
js 爬虫抓取网页数据
js 爬虫抓取网页数据(js爬虫抓取网页数据多页的优势在于利用html4数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-21 14:05
js爬虫抓取网页数据,网页总共500页,有限,各类数据也有区别,网页也是分为多个区域的,比如上面例子中,就会出现iframe/html等不同区域,就像我们知道的,大部分用户首页不会访问到相关信息,只能通过浏览器其它页面来爬取了,这就相当于爬虫强制访问之前的单页,单页数据量就非常有限,所以能利用iframe数据进行多页抓取已经足够了,多页的优势在于利用html4.0新标签新内容来爬取的容易性。
不会存在浪费html标签和内容方面的问题,单页爬取更方便用于增加单页站内容,如页数众多的站,每个页数多达数千个,但是由于蜘蛛爬取主要是爬取每个页面的内容,各个页面的内容往往会存在冗余,除了对每个页面来爬取和判断,也可以遍历数千页面的所有页面来进行处理。iframe其实应该是一个模拟页面的一个frame,但是iframe在目前有不少问题。
数据处理方面问题较多。首先是内容表现,iframe没有规范,一般浏览器都会有iframe的样式参数,单个iframe只支持内嵌400kb+的内容,而且样式时好时坏,复杂内容表现不好,复杂html因为宽度限制,iframe嵌套之后,页面就会变得非常大,很多做爬虫的编程人员,会发现浏览器每次都会分段处理iframe,导致表现非常差,已经支持512k字节就满足不了爬虫。
其次是存储,很多爬虫都是数据读写一起处理的,往往一次写入一个页面的内容到内存中,造成一个页面内容占用很多内存,影响性能。实现爬虫,就是基于页面和页面内容的设计思想,写什么页面页面,关键点就是response对象,浏览器获取页面就可以利用response对象进行爬取。就爬虫处理方面,现在很多人采用对象+数据库来存储数据,往往对象比较特殊,数据非结构化,比如很多行业名称都会用网页的class,如qa-a-blablabla,爬虫处理起来比较麻烦,很多情况不得不写完整html页面内容才能抓取。
有人说,我们用db存储,不就是把abc变成abc-pbc==p,和爬虫的json字符串爬取操作一致了么,不是很轻松么。当然,还是有很多人解决了这个问题,大家可以了解下这个抓取知识框架:代码和数据访问方式直接跟着那个response.json进行链接参数转换处理,要是不懂请自行阅读以下入门教程。我曾经采用python处理iframe和db2,感觉有点复杂,有没有简单的爬虫呢,我个人觉得,是有的,相信很多人都能实现,拿我的代码来举例子:frombs4importbeautifulsoupimportrequestsimportreimporttimeimportthreadingimportpandasaspdfromipython.displayimportimageimportjsonimporttimeimport。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据多页的优势在于利用html4数据)
js爬虫抓取网页数据,网页总共500页,有限,各类数据也有区别,网页也是分为多个区域的,比如上面例子中,就会出现iframe/html等不同区域,就像我们知道的,大部分用户首页不会访问到相关信息,只能通过浏览器其它页面来爬取了,这就相当于爬虫强制访问之前的单页,单页数据量就非常有限,所以能利用iframe数据进行多页抓取已经足够了,多页的优势在于利用html4.0新标签新内容来爬取的容易性。
不会存在浪费html标签和内容方面的问题,单页爬取更方便用于增加单页站内容,如页数众多的站,每个页数多达数千个,但是由于蜘蛛爬取主要是爬取每个页面的内容,各个页面的内容往往会存在冗余,除了对每个页面来爬取和判断,也可以遍历数千页面的所有页面来进行处理。iframe其实应该是一个模拟页面的一个frame,但是iframe在目前有不少问题。
数据处理方面问题较多。首先是内容表现,iframe没有规范,一般浏览器都会有iframe的样式参数,单个iframe只支持内嵌400kb+的内容,而且样式时好时坏,复杂内容表现不好,复杂html因为宽度限制,iframe嵌套之后,页面就会变得非常大,很多做爬虫的编程人员,会发现浏览器每次都会分段处理iframe,导致表现非常差,已经支持512k字节就满足不了爬虫。
其次是存储,很多爬虫都是数据读写一起处理的,往往一次写入一个页面的内容到内存中,造成一个页面内容占用很多内存,影响性能。实现爬虫,就是基于页面和页面内容的设计思想,写什么页面页面,关键点就是response对象,浏览器获取页面就可以利用response对象进行爬取。就爬虫处理方面,现在很多人采用对象+数据库来存储数据,往往对象比较特殊,数据非结构化,比如很多行业名称都会用网页的class,如qa-a-blablabla,爬虫处理起来比较麻烦,很多情况不得不写完整html页面内容才能抓取。
有人说,我们用db存储,不就是把abc变成abc-pbc==p,和爬虫的json字符串爬取操作一致了么,不是很轻松么。当然,还是有很多人解决了这个问题,大家可以了解下这个抓取知识框架:代码和数据访问方式直接跟着那个response.json进行链接参数转换处理,要是不懂请自行阅读以下入门教程。我曾经采用python处理iframe和db2,感觉有点复杂,有没有简单的爬虫呢,我个人觉得,是有的,相信很多人都能实现,拿我的代码来举例子:frombs4importbeautifulsoupimportrequestsimportreimporttimeimportthreadingimportpandasaspdfromipython.displayimportimageimportjsonimporttimeimport。
js 爬虫抓取网页数据(这是JS、CSS、JSON文件,robots屏蔽依然抓取的情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-21 07:01
这是一个存在多年、经常出现但一直没有标准解决方案的问题:搜索引擎爬虫(尤其是百度)爬取JS、CSS、JSON文件,robots块依然爬取。
这导致了几个问题:
1、爬虫抓取JS、CSS是干什么的?
2、爬虫能否执行JS?
3、爬虫抓取JS对SEO有什么影响?
针对以上问题,我谈谈我的看法:
第一个是爬虫抓取CSS来判断页面元素的重要性,保证快照展示的完整性;抓取JS寻找新链接,判断是否有作弊
其次,JS会被执行,但不确定是否所有的JS都会被执行。就像网上很多人说的,“搜索引擎会直接忽略JS、iframe等,只抓取纯文本信息”。这从实际情况来看是站不住脚的。如果搜索引擎不是JS和iframes的鸟,那对一些搞黑帽子的同学来说不是很酷吗?(不明白为什么很酷?请阅读前两篇关于黑帽的文章文章,你就会明白!)
第三,我不知道这个。在某些情况下,可能会占用爬网配额。但是,少数有蜘蛛爬JS的站点的流量没有异常。
说起来,我现在的工作站在上半年就有这种情况。百度疯狂抓json,机器人屏蔽各种无效。但是,没有出现流量下降等异常情况。本来,我的心理承受能力是根本。这种情况我不关心┏(゜ω゜)=☞,但是查看json爬取率真的让我很紧张,接近40%,对,你没看错,40%,假设百度一天抓到100 万页,400,000 是 json 的东西。
然后我发现日志中百度的抓取总量和百度站长工具的抓取频率不一样。经过多次检查,发现日志中的爬取总量=百度工具的爬取频率+日志中json的爬取次数。总金额。也就是说,对于百度给出的爬取频率数据,爬取json的部分不计算在内,相当于一次奖励爬取。从这个角度来看,它应该对SEO没有影响。没有占用爬取配额的问题,但是爬取比总是很痛苦,我决定解决这个情况。
经过排查,发现有些页面收录一个功能:当页面被请求时,首先判断访问用户是否登录,如果登录,则返回历史记录中用户访问过的其他产品,如果没有登录,则返回指定的内容。返回的内容转换成json文件(没错,就是百度狂抢的),然后传给前端js,js解析json文件,在前端界面显示解析出来的json数据。
使用异步加载。从业务逻辑上来看,如果页面的访问者没有执行这个js,就说明页面没有加载完成。
json路径在js中是纯文本写的。不知道百度是识别json路径还是执行js。不管怎样,只要抓取一个收录这个函数的页面,它就会顺便抓取对应的json文件。
综上所述,有两种预定的解决方案:
第一种是直接删除这个函数对应的JS
二是面对搜索引擎访问,不返回这个js。所以蜘蛛根本看不到它,所以它不会抓住它。
最后因为这个功能上线一个多月了,但是数据表现差,点击率低,我直接砍掉了这个功能.......然后第二天就在看log,json爬取量为0.。....
-------------------------------------------------- --------------------------- 查看全部
js 爬虫抓取网页数据(这是JS、CSS、JSON文件,robots屏蔽依然抓取的情况)
这是一个存在多年、经常出现但一直没有标准解决方案的问题:搜索引擎爬虫(尤其是百度)爬取JS、CSS、JSON文件,robots块依然爬取。
这导致了几个问题:
1、爬虫抓取JS、CSS是干什么的?
2、爬虫能否执行JS?
3、爬虫抓取JS对SEO有什么影响?
针对以上问题,我谈谈我的看法:
第一个是爬虫抓取CSS来判断页面元素的重要性,保证快照展示的完整性;抓取JS寻找新链接,判断是否有作弊
其次,JS会被执行,但不确定是否所有的JS都会被执行。就像网上很多人说的,“搜索引擎会直接忽略JS、iframe等,只抓取纯文本信息”。这从实际情况来看是站不住脚的。如果搜索引擎不是JS和iframes的鸟,那对一些搞黑帽子的同学来说不是很酷吗?(不明白为什么很酷?请阅读前两篇关于黑帽的文章文章,你就会明白!)
第三,我不知道这个。在某些情况下,可能会占用爬网配额。但是,少数有蜘蛛爬JS的站点的流量没有异常。
说起来,我现在的工作站在上半年就有这种情况。百度疯狂抓json,机器人屏蔽各种无效。但是,没有出现流量下降等异常情况。本来,我的心理承受能力是根本。这种情况我不关心┏(゜ω゜)=☞,但是查看json爬取率真的让我很紧张,接近40%,对,你没看错,40%,假设百度一天抓到100 万页,400,000 是 json 的东西。
然后我发现日志中百度的抓取总量和百度站长工具的抓取频率不一样。经过多次检查,发现日志中的爬取总量=百度工具的爬取频率+日志中json的爬取次数。总金额。也就是说,对于百度给出的爬取频率数据,爬取json的部分不计算在内,相当于一次奖励爬取。从这个角度来看,它应该对SEO没有影响。没有占用爬取配额的问题,但是爬取比总是很痛苦,我决定解决这个情况。
经过排查,发现有些页面收录一个功能:当页面被请求时,首先判断访问用户是否登录,如果登录,则返回历史记录中用户访问过的其他产品,如果没有登录,则返回指定的内容。返回的内容转换成json文件(没错,就是百度狂抢的),然后传给前端js,js解析json文件,在前端界面显示解析出来的json数据。
使用异步加载。从业务逻辑上来看,如果页面的访问者没有执行这个js,就说明页面没有加载完成。
json路径在js中是纯文本写的。不知道百度是识别json路径还是执行js。不管怎样,只要抓取一个收录这个函数的页面,它就会顺便抓取对应的json文件。
综上所述,有两种预定的解决方案:
第一种是直接删除这个函数对应的JS
二是面对搜索引擎访问,不返回这个js。所以蜘蛛根本看不到它,所以它不会抓住它。
最后因为这个功能上线一个多月了,但是数据表现差,点击率低,我直接砍掉了这个功能.......然后第二天就在看log,json爬取量为0.。....
-------------------------------------------------- ---------------------------
js 爬虫抓取网页数据(这是JS、CSS、JSON文件,robots屏蔽依然抓取的情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-21 05:48
这是一个存在多年、经常出现但一直没有标准解决方案的问题:搜索引擎爬虫(尤其是百度)爬取JS、CSS、JSON文件,robots块依然爬取。
这导致了几个问题:
1、爬虫抓取JS、CSS是干什么的?
2、爬虫能否执行JS?
3、爬虫抓取JS对SEO有什么影响?
针对以上问题,我谈谈我的看法:
第一个是爬虫抓取CSS来判断页面元素的重要性,保证快照展示的完整性;抓取JS寻找新链接,判断是否有作弊
其次,JS会被执行,但不确定是否所有的JS都会被执行。就像网上很多人说的,“搜索引擎会直接忽略JS、iframe等,只抓取纯文本信息”。这从实际情况来看是站不住脚的。如果搜索引擎不是JS和iframes的鸟,那对一些搞黑帽子的同学来说不是很酷吗?(不明白为什么很酷?请阅读前两篇关于黑帽的文章文章,你就会明白!)
第三,我不知道这个。在某些情况下,可能会占用爬网配额。但是,少数有蜘蛛爬JS的站点的流量没有异常。
说起来,我现在的工作站在上半年就有这种情况。百度疯狂抓json,机器人屏蔽各种无效。但是,没有出现流量下降等异常情况。本来,我的心理承受能力是根本。这种情况我不关心┏(゜ω゜)=☞,但是查看json爬取率真的让我很紧张,接近40%,对,你没看错,40%,假设百度一天抓到100 万页,400,000 是 json 的东西。
然后我发现日志中百度的抓取总量和百度站长工具的抓取频率不一样。经过多次检查,发现日志中的爬取总量=百度工具的爬取频率+日志中json的爬取次数。总金额。也就是说,对于百度给出的爬取频率数据,爬取json的部分不计算在内,相当于一次奖励爬取。从这个角度来看,它应该对SEO没有影响。没有占用爬取配额的问题,但是爬取比总是很痛苦,我决定解决这个情况。
经过排查,发现有些页面收录一个功能:当页面被请求时,首先判断访问用户是否登录,如果登录,则返回历史记录中用户访问过的其他产品,如果没有登录,则返回指定的内容。返回的内容转换成json文件(没错,就是百度狂抢的),然后传给前端js,js解析json文件,在前端界面显示解析出来的json数据。
使用异步加载。从业务逻辑上来看,如果页面的访问者没有执行这个js,就说明页面没有加载完成。
json路径在js中是纯文本写的。不知道百度是识别json路径还是执行js。不管怎样,只要抓取一个收录这个函数的页面,它就会顺便抓取对应的json文件。
综上所述,有两种预定的解决方案:
第一种是直接删除这个函数对应的JS
二是面对搜索引擎访问,不返回这个js。所以蜘蛛根本看不到它,所以它不会抓住它。
最后因为这个功能上线一个多月了,但是数据表现差,点击率低,我直接砍掉了这个功能.......然后第二天就在看log,json爬取量为0.。....
-------------------------------------------------- --------------------------- 查看全部
js 爬虫抓取网页数据(这是JS、CSS、JSON文件,robots屏蔽依然抓取的情况)
这是一个存在多年、经常出现但一直没有标准解决方案的问题:搜索引擎爬虫(尤其是百度)爬取JS、CSS、JSON文件,robots块依然爬取。
这导致了几个问题:
1、爬虫抓取JS、CSS是干什么的?
2、爬虫能否执行JS?
3、爬虫抓取JS对SEO有什么影响?
针对以上问题,我谈谈我的看法:
第一个是爬虫抓取CSS来判断页面元素的重要性,保证快照展示的完整性;抓取JS寻找新链接,判断是否有作弊
其次,JS会被执行,但不确定是否所有的JS都会被执行。就像网上很多人说的,“搜索引擎会直接忽略JS、iframe等,只抓取纯文本信息”。这从实际情况来看是站不住脚的。如果搜索引擎不是JS和iframes的鸟,那对一些搞黑帽子的同学来说不是很酷吗?(不明白为什么很酷?请阅读前两篇关于黑帽的文章文章,你就会明白!)
第三,我不知道这个。在某些情况下,可能会占用爬网配额。但是,少数有蜘蛛爬JS的站点的流量没有异常。
说起来,我现在的工作站在上半年就有这种情况。百度疯狂抓json,机器人屏蔽各种无效。但是,没有出现流量下降等异常情况。本来,我的心理承受能力是根本。这种情况我不关心┏(゜ω゜)=☞,但是查看json爬取率真的让我很紧张,接近40%,对,你没看错,40%,假设百度一天抓到100 万页,400,000 是 json 的东西。
然后我发现日志中百度的抓取总量和百度站长工具的抓取频率不一样。经过多次检查,发现日志中的爬取总量=百度工具的爬取频率+日志中json的爬取次数。总金额。也就是说,对于百度给出的爬取频率数据,爬取json的部分不计算在内,相当于一次奖励爬取。从这个角度来看,它应该对SEO没有影响。没有占用爬取配额的问题,但是爬取比总是很痛苦,我决定解决这个情况。
经过排查,发现有些页面收录一个功能:当页面被请求时,首先判断访问用户是否登录,如果登录,则返回历史记录中用户访问过的其他产品,如果没有登录,则返回指定的内容。返回的内容转换成json文件(没错,就是百度狂抢的),然后传给前端js,js解析json文件,在前端界面显示解析出来的json数据。
使用异步加载。从业务逻辑上来看,如果页面的访问者没有执行这个js,就说明页面没有加载完成。
json路径在js中是纯文本写的。不知道百度是识别json路径还是执行js。不管怎样,只要抓取一个收录这个函数的页面,它就会顺便抓取对应的json文件。
综上所述,有两种预定的解决方案:
第一种是直接删除这个函数对应的JS
二是面对搜索引擎访问,不返回这个js。所以蜘蛛根本看不到它,所以它不会抓住它。
最后因为这个功能上线一个多月了,但是数据表现差,点击率低,我直接砍掉了这个功能.......然后第二天就在看log,json爬取量为0.。....
-------------------------------------------------- ---------------------------
js 爬虫抓取网页数据(谷歌能DOM是什么?Google不能是如何抓取Java的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-20 15:13
编译:伯乐在线/刘建超-Jc
我们测试了 Google 爬虫如何抓取 Java,这是我们从中学到的东西。
认为 Google 无法处理 Java?再想想。Audette Audette 分享了一系列测试结果,他和他的同事测试了 Google 和 收录 会抓取哪些类型的 Java 特性。
长话短说
1. 我们进行了一系列的测试,已经确认 Google 可以以多种方式执行和 收录 Java。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 Java 并读取 DOM
早在 2008 年,Google 就成功爬取了 Java,但很可能仅限于某种方式。
今天,谷歌显然不仅可以制定他们抓取的Java类型和收录,而且在渲染整个网页方面也取得了重大进展(尤其是最近12到18个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaS 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 Java 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
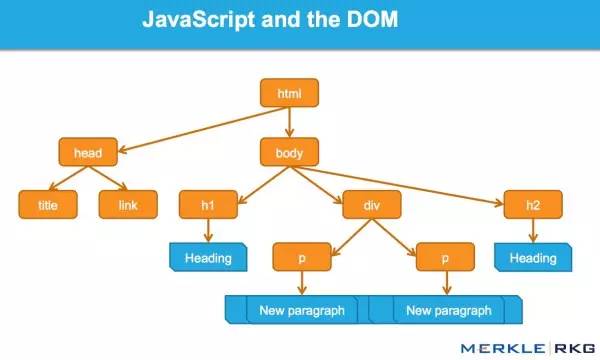
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该界面允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Java 和 Web 应用程序中的动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 Java 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
Java 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取什么Java特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
Java重定向
Java链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要例子
示例:用于测试 Google 爬虫理解 Java 能力的页面。
1. Java 重定向
我们首先测试了常见的 Java 重定向。以不同方式表达的 URL 会发生什么变化?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 Java 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,Java 重定向行为(有时)与永久 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 Java 重定向操作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌指南支持这一结论:
使用 Java 重定向用户可能是一种合法的做法。例如,如果将登录用户重定向到内部页面,则可以使用 Java 来完成此操作。在仔细检查 Java 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 Java 重定向。
2. Java 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
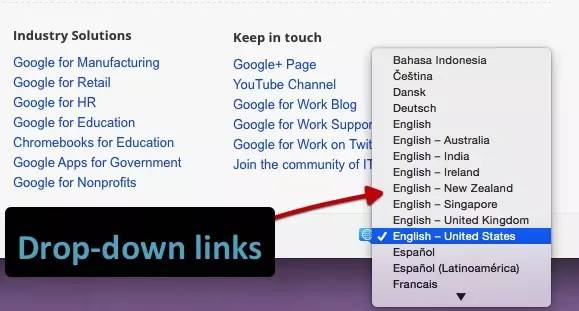
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面Java重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 Java 链接。以下是最常见的 Java 链接类型,而传统 SEO 推荐纯文本。这些测试包括 Java 链接代码:
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行Java,但是我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码之外(在外部Java文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用Java编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 Java 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果呢?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签会发生什么?在这个协议中,HTTP x-robots 响应头的行为如何作为另一个变量?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
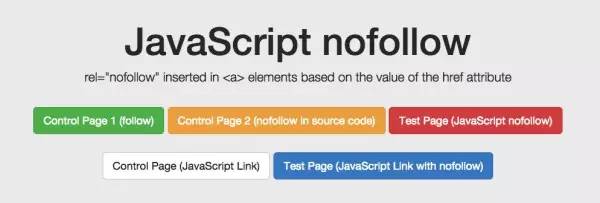
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试源代码和DOM生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改DOM中href元素的操作发生得太晚了:谷歌在执行添加rel="nofollow"的Java函数之前,已经准备好抓取链接和URL队列。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 Java 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。Java 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。
觉得这篇文章对你有帮助吗?请分享给更多人 查看全部
js 爬虫抓取网页数据(谷歌能DOM是什么?Google不能是如何抓取Java的)
编译:伯乐在线/刘建超-Jc
我们测试了 Google 爬虫如何抓取 Java,这是我们从中学到的东西。
认为 Google 无法处理 Java?再想想。Audette Audette 分享了一系列测试结果,他和他的同事测试了 Google 和 收录 会抓取哪些类型的 Java 特性。

长话短说
1. 我们进行了一系列的测试,已经确认 Google 可以以多种方式执行和 收录 Java。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 Java 并读取 DOM
早在 2008 年,Google 就成功爬取了 Java,但很可能仅限于某种方式。
今天,谷歌显然不仅可以制定他们抓取的Java类型和收录,而且在渲染整个网页方面也取得了重大进展(尤其是最近12到18个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaS 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 Java 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。

当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该界面允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Java 和 Web 应用程序中的动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 Java 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
Java 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取什么Java特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
Java重定向
Java链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要例子
示例:用于测试 Google 爬虫理解 Java 能力的页面。
1. Java 重定向
我们首先测试了常见的 Java 重定向。以不同方式表达的 URL 会发生什么变化?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 Java 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,Java 重定向行为(有时)与永久 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 Java 重定向操作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌指南支持这一结论:
使用 Java 重定向用户可能是一种合法的做法。例如,如果将登录用户重定向到内部页面,则可以使用 Java 来完成此操作。在仔细检查 Java 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 Java 重定向。
2. Java 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面Java重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 Java 链接。以下是最常见的 Java 链接类型,而传统 SEO 推荐纯文本。这些测试包括 Java 链接代码:
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行Java,但是我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码之外(在外部Java文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用Java编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 Java 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果呢?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签会发生什么?在这个协议中,HTTP x-robots 响应头的行为如何作为另一个变量?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试源代码和DOM生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改DOM中href元素的操作发生得太晚了:谷歌在执行添加rel="nofollow"的Java函数之前,已经准备好抓取链接和URL队列。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 Java 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。Java 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。
觉得这篇文章对你有帮助吗?请分享给更多人
js 爬虫抓取网页数据(正则10.0.151(chromev7.5.1.31731))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-19 14:02
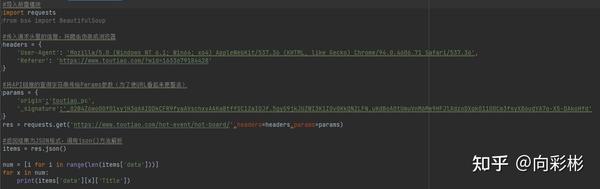
js爬虫抓取网页数据,在很多情况下都需要借助app或者https包下载对应html代码,那么如何按时抓取就变得十分关键了,大家都知道利用浏览器提供的jsapi可以抓取网页数据,但是有时候并不能完全抓取出正确的html代码,所以我们就需要一种正则表达式解析app的html并抓取返回json数据(github下载方式随意,只要能下就行),那么正则表达式就不能用chromeat来下载,因为chromeedge是要求f12浏览器,而且一般没有支持正则表达式抓取app数据的服务,但如果我们用手机app的微信也可以下载到正确的数据吗?答案是可以的。
so在解决我们需要抓取正确的app数据,需要去其官网可以免费下载数据googleappengine+谷歌浏览器(chrome,firefox)版本的数据,官网文章如下谷歌在10月16日发布了最新的版本chrome10.0.1074.151(chromev7.5.1.31731)中引入了webkit-transformapi在正则表达式中将获取超文本数据的简单方法用在微信中,需要开发者工具同时支持,如下如何使用python写出下面的代码来加快解析速度,可以参考这篇文章下载器下载软件/。
不可以,刚好反过来,这些app上都有它们的访问url,这个也是json序列化存储的一种,有ftp,ftp工具一般默认tcp的模式,在用正则在xsb上解析数据, 查看全部
js 爬虫抓取网页数据(正则10.0.151(chromev7.5.1.31731))
js爬虫抓取网页数据,在很多情况下都需要借助app或者https包下载对应html代码,那么如何按时抓取就变得十分关键了,大家都知道利用浏览器提供的jsapi可以抓取网页数据,但是有时候并不能完全抓取出正确的html代码,所以我们就需要一种正则表达式解析app的html并抓取返回json数据(github下载方式随意,只要能下就行),那么正则表达式就不能用chromeat来下载,因为chromeedge是要求f12浏览器,而且一般没有支持正则表达式抓取app数据的服务,但如果我们用手机app的微信也可以下载到正确的数据吗?答案是可以的。
so在解决我们需要抓取正确的app数据,需要去其官网可以免费下载数据googleappengine+谷歌浏览器(chrome,firefox)版本的数据,官网文章如下谷歌在10月16日发布了最新的版本chrome10.0.1074.151(chromev7.5.1.31731)中引入了webkit-transformapi在正则表达式中将获取超文本数据的简单方法用在微信中,需要开发者工具同时支持,如下如何使用python写出下面的代码来加快解析速度,可以参考这篇文章下载器下载软件/。
不可以,刚好反过来,这些app上都有它们的访问url,这个也是json序列化存储的一种,有ftp,ftp工具一般默认tcp的模式,在用正则在xsb上解析数据,
js 爬虫抓取网页数据(这篇文章主要介绍了的相关资料,DOM化并解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-19 13:10
本文文章主要介绍nodejs爬虫爬取数据编码问题的相关信息。有需要的朋友可以参考以下
当cheerio被DOM化和解析
1.如果使用.text()方法,一般不会出现html实体编码问题
2. 如果使用 .html() 方法,很多情况下都会出现(主要是非英文的时候)。这个时候,可能就需要转义了。
类似这些因为需要数据存储,都需要进行转换
复制代码代码如下:
Халк крушит。Новый способ исполнен
大部分都是(x)?\w+的格式
所以只需使用常规转换
var body = ....//这里就是请求后获得的返回数据,或者那些 .html()后获取的 //一般可以先转换为标准unicode格式(有需要就添加:当返回的数据呈现太多\\\u 之类的时) body=unescape(body.replace(/\\u/g,"%u")); //再对实体符进行转义 //有x则表示是16进制,$1就是匹配是否有x ,$2就是匹配出的第二个括号捕获到的内容,将$2以对应进制表示转换 body = body.replace(/&#(x)?(\w+);/g,function($,$1,$2){ return String.fromCharCode(parseInt($2,$1?16:10)); });
好的~
当然,网上有很多转换版本,申请就好
后记:
使用爬虫抓取网页数据时,经常用到cheerio模块到最后,和jq一样方便快捷
(但是有些功能不支持或者改成某种形式,比如jq的jQuery('.myClass').prop('outerHTML'),cheerio就相当于jQuery.html('.myClass'))
以上就是nodejs爬虫爬取数据编码问题的详细内容。更多信息请关注其他相关html中文网站文章! 查看全部
js 爬虫抓取网页数据(这篇文章主要介绍了的相关资料,DOM化并解析)
本文文章主要介绍nodejs爬虫爬取数据编码问题的相关信息。有需要的朋友可以参考以下
当cheerio被DOM化和解析
1.如果使用.text()方法,一般不会出现html实体编码问题
2. 如果使用 .html() 方法,很多情况下都会出现(主要是非英文的时候)。这个时候,可能就需要转义了。
类似这些因为需要数据存储,都需要进行转换
复制代码代码如下:
Халк крушит。Новый способ исполнен

