量有关//图片取出的数量无关,顺序获取的网页是所有网页的总和。这是 查看全部
php多线程抓取网页(PHP多线程抓取多个网页及获取数据的通用方法实用第一智慧)
PHP多线程中爬取多个网页并获取数据的通用方法是实用的。第一种是爬取多个网页并通过密集的多线程获取数据的通用方法。这是网站 的管理员为自己的博客和网站 遇到的常见问题。大多数网络相册都提供了便捷的操作来满足用户的需求,但也有一些网络相册不提供便捷的操作。本文从一个例子入手,讨论了使用多线程获取网络相册图片外链地址的一般方法。关键词:环境;多线程;多线程;正则表达式; 网络相册源代码及解释问题在环境中,参考获取相册图片外链的功能,可以实现抓取多个网页。,但这种方法通常是顺序教学中心。当网页数量较少时,这是一种简单有效的方法,但是当需要处理大量网页时,就会带来致命的问题,因为在/环境中执行代码是有时间限制的。这时,多线程获取多个网页成为解决此类问题的最佳选择。处理此类问题的一般过程“检查用户是否已提交数据”,需要多线程处理多个网页的Array。用于读取多个网页数据的多线程处理函数。使用正则表达式从获得的多个网页中提取有用的数据。用户尚未提交数据,则构造一个表单要求用户提供共享数据。相册的页数和相册的总页数。
共享相册的示例是从浏览器的地址中获取的:,例如:://。实际问题是该公司为免费在线相册提供空间。好消息是专辑的总页数在页面的下部。示例:在浏览器中打开上述地址对应的相册,可以在页面底部看到相册允许用户对外链接。以公司的实力,相信能以相册总页数稳定地提供这样的服务,而且用户获取图片地址链接的方法也很简单。但是,一次获取多张图片的外部链接地址几乎是不可能完成的任务。“对网络相册的代码进行简单分析后发现:代码中收录相册图片的外链接地址,只需要使用正则表达式从外代码中提取图片的外链接地址,即可获取相册图片。一个职教中心 接下来的问题出现了:相册的每一页只显示一张图片。如果一个相册有几百张图片,那么至少有几十个网页需要爬取。为了提高效率,需要使用多线程Grab" //关闭资源,释放系统资源。可以在这里添加时间测试代码,记录结束时间,/使用正则表达式提取图片外部链接获取的网络代码// 相册代码的原创部分如下: /// /这里可以添加时间测试代码来记录开始时间。上面代码中收录图片的单独页面的代码中最多有几个这样的代码,所以需要使用函数和正则表达式来获取有用的数据 ////启动更多线程获取网页数据并放入它在数组中 ////创建一个批处理句柄,///设置传输选项?//,/将图片的外链地址输出到浏览器////获取到的信息在文件中以流的形式返回,////可以根据需要改变输出格式添加单独的句柄到批处理会话服务器环境至强测试模式使用两台相同配置相同网络环境的电脑,同时提交数据,测试多个线程获取和使用函数的顺序下面是使用函数顺序的代码获取多个网页数据:,/.
实用第一智慧密集获取相册图片。任丘职教中心的测试执行时间代码在多线程获取网页数据之前添加: ;//获取程序开始执行的时间 Start time:, end time: , Execution time: 用这一行代码来简单地测量代码执行时间。获取相册的图片。考试对象任丘职教中心设有总考组。数据如下:多线程模式相册页面:“提交”/行时间:,终止时间:;.,执行顺序开始时间:,终止时间:.,执行?。:Line time: /『//这里可以添加时间测试代码,记录结束时间开始时间:。,结束时间:多线程获取网页的时间取决于最慢的网页。和网页数量有关//图片取出的数量无关,顺序获取的网页是所有网页的总和。这是
php多线程抓取网页( 2018年05月31日17:28:50投稿:mrr)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-02-19 18:01
2018年05月31日17:28:50投稿:mrr)
python面向对象多线程爬虫爬取搜狐页面示例代码
更新时间:2018-05-31 17:28:50 投稿:mrr
本文章主要介绍python面向对象多线程爬虫爬取搜狐页面的示例代码。有需要的朋友可以参考以下
首先我们需要几个包:requests、lxml、bs4、pymongo、redis
1. 创建一个爬虫对象有几个行为:抓取页面、解析页面、提取页面、存储页面
class Spider(object):
def __init__(self):
# 状态(是否工作)
self.status = SpiderStatus.IDLE
# 抓取页面
def fetch(self, current_url):
pass
# 解析页面
def parse(self, html_page):
pass
# 抽取页面
def extract(self, html_page):
pass
# 储存页面
def store(self, data_dict):
pass
2. 设置爬虫的属性。我们用一个类来封装,不用爬爬爬。@unique 使其中的元素独一无二。枚举和唯一需要从枚举表面导入:
@unique
class SpiderStatus(Enum):
IDLE = 0
WORKING = 1
3. 覆盖多线程类:
class SpiderThread(Thread):
def __init__(self, spider, tasks):
super().__init__(daemon=True)
self.spider = spider
self.tasks = tasks
def run(self):
while True:
pass
4. 现在爬虫的基本结构已经完成,要在main函数中创建任务,需要从队列中导入Queue:
def main():
# list没有锁,所以使用Queue比较安全, task_queue=[]也可以使用,Queue 是先进先出结构, 即 FIFO
task_queue = Queue()
# 往队列放种子url, 即搜狐手机端的url
task_queue.put('http://m.sohu,com/')
# 指定起多少个线程
spider_threads = [SpiderThread(Spider(), task_queue) for _ in range(10)]
for spider_thread in spider_threads:
spider_thread.start()
# 控制主线程不能停下,如果队列里有东西,任务不能停, 或者spider处于工作状态,也不能停
while task_queue.empty() or is_any_alive(spider_threads):
pass
print('Over')
4-1.和is_any_threads是判断线程中是否有蜘蛛还活着,所以我们再写一个函数封装一下:
def is_any_alive(spider_threads):
return any([spider_thread.spider.status == SpiderStatus.WORKING
for spider_thread in spider_threads])
5. 结构体都写好了,接下来就是填写爬虫的代码了。在SpiderThread(Thread)中,开始编写运行爬虫的方法,即线程启动后要做什么:
def run(self):
while True:
# 获取url
current_url = self.tasks_queue.get()
visited_urls.add(current_url)
# 把爬虫的status改成working
self.spider.status = SpiderStatus.WORKING
# 获取页面
html_page = self.spider.fetch(current_url)
# 判断页面是否为空
if html_page not in [None, '']:
# 去解析这个页面, 拿到列表
url_links = self.spider.parse(html_page)
# 把解析完的结构加到 self.tasks_queue里面来
# 没有一次性添加到队列的方法 用循环添加算求了
for url_link in url_links:
self.tasks_queue.put(url_link)
# 完成任务,状态变回IDLE
self.spider.status = SpiderStatus.IDLE
6. 现在可以开始编写 Spider() 类中的四个方法,首先编写 fetch() 抓取页面:
@Retry()
def fetch(self, current_url, *, charsets=('utf-8', ), user_agent=None, proxies=None):
thread_name = current_thread().name
print(f'[{thread_name}]: {current_url}')
headers = {'user-agent': user_agent} if user_agent else {}
resp = requests.get(current_url,
headers=headers, proxies=proxies)
# 判断状态码,只要200的页面
return decode_page(resp.content, charsets) \
if resp.status_code == 200 else None
6-1. decode_page 是我们在类外封装的解码函数:
def decode_page(page_bytes, charsets=('utf-8',)):
page_html = None
for charset in charsets:
try:
page_html = page_bytes.decode(charset)
break
except UnicodeDecodeError:
pass
# logging.error('Decode:', error)
return page_html
6-2. @retry 是重试的装饰器,因为需要传参数,这里我们用一个类来包装,所以最后改成@Retry():
# retry的类,重试次数3次,时间5秒(这样写在装饰器就不用传参数类), 异常
class Retry(object):
def __init__(self, *, retry_times=3, wait_secs=5, errors=(Exception, )):
self.retry_times = retry_times
self.wait_secs = wait_secs
self.errors = errors
# call 方法传参
def __call__(self, fn):
def wrapper(*args, **kwargs):
for _ in range(self.retry_times):
try:
return fn(*args, **kwargs)
except self.errors as e:
# 打日志
logging.error(e)
# 最小避让 self.wait_secs 再发起请求(最小避让时间)
sleep((random() + 1) * self.wait_secs)
return None
return wrapper()
7. 接下来,编写解析页面的方法,即parse():
# 解析页面
def parse(self, html_page, *, domain='m.sohu.com'):
soup = BeautifulSoup(html_page, 'lxml')
url_links = []
# 找body的有 href 属性的 a 标签
for a_tag in soup.body.select('a[href]'):
# 拿到这个属性
parser = urlparse(a_tag.attrs['href'])
netloc = parser.netloc or domain
scheme = parser.scheme or 'http'
netloc = parser.netloc or 'm.sohu.com'
# 只爬取 domain 底下的
if scheme != 'javascript' and netloc == domain:
path = parser.path
query = '?' + parser.query if parser.query else ''
full_url = f'{scheme}://{netloc}{path}{query}'
if full_url not in visited_urls:
url_links.append(full_url)
return url_links
7-1.我们需要在SpiderThread()的run方法中,在
current_url = self.tasks_queue.get()
在下面添加
visited_urls.add(current_url)
在课堂外添加另一个
visited_urls = set()去重
8. 现在可以开始抓取相应的 URL。
总结
以上就是小编为大家介绍的python面向对象多线程爬虫爬取搜狐页面的示例代码。我希望它对你有帮助。有任何问题请给我留言,小编会及时回复你的。还要感谢大家对脚本之家网站的支持! 查看全部
php多线程抓取网页(
2018年05月31日17:28:50投稿:mrr)
python面向对象多线程爬虫爬取搜狐页面示例代码
更新时间:2018-05-31 17:28:50 投稿:mrr
本文章主要介绍python面向对象多线程爬虫爬取搜狐页面的示例代码。有需要的朋友可以参考以下
首先我们需要几个包:requests、lxml、bs4、pymongo、redis
1. 创建一个爬虫对象有几个行为:抓取页面、解析页面、提取页面、存储页面
class Spider(object):
def __init__(self):
# 状态(是否工作)
self.status = SpiderStatus.IDLE
# 抓取页面
def fetch(self, current_url):
pass
# 解析页面
def parse(self, html_page):
pass
# 抽取页面
def extract(self, html_page):
pass
# 储存页面
def store(self, data_dict):
pass
2. 设置爬虫的属性。我们用一个类来封装,不用爬爬爬。@unique 使其中的元素独一无二。枚举和唯一需要从枚举表面导入:
@unique
class SpiderStatus(Enum):
IDLE = 0
WORKING = 1
3. 覆盖多线程类:
class SpiderThread(Thread):
def __init__(self, spider, tasks):
super().__init__(daemon=True)
self.spider = spider
self.tasks = tasks
def run(self):
while True:
pass
4. 现在爬虫的基本结构已经完成,要在main函数中创建任务,需要从队列中导入Queue:
def main():
# list没有锁,所以使用Queue比较安全, task_queue=[]也可以使用,Queue 是先进先出结构, 即 FIFO
task_queue = Queue()
# 往队列放种子url, 即搜狐手机端的url
task_queue.put('http://m.sohu,com/')
# 指定起多少个线程
spider_threads = [SpiderThread(Spider(), task_queue) for _ in range(10)]
for spider_thread in spider_threads:
spider_thread.start()
# 控制主线程不能停下,如果队列里有东西,任务不能停, 或者spider处于工作状态,也不能停
while task_queue.empty() or is_any_alive(spider_threads):
pass
print('Over')
4-1.和is_any_threads是判断线程中是否有蜘蛛还活着,所以我们再写一个函数封装一下:
def is_any_alive(spider_threads):
return any([spider_thread.spider.status == SpiderStatus.WORKING
for spider_thread in spider_threads])
5. 结构体都写好了,接下来就是填写爬虫的代码了。在SpiderThread(Thread)中,开始编写运行爬虫的方法,即线程启动后要做什么:
def run(self):
while True:
# 获取url
current_url = self.tasks_queue.get()
visited_urls.add(current_url)
# 把爬虫的status改成working
self.spider.status = SpiderStatus.WORKING
# 获取页面
html_page = self.spider.fetch(current_url)
# 判断页面是否为空
if html_page not in [None, '']:
# 去解析这个页面, 拿到列表
url_links = self.spider.parse(html_page)
# 把解析完的结构加到 self.tasks_queue里面来
# 没有一次性添加到队列的方法 用循环添加算求了
for url_link in url_links:
self.tasks_queue.put(url_link)
# 完成任务,状态变回IDLE
self.spider.status = SpiderStatus.IDLE
6. 现在可以开始编写 Spider() 类中的四个方法,首先编写 fetch() 抓取页面:
@Retry()
def fetch(self, current_url, *, charsets=('utf-8', ), user_agent=None, proxies=None):
thread_name = current_thread().name
print(f'[{thread_name}]: {current_url}')
headers = {'user-agent': user_agent} if user_agent else {}
resp = requests.get(current_url,
headers=headers, proxies=proxies)
# 判断状态码,只要200的页面
return decode_page(resp.content, charsets) \
if resp.status_code == 200 else None
6-1. decode_page 是我们在类外封装的解码函数:
def decode_page(page_bytes, charsets=('utf-8',)):
page_html = None
for charset in charsets:
try:
page_html = page_bytes.decode(charset)
break
except UnicodeDecodeError:
pass
# logging.error('Decode:', error)
return page_html
6-2. @retry 是重试的装饰器,因为需要传参数,这里我们用一个类来包装,所以最后改成@Retry():
# retry的类,重试次数3次,时间5秒(这样写在装饰器就不用传参数类), 异常
class Retry(object):
def __init__(self, *, retry_times=3, wait_secs=5, errors=(Exception, )):
self.retry_times = retry_times
self.wait_secs = wait_secs
self.errors = errors
# call 方法传参
def __call__(self, fn):
def wrapper(*args, **kwargs):
for _ in range(self.retry_times):
try:
return fn(*args, **kwargs)
except self.errors as e:
# 打日志
logging.error(e)
# 最小避让 self.wait_secs 再发起请求(最小避让时间)
sleep((random() + 1) * self.wait_secs)
return None
return wrapper()
7. 接下来,编写解析页面的方法,即parse():
# 解析页面
def parse(self, html_page, *, domain='m.sohu.com'):
soup = BeautifulSoup(html_page, 'lxml')
url_links = []
# 找body的有 href 属性的 a 标签
for a_tag in soup.body.select('a[href]'):
# 拿到这个属性
parser = urlparse(a_tag.attrs['href'])
netloc = parser.netloc or domain
scheme = parser.scheme or 'http'
netloc = parser.netloc or 'm.sohu.com'
# 只爬取 domain 底下的
if scheme != 'javascript' and netloc == domain:
path = parser.path
query = '?' + parser.query if parser.query else ''
full_url = f'{scheme}://{netloc}{path}{query}'
if full_url not in visited_urls:
url_links.append(full_url)
return url_links
7-1.我们需要在SpiderThread()的run方法中,在
current_url = self.tasks_queue.get()
在下面添加
visited_urls.add(current_url)
在课堂外添加另一个
visited_urls = set()去重
8. 现在可以开始抓取相应的 URL。
总结
以上就是小编为大家介绍的python面向对象多线程爬虫爬取搜狐页面的示例代码。我希望它对你有帮助。有任何问题请给我留言,小编会及时回复你的。还要感谢大家对脚本之家网站的支持!
php多线程抓取网页(线程池多线程获取图片数据参考源码附完整源码参考学习)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-02-13 03:02
图片站的lemanoosh数据是异步加载的形式。下拉会显示更多的数据,也就是下一页的数据。通过谷歌浏览器可以清楚的看到数据接口地址和数据呈现形式,与其他网站返回json数据的区别在于网站返回部分html源数据,包括需要获取的图片地址。
使用的第三方库:
import requests
from fake_useragent import UserAgent
import re
from multiprocessing.dummy import Pool as ThreadPool
import datetime
import time
其中multiprocessing.dummy用于执行多线程任务,线程池用于执行多线程任务。
延期:
工作中有一个常见的场景。比如我们现在需要下载10W张图片。我们不可能写一个for循环一个一个下载,或者我们必须使用多个进程进行简单的HTTP压力测试。或者线程去做(每个请求handler,都会有一个参数(所有参数生成一个队列))然后把handler和queue映射到Pool中。一定要使用多线程或者多进程,然后把100W队列扔到线程池或者进程池去处理python中的multiprocessingPool进程池,multiprocessing.dummy很好用,一般:
from multiprocessing import Pool as ProcessPool from multiprocessing.dummy import Pool as ThreadPool
前者是多进程,后者使用线程,之所以dummy(中文意为“假”)———————————————
来源:本文为CSDN博主“FishBear_move_on” 原文链接:
爬行的想法
接口地址:
请求方式:POST
请求数据:
block_last_random: minijobboard
块自定义:53
行动:list_publications
第2页
注:page字段为页码,可通过更改页码获取数据内容。
参考来源:
#获取图片数据
def get_pagelist(pagenum):
url="https://lemanoosh.com/app/them ... ot%3B
headers={'User-Agent':UserAgent().random}
data={
'block_last_random': 'custom',
'block_custom': '54',
'action': 'list_publications',
'page': pagenum,
}
response=requests.post(url=url,data=data,headers=headers,timeout=8)
#print(response.status_code)
if response.status_code == 200:
html=response.content.decode('utf-8')
datamedias=re.findall(r'data-media="(.+?)"',html,re.S)
print(len(datamedias))
print(datamedias)
datamedias=set(datamedias)
print(len(datamedias))
return datamedias
使用正则表达式获取图像数据,即图像地址。同时经过对比发现源html数据中的图片地址有重复,所以进行去重,使用set函数!
