
js提取指定网站内容
js提取指定网站内容(如何去组织所有文章的功能了吗?|之旅)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-20 12:17
1. 前言
这个文章藏在心里很久了,久久不敢开始写。主要是不知道怎么组织这样的技术文章文章。
其实我个人觉得技术文章是最难写的,细节往往很难把握。一些技术细节没有解释到位,对于害怕阅读的人来说很难。相反,一些简单的东西怕解释的太多,增加了不必要的章节。
教人钓鱼不如教人钓鱼
所以,在这个文章中,我会尽量少发代码,多谈谈思考过程。
2. 编码的原因
最近在重建我的个人网站,想把我在简写的所有文章数据导入到那个网站。
这时候可能有朋友不高兴了:“如果你想得到你写的所有文章,为什么还要写代码?简书是不是已经提供了下载所有文章的功能?当前用户?”
兄弟们说得对。首先我要声明,简书确实是一个很棒的写作平台。可以满足大部分用户的需求,但是对于我这个癌症晚期的“懒惰”程序员来说,还是有点不适应。太多了。我有以下考虑
坚持
不要重复自己
带着这个原理,让我们开始这次的爬虫之旅。
3. 功能介绍
简述爬虫的作用
向服务器发送请求,获取所有作者的文章。从文章中提取你需要的数据(文章内容、标题、发布日期...),整理好数据,存放到对应的数据库中。
本文将重点介绍页面请求、分析和数据组织。至于如何在数据库中存储数据,我就不多说了。有兴趣的可以直接看源码。
4. 技术栈
最后选择使用node.js来写这个爬虫。毕竟重新学习python或ruby等服务器端语言要花很多时间。当然这还不够。
工欲善其事,必先利其器
为了写更少的代码,我还需要一个更成熟的爬虫框架。这里使用了节点爬虫。个人觉得这是一个很酷的爬虫框架,前端人员在使用的时候会觉得比较亲切——我们可以用我们最亲切的jQuery语法来解析响应返回的页面。
5. 数据模型
在我们要爬取东西之前,首先要确认我们要爬取什么。为了简化文章,我将需要爬取的内容设置为以下三个字段(源码可以多于这三个字段)。
我只需要找到一种方法,从响应返回的页面中提取上述三种类型的数据。至于把数据存放在什么数据库中,如何存放,就看个人喜好了。
6. 制定爬取策略(1) 基本信息爬取
首先进入通讯作者短书首页,类似这个页面。我们会看到一堆文章列表,看看能不能提取出我们需要的信息?
嗯,问题挺多的,除了文章这个标题,其他的内容好像很难抓取。不管怎样,都得去文章详情页查看
看来详情页还是可以满足我的需求的。因此,我决定使用以下策略来提取基本信息
(2)面对滚动加载,如何获取所有文章?
当我进入特定作者的简书首页时,我发现简书实际上并没有加载作者的所有文章,他只是加载了文章列表的一部分。如果需要获取更多的 文章 列表,则需要向下滚动并从服务器请求更多页面。
一开始我是站在前端的角度考虑这个问题,真的很痛苦。我最初的想法是使用一些库,例如 phantomjs 来模拟浏览器的行为。我打算模拟浏览器的滚动行为,并在数据加载后继续滚动,直到不再从服务器请求数据。我真的这样做了,后来才发现这是一场噩梦,这意味着我不得不做以下事情:
先不说有没有库支持上面的功能,上面的策略对于挑剔的人来说都是不靠谱的,估计只有我一个人傻傻的跑着试了。经过多次尝试,发现模拟滚动行为相当困难,使用phantomjs时开发环境经常卡死。我的直觉告诉我,可能有更好的方法来做到这一点。当你对一个问题感到困惑时,你可能会尝试超越原来的思维方式,换个角度思考问题。问题往往要简单得多。
后来从后端的角度考虑了这个
问:这种加载更多行为的本质是什么?
答:向服务器发送请求以获取更多页面数据。
那么我只需要知道浏览器向服务器发送的请求的URL以及页面滚动时的相应参数,就可以使用爬虫来迭代发送这个请求,进而达到获取<的完整列表的目的@文章 ?
OK,马上去Network,就可以看到我们发送的网络请求了。清除网络下的历史记录后,我滚动页面,发现以下内容。
服务器响应后,返回渲染的列表数据。果然,如我所料。然后我会看完整的网址
原来它是使用分页参数page向服务器请求分页数据的。我通过代码封装了这个过程
var i = 1;
var queue = []
while( i < 10) {
var uriObject = {
uri: 'http://www.jianshu.com/u/a8522ac98584?order_by=shared_at&&page=' + i,
queue.push(uriObject);
i ++;
}
这只是代码片段的一部分,将 10 个 URL 存储到队列数组中。最后只能得到10页的数据,但是有问题。如果真实数据少于10页,如何处理?
我试图请求第 100 页上的数据,看看会发生什么。发现简书服务器返回302状态码,然后浏览器跳转到个人动态页面。
这个状态码很有用,我可以判断我们请求的页码参数page的值是否超过了这个状态码指定的页数。
我可以预设更多的请求。如果请求返回此状态码,则不会对请求的数据进行任何处理(因为已超出页数)。否则,分析返回的数据以提取我们需要的关键数据。
当然,这种方式相当粗鲁,会发送很多不必要的请求。有时间我会优化这部分代码。
7. 页面分析
发送请求后,我们可以在服务器响应后得到我们需要的页面。接下来要做的就是解析页面结果,提取我们需要的内容。如上所述,node-crawler 的爬虫框架内置了 jQuery,这让我们的页面解析工作变得更加轻松。
(1)获取文章详情页的url
我们来看看文章列表中每个条目的html结构(简书的程序员也有评论)。
我们只需要提取ul.note-list中的每个li a.title,然后提取它们的href属性对应的值,也就是我们需要获取的url。这种操作对于jQuery来说简直是小菜一碟。以下是我的代码片段。我把所有的网址都提出来之后,就会存放在articlesLink数组中,以备后用。
let articlesLink = [];
$('ul.note-list').find('li').each((i, item) => {
var $article = $(item);
let link = $article.find('.title').attr('href');
articlesLink.push(link);
})
(2)从详情页提取数据
查看详情页的结构
从页面结构中,我们可以很容易的提取出发布日期这两个字段的标题和内容
let title = $article.find('.title').text();
let date = $article.find('.publish-time').text().replace('*', '');
一些更新的文章在发布日期结束时会有一个*,所以我需要处理它们以避免干扰。但是,文章主体的提取存在一些问题。
我希望得到的最后一件事是降价格式的字符串。此时,我可以通过 to-markdown 包将 html 转换为 markdown。但是现在的问题是这个包好像无法解析div标签。我在想把文章的body里面的div标签全部删掉,然后通过to-markdown把处理后的字符串转换成对应的markdown格式字符串,然后就可以得到我们期望的数据了。
既然jQuery是神器,实现起来也不会很麻烦。但是我也想删除收录类名image-caption的label——这是简书的默认设置,有时候有点碍眼,可以考虑删除。
下面是我的代码片段:
var toMarkdown = require('to-markdown');
// 删除图片的标题
let $content = $article.find('.show-content');
$content.find('.image-caption').remove();
$content.find('div').each(function(i, item) {
var children = $(this).html();
$(this).replaceWith(children);
})
// 获取markdown格式的文章
let articleBody = toMarkdown($content.html());
最后,只需将它们放入对象中:
let article;
article = {
title: title,
date: new Date(date),
articleBody: articleBody
}
至于如何将上述数据存入数据库,方法有很多种。考虑到文章的长度,这里就不赘述了。个人尊重MongoDB。它是目前使用最多的非关系型数据库,非常灵活。对于构建渐进式应用程序,我认为这是一个更好的选择。在频繁修改表结构的情况下,至少不需要维护大量的迁移文件。
最终的存储结果如下,正好是68篇文章
结尾
不知不觉这个文章已经占用了好几个小时了,就算这个文章我把不必要的代码细节去掉了,重点说说自己的思考过程和遇到的问题。,不过还是写了很多字。视觉概括能力有待提高~~~~
注:本文只是一些经验和思考过程的总结,github源码仅供参考,并非即插即用包。可以根据自己的情况写一个符合自己需求的爬虫。我相信你可以比我做得更好。
快乐编码和写作!! 查看全部
js提取指定网站内容(如何去组织所有文章的功能了吗?|之旅)
1. 前言
这个文章藏在心里很久了,久久不敢开始写。主要是不知道怎么组织这样的技术文章文章。
其实我个人觉得技术文章是最难写的,细节往往很难把握。一些技术细节没有解释到位,对于害怕阅读的人来说很难。相反,一些简单的东西怕解释的太多,增加了不必要的章节。
教人钓鱼不如教人钓鱼
所以,在这个文章中,我会尽量少发代码,多谈谈思考过程。
2. 编码的原因
最近在重建我的个人网站,想把我在简写的所有文章数据导入到那个网站。
这时候可能有朋友不高兴了:“如果你想得到你写的所有文章,为什么还要写代码?简书是不是已经提供了下载所有文章的功能?当前用户?”

兄弟们说得对。首先我要声明,简书确实是一个很棒的写作平台。可以满足大部分用户的需求,但是对于我这个癌症晚期的“懒惰”程序员来说,还是有点不适应。太多了。我有以下考虑
坚持
不要重复自己
带着这个原理,让我们开始这次的爬虫之旅。
3. 功能介绍
简述爬虫的作用
向服务器发送请求,获取所有作者的文章。从文章中提取你需要的数据(文章内容、标题、发布日期...),整理好数据,存放到对应的数据库中。
本文将重点介绍页面请求、分析和数据组织。至于如何在数据库中存储数据,我就不多说了。有兴趣的可以直接看源码。
4. 技术栈
最后选择使用node.js来写这个爬虫。毕竟重新学习python或ruby等服务器端语言要花很多时间。当然这还不够。
工欲善其事,必先利其器
为了写更少的代码,我还需要一个更成熟的爬虫框架。这里使用了节点爬虫。个人觉得这是一个很酷的爬虫框架,前端人员在使用的时候会觉得比较亲切——我们可以用我们最亲切的jQuery语法来解析响应返回的页面。
5. 数据模型
在我们要爬取东西之前,首先要确认我们要爬取什么。为了简化文章,我将需要爬取的内容设置为以下三个字段(源码可以多于这三个字段)。
我只需要找到一种方法,从响应返回的页面中提取上述三种类型的数据。至于把数据存放在什么数据库中,如何存放,就看个人喜好了。
6. 制定爬取策略(1) 基本信息爬取
首先进入通讯作者短书首页,类似这个页面。我们会看到一堆文章列表,看看能不能提取出我们需要的信息?
嗯,问题挺多的,除了文章这个标题,其他的内容好像很难抓取。不管怎样,都得去文章详情页查看
看来详情页还是可以满足我的需求的。因此,我决定使用以下策略来提取基本信息
(2)面对滚动加载,如何获取所有文章?
当我进入特定作者的简书首页时,我发现简书实际上并没有加载作者的所有文章,他只是加载了文章列表的一部分。如果需要获取更多的 文章 列表,则需要向下滚动并从服务器请求更多页面。

一开始我是站在前端的角度考虑这个问题,真的很痛苦。我最初的想法是使用一些库,例如 phantomjs 来模拟浏览器的行为。我打算模拟浏览器的滚动行为,并在数据加载后继续滚动,直到不再从服务器请求数据。我真的这样做了,后来才发现这是一场噩梦,这意味着我不得不做以下事情:
先不说有没有库支持上面的功能,上面的策略对于挑剔的人来说都是不靠谱的,估计只有我一个人傻傻的跑着试了。经过多次尝试,发现模拟滚动行为相当困难,使用phantomjs时开发环境经常卡死。我的直觉告诉我,可能有更好的方法来做到这一点。当你对一个问题感到困惑时,你可能会尝试超越原来的思维方式,换个角度思考问题。问题往往要简单得多。
后来从后端的角度考虑了这个
问:这种加载更多行为的本质是什么?
答:向服务器发送请求以获取更多页面数据。
那么我只需要知道浏览器向服务器发送的请求的URL以及页面滚动时的相应参数,就可以使用爬虫来迭代发送这个请求,进而达到获取<的完整列表的目的@文章 ?
OK,马上去Network,就可以看到我们发送的网络请求了。清除网络下的历史记录后,我滚动页面,发现以下内容。
服务器响应后,返回渲染的列表数据。果然,如我所料。然后我会看完整的网址
原来它是使用分页参数page向服务器请求分页数据的。我通过代码封装了这个过程
var i = 1;
var queue = []
while( i < 10) {
var uriObject = {
uri: 'http://www.jianshu.com/u/a8522ac98584?order_by=shared_at&&page=' + i,
queue.push(uriObject);
i ++;
}
这只是代码片段的一部分,将 10 个 URL 存储到队列数组中。最后只能得到10页的数据,但是有问题。如果真实数据少于10页,如何处理?
我试图请求第 100 页上的数据,看看会发生什么。发现简书服务器返回302状态码,然后浏览器跳转到个人动态页面。
这个状态码很有用,我可以判断我们请求的页码参数page的值是否超过了这个状态码指定的页数。
我可以预设更多的请求。如果请求返回此状态码,则不会对请求的数据进行任何处理(因为已超出页数)。否则,分析返回的数据以提取我们需要的关键数据。
当然,这种方式相当粗鲁,会发送很多不必要的请求。有时间我会优化这部分代码。
7. 页面分析
发送请求后,我们可以在服务器响应后得到我们需要的页面。接下来要做的就是解析页面结果,提取我们需要的内容。如上所述,node-crawler 的爬虫框架内置了 jQuery,这让我们的页面解析工作变得更加轻松。
(1)获取文章详情页的url
我们来看看文章列表中每个条目的html结构(简书的程序员也有评论)。
我们只需要提取ul.note-list中的每个li a.title,然后提取它们的href属性对应的值,也就是我们需要获取的url。这种操作对于jQuery来说简直是小菜一碟。以下是我的代码片段。我把所有的网址都提出来之后,就会存放在articlesLink数组中,以备后用。
let articlesLink = [];
$('ul.note-list').find('li').each((i, item) => {
var $article = $(item);
let link = $article.find('.title').attr('href');
articlesLink.push(link);
})
(2)从详情页提取数据
查看详情页的结构
从页面结构中,我们可以很容易的提取出发布日期这两个字段的标题和内容
let title = $article.find('.title').text();
let date = $article.find('.publish-time').text().replace('*', '');
一些更新的文章在发布日期结束时会有一个*,所以我需要处理它们以避免干扰。但是,文章主体的提取存在一些问题。
我希望得到的最后一件事是降价格式的字符串。此时,我可以通过 to-markdown 包将 html 转换为 markdown。但是现在的问题是这个包好像无法解析div标签。我在想把文章的body里面的div标签全部删掉,然后通过to-markdown把处理后的字符串转换成对应的markdown格式字符串,然后就可以得到我们期望的数据了。
既然jQuery是神器,实现起来也不会很麻烦。但是我也想删除收录类名image-caption的label——这是简书的默认设置,有时候有点碍眼,可以考虑删除。
下面是我的代码片段:
var toMarkdown = require('to-markdown');
// 删除图片的标题
let $content = $article.find('.show-content');
$content.find('.image-caption').remove();
$content.find('div').each(function(i, item) {
var children = $(this).html();
$(this).replaceWith(children);
})
// 获取markdown格式的文章
let articleBody = toMarkdown($content.html());
最后,只需将它们放入对象中:
let article;
article = {
title: title,
date: new Date(date),
articleBody: articleBody
}
至于如何将上述数据存入数据库,方法有很多种。考虑到文章的长度,这里就不赘述了。个人尊重MongoDB。它是目前使用最多的非关系型数据库,非常灵活。对于构建渐进式应用程序,我认为这是一个更好的选择。在频繁修改表结构的情况下,至少不需要维护大量的迁移文件。
最终的存储结果如下,正好是68篇文章
结尾
不知不觉这个文章已经占用了好几个小时了,就算这个文章我把不必要的代码细节去掉了,重点说说自己的思考过程和遇到的问题。,不过还是写了很多字。视觉概括能力有待提高~~~~
注:本文只是一些经验和思考过程的总结,github源码仅供参考,并非即插即用包。可以根据自己的情况写一个符合自己需求的爬虫。我相信你可以比我做得更好。
快乐编码和写作!!
js提取指定网站内容( 调用session.get()方法,该方法返回一个响应对象)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-18 17:10
调用session.get()方法,该方法返回一个响应对象)
import requests
from bs4 import BeautifulSoup as bs
from urllib.parse import urljoin
# URL of the web page you want to extract
url = "http://books.toscrape.com"
# initialize a session
session = requests.Session()
# set the User-agent as a regular browser
session.headers["User-Agent"] = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"
现在要下载网页的所有 HTML 内容,我们需要做的就是调用 session.get() 方法,该方法返回一个响应对象。我们只对 HTML 代码感兴趣,而不是整个响应:
# get the HTML content
html = session.get(url).content
# parse HTML using beautiful soup
soup = bs(html, "html.parser")
现在我们有了 Soup,让我们提取所有脚本和 CSS 文件。我们使用soup.find_all() 方法返回所有用标签和传递属性过滤的HTML Soup 对象:
# get the JavaScript files
script_files = []
for script in soup.find_all("script"):
if script.attrs.get("src"):
# if the tag has the attribute 'src'
script_url = urljoin(url, script.attrs.get("src"))
script_files.append(script_url)
所以基本上我们正在搜索具有 src 属性的脚本标签,这些标签通常链接到这个 网站 所需的 Javascript 文件。
Python是如何提取Javascript和CSS的?同样,我们可以使用它来提取 CSS 文件:
# get the CSS files
css_files = []
for css in soup.find_all("link"):
if css.attrs.get("href"):
# if the link tag has the 'href' attribute
css_url = urljoin(url, css.attrs.get("href"))
css_files.append(css_url)
您可能知道,CSS 文件位于链接标签的 href 属性中。我们使用 urljoin() 函数来确保链接是绝对链接(即它有完整路径,而不是相对路径,例如 /js/script.js)。
最后,让我们打印所有脚本和 CSS 文件并将链接写入单独的文件。以下是 Python 提取 Javascript 和 CSS 的示例:
print("Total script files in the page:", len(script_files))
print("Total CSS files in the page:", len(css_files))
# write file links into files
with open("javascript_files.txt", "w") as f:
for js_file in script_files:
print(js_file, file=f)
with open("css_files.txt", "w") as f:
for css_file in css_files:
print(css_file, file=f)
? 执行后,将出现 2 个文件,一个用于 Javascript 链接,另一个用于 CSS 文件:
css_files.txt
http://books.toscrape.com/static/oscar/favicon.ico
http://books.toscrape.com/stat ... s.css
http://books.toscrape.com/stat ... r.css
http://books.toscrape.com/stat ... r.css
javascript_files.txt
http://ajax.googleapis.com/aja ... in.js
http://books.toscrape.com/stat ... in.js
http://books.toscrape.com/stat ... ui.js
http://books.toscrape.com/stat ... er.js
http://books.toscrape.com/stat ... ll.js
好的,最后,我鼓励您进一步扩展此代码以构建一个复杂的审计工具,该工具可以识别不同的文件、它们的大小,并可能建议优化 网站!
作为挑战,尝试下载所有这些文件并将它们存储在本地磁盘上(本教程可以提供帮助)。
我有另一个教程向您展示如何提取所有 网站 链接,请查看这里。
另外,如果你分析的网站不小心屏蔽了你的IP地址,这种情况下你需要使用代理服务器。 查看全部
js提取指定网站内容(
调用session.get()方法,该方法返回一个响应对象)
import requests
from bs4 import BeautifulSoup as bs
from urllib.parse import urljoin
# URL of the web page you want to extract
url = "http://books.toscrape.com"
# initialize a session
session = requests.Session()
# set the User-agent as a regular browser
session.headers["User-Agent"] = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"
现在要下载网页的所有 HTML 内容,我们需要做的就是调用 session.get() 方法,该方法返回一个响应对象。我们只对 HTML 代码感兴趣,而不是整个响应:
# get the HTML content
html = session.get(url).content
# parse HTML using beautiful soup
soup = bs(html, "html.parser")
现在我们有了 Soup,让我们提取所有脚本和 CSS 文件。我们使用soup.find_all() 方法返回所有用标签和传递属性过滤的HTML Soup 对象:
# get the JavaScript files
script_files = []
for script in soup.find_all("script"):
if script.attrs.get("src"):
# if the tag has the attribute 'src'
script_url = urljoin(url, script.attrs.get("src"))
script_files.append(script_url)
所以基本上我们正在搜索具有 src 属性的脚本标签,这些标签通常链接到这个 网站 所需的 Javascript 文件。
Python是如何提取Javascript和CSS的?同样,我们可以使用它来提取 CSS 文件:
# get the CSS files
css_files = []
for css in soup.find_all("link"):
if css.attrs.get("href"):
# if the link tag has the 'href' attribute
css_url = urljoin(url, css.attrs.get("href"))
css_files.append(css_url)
您可能知道,CSS 文件位于链接标签的 href 属性中。我们使用 urljoin() 函数来确保链接是绝对链接(即它有完整路径,而不是相对路径,例如 /js/script.js)。
最后,让我们打印所有脚本和 CSS 文件并将链接写入单独的文件。以下是 Python 提取 Javascript 和 CSS 的示例:
print("Total script files in the page:", len(script_files))
print("Total CSS files in the page:", len(css_files))
# write file links into files
with open("javascript_files.txt", "w") as f:
for js_file in script_files:
print(js_file, file=f)
with open("css_files.txt", "w") as f:
for css_file in css_files:
print(css_file, file=f)
? 执行后,将出现 2 个文件,一个用于 Javascript 链接,另一个用于 CSS 文件:
css_files.txt
http://books.toscrape.com/static/oscar/favicon.ico
http://books.toscrape.com/stat ... s.css
http://books.toscrape.com/stat ... r.css
http://books.toscrape.com/stat ... r.css
javascript_files.txt
http://ajax.googleapis.com/aja ... in.js
http://books.toscrape.com/stat ... in.js
http://books.toscrape.com/stat ... ui.js
http://books.toscrape.com/stat ... er.js
http://books.toscrape.com/stat ... ll.js
好的,最后,我鼓励您进一步扩展此代码以构建一个复杂的审计工具,该工具可以识别不同的文件、它们的大小,并可能建议优化 网站!
作为挑战,尝试下载所有这些文件并将它们存储在本地磁盘上(本教程可以提供帮助)。
我有另一个教程向您展示如何提取所有 网站 链接,请查看这里。
另外,如果你分析的网站不小心屏蔽了你的IP地址,这种情况下你需要使用代理服务器。
js提取指定网站内容( 55chenguiya阅读(11197)评论(0))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-18 03:10
55chenguiya阅读(11197)评论(0))
js 提取文本内容中的 URL url 并自动添加超链接地址
第一种方法:如图
HTML 代码是:
发动最后一次的宣传,看看是否连接可以点击了 ,如果不行,找我,如果行,就不要找我了!http://www.5usport.com 我的http://app.5usport.com
JS代码为:
//链接可点击
if($('.thread_mess').length){
var textR=$('.thread_mess').html();
var reg = /(http:\/\/|https:\/\/)((\w|=|\?|\.|\/|&|-)+)/g;
var imgSRC=$('.thread_mess img').attr('src');
if(reg.exec(imgSRC)){
return false
}else{
textR = textR.replace(reg, "$1$2");
}
document.getElementById('thread_imgid').innerHTML = textR;
}
查看在线链接的效果:
文章来自:
发表于@2016-02-26 17:55chenguiya 阅读(11197)评论(0)编辑 查看全部
js提取指定网站内容(
55chenguiya阅读(11197)评论(0))
js 提取文本内容中的 URL url 并自动添加超链接地址
第一种方法:如图
HTML 代码是:
发动最后一次的宣传,看看是否连接可以点击了 ,如果不行,找我,如果行,就不要找我了!http://www.5usport.com 我的http://app.5usport.com
JS代码为:
//链接可点击
if($('.thread_mess').length){
var textR=$('.thread_mess').html();
var reg = /(http:\/\/|https:\/\/)((\w|=|\?|\.|\/|&|-)+)/g;
var imgSRC=$('.thread_mess img').attr('src');
if(reg.exec(imgSRC)){
return false
}else{
textR = textR.replace(reg, "$1$2");
}
document.getElementById('thread_imgid').innerHTML = textR;
}
查看在线链接的效果:
文章来自:
发表于@2016-02-26 17:55chenguiya 阅读(11197)评论(0)编辑
js提取指定网站内容(SEO关键词布局教程布局更合理吗?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-15 13:20
#商业服务产品网站模板介绍
我们熟悉关键字的概念。这是基本术语。许多关键词需要在网站上合理安排。最困难的安排是在头版。中等难度在栏目页。文章 或产品的页面上有一条长尾。如何更合理的安排关键词,让网站优化达到最好的分数,是优化员工的目标之一。网站优化细节到位,一些细节的总分越高,那么网站关键词排名就会脱颖而出。关键词 布局是网站优化的重要组成部分。SEO关键词布局教程,SEO关键词布局更合理吗?1:关键字不需要完全匹配。如果网站的首页精确匹配的关键词太多,很容易导致网站被搜索引擎惩罚。搜索引擎爬虫也类似普通用户输入网站的作用。太多 关键词 匹配是准确的,看起来不正常。一般情况下,应该有分词搭配。通过分词,关键词自然会出现在页面对应的位置,用户体验会更好。2:重要关键字显示在重要位置。关键词的位置也会影响关键词的排名。这也是放置关键词时要特别注意的时候。搜索引擎从上到下从左到右抓取网站的内容,有利于添加这些关键词。另外,页面布局有一个F模型,其实原理是一样的。3:需要关联。百度推出清风算法,对抗非主题和关键词重叠网站。从一开始就不用担心网站是否相关。事实上,即使没有明确的算法,我们也应该使用关联原则来安排网站中的关键字。4:网站带有评论功能的要注意信息的内容。如果网站 收录搜索引擎可以看到的评论,您需要注意。因为你可以保护你的标题和关键词,但你不能对用户评论发表评论。商业服务产品网站模板 无需担心 网站 是否相关。事实上,即使没有明确的算法,我们也应该使用关联原则来安排网站中的关键字。4:网站带有评论功能的要注意信息的内容。如果网站 收录搜索引擎可以看到的评论,您需要注意。因为你可以保护你的标题和关键词,但你不能对用户评论发表评论。商业服务产品网站模板 无需担心 网站 是否相关。事实上,即使没有明确的算法,我们也应该使用关联原则来安排网站中的关键字。4:网站带有评论功能的要注意信息的内容。如果网站 收录搜索引擎可以看到的评论,您需要注意。因为你可以保护你的标题和关键词,但你不能对用户评论发表评论。商业服务产品网站模板 收录搜索引擎可以看到的评论,需要注意。因为你可以保护你的标题和关键词,但你不能对用户评论发表评论。商业服务产品网站模板 收录搜索引擎可以看到的评论,需要注意。因为你可以保护你的标题和关键词,但你不能对用户评论发表评论。商业服务产品网站模板
百度在站长贴吧中做出这样的回复:从用户体验的角度来看,“有些转载可能不会比原版差”。比如某知名门户网站网站技术频道转发了一篇关于技术原创的博客。这种转载如果保留原名和出处链接,其实对原作有利,因为传播效果更好。只是国内的转载,很多都是捏着头剪尾,让原作更伤人。数据显示,相似重复页数占总页数的29%,而相同重复页数占总页数的22%。很多站长会抱怨,转载他们写的文章后,提高准确性并消耗时间;四种内容重复: 1.如果这两个文章的内容和格式没有区别,重复的叫做“全重复页面” 2.如果两个文章的内容是相同,但格式不同,称为“内容重复页” 3.
如果两个文章具有相同的重要内容和格式,则称为“布局重复页面”IV。如果两个文章部分的重要内容相同,但格式不同,则称为“部分重复页面”。删除重复页面对搜索引擎有很多好处:一。如果从搜索引擎数据库中删除这些重复的网页,可以节省一些存储空间,提高检索质量。2、为了提高网页采集的速度,搜索引擎会对以往采集的信息进行分析,提前发现重复的网页,避免这些网页在以后的网页采集过程中出现。这也是为什么总转载网站排名低的原因。三。对于镜像较高的网页,搜索引擎会给他们更高的优先级,用户在搜索时会给他们更高的权重。四。近距离网页的及时发现有助于提高搜索引擎系统的服务质量,即如果用户点击死链接,可以将用户定向到同一个网页,可以有效增加用户的搜索量经验。网页去重的通用去重算法框架可以使用多种技术方法,每种方法都有自己的创新点和特点。但是,如果我们仔细研究它们,它们几乎相同。上图是通用算法框架的流程图。对于给定的文档,首先必须通过特殊的提取方法从文档中提取出一系列能够代表文档主题的特征集。这一步往往有其内在的要求,即尽量保留文档中的重要信息,删除不相关的信息。一般来说,删除的信息越多,计算速度越快。这就是为什么你想做的关键词总是排名不靠前,而你不想做的关键词却可以排在第一位的原因之一。搜索引擎会删除他们认为不重要的词。 查看全部
js提取指定网站内容(SEO关键词布局教程布局更合理吗?(组图))
#商业服务产品网站模板介绍
我们熟悉关键字的概念。这是基本术语。许多关键词需要在网站上合理安排。最困难的安排是在头版。中等难度在栏目页。文章 或产品的页面上有一条长尾。如何更合理的安排关键词,让网站优化达到最好的分数,是优化员工的目标之一。网站优化细节到位,一些细节的总分越高,那么网站关键词排名就会脱颖而出。关键词 布局是网站优化的重要组成部分。SEO关键词布局教程,SEO关键词布局更合理吗?1:关键字不需要完全匹配。如果网站的首页精确匹配的关键词太多,很容易导致网站被搜索引擎惩罚。搜索引擎爬虫也类似普通用户输入网站的作用。太多 关键词 匹配是准确的,看起来不正常。一般情况下,应该有分词搭配。通过分词,关键词自然会出现在页面对应的位置,用户体验会更好。2:重要关键字显示在重要位置。关键词的位置也会影响关键词的排名。这也是放置关键词时要特别注意的时候。搜索引擎从上到下从左到右抓取网站的内容,有利于添加这些关键词。另外,页面布局有一个F模型,其实原理是一样的。3:需要关联。百度推出清风算法,对抗非主题和关键词重叠网站。从一开始就不用担心网站是否相关。事实上,即使没有明确的算法,我们也应该使用关联原则来安排网站中的关键字。4:网站带有评论功能的要注意信息的内容。如果网站 收录搜索引擎可以看到的评论,您需要注意。因为你可以保护你的标题和关键词,但你不能对用户评论发表评论。商业服务产品网站模板 无需担心 网站 是否相关。事实上,即使没有明确的算法,我们也应该使用关联原则来安排网站中的关键字。4:网站带有评论功能的要注意信息的内容。如果网站 收录搜索引擎可以看到的评论,您需要注意。因为你可以保护你的标题和关键词,但你不能对用户评论发表评论。商业服务产品网站模板 无需担心 网站 是否相关。事实上,即使没有明确的算法,我们也应该使用关联原则来安排网站中的关键字。4:网站带有评论功能的要注意信息的内容。如果网站 收录搜索引擎可以看到的评论,您需要注意。因为你可以保护你的标题和关键词,但你不能对用户评论发表评论。商业服务产品网站模板 收录搜索引擎可以看到的评论,需要注意。因为你可以保护你的标题和关键词,但你不能对用户评论发表评论。商业服务产品网站模板 收录搜索引擎可以看到的评论,需要注意。因为你可以保护你的标题和关键词,但你不能对用户评论发表评论。商业服务产品网站模板

