
js提取指定网站内容
js提取指定网站内容(本文开发官网(/)的搭建思路,分享云开发结合流行框架与工具的实战经验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-09-04 21:21
关于作者:
董元新是云开发CloudBase团队的研发工程师。他专注于前端工程和节点服务开发。他在业余时间出没。
本文内容:
简介
随着腾讯云开发能力的提升,经验丰富的工程师已经可以独立完成产品的开发和上线。但是,与在线云开发相关的实战文章很少。很多开发者都知道云开发的能力,但不知道如何在现有的开发体系下引入云开发。
本文从云开发团队开发者+能力用户的角度,以搭建云开发官网的思路(/)为例,分享结合流行框架和工具的云开发实践经验。
涉及的知识点有:
React 框架:Next.jsCI 自动构建概述
系统设计图:
背景介绍
随着云开发团队业务的快速发展,团队需要一个官网来更直观、即时地向开发者展示云开发的相关能力,包括但不限于工具链、SDK、技术文档等。
同时,为了降低开发者的动手成本,积累行业优秀的实践经验,官网还承载着营造社区氛围、聚合重要信息、提升用户留存的重任。
我们最初使用 VuePress 作为静态 网站 工具,遇到了一些痛点:
我们使用“cms扩展”、“基础云开发能力”、“Next.js”、“CI工具”来解决以上问题。在实现网站内容动态的同时,保证SEO,运营同学也可以通过cms可视化管理内容。
安装cms
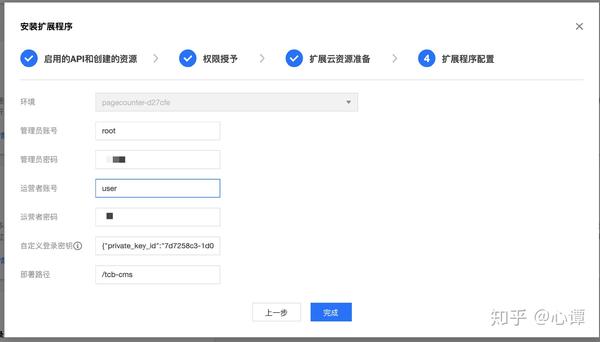
进入云开发拓展能力控制台,按照提示安装cms内容管理系统。
在配置扩展时,有两种类型的帐户:管理员帐户和操作员帐户。管理员账户具有更高的权限,可以创建新的数据集合;而operator账号只能对已有的数据集进行增删改查。
注意:
安装时间有点长,请耐心等待
安装成功后,云数据库会自动创建3个合集,分别是tcb-ext-cms-contents、tcb-ext-cms-users、tcb-ext-cms-webhooks和存储cms系统配置信息和内容数据。会自动创建三个云函数,分别是tcb-ext-cms-api、tcb-ext-cms-init、tcb-ext-cms-auth,它们封装了初始化、鉴权和数据流的相关逻辑。
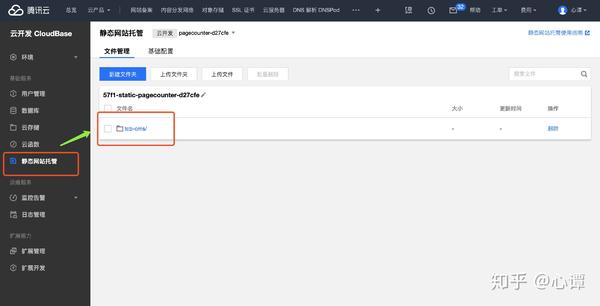
输入“static网站hosting”,可以看到cms系统的静态文件已经自动部署到tcb-cms/目录下:
点击上方的“基本配置”查看域名信息。
在浏览器中访问对应链接(/tcb-cms/)查看cms系统:
至此,无需任何开发成本,cms内容管理系统正式上线~
使用cms创建动态内容
对于动态数据内容,我们将其划分为不同的模块。每个内容模块对应一个cms系统的数据集合。例如,在“云开发官网”-“社区页面”中,推荐好课程的内容是动态的。
从图中可以看出,每节课都有多个属性。在云数据库中,每门课程对应一个文档,课程属性对应文档的字段。字段类型及含义如下:
name: 课程名称
time: 课程时间
cover: 课程封面
url: 课程链接
level: 课程难度
以管理员身份登录cms系统,在“内容设置页面”新建内容。在cms中支持多种高级数据类型,如url、image、markdown、富文本、标签数组、邮箱、URL等,这些类型被智能识别,显示更友好。
注意:
cms自带图床功能。当数据类型为“图片”时,图片会自动上传到当前云开发环境下的云存储中。图像信息以cloud://开头的特殊链接存储在数据集合中。
新建内容时,cms默认会自动填写4个字段:name、order、createTime、updateTime。您可以根据需要删除不需要的字段。
推荐:
order 字段是保留的,可以用于数据排序。对于运营商来说,数据的顺序值越大,在cms系统中显示的位置就越高;对于开发者来说,可以按照顺序进行排序和搜索。从而保证体验和逻辑的一致性。
根据字段创建集合后,cms会在系统左侧看到“推荐课程”。其对应的内容保存在云数据库的recome-course(创建时指定)集合中,其字段信息保存在云的tcb-ext-cms-contents(cms初始化时创建)集合中数据库。
根据设置添加新的课程内容后,再次进入“推荐课程”,如下图:
图片、链接等内容向运营商展示更友好。
项目建设
按照 Next.js Docs 的指南创建 Next.js 项目:
npm i --save next react react-dom
因为我们要部署网站到“静态托管”,所以需要用到Next.js的静态导出功能。 package.json 中的打包脚本更新为:
"scripts": {
"dev": "next",
"build": "next build && next export",
"start": "next start"
}
为了快速部署静态网站并发布云功能。需要全局安装@cloudbase/cli:
npm install -g @cloudbase/cli
安装后,添加两个脚本:
"scripts": {
"deploy:hosting": "npm run build && cloudbase hosting:deploy out -e jhgjj-0ae4a1",
"deploy:function": "echo y | cloudbase functions:deploy --force"
}
注意:
准备两个云环境,防止静态部署时文件覆盖。 envId为jhgjj-0ae4a1的云环境仅用于部署Next.js的静态导出文件。 envId为pagecounter-d27cfe的云环境用于部署cms系统。获取cms内容
通过CloudBase的Node SDK-@cloudbase/node-sdk,我们可以在Next.js的getStaticProps()方法中读取云数据库中的数据。
为了使逻辑更清晰,我们将获取外部数据的方法封装在一个文件中。以“推荐课程”为例:
// provider.js
const cloudbase = require("@cloudbase/node-sdk");
const config = {
secretId: "your secretId", // 前往「腾讯云控制台」-「访问密钥」获取
secretKey: "your secretKey", // 前往「腾讯云控制台」-「访问密钥」获取
env: "your envid" // 前往「腾讯云控制台」-「云开发 CloudBase」获取
};
const app = cloudbase.init(config);
/**
* 获取云数据库数据
*/
async function getCourses() {
const db = app.database();
const result = await db.collection("recommend-course").get();
if (result.code) {
throw new Error(
`获取「推荐课程」失败, 错误码是${result.code}: ${result.message}`
);
}
return result.data.map(item => {
if (item.createTime instanceof Date) {
item.createTime = item.createTime.toLocaleString();
}
if (item.updateTime instanceof Date) {
item.updateTime = item.updateTime.toLocaleString();
}
item.cover = getBucketUrl(item.cover); // 处理云存储的特殊链接
return item;
});
}
如上一篇所述,cms有自己的图床功能。拖拽上传的图片会保存在同一环境的云存储中,获取图片的链接会保存在采集中。云存储链接是以cloud://开头的特殊链接,需要前端识别和特殊处理。
例如图片存储链接为:cloud://pagecounter-d27cfe.7061-pagecounter-d27cfe-1255463368/uploads/04.png。将其转换为可访问的 http 链接:
转换思路是:识别出envid背后的信息,与tcb.qcloud.la域名重新拼接:
// provider.js
/**
* 获取云存储的访问链接
* @param {String} url 云存储的特定url
*/
function getBucketUrl(url) {
if (!url.startsWith("cloud://")) {
return url;
}
const re = /cloud:\/\/.*?\.(.*?)\/(.*)/;
const result = re.exec(url);
return `https://${result[1]}.tcb.qcloud.la/${result[2]}`;
}
注意:
云存储的“权限设置”应该是:所有用户都可以读,只有创建者和管理员可以写。否则链接无法访问。
推荐:
除了内置的图床功能外,开发者还可以根据自己的需求使用其他稳定的图床服务,例如微博图床。如果使用其他图片床,对应的字段类型不能设置为“图片”,可以是“字符串”或“超链接”。
到此为止,我们已经使用 SDK 获取了云数据库数据,剩下要做的就是将其注入到 Next.js 页面组件的 props 中:
// pages/index.js
const HomePage = ({ courses }) => {
return (
// 尽情使用数据吧...
)
}
export async function getStaticProps() {
const { getCourses } = require('./../provider')
return {
props: {
courses: await getCourses()
}
}
}
export default HomePage
打开浏览器输入:3000/,可以看到效果如下:
输入view-source::3000/,可以看到网页的html源码中收录了课程数据,解决了SEO问题:
注意:
Next.js 的一些方法会在两端运行,但 getStaticProps() 只会在服务器端运行自动构建和部署
到此,开发工作基本结束。执行npm run build命令,网站静态文件打包在out/目录下:
执行 npm run deploy:hosting 将 out/ 目录下的文件上传到“static网站hosting”。访问静态网站托管的链接:/,效果如下:
借助成熟的 CI 工具,例如 Travis、Circle 等,可以定期触发构建工作。这样,内容和开发就完全分离了。
在构建版本时,您需要使用 CloudBase CLI 工具。在CI工具中,不再使用cloudbase login进行交互式输入登录,而是使用一键登录:cloudbase login --apiKeyId $TCB_SECRET_ID --apiKey $TCB_SECRET_KEY。
注意:
前往 Cloud API Key 获取 TCB_SECRET_ID 和 TCB_SECRET_KEY 的值
在 CI 工具的控制台中,配置 TCB_SECRET_ID 和 TCB_SECRET_KEY。并向 package.json 添加一个新脚本:
"scripts": {
"login": "echo N | cloudbase login --apiKeyId $TCB_SECRET_ID --apiKey $TCB_SECRET_KEY"
}
总结起来,CI构建的过程是:
如果数据需要紧急修改在线,您可以在本地或在CI工具控制台手动触发构建。
终于
借助云开发cms,可以实现评论系统、预约系统、博客发帖等各种内容模板,快速搭建网站。在现有的开发体系下,合理使用云开发,大大降低了人工成本、开发成本、运维成本。实现前后端穿梭,形成“闭环”。
本文的实战只是开始。它涉及到部分云开发能力。还有更多好玩的东西等着你去探索,比如使用云函数实现SSR、托管后端服务、图片服务、各种端SDK等。
探索功能、多样化想法并以较低的成本开发高度可用的网络服务。云开发绝对是您的最佳选择!
更多信息: 查看全部
js提取指定网站内容(本文开发官网(/)的搭建思路,分享云开发结合流行框架与工具的实战经验)
关于作者:
董元新是云开发CloudBase团队的研发工程师。他专注于前端工程和节点服务开发。他在业余时间出没。
本文内容:
简介
随着腾讯云开发能力的提升,经验丰富的工程师已经可以独立完成产品的开发和上线。但是,与在线云开发相关的实战文章很少。很多开发者都知道云开发的能力,但不知道如何在现有的开发体系下引入云开发。
本文从云开发团队开发者+能力用户的角度,以搭建云开发官网的思路(/)为例,分享结合流行框架和工具的云开发实践经验。
涉及的知识点有:
React 框架:Next.jsCI 自动构建概述
系统设计图:
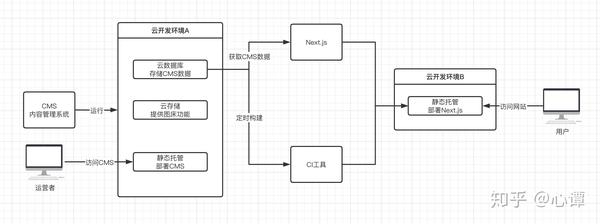
背景介绍
随着云开发团队业务的快速发展,团队需要一个官网来更直观、即时地向开发者展示云开发的相关能力,包括但不限于工具链、SDK、技术文档等。
同时,为了降低开发者的动手成本,积累行业优秀的实践经验,官网还承载着营造社区氛围、聚合重要信息、提升用户留存的重任。
我们最初使用 VuePress 作为静态 网站 工具,遇到了一些痛点:
我们使用“cms扩展”、“基础云开发能力”、“Next.js”、“CI工具”来解决以上问题。在实现网站内容动态的同时,保证SEO,运营同学也可以通过cms可视化管理内容。
安装cms
进入云开发拓展能力控制台,按照提示安装cms内容管理系统。
在配置扩展时,有两种类型的帐户:管理员帐户和操作员帐户。管理员账户具有更高的权限,可以创建新的数据集合;而operator账号只能对已有的数据集进行增删改查。
注意:
安装时间有点长,请耐心等待
安装成功后,云数据库会自动创建3个合集,分别是tcb-ext-cms-contents、tcb-ext-cms-users、tcb-ext-cms-webhooks和存储cms系统配置信息和内容数据。会自动创建三个云函数,分别是tcb-ext-cms-api、tcb-ext-cms-init、tcb-ext-cms-auth,它们封装了初始化、鉴权和数据流的相关逻辑。
输入“static网站hosting”,可以看到cms系统的静态文件已经自动部署到tcb-cms/目录下:
点击上方的“基本配置”查看域名信息。
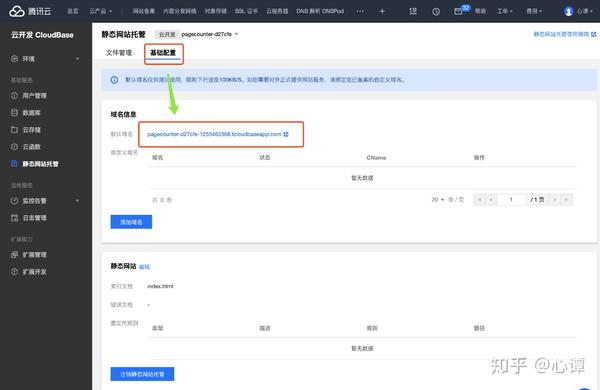
在浏览器中访问对应链接(/tcb-cms/)查看cms系统:
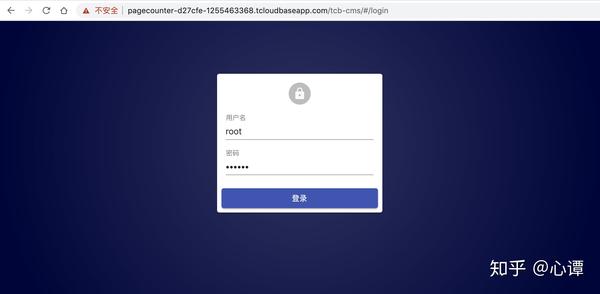
至此,无需任何开发成本,cms内容管理系统正式上线~
使用cms创建动态内容
对于动态数据内容,我们将其划分为不同的模块。每个内容模块对应一个cms系统的数据集合。例如,在“云开发官网”-“社区页面”中,推荐好课程的内容是动态的。
从图中可以看出,每节课都有多个属性。在云数据库中,每门课程对应一个文档,课程属性对应文档的字段。字段类型及含义如下:
name: 课程名称
time: 课程时间
cover: 课程封面
url: 课程链接
level: 课程难度
以管理员身份登录cms系统,在“内容设置页面”新建内容。在cms中支持多种高级数据类型,如url、image、markdown、富文本、标签数组、邮箱、URL等,这些类型被智能识别,显示更友好。
注意:
cms自带图床功能。当数据类型为“图片”时,图片会自动上传到当前云开发环境下的云存储中。图像信息以cloud://开头的特殊链接存储在数据集合中。
新建内容时,cms默认会自动填写4个字段:name、order、createTime、updateTime。您可以根据需要删除不需要的字段。
推荐:
order 字段是保留的,可以用于数据排序。对于运营商来说,数据的顺序值越大,在cms系统中显示的位置就越高;对于开发者来说,可以按照顺序进行排序和搜索。从而保证体验和逻辑的一致性。
根据字段创建集合后,cms会在系统左侧看到“推荐课程”。其对应的内容保存在云数据库的recome-course(创建时指定)集合中,其字段信息保存在云的tcb-ext-cms-contents(cms初始化时创建)集合中数据库。
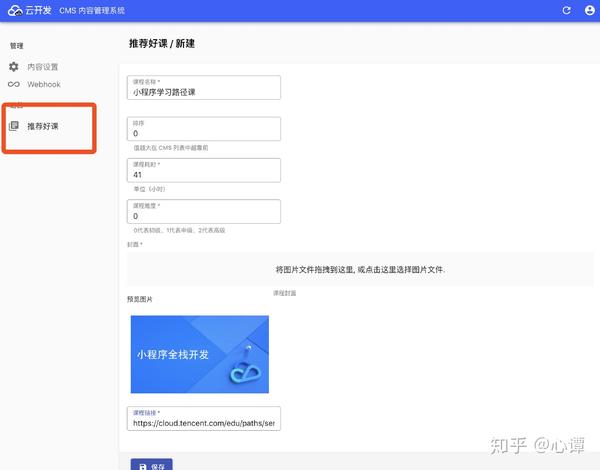
根据设置添加新的课程内容后,再次进入“推荐课程”,如下图:
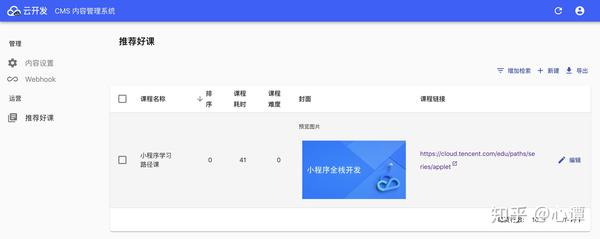
图片、链接等内容向运营商展示更友好。
项目建设
按照 Next.js Docs 的指南创建 Next.js 项目:
npm i --save next react react-dom
因为我们要部署网站到“静态托管”,所以需要用到Next.js的静态导出功能。 package.json 中的打包脚本更新为:
"scripts": {
"dev": "next",
"build": "next build && next export",
"start": "next start"
}
为了快速部署静态网站并发布云功能。需要全局安装@cloudbase/cli:
npm install -g @cloudbase/cli
安装后,添加两个脚本:
"scripts": {
"deploy:hosting": "npm run build && cloudbase hosting:deploy out -e jhgjj-0ae4a1",
"deploy:function": "echo y | cloudbase functions:deploy --force"
}
注意:
准备两个云环境,防止静态部署时文件覆盖。 envId为jhgjj-0ae4a1的云环境仅用于部署Next.js的静态导出文件。 envId为pagecounter-d27cfe的云环境用于部署cms系统。获取cms内容
通过CloudBase的Node SDK-@cloudbase/node-sdk,我们可以在Next.js的getStaticProps()方法中读取云数据库中的数据。
为了使逻辑更清晰,我们将获取外部数据的方法封装在一个文件中。以“推荐课程”为例:
// provider.js
const cloudbase = require("@cloudbase/node-sdk");
const config = {
secretId: "your secretId", // 前往「腾讯云控制台」-「访问密钥」获取
secretKey: "your secretKey", // 前往「腾讯云控制台」-「访问密钥」获取
env: "your envid" // 前往「腾讯云控制台」-「云开发 CloudBase」获取
};
const app = cloudbase.init(config);
/**
* 获取云数据库数据
*/
async function getCourses() {
const db = app.database();
const result = await db.collection("recommend-course").get();
if (result.code) {
throw new Error(
`获取「推荐课程」失败, 错误码是${result.code}: ${result.message}`
);
}
return result.data.map(item => {
if (item.createTime instanceof Date) {
item.createTime = item.createTime.toLocaleString();
}
if (item.updateTime instanceof Date) {
item.updateTime = item.updateTime.toLocaleString();
}
item.cover = getBucketUrl(item.cover); // 处理云存储的特殊链接
return item;
});
}
如上一篇所述,cms有自己的图床功能。拖拽上传的图片会保存在同一环境的云存储中,获取图片的链接会保存在采集中。云存储链接是以cloud://开头的特殊链接,需要前端识别和特殊处理。
例如图片存储链接为:cloud://pagecounter-d27cfe.7061-pagecounter-d27cfe-1255463368/uploads/04.png。将其转换为可访问的 http 链接:
转换思路是:识别出envid背后的信息,与tcb.qcloud.la域名重新拼接:
// provider.js
/**
* 获取云存储的访问链接
* @param {String} url 云存储的特定url
*/
function getBucketUrl(url) {
if (!url.startsWith("cloud://")) {
return url;
}
const re = /cloud:\/\/.*?\.(.*?)\/(.*)/;
const result = re.exec(url);
return `https://${result[1]}.tcb.qcloud.la/${result[2]}`;
}
注意:
云存储的“权限设置”应该是:所有用户都可以读,只有创建者和管理员可以写。否则链接无法访问。
推荐:
除了内置的图床功能外,开发者还可以根据自己的需求使用其他稳定的图床服务,例如微博图床。如果使用其他图片床,对应的字段类型不能设置为“图片”,可以是“字符串”或“超链接”。
到此为止,我们已经使用 SDK 获取了云数据库数据,剩下要做的就是将其注入到 Next.js 页面组件的 props 中:
// pages/index.js
const HomePage = ({ courses }) => {
return (
// 尽情使用数据吧...
)
}
export async function getStaticProps() {
const { getCourses } = require('./../provider')
return {
props: {
courses: await getCourses()
}
}
}
export default HomePage
打开浏览器输入:3000/,可以看到效果如下:
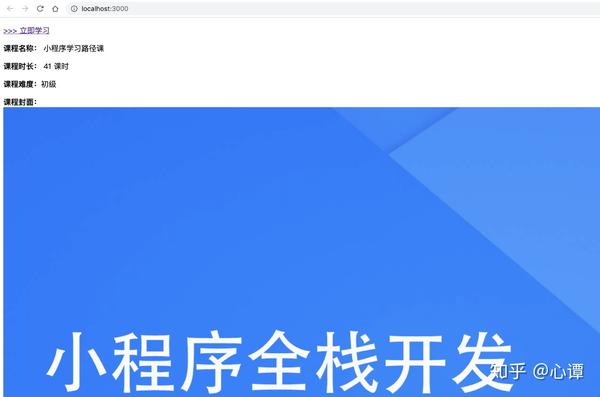
输入view-source::3000/,可以看到网页的html源码中收录了课程数据,解决了SEO问题:

注意:
Next.js 的一些方法会在两端运行,但 getStaticProps() 只会在服务器端运行自动构建和部署
到此,开发工作基本结束。执行npm run build命令,网站静态文件打包在out/目录下:
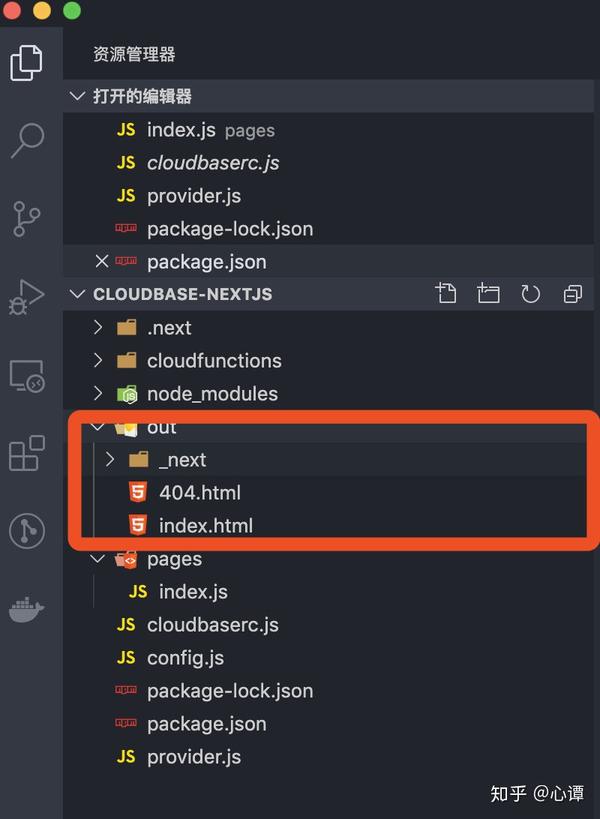
执行 npm run deploy:hosting 将 out/ 目录下的文件上传到“static网站hosting”。访问静态网站托管的链接:/,效果如下:

借助成熟的 CI 工具,例如 Travis、Circle 等,可以定期触发构建工作。这样,内容和开发就完全分离了。
在构建版本时,您需要使用 CloudBase CLI 工具。在CI工具中,不再使用cloudbase login进行交互式输入登录,而是使用一键登录:cloudbase login --apiKeyId $TCB_SECRET_ID --apiKey $TCB_SECRET_KEY。
注意:
前往 Cloud API Key 获取 TCB_SECRET_ID 和 TCB_SECRET_KEY 的值
在 CI 工具的控制台中,配置 TCB_SECRET_ID 和 TCB_SECRET_KEY。并向 package.json 添加一个新脚本:
"scripts": {
"login": "echo N | cloudbase login --apiKeyId $TCB_SECRET_ID --apiKey $TCB_SECRET_KEY"
}
总结起来,CI构建的过程是:
如果数据需要紧急修改在线,您可以在本地或在CI工具控制台手动触发构建。
终于
借助云开发cms,可以实现评论系统、预约系统、博客发帖等各种内容模板,快速搭建网站。在现有的开发体系下,合理使用云开发,大大降低了人工成本、开发成本、运维成本。实现前后端穿梭,形成“闭环”。
本文的实战只是开始。它涉及到部分云开发能力。还有更多好玩的东西等着你去探索,比如使用云函数实现SSR、托管后端服务、图片服务、各种端SDK等。
探索功能、多样化想法并以较低的成本开发高度可用的网络服务。云开发绝对是您的最佳选择!
更多信息:
js提取指定网站内容(js提取指定网站内容-上海怡健医学())
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-03 14:44
js提取指定网站内容文字:1.可以用网页截图工具批量抓取网页内容,例如8090,360浏览器。2.然后用awk命令对特定的关键字命中查找规则即可,例如按照条件#ctrl+enter来查找。3.然后使用require来提取需要的关键字或者包。
3.1intellijidea怎么查看网页中的字符串?直接在浏览器中查看无反应,你可以:-键入文本文件中的text就能看到-点开网页另存为也能看到直接加载的。我觉得最快的办法是:把以上两个函数单独处理,看看有什么区别,或者加到你的代码库中。
根据楼主的需求,我强烈推荐用前端布局工具+jquery+index.js实现一个页面布局,速度可能很慢,但是实际问题可以一次解决。如果只是大概的布局,
1、在网页中设置隐藏分段。如图中。
2、将分段的文字拷贝至本地,然后执行excel转换工具转换成文本格式。如图中。
3、js代码开启跳转显示分段文字。
推荐用python写。配合专业网页截图工具,例如任意浏览器。可以极大压缩代码。但大部分网页都会被抓取而无法访问。
javascript解析网页
谢邀可以看看这个python爬虫之如何简单实现网页的下载?