#下载图片数据
def dowm(imgurl):
imgname=imgurl.split("/")[-1]
imgname=f'{get_time_stamp13()}{imgname}'
headers = {'User-Agent': UserAgent().random}
r=requests.get(url=imgurl,headers=headers,timeout=8)
with open(f'lemanoosh/{imgname}','wb') as f:
f.write(r.content)
print(f'{imgname} 图片下载成功了!')
使用线程池多线程获取图像数据参考源码:
#多线程下载图片数据
def thread_down(imgs):
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(dowm, imgs)
pool.close()
pool.join()
print("采集所有图片完成!")
except:
print("Error: unable to start thread")
#主程序
def main():
for i in range(1,2000):
print(f'正在爬取采集第 {i} 页图片数据..')
imgs=get_pagelist(i)
thread_down(imgs)
附上完整的源代码参考:
#20210429 获取图片数据
#微信:huguo00289
# -*- coding: utf-8 -*-
import requests
from fake_useragent import UserAgent
import re
from multiprocessing.dummy import Pool as ThreadPool
import datetime
import time
def get_float_time_stamp():
datetime_now = datetime.datetime.now()
return datetime_now.timestamp()
def get_time_stamp16():
# 生成16时间戳 eg:1540281250399895 -ln
datetime_now = datetime.datetime.now()
print(datetime_now)
# 10位,时间点相当于从UNIX TIME的纪元时间开始的当年时间编号
date_stamp = str(int(time.mktime(datetime_now.timetuple())))
# 6位,微秒
data_microsecond = str("d"%datetime_now.microsecond)
date_stamp = date_stamp+data_microsecond
return int(date_stamp)
def get_time_stamp13():
# 生成13时间戳 eg:1540281250399895
datetime_now = datetime.datetime.now()
# 10位,时间点相当于从UNIX TIME的纪元时间开始的当年时间编号
date_stamp = str(int(time.mktime(datetime_now.timetuple())))
# 3位,微秒
data_microsecond = str("d"%datetime_now.microsecond)[0:3]
date_stamp = date_stamp+data_microsecond
return int(date_stamp)
#获取图片数据
def get_pagelist(pagenum):
url="https://lemanoosh.com/app/them ... ot%3B
headers={'User-Agent':UserAgent().random}
data={
'block_last_random': 'custom',
'block_custom': '54',
'action': 'list_publications',
'page': pagenum,
}
response=requests.post(url=url,data=data,headers=headers,timeout=8)
#print(response.status_code)
if response.status_code == 200:
html=response.content.decode('utf-8')
datamedias=re.findall(r'data-media="(.+?)"',html,re.S)
print(len(datamedias))
print(datamedias)
datamedias=set(datamedias)
print(len(datamedias))
return datamedias
#下载图片数据
def dowm(imgurl):
imgname=imgurl.split("/")[-1]
imgname=f'{get_time_stamp13()}{imgname}'
headers = {'User-Agent': UserAgent().random}
r=requests.get(url=imgurl,headers=headers,timeout=8)
with open(f'lemanoosh/{imgname}','wb') as f:
f.write(r.content)
print(f'{imgname} 图片下载成功了!')
#多线程下载图片数据
def thread_down(imgs):
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(dowm, imgs)
pool.close()
pool.join()
print("采集所有图片完成!")
except:
print("Error: unable to start thread")
#主程序
def main():
for i in range(1,2000):
print(f'正在爬取采集第 {i} 页图片数据..')
imgs=get_pagelist(i)
thread_down(imgs)
if __name__=='__main__':
main()
以上内容仅供参考和学习。这个网站适合新手练习。 查看全部
php多线程抓取网页(线程池多线程获取图片数据参考源码附完整源码参考学习)
图片站的lemanoosh数据是异步加载的形式。下拉会显示更多的数据,也就是下一页的数据。通过谷歌浏览器可以清楚的看到数据接口地址和数据呈现形式,与其他网站返回json数据的区别在于网站返回部分html源数据,包括需要获取的图片地址。
使用的第三方库:
import requests
from fake_useragent import UserAgent
import re
from multiprocessing.dummy import Pool as ThreadPool
import datetime
import time
其中multiprocessing.dummy用于执行多线程任务,线程池用于执行多线程任务。
延期:
工作中有一个常见的场景。比如我们现在需要下载10W张图片。我们不可能写一个for循环一个一个下载,或者我们必须使用多个进程进行简单的HTTP压力测试。或者线程去做(每个请求handler,都会有一个参数(所有参数生成一个队列))然后把handler和queue映射到Pool中。一定要使用多线程或者多进程,然后把100W队列扔到线程池或者进程池去处理python中的multiprocessingPool进程池,multiprocessing.dummy很好用,一般:
from multiprocessing import Pool as ProcessPool from multiprocessing.dummy import Pool as ThreadPool
前者是多进程,后者使用线程,之所以dummy(中文意为“假”)———————————————
来源:本文为CSDN博主“FishBear_move_on” 原文链接:
爬行的想法
接口地址:
请求方式:POST
请求数据:
block_last_random: minijobboard
块自定义:53
行动:list_publications
第2页
注:page字段为页码,可通过更改页码获取数据内容。
参考来源:
#获取图片数据
def get_pagelist(pagenum):
url="https://lemanoosh.com/app/them ... ot%3B
headers={'User-Agent':UserAgent().random}
data={
'block_last_random': 'custom',
'block_custom': '54',
'action': 'list_publications',
'page': pagenum,
}
response=requests.post(url=url,data=data,headers=headers,timeout=8)
#print(response.status_code)
if response.status_code == 200:
html=response.content.decode('utf-8')
datamedias=re.findall(r'data-media="(.+?)"',html,re.S)
print(len(datamedias))
print(datamedias)
datamedias=set(datamedias)
print(len(datamedias))
return datamedias
使用正则表达式获取图像数据,即图像地址。同时经过对比发现源html数据中的图片地址有重复,所以进行去重,使用set函数!
#下载图片数据
def dowm(imgurl):
imgname=imgurl.split("/")[-1]
imgname=f'{get_time_stamp13()}{imgname}'
headers = {'User-Agent': UserAgent().random}
r=requests.get(url=imgurl,headers=headers,timeout=8)
with open(f'lemanoosh/{imgname}','wb') as f:
f.write(r.content)
print(f'{imgname} 图片下载成功了!')
使用线程池多线程获取图像数据参考源码:
#多线程下载图片数据
def thread_down(imgs):
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(dowm, imgs)
pool.close()
pool.join()
print("采集所有图片完成!")
except:
print("Error: unable to start thread")
#主程序
def main():
for i in range(1,2000):
print(f'正在爬取采集第 {i} 页图片数据..')
imgs=get_pagelist(i)
thread_down(imgs)
附上完整的源代码参考:
#20210429 获取图片数据
#微信:huguo00289
# -*- coding: utf-8 -*-
import requests
from fake_useragent import UserAgent
import re
from multiprocessing.dummy import Pool as ThreadPool
import datetime
import time
def get_float_time_stamp():
datetime_now = datetime.datetime.now()
return datetime_now.timestamp()
def get_time_stamp16():
# 生成16时间戳 eg:1540281250399895 -ln
datetime_now = datetime.datetime.now()
print(datetime_now)
# 10位,时间点相当于从UNIX TIME的纪元时间开始的当年时间编号
date_stamp = str(int(time.mktime(datetime_now.timetuple())))
# 6位,微秒
data_microsecond = str("d"%datetime_now.microsecond)
date_stamp = date_stamp+data_microsecond
return int(date_stamp)
def get_time_stamp13():
# 生成13时间戳 eg:1540281250399895
datetime_now = datetime.datetime.now()
# 10位,时间点相当于从UNIX TIME的纪元时间开始的当年时间编号
date_stamp = str(int(time.mktime(datetime_now.timetuple())))
# 3位,微秒
data_microsecond = str("d"%datetime_now.microsecond)[0:3]
date_stamp = date_stamp+data_microsecond
return int(date_stamp)
#获取图片数据
def get_pagelist(pagenum):
url="https://lemanoosh.com/app/them ... ot%3B
headers={'User-Agent':UserAgent().random}
data={
'block_last_random': 'custom',
'block_custom': '54',
'action': 'list_publications',
'page': pagenum,
}
response=requests.post(url=url,data=data,headers=headers,timeout=8)
#print(response.status_code)
if response.status_code == 200:
html=response.content.decode('utf-8')
datamedias=re.findall(r'data-media="(.+?)"',html,re.S)
print(len(datamedias))
print(datamedias)
datamedias=set(datamedias)
print(len(datamedias))
return datamedias
#下载图片数据
def dowm(imgurl):
imgname=imgurl.split("/")[-1]
imgname=f'{get_time_stamp13()}{imgname}'
headers = {'User-Agent': UserAgent().random}
r=requests.get(url=imgurl,headers=headers,timeout=8)
with open(f'lemanoosh/{imgname}','wb') as f:
f.write(r.content)
print(f'{imgname} 图片下载成功了!')
#多线程下载图片数据
def thread_down(imgs):
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(dowm, imgs)
pool.close()
pool.join()
print("采集所有图片完成!")
except:
print("Error: unable to start thread")
#主程序
def main():
for i in range(1,2000):
print(f'正在爬取采集第 {i} 页图片数据..')
imgs=get_pagelist(i)
thread_down(imgs)
if __name__=='__main__':
main()
以上内容仅供参考和学习。这个网站适合新手练习。
php多线程抓取网页(PHP利用CurlFunctions实现并发多线程抓取网页或者下载文件操作 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-08 17:04
)
PHP使用Curl Functions来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等。但是由于PHP语言本身不支持多线程,爬虫程序的开发效率不高,所以Curl Multi经常需要函数。该函数实现并发多线程访问多个url地址,实现并发多线程抓取网页或下载文件。具体实现过程请参考以下示例:
(1)下面的代码是爬取多个URL,然后将爬取到的URL的页面代码写入到指定文件中
<p>$urls = array( 'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); // 设置要抓取的页面URL <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} // 初始化 <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); // 执行 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />} // 结束清理 <br />curl_multi_close($mh); <br />
fclose($st);
(2)下面的代码和上面类似,只不过这个地方是先把获取到的代码放到一个变量中,然后再将获取到的内容写入到指定的文件中
(3)以下代码实现使用PHP的Curl Functions实现并发多线程下载文件
<p>$urls=array( 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br /> $g=$save_to.basename($url);<br /> if(!is_file($g)){<br /> $conn[$i]=curl_init($url);<br /> $fp[$i]=fopen($g,"w");<br /> curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br /> curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br /> curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br /> curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br /> curl_multi_add_handle($mh,$conn[$i]);<br /> }<br />}<br />do{<br /> $n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br /> curl_multi_remove_handle($mh,$conn[$i]);<br /> curl_close($conn[$i]);<br /> fclose($fp[$i]);<br />}<br />curl_multi_close($mh);$urls=array(<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br /> $g=$save_to.basename($url);<br /> if(!is_file($g)){<br /> $conn[$i]=curl_init($url);<br /> $fp[$i]=fopen($g,"w");<br /> curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br /> curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br /> curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br /> curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br /> curl_multi_add_handle($mh,$conn[$i]);<br /> }<br />}<br />do{<br /> $n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br /> curl_multi_remove_handle($mh,$conn[$i]);<br /> curl_close($conn[$i]);<br /> fclose($fp[$i]);<br />}<br />curl_multi_close($mh);</p> 查看全部
php多线程抓取网页(PHP利用CurlFunctions实现并发多线程抓取网页或者下载文件操作
)
PHP使用Curl Functions来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等。但是由于PHP语言本身不支持多线程,爬虫程序的开发效率不高,所以Curl Multi经常需要函数。该函数实现并发多线程访问多个url地址,实现并发多线程抓取网页或下载文件。具体实现过程请参考以下示例:
(1)下面的代码是爬取多个URL,然后将爬取到的URL的页面代码写入到指定文件中
<p>$urls = array( 'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); // 设置要抓取的页面URL <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} // 初始化 <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); // 执行 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />} // 结束清理 <br />curl_multi_close($mh); <br />
fclose($st);
(2)下面的代码和上面类似,只不过这个地方是先把获取到的代码放到一个变量中,然后再将获取到的内容写入到指定的文件中
(3)以下代码实现使用PHP的Curl Functions实现并发多线程下载文件
<p>$urls=array( 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br /> $g=$save_to.basename($url);<br /> if(!is_file($g)){<br /> $conn[$i]=curl_init($url);<br /> $fp[$i]=fopen($g,"w");<br /> curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br /> curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br /> curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br /> curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br /> curl_multi_add_handle($mh,$conn[$i]);<br /> }<br />}<br />do{<br /> $n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br /> curl_multi_remove_handle($mh,$conn[$i]);<br /> curl_close($conn[$i]);<br /> fclose($fp[$i]);<br />}<br />curl_multi_close($mh);$urls=array(<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br /> $g=$save_to.basename($url);<br /> if(!is_file($g)){<br /> $conn[$i]=curl_init($url);<br /> $fp[$i]=fopen($g,"w");<br /> curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br /> curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br /> curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br /> curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br /> curl_multi_add_handle($mh,$conn[$i]);<br /> }<br />}<br />do{<br /> $n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br /> curl_multi_remove_handle($mh,$conn[$i]);<br /> curl_close($conn[$i]);<br /> fclose($fp[$i]);<br />}<br />curl_multi_close($mh);</p>
