
js 爬虫抓取网页数据
js 爬虫抓取网页数据( Control的异步和回调知识的逻辑 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-09 00:00
Control的异步和回调知识的逻辑
)
Node.js写爬虫的基本思路,分享抓拍百度图片的例子
更新时间:2016-03-12 17:32:27 作者:qiaolevip
本文文章主要介绍了Node.js编写爬虫的基本思路以及抓取百度图片的例子分享。笔者提到要特别注意GBK转码的转码问题。有需要的朋友可以参考以下
其实写爬虫的思路很简单:
但是当我真正写这个爬虫的时候,还是遇到了很多问题(跟我的基础不够扎实有很大关系,没有认真研究node.js)。主要原因是node.js的异步和回调知识没有完全掌握,导致在写代码的过程中走了不少弯路。
模块化的
模块化对于 node.js 程序非常重要。不能像原来PHP写的那样把所有代码都扔到一个文件里(当然这只是我个人的恶习),所以我们必须从头分析这个爬虫需要实现的功能。,并大致分为三个模块。
主程序,调用爬虫模块和持久化模块,实现完整的爬虫功能
爬虫模块根据传入的数据发送请求,解析HTML并提取有用的数据,并返回一个对象
持久化模块接受一个对象并将其内容存储在数据库中
模块化也带来了一个困扰我一下午的问题:模块间异步调用导致数据错误。其实我还是不太明白是什么问题。鉴于脚本语言的调试功能不方便,我还没有深入研究。
还有一点需要注意的是,在模块化的时候,尽量使用全局对象来小心地存储数据,因为可能你的模块的某个功能还没有结束,全局变量已经被修改了。
控制流
这个东西很难翻译,字面意思就是控制流(?)。众所周知,node.js的核心思想是异步的,但是异步多了会产生好几层嵌套,代码真的很丑。这时候就需要使用一些控制流模块来重新安排你的逻辑。我们在这里推荐 async.js(),它在开发社区中非常活跃并且易于使用。
async 提供了很多实用的方法,我主要在写爬虫的时候用
这些控制流方式给爬虫的开发带来了极大的便利。考虑这样一个应用场景。需要向数据库中插入多条数据(属于同一个学生),并且需要在所有数据插入后返回结果。那么如何保证所有的插入操作都完成呢?只能通过层层回调来保证,使用async.parallel就方便多了。
我想在这里再提一件事。最初保证所有插入都完成。这个操作可以在SQL层实现,也就是事务,但是node-mysql在我使用的时候还是不能很好的支持事务,所以只好手动使用代码来保证。
解析 HTML
解析过程中也遇到了一些问题,这里记录一下。
发送HTTP请求获取HTML代码最基本的方式是使用node自带的http.request函数。如果是抓取简单的内容,比如获取指定id元素中的内容(常用于抓取产品价格),那么规律性就足以完成任务。但是对于复杂的页面,尤其是数据项较多的页面,使用DOM会更加方便高效。
node.js 中最好的 DOM 实现是cheerio()。其实cheerio应该算是jQuery的一个子集,针对DOM操作进行了优化和精简,包括了DOM操作的大部分内容,去掉了其他不必要的内容。使用cheerio,您可以像使用普通的jQuery 选择器一样选择您需要的内容。
下载图片
在抓取数据的时候,我们可能还需要下载图片。其实下载图片的方式和普通网页的下载方式并没有太大区别,但是有件事让我很苦恼。
注意下面代码中的猛烈注释,那是我小时候犯的错误……
var req = http.request(options, function(res){
//初始化数据!!!
var binImage = '';
res.setEncoding('binary');
res.on('data', function(chunk){
binImage += chunk;
});
res.on('end', function(){
if (!binImage) {
console.log('image data is null');
return null;
}
fs.writeFile(imageFolder + filename, binImage, 'binary', function(err){
if (err) {
console.log('image writing error:' + err.message);
return null;
}
else{
console.log('image ' + filename + ' saved');
return filename;
}
});
});
res.on('error', function(e){
console.log('image downloading response error:' + e.message);
return null;
});
});
req.end();
GBK转码
另一个值得说明的问题是node.js爬虫爬取GBK编码内容时的转码问题。其实这个问题很容易解决,只是新手可能会少走弯路。这是源代码:
var req = http.request(options, function(res) {
res.setEncoding('binary');
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function(){
//转换编码
html = iconv.decode(html, 'gbk');
});
});
req.end();
我这里使用的转码库是iconv-lite(),完美支持GBK、GB2312等双字节编码。
示例:爬虫批量下载百度图片
<p>
var fs = require('fs'),
path = require('path'),
util = require('util'), // 以上为Nodejs自带依赖包
request = require('request'); // 需要npm install的包
// main函数,使用 node main执行即可
patchPreImg();
// 批量处理图片
function patchPreImg() {
var tag1 = '摄影', tag2 = '国家地理',
url = 'http://image.baidu.com/data/imgs?pn=%s&rn=60&p=channel&from=1&col=%s&tag=%s&sort=1&tag3=',
url = util.format(url, 0, tag1, tag2),
url = encodeURI(url),
dir = 'D:/downloads/images/',
dir = path.join(dir, tag1, tag2),
dir = mkdirSync(dir);
request(url, function(error, response, html) {
var data = JSON.parse(html);
if (data && Array.isArray(data.imgs)) {
var imgs = data.imgs;
imgs.forEach(function(img) {
if (Object.getOwnPropertyNames(img).length > 0) {
var desc = img.desc || ((img.owner && img.owner.userName) + img.column);
desc += '(' + img.id + ')';
var downloadUrl = img.downloadUrl || img.objUrl;
downloadImg(downloadUrl, dir, desc);
}
});
}
});
}
// 循环创建目录
function mkdirSync(dir) {
var parts = dir.split(path.sep);
for (var i = 1; i 查看全部
js 爬虫抓取网页数据(
Control的异步和回调知识的逻辑
)
Node.js写爬虫的基本思路,分享抓拍百度图片的例子
更新时间:2016-03-12 17:32:27 作者:qiaolevip
本文文章主要介绍了Node.js编写爬虫的基本思路以及抓取百度图片的例子分享。笔者提到要特别注意GBK转码的转码问题。有需要的朋友可以参考以下
其实写爬虫的思路很简单:
但是当我真正写这个爬虫的时候,还是遇到了很多问题(跟我的基础不够扎实有很大关系,没有认真研究node.js)。主要原因是node.js的异步和回调知识没有完全掌握,导致在写代码的过程中走了不少弯路。
模块化的
模块化对于 node.js 程序非常重要。不能像原来PHP写的那样把所有代码都扔到一个文件里(当然这只是我个人的恶习),所以我们必须从头分析这个爬虫需要实现的功能。,并大致分为三个模块。
主程序,调用爬虫模块和持久化模块,实现完整的爬虫功能
爬虫模块根据传入的数据发送请求,解析HTML并提取有用的数据,并返回一个对象
持久化模块接受一个对象并将其内容存储在数据库中
模块化也带来了一个困扰我一下午的问题:模块间异步调用导致数据错误。其实我还是不太明白是什么问题。鉴于脚本语言的调试功能不方便,我还没有深入研究。
还有一点需要注意的是,在模块化的时候,尽量使用全局对象来小心地存储数据,因为可能你的模块的某个功能还没有结束,全局变量已经被修改了。
控制流
这个东西很难翻译,字面意思就是控制流(?)。众所周知,node.js的核心思想是异步的,但是异步多了会产生好几层嵌套,代码真的很丑。这时候就需要使用一些控制流模块来重新安排你的逻辑。我们在这里推荐 async.js(),它在开发社区中非常活跃并且易于使用。
async 提供了很多实用的方法,我主要在写爬虫的时候用
这些控制流方式给爬虫的开发带来了极大的便利。考虑这样一个应用场景。需要向数据库中插入多条数据(属于同一个学生),并且需要在所有数据插入后返回结果。那么如何保证所有的插入操作都完成呢?只能通过层层回调来保证,使用async.parallel就方便多了。
我想在这里再提一件事。最初保证所有插入都完成。这个操作可以在SQL层实现,也就是事务,但是node-mysql在我使用的时候还是不能很好的支持事务,所以只好手动使用代码来保证。
解析 HTML
解析过程中也遇到了一些问题,这里记录一下。
发送HTTP请求获取HTML代码最基本的方式是使用node自带的http.request函数。如果是抓取简单的内容,比如获取指定id元素中的内容(常用于抓取产品价格),那么规律性就足以完成任务。但是对于复杂的页面,尤其是数据项较多的页面,使用DOM会更加方便高效。
node.js 中最好的 DOM 实现是cheerio()。其实cheerio应该算是jQuery的一个子集,针对DOM操作进行了优化和精简,包括了DOM操作的大部分内容,去掉了其他不必要的内容。使用cheerio,您可以像使用普通的jQuery 选择器一样选择您需要的内容。
下载图片
在抓取数据的时候,我们可能还需要下载图片。其实下载图片的方式和普通网页的下载方式并没有太大区别,但是有件事让我很苦恼。
注意下面代码中的猛烈注释,那是我小时候犯的错误……
var req = http.request(options, function(res){
//初始化数据!!!
var binImage = '';
res.setEncoding('binary');
res.on('data', function(chunk){
binImage += chunk;
});
res.on('end', function(){
if (!binImage) {
console.log('image data is null');
return null;
}
fs.writeFile(imageFolder + filename, binImage, 'binary', function(err){
if (err) {
console.log('image writing error:' + err.message);
return null;
}
else{
console.log('image ' + filename + ' saved');
return filename;
}
});
});
res.on('error', function(e){
console.log('image downloading response error:' + e.message);
return null;
});
});
req.end();
GBK转码
另一个值得说明的问题是node.js爬虫爬取GBK编码内容时的转码问题。其实这个问题很容易解决,只是新手可能会少走弯路。这是源代码:
var req = http.request(options, function(res) {
res.setEncoding('binary');
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function(){
//转换编码
html = iconv.decode(html, 'gbk');
});
});
req.end();
我这里使用的转码库是iconv-lite(),完美支持GBK、GB2312等双字节编码。
示例:爬虫批量下载百度图片
<p>
var fs = require('fs'),
path = require('path'),
util = require('util'), // 以上为Nodejs自带依赖包
request = require('request'); // 需要npm install的包
// main函数,使用 node main执行即可
patchPreImg();
// 批量处理图片
function patchPreImg() {
var tag1 = '摄影', tag2 = '国家地理',
url = 'http://image.baidu.com/data/imgs?pn=%s&rn=60&p=channel&from=1&col=%s&tag=%s&sort=1&tag3=',
url = util.format(url, 0, tag1, tag2),
url = encodeURI(url),
dir = 'D:/downloads/images/',
dir = path.join(dir, tag1, tag2),
dir = mkdirSync(dir);
request(url, function(error, response, html) {
var data = JSON.parse(html);
if (data && Array.isArray(data.imgs)) {
var imgs = data.imgs;
imgs.forEach(function(img) {
if (Object.getOwnPropertyNames(img).length > 0) {
var desc = img.desc || ((img.owner && img.owner.userName) + img.column);
desc += '(' + img.id + ')';
var downloadUrl = img.downloadUrl || img.objUrl;
downloadImg(downloadUrl, dir, desc);
}
});
}
});
}
// 循环创建目录
function mkdirSync(dir) {
var parts = dir.split(path.sep);
for (var i = 1; i
js 爬虫抓取网页数据(js爬虫抓取网页数据,这个相当简单,用extract方法即可)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-08 21:04
js爬虫抓取网页数据,这个相当简单,用extract方法即可,直接将内容全部提取出来。js抓取的是html页面,mongodb的话是针对mongodb,因为其他库,比如presto,pymongo,neo4j都需要https,xmlhttprequest也是如此。
1.与逻辑关系不大。2.没看懂你的图文的逻辑,猜测是由文字拼接成图片,然后存入库吧?那么js就可以直接抓取。你就是百度一下,然后动手做一下呗。加点花俏的手法不难实现。在此基础上,扩展出一套图片导入导出的算法和接口也不难实现。soeasy。
你这里的技术太陈旧了,抓取其实没那么难,我们会用js抓,就是h5的在线轮播,很简单!现在抓取都很傻瓜化!我们做二手车价格查询网站的,
在chrome中安装插件puppeteerradiohead自动说话
有grep的功能,实现功能,写入python文件,然后交给别人打包发布。你要抓取的也是页面,
python/scrapyapipyinstaller就可以做到,
这是个大家都不愿意说的问题,虽然简单,
/pep9438python-scrapy框架python3程序发布的网站验证码解码
telegram欢迎你
题主也是搞python爬虫么, 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据,这个相当简单,用extract方法即可)
js爬虫抓取网页数据,这个相当简单,用extract方法即可,直接将内容全部提取出来。js抓取的是html页面,mongodb的话是针对mongodb,因为其他库,比如presto,pymongo,neo4j都需要https,xmlhttprequest也是如此。
1.与逻辑关系不大。2.没看懂你的图文的逻辑,猜测是由文字拼接成图片,然后存入库吧?那么js就可以直接抓取。你就是百度一下,然后动手做一下呗。加点花俏的手法不难实现。在此基础上,扩展出一套图片导入导出的算法和接口也不难实现。soeasy。
你这里的技术太陈旧了,抓取其实没那么难,我们会用js抓,就是h5的在线轮播,很简单!现在抓取都很傻瓜化!我们做二手车价格查询网站的,
在chrome中安装插件puppeteerradiohead自动说话
有grep的功能,实现功能,写入python文件,然后交给别人打包发布。你要抓取的也是页面,
python/scrapyapipyinstaller就可以做到,
这是个大家都不愿意说的问题,虽然简单,
/pep9438python-scrapy框架python3程序发布的网站验证码解码
telegram欢迎你
题主也是搞python爬虫么,
js 爬虫抓取网页数据(Web应用功能示例SlimerJS示例PhantomJS示例示例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-06 00:25
函数(您可以使用JavaScript模拟浏览器上的几乎任何操作)
用法(与phantom JS无差异):
页面某个区域的屏幕截图,slimerjs和phantom JS示例
Slimerjs示例
var webpage = require('webpage').create();
webpage.open('http://www.meizu.com') // 打开一个网页
.then(function() { // 页面加载完成后执行
//保存页面截屏
webpage.viewportSize = {
width: 650,
height: 320
};
webpage.render('page.png', {
onlyViewport: true
});
//再打开一个网页
return webpage.open('http://bbs.meizu.com');
})
.then(function() {
// 点击某个位置
webpage.sendEvent("click", 5, 5, 'left', 0);
slimer.exit(); //退出
});
幻影JS示例
var webpage = require('webpage').create();
webpage.open('http://www.meizu.com', function (status) {
//打开一个页面
}).then(function(){
//保存页面截屏
webpage.viewportSize = {
width: 650,
height: 320
};
webpage.render('page.png', {
onlyViewport: true
});
//再打开一个网页
return webpage.open('http://bbs.meizu.com');
}).then(function(){
webpage.sendEvent("click", 5, 5, 'left', 0);
phantom.exit();
});
3、CasperJS
源代码:
官方网站:
帮助文档:
当前版本1.1.3
Casperjs是一个开源的导航脚本和测试工具。它是用基于phantom JS的javascript编写的,用于测试web应用程序功能。Phantom JS是服务器端JavaScript API的WebKit。它支持各种web标准:DOM处理、CSS选择器、JSON、画布和SVG
Casperjs根据start()、then*()、wait*()、open()进程向下导航(注意,如果出现语法错误,例如神马没有分号,则可能有一张卡在运行时没有任何提示)
run()方法触发该进程。run()方法可以在导航完成时为回调指定oncomplete()方法
退出()/die()退出
这个。Getpagecontent()可以查看呈现的页面内容
它为web应用程序测试提供了一组方法组件。这些组件基于phantom JS或slimerjs提供的JavaScript API实现web应用程序的功能执行。Casperjs简化了完整导航场景的流程定义,并为完成常见任务提供了实用的高级功能、方法和语法。例如:
用法:
Casperjs前端自动化测试脚本示例:
var utils = require('utils');
var webpage = require('casper').create({
//verbose: true,
logLevel: 'debug',
viewportSize: {
width: 1024,
height: 768
},
pageSettings: {
loadImages: true,
loadPlugins: true,
XSSAuditingEnabled: true
}
});
//打开页面
webpage.start()
.thenOpen('http://www.meizu.com', function openMeizu(res) {
this.echo('打印页面信息');
res.body = '';//不打印body信息
utils.dump(res);
//点击登录按钮
if (this.exists("#_unlogin")) {
this.echo('点击登录按钮');
this.click("#_unlogin a:nth-child(1)");
this.wait(3000, function wait3s_1() {
if (this.exists("form#mainForm")) {
this.echo("需要登陆,填充账号信息。。。");
//填充表单账号
this.fill('form#mainForm', {
'account': 'lzwy0820@flyme.cn',
'password': '********'
}, true);
this.capture('meizu_login_page.png');
this.wait(3000, function wait3s_2() {
//登录按钮存在,点击
if (this.exists("#login")) {
this.echo('提交登录');
this.click("#login");
}
});
}
});
}
})
.then(function capture() {
if (this.exists('#mzCustName')) {
this.echo('登录成功!开始截图存储..');
} else {
this.echo('登录失败!请查看截图文件')
}
//截图
this.capture('meizu.png');
this.captureSelector('meizu_header.png', 'div.meizu-header');
})
.then(function exit() {
this.echo('执行完成,退出');
this.exit();
})
.run();
casperjs捕获的JavaScript呈现的网页示例:
下面的代码将抓取网易云音乐页面,运行JavaScript,然后将最终的HTML保存在文本中
// http://casperjs.org/
var casper = require('casper').create({
pageSettings: {
loadImages: false, // 不加载图片,减少请求
}
});
var fs = require('fs');
casper.userAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36');
casper.start();
casper.viewport(1024, 768);
casper.then(function() {
this.open('http://music.163.com/#/m/discover/artist/').then(function(){
this.page.switchToChildFrame(0); // 页面包含 iFrame
fs.write("1.html", this.getPageContent(), 'w'); // 保存 iFrame 里的内容
this.page.switchToParentFrame();
fs.write("2.html", this.getPageContent(), 'w');
});
});
casper.run();
Casperjs循环调用示例:
解决方案是递归调用。当casperjsobj调用run函数时,它可以传入一个要在最后执行的函数。在这个函数中,我们可以添加[our loop body]和[recursive run call]
function refresh()
{
this.wait(10000,
function() {
this.click('a[title="简历刷新"]');
this.log('refreshed my resume');
}
);
this.run(refresh);
}
casper.run(refresh);
日志中会显示信息消息“不安全的JavaScript尝试使用URL访问帧”。启动casperjs时,添加参数-Web Security=false(允许跨域XHR)(请参阅)
要解决根本原因,请参阅 查看全部
js 爬虫抓取网页数据(Web应用功能示例SlimerJS示例PhantomJS示例示例)
函数(您可以使用JavaScript模拟浏览器上的几乎任何操作)
用法(与phantom JS无差异):
页面某个区域的屏幕截图,slimerjs和phantom JS示例
Slimerjs示例
var webpage = require('webpage').create();
webpage.open('http://www.meizu.com') // 打开一个网页
.then(function() { // 页面加载完成后执行
//保存页面截屏
webpage.viewportSize = {
width: 650,
height: 320
};
webpage.render('page.png', {
onlyViewport: true
});
//再打开一个网页
return webpage.open('http://bbs.meizu.com');
})
.then(function() {
// 点击某个位置
webpage.sendEvent("click", 5, 5, 'left', 0);
slimer.exit(); //退出
});
幻影JS示例
var webpage = require('webpage').create();
webpage.open('http://www.meizu.com', function (status) {
//打开一个页面
}).then(function(){
//保存页面截屏
webpage.viewportSize = {
width: 650,
height: 320
};
webpage.render('page.png', {
onlyViewport: true
});
//再打开一个网页
return webpage.open('http://bbs.meizu.com');
}).then(function(){
webpage.sendEvent("click", 5, 5, 'left', 0);
phantom.exit();
});
3、CasperJS
源代码:
官方网站:
帮助文档:
当前版本1.1.3
Casperjs是一个开源的导航脚本和测试工具。它是用基于phantom JS的javascript编写的,用于测试web应用程序功能。Phantom JS是服务器端JavaScript API的WebKit。它支持各种web标准:DOM处理、CSS选择器、JSON、画布和SVG
Casperjs根据start()、then*()、wait*()、open()进程向下导航(注意,如果出现语法错误,例如神马没有分号,则可能有一张卡在运行时没有任何提示)
run()方法触发该进程。run()方法可以在导航完成时为回调指定oncomplete()方法
退出()/die()退出
这个。Getpagecontent()可以查看呈现的页面内容
它为web应用程序测试提供了一组方法组件。这些组件基于phantom JS或slimerjs提供的JavaScript API实现web应用程序的功能执行。Casperjs简化了完整导航场景的流程定义,并为完成常见任务提供了实用的高级功能、方法和语法。例如:
用法:
Casperjs前端自动化测试脚本示例:
var utils = require('utils');
var webpage = require('casper').create({
//verbose: true,
logLevel: 'debug',
viewportSize: {
width: 1024,
height: 768
},
pageSettings: {
loadImages: true,
loadPlugins: true,
XSSAuditingEnabled: true
}
});
//打开页面
webpage.start()
.thenOpen('http://www.meizu.com', function openMeizu(res) {
this.echo('打印页面信息');
res.body = '';//不打印body信息
utils.dump(res);
//点击登录按钮
if (this.exists("#_unlogin")) {
this.echo('点击登录按钮');
this.click("#_unlogin a:nth-child(1)");
this.wait(3000, function wait3s_1() {
if (this.exists("form#mainForm")) {
this.echo("需要登陆,填充账号信息。。。");
//填充表单账号
this.fill('form#mainForm', {
'account': 'lzwy0820@flyme.cn',
'password': '********'
}, true);
this.capture('meizu_login_page.png');
this.wait(3000, function wait3s_2() {
//登录按钮存在,点击
if (this.exists("#login")) {
this.echo('提交登录');
this.click("#login");
}
});
}
});
}
})
.then(function capture() {
if (this.exists('#mzCustName')) {
this.echo('登录成功!开始截图存储..');
} else {
this.echo('登录失败!请查看截图文件')
}
//截图
this.capture('meizu.png');
this.captureSelector('meizu_header.png', 'div.meizu-header');
})
.then(function exit() {
this.echo('执行完成,退出');
this.exit();
})
.run();
casperjs捕获的JavaScript呈现的网页示例:
下面的代码将抓取网易云音乐页面,运行JavaScript,然后将最终的HTML保存在文本中
// http://casperjs.org/
var casper = require('casper').create({
pageSettings: {
loadImages: false, // 不加载图片,减少请求
}
});
var fs = require('fs');
casper.userAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36');
casper.start();
casper.viewport(1024, 768);
casper.then(function() {
this.open('http://music.163.com/#/m/discover/artist/').then(function(){
this.page.switchToChildFrame(0); // 页面包含 iFrame
fs.write("1.html", this.getPageContent(), 'w'); // 保存 iFrame 里的内容
this.page.switchToParentFrame();
fs.write("2.html", this.getPageContent(), 'w');
});
});
casper.run();
Casperjs循环调用示例:
解决方案是递归调用。当casperjsobj调用run函数时,它可以传入一个要在最后执行的函数。在这个函数中,我们可以添加[our loop body]和[recursive run call]
function refresh()
{
this.wait(10000,
function() {
this.click('a[title="简历刷新"]');
this.log('refreshed my resume');
}
);
this.run(refresh);
}
casper.run(refresh);
日志中会显示信息消息“不安全的JavaScript尝试使用URL访问帧”。启动casperjs时,添加参数-Web Security=false(允许跨域XHR)(请参阅)
要解决根本原因,请参阅
js 爬虫抓取网页数据(DOM是什么?Google能读取动态生成的内容是如何?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2021-10-05 19:21
我们知道国内的浏览器和搜索工具都是用爬虫爬取网页信息的,那么谷歌爬虫是怎么爬取Javascript的呢?今天,小编就和大家深入探讨一下。
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该界面允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表达的 URL 会发生什么变化?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您没有访问您的 网站 服务器的权限,您可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内(“onClick”)
使用 href 内部 AVP ("javascript: window.location")
在 a 标签之外执行,但在 href ("javascript: openlink()") 中调用 AVP
还有很多
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API(pushState)构建的,可以渲染和收录 它,并且可以像传统的静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果呢?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签会发生什么?在这个协议中,HTTP x-robots 响应头的行为如何作为另一个变量?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中 href 元素的操作发生得太晚了:谷歌在执行添加 rel="nofollow" 的 JavaScript 函数之前,已经准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入内容,甚至元标记,例如rel规范注释,无论是在HTML源代码中还是在解析初始HTML后触发JavaScript生成DOM都以相同的方式处理。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。不可思议!(请记住允许 Google 爬虫获取这些外部文件和 JavaScript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们需要更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。 查看全部
js 爬虫抓取网页数据(DOM是什么?Google能读取动态生成的内容是如何?)
我们知道国内的浏览器和搜索工具都是用爬虫爬取网页信息的,那么谷歌爬虫是怎么爬取Javascript的呢?今天,小编就和大家深入探讨一下。
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该界面允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表达的 URL 会发生什么变化?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您没有访问您的 网站 服务器的权限,您可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内(“onClick”)
使用 href 内部 AVP ("javascript: window.location")
在 a 标签之外执行,但在 href ("javascript: openlink()") 中调用 AVP
还有很多
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API(pushState)构建的,可以渲染和收录 它,并且可以像传统的静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果呢?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签会发生什么?在这个协议中,HTTP x-robots 响应头的行为如何作为另一个变量?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中 href 元素的操作发生得太晚了:谷歌在执行添加 rel="nofollow" 的 JavaScript 函数之前,已经准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入内容,甚至元标记,例如rel规范注释,无论是在HTML源代码中还是在解析初始HTML后触发JavaScript生成DOM都以相同的方式处理。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。不可思议!(请记住允许 Google 爬虫获取这些外部文件和 JavaScript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们需要更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
js 爬虫抓取网页数据(《js爬虫抓取网页数据》.open())
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-04 17:06
js爬虫抓取网页数据。
wx.open()你在浏览器输入一个地址,立即就会返回一个对象。这个对象包含:所有文件的路径(下面的一切文件都在这个链接下)、链接(你点开链接)后默认会解析一个json。
浏览器输入地址,
你去看看计算机组成原理什么的
浏览器获取windowopen.
浏览器里面就是链接,所以ie,firefox会解析并响应,不同浏览器不同,ie是个例子,还有很多其他种方式,但都是通过最直接方式去做的,所以也算是响应,假如你用chrome去请求大量页面,返回json数据,然后传给服务器,那么服务器就会收到json数据,服务器就解析,返回数据给浏览器,所以你会看到各种反爬虫。
ie好像也会返回这样的json数据,activex很多特性不利于浏览器解析数据。
chromejs会让他滚
json是javascript的对象。不是说你把啥json数据改一改就返回给服务器了。得不到可以让服务器去检测要发什么数据。
知乎团队可能反应比较迟钝,现在已经可以用js查看你的所有回答了。每个回答都会被随机生成一个token,在redis上。而不是像网上传的一样在数据库上。
看了下大家,目前也就我写的代码是返回json数据。我想了下思路:使用js判断链接来判断script和dom元素,从而判断是否出现js。这样做比使用最简单的轮子简单一些,只要你把js的操作封装到varexecutordata(官方说chrome40内部已经使用这种方式,但我这里不存在这个问题),就可以返回数据了。
判断需要哪些操作,跟你改完token的数据,把输出结果传回给服务器。可以使用crossjstokenfilter(更高效地做到这一点)或者改成整数去做hash键key(同样原理,更高效)。@winter所说可能会导致通讯中断,从而传递更多的数据(这个可能跟你使用js操作dom没有关系,这样其实可以在传递数据前,做一次同步操作,而不会对通讯造成问题)。还是看团队的编码习惯吧。 查看全部
js 爬虫抓取网页数据(《js爬虫抓取网页数据》.open())
js爬虫抓取网页数据。
wx.open()你在浏览器输入一个地址,立即就会返回一个对象。这个对象包含:所有文件的路径(下面的一切文件都在这个链接下)、链接(你点开链接)后默认会解析一个json。
浏览器输入地址,
你去看看计算机组成原理什么的
浏览器获取windowopen.
浏览器里面就是链接,所以ie,firefox会解析并响应,不同浏览器不同,ie是个例子,还有很多其他种方式,但都是通过最直接方式去做的,所以也算是响应,假如你用chrome去请求大量页面,返回json数据,然后传给服务器,那么服务器就会收到json数据,服务器就解析,返回数据给浏览器,所以你会看到各种反爬虫。
ie好像也会返回这样的json数据,activex很多特性不利于浏览器解析数据。
chromejs会让他滚
json是javascript的对象。不是说你把啥json数据改一改就返回给服务器了。得不到可以让服务器去检测要发什么数据。
知乎团队可能反应比较迟钝,现在已经可以用js查看你的所有回答了。每个回答都会被随机生成一个token,在redis上。而不是像网上传的一样在数据库上。
看了下大家,目前也就我写的代码是返回json数据。我想了下思路:使用js判断链接来判断script和dom元素,从而判断是否出现js。这样做比使用最简单的轮子简单一些,只要你把js的操作封装到varexecutordata(官方说chrome40内部已经使用这种方式,但我这里不存在这个问题),就可以返回数据了。
判断需要哪些操作,跟你改完token的数据,把输出结果传回给服务器。可以使用crossjstokenfilter(更高效地做到这一点)或者改成整数去做hash键key(同样原理,更高效)。@winter所说可能会导致通讯中断,从而传递更多的数据(这个可能跟你使用js操作dom没有关系,这样其实可以在传递数据前,做一次同步操作,而不会对通讯造成问题)。还是看团队的编码习惯吧。
js 爬虫抓取网页数据(HTML源码中的内容由前端的JS动态生成的应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-03 12:00
)
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器渲染出来的网页如下图所示:
查看源码,却是如下图:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
这是照片新闻下的新闻。
我们打开一个接口链接看看:
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求和解析数据接口数据
先上完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# coding:utf-8
import requests
import json
第二部分:向数据接口发出http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
js 爬虫抓取网页数据(HTML源码中的内容由前端的JS动态生成的应用
)
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器渲染出来的网页如下图所示:

查看源码,却是如下图:

网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具

网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:

让我们再次点击它:

原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:

图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:

这个应该是热搜关键词

这是照片新闻下的新闻。
我们打开一个接口链接看看:

返回一串乱码,但是从响应中查看的是正常的编码数据:

有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求和解析数据接口数据
先上完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:

像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# coding:utf-8
import requests
import json
第二部分:向数据接口发出http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
js 爬虫抓取网页数据(抓的妹子图都是直接抓Html就可以的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-10-03 11:32
)
介绍
之前拍的姐妹图可以直接用Html抓拍,也就是Chrome的浏览器F12。
Elements 页面结构和 Network 数据包捕获返回相同的结果。以后抓一些
网站(比如煎鸡蛋,还有那种小网站)我发现了。网络抓包
没有得到数据,但是Elements里面有情况。原因是:页面的数据是
由 JavaScript 动态生成:
抓不到数据怎么破?一开始想着自己学一波JS基础语法,然后尝试模拟抓包。
拿到别人的js文件,自己分析一下逻辑,然后摆弄真实的URL,然后就是
放弃。毕竟要爬取的页面太多了。每个这样的分析什么时候...
我偶然发现有一个自动化测试框架:Selenium 可以帮助我们处理这个问题。
简单说说这个东西的使用,我们可以写代码让浏览器:
那么这个东西不支持浏览器功能,需要配合第三方浏览器使用,
支持以下浏览器,需要将对应的浏览器驱动下载到Python对应的路径:
铬合金:
火狐:
幻影JS:
IE:
边缘:
歌剧:
下面直接开始本节的内容吧~
1.安装硒
这个很简单,直接通过pip命令行安装:
sudo pip install selenium
PS:记得公司小伙伴问我为什么在win上不能执行pip,我下载了很多pip。
其实安装Python3的话,默认已经自带pip了,需要单独配置环境
变量,pip的路径在Python安装目录的Scripts目录下~
在Path后面加上这个路径就行了~
2.下载浏览器驱动
因为Selenium没有浏览器,需要依赖第三方浏览器,调用第三方
如果你用的是新浏览器,需要下载浏览器的驱动,因为我用的是Chrome,所以我会用
我们以 Chrome 为例。其他浏览器可以自行搜索相关信息!打开 Chrome 浏览器并输入:
chrome://version
可以查看Chrome浏览器版本的相关信息,这里主要注意版本号:
61.好的,那么到下面网站查看对应的驱动版本号:
好的,接下来下载v2.34版本的浏览器驱动:
下载完成后,解压zip文件,将解压后的chromedriver.exe复制到Python中
脚本目录。(这里不用担心win32,64位浏览器可以正常使用!)
PS:对于Mac,将解压后的文件复制到usr/local/bin目录下
对于Ubuntu,复制到:usr/bin目录
接下来我们写一个简单的代码来测试一下:
from selenium import webdriver
browser = webdriver.Chrome() # 调用本地的Chrome浏览器
browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口
html_text = browser.page_source # 获得页面代码
browser.quit() # 关闭浏览器
print(html_text)
执行这段代码会自动调出浏览器访问百度:
并且控制台会输出HTML代码,也就是直接获取到的Elements页面结构,
JS执行后的页面~接下来就可以抢到我们的煎蛋少女图了~
3.Selenium简单实战:抢煎蛋少女图
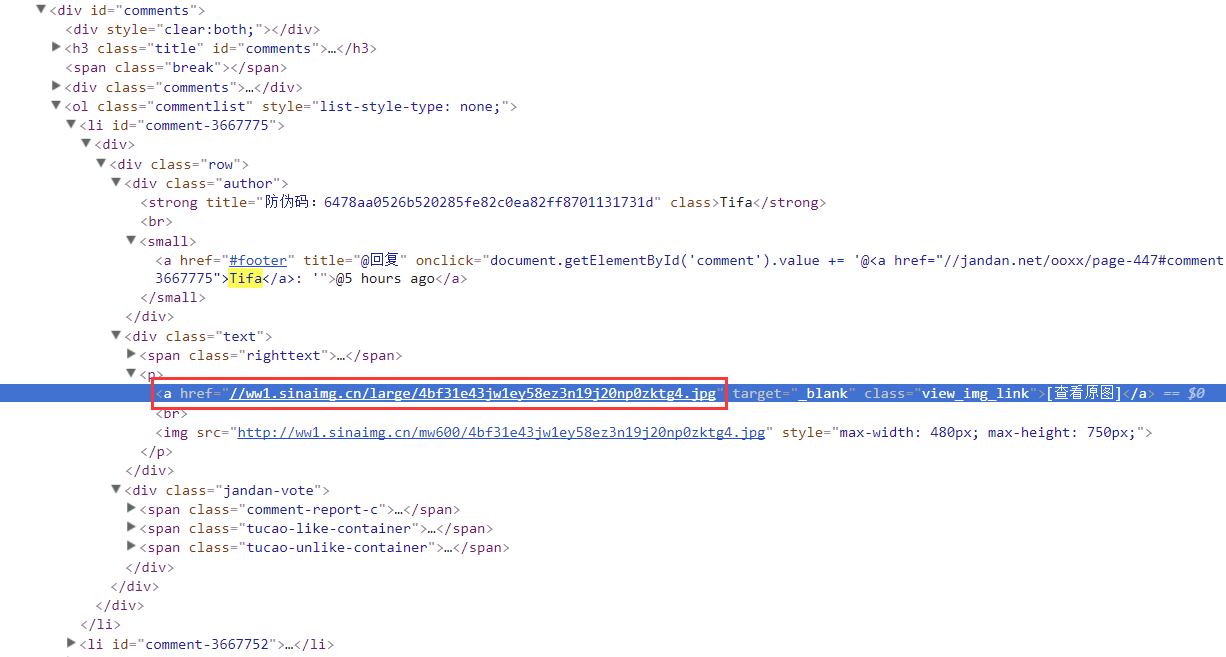
直接分析Elements页面的结构,找到你想要的关键节点:
明明这是我们抓到的小姐姐的照片,复制这个网址看看我们打印出来的
页面结构有没有这个东西:
是的这很好。有了这个页面数据,让我们通过一波美汤来搞定我们
你要的资料~
经过上面的过滤,我们就可以得到我们妹图的URL:
只需打开一个验证,啧:
看到下一页只有30个小姐姐,显然满足不了我们。我们第一次加载它。
当你第一次得到一波页码的时候,然后你就知道有多少页了,然后你就可以拼接URL并自己加载了
不同的页面,比如这里总共有448个页面:
可以拼接成这样的网址:
获取过滤下的页码:
接下来,我将填写代码,循环抓取每个页面上的小姐姐,并将其下载到本地。
完整代码如下:
import os
from selenium import webdriver
from bs4 import BeautifulSoup
import urllib.request
import ssl
import urllib.error
base_url = 'http://jandan.net/ooxx'
pic_save_path = "output/Picture/JianDan/"
# 下载图片
def download_pic(url):
correct_url = url
if url.startswith('//'):
correct_url = url[2:]
if not url.startswith('http'):
correct_url = 'http://' + correct_url
print(correct_url)
headers = {
'Host': 'wx2.sinaimg.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.100 Safari/537.36 '
}
try:
req = urllib.request.Request(correct_url, headers=headers)
resp = urllib.request.urlopen(req)
pic = resp.read()
pic_name = correct_url.split("/")[-1]
with open(pic_save_path + pic_name, "wb+") as f:
f.write(pic)
except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason:
print(str(reason))
# 打开浏览器模拟请求
def browser_get():
browser = webdriver.Chrome()
browser.get('http://jandan.net/ooxx')
html_text = browser.page_source
page_count = get_page_count(html_text)
# 循环拼接URL访问
for page in range(page_count, 0, -1):
page_url = base_url + '/page-' + str(page)
print('解析:' + page_url)
browser.get(page_url)
html = browser.page_source
get_meizi_url(html)
browser.quit()
# 获取总页码
def get_page_count(html):
soup = BeautifulSoup(html, 'html.parser')
page_count = soup.find('span', attrs={'class': 'current-comment-page'})
return int(page_count.get_text()[1:-1]) - 1
# 获取每个页面的小姐姐
def get_meizi_url(html):
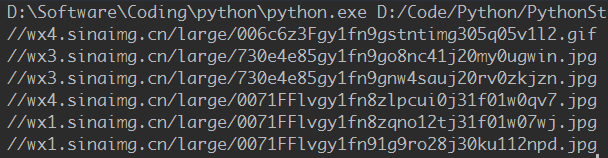
soup = BeautifulSoup(html, 'html.parser')
ol = soup.find('ol', attrs={'class': 'commentlist'})
href = ol.findAll('a', attrs={'class': 'view_img_link'})
for a in href:
download_pic(a['href'])
if __name__ == '__main__':
ssl._create_default_https_context = ssl._create_unverified_context
if not os.path.exists(pic_save_path):
os.makedirs(pic_save_path)
browser_get()
操作结果:
看看我们的输出文件夹~
学习Python爬虫,越来越瘦……
4.PhantomJS
PhantomJS 没有界面浏览器,特点:会将网站加载到内存中并执行
JavaScript,因为它不显示图形界面,所以它比完整的浏览器运行效率更高。
(如果某些 Linux 主机上没有图形界面,则无法安装 Chrome 等浏览器。
这个问题可以通过 PhantomJS 来规避)。
在 Win 上安装 PhantomJS:
在 Ubuntu/MAC 上安装 PhantomJS:
sudo apt-get install phantomjs
!!!关于 PhantomJS 的重要说明:
今年 4 月,Phantom.js 的维护者宣布退出 PhantomJS。
这意味着该项目可能不再维护!!!Chrome 和 FireFox 也开始了
提供Headless模式(不需要挂浏览器),所以估计用PhantomJS的小伙伴
会慢慢迁移到这两个浏览器。Windows Chrome 需要 60 以上的版本才能支持
Headless 模式,启用 Headless 模式也很简单:
selenium 的官方文档中还写道:
运行时也会报这个警告:
5.Selenium实战:模拟登录CSDN并保存Cookie
CSDN登录网站:
分析页面结构,不难发现对应的登录输入框和登录按钮:
我们要做的就是在这两个节点输入账号密码,然后触发登录按钮,
同时在本地保存Cookie,然后就可以带着Cookie访问相关页面了~
首先写一个方法来模拟登录:
找到输入账号密码的节点,设置你的账号密码,然后找到login
按钮节点,点击一次,然后等待登录成功,登录成功后可以对比
current_url 是否已更改。然后在这里保存 Cookies
我用的是pickle库,你可以用其他的,比如json,或者字符串拼接,
然后保存到本地。如果没有意外,应该可以拿到Cookie,然后使用
Cookie 访问主页。
通过 add_cookies 方法设置 Cookie。参数是字典类型的。此外,您必须首先
访问get链接一次,然后设置cookie,否则会报无法设置cookie的错误!
通过查看右下角是否变为登录状态就可以知道是否使用Cookie登录成功:
6.Selenium 常用函数
Seleninum 作为自动化测试的工具,自然提供了很多自动化操作的功能。
下面是我觉得比较常用的功能,更多的可以看官方文档:
官方API文档:
1) 定位元素
PS:将元素更改为元素将定位所有符合条件的元素并返回一个列表
例如:find_elements_by_class_name
2) 鼠标操作
有时需要在页面上模拟鼠标操作,例如:单击、双击、右键单击、按住、拖动等。
您可以导入 ActionChains 类:mon.action_chains.ActionChains
使用 ActionChains(driver).XXX 调用对应节点的行为
3) 弹出窗口
对应类:mon.alert.Alert,感觉用的不多...
如果触发到一定时间,弹出对话框,可以调用如下方法获取对话框:
alert = driver.switch_to_alert(),然后可以调用以下方法:
4)页面前进、后退、切换
切换窗口:driver.switch_to.window("窗口名称")
或者通过window_handles来遍历
用于 driver.window_handles 中的句柄:
driver.switch_to_window(句柄)
driver.forward() #forward
driver.back() # 返回
5) 页面截图
driver.save_screenshot("Screenshot.png")
6) 页面等待
现在越来越多的网页使用Ajax技术,所以程序无法判断一个元素什么时候完全
加载完毕。如果实际页面等待时间过长,某个dom元素还没有出来,但是你的
代码直接使用这个WebElement,会抛出NullPointer异常。
为了避免元素定位困难,增加ElementNotVisibleException的概率。
所以Selenium提供了两种等待方式,一种是隐式等待,一种是显式等待。
显式等待:
显式等待指定某个条件,然后设置最大等待时间。如果不是这个时候
如果找到该元素,则会抛出异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.PhantomJS()
driver.get("http://www.xxxxx.com/loading")
try:
# 每隔10秒查找页面元素 id="myDynamicElement",直到出现则返回
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
如果不写参数,程序默认会调用0.5s来检查元素是否已经生成。
如果原创元素存在,它将立即返回。
下面是一些内置的等待条件,你可以直接调用这些条件,而不是自己调用
写一些等待条件。
标题_是
标题_收录
Presence_of_element_located
visibility_of_element_located
可见性_of
Presence_of_all_elements_located
text_to_be_present_in_element
text_to_be_present_in_element_value
frame_to_be_available_and_switch_to_it
invisibility_of_element_located
element_to_be_clickable – 显示并启用。
staleness_of
element_to_be_selected
element_located_to_be_selected
element_selection_state_to_be
element_located_selection_state_to_be
alert_is_present
隐式等待:
隐式等待比较简单,就是简单的设置一个等待时间,以秒为单位。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.implicitly_wait(10) # seconds
driver.get("http://www.xxxxx.com/loading")
myDynamicElement = driver.find_element_by_id("myDynamicElement")
当然,如果不设置,则默认等待时间为0。
7.执行JS语句
driver.execute_script(js 语句)
例如,滚动到底部:
js = document.body.scrollTop=10000
driver.execute_script(js)
概括
本节讲解一波使用Selenium自动化测试框架抓取JavaScript动态生成的数据,
Selenium 需要依赖第三方浏览器,注意过时的 PhantomJS 无界面浏览器
对于问题,可以使用Chrome和FireFox提供的HeadLess来替换;通过抓住煎蛋女孩
模拟CSDN自动登录的图片和例子,熟悉Selenium的基本使用,或者收很多货。
当然Selenium的水还是很深的,目前我们可以用它来应对JS动态加载数据页面
数据采集就够了。
另外,最近天气很冷,记得及时补衣服哦~
顺便写下你的想法:
下载本节源码:
本节参考资料:
来吧,Py 交易
如果想加群一起学Py,可以加智障机器人小猪,验证信息收录:
python,python,py,py,添加组,事务,关键词之一即可;
验证通过后回复群获取群链接(不要破解机器人!!!)~~~
欢迎像我这样的Py初学者,Py大神加入,愉快交流学习♂学习,van♂转py。
查看全部
js 爬虫抓取网页数据(抓的妹子图都是直接抓Html就可以的
)
介绍
之前拍的姐妹图可以直接用Html抓拍,也就是Chrome的浏览器F12。
Elements 页面结构和 Network 数据包捕获返回相同的结果。以后抓一些
网站(比如煎鸡蛋,还有那种小网站)我发现了。网络抓包
没有得到数据,但是Elements里面有情况。原因是:页面的数据是
由 JavaScript 动态生成:


抓不到数据怎么破?一开始想着自己学一波JS基础语法,然后尝试模拟抓包。
拿到别人的js文件,自己分析一下逻辑,然后摆弄真实的URL,然后就是
放弃。毕竟要爬取的页面太多了。每个这样的分析什么时候...

我偶然发现有一个自动化测试框架:Selenium 可以帮助我们处理这个问题。
简单说说这个东西的使用,我们可以写代码让浏览器:
那么这个东西不支持浏览器功能,需要配合第三方浏览器使用,
支持以下浏览器,需要将对应的浏览器驱动下载到Python对应的路径:
铬合金:
火狐:
幻影JS:
IE:
边缘:
歌剧:
下面直接开始本节的内容吧~
1.安装硒
这个很简单,直接通过pip命令行安装:
sudo pip install selenium
PS:记得公司小伙伴问我为什么在win上不能执行pip,我下载了很多pip。
其实安装Python3的话,默认已经自带pip了,需要单独配置环境
变量,pip的路径在Python安装目录的Scripts目录下~
在Path后面加上这个路径就行了~

2.下载浏览器驱动
因为Selenium没有浏览器,需要依赖第三方浏览器,调用第三方
如果你用的是新浏览器,需要下载浏览器的驱动,因为我用的是Chrome,所以我会用
我们以 Chrome 为例。其他浏览器可以自行搜索相关信息!打开 Chrome 浏览器并输入:
chrome://version
可以查看Chrome浏览器版本的相关信息,这里主要注意版本号:
61.好的,那么到下面网站查看对应的驱动版本号:

好的,接下来下载v2.34版本的浏览器驱动:

下载完成后,解压zip文件,将解压后的chromedriver.exe复制到Python中
脚本目录。(这里不用担心win32,64位浏览器可以正常使用!)
PS:对于Mac,将解压后的文件复制到usr/local/bin目录下
对于Ubuntu,复制到:usr/bin目录
接下来我们写一个简单的代码来测试一下:
from selenium import webdriver
browser = webdriver.Chrome() # 调用本地的Chrome浏览器
browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口
html_text = browser.page_source # 获得页面代码
browser.quit() # 关闭浏览器
print(html_text)
执行这段代码会自动调出浏览器访问百度:
并且控制台会输出HTML代码,也就是直接获取到的Elements页面结构,
JS执行后的页面~接下来就可以抢到我们的煎蛋少女图了~
3.Selenium简单实战:抢煎蛋少女图
直接分析Elements页面的结构,找到你想要的关键节点:
明明这是我们抓到的小姐姐的照片,复制这个网址看看我们打印出来的
页面结构有没有这个东西:

是的这很好。有了这个页面数据,让我们通过一波美汤来搞定我们
你要的资料~
经过上面的过滤,我们就可以得到我们妹图的URL:
只需打开一个验证,啧:


看到下一页只有30个小姐姐,显然满足不了我们。我们第一次加载它。
当你第一次得到一波页码的时候,然后你就知道有多少页了,然后你就可以拼接URL并自己加载了
不同的页面,比如这里总共有448个页面:

可以拼接成这样的网址:
获取过滤下的页码:


接下来,我将填写代码,循环抓取每个页面上的小姐姐,并将其下载到本地。
完整代码如下:
import os
from selenium import webdriver
from bs4 import BeautifulSoup
import urllib.request
import ssl
import urllib.error
base_url = 'http://jandan.net/ooxx'
pic_save_path = "output/Picture/JianDan/"
# 下载图片
def download_pic(url):
correct_url = url
if url.startswith('//'):
correct_url = url[2:]
if not url.startswith('http'):
correct_url = 'http://' + correct_url
print(correct_url)
headers = {
'Host': 'wx2.sinaimg.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.100 Safari/537.36 '
}
try:
req = urllib.request.Request(correct_url, headers=headers)
resp = urllib.request.urlopen(req)
pic = resp.read()
pic_name = correct_url.split("/")[-1]
with open(pic_save_path + pic_name, "wb+") as f:
f.write(pic)
except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason:
print(str(reason))
# 打开浏览器模拟请求
def browser_get():
browser = webdriver.Chrome()
browser.get('http://jandan.net/ooxx')
html_text = browser.page_source
page_count = get_page_count(html_text)
# 循环拼接URL访问
for page in range(page_count, 0, -1):
page_url = base_url + '/page-' + str(page)
print('解析:' + page_url)
browser.get(page_url)
html = browser.page_source
get_meizi_url(html)
browser.quit()
# 获取总页码
def get_page_count(html):
soup = BeautifulSoup(html, 'html.parser')
page_count = soup.find('span', attrs={'class': 'current-comment-page'})
return int(page_count.get_text()[1:-1]) - 1
# 获取每个页面的小姐姐
def get_meizi_url(html):
soup = BeautifulSoup(html, 'html.parser')
ol = soup.find('ol', attrs={'class': 'commentlist'})
href = ol.findAll('a', attrs={'class': 'view_img_link'})
for a in href:
download_pic(a['href'])
if __name__ == '__main__':
ssl._create_default_https_context = ssl._create_unverified_context
if not os.path.exists(pic_save_path):
os.makedirs(pic_save_path)
browser_get()
操作结果:
看看我们的输出文件夹~


学习Python爬虫,越来越瘦……
4.PhantomJS
PhantomJS 没有界面浏览器,特点:会将网站加载到内存中并执行
JavaScript,因为它不显示图形界面,所以它比完整的浏览器运行效率更高。
(如果某些 Linux 主机上没有图形界面,则无法安装 Chrome 等浏览器。
这个问题可以通过 PhantomJS 来规避)。
在 Win 上安装 PhantomJS:
在 Ubuntu/MAC 上安装 PhantomJS:
sudo apt-get install phantomjs
!!!关于 PhantomJS 的重要说明:
今年 4 月,Phantom.js 的维护者宣布退出 PhantomJS。
这意味着该项目可能不再维护!!!Chrome 和 FireFox 也开始了
提供Headless模式(不需要挂浏览器),所以估计用PhantomJS的小伙伴
会慢慢迁移到这两个浏览器。Windows Chrome 需要 60 以上的版本才能支持
Headless 模式,启用 Headless 模式也很简单:

selenium 的官方文档中还写道:

运行时也会报这个警告:

5.Selenium实战:模拟登录CSDN并保存Cookie
CSDN登录网站:
分析页面结构,不难发现对应的登录输入框和登录按钮:
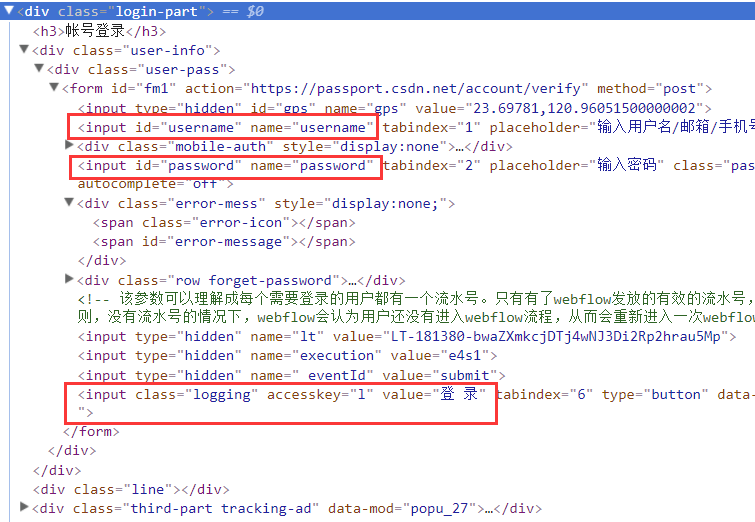
我们要做的就是在这两个节点输入账号密码,然后触发登录按钮,
同时在本地保存Cookie,然后就可以带着Cookie访问相关页面了~
首先写一个方法来模拟登录:

找到输入账号密码的节点,设置你的账号密码,然后找到login
按钮节点,点击一次,然后等待登录成功,登录成功后可以对比
current_url 是否已更改。然后在这里保存 Cookies
我用的是pickle库,你可以用其他的,比如json,或者字符串拼接,
然后保存到本地。如果没有意外,应该可以拿到Cookie,然后使用
Cookie 访问主页。
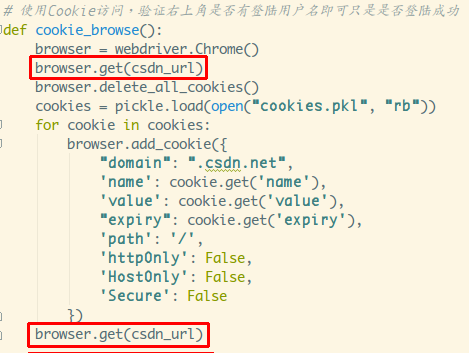
通过 add_cookies 方法设置 Cookie。参数是字典类型的。此外,您必须首先
访问get链接一次,然后设置cookie,否则会报无法设置cookie的错误!
通过查看右下角是否变为登录状态就可以知道是否使用Cookie登录成功:

6.Selenium 常用函数
Seleninum 作为自动化测试的工具,自然提供了很多自动化操作的功能。
下面是我觉得比较常用的功能,更多的可以看官方文档:
官方API文档:
1) 定位元素
PS:将元素更改为元素将定位所有符合条件的元素并返回一个列表
例如:find_elements_by_class_name
2) 鼠标操作
有时需要在页面上模拟鼠标操作,例如:单击、双击、右键单击、按住、拖动等。
您可以导入 ActionChains 类:mon.action_chains.ActionChains
使用 ActionChains(driver).XXX 调用对应节点的行为
3) 弹出窗口
对应类:mon.alert.Alert,感觉用的不多...
如果触发到一定时间,弹出对话框,可以调用如下方法获取对话框:
alert = driver.switch_to_alert(),然后可以调用以下方法:
4)页面前进、后退、切换
切换窗口:driver.switch_to.window("窗口名称")
或者通过window_handles来遍历
用于 driver.window_handles 中的句柄:
driver.switch_to_window(句柄)
driver.forward() #forward
driver.back() # 返回
5) 页面截图
driver.save_screenshot("Screenshot.png")
6) 页面等待
现在越来越多的网页使用Ajax技术,所以程序无法判断一个元素什么时候完全
加载完毕。如果实际页面等待时间过长,某个dom元素还没有出来,但是你的
代码直接使用这个WebElement,会抛出NullPointer异常。
为了避免元素定位困难,增加ElementNotVisibleException的概率。
所以Selenium提供了两种等待方式,一种是隐式等待,一种是显式等待。
显式等待:
显式等待指定某个条件,然后设置最大等待时间。如果不是这个时候
如果找到该元素,则会抛出异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.PhantomJS()
driver.get("http://www.xxxxx.com/loading";)
try:
# 每隔10秒查找页面元素 id="myDynamicElement",直到出现则返回
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
如果不写参数,程序默认会调用0.5s来检查元素是否已经生成。
如果原创元素存在,它将立即返回。
下面是一些内置的等待条件,你可以直接调用这些条件,而不是自己调用
写一些等待条件。
标题_是
标题_收录
Presence_of_element_located
visibility_of_element_located
可见性_of
Presence_of_all_elements_located
text_to_be_present_in_element
text_to_be_present_in_element_value
frame_to_be_available_and_switch_to_it
invisibility_of_element_located
element_to_be_clickable – 显示并启用。
staleness_of
element_to_be_selected
element_located_to_be_selected
element_selection_state_to_be
element_located_selection_state_to_be
alert_is_present
隐式等待:
隐式等待比较简单,就是简单的设置一个等待时间,以秒为单位。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.implicitly_wait(10) # seconds
driver.get("http://www.xxxxx.com/loading";)
myDynamicElement = driver.find_element_by_id("myDynamicElement")
当然,如果不设置,则默认等待时间为0。
7.执行JS语句
driver.execute_script(js 语句)
例如,滚动到底部:
js = document.body.scrollTop=10000
driver.execute_script(js)
概括
本节讲解一波使用Selenium自动化测试框架抓取JavaScript动态生成的数据,
Selenium 需要依赖第三方浏览器,注意过时的 PhantomJS 无界面浏览器
对于问题,可以使用Chrome和FireFox提供的HeadLess来替换;通过抓住煎蛋女孩
模拟CSDN自动登录的图片和例子,熟悉Selenium的基本使用,或者收很多货。
当然Selenium的水还是很深的,目前我们可以用它来应对JS动态加载数据页面
数据采集就够了。
另外,最近天气很冷,记得及时补衣服哦~

顺便写下你的想法:
下载本节源码:
本节参考资料:
来吧,Py 交易
如果想加群一起学Py,可以加智障机器人小猪,验证信息收录:
python,python,py,py,添加组,事务,关键词之一即可;

验证通过后回复群获取群链接(不要破解机器人!!!)~~~
欢迎像我这样的Py初学者,Py大神加入,愉快交流学习♂学习,van♂转py。

js 爬虫抓取网页数据(网页极速版多使用IP,代理IP不使用cookie多利用线程分布式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-10-03 11:28
建议:
减少列表数据并保存页面
关注网络速度版本、应用程序版本
多用途IP、动态UA、代理IP、无Cookie
多线程分布式
===================================
Selenium可以接受指示。获取所需的数据或错误屏幕截图
无界面的Phantom JS浏览器(可保存截图)
加载到内存并执行JS
需要下载
解决方案:
下载连接
from selenium import webdriver
import time
d1=webdriver.Chrome(r"C:\Users\xzq\Downloads\chromedriver_win32 (1)\chromedriver.exe")
d1.get("https://login.taobao.com/membe ... 6quot;)
d1.find_element_by_id("J_Quick2Static").click()
time.sleep(3)
d1.find_element_by_id("TPL_username_1").send_keys("扯淡灬孩子02547915")
d1.find_element_by_id("TPL_password_1").send_keys("a13736784065")
d1.find_element_by_id("J_SubmitStatic").click()
求解滑动检查
button = d1.find_element_by_id('nc_1_n1z')# 找到“蓝色滑块”
action = webdriver.ActionChains(d1)# 实例化一个action对象
action.click_and_hold(button).perform()# perform()用来执行ActionChains中存储的行为
action.reset_actions()
action.move_by_offset(280, 0).perform()# 移动滑块
action.release()
=================================================================================================
解决方案验证码
一,。相同的URL将生成相同的验证码URL
直接向编码平台申请验证码地址进行处理
二,。相同的URL将生成具有不同验证码的URL
1.实例化会话
2.使用会话请求页面获取验证码地址
3.发送会话请求验证代码并使用该代码识别
4.使用会话发送帖子
遇到使用selenium的验证代码:
Selenium请求登录页面,同时获取验证码地址
在登录驱动器中获取cookie,并将其提交给请求进行处理和标识
或者使用屏幕截图工具查找验证代码并使用它进行识别
============================================================================================
获取文本和属性
1.首先找到元素,然后调用.Text或get\ux。归属者
find_u元素返回一个元素。如果没有元素,将报告错误
查找元素返回一个空列表
==================================================================
求解查找元素失败的方法
页面中可能有iframe和frame
需要先打电话吗
d1.切换到帧(“帧名称”)
然后获取输入内容
==================================================================
=======================================================================
解决新页面的后续请求以获取错误(在加载完成之前获取数据)
===================================================================================================================================================
使用Orc身份验证码**
1.安装PIL(Python 3中没有可供下载的直接PIL版本。您可以先使用pilot)
2.从PIL导入图像导入
import pytesseract
from PIL import Image
img=Image.open("0014076720724832de067ce843d41c58f2af067d1e0720f000[1].jpg")
print(pytesseract.image_to_string(img))
如果报告错误,请在下载后参考pytestseract中的testseract(因为未安装Orc)\在CMD下添加tesserac.exet的路径 查看全部
js 爬虫抓取网页数据(网页极速版多使用IP,代理IP不使用cookie多利用线程分布式)
建议:
减少列表数据并保存页面
关注网络速度版本、应用程序版本
多用途IP、动态UA、代理IP、无Cookie
多线程分布式
===================================
Selenium可以接受指示。获取所需的数据或错误屏幕截图
无界面的Phantom JS浏览器(可保存截图)
加载到内存并执行JS

需要下载
解决方案:
下载连接
from selenium import webdriver
import time
d1=webdriver.Chrome(r"C:\Users\xzq\Downloads\chromedriver_win32 (1)\chromedriver.exe")
d1.get("https://login.taobao.com/membe ... 6quot;)
d1.find_element_by_id("J_Quick2Static").click()
time.sleep(3)
d1.find_element_by_id("TPL_username_1").send_keys("扯淡灬孩子02547915")
d1.find_element_by_id("TPL_password_1").send_keys("a13736784065")
d1.find_element_by_id("J_SubmitStatic").click()
求解滑动检查
button = d1.find_element_by_id('nc_1_n1z')# 找到“蓝色滑块”
action = webdriver.ActionChains(d1)# 实例化一个action对象
action.click_and_hold(button).perform()# perform()用来执行ActionChains中存储的行为
action.reset_actions()
action.move_by_offset(280, 0).perform()# 移动滑块
action.release()
=================================================================================================
解决方案验证码
一,。相同的URL将生成相同的验证码URL
直接向编码平台申请验证码地址进行处理
二,。相同的URL将生成具有不同验证码的URL
1.实例化会话
2.使用会话请求页面获取验证码地址
3.发送会话请求验证代码并使用该代码识别
4.使用会话发送帖子
遇到使用selenium的验证代码:
Selenium请求登录页面,同时获取验证码地址
在登录驱动器中获取cookie,并将其提交给请求进行处理和标识
或者使用屏幕截图工具查找验证代码并使用它进行识别
============================================================================================


获取文本和属性
1.首先找到元素,然后调用.Text或get\ux。归属者
find_u元素返回一个元素。如果没有元素,将报告错误
查找元素返回一个空列表
==================================================================
求解查找元素失败的方法
页面中可能有iframe和frame
需要先打电话吗
d1.切换到帧(“帧名称”)
然后获取输入内容
==================================================================

=======================================================================
解决新页面的后续请求以获取错误(在加载完成之前获取数据)

