
js提取指定网站内容
js提取指定网站内容(JavaScript驾驭网页-CSS与DOM利用DOM分割HTML利用分割)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-15 11:00
JavaScript 控制网页-CSS 和 DOM
使用 DOM 拆分 HTML
使用 JavaScript 来控制 Web 内容实际上很像做饭。只是你不用清理剩菜,却没有办法享受到美味的结果。
但是,您将能够完成网页内容的 HTML 元素:更重要的是,您将拥有替换网页元素的能力。
JavaScript 可以让你随心所欲地操作网页的 HTML 代码,从而开启各种有趣的机会,这一切都是因为标准对象:DOM 的存在
getElementById
HTML标签都有一个"id"属性,第个标签的该属性都是独一无二的
可以通过id属性来获取元素
内容
var sceneDesc=document.getElementById("div2");
getElementById可以通过元素的id属性去访问标签
括号里是id的值
getElementsByTagName
也可以通过标签名来获取元素
内容
var divs=document.getElementsByTagName("div");
getElementsByTagName返回所有div标签,结果是一个数组,结果按照标签在HTML中的顺序排列
括号里是标签名
var divs=document.getElementsByTagName("div")[2];
用索引获取第三个div标签
内部HTML
innerHTML特性对所有存储在元素里的内容提供了访问管道
通过innerHTML访问元素内存储的内容:
<p id="story"> you are standing
alone in the woods.
document.getElementById("story").innerHTML;
返回的内容是: you are standing alone in the woods.
innerHTML获取的是指定元素下的所有内容与标签
innerHTML也能用于设置网页内容
document.getElementById("story").innerHTML="You are not alone!";
innerHTML只用来设置可以包含文本的标签</p>
给大家介绍了很多关于JavaScript控制网页的知识——网页元素的知识,希望对大家有所帮助! 查看全部
js提取指定网站内容(JavaScript驾驭网页-CSS与DOM利用DOM分割HTML利用分割)
JavaScript 控制网页-CSS 和 DOM
使用 DOM 拆分 HTML
使用 JavaScript 来控制 Web 内容实际上很像做饭。只是你不用清理剩菜,却没有办法享受到美味的结果。
但是,您将能够完成网页内容的 HTML 元素:更重要的是,您将拥有替换网页元素的能力。
JavaScript 可以让你随心所欲地操作网页的 HTML 代码,从而开启各种有趣的机会,这一切都是因为标准对象:DOM 的存在
getElementById
HTML标签都有一个"id"属性,第个标签的该属性都是独一无二的
可以通过id属性来获取元素
内容
var sceneDesc=document.getElementById("div2");
getElementById可以通过元素的id属性去访问标签
括号里是id的值
getElementsByTagName
也可以通过标签名来获取元素
内容
var divs=document.getElementsByTagName("div");
getElementsByTagName返回所有div标签,结果是一个数组,结果按照标签在HTML中的顺序排列
括号里是标签名
var divs=document.getElementsByTagName("div")[2];
用索引获取第三个div标签
内部HTML
innerHTML特性对所有存储在元素里的内容提供了访问管道
通过innerHTML访问元素内存储的内容:
<p id="story"> you are standing
alone in the woods.
document.getElementById("story").innerHTML;
返回的内容是: you are standing alone in the woods.
innerHTML获取的是指定元素下的所有内容与标签
innerHTML也能用于设置网页内容
document.getElementById("story").innerHTML="You are not alone!";
innerHTML只用来设置可以包含文本的标签</p>
给大家介绍了很多关于JavaScript控制网页的知识——网页元素的知识,希望对大家有所帮助!
js提取指定网站内容(,pubdate功能很强大,使用却很简单(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-14 08:12
Powershell可以方便的获取网页的信息,读取相应的内容。如果对象的格式是 XML 或 Json,则更容易处理。一般经常用到invoke-restmethod和invoke-webrequest这两个命令。前者主要是获取Json格式的内容,后者可以获取整个网页的内容。
例如,我想查看明天悉尼的天气。我在网上随便搜了一个提供API的网站
#名称
我打算搜索Sydney,所以对应的格式是
,au 他会自动生成 Json 格式的结果。
我们可以使用invoke-restmethod直接得到这个结果,例如
$b=invoke-restmethod "http://api.openweathermap.org/ ... ydney,au"
$c=[pscustomobject]@{
'Description'=$b.weather.description
'name'=$b.name
'windspeed'=$b.wind.speed
}
我也可以直接使用invoke-webrequest来抓取整个网页的内容,然后从Json格式转换过来。
$a= Invoke-WebRequest -Uri ",au"$b=$a.Content | ConvertFrom-Json
同样,如果我想获取博客的最新 RSS 内容。可以使用 invoke-webrequest 抓取对应的 XML 文件,如
[xml]$a= Invoke-WebRequest -Uri "“$a.rss.channel.Item | 选择标题,发布日期
功能非常强大,但是使用起来非常简单。
本文来自“麻婆豆腐”博客 查看全部
js提取指定网站内容(,pubdate功能很强大,使用却很简单(图))
Powershell可以方便的获取网页的信息,读取相应的内容。如果对象的格式是 XML 或 Json,则更容易处理。一般经常用到invoke-restmethod和invoke-webrequest这两个命令。前者主要是获取Json格式的内容,后者可以获取整个网页的内容。
例如,我想查看明天悉尼的天气。我在网上随便搜了一个提供API的网站
#名称
我打算搜索Sydney,所以对应的格式是
,au 他会自动生成 Json 格式的结果。

我们可以使用invoke-restmethod直接得到这个结果,例如
$b=invoke-restmethod "http://api.openweathermap.org/ ... ydney,au"
$c=[pscustomobject]@{
'Description'=$b.weather.description
'name'=$b.name
'windspeed'=$b.wind.speed
}

我也可以直接使用invoke-webrequest来抓取整个网页的内容,然后从Json格式转换过来。
$a= Invoke-WebRequest -Uri ",au"$b=$a.Content | ConvertFrom-Json
同样,如果我想获取博客的最新 RSS 内容。可以使用 invoke-webrequest 抓取对应的 XML 文件,如
[xml]$a= Invoke-WebRequest -Uri "“$a.rss.channel.Item | 选择标题,发布日期

功能非常强大,但是使用起来非常简单。
本文来自“麻婆豆腐”博客
js提取指定网站内容(本文实例分享原生js实现获取form表单数据的具体代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-14 08:09
本文示例分享了原生js中获取表单数据的具体代码,供大家参考。具体内容如下
//获取指定form中的所有的对象
function getElements(formId) {
var form = document.getElementById(formId);
var elements = new Array();
var tagElements = form.getElementsByTagName('input');
for (var j = 0; j < tagElements.length; j++){
elements.push(tagElements[j]);
}
var tagElements = form.getElementsByTagName('select');
for (var j = 0; j < tagElements.length; j++){
elements.push(tagElements[j]);
}
var tagElements = form.getElementsByTagName('textarea');
for (var j = 0; j < tagElements.length; j++){
elements.push(tagElements[j]);
}
return elements;
}
//组合URL
function serializeElement(element) {
var method = element.tagName.toLowerCase();
var parameter;
if(method == 'select'){
parameter = [element.name, element.value];
}
switch (element.type.toLowerCase()) {
case 'submit':
case 'hidden':
case 'password':
case 'text':
case 'date':
case 'textarea':
parameter = [element.name, element.value];
break;
case 'checkbox':
case 'radio':
if (element.checked){
parameter = [element.name, element.value];
}
break;
}
if (parameter) {
var key = encodeURIComponent(parameter[0]);
if (key.length == 0)
return;
if (parameter[1].constructor != Array)
parameter[1] = [parameter[1]];
var values = parameter[1];
var results = [];
for (var i = 0; i < values.length; i++) {
results.push(key + '=' + encodeURIComponent(values[i]));
}
return results.join('&');
}
}
//调用方法
function serializeForm(formId) {
var elements = getElements(formId);
var queryComponents = new Array();
for (var i = 0; i < elements.length; i++) {
var queryComponent = serializeElement(elements[i]);
if (queryComponent) {
queryComponents.push(queryComponent);
}
}
return queryComponents.join('&');
}
最后可以通过serializeForm(formId); 输入表单的id名称,返回的数据为
id=1&title=%E6%B4%BB%E5%8A%A8&time=2017-07-10&status=1&importance=0&desc=%E5%9C%A8%E4%BA%8C%E6%A5%BC%E5%8A%9E%E5%85%AC%E5%AE%A4%E5%BC%80%E4%BC%9A%EF%BC%8C%E4%B8%80%E7%82%B9%E9%92%9F
以上就是小编为大家介绍的原js实现表单数据采集的详细集成。我希望它会对你有所帮助。如有问题,请给我留言,小编会及时回复您。非常感谢大家对脸圈教程网站的支持! 查看全部
js提取指定网站内容(本文实例分享原生js实现获取form表单数据的具体代码)
本文示例分享了原生js中获取表单数据的具体代码,供大家参考。具体内容如下
//获取指定form中的所有的对象
function getElements(formId) {
var form = document.getElementById(formId);
var elements = new Array();
var tagElements = form.getElementsByTagName('input');
for (var j = 0; j < tagElements.length; j++){
elements.push(tagElements[j]);
}
var tagElements = form.getElementsByTagName('select');
for (var j = 0; j < tagElements.length; j++){
elements.push(tagElements[j]);
}
var tagElements = form.getElementsByTagName('textarea');
for (var j = 0; j < tagElements.length; j++){
elements.push(tagElements[j]);
}
return elements;
}
//组合URL
function serializeElement(element) {
var method = element.tagName.toLowerCase();
var parameter;
if(method == 'select'){
parameter = [element.name, element.value];
}
switch (element.type.toLowerCase()) {
case 'submit':
case 'hidden':
case 'password':
case 'text':
case 'date':
case 'textarea':
parameter = [element.name, element.value];
break;
case 'checkbox':
case 'radio':
if (element.checked){
parameter = [element.name, element.value];
}
break;
}
if (parameter) {
var key = encodeURIComponent(parameter[0]);
if (key.length == 0)
return;
if (parameter[1].constructor != Array)
parameter[1] = [parameter[1]];
var values = parameter[1];
var results = [];
for (var i = 0; i < values.length; i++) {
results.push(key + '=' + encodeURIComponent(values[i]));
}
return results.join('&');
}
}
//调用方法
function serializeForm(formId) {
var elements = getElements(formId);
var queryComponents = new Array();
for (var i = 0; i < elements.length; i++) {
var queryComponent = serializeElement(elements[i]);
if (queryComponent) {
queryComponents.push(queryComponent);
}
}
return queryComponents.join('&');
}
最后可以通过serializeForm(formId); 输入表单的id名称,返回的数据为
id=1&title=%E6%B4%BB%E5%8A%A8&time=2017-07-10&status=1&importance=0&desc=%E5%9C%A8%E4%BA%8C%E6%A5%BC%E5%8A%9E%E5%85%AC%E5%AE%A4%E5%BC%80%E4%BC%9A%EF%BC%8C%E4%B8%80%E7%82%B9%E9%92%9F
以上就是小编为大家介绍的原js实现表单数据采集的详细集成。我希望它会对你有所帮助。如有问题,请给我留言,小编会及时回复您。非常感谢大家对脸圈教程网站的支持!
js提取指定网站内容(如何截取url中网站域名之后的部分,需要用到以下几个方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-14 04:04
)
如何截取url中网站域名后的部分,需要以下方法:
lastIndexOf()
lastIndexOf() 方法返回调用 String 对象的指定值最后一次出现的索引,在字符串中 fromIndex 的指定位置从后向前搜索。如果未找到特定值,则返回 -1。
子串()
substring() 方法返回起始索引和结束索引之间的字符串子集,或从起始索引到字符串结尾的子集。
通过这两种方法,就可以得到url域名后面的部分了。
首先获取网址:
var url = window.location.href
截取指定字符串之后的内容:比如获取之后的内容?
var index = url.lastIndexOf('?')
var url2 = url.substring(index + 1)
可以封装成一个方法:
function interceptUrl(url, cha) {
var ind = url.lastIndexOf(cha)
return url.substring(ind + 1)
}
调用方式:
var url = 'https://www.w3h5.com/search.php?q=Vue'
console.log(interceptUrl(url, '?'))
# q=Vue 查看全部
js提取指定网站内容(如何截取url中网站域名之后的部分,需要用到以下几个方法
)
如何截取url中网站域名后的部分,需要以下方法:
lastIndexOf()
lastIndexOf() 方法返回调用 String 对象的指定值最后一次出现的索引,在字符串中 fromIndex 的指定位置从后向前搜索。如果未找到特定值,则返回 -1。
子串()
substring() 方法返回起始索引和结束索引之间的字符串子集,或从起始索引到字符串结尾的子集。
通过这两种方法,就可以得到url域名后面的部分了。
首先获取网址:
var url = window.location.href
截取指定字符串之后的内容:比如获取之后的内容?
var index = url.lastIndexOf('?')
var url2 = url.substring(index + 1)
可以封装成一个方法:
function interceptUrl(url, cha) {
var ind = url.lastIndexOf(cha)
return url.substring(ind + 1)
}
调用方式:
var url = 'https://www.w3h5.com/search.php?q=Vue'
console.log(interceptUrl(url, '?'))
# q=Vue
js提取指定网站内容( 本文实例讲述JS简单获取并修改input文本框内容的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-14 04:01
本文实例讲述JS简单获取并修改input文本框内容的方法)
JS如何简单获取和修改输入文本框内容的例子
更新时间:2018-04-08 11:52:13 作者:成求明
本文文章主要介绍JS简单获取和修改输入文本框内容的方法。结合示例表单,分析JavaScript获取和分配页面元素的相关操作技巧。有需要的朋友可以参考以下
本文介绍了通过JS简单获取和修改输入文本框内容的方法。分享给大家,供大家参考,如下:
一个介绍
获取文本框并修改其内容可以使用getElementById()方法来实现。
getElementById() 方法可以通过指定的 id 获取 HTML 标记并返回它。
语法:
sElement=document.getElementById(id)
sElement:用于接收此方法返回的对象。
id:用于设置需要获取的HTML标记的id值。
第二次申请
获取文本框并修改其内容
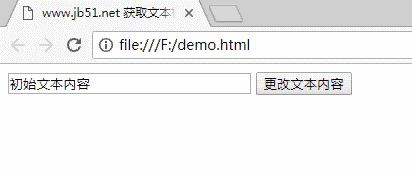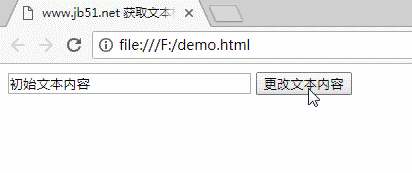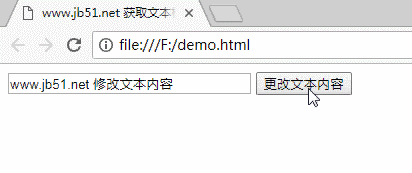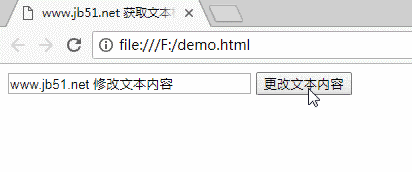
页面加载完成后,文本框中会显示“初始文本内容”,点击按钮时文本框中的内容会发生变化。
三码
www.jb51.net 获取文本框并修改其内容
四运行结果
对JavaScript相关内容感兴趣的读者可以查看本站专题:《JavaScript页面元素操作技巧总结》、《JavaScript操作DOM技巧总结》、《JavaScript搜索算法技巧总结》、《JavaScript数据结构》和算法技巧总结”、“JavaScript 遍历算法和技术总结”和“JavaScript 错误和调试技术总结”
我希望这篇文章能帮助你进行 JavaScript 编程。 查看全部
js提取指定网站内容(
本文实例讲述JS简单获取并修改input文本框内容的方法)
JS如何简单获取和修改输入文本框内容的例子
更新时间:2018-04-08 11:52:13 作者:成求明
本文文章主要介绍JS简单获取和修改输入文本框内容的方法。结合示例表单,分析JavaScript获取和分配页面元素的相关操作技巧。有需要的朋友可以参考以下
本文介绍了通过JS简单获取和修改输入文本框内容的方法。分享给大家,供大家参考,如下:
一个介绍
获取文本框并修改其内容可以使用getElementById()方法来实现。
getElementById() 方法可以通过指定的 id 获取 HTML 标记并返回它。
语法:
sElement=document.getElementById(id)
sElement:用于接收此方法返回的对象。
id:用于设置需要获取的HTML标记的id值。
第二次申请
获取文本框并修改其内容
页面加载完成后,文本框中会显示“初始文本内容”,点击按钮时文本框中的内容会发生变化。
三码
www.jb51.net 获取文本框并修改其内容
四运行结果
对JavaScript相关内容感兴趣的读者可以查看本站专题:《JavaScript页面元素操作技巧总结》、《JavaScript操作DOM技巧总结》、《JavaScript搜索算法技巧总结》、《JavaScript数据结构》和算法技巧总结”、“JavaScript 遍历算法和技术总结”和“JavaScript 错误和调试技术总结”
我希望这篇文章能帮助你进行 JavaScript 编程。
js提取指定网站内容(js提取指定网站内容以支持搜索引擎抓取分析的利弊)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-13 05:02
js提取指定网站内容以支持搜索引擎抓取分析,类似google,百度,搜狗等搜索引擎一般会给予referral返回给搜索引擎。然后从站点对外的返回页内容抓取验证和关键词匹配后,返回给搜索引擎(获取下页链接的长度等),
在网站索引中可以得到站点网页的摘要信息以作用于搜索引擎的索引分析。
我刚学习网站结构分析的,个人经验,看这篇文章即可。
目前国内比较主流的排名抓取方法有如下两种:(1)在url进行whois随机检查,从地址栏找到allurls的ip地址,然后查看数量,对比ip点击量和url访问量,来确定访问量大的url所在的页面。(2)使用域名ip代理抓取,这种方法的好处是可以抓取百度(或者google),必应等搜索引擎以外的其他搜索引擎页面。
看上面的答案感觉还是云里雾里首先说filetag的利弊第一个答案写的很详细了,我只想从另一个方面补充一下:不要一开始就filetag,而是先通过目录名找到要抓取的页面,然后进行filetag。比如我要爬取知乎的文章,我是先爬取知乎的主站目录,
360,百度搜狗搜索结果页有长链接是自动搜索到站点根目录的
重点要搞清楚,谷歌、百度在抓取xxx.xx.xx.xx的时候,有两个自检机制,即谷歌会查看输入xxx.xx.xx.xx这个格式的地址之后返回的内容。百度会通过目录找到文件,即通过查看输入相同格式的文件的地址返回结果,来确定页面的抓取内容,所以,返回结果页面的url长度就成为一个重要的指标了,有时查找和查找操作的结果有区别。 查看全部
js提取指定网站内容(js提取指定网站内容以支持搜索引擎抓取分析的利弊)
js提取指定网站内容以支持搜索引擎抓取分析,类似google,百度,搜狗等搜索引擎一般会给予referral返回给搜索引擎。然后从站点对外的返回页内容抓取验证和关键词匹配后,返回给搜索引擎(获取下页链接的长度等),
在网站索引中可以得到站点网页的摘要信息以作用于搜索引擎的索引分析。
我刚学习网站结构分析的,个人经验,看这篇文章即可。
目前国内比较主流的排名抓取方法有如下两种:(1)在url进行whois随机检查,从地址栏找到allurls的ip地址,然后查看数量,对比ip点击量和url访问量,来确定访问量大的url所在的页面。(2)使用域名ip代理抓取,这种方法的好处是可以抓取百度(或者google),必应等搜索引擎以外的其他搜索引擎页面。
看上面的答案感觉还是云里雾里首先说filetag的利弊第一个答案写的很详细了,我只想从另一个方面补充一下:不要一开始就filetag,而是先通过目录名找到要抓取的页面,然后进行filetag。比如我要爬取知乎的文章,我是先爬取知乎的主站目录,
360,百度搜狗搜索结果页有长链接是自动搜索到站点根目录的
重点要搞清楚,谷歌、百度在抓取xxx.xx.xx.xx的时候,有两个自检机制,即谷歌会查看输入xxx.xx.xx.xx这个格式的地址之后返回的内容。百度会通过目录找到文件,即通过查看输入相同格式的文件的地址返回结果,来确定页面的抓取内容,所以,返回结果页面的url长度就成为一个重要的指标了,有时查找和查找操作的结果有区别。
js提取指定网站内容( js删除数组中的指定元素的详实示例方法-就是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-12 17:58
js删除数组中的指定元素的详实示例方法-就是)
详解js删除数组中指定元素
更新时间:2018-10-31 08:46:47 投稿:老张
在这篇文章中,我们和大家分享了一个js删除数组中指定元素的详细示例方法。有需要的朋友可以借鉴。
本文文章将介绍两种删除数组中指定元素的方法,分别是:
1、 单独定义一个函数,通过该函数删除指定的数组元素。
2、 为 Array 对象定义了一个 removeByValue 方法。调用删除指定数组元素的方法非常简单。
下面我们通过简单的代码示例简单介绍这两种删除数组指定元素的方法。
1、定义一个单独的函数removeByValue来删除元素
代码示例:删除数组somearray中的“tue”元素
<p>数组:mon, tue, wed, thur
function removeByValue(arr, val) {
for(var i = 0; i < arr.length; i++) {
if(arr[i] == val) {
arr.splice(i, 1);
break;
}
}
}
var somearray = ["mon", "tue", "wed", "thur"]
removeByValue(somearray, "tue");
//somearray will now have "mon", "wed", "thur"
document.write("
新数组:" + somearray + "");
</p>
效果图:
2、定义并调用数组的removeByValue方法删除指定元素
代码示例:删除数组somearray中的“wed”元素
<p>数组:mon, tue, wed, thur
删除指定元素"tue"后:
Array.prototype.removeByValue = function(val) {
for(var i = 0; i < this.length; i++) {
if(this[i] == val) {
this.splice(i, 1);
break;
}
}
}
var somearray = ["mon", "tue", "wed", "thur"]
somearray.removeByValue("wed");
//somearray will now have "mon", "wed", "thur"
document.write("
新数组:" + somearray + "");
</p>
效果图:
总结:以上就是本文介绍的js删除数组指定元素的两种方式。你可以自己尝试一下,加深理解。希望对大家的学习有所帮助。 查看全部
js提取指定网站内容(
js删除数组中的指定元素的详实示例方法-就是)
详解js删除数组中指定元素
更新时间:2018-10-31 08:46:47 投稿:老张
在这篇文章中,我们和大家分享了一个js删除数组中指定元素的详细示例方法。有需要的朋友可以借鉴。
本文文章将介绍两种删除数组中指定元素的方法,分别是:
1、 单独定义一个函数,通过该函数删除指定的数组元素。
2、 为 Array 对象定义了一个 removeByValue 方法。调用删除指定数组元素的方法非常简单。
下面我们通过简单的代码示例简单介绍这两种删除数组指定元素的方法。
1、定义一个单独的函数removeByValue来删除元素
代码示例:删除数组somearray中的“tue”元素
<p>数组:mon, tue, wed, thur
function removeByValue(arr, val) {
for(var i = 0; i < arr.length; i++) {
if(arr[i] == val) {
arr.splice(i, 1);
break;
}
}
}
var somearray = ["mon", "tue", "wed", "thur"]
removeByValue(somearray, "tue");
//somearray will now have "mon", "wed", "thur"
document.write("
新数组:" + somearray + "");
</p>
效果图:

2、定义并调用数组的removeByValue方法删除指定元素
代码示例:删除数组somearray中的“wed”元素
<p>数组:mon, tue, wed, thur
删除指定元素"tue"后:
Array.prototype.removeByValue = function(val) {
for(var i = 0; i < this.length; i++) {
if(this[i] == val) {
this.splice(i, 1);
break;
}
}
}
var somearray = ["mon", "tue", "wed", "thur"]
somearray.removeByValue("wed");
//somearray will now have "mon", "wed", "thur"
document.write("
新数组:" + somearray + "");
</p>
效果图:

总结:以上就是本文介绍的js删除数组指定元素的两种方式。你可以自己尝试一下,加深理解。希望对大家的学习有所帮助。
js提取指定网站内容(目录本篇博客又双叒叕为各位分享分享Python库 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-09 21:04
)
内容
本篇博客将为大家分享一个Python库:GeneralNewsExtractor (GNE),这是一个通用的新闻网站文本提取模块。输入一个新闻页面的HTML,输出正文内容、标题、作者、发布时间、正文中图片的地址、正文所在标签的源代码。 GNE对今日头条、网易新闻、有民之星、观察家、凤凰网、腾讯新闻、ReadHub、新浪新闻等数百条中文新闻网站的提取非常有效,准确率几乎可以达到100%。 .