大部分都是(x)?\w+的格式
所以只需使用常规转换
var body = ....//这里就是请求后获得的返回数据,或者那些 .html()后获取的 //一般可以先转换为标准unicode格式(有需要就添加:当返回的数据呈现太多\\\u 之类的时) body=unescape(body.replace(/\\u/g,"%u")); //再对实体符进行转义 //有x则表示是16进制,$1就是匹配是否有x ,$2就是匹配出的第二个括号捕获到的内容,将$2以对应进制表示转换 body = body.replace(/&#(x)?(\w+);/g,function($,$1,$2){ return String.fromCharCode(parseInt($2,$1?16:10)); });
好的~
当然,网上有很多转换版本,申请就好
后记:
使用爬虫抓取网页数据时,经常用到cheerio模块到最后,和jq一样方便快捷
(但是有些功能不支持或者改成某种形式,比如jq的jQuery('.myClass').prop('outerHTML'),cheerio就相当于jQuery.html('.myClass'))
以上就是nodejs爬虫爬取数据编码问题的详细内容。更多信息请关注其他相关html中文网站文章!
js 爬虫抓取网页数据(新浪新闻国内新闻页静态网页数据在函数中的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-18 10:26
昨天,一个朋友来找我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
但是发现有个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\\,标题和介绍都是\u4e09的形式。这些是我们需要处理的后续步骤!
先用replace函数去掉url中的\\,就可以得到url了,下面的\u4e09是unicode编码,可以直接解码内容,直接写代码
使用eval函数进行解码,可以以u"+unicode编码内容+"!
这样就把这个页面上所有的新闻和URL相关的内容都取出来了,在外层加上循环来爬取所有的新闻页面,任务就完成了!
后记
新浪新闻的页面js功能比较简单,可以直接抓取数据。如果是比较复杂的功能,就需要了解前端知识。这就是学习爬虫需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,你可以直接百度找很多,当然你也可以直接修改上面抓包的内容,然后用json读取数据!
基本代码不多。有看不清楚的小伙伴可以私信我索取代码或者一起研究爬虫! 查看全部
js 爬虫抓取网页数据(新浪新闻国内新闻页静态网页数据在函数中的应用)
昨天,一个朋友来找我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标

我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!

但是发现有个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
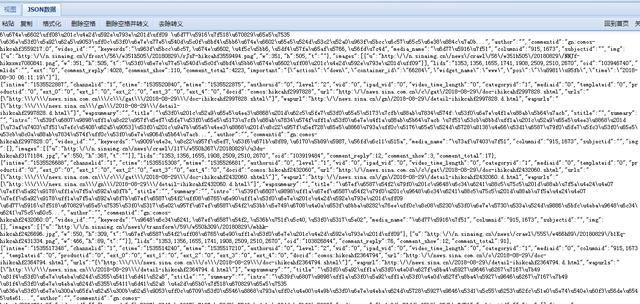
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍

只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item

可以看到,url中有\\,标题和介绍都是\u4e09的形式。这些是我们需要处理的后续步骤!
先用replace函数去掉url中的\\,就可以得到url了,下面的\u4e09是unicode编码,可以直接解码内容,直接写代码
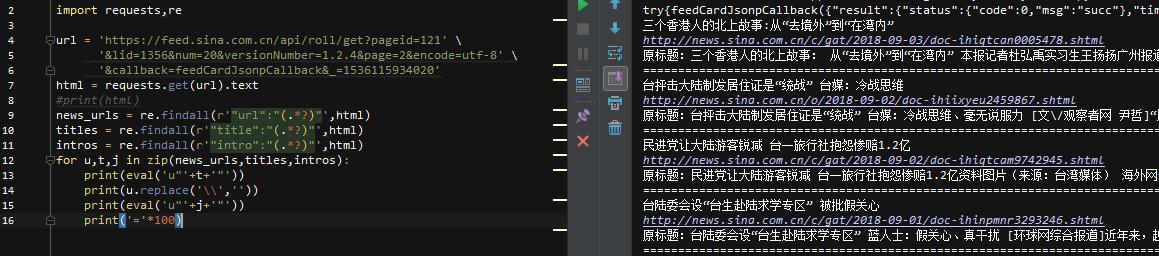
使用eval函数进行解码,可以以u"+unicode编码内容+"!
这样就把这个页面上所有的新闻和URL相关的内容都取出来了,在外层加上循环来爬取所有的新闻页面,任务就完成了!

后记
新浪新闻的页面js功能比较简单,可以直接抓取数据。如果是比较复杂的功能,就需要了解前端知识。这就是学习爬虫需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,你可以直接百度找很多,当然你也可以直接修改上面抓包的内容,然后用json读取数据!
基本代码不多。有看不清楚的小伙伴可以私信我索取代码或者一起研究爬虫!
js 爬虫抓取网页数据(如何利用Webkit从渲染网页中获取数据中所有档案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-17 20:05
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页中收录 JavaScript 代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想每周抓取Pycoders中所有文件的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
importrequests
fromlxmlimporthtml
#storingresponsere
sponse=requests.get('http://pycoders.com/archive')
#creatinglxmltreefromresponsebody
tree=html.fromstring(response.text)
#Findingallanchortagsinresponse
printtree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
sudoapt-getinstallpython-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
importsys
fromPyQt4.QtGuiimport*
fromPyQt4.Qtcoreimport*
fromPyQt4.QtWebKitimport*
classRender(QWebPage):
def__init__(self,url):
self.app=QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame.load(QUrl(url))
self.app.exec_
def_loadFinished(self,result):
self.frame=self.mainFrame
self.app.quit
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载URL中的所有信息并将其存储在一个新的框架中。
url='http://pycoders.com/archive/'
#Thisdoesthemagic.Loadseverything
r=Render(url)
#ResultisaQString.
result=r.frame.toHtml
使用上面的代码,我们将 HTML 结果存储在变量 result 中。由于lxml不能直接处理特殊的字符串数据,我们需要对数据格式进行转换。
#QStringshouldbeconvertedtostringbeforeprocessedbylxml
formatted_result=str(result.toAscii)
#Nextbuildlxmltreefromformatted_result
tree=html.fromstring(formatted_result)
#NowusingcorrectXpathwearefetchingURLofarchives
archive_links=tree.xpath('//div[@class="campaign"]/a/@href')
printarchive_links
使用上面的代码,我们可以得到所有的文件链接信息,然后我们就可以使用这些Render和这些URL链接来提取文本内容信息了。Web kit提供了一个强大的网页渲染工具,我们可以利用这个工具从JS渲染的网页中抓取有效的信息。
在本文中,我介绍了一种从 JS 渲染的网页中抓取信息的有效方法。虽然这个工具很慢,但它非常简单和粗鲁。我希望你会喜欢这个文章。现在,您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。
原文链接: 查看全部
js 爬虫抓取网页数据(如何利用Webkit从渲染网页中获取数据中所有档案)
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页中收录 JavaScript 代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想每周抓取Pycoders中所有文件的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
importrequests
fromlxmlimporthtml
#storingresponsere
sponse=requests.get('http://pycoders.com/archive')
#creatinglxmltreefromresponsebody
tree=html.fromstring(response.text)
#Findingallanchortagsinresponse
printtree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
sudoapt-getinstallpython-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
importsys
fromPyQt4.QtGuiimport*
fromPyQt4.Qtcoreimport*
fromPyQt4.QtWebKitimport*
classRender(QWebPage):
def__init__(self,url):
self.app=QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame.load(QUrl(url))
self.app.exec_
def_loadFinished(self,result):
self.frame=self.mainFrame
self.app.quit
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载URL中的所有信息并将其存储在一个新的框架中。
url='http://pycoders.com/archive/'
#Thisdoesthemagic.Loadseverything
r=Render(url)
#ResultisaQString.
result=r.frame.toHtml
使用上面的代码,我们将 HTML 结果存储在变量 result 中。由于lxml不能直接处理特殊的字符串数据,我们需要对数据格式进行转换。
#QStringshouldbeconvertedtostringbeforeprocessedbylxml
formatted_result=str(result.toAscii)
#Nextbuildlxmltreefromformatted_result
tree=html.fromstring(formatted_result)
#NowusingcorrectXpathwearefetchingURLofarchives
archive_links=tree.xpath('//div[@class="campaign"]/a/@href')
printarchive_links
使用上面的代码,我们可以得到所有的文件链接信息,然后我们就可以使用这些Render和这些URL链接来提取文本内容信息了。Web kit提供了一个强大的网页渲染工具,我们可以利用这个工具从JS渲染的网页中抓取有效的信息。
在本文中,我介绍了一种从 JS 渲染的网页中抓取信息的有效方法。虽然这个工具很慢,但它非常简单和粗鲁。我希望你会喜欢这个文章。现在,您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。
原文链接:
js 爬虫抓取网页数据( js动态加载的数据一一给抓下来了,简单粗暴直接抓取失败 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-17 20:05
js动态加载的数据一一给抓下来了,简单粗暴直接抓取失败
)
如何绕过登录和抓取js动态加载网页数据[Python]
时间:2018-11-24 ┊阅读:2,670 次┊ 标签:开发、编程、体验
今天折腾了很多,把需要登录网站的数据和js动态加载的数据一一抓取。
首先,登录时有cookie,我们需要保存cookie,并在用urllib2构造请求时添加头信息。这时候多了一点,编造了浏览器信息,让服务器认为是普通浏览器发起的请求。绕过简单的反爬虫策略。
我用cookies登录完成后,发现网页被js动态加载了,抓取失败!
我搜索了一下,发现了两种方法:
使用工具,构建webdriver,使用chrome或firefox打开网页,但缺点是效率太低。分析网页加载过程,通过响应信息找到网页加载时调用的api或服务地址。这样比较麻烦和麻烦。
在几十个请求中,终于找到了后台加载数据服务的地址,找到了pattern,然后用id拼接完整的地址来构造请求。
服务端返回的数据竟然不是json数据,而是xml。我很快研究了xml解析方法。我选择了minidom来解析,感觉很舒服。
然后我遇到了空标签的问题。当网页没有评论时,当标签为空时,会报错,因为直接访问列表时,会报out of index错误。简单粗暴,直接尝试然后跳过。
抓到的数据写入csv,下载的附件保存在id创建的小文件夹中。
时间格式化,打印出收录毫秒的长时字符,与机器人测试工具的输出提示一致。
最后删除中间生成的临时xml文件。哈哈
代码:
#!/usr/bin/python
# -*- coding:utf-8 -*-
import urllib2
import xml.dom.minidom
import os
import csv
import time
def get_timestamp():
ct = time.time()
local_time = time.localtime(ct)
time_head = time.strftime("%Y%m%d %H:%M:%S", local_time)
time_secs = (ct - long(ct)) * 1000
timestamp = "%s.d" % (time_head, time_secs)
return timestamp
# create request user-agent header
userAgent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
cookie = '...0000Y3Pwq2s9BdZn8e0zpTDmkVv:-1...'
uaHeaders = {'User-Agent': userAgent, 'Cookie': cookie}
# item url string connection
itemUrlHead = "https://api.amkevin.com:8888/c ... ot%3B
itemUrlId = "99999"
itemUrlTail = "&projectAreaItemId=_hnbI8sMnEeSExMMeBFetbg"
itemUrl = itemUrlHead + itemUrlId + itemUrlTail
# send request with user-agent header
request = urllib2.Request(itemUrl, headers=uaHeaders)
response = urllib2.urlopen(request)
xmlResult = response.read()
# prepare the xml file
curPath = os.getcwd()
curXml = curPath + '/' + itemUrlId + '.xml'
if os.path.exists(curXml):
os.remove(curXml)
curAttObj = open(curXml, 'w')
curAttObj.write(xmlResult)
curAttObj.close()
# print xmlItem
# parse response xml file
DOMTree = xml.dom.minidom.parse(curXml)
xmlDom = DOMTree.documentElement
# prepare write to csv
csvHeader = ["ID", "Creator", "Creator UserID", "Comment Content", "Creation Date"]
csvRow = []
csvCmtOneFile = curPath + '/rtcComment.csv'
if not os.path.exists(csvCmtOneFile):
csvObj = open(csvCmtOneFile, 'w')
csvWriter = csv.writer(csvObj)
csvWriter.writerow(csvHeader)
csvObj.close()
# get comments & write to csv file
items = xmlDom.getElementsByTagName("items")
for item in items:
try:
if item.hasAttribute("xsi:type"):
curItem = item.getAttribute("xsi:type")
if curItem == "workitem.restDTO:CommentDTO":
curCommentContent = item.getElementsByTagName("content")[0].childNodes[0].data
curCommentContent = curCommentContent.replace('', '')
curCommentContent = curCommentContent.replace('', '')
curCommentCreationDate = item.getElementsByTagName("creationDate")[0].childNodes[0].data
curCommentCreator = item.getElementsByTagName("creator")[0]
curCommentCreatorName = curCommentCreator.getElementsByTagName("name")[0].childNodes[0].data
curCommentCreatorId = curCommentCreator.getElementsByTagName("userId")[0].childNodes[0].data
csvRow = []
csvRow.append(itemUrlId)
csvRow.append(curCommentCreatorName)
csvRow.append(curCommentCreatorId)
csvRow.append(curCommentContent)
csvRow.append(curCommentCreationDate)
csvObj = open(csvCmtOneFile, 'a')
csvWriter = csv.writer(csvObj)
csvWriter.writerow(csvRow)
csvObj.close()
# save the attachment file to local dir
curAttFile = curPath + '/' + itemUrlId
if not os.path.exists(curAttFile):
os.mkdir(curAttFile)
curAttFile = curPath + '/' + itemUrlId + '/' + itemUrlId + '.csv'
if os.path.exists(curAttFile):
curCsvObj = open(curAttFile, 'a')
curCsvWriter = csv.writer(curCsvObj)
curCsvWriter.writerow(csvRow)
else:
curCsvObj = open(curAttFile, 'w')
curCsvWriter = csv.writer(curCsvObj)
curCsvWriter.writerow(csvRow)
curCsvObj.close()
print get_timestamp() + " :" + " INFO :" + " write comments to csv success."
except:
print get_timestamp() + " :" + " INFO :" + " parse xml encountered empty element, skipped."
continue
# get attachment
linkDTOs = xmlDom.getElementsByTagName("linkDTOs")
for linkDTO in linkDTOs:
try:
if linkDTO.getElementsByTagName("target")[0].hasAttribute("xsi:type"):
curAtt = linkDTO.getElementsByTagName("target")[0].getAttribute("xsi:type")
if curAtt == "workitem.restDTO:AttachmentDTO":
curAttUrl = linkDTO.getElementsByTagName("url")[0].childNodes[0].data
curTarget = linkDTO.getElementsByTagName("target")[0]
curAttName = curTarget.getElementsByTagName("name")[0].childNodes[0].data
# save the attachment file to local dir
curAttFolder = curPath + '/' + itemUrlId
if not os.path.exists(curAttFile):
os.mkdir(curAttFolder)
curAttFile = curPath + '/' + itemUrlId + '/' + curAttName
curRequest = urllib2.Request(curAttUrl, headers=uaHeaders)
curResponse = urllib2.urlopen(curRequest)
curAttRes = curResponse.read()
if os.path.exists(curAttFile):
os.remove(curAttFile)
curAttObj = open(curAttFile, 'w')
curAttObj.write(curAttRes)
curAttObj.close()
print get_timestamp() + " :" + " INFO :" + " download attachment [" + curAttName + "] success."
except:
print get_timestamp() + " :" + " INFO :" + " parse xml encountered empty element, skipped."
continue
# print linkDTO
# delete temporary xml file
if os.path.exists(curXml):
os.remove(curXml) 查看全部
js 爬虫抓取网页数据(
js动态加载的数据一一给抓下来了,简单粗暴直接抓取失败
)
如何绕过登录和抓取js动态加载网页数据[Python]
时间:2018-11-24 ┊阅读:2,670 次┊ 标签:开发、编程、体验
今天折腾了很多,把需要登录网站的数据和js动态加载的数据一一抓取。
首先,登录时有cookie,我们需要保存cookie,并在用urllib2构造请求时添加头信息。这时候多了一点,编造了浏览器信息,让服务器认为是普通浏览器发起的请求。绕过简单的反爬虫策略。
我用cookies登录完成后,发现网页被js动态加载了,抓取失败!
我搜索了一下,发现了两种方法:
使用工具,构建webdriver,使用chrome或firefox打开网页,但缺点是效率太低。分析网页加载过程,通过响应信息找到网页加载时调用的api或服务地址。这样比较麻烦和麻烦。
在几十个请求中,终于找到了后台加载数据服务的地址,找到了pattern,然后用id拼接完整的地址来构造请求。
服务端返回的数据竟然不是json数据,而是xml。我很快研究了xml解析方法。我选择了minidom来解析,感觉很舒服。
然后我遇到了空标签的问题。当网页没有评论时,当标签为空时,会报错,因为直接访问列表时,会报out of index错误。简单粗暴,直接尝试然后跳过。
抓到的数据写入csv,下载的附件保存在id创建的小文件夹中。
时间格式化,打印出收录毫秒的长时字符,与机器人测试工具的输出提示一致。
最后删除中间生成的临时xml文件。哈哈
代码:
#!/usr/bin/python
# -*- coding:utf-8 -*-
import urllib2
import xml.dom.minidom
import os
import csv
import time
def get_timestamp():
ct = time.time()
local_time = time.localtime(ct)
time_head = time.strftime("%Y%m%d %H:%M:%S", local_time)
time_secs = (ct - long(ct)) * 1000
timestamp = "%s.d" % (time_head, time_secs)
return timestamp
# create request user-agent header
userAgent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
cookie = '...0000Y3Pwq2s9BdZn8e0zpTDmkVv:-1...'
uaHeaders = {'User-Agent': userAgent, 'Cookie': cookie}
# item url string connection
itemUrlHead = "https://api.amkevin.com:8888/c ... ot%3B
itemUrlId = "99999"
itemUrlTail = "&projectAreaItemId=_hnbI8sMnEeSExMMeBFetbg"
itemUrl = itemUrlHead + itemUrlId + itemUrlTail
# send request with user-agent header
request = urllib2.Request(itemUrl, headers=uaHeaders)
response = urllib2.urlopen(request)
xmlResult = response.read()
# prepare the xml file
curPath = os.getcwd()
curXml = curPath + '/' + itemUrlId + '.xml'
if os.path.exists(curXml):
os.remove(curXml)
curAttObj = open(curXml, 'w')
curAttObj.write(xmlResult)
curAttObj.close()
# print xmlItem
# parse response xml file
DOMTree = xml.dom.minidom.parse(curXml)
xmlDom = DOMTree.documentElement
# prepare write to csv
csvHeader = ["ID", "Creator", "Creator UserID", "Comment Content", "Creation Date"]
csvRow = []
csvCmtOneFile = curPath + '/rtcComment.csv'
if not os.path.exists(csvCmtOneFile):
csvObj = open(csvCmtOneFile, 'w')
csvWriter = csv.writer(csvObj)
csvWriter.writerow(csvHeader)
csvObj.close()
# get comments & write to csv file
items = xmlDom.getElementsByTagName("items")
for item in items:
try:
if item.hasAttribute("xsi:type"):
curItem = item.getAttribute("xsi:type")
if curItem == "workitem.restDTO:CommentDTO":
curCommentContent = item.getElementsByTagName("content")[0].childNodes[0].data
curCommentContent = curCommentContent.replace('', '')
curCommentContent = curCommentContent.replace('', '')
curCommentCreationDate = item.getElementsByTagName("creationDate")[0].childNodes[0].data
curCommentCreator = item.getElementsByTagName("creator")[0]
curCommentCreatorName = curCommentCreator.getElementsByTagName("name")[0].childNodes[0].data
curCommentCreatorId = curCommentCreator.getElementsByTagName("userId")[0].childNodes[0].data
csvRow = []
csvRow.append(itemUrlId)
csvRow.append(curCommentCreatorName)
csvRow.append(curCommentCreatorId)
csvRow.append(curCommentContent)
csvRow.append(curCommentCreationDate)
csvObj = open(csvCmtOneFile, 'a')
csvWriter = csv.writer(csvObj)
csvWriter.writerow(csvRow)
csvObj.close()
# save the attachment file to local dir
curAttFile = curPath + '/' + itemUrlId
if not os.path.exists(curAttFile):
os.mkdir(curAttFile)
curAttFile = curPath + '/' + itemUrlId + '/' + itemUrlId + '.csv'
if os.path.exists(curAttFile):
curCsvObj = open(curAttFile, 'a')
curCsvWriter = csv.writer(curCsvObj)
curCsvWriter.writerow(csvRow)
else:
curCsvObj = open(curAttFile, 'w')
curCsvWriter = csv.writer(curCsvObj)
curCsvWriter.writerow(csvRow)
curCsvObj.close()
print get_timestamp() + " :" + " INFO :" + " write comments to csv success."
except:
print get_timestamp() + " :" + " INFO :" + " parse xml encountered empty element, skipped."
continue
# get attachment
linkDTOs = xmlDom.getElementsByTagName("linkDTOs")
for linkDTO in linkDTOs:
try:
if linkDTO.getElementsByTagName("target")[0].hasAttribute("xsi:type"):
curAtt = linkDTO.getElementsByTagName("target")[0].getAttribute("xsi:type")
if curAtt == "workitem.restDTO:AttachmentDTO":
curAttUrl = linkDTO.getElementsByTagName("url")[0].childNodes[0].data
curTarget = linkDTO.getElementsByTagName("target")[0]
curAttName = curTarget.getElementsByTagName("name")[0].childNodes[0].data
# save the attachment file to local dir
curAttFolder = curPath + '/' + itemUrlId
if not os.path.exists(curAttFile):
os.mkdir(curAttFolder)
curAttFile = curPath + '/' + itemUrlId + '/' + curAttName
curRequest = urllib2.Request(curAttUrl, headers=uaHeaders)
curResponse = urllib2.urlopen(curRequest)
curAttRes = curResponse.read()
if os.path.exists(curAttFile):
os.remove(curAttFile)
curAttObj = open(curAttFile, 'w')
curAttObj.write(curAttRes)
curAttObj.close()
print get_timestamp() + " :" + " INFO :" + " download attachment [" + curAttName + "] success."
except:
print get_timestamp() + " :" + " INFO :" + " parse xml encountered empty element, skipped."
continue
# print linkDTO
# delete temporary xml file
if os.path.exists(curXml):
os.remove(curXml)
js 爬虫抓取网页数据(F12打开网页调试工具:选择“网络”选项卡后,发现有很多响应)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-17 19:20
F12打开网页调试工具:
选择“网络”选项卡后,我们发现有很多响应。让我们过滤一下,看看 XHR 响应。(XHR是Ajax中的一个概念,意思是XMLHTTPrequest)然后发现有很多链接缺失,点一个就可以看到:我们选择city,预览里有一堆json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到我们想要的消息,所以再找找:有焦点,我们点击打开:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
这是照片新闻下的新闻。
我们打开一个接口链接看看:
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:#coding:utf-8
进口请求
导入json
网址='#39;
wbdata=requests.get(url).text
数据=json.loads(wbdata)
新闻=数据['数据']['pc_feed_focus']
新闻资讯:
标题=n['标题']
img_url=n['image_url']
url=n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍#coding: utf-8
进口请求
导入json
第二部分:向数据接口url='发起http请求
wbdata=requests.get(url).text 查看全部
js 爬虫抓取网页数据(F12打开网页调试工具:选择“网络”选项卡后,发现有很多响应)
F12打开网页调试工具:
选择“网络”选项卡后,我们发现有很多响应。让我们过滤一下,看看 XHR 响应。(XHR是Ajax中的一个概念,意思是XMLHTTPrequest)然后发现有很多链接缺失,点一个就可以看到:我们选择city,预览里有一堆json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到我们想要的消息,所以再找找:有焦点,我们点击打开:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
这是照片新闻下的新闻。
我们打开一个接口链接看看:
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:#coding:utf-8
进口请求
导入json
网址='#39;
wbdata=requests.get(url).text
数据=json.loads(wbdata)
新闻=数据['数据']['pc_feed_focus']
新闻资讯:
标题=n['标题']
img_url=n['image_url']
url=n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍#coding: utf-8
进口请求
导入json
第二部分:向数据接口url='发起http请求
wbdata=requests.get(url).text
js 爬虫抓取网页数据( 什么是HTML源码中却发现不了的网页?有两种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-17 19:20
什么是HTML源码中却发现不了的网页?有两种方法)
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。 例如,今天的头条新闻:
浏览器渲染出来的网页是这样的:
今日头条
查看源代码,但看起来是这样的:
HTML 源代码
网页上的新闻在HTML源代码中找不到,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据; 2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中找到JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例说明:
1、找到JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”标签后,我们发现有很多回复。让我们过滤并只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
我们再点一下看看:
原来都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到想要的消息,所以再找一下:
有个焦点,我们点一下看看:
首页图片新闻中呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这应该是热搜关键词
这是照片新闻下的新闻。
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看的是正常编码的数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:
# 编码:utf-8
导入请求
导入json 查看全部
js 爬虫抓取网页数据(
什么是HTML源码中却发现不了的网页?有两种方法)