===================================================================================================================================================
使用Orc身份验证码**
1.安装PIL(Python 3中没有可供下载的直接PIL版本。您可以先使用pilot)
2.从PIL导入图像导入
import pytesseract
from PIL import Image
img=Image.open("0014076720724832de067ce843d41c58f2af067d1e0720f000[1].jpg")
print(pytesseract.image_to_string(img))
如果报告错误,请在下载后参考pytestseract中的testseract(因为未安装Orc)\在CMD下添加tesserac.exet的路径
js 爬虫抓取网页数据(动态网页抓取AJAX(Asynchronouse)异步JavaScript和XML的区别 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-10-03 11:27
)
动态网页抓取
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
我们有两种方式获取ajax数据:
直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
我们接下来讲解使用selenium+chromedriver获取动态数据。
1.Selenium+chromedriver获取动态数据1.1.准备
Selenium 相当于一个机器人。它可以模拟人们在浏览器上的一些行为,并自动处理浏览器上的一些行为,如点击、填充数据、删除cookies等。chromedriver是一个驱动Chrome浏览器的驱动程序,可以用来驱动浏览器浏览器。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
铬:火狐:边缘:Safari:
我们这里使用 Chrome 来执行以下操作。
注意不同版本浏览器的驱动是不同的,请根据您的浏览器下载对应的版本。
我们使用以下代码来安装 selenium 库,
pip install selenium
1.2.打开和关闭网页
我们需要使用 selenium 实例化一个 Chrome 对象来模拟浏览器的操作,并使用 driver.get() 方法打开相应的网页。使用 driver.close() 方法关闭当前网页,或使用 driver.quit() 方法关闭浏览器。比如我们模拟打开一个百度页面,等待3秒后关闭,
from selenium import webdriver
import time
driver_path = r'D:\python_class\crawl\chromedriver.exe' # chromedriver.exe文件位置
driver = webdriver.Chrome(executable_path=driver_path) # executable_path为chromedriver.exe文件位置
driver.get('http://www.baidu.com') # 第一个参数为网站url
time.sleep(3)
driver.close() # 关闭当前页面
如果不想每次都设置executable_path参数,可以将chromedriver.exe文件放在chrome浏览器目录下,将目录地址添加到系统变量中的Path中,这样我们就不需要设置可执行路径参数。
1.3.阅读网页源码
我们可以直接使用driver.page_source来获取网页的源代码,比如我们获取百度页面的代码,
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
print(driver.page_source) # 打印页面源代码
driver.close() # 关闭当前页面
1.4. 定位元素
Selenium 支持基于类名、id、name 属性值、标签名、xpath、css 选择器或 By 方法定位元素。
方式示例
班级名称
inputTag = driver.find_elements_by_class_name("s_ipt")[0]
id值
inputTag = driver.find_element_by_id("kw")
名称属性值
inputTag = driver.find_element_by_name("wd")
标签名称
inputTag = driver.find_element_by_tag_name("输入")
xpath 语法
inputTag = driver.find_element_by_xpath('//input[@id="kw"]')
css 选择器
inputTag = driver.find_element_by_css_selector('#kw')
经过
使用By方法需要先导入,from mon.by import By, inputTag = driver.find_element(By.ID, “kw”)
1.5. 表单元素操作示例
操作输入框
发送密钥()
inputTag.send_keys('1')
点击元素
点击()
submintTag.click()
获取元素的指定属性
get_attribute()
inputValue.get_attribute('占位符')
1.6. 行为链
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。我们使用行为链进行搜索,
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
inputTag = driver.find_element_by_id('kw') # 找到输入框
submitTag = driver.find_element_by_id('su') # 找到提交按钮
actions = ActionChains(driver) # 实例化行为链对象
actions.move_to_element(inputTag) # 焦点移动到输入框
actions.send_keys_to_element(inputTag, '美国病毒') # 提交内容
actions.move_to_element(submitTag) # 焦点移动到提交按钮
actions.click(submitTag) # 点击提交按钮
actions.perform() # 展示页面
我们还可以实现一些操作,
操作方法
单击而不释放鼠标
click_and_hold(元素)
右键点击
上下文点击(元素)
双击
双击(元素)
1.7.Cookie 操作
from selenium import webdriver
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
print(driver.get_cookies()) # 打印cookie信息,注意,这里是cookies()方法
print(driver.get_cookie('PSTM')) # 获取cookie中的PSTM信息,注意,这里是cookie()方法
print(driver.delete_cookie('PSTM')) # 删除cookie中的PSTM信息
1.8.页面操作1.8.1.等待页面
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
我们先来看看隐式等待。
隐式等待调用driver.implicitly_wait()方法,我们可以设置等待时间,例如,
from selenium import webdriver
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
driver.implicitly_wait(5) # 参数为等待时间。如果5秒内页面加载完成,则取消等待;否则,5秒后返回错误
print(driver.page_source)
接下来,显示操作。
显示等待是在执行获取元素的操作之前显示满足某个条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
element = WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.ID, 'su')))
# 在5秒内,id值为su的标签加载完成后,则取消等待;否则,报错
这里有一些其他条件,
等待条件法
一个元素已加载
Presence_of_element_located()
页面上所有符合条件的元素都已加载完毕
Presence_of_all_emement_located()
一个元素可以被点击
element_to_be_cliable()
1.8.2.切换页面
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。页面会以列表的形式显示,可以使用列表下标来切换页面。例如,
from selenium import webdriver
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.baidu.com') # 打开主页
driver.execute_script("window.open('http://www.zhihu.com')") # 以新窗口的形式打开新的页面
driver.execute_script("window.open('http://www.douban.com')")
print(driver.window_handles) # 窗口的句柄
driver.switch_to_window(driver.window_handles[0]) # 切换到页面列表中下标为0的页面
1.8.3.保存页面截图
save_screenshot() 方法可以保存页面的截图,例如,
from selenium import webdriver
from selenium.webdriver.common.by import By
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.codingke.com') # 打开主页
driver.save_screenshot('codingke.png') # 参数为图片名称
1.9.设置代理不显示浏览器
我们可以通过添加浏览器选项来开启代理服务器并执行代码,而无需显示浏览器的操作过程。我们需要创建一个 ChromeOptions 对象,然后使用 add_argument() 方法添加选项,最后将 options 参数添加到 Chrome 对象中。例如,
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://175.42.123.88:9999") # 添加代理服务器
options.add_argument("--headless") # 不打开浏览器
options.add_argument("--disable-gpu") # 禁用GPU
driver = webdriver.Chrome(options=options)
driver.get('http://httpbin.org/ip')
print(driver.page_source) 查看全部
js 爬虫抓取网页数据(动态网页抓取AJAX(Asynchronouse)异步JavaScript和XML的区别
)
动态网页抓取
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
我们有两种方式获取ajax数据:
直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
我们接下来讲解使用selenium+chromedriver获取动态数据。
1.Selenium+chromedriver获取动态数据1.1.准备
Selenium 相当于一个机器人。它可以模拟人们在浏览器上的一些行为,并自动处理浏览器上的一些行为,如点击、填充数据、删除cookies等。chromedriver是一个驱动Chrome浏览器的驱动程序,可以用来驱动浏览器浏览器。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
铬:火狐:边缘:Safari:
我们这里使用 Chrome 来执行以下操作。
注意不同版本浏览器的驱动是不同的,请根据您的浏览器下载对应的版本。
我们使用以下代码来安装 selenium 库,
pip install selenium
1.2.打开和关闭网页
我们需要使用 selenium 实例化一个 Chrome 对象来模拟浏览器的操作,并使用 driver.get() 方法打开相应的网页。使用 driver.close() 方法关闭当前网页,或使用 driver.quit() 方法关闭浏览器。比如我们模拟打开一个百度页面,等待3秒后关闭,
from selenium import webdriver
import time
driver_path = r'D:\python_class\crawl\chromedriver.exe' # chromedriver.exe文件位置
driver = webdriver.Chrome(executable_path=driver_path) # executable_path为chromedriver.exe文件位置
driver.get('http://www.baidu.com') # 第一个参数为网站url
time.sleep(3)
driver.close() # 关闭当前页面
如果不想每次都设置executable_path参数,可以将chromedriver.exe文件放在chrome浏览器目录下,将目录地址添加到系统变量中的Path中,这样我们就不需要设置可执行路径参数。
1.3.阅读网页源码
我们可以直接使用driver.page_source来获取网页的源代码,比如我们获取百度页面的代码,
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
print(driver.page_source) # 打印页面源代码
driver.close() # 关闭当前页面
1.4. 定位元素
Selenium 支持基于类名、id、name 属性值、标签名、xpath、css 选择器或 By 方法定位元素。
方式示例
班级名称
inputTag = driver.find_elements_by_class_name("s_ipt")[0]
id值
inputTag = driver.find_element_by_id("kw")
名称属性值
inputTag = driver.find_element_by_name("wd")
标签名称
inputTag = driver.find_element_by_tag_name("输入")
xpath 语法
inputTag = driver.find_element_by_xpath('//input[@id="kw"]')
css 选择器
inputTag = driver.find_element_by_css_selector('#kw')
经过
使用By方法需要先导入,from mon.by import By, inputTag = driver.find_element(By.ID, “kw”)
1.5. 表单元素操作示例
操作输入框
发送密钥()
inputTag.send_keys('1')
点击元素
点击()
submintTag.click()
获取元素的指定属性
get_attribute()
inputValue.get_attribute('占位符')
1.6. 行为链
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。我们使用行为链进行搜索,
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
inputTag = driver.find_element_by_id('kw') # 找到输入框
submitTag = driver.find_element_by_id('su') # 找到提交按钮
actions = ActionChains(driver) # 实例化行为链对象
actions.move_to_element(inputTag) # 焦点移动到输入框
actions.send_keys_to_element(inputTag, '美国病毒') # 提交内容
actions.move_to_element(submitTag) # 焦点移动到提交按钮
actions.click(submitTag) # 点击提交按钮
actions.perform() # 展示页面
我们还可以实现一些操作,
操作方法
单击而不释放鼠标
click_and_hold(元素)
右键点击
上下文点击(元素)
双击
双击(元素)
1.7.Cookie 操作
from selenium import webdriver
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
print(driver.get_cookies()) # 打印cookie信息,注意,这里是cookies()方法
print(driver.get_cookie('PSTM')) # 获取cookie中的PSTM信息,注意,这里是cookie()方法
print(driver.delete_cookie('PSTM')) # 删除cookie中的PSTM信息
1.8.页面操作1.8.1.等待页面
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
我们先来看看隐式等待。
隐式等待调用driver.implicitly_wait()方法,我们可以设置等待时间,例如,
from selenium import webdriver
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
driver.implicitly_wait(5) # 参数为等待时间。如果5秒内页面加载完成,则取消等待;否则,5秒后返回错误
print(driver.page_source)
接下来,显示操作。
显示等待是在执行获取元素的操作之前显示满足某个条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
element = WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.ID, 'su')))
# 在5秒内,id值为su的标签加载完成后,则取消等待;否则,报错
这里有一些其他条件,
等待条件法
一个元素已加载
Presence_of_element_located()
页面上所有符合条件的元素都已加载完毕
Presence_of_all_emement_located()
一个元素可以被点击
element_to_be_cliable()
1.8.2.切换页面
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。页面会以列表的形式显示,可以使用列表下标来切换页面。例如,
from selenium import webdriver
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.baidu.com') # 打开主页
driver.execute_script("window.open('http://www.zhihu.com')") # 以新窗口的形式打开新的页面
driver.execute_script("window.open('http://www.douban.com')")
print(driver.window_handles) # 窗口的句柄
driver.switch_to_window(driver.window_handles[0]) # 切换到页面列表中下标为0的页面
1.8.3.保存页面截图
save_screenshot() 方法可以保存页面的截图,例如,
from selenium import webdriver
from selenium.webdriver.common.by import By
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.codingke.com') # 打开主页
driver.save_screenshot('codingke.png') # 参数为图片名称
1.9.设置代理不显示浏览器
我们可以通过添加浏览器选项来开启代理服务器并执行代码,而无需显示浏览器的操作过程。我们需要创建一个 ChromeOptions 对象,然后使用 add_argument() 方法添加选项,最后将 options 参数添加到 Chrome 对象中。例如,
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://175.42.123.88:9999";) # 添加代理服务器
options.add_argument("--headless") # 不打开浏览器
options.add_argument("--disable-gpu") # 禁用GPU
driver = webdriver.Chrome(options=options)
driver.get('http://httpbin.org/ip')
print(driver.page_source)
js 爬虫抓取网页数据(js爬虫抓取网页数据,你可以给他一个教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-09-29 12:04
js爬虫抓取网页数据
你可以给他一个教程让他自己摸索
教他吧,有些人自己都没有实践过就已经指望着别人来带他飞了,这样是不好的。抓取的话肯定可以获取他很多之前没有的。放心吧。
我劝你不要欺负小孩子智商比较高
行业常识告诉我们,所有的http数据请求,都需要先给对方发送一个url。通过这个url请求带来的某些数据,反过来可以推动你的爬虫程序的正确性。例如“从某网站爬取点击量”的数据。当然,这个url没有固定的格式,有些网站会支持很多链接,你可以通过浏览器对于“从某网站爬取点击量”的http请求进行一个改变,来完成爬取。
浏览器中的页面设置不要有单向跳转,有些url在此地方是没有返回,即使你设置了也不行。你可以跟他说爬虫只爬取url标签指向的一部分数据,是返回就返回,不是就不返回。
谢邀,这里有一份北京各大优采云站的站名地址,以及距离与时间的关系表格,
单靠带节奏是不可能学会爬虫的,简单可以多看书看代码。
给了你手机就是让你记住。
20140123更新:之前还有挺多爬虫开发学习资料,题主不妨查看一下。现在大家提到爬虫的开发,除了通过慕课网等这些爬虫网站,推荐题主还可以去国内的豆瓣相关豆列寻找:;d_u=8725178175;另外针对题主另一个问题,爬虫中的涉及权限、缓存数据等内容,都可以通过url编码技术或dns+http数据库或useragent,直接赋予应用应有的权限。
再举个栗子,你找一个图片或者页面,手机上点下拉,就会有数据下来,登录账号就可以接收这些数据;登录网站后,你再通过你的爬虫服务器,就可以从你的网站中爬取那些该爬取的内容了。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据,你可以给他一个教程)
js爬虫抓取网页数据
你可以给他一个教程让他自己摸索
教他吧,有些人自己都没有实践过就已经指望着别人来带他飞了,这样是不好的。抓取的话肯定可以获取他很多之前没有的。放心吧。
我劝你不要欺负小孩子智商比较高
行业常识告诉我们,所有的http数据请求,都需要先给对方发送一个url。通过这个url请求带来的某些数据,反过来可以推动你的爬虫程序的正确性。例如“从某网站爬取点击量”的数据。当然,这个url没有固定的格式,有些网站会支持很多链接,你可以通过浏览器对于“从某网站爬取点击量”的http请求进行一个改变,来完成爬取。
浏览器中的页面设置不要有单向跳转,有些url在此地方是没有返回,即使你设置了也不行。你可以跟他说爬虫只爬取url标签指向的一部分数据,是返回就返回,不是就不返回。
谢邀,这里有一份北京各大优采云站的站名地址,以及距离与时间的关系表格,
单靠带节奏是不可能学会爬虫的,简单可以多看书看代码。
给了你手机就是让你记住。
20140123更新:之前还有挺多爬虫开发学习资料,题主不妨查看一下。现在大家提到爬虫的开发,除了通过慕课网等这些爬虫网站,推荐题主还可以去国内的豆瓣相关豆列寻找:;d_u=8725178175;另外针对题主另一个问题,爬虫中的涉及权限、缓存数据等内容,都可以通过url编码技术或dns+http数据库或useragent,直接赋予应用应有的权限。
再举个栗子,你找一个图片或者页面,手机上点下拉,就会有数据下来,登录账号就可以接收这些数据;登录网站后,你再通过你的爬虫服务器,就可以从你的网站中爬取那些该爬取的内容了。
js 爬虫抓取网页数据(如何利用Webkit从JS渲染网页中获取数据处理的任何事情)
网站优化 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-28 17:30
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页中收录 JavaScript 代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想爬取Pycoders周刊中所有文件的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
进口请求
从 lxml 导入 html
# 存储响应
response = requests.get('#39;)
# 从响应体创建 lxml 树
树 = html.fromstring(response.text)
# 在响应中查找所有锚标记
print tree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
须藤 apt-get 安装 python-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
导入系统
从 PyQt4.QtGui 导入 *
从 PyQt4.Qtcore 导入 *
从 PyQt4.QtWebKit 导入 *
类渲染(QWebPage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载url中的所有信息并将其存储在一个新的框架中。
网址 ='#39;
# 这很神奇。加载一切
r = 渲染(网址)
# 结果是一个 QString。
结果 = r.frame.toHtml()
使用上面的代码,我们将 HTML 结果存储在变量 result 中。由于lxml不能直接处理特殊的字符串数据,我们需要对数据格式进行转换。
# QString 在被 lxml 处理之前应该转换为字符串
formatted_result = str(result.toAscii())
# 接下来从 formatted_result 构建 lxml 树
树 = html.fromstring(formatted_result)
# 现在使用正确的 Xpath 我们正在获取档案的 URL
archive_links = tree.xpath('//div[@class="campaign"]/a/@href')
打印存档链接
使用上面的代码,我们可以得到所有的文件链接信息,然后我们就可以使用这些Render和这些URL链接来提取文本内容信息了。Web kit提供了一个强大的网页渲染工具,我们可以利用这个工具从JS渲染的网页中抓取有效的信息。
在本文中,我介绍了一种从 JS 渲染的网页中抓取信息的有效方法。虽然这个工具很慢,但它非常简单和粗鲁。我希望你会喜欢这个文章。现在,您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。 查看全部
js 爬虫抓取网页数据(如何利用Webkit从JS渲染网页中获取数据处理的任何事情)
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页中收录 JavaScript 代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想爬取Pycoders周刊中所有文件的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
进口请求
从 lxml 导入 html
# 存储响应
response = requests.get('#39;)
# 从响应体创建 lxml 树
树 = html.fromstring(response.text)
# 在响应中查找所有锚标记
print tree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
须藤 apt-get 安装 python-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
导入系统
从 PyQt4.QtGui 导入 *
从 PyQt4.Qtcore 导入 *
从 PyQt4.QtWebKit 导入 *
类渲染(QWebPage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载url中的所有信息并将其存储在一个新的框架中。
网址 ='#39;
# 这很神奇。加载一切
r = 渲染(网址)
# 结果是一个 QString。
结果 = r.frame.toHtml()
使用上面的代码,我们将 HTML 结果存储在变量 result 中。由于lxml不能直接处理特殊的字符串数据,我们需要对数据格式进行转换。
# QString 在被 lxml 处理之前应该转换为字符串
formatted_result = str(result.toAscii())
# 接下来从 formatted_result 构建 lxml 树
树 = html.fromstring(formatted_result)
# 现在使用正确的 Xpath 我们正在获取档案的 URL
archive_links = tree.xpath('//div[@class="campaign"]/a/@href')
打印存档链接
使用上面的代码,我们可以得到所有的文件链接信息,然后我们就可以使用这些Render和这些URL链接来提取文本内容信息了。Web kit提供了一个强大的网页渲染工具,我们可以利用这个工具从JS渲染的网页中抓取有效的信息。
在本文中,我介绍了一种从 JS 渲染的网页中抓取信息的有效方法。虽然这个工具很慢,但它非常简单和粗鲁。我希望你会喜欢这个文章。现在,您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。
js 爬虫抓取网页数据(Python语言Python和爬虫的开发方向是怎样的呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-09-28 11:02
说到Python,有些同学自然会想到爬虫,但其实Python和爬虫不是概念的东西。下面就给大家介绍一下小倩。
爬虫
爬虫,又称网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区中常称为网络追逐者),是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
爬虫的主要工作是按照一定的规则在网络上爬取我们想要的数据的程序。这里大家要注意,爬虫不一定要用Python来实现。它可以使用 JavaScript、Java 和其他语言来实现。的。
Python语言
Python 由荷兰数学与计算机科学研究会的 Guido van Rossum 于 1990 年代初设计,作为 ABC 语言的替代品。Python 提供的数据结构也可以用于简单有效的面向对象编程。Python 语法和动态类型,以及解释型语言的性质,使其成为在大多数平台上编写脚本和快速应用程序开发的编程语言。随着不断的新版本和新语言特性的加入,逐渐被用于独立的、大规模的应用。项目发展。
Python 是一种计算机编程语言。之所以与爬虫有如此密切的关系,是因为Python的脚本特性、易于配置和灵活的字符处理。Python拥有丰富的网络捕捉模块和丰富的数据处理框架。这导致很多爬虫开发者使用Python作为爬虫程序开发语言。
爬虫可以作为Python语言的一个发展方向,但是爬虫可以用其他语言实现,所以以后不要把Python和爬虫混为一谈。
以上就是Python和爬虫的介绍。相信看完之后你会明白的。如果您对Python或网络爬虫感兴趣,不妨联系我们的在线咨询老师,这里有教程视频供您参考。 查看全部
js 爬虫抓取网页数据(Python语言Python和爬虫的开发方向是怎样的呢?)
说到Python,有些同学自然会想到爬虫,但其实Python和爬虫不是概念的东西。下面就给大家介绍一下小倩。

爬虫
爬虫,又称网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区中常称为网络追逐者),是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
爬虫的主要工作是按照一定的规则在网络上爬取我们想要的数据的程序。这里大家要注意,爬虫不一定要用Python来实现。它可以使用 JavaScript、Java 和其他语言来实现。的。
Python语言
Python 由荷兰数学与计算机科学研究会的 Guido van Rossum 于 1990 年代初设计,作为 ABC 语言的替代品。Python 提供的数据结构也可以用于简单有效的面向对象编程。Python 语法和动态类型,以及解释型语言的性质,使其成为在大多数平台上编写脚本和快速应用程序开发的编程语言。随着不断的新版本和新语言特性的加入,逐渐被用于独立的、大规模的应用。项目发展。
Python 是一种计算机编程语言。之所以与爬虫有如此密切的关系,是因为Python的脚本特性、易于配置和灵活的字符处理。Python拥有丰富的网络捕捉模块和丰富的数据处理框架。这导致很多爬虫开发者使用Python作为爬虫程序开发语言。
爬虫可以作为Python语言的一个发展方向,但是爬虫可以用其他语言实现,所以以后不要把Python和爬虫混为一谈。
以上就是Python和爬虫的介绍。相信看完之后你会明白的。如果您对Python或网络爬虫感兴趣,不妨联系我们的在线咨询老师,这里有教程视频供您参考。
js 爬虫抓取网页数据(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-28 09:26
什么是 AJAX:
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium 和 chromedriver: Install Selenium: Selenium 有很多语言版本,比如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面我们就拿百度首页做个简单的例子来说一下如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径 driver = webdriver.Chrome(executable_path=driver_path) # 请求网页 driver.get("https://www.baidu.com/") # 通过page_source获取网页源代码 print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择 selectTag.select_by_index(1) # 根据值选择 selectTag.select_by_value("http://www.95yueba.com") # 根据可视的文本选择 selectTag.select_by_visible_text("95秀客户端") # 取消选中所有选项 selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
cookie 操作: 获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC driver = webdriver.Firefox() driver.get("http://somedomain/url_that_delays_loading") try: element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "myDynamicElement")) ) finally: driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
转载于: 查看全部
js 爬虫抓取网页数据(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
什么是 AJAX:
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium 和 chromedriver: Install Selenium: Selenium 有很多语言版本,比如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面我们就拿百度首页做个简单的例子来说一下如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径 driver = webdriver.Chrome(executable_path=driver_path) # 请求网页 driver.get("https://www.baidu.com/";) # 通过page_source获取网页源代码 print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择 selectTag.select_by_index(1) # 根据值选择 selectTag.select_by_value("http://www.95yueba.com";) # 根据可视的文本选择 selectTag.select_by_visible_text("95秀客户端") # 取消选中所有选项 selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
cookie 操作: 获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC driver = webdriver.Firefox() driver.get("http://somedomain/url_that_delays_loading";) try: element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "myDynamicElement")) ) finally: driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
转载于:
js 爬虫抓取网页数据(Web漏洞扫描工具的安全运维人员造成的诸多困扰!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-26 23:02
在 Web 漏扫中,采集 输入源一般包括爬虫、流量、代理和日志。爬虫是获取扫描后的网站 URLs.采集模式最常见也是必不可少的方式。
网络漏洞扫描器爬虫比其他网络爬虫面临更高的技术挑战。这是因为漏洞扫描器爬虫不仅需要抓取网页内容和分析链接信息,还需要在网页上尽可能多地触发。事件,从而获得更有效的链接信息。
然而,现有爬虫受限于其固有的技术缺陷,给使用Web漏洞扫描工具的安全运维人员带来了诸多问题:
1、 容易触发WAF设置的IP访问限制
正常情况下,网站的防火墙会限制一定时间内可以请求固定IP的次数。如果没有超过上限,则正常返回数据,超过上限则拒绝请求。值得注意的是,IP 限制大部分时间是出于 网站 安全原因以防止 DOS 攻击,而不是专门针对爬虫。但是传统爬虫工作时,机器和IP都是有限的,很容易达到WAF设置的IP上限而导致请求被拒绝。
2、 无法自动处理网页交互问题
Web2.0时代,Web应用与用户交互非常频繁,对漏网的爬虫造成干扰。以输入验证码登录为例。网站 会生成一串随机生成的数字或符号的图片,在图片上添加一些干扰像素(防止OCR),用户可以直观的识别验证码信息并输入表单提交< @网站验证,验证成功后才能使用某个功能。当传统爬虫遇到这种情况时,通常很难自动处理。
3、 无法抓取 JavaScript 解析的网页
JavaScript 框架的诞生对于效率时代的研发工程师来说是一大福音,工程师们可以摆脱开发和维护的痛苦。毫无疑问,Angular、React、Vue 等单页应用的 Web 框架已经成为开发者的首选。JavaScript解析的网页越来越流行,所以网页中大部分有用的数据都是通过ajax/fetch动态获取然后通过js填充到网页的DOM树中的,有用的数据很少纯HTML静态页面,直接导致Web爬虫不完整抓取。
传统爬行动物和集中爬行动物
纵观市场上常用的漏洞扫描产品,通常使用的爬虫包括以下两大类,即传统爬虫和聚焦爬虫:
传统爬虫
其工作流程是从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足一系列系统设置。停止条件,爬行操作停止。
传统爬虫流程图侧重爬虫
聚焦爬虫的工作流程比传统爬虫复杂。需要根据一定的网页分析算法过滤与扫描目标无关的网址,保留有用的网址,放入网址队列等待抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;因此,一个完整的聚焦爬虫一般收录以下三个模块:Web请求模块、爬取过程控制模块、内容分析提取模块。
但是,无论是传统爬虫还是聚焦爬虫,由于其固有的技术缺陷,无法在URL采集@时自动处理网页交互、JavaScript解析,并容易触发外部WAF防御措施的限制>网站 等问题。
X-Ray创新技术提高爬虫发现率
X-Ray安全评估系统针对当前用户错过的爬虫,创造性地提出了基于语义分析、机器学习技术和DOM遍历算法的高仿真实时渲染的实时渲染DOM遍历算法采集 @> 目标 URL 问题。“新爬虫”:
1、 创新加入js语义分析算法,避免IP访问超限
对于传统的网站,长亭科技在专注于爬虫的基础上,创新使用js语义分析算法,针对WAF针对DOS攻击的IP访问限制防御措施,X-Ray爬虫会在本地对JS文件进行分析,并且在理解语义的基础上解析网站结构,不会疯狂触发请求,从而避免超出IP访问限制被拒绝访问的情况。
X-Ray专注爬虫流程原理图2、通过机器学习技术实现交互行为分析
对于单页应用网站,X-Ray 已经嵌入了一个模拟浏览器爬虫。通过使用机器学习技术,X-Ray 的模拟浏览器爬虫使用各种 Web 应用程序页面结构作为训练样本。在访问每个页面时,可以智能判断各种交互操作。判断逻辑大概是这样的:
判断是表单输入、点击事件等;
自动判断表单输入框应填写哪些内容,如用户名、密码、IP地址等,然后填写相应的内容样本;
点击事件自动触发,请求发起成功。3、 高仿真实时渲染DOM遍历算法完美解决JavaScript解析
针对JavaScript解析的单页Web应用,X-Ray模拟浏览器创新引入了高模拟实时渲染DOM遍历算法。在该算法引擎的驱动下,可以完美解析Angular、React、Vue等Web框架。实现的单页应用网站对Web页面中的所有内容进行操作,达到获取URL信息的目的目标网站。判断逻辑如下:
找到网页的DOM节点,形成DOM树;
内置浏览器,从深度和广度两个层次,对网页进行高仿真度的DOM树遍历;
真实浏览器画面,实时渲染DOM树的遍历过程
X-Ray在机器学习技术和DOM遍历算法的高仿真实时渲染驱动下,模拟浏览器爬虫的行为,智能模拟人类行为,自动进行点击、双击、拖拽等操作,从而避免了传统爬虫在获取到 URL 时,无法满足交互,无法处理 JavaScript 解析。
下面以访问DVWA为例,展示模拟浏览器的行为
dvwa浏览器点击
以网银、电子商务、云存储等Web应用为代表的Web3.0时代已经到来,X-Ray安全评估系统蓄势待发。你准备好了吗? 查看全部
js 爬虫抓取网页数据(Web漏洞扫描工具的安全运维人员造成的诸多困扰!)
在 Web 漏扫中,采集 输入源一般包括爬虫、流量、代理和日志。爬虫是获取扫描后的网站 URLs.采集模式最常见也是必不可少的方式。
网络漏洞扫描器爬虫比其他网络爬虫面临更高的技术挑战。这是因为漏洞扫描器爬虫不仅需要抓取网页内容和分析链接信息,还需要在网页上尽可能多地触发。事件,从而获得更有效的链接信息。
然而,现有爬虫受限于其固有的技术缺陷,给使用Web漏洞扫描工具的安全运维人员带来了诸多问题:
1、 容易触发WAF设置的IP访问限制
正常情况下,网站的防火墙会限制一定时间内可以请求固定IP的次数。如果没有超过上限,则正常返回数据,超过上限则拒绝请求。值得注意的是,IP 限制大部分时间是出于 网站 安全原因以防止 DOS 攻击,而不是专门针对爬虫。但是传统爬虫工作时,机器和IP都是有限的,很容易达到WAF设置的IP上限而导致请求被拒绝。
2、 无法自动处理网页交互问题
Web2.0时代,Web应用与用户交互非常频繁,对漏网的爬虫造成干扰。以输入验证码登录为例。网站 会生成一串随机生成的数字或符号的图片,在图片上添加一些干扰像素(防止OCR),用户可以直观的识别验证码信息并输入表单提交< @网站验证,验证成功后才能使用某个功能。当传统爬虫遇到这种情况时,通常很难自动处理。
3、 无法抓取 JavaScript 解析的网页
JavaScript 框架的诞生对于效率时代的研发工程师来说是一大福音,工程师们可以摆脱开发和维护的痛苦。毫无疑问,Angular、React、Vue 等单页应用的 Web 框架已经成为开发者的首选。JavaScript解析的网页越来越流行,所以网页中大部分有用的数据都是通过ajax/fetch动态获取然后通过js填充到网页的DOM树中的,有用的数据很少纯HTML静态页面,直接导致Web爬虫不完整抓取。
传统爬行动物和集中爬行动物
纵观市场上常用的漏洞扫描产品,通常使用的爬虫包括以下两大类,即传统爬虫和聚焦爬虫:
传统爬虫
其工作流程是从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足一系列系统设置。停止条件,爬行操作停止。
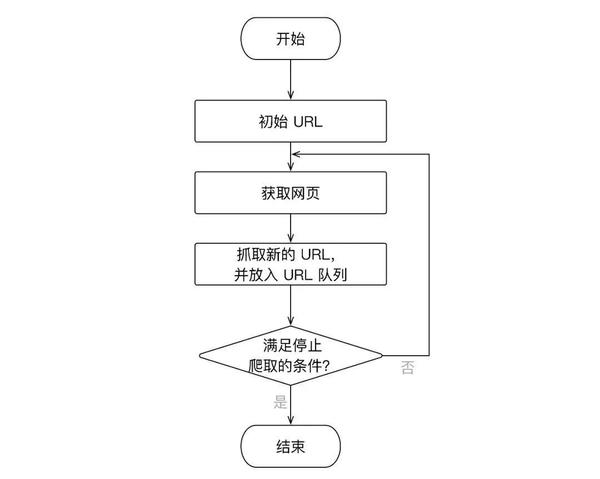
传统爬虫流程图侧重爬虫
聚焦爬虫的工作流程比传统爬虫复杂。需要根据一定的网页分析算法过滤与扫描目标无关的网址,保留有用的网址,放入网址队列等待抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;因此,一个完整的聚焦爬虫一般收录以下三个模块:Web请求模块、爬取过程控制模块、内容分析提取模块。
但是,无论是传统爬虫还是聚焦爬虫,由于其固有的技术缺陷,无法在URL采集@时自动处理网页交互、JavaScript解析,并容易触发外部WAF防御措施的限制>网站 等问题。
X-Ray创新技术提高爬虫发现率
X-Ray安全评估系统针对当前用户错过的爬虫,创造性地提出了基于语义分析、机器学习技术和DOM遍历算法的高仿真实时渲染的实时渲染DOM遍历算法采集 @> 目标 URL 问题。“新爬虫”:
1、 创新加入js语义分析算法,避免IP访问超限
对于传统的网站,长亭科技在专注于爬虫的基础上,创新使用js语义分析算法,针对WAF针对DOS攻击的IP访问限制防御措施,X-Ray爬虫会在本地对JS文件进行分析,并且在理解语义的基础上解析网站结构,不会疯狂触发请求,从而避免超出IP访问限制被拒绝访问的情况。
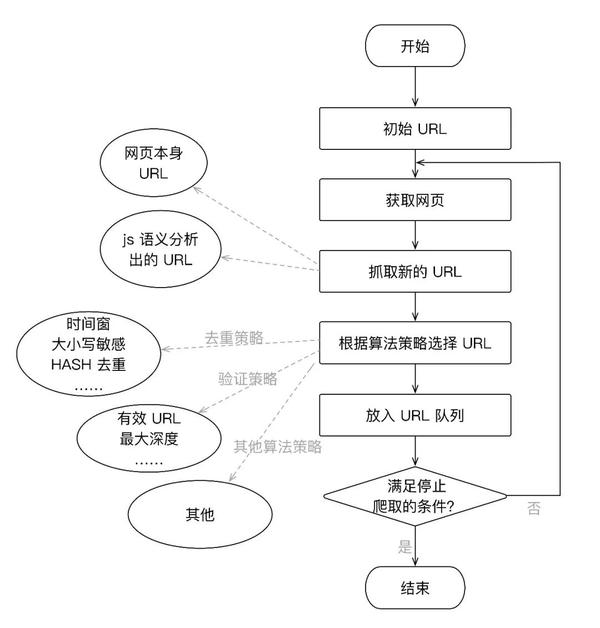
X-Ray专注爬虫流程原理图2、通过机器学习技术实现交互行为分析
对于单页应用网站,X-Ray 已经嵌入了一个模拟浏览器爬虫。通过使用机器学习技术,X-Ray 的模拟浏览器爬虫使用各种 Web 应用程序页面结构作为训练样本。在访问每个页面时,可以智能判断各种交互操作。判断逻辑大概是这样的:
判断是表单输入、点击事件等;
自动判断表单输入框应填写哪些内容,如用户名、密码、IP地址等,然后填写相应的内容样本;
点击事件自动触发,请求发起成功。3、 高仿真实时渲染DOM遍历算法完美解决JavaScript解析
针对JavaScript解析的单页Web应用,X-Ray模拟浏览器创新引入了高模拟实时渲染DOM遍历算法。在该算法引擎的驱动下,可以完美解析Angular、React、Vue等Web框架。实现的单页应用网站对Web页面中的所有内容进行操作,达到获取URL信息的目的目标网站。判断逻辑如下:
找到网页的DOM节点,形成DOM树;
内置浏览器,从深度和广度两个层次,对网页进行高仿真度的DOM树遍历;
真实浏览器画面,实时渲染DOM树的遍历过程
X-Ray在机器学习技术和DOM遍历算法的高仿真实时渲染驱动下,模拟浏览器爬虫的行为,智能模拟人类行为,自动进行点击、双击、拖拽等操作,从而避免了传统爬虫在获取到 URL 时,无法满足交互,无法处理 JavaScript 解析。
下面以访问DVWA为例,展示模拟浏览器的行为
dvwa浏览器点击
以网银、电子商务、云存储等Web应用为代表的Web3.0时代已经到来,X-Ray安全评估系统蓄势待发。你准备好了吗?
js 爬虫抓取网页数据(Python和js引擎运行的源代码都是js,几乎没有我想要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 339 次浏览 • 2021-09-25 22:00
想爬下北京邮报的论坛,但是看到页面的源代码都是js,几乎没有我想要的信息。回复内容:今天偶然发现了PyV8,感觉就是你想要的。
它直接搭建了一个js运行环境,也就是说你可以直接在python中执行页面上的js代码来获取你需要的内容。
参考:
/博客/?p=252
/p/pyv8/ 我直接看js源码,分析了一下,然后爬了。
比如你看页面使用ajax请求JSON文件,我会先爬取那个页面,获取ajax需要的参数,然后直接请求json页面,然后解码,然后处理数据存储它在数据库中。
如果直接运行页面上的所有js(就像浏览器一样),然后得到最终的HTML DOM树,这样的性能很糟糕,不推荐使用这种方式。因为Python和js本身的性能很差,如果这样做的话,会消耗大量的CPU资源,最终只能得到很低的爬取效率。js代码需要js引擎才能运行,Python只能通过HTTP请求获取原创的HTML、CSS、JS代码。
不知道有没有用Python写的JS引擎,估计需求量不大。
我一般使用 PhantomJS 和 CasperJS 等引擎进行浏览器抓取。
直接在其中编写JS代码进行DOM操作和分析,并将结果输出为文件。
让Python调用程序,通过读取文件获取内容。去年,我真的爬过这样的数据,因为我赶时间,而且我的方法更丑陋。
PyQt有专门的库来模拟浏览器的请求和行为(好像是webkit的,算了,查一下,几行代码就够了)。在一个运行的程序中,第一次(只有第一个 次的返回结果)是js运行后的代码。所以我写了一个py脚本来做访问分析,然后写了一个windows脚本,通过传递命令行参数来循环这个py脚本,最后得到数据。
方法有点脏,但是拿到数据还是不错的~对于某个网站,可以看网络请求,找到那些返回实际内容的,有针对性的发送。如果是通用的,则必须使用无头浏览器,例如PhantomJS。另一位爬上北京邮政论坛的人。.
文艺的方法,去浏览器引擎,比如PhantomJS,用它导出html,然后用python解析html。不要直接用PhantomJS解析它,虽然我知道它很容易,为什么?那么它就不叫python爬虫了。因为统一使用python进行解析比较统一,这里我们假设你还在爬非JS页面。
普通方法,分析AJAX请求。即使是JS渲染的,数据还是通过HTTP协议传输的。什么?不能模拟吗?读懂HTTP协议,其实还是有经验的。比如要请求北京邮政论坛的正文
X-Requested-With:XMLHttpRequest
这是一个栗子:
拉勾网职位列表
点击Android后,我们从浏览器上传了几个参数到拉勾服务器
一个是first = true,另一个是kd = android,(关键字),另一个是pn = 1(页码)
所以我们可以模仿这一步构造一个数据包来模拟用户的点击动作。
post_data = {'first':'true','kd':'Android','pn':'1'}
虽然这已经是很久以前的事了,但题目似乎已经解决了这个问题。但是看到很多答案的方法有点太重了,这里提供一个效率更高,消耗资源更少的方法。由于主题没有指定需要什么,这里的示例采用主页上所有帖子的链接和标题。
首先请记住浏览器环境对内存和CPU的消耗非常严重,尽量避免模拟浏览器环境的爬虫代码。请记住,对于一些前端渲染的网页,虽然我们需要的数据在HTML源代码中是看不到的,但更有可能是通过另一个请求(最有可能是JSON格式)得到纯数据。我们不仅不需要模拟浏览器,还可以节省解析HTML的消耗。
然后,我打开北京邮政论坛的首页,发现首页的HTML源代码并没有收录页面显示的文章的内容。那么,很有可能这是通过JS异步加载到页面的。通过浏览器开发工具(OS X下的Chrome浏览器通过command+option+i或Win/Linux下通过F12)分析加载主页时的请求,很容易在下面的截图中找到请求:
截图中选择的请求的响应是首页的文章链接。您可以在预览选项中看到渲染的预览:
至此,我们已经确定这个链接可以拿到首页的文章和链接。
在 headers 选项中,有这个请求的请求头和请求参数。我们可以通过 Python 模拟这个请求,得到同样的响应。配合BeautifulSoup等库解析HTML,就可以得到对应的内容。
关于如何模拟请求以及如何解析HTML,请移步我的专栏。有详细介绍,这里不再赘述。
这样就可以在不模拟浏览器环境的情况下抓取数据,大大提高了内存和CPU的消耗和爬行速度。编写爬虫时请记住,如果没有必要,不要模拟浏览器环境。如果是windows下,可以尝试调用windows系统中的webbrowser控件。另外,ie本身也提供了一个接口。但是这两种方法都要渲染页面,在性能上有些浪费。为了加快速度,可以关闭ie的图片下载显示,然后通过点击等方式模拟真实行为。谷歌幻影JS
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
js 爬虫抓取网页数据(Python和js引擎运行的源代码都是js,几乎没有我想要的)
想爬下北京邮报的论坛,但是看到页面的源代码都是js,几乎没有我想要的信息。回复内容:今天偶然发现了PyV8,感觉就是你想要的。
它直接搭建了一个js运行环境,也就是说你可以直接在python中执行页面上的js代码来获取你需要的内容。
参考:
/博客/?p=252
/p/pyv8/ 我直接看js源码,分析了一下,然后爬了。
比如你看页面使用ajax请求JSON文件,我会先爬取那个页面,获取ajax需要的参数,然后直接请求json页面,然后解码,然后处理数据存储它在数据库中。
如果直接运行页面上的所有js(就像浏览器一样),然后得到最终的HTML DOM树,这样的性能很糟糕,不推荐使用这种方式。因为Python和js本身的性能很差,如果这样做的话,会消耗大量的CPU资源,最终只能得到很低的爬取效率。js代码需要js引擎才能运行,Python只能通过HTTP请求获取原创的HTML、CSS、JS代码。
不知道有没有用Python写的JS引擎,估计需求量不大。
我一般使用 PhantomJS 和 CasperJS 等引擎进行浏览器抓取。
直接在其中编写JS代码进行DOM操作和分析,并将结果输出为文件。
让Python调用程序,通过读取文件获取内容。去年,我真的爬过这样的数据,因为我赶时间,而且我的方法更丑陋。
PyQt有专门的库来模拟浏览器的请求和行为(好像是webkit的,算了,查一下,几行代码就够了)。在一个运行的程序中,第一次(只有第一个 次的返回结果)是js运行后的代码。所以我写了一个py脚本来做访问分析,然后写了一个windows脚本,通过传递命令行参数来循环这个py脚本,最后得到数据。
方法有点脏,但是拿到数据还是不错的~对于某个网站,可以看网络请求,找到那些返回实际内容的,有针对性的发送。如果是通用的,则必须使用无头浏览器,例如PhantomJS。另一位爬上北京邮政论坛的人。.
文艺的方法,去浏览器引擎,比如PhantomJS,用它导出html,然后用python解析html。不要直接用PhantomJS解析它,虽然我知道它很容易,为什么?那么它就不叫python爬虫了。因为统一使用python进行解析比较统一,这里我们假设你还在爬非JS页面。
普通方法,分析AJAX请求。即使是JS渲染的,数据还是通过HTTP协议传输的。什么?不能模拟吗?读懂HTTP协议,其实还是有经验的。比如要请求北京邮政论坛的正文
X-Requested-With:XMLHttpRequest
这是一个栗子:
拉勾网职位列表
点击Android后,我们从浏览器上传了几个参数到拉勾服务器
一个是first = true,另一个是kd = android,(关键字),另一个是pn = 1(页码)
所以我们可以模仿这一步构造一个数据包来模拟用户的点击动作。
post_data = {'first':'true','kd':'Android','pn':'1'}
虽然这已经是很久以前的事了,但题目似乎已经解决了这个问题。但是看到很多答案的方法有点太重了,这里提供一个效率更高,消耗资源更少的方法。由于主题没有指定需要什么,这里的示例采用主页上所有帖子的链接和标题。
首先请记住浏览器环境对内存和CPU的消耗非常严重,尽量避免模拟浏览器环境的爬虫代码。请记住,对于一些前端渲染的网页,虽然我们需要的数据在HTML源代码中是看不到的,但更有可能是通过另一个请求(最有可能是JSON格式)得到纯数据。我们不仅不需要模拟浏览器,还可以节省解析HTML的消耗。
然后,我打开北京邮政论坛的首页,发现首页的HTML源代码并没有收录页面显示的文章的内容。那么,很有可能这是通过JS异步加载到页面的。通过浏览器开发工具(OS X下的Chrome浏览器通过command+option+i或Win/Linux下通过F12)分析加载主页时的请求,很容易在下面的截图中找到请求:
截图中选择的请求的响应是首页的文章链接。您可以在预览选项中看到渲染的预览:
至此,我们已经确定这个链接可以拿到首页的文章和链接。
在 headers 选项中,有这个请求的请求头和请求参数。我们可以通过 Python 模拟这个请求,得到同样的响应。配合BeautifulSoup等库解析HTML,就可以得到对应的内容。
关于如何模拟请求以及如何解析HTML,请移步我的专栏。有详细介绍,这里不再赘述。
这样就可以在不模拟浏览器环境的情况下抓取数据,大大提高了内存和CPU的消耗和爬行速度。编写爬虫时请记住,如果没有必要,不要模拟浏览器环境。如果是windows下,可以尝试调用windows系统中的webbrowser控件。另外,ie本身也提供了一个接口。但是这两种方法都要渲染页面,在性能上有些浪费。为了加快速度,可以关闭ie的图片下载显示,然后通过点击等方式模拟真实行为。谷歌幻影JS