需要明白:GeneralNewsExtractor(GNE)不是爬虫,是为了避免不必要的风险。因此,本项目的输入是HTML源代码,输出是字典。请使用适当的方法自行获取目标网站 HTML。
1、安装模块
GeneralNewsExtractor 模块的安装说明如下:
pip install gne
安装成功效果如下:
2、提取网页内容
这次打算提取最新时事,选择网易新闻,文章如下图:
右键查看本页源码文章,如下图:
复制源码 接下来,5行代码提取新闻内容,如下图:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
效果如下:
如果标题自动提取失败,可以指定XPath,代码如下:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html, title_xpath='//h5/text()')
print(result) 查看全部
js提取指定网站内容(目录本篇博客又双叒叕为各位分享分享Python库
)
内容
本篇博客将为大家分享一个Python库:GeneralNewsExtractor (GNE),这是一个通用的新闻网站文本提取模块。输入一个新闻页面的HTML,输出正文内容、标题、作者、发布时间、正文中图片的地址、正文所在标签的源代码。 GNE对今日头条、网易新闻、有民之星、观察家、凤凰网、腾讯新闻、ReadHub、新浪新闻等数百条中文新闻网站的提取非常有效,准确率几乎可以达到100%。 .
需要明白:GeneralNewsExtractor(GNE)不是爬虫,是为了避免不必要的风险。因此,本项目的输入是HTML源代码,输出是字典。请使用适当的方法自行获取目标网站 HTML。

1、安装模块
GeneralNewsExtractor 模块的安装说明如下:
pip install gne
安装成功效果如下:

2、提取网页内容
这次打算提取最新时事,选择网易新闻,文章如下图:

右键查看本页源码文章,如下图:


复制源码 接下来,5行代码提取新闻内容,如下图:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
效果如下:

如果标题自动提取失败,可以指定XPath,代码如下:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html, title_xpath='//h5/text()')
print(result)
js提取指定网站内容(JS实现一键复制”的文章数不胜数(js实现)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-09 21:03
经常在网站上看到各种“一键复制”友好体验按钮,不限于代码复制。如此友好的体验和方便快捷的操作对游客来说是无害的。我在网上搜索了关于“JS实现一键复制”的文章无数。用的最多的就是通过clipboard.min.js实现拷贝,毕竟现在各种浏览器都禁用了Flash等等。看了几十个文章,但是没有WordPress插件,也没有纯代码,只能自己动手。已经超过2天了。在朋友的帮助下,实现了“一键复制指定内容”的功能,代码也集成到了文章编辑器中,还是很方便的。
在WordPress中实现一键复制指定内容的步骤
1、下载clipboard.js文件。clipboard.js 是github上的一个开源项目,可以实现将纯JavaScript(无Flash)的浏览器内容复制到系统剪贴板的功能。
PS:以本站下载的压缩包中的clipboard.min.js和amazeui.css文件为例。
2、将以下代码放入footer.php。请自行修改clipboard.min.js的路径。
3、 在header.php中引入如下amazeui.css文件。下面的amazeui-2.css文件介绍了未删减的版本。也可以使用压缩包中的amazeui.css文件,自己选择。
“样式表”href="">
4、 引用 文章 中的按钮代码。写文章时,把代码放在合适的位置,修改data-clipboard-text的值“copy content”为指定的内容。
"itemCopyam-btnam-btn-warningam-roundam-btn-xs"id="TKLS"type="button"data-clipboard-text="copy content">一键复制
建议将此功能集成到主题编辑器中,方便操作。如果对代码比较模糊,不知道如何修改CSS代码,建议不要修改中间的id和class部分。
到这里差不多就完成了,说实话,感觉有点粗糙。但是在摸索的路上,我收获了很多。也希望路过的大佬指点一下,优化一下代码。制作更好更方便的复印功能。具体效果请到本文原文地址,点击“一键复制”按钮试试效果。 查看全部
js提取指定网站内容(JS实现一键复制”的文章数不胜数(js实现)(组图))
经常在网站上看到各种“一键复制”友好体验按钮,不限于代码复制。如此友好的体验和方便快捷的操作对游客来说是无害的。我在网上搜索了关于“JS实现一键复制”的文章无数。用的最多的就是通过clipboard.min.js实现拷贝,毕竟现在各种浏览器都禁用了Flash等等。看了几十个文章,但是没有WordPress插件,也没有纯代码,只能自己动手。已经超过2天了。在朋友的帮助下,实现了“一键复制指定内容”的功能,代码也集成到了文章编辑器中,还是很方便的。

在WordPress中实现一键复制指定内容的步骤
1、下载clipboard.js文件。clipboard.js 是github上的一个开源项目,可以实现将纯JavaScript(无Flash)的浏览器内容复制到系统剪贴板的功能。
PS:以本站下载的压缩包中的clipboard.min.js和amazeui.css文件为例。
2、将以下代码放入footer.php。请自行修改clipboard.min.js的路径。
3、 在header.php中引入如下amazeui.css文件。下面的amazeui-2.css文件介绍了未删减的版本。也可以使用压缩包中的amazeui.css文件,自己选择。
“样式表”href="">
4、 引用 文章 中的按钮代码。写文章时,把代码放在合适的位置,修改data-clipboard-text的值“copy content”为指定的内容。
"itemCopyam-btnam-btn-warningam-roundam-btn-xs"id="TKLS"type="button"data-clipboard-text="copy content">一键复制
建议将此功能集成到主题编辑器中,方便操作。如果对代码比较模糊,不知道如何修改CSS代码,建议不要修改中间的id和class部分。
到这里差不多就完成了,说实话,感觉有点粗糙。但是在摸索的路上,我收获了很多。也希望路过的大佬指点一下,优化一下代码。制作更好更方便的复印功能。具体效果请到本文原文地址,点击“一键复制”按钮试试效果。
js提取指定网站内容(前端的js脚本如何实现复制网页中指定的内容? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-06 12:12
)
前端js脚本可以将网页中指定的内容复制到剪贴板,如input中的内容,div元素中的内容等,具体实现方法请参考以下< @文章。
JS实现复制div(span)内容到剪贴板的方法
先看示例代码:
飞鸟慕鱼博客-复制DIV元素的内容
我是被复制的内容,可以写入系统的剪切板中!
点击我可以复制上面的内容
//定义一个复制函数
function copyText(text) {
var tag = document.createElement('input');
tag.setAttribute('id', 'copy_input');
tag.value = text;
document.getElementsByTagName('body')[0].appendChild(tag);
document.getElementById('copy_input').select();
document.execCommand('copy');
document.getElementById('copy_input').remove();
}
//点击按钮进行复制
document.getElementById('but').onclick = function () {
//获取DIV的内容
var text = document.getElementById('cent').innerText;
copyText(text);
}
上面JS复制DIV内容的操作过程只是模拟了用户手动复制输入框内容的操作。实现过程请参考以下分析!
分析:
1、 复制函数中新建一个输入元素,将要复制的内容写入元素中。
2、使用input元素的select()方法选择input中的所有内容!
3、复制内容
4:移动新创建的输入元素!
JS实现自动将输入框内容复制到剪贴板的方法
js 自动复制输入框中的内容,只需使用 select() 方法选择输入元素中的内容并复制即可。这个过程非常简单。可以参考下面的示例代码!
示例代码:
飞鸟慕鱼博客-复制DIV元素的内容
点击复制
//复制逻辑
document.getElementById('but').onclick = function () {
//选择input的内容
document.getElementById('host').select();
//进行copy
document.execCommand('copy');
} 查看全部
js提取指定网站内容(前端的js脚本如何实现复制网页中指定的内容?
)
前端js脚本可以将网页中指定的内容复制到剪贴板,如input中的内容,div元素中的内容等,具体实现方法请参考以下< @文章。
JS实现复制div(span)内容到剪贴板的方法
先看示例代码:
飞鸟慕鱼博客-复制DIV元素的内容
我是被复制的内容,可以写入系统的剪切板中!
点击我可以复制上面的内容
//定义一个复制函数
function copyText(text) {
var tag = document.createElement('input');
tag.setAttribute('id', 'copy_input');
tag.value = text;
document.getElementsByTagName('body')[0].appendChild(tag);
document.getElementById('copy_input').select();
document.execCommand('copy');
document.getElementById('copy_input').remove();
}
//点击按钮进行复制
document.getElementById('but').onclick = function () {
//获取DIV的内容
var text = document.getElementById('cent').innerText;
copyText(text);
}
上面JS复制DIV内容的操作过程只是模拟了用户手动复制输入框内容的操作。实现过程请参考以下分析!
分析:
1、 复制函数中新建一个输入元素,将要复制的内容写入元素中。
2、使用input元素的select()方法选择input中的所有内容!
3、复制内容
4:移动新创建的输入元素!
JS实现自动将输入框内容复制到剪贴板的方法
js 自动复制输入框中的内容,只需使用 select() 方法选择输入元素中的内容并复制即可。这个过程非常简单。可以参考下面的示例代码!
示例代码:
飞鸟慕鱼博客-复制DIV元素的内容
点击复制
//复制逻辑
document.getElementById('but').onclick = function () {
//选择input的内容
document.getElementById('host').select();
//进行copy
document.execCommand('copy');
}
js提取指定网站内容(Vue3CompositionAPI可以在大型项目中更好地组织代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-06 01:15
Vue3 Composition API 可以更好地组织大型项目中的代码。然而,随着使用几个不同的选项属性切换到单一的设置方法,许多开发人员面临的问题是......
这会不会更混乱,因为一切都在一种方法中
乍一看似乎很容易,但实际上编写可重用的模块化代码只需要一点时间。
让我们看看如何做到这一点。
问题
Vue.js 2.x 的 Options API 是一种非常直观的代码分离方式
export default {
data () {
return {
articles: [],
searchParameters: []
}
},
mounted () {
this.articles = ArticlesAPI.loadArticles()
},
methods: {
searchArticles (id) {
return this.articles.filter(() => {
// 一些搜索代码
})
}
}
}
问题在于,如果一个组件中有数百行代码,那么您必须在数据、方法、计算等的多个部分中为单个功能(例如搜索)添加代码。
这意味着只有一个函数的代码可能分散在数百行中并分布在多个不同的位置,从而导致难以阅读或调试。图片说明
这只是 Vue Composition API RFC 中的一个例子,展示了现在如何按功能组织代码。
现在,这是使用新 Composition API 的等效代码。
import { ref, onMounted } from 'vue'
export default {
setup () {
const articles = ref([])
const searchParameters = ref([])
onMounted(() => {
this.articles = ArticlesAPI.loadArticles()
})
const searchArticles = (id) => {
return articles.filter(() => {
// 一些搜索代码
})
}
return {
articles,
searchParameters,
searchArticles
}
}
}
现在,为了解决之前关于组织的问题,我们来看看一个很好的提取逻辑的方法。
提取逻辑
我们的最终目标是将每个函数提取到自己的方法中。这样,如果我们要调试它,所有代码都在一个地方。
这很简单,但是最后我们要记住,如果我们想要能够访问模板中的数据,我们仍然需要使用我们的setup方法来返回数据。
让我们创建一个新方法 useSearchArticles 并让它返回我们在 setup 方法中返回的所有内容。
const useSearchArticles = () => {
const articles = ref([])
const searchParameters = ref([])
onMounted(() => {
this.articles = ArticlesAPI.loadArticles()
})
const searchArticles = (id) => {
return articles.filter(() => {
// 一些搜索代码
})
}
return {
articles,
searchParameters,
searchArticles
}
}
现在,在我们的 setup 方法中,我们可以通过调用我们的方法来访问属性。而且,当然,我们还必须记住从 setup 方法中返回它们。
export default {
setup () {
const { articles, searchParameters, searchArticles } = useSearchArticles()
return {
articles,
searchParameters,
searchArticles
}
}
}
在提取的逻辑中访问组件属性
Composition API 的另一个新变化是这个引用的变化,这意味着我们不能再以同样的方式使用 props、attributes 或 events。
简而言之,我们将不得不使用 setup 方法的两个参数来访问 props、attributes、slot 或 emit 方法。如果我们只使用 setup 方法,一个快速的虚拟组件可能看起来像这样。
export default {
setup (props, context) {
onMounted(() => {
console.log(props)
context.emit('event', 'payload')
})
}
}
但是现在我们要提取我们的逻辑,我们想让我们的逻辑包装器方法也接受参数。这样,我们就可以从setup方法中传递我们的props和context属性,逻辑代码就可以访问它们了。
const checkProps = (props, context) => {
onMounted(() => {
console.log(props)
context.emit('event', 'payload')
})
}
export default {
setup (props, context) {
checkProps(props, context)
}
}
重用逻辑
最后,如果我们想写一些我们希望可以在多个组件中使用的逻辑,我们可以将逻辑提取到自己的文件中,然后将其导入到我们的组件中。
然后,我们可以像以前一样调用该方法。假设我们将 useSearchArticles 方法移动到名为 use-search-articles-logic.js 的文件中,如下所示
import { ref, onMounted } from 'vue'
export function useSearchArticles () {
const articles = ref([])
const searchParameters = ref([])
onMounted(() => {
this.articles = ArticlesAPI.loadArticles()
})
const searchArticles = (id) => {
return articles.filter(() => {
// 一些搜索代码
})
}
return {
articles,
searchParameters,
searchArticles
}
}
使用这个新文件,我们的原创组件将如下所示
import { useSearchArticles } from './logic/use-search-articles-logic'
export default {
setup (props,) {
const { articles, searchParameters, searchArticles } = useSearchArticles()
return {
articles,
searchParameters,
searchArticles
}
}
}
最后
我希望这篇文章可以帮助您更好地理解 Composition API 将如何改变我们的编码方式。
然而,与往常一样,项目的组织取决于开发人员设计优秀组件代码和创建可重用逻辑的意愿。
请记住,我们的目标是提高可读性,而在 Vue 中,Composition API 是实现这一目标的好方法。
至此,这篇关于Vue3 Composition API中抽取复用逻辑的详细讲解的文章就介绍到这里了。更多相关的Vue3 Composition提取和复用内容,请搜索之前的文章或继续浏览以下相关的文章 希望大家以后多多支持! 查看全部
js提取指定网站内容(Vue3CompositionAPI可以在大型项目中更好地组织代码)
Vue3 Composition API 可以更好地组织大型项目中的代码。然而,随着使用几个不同的选项属性切换到单一的设置方法,许多开发人员面临的问题是......
这会不会更混乱,因为一切都在一种方法中
乍一看似乎很容易,但实际上编写可重用的模块化代码只需要一点时间。
让我们看看如何做到这一点。
问题
Vue.js 2.x 的 Options API 是一种非常直观的代码分离方式
export default {
data () {
return {
articles: [],
searchParameters: []
}
},
mounted () {
this.articles = ArticlesAPI.loadArticles()
},
methods: {
searchArticles (id) {
return this.articles.filter(() => {
// 一些搜索代码
})
}
}
}
问题在于,如果一个组件中有数百行代码,那么您必须在数据、方法、计算等的多个部分中为单个功能(例如搜索)添加代码。
这意味着只有一个函数的代码可能分散在数百行中并分布在多个不同的位置,从而导致难以阅读或调试。图片说明
这只是 Vue Composition API RFC 中的一个例子,展示了现在如何按功能组织代码。
现在,这是使用新 Composition API 的等效代码。
import { ref, onMounted } from 'vue'
export default {
setup () {
const articles = ref([])
const searchParameters = ref([])
onMounted(() => {
this.articles = ArticlesAPI.loadArticles()
})
const searchArticles = (id) => {
return articles.filter(() => {
// 一些搜索代码
})
}
return {
articles,
searchParameters,
searchArticles
}
}
}
现在,为了解决之前关于组织的问题,我们来看看一个很好的提取逻辑的方法。
提取逻辑
我们的最终目标是将每个函数提取到自己的方法中。这样,如果我们要调试它,所有代码都在一个地方。
这很简单,但是最后我们要记住,如果我们想要能够访问模板中的数据,我们仍然需要使用我们的setup方法来返回数据。
让我们创建一个新方法 useSearchArticles 并让它返回我们在 setup 方法中返回的所有内容。
const useSearchArticles = () => {
const articles = ref([])
const searchParameters = ref([])
onMounted(() => {
this.articles = ArticlesAPI.loadArticles()
})
const searchArticles = (id) => {
return articles.filter(() => {
// 一些搜索代码
})
}
return {
articles,
searchParameters,
searchArticles
}
}
现在,在我们的 setup 方法中,我们可以通过调用我们的方法来访问属性。而且,当然,我们还必须记住从 setup 方法中返回它们。
export default {
setup () {
const { articles, searchParameters, searchArticles } = useSearchArticles()
return {
articles,
searchParameters,
searchArticles
}
}
}
在提取的逻辑中访问组件属性
Composition API 的另一个新变化是这个引用的变化,这意味着我们不能再以同样的方式使用 props、attributes 或 events。
简而言之,我们将不得不使用 setup 方法的两个参数来访问 props、attributes、slot 或 emit 方法。如果我们只使用 setup 方法,一个快速的虚拟组件可能看起来像这样。
export default {
setup (props, context) {
onMounted(() => {
console.log(props)
context.emit('event', 'payload')
})
}
}
但是现在我们要提取我们的逻辑,我们想让我们的逻辑包装器方法也接受参数。这样,我们就可以从setup方法中传递我们的props和context属性,逻辑代码就可以访问它们了。
const checkProps = (props, context) => {
onMounted(() => {
console.log(props)
context.emit('event', 'payload')
})
}
export default {
setup (props, context) {
checkProps(props, context)
}
}
重用逻辑
最后,如果我们想写一些我们希望可以在多个组件中使用的逻辑,我们可以将逻辑提取到自己的文件中,然后将其导入到我们的组件中。
然后,我们可以像以前一样调用该方法。假设我们将 useSearchArticles 方法移动到名为 use-search-articles-logic.js 的文件中,如下所示
import { ref, onMounted } from 'vue'
export function useSearchArticles () {
const articles = ref([])
const searchParameters = ref([])
onMounted(() => {
this.articles = ArticlesAPI.loadArticles()
})
const searchArticles = (id) => {
return articles.filter(() => {
// 一些搜索代码
})
}
return {
articles,
searchParameters,
searchArticles
}
}
使用这个新文件,我们的原创组件将如下所示
import { useSearchArticles } from './logic/use-search-articles-logic'
export default {
setup (props,) {
const { articles, searchParameters, searchArticles } = useSearchArticles()
return {
articles,
searchParameters,
searchArticles
}
}
}
最后
我希望这篇文章可以帮助您更好地理解 Composition API 将如何改变我们的编码方式。
然而,与往常一样,项目的组织取决于开发人员设计优秀组件代码和创建可重用逻辑的意愿。
请记住,我们的目标是提高可读性,而在 Vue 中,Composition API 是实现这一目标的好方法。
至此,这篇关于Vue3 Composition API中抽取复用逻辑的详细讲解的文章就介绍到这里了。更多相关的Vue3 Composition提取和复用内容,请搜索之前的文章或继续浏览以下相关的文章 希望大家以后多多支持!
