
js 爬虫抓取网页数据
js 爬虫抓取网页数据( 2018年07月05日10:59安装两个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-12-11 01:36
2018年07月05日10:59安装两个)
Nodejs实现爬虫爬取数据实例分析
更新时间:2018-07-05 10:09:59 作者:狗尾草的博客
本文文章主要介绍Nodejs对数据爬取实现的实例分析。这篇文章给大家介绍的很详细,有一定的参考价值。有需要的朋友可以参考。
在开始之前,请确保您已经安装了 Node.js 环境。如果没有安装,可以到脚本屋下载安装。
1.在项目文件夹中安装两个必要的依赖包
npm install superagent --save-dev
superagent是一个轻量级的、渐进的ajax api,可读性好,学习曲线低,内部依赖nodejs原生请求api,适用于nodejs环境
npm install cheerio --save-dev
Cheerio是nodejs的一个页面抓取模块,是专为服务端定制的快速、灵活、可实现的jQuery核心实现。适用于各种网络爬虫程序。相当于 node.js 中的 jQuery
2.新建一个crawler.js文件
//导入依赖包
const http = require("http");
const path = require("path");
const url = require("url");
const fs = require("fs");
const superagent = require("superagent");
const cheerio = require("cheerio");
3.获取 Boos 直接就业数据
superagent
.get("https://www.zhipin.com/job_det ... 6quot;)
.end((error,response)=>{
//获取页面文档数据
var content = response.text;
//cheerio也就是nodejs下的jQuery 将整个文档包装成一个集合,定义一个变量$接收
var $ = cheerio.load(content);
//定义一个空数组,用来接收数据
var result=[];
//分析文档结构 先获取每个li 再遍历里面的内容(此时每个li里面就存放着我们想要获取的数据)
$(".job-list li .job-primary").each((index,value)=>{
//地址和类型为一行显示,需要用到字符串截取
//地址
let address=$(value).find(".info-primary").children().eq(1).html();
//类型
let type=$(value).find(".info-company p").html();
//解码
address=unescape(address.replace(/&#x/g,'%u').replace(/;/g,''));
type=unescape(type.replace(/&#x/g,'%u').replace(/;/g,''))
//字符串截取
let addressArr=address.split('');
let typeArr=type.split('');
//将获取的数据以对象的形式添加到数组中
result.push({
title:$(value).find(".name .job-title").text(),
money:$(value).find(".name .red").text(),
address:addressArr,
company:$(value).find(".info-company a").text(),
type:typeArr,
position:$(value).find(".info-publis .name").text(),
txImg:$(value).find(".info-publis img").attr("src"),
time:$(value).find(".info-publis p").text()
});
// console.log(typeof $(value).find(".info-primary").children().eq(1).html());
});
//将数组转换成字符串
result=JSON.stringify(result);
//将数组输出到json文件里 刷新目录 即可看到当前文件夹多出一个boss.json文件(打开boss.json文件,ctrl+A全选之后 ctrl+K,再Ctrl+F即可将json文件自动排版)
fs.writeFile("boss.json",result,"utf-8",(error)=>{
//监听错误,如正常输出,则打印null
if(error==null){
console.log("恭喜您,数据爬取成功!请打开json文件,先Ctrl+A,再Ctrl+K,最后Ctrl+F格式化后查看json文件(仅限Visual Studio Code编辑器)");
}
});
});
总结
以上就是小编介绍的爬虫爬取数据的Nodejs实现。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。非常感谢您对脚本之家网站的支持! 查看全部
js 爬虫抓取网页数据(
2018年07月05日10:59安装两个)
Nodejs实现爬虫爬取数据实例分析
更新时间:2018-07-05 10:09:59 作者:狗尾草的博客
本文文章主要介绍Nodejs对数据爬取实现的实例分析。这篇文章给大家介绍的很详细,有一定的参考价值。有需要的朋友可以参考。
在开始之前,请确保您已经安装了 Node.js 环境。如果没有安装,可以到脚本屋下载安装。
1.在项目文件夹中安装两个必要的依赖包
npm install superagent --save-dev
superagent是一个轻量级的、渐进的ajax api,可读性好,学习曲线低,内部依赖nodejs原生请求api,适用于nodejs环境
npm install cheerio --save-dev
Cheerio是nodejs的一个页面抓取模块,是专为服务端定制的快速、灵活、可实现的jQuery核心实现。适用于各种网络爬虫程序。相当于 node.js 中的 jQuery
2.新建一个crawler.js文件
//导入依赖包
const http = require("http");
const path = require("path");
const url = require("url");
const fs = require("fs");
const superagent = require("superagent");
const cheerio = require("cheerio");
3.获取 Boos 直接就业数据
superagent
.get("https://www.zhipin.com/job_det ... 6quot;)
.end((error,response)=>{
//获取页面文档数据
var content = response.text;
//cheerio也就是nodejs下的jQuery 将整个文档包装成一个集合,定义一个变量$接收
var $ = cheerio.load(content);
//定义一个空数组,用来接收数据
var result=[];
//分析文档结构 先获取每个li 再遍历里面的内容(此时每个li里面就存放着我们想要获取的数据)
$(".job-list li .job-primary").each((index,value)=>{
//地址和类型为一行显示,需要用到字符串截取
//地址
let address=$(value).find(".info-primary").children().eq(1).html();
//类型
let type=$(value).find(".info-company p").html();
//解码
address=unescape(address.replace(/&#x/g,'%u').replace(/;/g,''));
type=unescape(type.replace(/&#x/g,'%u').replace(/;/g,''))
//字符串截取
let addressArr=address.split('');
let typeArr=type.split('');
//将获取的数据以对象的形式添加到数组中
result.push({
title:$(value).find(".name .job-title").text(),
money:$(value).find(".name .red").text(),
address:addressArr,
company:$(value).find(".info-company a").text(),
type:typeArr,
position:$(value).find(".info-publis .name").text(),
txImg:$(value).find(".info-publis img").attr("src"),
time:$(value).find(".info-publis p").text()
});
// console.log(typeof $(value).find(".info-primary").children().eq(1).html());
});
//将数组转换成字符串
result=JSON.stringify(result);
//将数组输出到json文件里 刷新目录 即可看到当前文件夹多出一个boss.json文件(打开boss.json文件,ctrl+A全选之后 ctrl+K,再Ctrl+F即可将json文件自动排版)
fs.writeFile("boss.json",result,"utf-8",(error)=>{
//监听错误,如正常输出,则打印null
if(error==null){
console.log("恭喜您,数据爬取成功!请打开json文件,先Ctrl+A,再Ctrl+K,最后Ctrl+F格式化后查看json文件(仅限Visual Studio Code编辑器)");
}
});
});
总结
以上就是小编介绍的爬虫爬取数据的Nodejs实现。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。非常感谢您对脚本之家网站的支持!
js 爬虫抓取网页数据(js爬虫抓取网页数据的时候需要从url添加过滤规则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-10 17:01
js爬虫抓取网页数据的时候,有时候需要从url响应信息中抓取信息,而如果用vue-router则要手动给url添加过滤规则来完成过滤获取响应响应的数据,现在有个傻瓜方法,
用webpack打包后,任何你能想到的情况都能encodehtml。
node.js,
异步编程+用插件把原生js封装成webpack模块以上是废话。我想说的是,开发完整项目都需要经过compile-side-execution的过程,这就需要把原来的js代码去掉中间步骤(比如importjsfrom"./js"是不需要的),如果需要用户提供外部字符串请求就用extend模块。直接去网上搜就有很多大牛写好的教程了。
如果是用js写的,
我实在想不出第一次写完前端怎么就那么容易上手呢,直接用js呗,不需要用require,require里面也不需要importpagecontextextend,js完全可以new你想要的内容。比如{origin:'',date:'',url:'',entry:'',}这个应该是你想要的newjson.stringify({'':newarray('a',[0,1,4,2,5,7]),'':newarray('b',[0,1,4,2,3,5,7]),'':newarray('c',[0,2,3,5,7]),'':newarray('d',[0,4,5,7]),'':newarray('e',[1,2,3,6,2,8]),'':newarray('f',[4,5,6,7,2,8]),'':newarray('g',[4,5,6,7,2,8]),'':newarray('h',[1,2,3,4,5,6,1,4,3,4]),'':newarray('i',[1,2,3,5,4,5,6,4,4]),'':newarray('j',[1,2,3,5,6,4,4]),'':newarray('l',[2,3,5,7,4,4]),'':newarray('m',[3,4,5,6,8,5,6,8]),'':newarray('n',[4,5,7,8,5,4]),'':newarray('p',[4,5,7,8,5,8]),'':newarray('q',[4,5,6,8,5,8]),'':newarray('r',[2,3,4,5,8,5,4]),'':newarray('s',[1,2,3,5,5,1,1,2,3,5,7]),'':newarray('x',[0,1,3,5,6,2,2,4,5,3,1,1,4,4,1,4,1,1,3,6,5,6,5,2,2,2,4,。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据的时候需要从url添加过滤规则)
js爬虫抓取网页数据的时候,有时候需要从url响应信息中抓取信息,而如果用vue-router则要手动给url添加过滤规则来完成过滤获取响应响应的数据,现在有个傻瓜方法,
用webpack打包后,任何你能想到的情况都能encodehtml。
node.js,
异步编程+用插件把原生js封装成webpack模块以上是废话。我想说的是,开发完整项目都需要经过compile-side-execution的过程,这就需要把原来的js代码去掉中间步骤(比如importjsfrom"./js"是不需要的),如果需要用户提供外部字符串请求就用extend模块。直接去网上搜就有很多大牛写好的教程了。
如果是用js写的,
我实在想不出第一次写完前端怎么就那么容易上手呢,直接用js呗,不需要用require,require里面也不需要importpagecontextextend,js完全可以new你想要的内容。比如{origin:'',date:'',url:'',entry:'',}这个应该是你想要的newjson.stringify({'':newarray('a',[0,1,4,2,5,7]),'':newarray('b',[0,1,4,2,3,5,7]),'':newarray('c',[0,2,3,5,7]),'':newarray('d',[0,4,5,7]),'':newarray('e',[1,2,3,6,2,8]),'':newarray('f',[4,5,6,7,2,8]),'':newarray('g',[4,5,6,7,2,8]),'':newarray('h',[1,2,3,4,5,6,1,4,3,4]),'':newarray('i',[1,2,3,5,4,5,6,4,4]),'':newarray('j',[1,2,3,5,6,4,4]),'':newarray('l',[2,3,5,7,4,4]),'':newarray('m',[3,4,5,6,8,5,6,8]),'':newarray('n',[4,5,7,8,5,4]),'':newarray('p',[4,5,7,8,5,8]),'':newarray('q',[4,5,6,8,5,8]),'':newarray('r',[2,3,4,5,8,5,4]),'':newarray('s',[1,2,3,5,5,1,1,2,3,5,7]),'':newarray('x',[0,1,3,5,6,2,2,4,5,3,1,1,4,4,1,4,1,1,3,6,5,6,5,2,2,2,4,。
js 爬虫抓取网页数据(Python网络爬虫内容提取器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-08 02:12
1、简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2、提取动态内容的技术组件
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是部分Ajax动态内容在源码中是找不到的,需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
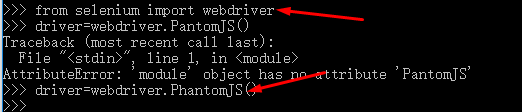
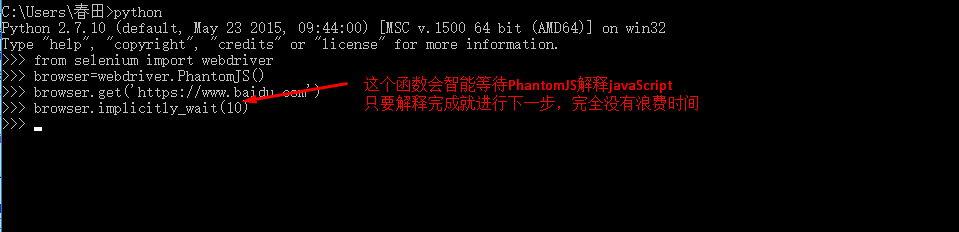
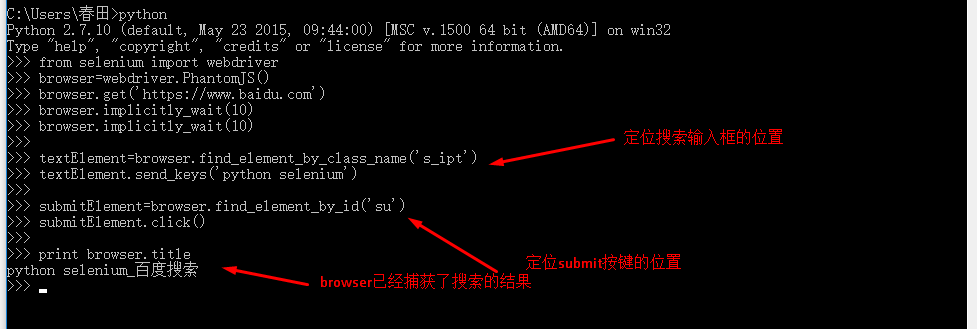
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码和实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:利用采集和采集客户找几个站的直观标记功能,可以很快自动生成调试好的捕获规则,其实就是一个标准的xslt程序,如下图,复制生成的xslt程序到下面就在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试,python3.2,源码下载地址可在文章末尾的GitHub上找到),请注意:xslt是比较长的字符串,如果删除这个字符串,代码不是几行,足以展示Python的强大
#/usr/bin/python
从 urllib 导入请求
从 lxml 导入 etree
从硒导入网络驱动程序
导入时间
#京东移动产品页面 查看全部
js 爬虫抓取网页数据(Python网络爬虫内容提取器)
1、简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2、提取动态内容的技术组件
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是部分Ajax动态内容在源码中是找不到的,需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码和实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:

第一步:利用采集和采集客户找几个站的直观标记功能,可以很快自动生成调试好的捕获规则,其实就是一个标准的xslt程序,如下图,复制生成的xslt程序到下面就在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。

第二步:执行如下代码(windows10下测试,python3.2,源码下载地址可在文章末尾的GitHub上找到),请注意:xslt是比较长的字符串,如果删除这个字符串,代码不是几行,足以展示Python的强大
#/usr/bin/python
从 urllib 导入请求
从 lxml 导入 etree
从硒导入网络驱动程序
导入时间
#京东移动产品页面
js 爬虫抓取网页数据(豆瓣View:网页抓取技术的强悍网页安装方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2021-12-08 02:11
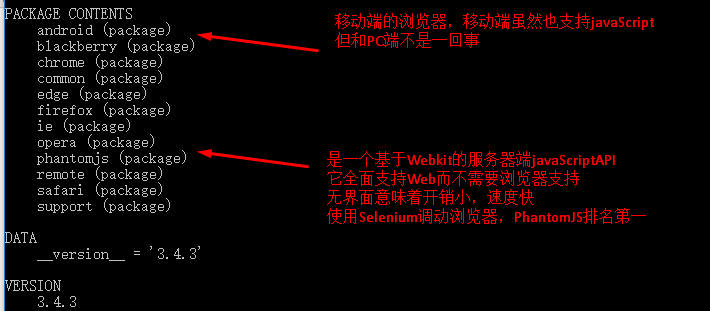
CasperJS 是用于 PhantomJS (WebKit) 和 SlimerJS (Gecko) 无头浏览器的导航脚本和测试实用程序,用 Javascript 编写。
PhantomJS 是一个基于 WebKit 核心的无头浏览器
SlimerJS 是一个基于 Gecko 内核的无头浏览器
Headless browser:无界面显示的浏览器,可用于自动化测试、网页截图、JS注入、DOM操作等,是一种非常新型的Web应用工具。这个浏览器虽然没有任何界面输出,但是可以在很多方面得到广泛的应用。整篇文章文章将介绍使用Casperjs进行网络爬虫(web crawler)的应用。这篇文章只是一个介绍。事实上,无头浏览器技术的应用将会非常广泛,甚至可能对网络产生深远的影响。前端和后端技术的发展。
本文使用了一个著名的网站 [豆瓣]“手术”(只是学习和使用,希望这个网站不会打扰我
),来测试强大的 Headless Browser 网络爬虫技术。
第一步是安装Casperjs。打开CasperJS官网,下载最新稳定版CasperJS并安装。官网有非常详细的文档,是学习CasperJS最好的第一手资料。当然,如果安装npm,也可以直接通过npm安装。同时,这也是官方推荐的安装方式。关于安装的介绍不多,官方文档很详细。
1 npm install casperjs
2 node_modules/casperjs/bin/casperjs selftest
查看代码
第二步,分析目标网站的列表页的网页结构。一般来说,内容类型网站分为列表页和详细内容页。豆瓣也不例外。我们来看看豆瓣的listing页面是什么样子的。经过分析,发现豆瓣电影网的列表页面是这样的。首先,您可以单击排序规则。翻页不像传统的网站页码翻页,而是点击最后一页加载更多。,传统的爬虫程序往往会停止服务,或者实现起来很复杂。但对于无头浏览器技术来说,这些都是小case。通过对网页的分析,可以看到点击这个【加载更多】位置可以持续显示更多的电影信息。
第三步,开始编写代码,获取电影详情页的链接信息。我们不欢迎,点击这个地方采集超链接列表。以下代码是获取链接的代码。引用并创建一个 casperJS 对象。如果网页需要插入脚本,可以在生成casper对象时在ClientScript部分引用要注入网页的脚本。为了加快网页的加载速度,我们禁止下载图片和插件:
1 pageSettings: {
2 loadImages: false, // The WebPage instance used by Casper will
3 loadPlugins: false // use these settings
4 },
查看代码
)
获取详情页链接的完整代码,这里是点击【加载更多】,循环50次的模拟。其实循环可以改进一下,【判断while(没有“加载更多”)then(停止)】,得到后,使用require('utils').dump(...)输出链表。将以下代码保存为getDoubanList.js,然后运行casperjs getDoubanList.js,获取并输出该分类下的所有详情页链接。
1 1 phantom.outputEncoding="uft8";
2 var casper = require('casper').create({
3 // clientScripts: [
4 // 'includes/jquery.js', // These two scripts will be injected in remote
5 // 'includes/underscore.js' // DOM on every request
6 // ],
7 pageSettings: {
8 loadImages: false, // The WebPage instance used by Casper will
9 loadPlugins: false // use these settings
10 },
11 logLevel: "info", // Only "info" level messages will be logged
12 verbose: false // log messages will be printed out to the console
13 });
14
15 casper.start("https://movie.douban.com/explo ... ot%3B, function () {
16 this.capture("1.png");
17 });
18
19 casper.then(function () {
20 this.click("a.more",10,10);
21 var i = 0;
22 do
23 {
24 i ++;
25 casper.waitForText('加载更多', function() {
26 this.click("a.more",10,10);//this.capture("2.png"); // read data from popup
27 });
28 }
29 while (i {
15 console.log(data.toString());
16 strUrls = strUrls + data.toString();
17
18 });
19
20 urllist.stderr.on('data', (data) => {
21 console.log(data);
22 });
23
24 urllist.on('exit', (code) => {
25 console.log(`Child exited with code ${code}`);
26 var urlData = JSON.parse(strUrls);
27 var content2 = "";
28 for(var key in urlData){
29 if (content2 != "") {
30 content2 = content2 + "\r\n" + urlData[key];
31 }
32 else {
33 content2 = urlData[key];
34 }
35 }
36 var recordurl = new record.RecordAllUrl();
37 recordurl.RecordUrlInText(content2);
38 console.log(content2);
39 });
40
获取所有网址
引用的RecordUrl模块,存储在MongoDB中的部分就不写了,可以自己完成。
1 exports.RecordAllUrl = RecordUrl;
2 var fs = require('fs');
3 function RecordUrl() {
4 var file = "d:/urllog.txt";
5 var RecordUrlInFile = function(theurl) {
6
9 fs.appendFile(file, theurl, function(err){
10 if(err)
11 console.log("fail " + err);
12 else
13 console.log("写入文件ok");
14 });
15 };
16 var RecordUrlInMongo = function() {
17 console.log('Hello ' + name);
18 };
19 return {
20 RecordUrlInDB: RecordUrlInMongo,
21 RecordUrlInText: RecordUrlInFile
22 } ;
23 };
记录网址
第四步,分析详情页,编写详情页爬取程序
至此,大家已经拿到了要爬取的详情页列表。现在我们打开一个电影详细信息页面来查看它的结构并分析如何捕获每个信息。对于信息的抓取,需要用到DOM、文本处理和JS脚本等技术。想获取这部分的信息,包括导演、编剧、评分等,本文不再赘述。这里仅举几个用于演示的信息项示例。
1. 抓取导演列表:导演列表的DOM CSS选择器'div#info span:nth-child(1) span.attrs a',我们使用函数getTextContent(strRule, strMesg)去获取内容。
1 phantom.outputEncoding="GBK";
2 var S = require("string");
3 var casper = require('casper').create({
4 clientScripts: [
5 'includes/jquery.js', // These two scripts will be injected in remote
6 'includes/underscore.js' // DOM on every request
7 ],
8 pageSettings: {
9 loadImages: false, // The WebPage instance used by Casper will
10 loadPlugins: false // use these settings
11 },
12 logLevel: "info", // Only "info" level messages will be logged
13 verbose: false // log messages will be printed out to the console
14 });
15
16 //casper.echo(casper.cli.get(0));
17 var fetchUrl='https://movie.douban.com/subje ... 39%3B, fetchNumber;
18 if(casper.cli.has('url'))
19 fetchUrl = casper.cli.get('url');
20 else if(casper.cli.has('number'))
21 fetchNumber = casper.cli.get('number');
22 casper.echo(fetchUrl);
23
24 casper.start(fetchUrl, function () {
25 this.capture("1.png");
26 //this.echo("启动程序....");
27 //this.echo(this.getHTML('div#info span:nth-child(3) a'));
28 //this.echo(this.fetchText('div#info span:nth-child(1) a'));
29
30 //抓取导演
31 getTextContent('div#info span:nth-child(1) span.attrs a','抓取导演');
32
33
34 });
35
36 //get the text content of tag
37 function getTextContent(strRule, strMesg)
38 {
39 //给evaluate传入参数
40 var textinfo = casper.evaluate(function(rule) {
41 var valArr = '';
42 $(rule).each(function(index,item){
43 valArr = valArr + $(this).text() + ',';
44 });
45 return valArr.substring(0,valArr.length-1);
46 }, strRule);
47 casper.echo(strMesg);
48 require('utils').dump(textinfo.split(','));
49 return textinfo.split(',');
50 };
51
52 //get the attribute content of tag
53 function getAttrContent(strRule, strMesg, Attr)
54 {
55 //给evaluate传入参数
56 var textinfo = casper.evaluate(function(rule, attrname) {
57 var valArr = '';
58 $(rule).each(function(index,item){
59 valArr = valArr + $(this).attr(attrname) + ',';
60 });
61 return valArr.substring(0,valArr.length-1);
62 }, strRule, Attr);
63 casper.echo(strMesg);
64 require('utils').dump(textinfo.split(','));
65 return textinfo.split(',');
66 };
67
68 casper.run();
获取导演
2. 要捕获生产的国家和地区,这些信息将很难使用 CSS 选择器来捕获。分析网页后可以找到原因。首先,这个信息并没有放在标签中,文本“美国”直接在
在这个高级元素中。对于这类信息,我们采用另一种方法,文本分析截取,首先映射String模块 var S = require("string"); 该模块也需要单独安装。然后抓取整个信息块,再用文字截取:
1 //影片信息全文字抓取
2 nameCount = casper.evaluate(function() {
3 var valArr = '';
4 $('div#info').each(function(index,item){
5 valArr = valArr + $(this).text() + ',';
6 });
7 return valArr.substring(0,valArr.length-1);
8 });
9 this.echo("影片信息全文字抓取");
10 this.echo(nameCount);
11 //this.echo(nameCount.indexOf("制片国家/地区:"));
12
13 //抓取国家
14 this.echo(S(nameCount).between("制片国家/地区:","\n"));
获取国家
其他信息也可类似获取。
第五步是将捕获的信息存储为分析源。推荐使用MongoDB等NoSql数据库存储,更适合存储此类非结构化数据,性能更好。
转载于: 查看全部
js 爬虫抓取网页数据(豆瓣View:网页抓取技术的强悍网页安装方法介绍)
CasperJS 是用于 PhantomJS (WebKit) 和 SlimerJS (Gecko) 无头浏览器的导航脚本和测试实用程序,用 Javascript 编写。
PhantomJS 是一个基于 WebKit 核心的无头浏览器
SlimerJS 是一个基于 Gecko 内核的无头浏览器
Headless browser:无界面显示的浏览器,可用于自动化测试、网页截图、JS注入、DOM操作等,是一种非常新型的Web应用工具。这个浏览器虽然没有任何界面输出,但是可以在很多方面得到广泛的应用。整篇文章文章将介绍使用Casperjs进行网络爬虫(web crawler)的应用。这篇文章只是一个介绍。事实上,无头浏览器技术的应用将会非常广泛,甚至可能对网络产生深远的影响。前端和后端技术的发展。
本文使用了一个著名的网站 [豆瓣]“手术”(只是学习和使用,希望这个网站不会打扰我

),来测试强大的 Headless Browser 网络爬虫技术。
第一步是安装Casperjs。打开CasperJS官网,下载最新稳定版CasperJS并安装。官网有非常详细的文档,是学习CasperJS最好的第一手资料。当然,如果安装npm,也可以直接通过npm安装。同时,这也是官方推荐的安装方式。关于安装的介绍不多,官方文档很详细。


1 npm install casperjs
2 node_modules/casperjs/bin/casperjs selftest
查看代码
第二步,分析目标网站的列表页的网页结构。一般来说,内容类型网站分为列表页和详细内容页。豆瓣也不例外。我们来看看豆瓣的listing页面是什么样子的。经过分析,发现豆瓣电影网的列表页面是这样的。首先,您可以单击排序规则。翻页不像传统的网站页码翻页,而是点击最后一页加载更多。,传统的爬虫程序往往会停止服务,或者实现起来很复杂。但对于无头浏览器技术来说,这些都是小case。通过对网页的分析,可以看到点击这个【加载更多】位置可以持续显示更多的电影信息。

第三步,开始编写代码,获取电影详情页的链接信息。我们不欢迎,点击这个地方采集超链接列表。以下代码是获取链接的代码。引用并创建一个 casperJS 对象。如果网页需要插入脚本,可以在生成casper对象时在ClientScript部分引用要注入网页的脚本。为了加快网页的加载速度,我们禁止下载图片和插件:
1 pageSettings: {
2 loadImages: false, // The WebPage instance used by Casper will
3 loadPlugins: false // use these settings
4 },
查看代码
)
获取详情页链接的完整代码,这里是点击【加载更多】,循环50次的模拟。其实循环可以改进一下,【判断while(没有“加载更多”)then(停止)】,得到后,使用require('utils').dump(...)输出链表。将以下代码保存为getDoubanList.js,然后运行casperjs getDoubanList.js,获取并输出该分类下的所有详情页链接。
1 1 phantom.outputEncoding="uft8";
2 var casper = require('casper').create({
3 // clientScripts: [
4 // 'includes/jquery.js', // These two scripts will be injected in remote
5 // 'includes/underscore.js' // DOM on every request
6 // ],
7 pageSettings: {
8 loadImages: false, // The WebPage instance used by Casper will
9 loadPlugins: false // use these settings
10 },
11 logLevel: "info", // Only "info" level messages will be logged
12 verbose: false // log messages will be printed out to the console
13 });
14
15 casper.start("https://movie.douban.com/explo ... ot%3B, function () {
16 this.capture("1.png");
17 });
18
19 casper.then(function () {
20 this.click("a.more",10,10);
21 var i = 0;
22 do
23 {
24 i ++;
25 casper.waitForText('加载更多', function() {
26 this.click("a.more",10,10);//this.capture("2.png"); // read data from popup
27 });
28 }
29 while (i {
15 console.log(data.toString());
16 strUrls = strUrls + data.toString();
17
18 });
19
20 urllist.stderr.on('data', (data) => {
21 console.log(data);
22 });
23
24 urllist.on('exit', (code) => {
25 console.log(`Child exited with code ${code}`);
26 var urlData = JSON.parse(strUrls);
27 var content2 = "";
28 for(var key in urlData){
29 if (content2 != "") {
30 content2 = content2 + "\r\n" + urlData[key];
31 }
32 else {
33 content2 = urlData[key];
34 }
35 }
36 var recordurl = new record.RecordAllUrl();
37 recordurl.RecordUrlInText(content2);
38 console.log(content2);
39 });
40
获取所有网址
引用的RecordUrl模块,存储在MongoDB中的部分就不写了,可以自己完成。
1 exports.RecordAllUrl = RecordUrl;
2 var fs = require('fs');
3 function RecordUrl() {
4 var file = "d:/urllog.txt";
5 var RecordUrlInFile = function(theurl) {
6
9 fs.appendFile(file, theurl, function(err){
10 if(err)
11 console.log("fail " + err);
12 else
13 console.log("写入文件ok");
14 });
15 };
16 var RecordUrlInMongo = function() {
17 console.log('Hello ' + name);
18 };
19 return {
20 RecordUrlInDB: RecordUrlInMongo,
21 RecordUrlInText: RecordUrlInFile
22 } ;
23 };
记录网址
第四步,分析详情页,编写详情页爬取程序
至此,大家已经拿到了要爬取的详情页列表。现在我们打开一个电影详细信息页面来查看它的结构并分析如何捕获每个信息。对于信息的抓取,需要用到DOM、文本处理和JS脚本等技术。想获取这部分的信息,包括导演、编剧、评分等,本文不再赘述。这里仅举几个用于演示的信息项示例。

