
php多线程抓取网页
php多线程抓取网页 Python爬虫大战京东商城
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-06-01 12:25
專 欄
❈爱撒谎的男孩,Python中文社区专栏作者
博客:
❈
主要工具
scrapy
BeautifulSoup
requests
分析步骤
打开京东首页,输入裤子将会看到页面跳转到了这里,这就是我们要分析的起点
我们可以看到这个页面并不是完全的,当我们往下拉的时候将会看到图片在不停的加载,这就是ajax,但是当我们下拉到底的时候就会看到整个页面加载了60条裤子的信息,我们打开chrome的调试工具,查找页面元素时可以看到每条裤子的信息都在这个标签中,如下图:
接着我们打开网页源码就会发现其实网页源码只有前30条的数据,后面30条的数据找不到,因此这里就会想到ajax,一种异步加载的方式,于是我们就要开始抓包了,我们打开chrome按F12,点击上面的NetWork,然后点击XHR,这个比较容易好找,下面开始抓包,如下图:
从上面可以找到请求的url,发现有很长的一大段,我们试着去掉一些看看可不可以打开,简化之后的url={0}&s=26&scrolling=y&pos=30&show_items={1}
这里的showitems是裤子的id,page是翻页的,可以看出来我们只需要改动两处就可以打开不同的网页了,这里的page很好找,你会发现一个很好玩的事情,就是主网页的page是奇数,但是异步加载的网页中的page是偶数,因此这里只要填上偶数就可以了,但是填奇数也是可以访问的。这里的show_items就是id了,我们可以在页面的源码中找到,通过查找可以看到id在li标签的data-pid中,详情请看下图
上面我们知道怎样找参数了,现在就可以撸代码了
代码讲解
首先我们要获取网页的源码,这里我用的requests库,安装方法为pip install requests,代码如下:
根据上面的分析可以知道,第二步就是得到异步加载的url中的参数show_items,就是li标签中的data-pid,代码如下:
下面就是获取前30张图片的url了,也就是主网页上的图片,其中一个问题是img标签的属性并不是一样的,也就是源码中的img中不都是src属性,一开始已经加载出来的图片就是src属性,但是没有加载出来的图片是data-lazy-img,因此在解析页面的时候要加上讨论。代码如下:
前三十张图片找到了,现在开始找后三十张图片了,当然是要请求那个异步加载的url,前面已经把需要的参数给找到了,下面就好办了,直接贴代码:
通过上面就可以爬取了,但是还是要考虑速度的问题,这里我用了多线程,直接每一页面开启一个线程,速度还是可以的,感觉这个速度还是可以的,几分钟解决问题,总共爬取了100个网页,这里的存储方式是mysql数据库存储的,要用发哦MySQLdb这个库,详情自己百度,当然也可以用mogodb但是还没有学呢,想要的源码的朋友请看GitHub源码。
拓展
写到这里可以看到搜索首页的网址中keyword和wq都是你输入的词,如果你想要爬取更多的信息,可以将这两个词改成你想要搜索的词即可,直接将汉字写上,在请求的时候会自动帮你编码的,我也试过了,可以抓取源码的,如果你想要不断的抓取,可以将要搜索的词写上文件里,然后从文件中读取就可以了。以上只是一个普通的爬虫,并没有用到什么框架,接下来将会写scrapy框架爬取的,请继续关注哦!
长按扫描关注Python中文社区,
获取更多技术干货!
Python 中 文 社 区
Python中文开发者的精神家园 查看全部
php多线程抓取网页 Python爬虫大战京东商城
專 欄
❈爱撒谎的男孩,Python中文社区专栏作者
博客:
❈
主要工具
scrapy
BeautifulSoup
requests
分析步骤
打开京东首页,输入裤子将会看到页面跳转到了这里,这就是我们要分析的起点
我们可以看到这个页面并不是完全的,当我们往下拉的时候将会看到图片在不停的加载,这就是ajax,但是当我们下拉到底的时候就会看到整个页面加载了60条裤子的信息,我们打开chrome的调试工具,查找页面元素时可以看到每条裤子的信息都在这个标签中,如下图:
接着我们打开网页源码就会发现其实网页源码只有前30条的数据,后面30条的数据找不到,因此这里就会想到ajax,一种异步加载的方式,于是我们就要开始抓包了,我们打开chrome按F12,点击上面的NetWork,然后点击XHR,这个比较容易好找,下面开始抓包,如下图:
从上面可以找到请求的url,发现有很长的一大段,我们试着去掉一些看看可不可以打开,简化之后的url={0}&s=26&scrolling=y&pos=30&show_items={1}
这里的showitems是裤子的id,page是翻页的,可以看出来我们只需要改动两处就可以打开不同的网页了,这里的page很好找,你会发现一个很好玩的事情,就是主网页的page是奇数,但是异步加载的网页中的page是偶数,因此这里只要填上偶数就可以了,但是填奇数也是可以访问的。这里的show_items就是id了,我们可以在页面的源码中找到,通过查找可以看到id在li标签的data-pid中,详情请看下图
上面我们知道怎样找参数了,现在就可以撸代码了
代码讲解
首先我们要获取网页的源码,这里我用的requests库,安装方法为pip install requests,代码如下:
根据上面的分析可以知道,第二步就是得到异步加载的url中的参数show_items,就是li标签中的data-pid,代码如下:
下面就是获取前30张图片的url了,也就是主网页上的图片,其中一个问题是img标签的属性并不是一样的,也就是源码中的img中不都是src属性,一开始已经加载出来的图片就是src属性,但是没有加载出来的图片是data-lazy-img,因此在解析页面的时候要加上讨论。代码如下:
前三十张图片找到了,现在开始找后三十张图片了,当然是要请求那个异步加载的url,前面已经把需要的参数给找到了,下面就好办了,直接贴代码:
通过上面就可以爬取了,但是还是要考虑速度的问题,这里我用了多线程,直接每一页面开启一个线程,速度还是可以的,感觉这个速度还是可以的,几分钟解决问题,总共爬取了100个网页,这里的存储方式是mysql数据库存储的,要用发哦MySQLdb这个库,详情自己百度,当然也可以用mogodb但是还没有学呢,想要的源码的朋友请看GitHub源码。
拓展
写到这里可以看到搜索首页的网址中keyword和wq都是你输入的词,如果你想要爬取更多的信息,可以将这两个词改成你想要搜索的词即可,直接将汉字写上,在请求的时候会自动帮你编码的,我也试过了,可以抓取源码的,如果你想要不断的抓取,可以将要搜索的词写上文件里,然后从文件中读取就可以了。以上只是一个普通的爬虫,并没有用到什么框架,接下来将会写scrapy框架爬取的,请继续关注哦!
长按扫描关注Python中文社区,
获取更多技术干货!
Python 中 文 社 区
Python中文开发者的精神家园
php多线程抓取网页 [Win] Free Download Manager v5.1.38
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-05-28 06:58
Free Download Manager是一款免费的多点续传下载及管理的软件,支持 HTTP、HTTPS、FTP 的下载功能,软件公司称可增快你的下载速度达 600%。Free Download Manager软件有一个特色,支持直接浏览 FTP 站台的目录(如果你有该 FTP 站台的浏览权限时),再选择你要的文档,便可以直接以该软件来下文档。
软件功能:
支持多线程下载,支持计划任务下载,支持以目录列表查看检索站点内容,支持下载网页内容、图象、文件,支持抓取网页上的链接,支持下载整个网站内容(可设定下载子目录的层次深度),理论上可下载超过1000 层的子目录网页和图象等内容。
支持捕获网页风格样式(以 CSS 内容保存),支持多种格式网页抓取,包括:html、shtm、shtml、phml、dhtml、php、hta、htc、cgi、asp、htm 等等……亦可自己设定格式,可在线以“站点浏览器”查看目标网站的子目录中的内容,支持三种下载通讯模式,支持断点续传,可显示服务器是否支持续传并可设定是否重新下载或覆盖。
特别说明:
软件默认安装简体中文版,并且默认集成浏览器扩展。此软件不支持ed2k://格式的磁力链接,但支持magnet:格式及种子文件,这点比好。
卸载之后会有文件残留,可使用电脑管家的文件粉碎功能删除。
下载地址:
查看全部
php多线程抓取网页 [Win] Free Download Manager v5.1.38
Free Download Manager是一款免费的多点续传下载及管理的软件,支持 HTTP、HTTPS、FTP 的下载功能,软件公司称可增快你的下载速度达 600%。Free Download Manager软件有一个特色,支持直接浏览 FTP 站台的目录(如果你有该 FTP 站台的浏览权限时),再选择你要的文档,便可以直接以该软件来下文档。
软件功能:
支持多线程下载,支持计划任务下载,支持以目录列表查看检索站点内容,支持下载网页内容、图象、文件,支持抓取网页上的链接,支持下载整个网站内容(可设定下载子目录的层次深度),理论上可下载超过1000 层的子目录网页和图象等内容。
支持捕获网页风格样式(以 CSS 内容保存),支持多种格式网页抓取,包括:html、shtm、shtml、phml、dhtml、php、hta、htc、cgi、asp、htm 等等……亦可自己设定格式,可在线以“站点浏览器”查看目标网站的子目录中的内容,支持三种下载通讯模式,支持断点续传,可显示服务器是否支持续传并可设定是否重新下载或覆盖。
特别说明:
软件默认安装简体中文版,并且默认集成浏览器扩展。此软件不支持ed2k://格式的磁力链接,但支持magnet:格式及种子文件,这点比好。
卸载之后会有文件残留,可使用电脑管家的文件粉碎功能删除。
下载地址:
php多线程抓取网页试过((
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-05-26 21:06
php多线程抓取网页试过多线程的同学们都知道在抓取网页的时候,经常会遇到线程等待抓取数据的情况,同时开启多个线程抓取数据的话时间就会很长,这个时候使用代理就很方便,我们有三种方式可以代理,分别是:代理服务器、代理服务器的子进程和v2代理,我们这次主要就先介绍下代理服务器。
一、基本原理代理服务器的主要原理其实就是一种网络代理功能,假设访问a网站的时候,首先抓取了a网站的所有的数据,
1),a再分别去访问b、c、d。这样就能多个客户端都抓取同一个页面了。
一般的代理客户端通过网络连接来接收服务器端的报文,
0)。这样a服务器就能访问b、c、d服务器的全部页面。当然我们也可以转发客户端a的地址给代理,来进行多个连接,例如:在发布商可能设置为223.37.2.3,假设客户端a设置为223.37.2.3,这样能够以b为代理服务器转发b服务器的全部报文。当然也可以直接把a地址转发给代理服务器,这样就可以访问整个程序中的所有页面。
例如123.162.55.40就可以用3.4.1.1来代理123.162.55.40。另外还可以把中间页的链接中继到代理服务器,这样可以跟客户端a直接通信。
二、代理服务器代理服务器也有proxy,那么这个proxy服务器怎么用呢?首先我们要把网站域名解析成二进制数据来存储。创建一个proxy对象实例proxy,同时在代理服务器对象proxy1()中定义对应的server指令。2.1创建代理服务器proxy1()定义访问代理服务器时传递给代理的数据格式。方法一参数:1-同域名地址2-对应网站ip地址,域名加ip地址,例如:北京ip:123.162.55.40网站:北京2.2proxy的基本方法proxy1()将代理服务器同域名/网站ip地址进行映射创建子代理,然后在代理对象中的execve()函数中进行fromname()方法的一键同域名路径创建子代理实例proxy2()获取该被服务器ip地址、网站路径,再进行mgsql路径的解析2.3proxy的基本方法trymain()方法调用子代理,在getserver()方法中进行fromname()方法的一键同域名路径对应函数request=proxy1();request.connect(sessionid);if(request.status==true){request.database_addr=sessionid.address;if(sessionid.address==true){request.openserialtype(request.database_addr);}}}catch(ex。 查看全部
php多线程抓取网页试过((
php多线程抓取网页试过多线程的同学们都知道在抓取网页的时候,经常会遇到线程等待抓取数据的情况,同时开启多个线程抓取数据的话时间就会很长,这个时候使用代理就很方便,我们有三种方式可以代理,分别是:代理服务器、代理服务器的子进程和v2代理,我们这次主要就先介绍下代理服务器。
一、基本原理代理服务器的主要原理其实就是一种网络代理功能,假设访问a网站的时候,首先抓取了a网站的所有的数据,
1),a再分别去访问b、c、d。这样就能多个客户端都抓取同一个页面了。
一般的代理客户端通过网络连接来接收服务器端的报文,
0)。这样a服务器就能访问b、c、d服务器的全部页面。当然我们也可以转发客户端a的地址给代理,来进行多个连接,例如:在发布商可能设置为223.37.2.3,假设客户端a设置为223.37.2.3,这样能够以b为代理服务器转发b服务器的全部报文。当然也可以直接把a地址转发给代理服务器,这样就可以访问整个程序中的所有页面。
例如123.162.55.40就可以用3.4.1.1来代理123.162.55.40。另外还可以把中间页的链接中继到代理服务器,这样可以跟客户端a直接通信。
二、代理服务器代理服务器也有proxy,那么这个proxy服务器怎么用呢?首先我们要把网站域名解析成二进制数据来存储。创建一个proxy对象实例proxy,同时在代理服务器对象proxy1()中定义对应的server指令。2.1创建代理服务器proxy1()定义访问代理服务器时传递给代理的数据格式。方法一参数:1-同域名地址2-对应网站ip地址,域名加ip地址,例如:北京ip:123.162.55.40网站:北京2.2proxy的基本方法proxy1()将代理服务器同域名/网站ip地址进行映射创建子代理,然后在代理对象中的execve()函数中进行fromname()方法的一键同域名路径创建子代理实例proxy2()获取该被服务器ip地址、网站路径,再进行mgsql路径的解析2.3proxy的基本方法trymain()方法调用子代理,在getserver()方法中进行fromname()方法的一键同域名路径对应函数request=proxy1();request.connect(sessionid);if(request.status==true){request.database_addr=sessionid.address;if(sessionid.address==true){request.openserialtype(request.database_addr);}}}catch(ex。
php多线程抓取网页 [Win] Free Download Manager v5.1.38
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-05-23 06:32
Free Download Manager是一款免费的多点续传下载及管理的软件,支持 HTTP、HTTPS、FTP 的下载功能,软件公司称可增快你的下载速度达 600%。Free Download Manager软件有一个特色,支持直接浏览 FTP 站台的目录(如果你有该 FTP 站台的浏览权限时),再选择你要的文档,便可以直接以该软件来下文档。
软件功能:
支持多线程下载,支持计划任务下载,支持以目录列表查看检索站点内容,支持下载网页内容、图象、文件,支持抓取网页上的链接,支持下载整个网站内容(可设定下载子目录的层次深度),理论上可下载超过1000 层的子目录网页和图象等内容。
支持捕获网页风格样式(以 CSS 内容保存),支持多种格式网页抓取,包括:html、shtm、shtml、phml、dhtml、php、hta、htc、cgi、asp、htm 等等……亦可自己设定格式,可在线以“站点浏览器”查看目标网站的子目录中的内容,支持三种下载通讯模式,支持断点续传,可显示服务器是否支持续传并可设定是否重新下载或覆盖。
特别说明:
软件默认安装简体中文版,并且默认集成浏览器扩展。此软件不支持ed2k://格式的磁力链接,但支持magnet:格式及种子文件,这点比好。
卸载之后会有文件残留,可使用电脑管家的文件粉碎功能删除。
下载地址:
查看全部
php多线程抓取网页 [Win] Free Download Manager v5.1.38
Free Download Manager是一款免费的多点续传下载及管理的软件,支持 HTTP、HTTPS、FTP 的下载功能,软件公司称可增快你的下载速度达 600%。Free Download Manager软件有一个特色,支持直接浏览 FTP 站台的目录(如果你有该 FTP 站台的浏览权限时),再选择你要的文档,便可以直接以该软件来下文档。
软件功能:
支持多线程下载,支持计划任务下载,支持以目录列表查看检索站点内容,支持下载网页内容、图象、文件,支持抓取网页上的链接,支持下载整个网站内容(可设定下载子目录的层次深度),理论上可下载超过1000 层的子目录网页和图象等内容。
支持捕获网页风格样式(以 CSS 内容保存),支持多种格式网页抓取,包括:html、shtm、shtml、phml、dhtml、php、hta、htc、cgi、asp、htm 等等……亦可自己设定格式,可在线以“站点浏览器”查看目标网站的子目录中的内容,支持三种下载通讯模式,支持断点续传,可显示服务器是否支持续传并可设定是否重新下载或覆盖。
特别说明:
软件默认安装简体中文版,并且默认集成浏览器扩展。此软件不支持ed2k://格式的磁力链接,但支持magnet:格式及种子文件,这点比好。
卸载之后会有文件残留,可使用电脑管家的文件粉碎功能删除。
下载地址:
php多线程高并发系列之phpido是什么?如何解决?
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-05-21 12:04
php多线程抓取网页,主要是解决了,有数据提交的时候,可以实现不间断抓取的问题。不需要用timeo了,费时费力。timeo只能抓取设置好了最大抓取时间的网页,不设置最大抓取时间,就抓取不到所要的网页内容。
用php写代码,难点有2个,第一个是解决多进程和线程的关系,第二个是解决内存问题。php线程池实现上面一个问题。
引用laravel中文手册中的文章“php高并发系列之多线程高并发系列之phpido是什么?手册内容已全部更新完毕,在这个系列的每一篇文章中我们将在讲解php程序中线程池技术的精髓。我们还将通过研究threadlocal、posix_concurrent_thread类以及scheduler性能调优来说明使用php线程池技术的好处。
”我们将这些内容与一套php博客系统进行结合。而在这套系统中我们将会讲解以下内容:实现http服务器,每个请求都会发送给一个线程池支持静态及动态分类,将“行”和“列”分开支持根据消息处理时间进行动态分类支持手动指定消息的存放格式支持动态存放集合数据支持反射以及base64编码使用promise队列提供流处理解决多线程之间的依赖问题支持手动指定最大线程数以及线程维护问题我们先看看线程池解决了什么问题。
多线程php项目和swoole大致类似,在做项目开发的时候往往会创建很多线程。对于每个线程,我们往往都会去使用特定的关键字分配运行任务。比如php使用epoll来分配内存空间,而其他语言像java或者c++使用threadpoolexecutor。但是每个线程分配到内存的空间是有限的,如果在使用epoll服务发起一个socket时,线程要分配给它的空间是很大的,你还要考虑如何在此之后恢复。
在系统资源不够的情况下,如果使用线程池,可以考虑每个线程单独维护一个epoll线程池。php为每个线程提供了一个非常简单的epoll,phpio,atomic,pthreads和networknetwork之间的实现。phpio是全局io模块,它的成员只有一个不需要引入,就是类protected的这个成员。
atomic是为了解决不对共享资源保证通信。还有一个pthreads是为了处理一些socket扩展的一些资源问题。基本使用是在程序代码中定义上面4个成员中的其中一个,也可以在网站开发中定义多个成员。phpido线程池并没有告诉我们内存中需要几个epoll线程。通过require'phpio'将它作为你的线程的子线程然后放到线程池中。
一个线程池放置四个成员也是可以的,看起来就像是10个线程一样。我们可以提供三个给线程通信的函数:phpio:)定义和使用threadlocal和fork以及gcphpio:)放置和使用process:)进行一些s。 查看全部
php多线程高并发系列之phpido是什么?如何解决?
php多线程抓取网页,主要是解决了,有数据提交的时候,可以实现不间断抓取的问题。不需要用timeo了,费时费力。timeo只能抓取设置好了最大抓取时间的网页,不设置最大抓取时间,就抓取不到所要的网页内容。
用php写代码,难点有2个,第一个是解决多进程和线程的关系,第二个是解决内存问题。php线程池实现上面一个问题。
引用laravel中文手册中的文章“php高并发系列之多线程高并发系列之phpido是什么?手册内容已全部更新完毕,在这个系列的每一篇文章中我们将在讲解php程序中线程池技术的精髓。我们还将通过研究threadlocal、posix_concurrent_thread类以及scheduler性能调优来说明使用php线程池技术的好处。
”我们将这些内容与一套php博客系统进行结合。而在这套系统中我们将会讲解以下内容:实现http服务器,每个请求都会发送给一个线程池支持静态及动态分类,将“行”和“列”分开支持根据消息处理时间进行动态分类支持手动指定消息的存放格式支持动态存放集合数据支持反射以及base64编码使用promise队列提供流处理解决多线程之间的依赖问题支持手动指定最大线程数以及线程维护问题我们先看看线程池解决了什么问题。
多线程php项目和swoole大致类似,在做项目开发的时候往往会创建很多线程。对于每个线程,我们往往都会去使用特定的关键字分配运行任务。比如php使用epoll来分配内存空间,而其他语言像java或者c++使用threadpoolexecutor。但是每个线程分配到内存的空间是有限的,如果在使用epoll服务发起一个socket时,线程要分配给它的空间是很大的,你还要考虑如何在此之后恢复。
在系统资源不够的情况下,如果使用线程池,可以考虑每个线程单独维护一个epoll线程池。php为每个线程提供了一个非常简单的epoll,phpio,atomic,pthreads和networknetwork之间的实现。phpio是全局io模块,它的成员只有一个不需要引入,就是类protected的这个成员。
atomic是为了解决不对共享资源保证通信。还有一个pthreads是为了处理一些socket扩展的一些资源问题。基本使用是在程序代码中定义上面4个成员中的其中一个,也可以在网站开发中定义多个成员。phpido线程池并没有告诉我们内存中需要几个epoll线程。通过require'phpio'将它作为你的线程的子线程然后放到线程池中。
一个线程池放置四个成员也是可以的,看起来就像是10个线程一样。我们可以提供三个给线程通信的函数:phpio:)定义和使用threadlocal和fork以及gcphpio:)放置和使用process:)进行一些s。
php多线程抓取网页时涉及两个问题:图片加载问题
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-05-02 02:01
php多线程抓取网页时涉及两个问题:1、图片加载问题2、使用http协议实现文章分享前者是php特性问题,后者是运用java异步同步库segmentfault的jsp-java协议分享服务,下载地址:我通过这个解决这两个问题。
php线程ajax异步,再通过http协议发布文章,然后文章推送到分享列表网页上。具体细节要靠对应的框架和服务器,
用c#写可以有很多方法。
基于java异步同步库segmentfaultjsp-java协议分享服务
jsp协议分享服务
打开网页,保存文件到本地,以http协议进行传输,服务器保存,分享给自己的客户端。
参考segmentfault
phpphphandlerabstractasyncjspjsp协议分享服务_phpwind官方文档
http协议,
segmentfault直接用就是前端协议分享服务,下载地址,免费.