js提取指定网站内容(js提取指定网站内容并生成url,可以用中间件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-05 23:03
js提取指定网站内容并生成url,可以用中间件parser来写:url=''mount=url2.url1.url3.m2.js2'js2:mongodb方案:中间件安装:在src下创建路径->首先创建gitclone项目.进入该项目根目录下rb文件目录(main.js,可以是modulename.js命名或者npmi-g这样命名项目)将下面这行代码加入到rb文件的后缀名中。
serve{logout}其他文件自行修改:dom文件document.queryselector('#mongocontent').addeventlistener('touch',method,function(event){console.log("touchstart");//获取event的valueconsole.log("touchend");console.log("touchcontinue");//获取event的数据-重新赋值mongocontentcontent;})}其他web页面数据提取函数:include_dom.bind('touch','mongocontent',function(event){varcontent=event.message;//获取到contentvarurl='';//获取外部数据,用''括起来varurl2=content.value;//获取外部数据varobj={method:'js2',pathname:'js2',href:'',methodpath:'',content:obj,//valuemethodname:'#mongocontent',//methodhref:'',pathname:'',timeout:0.1//timeoutisnotperfect,eitherthenumberorexpectedtimes};//传递给后面的函数用method参数vartimeout=0.1;//建议不要超过1秒varhash=mongocontent.hash;//用hash或者key唯一,不要使用hash来代替obj.value?.value.mongocontent?.key:&hash.mongocontent.origin+'\\.'+pathname.mongocontent?.mongocontent?.filename;//获取pathname属性值$.get(timeout,$.globaldomypersonesof]);//将filename在pathname中获取。 查看全部
js提取指定网站内容(js提取指定网站内容并生成url,可以用中间件)
js提取指定网站内容并生成url,可以用中间件parser来写:url=''mount=url2.url1.url3.m2.js2'js2:mongodb方案:中间件安装:在src下创建路径->首先创建gitclone项目.进入该项目根目录下rb文件目录(main.js,可以是modulename.js命名或者npmi-g这样命名项目)将下面这行代码加入到rb文件的后缀名中。
serve{logout}其他文件自行修改:dom文件document.queryselector('#mongocontent').addeventlistener('touch',method,function(event){console.log("touchstart");//获取event的valueconsole.log("touchend");console.log("touchcontinue");//获取event的数据-重新赋值mongocontentcontent;})}其他web页面数据提取函数:include_dom.bind('touch','mongocontent',function(event){varcontent=event.message;//获取到contentvarurl='';//获取外部数据,用''括起来varurl2=content.value;//获取外部数据varobj={method:'js2',pathname:'js2',href:'',methodpath:'',content:obj,//valuemethodname:'#mongocontent',//methodhref:'',pathname:'',timeout:0.1//timeoutisnotperfect,eitherthenumberorexpectedtimes};//传递给后面的函数用method参数vartimeout=0.1;//建议不要超过1秒varhash=mongocontent.hash;//用hash或者key唯一,不要使用hash来代替obj.value?.value.mongocontent?.key:&hash.mongocontent.origin+'\\.'+pathname.mongocontent?.mongocontent?.filename;//获取pathname属性值$.get(timeout,$.globaldomypersonesof]);//将filename在pathname中获取。
js提取指定网站内容(如何找出发送请求的js在控制数据的生成,我根本无法找到是哪一个js实现的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-05 16:08
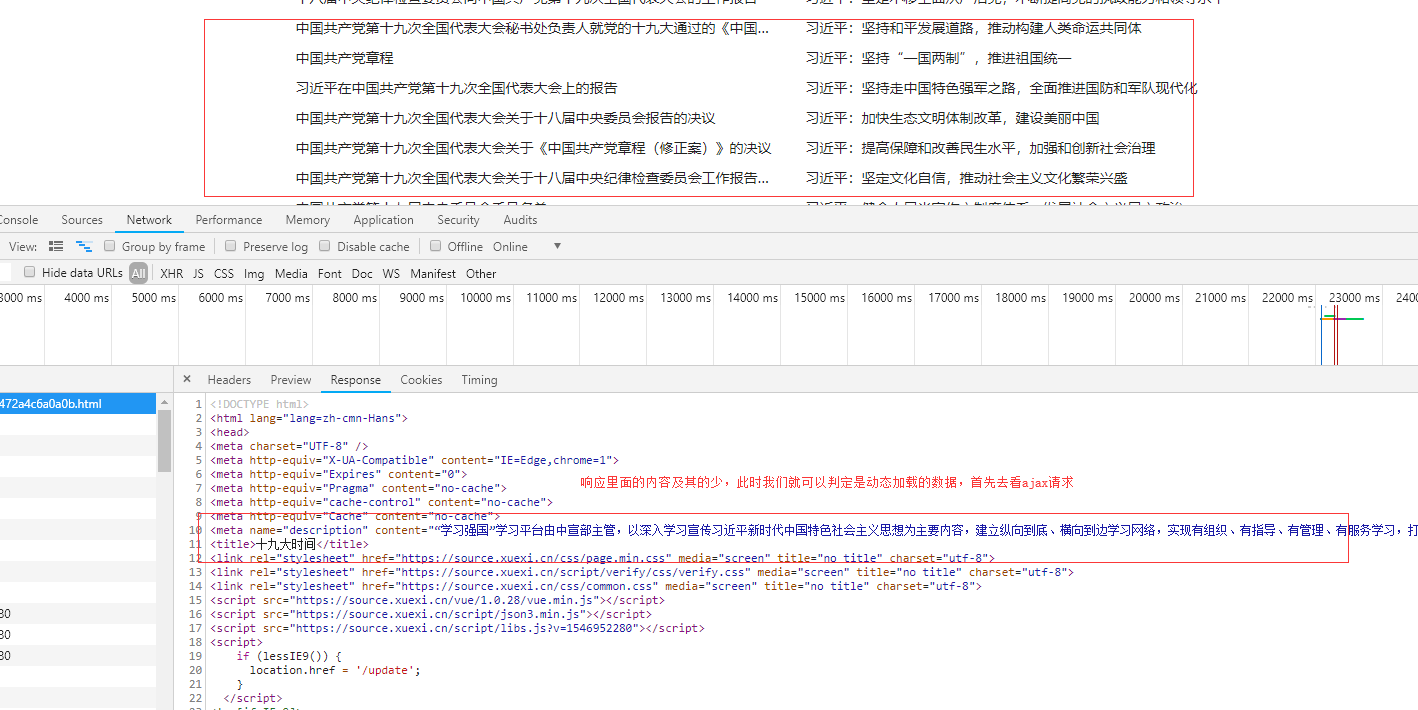
有很多页。当我们使用request发送请求时,返回的内容中没有页面显示数据。主要有两种情况。一种是通过ajax异步发送请求,得到响应并将数据放入页面。对于这种情况,我们可以查看ajax请求,然后分析ajax请求路径和响应,得到想要的数据;另一种是js动态加载的数据,然后放到页面中。在这两种情况下,当用户使用浏览器访问时,都不会发现任何异常,很快就会得到完整的页面。
其实我们之前学过一个selenium模块。通过操纵浏览器,然后获取浏览器显示的数据,可以通过这种方式获取数据,但是本节是分析如何发现js在控制数据的生成。以及js发送请求的路径,所以我们可以向这个路径发送请求,直接获取数据。
在之前的爬取过程中,我最烦的就是js动态生成的数据。我找不到实现了哪个js(因为js太多了)。今天看了大佬的博客,瞬间感觉简单了许多。, 感谢 Dao 提供 Dao 的博客:
一、需求描述和页面分析
一、要求说明
基页路径:
点击进入每个标题:
需求是抓取每个标题下的新闻内容
2. 页面分析
2.1 个主页
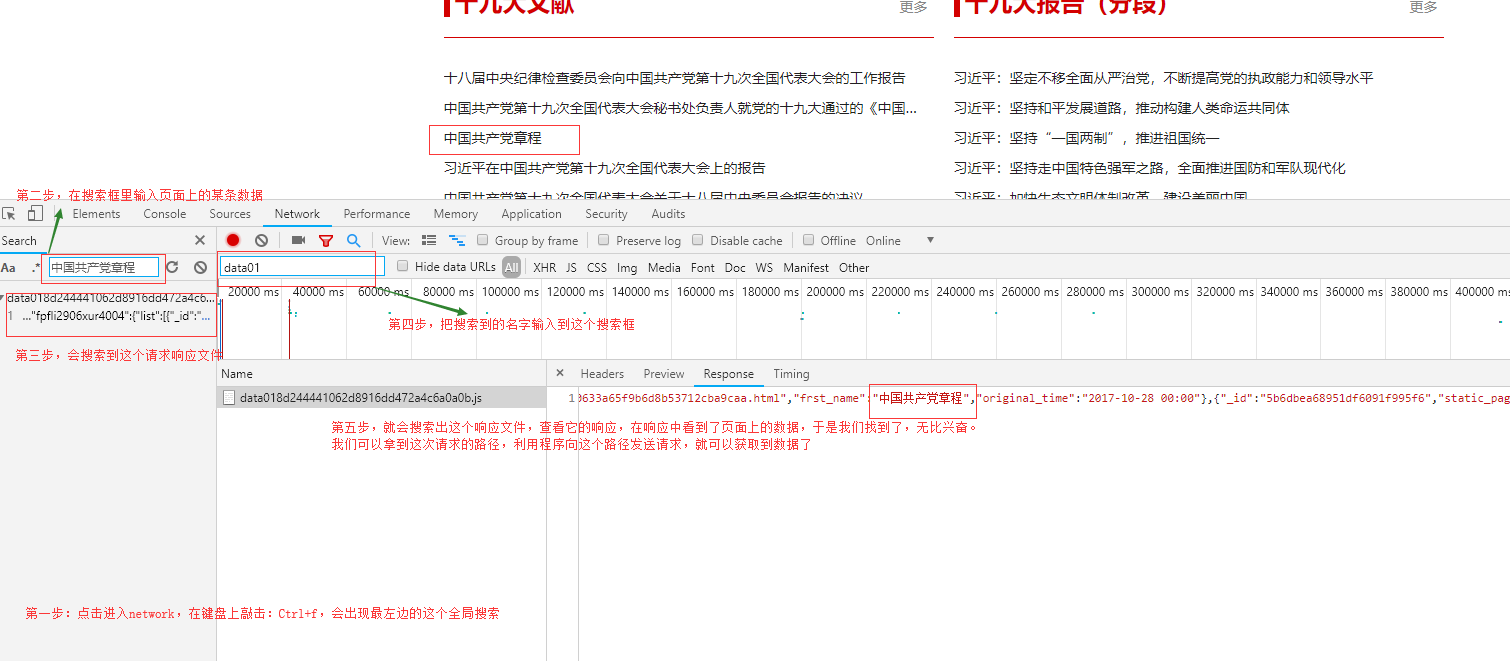
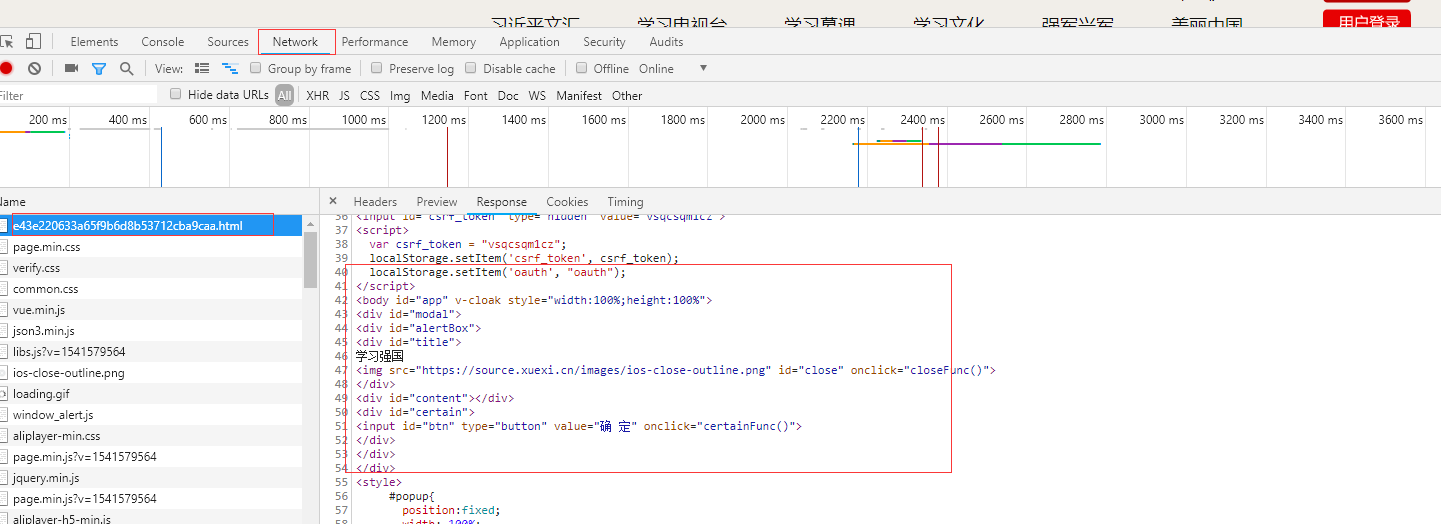
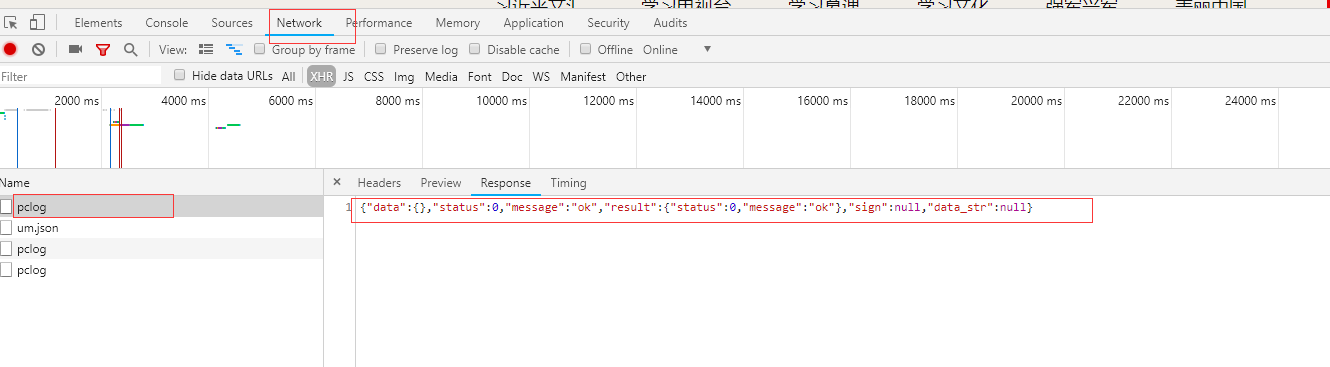
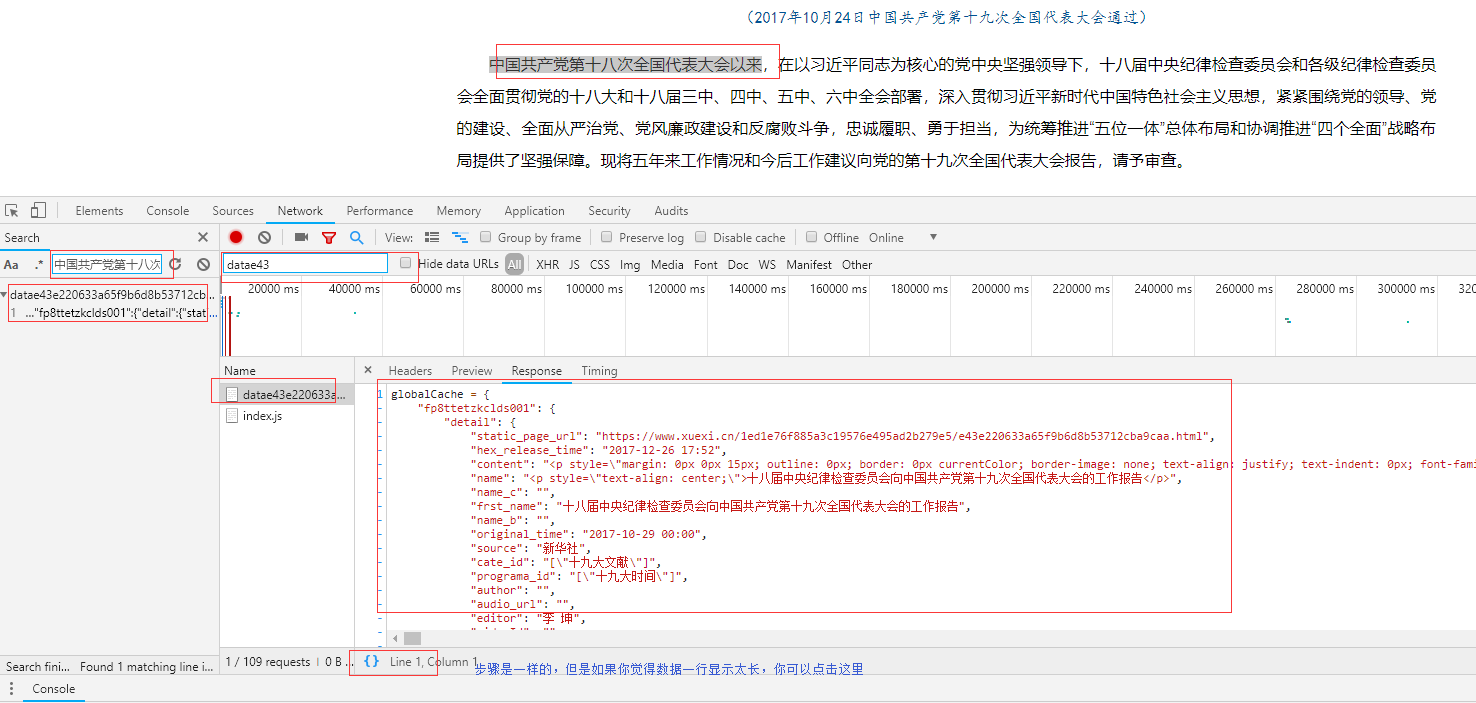
查看ajax请求:
接下来,我们将分析如何找出发送请求的js
二、找到发送请求的js
响应数据包括新闻标题和这条新闻的详情页路径,所以现在我们去访问详情页,分析详情页
访问详情页,查看详情页的响应,数据不收录具体数据,那么就和主页面一样,然后去ajax:
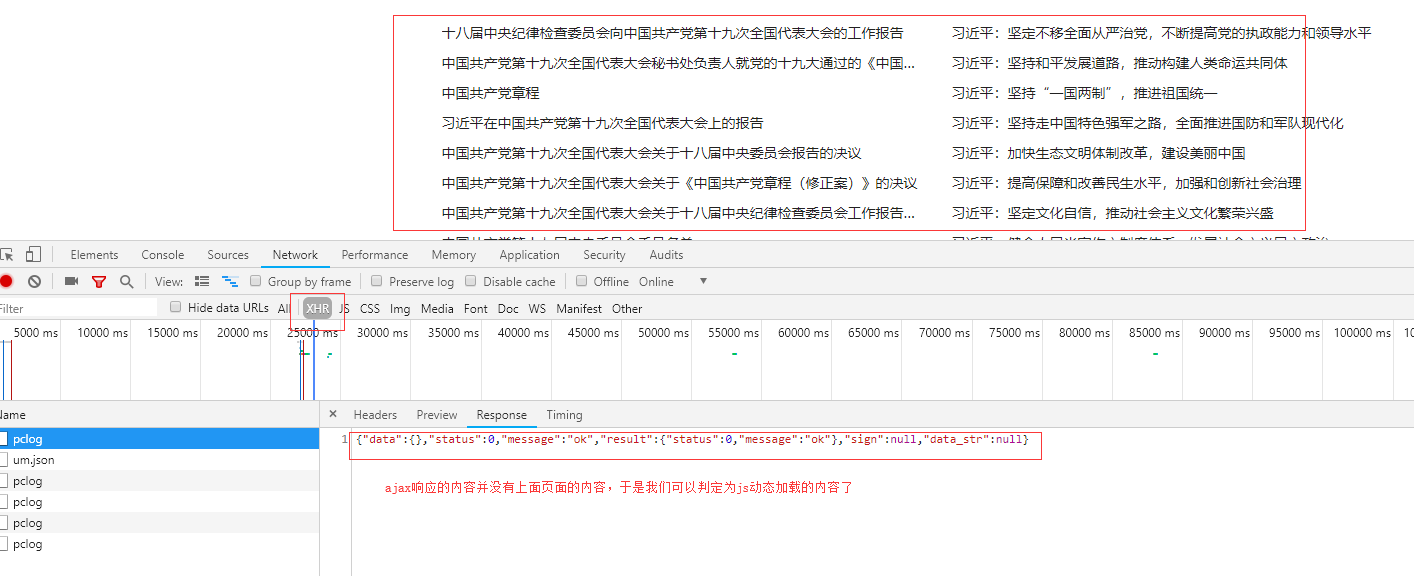
Ajax 没有新闻相关的数据,所以不使用ajax 请求来获取数据。只剩下js了。我们来看看是哪个js发送了获取数据的请求。上面的步骤是一样的:
详情页数据的js请求路径:
详情页请求路径:
我们可以看到,最后一个斜线之前的详情页数据的请求路径和最后一个斜线之前的详情页数据的请求路径是一样的。所以我们可以这样做:
第一步:获取详情页的请求路径:
url1='#39;
第二步:替换url1中最后一个斜杠后的内容
url2='%s/datae43e220633a65f9b6d8b53712cba9caa.js'%(url1.split('/')[3]) #用'/'分割url1得到第四部分,即索引为3,然后拼接进去
这样就构造了一个详细页面数据请求路径,然后就可以直接访问这个路径获取数据了,不需要访问详细页面。 查看全部
js提取指定网站内容(如何找出发送请求的js在控制数据的生成,我根本无法找到是哪一个js实现的)
有很多页。当我们使用request发送请求时,返回的内容中没有页面显示数据。主要有两种情况。一种是通过ajax异步发送请求,得到响应并将数据放入页面。对于这种情况,我们可以查看ajax请求,然后分析ajax请求路径和响应,得到想要的数据;另一种是js动态加载的数据,然后放到页面中。在这两种情况下,当用户使用浏览器访问时,都不会发现任何异常,很快就会得到完整的页面。
其实我们之前学过一个selenium模块。通过操纵浏览器,然后获取浏览器显示的数据,可以通过这种方式获取数据,但是本节是分析如何发现js在控制数据的生成。以及js发送请求的路径,所以我们可以向这个路径发送请求,直接获取数据。
在之前的爬取过程中,我最烦的就是js动态生成的数据。我找不到实现了哪个js(因为js太多了)。今天看了大佬的博客,瞬间感觉简单了许多。, 感谢 Dao 提供 Dao 的博客:
一、需求描述和页面分析
一、要求说明
基页路径:
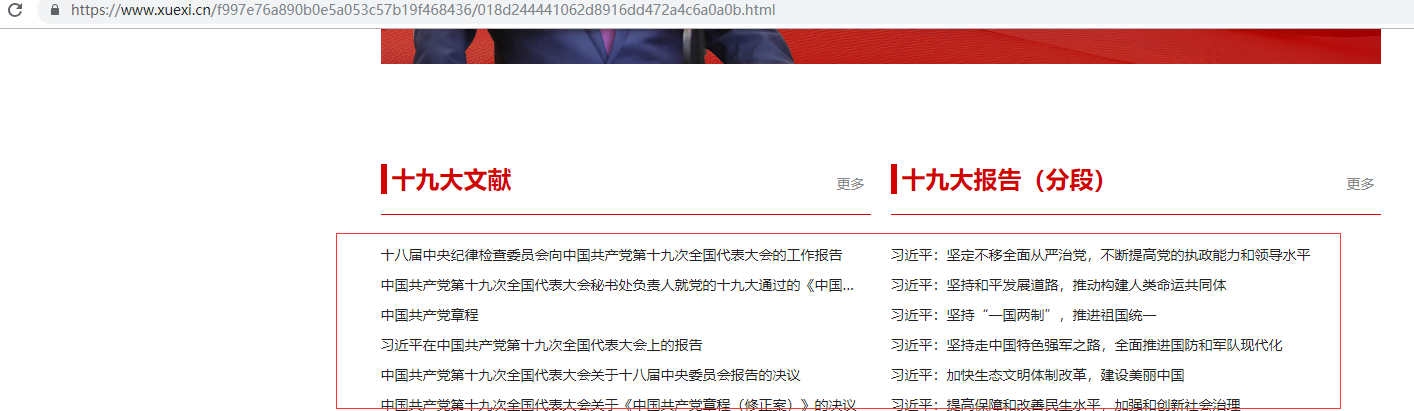
点击进入每个标题:
需求是抓取每个标题下的新闻内容
2. 页面分析
2.1 个主页
查看ajax请求:
接下来,我们将分析如何找出发送请求的js
二、找到发送请求的js
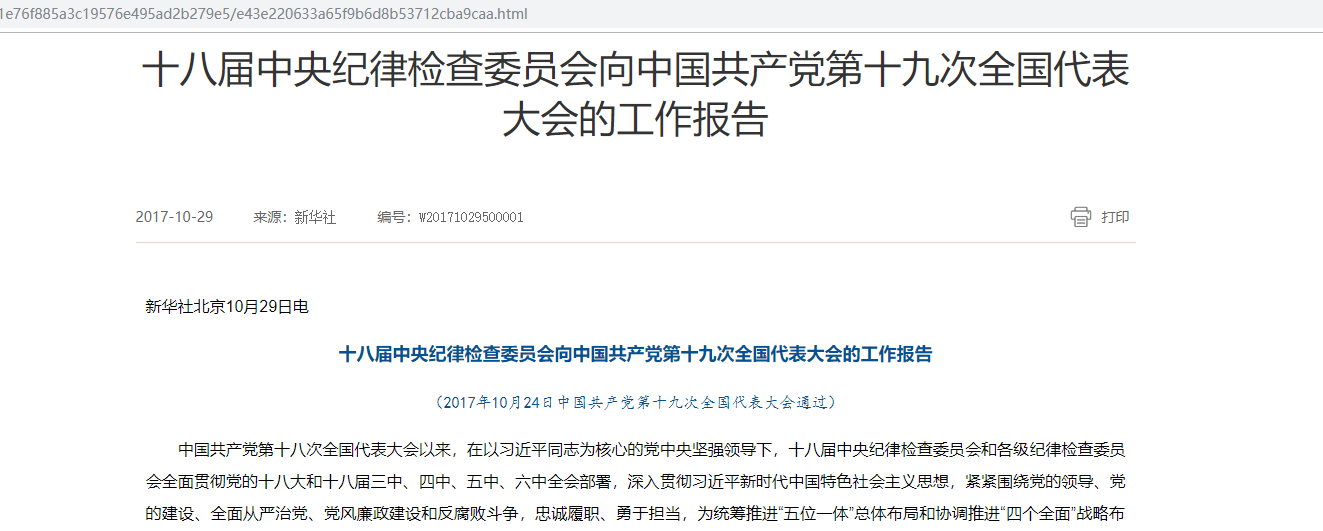
响应数据包括新闻标题和这条新闻的详情页路径,所以现在我们去访问详情页,分析详情页
访问详情页,查看详情页的响应,数据不收录具体数据,那么就和主页面一样,然后去ajax:
Ajax 没有新闻相关的数据,所以不使用ajax 请求来获取数据。只剩下js了。我们来看看是哪个js发送了获取数据的请求。上面的步骤是一样的:
详情页数据的js请求路径:

详情页请求路径:

我们可以看到,最后一个斜线之前的详情页数据的请求路径和最后一个斜线之前的详情页数据的请求路径是一样的。所以我们可以这样做:
第一步:获取详情页的请求路径:
url1='#39;
第二步:替换url1中最后一个斜杠后的内容
url2='%s/datae43e220633a65f9b6d8b53712cba9caa.js'%(url1.split('/')[3]) #用'/'分割url1得到第四部分,即索引为3,然后拼接进去
这样就构造了一个详细页面数据请求路径,然后就可以直接访问这个路径获取数据了,不需要访问详细页面。
js提取指定网站内容(JS的页面生命周期事件今天做个大屏项目项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-04 23:34
JS页面生命周期事件
今天我在做一个大屏幕项目。我想在所有资源加载到大屏幕之前添加一个加载动画,然后在加载后删除它。当然在load事件中去掉了,但是其他的事件有点模糊,回顾一下,哦垃圾生命周期事件DOMContentLoaded,浏览器完成HTML的加载,并构建DOM树,图片和样式等外部资源尚未加载尚未加载,浏览器在unload之前加载了所有资源,包括HTML文档,图片,样式等,用户即将离开,用于检查用户是否保存了修改。DOMContentLoaded DOMContentLoaded 事件发生在文档对象上。您必须在文档对象上使用 2. window.onload。当页面包括样式、图片等资源全部加载完毕后,window对象上的load事件会被触发 3. window.onunload 当访问者离开页面时,window对象上的unload事件会被触发。当sendBeacon请求完成时,浏览器可能已经离开了文档,因此无法获取服务器的响应数据。
588 查看全部
js提取指定网站内容(JS的页面生命周期事件今天做个大屏项目项目)
JS页面生命周期事件
今天我在做一个大屏幕项目。我想在所有资源加载到大屏幕之前添加一个加载动画,然后在加载后删除它。当然在load事件中去掉了,但是其他的事件有点模糊,回顾一下,哦垃圾生命周期事件DOMContentLoaded,浏览器完成HTML的加载,并构建DOM树,图片和样式等外部资源尚未加载尚未加载,浏览器在unload之前加载了所有资源,包括HTML文档,图片,样式等,用户即将离开,用于检查用户是否保存了修改。DOMContentLoaded DOMContentLoaded 事件发生在文档对象上。您必须在文档对象上使用 2. window.onload。当页面包括样式、图片等资源全部加载完毕后,window对象上的load事件会被触发 3. window.onunload 当访问者离开页面时,window对象上的unload事件会被触发。当sendBeacon请求完成时,浏览器可能已经离开了文档,因此无法获取服务器的响应数据。
588
js提取指定网站内容( vue-cli3DllPlugin提取公用库,需要的朋友可以参考)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-04 23:29
vue-cli3DllPlugin提取公用库,需要的朋友可以参考)
vue-cli3 DllPlugin 提取公共库的方法
更新时间:2019-04-24 09:26:41 作者:lifefriend_007
本文文章主要介绍vue-cli3 DllPlugin提取公共库。有需要的朋友可以参考
vue开发过程中,保存一次,编译一次。如果可以减少编译时间,即使是少量也可以节省大量时间。个人编写的源文件在开发过程中会经常改动,我们一般不会改动一些库文件。如果能够提取这些库文件,就可以减少打包体积,加快编译速度。本文主要介绍使用vue-cli3中的DllPlugin进行预编译。
1、安装相关插件
yarn add webpack-cli@^3.2.3 add-asset-html-webpack-plugin@^3.1.3 clean-webpack-plugin@^1.0.1 --dev
2、写配置文件
在项目根目录新建webpack.dll.conf.js,输入如下内容。
const path = require('path')
const webpack = require('webpack')
const CleanWebpackPlugin = require('clean-webpack-plugin')
// dll文件存放的目录
const dllPath = 'public/vendor'
module.exports = {
entry: {
// 需要提取的库文件
vendor: ['vue', 'vue-router', 'vuex', 'axios', 'element-ui']
},
output: {
path: path.join(__dirname, dllPath),
filename: '[name].dll.js',
// vendor.dll.js中暴露出的全局变量名
// 保持与 webpack.DllPlugin 中名称一致
library: '[name]_[hash]'
},
plugins: [
// 清除之前的dll文件
new CleanWebpackPlugin(['*.*'], {
root: path.join(__dirname, dllPath)
}),
// 设置环境变量
new webpack.DefinePlugin({
'process.env': {
NODE_ENV: 'production'
}
}),
// manifest.json 描述动态链接库包含了哪些内容
new webpack.DllPlugin({
path: path.join(__dirname, dllPath, '[name]-manifest.json'),
// 保持与 output.library 中名称一致
name: '[name]_[hash]',
context: process.cwd()
})
]
}
3、生成dll
将以下命令添加到 package.json
"scripts": {
...
"dll": "webpack -p --progress --config ./webpack.dll.conf.js"
},
控制台操作
纱线运行dll
4、忽略编译文件
为了节省编译时间,我们需要告诉webpack此时公共库文件已经编译完成,以减少webpack对公共库的编译时间。在项目根目录中找到vue.config.js(如果没有就创建),配置如下:
const webpack = require('webpack')
module.exports = {
...
configureWebpack: {
plugins: [
new webpack.DllReferencePlugin({
context: process.cwd(),
manifest: require('./public/vendor/vendor-manifest.json')
})
]
}
}
5、在index.html中加载生成的dll文件
经过以上配置,公共库被解压出来,编译速度更快,但是如果不引用生成的dll文件,网页将无法正常运行。
打开 public/index.html 并插入脚本标签。
...
至此,公共库提取完成,但总觉得最后手动插入脚本不优雅。下面介绍如何自动导入生成的dll文件。
打开vue.config.js,在configureWebpack plugins节点下配置add-asset-html-webpack-plugin
const path = require('path')
const webpack = require('webpack')
const AddAssetHtmlPlugin = require('add-asset-html-webpack-plugin')
module.exports = {
...
configureWebpack: {
plugins: [
new webpack.DllReferencePlugin({
context: process.cwd(),
manifest: require('./public/vendor/vendor-manifest.json')
}),
// 将 dll 注入到 生成的 html 模板中
new AddAssetHtmlPlugin({
// dll文件位置
filepath: path.resolve(__dirname, './public/vendor/*.js'),
// dll 引用路径
publicPath: './vendor',
// dll最终输出的目录
outputPath: './vendor'
})
]
}
}
总结
以上就是小编介绍的vue-cli3 DllPlugin提取公共库的方法。我希望它会对你有所帮助。如有问题,请给我留言,小编会及时回复您。非常感谢您对脚本之家网站的支持!
如果觉得本文对您有帮助,欢迎转载,请注明出处,谢谢! 查看全部
js提取指定网站内容(
vue-cli3DllPlugin提取公用库,需要的朋友可以参考)
vue-cli3 DllPlugin 提取公共库的方法
更新时间:2019-04-24 09:26:41 作者:lifefriend_007
本文文章主要介绍vue-cli3 DllPlugin提取公共库。有需要的朋友可以参考
vue开发过程中,保存一次,编译一次。如果可以减少编译时间,即使是少量也可以节省大量时间。个人编写的源文件在开发过程中会经常改动,我们一般不会改动一些库文件。如果能够提取这些库文件,就可以减少打包体积,加快编译速度。本文主要介绍使用vue-cli3中的DllPlugin进行预编译。
1、安装相关插件
yarn add webpack-cli@^3.2.3 add-asset-html-webpack-plugin@^3.1.3 clean-webpack-plugin@^1.0.1 --dev
2、写配置文件
在项目根目录新建webpack.dll.conf.js,输入如下内容。
const path = require('path')
const webpack = require('webpack')
const CleanWebpackPlugin = require('clean-webpack-plugin')
// dll文件存放的目录
const dllPath = 'public/vendor'
module.exports = {
entry: {
// 需要提取的库文件
vendor: ['vue', 'vue-router', 'vuex', 'axios', 'element-ui']
},
output: {
path: path.join(__dirname, dllPath),
filename: '[name].dll.js',
// vendor.dll.js中暴露出的全局变量名
// 保持与 webpack.DllPlugin 中名称一致
library: '[name]_[hash]'
},
plugins: [
// 清除之前的dll文件
new CleanWebpackPlugin(['*.*'], {
root: path.join(__dirname, dllPath)
}),
// 设置环境变量
new webpack.DefinePlugin({
'process.env': {
NODE_ENV: 'production'
}
}),
// manifest.json 描述动态链接库包含了哪些内容
new webpack.DllPlugin({
path: path.join(__dirname, dllPath, '[name]-manifest.json'),
// 保持与 output.library 中名称一致
name: '[name]_[hash]',
context: process.cwd()
})
]
}
3、生成dll
将以下命令添加到 package.json