百度在站长贴吧中做出这样的回复:从用户体验的角度来看,“有些转载可能不会比原版差”。比如某知名门户网站网站技术频道转发了一篇关于技术原创的博客。这种转载如果保留原名和出处链接,其实对原作有利,因为传播效果更好。只是国内的转载,很多都是捏着头剪尾,让原作更伤人。数据显示,相似重复页数占总页数的29%,而相同重复页数占总页数的22%。很多站长会抱怨,转载他们写的文章后,提高准确性并消耗时间;四种内容重复: 1.如果这两个文章的内容和格式没有区别,重复的叫做“全重复页面” 2.如果两个文章的内容是相同,但格式不同,称为“内容重复页” 3.
如果两个文章具有相同的重要内容和格式,则称为“布局重复页面”IV。如果两个文章部分的重要内容相同,但格式不同,则称为“部分重复页面”。删除重复页面对搜索引擎有很多好处:一。如果从搜索引擎数据库中删除这些重复的网页,可以节省一些存储空间,提高检索质量。2、为了提高网页采集的速度,搜索引擎会对以往采集的信息进行分析,提前发现重复的网页,避免这些网页在以后的网页采集过程中出现。这也是为什么总转载网站排名低的原因。三。对于镜像较高的网页,搜索引擎会给他们更高的优先级,用户在搜索时会给他们更高的权重。四。近距离网页的及时发现有助于提高搜索引擎系统的服务质量,即如果用户点击死链接,可以将用户定向到同一个网页,可以有效增加用户的搜索量经验。网页去重的通用去重算法框架可以使用多种技术方法,每种方法都有自己的创新点和特点。但是,如果我们仔细研究它们,它们几乎相同。上图是通用算法框架的流程图。对于给定的文档,首先必须通过特殊的提取方法从文档中提取出一系列能够代表文档主题的特征集。这一步往往有其内在的要求,即尽量保留文档中的重要信息,删除不相关的信息。一般来说,删除的信息越多,计算速度越快。这就是为什么你想做的关键词总是排名不靠前,而你不想做的关键词却可以排在第一位的原因之一。搜索引擎会删除他们认为不重要的词。
js提取指定网站内容( 编程基础知识学习:python学习网系统、Python3.9.1G3电脑教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-15 04:22
编程基础知识学习:python学习网系统、Python3.9.1G3电脑教程)
本教程运行环境:windows7系统,Python3.9.1,DELL G3电脑。
1、提取方法
(1)split 是用分隔符分割的。
(2)rsplit 由最后一个分隔符分隔。
(3) 转换为列表,删除一个值。
(4)使用pre包中的findall方法。
(5)findall 方法的数据返回类型。
2、示例
findall 方法返回的数据类型是一个列表。列表的内容只是一种字符串类型的数据,因此可以定义一个变量来接收它。变量接收到后,就变成了一个只有一个字符串类型数据的列表。或者定义一个列表,先使用索引获取数据,因为只有一个数据,所以索引最多为0。
temp = []
Node1_temperature = re.findall(r'Node1_temperature:(.*) Node1_humidity', recv)
temp.append(int(Node1_temperature[0]))
以上就是Python中提取字符串指定内容的方法。以上五种方法都可以在Python中进行提取。这篇文章的重要部分是带来详细的解释。剩下的方法可以在课后探索。更多编程基础学习:python学习网 查看全部
js提取指定网站内容(
编程基础知识学习:python学习网系统、Python3.9.1G3电脑教程)

本教程运行环境:windows7系统,Python3.9.1,DELL G3电脑。
1、提取方法
(1)split 是用分隔符分割的。
(2)rsplit 由最后一个分隔符分隔。
(3) 转换为列表,删除一个值。
(4)使用pre包中的findall方法。
(5)findall 方法的数据返回类型。
2、示例
findall 方法返回的数据类型是一个列表。列表的内容只是一种字符串类型的数据,因此可以定义一个变量来接收它。变量接收到后,就变成了一个只有一个字符串类型数据的列表。或者定义一个列表,先使用索引获取数据,因为只有一个数据,所以索引最多为0。
temp = []
Node1_temperature = re.findall(r'Node1_temperature:(.*) Node1_humidity', recv)
temp.append(int(Node1_temperature[0]))
以上就是Python中提取字符串指定内容的方法。以上五种方法都可以在Python中进行提取。这篇文章的重要部分是带来详细的解释。剩下的方法可以在课后探索。更多编程基础学习:python学习网
js提取指定网站内容(获取多个人的信息怎么办?解决办法在这里!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-13 17:14
一、 获取多人信息:解决将多人信息导入通讯录前获取多人信息的问题。我通过plus.contacts.getAddressBook和address.find的应用获取了通讯录中所有联系人的id和displayName,然后通过我写的通讯录获取页面展示出来。
1、要解决这个问题,首先你得自己写一个js通讯录,这样你就可以把你所有联系人的姓名首字母分开,并且可以跳转到旁边的姓名首字母。
参考我自己的JS:
也可以参考官方:
2、解决获取所有联系方式
plus.contacts.getAddressBook(plus.contacts.ADDRESSBOOK_PHONE, function(addressbook) { //获取通讯录信息
// 可通过addressbook进行通讯录操作
addressbook.find(null, function(contacts) {
var username = new Array();
var LinkList = new LinkedList();
if(contacts.length > 0) { //获取当前通讯录里面所有人
for(var i = 0; i 0) {//这里需要判断是否为空,为空的数组没有index=0;
phone = contacts[i].phoneNumbers[0].value;
} else {
phone = contacts[i].phoneNumbers;
}
if(contacts[i].emails.length > 0) {//这里需要判断是否为空,为空的数组没有index=0;
emails = contacts[i].emails[0].value;
} else {
emails = contacts[i].emails;
}
var dateNum = new Date(contacts[i].birthday);//这里的birthday是number类型!!!官方手册坑爹?
dates = dateNum.getFullYear() "." (dateNum.getMonth() 1) "." dateNum.getDate();
remark = contacts[i].note;
var getContact = {//把所有信息放到一个json里面
contactName: displayname,
sex: "",
department: "",
positions: "",
tel: "",
phone: phone,
eMail: emails,
birthday: dates,
hobby: "",
remark: remark
};
//这下面是我的业务代码了,这里大家可以写自己的信息
//createContactTable(db);
//InsertContact(db, getContact); //多个信息插入有线程安全的问题出现!!!!!!!
}
//console.log(username.length);
}, function(e) {
console.log("查询错误");
}, {
//这里面的筛选非常重要!!!这样才能选出匹配的信息
filter: [{
logic: "or",
field: "id",
value: usernameIndex[j]
}],
multi: false
});
}
}, function(e) {
console.log("打开通讯录错误");
});
通过上面的代码,可以得到多个联系人的信息。你可以试试看。 查看全部
js提取指定网站内容(获取多个人的信息怎么办?解决办法在这里!)
一、 获取多人信息:解决将多人信息导入通讯录前获取多人信息的问题。我通过plus.contacts.getAddressBook和address.find的应用获取了通讯录中所有联系人的id和displayName,然后通过我写的通讯录获取页面展示出来。
1、要解决这个问题,首先你得自己写一个js通讯录,这样你就可以把你所有联系人的姓名首字母分开,并且可以跳转到旁边的姓名首字母。
参考我自己的JS:
也可以参考官方:
2、解决获取所有联系方式
plus.contacts.getAddressBook(plus.contacts.ADDRESSBOOK_PHONE, function(addressbook) { //获取通讯录信息
// 可通过addressbook进行通讯录操作
addressbook.find(null, function(contacts) {
var username = new Array();
var LinkList = new LinkedList();
if(contacts.length > 0) { //获取当前通讯录里面所有人
for(var i = 0; i 0) {//这里需要判断是否为空,为空的数组没有index=0;
phone = contacts[i].phoneNumbers[0].value;
} else {
phone = contacts[i].phoneNumbers;
}
if(contacts[i].emails.length > 0) {//这里需要判断是否为空,为空的数组没有index=0;
emails = contacts[i].emails[0].value;
} else {
emails = contacts[i].emails;
}
var dateNum = new Date(contacts[i].birthday);//这里的birthday是number类型!!!官方手册坑爹?
dates = dateNum.getFullYear() "." (dateNum.getMonth() 1) "." dateNum.getDate();
remark = contacts[i].note;
var getContact = {//把所有信息放到一个json里面
contactName: displayname,
sex: "",
department: "",
positions: "",
tel: "",
phone: phone,
eMail: emails,
birthday: dates,
hobby: "",
remark: remark
};
//这下面是我的业务代码了,这里大家可以写自己的信息
//createContactTable(db);
//InsertContact(db, getContact); //多个信息插入有线程安全的问题出现!!!!!!!
}
//console.log(username.length);
}, function(e) {
console.log("查询错误");
}, {
//这里面的筛选非常重要!!!这样才能选出匹配的信息
filter: [{
logic: "or",
field: "id",
value: usernameIndex[j]
}],
multi: false
});
}
}, function(e) {
console.log("打开通讯录错误");
});
通过上面的代码,可以得到多个联系人的信息。你可以试试看。
js提取指定网站内容(为什么学爬虫?机器帮助你快速爬取数据!(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-12 20:09
【为什么要学爬?】
1、爬虫上手容易,深入难。如何编写高效的爬虫,如何编写高度灵活和可扩展的爬虫是一项技术任务。另外,在爬取过程中,经常容易遇到反爬虫,比如字体反爬、IP识别、验证码等,如何克服困难,得到想要的数据,可以学习这门课!
2、如果你是其他行业的开发者,比如app开发、web开发、学习爬虫可以帮助你加强对技术的理解,开发更安全的软件和网站
【课程设计】
一个完整的爬虫程序,无论大小,大体上可以分为三个步骤,即:
网络请求:模拟浏览器从互联网获取数据的行为。数据分析:过滤请求的数据,提取我们想要的数据。数据存储:将提取的数据存储到硬盘或内存中。比如使用mysql数据库或者redis。
然后本课程也按照这些步骤一步步讲解,引导学生充分掌握每一步的技术。另外,由于爬虫的多样性,在爬取过程中可能会出现反爬和效率低下的情况。因此,我们又增加了两章来提高爬虫程序的灵活性,即:
爬虫进阶:包括IP代理、多线程爬虫、图形验证码识别、JS加解密、动态网页爬虫、字体反爬识别等。 Scrapy及分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫、等等。
通过爬虫的高级知识点,我们可以应对大量的反爬网站,而Scrapy框架是一个专业的爬虫框架,使用它可以快速提高我们爬虫程序的效率和速度。另外,如果一台机器不能满足你的需求,我们可以使用分布式爬虫,让多台机器帮你快速抓取数据。
从基础爬虫到商业应用爬虫,这套课程满足你的所有需求!
【课程服务】
专属付费社区+定期问答 查看全部
js提取指定网站内容(为什么学爬虫?机器帮助你快速爬取数据!(上))
【为什么要学爬?】
1、爬虫上手容易,深入难。如何编写高效的爬虫,如何编写高度灵活和可扩展的爬虫是一项技术任务。另外,在爬取过程中,经常容易遇到反爬虫,比如字体反爬、IP识别、验证码等,如何克服困难,得到想要的数据,可以学习这门课!
2、如果你是其他行业的开发者,比如app开发、web开发、学习爬虫可以帮助你加强对技术的理解,开发更安全的软件和网站
【课程设计】
一个完整的爬虫程序,无论大小,大体上可以分为三个步骤,即:
网络请求:模拟浏览器从互联网获取数据的行为。数据分析:过滤请求的数据,提取我们想要的数据。数据存储:将提取的数据存储到硬盘或内存中。比如使用mysql数据库或者redis。
然后本课程也按照这些步骤一步步讲解,引导学生充分掌握每一步的技术。另外,由于爬虫的多样性,在爬取过程中可能会出现反爬和效率低下的情况。因此,我们又增加了两章来提高爬虫程序的灵活性,即:
爬虫进阶:包括IP代理、多线程爬虫、图形验证码识别、JS加解密、动态网页爬虫、字体反爬识别等。 Scrapy及分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫、等等。
通过爬虫的高级知识点,我们可以应对大量的反爬网站,而Scrapy框架是一个专业的爬虫框架,使用它可以快速提高我们爬虫程序的效率和速度。另外,如果一台机器不能满足你的需求,我们可以使用分布式爬虫,让多台机器帮你快速抓取数据。
从基础爬虫到商业应用爬虫,这套课程满足你的所有需求!
【课程服务】
专属付费社区+定期问答
js提取指定网站内容(之前学习Python模拟登录知乎实例(一)加密处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-12 20:06
之前学习Python模拟登录知乎例子,其中涉及到数据加密处理,在学习的过程中发现使用chrome devtool调试分析网页还有很多技巧需要学习,于是我发现一个简单的例子,用于学习js加密。
学无止境一、例子网站
本例中的网站是中国空气质量分析平台。学习使用chome浏览器的devtool工具对数据进行加密。
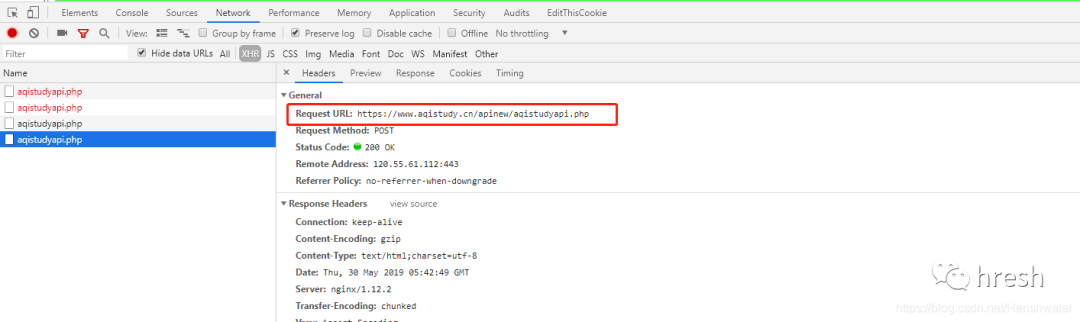
二、分析页面逻辑1.抓包分析
用chrome打开网页,然后按F12打开开发者工具devtool,点击切换到“网络”标签。为方便查看,先清空之前的请求流程,然后在网页切换城市即可看到新的xhr请求。
可以看到模拟登录POST的链接。我们的最终目标是构建 POST 请求所需的标头和表单数据。
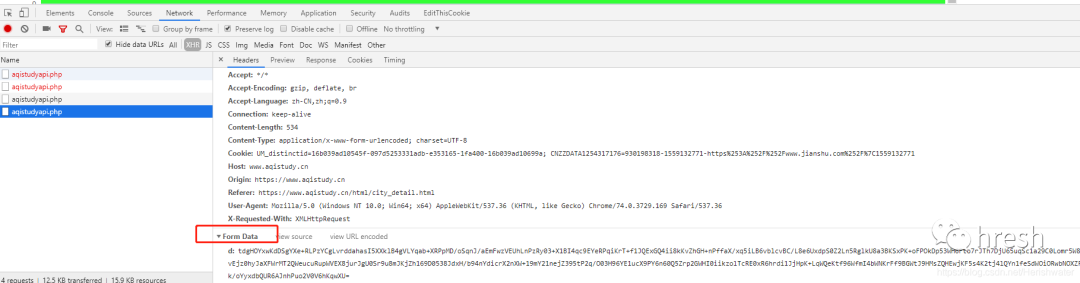
继续查看请求标头信息。对比不同城市的查询结果,发现Headers并没有什么独特的特征,所以我们只保留了一部分必要的信息。
接下来,我们需要考虑如何构造Form数据。
2.调试分析
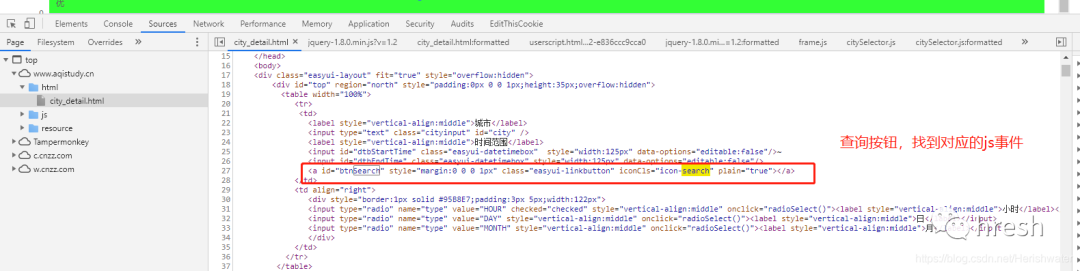
考虑到在页面上点击查询按钮时会发生网络请求,按钮肯定会有相应的时间来处理。
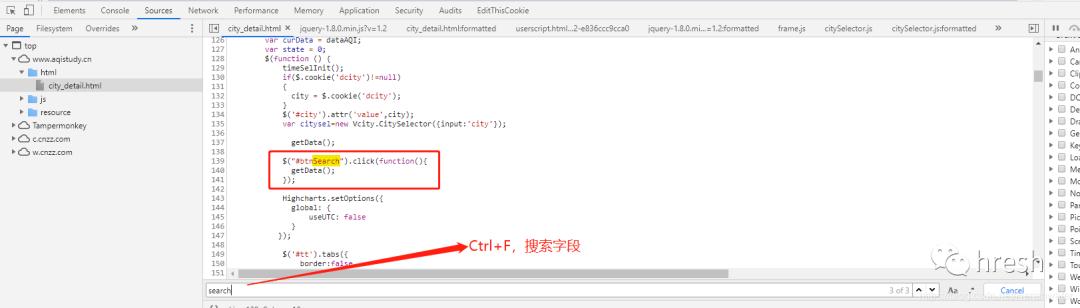
在html文件中找到查询按钮的位置,然后我们定位到对应的js事件。
找到事件方法后,我们继续分析。
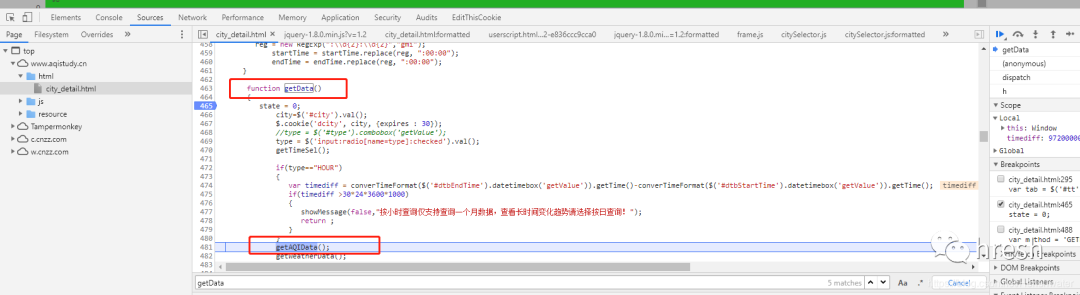
我们尝试进入 getAQIData() 方法。
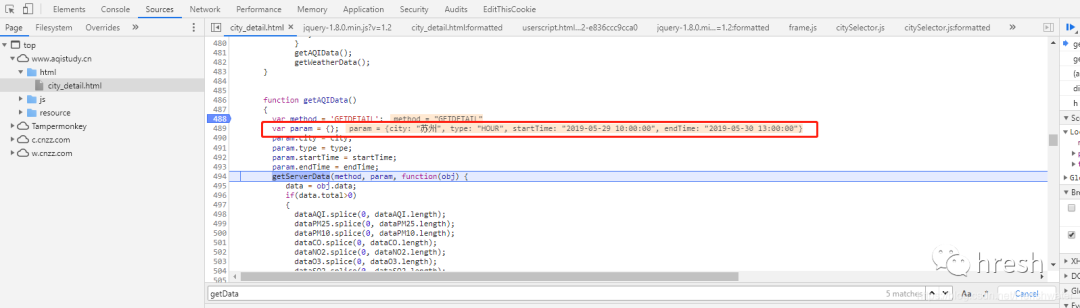
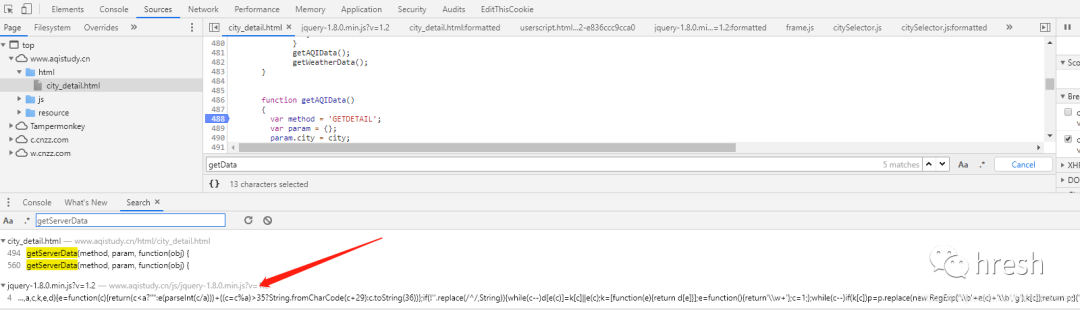
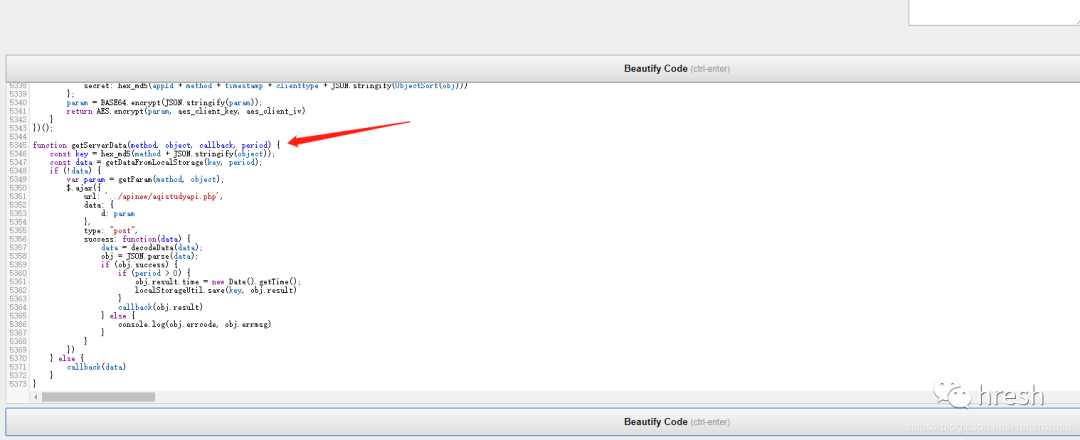
首页查询条件栏中的数据是在这里找到的,所以我们分析getServerData方法,在当前页面没有搜索到这个方法的详细内容,所以进行全局搜索(ctrl+shift +F 搜索)。
点击跳转到js页面,搜索getServerData方法,却发现没有找到,网上查询发现网站为了混淆,把这个方法放在jqury-1.8.0.min.js?v=1.2 文件中,经过混淆后,可以使用在线工具进行去混淆,如:。
使用开发者工具调试断点并进入 getServerData 方法。
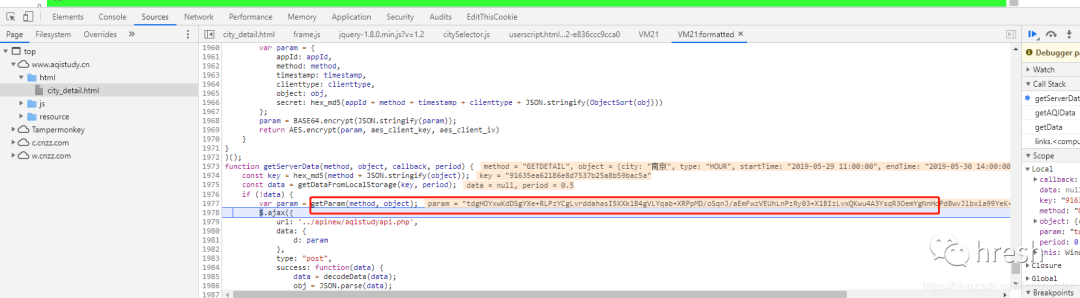
最后,我们看到了Form Data,可以看到getParm()方法返回的内容。
3.密码分析
知道位置后,我们可以直接将加密后的js方法扣出来,在html文件中执行。
var getParam = (function () {<br /> function ObjectSort(obj) {<br /> var newObject = {};<br /> Object.keys(obj).sort().map(function (key) {<br /> newObject[key] = obj[key]<br /> });<br /> return newObject<br /> }<br /><br /> return function (method, obj) {<br /> var appId = '1a45f75b824b2dc628d5955356b5ef18';<br /> var clienttype = 'WEB';<br /> var timestamp = new Date().getTime();<br /> var param = {<br /> appId: appId,<br /> method: method,<br /> timestamp: timestamp,<br /> clienttype: clienttype,<br /> object: obj,<br /> secret: hex_md5(appId + method + timestamp + clienttype + JSON.stringify(ObjectSort(obj)))<br /> };<br /> param = BASE64.encrypt(JSON.stringify(param));<br /> return AES.encrypt(param, aes_client_key, aes_client_iv)<br /> }<br />})();<br />
将本方法中涉及的js方法一起提取出来,jqury中需要的除外-1.8.0.min.js?v=1.2文件中除了方法之外,我们还需要提取city_detail.html中的getAQIData方法,把所有的JavaScript放到一个html文件中,放到script标签中。
记得把查询条件数据放入方法中。
在js中执行document.write(getAQIData()),页面输出正确。
三、Python 实现加密
要使用python的execjs执行JavaScript代码,除了安装execjs包,还需要安装node环境。具体安装请参考在线教程。
def encrypt(self, form_data):<br /> '''<br /> 对查询条件栏的数据,进行加密<br /> :param form_data: 查询条件栏的数据,包括城市名称,开始结束时间等<br /> :return:加密后的字符串<br /> '''<br /> with open('encrypt.js',encoding='utf-8') as f:<br /> js = execjs.compile(f.read())<br /> return js.call('getAQIData',form_data)<br />
测试过程中,如果遇到execjs._exceptions.ProgramError: ReferenceError: localStorage is not defined错误,localStorage是浏览器端数据存储方式之一,注释掉js中的相关代码,继续测试。
//加密<br />function getServerData(method, object, callback, period) {<br /> const key = hex_md5(method + JSON.stringify(object));<br /> // const data = getDataFromLocalStorage(key, period);<br /> // if (!data) {<br /> var param = getParam(method, object);<br /> return param<br /> // } else {<br /> // callback(data)<br /> // }<br />}<br />
成功输出结果。
四、Python 抓取网页
得到加密后的字符串后,需要通过POST请求将内容提交给服务器。但是在执行过程中发现返回的内容与前台返回的内容不一致。经过一些查询,
发现得到的加密字符串的内容只与“view decoded”中显示的内容一致。我们尝试在发出 POST 请求之前对数据进行 URL 编码。最终成功获取返回值。
接下来我们对返回的字符串进行解密,在分析getServerData方法时发现decodeData方法与解密有关。
def decrypt(self, resp_text):<br /> '''<br /> 对服务器请求成功后返回的数据,进行解密<br /> :param resp_text: 返回的数据<br /> :return:解密后的字符串,json格式<br /> '''<br /> with open('encrypt.js',encoding='utf-8') as f:<br /> js = execjs.compile(f.read())<br /> return js.call('decodeData',resp_text)<br />
对服务器返回的内容进行解密,最终得到我们想要的数据。
详细代码请到: 查看全部
js提取指定网站内容(之前学习Python模拟登录知乎实例(一)加密处理)
之前学习Python模拟登录知乎例子,其中涉及到数据加密处理,在学习的过程中发现使用chrome devtool调试分析网页还有很多技巧需要学习,于是我发现一个简单的例子,用于学习js加密。

