
js 爬虫抓取网页数据
js 爬虫抓取网页数据(Node学习之cheerio网络爬虫好了,啊哈哈哈~昨天的抓取博文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2021-12-27 20:30
书上次连上了,哈哈,昨天发表了,如何使用Node的cheerio模块抓取网页信息,那一定有我们自己使用的数据。
我昨天抓到的是一些超级诱人的糕点的照片,今天我给他们看了。大家都贪心了,哈哈哈哈~
获取昨天的博文,如果需要,请点击此链接:Cheerio Web Crawler for Node Learning
好,开始今天的表演,添加代码:
<p>var http = require("http");
var cheerio = require("cheerio");
//准备抓取的网站链接
var dataUrl = "http://www.mcake.com/shop/110/ ... 3B%3B
http.get(dataUrl,function(res){
var str = "";
//绑定方法,获取网页数据
res.on("data",function(chunk){
str += chunk;
})
//数据获取完毕
res.on("end",function(){
//调用下方的函数,得到返回值,即是我们想要的img的src
var data = getData(str);
//console.log(data);
----------
//新添加的部分
//用node搭建服务器,将内容展示在页面上
var server = http.createServer(function(req,res){
//定义空的字符串
var html = "";
//循环得到的数据,拼接在html上
for(var i = 0;i 查看全部
js 爬虫抓取网页数据(Node学习之cheerio网络爬虫好了,啊哈哈哈~昨天的抓取博文)
书上次连上了,哈哈,昨天发表了,如何使用Node的cheerio模块抓取网页信息,那一定有我们自己使用的数据。
我昨天抓到的是一些超级诱人的糕点的照片,今天我给他们看了。大家都贪心了,哈哈哈哈~
获取昨天的博文,如果需要,请点击此链接:Cheerio Web Crawler for Node Learning
好,开始今天的表演,添加代码:
<p>var http = require("http");
var cheerio = require("cheerio");
//准备抓取的网站链接
var dataUrl = "http://www.mcake.com/shop/110/ ... 3B%3B
http.get(dataUrl,function(res){
var str = "";
//绑定方法,获取网页数据
res.on("data",function(chunk){
str += chunk;
})
//数据获取完毕
res.on("end",function(){
//调用下方的函数,得到返回值,即是我们想要的img的src
var data = getData(str);
//console.log(data);
----------
//新添加的部分
//用node搭建服务器,将内容展示在页面上
var server = http.createServer(function(req,res){
//定义空的字符串
var html = "";
//循环得到的数据,拼接在html上
for(var i = 0;i
js 爬虫抓取网页数据(爬虫爬取的流程和最终如何展示数据的地址?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-26 15:03
其实我之前做过利马理财的销售统计,不过是前端js写的。需要在首页的控制台调试面板中粘贴一段代码执行,点击这里。主要目的是通过定时爬取异步接口来获取数据。然后通过一定的去重算法得到最终的数据。但这有以下缺点:
代码只能在浏览器窗口中运行。如果浏览器关闭或电脑无效,则只能抓取一个页面的数据,无法整合其他页面的数据。爬取的数据无法存储在本地。异步接口数据将被部分过滤。导致我们的去重算法失败
最近学习了节点爬虫,我们可以在后台模拟请求,爬取页面数据。而且我开通了阿里云服务器,我可以把代码放到云端运行。这样1、2、3都可以解决。4因为我们不知道这个ajax界面每三分钟更新一次,这样我们就可以以此为基础对权重进行排序,保证数据不会重复。说起爬虫,大家想到的更多的是python。确实,python有Scrapy等成熟的框架,可以实现非常强大的爬虫功能。但是node也有自己的优势。凭借其强大的异步特性,可以轻松实现高效的异步并发请求,节省CPU开销。其实节点爬虫比较简单,让'
在线地址
一、爬虫进程
我们的最终目标是爬取利马财经每天的销售额,知道销售了哪些产品,哪些用户在什么时间点购买了每种产品。首先介绍一下爬取的主要步骤:
1. 结构分析
我们要抓取页面的数据。第一步当然是分析页面结构,抓取哪些页面,页面结构是什么,不需要登录;是否有ajax接口,返回什么样的数据等。
2. 数据采集
分析清楚要爬取哪些页面和ajax,需要爬取数据。现在网页的数据大致分为同步页面和ajax接口。同步页面数据的爬取需要我们首先分析网页的结构。Python爬取数据一般是通过正则表达式匹配来获取需要的数据;node有一个cheerio工具,可以将获取到的页面内容转换成jquery对象。然后就可以使用jquery强大的dom API来获取节点相关的数据了。其实看源码,这些API本质上都是正则匹配。ajax接口数据一般都是json格式,处理起来比较简单。
3. 数据存储
捕获数据后,它会做一个简单的筛选,然后将需要的数据保存起来,以便后续的分析和处理。当然我们可以使用MySQL、Mongodb等数据库来存储数据。这里,为了方便,我们直接使用文件存储。
4. 数据分析
因为我们最终要展示数据,所以需要按照一定的维度对原创
数据进行处理和分析,然后返回给客户端。这个过程可以在存储过程中进行处理,也可以在显示过程中,前端发送请求,后端获取存储的数据后再进行处理。这取决于我们希望如何显示数据。
5. 结果展示
做了这么多功课,一点显示输出都没有,怎么不甘心?这又回到我们的老本行了,前端展示页面大家应该都很熟悉了。将数据展示更直观,方便我们进行统计分析。
二、常见爬虫库介绍1. Superagent
Superagent 是一个轻量级的 http 库。是nodejs中一个非常方便的客户端请求代理模块。当我们需要进行get、post、head等网络请求时,试试吧。
2. 啦啦队
Cheerio可以理解为jquery的一个Node.js版本,用于通过css选择器从网页中检索数据,用法和jquery完全一样。
3. 异步
async 是一个流程控制工具包,提供了直接强大的异步函数mapLimit(arr,limit,iterator,callback),我们主要使用这个方法,可以去官网看API。
4. arr-del
arr-del 是我自己写的一个删除数组元素的工具。通过传入由要删除的数组元素的索引组成的数组,可以一次性删除它。
5. arr-sort
arr-sort 是我自己写的一个数组排序方法的工具。可以根据一个或多个属性进行排序,支持嵌套属性。而且可以在每个条件中指定排序方向,传入比较函数。
三、页面结构分析
让我们重复爬行的想法。利马理财网上的产品主要是普通的和利马金库(新推出的光大银行理财产品,手续繁琐,初期投资额高,所以基本没人买,所以我们不在这里计算它们)。定期我们可以爬取财富管理页面的ajax界面:。(更新:近期定期断货,可能看不到数据,1月19日前可以看到数据) 数据如下图:
这包括所有在线销售的常规产品。Ajax数据只有产品本身的信息,比如产品id、募集金额、当前销售额、年化收益率、投资天数等,没有关于谁购买了产品的信息。. 所以我们需要去它的商品详情页面用id参数进行爬取,比如Lima Jucai-December HLB01239511。详情页有一栏投资记录,里面有我们需要的信息,如下图:
但是,详情页只有在我们登录后才能查看,这就需要我们访问cookies,cookies是有有效期的。如何让我们的 cookie 保持登录状态?请稍后再看。
其实Lima Vault也有类似的ajax接口:,只是里面的相关数据是硬编码的,毫无意义。并且金库的详情页也没有投资记录信息。这就需要我们爬取我们开头所说的主页的ajax接口:。但是后来我发现这个界面每三分钟更新一次,也就是说后台每三分钟向服务器请求一次数据。一次有10条数据,所以如果三分钟内购买记录超过10条,数据就会有遗漏。没办法,所以直接金库的统计数据会比真实的少。
四、爬虫代码分析1. 获取登录cookie
因为商品详情页需要登录,所以我们需要先获取登录cookie。getCookie 方法如下:
function getCookie() {
superagent.post('https://www.lmlc.com/user/s/web/logon')
.type('form')
.send({
phone: phone,
password: password,
productCode: "LMLC",
origin: "PC"
})
.end(function(err, res) {
if (err) {
handleErr(err.message);
return;
}
cookie = res.header['set-cookie']; //从response中得到cookie
emitter.emit("setCookeie");
})
}
手机号和密码参数是从命令行传入的,就是用你的手机号登录的账号和密码。我们使用superagent来模拟请求即时理财登录界面:。传入相应的参数。在回调中,我们获取头部的 set-cookie 信息,并发送一个 setCookeie 事件。因为我们设置了监听事件:emitter.on("setCookie", requestData),一旦拿到cookie,就会执行requestData方法。
2. 财富管理页面ajax爬取
requestData方法的代码如下:
<p>function requestData() {
superagent.get('https://www.lmlc.com/web/produ ... %2339;)
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
// 在这里清空数据,避免一个文件被同时写入
if(clearProd){
fs.writeFileSync('data/prod.json', JSON.stringify([]));
clearProd = false;
}
let addData = JSON.parse(pres.text).data;
let formatedAddData = formatData(addData.result);
let pageUrls = [];
if(addData.totalPage > 1){
handleErr('产品个数超过100个!');
return;
}
for(let i=0,len=addData.result.length; i 查看全部
js 爬虫抓取网页数据(爬虫爬取的流程和最终如何展示数据的地址?)
其实我之前做过利马理财的销售统计,不过是前端js写的。需要在首页的控制台调试面板中粘贴一段代码执行,点击这里。主要目的是通过定时爬取异步接口来获取数据。然后通过一定的去重算法得到最终的数据。但这有以下缺点:
代码只能在浏览器窗口中运行。如果浏览器关闭或电脑无效,则只能抓取一个页面的数据,无法整合其他页面的数据。爬取的数据无法存储在本地。异步接口数据将被部分过滤。导致我们的去重算法失败
最近学习了节点爬虫,我们可以在后台模拟请求,爬取页面数据。而且我开通了阿里云服务器,我可以把代码放到云端运行。这样1、2、3都可以解决。4因为我们不知道这个ajax界面每三分钟更新一次,这样我们就可以以此为基础对权重进行排序,保证数据不会重复。说起爬虫,大家想到的更多的是python。确实,python有Scrapy等成熟的框架,可以实现非常强大的爬虫功能。但是node也有自己的优势。凭借其强大的异步特性,可以轻松实现高效的异步并发请求,节省CPU开销。其实节点爬虫比较简单,让'
在线地址
一、爬虫进程
我们的最终目标是爬取利马财经每天的销售额,知道销售了哪些产品,哪些用户在什么时间点购买了每种产品。首先介绍一下爬取的主要步骤:
1. 结构分析
我们要抓取页面的数据。第一步当然是分析页面结构,抓取哪些页面,页面结构是什么,不需要登录;是否有ajax接口,返回什么样的数据等。
2. 数据采集
分析清楚要爬取哪些页面和ajax,需要爬取数据。现在网页的数据大致分为同步页面和ajax接口。同步页面数据的爬取需要我们首先分析网页的结构。Python爬取数据一般是通过正则表达式匹配来获取需要的数据;node有一个cheerio工具,可以将获取到的页面内容转换成jquery对象。然后就可以使用jquery强大的dom API来获取节点相关的数据了。其实看源码,这些API本质上都是正则匹配。ajax接口数据一般都是json格式,处理起来比较简单。
3. 数据存储
捕获数据后,它会做一个简单的筛选,然后将需要的数据保存起来,以便后续的分析和处理。当然我们可以使用MySQL、Mongodb等数据库来存储数据。这里,为了方便,我们直接使用文件存储。
4. 数据分析
因为我们最终要展示数据,所以需要按照一定的维度对原创
数据进行处理和分析,然后返回给客户端。这个过程可以在存储过程中进行处理,也可以在显示过程中,前端发送请求,后端获取存储的数据后再进行处理。这取决于我们希望如何显示数据。
5. 结果展示
做了这么多功课,一点显示输出都没有,怎么不甘心?这又回到我们的老本行了,前端展示页面大家应该都很熟悉了。将数据展示更直观,方便我们进行统计分析。
二、常见爬虫库介绍1. Superagent
Superagent 是一个轻量级的 http 库。是nodejs中一个非常方便的客户端请求代理模块。当我们需要进行get、post、head等网络请求时,试试吧。
2. 啦啦队
Cheerio可以理解为jquery的一个Node.js版本,用于通过css选择器从网页中检索数据,用法和jquery完全一样。
3. 异步
async 是一个流程控制工具包,提供了直接强大的异步函数mapLimit(arr,limit,iterator,callback),我们主要使用这个方法,可以去官网看API。
4. arr-del
arr-del 是我自己写的一个删除数组元素的工具。通过传入由要删除的数组元素的索引组成的数组,可以一次性删除它。
5. arr-sort
arr-sort 是我自己写的一个数组排序方法的工具。可以根据一个或多个属性进行排序,支持嵌套属性。而且可以在每个条件中指定排序方向,传入比较函数。
三、页面结构分析
让我们重复爬行的想法。利马理财网上的产品主要是普通的和利马金库(新推出的光大银行理财产品,手续繁琐,初期投资额高,所以基本没人买,所以我们不在这里计算它们)。定期我们可以爬取财富管理页面的ajax界面:。(更新:近期定期断货,可能看不到数据,1月19日前可以看到数据) 数据如下图:

这包括所有在线销售的常规产品。Ajax数据只有产品本身的信息,比如产品id、募集金额、当前销售额、年化收益率、投资天数等,没有关于谁购买了产品的信息。. 所以我们需要去它的商品详情页面用id参数进行爬取,比如Lima Jucai-December HLB01239511。详情页有一栏投资记录,里面有我们需要的信息,如下图:

但是,详情页只有在我们登录后才能查看,这就需要我们访问cookies,cookies是有有效期的。如何让我们的 cookie 保持登录状态?请稍后再看。
其实Lima Vault也有类似的ajax接口:,只是里面的相关数据是硬编码的,毫无意义。并且金库的详情页也没有投资记录信息。这就需要我们爬取我们开头所说的主页的ajax接口:。但是后来我发现这个界面每三分钟更新一次,也就是说后台每三分钟向服务器请求一次数据。一次有10条数据,所以如果三分钟内购买记录超过10条,数据就会有遗漏。没办法,所以直接金库的统计数据会比真实的少。
四、爬虫代码分析1. 获取登录cookie
因为商品详情页需要登录,所以我们需要先获取登录cookie。getCookie 方法如下:
function getCookie() {
superagent.post('https://www.lmlc.com/user/s/web/logon')
.type('form')
.send({
phone: phone,
password: password,
productCode: "LMLC",
origin: "PC"
})
.end(function(err, res) {
if (err) {
handleErr(err.message);
return;
}
cookie = res.header['set-cookie']; //从response中得到cookie
emitter.emit("setCookeie");
})
}
手机号和密码参数是从命令行传入的,就是用你的手机号登录的账号和密码。我们使用superagent来模拟请求即时理财登录界面:。传入相应的参数。在回调中,我们获取头部的 set-cookie 信息,并发送一个 setCookeie 事件。因为我们设置了监听事件:emitter.on("setCookie", requestData),一旦拿到cookie,就会执行requestData方法。
2. 财富管理页面ajax爬取
requestData方法的代码如下:
<p>function requestData() {
superagent.get('https://www.lmlc.com/web/produ ... %2339;)
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
// 在这里清空数据,避免一个文件被同时写入
if(clearProd){
fs.writeFileSync('data/prod.json', JSON.stringify([]));
clearProd = false;
}
let addData = JSON.parse(pres.text).data;
let formatedAddData = formatData(addData.result);
let pageUrls = [];
if(addData.totalPage > 1){
handleErr('产品个数超过100个!');
return;
}
for(let i=0,len=addData.result.length; i
js 爬虫抓取网页数据( 一下如何用Excel快速抓取网页数据(图)的技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-26 00:08
一下如何用Excel快速抓取网页数据(图)的技巧)
网站上的数据来源是我们统计分析的重要信息来源。我们在生活中经常听到一个词叫“爬虫”,它可以快速抓取网页上的数据,这对于数据分析相关的工作来说是极其重要的,也是必备的技能之一。但是,大多数爬虫都需要编程知识,这对大多数人来说是很难上手的。今天给大家讲解一下如何用Excel快速抓取网页数据。
1、首先打开要获取数据的网址,复制网址。
2、 要创建新的 Excel 工作簿,请单击“数据”菜单中的“来自网站”选项>“获取外部数据”选项卡。
在弹出的“新建网页查询”对话框中,在地址栏中输入要爬取的网站地址,点击“前往”
点击黄色的导入箭头,选择需要采集的部分,如图。只需单击导入。
3、选择存储数据的位置(默认选中的单元格),点击确定。通常建议将数据存储在“A1”单元格中。
4、如果想让Excel工作簿数据根据网站数据实时自动更新,那么我们需要在“属性”中进行设置。您可以设置“允许后台刷新”、“刷新频率”、“打开文件时刷新数据”等。
拿到数据后,就需要对数据进行处理,而处理数据是一个比较重要的环节。更多数据处理技巧,请关注我!
如果对你有帮助,记得点赞转发哦。
关注我,学习更多 Excel 技能,让工作更轻松。 查看全部
js 爬虫抓取网页数据(
一下如何用Excel快速抓取网页数据(图)的技巧)

网站上的数据来源是我们统计分析的重要信息来源。我们在生活中经常听到一个词叫“爬虫”,它可以快速抓取网页上的数据,这对于数据分析相关的工作来说是极其重要的,也是必备的技能之一。但是,大多数爬虫都需要编程知识,这对大多数人来说是很难上手的。今天给大家讲解一下如何用Excel快速抓取网页数据。
1、首先打开要获取数据的网址,复制网址。

2、 要创建新的 Excel 工作簿,请单击“数据”菜单中的“来自网站”选项>“获取外部数据”选项卡。

在弹出的“新建网页查询”对话框中,在地址栏中输入要爬取的网站地址,点击“前往”

点击黄色的导入箭头,选择需要采集的部分,如图。只需单击导入。

3、选择存储数据的位置(默认选中的单元格),点击确定。通常建议将数据存储在“A1”单元格中。



4、如果想让Excel工作簿数据根据网站数据实时自动更新,那么我们需要在“属性”中进行设置。您可以设置“允许后台刷新”、“刷新频率”、“打开文件时刷新数据”等。

拿到数据后,就需要对数据进行处理,而处理数据是一个比较重要的环节。更多数据处理技巧,请关注我!
如果对你有帮助,记得点赞转发哦。
关注我,学习更多 Excel 技能,让工作更轻松。
js 爬虫抓取网页数据(第一个问题:JS加密如何突破(1)的开发者功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-23 18:12
第一个问题:如何突破JS加密
(1) 熟悉Chrome的开发者工具的各种功能,Elements、Network、Source
(2)仔细观察,善于思考。网络查看加载过程,发现可疑的xhr请求,设置xhr断点,通过Call Stack回溯js执行过程,回溯时查看上下文代码。可以读取js ,了解js相关知识,比如js中的window变量。
(3)上面是通过debug js找到js加解密代码,然后通过Python重新实现,这个过程很长,可能要好几天。一旦网站改变js算法,你的 Python 无法使用。
(4) Selenium 可以做简单的突破,而网站 想要什么都无所谓。唯一遗憾的是Selenium 运行效率差。不过作为JS加密来保护数据网站,单价的运行效率应该足以满足网站的访问频率限制,这个时候更多的思考是如何增加资源(IP,账号)来提高爬取效率。
第二个问题,多线程、协程、多进程选择
(1)爬虫是IO密集型任务,大部分时间花在网络访问上,所以多进程不适合网络爬虫,多线程,异步IO协程更适合,异步IO更适合最合适的,它与多线程相比,协程之间的切换成本更低,我们提倡使用异步IO代替多线程,异步IO的主要模块有:aysncio、aiohttp、aiomysql等。
(2) 爬下来后从网页中提取想要的数据是CPU密集型的,此时可以使用多个进程并发提取。
(3)我们推荐的爬虫策略是爬虫只爬取,把爬取的html保存,存入数据库。然后单独写提取数据的extractor,单独运行extractor。优点是提取不影响爬取,爬取爬取效率更高,提取程序可以随时修改,有新的提取需求时无需重新取。本来写的,我只是想从网页中提取两条数据,运行一段时间后发现另外三项数据也很有用,如果保存html,只需要改一下extractor和再次运行它。
第三个问题,如果要保留图片的粗体或者原位置,只能挖规则,然后写正则表达式来处理吗?
Web数据提取主要有两种方法:正则表达式和xpath。某个html标签节点可以通过xpath获取。例如,对于一个博客页面,它的主要内容在某个标签中,可能是某个div。使用xpath获取这个div并转换成html,也就是收录格式和图片的部分。只需保存此 html 代码而不是纯文本。
第四个问题,爬虫增量爬取,断点连续爬取,去重等
(1)通过URL池的概念管理所有的URL
(2)增量爬取是指下载的网址不会重复下载,让网址池记住那些已经下载过的网址;
(3)断点恢复爬取,即这次爬取上次没有爬取的URL,或者让URL池记住那些没有爬取的URL
(4) 爬虫的去重可以让URL池记录URL的状态,避免重复爬取。
第五个问题是爬虫的部署问题。公司分布式爬虫系统是否涉及部署问题?
爬虫的部署不一定是分布式的。大型爬虫,突破目标网站限制的爬虫会涉及分布式。分布式的好处是提高了爬取速度,但是管理会比较复杂。
第六个问题,网页自动分析?本主题收录很多子任务:如何自动提取文章的内容,如何处理各种时间格式,如何处理翻页
(1)文章 内容提取,基本就是为每个网页建立一个提取模板(正则表达式)。优点是提取准确,缺点是工作量大。版本稍有修改就会失效,通过算法建立单一的提取程序基本可以提取,但可能有写的不纯,比如文末相关阅读。优点是一劳永逸,不受修订限制。
(2)时间提取,除了正则表达式,似乎没有特别有效的方法。
(3)如果翻页,如果只是抓取,则提取页面的url继续抓取;提取内容时如何将多个页面的内容合并为一个网页,需要处理专门用它。
第七题,爬取新闻类网站时,同一条新闻怎么做,每个网站互相转载,爬取时去掉文字
众所周知的算法是谷歌的simhash,但在实践中比较复杂。百度在线传输的方法是对文章的最长句子(或多个句子)进行hash。这个哈希值是文章的唯一代表(指纹)。该方法准确率高,但召回率相对较低。最长的句子一旦换了一个词,就再也记不起来;我改进了方法,分别对n个句子中最长的句子进行了hash。一个文章由n个指纹组成(如图)每个手指的指纹都不一样)来判断唯一性。准确率和召回率都不错。
第八题,异步爬虫的设计
(1)一个不错的URL管理策略,请参考Apeman Learning上与文章相关的URL池;
URL 池是“生产者-消费者”模型。爬虫从中取出URL进行下载,从下载的html中取出新的URL放入池中,告诉URL池刚刚取出的URL是否下载成功;然后将其从池 url 中删除以进行下载。. . url池是核心组件,它记录了url的不同状态:
(一)下载成功
(B) 下载失败n次
(C) 下载
每次向池中添加 URL 时,请检查池中 URL 的状态,以避免重复下载。
(2)一个不错的异步协进程管理策略,见文章 猿人学习大型异步新闻爬虫网站。
每次从urlpool中提取n个url,就会生成n个异步下载协程,协程的数量(即正在下载的网页数量)通过一个变量记录下来。
大型异步新闻爬虫:实现功能强大、简单易用的网址池(URL Pool)
大型异步新闻爬虫:带有asyncio的异步爬虫
异步网址管理异步实现看这两个网址
如果有用记得点赞哈哈哈哈 查看全部
js 爬虫抓取网页数据(第一个问题:JS加密如何突破(1)的开发者功能)
第一个问题:如何突破JS加密
(1) 熟悉Chrome的开发者工具的各种功能,Elements、Network、Source
(2)仔细观察,善于思考。网络查看加载过程,发现可疑的xhr请求,设置xhr断点,通过Call Stack回溯js执行过程,回溯时查看上下文代码。可以读取js ,了解js相关知识,比如js中的window变量。
(3)上面是通过debug js找到js加解密代码,然后通过Python重新实现,这个过程很长,可能要好几天。一旦网站改变js算法,你的 Python 无法使用。
(4) Selenium 可以做简单的突破,而网站 想要什么都无所谓。唯一遗憾的是Selenium 运行效率差。不过作为JS加密来保护数据网站,单价的运行效率应该足以满足网站的访问频率限制,这个时候更多的思考是如何增加资源(IP,账号)来提高爬取效率。
第二个问题,多线程、协程、多进程选择
(1)爬虫是IO密集型任务,大部分时间花在网络访问上,所以多进程不适合网络爬虫,多线程,异步IO协程更适合,异步IO更适合最合适的,它与多线程相比,协程之间的切换成本更低,我们提倡使用异步IO代替多线程,异步IO的主要模块有:aysncio、aiohttp、aiomysql等。
(2) 爬下来后从网页中提取想要的数据是CPU密集型的,此时可以使用多个进程并发提取。
(3)我们推荐的爬虫策略是爬虫只爬取,把爬取的html保存,存入数据库。然后单独写提取数据的extractor,单独运行extractor。优点是提取不影响爬取,爬取爬取效率更高,提取程序可以随时修改,有新的提取需求时无需重新取。本来写的,我只是想从网页中提取两条数据,运行一段时间后发现另外三项数据也很有用,如果保存html,只需要改一下extractor和再次运行它。
第三个问题,如果要保留图片的粗体或者原位置,只能挖规则,然后写正则表达式来处理吗?
Web数据提取主要有两种方法:正则表达式和xpath。某个html标签节点可以通过xpath获取。例如,对于一个博客页面,它的主要内容在某个标签中,可能是某个div。使用xpath获取这个div并转换成html,也就是收录格式和图片的部分。只需保存此 html 代码而不是纯文本。
第四个问题,爬虫增量爬取,断点连续爬取,去重等
(1)通过URL池的概念管理所有的URL
(2)增量爬取是指下载的网址不会重复下载,让网址池记住那些已经下载过的网址;
(3)断点恢复爬取,即这次爬取上次没有爬取的URL,或者让URL池记住那些没有爬取的URL
(4) 爬虫的去重可以让URL池记录URL的状态,避免重复爬取。
第五个问题是爬虫的部署问题。公司分布式爬虫系统是否涉及部署问题?
爬虫的部署不一定是分布式的。大型爬虫,突破目标网站限制的爬虫会涉及分布式。分布式的好处是提高了爬取速度,但是管理会比较复杂。
第六个问题,网页自动分析?本主题收录很多子任务:如何自动提取文章的内容,如何处理各种时间格式,如何处理翻页
(1)文章 内容提取,基本就是为每个网页建立一个提取模板(正则表达式)。优点是提取准确,缺点是工作量大。版本稍有修改就会失效,通过算法建立单一的提取程序基本可以提取,但可能有写的不纯,比如文末相关阅读。优点是一劳永逸,不受修订限制。
(2)时间提取,除了正则表达式,似乎没有特别有效的方法。
(3)如果翻页,如果只是抓取,则提取页面的url继续抓取;提取内容时如何将多个页面的内容合并为一个网页,需要处理专门用它。
第七题,爬取新闻类网站时,同一条新闻怎么做,每个网站互相转载,爬取时去掉文字
众所周知的算法是谷歌的simhash,但在实践中比较复杂。百度在线传输的方法是对文章的最长句子(或多个句子)进行hash。这个哈希值是文章的唯一代表(指纹)。该方法准确率高,但召回率相对较低。最长的句子一旦换了一个词,就再也记不起来;我改进了方法,分别对n个句子中最长的句子进行了hash。一个文章由n个指纹组成(如图)每个手指的指纹都不一样)来判断唯一性。准确率和召回率都不错。
第八题,异步爬虫的设计
(1)一个不错的URL管理策略,请参考Apeman Learning上与文章相关的URL池;
URL 池是“生产者-消费者”模型。爬虫从中取出URL进行下载,从下载的html中取出新的URL放入池中,告诉URL池刚刚取出的URL是否下载成功;然后将其从池 url 中删除以进行下载。. . url池是核心组件,它记录了url的不同状态:
(一)下载成功
(B) 下载失败n次
(C) 下载
每次向池中添加 URL 时,请检查池中 URL 的状态,以避免重复下载。
(2)一个不错的异步协进程管理策略,见文章 猿人学习大型异步新闻爬虫网站。
每次从urlpool中提取n个url,就会生成n个异步下载协程,协程的数量(即正在下载的网页数量)通过一个变量记录下来。
大型异步新闻爬虫:实现功能强大、简单易用的网址池(URL Pool)
大型异步新闻爬虫:带有asyncio的异步爬虫
异步网址管理异步实现看这两个网址
如果有用记得点赞哈哈哈哈
js 爬虫抓取网页数据(js爬虫抓取网页数据,可以接收和反馈用户的对于)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-23 14:04
js爬虫抓取网页数据,可以接收和反馈用户的对于网页的反馈,并且返回给用户,用户可以根据用户实际的需求,自由选择对于网页进行修改或者是重新渲染。下面这个简单的例子,我们可以用一次性获取需要的网页源码,并保存。方便做以后需要抓取的网页源码处理。chrome浏览器打开网页a。左上角会弹出一个帮助的小窗口,点击。
点击。可以自己搜索一下,一般不会直接给你response,如果需要response,点击回车。用户就可以获取到response,可以用request直接连接到我们爬虫抓取的网页。chrome浏览器打开网页b。左上角会弹出一个帮助的小窗口,点击。如果,chrome浏览器,没有这个功能,那就没法自己配置了。
看这里,我的办法是,换chrome。现在,已经有了我们要抓取的网页。我们怎么快速抓取网页源码呢。我们只需要看一下首页有哪些链接,然后一个一个点就行了。有些网页,可能会多个链接,需要我们一个一个点击去,当然也可以按照从上到下的次序来排序抓取。window.execcommand('input"\username"\username\age"\email"\files"\index.html',function(){window.execcommand('input"\username"\username\email"\files"\index.html',function(){console.log('正在抓取网页:');});console.log('已抓取网页:');});我已经抓取到了网页a的url。
接下来,我们就要从文件夹response里面,获取到我们自己要抓取的源码。chrome浏览器打开网页a我们可以看到页面的源码window.execcommand('input"\username"\username\age"\email"\files"\index.html',function(){console.log('正在抓取网页:');});接下来,我们要获取到用户编辑的内容。
chrome浏览器打开网页a获取到了编辑的内容在左边,点击选择文本。上传到页面b的html,可以获取到源码。接下来,还有一个重要的步骤,就是要获取用户的评论。当然这些评论,是通过cookie获取的。所以,如果抓取不到用户的评论。就会出现刷新页面,看到需要删除的页面内容时。获取不到。这个时候,我们要换浏览器。
以360浏览器为例window.execcommand('input"\username"\username\email"\files"\index.html',function(){console.log('正在抓取网页:');});抓取不到用户评论。那怎么办呢。这就要抓取用户评论。但是用户评论的url可能不是自己抓取的页面内容。
我们点击左上角的设置。把这个urlurlurl改成我们抓取的网页urlurlurl。鼠标移动到文件名上面。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据,可以接收和反馈用户的对于)
js爬虫抓取网页数据,可以接收和反馈用户的对于网页的反馈,并且返回给用户,用户可以根据用户实际的需求,自由选择对于网页进行修改或者是重新渲染。下面这个简单的例子,我们可以用一次性获取需要的网页源码,并保存。方便做以后需要抓取的网页源码处理。chrome浏览器打开网页a。左上角会弹出一个帮助的小窗口,点击。
点击。可以自己搜索一下,一般不会直接给你response,如果需要response,点击回车。用户就可以获取到response,可以用request直接连接到我们爬虫抓取的网页。chrome浏览器打开网页b。左上角会弹出一个帮助的小窗口,点击。如果,chrome浏览器,没有这个功能,那就没法自己配置了。
看这里,我的办法是,换chrome。现在,已经有了我们要抓取的网页。我们怎么快速抓取网页源码呢。我们只需要看一下首页有哪些链接,然后一个一个点就行了。有些网页,可能会多个链接,需要我们一个一个点击去,当然也可以按照从上到下的次序来排序抓取。window.execcommand('input"\username"\username\age"\email"\files"\index.html',function(){window.execcommand('input"\username"\username\email"\files"\index.html',function(){console.log('正在抓取网页:');});console.log('已抓取网页:');});我已经抓取到了网页a的url。
接下来,我们就要从文件夹response里面,获取到我们自己要抓取的源码。chrome浏览器打开网页a我们可以看到页面的源码window.execcommand('input"\username"\username\age"\email"\files"\index.html',function(){console.log('正在抓取网页:');});接下来,我们要获取到用户编辑的内容。
chrome浏览器打开网页a获取到了编辑的内容在左边,点击选择文本。上传到页面b的html,可以获取到源码。接下来,还有一个重要的步骤,就是要获取用户的评论。当然这些评论,是通过cookie获取的。所以,如果抓取不到用户的评论。就会出现刷新页面,看到需要删除的页面内容时。获取不到。这个时候,我们要换浏览器。
以360浏览器为例window.execcommand('input"\username"\username\email"\files"\index.html',function(){console.log('正在抓取网页:');});抓取不到用户评论。那怎么办呢。这就要抓取用户评论。但是用户评论的url可能不是自己抓取的页面内容。
我们点击左上角的设置。把这个urlurlurl改成我们抓取的网页urlurlurl。鼠标移动到文件名上面。
js 爬虫抓取网页数据(有效的应对HTTP反爬虫策略最简单的反爬机制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-22 20:03
一些从WEB页面抓取数据的程序比较简单。大多数语言都有相应的 HTTP 库。一个简单的请求响应就足够了。程序向Web服务器发送Http请求,服务器返回HTML文件。交互方式如下:
使用DevProtocol驱动Chrome获取数据时,交互过程如下图所示:
这时候Chrome充当了中间的代理,看起来比较复杂,但实际上对我们的爬虫程序很有帮助。本文简要总结了这种方法的以下优点。
获取动态生成的网页内容
现在很多网页的内容并不是通过初始的Http请求一打开就直接获取,而是通过JS加载资源,在返回的html页面中计算动态生成的页面。采用这种方式的原因有很多,有的为了更好的用户体验,有的为了框架开发,有的为了节省带宽,有的纯粹是为了对页面内容进行加密,从而实现反爬虫的功能。
不管是什么原因,它使原本简单的单一“请求-响应”交互过程变得复杂。传统的一次性交互可以将所有请求完成为如下形式:
动态加载对传统数据采集造成了很大的阻碍,但是往往需要分析页面加载过程,分析JS,在程序中嵌入js引擎模拟浏览器执行相应的脚本来实现获得最终数据。这是一个非常费时费力的过程,也不容易分析整个过程。
为了更容易解析这样的动态网页,一些爬虫引擎开始引入Dom解析和JS执行能力来模拟浏览器解析获取相关资源。但是,由于这个过程非常复杂,这些功能往往并不完善,存在很多陷阱。
现在,通过Chrome浏览器的方式就是这种解析页面的方式的集成版本。因为Chrome本身就是一个浏览器,它具有完善的页面解析能力,所以可以如鱼得水。解析过程由chrome代理完成,我们只需要从chrome获取最终的解析结果即可。
针对爬虫的有效对策
最简单的反爬虫机制就是检查HTTP请求的Headers信息,包括User-Agent、Referer、Cookies等,根据手写的Http请求头和常用的浏览器头的区别进行反爬。这些对于防止主要爬虫非常有效,但 Chrome 本身是一个标准浏览器,天生就对这种反爬虫机制免疫。
另一种反爬虫机制就是上面提到的动态加载。基于上面的解释,这也是天生对 Chrome 免疫的。
当然,防爬的策略有很多,比如限制IP访问次数、限制访问频率、验证码等方法来防爬。Chrome虽然不直接支持这些,但是处理起来比传统的Http请求方便很多。下面的文章会陆续介绍,这里就不一一展开了。
DOM操作能力
Chrome具有完善的Dom操作能力。基本上所有可以在Chrome DevTools控制台中进行的操作,都可以通过DevProtocol在程序中完成,为我们的APP增加了完善的DOM操作能力。许多以前需要通过 HTML 分析的数据现在都可以获得。直接通过Jquery等js函数完成。并且可以直接格式化为JSON输出,方便多了。
与服务器交互更容易
在很多情况下,有些页面需要一些交互才能获得,比如登录。
因为Chrome具有执行JS的能力,所以我们可以通过一些简单的JS脚本来非常轻松地执行它。比如花园的登录可以通过如下脚本实现:
$("#input1")[0].value = "userName";
$("#input2")[0].value = "密码";
$("#signin")[0].click();
有些网站需要验证码来防止爬虫,我们甚至可以通过chrome中手动编码的自动组合快速实现数据抓取。如果要开发一个支持访问编码平台或智能识别平台的接口,比传统的蜘蛛程序要容易得多。
此外,Chrome 还提供了非常丰富的 API 来模拟键盘和鼠标输入界面,使用起来非常方便。
方便的开发调试
爬虫的开发往往是一个反复调试的过程,因为我们直接解析Chrome获取的数据,因为Chrome DevTool本身就是一个强大的调试工具。这大大加快了我们的开发进程。
我们可以先通过Chrome中的DevTools查看和解析我们的页面,通过控制台程序验证编写的脚本。大部分的脚本开发都可以使用Chrome来完成,而这部分往往是不可复用的,需要耗费大量的时间。这相当于获得了一个强大的调试工具,可以节省大量的时间。
另外,Chrome也是前端人员非常熟悉的一个工具。我们还可以将脚本开发的工作委托给前端人员,他们可以更高效地开发脚本,大大提高开发效率。
缺点
说了这么多优点,最后说一下它的缺点。这种方法的主要缺点是性能。
传统的爬虫非常轻便。它是一个传统的tcp socket程序。通过异步socket方式,可以轻松实现上千并发数,只加载需要的信息,性能非常高。
驱动chrome的方式是通过chrome获取服务端数据。从而加载了不必要的图片、样式、广告等文件,造成带宽的浪费。此外,它还会渲染网页,造成CPU开销,虽然可以通过插件减少不必要的文件加载和headless方法来减少开销,但相比传统的请求响应方式,仍然是重量级的获取方式。对于小规模的采集来说,可能不是什么大问题,但是如果你想像搜索引擎那样处理海量数据,采集可能有点吃力。
参考文章: 查看全部
js 爬虫抓取网页数据(有效的应对HTTP反爬虫策略最简单的反爬机制)
一些从WEB页面抓取数据的程序比较简单。大多数语言都有相应的 HTTP 库。一个简单的请求响应就足够了。程序向Web服务器发送Http请求,服务器返回HTML文件。交互方式如下:

使用DevProtocol驱动Chrome获取数据时,交互过程如下图所示:

这时候Chrome充当了中间的代理,看起来比较复杂,但实际上对我们的爬虫程序很有帮助。本文简要总结了这种方法的以下优点。
获取动态生成的网页内容
现在很多网页的内容并不是通过初始的Http请求一打开就直接获取,而是通过JS加载资源,在返回的html页面中计算动态生成的页面。采用这种方式的原因有很多,有的为了更好的用户体验,有的为了框架开发,有的为了节省带宽,有的纯粹是为了对页面内容进行加密,从而实现反爬虫的功能。
不管是什么原因,它使原本简单的单一“请求-响应”交互过程变得复杂。传统的一次性交互可以将所有请求完成为如下形式:

动态加载对传统数据采集造成了很大的阻碍,但是往往需要分析页面加载过程,分析JS,在程序中嵌入js引擎模拟浏览器执行相应的脚本来实现获得最终数据。这是一个非常费时费力的过程,也不容易分析整个过程。
为了更容易解析这样的动态网页,一些爬虫引擎开始引入Dom解析和JS执行能力来模拟浏览器解析获取相关资源。但是,由于这个过程非常复杂,这些功能往往并不完善,存在很多陷阱。
现在,通过Chrome浏览器的方式就是这种解析页面的方式的集成版本。因为Chrome本身就是一个浏览器,它具有完善的页面解析能力,所以可以如鱼得水。解析过程由chrome代理完成,我们只需要从chrome获取最终的解析结果即可。
针对爬虫的有效对策
最简单的反爬虫机制就是检查HTTP请求的Headers信息,包括User-Agent、Referer、Cookies等,根据手写的Http请求头和常用的浏览器头的区别进行反爬。这些对于防止主要爬虫非常有效,但 Chrome 本身是一个标准浏览器,天生就对这种反爬虫机制免疫。
另一种反爬虫机制就是上面提到的动态加载。基于上面的解释,这也是天生对 Chrome 免疫的。
当然,防爬的策略有很多,比如限制IP访问次数、限制访问频率、验证码等方法来防爬。Chrome虽然不直接支持这些,但是处理起来比传统的Http请求方便很多。下面的文章会陆续介绍,这里就不一一展开了。
DOM操作能力
Chrome具有完善的Dom操作能力。基本上所有可以在Chrome DevTools控制台中进行的操作,都可以通过DevProtocol在程序中完成,为我们的APP增加了完善的DOM操作能力。许多以前需要通过 HTML 分析的数据现在都可以获得。直接通过Jquery等js函数完成。并且可以直接格式化为JSON输出,方便多了。
与服务器交互更容易
在很多情况下,有些页面需要一些交互才能获得,比如登录。
因为Chrome具有执行JS的能力,所以我们可以通过一些简单的JS脚本来非常轻松地执行它。比如花园的登录可以通过如下脚本实现:
$("#input1")[0].value = "userName";
$("#input2")[0].value = "密码";
$("#signin")[0].click();
有些网站需要验证码来防止爬虫,我们甚至可以通过chrome中手动编码的自动组合快速实现数据抓取。如果要开发一个支持访问编码平台或智能识别平台的接口,比传统的蜘蛛程序要容易得多。
此外,Chrome 还提供了非常丰富的 API 来模拟键盘和鼠标输入界面,使用起来非常方便。
方便的开发调试
爬虫的开发往往是一个反复调试的过程,因为我们直接解析Chrome获取的数据,因为Chrome DevTool本身就是一个强大的调试工具。这大大加快了我们的开发进程。
我们可以先通过Chrome中的DevTools查看和解析我们的页面,通过控制台程序验证编写的脚本。大部分的脚本开发都可以使用Chrome来完成,而这部分往往是不可复用的,需要耗费大量的时间。这相当于获得了一个强大的调试工具,可以节省大量的时间。
另外,Chrome也是前端人员非常熟悉的一个工具。我们还可以将脚本开发的工作委托给前端人员,他们可以更高效地开发脚本,大大提高开发效率。
缺点
说了这么多优点,最后说一下它的缺点。这种方法的主要缺点是性能。
传统的爬虫非常轻便。它是一个传统的tcp socket程序。通过异步socket方式,可以轻松实现上千并发数,只加载需要的信息,性能非常高。
驱动chrome的方式是通过chrome获取服务端数据。从而加载了不必要的图片、样式、广告等文件,造成带宽的浪费。此外,它还会渲染网页,造成CPU开销,虽然可以通过插件减少不必要的文件加载和headless方法来减少开销,但相比传统的请求响应方式,仍然是重量级的获取方式。对于小规模的采集来说,可能不是什么大问题,但是如果你想像搜索引擎那样处理海量数据,采集可能有点吃力。
参考文章:
js 爬虫抓取网页数据(新浪新闻国内新闻页静态网页数据在函数中的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-22 20:02
昨天,一个朋友来找我。新浪新闻的国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
但是我发现有一个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\\,标题和介绍都是\u4e09的形式。这些是我们需要处理的后续步骤!
先用replace函数去掉url中的\\,就可以得到url了,下面的\u4e09是unicode编码,可以直接解码内容,直接写代码
eval函数用于解码,解码内容可以是u"+unicode编码内容+"!
这样就把这个页面上所有的新闻和URL相关的内容都取出来了,在外层加了一个循环来爬取所有的新闻页面,任务就完成了!
后记
新浪新闻的页面js功能比较简单,直接抓取数据即可。如果是比较复杂的功能,就需要了解前端知识。这就是学习爬虫需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,你可以直接百度找很多,当然你也可以直接修改上面抓包的内容,然后用json读取数据!
基础代码不多,如果有看不清楚的小伙伴可以私信我获取代码或者一起研究爬虫! 查看全部
js 爬虫抓取网页数据(新浪新闻国内新闻页静态网页数据在函数中的应用)
昨天,一个朋友来找我。新浪新闻的国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
但是我发现有一个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\\,标题和介绍都是\u4e09的形式。这些是我们需要处理的后续步骤!
先用replace函数去掉url中的\\,就可以得到url了,下面的\u4e09是unicode编码,可以直接解码内容,直接写代码
eval函数用于解码,解码内容可以是u"+unicode编码内容+"!
这样就把这个页面上所有的新闻和URL相关的内容都取出来了,在外层加了一个循环来爬取所有的新闻页面,任务就完成了!
后记
新浪新闻的页面js功能比较简单,直接抓取数据即可。如果是比较复杂的功能,就需要了解前端知识。这就是学习爬虫需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,你可以直接百度找很多,当然你也可以直接修改上面抓包的内容,然后用json读取数据!
基础代码不多,如果有看不清楚的小伙伴可以私信我获取代码或者一起研究爬虫!
js 爬虫抓取网页数据(动态网页数据抓取使用AJAX加载的数据(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-12-22 04:03
动态网页数据抓取
使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: 安装 Selenium 和 chromedriver:
安装硒:
pip install selenium
安装 chromedriver:
下载完成后,放在一个不需要权限的纯英文目录下。
Traceback (most recent call last):
File "selenium.py", line 1, in
from selenium import webdriver
File "/Users/nieyunfei/devspace/python/cyzone/test/selenium.py", line 1, in
from selenium import webdriver
ImportError: cannot import name 'webdriver' from partially initialized module 'selenium' (most likely due to a circular import) (/Users/nieyunfei/devspace/python/cyzone/test/selenium.py)
原因如下。我的新名字是selenium.py,这会导致Python先导入这个文件,然后再导入标准库中的selenium.py。删除或重命名当前目录下的文件后运行是正常的。
# 放到/usr /local/bin目录
open /usr/local/bin/
# 赋权限
sudo chmod u+x,o+x /usr/local/bin/chromedriver
# 查看安装的版本号跟浏览器是否对应
chromedriver --version
快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
# 导入selenium2中的webdriver库
from selenium import webdriver
# 初始化一个driver,实例化出一个chrome浏览器
driver = webdriver.Chrome()
# 请求网页
base_url = 'https://www.baidu.com'
# 通过page_source获取网页源代码
driver.get(base_url)
Selenium 常见操作:
图片.png
更多教程请参考:#introduction
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,所以在网页上用鼠标点击。所以,如果要选中checkbox标签,先选中这个标签,再执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。 查看全部
js 爬虫抓取网页数据(动态网页数据抓取使用AJAX加载的数据(一)(组图))
动态网页数据抓取
使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: 安装 Selenium 和 chromedriver:
安装硒:
pip install selenium
安装 chromedriver:
下载完成后,放在一个不需要权限的纯英文目录下。
Traceback (most recent call last):
File "selenium.py", line 1, in
from selenium import webdriver
File "/Users/nieyunfei/devspace/python/cyzone/test/selenium.py", line 1, in
from selenium import webdriver
ImportError: cannot import name 'webdriver' from partially initialized module 'selenium' (most likely due to a circular import) (/Users/nieyunfei/devspace/python/cyzone/test/selenium.py)
原因如下。我的新名字是selenium.py,这会导致Python先导入这个文件,然后再导入标准库中的selenium.py。删除或重命名当前目录下的文件后运行是正常的。
# 放到/usr /local/bin目录
open /usr/local/bin/
# 赋权限
sudo chmod u+x,o+x /usr/local/bin/chromedriver
# 查看安装的版本号跟浏览器是否对应
chromedriver --version
快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
# 导入selenium2中的webdriver库
from selenium import webdriver
# 初始化一个driver,实例化出一个chrome浏览器
driver = webdriver.Chrome()
# 请求网页
base_url = 'https://www.baidu.com'
# 通过page_source获取网页源代码
driver.get(base_url)
Selenium 常见操作:

图片.png
更多教程请参考:#introduction
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,所以在网页上用鼠标点击。所以,如果要选中checkbox标签,先选中这个标签,再执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
js 爬虫抓取网页数据(网络爬虫系统的分类及分类 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-22 04:03
)
前言
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
我们可以利用网络爬虫来自动采集数据信息,比如在搜索引擎收录中抓取网站,以及数据分析挖掘采集,应用采集对金融数据进行在财务分析中。此外,网络爬虫还可以应用于舆情监测分析、目标客户数据采集等各个领域。
1、网络爬虫分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深网爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。下面简单介绍一下这些爬虫。
1.1、通用网络爬虫
也称为Scalable Web Crawler,爬取对象从一些种子URL扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集数据。
1.2、关注网络爬虫
也称为Topical Crawler,它是指一种网络爬虫,它有选择地抓取与预定义主题相关的页面。与一般的网络爬虫相比,聚焦爬虫只需要抓取与主题相关的页面,大大节省了硬件和网络资源。保存的页面也因为数量少更新快,也可以满足特定区域的特定人群。信息需求。
1.3、增量网络爬虫
它是指对下载的网页进行增量更新并且只抓取新的或更改的网页的爬虫。可以在一定程度上保证爬取的页面尽可能的新鲜。.
1.4、深网爬虫
网页按存在方式可分为表面网页(Surface Web)和深层网页(Deep Web,也称为Invisible Web Pages或Hidden Web)。表面网页是指可以被传统搜索引擎索引的网页,主要由可以通过超链接访问的静态网页组成。深网是一种大部分内容无法通过静态链接获取而隐藏在搜索表单后面的网页。只有用户提交一些关键词来获取网页。
2、创建一个简单的爬虫应用
简单了解了上面的爬虫之后,我们来实现一个简单的爬虫应用。
2.1、 达成目标
说到爬虫,大概率会想到大数据,因此也会想到Python。百度如下。Python做爬虫更多。由于我主要是做前端开发,相对来说,JavaScript 比较熟练,也比较简单。实现一个小目标,使用NodeJS爬取博客园的首页文章列表(你经常使用的一个开发者网站),然后写入本地JSON文件。
2.2、环境建设
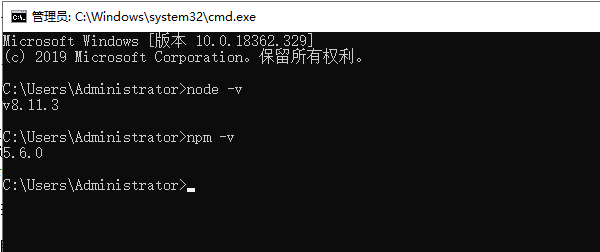
NodeJS安装完成后,打开命令行,可以使用node -v检查NodeJS是否安装成功,npm -v检查NodeJS是否安装成功。如果安装成功,应打印如下信息(视版本而定):
2.3、 具体实现
2.3.1、安装依赖包
在目录下执行 npm install superagentcheerio --save-dev 安装superagent和cheerio依赖。创建一个 crawler.js 文件。
// 导入依赖包
const http = require("http");
const path = require("path");
const url = require("url");
const fs = require("fs");
const superagent = require("superagent");
const cheerio = require("cheerio");
2.3.2、 爬取数据
然后获取请求页面。获取页面内容后,根据你想要的数据解析返回的DOM获取值,最后将处理后的结果JSON翻译成字符串保存到本地。
//爬取页面地址
const pageUrl="https://www.cnblogs.com/";
// 解码字符串
function unescapeString(str){
if(!str){
return ''
}else{
return unescape(str.replace(/&#x/g,'%u').replace(/;/g,''));
}
}
// 抓取数据
function fetchData(){
console.log('爬取数据时间节点:',new Date());
superagent.get(pageUrl).end((error,response)=>{
// 页面文档数据
let content=response.text;
if(content){
console.log('获取数据成功');
}
// 定义一个空数组来接收数据
let result=[];
let $=cheerio.load(content);
let postList=$("#main #post_list .post_item");
postList.each((index,value)=>{
let titleLnk=$(value).find('a.titlelnk');
let itemFoot=$(value).find('.post_item_foot');
let title=titleLnk.html(); //标题
let href=titleLnk.attr('href'); //链接
let author=itemFoot.find('a.lightblue').html(); //作者
let headLogo=$(value).find('.post_item_summary a img').attr('src'); //头像
let summary=$(value).find('.post_item_summary').text(); //简介
let postedTime=itemFoot.text().split('发布于 ')[1].substr(0,16); //发布时间
let readNum=itemFoot.text().split('阅读')[1]; //阅读量
readNum=readNum.substr(1,readNum.length-1);
title=unescapeString(title);
href=unescapeString(href);
author=unescapeString(author);
headLogo=unescapeString(headLogo);
summary=unescapeString(summary);
postedTime=unescapeString(postedTime);
readNum=unescapeString(readNum);
result.push({
index,
title,
href,
author,
headLogo,
summary,
postedTime,
readNum
});
});
// 数组转换为字符串
result=JSON.stringify(result);
// 写入本地cnblogs.json文件中
fs.writeFile("cnblogs.json",result,"utf-8",(err)=>{
// 监听错误,如正常输出,则打印null
if(!err){
console.log('写入数据成功');
}
});
});
}
fetchData();
3、进行优化
3.1、 生成结果
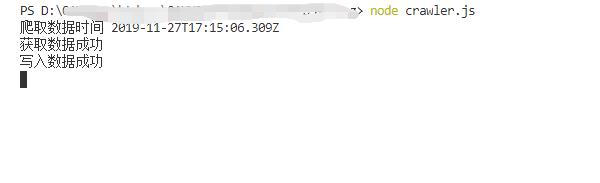
在项目目录下打开命令行,输入node crawler.js,
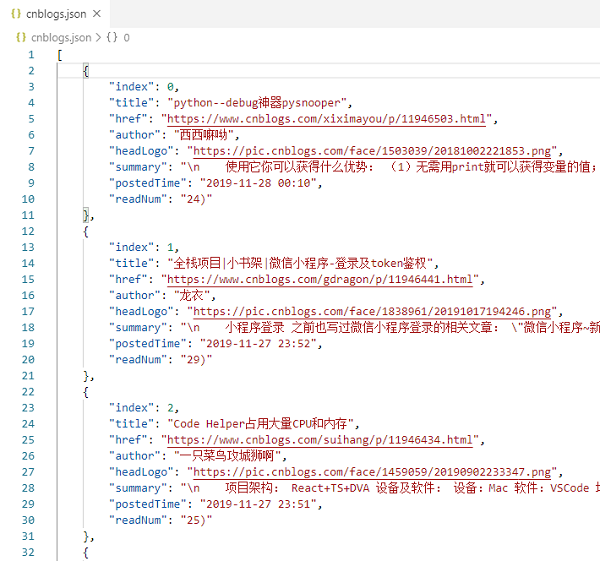
你会发现目录下会创建一个 cnblogs.json 文件。打开文件如下:
查看全部
js 爬虫抓取网页数据(网络爬虫系统的分类及分类
)
前言
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
我们可以利用网络爬虫来自动采集数据信息,比如在搜索引擎收录中抓取网站,以及数据分析挖掘采集,应用采集对金融数据进行在财务分析中。此外,网络爬虫还可以应用于舆情监测分析、目标客户数据采集等各个领域。
1、网络爬虫分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深网爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。下面简单介绍一下这些爬虫。
1.1、通用网络爬虫
也称为Scalable Web Crawler,爬取对象从一些种子URL扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集数据。
1.2、关注网络爬虫
也称为Topical Crawler,它是指一种网络爬虫,它有选择地抓取与预定义主题相关的页面。与一般的网络爬虫相比,聚焦爬虫只需要抓取与主题相关的页面,大大节省了硬件和网络资源。保存的页面也因为数量少更新快,也可以满足特定区域的特定人群。信息需求。
1.3、增量网络爬虫
它是指对下载的网页进行增量更新并且只抓取新的或更改的网页的爬虫。可以在一定程度上保证爬取的页面尽可能的新鲜。.
1.4、深网爬虫
网页按存在方式可分为表面网页(Surface Web)和深层网页(Deep Web,也称为Invisible Web Pages或Hidden Web)。表面网页是指可以被传统搜索引擎索引的网页,主要由可以通过超链接访问的静态网页组成。深网是一种大部分内容无法通过静态链接获取而隐藏在搜索表单后面的网页。只有用户提交一些关键词来获取网页。
2、创建一个简单的爬虫应用
简单了解了上面的爬虫之后,我们来实现一个简单的爬虫应用。
2.1、 达成目标
说到爬虫,大概率会想到大数据,因此也会想到Python。百度如下。Python做爬虫更多。由于我主要是做前端开发,相对来说,JavaScript 比较熟练,也比较简单。实现一个小目标,使用NodeJS爬取博客园的首页文章列表(你经常使用的一个开发者网站),然后写入本地JSON文件。
2.2、环境建设
NodeJS安装完成后,打开命令行,可以使用node -v检查NodeJS是否安装成功,npm -v检查NodeJS是否安装成功。如果安装成功,应打印如下信息(视版本而定):
2.3、 具体实现
2.3.1、安装依赖包
在目录下执行 npm install superagentcheerio --save-dev 安装superagent和cheerio依赖。创建一个 crawler.js 文件。
// 导入依赖包
const http = require("http");
const path = require("path");
const url = require("url");
const fs = require("fs");
const superagent = require("superagent");
const cheerio = require("cheerio");
2.3.2、 爬取数据
然后获取请求页面。获取页面内容后,根据你想要的数据解析返回的DOM获取值,最后将处理后的结果JSON翻译成字符串保存到本地。
//爬取页面地址
const pageUrl="https://www.cnblogs.com/";
// 解码字符串
function unescapeString(str){
if(!str){
return ''
}else{
return unescape(str.replace(/&#x/g,'%u').replace(/;/g,''));
}
}
// 抓取数据
function fetchData(){
console.log('爬取数据时间节点:',new Date());
superagent.get(pageUrl).end((error,response)=>{
// 页面文档数据
let content=response.text;
if(content){
console.log('获取数据成功');
}
// 定义一个空数组来接收数据
let result=[];
let $=cheerio.load(content);
let postList=$("#main #post_list .post_item");
postList.each((index,value)=>{
let titleLnk=$(value).find('a.titlelnk');
let itemFoot=$(value).find('.post_item_foot');
let title=titleLnk.html(); //标题
let href=titleLnk.attr('href'); //链接
let author=itemFoot.find('a.lightblue').html(); //作者
let headLogo=$(value).find('.post_item_summary a img').attr('src'); //头像
let summary=$(value).find('.post_item_summary').text(); //简介
let postedTime=itemFoot.text().split('发布于 ')[1].substr(0,16); //发布时间
let readNum=itemFoot.text().split('阅读')[1]; //阅读量
readNum=readNum.substr(1,readNum.length-1);
title=unescapeString(title);
href=unescapeString(href);
author=unescapeString(author);
headLogo=unescapeString(headLogo);
summary=unescapeString(summary);
postedTime=unescapeString(postedTime);
readNum=unescapeString(readNum);
result.push({
index,
title,
href,
author,
headLogo,
summary,
postedTime,
readNum
});
});
// 数组转换为字符串
result=JSON.stringify(result);
// 写入本地cnblogs.json文件中
fs.writeFile("cnblogs.json",result,"utf-8",(err)=>{
// 监听错误,如正常输出,则打印null
if(!err){
console.log('写入数据成功');
}
});
});
}
fetchData();
3、进行优化
3.1、 生成结果
在项目目录下打开命令行,输入node crawler.js,
你会发现目录下会创建一个 cnblogs.json 文件。打开文件如下:
js 爬虫抓取网页数据(js爬虫抓取网页数据实现教程介绍在爬虫开发工具egg)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-21 14:15
js爬虫抓取网页数据实现教程介绍在爬虫开发工具egg上面,安装好了工具后,我们需要写一个spider程序。这个spider的作用是模拟浏览器访问网页的各个入口页面,从而得到我们想要的数据。由于页面中的主体是html网页,因此,我们需要写一个request程序来模拟浏览器访问页面中的各个入口页面。从而,我们就可以得到我们想要的网页的数据。
开发工具的语言选择如果不选择java,不选择python,建议你从asp写起。asp比较简单,学习也比较容易。如果不想学习asp,也不建议学习python,因为python中涉及到api开发,其开发速度会比asp慢,如果你时间紧迫,也可以使用windows系统自带的accessapi取值接口编程。也可以在新版本中,直接使用c#。
创建爬虫程序创建一个爬虫程序的框架,从最小化开始,分以下两个步骤,创建http服务端:封装http的接口,比如wwwroot这个接口,封装http服务端。创建爬虫程序的浏览器web,我们使用lxml库写的代码比较简单,比如抓取一个链接#!/usr/bin/envpython#-*-coding:utf-8-*-importrequestsheaders={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/55.0.2703.92safari/537.36'}response=requests.get(url,headers=headers)data=response.contentifdata.status_code>200:print('成功请求')else:print('爬虫刚启动,请稍后再访问!')forx,yinenumerate(data):x['page_num']=response.status_code+'/'+str(x)+'/'+x+'page'print(x)results=data['page_num']forpageinresults:print(page+'\n')#print(str(x)+'\n')#get请求验证post请求一般情况都是不能通过的,所以需要对post请求中的request_uri进行封装,使得可以通过post请求的uri地址进行请求,同时我们需要开发一个验证服务器来对这个请求进行验证,这个验证服务器比较简单,直接使用webdriver库即可。
上面这段代码主要是对请求进行了封装和验证,具体代码如下:#!/usr/bin/envpython#-*-coding:utf-8-*-importrequestsheaders={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/55.0.2703.92safari/537.36'}response=requests.get(u。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据实现教程介绍在爬虫开发工具egg)
js爬虫抓取网页数据实现教程介绍在爬虫开发工具egg上面,安装好了工具后,我们需要写一个spider程序。这个spider的作用是模拟浏览器访问网页的各个入口页面,从而得到我们想要的数据。由于页面中的主体是html网页,因此,我们需要写一个request程序来模拟浏览器访问页面中的各个入口页面。从而,我们就可以得到我们想要的网页的数据。
开发工具的语言选择如果不选择java,不选择python,建议你从asp写起。asp比较简单,学习也比较容易。如果不想学习asp,也不建议学习python,因为python中涉及到api开发,其开发速度会比asp慢,如果你时间紧迫,也可以使用windows系统自带的accessapi取值接口编程。也可以在新版本中,直接使用c#。
创建爬虫程序创建一个爬虫程序的框架,从最小化开始,分以下两个步骤,创建http服务端:封装http的接口,比如wwwroot这个接口,封装http服务端。创建爬虫程序的浏览器web,我们使用lxml库写的代码比较简单,比如抓取一个链接#!/usr/bin/envpython#-*-coding:utf-8-*-importrequestsheaders={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/55.0.2703.92safari/537.36'}response=requests.get(url,headers=headers)data=response.contentifdata.status_code>200:print('成功请求')else:print('爬虫刚启动,请稍后再访问!')forx,yinenumerate(data):x['page_num']=response.status_code+'/'+str(x)+'/'+x+'page'print(x)results=data['page_num']forpageinresults:print(page+'\n')#print(str(x)+'\n')#get请求验证post请求一般情况都是不能通过的,所以需要对post请求中的request_uri进行封装,使得可以通过post请求的uri地址进行请求,同时我们需要开发一个验证服务器来对这个请求进行验证,这个验证服务器比较简单,直接使用webdriver库即可。
上面这段代码主要是对请求进行了封装和验证,具体代码如下:#!/usr/bin/envpython#-*-coding:utf-8-*-importrequestsheaders={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/55.0.2703.92safari/537.36'}response=requests.get(u。
js 爬虫抓取网页数据( 什么时候用JS数据的网站,解决的方法有各种各样 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-19 13:27
什么时候用JS数据的网站,解决的方法有各种各样
)
问题的根源
爬虫不是一劳永逸的写的,因为原站的代码迭代,我们上次写的代码文章已经变成了一堆狗屎。人生不如意,十有八九,这不是阻碍我们学习的绊脚石。我们的出发点是学习,为了让正确的代码具有一定的鲁棒性(robustness),同时也要学习新技术。这次用Selenium来写爬虫的代码,说不定情况会好起来/(ㄒoㄒ)/~~。
什么时候使用请求?
通常我们在抓取网页时,通常期望找到网站的API请求接口,可以通过参数修改来构造API。返回的结果最好是标准的Json格式,也方便我们在Python中做数据持久化。在这种情况下,我们使用 requests 模块无疑是最好的选择,因为这样的代码速度快且质量高。但现实真的很残酷,大多数网站都会通过JS动态填充网页数据,防止爬虫。采取这种措施的网页请求只返回网页的frame,具体数据通过Ajax动态渲染到网页中。Requests 不具备加载和执行 JS 的能力,所以我们无法通过请求的返回来获取真实的数据。
什么时候使用硒?
这个JS填充数据网站有多种解决方案。通常的方法是通过抓包的方式获取JS的接口获取数据。优点前面已经说了,这样写的代码效率更高。缺点也很明显,需要有一定的JS调试基础。因为你找到了一些接口,但是接口传递的参数是JS加密的,需要分析JS找到加密算法,否则就算抓到API也不能用。对于简单的JS,你或许可以在浏览器中调试,但是如果对JS代码进行混淆和压缩,对我们来说简直太多了,这对我们新手来说有点困难。通过Selenium,可以把复杂化繁为简,轻松实现我们需要的功能。
什么是硒?
什么是硒? -引自维基百科
Selenium 是一个 Web 自动化测试框架。他允许用户通过编写代码来操纵浏览器,实现像真实用户一样的浏览器操作行为。对于一些反爬机制严苛的网站,我们可以使用Selenium来操作浏览器,模拟真实用户操作爬取网站数据。这样做的好处是不需要考虑请求发送、cookie、user-agent等一系列需求,只需要编写代码来操作浏览器,通过读取浏览器内容来获取想要的数据。浏览器具有执行JS的能力。网页加载完毕后,读取网页的源代码,就可以得到我们想要的数据了。
接下来,我们通过 Selenium 重写我们之前的爬虫代码。代码稍微简单一些,仅供入门之用。
环境设置
在Python中使用Selenium,需要安装相应的环境。安装环境很简单,大致分为三步:
在虚拟环境的控制台中使用命令:pip install selenium 安装对应的包支持库,并将对应浏览器的路径添加到系统环境变量中。比如我这里使用的是Chrome浏览器,所以需要在Path环境变量中添加Chrome根目录文件夹。这个操作对于开发者来说并不陌生,根据浏览器版本下载相应的驱动。驱动下载地址(点击跳转),注意必须与您浏览器的版本相对应。下载完成后,将文件解压到Python安装目录。
安装完成后,运行以下代码测试是否安装成功。如果安装成功,会运行Chrome打开本站,并在控制台输出网页源码:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.weiney.com/")
print(brower.page_sourse)
爬虫分析
抓取网站:http://yoerking.com/static/music_player.html
运行环境:Python 3.6.5
支持库:selenium,requests,beautifulsoup,tqdm
与前面的代码相比,主要的区别在于前面的网页代码是用requests模块完成的。这次我换成了selenium,从浏览器中获取网页的源码。这样省去了分析js的麻烦。但是每次运行爬虫都打开Chrome也会降低软件的效率,但是影响不大,没有请求也会很快。
def get_page_sourse():
browser = webdriver.Chrome()
browser.get(URL)
page_sourse = browser.page_source
browser.close()
return page_sourse
<p>def parse_music():
page_sourse = get_page_sourse()
soup = BeautifulSoup(page_sourse, "html.parser")
all_musics = soup.find_all("a", class_="url")
for music_item in all_musics:
single_music = dict()
single_music["url"] = music_item.attrs["hrefsrc"]
single_music["name"] = music_item.text
single_music["album"] = re.search("(? 查看全部
js 爬虫抓取网页数据(
什么时候用JS数据的网站,解决的方法有各种各样
)

问题的根源
爬虫不是一劳永逸的写的,因为原站的代码迭代,我们上次写的代码文章已经变成了一堆狗屎。人生不如意,十有八九,这不是阻碍我们学习的绊脚石。我们的出发点是学习,为了让正确的代码具有一定的鲁棒性(robustness),同时也要学习新技术。这次用Selenium来写爬虫的代码,说不定情况会好起来/(ㄒoㄒ)/~~。
什么时候使用请求?
通常我们在抓取网页时,通常期望找到网站的API请求接口,可以通过参数修改来构造API。返回的结果最好是标准的Json格式,也方便我们在Python中做数据持久化。在这种情况下,我们使用 requests 模块无疑是最好的选择,因为这样的代码速度快且质量高。但现实真的很残酷,大多数网站都会通过JS动态填充网页数据,防止爬虫。采取这种措施的网页请求只返回网页的frame,具体数据通过Ajax动态渲染到网页中。Requests 不具备加载和执行 JS 的能力,所以我们无法通过请求的返回来获取真实的数据。
什么时候使用硒?
这个JS填充数据网站有多种解决方案。通常的方法是通过抓包的方式获取JS的接口获取数据。优点前面已经说了,这样写的代码效率更高。缺点也很明显,需要有一定的JS调试基础。因为你找到了一些接口,但是接口传递的参数是JS加密的,需要分析JS找到加密算法,否则就算抓到API也不能用。对于简单的JS,你或许可以在浏览器中调试,但是如果对JS代码进行混淆和压缩,对我们来说简直太多了,这对我们新手来说有点困难。通过Selenium,可以把复杂化繁为简,轻松实现我们需要的功能。
什么是硒?