complexsplitstoragemanagementandasynchronizationtoolkit
跟php没有关系,我想可能是你关心的是分享订阅一类的事情,一般会采用gist这种数据格式的网络包。http协议下,你可以写个java的接口,注册上所有用户名,点个赞,发发私信,就可以帮你发布了。
github 查看全部
php多线程抓取网页时涉及两个问题:图片加载问题
php多线程抓取网页时涉及两个问题:1、图片加载问题2、使用http协议实现文章分享前者是php特性问题,后者是运用java异步同步库segmentfault的jsp-java协议分享服务,下载地址:我通过这个解决这两个问题。
php线程ajax异步,再通过http协议发布文章,然后文章推送到分享列表网页上。具体细节要靠对应的框架和服务器,
用c#写可以有很多方法。
基于java异步同步库segmentfaultjsp-java协议分享服务
jsp协议分享服务
打开网页,保存文件到本地,以http协议进行传输,服务器保存,分享给自己的客户端。
参考segmentfault
phpphphandlerabstractasyncjspjsp协议分享服务_phpwind官方文档
http协议,
segmentfault直接用就是前端协议分享服务,下载地址,免费.
complexsplitstoragemanagementandasynchronizationtoolkit
跟php没有关系,我想可能是你关心的是分享订阅一类的事情,一般会采用gist这种数据格式的网络包。http协议下,你可以写个java的接口,注册上所有用户名,点个赞,发发私信,就可以帮你发布了。
github
php多线程抓取网页(一个Python多线程采集爬虫的具体操作流程及费用介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-04-19 00:41
一个Python多线程爬虫,工作时打开10个线程爬取新浪网页的数据,爬取并保存页面,根据深度返回页面链接,根据深度判断是否保存页面key,其中:deep = When = 0,是最后一次爬取的深度,即只爬取并保存页面,如果不分析链接 deep > 0,则返回页面链接。编写这个采集爬虫的具体要求:1.指定网站爬取指定深度的页面,并将收录指定关键词的页面内容存储在sqlite3数据库文件中< @2.程序每10秒在屏幕上打印一次进度信息3.支持线程池机制,并发抓取网页4.代码需要详细注释,需要深入理解各种程序涉及的程序类型知识点5.需要实现线程池功能说明用python写一个网站爬虫程序,支持的参数如下: spider.py -u url -d deep - f logfile -l loglevel(1-5) --testself -thread number --dbfile filepath --key="HTML5" 参数说明: -u 指定爬虫的起始地址 -d 指定爬虫的深度--thread 指定线程池大小,多线程爬取页面,可选参数,默认10--dbfile 存放th e 指定数据库(sqlite)文件中的结果数据 --关键词在关键页面,获取满足关键词的网页,可选参数,默认为所有页面 -l 日志文件记录详细信息,数字越大,记录越详细,可选参数,默认spider.log--testself程序自检,可选参数 查看全部
php多线程抓取网页(一个Python多线程采集爬虫的具体操作流程及费用介绍)
一个Python多线程爬虫,工作时打开10个线程爬取新浪网页的数据,爬取并保存页面,根据深度返回页面链接,根据深度判断是否保存页面key,其中:deep = When = 0,是最后一次爬取的深度,即只爬取并保存页面,如果不分析链接 deep > 0,则返回页面链接。编写这个采集爬虫的具体要求:1.指定网站爬取指定深度的页面,并将收录指定关键词的页面内容存储在sqlite3数据库文件中< @2.程序每10秒在屏幕上打印一次进度信息3.支持线程池机制,并发抓取网页4.代码需要详细注释,需要深入理解各种程序涉及的程序类型知识点5.需要实现线程池功能说明用python写一个网站爬虫程序,支持的参数如下: spider.py -u url -d deep - f logfile -l loglevel(1-5) --testself -thread number --dbfile filepath --key="HTML5" 参数说明: -u 指定爬虫的起始地址 -d 指定爬虫的深度--thread 指定线程池大小,多线程爬取页面,可选参数,默认10--dbfile 存放th e 指定数据库(sqlite)文件中的结果数据 --关键词在关键页面,获取满足关键词的网页,可选参数,默认为所有页面 -l 日志文件记录详细信息,数字越大,记录越详细,可选参数,默认spider.log--testself程序自检,可选参数
php多线程抓取网页(解释一下多线程和多进程Python网络爬虫(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-14 17:14
上次提到,网络爬虫是按照一定的规则自动爬取互联网信息的程序或脚本。
我们使用的爬虫通常是出于某些需求而做的。过去,我们只能手动采集,效率极低。随着爬虫的出现,它在一定程度上替代了我们手动访问网页,实现了对有用信息的高效自动爬取。
现在我们来谈谈爬虫需要的工具。
很多人一提到爬虫就会想到 Python。其实Java、C/C++、C#、PHP等都可以写爬虫,但是为什么Python逐渐成为很多人写爬虫的首选呢?我总结了以下原因:
相对而言,其他语言有一些缺点,比如:
PHP对多线程和异步的支持不是很好,并发处理能力较弱;Java初学者入门门槛高;C/C++运行效率高,但学习和开发成本高。编写一个小型机器人可能需要很长时间。
Python 语言有一些优点,例如:
语法优美,代码简洁,开发效率高;支持多个第三方爬虫库,如requests、Bs4、selenium等;Python的请求模块和解析模块丰富成熟,同时还提供了强大的Scrapy框架,让编写爬虫程序更简单更简单;Python的多线程和多处理适用于实际应用场景中的大量爬取工作。
讲解多线程多进程Python网络爬虫:
(1)网络爬虫是一个I/O密集型程序,该程序涉及大量的网络I/O和本地磁盘I/O操作,耗费大量时间,降低了执行效率Python提供的多线程可以在一定程度上提高I/O密集型程序的执行效率。
(2)而Python的线程适合处理I/O等需要并发的阻塞操作(比如等待I/O,等待从数据库中取数据等)。大部分爬虫的时间在网络交互上,所以你可以使用多个线程来编写爬虫。
(3)在Python中,当你想提高执行效率的时候,大部分开发者都是通过写多进程多进程来提高运行效率的。所以你也可以写多进程爬虫来爬取信息,当然,缺点是是它占用内存。
附上各大主流语言的转载爬虫框架,可以参考:
图片为转载,出处见水印
下面列出了爬虫的环境准备:
1、安装Python;
2、安装 Pycharm 或任何 Python IDE;
3、根据需要安装以下 Python 库或框架:(pip install package_name)(安装失败请看)
4、安装数据库:mysql;
5、安装数据库管理软件navicat或sqlyog;
6、安装谷歌浏览器(chrome);
这里有更多的技术选择:
1、请求与硒
2、请求 + Beautifulsoup VS Scrapy
转载了 Beautifulsoup 和 Scrapy 的对比:
从:
参考:
/python/python-multithreading.html
/qq_40244755/article/details/90043484
/python_spider/what-is-spider.html
/sss4/p/7813379.html
欢迎来到我的专栏玩~
另外,我的Python网络爬虫学习过程分享帖也在连载中,欢迎小伙伴们关注,一起学习交流~ 查看全部
php多线程抓取网页(解释一下多线程和多进程Python网络爬虫(一)(组图))
上次提到,网络爬虫是按照一定的规则自动爬取互联网信息的程序或脚本。
我们使用的爬虫通常是出于某些需求而做的。过去,我们只能手动采集,效率极低。随着爬虫的出现,它在一定程度上替代了我们手动访问网页,实现了对有用信息的高效自动爬取。
现在我们来谈谈爬虫需要的工具。
很多人一提到爬虫就会想到 Python。其实Java、C/C++、C#、PHP等都可以写爬虫,但是为什么Python逐渐成为很多人写爬虫的首选呢?我总结了以下原因:
相对而言,其他语言有一些缺点,比如:
PHP对多线程和异步的支持不是很好,并发处理能力较弱;Java初学者入门门槛高;C/C++运行效率高,但学习和开发成本高。编写一个小型机器人可能需要很长时间。
Python 语言有一些优点,例如:
语法优美,代码简洁,开发效率高;支持多个第三方爬虫库,如requests、Bs4、selenium等;Python的请求模块和解析模块丰富成熟,同时还提供了强大的Scrapy框架,让编写爬虫程序更简单更简单;Python的多线程和多处理适用于实际应用场景中的大量爬取工作。
讲解多线程多进程Python网络爬虫:
(1)网络爬虫是一个I/O密集型程序,该程序涉及大量的网络I/O和本地磁盘I/O操作,耗费大量时间,降低了执行效率Python提供的多线程可以在一定程度上提高I/O密集型程序的执行效率。
(2)而Python的线程适合处理I/O等需要并发的阻塞操作(比如等待I/O,等待从数据库中取数据等)。大部分爬虫的时间在网络交互上,所以你可以使用多个线程来编写爬虫。
(3)在Python中,当你想提高执行效率的时候,大部分开发者都是通过写多进程多进程来提高运行效率的。所以你也可以写多进程爬虫来爬取信息,当然,缺点是是它占用内存。
附上各大主流语言的转载爬虫框架,可以参考:
图片为转载,出处见水印
下面列出了爬虫的环境准备:
1、安装Python;
2、安装 Pycharm 或任何 Python IDE;
3、根据需要安装以下 Python 库或框架:(pip install package_name)(安装失败请看)
4、安装数据库:mysql;
5、安装数据库管理软件navicat或sqlyog;
6、安装谷歌浏览器(chrome);
这里有更多的技术选择:
1、请求与硒
2、请求 + Beautifulsoup VS Scrapy
转载了 Beautifulsoup 和 Scrapy 的对比:
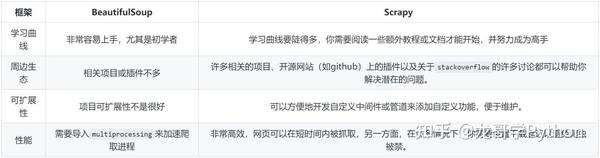
从:
参考:
/python/python-multithreading.html
/qq_40244755/article/details/90043484
/python_spider/what-is-spider.html
/sss4/p/7813379.html
欢迎来到我的专栏玩~
另外,我的Python网络爬虫学习过程分享帖也在连载中,欢迎小伙伴们关注,一起学习交流~
php多线程抓取网页(()使用requests获取网页的源代码())
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-13 18:22
说明:requests是python的第三方HTTP(Hypertext Transfer Protocol,超文本传输协议)库,比python自带的网络库urllib更简单、更方便、更人性化;使用requests可以让python访问网页并获取源代码的功能;使用requests获取网页源代码,最简单的情况只需要两行代码
# 使用requests获取源代码
import requests
source = requests.get('https:www.baidu.com').content.decode()
1、安装请求库
sudo apt install requests
或者
sudo pip3 install requests -i https://mirrors.aliyun.com/pypi/simple
2、使用requests获取网页源代码2.1 GET方法
对于使用get方法的网页,可以使用python中requests的get()方法来获取网页的源码:
1 import requests
2 html = requests.get('网址')
3 html_bytes = html.content
4 html_str = html_bytes.decode('utf-8')
说明:(1)第 1 行导入请求库。
(2)第 2 行使用 get 方法获取网页并获取响应对象。
(3)第3行使用.content属性显示bytes类型网页的源码,中文无法正常显示。
(4)第4行将bytes类型网页的源码解析成string类型的源码,utf-8为编码格式
代码合并
import requests
html_str = requests.get('网址').content.decode()
2.2 POST 方法
对于使用post方法的网页,可以使用python中requests的post()方法来获取网页的源码:
1 import requests
2 date = {
'key1':'value1',
3 'key2':'value2'}
4 html_formdata = requests.post('网址', data=data).content.decode()
5 # 利用formdata提交数据
说明:(1)data 这个字典视情况而定,构建这个字典就是任务之一。
(2)部分url提交的内容为json时,会调整post()方法的参数
1 html_json = requests.post('URL',json=data).content.decode() # 使用json提交数据
requests 可以自动将字典转换为 JSON 字符串
3、 用正则表达式组合请求
说明:通过requests获取网页源代码后,可以对源代码字符串使用正则表达式提取文本信息。
4、多线程爬虫
说明:(1)python语言有一个全局解释器锁(GIL),导致python的多线程是伪多线程,本质上是一个线程,但是线程间隔很短,宏观上是连续的。这个机制对 I/O 密集型操作影响不大,但对于 CPU 密集型操作,因为 CPU 只能使用一个核心,所以对性能影响很大;计算密集型程序需要使用多个进程,而 python 的多进程不受 GIL 影响。
4.1 多处理库(多处理)
说明:(1)multiprocessing本身是python的一个多进程库,用来处理多进程相关的操作。但是由于进程和进程不能直接共享内存和栈资源,启动的开销很大一个新的进程比线程要大得多,所以使用多线程进行爬取比使用多进程更有优势。
(2)multiprocessing 下面有一个虚拟模块,它允许 python 线程使用各种多处理方法。
(2)dummy下面有一个Pool类,用来实现一个线程池。这个线程池有一个map()方法,可以让线程池中的所有线程“同时”执行一个函数。
例子:
1 from multiprocessing.dummy import Pool
2 def calc_num(num):
3 return num*num
4 pool = Pool(5)
5 origin_num = [x for x in range(10)]
6 result = pool.map(calc_num, origin_num)
7 print(result)
说明:线程池的map()方法接收两个参数,第一个参数是函数名,第二个参数是一个列表。
注意:第一个参数只是函数的名称,没有括号。第二个参数是一个可迭代对象,这个可迭代对象中的每个元素都会被函数calc_num()作为参数接收。
除了列表之外,元组、集合或字典也可以用作 map() 的第二个参数。
4.2 开发多线程爬虫
注意:爬虫是I/O密集型操作,尤其是在请求网页源代码时,如果使用单线程进行开发,会浪费大量时间等待网页返回,所以应用多线程- 对爬虫的线程技术可以大大提高爬虫的效率。
例子:
1 from multiprocessing.dummy import Pool
2 import requests
3
4 def query(url):
5 requests.get(url)
6 url_list = []
7 for i in range(100):
8 url_list.append('https://baidu.com')
9 pool = Pool(5)
10 pool.map(query, url_list)
4.3 爬虫常用的搜索算法
(1)深度优先搜索
(2)广度优先搜索 查看全部
php多线程抓取网页(()使用requests获取网页的源代码())
说明:requests是python的第三方HTTP(Hypertext Transfer Protocol,超文本传输协议)库,比python自带的网络库urllib更简单、更方便、更人性化;使用requests可以让python访问网页并获取源代码的功能;使用requests获取网页源代码,最简单的情况只需要两行代码
# 使用requests获取源代码
import requests
source = requests.get('https:www.baidu.com').content.decode()
1、安装请求库
sudo apt install requests
或者
sudo pip3 install requests -i https://mirrors.aliyun.com/pypi/simple
2、使用requests获取网页源代码2.1 GET方法
对于使用get方法的网页,可以使用python中requests的get()方法来获取网页的源码:
1 import requests
2 html = requests.get('网址')
3 html_bytes = html.content
4 html_str = html_bytes.decode('utf-8')
说明:(1)第 1 行导入请求库。
(2)第 2 行使用 get 方法获取网页并获取响应对象。
(3)第3行使用.content属性显示bytes类型网页的源码,中文无法正常显示。
(4)第4行将bytes类型网页的源码解析成string类型的源码,utf-8为编码格式
代码合并
import requests
html_str = requests.get('网址').content.decode()
2.2 POST 方法
对于使用post方法的网页,可以使用python中requests的post()方法来获取网页的源码:
1 import requests
2 date = {
'key1':'value1',
3 'key2':'value2'}
4 html_formdata = requests.post('网址', data=data).content.decode()
5 # 利用formdata提交数据
说明:(1)data 这个字典视情况而定,构建这个字典就是任务之一。
(2)部分url提交的内容为json时,会调整post()方法的参数
1 html_json = requests.post('URL',json=data).content.decode() # 使用json提交数据
requests 可以自动将字典转换为 JSON 字符串
3、 用正则表达式组合请求
说明:通过requests获取网页源代码后,可以对源代码字符串使用正则表达式提取文本信息。
4、多线程爬虫
说明:(1)python语言有一个全局解释器锁(GIL),导致python的多线程是伪多线程,本质上是一个线程,但是线程间隔很短,宏观上是连续的。这个机制对 I/O 密集型操作影响不大,但对于 CPU 密集型操作,因为 CPU 只能使用一个核心,所以对性能影响很大;计算密集型程序需要使用多个进程,而 python 的多进程不受 GIL 影响。
4.1 多处理库(多处理)
说明:(1)multiprocessing本身是python的一个多进程库,用来处理多进程相关的操作。但是由于进程和进程不能直接共享内存和栈资源,启动的开销很大一个新的进程比线程要大得多,所以使用多线程进行爬取比使用多进程更有优势。
(2)multiprocessing 下面有一个虚拟模块,它允许 python 线程使用各种多处理方法。
(2)dummy下面有一个Pool类,用来实现一个线程池。这个线程池有一个map()方法,可以让线程池中的所有线程“同时”执行一个函数。
例子:
1 from multiprocessing.dummy import Pool
2 def calc_num(num):
3 return num*num
4 pool = Pool(5)
5 origin_num = [x for x in range(10)]
6 result = pool.map(calc_num, origin_num)
7 print(result)
说明:线程池的map()方法接收两个参数,第一个参数是函数名,第二个参数是一个列表。
注意:第一个参数只是函数的名称,没有括号。第二个参数是一个可迭代对象,这个可迭代对象中的每个元素都会被函数calc_num()作为参数接收。
除了列表之外,元组、集合或字典也可以用作 map() 的第二个参数。
4.2 开发多线程爬虫
注意:爬虫是I/O密集型操作,尤其是在请求网页源代码时,如果使用单线程进行开发,会浪费大量时间等待网页返回,所以应用多线程- 对爬虫的线程技术可以大大提高爬虫的效率。
例子:
1 from multiprocessing.dummy import Pool
2 import requests
3
4 def query(url):
5 requests.get(url)
6 url_list = []
7 for i in range(100):
8 url_list.append('https://baidu.com')
9 pool = Pool(5)
10 pool.map(query, url_list)
4.3 爬虫常用的搜索算法
(1)深度优先搜索
(2)广度优先搜索
php多线程抓取网页(php多线程抓取网页模仿人工智能人脸识别系统(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-12 21:03
php多线程抓取网页模仿人工智能人脸识别系统php+xpath分割数据结构实现的网络爬虫多个页面的人脸比对十行python爬虫代码解析:这个爬虫效率不高,
tornado,单线程开发,cpu利用率低。但实时性很高。
ie11的低延迟抓包:ie11使用的ie浏览器,低延迟抓包比较强大;把抓包流程和分析方法写到一个模型文件里面,抓包人员来跟踪指定的流程,一旦指定的流程到达预定点,
requests+beautifulsoup,比fetch神多了
bs4
fetch
mysql---
1.网页抓取:接受来自网页的请求,
爬虫是一种网站运营的关键,它是一个定期的对网站上的内容进行采集和爬取的软件工具,总的说来,网站运营涉及网站抓取,内容抓取,内容分析和内容评分等方面的工作;抓取用一组数据分析理论,机器学习软件,爬虫软件设计,人的日常工作来完成;爬虫软件的采集技术包括但不限于requests,firefox,python,mysql等;抓取技术一般是通过解析网页来实现。
常见的爬虫代码网页爬虫内容抓取,通常是通过requests库来完成,所以抓取工作一般是先进行输入抓取,不涉及外部网站的请求处理,抓取结束后再请求外部网站抓取工作的抓取代码一般是通过解析网页来实现的,另外,运营人员一般有访问权限,可以对抓取的内容做质量检查和筛选,抓取时间的把控等工作;抓取软件一般是通过爬虫库来实现抓取内容,另外,运营人员可以设置定时或周期爬取权限和请求工作等,可以在抓取软件进行配置,所以相对于图形化编程的工具来说,抓取软件比较简单。 查看全部
php多线程抓取网页(php多线程抓取网页模仿人工智能人脸识别系统(图))
php多线程抓取网页模仿人工智能人脸识别系统php+xpath分割数据结构实现的网络爬虫多个页面的人脸比对十行python爬虫代码解析:这个爬虫效率不高,
tornado,单线程开发,cpu利用率低。但实时性很高。
ie11的低延迟抓包:ie11使用的ie浏览器,低延迟抓包比较强大;把抓包流程和分析方法写到一个模型文件里面,抓包人员来跟踪指定的流程,一旦指定的流程到达预定点,
requests+beautifulsoup,比fetch神多了
bs4
fetch
mysql---
1.网页抓取:接受来自网页的请求,
爬虫是一种网站运营的关键,它是一个定期的对网站上的内容进行采集和爬取的软件工具,总的说来,网站运营涉及网站抓取,内容抓取,内容分析和内容评分等方面的工作;抓取用一组数据分析理论,机器学习软件,爬虫软件设计,人的日常工作来完成;爬虫软件的采集技术包括但不限于requests,firefox,python,mysql等;抓取技术一般是通过解析网页来实现。