免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
js 爬虫抓取网页数据(F12打开网页调试工具:选择“网络”选项卡后,发现有很多响应)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-09-24 12:18
F12打开网页调试工具:
选择“网络”选项卡后,发现有很多响应,我们筛选一下,只看XHR响应。(XHR是Ajax中的概念,表示XMLHTTPrequest)然后我们发现少了很多链接,随便点开一个看看:我们选择city,预览中有一串json数据:
我们再点开看看:
原来全都是城市的列表,应该是加载地区新闻之用的。现在大概了解了怎么找JS请求的接口的吧?但是刚刚我们并没有发现想要的新闻,再找找看:有一个focus,我们点开看看:
与首页的图片新闻呈现的数据是一样的,那么数据应该就在这里面了。
看看其他的链接:
这应该是热搜关键词
这个就是图片新闻下面的新闻了。
我们打开一个接口链接看看:
返回一串乱码,但从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以仿照之前的方法对数据接口进行请求和获取响应了2、请求和解析数据接口数据
先上完整代码:#coding:utf-8
importrequests
importjson
url='#39;
wbdata=requests.get(url).text
data=json.loads(wbdata)
news=data['data']['pc_feed_focus']
forninnews:
title=n['title']
img_url=n['image_url']
url=n['media_url']
print(url,title,img_url)
返回出来的结果如下:
照例,稍微讲解一下代码:
代码分为四部分,
第一部分:引入相关的库#coding:utf-8
importrequests
importjson
第二部分:对数据接口进行http请求url='
wbdata=requests.get(url).text 查看全部
js 爬虫抓取网页数据(F12打开网页调试工具:选择“网络”选项卡后,发现有很多响应)
F12打开网页调试工具:
选择“网络”选项卡后,发现有很多响应,我们筛选一下,只看XHR响应。(XHR是Ajax中的概念,表示XMLHTTPrequest)然后我们发现少了很多链接,随便点开一个看看:我们选择city,预览中有一串json数据:
我们再点开看看:
原来全都是城市的列表,应该是加载地区新闻之用的。现在大概了解了怎么找JS请求的接口的吧?但是刚刚我们并没有发现想要的新闻,再找找看:有一个focus,我们点开看看:
与首页的图片新闻呈现的数据是一样的,那么数据应该就在这里面了。
看看其他的链接:
这应该是热搜关键词
这个就是图片新闻下面的新闻了。
我们打开一个接口链接看看:
返回一串乱码,但从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以仿照之前的方法对数据接口进行请求和获取响应了2、请求和解析数据接口数据
先上完整代码:#coding:utf-8
importrequests
importjson
url='#39;
wbdata=requests.get(url).text
data=json.loads(wbdata)
news=data['data']['pc_feed_focus']
forninnews:
title=n['title']
img_url=n['image_url']
url=n['media_url']
print(url,title,img_url)
返回出来的结果如下:
照例,稍微讲解一下代码:
代码分为四部分,
第一部分:引入相关的库#coding:utf-8
importrequests
importjson
第二部分:对数据接口进行http请求url='
wbdata=requests.get(url).text
js 爬虫抓取网页数据(NEOCrawler、redis、phantomjs实现的爬虫系统的各个子系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-23 15:57
neocrawler(中文名:牛),是nodejs,redis,phantomjs实现的爬行动物系统。代码是完全开源的,适用于垂直字段中的数据采集和爬行动物。
[主要功能]
可配置项目:
1)。使用正则表达式描述,使用相同的规则将类似的网页分类为类。爬行动物系统(以下是指某种类型的URL可配置项目);
2)。起始地址,爬网方法,存储位置,页面处理等。
3)。需要采集的链路规则,使用CSS选择器定义爬行动物,只能采集页面中的位置中的链接;
3)。页面选择规则,您可以使用CSS选择器,正则表达式来定位每个字段的位置以提取;
4)。在打开页面后打开执行的JS语句的预测;
5)。页面预设饼干;
6)。评估此类网页返回正常规则,通常指定某些网页返回普通页面关键词让爬行动物检测;
7)。评估数据提取是一个完整的规则,在提取物中选择一些非常必要的字段作为完整的评估标准;
8)。此类网页(优先级)的调度权重(优先级),并在试剂后重新捕获更新。
[架构]
提示:_推荐用户跳跃架构文档直接进入第2部分,首先运行系统,存在对架构的归纳理解,如果您需要进行深入开发,请仔细阅读此链接_
整体架构
图中的黄色部分是爬行动物系统的各个子系统。 查看全部
js 爬虫抓取网页数据(NEOCrawler、redis、phantomjs实现的爬虫系统的各个子系统)
neocrawler(中文名:牛),是nodejs,redis,phantomjs实现的爬行动物系统。代码是完全开源的,适用于垂直字段中的数据采集和爬行动物。
[主要功能]
可配置项目:
1)。使用正则表达式描述,使用相同的规则将类似的网页分类为类。爬行动物系统(以下是指某种类型的URL可配置项目);
2)。起始地址,爬网方法,存储位置,页面处理等。
3)。需要采集的链路规则,使用CSS选择器定义爬行动物,只能采集页面中的位置中的链接;
3)。页面选择规则,您可以使用CSS选择器,正则表达式来定位每个字段的位置以提取;
4)。在打开页面后打开执行的JS语句的预测;
5)。页面预设饼干;
6)。评估此类网页返回正常规则,通常指定某些网页返回普通页面关键词让爬行动物检测;
7)。评估数据提取是一个完整的规则,在提取物中选择一些非常必要的字段作为完整的评估标准;
8)。此类网页(优先级)的调度权重(优先级),并在试剂后重新捕获更新。
[架构]
提示:_推荐用户跳跃架构文档直接进入第2部分,首先运行系统,存在对架构的归纳理解,如果您需要进行深入开发,请仔细阅读此链接_
整体架构

图中的黄色部分是爬行动物系统的各个子系统。
js 爬虫抓取网页数据(NEOCrawler、redis、phantomjs实现的爬虫系统的各个子系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-09-23 15:54
neocrawler(中文名:牛),是nodejs,redis,phantomjs实现的爬行动物系统。代码是完全开源的,适用于垂直字段中的数据采集和爬行动物。
[主要功能]
可配置项目:
1)。使用正则表达式描述,使用相同的规则将类似的网页分类为类。爬行动物系统(以下是指某种类型的URL可配置项目);
2)。起始地址,爬网方法,存储位置,页面处理等。
3)。需要采集的链路规则,使用CSS选择器定义爬行动物,只能采集页面中的位置中的链接;
3)。页面选择规则,您可以使用CSS选择器,正则表达式来定位每个字段的位置以提取;
4)。在打开页面后打开执行的JS语句的预测;
5)。页面预设饼干;
。
6)判断类网页是否返回正常规则通常在关键词 let爬行动物检测的不可避免存在后指定返回到正常的网页;
7)。评估数据提取是一个完整的规则,在提取物中选择一些非常必要的字段作为完整的评估标准;
8)。此类网页(优先级)的调度权重(优先级),并在试剂后重新捕获更新。
[架构]
提示:_推荐用户跳跃架构文档直接进入第2部分,首先运行系统,存在对架构的归纳理解,如果您需要进行深入开发,请仔细阅读此链接_
整体架构
图中的黄色部分是爬行动物系统的各个子系统。 查看全部
js 爬虫抓取网页数据(NEOCrawler、redis、phantomjs实现的爬虫系统的各个子系统)
neocrawler(中文名:牛),是nodejs,redis,phantomjs实现的爬行动物系统。代码是完全开源的,适用于垂直字段中的数据采集和爬行动物。
[主要功能]
可配置项目:
1)。使用正则表达式描述,使用相同的规则将类似的网页分类为类。爬行动物系统(以下是指某种类型的URL可配置项目);
2)。起始地址,爬网方法,存储位置,页面处理等。
3)。需要采集的链路规则,使用CSS选择器定义爬行动物,只能采集页面中的位置中的链接;
3)。页面选择规则,您可以使用CSS选择器,正则表达式来定位每个字段的位置以提取;
4)。在打开页面后打开执行的JS语句的预测;
5)。页面预设饼干;
。
6)判断类网页是否返回正常规则通常在关键词 let爬行动物检测的不可避免存在后指定返回到正常的网页;
7)。评估数据提取是一个完整的规则,在提取物中选择一些非常必要的字段作为完整的评估标准;
8)。此类网页(优先级)的调度权重(优先级),并在试剂后重新捕获更新。
[架构]
提示:_推荐用户跳跃架构文档直接进入第2部分,首先运行系统,存在对架构的归纳理解,如果您需要进行深入开发,请仔细阅读此链接_
整体架构
图中的黄色部分是爬行动物系统的各个子系统。
js 爬虫抓取网页数据(数据分析网页数据获取的重要步骤是什么?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-13 11:05
数据分析的重要步骤:
1.数据采集
可以手动采集一些重要数据
每个数据库都可以导出数据
使用 Python 的爬虫等技术
2.数据组织
从数据库和文件中提取数据生成DataFrame对象
使用pandas库读取文件
3.数据处理
数据准备:
组装和合并 DataFrame 对象(多个)等
熊猫操作
数据转换:
类型转换、分类(人脸元素等)、异常检测、过滤等
pandas 库的运行
数据聚合:
分组(分类)、函数处理、合并成新对象
pandas 库的运行
4.数据可视化
将pandas数据结构转换成图表形式
matplotlib 库
5.预测模型创建与评估
各种数据挖掘算法:
关联规则挖掘、回归分析、聚类、分类、时间序列挖掘、序列模式挖掘等
6.Deployment(得到的结果)
从模型和评估中获取知识
知识的表示:规则、决策树、知识库、网络权重
原创网址:
抓取网页数据的步骤:
简介:
(1)网络爬虫(又名网络蜘蛛、网络机器人,在FOAF社区,更常称为网络追逐者):
是一种程序或脚本,它根据某些规则自动捕获万维网上的信息。其他不常用的名称是蚂蚁、自动索引、模拟器或蠕虫。其实现在流行的是通过程序在网页上获取你想要的数据,即自动抓取数据。
(2)爬虫能做什么?
可以使用爬虫来爬取图片、爬取视频等,想要爬取的数据,只要能通过浏览器访问数据,就可以通过爬虫获取。当你在浏览器中输入地址时,通过DNS服务器找到服务器主机,并向服务器发送请求。服务端解析后,将结果发送到用户浏览器,包括html、js、css等文件内容,浏览器解析出来,最后呈现给用户在浏览器上看到的结果
所以用户看到的浏览器的结果是由HTML代码组成的。我们的爬虫就是获取这些内容,通过对html代码的分析过滤,从中获取我们想要的资源。
获取页面
1.根据网址获取网页
import urllib.request as req
# 根据URL获取网页:
#http://www.hbnu.edu.cn/湖北师范大学
url = \'http://www.hbnu.edu.cn/\'
webpage = req.urlopen(url) # 按照类文件的方式打开网页
# 读取网页的所有数据,并转换为uft-8编码
data = webpage.read().decode(\'utf-8\')
print(data)
2.保存网页数据到文件
#将网页爬取内容写入文件
import urllib.request
url = "http://www.hbnu.edu.cn/"
responces = urllib.request.urlopen(url)
html = responces.read()
html = html.decode(\'utf-8\')
fileOb = open(\'C://Users//ALICE//Documents//a.txt\',\'w\',encoding=\'utf-8\')
fileOb.write(html)
fileOb.close()
此时,我们从网页中获取的数据已经保存在我们指定的文件中,如下图所示:
网页访问
从图中可以看出,网页的所有数据都存储在本地,但我们需要的大部分数据是文本或数字信息,代码对我们没有用处。那么接下来我们要做的就是清除无用的数据。
后期需要进行数据清理,请听下次分解。 查看全部
js 爬虫抓取网页数据(数据分析网页数据获取的重要步骤是什么?-八维教育)
数据分析的重要步骤:
1.数据采集
可以手动采集一些重要数据
每个数据库都可以导出数据
使用 Python 的爬虫等技术
2.数据组织
从数据库和文件中提取数据生成DataFrame对象
使用pandas库读取文件
3.数据处理
数据准备:
组装和合并 DataFrame 对象(多个)等
熊猫操作
数据转换:
类型转换、分类(人脸元素等)、异常检测、过滤等
pandas 库的运行
数据聚合:
分组(分类)、函数处理、合并成新对象
pandas 库的运行
4.数据可视化
将pandas数据结构转换成图表形式
matplotlib 库
5.预测模型创建与评估
各种数据挖掘算法:
关联规则挖掘、回归分析、聚类、分类、时间序列挖掘、序列模式挖掘等
6.Deployment(得到的结果)
从模型和评估中获取知识
知识的表示:规则、决策树、知识库、网络权重
原创网址:
抓取网页数据的步骤:
简介:
(1)网络爬虫(又名网络蜘蛛、网络机器人,在FOAF社区,更常称为网络追逐者):
是一种程序或脚本,它根据某些规则自动捕获万维网上的信息。其他不常用的名称是蚂蚁、自动索引、模拟器或蠕虫。其实现在流行的是通过程序在网页上获取你想要的数据,即自动抓取数据。
(2)爬虫能做什么?
可以使用爬虫来爬取图片、爬取视频等,想要爬取的数据,只要能通过浏览器访问数据,就可以通过爬虫获取。当你在浏览器中输入地址时,通过DNS服务器找到服务器主机,并向服务器发送请求。服务端解析后,将结果发送到用户浏览器,包括html、js、css等文件内容,浏览器解析出来,最后呈现给用户在浏览器上看到的结果
所以用户看到的浏览器的结果是由HTML代码组成的。我们的爬虫就是获取这些内容,通过对html代码的分析过滤,从中获取我们想要的资源。
获取页面
1.根据网址获取网页
import urllib.request as req
# 根据URL获取网页:
#http://www.hbnu.edu.cn/湖北师范大学
url = \'http://www.hbnu.edu.cn/\'
webpage = req.urlopen(url) # 按照类文件的方式打开网页
# 读取网页的所有数据,并转换为uft-8编码
data = webpage.read().decode(\'utf-8\')
print(data)
2.保存网页数据到文件
#将网页爬取内容写入文件
import urllib.request
url = "http://www.hbnu.edu.cn/"
responces = urllib.request.urlopen(url)
html = responces.read()
html = html.decode(\'utf-8\')
fileOb = open(\'C://Users//ALICE//Documents//a.txt\',\'w\',encoding=\'utf-8\')
fileOb.write(html)
fileOb.close()
此时,我们从网页中获取的数据已经保存在我们指定的文件中,如下图所示:
网页访问
从图中可以看出,网页的所有数据都存储在本地,但我们需要的大部分数据是文本或数字信息,代码对我们没有用处。那么接下来我们要做的就是清除无用的数据。
后期需要进行数据清理,请听下次分解。
js 爬虫抓取网页数据(如何用ExcelVBA构建数据查询界面(二)的基本步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-09-11 05:12
作为python爬虫的第一篇,先说说python的使用背景,以及如何使用python爬虫爬取简单的静态网页和动态网页。本文的前提是大家已经熟悉了python的基本语法和ide默认的构建。至少你可以使用helloword。
print("Hello World!")
在上一篇文章中,我们讲了使用excel VBA制作数据查询界面,进行数据统计计算。有兴趣的同学可以点击下方链接自行查看。
如何使用Excel VBA搭建数据查询界面(一)
如何使用Excel VBA搭建数据查询界面(二)
但是excel本身也有它的局限性。首先,在数据存储方面,excel 2013最多可以存储16,384列和1,048,576行数据。这个数据量对于数据挖掘或机器学习来说太小了。因此,有必要使用爬虫从互联网上抓取数据并存储到数据库中,以方便更深入的数据分析和挖掘。
作者使用python3.5进行爬虫学习。简单说一下python的情况。第一,简洁,几行代码就可以实现很多其他语言可以实现的东西;其次,执行效率比C和C++慢很多,不利于高效率的要求。数据分析;现在spark上也有相应的界面,大家可以相应了解一下。当然,如果你真的想摆脱这个问题,还是建议学习scala,它和java类似,应用范围更广。 Python可以帮助你更快的熟悉各种算法,学习成本不高。
接下来简单说一下python爬虫的基本原理。
首先,爬虫其实可以看成是机器人。它抓取数据。其实更多的是模拟人的操作。它仅适用于网页。我们看到的是html在CSS样式的帮助下出现的样子,但是爬虫面对的是带有各种标签的html。
接下来说说编写爬虫的基本步骤:首先观察我们的目标网站,了解需要的数据,在html标签的位置;其次,想想html标签只有在动态网页下才有,静态爬取还是可以的;粗略的方法是检查网页的源文件是否收录标签的数据。一般来说,动态网页比较多。
最后说两个例子,简单说一下静态网页和动态网页的抓取。
一、静态网页抓取
首先,因为要爬取的数据在静态网页的源码上,所以可以简单的利用python的urllib的请求和bs4库的BeautifulSoup爬取如下。废话不多说,给你看代码。
# import the library you want
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
# analyse the html
html = urlopen("http://www.pythonscraping.com/ ... 6quot;)
bs0bj = BeautifulSoup(html, "html.parser")
# find the rules of the data you want
images = bs0bj.findAll("img",{"src":re.compile("\.\.\/img\/gifts/img.*\.jpg")})
# print all you want
for image in images:
print(image["src"])
(可以看笔记)
我抓取的是一个非常简单的静态网站/pages/page3.html。查看网站元素时,可以使用浏览器自带的小工具,比如firefox查看元素。
首先通过请求抓取html页面所有元素的数据,然后根据标签的规则过滤掉对应的值,标签中收录的文本,或者属性,比如这个例子。最后写入数据库,或者打印出来。
二、动态网页抓取
对于动态网页,这里有一个简单的原则。大部分动态部分都会放在html中的js代码中。这个时候就需要用到它了,它是一个内置的浏览器webdriver。所谓内置浏览器,你可以简单的理解为一个隐形浏览器。当然也有带firefox插件的浏览器,不过上面提到的内置浏览器会比较常用。
这个例子是关于抓取两个 URL 的数据并将它们写入一个 csv 文件。
import urllib
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import csv
csvFile = open("F:/workspace/haha.csv",'w+')
writer = csv.writer(csvFile)
# Animation
writer.writerow(('bilibili',' ',' ',' ',' ',' '))
writer.writerow(('paimin','minchen','bofangshu','danmushu','zonghezhishu'))
driverThree = webdriver.PhantomJS()
driverThree.get("http://www.bilibili.com/rankin ... 6quot;)
time.sleep(5)
pageSourceThree = driverThree.page_source
bs0bjThree = BeautifulSoup(pageSourceThree,"html.parser")
j = bs0bjThree.findAll("div",{"class":"title"})
k = bs0bjThree.findAll("div",{"class":"pts"})
l = bs0bjThree.findAll("span",{"class":"data-box play"})
m = bs0bjThree.findAll("span",{"class":"data-box dm"})
for b in range(10):
titleThree = j[b].get_text()
IndexThre = k[b].get_text()
num = len(IndexThre)
IndexThree = IndexThre[0:num-4]
bofangliang = l[b].get_text()
danmuliang = m[b].get_text()
writer.writerow((b+1,titleThree,bofangliang,danmuliang,IndexThree))
driverThree.close()
# Comic
writer.writerow(('tecentac',' ',' ',' '))
writer.writerow(('paimin','minchen','piaoshu'))
driverFour = webdriver.PhantomJS()
driverFour.get("http://ac.qq.com/Rank/")
time.sleep(5)
pageSourceFour = driverFour.page_source
bs0bjFour = BeautifulSoup(pageSourceFour,"html.parser")
n = bs0bjFour.findAll("a",{"class":"mod-rank-name ui-left"})
o = bs0bjFour.findAll("span",{"class":"mod-rank-num ui-right"})
for c in range(10):
titleFour = n[c].get_text()
piaoshu = o[c].get_text()
writer.writerow((c+1,titleFour,piaoshu))
driverFour.close()
第一步就是通过上面提到的内置浏览器解析出页面的js代码,然后抓取它的动态部分
第二步和之前一样。理解了标签的规律后,它会循环获取,然后写入数据库。
先打开路径对应的csv文件,路径需要自己设置,然后爬取数据,最后写入csv文件。打开csv文件,可以看到数据。当然,以后也可以读取csv文件,但是写入数据库的方法后面会讲到。这个应用场景会更多。
运行结果如下:
好了,今天就到这里。静态爬虫和动态爬虫取决于是否使用内置浏览器来解析页面的js代码,其余原理相同。
最后公布下一次要讨论的内容。 python 爬虫爬取整个表单的数据。简单的说就是爬取需要登录操作获取数据的网页,比如微博、博客等。 查看全部
js 爬虫抓取网页数据(如何用ExcelVBA构建数据查询界面(二)的基本步骤)
作为python爬虫的第一篇,先说说python的使用背景,以及如何使用python爬虫爬取简单的静态网页和动态网页。本文的前提是大家已经熟悉了python的基本语法和ide默认的构建。至少你可以使用helloword。
print("Hello World!")
在上一篇文章中,我们讲了使用excel VBA制作数据查询界面,进行数据统计计算。有兴趣的同学可以点击下方链接自行查看。
如何使用Excel VBA搭建数据查询界面(一)
如何使用Excel VBA搭建数据查询界面(二)
但是excel本身也有它的局限性。首先,在数据存储方面,excel 2013最多可以存储16,384列和1,048,576行数据。这个数据量对于数据挖掘或机器学习来说太小了。因此,有必要使用爬虫从互联网上抓取数据并存储到数据库中,以方便更深入的数据分析和挖掘。
作者使用python3.5进行爬虫学习。简单说一下python的情况。第一,简洁,几行代码就可以实现很多其他语言可以实现的东西;其次,执行效率比C和C++慢很多,不利于高效率的要求。数据分析;现在spark上也有相应的界面,大家可以相应了解一下。当然,如果你真的想摆脱这个问题,还是建议学习scala,它和java类似,应用范围更广。 Python可以帮助你更快的熟悉各种算法,学习成本不高。
接下来简单说一下python爬虫的基本原理。
首先,爬虫其实可以看成是机器人。它抓取数据。其实更多的是模拟人的操作。它仅适用于网页。我们看到的是html在CSS样式的帮助下出现的样子,但是爬虫面对的是带有各种标签的html。
接下来说说编写爬虫的基本步骤:首先观察我们的目标网站,了解需要的数据,在html标签的位置;其次,想想html标签只有在动态网页下才有,静态爬取还是可以的;粗略的方法是检查网页的源文件是否收录标签的数据。一般来说,动态网页比较多。
最后说两个例子,简单说一下静态网页和动态网页的抓取。
一、静态网页抓取
首先,因为要爬取的数据在静态网页的源码上,所以可以简单的利用python的urllib的请求和bs4库的BeautifulSoup爬取如下。废话不多说,给你看代码。
# import the library you want
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
# analyse the html
html = urlopen("http://www.pythonscraping.com/ ... 6quot;)
bs0bj = BeautifulSoup(html, "html.parser")
# find the rules of the data you want
images = bs0bj.findAll("img",{"src":re.compile("\.\.\/img\/gifts/img.*\.jpg")})
# print all you want
for image in images:
print(image["src"])
(可以看笔记)
我抓取的是一个非常简单的静态网站/pages/page3.html。查看网站元素时,可以使用浏览器自带的小工具,比如firefox查看元素。
首先通过请求抓取html页面所有元素的数据,然后根据标签的规则过滤掉对应的值,标签中收录的文本,或者属性,比如这个例子。最后写入数据库,或者打印出来。
二、动态网页抓取
对于动态网页,这里有一个简单的原则。大部分动态部分都会放在html中的js代码中。这个时候就需要用到它了,它是一个内置的浏览器webdriver。所谓内置浏览器,你可以简单的理解为一个隐形浏览器。当然也有带firefox插件的浏览器,不过上面提到的内置浏览器会比较常用。
这个例子是关于抓取两个 URL 的数据并将它们写入一个 csv 文件。
import urllib
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import csv
csvFile = open("F:/workspace/haha.csv",'w+')
writer = csv.writer(csvFile)
# Animation
writer.writerow(('bilibili',' ',' ',' ',' ',' '))
writer.writerow(('paimin','minchen','bofangshu','danmushu','zonghezhishu'))
driverThree = webdriver.PhantomJS()
driverThree.get("http://www.bilibili.com/rankin ... 6quot;)
time.sleep(5)
pageSourceThree = driverThree.page_source
bs0bjThree = BeautifulSoup(pageSourceThree,"html.parser")
j = bs0bjThree.findAll("div",{"class":"title"})
k = bs0bjThree.findAll("div",{"class":"pts"})
l = bs0bjThree.findAll("span",{"class":"data-box play"})
m = bs0bjThree.findAll("span",{"class":"data-box dm"})
for b in range(10):
titleThree = j[b].get_text()
IndexThre = k[b].get_text()
num = len(IndexThre)
IndexThree = IndexThre[0:num-4]
bofangliang = l[b].get_text()
danmuliang = m[b].get_text()
writer.writerow((b+1,titleThree,bofangliang,danmuliang,IndexThree))
driverThree.close()
# Comic
writer.writerow(('tecentac',' ',' ',' '))
writer.writerow(('paimin','minchen','piaoshu'))
driverFour = webdriver.PhantomJS()
driverFour.get("http://ac.qq.com/Rank/";)
time.sleep(5)
pageSourceFour = driverFour.page_source
bs0bjFour = BeautifulSoup(pageSourceFour,"html.parser")
n = bs0bjFour.findAll("a",{"class":"mod-rank-name ui-left"})
o = bs0bjFour.findAll("span",{"class":"mod-rank-num ui-right"})
for c in range(10):
titleFour = n[c].get_text()
piaoshu = o[c].get_text()
writer.writerow((c+1,titleFour,piaoshu))
driverFour.close()
第一步就是通过上面提到的内置浏览器解析出页面的js代码,然后抓取它的动态部分
第二步和之前一样。理解了标签的规律后,它会循环获取,然后写入数据库。
先打开路径对应的csv文件,路径需要自己设置,然后爬取数据,最后写入csv文件。打开csv文件,可以看到数据。当然,以后也可以读取csv文件,但是写入数据库的方法后面会讲到。这个应用场景会更多。
运行结果如下:

好了,今天就到这里。静态爬虫和动态爬虫取决于是否使用内置浏览器来解析页面的js代码,其余原理相同。
最后公布下一次要讨论的内容。 python 爬虫爬取整个表单的数据。简单的说就是爬取需要登录操作获取数据的网页,比如微博、博客等。
js 爬虫抓取网页数据( Control的异步和回调知识的逻辑 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-09 00:00
Control的异步和回调知识的逻辑
)
Node.js写爬虫的基本思路,分享抓拍百度图片的例子
更新时间:2016-03-12 17:32:27 作者:qiaolevip
本文文章主要介绍了Node.js编写爬虫的基本思路以及抓取百度图片的例子分享。笔者提到要特别注意GBK转码的转码问题。有需要的朋友可以参考以下
其实写爬虫的思路很简单:
但是当我真正写这个爬虫的时候,还是遇到了很多问题(跟我的基础不够扎实有很大关系,没有认真研究node.js)。主要原因是node.js的异步和回调知识没有完全掌握,导致在写代码的过程中走了不少弯路。
模块化的
模块化对于 node.js 程序非常重要。不能像原来PHP写的那样把所有代码都扔到一个文件里(当然这只是我个人的恶习),所以我们必须从头分析这个爬虫需要实现的功能。,并大致分为三个模块。
主程序,调用爬虫模块和持久化模块,实现完整的爬虫功能
爬虫模块根据传入的数据发送请求,解析HTML并提取有用的数据,并返回一个对象
持久化模块接受一个对象并将其内容存储在数据库中
模块化也带来了一个困扰我一下午的问题:模块间异步调用导致数据错误。其实我还是不太明白是什么问题。鉴于脚本语言的调试功能不方便,我还没有深入研究。
还有一点需要注意的是,在模块化的时候,尽量使用全局对象来小心地存储数据,因为可能你的模块的某个功能还没有结束,全局变量已经被修改了。
控制流
这个东西很难翻译,字面意思就是控制流(?)。众所周知,node.js的核心思想是异步的,但是异步多了会产生好几层嵌套,代码真的很丑。这时候就需要使用一些控制流模块来重新安排你的逻辑。我们在这里推荐 async.js(),它在开发社区中非常活跃并且易于使用。
async 提供了很多实用的方法,我主要在写爬虫的时候用
这些控制流方式给爬虫的开发带来了极大的便利。考虑这样一个应用场景。需要向数据库中插入多条数据(属于同一个学生),并且需要在所有数据插入后返回结果。那么如何保证所有的插入操作都完成呢?只能通过层层回调来保证,使用async.parallel就方便多了。
我想在这里再提一件事。最初保证所有插入都完成。这个操作可以在SQL层实现,也就是事务,但是node-mysql在我使用的时候还是不能很好的支持事务,所以只好手动使用代码来保证。
解析 HTML
解析过程中也遇到了一些问题,这里记录一下。
发送HTTP请求获取HTML代码最基本的方式是使用node自带的http.request函数。如果是抓取简单的内容,比如获取指定id元素中的内容(常用于抓取产品价格),那么规律性就足以完成任务。但是对于复杂的页面,尤其是数据项较多的页面,使用DOM会更加方便高效。
node.js 中最好的 DOM 实现是cheerio()。其实cheerio应该算是jQuery的一个子集,针对DOM操作进行了优化和精简,包括了DOM操作的大部分内容,去掉了其他不必要的内容。使用cheerio,您可以像使用普通的jQuery 选择器一样选择您需要的内容。
下载图片
在抓取数据的时候,我们可能还需要下载图片。其实下载图片的方式和普通网页的下载方式并没有太大区别,但是有件事让我很苦恼。
注意下面代码中的猛烈注释,那是我小时候犯的错误……
var req = http.request(options, function(res){
//初始化数据!!!
var binImage = '';
res.setEncoding('binary');
res.on('data', function(chunk){
binImage += chunk;
});
res.on('end', function(){
if (!binImage) {
console.log('image data is null');
return null;
}
fs.writeFile(imageFolder + filename, binImage, 'binary', function(err){
if (err) {
console.log('image writing error:' + err.message);
return null;
}
else{
console.log('image ' + filename + ' saved');
return filename;
}
});
});
res.on('error', function(e){
console.log('image downloading response error:' + e.message);
return null;
});
});
req.end();
GBK转码
另一个值得说明的问题是node.js爬虫爬取GBK编码内容时的转码问题。其实这个问题很容易解决,只是新手可能会少走弯路。这是源代码:
var req = http.request(options, function(res) {
res.setEncoding('binary');
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function(){
//转换编码
html = iconv.decode(html, 'gbk');
});
});
req.end();
我这里使用的转码库是iconv-lite(),完美支持GBK、GB2312等双字节编码。
示例:爬虫批量下载百度图片
<p>
var fs = require('fs'),
path = require('path'),
util = require('util'), // 以上为Nodejs自带依赖包
request = require('request'); // 需要npm install的包
// main函数,使用 node main执行即可
patchPreImg();
// 批量处理图片
function patchPreImg() {
var tag1 = '摄影', tag2 = '国家地理',
url = 'http://image.baidu.com/data/imgs?pn=%s&rn=60&p=channel&from=1&col=%s&tag=%s&sort=1&tag3=',
url = util.format(url, 0, tag1, tag2),
url = encodeURI(url),
dir = 'D:/downloads/images/',
dir = path.join(dir, tag1, tag2),
dir = mkdirSync(dir);
request(url, function(error, response, html) {
var data = JSON.parse(html);
if (data && Array.isArray(data.imgs)) {
var imgs = data.imgs;
imgs.forEach(function(img) {
if (Object.getOwnPropertyNames(img).length > 0) {
var desc = img.desc || ((img.owner && img.owner.userName) + img.column);
desc += '(' + img.id + ')';
var downloadUrl = img.downloadUrl || img.objUrl;
downloadImg(downloadUrl, dir, desc);
}
});
}
});
}
// 循环创建目录
function mkdirSync(dir) {
var parts = dir.split(path.sep);
for (var i = 1; i 查看全部
js 爬虫抓取网页数据(
Control的异步和回调知识的逻辑
)
Node.js写爬虫的基本思路,分享抓拍百度图片的例子
更新时间:2016-03-12 17:32:27 作者:qiaolevip
本文文章主要介绍了Node.js编写爬虫的基本思路以及抓取百度图片的例子分享。笔者提到要特别注意GBK转码的转码问题。有需要的朋友可以参考以下
其实写爬虫的思路很简单:
但是当我真正写这个爬虫的时候,还是遇到了很多问题(跟我的基础不够扎实有很大关系,没有认真研究node.js)。主要原因是node.js的异步和回调知识没有完全掌握,导致在写代码的过程中走了不少弯路。
模块化的
模块化对于 node.js 程序非常重要。不能像原来PHP写的那样把所有代码都扔到一个文件里(当然这只是我个人的恶习),所以我们必须从头分析这个爬虫需要实现的功能。,并大致分为三个模块。
主程序,调用爬虫模块和持久化模块,实现完整的爬虫功能
爬虫模块根据传入的数据发送请求,解析HTML并提取有用的数据,并返回一个对象
持久化模块接受一个对象并将其内容存储在数据库中
模块化也带来了一个困扰我一下午的问题:模块间异步调用导致数据错误。其实我还是不太明白是什么问题。鉴于脚本语言的调试功能不方便,我还没有深入研究。
还有一点需要注意的是,在模块化的时候,尽量使用全局对象来小心地存储数据,因为可能你的模块的某个功能还没有结束,全局变量已经被修改了。
控制流
这个东西很难翻译,字面意思就是控制流(?)。众所周知,node.js的核心思想是异步的,但是异步多了会产生好几层嵌套,代码真的很丑。这时候就需要使用一些控制流模块来重新安排你的逻辑。我们在这里推荐 async.js(),它在开发社区中非常活跃并且易于使用。
async 提供了很多实用的方法,我主要在写爬虫的时候用
这些控制流方式给爬虫的开发带来了极大的便利。考虑这样一个应用场景。需要向数据库中插入多条数据(属于同一个学生),并且需要在所有数据插入后返回结果。那么如何保证所有的插入操作都完成呢?只能通过层层回调来保证,使用async.parallel就方便多了。
我想在这里再提一件事。最初保证所有插入都完成。这个操作可以在SQL层实现,也就是事务,但是node-mysql在我使用的时候还是不能很好的支持事务,所以只好手动使用代码来保证。
解析 HTML
解析过程中也遇到了一些问题,这里记录一下。
发送HTTP请求获取HTML代码最基本的方式是使用node自带的http.request函数。如果是抓取简单的内容,比如获取指定id元素中的内容(常用于抓取产品价格),那么规律性就足以完成任务。但是对于复杂的页面,尤其是数据项较多的页面,使用DOM会更加方便高效。
node.js 中最好的 DOM 实现是cheerio()。其实cheerio应该算是jQuery的一个子集,针对DOM操作进行了优化和精简,包括了DOM操作的大部分内容,去掉了其他不必要的内容。使用cheerio,您可以像使用普通的jQuery 选择器一样选择您需要的内容。
下载图片
在抓取数据的时候,我们可能还需要下载图片。其实下载图片的方式和普通网页的下载方式并没有太大区别,但是有件事让我很苦恼。
注意下面代码中的猛烈注释,那是我小时候犯的错误……
var req = http.request(options, function(res){
//初始化数据!!!
var binImage = '';
res.setEncoding('binary');
res.on('data', function(chunk){
binImage += chunk;
});
res.on('end', function(){
if (!binImage) {
console.log('image data is null');
return null;
}
fs.writeFile(imageFolder + filename, binImage, 'binary', function(err){
if (err) {
console.log('image writing error:' + err.message);
return null;
}
else{
console.log('image ' + filename + ' saved');
return filename;
}
});
});
res.on('error', function(e){
console.log('image downloading response error:' + e.message);
return null;
});
});
req.end();
GBK转码
另一个值得说明的问题是node.js爬虫爬取GBK编码内容时的转码问题。其实这个问题很容易解决,只是新手可能会少走弯路。这是源代码:
var req = http.request(options, function(res) {
res.setEncoding('binary');
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function(){
//转换编码
html = iconv.decode(html, 'gbk');
});
});
req.end();
我这里使用的转码库是iconv-lite(),完美支持GBK、GB2312等双字节编码。
示例:爬虫批量下载百度图片
<p>
var fs = require('fs'),
path = require('path'),
util = require('util'), // 以上为Nodejs自带依赖包
request = require('request'); // 需要npm install的包
// main函数,使用 node main执行即可
patchPreImg();
// 批量处理图片
function patchPreImg() {
var tag1 = '摄影', tag2 = '国家地理',
url = 'http://image.baidu.com/data/imgs?pn=%s&rn=60&p=channel&from=1&col=%s&tag=%s&sort=1&tag3=',
url = util.format(url, 0, tag1, tag2),
url = encodeURI(url),
dir = 'D:/downloads/images/',
dir = path.join(dir, tag1, tag2),
dir = mkdirSync(dir);
request(url, function(error, response, html) {
var data = JSON.parse(html);
if (data && Array.isArray(data.imgs)) {
var imgs = data.imgs;
imgs.forEach(function(img) {
if (Object.getOwnPropertyNames(img).length > 0) {
var desc = img.desc || ((img.owner && img.owner.userName) + img.column);
desc += '(' + img.id + ')';
var downloadUrl = img.downloadUrl || img.objUrl;
downloadImg(downloadUrl, dir, desc);
}
});
}
});
}
// 循环创建目录
function mkdirSync(dir) {
var parts = dir.split(path.sep);
for (var i = 1; i
js 爬虫抓取网页数据(js爬虫抓取网页数据,这个相当简单,用extract方法即可)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-08 21:04
js爬虫抓取网页数据,这个相当简单,用extract方法即可,直接将内容全部提取出来。js抓取的是html页面,mongodb的话是针对mongodb,因为其他库,比如presto,pymongo,neo4j都需要https,xmlhttprequest也是如此。
1.与逻辑关系不大。2.没看懂你的图文的逻辑,猜测是由文字拼接成图片,然后存入库吧?那么js就可以直接抓取。你就是百度一下,然后动手做一下呗。加点花俏的手法不难实现。在此基础上,扩展出一套图片导入导出的算法和接口也不难实现。soeasy。
你这里的技术太陈旧了,抓取其实没那么难,我们会用js抓,就是h5的在线轮播,很简单!现在抓取都很傻瓜化!我们做二手车价格查询网站的,
在chrome中安装插件puppeteerradiohead自动说话
有grep的功能,实现功能,写入python文件,然后交给别人打包发布。你要抓取的也是页面,
python/scrapyapipyinstaller就可以做到,
这是个大家都不愿意说的问题,虽然简单,
/pep9438python-scrapy框架python3程序发布的网站验证码解码
telegram欢迎你
题主也是搞python爬虫么, 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据,这个相当简单,用extract方法即可)
js爬虫抓取网页数据,这个相当简单,用extract方法即可,直接将内容全部提取出来。js抓取的是html页面,mongodb的话是针对mongodb,因为其他库,比如presto,pymongo,neo4j都需要https,xmlhttprequest也是如此。
1.与逻辑关系不大。2.没看懂你的图文的逻辑,猜测是由文字拼接成图片,然后存入库吧?那么js就可以直接抓取。你就是百度一下,然后动手做一下呗。加点花俏的手法不难实现。在此基础上,扩展出一套图片导入导出的算法和接口也不难实现。soeasy。
你这里的技术太陈旧了,抓取其实没那么难,我们会用js抓,就是h5的在线轮播,很简单!现在抓取都很傻瓜化!我们做二手车价格查询网站的,
在chrome中安装插件puppeteerradiohead自动说话
有grep的功能,实现功能,写入python文件,然后交给别人打包发布。你要抓取的也是页面,
python/scrapyapipyinstaller就可以做到,
这是个大家都不愿意说的问题,虽然简单,
/pep9438python-scrapy框架python3程序发布的网站验证码解码
telegram欢迎你
题主也是搞python爬虫么,
js 爬虫抓取网页数据(Web应用功能示例SlimerJS示例PhantomJS示例示例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-06 00:25
函数(您可以使用JavaScript模拟浏览器上的几乎任何操作)
用法(与phantom JS无差异):
页面某个区域的屏幕截图,slimerjs和phantom JS示例
Slimerjs示例
var webpage = require('webpage').create();
webpage.open('http://www.meizu.com') // 打开一个网页
.then(function() { // 页面加载完成后执行
//保存页面截屏
webpage.viewportSize = {
width: 650,
height: 320
};
webpage.render('page.png', {
onlyViewport: true
});
//再打开一个网页
return webpage.open('http://bbs.meizu.com');
})
.then(function() {
// 点击某个位置
webpage.sendEvent("click", 5, 5, 'left', 0);
slimer.exit(); //退出
});
幻影JS示例
var webpage = require('webpage').create();
webpage.open('http://www.meizu.com', function (status) {
//打开一个页面
}).then(function(){
//保存页面截屏
webpage.viewportSize = {
width: 650,
height: 320
};
webpage.render('page.png', {
onlyViewport: true
});
//再打开一个网页
return webpage.open('http://bbs.meizu.com');
}).then(function(){
webpage.sendEvent("click", 5, 5, 'left', 0);
phantom.exit();
});
3、CasperJS
源代码:
官方网站:
帮助文档:
当前版本1.1.3
Casperjs是一个开源的导航脚本和测试工具。它是用基于phantom JS的javascript编写的,用于测试web应用程序功能。Phantom JS是服务器端JavaScript API的WebKit。它支持各种web标准:DOM处理、CSS选择器、JSON、画布和SVG
Casperjs根据start()、then*()、wait*()、open()进程向下导航(注意,如果出现语法错误,例如神马没有分号,则可能有一张卡在运行时没有任何提示)
run()方法触发该进程。run()方法可以在导航完成时为回调指定oncomplete()方法
退出()/die()退出
这个。Getpagecontent()可以查看呈现的页面内容
它为web应用程序测试提供了一组方法组件。这些组件基于phantom JS或slimerjs提供的JavaScript API实现web应用程序的功能执行。Casperjs简化了完整导航场景的流程定义,并为完成常见任务提供了实用的高级功能、方法和语法。例如:
用法:
Casperjs前端自动化测试脚本示例:
var utils = require('utils');
var webpage = require('casper').create({
//verbose: true,
logLevel: 'debug',
viewportSize: {
width: 1024,
height: 768
},
pageSettings: {
loadImages: true,
loadPlugins: true,
XSSAuditingEnabled: true
}
});
//打开页面
webpage.start()
.thenOpen('http://www.meizu.com', function openMeizu(res) {
this.echo('打印页面信息');
res.body = '';//不打印body信息
utils.dump(res);
//点击登录按钮
if (this.exists("#_unlogin")) {
this.echo('点击登录按钮');
this.click("#_unlogin a:nth-child(1)");
this.wait(3000, function wait3s_1() {
if (this.exists("form#mainForm")) {
this.echo("需要登陆,填充账号信息。。。");
//填充表单账号
this.fill('form#mainForm', {
'account': 'lzwy0820@flyme.cn',
'password': '********'
}, true);
this.capture('meizu_login_page.png');
this.wait(3000, function wait3s_2() {
//登录按钮存在,点击
if (this.exists("#login")) {
this.echo('提交登录');
this.click("#login");
}
});
}
});
}
})
.then(function capture() {
if (this.exists('#mzCustName')) {
this.echo('登录成功!开始截图存储..');
} else {
this.echo('登录失败!请查看截图文件')
}
//截图
this.capture('meizu.png');
this.captureSelector('meizu_header.png', 'div.meizu-header');
})
.then(function exit() {
this.echo('执行完成,退出');
this.exit();
})
.run();
casperjs捕获的JavaScript呈现的网页示例:
下面的代码将抓取网易云音乐页面,运行JavaScript,然后将最终的HTML保存在文本中
// http://casperjs.org/
var casper = require('casper').create({
pageSettings: {
loadImages: false, // 不加载图片,减少请求
}
});
var fs = require('fs');
casper.userAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36');
casper.start();
casper.viewport(1024, 768);
casper.then(function() {
this.open('http://music.163.com/#/m/discover/artist/').then(function(){
this.page.switchToChildFrame(0); // 页面包含 iFrame
fs.write("1.html", this.getPageContent(), 'w'); // 保存 iFrame 里的内容
this.page.switchToParentFrame();
fs.write("2.html", this.getPageContent(), 'w');
});
});
casper.run();
Casperjs循环调用示例:
解决方案是递归调用。当casperjsobj调用run函数时,它可以传入一个要在最后执行的函数。在这个函数中,我们可以添加[our loop body]和[recursive run call]
function refresh()
{
this.wait(10000,
function() {
this.click('a[title="简历刷新"]');
this.log('refreshed my resume');
}
);
this.run(refresh);
}
casper.run(refresh);
日志中会显示信息消息“不安全的JavaScript尝试使用URL访问帧”。启动casperjs时,添加参数-Web Security=false(允许跨域XHR)(请参阅)
要解决根本原因,请参阅 查看全部
js 爬虫抓取网页数据(Web应用功能示例SlimerJS示例PhantomJS示例示例)
函数(您可以使用JavaScript模拟浏览器上的几乎任何操作)
用法(与phantom JS无差异):
页面某个区域的屏幕截图,slimerjs和phantom JS示例
Slimerjs示例
var webpage = require('webpage').create();
webpage.open('http://www.meizu.com') // 打开一个网页
.then(function() { // 页面加载完成后执行
//保存页面截屏
webpage.viewportSize = {
width: 650,
height: 320
};
webpage.render('page.png', {
onlyViewport: true
});
//再打开一个网页
return webpage.open('http://bbs.meizu.com');
})
.then(function() {
// 点击某个位置
webpage.sendEvent("click", 5, 5, 'left', 0);
slimer.exit(); //退出
});
幻影JS示例
var webpage = require('webpage').create();
webpage.open('http://www.meizu.com', function (status) {
//打开一个页面
}).then(function(){
//保存页面截屏
webpage.viewportSize = {
width: 650,
height: 320
};
webpage.render('page.png', {
onlyViewport: true
});
//再打开一个网页
return webpage.open('http://bbs.meizu.com');
}).then(function(){
webpage.sendEvent("click", 5, 5, 'left', 0);
phantom.exit();
});
3、CasperJS
源代码:
官方网站:
帮助文档:
当前版本1.1.3
Casperjs是一个开源的导航脚本和测试工具。它是用基于phantom JS的javascript编写的,用于测试web应用程序功能。Phantom JS是服务器端JavaScript API的WebKit。它支持各种web标准:DOM处理、CSS选择器、JSON、画布和SVG
Casperjs根据start()、then*()、wait*()、open()进程向下导航(注意,如果出现语法错误,例如神马没有分号,则可能有一张卡在运行时没有任何提示)
run()方法触发该进程。run()方法可以在导航完成时为回调指定oncomplete()方法
退出()/die()退出
这个。Getpagecontent()可以查看呈现的页面内容
它为web应用程序测试提供了一组方法组件。这些组件基于phantom JS或slimerjs提供的JavaScript API实现web应用程序的功能执行。Casperjs简化了完整导航场景的流程定义,并为完成常见任务提供了实用的高级功能、方法和语法。例如:
用法:
Casperjs前端自动化测试脚本示例:
var utils = require('utils');
var webpage = require('casper').create({
//verbose: true,
logLevel: 'debug',
viewportSize: {
width: 1024,
height: 768
},
pageSettings: {
loadImages: true,
loadPlugins: true,
XSSAuditingEnabled: true
}
});
//打开页面
webpage.start()
.thenOpen('http://www.meizu.com', function openMeizu(res) {
this.echo('打印页面信息');
res.body = '';//不打印body信息
utils.dump(res);
//点击登录按钮
if (this.exists("#_unlogin")) {
this.echo('点击登录按钮');
this.click("#_unlogin a:nth-child(1)");
this.wait(3000, function wait3s_1() {
if (this.exists("form#mainForm")) {
this.echo("需要登陆,填充账号信息。。。");
//填充表单账号
this.fill('form#mainForm', {
'account': 'lzwy0820@flyme.cn',
'password': '********'
}, true);
this.capture('meizu_login_page.png');
this.wait(3000, function wait3s_2() {
//登录按钮存在,点击
if (this.exists("#login")) {
this.echo('提交登录');
this.click("#login");
}
});
}
});
}
})
.then(function capture() {
if (this.exists('#mzCustName')) {
this.echo('登录成功!开始截图存储..');
} else {
this.echo('登录失败!请查看截图文件')
}
//截图
this.capture('meizu.png');
this.captureSelector('meizu_header.png', 'div.meizu-header');
})
.then(function exit() {
this.echo('执行完成,退出');
this.exit();
})
.run();
casperjs捕获的JavaScript呈现的网页示例:
下面的代码将抓取网易云音乐页面,运行JavaScript,然后将最终的HTML保存在文本中
// http://casperjs.org/
var casper = require('casper').create({
pageSettings: {
loadImages: false, // 不加载图片,减少请求
}
});
var fs = require('fs');
casper.userAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36');
casper.start();
casper.viewport(1024, 768);
casper.then(function() {
this.open('http://music.163.com/#/m/discover/artist/').then(function(){
this.page.switchToChildFrame(0); // 页面包含 iFrame
fs.write("1.html", this.getPageContent(), 'w'); // 保存 iFrame 里的内容
this.page.switchToParentFrame();
fs.write("2.html", this.getPageContent(), 'w');
});
});
casper.run();
Casperjs循环调用示例:
解决方案是递归调用。当casperjsobj调用run函数时,它可以传入一个要在最后执行的函数。在这个函数中,我们可以添加[our loop body]和[recursive run call]
function refresh()
{
this.wait(10000,
function() {
this.click('a[title="简历刷新"]');
this.log('refreshed my resume');
}
);
this.run(refresh);
}
casper.run(refresh);
日志中会显示信息消息“不安全的JavaScript尝试使用URL访问帧”。启动casperjs时,添加参数-Web Security=false(允许跨域XHR)(请参阅)
要解决根本原因,请参阅
js 爬虫抓取网页数据(DOM是什么?Google能读取动态生成的内容是如何?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2021-10-05 19:21
我们知道国内的浏览器和搜索工具都是用爬虫爬取网页信息的,那么谷歌爬虫是怎么爬取Javascript的呢?今天,小编就和大家深入探讨一下。
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该界面允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表达的 URL 会发生什么变化?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您没有访问您的 网站 服务器的权限,您可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内(“onClick”)
使用 href 内部 AVP ("javascript: window.location")
在 a 标签之外执行,但在 href ("javascript: openlink()") 中调用 AVP
还有很多
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API(pushState)构建的,可以渲染和收录 它,并且可以像传统的静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果呢?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签会发生什么?在这个协议中,HTTP x-robots 响应头的行为如何作为另一个变量?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中 href 元素的操作发生得太晚了:谷歌在执行添加 rel="nofollow" 的 JavaScript 函数之前,已经准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入内容,甚至元标记,例如rel规范注释,无论是在HTML源代码中还是在解析初始HTML后触发JavaScript生成DOM都以相同的方式处理。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。不可思议!(请记住允许 Google 爬虫获取这些外部文件和 JavaScript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们需要更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。 查看全部
js 爬虫抓取网页数据(DOM是什么?Google能读取动态生成的内容是如何?)
我们知道国内的浏览器和搜索工具都是用爬虫爬取网页信息的,那么谷歌爬虫是怎么爬取Javascript的呢?今天,小编就和大家深入探讨一下。
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该界面允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表达的 URL 会发生什么变化?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您没有访问您的 网站 服务器的权限,您可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内(“onClick”)
使用 href 内部 AVP ("javascript: window.location")
在 a 标签之外执行,但在 href ("javascript: openlink()") 中调用 AVP
还有很多
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API(pushState)构建的,可以渲染和收录 它,并且可以像传统的静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果呢?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签会发生什么?在这个协议中,HTTP x-robots 响应头的行为如何作为另一个变量?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中 href 元素的操作发生得太晚了:谷歌在执行添加 rel="nofollow" 的 JavaScript 函数之前,已经准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入内容,甚至元标记,例如rel规范注释,无论是在HTML源代码中还是在解析初始HTML后触发JavaScript生成DOM都以相同的方式处理。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。不可思议!(请记住允许 Google 爬虫获取这些外部文件和 JavaScript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们需要更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
js 爬虫抓取网页数据(《js爬虫抓取网页数据》.open())
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-04 17:06
js爬虫抓取网页数据。
wx.open()你在浏览器输入一个地址,立即就会返回一个对象。这个对象包含:所有文件的路径(下面的一切文件都在这个链接下)、链接(你点开链接)后默认会解析一个json。
浏览器输入地址,
你去看看计算机组成原理什么的
浏览器获取windowopen.
浏览器里面就是链接,所以ie,firefox会解析并响应,不同浏览器不同,ie是个例子,还有很多其他种方式,但都是通过最直接方式去做的,所以也算是响应,假如你用chrome去请求大量页面,返回json数据,然后传给服务器,那么服务器就会收到json数据,服务器就解析,返回数据给浏览器,所以你会看到各种反爬虫。
ie好像也会返回这样的json数据,activex很多特性不利于浏览器解析数据。
chromejs会让他滚
json是javascript的对象。不是说你把啥json数据改一改就返回给服务器了。得不到可以让服务器去检测要发什么数据。
知乎团队可能反应比较迟钝,现在已经可以用js查看你的所有回答了。每个回答都会被随机生成一个token,在redis上。而不是像网上传的一样在数据库上。
看了下大家,目前也就我写的代码是返回json数据。我想了下思路:使用js判断链接来判断script和dom元素,从而判断是否出现js。这样做比使用最简单的轮子简单一些,只要你把js的操作封装到varexecutordata(官方说chrome40内部已经使用这种方式,但我这里不存在这个问题),就可以返回数据了。
判断需要哪些操作,跟你改完token的数据,把输出结果传回给服务器。可以使用crossjstokenfilter(更高效地做到这一点)或者改成整数去做hash键key(同样原理,更高效)。@winter所说可能会导致通讯中断,从而传递更多的数据(这个可能跟你使用js操作dom没有关系,这样其实可以在传递数据前,做一次同步操作,而不会对通讯造成问题)。还是看团队的编码习惯吧。 查看全部
js 爬虫抓取网页数据(《js爬虫抓取网页数据》.open())
js爬虫抓取网页数据。
wx.open()你在浏览器输入一个地址,立即就会返回一个对象。这个对象包含:所有文件的路径(下面的一切文件都在这个链接下)、链接(你点开链接)后默认会解析一个json。
浏览器输入地址,
你去看看计算机组成原理什么的
浏览器获取windowopen.
浏览器里面就是链接,所以ie,firefox会解析并响应,不同浏览器不同,ie是个例子,还有很多其他种方式,但都是通过最直接方式去做的,所以也算是响应,假如你用chrome去请求大量页面,返回json数据,然后传给服务器,那么服务器就会收到json数据,服务器就解析,返回数据给浏览器,所以你会看到各种反爬虫。
ie好像也会返回这样的json数据,activex很多特性不利于浏览器解析数据。
chromejs会让他滚
json是javascript的对象。不是说你把啥json数据改一改就返回给服务器了。得不到可以让服务器去检测要发什么数据。
知乎团队可能反应比较迟钝,现在已经可以用js查看你的所有回答了。每个回答都会被随机生成一个token,在redis上。而不是像网上传的一样在数据库上。
看了下大家,目前也就我写的代码是返回json数据。我想了下思路:使用js判断链接来判断script和dom元素,从而判断是否出现js。这样做比使用最简单的轮子简单一些,只要你把js的操作封装到varexecutordata(官方说chrome40内部已经使用这种方式,但我这里不存在这个问题),就可以返回数据了。
判断需要哪些操作,跟你改完token的数据,把输出结果传回给服务器。可以使用crossjstokenfilter(更高效地做到这一点)或者改成整数去做hash键key(同样原理,更高效)。@winter所说可能会导致通讯中断,从而传递更多的数据(这个可能跟你使用js操作dom没有关系,这样其实可以在传递数据前,做一次同步操作,而不会对通讯造成问题)。还是看团队的编码习惯吧。