什么是硒? -引自维基百科
Selenium 是一个 Web 自动化测试框架。他允许用户通过编写代码来操纵浏览器,实现像真实用户一样的浏览器操作行为。对于一些反爬机制严苛的网站,我们可以使用Selenium来操作浏览器,模拟真实用户操作爬取网站数据。这样做的好处是不需要考虑请求发送、cookie、user-agent等一系列需求,只需要编写代码来操作浏览器,通过读取浏览器内容来获取想要的数据。浏览器具有执行JS的能力。网页加载完毕后,读取网页的源代码,就可以得到我们想要的数据了。
接下来,我们通过 Selenium 重写我们之前的爬虫代码。代码稍微简单一些,仅供入门之用。
环境设置
在Python中使用Selenium,需要安装相应的环境。安装环境很简单,大致分为三步:
在虚拟环境的控制台中使用命令:pip install selenium 安装对应的包支持库,并将对应浏览器的路径添加到系统环境变量中。比如我这里使用的是Chrome浏览器,所以需要在Path环境变量中添加Chrome根目录文件夹。这个操作对于开发者来说并不陌生,根据浏览器版本下载相应的驱动。驱动下载地址(点击跳转),注意必须与您浏览器的版本相对应。下载完成后,将文件解压到Python安装目录。
安装完成后,运行以下代码测试是否安装成功。如果安装成功,会运行Chrome打开本站,并在控制台输出网页源码:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.weiney.com/";)
print(brower.page_sourse)
爬虫分析
抓取网站:http://yoerking.com/static/music_player.html
运行环境:Python 3.6.5
支持库:selenium,requests,beautifulsoup,tqdm
与前面的代码相比,主要的区别在于前面的网页代码是用requests模块完成的。这次我换成了selenium,从浏览器中获取网页的源码。这样省去了分析js的麻烦。但是每次运行爬虫都打开Chrome也会降低软件的效率,但是影响不大,没有请求也会很快。
def get_page_sourse():
browser = webdriver.Chrome()
browser.get(URL)
page_sourse = browser.page_source
browser.close()
return page_sourse
<p>def parse_music():
page_sourse = get_page_sourse()
soup = BeautifulSoup(page_sourse, "html.parser")
all_musics = soup.find_all("a", class_="url")
for music_item in all_musics:
single_music = dict()
single_music["url"] = music_item.attrs["hrefsrc"]
single_music["name"] = music_item.text
single_music["album"] = re.search("(?
js 爬虫抓取网页数据(简单来说,爬虫就是获取网页并提取和保存信息的自动化程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-18 20:14
履带概览
简单地说,爬虫是一种自动程序,它可以抓取网页并提取和保存信息。
爬虫可以概括为4个步骤:
1.获取网页
爬虫首先要做的就是获取网页,即获取网页的源代码。源代码收录了网页的部分有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
根据请求和响应的概念,向网站的服务器发送一个请求,返回的响应体就是网页的源代码。因此,最关键的部分是构造一个请求并发送给服务器,然后接收到响应并发送解析出来。
Python是一个非常有用的爬虫工具。它提供了很多库来帮助我们实现这个操作,比如urllib、request等,我们可以使用这些库来帮助我们实现HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,只需要解析数据结构的Body部分。
总结:
通过python爬虫相关库,实现HTTP请求操作,获取服务器响应,获取网页源码
2.提取信息
获取到网页的源代码后,下一步就是分析网页的源代码,从中提取出我们想要的数据。一般通用的方法是使用正则表达式提取。缺点是比较复杂,容易出错。
另外,由于网页结构的某些规则,python也有一些基于网页节点属性、CSS选择器或XPath提取网页信息的库,例如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效快速的提取网页信息,如节点属性、文本值等。
提取信息是爬虫的一个非常重要的部分。它可以从杂乱的数据中获取有效的信息,方便我们后续的数据处理和分析。
总结:
正则表达式是一种通用的抽取方式,也可以使用一些从网页节点属性、CSS选择器等中抽取信息的库,比如Beautiful Soup、pyquery、lxml等。
3.保存数据
提取信息后,我们一般会将提取的数据保存在某处以备后续使用。有很多方法可以保存它。简单处理可以保存为TXT或JSON文本。它也可以保存到数据库中,例如 MySQL 和 MongoDB。或者保存到远程服务器。
4.自动化程序
简单来说,爬虫可以在爬取过程中进行各种异常处理、错误重试等操作,持续高效地完成获取网页、提取信息、保存数据的工作。
爬虫可以抓取什么样的数据
[1] 最常见的爬取是HTML源代码。
[2] JSON字符串,有些网页返回的不是HTML代码,而是JSON字符串,尤其是API接口大多采用这种形式,这种格式的数据便于传输和分析,也可以抓取,数据提取更方便。
[3] 二进制数据,如图片、视频、音频等,使用爬虫我们可以抓取这些二进制数据并保存为相应的文件名。
[4] 各种扩展文件,如CSS、JavaScript 和配置文件。
JavaScript 渲染页面
有时,当我们使用 urlib 或 request 抓取网页时,我们得到的源代码实际上与我们在浏览器中看到的不同。
这是一个很常见的问题。由于越来越多的网页是使用Ajax和前端模块化工具构建的,整个网页可能会被JavaScript渲染,这意味着原来的HTML代码只是一个空壳。
例如,下面的 HTML 代码
This is a Demo
body节点中只有一个id为container的节点,但是在body节点之后引入了app.js,负责整个网站的渲染。
过程是在浏览器中打开页面时,首先加载HTML内容,然后浏览器会发现里面引入了一个app.js文件,就会请求这个文件。获取文件后,它会执行其中的JavaScript。代码,JavaScript 会改变 HTML 中的节点,向其添加内容,最后显示完整的页面。
当我们请求一个带有 urlib 或 request 等库的页面时,我们得到的只是这个 HTML 代码,它不会帮助我们加载这个 JavaScript 文件,所以我们在浏览器中看不到内容。
对于这种情况,我们可以分析其后端的Ajax接口,或者使用Selenium、Splash等库来实现模拟JavaScript渲染,后面会介绍。
本文总结参考《Python3 Web爬虫开发实战》 查看全部
js 爬虫抓取网页数据(简单来说,爬虫就是获取网页并提取和保存信息的自动化程序)
履带概览
简单地说,爬虫是一种自动程序,它可以抓取网页并提取和保存信息。
爬虫可以概括为4个步骤:

1.获取网页
爬虫首先要做的就是获取网页,即获取网页的源代码。源代码收录了网页的部分有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
根据请求和响应的概念,向网站的服务器发送一个请求,返回的响应体就是网页的源代码。因此,最关键的部分是构造一个请求并发送给服务器,然后接收到响应并发送解析出来。
Python是一个非常有用的爬虫工具。它提供了很多库来帮助我们实现这个操作,比如urllib、request等,我们可以使用这些库来帮助我们实现HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,只需要解析数据结构的Body部分。
总结:
通过python爬虫相关库,实现HTTP请求操作,获取服务器响应,获取网页源码
2.提取信息
获取到网页的源代码后,下一步就是分析网页的源代码,从中提取出我们想要的数据。一般通用的方法是使用正则表达式提取。缺点是比较复杂,容易出错。
另外,由于网页结构的某些规则,python也有一些基于网页节点属性、CSS选择器或XPath提取网页信息的库,例如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效快速的提取网页信息,如节点属性、文本值等。
提取信息是爬虫的一个非常重要的部分。它可以从杂乱的数据中获取有效的信息,方便我们后续的数据处理和分析。
总结:
正则表达式是一种通用的抽取方式,也可以使用一些从网页节点属性、CSS选择器等中抽取信息的库,比如Beautiful Soup、pyquery、lxml等。
3.保存数据
提取信息后,我们一般会将提取的数据保存在某处以备后续使用。有很多方法可以保存它。简单处理可以保存为TXT或JSON文本。它也可以保存到数据库中,例如 MySQL 和 MongoDB。或者保存到远程服务器。
4.自动化程序
简单来说,爬虫可以在爬取过程中进行各种异常处理、错误重试等操作,持续高效地完成获取网页、提取信息、保存数据的工作。
爬虫可以抓取什么样的数据
[1] 最常见的爬取是HTML源代码。
[2] JSON字符串,有些网页返回的不是HTML代码,而是JSON字符串,尤其是API接口大多采用这种形式,这种格式的数据便于传输和分析,也可以抓取,数据提取更方便。
[3] 二进制数据,如图片、视频、音频等,使用爬虫我们可以抓取这些二进制数据并保存为相应的文件名。
[4] 各种扩展文件,如CSS、JavaScript 和配置文件。
JavaScript 渲染页面
有时,当我们使用 urlib 或 request 抓取网页时,我们得到的源代码实际上与我们在浏览器中看到的不同。
这是一个很常见的问题。由于越来越多的网页是使用Ajax和前端模块化工具构建的,整个网页可能会被JavaScript渲染,这意味着原来的HTML代码只是一个空壳。
例如,下面的 HTML 代码
This is a Demo
body节点中只有一个id为container的节点,但是在body节点之后引入了app.js,负责整个网站的渲染。
过程是在浏览器中打开页面时,首先加载HTML内容,然后浏览器会发现里面引入了一个app.js文件,就会请求这个文件。获取文件后,它会执行其中的JavaScript。代码,JavaScript 会改变 HTML 中的节点,向其添加内容,最后显示完整的页面。
当我们请求一个带有 urlib 或 request 等库的页面时,我们得到的只是这个 HTML 代码,它不会帮助我们加载这个 JavaScript 文件,所以我们在浏览器中看不到内容。
对于这种情况,我们可以分析其后端的Ajax接口,或者使用Selenium、Splash等库来实现模拟JavaScript渲染,后面会介绍。
本文总结参考《Python3 Web爬虫开发实战》
js 爬虫抓取网页数据( 用get请求方式进行数据请求完成后我们可以执行一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-18 18:19
用get请求方式进行数据请求完成后我们可以执行一下)
var http = require("http");//引入标准的http模块
使用get请求方式进行数据请求
http.get(url,function(res){
//程序发送一个http请求的时候 此函数就会立马执行 res后端返回过来并且已经被解析的HTTP报文
var html ="";
res.on("data",function(chunk){
//有一段流接收到之后就会执行的回调函数
html += chunk;//把每一段流都拼接起来
});//监听
res.on("end",function(){
//所有信息传输完毕后所执行的回调函数
console.log(html);
});
});//向网络发送GET请求,请求网络资源
完成后我们就可以执行了,打开window键+R键打开操作,输入cmd打开命令行如下:
然后回车,你会发现已经获取到了目标页面的一些信息,但是只是以字符串的形式显示出来,并不整齐
这时候就需要cheerio包来解析字符串
存储爬取目标URL后引入cheerio包
var cheerio = require("cheerio");
然后进行DOM字符串解析
http.get(url,function(res){
//程序发送一个http请求的时候 此函数就会立马执行 res后端返回过来并且已经被解析的HTTP报文
var html ="";
res.on("data",function(chunk){
//有一段流接收到之后就会执行的回调函数
html+=chunk;//把每一段流都拼接起来
});//监听
res.on("end",function(){
var $ = cheerio.load(html);//解析Dom字符串
$("#right a").each(function(){
var articleUrl = $(this).attr("href");
http.get(articleUrl,function(res){
var html = "";
res.on("data",function(chunk){
html+=chunk;
});
res.on("end",function(){
console.log(html);
});
});
});
});
});//向网络发送GET请求,请求网络资源
然后继续爬取目标页面,但有时会因为网络原因出现错误
我们只需要执行错误处理操作
//监听错误事件
}).on("error",function(err){
//对程序意外错误进行处理
console.log(err.message);//在日志中打印错误具体描述
});
这时候,当你运行爬取网页的程序时,你会发现你的命令行会像Matrix一样爬取并打印网页的所有源代码,但我们需要的只是网页的数据信息页,并且不需要源代码字符串。显示,这次我们可以 res.on("end",function(){}); 再次执行字符串解析
res.on("end",function(){
var $ = cheerio.load(html);//解析Dom字符串
var oText = $("#artibody").text();
console.log(oText);
});
然后我们可以看到刚才爬取得到的数据已经被过滤掉了,只显示了需要的文字信息
如下所示:
爬取到需要的信息数据后,我们还可以对其进行文件流式操作,并将爬取到的信息保存到本地文件夹中
在进行文件流操作时,我们需要引入fs模块
var fs = require("fs");
然后我们在项目文件夹下新建一个文件夹news,然后在我们刚才提到的climb事件的最后写一个写文件操作。
fs.writeFile("./news/");
这时候我们需要提供一些参数,我们需要保证生成的txt文件的命名是唯一的,这样我们就可以在前面生成一个时间戳
var time = new Date().valueOf();//生成时间戳
然后将时间戳和开头的命名和文本放入
fs.writeFile("./news/nba"+time+".txt",oText);
然后再次运行程序,就可以生成我们的文件了 查看全部
js 爬虫抓取网页数据(
用get请求方式进行数据请求完成后我们可以执行一下)
var http = require("http");//引入标准的http模块
使用get请求方式进行数据请求
http.get(url,function(res){
//程序发送一个http请求的时候 此函数就会立马执行 res后端返回过来并且已经被解析的HTTP报文
var html ="";
res.on("data",function(chunk){
//有一段流接收到之后就会执行的回调函数
html += chunk;//把每一段流都拼接起来
});//监听
res.on("end",function(){
//所有信息传输完毕后所执行的回调函数
console.log(html);
});
});//向网络发送GET请求,请求网络资源
完成后我们就可以执行了,打开window键+R键打开操作,输入cmd打开命令行如下:

然后回车,你会发现已经获取到了目标页面的一些信息,但是只是以字符串的形式显示出来,并不整齐

这时候就需要cheerio包来解析字符串
存储爬取目标URL后引入cheerio包
var cheerio = require("cheerio");
然后进行DOM字符串解析
http.get(url,function(res){
//程序发送一个http请求的时候 此函数就会立马执行 res后端返回过来并且已经被解析的HTTP报文
var html ="";
res.on("data",function(chunk){
//有一段流接收到之后就会执行的回调函数
html+=chunk;//把每一段流都拼接起来
});//监听
res.on("end",function(){
var $ = cheerio.load(html);//解析Dom字符串
$("#right a").each(function(){
var articleUrl = $(this).attr("href");
http.get(articleUrl,function(res){
var html = "";
res.on("data",function(chunk){
html+=chunk;
});
res.on("end",function(){
console.log(html);
});
});
});
});
});//向网络发送GET请求,请求网络资源
然后继续爬取目标页面,但有时会因为网络原因出现错误
我们只需要执行错误处理操作
//监听错误事件
}).on("error",function(err){
//对程序意外错误进行处理
console.log(err.message);//在日志中打印错误具体描述
});
这时候,当你运行爬取网页的程序时,你会发现你的命令行会像Matrix一样爬取并打印网页的所有源代码,但我们需要的只是网页的数据信息页,并且不需要源代码字符串。显示,这次我们可以 res.on("end",function(){}); 再次执行字符串解析
res.on("end",function(){
var $ = cheerio.load(html);//解析Dom字符串
var oText = $("#artibody").text();
console.log(oText);
});
然后我们可以看到刚才爬取得到的数据已经被过滤掉了,只显示了需要的文字信息
如下所示:

爬取到需要的信息数据后,我们还可以对其进行文件流式操作,并将爬取到的信息保存到本地文件夹中
在进行文件流操作时,我们需要引入fs模块
var fs = require("fs");
然后我们在项目文件夹下新建一个文件夹news,然后在我们刚才提到的climb事件的最后写一个写文件操作。
fs.writeFile("./news/");
这时候我们需要提供一些参数,我们需要保证生成的txt文件的命名是唯一的,这样我们就可以在前面生成一个时间戳
var time = new Date().valueOf();//生成时间戳
然后将时间戳和开头的命名和文本放入
fs.writeFile("./news/nba"+time+".txt",oText);
然后再次运行程序,就可以生成我们的文件了
js 爬虫抓取网页数据(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-18 13:04
什么是 AJAX:
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: install Selenium 和 chromedriver: install Selenium: Selenium 有多种语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r\'D:\ProgramApp\chromedriver\chromedriver.exe\'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id(\'su\')
submitTag1 = driver.find_element(By.ID,\'su\')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name(\'su\')
submitTag1 = driver.find_element(By.CLASS_NAME,\'su\')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name(\'email\')
submitTag1 = driver.find_element(By.NAME,\'email\')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name(\'div\')
submitTag1 = driver.find_element(By.TAG_NAME,\'div\')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath(\'//div\')
submitTag1 = driver.find_element(By.XPATH,\'//div\')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector(\'//div\')
submitTag1 = driver.find_element(By.CSS_SELECTOR,\'//div\')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
inputTag.send_keys(\'python\')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,所以在网页上用鼠标点击。所以,如果要选中checkbox标签,先选中这个标签,再执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id(\'su\')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
submitTag = driver.find_element_by_id(\'su\')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,\'python\')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
cookie操作:获取所有cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open(\'"+url+"\')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(\'http://httpbin.org/ip\')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。 查看全部
js 爬虫抓取网页数据(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
什么是 AJAX:
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: install Selenium 和 chromedriver: install Selenium: Selenium 有多种语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r\'D:\ProgramApp\chromedriver\chromedriver.exe\'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id(\'su\')
submitTag1 = driver.find_element(By.ID,\'su\')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name(\'su\')
submitTag1 = driver.find_element(By.CLASS_NAME,\'su\')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name(\'email\')
submitTag1 = driver.find_element(By.NAME,\'email\')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name(\'div\')
submitTag1 = driver.find_element(By.TAG_NAME,\'div\')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath(\'//div\')
submitTag1 = driver.find_element(By.XPATH,\'//div\')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector(\'//div\')
submitTag1 = driver.find_element(By.CSS_SELECTOR,\'//div\')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
inputTag.send_keys(\'python\')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,所以在网页上用鼠标点击。所以,如果要选中checkbox标签,先选中这个标签,再执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id(\'su\')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
submitTag = driver.find_element_by_id(\'su\')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,\'python\')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
cookie操作:获取所有cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open(\'"+url+"\')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(\'http://httpbin.org/ip\')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
js 爬虫抓取网页数据(第三方库:cheerio,这个库就是用来处理dom节点的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-17 00:12
)
第三方库:cheerio,这个库是用来处理dom节点的,它的用法和jquery几乎一模一样,所以有了这个工具,写爬虫就很简单了
准备好工作了:
1. npm init --yes 初始化package.json
2.安装cheerio:npm installcheerio --save-dev
实现的目标是将每个文章需要爬取的部分(捕获文章标题、超链接、文章摘要、发布时间)组织成一个对象,放到一个数组中,如:
[ { title: '[置顶][js高手之路]从零开始打造一个javascript开源框架gdom与插件开发免费视频教程
连载中',
url: 'http://www.cnblogs.com/ghostwu/p/7470038.html',
entry: '摘要: 百度网盘下载地址:https://pan.baidu.com/s/1kULNXOF 优酷土豆观看地址:htt
p://v.youku.com/v_show/id_XMzAwNTY2MTE0MA==.html?spm=a2h0j.8191423.playlist_content.5!3~5~
5~A&&f',
listTime: '2017-09-05 17:08' },
{ title: '[js高手之路]Vue2.0基于vue-cli+webpack Vuex用法详解',
url: 'http://www.cnblogs.com/ghostwu/p/7521097.html',
entry: '摘要: 在这之前,我已经分享过组件与组件的通信机制以及父子组件之间的通信机制,而
我们的vuex就是为了解决组件通信问题的 vuex是什么东东呢? 组件通信的本质其实就是在组件之间传
递数据或组件的状态(这里将数据和状态统称为状态),但可以看到如果我们通过最基本的方式来进行
通信,一旦需要管理的状态多了,代码就会',
listTime: '2017-09-14 15:51' },
{ title: '[js高手之路]Vue2.0基于vue-cli+webpack同级组件之间的通信教程',
url: 'http://www.cnblogs.com/ghostwu/p/7518158.html',
entry: '摘要: 我们接着上文继续,本文我们讲解兄弟组件的通信,项目结构还是跟上文一样. 在
src/assets目录下建立文件EventHandler.js,该文件的作用在于给同级组件之间传递事件 EventHandl
er.js代码: 2,在Components目录下新建一个组件Brother1.vue 。通过Eve',
listTime: '2017-09-13 22:49' },
]
思路说明:
1.获取目标地址:所有html内容
2.提取所有文章html内容
3、提取每个文章下对应的文章(文章标题、超链接、文章摘要、发布时间)
1 var http = require('http');
2 var cheerio = require('cheerio');
3
4 var url = 'http://www.cnblogs.com/ghostwu/';
5
6 function filterHtml(html) {
7 var $ = cheerio.load(html);
8 var arcList = [];
9 var aPost = $("#content").find(".post-list-item");
10 aPost.each(function () {
11 var ele = $(this);
12 var title = ele.find("h2 a").text();
13 var url = ele.find("h2 a").attr("href");
14 ele.find(".c_b_p_desc a").remove();
15 var entry = ele.find(".c_b_p_desc").text();
16 ele.find("small a").remove();
17 var listTime = ele.find("small").text();
18 var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
19 listTime = listTime.match( re )[0];
20 arcList.push({
21 title: title,
22 url: url,
23 entry: entry,
24 listTime: listTime
25 });
26 });
27 return arcList;
28 }
29
30 http.get(url, function (res) {
31 var html = '';
32 var arcList = [];
33 // var arcInfo = {};
34 res.on('data', function (chunk) {
35 html += chunk;
36 });
37 res.on('end', function () {
38 arcList = filterHtml( html );
39 console.log( arcList );
40 });
41 });
有几个关键点需要解释:
1. res.on('数据', function(){})
http模块发送get请求后,会不断的抓取目标网页的源码内容。因此,我在 on 中监听 data 事件。chunk是传输的数据,数据累加到html变量中。当数据传输完毕后,就会触发结束事件。你可以在end事件中打印console.log(html),你会发现里面都是目标地址的html源代码。这就解决了我们的第一个问题:获取目标地址:所有html内容
2.有了完整的html内容后,我再封装一个函数filterHTML来过滤我需要的结果(每条文章信息)
3. var $ =cheerio.load(html); 通过cheerio的load方法加载html内容,然后就可以使用cheerio的节点进行操作了。为了兼容jquery操作,我用美元符号$保存了这个文档对象
4. var aPost = $("#content").find(".post-list-item"); 这就是所有的文章节点信息,拿到后,通过各个方法一一遍历,抓取自己需要的信息,组织成对象,然后放到一个数组中
1 arcList.push({
2 21 title: title,
3 22 url: url,
4 23 entry: entry,
5 24 listTime: listTime
6 25 });
这样做了,结果如上所示。如果博客风格和我的博客风格一样,应该是可以爬取的。
然后改进页面爬取,让整个博客都可以爬下来
<p> 1 var http = require('http');
2 var cheerio = require('cheerio');
3
4 var url = 'http://www.cnblogs.com/ghostwu/';
5
6 function filterHtml(html) {
7 var $ = cheerio.load(html);
8 var arcList = [];
9 var aPost = $("#content").find(".post-list-item");
10 aPost.each(function () {
11 var ele = $(this);
12 var title = ele.find("h2 a").text();
13 var url = ele.find("h2 a").attr("href");
14 ele.find(".c_b_p_desc a").remove();
15 var entry = ele.find(".c_b_p_desc").text();
16 ele.find("small a").remove();
17 var listTime = ele.find("small").text();
18 var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
19 listTime = listTime.match(re)[0];
20 arcList.push({
21 title: title,
22 url: url,
23 entry: entry,
24 listTime: listTime
25 });
26 });
27 return arcList;
28 }
29
30 function nextPage( html ){
31 var $ = cheerio.load(html);
32 var nextUrl = $("#pager a:last-child").attr('href');
33 if ( !nextUrl ) return ;
34 var curPage = $("#pager .current").text();
35 if( !curPage ) curPage = 1;
36 var nextPage = nextUrl.substring( nextUrl.indexOf( '=' ) + 1 );
37 if ( curPage 查看全部
js 爬虫抓取网页数据(第三方库:cheerio,这个库就是用来处理dom节点的
)
第三方库:cheerio,这个库是用来处理dom节点的,它的用法和jquery几乎一模一样,所以有了这个工具,写爬虫就很简单了
准备好工作了:
1. npm init --yes 初始化package.json
2.安装cheerio:npm installcheerio --save-dev
实现的目标是将每个文章需要爬取的部分(捕获文章标题、超链接、文章摘要、发布时间)组织成一个对象,放到一个数组中,如:
[ { title: '[置顶][js高手之路]从零开始打造一个javascript开源框架gdom与插件开发免费视频教程
连载中',
url: 'http://www.cnblogs.com/ghostwu/p/7470038.html',
entry: '摘要: 百度网盘下载地址:https://pan.baidu.com/s/1kULNXOF 优酷土豆观看地址:htt
p://v.youku.com/v_show/id_XMzAwNTY2MTE0MA==.html?spm=a2h0j.8191423.playlist_content.5!3~5~
5~A&&f',
listTime: '2017-09-05 17:08' },
{ title: '[js高手之路]Vue2.0基于vue-cli+webpack Vuex用法详解',
url: 'http://www.cnblogs.com/ghostwu/p/7521097.html',
entry: '摘要: 在这之前,我已经分享过组件与组件的通信机制以及父子组件之间的通信机制,而
我们的vuex就是为了解决组件通信问题的 vuex是什么东东呢? 组件通信的本质其实就是在组件之间传
递数据或组件的状态(这里将数据和状态统称为状态),但可以看到如果我们通过最基本的方式来进行
通信,一旦需要管理的状态多了,代码就会',
listTime: '2017-09-14 15:51' },
{ title: '[js高手之路]Vue2.0基于vue-cli+webpack同级组件之间的通信教程',
url: 'http://www.cnblogs.com/ghostwu/p/7518158.html',
entry: '摘要: 我们接着上文继续,本文我们讲解兄弟组件的通信,项目结构还是跟上文一样. 在
src/assets目录下建立文件EventHandler.js,该文件的作用在于给同级组件之间传递事件 EventHandl
er.js代码: 2,在Components目录下新建一个组件Brother1.vue 。通过Eve',
listTime: '2017-09-13 22:49' },
]
思路说明:
1.获取目标地址:所有html内容
2.提取所有文章html内容
3、提取每个文章下对应的文章(文章标题、超链接、文章摘要、发布时间)
1 var http = require('http');
2 var cheerio = require('cheerio');
3
4 var url = 'http://www.cnblogs.com/ghostwu/';
5
6 function filterHtml(html) {
7 var $ = cheerio.load(html);
8 var arcList = [];
9 var aPost = $("#content").find(".post-list-item");
10 aPost.each(function () {
11 var ele = $(this);
12 var title = ele.find("h2 a").text();
13 var url = ele.find("h2 a").attr("href");
14 ele.find(".c_b_p_desc a").remove();
15 var entry = ele.find(".c_b_p_desc").text();
16 ele.find("small a").remove();
17 var listTime = ele.find("small").text();
18 var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
19 listTime = listTime.match( re )[0];
20 arcList.push({
21 title: title,
22 url: url,
23 entry: entry,
24 listTime: listTime
25 });
26 });
27 return arcList;
28 }
29
30 http.get(url, function (res) {
31 var html = '';
32 var arcList = [];
33 // var arcInfo = {};
34 res.on('data', function (chunk) {
35 html += chunk;
36 });
37 res.on('end', function () {
38 arcList = filterHtml( html );
39 console.log( arcList );
40 });
41 });
有几个关键点需要解释:
1. res.on('数据', function(){})
http模块发送get请求后,会不断的抓取目标网页的源码内容。因此,我在 on 中监听 data 事件。chunk是传输的数据,数据累加到html变量中。当数据传输完毕后,就会触发结束事件。你可以在end事件中打印console.log(html),你会发现里面都是目标地址的html源代码。这就解决了我们的第一个问题:获取目标地址:所有html内容
2.有了完整的html内容后,我再封装一个函数filterHTML来过滤我需要的结果(每条文章信息)
3. var $ =cheerio.load(html); 通过cheerio的load方法加载html内容,然后就可以使用cheerio的节点进行操作了。为了兼容jquery操作,我用美元符号$保存了这个文档对象
4. var aPost = $("#content").find(".post-list-item"); 这就是所有的文章节点信息,拿到后,通过各个方法一一遍历,抓取自己需要的信息,组织成对象,然后放到一个数组中
1 arcList.push({
2 21 title: title,
3 22 url: url,
4 23 entry: entry,
5 24 listTime: listTime
6 25 });
这样做了,结果如上所示。如果博客风格和我的博客风格一样,应该是可以爬取的。
然后改进页面爬取,让整个博客都可以爬下来
<p> 1 var http = require('http');
2 var cheerio = require('cheerio');
3
4 var url = 'http://www.cnblogs.com/ghostwu/';
5
6 function filterHtml(html) {
7 var $ = cheerio.load(html);
8 var arcList = [];
9 var aPost = $("#content").find(".post-list-item");
10 aPost.each(function () {
11 var ele = $(this);
12 var title = ele.find("h2 a").text();
13 var url = ele.find("h2 a").attr("href");
14 ele.find(".c_b_p_desc a").remove();
15 var entry = ele.find(".c_b_p_desc").text();
16 ele.find("small a").remove();
17 var listTime = ele.find("small").text();
18 var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
19 listTime = listTime.match(re)[0];
20 arcList.push({
21 title: title,
22 url: url,
23 entry: entry,
24 listTime: listTime
25 });
26 });
27 return arcList;
28 }
29
30 function nextPage( html ){
31 var $ = cheerio.load(html);
32 var nextUrl = $("#pager a:last-child").attr('href');
33 if ( !nextUrl ) return ;
34 var curPage = $("#pager .current").text();
35 if( !curPage ) curPage = 1;
36 var nextPage = nextUrl.substring( nextUrl.indexOf( '=' ) + 1 );
37 if ( curPage
js 爬虫抓取网页数据(Python中的Node.js与爬虫的框架与资料分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-15 23:27
每当我看到爬虫或百度爬虫时,它都是Python爬虫。不得不说,爬虫的框架和材料基本上都是Python最多的,但事情要反过来。Python爬虫有几个问题:
1.Python好像对DOM的支持不是很好,网页的DOM处理也不是很好
2.Python对网页编码的处理。
3.最重要的是Python需要多线程。
以上问题都是我们即将使用的Node.js的优点!同样,Node.js 也有缺点。Node.js是单线异步的,很容易导致发起爬取请求的顺序和返回结果的顺序不一致。因此,我们需要添加请求序列号,然后将处理后的序列号重新排序,以实现结果和请求。一致。另外Node.js毕竟是前端,数据的处理比那个差很多,但是作为网站的数据爬取绝对够用。废话不多说,我们进入Node.js爬虫,Node.js爬虫步骤1.创建项目目录,不管你在哪里创建,但是路径最好不要有中文,谁知道会不会出错。比如我们的项目路径是:E:
E:cd E:\adt-bundle-windows-x86_64-20131030\Nodejs\nests_Datagetnpm init
npm init 是在当前目录下创建一个模块(即生成package.json),其文件属性描述如下。输入npm init后,会依次出现如下查询
$ npm initThis utility will walk you through creating a package.json file.It only covers the most common items, and tries to guess sensible defaults.See `npm help json` for definitive documentation on these fieldsand exactly what they do.Use `npm install --save` afterwards to install a package andsave it as a dependency in the package.json file.Press ^C at any time to quit.name: (node_modules) runoob # 模块名version: (1.0.0) #模块版本description: Node.js 测试模块(www.runoob.com) # 描述entry point: (index.js)test command: make testgit repository: https://github.com/runoob/runoob.git # Github 地址keywords: #关键字author: #作者license: (ISC) #许可类型About to write to ……/node_modules/package.json: # 生成地址{ "name": "runoob", "version": "1.0.0", "description": "Node.js 测试模块(www.runoob.com)", ……}Is this ok? (yes) yes
您可以根据自己的情况填写以上信息。信息填错没关系,我们可以随时通过package.json修改。3.安装请求和cheerio依赖的安装命令如下
npm install request --savenpm install cheerio
界面如下
4.接下来我们终于可以开始操作我们的js代码,新建一个js文件了。如果是主入口文件名,应该与package.json中的入口点一致。这里我们新建一个名为server.js的文件来建立依赖引用,代码如下
var request = require("request");var cheerio = require("cheerio");
接下来,我们将抓取百度首页链接为:
request('https://www.baidu.com/',function(err,result){ if(err){ console.log("错误:"+err); return; } console.log(result.body);})
在cmd中输入node server.js,回车,代码没有输入错误会出现如下界面
可以看出,我们已经获取到了网页的数据,我们已经迈出了重要的第一步。只要我们能得到完整的Html网页源代码,就很容易做到了。现在是数据处理。我们不是还有一个我们以前没有使用过的库吗?没错,就是cheerio库的使用。现在我们修改上面的代码,将成功获取的网页交给cheerio处理。至于如何通过DOM提取数据,我们通过UC浏览器访问,按F12进入开发者模式。对比一下我们要抓取的信息的位置,比如这里我们要抓取百度的标题
下一步是编写捕获的 DOM 语句。我不知道如何使用它。有DOM文档和JQuery文档。这里我们要获取标题的DOM是$('title').text(),所以代码改成如下:
//把 html 装载到 cheerio 中 var $ = cheerio.load(result.body); //通过 DOM 抓取网页数据 console.log($('title').text());
影响:
但是现在我们抓取的是静态页面,不像百度首页上的新闻我们获取不到。在下一篇文章中,我们将学习抓取动态页面。 查看全部
js 爬虫抓取网页数据(Python中的Node.js与爬虫的框架与资料分析)
每当我看到爬虫或百度爬虫时,它都是Python爬虫。不得不说,爬虫的框架和材料基本上都是Python最多的,但事情要反过来。Python爬虫有几个问题:
1.Python好像对DOM的支持不是很好,网页的DOM处理也不是很好
2.Python对网页编码的处理。
3.最重要的是Python需要多线程。
以上问题都是我们即将使用的Node.js的优点!同样,Node.js 也有缺点。Node.js是单线异步的,很容易导致发起爬取请求的顺序和返回结果的顺序不一致。因此,我们需要添加请求序列号,然后将处理后的序列号重新排序,以实现结果和请求。一致。另外Node.js毕竟是前端,数据的处理比那个差很多,但是作为网站的数据爬取绝对够用。废话不多说,我们进入Node.js爬虫,Node.js爬虫步骤1.创建项目目录,不管你在哪里创建,但是路径最好不要有中文,谁知道会不会出错。比如我们的项目路径是:E:
E:cd E:\adt-bundle-windows-x86_64-20131030\Nodejs\nests_Datagetnpm init
npm init 是在当前目录下创建一个模块(即生成package.json),其文件属性描述如下。输入npm init后,会依次出现如下查询
$ npm initThis utility will walk you through creating a package.json file.It only covers the most common items, and tries to guess sensible defaults.See `npm help json` for definitive documentation on these fieldsand exactly what they do.Use `npm install --save` afterwards to install a package andsave it as a dependency in the package.json file.Press ^C at any time to quit.name: (node_modules) runoob # 模块名version: (1.0.0) #模块版本description: Node.js 测试模块(www.runoob.com) # 描述entry point: (index.js)test command: make testgit repository: https://github.com/runoob/runoob.git # Github 地址keywords: #关键字author: #作者license: (ISC) #许可类型About to write to ……/node_modules/package.json: # 生成地址{ "name": "runoob", "version": "1.0.0", "description": "Node.js 测试模块(www.runoob.com)", ……}Is this ok? (yes) yes
您可以根据自己的情况填写以上信息。信息填错没关系,我们可以随时通过package.json修改。3.安装请求和cheerio依赖的安装命令如下
npm install request --savenpm install cheerio
界面如下


