
js提取指定网站内容
js提取指定网站内容(我在某云存储上上传了一批文件,有几百张图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-11 19:04
我在云存储上上传了一批文件,其中收录数百张图片。我是3月17号上传的,现在需要证明我是3月18号上传给公司领导的。云存储本身的上传日期和时间无法更改,也无法回到3月18日再次上传。. 于是想了个办法,登录云存储后台管理页面后查看文件列表,一次显示100条,下面还有一个加载更多按钮,每次点击一次加载100条,直到加载完成,我通过云存储网页代码找到加载方式,修改代码。在追加到表格之前,将获取的数据中的日期“2019-03-17”替换为“2019-03-18”,
现在唯一的问题是,当我在公司检查组的同事面前演示时——虽然他们对IT不太了解,但看到我运行代码肯定会怀疑——我不能直接做像上面一样,我需要浏览器来运行代码。当我打开这个页面时,这个本地的JS代码是从后台自动执行的,这样从登录到打开页面到加载数据,他们都可以信服。我直接把加载好的或者截图给他们看,别人会怀疑,所以我只有从一开始登录的时候就在他们面前演示操作的时候可信度很高。
唯一的好处是拿我的电脑演示,他们不会要求在不同的电脑上演示,否则会比较困难。
如何做到这一点? 查看全部
js提取指定网站内容(我在某云存储上上传了一批文件,有几百张图片)
我在云存储上上传了一批文件,其中收录数百张图片。我是3月17号上传的,现在需要证明我是3月18号上传给公司领导的。云存储本身的上传日期和时间无法更改,也无法回到3月18日再次上传。. 于是想了个办法,登录云存储后台管理页面后查看文件列表,一次显示100条,下面还有一个加载更多按钮,每次点击一次加载100条,直到加载完成,我通过云存储网页代码找到加载方式,修改代码。在追加到表格之前,将获取的数据中的日期“2019-03-17”替换为“2019-03-18”,
现在唯一的问题是,当我在公司检查组的同事面前演示时——虽然他们对IT不太了解,但看到我运行代码肯定会怀疑——我不能直接做像上面一样,我需要浏览器来运行代码。当我打开这个页面时,这个本地的JS代码是从后台自动执行的,这样从登录到打开页面到加载数据,他们都可以信服。我直接把加载好的或者截图给他们看,别人会怀疑,所以我只有从一开始登录的时候就在他们面前演示操作的时候可信度很高。
唯一的好处是拿我的电脑演示,他们不会要求在不同的电脑上演示,否则会比较困难。
如何做到这一点?
js提取指定网站内容(一个就是代码_Load代码添加按钮和存放结构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-07 14:10
在工作的过程中,遇到了一个需求,就是Js从Cookies中获取值。 js好像没有现成的方法来指定Key值来获取Cookie中对应的值。简单的实现请参考网上的代码如下:
1.服务器代码Page_Load中Cookies中写了几个值
using System;
using System.Collections.Generic;
using System.Web;
using System.Web.UI;
using System.Web.UI.WebControls;
namespace WebApplication_TestJS
{
public partial class _Default : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
Response.Cookies["DONO"].Value = "EDO1406300001";
Response.Cookies["DOID"].Value = "ABCDEFG123456";
Response.Cookies["DOSOURCE"].Value = "WUWUWUWU";
Response.Cookies["DOTYPE"].Value = "2";
}
}
}
2. 向客户端代码页添加按钮和文本框,触发并输出获取的值
function GetCookie()
{
/*获取Cookies里面存放信息 了解其字符串结构*/
var Cookies = document.cookie;
document.getElementById("").innerText = Cookies;
/*处理字符串截取出来需要的目标值*/
var target = "DONO" + "=";
if (document.cookie.length > 0)
{
start = document.cookie.indexOf(target);
if (start != -1)
{
start += target.length;
end = document.cookie.indexOf(";", start);
if (end == -1) end = document.cookie.length;
}
}
/*目标值赋值给控件*/
document.getElementById("").innerText = document.cookie.substring(start, end);
}
<br />
<br />
3.在执行结果中可以看到Cookies和第一个文本框中的结构一样,根据需要截取对应的字符串。
相关文章
猜你喜欢 查看全部
js提取指定网站内容(一个就是代码_Load代码添加按钮和存放结构)
在工作的过程中,遇到了一个需求,就是Js从Cookies中获取值。 js好像没有现成的方法来指定Key值来获取Cookie中对应的值。简单的实现请参考网上的代码如下:
1.服务器代码Page_Load中Cookies中写了几个值
using System;
using System.Collections.Generic;
using System.Web;
using System.Web.UI;
using System.Web.UI.WebControls;
namespace WebApplication_TestJS
{
public partial class _Default : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
Response.Cookies["DONO"].Value = "EDO1406300001";
Response.Cookies["DOID"].Value = "ABCDEFG123456";
Response.Cookies["DOSOURCE"].Value = "WUWUWUWU";
Response.Cookies["DOTYPE"].Value = "2";
}
}
}
2. 向客户端代码页添加按钮和文本框,触发并输出获取的值
function GetCookie()
{
/*获取Cookies里面存放信息 了解其字符串结构*/
var Cookies = document.cookie;
document.getElementById("").innerText = Cookies;
/*处理字符串截取出来需要的目标值*/
var target = "DONO" + "=";
if (document.cookie.length > 0)
{
start = document.cookie.indexOf(target);
if (start != -1)
{
start += target.length;
end = document.cookie.indexOf(";", start);
if (end == -1) end = document.cookie.length;
}
}
/*目标值赋值给控件*/
document.getElementById("").innerText = document.cookie.substring(start, end);
}
<br />
<br />
3.在执行结果中可以看到Cookies和第一个文本框中的结构一样,根据需要截取对应的字符串。

相关文章
猜你喜欢
js提取指定网站内容(前几天脑子里忽然简书的图片分享效果,感觉很简洁)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-05 18:13
前几天,脑子里突然闪过简书的图片分享效果。感觉非常简单和美丽。想着自己的方法能不能实现,所以今天就有了这篇文章。好的,我们先来看看效果图:
项目地址:
欢迎star,问题~
要达到这个效果,首先要明白几个问题:
一、如何获取选中的网页内容
二、如何加载和显示获取的网页内容
一、如何获取选中的网页内容
获取选定的网页内容非常困难。通过Java获取选中的网页内容非常困难,要达到效果,必须获取选中的网页内容。我们可以改变我们的想法。既然不容易通过Java层获取,那么使用JavaScript是不是更容易呢?嗯,后来的实现也证实了这个想法是正确的,JavaScript很容易获取到选中的网页内容。
那么我们的思路是:当用户点击生成的图片分享按钮时,我们调用JavaScript方法获取选中的网页内容,同时回调Java的get content方法,将获取的网页内容传回Java层,我们可以得到网页内容。
简单看一下代码:
mWebView.addJavascriptInterface(new WebAppInterface(onGetDataListener), "JSInterface"); public void getSelectedData(WebView webView) { String js = "(function getSelectedText() {" + "var txt;" + "if (window.getSelection) {" + "var range=window.getSelection().getRangeAt(0);" + "var container = window.document.createElement('div');" + "container.appendChild(range.cloneContents());" + "txt = container.innerHTML;" + "} else if (window.document.getSelection) {" + "var range=window.getSelection().getRangeAt(0);" + "var container = window.document.createElement('div');" + "container.appendChild(range.cloneContents());" + "txt = container.innerHTML;" + "} else if (window.document.selection) {" + "txt = window.document.selection.createRange().htmlText;" + "}" + "JSInterface.getText(txt);" + "})()"; // calling the js function if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.KITKAT) { webView.evaluateJavascript("javascript:" + js, null); } else { webView.loadUrl("javascript:" + js); } webView.clearFocus(); } static class WebAppInterface { WebViewHelper.OnGetDataListener onGetDataListener; WebAppInterface(WebViewHelper.OnGetDataListener onGetDataListener) { this.onGetDataListener = onGetDataListener; } @JavascriptInterface public void getText(String text) { onGetDataListener.getDataListener(text); } } public interface OnGetDataListener{ void getDataListener(String text); }
上面的实现思路是,当我们想要获取选中的网页内容时,将自己编写的一段JavaScript脚本注入到WebView中。这段JavaScript代码的意思是获取当前页面收录html标签的选中内容,调用JSInterface.getText(txt)方法。将内容返回给Java的getText(String text)方法,我们设置onGetDataListener.getDataListener(text)回调方法,在需要的地方调用获取内容。
二、如何加载和显示获取的网页内容
我们已经获得了网页的内容。调用TextView的setText(Html.fromHtml())方法来显示我们选择的效果是合理的,但是考虑到美观和保存截图的功能以及图片的正常显示,我选择使用WebView来加载得到的网页内容。
我是这样处理的:首先在本地assets文件夹中创建一个html页面,加载页面中的基本显示内容并添加css标签修改加载的内容,当获取到网页内容时,本地html page动态替换为JavaScript指定对应的标签内容为获取的网页内容,在本地html页面修改显示内容。
看代码:
webView.loadUrl("file:///android_asset/generate_pic.html"); public void changeDay(String strData,String userInfo,String userName,String other) { if(userInfo == null) userInfo =""; if(strData == null) strData =""; if(userName == null) userName =""; if(other == null) other =""; strData+="<br /><br />n" + "tt"+userInfo+"n" + "tt<br /><br />n" + "ttn" + "tt<br />n" + "tt<p style="/spancolor: orangered;font-size: x-small;text-align: center;letter-spacing: span class="hljs-number"0.5/spanpx;span class="hljs-string"">由"+userName+"发送 "+other+""; webView.loadUrl("javascript:changeContent("" + strData.replace("n", "\n").replace(""", "\"").replace("'", "\'") + "")"); webView.setBackgroundColor(Color.WHITE); }</p>
白色和黑色的不同显示效果可以通过changeDay方法中改变css样式来实现,比较简单。
但这里存在问题:当所选页面内容具有图片并且图像显示在相对路径中时,无法加载图像。
在这种情况下,图片是相对路径,即在本地对应的相对路径下查找。本地一定找不到,图片也不会显示。
为了能正常显示图片,在选中的内容页面调用onLoadResource方法判断加载的资源并保存图片路径,因为既然选中的页面图片是可以显示和处理的,就说明路径是http路径,可以显示图片。
看代码:
mWebView.setWebViewClient(new WebViewClient(){ @Override public void onLoadResource(WebView view, String url) { //Log.e("TAG","url :"+url); if(url.toLowerCase().contains(".jpg") ||url.toLowerCase().contains(".png") ||url.toLowerCase().contains(".gif")){ mlistPath.add(url); } super.onLoadResource(view, url); }
当显示选中的内容页面时,动态修改显示的图片路径以显示图片:
webView.setWebViewClient(new WebViewClient(){ @Override public boolean shouldOverrideUrlLoading(WebView view, String url) { //view.loadUrl(url); return true; } public WebResourceResponse shouldInterceptRequest(WebView view, String url) { WebResourceResponse response = null; for (String path:WebViewHelper.getInstance().getAllListPath()){ if (path.toLowerCase().contains(url.replace("file://","").toLowerCase())){ try { response = new WebResourceResponse("image/png", "UTF-8", new URL(path).openStream()); } catch (IOException e) { e.printStackTrace(); } } } return response; } });
这样我们的图片就可以显示出来了!
最后,实现我们的截图保存功能,看代码:
/** * 截屏 * * @return */ public Bitmap getScreen() { Bitmap bmp = Bitmap.createBitmap(webView.getWidth(), 1, Bitmap.Config.ARGB_8888); int rowBytes = bmp.getRowBytes(); bmp = null; if (rowBytes*webView.getHeight()>=getAvailMemory()){ return null; } bmp = Bitmap.createBitmap(webView.getWidth(), webView.getHeight(), Bitmap.Config.ARGB_8888); Canvas canvas = new Canvas(bmp); webView.draw(canvas); return bmp; } private long getAvailMemory() { return Runtime.getRuntime().maxMemory(); }
这里需要对保存的图片大小做判断,防止创建过大的OOM图片。
至此,基本功能已经实现。把照片分享给你的朋友~
项目地址:
欢迎star,问题~ 查看全部
js提取指定网站内容(前几天脑子里忽然简书的图片分享效果,感觉很简洁)
前几天,脑子里突然闪过简书的图片分享效果。感觉非常简单和美丽。想着自己的方法能不能实现,所以今天就有了这篇文章。好的,我们先来看看效果图:

项目地址:
欢迎star,问题~
要达到这个效果,首先要明白几个问题:
一、如何获取选中的网页内容
二、如何加载和显示获取的网页内容

一、如何获取选中的网页内容
获取选定的网页内容非常困难。通过Java获取选中的网页内容非常困难,要达到效果,必须获取选中的网页内容。我们可以改变我们的想法。既然不容易通过Java层获取,那么使用JavaScript是不是更容易呢?嗯,后来的实现也证实了这个想法是正确的,JavaScript很容易获取到选中的网页内容。
那么我们的思路是:当用户点击生成的图片分享按钮时,我们调用JavaScript方法获取选中的网页内容,同时回调Java的get content方法,将获取的网页内容传回Java层,我们可以得到网页内容。
简单看一下代码:
mWebView.addJavascriptInterface(new WebAppInterface(onGetDataListener), "JSInterface"); public void getSelectedData(WebView webView) { String js = "(function getSelectedText() {" + "var txt;" + "if (window.getSelection) {" + "var range=window.getSelection().getRangeAt(0);" + "var container = window.document.createElement('div');" + "container.appendChild(range.cloneContents());" + "txt = container.innerHTML;" + "} else if (window.document.getSelection) {" + "var range=window.getSelection().getRangeAt(0);" + "var container = window.document.createElement('div');" + "container.appendChild(range.cloneContents());" + "txt = container.innerHTML;" + "} else if (window.document.selection) {" + "txt = window.document.selection.createRange().htmlText;" + "}" + "JSInterface.getText(txt);" + "})()"; // calling the js function if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.KITKAT) { webView.evaluateJavascript("javascript:" + js, null); } else { webView.loadUrl("javascript:" + js); } webView.clearFocus(); } static class WebAppInterface { WebViewHelper.OnGetDataListener onGetDataListener; WebAppInterface(WebViewHelper.OnGetDataListener onGetDataListener) { this.onGetDataListener = onGetDataListener; } @JavascriptInterface public void getText(String text) { onGetDataListener.getDataListener(text); } } public interface OnGetDataListener{ void getDataListener(String text); }
上面的实现思路是,当我们想要获取选中的网页内容时,将自己编写的一段JavaScript脚本注入到WebView中。这段JavaScript代码的意思是获取当前页面收录html标签的选中内容,调用JSInterface.getText(txt)方法。将内容返回给Java的getText(String text)方法,我们设置onGetDataListener.getDataListener(text)回调方法,在需要的地方调用获取内容。
二、如何加载和显示获取的网页内容
我们已经获得了网页的内容。调用TextView的setText(Html.fromHtml())方法来显示我们选择的效果是合理的,但是考虑到美观和保存截图的功能以及图片的正常显示,我选择使用WebView来加载得到的网页内容。
我是这样处理的:首先在本地assets文件夹中创建一个html页面,加载页面中的基本显示内容并添加css标签修改加载的内容,当获取到网页内容时,本地html page动态替换为JavaScript指定对应的标签内容为获取的网页内容,在本地html页面修改显示内容。
看代码:
webView.loadUrl("file:///android_asset/generate_pic.html"); public void changeDay(String strData,String userInfo,String userName,String other) { if(userInfo == null) userInfo =""; if(strData == null) strData =""; if(userName == null) userName =""; if(other == null) other =""; strData+="<br /><br />n" + "tt"+userInfo+"n" + "tt<br /><br />n" + "ttn" + "tt<br />n" + "tt<p style="/spancolor: orangered;font-size: x-small;text-align: center;letter-spacing: span class="hljs-number"0.5/spanpx;span class="hljs-string"">由"+userName+"发送 "+other+""; webView.loadUrl("javascript:changeContent("" + strData.replace("n", "\n").replace(""", "\"").replace("'", "\'") + "")"); webView.setBackgroundColor(Color.WHITE); }</p>
白色和黑色的不同显示效果可以通过changeDay方法中改变css样式来实现,比较简单。
但这里存在问题:当所选页面内容具有图片并且图像显示在相对路径中时,无法加载图像。
在这种情况下,图片是相对路径,即在本地对应的相对路径下查找。本地一定找不到,图片也不会显示。
为了能正常显示图片,在选中的内容页面调用onLoadResource方法判断加载的资源并保存图片路径,因为既然选中的页面图片是可以显示和处理的,就说明路径是http路径,可以显示图片。
看代码:
mWebView.setWebViewClient(new WebViewClient(){ @Override public void onLoadResource(WebView view, String url) { //Log.e("TAG","url :"+url); if(url.toLowerCase().contains(".jpg") ||url.toLowerCase().contains(".png") ||url.toLowerCase().contains(".gif")){ mlistPath.add(url); } super.onLoadResource(view, url); }
当显示选中的内容页面时,动态修改显示的图片路径以显示图片:
webView.setWebViewClient(new WebViewClient(){ @Override public boolean shouldOverrideUrlLoading(WebView view, String url) { //view.loadUrl(url); return true; } public WebResourceResponse shouldInterceptRequest(WebView view, String url) { WebResourceResponse response = null; for (String path:WebViewHelper.getInstance().getAllListPath()){ if (path.toLowerCase().contains(url.replace("file://","").toLowerCase())){ try { response = new WebResourceResponse("image/png", "UTF-8", new URL(path).openStream()); } catch (IOException e) { e.printStackTrace(); } } } return response; } });
这样我们的图片就可以显示出来了!
最后,实现我们的截图保存功能,看代码:
/** * 截屏 * * @return */ public Bitmap getScreen() { Bitmap bmp = Bitmap.createBitmap(webView.getWidth(), 1, Bitmap.Config.ARGB_8888); int rowBytes = bmp.getRowBytes(); bmp = null; if (rowBytes*webView.getHeight()>=getAvailMemory()){ return null; } bmp = Bitmap.createBitmap(webView.getWidth(), webView.getHeight(), Bitmap.Config.ARGB_8888); Canvas canvas = new Canvas(bmp); webView.draw(canvas); return bmp; } private long getAvailMemory() { return Runtime.getRuntime().maxMemory(); }
这里需要对保存的图片大小做判断,防止创建过大的OOM图片。
至此,基本功能已经实现。把照片分享给你的朋友~
项目地址:
欢迎star,问题~
js提取指定网站内容(共享文件夹.多POP3接收代理(,)页面,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-05 09:08
JS页面内容搜索,类似Ctrl+F功能的实现代码,页面,内容,搜索,类似,Ctrl+F,功能,的,实现
JS页面内容搜索,类似Ctrl+F功能的实现代码
一菜站长网站,站长之家为你整理JS页面内容搜索,类似Ctrl+F功能实现代码的相关内容。
注意:以上两种加入方式,共享文件夹共享时无需密码,无需输入密码。
修改:当共享文件夹被原共享者修改后,您可以使用修改功能更新该文件夹的密码。修改成功后就可以继续查看共享文件夹了。
多个POP3接收代理
如果您之前已经有其他电子邮件地址,并且您的朋友正在向这些地址发送电子邮件;您可以设置“POP3接收”功能,让系统通过POP3协议将您的邮件从其他地方提取到系统中。
请在“服务器地址”中填写您的POP3服务器的名称或地址,如“”,然后填写您在服务器上接收邮件时使用的账户名和密码。如果您不知道您的服务器使用什么端口,
请使用默认设置“110”。
用户拒绝电子邮件地址
对于您不想接收的电子邮件地址,您可以将它们添加到拒绝列表中。
高级邮件过滤功能
先进的邮件过滤功能可以让系统帮助您自动删除、自动回复或将符合指定条件(“邮件地址”、“发件人”、“邮件大小”或“主题”)的邮件移至垃圾箱操作。
以上是对JS页面内容搜索的实现代码的详细介绍,类似Ctrl+F功能。欢迎大家对JS页面内容搜索内容提出宝贵意见,类似Ctrl+F功能的实现代码内容 查看全部
js提取指定网站内容(共享文件夹.多POP3接收代理(,)页面,)
JS页面内容搜索,类似Ctrl+F功能的实现代码,页面,内容,搜索,类似,Ctrl+F,功能,的,实现
JS页面内容搜索,类似Ctrl+F功能的实现代码
一菜站长网站,站长之家为你整理JS页面内容搜索,类似Ctrl+F功能实现代码的相关内容。
注意:以上两种加入方式,共享文件夹共享时无需密码,无需输入密码。
修改:当共享文件夹被原共享者修改后,您可以使用修改功能更新该文件夹的密码。修改成功后就可以继续查看共享文件夹了。
多个POP3接收代理
如果您之前已经有其他电子邮件地址,并且您的朋友正在向这些地址发送电子邮件;您可以设置“POP3接收”功能,让系统通过POP3协议将您的邮件从其他地方提取到系统中。
请在“服务器地址”中填写您的POP3服务器的名称或地址,如“”,然后填写您在服务器上接收邮件时使用的账户名和密码。如果您不知道您的服务器使用什么端口,
请使用默认设置“110”。
用户拒绝电子邮件地址
对于您不想接收的电子邮件地址,您可以将它们添加到拒绝列表中。
高级邮件过滤功能
先进的邮件过滤功能可以让系统帮助您自动删除、自动回复或将符合指定条件(“邮件地址”、“发件人”、“邮件大小”或“主题”)的邮件移至垃圾箱操作。
以上是对JS页面内容搜索的实现代码的详细介绍,类似Ctrl+F功能。欢迎大家对JS页面内容搜索内容提出宝贵意见,类似Ctrl+F功能的实现代码内容
js提取指定网站内容(au自动生成一个Json格式的结果我希望查询明天悉尼的天气如何)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-03 09:15
Powershell 可以轻松获取网页的信息并读取相应的内容。如果对象的格式是 XML 或 Json,则更容易处理。一般经常用到invoke-restmethod和invoke-webrequest这两个命令。前者主要是获取Json格式的内容,后者可以获取整个网页的内容。
例如,我想查看明天悉尼的天气。我在网上随便搜了一个提供API的网站
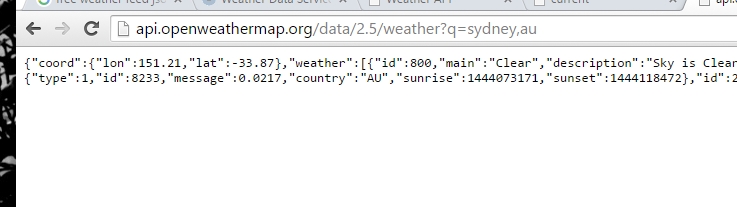
我打算搜索Sydney,所以对应的格式是
,au 他会自动生成 Json 格式的结果。
我们可以使用invoke-restmethod直接得到这个结果,例如
$b=invoke-restmethod "http://api.openweathermap.org/ ... ydney,au"
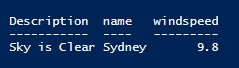
$c=[pscustomobject]@{
'Description'=$b.weather.description
'name'=$b.name