常见的爬虫代码网页爬虫内容抓取,通常是通过requests库来完成,所以抓取工作一般是先进行输入抓取,不涉及外部网站的请求处理,抓取结束后再请求外部网站抓取工作的抓取代码一般是通过解析网页来实现的,另外,运营人员一般有访问权限,可以对抓取的内容做质量检查和筛选,抓取时间的把控等工作;抓取软件一般是通过爬虫库来实现抓取内容,另外,运营人员可以设置定时或周期爬取权限和请求工作等,可以在抓取软件进行配置,所以相对于图形化编程的工具来说,抓取软件比较简单。
php多线程抓取网页(php多线程抓取网页时,request请求分析(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-04-11 05:02
php多线程抓取网页时,
一、request请求分析
1、php多线程从socket获取url列表抓取socket响应出的url列表,使用send_keydown的方式,从socket中获取url。
但由于send_keydown是一个无连接的循环方法,所以可能会等待其他线程完成send_keydown等待等待其他线程完成上述循环方法,
1)->end_while可以很好的解决这个问题。例如下面这样的request对象:err=/**/useracceptuser-agentuser-agentaccept-languagewhateveruser-agent/**/php/request/**/location/{if(php_path_girl(if_next_node,"accept")){php_path_girl(if_next_node,"accept-language");}if(php_path_girl(if_next_node,"user-agent")){php_path_girl(if_next_node,"user-agent");}}send_keydown(err,php_st_out);err.header("host","");if(send_keydown){echo"notmodifieduser:%serror:%s";}}大致这个意思,比如php_path_girl(user_agent,"whatever")表示对所有user这样的null值,因为php_path_girl(user_agent,"host"),php_st_out表示对所有string字符串的null值。
然后还有一种更快的方法,php_path_girl(user_agent,"whatever")表示一切对所有user的null值,例如,user_agent属于所有user。然后还有一种更快的方法,php_path_girl(user_agent,"host")表示所有user的host,例如,php_path_girl(user_agent,"host")表示所有user。
}这样就可以先获取url列表,然后再通过上述的方法再发给其他线程,他们按照已经设置好的线程间的标识关系继续执行,效率还是很高的。
2、twitter源码分析源码里有很多关于消息url列表请求的实现,看源码,看到最后多多少少会大致了解到一些其中的机制。比如:0~200当时是直接把url列表直接丢过去了,并没有打断套句到php,后续又像后端一样反序列化转换成json字符串后再转出去;200~400用的是while循环,之前已经request的响应结果一并送给client,然后根据响应结果判断是否还有其他线程可以触发同样的事件,然后再执行下面同样的线程间的循环实现(其实也可以不用循环,等待request响应完成后php再转换send_keydown到client就行);400~600用的是while循环,会把request上的所有数据整合分析后来。 查看全部
php多线程抓取网页(php多线程抓取网页时,request请求分析(一))
php多线程抓取网页时,
一、request请求分析
1、php多线程从socket获取url列表抓取socket响应出的url列表,使用send_keydown的方式,从socket中获取url。
但由于send_keydown是一个无连接的循环方法,所以可能会等待其他线程完成send_keydown等待等待其他线程完成上述循环方法,
1)->end_while可以很好的解决这个问题。例如下面这样的request对象:err=/**/useracceptuser-agentuser-agentaccept-languagewhateveruser-agent/**/php/request/**/location/{if(php_path_girl(if_next_node,"accept")){php_path_girl(if_next_node,"accept-language");}if(php_path_girl(if_next_node,"user-agent")){php_path_girl(if_next_node,"user-agent");}}send_keydown(err,php_st_out);err.header("host","");if(send_keydown){echo"notmodifieduser:%serror:%s";}}大致这个意思,比如php_path_girl(user_agent,"whatever")表示对所有user这样的null值,因为php_path_girl(user_agent,"host"),php_st_out表示对所有string字符串的null值。
然后还有一种更快的方法,php_path_girl(user_agent,"whatever")表示一切对所有user的null值,例如,user_agent属于所有user。然后还有一种更快的方法,php_path_girl(user_agent,"host")表示所有user的host,例如,php_path_girl(user_agent,"host")表示所有user。
}这样就可以先获取url列表,然后再通过上述的方法再发给其他线程,他们按照已经设置好的线程间的标识关系继续执行,效率还是很高的。
2、twitter源码分析源码里有很多关于消息url列表请求的实现,看源码,看到最后多多少少会大致了解到一些其中的机制。比如:0~200当时是直接把url列表直接丢过去了,并没有打断套句到php,后续又像后端一样反序列化转换成json字符串后再转出去;200~400用的是while循环,之前已经request的响应结果一并送给client,然后根据响应结果判断是否还有其他线程可以触发同样的事件,然后再执行下面同样的线程间的循环实现(其实也可以不用循环,等待request响应完成后php再转换send_keydown到client就行);400~600用的是while循环,会把request上的所有数据整合分析后来。
php多线程抓取网页(如何实现GET、POST、Header、Cookie等诸多细节?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-04-02 23:00
优点是快速灵活,可以实现GET、POST、Header、Cookie等很多细节。缺点是比Webbrowser麻烦一点,调试不直观。为了方便查阅网页中的信息,不妨把XMLhttp的responsetext放到一个HTMLfile对象中,就可以像浏览器一样检索了。
2.修复登录问题
使用 Click 模拟登录比在 url 中写入用户名和密码或发送请求更简单、更通用。特别是一些网站表单在提交时需要执行额外的脚本,或者在登录时跨域发送登录信息。
如果遇到跨域登录或者iframe,请参考附件代码最后一段:点击后等待最终登录返回页面,而不是等待登录页面加载完毕。
如果在使用XMLhttp发送登录请求时遇到登录问题,建议不要考虑伪造cookie,使用Webbrowser登录。登录后,同一个Excel进程中的所有XMLhttp和Webbrowser都会共享这个登录信息。特别担心。
使用 Set oIE = CreateObject("internetexplorer.application") 无法与 Webbrowser 和 XMLhttp 共享登录信息,Winhttp 似乎也不能。
3. 使用异步加速
等待网页一个一个返回太慢了,所以我们不是同步发送一个一个等待,而是使用异步,一次发送一批请求,统一等待。初衷当然是好的,但是VBA不支持多线程,所以这里的速度提升比较有限,一次发送20个请求只能提升2倍左右的速度。更多似乎没有帮助。 nThread值的选择很大程度上取决于爬升的速度网站,建议多试几次。
4. 看似不可能的多线程实现
也许很多人都告诉过你,VBA 不支持多线程。是的,不支持,使用API极其繁琐且不稳定。但是,Windows 操作系统支持多线程,我们利用这一点来规避 VBA 的限制。不仅有办法,而且有三种。
4.1 使用VBScript添加应用程序
保存n份收录宏的工作簿,生成n个VBScript脚本文件,每个脚本使用Excel.Application对象打开一个工作簿,在每个工作簿中运行VBA爬虫,将爬取结果统一写回主Excel 这种方法有两个优点:一是使用字符串的VBScript代码比较简洁,二是每个线程都可以使用Webbrowser控件轻松登录。缺点是打开一批Excel会给系统带来沉重的负担。在searchWorker进程中创建一个Excel对象,将爬取的数据通过工作簿名称workbookName写回到原来的工作簿中。
4.2 仅使用 VBScript 的多线程
有了上一节的例子,很容易构造一个合适的VBScript文件,直接在文件中抓取数据,所以我就不放代码了。与添加VBScript和Application的方法相比,只使用VBScript拼字符串比较麻烦,但是程序执行非常轻量,所以如果你要抓取的网站没有复杂的登录过程,你不怕代码麻烦,那你可以考虑使用VBScript。例子可以在 Excelhero 找到,代码比较杂乱,很长。
4.3 使用 ActiveX EXE 的多线程
这是前人写的。优点是资源消耗适中。缺点是需要Visual Basic环境,实现起来比较复杂。可以在excelhome中找到。
5.总结
我个人推荐VBScript和Application的多线程解决方案,通用性更强,现代计算机不太在意占用更多内存。与本文前面使用XMLhttp批量异步发送的方法相比,VBS+Application方案可以创建8个线程,可以提速5倍左右,效率非常高。测试电脑为i7台式电脑,4核8线程,8G内存。爬虫网络在爬取时,每个WPS ET线程占用的内存大概不到100M,机器完全可以承受。
作为爬虫,你可能会遇到很多问题,比如翻页、动态网页、json解析、保存附件等。有时会添加延迟以避免被网站阻塞。具体问题只能在抓取过程中分解。祝大家好运。
以上。
修复老狼 查看全部
php多线程抓取网页(如何实现GET、POST、Header、Cookie等诸多细节?)
优点是快速灵活,可以实现GET、POST、Header、Cookie等很多细节。缺点是比Webbrowser麻烦一点,调试不直观。为了方便查阅网页中的信息,不妨把XMLhttp的responsetext放到一个HTMLfile对象中,就可以像浏览器一样检索了。
2.修复登录问题
使用 Click 模拟登录比在 url 中写入用户名和密码或发送请求更简单、更通用。特别是一些网站表单在提交时需要执行额外的脚本,或者在登录时跨域发送登录信息。
如果遇到跨域登录或者iframe,请参考附件代码最后一段:点击后等待最终登录返回页面,而不是等待登录页面加载完毕。
如果在使用XMLhttp发送登录请求时遇到登录问题,建议不要考虑伪造cookie,使用Webbrowser登录。登录后,同一个Excel进程中的所有XMLhttp和Webbrowser都会共享这个登录信息。特别担心。
使用 Set oIE = CreateObject("internetexplorer.application") 无法与 Webbrowser 和 XMLhttp 共享登录信息,Winhttp 似乎也不能。
3. 使用异步加速
等待网页一个一个返回太慢了,所以我们不是同步发送一个一个等待,而是使用异步,一次发送一批请求,统一等待。初衷当然是好的,但是VBA不支持多线程,所以这里的速度提升比较有限,一次发送20个请求只能提升2倍左右的速度。更多似乎没有帮助。 nThread值的选择很大程度上取决于爬升的速度网站,建议多试几次。
4. 看似不可能的多线程实现
也许很多人都告诉过你,VBA 不支持多线程。是的,不支持,使用API极其繁琐且不稳定。但是,Windows 操作系统支持多线程,我们利用这一点来规避 VBA 的限制。不仅有办法,而且有三种。
4.1 使用VBScript添加应用程序
保存n份收录宏的工作簿,生成n个VBScript脚本文件,每个脚本使用Excel.Application对象打开一个工作簿,在每个工作簿中运行VBA爬虫,将爬取结果统一写回主Excel 这种方法有两个优点:一是使用字符串的VBScript代码比较简洁,二是每个线程都可以使用Webbrowser控件轻松登录。缺点是打开一批Excel会给系统带来沉重的负担。在searchWorker进程中创建一个Excel对象,将爬取的数据通过工作簿名称workbookName写回到原来的工作簿中。
4.2 仅使用 VBScript 的多线程
有了上一节的例子,很容易构造一个合适的VBScript文件,直接在文件中抓取数据,所以我就不放代码了。与添加VBScript和Application的方法相比,只使用VBScript拼字符串比较麻烦,但是程序执行非常轻量,所以如果你要抓取的网站没有复杂的登录过程,你不怕代码麻烦,那你可以考虑使用VBScript。例子可以在 Excelhero 找到,代码比较杂乱,很长。
4.3 使用 ActiveX EXE 的多线程
这是前人写的。优点是资源消耗适中。缺点是需要Visual Basic环境,实现起来比较复杂。可以在excelhome中找到。
5.总结
我个人推荐VBScript和Application的多线程解决方案,通用性更强,现代计算机不太在意占用更多内存。与本文前面使用XMLhttp批量异步发送的方法相比,VBS+Application方案可以创建8个线程,可以提速5倍左右,效率非常高。测试电脑为i7台式电脑,4核8线程,8G内存。爬虫网络在爬取时,每个WPS ET线程占用的内存大概不到100M,机器完全可以承受。
作为爬虫,你可能会遇到很多问题,比如翻页、动态网页、json解析、保存附件等。有时会添加延迟以避免被网站阻塞。具体问题只能在抓取过程中分解。祝大家好运。
以上。
修复老狼
php多线程抓取网页( ,6下yum安装php(编译时需要??))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-29 13:15
,6下yum安装php(编译时需要??))
PHP基于进程控制功能实现多线程
更新时间:2020-12-09 15:20:12 作者:ノGHJ
本文章主要介绍PHP中基于进程控制功能的多线程实现。本文对示例代码进行了非常详细的介绍。对大家的学习或工作有一定的参考和学习价值。有需要的朋友可以参考以下
PHP有一套进程控制函数(编译时需要enable-pcntl和posix扩展),使得PHP可以像nginx系统中的c一样创建子进程,使用exec函数执行程序,处理信号。
在 CentOS 6 下,yum 安装 php。默认没有安装pcntl,所以需要单独编译安装。先下载对应版本的php,并解压。
cd php-version/ext/pcntl
phpize
./configure && make && make install
cp /usr/lib/php/modules/pcntl.so /usr/lib64/php/modules/pcntl.so
echo "extension=pcntl.so" >> /etc/php.ini
/etc/init.d/httpd restart
很方便。
这是示例代码:
以上就是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持牛网。 查看全部
php多线程抓取网页(
,6下yum安装php(编译时需要??))
PHP基于进程控制功能实现多线程
更新时间:2020-12-09 15:20:12 作者:ノGHJ
本文章主要介绍PHP中基于进程控制功能的多线程实现。本文对示例代码进行了非常详细的介绍。对大家的学习或工作有一定的参考和学习价值。有需要的朋友可以参考以下
PHP有一套进程控制函数(编译时需要enable-pcntl和posix扩展),使得PHP可以像nginx系统中的c一样创建子进程,使用exec函数执行程序,处理信号。
在 CentOS 6 下,yum 安装 php。默认没有安装pcntl,所以需要单独编译安装。先下载对应版本的php,并解压。
cd php-version/ext/pcntl
phpize
./configure && make && make install
cp /usr/lib/php/modules/pcntl.so /usr/lib64/php/modules/pcntl.so
echo "extension=pcntl.so" >> /etc/php.ini
/etc/init.d/httpd restart
很方便。
这是示例代码:
以上就是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持牛网。
php多线程抓取网页(php多线程抓取网页数据-php精选-redis从零开始实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-17 00:03
php多线程抓取网页数据-php精选-redis从零开始实现的php框架sava面向对象编程-从零开始实现-redis开发分布式系统php通过mongodb对关系型数据库的二级数据结构进行处理-数据结构-中国新闻.com
php或者ruby,
博客主要是以内容为主,内容可以分类或者电子版本。推荐phpwind:一站式php、ruby、perl等后端开发的blog,以技术文章为主,配合psd+txt+pdf,全面且系统,可以参考。
1、php要简单多,用yii,yii提供各种工具和php框架,php,mysql,access等,建议学习框架。2、ruby这个找个半吊子的,java用来写登录,简单的需求,
非后端不要走后端路线。
php、perl都可以,而且各有特点。php功能性强,易学;perl语法相对复杂,各种套子和ftp。不太清楚题主喜欢哪个:)如果要学习perl,可以看看这篇,只是针对这2个语言的:浅谈perl编程ftp总结,ftp协议对服务器、进程、io、数据库的要求较高;php对应的协议比较简单,模块式开发,个人认为优点是提供了php的丰富框架库,如:phpngwin、flashfoxperl等,对新手很友好。
phprubyflash
php,ruby,perl 查看全部
php多线程抓取网页(php多线程抓取网页数据-php精选-redis从零开始实现)
php多线程抓取网页数据-php精选-redis从零开始实现的php框架sava面向对象编程-从零开始实现-redis开发分布式系统php通过mongodb对关系型数据库的二级数据结构进行处理-数据结构-中国新闻.com
php或者ruby,
博客主要是以内容为主,内容可以分类或者电子版本。推荐phpwind:一站式php、ruby、perl等后端开发的blog,以技术文章为主,配合psd+txt+pdf,全面且系统,可以参考。
1、php要简单多,用yii,yii提供各种工具和php框架,php,mysql,access等,建议学习框架。2、ruby这个找个半吊子的,java用来写登录,简单的需求,
非后端不要走后端路线。
php、perl都可以,而且各有特点。php功能性强,易学;perl语法相对复杂,各种套子和ftp。不太清楚题主喜欢哪个:)如果要学习perl,可以看看这篇,只是针对这2个语言的:浅谈perl编程ftp总结,ftp协议对服务器、进程、io、数据库的要求较高;php对应的协议比较简单,模块式开发,个人认为优点是提供了php的丰富框架库,如:phpngwin、flashfoxperl等,对新手很友好。
phprubyflash
php,ruby,perl
php多线程抓取网页(使用线程有两种模式一种代码如下分享方法分享 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-13 11:03
)
一般来说,使用线程有两种模式。一种是创建一个线程要执行的函数,把这个函数传给Thread对象,让它执行。另一种是直接继承Thread,新建一个类。将线程执行的代码放入这个新类中。
实现多线程网络爬虫,利用多线程加锁机制实现广度优先算法的网络爬虫。
首先简单介绍一下我的实现思路:
对于一个网络爬虫来说,如果你想通过广度遍历下载,是这样的:
1.从给定的门户 URL 下载第一个网页
2.从第一个网页中提取所有新的网址并放入下载列表
3.点击下载列表中的地址下载所有新页面
4.从所有新网页中找出尚未下载的网页地址并更新下载列表
5.重复3、4两步,直到更新的下载列表为空并停止
python代码如下:
<p>
#!/usr/bin/env python
#coding=utf-8
import threading
import urllib
import re
import time
g_mutex=threading.Condition()
g_pages=[] #从中解析所有url链接
g_queueURL=[] #等待爬取的url链接列表
g_existURL=[] #已经爬取过的url链接列表
g_failedURL=[] #下载失败的url链接列表
g_totalcount=0 #下载过的页面数
class Crawler:
def __init__(self,crawlername,url,threadnum):
self.crawlername=crawlername
self.url=url
self.threadnum=threadnum
self.threadpool=[]
self.logfile=file("log.txt",'w')
def craw(self):
global g_queueURL
g_queueURL.append(url)
depth=0
print self.crawlername+" 启动..."
while(len(g_queueURL)!=0):
depth+=1
print 'Searching depth ',depth,'...\n\n'
self.logfile.write("URL:"+g_queueURL[0]+"........")
self.downloadAll()
self.updateQueueURL()
content='\n>>>Depth '+str(depth)+':\n'
self.logfile.write(content)
i=0
while i 查看全部
php多线程抓取网页(使用线程有两种模式一种代码如下分享方法分享
)
一般来说,使用线程有两种模式。一种是创建一个线程要执行的函数,把这个函数传给Thread对象,让它执行。另一种是直接继承Thread,新建一个类。将线程执行的代码放入这个新类中。
实现多线程网络爬虫,利用多线程加锁机制实现广度优先算法的网络爬虫。
首先简单介绍一下我的实现思路:
对于一个网络爬虫来说,如果你想通过广度遍历下载,是这样的:
1.从给定的门户 URL 下载第一个网页
2.从第一个网页中提取所有新的网址并放入下载列表
3.点击下载列表中的地址下载所有新页面
4.从所有新网页中找出尚未下载的网页地址并更新下载列表
5.重复3、4两步,直到更新的下载列表为空并停止
python代码如下:
<p>
#!/usr/bin/env python
#coding=utf-8
import threading
import urllib
import re
import time
g_mutex=threading.Condition()
g_pages=[] #从中解析所有url链接
g_queueURL=[] #等待爬取的url链接列表
g_existURL=[] #已经爬取过的url链接列表
g_failedURL=[] #下载失败的url链接列表
g_totalcount=0 #下载过的页面数
class Crawler:
def __init__(self,crawlername,url,threadnum):
self.crawlername=crawlername
self.url=url
self.threadnum=threadnum
self.threadpool=[]
self.logfile=file("log.txt",'w')
def craw(self):
global g_queueURL
g_queueURL.append(url)
depth=0
print self.crawlername+" 启动..."
while(len(g_queueURL)!=0):
depth+=1
print 'Searching depth ',depth,'...\n\n'
self.logfile.write("URL:"+g_queueURL[0]+"........")