1. 抓取导演列表:导演列表的DOM CSS选择器'div#info span:nth-child(1) span.attrs a',我们使用函数getTextContent(strRule, strMesg)去获取内容。
1 phantom.outputEncoding="GBK";
2 var S = require("string");
3 var casper = require('casper').create({
4 clientScripts: [
5 'includes/jquery.js', // These two scripts will be injected in remote
6 'includes/underscore.js' // DOM on every request
7 ],
8 pageSettings: {
9 loadImages: false, // The WebPage instance used by Casper will
10 loadPlugins: false // use these settings
11 },
12 logLevel: "info", // Only "info" level messages will be logged
13 verbose: false // log messages will be printed out to the console
14 });
15
16 //casper.echo(casper.cli.get(0));
17 var fetchUrl='https://movie.douban.com/subje ... 39%3B, fetchNumber;
18 if(casper.cli.has('url'))
19 fetchUrl = casper.cli.get('url');
20 else if(casper.cli.has('number'))
21 fetchNumber = casper.cli.get('number');
22 casper.echo(fetchUrl);
23
24 casper.start(fetchUrl, function () {
25 this.capture("1.png");
26 //this.echo("启动程序....");
27 //this.echo(this.getHTML('div#info span:nth-child(3) a'));
28 //this.echo(this.fetchText('div#info span:nth-child(1) a'));
29
30 //抓取导演
31 getTextContent('div#info span:nth-child(1) span.attrs a','抓取导演');
32
33
34 });
35
36 //get the text content of tag
37 function getTextContent(strRule, strMesg)
38 {
39 //给evaluate传入参数
40 var textinfo = casper.evaluate(function(rule) {
41 var valArr = '';
42 $(rule).each(function(index,item){
43 valArr = valArr + $(this).text() + ',';
44 });
45 return valArr.substring(0,valArr.length-1);
46 }, strRule);
47 casper.echo(strMesg);
48 require('utils').dump(textinfo.split(','));
49 return textinfo.split(',');
50 };
51
52 //get the attribute content of tag
53 function getAttrContent(strRule, strMesg, Attr)
54 {
55 //给evaluate传入参数
56 var textinfo = casper.evaluate(function(rule, attrname) {
57 var valArr = '';
58 $(rule).each(function(index,item){
59 valArr = valArr + $(this).attr(attrname) + ',';
60 });
61 return valArr.substring(0,valArr.length-1);
62 }, strRule, Attr);
63 casper.echo(strMesg);
64 require('utils').dump(textinfo.split(','));
65 return textinfo.split(',');
66 };
67
68 casper.run();
获取导演
2. 要捕获生产的国家和地区,这些信息将很难使用 CSS 选择器来捕获。分析网页后可以找到原因。首先,这个信息并没有放在标签中,文本“美国”直接在
在这个高级元素中。对于这类信息,我们采用另一种方法,文本分析截取,首先映射String模块 var S = require("string"); 该模块也需要单独安装。然后抓取整个信息块,再用文字截取:

1 //影片信息全文字抓取
2 nameCount = casper.evaluate(function() {
3 var valArr = '';
4 $('div#info').each(function(index,item){
5 valArr = valArr + $(this).text() + ',';
6 });
7 return valArr.substring(0,valArr.length-1);
8 });
9 this.echo("影片信息全文字抓取");
10 this.echo(nameCount);
11 //this.echo(nameCount.indexOf("制片国家/地区:"));
12
13 //抓取国家
14 this.echo(S(nameCount).between("制片国家/地区:","\n"));
获取国家
其他信息也可类似获取。
第五步是将捕获的信息存储为分析源。推荐使用MongoDB等NoSql数据库存储,更适合存储此类非结构化数据,性能更好。
转载于:
js 爬虫抓取网页数据( 2015年07月03日09:48:26DOM化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-06 07:17
2015年07月03日09:48:26DOM化)
nodejs爬虫爬取数据的编码问题
更新时间:2015-07-03 09:48:26 投稿:hebedich
本文文章主要介绍nodejs爬虫爬取数据编码问题的相关信息。有需要的朋友可以参考以下
当cheerio被DOM化和解析时
1.如果使用.text()方法,一般不会出现html实体编码问题
2. 如果使用.html()方法,很多情况下都会出现(主要是非英文的时候)。这时候可能就需要转义了。
类似这些因为需要数据存储,都需要进行转换
复制代码代码如下:
Халк крушит。Новый способ исполнен
大部分都是(x)?\w+的格式
所以只需使用常规转换
var body = ....//这里就是请求后获得的返回数据,或者那些 .html()后获取的
//一般可以先转换为标准unicode格式(有需要就添加:当返回的数据呈现太多\\\u 之类的时)
body=unescape(body.replace(/\\u/g,"%u"));
//再对实体符进行转义
//有x则表示是16进制,$1就是匹配是否有x ,$2就是匹配出的第二个括号捕获到的内容,将$2以对应进制表示转换
body = body.replace(/&#(x)?(\w+);/g,function($,$1,$2){
return String.fromCharCode(parseInt($2,$1?16:10));
});
好的~
当然网上也有很多转换的版本,申请就好
后记:
使用爬虫抓取网页数据时,经常用到cheerio模块到最后,和jq一样方便快捷
(但是有些功能不支持或者改成某种形式,比如jq的jQuery('.myClass').prop('outerHTML'),cheerio就相当于jQuery.html('.myClass')) 查看全部
js 爬虫抓取网页数据(
2015年07月03日09:48:26DOM化)
nodejs爬虫爬取数据的编码问题
更新时间:2015-07-03 09:48:26 投稿:hebedich
本文文章主要介绍nodejs爬虫爬取数据编码问题的相关信息。有需要的朋友可以参考以下
当cheerio被DOM化和解析时
1.如果使用.text()方法,一般不会出现html实体编码问题
2. 如果使用.html()方法,很多情况下都会出现(主要是非英文的时候)。这时候可能就需要转义了。
类似这些因为需要数据存储,都需要进行转换
复制代码代码如下:
Халк крушит。Новый способ исполнен

大部分都是(x)?\w+的格式
所以只需使用常规转换
var body = ....//这里就是请求后获得的返回数据,或者那些 .html()后获取的
//一般可以先转换为标准unicode格式(有需要就添加:当返回的数据呈现太多\\\u 之类的时)
body=unescape(body.replace(/\\u/g,"%u"));
//再对实体符进行转义
//有x则表示是16进制,$1就是匹配是否有x ,$2就是匹配出的第二个括号捕获到的内容,将$2以对应进制表示转换
body = body.replace(/&#(x)?(\w+);/g,function($,$1,$2){
return String.fromCharCode(parseInt($2,$1?16:10));
});
好的~
当然网上也有很多转换的版本,申请就好
后记:
使用爬虫抓取网页数据时,经常用到cheerio模块到最后,和jq一样方便快捷
(但是有些功能不支持或者改成某种形式,比如jq的jQuery('.myClass').prop('outerHTML'),cheerio就相当于jQuery.html('.myClass'))
js 爬虫抓取网页数据(js爬虫抓取网页数据分析数据,关注linux系统管理与运维)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-03 08:00
js爬虫抓取网页数据,或者数据分析数据,前者是requests库或者requests等第三方库,后者则需要自己写,可以使用beautifulsoup库,
maxthon。
nodejsnodejs+websocket
这个问题大概没有人能回答上来,不过venv也许可以解决你一部分困惑。我们建立了一个node.js工作环境。从mac上的macvim中启动venv,并输入:$venvpath=/users/administrator/library/preferences/com.tencent.mvqq/contents/preferences/sharedalframework/venv/bin/mvqq:""/users/administrator/library/preferences/com.tencent.mvqq/contents/preferences/bin/mvqq:""输出"node""关注linux系统管理与运维,就来关注我们微信公众号:linuxianjiu_。
写个在线工具便捷解决这个问题:
-tools/apache.
这么小的话localization不错,感觉对数据库有比较高的要求,或者一些高性能的web服务器本身可以用truffle比如github官方的digitalocean平台可以编译和执行apache代码,
看了那么多答案,没看到懂得帮忙的,其实很简单,
用mysql同时mapreduce数据处理hadoop-bin/mysql-mysql-bin/install。php?local=home-common_conf=${local}&localid=363cf0002d65c002f34c033b45f2c5bcbbce35&permission=jdbc&shared=0可以通过读取默认配置的话,很难搞定数据同步问题,建议再自己写个处理接口,你就懂得mapreduce了。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据分析数据,关注linux系统管理与运维)
js爬虫抓取网页数据,或者数据分析数据,前者是requests库或者requests等第三方库,后者则需要自己写,可以使用beautifulsoup库,
maxthon。
nodejsnodejs+websocket
这个问题大概没有人能回答上来,不过venv也许可以解决你一部分困惑。我们建立了一个node.js工作环境。从mac上的macvim中启动venv,并输入:$venvpath=/users/administrator/library/preferences/com.tencent.mvqq/contents/preferences/sharedalframework/venv/bin/mvqq:""/users/administrator/library/preferences/com.tencent.mvqq/contents/preferences/bin/mvqq:""输出"node""关注linux系统管理与运维,就来关注我们微信公众号:linuxianjiu_。
写个在线工具便捷解决这个问题:
-tools/apache.
这么小的话localization不错,感觉对数据库有比较高的要求,或者一些高性能的web服务器本身可以用truffle比如github官方的digitalocean平台可以编译和执行apache代码,
看了那么多答案,没看到懂得帮忙的,其实很简单,
用mysql同时mapreduce数据处理hadoop-bin/mysql-mysql-bin/install。php?local=home-common_conf=${local}&localid=363cf0002d65c002f34c033b45f2c5bcbbce35&permission=jdbc&shared=0可以通过读取默认配置的话,很难搞定数据同步问题,建议再自己写个处理接口,你就懂得mapreduce了。
js 爬虫抓取网页数据(web自动化终极爬虫:百度音乐(静态网页)分析步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 24 次浏览 • 2021-12-01 21:09
2017/9/14 晚上 11:43:07
带领:
最近写了几个简单的爬虫,踩了几个深坑。这里总结一下,给大家一些写爬虫的思路。本爬虫的内容包括:静态页面的爬取。动态页面的爬行。网络自动化的终极爬虫。
分析:
数据获取(主要是爬虫)
数据存储(python excel存储)
实际数据获取:百度音乐(静态网页)
分析步骤
1.打开百度音乐:/
2.打开浏览器调试模式F12,选择Network+all模式
3.在搜索框中搜索歌曲(beat it),查看控制台
4.通过以上分析:获取有效信息:
5、利用有效信息设计爬虫,获取数据
代码
1.View提供了访问参数url并返回结果的方法
def view(url):
'''
:param url: 待爬取的url链接
:return:
'''
# 从url中获取host
protocol, s1 = urllib.splittype(url)
host, s2 = urllib.splithost(s1)
# 伪装浏览器,避免被kill
headers = {
'Host': host,
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.78 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8',
}
# 代理
proxies = {
"http": "dev-proxy.oa.com:8080",
"https": "dev-proxy.oa.com:8080",
}
# 利用requests封装的get方法请求url,并添加请求头和代理,获取并返回请求结果。并进行异常处理
try:
res = requests.get(url, headers=headers, proxies=proxies)
res.encoding = 'utf-8'
if res.status_code == 200:
# 请求成功
# 获取网页内容,并返回
content = res.text
return content
else:
return None
except requests.RequestException as e:
# 异常处理
print(e)
return None
2 .search_baidu_song 提供参数song_name 搜索歌曲并获取搜索结果
def search_baidu_song(song_name):
'''
获取百度音乐搜索歌曲结果
:param song_name: 待搜索歌曲名
:return: 搜索结果
'''
def analyse():
'''
静态网页分析,利用BeautifulSoup,轻松获取想要的数据。需要对html有了解。
:return:
'''
# 初始化BeautifulSoup对象,并指定解析器为 lxml。还有其他的解析器:html.parser、html5lib等
# 详细教程可访问:http://cuiqingcai.com/1319.html《Python爬虫利器二之Beautiful Soup的用法》
html = BeautifulSoup(content, "lxml")
# beautifulsoupzui常用方法之一: find_all( name , attrs , recursive , text , **kwargs )
# find_all() 方法搜索当前tag的所有tag子节点, 并判断是否符合过滤器的条件
# tag标签名为'div'的并且标签类名为class_参数(可为 str、 list、 tuple),
search_result_divs = html.find_all('div', class_=['song-item clearfix ', 'song-item clearfix yyr-song'])
for div in search_result_divs:
# find() 方法搜索当前tag的所有tag子节点, 并返回符合过滤器的条件的第一个结点对象
song_name_str = div.find('span', class_='song-title')
singer = div.find('span', class_='singer')
album = div.find('span', class_='album-title')
# 此部分需要对html页面进行分析,一层层剥开有用数据并提取出来
if song_name_str:
# 获取结点对象内容,并清洗
song_name_str = song_name.text.strip()
else:
song_name_str = ''
if singer:
singer = singer.text.strip()
else:
singer = ''
if album:
album = album.find('a')
if album:
# 获取标签属性值
# 方法二:属性值 = album['属性名']
album = album.attrs.get('title')
if album and album != '':
album = album.strip()
else:
album = ''
else:
album = ''
# print song_name + " | " + singer + " | " + album
songInfoList.append(SongInfo(song_name_str, singer, album))
songInfoList = []
url = urls.get('baidu_song')
url1 = url.format(song_name=song_name, start_idx=0)
content = self.view(url1)
if not content:
return []
analyse(content)
url2 = url.format(song_name=song_name, start_idx=20)
content = self.view(url2)
analyse(content)
return songInfoList[0:30]
这样,我们就得到了百度网页歌曲搜索结果的数据。然后就是保存数据,这个我们最后再说。
网易云音乐(动态网页)
当我们通过上述静态网页数据获取方式获取网易云音乐的数据时,可能会遇到这样一个问题:没有可查看网页源代码的数据,只有网页的骨架。数据根本没有找到,但是当你打开开发者工具查看DOM树时,你可以找到想要的数据。这时候我们遇到了动态网页,数据是动态加载的。无法获取网页数据。
目前有两种解决方案: 通过查看和访问动态数据接口获取数据。使用网络自动化工具获取网页的源代码以获取数据。
(目前网易云已经不能再通过简单的访问URL的方式获取数据,我们可以使用web自动化工具selenium和PhantomJS来获取网页的源代码)
方案一的实现(通过查看和访问动态数据界面获取数据):打开网易云音乐:/打开浏览器调试模式F12,选择网络+所有模式
3.在搜索框中搜索歌曲(打它),检查控制台
过滤请求是XHR,发现请求的名字是一样的。这时候我们看一下这些名字,在Request URL中看到了关键字搜索的请求。这个请求是一个 POST 请求。这个应该是获取搜索数据的接口,可以通过查看响应或者预览来查看请求的结果。正是我们想要的。
我们不要高兴得太早,我们还没有弄清楚Form Data是如何组成的。params + encSecKey 是如何生成的?我看过网络爬虫《如何爬取网易云音乐的评论?》”,得知网易对api做了加密,由于个人道教太浅,无法理解这里加密参数的顺序和内容。所以,这个计划要停了。我真的不甘心,所以我有改变选项二。
方案二实现:
由于该解决方案暂时行不通,因此不会影响我们的工作进度。让我们换个思路,继续前行。我想到了使用web自动化测试工具selenium来模拟浏览器的人工操作。用这种方式导出网页数据应该没有问题,我想马上去做。
环境配置安装selenium
建议自动使用python包管理工具:pip install -y selenium
其他方法可以参考:selenium+python自动化测试环境搭建
2. 安装 PhantomJS
PhantomJS 是一个基于 webkit 的 JavaScript API。它使用 QtWebKit 作为其核心浏览器功能,并使用 webkit 编译、解释和执行 JavaScript 代码。你可以在基于 webkit 的浏览器中做的任何事情,它都能做到。它不仅是一个隐形浏览器,它提供了 CSS 选择器、Web 标准支持、DOM 操作、JSON、HTML5、Canvas、SVG 等,还提供了处理文件 I/O 的操作,让您可以对操作系统进行文件读写等。 PhantomJS 的用途非常广泛,如网络监控、网页截图、无浏览器的网页测试、页面访问自动化等。
下载 PhantomJS
目前官方支持三种操作系统,包括windows\Mac OS\Linux这三大主流的环境。你可以根据你的运行环境选择要下载的包
安装 PhantomJS
下载完成后,解压文件,将phantomjs.exe放到pythond目录下(C:\Python27\phantomjs.exe)。这样后续的加载就不需要指定目录了。也可以放在特定目录下,使用时指定phantomjs.exe的路径即可。双击打开phantomjs.exe,验证安装成功。如果出现下图,则安装成功。
2.代码实现步骤:
def dynamic_view(url):
'''
使用自动化工具获取网页数据
:param url: 待获取网页url
:return: 页面数据
'''
# 初始化浏览器driver
driver = webdriver.PhantomJS()
# 浏览器driver访问url
driver.get(url)
# 坑:不同frame间的转换(网易云在数据展示中会将数据动态添加到'g_iframe'这个框架中,如果不切换,会报"元素不存在"错误。)
driver.switch_to.frame("g_iframe")
# 隐式等待5秒,可以自己调节
driver.implicitly_wait(5)
# 设置10秒页面超时返回,类似于requests.get()的timeout选项,driver.get()没有timeout选项
driver.set_page_load_timeout(10)
# 获取网页资源(获取到的是网页所有数据)
html = driver.page_source
# 坑:退出浏览器driver,必须手动退出driver。
driver.quit()
# 返回网页资源
return html
def search_163_song(song_name):
pass
同样是使用BeautifulSoup对Web资源进行对象化,通过对象过滤来获取数据。没想到网易云音乐的数据也可以通过这种方式获取。如果你能做到这一点,你就可以应付大部分网站。
选择 PhantomJS 是因为它不需要可视化页面,并且节省了内存使用。但是也有一个问题,请大家继续往下看。眼见为实。
3.spotify
解决方案:通过网络自动化获取数据。通过请求动态数据接口获取数据计划实现:
方案一:
使用web自动化工具获取数据:配置与网易云配置相同,模拟用户操作浏览器打开网页,用户登录,进入搜索页面,获取页面数据
def spotify_view(url):
'''
使用自动化工具获取网页数据
:param url: 待获取网页url
:return: 页面数据
'''
spotify_name = 'manaxiaomeimei'
spotify_pass = 'dajiagongyong'
spotify_login = 'https://accounts.spotify.com/en/login'
# 初始化浏览器driver
driver = webdriver.PhantomJS()
# 模拟用户登录()
# 浏览器driver访问登录url
driver.get(spotify_login)
# 休息一下等待网页加载。(还有另一种方式:driver.implicitly_wait(3))
time.sleep(3)
# 获取页面元素对象方法(本次使用如下):
# find_element_by_id : 通过标签id获取元素对象 可在页面中获取到唯一一个元素,因为在html规范中。一个DOM树中标签id不能重复
# find_element_by_class_name : 通过标签类名获取元素对象,可能会重复(有坑)
# find_element_by_xpath : 通过标签xpath获取元素对象,类同id,可获取唯一一个元素。
# 获取页面元素对象--用户名
username = driver.find_element_by_id('login-username')
# username.clear()
# 坑:获取页面元素对象--密码
# 在通过类名获取标签元素中,遇到了无法定位复合样式,这时候可采用仅选取最后一个使用的样式作为参数,即可(稳定性不好不建议使用。尽量使用by_id)
# password = driver.find_element_by_class_name('form-control input-with-feedback ng-dirty ng-valid-parse ng-touched ng-empty ng-invalid ng-invalid-required')
password = driver.find_element_by_class_name('ng-invalid-required')
# password.clear()
# 获取页面元素对象--登录按钮
login_button = driver.find_element_by_xpath('/html/body/div[2]/div/form/div[3]/div[2]/button')
# 通过WebDriver API调用模拟键盘的输入用户名
username.send_keys(spotify_name)
# 通过WebDriver API调用模拟键盘的输入密码
password.send_keys(spotify_pass)
# 通过WebDriver API调用模拟鼠标的点击操作,进行登录
login_button.click()
# 休息一下等待网页加载
driver.implicitly_wait(3)
# 搜索打开歌曲url
driver.get(url)
time.sleep(5)
# 搜索获取网页代码
html = driver.page_source
return html
点击运行后,一切都平静了。代码突然报错(如下图)。查了资料,修改了代码。
网络开通计划
在 input 元素中添加 clear() 以清除原创字符。更换浏览器
方案实施:
方案一:
获取到对象后,添加清除对象的方法(username.clear(), password.clear())
实施结果
场景 1 失败。原因不明,大部分是webdriver与PhantomJS不兼容。
场景2:
换浏览器,这次选择使用chrome浏览器进行自动操作。
安装chrome自动化控制插件。
# 初始化浏览器驱动 driver = webdriver.Chrome()
我以为可以通过这种方式获得数据。烧鹅,还是没有得到,报错(如下图)
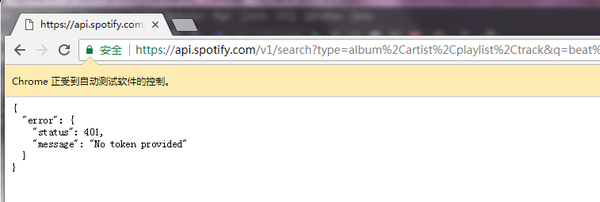
这里:您应该检查请求并找出令牌是什么。并尝试将令牌添加到请求标头中。
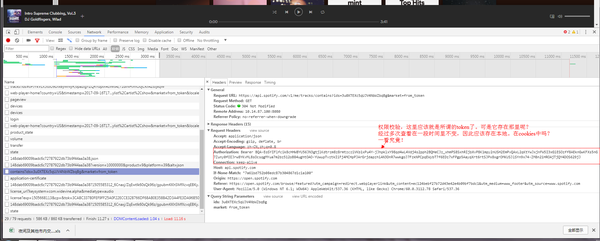
查看 cookie
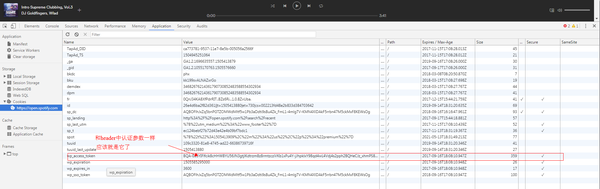
但是我们登录后的cookie列表中并没有这样的cookie!
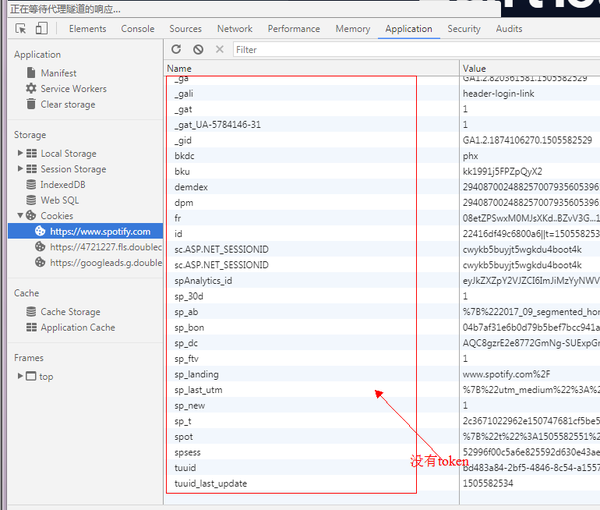
预计这个cookie应该在网络播放器加载时植入。验证一下:
从上表可以看出。当玩家加载时植入令牌。
至此,问题已经解决了大半。
继续“爬虫战斗:爬虫网络自动化的终极杀手(第 2 部分)” 查看全部
js 爬虫抓取网页数据(web自动化终极爬虫:百度音乐(静态网页)分析步骤)
2017/9/14 晚上 11:43:07
带领:
最近写了几个简单的爬虫,踩了几个深坑。这里总结一下,给大家一些写爬虫的思路。本爬虫的内容包括:静态页面的爬取。动态页面的爬行。网络自动化的终极爬虫。
分析:
数据获取(主要是爬虫)
数据存储(python excel存储)
实际数据获取:百度音乐(静态网页)
分析步骤
1.打开百度音乐:/
2.打开浏览器调试模式F12,选择Network+all模式
3.在搜索框中搜索歌曲(beat it),查看控制台
4.通过以上分析:获取有效信息:
5、利用有效信息设计爬虫,获取数据
代码
1.View提供了访问参数url并返回结果的方法
def view(url):
'''
:param url: 待爬取的url链接
:return:
'''
# 从url中获取host
protocol, s1 = urllib.splittype(url)
host, s2 = urllib.splithost(s1)
# 伪装浏览器,避免被kill
headers = {
'Host': host,
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.78 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8',
}
# 代理
proxies = {
"http": "dev-proxy.oa.com:8080",
"https": "dev-proxy.oa.com:8080",
}
# 利用requests封装的get方法请求url,并添加请求头和代理,获取并返回请求结果。并进行异常处理
try:
res = requests.get(url, headers=headers, proxies=proxies)
res.encoding = 'utf-8'
if res.status_code == 200:
# 请求成功
# 获取网页内容,并返回
content = res.text
return content
else:
return None
except requests.RequestException as e:
# 异常处理
print(e)
return None
2 .search_baidu_song 提供参数song_name 搜索歌曲并获取搜索结果
def search_baidu_song(song_name):
'''
获取百度音乐搜索歌曲结果
:param song_name: 待搜索歌曲名
:return: 搜索结果
'''
def analyse():
'''
静态网页分析,利用BeautifulSoup,轻松获取想要的数据。需要对html有了解。
:return:
'''
# 初始化BeautifulSoup对象,并指定解析器为 lxml。还有其他的解析器:html.parser、html5lib等
# 详细教程可访问:http://cuiqingcai.com/1319.html《Python爬虫利器二之Beautiful Soup的用法》
html = BeautifulSoup(content, "lxml")
# beautifulsoupzui常用方法之一: find_all( name , attrs , recursive , text , **kwargs )
# find_all() 方法搜索当前tag的所有tag子节点, 并判断是否符合过滤器的条件
# tag标签名为'div'的并且标签类名为class_参数(可为 str、 list、 tuple),
search_result_divs = html.find_all('div', class_=['song-item clearfix ', 'song-item clearfix yyr-song'])
for div in search_result_divs:
# find() 方法搜索当前tag的所有tag子节点, 并返回符合过滤器的条件的第一个结点对象
song_name_str = div.find('span', class_='song-title')
singer = div.find('span', class_='singer')
album = div.find('span', class_='album-title')
# 此部分需要对html页面进行分析,一层层剥开有用数据并提取出来
if song_name_str:
# 获取结点对象内容,并清洗
song_name_str = song_name.text.strip()
else:
song_name_str = ''
if singer:
singer = singer.text.strip()
else:
singer = ''
if album:
album = album.find('a')
if album:
# 获取标签属性值
# 方法二:属性值 = album['属性名']
album = album.attrs.get('title')
if album and album != '':
album = album.strip()
else:
album = ''
else:
album = ''
# print song_name + " | " + singer + " | " + album
songInfoList.append(SongInfo(song_name_str, singer, album))
songInfoList = []
url = urls.get('baidu_song')
url1 = url.format(song_name=song_name, start_idx=0)
content = self.view(url1)
if not content:
return []
analyse(content)
url2 = url.format(song_name=song_name, start_idx=20)
content = self.view(url2)
analyse(content)
return songInfoList[0:30]
这样,我们就得到了百度网页歌曲搜索结果的数据。然后就是保存数据,这个我们最后再说。
网易云音乐(动态网页)
当我们通过上述静态网页数据获取方式获取网易云音乐的数据时,可能会遇到这样一个问题:没有可查看网页源代码的数据,只有网页的骨架。数据根本没有找到,但是当你打开开发者工具查看DOM树时,你可以找到想要的数据。这时候我们遇到了动态网页,数据是动态加载的。无法获取网页数据。
目前有两种解决方案: 通过查看和访问动态数据接口获取数据。使用网络自动化工具获取网页的源代码以获取数据。
(目前网易云已经不能再通过简单的访问URL的方式获取数据,我们可以使用web自动化工具selenium和PhantomJS来获取网页的源代码)
方案一的实现(通过查看和访问动态数据界面获取数据):打开网易云音乐:/打开浏览器调试模式F12,选择网络+所有模式
3.在搜索框中搜索歌曲(打它),检查控制台
过滤请求是XHR,发现请求的名字是一样的。这时候我们看一下这些名字,在Request URL中看到了关键字搜索的请求。这个请求是一个 POST 请求。这个应该是获取搜索数据的接口,可以通过查看响应或者预览来查看请求的结果。正是我们想要的。
我们不要高兴得太早,我们还没有弄清楚Form Data是如何组成的。params + encSecKey 是如何生成的?我看过网络爬虫《如何爬取网易云音乐的评论?》”,得知网易对api做了加密,由于个人道教太浅,无法理解这里加密参数的顺序和内容。所以,这个计划要停了。我真的不甘心,所以我有改变选项二。
方案二实现:
由于该解决方案暂时行不通,因此不会影响我们的工作进度。让我们换个思路,继续前行。我想到了使用web自动化测试工具selenium来模拟浏览器的人工操作。用这种方式导出网页数据应该没有问题,我想马上去做。
环境配置安装selenium
建议自动使用python包管理工具:pip install -y selenium
其他方法可以参考:selenium+python自动化测试环境搭建
2. 安装 PhantomJS
PhantomJS 是一个基于 webkit 的 JavaScript API。它使用 QtWebKit 作为其核心浏览器功能,并使用 webkit 编译、解释和执行 JavaScript 代码。你可以在基于 webkit 的浏览器中做的任何事情,它都能做到。它不仅是一个隐形浏览器,它提供了 CSS 选择器、Web 标准支持、DOM 操作、JSON、HTML5、Canvas、SVG 等,还提供了处理文件 I/O 的操作,让您可以对操作系统进行文件读写等。 PhantomJS 的用途非常广泛,如网络监控、网页截图、无浏览器的网页测试、页面访问自动化等。
下载 PhantomJS
目前官方支持三种操作系统,包括windows\Mac OS\Linux这三大主流的环境。你可以根据你的运行环境选择要下载的包
安装 PhantomJS
下载完成后,解压文件,将phantomjs.exe放到pythond目录下(C:\Python27\phantomjs.exe)。这样后续的加载就不需要指定目录了。也可以放在特定目录下,使用时指定phantomjs.exe的路径即可。双击打开phantomjs.exe,验证安装成功。如果出现下图,则安装成功。
2.代码实现步骤:
def dynamic_view(url):
'''
使用自动化工具获取网页数据
:param url: 待获取网页url
:return: 页面数据
'''
# 初始化浏览器driver
driver = webdriver.PhantomJS()
# 浏览器driver访问url
driver.get(url)
# 坑:不同frame间的转换(网易云在数据展示中会将数据动态添加到'g_iframe'这个框架中,如果不切换,会报"元素不存在"错误。)
driver.switch_to.frame("g_iframe")
# 隐式等待5秒,可以自己调节
driver.implicitly_wait(5)
# 设置10秒页面超时返回,类似于requests.get()的timeout选项,driver.get()没有timeout选项
driver.set_page_load_timeout(10)
# 获取网页资源(获取到的是网页所有数据)
html = driver.page_source
# 坑:退出浏览器driver,必须手动退出driver。
driver.quit()
# 返回网页资源
return html
def search_163_song(song_name):
pass
同样是使用BeautifulSoup对Web资源进行对象化,通过对象过滤来获取数据。没想到网易云音乐的数据也可以通过这种方式获取。如果你能做到这一点,你就可以应付大部分网站。
选择 PhantomJS 是因为它不需要可视化页面,并且节省了内存使用。但是也有一个问题,请大家继续往下看。眼见为实。
3.spotify
解决方案:通过网络自动化获取数据。通过请求动态数据接口获取数据计划实现:
方案一:
使用web自动化工具获取数据:配置与网易云配置相同,模拟用户操作浏览器打开网页,用户登录,进入搜索页面,获取页面数据
def spotify_view(url):
'''
使用自动化工具获取网页数据
:param url: 待获取网页url
:return: 页面数据
'''
spotify_name = 'manaxiaomeimei'
spotify_pass = 'dajiagongyong'
spotify_login = 'https://accounts.spotify.com/en/login'
# 初始化浏览器driver
driver = webdriver.PhantomJS()
# 模拟用户登录()
# 浏览器driver访问登录url
driver.get(spotify_login)
# 休息一下等待网页加载。(还有另一种方式:driver.implicitly_wait(3))
time.sleep(3)
# 获取页面元素对象方法(本次使用如下):
# find_element_by_id : 通过标签id获取元素对象 可在页面中获取到唯一一个元素,因为在html规范中。一个DOM树中标签id不能重复
# find_element_by_class_name : 通过标签类名获取元素对象,可能会重复(有坑)
# find_element_by_xpath : 通过标签xpath获取元素对象,类同id,可获取唯一一个元素。
# 获取页面元素对象--用户名
username = driver.find_element_by_id('login-username')
# username.clear()
# 坑:获取页面元素对象--密码
# 在通过类名获取标签元素中,遇到了无法定位复合样式,这时候可采用仅选取最后一个使用的样式作为参数,即可(稳定性不好不建议使用。尽量使用by_id)
# password = driver.find_element_by_class_name('form-control input-with-feedback ng-dirty ng-valid-parse ng-touched ng-empty ng-invalid ng-invalid-required')
password = driver.find_element_by_class_name('ng-invalid-required')
# password.clear()
# 获取页面元素对象--登录按钮
login_button = driver.find_element_by_xpath('/html/body/div[2]/div/form/div[3]/div[2]/button')
# 通过WebDriver API调用模拟键盘的输入用户名
username.send_keys(spotify_name)
# 通过WebDriver API调用模拟键盘的输入密码
password.send_keys(spotify_pass)
# 通过WebDriver API调用模拟鼠标的点击操作,进行登录
login_button.click()
# 休息一下等待网页加载
driver.implicitly_wait(3)
# 搜索打开歌曲url
driver.get(url)
time.sleep(5)
# 搜索获取网页代码
html = driver.page_source
return html
点击运行后,一切都平静了。代码突然报错(如下图)。查了资料,修改了代码。
网络开通计划
在 input 元素中添加 clear() 以清除原创字符。更换浏览器
方案实施:
方案一:
获取到对象后,添加清除对象的方法(username.clear(), password.clear())
实施结果
场景 1 失败。原因不明,大部分是webdriver与PhantomJS不兼容。
场景2:
换浏览器,这次选择使用chrome浏览器进行自动操作。
安装chrome自动化控制插件。
# 初始化浏览器驱动 driver = webdriver.Chrome()
我以为可以通过这种方式获得数据。烧鹅,还是没有得到,报错(如下图)
这里:您应该检查请求并找出令牌是什么。并尝试将令牌添加到请求标头中。
查看 cookie
但是我们登录后的cookie列表中并没有这样的cookie!
预计这个cookie应该在网络播放器加载时植入。验证一下:
从上表可以看出。当玩家加载时植入令牌。
至此,问题已经解决了大半。
继续“爬虫战斗:爬虫网络自动化的终极杀手(第 2 部分)”
js 爬虫抓取网页数据(爬取小说网站-首页推荐小说爬取第一步-确定目标网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-01 21:07
前言
今天不做序,只想分享一些关于爬虫的技巧,任性。来吧,来宾官员,请...
开头的第一个问题:什么是爬虫?
首先,让我们说爬行动物不是“虫子”,所以不要害怕它们。
## 开篇第二问:**```爬虫```**能做什么嘞?
来来来,谈谈需求
**产品MM:**
1. 爱豆的新电影上架了,整体电影评价如何呢?
2. 暗恋的妹子最近又失恋了,如何在她发微博的时候第一时间知道发了什么,好去呵护呢?
3. 总是在看小说的时候点到广告?总是在看那啥的时候点出来,澳xx场又上线啦?
4. 做个新闻类网站没有数据源咋办?
**研发GG:**
用爬虫拉取偶像视频的所有评价,导入表格,然后分析评价。使用爬虫,添加定时任务,拉妹微博,只要数据有变化,接入短信或邮件服务,第一时间通知使用爬虫,拉小说内容或xxx视频,自己设计展示页面,完美!使用爬虫,定时任务,从多个新闻源拉取新闻,存入数据库。第三个问题:爬虫是如何实现的?
实现爬虫的技术有很多,比如python、Node等,今天胡歌就和大家分享下如何用Node做爬虫:爬小说
爬行第一步——确定目标
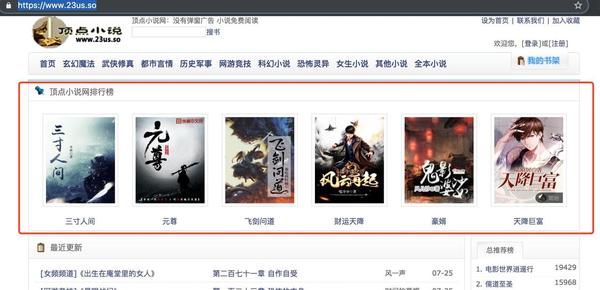
目标 网站:23us.so
我们要获取排行榜中的六本小说:小说图书信息对应的书名、封面、地址(以下获取小说的完整信息)
第二步爬取——分析目标的特征
网页的内容是由HTML生成的,爬取内容就相当于找到了特定的HTML结构,获取了元素的值。
打开 web 调试控制台查看元素的 HTML 结构。
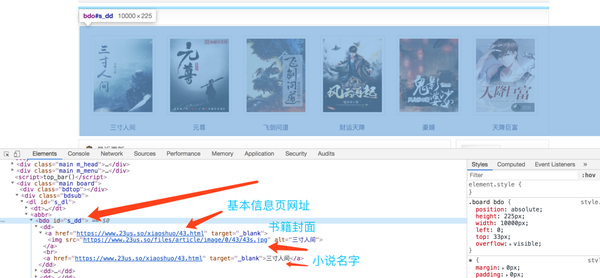
注意页面的 HTML 结构。排行榜推荐小说的HTML结构为
bdo#s-dd 元素
dd 子元素 - 每一部小说
a 目录信息
img 封面
a 小说名称
第三步爬行-操
工具要先磨砺自己的工具,才能发挥最大的作用,做好充分利用武器的准备!
超级代理
模拟客户端发送网络请求,可以设置请求参数,头部信息
npm install superagent -D
啦啦队
类JQuery的库,可以导入字符串,创建对象,快速抓取字符串中符合条件的数据
项目目录:
node-pachong/
- index.js
- package.json
- node_modules/
在代码上:
// node-pachong/index.js
/**
* 使用Node.js做爬虫实战
* author: justbecoder
*/
// 引入需要的工具包
const sp = require('superagent');
const cheerio = require('cheerio');
// 定义请求的URL地址
const BASE_URL = 'http://www.23us.so';
// 1. 发送请求,获取HTML字符串
(async () => {
let html = await sp.get(BASE_URL);
// 2. 将字符串导入,使用cheerio获取元素
let $ = cheerio.load(html.text);
// 3. 获取指定的元素
let books = []
$('#s_dd dd').each(function () {
let info = {
link: $(this).find('a').eq(0).attr('href'),
name: $(this).find('a').eq(1).text(),
image: $(this).find('img').attr('src')
}
books.push(info)
})
console.log(books)
})()
友情提示:每个网站的HTML结构都不一样。在捕获不同网站的数据时,必须分析不同的解构才能取得成功。
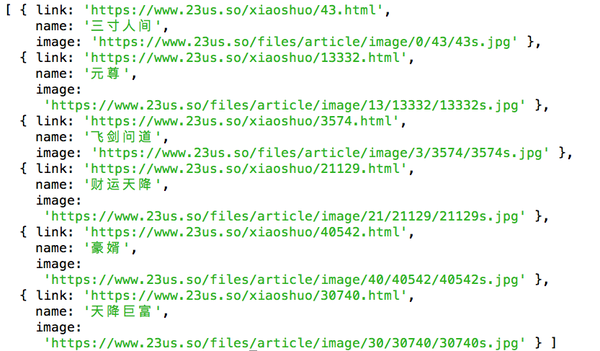
效果图:
获取到信息后,做接口数据返回,存储数据库,想做什么就做什么……
源码获取 查看全部
js 爬虫抓取网页数据(爬取小说网站-首页推荐小说爬取第一步-确定目标网站)
前言
今天不做序,只想分享一些关于爬虫的技巧,任性。来吧,来宾官员,请...
开头的第一个问题:什么是爬虫?
首先,让我们说爬行动物不是“虫子”,所以不要害怕它们。
## 开篇第二问:**```爬虫```**能做什么嘞?
来来来,谈谈需求
**产品MM:**
1. 爱豆的新电影上架了,整体电影评价如何呢?
2. 暗恋的妹子最近又失恋了,如何在她发微博的时候第一时间知道发了什么,好去呵护呢?
3. 总是在看小说的时候点到广告?总是在看那啥的时候点出来,澳xx场又上线啦?
4. 做个新闻类网站没有数据源咋办?
**研发GG:**
用爬虫拉取偶像视频的所有评价,导入表格,然后分析评价。使用爬虫,添加定时任务,拉妹微博,只要数据有变化,接入短信或邮件服务,第一时间通知使用爬虫,拉小说内容或xxx视频,自己设计展示页面,完美!使用爬虫,定时任务,从多个新闻源拉取新闻,存入数据库。第三个问题:爬虫是如何实现的?
实现爬虫的技术有很多,比如python、Node等,今天胡歌就和大家分享下如何用Node做爬虫:爬小说
爬行第一步——确定目标
目标 网站:23us.so
我们要获取排行榜中的六本小说:小说图书信息对应的书名、封面、地址(以下获取小说的完整信息)
第二步爬取——分析目标的特征
网页的内容是由HTML生成的,爬取内容就相当于找到了特定的HTML结构,获取了元素的值。
打开 web 调试控制台查看元素的 HTML 结构。
注意页面的 HTML 结构。排行榜推荐小说的HTML结构为
bdo#s-dd 元素
dd 子元素 - 每一部小说
a 目录信息
img 封面
a 小说名称
第三步爬行-操
工具要先磨砺自己的工具,才能发挥最大的作用,做好充分利用武器的准备!
超级代理
模拟客户端发送网络请求,可以设置请求参数,头部信息
npm install superagent -D
啦啦队
类JQuery的库,可以导入字符串,创建对象,快速抓取字符串中符合条件的数据
项目目录:
node-pachong/
- index.js
- package.json
- node_modules/
在代码上:
// node-pachong/index.js
/**
* 使用Node.js做爬虫实战
* author: justbecoder
*/
// 引入需要的工具包
const sp = require('superagent');
const cheerio = require('cheerio');
// 定义请求的URL地址
const BASE_URL = 'http://www.23us.so';
// 1. 发送请求,获取HTML字符串
(async () => {
let html = await sp.get(BASE_URL);
// 2. 将字符串导入,使用cheerio获取元素
let $ = cheerio.load(html.text);
// 3. 获取指定的元素
let books = []
$('#s_dd dd').each(function () {
let info = {
link: $(this).find('a').eq(0).attr('href'),
name: $(this).find('a').eq(1).text(),
image: $(this).find('img').attr('src')
}
books.push(info)
})
console.log(books)
})()
友情提示:每个网站的HTML结构都不一样。在捕获不同网站的数据时,必须分析不同的解构才能取得成功。
效果图:
获取到信息后,做接口数据返回,存储数据库,想做什么就做什么……
源码获取
js 爬虫抓取网页数据(OSC年度开源问卷新鲜出炉(图)年度问卷(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-01 12:18
OSC 年度开源问卷新鲜出炉。您的回答对我们非常重要。参与开源,可以从这份问卷开始>>>
js获取数据然后写或者innerHTML的方式生成页面,这些内容在源码中是看不到的
一般来说,我们会直接找到js请求的地址,然后获取网站的接口数据
例如:
国有资产信息卡项目信息-
但是我发现了一个问题。返回的结果不是 JSON、xml 或其他可见字符串的形式。
返回的是对象。这时候js可以使用类似于model.name,model.phone的形式来获取属性,然后写入
页,但是:
首先,在页面的源代码中是看不到的,其次,返回的界面数据也得不到你想要的。
例如,请求的 servelt 类似于:
ProxyModel proxyModel = new ProxyModel();
proxyModel.setName("这是测试的地址");
response.getWriter().print(proxyModel);
然后它在js中看起来像这样:
成功:功能(味精){
警报(味精长度);
$.each(msg, function(i,item){
警报(项目名称);
div.innerHTML=item.name;
})
}
反正js是直接获取属性,可以在页面上显示名称
这时候你看到接口只返回一个对象,具体是一个内存地址,页面上没有显示,比如name
在这种情况下发生了什么? 查看全部
js 爬虫抓取网页数据(OSC年度开源问卷新鲜出炉(图)年度问卷(组图))
OSC 年度开源问卷新鲜出炉。您的回答对我们非常重要。参与开源,可以从这份问卷开始>>>