'windspeed'=$b.wind.speed
}
我也可以直接用invoke-webrequest来抓取整个网页的内容,然后从Json格式转过来。
$a= Invoke-WebRequest -Uri "http://api.openweathermap.org/ ... ydney,au"
$b=$a.Content | ConvertFrom-Json
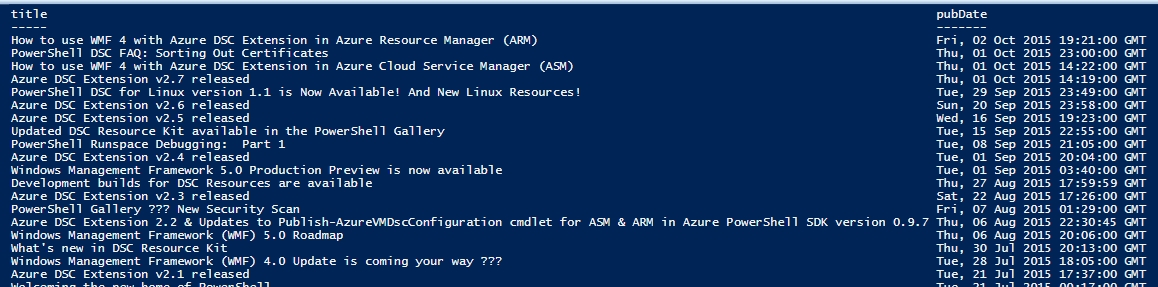
同样,如果我想获取博客的最新 RSS 内容。可以使用invoke-webrequest抓取对应的xml文件,如
[xml]$a= Invoke-WebRequest -Uri "http://blogs.msdn.com/b/powershell/rss.aspx“
$a.rss.channel.Item | select title,pubdate
功能很强大,但是使用起来很简单。 查看全部
js提取指定网站内容(au自动生成一个Json格式的结果我希望查询明天悉尼的天气如何)
Powershell 可以轻松获取网页的信息并读取相应的内容。如果对象的格式是 XML 或 Json,则更容易处理。一般经常用到invoke-restmethod和invoke-webrequest这两个命令。前者主要是获取Json格式的内容,后者可以获取整个网页的内容。
例如,我想查看明天悉尼的天气。我在网上随便搜了一个提供API的网站
我打算搜索Sydney,所以对应的格式是
,au 他会自动生成 Json 格式的结果。
我们可以使用invoke-restmethod直接得到这个结果,例如
$b=invoke-restmethod "http://api.openweathermap.org/ ... ydney,au"
$c=[pscustomobject]@{
'Description'=$b.weather.description
'name'=$b.name
'windspeed'=$b.wind.speed
}
我也可以直接用invoke-webrequest来抓取整个网页的内容,然后从Json格式转过来。
$a= Invoke-WebRequest -Uri "http://api.openweathermap.org/ ... ydney,au"
$b=$a.Content | ConvertFrom-Json
同样,如果我想获取博客的最新 RSS 内容。可以使用invoke-webrequest抓取对应的xml文件,如
[xml]$a= Invoke-WebRequest -Uri "http://blogs.msdn.com/b/powershell/rss.aspx“
$a.rss.channel.Item | select title,pubdate
功能很强大,但是使用起来很简单。
js提取指定网站内容(首页gtgt博客文章withpy2021-11-13(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-03 04:04
首页>博客文章使用JavaScript获取页面文档内容
withpy2021-11-13
简介 JavaScript 的 document 对象收录了页面的实际内容,因此可以使用 document 对象来获取页面内容,例如页面标题和各种表单值。 "/>
JavaScript 的 document 对象收录页面的实际内容,因此可以使用 document 对象获取页面的内容,例如页面标题和各种表单值。
1 DOCTYPE html>
2 js基础一. 用Document对象获得页面标题11 hr/>
12 >二. 用Document访问一下两个表单13
14 >第一个,文本框的值15
16 form name="textform"17 input ="textname" type="text" value="请输入文本"18 form19 >第二个,按钮的值20
21 ="submitform"22 ="submitname"="submit"="第一个表单内提交"23 24 25 >以下是获取到的值26 table border="1" cellspacing="4" cellpadding="2"27 tr28 td>获取到本页的标题是 : 29 > b>document.write(document.title)>本页包含表单 : 33 document.write(document.forms.length)34 35 36 >获取到文本框的值 : 37 document.write(window.document.textform.textname.value)38 39 40 >获取到按钮的值 : 41 document.write(window.document.submitform.submitname.value)42 43
44 table45
46 47 html>
总结
以上是本站为您采集整理的使用JavaScript获取的页面文档内容的全部内容。希望文章可以帮助大家解决使用JavaScript获取页面文档内容时遇到的程序开发问题。
如果您觉得本站网站的内容还不错,欢迎向程序员朋友推荐本站网站。 查看全部
js提取指定网站内容(首页gtgt博客文章withpy2021-11-13(图))
首页>博客文章使用JavaScript获取页面文档内容
withpy2021-11-13
简介 JavaScript 的 document 对象收录了页面的实际内容,因此可以使用 document 对象来获取页面内容,例如页面标题和各种表单值。 "/>
JavaScript 的 document 对象收录页面的实际内容,因此可以使用 document 对象获取页面的内容,例如页面标题和各种表单值。
1 DOCTYPE html>
2 js基础一. 用Document对象获得页面标题11 hr/>
12 >二. 用Document访问一下两个表单13
14 >第一个,文本框的值15
16 form name="textform"17 input ="textname" type="text" value="请输入文本"18 form19 >第二个,按钮的值20
21 ="submitform"22 ="submitname"="submit"="第一个表单内提交"23 24 25 >以下是获取到的值26 table border="1" cellspacing="4" cellpadding="2"27 tr28 td>获取到本页的标题是 : 29 > b>document.write(document.title)>本页包含表单 : 33 document.write(document.forms.length)34 35 36 >获取到文本框的值 : 37 document.write(window.document.textform.textname.value)38 39 40 >获取到按钮的值 : 41 document.write(window.document.submitform.submitname.value)42 43
44 table45
46 47 html>
总结
以上是本站为您采集整理的使用JavaScript获取的页面文档内容的全部内容。希望文章可以帮助大家解决使用JavaScript获取页面文档内容时遇到的程序开发问题。
如果您觉得本站网站的内容还不错,欢迎向程序员朋友推荐本站网站。
js提取指定网站内容( 2020年02月19日16:50:52作者huangtailangJS操作Fckeditor)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-03 04:02
2020年02月19日16:50:52作者huangtailangJS操作Fckeditor)
在 FCKeditor 编辑器中使用 Js 获取、插入和更改内容
更新时间:2020-02-19 16:50:52 作者:huangtailang
这个文章主要介绍了在FCKeditor编辑器中使用js获取、插入和更改内容,包括一些js操作Fckeditor的常用方法,有需要的朋友可以参考
FCKeditor 编辑器之前在一个系统中使用过。由于项目需要,需要在FCKeditor中添加一个自定义按钮来实现自己的需求。
主要是在FCKeditor编辑器中点击按钮时删除或添加内容
其实就是一个很简单的需求。我认为它可以在 FCKeditor 中轻松实现。
在 Google 上搜索自定义按钮和插件开发。经过近两个小时的探索,我还是没有意识到。不知道是我太笨还是自定义插件太难了。
通过JS方法处理
1.页面添加checkbox元素并绑定事件。当这个元素被选中时,“{#book#}”字符串会被添加到FCKeditor内容中(该字符串会在合适的时候被替换为其他内容),不选中时删除
2.添加Js处理FCKeditor内容(添加或删除“{#book#}”字符串),'txtContent'为FCKeditor的ID控件ID
//"添加/删除复选框"点击时如果按钮选中则添加"{#book#}"字符串到FCK内容里,反之删除字符串
//lineBook为FCK的ID号
function chk_but() {
if (window.FCKeditorAPI !== undefined && FCKeditorAPI.GetInstance('txtContent') !== undefined) {
if (document.getElementById('lineBook').checked) {
FCKeditorAPI.GetInstance('txtContent').EditorDocument.body.innerHTML += "{#book#}";
} else {
FCKeditorAPI.GetInstance('txtContent').EditorDocument.body.innerHTML = FCKeditorAPI.GetInstance('txtContent').EditorDocument.body.innerHTML.replace("{#book#}", "");
}
}
} //end function chk_lineBook()
//内容里如果有{#book#}则选中"添加/删除复选框"
if (document.getElementById('txtContent').value.indexOf('{#book#}') >= 0
&& window.FCKeditorAPI !== undefined
&& FCKeditorAPI.GetInstance('txtContent') !== undefined) {
document.getElementById('lineBook').checked = true;
}
参考:
官网:
获取或更改内容值:
创建插件:
接下来给大家分享一些JS操作Fckeditor的常用方法
//向编辑器插入指定代码
function insertHTMLToEditor(codeStr){
var oEditor = FCKeditorAPI.GetInstance("content");
oEditor.InsertHtml(codeStr); // "html"为HTML文本
}
//获取编辑器中HTML内容
function getEditorHTMLContents() {
var oEditor = FCKeditorAPI.GetInstance("content");
return(oEditor.GetXHTML(false));
}
// 获取编辑器中文字内容
function getEditorTextContents() {
var oEditor = FCKeditorAPI.GetInstance("content");
return(oEditor.EditorDocument.body.innerText);
}
// 设置编辑器中内容
function SetEditorContents(ContentStr) {
var oEditor = FCKeditorAPI.GetInstance("content") ;
oEditor.SetHTML(ContentStr) ;
}
//向编辑器插入指定代码
function insertHTMLToEditor(codeStr){
var oEditor = FCKeditorAPI.GetInstance( "content ");
if (oEditor.EditMode==FCK_EDITMODE_WYSIWYG){
oEditor.InsertHtml(codeStr);
}else{
return false;
}
}
//统计编辑器中内容的字数
function getLength(){
var oEditor = FCKeditorAPI.GetInstance( "content ");
var oDOM = oEditor.EditorDocument;
var iLength ;
if(document.all){
iLength = oDOM.body.innerText.length;
}else{
var r = oDOM.createRange();
r.selectNodeContents(oDOM.body);
iLength = r.toString().length;
}
alert(iLength);
}
//执行指定动作
function ExecuteCommand(commandName){
var oEditor = FCKeditorAPI.GetInstance( "content ") ;
oEditor.Commands.GetCommand(commandName).Execute() ;
}
这是文章关于在FCKeditor编辑器中使用Js获取、插入和更改内容的介绍。更多相关Js操作FCKeditor编辑器内容,请搜索之前的脚本首页文章或下方相关文章,希望大家以后多多支持Scripthome! 查看全部
js提取指定网站内容(
2020年02月19日16:50:52作者huangtailangJS操作Fckeditor)
在 FCKeditor 编辑器中使用 Js 获取、插入和更改内容
更新时间:2020-02-19 16:50:52 作者:huangtailang
这个文章主要介绍了在FCKeditor编辑器中使用js获取、插入和更改内容,包括一些js操作Fckeditor的常用方法,有需要的朋友可以参考
FCKeditor 编辑器之前在一个系统中使用过。由于项目需要,需要在FCKeditor中添加一个自定义按钮来实现自己的需求。
主要是在FCKeditor编辑器中点击按钮时删除或添加内容
其实就是一个很简单的需求。我认为它可以在 FCKeditor 中轻松实现。
在 Google 上搜索自定义按钮和插件开发。经过近两个小时的探索,我还是没有意识到。不知道是我太笨还是自定义插件太难了。
通过JS方法处理
1.页面添加checkbox元素并绑定事件。当这个元素被选中时,“{#book#}”字符串会被添加到FCKeditor内容中(该字符串会在合适的时候被替换为其他内容),不选中时删除
2.添加Js处理FCKeditor内容(添加或删除“{#book#}”字符串),'txtContent'为FCKeditor的ID控件ID
//"添加/删除复选框"点击时如果按钮选中则添加"{#book#}"字符串到FCK内容里,反之删除字符串
//lineBook为FCK的ID号
function chk_but() {
if (window.FCKeditorAPI !== undefined && FCKeditorAPI.GetInstance('txtContent') !== undefined) {
if (document.getElementById('lineBook').checked) {
FCKeditorAPI.GetInstance('txtContent').EditorDocument.body.innerHTML += "{#book#}";
} else {
FCKeditorAPI.GetInstance('txtContent').EditorDocument.body.innerHTML = FCKeditorAPI.GetInstance('txtContent').EditorDocument.body.innerHTML.replace("{#book#}", "");
}
}
} //end function chk_lineBook()
//内容里如果有{#book#}则选中"添加/删除复选框"
if (document.getElementById('txtContent').value.indexOf('{#book#}') >= 0
&& window.FCKeditorAPI !== undefined
&& FCKeditorAPI.GetInstance('txtContent') !== undefined) {
document.getElementById('lineBook').checked = true;
}
参考:
官网:
获取或更改内容值:
创建插件:
接下来给大家分享一些JS操作Fckeditor的常用方法
//向编辑器插入指定代码
function insertHTMLToEditor(codeStr){
var oEditor = FCKeditorAPI.GetInstance("content");
oEditor.InsertHtml(codeStr); // "html"为HTML文本
}
//获取编辑器中HTML内容
function getEditorHTMLContents() {
var oEditor = FCKeditorAPI.GetInstance("content");
return(oEditor.GetXHTML(false));
}
// 获取编辑器中文字内容
function getEditorTextContents() {
var oEditor = FCKeditorAPI.GetInstance("content");
return(oEditor.EditorDocument.body.innerText);
}
// 设置编辑器中内容
function SetEditorContents(ContentStr) {
var oEditor = FCKeditorAPI.GetInstance("content") ;
oEditor.SetHTML(ContentStr) ;
}
//向编辑器插入指定代码
function insertHTMLToEditor(codeStr){
var oEditor = FCKeditorAPI.GetInstance( "content ");
if (oEditor.EditMode==FCK_EDITMODE_WYSIWYG){
oEditor.InsertHtml(codeStr);
}else{
return false;
}
}
//统计编辑器中内容的字数
function getLength(){
var oEditor = FCKeditorAPI.GetInstance( "content ");
var oDOM = oEditor.EditorDocument;
var iLength ;
if(document.all){
iLength = oDOM.body.innerText.length;
}else{
var r = oDOM.createRange();
r.selectNodeContents(oDOM.body);
iLength = r.toString().length;
}
alert(iLength);
}
//执行指定动作
function ExecuteCommand(commandName){
var oEditor = FCKeditorAPI.GetInstance( "content ") ;
oEditor.Commands.GetCommand(commandName).Execute() ;
}
这是文章关于在FCKeditor编辑器中使用Js获取、插入和更改内容的介绍。更多相关Js操作FCKeditor编辑器内容,请搜索之前的脚本首页文章或下方相关文章,希望大家以后多多支持Scripthome!
js提取指定网站内容(如何使用RPA工具进行自动化工具?工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-31 06:18
背景
RPA工作流中最常见的场景是操作浏览器,对页面内容进行相关操作。本例以页面为例。带领大家初步探索如何使用RPA工具自动抓取页面文本内容。
本文将使用 JavaScript 开发 RPA 脚本。这里使用的RPA工具LeanRunner可以直接从Windows应用商店下载,支持使用node.js开源自动化库进行RPA开发。用户可以按照以下步骤逐步实现自己的 RPA 脚本。
脚步
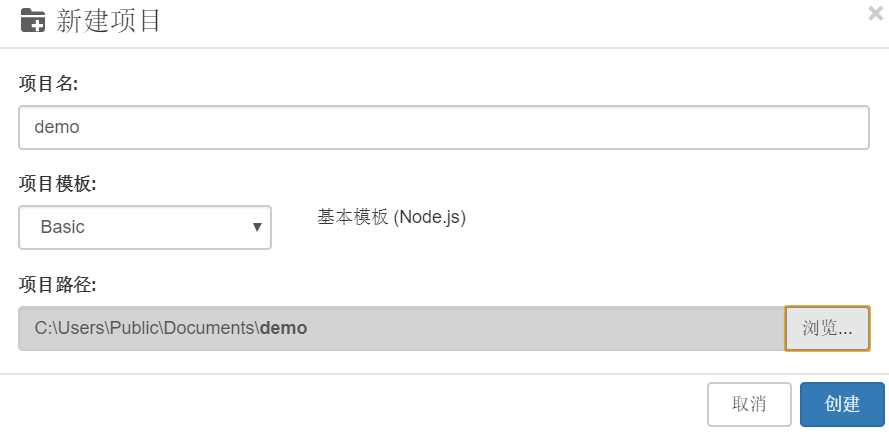
新项目
打开LeanRunner,选择【项目】-【新建】-【选择基本项目模板】,输入项目名称:demo,选择项目路径:
安装依赖库
Selenium-webdriver 是一个流行的操作 Web 自动化库。使用 chromedriver 库可以驱动 Chrome 自动化各种网页。当然,文本提取不是问题。本 RPA 使用这两个库来实现功能。所以创建项目后,需要安装相应的库。
点击LeanRunner打开命令行工具按钮
, 执行安装命令:
npm init -ynpm install chromedriver selenium-webdriver @types/selenium-webdriver --save
备注:npm是node.js的包管理机制,需要安装node.js环境才能使用
(下载链接:)
定义流程步骤
流程步骤被定义为使自动化流程可读。
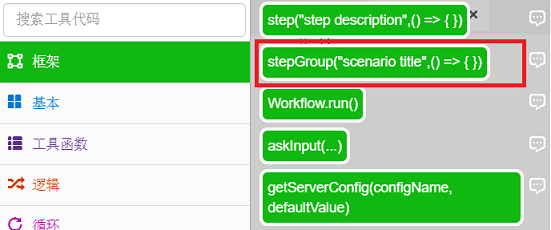
一个。打开main.js,在【Toolbox】-【Frame】中找到stepGroup方法,拖拽到js文件中。
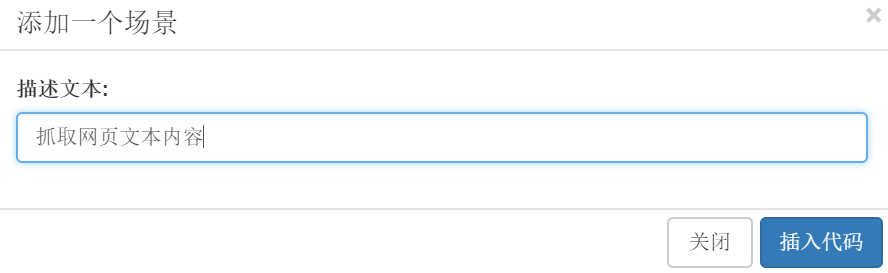
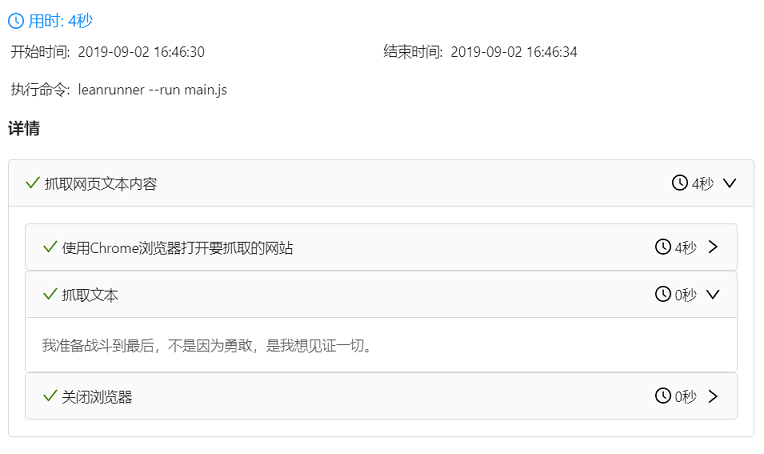
湾 在弹出的对话框中输入描述文字:抓取网页文字内容,点击插入代码。
C。此时,main.js文件的内容:
const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { })}
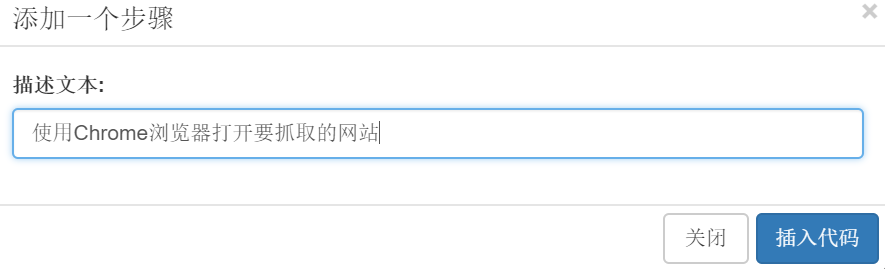
d. 继续拖拽【Toolbox】-【Frame】中的step方法来描述文字输入:使用Chrome浏览器打开你要截取的网站:
e. 按照上述步骤再次插入用于抓取文本和关闭浏览器的步骤定义。
main.js 如下:
const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}
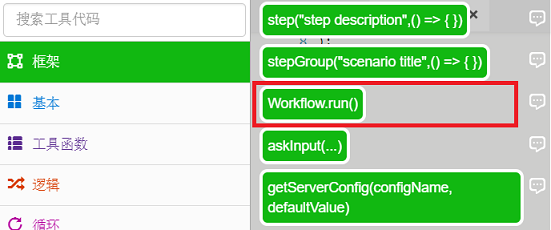
F。插入Workflow.run函数,RPA执行最终会被执行,在【Toolbox】-【Framework】中选择Workrun.run()函数:
G。在运行函数中输入“main”:
最后的代码是:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}Workflow.run(main);
实施步骤
参考 selenium-webdriver API
(). 分别实现以上操作步骤:
一个。使用Chrome浏览器打开你要截取的网站:
const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();const url = 'http://wufazhuce.com/one/2558';await driver.get(url);
上面的代码创建了一个 WebDriver 实例,打开一个浏览器窗口,并导航到目标 url。
湾 抓取文本:
let text = await driver.findElement({ css:'div[]'}).getText();console.log(text);
上面的代码使用css选择器定位要访问的元素并打印出来。
C。关闭浏览器
await driver.close();
最终代码如下:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');require('chromedriver');const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { const url = 'http://wufazhuce.com/one/2558'; await driver.get(url); }) await step("抓取文本", async (world) => { let text = await driver.findElement({ css:'div[]'}).getText(); console.log(text); world.attachText(text); }) await step("关闭浏览器", async (world) => { await driver.close() }) })}Workflow.run(main);
实施
单击“运行”按钮
, 或者点击“运行项目”按钮
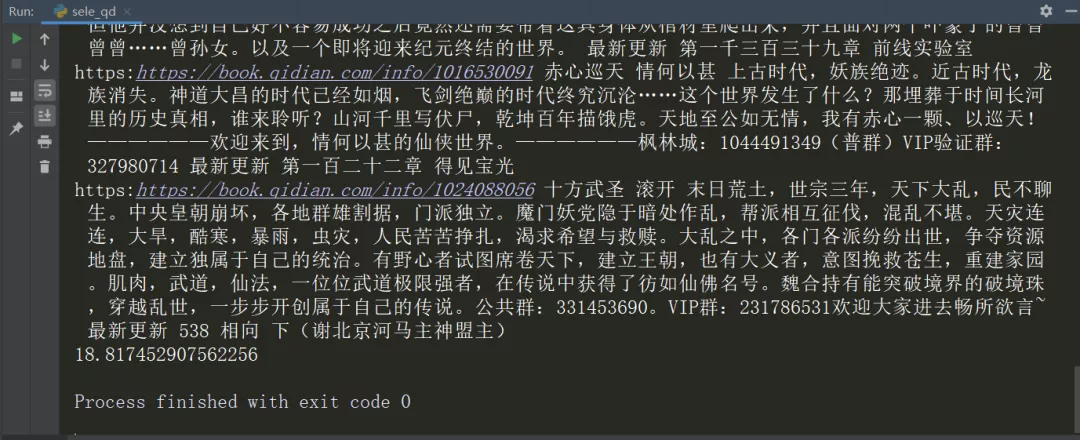
可以看到浏览器打开网页,在LeanRunner设计器的输出面板中打印出文本内容。
如果是运行项目,也会显示html运行报告:
对于用户来说,html 报告更具可读性。
总结
至此,我们已经完成了一个基本操作网页的RPA。后续的操作可以在这个RPA的基础上进一步深化,比如将抓取到的文本内容存入Excel表格或者存入数据库。
本文使用的 selenium-webdriver 自动化库是一个非常流行的开源库,可以支持各种类型的浏览器,并且可以及时更新以支持最新版本的浏览器。同时,Node.js 也是一个非常流行的开源平台。基于这些技术,开发RPA自动化脚本来维护RPA脚本的可用性和可维护性。结合LeanRunner RPA平台,可以帮助企业快速构建自己的流程自动化。 查看全部
js提取指定网站内容(如何使用RPA工具进行自动化工具?工具)
背景
RPA工作流中最常见的场景是操作浏览器,对页面内容进行相关操作。本例以页面为例。带领大家初步探索如何使用RPA工具自动抓取页面文本内容。
本文将使用 JavaScript 开发 RPA 脚本。这里使用的RPA工具LeanRunner可以直接从Windows应用商店下载,支持使用node.js开源自动化库进行RPA开发。用户可以按照以下步骤逐步实现自己的 RPA 脚本。
脚步
新项目
打开LeanRunner,选择【项目】-【新建】-【选择基本项目模板】,输入项目名称:demo,选择项目路径:
安装依赖库
Selenium-webdriver 是一个流行的操作 Web 自动化库。使用 chromedriver 库可以驱动 Chrome 自动化各种网页。当然,文本提取不是问题。本 RPA 使用这两个库来实现功能。所以创建项目后,需要安装相应的库。
点击LeanRunner打开命令行工具按钮

, 执行安装命令:
npm init -ynpm install chromedriver selenium-webdriver @types/selenium-webdriver --save
备注:npm是node.js的包管理机制,需要安装node.js环境才能使用
(下载链接:)
定义流程步骤
流程步骤被定义为使自动化流程可读。
一个。打开main.js,在【Toolbox】-【Frame】中找到stepGroup方法,拖拽到js文件中。
湾 在弹出的对话框中输入描述文字:抓取网页文字内容,点击插入代码。
C。此时,main.js文件的内容:
const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { })}
d. 继续拖拽【Toolbox】-【Frame】中的step方法来描述文字输入:使用Chrome浏览器打开你要截取的网站:
e. 按照上述步骤再次插入用于抓取文本和关闭浏览器的步骤定义。
main.js 如下:
const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}
F。插入Workflow.run函数,RPA执行最终会被执行,在【Toolbox】-【Framework】中选择Workrun.run()函数:
G。在运行函数中输入“main”:
最后的代码是:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}Workflow.run(main);
实施步骤
参考 selenium-webdriver API
(). 分别实现以上操作步骤:
一个。使用Chrome浏览器打开你要截取的网站:
const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();const url = 'http://wufazhuce.com/one/2558';await driver.get(url);
上面的代码创建了一个 WebDriver 实例,打开一个浏览器窗口,并导航到目标 url。
湾 抓取文本:
let text = await driver.findElement({ css:'div[]'}).getText();console.log(text);
上面的代码使用css选择器定位要访问的元素并打印出来。
C。关闭浏览器
await driver.close();
最终代码如下:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');require('chromedriver');const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { const url = 'http://wufazhuce.com/one/2558'; await driver.get(url); }) await step("抓取文本", async (world) => { let text = await driver.findElement({ css:'div[]'}).getText(); console.log(text); world.attachText(text); }) await step("关闭浏览器", async (world) => { await driver.close() }) })}Workflow.run(main);
实施
单击“运行”按钮

, 或者点击“运行项目”按钮

可以看到浏览器打开网页,在LeanRunner设计器的输出面板中打印出文本内容。

如果是运行项目,也会显示html运行报告:
对于用户来说,html 报告更具可读性。
总结
至此,我们已经完成了一个基本操作网页的RPA。后续的操作可以在这个RPA的基础上进一步深化,比如将抓取到的文本内容存入Excel表格或者存入数据库。
本文使用的 selenium-webdriver 自动化库是一个非常流行的开源库,可以支持各种类型的浏览器,并且可以及时更新以支持最新版本的浏览器。同时,Node.js 也是一个非常流行的开源平台。基于这些技术,开发RPA自动化脚本来维护RPA脚本的可用性和可维护性。结合LeanRunner RPA平台,可以帮助企业快速构建自己的流程自动化。
js提取指定网站内容(爬虫学哪个库好?Python爬虫库对比分析(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-25 08:17
读者经常在哪个图书馆学习爬虫?其实常用的Python爬虫库无非是requests、selenium和scrapy,每个库都有自己的特点。对我来说,没有最推荐的库,只有最合适的库。本文将基于一个简单的爬虫案例(Python爬取起点中文网站)对三个库进行对比分析(从时间角度)
目标需求是批量采集排名书信息,如下图:
页面结构易于分析。排行榜有100本书信息,一个静态页面收录20条数据。使用不同的第三方库来分析和提取数据,它们是:
然后在逻辑代码的开头和结尾加上时间戳,得到程序运行时间,比较效率。
这里,因为xpath是用来提取数据的,所以xpath语句的三种方式是类似的,这里先对数据分析做一下说明:
1. imgLink: //div[@class='book-img-text']/ul/li/div[1]/a/@href
2. title: //div[@class='book-img-text']/ul/li//div[2]/h4/a/text()
3. author: //div[@class='book-img-text']/ul/li/div[2]/p[1]/a[1]/text()
4. intro: //div[@class='book-img-text']/ul/li/div[2]/p[2]/text()
5. update://div[@class='book-img-text']/ul/li/div[2]/p[3]/a/text()
一、请求
首先导入相关库
from lxml import etree
import requests
import time
逻辑代码如下
start = time.time() # 开始计时⏲
url = 'https://www.qidian.com/rank/yu ... 39%3B
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
page = requests.get(url,headers=headers)
html = etree.HTML(page.content.decode('utf-8'))
books = html.xpath("//div[@class='book-img-text']/ul/li")
for book in books:
imglink = 'https:' + book.xpath("./div[1]/a/@href")[0]