4.接下来我们终于可以开始操作我们的js代码,新建一个js文件了。如果是主入口文件名,应该与package.json中的入口点一致。这里我们新建一个名为server.js的文件来建立依赖引用,代码如下
var request = require("request");var cheerio = require("cheerio");
接下来,我们将抓取百度首页链接为:
request('https://www.baidu.com/',function(err,result){ if(err){ console.log("错误:"+err); return; } console.log(result.body);})
在cmd中输入node server.js,回车,代码没有输入错误会出现如下界面

可以看出,我们已经获取到了网页的数据,我们已经迈出了重要的第一步。只要我们能得到完整的Html网页源代码,就很容易做到了。现在是数据处理。我们不是还有一个我们以前没有使用过的库吗?没错,就是cheerio库的使用。现在我们修改上面的代码,将成功获取的网页交给cheerio处理。至于如何通过DOM提取数据,我们通过UC浏览器访问,按F12进入开发者模式。对比一下我们要抓取的信息的位置,比如这里我们要抓取百度的标题
下一步是编写捕获的 DOM 语句。我不知道如何使用它。有DOM文档和JQuery文档。这里我们要获取标题的DOM是$('title').text(),所以代码改成如下:
//把 html 装载到 cheerio 中 var $ = cheerio.load(result.body); //通过 DOM 抓取网页数据 console.log($('title').text());
影响:

但是现在我们抓取的是静态页面,不像百度首页上的新闻我们获取不到。在下一篇文章中,我们将学习抓取动态页面。
js 爬虫抓取网页数据(1.岗位列表的第一页(图)代码分析(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-14 15:23
)
我一直听说有爬行动物之类的东西。查了一下资料,好像也不是很复杂。
只知道node.js,然后基于它的一个简单的爬虫。
1. 这个爬虫的目标:
从龙狗招聘网站中找出“前端开发”职位信息,分析对应页面,提取具体部分,如职位名称、职位薪资、职位公司、职位发布日期等。并显示捕获的信息。
初始钩子网站的接口信息如下:
2.设计方案:
爬虫实际上使用相应的技术来抓取页面上的特定信息。
这里我们主要抓取与上图所示的帖子列表相关的具体帖子信息。
首先,要爬取,首先得有地址url:
%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91?kd=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F% 91&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=label&lc=&workAddress=&city=%E5%85%A8%E5%9B%BD&requestId=&pn=1
此链接是职位列表第一页的网址。
我们分析地址的参数部分,不考虑其他选择的参数,只看最后的参数值:pn=1
我们的目的是爬取整个页面,所以设置为pn = page;
其次,爬虫为了获取特定信息,需要特定代表的标识符。
这里我们使用分析页面代码tag值、class值、id值来考虑。
通过 Firebug 检查这小部分元素
分析将获得哪些信息需要处理特定的标识符。
3.代码编写:
按照预定的方案,考虑到node.js的使用,通过其内置的http模块获取页面信息,通过cheerio.js模块解析DOM,然后转换成json格式数据,是由控制台直接输出或者将json数据发送回浏览器再次显示。
(cheerio.js的用法很简单,详细可以自己搜索。最重要的就是下面的代码,其余和jQuery的用法类似。
即先加载页面数据,形成特定的数据格式,然后通过类似jq的语法解析数据)
var cheerio = require(\'cheerio\'),
$ = cheerio.load(\'Hello world\');
$(\'h2.title\').text(\'Hello there!\');
$(\'h2\').addClass(\'welcome\');
$.html();
//=> Hello there!
采用express模块化开发后,按要求建立项目。进入项目目录,执行 npm install 安装需要的依赖。如果你不知道快递,你可以在这里查看
爬虫需要cheerio.js,所以需要另外一个进来,所以需要另外一个npm installcheerio
工程文件很多,为了简单的处理只修改了三个。(Index.ejs index.js style.css)
(1)直接修改路由中的index.js文件,也是核心部分。
看代码,注释够多
1 var express = require(\'express\');
2 var router = express.Router();
3 var http = require(\'http\');
4 var cheerio = require(\'cheerio\');
5
6 /* GET home page. */
7 router.get(\'/\', function(req, res, next) {
8 res.render(\'index\', { title: \'简单nodejs爬虫\' });
9 });
10 router.get(\'/getJobs\', function(req, res, next) { // 浏览器端发来get请求
11 var page = req.param(\'page\'); //获取get请求中的参数 page
12 console.log("page: "+page);
13 var Res = res; //保存,防止下边的修改
14 //url 获取信息的页面部分地址
15 var url = \'http://www.lagou.com/jobs/list_%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91?kd=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=label&lc=&workAddress=&city=%E5%85%A8%E5%9B%BD&requestId=&pn=\';
16
17 http.get(url+page,function(res){ //通过get方法获取对应地址中的页面信息
18 var chunks = [];
19 var size = 0;
20 res.on(\'data\',function(chunk){ //监听事件 传输
21 chunks.push(chunk);
22 size += chunk.length;
23 });
24 res.on(\'end\',function(){ //数据传输完
25 var data = Buffer.concat(chunks,size);
26 var html = data.toString();
27 // console.log(html);
28 var $ = cheerio.load(html); //cheerio模块开始处理 DOM处理
29 var jobs = [];
30
31 var jobs_list = $(".hot_pos li");
32 $(".hot_pos>li").each(function(){ //对页面岗位栏信息进行处理 每个岗位对应一个 li ,各标识符到页面进行分析得出
33 var job = {};
34 job.company = $(this).find(".hot_pos_r div").eq(1).find("a").html(); //公司名
35 job.period = $(this).find(".hot_pos_r span").eq(1).html(); //阶段
36 job.scale = $(this).find(".hot_pos_r span").eq(2).html(); //规模
37
38 job.name = $(this).find(".hot_pos_l a").attr("title"); //岗位名
39 job.src = $(this).find(".hot_pos_l a").attr("href"); //岗位链接
40 job.city = $(this).find(".hot_pos_l .c9").html(); //岗位所在城市
41 job.salary = $(this).find(".hot_pos_l span").eq(1).html(); //薪资
42 job.exp = $(this).find(".hot_pos_l span").eq(2).html(); //岗位所需经验
43 job.time = $(this).find(".hot_pos_l span").eq(5).html(); //发布时间
44
45 console.log(job.name); //控制台输出岗位名
46 jobs.push(job);
47 });
48 Res.json({ //返回json格式数据给浏览器端
49 jobs:jobs
50 });
51 });
52 });
53
54 });
55
56 module.exports = router;
(2)node.js抓取的核心代码就是以上部分。
下一步就是展示抓取到的数据,所以需要另外一个页面修改views中的index.ejs模板
1 DOCTYPE html>
2
3
4
5
6
7
8 【nodejs爬虫】 获取拉勾网招聘岗位--前端开发
9 初始化完成 ...
10 点击开始抓取第一页
11
12
13
14
15 数据抓取中 ... 请稍后
16 抓取上一页
17 抓取下一页
18
19
20
21 function getData(str){ //获取到的数据有杂乱..需要把前面部分去掉,只需要data(...... data)
22 if(str){
23 return str.slice(str.lastIndexOf(">")+1);
24 }
25 }
26
27 document.getElementById("btn1").style.visibility = "hidden";
28 document.getElementById("btn2").style.visibility = "hidden";
29 var currentPage = 0; //page初始0
30
31 function cheerFetch(_page){ //抓取数据处理函数
32 if(_page == 1){
33 currentPage = 1; //开始抓取则更改page
34 }
35 $(document).ajaxSend(function(event, xhr, settings) { //抓取中...
36 $(".fetching").css("display","block");
37 });
38 $(document).ajaxSuccess(function(event, xhr, settings) { //抓取成功
39 $(".fetching").css("display","none");
40 });
41 $.ajax({ //开始发送ajax请求至路径 /getJobs 进而作页面抓取处理
42 data:{page:_page}, //参数 page = _page
43 dataType: "json",
44 type: "get",
45 url: "/getJobs",
46 success: function(data){ //收到返回的json数据
47 console.log(data);
48 var html = "";
49 $(".container").empty();
50 if(data.jobs.length == 0){
51 alert("Error2: 未找到数据..");
52 return;
53 }
54 for(var i=0;i 1){
73 document.getElementById("btn1").style.visibility = "visible";
74 document.getElementById("btn2").style.visibility = "visible";
75 }
76 },
77 error: function(){
78 alert("Error1: 未找到数据..");
79 }
80 });
81 }
82
83
84
85
(3)当然也需要简单的修改public文件下的style.css
body {
padding: 20px 50px;
font: 14px "Lucida Grande", Helvetica, Arial, sans-serif;
}
a {
color: #00B7FF;
cursor: pointer;
}
.container{position: relative;width: 1100px;overflow: hidden;zoom:1;}
.jobs{margin: 30px; float: left;}
.jobs span{ color: green; font-weight: bold;}
.btn{cursor: pointer;}
.fetching{display: none;color: red;}
.footer{clear: both;}
只有这三个文件基本改变了。
因此,如果要测试,可以在新建项目后直接修改相应的三个文件。
修改成功后就可以测试了。
3.测试结果
1) 先在控制台执行 npm start
2) 接下来在浏览器中输入:3000/start 访问
3) 点击开始抓取(这里每次抓取15个条目,即原创URL对应的15个条目)
...
查看全部
js 爬虫抓取网页数据(1.岗位列表的第一页(图)代码分析(组图)
)
我一直听说有爬行动物之类的东西。查了一下资料,好像也不是很复杂。
只知道node.js,然后基于它的一个简单的爬虫。
1. 这个爬虫的目标:
从龙狗招聘网站中找出“前端开发”职位信息,分析对应页面,提取具体部分,如职位名称、职位薪资、职位公司、职位发布日期等。并显示捕获的信息。
初始钩子网站的接口信息如下:
2.设计方案:
爬虫实际上使用相应的技术来抓取页面上的特定信息。
这里我们主要抓取与上图所示的帖子列表相关的具体帖子信息。
首先,要爬取,首先得有地址url:
%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91?kd=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F% 91&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=label&lc=&workAddress=&city=%E5%85%A8%E5%9B%BD&requestId=&pn=1
此链接是职位列表第一页的网址。
我们分析地址的参数部分,不考虑其他选择的参数,只看最后的参数值:pn=1
我们的目的是爬取整个页面,所以设置为pn = page;
其次,爬虫为了获取特定信息,需要特定代表的标识符。
这里我们使用分析页面代码tag值、class值、id值来考虑。
通过 Firebug 检查这小部分元素
分析将获得哪些信息需要处理特定的标识符。
3.代码编写:
按照预定的方案,考虑到node.js的使用,通过其内置的http模块获取页面信息,通过cheerio.js模块解析DOM,然后转换成json格式数据,是由控制台直接输出或者将json数据发送回浏览器再次显示。
(cheerio.js的用法很简单,详细可以自己搜索。最重要的就是下面的代码,其余和jQuery的用法类似。
即先加载页面数据,形成特定的数据格式,然后通过类似jq的语法解析数据)
var cheerio = require(\'cheerio\'),
$ = cheerio.load(\'Hello world\');
$(\'h2.title\').text(\'Hello there!\');
$(\'h2\').addClass(\'welcome\');
$.html();
//=> Hello there!
采用express模块化开发后,按要求建立项目。进入项目目录,执行 npm install 安装需要的依赖。如果你不知道快递,你可以在这里查看
爬虫需要cheerio.js,所以需要另外一个进来,所以需要另外一个npm installcheerio
工程文件很多,为了简单的处理只修改了三个。(Index.ejs index.js style.css)
(1)直接修改路由中的index.js文件,也是核心部分。
看代码,注释够多
1 var express = require(\'express\');
2 var router = express.Router();
3 var http = require(\'http\');
4 var cheerio = require(\'cheerio\');
5
6 /* GET home page. */
7 router.get(\'/\', function(req, res, next) {
8 res.render(\'index\', { title: \'简单nodejs爬虫\' });
9 });
10 router.get(\'/getJobs\', function(req, res, next) { // 浏览器端发来get请求
11 var page = req.param(\'page\'); //获取get请求中的参数 page
12 console.log("page: "+page);
13 var Res = res; //保存,防止下边的修改
14 //url 获取信息的页面部分地址
15 var url = \'http://www.lagou.com/jobs/list_%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91?kd=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=label&lc=&workAddress=&city=%E5%85%A8%E5%9B%BD&requestId=&pn=\';
16
17 http.get(url+page,function(res){ //通过get方法获取对应地址中的页面信息
18 var chunks = [];
19 var size = 0;
20 res.on(\'data\',function(chunk){ //监听事件 传输
21 chunks.push(chunk);
22 size += chunk.length;
23 });
24 res.on(\'end\',function(){ //数据传输完
25 var data = Buffer.concat(chunks,size);
26 var html = data.toString();
27 // console.log(html);
28 var $ = cheerio.load(html); //cheerio模块开始处理 DOM处理
29 var jobs = [];
30
31 var jobs_list = $(".hot_pos li");
32 $(".hot_pos>li").each(function(){ //对页面岗位栏信息进行处理 每个岗位对应一个 li ,各标识符到页面进行分析得出
33 var job = {};
34 job.company = $(this).find(".hot_pos_r div").eq(1).find("a").html(); //公司名
35 job.period = $(this).find(".hot_pos_r span").eq(1).html(); //阶段
36 job.scale = $(this).find(".hot_pos_r span").eq(2).html(); //规模
37
38 job.name = $(this).find(".hot_pos_l a").attr("title"); //岗位名
39 job.src = $(this).find(".hot_pos_l a").attr("href"); //岗位链接
40 job.city = $(this).find(".hot_pos_l .c9").html(); //岗位所在城市
41 job.salary = $(this).find(".hot_pos_l span").eq(1).html(); //薪资
42 job.exp = $(this).find(".hot_pos_l span").eq(2).html(); //岗位所需经验
43 job.time = $(this).find(".hot_pos_l span").eq(5).html(); //发布时间
44
45 console.log(job.name); //控制台输出岗位名
46 jobs.push(job);
47 });
48 Res.json({ //返回json格式数据给浏览器端
49 jobs:jobs
50 });
51 });
52 });
53
54 });
55
56 module.exports = router;
(2)node.js抓取的核心代码就是以上部分。
下一步就是展示抓取到的数据,所以需要另外一个页面修改views中的index.ejs模板
1 DOCTYPE html>
2
3
4
5
6
7
8 【nodejs爬虫】 获取拉勾网招聘岗位--前端开发
9 初始化完成 ...
10 点击开始抓取第一页
11
12
13
14
15 数据抓取中 ... 请稍后
16 抓取上一页
17 抓取下一页
18
19
20
21 function getData(str){ //获取到的数据有杂乱..需要把前面部分去掉,只需要data(...... data)
22 if(str){
23 return str.slice(str.lastIndexOf(">")+1);
24 }
25 }
26
27 document.getElementById("btn1").style.visibility = "hidden";
28 document.getElementById("btn2").style.visibility = "hidden";
29 var currentPage = 0; //page初始0
30
31 function cheerFetch(_page){ //抓取数据处理函数
32 if(_page == 1){
33 currentPage = 1; //开始抓取则更改page
34 }
35 $(document).ajaxSend(function(event, xhr, settings) { //抓取中...
36 $(".fetching").css("display","block");
37 });
38 $(document).ajaxSuccess(function(event, xhr, settings) { //抓取成功
39 $(".fetching").css("display","none");
40 });
41 $.ajax({ //开始发送ajax请求至路径 /getJobs 进而作页面抓取处理
42 data:{page:_page}, //参数 page = _page
43 dataType: "json",
44 type: "get",
45 url: "/getJobs",
46 success: function(data){ //收到返回的json数据
47 console.log(data);
48 var html = "";
49 $(".container").empty();
50 if(data.jobs.length == 0){
51 alert("Error2: 未找到数据..");
52 return;
53 }
54 for(var i=0;i 1){
73 document.getElementById("btn1").style.visibility = "visible";
74 document.getElementById("btn2").style.visibility = "visible";
75 }
76 },
77 error: function(){
78 alert("Error1: 未找到数据..");
79 }
80 });
81 }
82
83
84
85
(3)当然也需要简单的修改public文件下的style.css
body {
padding: 20px 50px;
font: 14px "Lucida Grande", Helvetica, Arial, sans-serif;
}
a {
color: #00B7FF;
cursor: pointer;
}
.container{position: relative;width: 1100px;overflow: hidden;zoom:1;}
.jobs{margin: 30px; float: left;}
.jobs span{ color: green; font-weight: bold;}
.btn{cursor: pointer;}
.fetching{display: none;color: red;}
.footer{clear: both;}
只有这三个文件基本改变了。
因此,如果要测试,可以在新建项目后直接修改相应的三个文件。
修改成功后就可以测试了。
3.测试结果
1) 先在控制台执行 npm start
2) 接下来在浏览器中输入:3000/start 访问
3) 点击开始抓取(这里每次抓取15个条目,即原创URL对应的15个条目)
...
js 爬虫抓取网页数据(别的项目组什么项目突然心血来潮想研究一下爬虫、分析的简单原型)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-14 15:18
因为其他项目组都在做舆情预测项目,我只是手头没有项目,突然想研究一个爬虫的简单原型,心血来潮分析。网上查这方面的资料太多了,看得我眼花缭乱。Search Search 对于我这种新手,想做一个简单的爬虫程序,HttpClient + jsoup 是个不错的选择。前者是用来管理请求的,后者是用来解析页面的,主要是因为后者的select语法和jquery很像,对我这个用js的人来说太方便了。
昨天和他们聊天的时候,他们选择了几个知名的开源框架来使用,聊天后发现他们目前没有办法抓取动态网页,尤其是几个重要的数字,比如评论数量和数量的答复。等等,一般的理解,比如TRS爬虫需要写js脚本来调用js,但是分析量巨大。他们的技术人员告诉我们,如果他们配备了这样的模板,他们一天只能配备2到3个,更不用说我们这些中途出家的人了。碰巧挺有挑战性的,所以昨天就同意了,看看他们能不能找到一个相对简单的解决方案,当然,不考虑效率。
举个简单的例子,如下图
“我有话要说”后面的1307是后装的,但这些数字往往对舆论分析更重要。
对需求有了大致的了解之后,我们来分析一下如何解决。通常我们对一个请求得到的响应收录js代码和html元素,所以像jsoup这样的html解析器很难在这里利用它,因为它可以得到的html,1307还没有生成。这时候就需要一个可以运行js的平台,将运行js代码后的页面交给html进行解析,这样才能正确得到结果。
因为比较懒,一开始就放弃了写脚本的方式,因为分析一个页面太痛苦,代码乱七八糟。其中很多也使用了压缩方法,都是a()、b()方法。看的太累了。所以我的第一个想法是,为什么我不能让这个地址在某个浏览器中运行,然后将运行的结果传递给html解析器进行分析,那么整个问题就迎刃而解了。所以我的临时解决办法是在爬虫服务器上打开一个后台浏览器,或者一个带有浏览器内核的程序,把URL地址传给它来请求,然后从浏览器中取出页面的元素交给html解析器来解析,从而得到你想要的信息。
是的,最后还是用Selenium来实现上一篇我提到的问题。我没有尝试其他任何东西。我只试过火狐引擎。整体效果还是可以接受的。
继续昨天的话题,既然要实现上一篇提到的问题,就需要一个可以执行js代码的框架。我的第一选择是 htmlunit。先简单介绍一下htmlunit。以下段落摘自互联网。
htmlunit 是一个开源的java 页面分析工具。启动 htmlunit 后,将在底部启动一个无界面浏览器。用户可以指定浏览器类型:firefox、ie等,如果不指定,默认使用INTERNET_EXPLORER_7:
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_3_6);
通过一个简单的调用:
HtmlPage 页面 = webClient.getPage(url);
可以得到页面的HtmlPage表示,然后通过:
InputStream 是 = targetPage.getWebResponse().getContentAsStream()
可以获取页面的输入流,进而获取页面的源代码,这对于网络爬虫项目非常有用。
当然,你也可以从页面中获取更多的页面元素。
很重要的一点是 HtmlUnit 提供了对执行 javascript 的支持:
page.executeJavaScript(javascript)
js执行后返回一个ScriptResult对象,通过该对象可以获取js执行后的页面等信息。默认情况下,内部浏览器执行js后,会做一次页面跳转,跳转到执行js后生成的新页面。如果js执行失败,页面跳转将不会被执行。
最后可以通过获取 page.executeJavaScript(javascript).getNewPage() 来获取执行后的页面。也就是说,这里需要人工执行javascript。显然这不符合我的初衷。另外,也可能是我水平太差了。我在爬新浪新闻页面的时候总是出错。暂时没找到错误的地方,但是根据网上的查询结果分析,最可能的错误原因是htmlunit在执行一些带参数的请求时,请求失败并出现由于参数顺序或编码问题而报告错误。关键是我运行后没有得到我需要的结果。
然后我寻找了另一种解决方案。这时候我找到了SeleniumWebDriver,这就是我需要的解决方案。
参考资料和例子后,就可以开始使用了。示例代码如下。
<p> 1 File pathToBinary = new File("D:\\Program Files (x86)\\Mozilla Firefox\\firefox.exe");
2 FirefoxBinary ffBinary = new FirefoxBinary(pathToBinary);
3 FirefoxProfile firefoxProfile = new FirefoxProfile();
4 FirefoxDriver driver = new FirefoxDriver(ffBinary,firefoxProfile);
5
6
7 driver.get("http://cq.qq.com/baoliao/detail.htm?294064");
8
9 ArrayList list = new ArrayList();
10 list.add("http://www.sina.com.cn");
11 list.add("http://www.sohu.com");
12 list.add("http://www.163.com");
13 list.add("http://www.qq.com");
14
15 long start,end;
16
17 for(int i=0;i 查看全部
js 爬虫抓取网页数据(别的项目组什么项目突然心血来潮想研究一下爬虫、分析的简单原型)
因为其他项目组都在做舆情预测项目,我只是手头没有项目,突然想研究一个爬虫的简单原型,心血来潮分析。网上查这方面的资料太多了,看得我眼花缭乱。Search Search 对于我这种新手,想做一个简单的爬虫程序,HttpClient + jsoup 是个不错的选择。前者是用来管理请求的,后者是用来解析页面的,主要是因为后者的select语法和jquery很像,对我这个用js的人来说太方便了。
昨天和他们聊天的时候,他们选择了几个知名的开源框架来使用,聊天后发现他们目前没有办法抓取动态网页,尤其是几个重要的数字,比如评论数量和数量的答复。等等,一般的理解,比如TRS爬虫需要写js脚本来调用js,但是分析量巨大。他们的技术人员告诉我们,如果他们配备了这样的模板,他们一天只能配备2到3个,更不用说我们这些中途出家的人了。碰巧挺有挑战性的,所以昨天就同意了,看看他们能不能找到一个相对简单的解决方案,当然,不考虑效率。
举个简单的例子,如下图
“我有话要说”后面的1307是后装的,但这些数字往往对舆论分析更重要。
对需求有了大致的了解之后,我们来分析一下如何解决。通常我们对一个请求得到的响应收录js代码和html元素,所以像jsoup这样的html解析器很难在这里利用它,因为它可以得到的html,1307还没有生成。这时候就需要一个可以运行js的平台,将运行js代码后的页面交给html进行解析,这样才能正确得到结果。
因为比较懒,一开始就放弃了写脚本的方式,因为分析一个页面太痛苦,代码乱七八糟。其中很多也使用了压缩方法,都是a()、b()方法。看的太累了。所以我的第一个想法是,为什么我不能让这个地址在某个浏览器中运行,然后将运行的结果传递给html解析器进行分析,那么整个问题就迎刃而解了。所以我的临时解决办法是在爬虫服务器上打开一个后台浏览器,或者一个带有浏览器内核的程序,把URL地址传给它来请求,然后从浏览器中取出页面的元素交给html解析器来解析,从而得到你想要的信息。
是的,最后还是用Selenium来实现上一篇我提到的问题。我没有尝试其他任何东西。我只试过火狐引擎。整体效果还是可以接受的。
继续昨天的话题,既然要实现上一篇提到的问题,就需要一个可以执行js代码的框架。我的第一选择是 htmlunit。先简单介绍一下htmlunit。以下段落摘自互联网。
htmlunit 是一个开源的java 页面分析工具。启动 htmlunit 后,将在底部启动一个无界面浏览器。用户可以指定浏览器类型:firefox、ie等,如果不指定,默认使用INTERNET_EXPLORER_7:
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_3_6);
通过一个简单的调用:
HtmlPage 页面 = webClient.getPage(url);
可以得到页面的HtmlPage表示,然后通过:
InputStream 是 = targetPage.getWebResponse().getContentAsStream()
可以获取页面的输入流,进而获取页面的源代码,这对于网络爬虫项目非常有用。
当然,你也可以从页面中获取更多的页面元素。
很重要的一点是 HtmlUnit 提供了对执行 javascript 的支持:
page.executeJavaScript(javascript)
js执行后返回一个ScriptResult对象,通过该对象可以获取js执行后的页面等信息。默认情况下,内部浏览器执行js后,会做一次页面跳转,跳转到执行js后生成的新页面。如果js执行失败,页面跳转将不会被执行。
最后可以通过获取 page.executeJavaScript(javascript).getNewPage() 来获取执行后的页面。也就是说,这里需要人工执行javascript。显然这不符合我的初衷。另外,也可能是我水平太差了。我在爬新浪新闻页面的时候总是出错。暂时没找到错误的地方,但是根据网上的查询结果分析,最可能的错误原因是htmlunit在执行一些带参数的请求时,请求失败并出现由于参数顺序或编码问题而报告错误。关键是我运行后没有得到我需要的结果。
然后我寻找了另一种解决方案。这时候我找到了SeleniumWebDriver,这就是我需要的解决方案。
参考资料和例子后,就可以开始使用了。示例代码如下。
<p> 1 File pathToBinary = new File("D:\\Program Files (x86)\\Mozilla Firefox\\firefox.exe");
2 FirefoxBinary ffBinary = new FirefoxBinary(pathToBinary);
3 FirefoxProfile firefoxProfile = new FirefoxProfile();
4 FirefoxDriver driver = new FirefoxDriver(ffBinary,firefoxProfile);
5
6
7 driver.get("http://cq.qq.com/baoliao/detail.htm?294064";);
8
9 ArrayList list = new ArrayList();
10 list.add("http://www.sina.com.cn";);
11 list.add("http://www.sohu.com";);
12 list.add("http://www.163.com";);
13 list.add("http://www.qq.com";);
14
15 long start,end;
16
17 for(int i=0;i
js 爬虫抓取网页数据(#js爬虫抓取网页数据-jquery前端基础参数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-14 00:06
js爬虫抓取网页数据我这里使用的是chrome浏览器,这是我写的爬虫代码:js数据抓取--jquery前端基础这里的参数#lang=en-us这里是中文数据抓取框#lang=en-us#lang=en-us#lang=en-us#lang=en-usstdswriter.jsx#lang=en-us#lang=en-us#lang=en-us#lang=en-us#lang=en-us#lang=en-usdocx是对jsx文件文件进行分析,首先以jsx文件的标签语言,进行解析jsx。第一步,对jsx文件进行读取。
js的文件还是要有一个链接比较好,所以其实file->readthefile和as->readfile。如果是javascript文件,javascript.ts用的比较多。如果你是要参数和属性值之类的,这个就得找一些实例了。
一般都是lib中的attribute
网站包含javascript,javascript是javascript文件中的.js文件,js文件即javascript文件。现有的一般是a.js,b.js文件,也可以是其他结构的文件。一般用libs。现在很多网站的配置中,会用到esprima,html标签等辅助文件来校验搜索引擎等。
.es和.el文件。
javascript的文件用javascript.esdom标签可以包含动态构建的数据 查看全部
js 爬虫抓取网页数据(#js爬虫抓取网页数据-jquery前端基础参数)
js爬虫抓取网页数据我这里使用的是chrome浏览器,这是我写的爬虫代码:js数据抓取--jquery前端基础这里的参数#lang=en-us这里是中文数据抓取框#lang=en-us#lang=en-us#lang=en-us#lang=en-usstdswriter.jsx#lang=en-us#lang=en-us#lang=en-us#lang=en-us#lang=en-us#lang=en-usdocx是对jsx文件文件进行分析,首先以jsx文件的标签语言,进行解析jsx。第一步,对jsx文件进行读取。
js的文件还是要有一个链接比较好,所以其实file->readthefile和as->readfile。如果是javascript文件,javascript.ts用的比较多。如果你是要参数和属性值之类的,这个就得找一些实例了。
一般都是lib中的attribute
网站包含javascript,javascript是javascript文件中的.js文件,js文件即javascript文件。现有的一般是a.js,b.js文件,也可以是其他结构的文件。一般用libs。现在很多网站的配置中,会用到esprima,html标签等辅助文件来校验搜索引擎等。
.es和.el文件。
javascript的文件用javascript.esdom标签可以包含动态构建的数据
js 爬虫抓取网页数据(以前第一篇爬虫教程.js爬虫入门(一)爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-13 08:30
第一篇爬虫教程node.js爬虫介绍(一)爬取静态页面讲解了静态网页的爬取,很简单,但是如果遇到一些动态网页(ajax),直接使用前面的发送请求方法是不可能得到我们想要的数据的,这时候就需要通过爬取动态网页的方法了,selenium和puppeteer都不错,前端
在这里推荐 Puppeteer,不是为了别的,只是因为它是 Google 自己的,并且一直在维护更新。以下是官方文档介绍节点的翻译
Puppeteer 是一个 Node 库,通过 DevTools(开发者工具)协议提供了一系列高级接口来控制 Chrome 或 Chromium(谷歌开源)。默认运行在headless模式(无浏览器UI界面),配置后也可以运行在普通模式。网络
可以使用:ajax
首先,我们必须先安装它,然后才能使用它。最新的Chromium会默认安装下载,大小约300M。铬合金
npm install puppeteer
复制代码
如果你的机器上已经有较新版本的chrome,可以只安装核心版本,但是启动puppeteer时,需要配置本地chrome路径。数据库
npm install puppeteer-core // 核心版本
复制代码
假设我们要爬取拉勾的前端招聘信息。这是一个动态页面。使用此示例尝试抓取。新产品经理
由于chrome操作都是异步操作,为了不回调地狱,推荐使用es7 async await。这种语法具有高度可读性,官方文档也是如此。浏览器
首先使用puppeteer启动浏览器,打开动态页面
需要注意的是,如果使用的是本地浏览器,则需要在启动浏览器配置中传入本地chrome路径markdown。
const browser = await puppeteer.launch({
executablePath: 'C:/Users/Administrator/AppData/Local/Google/Chrome/Application/chrome.exe'
})
复制代码
在chrome环境中执行函数,获取需要的数据,然后返回到node的执行环境
上图可以看到我们需要的数据的dom位置。在chrome环境执行的函数中,我们需要获取和整理需要的数据。较少的
let list = document.querySelectorAll('.s_position_list .item_con_list li')
let res = []
for (let i = 0; i < list.length; i++) {
res.push({
name: list[i].getAttribute('data-positionname'),
company: list[i].getAttribute('data-company'),
salary: list[i].getAttribute('data-salary'),
require: list[i].querySelector('.li_b_l').childNodes[4].textContent.replace(/ |\n/g, ''),
})
}
return res
复制代码
这里有一个调试技巧,我们可以直接在chrome控制台中编写获取数据的函数,方便调试
最后附上完整代码
const puppeteer = require('puppeteer');
(async () => {
// 启动浏览器
const browser = await puppeteer.launch({
headless: false, // 默认是无头模式,这里为了示范因此使用正常模式
})
// 控制浏览器打开新标签页面
const page = await browser.newPage()
// 在新标签中打开要爬取的网页
await page.goto('https://www.lagou.com/jobs/list_web%E5%89%8D%E7%AB%AF?px=new&city=%E5%B9%BF%E5%B7%9E')
// 使用evaluate方法在浏览器中执行传入函数(彻底的浏览器环境,因此函数内能够直接使用window、document等全部对象和方法)
let data = await page.evaluate(() => {
let list = document.querySelectorAll('.s_position_list .item_con_list li')
let res = []
for (let i = 0; i < list.length; i++) {
res.push({
name: list[i].getAttribute('data-positionname'),
company: list[i].getAttribute('data-company'),
salary: list[i].getAttribute('data-salary'),
require: list[i].querySelector('.li_b_l').childNodes[4].textContent.replace(/ |\n/g, ''),
})
}
return res
})
console.log(data)
})()
复制代码
操作结果
动态网页的爬取也到此完成,但puppeteer的功能远不止这些,还有很多强大的API可用。能够移动到正式文件。
第三期会讲如何定时执行爬虫并存入数据库。 查看全部
js 爬虫抓取网页数据(以前第一篇爬虫教程.js爬虫入门(一)爬取)
第一篇爬虫教程node.js爬虫介绍(一)爬取静态页面讲解了静态网页的爬取,很简单,但是如果遇到一些动态网页(ajax),直接使用前面的发送请求方法是不可能得到我们想要的数据的,这时候就需要通过爬取动态网页的方法了,selenium和puppeteer都不错,前端
在这里推荐 Puppeteer,不是为了别的,只是因为它是 Google 自己的,并且一直在维护更新。以下是官方文档介绍节点的翻译
Puppeteer 是一个 Node 库,通过 DevTools(开发者工具)协议提供了一系列高级接口来控制 Chrome 或 Chromium(谷歌开源)。默认运行在headless模式(无浏览器UI界面),配置后也可以运行在普通模式。网络
可以使用:ajax
首先,我们必须先安装它,然后才能使用它。最新的Chromium会默认安装下载,大小约300M。铬合金
npm install puppeteer
复制代码
如果你的机器上已经有较新版本的chrome,可以只安装核心版本,但是启动puppeteer时,需要配置本地chrome路径。数据库
npm install puppeteer-core // 核心版本
复制代码
假设我们要爬取拉勾的前端招聘信息。这是一个动态页面。使用此示例尝试抓取。新产品经理
由于chrome操作都是异步操作,为了不回调地狱,推荐使用es7 async await。这种语法具有高度可读性,官方文档也是如此。浏览器
首先使用puppeteer启动浏览器,打开动态页面
需要注意的是,如果使用的是本地浏览器,则需要在启动浏览器配置中传入本地chrome路径markdown。
const browser = await puppeteer.launch({
executablePath: 'C:/Users/Administrator/AppData/Local/Google/Chrome/Application/chrome.exe'
})
复制代码
在chrome环境中执行函数,获取需要的数据,然后返回到node的执行环境
上图可以看到我们需要的数据的dom位置。在chrome环境执行的函数中,我们需要获取和整理需要的数据。较少的
let list = document.querySelectorAll('.s_position_list .item_con_list li')
let res = []
for (let i = 0; i < list.length; i++) {
res.push({
name: list[i].getAttribute('data-positionname'),
company: list[i].getAttribute('data-company'),
salary: list[i].getAttribute('data-salary'),
require: list[i].querySelector('.li_b_l').childNodes[4].textContent.replace(/ |\n/g, ''),
})
}
return res
复制代码
这里有一个调试技巧,我们可以直接在chrome控制台中编写获取数据的函数,方便调试
最后附上完整代码
const puppeteer = require('puppeteer');
(async () => {
// 启动浏览器
const browser = await puppeteer.launch({
headless: false, // 默认是无头模式,这里为了示范因此使用正常模式
})
// 控制浏览器打开新标签页面
const page = await browser.newPage()
// 在新标签中打开要爬取的网页
await page.goto('https://www.lagou.com/jobs/list_web%E5%89%8D%E7%AB%AF?px=new&city=%E5%B9%BF%E5%B7%9E')
// 使用evaluate方法在浏览器中执行传入函数(彻底的浏览器环境,因此函数内能够直接使用window、document等全部对象和方法)
let data = await page.evaluate(() => {
let list = document.querySelectorAll('.s_position_list .item_con_list li')
let res = []
for (let i = 0; i < list.length; i++) {
res.push({
name: list[i].getAttribute('data-positionname'),
company: list[i].getAttribute('data-company'),
salary: list[i].getAttribute('data-salary'),
require: list[i].querySelector('.li_b_l').childNodes[4].textContent.replace(/ |\n/g, ''),
})
}
return res
})
console.log(data)
})()
复制代码
操作结果
动态网页的爬取也到此完成,但puppeteer的功能远不止这些,还有很多强大的API可用。能够移动到正式文件。
第三期会讲如何定时执行爬虫并存入数据库。
js 爬虫抓取网页数据(Node学习之cheerio网络爬虫好了,啊哈哈哈~昨天的抓取博文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2021-12-27 20:30
书上次连上了,哈哈,昨天发表了,如何使用Node的cheerio模块抓取网页信息,那一定有我们自己使用的数据。
我昨天抓到的是一些超级诱人的糕点的照片,今天我给他们看了。大家都贪心了,哈哈哈哈~
获取昨天的博文,如果需要,请点击此链接:Cheerio Web Crawler for Node Learning
好,开始今天的表演,添加代码:
<p>var http = require("http");
var cheerio = require("cheerio");
//准备抓取的网站链接
var dataUrl = "http://www.mcake.com/shop/110/ ... 3B%3B
http.get(dataUrl,function(res){
var str = "";
//绑定方法,获取网页数据
res.on("data",function(chunk){
str += chunk;
})
//数据获取完毕
res.on("end",function(){
//调用下方的函数,得到返回值,即是我们想要的img的src
var data = getData(str);
//console.log(data);
----------
//新添加的部分
//用node搭建服务器,将内容展示在页面上
var server = http.createServer(function(req,res){
//定义空的字符串
var html = "";
//循环得到的数据,拼接在html上
for(var i = 0;i 查看全部
js 爬虫抓取网页数据(Node学习之cheerio网络爬虫好了,啊哈哈哈~昨天的抓取博文)
书上次连上了,哈哈,昨天发表了,如何使用Node的cheerio模块抓取网页信息,那一定有我们自己使用的数据。
我昨天抓到的是一些超级诱人的糕点的照片,今天我给他们看了。大家都贪心了,哈哈哈哈~
获取昨天的博文,如果需要,请点击此链接:Cheerio Web Crawler for Node Learning
好,开始今天的表演,添加代码:
<p>var http = require("http");
var cheerio = require("cheerio");
//准备抓取的网站链接
var dataUrl = "http://www.mcake.com/shop/110/ ... 3B%3B
http.get(dataUrl,function(res){
var str = "";
//绑定方法,获取网页数据
res.on("data",function(chunk){
str += chunk;
})
//数据获取完毕
res.on("end",function(){
//调用下方的函数,得到返回值,即是我们想要的img的src
var data = getData(str);
//console.log(data);
----------
//新添加的部分
//用node搭建服务器,将内容展示在页面上
var server = http.createServer(function(req,res){
//定义空的字符串
var html = "";
//循环得到的数据,拼接在html上
for(var i = 0;i
js 爬虫抓取网页数据(爬虫爬取的流程和最终如何展示数据的地址?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-26 15:03
其实我之前做过利马理财的销售统计,不过是前端js写的。需要在首页的控制台调试面板中粘贴一段代码执行,点击这里。主要目的是通过定时爬取异步接口来获取数据。然后通过一定的去重算法得到最终的数据。但这有以下缺点:
代码只能在浏览器窗口中运行。如果浏览器关闭或电脑无效,则只能抓取一个页面的数据,无法整合其他页面的数据。爬取的数据无法存储在本地。异步接口数据将被部分过滤。导致我们的去重算法失败
最近学习了节点爬虫,我们可以在后台模拟请求,爬取页面数据。而且我开通了阿里云服务器,我可以把代码放到云端运行。这样1、2、3都可以解决。4因为我们不知道这个ajax界面每三分钟更新一次,这样我们就可以以此为基础对权重进行排序,保证数据不会重复。说起爬虫,大家想到的更多的是python。确实,python有Scrapy等成熟的框架,可以实现非常强大的爬虫功能。但是node也有自己的优势。凭借其强大的异步特性,可以轻松实现高效的异步并发请求,节省CPU开销。其实节点爬虫比较简单,让'
在线地址
一、爬虫进程
我们的最终目标是爬取利马财经每天的销售额,知道销售了哪些产品,哪些用户在什么时间点购买了每种产品。首先介绍一下爬取的主要步骤:
1. 结构分析
我们要抓取页面的数据。第一步当然是分析页面结构,抓取哪些页面,页面结构是什么,不需要登录;是否有ajax接口,返回什么样的数据等。
2. 数据采集
分析清楚要爬取哪些页面和ajax,需要爬取数据。现在网页的数据大致分为同步页面和ajax接口。同步页面数据的爬取需要我们首先分析网页的结构。Python爬取数据一般是通过正则表达式匹配来获取需要的数据;node有一个cheerio工具,可以将获取到的页面内容转换成jquery对象。然后就可以使用jquery强大的dom API来获取节点相关的数据了。其实看源码,这些API本质上都是正则匹配。ajax接口数据一般都是json格式,处理起来比较简单。
3. 数据存储
捕获数据后,它会做一个简单的筛选,然后将需要的数据保存起来,以便后续的分析和处理。当然我们可以使用MySQL、Mongodb等数据库来存储数据。这里,为了方便,我们直接使用文件存储。
4. 数据分析
因为我们最终要展示数据,所以需要按照一定的维度对原创
数据进行处理和分析,然后返回给客户端。这个过程可以在存储过程中进行处理,也可以在显示过程中,前端发送请求,后端获取存储的数据后再进行处理。这取决于我们希望如何显示数据。
5. 结果展示
做了这么多功课,一点显示输出都没有,怎么不甘心?这又回到我们的老本行了,前端展示页面大家应该都很熟悉了。将数据展示更直观,方便我们进行统计分析。
二、常见爬虫库介绍1. Superagent
Superagent 是一个轻量级的 http 库。是nodejs中一个非常方便的客户端请求代理模块。当我们需要进行get、post、head等网络请求时,试试吧。
2. 啦啦队
Cheerio可以理解为jquery的一个Node.js版本,用于通过css选择器从网页中检索数据,用法和jquery完全一样。
3. 异步
async 是一个流程控制工具包,提供了直接强大的异步函数mapLimit(arr,limit,iterator,callback),我们主要使用这个方法,可以去官网看API。
4. arr-del
arr-del 是我自己写的一个删除数组元素的工具。通过传入由要删除的数组元素的索引组成的数组,可以一次性删除它。
5. arr-sort
arr-sort 是我自己写的一个数组排序方法的工具。可以根据一个或多个属性进行排序,支持嵌套属性。而且可以在每个条件中指定排序方向,传入比较函数。
三、页面结构分析
让我们重复爬行的想法。利马理财网上的产品主要是普通的和利马金库(新推出的光大银行理财产品,手续繁琐,初期投资额高,所以基本没人买,所以我们不在这里计算它们)。定期我们可以爬取财富管理页面的ajax界面:。(更新:近期定期断货,可能看不到数据,1月19日前可以看到数据) 数据如下图:
这包括所有在线销售的常规产品。Ajax数据只有产品本身的信息,比如产品id、募集金额、当前销售额、年化收益率、投资天数等,没有关于谁购买了产品的信息。. 所以我们需要去它的商品详情页面用id参数进行爬取,比如Lima Jucai-December HLB01239511。详情页有一栏投资记录,里面有我们需要的信息,如下图:
但是,详情页只有在我们登录后才能查看,这就需要我们访问cookies,cookies是有有效期的。如何让我们的 cookie 保持登录状态?请稍后再看。
其实Lima Vault也有类似的ajax接口:,只是里面的相关数据是硬编码的,毫无意义。并且金库的详情页也没有投资记录信息。这就需要我们爬取我们开头所说的主页的ajax接口:。但是后来我发现这个界面每三分钟更新一次,也就是说后台每三分钟向服务器请求一次数据。一次有10条数据,所以如果三分钟内购买记录超过10条,数据就会有遗漏。没办法,所以直接金库的统计数据会比真实的少。
四、爬虫代码分析1. 获取登录cookie
因为商品详情页需要登录,所以我们需要先获取登录cookie。getCookie 方法如下:
function getCookie() {
superagent.post('https://www.lmlc.com/user/s/web/logon')
.type('form')
.send({
phone: phone,
password: password,
productCode: "LMLC",
origin: "PC"
})
.end(function(err, res) {
if (err) {
handleErr(err.message);
return;
}
cookie = res.header['set-cookie']; //从response中得到cookie
emitter.emit("setCookeie");
})
}
手机号和密码参数是从命令行传入的,就是用你的手机号登录的账号和密码。我们使用superagent来模拟请求即时理财登录界面:。传入相应的参数。在回调中,我们获取头部的 set-cookie 信息,并发送一个 setCookeie 事件。因为我们设置了监听事件:emitter.on("setCookie", requestData),一旦拿到cookie,就会执行requestData方法。
2. 财富管理页面ajax爬取
requestData方法的代码如下:
<p>function requestData() {
superagent.get('https://www.lmlc.com/web/produ ... %2339;)
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
// 在这里清空数据,避免一个文件被同时写入
if(clearProd){
fs.writeFileSync('data/prod.json', JSON.stringify([]));
clearProd = false;
}
let addData = JSON.parse(pres.text).data;
let formatedAddData = formatData(addData.result);
let pageUrls = [];
if(addData.totalPage > 1){
handleErr('产品个数超过100个!');
return;
}
for(let i=0,len=addData.result.length; i 查看全部
js 爬虫抓取网页数据(爬虫爬取的流程和最终如何展示数据的地址?)
其实我之前做过利马理财的销售统计,不过是前端js写的。需要在首页的控制台调试面板中粘贴一段代码执行,点击这里。主要目的是通过定时爬取异步接口来获取数据。然后通过一定的去重算法得到最终的数据。但这有以下缺点:
代码只能在浏览器窗口中运行。如果浏览器关闭或电脑无效,则只能抓取一个页面的数据,无法整合其他页面的数据。爬取的数据无法存储在本地。异步接口数据将被部分过滤。导致我们的去重算法失败
最近学习了节点爬虫,我们可以在后台模拟请求,爬取页面数据。而且我开通了阿里云服务器,我可以把代码放到云端运行。这样1、2、3都可以解决。4因为我们不知道这个ajax界面每三分钟更新一次,这样我们就可以以此为基础对权重进行排序,保证数据不会重复。说起爬虫,大家想到的更多的是python。确实,python有Scrapy等成熟的框架,可以实现非常强大的爬虫功能。但是node也有自己的优势。凭借其强大的异步特性,可以轻松实现高效的异步并发请求,节省CPU开销。其实节点爬虫比较简单,让'
在线地址
一、爬虫进程
我们的最终目标是爬取利马财经每天的销售额,知道销售了哪些产品,哪些用户在什么时间点购买了每种产品。首先介绍一下爬取的主要步骤:
1. 结构分析
我们要抓取页面的数据。第一步当然是分析页面结构,抓取哪些页面,页面结构是什么,不需要登录;是否有ajax接口,返回什么样的数据等。
2. 数据采集
分析清楚要爬取哪些页面和ajax,需要爬取数据。现在网页的数据大致分为同步页面和ajax接口。同步页面数据的爬取需要我们首先分析网页的结构。Python爬取数据一般是通过正则表达式匹配来获取需要的数据;node有一个cheerio工具,可以将获取到的页面内容转换成jquery对象。然后就可以使用jquery强大的dom API来获取节点相关的数据了。其实看源码,这些API本质上都是正则匹配。ajax接口数据一般都是json格式,处理起来比较简单。
3. 数据存储
捕获数据后,它会做一个简单的筛选,然后将需要的数据保存起来,以便后续的分析和处理。当然我们可以使用MySQL、Mongodb等数据库来存储数据。这里,为了方便,我们直接使用文件存储。
4. 数据分析
因为我们最终要展示数据,所以需要按照一定的维度对原创
数据进行处理和分析,然后返回给客户端。这个过程可以在存储过程中进行处理,也可以在显示过程中,前端发送请求,后端获取存储的数据后再进行处理。这取决于我们希望如何显示数据。
5. 结果展示
做了这么多功课,一点显示输出都没有,怎么不甘心?这又回到我们的老本行了,前端展示页面大家应该都很熟悉了。将数据展示更直观,方便我们进行统计分析。
二、常见爬虫库介绍1. Superagent
Superagent 是一个轻量级的 http 库。是nodejs中一个非常方便的客户端请求代理模块。当我们需要进行get、post、head等网络请求时,试试吧。
2. 啦啦队
Cheerio可以理解为jquery的一个Node.js版本,用于通过css选择器从网页中检索数据,用法和jquery完全一样。
3. 异步
async 是一个流程控制工具包,提供了直接强大的异步函数mapLimit(arr,limit,iterator,callback),我们主要使用这个方法,可以去官网看API。
4. arr-del
arr-del 是我自己写的一个删除数组元素的工具。通过传入由要删除的数组元素的索引组成的数组,可以一次性删除它。
5. arr-sort
arr-sort 是我自己写的一个数组排序方法的工具。可以根据一个或多个属性进行排序,支持嵌套属性。而且可以在每个条件中指定排序方向,传入比较函数。
三、页面结构分析
让我们重复爬行的想法。利马理财网上的产品主要是普通的和利马金库(新推出的光大银行理财产品,手续繁琐,初期投资额高,所以基本没人买,所以我们不在这里计算它们)。定期我们可以爬取财富管理页面的ajax界面:。(更新:近期定期断货,可能看不到数据,1月19日前可以看到数据) 数据如下图:
这包括所有在线销售的常规产品。Ajax数据只有产品本身的信息,比如产品id、募集金额、当前销售额、年化收益率、投资天数等,没有关于谁购买了产品的信息。. 所以我们需要去它的商品详情页面用id参数进行爬取,比如Lima Jucai-December HLB01239511。详情页有一栏投资记录,里面有我们需要的信息,如下图:
但是,详情页只有在我们登录后才能查看,这就需要我们访问cookies,cookies是有有效期的。如何让我们的 cookie 保持登录状态?请稍后再看。
其实Lima Vault也有类似的ajax接口:,只是里面的相关数据是硬编码的,毫无意义。并且金库的详情页也没有投资记录信息。这就需要我们爬取我们开头所说的主页的ajax接口:。但是后来我发现这个界面每三分钟更新一次,也就是说后台每三分钟向服务器请求一次数据。一次有10条数据,所以如果三分钟内购买记录超过10条,数据就会有遗漏。没办法,所以直接金库的统计数据会比真实的少。
四、爬虫代码分析1. 获取登录cookie
因为商品详情页需要登录,所以我们需要先获取登录cookie。getCookie 方法如下:
function getCookie() {
superagent.post('https://www.lmlc.com/user/s/web/logon')
.type('form')
.send({
phone: phone,
password: password,
productCode: "LMLC",
origin: "PC"
})
.end(function(err, res) {
if (err) {
handleErr(err.message);
return;
}
cookie = res.header['set-cookie']; //从response中得到cookie
emitter.emit("setCookeie");
})
}
手机号和密码参数是从命令行传入的,就是用你的手机号登录的账号和密码。我们使用superagent来模拟请求即时理财登录界面:。传入相应的参数。在回调中,我们获取头部的 set-cookie 信息,并发送一个 setCookeie 事件。因为我们设置了监听事件:emitter.on("setCookie", requestData),一旦拿到cookie,就会执行requestData方法。
2. 财富管理页面ajax爬取
requestData方法的代码如下:
<p>function requestData() {
superagent.get('https://www.lmlc.com/web/produ ... %2339;)
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
// 在这里清空数据,避免一个文件被同时写入
if(clearProd){
fs.writeFileSync('data/prod.json', JSON.stringify([]));
clearProd = false;
}
let addData = JSON.parse(pres.text).data;
let formatedAddData = formatData(addData.result);
let pageUrls = [];
if(addData.totalPage > 1){
handleErr('产品个数超过100个!');
return;
}
for(let i=0,len=addData.result.length; i
js 爬虫抓取网页数据( 一下如何用Excel快速抓取网页数据(图)的技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-26 00:08
一下如何用Excel快速抓取网页数据(图)的技巧)
网站上的数据来源是我们统计分析的重要信息来源。我们在生活中经常听到一个词叫“爬虫”,它可以快速抓取网页上的数据,这对于数据分析相关的工作来说是极其重要的,也是必备的技能之一。但是,大多数爬虫都需要编程知识,这对大多数人来说是很难上手的。今天给大家讲解一下如何用Excel快速抓取网页数据。
1、首先打开要获取数据的网址,复制网址。
2、 要创建新的 Excel 工作簿,请单击“数据”菜单中的“来自网站”选项>“获取外部数据”选项卡。
在弹出的“新建网页查询”对话框中,在地址栏中输入要爬取的网站地址,点击“前往”
点击黄色的导入箭头,选择需要采集的部分,如图。只需单击导入。
3、选择存储数据的位置(默认选中的单元格),点击确定。通常建议将数据存储在“A1”单元格中。
4、如果想让Excel工作簿数据根据网站数据实时自动更新,那么我们需要在“属性”中进行设置。您可以设置“允许后台刷新”、“刷新频率”、“打开文件时刷新数据”等。
拿到数据后,就需要对数据进行处理,而处理数据是一个比较重要的环节。更多数据处理技巧,请关注我!
如果对你有帮助,记得点赞转发哦。
关注我,学习更多 Excel 技能,让工作更轻松。 查看全部
js 爬虫抓取网页数据(
一下如何用Excel快速抓取网页数据(图)的技巧)
网站上的数据来源是我们统计分析的重要信息来源。我们在生活中经常听到一个词叫“爬虫”,它可以快速抓取网页上的数据,这对于数据分析相关的工作来说是极其重要的,也是必备的技能之一。但是,大多数爬虫都需要编程知识,这对大多数人来说是很难上手的。今天给大家讲解一下如何用Excel快速抓取网页数据。
1、首先打开要获取数据的网址,复制网址。
2、 要创建新的 Excel 工作簿,请单击“数据”菜单中的“来自网站”选项>“获取外部数据”选项卡。
在弹出的“新建网页查询”对话框中,在地址栏中输入要爬取的网站地址,点击“前往”
点击黄色的导入箭头,选择需要采集的部分,如图。只需单击导入。
3、选择存储数据的位置(默认选中的单元格),点击确定。通常建议将数据存储在“A1”单元格中。
4、如果想让Excel工作簿数据根据网站数据实时自动更新,那么我们需要在“属性”中进行设置。您可以设置“允许后台刷新”、“刷新频率”、“打开文件时刷新数据”等。
拿到数据后,就需要对数据进行处理,而处理数据是一个比较重要的环节。更多数据处理技巧,请关注我!
如果对你有帮助,记得点赞转发哦。
关注我,学习更多 Excel 技能,让工作更轻松。
js 爬虫抓取网页数据(第一个问题:JS加密如何突破(1)的开发者功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-23 18:12
第一个问题:如何突破JS加密
(1) 熟悉Chrome的开发者工具的各种功能,Elements、Network、Source
(2)仔细观察,善于思考。网络查看加载过程,发现可疑的xhr请求,设置xhr断点,通过Call Stack回溯js执行过程,回溯时查看上下文代码。可以读取js ,了解js相关知识,比如js中的window变量。
(3)上面是通过debug js找到js加解密代码,然后通过Python重新实现,这个过程很长,可能要好几天。一旦网站改变js算法,你的 Python 无法使用。
(4) Selenium 可以做简单的突破,而网站 想要什么都无所谓。唯一遗憾的是Selenium 运行效率差。不过作为JS加密来保护数据网站,单价的运行效率应该足以满足网站的访问频率限制,这个时候更多的思考是如何增加资源(IP,账号)来提高爬取效率。
第二个问题,多线程、协程、多进程选择
(1)爬虫是IO密集型任务,大部分时间花在网络访问上,所以多进程不适合网络爬虫,多线程,异步IO协程更适合,异步IO更适合最合适的,它与多线程相比,协程之间的切换成本更低,我们提倡使用异步IO代替多线程,异步IO的主要模块有:aysncio、aiohttp、aiomysql等。
(2) 爬下来后从网页中提取想要的数据是CPU密集型的,此时可以使用多个进程并发提取。
(3)我们推荐的爬虫策略是爬虫只爬取,把爬取的html保存,存入数据库。然后单独写提取数据的extractor,单独运行extractor。优点是提取不影响爬取,爬取爬取效率更高,提取程序可以随时修改,有新的提取需求时无需重新取。本来写的,我只是想从网页中提取两条数据,运行一段时间后发现另外三项数据也很有用,如果保存html,只需要改一下extractor和再次运行它。
第三个问题,如果要保留图片的粗体或者原位置,只能挖规则,然后写正则表达式来处理吗?
Web数据提取主要有两种方法:正则表达式和xpath。某个html标签节点可以通过xpath获取。例如,对于一个博客页面,它的主要内容在某个标签中,可能是某个div。使用xpath获取这个div并转换成html,也就是收录格式和图片的部分。只需保存此 html 代码而不是纯文本。
第四个问题,爬虫增量爬取,断点连续爬取,去重等
(1)通过URL池的概念管理所有的URL
(2)增量爬取是指下载的网址不会重复下载,让网址池记住那些已经下载过的网址;
(3)断点恢复爬取,即这次爬取上次没有爬取的URL,或者让URL池记住那些没有爬取的URL
(4) 爬虫的去重可以让URL池记录URL的状态,避免重复爬取。
第五个问题是爬虫的部署问题。公司分布式爬虫系统是否涉及部署问题?
爬虫的部署不一定是分布式的。大型爬虫,突破目标网站限制的爬虫会涉及分布式。分布式的好处是提高了爬取速度,但是管理会比较复杂。
第六个问题,网页自动分析?本主题收录很多子任务:如何自动提取文章的内容,如何处理各种时间格式,如何处理翻页
(1)文章 内容提取,基本就是为每个网页建立一个提取模板(正则表达式)。优点是提取准确,缺点是工作量大。版本稍有修改就会失效,通过算法建立单一的提取程序基本可以提取,但可能有写的不纯,比如文末相关阅读。优点是一劳永逸,不受修订限制。
(2)时间提取,除了正则表达式,似乎没有特别有效的方法。
(3)如果翻页,如果只是抓取,则提取页面的url继续抓取;提取内容时如何将多个页面的内容合并为一个网页,需要处理专门用它。
第七题,爬取新闻类网站时,同一条新闻怎么做,每个网站互相转载,爬取时去掉文字
众所周知的算法是谷歌的simhash,但在实践中比较复杂。百度在线传输的方法是对文章的最长句子(或多个句子)进行hash。这个哈希值是文章的唯一代表(指纹)。该方法准确率高,但召回率相对较低。最长的句子一旦换了一个词,就再也记不起来;我改进了方法,分别对n个句子中最长的句子进行了hash。一个文章由n个指纹组成(如图)每个手指的指纹都不一样)来判断唯一性。准确率和召回率都不错。
第八题,异步爬虫的设计
(1)一个不错的URL管理策略,请参考Apeman Learning上与文章相关的URL池;
URL 池是“生产者-消费者”模型。爬虫从中取出URL进行下载,从下载的html中取出新的URL放入池中,告诉URL池刚刚取出的URL是否下载成功;然后将其从池 url 中删除以进行下载。. . url池是核心组件,它记录了url的不同状态:
(一)下载成功
(B) 下载失败n次
(C) 下载
每次向池中添加 URL 时,请检查池中 URL 的状态,以避免重复下载。
(2)一个不错的异步协进程管理策略,见文章 猿人学习大型异步新闻爬虫网站。
每次从urlpool中提取n个url,就会生成n个异步下载协程,协程的数量(即正在下载的网页数量)通过一个变量记录下来。
大型异步新闻爬虫:实现功能强大、简单易用的网址池(URL Pool)
大型异步新闻爬虫:带有asyncio的异步爬虫
异步网址管理异步实现看这两个网址
如果有用记得点赞哈哈哈哈 查看全部
js 爬虫抓取网页数据(第一个问题:JS加密如何突破(1)的开发者功能)
第一个问题:如何突破JS加密
(1) 熟悉Chrome的开发者工具的各种功能,Elements、Network、Source
(2)仔细观察,善于思考。网络查看加载过程,发现可疑的xhr请求,设置xhr断点,通过Call Stack回溯js执行过程,回溯时查看上下文代码。可以读取js ,了解js相关知识,比如js中的window变量。
(3)上面是通过debug js找到js加解密代码,然后通过Python重新实现,这个过程很长,可能要好几天。一旦网站改变js算法,你的 Python 无法使用。
(4) Selenium 可以做简单的突破,而网站 想要什么都无所谓。唯一遗憾的是Selenium 运行效率差。不过作为JS加密来保护数据网站,单价的运行效率应该足以满足网站的访问频率限制,这个时候更多的思考是如何增加资源(IP,账号)来提高爬取效率。
第二个问题,多线程、协程、多进程选择
(1)爬虫是IO密集型任务,大部分时间花在网络访问上,所以多进程不适合网络爬虫,多线程,异步IO协程更适合,异步IO更适合最合适的,它与多线程相比,协程之间的切换成本更低,我们提倡使用异步IO代替多线程,异步IO的主要模块有:aysncio、aiohttp、aiomysql等。
(2) 爬下来后从网页中提取想要的数据是CPU密集型的,此时可以使用多个进程并发提取。
(3)我们推荐的爬虫策略是爬虫只爬取,把爬取的html保存,存入数据库。然后单独写提取数据的extractor,单独运行extractor。优点是提取不影响爬取,爬取爬取效率更高,提取程序可以随时修改,有新的提取需求时无需重新取。本来写的,我只是想从网页中提取两条数据,运行一段时间后发现另外三项数据也很有用,如果保存html,只需要改一下extractor和再次运行它。
第三个问题,如果要保留图片的粗体或者原位置,只能挖规则,然后写正则表达式来处理吗?
Web数据提取主要有两种方法:正则表达式和xpath。某个html标签节点可以通过xpath获取。例如,对于一个博客页面,它的主要内容在某个标签中,可能是某个div。使用xpath获取这个div并转换成html,也就是收录格式和图片的部分。只需保存此 html 代码而不是纯文本。
第四个问题,爬虫增量爬取,断点连续爬取,去重等
(1)通过URL池的概念管理所有的URL
(2)增量爬取是指下载的网址不会重复下载,让网址池记住那些已经下载过的网址;
(3)断点恢复爬取,即这次爬取上次没有爬取的URL,或者让URL池记住那些没有爬取的URL
(4) 爬虫的去重可以让URL池记录URL的状态,避免重复爬取。
第五个问题是爬虫的部署问题。公司分布式爬虫系统是否涉及部署问题?
爬虫的部署不一定是分布式的。大型爬虫,突破目标网站限制的爬虫会涉及分布式。分布式的好处是提高了爬取速度,但是管理会比较复杂。
第六个问题,网页自动分析?本主题收录很多子任务:如何自动提取文章的内容,如何处理各种时间格式,如何处理翻页
(1)文章 内容提取,基本就是为每个网页建立一个提取模板(正则表达式)。优点是提取准确,缺点是工作量大。版本稍有修改就会失效,通过算法建立单一的提取程序基本可以提取,但可能有写的不纯,比如文末相关阅读。优点是一劳永逸,不受修订限制。
(2)时间提取,除了正则表达式,似乎没有特别有效的方法。
(3)如果翻页,如果只是抓取,则提取页面的url继续抓取;提取内容时如何将多个页面的内容合并为一个网页,需要处理专门用它。
第七题,爬取新闻类网站时,同一条新闻怎么做,每个网站互相转载,爬取时去掉文字
众所周知的算法是谷歌的simhash,但在实践中比较复杂。百度在线传输的方法是对文章的最长句子(或多个句子)进行hash。这个哈希值是文章的唯一代表(指纹)。该方法准确率高,但召回率相对较低。最长的句子一旦换了一个词,就再也记不起来;我改进了方法,分别对n个句子中最长的句子进行了hash。一个文章由n个指纹组成(如图)每个手指的指纹都不一样)来判断唯一性。准确率和召回率都不错。
第八题,异步爬虫的设计
(1)一个不错的URL管理策略,请参考Apeman Learning上与文章相关的URL池;
URL 池是“生产者-消费者”模型。爬虫从中取出URL进行下载,从下载的html中取出新的URL放入池中,告诉URL池刚刚取出的URL是否下载成功;然后将其从池 url 中删除以进行下载。. . url池是核心组件,它记录了url的不同状态:
(一)下载成功
(B) 下载失败n次
(C) 下载
每次向池中添加 URL 时,请检查池中 URL 的状态,以避免重复下载。
(2)一个不错的异步协进程管理策略,见文章 猿人学习大型异步新闻爬虫网站。
每次从urlpool中提取n个url,就会生成n个异步下载协程,协程的数量(即正在下载的网页数量)通过一个变量记录下来。
大型异步新闻爬虫:实现功能强大、简单易用的网址池(URL Pool)
大型异步新闻爬虫:带有asyncio的异步爬虫
异步网址管理异步实现看这两个网址
如果有用记得点赞哈哈哈哈
js 爬虫抓取网页数据(js爬虫抓取网页数据,可以接收和反馈用户的对于)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-23 14:04
js爬虫抓取网页数据,可以接收和反馈用户的对于网页的反馈,并且返回给用户,用户可以根据用户实际的需求,自由选择对于网页进行修改或者是重新渲染。下面这个简单的例子,我们可以用一次性获取需要的网页源码,并保存。方便做以后需要抓取的网页源码处理。chrome浏览器打开网页a。左上角会弹出一个帮助的小窗口,点击。
点击。可以自己搜索一下,一般不会直接给你response,如果需要response,点击回车。用户就可以获取到response,可以用request直接连接到我们爬虫抓取的网页。chrome浏览器打开网页b。左上角会弹出一个帮助的小窗口,点击。如果,chrome浏览器,没有这个功能,那就没法自己配置了。
看这里,我的办法是,换chrome。现在,已经有了我们要抓取的网页。我们怎么快速抓取网页源码呢。我们只需要看一下首页有哪些链接,然后一个一个点就行了。有些网页,可能会多个链接,需要我们一个一个点击去,当然也可以按照从上到下的次序来排序抓取。window.execcommand('input"\username"\username\age"\email"\files"\index.html',function(){window.execcommand('input"\username"\username\email"\files"\index.html',function(){console.log('正在抓取网页:');});console.log('已抓取网页:');});我已经抓取到了网页a的url。
接下来,我们就要从文件夹response里面,获取到我们自己要抓取的源码。chrome浏览器打开网页a我们可以看到页面的源码window.execcommand('input"\username"\username\age"\email"\files"\index.html',function(){console.log('正在抓取网页:');});接下来,我们要获取到用户编辑的内容。
chrome浏览器打开网页a获取到了编辑的内容在左边,点击选择文本。上传到页面b的html,可以获取到源码。接下来,还有一个重要的步骤,就是要获取用户的评论。当然这些评论,是通过cookie获取的。所以,如果抓取不到用户的评论。就会出现刷新页面,看到需要删除的页面内容时。获取不到。这个时候,我们要换浏览器。
以360浏览器为例window.execcommand('input"\username"\username\email"\files"\index.html',function(){console.log('正在抓取网页:');});抓取不到用户评论。那怎么办呢。这就要抓取用户评论。但是用户评论的url可能不是自己抓取的页面内容。
我们点击左上角的设置。把这个urlurlurl改成我们抓取的网页urlurlurl。鼠标移动到文件名上面。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据,可以接收和反馈用户的对于)
js爬虫抓取网页数据,可以接收和反馈用户的对于网页的反馈,并且返回给用户,用户可以根据用户实际的需求,自由选择对于网页进行修改或者是重新渲染。下面这个简单的例子,我们可以用一次性获取需要的网页源码,并保存。方便做以后需要抓取的网页源码处理。chrome浏览器打开网页a。左上角会弹出一个帮助的小窗口,点击。
点击。可以自己搜索一下,一般不会直接给你response,如果需要response,点击回车。用户就可以获取到response,可以用request直接连接到我们爬虫抓取的网页。chrome浏览器打开网页b。左上角会弹出一个帮助的小窗口,点击。如果,chrome浏览器,没有这个功能,那就没法自己配置了。
看这里,我的办法是,换chrome。现在,已经有了我们要抓取的网页。我们怎么快速抓取网页源码呢。我们只需要看一下首页有哪些链接,然后一个一个点就行了。有些网页,可能会多个链接,需要我们一个一个点击去,当然也可以按照从上到下的次序来排序抓取。window.execcommand('input"\username"\username\age"\email"\files"\index.html',function(){window.execcommand('input"\username"\username\email"\files"\index.html',function(){console.log('正在抓取网页:');});console.log('已抓取网页:');});我已经抓取到了网页a的url。
接下来,我们就要从文件夹response里面,获取到我们自己要抓取的源码。chrome浏览器打开网页a我们可以看到页面的源码window.execcommand('input"\username"\username\age"\email"\files"\index.html',function(){console.log('正在抓取网页:');});接下来,我们要获取到用户编辑的内容。
chrome浏览器打开网页a获取到了编辑的内容在左边,点击选择文本。上传到页面b的html,可以获取到源码。接下来,还有一个重要的步骤,就是要获取用户的评论。当然这些评论,是通过cookie获取的。所以,如果抓取不到用户的评论。就会出现刷新页面,看到需要删除的页面内容时。获取不到。这个时候,我们要换浏览器。
以360浏览器为例window.execcommand('input"\username"\username\email"\files"\index.html',function(){console.log('正在抓取网页:');});抓取不到用户评论。那怎么办呢。这就要抓取用户评论。但是用户评论的url可能不是自己抓取的页面内容。
我们点击左上角的设置。把这个urlurlurl改成我们抓取的网页urlurlurl。鼠标移动到文件名上面。
js 爬虫抓取网页数据(有效的应对HTTP反爬虫策略最简单的反爬机制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-22 20:03
一些从WEB页面抓取数据的程序比较简单。大多数语言都有相应的 HTTP 库。一个简单的请求响应就足够了。程序向Web服务器发送Http请求,服务器返回HTML文件。交互方式如下:
使用DevProtocol驱动Chrome获取数据时,交互过程如下图所示:
这时候Chrome充当了中间的代理,看起来比较复杂,但实际上对我们的爬虫程序很有帮助。本文简要总结了这种方法的以下优点。
获取动态生成的网页内容
现在很多网页的内容并不是通过初始的Http请求一打开就直接获取,而是通过JS加载资源,在返回的html页面中计算动态生成的页面。采用这种方式的原因有很多,有的为了更好的用户体验,有的为了框架开发,有的为了节省带宽,有的纯粹是为了对页面内容进行加密,从而实现反爬虫的功能。
不管是什么原因,它使原本简单的单一“请求-响应”交互过程变得复杂。传统的一次性交互可以将所有请求完成为如下形式:
动态加载对传统数据采集造成了很大的阻碍,但是往往需要分析页面加载过程,分析JS,在程序中嵌入js引擎模拟浏览器执行相应的脚本来实现获得最终数据。这是一个非常费时费力的过程,也不容易分析整个过程。
为了更容易解析这样的动态网页,一些爬虫引擎开始引入Dom解析和JS执行能力来模拟浏览器解析获取相关资源。但是,由于这个过程非常复杂,这些功能往往并不完善,存在很多陷阱。
现在,通过Chrome浏览器的方式就是这种解析页面的方式的集成版本。因为Chrome本身就是一个浏览器,它具有完善的页面解析能力,所以可以如鱼得水。解析过程由chrome代理完成,我们只需要从chrome获取最终的解析结果即可。
针对爬虫的有效对策
最简单的反爬虫机制就是检查HTTP请求的Headers信息,包括User-Agent、Referer、Cookies等,根据手写的Http请求头和常用的浏览器头的区别进行反爬。这些对于防止主要爬虫非常有效,但 Chrome 本身是一个标准浏览器,天生就对这种反爬虫机制免疫。
另一种反爬虫机制就是上面提到的动态加载。基于上面的解释,这也是天生对 Chrome 免疫的。
当然,防爬的策略有很多,比如限制IP访问次数、限制访问频率、验证码等方法来防爬。Chrome虽然不直接支持这些,但是处理起来比传统的Http请求方便很多。下面的文章会陆续介绍,这里就不一一展开了。
DOM操作能力
Chrome具有完善的Dom操作能力。基本上所有可以在Chrome DevTools控制台中进行的操作,都可以通过DevProtocol在程序中完成,为我们的APP增加了完善的DOM操作能力。许多以前需要通过 HTML 分析的数据现在都可以获得。直接通过Jquery等js函数完成。并且可以直接格式化为JSON输出,方便多了。
与服务器交互更容易
在很多情况下,有些页面需要一些交互才能获得,比如登录。
因为Chrome具有执行JS的能力,所以我们可以通过一些简单的JS脚本来非常轻松地执行它。比如花园的登录可以通过如下脚本实现:
$("#input1")[0].value = "userName";
$("#input2")[0].value = "密码";
$("#signin")[0].click();
有些网站需要验证码来防止爬虫,我们甚至可以通过chrome中手动编码的自动组合快速实现数据抓取。如果要开发一个支持访问编码平台或智能识别平台的接口,比传统的蜘蛛程序要容易得多。
此外,Chrome 还提供了非常丰富的 API 来模拟键盘和鼠标输入界面,使用起来非常方便。
方便的开发调试
爬虫的开发往往是一个反复调试的过程,因为我们直接解析Chrome获取的数据,因为Chrome DevTool本身就是一个强大的调试工具。这大大加快了我们的开发进程。
我们可以先通过Chrome中的DevTools查看和解析我们的页面,通过控制台程序验证编写的脚本。大部分的脚本开发都可以使用Chrome来完成,而这部分往往是不可复用的,需要耗费大量的时间。这相当于获得了一个强大的调试工具,可以节省大量的时间。
另外,Chrome也是前端人员非常熟悉的一个工具。我们还可以将脚本开发的工作委托给前端人员,他们可以更高效地开发脚本,大大提高开发效率。
缺点
说了这么多优点,最后说一下它的缺点。这种方法的主要缺点是性能。
传统的爬虫非常轻便。它是一个传统的tcp socket程序。通过异步socket方式,可以轻松实现上千并发数,只加载需要的信息,性能非常高。
驱动chrome的方式是通过chrome获取服务端数据。从而加载了不必要的图片、样式、广告等文件,造成带宽的浪费。此外,它还会渲染网页,造成CPU开销,虽然可以通过插件减少不必要的文件加载和headless方法来减少开销,但相比传统的请求响应方式,仍然是重量级的获取方式。对于小规模的采集来说,可能不是什么大问题,但是如果你想像搜索引擎那样处理海量数据,采集可能有点吃力。
参考文章: 查看全部
js 爬虫抓取网页数据(有效的应对HTTP反爬虫策略最简单的反爬机制)
一些从WEB页面抓取数据的程序比较简单。大多数语言都有相应的 HTTP 库。一个简单的请求响应就足够了。程序向Web服务器发送Http请求,服务器返回HTML文件。交互方式如下:
使用DevProtocol驱动Chrome获取数据时,交互过程如下图所示:
这时候Chrome充当了中间的代理,看起来比较复杂,但实际上对我们的爬虫程序很有帮助。本文简要总结了这种方法的以下优点。
获取动态生成的网页内容
现在很多网页的内容并不是通过初始的Http请求一打开就直接获取,而是通过JS加载资源,在返回的html页面中计算动态生成的页面。采用这种方式的原因有很多,有的为了更好的用户体验,有的为了框架开发,有的为了节省带宽,有的纯粹是为了对页面内容进行加密,从而实现反爬虫的功能。
不管是什么原因,它使原本简单的单一“请求-响应”交互过程变得复杂。传统的一次性交互可以将所有请求完成为如下形式:
动态加载对传统数据采集造成了很大的阻碍,但是往往需要分析页面加载过程,分析JS,在程序中嵌入js引擎模拟浏览器执行相应的脚本来实现获得最终数据。这是一个非常费时费力的过程,也不容易分析整个过程。
为了更容易解析这样的动态网页,一些爬虫引擎开始引入Dom解析和JS执行能力来模拟浏览器解析获取相关资源。但是,由于这个过程非常复杂,这些功能往往并不完善,存在很多陷阱。
现在,通过Chrome浏览器的方式就是这种解析页面的方式的集成版本。因为Chrome本身就是一个浏览器,它具有完善的页面解析能力,所以可以如鱼得水。解析过程由chrome代理完成,我们只需要从chrome获取最终的解析结果即可。
针对爬虫的有效对策
最简单的反爬虫机制就是检查HTTP请求的Headers信息,包括User-Agent、Referer、Cookies等,根据手写的Http请求头和常用的浏览器头的区别进行反爬。这些对于防止主要爬虫非常有效,但 Chrome 本身是一个标准浏览器,天生就对这种反爬虫机制免疫。
另一种反爬虫机制就是上面提到的动态加载。基于上面的解释,这也是天生对 Chrome 免疫的。
当然,防爬的策略有很多,比如限制IP访问次数、限制访问频率、验证码等方法来防爬。Chrome虽然不直接支持这些,但是处理起来比传统的Http请求方便很多。下面的文章会陆续介绍,这里就不一一展开了。
DOM操作能力
Chrome具有完善的Dom操作能力。基本上所有可以在Chrome DevTools控制台中进行的操作,都可以通过DevProtocol在程序中完成,为我们的APP增加了完善的DOM操作能力。许多以前需要通过 HTML 分析的数据现在都可以获得。直接通过Jquery等js函数完成。并且可以直接格式化为JSON输出,方便多了。
与服务器交互更容易
在很多情况下,有些页面需要一些交互才能获得,比如登录。
因为Chrome具有执行JS的能力,所以我们可以通过一些简单的JS脚本来非常轻松地执行它。比如花园的登录可以通过如下脚本实现:
$("#input1")[0].value = "userName";
$("#input2")[0].value = "密码";
$("#signin")[0].click();
有些网站需要验证码来防止爬虫,我们甚至可以通过chrome中手动编码的自动组合快速实现数据抓取。如果要开发一个支持访问编码平台或智能识别平台的接口,比传统的蜘蛛程序要容易得多。
此外,Chrome 还提供了非常丰富的 API 来模拟键盘和鼠标输入界面,使用起来非常方便。
方便的开发调试
爬虫的开发往往是一个反复调试的过程,因为我们直接解析Chrome获取的数据,因为Chrome DevTool本身就是一个强大的调试工具。这大大加快了我们的开发进程。
我们可以先通过Chrome中的DevTools查看和解析我们的页面,通过控制台程序验证编写的脚本。大部分的脚本开发都可以使用Chrome来完成,而这部分往往是不可复用的,需要耗费大量的时间。这相当于获得了一个强大的调试工具,可以节省大量的时间。
另外,Chrome也是前端人员非常熟悉的一个工具。我们还可以将脚本开发的工作委托给前端人员,他们可以更高效地开发脚本,大大提高开发效率。
缺点
说了这么多优点,最后说一下它的缺点。这种方法的主要缺点是性能。
传统的爬虫非常轻便。它是一个传统的tcp socket程序。通过异步socket方式,可以轻松实现上千并发数,只加载需要的信息,性能非常高。
驱动chrome的方式是通过chrome获取服务端数据。从而加载了不必要的图片、样式、广告等文件,造成带宽的浪费。此外,它还会渲染网页,造成CPU开销,虽然可以通过插件减少不必要的文件加载和headless方法来减少开销,但相比传统的请求响应方式,仍然是重量级的获取方式。对于小规模的采集来说,可能不是什么大问题,但是如果你想像搜索引擎那样处理海量数据,采集可能有点吃力。
参考文章:
js 爬虫抓取网页数据(新浪新闻国内新闻页静态网页数据在函数中的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-22 20:02
昨天,一个朋友来找我。新浪新闻的国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
但是我发现有一个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\\,标题和介绍都是\u4e09的形式。这些是我们需要处理的后续步骤!
先用replace函数去掉url中的\\,就可以得到url了,下面的\u4e09是unicode编码,可以直接解码内容,直接写代码
eval函数用于解码,解码内容可以是u"+unicode编码内容+"!
这样就把这个页面上所有的新闻和URL相关的内容都取出来了,在外层加了一个循环来爬取所有的新闻页面,任务就完成了!
后记
新浪新闻的页面js功能比较简单,直接抓取数据即可。如果是比较复杂的功能,就需要了解前端知识。这就是学习爬虫需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,你可以直接百度找很多,当然你也可以直接修改上面抓包的内容,然后用json读取数据!
基础代码不多,如果有看不清楚的小伙伴可以私信我获取代码或者一起研究爬虫! 查看全部
js 爬虫抓取网页数据(新浪新闻国内新闻页静态网页数据在函数中的应用)
昨天,一个朋友来找我。新浪新闻的国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
但是我发现有一个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\\,标题和介绍都是\u4e09的形式。这些是我们需要处理的后续步骤!
先用replace函数去掉url中的\\,就可以得到url了,下面的\u4e09是unicode编码,可以直接解码内容,直接写代码
eval函数用于解码,解码内容可以是u"+unicode编码内容+"!
这样就把这个页面上所有的新闻和URL相关的内容都取出来了,在外层加了一个循环来爬取所有的新闻页面,任务就完成了!
后记
新浪新闻的页面js功能比较简单,直接抓取数据即可。如果是比较复杂的功能,就需要了解前端知识。这就是学习爬虫需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,你可以直接百度找很多,当然你也可以直接修改上面抓包的内容,然后用json读取数据!
基础代码不多,如果有看不清楚的小伙伴可以私信我获取代码或者一起研究爬虫!
js 爬虫抓取网页数据(动态网页数据抓取使用AJAX加载的数据(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-12-22 04:03
动态网页数据抓取
使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: 安装 Selenium 和 chromedriver:
安装硒:
pip install selenium
安装 chromedriver:
下载完成后,放在一个不需要权限的纯英文目录下。
Traceback (most recent call last):
File "selenium.py", line 1, in
from selenium import webdriver
File "/Users/nieyunfei/devspace/python/cyzone/test/selenium.py", line 1, in
from selenium import webdriver
ImportError: cannot import name 'webdriver' from partially initialized module 'selenium' (most likely due to a circular import) (/Users/nieyunfei/devspace/python/cyzone/test/selenium.py)
原因如下。我的新名字是selenium.py,这会导致Python先导入这个文件,然后再导入标准库中的selenium.py。删除或重命名当前目录下的文件后运行是正常的。
# 放到/usr /local/bin目录
open /usr/local/bin/
# 赋权限
sudo chmod u+x,o+x /usr/local/bin/chromedriver
# 查看安装的版本号跟浏览器是否对应
chromedriver --version
快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
# 导入selenium2中的webdriver库
from selenium import webdriver
# 初始化一个driver,实例化出一个chrome浏览器
driver = webdriver.Chrome()
# 请求网页
base_url = 'https://www.baidu.com'
# 通过page_source获取网页源代码
driver.get(base_url)
Selenium 常见操作:
图片.png
更多教程请参考:#introduction
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,所以在网页上用鼠标点击。所以,如果要选中checkbox标签,先选中这个标签,再执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。 查看全部
js 爬虫抓取网页数据(动态网页数据抓取使用AJAX加载的数据(一)(组图))
动态网页数据抓取
使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: 安装 Selenium 和 chromedriver:
安装硒:
pip install selenium
安装 chromedriver:
下载完成后,放在一个不需要权限的纯英文目录下。
Traceback (most recent call last):
File "selenium.py", line 1, in
from selenium import webdriver
File "/Users/nieyunfei/devspace/python/cyzone/test/selenium.py", line 1, in
from selenium import webdriver
ImportError: cannot import name 'webdriver' from partially initialized module 'selenium' (most likely due to a circular import) (/Users/nieyunfei/devspace/python/cyzone/test/selenium.py)
原因如下。我的新名字是selenium.py,这会导致Python先导入这个文件,然后再导入标准库中的selenium.py。删除或重命名当前目录下的文件后运行是正常的。
# 放到/usr /local/bin目录
open /usr/local/bin/
# 赋权限
sudo chmod u+x,o+x /usr/local/bin/chromedriver
# 查看安装的版本号跟浏览器是否对应
chromedriver --version
快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
# 导入selenium2中的webdriver库
from selenium import webdriver
# 初始化一个driver,实例化出一个chrome浏览器
driver = webdriver.Chrome()
# 请求网页
base_url = 'https://www.baidu.com'
# 通过page_source获取网页源代码
driver.get(base_url)
Selenium 常见操作:
图片.png
更多教程请参考:#introduction
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,所以在网页上用鼠标点击。所以,如果要选中checkbox标签,先选中这个标签,再执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
js 爬虫抓取网页数据(网络爬虫系统的分类及分类 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-22 04:03
)
前言
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
我们可以利用网络爬虫来自动采集数据信息,比如在搜索引擎收录中抓取网站,以及数据分析挖掘采集,应用采集对金融数据进行在财务分析中。此外,网络爬虫还可以应用于舆情监测分析、目标客户数据采集等各个领域。
1、网络爬虫分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深网爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。下面简单介绍一下这些爬虫。
1.1、通用网络爬虫
也称为Scalable Web Crawler,爬取对象从一些种子URL扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集数据。
1.2、关注网络爬虫
也称为Topical Crawler,它是指一种网络爬虫,它有选择地抓取与预定义主题相关的页面。与一般的网络爬虫相比,聚焦爬虫只需要抓取与主题相关的页面,大大节省了硬件和网络资源。保存的页面也因为数量少更新快,也可以满足特定区域的特定人群。信息需求。
1.3、增量网络爬虫
它是指对下载的网页进行增量更新并且只抓取新的或更改的网页的爬虫。可以在一定程度上保证爬取的页面尽可能的新鲜。.
1.4、深网爬虫
网页按存在方式可分为表面网页(Surface Web)和深层网页(Deep Web,也称为Invisible Web Pages或Hidden Web)。表面网页是指可以被传统搜索引擎索引的网页,主要由可以通过超链接访问的静态网页组成。深网是一种大部分内容无法通过静态链接获取而隐藏在搜索表单后面的网页。只有用户提交一些关键词来获取网页。
2、创建一个简单的爬虫应用
简单了解了上面的爬虫之后,我们来实现一个简单的爬虫应用。
2.1、 达成目标
说到爬虫,大概率会想到大数据,因此也会想到Python。百度如下。Python做爬虫更多。由于我主要是做前端开发,相对来说,JavaScript 比较熟练,也比较简单。实现一个小目标,使用NodeJS爬取博客园的首页文章列表(你经常使用的一个开发者网站),然后写入本地JSON文件。
2.2、环境建设
NodeJS安装完成后,打开命令行,可以使用node -v检查NodeJS是否安装成功,npm -v检查NodeJS是否安装成功。如果安装成功,应打印如下信息(视版本而定):
2.3、 具体实现
2.3.1、安装依赖包
在目录下执行 npm install superagentcheerio --save-dev 安装superagent和cheerio依赖。创建一个 crawler.js 文件。
// 导入依赖包
const http = require("http");
const path = require("path");
const url = require("url");
const fs = require("fs");
const superagent = require("superagent");
const cheerio = require("cheerio");
2.3.2、 爬取数据
然后获取请求页面。获取页面内容后,根据你想要的数据解析返回的DOM获取值,最后将处理后的结果JSON翻译成字符串保存到本地。
//爬取页面地址
const pageUrl="https://www.cnblogs.com/";
// 解码字符串
function unescapeString(str){
if(!str){
return ''
}else{
return unescape(str.replace(/&#x/g,'%u').replace(/;/g,''));
}
}
// 抓取数据
function fetchData(){
console.log('爬取数据时间节点:',new Date());
superagent.get(pageUrl).end((error,response)=>{
// 页面文档数据
let content=response.text;
if(content){
console.log('获取数据成功');
}
// 定义一个空数组来接收数据
let result=[];
let $=cheerio.load(content);
let postList=$("#main #post_list .post_item");
postList.each((index,value)=>{
let titleLnk=$(value).find('a.titlelnk');
let itemFoot=$(value).find('.post_item_foot');
let title=titleLnk.html(); //标题
let href=titleLnk.attr('href'); //链接
let author=itemFoot.find('a.lightblue').html(); //作者
let headLogo=$(value).find('.post_item_summary a img').attr('src'); //头像
let summary=$(value).find('.post_item_summary').text(); //简介
let postedTime=itemFoot.text().split('发布于 ')[1].substr(0,16); //发布时间
let readNum=itemFoot.text().split('阅读')[1]; //阅读量
readNum=readNum.substr(1,readNum.length-1);
title=unescapeString(title);
href=unescapeString(href);
author=unescapeString(author);
headLogo=unescapeString(headLogo);
summary=unescapeString(summary);
postedTime=unescapeString(postedTime);
readNum=unescapeString(readNum);
result.push({
index,
title,
href,
author,
headLogo,
summary,
postedTime,
readNum
});
});
// 数组转换为字符串
result=JSON.stringify(result);
// 写入本地cnblogs.json文件中
fs.writeFile("cnblogs.json",result,"utf-8",(err)=>{
// 监听错误,如正常输出,则打印null
if(!err){
console.log('写入数据成功');
}
});
});
}
fetchData();
3、进行优化
3.1、 生成结果
在项目目录下打开命令行,输入node crawler.js,
你会发现目录下会创建一个 cnblogs.json 文件。打开文件如下:
查看全部
js 爬虫抓取网页数据(网络爬虫系统的分类及分类
)
前言
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
我们可以利用网络爬虫来自动采集数据信息,比如在搜索引擎收录中抓取网站,以及数据分析挖掘采集,应用采集对金融数据进行在财务分析中。此外,网络爬虫还可以应用于舆情监测分析、目标客户数据采集等各个领域。
1、网络爬虫分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深网爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。下面简单介绍一下这些爬虫。
1.1、通用网络爬虫
也称为Scalable Web Crawler,爬取对象从一些种子URL扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集数据。
1.2、关注网络爬虫
也称为Topical Crawler,它是指一种网络爬虫,它有选择地抓取与预定义主题相关的页面。与一般的网络爬虫相比,聚焦爬虫只需要抓取与主题相关的页面,大大节省了硬件和网络资源。保存的页面也因为数量少更新快,也可以满足特定区域的特定人群。信息需求。
1.3、增量网络爬虫
它是指对下载的网页进行增量更新并且只抓取新的或更改的网页的爬虫。可以在一定程度上保证爬取的页面尽可能的新鲜。.
1.4、深网爬虫
网页按存在方式可分为表面网页(Surface Web)和深层网页(Deep Web,也称为Invisible Web Pages或Hidden Web)。表面网页是指可以被传统搜索引擎索引的网页,主要由可以通过超链接访问的静态网页组成。深网是一种大部分内容无法通过静态链接获取而隐藏在搜索表单后面的网页。只有用户提交一些关键词来获取网页。
2、创建一个简单的爬虫应用
简单了解了上面的爬虫之后,我们来实现一个简单的爬虫应用。
2.1、 达成目标
说到爬虫,大概率会想到大数据,因此也会想到Python。百度如下。Python做爬虫更多。由于我主要是做前端开发,相对来说,JavaScript 比较熟练,也比较简单。实现一个小目标,使用NodeJS爬取博客园的首页文章列表(你经常使用的一个开发者网站),然后写入本地JSON文件。
2.2、环境建设
NodeJS安装完成后,打开命令行,可以使用node -v检查NodeJS是否安装成功,npm -v检查NodeJS是否安装成功。如果安装成功,应打印如下信息(视版本而定):
2.3、 具体实现
2.3.1、安装依赖包
在目录下执行 npm install superagentcheerio --save-dev 安装superagent和cheerio依赖。创建一个 crawler.js 文件。
// 导入依赖包
const http = require("http");
const path = require("path");
const url = require("url");
const fs = require("fs");
const superagent = require("superagent");
const cheerio = require("cheerio");
2.3.2、 爬取数据
然后获取请求页面。获取页面内容后,根据你想要的数据解析返回的DOM获取值,最后将处理后的结果JSON翻译成字符串保存到本地。
//爬取页面地址
const pageUrl="https://www.cnblogs.com/";
// 解码字符串
function unescapeString(str){
if(!str){
return ''
}else{
return unescape(str.replace(/&#x/g,'%u').replace(/;/g,''));
}
}
// 抓取数据
function fetchData(){
console.log('爬取数据时间节点:',new Date());
superagent.get(pageUrl).end((error,response)=>{
// 页面文档数据
let content=response.text;
if(content){
console.log('获取数据成功');
}
// 定义一个空数组来接收数据
let result=[];
let $=cheerio.load(content);
let postList=$("#main #post_list .post_item");
postList.each((index,value)=>{
let titleLnk=$(value).find('a.titlelnk');
let itemFoot=$(value).find('.post_item_foot');
let title=titleLnk.html(); //标题
let href=titleLnk.attr('href'); //链接
let author=itemFoot.find('a.lightblue').html(); //作者
let headLogo=$(value).find('.post_item_summary a img').attr('src'); //头像
let summary=$(value).find('.post_item_summary').text(); //简介
let postedTime=itemFoot.text().split('发布于 ')[1].substr(0,16); //发布时间
let readNum=itemFoot.text().split('阅读')[1]; //阅读量
readNum=readNum.substr(1,readNum.length-1);
title=unescapeString(title);
href=unescapeString(href);
author=unescapeString(author);
headLogo=unescapeString(headLogo);
summary=unescapeString(summary);
postedTime=unescapeString(postedTime);
readNum=unescapeString(readNum);
result.push({
index,
title,
href,
author,
headLogo,
summary,
postedTime,
readNum
});
});
// 数组转换为字符串
result=JSON.stringify(result);
// 写入本地cnblogs.json文件中
fs.writeFile("cnblogs.json",result,"utf-8",(err)=>{