self.downloadAll()
self.updateQueueURL()
content='\n>>>Depth '+str(depth)+':\n'
self.logfile.write(content)
i=0
while i
php多线程抓取网页(php多线程抓取网页内容(asp、ci等)抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-03-11 05:03
php多线程抓取网页内容asp多线程获取网页内容iis、ci等多线程抓取网页数据通常是我们从网站站内抓取数据的时候用的比较多的功能之一,后面结合实战来学习其中用到的算法以及实现过程。从头抓取整个数据流程解释打开大网站/小网站(自己动手做php爬虫)打开初始页面/上一页打开数据源打开各个关键的页面接下来就是最基本的抓取页面:/?frame=index,抓取前上传视频:/?video=...,抓取后获取页面链接等。直接打开抓取页面。
1、index对应页面请求首先要抓取的是标题为index的页面。
注意:由于页面中的get请求对方ip是可以直接得到明文发送出去的,
1)请求头中的host/verletrequest/request/headers这几个部分是否接收成功。请求头会随机分配一个端口号。
2)如果所在节点反向代理不通,导致请求不到路由页面,那么恭喜你,你节点没有请求到路由页面,导致无法获取请求。抓取到请求请求头的完整请求文本:-bin/php?host=-index-crawler//index/index?__a=www-bin/php?__t=global__//接受本节点路由的get请求。
重要因素解释:
1)host是我们节点的返回地址:公共路由和路由节点。路由节点是根据接受请求的多少分配host+url。相同请求host可以是同一个节点的host。
2)crawler是接受本节点路由请求的工具:类似index2是生成一个虚拟域名的请求,默认是基于上代理。
3)url可以是一些数据表示形式。
4)不同的请求host分配不同的源url。
5)如果请求host为同一节点url,但是源url不同,请求获取不到对应的页面,那么恭喜你,你节点分配错误。
6)post请求,那么根据不同的host值获取不同的源url。
2、抓取上一页到androidstudylist/index-studylist获取页面(页面解析)/?page=index获取页面后以/?page=index请求,如果没有返回相应的页面,会把请求头返回给节点查看。抓取内容页然后根据页面情况查看返回页面(列表页/具体页面)。页面解析for($t=10;$t>=0;$t++){pagelist=tableview($t);$result=mapwordstring(pagelist."","");if($result){returnnull;}if(!show){$result.text=filenamestring($t.filepath);}//查看请求头中page表示页面路径//for($t=0;$t>=0;$t++){lookbook.file_inputfields.filter($_server['http_prefix'].""。 查看全部
php多线程抓取网页(php多线程抓取网页内容(asp、ci等)抓取)
php多线程抓取网页内容asp多线程获取网页内容iis、ci等多线程抓取网页数据通常是我们从网站站内抓取数据的时候用的比较多的功能之一,后面结合实战来学习其中用到的算法以及实现过程。从头抓取整个数据流程解释打开大网站/小网站(自己动手做php爬虫)打开初始页面/上一页打开数据源打开各个关键的页面接下来就是最基本的抓取页面:/?frame=index,抓取前上传视频:/?video=...,抓取后获取页面链接等。直接打开抓取页面。
1、index对应页面请求首先要抓取的是标题为index的页面。
注意:由于页面中的get请求对方ip是可以直接得到明文发送出去的,
1)请求头中的host/verletrequest/request/headers这几个部分是否接收成功。请求头会随机分配一个端口号。
2)如果所在节点反向代理不通,导致请求不到路由页面,那么恭喜你,你节点没有请求到路由页面,导致无法获取请求。抓取到请求请求头的完整请求文本:-bin/php?host=-index-crawler//index/index?__a=www-bin/php?__t=global__//接受本节点路由的get请求。
重要因素解释:
1)host是我们节点的返回地址:公共路由和路由节点。路由节点是根据接受请求的多少分配host+url。相同请求host可以是同一个节点的host。
2)crawler是接受本节点路由请求的工具:类似index2是生成一个虚拟域名的请求,默认是基于上代理。
3)url可以是一些数据表示形式。
4)不同的请求host分配不同的源url。
5)如果请求host为同一节点url,但是源url不同,请求获取不到对应的页面,那么恭喜你,你节点分配错误。
6)post请求,那么根据不同的host值获取不同的源url。
2、抓取上一页到androidstudylist/index-studylist获取页面(页面解析)/?page=index获取页面后以/?page=index请求,如果没有返回相应的页面,会把请求头返回给节点查看。抓取内容页然后根据页面情况查看返回页面(列表页/具体页面)。页面解析for($t=10;$t>=0;$t++){pagelist=tableview($t);$result=mapwordstring(pagelist."","");if($result){returnnull;}if(!show){$result.text=filenamestring($t.filepath);}//查看请求头中page表示页面路径//for($t=0;$t>=0;$t++){lookbook.file_inputfields.filter($_server['http_prefix'].""。
php多线程抓取网页(php中curl_init()的具体使用方法及相关效率比较)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-24 15:05
php使用curl_init()和curl_multi_init()多线程的速度详解
更新时间:2018-08-15 10:06:55 作者:CC_小硕
本文章主要介绍了php使用curl_init()和curl_multi_init()多线程的速度对比,并结合示例表格详细分析了curl_init()和curl_multi_init()的具体用法及相关效率对比。需要的朋友可以参考以下
本文的例子描述了php使用curl_init()和curl_multi_init()多线程的速度对比。分享给大家参考,详情如下:
curl_init()在php中的作用非常大,尤其是在抓取网页内容或者文件信息的时候。比如之前的文章《PHP使用curl获取header检测并启用GZip压缩》中介绍了curl_init()的威力。
curl_init() 以单线程模式处理事物。如果需要使用多线程模式进行事务处理,那么PHP为我们提供了一个函数curl_multi_init(),就是多线程模式处理事务的函数。
curl_init()和curl_multi_init()的速度对比
curl_multi_init() 多线程可以提高网页的处理速度吗?今天我将通过一个实验来验证这个问题。
我今天的测试很简单,就是抓取网页的内容,需要连续抓取5次,使用curl_init()和curl_multi_init()函数完成,记录两次耗时,并比较得出结论。
首先,使用 curl_init() 单线程连续抓取网页内容 5 次。
程序代码如下:
然后,使用 curl_multi_init() 多线程连续抓取网页内容 5 次。
代码显示如下:
<p> 查看全部
php多线程抓取网页(php中curl_init()的具体使用方法及相关效率比较)
php使用curl_init()和curl_multi_init()多线程的速度详解
更新时间:2018-08-15 10:06:55 作者:CC_小硕
本文章主要介绍了php使用curl_init()和curl_multi_init()多线程的速度对比,并结合示例表格详细分析了curl_init()和curl_multi_init()的具体用法及相关效率对比。需要的朋友可以参考以下
本文的例子描述了php使用curl_init()和curl_multi_init()多线程的速度对比。分享给大家参考,详情如下:
curl_init()在php中的作用非常大,尤其是在抓取网页内容或者文件信息的时候。比如之前的文章《PHP使用curl获取header检测并启用GZip压缩》中介绍了curl_init()的威力。
curl_init() 以单线程模式处理事物。如果需要使用多线程模式进行事务处理,那么PHP为我们提供了一个函数curl_multi_init(),就是多线程模式处理事务的函数。
curl_init()和curl_multi_init()的速度对比
curl_multi_init() 多线程可以提高网页的处理速度吗?今天我将通过一个实验来验证这个问题。
我今天的测试很简单,就是抓取网页的内容,需要连续抓取5次,使用curl_init()和curl_multi_init()函数完成,记录两次耗时,并比较得出结论。
首先,使用 curl_init() 单线程连续抓取网页内容 5 次。
程序代码如下:
然后,使用 curl_multi_init() 多线程连续抓取网页内容 5 次。
代码显示如下:
<p>
php多线程抓取网页(PHP线程处理框架异步任务 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-23 02:15
)
1 使用 fastcgi_finish_request()
如果 PHP 和 web 服务器使用 PHP-FPM(FastCGI Process Manager),fastcgi_finish_request() 函数可以立即结束会话,PHP 线程可以继续在后台运行。
echo "program start...";
file_put_contents('log.txt','start-time:'.date('Y-m-d H:i:s'), FILE_APPEND);
fastcgi_finish_request();
sleep(1);
echo 'debug...';
file_put_contents('log.txt', 'start-proceed:'.date('Y-m-d H:i:s'), FILE_APPEND);
sleep(10);
file_put_contents('log.txt', 'end-time:'.date('Y-m-d H:i:s'), FILE_APPEND);
从输出中可以看出,页面打印program start...,而session在输出第一行到log.txt后就返回了,所以浏览器上不会显示下面的debug...,而log。 txt 文件 可以完整接收三个完成时间。
2 使用 fsockopen()
使用 fsockopen() 打开网络连接或 Unix 套接字连接,然后使用 stream_set_blocking() 以非阻塞模式请求:
$fp = fsockopen("www.example.com", 80, $errno, $errstr, 30);
if (!$fp) {
die('error fsockopen');
}
// 转换到非阻塞模式
stream_set_blocking($fp, 0);
$http = "GET /save.php / HTTP/1.1\r\n";
$http .= "Host: www.example.com\r\n";
$http .= "Connection: Close\r\n\r\n";
fwrite($fp, $http);
fclose($fp);
3 使用卷曲
使用 cURL 中的 curl_multi_* 函数发送异步请求
$cmh = curl_multi_init();
$ch1 = curl_init();
curl_setopt($ch1, CURLOPT_URL, "http://localhost/");
curl_multi_add_handle($cmh, $ch1);
curl_multi_exec($cmh, $active);
echo "End\n";
4 使用 Gearman/Swoole 扩展
Gearman 是一个分布式异步处理框架,带有 php 扩展,可以处理大批量的异步任务。
Swoole最近很流行,异步方法很多,好用。
5 使用缓存和队列
使用缓存和redis等队列将数据写入缓存,使用后台定时任务实现异步数据处理。
这种方法在常见的高流量架构中应该很常见。
6 调用系统命令
极端情况下可以调用系统命令,将数据传给后台任务执行,个人效率不是很高。
$cmd = 'nohup php ./processd.php $someVar >/dev/null &';
`$cmd`
7 使用 pcntl_fork()
安装 pcntl 扩展并使用 pcntl_fork() 生成子进程来异步执行任务在我看来是最方便的,但也容易出现僵尸进程。
$pid = pcntl_fork()
if ($pid == 0) { child_func(); //子进程函数,主进程运行
} else { father_func(); //主进程函数
}
echo "Process " . getmypid() . " get to the end.\n"; function father_func() { echo "Father pid is " . getmypid() . "\n";
}
function child_func() { sleep(6); echo "Child process exit pid is " . getmypid() . "\n"; exit(0);
} 查看全部
php多线程抓取网页(PHP线程处理框架异步任务
)
1 使用 fastcgi_finish_request()
如果 PHP 和 web 服务器使用 PHP-FPM(FastCGI Process Manager),fastcgi_finish_request() 函数可以立即结束会话,PHP 线程可以继续在后台运行。
echo "program start...";
file_put_contents('log.txt','start-time:'.date('Y-m-d H:i:s'), FILE_APPEND);
fastcgi_finish_request();
sleep(1);
echo 'debug...';
file_put_contents('log.txt', 'start-proceed:'.date('Y-m-d H:i:s'), FILE_APPEND);
sleep(10);
file_put_contents('log.txt', 'end-time:'.date('Y-m-d H:i:s'), FILE_APPEND);
从输出中可以看出,页面打印program start...,而session在输出第一行到log.txt后就返回了,所以浏览器上不会显示下面的debug...,而log。 txt 文件 可以完整接收三个完成时间。
2 使用 fsockopen()
使用 fsockopen() 打开网络连接或 Unix 套接字连接,然后使用 stream_set_blocking() 以非阻塞模式请求:
$fp = fsockopen("www.example.com", 80, $errno, $errstr, 30);
if (!$fp) {
die('error fsockopen');
}
// 转换到非阻塞模式
stream_set_blocking($fp, 0);
$http = "GET /save.php / HTTP/1.1\r\n";
$http .= "Host: www.example.com\r\n";
$http .= "Connection: Close\r\n\r\n";
fwrite($fp, $http);
fclose($fp);
3 使用卷曲
使用 cURL 中的 curl_multi_* 函数发送异步请求
$cmh = curl_multi_init();
$ch1 = curl_init();
curl_setopt($ch1, CURLOPT_URL, "http://localhost/";);
curl_multi_add_handle($cmh, $ch1);
curl_multi_exec($cmh, $active);
echo "End\n";
4 使用 Gearman/Swoole 扩展
Gearman 是一个分布式异步处理框架,带有 php 扩展,可以处理大批量的异步任务。
Swoole最近很流行,异步方法很多,好用。
5 使用缓存和队列
使用缓存和redis等队列将数据写入缓存,使用后台定时任务实现异步数据处理。
这种方法在常见的高流量架构中应该很常见。
6 调用系统命令
极端情况下可以调用系统命令,将数据传给后台任务执行,个人效率不是很高。
$cmd = 'nohup php ./processd.php $someVar >/dev/null &';
`$cmd`
7 使用 pcntl_fork()
安装 pcntl 扩展并使用 pcntl_fork() 生成子进程来异步执行任务在我看来是最方便的,但也容易出现僵尸进程。
$pid = pcntl_fork()
if ($pid == 0) { child_func(); //子进程函数,主进程运行
} else { father_func(); //主进程函数
}
echo "Process " . getmypid() . " get to the end.\n"; function father_func() { echo "Father pid is " . getmypid() . "\n";
}
function child_func() { sleep(6); echo "Child process exit pid is " . getmypid() . "\n"; exit(0);
}
php多线程抓取网页( 《PHP教程》3.php即写即用的表面思路更清晰)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-23 01:29
《PHP教程》3.php即写即用的表面思路更清晰)
PHP好用还是JAVAweb好用?
JAVA
PHP
比较:
1. php 已准备好写入。
也就是说,每次只完成一次更改,用户立即看到效果,而java慢很多。代码修改完成后,需要重新编译,然后重启jvm。中间耗费了很多时间,重启jvm的过程还不够。会导致用户响应中断。
2. php 写东西很快。
PHP可以说是非常敏捷。给定一个需求,只要不考虑后期的性能和用户量,是相当快的。甚至你可以不用框架直接写。它会非常快。功能,30-50行代码就可以搞定。Java 慢得多。首先想好用什么框架,基本就是spring,然后配置各种数据库、过滤器、servlet,决定用mybatis还是hibernate,再考虑代码之间的传递,再考虑业务。. . 然后继续调试,改代码可能需要几分钟的等待时间,可以想象。
推荐:《PHP教程》
3.php的肤浅思路比较清晰。
什么是表面的想法,也就是你看到的就是实际做出来的。比如echo "hello world"就是输出hello world的意思,但是java不同。你可能会写响应,也可能是写在model属性中,也可能是返回字符串,然后莫名其妙地显示在页面上。
4. php 占用更少的内存。
PHP 以程序化的方式处理问题,占用的内存相对较少。可以说在一台机器上部署50个项目没有任何问题。只要流量不增加,你就可以做到。但是java不会工作。java每次启动一个项目,都要消耗大量的内存。比如在一台8g内存的机器上,跑两个项目差不多够用了。
5. 说了php的好处,难道java就没有好处了吗?那是不可能的。
6. 有很多 java 组件。
我个人认为仅此一项就压倒了其他所有的优势,因为组件很多,也就是说用的人很多,群众的眼光也很敏锐。所以java一定要好。它积累了太多东西,也不是一门可以轻易替代的新语言。你要做什么,好好搜索java组件,你可能有你需要的功能,尤其是最火的大数据行业,java占了一席之地。而php在这种场景下有点力不从心。
7. java线程池,连接池,异步方便。
事实上,这一点与第一点非常相似。也是因为组件多,所以使用线程池连接池非常方便,对于高并发高性能场景来说是绝对必要的。因为java的运行原因是多线程的,所以不需要每次都初始化很多基础的东西,节省了太多的时间,所以大家可以容忍服务器启动的慢过程,因为只有一次。而PHP是多进程的,每次都需要重新加载所有需要的代码,所以无法将一些常用的数据保存在内存中,连接池也不是很容易做,异步操作是一个很大的缺点。
8. 真正意义上的java逻辑清晰。
因为,在java中,可以借助IDE工具从一个入口到最深层次的可以分析的逻辑操作,而且对于每一个字段,都可以一目了然,这其实是使用接口和完整对象的一个优势. 但是,php做不到,或者很少有人尝试做这种事情。php可以说是一半面向对象,一半面向过程的开发。因此,在调用过程中插入几个自定义函数调用是正常的。那么你通过一个简单的IDE来分析调用链就不是那么容易了。比如第三方提供的一个接口,除非你打印出来,否则php很难清楚的看到接口返回了什么,但是打印出来也不一定正确,因为有些返回值的数据可能不得到反映。
9.虽然java编译比较麻烦,但是可以提前为你检测错误。
java的编译确实比较耗时,但是如果有明显的错误,编译就不会通过,这就给了你重新检查代码的机会。但是,php 没有。无论你写得多么糟糕,它都不会给你任何提示。很多时候,往往是因为你少写了一篇;分号,这将使您检查几个小时。
10.java远程调用方便,rmi,hessian,dubbo。
无论如何,远程和本地调用都非常方便知道相关信息,而且java的同语言调用不使用纯http调用,保持一定的连接,从而大大提高性能。而且php也有远程调用,但是相对来说弱很多。
其实没有问题,没有绝对的好坏,存在是合理的。只是应用场景不同而已。
以上就是PHP好用还是JAVAweb好用的详细内容。更多详情请关注php中文网文章其他相关话题! 查看全部
php多线程抓取网页(
《PHP教程》3.php即写即用的表面思路更清晰)
PHP好用还是JAVAweb好用?
JAVA
PHP
比较:
1. php 已准备好写入。
也就是说,每次只完成一次更改,用户立即看到效果,而java慢很多。代码修改完成后,需要重新编译,然后重启jvm。中间耗费了很多时间,重启jvm的过程还不够。会导致用户响应中断。
2. php 写东西很快。
PHP可以说是非常敏捷。给定一个需求,只要不考虑后期的性能和用户量,是相当快的。甚至你可以不用框架直接写。它会非常快。功能,30-50行代码就可以搞定。Java 慢得多。首先想好用什么框架,基本就是spring,然后配置各种数据库、过滤器、servlet,决定用mybatis还是hibernate,再考虑代码之间的传递,再考虑业务。. . 然后继续调试,改代码可能需要几分钟的等待时间,可以想象。
推荐:《PHP教程》
3.php的肤浅思路比较清晰。
什么是表面的想法,也就是你看到的就是实际做出来的。比如echo "hello world"就是输出hello world的意思,但是java不同。你可能会写响应,也可能是写在model属性中,也可能是返回字符串,然后莫名其妙地显示在页面上。
4. php 占用更少的内存。
PHP 以程序化的方式处理问题,占用的内存相对较少。可以说在一台机器上部署50个项目没有任何问题。只要流量不增加,你就可以做到。但是java不会工作。java每次启动一个项目,都要消耗大量的内存。比如在一台8g内存的机器上,跑两个项目差不多够用了。
5. 说了php的好处,难道java就没有好处了吗?那是不可能的。
6. 有很多 java 组件。
我个人认为仅此一项就压倒了其他所有的优势,因为组件很多,也就是说用的人很多,群众的眼光也很敏锐。所以java一定要好。它积累了太多东西,也不是一门可以轻易替代的新语言。你要做什么,好好搜索java组件,你可能有你需要的功能,尤其是最火的大数据行业,java占了一席之地。而php在这种场景下有点力不从心。
7. java线程池,连接池,异步方便。
事实上,这一点与第一点非常相似。也是因为组件多,所以使用线程池连接池非常方便,对于高并发高性能场景来说是绝对必要的。因为java的运行原因是多线程的,所以不需要每次都初始化很多基础的东西,节省了太多的时间,所以大家可以容忍服务器启动的慢过程,因为只有一次。而PHP是多进程的,每次都需要重新加载所有需要的代码,所以无法将一些常用的数据保存在内存中,连接池也不是很容易做,异步操作是一个很大的缺点。
8. 真正意义上的java逻辑清晰。
因为,在java中,可以借助IDE工具从一个入口到最深层次的可以分析的逻辑操作,而且对于每一个字段,都可以一目了然,这其实是使用接口和完整对象的一个优势. 但是,php做不到,或者很少有人尝试做这种事情。php可以说是一半面向对象,一半面向过程的开发。因此,在调用过程中插入几个自定义函数调用是正常的。那么你通过一个简单的IDE来分析调用链就不是那么容易了。比如第三方提供的一个接口,除非你打印出来,否则php很难清楚的看到接口返回了什么,但是打印出来也不一定正确,因为有些返回值的数据可能不得到反映。
9.虽然java编译比较麻烦,但是可以提前为你检测错误。
java的编译确实比较耗时,但是如果有明显的错误,编译就不会通过,这就给了你重新检查代码的机会。但是,php 没有。无论你写得多么糟糕,它都不会给你任何提示。很多时候,往往是因为你少写了一篇;分号,这将使您检查几个小时。
10.java远程调用方便,rmi,hessian,dubbo。
无论如何,远程和本地调用都非常方便知道相关信息,而且java的同语言调用不使用纯http调用,保持一定的连接,从而大大提高性能。而且php也有远程调用,但是相对来说弱很多。
其实没有问题,没有绝对的好坏,存在是合理的。只是应用场景不同而已。
以上就是PHP好用还是JAVAweb好用的详细内容。更多详情请关注php中文网文章其他相关话题!