# 其它信息xpath提取,这里省略 ....
update = book.xpath("./div[2]/p[3]/a/text()")[0]
print(imglink,title,author,intro,update)
end = time.time() # 结束计时⏲
print(end-start)
程序运行结果如下
可以看到爬下所有数据需要0.823s。
二、 硒
首先导入相关库
import time
from selenium import webdriver
代码实现如下
url = 'https://www.qidian.com/rank/yu ... 39%3B
start = time.time() # 开始计时⏲
driver = webdriver.Chrome()
driver.get(url)
books = driver.find_elements_by_xpath("//div[@class='book-img-text']/ul/li")
for book in books:
imglink = 'https:' + book.find_element_by_xpath("./div[1]/a").get_attribute('href')
# 其它小说信息的定位提取语句,...
update = book.find_element_by_xpath("./div[2]/p[3]/a").text
print(imglink,title,author,intro,update)
end = time.time() # 结束计时⏲
print(end-start)
# 18.564752340316772
运行结果如下
可以看到时间是18.8174s
三、Scrapy
最后是Scrapy的实现,代码如下
import scrapy
import time
class QdSpider(scrapy.Spider):
name = 'qd'
allowed_domains = ['qidian.com']
start_urls = ['https://www.qidian.com/rank/yu ... 39%3B]
def parse(self, response):
start = time.time() # 开始计时⏲
books = response.xpath("//div[@class='book-img-text']/ul/li")
for book in books:
imglink = 'https:' + book.xpath("./div[1]/a/@href").extract_first()
# 其它信息的xpath提取语句,......
update = book.xpath("./div[2]/p[3]/a/text()").extract_first()
print(imglink, title, author, intro, update)
end = time.time() # 结束计时⏲
print(end - start)
运行结果如下
可以看到运行时间只用了0.016s
四、结果分析
从代码量来看:其实代码量没有太大区别,因为实现逻辑比较简单。
但是在运行时间方面:scrapy最快,只需要不到0.02s,selenium最慢,需要将近20s,运行效率是scrapy的1/1000。但是,与 requests 和 selenium 相比,在 scrapy 中开发和调试代码需要更长的时间。
我正在仔细研究原因
”
requests:请求模拟浏览器请求。下载请求的网页内容后,不会执行js代码。
为什么 selenium 最慢:首先,Selenium 是 Web 应用程序的自动化测试工具。Selenium 测试直接在浏览器中运行(支持多种浏览器,Google、Firefox 等)来模拟用户操作来获取网页渲染。导致selenium解析并执行网页的CSS和js代码,效率低下。
scrapy框架的爬取效率最高:首先,和requests一样,scrapy不执行web js代码,但是我们知道scrapy是一个提取结构化数据的应用框架。Scrapy 使用了 Twisted 异步 web 框架,可以加快我们的下载速度。, 并发性好,性能高,所以效率最高。
”
五、补充
通过上面的简单测试,我们可能会觉得selenium效率太低了。是不是因为数据采集在selenium中不常用?只能说,在可以爬取数据的前提下,采集 高效的方法会是首选。
所以这篇文章的目的不是要说明不要使用selenium。接下来我们来看看招聘网站--拉勾招聘页面数据采集。随机选择一个帖子java,页面如下:
5.1 请求实现
如果您使用 requests 来请求数据
你会发现没有数据,网页已经进行了反爬虫处理。这时候硒就派上用场了。无需分析网站反爬方法,直接模拟用户请求数据(大多数情况下也有反硒反爬方法)。攀登手段)
5.2 selenium 实现
上面提到,如果你使用requests或者scrapy爬虫来寻找反爬虫的措施,你可以试试selenium,这个有时候很简单
from selenium import webdriver
url = 'https://www.lagou.com/zhaopin/ ... 39%3B
driver = webdriver.Chrome()
driver.get(url)
items = driver.find_elements_by_xpath("//ul[@class='item_con_list']/li")
print(len(items))
for item in items:
title = item.find_element_by_xpath("./div[1]/div[1]/div[1]/a/h3").text
print(title)
运行结果如下:
页面的数据很容易提取!
因此,根据本文的案例分析,如果有爬虫需求,在某一个方法中冻结该方法并不是一个好的选择。大多数情况下,我们需要根据对应网站/app的特点和具体需求进行集成判断,选择最合适的爬虫库!
, 查看全部
js提取指定网站内容(爬虫学哪个库好?Python爬虫库对比分析(一))
读者经常在哪个图书馆学习爬虫?其实常用的Python爬虫库无非是requests、selenium和scrapy,每个库都有自己的特点。对我来说,没有最推荐的库,只有最合适的库。本文将基于一个简单的爬虫案例(Python爬取起点中文网站)对三个库进行对比分析(从时间角度)

目标需求是批量采集排名书信息,如下图:
页面结构易于分析。排行榜有100本书信息,一个静态页面收录20条数据。使用不同的第三方库来分析和提取数据,它们是:
然后在逻辑代码的开头和结尾加上时间戳,得到程序运行时间,比较效率。
这里,因为xpath是用来提取数据的,所以xpath语句的三种方式是类似的,这里先对数据分析做一下说明:
1. imgLink: //div[@class='book-img-text']/ul/li/div[1]/a/@href
2. title: //div[@class='book-img-text']/ul/li//div[2]/h4/a/text()
3. author: //div[@class='book-img-text']/ul/li/div[2]/p[1]/a[1]/text()
4. intro: //div[@class='book-img-text']/ul/li/div[2]/p[2]/text()
5. update://div[@class='book-img-text']/ul/li/div[2]/p[3]/a/text()
一、请求
首先导入相关库
from lxml import etree
import requests
import time
逻辑代码如下
start = time.time() # 开始计时⏲
url = 'https://www.qidian.com/rank/yu ... 39%3B
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
page = requests.get(url,headers=headers)
html = etree.HTML(page.content.decode('utf-8'))
books = html.xpath("//div[@class='book-img-text']/ul/li")
for book in books:
imglink = 'https:' + book.xpath("./div[1]/a/@href")[0]
# 其它信息xpath提取,这里省略 ....
update = book.xpath("./div[2]/p[3]/a/text()")[0]
print(imglink,title,author,intro,update)
end = time.time() # 结束计时⏲
print(end-start)
程序运行结果如下
可以看到爬下所有数据需要0.823s。
二、 硒
首先导入相关库
import time
from selenium import webdriver
代码实现如下
url = 'https://www.qidian.com/rank/yu ... 39%3B
start = time.time() # 开始计时⏲
driver = webdriver.Chrome()
driver.get(url)
books = driver.find_elements_by_xpath("//div[@class='book-img-text']/ul/li")
for book in books:
imglink = 'https:' + book.find_element_by_xpath("./div[1]/a").get_attribute('href')
# 其它小说信息的定位提取语句,...
update = book.find_element_by_xpath("./div[2]/p[3]/a").text
print(imglink,title,author,intro,update)
end = time.time() # 结束计时⏲
print(end-start)
# 18.564752340316772
运行结果如下
可以看到时间是18.8174s
三、Scrapy
最后是Scrapy的实现,代码如下
import scrapy
import time
class QdSpider(scrapy.Spider):
name = 'qd'
allowed_domains = ['qidian.com']
start_urls = ['https://www.qidian.com/rank/yu ... 39%3B]
def parse(self, response):
start = time.time() # 开始计时⏲
books = response.xpath("//div[@class='book-img-text']/ul/li")
for book in books:
imglink = 'https:' + book.xpath("./div[1]/a/@href").extract_first()
# 其它信息的xpath提取语句,......
update = book.xpath("./div[2]/p[3]/a/text()").extract_first()
print(imglink, title, author, intro, update)
end = time.time() # 结束计时⏲
print(end - start)
运行结果如下
可以看到运行时间只用了0.016s
四、结果分析
从代码量来看:其实代码量没有太大区别,因为实现逻辑比较简单。
但是在运行时间方面:scrapy最快,只需要不到0.02s,selenium最慢,需要将近20s,运行效率是scrapy的1/1000。但是,与 requests 和 selenium 相比,在 scrapy 中开发和调试代码需要更长的时间。
我正在仔细研究原因
”
requests:请求模拟浏览器请求。下载请求的网页内容后,不会执行js代码。
为什么 selenium 最慢:首先,Selenium 是 Web 应用程序的自动化测试工具。Selenium 测试直接在浏览器中运行(支持多种浏览器,Google、Firefox 等)来模拟用户操作来获取网页渲染。导致selenium解析并执行网页的CSS和js代码,效率低下。
scrapy框架的爬取效率最高:首先,和requests一样,scrapy不执行web js代码,但是我们知道scrapy是一个提取结构化数据的应用框架。Scrapy 使用了 Twisted 异步 web 框架,可以加快我们的下载速度。, 并发性好,性能高,所以效率最高。
”
五、补充
通过上面的简单测试,我们可能会觉得selenium效率太低了。是不是因为数据采集在selenium中不常用?只能说,在可以爬取数据的前提下,采集 高效的方法会是首选。
所以这篇文章的目的不是要说明不要使用selenium。接下来我们来看看招聘网站--拉勾招聘页面数据采集。随机选择一个帖子java,页面如下:
5.1 请求实现
如果您使用 requests 来请求数据
你会发现没有数据,网页已经进行了反爬虫处理。这时候硒就派上用场了。无需分析网站反爬方法,直接模拟用户请求数据(大多数情况下也有反硒反爬方法)。攀登手段)
5.2 selenium 实现
上面提到,如果你使用requests或者scrapy爬虫来寻找反爬虫的措施,你可以试试selenium,这个有时候很简单
from selenium import webdriver
url = 'https://www.lagou.com/zhaopin/ ... 39%3B
driver = webdriver.Chrome()
driver.get(url)
items = driver.find_elements_by_xpath("//ul[@class='item_con_list']/li")
print(len(items))
for item in items:
title = item.find_element_by_xpath("./div[1]/div[1]/div[1]/a/h3").text
print(title)
运行结果如下:
页面的数据很容易提取!
因此,根据本文的案例分析,如果有爬虫需求,在某一个方法中冻结该方法并不是一个好的选择。大多数情况下,我们需要根据对应网站/app的特点和具体需求进行集成判断,选择最合适的爬虫库!
,
js提取指定网站内容(Python脚本从动态网站收集数据的方法-元素为空 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-25 08:16
)
该元素为空。
从动态网站中采集数据的方法
我们已经看到,由于数据是使用JavaScript动态加载的,爬虫无法从动态的网站中抓取信息。在这种情况下,我们可以使用以下两种技术从依赖动态 JavaScript 的 网站 中抓取数据——
对 JavaScript 进行逆向工程
一个叫做逆向工程的过程会非常有用,它可以让我们了解网页是如何动态加载数据的。
为此,我们需要单击指定元素的检查元素选项卡。接下来,我们将单击 NETWORK 选项卡以查找对该网页发出的所有请求,包括带有 /ajax 路径的 search.json。除了从浏览器或通过 NETWORK 选项卡访问 AJAX 数据之外,我们还可以在以下 Python 脚本的帮助下进行 -
import requests
url=requests.get('http://example.webscraping.com ... %2339;)
url.json()
例子
上面的脚本允许我们使用 Python json 方法访问 JSON 响应。同样,我们可以下载原创字符串响应,并使用python的json.loads方法加载它。我们在以下 Python 脚本的帮助下完成此操作。基本上,通过搜索字母“a”,然后迭代 JSON 响应的结果页面,可以抓取所有国家/地区。
import requests
import string
PAGE_SIZE = 15
url = 'http://example.webscraping.com/ajax/' + 'search.json?page={}&page_size={}&search_term=a'
countries = set()
for letter in string.ascii_lowercase:
print('Searching with %s' % letter)
page = 0
while True:
response = requests.get(url.format(page, PAGE_SIZE, letter))
data = response.json()
print('adding %d records from the page %d' %(len(data.get('records')),page))
for record in data.get('records'):countries.add(record['country'])
page += 1
if page >= data['num_pages']:
break
with open('countries.txt', 'w') as countries_file:
countries_file.write('n'.join(sorted(countries)))
运行上述脚本后,我们将得到以下输出,并且记录将保存在一个名为 countrys.txt 的文件中。
输出
Searching with a
adding 15 records from the page 0
adding 15 records from the page 1
...
呈现 JavaScript
在上一节中,我们对网页进行了逆向工程,以了解 API 的工作原理以及如何使用它在单个请求中检索结果。但是,在执行逆向工程时,我们将面临以下困难 -
上述问题的解决方案是使用浏览器渲染引擎解析HTML,应用CSS格式,执行JavaScript来显示网页。
例子
在这个例子中,为了呈现 Java 脚本,我们将使用熟悉的 Python 模块 Selenium。以下 Python 代码将在 Selenium 的帮助下呈现网页 -
首先,我们需要从 selenium 导入 webdriver,如下所示:
from selenium import webdriver
现在,提供我们根据需要下载的 Web 驱动程序的路径-
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
driver = webdriver.Chrome(executable_path = path)
现在,提供我们要在此 Web 浏览器中打开的 URL,该 URL 现在由我们的 Python 脚本控制。
driver.get('http://example.webscraping.com/search')
现在,我们可以使用搜索工具箱的 ID 来设置要选择的元素。
driver.find_element_by_id('search_term').send_keys('.')
接下来,我们可以使用Java脚本来设置选择框的内容,如下图:
js = "document.getElementById('page_size').options[1].text = '100';"
driver.execute_script(js)
以下代码行显示您可以在网页上单击以进行搜索 -
driver.find_element_by_id('search').click()
下一行代码显示它将等待 45 秒来完成 AJAX 请求。
driver.implicitly_wait(45)
现在,要选择国家/地区链接,我们可以使用 CSS 选择器,如下所示:
links = driver.find_elements_by_css_selector('#results a')
现在可以提取每个链接的文本以创建国家/地区列表-
countries = [link.text for link in links]
print(countries)
driver.close() 查看全部
js提取指定网站内容(Python脚本从动态网站收集数据的方法-元素为空
)
该元素为空。
从动态网站中采集数据的方法
我们已经看到,由于数据是使用JavaScript动态加载的,爬虫无法从动态的网站中抓取信息。在这种情况下,我们可以使用以下两种技术从依赖动态 JavaScript 的 网站 中抓取数据——
对 JavaScript 进行逆向工程
一个叫做逆向工程的过程会非常有用,它可以让我们了解网页是如何动态加载数据的。
为此,我们需要单击指定元素的检查元素选项卡。接下来,我们将单击 NETWORK 选项卡以查找对该网页发出的所有请求,包括带有 /ajax 路径的 search.json。除了从浏览器或通过 NETWORK 选项卡访问 AJAX 数据之外,我们还可以在以下 Python 脚本的帮助下进行 -
import requests
url=requests.get('http://example.webscraping.com ... %2339;)
url.json()
例子
上面的脚本允许我们使用 Python json 方法访问 JSON 响应。同样,我们可以下载原创字符串响应,并使用python的json.loads方法加载它。我们在以下 Python 脚本的帮助下完成此操作。基本上,通过搜索字母“a”,然后迭代 JSON 响应的结果页面,可以抓取所有国家/地区。
import requests
import string
PAGE_SIZE = 15
url = 'http://example.webscraping.com/ajax/' + 'search.json?page={}&page_size={}&search_term=a'
countries = set()
for letter in string.ascii_lowercase:
print('Searching with %s' % letter)
page = 0
while True:
response = requests.get(url.format(page, PAGE_SIZE, letter))
data = response.json()
print('adding %d records from the page %d' %(len(data.get('records')),page))
for record in data.get('records'):countries.add(record['country'])
page += 1
if page >= data['num_pages']:
break
with open('countries.txt', 'w') as countries_file:
countries_file.write('n'.join(sorted(countries)))
运行上述脚本后,我们将得到以下输出,并且记录将保存在一个名为 countrys.txt 的文件中。
输出
Searching with a
adding 15 records from the page 0
adding 15 records from the page 1
...
呈现 JavaScript
在上一节中,我们对网页进行了逆向工程,以了解 API 的工作原理以及如何使用它在单个请求中检索结果。但是,在执行逆向工程时,我们将面临以下困难 -
上述问题的解决方案是使用浏览器渲染引擎解析HTML,应用CSS格式,执行JavaScript来显示网页。
例子
在这个例子中,为了呈现 Java 脚本,我们将使用熟悉的 Python 模块 Selenium。以下 Python 代码将在 Selenium 的帮助下呈现网页 -
首先,我们需要从 selenium 导入 webdriver,如下所示:
from selenium import webdriver
现在,提供我们根据需要下载的 Web 驱动程序的路径-
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
driver = webdriver.Chrome(executable_path = path)
现在,提供我们要在此 Web 浏览器中打开的 URL,该 URL 现在由我们的 Python 脚本控制。
driver.get('http://example.webscraping.com/search')
现在,我们可以使用搜索工具箱的 ID 来设置要选择的元素。
driver.find_element_by_id('search_term').send_keys('.')
接下来,我们可以使用Java脚本来设置选择框的内容,如下图:
js = "document.getElementById('page_size').options[1].text = '100';"
driver.execute_script(js)
以下代码行显示您可以在网页上单击以进行搜索 -
driver.find_element_by_id('search').click()
下一行代码显示它将等待 45 秒来完成 AJAX 请求。
driver.implicitly_wait(45)
现在,要选择国家/地区链接,我们可以使用 CSS 选择器,如下所示:
links = driver.find_elements_by_css_selector('#results a')
现在可以提取每个链接的文本以创建国家/地区列表-
countries = [link.text for link in links]
print(countries)
driver.close()
js提取指定网站内容(HTML中如何用JS获得其他网页的DOCUMENT对象__)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-24 23:16
HTML中如何使用JS获取其他网页的DOCUMENT对象-
______ 原来是这样写的,要在脚本中以这种方式获取输入的值。你在你的a.html页面中引用a_script.js,和你直接在你的页面中写脚步是一样的,直接写这个就行了。 document.getelementbyid("aa") 中的 "aa" 是你输入的 id.var aa = document.getelementbyid("aa").value;
JS获取网页中HTML元素的几种方法解析-
______ document.getelementbyid//除了byid,返回的都是伪数组 document.getelementbyclassname document.getelementbytagname 下面是高级选择器:document.queryselector() document.queryselectorall()
javascript如何获取HTML网页中另一个网页的变量值
______ 一个网页和另一个网页之间是否存在父子关系?如果是这样,您可以使用parent.XXX 来访问。如果两个网页没有关联,则只能使用URL传递参数。
如何使用html或js获取其他网站指定的行并使用
展示一下? -
______你可以用爬虫技术爬取其他网站然后解析出你想要的那一行数据
js 从另一个网页中提取信息 -
______ 亲爱的...这需要 name=username 通过表单提交到另一个页面...
有没有什么办法可以用javascript让网页的HTML代码完整-
______ 是否需要检索单独页面的html代码?您可以使用 ajax 方法。如果使用jquery,可以参考相关的api。如果是在页面中,可以试试outerHTML
JS获取页面的某个HTML代码-
______
如何提取别人的div网站?
______ div+css+js ok 网站全部由div制作
如何获取别人的网站完整的css和js文件?
______ 1、通过保存网页,可以得到对应页面上的js和css文件(部分js和css是编译或者压缩的,需要使用第三方工具反编译或者格式化)< @2、打开浏览器的开发模式。一般按快捷键f12打开即可。这里我以谷歌浏览器为例:点击标签资源,然后在对应的资源文件中找到你需要的文件,右键保存。具体操作如下:
JS获取网页代码-
______ 远程网页源码阅读/* 页面字体样式*/ body, ... 查看全部
js提取指定网站内容(HTML中如何用JS获得其他网页的DOCUMENT对象__)
HTML中如何使用JS获取其他网页的DOCUMENT对象-
______ 原来是这样写的,要在脚本中以这种方式获取输入的值。你在你的a.html页面中引用a_script.js,和你直接在你的页面中写脚步是一样的,直接写这个就行了。 document.getelementbyid("aa") 中的 "aa" 是你输入的 id.var aa = document.getelementbyid("aa").value;
JS获取网页中HTML元素的几种方法解析-
______ document.getelementbyid//除了byid,返回的都是伪数组 document.getelementbyclassname document.getelementbytagname 下面是高级选择器:document.queryselector() document.queryselectorall()
javascript如何获取HTML网页中另一个网页的变量值
______ 一个网页和另一个网页之间是否存在父子关系?如果是这样,您可以使用parent.XXX 来访问。如果两个网页没有关联,则只能使用URL传递参数。
如何使用html或js获取其他网站指定的行并使用
展示一下? -
______你可以用爬虫技术爬取其他网站然后解析出你想要的那一行数据
js 从另一个网页中提取信息 -
______ 亲爱的...这需要 name=username 通过表单提交到另一个页面...
有没有什么办法可以用javascript让网页的HTML代码完整-
______ 是否需要检索单独页面的html代码?您可以使用 ajax 方法。如果使用jquery,可以参考相关的api。如果是在页面中,可以试试outerHTML
JS获取页面的某个HTML代码-
______
如何提取别人的div网站?
______ div+css+js ok 网站全部由div制作
如何获取别人的网站完整的css和js文件?
______ 1、通过保存网页,可以得到对应页面上的js和css文件(部分js和css是编译或者压缩的,需要使用第三方工具反编译或者格式化)< @2、打开浏览器的开发模式。一般按快捷键f12打开即可。这里我以谷歌浏览器为例:点击标签资源,然后在对应的资源文件中找到你需要的文件,右键保存。具体操作如下:
JS获取网页代码-
______ 远程网页源码阅读/* 页面字体样式*/ body, ...
js提取指定网站内容(吃鸡ing3杀就快决赛圈了,突然老师丢给三个网站链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-24 17:17
昨天在吃鸡ing,3杀快要决赛了。突然老师丢了三个网站链接让我看看他们用的是哪个js框架。. .
说句公道话,第一次看到这个问题我头皮都麻了
怎么可能通过网页看到其他人是什么框架?大家不是都封装了吗?
写这个网站的人都是傻子吗?就让你看看核心js框架?
经过两天的试验和查资料,似乎可以看出来了。毕竟没有人是十全十美的,一百个秘密总是有隔阂的时候。
当然,这些只是我尝试过的一些方法。我的问题解决了,但不保证所有问题都会解决。如果遇到一个包装好的网站,那就认命吧。.
刚开始搜索的时候,别人的博客或者论坛会给你很多网站,让你输入你的网站,就可以看到网站的核心技术,推理真的没用.
例如,我试过的一个:
操作很简单,只需要输入网址,然后看看返回什么
这就是它用来回报我的所有技巧网站,但这不是我想要的o((>ω
还有另一个问题。如果框架是ASP.NET,那么网页访问应该有相应的后缀如:.aspx、ashx等。
我只觉得这件事让我很生气...
后来,我试着用英文在google上搜索这类问题。一个告诉我靠经验来获取,就是要多了解框架,了解每个框架的特点和关键词。然后一看就知道这是哪个框架。书面。. . 说到框架,你可以看看我的另一篇博客,看看有多少前端框架;另一种是将代码贴到Github上,使用html原生函数document.querySelector()获取dom信息。主要原理和第一人称意思差不多。
归结为:不同的框架有不同的框架使用的特定关键字。比如Angular中我们使用“ng-*”作为具体的指令标识符,而React中我们使用reactid等标识符,那么你可以通过搜索这些Keyword方法来获取网站的frame(当然,这个方法不是万能的,但也是一)的有效方法
代码显示如下:
if(!!window.React ||
!!document.querySelector('[data-reactroot], [data-reactid]'))
console.log('React.js');
if(!!window.angular ||
!!document.querySelector('.ng-binding, [ng-app], [data-ng-app], [ng-controller], [data-ng-controller], [ng-repeat], [data-ng-repeat]') ||
!!document.querySelector('script[src*="angular.js"], script[src*="angular.min.js"]'))
console.log('Angular.js');
if(!!window.Backbone) console.log('Backbone.js');
if(!!window.Ember) console.log('Ember.js');
if(!!window.Vue||!!document.querySelector('[v-if],[v-for],[v-show]')) console.log('Vue.js');
if(!!window.Meteor) console.log('Meteor.js');
if(!!window.Zepto) console.log('Zepto.js');
if(!!window.jQuery) console.log('jQuery.js');
将以上代码直接注入控制台
它会直接打印出你的前端js框架,但是对于一些不工作的页面,你需要一一打开多个页面。之前测试过一个我之前做过的项目,用Angular写的,在首页测试的时候失败了,但是点击登陆页面的时候会直接显示出来。使用这种方法时必须要有一定的耐心。
当然,对于一些网站,不管测试多少,都得点击Sources阅读代码。
估计不同的框架有不同的参考文件。我还需要慢慢仔细地寻找。我找了下这个页面的登录界面,然后发现在它请求该界面的地方有调用其他框架的功能。所以我确定了这个 网站 的框架
都来了这个网站前端js框架用的是Zepto,当然这只是我的解决方案,也许大佬有更好的解决方案,请分享
总结:我觉得这个技能反正好像没什么用,但是老师做完后不能放过,所以还是做吧。 查看全部
js提取指定网站内容(吃鸡ing3杀就快决赛圈了,突然老师丢给三个网站链接)
昨天在吃鸡ing,3杀快要决赛了。突然老师丢了三个网站链接让我看看他们用的是哪个js框架。. .
说句公道话,第一次看到这个问题我头皮都麻了
怎么可能通过网页看到其他人是什么框架?大家不是都封装了吗?
写这个网站的人都是傻子吗?就让你看看核心js框架?
经过两天的试验和查资料,似乎可以看出来了。毕竟没有人是十全十美的,一百个秘密总是有隔阂的时候。
当然,这些只是我尝试过的一些方法。我的问题解决了,但不保证所有问题都会解决。如果遇到一个包装好的网站,那就认命吧。.
刚开始搜索的时候,别人的博客或者论坛会给你很多网站,让你输入你的网站,就可以看到网站的核心技术,推理真的没用.