"scripts": {
...
"dll": "webpack -p --progress --config ./webpack.dll.conf.js"
},
控制台操作
纱线运行dll
4、忽略编译文件
为了节省编译时间,我们需要告诉webpack此时公共库文件已经编译完成,以减少webpack对公共库的编译时间。在项目根目录中找到vue.config.js(如果没有就创建),配置如下:
const webpack = require('webpack')
module.exports = {
...
configureWebpack: {
plugins: [
new webpack.DllReferencePlugin({
context: process.cwd(),
manifest: require('./public/vendor/vendor-manifest.json')
})
]
}
}
5、在index.html中加载生成的dll文件
经过以上配置,公共库被解压出来,编译速度更快,但是如果不引用生成的dll文件,网页将无法正常运行。
打开 public/index.html 并插入脚本标签。
...
至此,公共库提取完成,但总觉得最后手动插入脚本不优雅。下面介绍如何自动导入生成的dll文件。
打开vue.config.js,在configureWebpack plugins节点下配置add-asset-html-webpack-plugin
const path = require('path')
const webpack = require('webpack')
const AddAssetHtmlPlugin = require('add-asset-html-webpack-plugin')
module.exports = {
...
configureWebpack: {
plugins: [
new webpack.DllReferencePlugin({
context: process.cwd(),
manifest: require('./public/vendor/vendor-manifest.json')
}),
// 将 dll 注入到 生成的 html 模板中
new AddAssetHtmlPlugin({
// dll文件位置
filepath: path.resolve(__dirname, './public/vendor/*.js'),
// dll 引用路径
publicPath: './vendor',
// dll最终输出的目录
outputPath: './vendor'
})
]
}
}
总结
以上就是小编介绍的vue-cli3 DllPlugin提取公共库的方法。我希望它会对你有所帮助。如有问题,请给我留言,小编会及时回复您。非常感谢您对脚本之家网站的支持!
如果觉得本文对您有帮助,欢迎转载,请注明出处,谢谢!
js提取指定网站内容(宝哥教你怎么用代码网页存为图片(一)_宝哥)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-04 16:06
随着网络技术的发展,我们使用的截图越来越多。windows上有非常人性化的QQ截图。浏览器中还有一个方便的截图插件。今天包哥教你如何用代码截取网页并保存为图片。对于一些为各种目的编写自动化脚本的人以及一些 Linux 用户来说,这仍然非常需要。而且,即使对于windows用户来说,使用截屏工具来滚动截取需要滚动显示的网页内容,仍然非常困难。
phantomjs 有一个 api,专门用于截图。但是它只能截取网页和指定区域的截图,而且一个很常见的需求是我想截取一个文本区域或者一个网页的特定区域,但是我不想计算它的坐标和长度和宽度。为什么?管理?没关系,casperjs为我们关闭了。它有这个api。我写了一个支持命令行参数的casperjs脚本,放在MagicScripts里,叫做capture.js。
用法
casperjs /path/to/capture.js page_url 文件名.png [选择器]。
有兴趣的可以点击前面的链接查看git上的代码。如果您有自定义需求(例如支持指定坐标区域截图),您可以自由自定义fork代码。
(转载本站文章请注明开发部落出处-) 查看全部
js提取指定网站内容(宝哥教你怎么用代码网页存为图片(一)_宝哥)
随着网络技术的发展,我们使用的截图越来越多。windows上有非常人性化的QQ截图。浏览器中还有一个方便的截图插件。今天包哥教你如何用代码截取网页并保存为图片。对于一些为各种目的编写自动化脚本的人以及一些 Linux 用户来说,这仍然非常需要。而且,即使对于windows用户来说,使用截屏工具来滚动截取需要滚动显示的网页内容,仍然非常困难。
phantomjs 有一个 api,专门用于截图。但是它只能截取网页和指定区域的截图,而且一个很常见的需求是我想截取一个文本区域或者一个网页的特定区域,但是我不想计算它的坐标和长度和宽度。为什么?管理?没关系,casperjs为我们关闭了。它有这个api。我写了一个支持命令行参数的casperjs脚本,放在MagicScripts里,叫做capture.js。
用法
casperjs /path/to/capture.js page_url 文件名.png [选择器]。
有兴趣的可以点击前面的链接查看git上的代码。如果您有自定义需求(例如支持指定坐标区域截图),您可以自由自定义fork代码。
(转载本站文章请注明开发部落出处-)
js提取指定网站内容(搜索引擎爬虫爬取网页被重定向的操作方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 403 次浏览 • 2021-11-29 11:09
作者写的搜索引擎爬虫在爬取页面时遇到了网页被重定向的情况。所谓重定向就是通过各种方法(本文提到的三种)(URL)将各种网络请求重定向到其他位置。每个网站首页都是网站资源的入口。当重定向发生在网站的首页时,如果处理不当,很可能会遗漏网站的全部内容。
作者写的爬虫在爬取网页时遇到了三种重定向情况。
1.服务器端重定向是在服务器端完成的。一般来说爬虫是可以自适应的,不需要特殊处理,比如响应码301(永久重定向)、302(临时重定向)等,具体可以通过响应中的url和status_code这两个属性来判断requests 请求获取的对象。当status_code为301、302或其他代表重定向的code时,表示原请求被重定向;当响应对象的 url 属性与发送请求时的链接不一致时,也说明原来的请求被重定向并且已经被自动处理了。
#请求重定向#方法二
response.setStatus(302);
response.setHeader("location", "/day06/index.jsp");#方法二
response.sendRedirect("/day06/index.jsp");
scrapy shell 以获取重定向页面
scrapy shell -s ROBOTSTXT_OBEY=False --no-redirect ""fetch(response.headers['Location'])
2.meta refresh,即网页中的标签声明了网页重定向的链接。这个重定向是由浏览器完成的,需要通过编写代码来处理。比如下面HTML代码第三行的注释中如果出现某个重定向,浏览器可以自动跳转,但是爬虫只能获取跳转前的页面,不能自动跳转。
解决方法是通过获取跳转前的页面源代码来提取重定向url信息(上面代码第三行的url属性值)。具体操作:
①使用xpath('//meta[@http-equiv="refresh" and @content]/@content')提取content的值
②使用正则表达式提取重定向的url值。
3.js 重定向,重定向是以 JavaScript 代码的形式进行的。比如下面的JavaScript代码
网页收录内容的情况是最容易解决的。一般来说,它基本上是静态网页的硬编码内容,或者是动态网页,使用模板渲染。当浏览器获取到 HTML 时,它已经收录了所有的关键信息,所以你在网页上直接看到的内容可以通过特定的 HTML 标签加载 javascript 代码。这种情况是因为虽然网页显示时内容在HTML标签中,但实际上是通过执行js代码添加到标签中的。所以此时的内容在js代码中,js的执行是浏览器端的操作,所以当你使用程序请求网页地址时,得到的响应就是网页代码和js代码,这样就可以在浏览器端看到内容了,因为解析的时候没有执行js,所以指定的HTML标签下的内容必须是空的。这时候的处理方法一般是找到收录内容的js代码字符串,然后通过正则表达式获取对应的内容,而不是解析HTML标签。 查看全部
js提取指定网站内容(搜索引擎爬虫爬取网页被重定向的操作方法(图))
作者写的搜索引擎爬虫在爬取页面时遇到了网页被重定向的情况。所谓重定向就是通过各种方法(本文提到的三种)(URL)将各种网络请求重定向到其他位置。每个网站首页都是网站资源的入口。当重定向发生在网站的首页时,如果处理不当,很可能会遗漏网站的全部内容。
作者写的爬虫在爬取网页时遇到了三种重定向情况。
1.服务器端重定向是在服务器端完成的。一般来说爬虫是可以自适应的,不需要特殊处理,比如响应码301(永久重定向)、302(临时重定向)等,具体可以通过响应中的url和status_code这两个属性来判断requests 请求获取的对象。当status_code为301、302或其他代表重定向的code时,表示原请求被重定向;当响应对象的 url 属性与发送请求时的链接不一致时,也说明原来的请求被重定向并且已经被自动处理了。
#请求重定向#方法二
response.setStatus(302);
response.setHeader("location", "/day06/index.jsp");#方法二
response.sendRedirect("/day06/index.jsp");
scrapy shell 以获取重定向页面
scrapy shell -s ROBOTSTXT_OBEY=False --no-redirect ""fetch(response.headers['Location'])
2.meta refresh,即网页中的标签声明了网页重定向的链接。这个重定向是由浏览器完成的,需要通过编写代码来处理。比如下面HTML代码第三行的注释中如果出现某个重定向,浏览器可以自动跳转,但是爬虫只能获取跳转前的页面,不能自动跳转。
解决方法是通过获取跳转前的页面源代码来提取重定向url信息(上面代码第三行的url属性值)。具体操作:
①使用xpath('//meta[@http-equiv="refresh" and @content]/@content')提取content的值
②使用正则表达式提取重定向的url值。
3.js 重定向,重定向是以 JavaScript 代码的形式进行的。比如下面的JavaScript代码
网页收录内容的情况是最容易解决的。一般来说,它基本上是静态网页的硬编码内容,或者是动态网页,使用模板渲染。当浏览器获取到 HTML 时,它已经收录了所有的关键信息,所以你在网页上直接看到的内容可以通过特定的 HTML 标签加载 javascript 代码。这种情况是因为虽然网页显示时内容在HTML标签中,但实际上是通过执行js代码添加到标签中的。所以此时的内容在js代码中,js的执行是浏览器端的操作,所以当你使用程序请求网页地址时,得到的响应就是网页代码和js代码,这样就可以在浏览器端看到内容了,因为解析的时候没有执行js,所以指定的HTML标签下的内容必须是空的。这时候的处理方法一般是找到收录内容的js代码字符串,然后通过正则表达式获取对应的内容,而不是解析HTML标签。
js提取指定网站内容(Python即时网络爬虫GitHub源7,文档修改历史(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-28 07:10
1 简介
本文介绍了如何使用 Java 和 JavaScript 中的 GooSeeker API 接口下载内容提取器。这是一个示例程序。什么是内容提取器?为什么要使用这种方法?源自Python即时网络爬虫开源项目:通过生成内容提取器,大大节省了程序员的时间。详情请参考“内容提取器的定义”。
2.用Java下载内容提取器
这是一系列示例程序之一。从目前的编程语言发展来看,Java实现网页内容提取并不合适。除了语言不够灵活方便,整个生态不够活跃,可选库增长缓慢。另外,从JavaScript动态网页中提取内容,Java也很不方便,需要JavaScript引擎。使用 JavaScript 下载内容提取器可以直接跳转到第 3 部分的内容。
执行
注解:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回结果如下:
3. 使用 JavaScript 下载内容提取器
请注意,如果本示例中的 JavaScript 代码运行在网页上,由于跨域问题,无法抓取非站点网页的内容。因此,运行在有特权的 JavaScript 引擎上,例如浏览器扩展、自研浏览器以及自己程序中的 JavaScript 引擎。
为方便实验,本示例仍在网页上运行。为了避免跨域问题,目标网页被保存和修改,并在其中插入JavaScript。这么多手动操作只是为了实验,正式使用时还需要考虑其他方法。
执行
注解:
这是源代码:
// 目标网页网址为http://m.58.com/cs/qiuzu/22613961050143x.shtml,预先保存成本地html文件,并插入下述代码
$(document).ready(function(){
$.ajax({
type: "get",
url: "http://www.gooseeker.com/api/getextractor?key=申请的appKey&theme=规则主题名",
dataType: "xml",
success: function(xslt)
{
var result = convertXml(xslt, window.document);
alert("result:" + result);
}
});
});
/* 用xslt将dom转换为xml对象 */
function convertXml(xslt, dom)
{
// 定义XSLTProcessor对象
var xsltProcessor = new XSLTProcessor();
xsltProcessor.importStylesheet(xslt);
// transformToDocument方式
var result = xsltProcessor.transformToDocument(dom);
return result;
}
返回结果截图如下
4. 展望
您也可以使用 Python 来获取指定网页的内容。感觉Python的语法更简洁。稍后我们将添加 Python 语言的示例。有兴趣的朋友可以加入一起学习。
五、相关文件
1. Python即时网络爬虫:API说明
2.内容提取器的定义
6、采集GooSeeker开源代码下载
1. GooSeeker开源Python网络爬虫GitHub源码
7. 文档修改历史
1, 2016-06-20: V1.0
上一章 API-下载内容提取器 下一章 用 Python 驱动 Firefox 查看全部
js提取指定网站内容(Python即时网络爬虫GitHub源7,文档修改历史(组图))
1 简介
本文介绍了如何使用 Java 和 JavaScript 中的 GooSeeker API 接口下载内容提取器。这是一个示例程序。什么是内容提取器?为什么要使用这种方法?源自Python即时网络爬虫开源项目:通过生成内容提取器,大大节省了程序员的时间。详情请参考“内容提取器的定义”。
2.用Java下载内容提取器
这是一系列示例程序之一。从目前的编程语言发展来看,Java实现网页内容提取并不合适。除了语言不够灵活方便,整个生态不够活跃,可选库增长缓慢。另外,从JavaScript动态网页中提取内容,Java也很不方便,需要JavaScript引擎。使用 JavaScript 下载内容提取器可以直接跳转到第 3 部分的内容。
执行
注解:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回结果如下:

3. 使用 JavaScript 下载内容提取器
请注意,如果本示例中的 JavaScript 代码运行在网页上,由于跨域问题,无法抓取非站点网页的内容。因此,运行在有特权的 JavaScript 引擎上,例如浏览器扩展、自研浏览器以及自己程序中的 JavaScript 引擎。
为方便实验,本示例仍在网页上运行。为了避免跨域问题,目标网页被保存和修改,并在其中插入JavaScript。这么多手动操作只是为了实验,正式使用时还需要考虑其他方法。
执行
注解:
这是源代码:
// 目标网页网址为http://m.58.com/cs/qiuzu/22613961050143x.shtml,预先保存成本地html文件,并插入下述代码
$(document).ready(function(){
$.ajax({
type: "get",
url: "http://www.gooseeker.com/api/getextractor?key=申请的appKey&theme=规则主题名",
dataType: "xml",
success: function(xslt)
{
var result = convertXml(xslt, window.document);
alert("result:" + result);
}
});
});
/* 用xslt将dom转换为xml对象 */
function convertXml(xslt, dom)
{
// 定义XSLTProcessor对象
var xsltProcessor = new XSLTProcessor();
xsltProcessor.importStylesheet(xslt);
// transformToDocument方式
var result = xsltProcessor.transformToDocument(dom);
return result;
}
返回结果截图如下
4. 展望
您也可以使用 Python 来获取指定网页的内容。感觉Python的语法更简洁。稍后我们将添加 Python 语言的示例。有兴趣的朋友可以加入一起学习。
五、相关文件
1. Python即时网络爬虫:API说明
2.内容提取器的定义
6、采集GooSeeker开源代码下载
1. GooSeeker开源Python网络爬虫GitHub源码
7. 文档修改历史
1, 2016-06-20: V1.0
上一章 API-下载内容提取器 下一章 用 Python 驱动 Firefox
js提取指定网站内容(用requests模块获取网站数据时,网站的编码是个很麻烦的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-26 03:22
使用requests模块获取网站数据时,网站的编码是一个很麻烦的问题。一般来说,请求会自动识别网站的编码。如果网页未指定编码,则默认为 ISO-8859-1 编码。这时候可能会出现问题。
一般有几种方式,最简单的就是手动指定编码r.encoding = ‘utf-8’
但是,当采集数据时,您可能访问不同域名的网站。这时候,手动为每个网站分配一个正确的代码并不容易。以下是通用方法
if r.encoding == 'ISO-8859-1':
encodings = requests.utils.get_encodings_from_content(r.text)
if encodings:
encoding = encodings[0]
else:
encoding = r.apparent_encoding
return r.content.decode(encoding, 'replace')
else:
return r.text
本作品采用《CC协议》,转载需注明作者及本文链接 查看全部
js提取指定网站内容(用requests模块获取网站数据时,网站的编码是个很麻烦的问题)
使用requests模块获取网站数据时,网站的编码是一个很麻烦的问题。一般来说,请求会自动识别网站的编码。如果网页未指定编码,则默认为 ISO-8859-1 编码。这时候可能会出现问题。
一般有几种方式,最简单的就是手动指定编码r.encoding = ‘utf-8’
但是,当采集数据时,您可能访问不同域名的网站。这时候,手动为每个网站分配一个正确的代码并不容易。以下是通用方法
if r.encoding == 'ISO-8859-1':
encodings = requests.utils.get_encodings_from_content(r.text)
if encodings:
encoding = encodings[0]
else:
encoding = r.apparent_encoding
return r.content.decode(encoding, 'replace')
else:
return r.text
本作品采用《CC协议》,转载需注明作者及本文链接
js提取指定网站内容(JavaScript如何打印页面中的指定内容的效果,功能非常不错)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-25 11:09
很多网站都有这个功能。当您浏览到底部时,会有一个打印按钮。点击打印按钮完成打印功能。功能非常好,人性化。下面我们来介绍一下通过点击按钮实现打印的JavaScript。代码,需要的朋友参考
很多网站都有这个功能。当您浏览到底部时,会有一个打印按钮。点击打印按钮完成打印功能。功能很好,人性化,代码也很简单。
脚本之家
即只要调用window.print()函数,就可以打印当前页面。
但是上面的并不完美,因为有些网页上的很多内容是不需要打印的。下面是如何在页面上打印指定的内容。
代码显示如下:
指定被打印的内容 这是要被打印的内容欢迎您
特别注意:打印预览需要将代码复制到本地机器进行测试,否则会报错。