php多线程抓取网页(php多线程抓取网页的教程你可以在网上找一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-23 00:01
php多线程抓取网页的教程你可以在网上找一下,总的来说思路大致如下,找一个服务器,连接n多个网页线程,一个线程抓取一个网页,如果抓取100页就连接1000个线程,一直抓取10000页,然后线程连接下一个服务器,再抓取10000页,如此循环,直到服务器终止连接,这时的数据量已经相当大了,可以出去溜达溜达了。
php内置的gil,就是控制一个进程能在多线程中执行,否则一个进程线程数越多,cpu占用率就越低,还有编译时间,都是成本问题。
抓取结果自己存起来,
去吧!选择前面6个,
多多线程抓取,新浪一个个服务器,没必要的,要是同时上传100w数据,可能服务器撑不住。买云主机吧,效率高点,减少这些问题。另外补充一点,用mysql扩展,可以组合用,完全可以达到类似爬虫的效果。
明显php本身能比单台机器高效的执行任务,但是php连接不到多个服务器就算你得单台机器用sqlserver或者mysql,而只是jboss这种前端server也不一定带得动,多余的性能浪费应该是你想要的。
建议优先处理设备地址不同,如果tcp可以的话就优先用nginx。最后,io效率或者网络的速度不是唯一问题。 查看全部
php多线程抓取网页(php多线程抓取网页的教程你可以在网上找一下)
php多线程抓取网页的教程你可以在网上找一下,总的来说思路大致如下,找一个服务器,连接n多个网页线程,一个线程抓取一个网页,如果抓取100页就连接1000个线程,一直抓取10000页,然后线程连接下一个服务器,再抓取10000页,如此循环,直到服务器终止连接,这时的数据量已经相当大了,可以出去溜达溜达了。
php内置的gil,就是控制一个进程能在多线程中执行,否则一个进程线程数越多,cpu占用率就越低,还有编译时间,都是成本问题。
抓取结果自己存起来,
去吧!选择前面6个,
多多线程抓取,新浪一个个服务器,没必要的,要是同时上传100w数据,可能服务器撑不住。买云主机吧,效率高点,减少这些问题。另外补充一点,用mysql扩展,可以组合用,完全可以达到类似爬虫的效果。
明显php本身能比单台机器高效的执行任务,但是php连接不到多个服务器就算你得单台机器用sqlserver或者mysql,而只是jboss这种前端server也不一定带得动,多余的性能浪费应该是你想要的。
建议优先处理设备地址不同,如果tcp可以的话就优先用nginx。最后,io效率或者网络的速度不是唯一问题。
php多线程抓取网页 Python爬虫大战京东商城
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-06-01 12:25
專 欄
❈爱撒谎的男孩,Python中文社区专栏作者
博客:
❈
主要工具
scrapy
BeautifulSoup
requests
分析步骤
打开京东首页,输入裤子将会看到页面跳转到了这里,这就是我们要分析的起点
我们可以看到这个页面并不是完全的,当我们往下拉的时候将会看到图片在不停的加载,这就是ajax,但是当我们下拉到底的时候就会看到整个页面加载了60条裤子的信息,我们打开chrome的调试工具,查找页面元素时可以看到每条裤子的信息都在这个标签中,如下图:
接着我们打开网页源码就会发现其实网页源码只有前30条的数据,后面30条的数据找不到,因此这里就会想到ajax,一种异步加载的方式,于是我们就要开始抓包了,我们打开chrome按F12,点击上面的NetWork,然后点击XHR,这个比较容易好找,下面开始抓包,如下图:
从上面可以找到请求的url,发现有很长的一大段,我们试着去掉一些看看可不可以打开,简化之后的url={0}&s=26&scrolling=y&pos=30&show_items={1}
这里的showitems是裤子的id,page是翻页的,可以看出来我们只需要改动两处就可以打开不同的网页了,这里的page很好找,你会发现一个很好玩的事情,就是主网页的page是奇数,但是异步加载的网页中的page是偶数,因此这里只要填上偶数就可以了,但是填奇数也是可以访问的。这里的show_items就是id了,我们可以在页面的源码中找到,通过查找可以看到id在li标签的data-pid中,详情请看下图
上面我们知道怎样找参数了,现在就可以撸代码了
代码讲解
首先我们要获取网页的源码,这里我用的requests库,安装方法为pip install requests,代码如下:
根据上面的分析可以知道,第二步就是得到异步加载的url中的参数show_items,就是li标签中的data-pid,代码如下:
下面就是获取前30张图片的url了,也就是主网页上的图片,其中一个问题是img标签的属性并不是一样的,也就是源码中的img中不都是src属性,一开始已经加载出来的图片就是src属性,但是没有加载出来的图片是data-lazy-img,因此在解析页面的时候要加上讨论。代码如下:
前三十张图片找到了,现在开始找后三十张图片了,当然是要请求那个异步加载的url,前面已经把需要的参数给找到了,下面就好办了,直接贴代码:
通过上面就可以爬取了,但是还是要考虑速度的问题,这里我用了多线程,直接每一页面开启一个线程,速度还是可以的,感觉这个速度还是可以的,几分钟解决问题,总共爬取了100个网页,这里的存储方式是mysql数据库存储的,要用发哦MySQLdb这个库,详情自己百度,当然也可以用mogodb但是还没有学呢,想要的源码的朋友请看GitHub源码。
拓展
写到这里可以看到搜索首页的网址中keyword和wq都是你输入的词,如果你想要爬取更多的信息,可以将这两个词改成你想要搜索的词即可,直接将汉字写上,在请求的时候会自动帮你编码的,我也试过了,可以抓取源码的,如果你想要不断的抓取,可以将要搜索的词写上文件里,然后从文件中读取就可以了。以上只是一个普通的爬虫,并没有用到什么框架,接下来将会写scrapy框架爬取的,请继续关注哦!
长按扫描关注Python中文社区,
获取更多技术干货!
Python 中 文 社 区
Python中文开发者的精神家园 查看全部
php多线程抓取网页 Python爬虫大战京东商城
專 欄
❈爱撒谎的男孩,Python中文社区专栏作者
博客:
❈
主要工具
scrapy
BeautifulSoup
requests
分析步骤
打开京东首页,输入裤子将会看到页面跳转到了这里,这就是我们要分析的起点
我们可以看到这个页面并不是完全的,当我们往下拉的时候将会看到图片在不停的加载,这就是ajax,但是当我们下拉到底的时候就会看到整个页面加载了60条裤子的信息,我们打开chrome的调试工具,查找页面元素时可以看到每条裤子的信息都在这个标签中,如下图:
接着我们打开网页源码就会发现其实网页源码只有前30条的数据,后面30条的数据找不到,因此这里就会想到ajax,一种异步加载的方式,于是我们就要开始抓包了,我们打开chrome按F12,点击上面的NetWork,然后点击XHR,这个比较容易好找,下面开始抓包,如下图:
从上面可以找到请求的url,发现有很长的一大段,我们试着去掉一些看看可不可以打开,简化之后的url={0}&s=26&scrolling=y&pos=30&show_items={1}
这里的showitems是裤子的id,page是翻页的,可以看出来我们只需要改动两处就可以打开不同的网页了,这里的page很好找,你会发现一个很好玩的事情,就是主网页的page是奇数,但是异步加载的网页中的page是偶数,因此这里只要填上偶数就可以了,但是填奇数也是可以访问的。这里的show_items就是id了,我们可以在页面的源码中找到,通过查找可以看到id在li标签的data-pid中,详情请看下图
上面我们知道怎样找参数了,现在就可以撸代码了
代码讲解
首先我们要获取网页的源码,这里我用的requests库,安装方法为pip install requests,代码如下:
根据上面的分析可以知道,第二步就是得到异步加载的url中的参数show_items,就是li标签中的data-pid,代码如下:
下面就是获取前30张图片的url了,也就是主网页上的图片,其中一个问题是img标签的属性并不是一样的,也就是源码中的img中不都是src属性,一开始已经加载出来的图片就是src属性,但是没有加载出来的图片是data-lazy-img,因此在解析页面的时候要加上讨论。代码如下:
前三十张图片找到了,现在开始找后三十张图片了,当然是要请求那个异步加载的url,前面已经把需要的参数给找到了,下面就好办了,直接贴代码:
通过上面就可以爬取了,但是还是要考虑速度的问题,这里我用了多线程,直接每一页面开启一个线程,速度还是可以的,感觉这个速度还是可以的,几分钟解决问题,总共爬取了100个网页,这里的存储方式是mysql数据库存储的,要用发哦MySQLdb这个库,详情自己百度,当然也可以用mogodb但是还没有学呢,想要的源码的朋友请看GitHub源码。
拓展
写到这里可以看到搜索首页的网址中keyword和wq都是你输入的词,如果你想要爬取更多的信息,可以将这两个词改成你想要搜索的词即可,直接将汉字写上,在请求的时候会自动帮你编码的,我也试过了,可以抓取源码的,如果你想要不断的抓取,可以将要搜索的词写上文件里,然后从文件中读取就可以了。以上只是一个普通的爬虫,并没有用到什么框架,接下来将会写scrapy框架爬取的,请继续关注哦!
长按扫描关注Python中文社区,
获取更多技术干货!
Python 中 文 社 区
Python中文开发者的精神家园
php多线程抓取网页 [Win] Free Download Manager v5.1.38
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-05-28 06:58
Free Download Manager是一款免费的多点续传下载及管理的软件,支持 HTTP、HTTPS、FTP 的下载功能,软件公司称可增快你的下载速度达 600%。Free Download Manager软件有一个特色,支持直接浏览 FTP 站台的目录(如果你有该 FTP 站台的浏览权限时),再选择你要的文档,便可以直接以该软件来下文档。
软件功能:
支持多线程下载,支持计划任务下载,支持以目录列表查看检索站点内容,支持下载网页内容、图象、文件,支持抓取网页上的链接,支持下载整个网站内容(可设定下载子目录的层次深度),理论上可下载超过1000 层的子目录网页和图象等内容。
支持捕获网页风格样式(以 CSS 内容保存),支持多种格式网页抓取,包括:html、shtm、shtml、phml、dhtml、php、hta、htc、cgi、asp、htm 等等……亦可自己设定格式,可在线以“站点浏览器”查看目标网站的子目录中的内容,支持三种下载通讯模式,支持断点续传,可显示服务器是否支持续传并可设定是否重新下载或覆盖。
特别说明:
软件默认安装简体中文版,并且默认集成浏览器扩展。此软件不支持ed2k://格式的磁力链接,但支持magnet:格式及种子文件,这点比好。
卸载之后会有文件残留,可使用电脑管家的文件粉碎功能删除。
下载地址:
查看全部
php多线程抓取网页 [Win] Free Download Manager v5.1.38
Free Download Manager是一款免费的多点续传下载及管理的软件,支持 HTTP、HTTPS、FTP 的下载功能,软件公司称可增快你的下载速度达 600%。Free Download Manager软件有一个特色,支持直接浏览 FTP 站台的目录(如果你有该 FTP 站台的浏览权限时),再选择你要的文档,便可以直接以该软件来下文档。
软件功能:
支持多线程下载,支持计划任务下载,支持以目录列表查看检索站点内容,支持下载网页内容、图象、文件,支持抓取网页上的链接,支持下载整个网站内容(可设定下载子目录的层次深度),理论上可下载超过1000 层的子目录网页和图象等内容。
支持捕获网页风格样式(以 CSS 内容保存),支持多种格式网页抓取,包括:html、shtm、shtml、phml、dhtml、php、hta、htc、cgi、asp、htm 等等……亦可自己设定格式,可在线以“站点浏览器”查看目标网站的子目录中的内容,支持三种下载通讯模式,支持断点续传,可显示服务器是否支持续传并可设定是否重新下载或覆盖。
特别说明:
软件默认安装简体中文版,并且默认集成浏览器扩展。此软件不支持ed2k://格式的磁力链接,但支持magnet:格式及种子文件,这点比好。
卸载之后会有文件残留,可使用电脑管家的文件粉碎功能删除。
下载地址:
php多线程抓取网页试过((
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-05-26 21:06
php多线程抓取网页试过多线程的同学们都知道在抓取网页的时候,经常会遇到线程等待抓取数据的情况,同时开启多个线程抓取数据的话时间就会很长,这个时候使用代理就很方便,我们有三种方式可以代理,分别是:代理服务器、代理服务器的子进程和v2代理,我们这次主要就先介绍下代理服务器。
一、基本原理代理服务器的主要原理其实就是一种网络代理功能,假设访问a网站的时候,首先抓取了a网站的所有的数据,
1),a再分别去访问b、c、d。这样就能多个客户端都抓取同一个页面了。
一般的代理客户端通过网络连接来接收服务器端的报文,
0)。这样a服务器就能访问b、c、d服务器的全部页面。当然我们也可以转发客户端a的地址给代理,来进行多个连接,例如:在发布商可能设置为223.37.2.3,假设客户端a设置为223.37.2.3,这样能够以b为代理服务器转发b服务器的全部报文。当然也可以直接把a地址转发给代理服务器,这样就可以访问整个程序中的所有页面。
例如123.162.55.40就可以用3.4.1.1来代理123.162.55.40。另外还可以把中间页的链接中继到代理服务器,这样可以跟客户端a直接通信。
二、代理服务器代理服务器也有proxy,那么这个proxy服务器怎么用呢?首先我们要把网站域名解析成二进制数据来存储。创建一个proxy对象实例proxy,同时在代理服务器对象proxy1()中定义对应的server指令。2.1创建代理服务器proxy1()定义访问代理服务器时传递给代理的数据格式。方法一参数:1-同域名地址2-对应网站ip地址,域名加ip地址,例如:北京ip:123.162.55.40网站:北京2.2proxy的基本方法proxy1()将代理服务器同域名/网站ip地址进行映射创建子代理,然后在代理对象中的execve()函数中进行fromname()方法的一键同域名路径创建子代理实例proxy2()获取该被服务器ip地址、网站路径,再进行mgsql路径的解析2.3proxy的基本方法trymain()方法调用子代理,在getserver()方法中进行fromname()方法的一键同域名路径对应函数request=proxy1();request.connect(sessionid);if(request.status==true){request.database_addr=sessionid.address;if(sessionid.address==true){request.openserialtype(request.database_addr);}}}catch(ex。 查看全部
php多线程抓取网页试过((
php多线程抓取网页试过多线程的同学们都知道在抓取网页的时候,经常会遇到线程等待抓取数据的情况,同时开启多个线程抓取数据的话时间就会很长,这个时候使用代理就很方便,我们有三种方式可以代理,分别是:代理服务器、代理服务器的子进程和v2代理,我们这次主要就先介绍下代理服务器。
一、基本原理代理服务器的主要原理其实就是一种网络代理功能,假设访问a网站的时候,首先抓取了a网站的所有的数据,
1),a再分别去访问b、c、d。这样就能多个客户端都抓取同一个页面了。
一般的代理客户端通过网络连接来接收服务器端的报文,
0)。这样a服务器就能访问b、c、d服务器的全部页面。当然我们也可以转发客户端a的地址给代理,来进行多个连接,例如:在发布商可能设置为223.37.2.3,假设客户端a设置为223.37.2.3,这样能够以b为代理服务器转发b服务器的全部报文。当然也可以直接把a地址转发给代理服务器,这样就可以访问整个程序中的所有页面。
例如123.162.55.40就可以用3.4.1.1来代理123.162.55.40。另外还可以把中间页的链接中继到代理服务器,这样可以跟客户端a直接通信。
二、代理服务器代理服务器也有proxy,那么这个proxy服务器怎么用呢?首先我们要把网站域名解析成二进制数据来存储。创建一个proxy对象实例proxy,同时在代理服务器对象proxy1()中定义对应的server指令。2.1创建代理服务器proxy1()定义访问代理服务器时传递给代理的数据格式。方法一参数:1-同域名地址2-对应网站ip地址,域名加ip地址,例如:北京ip:123.162.55.40网站:北京2.2proxy的基本方法proxy1()将代理服务器同域名/网站ip地址进行映射创建子代理,然后在代理对象中的execve()函数中进行fromname()方法的一键同域名路径创建子代理实例proxy2()获取该被服务器ip地址、网站路径,再进行mgsql路径的解析2.3proxy的基本方法trymain()方法调用子代理,在getserver()方法中进行fromname()方法的一键同域名路径对应函数request=proxy1();request.connect(sessionid);if(request.status==true){request.database_addr=sessionid.address;if(sessionid.address==true){request.openserialtype(request.database_addr);}}}catch(ex。
php多线程抓取网页 [Win] Free Download Manager v5.1.38
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-05-23 06:32
Free Download Manager是一款免费的多点续传下载及管理的软件,支持 HTTP、HTTPS、FTP 的下载功能,软件公司称可增快你的下载速度达 600%。Free Download Manager软件有一个特色,支持直接浏览 FTP 站台的目录(如果你有该 FTP 站台的浏览权限时),再选择你要的文档,便可以直接以该软件来下文档。
软件功能:
支持多线程下载,支持计划任务下载,支持以目录列表查看检索站点内容,支持下载网页内容、图象、文件,支持抓取网页上的链接,支持下载整个网站内容(可设定下载子目录的层次深度),理论上可下载超过1000 层的子目录网页和图象等内容。
支持捕获网页风格样式(以 CSS 内容保存),支持多种格式网页抓取,包括:html、shtm、shtml、phml、dhtml、php、hta、htc、cgi、asp、htm 等等……亦可自己设定格式,可在线以“站点浏览器”查看目标网站的子目录中的内容,支持三种下载通讯模式,支持断点续传,可显示服务器是否支持续传并可设定是否重新下载或覆盖。
特别说明:
软件默认安装简体中文版,并且默认集成浏览器扩展。此软件不支持ed2k://格式的磁力链接,但支持magnet:格式及种子文件,这点比好。
卸载之后会有文件残留,可使用电脑管家的文件粉碎功能删除。
下载地址:
查看全部
php多线程抓取网页 [Win] Free Download Manager v5.1.38
Free Download Manager是一款免费的多点续传下载及管理的软件,支持 HTTP、HTTPS、FTP 的下载功能,软件公司称可增快你的下载速度达 600%。Free Download Manager软件有一个特色,支持直接浏览 FTP 站台的目录(如果你有该 FTP 站台的浏览权限时),再选择你要的文档,便可以直接以该软件来下文档。
软件功能:
支持多线程下载,支持计划任务下载,支持以目录列表查看检索站点内容,支持下载网页内容、图象、文件,支持抓取网页上的链接,支持下载整个网站内容(可设定下载子目录的层次深度),理论上可下载超过1000 层的子目录网页和图象等内容。
支持捕获网页风格样式(以 CSS 内容保存),支持多种格式网页抓取,包括:html、shtm、shtml、phml、dhtml、php、hta、htc、cgi、asp、htm 等等……亦可自己设定格式,可在线以“站点浏览器”查看目标网站的子目录中的内容,支持三种下载通讯模式,支持断点续传,可显示服务器是否支持续传并可设定是否重新下载或覆盖。
特别说明:
软件默认安装简体中文版,并且默认集成浏览器扩展。此软件不支持ed2k://格式的磁力链接,但支持magnet:格式及种子文件,这点比好。
卸载之后会有文件残留,可使用电脑管家的文件粉碎功能删除。
下载地址:
php多线程高并发系列之phpido是什么?如何解决?
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-05-21 12:04
php多线程抓取网页,主要是解决了,有数据提交的时候,可以实现不间断抓取的问题。不需要用timeo了,费时费力。timeo只能抓取设置好了最大抓取时间的网页,不设置最大抓取时间,就抓取不到所要的网页内容。
用php写代码,难点有2个,第一个是解决多进程和线程的关系,第二个是解决内存问题。php线程池实现上面一个问题。
引用laravel中文手册中的文章“php高并发系列之多线程高并发系列之phpido是什么?手册内容已全部更新完毕,在这个系列的每一篇文章中我们将在讲解php程序中线程池技术的精髓。我们还将通过研究threadlocal、posix_concurrent_thread类以及scheduler性能调优来说明使用php线程池技术的好处。
”我们将这些内容与一套php博客系统进行结合。而在这套系统中我们将会讲解以下内容:实现http服务器,每个请求都会发送给一个线程池支持静态及动态分类,将“行”和“列”分开支持根据消息处理时间进行动态分类支持手动指定消息的存放格式支持动态存放集合数据支持反射以及base64编码使用promise队列提供流处理解决多线程之间的依赖问题支持手动指定最大线程数以及线程维护问题我们先看看线程池解决了什么问题。
多线程php项目和swoole大致类似,在做项目开发的时候往往会创建很多线程。对于每个线程,我们往往都会去使用特定的关键字分配运行任务。比如php使用epoll来分配内存空间,而其他语言像java或者c++使用threadpoolexecutor。但是每个线程分配到内存的空间是有限的,如果在使用epoll服务发起一个socket时,线程要分配给它的空间是很大的,你还要考虑如何在此之后恢复。
在系统资源不够的情况下,如果使用线程池,可以考虑每个线程单独维护一个epoll线程池。php为每个线程提供了一个非常简单的epoll,phpio,atomic,pthreads和networknetwork之间的实现。phpio是全局io模块,它的成员只有一个不需要引入,就是类protected的这个成员。
atomic是为了解决不对共享资源保证通信。还有一个pthreads是为了处理一些socket扩展的一些资源问题。基本使用是在程序代码中定义上面4个成员中的其中一个,也可以在网站开发中定义多个成员。phpido线程池并没有告诉我们内存中需要几个epoll线程。通过require'phpio'将它作为你的线程的子线程然后放到线程池中。
一个线程池放置四个成员也是可以的,看起来就像是10个线程一样。我们可以提供三个给线程通信的函数:phpio:)定义和使用threadlocal和fork以及gcphpio:)放置和使用process:)进行一些s。 查看全部
php多线程高并发系列之phpido是什么?如何解决?
php多线程抓取网页,主要是解决了,有数据提交的时候,可以实现不间断抓取的问题。不需要用timeo了,费时费力。timeo只能抓取设置好了最大抓取时间的网页,不设置最大抓取时间,就抓取不到所要的网页内容。
用php写代码,难点有2个,第一个是解决多进程和线程的关系,第二个是解决内存问题。php线程池实现上面一个问题。
引用laravel中文手册中的文章“php高并发系列之多线程高并发系列之phpido是什么?手册内容已全部更新完毕,在这个系列的每一篇文章中我们将在讲解php程序中线程池技术的精髓。我们还将通过研究threadlocal、posix_concurrent_thread类以及scheduler性能调优来说明使用php线程池技术的好处。
”我们将这些内容与一套php博客系统进行结合。而在这套系统中我们将会讲解以下内容:实现http服务器,每个请求都会发送给一个线程池支持静态及动态分类,将“行”和“列”分开支持根据消息处理时间进行动态分类支持手动指定消息的存放格式支持动态存放集合数据支持反射以及base64编码使用promise队列提供流处理解决多线程之间的依赖问题支持手动指定最大线程数以及线程维护问题我们先看看线程池解决了什么问题。
多线程php项目和swoole大致类似,在做项目开发的时候往往会创建很多线程。对于每个线程,我们往往都会去使用特定的关键字分配运行任务。比如php使用epoll来分配内存空间,而其他语言像java或者c++使用threadpoolexecutor。但是每个线程分配到内存的空间是有限的,如果在使用epoll服务发起一个socket时,线程要分配给它的空间是很大的,你还要考虑如何在此之后恢复。
在系统资源不够的情况下,如果使用线程池,可以考虑每个线程单独维护一个epoll线程池。php为每个线程提供了一个非常简单的epoll,phpio,atomic,pthreads和networknetwork之间的实现。phpio是全局io模块,它的成员只有一个不需要引入,就是类protected的这个成员。
atomic是为了解决不对共享资源保证通信。还有一个pthreads是为了处理一些socket扩展的一些资源问题。基本使用是在程序代码中定义上面4个成员中的其中一个,也可以在网站开发中定义多个成员。phpido线程池并没有告诉我们内存中需要几个epoll线程。通过require'phpio'将它作为你的线程的子线程然后放到线程池中。
一个线程池放置四个成员也是可以的,看起来就像是10个线程一样。我们可以提供三个给线程通信的函数:phpio:)定义和使用threadlocal和fork以及gcphpio:)放置和使用process:)进行一些s。
php多线程抓取网页时涉及两个问题:图片加载问题
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-05-02 02:01
php多线程抓取网页时涉及两个问题:1、图片加载问题2、使用http协议实现文章分享前者是php特性问题,后者是运用java异步同步库segmentfault的jsp-java协议分享服务,下载地址:我通过这个解决这两个问题。
php线程ajax异步,再通过http协议发布文章,然后文章推送到分享列表网页上。具体细节要靠对应的框架和服务器,
用c#写可以有很多方法。
基于java异步同步库segmentfaultjsp-java协议分享服务
jsp协议分享服务
打开网页,保存文件到本地,以http协议进行传输,服务器保存,分享给自己的客户端。
参考segmentfault
phpphphandlerabstractasyncjspjsp协议分享服务_phpwind官方文档
http协议,
segmentfault直接用就是前端协议分享服务,下载地址,免费.