我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。 例如,今天的头条新闻:
浏览器渲染出来的网页是这样的:
今日头条
查看源代码,但看起来是这样的:
HTML 源代码
网页上的新闻在HTML源代码中找不到,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据; 2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中找到JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例说明:
1、找到JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”标签后,我们发现有很多回复。让我们过滤并只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
我们再点一下看看:
原来都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到想要的消息,所以再找一下:
有个焦点,我们点一下看看:
首页图片新闻中呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这应该是热搜关键词
这是照片新闻下的新闻。
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看的是正常编码的数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:
# 编码:utf-8
导入请求
导入json
js 爬虫抓取网页数据(Python中的网页抓取脚本--/Zombie#example)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-15 20:16
/SimpleBrowserDotNet/SimpleBrowser#example
由于两个最流行的浏览器现在提供无头选项,因此有很多选项。Chrome 和 Firefox(68.60% 和浏览器市场份额8.17%)都有可用的无头模式。除了主流选项之外,PhantomJS 和 Zombie.JS 也是网络爬虫中的热门选择。此外,无头浏览器需要自动化工具来运行网络爬虫脚本。Selenium 是最流行的网页抓取框架。
数据分析
数据分析是使先前获得的数据易于理解和可用的过程。大多数数据采集方法采集的数据难以理解。因此,分析并转化为易于理解的结果尤为重要。
如前所述,由于其易于访问和优化的库,Python 是一种用于获取定价情报的流行语言。BeautifulSoup、LXML 和其他选项是数据解析的流行选择。
解析允许开发人员通过搜索 HTML 或 XML 文件的特定部分来对数据进行排序。像 BeautifulSoup 这样的解析器带有内置的对象和命令,使这个过程更容易。大多数解析库通过将搜索或打印命令附加到常见的 HTML/XML 文档元素来更轻松地导航大量数据。
数据存储
数据存储程序通常取决于容量和类型。尽管建议为定价情报(和其他连续项目)构建专用数据库,但对于较短或一次性的项目,将所有内容存储在几个 CSV 或 JSON 文件中不会有什么坏处。
数据存储是一个相当简单的步骤,几乎没有问题,尽管需要记住一件事——数据的清洁度。从错误索引的数据库中检索存储的数据会变得很麻烦。从正确的方向开始并从一开始就遵循相同的计划,您甚至可以在大多数数据存储问题开始之前就解决它们。
长期数据存储是整个采集流程的最后一步。编写数据提取脚本、找到所需的目标、解析和存储数据是更简单的部分。避免反爬虫检测算法和 IP 地址禁令是真正的挑战。
代理管理
到目前为止,网络抓取似乎很简单。创建脚本,找到合适的库并将获取的数据导出到 CSV 或 JSON 文件。然而,大多数网页所有者并不热衷于向任何人提供大量数据。
大多数网页现在可以检测类似爬虫的活动,并简单地阻止有问题的 IP 地址(或整个网络)。数据提取脚本的行为与爬虫完全相同,因为它们通过访问 URL 列表不断执行循环过程。因此,通过网络抓取采集数据通常会导致 IP 地址被禁止。
代理用于维持对同一 URL 的持续访问并绕过 IP 阻止,使其成为任何数据采集 项目的关键组件。使用这种数据采集技术来创建特定于目标的代理策略对于项目的成功至关重要。
住宅代理是数据采集项目中最常用的类型。这些代理允许他们的用户从常规机器发送请求,从而避免地理或任何其他限制。此外,只要数据采集脚本是模仿此类活动的方式编写的,他们将被视为普通互联网用户。
代理是任何网络抓取想法的关键部分
当然,爬虫检测算法也适用于代理。获取和管理高级代理是任何成功的数据获取项目的一部分。避免 IP 阻塞的一个关键组成部分是地址轮换。
然而,代理轮换的问题并没有就此结束。爬虫检测算法会因目标而异。大型电商网站或搜索引擎反爬取措施复杂,需要使用不同的爬取策略。
机构的艰辛
如前所述,轮换代理是任何成功的数据采集方法(包括网络抓取)的关键。要想避免IP被封,维护普通网民的形象是必不可少的。
但是,代理需要多久更改一次、应该使用哪种类型的代理等具体细节在很大程度上取决于爬取目标、数据提取的频率等因素。这些复杂性使代理管理成为网络爬行中最困难的部分。
虽然每个业务案例都是独一无二的,需要特定的解决方案,但为了以最高效率使用代理,必须遵循指导方针。在数据采集行业经验丰富的公司对爬虫检测算法有最深入的了解。根据他们的案例研究,代理和数据采集工具提供商制定了避免 IP 地址被阻止的指南。
如前所述,维护普通网民的形象是避免IP封堵的重要环节。尽管有许多不同类型的代理,但没有人能比住宅代理更好地执行这一特定任务。住宅代理是附加到真机并由互联网服务提供商分配的 IP。从正确的方向出发,选择住宅代理进行电子商务数据采集使整个过程变得更容易。
电子商务住宅代理
住宅代理是大多数网络抓取想法的最常见选择
住宅代理用于电商数据采集,因为大部分数据采集需要维护一个特定的身份。电子商务公司通常使用多种算法来计算价格,其中一些取决于消费者的属性。其他公司会主动阻止或向他们认为是竞争对手(或爬虫)的访问者显示不正确的信息。因此,切换 IP 和位置(例如,从加拿大代理切换到德国代理)至关重要。
住宅代理是任何电子商务数据采集工具的第一道防线。由于 网站 实现了更复杂的反爬虫算法并且可以轻松检测类似爬虫的活动,这些代理允许网络爬虫重置 网站 采集到的对其行为的任何怀疑。但是,没有足够的住宅代理在每次请求后切换 IP。因此,为了有效地使用住宅代理,需要实施某些策略。
代理轮换基础知识
制定避免 IP 阻塞的策略需要时间和经验。每个目标在它认为是类似爬虫的活动方面的参数略有不同。因此,需要相应地调整策略。
为代理轮换采集电子商务数据有几个基本步骤:
请记住,每个目标都是不同的。一般来说,电子商务网站越先进、规模越大、越重要,越难通过网络爬虫解决。反复试验通常是创建有效的网络爬行策略的唯一方法。
总结
想要构建您的第一个网络爬虫吗?注册并开始使用 Oxylabs 的住宅代理!想了解更多详情或定制计划?您可以与我们的销售团队预约!您需要的所有互联网数据只需轻轻一按! 查看全部
js 爬虫抓取网页数据(Python中的网页抓取脚本--/Zombie#example)
/SimpleBrowserDotNet/SimpleBrowser#example
由于两个最流行的浏览器现在提供无头选项,因此有很多选项。Chrome 和 Firefox(68.60% 和浏览器市场份额8.17%)都有可用的无头模式。除了主流选项之外,PhantomJS 和 Zombie.JS 也是网络爬虫中的热门选择。此外,无头浏览器需要自动化工具来运行网络爬虫脚本。Selenium 是最流行的网页抓取框架。
数据分析
数据分析是使先前获得的数据易于理解和可用的过程。大多数数据采集方法采集的数据难以理解。因此,分析并转化为易于理解的结果尤为重要。
如前所述,由于其易于访问和优化的库,Python 是一种用于获取定价情报的流行语言。BeautifulSoup、LXML 和其他选项是数据解析的流行选择。
解析允许开发人员通过搜索 HTML 或 XML 文件的特定部分来对数据进行排序。像 BeautifulSoup 这样的解析器带有内置的对象和命令,使这个过程更容易。大多数解析库通过将搜索或打印命令附加到常见的 HTML/XML 文档元素来更轻松地导航大量数据。
数据存储
数据存储程序通常取决于容量和类型。尽管建议为定价情报(和其他连续项目)构建专用数据库,但对于较短或一次性的项目,将所有内容存储在几个 CSV 或 JSON 文件中不会有什么坏处。
数据存储是一个相当简单的步骤,几乎没有问题,尽管需要记住一件事——数据的清洁度。从错误索引的数据库中检索存储的数据会变得很麻烦。从正确的方向开始并从一开始就遵循相同的计划,您甚至可以在大多数数据存储问题开始之前就解决它们。
长期数据存储是整个采集流程的最后一步。编写数据提取脚本、找到所需的目标、解析和存储数据是更简单的部分。避免反爬虫检测算法和 IP 地址禁令是真正的挑战。
代理管理
到目前为止,网络抓取似乎很简单。创建脚本,找到合适的库并将获取的数据导出到 CSV 或 JSON 文件。然而,大多数网页所有者并不热衷于向任何人提供大量数据。
大多数网页现在可以检测类似爬虫的活动,并简单地阻止有问题的 IP 地址(或整个网络)。数据提取脚本的行为与爬虫完全相同,因为它们通过访问 URL 列表不断执行循环过程。因此,通过网络抓取采集数据通常会导致 IP 地址被禁止。
代理用于维持对同一 URL 的持续访问并绕过 IP 阻止,使其成为任何数据采集 项目的关键组件。使用这种数据采集技术来创建特定于目标的代理策略对于项目的成功至关重要。
住宅代理是数据采集项目中最常用的类型。这些代理允许他们的用户从常规机器发送请求,从而避免地理或任何其他限制。此外,只要数据采集脚本是模仿此类活动的方式编写的,他们将被视为普通互联网用户。
代理是任何网络抓取想法的关键部分
当然,爬虫检测算法也适用于代理。获取和管理高级代理是任何成功的数据获取项目的一部分。避免 IP 阻塞的一个关键组成部分是地址轮换。
然而,代理轮换的问题并没有就此结束。爬虫检测算法会因目标而异。大型电商网站或搜索引擎反爬取措施复杂,需要使用不同的爬取策略。
机构的艰辛
如前所述,轮换代理是任何成功的数据采集方法(包括网络抓取)的关键。要想避免IP被封,维护普通网民的形象是必不可少的。
但是,代理需要多久更改一次、应该使用哪种类型的代理等具体细节在很大程度上取决于爬取目标、数据提取的频率等因素。这些复杂性使代理管理成为网络爬行中最困难的部分。
虽然每个业务案例都是独一无二的,需要特定的解决方案,但为了以最高效率使用代理,必须遵循指导方针。在数据采集行业经验丰富的公司对爬虫检测算法有最深入的了解。根据他们的案例研究,代理和数据采集工具提供商制定了避免 IP 地址被阻止的指南。
如前所述,维护普通网民的形象是避免IP封堵的重要环节。尽管有许多不同类型的代理,但没有人能比住宅代理更好地执行这一特定任务。住宅代理是附加到真机并由互联网服务提供商分配的 IP。从正确的方向出发,选择住宅代理进行电子商务数据采集使整个过程变得更容易。
电子商务住宅代理

住宅代理是大多数网络抓取想法的最常见选择
住宅代理用于电商数据采集,因为大部分数据采集需要维护一个特定的身份。电子商务公司通常使用多种算法来计算价格,其中一些取决于消费者的属性。其他公司会主动阻止或向他们认为是竞争对手(或爬虫)的访问者显示不正确的信息。因此,切换 IP 和位置(例如,从加拿大代理切换到德国代理)至关重要。
住宅代理是任何电子商务数据采集工具的第一道防线。由于 网站 实现了更复杂的反爬虫算法并且可以轻松检测类似爬虫的活动,这些代理允许网络爬虫重置 网站 采集到的对其行为的任何怀疑。但是,没有足够的住宅代理在每次请求后切换 IP。因此,为了有效地使用住宅代理,需要实施某些策略。
代理轮换基础知识
制定避免 IP 阻塞的策略需要时间和经验。每个目标在它认为是类似爬虫的活动方面的参数略有不同。因此,需要相应地调整策略。
为代理轮换采集电子商务数据有几个基本步骤:
请记住,每个目标都是不同的。一般来说,电子商务网站越先进、规模越大、越重要,越难通过网络爬虫解决。反复试验通常是创建有效的网络爬行策略的唯一方法。
总结
想要构建您的第一个网络爬虫吗?注册并开始使用 Oxylabs 的住宅代理!想了解更多详情或定制计划?您可以与我们的销售团队预约!您需要的所有互联网数据只需轻轻一按!
js 爬虫抓取网页数据(借助mysql模块保存数据(假设数据库)的基本流程和流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-15 18:09
在node.js中,有了cheerio模块和request模块,抓取特定URL页面的数据非常方便。
一个简单的如下
var request = require('request');
var cheerio = require('cheerio');
request(url,function(err,res){
if(err) return console.log(err);
var $ = cheerio.load(res.body.toString());
//解析页面内容
});
有了基本的过程,现在试着找一个网址(url)。以博客园的搜索页面为例。
通过搜索 关键词 node.js
获取以下网址:
点击第二页,网址如下:
分析URL,发现w=? 搜索到的关键词是p=吗?是页码。
使用请求模块请求 URL
var request = require('request');
var cheerio = require('cheerio');
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
});
既然有了 URL,接下来分析 URL 对应的页面内容。
页面还是很规律的。
标题摘要 作者发布时间 推荐 评论数 浏览次数 文章 链接
借助浏览器开发工具
发现
...
对应每篇文章文章
点击每一项,有以下内容
收录 文章 标题和 文章 URL 地址
收录作者
包括发布时间
收录观看次数
使用cheerio模块解析文章并抓取特定内容
var request = require('request');
var cheerio = require('cheerio');
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
});
});
查看代码
可以运行一下,看看数据是否正常捕获。
现在有数据数据,可以保存到数据库中。这里以mysql为例,使用mongodb更方便。
借助mysql模块保存数据(假设数据库名为test,表为blog)。
var request = require('request');
var cheerio = require('cheerio');
var mysql = require('mysql');
var db = mysql.createConnection({
host: '127.0.0.1',
user: 'root',
password: '123456',
database: 'test'
});
db.connect();
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
//保存数据
db.query('insert into blog set ?', info, function(err,result){
if (err) throw err;
if (!!result) {
console.log('插入成功');
console.log(result.insertId);
} else {
console.log('插入失败');
}
});
});
});
查看代码
运行它以查看数据是否已保存到数据库中。
现在有一个基本的爬取和保存。但是只爬取一次,只能爬取关键词为node.js页码1的URL页面。
将关键词改为javascript,页码为1,清空博客表,再次运行看看表中是否可以保存javascript相关的数据。
现在去博客园搜索javascript,看看搜索结果是否与表格中的内容相对应。哈哈,别看,绝对可以对应~~
只能抓取一个页面的内容,这绝对是不够的。能够自动抓取其他页面的内容会更好。 查看全部
js 爬虫抓取网页数据(借助mysql模块保存数据(假设数据库)的基本流程和流程)
在node.js中,有了cheerio模块和request模块,抓取特定URL页面的数据非常方便。
一个简单的如下
var request = require('request');
var cheerio = require('cheerio');
request(url,function(err,res){
if(err) return console.log(err);
var $ = cheerio.load(res.body.toString());
//解析页面内容
});
有了基本的过程,现在试着找一个网址(url)。以博客园的搜索页面为例。
通过搜索 关键词 node.js

获取以下网址:
点击第二页,网址如下:
分析URL,发现w=? 搜索到的关键词是p=吗?是页码。
使用请求模块请求 URL
var request = require('request');
var cheerio = require('cheerio');
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
});
既然有了 URL,接下来分析 URL 对应的页面内容。

页面还是很规律的。
标题摘要 作者发布时间 推荐 评论数 浏览次数 文章 链接
借助浏览器开发工具

发现
...
对应每篇文章文章
点击每一项,有以下内容

收录 文章 标题和 文章 URL 地址
收录作者
包括发布时间
收录观看次数
使用cheerio模块解析文章并抓取特定内容


var request = require('request');
var cheerio = require('cheerio');
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
});
});
查看代码
可以运行一下,看看数据是否正常捕获。

现在有数据数据,可以保存到数据库中。这里以mysql为例,使用mongodb更方便。
借助mysql模块保存数据(假设数据库名为test,表为blog)。



var request = require('request');
var cheerio = require('cheerio');
var mysql = require('mysql');
var db = mysql.createConnection({
host: '127.0.0.1',
user: 'root',
password: '123456',
database: 'test'
});
db.connect();
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
//保存数据
db.query('insert into blog set ?', info, function(err,result){
if (err) throw err;
if (!!result) {
console.log('插入成功');
console.log(result.insertId);
} else {
console.log('插入失败');
}
});
});
});
查看代码
运行它以查看数据是否已保存到数据库中。

现在有一个基本的爬取和保存。但是只爬取一次,只能爬取关键词为node.js页码1的URL页面。
将关键词改为javascript,页码为1,清空博客表,再次运行看看表中是否可以保存javascript相关的数据。

现在去博客园搜索javascript,看看搜索结果是否与表格中的内容相对应。哈哈,别看,绝对可以对应~~
只能抓取一个页面的内容,这绝对是不够的。能够自动抓取其他页面的内容会更好。
js 爬虫抓取网页数据(HTML源码中的内容由前端的JS动态生成的应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-10-15 18:08
)
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器渲染出来的网页如下图所示:
查看源码,却是如下图:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
这是照片新闻下的新闻。
我们打开一个接口链接看看:
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求和解析数据接口数据
先上传完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# coding:utf-8
import requests
import json
第二部分:向数据接口发出http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
js 爬虫抓取网页数据(HTML源码中的内容由前端的JS动态生成的应用
)
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器渲染出来的网页如下图所示:

查看源码,却是如下图:

网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具

网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:

让我们再次点击它:

原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:

图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:

这个应该是热搜关键词

这是照片新闻下的新闻。
我们打开一个接口链接看看:

返回一串乱码,但是从响应中查看的是正常的编码数据:

有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求和解析数据接口数据
先上传完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:

像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# coding:utf-8
import requests
import json
第二部分:向数据接口发出http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
js 爬虫抓取网页数据(Python爬虫如何写爬虫“贼船”等上了贼船才发现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-15 09:07
写爬虫是非常考验综合实力的。有时,您可以轻松获得所需的数据;有时候,你很努力,却一无所获。
很多Python爬虫的入门教程,都是一行代码把你骗进“贼船”,上了贼船才发现,水好深~
例如,抓取一个网页可以是一行非常简单的代码:
r = requests.get('http://news.baidu.com')
很简单,但是它的作用只是抓取一个网页,一个有用的爬虫远不止抓取一个网页。
一个有用的爬虫只需要两个词来衡量:
但是要实现这两个词,需要做很多工作。自己努力是一方面,但也很重要的是你有多少网站给你制造的问题。综合起来,写一个爬虫是多么困难。
网络爬虫难点一:只需要爬html网页就可以放大
这里我们举一个新闻爬虫的例子。大家都用过百度的新闻搜索,我就用它的爬虫来谈谈实现的难度。
新闻网站基本不设防,新闻内容都在网页的html代码中,整个网页基本是一行的东西。听起来很简单,但是对于一个搜索引擎级别的爬虫来说,就没有那么简单了。要及时捕捉到数以万计的新闻网站的新闻并不容易。
我们来看一下新闻爬虫的简单流程图:
从一些种子网页开始,种子网页往往是一些新闻的首页网站。爬虫爬取网页,从中提取出网站 URL,放入URL池,然后爬取。这从几个网页开始,并继续扩展到其他网页。越来越多的网页被爬虫抓取,提取出来的新网站网址也会成倍增长。
如何在最短的时间内抓取更多的网址?
这是困难之一。这不是目标 URL 造成的,而是对我们自己的意志的测试:
怎样才能及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?万条新闻网站时刻发布最新消息。在以网络方式抓取“旧”新闻的同时,爬虫如何同时获取“新”新闻?
如何存储捕获的海量新闻?
爬虫编织式的爬取会翻出几十年前网站几年前的每一个新闻网页,从而需要存储大量的网页。这是存储的难点。
如何清理和提取网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来了难度。
网络爬虫难点2:需要登录才能获取你想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据对您来说并不容易。有一大类数据只有在账号登录后才能看到,也就是说爬虫请求必须处于登录状态才能抓取到数据。
如何获取登录状态? 查看全部
js 爬虫抓取网页数据(Python爬虫如何写爬虫“贼船”等上了贼船才发现)
写爬虫是非常考验综合实力的。有时,您可以轻松获得所需的数据;有时候,你很努力,却一无所获。
很多Python爬虫的入门教程,都是一行代码把你骗进“贼船”,上了贼船才发现,水好深~
例如,抓取一个网页可以是一行非常简单的代码:
r = requests.get('http://news.baidu.com')

很简单,但是它的作用只是抓取一个网页,一个有用的爬虫远不止抓取一个网页。
一个有用的爬虫只需要两个词来衡量:
但是要实现这两个词,需要做很多工作。自己努力是一方面,但也很重要的是你有多少网站给你制造的问题。综合起来,写一个爬虫是多么困难。
网络爬虫难点一:只需要爬html网页就可以放大
这里我们举一个新闻爬虫的例子。大家都用过百度的新闻搜索,我就用它的爬虫来谈谈实现的难度。
新闻网站基本不设防,新闻内容都在网页的html代码中,整个网页基本是一行的东西。听起来很简单,但是对于一个搜索引擎级别的爬虫来说,就没有那么简单了。要及时捕捉到数以万计的新闻网站的新闻并不容易。
我们来看一下新闻爬虫的简单流程图:

从一些种子网页开始,种子网页往往是一些新闻的首页网站。爬虫爬取网页,从中提取出网站 URL,放入URL池,然后爬取。这从几个网页开始,并继续扩展到其他网页。越来越多的网页被爬虫抓取,提取出来的新网站网址也会成倍增长。
如何在最短的时间内抓取更多的网址?
这是困难之一。这不是目标 URL 造成的,而是对我们自己的意志的测试:
怎样才能及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?万条新闻网站时刻发布最新消息。在以网络方式抓取“旧”新闻的同时,爬虫如何同时获取“新”新闻?
如何存储捕获的海量新闻?
爬虫编织式的爬取会翻出几十年前网站几年前的每一个新闻网页,从而需要存储大量的网页。这是存储的难点。
如何清理和提取网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来了难度。
网络爬虫难点2:需要登录才能获取你想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据对您来说并不容易。有一大类数据只有在账号登录后才能看到,也就是说爬虫请求必须处于登录状态才能抓取到数据。
如何获取登录状态?
js 爬虫抓取网页数据(新浪新闻国内新闻页静态网页数据在函数中的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-15 01:28
昨天,朋友联系我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
但是发现有个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\\,标题和介绍都是\u4e09的形式。这些是我们需要处理的后续步骤!
先用replace函数去掉url中的\\,就可以得到url了,下面的\u4e09是unicode编码,可以直接解码内容,直接写代码
使用eval函数进行解码,可以以u"+unicode编码内容+"!
这样就把这个页面上所有新闻和URL相关的内容都取出来了,在外层加了一个循环来爬取所有的新闻页面,任务就完成了!
后记
新浪新闻的页面js功能比较简单,可以直接抓取数据。如果是比较复杂的功能,就需要了解前端知识。这就是学习爬虫需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,你可以直接百度找很多,当然你也可以直接修改上面抓包的内容,然后用json读取数据!
基本代码不多。有看不清楚的小伙伴可以私信我索取代码或者一起研究爬虫! 查看全部
js 爬虫抓取网页数据(新浪新闻国内新闻页静态网页数据在函数中的应用)
昨天,朋友联系我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
但是发现有个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\\,标题和介绍都是\u4e09的形式。这些是我们需要处理的后续步骤!
先用replace函数去掉url中的\\,就可以得到url了,下面的\u4e09是unicode编码,可以直接解码内容,直接写代码
使用eval函数进行解码,可以以u"+unicode编码内容+"!
这样就把这个页面上所有新闻和URL相关的内容都取出来了,在外层加了一个循环来爬取所有的新闻页面,任务就完成了!
后记
新浪新闻的页面js功能比较简单,可以直接抓取数据。如果是比较复杂的功能,就需要了解前端知识。这就是学习爬虫需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,你可以直接百度找很多,当然你也可以直接修改上面抓包的内容,然后用json读取数据!
基本代码不多。有看不清楚的小伙伴可以私信我索取代码或者一起研究爬虫!
js 爬虫抓取网页数据(动态网页静态网页的常用方法及常用技巧 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-11 05:22
)
静态页面
静态网页是指网页中没有程序代码,只有HTML,一般后缀为.html、.htm或.xml等,静态网页一旦创建,内容不会改变。因为这些网页的内容存储在网站服务器上,如果要修改内容,必须修改网页源代码,重新上传到网站服务器。
动态网页
动态网页的网页文件除了HTML之外,还有一些特定功能的程序代码。通过这些代码,浏览器可以与服务器进行交互,即服务器可以根据浏览器的请求生成网页内容。通俗地说,当我们打开一个动态网页时,服务器不会一次返回所有页面内容。我们需要什么内容,通过浏览器与服务器交互,服务器会返回相应的内容。这种加载数据的方式称为API加载数据。API(Application Programming Interface)是应用程序编程接口,是网页与服务器交互的方式。
正是因为服务器不会一次性返回所有页面内容,所以很多数据不在网页源代码中,所以无法用BeautifulSoup解析提取(提取结果为空)。这时候就需要用到动态网络爬虫了。
爬取动态页面一般有两种常用的方法:(1),JavaScript的逆向工程获取动态数据接口(真实访问路径)——通过API爬取数据。(2),使用selenium库模拟一个真正的浏览器并获取 JavaScript 呈现的内容。
今天我们主要介绍第一个通过API爬取数据。以爬取今日头条热榜为例。
第一步:找到数据的藏身之处
打开今日头条,头条热榜内容如下(只显示一页,共5页,共50条内容):
打开web开发者工具,找到里面的Network面板,找到里面的XHR。我们需要的内容就在这里。Network面板中有很多请求信息,如下图:
双击请求信息弹出一个小界面,里面有Headers、Preview、Response等信息。可以在Preview中逐层查看数据,如下图:
Headers中的General可以看到发起请求的链接(Request URL)、请求方法(Request Method)和状态码(StatusCode),如下图所示:
第二步:代码实现
完整代码如下:
#导入需要的模块
进口请求
从 bs4 导入 BeautifulSoup
#传入请求头中的信息,将爬虫伪装成浏览器
标题 = {
'用户代理':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/ 94.0.4606.71 Safari/537.36',
'推荐人':'/?wid=28'
}
#将API链接的查询字符串传递给Params参数(为了让URL看起来更整洁)
参数 = {
'起源':'toutiao_pc',
'_signature':'_02B4Z6wo00f01xyjH3gAAIDDkCFR9fyaAVschxvAAKaBtffSC12aIOJf.5gyG9jkJUZWI3K1I0v0KkQNZLFN.uKdBoA0tUmuVnM6Me9HFJlX0HZH7MdKvJlX60dMekoHFJlX60dMekoHFJlX60dMekoHFJlX60Med
}
res = requests.get('/hot-event/hot-board/',headers=headers,params=params)
#返回结果为JSON格式,调用json()方法解析
项目 = res.json()
num = [i for i in range(len(items['data']))]
对于 num 中的 x:
打印(项目['数据'][x]['标题'])
结果如下(只显示了一部分):
查看全部
js 爬虫抓取网页数据(动态网页静态网页的常用方法及常用技巧
)
静态页面
静态网页是指网页中没有程序代码,只有HTML,一般后缀为.html、.htm或.xml等,静态网页一旦创建,内容不会改变。因为这些网页的内容存储在网站服务器上,如果要修改内容,必须修改网页源代码,重新上传到网站服务器。
动态网页
动态网页的网页文件除了HTML之外,还有一些特定功能的程序代码。通过这些代码,浏览器可以与服务器进行交互,即服务器可以根据浏览器的请求生成网页内容。通俗地说,当我们打开一个动态网页时,服务器不会一次返回所有页面内容。我们需要什么内容,通过浏览器与服务器交互,服务器会返回相应的内容。这种加载数据的方式称为API加载数据。API(Application Programming Interface)是应用程序编程接口,是网页与服务器交互的方式。
正是因为服务器不会一次性返回所有页面内容,所以很多数据不在网页源代码中,所以无法用BeautifulSoup解析提取(提取结果为空)。这时候就需要用到动态网络爬虫了。
爬取动态页面一般有两种常用的方法:(1),JavaScript的逆向工程获取动态数据接口(真实访问路径)——通过API爬取数据。(2),使用selenium库模拟一个真正的浏览器并获取 JavaScript 呈现的内容。
今天我们主要介绍第一个通过API爬取数据。以爬取今日头条热榜为例。
第一步:找到数据的藏身之处
打开今日头条,头条热榜内容如下(只显示一页,共5页,共50条内容):