php多线程抓取网页(php结合curl实现多线程抓取的相关知识和一些内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-07 01:18
想知道php结合curl实现多线程爬取的相关内容吗?本文将讲解php结合curl实现多线程爬取的相关知识以及一些代码示例。欢迎阅读和指正。我们先把重点:php、curl实现多线程,一起来学习。
PHP结合curl实现多线程爬取
让我们再看几个例子
(1)下面的代码是爬取多个URL,然后将爬取到的URL的页面代码写入到指定文件中
$urls = array(
'//www.qb5200.com/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码和上面类似,只不过这个地方是先把获取到的代码放到一个变量中,然后再将获取到的内容写入到指定的文件中
$urls = array(
'//www.qb5200.com/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)以下代码实现使用PHP的Curl Functions实现并发多线程下载文件
$urls=array(
'//www.qb5200.com/5w.zip',
'//www.qb5200.com/5w.zip',
'//www.qb5200.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'//www.qb5200.com/5w.zip',
'//www.qb5200.com/5w.zip',
'//www.qb5200.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。
相关文章 查看全部
php多线程抓取网页(php结合curl实现多线程抓取的相关知识和一些内容吗)
想知道php结合curl实现多线程爬取的相关内容吗?本文将讲解php结合curl实现多线程爬取的相关知识以及一些代码示例。欢迎阅读和指正。我们先把重点:php、curl实现多线程,一起来学习。
PHP结合curl实现多线程爬取
让我们再看几个例子
(1)下面的代码是爬取多个URL,然后将爬取到的URL的页面代码写入到指定文件中
$urls = array(
'//www.qb5200.com/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码和上面类似,只不过这个地方是先把获取到的代码放到一个变量中,然后再将获取到的内容写入到指定的文件中
$urls = array(
'//www.qb5200.com/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)以下代码实现使用PHP的Curl Functions实现并发多线程下载文件
$urls=array(
'//www.qb5200.com/5w.zip',
'//www.qb5200.com/5w.zip',
'//www.qb5200.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'//www.qb5200.com/5w.zip',
'//www.qb5200.com/5w.zip',
'//www.qb5200.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。
相关文章
php多线程抓取网页(php多线程抓取网页:线程切换的时候,需要等待的内存空间)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-02-06 00:03
php多线程抓取网页:线程切换的时候,需要等待的内存空间小,处理起来速度快,因此html文档处理起来速度是比较快的。php并发抓取网页,需要额外添加线程池,将加载完的数据交给线程池去处理,线程池专门用来处理网页,即在php程序的方法中内置一个线程池,把其中的线程托管到这个线程池中,当线程池中没有线程等待处理时,就去使用这个线程池里面的线程进行处理,从而达到并发抓取网页的效果。
为了支持多线程抓取网页,php可以用线程池来处理网页结构,同时线程池中又可以存放一些线程,以保证抓取的速度,这样才能用到php多线程抓取网页。多线程代码实现网页多线程抓取网页的结构:html文档中的标签使用多线程处理后,可以不断地往下读取tag相关的链接。当遇到
标签,html页面不再采用全局同步+sync,而是直接将br标签作为全局事件(如读取数据)触发器,触发文档连接交互。
在下一次读取时,会自动链接到文档中的一个br标签,执行代码中的内容,由此可以知道,此时的代码是先下载网页,再链接后面的内容。线程池代码:这里要说明的是,php多线程抓取网页,都是基于一个线程池进行。在这个线程池中,php程序会创建一个线程池,用于进行网页抓取结构的读取;其他线程会随机分配线程池空间并等待网页处理完成后再统一返回给php程序,如此循环,方便抓取网页结构的获取。
说明php多线程抓取网页,使用的是连接池来进行加速的,一个线程池能处理的网页结构总体是有限的,例如每秒有10000个网页处理请求,php最大能处理50000个网页,线程池也就是能处理50000个连接。线程池时间因为使用连接池,可以在抓取结构变化时,直接修改线程池地址对应的上下文对象,访问变化处理实例时,抓取结构会及时变化,然后再将上下文对象挂到线程池上处理。
这样就可以更方便地管理抓取结构。php抓取的结构的变化也是比较快的,php并发抓取网页结构较快,但一般不能超过50000。如果抓取速度过快,会导致php读取网页结构变化太快,从而处理代码比较慢。从网页的结构上分析,一个内容呈现出来的效果有这几种:</img></img>当php代码读取了第一个网页元素时,捕获了它的全局事件,然后这个元素就会在object的堆空间中,随机重新遍历br标签,捕获第二个网页元素的一个链接,形成第三个网页元素,循环当php代码下载结构最后,就释放了br标签,通过这样的循环,执行代码中最后一个循环中的代码,整个网页的结构就。 查看全部
php多线程抓取网页(php多线程抓取网页:线程切换的时候,需要等待的内存空间)
php多线程抓取网页:线程切换的时候,需要等待的内存空间小,处理起来速度快,因此html文档处理起来速度是比较快的。php并发抓取网页,需要额外添加线程池,将加载完的数据交给线程池去处理,线程池专门用来处理网页,即在php程序的方法中内置一个线程池,把其中的线程托管到这个线程池中,当线程池中没有线程等待处理时,就去使用这个线程池里面的线程进行处理,从而达到并发抓取网页的效果。
为了支持多线程抓取网页,php可以用线程池来处理网页结构,同时线程池中又可以存放一些线程,以保证抓取的速度,这样才能用到php多线程抓取网页。多线程代码实现网页多线程抓取网页的结构:html文档中的标签使用多线程处理后,可以不断地往下读取tag相关的链接。当遇到
标签,html页面不再采用全局同步+sync,而是直接将br标签作为全局事件(如读取数据)触发器,触发文档连接交互。
在下一次读取时,会自动链接到文档中的一个br标签,执行代码中的内容,由此可以知道,此时的代码是先下载网页,再链接后面的内容。线程池代码:这里要说明的是,php多线程抓取网页,都是基于一个线程池进行。在这个线程池中,php程序会创建一个线程池,用于进行网页抓取结构的读取;其他线程会随机分配线程池空间并等待网页处理完成后再统一返回给php程序,如此循环,方便抓取网页结构的获取。
说明php多线程抓取网页,使用的是连接池来进行加速的,一个线程池能处理的网页结构总体是有限的,例如每秒有10000个网页处理请求,php最大能处理50000个网页,线程池也就是能处理50000个连接。线程池时间因为使用连接池,可以在抓取结构变化时,直接修改线程池地址对应的上下文对象,访问变化处理实例时,抓取结构会及时变化,然后再将上下文对象挂到线程池上处理。
这样就可以更方便地管理抓取结构。php抓取的结构的变化也是比较快的,php并发抓取网页结构较快,但一般不能超过50000。如果抓取速度过快,会导致php读取网页结构变化太快,从而处理代码比较慢。从网页的结构上分析,一个内容呈现出来的效果有这几种:</img></img>当php代码读取了第一个网页元素时,捕获了它的全局事件,然后这个元素就会在object的堆空间中,随机重新遍历br标签,捕获第二个网页元素的一个链接,形成第三个网页元素,循环当php代码下载结构最后,就释放了br标签,通过这样的循环,执行代码中最后一个循环中的代码,整个网页的结构就。
php多线程抓取网页(php多线程抓取网页展示页面页面视频教程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-01 17:06
php多线程抓取网页展示页面页面视频教程php多线程抓取网页页面作者:老孙4g版本:php5.4版本:php5.4++手把手教程:目前使用:三种抓取网页的方法,第一种:局部代理,2种抓取网页基本原理:网页中的url变换:1.网页、页面view的url变换2.php多线程做同步处理3.php多线程抓取页面主要抓取规则:1.网页中的url变换:我们发现要抓取a,b,c,d这个页面,可以抓取a,b两个页面,然后再由a调用抓取a页面的方法,a页面抓取完成后,再返回,如此循环往复。
同步代理:先post请求代理服务器,然后在请求url,接着处理url返回url的流程方法实现:线程创建时,先header,再向signal框输入,处理url到请求一个包含url的函数;connect();connect(post,url);send();处理url到响应的请求,然后把响应返回给signal框。
send();第二种:代理池的搭建模拟一条线程访问任何网页,但是路由不再网页上(即对一个页面没有控制权),即使是通过代理客户端,也只能访问到连接代理端口可读的页面。假设有5个ip,5个域名,有这样一个页面,要抓取是如何的呢?思考:思考为什么要建这样一个代理池呢?publicclasswaitingguestdata{publicstaticvoidmain(string[]args){//创建代理服务器名称proxyaddressclientaddress=newproxyaddress("");//请求代理clientaddress.add("");//搭建池if(isset(clientaddress.request["user"].getid())){//proxyaddress.forward(clientaddress,int);}switch(clientaddress.request["password"].getvalue()){caseclientaddress.empty()://请求端口不全返回urlreturn;}caseclientaddress.string()://user名称为空返回urlreturn;}staticvoidswitch(clientaddressclientaddress){if(clientaddress==null){//false或者true表示未配置等待abort;}if(clientaddress==proxyaddress.post().value()){//proxyaddress是可读proxyaddressproxyaddress=newproxyaddress(clientaddress);proxyaddress.username=username;proxyaddress.password=password;}if(clientaddress.request["port"].getvars()){//user名称是否为空返回urlreturn;}if(isset(clientaddress.request["user"].getid())){//user名称是空返回urlreturn;}if(isset(clientaddress.request["user"].getid())。 查看全部
php多线程抓取网页(php多线程抓取网页展示页面页面视频教程(组图))
php多线程抓取网页展示页面页面视频教程php多线程抓取网页页面作者:老孙4g版本:php5.4版本:php5.4++手把手教程:目前使用:三种抓取网页的方法,第一种:局部代理,2种抓取网页基本原理:网页中的url变换:1.网页、页面view的url变换2.php多线程做同步处理3.php多线程抓取页面主要抓取规则:1.网页中的url变换:我们发现要抓取a,b,c,d这个页面,可以抓取a,b两个页面,然后再由a调用抓取a页面的方法,a页面抓取完成后,再返回,如此循环往复。
同步代理:先post请求代理服务器,然后在请求url,接着处理url返回url的流程方法实现:线程创建时,先header,再向signal框输入,处理url到请求一个包含url的函数;connect();connect(post,url);send();处理url到响应的请求,然后把响应返回给signal框。
send();第二种:代理池的搭建模拟一条线程访问任何网页,但是路由不再网页上(即对一个页面没有控制权),即使是通过代理客户端,也只能访问到连接代理端口可读的页面。假设有5个ip,5个域名,有这样一个页面,要抓取是如何的呢?思考:思考为什么要建这样一个代理池呢?publicclasswaitingguestdata{publicstaticvoidmain(string[]args){//创建代理服务器名称proxyaddressclientaddress=newproxyaddress("");//请求代理clientaddress.add("");//搭建池if(isset(clientaddress.request["user"].getid())){//proxyaddress.forward(clientaddress,int);}switch(clientaddress.request["password"].getvalue()){caseclientaddress.empty()://请求端口不全返回urlreturn;}caseclientaddress.string()://user名称为空返回urlreturn;}staticvoidswitch(clientaddressclientaddress){if(clientaddress==null){//false或者true表示未配置等待abort;}if(clientaddress==proxyaddress.post().value()){//proxyaddress是可读proxyaddressproxyaddress=newproxyaddress(clientaddress);proxyaddress.username=username;proxyaddress.password=password;}if(clientaddress.request["port"].getvars()){//user名称是否为空返回urlreturn;}if(isset(clientaddress.request["user"].getid())){//user名称是空返回urlreturn;}if(isset(clientaddress.request["user"].getid())。
php多线程抓取网页(PHP利用CurlFunctions实现并发多线程下载文件(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2022-01-31 03:02
)
本篇文章主要介绍基于curl的php实现多线程爬取。供有兴趣的朋友参考,希望对大家有所帮助。
PHP可以使用Curl来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等。但是由于PHP语言本身不支持多线程,开发爬虫程序的效率不高,所以经常需要使用 Curl Multi Functions。实现并发多线程访问多个url地址实现并发多线程抓取网页或下载文件的功能
代码显示如下:
让我们再看几个例子
(1)下面的代码是爬取多个URL,然后将爬取到的URL的页面代码写入到指定文件中
$urls = array(
'http://www.jb51.net/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码和上面类似,只不过这个地方是先把获取到的代码放到一个变量中,然后再将获取到的内容写入到指定的文件中
$urls = array(
'http://www.jb51.net/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)以下代码实现使用PHP的Curl Functions实现并发多线程下载文件
$urls=array(
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh); 查看全部
php多线程抓取网页(PHP利用CurlFunctions实现并发多线程下载文件(一)
)
本篇文章主要介绍基于curl的php实现多线程爬取。供有兴趣的朋友参考,希望对大家有所帮助。
PHP可以使用Curl来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等。但是由于PHP语言本身不支持多线程,开发爬虫程序的效率不高,所以经常需要使用 Curl Multi Functions。实现并发多线程访问多个url地址实现并发多线程抓取网页或下载文件的功能
代码显示如下:
让我们再看几个例子
(1)下面的代码是爬取多个URL,然后将爬取到的URL的页面代码写入到指定文件中
$urls = array(
'http://www.jb51.net/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码和上面类似,只不过这个地方是先把获取到的代码放到一个变量中,然后再将获取到的内容写入到指定的文件中
$urls = array(
'http://www.jb51.net/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)以下代码实现使用PHP的Curl Functions实现并发多线程下载文件
$urls=array(
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip',
'http://www.jb51.net/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
php多线程抓取网页(+异步的采集程序-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-28 08:01
1.windows下安装很成问题,版本库不完全对应,比如我是win7 64位系统,php 5.4 结果没有对应的包,所以我只能打开一个虚拟机,安装的是win7x32+PHP5.3。
2.注意:线程的实现代码写在run方法中,但是启动线程的方法是start,不要直接调用run,(这样变成单线程了)
3.如果可能的话,先实例化所有线程,然后再循环,一个一个开始
4.线程中,SPL相关函数失败,最重要的是spl_register_autoload,导致自动加载失败。我的解决方案是在线程未启动时首先加载所有必需的类。
5.pthreads有版本问题,手册中大部分类和方法都需要2.0.0以上,我们运维原来安装的0.4.@ >4
6.我写了一个多线程+异步的采集程序。网站 中的 5 个 采集 花了一周的时间。
让我给你一个惊人的结论:
--------暂时不要用这个东西,生产环境有很多问题
1. 频繁的内存泄漏
2.遇到一个奇怪的问题:在线程中创建一个对象,在构造的时候给对象的属性赋值,然后回去取回,值就没了~~~,这个问题不不可避免(与时间无关,与代码有关),我特地写了一个测试示例,没有错误。
3.一开始我用纯多线程写采集(不使用async),效率不高。然后我改变了组合方法。
4.下周的工作,我要摆脱线程部分,它太不稳定了。采集只使用异步。
吐槽:有些程序员分不清异步和并发。
补充:
经过调试,上述问题2已经解决,是由于框架中另一个位置的隐藏bug造成的。
它在虚拟机上运行良好,但尚未在服务器上运行。 查看全部
php多线程抓取网页(+异步的采集程序-上海怡健医学)
1.windows下安装很成问题,版本库不完全对应,比如我是win7 64位系统,php 5.4 结果没有对应的包,所以我只能打开一个虚拟机,安装的是win7x32+PHP5.3。
2.注意:线程的实现代码写在run方法中,但是启动线程的方法是start,不要直接调用run,(这样变成单线程了)
3.如果可能的话,先实例化所有线程,然后再循环,一个一个开始
4.线程中,SPL相关函数失败,最重要的是spl_register_autoload,导致自动加载失败。我的解决方案是在线程未启动时首先加载所有必需的类。
5.pthreads有版本问题,手册中大部分类和方法都需要2.0.0以上,我们运维原来安装的0.4.@ >4
6.我写了一个多线程+异步的采集程序。网站 中的 5 个 采集 花了一周的时间。
让我给你一个惊人的结论:
--------暂时不要用这个东西,生产环境有很多问题
1. 频繁的内存泄漏
2.遇到一个奇怪的问题:在线程中创建一个对象,在构造的时候给对象的属性赋值,然后回去取回,值就没了~~~,这个问题不不可避免(与时间无关,与代码有关),我特地写了一个测试示例,没有错误。
3.一开始我用纯多线程写采集(不使用async),效率不高。然后我改变了组合方法。
4.下周的工作,我要摆脱线程部分,它太不稳定了。采集只使用异步。
吐槽:有些程序员分不清异步和并发。
补充:
经过调试,上述问题2已经解决,是由于框架中另一个位置的隐藏bug造成的。
它在虚拟机上运行良好,但尚未在服务器上运行。
php多线程抓取网页(如何搭建PHP开发环境搭建只有两步:第一目标系统获取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-25 03:05
可以看出,很多PHP新手常年在各个技术群里问关于PHP的问题,很多时候都会被别人说:何不去搜索引擎寻找更远的地方?
我也觉得新人在学习的时候不能只问问题,容易产生惰性。但是,国内相对不乐观的情况,让很多新手在没有良好基础的情况下选择上手PHP。此外,围绕 PHP 的圈子往往是浮躁的。即使他们选择了搜索引擎,如果没有良好的基础,也很难选择哪种教程可靠。作为PHP入门必备的PHP开发环境的建立,这个问题就更加明显了。
无数的文章把本来很简单的PHP开发环境弄的极其复杂,而文章过分强调PHP语言的Web特性,强行绑架了PHP和Apache、Nginx、IIS不是的第三方应用部分PHP入门开发环节会导致很多PHPer新手误入歧途,忽略了PHP作为脚本语言的本质,从而忽略了学习更多基础知识的重要性,导致很多PHPer倾向于认为自己可以搭建一个网站只知道PHP的心态。
以上是吐槽。
如何搭建PHP开发环境
搭建PHP开发环境只需两步:
下载PHP二进制包(或源码包),解压到指定目录(源码包编译安装到指定目录);将解压缩(或安装)目录添加到环境变量中。
这篇文章就结束了。
只是在开玩笑。我的 文章 风格不仅仅是关于步骤,什么都没有。
估计很多看过很多环境搭建文章的PHPer都会说,怎么会有这样的事情发生呢?这也令人不解,一个开发环境怎么会对其他人如此复杂?到底是一个PHP开发环境,还是一整套HTTP服务?