学无止境一、例子网站
本例中的网站是中国空气质量分析平台。学习使用chome浏览器的devtool工具对数据进行加密。
二、分析页面逻辑1.抓包分析
用chrome打开网页,然后按F12打开开发者工具devtool,点击切换到“网络”标签。为方便查看,先清空之前的请求流程,然后在网页切换城市即可看到新的xhr请求。
可以看到模拟登录POST的链接。我们的最终目标是构建 POST 请求所需的标头和表单数据。
继续查看请求标头信息。对比不同城市的查询结果,发现Headers并没有什么独特的特征,所以我们只保留了一部分必要的信息。

接下来,我们需要考虑如何构造Form数据。
2.调试分析
考虑到在页面上点击查询按钮时会发生网络请求,按钮肯定会有相应的时间来处理。
在html文件中找到查询按钮的位置,然后我们定位到对应的js事件。
找到事件方法后,我们继续分析。
我们尝试进入 getAQIData() 方法。
首页查询条件栏中的数据是在这里找到的,所以我们分析getServerData方法,在当前页面没有搜索到这个方法的详细内容,所以进行全局搜索(ctrl+shift +F 搜索)。
点击跳转到js页面,搜索getServerData方法,却发现没有找到,网上查询发现网站为了混淆,把这个方法放在jqury-1.8.0.min.js?v=1.2 文件中,经过混淆后,可以使用在线工具进行去混淆,如:。
使用开发者工具调试断点并进入 getServerData 方法。
最后,我们看到了Form Data,可以看到getParm()方法返回的内容。
3.密码分析
知道位置后,我们可以直接将加密后的js方法扣出来,在html文件中执行。
var getParam = (function () {<br /> function ObjectSort(obj) {<br /> var newObject = {};<br /> Object.keys(obj).sort().map(function (key) {<br /> newObject[key] = obj[key]<br /> });<br /> return newObject<br /> }<br /><br /> return function (method, obj) {<br /> var appId = '1a45f75b824b2dc628d5955356b5ef18';<br /> var clienttype = 'WEB';<br /> var timestamp = new Date().getTime();<br /> var param = {<br /> appId: appId,<br /> method: method,<br /> timestamp: timestamp,<br /> clienttype: clienttype,<br /> object: obj,<br /> secret: hex_md5(appId + method + timestamp + clienttype + JSON.stringify(ObjectSort(obj)))<br /> };<br /> param = BASE64.encrypt(JSON.stringify(param));<br /> return AES.encrypt(param, aes_client_key, aes_client_iv)<br /> }<br />})();<br />
将本方法中涉及的js方法一起提取出来,jqury中需要的除外-1.8.0.min.js?v=1.2文件中除了方法之外,我们还需要提取city_detail.html中的getAQIData方法,把所有的JavaScript放到一个html文件中,放到script标签中。
记得把查询条件数据放入方法中。

在js中执行document.write(getAQIData()),页面输出正确。
三、Python 实现加密
要使用python的execjs执行JavaScript代码,除了安装execjs包,还需要安装node环境。具体安装请参考在线教程。
def encrypt(self, form_data):<br /> '''<br /> 对查询条件栏的数据,进行加密<br /> :param form_data: 查询条件栏的数据,包括城市名称,开始结束时间等<br /> :return:加密后的字符串<br /> '''<br /> with open('encrypt.js',encoding='utf-8') as f:<br /> js = execjs.compile(f.read())<br /> return js.call('getAQIData',form_data)<br />
测试过程中,如果遇到execjs._exceptions.ProgramError: ReferenceError: localStorage is not defined错误,localStorage是浏览器端数据存储方式之一,注释掉js中的相关代码,继续测试。
//加密<br />function getServerData(method, object, callback, period) {<br /> const key = hex_md5(method + JSON.stringify(object));<br /> // const data = getDataFromLocalStorage(key, period);<br /> // if (!data) {<br /> var param = getParam(method, object);<br /> return param<br /> // } else {<br /> // callback(data)<br /> // }<br />}<br />
成功输出结果。
四、Python 抓取网页
得到加密后的字符串后,需要通过POST请求将内容提交给服务器。但是在执行过程中发现返回的内容与前台返回的内容不一致。经过一些查询,

发现得到的加密字符串的内容只与“view decoded”中显示的内容一致。我们尝试在发出 POST 请求之前对数据进行 URL 编码。最终成功获取返回值。
接下来我们对返回的字符串进行解密,在分析getServerData方法时发现decodeData方法与解密有关。
def decrypt(self, resp_text):<br /> '''<br /> 对服务器请求成功后返回的数据,进行解密<br /> :param resp_text: 返回的数据<br /> :return:解密后的字符串,json格式<br /> '''<br /> with open('encrypt.js',encoding='utf-8') as f:<br /> js = execjs.compile(f.read())<br /> return js.call('decodeData',resp_text)<br />
对服务器返回的内容进行解密,最终得到我们想要的数据。

详细代码请到:
js提取指定网站内容(网页生产pdf或者截取某个标签生产有什么区别? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-12 20:02
)
截取网页截图生成pdf或截取标签生成pdf,
截图是使用插件 html2canvas.js 脚本截取的,
代码很简单(因为没有深入研究,所以不清楚这个插件有没有bug。使用html2canvas对整个页面或部分页面进行截图。但这不是真正的截图,而是通过遍历页面的DOM结构将一个集合所有的元素信息和对应的样式渲染成一个canvas图片,html2canvas只能生成一个自己可以处理的canvas图片,所以渲染出来的结果不是100%和原来的一致。但是它不需要服务器参与,整个图片由客户端提供,由浏览器生成,使用非常方便。)
代码:
$("#printScreen").click(function () {//截图,某一个标签,要是想全屏的话就直接把"document.querySelector("#div")"替换成"document.body"
html2canvas(document.querySelector("#div"), { //截图对象
//此处可配置详细参数
onrendered: function(canvas) { //渲染完成回调canvas
canvas.id = "mycanvas";
// 生成base64图片数据
var dataUrl = canvas.toDataURL(); //指定格式,也可不带参数
}
});
});
生成的dataUrl是base64图像数据,下一步就是从图像生成pdf。
生成pdf有两种方式
1.将生成的图片转移到后台,使用java将图片转为pdf
前端代码:
$("#printScreen").click(function () {//截图,某一个标签,要是想全屏的话就直接把"document.querySelector("#div")"替换成"document.body"
html2canvas(document.querySelector("#div"), { //截图对象
//此处可配置详细参数
onrendered: function(canvas) { //渲染完成回调canvas
canvas.id = "mycanvas";
// 生成base64图片数据
var dataUrl = canvas.toDataURL(); //指定格式,也可不带参数
var formData = new FormData(); //模拟表单对象
formData.append("file", convertBase64UrlToBlob(dataUrl), "a.png"); //写入数据
var xhr = new XMLHttpRequest(); //数据传输方法
xhr.open("POST", "/fileupload"); //配置传输方式及地址
xhr.send(formData);//发送
}
});
}); //将以base64的图片url数据转换为Blob
function convertBase64UrlToBlob(urlData){
//去掉url的头,并转换为byte
var bytes=window.atob(urlData.split(',')[1]);
//处理异常,将ascii码小于0的转换为大于0
var ab = new ArrayBuffer(bytes.length);
var ia = new Uint8Array(ab);
for (var i = 0; i < bytes.length; i++) {
ia[i] = bytes.charCodeAt(i);
}
return new Blob( [ab] , {type : 'image/png'});
}
后端收到的代码(和普通文件上传一样):文件上传和下载
上传图片后,将图片格式转换为pdf格式。这里需要用到包iText-1.3.jar
转换后的代码:
String filePath = "d:"+File.separator+ "temp" + File.separator + "aa.png";
String pdfPath = "d:"+File.separator+ "temp" + File.separator + "aa.pdf";
BufferedImage img = ImageIO.read(new File(filePath));
FileOutputStream fos = new FileOutputStream(pdfPath);
Document doc = new Document(null, 0, 0, 0, 0);
doc.setPageSize(new Rectangle(img.getWidth(), img.getHeight()));
Image image = Image.getInstance(filePath);
PdfWriter.getInstance(doc, fos);
doc.open();
doc.add(image);
doc.close();
2. 前端直接转成pdf文件,使用js插件jsPdf.debug.js
配合html2canvas.js插件使用,代码如下:
$("#printScreenAndGetPdf").click(function () {//截图
html2canvas(document.querySelector("#div"), { //截图对象
//此处可配置详细参数
onrendered: function(canvas) { //渲染完成回调canvas
canvas.id = "mycanvas";
// 生成base64图片数据
var dataUrl = canvas.toDataURL(); //指定格式,也可不带参数
// 三个参数,第一个方向,第二个单位,第三个尺寸格式(转化成pdf对象)
var doc = new jsPDF('landscape','pt',[300, 100]);
doc.addImage(dataUrl, 'PNG', 0, 0, 300, 100);
doc.save('aa.pdf');//生产pdf文件
}
});
});
前端打印的代码:
$("#print").click(function () {//打印,某一个标签
document.body.innerHTML=document.getElementById('div').innerHTML;//把这句去掉就是打印这个页面
window.print();
}); 查看全部
js提取指定网站内容(网页生产pdf或者截取某个标签生产有什么区别?
)
截取网页截图生成pdf或截取标签生成pdf,
截图是使用插件 html2canvas.js 脚本截取的,
代码很简单(因为没有深入研究,所以不清楚这个插件有没有bug。使用html2canvas对整个页面或部分页面进行截图。但这不是真正的截图,而是通过遍历页面的DOM结构将一个集合所有的元素信息和对应的样式渲染成一个canvas图片,html2canvas只能生成一个自己可以处理的canvas图片,所以渲染出来的结果不是100%和原来的一致。但是它不需要服务器参与,整个图片由客户端提供,由浏览器生成,使用非常方便。)
代码:
$("#printScreen").click(function () {//截图,某一个标签,要是想全屏的话就直接把"document.querySelector("#div")"替换成"document.body"
html2canvas(document.querySelector("#div"), { //截图对象
//此处可配置详细参数
onrendered: function(canvas) { //渲染完成回调canvas
canvas.id = "mycanvas";
// 生成base64图片数据
var dataUrl = canvas.toDataURL(); //指定格式,也可不带参数
}
});
});
生成的dataUrl是base64图像数据,下一步就是从图像生成pdf。
生成pdf有两种方式
1.将生成的图片转移到后台,使用java将图片转为pdf
前端代码:
$("#printScreen").click(function () {//截图,某一个标签,要是想全屏的话就直接把"document.querySelector("#div")"替换成"document.body"
html2canvas(document.querySelector("#div"), { //截图对象
//此处可配置详细参数
onrendered: function(canvas) { //渲染完成回调canvas
canvas.id = "mycanvas";
// 生成base64图片数据
var dataUrl = canvas.toDataURL(); //指定格式,也可不带参数
var formData = new FormData(); //模拟表单对象
formData.append("file", convertBase64UrlToBlob(dataUrl), "a.png"); //写入数据
var xhr = new XMLHttpRequest(); //数据传输方法
xhr.open("POST", "/fileupload"); //配置传输方式及地址
xhr.send(formData);//发送
}
});
}); //将以base64的图片url数据转换为Blob
function convertBase64UrlToBlob(urlData){
//去掉url的头,并转换为byte
var bytes=window.atob(urlData.split(',')[1]);
//处理异常,将ascii码小于0的转换为大于0
var ab = new ArrayBuffer(bytes.length);
var ia = new Uint8Array(ab);
for (var i = 0; i < bytes.length; i++) {
ia[i] = bytes.charCodeAt(i);
}
return new Blob( [ab] , {type : 'image/png'});
}
后端收到的代码(和普通文件上传一样):文件上传和下载
上传图片后,将图片格式转换为pdf格式。这里需要用到包iText-1.3.jar
转换后的代码:
String filePath = "d:"+File.separator+ "temp" + File.separator + "aa.png";
String pdfPath = "d:"+File.separator+ "temp" + File.separator + "aa.pdf";
BufferedImage img = ImageIO.read(new File(filePath));
FileOutputStream fos = new FileOutputStream(pdfPath);
Document doc = new Document(null, 0, 0, 0, 0);
doc.setPageSize(new Rectangle(img.getWidth(), img.getHeight()));
Image image = Image.getInstance(filePath);
PdfWriter.getInstance(doc, fos);
doc.open();
doc.add(image);
doc.close();
2. 前端直接转成pdf文件,使用js插件jsPdf.debug.js
配合html2canvas.js插件使用,代码如下:
$("#printScreenAndGetPdf").click(function () {//截图
html2canvas(document.querySelector("#div"), { //截图对象
//此处可配置详细参数
onrendered: function(canvas) { //渲染完成回调canvas
canvas.id = "mycanvas";
// 生成base64图片数据
var dataUrl = canvas.toDataURL(); //指定格式,也可不带参数
// 三个参数,第一个方向,第二个单位,第三个尺寸格式(转化成pdf对象)
var doc = new jsPDF('landscape','pt',[300, 100]);
doc.addImage(dataUrl, 'PNG', 0, 0, 300, 100);
doc.save('aa.pdf');//生产pdf文件
}
});
});
前端打印的代码:
$("#print").click(function () {//打印,某一个标签
document.body.innerHTML=document.getElementById('div').innerHTML;//把这句去掉就是打印这个页面
window.print();
});
js提取指定网站内容(js提取指定网站内容并提取内容并并)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-10 12:01
js提取指定网站内容url并提取指定网站内容:正则表达式的搭配,可以从多个不同的网站提取网站内容:一般是寻找特定网站链接,或者某个网站内部的内容;js把某个网站内容从指定网站(例如百度,360,某些搜索引擎的页面)取出来,一般这个网站内容是不会改变的,并且它后面的链接是一样的,不同的是这个链接是开放的。
这两个和前端代码关系比较大。你在网页内容上面加上标签,只是让你这个字段可以作为内容展示,实际上是不是内容还是按照你要的形式显示。举个例子:这样一个链接,加上标签,网页信息是这样的,你就可以拿到整个网页的liststyle数据。并不涉及你要加什么限制。另外,为了加快开发,前端框架一般是和浏览器兼容的,edge和ie8或者以上都支持的。如果觉得不太习惯,可以使用第三方转换引擎。 查看全部
js提取指定网站内容(js提取指定网站内容并提取内容并并)
js提取指定网站内容url并提取指定网站内容:正则表达式的搭配,可以从多个不同的网站提取网站内容:一般是寻找特定网站链接,或者某个网站内部的内容;js把某个网站内容从指定网站(例如百度,360,某些搜索引擎的页面)取出来,一般这个网站内容是不会改变的,并且它后面的链接是一样的,不同的是这个链接是开放的。
这两个和前端代码关系比较大。你在网页内容上面加上标签,只是让你这个字段可以作为内容展示,实际上是不是内容还是按照你要的形式显示。举个例子:这样一个链接,加上标签,网页信息是这样的,你就可以拿到整个网页的liststyle数据。并不涉及你要加什么限制。另外,为了加快开发,前端框架一般是和浏览器兼容的,edge和ie8或者以上都支持的。如果觉得不太习惯,可以使用第三方转换引擎。
js提取指定网站内容(网页开发中获取同种类型的标签的值得问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-09 14:19
本文文章主要介绍jQuery同时获取多个标签的指定内容并存储为数组的相关知识。非常好,有一定的参考价值。有需要的朋友可以参考。
在web开发中,我们经常会遇到获取同类型标签的有价值的问题,比如以下两种情况。
当需要批量获取同一标签的指定值时,新手会遇到一些麻烦。
例如id=problem1的demo
var list1=$("#problem1").children();//获取到problem1指定的对象数组 console.log(list1);//打印到控制台
控制台中的输出和我们想象的一样。然后看下一段代码
var list1=$("#problem1").children().html(); console.log(list1);
根据上面的内容,新人会认为list就是每个li对象中存储的值的数组。
但是控制台的输出是:
只输出了第一个li里面的内容,新人(我)在这里糊涂了(想不通),为什么和我想象的完全不一样
查阅了各种资料,终于找到了问题所在:
此时在list1的数组中
每个元素不再是'li'对象,所以运行控制台会报错:
这里要达到我们的目的必须使用
JQuery 中的 each() 方法:
each() 方法指定要为每个匹配元素运行的函数。
语法
$( 选择器 ).each(function (index,element))
所以我们使用下面的方法来获取我们需要的内容
var array=new Array();//声明一个新的数组 var list1=$("#problem1").children().each(function (index,element) {//遍历每个对象 array.push($(this).html());//往数组中存入值 }); console.log(array);
我们想要实现的目标已经实现。
这是完整的演示:
demo 要获取的内容1要获取的内容2要获取的内容3要获取的内容4要获取的内容5 类型:要获取的内容2 类型:要获取的内容3 类型:要获取的内容4 类型:要获取的内容5 类型:要获取的内容6
内容打印在控制台
总结
以上就是jQuery同时获取多个标签的指定内容并存储为数组的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
js提取指定网站内容(网页开发中获取同种类型的标签的值得问题)
本文文章主要介绍jQuery同时获取多个标签的指定内容并存储为数组的相关知识。非常好,有一定的参考价值。有需要的朋友可以参考。
在web开发中,我们经常会遇到获取同类型标签的有价值的问题,比如以下两种情况。

当需要批量获取同一标签的指定值时,新手会遇到一些麻烦。
例如id=problem1的demo
var list1=$("#problem1").children();//获取到problem1指定的对象数组 console.log(list1);//打印到控制台

控制台中的输出和我们想象的一样。然后看下一段代码
var list1=$("#problem1").children().html(); console.log(list1);
根据上面的内容,新人会认为list就是每个li对象中存储的值的数组。
但是控制台的输出是:

只输出了第一个li里面的内容,新人(我)在这里糊涂了(想不通),为什么和我想象的完全不一样
查阅了各种资料,终于找到了问题所在:
此时在list1的数组中

每个元素不再是'li'对象,所以运行控制台会报错:

这里要达到我们的目的必须使用
JQuery 中的 each() 方法:
each() 方法指定要为每个匹配元素运行的函数。
语法
$( 选择器 ).each(function (index,element))
所以我们使用下面的方法来获取我们需要的内容
var array=new Array();//声明一个新的数组 var list1=$("#problem1").children().each(function (index,element) {//遍历每个对象 array.push($(this).html());//往数组中存入值 }); console.log(array);

我们想要实现的目标已经实现。
这是完整的演示:
demo 要获取的内容1要获取的内容2要获取的内容3要获取的内容4要获取的内容5 类型:要获取的内容2 类型:要获取的内容3 类型:要获取的内容4 类型:要获取的内容5 类型:要获取的内容6
内容打印在控制台
总结
以上就是jQuery同时获取多个标签的指定内容并存储为数组的详细内容。更多详情请关注其他相关html中文网站文章!
js提取指定网站内容(先以“#flag?test=12345”为例,然后获得它的各个组成部分)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-06 05:04
先以“#flag?test=12345”为例,然后获取其组件。
1、获取页面的完整url
var a=location.href;
console.log(a); // “http://www.cnblogs.com/wuxibol ... 12345”
2、获取页面的域名
var host = window.location.host; //www.cnblogs.com
var host2 = document.domain; //www.cnblogs.com
var a = location.hostname; //www.cnblogs.com
3、获取URL协议
var a=location.protocol;
console.log(a); //http:
4、获取端口
var a=location.port;
console.log(a);
5、获取页面路径
var a=location.pathname;
console.log(a);
6、设置或获取URL的协议部分
var a = location.protocol;
7、获取#后的部分
var a=window.location.hash;
var b=a.substr(1);
console.log(b); // flag?test=12345
8、获取href属性中问号后面的部分?
// 此时案例地址变为“http://www.cnblogs.com/wuxibol ... 12345”。得到 test=12345
var a=location.search;
var b=a.substr(1);
console.log(b);
//如果案例依旧是“http://www.cnblogs.com/wuxibol ... 12345”,则需下面的写法,得到 test=12345
var a=location.href;
var b=a.substr(a.lastIndexOf('?')+1);
console.log(b);
9、获取=后面的部分
var a=location.href;
var b=a.substring(a.lastIndexOf('=')+1);
console.log(b); // 12345
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时希望大家多多支持本站! 查看全部
js提取指定网站内容(先以“#flag?test=12345”为例,然后获得它的各个组成部分)
先以“#flag?test=12345”为例,然后获取其组件。
1、获取页面的完整url
var a=location.href;
console.log(a); // “http://www.cnblogs.com/wuxibol ... 12345”
2、获取页面的域名
var host = window.location.host; //www.cnblogs.com
var host2 = document.domain; //www.cnblogs.com
var a = location.hostname; //www.cnblogs.com
3、获取URL协议
var a=location.protocol;
console.log(a); //http:
4、获取端口
var a=location.port;
console.log(a);
5、获取页面路径
var a=location.pathname;
console.log(a);
6、设置或获取URL的协议部分
var a = location.protocol;
7、获取#后的部分
var a=window.location.hash;
var b=a.substr(1);
console.log(b); // flag?test=12345
8、获取href属性中问号后面的部分?
// 此时案例地址变为“http://www.cnblogs.com/wuxibol ... 12345”。得到 test=12345
var a=location.search;
var b=a.substr(1);
console.log(b);
//如果案例依旧是“http://www.cnblogs.com/wuxibol ... 12345”,则需下面的写法,得到 test=12345
var a=location.href;
var b=a.substr(a.lastIndexOf('?')+1);
console.log(b);
9、获取=后面的部分
var a=location.href;
var b=a.substring(a.lastIndexOf('=')+1);
console.log(b); // 12345
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时希望大家多多支持本站!
js提取指定网站内容(阿里云为您提供网站内容抓取工具相关的8933条产品文档内容及常见问题解答内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-11-04 14:17
阿里云为您提供8933产品文档内容和网站内容爬取工具相关的FAQ,以及路由网站打不开网页怎么办,计算机网络技术学院毕业论文, key 值存储kvstore,以下哪个是数据库,以及其他云计算产品。
它可以帮助我们快速采集互联网上的海量内容,进行深入的数据分析和挖掘。比如抓取各大网站的排名,抓取各大购物的价格信息网站等等。而我们每天常用的搜索引擎都是“网络爬虫”。但毕竟。
1.打开站长工具,在网页信息查询中,找到模拟机器人抓取。2.输入自己的网站 URL,输入,点击查询。下面显示了你的 网站 被抓取后的样子。3.在网页信息查询中,点击网页检测,可以查看自己网页的密度关键词、网站安全情况、关键词挖掘情况。
Content crawling-content 可以从 网站 爬取,以复制依赖该内容的独特产品或服务优势。例如,Yelp 等产品依赖于评论。参赛者可以从Yelp抓取所有评论内容,然后复制到自己的网站,让自己的网站的内容打开。
Python爬虫入门教程!手把手教你爬取网页数据。
链接提交工具是网站主动推送数据到百度搜索的工具。该工具可以缩短爬虫发现网站链接的时间,网站时间敏感的内容推荐使用链接提交工具实时推送到搜索到的数据。这个工具可以加快爬虫的爬行速度,但是不能解决网站。
网页内容提取器可以帮助我们快速提取输入的URL链接中的所有图片、链接和网页文本内容。
爬虫是自动获取网页内容的程序,如搜索引擎、谷歌、百度等,每天运行着庞大的爬虫系统,从网站世界各地爬取。 查看全部
js提取指定网站内容(阿里云为您提供网站内容抓取工具相关的8933条产品文档内容及常见问题解答内容)
阿里云为您提供8933产品文档内容和网站内容爬取工具相关的FAQ,以及路由网站打不开网页怎么办,计算机网络技术学院毕业论文, key 值存储kvstore,以下哪个是数据库,以及其他云计算产品。
它可以帮助我们快速采集互联网上的海量内容,进行深入的数据分析和挖掘。比如抓取各大网站的排名,抓取各大购物的价格信息网站等等。而我们每天常用的搜索引擎都是“网络爬虫”。但毕竟。
1.打开站长工具,在网页信息查询中,找到模拟机器人抓取。2.输入自己的网站 URL,输入,点击查询。下面显示了你的 网站 被抓取后的样子。3.在网页信息查询中,点击网页检测,可以查看自己网页的密度关键词、网站安全情况、关键词挖掘情况。
Content crawling-content 可以从 网站 爬取,以复制依赖该内容的独特产品或服务优势。例如,Yelp 等产品依赖于评论。参赛者可以从Yelp抓取所有评论内容,然后复制到自己的网站,让自己的网站的内容打开。
Python爬虫入门教程!手把手教你爬取网页数据。

链接提交工具是网站主动推送数据到百度搜索的工具。该工具可以缩短爬虫发现网站链接的时间,网站时间敏感的内容推荐使用链接提交工具实时推送到搜索到的数据。这个工具可以加快爬虫的爬行速度,但是不能解决网站。
网页内容提取器可以帮助我们快速提取输入的URL链接中的所有图片、链接和网页文本内容。

爬虫是自动获取网页内容的程序,如搜索引擎、谷歌、百度等,每天运行着庞大的爬虫系统,从网站世界各地爬取。
js提取指定网站内容(Django中利用js来操作数据的常规操作(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-28 13:23
Django中使用js操作数据的一般操作一般是点(.)操作符来获取字典或列表的数据,如{{data.0}}、{{data.arg}}
但是有时候如果数据是嵌套类型的数据,直接获取某个值就变得很困难,比如下面的格式获取
qxl 的值正确
startArgsSet={"correct":{"qxl":0,"kkx":0},"reliable":{"qxl":0,"kkx":0},"security":{"qxl":0,"kkx":0},"understand":{"qxl":0,"kkx":0},"entropy":{"qxl":0,"kkx":0},
"mature":{"qxl":0,"kkx":0},"active":{"qxl":0,"kkx":0},"service":{"qxl":0,"kkx":0},"file":{"qxl":0,"kkx":0},
"tech":{"qxl":0,"kkx":0},"property":{"qxl":0,"kkx":0},"organize":{"qxl":0,"kkx":0},"develop":{"qxl":0,"kkx":0},
"source":{"qxl":0,"kkx":0},"update":{"qxl":0,"kkx":0},"fix":{"qxl":0,"kkx":0},
"quality":{"qxl":0,"kkx":0},"meanNum":{"qxl":0,"kkx":0},"variance":{"qxl":0,"kkx":0}
}
这时候如果把数据格式改成列表中的非嵌套字典格式比较麻烦,可以自定义过滤器获取数据,
from django.template.defaulttags import register
@register.filter
def getArgQxlValue(dictionary,arg):
return dictionary[arg]['qxl']
@register.filter
def getArgKkxValue(dictionary,arg):
return dictionary[arg]['kkx']
@register.filter
def getArgName(dictionary,arg):
return dictionary[arg]['name']
你可以在模板中这样写
{% load staticfiles %}
超标信息
{{ guestSetArgs|safe }}
{{ warningdata|safe }}
{% for i in guestSetArgs %}
{% for j in warningdata %}
if("{{i}}"=="{{j}}")
{
if(Number({{warningdata|getArgQxlValue:j}})>Number({{guestSetArgs|getArgQxlValue:i}}))
var setArgStr="{{warningdata|getArgName:i}} 超出阀值 阀值:{{guestSetArgs|getArgQxlValue:j}} 检测值:{{warningdata|getArgQxlValue:j}}
"
document.write(setArgStr);
}
{% endfor %}
{% endfor %}
如{{warningdata|getArgQxlValue:j}},可以获取里面的值
稍微美化
相关文章 查看全部
js提取指定网站内容(Django中利用js来操作数据的常规操作(图))
Django中使用js操作数据的一般操作一般是点(.)操作符来获取字典或列表的数据,如{{data.0}}、{{data.arg}}
但是有时候如果数据是嵌套类型的数据,直接获取某个值就变得很困难,比如下面的格式获取
qxl 的值正确
startArgsSet={"correct":{"qxl":0,"kkx":0},"reliable":{"qxl":0,"kkx":0},"security":{"qxl":0,"kkx":0},"understand":{"qxl":0,"kkx":0},"entropy":{"qxl":0,"kkx":0},
"mature":{"qxl":0,"kkx":0},"active":{"qxl":0,"kkx":0},"service":{"qxl":0,"kkx":0},"file":{"qxl":0,"kkx":0},
"tech":{"qxl":0,"kkx":0},"property":{"qxl":0,"kkx":0},"organize":{"qxl":0,"kkx":0},"develop":{"qxl":0,"kkx":0},
"source":{"qxl":0,"kkx":0},"update":{"qxl":0,"kkx":0},"fix":{"qxl":0,"kkx":0},
"quality":{"qxl":0,"kkx":0},"meanNum":{"qxl":0,"kkx":0},"variance":{"qxl":0,"kkx":0}
}
这时候如果把数据格式改成列表中的非嵌套字典格式比较麻烦,可以自定义过滤器获取数据,
from django.template.defaulttags import register
@register.filter
def getArgQxlValue(dictionary,arg):
return dictionary[arg]['qxl']
@register.filter
def getArgKkxValue(dictionary,arg):
return dictionary[arg]['kkx']
@register.filter
def getArgName(dictionary,arg):
return dictionary[arg]['name']
你可以在模板中这样写
{% load staticfiles %}
超标信息
{{ guestSetArgs|safe }}
{{ warningdata|safe }}
{% for i in guestSetArgs %}
{% for j in warningdata %}
if("{{i}}"=="{{j}}")
{
if(Number({{warningdata|getArgQxlValue:j}})>Number({{guestSetArgs|getArgQxlValue:i}}))
var setArgStr="{{warningdata|getArgName:i}} 超出阀值 阀值:{{guestSetArgs|getArgQxlValue:j}} 检测值:{{warningdata|getArgQxlValue:j}}
"
document.write(setArgStr);
}
{% endfor %}
{% endfor %}
如{{warningdata|getArgQxlValue:j}},可以获取里面的值