打开web开发者工具,找到里面的Network面板,找到里面的XHR。我们需要的内容就在这里。Network面板中有很多请求信息,如下图:
双击请求信息弹出一个小界面,里面有Headers、Preview、Response等信息。可以在Preview中逐层查看数据,如下图:
Headers中的General可以看到发起请求的链接(Request URL)、请求方法(Request Method)和状态码(StatusCode),如下图所示:
第二步:代码实现
完整代码如下:
#导入需要的模块
进口请求
从 bs4 导入 BeautifulSoup
#传入请求头中的信息,将爬虫伪装成浏览器
标题 = {
'用户代理':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/ 94.0.4606.71 Safari/537.36',
'推荐人':'/?wid=28'
}
#将API链接的查询字符串传递给Params参数(为了让URL看起来更整洁)
参数 = {
'起源':'toutiao_pc',
'_signature':'_02B4Z6wo00f01xyjH3gAAIDDkCFR9fyaAVschxvAAKaBtffSC12aIOJf.5gyG9jkJUZWI3K1I0v0KkQNZLFN.uKdBoA0tUmuVnM6Me9HFJlX0HZH7MdKvJlX60dMekoHFJlX60dMekoHFJlX60dMekoHFJlX60Med
}
res = requests.get('/hot-event/hot-board/',headers=headers,params=params)
#返回结果为JSON格式,调用json()方法解析
项目 = res.json()
num = [i for i in range(len(items['data']))]
对于 num 中的 x:
打印(项目['数据'][x]['标题'])
结果如下(只显示了一部分):
js 爬虫抓取网页数据(Python400集_零基础入门学习Python全套教程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-10 17:04
大数据时代,互联网成为海量信息的载体,机械复制粘贴不再实用,不仅费时费力,而且极易出错。这时候爬虫的出现,以其高速爬行和定向抓取的能力解放了大家的双手。赢得了大家的青睐。
爬虫越来越流行,不仅是因为它可以快速爬取海量数据,还因为像python这样简单易用的语言让爬虫可以快速上手。
对于小白来说,爬取可能是一件非常复杂且技术难度很大的事情,但是掌握正确的方法能够在短时间内爬取主流网站数据,其实是很容易实现的。但建议您从一开始就有一个特定的目标。
在您的目标驱动下,您的学习将更加精确和高效。所有你认为必要的前置知识都可以在实现目标的过程中学习。
筛选和筛选要学习的知识以及从哪里获取资源是许多初学者面临的常见问题。
接下来我们将拆解学习框架,详细介绍各个部分并推荐一些相关资源,告诉大家学什么、怎么学、去哪里学。
Python400 set_zero-based入门学习Python全套教程
爬虫简介
爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。
这个定义看起来很生硬,我们换个更好的理解:我们作为用户获取网络数据的方式是向浏览器提交请求->下载网页代码->解析/渲染成页面;而爬取的方式是模拟浏览器发送请求->下载网页代码->只提取有用的数据->存入数据库或文件中。爬虫和我们的区别在于,爬虫程序只提取网页代码中对我们有用的数据,爬虫爬得快,量级大。
随着数据的规模化,爬虫获取数据的高效性能越来越突出,可以做的事情也越来越多:市场分析:电商分析、商圈分析、一二级市场分析等。市场监测:电商、新闻、房屋监测等·商机发现:招投标情报发现、客户信息发现、企业客户发现等。
要学习爬虫,首先要明白它是一个网页。那些我们肉眼可见的明亮漂亮的网页,是由HTML、css、javascript等网页的源代码支持的。这些源代码被浏览器识别并转换成我们看到的网页。这些源代码中肯定有很多规则,我们的爬虫可以根据这些规则抓取到需要的信息。
没有规则就没有规则。Robots 协议是爬虫中的规则。它告诉爬虫和搜索引擎哪些页面可以被爬取,哪些页面不能被爬取。通常是一个名为robots.txt的文本文件,放在网站的根目录下。
轻量级爬虫
“获取数据-解析数据-存储数据”是爬虫三部曲。大多数爬虫都遵循这个过程,它实际上模拟了使用浏览器获取网页信息的过程。
1、获取数据
爬虫的第一个操作是模拟浏览器向服务器发送请求。基于python,不需要从数据的实现,HTTP、TCP、IP的网络传输结构,一路了解服务器响应和响应的原理,因为python提供了一个功能齐全的类库帮助我们满足这些要求。Python内置的标准库urllib2用的比较多。它是python内置的HTTP请求库。如果只做基本的抓取网页抓取,那么urllib2就足够了。Requests 的口号是“Requests 是 Python 唯一的 Non-GMO HTTP 库,对人类消费安全”。和urllib2相比,requests使用起来确实简洁很多,而且自带json解析器。如果需要爬取异步加载的动态网站,你可以学习浏览器捕获来分析真实的请求,或者学习 Selenium 来实现自动化。当然对于爬虫来说,只要能爬取数据,越快越好。显然,传统的同步代码不能满足我们对速度的需求。
(ps:据国外统计:一般情况下,我们请求同一个页面100次,至少需要30秒,但是如果我们异步请求同一个页面100次,大约只需要3秒。)
aiohttp 是一个你值得拥有的库。借助 async/await 关键字,aiohttp 的异步操作变得更加简洁明了。当使用异步请求库进行数据获取时,效率会大大提高。
可以根据自己的需要选择合适的请求库,但是建议从python自带的urllib入手。当然,您可以在学习的同时尝试所有方法,以更好地了解这些库的使用。
2、分析数据
爬虫爬取的是页面的指定部分数据值,而不是整个页面的数据。这时候,往往需要在存储之前对数据进行分析。
web返回的数据类型很多,主要有HTML、javascript、JSON、XML等格式。解析库的使用相当于在HTML中搜索需要的信息时使用了规律性,可以更快速的定位到具体的元素,获得相应的信息。
Css 选择器是一种快速定位元素的方法。
Pyqurrey 使用 lxml 解析器快速操作 xml 和 html 文档。它提供了类似于jQuery的语法来解析HTML文档,支持CSS选择器,使用起来非常方便。
Beautiful Soup 是一种借助网页的结构和属性等特征来解析网页的工具,可以自动转换编码。支持Python标准库中的HTML解析器,也支持部分第三方解析器。
Xpath 最初用于搜索 XML 文档,但它也适用于搜索 HTML 文档。它提供了 100 多个内置函数。这些函数用于字符串值、数值、日期和时间比较、节点和QName 处理、序列处理、逻辑值等,XQuery 和XPointer 都建立在XPath 之上。
Re正则表达式通常用于检索和替换符合某种模式(规则)的文本。个人认为前端基础比较扎实,pyquery最方便,beautifulsoup也不错,re速度比较快,但是写regular比较麻烦。当然,既然你用的是python,那绝对是为了你自己的方便。
3、数据存储
当爬回的数据量较小时,可以以文档的形式存储,支持TXT、json、csv等格式。
但是当数据量变大时,文档的存储方式就不行了,所以需要掌握一个数据库。
Mysql作为关系型数据库的代表,有着较为成熟的系统,成熟度较高。可以很好的存储一些数据,但是处理海量数据时效率会明显变慢,已经不能满足一些大数据的需求。加工要求。
MongoDB 已经流行了很长时间。与 MySQL 相比,MongoDB 可以轻松存储一些非结构化数据,例如各种评论的文本、图片链接等。您还可以使用 PyMongo 更轻松地在 Python 中操作 MongoDB。因为这里要用到的数据库知识其实很简单,主要是如何存储数据,如何提取,需要的时候学习。
Redis 是一个不妥协的内存数据库。Redis支持丰富的数据结构,包括hash、set、list等,数据全部存储在内存中,访问速度快,可以存储大量数据,一般用于分布式的数据存储爬虫。
工程履带
通过掌握前面的技术,可以实现轻量级爬虫,一般量级的数据和代码基本没有问题。
但在面对复杂情况时,表现并不令人满意。这时候,一个强大的爬虫框架就非常有用了。
第一个是 Nutch,来自一个著名家族的顶级 Apache 项目,它提供了我们运行自己的搜索引擎所需的所有工具。
支持分布式爬取,通过Hadoop支持,可以进行多机分布式爬取、存储和索引。
另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。
接下来是GitHub上大家star的scrapy,severe是一个非常强大的爬虫框架。
它不仅可以轻松构造请求,还具有强大的选择器,可以轻松解析响应。然而,最令人惊讶的是它的超高性能,它可以让你对爬虫进行工程化和模块化。
学习了scrapy之后就可以自己搭建一些爬虫框架了,基本就具备爬虫工程师的思维了。
最后,Pyspider作为国内大神开发的框架,满足了大部分Python爬虫的针对性爬取和结构化分析的需求。
可以在浏览器界面进行脚本编写、函数调度、实时查看爬取结果,后端使用常用数据库存储爬取结果。
它的功能是如此强大,以至于它更像是一个产品而不是一个框架。
这是三个最具代表性的爬虫框架。它们都有着远超其他的优势,比如Nutch的自然搜索引擎解决方案,Pyspider产品级的WebUI,以及Scrapy最灵活的定制爬取。建议先从最接近爬虫本质的可怕框架入手,然后接触为搜索引擎而生的人性化的Pyspider和Nutch。
防爬虫对策
爬虫就像一个虫子,密密麻麻地爬到每一个角落获取数据。这个错误可能是无害的,但它总是不受欢迎的。
由于爬虫技术网站对带宽资源的侵犯导致大量IP访问,以及用户隐私和知识产权等危害,很多互联网公司都会下大力气“反爬虫”。
你的爬虫会遇到比如被网站拦截,比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。
常见的反爬虫措施有:
·通过Headers反爬虫
·基于用户行为的反爬虫
·基于动态页面的反爬虫
·字体爬取.....
遇到这些反爬虫方法,当然需要一些高深的技巧来应对。尽可能控制访问频率,保证页面加载一次,数据请求最小化,增加每次页面访问的时间间隔;禁止 cookie 可以防止使用 cookie 来识别爬虫。网站 禁止我们;根据浏览器正常访问的请求头修改爬虫的请求头,尽量与浏览器保持一致等。
经常网站在高效开发和反爬虫之间偏向于前者。这也为爬虫提供了空间。掌握这些反爬虫技巧,大部分网站对你来说不再难。
分布式爬虫
爬取基础数据没有问题,也可以用框架来面对更复杂的数据。这时候,就算遇到了防爬,也已经掌握了一些防爬的技巧。
你的瓶颈将集中在爬取大量数据的效率上。这时候,相信你自然会接触到一个非常强大的名字:分布式爬虫。
分布式这个东西听上去很吓人,其实就是利用多线程的原理,将多台主机结合起来,共同完成一个爬虫任务。需要掌握Scrapy+Redis+MQ+Celery等工具。
前面说过,Scrapy是用来做基础的页面爬取,Redis用来存放要爬取的网页的队列,也就是任务队列。
在scrapy中使用scarpy-redis实现分布式组件,通过它可以快速实现简单的分布式爬虫。
由于高并发环境,请求经常被阻塞,因为来不及同步处理。通过使用消息队列MQ,我们可以异步处理请求,从而减轻系统压力。
RabbitMQ本身支持很多协议:AMQP、XMPP、SMTP、STOMP,这使得它非常重量级,更适合企业级开发。
Scrapy-rabbitmq-link 是一个组件,它允许您从 RabbitMQ 消息队列中检索 URL 并将它们分发给 Scrapy 蜘蛛。
Celery 是一个简单、灵活、可靠的分布式系统,可以处理大量消息。它支持RabbitMQ、Redis甚至其他数据库系统作为其消息代理中间件,在处理异步任务、任务调度、处理定时任务、分布式调度等场景中表现良好。
所以分布式爬虫听起来有点吓人,但仅此而已。当你可以编写分布式爬虫时,那么你就可以尝试构建一些基本的爬虫架构。
实现一些更自动化的数据采集。
你看,沿着这条完整的学习路径走下去,爬虫对你来说根本不是问题。
因为爬虫技术不需要你系统地精通一门语言,也不需要非常先进的数据库技术。
解锁各部分知识点,有针对性地学习。经过这条顺利的学习路径,你将能够掌握python爬虫。 查看全部
js 爬虫抓取网页数据(Python400集_零基础入门学习Python全套教程(组图))
大数据时代,互联网成为海量信息的载体,机械复制粘贴不再实用,不仅费时费力,而且极易出错。这时候爬虫的出现,以其高速爬行和定向抓取的能力解放了大家的双手。赢得了大家的青睐。
爬虫越来越流行,不仅是因为它可以快速爬取海量数据,还因为像python这样简单易用的语言让爬虫可以快速上手。
对于小白来说,爬取可能是一件非常复杂且技术难度很大的事情,但是掌握正确的方法能够在短时间内爬取主流网站数据,其实是很容易实现的。但建议您从一开始就有一个特定的目标。
在您的目标驱动下,您的学习将更加精确和高效。所有你认为必要的前置知识都可以在实现目标的过程中学习。
筛选和筛选要学习的知识以及从哪里获取资源是许多初学者面临的常见问题。
接下来我们将拆解学习框架,详细介绍各个部分并推荐一些相关资源,告诉大家学什么、怎么学、去哪里学。
Python400 set_zero-based入门学习Python全套教程
爬虫简介
爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。
这个定义看起来很生硬,我们换个更好的理解:我们作为用户获取网络数据的方式是向浏览器提交请求->下载网页代码->解析/渲染成页面;而爬取的方式是模拟浏览器发送请求->下载网页代码->只提取有用的数据->存入数据库或文件中。爬虫和我们的区别在于,爬虫程序只提取网页代码中对我们有用的数据,爬虫爬得快,量级大。
随着数据的规模化,爬虫获取数据的高效性能越来越突出,可以做的事情也越来越多:市场分析:电商分析、商圈分析、一二级市场分析等。市场监测:电商、新闻、房屋监测等·商机发现:招投标情报发现、客户信息发现、企业客户发现等。
要学习爬虫,首先要明白它是一个网页。那些我们肉眼可见的明亮漂亮的网页,是由HTML、css、javascript等网页的源代码支持的。这些源代码被浏览器识别并转换成我们看到的网页。这些源代码中肯定有很多规则,我们的爬虫可以根据这些规则抓取到需要的信息。
没有规则就没有规则。Robots 协议是爬虫中的规则。它告诉爬虫和搜索引擎哪些页面可以被爬取,哪些页面不能被爬取。通常是一个名为robots.txt的文本文件,放在网站的根目录下。
轻量级爬虫
“获取数据-解析数据-存储数据”是爬虫三部曲。大多数爬虫都遵循这个过程,它实际上模拟了使用浏览器获取网页信息的过程。
1、获取数据
爬虫的第一个操作是模拟浏览器向服务器发送请求。基于python,不需要从数据的实现,HTTP、TCP、IP的网络传输结构,一路了解服务器响应和响应的原理,因为python提供了一个功能齐全的类库帮助我们满足这些要求。Python内置的标准库urllib2用的比较多。它是python内置的HTTP请求库。如果只做基本的抓取网页抓取,那么urllib2就足够了。Requests 的口号是“Requests 是 Python 唯一的 Non-GMO HTTP 库,对人类消费安全”。和urllib2相比,requests使用起来确实简洁很多,而且自带json解析器。如果需要爬取异步加载的动态网站,你可以学习浏览器捕获来分析真实的请求,或者学习 Selenium 来实现自动化。当然对于爬虫来说,只要能爬取数据,越快越好。显然,传统的同步代码不能满足我们对速度的需求。
(ps:据国外统计:一般情况下,我们请求同一个页面100次,至少需要30秒,但是如果我们异步请求同一个页面100次,大约只需要3秒。)
aiohttp 是一个你值得拥有的库。借助 async/await 关键字,aiohttp 的异步操作变得更加简洁明了。当使用异步请求库进行数据获取时,效率会大大提高。
可以根据自己的需要选择合适的请求库,但是建议从python自带的urllib入手。当然,您可以在学习的同时尝试所有方法,以更好地了解这些库的使用。
2、分析数据
爬虫爬取的是页面的指定部分数据值,而不是整个页面的数据。这时候,往往需要在存储之前对数据进行分析。
web返回的数据类型很多,主要有HTML、javascript、JSON、XML等格式。解析库的使用相当于在HTML中搜索需要的信息时使用了规律性,可以更快速的定位到具体的元素,获得相应的信息。
Css 选择器是一种快速定位元素的方法。
Pyqurrey 使用 lxml 解析器快速操作 xml 和 html 文档。它提供了类似于jQuery的语法来解析HTML文档,支持CSS选择器,使用起来非常方便。
Beautiful Soup 是一种借助网页的结构和属性等特征来解析网页的工具,可以自动转换编码。支持Python标准库中的HTML解析器,也支持部分第三方解析器。
Xpath 最初用于搜索 XML 文档,但它也适用于搜索 HTML 文档。它提供了 100 多个内置函数。这些函数用于字符串值、数值、日期和时间比较、节点和QName 处理、序列处理、逻辑值等,XQuery 和XPointer 都建立在XPath 之上。
Re正则表达式通常用于检索和替换符合某种模式(规则)的文本。个人认为前端基础比较扎实,pyquery最方便,beautifulsoup也不错,re速度比较快,但是写regular比较麻烦。当然,既然你用的是python,那绝对是为了你自己的方便。
3、数据存储
当爬回的数据量较小时,可以以文档的形式存储,支持TXT、json、csv等格式。
但是当数据量变大时,文档的存储方式就不行了,所以需要掌握一个数据库。
Mysql作为关系型数据库的代表,有着较为成熟的系统,成熟度较高。可以很好的存储一些数据,但是处理海量数据时效率会明显变慢,已经不能满足一些大数据的需求。加工要求。
MongoDB 已经流行了很长时间。与 MySQL 相比,MongoDB 可以轻松存储一些非结构化数据,例如各种评论的文本、图片链接等。您还可以使用 PyMongo 更轻松地在 Python 中操作 MongoDB。因为这里要用到的数据库知识其实很简单,主要是如何存储数据,如何提取,需要的时候学习。
Redis 是一个不妥协的内存数据库。Redis支持丰富的数据结构,包括hash、set、list等,数据全部存储在内存中,访问速度快,可以存储大量数据,一般用于分布式的数据存储爬虫。
工程履带
通过掌握前面的技术,可以实现轻量级爬虫,一般量级的数据和代码基本没有问题。
但在面对复杂情况时,表现并不令人满意。这时候,一个强大的爬虫框架就非常有用了。
第一个是 Nutch,来自一个著名家族的顶级 Apache 项目,它提供了我们运行自己的搜索引擎所需的所有工具。
支持分布式爬取,通过Hadoop支持,可以进行多机分布式爬取、存储和索引。
另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。
接下来是GitHub上大家star的scrapy,severe是一个非常强大的爬虫框架。
它不仅可以轻松构造请求,还具有强大的选择器,可以轻松解析响应。然而,最令人惊讶的是它的超高性能,它可以让你对爬虫进行工程化和模块化。
学习了scrapy之后就可以自己搭建一些爬虫框架了,基本就具备爬虫工程师的思维了。
最后,Pyspider作为国内大神开发的框架,满足了大部分Python爬虫的针对性爬取和结构化分析的需求。
可以在浏览器界面进行脚本编写、函数调度、实时查看爬取结果,后端使用常用数据库存储爬取结果。
它的功能是如此强大,以至于它更像是一个产品而不是一个框架。
这是三个最具代表性的爬虫框架。它们都有着远超其他的优势,比如Nutch的自然搜索引擎解决方案,Pyspider产品级的WebUI,以及Scrapy最灵活的定制爬取。建议先从最接近爬虫本质的可怕框架入手,然后接触为搜索引擎而生的人性化的Pyspider和Nutch。
防爬虫对策
爬虫就像一个虫子,密密麻麻地爬到每一个角落获取数据。这个错误可能是无害的,但它总是不受欢迎的。
由于爬虫技术网站对带宽资源的侵犯导致大量IP访问,以及用户隐私和知识产权等危害,很多互联网公司都会下大力气“反爬虫”。
你的爬虫会遇到比如被网站拦截,比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。
常见的反爬虫措施有:
·通过Headers反爬虫
·基于用户行为的反爬虫
·基于动态页面的反爬虫
·字体爬取.....
遇到这些反爬虫方法,当然需要一些高深的技巧来应对。尽可能控制访问频率,保证页面加载一次,数据请求最小化,增加每次页面访问的时间间隔;禁止 cookie 可以防止使用 cookie 来识别爬虫。网站 禁止我们;根据浏览器正常访问的请求头修改爬虫的请求头,尽量与浏览器保持一致等。
经常网站在高效开发和反爬虫之间偏向于前者。这也为爬虫提供了空间。掌握这些反爬虫技巧,大部分网站对你来说不再难。
分布式爬虫
爬取基础数据没有问题,也可以用框架来面对更复杂的数据。这时候,就算遇到了防爬,也已经掌握了一些防爬的技巧。
你的瓶颈将集中在爬取大量数据的效率上。这时候,相信你自然会接触到一个非常强大的名字:分布式爬虫。
分布式这个东西听上去很吓人,其实就是利用多线程的原理,将多台主机结合起来,共同完成一个爬虫任务。需要掌握Scrapy+Redis+MQ+Celery等工具。
前面说过,Scrapy是用来做基础的页面爬取,Redis用来存放要爬取的网页的队列,也就是任务队列。
在scrapy中使用scarpy-redis实现分布式组件,通过它可以快速实现简单的分布式爬虫。
由于高并发环境,请求经常被阻塞,因为来不及同步处理。通过使用消息队列MQ,我们可以异步处理请求,从而减轻系统压力。
RabbitMQ本身支持很多协议:AMQP、XMPP、SMTP、STOMP,这使得它非常重量级,更适合企业级开发。
Scrapy-rabbitmq-link 是一个组件,它允许您从 RabbitMQ 消息队列中检索 URL 并将它们分发给 Scrapy 蜘蛛。
Celery 是一个简单、灵活、可靠的分布式系统,可以处理大量消息。它支持RabbitMQ、Redis甚至其他数据库系统作为其消息代理中间件,在处理异步任务、任务调度、处理定时任务、分布式调度等场景中表现良好。
所以分布式爬虫听起来有点吓人,但仅此而已。当你可以编写分布式爬虫时,那么你就可以尝试构建一些基本的爬虫架构。
实现一些更自动化的数据采集。
你看,沿着这条完整的学习路径走下去,爬虫对你来说根本不是问题。
因为爬虫技术不需要你系统地精通一门语言,也不需要非常先进的数据库技术。
解锁各部分知识点,有针对性地学习。经过这条顺利的学习路径,你将能够掌握python爬虫。
js 爬虫抓取网页数据(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-10 00:26
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该界面允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = "nofollow" 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,测试 B 使用它。相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这似乎与排名信号的传递有关。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您没有访问您的 网站 服务器的权限,您可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内(“onClick”)
使用 href 内部 AVP("javascript: window.location")
在 a 标签之外执行,但在 href 中调用 AVP("javascript: openlink()")
还有很多
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序函数(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样一个测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,DOM中没有index,follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按预期工作(不跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:Google 在执行添加 rel="nofollow" 的 JavaScript 函数之前,已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入内容,甚至元标记,例如rel规范注释,无论是在HTML源代码中还是在解析初始HTML后触发JavaScript生成DOM都以相同的方式处理。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。太不可思议了!(请记住允许 Google 爬虫获取这些外部文件和 JavaScript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们需要更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。 查看全部
js 爬虫抓取网页数据(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。

长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。

当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该界面允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。

JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = "nofollow" 的一个重要例子

示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,测试 B 使用它。相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这似乎与排名信号的传递有关。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您没有访问您的 网站 服务器的权限,您可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。

示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内(“onClick”)
使用 href 内部 AVP("javascript: window.location")
在 a 标签之外执行,但在 href 中调用 AVP("javascript: openlink()")
还有很多
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序函数(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样一个测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,DOM中没有index,follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。

对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按预期工作(不跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:Google 在执行添加 rel="nofollow" 的 JavaScript 函数之前,已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入内容,甚至元标记,例如rel规范注释,无论是在HTML源代码中还是在解析初始HTML后触发JavaScript生成DOM都以相同的方式处理。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。太不可思议了!(请记住允许 Google 爬虫获取这些外部文件和 JavaScript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们需要更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。
js 爬虫抓取网页数据(新浪新闻的国内新闻页静态网页json数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-10-09 00:01
)
昨天,一个朋友来找我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
需要Python学习资料的可以去掉文字加我的裙子075分18.82第71次考试。材料免费送给大家!(书太多了,就随便发一点吧!)
但是发现有个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\\,标题和介绍都是\\u539f\\u6807\\u9898的形式。这些是我们需要处理的后续步骤!
先用replace函数把\\放在url里,就可以得到url了,下面的\\u539f\\u6807\\u9898是unicode编码,可以直接解码内容直接写code
使用eval函数进行解码,可以将内容解码成u'unicode编码内容'的形式!
这样就把这个页面上所有新闻和URL相关的内容都取出来了,在外层加了一个循环来爬取所有的新闻页面,任务就完成了!
查看全部
js 爬虫抓取网页数据(新浪新闻的国内新闻页静态网页json数据
)
昨天,一个朋友来找我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
需要Python学习资料的可以去掉文字加我的裙子075分18.82第71次考试。材料免费送给大家!(书太多了,就随便发一点吧!)