// 监听错误,如正常输出,则打印null
if(!err){
console.log('写入数据成功');
}
});
});
}
fetchData();
3、进行优化
3.1、 生成结果
在项目目录下打开命令行,输入node crawler.js,
你会发现目录下会创建一个 cnblogs.json 文件。打开文件如下:
js 爬虫抓取网页数据(js爬虫抓取网页数据实现教程介绍在爬虫开发工具egg)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-21 14:15
js爬虫抓取网页数据实现教程介绍在爬虫开发工具egg上面,安装好了工具后,我们需要写一个spider程序。这个spider的作用是模拟浏览器访问网页的各个入口页面,从而得到我们想要的数据。由于页面中的主体是html网页,因此,我们需要写一个request程序来模拟浏览器访问页面中的各个入口页面。从而,我们就可以得到我们想要的网页的数据。
开发工具的语言选择如果不选择java,不选择python,建议你从asp写起。asp比较简单,学习也比较容易。如果不想学习asp,也不建议学习python,因为python中涉及到api开发,其开发速度会比asp慢,如果你时间紧迫,也可以使用windows系统自带的accessapi取值接口编程。也可以在新版本中,直接使用c#。
创建爬虫程序创建一个爬虫程序的框架,从最小化开始,分以下两个步骤,创建http服务端:封装http的接口,比如wwwroot这个接口,封装http服务端。创建爬虫程序的浏览器web,我们使用lxml库写的代码比较简单,比如抓取一个链接#!/usr/bin/envpython#-*-coding:utf-8-*-importrequestsheaders={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/55.0.2703.92safari/537.36'}response=requests.get(url,headers=headers)data=response.contentifdata.status_code>200:print('成功请求')else:print('爬虫刚启动,请稍后再访问!')forx,yinenumerate(data):x['page_num']=response.status_code+'/'+str(x)+'/'+x+'page'print(x)results=data['page_num']forpageinresults:print(page+'\n')#print(str(x)+'\n')#get请求验证post请求一般情况都是不能通过的,所以需要对post请求中的request_uri进行封装,使得可以通过post请求的uri地址进行请求,同时我们需要开发一个验证服务器来对这个请求进行验证,这个验证服务器比较简单,直接使用webdriver库即可。
上面这段代码主要是对请求进行了封装和验证,具体代码如下:#!/usr/bin/envpython#-*-coding:utf-8-*-importrequestsheaders={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/55.0.2703.92safari/537.36'}response=requests.get(u。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据实现教程介绍在爬虫开发工具egg)
js爬虫抓取网页数据实现教程介绍在爬虫开发工具egg上面,安装好了工具后,我们需要写一个spider程序。这个spider的作用是模拟浏览器访问网页的各个入口页面,从而得到我们想要的数据。由于页面中的主体是html网页,因此,我们需要写一个request程序来模拟浏览器访问页面中的各个入口页面。从而,我们就可以得到我们想要的网页的数据。
开发工具的语言选择如果不选择java,不选择python,建议你从asp写起。asp比较简单,学习也比较容易。如果不想学习asp,也不建议学习python,因为python中涉及到api开发,其开发速度会比asp慢,如果你时间紧迫,也可以使用windows系统自带的accessapi取值接口编程。也可以在新版本中,直接使用c#。
创建爬虫程序创建一个爬虫程序的框架,从最小化开始,分以下两个步骤,创建http服务端:封装http的接口,比如wwwroot这个接口,封装http服务端。创建爬虫程序的浏览器web,我们使用lxml库写的代码比较简单,比如抓取一个链接#!/usr/bin/envpython#-*-coding:utf-8-*-importrequestsheaders={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/55.0.2703.92safari/537.36'}response=requests.get(url,headers=headers)data=response.contentifdata.status_code>200:print('成功请求')else:print('爬虫刚启动,请稍后再访问!')forx,yinenumerate(data):x['page_num']=response.status_code+'/'+str(x)+'/'+x+'page'print(x)results=data['page_num']forpageinresults:print(page+'\n')#print(str(x)+'\n')#get请求验证post请求一般情况都是不能通过的,所以需要对post请求中的request_uri进行封装,使得可以通过post请求的uri地址进行请求,同时我们需要开发一个验证服务器来对这个请求进行验证,这个验证服务器比较简单,直接使用webdriver库即可。
上面这段代码主要是对请求进行了封装和验证,具体代码如下:#!/usr/bin/envpython#-*-coding:utf-8-*-importrequestsheaders={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/55.0.2703.92safari/537.36'}response=requests.get(u。
js 爬虫抓取网页数据( 什么时候用JS数据的网站,解决的方法有各种各样 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-19 13:27
什么时候用JS数据的网站,解决的方法有各种各样
)
问题的根源
爬虫不是一劳永逸的写的,因为原站的代码迭代,我们上次写的代码文章已经变成了一堆狗屎。人生不如意,十有八九,这不是阻碍我们学习的绊脚石。我们的出发点是学习,为了让正确的代码具有一定的鲁棒性(robustness),同时也要学习新技术。这次用Selenium来写爬虫的代码,说不定情况会好起来/(ㄒoㄒ)/~~。
什么时候使用请求?
通常我们在抓取网页时,通常期望找到网站的API请求接口,可以通过参数修改来构造API。返回的结果最好是标准的Json格式,也方便我们在Python中做数据持久化。在这种情况下,我们使用 requests 模块无疑是最好的选择,因为这样的代码速度快且质量高。但现实真的很残酷,大多数网站都会通过JS动态填充网页数据,防止爬虫。采取这种措施的网页请求只返回网页的frame,具体数据通过Ajax动态渲染到网页中。Requests 不具备加载和执行 JS 的能力,所以我们无法通过请求的返回来获取真实的数据。
什么时候使用硒?
这个JS填充数据网站有多种解决方案。通常的方法是通过抓包的方式获取JS的接口获取数据。优点前面已经说了,这样写的代码效率更高。缺点也很明显,需要有一定的JS调试基础。因为你找到了一些接口,但是接口传递的参数是JS加密的,需要分析JS找到加密算法,否则就算抓到API也不能用。对于简单的JS,你或许可以在浏览器中调试,但是如果对JS代码进行混淆和压缩,对我们来说简直太多了,这对我们新手来说有点困难。通过Selenium,可以把复杂化繁为简,轻松实现我们需要的功能。
什么是硒?
什么是硒? -引自维基百科
Selenium 是一个 Web 自动化测试框架。他允许用户通过编写代码来操纵浏览器,实现像真实用户一样的浏览器操作行为。对于一些反爬机制严苛的网站,我们可以使用Selenium来操作浏览器,模拟真实用户操作爬取网站数据。这样做的好处是不需要考虑请求发送、cookie、user-agent等一系列需求,只需要编写代码来操作浏览器,通过读取浏览器内容来获取想要的数据。浏览器具有执行JS的能力。网页加载完毕后,读取网页的源代码,就可以得到我们想要的数据了。
接下来,我们通过 Selenium 重写我们之前的爬虫代码。代码稍微简单一些,仅供入门之用。
环境设置
在Python中使用Selenium,需要安装相应的环境。安装环境很简单,大致分为三步:
在虚拟环境的控制台中使用命令:pip install selenium 安装对应的包支持库,并将对应浏览器的路径添加到系统环境变量中。比如我这里使用的是Chrome浏览器,所以需要在Path环境变量中添加Chrome根目录文件夹。这个操作对于开发者来说并不陌生,根据浏览器版本下载相应的驱动。驱动下载地址(点击跳转),注意必须与您浏览器的版本相对应。下载完成后,将文件解压到Python安装目录。
安装完成后,运行以下代码测试是否安装成功。如果安装成功,会运行Chrome打开本站,并在控制台输出网页源码:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.weiney.com/")
print(brower.page_sourse)
爬虫分析
抓取网站:http://yoerking.com/static/music_player.html
运行环境:Python 3.6.5
支持库:selenium,requests,beautifulsoup,tqdm
与前面的代码相比,主要的区别在于前面的网页代码是用requests模块完成的。这次我换成了selenium,从浏览器中获取网页的源码。这样省去了分析js的麻烦。但是每次运行爬虫都打开Chrome也会降低软件的效率,但是影响不大,没有请求也会很快。
def get_page_sourse():
browser = webdriver.Chrome()
browser.get(URL)
page_sourse = browser.page_source
browser.close()
return page_sourse
<p>def parse_music():
page_sourse = get_page_sourse()
soup = BeautifulSoup(page_sourse, "html.parser")
all_musics = soup.find_all("a", class_="url")
for music_item in all_musics:
single_music = dict()
single_music["url"] = music_item.attrs["hrefsrc"]
single_music["name"] = music_item.text
single_music["album"] = re.search("(? 查看全部
js 爬虫抓取网页数据(
什么时候用JS数据的网站,解决的方法有各种各样
)
问题的根源
爬虫不是一劳永逸的写的,因为原站的代码迭代,我们上次写的代码文章已经变成了一堆狗屎。人生不如意,十有八九,这不是阻碍我们学习的绊脚石。我们的出发点是学习,为了让正确的代码具有一定的鲁棒性(robustness),同时也要学习新技术。这次用Selenium来写爬虫的代码,说不定情况会好起来/(ㄒoㄒ)/~~。
什么时候使用请求?
通常我们在抓取网页时,通常期望找到网站的API请求接口,可以通过参数修改来构造API。返回的结果最好是标准的Json格式,也方便我们在Python中做数据持久化。在这种情况下,我们使用 requests 模块无疑是最好的选择,因为这样的代码速度快且质量高。但现实真的很残酷,大多数网站都会通过JS动态填充网页数据,防止爬虫。采取这种措施的网页请求只返回网页的frame,具体数据通过Ajax动态渲染到网页中。Requests 不具备加载和执行 JS 的能力,所以我们无法通过请求的返回来获取真实的数据。
什么时候使用硒?
这个JS填充数据网站有多种解决方案。通常的方法是通过抓包的方式获取JS的接口获取数据。优点前面已经说了,这样写的代码效率更高。缺点也很明显,需要有一定的JS调试基础。因为你找到了一些接口,但是接口传递的参数是JS加密的,需要分析JS找到加密算法,否则就算抓到API也不能用。对于简单的JS,你或许可以在浏览器中调试,但是如果对JS代码进行混淆和压缩,对我们来说简直太多了,这对我们新手来说有点困难。通过Selenium,可以把复杂化繁为简,轻松实现我们需要的功能。
什么是硒?
什么是硒? -引自维基百科
Selenium 是一个 Web 自动化测试框架。他允许用户通过编写代码来操纵浏览器,实现像真实用户一样的浏览器操作行为。对于一些反爬机制严苛的网站,我们可以使用Selenium来操作浏览器,模拟真实用户操作爬取网站数据。这样做的好处是不需要考虑请求发送、cookie、user-agent等一系列需求,只需要编写代码来操作浏览器,通过读取浏览器内容来获取想要的数据。浏览器具有执行JS的能力。网页加载完毕后,读取网页的源代码,就可以得到我们想要的数据了。
接下来,我们通过 Selenium 重写我们之前的爬虫代码。代码稍微简单一些,仅供入门之用。
环境设置
在Python中使用Selenium,需要安装相应的环境。安装环境很简单,大致分为三步:
在虚拟环境的控制台中使用命令:pip install selenium 安装对应的包支持库,并将对应浏览器的路径添加到系统环境变量中。比如我这里使用的是Chrome浏览器,所以需要在Path环境变量中添加Chrome根目录文件夹。这个操作对于开发者来说并不陌生,根据浏览器版本下载相应的驱动。驱动下载地址(点击跳转),注意必须与您浏览器的版本相对应。下载完成后,将文件解压到Python安装目录。
安装完成后,运行以下代码测试是否安装成功。如果安装成功,会运行Chrome打开本站,并在控制台输出网页源码:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.weiney.com/";)
print(brower.page_sourse)
爬虫分析
抓取网站:http://yoerking.com/static/music_player.html
运行环境:Python 3.6.5
支持库:selenium,requests,beautifulsoup,tqdm
与前面的代码相比,主要的区别在于前面的网页代码是用requests模块完成的。这次我换成了selenium,从浏览器中获取网页的源码。这样省去了分析js的麻烦。但是每次运行爬虫都打开Chrome也会降低软件的效率,但是影响不大,没有请求也会很快。
def get_page_sourse():
browser = webdriver.Chrome()
browser.get(URL)
page_sourse = browser.page_source
browser.close()
return page_sourse
<p>def parse_music():
page_sourse = get_page_sourse()
soup = BeautifulSoup(page_sourse, "html.parser")
all_musics = soup.find_all("a", class_="url")
for music_item in all_musics:
single_music = dict()
single_music["url"] = music_item.attrs["hrefsrc"]
single_music["name"] = music_item.text
single_music["album"] = re.search("(?
js 爬虫抓取网页数据(简单来说,爬虫就是获取网页并提取和保存信息的自动化程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-18 20:14
履带概览
简单地说,爬虫是一种自动程序,它可以抓取网页并提取和保存信息。
爬虫可以概括为4个步骤:
1.获取网页
爬虫首先要做的就是获取网页,即获取网页的源代码。源代码收录了网页的部分有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
根据请求和响应的概念,向网站的服务器发送一个请求,返回的响应体就是网页的源代码。因此,最关键的部分是构造一个请求并发送给服务器,然后接收到响应并发送解析出来。
Python是一个非常有用的爬虫工具。它提供了很多库来帮助我们实现这个操作,比如urllib、request等,我们可以使用这些库来帮助我们实现HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,只需要解析数据结构的Body部分。
总结:
通过python爬虫相关库,实现HTTP请求操作,获取服务器响应,获取网页源码
2.提取信息
获取到网页的源代码后,下一步就是分析网页的源代码,从中提取出我们想要的数据。一般通用的方法是使用正则表达式提取。缺点是比较复杂,容易出错。
另外,由于网页结构的某些规则,python也有一些基于网页节点属性、CSS选择器或XPath提取网页信息的库,例如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效快速的提取网页信息,如节点属性、文本值等。
提取信息是爬虫的一个非常重要的部分。它可以从杂乱的数据中获取有效的信息,方便我们后续的数据处理和分析。
总结:
正则表达式是一种通用的抽取方式,也可以使用一些从网页节点属性、CSS选择器等中抽取信息的库,比如Beautiful Soup、pyquery、lxml等。
3.保存数据
提取信息后,我们一般会将提取的数据保存在某处以备后续使用。有很多方法可以保存它。简单处理可以保存为TXT或JSON文本。它也可以保存到数据库中,例如 MySQL 和 MongoDB。或者保存到远程服务器。
4.自动化程序
简单来说,爬虫可以在爬取过程中进行各种异常处理、错误重试等操作,持续高效地完成获取网页、提取信息、保存数据的工作。
爬虫可以抓取什么样的数据
[1] 最常见的爬取是HTML源代码。
[2] JSON字符串,有些网页返回的不是HTML代码,而是JSON字符串,尤其是API接口大多采用这种形式,这种格式的数据便于传输和分析,也可以抓取,数据提取更方便。
[3] 二进制数据,如图片、视频、音频等,使用爬虫我们可以抓取这些二进制数据并保存为相应的文件名。
[4] 各种扩展文件,如CSS、JavaScript 和配置文件。
JavaScript 渲染页面
有时,当我们使用 urlib 或 request 抓取网页时,我们得到的源代码实际上与我们在浏览器中看到的不同。
这是一个很常见的问题。由于越来越多的网页是使用Ajax和前端模块化工具构建的,整个网页可能会被JavaScript渲染,这意味着原来的HTML代码只是一个空壳。
例如,下面的 HTML 代码
This is a Demo
body节点中只有一个id为container的节点,但是在body节点之后引入了app.js,负责整个网站的渲染。
过程是在浏览器中打开页面时,首先加载HTML内容,然后浏览器会发现里面引入了一个app.js文件,就会请求这个文件。获取文件后,它会执行其中的JavaScript。代码,JavaScript 会改变 HTML 中的节点,向其添加内容,最后显示完整的页面。
当我们请求一个带有 urlib 或 request 等库的页面时,我们得到的只是这个 HTML 代码,它不会帮助我们加载这个 JavaScript 文件,所以我们在浏览器中看不到内容。
对于这种情况,我们可以分析其后端的Ajax接口,或者使用Selenium、Splash等库来实现模拟JavaScript渲染,后面会介绍。
本文总结参考《Python3 Web爬虫开发实战》 查看全部
js 爬虫抓取网页数据(简单来说,爬虫就是获取网页并提取和保存信息的自动化程序)
履带概览
简单地说,爬虫是一种自动程序,它可以抓取网页并提取和保存信息。
爬虫可以概括为4个步骤:
1.获取网页
爬虫首先要做的就是获取网页,即获取网页的源代码。源代码收录了网页的部分有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
根据请求和响应的概念,向网站的服务器发送一个请求,返回的响应体就是网页的源代码。因此,最关键的部分是构造一个请求并发送给服务器,然后接收到响应并发送解析出来。
Python是一个非常有用的爬虫工具。它提供了很多库来帮助我们实现这个操作,比如urllib、request等,我们可以使用这些库来帮助我们实现HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,只需要解析数据结构的Body部分。
总结:
通过python爬虫相关库,实现HTTP请求操作,获取服务器响应,获取网页源码
2.提取信息
获取到网页的源代码后,下一步就是分析网页的源代码,从中提取出我们想要的数据。一般通用的方法是使用正则表达式提取。缺点是比较复杂,容易出错。
另外,由于网页结构的某些规则,python也有一些基于网页节点属性、CSS选择器或XPath提取网页信息的库,例如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效快速的提取网页信息,如节点属性、文本值等。
提取信息是爬虫的一个非常重要的部分。它可以从杂乱的数据中获取有效的信息,方便我们后续的数据处理和分析。
总结:
正则表达式是一种通用的抽取方式,也可以使用一些从网页节点属性、CSS选择器等中抽取信息的库,比如Beautiful Soup、pyquery、lxml等。
3.保存数据
提取信息后,我们一般会将提取的数据保存在某处以备后续使用。有很多方法可以保存它。简单处理可以保存为TXT或JSON文本。它也可以保存到数据库中,例如 MySQL 和 MongoDB。或者保存到远程服务器。
4.自动化程序
简单来说,爬虫可以在爬取过程中进行各种异常处理、错误重试等操作,持续高效地完成获取网页、提取信息、保存数据的工作。
爬虫可以抓取什么样的数据
[1] 最常见的爬取是HTML源代码。
[2] JSON字符串,有些网页返回的不是HTML代码,而是JSON字符串,尤其是API接口大多采用这种形式,这种格式的数据便于传输和分析,也可以抓取,数据提取更方便。
[3] 二进制数据,如图片、视频、音频等,使用爬虫我们可以抓取这些二进制数据并保存为相应的文件名。
[4] 各种扩展文件,如CSS、JavaScript 和配置文件。
JavaScript 渲染页面
有时,当我们使用 urlib 或 request 抓取网页时,我们得到的源代码实际上与我们在浏览器中看到的不同。
这是一个很常见的问题。由于越来越多的网页是使用Ajax和前端模块化工具构建的,整个网页可能会被JavaScript渲染,这意味着原来的HTML代码只是一个空壳。
例如,下面的 HTML 代码
This is a Demo
body节点中只有一个id为container的节点,但是在body节点之后引入了app.js,负责整个网站的渲染。
过程是在浏览器中打开页面时,首先加载HTML内容,然后浏览器会发现里面引入了一个app.js文件,就会请求这个文件。获取文件后,它会执行其中的JavaScript。代码,JavaScript 会改变 HTML 中的节点,向其添加内容,最后显示完整的页面。
当我们请求一个带有 urlib 或 request 等库的页面时,我们得到的只是这个 HTML 代码,它不会帮助我们加载这个 JavaScript 文件,所以我们在浏览器中看不到内容。
对于这种情况,我们可以分析其后端的Ajax接口,或者使用Selenium、Splash等库来实现模拟JavaScript渲染,后面会介绍。
本文总结参考《Python3 Web爬虫开发实战》
js 爬虫抓取网页数据( 用get请求方式进行数据请求完成后我们可以执行一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-18 18:19
用get请求方式进行数据请求完成后我们可以执行一下)
var http = require("http");//引入标准的http模块
使用get请求方式进行数据请求
http.get(url,function(res){
//程序发送一个http请求的时候 此函数就会立马执行 res后端返回过来并且已经被解析的HTTP报文
var html ="";
res.on("data",function(chunk){
//有一段流接收到之后就会执行的回调函数
html += chunk;//把每一段流都拼接起来
});//监听
res.on("end",function(){
//所有信息传输完毕后所执行的回调函数
console.log(html);
});
});//向网络发送GET请求,请求网络资源
完成后我们就可以执行了,打开window键+R键打开操作,输入cmd打开命令行如下:
然后回车,你会发现已经获取到了目标页面的一些信息,但是只是以字符串的形式显示出来,并不整齐
这时候就需要cheerio包来解析字符串
存储爬取目标URL后引入cheerio包
var cheerio = require("cheerio");
然后进行DOM字符串解析
http.get(url,function(res){
//程序发送一个http请求的时候 此函数就会立马执行 res后端返回过来并且已经被解析的HTTP报文
var html ="";
res.on("data",function(chunk){
//有一段流接收到之后就会执行的回调函数
html+=chunk;//把每一段流都拼接起来
});//监听
res.on("end",function(){
var $ = cheerio.load(html);//解析Dom字符串
$("#right a").each(function(){
var articleUrl = $(this).attr("href");
http.get(articleUrl,function(res){
var html = "";
res.on("data",function(chunk){
html+=chunk;
});
res.on("end",function(){
console.log(html);
});
});
});
});
});//向网络发送GET请求,请求网络资源
然后继续爬取目标页面,但有时会因为网络原因出现错误
我们只需要执行错误处理操作
//监听错误事件
}).on("error",function(err){
//对程序意外错误进行处理
console.log(err.message);//在日志中打印错误具体描述
});
这时候,当你运行爬取网页的程序时,你会发现你的命令行会像Matrix一样爬取并打印网页的所有源代码,但我们需要的只是网页的数据信息页,并且不需要源代码字符串。显示,这次我们可以 res.on("end",function(){}); 再次执行字符串解析
res.on("end",function(){
var $ = cheerio.load(html);//解析Dom字符串
var oText = $("#artibody").text();
console.log(oText);
});
然后我们可以看到刚才爬取得到的数据已经被过滤掉了,只显示了需要的文字信息
如下所示:
爬取到需要的信息数据后,我们还可以对其进行文件流式操作,并将爬取到的信息保存到本地文件夹中
在进行文件流操作时,我们需要引入fs模块
var fs = require("fs");
然后我们在项目文件夹下新建一个文件夹news,然后在我们刚才提到的climb事件的最后写一个写文件操作。
fs.writeFile("./news/");
这时候我们需要提供一些参数,我们需要保证生成的txt文件的命名是唯一的,这样我们就可以在前面生成一个时间戳
var time = new Date().valueOf();//生成时间戳
然后将时间戳和开头的命名和文本放入
fs.writeFile("./news/nba"+time+".txt",oText);
然后再次运行程序,就可以生成我们的文件了 查看全部
js 爬虫抓取网页数据(
用get请求方式进行数据请求完成后我们可以执行一下)
var http = require("http");//引入标准的http模块
使用get请求方式进行数据请求
http.get(url,function(res){
//程序发送一个http请求的时候 此函数就会立马执行 res后端返回过来并且已经被解析的HTTP报文
var html ="";
res.on("data",function(chunk){
//有一段流接收到之后就会执行的回调函数
html += chunk;//把每一段流都拼接起来
});//监听
res.on("end",function(){
//所有信息传输完毕后所执行的回调函数
console.log(html);
});
});//向网络发送GET请求,请求网络资源
完成后我们就可以执行了,打开window键+R键打开操作,输入cmd打开命令行如下:
然后回车,你会发现已经获取到了目标页面的一些信息,但是只是以字符串的形式显示出来,并不整齐
这时候就需要cheerio包来解析字符串
存储爬取目标URL后引入cheerio包
var cheerio = require("cheerio");
然后进行DOM字符串解析
http.get(url,function(res){
//程序发送一个http请求的时候 此函数就会立马执行 res后端返回过来并且已经被解析的HTTP报文
var html ="";
res.on("data",function(chunk){
//有一段流接收到之后就会执行的回调函数
html+=chunk;//把每一段流都拼接起来
});//监听
res.on("end",function(){
var $ = cheerio.load(html);//解析Dom字符串
$("#right a").each(function(){
var articleUrl = $(this).attr("href");
http.get(articleUrl,function(res){
var html = "";
res.on("data",function(chunk){
html+=chunk;
});
res.on("end",function(){
console.log(html);
});
});
});
});
});//向网络发送GET请求,请求网络资源
然后继续爬取目标页面,但有时会因为网络原因出现错误
我们只需要执行错误处理操作
//监听错误事件
}).on("error",function(err){
//对程序意外错误进行处理
console.log(err.message);//在日志中打印错误具体描述
});
这时候,当你运行爬取网页的程序时,你会发现你的命令行会像Matrix一样爬取并打印网页的所有源代码,但我们需要的只是网页的数据信息页,并且不需要源代码字符串。显示,这次我们可以 res.on("end",function(){}); 再次执行字符串解析
res.on("end",function(){
var $ = cheerio.load(html);//解析Dom字符串
var oText = $("#artibody").text();
console.log(oText);
});
然后我们可以看到刚才爬取得到的数据已经被过滤掉了,只显示了需要的文字信息
如下所示:
爬取到需要的信息数据后,我们还可以对其进行文件流式操作,并将爬取到的信息保存到本地文件夹中
在进行文件流操作时,我们需要引入fs模块
var fs = require("fs");
然后我们在项目文件夹下新建一个文件夹news,然后在我们刚才提到的climb事件的最后写一个写文件操作。
fs.writeFile("./news/");
这时候我们需要提供一些参数,我们需要保证生成的txt文件的命名是唯一的,这样我们就可以在前面生成一个时间戳
var time = new Date().valueOf();//生成时间戳
然后将时间戳和开头的命名和文本放入
fs.writeFile("./news/nba"+time+".txt",oText);
然后再次运行程序,就可以生成我们的文件了
js 爬虫抓取网页数据(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-18 13:04
什么是 AJAX:
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: install Selenium 和 chromedriver: install Selenium: Selenium 有多种语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r\'D:\ProgramApp\chromedriver\chromedriver.exe\'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id(\'su\')
submitTag1 = driver.find_element(By.ID,\'su\')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name(\'su\')
submitTag1 = driver.find_element(By.CLASS_NAME,\'su\')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name(\'email\')
submitTag1 = driver.find_element(By.NAME,\'email\')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name(\'div\')
submitTag1 = driver.find_element(By.TAG_NAME,\'div\')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath(\'//div\')
submitTag1 = driver.find_element(By.XPATH,\'//div\')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector(\'//div\')
submitTag1 = driver.find_element(By.CSS_SELECTOR,\'//div\')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
inputTag.send_keys(\'python\')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,所以在网页上用鼠标点击。所以,如果要选中checkbox标签,先选中这个标签,再执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id(\'su\')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
submitTag = driver.find_element_by_id(\'su\')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,\'python\')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
cookie操作:获取所有cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open(\'"+url+"\')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(\'http://httpbin.org/ip\')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。 查看全部
js 爬虫抓取网页数据(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
什么是 AJAX:
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: install Selenium 和 chromedriver: install Selenium: Selenium 有多种语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r\'D:\ProgramApp\chromedriver\chromedriver.exe\'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id(\'su\')
submitTag1 = driver.find_element(By.ID,\'su\')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name(\'su\')
submitTag1 = driver.find_element(By.CLASS_NAME,\'su\')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name(\'email\')
submitTag1 = driver.find_element(By.NAME,\'email\')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name(\'div\')
submitTag1 = driver.find_element(By.TAG_NAME,\'div\')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath(\'//div\')
submitTag1 = driver.find_element(By.XPATH,\'//div\')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector(\'//div\')
submitTag1 = driver.find_element(By.CSS_SELECTOR,\'//div\')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
inputTag.send_keys(\'python\')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,所以在网页上用鼠标点击。所以,如果要选中checkbox标签,先选中这个标签,再执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id(\'su\')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
submitTag = driver.find_element_by_id(\'su\')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,\'python\')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
cookie操作:获取所有cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open(\'"+url+"\')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(\'http://httpbin.org/ip\')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
js 爬虫抓取网页数据(第三方库:cheerio,这个库就是用来处理dom节点的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-17 00:12
)
第三方库:cheerio,这个库是用来处理dom节点的,它的用法和jquery几乎一模一样,所以有了这个工具,写爬虫就很简单了
准备好工作了:
1. npm init --yes 初始化package.json
2.安装cheerio:npm installcheerio --save-dev
实现的目标是将每个文章需要爬取的部分(捕获文章标题、超链接、文章摘要、发布时间)组织成一个对象,放到一个数组中,如:
[ { title: '[置顶][js高手之路]从零开始打造一个javascript开源框架gdom与插件开发免费视频教程
连载中',
url: 'http://www.cnblogs.com/ghostwu/p/7470038.html',
entry: '摘要: 百度网盘下载地址:https://pan.baidu.com/s/1kULNXOF 优酷土豆观看地址:htt
p://v.youku.com/v_show/id_XMzAwNTY2MTE0MA==.html?spm=a2h0j.8191423.playlist_content.5!3~5~
5~A&&f',
listTime: '2017-09-05 17:08' },
{ title: '[js高手之路]Vue2.0基于vue-cli+webpack Vuex用法详解',
url: 'http://www.cnblogs.com/ghostwu/p/7521097.html',
entry: '摘要: 在这之前,我已经分享过组件与组件的通信机制以及父子组件之间的通信机制,而
我们的vuex就是为了解决组件通信问题的 vuex是什么东东呢? 组件通信的本质其实就是在组件之间传
递数据或组件的状态(这里将数据和状态统称为状态),但可以看到如果我们通过最基本的方式来进行
通信,一旦需要管理的状态多了,代码就会',
listTime: '2017-09-14 15:51' },
{ title: '[js高手之路]Vue2.0基于vue-cli+webpack同级组件之间的通信教程',
url: 'http://www.cnblogs.com/ghostwu/p/7518158.html',
entry: '摘要: 我们接着上文继续,本文我们讲解兄弟组件的通信,项目结构还是跟上文一样. 在
src/assets目录下建立文件EventHandler.js,该文件的作用在于给同级组件之间传递事件 EventHandl
er.js代码: 2,在Components目录下新建一个组件Brother1.vue 。通过Eve',
listTime: '2017-09-13 22:49' },
]
思路说明:
1.获取目标地址:所有html内容
2.提取所有文章html内容
3、提取每个文章下对应的文章(文章标题、超链接、文章摘要、发布时间)
1 var http = require('http');
2 var cheerio = require('cheerio');
3
4 var url = 'http://www.cnblogs.com/ghostwu/';
5
6 function filterHtml(html) {
7 var $ = cheerio.load(html);
8 var arcList = [];
9 var aPost = $("#content").find(".post-list-item");
10 aPost.each(function () {
11 var ele = $(this);
12 var title = ele.find("h2 a").text();
13 var url = ele.find("h2 a").attr("href");
14 ele.find(".c_b_p_desc a").remove();
15 var entry = ele.find(".c_b_p_desc").text();
16 ele.find("small a").remove();
17 var listTime = ele.find("small").text();
18 var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
19 listTime = listTime.match( re )[0];
20 arcList.push({
21 title: title,
22 url: url,
23 entry: entry,
24 listTime: listTime
25 });
26 });
27 return arcList;
28 }
29
30 http.get(url, function (res) {
31 var html = '';
32 var arcList = [];
33 // var arcInfo = {};
34 res.on('data', function (chunk) {
35 html += chunk;
36 });
37 res.on('end', function () {
38 arcList = filterHtml( html );
39 console.log( arcList );
40 });
41 });
有几个关键点需要解释:
1. res.on('数据', function(){})
http模块发送get请求后,会不断的抓取目标网页的源码内容。因此,我在 on 中监听 data 事件。chunk是传输的数据,数据累加到html变量中。当数据传输完毕后,就会触发结束事件。你可以在end事件中打印console.log(html),你会发现里面都是目标地址的html源代码。这就解决了我们的第一个问题:获取目标地址:所有html内容
2.有了完整的html内容后,我再封装一个函数filterHTML来过滤我需要的结果(每条文章信息)
3. var $ =cheerio.load(html); 通过cheerio的load方法加载html内容,然后就可以使用cheerio的节点进行操作了。为了兼容jquery操作,我用美元符号$保存了这个文档对象
4. var aPost = $("#content").find(".post-list-item"); 这就是所有的文章节点信息,拿到后,通过各个方法一一遍历,抓取自己需要的信息,组织成对象,然后放到一个数组中
1 arcList.push({
2 21 title: title,
3 22 url: url,
4 23 entry: entry,
5 24 listTime: listTime
6 25 });
这样做了,结果如上所示。如果博客风格和我的博客风格一样,应该是可以爬取的。
然后改进页面爬取,让整个博客都可以爬下来
<p> 1 var http = require('http');
2 var cheerio = require('cheerio');
3
4 var url = 'http://www.cnblogs.com/ghostwu/';
5
6 function filterHtml(html) {
7 var $ = cheerio.load(html);
8 var arcList = [];
9 var aPost = $("#content").find(".post-list-item");
10 aPost.each(function () {
11 var ele = $(this);
12 var title = ele.find("h2 a").text();
13 var url = ele.find("h2 a").attr("href");
14 ele.find(".c_b_p_desc a").remove();
15 var entry = ele.find(".c_b_p_desc").text();
16 ele.find("small a").remove();
17 var listTime = ele.find("small").text();
18 var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
19 listTime = listTime.match(re)[0];
20 arcList.push({
21 title: title,
22 url: url,
23 entry: entry,
24 listTime: listTime
25 });
26 });
27 return arcList;
28 }
29
30 function nextPage( html ){
31 var $ = cheerio.load(html);
32 var nextUrl = $("#pager a:last-child").attr('href');
33 if ( !nextUrl ) return ;
34 var curPage = $("#pager .current").text();
35 if( !curPage ) curPage = 1;
36 var nextPage = nextUrl.substring( nextUrl.indexOf( '=' ) + 1 );
37 if ( curPage 查看全部
js 爬虫抓取网页数据(第三方库:cheerio,这个库就是用来处理dom节点的
)
第三方库:cheerio,这个库是用来处理dom节点的,它的用法和jquery几乎一模一样,所以有了这个工具,写爬虫就很简单了
准备好工作了:
1. npm init --yes 初始化package.json
2.安装cheerio:npm installcheerio --save-dev
实现的目标是将每个文章需要爬取的部分(捕获文章标题、超链接、文章摘要、发布时间)组织成一个对象,放到一个数组中,如:
[ { title: '[置顶][js高手之路]从零开始打造一个javascript开源框架gdom与插件开发免费视频教程
连载中',
url: 'http://www.cnblogs.com/ghostwu/p/7470038.html',
entry: '摘要: 百度网盘下载地址:https://pan.baidu.com/s/1kULNXOF 优酷土豆观看地址:htt
p://v.youku.com/v_show/id_XMzAwNTY2MTE0MA==.html?spm=a2h0j.8191423.playlist_content.5!3~5~
5~A&&f',
listTime: '2017-09-05 17:08' },
{ title: '[js高手之路]Vue2.0基于vue-cli+webpack Vuex用法详解',
url: 'http://www.cnblogs.com/ghostwu/p/7521097.html',
entry: '摘要: 在这之前,我已经分享过组件与组件的通信机制以及父子组件之间的通信机制,而
我们的vuex就是为了解决组件通信问题的 vuex是什么东东呢? 组件通信的本质其实就是在组件之间传
递数据或组件的状态(这里将数据和状态统称为状态),但可以看到如果我们通过最基本的方式来进行
通信,一旦需要管理的状态多了,代码就会',
listTime: '2017-09-14 15:51' },
{ title: '[js高手之路]Vue2.0基于vue-cli+webpack同级组件之间的通信教程',
url: 'http://www.cnblogs.com/ghostwu/p/7518158.html',
entry: '摘要: 我们接着上文继续,本文我们讲解兄弟组件的通信,项目结构还是跟上文一样. 在
src/assets目录下建立文件EventHandler.js,该文件的作用在于给同级组件之间传递事件 EventHandl
er.js代码: 2,在Components目录下新建一个组件Brother1.vue 。通过Eve',
listTime: '2017-09-13 22:49' },
]
思路说明:
1.获取目标地址:所有html内容
2.提取所有文章html内容
3、提取每个文章下对应的文章(文章标题、超链接、文章摘要、发布时间)
1 var http = require('http');
2 var cheerio = require('cheerio');
3
4 var url = 'http://www.cnblogs.com/ghostwu/';
5
6 function filterHtml(html) {
7 var $ = cheerio.load(html);
8 var arcList = [];
9 var aPost = $("#content").find(".post-list-item");
10 aPost.each(function () {
11 var ele = $(this);
12 var title = ele.find("h2 a").text();
13 var url = ele.find("h2 a").attr("href");
14 ele.find(".c_b_p_desc a").remove();
15 var entry = ele.find(".c_b_p_desc").text();
16 ele.find("small a").remove();
17 var listTime = ele.find("small").text();
18 var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
19 listTime = listTime.match( re )[0];
20 arcList.push({
21 title: title,
22 url: url,
23 entry: entry,
24 listTime: listTime
25 });
26 });
27 return arcList;
28 }
29
30 http.get(url, function (res) {
31 var html = '';
32 var arcList = [];
33 // var arcInfo = {};
34 res.on('data', function (chunk) {
35 html += chunk;
36 });
37 res.on('end', function () {
38 arcList = filterHtml( html );
39 console.log( arcList );
40 });
41 });
有几个关键点需要解释:
1. res.on('数据', function(){})
http模块发送get请求后,会不断的抓取目标网页的源码内容。因此,我在 on 中监听 data 事件。chunk是传输的数据,数据累加到html变量中。当数据传输完毕后,就会触发结束事件。你可以在end事件中打印console.log(html),你会发现里面都是目标地址的html源代码。这就解决了我们的第一个问题:获取目标地址:所有html内容
2.有了完整的html内容后,我再封装一个函数filterHTML来过滤我需要的结果(每条文章信息)
3. var $ =cheerio.load(html); 通过cheerio的load方法加载html内容,然后就可以使用cheerio的节点进行操作了。为了兼容jquery操作,我用美元符号$保存了这个文档对象
4. var aPost = $("#content").find(".post-list-item"); 这就是所有的文章节点信息,拿到后,通过各个方法一一遍历,抓取自己需要的信息,组织成对象,然后放到一个数组中
1 arcList.push({
2 21 title: title,
3 22 url: url,
4 23 entry: entry,
5 24 listTime: listTime
6 25 });
这样做了,结果如上所示。如果博客风格和我的博客风格一样,应该是可以爬取的。
然后改进页面爬取,让整个博客都可以爬下来
<p> 1 var http = require('http');
2 var cheerio = require('cheerio');
3
4 var url = 'http://www.cnblogs.com/ghostwu/';
5
6 function filterHtml(html) {
7 var $ = cheerio.load(html);
8 var arcList = [];
9 var aPost = $("#content").find(".post-list-item");
10 aPost.each(function () {
11 var ele = $(this);
12 var title = ele.find("h2 a").text();
13 var url = ele.find("h2 a").attr("href");
14 ele.find(".c_b_p_desc a").remove();
15 var entry = ele.find(".c_b_p_desc").text();
16 ele.find("small a").remove();
17 var listTime = ele.find("small").text();
18 var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
19 listTime = listTime.match(re)[0];
20 arcList.push({
21 title: title,
22 url: url,
23 entry: entry,
24 listTime: listTime
25 });
26 });
27 return arcList;
28 }
29
30 function nextPage( html ){
31 var $ = cheerio.load(html);
32 var nextUrl = $("#pager a:last-child").attr('href');
33 if ( !nextUrl ) return ;
34 var curPage = $("#pager .current").text();
35 if( !curPage ) curPage = 1;
36 var nextPage = nextUrl.substring( nextUrl.indexOf( '=' ) + 1 );
37 if ( curPage
js 爬虫抓取网页数据(Python中的Node.js与爬虫的框架与资料分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-15 23:27
每当我看到爬虫或百度爬虫时,它都是Python爬虫。不得不说,爬虫的框架和材料基本上都是Python最多的,但事情要反过来。Python爬虫有几个问题:
1.Python好像对DOM的支持不是很好,网页的DOM处理也不是很好
2.Python对网页编码的处理。
3.最重要的是Python需要多线程。