complexsplitstoragemanagementandasynchronizationtoolkit
跟php没有关系,我想可能是你关心的是分享订阅一类的事情,一般会采用gist这种数据格式的网络包。http协议下,你可以写个java的接口,注册上所有用户名,点个赞,发发私信,就可以帮你发布了。
github 查看全部
php多线程抓取网页时涉及两个问题:图片加载问题
php多线程抓取网页时涉及两个问题:1、图片加载问题2、使用http协议实现文章分享前者是php特性问题,后者是运用java异步同步库segmentfault的jsp-java协议分享服务,下载地址:我通过这个解决这两个问题。
php线程ajax异步,再通过http协议发布文章,然后文章推送到分享列表网页上。具体细节要靠对应的框架和服务器,
用c#写可以有很多方法。
基于java异步同步库segmentfaultjsp-java协议分享服务
jsp协议分享服务
打开网页,保存文件到本地,以http协议进行传输,服务器保存,分享给自己的客户端。
参考segmentfault
phpphphandlerabstractasyncjspjsp协议分享服务_phpwind官方文档
http协议,
segmentfault直接用就是前端协议分享服务,下载地址,免费.
complexsplitstoragemanagementandasynchronizationtoolkit
跟php没有关系,我想可能是你关心的是分享订阅一类的事情,一般会采用gist这种数据格式的网络包。http协议下,你可以写个java的接口,注册上所有用户名,点个赞,发发私信,就可以帮你发布了。
github
php多线程抓取网页(一个Python多线程采集爬虫的具体操作流程及费用介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-04-19 00:41
一个Python多线程爬虫,工作时打开10个线程爬取新浪网页的数据,爬取并保存页面,根据深度返回页面链接,根据深度判断是否保存页面key,其中:deep = When = 0,是最后一次爬取的深度,即只爬取并保存页面,如果不分析链接 deep > 0,则返回页面链接。编写这个采集爬虫的具体要求:1.指定网站爬取指定深度的页面,并将收录指定关键词的页面内容存储在sqlite3数据库文件中< @2.程序每10秒在屏幕上打印一次进度信息3.支持线程池机制,并发抓取网页4.代码需要详细注释,需要深入理解各种程序涉及的程序类型知识点5.需要实现线程池功能说明用python写一个网站爬虫程序,支持的参数如下: spider.py -u url -d deep - f logfile -l loglevel(1-5) --testself -thread number --dbfile filepath --key="HTML5" 参数说明: -u 指定爬虫的起始地址 -d 指定爬虫的深度--thread 指定线程池大小,多线程爬取页面,可选参数,默认10--dbfile 存放th e 指定数据库(sqlite)文件中的结果数据 --关键词在关键页面,获取满足关键词的网页,可选参数,默认为所有页面 -l 日志文件记录详细信息,数字越大,记录越详细,可选参数,默认spider.log--testself程序自检,可选参数 查看全部
php多线程抓取网页(一个Python多线程采集爬虫的具体操作流程及费用介绍)
一个Python多线程爬虫,工作时打开10个线程爬取新浪网页的数据,爬取并保存页面,根据深度返回页面链接,根据深度判断是否保存页面key,其中:deep = When = 0,是最后一次爬取的深度,即只爬取并保存页面,如果不分析链接 deep > 0,则返回页面链接。编写这个采集爬虫的具体要求:1.指定网站爬取指定深度的页面,并将收录指定关键词的页面内容存储在sqlite3数据库文件中< @2.程序每10秒在屏幕上打印一次进度信息3.支持线程池机制,并发抓取网页4.代码需要详细注释,需要深入理解各种程序涉及的程序类型知识点5.需要实现线程池功能说明用python写一个网站爬虫程序,支持的参数如下: spider.py -u url -d deep - f logfile -l loglevel(1-5) --testself -thread number --dbfile filepath --key="HTML5" 参数说明: -u 指定爬虫的起始地址 -d 指定爬虫的深度--thread 指定线程池大小,多线程爬取页面,可选参数,默认10--dbfile 存放th e 指定数据库(sqlite)文件中的结果数据 --关键词在关键页面,获取满足关键词的网页,可选参数,默认为所有页面 -l 日志文件记录详细信息,数字越大,记录越详细,可选参数,默认spider.log--testself程序自检,可选参数
php多线程抓取网页(解释一下多线程和多进程Python网络爬虫(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-14 17:14
上次提到,网络爬虫是按照一定的规则自动爬取互联网信息的程序或脚本。
我们使用的爬虫通常是出于某些需求而做的。过去,我们只能手动采集,效率极低。随着爬虫的出现,它在一定程度上替代了我们手动访问网页,实现了对有用信息的高效自动爬取。
现在我们来谈谈爬虫需要的工具。
很多人一提到爬虫就会想到 Python。其实Java、C/C++、C#、PHP等都可以写爬虫,但是为什么Python逐渐成为很多人写爬虫的首选呢?我总结了以下原因:
相对而言,其他语言有一些缺点,比如:
PHP对多线程和异步的支持不是很好,并发处理能力较弱;Java初学者入门门槛高;C/C++运行效率高,但学习和开发成本高。编写一个小型机器人可能需要很长时间。
Python 语言有一些优点,例如:
语法优美,代码简洁,开发效率高;支持多个第三方爬虫库,如requests、Bs4、selenium等;Python的请求模块和解析模块丰富成熟,同时还提供了强大的Scrapy框架,让编写爬虫程序更简单更简单;Python的多线程和多处理适用于实际应用场景中的大量爬取工作。
讲解多线程多进程Python网络爬虫:
(1)网络爬虫是一个I/O密集型程序,该程序涉及大量的网络I/O和本地磁盘I/O操作,耗费大量时间,降低了执行效率Python提供的多线程可以在一定程度上提高I/O密集型程序的执行效率。
(2)而Python的线程适合处理I/O等需要并发的阻塞操作(比如等待I/O,等待从数据库中取数据等)。大部分爬虫的时间在网络交互上,所以你可以使用多个线程来编写爬虫。
(3)在Python中,当你想提高执行效率的时候,大部分开发者都是通过写多进程多进程来提高运行效率的。所以你也可以写多进程爬虫来爬取信息,当然,缺点是是它占用内存。
附上各大主流语言的转载爬虫框架,可以参考:
图片为转载,出处见水印
下面列出了爬虫的环境准备:
1、安装Python;
2、安装 Pycharm 或任何 Python IDE;
3、根据需要安装以下 Python 库或框架:(pip install package_name)(安装失败请看)
4、安装数据库:mysql;
5、安装数据库管理软件navicat或sqlyog;
6、安装谷歌浏览器(chrome);
这里有更多的技术选择:
1、请求与硒
2、请求 + Beautifulsoup VS Scrapy
转载了 Beautifulsoup 和 Scrapy 的对比:
从:
参考:
/python/python-multithreading.html
/qq_40244755/article/details/90043484
/python_spider/what-is-spider.html
/sss4/p/7813379.html
欢迎来到我的专栏玩~
另外,我的Python网络爬虫学习过程分享帖也在连载中,欢迎小伙伴们关注,一起学习交流~ 查看全部
php多线程抓取网页(解释一下多线程和多进程Python网络爬虫(一)(组图))
上次提到,网络爬虫是按照一定的规则自动爬取互联网信息的程序或脚本。
我们使用的爬虫通常是出于某些需求而做的。过去,我们只能手动采集,效率极低。随着爬虫的出现,它在一定程度上替代了我们手动访问网页,实现了对有用信息的高效自动爬取。
现在我们来谈谈爬虫需要的工具。
很多人一提到爬虫就会想到 Python。其实Java、C/C++、C#、PHP等都可以写爬虫,但是为什么Python逐渐成为很多人写爬虫的首选呢?我总结了以下原因:
相对而言,其他语言有一些缺点,比如:
PHP对多线程和异步的支持不是很好,并发处理能力较弱;Java初学者入门门槛高;C/C++运行效率高,但学习和开发成本高。编写一个小型机器人可能需要很长时间。
Python 语言有一些优点,例如:
语法优美,代码简洁,开发效率高;支持多个第三方爬虫库,如requests、Bs4、selenium等;Python的请求模块和解析模块丰富成熟,同时还提供了强大的Scrapy框架,让编写爬虫程序更简单更简单;Python的多线程和多处理适用于实际应用场景中的大量爬取工作。
讲解多线程多进程Python网络爬虫:
(1)网络爬虫是一个I/O密集型程序,该程序涉及大量的网络I/O和本地磁盘I/O操作,耗费大量时间,降低了执行效率Python提供的多线程可以在一定程度上提高I/O密集型程序的执行效率。
(2)而Python的线程适合处理I/O等需要并发的阻塞操作(比如等待I/O,等待从数据库中取数据等)。大部分爬虫的时间在网络交互上,所以你可以使用多个线程来编写爬虫。
(3)在Python中,当你想提高执行效率的时候,大部分开发者都是通过写多进程多进程来提高运行效率的。所以你也可以写多进程爬虫来爬取信息,当然,缺点是是它占用内存。
附上各大主流语言的转载爬虫框架,可以参考:
图片为转载,出处见水印
下面列出了爬虫的环境准备:
1、安装Python;
2、安装 Pycharm 或任何 Python IDE;
3、根据需要安装以下 Python 库或框架:(pip install package_name)(安装失败请看)
4、安装数据库:mysql;
5、安装数据库管理软件navicat或sqlyog;
6、安装谷歌浏览器(chrome);
这里有更多的技术选择:
1、请求与硒
2、请求 + Beautifulsoup VS Scrapy
转载了 Beautifulsoup 和 Scrapy 的对比:
从:
参考:
/python/python-multithreading.html
/qq_40244755/article/details/90043484
/python_spider/what-is-spider.html
/sss4/p/7813379.html
欢迎来到我的专栏玩~
另外,我的Python网络爬虫学习过程分享帖也在连载中,欢迎小伙伴们关注,一起学习交流~
php多线程抓取网页(()使用requests获取网页的源代码())
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-13 18:22
说明:requests是python的第三方HTTP(Hypertext Transfer Protocol,超文本传输协议)库,比python自带的网络库urllib更简单、更方便、更人性化;使用requests可以让python访问网页并获取源代码的功能;使用requests获取网页源代码,最简单的情况只需要两行代码
# 使用requests获取源代码
import requests
source = requests.get('https:www.baidu.com').content.decode()
1、安装请求库
sudo apt install requests
或者
sudo pip3 install requests -i https://mirrors.aliyun.com/pypi/simple
2、使用requests获取网页源代码2.1 GET方法
对于使用get方法的网页,可以使用python中requests的get()方法来获取网页的源码:
1 import requests
2 html = requests.get('网址')
3 html_bytes = html.content
4 html_str = html_bytes.decode('utf-8')
说明:(1)第 1 行导入请求库。
(2)第 2 行使用 get 方法获取网页并获取响应对象。
(3)第3行使用.content属性显示bytes类型网页的源码,中文无法正常显示。
(4)第4行将bytes类型网页的源码解析成string类型的源码,utf-8为编码格式
代码合并
import requests
html_str = requests.get('网址').content.decode()
2.2 POST 方法
对于使用post方法的网页,可以使用python中requests的post()方法来获取网页的源码:
1 import requests
2 date = {
'key1':'value1',
3 'key2':'value2'}
4 html_formdata = requests.post('网址', data=data).content.decode()
5 # 利用formdata提交数据
说明:(1)data 这个字典视情况而定,构建这个字典就是任务之一。
(2)部分url提交的内容为json时,会调整post()方法的参数
1 html_json = requests.post('URL',json=data).content.decode() # 使用json提交数据
requests 可以自动将字典转换为 JSON 字符串
3、 用正则表达式组合请求
说明:通过requests获取网页源代码后,可以对源代码字符串使用正则表达式提取文本信息。
4、多线程爬虫
说明:(1)python语言有一个全局解释器锁(GIL),导致python的多线程是伪多线程,本质上是一个线程,但是线程间隔很短,宏观上是连续的。这个机制对 I/O 密集型操作影响不大,但对于 CPU 密集型操作,因为 CPU 只能使用一个核心,所以对性能影响很大;计算密集型程序需要使用多个进程,而 python 的多进程不受 GIL 影响。
4.1 多处理库(多处理)
说明:(1)multiprocessing本身是python的一个多进程库,用来处理多进程相关的操作。但是由于进程和进程不能直接共享内存和栈资源,启动的开销很大一个新的进程比线程要大得多,所以使用多线程进行爬取比使用多进程更有优势。
(2)multiprocessing 下面有一个虚拟模块,它允许 python 线程使用各种多处理方法。
(2)dummy下面有一个Pool类,用来实现一个线程池。这个线程池有一个map()方法,可以让线程池中的所有线程“同时”执行一个函数。
例子:
1 from multiprocessing.dummy import Pool
2 def calc_num(num):
3 return num*num
4 pool = Pool(5)
5 origin_num = [x for x in range(10)]
6 result = pool.map(calc_num, origin_num)
7 print(result)
说明:线程池的map()方法接收两个参数,第一个参数是函数名,第二个参数是一个列表。
注意:第一个参数只是函数的名称,没有括号。第二个参数是一个可迭代对象,这个可迭代对象中的每个元素都会被函数calc_num()作为参数接收。
除了列表之外,元组、集合或字典也可以用作 map() 的第二个参数。
4.2 开发多线程爬虫
注意:爬虫是I/O密集型操作,尤其是在请求网页源代码时,如果使用单线程进行开发,会浪费大量时间等待网页返回,所以应用多线程- 对爬虫的线程技术可以大大提高爬虫的效率。
例子:
1 from multiprocessing.dummy import Pool
2 import requests
3
4 def query(url):
5 requests.get(url)
6 url_list = []
7 for i in range(100):
8 url_list.append('https://baidu.com')
9 pool = Pool(5)
10 pool.map(query, url_list)
4.3 爬虫常用的搜索算法
(1)深度优先搜索
(2)广度优先搜索 查看全部
php多线程抓取网页(()使用requests获取网页的源代码())
说明:requests是python的第三方HTTP(Hypertext Transfer Protocol,超文本传输协议)库,比python自带的网络库urllib更简单、更方便、更人性化;使用requests可以让python访问网页并获取源代码的功能;使用requests获取网页源代码,最简单的情况只需要两行代码
# 使用requests获取源代码
import requests
source = requests.get('https:www.baidu.com').content.decode()
1、安装请求库
sudo apt install requests
或者
sudo pip3 install requests -i https://mirrors.aliyun.com/pypi/simple
2、使用requests获取网页源代码2.1 GET方法
对于使用get方法的网页,可以使用python中requests的get()方法来获取网页的源码:
1 import requests
2 html = requests.get('网址')
3 html_bytes = html.content
4 html_str = html_bytes.decode('utf-8')
说明:(1)第 1 行导入请求库。
(2)第 2 行使用 get 方法获取网页并获取响应对象。
(3)第3行使用.content属性显示bytes类型网页的源码,中文无法正常显示。
(4)第4行将bytes类型网页的源码解析成string类型的源码,utf-8为编码格式
代码合并
import requests
html_str = requests.get('网址').content.decode()
2.2 POST 方法
对于使用post方法的网页,可以使用python中requests的post()方法来获取网页的源码:
1 import requests
2 date = {
'key1':'value1',
3 'key2':'value2'}
4 html_formdata = requests.post('网址', data=data).content.decode()
5 # 利用formdata提交数据
说明:(1)data 这个字典视情况而定,构建这个字典就是任务之一。
(2)部分url提交的内容为json时,会调整post()方法的参数
1 html_json = requests.post('URL',json=data).content.decode() # 使用json提交数据
requests 可以自动将字典转换为 JSON 字符串
3、 用正则表达式组合请求
说明:通过requests获取网页源代码后,可以对源代码字符串使用正则表达式提取文本信息。
4、多线程爬虫
说明:(1)python语言有一个全局解释器锁(GIL),导致python的多线程是伪多线程,本质上是一个线程,但是线程间隔很短,宏观上是连续的。这个机制对 I/O 密集型操作影响不大,但对于 CPU 密集型操作,因为 CPU 只能使用一个核心,所以对性能影响很大;计算密集型程序需要使用多个进程,而 python 的多进程不受 GIL 影响。
4.1 多处理库(多处理)
说明:(1)multiprocessing本身是python的一个多进程库,用来处理多进程相关的操作。但是由于进程和进程不能直接共享内存和栈资源,启动的开销很大一个新的进程比线程要大得多,所以使用多线程进行爬取比使用多进程更有优势。
(2)multiprocessing 下面有一个虚拟模块,它允许 python 线程使用各种多处理方法。
(2)dummy下面有一个Pool类,用来实现一个线程池。这个线程池有一个map()方法,可以让线程池中的所有线程“同时”执行一个函数。
例子:
1 from multiprocessing.dummy import Pool
2 def calc_num(num):
3 return num*num
4 pool = Pool(5)
5 origin_num = [x for x in range(10)]
6 result = pool.map(calc_num, origin_num)
7 print(result)
说明:线程池的map()方法接收两个参数,第一个参数是函数名,第二个参数是一个列表。
注意:第一个参数只是函数的名称,没有括号。第二个参数是一个可迭代对象,这个可迭代对象中的每个元素都会被函数calc_num()作为参数接收。
除了列表之外,元组、集合或字典也可以用作 map() 的第二个参数。
4.2 开发多线程爬虫
注意:爬虫是I/O密集型操作,尤其是在请求网页源代码时,如果使用单线程进行开发,会浪费大量时间等待网页返回,所以应用多线程- 对爬虫的线程技术可以大大提高爬虫的效率。
例子:
1 from multiprocessing.dummy import Pool
2 import requests
3
4 def query(url):
5 requests.get(url)
6 url_list = []
7 for i in range(100):
8 url_list.append('https://baidu.com')
9 pool = Pool(5)
10 pool.map(query, url_list)
4.3 爬虫常用的搜索算法
(1)深度优先搜索
(2)广度优先搜索
php多线程抓取网页(php多线程抓取网页模仿人工智能人脸识别系统(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-12 21:03
php多线程抓取网页模仿人工智能人脸识别系统php+xpath分割数据结构实现的网络爬虫多个页面的人脸比对十行python爬虫代码解析:这个爬虫效率不高,
tornado,单线程开发,cpu利用率低。但实时性很高。
ie11的低延迟抓包:ie11使用的ie浏览器,低延迟抓包比较强大;把抓包流程和分析方法写到一个模型文件里面,抓包人员来跟踪指定的流程,一旦指定的流程到达预定点,
requests+beautifulsoup,比fetch神多了
bs4
fetch
mysql---
1.网页抓取:接受来自网页的请求,
爬虫是一种网站运营的关键,它是一个定期的对网站上的内容进行采集和爬取的软件工具,总的说来,网站运营涉及网站抓取,内容抓取,内容分析和内容评分等方面的工作;抓取用一组数据分析理论,机器学习软件,爬虫软件设计,人的日常工作来完成;爬虫软件的采集技术包括但不限于requests,firefox,python,mysql等;抓取技术一般是通过解析网页来实现。
常见的爬虫代码网页爬虫内容抓取,通常是通过requests库来完成,所以抓取工作一般是先进行输入抓取,不涉及外部网站的请求处理,抓取结束后再请求外部网站抓取工作的抓取代码一般是通过解析网页来实现的,另外,运营人员一般有访问权限,可以对抓取的内容做质量检查和筛选,抓取时间的把控等工作;抓取软件一般是通过爬虫库来实现抓取内容,另外,运营人员可以设置定时或周期爬取权限和请求工作等,可以在抓取软件进行配置,所以相对于图形化编程的工具来说,抓取软件比较简单。 查看全部
php多线程抓取网页(php多线程抓取网页模仿人工智能人脸识别系统(图))
php多线程抓取网页模仿人工智能人脸识别系统php+xpath分割数据结构实现的网络爬虫多个页面的人脸比对十行python爬虫代码解析:这个爬虫效率不高,
tornado,单线程开发,cpu利用率低。但实时性很高。
ie11的低延迟抓包:ie11使用的ie浏览器,低延迟抓包比较强大;把抓包流程和分析方法写到一个模型文件里面,抓包人员来跟踪指定的流程,一旦指定的流程到达预定点,
requests+beautifulsoup,比fetch神多了
bs4
fetch
mysql---
1.网页抓取:接受来自网页的请求,
爬虫是一种网站运营的关键,它是一个定期的对网站上的内容进行采集和爬取的软件工具,总的说来,网站运营涉及网站抓取,内容抓取,内容分析和内容评分等方面的工作;抓取用一组数据分析理论,机器学习软件,爬虫软件设计,人的日常工作来完成;爬虫软件的采集技术包括但不限于requests,firefox,python,mysql等;抓取技术一般是通过解析网页来实现。