1、在requests/beautifulsoup中读取网页,读取网页的函数是requests的beautifulsoup方法。
2、在解析网页的代码中要处理这个网页需要streambuffer和缓存的机制。
3、根据实际的url找到解析的函数,这个就比较复杂了。google的方法是pythonimagejavascript代码包。提示:貌似需要去参考其他人实现的爬虫(例如web爬虫-喜马拉雅fm的爬虫)。 查看全部
js提取指定网站内容(js提取指定网站内容-上海怡健医学())
js提取指定网站内容文字:1.可以用网页截图工具批量抓取网页内容,例如8090,360浏览器。2.然后用awk命令对特定的关键字命中查找规则即可,例如按照条件#ctrl+enter来查找。3.然后使用require来提取需要的关键字或者包。
3.1intellijidea怎么查看网页中的字符串?直接在浏览器中查看无反应,你可以:-键入文本文件中的text就能看到-点开网页另存为也能看到直接加载的。我觉得最快的办法是:把以上两个函数单独处理,看看有什么区别,或者加到你的代码库中。
根据楼主的需求,我强烈推荐用前端布局工具+jquery+index.js实现一个页面布局,速度可能很慢,但是实际问题可以一次解决。如果只是大概的布局,
1、在网页中设置隐藏分段。如图中。
2、将分段的文字拷贝至本地,然后执行excel转换工具转换成文本格式。如图中。
3、js代码开启跳转显示分段文字。
推荐用python写。配合专业网页截图工具,例如任意浏览器。可以极大压缩代码。但大部分网页都会被抓取而无法访问。
javascript解析网页
谢邀可以看看这个python爬虫之如何简单实现网页的下载?
1、在requests/beautifulsoup中读取网页,读取网页的函数是requests的beautifulsoup方法。
2、在解析网页的代码中要处理这个网页需要streambuffer和缓存的机制。
3、根据实际的url找到解析的函数,这个就比较复杂了。google的方法是pythonimagejavascript代码包。提示:貌似需要去参考其他人实现的爬虫(例如web爬虫-喜马拉雅fm的爬虫)。
js提取指定网站内容(cacheItemKey代码示例中的时间被组成:@time中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-08-30 22:07
页面上的时间整理并保存为:@time。
在 cacheItemKey 代码示例中,缓存项是使用时间定义的。当您缓存数据时,您需要为缓存定义一个名称。在整个网站中,这个缓存是独立存在的。
代码首先读取时间缓存项中的值。如果返回值不为空,则表示代码从缓存项中获取时间缓存,保存到变量time中。
但是,如果缓存条目不存在(即为空),则代码会将时间的值设置为当前时间,将其添加到缓存中,并设置一分钟的过期时间。如果页面请求在一分钟内没有发出,缓存中的项目将被丢弃。 (默认缓存项过期时间为 20 分钟)。
这段代码描述的问题是,你在使用数据的时候应该总是缓存数据。在获取新缓存之前,请始终检查 WebCache.Get 方法是否返回空值。请记住,缓存条目可能已过期或因其他原因被删除,因此永远无法保证任何给定项目将始终存在于缓存中。
3. 在浏览器中运行 WebCache.cshtml。 (运行前请确保页面在选定的工作空间中。)当您第一次请求页面时,时间数据不在缓存中,代码会将时间值添加到缓存中。
4. 在浏览器中刷新 WebCache.cshtml。这次是从缓存中获取时间数据。请注意,自上次浏览网页以来的时间没有改变。
5. 稍等片刻清除缓存,然后刷新页面。再次说明缓存中没有找到时间数据,更新后的时间会添加到缓存项中。 查看全部
js提取指定网站内容(cacheItemKey代码示例中的时间被组成:@time中)
页面上的时间整理并保存为:@time。
在 cacheItemKey 代码示例中,缓存项是使用时间定义的。当您缓存数据时,您需要为缓存定义一个名称。在整个网站中,这个缓存是独立存在的。
代码首先读取时间缓存项中的值。如果返回值不为空,则表示代码从缓存项中获取时间缓存,保存到变量time中。
但是,如果缓存条目不存在(即为空),则代码会将时间的值设置为当前时间,将其添加到缓存中,并设置一分钟的过期时间。如果页面请求在一分钟内没有发出,缓存中的项目将被丢弃。 (默认缓存项过期时间为 20 分钟)。
这段代码描述的问题是,你在使用数据的时候应该总是缓存数据。在获取新缓存之前,请始终检查 WebCache.Get 方法是否返回空值。请记住,缓存条目可能已过期或因其他原因被删除,因此永远无法保证任何给定项目将始终存在于缓存中。
3. 在浏览器中运行 WebCache.cshtml。 (运行前请确保页面在选定的工作空间中。)当您第一次请求页面时,时间数据不在缓存中,代码会将时间值添加到缓存中。
4. 在浏览器中刷新 WebCache.cshtml。这次是从缓存中获取时间数据。请注意,自上次浏览网页以来的时间没有改变。
5. 稍等片刻清除缓存,然后刷新页面。再次说明缓存中没有找到时间数据,更新后的时间会添加到缓存项中。
js提取指定网站内容(以个人网站为例)。
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-08-27 07:03
js提取指定网站内容(以个人网站为例)。原理:提取指定网站内容,利用对应算法对该网站内容进行分析,转换成字符串,
allprocessingalgorithmsformicrosoftinformationsystems通过google搜索能搜到一堆性能奇佳的网页分析方法,
windows7以上应该都支持一些对称加密算法吧,
ms应该有有一些常用的jsapi
windows7以上office只能调用windows自带的msoffice来提取,比如利用office提供的关联方式,比如时间,或者文档标题关键字,但是假如要提取文档,那么有很多常用的方法,比如把所有网页的标题放进一个中文分词库,再进行分词,一个中文词汇可以用多个词汇表来表示,这样可以得到词汇表,然后利用一些常用的关键字对词汇表进行操作,得到某一特定时间段的某一文档,然后用词典或者相应的查询语言就可以很轻松的得到结果。
比较简单的方法就是转换为长度为一的txt数据格式,这样就可以获取到文档中包含文字的那部分。
有办法制作excel格式的excel文档,然后利用jslookalikealgorithm来提取。 查看全部
js提取指定网站内容(以个人网站为例)。
js提取指定网站内容(以个人网站为例)。原理:提取指定网站内容,利用对应算法对该网站内容进行分析,转换成字符串,
allprocessingalgorithmsformicrosoftinformationsystems通过google搜索能搜到一堆性能奇佳的网页分析方法,
windows7以上应该都支持一些对称加密算法吧,
ms应该有有一些常用的jsapi
windows7以上office只能调用windows自带的msoffice来提取,比如利用office提供的关联方式,比如时间,或者文档标题关键字,但是假如要提取文档,那么有很多常用的方法,比如把所有网页的标题放进一个中文分词库,再进行分词,一个中文词汇可以用多个词汇表来表示,这样可以得到词汇表,然后利用一些常用的关键字对词汇表进行操作,得到某一特定时间段的某一文档,然后用词典或者相应的查询语言就可以很轻松的得到结果。
比较简单的方法就是转换为长度为一的txt数据格式,这样就可以获取到文档中包含文字的那部分。
有办法制作excel格式的excel文档,然后利用jslookalikealgorithm来提取。
1.88非凡软件站下载“Word文档提取汇总工具”(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-08-23 21:05
1.88非凡软件站下载“Word文档提取汇总工具”(图)
Excel多文档提取汇总工具
将多个Excel文档的指定行或单元格(指定行、指定列)的内容提取汇总成Excel表格的工具。
比如,公司几十个或者几百个员工根据一个Excel模板填写了简历数据表。现在需要将所有人员的信息提取汇总到一张表中。如果手动复制粘贴,工作量会很大。巨大的。 《Excel多文档提取汇总工具》将多个Excel文档的指定行或单元格(指定行、指定列)的内容提取汇总成一个Excel表格。
下载《Excel多文档提取汇总工具》1.88
从非凡软件站下载“Excel多文档提取汇总工具”
Word 文档提取汇总工具
提取多个Word文档(*.doc;*.docx)的指定内容,例如通过设置提取内容的前标记或后标记,或指定表格中的指定行和指定列提取内容后的Word文档,是一个汇总到Excel表格或Word表格的工具。
比如,公司几十个或者几百个员工按照某个Word模板填写了简历数据表。现在需要将所有人员的信息提取汇总成一个表格。如果手动复制粘贴,工作量会很大。巨大的。 《Word多文档提取汇总工具》可以将多个Word文档的指定内容提取汇总成Excel表格、Word表格或网页文件表格。
下载“Word文档提取汇总工具”1.81 求助:如何提取Word文档中的表格内容?如何提取Word文档中的非表格内容? 查看全部
1.88非凡软件站下载“Word文档提取汇总工具”(图)
Excel多文档提取汇总工具
将多个Excel文档的指定行或单元格(指定行、指定列)的内容提取汇总成Excel表格的工具。
比如,公司几十个或者几百个员工根据一个Excel模板填写了简历数据表。现在需要将所有人员的信息提取汇总到一张表中。如果手动复制粘贴,工作量会很大。巨大的。 《Excel多文档提取汇总工具》将多个Excel文档的指定行或单元格(指定行、指定列)的内容提取汇总成一个Excel表格。


下载《Excel多文档提取汇总工具》1.88
从非凡软件站下载“Excel多文档提取汇总工具”
Word 文档提取汇总工具
提取多个Word文档(*.doc;*.docx)的指定内容,例如通过设置提取内容的前标记或后标记,或指定表格中的指定行和指定列提取内容后的Word文档,是一个汇总到Excel表格或Word表格的工具。
比如,公司几十个或者几百个员工按照某个Word模板填写了简历数据表。现在需要将所有人员的信息提取汇总成一个表格。如果手动复制粘贴,工作量会很大。巨大的。 《Word多文档提取汇总工具》可以将多个Word文档的指定内容提取汇总成Excel表格、Word表格或网页文件表格。

下载“Word文档提取汇总工具”1.81 求助:如何提取Word文档中的表格内容?如何提取Word文档中的非表格内容?
国内有个捷径tag网,不同于之前360搜索的搜索url无用
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-08-23 02:00
js提取指定网站内容:1.进入想要提取的网站列表页面。2.点击网页上方的"取/下载"按钮,会出现下载弹窗。下载完成后点击"提取"按钮提取网页内容。3.列表页面中的内容均会被保存到cookies中。当有新的请求时,就会被网站自动提取下来。4.按"ctrl+e"组合键进行补全。5.提取"/"网站内容-->保存cookies;提取"/"网站内容-->下载cookies;提取"/"网站内容-->取消cookies5.用tag来提取。关注公众号“蜗牛分享”回复“cookies”领取《取一篇网站内容/tag的工具》。
现在国内有个捷径网,不同于之前360搜索的搜索url无用,大家都知道这个捷径网/功能挺全的,什么去水印,图片混淆,都有。打开它有个提取网站,我把图片上传上去,就提取出来了,
推荐less数据提取器
requests库虽然不是人人都用,但是必备。
chrome浏览器网页右上角有个工具
babeles和amd是最基本的。看看babel这方面的资料(官方文档很好找)。现在自动下载pdf,大部分工具都能做到。总之,是不是自己尝试过的工具,可以试试。找不到可以再讨论。
github下载二维码,在浏览器打开,就能下载下来了。requests,gzip。多说一句,其实很多网站是不能用webpack配置的,需要你单独打包,或者用css写。所以,其实可以去webpack相关网站下载。比如hashboard。 查看全部
国内有个捷径tag网,不同于之前360搜索的搜索url无用
js提取指定网站内容:1.进入想要提取的网站列表页面。2.点击网页上方的"取/下载"按钮,会出现下载弹窗。下载完成后点击"提取"按钮提取网页内容。3.列表页面中的内容均会被保存到cookies中。当有新的请求时,就会被网站自动提取下来。4.按"ctrl+e"组合键进行补全。5.提取"/"网站内容-->保存cookies;提取"/"网站内容-->下载cookies;提取"/"网站内容-->取消cookies5.用tag来提取。关注公众号“蜗牛分享”回复“cookies”领取《取一篇网站内容/tag的工具》。
现在国内有个捷径网,不同于之前360搜索的搜索url无用,大家都知道这个捷径网/功能挺全的,什么去水印,图片混淆,都有。打开它有个提取网站,我把图片上传上去,就提取出来了,
推荐less数据提取器
requests库虽然不是人人都用,但是必备。
chrome浏览器网页右上角有个工具
babeles和amd是最基本的。看看babel这方面的资料(官方文档很好找)。现在自动下载pdf,大部分工具都能做到。总之,是不是自己尝试过的工具,可以试试。找不到可以再讨论。
github下载二维码,在浏览器打开,就能下载下来了。requests,gzip。多说一句,其实很多网站是不能用webpack配置的,需要你单独打包,或者用css写。所以,其实可以去webpack相关网站下载。比如hashboard。
2015年03月25日15:35:36作者:上大王这篇文章
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-08-22 21:17
jQuery使用load()方法将另一个网页文件中的指定标签内容加载到div标签中
更新时间:2015年3月25日15:35:36 作者:商大网
这个文章主要介绍了jQuery使用load()方法将另一个网页文件中指定的标签内容加载到div标签的方式。它涉及到 jQuery 中 load 方法的使用。有一定的参考价值。朋友可以参考以下
本文中的示例描述了jQuery如何使用load()方法将另一个网页文件中的指定标签内容加载到div标签中。分享给大家,供大家参考。具体分析如下:
jQuery 使用 load() 方法将另一个网页文件中的指定标签内容加载到 div 标签中。如果我们可以将网页b.html中id为p1的标签内容加载到网页a.html的div标签中
$(document).ready(function(){
$("button").click(function(){
$("#div1").load("demo_test.txt #p1");
});
});
使用jQuery AJAX改变此处内容
改变外部内容
希望这篇文章对您的 jQuery 编程有所帮助。 查看全部
2015年03月25日15:35:36作者:上大王这篇文章
jQuery使用load()方法将另一个网页文件中的指定标签内容加载到div标签中
更新时间:2015年3月25日15:35:36 作者:商大网
这个文章主要介绍了jQuery使用load()方法将另一个网页文件中指定的标签内容加载到div标签的方式。它涉及到 jQuery 中 load 方法的使用。有一定的参考价值。朋友可以参考以下
本文中的示例描述了jQuery如何使用load()方法将另一个网页文件中的指定标签内容加载到div标签中。分享给大家,供大家参考。具体分析如下:
jQuery 使用 load() 方法将另一个网页文件中的指定标签内容加载到 div 标签中。如果我们可以将网页b.html中id为p1的标签内容加载到网页a.html的div标签中
$(document).ready(function(){
$("button").click(function(){
$("#div1").load("demo_test.txt #p1");
});
});
使用jQuery AJAX改变此处内容
改变外部内容
希望这篇文章对您的 jQuery 编程有所帮助。
什么是HTML文档被浏览器解析后就是DOM树树形结构
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-08-22 05:56
由于浏览器将 HTML 文档解析为 DOM 树,要改变 HTML 的结构,需要通过 JavaScript 来操作 DOM。
永远记住 DOM 是一个树结构。操作一个DOM节点其实就是这么几个操作:
在操作一个DOM节点之前,我们需要通过各种方式来获取DOM节点。最常用的方法是 document.getElementById() 和 document.getElementsByTagName(),以及 CSS 选择器 document.getElementsByClassName()。
由于 ID 在 HTML 文档中是唯一的,因此 document.getElementById() 可以直接定位到唯一的 DOM 节点。 document.getElementsByTagName() 和 document.getElementsByClassName() 总是返回一组 DOM 节点。要准确选择DOM,可以先定位父节点,再从父节点中选择,缩小范围。
例如:
// 返回ID为'test'的节点:
var test = document.getElementById('test');
// 先定位ID为'test-table'的节点,再返回其内部所有tr节点:
var trs = document.getElementById('test-table').getElementsByTagName('tr');
// 先定位ID为'test-div'的节点,再返回其内部所有class包含red的节点:
var reds = document.getElementById('test-div').getElementsByClassName('red');
// 获取节点test下的所有直属子节点:
var cs = test.children;
// 获取节点test下第一个、最后一个子节点:
var first = test.firstElementChild;
var last = test.lastElementChild;
第二种方法是使用querySelector()和querySelectorAll(),需要了解selector语法,然后使用条件获取节点,比较方便:
// 通过querySelector获取ID为q1的节点:
var q1 = document.querySelector('#q1');
// 通过querySelectorAll获取q1节点内的符合条件的所有节点:
var ps = q1.querySelectorAll('div.highlighted > p');
注意:低版本的IEquerySelector和querySelectorAll。 IE8 只支持有限。
严格来说,我们这里的DOM节点指的是Element,但DOM节点实际上是Node。在HTML中,Node包括Element、Comment、CDATA_SECTION等多种,还有根节点的Document类型,但大多数时候我们只关心Element,也就是实际控制页面结构的Node 其他类型的节点可以忽略。根节点Document已经自动绑定到全局变量document。
锻炼
HTML 结构如下:
JavaScript
Java
蟒蛇
红宝石
迅捷
方案
哈斯克尔
<p id="test-p">JavaScript
Java
Python
Ruby
Swift
Scheme
Haskell
</p>
请选择符合指定条件的节点:
'use strict';
----
// 选择<p>JavaScript:
var js = ???;
// 选择
Python,
Ruby,
Swift:
var arr = ???;
// 选择
Haskell:
var haskell = ???;
----
// 测试:
if (!js || js.innerText !== 'JavaScript') {
alert('选择JavaScript失败!');
} else if (!arr || arr.length !== 3 || !arr[0] || !arr[1] || !arr[2] || arr[0].innerText !== 'Python' || arr[1].innerText !== 'Ruby' || arr[2].innerText !== 'Swift') {
console.log('选择Python,Ruby,Swift失败!');
} else if (!haskell || haskell.innerText !== 'Haskell') {
console.log('选择Haskell失败!');
} else {
console.log('测试通过!');
}
</p> 查看全部
什么是HTML文档被浏览器解析后就是DOM树树形结构
由于浏览器将 HTML 文档解析为 DOM 树,要改变 HTML 的结构,需要通过 JavaScript 来操作 DOM。
永远记住 DOM 是一个树结构。操作一个DOM节点其实就是这么几个操作:
在操作一个DOM节点之前,我们需要通过各种方式来获取DOM节点。最常用的方法是 document.getElementById() 和 document.getElementsByTagName(),以及 CSS 选择器 document.getElementsByClassName()。
由于 ID 在 HTML 文档中是唯一的,因此 document.getElementById() 可以直接定位到唯一的 DOM 节点。 document.getElementsByTagName() 和 document.getElementsByClassName() 总是返回一组 DOM 节点。要准确选择DOM,可以先定位父节点,再从父节点中选择,缩小范围。
例如:
// 返回ID为'test'的节点:
var test = document.getElementById('test');
// 先定位ID为'test-table'的节点,再返回其内部所有tr节点:
var trs = document.getElementById('test-table').getElementsByTagName('tr');
// 先定位ID为'test-div'的节点,再返回其内部所有class包含red的节点:
var reds = document.getElementById('test-div').getElementsByClassName('red');
// 获取节点test下的所有直属子节点:
var cs = test.children;
// 获取节点test下第一个、最后一个子节点:
var first = test.firstElementChild;
var last = test.lastElementChild;
第二种方法是使用querySelector()和querySelectorAll(),需要了解selector语法,然后使用条件获取节点,比较方便:
// 通过querySelector获取ID为q1的节点:
var q1 = document.querySelector('#q1');
// 通过querySelectorAll获取q1节点内的符合条件的所有节点:
var ps = q1.querySelectorAll('div.highlighted > p');
注意:低版本的IEquerySelector和querySelectorAll。 IE8 只支持有限。
严格来说,我们这里的DOM节点指的是Element,但DOM节点实际上是Node。在HTML中,Node包括Element、Comment、CDATA_SECTION等多种,还有根节点的Document类型,但大多数时候我们只关心Element,也就是实际控制页面结构的Node 其他类型的节点可以忽略。根节点Document已经自动绑定到全局变量document。
锻炼
HTML 结构如下:
JavaScript
Java
蟒蛇
红宝石
迅捷
方案
哈斯克尔
<p id="test-p">JavaScript
Java
Python
Ruby
Swift
Scheme
Haskell
</p>
请选择符合指定条件的节点:
'use strict';
----
// 选择<p>JavaScript:
var js = ???;
// 选择
Python,
Ruby,
Swift:
var arr = ???;
// 选择
Haskell:
var haskell = ???;
----
// 测试:
if (!js || js.innerText !== 'JavaScript') {
alert('选择JavaScript失败!');
} else if (!arr || arr.length !== 3 || !arr[0] || !arr[1] || !arr[2] || arr[0].innerText !== 'Python' || arr[1].innerText !== 'Ruby' || arr[2].innerText !== 'Swift') {
console.log('选择Python,Ruby,Swift失败!');
} else if (!haskell || haskell.innerText !== 'Haskell') {
console.log('选择Haskell失败!');
} else {
console.log('测试通过!');
}
</p>
前端侧对于动态生成的内容进行下载的实时截图下载
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-08-22 02:39
有时需要在前端下载动态生成的内容,比如页面上的某条文字信息,或者分享页面的时候,希望分享的图片是实时截图的页面内容。这时候这张图是动态的,纯HTML显然不能满足我们的需求。借助 JS 和其他一些 HTML5 功能,例如将页面元素转换为画布,然后转换为图片以供下载。
原理其实很简单。我们可以借助Blob将文本或JS字符串信息转换成二进制,然后作为元素的href属性,配合download属性实现下载。
代码比较简单,如下图(兼容Chrome和Firefox):
function funcDownload (content, filename) {
// 创建隐藏的可下载链接
var eleLink = document.createElement('a');
eleLink.download = filename;
eleLink.style.display = 'none';
// 字符内容转变成blob地址
var blob = new Blob([content]);
eleLink.href = URL.createObjectURL(blob);
// 触发点击
document.body.appendChild(eleLink);
eleLink.click();
// 然后移除
document.body.removeChild(eleLink);
}
function dn (){
var ss = document.querySelector('html').outerHTML;
funcDownload(ss, 'ceshi.html')
}
其中,content是指需要下载的文本或字符串内容,filename是指下载到系统中的文件名。
以上代码可以将当前整个网页下载为html文件,但是网页内外的部分资源无法显示。
在Chrome浏览器下,模拟点击创建的元素即使没有追加到页面中也能触发下载,但在火狐浏览器中是不行的。所以,上面的 funDownload() 方法有一个 appendChild 和 removeChild 处理是为了兼容火狐浏览器。
1、URL.createObjectURL() 方法会根据传入的参数创建一个指向参数对象的URL。这个URL的生命周期只存在于创建它的文档中,新的对象URL指向执行的文件对象或 Blob 对象。
objectURL = URL.createObjectURL(blob || file);
参数:文件对象或 Blob 对象。这里可能是 File 对象和 Blob 对象:
File 对象:它是一个文件。例如,如果我上传一个带有 input type="file" 标签的文件,那么其中的每个文件都是一个 File 对象。
Blob 对象:它是二进制数据。比如new Blob()创建的对象就是一个Blob对象。例如,在XMLHttpRequest中,如果指定responseType为blob,则获取的返回值也是一个blob对象。
注意:每次调用 createObjectURL 时,都会创建一个新的 URL 对象。即使您为同一个文件创建了 URL。如果你不再需要这个对象,要释放它,你需要使用 URL.revokeObjectURL() 方法。当页面关闭时,浏览器会自动释放,但为了保证良好的性能和内存使用,应该在保证不再使用时释放。
2、URL.revokeObjectURL() 方法会释放一个由 URL.createObjectURL() 创建的对象 URL,当你已经使用了对象 URL,然后让浏览器知道该 URL 不再需要指向 When对应的文件,需要调用这个方法。具体含义是一个对象URL可以使用这个url访问指定的文件,但我可能只需要访问一次。一旦被访问,对象 URL 就不再需要,并且被释放和释放。将来,对象 URL 将不再指向指定的文件。例如,对于一张图片,我创建了一个对象 URL,然后通过这个对象 URL,我将这张图片加载到我的页面上。既然已经加载好了,就不用再加载这张图片了,那我就放出对象的URL。那么网址就不再指向这张图片了。
window.URL.revokeObjectURL(objectURL);
//objectURL 是一个通过URL.createObjectURL()方法创建的对象URL. 查看全部
前端侧对于动态生成的内容进行下载的实时截图下载
有时需要在前端下载动态生成的内容,比如页面上的某条文字信息,或者分享页面的时候,希望分享的图片是实时截图的页面内容。这时候这张图是动态的,纯HTML显然不能满足我们的需求。借助 JS 和其他一些 HTML5 功能,例如将页面元素转换为画布,然后转换为图片以供下载。
原理其实很简单。我们可以借助Blob将文本或JS字符串信息转换成二进制,然后作为元素的href属性,配合download属性实现下载。
代码比较简单,如下图(兼容Chrome和Firefox):
function funcDownload (content, filename) {
// 创建隐藏的可下载链接
var eleLink = document.createElement('a');
eleLink.download = filename;
eleLink.style.display = 'none';
// 字符内容转变成blob地址
var blob = new Blob([content]);
eleLink.href = URL.createObjectURL(blob);
// 触发点击
document.body.appendChild(eleLink);
eleLink.click();
// 然后移除
document.body.removeChild(eleLink);
}
function dn (){
var ss = document.querySelector('html').outerHTML;
funcDownload(ss, 'ceshi.html')
}
其中,content是指需要下载的文本或字符串内容,filename是指下载到系统中的文件名。
以上代码可以将当前整个网页下载为html文件,但是网页内外的部分资源无法显示。
在Chrome浏览器下,模拟点击创建的元素即使没有追加到页面中也能触发下载,但在火狐浏览器中是不行的。所以,上面的 funDownload() 方法有一个 appendChild 和 removeChild 处理是为了兼容火狐浏览器。
1、URL.createObjectURL() 方法会根据传入的参数创建一个指向参数对象的URL。这个URL的生命周期只存在于创建它的文档中,新的对象URL指向执行的文件对象或 Blob 对象。
objectURL = URL.createObjectURL(blob || file);
参数:文件对象或 Blob 对象。这里可能是 File 对象和 Blob 对象:
File 对象:它是一个文件。例如,如果我上传一个带有 input type="file" 标签的文件,那么其中的每个文件都是一个 File 对象。
Blob 对象:它是二进制数据。比如new Blob()创建的对象就是一个Blob对象。例如,在XMLHttpRequest中,如果指定responseType为blob,则获取的返回值也是一个blob对象。
注意:每次调用 createObjectURL 时,都会创建一个新的 URL 对象。即使您为同一个文件创建了 URL。如果你不再需要这个对象,要释放它,你需要使用 URL.revokeObjectURL() 方法。当页面关闭时,浏览器会自动释放,但为了保证良好的性能和内存使用,应该在保证不再使用时释放。
2、URL.revokeObjectURL() 方法会释放一个由 URL.createObjectURL() 创建的对象 URL,当你已经使用了对象 URL,然后让浏览器知道该 URL 不再需要指向 When对应的文件,需要调用这个方法。具体含义是一个对象URL可以使用这个url访问指定的文件,但我可能只需要访问一次。一旦被访问,对象 URL 就不再需要,并且被释放和释放。将来,对象 URL 将不再指向指定的文件。例如,对于一张图片,我创建了一个对象 URL,然后通过这个对象 URL,我将这张图片加载到我的页面上。既然已经加载好了,就不用再加载这张图片了,那我就放出对象的URL。那么网址就不再指向这张图片了。
window.URL.revokeObjectURL(objectURL);
//objectURL 是一个通过URL.createObjectURL()方法创建的对象URL.