不知道什么是 HTTP 服务?那么你需要 Apache、Nginx 和 IIS 来做什么?当然,目标不是学PHP,而是想用PHP快速创建一个网站,所以没说。另外,从 PHP 5.4 开始,PHP 自带了一个简单的 HTTP 服务器,对于常规开发来说基本足够了。
以下是正文:
第一个目标:根据目标系统获取PHP本身在Linux系统下通过包管理器获取PHP
常见的 Linux 发行版都自带包管理器,这些工具可以方便的获取打包好的 PHP 及其依赖的组件。由于发行版数量众多,这里仅以Ubuntu和CentOS为例,其他发行版操作类似。
Ubuntu:
sudo apt-get -y 安装 php
中央操作系统:
须藤百胜安装 -y php
需要注意的是,在不同的系统下,其包管理器自动安装的PHP版本可能不同,甚至有些系统的包管理器能提供的PHP版本更低。但是,大多数包管理器可以为已发布的软件指定存储库(源),并且一些组织提供收录更新版本的包管理器的存储库(源)。您还可以选择通过从源代码编译和安装来获取最新的 PHP。
OSX/macOS系统下通过包管理器(Homebrew)获取PHP
OSX/macOS下默认没有包管理器(有些Linux/Unix系统也没有包管理器),但是这个系统下有一个非常有名的包管理器Homebrew(),它的官网提供了一个方法安装自制软件。本文不再重复该过程。
安装 Homebrew 后,您可以使用以下命令安装 PHP:
冲泡安装php
如果要安装 PHP 7.0 的版本,可以使用以下命令安装:
冲泡安装php70
Linux/Unix系统下获取源码安装PHP
通过获取源代码,然后编译安装,可以轻松获取最新版本的 PHP 及其扩展,生成的 PHP 环境也是高度可定制的。
编译安装还是很简单的,但是相比于分发包的方式,编译安装最大的麻烦就是它的依赖组件包。根据你的配置项,在整个编译过程中会需要很多依赖。
处理依赖问题超出了本文的范围。依赖包也可以通过包管理器安装,也可以通过编译安装每个依赖包。显然,后者的(重复)工作量会非常大,所以大部分选择编译安装 PHP 及其依赖往往是通过脚本的方式完成的。
获取PHP源代码主要有两种方式:
下载并获取源代码的压缩文件,解压后解压源代码,在源代码目录执行如下命令编译安装:
$ ./configure
$ make
$ sudo make install
./configure是一个用来生成Makefile的脚本,里面收录了很多编译选项,比如设置最终编译的程序安装目录(即PHP安装目录),设置编译到核心的扩展,设置配置文件目录等。使用:./configure --help 以获得更多编译选项。
许多人害怕编译和安装。事实上,在当前环境下编译和安装都非常简单。所有的编译配置都很容易以统一的形式设置(即通过configure),设置完成后直接编译即可。很多人害怕的原因是配置选项太多,但这些也是套路。如果你的英文稍微好一点,通过查看各个编译选项的介绍,就可以一目了然地了解是否应该添加它们。此外,它确实不起作用,您可以使用其他常用的编译选项。
Windows下获取PHP
在 Windows 上安装 PHP 最简单的方法是先访问它,选择你需要的 PHP 版本,下载它,然后解压到你要安装的目录。
除了下载页面上的PHP版本,除了系统位选项,每个版本下还有两个选项:线程安全(Thread Safe)和非线程安全(Non Thread Safe),一般我们会选择非线程安全的threading Safe,这是因为 IIS 的 FastCGI 用于 Windows 上的主流情况,它使用多进程模型而不是早期的 ISAPI 多线程模型。在多进程模型下,线程安全非常鸡肋,性能很差。非线程安全可以换取更高的性能。
第二个目标:环境变量
什么是环境变量?简单来说,当你在控制台下执行 php 时,Windows 系统会在设置的名为 PATH 的环境变量中提供的(很多)路径中寻找 php.exe、php.bat 等的存在。 system 执行文件,Linux/Unix 系统也在名为PATH 的环境变量下设置的路径中搜索可执行目标文件。
如果你在Windows系统上,如果你的PHP安装在D:\Environment\php70,如果你当前的工作目录在D:\Development\Project,你需要在这个目录下运行一个PHP脚本(名为foo.php ),如果环境变量中没有添加 D:\Environment\php70,那么你必须输入命令来运行这个脚本:
D:\环境\php70\php.exe foo.php
如果将 PHP 安装目录添加到环境变量中,可以这样做:
php foo.php
在 Linux/Unix 下也是如此。比如你在/usr/local/php/70下编译安装PHP,工作目录是/home/developer/project,下面有一个文件foo.php。要执行 PHP,必须输入 PHP /usr/local/php/70/bin/php 的完整路径。
所以这里环境变量的作用就是提供一个全局路径,不管你的工作目录在哪里,都可以访问环境变量定义的目录下的可执行文件,比如PHP解释器在目录下环境变量,你可以随时随地调用PHP解释器来执行你的PHP脚本文件。既然可以随时随地执行PHP脚本,那不是说PHP开发环境没有问题吗?
这时候有人会疑惑,PHP不就是网站吗?可以看到这里,相信一般不会问这个问题吧?如果你真的有这个问题,那么我建议你老老实实从 PHP 官方文档开始阅读。
【结尾】
本作品采用《CC协议》,转载须注明作者及本文链接 查看全部
php多线程抓取网页(如何搭建PHP开发环境搭建只有两步:第一目标系统获取)
可以看出,很多PHP新手常年在各个技术群里问关于PHP的问题,很多时候都会被别人说:何不去搜索引擎寻找更远的地方?
我也觉得新人在学习的时候不能只问问题,容易产生惰性。但是,国内相对不乐观的情况,让很多新手在没有良好基础的情况下选择上手PHP。此外,围绕 PHP 的圈子往往是浮躁的。即使他们选择了搜索引擎,如果没有良好的基础,也很难选择哪种教程可靠。作为PHP入门必备的PHP开发环境的建立,这个问题就更加明显了。
无数的文章把本来很简单的PHP开发环境弄的极其复杂,而文章过分强调PHP语言的Web特性,强行绑架了PHP和Apache、Nginx、IIS不是的第三方应用部分PHP入门开发环节会导致很多PHPer新手误入歧途,忽略了PHP作为脚本语言的本质,从而忽略了学习更多基础知识的重要性,导致很多PHPer倾向于认为自己可以搭建一个网站只知道PHP的心态。
以上是吐槽。
如何搭建PHP开发环境
搭建PHP开发环境只需两步:
下载PHP二进制包(或源码包),解压到指定目录(源码包编译安装到指定目录);将解压缩(或安装)目录添加到环境变量中。
这篇文章就结束了。
只是在开玩笑。我的 文章 风格不仅仅是关于步骤,什么都没有。
估计很多看过很多环境搭建文章的PHPer都会说,怎么会有这样的事情发生呢?这也令人不解,一个开发环境怎么会对其他人如此复杂?到底是一个PHP开发环境,还是一整套HTTP服务?
不知道什么是 HTTP 服务?那么你需要 Apache、Nginx 和 IIS 来做什么?当然,目标不是学PHP,而是想用PHP快速创建一个网站,所以没说。另外,从 PHP 5.4 开始,PHP 自带了一个简单的 HTTP 服务器,对于常规开发来说基本足够了。
以下是正文:
第一个目标:根据目标系统获取PHP本身在Linux系统下通过包管理器获取PHP
常见的 Linux 发行版都自带包管理器,这些工具可以方便的获取打包好的 PHP 及其依赖的组件。由于发行版数量众多,这里仅以Ubuntu和CentOS为例,其他发行版操作类似。
Ubuntu:
sudo apt-get -y 安装 php
中央操作系统:
须藤百胜安装 -y php
需要注意的是,在不同的系统下,其包管理器自动安装的PHP版本可能不同,甚至有些系统的包管理器能提供的PHP版本更低。但是,大多数包管理器可以为已发布的软件指定存储库(源),并且一些组织提供收录更新版本的包管理器的存储库(源)。您还可以选择通过从源代码编译和安装来获取最新的 PHP。
OSX/macOS系统下通过包管理器(Homebrew)获取PHP
OSX/macOS下默认没有包管理器(有些Linux/Unix系统也没有包管理器),但是这个系统下有一个非常有名的包管理器Homebrew(),它的官网提供了一个方法安装自制软件。本文不再重复该过程。
安装 Homebrew 后,您可以使用以下命令安装 PHP:
冲泡安装php
如果要安装 PHP 7.0 的版本,可以使用以下命令安装:
冲泡安装php70
Linux/Unix系统下获取源码安装PHP
通过获取源代码,然后编译安装,可以轻松获取最新版本的 PHP 及其扩展,生成的 PHP 环境也是高度可定制的。
编译安装还是很简单的,但是相比于分发包的方式,编译安装最大的麻烦就是它的依赖组件包。根据你的配置项,在整个编译过程中会需要很多依赖。
处理依赖问题超出了本文的范围。依赖包也可以通过包管理器安装,也可以通过编译安装每个依赖包。显然,后者的(重复)工作量会非常大,所以大部分选择编译安装 PHP 及其依赖往往是通过脚本的方式完成的。
获取PHP源代码主要有两种方式:
下载并获取源代码的压缩文件,解压后解压源代码,在源代码目录执行如下命令编译安装:
$ ./configure
$ make
$ sudo make install
./configure是一个用来生成Makefile的脚本,里面收录了很多编译选项,比如设置最终编译的程序安装目录(即PHP安装目录),设置编译到核心的扩展,设置配置文件目录等。使用:./configure --help 以获得更多编译选项。
许多人害怕编译和安装。事实上,在当前环境下编译和安装都非常简单。所有的编译配置都很容易以统一的形式设置(即通过configure),设置完成后直接编译即可。很多人害怕的原因是配置选项太多,但这些也是套路。如果你的英文稍微好一点,通过查看各个编译选项的介绍,就可以一目了然地了解是否应该添加它们。此外,它确实不起作用,您可以使用其他常用的编译选项。
Windows下获取PHP
在 Windows 上安装 PHP 最简单的方法是先访问它,选择你需要的 PHP 版本,下载它,然后解压到你要安装的目录。
除了下载页面上的PHP版本,除了系统位选项,每个版本下还有两个选项:线程安全(Thread Safe)和非线程安全(Non Thread Safe),一般我们会选择非线程安全的threading Safe,这是因为 IIS 的 FastCGI 用于 Windows 上的主流情况,它使用多进程模型而不是早期的 ISAPI 多线程模型。在多进程模型下,线程安全非常鸡肋,性能很差。非线程安全可以换取更高的性能。
第二个目标:环境变量
什么是环境变量?简单来说,当你在控制台下执行 php 时,Windows 系统会在设置的名为 PATH 的环境变量中提供的(很多)路径中寻找 php.exe、php.bat 等的存在。 system 执行文件,Linux/Unix 系统也在名为PATH 的环境变量下设置的路径中搜索可执行目标文件。
如果你在Windows系统上,如果你的PHP安装在D:\Environment\php70,如果你当前的工作目录在D:\Development\Project,你需要在这个目录下运行一个PHP脚本(名为foo.php ),如果环境变量中没有添加 D:\Environment\php70,那么你必须输入命令来运行这个脚本:
D:\环境\php70\php.exe foo.php
如果将 PHP 安装目录添加到环境变量中,可以这样做:
php foo.php
在 Linux/Unix 下也是如此。比如你在/usr/local/php/70下编译安装PHP,工作目录是/home/developer/project,下面有一个文件foo.php。要执行 PHP,必须输入 PHP /usr/local/php/70/bin/php 的完整路径。
所以这里环境变量的作用就是提供一个全局路径,不管你的工作目录在哪里,都可以访问环境变量定义的目录下的可执行文件,比如PHP解释器在目录下环境变量,你可以随时随地调用PHP解释器来执行你的PHP脚本文件。既然可以随时随地执行PHP脚本,那不是说PHP开发环境没有问题吗?
这时候有人会疑惑,PHP不就是网站吗?可以看到这里,相信一般不会问这个问题吧?如果你真的有这个问题,那么我建议你老老实实从 PHP 官方文档开始阅读。
【结尾】
本作品采用《CC协议》,转载须注明作者及本文链接
php多线程抓取网页(什么是虚拟机?“语言级虚拟机”可能是不一样的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-17 17:03
来源:
什么是虚拟机?
“虚拟机”是一个很大的概念。从字面上看,“虚拟机”的意思是“虚拟计算机”。我们在学习服务器端编程的时候,相信大部分同学都接触过虚拟机。有这样一个场景,因为我们日常使用的电脑大部分都是Windows操作系统,而服务器软件大多运行在Linux系统上。如果我们在 Windows 上编程,我们不能直接在 Windows 上进行编程。测试非常不方便。基于这个场景,有一个虚拟机。它的作用是在windows系统的基础上运行Linux系统,然后我们可以很方便的在windows系统上测试Linux系统的程序。这个Linux操作系统是通过一些技术手段虚拟化的,
今天要讲的虚拟机和上面提到的虚拟机略有不同,但是它们解决的问题是一样的。上面提到的虚拟机虚拟化了一个完整的操作系统,我称之为“操作系统级虚拟机”。我们今天要讲的虚拟机是针对编程语言的。它可以达到的效果是相同的代码在不同的操作系统上运行,输出相同的结果。它可以编写一次,到处运行。我称之为“语言级虚拟机”。我们非常熟悉的编程语言,比如Java、PHP、Python等,其实都是基于虚拟机的语言,它们都是跨平台的。我们只需要编写一次代码,就可以在不同的操作系统上运行,
学过系统编程的同学应该都知道,不同的操作系统为同一个功能提供的“系统API”可能是不同的。例如,Windows 和 Linux 系统都提供了用于网络监控的 API,但它们对应的 SOCKET API 不同。假设我们使用的是平台相关的编程语言(如C、C++),我们在编程的时候一定要注意这个区别。并且针对不同的操作系统做相应的兼容性处理,否则程序在Linux系统上可以正常运行,但是Windows会报错。类似的区别还有很多,具体细节只能从相应的系统编程手册中了解。有些系统API完全不同,而有些只是个别参数不同,并且方法名称完全相同。程序员在写代码的时候需要时刻注意这些,这样才能写出健壮的跨平台代码,这对于新手来说是非常困难的。,而这样一来,程序员就需要将很大一部分精力花在兼容性问题上,而不是专注于实际功能的开发。
有了虚拟机,上面的问题就不存在了。虚拟机的角色只是一个中介代理。例如,我们是大城市的新手,想租房子。北京、上海、广州等大城市的房东那么多,如果没有房产中介(虚拟机),需要连接N个房东,然后才能租到合适的房子;有了房产中介(虚拟机),我们只需要告诉房产中介(虚拟机)我们要租什么样的房子,房产中介(虚拟机)会协调各个房东,我们就可以租到合适的房子,过程不同,结果是一样的。同理,以Socket API调用为例,我们把写好的代码交给虚拟机,然后虚拟机负责调用系统API,相当于在中间加了一层中介代理,虚拟机会根据操作系统选择正确的。Soekct API,帮助我们完成最终的功能。这样做的好处是程序员不再需要关注底层 API 的细节,可以专注于真实函数的编写。虚拟机帮助我们屏蔽了底层系统API的细节,编程的门槛也大大降低,代码的健壮性也大大提高。帮助我们完成最终的功能。这样做的好处是程序员不再需要关注底层 API 的细节,可以专注于真实函数的编写。虚拟机帮助我们屏蔽了底层系统API的细节,编程的门槛也大大降低,代码的健壮性也大大提高。帮助我们完成最终的功能。这样做的好处是程序员不再需要关注底层 API 的细节,可以专注于真实函数的编写。虚拟机帮助我们屏蔽了底层系统API的细节,编程的门槛也大大降低,代码的健壮性也大大提高。
PHP执行流程 PHP解释执行流程
了解PHP的同学都知道PHP是一种解释型语言,也称为脚本语言。它的特点是重量轻,使用方便。传统的编程语言需要经过编译链接后才能执行并输出结果。脚本语言(PHP)省略了这个过程,可以直接通过shell命令执行并输出相应的结果,非常轻量级、直观、易用。说实话,我进坑编程的时候也学过Java。为什么我终于进了PHP的坑?也许这些特点吸引了我。
刚才我们只讲了PHP的优点,但大多数时候,有得有失。我认为编程语言也是如此。PHP非常轻量级和好用,所以一定是以牺牲一些优势为代价的,否则为什么呢?其他编程语言不这样做。接下来说说PHP的执行过程。我想了解PHP的执行过程,然后才能了解PHP语言设计的选择。
以下是启用 Opcache 后 PHP 运行的主要流程。
图1
从图1可以看出,加载PHP代码文件后,首先通过词法分析器(re2c/lex),从代码中提取单词符号(token),再通过语法分析器(yacc/bison) , 从token中找到语法结构后,生成抽象语法树(AST),然后由静态编译器生成Opcode。最后,解释器模拟机器指令来执行每个 Opcode。
另外,当 PHP 打开 Opcache 时,ZendVM 会缓存 Opcode 并缓存在共享内存中。不仅如此,ZendVM 还会优化编译后的 Opcode。编译的优化技术包括方法内联、常量传播和重复代码删除。有了Opcache,不仅可以省去词法分析、语法分析、静态编译等步骤,而且还额外优化了Opcode,程序的执行效率比第一次执行要快。
以上就是PHP解释和执行的过程。虽然解释和执行对程序员非常友好,省略了静态编译这一步,但实际上这个过程并没有省略。它只是由虚拟机为我们完成,以牺牲一些性能为代价。重量轻、易于使用和灵活。其中,词法分析、语法分析、静态编译、解释执行等过程都是在执行过程中完成的。
编译语言执行过程
在了解了解释型语言的执行过程之后,我们再来看看编译型语言的执行过程作为对比,看看它与解释型语言有什么不同。
图 2
从图2可以看出,虚线框内的执行过程包括:词法分析、语法分析、编译。这三个步骤也收录在 PHP 的解释和执行中。唯一不同的是,C/C++的这三个步骤都是在编译过程中由编译器提前完成的,这样在运行时节省了大量的时间和开销。汇编代码生成后,第四步,链接汇编文件,生成可执行文件。这里的可执行文件是指二进制机器码,可以直接由CPU执行,无需额外翻译。这四个步骤统称为静态编译。可以清楚地看出,与解释型语言相比,编译型语言在前期需要做更多的工作,而是换取更高的性能和执行效率。因此,一般在大型项目中,由于性能要求比较高,代码量较大,如果使用解释型语言,执行效率会大大降低。使用静态编译可以达到更好的执行效率,降低服务器采购成本。
什么是 JIT?