例如,我试过的一个:
操作很简单,只需要输入网址,然后看看返回什么
这就是它用来回报我的所有技巧网站,但这不是我想要的o((>ω
还有另一个问题。如果框架是ASP.NET,那么网页访问应该有相应的后缀如:.aspx、ashx等。
我只觉得这件事让我很生气...
后来,我试着用英文在google上搜索这类问题。一个告诉我靠经验来获取,就是要多了解框架,了解每个框架的特点和关键词。然后一看就知道这是哪个框架。书面。. . 说到框架,你可以看看我的另一篇博客,看看有多少前端框架;另一种是将代码贴到Github上,使用html原生函数document.querySelector()获取dom信息。主要原理和第一人称意思差不多。
归结为:不同的框架有不同的框架使用的特定关键字。比如Angular中我们使用“ng-*”作为具体的指令标识符,而React中我们使用reactid等标识符,那么你可以通过搜索这些Keyword方法来获取网站的frame(当然,这个方法不是万能的,但也是一)的有效方法
代码显示如下:
if(!!window.React ||
!!document.querySelector('[data-reactroot], [data-reactid]'))
console.log('React.js');
if(!!window.angular ||
!!document.querySelector('.ng-binding, [ng-app], [data-ng-app], [ng-controller], [data-ng-controller], [ng-repeat], [data-ng-repeat]') ||
!!document.querySelector('script[src*="angular.js"], script[src*="angular.min.js"]'))
console.log('Angular.js');
if(!!window.Backbone) console.log('Backbone.js');
if(!!window.Ember) console.log('Ember.js');
if(!!window.Vue||!!document.querySelector('[v-if],[v-for],[v-show]')) console.log('Vue.js');
if(!!window.Meteor) console.log('Meteor.js');
if(!!window.Zepto) console.log('Zepto.js');
if(!!window.jQuery) console.log('jQuery.js');
将以上代码直接注入控制台

它会直接打印出你的前端js框架,但是对于一些不工作的页面,你需要一一打开多个页面。之前测试过一个我之前做过的项目,用Angular写的,在首页测试的时候失败了,但是点击登陆页面的时候会直接显示出来。使用这种方法时必须要有一定的耐心。
当然,对于一些网站,不管测试多少,都得点击Sources阅读代码。
估计不同的框架有不同的参考文件。我还需要慢慢仔细地寻找。我找了下这个页面的登录界面,然后发现在它请求该界面的地方有调用其他框架的功能。所以我确定了这个 网站 的框架

都来了这个网站前端js框架用的是Zepto,当然这只是我的解决方案,也许大佬有更好的解决方案,请分享
总结:我觉得这个技能反正好像没什么用,但是老师做完后不能放过,所以还是做吧。
js提取指定网站内容(实现在文本指定位置插入内容的简单,具有很好的参考价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-24 17:15
下面和大家分享一个简单的例子,JS是如何实现在文本的指定位置插入内容的。有很好的参考价值,希望对你有帮助。
示例如下:
function insertAtCursor(myField, myValue) {
//IE 浏览器
if (document.selection) {
myField.focus();
sel = document.selection.createRange();
sel.text = myValue;
sel.select();
}
//FireFox、Chrome等
else if (myField.selectionStart || myField.selectionStart == '0') {
var startPos = myField.selectionStart;
var endPos = myField.selectionEnd;
// 保存滚动条
var restoreTop = myField.scrollTop;
myField.value = myField.value.substring(0, startPos) + myValue + myField.value.substring(endPos, myField.value.length);
if (restoreTop > 0) {
myField.scrollTop = restoreTop;
}
myField.focus();
myField.selectionStart = startPos + myValue.length;
myField.selectionEnd = startPos + myValue.length;
} else {
myField.value += myValue;
myField.focus();
}
}
以上是我为你整理的,希望对你以后有帮助。
相关文章:
如何在 vue 中安装 Mint-UI
AngularJS中如何实现集合数据遍历展示
如何在 vue.js 中集成 mint-ui 中的轮播图
如何实现在Jstree中选中父节点时禁用的子节点也会被选中
关于Vue中过滤器的使用
Javascript 中的自适应处理方法
Webpack 打包配置(详细教程)
如何在 Webpack 中加载 SVG
vue-cli中如何实现移动端适配
以上就是在JS中如何在指定位置插入内容的详细内容。详情请关注其他相关php中文网站文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们 查看全部
js提取指定网站内容(实现在文本指定位置插入内容的简单,具有很好的参考价值)
下面和大家分享一个简单的例子,JS是如何实现在文本的指定位置插入内容的。有很好的参考价值,希望对你有帮助。
示例如下:
function insertAtCursor(myField, myValue) {
//IE 浏览器
if (document.selection) {
myField.focus();
sel = document.selection.createRange();
sel.text = myValue;
sel.select();
}
//FireFox、Chrome等
else if (myField.selectionStart || myField.selectionStart == '0') {
var startPos = myField.selectionStart;
var endPos = myField.selectionEnd;
// 保存滚动条
var restoreTop = myField.scrollTop;
myField.value = myField.value.substring(0, startPos) + myValue + myField.value.substring(endPos, myField.value.length);
if (restoreTop > 0) {
myField.scrollTop = restoreTop;
}
myField.focus();
myField.selectionStart = startPos + myValue.length;
myField.selectionEnd = startPos + myValue.length;
} else {
myField.value += myValue;
myField.focus();
}
}
以上是我为你整理的,希望对你以后有帮助。
相关文章:
如何在 vue 中安装 Mint-UI
AngularJS中如何实现集合数据遍历展示
如何在 vue.js 中集成 mint-ui 中的轮播图
如何实现在Jstree中选中父节点时禁用的子节点也会被选中
关于Vue中过滤器的使用
Javascript 中的自适应处理方法
Webpack 打包配置(详细教程)
如何在 Webpack 中加载 SVG
vue-cli中如何实现移动端适配
以上就是在JS中如何在指定位置插入内容的详细内容。详情请关注其他相关php中文网站文章!

免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们
js提取指定网站内容(JavaScript驾驭网页-CSS与DOM利用DOM分割HTML利用分割)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-20 20:14
JavaScript 控制网页-CSS 和 DOM
使用 DOM 拆分 HTML
使用 JavaScript 来控制 Web 内容实际上很像做饭。只是你不用清理剩菜,却没有办法享受到美味的结果。
但是,您将能够完成网页内容的 HTML 元素:更重要的是,您将拥有替换网页元素的能力。
JavaScript 可以让你随心所欲地操作网页的 HTML 代码,从而开启各种有趣的机会,这一切都是因为标准对象:DOM 的存在
getElementById
HTML标签都有一个"id"属性,第个标签的该属性都是独一无二的
可以通过id属性来获取元素
内容
var sceneDesc=document.getElementById("div2");
getElementById可以通过元素的id属性去访问标签
括号里是id的值
getElementsByTagName
也可以通过标签名来获取元素
内容
var divs=document.getElementsByTagName("div");
getElementsByTagName返回所有div标签,结果是一个数组,结果按照标签在HTML中的顺序排列
括号里是标签名
var divs=document.getElementsByTagName("div")[2];
用索引获取第三个div标签
内部HTML
innerHTML特性对所有存储在元素里的内容提供了访问管道
通过innerHTML访问元素内存储的内容:
<p id="story"> you are standing
alone in the woods.
document.getElementById("story").innerHTML;
返回的内容是: you are standing alone in the woods.
innerHTML获取的是指定元素下的所有内容与标签
innerHTML也能用于设置网页内容
document.getElementById("story").innerHTML="You are not alone!";
innerHTML只用来设置可以包含文本的标签</p>
给大家介绍了很多关于JavaScript控制网页的知识——网页元素的知识,希望对大家有所帮助! 查看全部
js提取指定网站内容(JavaScript驾驭网页-CSS与DOM利用DOM分割HTML利用分割)
JavaScript 控制网页-CSS 和 DOM
使用 DOM 拆分 HTML
使用 JavaScript 来控制 Web 内容实际上很像做饭。只是你不用清理剩菜,却没有办法享受到美味的结果。
但是,您将能够完成网页内容的 HTML 元素:更重要的是,您将拥有替换网页元素的能力。
JavaScript 可以让你随心所欲地操作网页的 HTML 代码,从而开启各种有趣的机会,这一切都是因为标准对象:DOM 的存在
getElementById
HTML标签都有一个"id"属性,第个标签的该属性都是独一无二的
可以通过id属性来获取元素
内容
var sceneDesc=document.getElementById("div2");
getElementById可以通过元素的id属性去访问标签
括号里是id的值
getElementsByTagName
也可以通过标签名来获取元素
内容
var divs=document.getElementsByTagName("div");
getElementsByTagName返回所有div标签,结果是一个数组,结果按照标签在HTML中的顺序排列
括号里是标签名
var divs=document.getElementsByTagName("div")[2];
用索引获取第三个div标签
内部HTML
innerHTML特性对所有存储在元素里的内容提供了访问管道
通过innerHTML访问元素内存储的内容:
<p id="story"> you are standing
alone in the woods.
document.getElementById("story").innerHTML;
返回的内容是: you are standing alone in the woods.
innerHTML获取的是指定元素下的所有内容与标签
innerHTML也能用于设置网页内容
document.getElementById("story").innerHTML="You are not alone!";
innerHTML只用来设置可以包含文本的标签</p>
给大家介绍了很多关于JavaScript控制网页的知识——网页元素的知识,希望对大家有所帮助!
js提取指定网站内容(HTTP客户端/awaitawait//async/)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-20 00:24
HTTP 客户端是一种工具,可以向服务器发送请求,然后接收服务器的响应。下面提到的所有工具的底层都是使用一个HTTP客户端来访问你想要抓取的网站。
要求
Request 是 Javascript 生态系统中使用最广泛的 HTTP 客户端之一,但 Request 库的作者已正式声明它已被弃用。但这并不意味着它不可用,相当多的库仍在使用它,并且非常易于使用。使用 Request 发出 HTTP 请求非常简单:
1const request = require('request')
2request('https://www.reddit.com/r/progr ... 27%3B, function (
3 error,
4 response,
5 body
6) {
7 console.error('error:', error)
8 console.log('body:', body)
9})
你可以在 Github 上找到 Request 库,安装非常简单。您还可以找到弃用通知及其含义。
阿克西奥斯
Axios 是一个基于 Promise 的 HTTP 客户端,可以在浏览器和 Node.js 中运行。如果您使用 Typescript,那么 axios 将为您覆盖内置类型。通过 Axios 发起 HTTP 请求非常简单。默认情况下,它带有 Promise 支持,而不是在请求中使用回调:
1const axios = require('axios')
2
3axios
4 .get('https://www.reddit.com/r/programming.json')
5 .then((response) => {
6 console.log(response)
7 })
8 .catch((error) => {
9 console.error(error)
10 });
如果你喜欢 Promises API 的 async/await 语法糖,你也可以使用它,但由于顶级 await 仍处于第 3 阶段,我们不得不使用异步函数来代替:
1async function getForum() {
2 try {
3 const response = await axios.get(
4 'https://www.reddit.com/r/progr ... 27%3B
5 )
6 console.log(response)
7 } catch (error) {
8 console.error(error)
9 }
10}
您所要做的就是致电 getForum!可以在 Axios 库上找到。
超级代理
与 Axios 一样,Superagent 是另一个强大的 HTTP 客户端,支持 Promise 和 async/await 语法糖。它有一个类似 Axios 的相当简单的 API,但由于更多的依赖关系,Superagent 不太受欢迎。
使用 promise、async/await 或回调向 Superagent 发出 HTTP 请求如下所示:
1const superagent = require("superagent")
2const forumURL = "https://www.reddit.com/r/programming.json"
3
4// callbacks
5superagent
6 .get(forumURL)
7 .end((error, response) => {
8 console.log(response)
9 })
10
11// promises
12superagent
13 .get(forumURL)
14 .then((response) => {
15 console.log(response)
16 })
17 .catch((error) => {
18 console.error(error)
19 })
20
21// promises with async/await
22async function getForum() {
23 try {
24 const response = await superagent.get(forumURL)
25 console.log(response)
26 } catch (error) {
27 console.error(error)
28 }
29}
您可以在以下位置找到 Superagent。
正则表达式:艰难的方式
在没有任何依赖的情况下,进行网络爬虫最简单的方法是在使用 HTTP 客户端查询网页时,在接收到的 HTML 字符串上使用一堆正则表达式。正则表达式不是那么灵活,许多专业人士和业余爱好者都很难写出正确的正则表达式。
试试看,假设有一个带有用户名的标签,而我们需要那个用户名,这类似于你依赖正则表达式时必须做的
1const htmlString = 'Username: John Doe'
2const result = htmlString.match(/(.+)/)
3
4console.log(result[1], result[1].split(": ")[1])
5// Username: John Doe, John Doe
在 Javascript 中,match() 通常返回一个数组,其中收录与正则表达式匹配的所有内容。第二个元素(在索引 1 中)将找到我们想要的标记的 textContent 或 innerHTML。但结果收录一些不必要的文本(“用户名:”),必须删除。
如您所见,对于一个非常简单的用例,有许多步骤和工作要做。这就是为什么你应该依赖 HTML 解析器的原因,我们将在后面讨论。
Cheerio:用于遍历 DOM 的核心 JQuery
Cheerio 是一个高效且可移植的库,它允许您在服务器端使用 JQuery 丰富而强大的 API。如果您之前使用过 JQuery,您就会熟悉 Cheerio。它消除了 DOM 的所有不一致和浏览器相关功能,并公开了一个有效的 API 来解析和操作 DOM。
1const cheerio = require('cheerio')
2const $ = cheerio.load('Hello world')
3
4$('h2.title').text('Hello there!')
5$('h2').addClass('welcome')
6
7$.html()
8// Hello there!
如您所见,Cheerio 与 JQuery 非常相似。
但是,即使它的工作方式与 Web 浏览器不同,这也意味着它不能:
因此,如果您尝试抓取的网站 或 web 应用程序严重依赖 Javascript(例如“单页应用程序”),那么 Cheerio 不是最佳选择,您可能不得不依赖其他选项稍后讨论。
为了展示 Cheerio 的强大功能,我们将尝试爬取 Reddit 中的 r/programming 论坛,并尝试获取一个帖子名称列表。
首先,通过运行以下命令安装 Cheerio 和 axios:npm installcheerio axios。
然后新建一个名为crawler.js的文件,复制粘贴以下代码:
1const axios = require('axios');
2const cheerio = require('cheerio');
3
4const getPostTitles = async () => {
5 try {
6 const { data } = await axios.get(
7 'https://old.reddit.com/r/programming/'
8 );
9 const $ = cheerio.load(data);
10 const postTitles = [];
11
12 $('div > p.title > a').each((_idx, el) => {
13 const postTitle = $(el).text()
14 postTitles.push(postTitle)
15 });
16
17 return postTitles;
18 } catch (error) {
19 throw error;
20 }
21};
22
23getPostTitles()
24.then((postTitles) => console.log(postTitles));
getPostTitles() 是一个异步函数,它将抓取旧的 reddit r/编程论坛。首先通过axios HTTP客户端库使用简单的HTTP GET请求获取网站的HTML,然后使用cheerio.load()函数将html数据输入到Cheerio中。
然后在浏览器的开发工具的帮助下,你可以得到一个可以定位所有列表项的选择器。如果你用过JQuery,你一定对$('div> p.title> a')非常熟悉。这将获得所有帖子,因为您只想单独获取每个帖子的标题,因此您必须遍历每个帖子。这些操作是在 each() 函数的帮助下完成的。
要从每个标题中提取文本,您必须在 Cheerio 的帮助下获取 DOM 元素(el 指的是当前元素)。然后在每个元素上调用 text() 为您提供文本。
现在,打开终端,运行node crawler.js,你会看到一个近似titles的数组,这个数组会很长。虽然这是一个非常简单的用例,但它展示了 Cheerio 提供的 API 的简单本质。
如果您的用例需要执行 Javascript 并加载外部源,那么以下选项会有所帮助。
JSDOM:节点的 DOM
JSDOM 是 Node.js 中使用的文档对象模型的纯 Javascript 实现。如前所述,DOM 对 Node 不可用,但 JSDOM 是最接近的。它或多或少地模仿了浏览器。
因为DOM是创建的,所以你可以通过编程与web应用或者你想爬取的网站进行交互,也可以模拟点击一个按钮。如果你熟悉 DOM 操作,使用 JSDOM 会非常简单。
1const { JSDOM } = require('jsdom')
2const { document } = new JSDOM(
3 'Hello world'
4).window
5const heading = document.querySelector('.title')
6heading.textContent = 'Hello there!'
7heading.classList.add('welcome')
8
9heading.innerHTML
10// Hello there!
在代码中用JSDOM创建一个DOM,然后你就可以用和浏览器DOM一样的方法和属性来操作这个DOM了。
为了演示如何使用JSDOM与网站进行交互,我们将获取Reddit r/programming论坛的第一篇帖子并对其进行投票,然后验证该帖子是否已被投票。
首先运行以下命令安装jsdom和axios: npm install jsdom axios
然后创建一个名为 crawler.js 的文件,并复制并粘贴以下代码:
1const { JSDOM } = require("jsdom")
2const axios = require('axios')
3
4const upvoteFirstPost = async () => {
5 try {
6 const { data } = await axios.get("https://old.reddit.com/r/programming/");
7 const dom = new JSDOM(data, {
8 runScripts: "dangerously",
9 resources: "usable"
10 });
11 const { document } = dom.window;
12 const firstPost = document.querySelector("div > div.midcol > div.arrow");
13 firstPost.click();
14 const isUpvoted = firstPost.classList.contains("upmod");
15 const msg = isUpvoted
16 ? "Post has been upvoted successfully!"
17 : "The post has not been upvoted!";
18
19 return msg;
20 } catch (error) {
21 throw error;
22 }
23};
24
25upvoteFirstPost().then(msg => console.log(msg));
upvoteFirstPost() 是一个异步函数,它将获得 r/programming 中的第一篇文章,然后对其进行投票。axios 发送 HTTP GET 请求以获取指定 URL 的 HTML。然后从之前获得的 HTML 创建一个新的 DOM。JSDOM 构造函数将 HTML 作为第一个参数,将选项作为第二个参数。添加的两个选项执行以下功能:
创建DOM后,使用相同的DOM方法获取第一篇文章文章的upvote按钮,然后点击。要验证它是否真的被点击,您可以检查 classList 中是否有名为 upmod 的类。如果它存在于 classList 中,则返回一条消息。
打开终端并运行 node crawler.js,然后您将看到一个整洁的字符串,表明该帖子是否已被点赞。虽然这个例子很简单,但你可以在这个基础上构建强大的东西,例如,一个对特定用户帖子进行投票的机器人。
如果你不喜欢缺乏表达能力的 JSDOM,并且在实践中依赖很多这样的操作,或者需要重新创建很多不同的 DOM,那么下面的将是更好的选择。
Puppeteer:无头浏览器
顾名思义,Puppeteer 允许您以编程方式操纵浏览器,就像操纵木偶一样。默认情况下,它为开发人员提供了高级 API 来控制无头版本的 Chrome。
摘自 Puppeter Docs Puppeteer 比上述工具更有用,因为它允许您像真人与浏览器交互一样抓取网络。这开辟了一些以前不可用的可能性:
它还可以在网络爬虫以外的任务中发挥重要作用,例如 UI 测试、辅助性能优化等。
通常你想截取网站的截图,也许是为了了解竞争对手的产品目录,你可以使用puppeteer来做。首先运行以下命令安装puppeteer: npm install puppeteer
这将下载 Chromium 的捆绑版本,大约 180 MB 到 300 MB,具体取决于操作系统。如果要禁用此功能。
我们尝试在 Reddit 中获取 r/programming 论坛的截图和 PDF,创建一个名为 crawler.js 的新文件,并复制并粘贴以下代码:
1const puppeteer = require('puppeteer')
2
3async function getVisual() {
4 try {
5 const URL = 'https://www.reddit.com/r/programming/'
6 const browser = await puppeteer.launch()
7 const page = await browser.newPage()
8
9 await page.goto(URL)
10 await page.screenshot({ path: 'screenshot.png' })
11 await page.pdf({ path: 'page.pdf' })
12
13 await browser.close()
14 } catch (error) {
15 console.error(error)
16 }
17}
18
19getVisual()
getVisual() 是一个异步函数,它将获取 URL 变量中的 url 对应的屏幕截图和 pdf。首先通过 puppeteer.launch() 创建一个浏览器实例,然后创建一个新页面。您可以将此页面视为常规浏览器中的选项卡。然后以 URL 为参数调用 page.goto() 将之前创建的页面定向到指定的 URL。最终,浏览器实例与页面一起被销毁。
操作完成并加载页面后,将分别使用 page.screenshot() 和 page.pdf() 获取屏幕截图和pdf。也可以监听javascript的load事件,进行这些操作,生产环境中强烈推荐使用。
在终端上运行 node crawler.js。几秒钟后,您会注意到已创建两个文件,名为 screenshot.jpg 和 page.pdf。
Nightmare:Puppeteer 的替代品
Nightmare 是一个类似于 Puppeteer 的高级浏览器自动化库。该库使用 Electron,但据说它的速度是其前身 PhantomJS 的两倍。
如果您在某种程度上不喜欢 Puppeteer 或对 Chromium 包的大小感到沮丧,那么 nightmare 是一个理想的选择。首先,运行以下命令安装 nightmare 库: npm install nightmare
然后,一旦下载了 nightmare,我们将使用它通过 Google 搜索引擎找到 ScrapingBee 的 网站。创建一个名为 crawler.js 的文件,然后将以下代码复制并粘贴到其中:
1const Nightmare = require('nightmare')
2const nightmare = Nightmare()
3
4nightmare
5 .goto('https://www.google.com/')
6 .type("input[title='Search']", 'ScrapingBee')
7 .click("input[value='Google Search']")
8 .wait('#rso > div:nth-child(1) > div > div > div.r > a')
9 .evaluate(
10 () =>
11 document.querySelector(
12 '#rso > div:nth-child(1) > div > div > div.r > a'
13 ).href
14 )
15 .end()
16 .then((link) => {
17 console.log('Scraping Bee Web Link': link)
18 })
19 .catch((error) => {
20 console.error('Search failed:', error)
21 })
首先创建一个 Nightmare 实例,然后通过调用 goto() 将该实例定向到 Google 搜索引擎。加载后,使用其选择器获取搜索框,然后使用搜索框的值(输入标签)将其更改为“ScrapingBee”。完成后,单击“Google 搜索”按钮提交搜索表单。然后告诉 Nightmare 等到第一个链接加载完毕。一旦完成,它将使用 DOM 方法获取收录链接的锚标记的 href 属性的值。
最后,在所有操作完成后,将链接打印到控制台。
总结 查看全部
js提取指定网站内容(HTTP客户端/awaitawait//async/)
HTTP 客户端是一种工具,可以向服务器发送请求,然后接收服务器的响应。下面提到的所有工具的底层都是使用一个HTTP客户端来访问你想要抓取的网站。
要求
Request 是 Javascript 生态系统中使用最广泛的 HTTP 客户端之一,但 Request 库的作者已正式声明它已被弃用。但这并不意味着它不可用,相当多的库仍在使用它,并且非常易于使用。使用 Request 发出 HTTP 请求非常简单:
1const request = require('request')
2request('https://www.reddit.com/r/progr ... 27%3B, function (
3 error,
4 response,
5 body
6) {
7 console.error('error:', error)
8 console.log('body:', body)
9})
你可以在 Github 上找到 Request 库,安装非常简单。您还可以找到弃用通知及其含义。
阿克西奥斯
Axios 是一个基于 Promise 的 HTTP 客户端,可以在浏览器和 Node.js 中运行。如果您使用 Typescript,那么 axios 将为您覆盖内置类型。通过 Axios 发起 HTTP 请求非常简单。默认情况下,它带有 Promise 支持,而不是在请求中使用回调:
1const axios = require('axios')
2
3axios
4 .get('https://www.reddit.com/r/programming.json')
5 .then((response) => {
6 console.log(response)
7 })
8 .catch((error) => {
9 console.error(error)
10 });
如果你喜欢 Promises API 的 async/await 语法糖,你也可以使用它,但由于顶级 await 仍处于第 3 阶段,我们不得不使用异步函数来代替:
1async function getForum() {
2 try {
3 const response = await axios.get(
4 'https://www.reddit.com/r/progr ... 27%3B
5 )
6 console.log(response)
7 } catch (error) {
8 console.error(error)
9 }
10}
您所要做的就是致电 getForum!可以在 Axios 库上找到。
超级代理
与 Axios 一样,Superagent 是另一个强大的 HTTP 客户端,支持 Promise 和 async/await 语法糖。它有一个类似 Axios 的相当简单的 API,但由于更多的依赖关系,Superagent 不太受欢迎。
使用 promise、async/await 或回调向 Superagent 发出 HTTP 请求如下所示:
1const superagent = require("superagent")
2const forumURL = "https://www.reddit.com/r/programming.json"
3
4// callbacks
5superagent
6 .get(forumURL)
7 .end((error, response) => {
8 console.log(response)
9 })
10
11// promises
12superagent
13 .get(forumURL)
14 .then((response) => {
15 console.log(response)
16 })
17 .catch((error) => {
18 console.error(error)
19 })
20
21// promises with async/await
22async function getForum() {
23 try {
24 const response = await superagent.get(forumURL)
25 console.log(response)
26 } catch (error) {
27 console.error(error)
28 }
29}
您可以在以下位置找到 Superagent。
正则表达式:艰难的方式
在没有任何依赖的情况下,进行网络爬虫最简单的方法是在使用 HTTP 客户端查询网页时,在接收到的 HTML 字符串上使用一堆正则表达式。正则表达式不是那么灵活,许多专业人士和业余爱好者都很难写出正确的正则表达式。
试试看,假设有一个带有用户名的标签,而我们需要那个用户名,这类似于你依赖正则表达式时必须做的
1const htmlString = 'Username: John Doe'
2const result = htmlString.match(/(.+)/)
3
4console.log(result[1], result[1].split(": ")[1])
5// Username: John Doe, John Doe
在 Javascript 中,match() 通常返回一个数组,其中收录与正则表达式匹配的所有内容。第二个元素(在索引 1 中)将找到我们想要的标记的 textContent 或 innerHTML。但结果收录一些不必要的文本(“用户名:”),必须删除。
如您所见,对于一个非常简单的用例,有许多步骤和工作要做。这就是为什么你应该依赖 HTML 解析器的原因,我们将在后面讨论。
Cheerio:用于遍历 DOM 的核心 JQuery
Cheerio 是一个高效且可移植的库,它允许您在服务器端使用 JQuery 丰富而强大的 API。如果您之前使用过 JQuery,您就会熟悉 Cheerio。它消除了 DOM 的所有不一致和浏览器相关功能,并公开了一个有效的 API 来解析和操作 DOM。
1const cheerio = require('cheerio')
2const $ = cheerio.load('Hello world')
3
4$('h2.title').text('Hello there!')