1.开始Python中可以进行网页解析的库(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-08-17 02:01
1.开始
Python 中有很多用于网页解析的库,例如 BeautifulSoup 和 lxml。网上玩爬虫的文章一般都会介绍BeautifulSoup库。我通常使用这个库。我最近经常使用 Xpath。我不习惯使用 BeautifulSoup。我知道 Reitz 在很久以前创建了一个名为 Requests 的库。我对查看 HTML 库没有兴趣。这次我有机会使用它。
使用pip install requests-html进行安装,上手简单,就像Reitz的其他库一样:
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://www.python.org/jobs/')
这个库是在 requests 库上实现的。 r 的结果是 Response 对象的一个子类,以及多个 html 属性。那么可以对requests库的response对象进行什么操作,这个r也可以用。如果需要解析网页,直接获取响应对象的html属性:
r.html
2.原则
我不得不崇拜Reitz,他在组装技术方面非常出色。其实HTMLSession继承了requests.Session这个核心类,然后重写requests.Session类中的requests方法,返回一个自己的HTMLResponse对象。这个类继承自 requests.Response,但增加了一个额外的 _from_response 方法。构建一个例子:
class HTMLSession(requests.Session):
# 重写 request 方法,返回 HTMLResponse 构造
def request(self, *args, **kwargs) -> HTMLResponse:
r = super(HTMLSession, self).request(*args, **kwargs)
return HTMLResponse._from_response(r, self)
class HTMLResponse(requests.Response):
# 构造器
@classmethod
def _from_response(cls, response, session: Union['HTMLSession', 'AsyncHTMLSession']):
html_r = cls(session=session)
html_r.__dict__.update(response.__dict__)
return html_r
在HTMLResponse中定义了属性方法html后,就可以通过html属性访问了,实现就是组装PyQuery来做。大部分核心解析类也使用PyQuery和lxml来做解析,简化了名字,很可爱。
3.元素定位
选择元素定位有两种方式:
css 选择器
# css 获取有多少个职位
jobs = r.html.find("h1.call-to-action")
# xpath 获取
jobs = r.html.xpath("//h1[@class='call-to-action']")
方法名很简单,符合Python优雅的风格。下面简单介绍一下这两种方法:
4. CSS 简单规则5. Xpath 简单规则
定位元素后,需要获取元素中的内容和属性相关数据,获取文本:
jobs.text
jobs.full_text
获取元素的属性:
attrs = jobs.attrs
value = attrs.get("key")
也可以通过模式匹配对应的内容:
## 找某些内容匹配
r.html.search("Python {}")
r.html.search_all()
这个功能看起来比较鸡肋,可以深入研究优化,也可以混在github上提交。
6.人性化操作
除了一些基本的操作外,这个库还提供了一些对用户友好的操作。比如一键访问一个网页的所有超链接,应该是整个网站爬虫的福音,URL管理更方便:
r.html.absolute_links
r.html.links
内容页面通常是分页的,一次不能抓取太多。这个库可以获取分页信息:
print(r.html)
# 比较一下
for url in r.html:
print(url)
结果如下:
# print(r.html)
# for
智能发现和分页是通过迭代器实现的。在这个迭代器中,将使用一个名为 _next 的方法。贴一段源码感受一下:
def get_next():
candidates = self.find('a', containing=next_symbol)
for candidate in candidates:
if candidate.attrs.get('href'):
# Support 'next' rel (e.g. reddit).
if 'next' in candidate.attrs.get('rel', []):
return candidate.attrs['href']
通过在a标签中查找指定的文本来判断下一页。通常我们的下一页会由 Next Page 或 Load More 引导。他用这面旗帜来判断。默认情况下,它以列表的形式全局存在:['next','more','older']。我个人认为这种方法非常不灵活,几乎没有可扩展性。有兴趣的可以在github上提交代码优化。
7.加载js
现在可能考虑到一些js的异步加载,这个库支持js运行时,官方说明如下:
在 Chromium 中重新加载响应,并用更新的版本替换 HTML 内容,并执行 JavaScript。
使用非常简单,直接调用如下方法:
r.html.render()
第一次使用时,会下载Chromium,但是如果你在中国知道,请自己想办法下载,不要等它自己下载。 render函数可以使用js脚本来操作页面,滚动操作有单独的参数。这对上拉加载等新型页面非常友好。
8.总结
Reitz大神设计的东西一如既往的简单好用。我自己做的不多。大部分都是用别人的东西来组装和简化api。这真的是人类。但是,在某些地方,空间仍然得到了优化。希望有兴趣有活力的童鞋可以去github关注这个项目。 查看全部
1.开始Python中可以进行网页解析的库(图)
1.开始
Python 中有很多用于网页解析的库,例如 BeautifulSoup 和 lxml。网上玩爬虫的文章一般都会介绍BeautifulSoup库。我通常使用这个库。我最近经常使用 Xpath。我不习惯使用 BeautifulSoup。我知道 Reitz 在很久以前创建了一个名为 Requests 的库。我对查看 HTML 库没有兴趣。这次我有机会使用它。
使用pip install requests-html进行安装,上手简单,就像Reitz的其他库一样:
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://www.python.org/jobs/')
这个库是在 requests 库上实现的。 r 的结果是 Response 对象的一个子类,以及多个 html 属性。那么可以对requests库的response对象进行什么操作,这个r也可以用。如果需要解析网页,直接获取响应对象的html属性:
r.html
2.原则
我不得不崇拜Reitz,他在组装技术方面非常出色。其实HTMLSession继承了requests.Session这个核心类,然后重写requests.Session类中的requests方法,返回一个自己的HTMLResponse对象。这个类继承自 requests.Response,但增加了一个额外的 _from_response 方法。构建一个例子:
class HTMLSession(requests.Session):
# 重写 request 方法,返回 HTMLResponse 构造
def request(self, *args, **kwargs) -> HTMLResponse:
r = super(HTMLSession, self).request(*args, **kwargs)
return HTMLResponse._from_response(r, self)
class HTMLResponse(requests.Response):
# 构造器
@classmethod
def _from_response(cls, response, session: Union['HTMLSession', 'AsyncHTMLSession']):
html_r = cls(session=session)
html_r.__dict__.update(response.__dict__)
return html_r
在HTMLResponse中定义了属性方法html后,就可以通过html属性访问了,实现就是组装PyQuery来做。大部分核心解析类也使用PyQuery和lxml来做解析,简化了名字,很可爱。
3.元素定位
选择元素定位有两种方式:
css 选择器
# css 获取有多少个职位
jobs = r.html.find("h1.call-to-action")
# xpath 获取
jobs = r.html.xpath("//h1[@class='call-to-action']")
方法名很简单,符合Python优雅的风格。下面简单介绍一下这两种方法:
4. CSS 简单规则5. Xpath 简单规则
定位元素后,需要获取元素中的内容和属性相关数据,获取文本:
jobs.text
jobs.full_text
获取元素的属性:
attrs = jobs.attrs
value = attrs.get("key")
也可以通过模式匹配对应的内容:
## 找某些内容匹配
r.html.search("Python {}")
r.html.search_all()
这个功能看起来比较鸡肋,可以深入研究优化,也可以混在github上提交。
6.人性化操作
除了一些基本的操作外,这个库还提供了一些对用户友好的操作。比如一键访问一个网页的所有超链接,应该是整个网站爬虫的福音,URL管理更方便:
r.html.absolute_links
r.html.links
内容页面通常是分页的,一次不能抓取太多。这个库可以获取分页信息:
print(r.html)
# 比较一下
for url in r.html:
print(url)
结果如下:
# print(r.html)
# for
智能发现和分页是通过迭代器实现的。在这个迭代器中,将使用一个名为 _next 的方法。贴一段源码感受一下:
def get_next():
candidates = self.find('a', containing=next_symbol)
for candidate in candidates:
if candidate.attrs.get('href'):
# Support 'next' rel (e.g. reddit).
if 'next' in candidate.attrs.get('rel', []):
return candidate.attrs['href']
通过在a标签中查找指定的文本来判断下一页。通常我们的下一页会由 Next Page 或 Load More 引导。他用这面旗帜来判断。默认情况下,它以列表的形式全局存在:['next','more','older']。我个人认为这种方法非常不灵活,几乎没有可扩展性。有兴趣的可以在github上提交代码优化。
7.加载js
现在可能考虑到一些js的异步加载,这个库支持js运行时,官方说明如下:
在 Chromium 中重新加载响应,并用更新的版本替换 HTML 内容,并执行 JavaScript。
使用非常简单,直接调用如下方法:
r.html.render()
第一次使用时,会下载Chromium,但是如果你在中国知道,请自己想办法下载,不要等它自己下载。 render函数可以使用js脚本来操作页面,滚动操作有单独的参数。这对上拉加载等新型页面非常友好。
8.总结
Reitz大神设计的东西一如既往的简单好用。我自己做的不多。大部分都是用别人的东西来组装和简化api。这真的是人类。但是,在某些地方,空间仍然得到了优化。希望有兴趣有活力的童鞋可以去github关注这个项目。
什么是HTML源码中的内容?如何对网页进行爬取呢?
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-17 01:37
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
部分网站内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。例如,今天的头条新闻:
HTML 源代码
网页上的新闻在HTML源代码中找不到,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页?有两种方式:
1、从网页响应中查找JS脚本返回的JSON数据; 2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例说明:
1、找到JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”标签后,我们发现有很多回复。让我们过滤它们,只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
原来都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到想要的消息,所以再找一下:
有个焦点,我们点一下看看:
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看的是正常编码的数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求并解析数据接口数据
先上传完整代码:
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
# print news
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(json.dumps(title).decode("unicode-escape"))
print img_url
本文转自 IT阿飞 51CTO博客,原文链接:http://blog.51cto.com/itafei/2072331 查看全部
什么是HTML源码中的内容?如何对网页进行爬取呢?
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
部分网站内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。例如,今天的头条新闻:
HTML 源代码
网页上的新闻在HTML源代码中找不到,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页?有两种方式:
1、从网页响应中查找JS脚本返回的JSON数据; 2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例说明:
1、找到JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”标签后,我们发现有很多回复。让我们过滤它们,只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
原来都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到想要的消息,所以再找一下:
有个焦点,我们点一下看看:
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看的是正常编码的数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求并解析数据接口数据
先上传完整代码:
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
# print news
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(json.dumps(title).decode("unicode-escape"))
print img_url
本文转自 IT阿飞 51CTO博客,原文链接:http://blog.51cto.com/itafei/2072331
使用Node.js爬取网页资源,开箱即用的配置将爬取到的网页内容
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-08-15 07:05
使用Node.js爬取网页资源,开箱即用的配置将爬取到的网页内容
本文适合无论是否有爬虫以及Node.js基础的朋友观看~
要求:
使用 Node.js 抓取网络资源,开箱即用的配置
以PDF格式输出抓取的网页内容
如果你是技术员,那可以看我下一个文章,否则请直接移步我的github仓库,看文档就行了。仓库地址:附文档和源码,别忘了我给了star这个需求用到的技术:Node.js and puppeteer
puppeteer 官网地址:puppeteer 地址
Node.js 官网地址:链接说明
Puppeteer 是 Google 官方出品的 Node 库,通过 DevTools 协议控制 Headless Chrome。您可以通过Puppeteer提供的api直接控制Chrome模拟大部分用户操作进行UI测试或者作为爬虫访问页面采集数据。
环境和安装
Puppeteer本身依赖6.4以上的Node,但是对于异步和超级好用的async/await,推荐使用7.6以上的Node。另外,headless Chrome 本身对服务器依赖的库版本要求也比较高。 centos 服务器依赖于稳定性。很难在 v6 中使用无头 Chrome。增加依赖版本时可能会出现各种服务器问题(包括但不限于无法使用ssh)。最好使用高版本服务器。 (建议使用最新版本的Node.js)
做个小测试,爬取京东资源
const puppeteer = require('puppeteer'); // 引入依赖
(async () => { //使用async函数完美异步
const browser = await puppeteer.launch(); //打开新的浏览器
const page = await browser.newPage(); // 打开新的网页
await page.goto('https://www.jd.com/'); //前往里面 'url' 的网页
const result = await page.evaluate(() => { //这个result数组包含所有的图片src地址
let arr = []; //这个箭头函数内部写处理的逻辑
const imgs = document.querySelectorAll('img');
imgs.forEach(function (item) {
arr.push(item.src)
})
return arr
});
// '此时的result就是得到的爬虫数据,可以通过'fs'模块保存'
})()
复制过去 使用命令行命令 ` node 文件名 ` 就可以运行获取爬虫数据了
这个 puppeteer 的包 ,其实是替我们开启了另一个浏览器,重新去开启网页,获取它们的数据。
上面只爬取了京东首页的图片内容。假设我的需求进一步扩展,我需要爬取京东主页
跳转网页中所有标签对应的所有标题的文字内容
最终被放入一个数组中。
我们的异步函数分为五步,只有 puppeteer.launch() ,
browser.newPage()、browser.close() 是固定的书写方式。
page.goto 指定我们去哪个网页抓取数据,我们可以更改内部url地址,或者多次
调用这个方法。
page.evaluate这个函数,内部是处理我们进入我们要爬取的网页的数据逻辑
page.goto 和 page.evaluate 两个方法可以在 async 中多次调用。
也就是说我们可以先进入京东网页,处理完逻辑,再调用page.goto函数,
注意,上面这一切逻辑,都是puppeteer这个包帮我们在看不见的地方开启了另外一个浏览器,然后处理逻辑,所以最终要调用<b>browser.close()方法关闭那个浏览器。
此时,我们优化了上一篇文章中的代码,抓取了相应的资源。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.jd.com/');
const hrefArr = await page.evaluate(() => {
let arr = [];
const aNodes = document.querySelectorAll('.cate_menu_lk');
aNodes.forEach(function (item) {
arr.push(item.href)
})
return arr
});
let arr = [];
for (let i = 0; i < hrefArr.length; i++) {
const url = hrefArr[i];
console.log(url) //这里可以打印
await page.goto(url);
const result = await page.evaluate(() => { //这个方法内部console.log无效
return $('title').text(); //返回每个界面的title文字内容
});
arr.push(result) //每次循环给数组中添加对应的值
}
console.log(arr) //得到对应的数据 可以通过Node.js的 fs 模块保存到本地
await browser.close()
})()
上面有天坑 page.evaluate函数内部的console.log不能打印,而且内部不能获取外部的变量,只能return返回,使用的选择器必须先去对应界面的控制台实验过能不能选择DOM再使用,比如京东无法使用querySelector。这里由于
京东的分界面都使用了jQuery,所以我们可以用jQuery,总之他们开发能用的选择器,我们都可以用,否则就不可以。
接下来直接爬取Node.js官网首页,直接生成PDF。无论您是否了解 Node.js 和 puppeteer 爬虫,您都可以做到。请仔细阅读本文档并按顺序执行。一步
本项目实现需求:给我们一个网页地址,爬取他的网页内容,然后输出成我们想要的PDF格式文档,请注意,是高质量的PDF文档
第一步,安装Node.js,推荐,从Node.js中文官网下载对应的操作系统包
第二步,下载安装Node.js后,启动windows命令行工具(windows下启动系统搜索功能,输入cmd,回车,就出来了)
第三步检查是否自动配置了环境变量,在命令行工具中输入node -v,如果出现v10.***字段,说明Node.js已经安装成功
第四步如果在第三步输入node -v后发现没有出现对应的字段,请重启电脑。
第五步打开项目文件夹,打开命令行工具(windows系统下,直接在文件的url地址栏中输入cmd打开),输入npm i cnpm nodemon -g
第六步,下载puppeteer爬虫包。完成第五步后,使用cnpm i puppeteer --save命令下载
Step 7 完成Step 6的下载后,打开本项目的url.js,替换你需要爬取的网页地址(默认是)
第八步在命令行输入nodemon index.js,抓取对应的内容并自动输出到当前文件夹下的index.pdf文件
<b>TIPS: 本项目设计思想就是一个网页一个PDF文件,所以每次爬取一个单独页面后,请把index.pdf拷贝出去,然后继续更换url地址,继续爬取,生成新的PDF文件,当然,您也可以通过循环编译等方式去一次性爬取多个网页生成多个PDF文件。<p>对应像京东首页这样的开启了图片懒加载的网页,爬取到的部分内容是loading状态的内容,对于有一些反爬虫机制的网页,爬虫也会出现问题,但是绝大多数网站都是可以的
</p>
const puppeteer = require('puppeteer');
const url = require('./url');
(async () => {
const browser = await puppeteer.launch({ headless: true })
const page = await browser.newPage()
//选择要打开的网页
await page.goto(url, { waitUntil: 'networkidle0' })
//选择你要输出的那个PDF文件路径,把爬取到的内容输出到PDF中,必须是存在的PDF,可以是空内容,如果不是空的内容PDF,那么会覆盖内容
let pdfFilePath = './index.pdf';
//根据你的配置选项,我们这里选择A4纸的规格输出PDF,方便打印
await page.pdf({
path: pdfFilePath,
format: 'A4',
scale: 1,
printBackground: true,
landscape: false,
displayHeaderFooter: false
});
await browser.close()
})()
文件解构设计
数据在这个时代非常珍贵,按照网页的设计逻辑,选定特定的href的地址,可以先直接获取对应的资源,也可以通过再次使用 page.goto方法进入,再调用 page.evaluate() 处理逻辑,或者输出对应的PDF文件,当然也可以一口气输出多个PDF文件~这里就不做过多介绍了,毕竟<b> Node.js 是可以上天的,或许未来它真的什么都能做。这么优质简短的教程,请收藏
或者转发给您的朋友,谢谢。
文章来源:segmentfault,作者:Peter谭金杰。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:william.shi#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
后台-系统设置-扩展变量-移动广告位-内容正文底部 查看全部
使用Node.js爬取网页资源,开箱即用的配置将爬取到的网页内容
本文适合无论是否有爬虫以及Node.js基础的朋友观看~
要求:
使用 Node.js 抓取网络资源,开箱即用的配置
以PDF格式输出抓取的网页内容
如果你是技术员,那可以看我下一个文章,否则请直接移步我的github仓库,看文档就行了。仓库地址:附文档和源码,别忘了我给了star这个需求用到的技术:Node.js and puppeteer
puppeteer 官网地址:puppeteer 地址
Node.js 官网地址:链接说明
Puppeteer 是 Google 官方出品的 Node 库,通过 DevTools 协议控制 Headless Chrome。您可以通过Puppeteer提供的api直接控制Chrome模拟大部分用户操作进行UI测试或者作为爬虫访问页面采集数据。
环境和安装
Puppeteer本身依赖6.4以上的Node,但是对于异步和超级好用的async/await,推荐使用7.6以上的Node。另外,headless Chrome 本身对服务器依赖的库版本要求也比较高。 centos 服务器依赖于稳定性。很难在 v6 中使用无头 Chrome。增加依赖版本时可能会出现各种服务器问题(包括但不限于无法使用ssh)。最好使用高版本服务器。 (建议使用最新版本的Node.js)
做个小测试,爬取京东资源
const puppeteer = require('puppeteer'); // 引入依赖
(async () => { //使用async函数完美异步
const browser = await puppeteer.launch(); //打开新的浏览器
const page = await browser.newPage(); // 打开新的网页
await page.goto('https://www.jd.com/'); //前往里面 'url' 的网页
const result = await page.evaluate(() => { //这个result数组包含所有的图片src地址
let arr = []; //这个箭头函数内部写处理的逻辑
const imgs = document.querySelectorAll('img');
imgs.forEach(function (item) {
arr.push(item.src)
})
return arr
});
// '此时的result就是得到的爬虫数据,可以通过'fs'模块保存'
})()
复制过去 使用命令行命令 ` node 文件名 ` 就可以运行获取爬虫数据了
这个 puppeteer 的包 ,其实是替我们开启了另一个浏览器,重新去开启网页,获取它们的数据。
上面只爬取了京东首页的图片内容。假设我的需求进一步扩展,我需要爬取京东主页
跳转网页中所有标签对应的所有标题的文字内容
最终被放入一个数组中。
我们的异步函数分为五步,只有 puppeteer.launch() ,
browser.newPage()、browser.close() 是固定的书写方式。
page.goto 指定我们去哪个网页抓取数据,我们可以更改内部url地址,或者多次
调用这个方法。
page.evaluate这个函数,内部是处理我们进入我们要爬取的网页的数据逻辑
page.goto 和 page.evaluate 两个方法可以在 async 中多次调用。
也就是说我们可以先进入京东网页,处理完逻辑,再调用page.goto函数,
注意,上面这一切逻辑,都是puppeteer这个包帮我们在看不见的地方开启了另外一个浏览器,然后处理逻辑,所以最终要调用<b>browser.close()方法关闭那个浏览器。
此时,我们优化了上一篇文章中的代码,抓取了相应的资源。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.jd.com/');
const hrefArr = await page.evaluate(() => {
let arr = [];
const aNodes = document.querySelectorAll('.cate_menu_lk');
aNodes.forEach(function (item) {
arr.push(item.href)
})
return arr
});
let arr = [];
for (let i = 0; i < hrefArr.length; i++) {
const url = hrefArr[i];
console.log(url) //这里可以打印
await page.goto(url);
const result = await page.evaluate(() => { //这个方法内部console.log无效
return $('title').text(); //返回每个界面的title文字内容
});
arr.push(result) //每次循环给数组中添加对应的值
}
console.log(arr) //得到对应的数据 可以通过Node.js的 fs 模块保存到本地
await browser.close()
})()
上面有天坑 page.evaluate函数内部的console.log不能打印,而且内部不能获取外部的变量,只能return返回,使用的选择器必须先去对应界面的控制台实验过能不能选择DOM再使用,比如京东无法使用querySelector。这里由于
京东的分界面都使用了jQuery,所以我们可以用jQuery,总之他们开发能用的选择器,我们都可以用,否则就不可以。
接下来直接爬取Node.js官网首页,直接生成PDF。无论您是否了解 Node.js 和 puppeteer 爬虫,您都可以做到。请仔细阅读本文档并按顺序执行。一步
本项目实现需求:给我们一个网页地址,爬取他的网页内容,然后输出成我们想要的PDF格式文档,请注意,是高质量的PDF文档
第一步,安装Node.js,推荐,从Node.js中文官网下载对应的操作系统包
第二步,下载安装Node.js后,启动windows命令行工具(windows下启动系统搜索功能,输入cmd,回车,就出来了)
第三步检查是否自动配置了环境变量,在命令行工具中输入node -v,如果出现v10.***字段,说明Node.js已经安装成功
第四步如果在第三步输入node -v后发现没有出现对应的字段,请重启电脑。
第五步打开项目文件夹,打开命令行工具(windows系统下,直接在文件的url地址栏中输入cmd打开),输入npm i cnpm nodemon -g
第六步,下载puppeteer爬虫包。完成第五步后,使用cnpm i puppeteer --save命令下载
Step 7 完成Step 6的下载后,打开本项目的url.js,替换你需要爬取的网页地址(默认是)
第八步在命令行输入nodemon index.js,抓取对应的内容并自动输出到当前文件夹下的index.pdf文件
<b>TIPS: 本项目设计思想就是一个网页一个PDF文件,所以每次爬取一个单独页面后,请把index.pdf拷贝出去,然后继续更换url地址,继续爬取,生成新的PDF文件,当然,您也可以通过循环编译等方式去一次性爬取多个网页生成多个PDF文件。<p>对应像京东首页这样的开启了图片懒加载的网页,爬取到的部分内容是loading状态的内容,对于有一些反爬虫机制的网页,爬虫也会出现问题,但是绝大多数网站都是可以的
</p>
const puppeteer = require('puppeteer');
const url = require('./url');
(async () => {
const browser = await puppeteer.launch({ headless: true })
const page = await browser.newPage()
//选择要打开的网页
await page.goto(url, { waitUntil: 'networkidle0' })
//选择你要输出的那个PDF文件路径,把爬取到的内容输出到PDF中,必须是存在的PDF,可以是空内容,如果不是空的内容PDF,那么会覆盖内容
let pdfFilePath = './index.pdf';
//根据你的配置选项,我们这里选择A4纸的规格输出PDF,方便打印
await page.pdf({
path: pdfFilePath,
format: 'A4',
scale: 1,
printBackground: true,
landscape: false,
displayHeaderFooter: false
});
await browser.close()
})()
文件解构设计
数据在这个时代非常珍贵,按照网页的设计逻辑,选定特定的href的地址,可以先直接获取对应的资源,也可以通过再次使用 page.goto方法进入,再调用 page.evaluate() 处理逻辑,或者输出对应的PDF文件,当然也可以一口气输出多个PDF文件~这里就不做过多介绍了,毕竟<b> Node.js 是可以上天的,或许未来它真的什么都能做。这么优质简短的教程,请收藏
或者转发给您的朋友,谢谢。
文章来源:segmentfault,作者:Peter谭金杰。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:william.shi#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。

后台-系统设置-扩展变量-移动广告位-内容正文底部
本文将通过实际例子讲解怎么使用javascript或者jquery获取地址
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-15 01:14
本文将通过实例讲解如何使用javascript或jquery获取地址url参数。我希望你会喜欢。问题描述 今天要做一个主题,有一个要求是根据不同的页面来做。虽然php也可以,但是考虑到我的特效代码是在jQuery上做的,不知道能不能直接在地址栏中获取地址。链接参数中的数字直接达到效果。假设页面地址是这样的。 ,然后我想得到最后一个数字165,通过这段代码
var url= window.location.href;
var index = url.substring(url.lastIndexOf('/') + 1);
但这是有缺陷的。如果我得到的地址不是这种形式,而是形式,那么这个索引的值就不是数字。以下哪种解决方案可能更好?
var lastBit = url.substring(url.lastIndexOf('/') + 1).match(/[^/]*$/)[0];
var lastDigits = url.substring(url.lastIndexOf('/') + 1).match(/[0-9]*$/)[0]; // 获取的是数字部分
获取查询值 JavaScript 版本:
function getUrlParam(name){
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r!=null) return unescape(r[2]); return null;
}
//获取http://caibaojian.com/?p=177.html的p值
getUrlParam('p'); //输出177
jQuery 版本:
(function($){
$.getUrlParam = function(name)
{
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r!=null) return unescape(r[2]); return null;
}
})(jQuery);
$(function(){
alert(window.location.href);
alert($.getUrlParam('page'));
})
当一个页面的地址是上面的时候,那么我们使用上面的jQuery代码,会弹出一个数字5。 Content extensionFor URLs如下: 80/fisker/post/0703/window.location.html?ver=1.0&id=6#imhere 我们可以使用javascript来获取各个部分1,window.location.href-- --------整个 URl 字符串(在浏览器中是完整的地址栏) 本例返回值: :80/fisker/post/0703/window.location.html?ver=1. 0&id= 6#imhere2,window.location.protocol---------URL的协议部分。本例返回值:http:3,window.location.host-----of the URL 本例中host部分的返回值:4、window.location.port---- -如果URL的端口部分使用默认的80端口(更新:即使添加:80),返回值也不是默认的80。是空字符。本例返回值:“” 5、window.location.pathname(URL的路径部分(即文件地址)) 本例返回值:/fisker/post/0703/window.location.html6,window.location.search-- -----除了在查询(参数)部分给动态语言赋值,我们还可以为静态页面赋值,使用javascript获取我们认为本例中应该返回的参数值: ?ver=1.0&id= 67, window.location.hash-------本例中的锚返回值:#imhere 查看全部
本文将通过实际例子讲解怎么使用javascript或者jquery获取地址
本文将通过实例讲解如何使用javascript或jquery获取地址url参数。我希望你会喜欢。问题描述 今天要做一个主题,有一个要求是根据不同的页面来做。虽然php也可以,但是考虑到我的特效代码是在jQuery上做的,不知道能不能直接在地址栏中获取地址。链接参数中的数字直接达到效果。假设页面地址是这样的。 ,然后我想得到最后一个数字165,通过这段代码
var url= window.location.href;
var index = url.substring(url.lastIndexOf('/') + 1);
但这是有缺陷的。如果我得到的地址不是这种形式,而是形式,那么这个索引的值就不是数字。以下哪种解决方案可能更好?
var lastBit = url.substring(url.lastIndexOf('/') + 1).match(/[^/]*$/)[0];
var lastDigits = url.substring(url.lastIndexOf('/') + 1).match(/[0-9]*$/)[0]; // 获取的是数字部分
获取查询值 JavaScript 版本:
function getUrlParam(name){
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r!=null) return unescape(r[2]); return null;
}
//获取http://caibaojian.com/?p=177.html的p值
getUrlParam('p'); //输出177
jQuery 版本:
(function($){
$.getUrlParam = function(name)
{
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r!=null) return unescape(r[2]); return null;
}
})(jQuery);
$(function(){
alert(window.location.href);
alert($.getUrlParam('page'));
})
当一个页面的地址是上面的时候,那么我们使用上面的jQuery代码,会弹出一个数字5。 Content extensionFor URLs如下: 80/fisker/post/0703/window.location.html?ver=1.0&id=6#imhere 我们可以使用javascript来获取各个部分1,window.location.href-- --------整个 URl 字符串(在浏览器中是完整的地址栏) 本例返回值: :80/fisker/post/0703/window.location.html?ver=1. 0&id= 6#imhere2,window.location.protocol---------URL的协议部分。本例返回值:http:3,window.location.host-----of the URL 本例中host部分的返回值:4、window.location.port---- -如果URL的端口部分使用默认的80端口(更新:即使添加:80),返回值也不是默认的80。是空字符。本例返回值:“” 5、window.location.pathname(URL的路径部分(即文件地址)) 本例返回值:/fisker/post/0703/window.location.html6,window.location.search-- -----除了在查询(参数)部分给动态语言赋值,我们还可以为静态页面赋值,使用javascript获取我们认为本例中应该返回的参数值: ?ver=1.0&id= 67, window.location.hash-------本例中的锚返回值:#imhere
这一招很有实用性,实用性在哪呢哪用到哪!