以上代码实现了打印网页指定内容的效果。下面简单介绍一下实现过程。
一. 实现原理:
在js代码中使用document.body.innerHTML =newstr,将原body中的内容动态替换为要打印的内容。打印后,恢复原创内容。原理就是这么简单。具体可以参考代码注释。
二.代码注释:
1.function printdiv(printpage){},声明一个控制打印的函数,参数是一个对象,这个对象的内容会被打印出来。
2.var newstr = printpage.innerHTML; 获取要打印的内容。
3.var oldstr = document.body.innerHTML,body 中的原创内容。
4. document.body.innerHTML =newstr,将原body中的内容替换为要打印的内容。
5.window.print(),开始打印。
6.document.body.innerHTML=oldstr,然后恢复原来body中的内容。 查看全部
js提取指定网站内容(JavaScript如何打印页面中的指定内容的效果,功能非常不错)
很多网站都有这个功能。当您浏览到底部时,会有一个打印按钮。点击打印按钮完成打印功能。功能非常好,人性化。下面我们来介绍一下通过点击按钮实现打印的JavaScript。代码,需要的朋友参考
很多网站都有这个功能。当您浏览到底部时,会有一个打印按钮。点击打印按钮完成打印功能。功能很好,人性化,代码也很简单。
脚本之家
即只要调用window.print()函数,就可以打印当前页面。
但是上面的并不完美,因为有些网页上的很多内容是不需要打印的。下面是如何在页面上打印指定的内容。
代码显示如下:
指定被打印的内容 这是要被打印的内容欢迎您
特别注意:打印预览需要将代码复制到本地机器进行测试,否则会报错。
以上代码实现了打印网页指定内容的效果。下面简单介绍一下实现过程。
一. 实现原理:
在js代码中使用document.body.innerHTML =newstr,将原body中的内容动态替换为要打印的内容。打印后,恢复原创内容。原理就是这么简单。具体可以参考代码注释。
二.代码注释:
1.function printdiv(printpage){},声明一个控制打印的函数,参数是一个对象,这个对象的内容会被打印出来。
2.var newstr = printpage.innerHTML; 获取要打印的内容。
3.var oldstr = document.body.innerHTML,body 中的原创内容。
4. document.body.innerHTML =newstr,将原body中的内容替换为要打印的内容。
5.window.print(),开始打印。
6.document.body.innerHTML=oldstr,然后恢复原来body中的内容。
js提取指定网站内容(JavaScript驾驭网页-CSS与DOM利用DOM分割HTML利用分割)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-15 11:00
JavaScript 控制网页-CSS 和 DOM
使用 DOM 拆分 HTML
使用 JavaScript 来控制 Web 内容实际上很像做饭。只是你不用清理剩菜,却没有办法享受到美味的结果。
但是,您将能够完成网页内容的 HTML 元素:更重要的是,您将拥有替换网页元素的能力。
JavaScript 可以让你随心所欲地操作网页的 HTML 代码,从而开启各种有趣的机会,这一切都是因为标准对象:DOM 的存在
getElementById
HTML标签都有一个"id"属性,第个标签的该属性都是独一无二的
可以通过id属性来获取元素
内容
var sceneDesc=document.getElementById("div2");
getElementById可以通过元素的id属性去访问标签
括号里是id的值
getElementsByTagName
也可以通过标签名来获取元素
内容
var divs=document.getElementsByTagName("div");
getElementsByTagName返回所有div标签,结果是一个数组,结果按照标签在HTML中的顺序排列
括号里是标签名
var divs=document.getElementsByTagName("div")[2];
用索引获取第三个div标签
内部HTML
innerHTML特性对所有存储在元素里的内容提供了访问管道
通过innerHTML访问元素内存储的内容:
<p id="story"> you are standing
alone in the woods.
document.getElementById("story").innerHTML;
返回的内容是: you are standing alone in the woods.
innerHTML获取的是指定元素下的所有内容与标签
innerHTML也能用于设置网页内容
document.getElementById("story").innerHTML="You are not alone!";
innerHTML只用来设置可以包含文本的标签</p>
给大家介绍了很多关于JavaScript控制网页的知识——网页元素的知识,希望对大家有所帮助! 查看全部
js提取指定网站内容(JavaScript驾驭网页-CSS与DOM利用DOM分割HTML利用分割)
JavaScript 控制网页-CSS 和 DOM
使用 DOM 拆分 HTML
使用 JavaScript 来控制 Web 内容实际上很像做饭。只是你不用清理剩菜,却没有办法享受到美味的结果。
但是,您将能够完成网页内容的 HTML 元素:更重要的是,您将拥有替换网页元素的能力。
JavaScript 可以让你随心所欲地操作网页的 HTML 代码,从而开启各种有趣的机会,这一切都是因为标准对象:DOM 的存在
getElementById
HTML标签都有一个"id"属性,第个标签的该属性都是独一无二的
可以通过id属性来获取元素
内容
var sceneDesc=document.getElementById("div2");
getElementById可以通过元素的id属性去访问标签
括号里是id的值
getElementsByTagName
也可以通过标签名来获取元素
内容
var divs=document.getElementsByTagName("div");
getElementsByTagName返回所有div标签,结果是一个数组,结果按照标签在HTML中的顺序排列
括号里是标签名
var divs=document.getElementsByTagName("div")[2];
用索引获取第三个div标签
内部HTML
innerHTML特性对所有存储在元素里的内容提供了访问管道
通过innerHTML访问元素内存储的内容:
<p id="story"> you are standing
alone in the woods.
document.getElementById("story").innerHTML;
返回的内容是: you are standing alone in the woods.
innerHTML获取的是指定元素下的所有内容与标签
innerHTML也能用于设置网页内容
document.getElementById("story").innerHTML="You are not alone!";
innerHTML只用来设置可以包含文本的标签</p>
给大家介绍了很多关于JavaScript控制网页的知识——网页元素的知识,希望对大家有所帮助!
js提取指定网站内容(,pubdate功能很强大,使用却很简单(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-14 08:12
Powershell可以方便的获取网页的信息,读取相应的内容。如果对象的格式是 XML 或 Json,则更容易处理。一般经常用到invoke-restmethod和invoke-webrequest这两个命令。前者主要是获取Json格式的内容,后者可以获取整个网页的内容。
例如,我想查看明天悉尼的天气。我在网上随便搜了一个提供API的网站
#名称
我打算搜索Sydney,所以对应的格式是
,au 他会自动生成 Json 格式的结果。
我们可以使用invoke-restmethod直接得到这个结果,例如
$b=invoke-restmethod "http://api.openweathermap.org/ ... ydney,au"
$c=[pscustomobject]@{
'Description'=$b.weather.description
'name'=$b.name
'windspeed'=$b.wind.speed
}
我也可以直接使用invoke-webrequest来抓取整个网页的内容,然后从Json格式转换过来。
$a= Invoke-WebRequest -Uri ",au"$b=$a.Content | ConvertFrom-Json
同样,如果我想获取博客的最新 RSS 内容。可以使用 invoke-webrequest 抓取对应的 XML 文件,如
[xml]$a= Invoke-WebRequest -Uri "“$a.rss.channel.Item | 选择标题,发布日期
功能非常强大,但是使用起来非常简单。
本文来自“麻婆豆腐”博客 查看全部
js提取指定网站内容(,pubdate功能很强大,使用却很简单(图))
Powershell可以方便的获取网页的信息,读取相应的内容。如果对象的格式是 XML 或 Json,则更容易处理。一般经常用到invoke-restmethod和invoke-webrequest这两个命令。前者主要是获取Json格式的内容,后者可以获取整个网页的内容。
例如,我想查看明天悉尼的天气。我在网上随便搜了一个提供API的网站
#名称
我打算搜索Sydney,所以对应的格式是
,au 他会自动生成 Json 格式的结果。
我们可以使用invoke-restmethod直接得到这个结果,例如
$b=invoke-restmethod "http://api.openweathermap.org/ ... ydney,au"
$c=[pscustomobject]@{
'Description'=$b.weather.description
'name'=$b.name
'windspeed'=$b.wind.speed
}
我也可以直接使用invoke-webrequest来抓取整个网页的内容,然后从Json格式转换过来。
$a= Invoke-WebRequest -Uri ",au"$b=$a.Content | ConvertFrom-Json
同样,如果我想获取博客的最新 RSS 内容。可以使用 invoke-webrequest 抓取对应的 XML 文件,如
[xml]$a= Invoke-WebRequest -Uri "“$a.rss.channel.Item | 选择标题,发布日期
功能非常强大,但是使用起来非常简单。
本文来自“麻婆豆腐”博客
js提取指定网站内容(本文实例分享原生js实现获取form表单数据的具体代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-14 08:09
本文示例分享了原生js中获取表单数据的具体代码,供大家参考。具体内容如下
//获取指定form中的所有的对象
function getElements(formId) {
var form = document.getElementById(formId);
var elements = new Array();
var tagElements = form.getElementsByTagName('input');
for (var j = 0; j < tagElements.length; j++){
elements.push(tagElements[j]);
}
var tagElements = form.getElementsByTagName('select');
for (var j = 0; j < tagElements.length; j++){
elements.push(tagElements[j]);
}
var tagElements = form.getElementsByTagName('textarea');
for (var j = 0; j < tagElements.length; j++){
elements.push(tagElements[j]);
}
return elements;
}
//组合URL
function serializeElement(element) {
var method = element.tagName.toLowerCase();
var parameter;
if(method == 'select'){
parameter = [element.name, element.value];
}
switch (element.type.toLowerCase()) {
case 'submit':
case 'hidden':
case 'password':
case 'text':
case 'date':
case 'textarea':
parameter = [element.name, element.value];
break;
case 'checkbox':
case 'radio':
if (element.checked){
parameter = [element.name, element.value];
}
break;
}
if (parameter) {
var key = encodeURIComponent(parameter[0]);
if (key.length == 0)
return;
if (parameter[1].constructor != Array)
parameter[1] = [parameter[1]];
var values = parameter[1];
var results = [];
for (var i = 0; i < values.length; i++) {
results.push(key + '=' + encodeURIComponent(values[i]));
}
return results.join('&');
}
}
//调用方法
function serializeForm(formId) {
var elements = getElements(formId);
var queryComponents = new Array();
for (var i = 0; i < elements.length; i++) {
var queryComponent = serializeElement(elements[i]);
if (queryComponent) {
queryComponents.push(queryComponent);
}
}
return queryComponents.join('&');
}
最后可以通过serializeForm(formId); 输入表单的id名称,返回的数据为
id=1&title=%E6%B4%BB%E5%8A%A8&time=2017-07-10&status=1&importance=0&desc=%E5%9C%A8%E4%BA%8C%E6%A5%BC%E5%8A%9E%E5%85%AC%E5%AE%A4%E5%BC%80%E4%BC%9A%EF%BC%8C%E4%B8%80%E7%82%B9%E9%92%9F
以上就是小编为大家介绍的原js实现表单数据采集的详细集成。我希望它会对你有所帮助。如有问题,请给我留言,小编会及时回复您。非常感谢大家对脸圈教程网站的支持! 查看全部
js提取指定网站内容(本文实例分享原生js实现获取form表单数据的具体代码)
本文示例分享了原生js中获取表单数据的具体代码,供大家参考。具体内容如下
//获取指定form中的所有的对象
function getElements(formId) {
var form = document.getElementById(formId);
var elements = new Array();
var tagElements = form.getElementsByTagName('input');
for (var j = 0; j < tagElements.length; j++){
elements.push(tagElements[j]);
}
var tagElements = form.getElementsByTagName('select');
for (var j = 0; j < tagElements.length; j++){
elements.push(tagElements[j]);
}
var tagElements = form.getElementsByTagName('textarea');
for (var j = 0; j < tagElements.length; j++){
elements.push(tagElements[j]);
}
return elements;
}
//组合URL
function serializeElement(element) {
var method = element.tagName.toLowerCase();
var parameter;
if(method == 'select'){
parameter = [element.name, element.value];
}
switch (element.type.toLowerCase()) {
case 'submit':
case 'hidden':
case 'password':
case 'text':
case 'date':
case 'textarea':
parameter = [element.name, element.value];
break;
case 'checkbox':
case 'radio':
if (element.checked){
parameter = [element.name, element.value];
}
break;
}
if (parameter) {
var key = encodeURIComponent(parameter[0]);
if (key.length == 0)
return;
if (parameter[1].constructor != Array)
parameter[1] = [parameter[1]];
var values = parameter[1];
var results = [];
for (var i = 0; i < values.length; i++) {
results.push(key + '=' + encodeURIComponent(values[i]));
}
return results.join('&');
}
}
//调用方法
function serializeForm(formId) {
var elements = getElements(formId);
var queryComponents = new Array();
for (var i = 0; i < elements.length; i++) {
var queryComponent = serializeElement(elements[i]);
if (queryComponent) {
queryComponents.push(queryComponent);
}
}
return queryComponents.join('&');
}
最后可以通过serializeForm(formId); 输入表单的id名称,返回的数据为
id=1&title=%E6%B4%BB%E5%8A%A8&time=2017-07-10&status=1&importance=0&desc=%E5%9C%A8%E4%BA%8C%E6%A5%BC%E5%8A%9E%E5%85%AC%E5%AE%A4%E5%BC%80%E4%BC%9A%EF%BC%8C%E4%B8%80%E7%82%B9%E9%92%9F
以上就是小编为大家介绍的原js实现表单数据采集的详细集成。我希望它会对你有所帮助。如有问题,请给我留言,小编会及时回复您。非常感谢大家对脸圈教程网站的支持!
js提取指定网站内容(如何截取url中网站域名之后的部分,需要用到以下几个方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-14 04:04
)
如何截取url中网站域名后的部分,需要以下方法:
lastIndexOf()
lastIndexOf() 方法返回调用 String 对象的指定值最后一次出现的索引,在字符串中 fromIndex 的指定位置从后向前搜索。如果未找到特定值,则返回 -1。
子串()
substring() 方法返回起始索引和结束索引之间的字符串子集,或从起始索引到字符串结尾的子集。
通过这两种方法,就可以得到url域名后面的部分了。
首先获取网址:
var url = window.location.href
截取指定字符串之后的内容:比如获取之后的内容?
var index = url.lastIndexOf('?')
var url2 = url.substring(index + 1)
可以封装成一个方法:
function interceptUrl(url, cha) {
var ind = url.lastIndexOf(cha)
return url.substring(ind + 1)
}
调用方式:
var url = 'https://www.w3h5.com/search.php?q=Vue'
console.log(interceptUrl(url, '?'))