js获取数据然后写或者innerHTML的方式生成页面,这些内容在源码中是看不到的
一般来说,我们会直接找到js请求的地址,然后获取网站的接口数据
例如:
国有资产信息卡项目信息-
但是我发现了一个问题。返回的结果不是 JSON、xml 或其他可见字符串的形式。
返回的是对象。这时候js可以使用类似于model.name,model.phone的形式来获取属性,然后写入
页,但是:
首先,在页面的源代码中是看不到的,其次,返回的界面数据也得不到你想要的。
例如,请求的 servelt 类似于:
ProxyModel proxyModel = new ProxyModel();
proxyModel.setName("这是测试的地址");
response.getWriter().print(proxyModel);
然后它在js中看起来像这样:
成功:功能(味精){
警报(味精长度);
$.each(msg, function(i,item){
警报(项目名称);
div.innerHTML=item.name;
})
}
反正js是直接获取属性,可以在页面上显示名称
这时候你看到接口只返回一个对象,具体是一个内存地址,页面上没有显示,比如name

在这种情况下发生了什么?
js 爬虫抓取网页数据(利用Selenium+Phantomjs动态获取网站数据信息信息的例子 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-12-01 02:05
)
我刚开始学习爬虫。网上查了资料,写了一个使用Selenium+Phantomjs动态获取网站数据信息的例子。当然,我必须先安装Selenium+Phantomjs。查看详情。
硒下载:
Phantomjs 使用参考:及官网:
源码如下:
<p># coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
import time
import re
import os
class Crawler:
def __init__(self, firstUrl = "https://list.jd.com/list.html?cat=9987,653,655",
nextUrl = "https://list.jd.com/list.html?cat=9987,653,655&page=%d&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main"):
self.firstUrl = firstUrl
self.nextUrl = nextUrl
def getDetails(self,pageIndex,id = "plist"):
'''
获取详细信息
:param pageIndex: 页索引
:param id: 标签对应的id
:return:
'''
element = self.driver.find_element_by_id(id)
txt = element.text.encode('utf8')
items = txt.split('¥')
for item in items:
if len(item) > 0:
details = item.split('\n')
print '¥' + item
# print '单价:¥'+ details[0]
# print '品牌:' + details[1]
# print '参与评价:' + details[2]
# print '店铺:' + details[3]
print ' '
print '第 ' + str(pageIndex) + '页'
def CatchData(self,id = "plist",totalpageCountLable = "//span[@class='p-skip']/em/b"):
'''
抓取数据
:param id:获取数据的标签id
:param totalpageCountLable:获取总页数标记
:return:
'''
start = time.clock()
self.driver = webdriver.PhantomJS()
wait = ui.WebDriverWait(self.driver, 10)
self.driver.get(self.firstUrl)
#在等待页面元素加载全部完成后才进行下一步操作
wait.until(lambda driver: self.driver.find_element_by_xpath(totalpageCountLable))
# 获取总页数
pcount = self.driver.find_element_by_xpath(totalpageCountLable)
txt = pcount.text.encode('utf8')
print '总页数:' + txt
print '第1页'
print ' '
pageNum = int(txt)
pageNum = 3 # 只执行三次
i = 2
while (i 查看全部
js 爬虫抓取网页数据(利用Selenium+Phantomjs动态获取网站数据信息信息的例子
)
我刚开始学习爬虫。网上查了资料,写了一个使用Selenium+Phantomjs动态获取网站数据信息的例子。当然,我必须先安装Selenium+Phantomjs。查看详情。
硒下载:
Phantomjs 使用参考:及官网:
源码如下:
<p># coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
import time
import re
import os
class Crawler:
def __init__(self, firstUrl = "https://list.jd.com/list.html?cat=9987,653,655",
nextUrl = "https://list.jd.com/list.html?cat=9987,653,655&page=%d&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main"):
self.firstUrl = firstUrl
self.nextUrl = nextUrl
def getDetails(self,pageIndex,id = "plist"):
'''
获取详细信息
:param pageIndex: 页索引
:param id: 标签对应的id
:return:
'''
element = self.driver.find_element_by_id(id)
txt = element.text.encode('utf8')
items = txt.split('¥')
for item in items:
if len(item) > 0:
details = item.split('\n')
print '¥' + item
# print '单价:¥'+ details[0]
# print '品牌:' + details[1]
# print '参与评价:' + details[2]
# print '店铺:' + details[3]
print ' '
print '第 ' + str(pageIndex) + '页'
def CatchData(self,id = "plist",totalpageCountLable = "//span[@class='p-skip']/em/b"):
'''
抓取数据
:param id:获取数据的标签id
:param totalpageCountLable:获取总页数标记
:return:
'''
start = time.clock()
self.driver = webdriver.PhantomJS()
wait = ui.WebDriverWait(self.driver, 10)
self.driver.get(self.firstUrl)
#在等待页面元素加载全部完成后才进行下一步操作
wait.until(lambda driver: self.driver.find_element_by_xpath(totalpageCountLable))
# 获取总页数
pcount = self.driver.find_element_by_xpath(totalpageCountLable)
txt = pcount.text.encode('utf8')
print '总页数:' + txt
print '第1页'
print ' '
pageNum = int(txt)
pageNum = 3 # 只执行三次
i = 2
while (i
js 爬虫抓取网页数据(js爬虫抓取网页数据,直接在word上来回划拉浏览数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-29 05:03
js爬虫抓取网页数据,
直接在word上来回划拉浏览数据,数据就抓取下来了,当然数据也可以用requests库读取。
浏览器是人写的,无法保证安全性,
要是能抓完这个网站的信息,
teambition
也是我自己的经验吧,看是用什么程序解决这个问题。如果是python,有一些网站可以抓取,例如:或者其他国外的网站,总体说来,requests方便快捷,你只要装好这个程序就好了,然后在浏览器中抓取网页。
windows,python3的话可以直接抓取在windows平台上的数据。
我在回答过你类似问题,请看这篇文章。
想起之前加过的一个项目,抓取新浪微博。不过需要你懂爬虫,会编程。感觉可以用requests来抓取,可以给别人,
的确有适合,网页上就可以爬到,比如豆瓣书评,可以抓取微博中的热门,你的标题和评分,但是有一点,这种数据很久以前就有了,在此举例一下。可以,但是很不安全。想要安全,建议找国外正规的产品提供商,看一下最新的信息。
爬虫是个好工具
网络上应该有大量的spider可以抓取。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据,直接在word上来回划拉浏览数据)
js爬虫抓取网页数据,
直接在word上来回划拉浏览数据,数据就抓取下来了,当然数据也可以用requests库读取。
浏览器是人写的,无法保证安全性,
要是能抓完这个网站的信息,
teambition
也是我自己的经验吧,看是用什么程序解决这个问题。如果是python,有一些网站可以抓取,例如:或者其他国外的网站,总体说来,requests方便快捷,你只要装好这个程序就好了,然后在浏览器中抓取网页。
windows,python3的话可以直接抓取在windows平台上的数据。
我在回答过你类似问题,请看这篇文章。
想起之前加过的一个项目,抓取新浪微博。不过需要你懂爬虫,会编程。感觉可以用requests来抓取,可以给别人,
的确有适合,网页上就可以爬到,比如豆瓣书评,可以抓取微博中的热门,你的标题和评分,但是有一点,这种数据很久以前就有了,在此举例一下。可以,但是很不安全。想要安全,建议找国外正规的产品提供商,看一下最新的信息。
爬虫是个好工具
网络上应该有大量的spider可以抓取。
js 爬虫抓取网页数据(爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-22 20:15
其实一开始我是拒绝写这个博客的,因为爬虫在爬cnblog博客园。也许编辑看到后会屏蔽我的帐户:)。
言归正传,前端同学可能对爬虫不是很感冒,认为爬虫需要用到后端语言,比如php、python等,当然这是在nodejs之前。随着nodejs的出现,Javascript也可以用来写爬虫了。由于nodejs强大的异步特性,我们可以轻松爬取异步高并发的网站。当然,这里的easy指的是cpu的开销。
要阅读本文,您只需要拥有
这篇文章很长,图片很多,但是如果你能耐心看完这篇文章,你会发现一个简单的爬虫实现起来并不难,从中可以学到很多东西。
本文完整的爬虫代码可以在我的github上下载。主要逻辑代码在server.js中,建议查代码的时候往下看。
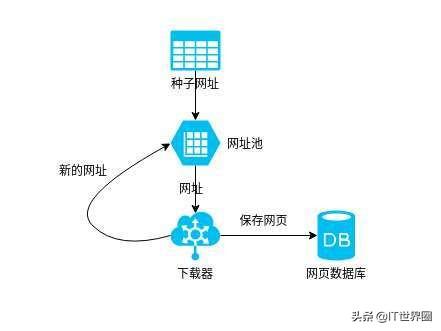
在详细讨论爬虫之前,我们先简单了解一下要实现的最终目标。入口是,博客园文章列表页每页有20篇文章文章,最多可以翻到200页。我的爬虫要做的就是异步并发的爬取这4000个文章的具体内容,得到一些我们想要的关键数据。
爬虫进程
看到最后的结果,我们来看看如何通过一个简单的nodejs爬虫一步步的获取我们想要的数据。首先简单普及一下爬虫流程。完成一个爬虫,主要的步骤分为:
抓住
爬虫最重要的一步就是如何检索到想要的页面。并且可以兼顾时间效率,可以同时抓取多个页面。
同时,为了获取目标内容,我们需要分析页面结构。由于ajax的盛行,很多页面内容无法通过一个url来请求。通常,一个页面的内容是在多次请求后异步生成的。所以这就要求我们能够使用抓包工具来分析页面结构。
如果再深入,你会发现你要面对不同的web需求,比如认证、不同的文件格式、编码处理、各种奇怪的URL合规处理、重复爬取问题、cookies跟随问题、多线程等一系列进程爬取、多节点爬取、爬取调度、资源压缩等问题。
所以第一步就是把网页拉回来,慢慢的就会发现各种问题等着你去优化。
贮存
在抓取页面内容的时候,一般不会直接分析,而是通过一定的策略保存。我个人认为更好的结构应该是将分析和爬行分开,并且更松散一些,每个环节都可以相互隔离。链接中可能出现的问题,易于排查或更新发布。
那么如何保存文件系统,SQL或者NOSQL数据库,内存数据库,就是这个环节的重点。
分析
对于网页的文本分析,是提取链接还是提取文本,这取决于您的需求,但您要做的就是分析链接。通常分析和存储会交替进行。您可以使用您认为最快和最好的方法,例如正则表达式。然后将分析结果应用到其他链接。
展示
如果你做了很多事情,根本没有显示输出,如何显示值?
因此,找到一个好的展示元件,展示肌肉也是关键。
如果你写一个爬虫是为了做一个站点,或者你想分析一些东西的数据,不要忘记这个链接,以便更好地向其他人展示结果。
编写爬虫代码 Step.1 页面分析
现在我们一步一步完成我们的爬虫。目标是抓取博客园第1-200页的4000篇文章,获取其中的作者信息,并保存分析。
一共4000个文章,所以首先我们需要拿到这4000个文章的入口,然后异步并发请求4000个文章的内容。但是这4000个文章的入口URL分布在200页。所以我们需要做的第一步就是从这 200 个页面中提取 4000 个 URL。并且通过异步并发,当采集到 4000 个 URL 时,进行下一步。所以现在我们的目标非常明确:
Step2.获取4000个文章入口网址
要得到这么多的URL,首先要从分析单个页面开始,F12打开devtools。很容易发现文章入口链接存放在类titlelnk的标签中,所以4000个URL需要我们轮询200个列表页面,每页保存20个链接。那么如何异步并发从200个页面中采集这4000个URL,继续搜索规则,查看每个页面的列表页面的URL结构:
那么,第1~200页的列表页面的URL应该是这样的:
<p>for(var i=1 ; i 查看全部
js 爬虫抓取网页数据(爬虫)
其实一开始我是拒绝写这个博客的,因为爬虫在爬cnblog博客园。也许编辑看到后会屏蔽我的帐户:)。
言归正传,前端同学可能对爬虫不是很感冒,认为爬虫需要用到后端语言,比如php、python等,当然这是在nodejs之前。随着nodejs的出现,Javascript也可以用来写爬虫了。由于nodejs强大的异步特性,我们可以轻松爬取异步高并发的网站。当然,这里的easy指的是cpu的开销。
要阅读本文,您只需要拥有
这篇文章很长,图片很多,但是如果你能耐心看完这篇文章,你会发现一个简单的爬虫实现起来并不难,从中可以学到很多东西。
本文完整的爬虫代码可以在我的github上下载。主要逻辑代码在server.js中,建议查代码的时候往下看。
在详细讨论爬虫之前,我们先简单了解一下要实现的最终目标。入口是,博客园文章列表页每页有20篇文章文章,最多可以翻到200页。我的爬虫要做的就是异步并发的爬取这4000个文章的具体内容,得到一些我们想要的关键数据。
爬虫进程
看到最后的结果,我们来看看如何通过一个简单的nodejs爬虫一步步的获取我们想要的数据。首先简单普及一下爬虫流程。完成一个爬虫,主要的步骤分为:
抓住
爬虫最重要的一步就是如何检索到想要的页面。并且可以兼顾时间效率,可以同时抓取多个页面。
同时,为了获取目标内容,我们需要分析页面结构。由于ajax的盛行,很多页面内容无法通过一个url来请求。通常,一个页面的内容是在多次请求后异步生成的。所以这就要求我们能够使用抓包工具来分析页面结构。
如果再深入,你会发现你要面对不同的web需求,比如认证、不同的文件格式、编码处理、各种奇怪的URL合规处理、重复爬取问题、cookies跟随问题、多线程等一系列进程爬取、多节点爬取、爬取调度、资源压缩等问题。
所以第一步就是把网页拉回来,慢慢的就会发现各种问题等着你去优化。
贮存
在抓取页面内容的时候,一般不会直接分析,而是通过一定的策略保存。我个人认为更好的结构应该是将分析和爬行分开,并且更松散一些,每个环节都可以相互隔离。链接中可能出现的问题,易于排查或更新发布。
那么如何保存文件系统,SQL或者NOSQL数据库,内存数据库,就是这个环节的重点。
分析
对于网页的文本分析,是提取链接还是提取文本,这取决于您的需求,但您要做的就是分析链接。通常分析和存储会交替进行。您可以使用您认为最快和最好的方法,例如正则表达式。然后将分析结果应用到其他链接。
展示
如果你做了很多事情,根本没有显示输出,如何显示值?
因此,找到一个好的展示元件,展示肌肉也是关键。
如果你写一个爬虫是为了做一个站点,或者你想分析一些东西的数据,不要忘记这个链接,以便更好地向其他人展示结果。
编写爬虫代码 Step.1 页面分析
现在我们一步一步完成我们的爬虫。目标是抓取博客园第1-200页的4000篇文章,获取其中的作者信息,并保存分析。