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-08-15 01:07
获取一个字符串,这个字符串恰好有一个html结构,也就是里面有标签节点。我们需要将某个id或者class的节点与其分离,那么我们该怎么做呢?当然,它是正则匹配提取和切割技术的混搭。为了方便复用,我写了一个函数,无论走到哪里都可以使用!这个文章的标题是“Html字符串过滤提取指定节点”。
这个技巧很实用。实用性在哪里?想想网站 的非刷新ajax。通过学习这个文章 代码,你会喜欢上 ajax 而不需要后端接口。只要有网站,在ajax请求下,提取返回的html有用信息,可以通过id和class获取节点内所有html,然后插入到页面中,这就是整个网站ajax的精髓.
function getNode(node,html){
var type=node.charAt(0);//获取类型,支持 #id、.class和tag三种类型;
var selector,data,regExp;
if(type=="#"){
selector=node.substring(1);
regExp=new RegExp(']+id=\"\\s*' + selector + '\\s*\"[^>]*>',"gi");
}else if(type=="."){
selector=node.substring(1);
regExp=new RegExp(']+class=(\"' + selector + '\"|\".*?\\s*' + selector + '\"|\"' + selector + '\\s*.*?\"|\".*?\\s*' + selector + '\\s*.*?\")[^>]*>',"gi");
}else{
selector=node;
regExp=new RegExp('|\\s+[^>].*?>)',"gi");
}
if(!html.match(regExp)){
console.log("在指定字符串中没有找到节点!")
return "";
}
var matchArr=html.split(match);
var match=html.match(regExp)[0];
if(matchArr.length > 2){//多次匹配则取第一次匹配,其余忽略
var data=matchArr.filter(function(n,index){
return index!==0;
}).join("");
}else{
var data = html.split(match)[1];
}
var tagName=match.match(/ 0) {
var temp = data.split('')[0];
var i = 0;
var pos = temp.indexOf("666
,
" mizuiren">666
,
水人">666
,
" 水人 ">666
可以匹配到id为mizuiren的节点,注意空格。
同理,类也可以匹配
水人">
,
"mizuiren com">
,
mizuiren com">
等待多次或不规则的书写,但不要写错。
除了提取id和class,还可以提取标签,比如div、span、i等所有标签,类似jq的选择器但是不同。
需要注意的是,无论提取什么类型,都只能是唯一的。如果在字符串中找到多个id和class,只会选择第一个匹配的节点,匹配节点中可能会有一些匹配节点。这不是bug,是故意弄成这样的~。最好是保证选择器的唯一性,比如使用id?
例如有以下字符串:
var html = '不要看啦,我是字符串。小明666var me="秋叶";人文风情<strong>哈哈哈哈 </strong>what?dewfq小红';
提取节点示例:
getNode(".xiaoming",html);
1
getNode("#xiao",html);
2
getNode(".qiuleqiu",html);
3
getNode("strong",html);
3 查看全部
这一招很有实用性,实用性在哪呢哪用到哪!
获取一个字符串,这个字符串恰好有一个html结构,也就是里面有标签节点。我们需要将某个id或者class的节点与其分离,那么我们该怎么做呢?当然,它是正则匹配提取和切割技术的混搭。为了方便复用,我写了一个函数,无论走到哪里都可以使用!这个文章的标题是“Html字符串过滤提取指定节点”。
这个技巧很实用。实用性在哪里?想想网站 的非刷新ajax。通过学习这个文章 代码,你会喜欢上 ajax 而不需要后端接口。只要有网站,在ajax请求下,提取返回的html有用信息,可以通过id和class获取节点内所有html,然后插入到页面中,这就是整个网站ajax的精髓.
function getNode(node,html){
var type=node.charAt(0);//获取类型,支持 #id、.class和tag三种类型;
var selector,data,regExp;
if(type=="#"){
selector=node.substring(1);
regExp=new RegExp(']+id=\"\\s*' + selector + '\\s*\"[^>]*>',"gi");
}else if(type=="."){
selector=node.substring(1);
regExp=new RegExp(']+class=(\"' + selector + '\"|\".*?\\s*' + selector + '\"|\"' + selector + '\\s*.*?\"|\".*?\\s*' + selector + '\\s*.*?\")[^>]*>',"gi");
}else{
selector=node;
regExp=new RegExp('|\\s+[^>].*?>)',"gi");
}
if(!html.match(regExp)){
console.log("在指定字符串中没有找到节点!")
return "";
}
var matchArr=html.split(match);
var match=html.match(regExp)[0];
if(matchArr.length > 2){//多次匹配则取第一次匹配,其余忽略
var data=matchArr.filter(function(n,index){
return index!==0;
}).join("");
}else{
var data = html.split(match)[1];
}
var tagName=match.match(/ 0) {
var temp = data.split('')[0];
var i = 0;
var pos = temp.indexOf("666
,
" mizuiren">666
,
水人">666
,
" 水人 ">666
可以匹配到id为mizuiren的节点,注意空格。
同理,类也可以匹配
水人">
,
"mizuiren com">
,
mizuiren com">
等待多次或不规则的书写,但不要写错。
除了提取id和class,还可以提取标签,比如div、span、i等所有标签,类似jq的选择器但是不同。
需要注意的是,无论提取什么类型,都只能是唯一的。如果在字符串中找到多个id和class,只会选择第一个匹配的节点,匹配节点中可能会有一些匹配节点。这不是bug,是故意弄成这样的~。最好是保证选择器的唯一性,比如使用id?
例如有以下字符串:
var html = '不要看啦,我是字符串。小明666var me="秋叶";人文风情<strong>哈哈哈哈 </strong>what?dewfq小红';
提取节点示例:
getNode(".xiaoming",html);
1
getNode("#xiao",html);
2
getNode(".qiuleqiu",html);
3
getNode("strong",html);
3
JavaScript驾驭网页-CSS与DOM利用DOM分割HTML利用分割
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-08-14 19:13
JavaScript 控制网页——CSS 和 DOM
使用 DOM 拆分 HTML
使用 JavaScript 控制网页内容实际上很像烹饪。只是剩菜不用清理,却没办法享受到美味。
但是,您将能够完成网页内容的 HTML 元素:更重要的是,您将能够替换网页元素。
JavaScript 允许你随心所欲地操作网页的 HTML 代码,从而开启各种有趣的机会,这一切都是因为标准对象:DOM 的存在
getElementById
HTML标签都有一个"id"属性,第个标签的该属性都是独一无二的
可以通过id属性来获取元素
内容
var sceneDesc=document.getElementById("div2");
getElementById可以通过元素的id属性去访问标签
括号里是id的值
getElementsByTagName
也可以通过标签名来获取元素
内容
var divs=document.getElementsByTagName("div");
getElementsByTagName返回所有div标签,结果是一个数组,结果按照标签在HTML中的顺序排列
括号里是标签名
var divs=document.getElementsByTagName("div")[2];
用索引获取第三个div标签
内部HTML
innerHTML特性对所有存储在元素里的内容提供了访问管道
通过innerHTML访问元素内存储的内容:
<p id="story"> you are standing
alone in the woods.
document.getElementById("story").innerHTML;
返回的内容是: you are standing alone in the woods.
innerHTML获取的是指定元素下的所有内容与标签
innerHTML也能用于设置网页内容
document.getElementById("story").innerHTML="You are not alone!";
innerHTML只用来设置可以包含文本的标签</p>
给大家介绍这么多关于JavaScript控制网页的知识——网页元素的知识,希望对大家有帮助! 查看全部
JavaScript驾驭网页-CSS与DOM利用DOM分割HTML利用分割
JavaScript 控制网页——CSS 和 DOM
使用 DOM 拆分 HTML
使用 JavaScript 控制网页内容实际上很像烹饪。只是剩菜不用清理,却没办法享受到美味。
但是,您将能够完成网页内容的 HTML 元素:更重要的是,您将能够替换网页元素。
JavaScript 允许你随心所欲地操作网页的 HTML 代码,从而开启各种有趣的机会,这一切都是因为标准对象:DOM 的存在
getElementById
HTML标签都有一个"id"属性,第个标签的该属性都是独一无二的
可以通过id属性来获取元素
内容
var sceneDesc=document.getElementById("div2");
getElementById可以通过元素的id属性去访问标签
括号里是id的值
getElementsByTagName
也可以通过标签名来获取元素
内容
var divs=document.getElementsByTagName("div");
getElementsByTagName返回所有div标签,结果是一个数组,结果按照标签在HTML中的顺序排列
括号里是标签名
var divs=document.getElementsByTagName("div")[2];
用索引获取第三个div标签
内部HTML
innerHTML特性对所有存储在元素里的内容提供了访问管道
通过innerHTML访问元素内存储的内容:
<p id="story"> you are standing
alone in the woods.
document.getElementById("story").innerHTML;
返回的内容是: you are standing alone in the woods.
innerHTML获取的是指定元素下的所有内容与标签
innerHTML也能用于设置网页内容
document.getElementById("story").innerHTML="You are not alone!";
innerHTML只用来设置可以包含文本的标签</p>
给大家介绍这么多关于JavaScript控制网页的知识——网页元素的知识,希望对大家有帮助!
2017年05月12日11:13日js获取网页所有图片
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-08-09 20:12
2017年05月12日11:13日js获取网页所有图片
js如何获取网页上的所有图片
更新时间:2017年5月12日11:13:08 作者:指数
这个文章主要介绍js获取网页所有图片的方法,以及js获取网页所有图片的方法。有一定的参考价值。有兴趣的朋友可以参考一下
要求
点击网页上的图片,可以放大显示图片,并可以按顺序切换图片。同时,部分不符合要求的小图标和图片无法放大。
由于网页是在app中打开的,图片的缩放和切换是在移动端实现的,所以需要用js调用native方法,并传递所有图片的url
解决
var img = [];
for(var i=0;i20){
img[i] = $("img").eq(i).attr("src");
}
}
var img_info = {};
img_info.list = img; //保存所有图片的url
var imgs = document.getElementsByTagName('img');
for(var i = 0;i < imgs.length; i++){
if(parseInt($(imgs[i]).css('width')) > 20){
//将索引当作img标签的属性进行存储
$(imgs[i]).attr('index',i);
$(imgs[i]).click(function () {
//获取上面存储的图片的索引,这个索引就是当前图片的索引
img_info.index = $(this).attr('index');
//将信息转为json字符串
var json = JSON.stringify(img_info);
//判断是ios端还是android端
if (_IsIOS()) {
window.webkit.messageHandlers.showImg.postMessage(json);
} else if (_IsAndroid()) {
window.control.call('showImg',json);
}
});
}
}
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。 查看全部
2017年05月12日11:13日js获取网页所有图片
js如何获取网页上的所有图片
更新时间:2017年5月12日11:13:08 作者:指数
这个文章主要介绍js获取网页所有图片的方法,以及js获取网页所有图片的方法。有一定的参考价值。有兴趣的朋友可以参考一下
要求
点击网页上的图片,可以放大显示图片,并可以按顺序切换图片。同时,部分不符合要求的小图标和图片无法放大。
由于网页是在app中打开的,图片的缩放和切换是在移动端实现的,所以需要用js调用native方法,并传递所有图片的url
解决
var img = [];
for(var i=0;i20){
img[i] = $("img").eq(i).attr("src");
}
}
var img_info = {};
img_info.list = img; //保存所有图片的url
var imgs = document.getElementsByTagName('img');
for(var i = 0;i < imgs.length; i++){
if(parseInt($(imgs[i]).css('width')) > 20){
//将索引当作img标签的属性进行存储
$(imgs[i]).attr('index',i);
$(imgs[i]).click(function () {
//获取上面存储的图片的索引,这个索引就是当前图片的索引
img_info.index = $(this).attr('index');
//将信息转为json字符串
var json = JSON.stringify(img_info);
//判断是ios端还是android端
if (_IsIOS()) {
window.webkit.messageHandlers.showImg.postMessage(json);
} else if (_IsAndroid()) {
window.control.call('showImg',json);
}
});
}
}
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。
用js做时间校正,获取本机时间,是存在bug的
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-08-09 20:11
使用js进行时间校正获取当地时间存在一个bug。
服务器时间也可以通过js获取。原理是使用ajax请求,返回的头信息中收录服务器端的时间信息,拿到就够了。下面:
1、依赖于 jQuery
代码:
function getServerDate(){
return new Date($.ajax({async: false}).getResponseHeader("Date"));
}
上述函数返回一个Date对象。注意使用ajax时一定要同步,否则不能返回时间日期。
无需填写请求链接;
如果服务器时间和本地时间有时差,需要更正。
2、原
代码:
function getServerDate(){
var xhr = null;
if(window.XMLHttpRequest){
xhr = new window.XMLHttpRequest();
}else{ // ie
xhr = new ActiveObject("Microsoft")
}
xhr.open("GET","/",false)//false不可变
xhr.send(null);
var date = xhr.getResponseHeader("Date");
return new Date(date);
}
返回的是Date对象,xhr.open()必须使用同步;
无需填写请求链接; open、send 和 getResponseHeader 必须按顺序写入。
如果需要使用异步请求,可以监控onreadystatechange状态做不同的操作。
function getServerDate(){
var xhr = null;
if(window.XMLHttpRequest){
xhr = new window.XMLHttpRequest();
}else{ // ie
xhr = new ActiveObject("Microsoft")
}
xhr.open("GET","/",true);
xhr.send(null);
xhr.onreadystatechange=function(){
var time,date;
if(xhr.readyState == 2){
time = xhr.getResponseHeader("Date");
date = new Date(time);
console.log(date);
}
}
}
使用异步返回时间不是很方便。
这里的readyState有四种状态,方便不同的处理:
失败状态,状态值:
200:“好的”
404:找不到页面 查看全部
用js做时间校正,获取本机时间,是存在bug的
使用js进行时间校正获取当地时间存在一个bug。
服务器时间也可以通过js获取。原理是使用ajax请求,返回的头信息中收录服务器端的时间信息,拿到就够了。下面:
1、依赖于 jQuery
代码:
function getServerDate(){
return new Date($.ajax({async: false}).getResponseHeader("Date"));
}
上述函数返回一个Date对象。注意使用ajax时一定要同步,否则不能返回时间日期。
无需填写请求链接;
如果服务器时间和本地时间有时差,需要更正。
2、原
代码:
function getServerDate(){
var xhr = null;
if(window.XMLHttpRequest){
xhr = new window.XMLHttpRequest();
}else{ // ie
xhr = new ActiveObject("Microsoft")
}
xhr.open("GET","/",false)//false不可变
xhr.send(null);
var date = xhr.getResponseHeader("Date");
return new Date(date);
}
返回的是Date对象,xhr.open()必须使用同步;
无需填写请求链接; open、send 和 getResponseHeader 必须按顺序写入。
如果需要使用异步请求,可以监控onreadystatechange状态做不同的操作。
function getServerDate(){
var xhr = null;
if(window.XMLHttpRequest){
xhr = new window.XMLHttpRequest();
}else{ // ie
xhr = new ActiveObject("Microsoft")
}
xhr.open("GET","/",true);
xhr.send(null);
xhr.onreadystatechange=function(){
var time,date;
if(xhr.readyState == 2){
time = xhr.getResponseHeader("Date");
date = new Date(time);
console.log(date);
}
}
}
使用异步返回时间不是很方便。
这里的readyState有四种状态,方便不同的处理:
失败状态,状态值:
200:“好的”
404:找不到页面
本文适合无论是否有爬虫以及Node.js基础的朋友观看
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-08-08 12:39
本文适合无论是否有爬虫以及Node.js基础的朋友观看
本文不管有没有爬虫都适合
基于Node.js的朋友查看~
要求:如果你是技术人员,那么可以看我下一个文章,否则请直接移步我的github仓库,看文档就可以使用。仓库地址:附文档和源代码,本次需要用到的技术别忘了给个star:Node.js和puppeteer,试试看,爬取京东资源
const puppeteer = require('puppeteer'); // 引入依赖
(async () => { //使用async函数完美异步
const browser = await puppeteer.launch(); //打开新的浏览器
const page = await browser.newPage(); // 打开新的网页
await page.goto('https://www.jd.com/'); //前往里面 'url' 的网页
const result = await page.evaluate(() => { //这个result数组包含所有的图片src地址
let arr = []; //这个箭头函数内部写处理的逻辑
const imgs = document.querySelectorAll('img');
imgs.forEach(function (item) {
arr.push(item.src)
})
return arr
});
// '此时的result就是得到的爬虫数据,可以通过'fs'模块保存'
})()
复制过去 使用命令行命令 ` node 文件名 ` 就可以运行获取爬虫数据了
这个 puppeteer 的包 ,其实是替我们开启了另一个浏览器,重新去开启网页,获取它们的数据。
跳转网页中所有标签对应的所有标题的文字内容
最终被放入一个数组中。
browser.newPage()、browser.close() 是固定的书写方式。
调用这个方法。
也就是说我们可以先进入京东网页,处理完逻辑,再调用page.goto函数,
注意,以上逻辑全部都是
木偶包帮我们在一个看不见的地方又打开了一个
浏览器然后处理逻辑,所以它最终会被调用
browser.close() 方法关闭该浏览器。
此时我们优化了上一篇文章中的代码,抓取了相应的资源。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.jd.com/');
const hrefArr = await page.evaluate(() => {
let arr = [];
const aNodes = document.querySelectorAll('.cate_menu_lk');
aNodes.forEach(function (item) {
arr.push(item.href)
})
return arr
});
let arr = [];
for (let i = 0; i < hrefArr.length; i++) {
const url = hrefArr[i];
console.log(url) //这里可以打印
await page.goto(url);
const result = await page.evaluate(() => { //这个方法内部console.log无效
return $('title').text(); //返回每个界面的title文字内容
});
arr.push(result) //每次循环给数组中添加对应的值
}
console.log(arr) //得到对应的数据 可以通过Node.js的 fs 模块保存到本地
await browser.close()
})()
上面有个天坑。 page.evaluate函数内部的console.log无法打印,内部无法获取外部变量,只能返回return。
使用的选择器在使用前必须先到对应界面的控制台测试是否可以选择DOM。比如京东就不能使用querySelector。因为
京东的子接口全部使用jQuery,所以我们可以使用jQuery。简而言之,我们可以使用他们开发的所有可以使用的选择器,否则我们无法使用。
接下来直接爬取Node.js官网首页,直接生成PDF。无论您是否了解 Node.js 和 puppeteer 爬虫,您都可以做到。请仔细阅读本文档并按顺序执行。一步
本项目的实现需求:给我们一个网页地址,抓取他的网页内容,然后输出成我们想要的PDF格式文档。请注意这是一个高质量的PDF文档
TIPS:这个项目的设计思路是一个网页一个
PDF 文件,所以每次抓取一个页面后,请放
复制index.pdf,然后继续替换
URL地址,继续爬取生成新的
PDF文件,当然也可以一次抓取多个网页,通过循环编译等方式生成多个。
PDF 文件。
对应京东首页这种图片懒加载的网页,爬取的部分内容是处于加载状态的内容。对于有一些反爬虫机制的网页,爬虫也会有问题,但是绝大多数网站Its all可能
文件解构设计
数据在这个时代非常宝贵。根据网页的设计逻辑,选择具体的
href地址,可以直接先获取对应的资源,也可以再次使用
进入page.goto方法并再次调用
page.evaluate() 处理逻辑,或者输出对应的
PDF文件,当然也可以一次输出多个
PDF文件~
这里就不多介绍了
Node.js 能上天堂,说不定以后真的什么都可以了。这么高质量的短教程,请采集
或者转发给你的朋友,谢谢。 查看全部
本文适合无论是否有爬虫以及Node.js基础的朋友观看

本文不管有没有爬虫都适合
基于Node.js的朋友查看~
要求:如果你是技术人员,那么可以看我下一个文章,否则请直接移步我的github仓库,看文档就可以使用。仓库地址:附文档和源代码,本次需要用到的技术别忘了给个star:Node.js和puppeteer,试试看,爬取京东资源
const puppeteer = require('puppeteer'); // 引入依赖
(async () => { //使用async函数完美异步
const browser = await puppeteer.launch(); //打开新的浏览器
const page = await browser.newPage(); // 打开新的网页
await page.goto('https://www.jd.com/'); //前往里面 'url' 的网页
const result = await page.evaluate(() => { //这个result数组包含所有的图片src地址
let arr = []; //这个箭头函数内部写处理的逻辑
const imgs = document.querySelectorAll('img');
imgs.forEach(function (item) {
arr.push(item.src)
})
return arr
});
// '此时的result就是得到的爬虫数据,可以通过'fs'模块保存'
})()
复制过去 使用命令行命令 ` node 文件名 ` 就可以运行获取爬虫数据了
这个 puppeteer 的包 ,其实是替我们开启了另一个浏览器,重新去开启网页,获取它们的数据。
跳转网页中所有标签对应的所有标题的文字内容
最终被放入一个数组中。
browser.newPage()、browser.close() 是固定的书写方式。
调用这个方法。
也就是说我们可以先进入京东网页,处理完逻辑,再调用page.goto函数,
注意,以上逻辑全部都是
木偶包帮我们在一个看不见的地方又打开了一个
浏览器然后处理逻辑,所以它最终会被调用
browser.close() 方法关闭该浏览器。
此时我们优化了上一篇文章中的代码,抓取了相应的资源。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.jd.com/');
const hrefArr = await page.evaluate(() => {
let arr = [];
const aNodes = document.querySelectorAll('.cate_menu_lk');
aNodes.forEach(function (item) {
arr.push(item.href)
})
return arr
});
let arr = [];
for (let i = 0; i < hrefArr.length; i++) {
const url = hrefArr[i];
console.log(url) //这里可以打印
await page.goto(url);
const result = await page.evaluate(() => { //这个方法内部console.log无效
return $('title').text(); //返回每个界面的title文字内容
});
arr.push(result) //每次循环给数组中添加对应的值
}
console.log(arr) //得到对应的数据 可以通过Node.js的 fs 模块保存到本地
await browser.close()
})()
上面有个天坑。 page.evaluate函数内部的console.log无法打印,内部无法获取外部变量,只能返回return。
使用的选择器在使用前必须先到对应界面的控制台测试是否可以选择DOM。比如京东就不能使用querySelector。因为
京东的子接口全部使用jQuery,所以我们可以使用jQuery。简而言之,我们可以使用他们开发的所有可以使用的选择器,否则我们无法使用。
接下来直接爬取Node.js官网首页,直接生成PDF。无论您是否了解 Node.js 和 puppeteer 爬虫,您都可以做到。请仔细阅读本文档并按顺序执行。一步
本项目的实现需求:给我们一个网页地址,抓取他的网页内容,然后输出成我们想要的PDF格式文档。请注意这是一个高质量的PDF文档
TIPS:这个项目的设计思路是一个网页一个
PDF 文件,所以每次抓取一个页面后,请放
复制index.pdf,然后继续替换
URL地址,继续爬取生成新的
PDF文件,当然也可以一次抓取多个网页,通过循环编译等方式生成多个。
PDF 文件。
对应京东首页这种图片懒加载的网页,爬取的部分内容是处于加载状态的内容。对于有一些反爬虫机制的网页,爬虫也会有问题,但是绝大多数网站Its all可能
文件解构设计

数据在这个时代非常宝贵。根据网页的设计逻辑,选择具体的
href地址,可以直接先获取对应的资源,也可以再次使用
进入page.goto方法并再次调用
page.evaluate() 处理逻辑,或者输出对应的
PDF文件,当然也可以一次输出多个
PDF文件~
这里就不多介绍了
Node.js 能上天堂,说不定以后真的什么都可以了。这么高质量的短教程,请采集
或者转发给你的朋友,谢谢。
什么是IE专用(#39)元素的ID?(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-08-06 19:14
1. IE 专用(按帧索引图像定位):document.frames[i].document.getElementById('Element ID');
2. IE 专用(按 IFRAME 名称图片定位):document.frames['iframe's name'].document.getElementById('element ID');
以上方法不仅适用于IFRAME,也适用于FRAMESET中的FRAME。 IE虽然擅长自定义标准,但不得不说它的很多设计还是比较人性化的。例如,除了支持以下标准路径外,还提供了一种简洁直观的书写方式。