5$('h2').addClass('welcome')
6
7$.html()
8// Hello there!
如您所见,Cheerio 与 JQuery 非常相似。
但是,即使它的工作方式与 Web 浏览器不同,这也意味着它不能:
因此,如果您尝试抓取的网站 或 web 应用程序严重依赖 Javascript(例如“单页应用程序”),那么 Cheerio 不是最佳选择,您可能不得不依赖其他选项稍后讨论。
为了展示 Cheerio 的强大功能,我们将尝试爬取 Reddit 中的 r/programming 论坛,并尝试获取一个帖子名称列表。
首先,通过运行以下命令安装 Cheerio 和 axios:npm installcheerio axios。
然后新建一个名为crawler.js的文件,复制粘贴以下代码:
1const axios = require('axios');
2const cheerio = require('cheerio');
3
4const getPostTitles = async () => {
5 try {
6 const { data } = await axios.get(
7 'https://old.reddit.com/r/programming/'
8 );
9 const $ = cheerio.load(data);
10 const postTitles = [];
11
12 $('div > p.title > a').each((_idx, el) => {
13 const postTitle = $(el).text()
14 postTitles.push(postTitle)
15 });
16
17 return postTitles;
18 } catch (error) {
19 throw error;
20 }
21};
22
23getPostTitles()
24.then((postTitles) => console.log(postTitles));
getPostTitles() 是一个异步函数,它将抓取旧的 reddit r/编程论坛。首先通过axios HTTP客户端库使用简单的HTTP GET请求获取网站的HTML,然后使用cheerio.load()函数将html数据输入到Cheerio中。
然后在浏览器的开发工具的帮助下,你可以得到一个可以定位所有列表项的选择器。如果你用过JQuery,你一定对$('div> p.title> a')非常熟悉。这将获得所有帖子,因为您只想单独获取每个帖子的标题,因此您必须遍历每个帖子。这些操作是在 each() 函数的帮助下完成的。
要从每个标题中提取文本,您必须在 Cheerio 的帮助下获取 DOM 元素(el 指的是当前元素)。然后在每个元素上调用 text() 为您提供文本。
现在,打开终端,运行node crawler.js,你会看到一个近似titles的数组,这个数组会很长。虽然这是一个非常简单的用例,但它展示了 Cheerio 提供的 API 的简单本质。
如果您的用例需要执行 Javascript 并加载外部源,那么以下选项会有所帮助。
JSDOM:节点的 DOM
JSDOM 是 Node.js 中使用的文档对象模型的纯 Javascript 实现。如前所述,DOM 对 Node 不可用,但 JSDOM 是最接近的。它或多或少地模仿了浏览器。
因为DOM是创建的,所以你可以通过编程与web应用或者你想爬取的网站进行交互,也可以模拟点击一个按钮。如果你熟悉 DOM 操作,使用 JSDOM 会非常简单。
1const { JSDOM } = require('jsdom')
2const { document } = new JSDOM(
3 'Hello world'
4).window
5const heading = document.querySelector('.title')
6heading.textContent = 'Hello there!'
7heading.classList.add('welcome')
8
9heading.innerHTML
10// Hello there!
在代码中用JSDOM创建一个DOM,然后你就可以用和浏览器DOM一样的方法和属性来操作这个DOM了。
为了演示如何使用JSDOM与网站进行交互,我们将获取Reddit r/programming论坛的第一篇帖子并对其进行投票,然后验证该帖子是否已被投票。
首先运行以下命令安装jsdom和axios: npm install jsdom axios
然后创建一个名为 crawler.js 的文件,并复制并粘贴以下代码:
1const { JSDOM } = require("jsdom")
2const axios = require('axios')
3
4const upvoteFirstPost = async () => {
5 try {
6 const { data } = await axios.get("https://old.reddit.com/r/programming/";);
7 const dom = new JSDOM(data, {
8 runScripts: "dangerously",
9 resources: "usable"
10 });
11 const { document } = dom.window;
12 const firstPost = document.querySelector("div > div.midcol > div.arrow");
13 firstPost.click();
14 const isUpvoted = firstPost.classList.contains("upmod");
15 const msg = isUpvoted
16 ? "Post has been upvoted successfully!"
17 : "The post has not been upvoted!";
18
19 return msg;
20 } catch (error) {
21 throw error;
22 }
23};
24
25upvoteFirstPost().then(msg => console.log(msg));
upvoteFirstPost() 是一个异步函数,它将获得 r/programming 中的第一篇文章,然后对其进行投票。axios 发送 HTTP GET 请求以获取指定 URL 的 HTML。然后从之前获得的 HTML 创建一个新的 DOM。JSDOM 构造函数将 HTML 作为第一个参数,将选项作为第二个参数。添加的两个选项执行以下功能:
创建DOM后,使用相同的DOM方法获取第一篇文章文章的upvote按钮,然后点击。要验证它是否真的被点击,您可以检查 classList 中是否有名为 upmod 的类。如果它存在于 classList 中,则返回一条消息。
打开终端并运行 node crawler.js,然后您将看到一个整洁的字符串,表明该帖子是否已被点赞。虽然这个例子很简单,但你可以在这个基础上构建强大的东西,例如,一个对特定用户帖子进行投票的机器人。
如果你不喜欢缺乏表达能力的 JSDOM,并且在实践中依赖很多这样的操作,或者需要重新创建很多不同的 DOM,那么下面的将是更好的选择。
Puppeteer:无头浏览器
顾名思义,Puppeteer 允许您以编程方式操纵浏览器,就像操纵木偶一样。默认情况下,它为开发人员提供了高级 API 来控制无头版本的 Chrome。
摘自 Puppeter Docs Puppeteer 比上述工具更有用,因为它允许您像真人与浏览器交互一样抓取网络。这开辟了一些以前不可用的可能性:
它还可以在网络爬虫以外的任务中发挥重要作用,例如 UI 测试、辅助性能优化等。
通常你想截取网站的截图,也许是为了了解竞争对手的产品目录,你可以使用puppeteer来做。首先运行以下命令安装puppeteer: npm install puppeteer
这将下载 Chromium 的捆绑版本,大约 180 MB 到 300 MB,具体取决于操作系统。如果要禁用此功能。
我们尝试在 Reddit 中获取 r/programming 论坛的截图和 PDF,创建一个名为 crawler.js 的新文件,并复制并粘贴以下代码:
1const puppeteer = require('puppeteer')
2
3async function getVisual() {
4 try {
5 const URL = 'https://www.reddit.com/r/programming/'
6 const browser = await puppeteer.launch()
7 const page = await browser.newPage()
8
9 await page.goto(URL)
10 await page.screenshot({ path: 'screenshot.png' })
11 await page.pdf({ path: 'page.pdf' })
12
13 await browser.close()
14 } catch (error) {
15 console.error(error)
16 }
17}
18
19getVisual()
getVisual() 是一个异步函数,它将获取 URL 变量中的 url 对应的屏幕截图和 pdf。首先通过 puppeteer.launch() 创建一个浏览器实例,然后创建一个新页面。您可以将此页面视为常规浏览器中的选项卡。然后以 URL 为参数调用 page.goto() 将之前创建的页面定向到指定的 URL。最终,浏览器实例与页面一起被销毁。
操作完成并加载页面后,将分别使用 page.screenshot() 和 page.pdf() 获取屏幕截图和pdf。也可以监听javascript的load事件,进行这些操作,生产环境中强烈推荐使用。
在终端上运行 node crawler.js。几秒钟后,您会注意到已创建两个文件,名为 screenshot.jpg 和 page.pdf。
Nightmare:Puppeteer 的替代品
Nightmare 是一个类似于 Puppeteer 的高级浏览器自动化库。该库使用 Electron,但据说它的速度是其前身 PhantomJS 的两倍。
如果您在某种程度上不喜欢 Puppeteer 或对 Chromium 包的大小感到沮丧,那么 nightmare 是一个理想的选择。首先,运行以下命令安装 nightmare 库: npm install nightmare
然后,一旦下载了 nightmare,我们将使用它通过 Google 搜索引擎找到 ScrapingBee 的 网站。创建一个名为 crawler.js 的文件,然后将以下代码复制并粘贴到其中:
1const Nightmare = require('nightmare')
2const nightmare = Nightmare()
3
4nightmare
5 .goto('https://www.google.com/')
6 .type("input[title='Search']", 'ScrapingBee')
7 .click("input[value='Google Search']")
8 .wait('#rso > div:nth-child(1) > div > div > div.r > a')
9 .evaluate(
10 () =>
11 document.querySelector(
12 '#rso > div:nth-child(1) > div > div > div.r > a'
13 ).href
14 )
15 .end()
16 .then((link) => {
17 console.log('Scraping Bee Web Link': link)
18 })
19 .catch((error) => {
20 console.error('Search failed:', error)
21 })
首先创建一个 Nightmare 实例,然后通过调用 goto() 将该实例定向到 Google 搜索引擎。加载后,使用其选择器获取搜索框,然后使用搜索框的值(输入标签)将其更改为“ScrapingBee”。完成后,单击“Google 搜索”按钮提交搜索表单。然后告诉 Nightmare 等到第一个链接加载完毕。一旦完成,它将使用 DOM 方法获取收录链接的锚标记的 href 属性的值。
最后,在所有操作完成后,将链接打印到控制台。
总结
js提取指定网站内容(如何用MSScriptControl组件执行一段数学代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-19 05:06
在抓取网页的过程中,很多网页内容都预先存储在JAVASCRIPT变量中。如果只用SUBSTRING进行拦截分析,效率低,错误率高。
我们怎样才能更好地解决它?使用 MSScriptControl
在C#中,我们也可以通过Com组件来执行一段javascript代码。
以下代码展示了如何使用 MSScriptControl 组件执行数学表达式:
MSScriptControl.ScriptControlClass sc = new MSScriptControl.ScriptControlClass();
sc.Language = "javascript";
object obj = sc.Eval(" 1 + 2 * (3 + 4)");
Console.WriteLine(obj);
要使用MSScriptControl,需要引用com组件Microsoft Script Control1.0。
上一篇文章已经详细解释了,当然代码中也有一些错误。 “MSScriptControl.IScriptControl.Timeout”和“MSScriptControl.DScriptControlSource_Event.Timeout”之间存在歧义
原创代码:
///
//// 获取或设置脚本执行时间,单位为毫秒
///
公共整数超时
{
get {return this.msc.Timeout; }
设置{this.msc.Timeout = value; }
}
修改为:
///
//// 获取或设置脚本执行时间,单位为毫秒
///
公共整数超时
{
get {return ((IScriptControl)this.msc).Timeout; }
set {((IScriptControl)this.msc).Timeout = value; }
}
是的,可以用测试,这样抓数据和介绍更方便,直接让JS输出结果即可。
结合一些技术可以做很多事情,例如:
1、ALEXA排名作弊,处理完EXE后执行POST,或者申请证书进行页面处理,数据属实。
2、一些点击或展示广告作弊,原理同上,结合ACTIVEX插件,效果不错
ActiveX 是 Microsoft 对一系列战略性面向对象编程技术和工具的名称,其中主要技术是组件对象模型 (COM)。在具有目录和其他支持的网络中,COM 已成为分布式 COM (DCOM)。创建ActiveX程序时,主要的工作是组件,一个可以运行在ActiveX网络中的自给自足的程序(目前的网络主要包括Windows和Mac)。该组件是 ActiveX Near 控件。 ActiveX 是 Microsoft 提出的,用于对抗 Sun Microsystems 的 JAVA 技术。该控件的功能类似于JAVA小程序。
如果您使用的是 Windows 操作系统,您可能会注意到一些以 OCX 结尾的文件。 OCX 代表“对象链接和嵌入控制”(OLE)。该技术是微软为混合使用桌面文件而提出的一种程序技术。现在COM的概念已经取代了一部分OLE,微软也用ActiveX控件来表示组件对象。
组件的优点之一是它们可以被大多数应用程序重用(这些应用程序称为组件容器)。一个COM组件(ActiveX控件)可以用不同语言的开发工具开发,包括C++和Visual Basic或PowerBuilder,甚至一些技术语言如VBScript。
目前,ActiveX 控件运行在 Windows 95/NT 和 Macintosh 上,微软也准备在 UNIX 上支持 ActiveX 控件。
转载于: 查看全部
js提取指定网站内容(如何用MSScriptControl组件执行一段数学代码)
在抓取网页的过程中,很多网页内容都预先存储在JAVASCRIPT变量中。如果只用SUBSTRING进行拦截分析,效率低,错误率高。
我们怎样才能更好地解决它?使用 MSScriptControl
在C#中,我们也可以通过Com组件来执行一段javascript代码。
以下代码展示了如何使用 MSScriptControl 组件执行数学表达式:
MSScriptControl.ScriptControlClass sc = new MSScriptControl.ScriptControlClass();
sc.Language = "javascript";
object obj = sc.Eval(" 1 + 2 * (3 + 4)");
Console.WriteLine(obj);
要使用MSScriptControl,需要引用com组件Microsoft Script Control1.0。
上一篇文章已经详细解释了,当然代码中也有一些错误。 “MSScriptControl.IScriptControl.Timeout”和“MSScriptControl.DScriptControlSource_Event.Timeout”之间存在歧义
原创代码:
///
//// 获取或设置脚本执行时间,单位为毫秒
///
公共整数超时
{
get {return this.msc.Timeout; }
设置{this.msc.Timeout = value; }
}
修改为:
///
//// 获取或设置脚本执行时间,单位为毫秒
///
公共整数超时
{
get {return ((IScriptControl)this.msc).Timeout; }
set {((IScriptControl)this.msc).Timeout = value; }
}
是的,可以用测试,这样抓数据和介绍更方便,直接让JS输出结果即可。
结合一些技术可以做很多事情,例如:
1、ALEXA排名作弊,处理完EXE后执行POST,或者申请证书进行页面处理,数据属实。
2、一些点击或展示广告作弊,原理同上,结合ACTIVEX插件,效果不错
ActiveX 是 Microsoft 对一系列战略性面向对象编程技术和工具的名称,其中主要技术是组件对象模型 (COM)。在具有目录和其他支持的网络中,COM 已成为分布式 COM (DCOM)。创建ActiveX程序时,主要的工作是组件,一个可以运行在ActiveX网络中的自给自足的程序(目前的网络主要包括Windows和Mac)。该组件是 ActiveX Near 控件。 ActiveX 是 Microsoft 提出的,用于对抗 Sun Microsystems 的 JAVA 技术。该控件的功能类似于JAVA小程序。
如果您使用的是 Windows 操作系统,您可能会注意到一些以 OCX 结尾的文件。 OCX 代表“对象链接和嵌入控制”(OLE)。该技术是微软为混合使用桌面文件而提出的一种程序技术。现在COM的概念已经取代了一部分OLE,微软也用ActiveX控件来表示组件对象。
组件的优点之一是它们可以被大多数应用程序重用(这些应用程序称为组件容器)。一个COM组件(ActiveX控件)可以用不同语言的开发工具开发,包括C++和Visual Basic或PowerBuilder,甚至一些技术语言如VBScript。
目前,ActiveX 控件运行在 Windows 95/NT 和 Macintosh 上,微软也准备在 UNIX 上支持 ActiveX 控件。
转载于:
js提取指定网站内容(使用Python爬取网页数据使用urllib.request获取网页urllib)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-17 15:02
使用 Python 抓取网页数据
使用 urllib.request 获取网页 urllib 是 Python 中内置的 HTTP 库。使用urllib可以非常简单的步骤高效地采集数据;用Beautiful等HTML伪造请求体爬取一些网站 当需要POST数据到服务器时,此时需要伪造请求体;为了实现有道词典在线翻译脚本,在Chrome中打开开发工具,找到Network下的方法为POST。注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源,大型分布式爬虫可以爬取一个站点甚至对该站点发起DDOS攻击;因此,您在使用爬虫爬取数据时,应合理安排爬取频率和时间;例如:服务器比较空闲 是时候检测网页的编码方式了 虽然大部分网页都是用UTF-8编码的,但是有时候你会遇到使用其他编码方式的网页,所以你必须知道网页的编码方式才能正确解码抓取到的页;Chardet 是python的第三方模块,用于获取跳转链接。有时一个网页的某个页面需要根据原创URL跳转一次甚至多次才能最终到达目的页面,所以需要正确处理;通过head(请求模块的))函数获取跳转链接的URL,Chardet 是python的第三方模块,用于获取跳转链接。有时一个网页的某个页面需要根据原创URL跳转一次甚至多次才能最终到达目的页面,所以需要正确处理;通过head(请求模块的))函数获取跳转链接的URL,Chardet 是python的第三方模块,用于获取跳转链接。有时一个网页的某个页面需要根据原创URL跳转一次甚至多次才能最终到达目的页面,所以需要正确处理;通过head(请求模块的))函数获取跳转链接的URL,
483 查看全部
js提取指定网站内容(使用Python爬取网页数据使用urllib.request获取网页urllib)
使用 Python 抓取网页数据
使用 urllib.request 获取网页 urllib 是 Python 中内置的 HTTP 库。使用urllib可以非常简单的步骤高效地采集数据;用Beautiful等HTML伪造请求体爬取一些网站 当需要POST数据到服务器时,此时需要伪造请求体;为了实现有道词典在线翻译脚本,在Chrome中打开开发工具,找到Network下的方法为POST。注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源,大型分布式爬虫可以爬取一个站点甚至对该站点发起DDOS攻击;因此,您在使用爬虫爬取数据时,应合理安排爬取频率和时间;例如:服务器比较空闲 是时候检测网页的编码方式了 虽然大部分网页都是用UTF-8编码的,但是有时候你会遇到使用其他编码方式的网页,所以你必须知道网页的编码方式才能正确解码抓取到的页;Chardet 是python的第三方模块,用于获取跳转链接。有时一个网页的某个页面需要根据原创URL跳转一次甚至多次才能最终到达目的页面,所以需要正确处理;通过head(请求模块的))函数获取跳转链接的URL,Chardet 是python的第三方模块,用于获取跳转链接。有时一个网页的某个页面需要根据原创URL跳转一次甚至多次才能最终到达目的页面,所以需要正确处理;通过head(请求模块的))函数获取跳转链接的URL,Chardet 是python的第三方模块,用于获取跳转链接。有时一个网页的某个页面需要根据原创URL跳转一次甚至多次才能最终到达目的页面,所以需要正确处理;通过head(请求模块的))函数获取跳转链接的URL,
483
js提取指定网站内容( 2017年12月14日14:16:47一个实例教学如何用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-15 20:14
2017年12月14日14:16:47一个实例教学如何用
)
Nodejs实现了抓取网站图片的功能
更新时间:2017年12月14日14:16:47投稿人:老张
下面是一个示例,教您如何使用nodejs实现抓取网站图片的功能。感兴趣的朋友可以采集
通过一个例子,我们将说明nodejs实现了抓取网站图片的功能。以下是全部内容:
原则:
爬虫是最明显的IO密集型应用场景。节点的使用明显减少了I/O等待开销,数据挖掘更加方便
使用express模块构建节点服务
并使用请求模块获取目标页面的HTML代码
下载cherio模块以处理HTML代码(cherio类似于jQuery语法,因此易于使用和方便)
环境配置:
(1)介绍每个模块
var http = require('http');
var request = require('request);
var cheerio = require('cheerio');
var fs = require('fs'); //用来操作文件
var url = 'https://movie.douban.com/cinema/nowplaying/beijing/' //定义要爬的页面
(2)发送请求
http.get(function(res){
var html = '';
var titles = [];
res.setEncoding('utf-8') //防止中文乱码
res.on('data',function(chunk){
html += chrunk; //监听data事件 每次取一块数据
})
res.on('end',function(){
var $ = cheerio.load(html); //获取数据完成后,解析html
//将获取的图片存到images文件夹中
$('.mod-bd img').each(function(index, item){
//获取图片属性
var imgName = $(this).parent().next().text().trimg()
var imgfile = imgName + '.jpeg';
var imgSrc = $(this).attr('src')
//采用request模块,向服务器发起请求 获取图片资源
request.head(imgSrc, function(error, res,body){
if(error){
console.log('失败了')
}
});
//通过管道的方式用fs模块将图片写到本地的images文件下
request(imgSrc).pipe.(fs.createWriteStream('./images/' + imgfile));
})
})
}) 查看全部
js提取指定网站内容(
2017年12月14日14:16:47一个实例教学如何用
)
Nodejs实现了抓取网站图片的功能
更新时间:2017年12月14日14:16:47投稿人:老张
下面是一个示例,教您如何使用nodejs实现抓取网站图片的功能。感兴趣的朋友可以采集
通过一个例子,我们将说明nodejs实现了抓取网站图片的功能。以下是全部内容:
原则:
爬虫是最明显的IO密集型应用场景。节点的使用明显减少了I/O等待开销,数据挖掘更加方便
使用express模块构建节点服务
并使用请求模块获取目标页面的HTML代码
下载cherio模块以处理HTML代码(cherio类似于jQuery语法,因此易于使用和方便)
环境配置:
(1)介绍每个模块
var http = require('http');
var request = require('request);
var cheerio = require('cheerio');
var fs = require('fs'); //用来操作文件
var url = 'https://movie.douban.com/cinema/nowplaying/beijing/' //定义要爬的页面
(2)发送请求
http.get(function(res){
var html = '';
var titles = [];
res.setEncoding('utf-8') //防止中文乱码
res.on('data',function(chunk){
html += chrunk; //监听data事件 每次取一块数据
})
res.on('end',function(){
var $ = cheerio.load(html); //获取数据完成后,解析html
//将获取的图片存到images文件夹中
$('.mod-bd img').each(function(index, item){
//获取图片属性
var imgName = $(this).parent().next().text().trimg()
var imgfile = imgName + '.jpeg';
var imgSrc = $(this).attr('src')
//采用request模块,向服务器发起请求 获取图片资源
request.head(imgSrc, function(error, res,body){
if(error){
console.log('失败了')
}
});
//通过管道的方式用fs模块将图片写到本地的images文件下
request(imgSrc).pipe.(fs.createWriteStream('./images/' + imgfile));
})
})
})
js提取指定网站内容(如何用JS在网页中常用的webserver(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-15 13:17
1、首先要懂js,然后用iframe加载原网页,然后调用js
2、js很简单,写成一个网页,用winform加载网页,nodejs比较复杂,首先得让用户在windows上安装nodejs(我没试过),然后调用nodejs环境, linux下使用nodejs服务器,与windows程序不兼容。
尽管有可能,但 nodejs 通常不会直接用作 Web 服务器。node js中常用的web服务器是express。在express中,可以使用req.param('key')来获取post返回的参数。
通过设置formData使用请求模块发送。关于 formData,请参阅此处了解有关如何使用它的详细信息:
支持者都是市场上最新最热的知识点。名师录的高清视频应该可以帮到你。
尽管有可能,但 nodejs 通常不会直接用作 Web 服务器。node js中常用的web服务器是express。在express中,可以使用req.param('key')来获取post返回的参数。
如何使用JS在一个网页中引用另一个网页的内容
------ 使用javascript和AJAX非常方便的传输html文档。
JQuery很好的封装了AJAX,使用起来非常方便。
最简单的方便就是使用jQuery的load方法,可以很方便的加载包括html在内的文档。
例如:
$('#result').load('ajax/test.html', function() {
alert('加载完成。');
});
如果导入了jQuery,并且指定的html文档也存在,系统会将test.html中的内容导入#result元素中。
我可以在别人的 网站 上嵌入 js 代码吗?具体怎么做,没有恶意,就是想采集一些资料。
------ 至少你得有FTP控制吧?而且js采集信息涉及到跨域等问题!
如何把自己写的javascript脚本放到别人的网页中——
------ 只有这样才能搞定:登录应用服务器,把你的JS脚本放到服务器上,嵌入到那个页面中,这样就可以了,不然就别想了。想想看,如果你登录银行网站,如果写的外部js可以...
如何在一个 js 中使用另一种 js 方法-
------ 我们知道在html中,两个引入的js是不能互相调用的。那么如何解决呢?当然,你可以把代码全部复制过来,也许你不喜欢这样。例如有这样一个...
如何在Javascript中调用另一个JS文件中的网页-
------ 哈哈,使用js调用:注意这种方式js其实是普通文本,没有指定页面语言,如果指定了就用
如何使用JS弹出另一个网站页面?
------ 如果window.open 不起作用,就没有其他办法了。用360安全浏览器可以看到它的拦截程序导致弹窗无效,但是你可以尝试用框架直接放到你的页面上。种类
如何让多个网页共享javascript效果-
------ 将js代码另存为.js文件,这样引用
如何使用 JavaScript 读取另一个网页的源代码-
------ 考虑到目前浏览器的安全问题,javascript只能读取知岛子网页的内容,无法读取内兄弟网页和父网页的内容,可以使用javascript的window.open方法进行另一个网页 打开弹出窗口,然后您可以阅读另一个网页的源代码。
如何将别人的代码应用到自己的网站-
------ 只需在需要的地方添加代码即可。如果您的 CSS 文件不可用,只需将其 CSS 代码添加到您的 CSS 文件中。
js 文件,任何 网站 调用 js-
------ script标签本来是支持跨域的,你可以直接在script标签的src属性里写你的js URL地址。
视频链接:\\\\\\JavaWeb视频教程_380-JSP-介绍案例-使用JSP显示动态数据\\06.处理JS分页加载的网页_recv \\JS教程10.@ >讲解网页日历的开发过程\\JS网页制作实例实现导航高亮方法\\\\ 查看全部
js提取指定网站内容(如何用JS在网页中常用的webserver(图))
1、首先要懂js,然后用iframe加载原网页,然后调用js
2、js很简单,写成一个网页,用winform加载网页,nodejs比较复杂,首先得让用户在windows上安装nodejs(我没试过),然后调用nodejs环境, linux下使用nodejs服务器,与windows程序不兼容。
尽管有可能,但 nodejs 通常不会直接用作 Web 服务器。node js中常用的web服务器是express。在express中,可以使用req.param('key')来获取post返回的参数。
通过设置formData使用请求模块发送。关于 formData,请参阅此处了解有关如何使用它的详细信息:
支持者都是市场上最新最热的知识点。名师录的高清视频应该可以帮到你。
尽管有可能,但 nodejs 通常不会直接用作 Web 服务器。node js中常用的web服务器是express。在express中,可以使用req.param('key')来获取post返回的参数。
如何使用JS在一个网页中引用另一个网页的内容
------ 使用javascript和AJAX非常方便的传输html文档。
JQuery很好的封装了AJAX,使用起来非常方便。
最简单的方便就是使用jQuery的load方法,可以很方便的加载包括html在内的文档。
例如:
$('#result').load('ajax/test.html', function() {
alert('加载完成。');
});
如果导入了jQuery,并且指定的html文档也存在,系统会将test.html中的内容导入#result元素中。
我可以在别人的 网站 上嵌入 js 代码吗?具体怎么做,没有恶意,就是想采集一些资料。
------ 至少你得有FTP控制吧?而且js采集信息涉及到跨域等问题!