# q=Vue 查看全部
js提取指定网站内容(如何截取url中网站域名之后的部分,需要用到以下几个方法
)
如何截取url中网站域名后的部分,需要以下方法:
lastIndexOf()
lastIndexOf() 方法返回调用 String 对象的指定值最后一次出现的索引,在字符串中 fromIndex 的指定位置从后向前搜索。如果未找到特定值,则返回 -1。
子串()
substring() 方法返回起始索引和结束索引之间的字符串子集,或从起始索引到字符串结尾的子集。
通过这两种方法,就可以得到url域名后面的部分了。
首先获取网址:
var url = window.location.href
截取指定字符串之后的内容:比如获取之后的内容?
var index = url.lastIndexOf('?')
var url2 = url.substring(index + 1)
可以封装成一个方法:
function interceptUrl(url, cha) {
var ind = url.lastIndexOf(cha)
return url.substring(ind + 1)
}
调用方式:
var url = 'https://www.w3h5.com/search.php?q=Vue'
console.log(interceptUrl(url, '?'))
# q=Vue
js提取指定网站内容( 本文实例讲述JS简单获取并修改input文本框内容的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-14 04:01
本文实例讲述JS简单获取并修改input文本框内容的方法)
JS如何简单获取和修改输入文本框内容的例子
更新时间:2018-04-08 11:52:13 作者:成求明
本文文章主要介绍JS简单获取和修改输入文本框内容的方法。结合示例表单,分析JavaScript获取和分配页面元素的相关操作技巧。有需要的朋友可以参考以下
本文介绍了通过JS简单获取和修改输入文本框内容的方法。分享给大家,供大家参考,如下:
一个介绍
获取文本框并修改其内容可以使用getElementById()方法来实现。
getElementById() 方法可以通过指定的 id 获取 HTML 标记并返回它。
语法:
sElement=document.getElementById(id)
sElement:用于接收此方法返回的对象。
id:用于设置需要获取的HTML标记的id值。
第二次申请
获取文本框并修改其内容
页面加载完成后,文本框中会显示“初始文本内容”,点击按钮时文本框中的内容会发生变化。
三码
www.jb51.net 获取文本框并修改其内容
四运行结果
对JavaScript相关内容感兴趣的读者可以查看本站专题:《JavaScript页面元素操作技巧总结》、《JavaScript操作DOM技巧总结》、《JavaScript搜索算法技巧总结》、《JavaScript数据结构》和算法技巧总结”、“JavaScript 遍历算法和技术总结”和“JavaScript 错误和调试技术总结”
我希望这篇文章能帮助你进行 JavaScript 编程。 查看全部
js提取指定网站内容(
本文实例讲述JS简单获取并修改input文本框内容的方法)
JS如何简单获取和修改输入文本框内容的例子
更新时间:2018-04-08 11:52:13 作者:成求明
本文文章主要介绍JS简单获取和修改输入文本框内容的方法。结合示例表单,分析JavaScript获取和分配页面元素的相关操作技巧。有需要的朋友可以参考以下
本文介绍了通过JS简单获取和修改输入文本框内容的方法。分享给大家,供大家参考,如下:
一个介绍
获取文本框并修改其内容可以使用getElementById()方法来实现。
getElementById() 方法可以通过指定的 id 获取 HTML 标记并返回它。
语法:
sElement=document.getElementById(id)
sElement:用于接收此方法返回的对象。
id:用于设置需要获取的HTML标记的id值。
第二次申请
获取文本框并修改其内容
页面加载完成后,文本框中会显示“初始文本内容”,点击按钮时文本框中的内容会发生变化。
三码
www.jb51.net 获取文本框并修改其内容
四运行结果
对JavaScript相关内容感兴趣的读者可以查看本站专题:《JavaScript页面元素操作技巧总结》、《JavaScript操作DOM技巧总结》、《JavaScript搜索算法技巧总结》、《JavaScript数据结构》和算法技巧总结”、“JavaScript 遍历算法和技术总结”和“JavaScript 错误和调试技术总结”
我希望这篇文章能帮助你进行 JavaScript 编程。
js提取指定网站内容(js提取指定网站内容以支持搜索引擎抓取分析的利弊)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-13 05:02
js提取指定网站内容以支持搜索引擎抓取分析,类似google,百度,搜狗等搜索引擎一般会给予referral返回给搜索引擎。然后从站点对外的返回页内容抓取验证和关键词匹配后,返回给搜索引擎(获取下页链接的长度等),
在网站索引中可以得到站点网页的摘要信息以作用于搜索引擎的索引分析。
我刚学习网站结构分析的,个人经验,看这篇文章即可。
目前国内比较主流的排名抓取方法有如下两种:(1)在url进行whois随机检查,从地址栏找到allurls的ip地址,然后查看数量,对比ip点击量和url访问量,来确定访问量大的url所在的页面。(2)使用域名ip代理抓取,这种方法的好处是可以抓取百度(或者google),必应等搜索引擎以外的其他搜索引擎页面。
看上面的答案感觉还是云里雾里首先说filetag的利弊第一个答案写的很详细了,我只想从另一个方面补充一下:不要一开始就filetag,而是先通过目录名找到要抓取的页面,然后进行filetag。比如我要爬取知乎的文章,我是先爬取知乎的主站目录,
360,百度搜狗搜索结果页有长链接是自动搜索到站点根目录的
重点要搞清楚,谷歌、百度在抓取xxx.xx.xx.xx的时候,有两个自检机制,即谷歌会查看输入xxx.xx.xx.xx这个格式的地址之后返回的内容。百度会通过目录找到文件,即通过查看输入相同格式的文件的地址返回结果,来确定页面的抓取内容,所以,返回结果页面的url长度就成为一个重要的指标了,有时查找和查找操作的结果有区别。 查看全部
js提取指定网站内容(js提取指定网站内容以支持搜索引擎抓取分析的利弊)
js提取指定网站内容以支持搜索引擎抓取分析,类似google,百度,搜狗等搜索引擎一般会给予referral返回给搜索引擎。然后从站点对外的返回页内容抓取验证和关键词匹配后,返回给搜索引擎(获取下页链接的长度等),
在网站索引中可以得到站点网页的摘要信息以作用于搜索引擎的索引分析。
我刚学习网站结构分析的,个人经验,看这篇文章即可。
目前国内比较主流的排名抓取方法有如下两种:(1)在url进行whois随机检查,从地址栏找到allurls的ip地址,然后查看数量,对比ip点击量和url访问量,来确定访问量大的url所在的页面。(2)使用域名ip代理抓取,这种方法的好处是可以抓取百度(或者google),必应等搜索引擎以外的其他搜索引擎页面。
看上面的答案感觉还是云里雾里首先说filetag的利弊第一个答案写的很详细了,我只想从另一个方面补充一下:不要一开始就filetag,而是先通过目录名找到要抓取的页面,然后进行filetag。比如我要爬取知乎的文章,我是先爬取知乎的主站目录,
360,百度搜狗搜索结果页有长链接是自动搜索到站点根目录的
重点要搞清楚,谷歌、百度在抓取xxx.xx.xx.xx的时候,有两个自检机制,即谷歌会查看输入xxx.xx.xx.xx这个格式的地址之后返回的内容。百度会通过目录找到文件,即通过查看输入相同格式的文件的地址返回结果,来确定页面的抓取内容,所以,返回结果页面的url长度就成为一个重要的指标了,有时查找和查找操作的结果有区别。
js提取指定网站内容( js删除数组中的指定元素的详实示例方法-就是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-12 17:58
js删除数组中的指定元素的详实示例方法-就是)
详解js删除数组中指定元素
更新时间:2018-10-31 08:46:47 投稿:老张
在这篇文章中,我们和大家分享了一个js删除数组中指定元素的详细示例方法。有需要的朋友可以借鉴。
本文文章将介绍两种删除数组中指定元素的方法,分别是:
1、 单独定义一个函数,通过该函数删除指定的数组元素。
2、 为 Array 对象定义了一个 removeByValue 方法。调用删除指定数组元素的方法非常简单。
下面我们通过简单的代码示例简单介绍这两种删除数组指定元素的方法。
1、定义一个单独的函数removeByValue来删除元素
代码示例:删除数组somearray中的“tue”元素
<p>数组:mon, tue, wed, thur
function removeByValue(arr, val) {
for(var i = 0; i < arr.length; i++) {
if(arr[i] == val) {
arr.splice(i, 1);
break;
}
}
}
var somearray = ["mon", "tue", "wed", "thur"]
removeByValue(somearray, "tue");
//somearray will now have "mon", "wed", "thur"
document.write("
新数组:" + somearray + "");
</p>
效果图:
2、定义并调用数组的removeByValue方法删除指定元素
代码示例:删除数组somearray中的“wed”元素
<p>数组:mon, tue, wed, thur
删除指定元素"tue"后:
Array.prototype.removeByValue = function(val) {
for(var i = 0; i < this.length; i++) {
if(this[i] == val) {
this.splice(i, 1);
break;
}
}
}
var somearray = ["mon", "tue", "wed", "thur"]
somearray.removeByValue("wed");
//somearray will now have "mon", "wed", "thur"
document.write("
新数组:" + somearray + "");
</p>
效果图:
总结:以上就是本文介绍的js删除数组指定元素的两种方式。你可以自己尝试一下,加深理解。希望对大家的学习有所帮助。 查看全部
js提取指定网站内容(
js删除数组中的指定元素的详实示例方法-就是)
详解js删除数组中指定元素
更新时间:2018-10-31 08:46:47 投稿:老张
在这篇文章中,我们和大家分享了一个js删除数组中指定元素的详细示例方法。有需要的朋友可以借鉴。
本文文章将介绍两种删除数组中指定元素的方法,分别是:
1、 单独定义一个函数,通过该函数删除指定的数组元素。
2、 为 Array 对象定义了一个 removeByValue 方法。调用删除指定数组元素的方法非常简单。
下面我们通过简单的代码示例简单介绍这两种删除数组指定元素的方法。
1、定义一个单独的函数removeByValue来删除元素
代码示例:删除数组somearray中的“tue”元素
<p>数组:mon, tue, wed, thur
function removeByValue(arr, val) {
for(var i = 0; i < arr.length; i++) {
if(arr[i] == val) {
arr.splice(i, 1);
break;
}
}
}
var somearray = ["mon", "tue", "wed", "thur"]
removeByValue(somearray, "tue");
//somearray will now have "mon", "wed", "thur"
document.write("
新数组:" + somearray + "");
</p>
效果图:
2、定义并调用数组的removeByValue方法删除指定元素
代码示例:删除数组somearray中的“wed”元素
<p>数组:mon, tue, wed, thur
删除指定元素"tue"后:
Array.prototype.removeByValue = function(val) {
for(var i = 0; i < this.length; i++) {
if(this[i] == val) {
this.splice(i, 1);
break;
}
}
}
var somearray = ["mon", "tue", "wed", "thur"]
somearray.removeByValue("wed");
//somearray will now have "mon", "wed", "thur"
document.write("
新数组:" + somearray + "");
</p>
效果图:
总结:以上就是本文介绍的js删除数组指定元素的两种方式。你可以自己尝试一下,加深理解。希望对大家的学习有所帮助。
js提取指定网站内容(目录本篇博客又双叒叕为各位分享分享Python库 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-09 21:04
)
内容
本篇博客将为大家分享一个Python库:GeneralNewsExtractor (GNE),这是一个通用的新闻网站文本提取模块。输入一个新闻页面的HTML,输出正文内容、标题、作者、发布时间、正文中图片的地址、正文所在标签的源代码。 GNE对今日头条、网易新闻、有民之星、观察家、凤凰网、腾讯新闻、ReadHub、新浪新闻等数百条中文新闻网站的提取非常有效,准确率几乎可以达到100%。 .
需要明白:GeneralNewsExtractor(GNE)不是爬虫,是为了避免不必要的风险。因此,本项目的输入是HTML源代码,输出是字典。请使用适当的方法自行获取目标网站 HTML。
1、安装模块
GeneralNewsExtractor 模块的安装说明如下:
pip install gne
安装成功效果如下:
2、提取网页内容
这次打算提取最新时事,选择网易新闻,文章如下图:
右键查看本页源码文章,如下图:
复制源码 接下来,5行代码提取新闻内容,如下图:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
效果如下:
如果标题自动提取失败,可以指定XPath,代码如下:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html, title_xpath='//h5/text()')
print(result) 查看全部
js提取指定网站内容(目录本篇博客又双叒叕为各位分享分享Python库
)
内容
本篇博客将为大家分享一个Python库:GeneralNewsExtractor (GNE),这是一个通用的新闻网站文本提取模块。输入一个新闻页面的HTML,输出正文内容、标题、作者、发布时间、正文中图片的地址、正文所在标签的源代码。 GNE对今日头条、网易新闻、有民之星、观察家、凤凰网、腾讯新闻、ReadHub、新浪新闻等数百条中文新闻网站的提取非常有效,准确率几乎可以达到100%。 .
需要明白:GeneralNewsExtractor(GNE)不是爬虫,是为了避免不必要的风险。因此,本项目的输入是HTML源代码,输出是字典。请使用适当的方法自行获取目标网站 HTML。
1、安装模块
GeneralNewsExtractor 模块的安装说明如下:
pip install gne
安装成功效果如下:
2、提取网页内容
这次打算提取最新时事,选择网易新闻,文章如下图:
右键查看本页源码文章,如下图:
复制源码 接下来,5行代码提取新闻内容,如下图:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
效果如下:
如果标题自动提取失败,可以指定XPath,代码如下:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html, title_xpath='//h5/text()')
print(result)
js提取指定网站内容(JS实现一键复制”的文章数不胜数(js实现)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-09 21:03
经常在网站上看到各种“一键复制”友好体验按钮,不限于代码复制。如此友好的体验和方便快捷的操作对游客来说是无害的。我在网上搜索了关于“JS实现一键复制”的文章无数。用的最多的就是通过clipboard.min.js实现拷贝,毕竟现在各种浏览器都禁用了Flash等等。看了几十个文章,但是没有WordPress插件,也没有纯代码,只能自己动手。已经超过2天了。在朋友的帮助下,实现了“一键复制指定内容”的功能,代码也集成到了文章编辑器中,还是很方便的。
在WordPress中实现一键复制指定内容的步骤
1、下载clipboard.js文件。clipboard.js 是github上的一个开源项目,可以实现将纯JavaScript(无Flash)的浏览器内容复制到系统剪贴板的功能。
PS:以本站下载的压缩包中的clipboard.min.js和amazeui.css文件为例。
2、将以下代码放入footer.php。请自行修改clipboard.min.js的路径。
3、 在header.php中引入如下amazeui.css文件。下面的amazeui-2.css文件介绍了未删减的版本。也可以使用压缩包中的amazeui.css文件,自己选择。
“样式表”href="">
4、 引用 文章 中的按钮代码。写文章时,把代码放在合适的位置,修改data-clipboard-text的值“copy content”为指定的内容。
"itemCopyam-btnam-btn-warningam-roundam-btn-xs"id="TKLS"type="button"data-clipboard-text="copy content">一键复制
建议将此功能集成到主题编辑器中,方便操作。如果对代码比较模糊,不知道如何修改CSS代码,建议不要修改中间的id和class部分。
到这里差不多就完成了,说实话,感觉有点粗糙。但是在摸索的路上,我收获了很多。也希望路过的大佬指点一下,优化一下代码。制作更好更方便的复印功能。具体效果请到本文原文地址,点击“一键复制”按钮试试效果。 查看全部
js提取指定网站内容(JS实现一键复制”的文章数不胜数(js实现)(组图))
经常在网站上看到各种“一键复制”友好体验按钮,不限于代码复制。如此友好的体验和方便快捷的操作对游客来说是无害的。我在网上搜索了关于“JS实现一键复制”的文章无数。用的最多的就是通过clipboard.min.js实现拷贝,毕竟现在各种浏览器都禁用了Flash等等。看了几十个文章,但是没有WordPress插件,也没有纯代码,只能自己动手。已经超过2天了。在朋友的帮助下,实现了“一键复制指定内容”的功能,代码也集成到了文章编辑器中,还是很方便的。
在WordPress中实现一键复制指定内容的步骤
1、下载clipboard.js文件。clipboard.js 是github上的一个开源项目,可以实现将纯JavaScript(无Flash)的浏览器内容复制到系统剪贴板的功能。
PS:以本站下载的压缩包中的clipboard.min.js和amazeui.css文件为例。
2、将以下代码放入footer.php。请自行修改clipboard.min.js的路径。
3、 在header.php中引入如下amazeui.css文件。下面的amazeui-2.css文件介绍了未删减的版本。也可以使用压缩包中的amazeui.css文件,自己选择。
“样式表”href="">
4、 引用 文章 中的按钮代码。写文章时,把代码放在合适的位置,修改data-clipboard-text的值“copy content”为指定的内容。
"itemCopyam-btnam-btn-warningam-roundam-btn-xs"id="TKLS"type="button"data-clipboard-text="copy content">一键复制
建议将此功能集成到主题编辑器中,方便操作。如果对代码比较模糊,不知道如何修改CSS代码,建议不要修改中间的id和class部分。
到这里差不多就完成了,说实话,感觉有点粗糙。但是在摸索的路上,我收获了很多。也希望路过的大佬指点一下,优化一下代码。制作更好更方便的复印功能。具体效果请到本文原文地址,点击“一键复制”按钮试试效果。
js提取指定网站内容(前端的js脚本如何实现复制网页中指定的内容? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-06 12:12
)
前端js脚本可以将网页中指定的内容复制到剪贴板,如input中的内容,div元素中的内容等,具体实现方法请参考以下< @文章。
JS实现复制div(span)内容到剪贴板的方法
先看示例代码:
飞鸟慕鱼博客-复制DIV元素的内容
我是被复制的内容,可以写入系统的剪切板中!
点击我可以复制上面的内容
//定义一个复制函数
function copyText(text) {
var tag = document.createElement('input');
tag.setAttribute('id', 'copy_input');
tag.value = text;
document.getElementsByTagName('body')[0].appendChild(tag);
document.getElementById('copy_input').select();
document.execCommand('copy');
document.getElementById('copy_input').remove();
}
//点击按钮进行复制
document.getElementById('but').onclick = function () {
//获取DIV的内容
var text = document.getElementById('cent').innerText;
copyText(text);
}
上面JS复制DIV内容的操作过程只是模拟了用户手动复制输入框内容的操作。实现过程请参考以下分析!
分析:
1、 复制函数中新建一个输入元素,将要复制的内容写入元素中。
2、使用input元素的select()方法选择input中的所有内容!
3、复制内容
4:移动新创建的输入元素!
JS实现自动将输入框内容复制到剪贴板的方法
js 自动复制输入框中的内容,只需使用 select() 方法选择输入元素中的内容并复制即可。这个过程非常简单。可以参考下面的示例代码!
示例代码:
飞鸟慕鱼博客-复制DIV元素的内容
点击复制
//复制逻辑
document.getElementById('but').onclick = function () {
//选择input的内容
document.getElementById('host').select();
//进行copy
document.execCommand('copy');
} 查看全部
js提取指定网站内容(前端的js脚本如何实现复制网页中指定的内容?
)
前端js脚本可以将网页中指定的内容复制到剪贴板,如input中的内容,div元素中的内容等,具体实现方法请参考以下< @文章。
JS实现复制div(span)内容到剪贴板的方法
先看示例代码:
飞鸟慕鱼博客-复制DIV元素的内容
我是被复制的内容,可以写入系统的剪切板中!
点击我可以复制上面的内容
//定义一个复制函数
function copyText(text) {
var tag = document.createElement('input');
tag.setAttribute('id', 'copy_input');
tag.value = text;
document.getElementsByTagName('body')[0].appendChild(tag);
document.getElementById('copy_input').select();
document.execCommand('copy');
document.getElementById('copy_input').remove();
}
//点击按钮进行复制
document.getElementById('but').onclick = function () {
//获取DIV的内容
var text = document.getElementById('cent').innerText;
copyText(text);
}
上面JS复制DIV内容的操作过程只是模拟了用户手动复制输入框内容的操作。实现过程请参考以下分析!
分析:
1、 复制函数中新建一个输入元素,将要复制的内容写入元素中。
2、使用input元素的select()方法选择input中的所有内容!
3、复制内容
4:移动新创建的输入元素!
JS实现自动将输入框内容复制到剪贴板的方法
js 自动复制输入框中的内容,只需使用 select() 方法选择输入元素中的内容并复制即可。这个过程非常简单。可以参考下面的示例代码!
示例代码:
飞鸟慕鱼博客-复制DIV元素的内容
点击复制
//复制逻辑
document.getElementById('but').onclick = function () {
//选择input的内容
document.getElementById('host').select();
//进行copy
document.execCommand('copy');
}
js提取指定网站内容(Vue3CompositionAPI可以在大型项目中更好地组织代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-06 01:15
Vue3 Composition API 可以更好地组织大型项目中的代码。然而,随着使用几个不同的选项属性切换到单一的设置方法,许多开发人员面临的问题是......