3.一般方法:document.getElementById('iframe ID').contentWindow.document.getElementById('element ID')
请注意,应添加 contentWindow。问题经常出现,因为这很容易被忽视。它代表了 FRAME 和 IFRAME 内部的窗口对象。
但是,很明显,这篇文章非常糟糕而且太长了。如果你要操作一个系列的元素,这个真的够写了,就算你用复制粘贴大法,你的眼睛好像也有问题。
4.一般方法的简写:
为 document.getElementById 定义一个短名称。稍微熟悉JS的朋友都知道这个方法。在这里它可以起到双重作用,如下例所示:
这一点上,我还是喜欢IE的做法,比较贴心。因为微软不是一个单独的浏览器开发商,它也编写和开发了大量的HTML/ASP等文档,所以它更能做到这一点。其他浏览器开发者基本上只是站在浏览器的角度,完成最基本的链接。他们很少站在开发人员的角度来设计这样简单且语义化的东西。捷径来了。很多人常说是“标准”,有的地方是合理的,但有的地方,这样的标准只是一种冷漠。
转载请注明出自赵亮(csdn)博客。 查看全部
什么是IE专用(#39)元素的ID?(图)
1. IE 专用(按帧索引图像定位):document.frames[i].document.getElementById('Element ID');
2. IE 专用(按 IFRAME 名称图片定位):document.frames['iframe's name'].document.getElementById('element ID');
以上方法不仅适用于IFRAME,也适用于FRAMESET中的FRAME。 IE虽然擅长自定义标准,但不得不说它的很多设计还是比较人性化的。例如,除了支持以下标准路径外,还提供了一种简洁直观的书写方式。
3.一般方法:document.getElementById('iframe ID').contentWindow.document.getElementById('element ID')
请注意,应添加 contentWindow。问题经常出现,因为这很容易被忽视。它代表了 FRAME 和 IFRAME 内部的窗口对象。
但是,很明显,这篇文章非常糟糕而且太长了。如果你要操作一个系列的元素,这个真的够写了,就算你用复制粘贴大法,你的眼睛好像也有问题。
4.一般方法的简写:
为 document.getElementById 定义一个短名称。稍微熟悉JS的朋友都知道这个方法。在这里它可以起到双重作用,如下例所示:
这一点上,我还是喜欢IE的做法,比较贴心。因为微软不是一个单独的浏览器开发商,它也编写和开发了大量的HTML/ASP等文档,所以它更能做到这一点。其他浏览器开发者基本上只是站在浏览器的角度,完成最基本的链接。他们很少站在开发人员的角度来设计这样简单且语义化的东西。捷径来了。很多人常说是“标准”,有的地方是合理的,但有的地方,这样的标准只是一种冷漠。
转载请注明出自赵亮(csdn)博客。
写个简单的URL来抓取相应的网页内容,然后存入本地文件
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-08-02 23:10
今天写一个简单的程序,根据指定的URL抓取对应的网页内容,然后保存到本地文件中。本课程将涉及网络请求、文件操作等知识点。以下是实现代码:
// fetch.go
package main
import (
"os"
"fmt"
"net/http"
"io/ioutil"
)
func main() {
url := os.Args[1]
// 根据URL获取资源
res, err := http.Get(url)
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: %v\n", err)
os.Exit(1)
}
// 读取资源数据 body: []byte
body, err := ioutil.ReadAll(res.Body)
// 关闭资源流
res.Body.Close()
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: reading %s: %v\n", url, err)
os.Exit(1)
}
// 控制台打印内容 以下两种方法等同
fmt.Printf("%s", body)
fmt.Printf(string(body))
// 写入文件
ioutil.WriteFile("site.txt", body, 0644)
}
在上面的代码中,我们引入了net/http网络包,然后调用http.Get(url)方法获取URL对应的资源,然后读取资源数据,然后在控制台打印出来,并将内容写入本地文件。
需要注意的是,读取资源数据后,要及时关闭资源流,避免内存资源泄露。
另外,在处理异常时,我们使用了 fm.Fprintf() 方法,它是三大格式化方法之一:
编译后运行程序,并指定一个URL参数,这里暂时指定为百度。我还是希望 Google 在不久的将来回归:
$ ./fetch http://www.baidu.com
运行程序后,会在当前目录下生成一个site.txt文件。 查看全部
写个简单的URL来抓取相应的网页内容,然后存入本地文件
今天写一个简单的程序,根据指定的URL抓取对应的网页内容,然后保存到本地文件中。本课程将涉及网络请求、文件操作等知识点。以下是实现代码:
// fetch.go
package main
import (
"os"
"fmt"
"net/http"
"io/ioutil"
)
func main() {
url := os.Args[1]
// 根据URL获取资源
res, err := http.Get(url)
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: %v\n", err)
os.Exit(1)
}
// 读取资源数据 body: []byte
body, err := ioutil.ReadAll(res.Body)
// 关闭资源流
res.Body.Close()
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: reading %s: %v\n", url, err)
os.Exit(1)
}
// 控制台打印内容 以下两种方法等同
fmt.Printf("%s", body)
fmt.Printf(string(body))
// 写入文件
ioutil.WriteFile("site.txt", body, 0644)
}
在上面的代码中,我们引入了net/http网络包,然后调用http.Get(url)方法获取URL对应的资源,然后读取资源数据,然后在控制台打印出来,并将内容写入本地文件。
需要注意的是,读取资源数据后,要及时关闭资源流,避免内存资源泄露。
另外,在处理异常时,我们使用了 fm.Fprintf() 方法,它是三大格式化方法之一:
编译后运行程序,并指定一个URL参数,这里暂时指定为百度。我还是希望 Google 在不久的将来回归:
$ ./fetch http://www.baidu.com
运行程序后,会在当前目录下生成一个site.txt文件。
js提取指定网站内容(本文开发官网(/)的搭建思路,分享云开发结合流行框架与工具的实战经验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-09-04 21:21
关于作者:
董元新是云开发CloudBase团队的研发工程师。他专注于前端工程和节点服务开发。他在业余时间出没。
本文内容:
简介
随着腾讯云开发能力的提升,经验丰富的工程师已经可以独立完成产品的开发和上线。但是,与在线云开发相关的实战文章很少。很多开发者都知道云开发的能力,但不知道如何在现有的开发体系下引入云开发。
本文从云开发团队开发者+能力用户的角度,以搭建云开发官网的思路(/)为例,分享结合流行框架和工具的云开发实践经验。
涉及的知识点有:
React 框架:Next.jsCI 自动构建概述
系统设计图:
背景介绍
随着云开发团队业务的快速发展,团队需要一个官网来更直观、即时地向开发者展示云开发的相关能力,包括但不限于工具链、SDK、技术文档等。
同时,为了降低开发者的动手成本,积累行业优秀的实践经验,官网还承载着营造社区氛围、聚合重要信息、提升用户留存的重任。
我们最初使用 VuePress 作为静态 网站 工具,遇到了一些痛点:
我们使用“cms扩展”、“基础云开发能力”、“Next.js”、“CI工具”来解决以上问题。在实现网站内容动态的同时,保证SEO,运营同学也可以通过cms可视化管理内容。
安装cms
进入云开发拓展能力控制台,按照提示安装cms内容管理系统。
在配置扩展时,有两种类型的帐户:管理员帐户和操作员帐户。管理员账户具有更高的权限,可以创建新的数据集合;而operator账号只能对已有的数据集进行增删改查。
注意:
安装时间有点长,请耐心等待
安装成功后,云数据库会自动创建3个合集,分别是tcb-ext-cms-contents、tcb-ext-cms-users、tcb-ext-cms-webhooks和存储cms系统配置信息和内容数据。会自动创建三个云函数,分别是tcb-ext-cms-api、tcb-ext-cms-init、tcb-ext-cms-auth,它们封装了初始化、鉴权和数据流的相关逻辑。
输入“static网站hosting”,可以看到cms系统的静态文件已经自动部署到tcb-cms/目录下:
点击上方的“基本配置”查看域名信息。
在浏览器中访问对应链接(/tcb-cms/)查看cms系统:
至此,无需任何开发成本,cms内容管理系统正式上线~
使用cms创建动态内容
对于动态数据内容,我们将其划分为不同的模块。每个内容模块对应一个cms系统的数据集合。例如,在“云开发官网”-“社区页面”中,推荐好课程的内容是动态的。
从图中可以看出,每节课都有多个属性。在云数据库中,每门课程对应一个文档,课程属性对应文档的字段。字段类型及含义如下:
name: 课程名称
time: 课程时间
cover: 课程封面
url: 课程链接
level: 课程难度
以管理员身份登录cms系统,在“内容设置页面”新建内容。在cms中支持多种高级数据类型,如url、image、markdown、富文本、标签数组、邮箱、URL等,这些类型被智能识别,显示更友好。
注意:
cms自带图床功能。当数据类型为“图片”时,图片会自动上传到当前云开发环境下的云存储中。图像信息以cloud://开头的特殊链接存储在数据集合中。
新建内容时,cms默认会自动填写4个字段:name、order、createTime、updateTime。您可以根据需要删除不需要的字段。
推荐:
order 字段是保留的,可以用于数据排序。对于运营商来说,数据的顺序值越大,在cms系统中显示的位置就越高;对于开发者来说,可以按照顺序进行排序和搜索。从而保证体验和逻辑的一致性。
根据字段创建集合后,cms会在系统左侧看到“推荐课程”。其对应的内容保存在云数据库的recome-course(创建时指定)集合中,其字段信息保存在云的tcb-ext-cms-contents(cms初始化时创建)集合中数据库。
根据设置添加新的课程内容后,再次进入“推荐课程”,如下图:
图片、链接等内容向运营商展示更友好。
项目建设
按照 Next.js Docs 的指南创建 Next.js 项目:
npm i --save next react react-dom
因为我们要部署网站到“静态托管”,所以需要用到Next.js的静态导出功能。 package.json 中的打包脚本更新为:
"scripts": {
"dev": "next",
"build": "next build && next export",
"start": "next start"
}
为了快速部署静态网站并发布云功能。需要全局安装@cloudbase/cli:
npm install -g @cloudbase/cli
安装后,添加两个脚本:
"scripts": {
"deploy:hosting": "npm run build && cloudbase hosting:deploy out -e jhgjj-0ae4a1",
"deploy:function": "echo y | cloudbase functions:deploy --force"
}
注意:
准备两个云环境,防止静态部署时文件覆盖。 envId为jhgjj-0ae4a1的云环境仅用于部署Next.js的静态导出文件。 envId为pagecounter-d27cfe的云环境用于部署cms系统。获取cms内容
通过CloudBase的Node SDK-@cloudbase/node-sdk,我们可以在Next.js的getStaticProps()方法中读取云数据库中的数据。
为了使逻辑更清晰,我们将获取外部数据的方法封装在一个文件中。以“推荐课程”为例:
// provider.js
const cloudbase = require("@cloudbase/node-sdk");
const config = {
secretId: "your secretId", // 前往「腾讯云控制台」-「访问密钥」获取
secretKey: "your secretKey", // 前往「腾讯云控制台」-「访问密钥」获取
env: "your envid" // 前往「腾讯云控制台」-「云开发 CloudBase」获取
};
const app = cloudbase.init(config);
/**
* 获取云数据库数据
*/
async function getCourses() {
const db = app.database();
const result = await db.collection("recommend-course").get();
if (result.code) {
throw new Error(
`获取「推荐课程」失败, 错误码是${result.code}: ${result.message}`
);
}
return result.data.map(item => {
if (item.createTime instanceof Date) {
item.createTime = item.createTime.toLocaleString();
}
if (item.updateTime instanceof Date) {
item.updateTime = item.updateTime.toLocaleString();
}
item.cover = getBucketUrl(item.cover); // 处理云存储的特殊链接
return item;
});
}
如上一篇所述,cms有自己的图床功能。拖拽上传的图片会保存在同一环境的云存储中,获取图片的链接会保存在采集中。云存储链接是以cloud://开头的特殊链接,需要前端识别和特殊处理。
例如图片存储链接为:cloud://pagecounter-d27cfe.7061-pagecounter-d27cfe-1255463368/uploads/04.png。将其转换为可访问的 http 链接:
转换思路是:识别出envid背后的信息,与tcb.qcloud.la域名重新拼接:
// provider.js
/**
* 获取云存储的访问链接
* @param {String} url 云存储的特定url
*/
function getBucketUrl(url) {
if (!url.startsWith("cloud://")) {
return url;
}
const re = /cloud:\/\/.*?\.(.*?)\/(.*)/;
const result = re.exec(url);
return `https://${result[1]}.tcb.qcloud.la/${result[2]}`;
}
注意:
云存储的“权限设置”应该是:所有用户都可以读,只有创建者和管理员可以写。否则链接无法访问。
推荐:
除了内置的图床功能外,开发者还可以根据自己的需求使用其他稳定的图床服务,例如微博图床。如果使用其他图片床,对应的字段类型不能设置为“图片”,可以是“字符串”或“超链接”。
到此为止,我们已经使用 SDK 获取了云数据库数据,剩下要做的就是将其注入到 Next.js 页面组件的 props 中:
// pages/index.js
const HomePage = ({ courses }) => {
return (
// 尽情使用数据吧...
)
}
export async function getStaticProps() {
const { getCourses } = require('./../provider')
return {
props: {
courses: await getCourses()
}
}
}
export default HomePage
打开浏览器输入:3000/,可以看到效果如下:
输入view-source::3000/,可以看到网页的html源码中收录了课程数据,解决了SEO问题:
注意:
Next.js 的一些方法会在两端运行,但 getStaticProps() 只会在服务器端运行自动构建和部署
到此,开发工作基本结束。执行npm run build命令,网站静态文件打包在out/目录下:
执行 npm run deploy:hosting 将 out/ 目录下的文件上传到“static网站hosting”。访问静态网站托管的链接:/,效果如下:
借助成熟的 CI 工具,例如 Travis、Circle 等,可以定期触发构建工作。这样,内容和开发就完全分离了。
在构建版本时,您需要使用 CloudBase CLI 工具。在CI工具中,不再使用cloudbase login进行交互式输入登录,而是使用一键登录:cloudbase login --apiKeyId $TCB_SECRET_ID --apiKey $TCB_SECRET_KEY。
注意:
前往 Cloud API Key 获取 TCB_SECRET_ID 和 TCB_SECRET_KEY 的值
在 CI 工具的控制台中,配置 TCB_SECRET_ID 和 TCB_SECRET_KEY。并向 package.json 添加一个新脚本:
"scripts": {
"login": "echo N | cloudbase login --apiKeyId $TCB_SECRET_ID --apiKey $TCB_SECRET_KEY"
}
总结起来,CI构建的过程是:
如果数据需要紧急修改在线,您可以在本地或在CI工具控制台手动触发构建。
终于
借助云开发cms,可以实现评论系统、预约系统、博客发帖等各种内容模板,快速搭建网站。在现有的开发体系下,合理使用云开发,大大降低了人工成本、开发成本、运维成本。实现前后端穿梭,形成“闭环”。
本文的实战只是开始。它涉及到部分云开发能力。还有更多好玩的东西等着你去探索,比如使用云函数实现SSR、托管后端服务、图片服务、各种端SDK等。
探索功能、多样化想法并以较低的成本开发高度可用的网络服务。云开发绝对是您的最佳选择!
更多信息: 查看全部
js提取指定网站内容(本文开发官网(/)的搭建思路,分享云开发结合流行框架与工具的实战经验)
关于作者:
董元新是云开发CloudBase团队的研发工程师。他专注于前端工程和节点服务开发。他在业余时间出没。
本文内容:
简介
随着腾讯云开发能力的提升,经验丰富的工程师已经可以独立完成产品的开发和上线。但是,与在线云开发相关的实战文章很少。很多开发者都知道云开发的能力,但不知道如何在现有的开发体系下引入云开发。
本文从云开发团队开发者+能力用户的角度,以搭建云开发官网的思路(/)为例,分享结合流行框架和工具的云开发实践经验。
涉及的知识点有:
React 框架:Next.jsCI 自动构建概述
系统设计图:
背景介绍
随着云开发团队业务的快速发展,团队需要一个官网来更直观、即时地向开发者展示云开发的相关能力,包括但不限于工具链、SDK、技术文档等。
同时,为了降低开发者的动手成本,积累行业优秀的实践经验,官网还承载着营造社区氛围、聚合重要信息、提升用户留存的重任。
我们最初使用 VuePress 作为静态 网站 工具,遇到了一些痛点:
我们使用“cms扩展”、“基础云开发能力”、“Next.js”、“CI工具”来解决以上问题。在实现网站内容动态的同时,保证SEO,运营同学也可以通过cms可视化管理内容。
安装cms
进入云开发拓展能力控制台,按照提示安装cms内容管理系统。
在配置扩展时,有两种类型的帐户:管理员帐户和操作员帐户。管理员账户具有更高的权限,可以创建新的数据集合;而operator账号只能对已有的数据集进行增删改查。
注意:
安装时间有点长,请耐心等待
安装成功后,云数据库会自动创建3个合集,分别是tcb-ext-cms-contents、tcb-ext-cms-users、tcb-ext-cms-webhooks和存储cms系统配置信息和内容数据。会自动创建三个云函数,分别是tcb-ext-cms-api、tcb-ext-cms-init、tcb-ext-cms-auth,它们封装了初始化、鉴权和数据流的相关逻辑。
输入“static网站hosting”,可以看到cms系统的静态文件已经自动部署到tcb-cms/目录下:
点击上方的“基本配置”查看域名信息。
在浏览器中访问对应链接(/tcb-cms/)查看cms系统:
至此,无需任何开发成本,cms内容管理系统正式上线~
使用cms创建动态内容
对于动态数据内容,我们将其划分为不同的模块。每个内容模块对应一个cms系统的数据集合。例如,在“云开发官网”-“社区页面”中,推荐好课程的内容是动态的。
从图中可以看出,每节课都有多个属性。在云数据库中,每门课程对应一个文档,课程属性对应文档的字段。字段类型及含义如下:
name: 课程名称
time: 课程时间
cover: 课程封面
url: 课程链接
level: 课程难度
以管理员身份登录cms系统,在“内容设置页面”新建内容。在cms中支持多种高级数据类型,如url、image、markdown、富文本、标签数组、邮箱、URL等,这些类型被智能识别,显示更友好。
注意:
cms自带图床功能。当数据类型为“图片”时,图片会自动上传到当前云开发环境下的云存储中。图像信息以cloud://开头的特殊链接存储在数据集合中。
新建内容时,cms默认会自动填写4个字段:name、order、createTime、updateTime。您可以根据需要删除不需要的字段。
推荐:
order 字段是保留的,可以用于数据排序。对于运营商来说,数据的顺序值越大,在cms系统中显示的位置就越高;对于开发者来说,可以按照顺序进行排序和搜索。从而保证体验和逻辑的一致性。
根据字段创建集合后,cms会在系统左侧看到“推荐课程”。其对应的内容保存在云数据库的recome-course(创建时指定)集合中,其字段信息保存在云的tcb-ext-cms-contents(cms初始化时创建)集合中数据库。
根据设置添加新的课程内容后,再次进入“推荐课程”,如下图:
图片、链接等内容向运营商展示更友好。
项目建设
按照 Next.js Docs 的指南创建 Next.js 项目:
npm i --save next react react-dom
因为我们要部署网站到“静态托管”,所以需要用到Next.js的静态导出功能。 package.json 中的打包脚本更新为:
"scripts": {
"dev": "next",
"build": "next build && next export",
"start": "next start"
}
为了快速部署静态网站并发布云功能。需要全局安装@cloudbase/cli:
npm install -g @cloudbase/cli
安装后,添加两个脚本:
"scripts": {
"deploy:hosting": "npm run build && cloudbase hosting:deploy out -e jhgjj-0ae4a1",
"deploy:function": "echo y | cloudbase functions:deploy --force"
}
注意:
准备两个云环境,防止静态部署时文件覆盖。 envId为jhgjj-0ae4a1的云环境仅用于部署Next.js的静态导出文件。 envId为pagecounter-d27cfe的云环境用于部署cms系统。获取cms内容
通过CloudBase的Node SDK-@cloudbase/node-sdk,我们可以在Next.js的getStaticProps()方法中读取云数据库中的数据。
为了使逻辑更清晰,我们将获取外部数据的方法封装在一个文件中。以“推荐课程”为例:
// provider.js
const cloudbase = require("@cloudbase/node-sdk");
const config = {
secretId: "your secretId", // 前往「腾讯云控制台」-「访问密钥」获取
secretKey: "your secretKey", // 前往「腾讯云控制台」-「访问密钥」获取
env: "your envid" // 前往「腾讯云控制台」-「云开发 CloudBase」获取
};
const app = cloudbase.init(config);
/**
* 获取云数据库数据
*/
async function getCourses() {
const db = app.database();
const result = await db.collection("recommend-course").get();
if (result.code) {
throw new Error(
`获取「推荐课程」失败, 错误码是${result.code}: ${result.message}`
);
}
return result.data.map(item => {
if (item.createTime instanceof Date) {
item.createTime = item.createTime.toLocaleString();
}
if (item.updateTime instanceof Date) {
item.updateTime = item.updateTime.toLocaleString();
}
item.cover = getBucketUrl(item.cover); // 处理云存储的特殊链接
return item;
});
}
如上一篇所述,cms有自己的图床功能。拖拽上传的图片会保存在同一环境的云存储中,获取图片的链接会保存在采集中。云存储链接是以cloud://开头的特殊链接,需要前端识别和特殊处理。
例如图片存储链接为:cloud://pagecounter-d27cfe.7061-pagecounter-d27cfe-1255463368/uploads/04.png。将其转换为可访问的 http 链接:
转换思路是:识别出envid背后的信息,与tcb.qcloud.la域名重新拼接:
// provider.js
/**
* 获取云存储的访问链接
* @param {String} url 云存储的特定url
*/
function getBucketUrl(url) {
if (!url.startsWith("cloud://")) {
return url;
}
const re = /cloud:\/\/.*?\.(.*?)\/(.*)/;
const result = re.exec(url);
return `https://${result[1]}.tcb.qcloud.la/${result[2]}`;
}
注意:
云存储的“权限设置”应该是:所有用户都可以读,只有创建者和管理员可以写。否则链接无法访问。
推荐:
除了内置的图床功能外,开发者还可以根据自己的需求使用其他稳定的图床服务,例如微博图床。如果使用其他图片床,对应的字段类型不能设置为“图片”,可以是“字符串”或“超链接”。
到此为止,我们已经使用 SDK 获取了云数据库数据,剩下要做的就是将其注入到 Next.js 页面组件的 props 中:
// pages/index.js
const HomePage = ({ courses }) => {
return (
// 尽情使用数据吧...
)
}
export async function getStaticProps() {
const { getCourses } = require('./../provider')
return {
props: {
courses: await getCourses()
}
}
}
export default HomePage
打开浏览器输入:3000/,可以看到效果如下:
输入view-source::3000/,可以看到网页的html源码中收录了课程数据,解决了SEO问题:
注意:
Next.js 的一些方法会在两端运行,但 getStaticProps() 只会在服务器端运行自动构建和部署
到此,开发工作基本结束。执行npm run build命令,网站静态文件打包在out/目录下:
执行 npm run deploy:hosting 将 out/ 目录下的文件上传到“static网站hosting”。访问静态网站托管的链接:/,效果如下:
借助成熟的 CI 工具,例如 Travis、Circle 等,可以定期触发构建工作。这样,内容和开发就完全分离了。
在构建版本时,您需要使用 CloudBase CLI 工具。在CI工具中,不再使用cloudbase login进行交互式输入登录,而是使用一键登录:cloudbase login --apiKeyId $TCB_SECRET_ID --apiKey $TCB_SECRET_KEY。
注意:
前往 Cloud API Key 获取 TCB_SECRET_ID 和 TCB_SECRET_KEY 的值
在 CI 工具的控制台中,配置 TCB_SECRET_ID 和 TCB_SECRET_KEY。并向 package.json 添加一个新脚本:
"scripts": {
"login": "echo N | cloudbase login --apiKeyId $TCB_SECRET_ID --apiKey $TCB_SECRET_KEY"
}
总结起来,CI构建的过程是:
如果数据需要紧急修改在线,您可以在本地或在CI工具控制台手动触发构建。
终于
借助云开发cms,可以实现评论系统、预约系统、博客发帖等各种内容模板,快速搭建网站。在现有的开发体系下,合理使用云开发,大大降低了人工成本、开发成本、运维成本。实现前后端穿梭,形成“闭环”。
本文的实战只是开始。它涉及到部分云开发能力。还有更多好玩的东西等着你去探索,比如使用云函数实现SSR、托管后端服务、图片服务、各种端SDK等。
探索功能、多样化想法并以较低的成本开发高度可用的网络服务。云开发绝对是您的最佳选择!
更多信息:
js提取指定网站内容(js提取指定网站内容-上海怡健医学())
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-03 14:44
js提取指定网站内容文字:1.可以用网页截图工具批量抓取网页内容,例如8090,360浏览器。2.然后用awk命令对特定的关键字命中查找规则即可,例如按照条件#ctrl+enter来查找。3.然后使用require来提取需要的关键字或者包。
3.1intellijidea怎么查看网页中的字符串?直接在浏览器中查看无反应,你可以:-键入文本文件中的text就能看到-点开网页另存为也能看到直接加载的。我觉得最快的办法是:把以上两个函数单独处理,看看有什么区别,或者加到你的代码库中。
根据楼主的需求,我强烈推荐用前端布局工具+jquery+index.js实现一个页面布局,速度可能很慢,但是实际问题可以一次解决。如果只是大概的布局,
1、在网页中设置隐藏分段。如图中。
2、将分段的文字拷贝至本地,然后执行excel转换工具转换成文本格式。如图中。
3、js代码开启跳转显示分段文字。
推荐用python写。配合专业网页截图工具,例如任意浏览器。可以极大压缩代码。但大部分网页都会被抓取而无法访问。
javascript解析网页
谢邀可以看看这个python爬虫之如何简单实现网页的下载?
1、在requests/beautifulsoup中读取网页,读取网页的函数是requests的beautifulsoup方法。
2、在解析网页的代码中要处理这个网页需要streambuffer和缓存的机制。
3、根据实际的url找到解析的函数,这个就比较复杂了。google的方法是pythonimagejavascript代码包。提示:貌似需要去参考其他人实现的爬虫(例如web爬虫-喜马拉雅fm的爬虫)。 查看全部
js提取指定网站内容(js提取指定网站内容-上海怡健医学())
js提取指定网站内容文字:1.可以用网页截图工具批量抓取网页内容,例如8090,360浏览器。2.然后用awk命令对特定的关键字命中查找规则即可,例如按照条件#ctrl+enter来查找。3.然后使用require来提取需要的关键字或者包。
3.1intellijidea怎么查看网页中的字符串?直接在浏览器中查看无反应,你可以:-键入文本文件中的text就能看到-点开网页另存为也能看到直接加载的。我觉得最快的办法是:把以上两个函数单独处理,看看有什么区别,或者加到你的代码库中。
根据楼主的需求,我强烈推荐用前端布局工具+jquery+index.js实现一个页面布局,速度可能很慢,但是实际问题可以一次解决。如果只是大概的布局,
1、在网页中设置隐藏分段。如图中。
2、将分段的文字拷贝至本地,然后执行excel转换工具转换成文本格式。如图中。
3、js代码开启跳转显示分段文字。
推荐用python写。配合专业网页截图工具,例如任意浏览器。可以极大压缩代码。但大部分网页都会被抓取而无法访问。
javascript解析网页
谢邀可以看看这个python爬虫之如何简单实现网页的下载?