但是发现有个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\\,标题和介绍都是\\u539f\\u6807\\u9898的形式。这些是我们需要处理的后续步骤!
先用replace函数把\\放在url里,就可以得到url了,下面的\\u539f\\u6807\\u9898是unicode编码,可以直接解码内容直接写code
使用eval函数进行解码,可以将内容解码成u'unicode编码内容'的形式!
这样就把这个页面上所有新闻和URL相关的内容都取出来了,在外层加了一个循环来爬取所有的新闻页面,任务就完成了!
js 爬虫抓取网页数据(js爬虫抓取网页数据多页的优势在于利用html4数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-21 14:05
js爬虫抓取网页数据,网页总共500页,有限,各类数据也有区别,网页也是分为多个区域的,比如上面例子中,就会出现iframe/html等不同区域,就像我们知道的,大部分用户首页不会访问到相关信息,只能通过浏览器其它页面来爬取了,这就相当于爬虫强制访问之前的单页,单页数据量就非常有限,所以能利用iframe数据进行多页抓取已经足够了,多页的优势在于利用html4.0新标签新内容来爬取的容易性。
不会存在浪费html标签和内容方面的问题,单页爬取更方便用于增加单页站内容,如页数众多的站,每个页数多达数千个,但是由于蜘蛛爬取主要是爬取每个页面的内容,各个页面的内容往往会存在冗余,除了对每个页面来爬取和判断,也可以遍历数千页面的所有页面来进行处理。iframe其实应该是一个模拟页面的一个frame,但是iframe在目前有不少问题。
数据处理方面问题较多。首先是内容表现,iframe没有规范,一般浏览器都会有iframe的样式参数,单个iframe只支持内嵌400kb+的内容,而且样式时好时坏,复杂内容表现不好,复杂html因为宽度限制,iframe嵌套之后,页面就会变得非常大,很多做爬虫的编程人员,会发现浏览器每次都会分段处理iframe,导致表现非常差,已经支持512k字节就满足不了爬虫。
其次是存储,很多爬虫都是数据读写一起处理的,往往一次写入一个页面的内容到内存中,造成一个页面内容占用很多内存,影响性能。实现爬虫,就是基于页面和页面内容的设计思想,写什么页面页面,关键点就是response对象,浏览器获取页面就可以利用response对象进行爬取。就爬虫处理方面,现在很多人采用对象+数据库来存储数据,往往对象比较特殊,数据非结构化,比如很多行业名称都会用网页的class,如qa-a-blablabla,爬虫处理起来比较麻烦,很多情况不得不写完整html页面内容才能抓取。
有人说,我们用db存储,不就是把abc变成abc-pbc==p,和爬虫的json字符串爬取操作一致了么,不是很轻松么。当然,还是有很多人解决了这个问题,大家可以了解下这个抓取知识框架:代码和数据访问方式直接跟着那个response.json进行链接参数转换处理,要是不懂请自行阅读以下入门教程。我曾经采用python处理iframe和db2,感觉有点复杂,有没有简单的爬虫呢,我个人觉得,是有的,相信很多人都能实现,拿我的代码来举例子:frombs4importbeautifulsoupimportrequestsimportreimporttimeimportthreadingimportpandasaspdfromipython.displayimportimageimportjsonimporttimeimport。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据多页的优势在于利用html4数据)
js爬虫抓取网页数据,网页总共500页,有限,各类数据也有区别,网页也是分为多个区域的,比如上面例子中,就会出现iframe/html等不同区域,就像我们知道的,大部分用户首页不会访问到相关信息,只能通过浏览器其它页面来爬取了,这就相当于爬虫强制访问之前的单页,单页数据量就非常有限,所以能利用iframe数据进行多页抓取已经足够了,多页的优势在于利用html4.0新标签新内容来爬取的容易性。
不会存在浪费html标签和内容方面的问题,单页爬取更方便用于增加单页站内容,如页数众多的站,每个页数多达数千个,但是由于蜘蛛爬取主要是爬取每个页面的内容,各个页面的内容往往会存在冗余,除了对每个页面来爬取和判断,也可以遍历数千页面的所有页面来进行处理。iframe其实应该是一个模拟页面的一个frame,但是iframe在目前有不少问题。
数据处理方面问题较多。首先是内容表现,iframe没有规范,一般浏览器都会有iframe的样式参数,单个iframe只支持内嵌400kb+的内容,而且样式时好时坏,复杂内容表现不好,复杂html因为宽度限制,iframe嵌套之后,页面就会变得非常大,很多做爬虫的编程人员,会发现浏览器每次都会分段处理iframe,导致表现非常差,已经支持512k字节就满足不了爬虫。
其次是存储,很多爬虫都是数据读写一起处理的,往往一次写入一个页面的内容到内存中,造成一个页面内容占用很多内存,影响性能。实现爬虫,就是基于页面和页面内容的设计思想,写什么页面页面,关键点就是response对象,浏览器获取页面就可以利用response对象进行爬取。就爬虫处理方面,现在很多人采用对象+数据库来存储数据,往往对象比较特殊,数据非结构化,比如很多行业名称都会用网页的class,如qa-a-blablabla,爬虫处理起来比较麻烦,很多情况不得不写完整html页面内容才能抓取。
有人说,我们用db存储,不就是把abc变成abc-pbc==p,和爬虫的json字符串爬取操作一致了么,不是很轻松么。当然,还是有很多人解决了这个问题,大家可以了解下这个抓取知识框架:代码和数据访问方式直接跟着那个response.json进行链接参数转换处理,要是不懂请自行阅读以下入门教程。我曾经采用python处理iframe和db2,感觉有点复杂,有没有简单的爬虫呢,我个人觉得,是有的,相信很多人都能实现,拿我的代码来举例子:frombs4importbeautifulsoupimportrequestsimportreimporttimeimportthreadingimportpandasaspdfromipython.displayimportimageimportjsonimporttimeimport。
js 爬虫抓取网页数据(这是JS、CSS、JSON文件,robots屏蔽依然抓取的情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-21 07:01
这是一个存在多年、经常出现但一直没有标准解决方案的问题:搜索引擎爬虫(尤其是百度)爬取JS、CSS、JSON文件,robots块依然爬取。
这导致了几个问题:
1、爬虫抓取JS、CSS是干什么的?
2、爬虫能否执行JS?
3、爬虫抓取JS对SEO有什么影响?
针对以上问题,我谈谈我的看法:
第一个是爬虫抓取CSS来判断页面元素的重要性,保证快照展示的完整性;抓取JS寻找新链接,判断是否有作弊
其次,JS会被执行,但不确定是否所有的JS都会被执行。就像网上很多人说的,“搜索引擎会直接忽略JS、iframe等,只抓取纯文本信息”。这从实际情况来看是站不住脚的。如果搜索引擎不是JS和iframes的鸟,那对一些搞黑帽子的同学来说不是很酷吗?(不明白为什么很酷?请阅读前两篇关于黑帽的文章文章,你就会明白!)
第三,我不知道这个。在某些情况下,可能会占用爬网配额。但是,少数有蜘蛛爬JS的站点的流量没有异常。
说起来,我现在的工作站在上半年就有这种情况。百度疯狂抓json,机器人屏蔽各种无效。但是,没有出现流量下降等异常情况。本来,我的心理承受能力是根本。这种情况我不关心┏(゜ω゜)=☞,但是查看json爬取率真的让我很紧张,接近40%,对,你没看错,40%,假设百度一天抓到100 万页,400,000 是 json 的东西。
然后我发现日志中百度的抓取总量和百度站长工具的抓取频率不一样。经过多次检查,发现日志中的爬取总量=百度工具的爬取频率+日志中json的爬取次数。总金额。也就是说,对于百度给出的爬取频率数据,爬取json的部分不计算在内,相当于一次奖励爬取。从这个角度来看,它应该对SEO没有影响。没有占用爬取配额的问题,但是爬取比总是很痛苦,我决定解决这个情况。
经过排查,发现有些页面收录一个功能:当页面被请求时,首先判断访问用户是否登录,如果登录,则返回历史记录中用户访问过的其他产品,如果没有登录,则返回指定的内容。返回的内容转换成json文件(没错,就是百度狂抢的),然后传给前端js,js解析json文件,在前端界面显示解析出来的json数据。
使用异步加载。从业务逻辑上来看,如果页面的访问者没有执行这个js,就说明页面没有加载完成。
json路径在js中是纯文本写的。不知道百度是识别json路径还是执行js。不管怎样,只要抓取一个收录这个函数的页面,它就会顺便抓取对应的json文件。
综上所述,有两种预定的解决方案:
第一种是直接删除这个函数对应的JS
二是面对搜索引擎访问,不返回这个js。所以蜘蛛根本看不到它,所以它不会抓住它。
最后因为这个功能上线一个多月了,但是数据表现差,点击率低,我直接砍掉了这个功能.......然后第二天就在看log,json爬取量为0.。....
-------------------------------------------------- --------------------------- 查看全部
js 爬虫抓取网页数据(这是JS、CSS、JSON文件,robots屏蔽依然抓取的情况)
这是一个存在多年、经常出现但一直没有标准解决方案的问题:搜索引擎爬虫(尤其是百度)爬取JS、CSS、JSON文件,robots块依然爬取。
这导致了几个问题:
1、爬虫抓取JS、CSS是干什么的?
2、爬虫能否执行JS?
3、爬虫抓取JS对SEO有什么影响?
针对以上问题,我谈谈我的看法:
第一个是爬虫抓取CSS来判断页面元素的重要性,保证快照展示的完整性;抓取JS寻找新链接,判断是否有作弊
其次,JS会被执行,但不确定是否所有的JS都会被执行。就像网上很多人说的,“搜索引擎会直接忽略JS、iframe等,只抓取纯文本信息”。这从实际情况来看是站不住脚的。如果搜索引擎不是JS和iframes的鸟,那对一些搞黑帽子的同学来说不是很酷吗?(不明白为什么很酷?请阅读前两篇关于黑帽的文章文章,你就会明白!)
第三,我不知道这个。在某些情况下,可能会占用爬网配额。但是,少数有蜘蛛爬JS的站点的流量没有异常。
说起来,我现在的工作站在上半年就有这种情况。百度疯狂抓json,机器人屏蔽各种无效。但是,没有出现流量下降等异常情况。本来,我的心理承受能力是根本。这种情况我不关心┏(゜ω゜)=☞,但是查看json爬取率真的让我很紧张,接近40%,对,你没看错,40%,假设百度一天抓到100 万页,400,000 是 json 的东西。
然后我发现日志中百度的抓取总量和百度站长工具的抓取频率不一样。经过多次检查,发现日志中的爬取总量=百度工具的爬取频率+日志中json的爬取次数。总金额。也就是说,对于百度给出的爬取频率数据,爬取json的部分不计算在内,相当于一次奖励爬取。从这个角度来看,它应该对SEO没有影响。没有占用爬取配额的问题,但是爬取比总是很痛苦,我决定解决这个情况。
经过排查,发现有些页面收录一个功能:当页面被请求时,首先判断访问用户是否登录,如果登录,则返回历史记录中用户访问过的其他产品,如果没有登录,则返回指定的内容。返回的内容转换成json文件(没错,就是百度狂抢的),然后传给前端js,js解析json文件,在前端界面显示解析出来的json数据。
使用异步加载。从业务逻辑上来看,如果页面的访问者没有执行这个js,就说明页面没有加载完成。
json路径在js中是纯文本写的。不知道百度是识别json路径还是执行js。不管怎样,只要抓取一个收录这个函数的页面,它就会顺便抓取对应的json文件。
综上所述,有两种预定的解决方案:
第一种是直接删除这个函数对应的JS
二是面对搜索引擎访问,不返回这个js。所以蜘蛛根本看不到它,所以它不会抓住它。
最后因为这个功能上线一个多月了,但是数据表现差,点击率低,我直接砍掉了这个功能.......然后第二天就在看log,json爬取量为0.。....
-------------------------------------------------- ---------------------------
js 爬虫抓取网页数据(这是JS、CSS、JSON文件,robots屏蔽依然抓取的情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-21 05:48
这是一个存在多年、经常出现但一直没有标准解决方案的问题:搜索引擎爬虫(尤其是百度)爬取JS、CSS、JSON文件,robots块依然爬取。
这导致了几个问题:
1、爬虫抓取JS、CSS是干什么的?
2、爬虫能否执行JS?
3、爬虫抓取JS对SEO有什么影响?
针对以上问题,我谈谈我的看法:
第一个是爬虫抓取CSS来判断页面元素的重要性,保证快照展示的完整性;抓取JS寻找新链接,判断是否有作弊
其次,JS会被执行,但不确定是否所有的JS都会被执行。就像网上很多人说的,“搜索引擎会直接忽略JS、iframe等,只抓取纯文本信息”。这从实际情况来看是站不住脚的。如果搜索引擎不是JS和iframes的鸟,那对一些搞黑帽子的同学来说不是很酷吗?(不明白为什么很酷?请阅读前两篇关于黑帽的文章文章,你就会明白!)
第三,我不知道这个。在某些情况下,可能会占用爬网配额。但是,少数有蜘蛛爬JS的站点的流量没有异常。
说起来,我现在的工作站在上半年就有这种情况。百度疯狂抓json,机器人屏蔽各种无效。但是,没有出现流量下降等异常情况。本来,我的心理承受能力是根本。这种情况我不关心┏(゜ω゜)=☞,但是查看json爬取率真的让我很紧张,接近40%,对,你没看错,40%,假设百度一天抓到100 万页,400,000 是 json 的东西。
然后我发现日志中百度的抓取总量和百度站长工具的抓取频率不一样。经过多次检查,发现日志中的爬取总量=百度工具的爬取频率+日志中json的爬取次数。总金额。也就是说,对于百度给出的爬取频率数据,爬取json的部分不计算在内,相当于一次奖励爬取。从这个角度来看,它应该对SEO没有影响。没有占用爬取配额的问题,但是爬取比总是很痛苦,我决定解决这个情况。
经过排查,发现有些页面收录一个功能:当页面被请求时,首先判断访问用户是否登录,如果登录,则返回历史记录中用户访问过的其他产品,如果没有登录,则返回指定的内容。返回的内容转换成json文件(没错,就是百度狂抢的),然后传给前端js,js解析json文件,在前端界面显示解析出来的json数据。
使用异步加载。从业务逻辑上来看,如果页面的访问者没有执行这个js,就说明页面没有加载完成。
json路径在js中是纯文本写的。不知道百度是识别json路径还是执行js。不管怎样,只要抓取一个收录这个函数的页面,它就会顺便抓取对应的json文件。
综上所述,有两种预定的解决方案:
第一种是直接删除这个函数对应的JS
二是面对搜索引擎访问,不返回这个js。所以蜘蛛根本看不到它,所以它不会抓住它。
最后因为这个功能上线一个多月了,但是数据表现差,点击率低,我直接砍掉了这个功能.......然后第二天就在看log,json爬取量为0.。....
-------------------------------------------------- --------------------------- 查看全部
js 爬虫抓取网页数据(这是JS、CSS、JSON文件,robots屏蔽依然抓取的情况)
这是一个存在多年、经常出现但一直没有标准解决方案的问题:搜索引擎爬虫(尤其是百度)爬取JS、CSS、JSON文件,robots块依然爬取。
这导致了几个问题:
1、爬虫抓取JS、CSS是干什么的?
2、爬虫能否执行JS?
3、爬虫抓取JS对SEO有什么影响?
针对以上问题,我谈谈我的看法:
第一个是爬虫抓取CSS来判断页面元素的重要性,保证快照展示的完整性;抓取JS寻找新链接,判断是否有作弊
其次,JS会被执行,但不确定是否所有的JS都会被执行。就像网上很多人说的,“搜索引擎会直接忽略JS、iframe等,只抓取纯文本信息”。这从实际情况来看是站不住脚的。如果搜索引擎不是JS和iframes的鸟,那对一些搞黑帽子的同学来说不是很酷吗?(不明白为什么很酷?请阅读前两篇关于黑帽的文章文章,你就会明白!)
第三,我不知道这个。在某些情况下,可能会占用爬网配额。但是,少数有蜘蛛爬JS的站点的流量没有异常。
说起来,我现在的工作站在上半年就有这种情况。百度疯狂抓json,机器人屏蔽各种无效。但是,没有出现流量下降等异常情况。本来,我的心理承受能力是根本。这种情况我不关心┏(゜ω゜)=☞,但是查看json爬取率真的让我很紧张,接近40%,对,你没看错,40%,假设百度一天抓到100 万页,400,000 是 json 的东西。
然后我发现日志中百度的抓取总量和百度站长工具的抓取频率不一样。经过多次检查,发现日志中的爬取总量=百度工具的爬取频率+日志中json的爬取次数。总金额。也就是说,对于百度给出的爬取频率数据,爬取json的部分不计算在内,相当于一次奖励爬取。从这个角度来看,它应该对SEO没有影响。没有占用爬取配额的问题,但是爬取比总是很痛苦,我决定解决这个情况。
经过排查,发现有些页面收录一个功能:当页面被请求时,首先判断访问用户是否登录,如果登录,则返回历史记录中用户访问过的其他产品,如果没有登录,则返回指定的内容。返回的内容转换成json文件(没错,就是百度狂抢的),然后传给前端js,js解析json文件,在前端界面显示解析出来的json数据。
使用异步加载。从业务逻辑上来看,如果页面的访问者没有执行这个js,就说明页面没有加载完成。
json路径在js中是纯文本写的。不知道百度是识别json路径还是执行js。不管怎样,只要抓取一个收录这个函数的页面,它就会顺便抓取对应的json文件。
综上所述,有两种预定的解决方案:
第一种是直接删除这个函数对应的JS
二是面对搜索引擎访问,不返回这个js。所以蜘蛛根本看不到它,所以它不会抓住它。
最后因为这个功能上线一个多月了,但是数据表现差,点击率低,我直接砍掉了这个功能.......然后第二天就在看log,json爬取量为0.。....
-------------------------------------------------- ---------------------------
js 爬虫抓取网页数据(谷歌能DOM是什么?Google不能是如何抓取Java的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-20 15:13
编译:伯乐在线/刘建超-Jc
我们测试了 Google 爬虫如何抓取 Java,这是我们从中学到的东西。
认为 Google 无法处理 Java?再想想。Audette Audette 分享了一系列测试结果,他和他的同事测试了 Google 和 收录 会抓取哪些类型的 Java 特性。
长话短说
1. 我们进行了一系列的测试,已经确认 Google 可以以多种方式执行和 收录 Java。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 Java 并读取 DOM
早在 2008 年,Google 就成功爬取了 Java,但很可能仅限于某种方式。
今天,谷歌显然不仅可以制定他们抓取的Java类型和收录,而且在渲染整个网页方面也取得了重大进展(尤其是最近12到18个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaS 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 Java 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该界面允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Java 和 Web 应用程序中的动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 Java 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
Java 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取什么Java特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
Java重定向
Java链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要例子
示例:用于测试 Google 爬虫理解 Java 能力的页面。
1. Java 重定向
我们首先测试了常见的 Java 重定向。以不同方式表达的 URL 会发生什么变化?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 Java 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,Java 重定向行为(有时)与永久 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 Java 重定向操作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌指南支持这一结论:
使用 Java 重定向用户可能是一种合法的做法。例如,如果将登录用户重定向到内部页面,则可以使用 Java 来完成此操作。在仔细检查 Java 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 Java 重定向。
2. Java 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面Java重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 Java 链接。以下是最常见的 Java 链接类型,而传统 SEO 推荐纯文本。这些测试包括 Java 链接代码:
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行Java,但是我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码之外(在外部Java文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用Java编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 Java 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果呢?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签会发生什么?在这个协议中,HTTP x-robots 响应头的行为如何作为另一个变量?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试源代码和DOM生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改DOM中href元素的操作发生得太晚了:谷歌在执行添加rel="nofollow"的Java函数之前,已经准备好抓取链接和URL队列。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 Java 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。Java 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。
觉得这篇文章对你有帮助吗?请分享给更多人 查看全部
js 爬虫抓取网页数据(谷歌能DOM是什么?Google不能是如何抓取Java的)
编译:伯乐在线/刘建超-Jc
我们测试了 Google 爬虫如何抓取 Java,这是我们从中学到的东西。
认为 Google 无法处理 Java?再想想。Audette Audette 分享了一系列测试结果,他和他的同事测试了 Google 和 收录 会抓取哪些类型的 Java 特性。
长话短说
1. 我们进行了一系列的测试,已经确认 Google 可以以多种方式执行和 收录 Java。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 Java 并读取 DOM
早在 2008 年,Google 就成功爬取了 Java,但很可能仅限于某种方式。
今天,谷歌显然不仅可以制定他们抓取的Java类型和收录,而且在渲染整个网页方面也取得了重大进展(尤其是最近12到18个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaS 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 Java 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该界面允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Java 和 Web 应用程序中的动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 Java 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
Java 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取什么Java特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
Java重定向
Java链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要例子
示例:用于测试 Google 爬虫理解 Java 能力的页面。
1. Java 重定向
我们首先测试了常见的 Java 重定向。以不同方式表达的 URL 会发生什么变化?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 Java 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,Java 重定向行为(有时)与永久 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 Java 重定向操作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌指南支持这一结论:
使用 Java 重定向用户可能是一种合法的做法。例如,如果将登录用户重定向到内部页面,则可以使用 Java 来完成此操作。在仔细检查 Java 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 Java 重定向。
2. Java 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面Java重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 Java 链接。以下是最常见的 Java 链接类型,而传统 SEO 推荐纯文本。这些测试包括 Java 链接代码:
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行Java,但是我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码之外(在外部Java文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用Java编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 Java 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果呢?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签会发生什么?在这个协议中,HTTP x-robots 响应头的行为如何作为另一个变量?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试源代码和DOM生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改DOM中href元素的操作发生得太晚了:谷歌在执行添加rel="nofollow"的Java函数之前,已经准备好抓取链接和URL队列。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 Java 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。Java 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。
觉得这篇文章对你有帮助吗?请分享给更多人
js 爬虫抓取网页数据(正则10.0.151(chromev7.5.1.31731))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-19 14:02
js爬虫抓取网页数据,在很多情况下都需要借助app或者https包下载对应html代码,那么如何按时抓取就变得十分关键了,大家都知道利用浏览器提供的jsapi可以抓取网页数据,但是有时候并不能完全抓取出正确的html代码,所以我们就需要一种正则表达式解析app的html并抓取返回json数据(github下载方式随意,只要能下就行),那么正则表达式就不能用chromeat来下载,因为chromeedge是要求f12浏览器,而且一般没有支持正则表达式抓取app数据的服务,但如果我们用手机app的微信也可以下载到正确的数据吗?答案是可以的。
so在解决我们需要抓取正确的app数据,需要去其官网可以免费下载数据googleappengine+谷歌浏览器(chrome,firefox)版本的数据,官网文章如下谷歌在10月16日发布了最新的版本chrome10.0.1074.151(chromev7.5.1.31731)中引入了webkit-transformapi在正则表达式中将获取超文本数据的简单方法用在微信中,需要开发者工具同时支持,如下如何使用python写出下面的代码来加快解析速度,可以参考这篇文章下载器下载软件/。
不可以,刚好反过来,这些app上都有它们的访问url,这个也是json序列化存储的一种,有ftp,ftp工具一般默认tcp的模式,在用正则在xsb上解析数据, 查看全部
js 爬虫抓取网页数据(正则10.0.151(chromev7.5.1.31731))
js爬虫抓取网页数据,在很多情况下都需要借助app或者https包下载对应html代码,那么如何按时抓取就变得十分关键了,大家都知道利用浏览器提供的jsapi可以抓取网页数据,但是有时候并不能完全抓取出正确的html代码,所以我们就需要一种正则表达式解析app的html并抓取返回json数据(github下载方式随意,只要能下就行),那么正则表达式就不能用chromeat来下载,因为chromeedge是要求f12浏览器,而且一般没有支持正则表达式抓取app数据的服务,但如果我们用手机app的微信也可以下载到正确的数据吗?答案是可以的。
so在解决我们需要抓取正确的app数据,需要去其官网可以免费下载数据googleappengine+谷歌浏览器(chrome,firefox)版本的数据,官网文章如下谷歌在10月16日发布了最新的版本chrome10.0.1074.151(chromev7.5.1.31731)中引入了webkit-transformapi在正则表达式中将获取超文本数据的简单方法用在微信中,需要开发者工具同时支持,如下如何使用python写出下面的代码来加快解析速度,可以参考这篇文章下载器下载软件/。
不可以,刚好反过来,这些app上都有它们的访问url,这个也是json序列化存储的一种,有ftp,ftp工具一般默认tcp的模式,在用正则在xsb上解析数据,
js 爬虫抓取网页数据(这篇文章主要介绍了的相关资料,DOM化并解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-19 13:10
本文文章主要介绍nodejs爬虫爬取数据编码问题的相关信息。有需要的朋友可以参考以下
当cheerio被DOM化和解析
1.如果使用.text()方法,一般不会出现html实体编码问题
2. 如果使用 .html() 方法,很多情况下都会出现(主要是非英文的时候)。这个时候,可能就需要转义了。
类似这些因为需要数据存储,都需要进行转换
复制代码代码如下:
Халк крушит。Новый способ исполнен
大部分都是(x)?\w+的格式
所以只需使用常规转换
var body = ....//这里就是请求后获得的返回数据,或者那些 .html()后获取的 //一般可以先转换为标准unicode格式(有需要就添加:当返回的数据呈现太多\\\u 之类的时) body=unescape(body.replace(/\\u/g,"%u")); //再对实体符进行转义 //有x则表示是16进制,$1就是匹配是否有x ,$2就是匹配出的第二个括号捕获到的内容,将$2以对应进制表示转换 body = body.replace(/&#(x)?(\w+);/g,function($,$1,$2){ return String.fromCharCode(parseInt($2,$1?16:10)); });
好的~
当然,网上有很多转换版本,申请就好
后记:
使用爬虫抓取网页数据时,经常用到cheerio模块到最后,和jq一样方便快捷
(但是有些功能不支持或者改成某种形式,比如jq的jQuery('.myClass').prop('outerHTML'),cheerio就相当于jQuery.html('.myClass'))
以上就是nodejs爬虫爬取数据编码问题的详细内容。更多信息请关注其他相关html中文网站文章! 查看全部
js 爬虫抓取网页数据(这篇文章主要介绍了的相关资料,DOM化并解析)
本文文章主要介绍nodejs爬虫爬取数据编码问题的相关信息。有需要的朋友可以参考以下
当cheerio被DOM化和解析
1.如果使用.text()方法,一般不会出现html实体编码问题
2. 如果使用 .html() 方法,很多情况下都会出现(主要是非英文的时候)。这个时候,可能就需要转义了。
类似这些因为需要数据存储,都需要进行转换
复制代码代码如下:
Халк крушит。Новый способ исполнен
大部分都是(x)?\w+的格式
所以只需使用常规转换