js 爬虫抓取网页数据(HTML源码中的内容由前端的JS动态生成的应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-03 12:00
)
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器渲染出来的网页如下图所示:
查看源码,却是如下图:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
这是照片新闻下的新闻。
我们打开一个接口链接看看:
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求和解析数据接口数据
先上完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# coding:utf-8
import requests
import json
第二部分:向数据接口发出http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
js 爬虫抓取网页数据(HTML源码中的内容由前端的JS动态生成的应用
)
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器渲染出来的网页如下图所示:
查看源码,却是如下图:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
这是照片新闻下的新闻。
我们打开一个接口链接看看:
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求和解析数据接口数据
先上完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# coding:utf-8
import requests
import json
第二部分:向数据接口发出http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
js 爬虫抓取网页数据(抓的妹子图都是直接抓Html就可以的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-10-03 11:32
)
介绍
之前拍的姐妹图可以直接用Html抓拍,也就是Chrome的浏览器F12。
Elements 页面结构和 Network 数据包捕获返回相同的结果。以后抓一些
网站(比如煎鸡蛋,还有那种小网站)我发现了。网络抓包
没有得到数据,但是Elements里面有情况。原因是:页面的数据是
由 JavaScript 动态生成:
抓不到数据怎么破?一开始想着自己学一波JS基础语法,然后尝试模拟抓包。
拿到别人的js文件,自己分析一下逻辑,然后摆弄真实的URL,然后就是
放弃。毕竟要爬取的页面太多了。每个这样的分析什么时候...
我偶然发现有一个自动化测试框架:Selenium 可以帮助我们处理这个问题。
简单说说这个东西的使用,我们可以写代码让浏览器:
那么这个东西不支持浏览器功能,需要配合第三方浏览器使用,
支持以下浏览器,需要将对应的浏览器驱动下载到Python对应的路径:
铬合金:
火狐:
幻影JS:
IE:
边缘:
歌剧:
下面直接开始本节的内容吧~
1.安装硒
这个很简单,直接通过pip命令行安装:
sudo pip install selenium
PS:记得公司小伙伴问我为什么在win上不能执行pip,我下载了很多pip。
其实安装Python3的话,默认已经自带pip了,需要单独配置环境
变量,pip的路径在Python安装目录的Scripts目录下~
在Path后面加上这个路径就行了~
2.下载浏览器驱动
因为Selenium没有浏览器,需要依赖第三方浏览器,调用第三方
如果你用的是新浏览器,需要下载浏览器的驱动,因为我用的是Chrome,所以我会用
我们以 Chrome 为例。其他浏览器可以自行搜索相关信息!打开 Chrome 浏览器并输入:
chrome://version
可以查看Chrome浏览器版本的相关信息,这里主要注意版本号:
61.好的,那么到下面网站查看对应的驱动版本号:
好的,接下来下载v2.34版本的浏览器驱动:
下载完成后,解压zip文件,将解压后的chromedriver.exe复制到Python中
脚本目录。(这里不用担心win32,64位浏览器可以正常使用!)
PS:对于Mac,将解压后的文件复制到usr/local/bin目录下
对于Ubuntu,复制到:usr/bin目录
接下来我们写一个简单的代码来测试一下:
from selenium import webdriver
browser = webdriver.Chrome() # 调用本地的Chrome浏览器
browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口
html_text = browser.page_source # 获得页面代码
browser.quit() # 关闭浏览器
print(html_text)
执行这段代码会自动调出浏览器访问百度:
并且控制台会输出HTML代码,也就是直接获取到的Elements页面结构,
JS执行后的页面~接下来就可以抢到我们的煎蛋少女图了~
3.Selenium简单实战:抢煎蛋少女图
直接分析Elements页面的结构,找到你想要的关键节点:
明明这是我们抓到的小姐姐的照片,复制这个网址看看我们打印出来的
页面结构有没有这个东西:
是的这很好。有了这个页面数据,让我们通过一波美汤来搞定我们
你要的资料~
经过上面的过滤,我们就可以得到我们妹图的URL:
只需打开一个验证,啧:
看到下一页只有30个小姐姐,显然满足不了我们。我们第一次加载它。
当你第一次得到一波页码的时候,然后你就知道有多少页了,然后你就可以拼接URL并自己加载了
不同的页面,比如这里总共有448个页面:
可以拼接成这样的网址:
获取过滤下的页码:
接下来,我将填写代码,循环抓取每个页面上的小姐姐,并将其下载到本地。
完整代码如下:
import os
from selenium import webdriver
from bs4 import BeautifulSoup
import urllib.request
import ssl
import urllib.error
base_url = 'http://jandan.net/ooxx'
pic_save_path = "output/Picture/JianDan/"
# 下载图片
def download_pic(url):
correct_url = url
if url.startswith('//'):
correct_url = url[2:]
if not url.startswith('http'):
correct_url = 'http://' + correct_url
print(correct_url)
headers = {
'Host': 'wx2.sinaimg.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.100 Safari/537.36 '
}
try:
req = urllib.request.Request(correct_url, headers=headers)
resp = urllib.request.urlopen(req)
pic = resp.read()
pic_name = correct_url.split("/")[-1]
with open(pic_save_path + pic_name, "wb+") as f:
f.write(pic)
except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason:
print(str(reason))
# 打开浏览器模拟请求
def browser_get():
browser = webdriver.Chrome()
browser.get('http://jandan.net/ooxx')
html_text = browser.page_source
page_count = get_page_count(html_text)
# 循环拼接URL访问
for page in range(page_count, 0, -1):
page_url = base_url + '/page-' + str(page)
print('解析:' + page_url)
browser.get(page_url)
html = browser.page_source
get_meizi_url(html)
browser.quit()
# 获取总页码
def get_page_count(html):
soup = BeautifulSoup(html, 'html.parser')
page_count = soup.find('span', attrs={'class': 'current-comment-page'})
return int(page_count.get_text()[1:-1]) - 1
# 获取每个页面的小姐姐
def get_meizi_url(html):
soup = BeautifulSoup(html, 'html.parser')
ol = soup.find('ol', attrs={'class': 'commentlist'})
href = ol.findAll('a', attrs={'class': 'view_img_link'})
for a in href:
download_pic(a['href'])
if __name__ == '__main__':
ssl._create_default_https_context = ssl._create_unverified_context
if not os.path.exists(pic_save_path):
os.makedirs(pic_save_path)
browser_get()
操作结果:
看看我们的输出文件夹~
学习Python爬虫,越来越瘦……
4.PhantomJS
PhantomJS 没有界面浏览器,特点:会将网站加载到内存中并执行
JavaScript,因为它不显示图形界面,所以它比完整的浏览器运行效率更高。
(如果某些 Linux 主机上没有图形界面,则无法安装 Chrome 等浏览器。
这个问题可以通过 PhantomJS 来规避)。
在 Win 上安装 PhantomJS:
在 Ubuntu/MAC 上安装 PhantomJS:
sudo apt-get install phantomjs
!!!关于 PhantomJS 的重要说明:
今年 4 月,Phantom.js 的维护者宣布退出 PhantomJS。
这意味着该项目可能不再维护!!!Chrome 和 FireFox 也开始了
提供Headless模式(不需要挂浏览器),所以估计用PhantomJS的小伙伴
会慢慢迁移到这两个浏览器。Windows Chrome 需要 60 以上的版本才能支持
Headless 模式,启用 Headless 模式也很简单:
selenium 的官方文档中还写道:
运行时也会报这个警告:
5.Selenium实战:模拟登录CSDN并保存Cookie
CSDN登录网站:
分析页面结构,不难发现对应的登录输入框和登录按钮:
我们要做的就是在这两个节点输入账号密码,然后触发登录按钮,
同时在本地保存Cookie,然后就可以带着Cookie访问相关页面了~
首先写一个方法来模拟登录:
找到输入账号密码的节点,设置你的账号密码,然后找到login
按钮节点,点击一次,然后等待登录成功,登录成功后可以对比
current_url 是否已更改。然后在这里保存 Cookies
我用的是pickle库,你可以用其他的,比如json,或者字符串拼接,
然后保存到本地。如果没有意外,应该可以拿到Cookie,然后使用
Cookie 访问主页。
通过 add_cookies 方法设置 Cookie。参数是字典类型的。此外,您必须首先
访问get链接一次,然后设置cookie,否则会报无法设置cookie的错误!
通过查看右下角是否变为登录状态就可以知道是否使用Cookie登录成功:
6.Selenium 常用函数
Seleninum 作为自动化测试的工具,自然提供了很多自动化操作的功能。
下面是我觉得比较常用的功能,更多的可以看官方文档:
官方API文档:
1) 定位元素
PS:将元素更改为元素将定位所有符合条件的元素并返回一个列表
例如:find_elements_by_class_name
2) 鼠标操作
有时需要在页面上模拟鼠标操作,例如:单击、双击、右键单击、按住、拖动等。
您可以导入 ActionChains 类:mon.action_chains.ActionChains
使用 ActionChains(driver).XXX 调用对应节点的行为
3) 弹出窗口
对应类:mon.alert.Alert,感觉用的不多...
如果触发到一定时间,弹出对话框,可以调用如下方法获取对话框:
alert = driver.switch_to_alert(),然后可以调用以下方法:
4)页面前进、后退、切换
切换窗口:driver.switch_to.window("窗口名称")
或者通过window_handles来遍历
用于 driver.window_handles 中的句柄:
driver.switch_to_window(句柄)
driver.forward() #forward
driver.back() # 返回
5) 页面截图
driver.save_screenshot("Screenshot.png")
6) 页面等待
现在越来越多的网页使用Ajax技术,所以程序无法判断一个元素什么时候完全
加载完毕。如果实际页面等待时间过长,某个dom元素还没有出来,但是你的
代码直接使用这个WebElement,会抛出NullPointer异常。
为了避免元素定位困难,增加ElementNotVisibleException的概率。
所以Selenium提供了两种等待方式,一种是隐式等待,一种是显式等待。
显式等待:
显式等待指定某个条件,然后设置最大等待时间。如果不是这个时候
如果找到该元素,则会抛出异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.PhantomJS()
driver.get("http://www.xxxxx.com/loading")
try:
# 每隔10秒查找页面元素 id="myDynamicElement",直到出现则返回
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
如果不写参数,程序默认会调用0.5s来检查元素是否已经生成。
如果原创元素存在,它将立即返回。
下面是一些内置的等待条件,你可以直接调用这些条件,而不是自己调用
写一些等待条件。
标题_是
标题_收录
Presence_of_element_located
visibility_of_element_located
可见性_of
Presence_of_all_elements_located
text_to_be_present_in_element
text_to_be_present_in_element_value
frame_to_be_available_and_switch_to_it
invisibility_of_element_located
element_to_be_clickable – 显示并启用。
staleness_of
element_to_be_selected
element_located_to_be_selected
element_selection_state_to_be
element_located_selection_state_to_be
alert_is_present
隐式等待:
隐式等待比较简单,就是简单的设置一个等待时间,以秒为单位。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.implicitly_wait(10) # seconds
driver.get("http://www.xxxxx.com/loading")
myDynamicElement = driver.find_element_by_id("myDynamicElement")
当然,如果不设置,则默认等待时间为0。
7.执行JS语句
driver.execute_script(js 语句)
例如,滚动到底部:
js = document.body.scrollTop=10000
driver.execute_script(js)
概括
本节讲解一波使用Selenium自动化测试框架抓取JavaScript动态生成的数据,
Selenium 需要依赖第三方浏览器,注意过时的 PhantomJS 无界面浏览器
对于问题,可以使用Chrome和FireFox提供的HeadLess来替换;通过抓住煎蛋女孩
模拟CSDN自动登录的图片和例子,熟悉Selenium的基本使用,或者收很多货。
当然Selenium的水还是很深的,目前我们可以用它来应对JS动态加载数据页面
数据采集就够了。
另外,最近天气很冷,记得及时补衣服哦~
顺便写下你的想法:
下载本节源码:
本节参考资料:
来吧,Py 交易
如果想加群一起学Py,可以加智障机器人小猪,验证信息收录:
python,python,py,py,添加组,事务,关键词之一即可;
验证通过后回复群获取群链接(不要破解机器人!!!)~~~
欢迎像我这样的Py初学者,Py大神加入,愉快交流学习♂学习,van♂转py。
查看全部
js 爬虫抓取网页数据(抓的妹子图都是直接抓Html就可以的
)
介绍
之前拍的姐妹图可以直接用Html抓拍,也就是Chrome的浏览器F12。
Elements 页面结构和 Network 数据包捕获返回相同的结果。以后抓一些
网站(比如煎鸡蛋,还有那种小网站)我发现了。网络抓包
没有得到数据,但是Elements里面有情况。原因是:页面的数据是
由 JavaScript 动态生成:
抓不到数据怎么破?一开始想着自己学一波JS基础语法,然后尝试模拟抓包。
拿到别人的js文件,自己分析一下逻辑,然后摆弄真实的URL,然后就是
放弃。毕竟要爬取的页面太多了。每个这样的分析什么时候...
我偶然发现有一个自动化测试框架:Selenium 可以帮助我们处理这个问题。
简单说说这个东西的使用,我们可以写代码让浏览器:
那么这个东西不支持浏览器功能,需要配合第三方浏览器使用,
支持以下浏览器,需要将对应的浏览器驱动下载到Python对应的路径:
铬合金:
火狐:
幻影JS:
IE:
边缘:
歌剧:
下面直接开始本节的内容吧~
1.安装硒
这个很简单,直接通过pip命令行安装:
sudo pip install selenium
PS:记得公司小伙伴问我为什么在win上不能执行pip,我下载了很多pip。
其实安装Python3的话,默认已经自带pip了,需要单独配置环境
变量,pip的路径在Python安装目录的Scripts目录下~
在Path后面加上这个路径就行了~
2.下载浏览器驱动
因为Selenium没有浏览器,需要依赖第三方浏览器,调用第三方
如果你用的是新浏览器,需要下载浏览器的驱动,因为我用的是Chrome,所以我会用
我们以 Chrome 为例。其他浏览器可以自行搜索相关信息!打开 Chrome 浏览器并输入:
chrome://version
可以查看Chrome浏览器版本的相关信息,这里主要注意版本号:
61.好的,那么到下面网站查看对应的驱动版本号:
好的,接下来下载v2.34版本的浏览器驱动:
下载完成后,解压zip文件,将解压后的chromedriver.exe复制到Python中
脚本目录。(这里不用担心win32,64位浏览器可以正常使用!)
PS:对于Mac,将解压后的文件复制到usr/local/bin目录下
对于Ubuntu,复制到:usr/bin目录
接下来我们写一个简单的代码来测试一下:
from selenium import webdriver
browser = webdriver.Chrome() # 调用本地的Chrome浏览器
browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口
html_text = browser.page_source # 获得页面代码
browser.quit() # 关闭浏览器
print(html_text)
执行这段代码会自动调出浏览器访问百度:
并且控制台会输出HTML代码,也就是直接获取到的Elements页面结构,
JS执行后的页面~接下来就可以抢到我们的煎蛋少女图了~
3.Selenium简单实战:抢煎蛋少女图
直接分析Elements页面的结构,找到你想要的关键节点:
明明这是我们抓到的小姐姐的照片,复制这个网址看看我们打印出来的
页面结构有没有这个东西:
是的这很好。有了这个页面数据,让我们通过一波美汤来搞定我们
你要的资料~
经过上面的过滤,我们就可以得到我们妹图的URL:
只需打开一个验证,啧:
看到下一页只有30个小姐姐,显然满足不了我们。我们第一次加载它。
当你第一次得到一波页码的时候,然后你就知道有多少页了,然后你就可以拼接URL并自己加载了
不同的页面,比如这里总共有448个页面:
可以拼接成这样的网址:
获取过滤下的页码:
接下来,我将填写代码,循环抓取每个页面上的小姐姐,并将其下载到本地。
完整代码如下:
import os
from selenium import webdriver
from bs4 import BeautifulSoup
import urllib.request
import ssl
import urllib.error
base_url = 'http://jandan.net/ooxx'
pic_save_path = "output/Picture/JianDan/"
# 下载图片
def download_pic(url):
correct_url = url
if url.startswith('//'):
correct_url = url[2:]
if not url.startswith('http'):
correct_url = 'http://' + correct_url
print(correct_url)
headers = {
'Host': 'wx2.sinaimg.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.100 Safari/537.36 '
}
try:
req = urllib.request.Request(correct_url, headers=headers)
resp = urllib.request.urlopen(req)
pic = resp.read()
pic_name = correct_url.split("/")[-1]
with open(pic_save_path + pic_name, "wb+") as f:
f.write(pic)
except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason:
print(str(reason))
# 打开浏览器模拟请求
def browser_get():
browser = webdriver.Chrome()
browser.get('http://jandan.net/ooxx')
html_text = browser.page_source
page_count = get_page_count(html_text)
# 循环拼接URL访问
for page in range(page_count, 0, -1):
page_url = base_url + '/page-' + str(page)
print('解析:' + page_url)
browser.get(page_url)
html = browser.page_source
get_meizi_url(html)
browser.quit()
# 获取总页码
def get_page_count(html):
soup = BeautifulSoup(html, 'html.parser')
page_count = soup.find('span', attrs={'class': 'current-comment-page'})
return int(page_count.get_text()[1:-1]) - 1
# 获取每个页面的小姐姐
def get_meizi_url(html):
soup = BeautifulSoup(html, 'html.parser')
ol = soup.find('ol', attrs={'class': 'commentlist'})
href = ol.findAll('a', attrs={'class': 'view_img_link'})
for a in href:
download_pic(a['href'])
if __name__ == '__main__':
ssl._create_default_https_context = ssl._create_unverified_context
if not os.path.exists(pic_save_path):
os.makedirs(pic_save_path)
browser_get()
操作结果:
看看我们的输出文件夹~
学习Python爬虫,越来越瘦……
4.PhantomJS
PhantomJS 没有界面浏览器,特点:会将网站加载到内存中并执行
JavaScript,因为它不显示图形界面,所以它比完整的浏览器运行效率更高。
(如果某些 Linux 主机上没有图形界面,则无法安装 Chrome 等浏览器。
这个问题可以通过 PhantomJS 来规避)。
在 Win 上安装 PhantomJS:
在 Ubuntu/MAC 上安装 PhantomJS:
sudo apt-get install phantomjs
!!!关于 PhantomJS 的重要说明:
今年 4 月,Phantom.js 的维护者宣布退出 PhantomJS。
这意味着该项目可能不再维护!!!Chrome 和 FireFox 也开始了
提供Headless模式(不需要挂浏览器),所以估计用PhantomJS的小伙伴
会慢慢迁移到这两个浏览器。Windows Chrome 需要 60 以上的版本才能支持
Headless 模式,启用 Headless 模式也很简单:
selenium 的官方文档中还写道:
运行时也会报这个警告:
5.Selenium实战:模拟登录CSDN并保存Cookie
CSDN登录网站:
分析页面结构,不难发现对应的登录输入框和登录按钮:
我们要做的就是在这两个节点输入账号密码,然后触发登录按钮,
同时在本地保存Cookie,然后就可以带着Cookie访问相关页面了~
首先写一个方法来模拟登录:
找到输入账号密码的节点,设置你的账号密码,然后找到login
按钮节点,点击一次,然后等待登录成功,登录成功后可以对比
current_url 是否已更改。然后在这里保存 Cookies
我用的是pickle库,你可以用其他的,比如json,或者字符串拼接,
然后保存到本地。如果没有意外,应该可以拿到Cookie,然后使用
Cookie 访问主页。
通过 add_cookies 方法设置 Cookie。参数是字典类型的。此外,您必须首先
访问get链接一次,然后设置cookie,否则会报无法设置cookie的错误!
通过查看右下角是否变为登录状态就可以知道是否使用Cookie登录成功:
6.Selenium 常用函数
Seleninum 作为自动化测试的工具,自然提供了很多自动化操作的功能。
下面是我觉得比较常用的功能,更多的可以看官方文档:
官方API文档:
1) 定位元素
PS:将元素更改为元素将定位所有符合条件的元素并返回一个列表
例如:find_elements_by_class_name
2) 鼠标操作
有时需要在页面上模拟鼠标操作,例如:单击、双击、右键单击、按住、拖动等。
您可以导入 ActionChains 类:mon.action_chains.ActionChains
使用 ActionChains(driver).XXX 调用对应节点的行为
3) 弹出窗口
对应类:mon.alert.Alert,感觉用的不多...
如果触发到一定时间,弹出对话框,可以调用如下方法获取对话框:
alert = driver.switch_to_alert(),然后可以调用以下方法:
4)页面前进、后退、切换
切换窗口:driver.switch_to.window("窗口名称")
或者通过window_handles来遍历
用于 driver.window_handles 中的句柄:
driver.switch_to_window(句柄)
driver.forward() #forward
driver.back() # 返回
5) 页面截图
driver.save_screenshot("Screenshot.png")
6) 页面等待
现在越来越多的网页使用Ajax技术,所以程序无法判断一个元素什么时候完全
加载完毕。如果实际页面等待时间过长,某个dom元素还没有出来,但是你的
代码直接使用这个WebElement,会抛出NullPointer异常。
为了避免元素定位困难,增加ElementNotVisibleException的概率。
所以Selenium提供了两种等待方式,一种是隐式等待,一种是显式等待。
显式等待:
显式等待指定某个条件,然后设置最大等待时间。如果不是这个时候
如果找到该元素,则会抛出异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.PhantomJS()
driver.get("http://www.xxxxx.com/loading";)
try:
# 每隔10秒查找页面元素 id="myDynamicElement",直到出现则返回
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
如果不写参数,程序默认会调用0.5s来检查元素是否已经生成。
如果原创元素存在,它将立即返回。
下面是一些内置的等待条件,你可以直接调用这些条件,而不是自己调用
写一些等待条件。
标题_是
标题_收录
Presence_of_element_located
visibility_of_element_located
可见性_of
Presence_of_all_elements_located
text_to_be_present_in_element
text_to_be_present_in_element_value
frame_to_be_available_and_switch_to_it
invisibility_of_element_located
element_to_be_clickable – 显示并启用。
staleness_of
element_to_be_selected
element_located_to_be_selected
element_selection_state_to_be
element_located_selection_state_to_be
alert_is_present
隐式等待:
隐式等待比较简单,就是简单的设置一个等待时间,以秒为单位。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.implicitly_wait(10) # seconds
driver.get("http://www.xxxxx.com/loading";)
myDynamicElement = driver.find_element_by_id("myDynamicElement")
当然,如果不设置,则默认等待时间为0。
7.执行JS语句
driver.execute_script(js 语句)
例如,滚动到底部:
js = document.body.scrollTop=10000
driver.execute_script(js)
概括
本节讲解一波使用Selenium自动化测试框架抓取JavaScript动态生成的数据,
Selenium 需要依赖第三方浏览器,注意过时的 PhantomJS 无界面浏览器
对于问题,可以使用Chrome和FireFox提供的HeadLess来替换;通过抓住煎蛋女孩
模拟CSDN自动登录的图片和例子,熟悉Selenium的基本使用,或者收很多货。
当然Selenium的水还是很深的,目前我们可以用它来应对JS动态加载数据页面
数据采集就够了。
另外,最近天气很冷,记得及时补衣服哦~
顺便写下你的想法:
下载本节源码:
本节参考资料:
来吧,Py 交易
如果想加群一起学Py,可以加智障机器人小猪,验证信息收录:
python,python,py,py,添加组,事务,关键词之一即可;
验证通过后回复群获取群链接(不要破解机器人!!!)~~~
欢迎像我这样的Py初学者,Py大神加入,愉快交流学习♂学习,van♂转py。
js 爬虫抓取网页数据(网页极速版多使用IP,代理IP不使用cookie多利用线程分布式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-10-03 11:28
建议:
减少列表数据并保存页面
关注网络速度版本、应用程序版本
多用途IP、动态UA、代理IP、无Cookie
多线程分布式
===================================
Selenium可以接受指示。获取所需的数据或错误屏幕截图
无界面的Phantom JS浏览器(可保存截图)
加载到内存并执行JS
需要下载
解决方案:
下载连接
from selenium import webdriver
import time
d1=webdriver.Chrome(r"C:\Users\xzq\Downloads\chromedriver_win32 (1)\chromedriver.exe")
d1.get("https://login.taobao.com/membe ... 6quot;)
d1.find_element_by_id("J_Quick2Static").click()
time.sleep(3)
d1.find_element_by_id("TPL_username_1").send_keys("扯淡灬孩子02547915")
d1.find_element_by_id("TPL_password_1").send_keys("a13736784065")
d1.find_element_by_id("J_SubmitStatic").click()
求解滑动检查
button = d1.find_element_by_id('nc_1_n1z')# 找到“蓝色滑块”
action = webdriver.ActionChains(d1)# 实例化一个action对象
action.click_and_hold(button).perform()# perform()用来执行ActionChains中存储的行为
action.reset_actions()
action.move_by_offset(280, 0).perform()# 移动滑块
action.release()
=================================================================================================
解决方案验证码
一,。相同的URL将生成相同的验证码URL
直接向编码平台申请验证码地址进行处理
二,。相同的URL将生成具有不同验证码的URL
1.实例化会话
2.使用会话请求页面获取验证码地址
3.发送会话请求验证代码并使用该代码识别
4.使用会话发送帖子
遇到使用selenium的验证代码:
Selenium请求登录页面,同时获取验证码地址
在登录驱动器中获取cookie,并将其提交给请求进行处理和标识
或者使用屏幕截图工具查找验证代码并使用它进行识别
============================================================================================
获取文本和属性
1.首先找到元素,然后调用.Text或get\ux。归属者
find_u元素返回一个元素。如果没有元素,将报告错误
查找元素返回一个空列表
==================================================================
求解查找元素失败的方法
页面中可能有iframe和frame
需要先打电话吗
d1.切换到帧(“帧名称”)
然后获取输入内容
==================================================================
=======================================================================
解决新页面的后续请求以获取错误(在加载完成之前获取数据)
===================================================================================================================================================
使用Orc身份验证码**
1.安装PIL(Python 3中没有可供下载的直接PIL版本。您可以先使用pilot)
2.从PIL导入图像导入
import pytesseract
from PIL import Image
img=Image.open("0014076720724832de067ce843d41c58f2af067d1e0720f000[1].jpg")
print(pytesseract.image_to_string(img))
如果报告错误,请在下载后参考pytestseract中的testseract(因为未安装Orc)\在CMD下添加tesserac.exet的路径 查看全部
js 爬虫抓取网页数据(网页极速版多使用IP,代理IP不使用cookie多利用线程分布式)
建议:
减少列表数据并保存页面
关注网络速度版本、应用程序版本
多用途IP、动态UA、代理IP、无Cookie
多线程分布式
===================================
Selenium可以接受指示。获取所需的数据或错误屏幕截图
无界面的Phantom JS浏览器(可保存截图)
加载到内存并执行JS
需要下载
解决方案:
下载连接
from selenium import webdriver
import time
d1=webdriver.Chrome(r"C:\Users\xzq\Downloads\chromedriver_win32 (1)\chromedriver.exe")
d1.get("https://login.taobao.com/membe ... 6quot;)
d1.find_element_by_id("J_Quick2Static").click()
time.sleep(3)
d1.find_element_by_id("TPL_username_1").send_keys("扯淡灬孩子02547915")
d1.find_element_by_id("TPL_password_1").send_keys("a13736784065")
d1.find_element_by_id("J_SubmitStatic").click()
求解滑动检查
button = d1.find_element_by_id('nc_1_n1z')# 找到“蓝色滑块”
action = webdriver.ActionChains(d1)# 实例化一个action对象
action.click_and_hold(button).perform()# perform()用来执行ActionChains中存储的行为
action.reset_actions()
action.move_by_offset(280, 0).perform()# 移动滑块
action.release()
=================================================================================================
解决方案验证码
一,。相同的URL将生成相同的验证码URL
直接向编码平台申请验证码地址进行处理
二,。相同的URL将生成具有不同验证码的URL
1.实例化会话
2.使用会话请求页面获取验证码地址
3.发送会话请求验证代码并使用该代码识别
4.使用会话发送帖子
遇到使用selenium的验证代码:
Selenium请求登录页面,同时获取验证码地址
在登录驱动器中获取cookie,并将其提交给请求进行处理和标识
或者使用屏幕截图工具查找验证代码并使用它进行识别
============================================================================================
获取文本和属性
1.首先找到元素,然后调用.Text或get\ux。归属者
find_u元素返回一个元素。如果没有元素,将报告错误
查找元素返回一个空列表
==================================================================
求解查找元素失败的方法
页面中可能有iframe和frame
需要先打电话吗
d1.切换到帧(“帧名称”)
然后获取输入内容
==================================================================
=======================================================================
解决新页面的后续请求以获取错误(在加载完成之前获取数据)
===================================================================================================================================================
使用Orc身份验证码**
1.安装PIL(Python 3中没有可供下载的直接PIL版本。您可以先使用pilot)
2.从PIL导入图像导入
import pytesseract
from PIL import Image
img=Image.open("0014076720724832de067ce843d41c58f2af067d1e0720f000[1].jpg")
print(pytesseract.image_to_string(img))
如果报告错误,请在下载后参考pytestseract中的testseract(因为未安装Orc)\在CMD下添加tesserac.exet的路径
js 爬虫抓取网页数据(动态网页抓取AJAX(Asynchronouse)异步JavaScript和XML的区别 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-10-03 11:27
)
动态网页抓取
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
我们有两种方式获取ajax数据:
直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
我们接下来讲解使用selenium+chromedriver获取动态数据。
1.Selenium+chromedriver获取动态数据1.1.准备
Selenium 相当于一个机器人。它可以模拟人们在浏览器上的一些行为,并自动处理浏览器上的一些行为,如点击、填充数据、删除cookies等。chromedriver是一个驱动Chrome浏览器的驱动程序,可以用来驱动浏览器浏览器。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
铬:火狐:边缘:Safari:
我们这里使用 Chrome 来执行以下操作。
注意不同版本浏览器的驱动是不同的,请根据您的浏览器下载对应的版本。
我们使用以下代码来安装 selenium 库,
pip install selenium
1.2.打开和关闭网页