JIT可以说是虚拟机中技术含量最高的技术。刚才我们讲了解释型语言和编译型语言的执行过程,分析了各自的优缺点。我们可以思考一下,是否有一种技术,它不仅在解释语言中具有轻量级和易于使用的优点,而且还具有编译语言的高性能。结论是 JIT。下面我们要介绍的是编程语言中的JIT技术。它的全称是“即时编译”。这是什么意思?我们先来看看维基百科对即时编译的定义。
在计算机技术中,即时编译(英文:just-in-time compilation,缩写为JIT;也译作即时编译、实时编译),又称动态翻译或运行时编译,是一种执行计算机代码的方法,其中一种方法涉及在程序执行期间(在运行时)而不是在执行之前进行编译。通常,这涉及将源代码或更常见的字节码转换为机器代码,然后直接执行。实现 JIT 编译器的系统通常会不断分析正在执行的代码,并确定代码的某些部分在哪里编译或重新编译。
正如我们刚才所说,JIT不仅具有解释语言的轻量级易用性,而且具有高性能,那么它是如何实现的呢?以PHP8新增的JIT特性为例,下图描述了PHP开启JIT特性后的执行过程。PHP8-JIT基于对Opcache的优化,在编译前对保存在Opcache中的Opcode进行优化。将Opcode编译成CPU可识别的可执行文件,即二进制文件,相当于C++编译后的可执行文件,但是这个过程不需要在运行前完成,而是在运行时虚拟机启动一个后台线程, 将Opcode转换成二进制文件,二进制文件缓存后,下次执行逻辑时,CPU直接执行即可,无需多说,理论性能与C++相同。这样做的好处是在实现高性能的同时,保留了 PHP 语言的易用性和灵活性。
图 3
JIT的触发条件
JIT实际上是将运行时的一部分代码转换成可执行文件并缓存起来,以加快下一段代码的执行速度。那么程序启动后会触发JIT吗?
程序第一次启动时,JIT 不起作用。可以理解为,PHP/Java代码第一次执行时,依然是以解释的形式运行。程序运行一段时间后需要触发JIT。说到这里,你有没有和我一样的疑问,为什么JIT在程序启动的时候会把所有的代码都转换成可执行文件并缓存起来,就像C++一样,这样不是更高效吗?Java 语言中确实有少量这样的应用,但都不是主流。主要有以下几个原因
全部编译成二进制文件需要很多时间,而且程序启动会很慢,这对于大型项目来说是无法接受的。并不是所有的代码都是性能优化所必需的,大部分代码在实际场景中用的不多。编译成二进制会占用大量容量。提前编译相当于静态编译。与静态编译相比,JIT 编译具有许多不可替代的优势。
JIT的触发条件主要基于“计数器的热点检测”。虚拟机为每个方法(或代码块)建立一个计数器。如果执行次数超过某个阈值,则认为是“热方法”。达到阈值后,虚拟机启动后台线程,将代码块编译成可执行文件,缓存在内存中,加快下一次执行的速度。以上只是对热代码的触发规则的简单说明。实际虚拟机采用的规则会比这个复杂。
JIT和提前编译的优缺点
JIT 编译器是在运行时执行的,我们可以很容易地看出,与提前编译相比,它有几个明显的缺点。首先,JIT 编译需要消耗运行时计算资源。最初,这些资源可用于执行程序。不管JIT编译器怎么优化(比如分层编译),这都是一个无法回避的问题,而最耗费资源的一步就是“过程间分析”,比如分析方法是否永远不能被调用,抽象是否方法只会调用单个版本的结论,这些信息对于生成高质量代码非常有价值,但是要准确获取这些信息必须经过大量耗时的计算,消耗大量的运行时计算资源. 反过来,
说了这么多,JIT编译和提前编译在性能优化上真的没有优势吗?结论是否定的,JIT 编译具有提前编译的许多不可替代的优点。正是因为JIT编译器是在运行时进行的,所以JIT编译器才能获取程序的真实数据。通过在程序运行时不断的采集监控信息,分析数据,JIT编译器可以对程序做一些事情。提前静态编译器无法进行的激进优化。
一是性能分析指导优化。比如JIT编译器在运行的时候,通过程序运行的监控数据,如果发现一些代码块执行的非常频繁,可以重点优化这块代码,例如:分配更好的寄存器、缓存等到此代码。
然后是积极的预测优化。比如有一个接口有3个实现类,但在实际运行过程中,实现类A的运行时间超过95%。通过数据分析,可以从根本上进行预测。每次执行 A。如果多次发现预测错误,可以返回解释状态再次执行,但这只是小概率事件,不影响程序执行结果。
最后是链接时优化。传统的编译步骤是将编译优化和链接分开。这意味着什么?添加一个程序需要用到A、B、C三个库。编译器首先编译这3个类库,并通过各种手段进行优化,转换成汇编代码保存在一个文件中。最后一步是转换这 3 个库。汇编文件链接在一起,最后转换成可执行文件。这里有一个问题。三个库 A、B 和 C 在编译时分别进行优化。不可能假设 A 和 B 中的某些方法被重复执行,或者可以通过方法内联进行优化。但是JIT编译器的不同之处在于它在运行时是动态链接的,可以优化整个程序的调用栈,
总结
写这篇博客的主要目的是总结这段时间学到的虚拟机相关技术。google了一下PHP虚拟机相关的文章,发现可以参考的文章很少。由于Java和PHP的执行原理非常相似,所以我想通过学习Java虚拟机可以理解ZendVM的工作原理。Java虚拟机非常成熟,可以说是虚拟机的鼻祖。有很多关于 JVM 世界的优秀书籍。它给我带来了一个新的世界,让我对虚拟机有了新的认识,JIT技术更让我惊喜。
最后,PHP 是世界上最好的语言!
参考 查看全部
php多线程抓取网页(什么是虚拟机?“语言级虚拟机”可能是不一样的)
来源:
什么是虚拟机?
“虚拟机”是一个很大的概念。从字面上看,“虚拟机”的意思是“虚拟计算机”。我们在学习服务器端编程的时候,相信大部分同学都接触过虚拟机。有这样一个场景,因为我们日常使用的电脑大部分都是Windows操作系统,而服务器软件大多运行在Linux系统上。如果我们在 Windows 上编程,我们不能直接在 Windows 上进行编程。测试非常不方便。基于这个场景,有一个虚拟机。它的作用是在windows系统的基础上运行Linux系统,然后我们可以很方便的在windows系统上测试Linux系统的程序。这个Linux操作系统是通过一些技术手段虚拟化的,
今天要讲的虚拟机和上面提到的虚拟机略有不同,但是它们解决的问题是一样的。上面提到的虚拟机虚拟化了一个完整的操作系统,我称之为“操作系统级虚拟机”。我们今天要讲的虚拟机是针对编程语言的。它可以达到的效果是相同的代码在不同的操作系统上运行,输出相同的结果。它可以编写一次,到处运行。我称之为“语言级虚拟机”。我们非常熟悉的编程语言,比如Java、PHP、Python等,其实都是基于虚拟机的语言,它们都是跨平台的。我们只需要编写一次代码,就可以在不同的操作系统上运行,
学过系统编程的同学应该都知道,不同的操作系统为同一个功能提供的“系统API”可能是不同的。例如,Windows 和 Linux 系统都提供了用于网络监控的 API,但它们对应的 SOCKET API 不同。假设我们使用的是平台相关的编程语言(如C、C++),我们在编程的时候一定要注意这个区别。并且针对不同的操作系统做相应的兼容性处理,否则程序在Linux系统上可以正常运行,但是Windows会报错。类似的区别还有很多,具体细节只能从相应的系统编程手册中了解。有些系统API完全不同,而有些只是个别参数不同,并且方法名称完全相同。程序员在写代码的时候需要时刻注意这些,这样才能写出健壮的跨平台代码,这对于新手来说是非常困难的。,而这样一来,程序员就需要将很大一部分精力花在兼容性问题上,而不是专注于实际功能的开发。
有了虚拟机,上面的问题就不存在了。虚拟机的角色只是一个中介代理。例如,我们是大城市的新手,想租房子。北京、上海、广州等大城市的房东那么多,如果没有房产中介(虚拟机),需要连接N个房东,然后才能租到合适的房子;有了房产中介(虚拟机),我们只需要告诉房产中介(虚拟机)我们要租什么样的房子,房产中介(虚拟机)会协调各个房东,我们就可以租到合适的房子,过程不同,结果是一样的。同理,以Socket API调用为例,我们把写好的代码交给虚拟机,然后虚拟机负责调用系统API,相当于在中间加了一层中介代理,虚拟机会根据操作系统选择正确的。Soekct API,帮助我们完成最终的功能。这样做的好处是程序员不再需要关注底层 API 的细节,可以专注于真实函数的编写。虚拟机帮助我们屏蔽了底层系统API的细节,编程的门槛也大大降低,代码的健壮性也大大提高。帮助我们完成最终的功能。这样做的好处是程序员不再需要关注底层 API 的细节,可以专注于真实函数的编写。虚拟机帮助我们屏蔽了底层系统API的细节,编程的门槛也大大降低,代码的健壮性也大大提高。帮助我们完成最终的功能。这样做的好处是程序员不再需要关注底层 API 的细节,可以专注于真实函数的编写。虚拟机帮助我们屏蔽了底层系统API的细节,编程的门槛也大大降低,代码的健壮性也大大提高。
PHP执行流程 PHP解释执行流程
了解PHP的同学都知道PHP是一种解释型语言,也称为脚本语言。它的特点是重量轻,使用方便。传统的编程语言需要经过编译链接后才能执行并输出结果。脚本语言(PHP)省略了这个过程,可以直接通过shell命令执行并输出相应的结果,非常轻量级、直观、易用。说实话,我进坑编程的时候也学过Java。为什么我终于进了PHP的坑?也许这些特点吸引了我。
刚才我们只讲了PHP的优点,但大多数时候,有得有失。我认为编程语言也是如此。PHP非常轻量级和好用,所以一定是以牺牲一些优势为代价的,否则为什么呢?其他编程语言不这样做。接下来说说PHP的执行过程。我想了解PHP的执行过程,然后才能了解PHP语言设计的选择。
以下是启用 Opcache 后 PHP 运行的主要流程。
图1
从图1可以看出,加载PHP代码文件后,首先通过词法分析器(re2c/lex),从代码中提取单词符号(token),再通过语法分析器(yacc/bison) , 从token中找到语法结构后,生成抽象语法树(AST),然后由静态编译器生成Opcode。最后,解释器模拟机器指令来执行每个 Opcode。
另外,当 PHP 打开 Opcache 时,ZendVM 会缓存 Opcode 并缓存在共享内存中。不仅如此,ZendVM 还会优化编译后的 Opcode。编译的优化技术包括方法内联、常量传播和重复代码删除。有了Opcache,不仅可以省去词法分析、语法分析、静态编译等步骤,而且还额外优化了Opcode,程序的执行效率比第一次执行要快。
以上就是PHP解释和执行的过程。虽然解释和执行对程序员非常友好,省略了静态编译这一步,但实际上这个过程并没有省略。它只是由虚拟机为我们完成,以牺牲一些性能为代价。重量轻、易于使用和灵活。其中,词法分析、语法分析、静态编译、解释执行等过程都是在执行过程中完成的。
编译语言执行过程
在了解了解释型语言的执行过程之后,我们再来看看编译型语言的执行过程作为对比,看看它与解释型语言有什么不同。
图 2
从图2可以看出,虚线框内的执行过程包括:词法分析、语法分析、编译。这三个步骤也收录在 PHP 的解释和执行中。唯一不同的是,C/C++的这三个步骤都是在编译过程中由编译器提前完成的,这样在运行时节省了大量的时间和开销。汇编代码生成后,第四步,链接汇编文件,生成可执行文件。这里的可执行文件是指二进制机器码,可以直接由CPU执行,无需额外翻译。这四个步骤统称为静态编译。可以清楚地看出,与解释型语言相比,编译型语言在前期需要做更多的工作,而是换取更高的性能和执行效率。因此,一般在大型项目中,由于性能要求比较高,代码量较大,如果使用解释型语言,执行效率会大大降低。使用静态编译可以达到更好的执行效率,降低服务器采购成本。
什么是 JIT?
JIT可以说是虚拟机中技术含量最高的技术。刚才我们讲了解释型语言和编译型语言的执行过程,分析了各自的优缺点。我们可以思考一下,是否有一种技术,它不仅在解释语言中具有轻量级和易于使用的优点,而且还具有编译语言的高性能。结论是 JIT。下面我们要介绍的是编程语言中的JIT技术。它的全称是“即时编译”。这是什么意思?我们先来看看维基百科对即时编译的定义。
在计算机技术中,即时编译(英文:just-in-time compilation,缩写为JIT;也译作即时编译、实时编译),又称动态翻译或运行时编译,是一种执行计算机代码的方法,其中一种方法涉及在程序执行期间(在运行时)而不是在执行之前进行编译。通常,这涉及将源代码或更常见的字节码转换为机器代码,然后直接执行。实现 JIT 编译器的系统通常会不断分析正在执行的代码,并确定代码的某些部分在哪里编译或重新编译。
正如我们刚才所说,JIT不仅具有解释语言的轻量级易用性,而且具有高性能,那么它是如何实现的呢?以PHP8新增的JIT特性为例,下图描述了PHP开启JIT特性后的执行过程。PHP8-JIT基于对Opcache的优化,在编译前对保存在Opcache中的Opcode进行优化。将Opcode编译成CPU可识别的可执行文件,即二进制文件,相当于C++编译后的可执行文件,但是这个过程不需要在运行前完成,而是在运行时虚拟机启动一个后台线程, 将Opcode转换成二进制文件,二进制文件缓存后,下次执行逻辑时,CPU直接执行即可,无需多说,理论性能与C++相同。这样做的好处是在实现高性能的同时,保留了 PHP 语言的易用性和灵活性。
图 3
JIT的触发条件
JIT实际上是将运行时的一部分代码转换成可执行文件并缓存起来,以加快下一段代码的执行速度。那么程序启动后会触发JIT吗?
程序第一次启动时,JIT 不起作用。可以理解为,PHP/Java代码第一次执行时,依然是以解释的形式运行。程序运行一段时间后需要触发JIT。说到这里,你有没有和我一样的疑问,为什么JIT在程序启动的时候会把所有的代码都转换成可执行文件并缓存起来,就像C++一样,这样不是更高效吗?Java 语言中确实有少量这样的应用,但都不是主流。主要有以下几个原因
全部编译成二进制文件需要很多时间,而且程序启动会很慢,这对于大型项目来说是无法接受的。并不是所有的代码都是性能优化所必需的,大部分代码在实际场景中用的不多。编译成二进制会占用大量容量。提前编译相当于静态编译。与静态编译相比,JIT 编译具有许多不可替代的优势。
JIT的触发条件主要基于“计数器的热点检测”。虚拟机为每个方法(或代码块)建立一个计数器。如果执行次数超过某个阈值,则认为是“热方法”。达到阈值后,虚拟机启动后台线程,将代码块编译成可执行文件,缓存在内存中,加快下一次执行的速度。以上只是对热代码的触发规则的简单说明。实际虚拟机采用的规则会比这个复杂。
JIT和提前编译的优缺点
JIT 编译器是在运行时执行的,我们可以很容易地看出,与提前编译相比,它有几个明显的缺点。首先,JIT 编译需要消耗运行时计算资源。最初,这些资源可用于执行程序。不管JIT编译器怎么优化(比如分层编译),这都是一个无法回避的问题,而最耗费资源的一步就是“过程间分析”,比如分析方法是否永远不能被调用,抽象是否方法只会调用单个版本的结论,这些信息对于生成高质量代码非常有价值,但是要准确获取这些信息必须经过大量耗时的计算,消耗大量的运行时计算资源. 反过来,
说了这么多,JIT编译和提前编译在性能优化上真的没有优势吗?结论是否定的,JIT 编译具有提前编译的许多不可替代的优点。正是因为JIT编译器是在运行时进行的,所以JIT编译器才能获取程序的真实数据。通过在程序运行时不断的采集监控信息,分析数据,JIT编译器可以对程序做一些事情。提前静态编译器无法进行的激进优化。
一是性能分析指导优化。比如JIT编译器在运行的时候,通过程序运行的监控数据,如果发现一些代码块执行的非常频繁,可以重点优化这块代码,例如:分配更好的寄存器、缓存等到此代码。
然后是积极的预测优化。比如有一个接口有3个实现类,但在实际运行过程中,实现类A的运行时间超过95%。通过数据分析,可以从根本上进行预测。每次执行 A。如果多次发现预测错误,可以返回解释状态再次执行,但这只是小概率事件,不影响程序执行结果。
最后是链接时优化。传统的编译步骤是将编译优化和链接分开。这意味着什么?添加一个程序需要用到A、B、C三个库。编译器首先编译这3个类库,并通过各种手段进行优化,转换成汇编代码保存在一个文件中。最后一步是转换这 3 个库。汇编文件链接在一起,最后转换成可执行文件。这里有一个问题。三个库 A、B 和 C 在编译时分别进行优化。不可能假设 A 和 B 中的某些方法被重复执行,或者可以通过方法内联进行优化。但是JIT编译器的不同之处在于它在运行时是动态链接的,可以优化整个程序的调用栈,
总结
写这篇博客的主要目的是总结这段时间学到的虚拟机相关技术。google了一下PHP虚拟机相关的文章,发现可以参考的文章很少。由于Java和PHP的执行原理非常相似,所以我想通过学习Java虚拟机可以理解ZendVM的工作原理。Java虚拟机非常成熟,可以说是虚拟机的鼻祖。有很多关于 JVM 世界的优秀书籍。它给我带来了一个新的世界,让我对虚拟机有了新的认识,JIT技术更让我惊喜。
最后,PHP 是世界上最好的语言!