var body = ....//这里就是请求后获得的返回数据,或者那些 .html()后获取的 //一般可以先转换为标准unicode格式(有需要就添加:当返回的数据呈现太多\\\u 之类的时) body=unescape(body.replace(/\\u/g,"%u")); //再对实体符进行转义 //有x则表示是16进制,$1就是匹配是否有x ,$2就是匹配出的第二个括号捕获到的内容,将$2以对应进制表示转换 body = body.replace(/&#(x)?(\w+);/g,function($,$1,$2){ return String.fromCharCode(parseInt($2,$1?16:10)); });
好的~
当然,网上有很多转换版本,申请就好
后记:
使用爬虫抓取网页数据时,经常用到cheerio模块到最后,和jq一样方便快捷
(但是有些功能不支持或者改成某种形式,比如jq的jQuery('.myClass').prop('outerHTML'),cheerio就相当于jQuery.html('.myClass'))
以上就是nodejs爬虫爬取数据编码问题的详细内容。更多信息请关注其他相关html中文网站文章!
js 爬虫抓取网页数据(新浪新闻国内新闻页静态网页数据在函数中的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-18 10:26
昨天,一个朋友来找我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
但是发现有个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\\,标题和介绍都是\u4e09的形式。这些是我们需要处理的后续步骤!
先用replace函数去掉url中的\\,就可以得到url了,下面的\u4e09是unicode编码,可以直接解码内容,直接写代码
使用eval函数进行解码,可以以u"+unicode编码内容+"!
这样就把这个页面上所有的新闻和URL相关的内容都取出来了,在外层加上循环来爬取所有的新闻页面,任务就完成了!
后记
新浪新闻的页面js功能比较简单,可以直接抓取数据。如果是比较复杂的功能,就需要了解前端知识。这就是学习爬虫需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,你可以直接百度找很多,当然你也可以直接修改上面抓包的内容,然后用json读取数据!
基本代码不多。有看不清楚的小伙伴可以私信我索取代码或者一起研究爬虫! 查看全部
js 爬虫抓取网页数据(新浪新闻国内新闻页静态网页数据在函数中的应用)
昨天,一个朋友来找我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
但是发现有个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\\,标题和介绍都是\u4e09的形式。这些是我们需要处理的后续步骤!
先用replace函数去掉url中的\\,就可以得到url了,下面的\u4e09是unicode编码,可以直接解码内容,直接写代码
使用eval函数进行解码,可以以u"+unicode编码内容+"!
这样就把这个页面上所有的新闻和URL相关的内容都取出来了,在外层加上循环来爬取所有的新闻页面,任务就完成了!
后记
新浪新闻的页面js功能比较简单,可以直接抓取数据。如果是比较复杂的功能,就需要了解前端知识。这就是学习爬虫需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,你可以直接百度找很多,当然你也可以直接修改上面抓包的内容,然后用json读取数据!
基本代码不多。有看不清楚的小伙伴可以私信我索取代码或者一起研究爬虫!
js 爬虫抓取网页数据(如何利用Webkit从渲染网页中获取数据中所有档案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-17 20:05
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页中收录 JavaScript 代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想每周抓取Pycoders中所有文件的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
importrequests
fromlxmlimporthtml
#storingresponsere
sponse=requests.get('http://pycoders.com/archive')
#creatinglxmltreefromresponsebody
tree=html.fromstring(response.text)
#Findingallanchortagsinresponse
printtree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
sudoapt-getinstallpython-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
importsys
fromPyQt4.QtGuiimport*
fromPyQt4.Qtcoreimport*
fromPyQt4.QtWebKitimport*
classRender(QWebPage):
def__init__(self,url):
self.app=QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame.load(QUrl(url))
self.app.exec_
def_loadFinished(self,result):
self.frame=self.mainFrame
self.app.quit
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载URL中的所有信息并将其存储在一个新的框架中。
url='http://pycoders.com/archive/'
#Thisdoesthemagic.Loadseverything
r=Render(url)
#ResultisaQString.
result=r.frame.toHtml
使用上面的代码,我们将 HTML 结果存储在变量 result 中。由于lxml不能直接处理特殊的字符串数据,我们需要对数据格式进行转换。
#QStringshouldbeconvertedtostringbeforeprocessedbylxml
formatted_result=str(result.toAscii)
#Nextbuildlxmltreefromformatted_result
tree=html.fromstring(formatted_result)
#NowusingcorrectXpathwearefetchingURLofarchives
archive_links=tree.xpath('//div[@class="campaign"]/a/@href')
printarchive_links
使用上面的代码,我们可以得到所有的文件链接信息,然后我们就可以使用这些Render和这些URL链接来提取文本内容信息了。Web kit提供了一个强大的网页渲染工具,我们可以利用这个工具从JS渲染的网页中抓取有效的信息。
在本文中,我介绍了一种从 JS 渲染的网页中抓取信息的有效方法。虽然这个工具很慢,但它非常简单和粗鲁。我希望你会喜欢这个文章。现在,您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。
原文链接: 查看全部
js 爬虫抓取网页数据(如何利用Webkit从渲染网页中获取数据中所有档案)
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页中收录 JavaScript 代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想每周抓取Pycoders中所有文件的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
importrequests
fromlxmlimporthtml
#storingresponsere
sponse=requests.get('http://pycoders.com/archive')
#creatinglxmltreefromresponsebody
tree=html.fromstring(response.text)
#Findingallanchortagsinresponse
printtree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
sudoapt-getinstallpython-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
importsys
fromPyQt4.QtGuiimport*
fromPyQt4.Qtcoreimport*
fromPyQt4.QtWebKitimport*
classRender(QWebPage):
def__init__(self,url):
self.app=QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame.load(QUrl(url))
self.app.exec_
def_loadFinished(self,result):
self.frame=self.mainFrame
self.app.quit
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载URL中的所有信息并将其存储在一个新的框架中。
url='http://pycoders.com/archive/'
#Thisdoesthemagic.Loadseverything
r=Render(url)
#ResultisaQString.
result=r.frame.toHtml
使用上面的代码,我们将 HTML 结果存储在变量 result 中。由于lxml不能直接处理特殊的字符串数据,我们需要对数据格式进行转换。
#QStringshouldbeconvertedtostringbeforeprocessedbylxml
formatted_result=str(result.toAscii)
#Nextbuildlxmltreefromformatted_result
tree=html.fromstring(formatted_result)
#NowusingcorrectXpathwearefetchingURLofarchives
archive_links=tree.xpath('//div[@class="campaign"]/a/@href')
printarchive_links
使用上面的代码,我们可以得到所有的文件链接信息,然后我们就可以使用这些Render和这些URL链接来提取文本内容信息了。Web kit提供了一个强大的网页渲染工具,我们可以利用这个工具从JS渲染的网页中抓取有效的信息。
在本文中,我介绍了一种从 JS 渲染的网页中抓取信息的有效方法。虽然这个工具很慢,但它非常简单和粗鲁。我希望你会喜欢这个文章。现在,您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。
原文链接:
js 爬虫抓取网页数据( js动态加载的数据一一给抓下来了,简单粗暴直接抓取失败 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-17 20:05
js动态加载的数据一一给抓下来了,简单粗暴直接抓取失败
)
如何绕过登录和抓取js动态加载网页数据[Python]
时间:2018-11-24 ┊阅读:2,670 次┊ 标签:开发、编程、体验
今天折腾了很多,把需要登录网站的数据和js动态加载的数据一一抓取。
首先,登录时有cookie,我们需要保存cookie,并在用urllib2构造请求时添加头信息。这时候多了一点,编造了浏览器信息,让服务器认为是普通浏览器发起的请求。绕过简单的反爬虫策略。
我用cookies登录完成后,发现网页被js动态加载了,抓取失败!
我搜索了一下,发现了两种方法:
使用工具,构建webdriver,使用chrome或firefox打开网页,但缺点是效率太低。分析网页加载过程,通过响应信息找到网页加载时调用的api或服务地址。这样比较麻烦和麻烦。
在几十个请求中,终于找到了后台加载数据服务的地址,找到了pattern,然后用id拼接完整的地址来构造请求。
服务端返回的数据竟然不是json数据,而是xml。我很快研究了xml解析方法。我选择了minidom来解析,感觉很舒服。
然后我遇到了空标签的问题。当网页没有评论时,当标签为空时,会报错,因为直接访问列表时,会报out of index错误。简单粗暴,直接尝试然后跳过。
抓到的数据写入csv,下载的附件保存在id创建的小文件夹中。
时间格式化,打印出收录毫秒的长时字符,与机器人测试工具的输出提示一致。
最后删除中间生成的临时xml文件。哈哈
代码:
#!/usr/bin/python
# -*- coding:utf-8 -*-
import urllib2
import xml.dom.minidom
import os
import csv
import time
def get_timestamp():
ct = time.time()
local_time = time.localtime(ct)
time_head = time.strftime("%Y%m%d %H:%M:%S", local_time)
time_secs = (ct - long(ct)) * 1000
timestamp = "%s.d" % (time_head, time_secs)
return timestamp
# create request user-agent header
userAgent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
cookie = '...0000Y3Pwq2s9BdZn8e0zpTDmkVv:-1...'
uaHeaders = {'User-Agent': userAgent, 'Cookie': cookie}
# item url string connection
itemUrlHead = "https://api.amkevin.com:8888/c ... ot%3B
itemUrlId = "99999"
itemUrlTail = "&projectAreaItemId=_hnbI8sMnEeSExMMeBFetbg"
itemUrl = itemUrlHead + itemUrlId + itemUrlTail
# send request with user-agent header
request = urllib2.Request(itemUrl, headers=uaHeaders)
response = urllib2.urlopen(request)
xmlResult = response.read()
# prepare the xml file
curPath = os.getcwd()
curXml = curPath + '/' + itemUrlId + '.xml'
if os.path.exists(curXml):
os.remove(curXml)
curAttObj = open(curXml, 'w')
curAttObj.write(xmlResult)
curAttObj.close()
# print xmlItem
# parse response xml file
DOMTree = xml.dom.minidom.parse(curXml)
xmlDom = DOMTree.documentElement
# prepare write to csv
csvHeader = ["ID", "Creator", "Creator UserID", "Comment Content", "Creation Date"]
csvRow = []
csvCmtOneFile = curPath + '/rtcComment.csv'
if not os.path.exists(csvCmtOneFile):
csvObj = open(csvCmtOneFile, 'w')
csvWriter = csv.writer(csvObj)
csvWriter.writerow(csvHeader)
csvObj.close()
# get comments & write to csv file
items = xmlDom.getElementsByTagName("items")
for item in items:
try:
if item.hasAttribute("xsi:type"):
curItem = item.getAttribute("xsi:type")
if curItem == "workitem.restDTO:CommentDTO":
curCommentContent = item.getElementsByTagName("content")[0].childNodes[0].data
curCommentContent = curCommentContent.replace('', '')
curCommentContent = curCommentContent.replace('', '')
curCommentCreationDate = item.getElementsByTagName("creationDate")[0].childNodes[0].data
curCommentCreator = item.getElementsByTagName("creator")[0]
curCommentCreatorName = curCommentCreator.getElementsByTagName("name")[0].childNodes[0].data
curCommentCreatorId = curCommentCreator.getElementsByTagName("userId")[0].childNodes[0].data
csvRow = []
csvRow.append(itemUrlId)
csvRow.append(curCommentCreatorName)
csvRow.append(curCommentCreatorId)
csvRow.append(curCommentContent)
csvRow.append(curCommentCreationDate)
csvObj = open(csvCmtOneFile, 'a')
csvWriter = csv.writer(csvObj)
csvWriter.writerow(csvRow)
csvObj.close()
# save the attachment file to local dir
curAttFile = curPath + '/' + itemUrlId
if not os.path.exists(curAttFile):
os.mkdir(curAttFile)
curAttFile = curPath + '/' + itemUrlId + '/' + itemUrlId + '.csv'
if os.path.exists(curAttFile):
curCsvObj = open(curAttFile, 'a')
curCsvWriter = csv.writer(curCsvObj)
curCsvWriter.writerow(csvRow)
else:
curCsvObj = open(curAttFile, 'w')
curCsvWriter = csv.writer(curCsvObj)
curCsvWriter.writerow(csvRow)
curCsvObj.close()
print get_timestamp() + " :" + " INFO :" + " write comments to csv success."
except:
print get_timestamp() + " :" + " INFO :" + " parse xml encountered empty element, skipped."
continue
# get attachment
linkDTOs = xmlDom.getElementsByTagName("linkDTOs")
for linkDTO in linkDTOs:
try:
if linkDTO.getElementsByTagName("target")[0].hasAttribute("xsi:type"):
curAtt = linkDTO.getElementsByTagName("target")[0].getAttribute("xsi:type")
if curAtt == "workitem.restDTO:AttachmentDTO":
curAttUrl = linkDTO.getElementsByTagName("url")[0].childNodes[0].data
curTarget = linkDTO.getElementsByTagName("target")[0]
curAttName = curTarget.getElementsByTagName("name")[0].childNodes[0].data
# save the attachment file to local dir
curAttFolder = curPath + '/' + itemUrlId
if not os.path.exists(curAttFile):
os.mkdir(curAttFolder)
curAttFile = curPath + '/' + itemUrlId + '/' + curAttName
curRequest = urllib2.Request(curAttUrl, headers=uaHeaders)
curResponse = urllib2.urlopen(curRequest)
curAttRes = curResponse.read()
if os.path.exists(curAttFile):
os.remove(curAttFile)
curAttObj = open(curAttFile, 'w')
curAttObj.write(curAttRes)
curAttObj.close()
print get_timestamp() + " :" + " INFO :" + " download attachment [" + curAttName + "] success."
except:
print get_timestamp() + " :" + " INFO :" + " parse xml encountered empty element, skipped."
continue
# print linkDTO
# delete temporary xml file
if os.path.exists(curXml):
os.remove(curXml) 查看全部
js 爬虫抓取网页数据(
js动态加载的数据一一给抓下来了,简单粗暴直接抓取失败
)
如何绕过登录和抓取js动态加载网页数据[Python]
时间:2018-11-24 ┊阅读:2,670 次┊ 标签:开发、编程、体验
今天折腾了很多,把需要登录网站的数据和js动态加载的数据一一抓取。
首先,登录时有cookie,我们需要保存cookie,并在用urllib2构造请求时添加头信息。这时候多了一点,编造了浏览器信息,让服务器认为是普通浏览器发起的请求。绕过简单的反爬虫策略。
我用cookies登录完成后,发现网页被js动态加载了,抓取失败!
我搜索了一下,发现了两种方法:
使用工具,构建webdriver,使用chrome或firefox打开网页,但缺点是效率太低。分析网页加载过程,通过响应信息找到网页加载时调用的api或服务地址。这样比较麻烦和麻烦。
在几十个请求中,终于找到了后台加载数据服务的地址,找到了pattern,然后用id拼接完整的地址来构造请求。
服务端返回的数据竟然不是json数据,而是xml。我很快研究了xml解析方法。我选择了minidom来解析,感觉很舒服。
然后我遇到了空标签的问题。当网页没有评论时,当标签为空时,会报错,因为直接访问列表时,会报out of index错误。简单粗暴,直接尝试然后跳过。
抓到的数据写入csv,下载的附件保存在id创建的小文件夹中。
时间格式化,打印出收录毫秒的长时字符,与机器人测试工具的输出提示一致。
最后删除中间生成的临时xml文件。哈哈
代码:
#!/usr/bin/python
# -*- coding:utf-8 -*-
import urllib2
import xml.dom.minidom
import os
import csv
import time
def get_timestamp():
ct = time.time()
local_time = time.localtime(ct)
time_head = time.strftime("%Y%m%d %H:%M:%S", local_time)
time_secs = (ct - long(ct)) * 1000
timestamp = "%s.d" % (time_head, time_secs)
return timestamp
# create request user-agent header
userAgent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
cookie = '...0000Y3Pwq2s9BdZn8e0zpTDmkVv:-1...'
uaHeaders = {'User-Agent': userAgent, 'Cookie': cookie}
# item url string connection
itemUrlHead = "https://api.amkevin.com:8888/c ... ot%3B
itemUrlId = "99999"
itemUrlTail = "&projectAreaItemId=_hnbI8sMnEeSExMMeBFetbg"
itemUrl = itemUrlHead + itemUrlId + itemUrlTail
# send request with user-agent header
request = urllib2.Request(itemUrl, headers=uaHeaders)
response = urllib2.urlopen(request)
xmlResult = response.read()
# prepare the xml file
curPath = os.getcwd()
curXml = curPath + '/' + itemUrlId + '.xml'
if os.path.exists(curXml):
os.remove(curXml)
curAttObj = open(curXml, 'w')
curAttObj.write(xmlResult)
curAttObj.close()
# print xmlItem
# parse response xml file
DOMTree = xml.dom.minidom.parse(curXml)
xmlDom = DOMTree.documentElement
# prepare write to csv
csvHeader = ["ID", "Creator", "Creator UserID", "Comment Content", "Creation Date"]
csvRow = []
csvCmtOneFile = curPath + '/rtcComment.csv'
if not os.path.exists(csvCmtOneFile):
csvObj = open(csvCmtOneFile, 'w')
csvWriter = csv.writer(csvObj)
csvWriter.writerow(csvHeader)
csvObj.close()
# get comments & write to csv file
items = xmlDom.getElementsByTagName("items")
for item in items:
try:
if item.hasAttribute("xsi:type"):
curItem = item.getAttribute("xsi:type")
if curItem == "workitem.restDTO:CommentDTO":
curCommentContent = item.getElementsByTagName("content")[0].childNodes[0].data
curCommentContent = curCommentContent.replace('', '')
curCommentContent = curCommentContent.replace('', '')
curCommentCreationDate = item.getElementsByTagName("creationDate")[0].childNodes[0].data
curCommentCreator = item.getElementsByTagName("creator")[0]
curCommentCreatorName = curCommentCreator.getElementsByTagName("name")[0].childNodes[0].data
curCommentCreatorId = curCommentCreator.getElementsByTagName("userId")[0].childNodes[0].data
csvRow = []
csvRow.append(itemUrlId)
csvRow.append(curCommentCreatorName)
csvRow.append(curCommentCreatorId)
csvRow.append(curCommentContent)
csvRow.append(curCommentCreationDate)
csvObj = open(csvCmtOneFile, 'a')
csvWriter = csv.writer(csvObj)
csvWriter.writerow(csvRow)
csvObj.close()
# save the attachment file to local dir
curAttFile = curPath + '/' + itemUrlId
if not os.path.exists(curAttFile):
os.mkdir(curAttFile)
curAttFile = curPath + '/' + itemUrlId + '/' + itemUrlId + '.csv'
if os.path.exists(curAttFile):
curCsvObj = open(curAttFile, 'a')
curCsvWriter = csv.writer(curCsvObj)
curCsvWriter.writerow(csvRow)
else:
curCsvObj = open(curAttFile, 'w')
curCsvWriter = csv.writer(curCsvObj)
curCsvWriter.writerow(csvRow)
curCsvObj.close()
print get_timestamp() + " :" + " INFO :" + " write comments to csv success."
except:
print get_timestamp() + " :" + " INFO :" + " parse xml encountered empty element, skipped."
continue
# get attachment
linkDTOs = xmlDom.getElementsByTagName("linkDTOs")
for linkDTO in linkDTOs:
try:
if linkDTO.getElementsByTagName("target")[0].hasAttribute("xsi:type"):
curAtt = linkDTO.getElementsByTagName("target")[0].getAttribute("xsi:type")
if curAtt == "workitem.restDTO:AttachmentDTO":
curAttUrl = linkDTO.getElementsByTagName("url")[0].childNodes[0].data
curTarget = linkDTO.getElementsByTagName("target")[0]
curAttName = curTarget.getElementsByTagName("name")[0].childNodes[0].data
# save the attachment file to local dir
curAttFolder = curPath + '/' + itemUrlId
if not os.path.exists(curAttFile):
os.mkdir(curAttFolder)
curAttFile = curPath + '/' + itemUrlId + '/' + curAttName
curRequest = urllib2.Request(curAttUrl, headers=uaHeaders)
curResponse = urllib2.urlopen(curRequest)
curAttRes = curResponse.read()
if os.path.exists(curAttFile):
os.remove(curAttFile)
curAttObj = open(curAttFile, 'w')
curAttObj.write(curAttRes)
curAttObj.close()
print get_timestamp() + " :" + " INFO :" + " download attachment [" + curAttName + "] success."
except:
print get_timestamp() + " :" + " INFO :" + " parse xml encountered empty element, skipped."
continue
# print linkDTO
# delete temporary xml file
if os.path.exists(curXml):
os.remove(curXml)