如何把自己写的javascript脚本放到别人的网页中——
------ 只有这样才能搞定:登录应用服务器,把你的JS脚本放到服务器上,嵌入到那个页面中,这样就可以了,不然就别想了。想想看,如果你登录银行网站,如果写的外部js可以...
如何在一个 js 中使用另一种 js 方法-
------ 我们知道在html中,两个引入的js是不能互相调用的。那么如何解决呢?当然,你可以把代码全部复制过来,也许你不喜欢这样。例如有这样一个...
如何在Javascript中调用另一个JS文件中的网页-
------ 哈哈,使用js调用:注意这种方式js其实是普通文本,没有指定页面语言,如果指定了就用
如何使用JS弹出另一个网站页面?
------ 如果window.open 不起作用,就没有其他办法了。用360安全浏览器可以看到它的拦截程序导致弹窗无效,但是你可以尝试用框架直接放到你的页面上。种类
如何让多个网页共享javascript效果-
------ 将js代码另存为.js文件,这样引用
如何使用 JavaScript 读取另一个网页的源代码-
------ 考虑到目前浏览器的安全问题,javascript只能读取知岛子网页的内容,无法读取内兄弟网页和父网页的内容,可以使用javascript的window.open方法进行另一个网页 打开弹出窗口,然后您可以阅读另一个网页的源代码。
如何将别人的代码应用到自己的网站-
------ 只需在需要的地方添加代码即可。如果您的 CSS 文件不可用,只需将其 CSS 代码添加到您的 CSS 文件中。
js 文件,任何 网站 调用 js-
------ script标签本来是支持跨域的,你可以直接在script标签的src属性里写你的js URL地址。
视频链接:\\\\\\JavaWeb视频教程_380-JSP-介绍案例-使用JSP显示动态数据\\06.处理JS分页加载的网页_recv \\JS教程10.@ >讲解网页日历的开发过程\\JS网页制作实例实现导航高亮方法\\\\
js提取指定网站内容(京东资源复制过去使用命令行.js和puppeteer小试牛刀`)
网站优化 • 优采云 发表了文章 • 0 个评论 • 39 次浏览 • 2021-12-15 13:10
需要:
如果你是技术员,那可以看我下一个文章,否则请直接移到我的github仓库看文档直接使用
仓库地址:附文件和源代码
此要求中使用的技术:Node.js 和 puppeteer
做个小测试,爬取京东资源
const puppeteer = require('puppeteer'); // 引入依赖
(async () => { //使用async函数完美异步
const browser = await puppeteer.launch(); //打开新的浏览器
const page = await browser.newPage(); // 打开新的网页
await page.goto('https://www.jd.com/'); //前往里面 'url' 的网页
const result = await page.evaluate(() => { //这个result数组包含所有的图片src地址
let arr = []; //这个箭头函数内部写处理的逻辑
const imgs = document.querySelectorAll('img');
imgs.forEach(function (item) {
arr.push(item.src)
})
return arr
});
// '此时的result就是得到的爬虫数据,可以通过'fs'模块保存'
})()
复制过去,使用命令行命令`node file name`运行获取爬虫数据。这个 puppeteer 包实际上为我们打开了另一个浏览器,重新打开了网页,并获取了他们的数据。
注意上面所有的逻辑都是puppeteer包帮助我们在不可见的地方打开另一个浏览器,然后处理逻辑,所以我们最后调用browser.close()方法关闭那个浏览器。
这时候我们优化了上一篇的代码,爬取了相应的资源。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.jd.com/');
const hrefArr = await page.evaluate(() => {
let arr = [];
const aNodes = document.querySelectorAll('.cate_menu_lk');
aNodes.forEach(function (item) {
arr.push(item.href)
})
return arr
});
let arr = [];
for (let i = 0; i < hrefArr.length; i++) {
const url = hrefArr[i];
console.log(url) //这里可以打印
await page.goto(url);
const result = await page.evaluate(() => { //这个方法内部console.log无效
return $('title').text(); //返回每个界面的title文字内容
});
arr.push(result) //每次循环给数组中添加对应的值
}
console.log(arr) //得到对应的数据 可以通过Node.js的 fs 模块保存到本地
await browser.close()
})()
有一个天坑page.evaluate函数。内部console.log无法打印,内部无法获取外部变量,只能使用return。
要使用选择器,必须先到对应界面的控制台测试是否可以选择DOM,然后才能使用。比如京东就不能使用querySelector。这里因为
京东的界面使用了jQuery,所以我们可以使用jQuery。简而言之,他们可以开发任何可以使用的选择器。我们可以使用它们,否则我们不能。
接下来直接爬取Node.js的官网首页,直接生成PDF
无论您是否了解 Node.js 和 puppeteer 爬虫,您都可以做到。请仔细阅读本文档并按顺序执行每个步骤。
本项目的实现需求:给我们一个网页地址,抓取他的网页内容,然后输出成我们想要的PDF格式文档,请注意是高质量的PDF文档
TIPS:本项目的设计思路是每个网页一个PDF文件,所以每次爬取单个页面时,请复制index.pdf,然后继续更改URL地址,继续爬取,生成一个新的PDF 文件。当然,你也可以通过循环编译等方式一次抓取多个网页生成多个PDF文件。
对应京东首页这种图片懒加载的网页,爬取的部分内容是处于加载状态的内容。对于有一些反爬虫机制的网页,爬虫也会有问题,但是绝大多数网站都是有可能的
const puppeteer = require('puppeteer');
const url = require('./url');
(async () => {
const browser = await puppeteer.launch({ headless: true })
const page = await browser.newPage()
//选择要打开的网页
await page.goto(url, { waitUntil: 'networkidle0' })
//选择你要输出的那个PDF文件路径,把爬取到的内容输出到PDF中,必须是存在的PDF,可以是空内容,如果不是空的内容PDF,那么会覆盖内容
let pdfFilePath = './index.pdf';
//根据你的配置选项,我们这里选择A4纸的规格输出PDF,方便打印
await page.pdf({
path: pdfFilePath,
format: 'A4',
scale: 1,
printBackground: true,
landscape: false,
displayHeaderFooter: false
});
await browser.close()
})()
文件解构设计
数据在这个时代非常宝贵。根据网页的设计逻辑,通过选择特定href的地址,可以直接先获取对应的资源,也可以再次使用page.goto方法进入,然后调用page.evaluate( ) 处理逻辑。或者输出对应的PDF文件,当然也可以一次输出多个PDF文件~
这里就不过多介绍了,毕竟Node.js可以上天堂,说不定以后真的什么都可以了。这么高质量的短教程,请采集
或者转发给你的朋友,谢谢。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持面圈教程。 查看全部
js提取指定网站内容(京东资源复制过去使用命令行.js和puppeteer小试牛刀`)
需要:
如果你是技术员,那可以看我下一个文章,否则请直接移到我的github仓库看文档直接使用
仓库地址:附文件和源代码
此要求中使用的技术:Node.js 和 puppeteer
做个小测试,爬取京东资源
const puppeteer = require('puppeteer'); // 引入依赖
(async () => { //使用async函数完美异步
const browser = await puppeteer.launch(); //打开新的浏览器
const page = await browser.newPage(); // 打开新的网页
await page.goto('https://www.jd.com/'); //前往里面 'url' 的网页
const result = await page.evaluate(() => { //这个result数组包含所有的图片src地址
let arr = []; //这个箭头函数内部写处理的逻辑
const imgs = document.querySelectorAll('img');
imgs.forEach(function (item) {
arr.push(item.src)
})
return arr
});
// '此时的result就是得到的爬虫数据,可以通过'fs'模块保存'
})()
复制过去,使用命令行命令`node file name`运行获取爬虫数据。这个 puppeteer 包实际上为我们打开了另一个浏览器,重新打开了网页,并获取了他们的数据。
注意上面所有的逻辑都是puppeteer包帮助我们在不可见的地方打开另一个浏览器,然后处理逻辑,所以我们最后调用browser.close()方法关闭那个浏览器。
这时候我们优化了上一篇的代码,爬取了相应的资源。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.jd.com/');
const hrefArr = await page.evaluate(() => {
let arr = [];
const aNodes = document.querySelectorAll('.cate_menu_lk');
aNodes.forEach(function (item) {
arr.push(item.href)
})
return arr
});
let arr = [];
for (let i = 0; i < hrefArr.length; i++) {
const url = hrefArr[i];
console.log(url) //这里可以打印
await page.goto(url);
const result = await page.evaluate(() => { //这个方法内部console.log无效
return $('title').text(); //返回每个界面的title文字内容
});
arr.push(result) //每次循环给数组中添加对应的值
}
console.log(arr) //得到对应的数据 可以通过Node.js的 fs 模块保存到本地
await browser.close()
})()
有一个天坑page.evaluate函数。内部console.log无法打印,内部无法获取外部变量,只能使用return。
要使用选择器,必须先到对应界面的控制台测试是否可以选择DOM,然后才能使用。比如京东就不能使用querySelector。这里因为
京东的界面使用了jQuery,所以我们可以使用jQuery。简而言之,他们可以开发任何可以使用的选择器。我们可以使用它们,否则我们不能。
接下来直接爬取Node.js的官网首页,直接生成PDF
无论您是否了解 Node.js 和 puppeteer 爬虫,您都可以做到。请仔细阅读本文档并按顺序执行每个步骤。
本项目的实现需求:给我们一个网页地址,抓取他的网页内容,然后输出成我们想要的PDF格式文档,请注意是高质量的PDF文档
TIPS:本项目的设计思路是每个网页一个PDF文件,所以每次爬取单个页面时,请复制index.pdf,然后继续更改URL地址,继续爬取,生成一个新的PDF 文件。当然,你也可以通过循环编译等方式一次抓取多个网页生成多个PDF文件。
对应京东首页这种图片懒加载的网页,爬取的部分内容是处于加载状态的内容。对于有一些反爬虫机制的网页,爬虫也会有问题,但是绝大多数网站都是有可能的
const puppeteer = require('puppeteer');
const url = require('./url');
(async () => {
const browser = await puppeteer.launch({ headless: true })
const page = await browser.newPage()
//选择要打开的网页
await page.goto(url, { waitUntil: 'networkidle0' })
//选择你要输出的那个PDF文件路径,把爬取到的内容输出到PDF中,必须是存在的PDF,可以是空内容,如果不是空的内容PDF,那么会覆盖内容
let pdfFilePath = './index.pdf';
//根据你的配置选项,我们这里选择A4纸的规格输出PDF,方便打印
await page.pdf({
path: pdfFilePath,
format: 'A4',
scale: 1,
printBackground: true,
landscape: false,
displayHeaderFooter: false
});
await browser.close()
})()
文件解构设计

数据在这个时代非常宝贵。根据网页的设计逻辑,通过选择特定href的地址,可以直接先获取对应的资源,也可以再次使用page.goto方法进入,然后调用page.evaluate( ) 处理逻辑。或者输出对应的PDF文件,当然也可以一次输出多个PDF文件~
这里就不过多介绍了,毕竟Node.js可以上天堂,说不定以后真的什么都可以了。这么高质量的短教程,请采集
或者转发给你的朋友,谢谢。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持面圈教程。
js提取指定网站内容(我在某云存储上上传了一批文件,有几百张图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-11 19:04
我在云存储上上传了一批文件,其中收录数百张图片。我是3月17号上传的,现在需要证明我是3月18号上传给公司领导的。云存储本身的上传日期和时间无法更改,也无法回到3月18日再次上传。. 于是想了个办法,登录云存储后台管理页面后查看文件列表,一次显示100条,下面还有一个加载更多按钮,每次点击一次加载100条,直到加载完成,我通过云存储网页代码找到加载方式,修改代码。在追加到表格之前,将获取的数据中的日期“2019-03-17”替换为“2019-03-18”,
现在唯一的问题是,当我在公司检查组的同事面前演示时——虽然他们对IT不太了解,但看到我运行代码肯定会怀疑——我不能直接做像上面一样,我需要浏览器来运行代码。当我打开这个页面时,这个本地的JS代码是从后台自动执行的,这样从登录到打开页面到加载数据,他们都可以信服。我直接把加载好的或者截图给他们看,别人会怀疑,所以我只有从一开始登录的时候就在他们面前演示操作的时候可信度很高。
唯一的好处是拿我的电脑演示,他们不会要求在不同的电脑上演示,否则会比较困难。
如何做到这一点? 查看全部
js提取指定网站内容(我在某云存储上上传了一批文件,有几百张图片)
我在云存储上上传了一批文件,其中收录数百张图片。我是3月17号上传的,现在需要证明我是3月18号上传给公司领导的。云存储本身的上传日期和时间无法更改,也无法回到3月18日再次上传。. 于是想了个办法,登录云存储后台管理页面后查看文件列表,一次显示100条,下面还有一个加载更多按钮,每次点击一次加载100条,直到加载完成,我通过云存储网页代码找到加载方式,修改代码。在追加到表格之前,将获取的数据中的日期“2019-03-17”替换为“2019-03-18”,
现在唯一的问题是,当我在公司检查组的同事面前演示时——虽然他们对IT不太了解,但看到我运行代码肯定会怀疑——我不能直接做像上面一样,我需要浏览器来运行代码。当我打开这个页面时,这个本地的JS代码是从后台自动执行的,这样从登录到打开页面到加载数据,他们都可以信服。我直接把加载好的或者截图给他们看,别人会怀疑,所以我只有从一开始登录的时候就在他们面前演示操作的时候可信度很高。
唯一的好处是拿我的电脑演示,他们不会要求在不同的电脑上演示,否则会比较困难。
如何做到这一点?
js提取指定网站内容(一个就是代码_Load代码添加按钮和存放结构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-07 14:10
在工作的过程中,遇到了一个需求,就是Js从Cookies中获取值。 js好像没有现成的方法来指定Key值来获取Cookie中对应的值。简单的实现请参考网上的代码如下:
1.服务器代码Page_Load中Cookies中写了几个值
using System;
using System.Collections.Generic;
using System.Web;
using System.Web.UI;
using System.Web.UI.WebControls;
namespace WebApplication_TestJS
{
public partial class _Default : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
Response.Cookies["DONO"].Value = "EDO1406300001";
Response.Cookies["DOID"].Value = "ABCDEFG123456";
Response.Cookies["DOSOURCE"].Value = "WUWUWUWU";
Response.Cookies["DOTYPE"].Value = "2";
}
}
}
2. 向客户端代码页添加按钮和文本框,触发并输出获取的值
function GetCookie()
{
/*获取Cookies里面存放信息 了解其字符串结构*/
var Cookies = document.cookie;
document.getElementById("").innerText = Cookies;
/*处理字符串截取出来需要的目标值*/
var target = "DONO" + "=";
if (document.cookie.length > 0)
{
start = document.cookie.indexOf(target);
if (start != -1)
{
start += target.length;
end = document.cookie.indexOf(";", start);
if (end == -1) end = document.cookie.length;
}
}
/*目标值赋值给控件*/
document.getElementById("").innerText = document.cookie.substring(start, end);
}
<br />
<br />
3.在执行结果中可以看到Cookies和第一个文本框中的结构一样,根据需要截取对应的字符串。
相关文章
猜你喜欢 查看全部
js提取指定网站内容(一个就是代码_Load代码添加按钮和存放结构)
在工作的过程中,遇到了一个需求,就是Js从Cookies中获取值。 js好像没有现成的方法来指定Key值来获取Cookie中对应的值。简单的实现请参考网上的代码如下:
1.服务器代码Page_Load中Cookies中写了几个值
using System;
using System.Collections.Generic;
using System.Web;
using System.Web.UI;
using System.Web.UI.WebControls;
namespace WebApplication_TestJS
{
public partial class _Default : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
Response.Cookies["DONO"].Value = "EDO1406300001";
Response.Cookies["DOID"].Value = "ABCDEFG123456";
Response.Cookies["DOSOURCE"].Value = "WUWUWUWU";
Response.Cookies["DOTYPE"].Value = "2";
}
}
}
2. 向客户端代码页添加按钮和文本框,触发并输出获取的值
function GetCookie()
{
/*获取Cookies里面存放信息 了解其字符串结构*/
var Cookies = document.cookie;
document.getElementById("").innerText = Cookies;
/*处理字符串截取出来需要的目标值*/
var target = "DONO" + "=";
if (document.cookie.length > 0)
{
start = document.cookie.indexOf(target);
if (start != -1)
{
start += target.length;
end = document.cookie.indexOf(";", start);
if (end == -1) end = document.cookie.length;
}
}
/*目标值赋值给控件*/
document.getElementById("").innerText = document.cookie.substring(start, end);
}
<br />
<br />
3.在执行结果中可以看到Cookies和第一个文本框中的结构一样,根据需要截取对应的字符串。
相关文章
猜你喜欢
js提取指定网站内容(前几天脑子里忽然简书的图片分享效果,感觉很简洁)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-05 18:13
前几天,脑子里突然闪过简书的图片分享效果。感觉非常简单和美丽。想着自己的方法能不能实现,所以今天就有了这篇文章。好的,我们先来看看效果图:
项目地址:
欢迎star,问题~
要达到这个效果,首先要明白几个问题:
一、如何获取选中的网页内容
二、如何加载和显示获取的网页内容
一、如何获取选中的网页内容
获取选定的网页内容非常困难。通过Java获取选中的网页内容非常困难,要达到效果,必须获取选中的网页内容。我们可以改变我们的想法。既然不容易通过Java层获取,那么使用JavaScript是不是更容易呢?嗯,后来的实现也证实了这个想法是正确的,JavaScript很容易获取到选中的网页内容。
那么我们的思路是:当用户点击生成的图片分享按钮时,我们调用JavaScript方法获取选中的网页内容,同时回调Java的get content方法,将获取的网页内容传回Java层,我们可以得到网页内容。
简单看一下代码:
mWebView.addJavascriptInterface(new WebAppInterface(onGetDataListener), "JSInterface"); public void getSelectedData(WebView webView) { String js = "(function getSelectedText() {" + "var txt;" + "if (window.getSelection) {" + "var range=window.getSelection().getRangeAt(0);" + "var container = window.document.createElement('div');" + "container.appendChild(range.cloneContents());" + "txt = container.innerHTML;" + "} else if (window.document.getSelection) {" + "var range=window.getSelection().getRangeAt(0);" + "var container = window.document.createElement('div');" + "container.appendChild(range.cloneContents());" + "txt = container.innerHTML;" + "} else if (window.document.selection) {" + "txt = window.document.selection.createRange().htmlText;" + "}" + "JSInterface.getText(txt);" + "})()"; // calling the js function if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.KITKAT) { webView.evaluateJavascript("javascript:" + js, null); } else { webView.loadUrl("javascript:" + js); } webView.clearFocus(); } static class WebAppInterface { WebViewHelper.OnGetDataListener onGetDataListener; WebAppInterface(WebViewHelper.OnGetDataListener onGetDataListener) { this.onGetDataListener = onGetDataListener; } @JavascriptInterface public void getText(String text) { onGetDataListener.getDataListener(text); } } public interface OnGetDataListener{ void getDataListener(String text); }
上面的实现思路是,当我们想要获取选中的网页内容时,将自己编写的一段JavaScript脚本注入到WebView中。这段JavaScript代码的意思是获取当前页面收录html标签的选中内容,调用JSInterface.getText(txt)方法。将内容返回给Java的getText(String text)方法,我们设置onGetDataListener.getDataListener(text)回调方法,在需要的地方调用获取内容。
二、如何加载和显示获取的网页内容
我们已经获得了网页的内容。调用TextView的setText(Html.fromHtml())方法来显示我们选择的效果是合理的,但是考虑到美观和保存截图的功能以及图片的正常显示,我选择使用WebView来加载得到的网页内容。
我是这样处理的:首先在本地assets文件夹中创建一个html页面,加载页面中的基本显示内容并添加css标签修改加载的内容,当获取到网页内容时,本地html page动态替换为JavaScript指定对应的标签内容为获取的网页内容,在本地html页面修改显示内容。
看代码:
webView.loadUrl("file:///android_asset/generate_pic.html"); public void changeDay(String strData,String userInfo,String userName,String other) { if(userInfo == null) userInfo =""; if(strData == null) strData =""; if(userName == null) userName =""; if(other == null) other =""; strData+="<br /><br />n" + "tt"+userInfo+"n" + "tt<br /><br />n" + "ttn" + "tt<br />n" + "tt<p style="/spancolor: orangered;font-size: x-small;text-align: center;letter-spacing: span class="hljs-number"0.5/spanpx;span class="hljs-string"">由"+userName+"发送 "+other+""; webView.loadUrl("javascript:changeContent("" + strData.replace("n", "\n").replace(""", "\"").replace("'", "\'") + "")"); webView.setBackgroundColor(Color.WHITE); }</p>
白色和黑色的不同显示效果可以通过changeDay方法中改变css样式来实现,比较简单。
但这里存在问题:当所选页面内容具有图片并且图像显示在相对路径中时,无法加载图像。
在这种情况下,图片是相对路径,即在本地对应的相对路径下查找。本地一定找不到,图片也不会显示。
为了能正常显示图片,在选中的内容页面调用onLoadResource方法判断加载的资源并保存图片路径,因为既然选中的页面图片是可以显示和处理的,就说明路径是http路径,可以显示图片。
看代码:
mWebView.setWebViewClient(new WebViewClient(){ @Override public void onLoadResource(WebView view, String url) { //Log.e("TAG","url :"+url); if(url.toLowerCase().contains(".jpg") ||url.toLowerCase().contains(".png") ||url.toLowerCase().contains(".gif")){ mlistPath.add(url); } super.onLoadResource(view, url); }
当显示选中的内容页面时,动态修改显示的图片路径以显示图片:
webView.setWebViewClient(new WebViewClient(){ @Override public boolean shouldOverrideUrlLoading(WebView view, String url) { //view.loadUrl(url); return true; } public WebResourceResponse shouldInterceptRequest(WebView view, String url) { WebResourceResponse response = null; for (String path:WebViewHelper.getInstance().getAllListPath()){ if (path.toLowerCase().contains(url.replace("file://","").toLowerCase())){ try { response = new WebResourceResponse("image/png", "UTF-8", new URL(path).openStream()); } catch (IOException e) { e.printStackTrace(); } } } return response; } });
这样我们的图片就可以显示出来了!
最后,实现我们的截图保存功能,看代码:
/** * 截屏 * * @return */ public Bitmap getScreen() { Bitmap bmp = Bitmap.createBitmap(webView.getWidth(), 1, Bitmap.Config.ARGB_8888); int rowBytes = bmp.getRowBytes(); bmp = null; if (rowBytes*webView.getHeight()>=getAvailMemory()){ return null; } bmp = Bitmap.createBitmap(webView.getWidth(), webView.getHeight(), Bitmap.Config.ARGB_8888); Canvas canvas = new Canvas(bmp); webView.draw(canvas); return bmp; } private long getAvailMemory() { return Runtime.getRuntime().maxMemory(); }
这里需要对保存的图片大小做判断,防止创建过大的OOM图片。
至此,基本功能已经实现。把照片分享给你的朋友~
项目地址:
欢迎star,问题~ 查看全部
js提取指定网站内容(前几天脑子里忽然简书的图片分享效果,感觉很简洁)
前几天,脑子里突然闪过简书的图片分享效果。感觉非常简单和美丽。想着自己的方法能不能实现,所以今天就有了这篇文章。好的,我们先来看看效果图:
项目地址:
欢迎star,问题~
要达到这个效果,首先要明白几个问题:
一、如何获取选中的网页内容
二、如何加载和显示获取的网页内容
一、如何获取选中的网页内容
获取选定的网页内容非常困难。通过Java获取选中的网页内容非常困难,要达到效果,必须获取选中的网页内容。我们可以改变我们的想法。既然不容易通过Java层获取,那么使用JavaScript是不是更容易呢?嗯,后来的实现也证实了这个想法是正确的,JavaScript很容易获取到选中的网页内容。
那么我们的思路是:当用户点击生成的图片分享按钮时,我们调用JavaScript方法获取选中的网页内容,同时回调Java的get content方法,将获取的网页内容传回Java层,我们可以得到网页内容。
简单看一下代码:
mWebView.addJavascriptInterface(new WebAppInterface(onGetDataListener), "JSInterface"); public void getSelectedData(WebView webView) { String js = "(function getSelectedText() {" + "var txt;" + "if (window.getSelection) {" + "var range=window.getSelection().getRangeAt(0);" + "var container = window.document.createElement('div');" + "container.appendChild(range.cloneContents());" + "txt = container.innerHTML;" + "} else if (window.document.getSelection) {" + "var range=window.getSelection().getRangeAt(0);" + "var container = window.document.createElement('div');" + "container.appendChild(range.cloneContents());" + "txt = container.innerHTML;" + "} else if (window.document.selection) {" + "txt = window.document.selection.createRange().htmlText;" + "}" + "JSInterface.getText(txt);" + "})()"; // calling the js function if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.KITKAT) { webView.evaluateJavascript("javascript:" + js, null); } else { webView.loadUrl("javascript:" + js); } webView.clearFocus(); } static class WebAppInterface { WebViewHelper.OnGetDataListener onGetDataListener; WebAppInterface(WebViewHelper.OnGetDataListener onGetDataListener) { this.onGetDataListener = onGetDataListener; } @JavascriptInterface public void getText(String text) { onGetDataListener.getDataListener(text); } } public interface OnGetDataListener{ void getDataListener(String text); }
上面的实现思路是,当我们想要获取选中的网页内容时,将自己编写的一段JavaScript脚本注入到WebView中。这段JavaScript代码的意思是获取当前页面收录html标签的选中内容,调用JSInterface.getText(txt)方法。将内容返回给Java的getText(String text)方法,我们设置onGetDataListener.getDataListener(text)回调方法,在需要的地方调用获取内容。
二、如何加载和显示获取的网页内容
我们已经获得了网页的内容。调用TextView的setText(Html.fromHtml())方法来显示我们选择的效果是合理的,但是考虑到美观和保存截图的功能以及图片的正常显示,我选择使用WebView来加载得到的网页内容。
我是这样处理的:首先在本地assets文件夹中创建一个html页面,加载页面中的基本显示内容并添加css标签修改加载的内容,当获取到网页内容时,本地html page动态替换为JavaScript指定对应的标签内容为获取的网页内容,在本地html页面修改显示内容。
看代码:
webView.loadUrl("file:///android_asset/generate_pic.html"); public void changeDay(String strData,String userInfo,String userName,String other) { if(userInfo == null) userInfo =""; if(strData == null) strData =""; if(userName == null) userName =""; if(other == null) other =""; strData+="<br /><br />n" + "tt"+userInfo+"n" + "tt<br /><br />n" + "ttn" + "tt<br />n" + "tt<p style="/spancolor: orangered;font-size: x-small;text-align: center;letter-spacing: span class="hljs-number"0.5/spanpx;span class="hljs-string"">由"+userName+"发送 "+other+""; webView.loadUrl("javascript:changeContent("" + strData.replace("n", "\n").replace(""", "\"").replace("'", "\'") + "")"); webView.setBackgroundColor(Color.WHITE); }</p>
白色和黑色的不同显示效果可以通过changeDay方法中改变css样式来实现,比较简单。
但这里存在问题:当所选页面内容具有图片并且图像显示在相对路径中时,无法加载图像。
在这种情况下,图片是相对路径,即在本地对应的相对路径下查找。本地一定找不到,图片也不会显示。
为了能正常显示图片,在选中的内容页面调用onLoadResource方法判断加载的资源并保存图片路径,因为既然选中的页面图片是可以显示和处理的,就说明路径是http路径,可以显示图片。
看代码:
mWebView.setWebViewClient(new WebViewClient(){ @Override public void onLoadResource(WebView view, String url) { //Log.e("TAG","url :"+url); if(url.toLowerCase().contains(".jpg") ||url.toLowerCase().contains(".png") ||url.toLowerCase().contains(".gif")){ mlistPath.add(url); } super.onLoadResource(view, url); }
当显示选中的内容页面时,动态修改显示的图片路径以显示图片:
webView.setWebViewClient(new WebViewClient(){ @Override public boolean shouldOverrideUrlLoading(WebView view, String url) { //view.loadUrl(url); return true; } public WebResourceResponse shouldInterceptRequest(WebView view, String url) { WebResourceResponse response = null; for (String path:WebViewHelper.getInstance().getAllListPath()){ if (path.toLowerCase().contains(url.replace("file://","").toLowerCase())){ try { response = new WebResourceResponse("image/png", "UTF-8", new URL(path).openStream()); } catch (IOException e) { e.printStackTrace(); } } } return response; } });
这样我们的图片就可以显示出来了!