参考
php多线程抓取网页(什么是网络爬虫?PHP和Python都写过爬虫和提取程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-14 19:14
什么是网络爬虫?
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
爬行动物有什么用?
很多语言都可以用来编写爬虫,比如Java、PHP、Python等,它们各有优缺点。
PHP 和 Python 都编写了爬虫和文本提取器。
我开始使用PHP,那么我们来谈谈PHP的优点:
1.语言比较简单,PHP是一门很随意的语言。它很容易编写,让您专注于您正在尝试做的事情,而不是各种语法规则等等。
2.各种功能模块齐全,分为两部分:
1.网页下载:curl等扩展库;
2.文档解析:dom、xpath、tidy、各种转码工具,可能和题主的问题不太一样,我的爬虫需要提取文本,所以需要很复杂的文本处理,所以各种方便的文本处理工具是我的最爱。;
总之,很容易上手。
缺点:
1.并发处理能力弱:由于当时PHP没有线程和进程功能,为了实现并发,需要借用多通道消费模型,而PHP使用了select模型。实现起来比较麻烦,可能是因为level的问题,我的程序经常会出现一些错误,导致错过catch。
让我们谈谈Python:
优势:
1.各种爬虫框架,方便高效的下载网页;
2.多线程,成熟稳定的进程模型,爬虫是典型的多任务场景,请求一个页面会有很长的延迟,一般会多等待。多线程或多进程将优化程序效率,提高整个系统的下载和分析能力。
3.GAE的支持,我写爬虫的时候刚好有GAE,而且只支持Python。使用 GAE 创建的爬虫几乎是免费的。最多,我有将近一千个应用程序实例在工作。
缺点:
1. 对非标准HTML的适应性差:比如一个页面同时收录GB18030字符集中文和UTF-8字符集中文,Python处理不像PHP那么简单,需要自己做很多的判断工作。当然,这在提取文本时很麻烦。
Java和C++当时也在研究,比脚本语言更麻烦,所以放弃了。
总之,如果你开发一个小规模的爬虫脚本语言,它是一门各方面都有优势的语言。如果你想开发复杂的爬虫系统,Java可能是一个额外的选择,而C++我觉得写一个模块更合适。对于爬虫系统来说,下载和内容解析只是两个基本功能。一个真正好的系统还包括完整的任务调度、监控、存储、页面数据保存和更新逻辑、重新加载等等。爬虫是一个消耗带宽的应用程序。一个好的设计会节省大量的带宽和服务器资源,好坏差距很大。
全面的
编写爬虫是同时编写和测试。测试但再次更改。这个程序用python写是最方便的。
而python相关的库也是最方便的,比如request、jieba、redis、gevent、NLTK、lxml、pyquery、BeautifulSoup、Pillow。无论是最简单的爬虫还是非常复杂的爬虫,都可以轻松搞定。
如果你从成为python工程师还是新手,可以从“我的专栏”开始学习。 查看全部
php多线程抓取网页(什么是网络爬虫?PHP和Python都写过爬虫和提取程序)
什么是网络爬虫?
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
爬行动物有什么用?
很多语言都可以用来编写爬虫,比如Java、PHP、Python等,它们各有优缺点。
PHP 和 Python 都编写了爬虫和文本提取器。
我开始使用PHP,那么我们来谈谈PHP的优点:
1.语言比较简单,PHP是一门很随意的语言。它很容易编写,让您专注于您正在尝试做的事情,而不是各种语法规则等等。
2.各种功能模块齐全,分为两部分:
1.网页下载:curl等扩展库;
2.文档解析:dom、xpath、tidy、各种转码工具,可能和题主的问题不太一样,我的爬虫需要提取文本,所以需要很复杂的文本处理,所以各种方便的文本处理工具是我的最爱。;
总之,很容易上手。
缺点:
1.并发处理能力弱:由于当时PHP没有线程和进程功能,为了实现并发,需要借用多通道消费模型,而PHP使用了select模型。实现起来比较麻烦,可能是因为level的问题,我的程序经常会出现一些错误,导致错过catch。
让我们谈谈Python:
优势:
1.各种爬虫框架,方便高效的下载网页;
2.多线程,成熟稳定的进程模型,爬虫是典型的多任务场景,请求一个页面会有很长的延迟,一般会多等待。多线程或多进程将优化程序效率,提高整个系统的下载和分析能力。
3.GAE的支持,我写爬虫的时候刚好有GAE,而且只支持Python。使用 GAE 创建的爬虫几乎是免费的。最多,我有将近一千个应用程序实例在工作。
缺点:
1. 对非标准HTML的适应性差:比如一个页面同时收录GB18030字符集中文和UTF-8字符集中文,Python处理不像PHP那么简单,需要自己做很多的判断工作。当然,这在提取文本时很麻烦。
Java和C++当时也在研究,比脚本语言更麻烦,所以放弃了。
总之,如果你开发一个小规模的爬虫脚本语言,它是一门各方面都有优势的语言。如果你想开发复杂的爬虫系统,Java可能是一个额外的选择,而C++我觉得写一个模块更合适。对于爬虫系统来说,下载和内容解析只是两个基本功能。一个真正好的系统还包括完整的任务调度、监控、存储、页面数据保存和更新逻辑、重新加载等等。爬虫是一个消耗带宽的应用程序。一个好的设计会节省大量的带宽和服务器资源,好坏差距很大。
全面的
编写爬虫是同时编写和测试。测试但再次更改。这个程序用python写是最方便的。
而python相关的库也是最方便的,比如request、jieba、redis、gevent、NLTK、lxml、pyquery、BeautifulSoup、Pillow。无论是最简单的爬虫还是非常复杂的爬虫,都可以轻松搞定。
如果你从成为python工程师还是新手,可以从“我的专栏”开始学习。
php多线程抓取网页(php里提供了一个函数curl_multi_init(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-14 08:10
curl_init() 以单线程模式处理事物。如果需要使用多线程模式进行事务处理,那么PHP为我们提供了一个函数curl_multi_init(),就是多线程模式处理事务的函数。
curl_multi_init() 多线程可以提高网页的处理速度吗?今天我将通过一个实验来验证这个问题。
我今天的测试很简单,就是抓取网页的内容,需要连续抓取5次,使用curl_init()和curl_multi_init()函数完成,记录两次耗时,并比较得出结论。
首先,使用 curl_init() 单线程连续抓取网页内容 5 次。
然后,使用 curl_multi_init() 多线程连续抓取网页内容 5 次。
为了避免随机性,我测试了5次(通过CTRL+F5强制刷新),数据如下:
curl_init():
第一次
第二次
第三次
第四次
第五次
平均
时间(毫秒)
3724
3615
2540
1957年
2794
2926
curl_multi_init():
第一次
第二次
第三次
第四次
第五次
平均
时间(毫秒)
4275
2912
3691
4198
3891
3793
从测试结果来看,我们发现两种方式的耗时相差不大,只有700多毫秒。很多人原本以为多线程会比单线程花更少的时间,但事实并非如此。从数据上看,多线程比单线程花费的时间要多一点。但是对于一些事务来说,多线程处理不一定是追求速度,需要注意。
关于 curl_multi_init()
一般来说,考虑使用curl_multi_init()的时候,目的是同时请求多个url,而不是一个一个,否则需要curl_init()。
但是在使用curl_multi的时候,可能会遇到cpu消耗高、网页假死等现象。可以阅读《PHP使用curl_multi_select解决curl_multi网页假死问题》
curl_multi的使用步骤总结如下:
各功能作用说明:
curl_multi_init()
初始化 curl 批处理句柄资源。
curl_multi_add_handle()
将单独的 curl 句柄资源添加到 curl 批处理会话。curl_multi_add_handle()函数有两个参数,第一个参数代表一个curl批量句柄资源,第二个参数代表单个curl句柄资源。
curl_multi_exec()
解析一个curl批处理句柄,curl_multi_exec()函数有两个参数,第一个参数代表一个批处理句柄资源,第二个参数是一个引用值参数,表示剩余的单个curl句柄资源需要处理的数量。
curl_multi_remove_handle()
curl_multi_remove_handle()函数有两个参数,第一个参数代表一个curl批处理句柄资源,第二个参数代表一个单独的curl句柄资源。
curl_multi_close()
关闭批处理资源。
curl_multi_getcontent()
如果设置了 CURLOPT_RETURNTRANSFER,则返回获取的输出的文本流。
curl_multi_info_read()
获取当前解析的 curl 的相关传输信息。
原文链接: 查看全部
php多线程抓取网页(php里提供了一个函数curl_multi_init(组图))
curl_init() 以单线程模式处理事物。如果需要使用多线程模式进行事务处理,那么PHP为我们提供了一个函数curl_multi_init(),就是多线程模式处理事务的函数。
curl_multi_init() 多线程可以提高网页的处理速度吗?今天我将通过一个实验来验证这个问题。
我今天的测试很简单,就是抓取网页的内容,需要连续抓取5次,使用curl_init()和curl_multi_init()函数完成,记录两次耗时,并比较得出结论。
首先,使用 curl_init() 单线程连续抓取网页内容 5 次。
然后,使用 curl_multi_init() 多线程连续抓取网页内容 5 次。
为了避免随机性,我测试了5次(通过CTRL+F5强制刷新),数据如下:
curl_init():
第一次
第二次
第三次
第四次
第五次
平均
时间(毫秒)
3724
3615
2540
1957年
2794
2926
curl_multi_init():
第一次
第二次
第三次
第四次
第五次
平均
时间(毫秒)
4275
2912
3691
4198
3891
3793
从测试结果来看,我们发现两种方式的耗时相差不大,只有700多毫秒。很多人原本以为多线程会比单线程花更少的时间,但事实并非如此。从数据上看,多线程比单线程花费的时间要多一点。但是对于一些事务来说,多线程处理不一定是追求速度,需要注意。
关于 curl_multi_init()
一般来说,考虑使用curl_multi_init()的时候,目的是同时请求多个url,而不是一个一个,否则需要curl_init()。
但是在使用curl_multi的时候,可能会遇到cpu消耗高、网页假死等现象。可以阅读《PHP使用curl_multi_select解决curl_multi网页假死问题》
curl_multi的使用步骤总结如下:
各功能作用说明:
curl_multi_init()
初始化 curl 批处理句柄资源。
curl_multi_add_handle()
将单独的 curl 句柄资源添加到 curl 批处理会话。curl_multi_add_handle()函数有两个参数,第一个参数代表一个curl批量句柄资源,第二个参数代表单个curl句柄资源。
curl_multi_exec()
解析一个curl批处理句柄,curl_multi_exec()函数有两个参数,第一个参数代表一个批处理句柄资源,第二个参数是一个引用值参数,表示剩余的单个curl句柄资源需要处理的数量。
curl_multi_remove_handle()
curl_multi_remove_handle()函数有两个参数,第一个参数代表一个curl批处理句柄资源,第二个参数代表一个单独的curl句柄资源。
curl_multi_close()
关闭批处理资源。
curl_multi_getcontent()
如果设置了 CURLOPT_RETURNTRANSFER,则返回获取的输出的文本流。
curl_multi_info_read()
获取当前解析的 curl 的相关传输信息。
原文链接:
php多线程抓取网页(一下如何使用缓存(Redis)实现分布式锁(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-11 17:04
分布式锁是指在分布式部署环境中,多个客户端可以通过锁机制互斥访问共享资源。
目前比较常见的分布式锁实现方案有以下几种:
下面介绍如何使用缓存(Redis)实现分布式锁。
使用 Redis 实现分布式锁的最简单方法是使用命令 SETNX。SETNX(SET if Not eXist)的用法是:SETNX键值。只有当key key 不存在时,key key 的value 才设置为value。如果 key key 存在,SETNX 什么也不做。SETNX 设置成功返回,设置失败返回0。当你想获取锁时,直接使用SETNX获取锁。当要解除锁定时,使用 DEL 命令删除对应的键键。
上述方案有一个致命的问题,就是线程由于一些异常因素(如宕机)而获得锁后,无法正常进行解锁操作,锁永远不会被释放。为此,我们可以为此锁添加超时。第一次我们会想到Redis的EXPIRE命令(EXPIRE键秒)。但是这里我们不能使用EXPIRE来实现分布式锁,因为它是和SETNX一起的两个操作,这两个操作之间可能会出现异常,所以还是达不到预期的效果。示例如下:
// STEP 1<br style="-webkit-tap-highlight-color: transparent;">SETNX key value<br style="-webkit-tap-highlight-color: transparent;">// 若在这里(STEP1和STEP2之间)程序突然崩溃,则无法设置过期时间,将有可能无法释放锁<br style="-webkit-tap-highlight-color: transparent;">// STEP 2<br style="-webkit-tap-highlight-color: transparent;">EXPIRE key expireTime<br style="-webkit-tap-highlight-color: transparent;">
正确的手势是使用命令“SET key value [EX seconds] [PX milliseconds] [NX|XX]”。
从 Redis 2.6.12 开始,可以通过一系列参数来修改 SET 命令的行为:
比如我们需要创建一个分布式锁,并将过期时间设置为10s,那么我们可以执行如下命令:
SET lockKey lockValue EX 10 NX<br style="-webkit-tap-highlight-color: transparent;">或者<br style="-webkit-tap-highlight-color: transparent;">SET lockKey lockValue PX 10000 NX<br style="-webkit-tap-highlight-color: transparent;">
注意EX和PX不能同时使用,否则会报错:ERR syntax error。
解锁时,使用 DEL 命令解锁。
修改后的方案看起来很完美,但实际上还是有问题。想象一下,线程A获取了一个锁,设置过期时间为10s,然后执行业务逻辑需要15s。此时线程A获取的锁已经被Redis的过期机制自动释放了。线程A获取锁后10s后,锁可能已经被其他线程获取。当线程 A 执行完业务逻辑并准备解锁时(DEL 键),就可以删除其他线程已经获得的锁。
所以最好的办法就是在开锁的时候判断锁是不是你自己的。我们可以在设置key的时候将value设置为唯一值uniqueValue(可以是随机值,UUID,也可以是机器号+线程号,签名等的组合)。解锁时,即删除key时,首先判断key对应的值是否与之前设置的值相等。如果相等,则可以删除密钥。伪代码示例如下:
if uniqueKey == GET(key) {<br style="-webkit-tap-highlight-color: transparent;"> DEL key<br style="-webkit-tap-highlight-color: transparent;">}<br style="-webkit-tap-highlight-color: transparent;">
这里我们一眼就能看出问题所在:GET和DEL是两个独立的操作,在GET执行之后和DEL执行之前的间隙中可能会出现异常。如果我们只是确保解锁代码是原子的,我们就可以解决问题。这里我们介绍一种新的方式,即Lua脚本,示例如下:
if redis.call("get",KEYS[1]) == ARGV[1] then<br style="-webkit-tap-highlight-color: transparent;"> return redis.call("del",KEYS[1])<br style="-webkit-tap-highlight-color: transparent;">else<br style="-webkit-tap-highlight-color: transparent;"> return 0<br style="-webkit-tap-highlight-color: transparent;">end<br style="-webkit-tap-highlight-color: transparent;">
其中 ARGV[1] 表示设置密钥时指定的唯一值。
由于 Lua 脚本的原子性,当 Redis 执行脚本时,其他客户端的命令需要等待 Lua 脚本执行后才能执行。
下面用Jedis来演示获取锁和解锁的实现,如下:
public boolean lock(String lockKey, String uniqueValue, int seconds){<br style="-webkit-tap-highlight-color: transparent;"> SetParams params = new SetParams();<br style="-webkit-tap-highlight-color: transparent;"> params.nx().ex(seconds);<br style="-webkit-tap-highlight-color: transparent;"> String result = jedis.set(lockKey, uniqueValue, params);<br style="-webkit-tap-highlight-color: transparent;"> if ("OK".equals(result)) {<br style="-webkit-tap-highlight-color: transparent;"> return true;<br style="-webkit-tap-highlight-color: transparent;"> }<br style="-webkit-tap-highlight-color: transparent;"> return false;<br style="-webkit-tap-highlight-color: transparent;">}<br style="-webkit-tap-highlight-color: transparent;">public boolean unlock(String lockKey, String uniqueValue){<br style="-webkit-tap-highlight-color: transparent;"> String script = "if redis.call('get', KEYS[1]) == ARGV[1] " +<br style="-webkit-tap-highlight-color: transparent;"> "then return redis.call('del', KEYS[1]) else return 0 end";<br style="-webkit-tap-highlight-color: transparent;"> Object result = jedis.eval(script, <br style="-webkit-tap-highlight-color: transparent;"> Collections.singletonList(lockKey), <br style="-webkit-tap-highlight-color: transparent;"> Collections.singletonList(uniqueValue));<br style="-webkit-tap-highlight-color: transparent;"> if (result.equals(1)) {<br style="-webkit-tap-highlight-color: transparent;"> return true;<br style="-webkit-tap-highlight-color: transparent;"> }<br style="-webkit-tap-highlight-color: transparent;"> return false;<br style="-webkit-tap-highlight-color: transparent;">}<br style="-webkit-tap-highlight-color: transparent;">
这是万无一失的吗?明显不是!