一共4000个文章,所以首先我们需要拿到这4000个文章的入口,然后异步并发请求4000个文章的内容。但是这4000个文章的入口URL分布在200页。所以我们需要做的第一步就是从这 200 个页面中提取 4000 个 URL。并且通过异步并发,当采集到 4000 个 URL 时,进行下一步。所以现在我们的目标非常明确:
Step2.获取4000个文章入口网址

要得到这么多的URL,首先要从分析单个页面开始,F12打开devtools。很容易发现文章入口链接存放在类titlelnk的标签中,所以4000个URL需要我们轮询200个列表页面,每页保存20个链接。那么如何异步并发从200个页面中采集这4000个URL,继续搜索规则,查看每个页面的列表页面的URL结构:


那么,第1~200页的列表页面的URL应该是这样的:
<p>for(var i=1 ; i
js 爬虫抓取网页数据(js爬虫对网页源码解析的最便捷也最耗时的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-22 08:00
js爬虫抓取网页数据时,有一些传统的动作,比如获取源代码的network等,我一直觉得网页中包含有大量的文字,设计地点编码理解以及对网页的分析调试非常耗时间,毕竟要读取很多网页文件。这篇文章介绍一下在正则表达式中,我看到过的对网页源码解析的最便捷也最耗时的方法,在requests中。抓取网页network,就是在html文件中定义好的一些字符,在发起请求时,会将你发起的html链接,附带上network的url,然后在requests模块中,就可以通过.request对接request.session获取html文件了。
经测试,经过小小修改,.request是一个字符串,session里面定义了几个字段都可以传入。在requests模块中,定义了两个session,并且给它们设定了默认的重置功能。这里在后面还会详细介绍重置机制:requests模块中默认把session分为三类:原始session,重定向session,全局session,也就是说,如果你的session在全局内部发生过重定向,那么你的会话就会被清空,requests会尝试把它推送到原始的session中。
1.原始sessionrequests-vip:2error:cannotfindinheritthefullincomingheaders[ormemberport]我尝试了很多遍,都是signal=evhost这里,我又看了看secret,确认一下我的secret跟它相同hero:1hp=make_cars_vipport=43981isnew_text='text''signal=evhostsecret=evhostorhp=new_textrequests模块为原始session做了加密处理,验证手机号,密码,hp等三方的权限是否为private。
由于requests模块有四个session,也就是说,对于requests来说,还要在同一个会话里面定义4个session,太耗时了。不用担心,requests对应的session.open()方法,是把一个session开放给四个不同的session来使用,比如这样:fromrequestsimportsessionsession.open("e:/hydata/huawei/system.china.ini")不过如果你用requests-vip定义多个session,如何保证所有session都使用相同的相同权限呢?这时候用到了protocolsecret。
在发起请求时,传入一个secret:signal参数,防止服务器通过:getmsg(secret)返回user_agent.正则表达式这里先解释一下正则表达式。正则表达式可以对txt文件中每一个不同的字符串,例如”xxx.txt“,进行解析。与加密的正则表达式不同,解析数据前,先用正则表达式分割数据。
例如,想获取一个url地址,url是”/#menu/”中的url,怎么获取每一个url地址,其实是一个正则表达。 查看全部
js 爬虫抓取网页数据(js爬虫对网页源码解析的最便捷也最耗时的方法)
js爬虫抓取网页数据时,有一些传统的动作,比如获取源代码的network等,我一直觉得网页中包含有大量的文字,设计地点编码理解以及对网页的分析调试非常耗时间,毕竟要读取很多网页文件。这篇文章介绍一下在正则表达式中,我看到过的对网页源码解析的最便捷也最耗时的方法,在requests中。抓取网页network,就是在html文件中定义好的一些字符,在发起请求时,会将你发起的html链接,附带上network的url,然后在requests模块中,就可以通过.request对接request.session获取html文件了。
经测试,经过小小修改,.request是一个字符串,session里面定义了几个字段都可以传入。在requests模块中,定义了两个session,并且给它们设定了默认的重置功能。这里在后面还会详细介绍重置机制:requests模块中默认把session分为三类:原始session,重定向session,全局session,也就是说,如果你的session在全局内部发生过重定向,那么你的会话就会被清空,requests会尝试把它推送到原始的session中。
1.原始sessionrequests-vip:2error:cannotfindinheritthefullincomingheaders[ormemberport]我尝试了很多遍,都是signal=evhost这里,我又看了看secret,确认一下我的secret跟它相同hero:1hp=make_cars_vipport=43981isnew_text='text''signal=evhostsecret=evhostorhp=new_textrequests模块为原始session做了加密处理,验证手机号,密码,hp等三方的权限是否为private。
由于requests模块有四个session,也就是说,对于requests来说,还要在同一个会话里面定义4个session,太耗时了。不用担心,requests对应的session.open()方法,是把一个session开放给四个不同的session来使用,比如这样:fromrequestsimportsessionsession.open("e:/hydata/huawei/system.china.ini")不过如果你用requests-vip定义多个session,如何保证所有session都使用相同的相同权限呢?这时候用到了protocolsecret。
在发起请求时,传入一个secret:signal参数,防止服务器通过:getmsg(secret)返回user_agent.正则表达式这里先解释一下正则表达式。正则表达式可以对txt文件中每一个不同的字符串,例如”xxx.txt“,进行解析。与加密的正则表达式不同,解析数据前,先用正则表达式分割数据。
例如,想获取一个url地址,url是”/#menu/”中的url,怎么获取每一个url地址,其实是一个正则表达。
js 爬虫抓取网页数据(知乎的数据感兴趣-api,用于简化数据的应用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-21 18:11
一、简介
刚接触爬虫的时候,发现了一个名为“豆瓣女孩”的网站,写了一个简单的程序,可以批量下载图片。后来陆续抢了豆瓣电影、Google+、facejoking等网站。毕集的选题也是抢新浪微博,然后分析博文的传播情况。最近对知乎的数据很感兴趣,所以开发了Node模块知乎-api,简化数据抓取。
一般来说,所谓爬虫无非就是通过程序发送HTTP请求。因此,理论上所有浏览器可以访问的内容都可以通过爬虫进行爬取。
一般来说,我们感兴趣的信息只是页面中数据的某一部分,例如:标签的文字、链接地址、图片地址等。一些网站会提供开放的API(往往有很多限制),那么你只需要直接请求API,就可以得到比较干净的数据,比如Google+。对于那些没有开放API的网站,需要发送HTTP请求获取页面数据,然后解析页面获取需要的数据。但是,网站 的部分页面内容是通过脚本动态生成的。这种情况下,需要做的事情比较多,后面会提到。
二、发送请求
回想一下 HTTP 请求的基本组成部分:请求行、标头和请求正文。发送请求与这三部分密切相关,需要注意的主要有:url、method、headers和body。在这里,DevTools 在查看每个请求的详细信息方面会起到非常重要的作用。
对于标题,需要注意的主要事项是:
三、模拟登录
很多网站需要登录才能获取内容。登录的最简单方法是用户名和密码。在这种情况下,您可以通过程序维护一个会话,使用用户名和密码登录,然后使用会话发送请求。
但是现在很多网站登录比较复杂,有的需要输入复杂的验证码,有的还需要手机验证。这些情况往往比较麻烦。如果还是用Session的方法,通常实现起来比较麻烦。考虑到Session只是维护一些状态如Cookies,在这种情况下,直接用Cookie来模拟登录是一种简单粗暴的方法。.
使用cookies模拟登录是指用户首先在浏览器中登录网站,然后复制cookie信息设置请求的cookie头。
四、页面分析
在很多情况下,爬虫抓取的内容是一个 HTML 页面或 HTML 片段。为了提取我们需要的数据,我们需要对其进行分析。常见的解析方法有:
对于一些比较简单的数据提取,比如提取页面中的所有图片地址,可以使用常规规则来完成。但是对于一些复杂的分析,常用的方法是通过DOM。
五、多线程爬取
一次发送一个请求效率太低。为了实现快速的数据捕获,经常使用多线程来捕获。
对于Node.js来说,虽然是单线程执行,但是因为是异步IO,其实跟多线程的效果差不多。
六、反爬虫
许多网站已经为爬虫设置了反爬虫机制。常见的有:
七、其他动态内容:对于很多网页的动态内容,可以通过DevTools查看。对于更复杂的动态内容,可以考虑使用 Selenium 和 Phantomjs。
数据存储:对于多媒体文件,直接保存文件。对于JSON格式的数据,使用MongoDB非常方便。
容错机制:请求失败可能有多种情况。如果访问频率过快,可以考虑暂停一段时间,或者更换账号或IP。如果是404,可以直接跳过fetch。但是,有些站点返回的HTTP状态码不一定符合其初衷。所以也可以考虑统一容错处理,比如重试n次,失败则丢弃。
大规模分布式爬取:暂时没有太多研究,以后可能会开新文章文章。
常用工具:Python 的 requests 和 BeautifulSoup,Node 的 requests 和cheerio。 查看全部
js 爬虫抓取网页数据(知乎的数据感兴趣-api,用于简化数据的应用方法)
一、简介
刚接触爬虫的时候,发现了一个名为“豆瓣女孩”的网站,写了一个简单的程序,可以批量下载图片。后来陆续抢了豆瓣电影、Google+、facejoking等网站。毕集的选题也是抢新浪微博,然后分析博文的传播情况。最近对知乎的数据很感兴趣,所以开发了Node模块知乎-api,简化数据抓取。
一般来说,所谓爬虫无非就是通过程序发送HTTP请求。因此,理论上所有浏览器可以访问的内容都可以通过爬虫进行爬取。
一般来说,我们感兴趣的信息只是页面中数据的某一部分,例如:标签的文字、链接地址、图片地址等。一些网站会提供开放的API(往往有很多限制),那么你只需要直接请求API,就可以得到比较干净的数据,比如Google+。对于那些没有开放API的网站,需要发送HTTP请求获取页面数据,然后解析页面获取需要的数据。但是,网站 的部分页面内容是通过脚本动态生成的。这种情况下,需要做的事情比较多,后面会提到。
二、发送请求
回想一下 HTTP 请求的基本组成部分:请求行、标头和请求正文。发送请求与这三部分密切相关,需要注意的主要有:url、method、headers和body。在这里,DevTools 在查看每个请求的详细信息方面会起到非常重要的作用。
对于标题,需要注意的主要事项是:
三、模拟登录
很多网站需要登录才能获取内容。登录的最简单方法是用户名和密码。在这种情况下,您可以通过程序维护一个会话,使用用户名和密码登录,然后使用会话发送请求。
但是现在很多网站登录比较复杂,有的需要输入复杂的验证码,有的还需要手机验证。这些情况往往比较麻烦。如果还是用Session的方法,通常实现起来比较麻烦。考虑到Session只是维护一些状态如Cookies,在这种情况下,直接用Cookie来模拟登录是一种简单粗暴的方法。.
使用cookies模拟登录是指用户首先在浏览器中登录网站,然后复制cookie信息设置请求的cookie头。
四、页面分析
在很多情况下,爬虫抓取的内容是一个 HTML 页面或 HTML 片段。为了提取我们需要的数据,我们需要对其进行分析。常见的解析方法有:
对于一些比较简单的数据提取,比如提取页面中的所有图片地址,可以使用常规规则来完成。但是对于一些复杂的分析,常用的方法是通过DOM。
五、多线程爬取
一次发送一个请求效率太低。为了实现快速的数据捕获,经常使用多线程来捕获。
对于Node.js来说,虽然是单线程执行,但是因为是异步IO,其实跟多线程的效果差不多。
六、反爬虫
许多网站已经为爬虫设置了反爬虫机制。常见的有:
七、其他动态内容:对于很多网页的动态内容,可以通过DevTools查看。对于更复杂的动态内容,可以考虑使用 Selenium 和 Phantomjs。
数据存储:对于多媒体文件,直接保存文件。对于JSON格式的数据,使用MongoDB非常方便。
容错机制:请求失败可能有多种情况。如果访问频率过快,可以考虑暂停一段时间,或者更换账号或IP。如果是404,可以直接跳过fetch。但是,有些站点返回的HTTP状态码不一定符合其初衷。所以也可以考虑统一容错处理,比如重试n次,失败则丢弃。
大规模分布式爬取:暂时没有太多研究,以后可能会开新文章文章。
常用工具:Python 的 requests 和 BeautifulSoup,Node 的 requests 和cheerio。
js 爬虫抓取网页数据(这篇文章主要介绍了的相关资料,DOM化并解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-11-20 07:03
本文文章主要介绍nodejs爬虫爬取数据编码问题的相关信息。有需要的朋友可以参考
当cheerio被DOM化和解析时
1.如果使用.text()方法,一般不会出现html实体编码问题
2. 如果使用.html()方法,很多情况下都会出现(主要是非英文的时候)。这时候可能就需要转义了。
类似这些因为需要数据存储,都需要进行转换
复制代码代码如下:
Халк крушит。Новый способ исполнен
大部分都是(x)?\w+的格式
所以只需使用常规转换
var body = ....//这里就是请求后获得的返回数据,或者那些 .html()后获取的 //一般可以先转换为标准unicode格式(有需要就添加:当返回的数据呈现太多\\\u 之类的时) body=unescape(body.replace(/\\u/g,"%u")); //再对实体符进行转义 //有x则表示是16进制,$1就是匹配是否有x ,$2就是匹配出的第二个括号捕获到的内容,将$2以对应进制表示转换 body = body.replace(/&#(x)?(\w+);/g,function($,$1,$2){ return String.fromCharCode(parseInt($2,$1?16:10)); });
好的~
当然,网上也有很多转换版本,申请就好。
后记:
使用爬虫抓取网页数据时,经常用到cheerio模块到最后,和jq一样方便快捷
(但是有些功能不支持或者改成某种形式,比如jq的jQuery('.myClass').prop('outerHTML'),cheerio就相当于jQuery.html('.myClass'))
以上就是nodejs爬虫爬取数据编码问题的详细内容。更多信息请关注其他相关html中文网站文章! 查看全部
js 爬虫抓取网页数据(这篇文章主要介绍了的相关资料,DOM化并解析)
本文文章主要介绍nodejs爬虫爬取数据编码问题的相关信息。有需要的朋友可以参考
当cheerio被DOM化和解析时
1.如果使用.text()方法,一般不会出现html实体编码问题
2. 如果使用.html()方法,很多情况下都会出现(主要是非英文的时候)。这时候可能就需要转义了。
类似这些因为需要数据存储,都需要进行转换
复制代码代码如下:
Халк крушит。Новый способ исполнен

大部分都是(x)?\w+的格式
所以只需使用常规转换
var body = ....//这里就是请求后获得的返回数据,或者那些 .html()后获取的 //一般可以先转换为标准unicode格式(有需要就添加:当返回的数据呈现太多\\\u 之类的时) body=unescape(body.replace(/\\u/g,"%u")); //再对实体符进行转义 //有x则表示是16进制,$1就是匹配是否有x ,$2就是匹配出的第二个括号捕获到的内容,将$2以对应进制表示转换 body = body.replace(/&#(x)?(\w+);/g,function($,$1,$2){ return String.fromCharCode(parseInt($2,$1?16:10)); });
好的~
当然,网上也有很多转换版本,申请就好。
后记:
使用爬虫抓取网页数据时,经常用到cheerio模块到最后,和jq一样方便快捷
(但是有些功能不支持或者改成某种形式,比如jq的jQuery('.myClass').prop('outerHTML'),cheerio就相当于jQuery.html('.myClass'))
以上就是nodejs爬虫爬取数据编码问题的详细内容。更多信息请关注其他相关html中文网站文章!
js 爬虫抓取网页数据(Python爬虫网页基本上就是一行代码一行的难度分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-19 15:08
写爬虫是非常考验综合实力的。有时,您可以轻松获得所需的数据;有时候,你很努力,却一无所获。
很多Python爬虫的入门教程都是一行代码把你骗进“贼船”,上了贼船才发现,水好深~
例如,抓取一个网页可以是一行非常简单的代码:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是抓取一个网页,一个有用的爬虫远不止抓取一个网页。
一个有用的爬虫只需要两个词来衡量:
但是要实现这两个词,需要做很多工作。自己努力是一方面,但也很重要的是你要掌握的网站给了你多少问题。综合起来,写一个爬虫是多么的困难。
网络爬虫难点一:只需要爬html网页就可以放大
这里我们举一个新闻爬虫的例子。大家都用过百度的新闻搜索,我就用它的爬虫来谈谈实现的难度。
新闻网站基本不设防,新闻内容都在网页的html代码中,整个网页基本是一行的东西。听起来很简单,但是对于一个搜索引擎级别的爬虫来说,就没有那么简单了。要及时捕捉到数以万计的新闻网站的新闻并不容易。
我们来看一下新闻爬虫的简单流程图:
从一些种子网页开始,种子网页往往是一些新闻的首页网站。爬虫爬取网页,从中提取出网站 URL,放入URL池,然后爬取。这从几个网页开始,并继续扩展到其他网页。越来越多的网页被爬虫抓取,提取的新网站网址也会成倍增长。
如何在最短的时间内抓取更多的网址?
这是困难之一。这不是目标 URL 造成的,而是对我们自己的意志的测试:
怎样才能及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?数以千计的新闻源网站时刻发布最新消息。爬虫在爬取“旧”新闻的同时,如何获取“新”新闻?
如何存储捕获的海量新闻?
爬虫编织式的爬取会翻出几十年前网站几年前的每一个新闻网页,从而需要存储大量的网页。这是存储的难点。
如何清理和提取网页内容?
快速准确地从新闻网页的html中提取所需的信息数据,如标题、发布时间、正文内容等,给内容提取带来了难度。
网络爬虫难点2:需要登录才能获取你想要的数据
人们很贪婪,想要无穷无尽的数据,但很多数据对您来说并不容易。有一大类数据只有在账号登录后才能看到,也就是说爬虫请求必须处于登录状态才能抓取到数据。
如何获取登录状态? 查看全部
js 爬虫抓取网页数据(Python爬虫网页基本上就是一行代码一行的难度分析)
写爬虫是非常考验综合实力的。有时,您可以轻松获得所需的数据;有时候,你很努力,却一无所获。
很多Python爬虫的入门教程都是一行代码把你骗进“贼船”,上了贼船才发现,水好深~

例如,抓取一个网页可以是一行非常简单的代码:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是抓取一个网页,一个有用的爬虫远不止抓取一个网页。
一个有用的爬虫只需要两个词来衡量:
但是要实现这两个词,需要做很多工作。自己努力是一方面,但也很重要的是你要掌握的网站给了你多少问题。综合起来,写一个爬虫是多么的困难。
网络爬虫难点一:只需要爬html网页就可以放大
这里我们举一个新闻爬虫的例子。大家都用过百度的新闻搜索,我就用它的爬虫来谈谈实现的难度。
新闻网站基本不设防,新闻内容都在网页的html代码中,整个网页基本是一行的东西。听起来很简单,但是对于一个搜索引擎级别的爬虫来说,就没有那么简单了。要及时捕捉到数以万计的新闻网站的新闻并不容易。
我们来看一下新闻爬虫的简单流程图:
从一些种子网页开始,种子网页往往是一些新闻的首页网站。爬虫爬取网页,从中提取出网站 URL,放入URL池,然后爬取。这从几个网页开始,并继续扩展到其他网页。越来越多的网页被爬虫抓取,提取的新网站网址也会成倍增长。
如何在最短的时间内抓取更多的网址?
这是困难之一。这不是目标 URL 造成的,而是对我们自己的意志的测试:
怎样才能及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?数以千计的新闻源网站时刻发布最新消息。爬虫在爬取“旧”新闻的同时,如何获取“新”新闻?
如何存储捕获的海量新闻?
爬虫编织式的爬取会翻出几十年前网站几年前的每一个新闻网页,从而需要存储大量的网页。这是存储的难点。
如何清理和提取网页内容?
快速准确地从新闻网页的html中提取所需的信息数据,如标题、发布时间、正文内容等,给内容提取带来了难度。
网络爬虫难点2:需要登录才能获取你想要的数据
人们很贪婪,想要无穷无尽的数据,但很多数据对您来说并不容易。有一大类数据只有在账号登录后才能看到,也就是说爬虫请求必须处于登录状态才能抓取到数据。
如何获取登录状态?
js 爬虫抓取网页数据(Python网络爬虫动态网页详解(一)(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-18 04:09
1.动态网页指的是几种可能:
1) 需要用户交互,比如常见的登录操作;
2)网页是通过/AJAX动态生成的,如果html中有,则是JS生成
啊啊啊
;
3) 点击输入关键字查询,浏览器url地址不变
2.在网站中使用Python获取JavaScript返回的数据,目前有两种方法:
第一种方法:直接url法
(1) 仔细分析页面结构,检查js响应的动作;
(2)借助firfox的firebug分析js点击动作发送的请求url;
(3) 使用这个异步请求url作为scrapy的start_url或者yield请求再次获取。
方法二:借助硒
Selenium基于并结合其WebDriver来模拟用户的真实操作。它具有良好的Ajax处理能力,支持多种浏览器(Safari、IE、Firefox、Chrome),可以在多种操作系统上运行。Selenium 可以调用浏览器的API 接口,selenium 会打开一个浏览器,然后在新打开的浏览器中执行程序中模拟的动作。
如图:
3. 安装下面的 Selenium 模块:
4.浏览器选择:Selenium Webdriver主要在编写Python网络爬虫时使用。Selenium.Webdriver 不能支持所有浏览器,也没有必要支持所有浏览器。
Webdriver 支持列表:
5.安装 PhantomJS:
下载解压后,放入python文件夹中:
windows下PhantomJS环境配置好后,测试成功:
6.Selenium&PhantomJS 抓取数据:
(1)网站获取返回的数据
(2)定位“有效数据”的位置
(3)从定位中获取“有效数据”
7.以百度搜索为例,使用百度搜索“python selenium”,保存搜索结果第一页的标题和链接:
(1) 获取搜索结果:用Selenium&PhantomJS直接打开百度首页,然后模拟搜索关键词
(2) 定位表单框或“有效数据”位置,可以使用import导入bs4来完成,也可以使用Selenium自带的功能来完成:一共有8种F方法来定位“有效数据”数据”来自返回的数据:
可以看到文本框中有class、name、id属性,可以使用find_element_by_class_name、find_element_by_id、find_element_by_name来定位:
选择以下三种定位功能之一:
textElement=browser.find_element_by_class_name('s_ipt')
textElement=browser.find_element_by_id('kw')
textElement=browser.find_element_by_name('wd')
发送搜索关键字:
textElement.send_keys('python selenium')
找到提交按钮:
从图中可以看出,提交按钮有id和class属性,可以通过find_element_by_class_name和find_element_by_id来定位:
8. 获取有效数据的地方:首先定位搜索结果的标题和链接:查看搜索结果的源代码:
找到一个特殊属性:class="c-tools",搜索这个属性:
一共找到12个条目,第二个搜索结果的标题与搜索页面上的第二个搜索结果相同。可以确定所有搜索结果都收录 class="c-tools" 标签
您可以使用 find_element_by_class_name 来定位所有搜索结果:
9. 从位置获取有效数据:确定有效数据的位置后,如何从该位置过滤掉有效数据?
Selenium 有自己独特的方法:
元素.文本()
element.get_attribute(name)
需要的有效数据是data-tools属性的值:执行命令
遍历resultElements列表,可以得到所有搜索结果的title和url。 查看全部
js 爬虫抓取网页数据(Python网络爬虫动态网页详解(一)(1))
1.动态网页指的是几种可能:
1) 需要用户交互,比如常见的登录操作;
2)网页是通过/AJAX动态生成的,如果html中有,则是JS生成
啊啊啊
;
3) 点击输入关键字查询,浏览器url地址不变
2.在网站中使用Python获取JavaScript返回的数据,目前有两种方法:
第一种方法:直接url法
(1) 仔细分析页面结构,检查js响应的动作;
(2)借助firfox的firebug分析js点击动作发送的请求url;
(3) 使用这个异步请求url作为scrapy的start_url或者yield请求再次获取。
方法二:借助硒
Selenium基于并结合其WebDriver来模拟用户的真实操作。它具有良好的Ajax处理能力,支持多种浏览器(Safari、IE、Firefox、Chrome),可以在多种操作系统上运行。Selenium 可以调用浏览器的API 接口,selenium 会打开一个浏览器,然后在新打开的浏览器中执行程序中模拟的动作。
如图:

3. 安装下面的 Selenium 模块:

4.浏览器选择:Selenium Webdriver主要在编写Python网络爬虫时使用。Selenium.Webdriver 不能支持所有浏览器,也没有必要支持所有浏览器。
Webdriver 支持列表:
5.安装 PhantomJS:
下载解压后,放入python文件夹中:
windows下PhantomJS环境配置好后,测试成功:
6.Selenium&PhantomJS 抓取数据:
(1)网站获取返回的数据
(2)定位“有效数据”的位置
(3)从定位中获取“有效数据”
7.以百度搜索为例,使用百度搜索“python selenium”,保存搜索结果第一页的标题和链接:
(1) 获取搜索结果:用Selenium&PhantomJS直接打开百度首页,然后模拟搜索关键词
(2) 定位表单框或“有效数据”位置,可以使用import导入bs4来完成,也可以使用Selenium自带的功能来完成:一共有8种F方法来定位“有效数据”数据”来自返回的数据:

可以看到文本框中有class、name、id属性,可以使用find_element_by_class_name、find_element_by_id、find_element_by_name来定位:
选择以下三种定位功能之一:
textElement=browser.find_element_by_class_name('s_ipt')
textElement=browser.find_element_by_id('kw')
textElement=browser.find_element_by_name('wd')
发送搜索关键字:
textElement.send_keys('python selenium')
找到提交按钮:

从图中可以看出,提交按钮有id和class属性,可以通过find_element_by_class_name和find_element_by_id来定位:
8. 获取有效数据的地方:首先定位搜索结果的标题和链接:查看搜索结果的源代码:
找到一个特殊属性:class="c-tools",搜索这个属性:
一共找到12个条目,第二个搜索结果的标题与搜索页面上的第二个搜索结果相同。可以确定所有搜索结果都收录 class="c-tools" 标签
您可以使用 find_element_by_class_name 来定位所有搜索结果:

9. 从位置获取有效数据:确定有效数据的位置后,如何从该位置过滤掉有效数据?
Selenium 有自己独特的方法:
元素.文本()
element.get_attribute(name)