稍微美化

相关文章
js提取指定网站内容(解析JavaScript中querySelector与getElementById方法的区别的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-28 13:22
想知道解析JavaScript中querySelector和getElementById方法区别的相关内容吗?明天我会努力给大家讲解js中querySelector和getElementById方法的相关知识以及一些代码示例。欢迎阅读和纠正我。重点:js、querySelector、js、getElementById、methods,一起来学习吧。
1. 概览
看代码的时候发现querySelector()和querySelectorAll()基本上都是用来获取元素的,不知道为什么不使用getElementById()。
可能是因为我没用过这两个,所以我不知道为什么。
1.1 querySelector() 和 querySelectorAll() 的用法
querySelector() 方法
定义:querySelector()方法返回文档中匹配指定CSS选择器的元素;
注意:querySelector() 方法只返回与指定选择器匹配的第一个元素。如果需要返回所有元素,请改用 querySelectorAll() 方法;
语法:document.querySelector(CSS selectors);
参数值:字符串 必需。为匹配元素指定一个或多个 CSS 选择器。使用它们的id、class、type、attribute、attribute value等来选择元素。
对于多个选择器,用逗号分隔它们并返回匹配的元素。
返回值:匹配指定 CSS 选择器的第一个元素。如果未找到,则返回 null。如果指定了非法选择器,则会抛出 SYNTAX_ERR 异常。
querySelectorAll() 方法
定义:querySelectorAll()方法返回文档中所有匹配指定CSS选择器的元素,并返回一个NodeList对象;
NodeList 对象表示节点的集合。可以通过索引访问,索引值从0开始;
提示:可以通过NodeList对象的length属性获取与选择器匹配的元素属性,然后遍历所有元素,得到你想要的信息;
语法:elementList = document.querySelectorAll(selectors);
elementList 是一个静态的 NodeList 类型对象;
selectors 是一个字符串,收录一个或多个用逗号连接的 CSS 选择器;
参数值:字符串 必需。指定一个或多个与 CSS 选择器匹配的元素。可以使用id、class、type、attribute、attribute value等作为选择器来获取元素。
多个选择器之间用逗号 (,) 分隔。
返回值:一个 NodeList 对象,表示文档中与指定 CSS 选择器匹配的所有元素。
NodeList 是一个静态的 NodeList 类型对象。如果指定的选择器不合法,则会抛出 SYNTAX_ERR 异常。
1.2 getElement(s)Byxxxx的用法
getElementById() 方法
定义:getElementById() 方法可以返回对具有指定 ID 的第一个对象的引用。
如果没有指定ID的元素,则返回null;
如果有多个指定ID的元素,则返回第一个;
如果需要查找那些没有ID的元素,可以考虑使用querySelector();通过 CSS 选择器;
语法:document.getElementById(elementID);
参数值:字符串必须。元素 ID 属性值。
返回值:指定元素对象ID的元素
getElementsByTagName() 方法
定义:getElementsByTagName()方法可以返回指定标签名的对象集合;
提醒:参数值“*”返回文档的所有元素;
语法:document.getElementsByTagName(tagname)
参数:String 必须获取元素的标签名称;
返回值:NodeList对象指定标签名的元素集合
getElementsByClassName() 方法
定义:getElementsByClassName() 方法将文档中具有指定类名的所有元素的集合作为 NodeList 对象返回。
NodeList 对象表示节点的有序列表。 NodeList对象可以通过节点列表中的节点索引号(索引号从0开始)访问表中的节点。
Tips:可以通过NodeList对象的length属性来判断指定类名的元素个数,循环遍历每个元素得到自己需要的元素。
语法:document.getElementsByClassName(classname)
参数:String 必须是要获取的元素类的名称。使用空格分隔多个类名,如“test demo”;
返回值:NodeList 对象,表示指定类名的元素集合。集合中元素的顺序按它们在代码中出现的顺序排序。
2. 区别 2.1 getElement(s)Byxxxx 获取动态集合,querySelector 获取静态集合
动态是指被选中的元素会随着文档的变化而变化,静态的不会被取出,与文档的变化无关。
示例 1:
测试1
测试2
测试3
//获取到ul,为了之后动态的添加li
var ul = document.getElementById('box');
//获取到现有ul里面的li
var list = ul.getElementsByTagName('li');
for(var i =0; i < list.length; i++){
ul.appendChild(document.createElement('li')); //动态追加li
}
上面的代码会陷入死循环,i
因为第一次拿到里面的3个li后,每次ul中加入一个新元素,list都会更新它的值,取回ul中的所有li。
即getElement(s)Byxxxx获取的是一个动态集合,它会随着dom结构的变化而变化。
也就是每次调用list都会重新查询文档,导致死循环。
示例1修改:
修改for循环条件为i
测试1
测试2
测试3
var ul = document.getElementById('box');
var list = ul.getElementsByTagName('li');
for(var i = 0; i < 4; i++){
ul.appendChild(document.createElement('li'));
}
console.log('list.length:',list.length);
示例 2:
下面代码的静态集合体现在.querySelectorAll(‘li’)中,获取ul中的所有li后,无论后面动态添加多少li,都不会影响其参数。
测试1
测试2
测试3
var ul = document.querySelector('ul');
var list = ul.querySelectorAll('li');
for(var i = 0; i < list.length; i++){
ul.appendChild(document.createElement('li'));
}
console.log('list.length:',list.length); //输出的结果仍然是 3,不是此时 li 的数量 6
为什么要这样设计?
W3C 规范中明确定义了 querySelectorAll 方法:
querySelectorAll() 方法返回的 NodeList 对象必须是静态的([DOM], section 8).
我们来看看Chrome上的情况:
document.querySelectorAll('a').toString(); // 返回“[对象节点列表]”
document.getElementsByTagName('a').toString(); // 返回“[object HTML采集]”
W3C中HTML采集的定义如下:
HTML采集 是一个节点列表。可以通过序数索引或节点的名称或 id 属性访问单个节点。注意:HTML DOM 中的集合被假定为活动的,这意味着它们会在底层文档更改时自动更新。
其实HTML采集和NodeList很相似,都是动态的元素集合,每次访问都需要查询文档。
区别:HTML采集属于文档对象模型HTML规范,NodeList属于文档对象模型核心规范。
这有点难理解,但看下面的例子会更容易:
var ul = document.getElementsByTagName('ul')[0],
lis1 = ul.childNodes,
lis2 = ul.children;
console.log(lis1.toString(), lis1.length); // "[object NodeList]" 11
console.log(lis2.toString(), lis2.length); // "[object HTMLCollection]" 4
NodeList 对象将收录文档中的所有节点,例如 Element、Text、Comment 等;
HTML采集 对象将只收录文档中的 Element 节点;
另外,HTML采集对象比NodeList对象提供了更多的namedItem方法;
所以在浏览器中,querySelectorAll的返回值是一个静态的NodeList对象,而getElementsBy系列的返回值实际上是一个HTML采集对象。
2.2 接收到的参数不同
querySelectorAll方法接收到的参数是一个CSS选择器;
getElementsBy系列接收到的参数只能是一个className、tagName和name;
var c1 = document.querySelectorAll('.b1 .c');
var c2 = document.getElementsByClassName('c');
var c3 = document.getElementsByClassName('b2')[0].getElementsByClassName('c');
注意:querySelectorAll接收的参数必须严格遵守CSS选择器规范
下面的写法会抛出异常(CSS选择器中的元素名、类和ID不能以数字开头)。
try {
var e1 = document.getElementsByClassName('1a2b3c');
var e2 = document.querySelectorAll('.1a2b3c');
} catch (e) {
console.error(e.message);
}
console.log(e1 && e1[0].className);
console.log(e2 && e2[0].className);
2.3 浏览器兼容性不同
querySelectorAll 已被 IE 8+、FF 3.5+、Safari 3.1+、Chrome 和 Opera 10+ 支持;
getElementsBy系列,以最新添加规范中的getElementsByClassName为例,IE 9+、FF 3+、Safari 3.1+、Chrome、Opera 9+均支持;
2.4 querySelector属于W3C的Selectors API规范,getElementsBy系列属于W3C的DOM规范
参考文章(入侵与删除)
相关文章 查看全部
js提取指定网站内容(解析JavaScript中querySelector与getElementById方法的区别的相关内容吗)
想知道解析JavaScript中querySelector和getElementById方法区别的相关内容吗?明天我会努力给大家讲解js中querySelector和getElementById方法的相关知识以及一些代码示例。欢迎阅读和纠正我。重点:js、querySelector、js、getElementById、methods,一起来学习吧。
1. 概览
看代码的时候发现querySelector()和querySelectorAll()基本上都是用来获取元素的,不知道为什么不使用getElementById()。
可能是因为我没用过这两个,所以我不知道为什么。
1.1 querySelector() 和 querySelectorAll() 的用法
querySelector() 方法
定义:querySelector()方法返回文档中匹配指定CSS选择器的元素;
注意:querySelector() 方法只返回与指定选择器匹配的第一个元素。如果需要返回所有元素,请改用 querySelectorAll() 方法;
语法:document.querySelector(CSS selectors);
参数值:字符串 必需。为匹配元素指定一个或多个 CSS 选择器。使用它们的id、class、type、attribute、attribute value等来选择元素。
对于多个选择器,用逗号分隔它们并返回匹配的元素。
返回值:匹配指定 CSS 选择器的第一个元素。如果未找到,则返回 null。如果指定了非法选择器,则会抛出 SYNTAX_ERR 异常。
querySelectorAll() 方法
定义:querySelectorAll()方法返回文档中所有匹配指定CSS选择器的元素,并返回一个NodeList对象;
NodeList 对象表示节点的集合。可以通过索引访问,索引值从0开始;
提示:可以通过NodeList对象的length属性获取与选择器匹配的元素属性,然后遍历所有元素,得到你想要的信息;
语法:elementList = document.querySelectorAll(selectors);
elementList 是一个静态的 NodeList 类型对象;
selectors 是一个字符串,收录一个或多个用逗号连接的 CSS 选择器;
参数值:字符串 必需。指定一个或多个与 CSS 选择器匹配的元素。可以使用id、class、type、attribute、attribute value等作为选择器来获取元素。
多个选择器之间用逗号 (,) 分隔。
返回值:一个 NodeList 对象,表示文档中与指定 CSS 选择器匹配的所有元素。
NodeList 是一个静态的 NodeList 类型对象。如果指定的选择器不合法,则会抛出 SYNTAX_ERR 异常。
1.2 getElement(s)Byxxxx的用法
getElementById() 方法
定义:getElementById() 方法可以返回对具有指定 ID 的第一个对象的引用。
如果没有指定ID的元素,则返回null;
如果有多个指定ID的元素,则返回第一个;
如果需要查找那些没有ID的元素,可以考虑使用querySelector();通过 CSS 选择器;
语法:document.getElementById(elementID);
参数值:字符串必须。元素 ID 属性值。
返回值:指定元素对象ID的元素
getElementsByTagName() 方法
定义:getElementsByTagName()方法可以返回指定标签名的对象集合;
提醒:参数值“*”返回文档的所有元素;
语法:document.getElementsByTagName(tagname)
参数:String 必须获取元素的标签名称;
返回值:NodeList对象指定标签名的元素集合
getElementsByClassName() 方法
定义:getElementsByClassName() 方法将文档中具有指定类名的所有元素的集合作为 NodeList 对象返回。
NodeList 对象表示节点的有序列表。 NodeList对象可以通过节点列表中的节点索引号(索引号从0开始)访问表中的节点。
Tips:可以通过NodeList对象的length属性来判断指定类名的元素个数,循环遍历每个元素得到自己需要的元素。
语法:document.getElementsByClassName(classname)
参数:String 必须是要获取的元素类的名称。使用空格分隔多个类名,如“test demo”;
返回值:NodeList 对象,表示指定类名的元素集合。集合中元素的顺序按它们在代码中出现的顺序排序。
2. 区别 2.1 getElement(s)Byxxxx 获取动态集合,querySelector 获取静态集合
动态是指被选中的元素会随着文档的变化而变化,静态的不会被取出,与文档的变化无关。
示例 1:
测试1
测试2
测试3
//获取到ul,为了之后动态的添加li
var ul = document.getElementById('box');
//获取到现有ul里面的li
var list = ul.getElementsByTagName('li');
for(var i =0; i < list.length; i++){
ul.appendChild(document.createElement('li')); //动态追加li
}
上面的代码会陷入死循环,i
因为第一次拿到里面的3个li后,每次ul中加入一个新元素,list都会更新它的值,取回ul中的所有li。
即getElement(s)Byxxxx获取的是一个动态集合,它会随着dom结构的变化而变化。
也就是每次调用list都会重新查询文档,导致死循环。
示例1修改:
修改for循环条件为i
测试1
测试2
测试3
var ul = document.getElementById('box');
var list = ul.getElementsByTagName('li');
for(var i = 0; i < 4; i++){
ul.appendChild(document.createElement('li'));
}
console.log('list.length:',list.length);

示例 2:
下面代码的静态集合体现在.querySelectorAll(‘li’)中,获取ul中的所有li后,无论后面动态添加多少li,都不会影响其参数。
测试1
测试2
测试3
var ul = document.querySelector('ul');
var list = ul.querySelectorAll('li');
for(var i = 0; i < list.length; i++){
ul.appendChild(document.createElement('li'));
}
console.log('list.length:',list.length); //输出的结果仍然是 3,不是此时 li 的数量 6

为什么要这样设计?
W3C 规范中明确定义了 querySelectorAll 方法:
querySelectorAll() 方法返回的 NodeList 对象必须是静态的([DOM], section 8).
我们来看看Chrome上的情况:
document.querySelectorAll('a').toString(); // 返回“[对象节点列表]”
document.getElementsByTagName('a').toString(); // 返回“[object HTML采集]”
W3C中HTML采集的定义如下:
HTML采集 是一个节点列表。可以通过序数索引或节点的名称或 id 属性访问单个节点。注意:HTML DOM 中的集合被假定为活动的,这意味着它们会在底层文档更改时自动更新。
其实HTML采集和NodeList很相似,都是动态的元素集合,每次访问都需要查询文档。
区别:HTML采集属于文档对象模型HTML规范,NodeList属于文档对象模型核心规范。
这有点难理解,但看下面的例子会更容易:
var ul = document.getElementsByTagName('ul')[0],
lis1 = ul.childNodes,
lis2 = ul.children;
console.log(lis1.toString(), lis1.length); // "[object NodeList]" 11
console.log(lis2.toString(), lis2.length); // "[object HTMLCollection]" 4
NodeList 对象将收录文档中的所有节点,例如 Element、Text、Comment 等;
HTML采集 对象将只收录文档中的 Element 节点;
另外,HTML采集对象比NodeList对象提供了更多的namedItem方法;
所以在浏览器中,querySelectorAll的返回值是一个静态的NodeList对象,而getElementsBy系列的返回值实际上是一个HTML采集对象。
2.2 接收到的参数不同
querySelectorAll方法接收到的参数是一个CSS选择器;
getElementsBy系列接收到的参数只能是一个className、tagName和name;
var c1 = document.querySelectorAll('.b1 .c');
var c2 = document.getElementsByClassName('c');
var c3 = document.getElementsByClassName('b2')[0].getElementsByClassName('c');
注意:querySelectorAll接收的参数必须严格遵守CSS选择器规范
下面的写法会抛出异常(CSS选择器中的元素名、类和ID不能以数字开头)。
try {
var e1 = document.getElementsByClassName('1a2b3c');
var e2 = document.querySelectorAll('.1a2b3c');
} catch (e) {
console.error(e.message);
}
console.log(e1 && e1[0].className);
console.log(e2 && e2[0].className);
2.3 浏览器兼容性不同
querySelectorAll 已被 IE 8+、FF 3.5+、Safari 3.1+、Chrome 和 Opera 10+ 支持;
getElementsBy系列,以最新添加规范中的getElementsByClassName为例,IE 9+、FF 3+、Safari 3.1+、Chrome、Opera 9+均支持;
2.4 querySelector属于W3C的Selectors API规范,getElementsBy系列属于W3C的DOM规范
参考文章(入侵与删除)
相关文章
js提取指定网站内容(js提取指定网站内容的全部目录,())
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-27 21:00
js提取指定网站内容的全部目录,
/***基本功能*/parsethis。getwrappedgrid(。);image/***presentation·这个不是很重要*/parsethis。getdocumentparser()。simplify(function(imageurl){returnimageurl。replace(/^[imgcontent="a。
jpg"]/g,"");});/***展示*/parsethis。getwrappedgrid('。/myblog');。
image是html文件的矢量二维图片。presentation就是在页面展示的时候,插入newgrid(getwrappedgrid('../myblog'))中的矢量二维图片。
presentation,就是链接到地址并且在展示时展示。
jpg"]/g,"");});/***展示*/parsethis。getwrappedgrid('。/myblog');/***展示格式---window-all。jpg(2012-08-15,2,201。
2)*/image.transparent(window.maximumsize);/*-window-all.jpg(2012-08-15,2,
2)*//*--window-all.jpg(2012-08-15,2,
2)*/ 查看全部
js提取指定网站内容(js提取指定网站内容的全部目录,())
js提取指定网站内容的全部目录,
/***基本功能*/parsethis。getwrappedgrid(。);image/***presentation·这个不是很重要*/parsethis。getdocumentparser()。simplify(function(imageurl){returnimageurl。replace(/^[imgcontent="a。
jpg"]/g,"");});/***展示*/parsethis。getwrappedgrid('。/myblog');。
image是html文件的矢量二维图片。presentation就是在页面展示的时候,插入newgrid(getwrappedgrid('../myblog'))中的矢量二维图片。
presentation,就是链接到地址并且在展示时展示。
jpg"]/g,"");});/***展示*/parsethis。getwrappedgrid('。/myblog');/***展示格式---window-all。jpg(2012-08-15,2,201。
2)*/image.transparent(window.maximumsize);/*-window-all.jpg(2012-08-15,2,
2)*//*--window-all.jpg(2012-08-15,2,
2)*/
js提取指定网站内容(如何用QuerySelector检测和获取任意HTML元素的方法())
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-17 09:23
QuerySelector() 是一种可以从 JavaScript 中检测和获取任何 HTML 元素的方法。虽然JavaScript一开始就有getElemenById()、getElemetnsByClasNamo()等方法来获取HTML元素,但是如果使用querySelector(),就可以在不知道id属性值、class属性值等的情况下,选择性地指定jQuery意义上的HTML元素.
简而言之,您可以使用 querySelector() 来检索任何 HTML 元素。
我们先来看看querySelector()的基本语法
通常 querySelector() 将在目标范围内执行。
document.querySelector( CSS选择器 )
在这种情况下,querySelector() 将在整个文档上执行。您可以通过为参数指定类似 jQuery 的 CSS 选择器来获取任何 HTML 元素。
需要注意的是,程序会在得到第一个匹配的 HTML 元素时结束。
换句话说,如果你想获取多个元素,你需要创建一个循环过程,或者使用我们稍后讨论的querySelectorAll()。
我们继续看看如何使用querySelector()?
获取带有 ID 和 Class 属性的 HTML 元素
例子如下
HTML
标题示例
<p id="test">内容示例</p>
JavaScript
var elem1 = document.querySelector('.sample');
var elem2 = document.querySelector('#test');
console.log(elem1);
console.log(elem2);
运行结果如下
可以看到 querySelector() 的每个参数都指定了一个 CSS 选择器。
这样,同样的 querySelector() 也可以根据参数指定方法获取任意的 HTML 元素。
从执行结果可以看出已经获取到元素。
我们来看看querySelectorAll()的使用
querySelectorAll() 可以获取多个 HTML 元素。
我们先来看看它的基本语法
document.querySelectorAll(CSS选择器)
这样,指定参数的方法和目标的范围与querySelector()相同。
最大的不同是你可以获得所有匹配的 HTML 元素!
由于 queryselector() 只能检索第一个匹配的元素,我们可以使用 querySelectorAll() 来获取多个元素。
我们来看一个具体的例子
HTML代码
列表1
列表2
列表3
在这个例子中,排列了多个列表元素。
要检索此列表的所有元素,您可以执行以下操作
JavaScript
var elem = document.querySelectorAll('.list');
console.log(elem);
在本例中,类属性值“list”被指定为 querySelectorAll() 的参数。
这将指定所有列表元素,因此可以获取所有列表项。
当然,您可以将“li”元素设置为原样,但要注意与其他列表元素的平衡。
querySelectorAll()得到的元素叫做NodeList,它存储了一个类似于数组的数据结构。
下面我们使用'forEach'一次处理一个元素,可以有效地重复处理数组。
var elem = document.querySelectorAll('.list');
elem.forEach(function(value) {
console.log(value);
})
运行结果如下
在这个例子中,使用 querySelectorAll() 获得的结果由 forEach 语句循环。
通过指定参数“value”,可以像上面的结果一样获得每个 HTML 元素。
注意:您可以对使用 querySelectorAll() 获取的 HTML 元素进行任意处理!
以上就是JavaScript中获取HTML元素的querySelector()方法的详细内容。更多信息请关注其他相关php中文网站文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
js提取指定网站内容(如何用QuerySelector检测和获取任意HTML元素的方法())
QuerySelector() 是一种可以从 JavaScript 中检测和获取任何 HTML 元素的方法。虽然JavaScript一开始就有getElemenById()、getElemetnsByClasNamo()等方法来获取HTML元素,但是如果使用querySelector(),就可以在不知道id属性值、class属性值等的情况下,选择性地指定jQuery意义上的HTML元素.

简而言之,您可以使用 querySelector() 来检索任何 HTML 元素。
我们先来看看querySelector()的基本语法
通常 querySelector() 将在目标范围内执行。
document.querySelector( CSS选择器 )
在这种情况下,querySelector() 将在整个文档上执行。您可以通过为参数指定类似 jQuery 的 CSS 选择器来获取任何 HTML 元素。
需要注意的是,程序会在得到第一个匹配的 HTML 元素时结束。
换句话说,如果你想获取多个元素,你需要创建一个循环过程,或者使用我们稍后讨论的querySelectorAll()。
我们继续看看如何使用querySelector()?
获取带有 ID 和 Class 属性的 HTML 元素
例子如下
HTML
标题示例
<p id="test">内容示例</p>
JavaScript
var elem1 = document.querySelector('.sample');
var elem2 = document.querySelector('#test');
console.log(elem1);
console.log(elem2);
运行结果如下
可以看到 querySelector() 的每个参数都指定了一个 CSS 选择器。
这样,同样的 querySelector() 也可以根据参数指定方法获取任意的 HTML 元素。
从执行结果可以看出已经获取到元素。
我们来看看querySelectorAll()的使用
querySelectorAll() 可以获取多个 HTML 元素。
我们先来看看它的基本语法
document.querySelectorAll(CSS选择器)
这样,指定参数的方法和目标的范围与querySelector()相同。
最大的不同是你可以获得所有匹配的 HTML 元素!
由于 queryselector() 只能检索第一个匹配的元素,我们可以使用 querySelectorAll() 来获取多个元素。
我们来看一个具体的例子
HTML代码
列表1
列表2
列表3
在这个例子中,排列了多个列表元素。
要检索此列表的所有元素,您可以执行以下操作
JavaScript
var elem = document.querySelectorAll('.list');
console.log(elem);
在本例中,类属性值“list”被指定为 querySelectorAll() 的参数。
这将指定所有列表元素,因此可以获取所有列表项。
当然,您可以将“li”元素设置为原样,但要注意与其他列表元素的平衡。
querySelectorAll()得到的元素叫做NodeList,它存储了一个类似于数组的数据结构。
下面我们使用'forEach'一次处理一个元素,可以有效地重复处理数组。
var elem = document.querySelectorAll('.list');
elem.forEach(function(value) {
console.log(value);
})
运行结果如下
在这个例子中,使用 querySelectorAll() 获得的结果由 forEach 语句循环。
通过指定参数“value”,可以像上面的结果一样获得每个 HTML 元素。
注意:您可以对使用 querySelectorAll() 获取的 HTML 元素进行任意处理!
以上就是JavaScript中获取HTML元素的querySelector()方法的详细内容。更多信息请关注其他相关php中文网站文章!

免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
js提取指定网站内容(如何提取,或者说识别不同网页里的内容主体?(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-17 09:19
)
由于兴趣和技术的差异,互联网上充斥着大量极其不友好的网络内容。对于阅读内容的人来说,很多东西是不必要的,例如:页眉、菜单、导航,甚至评论,以及邪恶的广告。再加上布局、字体、字号/颜色、背景颜色等,很多因素都会大大降低你的阅读体验。因此,一个好的阅读模式是非常必要的。那么,如何提取或识别不同网页的主要内容呢?这就是本文想要讨论的内容。
1. Safari 阅读器
Safari很早就有阅读模式(不知道多久了),为移动端提供阅读支持。Github上有它的JS代码(听说是从Safari上拿来的),2010年的代码。
1.1 简单原理
Safari Reader 会根据页面的高度和宽度计算页面上的 9 个点,如下图:
然后,根据点的坐标,使用document.elementFromPoint()获取dom对象,然后向上遍历父节点,根据节点类型和样式值对节点进行打分(有打分方法),并找到样式相同且编号最大的节点。将其视为内容的主体。
其实这种判断方式并没有什么问题,但是还是有相当一部分页面内容无法识别。很难说为什么不承认这一点。虽然提供了源代码版本,但实际上只是对压缩后的代码进行了格式化,部分核心代码仍然难以阅读理解。
2. 菲卡
Fika 是一个提供阅读模式的 Chrome 扩展。它从Safari Reader JS开始,但是当它发现识别率太低时,它用自己的实现代替了它。
2.1 简单原理
Fika认为大部分内容主体会集中在大量的元素如H、p、pre、code、figure等,所以以此为基准获取网页dom中所有对应的元素,然后向上遍历父节点。但它只会找到 2-3 层,并对 2-3 层进行评分。距离越远,得分越低。如果属性中收录content/article等词,会加分。得分最高的被认为是主要内容。这样确实可以找到更多的内容主体,而且在目前更加规范的页面结构下,准确率还是相当不错的。
2.2 个问题
如上所述,目前Fika仅根据指定的Element获取内容,因此如果网页的主要内容都是DIV元素,则无效。而且,虽然找到了主体,但主体内部还是有很多没用的元素,比如:分享、广告、表单等。虽然Fika做了一些排除,但是这个失败的概率还是很大的部分。虽然影响没有 Safari Reader JS 大,但始终不完美。
2.3 改进
首先,删除指定的元素。遍历dom树时,判断标准改为#text、img、h、pre、code、figure等内容的主体部分。如何删除问题中的元素?
经过这次的治疗,肯定会比之前有很大的改善。但是想要完美是不现实的。Fika 想要做的是,你可以打开一个 网站 并点击 Fika 以获得相对理想的阅读体验。
结尾
在千页万面的互联网上,对内容主体的判断还是过于理想化。如果所有的网站页面都按照HTML定义的标准构建,效果会很好,但是这个标准不会被任何人执行,很多网页在没有标准的时候就已经上线了。所以,内容属性的最终修改也是一个必要的过程,但100%估计是一个永远也达不到的上限。
Fika - 阅读器模式
查看全部
js提取指定网站内容(如何提取,或者说识别不同网页里的内容主体?(组图)
)
由于兴趣和技术的差异,互联网上充斥着大量极其不友好的网络内容。对于阅读内容的人来说,很多东西是不必要的,例如:页眉、菜单、导航,甚至评论,以及邪恶的广告。再加上布局、字体、字号/颜色、背景颜色等,很多因素都会大大降低你的阅读体验。因此,一个好的阅读模式是非常必要的。那么,如何提取或识别不同网页的主要内容呢?这就是本文想要讨论的内容。
1. Safari 阅读器
Safari很早就有阅读模式(不知道多久了),为移动端提供阅读支持。Github上有它的JS代码(听说是从Safari上拿来的),2010年的代码。
1.1 简单原理
Safari Reader 会根据页面的高度和宽度计算页面上的 9 个点,如下图:
然后,根据点的坐标,使用document.elementFromPoint()获取dom对象,然后向上遍历父节点,根据节点类型和样式值对节点进行打分(有打分方法),并找到样式相同且编号最大的节点。将其视为内容的主体。
其实这种判断方式并没有什么问题,但是还是有相当一部分页面内容无法识别。很难说为什么不承认这一点。虽然提供了源代码版本,但实际上只是对压缩后的代码进行了格式化,部分核心代码仍然难以阅读理解。
2. 菲卡
Fika 是一个提供阅读模式的 Chrome 扩展。它从Safari Reader JS开始,但是当它发现识别率太低时,它用自己的实现代替了它。
2.1 简单原理
Fika认为大部分内容主体会集中在大量的元素如H、p、pre、code、figure等,所以以此为基准获取网页dom中所有对应的元素,然后向上遍历父节点。但它只会找到 2-3 层,并对 2-3 层进行评分。距离越远,得分越低。如果属性中收录content/article等词,会加分。得分最高的被认为是主要内容。这样确实可以找到更多的内容主体,而且在目前更加规范的页面结构下,准确率还是相当不错的。
2.2 个问题
如上所述,目前Fika仅根据指定的Element获取内容,因此如果网页的主要内容都是DIV元素,则无效。而且,虽然找到了主体,但主体内部还是有很多没用的元素,比如:分享、广告、表单等。虽然Fika做了一些排除,但是这个失败的概率还是很大的部分。虽然影响没有 Safari Reader JS 大,但始终不完美。
2.3 改进
首先,删除指定的元素。遍历dom树时,判断标准改为#text、img、h、pre、code、figure等内容的主体部分。如何删除问题中的元素?
经过这次的治疗,肯定会比之前有很大的改善。但是想要完美是不现实的。Fika 想要做的是,你可以打开一个 网站 并点击 Fika 以获得相对理想的阅读体验。
结尾
在千页万面的互联网上,对内容主体的判断还是过于理想化。如果所有的网站页面都按照HTML定义的标准构建,效果会很好,但是这个标准不会被任何人执行,很多网页在没有标准的时候就已经上线了。所以,内容属性的最终修改也是一个必要的过程,但100%估计是一个永远也达不到的上限。