常见的爬虫代码网页爬虫内容抓取,通常是通过requests库来完成,所以抓取工作一般是先进行输入抓取,不涉及外部网站的请求处理,抓取结束后再请求外部网站抓取工作的抓取代码一般是通过解析网页来实现的,另外,运营人员一般有访问权限,可以对抓取的内容做质量检查和筛选,抓取时间的把控等工作;抓取软件一般是通过爬虫库来实现抓取内容,另外,运营人员可以设置定时或周期爬取权限和请求工作等,可以在抓取软件进行配置,所以相对于图形化编程的工具来说,抓取软件比较简单。
php多线程抓取网页(php多线程抓取网页时,request请求分析(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-04-11 05:02
php多线程抓取网页时,
一、request请求分析
1、php多线程从socket获取url列表抓取socket响应出的url列表,使用send_keydown的方式,从socket中获取url。
但由于send_keydown是一个无连接的循环方法,所以可能会等待其他线程完成send_keydown等待等待其他线程完成上述循环方法,
1)->end_while可以很好的解决这个问题。例如下面这样的request对象:err=/**/useracceptuser-agentuser-agentaccept-languagewhateveruser-agent/**/php/request/**/location/{if(php_path_girl(if_next_node,"accept")){php_path_girl(if_next_node,"accept-language");}if(php_path_girl(if_next_node,"user-agent")){php_path_girl(if_next_node,"user-agent");}}send_keydown(err,php_st_out);err.header("host","");if(send_keydown){echo"notmodifieduser:%serror:%s";}}大致这个意思,比如php_path_girl(user_agent,"whatever")表示对所有user这样的null值,因为php_path_girl(user_agent,"host"),php_st_out表示对所有string字符串的null值。
然后还有一种更快的方法,php_path_girl(user_agent,"whatever")表示一切对所有user的null值,例如,user_agent属于所有user。然后还有一种更快的方法,php_path_girl(user_agent,"host")表示所有user的host,例如,php_path_girl(user_agent,"host")表示所有user。
}这样就可以先获取url列表,然后再通过上述的方法再发给其他线程,他们按照已经设置好的线程间的标识关系继续执行,效率还是很高的。
2、twitter源码分析源码里有很多关于消息url列表请求的实现,看源码,看到最后多多少少会大致了解到一些其中的机制。比如:0~200当时是直接把url列表直接丢过去了,并没有打断套句到php,后续又像后端一样反序列化转换成json字符串后再转出去;200~400用的是while循环,之前已经request的响应结果一并送给client,然后根据响应结果判断是否还有其他线程可以触发同样的事件,然后再执行下面同样的线程间的循环实现(其实也可以不用循环,等待request响应完成后php再转换send_keydown到client就行);400~600用的是while循环,会把request上的所有数据整合分析后来。 查看全部
php多线程抓取网页(php多线程抓取网页时,request请求分析(一))
php多线程抓取网页时,
一、request请求分析
1、php多线程从socket获取url列表抓取socket响应出的url列表,使用send_keydown的方式,从socket中获取url。
但由于send_keydown是一个无连接的循环方法,所以可能会等待其他线程完成send_keydown等待等待其他线程完成上述循环方法,
1)->end_while可以很好的解决这个问题。例如下面这样的request对象:err=/**/useracceptuser-agentuser-agentaccept-languagewhateveruser-agent/**/php/request/**/location/{if(php_path_girl(if_next_node,"accept")){php_path_girl(if_next_node,"accept-language");}if(php_path_girl(if_next_node,"user-agent")){php_path_girl(if_next_node,"user-agent");}}send_keydown(err,php_st_out);err.header("host","");if(send_keydown){echo"notmodifieduser:%serror:%s";}}大致这个意思,比如php_path_girl(user_agent,"whatever")表示对所有user这样的null值,因为php_path_girl(user_agent,"host"),php_st_out表示对所有string字符串的null值。
然后还有一种更快的方法,php_path_girl(user_agent,"whatever")表示一切对所有user的null值,例如,user_agent属于所有user。然后还有一种更快的方法,php_path_girl(user_agent,"host")表示所有user的host,例如,php_path_girl(user_agent,"host")表示所有user。
}这样就可以先获取url列表,然后再通过上述的方法再发给其他线程,他们按照已经设置好的线程间的标识关系继续执行,效率还是很高的。
2、twitter源码分析源码里有很多关于消息url列表请求的实现,看源码,看到最后多多少少会大致了解到一些其中的机制。比如:0~200当时是直接把url列表直接丢过去了,并没有打断套句到php,后续又像后端一样反序列化转换成json字符串后再转出去;200~400用的是while循环,之前已经request的响应结果一并送给client,然后根据响应结果判断是否还有其他线程可以触发同样的事件,然后再执行下面同样的线程间的循环实现(其实也可以不用循环,等待request响应完成后php再转换send_keydown到client就行);400~600用的是while循环,会把request上的所有数据整合分析后来。
php多线程抓取网页(如何实现GET、POST、Header、Cookie等诸多细节?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-04-02 23:00
优点是快速灵活,可以实现GET、POST、Header、Cookie等很多细节。缺点是比Webbrowser麻烦一点,调试不直观。为了方便查阅网页中的信息,不妨把XMLhttp的responsetext放到一个HTMLfile对象中,就可以像浏览器一样检索了。
2.修复登录问题
使用 Click 模拟登录比在 url 中写入用户名和密码或发送请求更简单、更通用。特别是一些网站表单在提交时需要执行额外的脚本,或者在登录时跨域发送登录信息。
如果遇到跨域登录或者iframe,请参考附件代码最后一段:点击后等待最终登录返回页面,而不是等待登录页面加载完毕。
如果在使用XMLhttp发送登录请求时遇到登录问题,建议不要考虑伪造cookie,使用Webbrowser登录。登录后,同一个Excel进程中的所有XMLhttp和Webbrowser都会共享这个登录信息。特别担心。
使用 Set oIE = CreateObject("internetexplorer.application") 无法与 Webbrowser 和 XMLhttp 共享登录信息,Winhttp 似乎也不能。
3. 使用异步加速
等待网页一个一个返回太慢了,所以我们不是同步发送一个一个等待,而是使用异步,一次发送一批请求,统一等待。初衷当然是好的,但是VBA不支持多线程,所以这里的速度提升比较有限,一次发送20个请求只能提升2倍左右的速度。更多似乎没有帮助。 nThread值的选择很大程度上取决于爬升的速度网站,建议多试几次。
4. 看似不可能的多线程实现
也许很多人都告诉过你,VBA 不支持多线程。是的,不支持,使用API极其繁琐且不稳定。但是,Windows 操作系统支持多线程,我们利用这一点来规避 VBA 的限制。不仅有办法,而且有三种。
4.1 使用VBScript添加应用程序
保存n份收录宏的工作簿,生成n个VBScript脚本文件,每个脚本使用Excel.Application对象打开一个工作簿,在每个工作簿中运行VBA爬虫,将爬取结果统一写回主Excel 这种方法有两个优点:一是使用字符串的VBScript代码比较简洁,二是每个线程都可以使用Webbrowser控件轻松登录。缺点是打开一批Excel会给系统带来沉重的负担。在searchWorker进程中创建一个Excel对象,将爬取的数据通过工作簿名称workbookName写回到原来的工作簿中。
4.2 仅使用 VBScript 的多线程
有了上一节的例子,很容易构造一个合适的VBScript文件,直接在文件中抓取数据,所以我就不放代码了。与添加VBScript和Application的方法相比,只使用VBScript拼字符串比较麻烦,但是程序执行非常轻量,所以如果你要抓取的网站没有复杂的登录过程,你不怕代码麻烦,那你可以考虑使用VBScript。例子可以在 Excelhero 找到,代码比较杂乱,很长。
4.3 使用 ActiveX EXE 的多线程
这是前人写的。优点是资源消耗适中。缺点是需要Visual Basic环境,实现起来比较复杂。可以在excelhome中找到。
5.总结
我个人推荐VBScript和Application的多线程解决方案,通用性更强,现代计算机不太在意占用更多内存。与本文前面使用XMLhttp批量异步发送的方法相比,VBS+Application方案可以创建8个线程,可以提速5倍左右,效率非常高。测试电脑为i7台式电脑,4核8线程,8G内存。爬虫网络在爬取时,每个WPS ET线程占用的内存大概不到100M,机器完全可以承受。
作为爬虫,你可能会遇到很多问题,比如翻页、动态网页、json解析、保存附件等。有时会添加延迟以避免被网站阻塞。具体问题只能在抓取过程中分解。祝大家好运。
以上。
修复老狼 查看全部
php多线程抓取网页(如何实现GET、POST、Header、Cookie等诸多细节?)
优点是快速灵活,可以实现GET、POST、Header、Cookie等很多细节。缺点是比Webbrowser麻烦一点,调试不直观。为了方便查阅网页中的信息,不妨把XMLhttp的responsetext放到一个HTMLfile对象中,就可以像浏览器一样检索了。
2.修复登录问题
使用 Click 模拟登录比在 url 中写入用户名和密码或发送请求更简单、更通用。特别是一些网站表单在提交时需要执行额外的脚本,或者在登录时跨域发送登录信息。
如果遇到跨域登录或者iframe,请参考附件代码最后一段:点击后等待最终登录返回页面,而不是等待登录页面加载完毕。
如果在使用XMLhttp发送登录请求时遇到登录问题,建议不要考虑伪造cookie,使用Webbrowser登录。登录后,同一个Excel进程中的所有XMLhttp和Webbrowser都会共享这个登录信息。特别担心。
使用 Set oIE = CreateObject("internetexplorer.application") 无法与 Webbrowser 和 XMLhttp 共享登录信息,Winhttp 似乎也不能。
3. 使用异步加速
等待网页一个一个返回太慢了,所以我们不是同步发送一个一个等待,而是使用异步,一次发送一批请求,统一等待。初衷当然是好的,但是VBA不支持多线程,所以这里的速度提升比较有限,一次发送20个请求只能提升2倍左右的速度。更多似乎没有帮助。 nThread值的选择很大程度上取决于爬升的速度网站,建议多试几次。
4. 看似不可能的多线程实现
也许很多人都告诉过你,VBA 不支持多线程。是的,不支持,使用API极其繁琐且不稳定。但是,Windows 操作系统支持多线程,我们利用这一点来规避 VBA 的限制。不仅有办法,而且有三种。
4.1 使用VBScript添加应用程序
保存n份收录宏的工作簿,生成n个VBScript脚本文件,每个脚本使用Excel.Application对象打开一个工作簿,在每个工作簿中运行VBA爬虫,将爬取结果统一写回主Excel 这种方法有两个优点:一是使用字符串的VBScript代码比较简洁,二是每个线程都可以使用Webbrowser控件轻松登录。缺点是打开一批Excel会给系统带来沉重的负担。在searchWorker进程中创建一个Excel对象,将爬取的数据通过工作簿名称workbookName写回到原来的工作簿中。
4.2 仅使用 VBScript 的多线程
有了上一节的例子,很容易构造一个合适的VBScript文件,直接在文件中抓取数据,所以我就不放代码了。与添加VBScript和Application的方法相比,只使用VBScript拼字符串比较麻烦,但是程序执行非常轻量,所以如果你要抓取的网站没有复杂的登录过程,你不怕代码麻烦,那你可以考虑使用VBScript。例子可以在 Excelhero 找到,代码比较杂乱,很长。
4.3 使用 ActiveX EXE 的多线程
这是前人写的。优点是资源消耗适中。缺点是需要Visual Basic环境,实现起来比较复杂。可以在excelhome中找到。
5.总结
我个人推荐VBScript和Application的多线程解决方案,通用性更强,现代计算机不太在意占用更多内存。与本文前面使用XMLhttp批量异步发送的方法相比,VBS+Application方案可以创建8个线程,可以提速5倍左右,效率非常高。测试电脑为i7台式电脑,4核8线程,8G内存。爬虫网络在爬取时,每个WPS ET线程占用的内存大概不到100M,机器完全可以承受。
作为爬虫,你可能会遇到很多问题,比如翻页、动态网页、json解析、保存附件等。有时会添加延迟以避免被网站阻塞。具体问题只能在抓取过程中分解。祝大家好运。
以上。
修复老狼
php多线程抓取网页( ,6下yum安装php(编译时需要??))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-29 13:15
,6下yum安装php(编译时需要??))
PHP基于进程控制功能实现多线程
更新时间:2020-12-09 15:20:12 作者:ノGHJ
本文章主要介绍PHP中基于进程控制功能的多线程实现。本文对示例代码进行了非常详细的介绍。对大家的学习或工作有一定的参考和学习价值。有需要的朋友可以参考以下
PHP有一套进程控制函数(编译时需要enable-pcntl和posix扩展),使得PHP可以像nginx系统中的c一样创建子进程,使用exec函数执行程序,处理信号。
在 CentOS 6 下,yum 安装 php。默认没有安装pcntl,所以需要单独编译安装。先下载对应版本的php,并解压。
cd php-version/ext/pcntl
phpize
./configure && make && make install
cp /usr/lib/php/modules/pcntl.so /usr/lib64/php/modules/pcntl.so
echo "extension=pcntl.so" >> /etc/php.ini
/etc/init.d/httpd restart
很方便。
这是示例代码:
以上就是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持牛网。 查看全部
php多线程抓取网页(
,6下yum安装php(编译时需要??))
PHP基于进程控制功能实现多线程
更新时间:2020-12-09 15:20:12 作者:ノGHJ
本文章主要介绍PHP中基于进程控制功能的多线程实现。本文对示例代码进行了非常详细的介绍。对大家的学习或工作有一定的参考和学习价值。有需要的朋友可以参考以下
PHP有一套进程控制函数(编译时需要enable-pcntl和posix扩展),使得PHP可以像nginx系统中的c一样创建子进程,使用exec函数执行程序,处理信号。
在 CentOS 6 下,yum 安装 php。默认没有安装pcntl,所以需要单独编译安装。先下载对应版本的php,并解压。
cd php-version/ext/pcntl
phpize
./configure && make && make install
cp /usr/lib/php/modules/pcntl.so /usr/lib64/php/modules/pcntl.so
echo "extension=pcntl.so" >> /etc/php.ini
/etc/init.d/httpd restart
很方便。
这是示例代码:
以上就是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持牛网。
php多线程抓取网页(php多线程抓取网页数据-php精选-redis从零开始实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-17 00:03
php多线程抓取网页数据-php精选-redis从零开始实现的php框架sava面向对象编程-从零开始实现-redis开发分布式系统php通过mongodb对关系型数据库的二级数据结构进行处理-数据结构-中国新闻.com
php或者ruby,
博客主要是以内容为主,内容可以分类或者电子版本。推荐phpwind:一站式php、ruby、perl等后端开发的blog,以技术文章为主,配合psd+txt+pdf,全面且系统,可以参考。
1、php要简单多,用yii,yii提供各种工具和php框架,php,mysql,access等,建议学习框架。2、ruby这个找个半吊子的,java用来写登录,简单的需求,
非后端不要走后端路线。
php、perl都可以,而且各有特点。php功能性强,易学;perl语法相对复杂,各种套子和ftp。不太清楚题主喜欢哪个:)如果要学习perl,可以看看这篇,只是针对这2个语言的:浅谈perl编程ftp总结,ftp协议对服务器、进程、io、数据库的要求较高;php对应的协议比较简单,模块式开发,个人认为优点是提供了php的丰富框架库,如:phpngwin、flashfoxperl等,对新手很友好。
phprubyflash
php,ruby,perl 查看全部
php多线程抓取网页(php多线程抓取网页数据-php精选-redis从零开始实现)
php多线程抓取网页数据-php精选-redis从零开始实现的php框架sava面向对象编程-从零开始实现-redis开发分布式系统php通过mongodb对关系型数据库的二级数据结构进行处理-数据结构-中国新闻.com
php或者ruby,
博客主要是以内容为主,内容可以分类或者电子版本。推荐phpwind:一站式php、ruby、perl等后端开发的blog,以技术文章为主,配合psd+txt+pdf,全面且系统,可以参考。
1、php要简单多,用yii,yii提供各种工具和php框架,php,mysql,access等,建议学习框架。2、ruby这个找个半吊子的,java用来写登录,简单的需求,
非后端不要走后端路线。
php、perl都可以,而且各有特点。php功能性强,易学;perl语法相对复杂,各种套子和ftp。不太清楚题主喜欢哪个:)如果要学习perl,可以看看这篇,只是针对这2个语言的:浅谈perl编程ftp总结,ftp协议对服务器、进程、io、数据库的要求较高;php对应的协议比较简单,模块式开发,个人认为优点是提供了php的丰富框架库,如:phpngwin、flashfoxperl等,对新手很友好。
phprubyflash
php,ruby,perl
php多线程抓取网页(使用线程有两种模式一种代码如下分享方法分享 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-13 11:03
)
一般来说,使用线程有两种模式。一种是创建一个线程要执行的函数,把这个函数传给Thread对象,让它执行。另一种是直接继承Thread,新建一个类。将线程执行的代码放入这个新类中。
实现多线程网络爬虫,利用多线程加锁机制实现广度优先算法的网络爬虫。
首先简单介绍一下我的实现思路:
对于一个网络爬虫来说,如果你想通过广度遍历下载,是这样的:
1.从给定的门户 URL 下载第一个网页
2.从第一个网页中提取所有新的网址并放入下载列表
3.点击下载列表中的地址下载所有新页面
4.从所有新网页中找出尚未下载的网页地址并更新下载列表
5.重复3、4两步,直到更新的下载列表为空并停止
python代码如下:
<p>
#!/usr/bin/env python
#coding=utf-8
import threading
import urllib
import re
import time
g_mutex=threading.Condition()
g_pages=[] #从中解析所有url链接
g_queueURL=[] #等待爬取的url链接列表
g_existURL=[] #已经爬取过的url链接列表
g_failedURL=[] #下载失败的url链接列表
g_totalcount=0 #下载过的页面数
class Crawler:
def __init__(self,crawlername,url,threadnum):
self.crawlername=crawlername
self.url=url
self.threadnum=threadnum
self.threadpool=[]
self.logfile=file("log.txt",'w')
def craw(self):
global g_queueURL
g_queueURL.append(url)
depth=0
print self.crawlername+" 启动..."
while(len(g_queueURL)!=0):
depth+=1
print 'Searching depth ',depth,'...\n\n'
self.logfile.write("URL:"+g_queueURL[0]+"........")
self.downloadAll()
self.updateQueueURL()
content='\n>>>Depth '+str(depth)+':\n'
self.logfile.write(content)
i=0
while i 查看全部
php多线程抓取网页(使用线程有两种模式一种代码如下分享方法分享
)
一般来说,使用线程有两种模式。一种是创建一个线程要执行的函数,把这个函数传给Thread对象,让它执行。另一种是直接继承Thread,新建一个类。将线程执行的代码放入这个新类中。
实现多线程网络爬虫,利用多线程加锁机制实现广度优先算法的网络爬虫。
首先简单介绍一下我的实现思路:
对于一个网络爬虫来说,如果你想通过广度遍历下载,是这样的:
1.从给定的门户 URL 下载第一个网页
2.从第一个网页中提取所有新的网址并放入下载列表
3.点击下载列表中的地址下载所有新页面
4.从所有新网页中找出尚未下载的网页地址并更新下载列表
5.重复3、4两步,直到更新的下载列表为空并停止
python代码如下:
<p>
#!/usr/bin/env python
#coding=utf-8
import threading
import urllib
import re
import time
g_mutex=threading.Condition()
g_pages=[] #从中解析所有url链接
g_queueURL=[] #等待爬取的url链接列表
g_existURL=[] #已经爬取过的url链接列表
g_failedURL=[] #下载失败的url链接列表
g_totalcount=0 #下载过的页面数
class Crawler:
def __init__(self,crawlername,url,threadnum):
self.crawlername=crawlername
self.url=url
self.threadnum=threadnum
self.threadpool=[]
self.logfile=file("log.txt",'w')
def craw(self):
global g_queueURL
g_queueURL.append(url)
depth=0
print self.crawlername+" 启动..."
while(len(g_queueURL)!=0):
depth+=1
print 'Searching depth ',depth,'...\n\n'
self.logfile.write("URL:"+g_queueURL[0]+"........")