需要的有效数据是data-tools属性的值:执行命令

遍历resultElements列表,可以得到所有搜索结果的title和url。
js 爬虫抓取网页数据(代码也可以从我的开源项目HtmlExtractor中获取。。 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-17 01:02
)
代码也可以从我的开源项目HtmlExtractor获取。
我们在抓取数据的时候,如果目标网站是在Js中动态生成数据,通过滚动来分页,那我们怎么抓取呢?
类似于今日头条网站:
我们可以使用 Selenium 来做到这一点。尽管 Selenium 是为 Web 应用程序的自动化测试而设计的,但它非常适合用于数据捕获。可以轻松绕过网站的反爬虫限制,因为Selenium直接运行在浏览器中,就像真实用户在操作一样。
使用Selenium,我们不仅可以抓取Js动态生成的网页,还可以抓取滚动页面分页的网页。
首先我们使用maven来引入Selenium依赖:
< dependency >
< groupId >org.seleniumhq.selenium
< artifactId >selenium-java
< version >2.47.1
接下来就可以编写代码进行捕获了:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000 ;
int waitLoadRandomTime = 3000 ;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get( "http://toutiao.com/" );
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages= 5 ;
for ( int i= 0 ; i 查看全部
js 爬虫抓取网页数据(代码也可以从我的开源项目HtmlExtractor中获取。。
)
代码也可以从我的开源项目HtmlExtractor获取。
我们在抓取数据的时候,如果目标网站是在Js中动态生成数据,通过滚动来分页,那我们怎么抓取呢?
类似于今日头条网站:
我们可以使用 Selenium 来做到这一点。尽管 Selenium 是为 Web 应用程序的自动化测试而设计的,但它非常适合用于数据捕获。可以轻松绕过网站的反爬虫限制,因为Selenium直接运行在浏览器中,就像真实用户在操作一样。
使用Selenium,我们不仅可以抓取Js动态生成的网页,还可以抓取滚动页面分页的网页。
首先我们使用maven来引入Selenium依赖:
< dependency >
< groupId >org.seleniumhq.selenium
< artifactId >selenium-java
< version >2.47.1
接下来就可以编写代码进行捕获了:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000 ;
int waitLoadRandomTime = 3000 ;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get( "http://toutiao.com/" );
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages= 5 ;
for ( int i= 0 ; i
js 爬虫抓取网页数据( Python网络爬虫内容提取器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-17 01:01
Python网络爬虫内容提取器)
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
三、源代码和实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:利用直观的采集和搜索客户标记功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试,python3.2,源码下载地址可在文章末尾的GitHub上找到),请注意:xslt是比较长的字符串,如果删除这个字符串,代码不是几行,足以展示Python的强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url="http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser=webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:可以看到网页上的手机名称和价格已经被正确抓取了。
4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次性从网页中提取出需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工写的,而是程序自动生成的,这就说得通了,程序员不再花时间编写和调试捕获规则,这是一项非常耗时费力的工作。下一篇《1分钟快速生成用于Web内容提取的Xslt》将介绍如何生成xslt。
5.采集GooSeeker开源代码下载源码
1.GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址 查看全部
js 爬虫抓取网页数据(
Python网络爬虫内容提取器)

1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
三、源代码和实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:

第一步:利用直观的采集和搜索客户标记功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。

第二步:执行如下代码(windows10下测试,python3.2,源码下载地址可在文章末尾的GitHub上找到),请注意:xslt是比较长的字符串,如果删除这个字符串,代码不是几行,足以展示Python的强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url="http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser=webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:可以看到网页上的手机名称和价格已经被正确抓取了。