这会不会更混乱,因为一切都在一种方法中
乍一看似乎很容易,但实际上编写可重用的模块化代码只需要一点时间。
让我们看看如何做到这一点。
问题
Vue.js 2.x 的 Options API 是一种非常直观的代码分离方式
export default {
data () {
return {
articles: [],
searchParameters: []
}
},
mounted () {
this.articles = ArticlesAPI.loadArticles()
},
methods: {
searchArticles (id) {
return this.articles.filter(() => {
// 一些搜索代码
})
}
}
}
问题在于,如果一个组件中有数百行代码,那么您必须在数据、方法、计算等的多个部分中为单个功能(例如搜索)添加代码。
这意味着只有一个函数的代码可能分散在数百行中并分布在多个不同的位置,从而导致难以阅读或调试。图片说明
这只是 Vue Composition API RFC 中的一个例子,展示了现在如何按功能组织代码。
现在,这是使用新 Composition API 的等效代码。
import { ref, onMounted } from 'vue'
export default {
setup () {
const articles = ref([])
const searchParameters = ref([])
onMounted(() => {
this.articles = ArticlesAPI.loadArticles()
})
const searchArticles = (id) => {
return articles.filter(() => {
// 一些搜索代码
})
}
return {
articles,
searchParameters,
searchArticles
}
}
}
现在,为了解决之前关于组织的问题,我们来看看一个很好的提取逻辑的方法。
提取逻辑
我们的最终目标是将每个函数提取到自己的方法中。这样,如果我们要调试它,所有代码都在一个地方。
这很简单,但是最后我们要记住,如果我们想要能够访问模板中的数据,我们仍然需要使用我们的setup方法来返回数据。
让我们创建一个新方法 useSearchArticles 并让它返回我们在 setup 方法中返回的所有内容。
const useSearchArticles = () => {
const articles = ref([])
const searchParameters = ref([])
onMounted(() => {
this.articles = ArticlesAPI.loadArticles()
})
const searchArticles = (id) => {
return articles.filter(() => {
// 一些搜索代码
})
}
return {
articles,
searchParameters,
searchArticles
}
}
现在,在我们的 setup 方法中,我们可以通过调用我们的方法来访问属性。而且,当然,我们还必须记住从 setup 方法中返回它们。
export default {
setup () {
const { articles, searchParameters, searchArticles } = useSearchArticles()
return {
articles,
searchParameters,
searchArticles
}
}
}
在提取的逻辑中访问组件属性
Composition API 的另一个新变化是这个引用的变化,这意味着我们不能再以同样的方式使用 props、attributes 或 events。
简而言之,我们将不得不使用 setup 方法的两个参数来访问 props、attributes、slot 或 emit 方法。如果我们只使用 setup 方法,一个快速的虚拟组件可能看起来像这样。
export default {
setup (props, context) {
onMounted(() => {
console.log(props)
context.emit('event', 'payload')
})
}
}
但是现在我们要提取我们的逻辑,我们想让我们的逻辑包装器方法也接受参数。这样,我们就可以从setup方法中传递我们的props和context属性,逻辑代码就可以访问它们了。
const checkProps = (props, context) => {
onMounted(() => {
console.log(props)
context.emit('event', 'payload')
})
}
export default {
setup (props, context) {
checkProps(props, context)
}
}
重用逻辑
最后,如果我们想写一些我们希望可以在多个组件中使用的逻辑,我们可以将逻辑提取到自己的文件中,然后将其导入到我们的组件中。
然后,我们可以像以前一样调用该方法。假设我们将 useSearchArticles 方法移动到名为 use-search-articles-logic.js 的文件中,如下所示
import { ref, onMounted } from 'vue'
export function useSearchArticles () {
const articles = ref([])
const searchParameters = ref([])
onMounted(() => {
this.articles = ArticlesAPI.loadArticles()
})
const searchArticles = (id) => {
return articles.filter(() => {
// 一些搜索代码
})
}
return {
articles,
searchParameters,
searchArticles
}
}
使用这个新文件,我们的原创组件将如下所示
import { useSearchArticles } from './logic/use-search-articles-logic'
export default {
setup (props,) {
const { articles, searchParameters, searchArticles } = useSearchArticles()
return {
articles,
searchParameters,
searchArticles
}
}
}
最后
我希望这篇文章可以帮助您更好地理解 Composition API 将如何改变我们的编码方式。
然而,与往常一样,项目的组织取决于开发人员设计优秀组件代码和创建可重用逻辑的意愿。
请记住,我们的目标是提高可读性,而在 Vue 中,Composition API 是实现这一目标的好方法。
至此,这篇关于Vue3 Composition API中抽取复用逻辑的详细讲解的文章就介绍到这里了。更多相关的Vue3 Composition提取和复用内容,请搜索之前的文章或继续浏览以下相关的文章 希望大家以后多多支持! 查看全部
js提取指定网站内容(Vue3CompositionAPI可以在大型项目中更好地组织代码)
Vue3 Composition API 可以更好地组织大型项目中的代码。然而,随着使用几个不同的选项属性切换到单一的设置方法,许多开发人员面临的问题是......
这会不会更混乱,因为一切都在一种方法中
乍一看似乎很容易,但实际上编写可重用的模块化代码只需要一点时间。
让我们看看如何做到这一点。
问题
Vue.js 2.x 的 Options API 是一种非常直观的代码分离方式
export default {
data () {
return {
articles: [],
searchParameters: []
}
},
mounted () {
this.articles = ArticlesAPI.loadArticles()
},
methods: {
searchArticles (id) {
return this.articles.filter(() => {
// 一些搜索代码
})
}
}
}
问题在于,如果一个组件中有数百行代码,那么您必须在数据、方法、计算等的多个部分中为单个功能(例如搜索)添加代码。
这意味着只有一个函数的代码可能分散在数百行中并分布在多个不同的位置,从而导致难以阅读或调试。图片说明
这只是 Vue Composition API RFC 中的一个例子,展示了现在如何按功能组织代码。
现在,这是使用新 Composition API 的等效代码。
import { ref, onMounted } from 'vue'
export default {
setup () {
const articles = ref([])
const searchParameters = ref([])
onMounted(() => {
this.articles = ArticlesAPI.loadArticles()
})
const searchArticles = (id) => {
return articles.filter(() => {
// 一些搜索代码
})
}
return {
articles,
searchParameters,
searchArticles
}
}
}
现在,为了解决之前关于组织的问题,我们来看看一个很好的提取逻辑的方法。
提取逻辑
我们的最终目标是将每个函数提取到自己的方法中。这样,如果我们要调试它,所有代码都在一个地方。
这很简单,但是最后我们要记住,如果我们想要能够访问模板中的数据,我们仍然需要使用我们的setup方法来返回数据。
让我们创建一个新方法 useSearchArticles 并让它返回我们在 setup 方法中返回的所有内容。
const useSearchArticles = () => {
const articles = ref([])
const searchParameters = ref([])
onMounted(() => {
this.articles = ArticlesAPI.loadArticles()
})
const searchArticles = (id) => {
return articles.filter(() => {
// 一些搜索代码
})
}
return {
articles,
searchParameters,
searchArticles
}
}
现在,在我们的 setup 方法中,我们可以通过调用我们的方法来访问属性。而且,当然,我们还必须记住从 setup 方法中返回它们。
export default {
setup () {
const { articles, searchParameters, searchArticles } = useSearchArticles()
return {
articles,
searchParameters,
searchArticles
}
}
}
在提取的逻辑中访问组件属性
Composition API 的另一个新变化是这个引用的变化,这意味着我们不能再以同样的方式使用 props、attributes 或 events。
简而言之,我们将不得不使用 setup 方法的两个参数来访问 props、attributes、slot 或 emit 方法。如果我们只使用 setup 方法,一个快速的虚拟组件可能看起来像这样。
export default {
setup (props, context) {
onMounted(() => {
console.log(props)
context.emit('event', 'payload')
})
}
}
但是现在我们要提取我们的逻辑,我们想让我们的逻辑包装器方法也接受参数。这样,我们就可以从setup方法中传递我们的props和context属性,逻辑代码就可以访问它们了。
const checkProps = (props, context) => {
onMounted(() => {
console.log(props)
context.emit('event', 'payload')
})
}
export default {
setup (props, context) {
checkProps(props, context)
}
}
重用逻辑
最后,如果我们想写一些我们希望可以在多个组件中使用的逻辑,我们可以将逻辑提取到自己的文件中,然后将其导入到我们的组件中。
然后,我们可以像以前一样调用该方法。假设我们将 useSearchArticles 方法移动到名为 use-search-articles-logic.js 的文件中,如下所示
import { ref, onMounted } from 'vue'
export function useSearchArticles () {
const articles = ref([])
const searchParameters = ref([])
onMounted(() => {
this.articles = ArticlesAPI.loadArticles()
})
const searchArticles = (id) => {
return articles.filter(() => {
// 一些搜索代码
})
}
return {
articles,
searchParameters,
searchArticles
}
}
使用这个新文件,我们的原创组件将如下所示
import { useSearchArticles } from './logic/use-search-articles-logic'
export default {
setup (props,) {
const { articles, searchParameters, searchArticles } = useSearchArticles()
return {
articles,
searchParameters,
searchArticles
}
}
}
最后
我希望这篇文章可以帮助您更好地理解 Composition API 将如何改变我们的编码方式。
然而,与往常一样,项目的组织取决于开发人员设计优秀组件代码和创建可重用逻辑的意愿。
请记住,我们的目标是提高可读性,而在 Vue 中,Composition API 是实现这一目标的好方法。
至此,这篇关于Vue3 Composition API中抽取复用逻辑的详细讲解的文章就介绍到这里了。更多相关的Vue3 Composition提取和复用内容,请搜索之前的文章或继续浏览以下相关的文章 希望大家以后多多支持!
js提取指定网站内容(js提取指定网站内容并生成url,可以用中间件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-05 23:03
js提取指定网站内容并生成url,可以用中间件parser来写:url=''mount=url2.url1.url3.m2.js2'js2:mongodb方案:中间件安装:在src下创建路径->首先创建gitclone项目.进入该项目根目录下rb文件目录(main.js,可以是modulename.js命名或者npmi-g这样命名项目)将下面这行代码加入到rb文件的后缀名中。
serve{logout}其他文件自行修改:dom文件document.queryselector('#mongocontent').addeventlistener('touch',method,function(event){console.log("touchstart");//获取event的valueconsole.log("touchend");console.log("touchcontinue");//获取event的数据-重新赋值mongocontentcontent;})}其他web页面数据提取函数:include_dom.bind('touch','mongocontent',function(event){varcontent=event.message;//获取到contentvarurl='';//获取外部数据,用''括起来varurl2=content.value;//获取外部数据varobj={method:'js2',pathname:'js2',href:'',methodpath:'',content:obj,//valuemethodname:'#mongocontent',//methodhref:'',pathname:'',timeout:0.1//timeoutisnotperfect,eitherthenumberorexpectedtimes};//传递给后面的函数用method参数vartimeout=0.1;//建议不要超过1秒varhash=mongocontent.hash;//用hash或者key唯一,不要使用hash来代替obj.value?.value.mongocontent?.key:&hash.mongocontent.origin+'\\.'+pathname.mongocontent?.mongocontent?.filename;//获取pathname属性值$.get(timeout,$.globaldomypersonesof]);//将filename在pathname中获取。 查看全部
js提取指定网站内容(js提取指定网站内容并生成url,可以用中间件)
js提取指定网站内容并生成url,可以用中间件parser来写:url=''mount=url2.url1.url3.m2.js2'js2:mongodb方案:中间件安装:在src下创建路径->首先创建gitclone项目.进入该项目根目录下rb文件目录(main.js,可以是modulename.js命名或者npmi-g这样命名项目)将下面这行代码加入到rb文件的后缀名中。
serve{logout}其他文件自行修改:dom文件document.queryselector('#mongocontent').addeventlistener('touch',method,function(event){console.log("touchstart");//获取event的valueconsole.log("touchend");console.log("touchcontinue");//获取event的数据-重新赋值mongocontentcontent;})}其他web页面数据提取函数:include_dom.bind('touch','mongocontent',function(event){varcontent=event.message;//获取到contentvarurl='';//获取外部数据,用''括起来varurl2=content.value;//获取外部数据varobj={method:'js2',pathname:'js2',href:'',methodpath:'',content:obj,//valuemethodname:'#mongocontent',//methodhref:'',pathname:'',timeout:0.1//timeoutisnotperfect,eitherthenumberorexpectedtimes};//传递给后面的函数用method参数vartimeout=0.1;//建议不要超过1秒varhash=mongocontent.hash;//用hash或者key唯一,不要使用hash来代替obj.value?.value.mongocontent?.key:&hash.mongocontent.origin+'\\.'+pathname.mongocontent?.mongocontent?.filename;//获取pathname属性值$.get(timeout,$.globaldomypersonesof]);//将filename在pathname中获取。
js提取指定网站内容(如何找出发送请求的js在控制数据的生成,我根本无法找到是哪一个js实现的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-05 16:08
有很多页。当我们使用request发送请求时,返回的内容中没有页面显示数据。主要有两种情况。一种是通过ajax异步发送请求,得到响应并将数据放入页面。对于这种情况,我们可以查看ajax请求,然后分析ajax请求路径和响应,得到想要的数据;另一种是js动态加载的数据,然后放到页面中。在这两种情况下,当用户使用浏览器访问时,都不会发现任何异常,很快就会得到完整的页面。
其实我们之前学过一个selenium模块。通过操纵浏览器,然后获取浏览器显示的数据,可以通过这种方式获取数据,但是本节是分析如何发现js在控制数据的生成。以及js发送请求的路径,所以我们可以向这个路径发送请求,直接获取数据。
在之前的爬取过程中,我最烦的就是js动态生成的数据。我找不到实现了哪个js(因为js太多了)。今天看了大佬的博客,瞬间感觉简单了许多。, 感谢 Dao 提供 Dao 的博客:
一、需求描述和页面分析
一、要求说明
基页路径:
点击进入每个标题:
需求是抓取每个标题下的新闻内容
2. 页面分析
2.1 个主页
查看ajax请求:
接下来,我们将分析如何找出发送请求的js
二、找到发送请求的js
响应数据包括新闻标题和这条新闻的详情页路径,所以现在我们去访问详情页,分析详情页
访问详情页,查看详情页的响应,数据不收录具体数据,那么就和主页面一样,然后去ajax:
Ajax 没有新闻相关的数据,所以不使用ajax 请求来获取数据。只剩下js了。我们来看看是哪个js发送了获取数据的请求。上面的步骤是一样的:
详情页数据的js请求路径:
详情页请求路径:
我们可以看到,最后一个斜线之前的详情页数据的请求路径和最后一个斜线之前的详情页数据的请求路径是一样的。所以我们可以这样做:
第一步:获取详情页的请求路径:
url1='#39;
第二步:替换url1中最后一个斜杠后的内容
url2='%s/datae43e220633a65f9b6d8b53712cba9caa.js'%(url1.split('/')[3]) #用'/'分割url1得到第四部分,即索引为3,然后拼接进去
这样就构造了一个详细页面数据请求路径,然后就可以直接访问这个路径获取数据了,不需要访问详细页面。 查看全部
js提取指定网站内容(如何找出发送请求的js在控制数据的生成,我根本无法找到是哪一个js实现的)
有很多页。当我们使用request发送请求时,返回的内容中没有页面显示数据。主要有两种情况。一种是通过ajax异步发送请求,得到响应并将数据放入页面。对于这种情况,我们可以查看ajax请求,然后分析ajax请求路径和响应,得到想要的数据;另一种是js动态加载的数据,然后放到页面中。在这两种情况下,当用户使用浏览器访问时,都不会发现任何异常,很快就会得到完整的页面。
其实我们之前学过一个selenium模块。通过操纵浏览器,然后获取浏览器显示的数据,可以通过这种方式获取数据,但是本节是分析如何发现js在控制数据的生成。以及js发送请求的路径,所以我们可以向这个路径发送请求,直接获取数据。
在之前的爬取过程中,我最烦的就是js动态生成的数据。我找不到实现了哪个js(因为js太多了)。今天看了大佬的博客,瞬间感觉简单了许多。, 感谢 Dao 提供 Dao 的博客:
一、需求描述和页面分析
一、要求说明
基页路径:
点击进入每个标题:
需求是抓取每个标题下的新闻内容
2. 页面分析
2.1 个主页
查看ajax请求:
接下来,我们将分析如何找出发送请求的js
二、找到发送请求的js
响应数据包括新闻标题和这条新闻的详情页路径,所以现在我们去访问详情页,分析详情页
访问详情页,查看详情页的响应,数据不收录具体数据,那么就和主页面一样,然后去ajax:
Ajax 没有新闻相关的数据,所以不使用ajax 请求来获取数据。只剩下js了。我们来看看是哪个js发送了获取数据的请求。上面的步骤是一样的:
详情页数据的js请求路径:
详情页请求路径:
我们可以看到,最后一个斜线之前的详情页数据的请求路径和最后一个斜线之前的详情页数据的请求路径是一样的。所以我们可以这样做:
第一步:获取详情页的请求路径:
url1='#39;
第二步:替换url1中最后一个斜杠后的内容
url2='%s/datae43e220633a65f9b6d8b53712cba9caa.js'%(url1.split('/')[3]) #用'/'分割url1得到第四部分,即索引为3,然后拼接进去
这样就构造了一个详细页面数据请求路径,然后就可以直接访问这个路径获取数据了,不需要访问详细页面。
js提取指定网站内容(JS的页面生命周期事件今天做个大屏项目项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-04 23:34
JS页面生命周期事件
今天我在做一个大屏幕项目。我想在所有资源加载到大屏幕之前添加一个加载动画,然后在加载后删除它。当然在load事件中去掉了,但是其他的事件有点模糊,回顾一下,哦垃圾生命周期事件DOMContentLoaded,浏览器完成HTML的加载,并构建DOM树,图片和样式等外部资源尚未加载尚未加载,浏览器在unload之前加载了所有资源,包括HTML文档,图片,样式等,用户即将离开,用于检查用户是否保存了修改。DOMContentLoaded DOMContentLoaded 事件发生在文档对象上。您必须在文档对象上使用 2. window.onload。当页面包括样式、图片等资源全部加载完毕后,window对象上的load事件会被触发 3. window.onunload 当访问者离开页面时,window对象上的unload事件会被触发。当sendBeacon请求完成时,浏览器可能已经离开了文档,因此无法获取服务器的响应数据。
588 查看全部
js提取指定网站内容(JS的页面生命周期事件今天做个大屏项目项目)
JS页面生命周期事件
今天我在做一个大屏幕项目。我想在所有资源加载到大屏幕之前添加一个加载动画,然后在加载后删除它。当然在load事件中去掉了,但是其他的事件有点模糊,回顾一下,哦垃圾生命周期事件DOMContentLoaded,浏览器完成HTML的加载,并构建DOM树,图片和样式等外部资源尚未加载尚未加载,浏览器在unload之前加载了所有资源,包括HTML文档,图片,样式等,用户即将离开,用于检查用户是否保存了修改。DOMContentLoaded DOMContentLoaded 事件发生在文档对象上。您必须在文档对象上使用 2. window.onload。当页面包括样式、图片等资源全部加载完毕后,window对象上的load事件会被触发 3. window.onunload 当访问者离开页面时,window对象上的unload事件会被触发。当sendBeacon请求完成时,浏览器可能已经离开了文档,因此无法获取服务器的响应数据。
588
js提取指定网站内容( vue-cli3DllPlugin提取公用库,需要的朋友可以参考)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-04 23:29
vue-cli3DllPlugin提取公用库,需要的朋友可以参考)
vue-cli3 DllPlugin 提取公共库的方法
更新时间:2019-04-24 09:26:41 作者:lifefriend_007
本文文章主要介绍vue-cli3 DllPlugin提取公共库。有需要的朋友可以参考
vue开发过程中,保存一次,编译一次。如果可以减少编译时间,即使是少量也可以节省大量时间。个人编写的源文件在开发过程中会经常改动,我们一般不会改动一些库文件。如果能够提取这些库文件,就可以减少打包体积,加快编译速度。本文主要介绍使用vue-cli3中的DllPlugin进行预编译。
1、安装相关插件
yarn add webpack-cli@^3.2.3 add-asset-html-webpack-plugin@^3.1.3 clean-webpack-plugin@^1.0.1 --dev
2、写配置文件
在项目根目录新建webpack.dll.conf.js,输入如下内容。
const path = require('path')
const webpack = require('webpack')
const CleanWebpackPlugin = require('clean-webpack-plugin')
// dll文件存放的目录
const dllPath = 'public/vendor'
module.exports = {
entry: {
// 需要提取的库文件
vendor: ['vue', 'vue-router', 'vuex', 'axios', 'element-ui']
},
output: {
path: path.join(__dirname, dllPath),
filename: '[name].dll.js',
// vendor.dll.js中暴露出的全局变量名
// 保持与 webpack.DllPlugin 中名称一致
library: '[name]_[hash]'
},
plugins: [
// 清除之前的dll文件
new CleanWebpackPlugin(['*.*'], {
root: path.join(__dirname, dllPath)
}),
// 设置环境变量
new webpack.DefinePlugin({
'process.env': {
NODE_ENV: 'production'
}
}),
// manifest.json 描述动态链接库包含了哪些内容
new webpack.DllPlugin({
path: path.join(__dirname, dllPath, '[name]-manifest.json'),
// 保持与 output.library 中名称一致
name: '[name]_[hash]',
context: process.cwd()
})
]
}
3、生成dll
将以下命令添加到 package.json
"scripts": {
...
"dll": "webpack -p --progress --config ./webpack.dll.conf.js"
},
控制台操作
纱线运行dll
4、忽略编译文件
为了节省编译时间,我们需要告诉webpack此时公共库文件已经编译完成,以减少webpack对公共库的编译时间。在项目根目录中找到vue.config.js(如果没有就创建),配置如下:
const webpack = require('webpack')
module.exports = {
...
configureWebpack: {
plugins: [
new webpack.DllReferencePlugin({
context: process.cwd(),
manifest: require('./public/vendor/vendor-manifest.json')
})
]
}
}
5、在index.html中加载生成的dll文件
经过以上配置,公共库被解压出来,编译速度更快,但是如果不引用生成的dll文件,网页将无法正常运行。
打开 public/index.html 并插入脚本标签。
...
至此,公共库提取完成,但总觉得最后手动插入脚本不优雅。下面介绍如何自动导入生成的dll文件。
打开vue.config.js,在configureWebpack plugins节点下配置add-asset-html-webpack-plugin
const path = require('path')
const webpack = require('webpack')
const AddAssetHtmlPlugin = require('add-asset-html-webpack-plugin')
module.exports = {
...
configureWebpack: {
plugins: [
new webpack.DllReferencePlugin({
context: process.cwd(),
manifest: require('./public/vendor/vendor-manifest.json')
}),
// 将 dll 注入到 生成的 html 模板中
new AddAssetHtmlPlugin({
// dll文件位置
filepath: path.resolve(__dirname, './public/vendor/*.js'),
// dll 引用路径
publicPath: './vendor',
// dll最终输出的目录
outputPath: './vendor'
})
]
}
}
总结
以上就是小编介绍的vue-cli3 DllPlugin提取公共库的方法。我希望它会对你有所帮助。如有问题,请给我留言,小编会及时回复您。非常感谢您对脚本之家网站的支持!