我们需要使用 selenium 实例化一个 Chrome 对象来模拟浏览器的操作,并使用 driver.get() 方法打开相应的网页。使用 driver.close() 方法关闭当前网页,或使用 driver.quit() 方法关闭浏览器。比如我们模拟打开一个百度页面,等待3秒后关闭,
from selenium import webdriver
import time
driver_path = r'D:\python_class\crawl\chromedriver.exe' # chromedriver.exe文件位置
driver = webdriver.Chrome(executable_path=driver_path) # executable_path为chromedriver.exe文件位置
driver.get('http://www.baidu.com') # 第一个参数为网站url
time.sleep(3)
driver.close() # 关闭当前页面
如果不想每次都设置executable_path参数,可以将chromedriver.exe文件放在chrome浏览器目录下,将目录地址添加到系统变量中的Path中,这样我们就不需要设置可执行路径参数。
1.3.阅读网页源码
我们可以直接使用driver.page_source来获取网页的源代码,比如我们获取百度页面的代码,
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
print(driver.page_source) # 打印页面源代码
driver.close() # 关闭当前页面
1.4. 定位元素
Selenium 支持基于类名、id、name 属性值、标签名、xpath、css 选择器或 By 方法定位元素。
方式示例
班级名称
inputTag = driver.find_elements_by_class_name("s_ipt")[0]
id值
inputTag = driver.find_element_by_id("kw")
名称属性值
inputTag = driver.find_element_by_name("wd")
标签名称
inputTag = driver.find_element_by_tag_name("输入")
xpath 语法
inputTag = driver.find_element_by_xpath('//input[@id="kw"]')
css 选择器
inputTag = driver.find_element_by_css_selector('#kw')
经过
使用By方法需要先导入,from mon.by import By, inputTag = driver.find_element(By.ID, “kw”)
1.5. 表单元素操作示例
操作输入框
发送密钥()
inputTag.send_keys('1')
点击元素
点击()
submintTag.click()
获取元素的指定属性
get_attribute()
inputValue.get_attribute('占位符')
1.6. 行为链
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。我们使用行为链进行搜索,
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
inputTag = driver.find_element_by_id('kw') # 找到输入框
submitTag = driver.find_element_by_id('su') # 找到提交按钮
actions = ActionChains(driver) # 实例化行为链对象
actions.move_to_element(inputTag) # 焦点移动到输入框
actions.send_keys_to_element(inputTag, '美国病毒') # 提交内容
actions.move_to_element(submitTag) # 焦点移动到提交按钮
actions.click(submitTag) # 点击提交按钮
actions.perform() # 展示页面
我们还可以实现一些操作,
操作方法
单击而不释放鼠标
click_and_hold(元素)
右键点击
上下文点击(元素)
双击
双击(元素)
1.7.Cookie 操作
from selenium import webdriver
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
print(driver.get_cookies()) # 打印cookie信息,注意,这里是cookies()方法
print(driver.get_cookie('PSTM')) # 获取cookie中的PSTM信息,注意,这里是cookie()方法
print(driver.delete_cookie('PSTM')) # 删除cookie中的PSTM信息
1.8.页面操作1.8.1.等待页面
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
我们先来看看隐式等待。
隐式等待调用driver.implicitly_wait()方法,我们可以设置等待时间,例如,
from selenium import webdriver
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
driver.implicitly_wait(5) # 参数为等待时间。如果5秒内页面加载完成,则取消等待;否则,5秒后返回错误
print(driver.page_source)
接下来,显示操作。
显示等待是在执行获取元素的操作之前显示满足某个条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
element = WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.ID, 'su')))
# 在5秒内,id值为su的标签加载完成后,则取消等待;否则,报错
这里有一些其他条件,
等待条件法
一个元素已加载
Presence_of_element_located()
页面上所有符合条件的元素都已加载完毕
Presence_of_all_emement_located()
一个元素可以被点击
element_to_be_cliable()
1.8.2.切换页面
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。页面会以列表的形式显示,可以使用列表下标来切换页面。例如,
from selenium import webdriver
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.baidu.com') # 打开主页
driver.execute_script("window.open('http://www.zhihu.com')") # 以新窗口的形式打开新的页面
driver.execute_script("window.open('http://www.douban.com')")
print(driver.window_handles) # 窗口的句柄
driver.switch_to_window(driver.window_handles[0]) # 切换到页面列表中下标为0的页面
1.8.3.保存页面截图
save_screenshot() 方法可以保存页面的截图,例如,
from selenium import webdriver
from selenium.webdriver.common.by import By
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.codingke.com') # 打开主页
driver.save_screenshot('codingke.png') # 参数为图片名称
1.9.设置代理不显示浏览器
我们可以通过添加浏览器选项来开启代理服务器并执行代码,而无需显示浏览器的操作过程。我们需要创建一个 ChromeOptions 对象,然后使用 add_argument() 方法添加选项,最后将 options 参数添加到 Chrome 对象中。例如,
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://175.42.123.88:9999") # 添加代理服务器
options.add_argument("--headless") # 不打开浏览器
options.add_argument("--disable-gpu") # 禁用GPU
driver = webdriver.Chrome(options=options)
driver.get('http://httpbin.org/ip')
print(driver.page_source) 查看全部
js 爬虫抓取网页数据(动态网页抓取AJAX(Asynchronouse)异步JavaScript和XML的区别
)
动态网页抓取
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
我们有两种方式获取ajax数据:
直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
我们接下来讲解使用selenium+chromedriver获取动态数据。
1.Selenium+chromedriver获取动态数据1.1.准备
Selenium 相当于一个机器人。它可以模拟人们在浏览器上的一些行为,并自动处理浏览器上的一些行为,如点击、填充数据、删除cookies等。chromedriver是一个驱动Chrome浏览器的驱动程序,可以用来驱动浏览器浏览器。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
铬:火狐:边缘:Safari:
我们这里使用 Chrome 来执行以下操作。
注意不同版本浏览器的驱动是不同的,请根据您的浏览器下载对应的版本。
我们使用以下代码来安装 selenium 库,
pip install selenium
1.2.打开和关闭网页
我们需要使用 selenium 实例化一个 Chrome 对象来模拟浏览器的操作,并使用 driver.get() 方法打开相应的网页。使用 driver.close() 方法关闭当前网页,或使用 driver.quit() 方法关闭浏览器。比如我们模拟打开一个百度页面,等待3秒后关闭,
from selenium import webdriver
import time
driver_path = r'D:\python_class\crawl\chromedriver.exe' # chromedriver.exe文件位置
driver = webdriver.Chrome(executable_path=driver_path) # executable_path为chromedriver.exe文件位置
driver.get('http://www.baidu.com') # 第一个参数为网站url
time.sleep(3)
driver.close() # 关闭当前页面
如果不想每次都设置executable_path参数,可以将chromedriver.exe文件放在chrome浏览器目录下,将目录地址添加到系统变量中的Path中,这样我们就不需要设置可执行路径参数。
1.3.阅读网页源码
我们可以直接使用driver.page_source来获取网页的源代码,比如我们获取百度页面的代码,
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
print(driver.page_source) # 打印页面源代码
driver.close() # 关闭当前页面
1.4. 定位元素
Selenium 支持基于类名、id、name 属性值、标签名、xpath、css 选择器或 By 方法定位元素。
方式示例
班级名称
inputTag = driver.find_elements_by_class_name("s_ipt")[0]
id值
inputTag = driver.find_element_by_id("kw")
名称属性值
inputTag = driver.find_element_by_name("wd")
标签名称
inputTag = driver.find_element_by_tag_name("输入")
xpath 语法
inputTag = driver.find_element_by_xpath('//input[@id="kw"]')
css 选择器
inputTag = driver.find_element_by_css_selector('#kw')
经过
使用By方法需要先导入,from mon.by import By, inputTag = driver.find_element(By.ID, “kw”)
1.5. 表单元素操作示例
操作输入框
发送密钥()
inputTag.send_keys('1')
点击元素
点击()
submintTag.click()
获取元素的指定属性
get_attribute()
inputValue.get_attribute('占位符')
1.6. 行为链
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。我们使用行为链进行搜索,
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
inputTag = driver.find_element_by_id('kw') # 找到输入框
submitTag = driver.find_element_by_id('su') # 找到提交按钮
actions = ActionChains(driver) # 实例化行为链对象
actions.move_to_element(inputTag) # 焦点移动到输入框
actions.send_keys_to_element(inputTag, '美国病毒') # 提交内容
actions.move_to_element(submitTag) # 焦点移动到提交按钮
actions.click(submitTag) # 点击提交按钮
actions.perform() # 展示页面
我们还可以实现一些操作,
操作方法
单击而不释放鼠标
click_and_hold(元素)
右键点击
上下文点击(元素)
双击
双击(元素)
1.7.Cookie 操作
from selenium import webdriver
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
print(driver.get_cookies()) # 打印cookie信息,注意,这里是cookies()方法
print(driver.get_cookie('PSTM')) # 获取cookie中的PSTM信息,注意,这里是cookie()方法
print(driver.delete_cookie('PSTM')) # 删除cookie中的PSTM信息
1.8.页面操作1.8.1.等待页面
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
我们先来看看隐式等待。
隐式等待调用driver.implicitly_wait()方法,我们可以设置等待时间,例如,
from selenium import webdriver
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
driver.implicitly_wait(5) # 参数为等待时间。如果5秒内页面加载完成,则取消等待;否则,5秒后返回错误
print(driver.page_source)
接下来,显示操作。
显示等待是在执行获取元素的操作之前显示满足某个条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
element = WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.ID, 'su')))
# 在5秒内,id值为su的标签加载完成后,则取消等待;否则,报错
这里有一些其他条件,
等待条件法
一个元素已加载
Presence_of_element_located()
页面上所有符合条件的元素都已加载完毕
Presence_of_all_emement_located()
一个元素可以被点击
element_to_be_cliable()
1.8.2.切换页面
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。页面会以列表的形式显示,可以使用列表下标来切换页面。例如,
from selenium import webdriver
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.baidu.com') # 打开主页
driver.execute_script("window.open('http://www.zhihu.com')") # 以新窗口的形式打开新的页面
driver.execute_script("window.open('http://www.douban.com')")
print(driver.window_handles) # 窗口的句柄
driver.switch_to_window(driver.window_handles[0]) # 切换到页面列表中下标为0的页面
1.8.3.保存页面截图
save_screenshot() 方法可以保存页面的截图,例如,
from selenium import webdriver
from selenium.webdriver.common.by import By
# 实例化driver对象
driver = webdriver.Chrome()
driver.get('https://www.codingke.com') # 打开主页
driver.save_screenshot('codingke.png') # 参数为图片名称
1.9.设置代理不显示浏览器
我们可以通过添加浏览器选项来开启代理服务器并执行代码,而无需显示浏览器的操作过程。我们需要创建一个 ChromeOptions 对象,然后使用 add_argument() 方法添加选项,最后将 options 参数添加到 Chrome 对象中。例如,
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://175.42.123.88:9999";) # 添加代理服务器
options.add_argument("--headless") # 不打开浏览器
options.add_argument("--disable-gpu") # 禁用GPU
driver = webdriver.Chrome(options=options)
driver.get('http://httpbin.org/ip')
print(driver.page_source)
js 爬虫抓取网页数据(js爬虫抓取网页数据,你可以给他一个教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-09-29 12:04
js爬虫抓取网页数据
你可以给他一个教程让他自己摸索
教他吧,有些人自己都没有实践过就已经指望着别人来带他飞了,这样是不好的。抓取的话肯定可以获取他很多之前没有的。放心吧。
我劝你不要欺负小孩子智商比较高
行业常识告诉我们,所有的http数据请求,都需要先给对方发送一个url。通过这个url请求带来的某些数据,反过来可以推动你的爬虫程序的正确性。例如“从某网站爬取点击量”的数据。当然,这个url没有固定的格式,有些网站会支持很多链接,你可以通过浏览器对于“从某网站爬取点击量”的http请求进行一个改变,来完成爬取。
浏览器中的页面设置不要有单向跳转,有些url在此地方是没有返回,即使你设置了也不行。你可以跟他说爬虫只爬取url标签指向的一部分数据,是返回就返回,不是就不返回。
谢邀,这里有一份北京各大优采云站的站名地址,以及距离与时间的关系表格,
单靠带节奏是不可能学会爬虫的,简单可以多看书看代码。
给了你手机就是让你记住。
20140123更新:之前还有挺多爬虫开发学习资料,题主不妨查看一下。现在大家提到爬虫的开发,除了通过慕课网等这些爬虫网站,推荐题主还可以去国内的豆瓣相关豆列寻找:;d_u=8725178175;另外针对题主另一个问题,爬虫中的涉及权限、缓存数据等内容,都可以通过url编码技术或dns+http数据库或useragent,直接赋予应用应有的权限。
再举个栗子,你找一个图片或者页面,手机上点下拉,就会有数据下来,登录账号就可以接收这些数据;登录网站后,你再通过你的爬虫服务器,就可以从你的网站中爬取那些该爬取的内容了。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据,你可以给他一个教程)
js爬虫抓取网页数据
你可以给他一个教程让他自己摸索
教他吧,有些人自己都没有实践过就已经指望着别人来带他飞了,这样是不好的。抓取的话肯定可以获取他很多之前没有的。放心吧。
我劝你不要欺负小孩子智商比较高
行业常识告诉我们,所有的http数据请求,都需要先给对方发送一个url。通过这个url请求带来的某些数据,反过来可以推动你的爬虫程序的正确性。例如“从某网站爬取点击量”的数据。当然,这个url没有固定的格式,有些网站会支持很多链接,你可以通过浏览器对于“从某网站爬取点击量”的http请求进行一个改变,来完成爬取。
浏览器中的页面设置不要有单向跳转,有些url在此地方是没有返回,即使你设置了也不行。你可以跟他说爬虫只爬取url标签指向的一部分数据,是返回就返回,不是就不返回。
谢邀,这里有一份北京各大优采云站的站名地址,以及距离与时间的关系表格,
单靠带节奏是不可能学会爬虫的,简单可以多看书看代码。
给了你手机就是让你记住。
20140123更新:之前还有挺多爬虫开发学习资料,题主不妨查看一下。现在大家提到爬虫的开发,除了通过慕课网等这些爬虫网站,推荐题主还可以去国内的豆瓣相关豆列寻找:;d_u=8725178175;另外针对题主另一个问题,爬虫中的涉及权限、缓存数据等内容,都可以通过url编码技术或dns+http数据库或useragent,直接赋予应用应有的权限。
再举个栗子,你找一个图片或者页面,手机上点下拉,就会有数据下来,登录账号就可以接收这些数据;登录网站后,你再通过你的爬虫服务器,就可以从你的网站中爬取那些该爬取的内容了。
js 爬虫抓取网页数据(如何利用Webkit从JS渲染网页中获取数据处理的任何事情)
网站优化 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-28 17:30
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页中收录 JavaScript 代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想爬取Pycoders周刊中所有文件的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
进口请求
从 lxml 导入 html
# 存储响应
response = requests.get('#39;)
# 从响应体创建 lxml 树
树 = html.fromstring(response.text)
# 在响应中查找所有锚标记
print tree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
须藤 apt-get 安装 python-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
导入系统
从 PyQt4.QtGui 导入 *
从 PyQt4.Qtcore 导入 *
从 PyQt4.QtWebKit 导入 *
类渲染(QWebPage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载url中的所有信息并将其存储在一个新的框架中。
网址 ='#39;
# 这很神奇。加载一切
r = 渲染(网址)
# 结果是一个 QString。
结果 = r.frame.toHtml()
使用上面的代码,我们将 HTML 结果存储在变量 result 中。由于lxml不能直接处理特殊的字符串数据,我们需要对数据格式进行转换。
# QString 在被 lxml 处理之前应该转换为字符串
formatted_result = str(result.toAscii())
# 接下来从 formatted_result 构建 lxml 树
树 = html.fromstring(formatted_result)
# 现在使用正确的 Xpath 我们正在获取档案的 URL
archive_links = tree.xpath('//div[@class="campaign"]/a/@href')
打印存档链接
使用上面的代码,我们可以得到所有的文件链接信息,然后我们就可以使用这些Render和这些URL链接来提取文本内容信息了。Web kit提供了一个强大的网页渲染工具,我们可以利用这个工具从JS渲染的网页中抓取有效的信息。
在本文中,我介绍了一种从 JS 渲染的网页中抓取信息的有效方法。虽然这个工具很慢,但它非常简单和粗鲁。我希望你会喜欢这个文章。现在,您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。 查看全部
js 爬虫抓取网页数据(如何利用Webkit从JS渲染网页中获取数据处理的任何事情)
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页中收录 JavaScript 代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想爬取Pycoders周刊中所有文件的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
进口请求
从 lxml 导入 html
# 存储响应
response = requests.get('#39;)
# 从响应体创建 lxml 树
树 = html.fromstring(response.text)
# 在响应中查找所有锚标记
print tree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
须藤 apt-get 安装 python-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
导入系统
从 PyQt4.QtGui 导入 *
从 PyQt4.Qtcore 导入 *
从 PyQt4.QtWebKit 导入 *
类渲染(QWebPage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载url中的所有信息并将其存储在一个新的框架中。
网址 ='#39;
# 这很神奇。加载一切
r = 渲染(网址)
# 结果是一个 QString。
结果 = r.frame.toHtml()
使用上面的代码,我们将 HTML 结果存储在变量 result 中。由于lxml不能直接处理特殊的字符串数据,我们需要对数据格式进行转换。
# QString 在被 lxml 处理之前应该转换为字符串
formatted_result = str(result.toAscii())
# 接下来从 formatted_result 构建 lxml 树
树 = html.fromstring(formatted_result)
# 现在使用正确的 Xpath 我们正在获取档案的 URL
archive_links = tree.xpath('//div[@class="campaign"]/a/@href')
打印存档链接
使用上面的代码,我们可以得到所有的文件链接信息,然后我们就可以使用这些Render和这些URL链接来提取文本内容信息了。Web kit提供了一个强大的网页渲染工具,我们可以利用这个工具从JS渲染的网页中抓取有效的信息。
在本文中,我介绍了一种从 JS 渲染的网页中抓取信息的有效方法。虽然这个工具很慢,但它非常简单和粗鲁。我希望你会喜欢这个文章。现在,您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。
js 爬虫抓取网页数据(Python语言Python和爬虫的开发方向是怎样的呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-09-28 11:02
说到Python,有些同学自然会想到爬虫,但其实Python和爬虫不是概念的东西。下面就给大家介绍一下小倩。
爬虫
爬虫,又称网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区中常称为网络追逐者),是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
爬虫的主要工作是按照一定的规则在网络上爬取我们想要的数据的程序。这里大家要注意,爬虫不一定要用Python来实现。它可以使用 JavaScript、Java 和其他语言来实现。的。
Python语言
Python 由荷兰数学与计算机科学研究会的 Guido van Rossum 于 1990 年代初设计,作为 ABC 语言的替代品。Python 提供的数据结构也可以用于简单有效的面向对象编程。Python 语法和动态类型,以及解释型语言的性质,使其成为在大多数平台上编写脚本和快速应用程序开发的编程语言。随着不断的新版本和新语言特性的加入,逐渐被用于独立的、大规模的应用。项目发展。
Python 是一种计算机编程语言。之所以与爬虫有如此密切的关系,是因为Python的脚本特性、易于配置和灵活的字符处理。Python拥有丰富的网络捕捉模块和丰富的数据处理框架。这导致很多爬虫开发者使用Python作为爬虫程序开发语言。
爬虫可以作为Python语言的一个发展方向,但是爬虫可以用其他语言实现,所以以后不要把Python和爬虫混为一谈。
以上就是Python和爬虫的介绍。相信看完之后你会明白的。如果您对Python或网络爬虫感兴趣,不妨联系我们的在线咨询老师,这里有教程视频供您参考。 查看全部
js 爬虫抓取网页数据(Python语言Python和爬虫的开发方向是怎样的呢?)
说到Python,有些同学自然会想到爬虫,但其实Python和爬虫不是概念的东西。下面就给大家介绍一下小倩。
爬虫
爬虫,又称网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区中常称为网络追逐者),是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
爬虫的主要工作是按照一定的规则在网络上爬取我们想要的数据的程序。这里大家要注意,爬虫不一定要用Python来实现。它可以使用 JavaScript、Java 和其他语言来实现。的。
Python语言
Python 由荷兰数学与计算机科学研究会的 Guido van Rossum 于 1990 年代初设计,作为 ABC 语言的替代品。Python 提供的数据结构也可以用于简单有效的面向对象编程。Python 语法和动态类型,以及解释型语言的性质,使其成为在大多数平台上编写脚本和快速应用程序开发的编程语言。随着不断的新版本和新语言特性的加入,逐渐被用于独立的、大规模的应用。项目发展。
Python 是一种计算机编程语言。之所以与爬虫有如此密切的关系,是因为Python的脚本特性、易于配置和灵活的字符处理。Python拥有丰富的网络捕捉模块和丰富的数据处理框架。这导致很多爬虫开发者使用Python作为爬虫程序开发语言。
爬虫可以作为Python语言的一个发展方向,但是爬虫可以用其他语言实现,所以以后不要把Python和爬虫混为一谈。
以上就是Python和爬虫的介绍。相信看完之后你会明白的。如果您对Python或网络爬虫感兴趣,不妨联系我们的在线咨询老师,这里有教程视频供您参考。
js 爬虫抓取网页数据(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-28 09:26
什么是 AJAX:
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium 和 chromedriver: Install Selenium: Selenium 有很多语言版本,比如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面我们就拿百度首页做个简单的例子来说一下如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径 driver = webdriver.Chrome(executable_path=driver_path) # 请求网页 driver.get("https://www.baidu.com/") # 通过page_source获取网页源代码 print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择 selectTag.select_by_index(1) # 根据值选择 selectTag.select_by_value("http://www.95yueba.com") # 根据可视的文本选择 selectTag.select_by_visible_text("95秀客户端") # 取消选中所有选项 selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
cookie 操作: 获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC driver = webdriver.Firefox() driver.get("http://somedomain/url_that_delays_loading") try: element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "myDynamicElement")) ) finally: driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
转载于: 查看全部
js 爬虫抓取网页数据(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
什么是 AJAX:
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium 和 chromedriver: Install Selenium: Selenium 有很多语言版本,比如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面我们就拿百度首页做个简单的例子来说一下如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径 driver = webdriver.Chrome(executable_path=driver_path) # 请求网页 driver.get("https://www.baidu.com/";) # 通过page_source获取网页源代码 print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择 selectTag.select_by_index(1) # 根据值选择 selectTag.select_by_value("http://www.95yueba.com";) # 根据可视的文本选择 selectTag.select_by_visible_text("95秀客户端") # 取消选中所有选项 selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
cookie 操作: 获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC driver = webdriver.Firefox() driver.get("http://somedomain/url_that_delays_loading";) try: element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "myDynamicElement")) ) finally: driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
转载于:
js 爬虫抓取网页数据(Web漏洞扫描工具的安全运维人员造成的诸多困扰!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-26 23:02
在 Web 漏扫中,采集 输入源一般包括爬虫、流量、代理和日志。爬虫是获取扫描后的网站 URLs.采集模式最常见也是必不可少的方式。
网络漏洞扫描器爬虫比其他网络爬虫面临更高的技术挑战。这是因为漏洞扫描器爬虫不仅需要抓取网页内容和分析链接信息,还需要在网页上尽可能多地触发。事件,从而获得更有效的链接信息。
然而,现有爬虫受限于其固有的技术缺陷,给使用Web漏洞扫描工具的安全运维人员带来了诸多问题:
1、 容易触发WAF设置的IP访问限制
正常情况下,网站的防火墙会限制一定时间内可以请求固定IP的次数。如果没有超过上限,则正常返回数据,超过上限则拒绝请求。值得注意的是,IP 限制大部分时间是出于 网站 安全原因以防止 DOS 攻击,而不是专门针对爬虫。但是传统爬虫工作时,机器和IP都是有限的,很容易达到WAF设置的IP上限而导致请求被拒绝。
2、 无法自动处理网页交互问题
Web2.0时代,Web应用与用户交互非常频繁,对漏网的爬虫造成干扰。以输入验证码登录为例。网站 会生成一串随机生成的数字或符号的图片,在图片上添加一些干扰像素(防止OCR),用户可以直观的识别验证码信息并输入表单提交< @网站验证,验证成功后才能使用某个功能。当传统爬虫遇到这种情况时,通常很难自动处理。
3、 无法抓取 JavaScript 解析的网页
JavaScript 框架的诞生对于效率时代的研发工程师来说是一大福音,工程师们可以摆脱开发和维护的痛苦。毫无疑问,Angular、React、Vue 等单页应用的 Web 框架已经成为开发者的首选。JavaScript解析的网页越来越流行,所以网页中大部分有用的数据都是通过ajax/fetch动态获取然后通过js填充到网页的DOM树中的,有用的数据很少纯HTML静态页面,直接导致Web爬虫不完整抓取。
传统爬行动物和集中爬行动物
纵观市场上常用的漏洞扫描产品,通常使用的爬虫包括以下两大类,即传统爬虫和聚焦爬虫:
传统爬虫
其工作流程是从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足一系列系统设置。停止条件,爬行操作停止。
传统爬虫流程图侧重爬虫
聚焦爬虫的工作流程比传统爬虫复杂。需要根据一定的网页分析算法过滤与扫描目标无关的网址,保留有用的网址,放入网址队列等待抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;因此,一个完整的聚焦爬虫一般收录以下三个模块:Web请求模块、爬取过程控制模块、内容分析提取模块。
但是,无论是传统爬虫还是聚焦爬虫,由于其固有的技术缺陷,无法在URL采集@时自动处理网页交互、JavaScript解析,并容易触发外部WAF防御措施的限制>网站 等问题。
X-Ray创新技术提高爬虫发现率
X-Ray安全评估系统针对当前用户错过的爬虫,创造性地提出了基于语义分析、机器学习技术和DOM遍历算法的高仿真实时渲染的实时渲染DOM遍历算法采集 @> 目标 URL 问题。“新爬虫”:
1、 创新加入js语义分析算法,避免IP访问超限
对于传统的网站,长亭科技在专注于爬虫的基础上,创新使用js语义分析算法,针对WAF针对DOS攻击的IP访问限制防御措施,X-Ray爬虫会在本地对JS文件进行分析,并且在理解语义的基础上解析网站结构,不会疯狂触发请求,从而避免超出IP访问限制被拒绝访问的情况。
X-Ray专注爬虫流程原理图2、通过机器学习技术实现交互行为分析
对于单页应用网站,X-Ray 已经嵌入了一个模拟浏览器爬虫。通过使用机器学习技术,X-Ray 的模拟浏览器爬虫使用各种 Web 应用程序页面结构作为训练样本。在访问每个页面时,可以智能判断各种交互操作。判断逻辑大概是这样的:
判断是表单输入、点击事件等;
自动判断表单输入框应填写哪些内容,如用户名、密码、IP地址等,然后填写相应的内容样本;
点击事件自动触发,请求发起成功。3、 高仿真实时渲染DOM遍历算法完美解决JavaScript解析
针对JavaScript解析的单页Web应用,X-Ray模拟浏览器创新引入了高模拟实时渲染DOM遍历算法。在该算法引擎的驱动下,可以完美解析Angular、React、Vue等Web框架。实现的单页应用网站对Web页面中的所有内容进行操作,达到获取URL信息的目的目标网站。判断逻辑如下:
找到网页的DOM节点,形成DOM树;
内置浏览器,从深度和广度两个层次,对网页进行高仿真度的DOM树遍历;
真实浏览器画面,实时渲染DOM树的遍历过程
X-Ray在机器学习技术和DOM遍历算法的高仿真实时渲染驱动下,模拟浏览器爬虫的行为,智能模拟人类行为,自动进行点击、双击、拖拽等操作,从而避免了传统爬虫在获取到 URL 时,无法满足交互,无法处理 JavaScript 解析。
下面以访问DVWA为例,展示模拟浏览器的行为
dvwa浏览器点击
以网银、电子商务、云存储等Web应用为代表的Web3.0时代已经到来,X-Ray安全评估系统蓄势待发。你准备好了吗? 查看全部
js 爬虫抓取网页数据(Web漏洞扫描工具的安全运维人员造成的诸多困扰!)
在 Web 漏扫中,采集 输入源一般包括爬虫、流量、代理和日志。爬虫是获取扫描后的网站 URLs.采集模式最常见也是必不可少的方式。
网络漏洞扫描器爬虫比其他网络爬虫面临更高的技术挑战。这是因为漏洞扫描器爬虫不仅需要抓取网页内容和分析链接信息,还需要在网页上尽可能多地触发。事件,从而获得更有效的链接信息。
然而,现有爬虫受限于其固有的技术缺陷,给使用Web漏洞扫描工具的安全运维人员带来了诸多问题:
1、 容易触发WAF设置的IP访问限制
正常情况下,网站的防火墙会限制一定时间内可以请求固定IP的次数。如果没有超过上限,则正常返回数据,超过上限则拒绝请求。值得注意的是,IP 限制大部分时间是出于 网站 安全原因以防止 DOS 攻击,而不是专门针对爬虫。但是传统爬虫工作时,机器和IP都是有限的,很容易达到WAF设置的IP上限而导致请求被拒绝。
2、 无法自动处理网页交互问题
Web2.0时代,Web应用与用户交互非常频繁,对漏网的爬虫造成干扰。以输入验证码登录为例。网站 会生成一串随机生成的数字或符号的图片,在图片上添加一些干扰像素(防止OCR),用户可以直观的识别验证码信息并输入表单提交< @网站验证,验证成功后才能使用某个功能。当传统爬虫遇到这种情况时,通常很难自动处理。
3、 无法抓取 JavaScript 解析的网页
JavaScript 框架的诞生对于效率时代的研发工程师来说是一大福音,工程师们可以摆脱开发和维护的痛苦。毫无疑问,Angular、React、Vue 等单页应用的 Web 框架已经成为开发者的首选。JavaScript解析的网页越来越流行,所以网页中大部分有用的数据都是通过ajax/fetch动态获取然后通过js填充到网页的DOM树中的,有用的数据很少纯HTML静态页面,直接导致Web爬虫不完整抓取。
传统爬行动物和集中爬行动物
纵观市场上常用的漏洞扫描产品,通常使用的爬虫包括以下两大类,即传统爬虫和聚焦爬虫:
传统爬虫
其工作流程是从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足一系列系统设置。停止条件,爬行操作停止。
传统爬虫流程图侧重爬虫
聚焦爬虫的工作流程比传统爬虫复杂。需要根据一定的网页分析算法过滤与扫描目标无关的网址,保留有用的网址,放入网址队列等待抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;因此,一个完整的聚焦爬虫一般收录以下三个模块:Web请求模块、爬取过程控制模块、内容分析提取模块。