从表面上看,这种方法似乎行得通,但是有一个问题:我们的系统架构存在单点故障,如果 Redis 主节点宕机了怎么办?可能有人会说:加个从节点!只在主人宕机时使用奴隶!
但实际上,这种方案显然是不可行的,因为 Redis 复制是异步的。例如:
线程 A 获得主节点上的锁。在将 A 创建的密钥写入从节点之前,主节点已关闭。从节点成为主节点。线程 B 也获得了与 A 相同的锁。(因为在原来的slave中没有A持有锁的信息)
当然,在某些场景下,这个方案是没有问题的,比如业务模型允许同时持有锁的情况,所以使用这个方案也不是没有道理。
例如,一个服务有 2 个服务实例:A 和 B。最初,A 获取锁,然后对资源进行操作(可以假设此操作非常占用资源),而 B 不获取锁并执行不执行任何操作。时间B可以看成是A的热备份,当A异常时,B可以“正”。当锁异常时,比如 Redis master 宕机了,那么 B 可能会持有锁,同时对资源进行操作。如果运算的结果是幂等的(或其他情况),也可以使用这种方案。这里引入分布式锁可以让服务避免正常情况下重复计算造成的资源浪费。
针对这种情况,antriez 提出了 Redlock 算法。Redlock算法的主要思想是:假设我们有N个Redis主节点,这些节点是完全独立的,我们可以使用前面的方案来获取和解锁之前的单个Redis主节点,如果我们一般可以在在合理的范围内或者N/2+1个锁,那么我们可以认为锁已经被成功获取了,否则锁没有被获取(类似于Quorum模型)。Redlock的原理虽然很好理解,但其内部实现细节非常复杂,需要考虑的因素很多。
Redlock 的算法不是“灵丹妙药”。除了条件苛刻之外,它的算法本身也受到了质疑。关于 Redis 分布式锁的安全性,分布式系统专家 Martin Kleppmann 和 Redis 的作者 antirez 有过争论。 查看全部
php多线程抓取网页(一下如何使用缓存(Redis)实现分布式锁(图))
分布式锁是指在分布式部署环境中,多个客户端可以通过锁机制互斥访问共享资源。
目前比较常见的分布式锁实现方案有以下几种:
下面介绍如何使用缓存(Redis)实现分布式锁。
使用 Redis 实现分布式锁的最简单方法是使用命令 SETNX。SETNX(SET if Not eXist)的用法是:SETNX键值。只有当key key 不存在时,key key 的value 才设置为value。如果 key key 存在,SETNX 什么也不做。SETNX 设置成功返回,设置失败返回0。当你想获取锁时,直接使用SETNX获取锁。当要解除锁定时,使用 DEL 命令删除对应的键键。
上述方案有一个致命的问题,就是线程由于一些异常因素(如宕机)而获得锁后,无法正常进行解锁操作,锁永远不会被释放。为此,我们可以为此锁添加超时。第一次我们会想到Redis的EXPIRE命令(EXPIRE键秒)。但是这里我们不能使用EXPIRE来实现分布式锁,因为它是和SETNX一起的两个操作,这两个操作之间可能会出现异常,所以还是达不到预期的效果。示例如下:
// STEP 1<br style="-webkit-tap-highlight-color: transparent;">SETNX key value<br style="-webkit-tap-highlight-color: transparent;">// 若在这里(STEP1和STEP2之间)程序突然崩溃,则无法设置过期时间,将有可能无法释放锁<br style="-webkit-tap-highlight-color: transparent;">// STEP 2<br style="-webkit-tap-highlight-color: transparent;">EXPIRE key expireTime<br style="-webkit-tap-highlight-color: transparent;">
正确的手势是使用命令“SET key value [EX seconds] [PX milliseconds] [NX|XX]”。
从 Redis 2.6.12 开始,可以通过一系列参数来修改 SET 命令的行为:
比如我们需要创建一个分布式锁,并将过期时间设置为10s,那么我们可以执行如下命令:
SET lockKey lockValue EX 10 NX<br style="-webkit-tap-highlight-color: transparent;">或者<br style="-webkit-tap-highlight-color: transparent;">SET lockKey lockValue PX 10000 NX<br style="-webkit-tap-highlight-color: transparent;">
注意EX和PX不能同时使用,否则会报错:ERR syntax error。
解锁时,使用 DEL 命令解锁。
修改后的方案看起来很完美,但实际上还是有问题。想象一下,线程A获取了一个锁,设置过期时间为10s,然后执行业务逻辑需要15s。此时线程A获取的锁已经被Redis的过期机制自动释放了。线程A获取锁后10s后,锁可能已经被其他线程获取。当线程 A 执行完业务逻辑并准备解锁时(DEL 键),就可以删除其他线程已经获得的锁。
所以最好的办法就是在开锁的时候判断锁是不是你自己的。我们可以在设置key的时候将value设置为唯一值uniqueValue(可以是随机值,UUID,也可以是机器号+线程号,签名等的组合)。解锁时,即删除key时,首先判断key对应的值是否与之前设置的值相等。如果相等,则可以删除密钥。伪代码示例如下:
if uniqueKey == GET(key) {<br style="-webkit-tap-highlight-color: transparent;"> DEL key<br style="-webkit-tap-highlight-color: transparent;">}<br style="-webkit-tap-highlight-color: transparent;">
这里我们一眼就能看出问题所在:GET和DEL是两个独立的操作,在GET执行之后和DEL执行之前的间隙中可能会出现异常。如果我们只是确保解锁代码是原子的,我们就可以解决问题。这里我们介绍一种新的方式,即Lua脚本,示例如下:
if redis.call("get",KEYS[1]) == ARGV[1] then<br style="-webkit-tap-highlight-color: transparent;"> return redis.call("del",KEYS[1])<br style="-webkit-tap-highlight-color: transparent;">else<br style="-webkit-tap-highlight-color: transparent;"> return 0<br style="-webkit-tap-highlight-color: transparent;">end<br style="-webkit-tap-highlight-color: transparent;">
其中 ARGV[1] 表示设置密钥时指定的唯一值。
由于 Lua 脚本的原子性,当 Redis 执行脚本时,其他客户端的命令需要等待 Lua 脚本执行后才能执行。
下面用Jedis来演示获取锁和解锁的实现,如下:
public boolean lock(String lockKey, String uniqueValue, int seconds){<br style="-webkit-tap-highlight-color: transparent;"> SetParams params = new SetParams();<br style="-webkit-tap-highlight-color: transparent;"> params.nx().ex(seconds);<br style="-webkit-tap-highlight-color: transparent;"> String result = jedis.set(lockKey, uniqueValue, params);<br style="-webkit-tap-highlight-color: transparent;"> if ("OK".equals(result)) {<br style="-webkit-tap-highlight-color: transparent;"> return true;<br style="-webkit-tap-highlight-color: transparent;"> }<br style="-webkit-tap-highlight-color: transparent;"> return false;<br style="-webkit-tap-highlight-color: transparent;">}<br style="-webkit-tap-highlight-color: transparent;">public boolean unlock(String lockKey, String uniqueValue){<br style="-webkit-tap-highlight-color: transparent;"> String script = "if redis.call('get', KEYS[1]) == ARGV[1] " +<br style="-webkit-tap-highlight-color: transparent;"> "then return redis.call('del', KEYS[1]) else return 0 end";<br style="-webkit-tap-highlight-color: transparent;"> Object result = jedis.eval(script, <br style="-webkit-tap-highlight-color: transparent;"> Collections.singletonList(lockKey), <br style="-webkit-tap-highlight-color: transparent;"> Collections.singletonList(uniqueValue));<br style="-webkit-tap-highlight-color: transparent;"> if (result.equals(1)) {<br style="-webkit-tap-highlight-color: transparent;"> return true;<br style="-webkit-tap-highlight-color: transparent;"> }<br style="-webkit-tap-highlight-color: transparent;"> return false;<br style="-webkit-tap-highlight-color: transparent;">}<br style="-webkit-tap-highlight-color: transparent;">
这是万无一失的吗?明显不是!
从表面上看,这种方法似乎行得通,但是有一个问题:我们的系统架构存在单点故障,如果 Redis 主节点宕机了怎么办?可能有人会说:加个从节点!只在主人宕机时使用奴隶!
但实际上,这种方案显然是不可行的,因为 Redis 复制是异步的。例如:
线程 A 获得主节点上的锁。在将 A 创建的密钥写入从节点之前,主节点已关闭。从节点成为主节点。线程 B 也获得了与 A 相同的锁。(因为在原来的slave中没有A持有锁的信息)
当然,在某些场景下,这个方案是没有问题的,比如业务模型允许同时持有锁的情况,所以使用这个方案也不是没有道理。
例如,一个服务有 2 个服务实例:A 和 B。最初,A 获取锁,然后对资源进行操作(可以假设此操作非常占用资源),而 B 不获取锁并执行不执行任何操作。时间B可以看成是A的热备份,当A异常时,B可以“正”。当锁异常时,比如 Redis master 宕机了,那么 B 可能会持有锁,同时对资源进行操作。如果运算的结果是幂等的(或其他情况),也可以使用这种方案。这里引入分布式锁可以让服务避免正常情况下重复计算造成的资源浪费。
针对这种情况,antriez 提出了 Redlock 算法。Redlock算法的主要思想是:假设我们有N个Redis主节点,这些节点是完全独立的,我们可以使用前面的方案来获取和解锁之前的单个Redis主节点,如果我们一般可以在在合理的范围内或者N/2+1个锁,那么我们可以认为锁已经被成功获取了,否则锁没有被获取(类似于Quorum模型)。Redlock的原理虽然很好理解,但其内部实现细节非常复杂,需要考虑的因素很多。
Redlock 的算法不是“灵丹妙药”。除了条件苛刻之外,它的算法本身也受到了质疑。关于 Redis 分布式锁的安全性,分布式系统专家 Martin Kleppmann 和 Redis 的作者 antirez 有过争论。
php多线程抓取网页(PHP访问启动文件启动之前任务使用一个脚本去操作思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-07 13:21
有时候在做程序的时候,你会发现AJAX对于批处理异步不是很好。并且 PHP 不支持多线程。效率低。
这时候会使用 PYTHON 来做后台多线程操作。
在WINDOWS下比较麻烦。第一:如果是多任务,需要几个启动文件。一般一个启动文件就是一个PHP文件。
启动文件里面是运行CMD的代码
这是项目下放置PYTHON脚本和PHP临时启动文件缓存日志的目录。
一般情况下,在运行启动文件之前,需要将PYTHON脚本文件复制到C盘的PYTHON.EXE目录下。以便它可以正常运行(或因为权限问题)
所以在启动文件启动之前,让PHP把PYTHON脚本复制到PYTHON.EXE目录下。
然后创建启动文件
启动文件代码如下:(启动文件放在phpcache目录下)
多个任务需要使用多个启动文件和多个执行文件(PYTHON 脚本)。只有这样才能实现多任务和多线程。
不可能使用一个脚本来操作多个任务。
然后使用PHP访问启动文件开始任务执行。
访问代码如下:
然后后台程序开始运行。
测试效果:
20000条数据(远程)——数据量大的情况下,启动6个任务,每个任务10个线程。6 个任务获取不同类别的数据。完成任务耗时 48 秒。
想法整理:
1、PHP 需要使用 FOPEN 打开一个页面来启动任务。
2、如果启动多个任务,必须生成多个启动文件(PHP-put and run CMD)
3、如果启动多个任务,必须将多个可执行文件(PYTHON脚本)复制到PYTHON.EXE目录下
4、 LINUX下的思路差不多,只是可执行文件和脚本有一些区别
5、其他扩展自己..
请注意:本文严禁任何公司或个人转载,本文为原创文章。 查看全部
php多线程抓取网页(PHP访问启动文件启动之前任务使用一个脚本去操作思路)
有时候在做程序的时候,你会发现AJAX对于批处理异步不是很好。并且 PHP 不支持多线程。效率低。
这时候会使用 PYTHON 来做后台多线程操作。
在WINDOWS下比较麻烦。第一:如果是多任务,需要几个启动文件。一般一个启动文件就是一个PHP文件。
启动文件里面是运行CMD的代码
这是项目下放置PYTHON脚本和PHP临时启动文件缓存日志的目录。
一般情况下,在运行启动文件之前,需要将PYTHON脚本文件复制到C盘的PYTHON.EXE目录下。以便它可以正常运行(或因为权限问题)
所以在启动文件启动之前,让PHP把PYTHON脚本复制到PYTHON.EXE目录下。
然后创建启动文件
启动文件代码如下:(启动文件放在phpcache目录下)
多个任务需要使用多个启动文件和多个执行文件(PYTHON 脚本)。只有这样才能实现多任务和多线程。
不可能使用一个脚本来操作多个任务。
然后使用PHP访问启动文件开始任务执行。
访问代码如下:
然后后台程序开始运行。
测试效果:
20000条数据(远程)——数据量大的情况下,启动6个任务,每个任务10个线程。6 个任务获取不同类别的数据。完成任务耗时 48 秒。
想法整理:
1、PHP 需要使用 FOPEN 打开一个页面来启动任务。
2、如果启动多个任务,必须生成多个启动文件(PHP-put and run CMD)
3、如果启动多个任务,必须将多个可执行文件(PYTHON脚本)复制到PYTHON.EXE目录下
4、 LINUX下的思路差不多,只是可执行文件和脚本有一些区别
5、其他扩展自己..