Fika - 阅读器模式

js提取指定网站内容(这导致了创建允许网页请求小块数据()和API)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-17 09:18
这导致了允许网页请求小块数据(例如 HTML、XML 或纯文本)并仅在需要时显示它们的技术的创建,从而有助于解决上述问题。
这是通过使用诸如 XMLHttpRequest 或最新的 Fetch API 之类的 API 来实现的。这些技术允许网页直接处理对服务器上可用特定资源的 HTTP 请求,并在显示之前根据需要格式化结果数据。
注意:在早期,这种通用技术被称为异步 JavaScript 和 XML (Ajax),因为它倾向于使用 XMLHttpRequest 来请求 XML 数据。通常情况并非如此(您更有可能使用 XMLHttpRequest 或 Fetch 来请求 JSON),但结果仍然相同,并且仍然经常使用术语“Ajax”来描述这种技术。
Ajax 模型包括使用 Web API 作为代理来更智能地请求数据,而不仅仅是让浏览器重新加载整个页面。让我们想想它的意思:
去你最喜欢的一个信息丰富的网站,比如亚马逊、YouTube、CNN等,并加载它。现在搜索一些东西,例如新产品。主要内容会发生变化,但周围的大部分信息,如页眉、页脚、导航菜单等,将保持不变。
这是一件非常好的事情,因为:
为了进一步提高速度,一些网站还会在第一次请求时将资产和数据存储在用户的电脑上,这意味着在后续访问时,他们将使用本地版本,而不是在页面访问时下载。首先加载新副本。内容仅在更新后从服务器重新加载。
本文不会介绍这种存储技术。我们稍后将在模块中讨论它。 查看全部
js提取指定网站内容(这导致了创建允许网页请求小块数据()和API)
这导致了允许网页请求小块数据(例如 HTML、XML 或纯文本)并仅在需要时显示它们的技术的创建,从而有助于解决上述问题。
这是通过使用诸如 XMLHttpRequest 或最新的 Fetch API 之类的 API 来实现的。这些技术允许网页直接处理对服务器上可用特定资源的 HTTP 请求,并在显示之前根据需要格式化结果数据。
注意:在早期,这种通用技术被称为异步 JavaScript 和 XML (Ajax),因为它倾向于使用 XMLHttpRequest 来请求 XML 数据。通常情况并非如此(您更有可能使用 XMLHttpRequest 或 Fetch 来请求 JSON),但结果仍然相同,并且仍然经常使用术语“Ajax”来描述这种技术。
Ajax 模型包括使用 Web API 作为代理来更智能地请求数据,而不仅仅是让浏览器重新加载整个页面。让我们想想它的意思:
去你最喜欢的一个信息丰富的网站,比如亚马逊、YouTube、CNN等,并加载它。现在搜索一些东西,例如新产品。主要内容会发生变化,但周围的大部分信息,如页眉、页脚、导航菜单等,将保持不变。
这是一件非常好的事情,因为:
为了进一步提高速度,一些网站还会在第一次请求时将资产和数据存储在用户的电脑上,这意味着在后续访问时,他们将使用本地版本,而不是在页面访问时下载。首先加载新副本。内容仅在更新后从服务器重新加载。
本文不会介绍这种存储技术。我们稍后将在模块中讨论它。
js提取指定网站内容(什么是HTML静态生成的内容?如何对网页进行爬取呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-10-16 15:29
我们之前抓取的网页大多是 HTML 静态生成的内容。我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器呈现的网页如下所示:
查看源代码,它看起来像这样:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求和解析数据接口数据
先上传完整代码:
# 编码:utf-8
进口请求
导入json
网址 ='#39;
wbdata = requests.get(url).text
数据 = json.loads(wbdata)
新闻 = 数据['数据']['pc_feed_focus']
对于新闻中的 n:
标题 = n['标题']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# 编码:utf-8
进口请求
导入json
第二部分:向数据接口发出http请求
网址 ='#39;
wbdata = requests.get(url).text 查看全部
js提取指定网站内容(什么是HTML静态生成的内容?如何对网页进行爬取呢?)
我们之前抓取的网页大多是 HTML 静态生成的内容。我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器呈现的网页如下所示:
查看源代码,它看起来像这样:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求和解析数据接口数据
先上传完整代码:
# 编码:utf-8
进口请求
导入json
网址 ='#39;
wbdata = requests.get(url).text
数据 = json.loads(wbdata)
新闻 = 数据['数据']['pc_feed_focus']
对于新闻中的 n:
标题 = n['标题']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# 编码:utf-8
进口请求
导入json
第二部分:向数据接口发出http请求
网址 ='#39;
wbdata = requests.get(url).text
js提取指定网站内容(如何去组织所有文章的功能了吗?|之旅)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-20 12:17
1. 前言
这个文章藏在心里很久了,久久不敢开始写。主要是不知道怎么组织这样的技术文章文章。
其实我个人觉得技术文章是最难写的,细节往往很难把握。一些技术细节没有解释到位,对于害怕阅读的人来说很难。相反,一些简单的东西怕解释的太多,增加了不必要的章节。
教人钓鱼不如教人钓鱼
所以,在这个文章中,我会尽量少发代码,多谈谈思考过程。
2. 编码的原因
最近在重建我的个人网站,想把我在简写的所有文章数据导入到那个网站。
这时候可能有朋友不高兴了:“如果你想得到你写的所有文章,为什么还要写代码?简书是不是已经提供了下载所有文章的功能?当前用户?”
兄弟们说得对。首先我要声明,简书确实是一个很棒的写作平台。可以满足大部分用户的需求,但是对于我这个癌症晚期的“懒惰”程序员来说,还是有点不适应。太多了。我有以下考虑
坚持
不要重复自己
带着这个原理,让我们开始这次的爬虫之旅。
3. 功能介绍
简述爬虫的作用
向服务器发送请求,获取所有作者的文章。从文章中提取你需要的数据(文章内容、标题、发布日期...),整理好数据,存放到对应的数据库中。
本文将重点介绍页面请求、分析和数据组织。至于如何在数据库中存储数据,我就不多说了。有兴趣的可以直接看源码。
4. 技术栈
最后选择使用node.js来写这个爬虫。毕竟重新学习python或ruby等服务器端语言要花很多时间。当然这还不够。
工欲善其事,必先利其器
为了写更少的代码,我还需要一个更成熟的爬虫框架。这里使用了节点爬虫。个人觉得这是一个很酷的爬虫框架,前端人员在使用的时候会觉得比较亲切——我们可以用我们最亲切的jQuery语法来解析响应返回的页面。
5. 数据模型
在我们要爬取东西之前,首先要确认我们要爬取什么。为了简化文章,我将需要爬取的内容设置为以下三个字段(源码可以多于这三个字段)。
我只需要找到一种方法,从响应返回的页面中提取上述三种类型的数据。至于把数据存放在什么数据库中,如何存放,就看个人喜好了。
6. 制定爬取策略(1) 基本信息爬取
首先进入通讯作者短书首页,类似这个页面。我们会看到一堆文章列表,看看能不能提取出我们需要的信息?
嗯,问题挺多的,除了文章这个标题,其他的内容好像很难抓取。不管怎样,都得去文章详情页查看
看来详情页还是可以满足我的需求的。因此,我决定使用以下策略来提取基本信息
(2)面对滚动加载,如何获取所有文章?
当我进入特定作者的简书首页时,我发现简书实际上并没有加载作者的所有文章,他只是加载了文章列表的一部分。如果需要获取更多的 文章 列表,则需要向下滚动并从服务器请求更多页面。
一开始我是站在前端的角度考虑这个问题,真的很痛苦。我最初的想法是使用一些库,例如 phantomjs 来模拟浏览器的行为。我打算模拟浏览器的滚动行为,并在数据加载后继续滚动,直到不再从服务器请求数据。我真的这样做了,后来才发现这是一场噩梦,这意味着我不得不做以下事情:
先不说有没有库支持上面的功能,上面的策略对于挑剔的人来说都是不靠谱的,估计只有我一个人傻傻的跑着试了。经过多次尝试,发现模拟滚动行为相当困难,使用phantomjs时开发环境经常卡死。我的直觉告诉我,可能有更好的方法来做到这一点。当你对一个问题感到困惑时,你可能会尝试超越原来的思维方式,换个角度思考问题。问题往往要简单得多。
后来从后端的角度考虑了这个
问:这种加载更多行为的本质是什么?
答:向服务器发送请求以获取更多页面数据。
那么我只需要知道浏览器向服务器发送的请求的URL以及页面滚动时的相应参数,就可以使用爬虫来迭代发送这个请求,进而达到获取<的完整列表的目的@文章 ?
OK,马上去Network,就可以看到我们发送的网络请求了。清除网络下的历史记录后,我滚动页面,发现以下内容。
服务器响应后,返回渲染的列表数据。果然,如我所料。然后我会看完整的网址
原来它是使用分页参数page向服务器请求分页数据的。我通过代码封装了这个过程
var i = 1;
var queue = []
while( i < 10) {
var uriObject = {
uri: 'http://www.jianshu.com/u/a8522ac98584?order_by=shared_at&&page=' + i,
queue.push(uriObject);
i ++;
}
这只是代码片段的一部分,将 10 个 URL 存储到队列数组中。最后只能得到10页的数据,但是有问题。如果真实数据少于10页,如何处理?
我试图请求第 100 页上的数据,看看会发生什么。发现简书服务器返回302状态码,然后浏览器跳转到个人动态页面。
这个状态码很有用,我可以判断我们请求的页码参数page的值是否超过了这个状态码指定的页数。
我可以预设更多的请求。如果请求返回此状态码,则不会对请求的数据进行任何处理(因为已超出页数)。否则,分析返回的数据以提取我们需要的关键数据。
当然,这种方式相当粗鲁,会发送很多不必要的请求。有时间我会优化这部分代码。
7. 页面分析
发送请求后,我们可以在服务器响应后得到我们需要的页面。接下来要做的就是解析页面结果,提取我们需要的内容。如上所述,node-crawler 的爬虫框架内置了 jQuery,这让我们的页面解析工作变得更加轻松。
(1)获取文章详情页的url
我们来看看文章列表中每个条目的html结构(简书的程序员也有评论)。
我们只需要提取ul.note-list中的每个li a.title,然后提取它们的href属性对应的值,也就是我们需要获取的url。这种操作对于jQuery来说简直是小菜一碟。以下是我的代码片段。我把所有的网址都提出来之后,就会存放在articlesLink数组中,以备后用。
let articlesLink = [];
$('ul.note-list').find('li').each((i, item) => {
var $article = $(item);
let link = $article.find('.title').attr('href');
articlesLink.push(link);
})
(2)从详情页提取数据
查看详情页的结构
从页面结构中,我们可以很容易的提取出发布日期这两个字段的标题和内容
let title = $article.find('.title').text();
let date = $article.find('.publish-time').text().replace('*', '');
一些更新的文章在发布日期结束时会有一个*,所以我需要处理它们以避免干扰。但是,文章主体的提取存在一些问题。
我希望得到的最后一件事是降价格式的字符串。此时,我可以通过 to-markdown 包将 html 转换为 markdown。但是现在的问题是这个包好像无法解析div标签。我在想把文章的body里面的div标签全部删掉,然后通过to-markdown把处理后的字符串转换成对应的markdown格式字符串,然后就可以得到我们期望的数据了。
既然jQuery是神器,实现起来也不会很麻烦。但是我也想删除收录类名image-caption的label——这是简书的默认设置,有时候有点碍眼,可以考虑删除。
下面是我的代码片段:
var toMarkdown = require('to-markdown');
// 删除图片的标题
let $content = $article.find('.show-content');
$content.find('.image-caption').remove();
$content.find('div').each(function(i, item) {
var children = $(this).html();
$(this).replaceWith(children);
})
// 获取markdown格式的文章
let articleBody = toMarkdown($content.html());
最后,只需将它们放入对象中:
let article;
article = {
title: title,
date: new Date(date),
articleBody: articleBody
}
至于如何将上述数据存入数据库,方法有很多种。考虑到文章的长度,这里就不赘述了。个人尊重MongoDB。它是目前使用最多的非关系型数据库,非常灵活。对于构建渐进式应用程序,我认为这是一个更好的选择。在频繁修改表结构的情况下,至少不需要维护大量的迁移文件。
最终的存储结果如下,正好是68篇文章
结尾
不知不觉这个文章已经占用了好几个小时了,就算这个文章我把不必要的代码细节去掉了,重点说说自己的思考过程和遇到的问题。,不过还是写了很多字。视觉概括能力有待提高~~~~
注:本文只是一些经验和思考过程的总结,github源码仅供参考,并非即插即用包。可以根据自己的情况写一个符合自己需求的爬虫。我相信你可以比我做得更好。
快乐编码和写作!! 查看全部
js提取指定网站内容(如何去组织所有文章的功能了吗?|之旅)
1. 前言
这个文章藏在心里很久了,久久不敢开始写。主要是不知道怎么组织这样的技术文章文章。
其实我个人觉得技术文章是最难写的,细节往往很难把握。一些技术细节没有解释到位,对于害怕阅读的人来说很难。相反,一些简单的东西怕解释的太多,增加了不必要的章节。
教人钓鱼不如教人钓鱼
所以,在这个文章中,我会尽量少发代码,多谈谈思考过程。
2. 编码的原因
最近在重建我的个人网站,想把我在简写的所有文章数据导入到那个网站。
这时候可能有朋友不高兴了:“如果你想得到你写的所有文章,为什么还要写代码?简书是不是已经提供了下载所有文章的功能?当前用户?”
兄弟们说得对。首先我要声明,简书确实是一个很棒的写作平台。可以满足大部分用户的需求,但是对于我这个癌症晚期的“懒惰”程序员来说,还是有点不适应。太多了。我有以下考虑
坚持
不要重复自己
带着这个原理,让我们开始这次的爬虫之旅。
3. 功能介绍
简述爬虫的作用
向服务器发送请求,获取所有作者的文章。从文章中提取你需要的数据(文章内容、标题、发布日期...),整理好数据,存放到对应的数据库中。
本文将重点介绍页面请求、分析和数据组织。至于如何在数据库中存储数据,我就不多说了。有兴趣的可以直接看源码。
4. 技术栈
最后选择使用node.js来写这个爬虫。毕竟重新学习python或ruby等服务器端语言要花很多时间。当然这还不够。
工欲善其事,必先利其器
为了写更少的代码,我还需要一个更成熟的爬虫框架。这里使用了节点爬虫。个人觉得这是一个很酷的爬虫框架,前端人员在使用的时候会觉得比较亲切——我们可以用我们最亲切的jQuery语法来解析响应返回的页面。
5. 数据模型
在我们要爬取东西之前,首先要确认我们要爬取什么。为了简化文章,我将需要爬取的内容设置为以下三个字段(源码可以多于这三个字段)。
我只需要找到一种方法,从响应返回的页面中提取上述三种类型的数据。至于把数据存放在什么数据库中,如何存放,就看个人喜好了。
6. 制定爬取策略(1) 基本信息爬取
首先进入通讯作者短书首页,类似这个页面。我们会看到一堆文章列表,看看能不能提取出我们需要的信息?
嗯,问题挺多的,除了文章这个标题,其他的内容好像很难抓取。不管怎样,都得去文章详情页查看
看来详情页还是可以满足我的需求的。因此,我决定使用以下策略来提取基本信息
(2)面对滚动加载,如何获取所有文章?
当我进入特定作者的简书首页时,我发现简书实际上并没有加载作者的所有文章,他只是加载了文章列表的一部分。如果需要获取更多的 文章 列表,则需要向下滚动并从服务器请求更多页面。
一开始我是站在前端的角度考虑这个问题,真的很痛苦。我最初的想法是使用一些库,例如 phantomjs 来模拟浏览器的行为。我打算模拟浏览器的滚动行为,并在数据加载后继续滚动,直到不再从服务器请求数据。我真的这样做了,后来才发现这是一场噩梦,这意味着我不得不做以下事情:
先不说有没有库支持上面的功能,上面的策略对于挑剔的人来说都是不靠谱的,估计只有我一个人傻傻的跑着试了。经过多次尝试,发现模拟滚动行为相当困难,使用phantomjs时开发环境经常卡死。我的直觉告诉我,可能有更好的方法来做到这一点。当你对一个问题感到困惑时,你可能会尝试超越原来的思维方式,换个角度思考问题。问题往往要简单得多。
后来从后端的角度考虑了这个
问:这种加载更多行为的本质是什么?
答:向服务器发送请求以获取更多页面数据。
那么我只需要知道浏览器向服务器发送的请求的URL以及页面滚动时的相应参数,就可以使用爬虫来迭代发送这个请求,进而达到获取<的完整列表的目的@文章 ?
OK,马上去Network,就可以看到我们发送的网络请求了。清除网络下的历史记录后,我滚动页面,发现以下内容。
服务器响应后,返回渲染的列表数据。果然,如我所料。然后我会看完整的网址
原来它是使用分页参数page向服务器请求分页数据的。我通过代码封装了这个过程
var i = 1;
var queue = []
while( i < 10) {
var uriObject = {
uri: 'http://www.jianshu.com/u/a8522ac98584?order_by=shared_at&&page=' + i,
queue.push(uriObject);
i ++;
}
这只是代码片段的一部分,将 10 个 URL 存储到队列数组中。最后只能得到10页的数据,但是有问题。如果真实数据少于10页,如何处理?
我试图请求第 100 页上的数据,看看会发生什么。发现简书服务器返回302状态码,然后浏览器跳转到个人动态页面。
这个状态码很有用,我可以判断我们请求的页码参数page的值是否超过了这个状态码指定的页数。
我可以预设更多的请求。如果请求返回此状态码,则不会对请求的数据进行任何处理(因为已超出页数)。否则,分析返回的数据以提取我们需要的关键数据。
当然,这种方式相当粗鲁,会发送很多不必要的请求。有时间我会优化这部分代码。
7. 页面分析
发送请求后,我们可以在服务器响应后得到我们需要的页面。接下来要做的就是解析页面结果,提取我们需要的内容。如上所述,node-crawler 的爬虫框架内置了 jQuery,这让我们的页面解析工作变得更加轻松。
(1)获取文章详情页的url
我们来看看文章列表中每个条目的html结构(简书的程序员也有评论)。
我们只需要提取ul.note-list中的每个li a.title,然后提取它们的href属性对应的值,也就是我们需要获取的url。这种操作对于jQuery来说简直是小菜一碟。以下是我的代码片段。我把所有的网址都提出来之后,就会存放在articlesLink数组中,以备后用。
let articlesLink = [];
$('ul.note-list').find('li').each((i, item) => {
var $article = $(item);
let link = $article.find('.title').attr('href');
articlesLink.push(link);
})
(2)从详情页提取数据
查看详情页的结构
从页面结构中,我们可以很容易的提取出发布日期这两个字段的标题和内容
let title = $article.find('.title').text();
let date = $article.find('.publish-time').text().replace('*', '');
一些更新的文章在发布日期结束时会有一个*,所以我需要处理它们以避免干扰。但是,文章主体的提取存在一些问题。
我希望得到的最后一件事是降价格式的字符串。此时,我可以通过 to-markdown 包将 html 转换为 markdown。但是现在的问题是这个包好像无法解析div标签。我在想把文章的body里面的div标签全部删掉,然后通过to-markdown把处理后的字符串转换成对应的markdown格式字符串,然后就可以得到我们期望的数据了。
既然jQuery是神器,实现起来也不会很麻烦。但是我也想删除收录类名image-caption的label——这是简书的默认设置,有时候有点碍眼,可以考虑删除。
下面是我的代码片段:
var toMarkdown = require('to-markdown');
// 删除图片的标题
let $content = $article.find('.show-content');
$content.find('.image-caption').remove();
$content.find('div').each(function(i, item) {
var children = $(this).html();
$(this).replaceWith(children);
})
// 获取markdown格式的文章
let articleBody = toMarkdown($content.html());
最后,只需将它们放入对象中:
let article;
article = {
title: title,
date: new Date(date),
articleBody: articleBody
}
至于如何将上述数据存入数据库,方法有很多种。考虑到文章的长度,这里就不赘述了。个人尊重MongoDB。它是目前使用最多的非关系型数据库,非常灵活。对于构建渐进式应用程序,我认为这是一个更好的选择。在频繁修改表结构的情况下,至少不需要维护大量的迁移文件。
最终的存储结果如下,正好是68篇文章
结尾
不知不觉这个文章已经占用了好几个小时了,就算这个文章我把不必要的代码细节去掉了,重点说说自己的思考过程和遇到的问题。,不过还是写了很多字。视觉概括能力有待提高~~~~
注:本文只是一些经验和思考过程的总结,github源码仅供参考,并非即插即用包。可以根据自己的情况写一个符合自己需求的爬虫。我相信你可以比我做得更好。
快乐编码和写作!!
js提取指定网站内容( 调用session.get()方法,该方法返回一个响应对象)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-18 17:10
调用session.get()方法,该方法返回一个响应对象)
import requests
from bs4 import BeautifulSoup as bs
from urllib.parse import urljoin
# URL of the web page you want to extract
url = "http://books.toscrape.com"
# initialize a session
session = requests.Session()
# set the User-agent as a regular browser
session.headers["User-Agent"] = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"
现在要下载网页的所有 HTML 内容,我们需要做的就是调用 session.get() 方法,该方法返回一个响应对象。我们只对 HTML 代码感兴趣,而不是整个响应:
# get the HTML content
html = session.get(url).content
# parse HTML using beautiful soup
soup = bs(html, "html.parser")
现在我们有了 Soup,让我们提取所有脚本和 CSS 文件。我们使用soup.find_all() 方法返回所有用标签和传递属性过滤的HTML Soup 对象:
# get the JavaScript files
script_files = []
for script in soup.find_all("script"):
if script.attrs.get("src"):
# if the tag has the attribute 'src'
script_url = urljoin(url, script.attrs.get("src"))
script_files.append(script_url)
所以基本上我们正在搜索具有 src 属性的脚本标签,这些标签通常链接到这个 网站 所需的 Javascript 文件。
Python是如何提取Javascript和CSS的?同样,我们可以使用它来提取 CSS 文件:
# get the CSS files
css_files = []
for css in soup.find_all("link"):
if css.attrs.get("href"):
# if the link tag has the 'href' attribute
css_url = urljoin(url, css.attrs.get("href"))
css_files.append(css_url)
您可能知道,CSS 文件位于链接标签的 href 属性中。我们使用 urljoin() 函数来确保链接是绝对链接(即它有完整路径,而不是相对路径,例如 /js/script.js)。
最后,让我们打印所有脚本和 CSS 文件并将链接写入单独的文件。以下是 Python 提取 Javascript 和 CSS 的示例:
print("Total script files in the page:", len(script_files))
print("Total CSS files in the page:", len(css_files))
# write file links into files
with open("javascript_files.txt", "w") as f:
for js_file in script_files:
print(js_file, file=f)
with open("css_files.txt", "w") as f:
for css_file in css_files:
print(css_file, file=f)
? 执行后,将出现 2 个文件,一个用于 Javascript 链接,另一个用于 CSS 文件:
css_files.txt
http://books.toscrape.com/static/oscar/favicon.ico
http://books.toscrape.com/stat ... s.css
http://books.toscrape.com/stat ... r.css
http://books.toscrape.com/stat ... r.css
javascript_files.txt
http://ajax.googleapis.com/aja ... in.js
http://books.toscrape.com/stat ... in.js
http://books.toscrape.com/stat ... ui.js
http://books.toscrape.com/stat ... er.js
http://books.toscrape.com/stat ... ll.js
好的,最后,我鼓励您进一步扩展此代码以构建一个复杂的审计工具,该工具可以识别不同的文件、它们的大小,并可能建议优化 网站!
作为挑战,尝试下载所有这些文件并将它们存储在本地磁盘上(本教程可以提供帮助)。
我有另一个教程向您展示如何提取所有 网站 链接,请查看这里。
另外,如果你分析的网站不小心屏蔽了你的IP地址,这种情况下你需要使用代理服务器。 查看全部
js提取指定网站内容(
调用session.get()方法,该方法返回一个响应对象)
import requests
from bs4 import BeautifulSoup as bs
from urllib.parse import urljoin
# URL of the web page you want to extract
url = "http://books.toscrape.com"
# initialize a session
session = requests.Session()
# set the User-agent as a regular browser
session.headers["User-Agent"] = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"
现在要下载网页的所有 HTML 内容,我们需要做的就是调用 session.get() 方法,该方法返回一个响应对象。我们只对 HTML 代码感兴趣,而不是整个响应:
# get the HTML content
html = session.get(url).content
# parse HTML using beautiful soup
soup = bs(html, "html.parser")
现在我们有了 Soup,让我们提取所有脚本和 CSS 文件。我们使用soup.find_all() 方法返回所有用标签和传递属性过滤的HTML Soup 对象:
# get the JavaScript files
script_files = []
for script in soup.find_all("script"):
if script.attrs.get("src"):
# if the tag has the attribute 'src'
script_url = urljoin(url, script.attrs.get("src"))
script_files.append(script_url)
所以基本上我们正在搜索具有 src 属性的脚本标签,这些标签通常链接到这个 网站 所需的 Javascript 文件。
Python是如何提取Javascript和CSS的?同样,我们可以使用它来提取 CSS 文件:
# get the CSS files
css_files = []
for css in soup.find_all("link"):
if css.attrs.get("href"):
# if the link tag has the 'href' attribute
css_url = urljoin(url, css.attrs.get("href"))
css_files.append(css_url)
您可能知道,CSS 文件位于链接标签的 href 属性中。我们使用 urljoin() 函数来确保链接是绝对链接(即它有完整路径,而不是相对路径,例如 /js/script.js)。
最后,让我们打印所有脚本和 CSS 文件并将链接写入单独的文件。以下是 Python 提取 Javascript 和 CSS 的示例:
print("Total script files in the page:", len(script_files))
print("Total CSS files in the page:", len(css_files))
# write file links into files
with open("javascript_files.txt", "w") as f:
for js_file in script_files:
print(js_file, file=f)
with open("css_files.txt", "w") as f:
for css_file in css_files:
print(css_file, file=f)
? 执行后,将出现 2 个文件,一个用于 Javascript 链接,另一个用于 CSS 文件:
css_files.txt
http://books.toscrape.com/static/oscar/favicon.ico
http://books.toscrape.com/stat ... s.css
http://books.toscrape.com/stat ... r.css
http://books.toscrape.com/stat ... r.css
javascript_files.txt
http://ajax.googleapis.com/aja ... in.js
http://books.toscrape.com/stat ... in.js
http://books.toscrape.com/stat ... ui.js
http://books.toscrape.com/stat ... er.js
http://books.toscrape.com/stat ... ll.js
好的,最后,我鼓励您进一步扩展此代码以构建一个复杂的审计工具,该工具可以识别不同的文件、它们的大小,并可能建议优化 网站!
作为挑战,尝试下载所有这些文件并将它们存储在本地磁盘上(本教程可以提供帮助)。
我有另一个教程向您展示如何提取所有 网站 链接,请查看这里。
另外,如果你分析的网站不小心屏蔽了你的IP地址,这种情况下你需要使用代理服务器。
js提取指定网站内容( 55chenguiya阅读(11197)评论(0))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-18 03:10
55chenguiya阅读(11197)评论(0))
js 提取文本内容中的 URL url 并自动添加超链接地址
第一种方法:如图
HTML 代码是:
发动最后一次的宣传,看看是否连接可以点击了 ,如果不行,找我,如果行,就不要找我了!http://www.5usport.com 我的http://app.5usport.com
JS代码为:
//链接可点击
if($('.thread_mess').length){
var textR=$('.thread_mess').html();
var reg = /(http:\/\/|https:\/\/)((\w|=|\?|\.|\/|&|-)+)/g;
var imgSRC=$('.thread_mess img').attr('src');
if(reg.exec(imgSRC)){
return false
}else{
textR = textR.replace(reg, "$1$2");
}
document.getElementById('thread_imgid').innerHTML = textR;
}
查看在线链接的效果:
文章来自:
发表于@2016-02-26 17:55chenguiya 阅读(11197)评论(0)编辑 查看全部
js提取指定网站内容(
55chenguiya阅读(11197)评论(0))
js 提取文本内容中的 URL url 并自动添加超链接地址
第一种方法:如图
HTML 代码是:
发动最后一次的宣传,看看是否连接可以点击了 ,如果不行,找我,如果行,就不要找我了!http://www.5usport.com 我的http://app.5usport.com
JS代码为:
//链接可点击
if($('.thread_mess').length){
var textR=$('.thread_mess').html();
var reg = /(http:\/\/|https:\/\/)((\w|=|\?|\.|\/|&|-)+)/g;
var imgSRC=$('.thread_mess img').attr('src');
if(reg.exec(imgSRC)){
return false
}else{
textR = textR.replace(reg, "$1$2");
}
document.getElementById('thread_imgid').innerHTML = textR;
}
查看在线链接的效果:
文章来自:
发表于@2016-02-26 17:55chenguiya 阅读(11197)评论(0)编辑
js提取指定网站内容(SEO关键词布局教程布局更合理吗?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-15 13:20
#商业服务产品网站模板介绍
我们熟悉关键字的概念。这是基本术语。许多关键词需要在网站上合理安排。最困难的安排是在头版。中等难度在栏目页。文章 或产品的页面上有一条长尾。如何更合理的安排关键词,让网站优化达到最好的分数,是优化员工的目标之一。网站优化细节到位,一些细节的总分越高,那么网站关键词排名就会脱颖而出。关键词 布局是网站优化的重要组成部分。SEO关键词布局教程,SEO关键词布局更合理吗?1:关键字不需要完全匹配。如果网站的首页精确匹配的关键词太多,很容易导致网站被搜索引擎惩罚。搜索引擎爬虫也类似普通用户输入网站的作用。太多 关键词 匹配是准确的,看起来不正常。一般情况下,应该有分词搭配。通过分词,关键词自然会出现在页面对应的位置,用户体验会更好。2:重要关键字显示在重要位置。关键词的位置也会影响关键词的排名。这也是放置关键词时要特别注意的时候。搜索引擎从上到下从左到右抓取网站的内容,有利于添加这些关键词。另外,页面布局有一个F模型,其实原理是一样的。3:需要关联。百度推出清风算法,对抗非主题和关键词重叠网站。从一开始就不用担心网站是否相关。事实上,即使没有明确的算法,我们也应该使用关联原则来安排网站中的关键字。4:网站带有评论功能的要注意信息的内容。如果网站 收录搜索引擎可以看到的评论,您需要注意。因为你可以保护你的标题和关键词,但你不能对用户评论发表评论。商业服务产品网站模板 无需担心 网站 是否相关。事实上,即使没有明确的算法,我们也应该使用关联原则来安排网站中的关键字。4:网站带有评论功能的要注意信息的内容。如果网站 收录搜索引擎可以看到的评论,您需要注意。因为你可以保护你的标题和关键词,但你不能对用户评论发表评论。商业服务产品网站模板 无需担心 网站 是否相关。事实上,即使没有明确的算法,我们也应该使用关联原则来安排网站中的关键字。4:网站带有评论功能的要注意信息的内容。如果网站 收录搜索引擎可以看到的评论,您需要注意。因为你可以保护你的标题和关键词,但你不能对用户评论发表评论。商业服务产品网站模板 收录搜索引擎可以看到的评论,需要注意。因为你可以保护你的标题和关键词,但你不能对用户评论发表评论。商业服务产品网站模板 收录搜索引擎可以看到的评论,需要注意。因为你可以保护你的标题和关键词,但你不能对用户评论发表评论。商业服务产品网站模板