1、在requests/beautifulsoup中读取网页,读取网页的函数是requests的beautifulsoup方法。
2、在解析网页的代码中要处理这个网页需要streambuffer和缓存的机制。
3、根据实际的url找到解析的函数,这个就比较复杂了。google的方法是pythonimagejavascript代码包。提示:貌似需要去参考其他人实现的爬虫(例如web爬虫-喜马拉雅fm的爬虫)。
js提取指定网站内容(cacheItemKey代码示例中的时间被组成:@time中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-08-30 22:07
页面上的时间整理并保存为:@time。
在 cacheItemKey 代码示例中,缓存项是使用时间定义的。当您缓存数据时,您需要为缓存定义一个名称。在整个网站中,这个缓存是独立存在的。
代码首先读取时间缓存项中的值。如果返回值不为空,则表示代码从缓存项中获取时间缓存,保存到变量time中。
但是,如果缓存条目不存在(即为空),则代码会将时间的值设置为当前时间,将其添加到缓存中,并设置一分钟的过期时间。如果页面请求在一分钟内没有发出,缓存中的项目将被丢弃。 (默认缓存项过期时间为 20 分钟)。
这段代码描述的问题是,你在使用数据的时候应该总是缓存数据。在获取新缓存之前,请始终检查 WebCache.Get 方法是否返回空值。请记住,缓存条目可能已过期或因其他原因被删除,因此永远无法保证任何给定项目将始终存在于缓存中。
3. 在浏览器中运行 WebCache.cshtml。 (运行前请确保页面在选定的工作空间中。)当您第一次请求页面时,时间数据不在缓存中,代码会将时间值添加到缓存中。
4. 在浏览器中刷新 WebCache.cshtml。这次是从缓存中获取时间数据。请注意,自上次浏览网页以来的时间没有改变。
5. 稍等片刻清除缓存,然后刷新页面。再次说明缓存中没有找到时间数据,更新后的时间会添加到缓存项中。 查看全部
js提取指定网站内容(cacheItemKey代码示例中的时间被组成:@time中)
页面上的时间整理并保存为:@time。
在 cacheItemKey 代码示例中,缓存项是使用时间定义的。当您缓存数据时,您需要为缓存定义一个名称。在整个网站中,这个缓存是独立存在的。
代码首先读取时间缓存项中的值。如果返回值不为空,则表示代码从缓存项中获取时间缓存,保存到变量time中。
但是,如果缓存条目不存在(即为空),则代码会将时间的值设置为当前时间,将其添加到缓存中,并设置一分钟的过期时间。如果页面请求在一分钟内没有发出,缓存中的项目将被丢弃。 (默认缓存项过期时间为 20 分钟)。
这段代码描述的问题是,你在使用数据的时候应该总是缓存数据。在获取新缓存之前,请始终检查 WebCache.Get 方法是否返回空值。请记住,缓存条目可能已过期或因其他原因被删除,因此永远无法保证任何给定项目将始终存在于缓存中。
3. 在浏览器中运行 WebCache.cshtml。 (运行前请确保页面在选定的工作空间中。)当您第一次请求页面时,时间数据不在缓存中,代码会将时间值添加到缓存中。
4. 在浏览器中刷新 WebCache.cshtml。这次是从缓存中获取时间数据。请注意,自上次浏览网页以来的时间没有改变。
5. 稍等片刻清除缓存,然后刷新页面。再次说明缓存中没有找到时间数据,更新后的时间会添加到缓存项中。
js提取指定网站内容(以个人网站为例)。
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-08-27 07:03
js提取指定网站内容(以个人网站为例)。原理:提取指定网站内容,利用对应算法对该网站内容进行分析,转换成字符串,
allprocessingalgorithmsformicrosoftinformationsystems通过google搜索能搜到一堆性能奇佳的网页分析方法,
windows7以上应该都支持一些对称加密算法吧,
ms应该有有一些常用的jsapi
windows7以上office只能调用windows自带的msoffice来提取,比如利用office提供的关联方式,比如时间,或者文档标题关键字,但是假如要提取文档,那么有很多常用的方法,比如把所有网页的标题放进一个中文分词库,再进行分词,一个中文词汇可以用多个词汇表来表示,这样可以得到词汇表,然后利用一些常用的关键字对词汇表进行操作,得到某一特定时间段的某一文档,然后用词典或者相应的查询语言就可以很轻松的得到结果。
比较简单的方法就是转换为长度为一的txt数据格式,这样就可以获取到文档中包含文字的那部分。
有办法制作excel格式的excel文档,然后利用jslookalikealgorithm来提取。 查看全部
js提取指定网站内容(以个人网站为例)。
js提取指定网站内容(以个人网站为例)。原理:提取指定网站内容,利用对应算法对该网站内容进行分析,转换成字符串,
allprocessingalgorithmsformicrosoftinformationsystems通过google搜索能搜到一堆性能奇佳的网页分析方法,
windows7以上应该都支持一些对称加密算法吧,
ms应该有有一些常用的jsapi
windows7以上office只能调用windows自带的msoffice来提取,比如利用office提供的关联方式,比如时间,或者文档标题关键字,但是假如要提取文档,那么有很多常用的方法,比如把所有网页的标题放进一个中文分词库,再进行分词,一个中文词汇可以用多个词汇表来表示,这样可以得到词汇表,然后利用一些常用的关键字对词汇表进行操作,得到某一特定时间段的某一文档,然后用词典或者相应的查询语言就可以很轻松的得到结果。
比较简单的方法就是转换为长度为一的txt数据格式,这样就可以获取到文档中包含文字的那部分。
有办法制作excel格式的excel文档,然后利用jslookalikealgorithm来提取。
1.88非凡软件站下载“Word文档提取汇总工具”(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-08-23 21:05
1.88非凡软件站下载“Word文档提取汇总工具”(图)
Excel多文档提取汇总工具
将多个Excel文档的指定行或单元格(指定行、指定列)的内容提取汇总成Excel表格的工具。
比如,公司几十个或者几百个员工根据一个Excel模板填写了简历数据表。现在需要将所有人员的信息提取汇总到一张表中。如果手动复制粘贴,工作量会很大。巨大的。 《Excel多文档提取汇总工具》将多个Excel文档的指定行或单元格(指定行、指定列)的内容提取汇总成一个Excel表格。
下载《Excel多文档提取汇总工具》1.88
从非凡软件站下载“Excel多文档提取汇总工具”
Word 文档提取汇总工具
提取多个Word文档(*.doc;*.docx)的指定内容,例如通过设置提取内容的前标记或后标记,或指定表格中的指定行和指定列提取内容后的Word文档,是一个汇总到Excel表格或Word表格的工具。
比如,公司几十个或者几百个员工按照某个Word模板填写了简历数据表。现在需要将所有人员的信息提取汇总成一个表格。如果手动复制粘贴,工作量会很大。巨大的。 《Word多文档提取汇总工具》可以将多个Word文档的指定内容提取汇总成Excel表格、Word表格或网页文件表格。
下载“Word文档提取汇总工具”1.81 求助:如何提取Word文档中的表格内容?如何提取Word文档中的非表格内容? 查看全部
1.88非凡软件站下载“Word文档提取汇总工具”(图)
Excel多文档提取汇总工具
将多个Excel文档的指定行或单元格(指定行、指定列)的内容提取汇总成Excel表格的工具。
比如,公司几十个或者几百个员工根据一个Excel模板填写了简历数据表。现在需要将所有人员的信息提取汇总到一张表中。如果手动复制粘贴,工作量会很大。巨大的。 《Excel多文档提取汇总工具》将多个Excel文档的指定行或单元格(指定行、指定列)的内容提取汇总成一个Excel表格。
下载《Excel多文档提取汇总工具》1.88
从非凡软件站下载“Excel多文档提取汇总工具”
Word 文档提取汇总工具
提取多个Word文档(*.doc;*.docx)的指定内容,例如通过设置提取内容的前标记或后标记,或指定表格中的指定行和指定列提取内容后的Word文档,是一个汇总到Excel表格或Word表格的工具。
比如,公司几十个或者几百个员工按照某个Word模板填写了简历数据表。现在需要将所有人员的信息提取汇总成一个表格。如果手动复制粘贴,工作量会很大。巨大的。 《Word多文档提取汇总工具》可以将多个Word文档的指定内容提取汇总成Excel表格、Word表格或网页文件表格。
下载“Word文档提取汇总工具”1.81 求助:如何提取Word文档中的表格内容?如何提取Word文档中的非表格内容?
国内有个捷径tag网,不同于之前360搜索的搜索url无用
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-08-23 02:00
js提取指定网站内容:1.进入想要提取的网站列表页面。2.点击网页上方的"取/下载"按钮,会出现下载弹窗。下载完成后点击"提取"按钮提取网页内容。3.列表页面中的内容均会被保存到cookies中。当有新的请求时,就会被网站自动提取下来。4.按"ctrl+e"组合键进行补全。5.提取"/"网站内容-->保存cookies;提取"/"网站内容-->下载cookies;提取"/"网站内容-->取消cookies5.用tag来提取。关注公众号“蜗牛分享”回复“cookies”领取《取一篇网站内容/tag的工具》。
现在国内有个捷径网,不同于之前360搜索的搜索url无用,大家都知道这个捷径网/功能挺全的,什么去水印,图片混淆,都有。打开它有个提取网站,我把图片上传上去,就提取出来了,
推荐less数据提取器
requests库虽然不是人人都用,但是必备。
chrome浏览器网页右上角有个工具
babeles和amd是最基本的。看看babel这方面的资料(官方文档很好找)。现在自动下载pdf,大部分工具都能做到。总之,是不是自己尝试过的工具,可以试试。找不到可以再讨论。
github下载二维码,在浏览器打开,就能下载下来了。requests,gzip。多说一句,其实很多网站是不能用webpack配置的,需要你单独打包,或者用css写。所以,其实可以去webpack相关网站下载。比如hashboard。 查看全部
国内有个捷径tag网,不同于之前360搜索的搜索url无用
js提取指定网站内容:1.进入想要提取的网站列表页面。2.点击网页上方的"取/下载"按钮,会出现下载弹窗。下载完成后点击"提取"按钮提取网页内容。3.列表页面中的内容均会被保存到cookies中。当有新的请求时,就会被网站自动提取下来。4.按"ctrl+e"组合键进行补全。5.提取"/"网站内容-->保存cookies;提取"/"网站内容-->下载cookies;提取"/"网站内容-->取消cookies5.用tag来提取。关注公众号“蜗牛分享”回复“cookies”领取《取一篇网站内容/tag的工具》。
现在国内有个捷径网,不同于之前360搜索的搜索url无用,大家都知道这个捷径网/功能挺全的,什么去水印,图片混淆,都有。打开它有个提取网站,我把图片上传上去,就提取出来了,
推荐less数据提取器
requests库虽然不是人人都用,但是必备。
chrome浏览器网页右上角有个工具
babeles和amd是最基本的。看看babel这方面的资料(官方文档很好找)。现在自动下载pdf,大部分工具都能做到。总之,是不是自己尝试过的工具,可以试试。找不到可以再讨论。
github下载二维码,在浏览器打开,就能下载下来了。requests,gzip。多说一句,其实很多网站是不能用webpack配置的,需要你单独打包,或者用css写。所以,其实可以去webpack相关网站下载。比如hashboard。
2015年03月25日15:35:36作者:上大王这篇文章
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-08-22 21:17
jQuery使用load()方法将另一个网页文件中的指定标签内容加载到div标签中
更新时间:2015年3月25日15:35:36 作者:商大网
这个文章主要介绍了jQuery使用load()方法将另一个网页文件中指定的标签内容加载到div标签的方式。它涉及到 jQuery 中 load 方法的使用。有一定的参考价值。朋友可以参考以下
本文中的示例描述了jQuery如何使用load()方法将另一个网页文件中的指定标签内容加载到div标签中。分享给大家,供大家参考。具体分析如下:
jQuery 使用 load() 方法将另一个网页文件中的指定标签内容加载到 div 标签中。如果我们可以将网页b.html中id为p1的标签内容加载到网页a.html的div标签中
$(document).ready(function(){
$("button").click(function(){
$("#div1").load("demo_test.txt #p1");
});
});
使用jQuery AJAX改变此处内容
改变外部内容
希望这篇文章对您的 jQuery 编程有所帮助。 查看全部
2015年03月25日15:35:36作者:上大王这篇文章
jQuery使用load()方法将另一个网页文件中的指定标签内容加载到div标签中
更新时间:2015年3月25日15:35:36 作者:商大网
这个文章主要介绍了jQuery使用load()方法将另一个网页文件中指定的标签内容加载到div标签的方式。它涉及到 jQuery 中 load 方法的使用。有一定的参考价值。朋友可以参考以下
本文中的示例描述了jQuery如何使用load()方法将另一个网页文件中的指定标签内容加载到div标签中。分享给大家,供大家参考。具体分析如下:
jQuery 使用 load() 方法将另一个网页文件中的指定标签内容加载到 div 标签中。如果我们可以将网页b.html中id为p1的标签内容加载到网页a.html的div标签中
$(document).ready(function(){
$("button").click(function(){
$("#div1").load("demo_test.txt #p1");
});
});
使用jQuery AJAX改变此处内容
改变外部内容
希望这篇文章对您的 jQuery 编程有所帮助。
什么是HTML文档被浏览器解析后就是DOM树树形结构
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-08-22 05:56
由于浏览器将 HTML 文档解析为 DOM 树,要改变 HTML 的结构,需要通过 JavaScript 来操作 DOM。
永远记住 DOM 是一个树结构。操作一个DOM节点其实就是这么几个操作:
在操作一个DOM节点之前,我们需要通过各种方式来获取DOM节点。最常用的方法是 document.getElementById() 和 document.getElementsByTagName(),以及 CSS 选择器 document.getElementsByClassName()。
由于 ID 在 HTML 文档中是唯一的,因此 document.getElementById() 可以直接定位到唯一的 DOM 节点。 document.getElementsByTagName() 和 document.getElementsByClassName() 总是返回一组 DOM 节点。要准确选择DOM,可以先定位父节点,再从父节点中选择,缩小范围。
例如:
// 返回ID为'test'的节点:
var test = document.getElementById('test');
// 先定位ID为'test-table'的节点,再返回其内部所有tr节点:
var trs = document.getElementById('test-table').getElementsByTagName('tr');
// 先定位ID为'test-div'的节点,再返回其内部所有class包含red的节点:
var reds = document.getElementById('test-div').getElementsByClassName('red');
// 获取节点test下的所有直属子节点:
var cs = test.children;
// 获取节点test下第一个、最后一个子节点:
var first = test.firstElementChild;
var last = test.lastElementChild;
第二种方法是使用querySelector()和querySelectorAll(),需要了解selector语法,然后使用条件获取节点,比较方便:
// 通过querySelector获取ID为q1的节点:
var q1 = document.querySelector('#q1');
// 通过querySelectorAll获取q1节点内的符合条件的所有节点:
var ps = q1.querySelectorAll('div.highlighted > p');
注意:低版本的IEquerySelector和querySelectorAll。 IE8 只支持有限。
严格来说,我们这里的DOM节点指的是Element,但DOM节点实际上是Node。在HTML中,Node包括Element、Comment、CDATA_SECTION等多种,还有根节点的Document类型,但大多数时候我们只关心Element,也就是实际控制页面结构的Node 其他类型的节点可以忽略。根节点Document已经自动绑定到全局变量document。
锻炼
HTML 结构如下:
JavaScript
Java
蟒蛇
红宝石
迅捷
方案
哈斯克尔
<p id="test-p">JavaScript
Java
Python
Ruby
Swift
Scheme
Haskell
</p>
请选择符合指定条件的节点:
'use strict';
----
// 选择<p>JavaScript:
var js = ???;
// 选择
Python,
Ruby,
Swift:
var arr = ???;
// 选择
Haskell:
var haskell = ???;
----
// 测试:
if (!js || js.innerText !== 'JavaScript') {
alert('选择JavaScript失败!');
} else if (!arr || arr.length !== 3 || !arr[0] || !arr[1] || !arr[2] || arr[0].innerText !== 'Python' || arr[1].innerText !== 'Ruby' || arr[2].innerText !== 'Swift') {
console.log('选择Python,Ruby,Swift失败!');
} else if (!haskell || haskell.innerText !== 'Haskell') {
console.log('选择Haskell失败!');
} else {
console.log('测试通过!');
}
</p> 查看全部
什么是HTML文档被浏览器解析后就是DOM树树形结构
由于浏览器将 HTML 文档解析为 DOM 树,要改变 HTML 的结构,需要通过 JavaScript 来操作 DOM。
永远记住 DOM 是一个树结构。操作一个DOM节点其实就是这么几个操作:
在操作一个DOM节点之前,我们需要通过各种方式来获取DOM节点。最常用的方法是 document.getElementById() 和 document.getElementsByTagName(),以及 CSS 选择器 document.getElementsByClassName()。
由于 ID 在 HTML 文档中是唯一的,因此 document.getElementById() 可以直接定位到唯一的 DOM 节点。 document.getElementsByTagName() 和 document.getElementsByClassName() 总是返回一组 DOM 节点。要准确选择DOM,可以先定位父节点,再从父节点中选择,缩小范围。
例如:
// 返回ID为'test'的节点:
var test = document.getElementById('test');
// 先定位ID为'test-table'的节点,再返回其内部所有tr节点:
var trs = document.getElementById('test-table').getElementsByTagName('tr');
// 先定位ID为'test-div'的节点,再返回其内部所有class包含red的节点:
var reds = document.getElementById('test-div').getElementsByClassName('red');
// 获取节点test下的所有直属子节点:
var cs = test.children;
// 获取节点test下第一个、最后一个子节点:
var first = test.firstElementChild;
var last = test.lastElementChild;
第二种方法是使用querySelector()和querySelectorAll(),需要了解selector语法,然后使用条件获取节点,比较方便:
// 通过querySelector获取ID为q1的节点:
var q1 = document.querySelector('#q1');
// 通过querySelectorAll获取q1节点内的符合条件的所有节点:
var ps = q1.querySelectorAll('div.highlighted > p');
注意:低版本的IEquerySelector和querySelectorAll。 IE8 只支持有限。
严格来说,我们这里的DOM节点指的是Element,但DOM节点实际上是Node。在HTML中,Node包括Element、Comment、CDATA_SECTION等多种,还有根节点的Document类型,但大多数时候我们只关心Element,也就是实际控制页面结构的Node 其他类型的节点可以忽略。根节点Document已经自动绑定到全局变量document。
锻炼
HTML 结构如下:
JavaScript
Java
蟒蛇
红宝石
迅捷
方案
哈斯克尔
<p id="test-p">JavaScript
Java
Python
Ruby
Swift
Scheme
Haskell
</p>
请选择符合指定条件的节点:
'use strict';
----
// 选择<p>JavaScript:
var js = ???;
// 选择
Python,
Ruby,
Swift:
var arr = ???;
// 选择
Haskell:
var haskell = ???;
----
// 测试:
if (!js || js.innerText !== 'JavaScript') {
alert('选择JavaScript失败!');
} else if (!arr || arr.length !== 3 || !arr[0] || !arr[1] || !arr[2] || arr[0].innerText !== 'Python' || arr[1].innerText !== 'Ruby' || arr[2].innerText !== 'Swift') {
console.log('选择Python,Ruby,Swift失败!');
} else if (!haskell || haskell.innerText !== 'Haskell') {
console.log('选择Haskell失败!');
} else {
console.log('测试通过!');
}
</p>
前端侧对于动态生成的内容进行下载的实时截图下载
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-08-22 02:39
有时需要在前端下载动态生成的内容,比如页面上的某条文字信息,或者分享页面的时候,希望分享的图片是实时截图的页面内容。这时候这张图是动态的,纯HTML显然不能满足我们的需求。借助 JS 和其他一些 HTML5 功能,例如将页面元素转换为画布,然后转换为图片以供下载。
原理其实很简单。我们可以借助Blob将文本或JS字符串信息转换成二进制,然后作为元素的href属性,配合download属性实现下载。
代码比较简单,如下图(兼容Chrome和Firefox):
function funcDownload (content, filename) {
// 创建隐藏的可下载链接
var eleLink = document.createElement('a');
eleLink.download = filename;
eleLink.style.display = 'none';
// 字符内容转变成blob地址
var blob = new Blob([content]);
eleLink.href = URL.createObjectURL(blob);
// 触发点击
document.body.appendChild(eleLink);
eleLink.click();
// 然后移除
document.body.removeChild(eleLink);
}
function dn (){
var ss = document.querySelector('html').outerHTML;
funcDownload(ss, 'ceshi.html')
}
其中,content是指需要下载的文本或字符串内容,filename是指下载到系统中的文件名。
以上代码可以将当前整个网页下载为html文件,但是网页内外的部分资源无法显示。
在Chrome浏览器下,模拟点击创建的元素即使没有追加到页面中也能触发下载,但在火狐浏览器中是不行的。所以,上面的 funDownload() 方法有一个 appendChild 和 removeChild 处理是为了兼容火狐浏览器。
1、URL.createObjectURL() 方法会根据传入的参数创建一个指向参数对象的URL。这个URL的生命周期只存在于创建它的文档中,新的对象URL指向执行的文件对象或 Blob 对象。
objectURL = URL.createObjectURL(blob || file);
参数:文件对象或 Blob 对象。这里可能是 File 对象和 Blob 对象:
File 对象:它是一个文件。例如,如果我上传一个带有 input type="file" 标签的文件,那么其中的每个文件都是一个 File 对象。
Blob 对象:它是二进制数据。比如new Blob()创建的对象就是一个Blob对象。例如,在XMLHttpRequest中,如果指定responseType为blob,则获取的返回值也是一个blob对象。
注意:每次调用 createObjectURL 时,都会创建一个新的 URL 对象。即使您为同一个文件创建了 URL。如果你不再需要这个对象,要释放它,你需要使用 URL.revokeObjectURL() 方法。当页面关闭时,浏览器会自动释放,但为了保证良好的性能和内存使用,应该在保证不再使用时释放。
2、URL.revokeObjectURL() 方法会释放一个由 URL.createObjectURL() 创建的对象 URL,当你已经使用了对象 URL,然后让浏览器知道该 URL 不再需要指向 When对应的文件,需要调用这个方法。具体含义是一个对象URL可以使用这个url访问指定的文件,但我可能只需要访问一次。一旦被访问,对象 URL 就不再需要,并且被释放和释放。将来,对象 URL 将不再指向指定的文件。例如,对于一张图片,我创建了一个对象 URL,然后通过这个对象 URL,我将这张图片加载到我的页面上。既然已经加载好了,就不用再加载这张图片了,那我就放出对象的URL。那么网址就不再指向这张图片了。
window.URL.revokeObjectURL(objectURL);
//objectURL 是一个通过URL.createObjectURL()方法创建的对象URL. 查看全部
前端侧对于动态生成的内容进行下载的实时截图下载
有时需要在前端下载动态生成的内容,比如页面上的某条文字信息,或者分享页面的时候,希望分享的图片是实时截图的页面内容。这时候这张图是动态的,纯HTML显然不能满足我们的需求。借助 JS 和其他一些 HTML5 功能,例如将页面元素转换为画布,然后转换为图片以供下载。
原理其实很简单。我们可以借助Blob将文本或JS字符串信息转换成二进制,然后作为元素的href属性,配合download属性实现下载。
代码比较简单,如下图(兼容Chrome和Firefox):
function funcDownload (content, filename) {
// 创建隐藏的可下载链接
var eleLink = document.createElement('a');
eleLink.download = filename;
eleLink.style.display = 'none';
// 字符内容转变成blob地址
var blob = new Blob([content]);
eleLink.href = URL.createObjectURL(blob);
// 触发点击
document.body.appendChild(eleLink);
eleLink.click();
// 然后移除
document.body.removeChild(eleLink);
}
function dn (){
var ss = document.querySelector('html').outerHTML;
funcDownload(ss, 'ceshi.html')
}
其中,content是指需要下载的文本或字符串内容,filename是指下载到系统中的文件名。
以上代码可以将当前整个网页下载为html文件,但是网页内外的部分资源无法显示。
在Chrome浏览器下,模拟点击创建的元素即使没有追加到页面中也能触发下载,但在火狐浏览器中是不行的。所以,上面的 funDownload() 方法有一个 appendChild 和 removeChild 处理是为了兼容火狐浏览器。
1、URL.createObjectURL() 方法会根据传入的参数创建一个指向参数对象的URL。这个URL的生命周期只存在于创建它的文档中,新的对象URL指向执行的文件对象或 Blob 对象。
objectURL = URL.createObjectURL(blob || file);
参数:文件对象或 Blob 对象。这里可能是 File 对象和 Blob 对象:
File 对象:它是一个文件。例如,如果我上传一个带有 input type="file" 标签的文件,那么其中的每个文件都是一个 File 对象。
Blob 对象:它是二进制数据。比如new Blob()创建的对象就是一个Blob对象。例如,在XMLHttpRequest中,如果指定responseType为blob,则获取的返回值也是一个blob对象。
注意:每次调用 createObjectURL 时,都会创建一个新的 URL 对象。即使您为同一个文件创建了 URL。如果你不再需要这个对象,要释放它,你需要使用 URL.revokeObjectURL() 方法。当页面关闭时,浏览器会自动释放,但为了保证良好的性能和内存使用,应该在保证不再使用时释放。
2、URL.revokeObjectURL() 方法会释放一个由 URL.createObjectURL() 创建的对象 URL,当你已经使用了对象 URL,然后让浏览器知道该 URL 不再需要指向 When对应的文件,需要调用这个方法。具体含义是一个对象URL可以使用这个url访问指定的文件,但我可能只需要访问一次。一旦被访问,对象 URL 就不再需要,并且被释放和释放。将来,对象 URL 将不再指向指定的文件。例如,对于一张图片,我创建了一个对象 URL,然后通过这个对象 URL,我将这张图片加载到我的页面上。既然已经加载好了,就不用再加载这张图片了,那我就放出对象的URL。那么网址就不再指向这张图片了。
window.URL.revokeObjectURL(objectURL);
//objectURL 是一个通过URL.createObjectURL()方法创建的对象URL.