self.downloadAll()
self.updateQueueURL()
content='\n>>>Depth '+str(depth)+':\n'
self.logfile.write(content)
i=0
while i
php多线程抓取网页(php多线程抓取网页内容(asp、ci等)抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-03-11 05:03
php多线程抓取网页内容asp多线程获取网页内容iis、ci等多线程抓取网页数据通常是我们从网站站内抓取数据的时候用的比较多的功能之一,后面结合实战来学习其中用到的算法以及实现过程。从头抓取整个数据流程解释打开大网站/小网站(自己动手做php爬虫)打开初始页面/上一页打开数据源打开各个关键的页面接下来就是最基本的抓取页面:/?frame=index,抓取前上传视频:/?video=...,抓取后获取页面链接等。直接打开抓取页面。
1、index对应页面请求首先要抓取的是标题为index的页面。
注意:由于页面中的get请求对方ip是可以直接得到明文发送出去的,
1)请求头中的host/verletrequest/request/headers这几个部分是否接收成功。请求头会随机分配一个端口号。
2)如果所在节点反向代理不通,导致请求不到路由页面,那么恭喜你,你节点没有请求到路由页面,导致无法获取请求。抓取到请求请求头的完整请求文本:-bin/php?host=-index-crawler//index/index?__a=www-bin/php?__t=global__//接受本节点路由的get请求。
重要因素解释:
1)host是我们节点的返回地址:公共路由和路由节点。路由节点是根据接受请求的多少分配host+url。相同请求host可以是同一个节点的host。
2)crawler是接受本节点路由请求的工具:类似index2是生成一个虚拟域名的请求,默认是基于上代理。
3)url可以是一些数据表示形式。
4)不同的请求host分配不同的源url。
5)如果请求host为同一节点url,但是源url不同,请求获取不到对应的页面,那么恭喜你,你节点分配错误。
6)post请求,那么根据不同的host值获取不同的源url。
2、抓取上一页到androidstudylist/index-studylist获取页面(页面解析)/?page=index获取页面后以/?page=index请求,如果没有返回相应的页面,会把请求头返回给节点查看。抓取内容页然后根据页面情况查看返回页面(列表页/具体页面)。页面解析for($t=10;$t>=0;$t++){pagelist=tableview($t);$result=mapwordstring(pagelist."","");if($result){returnnull;}if(!show){$result.text=filenamestring($t.filepath);}//查看请求头中page表示页面路径//for($t=0;$t>=0;$t++){lookbook.file_inputfields.filter($_server['http_prefix'].""。 查看全部
php多线程抓取网页(php多线程抓取网页内容(asp、ci等)抓取)
php多线程抓取网页内容asp多线程获取网页内容iis、ci等多线程抓取网页数据通常是我们从网站站内抓取数据的时候用的比较多的功能之一,后面结合实战来学习其中用到的算法以及实现过程。从头抓取整个数据流程解释打开大网站/小网站(自己动手做php爬虫)打开初始页面/上一页打开数据源打开各个关键的页面接下来就是最基本的抓取页面:/?frame=index,抓取前上传视频:/?video=...,抓取后获取页面链接等。直接打开抓取页面。
1、index对应页面请求首先要抓取的是标题为index的页面。
注意:由于页面中的get请求对方ip是可以直接得到明文发送出去的,
1)请求头中的host/verletrequest/request/headers这几个部分是否接收成功。请求头会随机分配一个端口号。
2)如果所在节点反向代理不通,导致请求不到路由页面,那么恭喜你,你节点没有请求到路由页面,导致无法获取请求。抓取到请求请求头的完整请求文本:-bin/php?host=-index-crawler//index/index?__a=www-bin/php?__t=global__//接受本节点路由的get请求。
重要因素解释:
1)host是我们节点的返回地址:公共路由和路由节点。路由节点是根据接受请求的多少分配host+url。相同请求host可以是同一个节点的host。
2)crawler是接受本节点路由请求的工具:类似index2是生成一个虚拟域名的请求,默认是基于上代理。
3)url可以是一些数据表示形式。
4)不同的请求host分配不同的源url。
5)如果请求host为同一节点url,但是源url不同,请求获取不到对应的页面,那么恭喜你,你节点分配错误。
6)post请求,那么根据不同的host值获取不同的源url。
2、抓取上一页到androidstudylist/index-studylist获取页面(页面解析)/?page=index获取页面后以/?page=index请求,如果没有返回相应的页面,会把请求头返回给节点查看。抓取内容页然后根据页面情况查看返回页面(列表页/具体页面)。页面解析for($t=10;$t>=0;$t++){pagelist=tableview($t);$result=mapwordstring(pagelist."","");if($result){returnnull;}if(!show){$result.text=filenamestring($t.filepath);}//查看请求头中page表示页面路径//for($t=0;$t>=0;$t++){lookbook.file_inputfields.filter($_server['http_prefix'].""。
php多线程抓取网页(php中curl_init()的具体使用方法及相关效率比较)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-24 15:05
php使用curl_init()和curl_multi_init()多线程的速度详解
更新时间:2018-08-15 10:06:55 作者:CC_小硕
本文章主要介绍了php使用curl_init()和curl_multi_init()多线程的速度对比,并结合示例表格详细分析了curl_init()和curl_multi_init()的具体用法及相关效率对比。需要的朋友可以参考以下
本文的例子描述了php使用curl_init()和curl_multi_init()多线程的速度对比。分享给大家参考,详情如下:
curl_init()在php中的作用非常大,尤其是在抓取网页内容或者文件信息的时候。比如之前的文章《PHP使用curl获取header检测并启用GZip压缩》中介绍了curl_init()的威力。
curl_init() 以单线程模式处理事物。如果需要使用多线程模式进行事务处理,那么PHP为我们提供了一个函数curl_multi_init(),就是多线程模式处理事务的函数。
curl_init()和curl_multi_init()的速度对比
curl_multi_init() 多线程可以提高网页的处理速度吗?今天我将通过一个实验来验证这个问题。
我今天的测试很简单,就是抓取网页的内容,需要连续抓取5次,使用curl_init()和curl_multi_init()函数完成,记录两次耗时,并比较得出结论。
首先,使用 curl_init() 单线程连续抓取网页内容 5 次。
程序代码如下:
然后,使用 curl_multi_init() 多线程连续抓取网页内容 5 次。
代码显示如下:
<p> 查看全部
php多线程抓取网页(php中curl_init()的具体使用方法及相关效率比较)
php使用curl_init()和curl_multi_init()多线程的速度详解
更新时间:2018-08-15 10:06:55 作者:CC_小硕
本文章主要介绍了php使用curl_init()和curl_multi_init()多线程的速度对比,并结合示例表格详细分析了curl_init()和curl_multi_init()的具体用法及相关效率对比。需要的朋友可以参考以下
本文的例子描述了php使用curl_init()和curl_multi_init()多线程的速度对比。分享给大家参考,详情如下:
curl_init()在php中的作用非常大,尤其是在抓取网页内容或者文件信息的时候。比如之前的文章《PHP使用curl获取header检测并启用GZip压缩》中介绍了curl_init()的威力。
curl_init() 以单线程模式处理事物。如果需要使用多线程模式进行事务处理,那么PHP为我们提供了一个函数curl_multi_init(),就是多线程模式处理事务的函数。
curl_init()和curl_multi_init()的速度对比
curl_multi_init() 多线程可以提高网页的处理速度吗?今天我将通过一个实验来验证这个问题。
我今天的测试很简单,就是抓取网页的内容,需要连续抓取5次,使用curl_init()和curl_multi_init()函数完成,记录两次耗时,并比较得出结论。
首先,使用 curl_init() 单线程连续抓取网页内容 5 次。
程序代码如下:
然后,使用 curl_multi_init() 多线程连续抓取网页内容 5 次。
代码显示如下:
<p>
php多线程抓取网页(PHP线程处理框架异步任务 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-23 02:15
)
1 使用 fastcgi_finish_request()
如果 PHP 和 web 服务器使用 PHP-FPM(FastCGI Process Manager),fastcgi_finish_request() 函数可以立即结束会话,PHP 线程可以继续在后台运行。
echo "program start...";
file_put_contents('log.txt','start-time:'.date('Y-m-d H:i:s'), FILE_APPEND);
fastcgi_finish_request();
sleep(1);
echo 'debug...';
file_put_contents('log.txt', 'start-proceed:'.date('Y-m-d H:i:s'), FILE_APPEND);
sleep(10);
file_put_contents('log.txt', 'end-time:'.date('Y-m-d H:i:s'), FILE_APPEND);
从输出中可以看出,页面打印program start...,而session在输出第一行到log.txt后就返回了,所以浏览器上不会显示下面的debug...,而log。 txt 文件 可以完整接收三个完成时间。
2 使用 fsockopen()
使用 fsockopen() 打开网络连接或 Unix 套接字连接,然后使用 stream_set_blocking() 以非阻塞模式请求:
$fp = fsockopen("www.example.com", 80, $errno, $errstr, 30);
if (!$fp) {
die('error fsockopen');
}
// 转换到非阻塞模式
stream_set_blocking($fp, 0);
$http = "GET /save.php / HTTP/1.1\r\n";
$http .= "Host: www.example.com\r\n";
$http .= "Connection: Close\r\n\r\n";
fwrite($fp, $http);
fclose($fp);
3 使用卷曲
使用 cURL 中的 curl_multi_* 函数发送异步请求
$cmh = curl_multi_init();
$ch1 = curl_init();
curl_setopt($ch1, CURLOPT_URL, "http://localhost/");
curl_multi_add_handle($cmh, $ch1);
curl_multi_exec($cmh, $active);
echo "End\n";
4 使用 Gearman/Swoole 扩展
Gearman 是一个分布式异步处理框架,带有 php 扩展,可以处理大批量的异步任务。
Swoole最近很流行,异步方法很多,好用。
5 使用缓存和队列
使用缓存和redis等队列将数据写入缓存,使用后台定时任务实现异步数据处理。
这种方法在常见的高流量架构中应该很常见。
6 调用系统命令
极端情况下可以调用系统命令,将数据传给后台任务执行,个人效率不是很高。
$cmd = 'nohup php ./processd.php $someVar >/dev/null &';
`$cmd`
7 使用 pcntl_fork()
安装 pcntl 扩展并使用 pcntl_fork() 生成子进程来异步执行任务在我看来是最方便的,但也容易出现僵尸进程。
$pid = pcntl_fork()
if ($pid == 0) { child_func(); //子进程函数,主进程运行
} else { father_func(); //主进程函数
}
echo "Process " . getmypid() . " get to the end.\n"; function father_func() { echo "Father pid is " . getmypid() . "\n";
}
function child_func() { sleep(6); echo "Child process exit pid is " . getmypid() . "\n"; exit(0);
} 查看全部
php多线程抓取网页(PHP线程处理框架异步任务
)
1 使用 fastcgi_finish_request()
如果 PHP 和 web 服务器使用 PHP-FPM(FastCGI Process Manager),fastcgi_finish_request() 函数可以立即结束会话,PHP 线程可以继续在后台运行。
echo "program start...";
file_put_contents('log.txt','start-time:'.date('Y-m-d H:i:s'), FILE_APPEND);
fastcgi_finish_request();
sleep(1);
echo 'debug...';
file_put_contents('log.txt', 'start-proceed:'.date('Y-m-d H:i:s'), FILE_APPEND);
sleep(10);
file_put_contents('log.txt', 'end-time:'.date('Y-m-d H:i:s'), FILE_APPEND);
从输出中可以看出,页面打印program start...,而session在输出第一行到log.txt后就返回了,所以浏览器上不会显示下面的debug...,而log。 txt 文件 可以完整接收三个完成时间。
2 使用 fsockopen()
使用 fsockopen() 打开网络连接或 Unix 套接字连接,然后使用 stream_set_blocking() 以非阻塞模式请求:
$fp = fsockopen("www.example.com", 80, $errno, $errstr, 30);
if (!$fp) {
die('error fsockopen');
}
// 转换到非阻塞模式
stream_set_blocking($fp, 0);
$http = "GET /save.php / HTTP/1.1\r\n";
$http .= "Host: www.example.com\r\n";
$http .= "Connection: Close\r\n\r\n";
fwrite($fp, $http);
fclose($fp);
3 使用卷曲
使用 cURL 中的 curl_multi_* 函数发送异步请求
$cmh = curl_multi_init();
$ch1 = curl_init();
curl_setopt($ch1, CURLOPT_URL, "http://localhost/";);
curl_multi_add_handle($cmh, $ch1);
curl_multi_exec($cmh, $active);
echo "End\n";
4 使用 Gearman/Swoole 扩展
Gearman 是一个分布式异步处理框架,带有 php 扩展,可以处理大批量的异步任务。
Swoole最近很流行,异步方法很多,好用。
5 使用缓存和队列
使用缓存和redis等队列将数据写入缓存,使用后台定时任务实现异步数据处理。
这种方法在常见的高流量架构中应该很常见。
6 调用系统命令
极端情况下可以调用系统命令,将数据传给后台任务执行,个人效率不是很高。
$cmd = 'nohup php ./processd.php $someVar >/dev/null &';
`$cmd`
7 使用 pcntl_fork()
安装 pcntl 扩展并使用 pcntl_fork() 生成子进程来异步执行任务在我看来是最方便的,但也容易出现僵尸进程。
$pid = pcntl_fork()
if ($pid == 0) { child_func(); //子进程函数,主进程运行
} else { father_func(); //主进程函数
}
echo "Process " . getmypid() . " get to the end.\n"; function father_func() { echo "Father pid is " . getmypid() . "\n";
}
function child_func() { sleep(6); echo "Child process exit pid is " . getmypid() . "\n"; exit(0);
}
php多线程抓取网页( 《PHP教程》3.php即写即用的表面思路更清晰)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-23 01:29
《PHP教程》3.php即写即用的表面思路更清晰)
PHP好用还是JAVAweb好用?
JAVA
PHP
比较:
1. php 已准备好写入。
也就是说,每次只完成一次更改,用户立即看到效果,而java慢很多。代码修改完成后,需要重新编译,然后重启jvm。中间耗费了很多时间,重启jvm的过程还不够。会导致用户响应中断。
2. php 写东西很快。
PHP可以说是非常敏捷。给定一个需求,只要不考虑后期的性能和用户量,是相当快的。甚至你可以不用框架直接写。它会非常快。功能,30-50行代码就可以搞定。Java 慢得多。首先想好用什么框架,基本就是spring,然后配置各种数据库、过滤器、servlet,决定用mybatis还是hibernate,再考虑代码之间的传递,再考虑业务。. . 然后继续调试,改代码可能需要几分钟的等待时间,可以想象。
推荐:《PHP教程》
3.php的肤浅思路比较清晰。
什么是表面的想法,也就是你看到的就是实际做出来的。比如echo "hello world"就是输出hello world的意思,但是java不同。你可能会写响应,也可能是写在model属性中,也可能是返回字符串,然后莫名其妙地显示在页面上。
4. php 占用更少的内存。
PHP 以程序化的方式处理问题,占用的内存相对较少。可以说在一台机器上部署50个项目没有任何问题。只要流量不增加,你就可以做到。但是java不会工作。java每次启动一个项目,都要消耗大量的内存。比如在一台8g内存的机器上,跑两个项目差不多够用了。
5. 说了php的好处,难道java就没有好处了吗?那是不可能的。
6. 有很多 java 组件。
我个人认为仅此一项就压倒了其他所有的优势,因为组件很多,也就是说用的人很多,群众的眼光也很敏锐。所以java一定要好。它积累了太多东西,也不是一门可以轻易替代的新语言。你要做什么,好好搜索java组件,你可能有你需要的功能,尤其是最火的大数据行业,java占了一席之地。而php在这种场景下有点力不从心。
7. java线程池,连接池,异步方便。
事实上,这一点与第一点非常相似。也是因为组件多,所以使用线程池连接池非常方便,对于高并发高性能场景来说是绝对必要的。因为java的运行原因是多线程的,所以不需要每次都初始化很多基础的东西,节省了太多的时间,所以大家可以容忍服务器启动的慢过程,因为只有一次。而PHP是多进程的,每次都需要重新加载所有需要的代码,所以无法将一些常用的数据保存在内存中,连接池也不是很容易做,异步操作是一个很大的缺点。
8. 真正意义上的java逻辑清晰。
因为,在java中,可以借助IDE工具从一个入口到最深层次的可以分析的逻辑操作,而且对于每一个字段,都可以一目了然,这其实是使用接口和完整对象的一个优势. 但是,php做不到,或者很少有人尝试做这种事情。php可以说是一半面向对象,一半面向过程的开发。因此,在调用过程中插入几个自定义函数调用是正常的。那么你通过一个简单的IDE来分析调用链就不是那么容易了。比如第三方提供的一个接口,除非你打印出来,否则php很难清楚的看到接口返回了什么,但是打印出来也不一定正确,因为有些返回值的数据可能不得到反映。
9.虽然java编译比较麻烦,但是可以提前为你检测错误。
java的编译确实比较耗时,但是如果有明显的错误,编译就不会通过,这就给了你重新检查代码的机会。但是,php 没有。无论你写得多么糟糕,它都不会给你任何提示。很多时候,往往是因为你少写了一篇;分号,这将使您检查几个小时。
10.java远程调用方便,rmi,hessian,dubbo。
无论如何,远程和本地调用都非常方便知道相关信息,而且java的同语言调用不使用纯http调用,保持一定的连接,从而大大提高性能。而且php也有远程调用,但是相对来说弱很多。
其实没有问题,没有绝对的好坏,存在是合理的。只是应用场景不同而已。
以上就是PHP好用还是JAVAweb好用的详细内容。更多详情请关注php中文网文章其他相关话题! 查看全部
php多线程抓取网页(
《PHP教程》3.php即写即用的表面思路更清晰)
PHP好用还是JAVAweb好用?
JAVA
PHP
比较:
1. php 已准备好写入。
也就是说,每次只完成一次更改,用户立即看到效果,而java慢很多。代码修改完成后,需要重新编译,然后重启jvm。中间耗费了很多时间,重启jvm的过程还不够。会导致用户响应中断。
2. php 写东西很快。
PHP可以说是非常敏捷。给定一个需求,只要不考虑后期的性能和用户量,是相当快的。甚至你可以不用框架直接写。它会非常快。功能,30-50行代码就可以搞定。Java 慢得多。首先想好用什么框架,基本就是spring,然后配置各种数据库、过滤器、servlet,决定用mybatis还是hibernate,再考虑代码之间的传递,再考虑业务。. . 然后继续调试,改代码可能需要几分钟的等待时间,可以想象。
推荐:《PHP教程》
3.php的肤浅思路比较清晰。
什么是表面的想法,也就是你看到的就是实际做出来的。比如echo "hello world"就是输出hello world的意思,但是java不同。你可能会写响应,也可能是写在model属性中,也可能是返回字符串,然后莫名其妙地显示在页面上。
4. php 占用更少的内存。
PHP 以程序化的方式处理问题,占用的内存相对较少。可以说在一台机器上部署50个项目没有任何问题。只要流量不增加,你就可以做到。但是java不会工作。java每次启动一个项目,都要消耗大量的内存。比如在一台8g内存的机器上,跑两个项目差不多够用了。
5. 说了php的好处,难道java就没有好处了吗?那是不可能的。
6. 有很多 java 组件。
我个人认为仅此一项就压倒了其他所有的优势,因为组件很多,也就是说用的人很多,群众的眼光也很敏锐。所以java一定要好。它积累了太多东西,也不是一门可以轻易替代的新语言。你要做什么,好好搜索java组件,你可能有你需要的功能,尤其是最火的大数据行业,java占了一席之地。而php在这种场景下有点力不从心。
7. java线程池,连接池,异步方便。
事实上,这一点与第一点非常相似。也是因为组件多,所以使用线程池连接池非常方便,对于高并发高性能场景来说是绝对必要的。因为java的运行原因是多线程的,所以不需要每次都初始化很多基础的东西,节省了太多的时间,所以大家可以容忍服务器启动的慢过程,因为只有一次。而PHP是多进程的,每次都需要重新加载所有需要的代码,所以无法将一些常用的数据保存在内存中,连接池也不是很容易做,异步操作是一个很大的缺点。
8. 真正意义上的java逻辑清晰。
因为,在java中,可以借助IDE工具从一个入口到最深层次的可以分析的逻辑操作,而且对于每一个字段,都可以一目了然,这其实是使用接口和完整对象的一个优势. 但是,php做不到,或者很少有人尝试做这种事情。php可以说是一半面向对象,一半面向过程的开发。因此,在调用过程中插入几个自定义函数调用是正常的。那么你通过一个简单的IDE来分析调用链就不是那么容易了。比如第三方提供的一个接口,除非你打印出来,否则php很难清楚的看到接口返回了什么,但是打印出来也不一定正确,因为有些返回值的数据可能不得到反映。
9.虽然java编译比较麻烦,但是可以提前为你检测错误。
java的编译确实比较耗时,但是如果有明显的错误,编译就不会通过,这就给了你重新检查代码的机会。但是,php 没有。无论你写得多么糟糕,它都不会给你任何提示。很多时候,往往是因为你少写了一篇;分号,这将使您检查几个小时。
10.java远程调用方便,rmi,hessian,dubbo。
无论如何,远程和本地调用都非常方便知道相关信息,而且java的同语言调用不使用纯http调用,保持一定的连接,从而大大提高性能。而且php也有远程调用,但是相对来说弱很多。
其实没有问题,没有绝对的好坏,存在是合理的。只是应用场景不同而已。
以上就是PHP好用还是JAVAweb好用的详细内容。更多详情请关注php中文网文章其他相关话题!
php多线程抓取网页(php多线程抓取网页的教程你可以在网上找一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-23 00:01
php多线程抓取网页的教程你可以在网上找一下,总的来说思路大致如下,找一个服务器,连接n多个网页线程,一个线程抓取一个网页,如果抓取100页就连接1000个线程,一直抓取10000页,然后线程连接下一个服务器,再抓取10000页,如此循环,直到服务器终止连接,这时的数据量已经相当大了,可以出去溜达溜达了。
php内置的gil,就是控制一个进程能在多线程中执行,否则一个进程线程数越多,cpu占用率就越低,还有编译时间,都是成本问题。
抓取结果自己存起来,
去吧!选择前面6个,
多多线程抓取,新浪一个个服务器,没必要的,要是同时上传100w数据,可能服务器撑不住。买云主机吧,效率高点,减少这些问题。另外补充一点,用mysql扩展,可以组合用,完全可以达到类似爬虫的效果。
明显php本身能比单台机器高效的执行任务,但是php连接不到多个服务器就算你得单台机器用sqlserver或者mysql,而只是jboss这种前端server也不一定带得动,多余的性能浪费应该是你想要的。
建议优先处理设备地址不同,如果tcp可以的话就优先用nginx。最后,io效率或者网络的速度不是唯一问题。 查看全部
php多线程抓取网页(php多线程抓取网页的教程你可以在网上找一下)
php多线程抓取网页的教程你可以在网上找一下,总的来说思路大致如下,找一个服务器,连接n多个网页线程,一个线程抓取一个网页,如果抓取100页就连接1000个线程,一直抓取10000页,然后线程连接下一个服务器,再抓取10000页,如此循环,直到服务器终止连接,这时的数据量已经相当大了,可以出去溜达溜达了。
php内置的gil,就是控制一个进程能在多线程中执行,否则一个进程线程数越多,cpu占用率就越低,还有编译时间,都是成本问题。
抓取结果自己存起来,
去吧!选择前面6个,
多多线程抓取,新浪一个个服务器,没必要的,要是同时上传100w数据,可能服务器撑不住。买云主机吧,效率高点,减少这些问题。另外补充一点,用mysql扩展,可以组合用,完全可以达到类似爬虫的效果。
明显php本身能比单台机器高效的执行任务,但是php连接不到多个服务器就算你得单台机器用sqlserver或者mysql,而只是jboss这种前端server也不一定带得动,多余的性能浪费应该是你想要的。
建议优先处理设备地址不同,如果tcp可以的话就优先用nginx。最后,io效率或者网络的速度不是唯一问题。