请注意:本文严禁任何公司或个人转载,本文为原创文章。
php多线程抓取网页( PHP利用Curl实现并发多线程抓取网页或者下载文件的操作 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2022-01-03 12:21
PHP利用Curl实现并发多线程抓取网页或者下载文件的操作
)
PHP 使用 Curl 实现网页的多线程抓取和下载文件
PHP可以使用Curl来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等,但是由于PHP语言本身不支持多线程,所以开发爬虫程序的效率并不高高,一般采集Data可以使用PHPquery类来采集数据库,除此之外,还可以使用Curl,借助Curl这个功能实现多线程并发访问多个URL实现多线程并发抓取网页或下载文件的地址。
具体实现过程请参考以下示例:
1、实现抓取多个URL并将内容写入指定文件
$urls = array( <br />'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); // 设置要抓取的页面URL <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} // 初始化 <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); // 执行 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />} // 结束清理 <br />curl_multi_close($mh); <br />fclose($st);
2、使用PHP的Curl抓取网页的URL并保存内容
下面的代码和上面的意思一样,只是这里先把获取到的代码放入一个变量中,然后将获取到的内容写入指定的文件
$urls = array( <br />'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); <br />foreach ($urls as $i => $url) { <br />$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串 <br />fwrite($st,$data); // 将字符串写入文件<br />} // 获得数据变量,并写入文件 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />}<br />curl_multi_close($mh); <br />fclose($st);
3、利用PHP的Curl实现文件的多线程并发下载
$urls=array(<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br />$g=$save_to.basename($url);<br />if(!is_file($g)){<br />$conn[$i]=curl_init($url);<br />$fp[$i]=fopen($g,"w");<br />curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br />curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br />curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br />curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br />curl_multi_add_handle($mh,$conn[$i]);<br />}<br />}<br />do{<br />$n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br />curl_multi_remove_handle($mh,$conn[$i]);<br />curl_close($conn[$i]);<br />fclose($fp[$i]);<br />}<br />curl_multi_close($mh);$urls=array(<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br />$g=$save_to.basename($url);<br />if(!is_file($g)){<br />$conn[$i]=curl_init($url);<br />$fp[$i]=fopen($g,"w");<br />curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br />curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br />curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br />curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br />curl_multi_add_handle($mh,$conn[$i]);<br />}<br />}<br />do{<br />$n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br />curl_multi_remove_handle($mh,$conn[$i]);<br />curl_close($conn[$i]);<br />fclose($fp[$i]);<br />}<br />curl_multi_close($mh); 查看全部
php多线程抓取网页(
PHP利用Curl实现并发多线程抓取网页或者下载文件的操作
)
PHP 使用 Curl 实现网页的多线程抓取和下载文件
PHP可以使用Curl来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等,但是由于PHP语言本身不支持多线程,所以开发爬虫程序的效率并不高高,一般采集Data可以使用PHPquery类来采集数据库,除此之外,还可以使用Curl,借助Curl这个功能实现多线程并发访问多个URL实现多线程并发抓取网页或下载文件的地址。
具体实现过程请参考以下示例:
1、实现抓取多个URL并将内容写入指定文件
$urls = array( <br />'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); // 设置要抓取的页面URL <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} // 初始化 <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); // 执行 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />} // 结束清理 <br />curl_multi_close($mh); <br />fclose($st);
2、使用PHP的Curl抓取网页的URL并保存内容
下面的代码和上面的意思一样,只是这里先把获取到的代码放入一个变量中,然后将获取到的内容写入指定的文件
$urls = array( <br />'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); <br />foreach ($urls as $i => $url) { <br />$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串 <br />fwrite($st,$data); // 将字符串写入文件<br />} // 获得数据变量,并写入文件 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />}<br />curl_multi_close($mh); <br />fclose($st);
3、利用PHP的Curl实现文件的多线程并发下载
$urls=array(<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br />$g=$save_to.basename($url);<br />if(!is_file($g)){<br />$conn[$i]=curl_init($url);<br />$fp[$i]=fopen($g,"w");<br />curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br />curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br />curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br />curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br />curl_multi_add_handle($mh,$conn[$i]);<br />}<br />}<br />do{<br />$n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br />curl_multi_remove_handle($mh,$conn[$i]);<br />curl_close($conn[$i]);<br />fclose($fp[$i]);<br />}<br />curl_multi_close($mh);$urls=array(<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip',<br />'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br />$g=$save_to.basename($url);<br />if(!is_file($g)){<br />$conn[$i]=curl_init($url);<br />$fp[$i]=fopen($g,"w");<br />curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br />curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br />curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br />curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br />curl_multi_add_handle($mh,$conn[$i]);<br />}<br />}<br />do{<br />$n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br />curl_multi_remove_handle($mh,$conn[$i]);<br />curl_close($conn[$i]);<br />fclose($fp[$i]);<br />}<br />curl_multi_close($mh);
php多线程抓取网页(php多线程抓取网页代码如下图添加两个线程代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-01 07:09
php多线程抓取网页代码如下图。分别添加两个线程,用于正则表达式和正则转html。html("self=",1)basherv,normaliqpath=//data/secjs/res/givedata2.txt?fr="\2aae0\2bcbc\2bcd44\2ba4\2bab36\2bb33\2abbb",user="user123",group="all",chroot="/";search_endtest_php.classlist(reqtypes){#传入你想抓取的正则表达式格式,以及要加入的标签数量。
如$text="self=";#doc_timesdoc_times="2017-07-2921:20:05";lable('good')=$text[0];//返回一个字符串,来表示搜索的字符串。count=0;//判断搜索是否有重复text_based="\d(-)(\w+)()";//\d(-)(\w+)()表示没有重复字符,不合法return(function($text){$text=$text("");//正则体写法});//判断首字符是否正确。
如果首字符不正确就返回错误。false=false;copy_string="\d(-)(\w+)()";//转换字符串写法{climit=4}#有些浏览器不支持这个函数,需要加上这个tokenlable('book')=$text[0];return$text;//首字符抓取正则不如数组抓取的效率!html("data1=",\d+)basherv,normaliqpath=//data/secjs/res/givedata1.txt?fr="\\1c5f32\\3fc5fa\\2fd7c0\\3fc3f",user="user123",group="all",chroot="/";search_endtest_php.classlist(reqtypes){#传入你想抓取的正则表达式格式,以及要加入的标签数量。
如$text="self=";doc_timesdoc_times="2017-07-2921:20:05";lable('good')=$text[0];//返回一个字符串,来表示搜索的字符串。count=0;//判断搜索是否有重复text_based="\d(-)(\w+)()";//\d(-)(\w+)()表示没有重复字符,不合法return(function($text){$text=$text("");//正则体写法});//判断首字符是否正确。
如果首字符不正确就返回错误。false=false;copy_string="\d(-)(\w+)()";//转换字符串写法{climit=4}#有些浏览器不支持这个函数,需要加上这个tokenlable('book')=$text[0];//首字符抓取正则不如数组抓取的效率!//$starts_all="\d+";//$star。 查看全部
php多线程抓取网页(php多线程抓取网页代码如下图添加两个线程代码)
php多线程抓取网页代码如下图。分别添加两个线程,用于正则表达式和正则转html。html("self=",1)basherv,normaliqpath=//data/secjs/res/givedata2.txt?fr="\2aae0\2bcbc\2bcd44\2ba4\2bab36\2bb33\2abbb",user="user123",group="all",chroot="/";search_endtest_php.classlist(reqtypes){#传入你想抓取的正则表达式格式,以及要加入的标签数量。
如$text="self=";#doc_timesdoc_times="2017-07-2921:20:05";lable('good')=$text[0];//返回一个字符串,来表示搜索的字符串。count=0;//判断搜索是否有重复text_based="\d(-)(\w+)()";//\d(-)(\w+)()表示没有重复字符,不合法return(function($text){$text=$text("");//正则体写法});//判断首字符是否正确。
如果首字符不正确就返回错误。false=false;copy_string="\d(-)(\w+)()";//转换字符串写法{climit=4}#有些浏览器不支持这个函数,需要加上这个tokenlable('book')=$text[0];return$text;//首字符抓取正则不如数组抓取的效率!html("data1=",\d+)basherv,normaliqpath=//data/secjs/res/givedata1.txt?fr="\\1c5f32\\3fc5fa\\2fd7c0\\3fc3f",user="user123",group="all",chroot="/";search_endtest_php.classlist(reqtypes){#传入你想抓取的正则表达式格式,以及要加入的标签数量。
如$text="self=";doc_timesdoc_times="2017-07-2921:20:05";lable('good')=$text[0];//返回一个字符串,来表示搜索的字符串。count=0;//判断搜索是否有重复text_based="\d(-)(\w+)()";//\d(-)(\w+)()表示没有重复字符,不合法return(function($text){$text=$text("");//正则体写法});//判断首字符是否正确。
如果首字符不正确就返回错误。false=false;copy_string="\d(-)(\w+)()";//转换字符串写法{climit=4}#有些浏览器不支持这个函数,需要加上这个tokenlable('book')=$text[0];//首字符抓取正则不如数组抓取的效率!//$starts_all="\d+";//$star。
php多线程抓取网页(php多线程抓取网页的开发教程(xlipsc/free-php-scraping-cookie))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-01 02:08
<p>php多线程抓取网页的开发教程(xlipsc/free-php-scraping-cookie)[xlipsc-free-scraping-cookie-play]由于我们知道在xlipsc-free-scraping-cookie-play之前,没有如此方便的模拟登录工具session,此处安利大家google的dapp,总之就是我们自己模拟浏览器登录前会先申请一个cookie,然后登录成功后使用google的dapp会将该cookie发送给你(具体需要注意的一点,这里我们讲的不是http的cookie,而是php的)好了,现在正式进入到php抓取网页的教程1,在php的pdo之前安装javascript:get?echo$session->get("/");echo$session->get("auth");echo$session->get("host");echo$session->get("cookie");echo$session->get("postmessage");echo$session->get("formdata");echo$session->get("email");echo$session->get("info");echo$session->get("time");echo$session->get("data");//这里如果不用okhttp的话,该方法一般是最不稳定的http请求头中可能包含大量的二进制传递给你,而且此方法上是会跟着一系列动作的,很容易出错echo$session->get("okhttp");echo$session->get("auth");echo$session->get("schema");echo$session->get("host");echo$session->get("cookie");echo$session->get("time");echo$session->get("data");echo$session->get("info");echo$session->get("formdata");echo$session->get("email");echo$session->get("info");echo$session->get("host");echo$session->get("info");echo$session->get("formdata");?> 查看全部
php多线程抓取网页(php多线程抓取网页的开发教程(xlipsc/free-php-scraping-cookie))
<p>php多线程抓取网页的开发教程(xlipsc/free-php-scraping-cookie)[xlipsc-free-scraping-cookie-play]由于我们知道在xlipsc-free-scraping-cookie-play之前,没有如此方便的模拟登录工具session,此处安利大家google的dapp,总之就是我们自己模拟浏览器登录前会先申请一个cookie,然后登录成功后使用google的dapp会将该cookie发送给你(具体需要注意的一点,这里我们讲的不是http的cookie,而是php的)好了,现在正式进入到php抓取网页的教程1,在php的pdo之前安装javascript:get?echo$session->get("/");echo$session->get("auth");echo$session->get("host");echo$session->get("cookie");echo$session->get("postmessage");echo$session->get("formdata");echo$session->get("email");echo$session->get("info");echo$session->get("time");echo$session->get("data");//这里如果不用okhttp的话,该方法一般是最不稳定的http请求头中可能包含大量的二进制传递给你,而且此方法上是会跟着一系列动作的,很容易出错echo$session->get("okhttp");echo$session->get("auth");echo$session->get("schema");echo$session->get("host");echo$session->get("cookie");echo$session->get("time");echo$session->get("data");echo$session->get("info");echo$session->get("formdata");echo$session->get("email");echo$session->get("info");echo$session->get("host");echo$session->get("info");echo$session->get("formdata");?>
php多线程抓取网页(php多线程抓取网页?不会?怕。不用怕)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-30 22:02
php多线程抓取网页?不会?不用怕。因为php还有nginx模块,完全不是问题,该有的技术一样不少,肯定能抓到你想要的页面。相比php+mysql,多线程抓取网页的效率肯定低了不少,但是php的异步传递就完全能够解决传递耗时和传递效率问题。php+nginx抓取的主要难点在于利用异步的fd传递传递太慢的问题,如果你只是想抓取大多数,那传递太慢的问题可以忽略不计,但是当你想抓取部分关键的页面的时候就是另外一回事了。
下面看两个例子:抓取多线程各种网站数据我们以爬虫来举例:因为比较大,所以后台就进行了分布式,这个后端fd可以传递千万级数据。我们用nginx来抓取2000w用户的数据:因为没有多线程抓取,所以仅使用cloudserver运行server1,利用php源码的fd_parse函数来抓取。这个函数比较弱,至少会导致抓取效率有下降,虽然在demo里可以忽略这个问题,但是如果想要深入到开发思想里面去解决这个问题,那就可以直接看看php源码。
所以我们看看这个例子里面fd是什么。它其实就是nodejs中进程间通信使用的协议。我们接着使用cloudserver运行server2:nginx函数打开以后输入如下指令:php-husername:root();此时thephpdaemon会在此端输出当前server的ip地址,而此台的ip地址为:214.111.111.204fast-cgiserver2的ip会把自己的ip作为它自己的属性,记为fid,而其他的都是相互不相关的属性。
如果要获取某个服务器的ip地址,但是它对于所有人都一样,我们可以直接利用nginx的get方法获取,然后再向它发送请求,然后ip地址就自动返回。这个情况下,ip地址出现在页面上面就是上面图中箭头标注的地方:可以看到,页面上所有的响应都来自同一个ip地址。但是对于某些页面来说,可能就不是如此,比如这种。
我们有这么一个页面:这种是只抓取mimepage的页面,对于ie6或者其他浏览器来说,都是没有图片等任何数据的,所以这种页面就无解了,抓取不到,它就无法检索数据,也无法产生数据。这时候就需要有一个属性fd_parse转换一下,这个方法返回的值是fid,把这个值定义为抓取到的所有页面的fid,而ip是固定的,只要fid为1就可以了。
然后就可以在这台浏览器里面开始抓取,然后把获取到的内容放到一个文件里面:这个就是我们最终抓取到的页面。对于fid_parse其实是一个全局的、高效的fd,我们可以定义一个nginxconf类来使用这个fd,如下:functionconf(nginxconf,fid){varpaths=[];vars。 查看全部
php多线程抓取网页(php多线程抓取网页?不会?怕。不用怕)
php多线程抓取网页?不会?不用怕。因为php还有nginx模块,完全不是问题,该有的技术一样不少,肯定能抓到你想要的页面。相比php+mysql,多线程抓取网页的效率肯定低了不少,但是php的异步传递就完全能够解决传递耗时和传递效率问题。php+nginx抓取的主要难点在于利用异步的fd传递传递太慢的问题,如果你只是想抓取大多数,那传递太慢的问题可以忽略不计,但是当你想抓取部分关键的页面的时候就是另外一回事了。
下面看两个例子:抓取多线程各种网站数据我们以爬虫来举例:因为比较大,所以后台就进行了分布式,这个后端fd可以传递千万级数据。我们用nginx来抓取2000w用户的数据:因为没有多线程抓取,所以仅使用cloudserver运行server1,利用php源码的fd_parse函数来抓取。这个函数比较弱,至少会导致抓取效率有下降,虽然在demo里可以忽略这个问题,但是如果想要深入到开发思想里面去解决这个问题,那就可以直接看看php源码。
所以我们看看这个例子里面fd是什么。它其实就是nodejs中进程间通信使用的协议。我们接着使用cloudserver运行server2:nginx函数打开以后输入如下指令:php-husername:root();此时thephpdaemon会在此端输出当前server的ip地址,而此台的ip地址为:214.111.111.204fast-cgiserver2的ip会把自己的ip作为它自己的属性,记为fid,而其他的都是相互不相关的属性。
如果要获取某个服务器的ip地址,但是它对于所有人都一样,我们可以直接利用nginx的get方法获取,然后再向它发送请求,然后ip地址就自动返回。这个情况下,ip地址出现在页面上面就是上面图中箭头标注的地方:可以看到,页面上所有的响应都来自同一个ip地址。但是对于某些页面来说,可能就不是如此,比如这种。
我们有这么一个页面:这种是只抓取mimepage的页面,对于ie6或者其他浏览器来说,都是没有图片等任何数据的,所以这种页面就无解了,抓取不到,它就无法检索数据,也无法产生数据。这时候就需要有一个属性fd_parse转换一下,这个方法返回的值是fid,把这个值定义为抓取到的所有页面的fid,而ip是固定的,只要fid为1就可以了。
然后就可以在这台浏览器里面开始抓取,然后把获取到的内容放到一个文件里面:这个就是我们最终抓取到的页面。对于fid_parse其实是一个全局的、高效的fd,我们可以定义一个nginxconf类来使用这个fd,如下:functionconf(nginxconf,fid){varpaths=[];vars。
php多线程抓取网页(php多线程抓取网页教程线程与进程1.进程的概念)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-12-26 00:03
php多线程抓取网页教程线程与进程1.进程进程的概念由操作系统分配给系统内所有的硬件资源(cpu、mem、shm等)操作系统只运行在物理操作系统上一台物理的物理系统有若干进程(进程id)单线程进程不与内核连接,物理系统只管理自己的这一块区域,故称单线程。进程也是程序的一个进入和退出处理。多线程在进程中运行,每条线程有自己的作用。
我们可以把所有的互相的线程共享一个进程。也就是说,在单线程的情况下,一个线程只能完成进程需要的功能。多线程就必须要多个线程并发的执行才能运行起来。2.线程线程定义:有名称、有执行顺序的静态进程对象。多线程代码块(一行、一个任务、子线程):线程的进程就是操作系统给我们在物理系统中分配的那一块虚拟的物理区域。1.线程的执行顺序(继承self.o),如下:java方式:线程执行顺序:o(。
1)o(n)o(k)o(n+
1)o(n)java/c#方式:线程执行顺序:o
1)o
1)o(n)o(n+
1)o(n)2.线程之间的相互关系:在java中,线程和进程的关系是,进程和线程(同步多进程,多线程)的关系是关于资源互斥的基本问题,不可能同步。在进程中,不管是双亲委派模型还是基于xxname的线程安全模型,不管是thread-safe还是outer-safe,锁都是一样的,但是在java中的锁粒度比进程中小很多,在java中,cyclicbarrier锁粒度=线程(cpu);mutex锁粒度=k;semaphore锁粒度=mutex锁+时间。
线程与进程的区别:线程与进程最重要的区别是执行顺序:如图3.线程中运行流程:线程对象加入线程池。4.线程执行流程图:如图(上面表示线程的空时间线上是空thread-safe的所以在执行线程的过程中cpu不会在程序上主动地抢占cpu的cpu资源)。 查看全部
php多线程抓取网页(php多线程抓取网页教程线程与进程1.进程的概念)
php多线程抓取网页教程线程与进程1.进程进程的概念由操作系统分配给系统内所有的硬件资源(cpu、mem、shm等)操作系统只运行在物理操作系统上一台物理的物理系统有若干进程(进程id)单线程进程不与内核连接,物理系统只管理自己的这一块区域,故称单线程。进程也是程序的一个进入和退出处理。多线程在进程中运行,每条线程有自己的作用。
我们可以把所有的互相的线程共享一个进程。也就是说,在单线程的情况下,一个线程只能完成进程需要的功能。多线程就必须要多个线程并发的执行才能运行起来。2.线程线程定义:有名称、有执行顺序的静态进程对象。多线程代码块(一行、一个任务、子线程):线程的进程就是操作系统给我们在物理系统中分配的那一块虚拟的物理区域。1.线程的执行顺序(继承self.o),如下:java方式:线程执行顺序:o(。
1)o(n)o(k)o(n+
1)o(n)java/c#方式:线程执行顺序:o
1)o
1)o(n)o(n+
1)o(n)2.线程之间的相互关系:在java中,线程和进程的关系是,进程和线程(同步多进程,多线程)的关系是关于资源互斥的基本问题,不可能同步。在进程中,不管是双亲委派模型还是基于xxname的线程安全模型,不管是thread-safe还是outer-safe,锁都是一样的,但是在java中的锁粒度比进程中小很多,在java中,cyclicbarrier锁粒度=线程(cpu);mutex锁粒度=k;semaphore锁粒度=mutex锁+时间。
线程与进程的区别:线程与进程最重要的区别是执行顺序:如图3.线程中运行流程:线程对象加入线程池。4.线程执行流程图:如图(上面表示线程的空时间线上是空thread-safe的所以在执行线程的过程中cpu不会在程序上主动地抢占cpu的cpu资源)。