js 爬虫抓取网页数据(F12打开网页调试工具:选择“网络”选项卡后,发现有很多响应)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-17 19:20
F12打开网页调试工具:
选择“网络”选项卡后,我们发现有很多响应。让我们过滤一下,看看 XHR 响应。(XHR是Ajax中的一个概念,意思是XMLHTTPrequest)然后发现有很多链接缺失,点一个就可以看到:我们选择city,预览里有一堆json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到我们想要的消息,所以再找找:有焦点,我们点击打开:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
这是照片新闻下的新闻。
我们打开一个接口链接看看:
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:#coding:utf-8
进口请求
导入json
网址='#39;
wbdata=requests.get(url).text
数据=json.loads(wbdata)
新闻=数据['数据']['pc_feed_focus']
新闻资讯:
标题=n['标题']
img_url=n['image_url']
url=n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍#coding: utf-8
进口请求
导入json
第二部分:向数据接口url='发起http请求
wbdata=requests.get(url).text 查看全部
js 爬虫抓取网页数据(F12打开网页调试工具:选择“网络”选项卡后,发现有很多响应)
F12打开网页调试工具:
选择“网络”选项卡后,我们发现有很多响应。让我们过滤一下,看看 XHR 响应。(XHR是Ajax中的一个概念,意思是XMLHTTPrequest)然后发现有很多链接缺失,点一个就可以看到:我们选择city,预览里有一堆json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到我们想要的消息,所以再找找:有焦点,我们点击打开:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
这是照片新闻下的新闻。
我们打开一个接口链接看看:
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:#coding:utf-8
进口请求
导入json
网址='#39;
wbdata=requests.get(url).text
数据=json.loads(wbdata)
新闻=数据['数据']['pc_feed_focus']
新闻资讯:
标题=n['标题']
img_url=n['image_url']
url=n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍#coding: utf-8
进口请求
导入json
第二部分:向数据接口url='发起http请求
wbdata=requests.get(url).text
js 爬虫抓取网页数据( 什么是HTML源码中却发现不了的网页?有两种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-17 19:20
什么是HTML源码中却发现不了的网页?有两种方法)
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。 例如,今天的头条新闻:
浏览器渲染出来的网页是这样的:
今日头条
查看源代码,但看起来是这样的:
HTML 源代码
网页上的新闻在HTML源代码中找不到,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据; 2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中找到JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例说明:
1、找到JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”标签后,我们发现有很多回复。让我们过滤并只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
我们再点一下看看:
原来都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到想要的消息,所以再找一下:
有个焦点,我们点一下看看:
首页图片新闻中呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这应该是热搜关键词
这是照片新闻下的新闻。
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看的是正常编码的数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:
# 编码:utf-8
导入请求
导入json 查看全部
js 爬虫抓取网页数据(
什么是HTML源码中却发现不了的网页?有两种方法)
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。 例如,今天的头条新闻:
浏览器渲染出来的网页是这样的:
今日头条
查看源代码,但看起来是这样的:
HTML 源代码
网页上的新闻在HTML源代码中找不到,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据; 2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中找到JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例说明:
1、找到JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”标签后,我们发现有很多回复。让我们过滤并只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
我们再点一下看看:
原来都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到想要的消息,所以再找一下:
有个焦点,我们点一下看看:
首页图片新闻中呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这应该是热搜关键词
这是照片新闻下的新闻。
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看的是正常编码的数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:
# 编码:utf-8
导入请求
导入json
js 爬虫抓取网页数据(Python中的网页抓取脚本--/Zombie#example)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-15 20:16
/SimpleBrowserDotNet/SimpleBrowser#example
由于两个最流行的浏览器现在提供无头选项,因此有很多选项。Chrome 和 Firefox(68.60% 和浏览器市场份额8.17%)都有可用的无头模式。除了主流选项之外,PhantomJS 和 Zombie.JS 也是网络爬虫中的热门选择。此外,无头浏览器需要自动化工具来运行网络爬虫脚本。Selenium 是最流行的网页抓取框架。
数据分析
数据分析是使先前获得的数据易于理解和可用的过程。大多数数据采集方法采集的数据难以理解。因此,分析并转化为易于理解的结果尤为重要。
如前所述,由于其易于访问和优化的库,Python 是一种用于获取定价情报的流行语言。BeautifulSoup、LXML 和其他选项是数据解析的流行选择。
解析允许开发人员通过搜索 HTML 或 XML 文件的特定部分来对数据进行排序。像 BeautifulSoup 这样的解析器带有内置的对象和命令,使这个过程更容易。大多数解析库通过将搜索或打印命令附加到常见的 HTML/XML 文档元素来更轻松地导航大量数据。
数据存储
数据存储程序通常取决于容量和类型。尽管建议为定价情报(和其他连续项目)构建专用数据库,但对于较短或一次性的项目,将所有内容存储在几个 CSV 或 JSON 文件中不会有什么坏处。
数据存储是一个相当简单的步骤,几乎没有问题,尽管需要记住一件事——数据的清洁度。从错误索引的数据库中检索存储的数据会变得很麻烦。从正确的方向开始并从一开始就遵循相同的计划,您甚至可以在大多数数据存储问题开始之前就解决它们。
长期数据存储是整个采集流程的最后一步。编写数据提取脚本、找到所需的目标、解析和存储数据是更简单的部分。避免反爬虫检测算法和 IP 地址禁令是真正的挑战。
代理管理
到目前为止,网络抓取似乎很简单。创建脚本,找到合适的库并将获取的数据导出到 CSV 或 JSON 文件。然而,大多数网页所有者并不热衷于向任何人提供大量数据。
大多数网页现在可以检测类似爬虫的活动,并简单地阻止有问题的 IP 地址(或整个网络)。数据提取脚本的行为与爬虫完全相同,因为它们通过访问 URL 列表不断执行循环过程。因此,通过网络抓取采集数据通常会导致 IP 地址被禁止。
代理用于维持对同一 URL 的持续访问并绕过 IP 阻止,使其成为任何数据采集 项目的关键组件。使用这种数据采集技术来创建特定于目标的代理策略对于项目的成功至关重要。
住宅代理是数据采集项目中最常用的类型。这些代理允许他们的用户从常规机器发送请求,从而避免地理或任何其他限制。此外,只要数据采集脚本是模仿此类活动的方式编写的,他们将被视为普通互联网用户。
代理是任何网络抓取想法的关键部分
当然,爬虫检测算法也适用于代理。获取和管理高级代理是任何成功的数据获取项目的一部分。避免 IP 阻塞的一个关键组成部分是地址轮换。
然而,代理轮换的问题并没有就此结束。爬虫检测算法会因目标而异。大型电商网站或搜索引擎反爬取措施复杂,需要使用不同的爬取策略。
机构的艰辛
如前所述,轮换代理是任何成功的数据采集方法(包括网络抓取)的关键。要想避免IP被封,维护普通网民的形象是必不可少的。
但是,代理需要多久更改一次、应该使用哪种类型的代理等具体细节在很大程度上取决于爬取目标、数据提取的频率等因素。这些复杂性使代理管理成为网络爬行中最困难的部分。
虽然每个业务案例都是独一无二的,需要特定的解决方案,但为了以最高效率使用代理,必须遵循指导方针。在数据采集行业经验丰富的公司对爬虫检测算法有最深入的了解。根据他们的案例研究,代理和数据采集工具提供商制定了避免 IP 地址被阻止的指南。
如前所述,维护普通网民的形象是避免IP封堵的重要环节。尽管有许多不同类型的代理,但没有人能比住宅代理更好地执行这一特定任务。住宅代理是附加到真机并由互联网服务提供商分配的 IP。从正确的方向出发,选择住宅代理进行电子商务数据采集使整个过程变得更容易。
电子商务住宅代理
住宅代理是大多数网络抓取想法的最常见选择
住宅代理用于电商数据采集,因为大部分数据采集需要维护一个特定的身份。电子商务公司通常使用多种算法来计算价格,其中一些取决于消费者的属性。其他公司会主动阻止或向他们认为是竞争对手(或爬虫)的访问者显示不正确的信息。因此,切换 IP 和位置(例如,从加拿大代理切换到德国代理)至关重要。
住宅代理是任何电子商务数据采集工具的第一道防线。由于 网站 实现了更复杂的反爬虫算法并且可以轻松检测类似爬虫的活动,这些代理允许网络爬虫重置 网站 采集到的对其行为的任何怀疑。但是,没有足够的住宅代理在每次请求后切换 IP。因此,为了有效地使用住宅代理,需要实施某些策略。
代理轮换基础知识
制定避免 IP 阻塞的策略需要时间和经验。每个目标在它认为是类似爬虫的活动方面的参数略有不同。因此,需要相应地调整策略。
为代理轮换采集电子商务数据有几个基本步骤:
请记住,每个目标都是不同的。一般来说,电子商务网站越先进、规模越大、越重要,越难通过网络爬虫解决。反复试验通常是创建有效的网络爬行策略的唯一方法。
总结
想要构建您的第一个网络爬虫吗?注册并开始使用 Oxylabs 的住宅代理!想了解更多详情或定制计划?您可以与我们的销售团队预约!您需要的所有互联网数据只需轻轻一按! 查看全部
js 爬虫抓取网页数据(Python中的网页抓取脚本--/Zombie#example)
/SimpleBrowserDotNet/SimpleBrowser#example
由于两个最流行的浏览器现在提供无头选项,因此有很多选项。Chrome 和 Firefox(68.60% 和浏览器市场份额8.17%)都有可用的无头模式。除了主流选项之外,PhantomJS 和 Zombie.JS 也是网络爬虫中的热门选择。此外,无头浏览器需要自动化工具来运行网络爬虫脚本。Selenium 是最流行的网页抓取框架。
数据分析
数据分析是使先前获得的数据易于理解和可用的过程。大多数数据采集方法采集的数据难以理解。因此,分析并转化为易于理解的结果尤为重要。
如前所述,由于其易于访问和优化的库,Python 是一种用于获取定价情报的流行语言。BeautifulSoup、LXML 和其他选项是数据解析的流行选择。
解析允许开发人员通过搜索 HTML 或 XML 文件的特定部分来对数据进行排序。像 BeautifulSoup 这样的解析器带有内置的对象和命令,使这个过程更容易。大多数解析库通过将搜索或打印命令附加到常见的 HTML/XML 文档元素来更轻松地导航大量数据。
数据存储
数据存储程序通常取决于容量和类型。尽管建议为定价情报(和其他连续项目)构建专用数据库,但对于较短或一次性的项目,将所有内容存储在几个 CSV 或 JSON 文件中不会有什么坏处。
数据存储是一个相当简单的步骤,几乎没有问题,尽管需要记住一件事——数据的清洁度。从错误索引的数据库中检索存储的数据会变得很麻烦。从正确的方向开始并从一开始就遵循相同的计划,您甚至可以在大多数数据存储问题开始之前就解决它们。
长期数据存储是整个采集流程的最后一步。编写数据提取脚本、找到所需的目标、解析和存储数据是更简单的部分。避免反爬虫检测算法和 IP 地址禁令是真正的挑战。
代理管理
到目前为止,网络抓取似乎很简单。创建脚本,找到合适的库并将获取的数据导出到 CSV 或 JSON 文件。然而,大多数网页所有者并不热衷于向任何人提供大量数据。
大多数网页现在可以检测类似爬虫的活动,并简单地阻止有问题的 IP 地址(或整个网络)。数据提取脚本的行为与爬虫完全相同,因为它们通过访问 URL 列表不断执行循环过程。因此,通过网络抓取采集数据通常会导致 IP 地址被禁止。
代理用于维持对同一 URL 的持续访问并绕过 IP 阻止,使其成为任何数据采集 项目的关键组件。使用这种数据采集技术来创建特定于目标的代理策略对于项目的成功至关重要。
住宅代理是数据采集项目中最常用的类型。这些代理允许他们的用户从常规机器发送请求,从而避免地理或任何其他限制。此外,只要数据采集脚本是模仿此类活动的方式编写的,他们将被视为普通互联网用户。
代理是任何网络抓取想法的关键部分
当然,爬虫检测算法也适用于代理。获取和管理高级代理是任何成功的数据获取项目的一部分。避免 IP 阻塞的一个关键组成部分是地址轮换。
然而,代理轮换的问题并没有就此结束。爬虫检测算法会因目标而异。大型电商网站或搜索引擎反爬取措施复杂,需要使用不同的爬取策略。
机构的艰辛
如前所述,轮换代理是任何成功的数据采集方法(包括网络抓取)的关键。要想避免IP被封,维护普通网民的形象是必不可少的。
但是,代理需要多久更改一次、应该使用哪种类型的代理等具体细节在很大程度上取决于爬取目标、数据提取的频率等因素。这些复杂性使代理管理成为网络爬行中最困难的部分。
虽然每个业务案例都是独一无二的,需要特定的解决方案,但为了以最高效率使用代理,必须遵循指导方针。在数据采集行业经验丰富的公司对爬虫检测算法有最深入的了解。根据他们的案例研究,代理和数据采集工具提供商制定了避免 IP 地址被阻止的指南。
如前所述,维护普通网民的形象是避免IP封堵的重要环节。尽管有许多不同类型的代理,但没有人能比住宅代理更好地执行这一特定任务。住宅代理是附加到真机并由互联网服务提供商分配的 IP。从正确的方向出发,选择住宅代理进行电子商务数据采集使整个过程变得更容易。
电子商务住宅代理
住宅代理是大多数网络抓取想法的最常见选择
住宅代理用于电商数据采集,因为大部分数据采集需要维护一个特定的身份。电子商务公司通常使用多种算法来计算价格,其中一些取决于消费者的属性。其他公司会主动阻止或向他们认为是竞争对手(或爬虫)的访问者显示不正确的信息。因此,切换 IP 和位置(例如,从加拿大代理切换到德国代理)至关重要。
住宅代理是任何电子商务数据采集工具的第一道防线。由于 网站 实现了更复杂的反爬虫算法并且可以轻松检测类似爬虫的活动,这些代理允许网络爬虫重置 网站 采集到的对其行为的任何怀疑。但是,没有足够的住宅代理在每次请求后切换 IP。因此,为了有效地使用住宅代理,需要实施某些策略。
代理轮换基础知识
制定避免 IP 阻塞的策略需要时间和经验。每个目标在它认为是类似爬虫的活动方面的参数略有不同。因此,需要相应地调整策略。
为代理轮换采集电子商务数据有几个基本步骤:
请记住,每个目标都是不同的。一般来说,电子商务网站越先进、规模越大、越重要,越难通过网络爬虫解决。反复试验通常是创建有效的网络爬行策略的唯一方法。
总结
想要构建您的第一个网络爬虫吗?注册并开始使用 Oxylabs 的住宅代理!想了解更多详情或定制计划?您可以与我们的销售团队预约!您需要的所有互联网数据只需轻轻一按!
js 爬虫抓取网页数据(借助mysql模块保存数据(假设数据库)的基本流程和流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-15 18:09
在node.js中,有了cheerio模块和request模块,抓取特定URL页面的数据非常方便。
一个简单的如下
var request = require('request');
var cheerio = require('cheerio');
request(url,function(err,res){
if(err) return console.log(err);
var $ = cheerio.load(res.body.toString());
//解析页面内容
});
有了基本的过程,现在试着找一个网址(url)。以博客园的搜索页面为例。
通过搜索 关键词 node.js
获取以下网址:
点击第二页,网址如下:
分析URL,发现w=? 搜索到的关键词是p=吗?是页码。
使用请求模块请求 URL
var request = require('request');
var cheerio = require('cheerio');
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
});
既然有了 URL,接下来分析 URL 对应的页面内容。
页面还是很规律的。
标题摘要 作者发布时间 推荐 评论数 浏览次数 文章 链接
借助浏览器开发工具
发现
...
对应每篇文章文章
点击每一项,有以下内容
收录 文章 标题和 文章 URL 地址
收录作者
包括发布时间
收录观看次数
使用cheerio模块解析文章并抓取特定内容
var request = require('request');
var cheerio = require('cheerio');
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
});
});
查看代码
可以运行一下,看看数据是否正常捕获。
现在有数据数据,可以保存到数据库中。这里以mysql为例,使用mongodb更方便。
借助mysql模块保存数据(假设数据库名为test,表为blog)。
var request = require('request');
var cheerio = require('cheerio');
var mysql = require('mysql');
var db = mysql.createConnection({
host: '127.0.0.1',
user: 'root',
password: '123456',
database: 'test'
});
db.connect();
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
//保存数据
db.query('insert into blog set ?', info, function(err,result){
if (err) throw err;
if (!!result) {
console.log('插入成功');
console.log(result.insertId);
} else {
console.log('插入失败');
}
});
});
});
查看代码
运行它以查看数据是否已保存到数据库中。
现在有一个基本的爬取和保存。但是只爬取一次,只能爬取关键词为node.js页码1的URL页面。
将关键词改为javascript,页码为1,清空博客表,再次运行看看表中是否可以保存javascript相关的数据。
现在去博客园搜索javascript,看看搜索结果是否与表格中的内容相对应。哈哈,别看,绝对可以对应~~
只能抓取一个页面的内容,这绝对是不够的。能够自动抓取其他页面的内容会更好。 查看全部
js 爬虫抓取网页数据(借助mysql模块保存数据(假设数据库)的基本流程和流程)
在node.js中,有了cheerio模块和request模块,抓取特定URL页面的数据非常方便。
一个简单的如下
var request = require('request');
var cheerio = require('cheerio');
request(url,function(err,res){
if(err) return console.log(err);
var $ = cheerio.load(res.body.toString());
//解析页面内容
});
有了基本的过程,现在试着找一个网址(url)。以博客园的搜索页面为例。
通过搜索 关键词 node.js
获取以下网址:
点击第二页,网址如下:
分析URL,发现w=? 搜索到的关键词是p=吗?是页码。
使用请求模块请求 URL
var request = require('request');
var cheerio = require('cheerio');
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
});
既然有了 URL,接下来分析 URL 对应的页面内容。
页面还是很规律的。
标题摘要 作者发布时间 推荐 评论数 浏览次数 文章 链接
借助浏览器开发工具
发现
...
对应每篇文章文章
点击每一项,有以下内容
收录 文章 标题和 文章 URL 地址
收录作者
包括发布时间
收录观看次数
使用cheerio模块解析文章并抓取特定内容
var request = require('request');
var cheerio = require('cheerio');
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
});
});
查看代码
可以运行一下,看看数据是否正常捕获。
现在有数据数据,可以保存到数据库中。这里以mysql为例,使用mongodb更方便。
借助mysql模块保存数据(假设数据库名为test,表为blog)。
var request = require('request');
var cheerio = require('cheerio');
var mysql = require('mysql');
var db = mysql.createConnection({
host: '127.0.0.1',
user: 'root',
password: '123456',
database: 'test'
});
db.connect();
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
//保存数据
db.query('insert into blog set ?', info, function(err,result){
if (err) throw err;
if (!!result) {
console.log('插入成功');
console.log(result.insertId);
} else {
console.log('插入失败');
}
});
});
});
查看代码
运行它以查看数据是否已保存到数据库中。
现在有一个基本的爬取和保存。但是只爬取一次,只能爬取关键词为node.js页码1的URL页面。
将关键词改为javascript,页码为1,清空博客表,再次运行看看表中是否可以保存javascript相关的数据。
现在去博客园搜索javascript,看看搜索结果是否与表格中的内容相对应。哈哈,别看,绝对可以对应~~
只能抓取一个页面的内容,这绝对是不够的。能够自动抓取其他页面的内容会更好。
js 爬虫抓取网页数据(HTML源码中的内容由前端的JS动态生成的应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-10-15 18:08
)
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器渲染出来的网页如下图所示:
查看源码,却是如下图:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
这是照片新闻下的新闻。
我们打开一个接口链接看看:
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求和解析数据接口数据
先上传完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# coding:utf-8
import requests
import json
第二部分:向数据接口发出http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
js 爬虫抓取网页数据(HTML源码中的内容由前端的JS动态生成的应用
)
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器渲染出来的网页如下图所示:
查看源码,却是如下图:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
这是照片新闻下的新闻。
我们打开一个接口链接看看:
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求和解析数据接口数据
先上传完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# coding:utf-8
import requests
import json
第二部分:向数据接口发出http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
js 爬虫抓取网页数据(Python爬虫如何写爬虫“贼船”等上了贼船才发现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-15 09:07
写爬虫是非常考验综合实力的。有时,您可以轻松获得所需的数据;有时候,你很努力,却一无所获。
很多Python爬虫的入门教程,都是一行代码把你骗进“贼船”,上了贼船才发现,水好深~
例如,抓取一个网页可以是一行非常简单的代码:
r = requests.get('http://news.baidu.com')
很简单,但是它的作用只是抓取一个网页,一个有用的爬虫远不止抓取一个网页。
一个有用的爬虫只需要两个词来衡量:
但是要实现这两个词,需要做很多工作。自己努力是一方面,但也很重要的是你有多少网站给你制造的问题。综合起来,写一个爬虫是多么困难。
网络爬虫难点一:只需要爬html网页就可以放大
这里我们举一个新闻爬虫的例子。大家都用过百度的新闻搜索,我就用它的爬虫来谈谈实现的难度。
新闻网站基本不设防,新闻内容都在网页的html代码中,整个网页基本是一行的东西。听起来很简单,但是对于一个搜索引擎级别的爬虫来说,就没有那么简单了。要及时捕捉到数以万计的新闻网站的新闻并不容易。
我们来看一下新闻爬虫的简单流程图:
从一些种子网页开始,种子网页往往是一些新闻的首页网站。爬虫爬取网页,从中提取出网站 URL,放入URL池,然后爬取。这从几个网页开始,并继续扩展到其他网页。越来越多的网页被爬虫抓取,提取出来的新网站网址也会成倍增长。
如何在最短的时间内抓取更多的网址?
这是困难之一。这不是目标 URL 造成的,而是对我们自己的意志的测试:
怎样才能及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?万条新闻网站时刻发布最新消息。在以网络方式抓取“旧”新闻的同时,爬虫如何同时获取“新”新闻?
如何存储捕获的海量新闻?
爬虫编织式的爬取会翻出几十年前网站几年前的每一个新闻网页,从而需要存储大量的网页。这是存储的难点。
如何清理和提取网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来了难度。
网络爬虫难点2:需要登录才能获取你想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据对您来说并不容易。有一大类数据只有在账号登录后才能看到,也就是说爬虫请求必须处于登录状态才能抓取到数据。
如何获取登录状态? 查看全部
js 爬虫抓取网页数据(Python爬虫如何写爬虫“贼船”等上了贼船才发现)
写爬虫是非常考验综合实力的。有时,您可以轻松获得所需的数据;有时候,你很努力,却一无所获。
很多Python爬虫的入门教程,都是一行代码把你骗进“贼船”,上了贼船才发现,水好深~
例如,抓取一个网页可以是一行非常简单的代码:
r = requests.get('http://news.baidu.com')
很简单,但是它的作用只是抓取一个网页,一个有用的爬虫远不止抓取一个网页。
一个有用的爬虫只需要两个词来衡量:
但是要实现这两个词,需要做很多工作。自己努力是一方面,但也很重要的是你有多少网站给你制造的问题。综合起来,写一个爬虫是多么困难。
网络爬虫难点一:只需要爬html网页就可以放大
这里我们举一个新闻爬虫的例子。大家都用过百度的新闻搜索,我就用它的爬虫来谈谈实现的难度。
新闻网站基本不设防,新闻内容都在网页的html代码中,整个网页基本是一行的东西。听起来很简单,但是对于一个搜索引擎级别的爬虫来说,就没有那么简单了。要及时捕捉到数以万计的新闻网站的新闻并不容易。
我们来看一下新闻爬虫的简单流程图:
从一些种子网页开始,种子网页往往是一些新闻的首页网站。爬虫爬取网页,从中提取出网站 URL,放入URL池,然后爬取。这从几个网页开始,并继续扩展到其他网页。越来越多的网页被爬虫抓取,提取出来的新网站网址也会成倍增长。
如何在最短的时间内抓取更多的网址?
这是困难之一。这不是目标 URL 造成的,而是对我们自己的意志的测试:
怎样才能及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?万条新闻网站时刻发布最新消息。在以网络方式抓取“旧”新闻的同时,爬虫如何同时获取“新”新闻?
如何存储捕获的海量新闻?
爬虫编织式的爬取会翻出几十年前网站几年前的每一个新闻网页,从而需要存储大量的网页。这是存储的难点。
如何清理和提取网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来了难度。
网络爬虫难点2:需要登录才能获取你想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据对您来说并不容易。有一大类数据只有在账号登录后才能看到,也就是说爬虫请求必须处于登录状态才能抓取到数据。
如何获取登录状态?
js 爬虫抓取网页数据(新浪新闻国内新闻页静态网页数据在函数中的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-15 01:28
昨天,朋友联系我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
但是发现有个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\\,标题和介绍都是\u4e09的形式。这些是我们需要处理的后续步骤!
先用replace函数去掉url中的\\,就可以得到url了,下面的\u4e09是unicode编码,可以直接解码内容,直接写代码
使用eval函数进行解码,可以以u"+unicode编码内容+"!
这样就把这个页面上所有新闻和URL相关的内容都取出来了,在外层加了一个循环来爬取所有的新闻页面,任务就完成了!
后记
新浪新闻的页面js功能比较简单,可以直接抓取数据。如果是比较复杂的功能,就需要了解前端知识。这就是学习爬虫需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,你可以直接百度找很多,当然你也可以直接修改上面抓包的内容,然后用json读取数据!
基本代码不多。有看不清楚的小伙伴可以私信我索取代码或者一起研究爬虫! 查看全部
js 爬虫抓取网页数据(新浪新闻国内新闻页静态网页数据在函数中的应用)
昨天,朋友联系我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
但是发现有个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\\,标题和介绍都是\u4e09的形式。这些是我们需要处理的后续步骤!
先用replace函数去掉url中的\\,就可以得到url了,下面的\u4e09是unicode编码,可以直接解码内容,直接写代码
使用eval函数进行解码,可以以u"+unicode编码内容+"!
这样就把这个页面上所有新闻和URL相关的内容都取出来了,在外层加了一个循环来爬取所有的新闻页面,任务就完成了!
后记
新浪新闻的页面js功能比较简单,可以直接抓取数据。如果是比较复杂的功能,就需要了解前端知识。这就是学习爬虫需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,你可以直接百度找很多,当然你也可以直接修改上面抓包的内容,然后用json读取数据!
基本代码不多。有看不清楚的小伙伴可以私信我索取代码或者一起研究爬虫!
js 爬虫抓取网页数据(动态网页静态网页的常用方法及常用技巧 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-11 05:22
)
静态页面
静态网页是指网页中没有程序代码,只有HTML,一般后缀为.html、.htm或.xml等,静态网页一旦创建,内容不会改变。因为这些网页的内容存储在网站服务器上,如果要修改内容,必须修改网页源代码,重新上传到网站服务器。