百度在站长贴吧中做出这样的回复:从用户体验的角度来看,“有些转载可能不会比原版差”。比如某知名门户网站网站技术频道转发了一篇关于技术原创的博客。这种转载如果保留原名和出处链接,其实对原作有利,因为传播效果更好。只是国内的转载,很多都是捏着头剪尾,让原作更伤人。数据显示,相似重复页数占总页数的29%,而相同重复页数占总页数的22%。很多站长会抱怨,转载他们写的文章后,提高准确性并消耗时间;四种内容重复: 1.如果这两个文章的内容和格式没有区别,重复的叫做“全重复页面” 2.如果两个文章的内容是相同,但格式不同,称为“内容重复页” 3.
如果两个文章具有相同的重要内容和格式,则称为“布局重复页面”IV。如果两个文章部分的重要内容相同,但格式不同,则称为“部分重复页面”。删除重复页面对搜索引擎有很多好处:一。如果从搜索引擎数据库中删除这些重复的网页,可以节省一些存储空间,提高检索质量。2、为了提高网页采集的速度,搜索引擎会对以往采集的信息进行分析,提前发现重复的网页,避免这些网页在以后的网页采集过程中出现。这也是为什么总转载网站排名低的原因。三。对于镜像较高的网页,搜索引擎会给他们更高的优先级,用户在搜索时会给他们更高的权重。四。近距离网页的及时发现有助于提高搜索引擎系统的服务质量,即如果用户点击死链接,可以将用户定向到同一个网页,可以有效增加用户的搜索量经验。网页去重的通用去重算法框架可以使用多种技术方法,每种方法都有自己的创新点和特点。但是,如果我们仔细研究它们,它们几乎相同。上图是通用算法框架的流程图。对于给定的文档,首先必须通过特殊的提取方法从文档中提取出一系列能够代表文档主题的特征集。这一步往往有其内在的要求,即尽量保留文档中的重要信息,删除不相关的信息。一般来说,删除的信息越多,计算速度越快。这就是为什么你想做的关键词总是排名不靠前,而你不想做的关键词却可以排在第一位的原因之一。搜索引擎会删除他们认为不重要的词。 查看全部
js提取指定网站内容(SEO关键词布局教程布局更合理吗?(组图))
#商业服务产品网站模板介绍
我们熟悉关键字的概念。这是基本术语。许多关键词需要在网站上合理安排。最困难的安排是在头版。中等难度在栏目页。文章 或产品的页面上有一条长尾。如何更合理的安排关键词,让网站优化达到最好的分数,是优化员工的目标之一。网站优化细节到位,一些细节的总分越高,那么网站关键词排名就会脱颖而出。关键词 布局是网站优化的重要组成部分。SEO关键词布局教程,SEO关键词布局更合理吗?1:关键字不需要完全匹配。如果网站的首页精确匹配的关键词太多,很容易导致网站被搜索引擎惩罚。搜索引擎爬虫也类似普通用户输入网站的作用。太多 关键词 匹配是准确的,看起来不正常。一般情况下,应该有分词搭配。通过分词,关键词自然会出现在页面对应的位置,用户体验会更好。2:重要关键字显示在重要位置。关键词的位置也会影响关键词的排名。这也是放置关键词时要特别注意的时候。搜索引擎从上到下从左到右抓取网站的内容,有利于添加这些关键词。另外,页面布局有一个F模型,其实原理是一样的。3:需要关联。百度推出清风算法,对抗非主题和关键词重叠网站。从一开始就不用担心网站是否相关。事实上,即使没有明确的算法,我们也应该使用关联原则来安排网站中的关键字。4:网站带有评论功能的要注意信息的内容。如果网站 收录搜索引擎可以看到的评论,您需要注意。因为你可以保护你的标题和关键词,但你不能对用户评论发表评论。商业服务产品网站模板 无需担心 网站 是否相关。事实上,即使没有明确的算法,我们也应该使用关联原则来安排网站中的关键字。4:网站带有评论功能的要注意信息的内容。如果网站 收录搜索引擎可以看到的评论,您需要注意。因为你可以保护你的标题和关键词,但你不能对用户评论发表评论。商业服务产品网站模板 无需担心 网站 是否相关。事实上,即使没有明确的算法,我们也应该使用关联原则来安排网站中的关键字。4:网站带有评论功能的要注意信息的内容。如果网站 收录搜索引擎可以看到的评论,您需要注意。因为你可以保护你的标题和关键词,但你不能对用户评论发表评论。商业服务产品网站模板 收录搜索引擎可以看到的评论,需要注意。因为你可以保护你的标题和关键词,但你不能对用户评论发表评论。商业服务产品网站模板 收录搜索引擎可以看到的评论,需要注意。因为你可以保护你的标题和关键词,但你不能对用户评论发表评论。商业服务产品网站模板
百度在站长贴吧中做出这样的回复:从用户体验的角度来看,“有些转载可能不会比原版差”。比如某知名门户网站网站技术频道转发了一篇关于技术原创的博客。这种转载如果保留原名和出处链接,其实对原作有利,因为传播效果更好。只是国内的转载,很多都是捏着头剪尾,让原作更伤人。数据显示,相似重复页数占总页数的29%,而相同重复页数占总页数的22%。很多站长会抱怨,转载他们写的文章后,提高准确性并消耗时间;四种内容重复: 1.如果这两个文章的内容和格式没有区别,重复的叫做“全重复页面” 2.如果两个文章的内容是相同,但格式不同,称为“内容重复页” 3.
如果两个文章具有相同的重要内容和格式,则称为“布局重复页面”IV。如果两个文章部分的重要内容相同,但格式不同,则称为“部分重复页面”。删除重复页面对搜索引擎有很多好处:一。如果从搜索引擎数据库中删除这些重复的网页,可以节省一些存储空间,提高检索质量。2、为了提高网页采集的速度,搜索引擎会对以往采集的信息进行分析,提前发现重复的网页,避免这些网页在以后的网页采集过程中出现。这也是为什么总转载网站排名低的原因。三。对于镜像较高的网页,搜索引擎会给他们更高的优先级,用户在搜索时会给他们更高的权重。四。近距离网页的及时发现有助于提高搜索引擎系统的服务质量,即如果用户点击死链接,可以将用户定向到同一个网页,可以有效增加用户的搜索量经验。网页去重的通用去重算法框架可以使用多种技术方法,每种方法都有自己的创新点和特点。但是,如果我们仔细研究它们,它们几乎相同。上图是通用算法框架的流程图。对于给定的文档,首先必须通过特殊的提取方法从文档中提取出一系列能够代表文档主题的特征集。这一步往往有其内在的要求,即尽量保留文档中的重要信息,删除不相关的信息。一般来说,删除的信息越多,计算速度越快。这就是为什么你想做的关键词总是排名不靠前,而你不想做的关键词却可以排在第一位的原因之一。搜索引擎会删除他们认为不重要的词。
js提取指定网站内容( 编程基础知识学习:python学习网系统、Python3.9.1G3电脑教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-15 04:22
编程基础知识学习:python学习网系统、Python3.9.1G3电脑教程)
本教程运行环境:windows7系统,Python3.9.1,DELL G3电脑。
1、提取方法
(1)split 是用分隔符分割的。
(2)rsplit 由最后一个分隔符分隔。
(3) 转换为列表,删除一个值。
(4)使用pre包中的findall方法。
(5)findall 方法的数据返回类型。
2、示例
findall 方法返回的数据类型是一个列表。列表的内容只是一种字符串类型的数据,因此可以定义一个变量来接收它。变量接收到后,就变成了一个只有一个字符串类型数据的列表。或者定义一个列表,先使用索引获取数据,因为只有一个数据,所以索引最多为0。
temp = []
Node1_temperature = re.findall(r'Node1_temperature:(.*) Node1_humidity', recv)
temp.append(int(Node1_temperature[0]))
以上就是Python中提取字符串指定内容的方法。以上五种方法都可以在Python中进行提取。这篇文章的重要部分是带来详细的解释。剩下的方法可以在课后探索。更多编程基础学习:python学习网 查看全部
js提取指定网站内容(
编程基础知识学习:python学习网系统、Python3.9.1G3电脑教程)
本教程运行环境:windows7系统,Python3.9.1,DELL G3电脑。
1、提取方法
(1)split 是用分隔符分割的。
(2)rsplit 由最后一个分隔符分隔。
(3) 转换为列表,删除一个值。
(4)使用pre包中的findall方法。
(5)findall 方法的数据返回类型。
2、示例
findall 方法返回的数据类型是一个列表。列表的内容只是一种字符串类型的数据,因此可以定义一个变量来接收它。变量接收到后,就变成了一个只有一个字符串类型数据的列表。或者定义一个列表,先使用索引获取数据,因为只有一个数据,所以索引最多为0。
temp = []
Node1_temperature = re.findall(r'Node1_temperature:(.*) Node1_humidity', recv)
temp.append(int(Node1_temperature[0]))
以上就是Python中提取字符串指定内容的方法。以上五种方法都可以在Python中进行提取。这篇文章的重要部分是带来详细的解释。剩下的方法可以在课后探索。更多编程基础学习:python学习网
js提取指定网站内容(获取多个人的信息怎么办?解决办法在这里!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-13 17:14
一、 获取多人信息:解决将多人信息导入通讯录前获取多人信息的问题。我通过plus.contacts.getAddressBook和address.find的应用获取了通讯录中所有联系人的id和displayName,然后通过我写的通讯录获取页面展示出来。
1、要解决这个问题,首先你得自己写一个js通讯录,这样你就可以把你所有联系人的姓名首字母分开,并且可以跳转到旁边的姓名首字母。
参考我自己的JS:
也可以参考官方:
2、解决获取所有联系方式
plus.contacts.getAddressBook(plus.contacts.ADDRESSBOOK_PHONE, function(addressbook) { //获取通讯录信息
// 可通过addressbook进行通讯录操作
addressbook.find(null, function(contacts) {
var username = new Array();
var LinkList = new LinkedList();
if(contacts.length > 0) { //获取当前通讯录里面所有人
for(var i = 0; i 0) {//这里需要判断是否为空,为空的数组没有index=0;
phone = contacts[i].phoneNumbers[0].value;
} else {
phone = contacts[i].phoneNumbers;
}
if(contacts[i].emails.length > 0) {//这里需要判断是否为空,为空的数组没有index=0;
emails = contacts[i].emails[0].value;
} else {
emails = contacts[i].emails;
}
var dateNum = new Date(contacts[i].birthday);//这里的birthday是number类型!!!官方手册坑爹?
dates = dateNum.getFullYear() "." (dateNum.getMonth() 1) "." dateNum.getDate();
remark = contacts[i].note;
var getContact = {//把所有信息放到一个json里面
contactName: displayname,
sex: "",
department: "",
positions: "",
tel: "",
phone: phone,
eMail: emails,
birthday: dates,
hobby: "",
remark: remark
};
//这下面是我的业务代码了,这里大家可以写自己的信息
//createContactTable(db);
//InsertContact(db, getContact); //多个信息插入有线程安全的问题出现!!!!!!!
}
//console.log(username.length);
}, function(e) {
console.log("查询错误");
}, {
//这里面的筛选非常重要!!!这样才能选出匹配的信息
filter: [{
logic: "or",
field: "id",
value: usernameIndex[j]
}],
multi: false
});
}
}, function(e) {
console.log("打开通讯录错误");
});
通过上面的代码,可以得到多个联系人的信息。你可以试试看。 查看全部
js提取指定网站内容(获取多个人的信息怎么办?解决办法在这里!)
一、 获取多人信息:解决将多人信息导入通讯录前获取多人信息的问题。我通过plus.contacts.getAddressBook和address.find的应用获取了通讯录中所有联系人的id和displayName,然后通过我写的通讯录获取页面展示出来。
1、要解决这个问题,首先你得自己写一个js通讯录,这样你就可以把你所有联系人的姓名首字母分开,并且可以跳转到旁边的姓名首字母。
参考我自己的JS:
也可以参考官方:
2、解决获取所有联系方式
plus.contacts.getAddressBook(plus.contacts.ADDRESSBOOK_PHONE, function(addressbook) { //获取通讯录信息
// 可通过addressbook进行通讯录操作
addressbook.find(null, function(contacts) {
var username = new Array();
var LinkList = new LinkedList();
if(contacts.length > 0) { //获取当前通讯录里面所有人
for(var i = 0; i 0) {//这里需要判断是否为空,为空的数组没有index=0;
phone = contacts[i].phoneNumbers[0].value;
} else {
phone = contacts[i].phoneNumbers;
}
if(contacts[i].emails.length > 0) {//这里需要判断是否为空,为空的数组没有index=0;
emails = contacts[i].emails[0].value;
} else {
emails = contacts[i].emails;
}
var dateNum = new Date(contacts[i].birthday);//这里的birthday是number类型!!!官方手册坑爹?
dates = dateNum.getFullYear() "." (dateNum.getMonth() 1) "." dateNum.getDate();
remark = contacts[i].note;
var getContact = {//把所有信息放到一个json里面
contactName: displayname,
sex: "",
department: "",
positions: "",
tel: "",
phone: phone,
eMail: emails,
birthday: dates,
hobby: "",
remark: remark
};
//这下面是我的业务代码了,这里大家可以写自己的信息
//createContactTable(db);
//InsertContact(db, getContact); //多个信息插入有线程安全的问题出现!!!!!!!
}
//console.log(username.length);
}, function(e) {
console.log("查询错误");
}, {
//这里面的筛选非常重要!!!这样才能选出匹配的信息
filter: [{
logic: "or",
field: "id",
value: usernameIndex[j]
}],
multi: false
});
}
}, function(e) {
console.log("打开通讯录错误");
});
通过上面的代码,可以得到多个联系人的信息。你可以试试看。
js提取指定网站内容(为什么学爬虫?机器帮助你快速爬取数据!(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-12 20:09
【为什么要学爬?】
1、爬虫上手容易,深入难。如何编写高效的爬虫,如何编写高度灵活和可扩展的爬虫是一项技术任务。另外,在爬取过程中,经常容易遇到反爬虫,比如字体反爬、IP识别、验证码等,如何克服困难,得到想要的数据,可以学习这门课!
2、如果你是其他行业的开发者,比如app开发、web开发、学习爬虫可以帮助你加强对技术的理解,开发更安全的软件和网站
【课程设计】
一个完整的爬虫程序,无论大小,大体上可以分为三个步骤,即:
网络请求:模拟浏览器从互联网获取数据的行为。数据分析:过滤请求的数据,提取我们想要的数据。数据存储:将提取的数据存储到硬盘或内存中。比如使用mysql数据库或者redis。
然后本课程也按照这些步骤一步步讲解,引导学生充分掌握每一步的技术。另外,由于爬虫的多样性,在爬取过程中可能会出现反爬和效率低下的情况。因此,我们又增加了两章来提高爬虫程序的灵活性,即:
爬虫进阶:包括IP代理、多线程爬虫、图形验证码识别、JS加解密、动态网页爬虫、字体反爬识别等。 Scrapy及分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫、等等。
通过爬虫的高级知识点,我们可以应对大量的反爬网站,而Scrapy框架是一个专业的爬虫框架,使用它可以快速提高我们爬虫程序的效率和速度。另外,如果一台机器不能满足你的需求,我们可以使用分布式爬虫,让多台机器帮你快速抓取数据。
从基础爬虫到商业应用爬虫,这套课程满足你的所有需求!
【课程服务】
专属付费社区+定期问答 查看全部
js提取指定网站内容(为什么学爬虫?机器帮助你快速爬取数据!(上))
【为什么要学爬?】
1、爬虫上手容易,深入难。如何编写高效的爬虫,如何编写高度灵活和可扩展的爬虫是一项技术任务。另外,在爬取过程中,经常容易遇到反爬虫,比如字体反爬、IP识别、验证码等,如何克服困难,得到想要的数据,可以学习这门课!
2、如果你是其他行业的开发者,比如app开发、web开发、学习爬虫可以帮助你加强对技术的理解,开发更安全的软件和网站
【课程设计】
一个完整的爬虫程序,无论大小,大体上可以分为三个步骤,即:
网络请求:模拟浏览器从互联网获取数据的行为。数据分析:过滤请求的数据,提取我们想要的数据。数据存储:将提取的数据存储到硬盘或内存中。比如使用mysql数据库或者redis。
然后本课程也按照这些步骤一步步讲解,引导学生充分掌握每一步的技术。另外,由于爬虫的多样性,在爬取过程中可能会出现反爬和效率低下的情况。因此,我们又增加了两章来提高爬虫程序的灵活性,即:
爬虫进阶:包括IP代理、多线程爬虫、图形验证码识别、JS加解密、动态网页爬虫、字体反爬识别等。 Scrapy及分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫、等等。
通过爬虫的高级知识点,我们可以应对大量的反爬网站,而Scrapy框架是一个专业的爬虫框架,使用它可以快速提高我们爬虫程序的效率和速度。另外,如果一台机器不能满足你的需求,我们可以使用分布式爬虫,让多台机器帮你快速抓取数据。
从基础爬虫到商业应用爬虫,这套课程满足你的所有需求!
【课程服务】
专属付费社区+定期问答
js提取指定网站内容(之前学习Python模拟登录知乎实例(一)加密处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-12 20:06
之前学习Python模拟登录知乎例子,其中涉及到数据加密处理,在学习的过程中发现使用chrome devtool调试分析网页还有很多技巧需要学习,于是我发现一个简单的例子,用于学习js加密。
学无止境一、例子网站
本例中的网站是中国空气质量分析平台。学习使用chome浏览器的devtool工具对数据进行加密。
二、分析页面逻辑1.抓包分析
用chrome打开网页,然后按F12打开开发者工具devtool,点击切换到“网络”标签。为方便查看,先清空之前的请求流程,然后在网页切换城市即可看到新的xhr请求。
可以看到模拟登录POST的链接。我们的最终目标是构建 POST 请求所需的标头和表单数据。
继续查看请求标头信息。对比不同城市的查询结果,发现Headers并没有什么独特的特征,所以我们只保留了一部分必要的信息。
接下来,我们需要考虑如何构造Form数据。
2.调试分析
考虑到在页面上点击查询按钮时会发生网络请求,按钮肯定会有相应的时间来处理。
在html文件中找到查询按钮的位置,然后我们定位到对应的js事件。
找到事件方法后,我们继续分析。
我们尝试进入 getAQIData() 方法。
首页查询条件栏中的数据是在这里找到的,所以我们分析getServerData方法,在当前页面没有搜索到这个方法的详细内容,所以进行全局搜索(ctrl+shift +F 搜索)。
点击跳转到js页面,搜索getServerData方法,却发现没有找到,网上查询发现网站为了混淆,把这个方法放在jqury-1.8.0.min.js?v=1.2 文件中,经过混淆后,可以使用在线工具进行去混淆,如:。
使用开发者工具调试断点并进入 getServerData 方法。
最后,我们看到了Form Data,可以看到getParm()方法返回的内容。
3.密码分析
知道位置后,我们可以直接将加密后的js方法扣出来,在html文件中执行。
var getParam = (function () {<br /> function ObjectSort(obj) {<br /> var newObject = {};<br /> Object.keys(obj).sort().map(function (key) {<br /> newObject[key] = obj[key]<br /> });<br /> return newObject<br /> }<br /><br /> return function (method, obj) {<br /> var appId = '1a45f75b824b2dc628d5955356b5ef18';<br /> var clienttype = 'WEB';<br /> var timestamp = new Date().getTime();<br /> var param = {<br /> appId: appId,<br /> method: method,<br /> timestamp: timestamp,<br /> clienttype: clienttype,<br /> object: obj,<br /> secret: hex_md5(appId + method + timestamp + clienttype + JSON.stringify(ObjectSort(obj)))<br /> };<br /> param = BASE64.encrypt(JSON.stringify(param));<br /> return AES.encrypt(param, aes_client_key, aes_client_iv)<br /> }<br />})();<br />
将本方法中涉及的js方法一起提取出来,jqury中需要的除外-1.8.0.min.js?v=1.2文件中除了方法之外,我们还需要提取city_detail.html中的getAQIData方法,把所有的JavaScript放到一个html文件中,放到script标签中。
记得把查询条件数据放入方法中。
在js中执行document.write(getAQIData()),页面输出正确。
三、Python 实现加密
要使用python的execjs执行JavaScript代码,除了安装execjs包,还需要安装node环境。具体安装请参考在线教程。
def encrypt(self, form_data):<br /> '''<br /> 对查询条件栏的数据,进行加密<br /> :param form_data: 查询条件栏的数据,包括城市名称,开始结束时间等<br /> :return:加密后的字符串<br /> '''<br /> with open('encrypt.js',encoding='utf-8') as f:<br /> js = execjs.compile(f.read())<br /> return js.call('getAQIData',form_data)<br />
测试过程中,如果遇到execjs._exceptions.ProgramError: ReferenceError: localStorage is not defined错误,localStorage是浏览器端数据存储方式之一,注释掉js中的相关代码,继续测试。
//加密<br />function getServerData(method, object, callback, period) {<br /> const key = hex_md5(method + JSON.stringify(object));<br /> // const data = getDataFromLocalStorage(key, period);<br /> // if (!data) {<br /> var param = getParam(method, object);<br /> return param<br /> // } else {<br /> // callback(data)<br /> // }<br />}<br />
成功输出结果。
四、Python 抓取网页
得到加密后的字符串后,需要通过POST请求将内容提交给服务器。但是在执行过程中发现返回的内容与前台返回的内容不一致。经过一些查询,
发现得到的加密字符串的内容只与“view decoded”中显示的内容一致。我们尝试在发出 POST 请求之前对数据进行 URL 编码。最终成功获取返回值。
接下来我们对返回的字符串进行解密,在分析getServerData方法时发现decodeData方法与解密有关。
def decrypt(self, resp_text):<br /> '''<br /> 对服务器请求成功后返回的数据,进行解密<br /> :param resp_text: 返回的数据<br /> :return:解密后的字符串,json格式<br /> '''<br /> with open('encrypt.js',encoding='utf-8') as f:<br /> js = execjs.compile(f.read())<br /> return js.call('decodeData',resp_text)<br />
对服务器返回的内容进行解密,最终得到我们想要的数据。
详细代码请到: 查看全部
js提取指定网站内容(之前学习Python模拟登录知乎实例(一)加密处理)
之前学习Python模拟登录知乎例子,其中涉及到数据加密处理,在学习的过程中发现使用chrome devtool调试分析网页还有很多技巧需要学习,于是我发现一个简单的例子,用于学习js加密。
学无止境一、例子网站
本例中的网站是中国空气质量分析平台。学习使用chome浏览器的devtool工具对数据进行加密。
二、分析页面逻辑1.抓包分析
用chrome打开网页,然后按F12打开开发者工具devtool,点击切换到“网络”标签。为方便查看,先清空之前的请求流程,然后在网页切换城市即可看到新的xhr请求。
可以看到模拟登录POST的链接。我们的最终目标是构建 POST 请求所需的标头和表单数据。
继续查看请求标头信息。对比不同城市的查询结果,发现Headers并没有什么独特的特征,所以我们只保留了一部分必要的信息。
接下来,我们需要考虑如何构造Form数据。
2.调试分析
考虑到在页面上点击查询按钮时会发生网络请求,按钮肯定会有相应的时间来处理。
在html文件中找到查询按钮的位置,然后我们定位到对应的js事件。
找到事件方法后,我们继续分析。
我们尝试进入 getAQIData() 方法。
首页查询条件栏中的数据是在这里找到的,所以我们分析getServerData方法,在当前页面没有搜索到这个方法的详细内容,所以进行全局搜索(ctrl+shift +F 搜索)。
点击跳转到js页面,搜索getServerData方法,却发现没有找到,网上查询发现网站为了混淆,把这个方法放在jqury-1.8.0.min.js?v=1.2 文件中,经过混淆后,可以使用在线工具进行去混淆,如:。
使用开发者工具调试断点并进入 getServerData 方法。
最后,我们看到了Form Data,可以看到getParm()方法返回的内容。
3.密码分析
知道位置后,我们可以直接将加密后的js方法扣出来,在html文件中执行。
var getParam = (function () {<br /> function ObjectSort(obj) {<br /> var newObject = {};<br /> Object.keys(obj).sort().map(function (key) {<br /> newObject[key] = obj[key]<br /> });<br /> return newObject<br /> }<br /><br /> return function (method, obj) {<br /> var appId = '1a45f75b824b2dc628d5955356b5ef18';<br /> var clienttype = 'WEB';<br /> var timestamp = new Date().getTime();<br /> var param = {<br /> appId: appId,<br /> method: method,<br /> timestamp: timestamp,<br /> clienttype: clienttype,<br /> object: obj,<br /> secret: hex_md5(appId + method + timestamp + clienttype + JSON.stringify(ObjectSort(obj)))<br /> };<br /> param = BASE64.encrypt(JSON.stringify(param));<br /> return AES.encrypt(param, aes_client_key, aes_client_iv)<br /> }<br />})();<br />
将本方法中涉及的js方法一起提取出来,jqury中需要的除外-1.8.0.min.js?v=1.2文件中除了方法之外,我们还需要提取city_detail.html中的getAQIData方法,把所有的JavaScript放到一个html文件中,放到script标签中。
记得把查询条件数据放入方法中。
在js中执行document.write(getAQIData()),页面输出正确。
三、Python 实现加密
要使用python的execjs执行JavaScript代码,除了安装execjs包,还需要安装node环境。具体安装请参考在线教程。
def encrypt(self, form_data):<br /> '''<br /> 对查询条件栏的数据,进行加密<br /> :param form_data: 查询条件栏的数据,包括城市名称,开始结束时间等<br /> :return:加密后的字符串<br /> '''<br /> with open('encrypt.js',encoding='utf-8') as f:<br /> js = execjs.compile(f.read())<br /> return js.call('getAQIData',form_data)<br />
测试过程中,如果遇到execjs._exceptions.ProgramError: ReferenceError: localStorage is not defined错误,localStorage是浏览器端数据存储方式之一,注释掉js中的相关代码,继续测试。
//加密<br />function getServerData(method, object, callback, period) {<br /> const key = hex_md5(method + JSON.stringify(object));<br /> // const data = getDataFromLocalStorage(key, period);<br /> // if (!data) {<br /> var param = getParam(method, object);<br /> return param<br /> // } else {<br /> // callback(data)<br /> // }<br />}<br />
成功输出结果。
四、Python 抓取网页
得到加密后的字符串后,需要通过POST请求将内容提交给服务器。但是在执行过程中发现返回的内容与前台返回的内容不一致。经过一些查询,
发现得到的加密字符串的内容只与“view decoded”中显示的内容一致。我们尝试在发出 POST 请求之前对数据进行 URL 编码。最终成功获取返回值。
接下来我们对返回的字符串进行解密,在分析getServerData方法时发现decodeData方法与解密有关。
def decrypt(self, resp_text):<br /> '''<br /> 对服务器请求成功后返回的数据,进行解密<br /> :param resp_text: 返回的数据<br /> :return:解密后的字符串,json格式<br /> '''<br /> with open('encrypt.js',encoding='utf-8') as f:<br /> js = execjs.compile(f.read())<br /> return js.call('decodeData',resp_text)<br />
对服务器返回的内容进行解密,最终得到我们想要的数据。
详细代码请到:
js提取指定网站内容(网页生产pdf或者截取某个标签生产有什么区别? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-12 20:02
)
截取网页截图生成pdf或截取标签生成pdf,
截图是使用插件 html2canvas.js 脚本截取的,
代码很简单(因为没有深入研究,所以不清楚这个插件有没有bug。使用html2canvas对整个页面或部分页面进行截图。但这不是真正的截图,而是通过遍历页面的DOM结构将一个集合所有的元素信息和对应的样式渲染成一个canvas图片,html2canvas只能生成一个自己可以处理的canvas图片,所以渲染出来的结果不是100%和原来的一致。但是它不需要服务器参与,整个图片由客户端提供,由浏览器生成,使用非常方便。)
代码:
$("#printScreen").click(function () {//截图,某一个标签,要是想全屏的话就直接把"document.querySelector("#div")"替换成"document.body"
html2canvas(document.querySelector("#div"), { //截图对象
//此处可配置详细参数
onrendered: function(canvas) { //渲染完成回调canvas
canvas.id = "mycanvas";
// 生成base64图片数据
var dataUrl = canvas.toDataURL(); //指定格式,也可不带参数
}
});
});
生成的dataUrl是base64图像数据,下一步就是从图像生成pdf。
生成pdf有两种方式
1.将生成的图片转移到后台,使用java将图片转为pdf
前端代码:
$("#printScreen").click(function () {//截图,某一个标签,要是想全屏的话就直接把"document.querySelector("#div")"替换成"document.body"
html2canvas(document.querySelector("#div"), { //截图对象
//此处可配置详细参数
onrendered: function(canvas) { //渲染完成回调canvas
canvas.id = "mycanvas";
// 生成base64图片数据
var dataUrl = canvas.toDataURL(); //指定格式,也可不带参数
var formData = new FormData(); //模拟表单对象
formData.append("file", convertBase64UrlToBlob(dataUrl), "a.png"); //写入数据
var xhr = new XMLHttpRequest(); //数据传输方法
xhr.open("POST", "/fileupload"); //配置传输方式及地址
xhr.send(formData);//发送
}
});
}); //将以base64的图片url数据转换为Blob
function convertBase64UrlToBlob(urlData){
//去掉url的头,并转换为byte
var bytes=window.atob(urlData.split(',')[1]);
//处理异常,将ascii码小于0的转换为大于0