如果觉得本文对您有帮助,欢迎转载,请注明出处,谢谢! 查看全部
js提取指定网站内容(
vue-cli3DllPlugin提取公用库,需要的朋友可以参考)
vue-cli3 DllPlugin 提取公共库的方法
更新时间:2019-04-24 09:26:41 作者:lifefriend_007
本文文章主要介绍vue-cli3 DllPlugin提取公共库。有需要的朋友可以参考
vue开发过程中,保存一次,编译一次。如果可以减少编译时间,即使是少量也可以节省大量时间。个人编写的源文件在开发过程中会经常改动,我们一般不会改动一些库文件。如果能够提取这些库文件,就可以减少打包体积,加快编译速度。本文主要介绍使用vue-cli3中的DllPlugin进行预编译。
1、安装相关插件
yarn add webpack-cli@^3.2.3 add-asset-html-webpack-plugin@^3.1.3 clean-webpack-plugin@^1.0.1 --dev
2、写配置文件
在项目根目录新建webpack.dll.conf.js,输入如下内容。
const path = require('path')
const webpack = require('webpack')
const CleanWebpackPlugin = require('clean-webpack-plugin')
// dll文件存放的目录
const dllPath = 'public/vendor'
module.exports = {
entry: {
// 需要提取的库文件
vendor: ['vue', 'vue-router', 'vuex', 'axios', 'element-ui']
},
output: {
path: path.join(__dirname, dllPath),
filename: '[name].dll.js',
// vendor.dll.js中暴露出的全局变量名
// 保持与 webpack.DllPlugin 中名称一致
library: '[name]_[hash]'
},
plugins: [
// 清除之前的dll文件
new CleanWebpackPlugin(['*.*'], {
root: path.join(__dirname, dllPath)
}),
// 设置环境变量
new webpack.DefinePlugin({
'process.env': {
NODE_ENV: 'production'
}
}),
// manifest.json 描述动态链接库包含了哪些内容
new webpack.DllPlugin({
path: path.join(__dirname, dllPath, '[name]-manifest.json'),
// 保持与 output.library 中名称一致
name: '[name]_[hash]',
context: process.cwd()
})
]
}
3、生成dll
将以下命令添加到 package.json
"scripts": {
...
"dll": "webpack -p --progress --config ./webpack.dll.conf.js"
},
控制台操作
纱线运行dll
4、忽略编译文件
为了节省编译时间,我们需要告诉webpack此时公共库文件已经编译完成,以减少webpack对公共库的编译时间。在项目根目录中找到vue.config.js(如果没有就创建),配置如下:
const webpack = require('webpack')
module.exports = {
...
configureWebpack: {
plugins: [
new webpack.DllReferencePlugin({
context: process.cwd(),
manifest: require('./public/vendor/vendor-manifest.json')
})
]
}
}
5、在index.html中加载生成的dll文件
经过以上配置,公共库被解压出来,编译速度更快,但是如果不引用生成的dll文件,网页将无法正常运行。
打开 public/index.html 并插入脚本标签。
...
至此,公共库提取完成,但总觉得最后手动插入脚本不优雅。下面介绍如何自动导入生成的dll文件。
打开vue.config.js,在configureWebpack plugins节点下配置add-asset-html-webpack-plugin
const path = require('path')
const webpack = require('webpack')
const AddAssetHtmlPlugin = require('add-asset-html-webpack-plugin')
module.exports = {
...
configureWebpack: {
plugins: [
new webpack.DllReferencePlugin({
context: process.cwd(),
manifest: require('./public/vendor/vendor-manifest.json')
}),
// 将 dll 注入到 生成的 html 模板中
new AddAssetHtmlPlugin({
// dll文件位置
filepath: path.resolve(__dirname, './public/vendor/*.js'),
// dll 引用路径
publicPath: './vendor',
// dll最终输出的目录
outputPath: './vendor'
})
]
}
}
总结
以上就是小编介绍的vue-cli3 DllPlugin提取公共库的方法。我希望它会对你有所帮助。如有问题,请给我留言,小编会及时回复您。非常感谢您对脚本之家网站的支持!
如果觉得本文对您有帮助,欢迎转载,请注明出处,谢谢!
js提取指定网站内容(宝哥教你怎么用代码网页存为图片(一)_宝哥)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-04 16:06
随着网络技术的发展,我们使用的截图越来越多。windows上有非常人性化的QQ截图。浏览器中还有一个方便的截图插件。今天包哥教你如何用代码截取网页并保存为图片。对于一些为各种目的编写自动化脚本的人以及一些 Linux 用户来说,这仍然非常需要。而且,即使对于windows用户来说,使用截屏工具来滚动截取需要滚动显示的网页内容,仍然非常困难。
phantomjs 有一个 api,专门用于截图。但是它只能截取网页和指定区域的截图,而且一个很常见的需求是我想截取一个文本区域或者一个网页的特定区域,但是我不想计算它的坐标和长度和宽度。为什么?管理?没关系,casperjs为我们关闭了。它有这个api。我写了一个支持命令行参数的casperjs脚本,放在MagicScripts里,叫做capture.js。
用法
casperjs /path/to/capture.js page_url 文件名.png [选择器]。
有兴趣的可以点击前面的链接查看git上的代码。如果您有自定义需求(例如支持指定坐标区域截图),您可以自由自定义fork代码。
(转载本站文章请注明开发部落出处-) 查看全部
js提取指定网站内容(宝哥教你怎么用代码网页存为图片(一)_宝哥)
随着网络技术的发展,我们使用的截图越来越多。windows上有非常人性化的QQ截图。浏览器中还有一个方便的截图插件。今天包哥教你如何用代码截取网页并保存为图片。对于一些为各种目的编写自动化脚本的人以及一些 Linux 用户来说,这仍然非常需要。而且,即使对于windows用户来说,使用截屏工具来滚动截取需要滚动显示的网页内容,仍然非常困难。
phantomjs 有一个 api,专门用于截图。但是它只能截取网页和指定区域的截图,而且一个很常见的需求是我想截取一个文本区域或者一个网页的特定区域,但是我不想计算它的坐标和长度和宽度。为什么?管理?没关系,casperjs为我们关闭了。它有这个api。我写了一个支持命令行参数的casperjs脚本,放在MagicScripts里,叫做capture.js。
用法
casperjs /path/to/capture.js page_url 文件名.png [选择器]。
有兴趣的可以点击前面的链接查看git上的代码。如果您有自定义需求(例如支持指定坐标区域截图),您可以自由自定义fork代码。
(转载本站文章请注明开发部落出处-)
js提取指定网站内容(搜索引擎爬虫爬取网页被重定向的操作方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 403 次浏览 • 2021-11-29 11:09
作者写的搜索引擎爬虫在爬取页面时遇到了网页被重定向的情况。所谓重定向就是通过各种方法(本文提到的三种)(URL)将各种网络请求重定向到其他位置。每个网站首页都是网站资源的入口。当重定向发生在网站的首页时,如果处理不当,很可能会遗漏网站的全部内容。
作者写的爬虫在爬取网页时遇到了三种重定向情况。
1.服务器端重定向是在服务器端完成的。一般来说爬虫是可以自适应的,不需要特殊处理,比如响应码301(永久重定向)、302(临时重定向)等,具体可以通过响应中的url和status_code这两个属性来判断requests 请求获取的对象。当status_code为301、302或其他代表重定向的code时,表示原请求被重定向;当响应对象的 url 属性与发送请求时的链接不一致时,也说明原来的请求被重定向并且已经被自动处理了。
#请求重定向#方法二
response.setStatus(302);
response.setHeader("location", "/day06/index.jsp");#方法二
response.sendRedirect("/day06/index.jsp");
scrapy shell 以获取重定向页面
scrapy shell -s ROBOTSTXT_OBEY=False --no-redirect ""fetch(response.headers['Location'])
2.meta refresh,即网页中的标签声明了网页重定向的链接。这个重定向是由浏览器完成的,需要通过编写代码来处理。比如下面HTML代码第三行的注释中如果出现某个重定向,浏览器可以自动跳转,但是爬虫只能获取跳转前的页面,不能自动跳转。
解决方法是通过获取跳转前的页面源代码来提取重定向url信息(上面代码第三行的url属性值)。具体操作:
①使用xpath('//meta[@http-equiv="refresh" and @content]/@content')提取content的值
②使用正则表达式提取重定向的url值。
3.js 重定向,重定向是以 JavaScript 代码的形式进行的。比如下面的JavaScript代码
网页收录内容的情况是最容易解决的。一般来说,它基本上是静态网页的硬编码内容,或者是动态网页,使用模板渲染。当浏览器获取到 HTML 时,它已经收录了所有的关键信息,所以你在网页上直接看到的内容可以通过特定的 HTML 标签加载 javascript 代码。这种情况是因为虽然网页显示时内容在HTML标签中,但实际上是通过执行js代码添加到标签中的。所以此时的内容在js代码中,js的执行是浏览器端的操作,所以当你使用程序请求网页地址时,得到的响应就是网页代码和js代码,这样就可以在浏览器端看到内容了,因为解析的时候没有执行js,所以指定的HTML标签下的内容必须是空的。这时候的处理方法一般是找到收录内容的js代码字符串,然后通过正则表达式获取对应的内容,而不是解析HTML标签。 查看全部
js提取指定网站内容(搜索引擎爬虫爬取网页被重定向的操作方法(图))
作者写的搜索引擎爬虫在爬取页面时遇到了网页被重定向的情况。所谓重定向就是通过各种方法(本文提到的三种)(URL)将各种网络请求重定向到其他位置。每个网站首页都是网站资源的入口。当重定向发生在网站的首页时,如果处理不当,很可能会遗漏网站的全部内容。
作者写的爬虫在爬取网页时遇到了三种重定向情况。
1.服务器端重定向是在服务器端完成的。一般来说爬虫是可以自适应的,不需要特殊处理,比如响应码301(永久重定向)、302(临时重定向)等,具体可以通过响应中的url和status_code这两个属性来判断requests 请求获取的对象。当status_code为301、302或其他代表重定向的code时,表示原请求被重定向;当响应对象的 url 属性与发送请求时的链接不一致时,也说明原来的请求被重定向并且已经被自动处理了。
#请求重定向#方法二
response.setStatus(302);
response.setHeader("location", "/day06/index.jsp");#方法二
response.sendRedirect("/day06/index.jsp");
scrapy shell 以获取重定向页面
scrapy shell -s ROBOTSTXT_OBEY=False --no-redirect ""fetch(response.headers['Location'])
2.meta refresh,即网页中的标签声明了网页重定向的链接。这个重定向是由浏览器完成的,需要通过编写代码来处理。比如下面HTML代码第三行的注释中如果出现某个重定向,浏览器可以自动跳转,但是爬虫只能获取跳转前的页面,不能自动跳转。
解决方法是通过获取跳转前的页面源代码来提取重定向url信息(上面代码第三行的url属性值)。具体操作:
①使用xpath('//meta[@http-equiv="refresh" and @content]/@content')提取content的值
②使用正则表达式提取重定向的url值。
3.js 重定向,重定向是以 JavaScript 代码的形式进行的。比如下面的JavaScript代码
网页收录内容的情况是最容易解决的。一般来说,它基本上是静态网页的硬编码内容,或者是动态网页,使用模板渲染。当浏览器获取到 HTML 时,它已经收录了所有的关键信息,所以你在网页上直接看到的内容可以通过特定的 HTML 标签加载 javascript 代码。这种情况是因为虽然网页显示时内容在HTML标签中,但实际上是通过执行js代码添加到标签中的。所以此时的内容在js代码中,js的执行是浏览器端的操作,所以当你使用程序请求网页地址时,得到的响应就是网页代码和js代码,这样就可以在浏览器端看到内容了,因为解析的时候没有执行js,所以指定的HTML标签下的内容必须是空的。这时候的处理方法一般是找到收录内容的js代码字符串,然后通过正则表达式获取对应的内容,而不是解析HTML标签。
js提取指定网站内容(Python即时网络爬虫GitHub源7,文档修改历史(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-28 07:10
1 简介
本文介绍了如何使用 Java 和 JavaScript 中的 GooSeeker API 接口下载内容提取器。这是一个示例程序。什么是内容提取器?为什么要使用这种方法?源自Python即时网络爬虫开源项目:通过生成内容提取器,大大节省了程序员的时间。详情请参考“内容提取器的定义”。
2.用Java下载内容提取器
这是一系列示例程序之一。从目前的编程语言发展来看,Java实现网页内容提取并不合适。除了语言不够灵活方便,整个生态不够活跃,可选库增长缓慢。另外,从JavaScript动态网页中提取内容,Java也很不方便,需要JavaScript引擎。使用 JavaScript 下载内容提取器可以直接跳转到第 3 部分的内容。
执行
注解:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回结果如下:
3. 使用 JavaScript 下载内容提取器
请注意,如果本示例中的 JavaScript 代码运行在网页上,由于跨域问题,无法抓取非站点网页的内容。因此,运行在有特权的 JavaScript 引擎上,例如浏览器扩展、自研浏览器以及自己程序中的 JavaScript 引擎。
为方便实验,本示例仍在网页上运行。为了避免跨域问题,目标网页被保存和修改,并在其中插入JavaScript。这么多手动操作只是为了实验,正式使用时还需要考虑其他方法。
执行
注解:
这是源代码:
// 目标网页网址为http://m.58.com/cs/qiuzu/22613961050143x.shtml,预先保存成本地html文件,并插入下述代码
$(document).ready(function(){
$.ajax({
type: "get",
url: "http://www.gooseeker.com/api/getextractor?key=申请的appKey&theme=规则主题名",
dataType: "xml",
success: function(xslt)
{
var result = convertXml(xslt, window.document);
alert("result:" + result);
}
});
});
/* 用xslt将dom转换为xml对象 */
function convertXml(xslt, dom)
{
// 定义XSLTProcessor对象
var xsltProcessor = new XSLTProcessor();
xsltProcessor.importStylesheet(xslt);
// transformToDocument方式
var result = xsltProcessor.transformToDocument(dom);
return result;
}
返回结果截图如下
4. 展望
您也可以使用 Python 来获取指定网页的内容。感觉Python的语法更简洁。稍后我们将添加 Python 语言的示例。有兴趣的朋友可以加入一起学习。
五、相关文件
1. Python即时网络爬虫:API说明
2.内容提取器的定义
6、采集GooSeeker开源代码下载
1. GooSeeker开源Python网络爬虫GitHub源码
7. 文档修改历史
1, 2016-06-20: V1.0
上一章 API-下载内容提取器 下一章 用 Python 驱动 Firefox 查看全部
js提取指定网站内容(Python即时网络爬虫GitHub源7,文档修改历史(组图))
1 简介
本文介绍了如何使用 Java 和 JavaScript 中的 GooSeeker API 接口下载内容提取器。这是一个示例程序。什么是内容提取器?为什么要使用这种方法?源自Python即时网络爬虫开源项目:通过生成内容提取器,大大节省了程序员的时间。详情请参考“内容提取器的定义”。
2.用Java下载内容提取器
这是一系列示例程序之一。从目前的编程语言发展来看,Java实现网页内容提取并不合适。除了语言不够灵活方便,整个生态不够活跃,可选库增长缓慢。另外,从JavaScript动态网页中提取内容,Java也很不方便,需要JavaScript引擎。使用 JavaScript 下载内容提取器可以直接跳转到第 3 部分的内容。
执行
注解:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回结果如下:
3. 使用 JavaScript 下载内容提取器
请注意,如果本示例中的 JavaScript 代码运行在网页上,由于跨域问题,无法抓取非站点网页的内容。因此,运行在有特权的 JavaScript 引擎上,例如浏览器扩展、自研浏览器以及自己程序中的 JavaScript 引擎。
为方便实验,本示例仍在网页上运行。为了避免跨域问题,目标网页被保存和修改,并在其中插入JavaScript。这么多手动操作只是为了实验,正式使用时还需要考虑其他方法。
执行
注解:
这是源代码:
// 目标网页网址为http://m.58.com/cs/qiuzu/22613961050143x.shtml,预先保存成本地html文件,并插入下述代码
$(document).ready(function(){
$.ajax({
type: "get",
url: "http://www.gooseeker.com/api/getextractor?key=申请的appKey&theme=规则主题名",
dataType: "xml",
success: function(xslt)
{
var result = convertXml(xslt, window.document);
alert("result:" + result);
}
});
});
/* 用xslt将dom转换为xml对象 */
function convertXml(xslt, dom)
{
// 定义XSLTProcessor对象
var xsltProcessor = new XSLTProcessor();
xsltProcessor.importStylesheet(xslt);
// transformToDocument方式
var result = xsltProcessor.transformToDocument(dom);
return result;
}
返回结果截图如下
4. 展望
您也可以使用 Python 来获取指定网页的内容。感觉Python的语法更简洁。稍后我们将添加 Python 语言的示例。有兴趣的朋友可以加入一起学习。
五、相关文件
1. Python即时网络爬虫:API说明
2.内容提取器的定义
6、采集GooSeeker开源代码下载
1. GooSeeker开源Python网络爬虫GitHub源码
7. 文档修改历史
1, 2016-06-20: V1.0
上一章 API-下载内容提取器 下一章 用 Python 驱动 Firefox
js提取指定网站内容(用requests模块获取网站数据时,网站的编码是个很麻烦的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-26 03:22
使用requests模块获取网站数据时,网站的编码是一个很麻烦的问题。一般来说,请求会自动识别网站的编码。如果网页未指定编码,则默认为 ISO-8859-1 编码。这时候可能会出现问题。
一般有几种方式,最简单的就是手动指定编码r.encoding = ‘utf-8’
但是,当采集数据时,您可能访问不同域名的网站。这时候,手动为每个网站分配一个正确的代码并不容易。以下是通用方法
if r.encoding == 'ISO-8859-1':
encodings = requests.utils.get_encodings_from_content(r.text)
if encodings:
encoding = encodings[0]
else:
encoding = r.apparent_encoding
return r.content.decode(encoding, 'replace')
else:
return r.text
本作品采用《CC协议》,转载需注明作者及本文链接 查看全部
js提取指定网站内容(用requests模块获取网站数据时,网站的编码是个很麻烦的问题)
使用requests模块获取网站数据时,网站的编码是一个很麻烦的问题。一般来说,请求会自动识别网站的编码。如果网页未指定编码,则默认为 ISO-8859-1 编码。这时候可能会出现问题。
一般有几种方式,最简单的就是手动指定编码r.encoding = ‘utf-8’
但是,当采集数据时,您可能访问不同域名的网站。这时候,手动为每个网站分配一个正确的代码并不容易。以下是通用方法
if r.encoding == 'ISO-8859-1':
encodings = requests.utils.get_encodings_from_content(r.text)
if encodings:
encoding = encodings[0]
else:
encoding = r.apparent_encoding
return r.content.decode(encoding, 'replace')
else:
return r.text
本作品采用《CC协议》,转载需注明作者及本文链接
js提取指定网站内容(JavaScript如何打印页面中的指定内容的效果,功能非常不错)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-25 11:09
很多网站都有这个功能。当您浏览到底部时,会有一个打印按钮。点击打印按钮完成打印功能。功能非常好,人性化。下面我们来介绍一下通过点击按钮实现打印的JavaScript。代码,需要的朋友参考
很多网站都有这个功能。当您浏览到底部时,会有一个打印按钮。点击打印按钮完成打印功能。功能很好,人性化,代码也很简单。
脚本之家
即只要调用window.print()函数,就可以打印当前页面。
但是上面的并不完美,因为有些网页上的很多内容是不需要打印的。下面是如何在页面上打印指定的内容。
代码显示如下:
指定被打印的内容 这是要被打印的内容欢迎您
特别注意:打印预览需要将代码复制到本地机器进行测试,否则会报错。
以上代码实现了打印网页指定内容的效果。下面简单介绍一下实现过程。
一. 实现原理:
在js代码中使用document.body.innerHTML =newstr,将原body中的内容动态替换为要打印的内容。打印后,恢复原创内容。原理就是这么简单。具体可以参考代码注释。
二.代码注释:
1.function printdiv(printpage){},声明一个控制打印的函数,参数是一个对象,这个对象的内容会被打印出来。
2.var newstr = printpage.innerHTML; 获取要打印的内容。
3.var oldstr = document.body.innerHTML,body 中的原创内容。
4. document.body.innerHTML =newstr,将原body中的内容替换为要打印的内容。
5.window.print(),开始打印。
6.document.body.innerHTML=oldstr,然后恢复原来body中的内容。 查看全部
js提取指定网站内容(JavaScript如何打印页面中的指定内容的效果,功能非常不错)
很多网站都有这个功能。当您浏览到底部时,会有一个打印按钮。点击打印按钮完成打印功能。功能非常好,人性化。下面我们来介绍一下通过点击按钮实现打印的JavaScript。代码,需要的朋友参考
很多网站都有这个功能。当您浏览到底部时,会有一个打印按钮。点击打印按钮完成打印功能。功能很好,人性化,代码也很简单。
脚本之家
即只要调用window.print()函数,就可以打印当前页面。
但是上面的并不完美,因为有些网页上的很多内容是不需要打印的。下面是如何在页面上打印指定的内容。
代码显示如下:
指定被打印的内容 这是要被打印的内容欢迎您
特别注意:打印预览需要将代码复制到本地机器进行测试,否则会报错。
以上代码实现了打印网页指定内容的效果。下面简单介绍一下实现过程。
一. 实现原理:
在js代码中使用document.body.innerHTML =newstr,将原body中的内容动态替换为要打印的内容。打印后,恢复原创内容。原理就是这么简单。具体可以参考代码注释。
二.代码注释:
1.function printdiv(printpage){},声明一个控制打印的函数,参数是一个对象,这个对象的内容会被打印出来。
2.var newstr = printpage.innerHTML; 获取要打印的内容。
3.var oldstr = document.body.innerHTML,body 中的原创内容。
4. document.body.innerHTML =newstr,将原body中的内容替换为要打印的内容。
5.window.print(),开始打印。
6.document.body.innerHTML=oldstr,然后恢复原来body中的内容。