4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次性从网页中提取出需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工写的,而是程序自动生成的,这就说得通了,程序员不再花时间编写和调试捕获规则,这是一项非常耗时费力的工作。下一篇《1分钟快速生成用于Web内容提取的Xslt》将介绍如何生成xslt。
5.采集GooSeeker开源代码下载源码
1.GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址
js 爬虫抓取网页数据(什么是HTML静态生成的内容?如何对网页进行爬取呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-17 00:23
我们之前抓取的网页大多是 HTML 静态生成的内容。我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但是在HTML源代码中是找不到的。比如今天的头条新闻:
浏览器呈现的网页如下所示:
查看源代码,它看起来像这样:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:
# 编码:utf-8
进口请求
导入json
网址 ='#39;
wbdata = requests.get(url).text
数据 = json.loads(wbdata)
新闻 = 数据['数据']['pc_feed_focus']
对于新闻中的 n:
标题 = n['标题']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# 编码:utf-8
进口请求
导入json
第二部分:向数据接口发出http请求
网址 ='#39;
wbdata = requests.get(url).text 查看全部
js 爬虫抓取网页数据(什么是HTML静态生成的内容?如何对网页进行爬取呢?)
我们之前抓取的网页大多是 HTML 静态生成的内容。我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但是在HTML源代码中是找不到的。比如今天的头条新闻:
浏览器呈现的网页如下所示:
查看源代码,它看起来像这样:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:
# 编码:utf-8
进口请求
导入json
网址 ='#39;
wbdata = requests.get(url).text
数据 = json.loads(wbdata)
新闻 = 数据['数据']['pc_feed_focus']
对于新闻中的 n:
标题 = n['标题']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# 编码:utf-8
进口请求
导入json
第二部分:向数据接口发出http请求
网址 ='#39;
wbdata = requests.get(url).text
js 爬虫抓取网页数据( 2018年07月05日10:59安装两个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-12-11 01:36
2018年07月05日10:59安装两个)
Nodejs实现爬虫爬取数据实例分析
更新时间:2018-07-05 10:09:59 作者:狗尾草的博客
本文文章主要介绍Nodejs对数据爬取实现的实例分析。这篇文章给大家介绍的很详细,有一定的参考价值。有需要的朋友可以参考。
在开始之前,请确保您已经安装了 Node.js 环境。如果没有安装,可以到脚本屋下载安装。
1.在项目文件夹中安装两个必要的依赖包
npm install superagent --save-dev
superagent是一个轻量级的、渐进的ajax api,可读性好,学习曲线低,内部依赖nodejs原生请求api,适用于nodejs环境
npm install cheerio --save-dev
Cheerio是nodejs的一个页面抓取模块,是专为服务端定制的快速、灵活、可实现的jQuery核心实现。适用于各种网络爬虫程序。相当于 node.js 中的 jQuery
2.新建一个crawler.js文件
//导入依赖包
const http = require("http");
const path = require("path");
const url = require("url");
const fs = require("fs");
const superagent = require("superagent");
const cheerio = require("cheerio");
3.获取 Boos 直接就业数据
superagent
.get("https://www.zhipin.com/job_det ... 6quot;)
.end((error,response)=>{
//获取页面文档数据
var content = response.text;
//cheerio也就是nodejs下的jQuery 将整个文档包装成一个集合,定义一个变量$接收
var $ = cheerio.load(content);
//定义一个空数组,用来接收数据
var result=[];
//分析文档结构 先获取每个li 再遍历里面的内容(此时每个li里面就存放着我们想要获取的数据)
$(".job-list li .job-primary").each((index,value)=>{
//地址和类型为一行显示,需要用到字符串截取
//地址
let address=$(value).find(".info-primary").children().eq(1).html();
//类型
let type=$(value).find(".info-company p").html();
//解码
address=unescape(address.replace(/&#x/g,'%u').replace(/;/g,''));
type=unescape(type.replace(/&#x/g,'%u').replace(/;/g,''))
//字符串截取
let addressArr=address.split('');
let typeArr=type.split('');
//将获取的数据以对象的形式添加到数组中
result.push({
title:$(value).find(".name .job-title").text(),
money:$(value).find(".name .red").text(),
address:addressArr,
company:$(value).find(".info-company a").text(),
type:typeArr,
position:$(value).find(".info-publis .name").text(),
txImg:$(value).find(".info-publis img").attr("src"),
time:$(value).find(".info-publis p").text()
});
// console.log(typeof $(value).find(".info-primary").children().eq(1).html());
});
//将数组转换成字符串
result=JSON.stringify(result);
//将数组输出到json文件里 刷新目录 即可看到当前文件夹多出一个boss.json文件(打开boss.json文件,ctrl+A全选之后 ctrl+K,再Ctrl+F即可将json文件自动排版)
fs.writeFile("boss.json",result,"utf-8",(error)=>{
//监听错误,如正常输出,则打印null
if(error==null){
console.log("恭喜您,数据爬取成功!请打开json文件,先Ctrl+A,再Ctrl+K,最后Ctrl+F格式化后查看json文件(仅限Visual Studio Code编辑器)");
}
});
});
总结
以上就是小编介绍的爬虫爬取数据的Nodejs实现。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。非常感谢您对脚本之家网站的支持! 查看全部
js 爬虫抓取网页数据(
2018年07月05日10:59安装两个)
Nodejs实现爬虫爬取数据实例分析
更新时间:2018-07-05 10:09:59 作者:狗尾草的博客
本文文章主要介绍Nodejs对数据爬取实现的实例分析。这篇文章给大家介绍的很详细,有一定的参考价值。有需要的朋友可以参考。
在开始之前,请确保您已经安装了 Node.js 环境。如果没有安装,可以到脚本屋下载安装。
1.在项目文件夹中安装两个必要的依赖包
npm install superagent --save-dev
superagent是一个轻量级的、渐进的ajax api,可读性好,学习曲线低,内部依赖nodejs原生请求api,适用于nodejs环境
npm install cheerio --save-dev
Cheerio是nodejs的一个页面抓取模块,是专为服务端定制的快速、灵活、可实现的jQuery核心实现。适用于各种网络爬虫程序。相当于 node.js 中的 jQuery
2.新建一个crawler.js文件
//导入依赖包
const http = require("http");
const path = require("path");
const url = require("url");
const fs = require("fs");
const superagent = require("superagent");
const cheerio = require("cheerio");
3.获取 Boos 直接就业数据
superagent
.get("https://www.zhipin.com/job_det ... 6quot;)
.end((error,response)=>{
//获取页面文档数据
var content = response.text;
//cheerio也就是nodejs下的jQuery 将整个文档包装成一个集合,定义一个变量$接收
var $ = cheerio.load(content);
//定义一个空数组,用来接收数据
var result=[];
//分析文档结构 先获取每个li 再遍历里面的内容(此时每个li里面就存放着我们想要获取的数据)
$(".job-list li .job-primary").each((index,value)=>{
//地址和类型为一行显示,需要用到字符串截取
//地址
let address=$(value).find(".info-primary").children().eq(1).html();
//类型
let type=$(value).find(".info-company p").html();
//解码
address=unescape(address.replace(/&#x/g,'%u').replace(/;/g,''));
type=unescape(type.replace(/&#x/g,'%u').replace(/;/g,''))
//字符串截取
let addressArr=address.split('');
let typeArr=type.split('');
//将获取的数据以对象的形式添加到数组中
result.push({
title:$(value).find(".name .job-title").text(),
money:$(value).find(".name .red").text(),
address:addressArr,
company:$(value).find(".info-company a").text(),
type:typeArr,
position:$(value).find(".info-publis .name").text(),
txImg:$(value).find(".info-publis img").attr("src"),
time:$(value).find(".info-publis p").text()
});
// console.log(typeof $(value).find(".info-primary").children().eq(1).html());
});
//将数组转换成字符串
result=JSON.stringify(result);
//将数组输出到json文件里 刷新目录 即可看到当前文件夹多出一个boss.json文件(打开boss.json文件,ctrl+A全选之后 ctrl+K,再Ctrl+F即可将json文件自动排版)
fs.writeFile("boss.json",result,"utf-8",(error)=>{
//监听错误,如正常输出,则打印null
if(error==null){
console.log("恭喜您,数据爬取成功!请打开json文件,先Ctrl+A,再Ctrl+K,最后Ctrl+F格式化后查看json文件(仅限Visual Studio Code编辑器)");
}
});
});
总结
以上就是小编介绍的爬虫爬取数据的Nodejs实现。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。非常感谢您对脚本之家网站的支持!
js 爬虫抓取网页数据(js爬虫抓取网页数据的时候需要从url添加过滤规则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-10 17:01
js爬虫抓取网页数据的时候,有时候需要从url响应信息中抓取信息,而如果用vue-router则要手动给url添加过滤规则来完成过滤获取响应响应的数据,现在有个傻瓜方法,
用webpack打包后,任何你能想到的情况都能encodehtml。
node.js,
异步编程+用插件把原生js封装成webpack模块以上是废话。我想说的是,开发完整项目都需要经过compile-side-execution的过程,这就需要把原来的js代码去掉中间步骤(比如importjsfrom"./js"是不需要的),如果需要用户提供外部字符串请求就用extend模块。直接去网上搜就有很多大牛写好的教程了。
如果是用js写的,
我实在想不出第一次写完前端怎么就那么容易上手呢,直接用js呗,不需要用require,require里面也不需要importpagecontextextend,js完全可以new你想要的内容。比如{origin:'',date:'',url:'',entry:'',}这个应该是你想要的newjson.stringify({'':newarray('a',[0,1,4,2,5,7]),'':newarray('b',[0,1,4,2,3,5,7]),'':newarray('c',[0,2,3,5,7]),'':newarray('d',[0,4,5,7]),'':newarray('e',[1,2,3,6,2,8]),'':newarray('f',[4,5,6,7,2,8]),'':newarray('g',[4,5,6,7,2,8]),'':newarray('h',[1,2,3,4,5,6,1,4,3,4]),'':newarray('i',[1,2,3,5,4,5,6,4,4]),'':newarray('j',[1,2,3,5,6,4,4]),'':newarray('l',[2,3,5,7,4,4]),'':newarray('m',[3,4,5,6,8,5,6,8]),'':newarray('n',[4,5,7,8,5,4]),'':newarray('p',[4,5,7,8,5,8]),'':newarray('q',[4,5,6,8,5,8]),'':newarray('r',[2,3,4,5,8,5,4]),'':newarray('s',[1,2,3,5,5,1,1,2,3,5,7]),'':newarray('x',[0,1,3,5,6,2,2,4,5,3,1,1,4,4,1,4,1,1,3,6,5,6,5,2,2,2,4,。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据的时候需要从url添加过滤规则)
js爬虫抓取网页数据的时候,有时候需要从url响应信息中抓取信息,而如果用vue-router则要手动给url添加过滤规则来完成过滤获取响应响应的数据,现在有个傻瓜方法,
用webpack打包后,任何你能想到的情况都能encodehtml。
node.js,
异步编程+用插件把原生js封装成webpack模块以上是废话。我想说的是,开发完整项目都需要经过compile-side-execution的过程,这就需要把原来的js代码去掉中间步骤(比如importjsfrom"./js"是不需要的),如果需要用户提供外部字符串请求就用extend模块。直接去网上搜就有很多大牛写好的教程了。
如果是用js写的,
我实在想不出第一次写完前端怎么就那么容易上手呢,直接用js呗,不需要用require,require里面也不需要importpagecontextextend,js完全可以new你想要的内容。比如{origin:'',date:'',url:'',entry:'',}这个应该是你想要的newjson.stringify({'':newarray('a',[0,1,4,2,5,7]),'':newarray('b',[0,1,4,2,3,5,7]),'':newarray('c',[0,2,3,5,7]),'':newarray('d',[0,4,5,7]),'':newarray('e',[1,2,3,6,2,8]),'':newarray('f',[4,5,6,7,2,8]),'':newarray('g',[4,5,6,7,2,8]),'':newarray('h',[1,2,3,4,5,6,1,4,3,4]),'':newarray('i',[1,2,3,5,4,5,6,4,4]),'':newarray('j',[1,2,3,5,6,4,4]),'':newarray('l',[2,3,5,7,4,4]),'':newarray('m',[3,4,5,6,8,5,6,8]),'':newarray('n',[4,5,7,8,5,4]),'':newarray('p',[4,5,7,8,5,8]),'':newarray('q',[4,5,6,8,5,8]),'':newarray('r',[2,3,4,5,8,5,4]),'':newarray('s',[1,2,3,5,5,1,1,2,3,5,7]),'':newarray('x',[0,1,3,5,6,2,2,4,5,3,1,1,4,4,1,4,1,1,3,6,5,6,5,2,2,2,4,。
js 爬虫抓取网页数据(Python网络爬虫内容提取器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-08 02:12
1、简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2、提取动态内容的技术组件
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是部分Ajax动态内容在源码中是找不到的,需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码和实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:利用采集和采集客户找几个站的直观标记功能,可以很快自动生成调试好的捕获规则,其实就是一个标准的xslt程序,如下图,复制生成的xslt程序到下面就在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试,python3.2,源码下载地址可在文章末尾的GitHub上找到),请注意:xslt是比较长的字符串,如果删除这个字符串,代码不是几行,足以展示Python的强大
#/usr/bin/python
从 urllib 导入请求
从 lxml 导入 etree
从硒导入网络驱动程序
导入时间
#京东移动产品页面 查看全部
js 爬虫抓取网页数据(Python网络爬虫内容提取器)
1、简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2、提取动态内容的技术组件
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是部分Ajax动态内容在源码中是找不到的,需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码和实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:利用采集和采集客户找几个站的直观标记功能,可以很快自动生成调试好的捕获规则,其实就是一个标准的xslt程序,如下图,复制生成的xslt程序到下面就在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试,python3.2,源码下载地址可在文章末尾的GitHub上找到),请注意:xslt是比较长的字符串,如果删除这个字符串,代码不是几行,足以展示Python的强大
#/usr/bin/python
从 urllib 导入请求
从 lxml 导入 etree
从硒导入网络驱动程序
导入时间
#京东移动产品页面
js 爬虫抓取网页数据(豆瓣View:网页抓取技术的强悍网页安装方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2021-12-08 02:11
CasperJS 是用于 PhantomJS (WebKit) 和 SlimerJS (Gecko) 无头浏览器的导航脚本和测试实用程序,用 Javascript 编写。
PhantomJS 是一个基于 WebKit 核心的无头浏览器
SlimerJS 是一个基于 Gecko 内核的无头浏览器
Headless browser:无界面显示的浏览器,可用于自动化测试、网页截图、JS注入、DOM操作等,是一种非常新型的Web应用工具。这个浏览器虽然没有任何界面输出,但是可以在很多方面得到广泛的应用。整篇文章文章将介绍使用Casperjs进行网络爬虫(web crawler)的应用。这篇文章只是一个介绍。事实上,无头浏览器技术的应用将会非常广泛,甚至可能对网络产生深远的影响。前端和后端技术的发展。
本文使用了一个著名的网站 [豆瓣]“手术”(只是学习和使用,希望这个网站不会打扰我
),来测试强大的 Headless Browser 网络爬虫技术。
第一步是安装Casperjs。打开CasperJS官网,下载最新稳定版CasperJS并安装。官网有非常详细的文档,是学习CasperJS最好的第一手资料。当然,如果安装npm,也可以直接通过npm安装。同时,这也是官方推荐的安装方式。关于安装的介绍不多,官方文档很详细。
1 npm install casperjs
2 node_modules/casperjs/bin/casperjs selftest
查看代码
第二步,分析目标网站的列表页的网页结构。一般来说,内容类型网站分为列表页和详细内容页。豆瓣也不例外。我们来看看豆瓣的listing页面是什么样子的。经过分析,发现豆瓣电影网的列表页面是这样的。首先,您可以单击排序规则。翻页不像传统的网站页码翻页,而是点击最后一页加载更多。,传统的爬虫程序往往会停止服务,或者实现起来很复杂。但对于无头浏览器技术来说,这些都是小case。通过对网页的分析,可以看到点击这个【加载更多】位置可以持续显示更多的电影信息。
第三步,开始编写代码,获取电影详情页的链接信息。我们不欢迎,点击这个地方采集超链接列表。以下代码是获取链接的代码。引用并创建一个 casperJS 对象。如果网页需要插入脚本,可以在生成casper对象时在ClientScript部分引用要注入网页的脚本。为了加快网页的加载速度,我们禁止下载图片和插件:
1 pageSettings: {
2 loadImages: false, // The WebPage instance used by Casper will
3 loadPlugins: false // use these settings
4 },
查看代码
)
获取详情页链接的完整代码,这里是点击【加载更多】,循环50次的模拟。其实循环可以改进一下,【判断while(没有“加载更多”)then(停止)】,得到后,使用require('utils').dump(...)输出链表。将以下代码保存为getDoubanList.js,然后运行casperjs getDoubanList.js,获取并输出该分类下的所有详情页链接。
1 1 phantom.outputEncoding="uft8";
2 var casper = require('casper').create({
3 // clientScripts: [
4 // 'includes/jquery.js', // These two scripts will be injected in remote
5 // 'includes/underscore.js' // DOM on every request
6 // ],
7 pageSettings: {
8 loadImages: false, // The WebPage instance used by Casper will
9 loadPlugins: false // use these settings
10 },
11 logLevel: "info", // Only "info" level messages will be logged
12 verbose: false // log messages will be printed out to the console
13 });
14
15 casper.start("https://movie.douban.com/explo ... ot%3B, function () {
16 this.capture("1.png");
17 });
18
19 casper.then(function () {
20 this.click("a.more",10,10);
21 var i = 0;
22 do
23 {
24 i ++;
25 casper.waitForText('加载更多', function() {
26 this.click("a.more",10,10);//this.capture("2.png"); // read data from popup
27 });
28 }
29 while (i {
15 console.log(data.toString());
16 strUrls = strUrls + data.toString();
17
18 });
19
20 urllist.stderr.on('data', (data) => {
21 console.log(data);
22 });
23
24 urllist.on('exit', (code) => {
25 console.log(`Child exited with code ${code}`);
26 var urlData = JSON.parse(strUrls);
27 var content2 = "";
28 for(var key in urlData){
29 if (content2 != "") {
30 content2 = content2 + "\r\n" + urlData[key];
31 }
32 else {
33 content2 = urlData[key];
34 }
35 }
36 var recordurl = new record.RecordAllUrl();
37 recordurl.RecordUrlInText(content2);
38 console.log(content2);
39 });
40
获取所有网址
引用的RecordUrl模块,存储在MongoDB中的部分就不写了,可以自己完成。
1 exports.RecordAllUrl = RecordUrl;
2 var fs = require('fs');
3 function RecordUrl() {
4 var file = "d:/urllog.txt";
5 var RecordUrlInFile = function(theurl) {
6
9 fs.appendFile(file, theurl, function(err){
10 if(err)
11 console.log("fail " + err);
12 else
13 console.log("写入文件ok");
14 });
15 };
16 var RecordUrlInMongo = function() {
17 console.log('Hello ' + name);
18 };
19 return {
20 RecordUrlInDB: RecordUrlInMongo,
21 RecordUrlInText: RecordUrlInFile
22 } ;
23 };
记录网址
第四步,分析详情页,编写详情页爬取程序
至此,大家已经拿到了要爬取的详情页列表。现在我们打开一个电影详细信息页面来查看它的结构并分析如何捕获每个信息。对于信息的抓取,需要用到DOM、文本处理和JS脚本等技术。想获取这部分的信息,包括导演、编剧、评分等,本文不再赘述。这里仅举几个用于演示的信息项示例。
1. 抓取导演列表:导演列表的DOM CSS选择器'div#info span:nth-child(1) span.attrs a',我们使用函数getTextContent(strRule, strMesg)去获取内容。
1 phantom.outputEncoding="GBK";
2 var S = require("string");
3 var casper = require('casper').create({
4 clientScripts: [
5 'includes/jquery.js', // These two scripts will be injected in remote
6 'includes/underscore.js' // DOM on every request
7 ],
8 pageSettings: {
9 loadImages: false, // The WebPage instance used by Casper will
10 loadPlugins: false // use these settings
11 },
12 logLevel: "info", // Only "info" level messages will be logged
13 verbose: false // log messages will be printed out to the console
14 });
15
16 //casper.echo(casper.cli.get(0));
17 var fetchUrl='https://movie.douban.com/subje ... 39%3B, fetchNumber;
18 if(casper.cli.has('url'))
19 fetchUrl = casper.cli.get('url');
20 else if(casper.cli.has('number'))
21 fetchNumber = casper.cli.get('number');
22 casper.echo(fetchUrl);
23
24 casper.start(fetchUrl, function () {
25 this.capture("1.png");
26 //this.echo("启动程序....");
27 //this.echo(this.getHTML('div#info span:nth-child(3) a'));
28 //this.echo(this.fetchText('div#info span:nth-child(1) a'));
29
30 //抓取导演
31 getTextContent('div#info span:nth-child(1) span.attrs a','抓取导演');
32
33
34 });
35
36 //get the text content of tag
37 function getTextContent(strRule, strMesg)
38 {
39 //给evaluate传入参数
40 var textinfo = casper.evaluate(function(rule) {
41 var valArr = '';
42 $(rule).each(function(index,item){
43 valArr = valArr + $(this).text() + ',';
44 });
45 return valArr.substring(0,valArr.length-1);
46 }, strRule);
47 casper.echo(strMesg);
48 require('utils').dump(textinfo.split(','));
49 return textinfo.split(',');
50 };
51
52 //get the attribute content of tag
53 function getAttrContent(strRule, strMesg, Attr)
54 {
55 //给evaluate传入参数
56 var textinfo = casper.evaluate(function(rule, attrname) {
57 var valArr = '';
58 $(rule).each(function(index,item){
59 valArr = valArr + $(this).attr(attrname) + ',';
60 });
61 return valArr.substring(0,valArr.length-1);
62 }, strRule, Attr);
63 casper.echo(strMesg);
64 require('utils').dump(textinfo.split(','));
65 return textinfo.split(',');
66 };
67
68 casper.run();
获取导演
2. 要捕获生产的国家和地区,这些信息将很难使用 CSS 选择器来捕获。分析网页后可以找到原因。首先,这个信息并没有放在标签中,文本“美国”直接在
在这个高级元素中。对于这类信息,我们采用另一种方法,文本分析截取,首先映射String模块 var S = require("string"); 该模块也需要单独安装。然后抓取整个信息块,再用文字截取:
1 //影片信息全文字抓取
2 nameCount = casper.evaluate(function() {
3 var valArr = '';
4 $('div#info').each(function(index,item){
5 valArr = valArr + $(this).text() + ',';
6 });
7 return valArr.substring(0,valArr.length-1);
8 });
9 this.echo("影片信息全文字抓取");
10 this.echo(nameCount);
11 //this.echo(nameCount.indexOf("制片国家/地区:"));
12
13 //抓取国家
14 this.echo(S(nameCount).between("制片国家/地区:","\n"));
获取国家
其他信息也可类似获取。
第五步是将捕获的信息存储为分析源。推荐使用MongoDB等NoSql数据库存储,更适合存储此类非结构化数据,性能更好。
转载于: 查看全部
js 爬虫抓取网页数据(豆瓣View:网页抓取技术的强悍网页安装方法介绍)
CasperJS 是用于 PhantomJS (WebKit) 和 SlimerJS (Gecko) 无头浏览器的导航脚本和测试实用程序,用 Javascript 编写。
PhantomJS 是一个基于 WebKit 核心的无头浏览器
SlimerJS 是一个基于 Gecko 内核的无头浏览器
Headless browser:无界面显示的浏览器,可用于自动化测试、网页截图、JS注入、DOM操作等,是一种非常新型的Web应用工具。这个浏览器虽然没有任何界面输出,但是可以在很多方面得到广泛的应用。整篇文章文章将介绍使用Casperjs进行网络爬虫(web crawler)的应用。这篇文章只是一个介绍。事实上,无头浏览器技术的应用将会非常广泛,甚至可能对网络产生深远的影响。前端和后端技术的发展。
本文使用了一个著名的网站 [豆瓣]“手术”(只是学习和使用,希望这个网站不会打扰我
),来测试强大的 Headless Browser 网络爬虫技术。
第一步是安装Casperjs。打开CasperJS官网,下载最新稳定版CasperJS并安装。官网有非常详细的文档,是学习CasperJS最好的第一手资料。当然,如果安装npm,也可以直接通过npm安装。同时,这也是官方推荐的安装方式。关于安装的介绍不多,官方文档很详细。
1 npm install casperjs
2 node_modules/casperjs/bin/casperjs selftest
查看代码
第二步,分析目标网站的列表页的网页结构。一般来说,内容类型网站分为列表页和详细内容页。豆瓣也不例外。我们来看看豆瓣的listing页面是什么样子的。经过分析,发现豆瓣电影网的列表页面是这样的。首先,您可以单击排序规则。翻页不像传统的网站页码翻页,而是点击最后一页加载更多。,传统的爬虫程序往往会停止服务,或者实现起来很复杂。但对于无头浏览器技术来说,这些都是小case。通过对网页的分析,可以看到点击这个【加载更多】位置可以持续显示更多的电影信息。
第三步,开始编写代码,获取电影详情页的链接信息。我们不欢迎,点击这个地方采集超链接列表。以下代码是获取链接的代码。引用并创建一个 casperJS 对象。如果网页需要插入脚本,可以在生成casper对象时在ClientScript部分引用要注入网页的脚本。为了加快网页的加载速度,我们禁止下载图片和插件:
1 pageSettings: {
2 loadImages: false, // The WebPage instance used by Casper will
3 loadPlugins: false // use these settings
4 },
查看代码
)
获取详情页链接的完整代码,这里是点击【加载更多】,循环50次的模拟。其实循环可以改进一下,【判断while(没有“加载更多”)then(停止)】,得到后,使用require('utils').dump(...)输出链表。将以下代码保存为getDoubanList.js,然后运行casperjs getDoubanList.js,获取并输出该分类下的所有详情页链接。
1 1 phantom.outputEncoding="uft8";
2 var casper = require('casper').create({
3 // clientScripts: [
4 // 'includes/jquery.js', // These two scripts will be injected in remote
5 // 'includes/underscore.js' // DOM on every request
6 // ],
7 pageSettings: {
8 loadImages: false, // The WebPage instance used by Casper will
9 loadPlugins: false // use these settings
10 },
11 logLevel: "info", // Only "info" level messages will be logged
12 verbose: false // log messages will be printed out to the console
13 });
14
15 casper.start("https://movie.douban.com/explo ... ot%3B, function () {
16 this.capture("1.png");
17 });
18
19 casper.then(function () {
20 this.click("a.more",10,10);
21 var i = 0;
22 do
23 {
24 i ++;
25 casper.waitForText('加载更多', function() {
26 this.click("a.more",10,10);//this.capture("2.png"); // read data from popup
27 });
28 }
29 while (i {
15 console.log(data.toString());
16 strUrls = strUrls + data.toString();
17
18 });
19
20 urllist.stderr.on('data', (data) => {
21 console.log(data);
22 });
23
24 urllist.on('exit', (code) => {
25 console.log(`Child exited with code ${code}`);
26 var urlData = JSON.parse(strUrls);
27 var content2 = "";
28 for(var key in urlData){
29 if (content2 != "") {
30 content2 = content2 + "\r\n" + urlData[key];
31 }
32 else {
33 content2 = urlData[key];
34 }
35 }
36 var recordurl = new record.RecordAllUrl();
37 recordurl.RecordUrlInText(content2);
38 console.log(content2);
39 });
40
获取所有网址
引用的RecordUrl模块,存储在MongoDB中的部分就不写了,可以自己完成。
1 exports.RecordAllUrl = RecordUrl;
2 var fs = require('fs');
3 function RecordUrl() {
4 var file = "d:/urllog.txt";
5 var RecordUrlInFile = function(theurl) {
6
9 fs.appendFile(file, theurl, function(err){
10 if(err)
11 console.log("fail " + err);
12 else
13 console.log("写入文件ok");
14 });
15 };
16 var RecordUrlInMongo = function() {
17 console.log('Hello ' + name);
18 };
19 return {
20 RecordUrlInDB: RecordUrlInMongo,
21 RecordUrlInText: RecordUrlInFile
22 } ;
23 };
记录网址
第四步,分析详情页,编写详情页爬取程序
至此,大家已经拿到了要爬取的详情页列表。现在我们打开一个电影详细信息页面来查看它的结构并分析如何捕获每个信息。对于信息的抓取,需要用到DOM、文本处理和JS脚本等技术。想获取这部分的信息,包括导演、编剧、评分等,本文不再赘述。这里仅举几个用于演示的信息项示例。
1. 抓取导演列表:导演列表的DOM CSS选择器'div#info span:nth-child(1) span.attrs a',我们使用函数getTextContent(strRule, strMesg)去获取内容。
1 phantom.outputEncoding="GBK";
2 var S = require("string");
3 var casper = require('casper').create({
4 clientScripts: [
5 'includes/jquery.js', // These two scripts will be injected in remote
6 'includes/underscore.js' // DOM on every request
7 ],
8 pageSettings: {
9 loadImages: false, // The WebPage instance used by Casper will
10 loadPlugins: false // use these settings
11 },
12 logLevel: "info", // Only "info" level messages will be logged
13 verbose: false // log messages will be printed out to the console
14 });
15
16 //casper.echo(casper.cli.get(0));
17 var fetchUrl='https://movie.douban.com/subje ... 39%3B, fetchNumber;
18 if(casper.cli.has('url'))
19 fetchUrl = casper.cli.get('url');
20 else if(casper.cli.has('number'))
21 fetchNumber = casper.cli.get('number');
22 casper.echo(fetchUrl);
23
24 casper.start(fetchUrl, function () {
25 this.capture("1.png");
26 //this.echo("启动程序....");
27 //this.echo(this.getHTML('div#info span:nth-child(3) a'));
28 //this.echo(this.fetchText('div#info span:nth-child(1) a'));
29
30 //抓取导演
31 getTextContent('div#info span:nth-child(1) span.attrs a','抓取导演');
32
33
34 });
35
36 //get the text content of tag
37 function getTextContent(strRule, strMesg)
38 {
39 //给evaluate传入参数
40 var textinfo = casper.evaluate(function(rule) {
41 var valArr = '';
42 $(rule).each(function(index,item){
43 valArr = valArr + $(this).text() + ',';
44 });
45 return valArr.substring(0,valArr.length-1);
46 }, strRule);
47 casper.echo(strMesg);
48 require('utils').dump(textinfo.split(','));
49 return textinfo.split(',');
50 };
51
52 //get the attribute content of tag
53 function getAttrContent(strRule, strMesg, Attr)
54 {
55 //给evaluate传入参数
56 var textinfo = casper.evaluate(function(rule, attrname) {
57 var valArr = '';
58 $(rule).each(function(index,item){
59 valArr = valArr + $(this).attr(attrname) + ',';
60 });
61 return valArr.substring(0,valArr.length-1);
62 }, strRule, Attr);
63 casper.echo(strMesg);
64 require('utils').dump(textinfo.split(','));
65 return textinfo.split(',');
66 };
67
68 casper.run();
获取导演
2. 要捕获生产的国家和地区,这些信息将很难使用 CSS 选择器来捕获。分析网页后可以找到原因。首先,这个信息并没有放在标签中,文本“美国”直接在
在这个高级元素中。对于这类信息,我们采用另一种方法,文本分析截取,首先映射String模块 var S = require("string"); 该模块也需要单独安装。然后抓取整个信息块,再用文字截取:
1 //影片信息全文字抓取
2 nameCount = casper.evaluate(function() {
3 var valArr = '';
4 $('div#info').each(function(index,item){
5 valArr = valArr + $(this).text() + ',';
6 });
7 return valArr.substring(0,valArr.length-1);
8 });
9 this.echo("影片信息全文字抓取");
10 this.echo(nameCount);
11 //this.echo(nameCount.indexOf("制片国家/地区:"));
12
13 //抓取国家
14 this.echo(S(nameCount).between("制片国家/地区:","\n"));
获取国家
其他信息也可类似获取。
第五步是将捕获的信息存储为分析源。推荐使用MongoDB等NoSql数据库存储,更适合存储此类非结构化数据,性能更好。
转载于:
js 爬虫抓取网页数据( 2015年07月03日09:48:26DOM化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-06 07:17
2015年07月03日09:48:26DOM化)
nodejs爬虫爬取数据的编码问题
更新时间:2015-07-03 09:48:26 投稿:hebedich
本文文章主要介绍nodejs爬虫爬取数据编码问题的相关信息。有需要的朋友可以参考以下
当cheerio被DOM化和解析时
1.如果使用.text()方法,一般不会出现html实体编码问题
2. 如果使用.html()方法,很多情况下都会出现(主要是非英文的时候)。这时候可能就需要转义了。
类似这些因为需要数据存储,都需要进行转换
复制代码代码如下:
Халк крушит。Новый способ исполнен
大部分都是(x)?\w+的格式
所以只需使用常规转换
var body = ....//这里就是请求后获得的返回数据,或者那些 .html()后获取的
//一般可以先转换为标准unicode格式(有需要就添加:当返回的数据呈现太多\\\u 之类的时)
body=unescape(body.replace(/\\u/g,"%u"));
//再对实体符进行转义
//有x则表示是16进制,$1就是匹配是否有x ,$2就是匹配出的第二个括号捕获到的内容,将$2以对应进制表示转换
body = body.replace(/&#(x)?(\w+);/g,function($,$1,$2){