var ab = new ArrayBuffer(bytes.length);
var ia = new Uint8Array(ab);
for (var i = 0; i < bytes.length; i++) {
ia[i] = bytes.charCodeAt(i);
}
return new Blob( [ab] , {type : 'image/png'});
}
后端收到的代码(和普通文件上传一样):文件上传和下载
上传图片后,将图片格式转换为pdf格式。这里需要用到包iText-1.3.jar
转换后的代码:
String filePath = "d:"+File.separator+ "temp" + File.separator + "aa.png";
String pdfPath = "d:"+File.separator+ "temp" + File.separator + "aa.pdf";
BufferedImage img = ImageIO.read(new File(filePath));
FileOutputStream fos = new FileOutputStream(pdfPath);
Document doc = new Document(null, 0, 0, 0, 0);
doc.setPageSize(new Rectangle(img.getWidth(), img.getHeight()));
Image image = Image.getInstance(filePath);
PdfWriter.getInstance(doc, fos);
doc.open();
doc.add(image);
doc.close();
2. 前端直接转成pdf文件,使用js插件jsPdf.debug.js
配合html2canvas.js插件使用,代码如下:
$("#printScreenAndGetPdf").click(function () {//截图
html2canvas(document.querySelector("#div"), { //截图对象
//此处可配置详细参数
onrendered: function(canvas) { //渲染完成回调canvas
canvas.id = "mycanvas";
// 生成base64图片数据
var dataUrl = canvas.toDataURL(); //指定格式,也可不带参数
// 三个参数,第一个方向,第二个单位,第三个尺寸格式(转化成pdf对象)
var doc = new jsPDF('landscape','pt',[300, 100]);
doc.addImage(dataUrl, 'PNG', 0, 0, 300, 100);
doc.save('aa.pdf');//生产pdf文件
}
});
});
前端打印的代码:
$("#print").click(function () {//打印,某一个标签
document.body.innerHTML=document.getElementById('div').innerHTML;//把这句去掉就是打印这个页面
window.print();
}); 查看全部
js提取指定网站内容(网页生产pdf或者截取某个标签生产有什么区别?
)
截取网页截图生成pdf或截取标签生成pdf,
截图是使用插件 html2canvas.js 脚本截取的,
代码很简单(因为没有深入研究,所以不清楚这个插件有没有bug。使用html2canvas对整个页面或部分页面进行截图。但这不是真正的截图,而是通过遍历页面的DOM结构将一个集合所有的元素信息和对应的样式渲染成一个canvas图片,html2canvas只能生成一个自己可以处理的canvas图片,所以渲染出来的结果不是100%和原来的一致。但是它不需要服务器参与,整个图片由客户端提供,由浏览器生成,使用非常方便。)
代码:
$("#printScreen").click(function () {//截图,某一个标签,要是想全屏的话就直接把"document.querySelector("#div")"替换成"document.body"
html2canvas(document.querySelector("#div"), { //截图对象
//此处可配置详细参数
onrendered: function(canvas) { //渲染完成回调canvas
canvas.id = "mycanvas";
// 生成base64图片数据
var dataUrl = canvas.toDataURL(); //指定格式,也可不带参数
}
});
});
生成的dataUrl是base64图像数据,下一步就是从图像生成pdf。
生成pdf有两种方式
1.将生成的图片转移到后台,使用java将图片转为pdf
前端代码:
$("#printScreen").click(function () {//截图,某一个标签,要是想全屏的话就直接把"document.querySelector("#div")"替换成"document.body"
html2canvas(document.querySelector("#div"), { //截图对象
//此处可配置详细参数
onrendered: function(canvas) { //渲染完成回调canvas
canvas.id = "mycanvas";
// 生成base64图片数据
var dataUrl = canvas.toDataURL(); //指定格式,也可不带参数
var formData = new FormData(); //模拟表单对象
formData.append("file", convertBase64UrlToBlob(dataUrl), "a.png"); //写入数据
var xhr = new XMLHttpRequest(); //数据传输方法
xhr.open("POST", "/fileupload"); //配置传输方式及地址
xhr.send(formData);//发送
}
});
}); //将以base64的图片url数据转换为Blob
function convertBase64UrlToBlob(urlData){
//去掉url的头,并转换为byte
var bytes=window.atob(urlData.split(',')[1]);
//处理异常,将ascii码小于0的转换为大于0
var ab = new ArrayBuffer(bytes.length);
var ia = new Uint8Array(ab);
for (var i = 0; i < bytes.length; i++) {
ia[i] = bytes.charCodeAt(i);
}
return new Blob( [ab] , {type : 'image/png'});
}
后端收到的代码(和普通文件上传一样):文件上传和下载
上传图片后,将图片格式转换为pdf格式。这里需要用到包iText-1.3.jar
转换后的代码:
String filePath = "d:"+File.separator+ "temp" + File.separator + "aa.png";
String pdfPath = "d:"+File.separator+ "temp" + File.separator + "aa.pdf";
BufferedImage img = ImageIO.read(new File(filePath));
FileOutputStream fos = new FileOutputStream(pdfPath);
Document doc = new Document(null, 0, 0, 0, 0);
doc.setPageSize(new Rectangle(img.getWidth(), img.getHeight()));
Image image = Image.getInstance(filePath);
PdfWriter.getInstance(doc, fos);
doc.open();
doc.add(image);
doc.close();
2. 前端直接转成pdf文件,使用js插件jsPdf.debug.js
配合html2canvas.js插件使用,代码如下:
$("#printScreenAndGetPdf").click(function () {//截图
html2canvas(document.querySelector("#div"), { //截图对象
//此处可配置详细参数
onrendered: function(canvas) { //渲染完成回调canvas
canvas.id = "mycanvas";
// 生成base64图片数据
var dataUrl = canvas.toDataURL(); //指定格式,也可不带参数
// 三个参数,第一个方向,第二个单位,第三个尺寸格式(转化成pdf对象)
var doc = new jsPDF('landscape','pt',[300, 100]);
doc.addImage(dataUrl, 'PNG', 0, 0, 300, 100);
doc.save('aa.pdf');//生产pdf文件
}
});
});
前端打印的代码:
$("#print").click(function () {//打印,某一个标签
document.body.innerHTML=document.getElementById('div').innerHTML;//把这句去掉就是打印这个页面
window.print();
});
js提取指定网站内容(js提取指定网站内容并提取内容并并)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-10 12:01
js提取指定网站内容url并提取指定网站内容:正则表达式的搭配,可以从多个不同的网站提取网站内容:一般是寻找特定网站链接,或者某个网站内部的内容;js把某个网站内容从指定网站(例如百度,360,某些搜索引擎的页面)取出来,一般这个网站内容是不会改变的,并且它后面的链接是一样的,不同的是这个链接是开放的。
这两个和前端代码关系比较大。你在网页内容上面加上标签,只是让你这个字段可以作为内容展示,实际上是不是内容还是按照你要的形式显示。举个例子:这样一个链接,加上标签,网页信息是这样的,你就可以拿到整个网页的liststyle数据。并不涉及你要加什么限制。另外,为了加快开发,前端框架一般是和浏览器兼容的,edge和ie8或者以上都支持的。如果觉得不太习惯,可以使用第三方转换引擎。 查看全部
js提取指定网站内容(js提取指定网站内容并提取内容并并)
js提取指定网站内容url并提取指定网站内容:正则表达式的搭配,可以从多个不同的网站提取网站内容:一般是寻找特定网站链接,或者某个网站内部的内容;js把某个网站内容从指定网站(例如百度,360,某些搜索引擎的页面)取出来,一般这个网站内容是不会改变的,并且它后面的链接是一样的,不同的是这个链接是开放的。
这两个和前端代码关系比较大。你在网页内容上面加上标签,只是让你这个字段可以作为内容展示,实际上是不是内容还是按照你要的形式显示。举个例子:这样一个链接,加上标签,网页信息是这样的,你就可以拿到整个网页的liststyle数据。并不涉及你要加什么限制。另外,为了加快开发,前端框架一般是和浏览器兼容的,edge和ie8或者以上都支持的。如果觉得不太习惯,可以使用第三方转换引擎。
js提取指定网站内容(网页开发中获取同种类型的标签的值得问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-09 14:19
本文文章主要介绍jQuery同时获取多个标签的指定内容并存储为数组的相关知识。非常好,有一定的参考价值。有需要的朋友可以参考。
在web开发中,我们经常会遇到获取同类型标签的有价值的问题,比如以下两种情况。
当需要批量获取同一标签的指定值时,新手会遇到一些麻烦。
例如id=problem1的demo
var list1=$("#problem1").children();//获取到problem1指定的对象数组 console.log(list1);//打印到控制台
控制台中的输出和我们想象的一样。然后看下一段代码
var list1=$("#problem1").children().html(); console.log(list1);
根据上面的内容,新人会认为list就是每个li对象中存储的值的数组。
但是控制台的输出是:
只输出了第一个li里面的内容,新人(我)在这里糊涂了(想不通),为什么和我想象的完全不一样
查阅了各种资料,终于找到了问题所在:
此时在list1的数组中
每个元素不再是'li'对象,所以运行控制台会报错:
这里要达到我们的目的必须使用
JQuery 中的 each() 方法:
each() 方法指定要为每个匹配元素运行的函数。
语法
$( 选择器 ).each(function (index,element))
所以我们使用下面的方法来获取我们需要的内容
var array=new Array();//声明一个新的数组 var list1=$("#problem1").children().each(function (index,element) {//遍历每个对象 array.push($(this).html());//往数组中存入值 }); console.log(array);
我们想要实现的目标已经实现。
这是完整的演示:
demo 要获取的内容1要获取的内容2要获取的内容3要获取的内容4要获取的内容5 类型:要获取的内容2 类型:要获取的内容3 类型:要获取的内容4 类型:要获取的内容5 类型:要获取的内容6
内容打印在控制台
总结
以上就是jQuery同时获取多个标签的指定内容并存储为数组的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
js提取指定网站内容(网页开发中获取同种类型的标签的值得问题)
本文文章主要介绍jQuery同时获取多个标签的指定内容并存储为数组的相关知识。非常好,有一定的参考价值。有需要的朋友可以参考。
在web开发中,我们经常会遇到获取同类型标签的有价值的问题,比如以下两种情况。
当需要批量获取同一标签的指定值时,新手会遇到一些麻烦。
例如id=problem1的demo
var list1=$("#problem1").children();//获取到problem1指定的对象数组 console.log(list1);//打印到控制台
控制台中的输出和我们想象的一样。然后看下一段代码
var list1=$("#problem1").children().html(); console.log(list1);
根据上面的内容,新人会认为list就是每个li对象中存储的值的数组。
但是控制台的输出是:
只输出了第一个li里面的内容,新人(我)在这里糊涂了(想不通),为什么和我想象的完全不一样
查阅了各种资料,终于找到了问题所在:
此时在list1的数组中
每个元素不再是'li'对象,所以运行控制台会报错:
这里要达到我们的目的必须使用
JQuery 中的 each() 方法:
each() 方法指定要为每个匹配元素运行的函数。
语法
$( 选择器 ).each(function (index,element))
所以我们使用下面的方法来获取我们需要的内容
var array=new Array();//声明一个新的数组 var list1=$("#problem1").children().each(function (index,element) {//遍历每个对象 array.push($(this).html());//往数组中存入值 }); console.log(array);
我们想要实现的目标已经实现。
这是完整的演示:
demo 要获取的内容1要获取的内容2要获取的内容3要获取的内容4要获取的内容5 类型:要获取的内容2 类型:要获取的内容3 类型:要获取的内容4 类型:要获取的内容5 类型:要获取的内容6
内容打印在控制台
总结
以上就是jQuery同时获取多个标签的指定内容并存储为数组的详细内容。更多详情请关注其他相关html中文网站文章!
js提取指定网站内容(先以“#flag?test=12345”为例,然后获得它的各个组成部分)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-06 05:04
先以“#flag?test=12345”为例,然后获取其组件。
1、获取页面的完整url
var a=location.href;
console.log(a); // “http://www.cnblogs.com/wuxibol ... 12345”
2、获取页面的域名
var host = window.location.host; //www.cnblogs.com
var host2 = document.domain; //www.cnblogs.com
var a = location.hostname; //www.cnblogs.com
3、获取URL协议
var a=location.protocol;
console.log(a); //http:
4、获取端口
var a=location.port;
console.log(a);
5、获取页面路径
var a=location.pathname;
console.log(a);
6、设置或获取URL的协议部分
var a = location.protocol;
7、获取#后的部分
var a=window.location.hash;
var b=a.substr(1);
console.log(b); // flag?test=12345
8、获取href属性中问号后面的部分?
// 此时案例地址变为“http://www.cnblogs.com/wuxibol ... 12345”。得到 test=12345
var a=location.search;
var b=a.substr(1);
console.log(b);
//如果案例依旧是“http://www.cnblogs.com/wuxibol ... 12345”,则需下面的写法,得到 test=12345
var a=location.href;
var b=a.substr(a.lastIndexOf('?')+1);
console.log(b);
9、获取=后面的部分
var a=location.href;
var b=a.substring(a.lastIndexOf('=')+1);
console.log(b); // 12345
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时希望大家多多支持本站! 查看全部
js提取指定网站内容(先以“#flag?test=12345”为例,然后获得它的各个组成部分)
先以“#flag?test=12345”为例,然后获取其组件。
1、获取页面的完整url
var a=location.href;
console.log(a); // “http://www.cnblogs.com/wuxibol ... 12345”
2、获取页面的域名
var host = window.location.host; //www.cnblogs.com
var host2 = document.domain; //www.cnblogs.com
var a = location.hostname; //www.cnblogs.com
3、获取URL协议
var a=location.protocol;
console.log(a); //http:
4、获取端口
var a=location.port;
console.log(a);
5、获取页面路径
var a=location.pathname;
console.log(a);
6、设置或获取URL的协议部分
var a = location.protocol;
7、获取#后的部分
var a=window.location.hash;
var b=a.substr(1);
console.log(b); // flag?test=12345
8、获取href属性中问号后面的部分?
// 此时案例地址变为“http://www.cnblogs.com/wuxibol ... 12345”。得到 test=12345
var a=location.search;
var b=a.substr(1);
console.log(b);
//如果案例依旧是“http://www.cnblogs.com/wuxibol ... 12345”,则需下面的写法,得到 test=12345
var a=location.href;
var b=a.substr(a.lastIndexOf('?')+1);
console.log(b);
9、获取=后面的部分
var a=location.href;
var b=a.substring(a.lastIndexOf('=')+1);
console.log(b); // 12345
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时希望大家多多支持本站!
js提取指定网站内容(阿里云为您提供网站内容抓取工具相关的8933条产品文档内容及常见问题解答内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-11-04 14:17
阿里云为您提供8933产品文档内容和网站内容爬取工具相关的FAQ,以及路由网站打不开网页怎么办,计算机网络技术学院毕业论文, key 值存储kvstore,以下哪个是数据库,以及其他云计算产品。
它可以帮助我们快速采集互联网上的海量内容,进行深入的数据分析和挖掘。比如抓取各大网站的排名,抓取各大购物的价格信息网站等等。而我们每天常用的搜索引擎都是“网络爬虫”。但毕竟。
1.打开站长工具,在网页信息查询中,找到模拟机器人抓取。2.输入自己的网站 URL,输入,点击查询。下面显示了你的 网站 被抓取后的样子。3.在网页信息查询中,点击网页检测,可以查看自己网页的密度关键词、网站安全情况、关键词挖掘情况。
Content crawling-content 可以从 网站 爬取,以复制依赖该内容的独特产品或服务优势。例如,Yelp 等产品依赖于评论。参赛者可以从Yelp抓取所有评论内容,然后复制到自己的网站,让自己的网站的内容打开。
Python爬虫入门教程!手把手教你爬取网页数据。
链接提交工具是网站主动推送数据到百度搜索的工具。该工具可以缩短爬虫发现网站链接的时间,网站时间敏感的内容推荐使用链接提交工具实时推送到搜索到的数据。这个工具可以加快爬虫的爬行速度,但是不能解决网站。
网页内容提取器可以帮助我们快速提取输入的URL链接中的所有图片、链接和网页文本内容。
爬虫是自动获取网页内容的程序,如搜索引擎、谷歌、百度等,每天运行着庞大的爬虫系统,从网站世界各地爬取。 查看全部
js提取指定网站内容(阿里云为您提供网站内容抓取工具相关的8933条产品文档内容及常见问题解答内容)
阿里云为您提供8933产品文档内容和网站内容爬取工具相关的FAQ,以及路由网站打不开网页怎么办,计算机网络技术学院毕业论文, key 值存储kvstore,以下哪个是数据库,以及其他云计算产品。
它可以帮助我们快速采集互联网上的海量内容,进行深入的数据分析和挖掘。比如抓取各大网站的排名,抓取各大购物的价格信息网站等等。而我们每天常用的搜索引擎都是“网络爬虫”。但毕竟。
1.打开站长工具,在网页信息查询中,找到模拟机器人抓取。2.输入自己的网站 URL,输入,点击查询。下面显示了你的 网站 被抓取后的样子。3.在网页信息查询中,点击网页检测,可以查看自己网页的密度关键词、网站安全情况、关键词挖掘情况。
Content crawling-content 可以从 网站 爬取,以复制依赖该内容的独特产品或服务优势。例如,Yelp 等产品依赖于评论。参赛者可以从Yelp抓取所有评论内容,然后复制到自己的网站,让自己的网站的内容打开。
Python爬虫入门教程!手把手教你爬取网页数据。
链接提交工具是网站主动推送数据到百度搜索的工具。该工具可以缩短爬虫发现网站链接的时间,网站时间敏感的内容推荐使用链接提交工具实时推送到搜索到的数据。这个工具可以加快爬虫的爬行速度,但是不能解决网站。
网页内容提取器可以帮助我们快速提取输入的URL链接中的所有图片、链接和网页文本内容。
爬虫是自动获取网页内容的程序,如搜索引擎、谷歌、百度等,每天运行着庞大的爬虫系统,从网站世界各地爬取。
js提取指定网站内容(Django中利用js来操作数据的常规操作(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-28 13:23
Django中使用js操作数据的一般操作一般是点(.)操作符来获取字典或列表的数据,如{{data.0}}、{{data.arg}}
但是有时候如果数据是嵌套类型的数据,直接获取某个值就变得很困难,比如下面的格式获取
qxl 的值正确
startArgsSet={"correct":{"qxl":0,"kkx":0},"reliable":{"qxl":0,"kkx":0},"security":{"qxl":0,"kkx":0},"understand":{"qxl":0,"kkx":0},"entropy":{"qxl":0,"kkx":0},
"mature":{"qxl":0,"kkx":0},"active":{"qxl":0,"kkx":0},"service":{"qxl":0,"kkx":0},"file":{"qxl":0,"kkx":0},
"tech":{"qxl":0,"kkx":0},"property":{"qxl":0,"kkx":0},"organize":{"qxl":0,"kkx":0},"develop":{"qxl":0,"kkx":0},
"source":{"qxl":0,"kkx":0},"update":{"qxl":0,"kkx":0},"fix":{"qxl":0,"kkx":0},
"quality":{"qxl":0,"kkx":0},"meanNum":{"qxl":0,"kkx":0},"variance":{"qxl":0,"kkx":0}
}
这时候如果把数据格式改成列表中的非嵌套字典格式比较麻烦,可以自定义过滤器获取数据,
from django.template.defaulttags import register
@register.filter
def getArgQxlValue(dictionary,arg):
return dictionary[arg]['qxl']
@register.filter
def getArgKkxValue(dictionary,arg):
return dictionary[arg]['kkx']
@register.filter
def getArgName(dictionary,arg):
return dictionary[arg]['name']
你可以在模板中这样写
{% load staticfiles %}
超标信息
{{ guestSetArgs|safe }}
{{ warningdata|safe }}
{% for i in guestSetArgs %}
{% for j in warningdata %}
if("{{i}}"=="{{j}}")
{
if(Number({{warningdata|getArgQxlValue:j}})>Number({{guestSetArgs|getArgQxlValue:i}}))
var setArgStr="{{warningdata|getArgName:i}} 超出阀值 阀值:{{guestSetArgs|getArgQxlValue:j}} 检测值:{{warningdata|getArgQxlValue:j}}
"
document.write(setArgStr);
}
{% endfor %}
{% endfor %}
如{{warningdata|getArgQxlValue:j}},可以获取里面的值
稍微美化
相关文章 查看全部
js提取指定网站内容(Django中利用js来操作数据的常规操作(图))
Django中使用js操作数据的一般操作一般是点(.)操作符来获取字典或列表的数据,如{{data.0}}、{{data.arg}}
但是有时候如果数据是嵌套类型的数据,直接获取某个值就变得很困难,比如下面的格式获取
qxl 的值正确
startArgsSet={"correct":{"qxl":0,"kkx":0},"reliable":{"qxl":0,"kkx":0},"security":{"qxl":0,"kkx":0},"understand":{"qxl":0,"kkx":0},"entropy":{"qxl":0,"kkx":0},
"mature":{"qxl":0,"kkx":0},"active":{"qxl":0,"kkx":0},"service":{"qxl":0,"kkx":0},"file":{"qxl":0,"kkx":0},
"tech":{"qxl":0,"kkx":0},"property":{"qxl":0,"kkx":0},"organize":{"qxl":0,"kkx":0},"develop":{"qxl":0,"kkx":0},
"source":{"qxl":0,"kkx":0},"update":{"qxl":0,"kkx":0},"fix":{"qxl":0,"kkx":0},
"quality":{"qxl":0,"kkx":0},"meanNum":{"qxl":0,"kkx":0},"variance":{"qxl":0,"kkx":0}
}
这时候如果把数据格式改成列表中的非嵌套字典格式比较麻烦,可以自定义过滤器获取数据,
from django.template.defaulttags import register
@register.filter
def getArgQxlValue(dictionary,arg):
return dictionary[arg]['qxl']
@register.filter
def getArgKkxValue(dictionary,arg):
return dictionary[arg]['kkx']
@register.filter
def getArgName(dictionary,arg):
return dictionary[arg]['name']
你可以在模板中这样写
{% load staticfiles %}
超标信息
{{ guestSetArgs|safe }}
{{ warningdata|safe }}
{% for i in guestSetArgs %}
{% for j in warningdata %}
if("{{i}}"=="{{j}}")
{
if(Number({{warningdata|getArgQxlValue:j}})>Number({{guestSetArgs|getArgQxlValue:i}}))
var setArgStr="{{warningdata|getArgName:i}} 超出阀值 阀值:{{guestSetArgs|getArgQxlValue:j}} 检测值:{{warningdata|getArgQxlValue:j}}
"
document.write(setArgStr);
}
{% endfor %}
{% endfor %}
如{{warningdata|getArgQxlValue:j}},可以获取里面的值
稍微美化
相关文章
js提取指定网站内容(解析JavaScript中querySelector与getElementById方法的区别的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-28 13:22
想知道解析JavaScript中querySelector和getElementById方法区别的相关内容吗?明天我会努力给大家讲解js中querySelector和getElementById方法的相关知识以及一些代码示例。欢迎阅读和纠正我。重点:js、querySelector、js、getElementById、methods,一起来学习吧。
1. 概览
看代码的时候发现querySelector()和querySelectorAll()基本上都是用来获取元素的,不知道为什么不使用getElementById()。
可能是因为我没用过这两个,所以我不知道为什么。
1.1 querySelector() 和 querySelectorAll() 的用法
querySelector() 方法
定义:querySelector()方法返回文档中匹配指定CSS选择器的元素;
注意:querySelector() 方法只返回与指定选择器匹配的第一个元素。如果需要返回所有元素,请改用 querySelectorAll() 方法;
语法:document.querySelector(CSS selectors);
参数值:字符串 必需。为匹配元素指定一个或多个 CSS 选择器。使用它们的id、class、type、attribute、attribute value等来选择元素。
对于多个选择器,用逗号分隔它们并返回匹配的元素。
返回值:匹配指定 CSS 选择器的第一个元素。如果未找到,则返回 null。如果指定了非法选择器,则会抛出 SYNTAX_ERR 异常。
querySelectorAll() 方法
定义:querySelectorAll()方法返回文档中所有匹配指定CSS选择器的元素,并返回一个NodeList对象;
NodeList 对象表示节点的集合。可以通过索引访问,索引值从0开始;
提示:可以通过NodeList对象的length属性获取与选择器匹配的元素属性,然后遍历所有元素,得到你想要的信息;
语法:elementList = document.querySelectorAll(selectors);
elementList 是一个静态的 NodeList 类型对象;
selectors 是一个字符串,收录一个或多个用逗号连接的 CSS 选择器;
参数值:字符串 必需。指定一个或多个与 CSS 选择器匹配的元素。可以使用id、class、type、attribute、attribute value等作为选择器来获取元素。
多个选择器之间用逗号 (,) 分隔。
返回值:一个 NodeList 对象,表示文档中与指定 CSS 选择器匹配的所有元素。
NodeList 是一个静态的 NodeList 类型对象。如果指定的选择器不合法,则会抛出 SYNTAX_ERR 异常。
1.2 getElement(s)Byxxxx的用法
getElementById() 方法
定义:getElementById() 方法可以返回对具有指定 ID 的第一个对象的引用。
如果没有指定ID的元素,则返回null;
如果有多个指定ID的元素,则返回第一个;
如果需要查找那些没有ID的元素,可以考虑使用querySelector();通过 CSS 选择器;
语法:document.getElementById(elementID);
参数值:字符串必须。元素 ID 属性值。
返回值:指定元素对象ID的元素
getElementsByTagName() 方法
定义:getElementsByTagName()方法可以返回指定标签名的对象集合;
提醒:参数值“*”返回文档的所有元素;
语法:document.getElementsByTagName(tagname)
参数:String 必须获取元素的标签名称;
返回值:NodeList对象指定标签名的元素集合
getElementsByClassName() 方法
定义:getElementsByClassName() 方法将文档中具有指定类名的所有元素的集合作为 NodeList 对象返回。
NodeList 对象表示节点的有序列表。 NodeList对象可以通过节点列表中的节点索引号(索引号从0开始)访问表中的节点。
Tips:可以通过NodeList对象的length属性来判断指定类名的元素个数,循环遍历每个元素得到自己需要的元素。
语法:document.getElementsByClassName(classname)
参数:String 必须是要获取的元素类的名称。使用空格分隔多个类名,如“test demo”;
返回值:NodeList 对象,表示指定类名的元素集合。集合中元素的顺序按它们在代码中出现的顺序排序。
2. 区别 2.1 getElement(s)Byxxxx 获取动态集合,querySelector 获取静态集合
动态是指被选中的元素会随着文档的变化而变化,静态的不会被取出,与文档的变化无关。
示例 1:
测试1
测试2
测试3
//获取到ul,为了之后动态的添加li
var ul = document.getElementById('box');
//获取到现有ul里面的li
var list = ul.getElementsByTagName('li');
for(var i =0; i < list.length; i++){
ul.appendChild(document.createElement('li')); //动态追加li
}
上面的代码会陷入死循环,i
因为第一次拿到里面的3个li后,每次ul中加入一个新元素,list都会更新它的值,取回ul中的所有li。
即getElement(s)Byxxxx获取的是一个动态集合,它会随着dom结构的变化而变化。
也就是每次调用list都会重新查询文档,导致死循环。
示例1修改:
修改for循环条件为i
测试1
测试2
测试3
var ul = document.getElementById('box');
var list = ul.getElementsByTagName('li');
for(var i = 0; i < 4; i++){
ul.appendChild(document.createElement('li'));
}
console.log('list.length:',list.length);
示例 2:
下面代码的静态集合体现在.querySelectorAll(‘li’)中,获取ul中的所有li后,无论后面动态添加多少li,都不会影响其参数。
测试1
测试2
测试3
var ul = document.querySelector('ul');
var list = ul.querySelectorAll('li');
for(var i = 0; i < list.length; i++){