最后,实现我们的截图保存功能,看代码:
/** * 截屏 * * @return */ public Bitmap getScreen() { Bitmap bmp = Bitmap.createBitmap(webView.getWidth(), 1, Bitmap.Config.ARGB_8888); int rowBytes = bmp.getRowBytes(); bmp = null; if (rowBytes*webView.getHeight()>=getAvailMemory()){ return null; } bmp = Bitmap.createBitmap(webView.getWidth(), webView.getHeight(), Bitmap.Config.ARGB_8888); Canvas canvas = new Canvas(bmp); webView.draw(canvas); return bmp; } private long getAvailMemory() { return Runtime.getRuntime().maxMemory(); }
这里需要对保存的图片大小做判断,防止创建过大的OOM图片。
至此,基本功能已经实现。把照片分享给你的朋友~
项目地址:
欢迎star,问题~
js提取指定网站内容(共享文件夹.多POP3接收代理(,)页面,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-05 09:08
JS页面内容搜索,类似Ctrl+F功能的实现代码,页面,内容,搜索,类似,Ctrl+F,功能,的,实现
JS页面内容搜索,类似Ctrl+F功能的实现代码
一菜站长网站,站长之家为你整理JS页面内容搜索,类似Ctrl+F功能实现代码的相关内容。
注意:以上两种加入方式,共享文件夹共享时无需密码,无需输入密码。
修改:当共享文件夹被原共享者修改后,您可以使用修改功能更新该文件夹的密码。修改成功后就可以继续查看共享文件夹了。
多个POP3接收代理
如果您之前已经有其他电子邮件地址,并且您的朋友正在向这些地址发送电子邮件;您可以设置“POP3接收”功能,让系统通过POP3协议将您的邮件从其他地方提取到系统中。
请在“服务器地址”中填写您的POP3服务器的名称或地址,如“”,然后填写您在服务器上接收邮件时使用的账户名和密码。如果您不知道您的服务器使用什么端口,
请使用默认设置“110”。
用户拒绝电子邮件地址
对于您不想接收的电子邮件地址,您可以将它们添加到拒绝列表中。
高级邮件过滤功能
先进的邮件过滤功能可以让系统帮助您自动删除、自动回复或将符合指定条件(“邮件地址”、“发件人”、“邮件大小”或“主题”)的邮件移至垃圾箱操作。
以上是对JS页面内容搜索的实现代码的详细介绍,类似Ctrl+F功能。欢迎大家对JS页面内容搜索内容提出宝贵意见,类似Ctrl+F功能的实现代码内容 查看全部
js提取指定网站内容(共享文件夹.多POP3接收代理(,)页面,)
JS页面内容搜索,类似Ctrl+F功能的实现代码,页面,内容,搜索,类似,Ctrl+F,功能,的,实现
JS页面内容搜索,类似Ctrl+F功能的实现代码
一菜站长网站,站长之家为你整理JS页面内容搜索,类似Ctrl+F功能实现代码的相关内容。
注意:以上两种加入方式,共享文件夹共享时无需密码,无需输入密码。
修改:当共享文件夹被原共享者修改后,您可以使用修改功能更新该文件夹的密码。修改成功后就可以继续查看共享文件夹了。
多个POP3接收代理
如果您之前已经有其他电子邮件地址,并且您的朋友正在向这些地址发送电子邮件;您可以设置“POP3接收”功能,让系统通过POP3协议将您的邮件从其他地方提取到系统中。
请在“服务器地址”中填写您的POP3服务器的名称或地址,如“”,然后填写您在服务器上接收邮件时使用的账户名和密码。如果您不知道您的服务器使用什么端口,
请使用默认设置“110”。
用户拒绝电子邮件地址
对于您不想接收的电子邮件地址,您可以将它们添加到拒绝列表中。
高级邮件过滤功能
先进的邮件过滤功能可以让系统帮助您自动删除、自动回复或将符合指定条件(“邮件地址”、“发件人”、“邮件大小”或“主题”)的邮件移至垃圾箱操作。
以上是对JS页面内容搜索的实现代码的详细介绍,类似Ctrl+F功能。欢迎大家对JS页面内容搜索内容提出宝贵意见,类似Ctrl+F功能的实现代码内容
js提取指定网站内容(au自动生成一个Json格式的结果我希望查询明天悉尼的天气如何)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-03 09:15
Powershell 可以轻松获取网页的信息并读取相应的内容。如果对象的格式是 XML 或 Json,则更容易处理。一般经常用到invoke-restmethod和invoke-webrequest这两个命令。前者主要是获取Json格式的内容,后者可以获取整个网页的内容。
例如,我想查看明天悉尼的天气。我在网上随便搜了一个提供API的网站
我打算搜索Sydney,所以对应的格式是
,au 他会自动生成 Json 格式的结果。
我们可以使用invoke-restmethod直接得到这个结果,例如
$b=invoke-restmethod "http://api.openweathermap.org/ ... ydney,au"
$c=[pscustomobject]@{
'Description'=$b.weather.description
'name'=$b.name
'windspeed'=$b.wind.speed
}
我也可以直接用invoke-webrequest来抓取整个网页的内容,然后从Json格式转过来。
$a= Invoke-WebRequest -Uri "http://api.openweathermap.org/ ... ydney,au"
$b=$a.Content | ConvertFrom-Json
同样,如果我想获取博客的最新 RSS 内容。可以使用invoke-webrequest抓取对应的xml文件,如
[xml]$a= Invoke-WebRequest -Uri "http://blogs.msdn.com/b/powershell/rss.aspx“
$a.rss.channel.Item | select title,pubdate
功能很强大,但是使用起来很简单。 查看全部
js提取指定网站内容(au自动生成一个Json格式的结果我希望查询明天悉尼的天气如何)
Powershell 可以轻松获取网页的信息并读取相应的内容。如果对象的格式是 XML 或 Json,则更容易处理。一般经常用到invoke-restmethod和invoke-webrequest这两个命令。前者主要是获取Json格式的内容,后者可以获取整个网页的内容。
例如,我想查看明天悉尼的天气。我在网上随便搜了一个提供API的网站
我打算搜索Sydney,所以对应的格式是
,au 他会自动生成 Json 格式的结果。
我们可以使用invoke-restmethod直接得到这个结果,例如
$b=invoke-restmethod "http://api.openweathermap.org/ ... ydney,au"
$c=[pscustomobject]@{
'Description'=$b.weather.description
'name'=$b.name
'windspeed'=$b.wind.speed
}
我也可以直接用invoke-webrequest来抓取整个网页的内容,然后从Json格式转过来。
$a= Invoke-WebRequest -Uri "http://api.openweathermap.org/ ... ydney,au"
$b=$a.Content | ConvertFrom-Json
同样,如果我想获取博客的最新 RSS 内容。可以使用invoke-webrequest抓取对应的xml文件,如
[xml]$a= Invoke-WebRequest -Uri "http://blogs.msdn.com/b/powershell/rss.aspx“
$a.rss.channel.Item | select title,pubdate
功能很强大,但是使用起来很简单。
js提取指定网站内容(首页gtgt博客文章withpy2021-11-13(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-03 04:04
首页>博客文章使用JavaScript获取页面文档内容
withpy2021-11-13
简介 JavaScript 的 document 对象收录了页面的实际内容,因此可以使用 document 对象来获取页面内容,例如页面标题和各种表单值。 "/>
JavaScript 的 document 对象收录页面的实际内容,因此可以使用 document 对象获取页面的内容,例如页面标题和各种表单值。
1 DOCTYPE html>
2 js基础一. 用Document对象获得页面标题11 hr/>
12 >二. 用Document访问一下两个表单13
14 >第一个,文本框的值15
16 form name="textform"17 input ="textname" type="text" value="请输入文本"18 form19 >第二个,按钮的值20
21 ="submitform"22 ="submitname"="submit"="第一个表单内提交"23 24 25 >以下是获取到的值26 table border="1" cellspacing="4" cellpadding="2"27 tr28 td>获取到本页的标题是 : 29 > b>document.write(document.title)>本页包含表单 : 33 document.write(document.forms.length)34 35 36 >获取到文本框的值 : 37 document.write(window.document.textform.textname.value)38 39 40 >获取到按钮的值 : 41 document.write(window.document.submitform.submitname.value)42 43
44 table45
46 47 html>
总结
以上是本站为您采集整理的使用JavaScript获取的页面文档内容的全部内容。希望文章可以帮助大家解决使用JavaScript获取页面文档内容时遇到的程序开发问题。
如果您觉得本站网站的内容还不错,欢迎向程序员朋友推荐本站网站。 查看全部
js提取指定网站内容(首页gtgt博客文章withpy2021-11-13(图))
首页>博客文章使用JavaScript获取页面文档内容
withpy2021-11-13
简介 JavaScript 的 document 对象收录了页面的实际内容,因此可以使用 document 对象来获取页面内容,例如页面标题和各种表单值。 "/>
JavaScript 的 document 对象收录页面的实际内容,因此可以使用 document 对象获取页面的内容,例如页面标题和各种表单值。
1 DOCTYPE html>
2 js基础一. 用Document对象获得页面标题11 hr/>
12 >二. 用Document访问一下两个表单13
14 >第一个,文本框的值15
16 form name="textform"17 input ="textname" type="text" value="请输入文本"18 form19 >第二个,按钮的值20
21 ="submitform"22 ="submitname"="submit"="第一个表单内提交"23 24 25 >以下是获取到的值26 table border="1" cellspacing="4" cellpadding="2"27 tr28 td>获取到本页的标题是 : 29 > b>document.write(document.title)>本页包含表单 : 33 document.write(document.forms.length)34 35 36 >获取到文本框的值 : 37 document.write(window.document.textform.textname.value)38 39 40 >获取到按钮的值 : 41 document.write(window.document.submitform.submitname.value)42 43
44 table45
46 47 html>
总结
以上是本站为您采集整理的使用JavaScript获取的页面文档内容的全部内容。希望文章可以帮助大家解决使用JavaScript获取页面文档内容时遇到的程序开发问题。
如果您觉得本站网站的内容还不错,欢迎向程序员朋友推荐本站网站。
js提取指定网站内容( 2020年02月19日16:50:52作者huangtailangJS操作Fckeditor)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-03 04:02
2020年02月19日16:50:52作者huangtailangJS操作Fckeditor)
在 FCKeditor 编辑器中使用 Js 获取、插入和更改内容
更新时间:2020-02-19 16:50:52 作者:huangtailang
这个文章主要介绍了在FCKeditor编辑器中使用js获取、插入和更改内容,包括一些js操作Fckeditor的常用方法,有需要的朋友可以参考
FCKeditor 编辑器之前在一个系统中使用过。由于项目需要,需要在FCKeditor中添加一个自定义按钮来实现自己的需求。
主要是在FCKeditor编辑器中点击按钮时删除或添加内容
其实就是一个很简单的需求。我认为它可以在 FCKeditor 中轻松实现。
在 Google 上搜索自定义按钮和插件开发。经过近两个小时的探索,我还是没有意识到。不知道是我太笨还是自定义插件太难了。
通过JS方法处理
1.页面添加checkbox元素并绑定事件。当这个元素被选中时,“{#book#}”字符串会被添加到FCKeditor内容中(该字符串会在合适的时候被替换为其他内容),不选中时删除
2.添加Js处理FCKeditor内容(添加或删除“{#book#}”字符串),'txtContent'为FCKeditor的ID控件ID
//"添加/删除复选框"点击时如果按钮选中则添加"{#book#}"字符串到FCK内容里,反之删除字符串
//lineBook为FCK的ID号
function chk_but() {
if (window.FCKeditorAPI !== undefined && FCKeditorAPI.GetInstance('txtContent') !== undefined) {
if (document.getElementById('lineBook').checked) {
FCKeditorAPI.GetInstance('txtContent').EditorDocument.body.innerHTML += "{#book#}";
} else {
FCKeditorAPI.GetInstance('txtContent').EditorDocument.body.innerHTML = FCKeditorAPI.GetInstance('txtContent').EditorDocument.body.innerHTML.replace("{#book#}", "");
}
}
} //end function chk_lineBook()
//内容里如果有{#book#}则选中"添加/删除复选框"
if (document.getElementById('txtContent').value.indexOf('{#book#}') >= 0
&& window.FCKeditorAPI !== undefined
&& FCKeditorAPI.GetInstance('txtContent') !== undefined) {
document.getElementById('lineBook').checked = true;
}
参考:
官网:
获取或更改内容值:
创建插件:
接下来给大家分享一些JS操作Fckeditor的常用方法
//向编辑器插入指定代码
function insertHTMLToEditor(codeStr){
var oEditor = FCKeditorAPI.GetInstance("content");
oEditor.InsertHtml(codeStr); // "html"为HTML文本
}
//获取编辑器中HTML内容
function getEditorHTMLContents() {
var oEditor = FCKeditorAPI.GetInstance("content");
return(oEditor.GetXHTML(false));
}
// 获取编辑器中文字内容
function getEditorTextContents() {
var oEditor = FCKeditorAPI.GetInstance("content");
return(oEditor.EditorDocument.body.innerText);
}
// 设置编辑器中内容
function SetEditorContents(ContentStr) {
var oEditor = FCKeditorAPI.GetInstance("content") ;
oEditor.SetHTML(ContentStr) ;
}
//向编辑器插入指定代码
function insertHTMLToEditor(codeStr){
var oEditor = FCKeditorAPI.GetInstance( "content ");
if (oEditor.EditMode==FCK_EDITMODE_WYSIWYG){
oEditor.InsertHtml(codeStr);
}else{
return false;
}
}
//统计编辑器中内容的字数
function getLength(){
var oEditor = FCKeditorAPI.GetInstance( "content ");
var oDOM = oEditor.EditorDocument;
var iLength ;
if(document.all){
iLength = oDOM.body.innerText.length;
}else{
var r = oDOM.createRange();
r.selectNodeContents(oDOM.body);
iLength = r.toString().length;
}
alert(iLength);
}
//执行指定动作
function ExecuteCommand(commandName){
var oEditor = FCKeditorAPI.GetInstance( "content ") ;
oEditor.Commands.GetCommand(commandName).Execute() ;
}
这是文章关于在FCKeditor编辑器中使用Js获取、插入和更改内容的介绍。更多相关Js操作FCKeditor编辑器内容,请搜索之前的脚本首页文章或下方相关文章,希望大家以后多多支持Scripthome! 查看全部
js提取指定网站内容(
2020年02月19日16:50:52作者huangtailangJS操作Fckeditor)
在 FCKeditor 编辑器中使用 Js 获取、插入和更改内容
更新时间:2020-02-19 16:50:52 作者:huangtailang
这个文章主要介绍了在FCKeditor编辑器中使用js获取、插入和更改内容,包括一些js操作Fckeditor的常用方法,有需要的朋友可以参考
FCKeditor 编辑器之前在一个系统中使用过。由于项目需要,需要在FCKeditor中添加一个自定义按钮来实现自己的需求。
主要是在FCKeditor编辑器中点击按钮时删除或添加内容
其实就是一个很简单的需求。我认为它可以在 FCKeditor 中轻松实现。
在 Google 上搜索自定义按钮和插件开发。经过近两个小时的探索,我还是没有意识到。不知道是我太笨还是自定义插件太难了。
通过JS方法处理
1.页面添加checkbox元素并绑定事件。当这个元素被选中时,“{#book#}”字符串会被添加到FCKeditor内容中(该字符串会在合适的时候被替换为其他内容),不选中时删除
2.添加Js处理FCKeditor内容(添加或删除“{#book#}”字符串),'txtContent'为FCKeditor的ID控件ID
//"添加/删除复选框"点击时如果按钮选中则添加"{#book#}"字符串到FCK内容里,反之删除字符串
//lineBook为FCK的ID号
function chk_but() {
if (window.FCKeditorAPI !== undefined && FCKeditorAPI.GetInstance('txtContent') !== undefined) {
if (document.getElementById('lineBook').checked) {
FCKeditorAPI.GetInstance('txtContent').EditorDocument.body.innerHTML += "{#book#}";
} else {
FCKeditorAPI.GetInstance('txtContent').EditorDocument.body.innerHTML = FCKeditorAPI.GetInstance('txtContent').EditorDocument.body.innerHTML.replace("{#book#}", "");
}
}
} //end function chk_lineBook()
//内容里如果有{#book#}则选中"添加/删除复选框"
if (document.getElementById('txtContent').value.indexOf('{#book#}') >= 0
&& window.FCKeditorAPI !== undefined
&& FCKeditorAPI.GetInstance('txtContent') !== undefined) {
document.getElementById('lineBook').checked = true;
}
参考:
官网:
获取或更改内容值:
创建插件:
接下来给大家分享一些JS操作Fckeditor的常用方法
//向编辑器插入指定代码
function insertHTMLToEditor(codeStr){
var oEditor = FCKeditorAPI.GetInstance("content");
oEditor.InsertHtml(codeStr); // "html"为HTML文本
}
//获取编辑器中HTML内容
function getEditorHTMLContents() {
var oEditor = FCKeditorAPI.GetInstance("content");
return(oEditor.GetXHTML(false));
}
// 获取编辑器中文字内容
function getEditorTextContents() {
var oEditor = FCKeditorAPI.GetInstance("content");
return(oEditor.EditorDocument.body.innerText);
}
// 设置编辑器中内容
function SetEditorContents(ContentStr) {
var oEditor = FCKeditorAPI.GetInstance("content") ;
oEditor.SetHTML(ContentStr) ;
}
//向编辑器插入指定代码
function insertHTMLToEditor(codeStr){
var oEditor = FCKeditorAPI.GetInstance( "content ");
if (oEditor.EditMode==FCK_EDITMODE_WYSIWYG){
oEditor.InsertHtml(codeStr);
}else{
return false;
}
}
//统计编辑器中内容的字数
function getLength(){
var oEditor = FCKeditorAPI.GetInstance( "content ");
var oDOM = oEditor.EditorDocument;
var iLength ;
if(document.all){
iLength = oDOM.body.innerText.length;
}else{
var r = oDOM.createRange();
r.selectNodeContents(oDOM.body);
iLength = r.toString().length;
}
alert(iLength);
}
//执行指定动作
function ExecuteCommand(commandName){
var oEditor = FCKeditorAPI.GetInstance( "content ") ;
oEditor.Commands.GetCommand(commandName).Execute() ;
}
这是文章关于在FCKeditor编辑器中使用Js获取、插入和更改内容的介绍。更多相关Js操作FCKeditor编辑器内容,请搜索之前的脚本首页文章或下方相关文章,希望大家以后多多支持Scripthome!
js提取指定网站内容(如何使用RPA工具进行自动化工具?工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-31 06:18
背景
RPA工作流中最常见的场景是操作浏览器,对页面内容进行相关操作。本例以页面为例。带领大家初步探索如何使用RPA工具自动抓取页面文本内容。
本文将使用 JavaScript 开发 RPA 脚本。这里使用的RPA工具LeanRunner可以直接从Windows应用商店下载,支持使用node.js开源自动化库进行RPA开发。用户可以按照以下步骤逐步实现自己的 RPA 脚本。
脚步
新项目
打开LeanRunner,选择【项目】-【新建】-【选择基本项目模板】,输入项目名称:demo,选择项目路径:
安装依赖库
Selenium-webdriver 是一个流行的操作 Web 自动化库。使用 chromedriver 库可以驱动 Chrome 自动化各种网页。当然,文本提取不是问题。本 RPA 使用这两个库来实现功能。所以创建项目后,需要安装相应的库。
点击LeanRunner打开命令行工具按钮
, 执行安装命令:
npm init -ynpm install chromedriver selenium-webdriver @types/selenium-webdriver --save
备注:npm是node.js的包管理机制,需要安装node.js环境才能使用
(下载链接:)
定义流程步骤
流程步骤被定义为使自动化流程可读。
一个。打开main.js,在【Toolbox】-【Frame】中找到stepGroup方法,拖拽到js文件中。
湾 在弹出的对话框中输入描述文字:抓取网页文字内容,点击插入代码。
C。此时,main.js文件的内容:
const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { })}
d. 继续拖拽【Toolbox】-【Frame】中的step方法来描述文字输入:使用Chrome浏览器打开你要截取的网站:
e. 按照上述步骤再次插入用于抓取文本和关闭浏览器的步骤定义。
main.js 如下:
const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}
F。插入Workflow.run函数,RPA执行最终会被执行,在【Toolbox】-【Framework】中选择Workrun.run()函数:
G。在运行函数中输入“main”:
最后的代码是:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}Workflow.run(main);
实施步骤
参考 selenium-webdriver API
(). 分别实现以上操作步骤:
一个。使用Chrome浏览器打开你要截取的网站:
const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();const url = 'http://wufazhuce.com/one/2558';await driver.get(url);
上面的代码创建了一个 WebDriver 实例,打开一个浏览器窗口,并导航到目标 url。
湾 抓取文本:
let text = await driver.findElement({ css:'div[]'}).getText();console.log(text);
上面的代码使用css选择器定位要访问的元素并打印出来。
C。关闭浏览器
await driver.close();
最终代码如下:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');require('chromedriver');const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { const url = 'http://wufazhuce.com/one/2558'; await driver.get(url); }) await step("抓取文本", async (world) => { let text = await driver.findElement({ css:'div[]'}).getText(); console.log(text); world.attachText(text); }) await step("关闭浏览器", async (world) => { await driver.close() }) })}Workflow.run(main);
实施
单击“运行”按钮
, 或者点击“运行项目”按钮
可以看到浏览器打开网页,在LeanRunner设计器的输出面板中打印出文本内容。
如果是运行项目,也会显示html运行报告:
对于用户来说,html 报告更具可读性。
总结
至此,我们已经完成了一个基本操作网页的RPA。后续的操作可以在这个RPA的基础上进一步深化,比如将抓取到的文本内容存入Excel表格或者存入数据库。
本文使用的 selenium-webdriver 自动化库是一个非常流行的开源库,可以支持各种类型的浏览器,并且可以及时更新以支持最新版本的浏览器。同时,Node.js 也是一个非常流行的开源平台。基于这些技术,开发RPA自动化脚本来维护RPA脚本的可用性和可维护性。结合LeanRunner RPA平台,可以帮助企业快速构建自己的流程自动化。 查看全部
js提取指定网站内容(如何使用RPA工具进行自动化工具?工具)
背景
RPA工作流中最常见的场景是操作浏览器,对页面内容进行相关操作。本例以页面为例。带领大家初步探索如何使用RPA工具自动抓取页面文本内容。
本文将使用 JavaScript 开发 RPA 脚本。这里使用的RPA工具LeanRunner可以直接从Windows应用商店下载,支持使用node.js开源自动化库进行RPA开发。用户可以按照以下步骤逐步实现自己的 RPA 脚本。
脚步
新项目
打开LeanRunner,选择【项目】-【新建】-【选择基本项目模板】,输入项目名称:demo,选择项目路径:
安装依赖库
Selenium-webdriver 是一个流行的操作 Web 自动化库。使用 chromedriver 库可以驱动 Chrome 自动化各种网页。当然,文本提取不是问题。本 RPA 使用这两个库来实现功能。所以创建项目后,需要安装相应的库。
点击LeanRunner打开命令行工具按钮
, 执行安装命令:
npm init -ynpm install chromedriver selenium-webdriver @types/selenium-webdriver --save
备注:npm是node.js的包管理机制,需要安装node.js环境才能使用
(下载链接:)
定义流程步骤
流程步骤被定义为使自动化流程可读。
一个。打开main.js,在【Toolbox】-【Frame】中找到stepGroup方法,拖拽到js文件中。
湾 在弹出的对话框中输入描述文字:抓取网页文字内容,点击插入代码。
C。此时,main.js文件的内容:
const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { })}
d. 继续拖拽【Toolbox】-【Frame】中的step方法来描述文字输入:使用Chrome浏览器打开你要截取的网站:
e. 按照上述步骤再次插入用于抓取文本和关闭浏览器的步骤定义。
main.js 如下:
const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}
F。插入Workflow.run函数,RPA执行最终会被执行,在【Toolbox】-【Framework】中选择Workrun.run()函数:
G。在运行函数中输入“main”:
最后的代码是:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}Workflow.run(main);
实施步骤
参考 selenium-webdriver API
(). 分别实现以上操作步骤:
一个。使用Chrome浏览器打开你要截取的网站:
const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();const url = 'http://wufazhuce.com/one/2558';await driver.get(url);
上面的代码创建了一个 WebDriver 实例,打开一个浏览器窗口,并导航到目标 url。
湾 抓取文本:
let text = await driver.findElement({ css:'div[]'}).getText();console.log(text);
上面的代码使用css选择器定位要访问的元素并打印出来。
C。关闭浏览器
await driver.close();
最终代码如下:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');require('chromedriver');const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { const url = 'http://wufazhuce.com/one/2558'; await driver.get(url); }) await step("抓取文本", async (world) => { let text = await driver.findElement({ css:'div[]'}).getText(); console.log(text); world.attachText(text); }) await step("关闭浏览器", async (world) => { await driver.close() }) })}Workflow.run(main);
实施
单击“运行”按钮
, 或者点击“运行项目”按钮
可以看到浏览器打开网页,在LeanRunner设计器的输出面板中打印出文本内容。
如果是运行项目,也会显示html运行报告:
对于用户来说,html 报告更具可读性。
总结
至此,我们已经完成了一个基本操作网页的RPA。后续的操作可以在这个RPA的基础上进一步深化,比如将抓取到的文本内容存入Excel表格或者存入数据库。
本文使用的 selenium-webdriver 自动化库是一个非常流行的开源库,可以支持各种类型的浏览器,并且可以及时更新以支持最新版本的浏览器。同时,Node.js 也是一个非常流行的开源平台。基于这些技术,开发RPA自动化脚本来维护RPA脚本的可用性和可维护性。结合LeanRunner RPA平台,可以帮助企业快速构建自己的流程自动化。
js提取指定网站内容(爬虫学哪个库好?Python爬虫库对比分析(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-25 08:17
读者经常在哪个图书馆学习爬虫?其实常用的Python爬虫库无非是requests、selenium和scrapy,每个库都有自己的特点。对我来说,没有最推荐的库,只有最合适的库。本文将基于一个简单的爬虫案例(Python爬取起点中文网站)对三个库进行对比分析(从时间角度)
目标需求是批量采集排名书信息,如下图:
页面结构易于分析。排行榜有100本书信息,一个静态页面收录20条数据。使用不同的第三方库来分析和提取数据,它们是:
然后在逻辑代码的开头和结尾加上时间戳,得到程序运行时间,比较效率。
这里,因为xpath是用来提取数据的,所以xpath语句的三种方式是类似的,这里先对数据分析做一下说明:
1. imgLink: //div[@class='book-img-text']/ul/li/div[1]/a/@href
2. title: //div[@class='book-img-text']/ul/li//div[2]/h4/a/text()
3. author: //div[@class='book-img-text']/ul/li/div[2]/p[1]/a[1]/text()
4. intro: //div[@class='book-img-text']/ul/li/div[2]/p[2]/text()
5. update://div[@class='book-img-text']/ul/li/div[2]/p[3]/a/text()
一、请求
首先导入相关库
from lxml import etree
import requests
import time
逻辑代码如下
start = time.time() # 开始计时⏲
url = 'https://www.qidian.com/rank/yu ... 39%3B
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
page = requests.get(url,headers=headers)
html = etree.HTML(page.content.decode('utf-8'))
books = html.xpath("//div[@class='book-img-text']/ul/li")
for book in books:
imglink = 'https:' + book.xpath("./div[1]/a/@href")[0]