return String.fromCharCode(parseInt($2,$1?16:10));
});
好的~
当然网上也有很多转换的版本,申请就好
后记:
使用爬虫抓取网页数据时,经常用到cheerio模块到最后,和jq一样方便快捷
(但是有些功能不支持或者改成某种形式,比如jq的jQuery('.myClass').prop('outerHTML'),cheerio就相当于jQuery.html('.myClass')) 查看全部
js 爬虫抓取网页数据(
2015年07月03日09:48:26DOM化)
nodejs爬虫爬取数据的编码问题
更新时间:2015-07-03 09:48:26 投稿:hebedich
本文文章主要介绍nodejs爬虫爬取数据编码问题的相关信息。有需要的朋友可以参考以下
当cheerio被DOM化和解析时
1.如果使用.text()方法,一般不会出现html实体编码问题
2. 如果使用.html()方法,很多情况下都会出现(主要是非英文的时候)。这时候可能就需要转义了。
类似这些因为需要数据存储,都需要进行转换
复制代码代码如下:
Халк крушит。Новый способ исполнен
大部分都是(x)?\w+的格式
所以只需使用常规转换
var body = ....//这里就是请求后获得的返回数据,或者那些 .html()后获取的
//一般可以先转换为标准unicode格式(有需要就添加:当返回的数据呈现太多\\\u 之类的时)
body=unescape(body.replace(/\\u/g,"%u"));
//再对实体符进行转义
//有x则表示是16进制,$1就是匹配是否有x ,$2就是匹配出的第二个括号捕获到的内容,将$2以对应进制表示转换
body = body.replace(/&#(x)?(\w+);/g,function($,$1,$2){
return String.fromCharCode(parseInt($2,$1?16:10));
});
好的~
当然网上也有很多转换的版本,申请就好
后记:
使用爬虫抓取网页数据时,经常用到cheerio模块到最后,和jq一样方便快捷
(但是有些功能不支持或者改成某种形式,比如jq的jQuery('.myClass').prop('outerHTML'),cheerio就相当于jQuery.html('.myClass'))
js 爬虫抓取网页数据(js爬虫抓取网页数据分析数据,关注linux系统管理与运维)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-03 08:00
js爬虫抓取网页数据,或者数据分析数据,前者是requests库或者requests等第三方库,后者则需要自己写,可以使用beautifulsoup库,
maxthon。
nodejsnodejs+websocket
这个问题大概没有人能回答上来,不过venv也许可以解决你一部分困惑。我们建立了一个node.js工作环境。从mac上的macvim中启动venv,并输入:$venvpath=/users/administrator/library/preferences/com.tencent.mvqq/contents/preferences/sharedalframework/venv/bin/mvqq:""/users/administrator/library/preferences/com.tencent.mvqq/contents/preferences/bin/mvqq:""输出"node""关注linux系统管理与运维,就来关注我们微信公众号:linuxianjiu_。
写个在线工具便捷解决这个问题:
-tools/apache.
这么小的话localization不错,感觉对数据库有比较高的要求,或者一些高性能的web服务器本身可以用truffle比如github官方的digitalocean平台可以编译和执行apache代码,
看了那么多答案,没看到懂得帮忙的,其实很简单,
用mysql同时mapreduce数据处理hadoop-bin/mysql-mysql-bin/install。php?local=home-common_conf=${local}&localid=363cf0002d65c002f34c033b45f2c5bcbbce35&permission=jdbc&shared=0可以通过读取默认配置的话,很难搞定数据同步问题,建议再自己写个处理接口,你就懂得mapreduce了。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据分析数据,关注linux系统管理与运维)
js爬虫抓取网页数据,或者数据分析数据,前者是requests库或者requests等第三方库,后者则需要自己写,可以使用beautifulsoup库,
maxthon。
nodejsnodejs+websocket
这个问题大概没有人能回答上来,不过venv也许可以解决你一部分困惑。我们建立了一个node.js工作环境。从mac上的macvim中启动venv,并输入:$venvpath=/users/administrator/library/preferences/com.tencent.mvqq/contents/preferences/sharedalframework/venv/bin/mvqq:""/users/administrator/library/preferences/com.tencent.mvqq/contents/preferences/bin/mvqq:""输出"node""关注linux系统管理与运维,就来关注我们微信公众号:linuxianjiu_。
写个在线工具便捷解决这个问题:
-tools/apache.
这么小的话localization不错,感觉对数据库有比较高的要求,或者一些高性能的web服务器本身可以用truffle比如github官方的digitalocean平台可以编译和执行apache代码,
看了那么多答案,没看到懂得帮忙的,其实很简单,
用mysql同时mapreduce数据处理hadoop-bin/mysql-mysql-bin/install。php?local=home-common_conf=${local}&localid=363cf0002d65c002f34c033b45f2c5bcbbce35&permission=jdbc&shared=0可以通过读取默认配置的话,很难搞定数据同步问题,建议再自己写个处理接口,你就懂得mapreduce了。
js 爬虫抓取网页数据(web自动化终极爬虫:百度音乐(静态网页)分析步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 24 次浏览 • 2021-12-01 21:09
2017/9/14 晚上 11:43:07
带领:
最近写了几个简单的爬虫,踩了几个深坑。这里总结一下,给大家一些写爬虫的思路。本爬虫的内容包括:静态页面的爬取。动态页面的爬行。网络自动化的终极爬虫。
分析:
数据获取(主要是爬虫)
数据存储(python excel存储)
实际数据获取:百度音乐(静态网页)
分析步骤
1.打开百度音乐:/
2.打开浏览器调试模式F12,选择Network+all模式
3.在搜索框中搜索歌曲(beat it),查看控制台
4.通过以上分析:获取有效信息:
5、利用有效信息设计爬虫,获取数据
代码
1.View提供了访问参数url并返回结果的方法
def view(url):
'''
:param url: 待爬取的url链接
:return:
'''
# 从url中获取host
protocol, s1 = urllib.splittype(url)
host, s2 = urllib.splithost(s1)
# 伪装浏览器,避免被kill
headers = {
'Host': host,
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.78 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8',
}
# 代理
proxies = {
"http": "dev-proxy.oa.com:8080",
"https": "dev-proxy.oa.com:8080",
}
# 利用requests封装的get方法请求url,并添加请求头和代理,获取并返回请求结果。并进行异常处理
try:
res = requests.get(url, headers=headers, proxies=proxies)
res.encoding = 'utf-8'
if res.status_code == 200:
# 请求成功
# 获取网页内容,并返回
content = res.text
return content
else:
return None
except requests.RequestException as e:
# 异常处理
print(e)
return None
2 .search_baidu_song 提供参数song_name 搜索歌曲并获取搜索结果
def search_baidu_song(song_name):
'''
获取百度音乐搜索歌曲结果
:param song_name: 待搜索歌曲名
:return: 搜索结果
'''
def analyse():
'''
静态网页分析,利用BeautifulSoup,轻松获取想要的数据。需要对html有了解。
:return:
'''
# 初始化BeautifulSoup对象,并指定解析器为 lxml。还有其他的解析器:html.parser、html5lib等
# 详细教程可访问:http://cuiqingcai.com/1319.html《Python爬虫利器二之Beautiful Soup的用法》
html = BeautifulSoup(content, "lxml")
# beautifulsoupzui常用方法之一: find_all( name , attrs , recursive , text , **kwargs )
# find_all() 方法搜索当前tag的所有tag子节点, 并判断是否符合过滤器的条件
# tag标签名为'div'的并且标签类名为class_参数(可为 str、 list、 tuple),
search_result_divs = html.find_all('div', class_=['song-item clearfix ', 'song-item clearfix yyr-song'])
for div in search_result_divs:
# find() 方法搜索当前tag的所有tag子节点, 并返回符合过滤器的条件的第一个结点对象
song_name_str = div.find('span', class_='song-title')
singer = div.find('span', class_='singer')
album = div.find('span', class_='album-title')
# 此部分需要对html页面进行分析,一层层剥开有用数据并提取出来
if song_name_str:
# 获取结点对象内容,并清洗
song_name_str = song_name.text.strip()
else:
song_name_str = ''
if singer:
singer = singer.text.strip()
else:
singer = ''
if album:
album = album.find('a')
if album:
# 获取标签属性值
# 方法二:属性值 = album['属性名']
album = album.attrs.get('title')
if album and album != '':
album = album.strip()
else:
album = ''
else:
album = ''
# print song_name + " | " + singer + " | " + album
songInfoList.append(SongInfo(song_name_str, singer, album))
songInfoList = []
url = urls.get('baidu_song')
url1 = url.format(song_name=song_name, start_idx=0)
content = self.view(url1)
if not content:
return []
analyse(content)
url2 = url.format(song_name=song_name, start_idx=20)
content = self.view(url2)
analyse(content)
return songInfoList[0:30]
这样,我们就得到了百度网页歌曲搜索结果的数据。然后就是保存数据,这个我们最后再说。
网易云音乐(动态网页)
当我们通过上述静态网页数据获取方式获取网易云音乐的数据时,可能会遇到这样一个问题:没有可查看网页源代码的数据,只有网页的骨架。数据根本没有找到,但是当你打开开发者工具查看DOM树时,你可以找到想要的数据。这时候我们遇到了动态网页,数据是动态加载的。无法获取网页数据。
目前有两种解决方案: 通过查看和访问动态数据接口获取数据。使用网络自动化工具获取网页的源代码以获取数据。
(目前网易云已经不能再通过简单的访问URL的方式获取数据,我们可以使用web自动化工具selenium和PhantomJS来获取网页的源代码)
方案一的实现(通过查看和访问动态数据界面获取数据):打开网易云音乐:/打开浏览器调试模式F12,选择网络+所有模式
3.在搜索框中搜索歌曲(打它),检查控制台
过滤请求是XHR,发现请求的名字是一样的。这时候我们看一下这些名字,在Request URL中看到了关键字搜索的请求。这个请求是一个 POST 请求。这个应该是获取搜索数据的接口,可以通过查看响应或者预览来查看请求的结果。正是我们想要的。
我们不要高兴得太早,我们还没有弄清楚Form Data是如何组成的。params + encSecKey 是如何生成的?我看过网络爬虫《如何爬取网易云音乐的评论?》”,得知网易对api做了加密,由于个人道教太浅,无法理解这里加密参数的顺序和内容。所以,这个计划要停了。我真的不甘心,所以我有改变选项二。
方案二实现:
由于该解决方案暂时行不通,因此不会影响我们的工作进度。让我们换个思路,继续前行。我想到了使用web自动化测试工具selenium来模拟浏览器的人工操作。用这种方式导出网页数据应该没有问题,我想马上去做。
环境配置安装selenium
建议自动使用python包管理工具:pip install -y selenium
其他方法可以参考:selenium+python自动化测试环境搭建
2. 安装 PhantomJS
PhantomJS 是一个基于 webkit 的 JavaScript API。它使用 QtWebKit 作为其核心浏览器功能,并使用 webkit 编译、解释和执行 JavaScript 代码。你可以在基于 webkit 的浏览器中做的任何事情,它都能做到。它不仅是一个隐形浏览器,它提供了 CSS 选择器、Web 标准支持、DOM 操作、JSON、HTML5、Canvas、SVG 等,还提供了处理文件 I/O 的操作,让您可以对操作系统进行文件读写等。 PhantomJS 的用途非常广泛,如网络监控、网页截图、无浏览器的网页测试、页面访问自动化等。
下载 PhantomJS
目前官方支持三种操作系统,包括windows\Mac OS\Linux这三大主流的环境。你可以根据你的运行环境选择要下载的包
安装 PhantomJS
下载完成后,解压文件,将phantomjs.exe放到pythond目录下(C:\Python27\phantomjs.exe)。这样后续的加载就不需要指定目录了。也可以放在特定目录下,使用时指定phantomjs.exe的路径即可。双击打开phantomjs.exe,验证安装成功。如果出现下图,则安装成功。
2.代码实现步骤:
def dynamic_view(url):
'''
使用自动化工具获取网页数据
:param url: 待获取网页url
:return: 页面数据
'''
# 初始化浏览器driver
driver = webdriver.PhantomJS()
# 浏览器driver访问url
driver.get(url)
# 坑:不同frame间的转换(网易云在数据展示中会将数据动态添加到'g_iframe'这个框架中,如果不切换,会报"元素不存在"错误。)
driver.switch_to.frame("g_iframe")
# 隐式等待5秒,可以自己调节
driver.implicitly_wait(5)
# 设置10秒页面超时返回,类似于requests.get()的timeout选项,driver.get()没有timeout选项
driver.set_page_load_timeout(10)
# 获取网页资源(获取到的是网页所有数据)
html = driver.page_source
# 坑:退出浏览器driver,必须手动退出driver。
driver.quit()
# 返回网页资源
return html
def search_163_song(song_name):
pass
同样是使用BeautifulSoup对Web资源进行对象化,通过对象过滤来获取数据。没想到网易云音乐的数据也可以通过这种方式获取。如果你能做到这一点,你就可以应付大部分网站。
选择 PhantomJS 是因为它不需要可视化页面,并且节省了内存使用。但是也有一个问题,请大家继续往下看。眼见为实。
3.spotify
解决方案:通过网络自动化获取数据。通过请求动态数据接口获取数据计划实现:
方案一:
使用web自动化工具获取数据:配置与网易云配置相同,模拟用户操作浏览器打开网页,用户登录,进入搜索页面,获取页面数据
def spotify_view(url):
'''
使用自动化工具获取网页数据
:param url: 待获取网页url
:return: 页面数据
'''
spotify_name = 'manaxiaomeimei'
spotify_pass = 'dajiagongyong'
spotify_login = 'https://accounts.spotify.com/en/login'
# 初始化浏览器driver
driver = webdriver.PhantomJS()
# 模拟用户登录()
# 浏览器driver访问登录url
driver.get(spotify_login)
# 休息一下等待网页加载。(还有另一种方式:driver.implicitly_wait(3))
time.sleep(3)
# 获取页面元素对象方法(本次使用如下):
# find_element_by_id : 通过标签id获取元素对象 可在页面中获取到唯一一个元素,因为在html规范中。一个DOM树中标签id不能重复
# find_element_by_class_name : 通过标签类名获取元素对象,可能会重复(有坑)
# find_element_by_xpath : 通过标签xpath获取元素对象,类同id,可获取唯一一个元素。
# 获取页面元素对象--用户名
username = driver.find_element_by_id('login-username')
# username.clear()
# 坑:获取页面元素对象--密码
# 在通过类名获取标签元素中,遇到了无法定位复合样式,这时候可采用仅选取最后一个使用的样式作为参数,即可(稳定性不好不建议使用。尽量使用by_id)
# password = driver.find_element_by_class_name('form-control input-with-feedback ng-dirty ng-valid-parse ng-touched ng-empty ng-invalid ng-invalid-required')
password = driver.find_element_by_class_name('ng-invalid-required')
# password.clear()
# 获取页面元素对象--登录按钮
login_button = driver.find_element_by_xpath('/html/body/div[2]/div/form/div[3]/div[2]/button')
# 通过WebDriver API调用模拟键盘的输入用户名
username.send_keys(spotify_name)
# 通过WebDriver API调用模拟键盘的输入密码
password.send_keys(spotify_pass)
# 通过WebDriver API调用模拟鼠标的点击操作,进行登录
login_button.click()
# 休息一下等待网页加载
driver.implicitly_wait(3)
# 搜索打开歌曲url
driver.get(url)
time.sleep(5)
# 搜索获取网页代码
html = driver.page_source
return html
点击运行后,一切都平静了。代码突然报错(如下图)。查了资料,修改了代码。
网络开通计划
在 input 元素中添加 clear() 以清除原创字符。更换浏览器
方案实施:
方案一:
获取到对象后,添加清除对象的方法(username.clear(), password.clear())
实施结果
场景 1 失败。原因不明,大部分是webdriver与PhantomJS不兼容。
场景2:
换浏览器,这次选择使用chrome浏览器进行自动操作。
安装chrome自动化控制插件。
# 初始化浏览器驱动 driver = webdriver.Chrome()
我以为可以通过这种方式获得数据。烧鹅,还是没有得到,报错(如下图)
这里:您应该检查请求并找出令牌是什么。并尝试将令牌添加到请求标头中。
查看 cookie
但是我们登录后的cookie列表中并没有这样的cookie!
预计这个cookie应该在网络播放器加载时植入。验证一下:
从上表可以看出。当玩家加载时植入令牌。
至此,问题已经解决了大半。
继续“爬虫战斗:爬虫网络自动化的终极杀手(第 2 部分)” 查看全部
js 爬虫抓取网页数据(web自动化终极爬虫:百度音乐(静态网页)分析步骤)
2017/9/14 晚上 11:43:07
带领:
最近写了几个简单的爬虫,踩了几个深坑。这里总结一下,给大家一些写爬虫的思路。本爬虫的内容包括:静态页面的爬取。动态页面的爬行。网络自动化的终极爬虫。
分析:
数据获取(主要是爬虫)
数据存储(python excel存储)
实际数据获取:百度音乐(静态网页)
分析步骤
1.打开百度音乐:/
2.打开浏览器调试模式F12,选择Network+all模式
3.在搜索框中搜索歌曲(beat it),查看控制台
4.通过以上分析:获取有效信息:
5、利用有效信息设计爬虫,获取数据
代码
1.View提供了访问参数url并返回结果的方法
def view(url):
'''
:param url: 待爬取的url链接
:return:
'''
# 从url中获取host
protocol, s1 = urllib.splittype(url)
host, s2 = urllib.splithost(s1)
# 伪装浏览器,避免被kill
headers = {
'Host': host,
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.78 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8',
}
# 代理
proxies = {
"http": "dev-proxy.oa.com:8080",
"https": "dev-proxy.oa.com:8080",
}
# 利用requests封装的get方法请求url,并添加请求头和代理,获取并返回请求结果。并进行异常处理
try:
res = requests.get(url, headers=headers, proxies=proxies)
res.encoding = 'utf-8'
if res.status_code == 200:
# 请求成功
# 获取网页内容,并返回
content = res.text
return content
else:
return None
except requests.RequestException as e:
# 异常处理
print(e)
return None
2 .search_baidu_song 提供参数song_name 搜索歌曲并获取搜索结果
def search_baidu_song(song_name):
'''
获取百度音乐搜索歌曲结果
:param song_name: 待搜索歌曲名
:return: 搜索结果
'''
def analyse():
'''
静态网页分析,利用BeautifulSoup,轻松获取想要的数据。需要对html有了解。
:return:
'''
# 初始化BeautifulSoup对象,并指定解析器为 lxml。还有其他的解析器:html.parser、html5lib等
# 详细教程可访问:http://cuiqingcai.com/1319.html《Python爬虫利器二之Beautiful Soup的用法》
html = BeautifulSoup(content, "lxml")
# beautifulsoupzui常用方法之一: find_all( name , attrs , recursive , text , **kwargs )
# find_all() 方法搜索当前tag的所有tag子节点, 并判断是否符合过滤器的条件
# tag标签名为'div'的并且标签类名为class_参数(可为 str、 list、 tuple),
search_result_divs = html.find_all('div', class_=['song-item clearfix ', 'song-item clearfix yyr-song'])
for div in search_result_divs:
# find() 方法搜索当前tag的所有tag子节点, 并返回符合过滤器的条件的第一个结点对象
song_name_str = div.find('span', class_='song-title')
singer = div.find('span', class_='singer')
album = div.find('span', class_='album-title')
# 此部分需要对html页面进行分析,一层层剥开有用数据并提取出来
if song_name_str:
# 获取结点对象内容,并清洗
song_name_str = song_name.text.strip()
else:
song_name_str = ''
if singer:
singer = singer.text.strip()
else:
singer = ''
if album:
album = album.find('a')
if album:
# 获取标签属性值
# 方法二:属性值 = album['属性名']
album = album.attrs.get('title')
if album and album != '':
album = album.strip()
else:
album = ''
else:
album = ''
# print song_name + " | " + singer + " | " + album
songInfoList.append(SongInfo(song_name_str, singer, album))
songInfoList = []
url = urls.get('baidu_song')
url1 = url.format(song_name=song_name, start_idx=0)
content = self.view(url1)
if not content:
return []
analyse(content)
url2 = url.format(song_name=song_name, start_idx=20)
content = self.view(url2)
analyse(content)
return songInfoList[0:30]
这样,我们就得到了百度网页歌曲搜索结果的数据。然后就是保存数据,这个我们最后再说。
网易云音乐(动态网页)
当我们通过上述静态网页数据获取方式获取网易云音乐的数据时,可能会遇到这样一个问题:没有可查看网页源代码的数据,只有网页的骨架。数据根本没有找到,但是当你打开开发者工具查看DOM树时,你可以找到想要的数据。这时候我们遇到了动态网页,数据是动态加载的。无法获取网页数据。
目前有两种解决方案: 通过查看和访问动态数据接口获取数据。使用网络自动化工具获取网页的源代码以获取数据。
(目前网易云已经不能再通过简单的访问URL的方式获取数据,我们可以使用web自动化工具selenium和PhantomJS来获取网页的源代码)
方案一的实现(通过查看和访问动态数据界面获取数据):打开网易云音乐:/打开浏览器调试模式F12,选择网络+所有模式
3.在搜索框中搜索歌曲(打它),检查控制台
过滤请求是XHR,发现请求的名字是一样的。这时候我们看一下这些名字,在Request URL中看到了关键字搜索的请求。这个请求是一个 POST 请求。这个应该是获取搜索数据的接口,可以通过查看响应或者预览来查看请求的结果。正是我们想要的。
我们不要高兴得太早,我们还没有弄清楚Form Data是如何组成的。params + encSecKey 是如何生成的?我看过网络爬虫《如何爬取网易云音乐的评论?》”,得知网易对api做了加密,由于个人道教太浅,无法理解这里加密参数的顺序和内容。所以,这个计划要停了。我真的不甘心,所以我有改变选项二。
方案二实现:
由于该解决方案暂时行不通,因此不会影响我们的工作进度。让我们换个思路,继续前行。我想到了使用web自动化测试工具selenium来模拟浏览器的人工操作。用这种方式导出网页数据应该没有问题,我想马上去做。
环境配置安装selenium
建议自动使用python包管理工具:pip install -y selenium
其他方法可以参考:selenium+python自动化测试环境搭建
2. 安装 PhantomJS
PhantomJS 是一个基于 webkit 的 JavaScript API。它使用 QtWebKit 作为其核心浏览器功能,并使用 webkit 编译、解释和执行 JavaScript 代码。你可以在基于 webkit 的浏览器中做的任何事情,它都能做到。它不仅是一个隐形浏览器,它提供了 CSS 选择器、Web 标准支持、DOM 操作、JSON、HTML5、Canvas、SVG 等,还提供了处理文件 I/O 的操作,让您可以对操作系统进行文件读写等。 PhantomJS 的用途非常广泛,如网络监控、网页截图、无浏览器的网页测试、页面访问自动化等。
下载 PhantomJS
目前官方支持三种操作系统,包括windows\Mac OS\Linux这三大主流的环境。你可以根据你的运行环境选择要下载的包
安装 PhantomJS
下载完成后,解压文件,将phantomjs.exe放到pythond目录下(C:\Python27\phantomjs.exe)。这样后续的加载就不需要指定目录了。也可以放在特定目录下,使用时指定phantomjs.exe的路径即可。双击打开phantomjs.exe,验证安装成功。如果出现下图,则安装成功。
2.代码实现步骤:
def dynamic_view(url):
'''
使用自动化工具获取网页数据
:param url: 待获取网页url
:return: 页面数据
'''
# 初始化浏览器driver
driver = webdriver.PhantomJS()
# 浏览器driver访问url
driver.get(url)
# 坑:不同frame间的转换(网易云在数据展示中会将数据动态添加到'g_iframe'这个框架中,如果不切换,会报"元素不存在"错误。)
driver.switch_to.frame("g_iframe")
# 隐式等待5秒,可以自己调节
driver.implicitly_wait(5)
# 设置10秒页面超时返回,类似于requests.get()的timeout选项,driver.get()没有timeout选项
driver.set_page_load_timeout(10)
# 获取网页资源(获取到的是网页所有数据)
html = driver.page_source
# 坑:退出浏览器driver,必须手动退出driver。
driver.quit()
# 返回网页资源
return html
def search_163_song(song_name):
pass
同样是使用BeautifulSoup对Web资源进行对象化,通过对象过滤来获取数据。没想到网易云音乐的数据也可以通过这种方式获取。如果你能做到这一点,你就可以应付大部分网站。
选择 PhantomJS 是因为它不需要可视化页面,并且节省了内存使用。但是也有一个问题,请大家继续往下看。眼见为实。
3.spotify
解决方案:通过网络自动化获取数据。通过请求动态数据接口获取数据计划实现:
方案一:
使用web自动化工具获取数据:配置与网易云配置相同,模拟用户操作浏览器打开网页,用户登录,进入搜索页面,获取页面数据
def spotify_view(url):
'''
使用自动化工具获取网页数据
:param url: 待获取网页url
:return: 页面数据
'''
spotify_name = 'manaxiaomeimei'
spotify_pass = 'dajiagongyong'
spotify_login = 'https://accounts.spotify.com/en/login'
# 初始化浏览器driver
driver = webdriver.PhantomJS()
# 模拟用户登录()
# 浏览器driver访问登录url
driver.get(spotify_login)
# 休息一下等待网页加载。(还有另一种方式:driver.implicitly_wait(3))
time.sleep(3)
# 获取页面元素对象方法(本次使用如下):
# find_element_by_id : 通过标签id获取元素对象 可在页面中获取到唯一一个元素,因为在html规范中。一个DOM树中标签id不能重复
# find_element_by_class_name : 通过标签类名获取元素对象,可能会重复(有坑)
# find_element_by_xpath : 通过标签xpath获取元素对象,类同id,可获取唯一一个元素。
# 获取页面元素对象--用户名
username = driver.find_element_by_id('login-username')
# username.clear()
# 坑:获取页面元素对象--密码
# 在通过类名获取标签元素中,遇到了无法定位复合样式,这时候可采用仅选取最后一个使用的样式作为参数,即可(稳定性不好不建议使用。尽量使用by_id)
# password = driver.find_element_by_class_name('form-control input-with-feedback ng-dirty ng-valid-parse ng-touched ng-empty ng-invalid ng-invalid-required')
password = driver.find_element_by_class_name('ng-invalid-required')
# password.clear()
# 获取页面元素对象--登录按钮
login_button = driver.find_element_by_xpath('/html/body/div[2]/div/form/div[3]/div[2]/button')
# 通过WebDriver API调用模拟键盘的输入用户名
username.send_keys(spotify_name)
# 通过WebDriver API调用模拟键盘的输入密码
password.send_keys(spotify_pass)
# 通过WebDriver API调用模拟鼠标的点击操作,进行登录
login_button.click()
# 休息一下等待网页加载
driver.implicitly_wait(3)
# 搜索打开歌曲url
driver.get(url)
time.sleep(5)
# 搜索获取网页代码
html = driver.page_source
return html
点击运行后,一切都平静了。代码突然报错(如下图)。查了资料,修改了代码。
网络开通计划
在 input 元素中添加 clear() 以清除原创字符。更换浏览器
方案实施:
方案一:
获取到对象后,添加清除对象的方法(username.clear(), password.clear())
实施结果
场景 1 失败。原因不明,大部分是webdriver与PhantomJS不兼容。
场景2:
换浏览器,这次选择使用chrome浏览器进行自动操作。
安装chrome自动化控制插件。
# 初始化浏览器驱动 driver = webdriver.Chrome()
我以为可以通过这种方式获得数据。烧鹅,还是没有得到,报错(如下图)
这里:您应该检查请求并找出令牌是什么。并尝试将令牌添加到请求标头中。
查看 cookie
但是我们登录后的cookie列表中并没有这样的cookie!
预计这个cookie应该在网络播放器加载时植入。验证一下:
从上表可以看出。当玩家加载时植入令牌。
至此,问题已经解决了大半。
继续“爬虫战斗:爬虫网络自动化的终极杀手(第 2 部分)”
js 爬虫抓取网页数据(爬取小说网站-首页推荐小说爬取第一步-确定目标网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-01 21:07
前言
今天不做序,只想分享一些关于爬虫的技巧,任性。来吧,来宾官员,请...
开头的第一个问题:什么是爬虫?
首先,让我们说爬行动物不是“虫子”,所以不要害怕它们。
## 开篇第二问:**```爬虫```**能做什么嘞?
来来来,谈谈需求
**产品MM:**
1. 爱豆的新电影上架了,整体电影评价如何呢?
2. 暗恋的妹子最近又失恋了,如何在她发微博的时候第一时间知道发了什么,好去呵护呢?
3. 总是在看小说的时候点到广告?总是在看那啥的时候点出来,澳xx场又上线啦?
4. 做个新闻类网站没有数据源咋办?
**研发GG:**
用爬虫拉取偶像视频的所有评价,导入表格,然后分析评价。使用爬虫,添加定时任务,拉妹微博,只要数据有变化,接入短信或邮件服务,第一时间通知使用爬虫,拉小说内容或xxx视频,自己设计展示页面,完美!使用爬虫,定时任务,从多个新闻源拉取新闻,存入数据库。第三个问题:爬虫是如何实现的?
实现爬虫的技术有很多,比如python、Node等,今天胡歌就和大家分享下如何用Node做爬虫:爬小说
爬行第一步——确定目标
目标 网站:23us.so
我们要获取排行榜中的六本小说:小说图书信息对应的书名、封面、地址(以下获取小说的完整信息)
第二步爬取——分析目标的特征
网页的内容是由HTML生成的,爬取内容就相当于找到了特定的HTML结构,获取了元素的值。
打开 web 调试控制台查看元素的 HTML 结构。
注意页面的 HTML 结构。排行榜推荐小说的HTML结构为
bdo#s-dd 元素
dd 子元素 - 每一部小说
a 目录信息
img 封面
a 小说名称
第三步爬行-操
工具要先磨砺自己的工具,才能发挥最大的作用,做好充分利用武器的准备!
超级代理
模拟客户端发送网络请求,可以设置请求参数,头部信息
npm install superagent -D
啦啦队
类JQuery的库,可以导入字符串,创建对象,快速抓取字符串中符合条件的数据
项目目录:
node-pachong/
- index.js
- package.json
- node_modules/
在代码上:
// node-pachong/index.js
/**
* 使用Node.js做爬虫实战
* author: justbecoder
*/
// 引入需要的工具包
const sp = require('superagent');
const cheerio = require('cheerio');
// 定义请求的URL地址
const BASE_URL = 'http://www.23us.so';
// 1. 发送请求,获取HTML字符串
(async () => {
let html = await sp.get(BASE_URL);
// 2. 将字符串导入,使用cheerio获取元素
let $ = cheerio.load(html.text);
// 3. 获取指定的元素
let books = []
$('#s_dd dd').each(function () {
let info = {
link: $(this).find('a').eq(0).attr('href'),
name: $(this).find('a').eq(1).text(),
image: $(this).find('img').attr('src')
}
books.push(info)
})
console.log(books)
})()
友情提示:每个网站的HTML结构都不一样。在捕获不同网站的数据时,必须分析不同的解构才能取得成功。
效果图:
获取到信息后,做接口数据返回,存储数据库,想做什么就做什么……
源码获取 查看全部
js 爬虫抓取网页数据(爬取小说网站-首页推荐小说爬取第一步-确定目标网站)
前言
今天不做序,只想分享一些关于爬虫的技巧,任性。来吧,来宾官员,请...
开头的第一个问题:什么是爬虫?
首先,让我们说爬行动物不是“虫子”,所以不要害怕它们。
## 开篇第二问:**```爬虫```**能做什么嘞?
来来来,谈谈需求
**产品MM:**
1. 爱豆的新电影上架了,整体电影评价如何呢?
2. 暗恋的妹子最近又失恋了,如何在她发微博的时候第一时间知道发了什么,好去呵护呢?
3. 总是在看小说的时候点到广告?总是在看那啥的时候点出来,澳xx场又上线啦?
4. 做个新闻类网站没有数据源咋办?
**研发GG:**
用爬虫拉取偶像视频的所有评价,导入表格,然后分析评价。使用爬虫,添加定时任务,拉妹微博,只要数据有变化,接入短信或邮件服务,第一时间通知使用爬虫,拉小说内容或xxx视频,自己设计展示页面,完美!使用爬虫,定时任务,从多个新闻源拉取新闻,存入数据库。第三个问题:爬虫是如何实现的?
实现爬虫的技术有很多,比如python、Node等,今天胡歌就和大家分享下如何用Node做爬虫:爬小说
爬行第一步——确定目标
目标 网站:23us.so
我们要获取排行榜中的六本小说:小说图书信息对应的书名、封面、地址(以下获取小说的完整信息)
第二步爬取——分析目标的特征
网页的内容是由HTML生成的,爬取内容就相当于找到了特定的HTML结构,获取了元素的值。
打开 web 调试控制台查看元素的 HTML 结构。
注意页面的 HTML 结构。排行榜推荐小说的HTML结构为
bdo#s-dd 元素
dd 子元素 - 每一部小说
a 目录信息
img 封面
a 小说名称
第三步爬行-操
工具要先磨砺自己的工具,才能发挥最大的作用,做好充分利用武器的准备!
超级代理
模拟客户端发送网络请求,可以设置请求参数,头部信息
npm install superagent -D
啦啦队
类JQuery的库,可以导入字符串,创建对象,快速抓取字符串中符合条件的数据
项目目录:
node-pachong/
- index.js
- package.json
- node_modules/
在代码上:
// node-pachong/index.js
/**
* 使用Node.js做爬虫实战
* author: justbecoder
*/
// 引入需要的工具包
const sp = require('superagent');
const cheerio = require('cheerio');
// 定义请求的URL地址
const BASE_URL = 'http://www.23us.so';
// 1. 发送请求,获取HTML字符串
(async () => {
let html = await sp.get(BASE_URL);
// 2. 将字符串导入,使用cheerio获取元素
let $ = cheerio.load(html.text);
// 3. 获取指定的元素
let books = []
$('#s_dd dd').each(function () {
let info = {
link: $(this).find('a').eq(0).attr('href'),
name: $(this).find('a').eq(1).text(),
image: $(this).find('img').attr('src')
}
books.push(info)
})
console.log(books)
})()
友情提示:每个网站的HTML结构都不一样。在捕获不同网站的数据时,必须分析不同的解构才能取得成功。
效果图:
获取到信息后,做接口数据返回,存储数据库,想做什么就做什么……
源码获取
js 爬虫抓取网页数据(OSC年度开源问卷新鲜出炉(图)年度问卷(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-01 12:18
OSC 年度开源问卷新鲜出炉。您的回答对我们非常重要。参与开源,可以从这份问卷开始>>>
js获取数据然后写或者innerHTML的方式生成页面,这些内容在源码中是看不到的
一般来说,我们会直接找到js请求的地址,然后获取网站的接口数据
例如:
国有资产信息卡项目信息-
但是我发现了一个问题。返回的结果不是 JSON、xml 或其他可见字符串的形式。
返回的是对象。这时候js可以使用类似于model.name,model.phone的形式来获取属性,然后写入
页,但是:
首先,在页面的源代码中是看不到的,其次,返回的界面数据也得不到你想要的。
例如,请求的 servelt 类似于:
ProxyModel proxyModel = new ProxyModel();
proxyModel.setName("这是测试的地址");
response.getWriter().print(proxyModel);
然后它在js中看起来像这样:
成功:功能(味精){
警报(味精长度);
$.each(msg, function(i,item){
警报(项目名称);
div.innerHTML=item.name;
})
}
反正js是直接获取属性,可以在页面上显示名称
这时候你看到接口只返回一个对象,具体是一个内存地址,页面上没有显示,比如name
在这种情况下发生了什么? 查看全部
js 爬虫抓取网页数据(OSC年度开源问卷新鲜出炉(图)年度问卷(组图))
OSC 年度开源问卷新鲜出炉。您的回答对我们非常重要。参与开源,可以从这份问卷开始>>>
js获取数据然后写或者innerHTML的方式生成页面,这些内容在源码中是看不到的
一般来说,我们会直接找到js请求的地址,然后获取网站的接口数据
例如:
国有资产信息卡项目信息-
但是我发现了一个问题。返回的结果不是 JSON、xml 或其他可见字符串的形式。
返回的是对象。这时候js可以使用类似于model.name,model.phone的形式来获取属性,然后写入
页,但是:
首先,在页面的源代码中是看不到的,其次,返回的界面数据也得不到你想要的。
例如,请求的 servelt 类似于:
ProxyModel proxyModel = new ProxyModel();
proxyModel.setName("这是测试的地址");
response.getWriter().print(proxyModel);
然后它在js中看起来像这样:
成功:功能(味精){
警报(味精长度);
$.each(msg, function(i,item){
警报(项目名称);
div.innerHTML=item.name;
})
}
反正js是直接获取属性,可以在页面上显示名称
这时候你看到接口只返回一个对象,具体是一个内存地址,页面上没有显示,比如name
在这种情况下发生了什么?
js 爬虫抓取网页数据(利用Selenium+Phantomjs动态获取网站数据信息信息的例子 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-12-01 02:05
)
我刚开始学习爬虫。网上查了资料,写了一个使用Selenium+Phantomjs动态获取网站数据信息的例子。当然,我必须先安装Selenium+Phantomjs。查看详情。
硒下载:
Phantomjs 使用参考:及官网:
源码如下:
<p># coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
import time
import re
import os
class Crawler:
def __init__(self, firstUrl = "https://list.jd.com/list.html?cat=9987,653,655",
nextUrl = "https://list.jd.com/list.html?cat=9987,653,655&page=%d&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main"):
self.firstUrl = firstUrl
self.nextUrl = nextUrl
def getDetails(self,pageIndex,id = "plist"):
'''
获取详细信息
:param pageIndex: 页索引
:param id: 标签对应的id
:return:
'''
element = self.driver.find_element_by_id(id)
txt = element.text.encode('utf8')
items = txt.split('¥')
for item in items:
if len(item) > 0:
details = item.split('\n')
print '¥' + item
# print '单价:¥'+ details[0]
# print '品牌:' + details[1]
# print '参与评价:' + details[2]
# print '店铺:' + details[3]
print ' '
print '第 ' + str(pageIndex) + '页'
def CatchData(self,id = "plist",totalpageCountLable = "//span[@class='p-skip']/em/b"):
'''
抓取数据
:param id:获取数据的标签id
:param totalpageCountLable:获取总页数标记
:return:
'''
start = time.clock()
self.driver = webdriver.PhantomJS()
wait = ui.WebDriverWait(self.driver, 10)
self.driver.get(self.firstUrl)
#在等待页面元素加载全部完成后才进行下一步操作
wait.until(lambda driver: self.driver.find_element_by_xpath(totalpageCountLable))
# 获取总页数
pcount = self.driver.find_element_by_xpath(totalpageCountLable)
txt = pcount.text.encode('utf8')
print '总页数:' + txt
print '第1页'
print ' '
pageNum = int(txt)
pageNum = 3 # 只执行三次
i = 2
while (i 查看全部
js 爬虫抓取网页数据(利用Selenium+Phantomjs动态获取网站数据信息信息的例子