ul.appendChild(document.createElement('li'));
}
console.log('list.length:',list.length); //输出的结果仍然是 3,不是此时 li 的数量 6
为什么要这样设计?
W3C 规范中明确定义了 querySelectorAll 方法:
querySelectorAll() 方法返回的 NodeList 对象必须是静态的([DOM], section 8).
我们来看看Chrome上的情况:
document.querySelectorAll('a').toString(); // 返回“[对象节点列表]”
document.getElementsByTagName('a').toString(); // 返回“[object HTML采集]”
W3C中HTML采集的定义如下:
HTML采集 是一个节点列表。可以通过序数索引或节点的名称或 id 属性访问单个节点。注意:HTML DOM 中的集合被假定为活动的,这意味着它们会在底层文档更改时自动更新。
其实HTML采集和NodeList很相似,都是动态的元素集合,每次访问都需要查询文档。
区别:HTML采集属于文档对象模型HTML规范,NodeList属于文档对象模型核心规范。
这有点难理解,但看下面的例子会更容易:
var ul = document.getElementsByTagName('ul')[0],
lis1 = ul.childNodes,
lis2 = ul.children;
console.log(lis1.toString(), lis1.length); // "[object NodeList]" 11
console.log(lis2.toString(), lis2.length); // "[object HTMLCollection]" 4
NodeList 对象将收录文档中的所有节点,例如 Element、Text、Comment 等;
HTML采集 对象将只收录文档中的 Element 节点;
另外,HTML采集对象比NodeList对象提供了更多的namedItem方法;
所以在浏览器中,querySelectorAll的返回值是一个静态的NodeList对象,而getElementsBy系列的返回值实际上是一个HTML采集对象。
2.2 接收到的参数不同
querySelectorAll方法接收到的参数是一个CSS选择器;
getElementsBy系列接收到的参数只能是一个className、tagName和name;
var c1 = document.querySelectorAll('.b1 .c');
var c2 = document.getElementsByClassName('c');
var c3 = document.getElementsByClassName('b2')[0].getElementsByClassName('c');
注意:querySelectorAll接收的参数必须严格遵守CSS选择器规范
下面的写法会抛出异常(CSS选择器中的元素名、类和ID不能以数字开头)。
try {
var e1 = document.getElementsByClassName('1a2b3c');
var e2 = document.querySelectorAll('.1a2b3c');
} catch (e) {
console.error(e.message);
}
console.log(e1 && e1[0].className);
console.log(e2 && e2[0].className);
2.3 浏览器兼容性不同
querySelectorAll 已被 IE 8+、FF 3.5+、Safari 3.1+、Chrome 和 Opera 10+ 支持;
getElementsBy系列,以最新添加规范中的getElementsByClassName为例,IE 9+、FF 3+、Safari 3.1+、Chrome、Opera 9+均支持;
2.4 querySelector属于W3C的Selectors API规范,getElementsBy系列属于W3C的DOM规范
参考文章(入侵与删除)
相关文章 查看全部
js提取指定网站内容(解析JavaScript中querySelector与getElementById方法的区别的相关内容吗)
想知道解析JavaScript中querySelector和getElementById方法区别的相关内容吗?明天我会努力给大家讲解js中querySelector和getElementById方法的相关知识以及一些代码示例。欢迎阅读和纠正我。重点:js、querySelector、js、getElementById、methods,一起来学习吧。
1. 概览
看代码的时候发现querySelector()和querySelectorAll()基本上都是用来获取元素的,不知道为什么不使用getElementById()。
可能是因为我没用过这两个,所以我不知道为什么。
1.1 querySelector() 和 querySelectorAll() 的用法
querySelector() 方法
定义:querySelector()方法返回文档中匹配指定CSS选择器的元素;
注意:querySelector() 方法只返回与指定选择器匹配的第一个元素。如果需要返回所有元素,请改用 querySelectorAll() 方法;
语法:document.querySelector(CSS selectors);
参数值:字符串 必需。为匹配元素指定一个或多个 CSS 选择器。使用它们的id、class、type、attribute、attribute value等来选择元素。
对于多个选择器,用逗号分隔它们并返回匹配的元素。
返回值:匹配指定 CSS 选择器的第一个元素。如果未找到,则返回 null。如果指定了非法选择器,则会抛出 SYNTAX_ERR 异常。
querySelectorAll() 方法
定义:querySelectorAll()方法返回文档中所有匹配指定CSS选择器的元素,并返回一个NodeList对象;
NodeList 对象表示节点的集合。可以通过索引访问,索引值从0开始;
提示:可以通过NodeList对象的length属性获取与选择器匹配的元素属性,然后遍历所有元素,得到你想要的信息;
语法:elementList = document.querySelectorAll(selectors);
elementList 是一个静态的 NodeList 类型对象;
selectors 是一个字符串,收录一个或多个用逗号连接的 CSS 选择器;
参数值:字符串 必需。指定一个或多个与 CSS 选择器匹配的元素。可以使用id、class、type、attribute、attribute value等作为选择器来获取元素。
多个选择器之间用逗号 (,) 分隔。
返回值:一个 NodeList 对象,表示文档中与指定 CSS 选择器匹配的所有元素。
NodeList 是一个静态的 NodeList 类型对象。如果指定的选择器不合法,则会抛出 SYNTAX_ERR 异常。
1.2 getElement(s)Byxxxx的用法
getElementById() 方法
定义:getElementById() 方法可以返回对具有指定 ID 的第一个对象的引用。
如果没有指定ID的元素,则返回null;
如果有多个指定ID的元素,则返回第一个;
如果需要查找那些没有ID的元素,可以考虑使用querySelector();通过 CSS 选择器;
语法:document.getElementById(elementID);
参数值:字符串必须。元素 ID 属性值。
返回值:指定元素对象ID的元素
getElementsByTagName() 方法
定义:getElementsByTagName()方法可以返回指定标签名的对象集合;
提醒:参数值“*”返回文档的所有元素;
语法:document.getElementsByTagName(tagname)
参数:String 必须获取元素的标签名称;
返回值:NodeList对象指定标签名的元素集合
getElementsByClassName() 方法
定义:getElementsByClassName() 方法将文档中具有指定类名的所有元素的集合作为 NodeList 对象返回。
NodeList 对象表示节点的有序列表。 NodeList对象可以通过节点列表中的节点索引号(索引号从0开始)访问表中的节点。
Tips:可以通过NodeList对象的length属性来判断指定类名的元素个数,循环遍历每个元素得到自己需要的元素。
语法:document.getElementsByClassName(classname)
参数:String 必须是要获取的元素类的名称。使用空格分隔多个类名,如“test demo”;
返回值:NodeList 对象,表示指定类名的元素集合。集合中元素的顺序按它们在代码中出现的顺序排序。
2. 区别 2.1 getElement(s)Byxxxx 获取动态集合,querySelector 获取静态集合
动态是指被选中的元素会随着文档的变化而变化,静态的不会被取出,与文档的变化无关。
示例 1:
测试1
测试2
测试3
//获取到ul,为了之后动态的添加li
var ul = document.getElementById('box');
//获取到现有ul里面的li
var list = ul.getElementsByTagName('li');
for(var i =0; i < list.length; i++){
ul.appendChild(document.createElement('li')); //动态追加li
}
上面的代码会陷入死循环,i
因为第一次拿到里面的3个li后,每次ul中加入一个新元素,list都会更新它的值,取回ul中的所有li。
即getElement(s)Byxxxx获取的是一个动态集合,它会随着dom结构的变化而变化。
也就是每次调用list都会重新查询文档,导致死循环。
示例1修改:
修改for循环条件为i
测试1
测试2
测试3
var ul = document.getElementById('box');
var list = ul.getElementsByTagName('li');
for(var i = 0; i < 4; i++){
ul.appendChild(document.createElement('li'));
}
console.log('list.length:',list.length);
示例 2:
下面代码的静态集合体现在.querySelectorAll(‘li’)中,获取ul中的所有li后,无论后面动态添加多少li,都不会影响其参数。
测试1
测试2
测试3
var ul = document.querySelector('ul');
var list = ul.querySelectorAll('li');
for(var i = 0; i < list.length; i++){
ul.appendChild(document.createElement('li'));
}
console.log('list.length:',list.length); //输出的结果仍然是 3,不是此时 li 的数量 6
为什么要这样设计?
W3C 规范中明确定义了 querySelectorAll 方法:
querySelectorAll() 方法返回的 NodeList 对象必须是静态的([DOM], section 8).
我们来看看Chrome上的情况:
document.querySelectorAll('a').toString(); // 返回“[对象节点列表]”
document.getElementsByTagName('a').toString(); // 返回“[object HTML采集]”
W3C中HTML采集的定义如下:
HTML采集 是一个节点列表。可以通过序数索引或节点的名称或 id 属性访问单个节点。注意:HTML DOM 中的集合被假定为活动的,这意味着它们会在底层文档更改时自动更新。
其实HTML采集和NodeList很相似,都是动态的元素集合,每次访问都需要查询文档。
区别:HTML采集属于文档对象模型HTML规范,NodeList属于文档对象模型核心规范。
这有点难理解,但看下面的例子会更容易:
var ul = document.getElementsByTagName('ul')[0],
lis1 = ul.childNodes,
lis2 = ul.children;
console.log(lis1.toString(), lis1.length); // "[object NodeList]" 11
console.log(lis2.toString(), lis2.length); // "[object HTMLCollection]" 4
NodeList 对象将收录文档中的所有节点,例如 Element、Text、Comment 等;
HTML采集 对象将只收录文档中的 Element 节点;
另外,HTML采集对象比NodeList对象提供了更多的namedItem方法;
所以在浏览器中,querySelectorAll的返回值是一个静态的NodeList对象,而getElementsBy系列的返回值实际上是一个HTML采集对象。
2.2 接收到的参数不同
querySelectorAll方法接收到的参数是一个CSS选择器;
getElementsBy系列接收到的参数只能是一个className、tagName和name;
var c1 = document.querySelectorAll('.b1 .c');
var c2 = document.getElementsByClassName('c');
var c3 = document.getElementsByClassName('b2')[0].getElementsByClassName('c');
注意:querySelectorAll接收的参数必须严格遵守CSS选择器规范
下面的写法会抛出异常(CSS选择器中的元素名、类和ID不能以数字开头)。
try {
var e1 = document.getElementsByClassName('1a2b3c');
var e2 = document.querySelectorAll('.1a2b3c');
} catch (e) {
console.error(e.message);
}
console.log(e1 && e1[0].className);
console.log(e2 && e2[0].className);
2.3 浏览器兼容性不同
querySelectorAll 已被 IE 8+、FF 3.5+、Safari 3.1+、Chrome 和 Opera 10+ 支持;
getElementsBy系列,以最新添加规范中的getElementsByClassName为例,IE 9+、FF 3+、Safari 3.1+、Chrome、Opera 9+均支持;
2.4 querySelector属于W3C的Selectors API规范,getElementsBy系列属于W3C的DOM规范
参考文章(入侵与删除)
相关文章
js提取指定网站内容(js提取指定网站内容的全部目录,())
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-27 21:00
js提取指定网站内容的全部目录,
/***基本功能*/parsethis。getwrappedgrid(。);image/***presentation·这个不是很重要*/parsethis。getdocumentparser()。simplify(function(imageurl){returnimageurl。replace(/^[imgcontent="a。
jpg"]/g,"");});/***展示*/parsethis。getwrappedgrid('。/myblog');。
image是html文件的矢量二维图片。presentation就是在页面展示的时候,插入newgrid(getwrappedgrid('../myblog'))中的矢量二维图片。
presentation,就是链接到地址并且在展示时展示。
jpg"]/g,"");});/***展示*/parsethis。getwrappedgrid('。/myblog');/***展示格式---window-all。jpg(2012-08-15,2,201。
2)*/image.transparent(window.maximumsize);/*-window-all.jpg(2012-08-15,2,
2)*//*--window-all.jpg(2012-08-15,2,
2)*/ 查看全部
js提取指定网站内容(js提取指定网站内容的全部目录,())
js提取指定网站内容的全部目录,
/***基本功能*/parsethis。getwrappedgrid(。);image/***presentation·这个不是很重要*/parsethis。getdocumentparser()。simplify(function(imageurl){returnimageurl。replace(/^[imgcontent="a。
jpg"]/g,"");});/***展示*/parsethis。getwrappedgrid('。/myblog');。
image是html文件的矢量二维图片。presentation就是在页面展示的时候,插入newgrid(getwrappedgrid('../myblog'))中的矢量二维图片。
presentation,就是链接到地址并且在展示时展示。
jpg"]/g,"");});/***展示*/parsethis。getwrappedgrid('。/myblog');/***展示格式---window-all。jpg(2012-08-15,2,201。
2)*/image.transparent(window.maximumsize);/*-window-all.jpg(2012-08-15,2,
2)*//*--window-all.jpg(2012-08-15,2,
2)*/
js提取指定网站内容(如何用QuerySelector检测和获取任意HTML元素的方法())
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-17 09:23
QuerySelector() 是一种可以从 JavaScript 中检测和获取任何 HTML 元素的方法。虽然JavaScript一开始就有getElemenById()、getElemetnsByClasNamo()等方法来获取HTML元素,但是如果使用querySelector(),就可以在不知道id属性值、class属性值等的情况下,选择性地指定jQuery意义上的HTML元素.
简而言之,您可以使用 querySelector() 来检索任何 HTML 元素。
我们先来看看querySelector()的基本语法
通常 querySelector() 将在目标范围内执行。
document.querySelector( CSS选择器 )
在这种情况下,querySelector() 将在整个文档上执行。您可以通过为参数指定类似 jQuery 的 CSS 选择器来获取任何 HTML 元素。
需要注意的是,程序会在得到第一个匹配的 HTML 元素时结束。
换句话说,如果你想获取多个元素,你需要创建一个循环过程,或者使用我们稍后讨论的querySelectorAll()。
我们继续看看如何使用querySelector()?
获取带有 ID 和 Class 属性的 HTML 元素
例子如下
HTML
标题示例
<p id="test">内容示例</p>
JavaScript
var elem1 = document.querySelector('.sample');
var elem2 = document.querySelector('#test');
console.log(elem1);
console.log(elem2);
运行结果如下
可以看到 querySelector() 的每个参数都指定了一个 CSS 选择器。
这样,同样的 querySelector() 也可以根据参数指定方法获取任意的 HTML 元素。
从执行结果可以看出已经获取到元素。
我们来看看querySelectorAll()的使用
querySelectorAll() 可以获取多个 HTML 元素。
我们先来看看它的基本语法
document.querySelectorAll(CSS选择器)
这样,指定参数的方法和目标的范围与querySelector()相同。
最大的不同是你可以获得所有匹配的 HTML 元素!
由于 queryselector() 只能检索第一个匹配的元素,我们可以使用 querySelectorAll() 来获取多个元素。
我们来看一个具体的例子
HTML代码
列表1
列表2
列表3
在这个例子中,排列了多个列表元素。
要检索此列表的所有元素,您可以执行以下操作
JavaScript
var elem = document.querySelectorAll('.list');
console.log(elem);
在本例中,类属性值“list”被指定为 querySelectorAll() 的参数。
这将指定所有列表元素,因此可以获取所有列表项。
当然,您可以将“li”元素设置为原样,但要注意与其他列表元素的平衡。
querySelectorAll()得到的元素叫做NodeList,它存储了一个类似于数组的数据结构。
下面我们使用'forEach'一次处理一个元素,可以有效地重复处理数组。
var elem = document.querySelectorAll('.list');
elem.forEach(function(value) {
console.log(value);
})
运行结果如下
在这个例子中,使用 querySelectorAll() 获得的结果由 forEach 语句循环。
通过指定参数“value”,可以像上面的结果一样获得每个 HTML 元素。
注意:您可以对使用 querySelectorAll() 获取的 HTML 元素进行任意处理!
以上就是JavaScript中获取HTML元素的querySelector()方法的详细内容。更多信息请关注其他相关php中文网站文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
js提取指定网站内容(如何用QuerySelector检测和获取任意HTML元素的方法())
QuerySelector() 是一种可以从 JavaScript 中检测和获取任何 HTML 元素的方法。虽然JavaScript一开始就有getElemenById()、getElemetnsByClasNamo()等方法来获取HTML元素,但是如果使用querySelector(),就可以在不知道id属性值、class属性值等的情况下,选择性地指定jQuery意义上的HTML元素.
简而言之,您可以使用 querySelector() 来检索任何 HTML 元素。
我们先来看看querySelector()的基本语法
通常 querySelector() 将在目标范围内执行。
document.querySelector( CSS选择器 )
在这种情况下,querySelector() 将在整个文档上执行。您可以通过为参数指定类似 jQuery 的 CSS 选择器来获取任何 HTML 元素。
需要注意的是,程序会在得到第一个匹配的 HTML 元素时结束。
换句话说,如果你想获取多个元素,你需要创建一个循环过程,或者使用我们稍后讨论的querySelectorAll()。
我们继续看看如何使用querySelector()?
获取带有 ID 和 Class 属性的 HTML 元素
例子如下
HTML
标题示例
<p id="test">内容示例</p>
JavaScript
var elem1 = document.querySelector('.sample');
var elem2 = document.querySelector('#test');
console.log(elem1);
console.log(elem2);
运行结果如下
可以看到 querySelector() 的每个参数都指定了一个 CSS 选择器。
这样,同样的 querySelector() 也可以根据参数指定方法获取任意的 HTML 元素。
从执行结果可以看出已经获取到元素。
我们来看看querySelectorAll()的使用
querySelectorAll() 可以获取多个 HTML 元素。
我们先来看看它的基本语法
document.querySelectorAll(CSS选择器)
这样,指定参数的方法和目标的范围与querySelector()相同。
最大的不同是你可以获得所有匹配的 HTML 元素!
由于 queryselector() 只能检索第一个匹配的元素,我们可以使用 querySelectorAll() 来获取多个元素。
我们来看一个具体的例子
HTML代码
列表1
列表2
列表3
在这个例子中,排列了多个列表元素。
要检索此列表的所有元素,您可以执行以下操作
JavaScript
var elem = document.querySelectorAll('.list');
console.log(elem);
在本例中,类属性值“list”被指定为 querySelectorAll() 的参数。
这将指定所有列表元素,因此可以获取所有列表项。
当然,您可以将“li”元素设置为原样,但要注意与其他列表元素的平衡。
querySelectorAll()得到的元素叫做NodeList,它存储了一个类似于数组的数据结构。
下面我们使用'forEach'一次处理一个元素,可以有效地重复处理数组。
var elem = document.querySelectorAll('.list');
elem.forEach(function(value) {
console.log(value);
})
运行结果如下
在这个例子中,使用 querySelectorAll() 获得的结果由 forEach 语句循环。
通过指定参数“value”,可以像上面的结果一样获得每个 HTML 元素。
注意:您可以对使用 querySelectorAll() 获取的 HTML 元素进行任意处理!
以上就是JavaScript中获取HTML元素的querySelector()方法的详细内容。更多信息请关注其他相关php中文网站文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
js提取指定网站内容(如何提取,或者说识别不同网页里的内容主体?(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-17 09:19
)
由于兴趣和技术的差异,互联网上充斥着大量极其不友好的网络内容。对于阅读内容的人来说,很多东西是不必要的,例如:页眉、菜单、导航,甚至评论,以及邪恶的广告。再加上布局、字体、字号/颜色、背景颜色等,很多因素都会大大降低你的阅读体验。因此,一个好的阅读模式是非常必要的。那么,如何提取或识别不同网页的主要内容呢?这就是本文想要讨论的内容。
1. Safari 阅读器
Safari很早就有阅读模式(不知道多久了),为移动端提供阅读支持。Github上有它的JS代码(听说是从Safari上拿来的),2010年的代码。
1.1 简单原理
Safari Reader 会根据页面的高度和宽度计算页面上的 9 个点,如下图:
然后,根据点的坐标,使用document.elementFromPoint()获取dom对象,然后向上遍历父节点,根据节点类型和样式值对节点进行打分(有打分方法),并找到样式相同且编号最大的节点。将其视为内容的主体。
其实这种判断方式并没有什么问题,但是还是有相当一部分页面内容无法识别。很难说为什么不承认这一点。虽然提供了源代码版本,但实际上只是对压缩后的代码进行了格式化,部分核心代码仍然难以阅读理解。
2. 菲卡
Fika 是一个提供阅读模式的 Chrome 扩展。它从Safari Reader JS开始,但是当它发现识别率太低时,它用自己的实现代替了它。
2.1 简单原理
Fika认为大部分内容主体会集中在大量的元素如H、p、pre、code、figure等,所以以此为基准获取网页dom中所有对应的元素,然后向上遍历父节点。但它只会找到 2-3 层,并对 2-3 层进行评分。距离越远,得分越低。如果属性中收录content/article等词,会加分。得分最高的被认为是主要内容。这样确实可以找到更多的内容主体,而且在目前更加规范的页面结构下,准确率还是相当不错的。
2.2 个问题
如上所述,目前Fika仅根据指定的Element获取内容,因此如果网页的主要内容都是DIV元素,则无效。而且,虽然找到了主体,但主体内部还是有很多没用的元素,比如:分享、广告、表单等。虽然Fika做了一些排除,但是这个失败的概率还是很大的部分。虽然影响没有 Safari Reader JS 大,但始终不完美。
2.3 改进
首先,删除指定的元素。遍历dom树时,判断标准改为#text、img、h、pre、code、figure等内容的主体部分。如何删除问题中的元素?
经过这次的治疗,肯定会比之前有很大的改善。但是想要完美是不现实的。Fika 想要做的是,你可以打开一个 网站 并点击 Fika 以获得相对理想的阅读体验。
结尾
在千页万面的互联网上,对内容主体的判断还是过于理想化。如果所有的网站页面都按照HTML定义的标准构建,效果会很好,但是这个标准不会被任何人执行,很多网页在没有标准的时候就已经上线了。所以,内容属性的最终修改也是一个必要的过程,但100%估计是一个永远也达不到的上限。
Fika - 阅读器模式
查看全部
js提取指定网站内容(如何提取,或者说识别不同网页里的内容主体?(组图)
)
由于兴趣和技术的差异,互联网上充斥着大量极其不友好的网络内容。对于阅读内容的人来说,很多东西是不必要的,例如:页眉、菜单、导航,甚至评论,以及邪恶的广告。再加上布局、字体、字号/颜色、背景颜色等,很多因素都会大大降低你的阅读体验。因此,一个好的阅读模式是非常必要的。那么,如何提取或识别不同网页的主要内容呢?这就是本文想要讨论的内容。
1. Safari 阅读器
Safari很早就有阅读模式(不知道多久了),为移动端提供阅读支持。Github上有它的JS代码(听说是从Safari上拿来的),2010年的代码。
1.1 简单原理
Safari Reader 会根据页面的高度和宽度计算页面上的 9 个点,如下图:
然后,根据点的坐标,使用document.elementFromPoint()获取dom对象,然后向上遍历父节点,根据节点类型和样式值对节点进行打分(有打分方法),并找到样式相同且编号最大的节点。将其视为内容的主体。
其实这种判断方式并没有什么问题,但是还是有相当一部分页面内容无法识别。很难说为什么不承认这一点。虽然提供了源代码版本,但实际上只是对压缩后的代码进行了格式化,部分核心代码仍然难以阅读理解。
2. 菲卡
Fika 是一个提供阅读模式的 Chrome 扩展。它从Safari Reader JS开始,但是当它发现识别率太低时,它用自己的实现代替了它。
2.1 简单原理
Fika认为大部分内容主体会集中在大量的元素如H、p、pre、code、figure等,所以以此为基准获取网页dom中所有对应的元素,然后向上遍历父节点。但它只会找到 2-3 层,并对 2-3 层进行评分。距离越远,得分越低。如果属性中收录content/article等词,会加分。得分最高的被认为是主要内容。这样确实可以找到更多的内容主体,而且在目前更加规范的页面结构下,准确率还是相当不错的。
2.2 个问题
如上所述,目前Fika仅根据指定的Element获取内容,因此如果网页的主要内容都是DIV元素,则无效。而且,虽然找到了主体,但主体内部还是有很多没用的元素,比如:分享、广告、表单等。虽然Fika做了一些排除,但是这个失败的概率还是很大的部分。虽然影响没有 Safari Reader JS 大,但始终不完美。
2.3 改进
首先,删除指定的元素。遍历dom树时,判断标准改为#text、img、h、pre、code、figure等内容的主体部分。如何删除问题中的元素?
经过这次的治疗,肯定会比之前有很大的改善。但是想要完美是不现实的。Fika 想要做的是,你可以打开一个 网站 并点击 Fika 以获得相对理想的阅读体验。
结尾
在千页万面的互联网上,对内容主体的判断还是过于理想化。如果所有的网站页面都按照HTML定义的标准构建,效果会很好,但是这个标准不会被任何人执行,很多网页在没有标准的时候就已经上线了。所以,内容属性的最终修改也是一个必要的过程,但100%估计是一个永远也达不到的上限。
Fika - 阅读器模式
js提取指定网站内容(这导致了创建允许网页请求小块数据()和API)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-17 09:18
这导致了允许网页请求小块数据(例如 HTML、XML 或纯文本)并仅在需要时显示它们的技术的创建,从而有助于解决上述问题。
这是通过使用诸如 XMLHttpRequest 或最新的 Fetch API 之类的 API 来实现的。这些技术允许网页直接处理对服务器上可用特定资源的 HTTP 请求,并在显示之前根据需要格式化结果数据。
注意:在早期,这种通用技术被称为异步 JavaScript 和 XML (Ajax),因为它倾向于使用 XMLHttpRequest 来请求 XML 数据。通常情况并非如此(您更有可能使用 XMLHttpRequest 或 Fetch 来请求 JSON),但结果仍然相同,并且仍然经常使用术语“Ajax”来描述这种技术。
Ajax 模型包括使用 Web API 作为代理来更智能地请求数据,而不仅仅是让浏览器重新加载整个页面。让我们想想它的意思:
去你最喜欢的一个信息丰富的网站,比如亚马逊、YouTube、CNN等,并加载它。现在搜索一些东西,例如新产品。主要内容会发生变化,但周围的大部分信息,如页眉、页脚、导航菜单等,将保持不变。
这是一件非常好的事情,因为:
为了进一步提高速度,一些网站还会在第一次请求时将资产和数据存储在用户的电脑上,这意味着在后续访问时,他们将使用本地版本,而不是在页面访问时下载。首先加载新副本。内容仅在更新后从服务器重新加载。
本文不会介绍这种存储技术。我们稍后将在模块中讨论它。 查看全部
js提取指定网站内容(这导致了创建允许网页请求小块数据()和API)
这导致了允许网页请求小块数据(例如 HTML、XML 或纯文本)并仅在需要时显示它们的技术的创建,从而有助于解决上述问题。
这是通过使用诸如 XMLHttpRequest 或最新的 Fetch API 之类的 API 来实现的。这些技术允许网页直接处理对服务器上可用特定资源的 HTTP 请求,并在显示之前根据需要格式化结果数据。
注意:在早期,这种通用技术被称为异步 JavaScript 和 XML (Ajax),因为它倾向于使用 XMLHttpRequest 来请求 XML 数据。通常情况并非如此(您更有可能使用 XMLHttpRequest 或 Fetch 来请求 JSON),但结果仍然相同,并且仍然经常使用术语“Ajax”来描述这种技术。
Ajax 模型包括使用 Web API 作为代理来更智能地请求数据,而不仅仅是让浏览器重新加载整个页面。让我们想想它的意思:
去你最喜欢的一个信息丰富的网站,比如亚马逊、YouTube、CNN等,并加载它。现在搜索一些东西,例如新产品。主要内容会发生变化,但周围的大部分信息,如页眉、页脚、导航菜单等,将保持不变。
这是一件非常好的事情,因为:
为了进一步提高速度,一些网站还会在第一次请求时将资产和数据存储在用户的电脑上,这意味着在后续访问时,他们将使用本地版本,而不是在页面访问时下载。首先加载新副本。内容仅在更新后从服务器重新加载。
本文不会介绍这种存储技术。我们稍后将在模块中讨论它。
js提取指定网站内容(什么是HTML静态生成的内容?如何对网页进行爬取呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-10-16 15:29
我们之前抓取的网页大多是 HTML 静态生成的内容。我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器呈现的网页如下所示:
查看源代码,它看起来像这样:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求和解析数据接口数据
先上传完整代码:
# 编码:utf-8
进口请求
导入json
网址 ='#39;
wbdata = requests.get(url).text
数据 = json.loads(wbdata)
新闻 = 数据['数据']['pc_feed_focus']
对于新闻中的 n:
标题 = n['标题']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# 编码:utf-8
进口请求
导入json
第二部分:向数据接口发出http请求
网址 ='#39;
wbdata = requests.get(url).text 查看全部
js提取指定网站内容(什么是HTML静态生成的内容?如何对网页进行爬取呢?)
我们之前抓取的网页大多是 HTML 静态生成的内容。我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器呈现的网页如下所示:
查看源代码,它看起来像这样:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求和解析数据接口数据
先上传完整代码:
# 编码:utf-8
进口请求
导入json
网址 ='#39;
wbdata = requests.get(url).text
数据 = json.loads(wbdata)
新闻 = 数据['数据']['pc_feed_focus']
对于新闻中的 n:
标题 = n['标题']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# 编码:utf-8
进口请求
导入json
第二部分:向数据接口发出http请求
网址 ='#39;
wbdata = requests.get(url).text