以上问题都是我们即将使用的Node.js的优点!同样,Node.js 也有缺点。Node.js是单线异步的,很容易导致发起爬取请求的顺序和返回结果的顺序不一致。因此,我们需要添加请求序列号,然后将处理后的序列号重新排序,以实现结果和请求。一致。另外Node.js毕竟是前端,数据的处理比那个差很多,但是作为网站的数据爬取绝对够用。废话不多说,我们进入Node.js爬虫,Node.js爬虫步骤1.创建项目目录,不管你在哪里创建,但是路径最好不要有中文,谁知道会不会出错。比如我们的项目路径是:E:
E:cd E:\adt-bundle-windows-x86_64-20131030\Nodejs\nests_Datagetnpm init
npm init 是在当前目录下创建一个模块(即生成package.json),其文件属性描述如下。输入npm init后,会依次出现如下查询
$ npm initThis utility will walk you through creating a package.json file.It only covers the most common items, and tries to guess sensible defaults.See `npm help json` for definitive documentation on these fieldsand exactly what they do.Use `npm install --save` afterwards to install a package andsave it as a dependency in the package.json file.Press ^C at any time to quit.name: (node_modules) runoob # 模块名version: (1.0.0) #模块版本description: Node.js 测试模块(www.runoob.com) # 描述entry point: (index.js)test command: make testgit repository: https://github.com/runoob/runoob.git # Github 地址keywords: #关键字author: #作者license: (ISC) #许可类型About to write to ……/node_modules/package.json: # 生成地址{ "name": "runoob", "version": "1.0.0", "description": "Node.js 测试模块(www.runoob.com)", ……}Is this ok? (yes) yes
您可以根据自己的情况填写以上信息。信息填错没关系,我们可以随时通过package.json修改。3.安装请求和cheerio依赖的安装命令如下
npm install request --savenpm install cheerio
界面如下
4.接下来我们终于可以开始操作我们的js代码,新建一个js文件了。如果是主入口文件名,应该与package.json中的入口点一致。这里我们新建一个名为server.js的文件来建立依赖引用,代码如下
var request = require("request");var cheerio = require("cheerio");
接下来,我们将抓取百度首页链接为:
request('https://www.baidu.com/',function(err,result){ if(err){ console.log("错误:"+err); return; } console.log(result.body);})
在cmd中输入node server.js,回车,代码没有输入错误会出现如下界面
可以看出,我们已经获取到了网页的数据,我们已经迈出了重要的第一步。只要我们能得到完整的Html网页源代码,就很容易做到了。现在是数据处理。我们不是还有一个我们以前没有使用过的库吗?没错,就是cheerio库的使用。现在我们修改上面的代码,将成功获取的网页交给cheerio处理。至于如何通过DOM提取数据,我们通过UC浏览器访问,按F12进入开发者模式。对比一下我们要抓取的信息的位置,比如这里我们要抓取百度的标题
下一步是编写捕获的 DOM 语句。我不知道如何使用它。有DOM文档和JQuery文档。这里我们要获取标题的DOM是$('title').text(),所以代码改成如下:
//把 html 装载到 cheerio 中 var $ = cheerio.load(result.body); //通过 DOM 抓取网页数据 console.log($('title').text());
影响:
但是现在我们抓取的是静态页面,不像百度首页上的新闻我们获取不到。在下一篇文章中,我们将学习抓取动态页面。 查看全部
js 爬虫抓取网页数据(Python中的Node.js与爬虫的框架与资料分析)
每当我看到爬虫或百度爬虫时,它都是Python爬虫。不得不说,爬虫的框架和材料基本上都是Python最多的,但事情要反过来。Python爬虫有几个问题:
1.Python好像对DOM的支持不是很好,网页的DOM处理也不是很好
2.Python对网页编码的处理。
3.最重要的是Python需要多线程。
以上问题都是我们即将使用的Node.js的优点!同样,Node.js 也有缺点。Node.js是单线异步的,很容易导致发起爬取请求的顺序和返回结果的顺序不一致。因此,我们需要添加请求序列号,然后将处理后的序列号重新排序,以实现结果和请求。一致。另外Node.js毕竟是前端,数据的处理比那个差很多,但是作为网站的数据爬取绝对够用。废话不多说,我们进入Node.js爬虫,Node.js爬虫步骤1.创建项目目录,不管你在哪里创建,但是路径最好不要有中文,谁知道会不会出错。比如我们的项目路径是:E:
E:cd E:\adt-bundle-windows-x86_64-20131030\Nodejs\nests_Datagetnpm init
npm init 是在当前目录下创建一个模块(即生成package.json),其文件属性描述如下。输入npm init后,会依次出现如下查询
$ npm initThis utility will walk you through creating a package.json file.It only covers the most common items, and tries to guess sensible defaults.See `npm help json` for definitive documentation on these fieldsand exactly what they do.Use `npm install --save` afterwards to install a package andsave it as a dependency in the package.json file.Press ^C at any time to quit.name: (node_modules) runoob # 模块名version: (1.0.0) #模块版本description: Node.js 测试模块(www.runoob.com) # 描述entry point: (index.js)test command: make testgit repository: https://github.com/runoob/runoob.git # Github 地址keywords: #关键字author: #作者license: (ISC) #许可类型About to write to ……/node_modules/package.json: # 生成地址{ "name": "runoob", "version": "1.0.0", "description": "Node.js 测试模块(www.runoob.com)", ……}Is this ok? (yes) yes
您可以根据自己的情况填写以上信息。信息填错没关系,我们可以随时通过package.json修改。3.安装请求和cheerio依赖的安装命令如下
npm install request --savenpm install cheerio
界面如下
4.接下来我们终于可以开始操作我们的js代码,新建一个js文件了。如果是主入口文件名,应该与package.json中的入口点一致。这里我们新建一个名为server.js的文件来建立依赖引用,代码如下
var request = require("request");var cheerio = require("cheerio");
接下来,我们将抓取百度首页链接为:
request('https://www.baidu.com/',function(err,result){ if(err){ console.log("错误:"+err); return; } console.log(result.body);})
在cmd中输入node server.js,回车,代码没有输入错误会出现如下界面
可以看出,我们已经获取到了网页的数据,我们已经迈出了重要的第一步。只要我们能得到完整的Html网页源代码,就很容易做到了。现在是数据处理。我们不是还有一个我们以前没有使用过的库吗?没错,就是cheerio库的使用。现在我们修改上面的代码,将成功获取的网页交给cheerio处理。至于如何通过DOM提取数据,我们通过UC浏览器访问,按F12进入开发者模式。对比一下我们要抓取的信息的位置,比如这里我们要抓取百度的标题
下一步是编写捕获的 DOM 语句。我不知道如何使用它。有DOM文档和JQuery文档。这里我们要获取标题的DOM是$('title').text(),所以代码改成如下:
//把 html 装载到 cheerio 中 var $ = cheerio.load(result.body); //通过 DOM 抓取网页数据 console.log($('title').text());
影响:
但是现在我们抓取的是静态页面,不像百度首页上的新闻我们获取不到。在下一篇文章中,我们将学习抓取动态页面。
js 爬虫抓取网页数据(1.岗位列表的第一页(图)代码分析(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-14 15:23
)
我一直听说有爬行动物之类的东西。查了一下资料,好像也不是很复杂。
只知道node.js,然后基于它的一个简单的爬虫。
1. 这个爬虫的目标:
从龙狗招聘网站中找出“前端开发”职位信息,分析对应页面,提取具体部分,如职位名称、职位薪资、职位公司、职位发布日期等。并显示捕获的信息。
初始钩子网站的接口信息如下:
2.设计方案:
爬虫实际上使用相应的技术来抓取页面上的特定信息。
这里我们主要抓取与上图所示的帖子列表相关的具体帖子信息。
首先,要爬取,首先得有地址url:
%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91?kd=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F% 91&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=label&lc=&workAddress=&city=%E5%85%A8%E5%9B%BD&requestId=&pn=1
此链接是职位列表第一页的网址。
我们分析地址的参数部分,不考虑其他选择的参数,只看最后的参数值:pn=1
我们的目的是爬取整个页面,所以设置为pn = page;
其次,爬虫为了获取特定信息,需要特定代表的标识符。
这里我们使用分析页面代码tag值、class值、id值来考虑。
通过 Firebug 检查这小部分元素
分析将获得哪些信息需要处理特定的标识符。
3.代码编写:
按照预定的方案,考虑到node.js的使用,通过其内置的http模块获取页面信息,通过cheerio.js模块解析DOM,然后转换成json格式数据,是由控制台直接输出或者将json数据发送回浏览器再次显示。
(cheerio.js的用法很简单,详细可以自己搜索。最重要的就是下面的代码,其余和jQuery的用法类似。
即先加载页面数据,形成特定的数据格式,然后通过类似jq的语法解析数据)
var cheerio = require(\'cheerio\'),
$ = cheerio.load(\'Hello world\');
$(\'h2.title\').text(\'Hello there!\');
$(\'h2\').addClass(\'welcome\');
$.html();
//=> Hello there!
采用express模块化开发后,按要求建立项目。进入项目目录,执行 npm install 安装需要的依赖。如果你不知道快递,你可以在这里查看
爬虫需要cheerio.js,所以需要另外一个进来,所以需要另外一个npm installcheerio
工程文件很多,为了简单的处理只修改了三个。(Index.ejs index.js style.css)
(1)直接修改路由中的index.js文件,也是核心部分。
看代码,注释够多
1 var express = require(\'express\');
2 var router = express.Router();
3 var http = require(\'http\');
4 var cheerio = require(\'cheerio\');
5
6 /* GET home page. */
7 router.get(\'/\', function(req, res, next) {
8 res.render(\'index\', { title: \'简单nodejs爬虫\' });
9 });
10 router.get(\'/getJobs\', function(req, res, next) { // 浏览器端发来get请求
11 var page = req.param(\'page\'); //获取get请求中的参数 page
12 console.log("page: "+page);
13 var Res = res; //保存,防止下边的修改
14 //url 获取信息的页面部分地址
15 var url = \'http://www.lagou.com/jobs/list_%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91?kd=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=label&lc=&workAddress=&city=%E5%85%A8%E5%9B%BD&requestId=&pn=\';
16
17 http.get(url+page,function(res){ //通过get方法获取对应地址中的页面信息
18 var chunks = [];
19 var size = 0;
20 res.on(\'data\',function(chunk){ //监听事件 传输
21 chunks.push(chunk);
22 size += chunk.length;
23 });
24 res.on(\'end\',function(){ //数据传输完
25 var data = Buffer.concat(chunks,size);
26 var html = data.toString();
27 // console.log(html);
28 var $ = cheerio.load(html); //cheerio模块开始处理 DOM处理
29 var jobs = [];
30
31 var jobs_list = $(".hot_pos li");
32 $(".hot_pos>li").each(function(){ //对页面岗位栏信息进行处理 每个岗位对应一个 li ,各标识符到页面进行分析得出
33 var job = {};
34 job.company = $(this).find(".hot_pos_r div").eq(1).find("a").html(); //公司名
35 job.period = $(this).find(".hot_pos_r span").eq(1).html(); //阶段
36 job.scale = $(this).find(".hot_pos_r span").eq(2).html(); //规模
37
38 job.name = $(this).find(".hot_pos_l a").attr("title"); //岗位名
39 job.src = $(this).find(".hot_pos_l a").attr("href"); //岗位链接
40 job.city = $(this).find(".hot_pos_l .c9").html(); //岗位所在城市
41 job.salary = $(this).find(".hot_pos_l span").eq(1).html(); //薪资
42 job.exp = $(this).find(".hot_pos_l span").eq(2).html(); //岗位所需经验
43 job.time = $(this).find(".hot_pos_l span").eq(5).html(); //发布时间
44
45 console.log(job.name); //控制台输出岗位名
46 jobs.push(job);
47 });
48 Res.json({ //返回json格式数据给浏览器端
49 jobs:jobs
50 });
51 });
52 });
53
54 });
55
56 module.exports = router;
(2)node.js抓取的核心代码就是以上部分。
下一步就是展示抓取到的数据,所以需要另外一个页面修改views中的index.ejs模板
1 DOCTYPE html>
2
3
4
5
6
7
8 【nodejs爬虫】 获取拉勾网招聘岗位--前端开发
9 初始化完成 ...
10 点击开始抓取第一页
11
12
13
14
15 数据抓取中 ... 请稍后
16 抓取上一页
17 抓取下一页
18
19
20
21 function getData(str){ //获取到的数据有杂乱..需要把前面部分去掉,只需要data(...... data)
22 if(str){
23 return str.slice(str.lastIndexOf(">")+1);
24 }
25 }
26
27 document.getElementById("btn1").style.visibility = "hidden";
28 document.getElementById("btn2").style.visibility = "hidden";
29 var currentPage = 0; //page初始0
30
31 function cheerFetch(_page){ //抓取数据处理函数
32 if(_page == 1){
33 currentPage = 1; //开始抓取则更改page
34 }
35 $(document).ajaxSend(function(event, xhr, settings) { //抓取中...
36 $(".fetching").css("display","block");
37 });
38 $(document).ajaxSuccess(function(event, xhr, settings) { //抓取成功
39 $(".fetching").css("display","none");
40 });
41 $.ajax({ //开始发送ajax请求至路径 /getJobs 进而作页面抓取处理
42 data:{page:_page}, //参数 page = _page
43 dataType: "json",
44 type: "get",
45 url: "/getJobs",
46 success: function(data){ //收到返回的json数据
47 console.log(data);
48 var html = "";
49 $(".container").empty();
50 if(data.jobs.length == 0){
51 alert("Error2: 未找到数据..");
52 return;
53 }
54 for(var i=0;i 1){
73 document.getElementById("btn1").style.visibility = "visible";
74 document.getElementById("btn2").style.visibility = "visible";
75 }
76 },
77 error: function(){
78 alert("Error1: 未找到数据..");
79 }
80 });
81 }
82
83
84
85
(3)当然也需要简单的修改public文件下的style.css
body {
padding: 20px 50px;
font: 14px "Lucida Grande", Helvetica, Arial, sans-serif;
}
a {
color: #00B7FF;
cursor: pointer;
}
.container{position: relative;width: 1100px;overflow: hidden;zoom:1;}
.jobs{margin: 30px; float: left;}
.jobs span{ color: green; font-weight: bold;}
.btn{cursor: pointer;}
.fetching{display: none;color: red;}
.footer{clear: both;}
只有这三个文件基本改变了。
因此,如果要测试,可以在新建项目后直接修改相应的三个文件。
修改成功后就可以测试了。
3.测试结果
1) 先在控制台执行 npm start
2) 接下来在浏览器中输入:3000/start 访问
3) 点击开始抓取(这里每次抓取15个条目,即原创URL对应的15个条目)
...
查看全部
js 爬虫抓取网页数据(1.岗位列表的第一页(图)代码分析(组图)
)
我一直听说有爬行动物之类的东西。查了一下资料,好像也不是很复杂。
只知道node.js,然后基于它的一个简单的爬虫。
1. 这个爬虫的目标:
从龙狗招聘网站中找出“前端开发”职位信息,分析对应页面,提取具体部分,如职位名称、职位薪资、职位公司、职位发布日期等。并显示捕获的信息。
初始钩子网站的接口信息如下:
2.设计方案:
爬虫实际上使用相应的技术来抓取页面上的特定信息。
这里我们主要抓取与上图所示的帖子列表相关的具体帖子信息。
首先,要爬取,首先得有地址url:
%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91?kd=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F% 91&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=label&lc=&workAddress=&city=%E5%85%A8%E5%9B%BD&requestId=&pn=1
此链接是职位列表第一页的网址。
我们分析地址的参数部分,不考虑其他选择的参数,只看最后的参数值:pn=1
我们的目的是爬取整个页面,所以设置为pn = page;
其次,爬虫为了获取特定信息,需要特定代表的标识符。
这里我们使用分析页面代码tag值、class值、id值来考虑。
通过 Firebug 检查这小部分元素
分析将获得哪些信息需要处理特定的标识符。
3.代码编写:
按照预定的方案,考虑到node.js的使用,通过其内置的http模块获取页面信息,通过cheerio.js模块解析DOM,然后转换成json格式数据,是由控制台直接输出或者将json数据发送回浏览器再次显示。
(cheerio.js的用法很简单,详细可以自己搜索。最重要的就是下面的代码,其余和jQuery的用法类似。
即先加载页面数据,形成特定的数据格式,然后通过类似jq的语法解析数据)
var cheerio = require(\'cheerio\'),
$ = cheerio.load(\'Hello world\');
$(\'h2.title\').text(\'Hello there!\');
$(\'h2\').addClass(\'welcome\');
$.html();
//=> Hello there!
采用express模块化开发后,按要求建立项目。进入项目目录,执行 npm install 安装需要的依赖。如果你不知道快递,你可以在这里查看
爬虫需要cheerio.js,所以需要另外一个进来,所以需要另外一个npm installcheerio
工程文件很多,为了简单的处理只修改了三个。(Index.ejs index.js style.css)
(1)直接修改路由中的index.js文件,也是核心部分。
看代码,注释够多
1 var express = require(\'express\');
2 var router = express.Router();
3 var http = require(\'http\');
4 var cheerio = require(\'cheerio\');
5
6 /* GET home page. */
7 router.get(\'/\', function(req, res, next) {
8 res.render(\'index\', { title: \'简单nodejs爬虫\' });
9 });
10 router.get(\'/getJobs\', function(req, res, next) { // 浏览器端发来get请求
11 var page = req.param(\'page\'); //获取get请求中的参数 page
12 console.log("page: "+page);
13 var Res = res; //保存,防止下边的修改
14 //url 获取信息的页面部分地址
15 var url = \'http://www.lagou.com/jobs/list_%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91?kd=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=label&lc=&workAddress=&city=%E5%85%A8%E5%9B%BD&requestId=&pn=\';
16
17 http.get(url+page,function(res){ //通过get方法获取对应地址中的页面信息
18 var chunks = [];
19 var size = 0;
20 res.on(\'data\',function(chunk){ //监听事件 传输
21 chunks.push(chunk);
22 size += chunk.length;
23 });
24 res.on(\'end\',function(){ //数据传输完
25 var data = Buffer.concat(chunks,size);
26 var html = data.toString();
27 // console.log(html);
28 var $ = cheerio.load(html); //cheerio模块开始处理 DOM处理
29 var jobs = [];
30
31 var jobs_list = $(".hot_pos li");
32 $(".hot_pos>li").each(function(){ //对页面岗位栏信息进行处理 每个岗位对应一个 li ,各标识符到页面进行分析得出
33 var job = {};
34 job.company = $(this).find(".hot_pos_r div").eq(1).find("a").html(); //公司名
35 job.period = $(this).find(".hot_pos_r span").eq(1).html(); //阶段
36 job.scale = $(this).find(".hot_pos_r span").eq(2).html(); //规模
37
38 job.name = $(this).find(".hot_pos_l a").attr("title"); //岗位名
39 job.src = $(this).find(".hot_pos_l a").attr("href"); //岗位链接
40 job.city = $(this).find(".hot_pos_l .c9").html(); //岗位所在城市
41 job.salary = $(this).find(".hot_pos_l span").eq(1).html(); //薪资
42 job.exp = $(this).find(".hot_pos_l span").eq(2).html(); //岗位所需经验
43 job.time = $(this).find(".hot_pos_l span").eq(5).html(); //发布时间
44
45 console.log(job.name); //控制台输出岗位名
46 jobs.push(job);
47 });
48 Res.json({ //返回json格式数据给浏览器端
49 jobs:jobs
50 });
51 });
52 });
53
54 });
55
56 module.exports = router;
(2)node.js抓取的核心代码就是以上部分。
下一步就是展示抓取到的数据,所以需要另外一个页面修改views中的index.ejs模板
1 DOCTYPE html>
2
3
4
5
6
7
8 【nodejs爬虫】 获取拉勾网招聘岗位--前端开发
9 初始化完成 ...
10 点击开始抓取第一页
11
12
13
14
15 数据抓取中 ... 请稍后
16 抓取上一页
17 抓取下一页
18
19
20
21 function getData(str){ //获取到的数据有杂乱..需要把前面部分去掉,只需要data(...... data)
22 if(str){
23 return str.slice(str.lastIndexOf(">")+1);
24 }
25 }
26
27 document.getElementById("btn1").style.visibility = "hidden";
28 document.getElementById("btn2").style.visibility = "hidden";
29 var currentPage = 0; //page初始0
30
31 function cheerFetch(_page){ //抓取数据处理函数
32 if(_page == 1){
33 currentPage = 1; //开始抓取则更改page
34 }
35 $(document).ajaxSend(function(event, xhr, settings) { //抓取中...
36 $(".fetching").css("display","block");
37 });
38 $(document).ajaxSuccess(function(event, xhr, settings) { //抓取成功
39 $(".fetching").css("display","none");
40 });
41 $.ajax({ //开始发送ajax请求至路径 /getJobs 进而作页面抓取处理
42 data:{page:_page}, //参数 page = _page
43 dataType: "json",
44 type: "get",
45 url: "/getJobs",
46 success: function(data){ //收到返回的json数据
47 console.log(data);
48 var html = "";
49 $(".container").empty();
50 if(data.jobs.length == 0){
51 alert("Error2: 未找到数据..");
52 return;
53 }
54 for(var i=0;i 1){
73 document.getElementById("btn1").style.visibility = "visible";
74 document.getElementById("btn2").style.visibility = "visible";
75 }
76 },
77 error: function(){
78 alert("Error1: 未找到数据..");
79 }
80 });
81 }
82
83
84
85
(3)当然也需要简单的修改public文件下的style.css
body {
padding: 20px 50px;
font: 14px "Lucida Grande", Helvetica, Arial, sans-serif;
}
a {
color: #00B7FF;
cursor: pointer;
}
.container{position: relative;width: 1100px;overflow: hidden;zoom:1;}
.jobs{margin: 30px; float: left;}
.jobs span{ color: green; font-weight: bold;}
.btn{cursor: pointer;}
.fetching{display: none;color: red;}
.footer{clear: both;}
只有这三个文件基本改变了。
因此,如果要测试,可以在新建项目后直接修改相应的三个文件。
修改成功后就可以测试了。
3.测试结果
1) 先在控制台执行 npm start
2) 接下来在浏览器中输入:3000/start 访问
3) 点击开始抓取(这里每次抓取15个条目,即原创URL对应的15个条目)
...
js 爬虫抓取网页数据(别的项目组什么项目突然心血来潮想研究一下爬虫、分析的简单原型)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-14 15:18
因为其他项目组都在做舆情预测项目,我只是手头没有项目,突然想研究一个爬虫的简单原型,心血来潮分析。网上查这方面的资料太多了,看得我眼花缭乱。Search Search 对于我这种新手,想做一个简单的爬虫程序,HttpClient + jsoup 是个不错的选择。前者是用来管理请求的,后者是用来解析页面的,主要是因为后者的select语法和jquery很像,对我这个用js的人来说太方便了。
昨天和他们聊天的时候,他们选择了几个知名的开源框架来使用,聊天后发现他们目前没有办法抓取动态网页,尤其是几个重要的数字,比如评论数量和数量的答复。等等,一般的理解,比如TRS爬虫需要写js脚本来调用js,但是分析量巨大。他们的技术人员告诉我们,如果他们配备了这样的模板,他们一天只能配备2到3个,更不用说我们这些中途出家的人了。碰巧挺有挑战性的,所以昨天就同意了,看看他们能不能找到一个相对简单的解决方案,当然,不考虑效率。
举个简单的例子,如下图
“我有话要说”后面的1307是后装的,但这些数字往往对舆论分析更重要。
对需求有了大致的了解之后,我们来分析一下如何解决。通常我们对一个请求得到的响应收录js代码和html元素,所以像jsoup这样的html解析器很难在这里利用它,因为它可以得到的html,1307还没有生成。这时候就需要一个可以运行js的平台,将运行js代码后的页面交给html进行解析,这样才能正确得到结果。
因为比较懒,一开始就放弃了写脚本的方式,因为分析一个页面太痛苦,代码乱七八糟。其中很多也使用了压缩方法,都是a()、b()方法。看的太累了。所以我的第一个想法是,为什么我不能让这个地址在某个浏览器中运行,然后将运行的结果传递给html解析器进行分析,那么整个问题就迎刃而解了。所以我的临时解决办法是在爬虫服务器上打开一个后台浏览器,或者一个带有浏览器内核的程序,把URL地址传给它来请求,然后从浏览器中取出页面的元素交给html解析器来解析,从而得到你想要的信息。
是的,最后还是用Selenium来实现上一篇我提到的问题。我没有尝试其他任何东西。我只试过火狐引擎。整体效果还是可以接受的。
继续昨天的话题,既然要实现上一篇提到的问题,就需要一个可以执行js代码的框架。我的第一选择是 htmlunit。先简单介绍一下htmlunit。以下段落摘自互联网。
htmlunit 是一个开源的java 页面分析工具。启动 htmlunit 后,将在底部启动一个无界面浏览器。用户可以指定浏览器类型:firefox、ie等,如果不指定,默认使用INTERNET_EXPLORER_7:
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_3_6);
通过一个简单的调用:
HtmlPage 页面 = webClient.getPage(url);
可以得到页面的HtmlPage表示,然后通过:
InputStream 是 = targetPage.getWebResponse().getContentAsStream()
可以获取页面的输入流,进而获取页面的源代码,这对于网络爬虫项目非常有用。
当然,你也可以从页面中获取更多的页面元素。
很重要的一点是 HtmlUnit 提供了对执行 javascript 的支持:
page.executeJavaScript(javascript)
js执行后返回一个ScriptResult对象,通过该对象可以获取js执行后的页面等信息。默认情况下,内部浏览器执行js后,会做一次页面跳转,跳转到执行js后生成的新页面。如果js执行失败,页面跳转将不会被执行。
最后可以通过获取 page.executeJavaScript(javascript).getNewPage() 来获取执行后的页面。也就是说,这里需要人工执行javascript。显然这不符合我的初衷。另外,也可能是我水平太差了。我在爬新浪新闻页面的时候总是出错。暂时没找到错误的地方,但是根据网上的查询结果分析,最可能的错误原因是htmlunit在执行一些带参数的请求时,请求失败并出现由于参数顺序或编码问题而报告错误。关键是我运行后没有得到我需要的结果。
然后我寻找了另一种解决方案。这时候我找到了SeleniumWebDriver,这就是我需要的解决方案。
参考资料和例子后,就可以开始使用了。示例代码如下。
<p> 1 File pathToBinary = new File("D:\\Program Files (x86)\\Mozilla Firefox\\firefox.exe");
2 FirefoxBinary ffBinary = new FirefoxBinary(pathToBinary);
3 FirefoxProfile firefoxProfile = new FirefoxProfile();
4 FirefoxDriver driver = new FirefoxDriver(ffBinary,firefoxProfile);
5
6
7 driver.get("http://cq.qq.com/baoliao/detail.htm?294064");
8
9 ArrayList list = new ArrayList();
10 list.add("http://www.sina.com.cn");
11 list.add("http://www.sohu.com");
12 list.add("http://www.163.com");
13 list.add("http://www.qq.com");
14
15 long start,end;
16
17 for(int i=0;i 查看全部
js 爬虫抓取网页数据(别的项目组什么项目突然心血来潮想研究一下爬虫、分析的简单原型)
因为其他项目组都在做舆情预测项目,我只是手头没有项目,突然想研究一个爬虫的简单原型,心血来潮分析。网上查这方面的资料太多了,看得我眼花缭乱。Search Search 对于我这种新手,想做一个简单的爬虫程序,HttpClient + jsoup 是个不错的选择。前者是用来管理请求的,后者是用来解析页面的,主要是因为后者的select语法和jquery很像,对我这个用js的人来说太方便了。
昨天和他们聊天的时候,他们选择了几个知名的开源框架来使用,聊天后发现他们目前没有办法抓取动态网页,尤其是几个重要的数字,比如评论数量和数量的答复。等等,一般的理解,比如TRS爬虫需要写js脚本来调用js,但是分析量巨大。他们的技术人员告诉我们,如果他们配备了这样的模板,他们一天只能配备2到3个,更不用说我们这些中途出家的人了。碰巧挺有挑战性的,所以昨天就同意了,看看他们能不能找到一个相对简单的解决方案,当然,不考虑效率。
举个简单的例子,如下图
“我有话要说”后面的1307是后装的,但这些数字往往对舆论分析更重要。
对需求有了大致的了解之后,我们来分析一下如何解决。通常我们对一个请求得到的响应收录js代码和html元素,所以像jsoup这样的html解析器很难在这里利用它,因为它可以得到的html,1307还没有生成。这时候就需要一个可以运行js的平台,将运行js代码后的页面交给html进行解析,这样才能正确得到结果。
因为比较懒,一开始就放弃了写脚本的方式,因为分析一个页面太痛苦,代码乱七八糟。其中很多也使用了压缩方法,都是a()、b()方法。看的太累了。所以我的第一个想法是,为什么我不能让这个地址在某个浏览器中运行,然后将运行的结果传递给html解析器进行分析,那么整个问题就迎刃而解了。所以我的临时解决办法是在爬虫服务器上打开一个后台浏览器,或者一个带有浏览器内核的程序,把URL地址传给它来请求,然后从浏览器中取出页面的元素交给html解析器来解析,从而得到你想要的信息。
是的,最后还是用Selenium来实现上一篇我提到的问题。我没有尝试其他任何东西。我只试过火狐引擎。整体效果还是可以接受的。
继续昨天的话题,既然要实现上一篇提到的问题,就需要一个可以执行js代码的框架。我的第一选择是 htmlunit。先简单介绍一下htmlunit。以下段落摘自互联网。
htmlunit 是一个开源的java 页面分析工具。启动 htmlunit 后,将在底部启动一个无界面浏览器。用户可以指定浏览器类型:firefox、ie等,如果不指定,默认使用INTERNET_EXPLORER_7:
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_3_6);
通过一个简单的调用:
HtmlPage 页面 = webClient.getPage(url);
可以得到页面的HtmlPage表示,然后通过:
InputStream 是 = targetPage.getWebResponse().getContentAsStream()
可以获取页面的输入流,进而获取页面的源代码,这对于网络爬虫项目非常有用。
当然,你也可以从页面中获取更多的页面元素。
很重要的一点是 HtmlUnit 提供了对执行 javascript 的支持:
page.executeJavaScript(javascript)
js执行后返回一个ScriptResult对象,通过该对象可以获取js执行后的页面等信息。默认情况下,内部浏览器执行js后,会做一次页面跳转,跳转到执行js后生成的新页面。如果js执行失败,页面跳转将不会被执行。
最后可以通过获取 page.executeJavaScript(javascript).getNewPage() 来获取执行后的页面。也就是说,这里需要人工执行javascript。显然这不符合我的初衷。另外,也可能是我水平太差了。我在爬新浪新闻页面的时候总是出错。暂时没找到错误的地方,但是根据网上的查询结果分析,最可能的错误原因是htmlunit在执行一些带参数的请求时,请求失败并出现由于参数顺序或编码问题而报告错误。关键是我运行后没有得到我需要的结果。
然后我寻找了另一种解决方案。这时候我找到了SeleniumWebDriver,这就是我需要的解决方案。
参考资料和例子后,就可以开始使用了。示例代码如下。
<p> 1 File pathToBinary = new File("D:\\Program Files (x86)\\Mozilla Firefox\\firefox.exe");
2 FirefoxBinary ffBinary = new FirefoxBinary(pathToBinary);
3 FirefoxProfile firefoxProfile = new FirefoxProfile();
4 FirefoxDriver driver = new FirefoxDriver(ffBinary,firefoxProfile);
5
6
7 driver.get("http://cq.qq.com/baoliao/detail.htm?294064";);
8
9 ArrayList list = new ArrayList();
10 list.add("http://www.sina.com.cn";);
11 list.add("http://www.sohu.com";);
12 list.add("http://www.163.com";);
13 list.add("http://www.qq.com";);
14
15 long start,end;
16
17 for(int i=0;i
js 爬虫抓取网页数据(#js爬虫抓取网页数据-jquery前端基础参数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-14 00:06
js爬虫抓取网页数据我这里使用的是chrome浏览器,这是我写的爬虫代码:js数据抓取--jquery前端基础这里的参数#lang=en-us这里是中文数据抓取框#lang=en-us#lang=en-us#lang=en-us#lang=en-usstdswriter.jsx#lang=en-us#lang=en-us#lang=en-us#lang=en-us#lang=en-us#lang=en-usdocx是对jsx文件文件进行分析,首先以jsx文件的标签语言,进行解析jsx。第一步,对jsx文件进行读取。
js的文件还是要有一个链接比较好,所以其实file->readthefile和as->readfile。如果是javascript文件,javascript.ts用的比较多。如果你是要参数和属性值之类的,这个就得找一些实例了。
一般都是lib中的attribute
网站包含javascript,javascript是javascript文件中的.js文件,js文件即javascript文件。现有的一般是a.js,b.js文件,也可以是其他结构的文件。一般用libs。现在很多网站的配置中,会用到esprima,html标签等辅助文件来校验搜索引擎等。
.es和.el文件。
javascript的文件用javascript.esdom标签可以包含动态构建的数据 查看全部
js 爬虫抓取网页数据(#js爬虫抓取网页数据-jquery前端基础参数)
js爬虫抓取网页数据我这里使用的是chrome浏览器,这是我写的爬虫代码:js数据抓取--jquery前端基础这里的参数#lang=en-us这里是中文数据抓取框#lang=en-us#lang=en-us#lang=en-us#lang=en-usstdswriter.jsx#lang=en-us#lang=en-us#lang=en-us#lang=en-us#lang=en-us#lang=en-usdocx是对jsx文件文件进行分析,首先以jsx文件的标签语言,进行解析jsx。第一步,对jsx文件进行读取。
js的文件还是要有一个链接比较好,所以其实file->readthefile和as->readfile。如果是javascript文件,javascript.ts用的比较多。如果你是要参数和属性值之类的,这个就得找一些实例了。
一般都是lib中的attribute
网站包含javascript,javascript是javascript文件中的.js文件,js文件即javascript文件。现有的一般是a.js,b.js文件,也可以是其他结构的文件。一般用libs。现在很多网站的配置中,会用到esprima,html标签等辅助文件来校验搜索引擎等。
.es和.el文件。
javascript的文件用javascript.esdom标签可以包含动态构建的数据
js 爬虫抓取网页数据(以前第一篇爬虫教程.js爬虫入门(一)爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-13 08:30
第一篇爬虫教程node.js爬虫介绍(一)爬取静态页面讲解了静态网页的爬取,很简单,但是如果遇到一些动态网页(ajax),直接使用前面的发送请求方法是不可能得到我们想要的数据的,这时候就需要通过爬取动态网页的方法了,selenium和puppeteer都不错,前端
在这里推荐 Puppeteer,不是为了别的,只是因为它是 Google 自己的,并且一直在维护更新。以下是官方文档介绍节点的翻译
Puppeteer 是一个 Node 库,通过 DevTools(开发者工具)协议提供了一系列高级接口来控制 Chrome 或 Chromium(谷歌开源)。默认运行在headless模式(无浏览器UI界面),配置后也可以运行在普通模式。网络
可以使用:ajax
首先,我们必须先安装它,然后才能使用它。最新的Chromium会默认安装下载,大小约300M。铬合金
npm install puppeteer
复制代码
如果你的机器上已经有较新版本的chrome,可以只安装核心版本,但是启动puppeteer时,需要配置本地chrome路径。数据库
npm install puppeteer-core // 核心版本
复制代码
假设我们要爬取拉勾的前端招聘信息。这是一个动态页面。使用此示例尝试抓取。新产品经理
由于chrome操作都是异步操作,为了不回调地狱,推荐使用es7 async await。这种语法具有高度可读性,官方文档也是如此。浏览器
首先使用puppeteer启动浏览器,打开动态页面
需要注意的是,如果使用的是本地浏览器,则需要在启动浏览器配置中传入本地chrome路径markdown。
const browser = await puppeteer.launch({
executablePath: 'C:/Users/Administrator/AppData/Local/Google/Chrome/Application/chrome.exe'
})
复制代码
在chrome环境中执行函数,获取需要的数据,然后返回到node的执行环境
上图可以看到我们需要的数据的dom位置。在chrome环境执行的函数中,我们需要获取和整理需要的数据。较少的
let list = document.querySelectorAll('.s_position_list .item_con_list li')
let res = []
for (let i = 0; i < list.length; i++) {
res.push({
name: list[i].getAttribute('data-positionname'),
company: list[i].getAttribute('data-company'),
salary: list[i].getAttribute('data-salary'),
require: list[i].querySelector('.li_b_l').childNodes[4].textContent.replace(/ |\n/g, ''),
})
}
return res
复制代码
这里有一个调试技巧,我们可以直接在chrome控制台中编写获取数据的函数,方便调试
最后附上完整代码
const puppeteer = require('puppeteer');
(async () => {
// 启动浏览器
const browser = await puppeteer.launch({
headless: false, // 默认是无头模式,这里为了示范因此使用正常模式
})
// 控制浏览器打开新标签页面
const page = await browser.newPage()
// 在新标签中打开要爬取的网页
await page.goto('https://www.lagou.com/jobs/list_web%E5%89%8D%E7%AB%AF?px=new&city=%E5%B9%BF%E5%B7%9E')
// 使用evaluate方法在浏览器中执行传入函数(彻底的浏览器环境,因此函数内能够直接使用window、document等全部对象和方法)
let data = await page.evaluate(() => {
let list = document.querySelectorAll('.s_position_list .item_con_list li')
let res = []
for (let i = 0; i < list.length; i++) {
res.push({
name: list[i].getAttribute('data-positionname'),
company: list[i].getAttribute('data-company'),
salary: list[i].getAttribute('data-salary'),
require: list[i].querySelector('.li_b_l').childNodes[4].textContent.replace(/ |\n/g, ''),
})
}
return res
})
console.log(data)
})()
复制代码
操作结果
动态网页的爬取也到此完成,但puppeteer的功能远不止这些,还有很多强大的API可用。能够移动到正式文件。
第三期会讲如何定时执行爬虫并存入数据库。 查看全部
js 爬虫抓取网页数据(以前第一篇爬虫教程.js爬虫入门(一)爬取)
第一篇爬虫教程node.js爬虫介绍(一)爬取静态页面讲解了静态网页的爬取,很简单,但是如果遇到一些动态网页(ajax),直接使用前面的发送请求方法是不可能得到我们想要的数据的,这时候就需要通过爬取动态网页的方法了,selenium和puppeteer都不错,前端
在这里推荐 Puppeteer,不是为了别的,只是因为它是 Google 自己的,并且一直在维护更新。以下是官方文档介绍节点的翻译
Puppeteer 是一个 Node 库,通过 DevTools(开发者工具)协议提供了一系列高级接口来控制 Chrome 或 Chromium(谷歌开源)。默认运行在headless模式(无浏览器UI界面),配置后也可以运行在普通模式。网络
可以使用:ajax
首先,我们必须先安装它,然后才能使用它。最新的Chromium会默认安装下载,大小约300M。铬合金
npm install puppeteer
复制代码
如果你的机器上已经有较新版本的chrome,可以只安装核心版本,但是启动puppeteer时,需要配置本地chrome路径。数据库
npm install puppeteer-core // 核心版本
复制代码
假设我们要爬取拉勾的前端招聘信息。这是一个动态页面。使用此示例尝试抓取。新产品经理
由于chrome操作都是异步操作,为了不回调地狱,推荐使用es7 async await。这种语法具有高度可读性,官方文档也是如此。浏览器
首先使用puppeteer启动浏览器,打开动态页面
需要注意的是,如果使用的是本地浏览器,则需要在启动浏览器配置中传入本地chrome路径markdown。
const browser = await puppeteer.launch({
executablePath: 'C:/Users/Administrator/AppData/Local/Google/Chrome/Application/chrome.exe'
})
复制代码
在chrome环境中执行函数,获取需要的数据,然后返回到node的执行环境
上图可以看到我们需要的数据的dom位置。在chrome环境执行的函数中,我们需要获取和整理需要的数据。较少的
let list = document.querySelectorAll('.s_position_list .item_con_list li')
let res = []
for (let i = 0; i < list.length; i++) {
res.push({
name: list[i].getAttribute('data-positionname'),
company: list[i].getAttribute('data-company'),
salary: list[i].getAttribute('data-salary'),
require: list[i].querySelector('.li_b_l').childNodes[4].textContent.replace(/ |\n/g, ''),
})
}
return res
复制代码
这里有一个调试技巧,我们可以直接在chrome控制台中编写获取数据的函数,方便调试
最后附上完整代码
const puppeteer = require('puppeteer');
(async () => {
// 启动浏览器
const browser = await puppeteer.launch({
headless: false, // 默认是无头模式,这里为了示范因此使用正常模式
})
// 控制浏览器打开新标签页面
const page = await browser.newPage()
// 在新标签中打开要爬取的网页
await page.goto('https://www.lagou.com/jobs/list_web%E5%89%8D%E7%AB%AF?px=new&city=%E5%B9%BF%E5%B7%9E')
// 使用evaluate方法在浏览器中执行传入函数(彻底的浏览器环境,因此函数内能够直接使用window、document等全部对象和方法)
let data = await page.evaluate(() => {
let list = document.querySelectorAll('.s_position_list .item_con_list li')
let res = []
for (let i = 0; i < list.length; i++) {
res.push({
name: list[i].getAttribute('data-positionname'),
company: list[i].getAttribute('data-company'),
salary: list[i].getAttribute('data-salary'),
require: list[i].querySelector('.li_b_l').childNodes[4].textContent.replace(/ |\n/g, ''),
})
}
return res
})
console.log(data)
})()
复制代码
操作结果
动态网页的爬取也到此完成,但puppeteer的功能远不止这些,还有很多强大的API可用。能够移动到正式文件。
第三期会讲如何定时执行爬虫并存入数据库。