)
我刚开始学习爬虫。网上查了资料,写了一个使用Selenium+Phantomjs动态获取网站数据信息的例子。当然,我必须先安装Selenium+Phantomjs。查看详情。
硒下载:
Phantomjs 使用参考:及官网:
源码如下:
<p># coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
import time
import re
import os
class Crawler:
def __init__(self, firstUrl = "https://list.jd.com/list.html?cat=9987,653,655",
nextUrl = "https://list.jd.com/list.html?cat=9987,653,655&page=%d&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main"):
self.firstUrl = firstUrl
self.nextUrl = nextUrl
def getDetails(self,pageIndex,id = "plist"):
'''
获取详细信息
:param pageIndex: 页索引
:param id: 标签对应的id
:return:
'''
element = self.driver.find_element_by_id(id)
txt = element.text.encode('utf8')
items = txt.split('¥')
for item in items:
if len(item) > 0:
details = item.split('\n')
print '¥' + item
# print '单价:¥'+ details[0]
# print '品牌:' + details[1]
# print '参与评价:' + details[2]
# print '店铺:' + details[3]
print ' '
print '第 ' + str(pageIndex) + '页'
def CatchData(self,id = "plist",totalpageCountLable = "//span[@class='p-skip']/em/b"):
'''
抓取数据
:param id:获取数据的标签id
:param totalpageCountLable:获取总页数标记
:return:
'''
start = time.clock()
self.driver = webdriver.PhantomJS()
wait = ui.WebDriverWait(self.driver, 10)
self.driver.get(self.firstUrl)
#在等待页面元素加载全部完成后才进行下一步操作
wait.until(lambda driver: self.driver.find_element_by_xpath(totalpageCountLable))
# 获取总页数
pcount = self.driver.find_element_by_xpath(totalpageCountLable)
txt = pcount.text.encode('utf8')
print '总页数:' + txt
print '第1页'
print ' '
pageNum = int(txt)
pageNum = 3 # 只执行三次
i = 2
while (i
js 爬虫抓取网页数据(js爬虫抓取网页数据,直接在word上来回划拉浏览数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-29 05:03
js爬虫抓取网页数据,
直接在word上来回划拉浏览数据,数据就抓取下来了,当然数据也可以用requests库读取。
浏览器是人写的,无法保证安全性,
要是能抓完这个网站的信息,
teambition
也是我自己的经验吧,看是用什么程序解决这个问题。如果是python,有一些网站可以抓取,例如:或者其他国外的网站,总体说来,requests方便快捷,你只要装好这个程序就好了,然后在浏览器中抓取网页。
windows,python3的话可以直接抓取在windows平台上的数据。
我在回答过你类似问题,请看这篇文章。
想起之前加过的一个项目,抓取新浪微博。不过需要你懂爬虫,会编程。感觉可以用requests来抓取,可以给别人,
的确有适合,网页上就可以爬到,比如豆瓣书评,可以抓取微博中的热门,你的标题和评分,但是有一点,这种数据很久以前就有了,在此举例一下。可以,但是很不安全。想要安全,建议找国外正规的产品提供商,看一下最新的信息。
爬虫是个好工具
网络上应该有大量的spider可以抓取。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据,直接在word上来回划拉浏览数据)
js爬虫抓取网页数据,
直接在word上来回划拉浏览数据,数据就抓取下来了,当然数据也可以用requests库读取。
浏览器是人写的,无法保证安全性,
要是能抓完这个网站的信息,
teambition
也是我自己的经验吧,看是用什么程序解决这个问题。如果是python,有一些网站可以抓取,例如:或者其他国外的网站,总体说来,requests方便快捷,你只要装好这个程序就好了,然后在浏览器中抓取网页。
windows,python3的话可以直接抓取在windows平台上的数据。
我在回答过你类似问题,请看这篇文章。
想起之前加过的一个项目,抓取新浪微博。不过需要你懂爬虫,会编程。感觉可以用requests来抓取,可以给别人,
的确有适合,网页上就可以爬到,比如豆瓣书评,可以抓取微博中的热门,你的标题和评分,但是有一点,这种数据很久以前就有了,在此举例一下。可以,但是很不安全。想要安全,建议找国外正规的产品提供商,看一下最新的信息。
爬虫是个好工具
网络上应该有大量的spider可以抓取。
js 爬虫抓取网页数据(爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-22 20:15
其实一开始我是拒绝写这个博客的,因为爬虫在爬cnblog博客园。也许编辑看到后会屏蔽我的帐户:)。
言归正传,前端同学可能对爬虫不是很感冒,认为爬虫需要用到后端语言,比如php、python等,当然这是在nodejs之前。随着nodejs的出现,Javascript也可以用来写爬虫了。由于nodejs强大的异步特性,我们可以轻松爬取异步高并发的网站。当然,这里的easy指的是cpu的开销。
要阅读本文,您只需要拥有
这篇文章很长,图片很多,但是如果你能耐心看完这篇文章,你会发现一个简单的爬虫实现起来并不难,从中可以学到很多东西。
本文完整的爬虫代码可以在我的github上下载。主要逻辑代码在server.js中,建议查代码的时候往下看。
在详细讨论爬虫之前,我们先简单了解一下要实现的最终目标。入口是,博客园文章列表页每页有20篇文章文章,最多可以翻到200页。我的爬虫要做的就是异步并发的爬取这4000个文章的具体内容,得到一些我们想要的关键数据。
爬虫进程
看到最后的结果,我们来看看如何通过一个简单的nodejs爬虫一步步的获取我们想要的数据。首先简单普及一下爬虫流程。完成一个爬虫,主要的步骤分为:
抓住
爬虫最重要的一步就是如何检索到想要的页面。并且可以兼顾时间效率,可以同时抓取多个页面。
同时,为了获取目标内容,我们需要分析页面结构。由于ajax的盛行,很多页面内容无法通过一个url来请求。通常,一个页面的内容是在多次请求后异步生成的。所以这就要求我们能够使用抓包工具来分析页面结构。
如果再深入,你会发现你要面对不同的web需求,比如认证、不同的文件格式、编码处理、各种奇怪的URL合规处理、重复爬取问题、cookies跟随问题、多线程等一系列进程爬取、多节点爬取、爬取调度、资源压缩等问题。
所以第一步就是把网页拉回来,慢慢的就会发现各种问题等着你去优化。
贮存
在抓取页面内容的时候,一般不会直接分析,而是通过一定的策略保存。我个人认为更好的结构应该是将分析和爬行分开,并且更松散一些,每个环节都可以相互隔离。链接中可能出现的问题,易于排查或更新发布。
那么如何保存文件系统,SQL或者NOSQL数据库,内存数据库,就是这个环节的重点。
分析
对于网页的文本分析,是提取链接还是提取文本,这取决于您的需求,但您要做的就是分析链接。通常分析和存储会交替进行。您可以使用您认为最快和最好的方法,例如正则表达式。然后将分析结果应用到其他链接。
展示
如果你做了很多事情,根本没有显示输出,如何显示值?
因此,找到一个好的展示元件,展示肌肉也是关键。
如果你写一个爬虫是为了做一个站点,或者你想分析一些东西的数据,不要忘记这个链接,以便更好地向其他人展示结果。
编写爬虫代码 Step.1 页面分析
现在我们一步一步完成我们的爬虫。目标是抓取博客园第1-200页的4000篇文章,获取其中的作者信息,并保存分析。
一共4000个文章,所以首先我们需要拿到这4000个文章的入口,然后异步并发请求4000个文章的内容。但是这4000个文章的入口URL分布在200页。所以我们需要做的第一步就是从这 200 个页面中提取 4000 个 URL。并且通过异步并发,当采集到 4000 个 URL 时,进行下一步。所以现在我们的目标非常明确:
Step2.获取4000个文章入口网址
要得到这么多的URL,首先要从分析单个页面开始,F12打开devtools。很容易发现文章入口链接存放在类titlelnk的标签中,所以4000个URL需要我们轮询200个列表页面,每页保存20个链接。那么如何异步并发从200个页面中采集这4000个URL,继续搜索规则,查看每个页面的列表页面的URL结构:
那么,第1~200页的列表页面的URL应该是这样的:
<p>for(var i=1 ; i 查看全部
js 爬虫抓取网页数据(爬虫)
其实一开始我是拒绝写这个博客的,因为爬虫在爬cnblog博客园。也许编辑看到后会屏蔽我的帐户:)。
言归正传,前端同学可能对爬虫不是很感冒,认为爬虫需要用到后端语言,比如php、python等,当然这是在nodejs之前。随着nodejs的出现,Javascript也可以用来写爬虫了。由于nodejs强大的异步特性,我们可以轻松爬取异步高并发的网站。当然,这里的easy指的是cpu的开销。
要阅读本文,您只需要拥有
这篇文章很长,图片很多,但是如果你能耐心看完这篇文章,你会发现一个简单的爬虫实现起来并不难,从中可以学到很多东西。
本文完整的爬虫代码可以在我的github上下载。主要逻辑代码在server.js中,建议查代码的时候往下看。
在详细讨论爬虫之前,我们先简单了解一下要实现的最终目标。入口是,博客园文章列表页每页有20篇文章文章,最多可以翻到200页。我的爬虫要做的就是异步并发的爬取这4000个文章的具体内容,得到一些我们想要的关键数据。
爬虫进程
看到最后的结果,我们来看看如何通过一个简单的nodejs爬虫一步步的获取我们想要的数据。首先简单普及一下爬虫流程。完成一个爬虫,主要的步骤分为:
抓住
爬虫最重要的一步就是如何检索到想要的页面。并且可以兼顾时间效率,可以同时抓取多个页面。
同时,为了获取目标内容,我们需要分析页面结构。由于ajax的盛行,很多页面内容无法通过一个url来请求。通常,一个页面的内容是在多次请求后异步生成的。所以这就要求我们能够使用抓包工具来分析页面结构。
如果再深入,你会发现你要面对不同的web需求,比如认证、不同的文件格式、编码处理、各种奇怪的URL合规处理、重复爬取问题、cookies跟随问题、多线程等一系列进程爬取、多节点爬取、爬取调度、资源压缩等问题。
所以第一步就是把网页拉回来,慢慢的就会发现各种问题等着你去优化。
贮存
在抓取页面内容的时候,一般不会直接分析,而是通过一定的策略保存。我个人认为更好的结构应该是将分析和爬行分开,并且更松散一些,每个环节都可以相互隔离。链接中可能出现的问题,易于排查或更新发布。
那么如何保存文件系统,SQL或者NOSQL数据库,内存数据库,就是这个环节的重点。
分析
对于网页的文本分析,是提取链接还是提取文本,这取决于您的需求,但您要做的就是分析链接。通常分析和存储会交替进行。您可以使用您认为最快和最好的方法,例如正则表达式。然后将分析结果应用到其他链接。
展示
如果你做了很多事情,根本没有显示输出,如何显示值?
因此,找到一个好的展示元件,展示肌肉也是关键。
如果你写一个爬虫是为了做一个站点,或者你想分析一些东西的数据,不要忘记这个链接,以便更好地向其他人展示结果。
编写爬虫代码 Step.1 页面分析
现在我们一步一步完成我们的爬虫。目标是抓取博客园第1-200页的4000篇文章,获取其中的作者信息,并保存分析。
一共4000个文章,所以首先我们需要拿到这4000个文章的入口,然后异步并发请求4000个文章的内容。但是这4000个文章的入口URL分布在200页。所以我们需要做的第一步就是从这 200 个页面中提取 4000 个 URL。并且通过异步并发,当采集到 4000 个 URL 时,进行下一步。所以现在我们的目标非常明确:
Step2.获取4000个文章入口网址
要得到这么多的URL,首先要从分析单个页面开始,F12打开devtools。很容易发现文章入口链接存放在类titlelnk的标签中,所以4000个URL需要我们轮询200个列表页面,每页保存20个链接。那么如何异步并发从200个页面中采集这4000个URL,继续搜索规则,查看每个页面的列表页面的URL结构:
那么,第1~200页的列表页面的URL应该是这样的:
<p>for(var i=1 ; i
js 爬虫抓取网页数据(js爬虫对网页源码解析的最便捷也最耗时的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-22 08:00
js爬虫抓取网页数据时,有一些传统的动作,比如获取源代码的network等,我一直觉得网页中包含有大量的文字,设计地点编码理解以及对网页的分析调试非常耗时间,毕竟要读取很多网页文件。这篇文章介绍一下在正则表达式中,我看到过的对网页源码解析的最便捷也最耗时的方法,在requests中。抓取网页network,就是在html文件中定义好的一些字符,在发起请求时,会将你发起的html链接,附带上network的url,然后在requests模块中,就可以通过.request对接request.session获取html文件了。
经测试,经过小小修改,.request是一个字符串,session里面定义了几个字段都可以传入。在requests模块中,定义了两个session,并且给它们设定了默认的重置功能。这里在后面还会详细介绍重置机制:requests模块中默认把session分为三类:原始session,重定向session,全局session,也就是说,如果你的session在全局内部发生过重定向,那么你的会话就会被清空,requests会尝试把它推送到原始的session中。
1.原始sessionrequests-vip:2error:cannotfindinheritthefullincomingheaders[ormemberport]我尝试了很多遍,都是signal=evhost这里,我又看了看secret,确认一下我的secret跟它相同hero:1hp=make_cars_vipport=43981isnew_text='text''signal=evhostsecret=evhostorhp=new_textrequests模块为原始session做了加密处理,验证手机号,密码,hp等三方的权限是否为private。
由于requests模块有四个session,也就是说,对于requests来说,还要在同一个会话里面定义4个session,太耗时了。不用担心,requests对应的session.open()方法,是把一个session开放给四个不同的session来使用,比如这样:fromrequestsimportsessionsession.open("e:/hydata/huawei/system.china.ini")不过如果你用requests-vip定义多个session,如何保证所有session都使用相同的相同权限呢?这时候用到了protocolsecret。
在发起请求时,传入一个secret:signal参数,防止服务器通过:getmsg(secret)返回user_agent.正则表达式这里先解释一下正则表达式。正则表达式可以对txt文件中每一个不同的字符串,例如”xxx.txt“,进行解析。与加密的正则表达式不同,解析数据前,先用正则表达式分割数据。
例如,想获取一个url地址,url是”/#menu/”中的url,怎么获取每一个url地址,其实是一个正则表达。 查看全部
js 爬虫抓取网页数据(js爬虫对网页源码解析的最便捷也最耗时的方法)
js爬虫抓取网页数据时,有一些传统的动作,比如获取源代码的network等,我一直觉得网页中包含有大量的文字,设计地点编码理解以及对网页的分析调试非常耗时间,毕竟要读取很多网页文件。这篇文章介绍一下在正则表达式中,我看到过的对网页源码解析的最便捷也最耗时的方法,在requests中。抓取网页network,就是在html文件中定义好的一些字符,在发起请求时,会将你发起的html链接,附带上network的url,然后在requests模块中,就可以通过.request对接request.session获取html文件了。
经测试,经过小小修改,.request是一个字符串,session里面定义了几个字段都可以传入。在requests模块中,定义了两个session,并且给它们设定了默认的重置功能。这里在后面还会详细介绍重置机制:requests模块中默认把session分为三类:原始session,重定向session,全局session,也就是说,如果你的session在全局内部发生过重定向,那么你的会话就会被清空,requests会尝试把它推送到原始的session中。
1.原始sessionrequests-vip:2error:cannotfindinheritthefullincomingheaders[ormemberport]我尝试了很多遍,都是signal=evhost这里,我又看了看secret,确认一下我的secret跟它相同hero:1hp=make_cars_vipport=43981isnew_text='text''signal=evhostsecret=evhostorhp=new_textrequests模块为原始session做了加密处理,验证手机号,密码,hp等三方的权限是否为private。
由于requests模块有四个session,也就是说,对于requests来说,还要在同一个会话里面定义4个session,太耗时了。不用担心,requests对应的session.open()方法,是把一个session开放给四个不同的session来使用,比如这样:fromrequestsimportsessionsession.open("e:/hydata/huawei/system.china.ini")不过如果你用requests-vip定义多个session,如何保证所有session都使用相同的相同权限呢?这时候用到了protocolsecret。
在发起请求时,传入一个secret:signal参数,防止服务器通过:getmsg(secret)返回user_agent.正则表达式这里先解释一下正则表达式。正则表达式可以对txt文件中每一个不同的字符串,例如”xxx.txt“,进行解析。与加密的正则表达式不同,解析数据前,先用正则表达式分割数据。
例如,想获取一个url地址,url是”/#menu/”中的url,怎么获取每一个url地址,其实是一个正则表达。
js 爬虫抓取网页数据(知乎的数据感兴趣-api,用于简化数据的应用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-21 18:11
一、简介
刚接触爬虫的时候,发现了一个名为“豆瓣女孩”的网站,写了一个简单的程序,可以批量下载图片。后来陆续抢了豆瓣电影、Google+、facejoking等网站。毕集的选题也是抢新浪微博,然后分析博文的传播情况。最近对知乎的数据很感兴趣,所以开发了Node模块知乎-api,简化数据抓取。
一般来说,所谓爬虫无非就是通过程序发送HTTP请求。因此,理论上所有浏览器可以访问的内容都可以通过爬虫进行爬取。
一般来说,我们感兴趣的信息只是页面中数据的某一部分,例如:标签的文字、链接地址、图片地址等。一些网站会提供开放的API(往往有很多限制),那么你只需要直接请求API,就可以得到比较干净的数据,比如Google+。对于那些没有开放API的网站,需要发送HTTP请求获取页面数据,然后解析页面获取需要的数据。但是,网站 的部分页面内容是通过脚本动态生成的。这种情况下,需要做的事情比较多,后面会提到。
二、发送请求
回想一下 HTTP 请求的基本组成部分:请求行、标头和请求正文。发送请求与这三部分密切相关,需要注意的主要有:url、method、headers和body。在这里,DevTools 在查看每个请求的详细信息方面会起到非常重要的作用。
对于标题,需要注意的主要事项是:
三、模拟登录
很多网站需要登录才能获取内容。登录的最简单方法是用户名和密码。在这种情况下,您可以通过程序维护一个会话,使用用户名和密码登录,然后使用会话发送请求。
但是现在很多网站登录比较复杂,有的需要输入复杂的验证码,有的还需要手机验证。这些情况往往比较麻烦。如果还是用Session的方法,通常实现起来比较麻烦。考虑到Session只是维护一些状态如Cookies,在这种情况下,直接用Cookie来模拟登录是一种简单粗暴的方法。.
使用cookies模拟登录是指用户首先在浏览器中登录网站,然后复制cookie信息设置请求的cookie头。
四、页面分析
在很多情况下,爬虫抓取的内容是一个 HTML 页面或 HTML 片段。为了提取我们需要的数据,我们需要对其进行分析。常见的解析方法有:
对于一些比较简单的数据提取,比如提取页面中的所有图片地址,可以使用常规规则来完成。但是对于一些复杂的分析,常用的方法是通过DOM。
五、多线程爬取
一次发送一个请求效率太低。为了实现快速的数据捕获,经常使用多线程来捕获。
对于Node.js来说,虽然是单线程执行,但是因为是异步IO,其实跟多线程的效果差不多。
六、反爬虫
许多网站已经为爬虫设置了反爬虫机制。常见的有:
七、其他动态内容:对于很多网页的动态内容,可以通过DevTools查看。对于更复杂的动态内容,可以考虑使用 Selenium 和 Phantomjs。
数据存储:对于多媒体文件,直接保存文件。对于JSON格式的数据,使用MongoDB非常方便。
容错机制:请求失败可能有多种情况。如果访问频率过快,可以考虑暂停一段时间,或者更换账号或IP。如果是404,可以直接跳过fetch。但是,有些站点返回的HTTP状态码不一定符合其初衷。所以也可以考虑统一容错处理,比如重试n次,失败则丢弃。
大规模分布式爬取:暂时没有太多研究,以后可能会开新文章文章。
常用工具:Python 的 requests 和 BeautifulSoup,Node 的 requests 和cheerio。 查看全部
js 爬虫抓取网页数据(知乎的数据感兴趣-api,用于简化数据的应用方法)
一、简介
刚接触爬虫的时候,发现了一个名为“豆瓣女孩”的网站,写了一个简单的程序,可以批量下载图片。后来陆续抢了豆瓣电影、Google+、facejoking等网站。毕集的选题也是抢新浪微博,然后分析博文的传播情况。最近对知乎的数据很感兴趣,所以开发了Node模块知乎-api,简化数据抓取。
一般来说,所谓爬虫无非就是通过程序发送HTTP请求。因此,理论上所有浏览器可以访问的内容都可以通过爬虫进行爬取。
一般来说,我们感兴趣的信息只是页面中数据的某一部分,例如:标签的文字、链接地址、图片地址等。一些网站会提供开放的API(往往有很多限制),那么你只需要直接请求API,就可以得到比较干净的数据,比如Google+。对于那些没有开放API的网站,需要发送HTTP请求获取页面数据,然后解析页面获取需要的数据。但是,网站 的部分页面内容是通过脚本动态生成的。这种情况下,需要做的事情比较多,后面会提到。
二、发送请求
回想一下 HTTP 请求的基本组成部分:请求行、标头和请求正文。发送请求与这三部分密切相关,需要注意的主要有:url、method、headers和body。在这里,DevTools 在查看每个请求的详细信息方面会起到非常重要的作用。
对于标题,需要注意的主要事项是:
三、模拟登录
很多网站需要登录才能获取内容。登录的最简单方法是用户名和密码。在这种情况下,您可以通过程序维护一个会话,使用用户名和密码登录,然后使用会话发送请求。
但是现在很多网站登录比较复杂,有的需要输入复杂的验证码,有的还需要手机验证。这些情况往往比较麻烦。如果还是用Session的方法,通常实现起来比较麻烦。考虑到Session只是维护一些状态如Cookies,在这种情况下,直接用Cookie来模拟登录是一种简单粗暴的方法。.
使用cookies模拟登录是指用户首先在浏览器中登录网站,然后复制cookie信息设置请求的cookie头。
四、页面分析
在很多情况下,爬虫抓取的内容是一个 HTML 页面或 HTML 片段。为了提取我们需要的数据,我们需要对其进行分析。常见的解析方法有:
对于一些比较简单的数据提取,比如提取页面中的所有图片地址,可以使用常规规则来完成。但是对于一些复杂的分析,常用的方法是通过DOM。
五、多线程爬取
一次发送一个请求效率太低。为了实现快速的数据捕获,经常使用多线程来捕获。
对于Node.js来说,虽然是单线程执行,但是因为是异步IO,其实跟多线程的效果差不多。
六、反爬虫
许多网站已经为爬虫设置了反爬虫机制。常见的有:
七、其他动态内容:对于很多网页的动态内容,可以通过DevTools查看。对于更复杂的动态内容,可以考虑使用 Selenium 和 Phantomjs。
数据存储:对于多媒体文件,直接保存文件。对于JSON格式的数据,使用MongoDB非常方便。
容错机制:请求失败可能有多种情况。如果访问频率过快,可以考虑暂停一段时间,或者更换账号或IP。如果是404,可以直接跳过fetch。但是,有些站点返回的HTTP状态码不一定符合其初衷。所以也可以考虑统一容错处理,比如重试n次,失败则丢弃。
大规模分布式爬取:暂时没有太多研究,以后可能会开新文章文章。
常用工具:Python 的 requests 和 BeautifulSoup,Node 的 requests 和cheerio。
js 爬虫抓取网页数据(这篇文章主要介绍了的相关资料,DOM化并解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-11-20 07:03
本文文章主要介绍nodejs爬虫爬取数据编码问题的相关信息。有需要的朋友可以参考
当cheerio被DOM化和解析时
1.如果使用.text()方法,一般不会出现html实体编码问题
2. 如果使用.html()方法,很多情况下都会出现(主要是非英文的时候)。这时候可能就需要转义了。
类似这些因为需要数据存储,都需要进行转换
复制代码代码如下:
Халк крушит。Новый способ исполнен
大部分都是(x)?\w+的格式
所以只需使用常规转换
var body = ....//这里就是请求后获得的返回数据,或者那些 .html()后获取的 //一般可以先转换为标准unicode格式(有需要就添加:当返回的数据呈现太多\\\u 之类的时) body=unescape(body.replace(/\\u/g,"%u")); //再对实体符进行转义 //有x则表示是16进制,$1就是匹配是否有x ,$2就是匹配出的第二个括号捕获到的内容,将$2以对应进制表示转换 body = body.replace(/&#(x)?(\w+);/g,function($,$1,$2){ return String.fromCharCode(parseInt($2,$1?16:10)); });
好的~
当然,网上也有很多转换版本,申请就好。
后记:
使用爬虫抓取网页数据时,经常用到cheerio模块到最后,和jq一样方便快捷
(但是有些功能不支持或者改成某种形式,比如jq的jQuery('.myClass').prop('outerHTML'),cheerio就相当于jQuery.html('.myClass'))
以上就是nodejs爬虫爬取数据编码问题的详细内容。更多信息请关注其他相关html中文网站文章! 查看全部
js 爬虫抓取网页数据(这篇文章主要介绍了的相关资料,DOM化并解析)
本文文章主要介绍nodejs爬虫爬取数据编码问题的相关信息。有需要的朋友可以参考
当cheerio被DOM化和解析时
1.如果使用.text()方法,一般不会出现html实体编码问题
2. 如果使用.html()方法,很多情况下都会出现(主要是非英文的时候)。这时候可能就需要转义了。
类似这些因为需要数据存储,都需要进行转换
复制代码代码如下:
Халк крушит。Новый способ исполнен
大部分都是(x)?\w+的格式
所以只需使用常规转换
var body = ....//这里就是请求后获得的返回数据,或者那些 .html()后获取的 //一般可以先转换为标准unicode格式(有需要就添加:当返回的数据呈现太多\\\u 之类的时) body=unescape(body.replace(/\\u/g,"%u")); //再对实体符进行转义 //有x则表示是16进制,$1就是匹配是否有x ,$2就是匹配出的第二个括号捕获到的内容,将$2以对应进制表示转换 body = body.replace(/&#(x)?(\w+);/g,function($,$1,$2){ return String.fromCharCode(parseInt($2,$1?16:10)); });
好的~
当然,网上也有很多转换版本,申请就好。
后记:
使用爬虫抓取网页数据时,经常用到cheerio模块到最后,和jq一样方便快捷
(但是有些功能不支持或者改成某种形式,比如jq的jQuery('.myClass').prop('outerHTML'),cheerio就相当于jQuery.html('.myClass'))
以上就是nodejs爬虫爬取数据编码问题的详细内容。更多信息请关注其他相关html中文网站文章!
js 爬虫抓取网页数据(Python爬虫网页基本上就是一行代码一行的难度分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-19 15:08
写爬虫是非常考验综合实力的。有时,您可以轻松获得所需的数据;有时候,你很努力,却一无所获。
很多Python爬虫的入门教程都是一行代码把你骗进“贼船”,上了贼船才发现,水好深~
例如,抓取一个网页可以是一行非常简单的代码:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是抓取一个网页,一个有用的爬虫远不止抓取一个网页。
一个有用的爬虫只需要两个词来衡量:
但是要实现这两个词,需要做很多工作。自己努力是一方面,但也很重要的是你要掌握的网站给了你多少问题。综合起来,写一个爬虫是多么的困难。
网络爬虫难点一:只需要爬html网页就可以放大
这里我们举一个新闻爬虫的例子。大家都用过百度的新闻搜索,我就用它的爬虫来谈谈实现的难度。
新闻网站基本不设防,新闻内容都在网页的html代码中,整个网页基本是一行的东西。听起来很简单,但是对于一个搜索引擎级别的爬虫来说,就没有那么简单了。要及时捕捉到数以万计的新闻网站的新闻并不容易。
我们来看一下新闻爬虫的简单流程图:
从一些种子网页开始,种子网页往往是一些新闻的首页网站。爬虫爬取网页,从中提取出网站 URL,放入URL池,然后爬取。这从几个网页开始,并继续扩展到其他网页。越来越多的网页被爬虫抓取,提取的新网站网址也会成倍增长。
如何在最短的时间内抓取更多的网址?
这是困难之一。这不是目标 URL 造成的,而是对我们自己的意志的测试:
怎样才能及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?数以千计的新闻源网站时刻发布最新消息。爬虫在爬取“旧”新闻的同时,如何获取“新”新闻?
如何存储捕获的海量新闻?
爬虫编织式的爬取会翻出几十年前网站几年前的每一个新闻网页,从而需要存储大量的网页。这是存储的难点。
如何清理和提取网页内容?
快速准确地从新闻网页的html中提取所需的信息数据,如标题、发布时间、正文内容等,给内容提取带来了难度。
网络爬虫难点2:需要登录才能获取你想要的数据
人们很贪婪,想要无穷无尽的数据,但很多数据对您来说并不容易。有一大类数据只有在账号登录后才能看到,也就是说爬虫请求必须处于登录状态才能抓取到数据。
如何获取登录状态? 查看全部
js 爬虫抓取网页数据(Python爬虫网页基本上就是一行代码一行的难度分析)
写爬虫是非常考验综合实力的。有时,您可以轻松获得所需的数据;有时候,你很努力,却一无所获。
很多Python爬虫的入门教程都是一行代码把你骗进“贼船”,上了贼船才发现,水好深~
例如,抓取一个网页可以是一行非常简单的代码:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是抓取一个网页,一个有用的爬虫远不止抓取一个网页。
一个有用的爬虫只需要两个词来衡量:
但是要实现这两个词,需要做很多工作。自己努力是一方面,但也很重要的是你要掌握的网站给了你多少问题。综合起来,写一个爬虫是多么的困难。
网络爬虫难点一:只需要爬html网页就可以放大
这里我们举一个新闻爬虫的例子。大家都用过百度的新闻搜索,我就用它的爬虫来谈谈实现的难度。
新闻网站基本不设防,新闻内容都在网页的html代码中,整个网页基本是一行的东西。听起来很简单,但是对于一个搜索引擎级别的爬虫来说,就没有那么简单了。要及时捕捉到数以万计的新闻网站的新闻并不容易。
我们来看一下新闻爬虫的简单流程图:
从一些种子网页开始,种子网页往往是一些新闻的首页网站。爬虫爬取网页,从中提取出网站 URL,放入URL池,然后爬取。这从几个网页开始,并继续扩展到其他网页。越来越多的网页被爬虫抓取,提取的新网站网址也会成倍增长。
如何在最短的时间内抓取更多的网址?
这是困难之一。这不是目标 URL 造成的,而是对我们自己的意志的测试:
怎样才能及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?数以千计的新闻源网站时刻发布最新消息。爬虫在爬取“旧”新闻的同时,如何获取“新”新闻?
如何存储捕获的海量新闻?
爬虫编织式的爬取会翻出几十年前网站几年前的每一个新闻网页,从而需要存储大量的网页。这是存储的难点。
如何清理和提取网页内容?
快速准确地从新闻网页的html中提取所需的信息数据,如标题、发布时间、正文内容等,给内容提取带来了难度。
网络爬虫难点2:需要登录才能获取你想要的数据
人们很贪婪,想要无穷无尽的数据,但很多数据对您来说并不容易。有一大类数据只有在账号登录后才能看到,也就是说爬虫请求必须处于登录状态才能抓取到数据。
如何获取登录状态?
js 爬虫抓取网页数据(Python网络爬虫动态网页详解(一)(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-18 04:09
1.动态网页指的是几种可能:
1) 需要用户交互,比如常见的登录操作;
2)网页是通过/AJAX动态生成的,如果html中有,则是JS生成
啊啊啊
;
3) 点击输入关键字查询,浏览器url地址不变
2.在网站中使用Python获取JavaScript返回的数据,目前有两种方法:
第一种方法:直接url法
(1) 仔细分析页面结构,检查js响应的动作;
(2)借助firfox的firebug分析js点击动作发送的请求url;
(3) 使用这个异步请求url作为scrapy的start_url或者yield请求再次获取。
方法二:借助硒
Selenium基于并结合其WebDriver来模拟用户的真实操作。它具有良好的Ajax处理能力,支持多种浏览器(Safari、IE、Firefox、Chrome),可以在多种操作系统上运行。Selenium 可以调用浏览器的API 接口,selenium 会打开一个浏览器,然后在新打开的浏览器中执行程序中模拟的动作。
如图:
3. 安装下面的 Selenium 模块:
4.浏览器选择:Selenium Webdriver主要在编写Python网络爬虫时使用。Selenium.Webdriver 不能支持所有浏览器,也没有必要支持所有浏览器。
Webdriver 支持列表:
5.安装 PhantomJS:
下载解压后,放入python文件夹中:
windows下PhantomJS环境配置好后,测试成功:
6.Selenium&PhantomJS 抓取数据:
(1)网站获取返回的数据
(2)定位“有效数据”的位置
(3)从定位中获取“有效数据”
7.以百度搜索为例,使用百度搜索“python selenium”,保存搜索结果第一页的标题和链接:
(1) 获取搜索结果:用Selenium&PhantomJS直接打开百度首页,然后模拟搜索关键词
(2) 定位表单框或“有效数据”位置,可以使用import导入bs4来完成,也可以使用Selenium自带的功能来完成:一共有8种F方法来定位“有效数据”数据”来自返回的数据:
可以看到文本框中有class、name、id属性,可以使用find_element_by_class_name、find_element_by_id、find_element_by_name来定位:
选择以下三种定位功能之一:
textElement=browser.find_element_by_class_name('s_ipt')
textElement=browser.find_element_by_id('kw')
textElement=browser.find_element_by_name('wd')
发送搜索关键字:
textElement.send_keys('python selenium')
找到提交按钮:
从图中可以看出,提交按钮有id和class属性,可以通过find_element_by_class_name和find_element_by_id来定位:
8. 获取有效数据的地方:首先定位搜索结果的标题和链接:查看搜索结果的源代码:
找到一个特殊属性:class="c-tools",搜索这个属性:
一共找到12个条目,第二个搜索结果的标题与搜索页面上的第二个搜索结果相同。可以确定所有搜索结果都收录 class="c-tools" 标签
您可以使用 find_element_by_class_name 来定位所有搜索结果:
9. 从位置获取有效数据:确定有效数据的位置后,如何从该位置过滤掉有效数据?
Selenium 有自己独特的方法:
元素.文本()
element.get_attribute(name)
需要的有效数据是data-tools属性的值:执行命令
遍历resultElements列表,可以得到所有搜索结果的title和url。 查看全部
js 爬虫抓取网页数据(Python网络爬虫动态网页详解(一)(1))
1.动态网页指的是几种可能:
1) 需要用户交互,比如常见的登录操作;
2)网页是通过/AJAX动态生成的,如果html中有,则是JS生成
啊啊啊
;
3) 点击输入关键字查询,浏览器url地址不变
2.在网站中使用Python获取JavaScript返回的数据,目前有两种方法:
第一种方法:直接url法
(1) 仔细分析页面结构,检查js响应的动作;
(2)借助firfox的firebug分析js点击动作发送的请求url;
(3) 使用这个异步请求url作为scrapy的start_url或者yield请求再次获取。
方法二:借助硒
Selenium基于并结合其WebDriver来模拟用户的真实操作。它具有良好的Ajax处理能力,支持多种浏览器(Safari、IE、Firefox、Chrome),可以在多种操作系统上运行。Selenium 可以调用浏览器的API 接口,selenium 会打开一个浏览器,然后在新打开的浏览器中执行程序中模拟的动作。
如图:
3. 安装下面的 Selenium 模块:
4.浏览器选择:Selenium Webdriver主要在编写Python网络爬虫时使用。Selenium.Webdriver 不能支持所有浏览器,也没有必要支持所有浏览器。
Webdriver 支持列表:
5.安装 PhantomJS:
下载解压后,放入python文件夹中:
windows下PhantomJS环境配置好后,测试成功:
6.Selenium&PhantomJS 抓取数据:
(1)网站获取返回的数据
(2)定位“有效数据”的位置
(3)从定位中获取“有效数据”
7.以百度搜索为例,使用百度搜索“python selenium”,保存搜索结果第一页的标题和链接:
(1) 获取搜索结果:用Selenium&PhantomJS直接打开百度首页,然后模拟搜索关键词
(2) 定位表单框或“有效数据”位置,可以使用import导入bs4来完成,也可以使用Selenium自带的功能来完成:一共有8种F方法来定位“有效数据”数据”来自返回的数据:
可以看到文本框中有class、name、id属性,可以使用find_element_by_class_name、find_element_by_id、find_element_by_name来定位:
选择以下三种定位功能之一:
textElement=browser.find_element_by_class_name('s_ipt')
textElement=browser.find_element_by_id('kw')
textElement=browser.find_element_by_name('wd')
发送搜索关键字:
textElement.send_keys('python selenium')
找到提交按钮:
从图中可以看出,提交按钮有id和class属性,可以通过find_element_by_class_name和find_element_by_id来定位:
8. 获取有效数据的地方:首先定位搜索结果的标题和链接:查看搜索结果的源代码:
找到一个特殊属性:class="c-tools",搜索这个属性:
一共找到12个条目,第二个搜索结果的标题与搜索页面上的第二个搜索结果相同。可以确定所有搜索结果都收录 class="c-tools" 标签
您可以使用 find_element_by_class_name 来定位所有搜索结果:
9. 从位置获取有效数据:确定有效数据的位置后,如何从该位置过滤掉有效数据?
Selenium 有自己独特的方法:
元素.文本()
element.get_attribute(name)
需要的有效数据是data-tools属性的值:执行命令
遍历resultElements列表,可以得到所有搜索结果的title和url。
js 爬虫抓取网页数据(代码也可以从我的开源项目HtmlExtractor中获取。。 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-17 01:02
)
代码也可以从我的开源项目HtmlExtractor获取。
我们在抓取数据的时候,如果目标网站是在Js中动态生成数据,通过滚动来分页,那我们怎么抓取呢?
类似于今日头条网站:
我们可以使用 Selenium 来做到这一点。尽管 Selenium 是为 Web 应用程序的自动化测试而设计的,但它非常适合用于数据捕获。可以轻松绕过网站的反爬虫限制,因为Selenium直接运行在浏览器中,就像真实用户在操作一样。
使用Selenium,我们不仅可以抓取Js动态生成的网页,还可以抓取滚动页面分页的网页。
首先我们使用maven来引入Selenium依赖:
< dependency >
< groupId >org.seleniumhq.selenium
< artifactId >selenium-java
< version >2.47.1
接下来就可以编写代码进行捕获了:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000 ;
int waitLoadRandomTime = 3000 ;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get( "http://toutiao.com/" );
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages= 5 ;
for ( int i= 0 ; i 查看全部
js 爬虫抓取网页数据(代码也可以从我的开源项目HtmlExtractor中获取。。
)
代码也可以从我的开源项目HtmlExtractor获取。
我们在抓取数据的时候,如果目标网站是在Js中动态生成数据,通过滚动来分页,那我们怎么抓取呢?
类似于今日头条网站:
我们可以使用 Selenium 来做到这一点。尽管 Selenium 是为 Web 应用程序的自动化测试而设计的,但它非常适合用于数据捕获。可以轻松绕过网站的反爬虫限制,因为Selenium直接运行在浏览器中,就像真实用户在操作一样。
使用Selenium,我们不仅可以抓取Js动态生成的网页,还可以抓取滚动页面分页的网页。
首先我们使用maven来引入Selenium依赖:
< dependency >
< groupId >org.seleniumhq.selenium
< artifactId >selenium-java
< version >2.47.1
接下来就可以编写代码进行捕获了:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000 ;
int waitLoadRandomTime = 3000 ;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get( "http://toutiao.com/" );
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages= 5 ;
for ( int i= 0 ; i
js 爬虫抓取网页数据( Python网络爬虫内容提取器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-17 01:01
Python网络爬虫内容提取器)
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
三、源代码和实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:利用直观的采集和搜索客户标记功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试,python3.2,源码下载地址可在文章末尾的GitHub上找到),请注意:xslt是比较长的字符串,如果删除这个字符串,代码不是几行,足以展示Python的强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url="http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser=webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:可以看到网页上的手机名称和价格已经被正确抓取了。
4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次性从网页中提取出需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工写的,而是程序自动生成的,这就说得通了,程序员不再花时间编写和调试捕获规则,这是一项非常耗时费力的工作。下一篇《1分钟快速生成用于Web内容提取的Xslt》将介绍如何生成xslt。
5.采集GooSeeker开源代码下载源码
1.GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址 查看全部
js 爬虫抓取网页数据(
Python网络爬虫内容提取器)
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
三、源代码和实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:利用直观的采集和搜索客户标记功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试,python3.2,源码下载地址可在文章末尾的GitHub上找到),请注意:xslt是比较长的字符串,如果删除这个字符串,代码不是几行,足以展示Python的强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url="http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser=webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:可以看到网页上的手机名称和价格已经被正确抓取了。
4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次性从网页中提取出需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工写的,而是程序自动生成的,这就说得通了,程序员不再花时间编写和调试捕获规则,这是一项非常耗时费力的工作。下一篇《1分钟快速生成用于Web内容提取的Xslt》将介绍如何生成xslt。
5.采集GooSeeker开源代码下载源码
1.GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址
js 爬虫抓取网页数据(什么是HTML静态生成的内容?如何对网页进行爬取呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-17 00:23
我们之前抓取的网页大多是 HTML 静态生成的内容。我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但是在HTML源代码中是找不到的。比如今天的头条新闻:
浏览器呈现的网页如下所示:
查看源代码,它看起来像这样:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:
# 编码:utf-8
进口请求
导入json
网址 ='#39;
wbdata = requests.get(url).text
数据 = json.loads(wbdata)
新闻 = 数据['数据']['pc_feed_focus']
对于新闻中的 n:
标题 = n['标题']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# 编码:utf-8
进口请求
导入json
第二部分:向数据接口发出http请求
网址 ='#39;
wbdata = requests.get(url).text 查看全部
js 爬虫抓取网页数据(什么是HTML静态生成的内容?如何对网页进行爬取呢?)
我们之前抓取的网页大多是 HTML 静态生成的内容。我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但是在HTML源代码中是找不到的。比如今天的头条新闻:
浏览器呈现的网页如下所示:
查看源代码,它看起来像这样:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:
# 编码:utf-8
进口请求
导入json
网址 ='#39;
wbdata = requests.get(url).text
数据 = json.loads(wbdata)
新闻 = 数据['数据']['pc_feed_focus']
对于新闻中的 n:
标题 = n['标题']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# 编码:utf-8
进口请求
导入json
第二部分:向数据接口发出http请求
网址 ='#39;
wbdata = requests.get(url).text