1.开始Python中可以进行网页解析的库(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-08-17 02:01
1.开始
Python 中有很多用于网页解析的库,例如 BeautifulSoup 和 lxml。网上玩爬虫的文章一般都会介绍BeautifulSoup库。我通常使用这个库。我最近经常使用 Xpath。我不习惯使用 BeautifulSoup。我知道 Reitz 在很久以前创建了一个名为 Requests 的库。我对查看 HTML 库没有兴趣。这次我有机会使用它。
使用pip install requests-html进行安装,上手简单,就像Reitz的其他库一样:
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://www.python.org/jobs/')
这个库是在 requests 库上实现的。 r 的结果是 Response 对象的一个子类,以及多个 html 属性。那么可以对requests库的response对象进行什么操作,这个r也可以用。如果需要解析网页,直接获取响应对象的html属性:
r.html
2.原则
我不得不崇拜Reitz,他在组装技术方面非常出色。其实HTMLSession继承了requests.Session这个核心类,然后重写requests.Session类中的requests方法,返回一个自己的HTMLResponse对象。这个类继承自 requests.Response,但增加了一个额外的 _from_response 方法。构建一个例子:
class HTMLSession(requests.Session):
# 重写 request 方法,返回 HTMLResponse 构造
def request(self, *args, **kwargs) -> HTMLResponse:
r = super(HTMLSession, self).request(*args, **kwargs)
return HTMLResponse._from_response(r, self)
class HTMLResponse(requests.Response):
# 构造器
@classmethod
def _from_response(cls, response, session: Union['HTMLSession', 'AsyncHTMLSession']):
html_r = cls(session=session)
html_r.__dict__.update(response.__dict__)
return html_r
在HTMLResponse中定义了属性方法html后,就可以通过html属性访问了,实现就是组装PyQuery来做。大部分核心解析类也使用PyQuery和lxml来做解析,简化了名字,很可爱。
3.元素定位
选择元素定位有两种方式:
css 选择器
# css 获取有多少个职位
jobs = r.html.find("h1.call-to-action")
# xpath 获取
jobs = r.html.xpath("//h1[@class='call-to-action']")
方法名很简单,符合Python优雅的风格。下面简单介绍一下这两种方法:
4. CSS 简单规则5. Xpath 简单规则
定位元素后,需要获取元素中的内容和属性相关数据,获取文本:
jobs.text
jobs.full_text
获取元素的属性:
attrs = jobs.attrs
value = attrs.get("key")
也可以通过模式匹配对应的内容:
## 找某些内容匹配
r.html.search("Python {}")
r.html.search_all()
这个功能看起来比较鸡肋,可以深入研究优化,也可以混在github上提交。
6.人性化操作
除了一些基本的操作外,这个库还提供了一些对用户友好的操作。比如一键访问一个网页的所有超链接,应该是整个网站爬虫的福音,URL管理更方便:
r.html.absolute_links
r.html.links
内容页面通常是分页的,一次不能抓取太多。这个库可以获取分页信息:
print(r.html)
# 比较一下
for url in r.html:
print(url)
结果如下:
# print(r.html)
# for
智能发现和分页是通过迭代器实现的。在这个迭代器中,将使用一个名为 _next 的方法。贴一段源码感受一下:
def get_next():
candidates = self.find('a', containing=next_symbol)
for candidate in candidates:
if candidate.attrs.get('href'):
# Support 'next' rel (e.g. reddit).
if 'next' in candidate.attrs.get('rel', []):
return candidate.attrs['href']
通过在a标签中查找指定的文本来判断下一页。通常我们的下一页会由 Next Page 或 Load More 引导。他用这面旗帜来判断。默认情况下,它以列表的形式全局存在:['next','more','older']。我个人认为这种方法非常不灵活,几乎没有可扩展性。有兴趣的可以在github上提交代码优化。
7.加载js
现在可能考虑到一些js的异步加载,这个库支持js运行时,官方说明如下:
在 Chromium 中重新加载响应,并用更新的版本替换 HTML 内容,并执行 JavaScript。
使用非常简单,直接调用如下方法:
r.html.render()
第一次使用时,会下载Chromium,但是如果你在中国知道,请自己想办法下载,不要等它自己下载。 render函数可以使用js脚本来操作页面,滚动操作有单独的参数。这对上拉加载等新型页面非常友好。
8.总结
Reitz大神设计的东西一如既往的简单好用。我自己做的不多。大部分都是用别人的东西来组装和简化api。这真的是人类。但是,在某些地方,空间仍然得到了优化。希望有兴趣有活力的童鞋可以去github关注这个项目。 查看全部
1.开始Python中可以进行网页解析的库(图)
1.开始
Python 中有很多用于网页解析的库,例如 BeautifulSoup 和 lxml。网上玩爬虫的文章一般都会介绍BeautifulSoup库。我通常使用这个库。我最近经常使用 Xpath。我不习惯使用 BeautifulSoup。我知道 Reitz 在很久以前创建了一个名为 Requests 的库。我对查看 HTML 库没有兴趣。这次我有机会使用它。
使用pip install requests-html进行安装,上手简单,就像Reitz的其他库一样:
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://www.python.org/jobs/')
这个库是在 requests 库上实现的。 r 的结果是 Response 对象的一个子类,以及多个 html 属性。那么可以对requests库的response对象进行什么操作,这个r也可以用。如果需要解析网页,直接获取响应对象的html属性:
r.html
2.原则
我不得不崇拜Reitz,他在组装技术方面非常出色。其实HTMLSession继承了requests.Session这个核心类,然后重写requests.Session类中的requests方法,返回一个自己的HTMLResponse对象。这个类继承自 requests.Response,但增加了一个额外的 _from_response 方法。构建一个例子:
class HTMLSession(requests.Session):
# 重写 request 方法,返回 HTMLResponse 构造
def request(self, *args, **kwargs) -> HTMLResponse:
r = super(HTMLSession, self).request(*args, **kwargs)
return HTMLResponse._from_response(r, self)
class HTMLResponse(requests.Response):
# 构造器
@classmethod
def _from_response(cls, response, session: Union['HTMLSession', 'AsyncHTMLSession']):
html_r = cls(session=session)
html_r.__dict__.update(response.__dict__)
return html_r
在HTMLResponse中定义了属性方法html后,就可以通过html属性访问了,实现就是组装PyQuery来做。大部分核心解析类也使用PyQuery和lxml来做解析,简化了名字,很可爱。
3.元素定位
选择元素定位有两种方式:
css 选择器
# css 获取有多少个职位
jobs = r.html.find("h1.call-to-action")
# xpath 获取
jobs = r.html.xpath("//h1[@class='call-to-action']")
方法名很简单,符合Python优雅的风格。下面简单介绍一下这两种方法:
4. CSS 简单规则5. Xpath 简单规则
定位元素后,需要获取元素中的内容和属性相关数据,获取文本:
jobs.text
jobs.full_text
获取元素的属性:
attrs = jobs.attrs
value = attrs.get("key")
也可以通过模式匹配对应的内容:
## 找某些内容匹配
r.html.search("Python {}")
r.html.search_all()
这个功能看起来比较鸡肋,可以深入研究优化,也可以混在github上提交。
6.人性化操作
除了一些基本的操作外,这个库还提供了一些对用户友好的操作。比如一键访问一个网页的所有超链接,应该是整个网站爬虫的福音,URL管理更方便:
r.html.absolute_links
r.html.links
内容页面通常是分页的,一次不能抓取太多。这个库可以获取分页信息:
print(r.html)
# 比较一下
for url in r.html:
print(url)
结果如下:
# print(r.html)
# for
智能发现和分页是通过迭代器实现的。在这个迭代器中,将使用一个名为 _next 的方法。贴一段源码感受一下:
def get_next():
candidates = self.find('a', containing=next_symbol)
for candidate in candidates:
if candidate.attrs.get('href'):
# Support 'next' rel (e.g. reddit).
if 'next' in candidate.attrs.get('rel', []):
return candidate.attrs['href']
通过在a标签中查找指定的文本来判断下一页。通常我们的下一页会由 Next Page 或 Load More 引导。他用这面旗帜来判断。默认情况下,它以列表的形式全局存在:['next','more','older']。我个人认为这种方法非常不灵活,几乎没有可扩展性。有兴趣的可以在github上提交代码优化。
7.加载js
现在可能考虑到一些js的异步加载,这个库支持js运行时,官方说明如下:
在 Chromium 中重新加载响应,并用更新的版本替换 HTML 内容,并执行 JavaScript。
使用非常简单,直接调用如下方法:
r.html.render()
第一次使用时,会下载Chromium,但是如果你在中国知道,请自己想办法下载,不要等它自己下载。 render函数可以使用js脚本来操作页面,滚动操作有单独的参数。这对上拉加载等新型页面非常友好。
8.总结
Reitz大神设计的东西一如既往的简单好用。我自己做的不多。大部分都是用别人的东西来组装和简化api。这真的是人类。但是,在某些地方,空间仍然得到了优化。希望有兴趣有活力的童鞋可以去github关注这个项目。
什么是HTML源码中的内容?如何对网页进行爬取呢?
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-17 01:37
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
部分网站内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。例如,今天的头条新闻:
HTML 源代码
网页上的新闻在HTML源代码中找不到,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页?有两种方式:
1、从网页响应中查找JS脚本返回的JSON数据; 2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例说明:
1、找到JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”标签后,我们发现有很多回复。让我们过滤它们,只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
原来都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到想要的消息,所以再找一下:
有个焦点,我们点一下看看:
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看的是正常编码的数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求并解析数据接口数据
先上传完整代码:
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
# print news
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(json.dumps(title).decode("unicode-escape"))
print img_url
本文转自 IT阿飞 51CTO博客,原文链接:http://blog.51cto.com/itafei/2072331 查看全部
什么是HTML源码中的内容?如何对网页进行爬取呢?
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
部分网站内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。例如,今天的头条新闻:
HTML 源代码
网页上的新闻在HTML源代码中找不到,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页?有两种方式:
1、从网页响应中查找JS脚本返回的JSON数据; 2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例说明:
1、找到JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”标签后,我们发现有很多回复。让我们过滤它们,只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
原来都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到想要的消息,所以再找一下:
有个焦点,我们点一下看看:
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看的是正常编码的数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求并解析数据接口数据
先上传完整代码:
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
# print news
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(json.dumps(title).decode("unicode-escape"))
print img_url
本文转自 IT阿飞 51CTO博客,原文链接:http://blog.51cto.com/itafei/2072331
使用Node.js爬取网页资源,开箱即用的配置将爬取到的网页内容
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-08-15 07:05
使用Node.js爬取网页资源,开箱即用的配置将爬取到的网页内容
本文适合无论是否有爬虫以及Node.js基础的朋友观看~
要求:
使用 Node.js 抓取网络资源,开箱即用的配置
以PDF格式输出抓取的网页内容
如果你是技术员,那可以看我下一个文章,否则请直接移步我的github仓库,看文档就行了。仓库地址:附文档和源码,别忘了我给了star这个需求用到的技术:Node.js and puppeteer
puppeteer 官网地址:puppeteer 地址
Node.js 官网地址:链接说明
Puppeteer 是 Google 官方出品的 Node 库,通过 DevTools 协议控制 Headless Chrome。您可以通过Puppeteer提供的api直接控制Chrome模拟大部分用户操作进行UI测试或者作为爬虫访问页面采集数据。
环境和安装
Puppeteer本身依赖6.4以上的Node,但是对于异步和超级好用的async/await,推荐使用7.6以上的Node。另外,headless Chrome 本身对服务器依赖的库版本要求也比较高。 centos 服务器依赖于稳定性。很难在 v6 中使用无头 Chrome。增加依赖版本时可能会出现各种服务器问题(包括但不限于无法使用ssh)。最好使用高版本服务器。 (建议使用最新版本的Node.js)
做个小测试,爬取京东资源
const puppeteer = require('puppeteer'); // 引入依赖
(async () => { //使用async函数完美异步
const browser = await puppeteer.launch(); //打开新的浏览器
const page = await browser.newPage(); // 打开新的网页
await page.goto('https://www.jd.com/'); //前往里面 'url' 的网页
const result = await page.evaluate(() => { //这个result数组包含所有的图片src地址
let arr = []; //这个箭头函数内部写处理的逻辑
const imgs = document.querySelectorAll('img');
imgs.forEach(function (item) {
arr.push(item.src)
})
return arr
});
// '此时的result就是得到的爬虫数据,可以通过'fs'模块保存'
})()
复制过去 使用命令行命令 ` node 文件名 ` 就可以运行获取爬虫数据了
这个 puppeteer 的包 ,其实是替我们开启了另一个浏览器,重新去开启网页,获取它们的数据。
上面只爬取了京东首页的图片内容。假设我的需求进一步扩展,我需要爬取京东主页
跳转网页中所有标签对应的所有标题的文字内容
最终被放入一个数组中。
我们的异步函数分为五步,只有 puppeteer.launch() ,
browser.newPage()、browser.close() 是固定的书写方式。
page.goto 指定我们去哪个网页抓取数据,我们可以更改内部url地址,或者多次
调用这个方法。
page.evaluate这个函数,内部是处理我们进入我们要爬取的网页的数据逻辑
page.goto 和 page.evaluate 两个方法可以在 async 中多次调用。
也就是说我们可以先进入京东网页,处理完逻辑,再调用page.goto函数,
注意,上面这一切逻辑,都是puppeteer这个包帮我们在看不见的地方开启了另外一个浏览器,然后处理逻辑,所以最终要调用<b>browser.close()方法关闭那个浏览器。
此时,我们优化了上一篇文章中的代码,抓取了相应的资源。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.jd.com/');
const hrefArr = await page.evaluate(() => {
let arr = [];
const aNodes = document.querySelectorAll('.cate_menu_lk');
aNodes.forEach(function (item) {
arr.push(item.href)
})
return arr
});
let arr = [];
for (let i = 0; i < hrefArr.length; i++) {
const url = hrefArr[i];
console.log(url) //这里可以打印
await page.goto(url);
const result = await page.evaluate(() => { //这个方法内部console.log无效
return $('title').text(); //返回每个界面的title文字内容
});
arr.push(result) //每次循环给数组中添加对应的值
}
console.log(arr) //得到对应的数据 可以通过Node.js的 fs 模块保存到本地
await browser.close()
})()
上面有天坑 page.evaluate函数内部的console.log不能打印,而且内部不能获取外部的变量,只能return返回,使用的选择器必须先去对应界面的控制台实验过能不能选择DOM再使用,比如京东无法使用querySelector。这里由于
京东的分界面都使用了jQuery,所以我们可以用jQuery,总之他们开发能用的选择器,我们都可以用,否则就不可以。
接下来直接爬取Node.js官网首页,直接生成PDF。无论您是否了解 Node.js 和 puppeteer 爬虫,您都可以做到。请仔细阅读本文档并按顺序执行。一步
本项目实现需求:给我们一个网页地址,爬取他的网页内容,然后输出成我们想要的PDF格式文档,请注意,是高质量的PDF文档
第一步,安装Node.js,推荐,从Node.js中文官网下载对应的操作系统包
第二步,下载安装Node.js后,启动windows命令行工具(windows下启动系统搜索功能,输入cmd,回车,就出来了)
第三步检查是否自动配置了环境变量,在命令行工具中输入node -v,如果出现v10.***字段,说明Node.js已经安装成功
第四步如果在第三步输入node -v后发现没有出现对应的字段,请重启电脑。
第五步打开项目文件夹,打开命令行工具(windows系统下,直接在文件的url地址栏中输入cmd打开),输入npm i cnpm nodemon -g
第六步,下载puppeteer爬虫包。完成第五步后,使用cnpm i puppeteer --save命令下载
Step 7 完成Step 6的下载后,打开本项目的url.js,替换你需要爬取的网页地址(默认是)
第八步在命令行输入nodemon index.js,抓取对应的内容并自动输出到当前文件夹下的index.pdf文件
<b>TIPS: 本项目设计思想就是一个网页一个PDF文件,所以每次爬取一个单独页面后,请把index.pdf拷贝出去,然后继续更换url地址,继续爬取,生成新的PDF文件,当然,您也可以通过循环编译等方式去一次性爬取多个网页生成多个PDF文件。<p>对应像京东首页这样的开启了图片懒加载的网页,爬取到的部分内容是loading状态的内容,对于有一些反爬虫机制的网页,爬虫也会出现问题,但是绝大多数网站都是可以的
</p>
const puppeteer = require('puppeteer');
const url = require('./url');
(async () => {
const browser = await puppeteer.launch({ headless: true })
const page = await browser.newPage()
//选择要打开的网页
await page.goto(url, { waitUntil: 'networkidle0' })
//选择你要输出的那个PDF文件路径,把爬取到的内容输出到PDF中,必须是存在的PDF,可以是空内容,如果不是空的内容PDF,那么会覆盖内容
let pdfFilePath = './index.pdf';
//根据你的配置选项,我们这里选择A4纸的规格输出PDF,方便打印
await page.pdf({
path: pdfFilePath,
format: 'A4',
scale: 1,
printBackground: true,
landscape: false,
displayHeaderFooter: false
});
await browser.close()
})()
文件解构设计
数据在这个时代非常珍贵,按照网页的设计逻辑,选定特定的href的地址,可以先直接获取对应的资源,也可以通过再次使用 page.goto方法进入,再调用 page.evaluate() 处理逻辑,或者输出对应的PDF文件,当然也可以一口气输出多个PDF文件~这里就不做过多介绍了,毕竟<b> Node.js 是可以上天的,或许未来它真的什么都能做。这么优质简短的教程,请收藏
或者转发给您的朋友,谢谢。
文章来源:segmentfault,作者:Peter谭金杰。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:william.shi#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
后台-系统设置-扩展变量-移动广告位-内容正文底部 查看全部
使用Node.js爬取网页资源,开箱即用的配置将爬取到的网页内容
本文适合无论是否有爬虫以及Node.js基础的朋友观看~
要求:
使用 Node.js 抓取网络资源,开箱即用的配置
以PDF格式输出抓取的网页内容
如果你是技术员,那可以看我下一个文章,否则请直接移步我的github仓库,看文档就行了。仓库地址:附文档和源码,别忘了我给了star这个需求用到的技术:Node.js and puppeteer
puppeteer 官网地址:puppeteer 地址
Node.js 官网地址:链接说明
Puppeteer 是 Google 官方出品的 Node 库,通过 DevTools 协议控制 Headless Chrome。您可以通过Puppeteer提供的api直接控制Chrome模拟大部分用户操作进行UI测试或者作为爬虫访问页面采集数据。
环境和安装
Puppeteer本身依赖6.4以上的Node,但是对于异步和超级好用的async/await,推荐使用7.6以上的Node。另外,headless Chrome 本身对服务器依赖的库版本要求也比较高。 centos 服务器依赖于稳定性。很难在 v6 中使用无头 Chrome。增加依赖版本时可能会出现各种服务器问题(包括但不限于无法使用ssh)。最好使用高版本服务器。 (建议使用最新版本的Node.js)
做个小测试,爬取京东资源
const puppeteer = require('puppeteer'); // 引入依赖
(async () => { //使用async函数完美异步
const browser = await puppeteer.launch(); //打开新的浏览器
const page = await browser.newPage(); // 打开新的网页
await page.goto('https://www.jd.com/'); //前往里面 'url' 的网页
const result = await page.evaluate(() => { //这个result数组包含所有的图片src地址
let arr = []; //这个箭头函数内部写处理的逻辑
const imgs = document.querySelectorAll('img');
imgs.forEach(function (item) {
arr.push(item.src)
})
return arr
});
// '此时的result就是得到的爬虫数据,可以通过'fs'模块保存'
})()
复制过去 使用命令行命令 ` node 文件名 ` 就可以运行获取爬虫数据了
这个 puppeteer 的包 ,其实是替我们开启了另一个浏览器,重新去开启网页,获取它们的数据。
上面只爬取了京东首页的图片内容。假设我的需求进一步扩展,我需要爬取京东主页
跳转网页中所有标签对应的所有标题的文字内容
最终被放入一个数组中。
我们的异步函数分为五步,只有 puppeteer.launch() ,
browser.newPage()、browser.close() 是固定的书写方式。
page.goto 指定我们去哪个网页抓取数据,我们可以更改内部url地址,或者多次
调用这个方法。
page.evaluate这个函数,内部是处理我们进入我们要爬取的网页的数据逻辑
page.goto 和 page.evaluate 两个方法可以在 async 中多次调用。
也就是说我们可以先进入京东网页,处理完逻辑,再调用page.goto函数,
注意,上面这一切逻辑,都是puppeteer这个包帮我们在看不见的地方开启了另外一个浏览器,然后处理逻辑,所以最终要调用<b>browser.close()方法关闭那个浏览器。
此时,我们优化了上一篇文章中的代码,抓取了相应的资源。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.jd.com/');
const hrefArr = await page.evaluate(() => {
let arr = [];
const aNodes = document.querySelectorAll('.cate_menu_lk');
aNodes.forEach(function (item) {
arr.push(item.href)
})
return arr
});
let arr = [];
for (let i = 0; i < hrefArr.length; i++) {
const url = hrefArr[i];
console.log(url) //这里可以打印
await page.goto(url);
const result = await page.evaluate(() => { //这个方法内部console.log无效
return $('title').text(); //返回每个界面的title文字内容
});
arr.push(result) //每次循环给数组中添加对应的值
}
console.log(arr) //得到对应的数据 可以通过Node.js的 fs 模块保存到本地
await browser.close()
})()
上面有天坑 page.evaluate函数内部的console.log不能打印,而且内部不能获取外部的变量,只能return返回,使用的选择器必须先去对应界面的控制台实验过能不能选择DOM再使用,比如京东无法使用querySelector。这里由于
京东的分界面都使用了jQuery,所以我们可以用jQuery,总之他们开发能用的选择器,我们都可以用,否则就不可以。
接下来直接爬取Node.js官网首页,直接生成PDF。无论您是否了解 Node.js 和 puppeteer 爬虫,您都可以做到。请仔细阅读本文档并按顺序执行。一步
本项目实现需求:给我们一个网页地址,爬取他的网页内容,然后输出成我们想要的PDF格式文档,请注意,是高质量的PDF文档
第一步,安装Node.js,推荐,从Node.js中文官网下载对应的操作系统包
第二步,下载安装Node.js后,启动windows命令行工具(windows下启动系统搜索功能,输入cmd,回车,就出来了)
第三步检查是否自动配置了环境变量,在命令行工具中输入node -v,如果出现v10.***字段,说明Node.js已经安装成功
第四步如果在第三步输入node -v后发现没有出现对应的字段,请重启电脑。
第五步打开项目文件夹,打开命令行工具(windows系统下,直接在文件的url地址栏中输入cmd打开),输入npm i cnpm nodemon -g
第六步,下载puppeteer爬虫包。完成第五步后,使用cnpm i puppeteer --save命令下载
Step 7 完成Step 6的下载后,打开本项目的url.js,替换你需要爬取的网页地址(默认是)
第八步在命令行输入nodemon index.js,抓取对应的内容并自动输出到当前文件夹下的index.pdf文件
<b>TIPS: 本项目设计思想就是一个网页一个PDF文件,所以每次爬取一个单独页面后,请把index.pdf拷贝出去,然后继续更换url地址,继续爬取,生成新的PDF文件,当然,您也可以通过循环编译等方式去一次性爬取多个网页生成多个PDF文件。<p>对应像京东首页这样的开启了图片懒加载的网页,爬取到的部分内容是loading状态的内容,对于有一些反爬虫机制的网页,爬虫也会出现问题,但是绝大多数网站都是可以的
</p>
const puppeteer = require('puppeteer');
const url = require('./url');
(async () => {
const browser = await puppeteer.launch({ headless: true })
const page = await browser.newPage()
//选择要打开的网页
await page.goto(url, { waitUntil: 'networkidle0' })
//选择你要输出的那个PDF文件路径,把爬取到的内容输出到PDF中,必须是存在的PDF,可以是空内容,如果不是空的内容PDF,那么会覆盖内容
let pdfFilePath = './index.pdf';
//根据你的配置选项,我们这里选择A4纸的规格输出PDF,方便打印
await page.pdf({
path: pdfFilePath,
format: 'A4',
scale: 1,
printBackground: true,
landscape: false,
displayHeaderFooter: false
});
await browser.close()
})()
文件解构设计
数据在这个时代非常珍贵,按照网页的设计逻辑,选定特定的href的地址,可以先直接获取对应的资源,也可以通过再次使用 page.goto方法进入,再调用 page.evaluate() 处理逻辑,或者输出对应的PDF文件,当然也可以一口气输出多个PDF文件~这里就不做过多介绍了,毕竟<b> Node.js 是可以上天的,或许未来它真的什么都能做。这么优质简短的教程,请收藏
或者转发给您的朋友,谢谢。
文章来源:segmentfault,作者:Peter谭金杰。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:william.shi#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
后台-系统设置-扩展变量-移动广告位-内容正文底部
本文将通过实际例子讲解怎么使用javascript或者jquery获取地址
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-15 01:14
本文将通过实例讲解如何使用javascript或jquery获取地址url参数。我希望你会喜欢。问题描述 今天要做一个主题,有一个要求是根据不同的页面来做。虽然php也可以,但是考虑到我的特效代码是在jQuery上做的,不知道能不能直接在地址栏中获取地址。链接参数中的数字直接达到效果。假设页面地址是这样的。 ,然后我想得到最后一个数字165,通过这段代码
var url= window.location.href;
var index = url.substring(url.lastIndexOf('/') + 1);
但这是有缺陷的。如果我得到的地址不是这种形式,而是形式,那么这个索引的值就不是数字。以下哪种解决方案可能更好?
var lastBit = url.substring(url.lastIndexOf('/') + 1).match(/[^/]*$/)[0];
var lastDigits = url.substring(url.lastIndexOf('/') + 1).match(/[0-9]*$/)[0]; // 获取的是数字部分
获取查询值 JavaScript 版本:
function getUrlParam(name){
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r!=null) return unescape(r[2]); return null;
}
//获取http://caibaojian.com/?p=177.html的p值
getUrlParam('p'); //输出177
jQuery 版本:
(function($){
$.getUrlParam = function(name)
{
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r!=null) return unescape(r[2]); return null;
}
})(jQuery);
$(function(){
alert(window.location.href);
alert($.getUrlParam('page'));
})
当一个页面的地址是上面的时候,那么我们使用上面的jQuery代码,会弹出一个数字5。 Content extensionFor URLs如下: 80/fisker/post/0703/window.location.html?ver=1.0&id=6#imhere 我们可以使用javascript来获取各个部分1,window.location.href-- --------整个 URl 字符串(在浏览器中是完整的地址栏) 本例返回值: :80/fisker/post/0703/window.location.html?ver=1. 0&id= 6#imhere2,window.location.protocol---------URL的协议部分。本例返回值:http:3,window.location.host-----of the URL 本例中host部分的返回值:4、window.location.port---- -如果URL的端口部分使用默认的80端口(更新:即使添加:80),返回值也不是默认的80。是空字符。本例返回值:“” 5、window.location.pathname(URL的路径部分(即文件地址)) 本例返回值:/fisker/post/0703/window.location.html6,window.location.search-- -----除了在查询(参数)部分给动态语言赋值,我们还可以为静态页面赋值,使用javascript获取我们认为本例中应该返回的参数值: ?ver=1.0&id= 67, window.location.hash-------本例中的锚返回值:#imhere 查看全部
本文将通过实际例子讲解怎么使用javascript或者jquery获取地址
本文将通过实例讲解如何使用javascript或jquery获取地址url参数。我希望你会喜欢。问题描述 今天要做一个主题,有一个要求是根据不同的页面来做。虽然php也可以,但是考虑到我的特效代码是在jQuery上做的,不知道能不能直接在地址栏中获取地址。链接参数中的数字直接达到效果。假设页面地址是这样的。 ,然后我想得到最后一个数字165,通过这段代码
var url= window.location.href;
var index = url.substring(url.lastIndexOf('/') + 1);
但这是有缺陷的。如果我得到的地址不是这种形式,而是形式,那么这个索引的值就不是数字。以下哪种解决方案可能更好?
var lastBit = url.substring(url.lastIndexOf('/') + 1).match(/[^/]*$/)[0];
var lastDigits = url.substring(url.lastIndexOf('/') + 1).match(/[0-9]*$/)[0]; // 获取的是数字部分
获取查询值 JavaScript 版本:
function getUrlParam(name){
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r!=null) return unescape(r[2]); return null;
}
//获取http://caibaojian.com/?p=177.html的p值
getUrlParam('p'); //输出177
jQuery 版本:
(function($){
$.getUrlParam = function(name)
{
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r!=null) return unescape(r[2]); return null;
}
})(jQuery);
$(function(){
alert(window.location.href);
alert($.getUrlParam('page'));
})
当一个页面的地址是上面的时候,那么我们使用上面的jQuery代码,会弹出一个数字5。 Content extensionFor URLs如下: 80/fisker/post/0703/window.location.html?ver=1.0&id=6#imhere 我们可以使用javascript来获取各个部分1,window.location.href-- --------整个 URl 字符串(在浏览器中是完整的地址栏) 本例返回值: :80/fisker/post/0703/window.location.html?ver=1. 0&id= 6#imhere2,window.location.protocol---------URL的协议部分。本例返回值:http:3,window.location.host-----of the URL 本例中host部分的返回值:4、window.location.port---- -如果URL的端口部分使用默认的80端口(更新:即使添加:80),返回值也不是默认的80。是空字符。本例返回值:“” 5、window.location.pathname(URL的路径部分(即文件地址)) 本例返回值:/fisker/post/0703/window.location.html6,window.location.search-- -----除了在查询(参数)部分给动态语言赋值,我们还可以为静态页面赋值,使用javascript获取我们认为本例中应该返回的参数值: ?ver=1.0&id= 67, window.location.hash-------本例中的锚返回值:#imhere
这一招很有实用性,实用性在哪呢哪用到哪!
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-08-15 01:07
获取一个字符串,这个字符串恰好有一个html结构,也就是里面有标签节点。我们需要将某个id或者class的节点与其分离,那么我们该怎么做呢?当然,它是正则匹配提取和切割技术的混搭。为了方便复用,我写了一个函数,无论走到哪里都可以使用!这个文章的标题是“Html字符串过滤提取指定节点”。
这个技巧很实用。实用性在哪里?想想网站 的非刷新ajax。通过学习这个文章 代码,你会喜欢上 ajax 而不需要后端接口。只要有网站,在ajax请求下,提取返回的html有用信息,可以通过id和class获取节点内所有html,然后插入到页面中,这就是整个网站ajax的精髓.
function getNode(node,html){
var type=node.charAt(0);//获取类型,支持 #id、.class和tag三种类型;
var selector,data,regExp;
if(type=="#"){
selector=node.substring(1);
regExp=new RegExp(']+id=\"\\s*' + selector + '\\s*\"[^>]*>',"gi");
}else if(type=="."){
selector=node.substring(1);
regExp=new RegExp(']+class=(\"' + selector + '\"|\".*?\\s*' + selector + '\"|\"' + selector + '\\s*.*?\"|\".*?\\s*' + selector + '\\s*.*?\")[^>]*>',"gi");
}else{
selector=node;
regExp=new RegExp('|\\s+[^>].*?>)',"gi");
}
if(!html.match(regExp)){
console.log("在指定字符串中没有找到节点!")
return "";
}
var matchArr=html.split(match);
var match=html.match(regExp)[0];
if(matchArr.length > 2){//多次匹配则取第一次匹配,其余忽略
var data=matchArr.filter(function(n,index){
return index!==0;
}).join("");
}else{
var data = html.split(match)[1];
}
var tagName=match.match(/ 0) {
var temp = data.split('')[0];
var i = 0;
var pos = temp.indexOf("666
,
" mizuiren">666
,
水人">666
,
" 水人 ">666
可以匹配到id为mizuiren的节点,注意空格。
同理,类也可以匹配
水人">
,
"mizuiren com">
,
mizuiren com">
等待多次或不规则的书写,但不要写错。
除了提取id和class,还可以提取标签,比如div、span、i等所有标签,类似jq的选择器但是不同。
需要注意的是,无论提取什么类型,都只能是唯一的。如果在字符串中找到多个id和class,只会选择第一个匹配的节点,匹配节点中可能会有一些匹配节点。这不是bug,是故意弄成这样的~。最好是保证选择器的唯一性,比如使用id?