但是,无论是传统爬虫还是聚焦爬虫,由于其固有的技术缺陷,无法在URL采集@时自动处理网页交互、JavaScript解析,并容易触发外部WAF防御措施的限制>网站 等问题。
X-Ray创新技术提高爬虫发现率
X-Ray安全评估系统针对当前用户错过的爬虫,创造性地提出了基于语义分析、机器学习技术和DOM遍历算法的高仿真实时渲染的实时渲染DOM遍历算法采集 @> 目标 URL 问题。“新爬虫”:
1、 创新加入js语义分析算法,避免IP访问超限
对于传统的网站,长亭科技在专注于爬虫的基础上,创新使用js语义分析算法,针对WAF针对DOS攻击的IP访问限制防御措施,X-Ray爬虫会在本地对JS文件进行分析,并且在理解语义的基础上解析网站结构,不会疯狂触发请求,从而避免超出IP访问限制被拒绝访问的情况。
X-Ray专注爬虫流程原理图2、通过机器学习技术实现交互行为分析
对于单页应用网站,X-Ray 已经嵌入了一个模拟浏览器爬虫。通过使用机器学习技术,X-Ray 的模拟浏览器爬虫使用各种 Web 应用程序页面结构作为训练样本。在访问每个页面时,可以智能判断各种交互操作。判断逻辑大概是这样的:
判断是表单输入、点击事件等;
自动判断表单输入框应填写哪些内容,如用户名、密码、IP地址等,然后填写相应的内容样本;
点击事件自动触发,请求发起成功。3、 高仿真实时渲染DOM遍历算法完美解决JavaScript解析
针对JavaScript解析的单页Web应用,X-Ray模拟浏览器创新引入了高模拟实时渲染DOM遍历算法。在该算法引擎的驱动下,可以完美解析Angular、React、Vue等Web框架。实现的单页应用网站对Web页面中的所有内容进行操作,达到获取URL信息的目的目标网站。判断逻辑如下:
找到网页的DOM节点,形成DOM树;
内置浏览器,从深度和广度两个层次,对网页进行高仿真度的DOM树遍历;
真实浏览器画面,实时渲染DOM树的遍历过程
X-Ray在机器学习技术和DOM遍历算法的高仿真实时渲染驱动下,模拟浏览器爬虫的行为,智能模拟人类行为,自动进行点击、双击、拖拽等操作,从而避免了传统爬虫在获取到 URL 时,无法满足交互,无法处理 JavaScript 解析。
下面以访问DVWA为例,展示模拟浏览器的行为
dvwa浏览器点击
以网银、电子商务、云存储等Web应用为代表的Web3.0时代已经到来,X-Ray安全评估系统蓄势待发。你准备好了吗?
js 爬虫抓取网页数据(Python和js引擎运行的源代码都是js,几乎没有我想要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 339 次浏览 • 2021-09-25 22:00
想爬下北京邮报的论坛,但是看到页面的源代码都是js,几乎没有我想要的信息。回复内容:今天偶然发现了PyV8,感觉就是你想要的。
它直接搭建了一个js运行环境,也就是说你可以直接在python中执行页面上的js代码来获取你需要的内容。
参考:
/博客/?p=252
/p/pyv8/ 我直接看js源码,分析了一下,然后爬了。
比如你看页面使用ajax请求JSON文件,我会先爬取那个页面,获取ajax需要的参数,然后直接请求json页面,然后解码,然后处理数据存储它在数据库中。
如果直接运行页面上的所有js(就像浏览器一样),然后得到最终的HTML DOM树,这样的性能很糟糕,不推荐使用这种方式。因为Python和js本身的性能很差,如果这样做的话,会消耗大量的CPU资源,最终只能得到很低的爬取效率。js代码需要js引擎才能运行,Python只能通过HTTP请求获取原创的HTML、CSS、JS代码。
不知道有没有用Python写的JS引擎,估计需求量不大。
我一般使用 PhantomJS 和 CasperJS 等引擎进行浏览器抓取。
直接在其中编写JS代码进行DOM操作和分析,并将结果输出为文件。
让Python调用程序,通过读取文件获取内容。去年,我真的爬过这样的数据,因为我赶时间,而且我的方法更丑陋。
PyQt有专门的库来模拟浏览器的请求和行为(好像是webkit的,算了,查一下,几行代码就够了)。在一个运行的程序中,第一次(只有第一个 次的返回结果)是js运行后的代码。所以我写了一个py脚本来做访问分析,然后写了一个windows脚本,通过传递命令行参数来循环这个py脚本,最后得到数据。
方法有点脏,但是拿到数据还是不错的~对于某个网站,可以看网络请求,找到那些返回实际内容的,有针对性的发送。如果是通用的,则必须使用无头浏览器,例如PhantomJS。另一位爬上北京邮政论坛的人。.
文艺的方法,去浏览器引擎,比如PhantomJS,用它导出html,然后用python解析html。不要直接用PhantomJS解析它,虽然我知道它很容易,为什么?那么它就不叫python爬虫了。因为统一使用python进行解析比较统一,这里我们假设你还在爬非JS页面。
普通方法,分析AJAX请求。即使是JS渲染的,数据还是通过HTTP协议传输的。什么?不能模拟吗?读懂HTTP协议,其实还是有经验的。比如要请求北京邮政论坛的正文
X-Requested-With:XMLHttpRequest
这是一个栗子:
拉勾网职位列表
点击Android后,我们从浏览器上传了几个参数到拉勾服务器
一个是first = true,另一个是kd = android,(关键字),另一个是pn = 1(页码)
所以我们可以模仿这一步构造一个数据包来模拟用户的点击动作。
post_data = {'first':'true','kd':'Android','pn':'1'}
虽然这已经是很久以前的事了,但题目似乎已经解决了这个问题。但是看到很多答案的方法有点太重了,这里提供一个效率更高,消耗资源更少的方法。由于主题没有指定需要什么,这里的示例采用主页上所有帖子的链接和标题。
首先请记住浏览器环境对内存和CPU的消耗非常严重,尽量避免模拟浏览器环境的爬虫代码。请记住,对于一些前端渲染的网页,虽然我们需要的数据在HTML源代码中是看不到的,但更有可能是通过另一个请求(最有可能是JSON格式)得到纯数据。我们不仅不需要模拟浏览器,还可以节省解析HTML的消耗。
然后,我打开北京邮政论坛的首页,发现首页的HTML源代码并没有收录页面显示的文章的内容。那么,很有可能这是通过JS异步加载到页面的。通过浏览器开发工具(OS X下的Chrome浏览器通过command+option+i或Win/Linux下通过F12)分析加载主页时的请求,很容易在下面的截图中找到请求:
截图中选择的请求的响应是首页的文章链接。您可以在预览选项中看到渲染的预览:
至此,我们已经确定这个链接可以拿到首页的文章和链接。
在 headers 选项中,有这个请求的请求头和请求参数。我们可以通过 Python 模拟这个请求,得到同样的响应。配合BeautifulSoup等库解析HTML,就可以得到对应的内容。
关于如何模拟请求以及如何解析HTML,请移步我的专栏。有详细介绍,这里不再赘述。
这样就可以在不模拟浏览器环境的情况下抓取数据,大大提高了内存和CPU的消耗和爬行速度。编写爬虫时请记住,如果没有必要,不要模拟浏览器环境。如果是windows下,可以尝试调用windows系统中的webbrowser控件。另外,ie本身也提供了一个接口。但是这两种方法都要渲染页面,在性能上有些浪费。为了加快速度,可以关闭ie的图片下载显示,然后通过点击等方式模拟真实行为。谷歌幻影JS
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
js 爬虫抓取网页数据(Python和js引擎运行的源代码都是js,几乎没有我想要的)
想爬下北京邮报的论坛,但是看到页面的源代码都是js,几乎没有我想要的信息。回复内容:今天偶然发现了PyV8,感觉就是你想要的。
它直接搭建了一个js运行环境,也就是说你可以直接在python中执行页面上的js代码来获取你需要的内容。
参考:
/博客/?p=252
/p/pyv8/ 我直接看js源码,分析了一下,然后爬了。
比如你看页面使用ajax请求JSON文件,我会先爬取那个页面,获取ajax需要的参数,然后直接请求json页面,然后解码,然后处理数据存储它在数据库中。
如果直接运行页面上的所有js(就像浏览器一样),然后得到最终的HTML DOM树,这样的性能很糟糕,不推荐使用这种方式。因为Python和js本身的性能很差,如果这样做的话,会消耗大量的CPU资源,最终只能得到很低的爬取效率。js代码需要js引擎才能运行,Python只能通过HTTP请求获取原创的HTML、CSS、JS代码。
不知道有没有用Python写的JS引擎,估计需求量不大。
我一般使用 PhantomJS 和 CasperJS 等引擎进行浏览器抓取。
直接在其中编写JS代码进行DOM操作和分析,并将结果输出为文件。
让Python调用程序,通过读取文件获取内容。去年,我真的爬过这样的数据,因为我赶时间,而且我的方法更丑陋。
PyQt有专门的库来模拟浏览器的请求和行为(好像是webkit的,算了,查一下,几行代码就够了)。在一个运行的程序中,第一次(只有第一个 次的返回结果)是js运行后的代码。所以我写了一个py脚本来做访问分析,然后写了一个windows脚本,通过传递命令行参数来循环这个py脚本,最后得到数据。
方法有点脏,但是拿到数据还是不错的~对于某个网站,可以看网络请求,找到那些返回实际内容的,有针对性的发送。如果是通用的,则必须使用无头浏览器,例如PhantomJS。另一位爬上北京邮政论坛的人。.
文艺的方法,去浏览器引擎,比如PhantomJS,用它导出html,然后用python解析html。不要直接用PhantomJS解析它,虽然我知道它很容易,为什么?那么它就不叫python爬虫了。因为统一使用python进行解析比较统一,这里我们假设你还在爬非JS页面。
普通方法,分析AJAX请求。即使是JS渲染的,数据还是通过HTTP协议传输的。什么?不能模拟吗?读懂HTTP协议,其实还是有经验的。比如要请求北京邮政论坛的正文
X-Requested-With:XMLHttpRequest
这是一个栗子:
拉勾网职位列表
点击Android后,我们从浏览器上传了几个参数到拉勾服务器
一个是first = true,另一个是kd = android,(关键字),另一个是pn = 1(页码)
所以我们可以模仿这一步构造一个数据包来模拟用户的点击动作。
post_data = {'first':'true','kd':'Android','pn':'1'}
虽然这已经是很久以前的事了,但题目似乎已经解决了这个问题。但是看到很多答案的方法有点太重了,这里提供一个效率更高,消耗资源更少的方法。由于主题没有指定需要什么,这里的示例采用主页上所有帖子的链接和标题。
首先请记住浏览器环境对内存和CPU的消耗非常严重,尽量避免模拟浏览器环境的爬虫代码。请记住,对于一些前端渲染的网页,虽然我们需要的数据在HTML源代码中是看不到的,但更有可能是通过另一个请求(最有可能是JSON格式)得到纯数据。我们不仅不需要模拟浏览器,还可以节省解析HTML的消耗。
然后,我打开北京邮政论坛的首页,发现首页的HTML源代码并没有收录页面显示的文章的内容。那么,很有可能这是通过JS异步加载到页面的。通过浏览器开发工具(OS X下的Chrome浏览器通过command+option+i或Win/Linux下通过F12)分析加载主页时的请求,很容易在下面的截图中找到请求:
截图中选择的请求的响应是首页的文章链接。您可以在预览选项中看到渲染的预览:
至此,我们已经确定这个链接可以拿到首页的文章和链接。
在 headers 选项中,有这个请求的请求头和请求参数。我们可以通过 Python 模拟这个请求,得到同样的响应。配合BeautifulSoup等库解析HTML,就可以得到对应的内容。
关于如何模拟请求以及如何解析HTML,请移步我的专栏。有详细介绍,这里不再赘述。
这样就可以在不模拟浏览器环境的情况下抓取数据,大大提高了内存和CPU的消耗和爬行速度。编写爬虫时请记住,如果没有必要,不要模拟浏览器环境。如果是windows下,可以尝试调用windows系统中的webbrowser控件。另外,ie本身也提供了一个接口。但是这两种方法都要渲染页面,在性能上有些浪费。为了加快速度,可以关闭ie的图片下载显示,然后通过点击等方式模拟真实行为。谷歌幻影JS
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
js 爬虫抓取网页数据(F12打开网页调试工具:选择“网络”选项卡后,发现有很多响应)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-09-24 12:18
F12打开网页调试工具:
选择“网络”选项卡后,发现有很多响应,我们筛选一下,只看XHR响应。(XHR是Ajax中的概念,表示XMLHTTPrequest)然后我们发现少了很多链接,随便点开一个看看:我们选择city,预览中有一串json数据:
我们再点开看看:
原来全都是城市的列表,应该是加载地区新闻之用的。现在大概了解了怎么找JS请求的接口的吧?但是刚刚我们并没有发现想要的新闻,再找找看:有一个focus,我们点开看看:
与首页的图片新闻呈现的数据是一样的,那么数据应该就在这里面了。
看看其他的链接:
这应该是热搜关键词
这个就是图片新闻下面的新闻了。
我们打开一个接口链接看看:
返回一串乱码,但从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以仿照之前的方法对数据接口进行请求和获取响应了2、请求和解析数据接口数据
先上完整代码:#coding:utf-8
importrequests
importjson
url='#39;
wbdata=requests.get(url).text
data=json.loads(wbdata)
news=data['data']['pc_feed_focus']
forninnews:
title=n['title']
img_url=n['image_url']
url=n['media_url']
print(url,title,img_url)
返回出来的结果如下:
照例,稍微讲解一下代码:
代码分为四部分,
第一部分:引入相关的库#coding:utf-8
importrequests
importjson
第二部分:对数据接口进行http请求url='
wbdata=requests.get(url).text 查看全部
js 爬虫抓取网页数据(F12打开网页调试工具:选择“网络”选项卡后,发现有很多响应)
F12打开网页调试工具:
选择“网络”选项卡后,发现有很多响应,我们筛选一下,只看XHR响应。(XHR是Ajax中的概念,表示XMLHTTPrequest)然后我们发现少了很多链接,随便点开一个看看:我们选择city,预览中有一串json数据:
我们再点开看看:
原来全都是城市的列表,应该是加载地区新闻之用的。现在大概了解了怎么找JS请求的接口的吧?但是刚刚我们并没有发现想要的新闻,再找找看:有一个focus,我们点开看看:
与首页的图片新闻呈现的数据是一样的,那么数据应该就在这里面了。
看看其他的链接:
这应该是热搜关键词
这个就是图片新闻下面的新闻了。
我们打开一个接口链接看看:
返回一串乱码,但从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以仿照之前的方法对数据接口进行请求和获取响应了2、请求和解析数据接口数据
先上完整代码:#coding:utf-8
importrequests
importjson
url='#39;
wbdata=requests.get(url).text
data=json.loads(wbdata)
news=data['data']['pc_feed_focus']
forninnews:
title=n['title']
img_url=n['image_url']
url=n['media_url']
print(url,title,img_url)
返回出来的结果如下:
照例,稍微讲解一下代码:
代码分为四部分,
第一部分:引入相关的库#coding:utf-8
importrequests
importjson
第二部分:对数据接口进行http请求url='
wbdata=requests.get(url).text
js 爬虫抓取网页数据(NEOCrawler、redis、phantomjs实现的爬虫系统的各个子系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-23 15:57
neocrawler(中文名:牛),是nodejs,redis,phantomjs实现的爬行动物系统。代码是完全开源的,适用于垂直字段中的数据采集和爬行动物。
[主要功能]
可配置项目:
1)。使用正则表达式描述,使用相同的规则将类似的网页分类为类。爬行动物系统(以下是指某种类型的URL可配置项目);
2)。起始地址,爬网方法,存储位置,页面处理等。
3)。需要采集的链路规则,使用CSS选择器定义爬行动物,只能采集页面中的位置中的链接;
3)。页面选择规则,您可以使用CSS选择器,正则表达式来定位每个字段的位置以提取;
4)。在打开页面后打开执行的JS语句的预测;
5)。页面预设饼干;
6)。评估此类网页返回正常规则,通常指定某些网页返回普通页面关键词让爬行动物检测;
7)。评估数据提取是一个完整的规则,在提取物中选择一些非常必要的字段作为完整的评估标准;
8)。此类网页(优先级)的调度权重(优先级),并在试剂后重新捕获更新。
[架构]
提示:_推荐用户跳跃架构文档直接进入第2部分,首先运行系统,存在对架构的归纳理解,如果您需要进行深入开发,请仔细阅读此链接_
整体架构
图中的黄色部分是爬行动物系统的各个子系统。 查看全部
js 爬虫抓取网页数据(NEOCrawler、redis、phantomjs实现的爬虫系统的各个子系统)
neocrawler(中文名:牛),是nodejs,redis,phantomjs实现的爬行动物系统。代码是完全开源的,适用于垂直字段中的数据采集和爬行动物。
[主要功能]
可配置项目:
1)。使用正则表达式描述,使用相同的规则将类似的网页分类为类。爬行动物系统(以下是指某种类型的URL可配置项目);
2)。起始地址,爬网方法,存储位置,页面处理等。
3)。需要采集的链路规则,使用CSS选择器定义爬行动物,只能采集页面中的位置中的链接;
3)。页面选择规则,您可以使用CSS选择器,正则表达式来定位每个字段的位置以提取;
4)。在打开页面后打开执行的JS语句的预测;
5)。页面预设饼干;
6)。评估此类网页返回正常规则,通常指定某些网页返回普通页面关键词让爬行动物检测;
7)。评估数据提取是一个完整的规则,在提取物中选择一些非常必要的字段作为完整的评估标准;
8)。此类网页(优先级)的调度权重(优先级),并在试剂后重新捕获更新。
[架构]
提示:_推荐用户跳跃架构文档直接进入第2部分,首先运行系统,存在对架构的归纳理解,如果您需要进行深入开发,请仔细阅读此链接_
整体架构
图中的黄色部分是爬行动物系统的各个子系统。
js 爬虫抓取网页数据(NEOCrawler、redis、phantomjs实现的爬虫系统的各个子系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-09-23 15:54
neocrawler(中文名:牛),是nodejs,redis,phantomjs实现的爬行动物系统。代码是完全开源的,适用于垂直字段中的数据采集和爬行动物。
[主要功能]
可配置项目:
1)。使用正则表达式描述,使用相同的规则将类似的网页分类为类。爬行动物系统(以下是指某种类型的URL可配置项目);
2)。起始地址,爬网方法,存储位置,页面处理等。
3)。需要采集的链路规则,使用CSS选择器定义爬行动物,只能采集页面中的位置中的链接;
3)。页面选择规则,您可以使用CSS选择器,正则表达式来定位每个字段的位置以提取;
4)。在打开页面后打开执行的JS语句的预测;
5)。页面预设饼干;
。
6)判断类网页是否返回正常规则通常在关键词 let爬行动物检测的不可避免存在后指定返回到正常的网页;
7)。评估数据提取是一个完整的规则,在提取物中选择一些非常必要的字段作为完整的评估标准;
8)。此类网页(优先级)的调度权重(优先级),并在试剂后重新捕获更新。
[架构]
提示:_推荐用户跳跃架构文档直接进入第2部分,首先运行系统,存在对架构的归纳理解,如果您需要进行深入开发,请仔细阅读此链接_
整体架构
图中的黄色部分是爬行动物系统的各个子系统。 查看全部
js 爬虫抓取网页数据(NEOCrawler、redis、phantomjs实现的爬虫系统的各个子系统)
neocrawler(中文名:牛),是nodejs,redis,phantomjs实现的爬行动物系统。代码是完全开源的,适用于垂直字段中的数据采集和爬行动物。
[主要功能]
可配置项目:
1)。使用正则表达式描述,使用相同的规则将类似的网页分类为类。爬行动物系统(以下是指某种类型的URL可配置项目);
2)。起始地址,爬网方法,存储位置,页面处理等。
3)。需要采集的链路规则,使用CSS选择器定义爬行动物,只能采集页面中的位置中的链接;
3)。页面选择规则,您可以使用CSS选择器,正则表达式来定位每个字段的位置以提取;
4)。在打开页面后打开执行的JS语句的预测;
5)。页面预设饼干;
。
6)判断类网页是否返回正常规则通常在关键词 let爬行动物检测的不可避免存在后指定返回到正常的网页;
7)。评估数据提取是一个完整的规则,在提取物中选择一些非常必要的字段作为完整的评估标准;
8)。此类网页(优先级)的调度权重(优先级),并在试剂后重新捕获更新。
[架构]
提示:_推荐用户跳跃架构文档直接进入第2部分,首先运行系统,存在对架构的归纳理解,如果您需要进行深入开发,请仔细阅读此链接_
整体架构
图中的黄色部分是爬行动物系统的各个子系统。
js 爬虫抓取网页数据(数据分析网页数据获取的重要步骤是什么?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-13 11:05
数据分析的重要步骤:
1.数据采集
可以手动采集一些重要数据
每个数据库都可以导出数据
使用 Python 的爬虫等技术
2.数据组织
从数据库和文件中提取数据生成DataFrame对象
使用pandas库读取文件
3.数据处理
数据准备:
组装和合并 DataFrame 对象(多个)等
熊猫操作
数据转换:
类型转换、分类(人脸元素等)、异常检测、过滤等
pandas 库的运行
数据聚合:
分组(分类)、函数处理、合并成新对象
pandas 库的运行
4.数据可视化
将pandas数据结构转换成图表形式
matplotlib 库
5.预测模型创建与评估
各种数据挖掘算法:
关联规则挖掘、回归分析、聚类、分类、时间序列挖掘、序列模式挖掘等
6.Deployment(得到的结果)
从模型和评估中获取知识
知识的表示:规则、决策树、知识库、网络权重
原创网址:
抓取网页数据的步骤:
简介:
(1)网络爬虫(又名网络蜘蛛、网络机器人,在FOAF社区,更常称为网络追逐者):
是一种程序或脚本,它根据某些规则自动捕获万维网上的信息。其他不常用的名称是蚂蚁、自动索引、模拟器或蠕虫。其实现在流行的是通过程序在网页上获取你想要的数据,即自动抓取数据。
(2)爬虫能做什么?
可以使用爬虫来爬取图片、爬取视频等,想要爬取的数据,只要能通过浏览器访问数据,就可以通过爬虫获取。当你在浏览器中输入地址时,通过DNS服务器找到服务器主机,并向服务器发送请求。服务端解析后,将结果发送到用户浏览器,包括html、js、css等文件内容,浏览器解析出来,最后呈现给用户在浏览器上看到的结果
所以用户看到的浏览器的结果是由HTML代码组成的。我们的爬虫就是获取这些内容,通过对html代码的分析过滤,从中获取我们想要的资源。
获取页面
1.根据网址获取网页
import urllib.request as req
# 根据URL获取网页:
#http://www.hbnu.edu.cn/湖北师范大学
url = \'http://www.hbnu.edu.cn/\'
webpage = req.urlopen(url) # 按照类文件的方式打开网页
# 读取网页的所有数据,并转换为uft-8编码
data = webpage.read().decode(\'utf-8\')
print(data)
2.保存网页数据到文件
#将网页爬取内容写入文件
import urllib.request
url = "http://www.hbnu.edu.cn/"
responces = urllib.request.urlopen(url)
html = responces.read()
html = html.decode(\'utf-8\')
fileOb = open(\'C://Users//ALICE//Documents//a.txt\',\'w\',encoding=\'utf-8\')
fileOb.write(html)
fileOb.close()
此时,我们从网页中获取的数据已经保存在我们指定的文件中,如下图所示:
网页访问
从图中可以看出,网页的所有数据都存储在本地,但我们需要的大部分数据是文本或数字信息,代码对我们没有用处。那么接下来我们要做的就是清除无用的数据。
后期需要进行数据清理,请听下次分解。 查看全部
js 爬虫抓取网页数据(数据分析网页数据获取的重要步骤是什么?-八维教育)
数据分析的重要步骤:
1.数据采集
可以手动采集一些重要数据
每个数据库都可以导出数据
使用 Python 的爬虫等技术
2.数据组织
从数据库和文件中提取数据生成DataFrame对象
使用pandas库读取文件
3.数据处理
数据准备:
组装和合并 DataFrame 对象(多个)等
熊猫操作
数据转换:
类型转换、分类(人脸元素等)、异常检测、过滤等
pandas 库的运行
数据聚合:
分组(分类)、函数处理、合并成新对象
pandas 库的运行
4.数据可视化
将pandas数据结构转换成图表形式
matplotlib 库
5.预测模型创建与评估
各种数据挖掘算法:
关联规则挖掘、回归分析、聚类、分类、时间序列挖掘、序列模式挖掘等
6.Deployment(得到的结果)
从模型和评估中获取知识
知识的表示:规则、决策树、知识库、网络权重
原创网址:
抓取网页数据的步骤:
简介:
(1)网络爬虫(又名网络蜘蛛、网络机器人,在FOAF社区,更常称为网络追逐者):
是一种程序或脚本,它根据某些规则自动捕获万维网上的信息。其他不常用的名称是蚂蚁、自动索引、模拟器或蠕虫。其实现在流行的是通过程序在网页上获取你想要的数据,即自动抓取数据。
(2)爬虫能做什么?
可以使用爬虫来爬取图片、爬取视频等,想要爬取的数据,只要能通过浏览器访问数据,就可以通过爬虫获取。当你在浏览器中输入地址时,通过DNS服务器找到服务器主机,并向服务器发送请求。服务端解析后,将结果发送到用户浏览器,包括html、js、css等文件内容,浏览器解析出来,最后呈现给用户在浏览器上看到的结果
所以用户看到的浏览器的结果是由HTML代码组成的。我们的爬虫就是获取这些内容,通过对html代码的分析过滤,从中获取我们想要的资源。
获取页面
1.根据网址获取网页
import urllib.request as req
# 根据URL获取网页:
#http://www.hbnu.edu.cn/湖北师范大学
url = \'http://www.hbnu.edu.cn/\'
webpage = req.urlopen(url) # 按照类文件的方式打开网页
# 读取网页的所有数据,并转换为uft-8编码
data = webpage.read().decode(\'utf-8\')
print(data)
2.保存网页数据到文件
#将网页爬取内容写入文件
import urllib.request
url = "http://www.hbnu.edu.cn/"
responces = urllib.request.urlopen(url)
html = responces.read()
html = html.decode(\'utf-8\')
fileOb = open(\'C://Users//ALICE//Documents//a.txt\',\'w\',encoding=\'utf-8\')
fileOb.write(html)
fileOb.close()
此时,我们从网页中获取的数据已经保存在我们指定的文件中,如下图所示:
网页访问
从图中可以看出,网页的所有数据都存储在本地,但我们需要的大部分数据是文本或数字信息,代码对我们没有用处。那么接下来我们要做的就是清除无用的数据。
后期需要进行数据清理,请听下次分解。
js 爬虫抓取网页数据(如何用ExcelVBA构建数据查询界面(二)的基本步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-09-11 05:12
作为python爬虫的第一篇,先说说python的使用背景,以及如何使用python爬虫爬取简单的静态网页和动态网页。本文的前提是大家已经熟悉了python的基本语法和ide默认的构建。至少你可以使用helloword。
print("Hello World!")
在上一篇文章中,我们讲了使用excel VBA制作数据查询界面,进行数据统计计算。有兴趣的同学可以点击下方链接自行查看。
如何使用Excel VBA搭建数据查询界面(一)
如何使用Excel VBA搭建数据查询界面(二)
但是excel本身也有它的局限性。首先,在数据存储方面,excel 2013最多可以存储16,384列和1,048,576行数据。这个数据量对于数据挖掘或机器学习来说太小了。因此,有必要使用爬虫从互联网上抓取数据并存储到数据库中,以方便更深入的数据分析和挖掘。
作者使用python3.5进行爬虫学习。简单说一下python的情况。第一,简洁,几行代码就可以实现很多其他语言可以实现的东西;其次,执行效率比C和C++慢很多,不利于高效率的要求。数据分析;现在spark上也有相应的界面,大家可以相应了解一下。当然,如果你真的想摆脱这个问题,还是建议学习scala,它和java类似,应用范围更广。 Python可以帮助你更快的熟悉各种算法,学习成本不高。
接下来简单说一下python爬虫的基本原理。
首先,爬虫其实可以看成是机器人。它抓取数据。其实更多的是模拟人的操作。它仅适用于网页。我们看到的是html在CSS样式的帮助下出现的样子,但是爬虫面对的是带有各种标签的html。
接下来说说编写爬虫的基本步骤:首先观察我们的目标网站,了解需要的数据,在html标签的位置;其次,想想html标签只有在动态网页下才有,静态爬取还是可以的;粗略的方法是检查网页的源文件是否收录标签的数据。一般来说,动态网页比较多。
最后说两个例子,简单说一下静态网页和动态网页的抓取。
一、静态网页抓取
首先,因为要爬取的数据在静态网页的源码上,所以可以简单的利用python的urllib的请求和bs4库的BeautifulSoup爬取如下。废话不多说,给你看代码。
# import the library you want
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
# analyse the html
html = urlopen("http://www.pythonscraping.com/ ... 6quot;)
bs0bj = BeautifulSoup(html, "html.parser")
# find the rules of the data you want
images = bs0bj.findAll("img",{"src":re.compile("\.\.\/img\/gifts/img.*\.jpg")})
# print all you want
for image in images:
print(image["src"])
(可以看笔记)
我抓取的是一个非常简单的静态网站/pages/page3.html。查看网站元素时,可以使用浏览器自带的小工具,比如firefox查看元素。
首先通过请求抓取html页面所有元素的数据,然后根据标签的规则过滤掉对应的值,标签中收录的文本,或者属性,比如这个例子。最后写入数据库,或者打印出来。
二、动态网页抓取
对于动态网页,这里有一个简单的原则。大部分动态部分都会放在html中的js代码中。这个时候就需要用到它了,它是一个内置的浏览器webdriver。所谓内置浏览器,你可以简单的理解为一个隐形浏览器。当然也有带firefox插件的浏览器,不过上面提到的内置浏览器会比较常用。
这个例子是关于抓取两个 URL 的数据并将它们写入一个 csv 文件。
import urllib
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import csv
csvFile = open("F:/workspace/haha.csv",'w+')
writer = csv.writer(csvFile)
# Animation
writer.writerow(('bilibili',' ',' ',' ',' ',' '))
writer.writerow(('paimin','minchen','bofangshu','danmushu','zonghezhishu'))
driverThree = webdriver.PhantomJS()
driverThree.get("http://www.bilibili.com/rankin ... 6quot;)
time.sleep(5)
pageSourceThree = driverThree.page_source
bs0bjThree = BeautifulSoup(pageSourceThree,"html.parser")
j = bs0bjThree.findAll("div",{"class":"title"})
k = bs0bjThree.findAll("div",{"class":"pts"})
l = bs0bjThree.findAll("span",{"class":"data-box play"})
m = bs0bjThree.findAll("span",{"class":"data-box dm"})
for b in range(10):
titleThree = j[b].get_text()
IndexThre = k[b].get_text()
num = len(IndexThre)
IndexThree = IndexThre[0:num-4]
bofangliang = l[b].get_text()
danmuliang = m[b].get_text()
writer.writerow((b+1,titleThree,bofangliang,danmuliang,IndexThree))
driverThree.close()
# Comic
writer.writerow(('tecentac',' ',' ',' '))
writer.writerow(('paimin','minchen','piaoshu'))
driverFour = webdriver.PhantomJS()
driverFour.get("http://ac.qq.com/Rank/")
time.sleep(5)
pageSourceFour = driverFour.page_source
bs0bjFour = BeautifulSoup(pageSourceFour,"html.parser")
n = bs0bjFour.findAll("a",{"class":"mod-rank-name ui-left"})
o = bs0bjFour.findAll("span",{"class":"mod-rank-num ui-right"})
for c in range(10):
titleFour = n[c].get_text()
piaoshu = o[c].get_text()
writer.writerow((c+1,titleFour,piaoshu))
driverFour.close()
第一步就是通过上面提到的内置浏览器解析出页面的js代码,然后抓取它的动态部分
第二步和之前一样。理解了标签的规律后,它会循环获取,然后写入数据库。
先打开路径对应的csv文件,路径需要自己设置,然后爬取数据,最后写入csv文件。打开csv文件,可以看到数据。当然,以后也可以读取csv文件,但是写入数据库的方法后面会讲到。这个应用场景会更多。
运行结果如下:
好了,今天就到这里。静态爬虫和动态爬虫取决于是否使用内置浏览器来解析页面的js代码,其余原理相同。
最后公布下一次要讨论的内容。 python 爬虫爬取整个表单的数据。简单的说就是爬取需要登录操作获取数据的网页,比如微博、博客等。 查看全部
js 爬虫抓取网页数据(如何用ExcelVBA构建数据查询界面(二)的基本步骤)
作为python爬虫的第一篇,先说说python的使用背景,以及如何使用python爬虫爬取简单的静态网页和动态网页。本文的前提是大家已经熟悉了python的基本语法和ide默认的构建。至少你可以使用helloword。
print("Hello World!")
在上一篇文章中,我们讲了使用excel VBA制作数据查询界面,进行数据统计计算。有兴趣的同学可以点击下方链接自行查看。
如何使用Excel VBA搭建数据查询界面(一)
如何使用Excel VBA搭建数据查询界面(二)
但是excel本身也有它的局限性。首先,在数据存储方面,excel 2013最多可以存储16,384列和1,048,576行数据。这个数据量对于数据挖掘或机器学习来说太小了。因此,有必要使用爬虫从互联网上抓取数据并存储到数据库中,以方便更深入的数据分析和挖掘。
作者使用python3.5进行爬虫学习。简单说一下python的情况。第一,简洁,几行代码就可以实现很多其他语言可以实现的东西;其次,执行效率比C和C++慢很多,不利于高效率的要求。数据分析;现在spark上也有相应的界面,大家可以相应了解一下。当然,如果你真的想摆脱这个问题,还是建议学习scala,它和java类似,应用范围更广。 Python可以帮助你更快的熟悉各种算法,学习成本不高。
接下来简单说一下python爬虫的基本原理。
首先,爬虫其实可以看成是机器人。它抓取数据。其实更多的是模拟人的操作。它仅适用于网页。我们看到的是html在CSS样式的帮助下出现的样子,但是爬虫面对的是带有各种标签的html。
接下来说说编写爬虫的基本步骤:首先观察我们的目标网站,了解需要的数据,在html标签的位置;其次,想想html标签只有在动态网页下才有,静态爬取还是可以的;粗略的方法是检查网页的源文件是否收录标签的数据。一般来说,动态网页比较多。
最后说两个例子,简单说一下静态网页和动态网页的抓取。
一、静态网页抓取
首先,因为要爬取的数据在静态网页的源码上,所以可以简单的利用python的urllib的请求和bs4库的BeautifulSoup爬取如下。废话不多说,给你看代码。
# import the library you want
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
# analyse the html
html = urlopen("http://www.pythonscraping.com/ ... 6quot;)
bs0bj = BeautifulSoup(html, "html.parser")
# find the rules of the data you want
images = bs0bj.findAll("img",{"src":re.compile("\.\.\/img\/gifts/img.*\.jpg")})
# print all you want
for image in images:
print(image["src"])
(可以看笔记)
我抓取的是一个非常简单的静态网站/pages/page3.html。查看网站元素时,可以使用浏览器自带的小工具,比如firefox查看元素。
首先通过请求抓取html页面所有元素的数据,然后根据标签的规则过滤掉对应的值,标签中收录的文本,或者属性,比如这个例子。最后写入数据库,或者打印出来。
二、动态网页抓取
对于动态网页,这里有一个简单的原则。大部分动态部分都会放在html中的js代码中。这个时候就需要用到它了,它是一个内置的浏览器webdriver。所谓内置浏览器,你可以简单的理解为一个隐形浏览器。当然也有带firefox插件的浏览器,不过上面提到的内置浏览器会比较常用。
这个例子是关于抓取两个 URL 的数据并将它们写入一个 csv 文件。
import urllib
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import csv
csvFile = open("F:/workspace/haha.csv",'w+')
writer = csv.writer(csvFile)
# Animation
writer.writerow(('bilibili',' ',' ',' ',' ',' '))
writer.writerow(('paimin','minchen','bofangshu','danmushu','zonghezhishu'))
driverThree = webdriver.PhantomJS()
driverThree.get("http://www.bilibili.com/rankin ... 6quot;)
time.sleep(5)
pageSourceThree = driverThree.page_source
bs0bjThree = BeautifulSoup(pageSourceThree,"html.parser")
j = bs0bjThree.findAll("div",{"class":"title"})
k = bs0bjThree.findAll("div",{"class":"pts"})
l = bs0bjThree.findAll("span",{"class":"data-box play"})
m = bs0bjThree.findAll("span",{"class":"data-box dm"})
for b in range(10):
titleThree = j[b].get_text()
IndexThre = k[b].get_text()
num = len(IndexThre)
IndexThree = IndexThre[0:num-4]
bofangliang = l[b].get_text()
danmuliang = m[b].get_text()
writer.writerow((b+1,titleThree,bofangliang,danmuliang,IndexThree))
driverThree.close()
# Comic
writer.writerow(('tecentac',' ',' ',' '))
writer.writerow(('paimin','minchen','piaoshu'))
driverFour = webdriver.PhantomJS()
driverFour.get("http://ac.qq.com/Rank/";)
time.sleep(5)
pageSourceFour = driverFour.page_source
bs0bjFour = BeautifulSoup(pageSourceFour,"html.parser")
n = bs0bjFour.findAll("a",{"class":"mod-rank-name ui-left"})
o = bs0bjFour.findAll("span",{"class":"mod-rank-num ui-right"})
for c in range(10):
titleFour = n[c].get_text()
piaoshu = o[c].get_text()
writer.writerow((c+1,titleFour,piaoshu))
driverFour.close()
第一步就是通过上面提到的内置浏览器解析出页面的js代码,然后抓取它的动态部分
第二步和之前一样。理解了标签的规律后,它会循环获取,然后写入数据库。
先打开路径对应的csv文件,路径需要自己设置,然后爬取数据,最后写入csv文件。打开csv文件,可以看到数据。当然,以后也可以读取csv文件,但是写入数据库的方法后面会讲到。这个应用场景会更多。
运行结果如下:
好了,今天就到这里。静态爬虫和动态爬虫取决于是否使用内置浏览器来解析页面的js代码,其余原理相同。
最后公布下一次要讨论的内容。 python 爬虫爬取整个表单的数据。简单的说就是爬取需要登录操作获取数据的网页,比如微博、博客等。