动态网页
动态网页的网页文件除了HTML之外,还有一些特定功能的程序代码。通过这些代码,浏览器可以与服务器进行交互,即服务器可以根据浏览器的请求生成网页内容。通俗地说,当我们打开一个动态网页时,服务器不会一次返回所有页面内容。我们需要什么内容,通过浏览器与服务器交互,服务器会返回相应的内容。这种加载数据的方式称为API加载数据。API(Application Programming Interface)是应用程序编程接口,是网页与服务器交互的方式。
正是因为服务器不会一次性返回所有页面内容,所以很多数据不在网页源代码中,所以无法用BeautifulSoup解析提取(提取结果为空)。这时候就需要用到动态网络爬虫了。
爬取动态页面一般有两种常用的方法:(1),JavaScript的逆向工程获取动态数据接口(真实访问路径)——通过API爬取数据。(2),使用selenium库模拟一个真正的浏览器并获取 JavaScript 呈现的内容。
今天我们主要介绍第一个通过API爬取数据。以爬取今日头条热榜为例。
第一步:找到数据的藏身之处
打开今日头条,头条热榜内容如下(只显示一页,共5页,共50条内容):
打开web开发者工具,找到里面的Network面板,找到里面的XHR。我们需要的内容就在这里。Network面板中有很多请求信息,如下图:
双击请求信息弹出一个小界面,里面有Headers、Preview、Response等信息。可以在Preview中逐层查看数据,如下图:
Headers中的General可以看到发起请求的链接(Request URL)、请求方法(Request Method)和状态码(StatusCode),如下图所示:
第二步:代码实现
完整代码如下:
#导入需要的模块
进口请求
从 bs4 导入 BeautifulSoup
#传入请求头中的信息,将爬虫伪装成浏览器
标题 = {
'用户代理':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/ 94.0.4606.71 Safari/537.36',
'推荐人':'/?wid=28'
}
#将API链接的查询字符串传递给Params参数(为了让URL看起来更整洁)
参数 = {
'起源':'toutiao_pc',
'_signature':'_02B4Z6wo00f01xyjH3gAAIDDkCFR9fyaAVschxvAAKaBtffSC12aIOJf.5gyG9jkJUZWI3K1I0v0KkQNZLFN.uKdBoA0tUmuVnM6Me9HFJlX0HZH7MdKvJlX60dMekoHFJlX60dMekoHFJlX60dMekoHFJlX60Med
}
res = requests.get('/hot-event/hot-board/',headers=headers,params=params)
#返回结果为JSON格式,调用json()方法解析
项目 = res.json()
num = [i for i in range(len(items['data']))]
对于 num 中的 x:
打印(项目['数据'][x]['标题'])
结果如下(只显示了一部分):
查看全部
js 爬虫抓取网页数据(动态网页静态网页的常用方法及常用技巧
)
静态页面
静态网页是指网页中没有程序代码,只有HTML,一般后缀为.html、.htm或.xml等,静态网页一旦创建,内容不会改变。因为这些网页的内容存储在网站服务器上,如果要修改内容,必须修改网页源代码,重新上传到网站服务器。
动态网页
动态网页的网页文件除了HTML之外,还有一些特定功能的程序代码。通过这些代码,浏览器可以与服务器进行交互,即服务器可以根据浏览器的请求生成网页内容。通俗地说,当我们打开一个动态网页时,服务器不会一次返回所有页面内容。我们需要什么内容,通过浏览器与服务器交互,服务器会返回相应的内容。这种加载数据的方式称为API加载数据。API(Application Programming Interface)是应用程序编程接口,是网页与服务器交互的方式。
正是因为服务器不会一次性返回所有页面内容,所以很多数据不在网页源代码中,所以无法用BeautifulSoup解析提取(提取结果为空)。这时候就需要用到动态网络爬虫了。
爬取动态页面一般有两种常用的方法:(1),JavaScript的逆向工程获取动态数据接口(真实访问路径)——通过API爬取数据。(2),使用selenium库模拟一个真正的浏览器并获取 JavaScript 呈现的内容。
今天我们主要介绍第一个通过API爬取数据。以爬取今日头条热榜为例。
第一步:找到数据的藏身之处
打开今日头条,头条热榜内容如下(只显示一页,共5页,共50条内容):
打开web开发者工具,找到里面的Network面板,找到里面的XHR。我们需要的内容就在这里。Network面板中有很多请求信息,如下图:
双击请求信息弹出一个小界面,里面有Headers、Preview、Response等信息。可以在Preview中逐层查看数据,如下图:
Headers中的General可以看到发起请求的链接(Request URL)、请求方法(Request Method)和状态码(StatusCode),如下图所示:
第二步:代码实现
完整代码如下:
#导入需要的模块
进口请求
从 bs4 导入 BeautifulSoup
#传入请求头中的信息,将爬虫伪装成浏览器
标题 = {
'用户代理':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/ 94.0.4606.71 Safari/537.36',
'推荐人':'/?wid=28'
}
#将API链接的查询字符串传递给Params参数(为了让URL看起来更整洁)
参数 = {
'起源':'toutiao_pc',
'_signature':'_02B4Z6wo00f01xyjH3gAAIDDkCFR9fyaAVschxvAAKaBtffSC12aIOJf.5gyG9jkJUZWI3K1I0v0KkQNZLFN.uKdBoA0tUmuVnM6Me9HFJlX0HZH7MdKvJlX60dMekoHFJlX60dMekoHFJlX60dMekoHFJlX60Med
}
res = requests.get('/hot-event/hot-board/',headers=headers,params=params)
#返回结果为JSON格式,调用json()方法解析
项目 = res.json()
num = [i for i in range(len(items['data']))]
对于 num 中的 x:
打印(项目['数据'][x]['标题'])
结果如下(只显示了一部分):
js 爬虫抓取网页数据(Python400集_零基础入门学习Python全套教程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-10 17:04
大数据时代,互联网成为海量信息的载体,机械复制粘贴不再实用,不仅费时费力,而且极易出错。这时候爬虫的出现,以其高速爬行和定向抓取的能力解放了大家的双手。赢得了大家的青睐。
爬虫越来越流行,不仅是因为它可以快速爬取海量数据,还因为像python这样简单易用的语言让爬虫可以快速上手。
对于小白来说,爬取可能是一件非常复杂且技术难度很大的事情,但是掌握正确的方法能够在短时间内爬取主流网站数据,其实是很容易实现的。但建议您从一开始就有一个特定的目标。
在您的目标驱动下,您的学习将更加精确和高效。所有你认为必要的前置知识都可以在实现目标的过程中学习。
筛选和筛选要学习的知识以及从哪里获取资源是许多初学者面临的常见问题。
接下来我们将拆解学习框架,详细介绍各个部分并推荐一些相关资源,告诉大家学什么、怎么学、去哪里学。
Python400 set_zero-based入门学习Python全套教程
爬虫简介
爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。
这个定义看起来很生硬,我们换个更好的理解:我们作为用户获取网络数据的方式是向浏览器提交请求->下载网页代码->解析/渲染成页面;而爬取的方式是模拟浏览器发送请求->下载网页代码->只提取有用的数据->存入数据库或文件中。爬虫和我们的区别在于,爬虫程序只提取网页代码中对我们有用的数据,爬虫爬得快,量级大。
随着数据的规模化,爬虫获取数据的高效性能越来越突出,可以做的事情也越来越多:市场分析:电商分析、商圈分析、一二级市场分析等。市场监测:电商、新闻、房屋监测等·商机发现:招投标情报发现、客户信息发现、企业客户发现等。
要学习爬虫,首先要明白它是一个网页。那些我们肉眼可见的明亮漂亮的网页,是由HTML、css、javascript等网页的源代码支持的。这些源代码被浏览器识别并转换成我们看到的网页。这些源代码中肯定有很多规则,我们的爬虫可以根据这些规则抓取到需要的信息。
没有规则就没有规则。Robots 协议是爬虫中的规则。它告诉爬虫和搜索引擎哪些页面可以被爬取,哪些页面不能被爬取。通常是一个名为robots.txt的文本文件,放在网站的根目录下。
轻量级爬虫
“获取数据-解析数据-存储数据”是爬虫三部曲。大多数爬虫都遵循这个过程,它实际上模拟了使用浏览器获取网页信息的过程。
1、获取数据
爬虫的第一个操作是模拟浏览器向服务器发送请求。基于python,不需要从数据的实现,HTTP、TCP、IP的网络传输结构,一路了解服务器响应和响应的原理,因为python提供了一个功能齐全的类库帮助我们满足这些要求。Python内置的标准库urllib2用的比较多。它是python内置的HTTP请求库。如果只做基本的抓取网页抓取,那么urllib2就足够了。Requests 的口号是“Requests 是 Python 唯一的 Non-GMO HTTP 库,对人类消费安全”。和urllib2相比,requests使用起来确实简洁很多,而且自带json解析器。如果需要爬取异步加载的动态网站,你可以学习浏览器捕获来分析真实的请求,或者学习 Selenium 来实现自动化。当然对于爬虫来说,只要能爬取数据,越快越好。显然,传统的同步代码不能满足我们对速度的需求。
(ps:据国外统计:一般情况下,我们请求同一个页面100次,至少需要30秒,但是如果我们异步请求同一个页面100次,大约只需要3秒。)
aiohttp 是一个你值得拥有的库。借助 async/await 关键字,aiohttp 的异步操作变得更加简洁明了。当使用异步请求库进行数据获取时,效率会大大提高。
可以根据自己的需要选择合适的请求库,但是建议从python自带的urllib入手。当然,您可以在学习的同时尝试所有方法,以更好地了解这些库的使用。
2、分析数据
爬虫爬取的是页面的指定部分数据值,而不是整个页面的数据。这时候,往往需要在存储之前对数据进行分析。
web返回的数据类型很多,主要有HTML、javascript、JSON、XML等格式。解析库的使用相当于在HTML中搜索需要的信息时使用了规律性,可以更快速的定位到具体的元素,获得相应的信息。
Css 选择器是一种快速定位元素的方法。
Pyqurrey 使用 lxml 解析器快速操作 xml 和 html 文档。它提供了类似于jQuery的语法来解析HTML文档,支持CSS选择器,使用起来非常方便。
Beautiful Soup 是一种借助网页的结构和属性等特征来解析网页的工具,可以自动转换编码。支持Python标准库中的HTML解析器,也支持部分第三方解析器。
Xpath 最初用于搜索 XML 文档,但它也适用于搜索 HTML 文档。它提供了 100 多个内置函数。这些函数用于字符串值、数值、日期和时间比较、节点和QName 处理、序列处理、逻辑值等,XQuery 和XPointer 都建立在XPath 之上。
Re正则表达式通常用于检索和替换符合某种模式(规则)的文本。个人认为前端基础比较扎实,pyquery最方便,beautifulsoup也不错,re速度比较快,但是写regular比较麻烦。当然,既然你用的是python,那绝对是为了你自己的方便。
3、数据存储
当爬回的数据量较小时,可以以文档的形式存储,支持TXT、json、csv等格式。
但是当数据量变大时,文档的存储方式就不行了,所以需要掌握一个数据库。
Mysql作为关系型数据库的代表,有着较为成熟的系统,成熟度较高。可以很好的存储一些数据,但是处理海量数据时效率会明显变慢,已经不能满足一些大数据的需求。加工要求。
MongoDB 已经流行了很长时间。与 MySQL 相比,MongoDB 可以轻松存储一些非结构化数据,例如各种评论的文本、图片链接等。您还可以使用 PyMongo 更轻松地在 Python 中操作 MongoDB。因为这里要用到的数据库知识其实很简单,主要是如何存储数据,如何提取,需要的时候学习。
Redis 是一个不妥协的内存数据库。Redis支持丰富的数据结构,包括hash、set、list等,数据全部存储在内存中,访问速度快,可以存储大量数据,一般用于分布式的数据存储爬虫。
工程履带
通过掌握前面的技术,可以实现轻量级爬虫,一般量级的数据和代码基本没有问题。
但在面对复杂情况时,表现并不令人满意。这时候,一个强大的爬虫框架就非常有用了。
第一个是 Nutch,来自一个著名家族的顶级 Apache 项目,它提供了我们运行自己的搜索引擎所需的所有工具。
支持分布式爬取,通过Hadoop支持,可以进行多机分布式爬取、存储和索引。
另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。
接下来是GitHub上大家star的scrapy,severe是一个非常强大的爬虫框架。
它不仅可以轻松构造请求,还具有强大的选择器,可以轻松解析响应。然而,最令人惊讶的是它的超高性能,它可以让你对爬虫进行工程化和模块化。
学习了scrapy之后就可以自己搭建一些爬虫框架了,基本就具备爬虫工程师的思维了。
最后,Pyspider作为国内大神开发的框架,满足了大部分Python爬虫的针对性爬取和结构化分析的需求。
可以在浏览器界面进行脚本编写、函数调度、实时查看爬取结果,后端使用常用数据库存储爬取结果。
它的功能是如此强大,以至于它更像是一个产品而不是一个框架。
这是三个最具代表性的爬虫框架。它们都有着远超其他的优势,比如Nutch的自然搜索引擎解决方案,Pyspider产品级的WebUI,以及Scrapy最灵活的定制爬取。建议先从最接近爬虫本质的可怕框架入手,然后接触为搜索引擎而生的人性化的Pyspider和Nutch。
防爬虫对策
爬虫就像一个虫子,密密麻麻地爬到每一个角落获取数据。这个错误可能是无害的,但它总是不受欢迎的。
由于爬虫技术网站对带宽资源的侵犯导致大量IP访问,以及用户隐私和知识产权等危害,很多互联网公司都会下大力气“反爬虫”。
你的爬虫会遇到比如被网站拦截,比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。
常见的反爬虫措施有:
·通过Headers反爬虫
·基于用户行为的反爬虫
·基于动态页面的反爬虫
·字体爬取.....
遇到这些反爬虫方法,当然需要一些高深的技巧来应对。尽可能控制访问频率,保证页面加载一次,数据请求最小化,增加每次页面访问的时间间隔;禁止 cookie 可以防止使用 cookie 来识别爬虫。网站 禁止我们;根据浏览器正常访问的请求头修改爬虫的请求头,尽量与浏览器保持一致等。
经常网站在高效开发和反爬虫之间偏向于前者。这也为爬虫提供了空间。掌握这些反爬虫技巧,大部分网站对你来说不再难。
分布式爬虫
爬取基础数据没有问题,也可以用框架来面对更复杂的数据。这时候,就算遇到了防爬,也已经掌握了一些防爬的技巧。
你的瓶颈将集中在爬取大量数据的效率上。这时候,相信你自然会接触到一个非常强大的名字:分布式爬虫。
分布式这个东西听上去很吓人,其实就是利用多线程的原理,将多台主机结合起来,共同完成一个爬虫任务。需要掌握Scrapy+Redis+MQ+Celery等工具。
前面说过,Scrapy是用来做基础的页面爬取,Redis用来存放要爬取的网页的队列,也就是任务队列。
在scrapy中使用scarpy-redis实现分布式组件,通过它可以快速实现简单的分布式爬虫。
由于高并发环境,请求经常被阻塞,因为来不及同步处理。通过使用消息队列MQ,我们可以异步处理请求,从而减轻系统压力。
RabbitMQ本身支持很多协议:AMQP、XMPP、SMTP、STOMP,这使得它非常重量级,更适合企业级开发。
Scrapy-rabbitmq-link 是一个组件,它允许您从 RabbitMQ 消息队列中检索 URL 并将它们分发给 Scrapy 蜘蛛。
Celery 是一个简单、灵活、可靠的分布式系统,可以处理大量消息。它支持RabbitMQ、Redis甚至其他数据库系统作为其消息代理中间件,在处理异步任务、任务调度、处理定时任务、分布式调度等场景中表现良好。
所以分布式爬虫听起来有点吓人,但仅此而已。当你可以编写分布式爬虫时,那么你就可以尝试构建一些基本的爬虫架构。
实现一些更自动化的数据采集。
你看,沿着这条完整的学习路径走下去,爬虫对你来说根本不是问题。
因为爬虫技术不需要你系统地精通一门语言,也不需要非常先进的数据库技术。
解锁各部分知识点,有针对性地学习。经过这条顺利的学习路径,你将能够掌握python爬虫。 查看全部
js 爬虫抓取网页数据(Python400集_零基础入门学习Python全套教程(组图))
大数据时代,互联网成为海量信息的载体,机械复制粘贴不再实用,不仅费时费力,而且极易出错。这时候爬虫的出现,以其高速爬行和定向抓取的能力解放了大家的双手。赢得了大家的青睐。
爬虫越来越流行,不仅是因为它可以快速爬取海量数据,还因为像python这样简单易用的语言让爬虫可以快速上手。
对于小白来说,爬取可能是一件非常复杂且技术难度很大的事情,但是掌握正确的方法能够在短时间内爬取主流网站数据,其实是很容易实现的。但建议您从一开始就有一个特定的目标。
在您的目标驱动下,您的学习将更加精确和高效。所有你认为必要的前置知识都可以在实现目标的过程中学习。
筛选和筛选要学习的知识以及从哪里获取资源是许多初学者面临的常见问题。
接下来我们将拆解学习框架,详细介绍各个部分并推荐一些相关资源,告诉大家学什么、怎么学、去哪里学。
Python400 set_zero-based入门学习Python全套教程
爬虫简介
爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。
这个定义看起来很生硬,我们换个更好的理解:我们作为用户获取网络数据的方式是向浏览器提交请求->下载网页代码->解析/渲染成页面;而爬取的方式是模拟浏览器发送请求->下载网页代码->只提取有用的数据->存入数据库或文件中。爬虫和我们的区别在于,爬虫程序只提取网页代码中对我们有用的数据,爬虫爬得快,量级大。
随着数据的规模化,爬虫获取数据的高效性能越来越突出,可以做的事情也越来越多:市场分析:电商分析、商圈分析、一二级市场分析等。市场监测:电商、新闻、房屋监测等·商机发现:招投标情报发现、客户信息发现、企业客户发现等。
要学习爬虫,首先要明白它是一个网页。那些我们肉眼可见的明亮漂亮的网页,是由HTML、css、javascript等网页的源代码支持的。这些源代码被浏览器识别并转换成我们看到的网页。这些源代码中肯定有很多规则,我们的爬虫可以根据这些规则抓取到需要的信息。
没有规则就没有规则。Robots 协议是爬虫中的规则。它告诉爬虫和搜索引擎哪些页面可以被爬取,哪些页面不能被爬取。通常是一个名为robots.txt的文本文件,放在网站的根目录下。
轻量级爬虫
“获取数据-解析数据-存储数据”是爬虫三部曲。大多数爬虫都遵循这个过程,它实际上模拟了使用浏览器获取网页信息的过程。
1、获取数据
爬虫的第一个操作是模拟浏览器向服务器发送请求。基于python,不需要从数据的实现,HTTP、TCP、IP的网络传输结构,一路了解服务器响应和响应的原理,因为python提供了一个功能齐全的类库帮助我们满足这些要求。Python内置的标准库urllib2用的比较多。它是python内置的HTTP请求库。如果只做基本的抓取网页抓取,那么urllib2就足够了。Requests 的口号是“Requests 是 Python 唯一的 Non-GMO HTTP 库,对人类消费安全”。和urllib2相比,requests使用起来确实简洁很多,而且自带json解析器。如果需要爬取异步加载的动态网站,你可以学习浏览器捕获来分析真实的请求,或者学习 Selenium 来实现自动化。当然对于爬虫来说,只要能爬取数据,越快越好。显然,传统的同步代码不能满足我们对速度的需求。
(ps:据国外统计:一般情况下,我们请求同一个页面100次,至少需要30秒,但是如果我们异步请求同一个页面100次,大约只需要3秒。)
aiohttp 是一个你值得拥有的库。借助 async/await 关键字,aiohttp 的异步操作变得更加简洁明了。当使用异步请求库进行数据获取时,效率会大大提高。
可以根据自己的需要选择合适的请求库,但是建议从python自带的urllib入手。当然,您可以在学习的同时尝试所有方法,以更好地了解这些库的使用。
2、分析数据
爬虫爬取的是页面的指定部分数据值,而不是整个页面的数据。这时候,往往需要在存储之前对数据进行分析。
web返回的数据类型很多,主要有HTML、javascript、JSON、XML等格式。解析库的使用相当于在HTML中搜索需要的信息时使用了规律性,可以更快速的定位到具体的元素,获得相应的信息。
Css 选择器是一种快速定位元素的方法。
Pyqurrey 使用 lxml 解析器快速操作 xml 和 html 文档。它提供了类似于jQuery的语法来解析HTML文档,支持CSS选择器,使用起来非常方便。
Beautiful Soup 是一种借助网页的结构和属性等特征来解析网页的工具,可以自动转换编码。支持Python标准库中的HTML解析器,也支持部分第三方解析器。
Xpath 最初用于搜索 XML 文档,但它也适用于搜索 HTML 文档。它提供了 100 多个内置函数。这些函数用于字符串值、数值、日期和时间比较、节点和QName 处理、序列处理、逻辑值等,XQuery 和XPointer 都建立在XPath 之上。
Re正则表达式通常用于检索和替换符合某种模式(规则)的文本。个人认为前端基础比较扎实,pyquery最方便,beautifulsoup也不错,re速度比较快,但是写regular比较麻烦。当然,既然你用的是python,那绝对是为了你自己的方便。
3、数据存储
当爬回的数据量较小时,可以以文档的形式存储,支持TXT、json、csv等格式。
但是当数据量变大时,文档的存储方式就不行了,所以需要掌握一个数据库。
Mysql作为关系型数据库的代表,有着较为成熟的系统,成熟度较高。可以很好的存储一些数据,但是处理海量数据时效率会明显变慢,已经不能满足一些大数据的需求。加工要求。
MongoDB 已经流行了很长时间。与 MySQL 相比,MongoDB 可以轻松存储一些非结构化数据,例如各种评论的文本、图片链接等。您还可以使用 PyMongo 更轻松地在 Python 中操作 MongoDB。因为这里要用到的数据库知识其实很简单,主要是如何存储数据,如何提取,需要的时候学习。
Redis 是一个不妥协的内存数据库。Redis支持丰富的数据结构,包括hash、set、list等,数据全部存储在内存中,访问速度快,可以存储大量数据,一般用于分布式的数据存储爬虫。
工程履带
通过掌握前面的技术,可以实现轻量级爬虫,一般量级的数据和代码基本没有问题。
但在面对复杂情况时,表现并不令人满意。这时候,一个强大的爬虫框架就非常有用了。
第一个是 Nutch,来自一个著名家族的顶级 Apache 项目,它提供了我们运行自己的搜索引擎所需的所有工具。
支持分布式爬取,通过Hadoop支持,可以进行多机分布式爬取、存储和索引。
另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。
接下来是GitHub上大家star的scrapy,severe是一个非常强大的爬虫框架。
它不仅可以轻松构造请求,还具有强大的选择器,可以轻松解析响应。然而,最令人惊讶的是它的超高性能,它可以让你对爬虫进行工程化和模块化。
学习了scrapy之后就可以自己搭建一些爬虫框架了,基本就具备爬虫工程师的思维了。
最后,Pyspider作为国内大神开发的框架,满足了大部分Python爬虫的针对性爬取和结构化分析的需求。
可以在浏览器界面进行脚本编写、函数调度、实时查看爬取结果,后端使用常用数据库存储爬取结果。
它的功能是如此强大,以至于它更像是一个产品而不是一个框架。
这是三个最具代表性的爬虫框架。它们都有着远超其他的优势,比如Nutch的自然搜索引擎解决方案,Pyspider产品级的WebUI,以及Scrapy最灵活的定制爬取。建议先从最接近爬虫本质的可怕框架入手,然后接触为搜索引擎而生的人性化的Pyspider和Nutch。
防爬虫对策
爬虫就像一个虫子,密密麻麻地爬到每一个角落获取数据。这个错误可能是无害的,但它总是不受欢迎的。
由于爬虫技术网站对带宽资源的侵犯导致大量IP访问,以及用户隐私和知识产权等危害,很多互联网公司都会下大力气“反爬虫”。
你的爬虫会遇到比如被网站拦截,比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。
常见的反爬虫措施有:
·通过Headers反爬虫
·基于用户行为的反爬虫
·基于动态页面的反爬虫
·字体爬取.....
遇到这些反爬虫方法,当然需要一些高深的技巧来应对。尽可能控制访问频率,保证页面加载一次,数据请求最小化,增加每次页面访问的时间间隔;禁止 cookie 可以防止使用 cookie 来识别爬虫。网站 禁止我们;根据浏览器正常访问的请求头修改爬虫的请求头,尽量与浏览器保持一致等。
经常网站在高效开发和反爬虫之间偏向于前者。这也为爬虫提供了空间。掌握这些反爬虫技巧,大部分网站对你来说不再难。
分布式爬虫
爬取基础数据没有问题,也可以用框架来面对更复杂的数据。这时候,就算遇到了防爬,也已经掌握了一些防爬的技巧。
你的瓶颈将集中在爬取大量数据的效率上。这时候,相信你自然会接触到一个非常强大的名字:分布式爬虫。
分布式这个东西听上去很吓人,其实就是利用多线程的原理,将多台主机结合起来,共同完成一个爬虫任务。需要掌握Scrapy+Redis+MQ+Celery等工具。
前面说过,Scrapy是用来做基础的页面爬取,Redis用来存放要爬取的网页的队列,也就是任务队列。
在scrapy中使用scarpy-redis实现分布式组件,通过它可以快速实现简单的分布式爬虫。
由于高并发环境,请求经常被阻塞,因为来不及同步处理。通过使用消息队列MQ,我们可以异步处理请求,从而减轻系统压力。
RabbitMQ本身支持很多协议:AMQP、XMPP、SMTP、STOMP,这使得它非常重量级,更适合企业级开发。
Scrapy-rabbitmq-link 是一个组件,它允许您从 RabbitMQ 消息队列中检索 URL 并将它们分发给 Scrapy 蜘蛛。
Celery 是一个简单、灵活、可靠的分布式系统,可以处理大量消息。它支持RabbitMQ、Redis甚至其他数据库系统作为其消息代理中间件,在处理异步任务、任务调度、处理定时任务、分布式调度等场景中表现良好。
所以分布式爬虫听起来有点吓人,但仅此而已。当你可以编写分布式爬虫时,那么你就可以尝试构建一些基本的爬虫架构。
实现一些更自动化的数据采集。
你看,沿着这条完整的学习路径走下去,爬虫对你来说根本不是问题。
因为爬虫技术不需要你系统地精通一门语言,也不需要非常先进的数据库技术。
解锁各部分知识点,有针对性地学习。经过这条顺利的学习路径,你将能够掌握python爬虫。
js 爬虫抓取网页数据(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-10 00:26
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该界面允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = "nofollow" 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,测试 B 使用它。相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这似乎与排名信号的传递有关。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您没有访问您的 网站 服务器的权限,您可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内(“onClick”)
使用 href 内部 AVP("javascript: window.location")
在 a 标签之外执行,但在 href 中调用 AVP("javascript: openlink()")
还有很多
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序函数(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样一个测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,DOM中没有index,follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按预期工作(不跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:Google 在执行添加 rel="nofollow" 的 JavaScript 函数之前,已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入内容,甚至元标记,例如rel规范注释,无论是在HTML源代码中还是在解析初始HTML后触发JavaScript生成DOM都以相同的方式处理。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。太不可思议了!(请记住允许 Google 爬虫获取这些外部文件和 JavaScript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们需要更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。 查看全部
js 爬虫抓取网页数据(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该界面允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = "nofollow" 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,测试 B 使用它。相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这似乎与排名信号的传递有关。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您没有访问您的 网站 服务器的权限,您可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内(“onClick”)
使用 href 内部 AVP("javascript: window.location")
在 a 标签之外执行,但在 href 中调用 AVP("javascript: openlink()")
还有很多
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序函数(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样一个测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,DOM中没有index,follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按预期工作(不跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:Google 在执行添加 rel="nofollow" 的 JavaScript 函数之前,已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入内容,甚至元标记,例如rel规范注释,无论是在HTML源代码中还是在解析初始HTML后触发JavaScript生成DOM都以相同的方式处理。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。太不可思议了!(请记住允许 Google 爬虫获取这些外部文件和 JavaScript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们需要更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。
js 爬虫抓取网页数据(新浪新闻的国内新闻页静态网页json数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-10-09 00:01
)
昨天,一个朋友来找我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
需要Python学习资料的可以去掉文字加我的裙子075分18.82第71次考试。材料免费送给大家!(书太多了,就随便发一点吧!)
但是发现有个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\\,标题和介绍都是\\u539f\\u6807\\u9898的形式。这些是我们需要处理的后续步骤!
先用replace函数把\\放在url里,就可以得到url了,下面的\\u539f\\u6807\\u9898是unicode编码,可以直接解码内容直接写code
使用eval函数进行解码,可以将内容解码成u'unicode编码内容'的形式!
这样就把这个页面上所有新闻和URL相关的内容都取出来了,在外层加了一个循环来爬取所有的新闻页面,任务就完成了!
查看全部
js 爬虫抓取网页数据(新浪新闻的国内新闻页静态网页json数据
)
昨天,一个朋友来找我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
需要Python学习资料的可以去掉文字加我的裙子075分18.82第71次考试。材料免费送给大家!(书太多了,就随便发一点吧!)
但是发现有个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\\,标题和介绍都是\\u539f\\u6807\\u9898的形式。这些是我们需要处理的后续步骤!
先用replace函数把\\放在url里,就可以得到url了,下面的\\u539f\\u6807\\u9898是unicode编码,可以直接解码内容直接写code
使用eval函数进行解码,可以将内容解码成u'unicode编码内容'的形式!
这样就把这个页面上所有新闻和URL相关的内容都取出来了,在外层加了一个循环来爬取所有的新闻页面,任务就完成了!