例如有以下字符串:
var html = '不要看啦,我是字符串。小明666var me="秋叶";人文风情<strong>哈哈哈哈 </strong>what?dewfq小红';
提取节点示例:
getNode(".xiaoming",html);
1
getNode("#xiao",html);
2
getNode(".qiuleqiu",html);
3
getNode("strong",html);
3 查看全部
这一招很有实用性,实用性在哪呢哪用到哪!
获取一个字符串,这个字符串恰好有一个html结构,也就是里面有标签节点。我们需要将某个id或者class的节点与其分离,那么我们该怎么做呢?当然,它是正则匹配提取和切割技术的混搭。为了方便复用,我写了一个函数,无论走到哪里都可以使用!这个文章的标题是“Html字符串过滤提取指定节点”。
这个技巧很实用。实用性在哪里?想想网站 的非刷新ajax。通过学习这个文章 代码,你会喜欢上 ajax 而不需要后端接口。只要有网站,在ajax请求下,提取返回的html有用信息,可以通过id和class获取节点内所有html,然后插入到页面中,这就是整个网站ajax的精髓.
function getNode(node,html){
var type=node.charAt(0);//获取类型,支持 #id、.class和tag三种类型;
var selector,data,regExp;
if(type=="#"){
selector=node.substring(1);
regExp=new RegExp(']+id=\"\\s*' + selector + '\\s*\"[^>]*>',"gi");
}else if(type=="."){
selector=node.substring(1);
regExp=new RegExp(']+class=(\"' + selector + '\"|\".*?\\s*' + selector + '\"|\"' + selector + '\\s*.*?\"|\".*?\\s*' + selector + '\\s*.*?\")[^>]*>',"gi");
}else{
selector=node;
regExp=new RegExp('|\\s+[^>].*?>)',"gi");
}
if(!html.match(regExp)){
console.log("在指定字符串中没有找到节点!")
return "";
}
var matchArr=html.split(match);
var match=html.match(regExp)[0];
if(matchArr.length > 2){//多次匹配则取第一次匹配,其余忽略
var data=matchArr.filter(function(n,index){
return index!==0;
}).join("");
}else{
var data = html.split(match)[1];
}
var tagName=match.match(/ 0) {
var temp = data.split('')[0];
var i = 0;
var pos = temp.indexOf("666
,
" mizuiren">666
,
水人">666
,
" 水人 ">666
可以匹配到id为mizuiren的节点,注意空格。
同理,类也可以匹配
水人">
,
"mizuiren com">
,
mizuiren com">
等待多次或不规则的书写,但不要写错。
除了提取id和class,还可以提取标签,比如div、span、i等所有标签,类似jq的选择器但是不同。
需要注意的是,无论提取什么类型,都只能是唯一的。如果在字符串中找到多个id和class,只会选择第一个匹配的节点,匹配节点中可能会有一些匹配节点。这不是bug,是故意弄成这样的~。最好是保证选择器的唯一性,比如使用id?
例如有以下字符串:
var html = '不要看啦,我是字符串。小明666var me="秋叶";人文风情<strong>哈哈哈哈 </strong>what?dewfq小红';
提取节点示例:
getNode(".xiaoming",html);
1
getNode("#xiao",html);
2
getNode(".qiuleqiu",html);
3
getNode("strong",html);
3
JavaScript驾驭网页-CSS与DOM利用DOM分割HTML利用分割
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-08-14 19:13
JavaScript 控制网页——CSS 和 DOM
使用 DOM 拆分 HTML
使用 JavaScript 控制网页内容实际上很像烹饪。只是剩菜不用清理,却没办法享受到美味。
但是,您将能够完成网页内容的 HTML 元素:更重要的是,您将能够替换网页元素。
JavaScript 允许你随心所欲地操作网页的 HTML 代码,从而开启各种有趣的机会,这一切都是因为标准对象:DOM 的存在
getElementById
HTML标签都有一个"id"属性,第个标签的该属性都是独一无二的
可以通过id属性来获取元素
内容
var sceneDesc=document.getElementById("div2");
getElementById可以通过元素的id属性去访问标签
括号里是id的值
getElementsByTagName
也可以通过标签名来获取元素
内容
var divs=document.getElementsByTagName("div");
getElementsByTagName返回所有div标签,结果是一个数组,结果按照标签在HTML中的顺序排列
括号里是标签名
var divs=document.getElementsByTagName("div")[2];
用索引获取第三个div标签
内部HTML
innerHTML特性对所有存储在元素里的内容提供了访问管道
通过innerHTML访问元素内存储的内容:
<p id="story"> you are standing
alone in the woods.
document.getElementById("story").innerHTML;
返回的内容是: you are standing alone in the woods.
innerHTML获取的是指定元素下的所有内容与标签
innerHTML也能用于设置网页内容
document.getElementById("story").innerHTML="You are not alone!";
innerHTML只用来设置可以包含文本的标签</p>
给大家介绍这么多关于JavaScript控制网页的知识——网页元素的知识,希望对大家有帮助! 查看全部
JavaScript驾驭网页-CSS与DOM利用DOM分割HTML利用分割
JavaScript 控制网页——CSS 和 DOM
使用 DOM 拆分 HTML
使用 JavaScript 控制网页内容实际上很像烹饪。只是剩菜不用清理,却没办法享受到美味。
但是,您将能够完成网页内容的 HTML 元素:更重要的是,您将能够替换网页元素。
JavaScript 允许你随心所欲地操作网页的 HTML 代码,从而开启各种有趣的机会,这一切都是因为标准对象:DOM 的存在
getElementById
HTML标签都有一个"id"属性,第个标签的该属性都是独一无二的
可以通过id属性来获取元素
内容
var sceneDesc=document.getElementById("div2");
getElementById可以通过元素的id属性去访问标签
括号里是id的值
getElementsByTagName
也可以通过标签名来获取元素
内容
var divs=document.getElementsByTagName("div");
getElementsByTagName返回所有div标签,结果是一个数组,结果按照标签在HTML中的顺序排列
括号里是标签名
var divs=document.getElementsByTagName("div")[2];
用索引获取第三个div标签
内部HTML
innerHTML特性对所有存储在元素里的内容提供了访问管道
通过innerHTML访问元素内存储的内容:
<p id="story"> you are standing
alone in the woods.
document.getElementById("story").innerHTML;
返回的内容是: you are standing alone in the woods.
innerHTML获取的是指定元素下的所有内容与标签
innerHTML也能用于设置网页内容
document.getElementById("story").innerHTML="You are not alone!";
innerHTML只用来设置可以包含文本的标签</p>
给大家介绍这么多关于JavaScript控制网页的知识——网页元素的知识,希望对大家有帮助!
2017年05月12日11:13日js获取网页所有图片
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-08-09 20:12
2017年05月12日11:13日js获取网页所有图片
js如何获取网页上的所有图片
更新时间:2017年5月12日11:13:08 作者:指数
这个文章主要介绍js获取网页所有图片的方法,以及js获取网页所有图片的方法。有一定的参考价值。有兴趣的朋友可以参考一下
要求
点击网页上的图片,可以放大显示图片,并可以按顺序切换图片。同时,部分不符合要求的小图标和图片无法放大。
由于网页是在app中打开的,图片的缩放和切换是在移动端实现的,所以需要用js调用native方法,并传递所有图片的url
解决
var img = [];
for(var i=0;i20){
img[i] = $("img").eq(i).attr("src");
}
}
var img_info = {};
img_info.list = img; //保存所有图片的url
var imgs = document.getElementsByTagName('img');
for(var i = 0;i < imgs.length; i++){
if(parseInt($(imgs[i]).css('width')) > 20){
//将索引当作img标签的属性进行存储
$(imgs[i]).attr('index',i);
$(imgs[i]).click(function () {
//获取上面存储的图片的索引,这个索引就是当前图片的索引
img_info.index = $(this).attr('index');
//将信息转为json字符串
var json = JSON.stringify(img_info);
//判断是ios端还是android端
if (_IsIOS()) {
window.webkit.messageHandlers.showImg.postMessage(json);
} else if (_IsAndroid()) {
window.control.call('showImg',json);
}
});
}
}
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。 查看全部
2017年05月12日11:13日js获取网页所有图片
js如何获取网页上的所有图片
更新时间:2017年5月12日11:13:08 作者:指数
这个文章主要介绍js获取网页所有图片的方法,以及js获取网页所有图片的方法。有一定的参考价值。有兴趣的朋友可以参考一下
要求
点击网页上的图片,可以放大显示图片,并可以按顺序切换图片。同时,部分不符合要求的小图标和图片无法放大。
由于网页是在app中打开的,图片的缩放和切换是在移动端实现的,所以需要用js调用native方法,并传递所有图片的url
解决
var img = [];
for(var i=0;i20){
img[i] = $("img").eq(i).attr("src");
}
}
var img_info = {};
img_info.list = img; //保存所有图片的url
var imgs = document.getElementsByTagName('img');
for(var i = 0;i < imgs.length; i++){
if(parseInt($(imgs[i]).css('width')) > 20){
//将索引当作img标签的属性进行存储
$(imgs[i]).attr('index',i);
$(imgs[i]).click(function () {
//获取上面存储的图片的索引,这个索引就是当前图片的索引
img_info.index = $(this).attr('index');
//将信息转为json字符串
var json = JSON.stringify(img_info);
//判断是ios端还是android端
if (_IsIOS()) {
window.webkit.messageHandlers.showImg.postMessage(json);
} else if (_IsAndroid()) {
window.control.call('showImg',json);
}
});
}
}
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。
用js做时间校正,获取本机时间,是存在bug的
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-08-09 20:11
使用js进行时间校正获取当地时间存在一个bug。
服务器时间也可以通过js获取。原理是使用ajax请求,返回的头信息中收录服务器端的时间信息,拿到就够了。下面:
1、依赖于 jQuery
代码:
function getServerDate(){
return new Date($.ajax({async: false}).getResponseHeader("Date"));
}
上述函数返回一个Date对象。注意使用ajax时一定要同步,否则不能返回时间日期。
无需填写请求链接;
如果服务器时间和本地时间有时差,需要更正。
2、原
代码:
function getServerDate(){
var xhr = null;
if(window.XMLHttpRequest){
xhr = new window.XMLHttpRequest();
}else{ // ie
xhr = new ActiveObject("Microsoft")
}
xhr.open("GET","/",false)//false不可变
xhr.send(null);
var date = xhr.getResponseHeader("Date");
return new Date(date);
}
返回的是Date对象,xhr.open()必须使用同步;
无需填写请求链接; open、send 和 getResponseHeader 必须按顺序写入。
如果需要使用异步请求,可以监控onreadystatechange状态做不同的操作。
function getServerDate(){
var xhr = null;
if(window.XMLHttpRequest){
xhr = new window.XMLHttpRequest();
}else{ // ie
xhr = new ActiveObject("Microsoft")
}
xhr.open("GET","/",true);
xhr.send(null);
xhr.onreadystatechange=function(){
var time,date;
if(xhr.readyState == 2){
time = xhr.getResponseHeader("Date");
date = new Date(time);
console.log(date);
}
}
}
使用异步返回时间不是很方便。
这里的readyState有四种状态,方便不同的处理:
失败状态,状态值:
200:“好的”
404:找不到页面 查看全部
用js做时间校正,获取本机时间,是存在bug的
使用js进行时间校正获取当地时间存在一个bug。
服务器时间也可以通过js获取。原理是使用ajax请求,返回的头信息中收录服务器端的时间信息,拿到就够了。下面:
1、依赖于 jQuery
代码:
function getServerDate(){
return new Date($.ajax({async: false}).getResponseHeader("Date"));
}
上述函数返回一个Date对象。注意使用ajax时一定要同步,否则不能返回时间日期。
无需填写请求链接;
如果服务器时间和本地时间有时差,需要更正。
2、原
代码:
function getServerDate(){
var xhr = null;
if(window.XMLHttpRequest){
xhr = new window.XMLHttpRequest();
}else{ // ie
xhr = new ActiveObject("Microsoft")
}
xhr.open("GET","/",false)//false不可变
xhr.send(null);
var date = xhr.getResponseHeader("Date");
return new Date(date);
}
返回的是Date对象,xhr.open()必须使用同步;
无需填写请求链接; open、send 和 getResponseHeader 必须按顺序写入。
如果需要使用异步请求,可以监控onreadystatechange状态做不同的操作。
function getServerDate(){
var xhr = null;
if(window.XMLHttpRequest){
xhr = new window.XMLHttpRequest();
}else{ // ie
xhr = new ActiveObject("Microsoft")
}
xhr.open("GET","/",true);
xhr.send(null);
xhr.onreadystatechange=function(){
var time,date;
if(xhr.readyState == 2){
time = xhr.getResponseHeader("Date");
date = new Date(time);
console.log(date);
}
}
}
使用异步返回时间不是很方便。
这里的readyState有四种状态,方便不同的处理:
失败状态,状态值:
200:“好的”
404:找不到页面
本文适合无论是否有爬虫以及Node.js基础的朋友观看
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-08-08 12:39
本文适合无论是否有爬虫以及Node.js基础的朋友观看
本文不管有没有爬虫都适合
基于Node.js的朋友查看~
要求:如果你是技术人员,那么可以看我下一个文章,否则请直接移步我的github仓库,看文档就可以使用。仓库地址:附文档和源代码,本次需要用到的技术别忘了给个star:Node.js和puppeteer,试试看,爬取京东资源
const puppeteer = require('puppeteer'); // 引入依赖
(async () => { //使用async函数完美异步
const browser = await puppeteer.launch(); //打开新的浏览器
const page = await browser.newPage(); // 打开新的网页
await page.goto('https://www.jd.com/'); //前往里面 'url' 的网页
const result = await page.evaluate(() => { //这个result数组包含所有的图片src地址
let arr = []; //这个箭头函数内部写处理的逻辑
const imgs = document.querySelectorAll('img');
imgs.forEach(function (item) {
arr.push(item.src)
})
return arr
});
// '此时的result就是得到的爬虫数据,可以通过'fs'模块保存'
})()
复制过去 使用命令行命令 ` node 文件名 ` 就可以运行获取爬虫数据了
这个 puppeteer 的包 ,其实是替我们开启了另一个浏览器,重新去开启网页,获取它们的数据。
跳转网页中所有标签对应的所有标题的文字内容
最终被放入一个数组中。
browser.newPage()、browser.close() 是固定的书写方式。
调用这个方法。
也就是说我们可以先进入京东网页,处理完逻辑,再调用page.goto函数,
注意,以上逻辑全部都是
木偶包帮我们在一个看不见的地方又打开了一个
浏览器然后处理逻辑,所以它最终会被调用
browser.close() 方法关闭该浏览器。
此时我们优化了上一篇文章中的代码,抓取了相应的资源。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.jd.com/');
const hrefArr = await page.evaluate(() => {
let arr = [];
const aNodes = document.querySelectorAll('.cate_menu_lk');
aNodes.forEach(function (item) {
arr.push(item.href)
})
return arr
});
let arr = [];
for (let i = 0; i < hrefArr.length; i++) {
const url = hrefArr[i];
console.log(url) //这里可以打印
await page.goto(url);
const result = await page.evaluate(() => { //这个方法内部console.log无效
return $('title').text(); //返回每个界面的title文字内容
});
arr.push(result) //每次循环给数组中添加对应的值
}
console.log(arr) //得到对应的数据 可以通过Node.js的 fs 模块保存到本地
await browser.close()
})()
上面有个天坑。 page.evaluate函数内部的console.log无法打印,内部无法获取外部变量,只能返回return。
使用的选择器在使用前必须先到对应界面的控制台测试是否可以选择DOM。比如京东就不能使用querySelector。因为
京东的子接口全部使用jQuery,所以我们可以使用jQuery。简而言之,我们可以使用他们开发的所有可以使用的选择器,否则我们无法使用。
接下来直接爬取Node.js官网首页,直接生成PDF。无论您是否了解 Node.js 和 puppeteer 爬虫,您都可以做到。请仔细阅读本文档并按顺序执行。一步
本项目的实现需求:给我们一个网页地址,抓取他的网页内容,然后输出成我们想要的PDF格式文档。请注意这是一个高质量的PDF文档
TIPS:这个项目的设计思路是一个网页一个
PDF 文件,所以每次抓取一个页面后,请放
复制index.pdf,然后继续替换
URL地址,继续爬取生成新的
PDF文件,当然也可以一次抓取多个网页,通过循环编译等方式生成多个。
PDF 文件。
对应京东首页这种图片懒加载的网页,爬取的部分内容是处于加载状态的内容。对于有一些反爬虫机制的网页,爬虫也会有问题,但是绝大多数网站Its all可能
文件解构设计
数据在这个时代非常宝贵。根据网页的设计逻辑,选择具体的
href地址,可以直接先获取对应的资源,也可以再次使用
进入page.goto方法并再次调用
page.evaluate() 处理逻辑,或者输出对应的
PDF文件,当然也可以一次输出多个
PDF文件~
这里就不多介绍了
Node.js 能上天堂,说不定以后真的什么都可以了。这么高质量的短教程,请采集
或者转发给你的朋友,谢谢。 查看全部
本文适合无论是否有爬虫以及Node.js基础的朋友观看
本文不管有没有爬虫都适合
基于Node.js的朋友查看~
要求:如果你是技术人员,那么可以看我下一个文章,否则请直接移步我的github仓库,看文档就可以使用。仓库地址:附文档和源代码,本次需要用到的技术别忘了给个star:Node.js和puppeteer,试试看,爬取京东资源
const puppeteer = require('puppeteer'); // 引入依赖
(async () => { //使用async函数完美异步
const browser = await puppeteer.launch(); //打开新的浏览器
const page = await browser.newPage(); // 打开新的网页
await page.goto('https://www.jd.com/'); //前往里面 'url' 的网页
const result = await page.evaluate(() => { //这个result数组包含所有的图片src地址
let arr = []; //这个箭头函数内部写处理的逻辑
const imgs = document.querySelectorAll('img');
imgs.forEach(function (item) {
arr.push(item.src)
})
return arr
});
// '此时的result就是得到的爬虫数据,可以通过'fs'模块保存'
})()
复制过去 使用命令行命令 ` node 文件名 ` 就可以运行获取爬虫数据了
这个 puppeteer 的包 ,其实是替我们开启了另一个浏览器,重新去开启网页,获取它们的数据。
跳转网页中所有标签对应的所有标题的文字内容
最终被放入一个数组中。
browser.newPage()、browser.close() 是固定的书写方式。
调用这个方法。
也就是说我们可以先进入京东网页,处理完逻辑,再调用page.goto函数,
注意,以上逻辑全部都是
木偶包帮我们在一个看不见的地方又打开了一个
浏览器然后处理逻辑,所以它最终会被调用
browser.close() 方法关闭该浏览器。
此时我们优化了上一篇文章中的代码,抓取了相应的资源。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.jd.com/');
const hrefArr = await page.evaluate(() => {
let arr = [];
const aNodes = document.querySelectorAll('.cate_menu_lk');
aNodes.forEach(function (item) {
arr.push(item.href)
})
return arr
});
let arr = [];
for (let i = 0; i < hrefArr.length; i++) {
const url = hrefArr[i];
console.log(url) //这里可以打印
await page.goto(url);
const result = await page.evaluate(() => { //这个方法内部console.log无效
return $('title').text(); //返回每个界面的title文字内容
});
arr.push(result) //每次循环给数组中添加对应的值
}
console.log(arr) //得到对应的数据 可以通过Node.js的 fs 模块保存到本地
await browser.close()
})()
上面有个天坑。 page.evaluate函数内部的console.log无法打印,内部无法获取外部变量,只能返回return。
使用的选择器在使用前必须先到对应界面的控制台测试是否可以选择DOM。比如京东就不能使用querySelector。因为
京东的子接口全部使用jQuery,所以我们可以使用jQuery。简而言之,我们可以使用他们开发的所有可以使用的选择器,否则我们无法使用。
接下来直接爬取Node.js官网首页,直接生成PDF。无论您是否了解 Node.js 和 puppeteer 爬虫,您都可以做到。请仔细阅读本文档并按顺序执行。一步
本项目的实现需求:给我们一个网页地址,抓取他的网页内容,然后输出成我们想要的PDF格式文档。请注意这是一个高质量的PDF文档
TIPS:这个项目的设计思路是一个网页一个
PDF 文件,所以每次抓取一个页面后,请放
复制index.pdf,然后继续替换
URL地址,继续爬取生成新的
PDF文件,当然也可以一次抓取多个网页,通过循环编译等方式生成多个。
PDF 文件。
对应京东首页这种图片懒加载的网页,爬取的部分内容是处于加载状态的内容。对于有一些反爬虫机制的网页,爬虫也会有问题,但是绝大多数网站Its all可能
文件解构设计
数据在这个时代非常宝贵。根据网页的设计逻辑,选择具体的
href地址,可以直接先获取对应的资源,也可以再次使用
进入page.goto方法并再次调用
page.evaluate() 处理逻辑,或者输出对应的
PDF文件,当然也可以一次输出多个
PDF文件~
这里就不多介绍了
Node.js 能上天堂,说不定以后真的什么都可以了。这么高质量的短教程,请采集
或者转发给你的朋友,谢谢。
什么是IE专用(#39)元素的ID?(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-08-06 19:14
1. IE 专用(按帧索引图像定位):document.frames[i].document.getElementById('Element ID');
2. IE 专用(按 IFRAME 名称图片定位):document.frames['iframe's name'].document.getElementById('element ID');
以上方法不仅适用于IFRAME,也适用于FRAMESET中的FRAME。 IE虽然擅长自定义标准,但不得不说它的很多设计还是比较人性化的。例如,除了支持以下标准路径外,还提供了一种简洁直观的书写方式。
3.一般方法:document.getElementById('iframe ID').contentWindow.document.getElementById('element ID')
请注意,应添加 contentWindow。问题经常出现,因为这很容易被忽视。它代表了 FRAME 和 IFRAME 内部的窗口对象。
但是,很明显,这篇文章非常糟糕而且太长了。如果你要操作一个系列的元素,这个真的够写了,就算你用复制粘贴大法,你的眼睛好像也有问题。
4.一般方法的简写:
为 document.getElementById 定义一个短名称。稍微熟悉JS的朋友都知道这个方法。在这里它可以起到双重作用,如下例所示:
这一点上,我还是喜欢IE的做法,比较贴心。因为微软不是一个单独的浏览器开发商,它也编写和开发了大量的HTML/ASP等文档,所以它更能做到这一点。其他浏览器开发者基本上只是站在浏览器的角度,完成最基本的链接。他们很少站在开发人员的角度来设计这样简单且语义化的东西。捷径来了。很多人常说是“标准”,有的地方是合理的,但有的地方,这样的标准只是一种冷漠。
转载请注明出自赵亮(csdn)博客。 查看全部
什么是IE专用(#39)元素的ID?(图)
1. IE 专用(按帧索引图像定位):document.frames[i].document.getElementById('Element ID');
2. IE 专用(按 IFRAME 名称图片定位):document.frames['iframe's name'].document.getElementById('element ID');
以上方法不仅适用于IFRAME,也适用于FRAMESET中的FRAME。 IE虽然擅长自定义标准,但不得不说它的很多设计还是比较人性化的。例如,除了支持以下标准路径外,还提供了一种简洁直观的书写方式。
3.一般方法:document.getElementById('iframe ID').contentWindow.document.getElementById('element ID')
请注意,应添加 contentWindow。问题经常出现,因为这很容易被忽视。它代表了 FRAME 和 IFRAME 内部的窗口对象。
但是,很明显,这篇文章非常糟糕而且太长了。如果你要操作一个系列的元素,这个真的够写了,就算你用复制粘贴大法,你的眼睛好像也有问题。
4.一般方法的简写:
为 document.getElementById 定义一个短名称。稍微熟悉JS的朋友都知道这个方法。在这里它可以起到双重作用,如下例所示:
这一点上,我还是喜欢IE的做法,比较贴心。因为微软不是一个单独的浏览器开发商,它也编写和开发了大量的HTML/ASP等文档,所以它更能做到这一点。其他浏览器开发者基本上只是站在浏览器的角度,完成最基本的链接。他们很少站在开发人员的角度来设计这样简单且语义化的东西。捷径来了。很多人常说是“标准”,有的地方是合理的,但有的地方,这样的标准只是一种冷漠。
转载请注明出自赵亮(csdn)博客。
写个简单的URL来抓取相应的网页内容,然后存入本地文件
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-08-02 23:10
今天写一个简单的程序,根据指定的URL抓取对应的网页内容,然后保存到本地文件中。本课程将涉及网络请求、文件操作等知识点。以下是实现代码:
// fetch.go
package main
import (
"os"
"fmt"
"net/http"
"io/ioutil"
)
func main() {
url := os.Args[1]
// 根据URL获取资源
res, err := http.Get(url)
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: %v\n", err)
os.Exit(1)
}
// 读取资源数据 body: []byte
body, err := ioutil.ReadAll(res.Body)
// 关闭资源流
res.Body.Close()
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: reading %s: %v\n", url, err)
os.Exit(1)
}
// 控制台打印内容 以下两种方法等同
fmt.Printf("%s", body)
fmt.Printf(string(body))
// 写入文件
ioutil.WriteFile("site.txt", body, 0644)
}
在上面的代码中,我们引入了net/http网络包,然后调用http.Get(url)方法获取URL对应的资源,然后读取资源数据,然后在控制台打印出来,并将内容写入本地文件。
需要注意的是,读取资源数据后,要及时关闭资源流,避免内存资源泄露。
另外,在处理异常时,我们使用了 fm.Fprintf() 方法,它是三大格式化方法之一:
编译后运行程序,并指定一个URL参数,这里暂时指定为百度。我还是希望 Google 在不久的将来回归:
$ ./fetch http://www.baidu.com
运行程序后,会在当前目录下生成一个site.txt文件。 查看全部
写个简单的URL来抓取相应的网页内容,然后存入本地文件
今天写一个简单的程序,根据指定的URL抓取对应的网页内容,然后保存到本地文件中。本课程将涉及网络请求、文件操作等知识点。以下是实现代码:
// fetch.go
package main
import (
"os"
"fmt"
"net/http"
"io/ioutil"
)
func main() {
url := os.Args[1]
// 根据URL获取资源
res, err := http.Get(url)
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: %v\n", err)
os.Exit(1)
}
// 读取资源数据 body: []byte
body, err := ioutil.ReadAll(res.Body)
// 关闭资源流
res.Body.Close()
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: reading %s: %v\n", url, err)
os.Exit(1)
}
// 控制台打印内容 以下两种方法等同
fmt.Printf("%s", body)
fmt.Printf(string(body))
// 写入文件
ioutil.WriteFile("site.txt", body, 0644)
}
在上面的代码中,我们引入了net/http网络包,然后调用http.Get(url)方法获取URL对应的资源,然后读取资源数据,然后在控制台打印出来,并将内容写入本地文件。
需要注意的是,读取资源数据后,要及时关闭资源流,避免内存资源泄露。
另外,在处理异常时,我们使用了 fm.Fprintf() 方法,它是三大格式化方法之一:
编译后运行程序,并指定一个URL参数,这里暂时指定为百度。我还是希望 Google 在不久的将来回归:
$ ./fetch http://www.baidu.com
运行程序后,会在当前目录下生成一个site.txt文件。