# 其它信息xpath提取,这里省略 ....
update = book.xpath("./div[2]/p[3]/a/text()")[0]
print(imglink,title,author,intro,update)
end = time.time() # 结束计时⏲
print(end-start)
程序运行结果如下
可以看到爬下所有数据需要0.823s。
二、 硒
首先导入相关库
import time
from selenium import webdriver
代码实现如下
url = 'https://www.qidian.com/rank/yu ... 39%3B
start = time.time() # 开始计时⏲
driver = webdriver.Chrome()
driver.get(url)
books = driver.find_elements_by_xpath("//div[@class='book-img-text']/ul/li")
for book in books:
imglink = 'https:' + book.find_element_by_xpath("./div[1]/a").get_attribute('href')
# 其它小说信息的定位提取语句,...
update = book.find_element_by_xpath("./div[2]/p[3]/a").text
print(imglink,title,author,intro,update)
end = time.time() # 结束计时⏲
print(end-start)
# 18.564752340316772
运行结果如下
可以看到时间是18.8174s
三、Scrapy
最后是Scrapy的实现,代码如下
import scrapy
import time
class QdSpider(scrapy.Spider):
name = 'qd'
allowed_domains = ['qidian.com']
start_urls = ['https://www.qidian.com/rank/yu ... 39%3B]
def parse(self, response):
start = time.time() # 开始计时⏲
books = response.xpath("//div[@class='book-img-text']/ul/li")
for book in books:
imglink = 'https:' + book.xpath("./div[1]/a/@href").extract_first()
# 其它信息的xpath提取语句,......
update = book.xpath("./div[2]/p[3]/a/text()").extract_first()
print(imglink, title, author, intro, update)
end = time.time() # 结束计时⏲
print(end - start)
运行结果如下
可以看到运行时间只用了0.016s
四、结果分析
从代码量来看:其实代码量没有太大区别,因为实现逻辑比较简单。
但是在运行时间方面:scrapy最快,只需要不到0.02s,selenium最慢,需要将近20s,运行效率是scrapy的1/1000。但是,与 requests 和 selenium 相比,在 scrapy 中开发和调试代码需要更长的时间。
我正在仔细研究原因
”
requests:请求模拟浏览器请求。下载请求的网页内容后,不会执行js代码。
为什么 selenium 最慢:首先,Selenium 是 Web 应用程序的自动化测试工具。Selenium 测试直接在浏览器中运行(支持多种浏览器,Google、Firefox 等)来模拟用户操作来获取网页渲染。导致selenium解析并执行网页的CSS和js代码,效率低下。
scrapy框架的爬取效率最高:首先,和requests一样,scrapy不执行web js代码,但是我们知道scrapy是一个提取结构化数据的应用框架。Scrapy 使用了 Twisted 异步 web 框架,可以加快我们的下载速度。, 并发性好,性能高,所以效率最高。
”
五、补充
通过上面的简单测试,我们可能会觉得selenium效率太低了。是不是因为数据采集在selenium中不常用?只能说,在可以爬取数据的前提下,采集 高效的方法会是首选。
所以这篇文章的目的不是要说明不要使用selenium。接下来我们来看看招聘网站--拉勾招聘页面数据采集。随机选择一个帖子java,页面如下:
5.1 请求实现
如果您使用 requests 来请求数据
你会发现没有数据,网页已经进行了反爬虫处理。这时候硒就派上用场了。无需分析网站反爬方法,直接模拟用户请求数据(大多数情况下也有反硒反爬方法)。攀登手段)
5.2 selenium 实现
上面提到,如果你使用requests或者scrapy爬虫来寻找反爬虫的措施,你可以试试selenium,这个有时候很简单
from selenium import webdriver
url = 'https://www.lagou.com/zhaopin/ ... 39%3B
driver = webdriver.Chrome()
driver.get(url)
items = driver.find_elements_by_xpath("//ul[@class='item_con_list']/li")
print(len(items))
for item in items:
title = item.find_element_by_xpath("./div[1]/div[1]/div[1]/a/h3").text
print(title)
运行结果如下:
页面的数据很容易提取!
因此,根据本文的案例分析,如果有爬虫需求,在某一个方法中冻结该方法并不是一个好的选择。大多数情况下,我们需要根据对应网站/app的特点和具体需求进行集成判断,选择最合适的爬虫库!
, 查看全部
js提取指定网站内容(爬虫学哪个库好?Python爬虫库对比分析(一))
读者经常在哪个图书馆学习爬虫?其实常用的Python爬虫库无非是requests、selenium和scrapy,每个库都有自己的特点。对我来说,没有最推荐的库,只有最合适的库。本文将基于一个简单的爬虫案例(Python爬取起点中文网站)对三个库进行对比分析(从时间角度)
目标需求是批量采集排名书信息,如下图:
页面结构易于分析。排行榜有100本书信息,一个静态页面收录20条数据。使用不同的第三方库来分析和提取数据,它们是:
然后在逻辑代码的开头和结尾加上时间戳,得到程序运行时间,比较效率。
这里,因为xpath是用来提取数据的,所以xpath语句的三种方式是类似的,这里先对数据分析做一下说明:
1. imgLink: //div[@class='book-img-text']/ul/li/div[1]/a/@href
2. title: //div[@class='book-img-text']/ul/li//div[2]/h4/a/text()
3. author: //div[@class='book-img-text']/ul/li/div[2]/p[1]/a[1]/text()
4. intro: //div[@class='book-img-text']/ul/li/div[2]/p[2]/text()
5. update://div[@class='book-img-text']/ul/li/div[2]/p[3]/a/text()
一、请求
首先导入相关库
from lxml import etree
import requests
import time
逻辑代码如下
start = time.time() # 开始计时⏲
url = 'https://www.qidian.com/rank/yu ... 39%3B
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
page = requests.get(url,headers=headers)
html = etree.HTML(page.content.decode('utf-8'))
books = html.xpath("//div[@class='book-img-text']/ul/li")
for book in books:
imglink = 'https:' + book.xpath("./div[1]/a/@href")[0]
# 其它信息xpath提取,这里省略 ....
update = book.xpath("./div[2]/p[3]/a/text()")[0]
print(imglink,title,author,intro,update)
end = time.time() # 结束计时⏲
print(end-start)
程序运行结果如下
可以看到爬下所有数据需要0.823s。
二、 硒
首先导入相关库
import time
from selenium import webdriver
代码实现如下
url = 'https://www.qidian.com/rank/yu ... 39%3B
start = time.time() # 开始计时⏲
driver = webdriver.Chrome()
driver.get(url)
books = driver.find_elements_by_xpath("//div[@class='book-img-text']/ul/li")
for book in books:
imglink = 'https:' + book.find_element_by_xpath("./div[1]/a").get_attribute('href')
# 其它小说信息的定位提取语句,...
update = book.find_element_by_xpath("./div[2]/p[3]/a").text
print(imglink,title,author,intro,update)
end = time.time() # 结束计时⏲
print(end-start)
# 18.564752340316772
运行结果如下
可以看到时间是18.8174s
三、Scrapy
最后是Scrapy的实现,代码如下
import scrapy
import time
class QdSpider(scrapy.Spider):
name = 'qd'
allowed_domains = ['qidian.com']
start_urls = ['https://www.qidian.com/rank/yu ... 39%3B]
def parse(self, response):
start = time.time() # 开始计时⏲
books = response.xpath("//div[@class='book-img-text']/ul/li")
for book in books:
imglink = 'https:' + book.xpath("./div[1]/a/@href").extract_first()
# 其它信息的xpath提取语句,......
update = book.xpath("./div[2]/p[3]/a/text()").extract_first()
print(imglink, title, author, intro, update)
end = time.time() # 结束计时⏲
print(end - start)
运行结果如下
可以看到运行时间只用了0.016s
四、结果分析
从代码量来看:其实代码量没有太大区别,因为实现逻辑比较简单。
但是在运行时间方面:scrapy最快,只需要不到0.02s,selenium最慢,需要将近20s,运行效率是scrapy的1/1000。但是,与 requests 和 selenium 相比,在 scrapy 中开发和调试代码需要更长的时间。
我正在仔细研究原因
”
requests:请求模拟浏览器请求。下载请求的网页内容后,不会执行js代码。
为什么 selenium 最慢:首先,Selenium 是 Web 应用程序的自动化测试工具。Selenium 测试直接在浏览器中运行(支持多种浏览器,Google、Firefox 等)来模拟用户操作来获取网页渲染。导致selenium解析并执行网页的CSS和js代码,效率低下。
scrapy框架的爬取效率最高:首先,和requests一样,scrapy不执行web js代码,但是我们知道scrapy是一个提取结构化数据的应用框架。Scrapy 使用了 Twisted 异步 web 框架,可以加快我们的下载速度。, 并发性好,性能高,所以效率最高。
”
五、补充
通过上面的简单测试,我们可能会觉得selenium效率太低了。是不是因为数据采集在selenium中不常用?只能说,在可以爬取数据的前提下,采集 高效的方法会是首选。
所以这篇文章的目的不是要说明不要使用selenium。接下来我们来看看招聘网站--拉勾招聘页面数据采集。随机选择一个帖子java,页面如下:
5.1 请求实现
如果您使用 requests 来请求数据
你会发现没有数据,网页已经进行了反爬虫处理。这时候硒就派上用场了。无需分析网站反爬方法,直接模拟用户请求数据(大多数情况下也有反硒反爬方法)。攀登手段)
5.2 selenium 实现
上面提到,如果你使用requests或者scrapy爬虫来寻找反爬虫的措施,你可以试试selenium,这个有时候很简单
from selenium import webdriver
url = 'https://www.lagou.com/zhaopin/ ... 39%3B
driver = webdriver.Chrome()
driver.get(url)
items = driver.find_elements_by_xpath("//ul[@class='item_con_list']/li")
print(len(items))
for item in items:
title = item.find_element_by_xpath("./div[1]/div[1]/div[1]/a/h3").text
print(title)
运行结果如下:
页面的数据很容易提取!
因此,根据本文的案例分析,如果有爬虫需求,在某一个方法中冻结该方法并不是一个好的选择。大多数情况下,我们需要根据对应网站/app的特点和具体需求进行集成判断,选择最合适的爬虫库!
,
js提取指定网站内容(Python脚本从动态网站收集数据的方法-元素为空 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-25 08:16
)
该元素为空。
从动态网站中采集数据的方法
我们已经看到,由于数据是使用JavaScript动态加载的,爬虫无法从动态的网站中抓取信息。在这种情况下,我们可以使用以下两种技术从依赖动态 JavaScript 的 网站 中抓取数据——
对 JavaScript 进行逆向工程
一个叫做逆向工程的过程会非常有用,它可以让我们了解网页是如何动态加载数据的。
为此,我们需要单击指定元素的检查元素选项卡。接下来,我们将单击 NETWORK 选项卡以查找对该网页发出的所有请求,包括带有 /ajax 路径的 search.json。除了从浏览器或通过 NETWORK 选项卡访问 AJAX 数据之外,我们还可以在以下 Python 脚本的帮助下进行 -
import requests
url=requests.get('http://example.webscraping.com ... %2339;)
url.json()
例子
上面的脚本允许我们使用 Python json 方法访问 JSON 响应。同样,我们可以下载原创字符串响应,并使用python的json.loads方法加载它。我们在以下 Python 脚本的帮助下完成此操作。基本上,通过搜索字母“a”,然后迭代 JSON 响应的结果页面,可以抓取所有国家/地区。
import requests
import string
PAGE_SIZE = 15
url = 'http://example.webscraping.com/ajax/' + 'search.json?page={}&page_size={}&search_term=a'
countries = set()
for letter in string.ascii_lowercase:
print('Searching with %s' % letter)
page = 0
while True:
response = requests.get(url.format(page, PAGE_SIZE, letter))
data = response.json()
print('adding %d records from the page %d' %(len(data.get('records')),page))
for record in data.get('records'):countries.add(record['country'])
page += 1
if page >= data['num_pages']:
break
with open('countries.txt', 'w') as countries_file:
countries_file.write('n'.join(sorted(countries)))
运行上述脚本后,我们将得到以下输出,并且记录将保存在一个名为 countrys.txt 的文件中。
输出
Searching with a
adding 15 records from the page 0
adding 15 records from the page 1
...
呈现 JavaScript
在上一节中,我们对网页进行了逆向工程,以了解 API 的工作原理以及如何使用它在单个请求中检索结果。但是,在执行逆向工程时,我们将面临以下困难 -
上述问题的解决方案是使用浏览器渲染引擎解析HTML,应用CSS格式,执行JavaScript来显示网页。
例子
在这个例子中,为了呈现 Java 脚本,我们将使用熟悉的 Python 模块 Selenium。以下 Python 代码将在 Selenium 的帮助下呈现网页 -
首先,我们需要从 selenium 导入 webdriver,如下所示:
from selenium import webdriver
现在,提供我们根据需要下载的 Web 驱动程序的路径-
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
driver = webdriver.Chrome(executable_path = path)
现在,提供我们要在此 Web 浏览器中打开的 URL,该 URL 现在由我们的 Python 脚本控制。
driver.get('http://example.webscraping.com/search')
现在,我们可以使用搜索工具箱的 ID 来设置要选择的元素。
driver.find_element_by_id('search_term').send_keys('.')
接下来,我们可以使用Java脚本来设置选择框的内容,如下图:
js = "document.getElementById('page_size').options[1].text = '100';"
driver.execute_script(js)
以下代码行显示您可以在网页上单击以进行搜索 -
driver.find_element_by_id('search').click()
下一行代码显示它将等待 45 秒来完成 AJAX 请求。
driver.implicitly_wait(45)
现在,要选择国家/地区链接,我们可以使用 CSS 选择器,如下所示:
links = driver.find_elements_by_css_selector('#results a')
现在可以提取每个链接的文本以创建国家/地区列表-
countries = [link.text for link in links]
print(countries)
driver.close() 查看全部
js提取指定网站内容(Python脚本从动态网站收集数据的方法-元素为空
)
该元素为空。
从动态网站中采集数据的方法
我们已经看到,由于数据是使用JavaScript动态加载的,爬虫无法从动态的网站中抓取信息。在这种情况下,我们可以使用以下两种技术从依赖动态 JavaScript 的 网站 中抓取数据——
对 JavaScript 进行逆向工程
一个叫做逆向工程的过程会非常有用,它可以让我们了解网页是如何动态加载数据的。
为此,我们需要单击指定元素的检查元素选项卡。接下来,我们将单击 NETWORK 选项卡以查找对该网页发出的所有请求,包括带有 /ajax 路径的 search.json。除了从浏览器或通过 NETWORK 选项卡访问 AJAX 数据之外,我们还可以在以下 Python 脚本的帮助下进行 -
import requests
url=requests.get('http://example.webscraping.com ... %2339;)
url.json()
例子
上面的脚本允许我们使用 Python json 方法访问 JSON 响应。同样,我们可以下载原创字符串响应,并使用python的json.loads方法加载它。我们在以下 Python 脚本的帮助下完成此操作。基本上,通过搜索字母“a”,然后迭代 JSON 响应的结果页面,可以抓取所有国家/地区。
import requests
import string
PAGE_SIZE = 15
url = 'http://example.webscraping.com/ajax/' + 'search.json?page={}&page_size={}&search_term=a'
countries = set()
for letter in string.ascii_lowercase:
print('Searching with %s' % letter)
page = 0
while True:
response = requests.get(url.format(page, PAGE_SIZE, letter))
data = response.json()
print('adding %d records from the page %d' %(len(data.get('records')),page))
for record in data.get('records'):countries.add(record['country'])
page += 1
if page >= data['num_pages']:
break
with open('countries.txt', 'w') as countries_file:
countries_file.write('n'.join(sorted(countries)))
运行上述脚本后,我们将得到以下输出,并且记录将保存在一个名为 countrys.txt 的文件中。
输出
Searching with a
adding 15 records from the page 0
adding 15 records from the page 1
...
呈现 JavaScript
在上一节中,我们对网页进行了逆向工程,以了解 API 的工作原理以及如何使用它在单个请求中检索结果。但是,在执行逆向工程时,我们将面临以下困难 -
上述问题的解决方案是使用浏览器渲染引擎解析HTML,应用CSS格式,执行JavaScript来显示网页。
例子
在这个例子中,为了呈现 Java 脚本,我们将使用熟悉的 Python 模块 Selenium。以下 Python 代码将在 Selenium 的帮助下呈现网页 -
首先,我们需要从 selenium 导入 webdriver,如下所示:
from selenium import webdriver
现在,提供我们根据需要下载的 Web 驱动程序的路径-
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
driver = webdriver.Chrome(executable_path = path)
现在,提供我们要在此 Web 浏览器中打开的 URL,该 URL 现在由我们的 Python 脚本控制。
driver.get('http://example.webscraping.com/search')
现在,我们可以使用搜索工具箱的 ID 来设置要选择的元素。
driver.find_element_by_id('search_term').send_keys('.')
接下来,我们可以使用Java脚本来设置选择框的内容,如下图:
js = "document.getElementById('page_size').options[1].text = '100';"
driver.execute_script(js)
以下代码行显示您可以在网页上单击以进行搜索 -
driver.find_element_by_id('search').click()
下一行代码显示它将等待 45 秒来完成 AJAX 请求。
driver.implicitly_wait(45)
现在,要选择国家/地区链接,我们可以使用 CSS 选择器,如下所示:
links = driver.find_elements_by_css_selector('#results a')
现在可以提取每个链接的文本以创建国家/地区列表-
countries = [link.text for link in links]
print(countries)
driver.close()
js提取指定网站内容(HTML中如何用JS获得其他网页的DOCUMENT对象__)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-24 23:16
HTML中如何使用JS获取其他网页的DOCUMENT对象-
______ 原来是这样写的,要在脚本中以这种方式获取输入的值。你在你的a.html页面中引用a_script.js,和你直接在你的页面中写脚步是一样的,直接写这个就行了。 document.getelementbyid("aa") 中的 "aa" 是你输入的 id.var aa = document.getelementbyid("aa").value;
JS获取网页中HTML元素的几种方法解析-
______ document.getelementbyid//除了byid,返回的都是伪数组 document.getelementbyclassname document.getelementbytagname 下面是高级选择器:document.queryselector() document.queryselectorall()
javascript如何获取HTML网页中另一个网页的变量值
______ 一个网页和另一个网页之间是否存在父子关系?如果是这样,您可以使用parent.XXX 来访问。如果两个网页没有关联,则只能使用URL传递参数。
如何使用html或js获取其他网站指定的行并使用
展示一下? -
______你可以用爬虫技术爬取其他网站然后解析出你想要的那一行数据
js 从另一个网页中提取信息 -
______ 亲爱的...这需要 name=username 通过表单提交到另一个页面...
有没有什么办法可以用javascript让网页的HTML代码完整-
______ 是否需要检索单独页面的html代码?您可以使用 ajax 方法。如果使用jquery,可以参考相关的api。如果是在页面中,可以试试outerHTML
JS获取页面的某个HTML代码-
______
如何提取别人的div网站?
______ div+css+js ok 网站全部由div制作
如何获取别人的网站完整的css和js文件?
______ 1、通过保存网页,可以得到对应页面上的js和css文件(部分js和css是编译或者压缩的,需要使用第三方工具反编译或者格式化)< @2、打开浏览器的开发模式。一般按快捷键f12打开即可。这里我以谷歌浏览器为例:点击标签资源,然后在对应的资源文件中找到你需要的文件,右键保存。具体操作如下:
JS获取网页代码-
______ 远程网页源码阅读/* 页面字体样式*/ body, ... 查看全部
js提取指定网站内容(HTML中如何用JS获得其他网页的DOCUMENT对象__)
HTML中如何使用JS获取其他网页的DOCUMENT对象-
______ 原来是这样写的,要在脚本中以这种方式获取输入的值。你在你的a.html页面中引用a_script.js,和你直接在你的页面中写脚步是一样的,直接写这个就行了。 document.getelementbyid("aa") 中的 "aa" 是你输入的 id.var aa = document.getelementbyid("aa").value;
JS获取网页中HTML元素的几种方法解析-
______ document.getelementbyid//除了byid,返回的都是伪数组 document.getelementbyclassname document.getelementbytagname 下面是高级选择器:document.queryselector() document.queryselectorall()
javascript如何获取HTML网页中另一个网页的变量值
______ 一个网页和另一个网页之间是否存在父子关系?如果是这样,您可以使用parent.XXX 来访问。如果两个网页没有关联,则只能使用URL传递参数。
如何使用html或js获取其他网站指定的行并使用
展示一下? -
______你可以用爬虫技术爬取其他网站然后解析出你想要的那一行数据
js 从另一个网页中提取信息 -
______ 亲爱的...这需要 name=username 通过表单提交到另一个页面...
有没有什么办法可以用javascript让网页的HTML代码完整-
______ 是否需要检索单独页面的html代码?您可以使用 ajax 方法。如果使用jquery,可以参考相关的api。如果是在页面中,可以试试outerHTML
JS获取页面的某个HTML代码-
______
如何提取别人的div网站?
______ div+css+js ok 网站全部由div制作
如何获取别人的网站完整的css和js文件?
______ 1、通过保存网页,可以得到对应页面上的js和css文件(部分js和css是编译或者压缩的,需要使用第三方工具反编译或者格式化)< @2、打开浏览器的开发模式。一般按快捷键f12打开即可。这里我以谷歌浏览器为例:点击标签资源,然后在对应的资源文件中找到你需要的文件,右键保存。具体操作如下:
JS获取网页代码-
______ 远程网页源码阅读/* 页面字体样式*/ body, ...
js提取指定网站内容(吃鸡ing3杀就快决赛圈了,突然老师丢给三个网站链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-24 17:17
昨天在吃鸡ing,3杀快要决赛了。突然老师丢了三个网站链接让我看看他们用的是哪个js框架。. .
说句公道话,第一次看到这个问题我头皮都麻了
怎么可能通过网页看到其他人是什么框架?大家不是都封装了吗?
写这个网站的人都是傻子吗?就让你看看核心js框架?
经过两天的试验和查资料,似乎可以看出来了。毕竟没有人是十全十美的,一百个秘密总是有隔阂的时候。
当然,这些只是我尝试过的一些方法。我的问题解决了,但不保证所有问题都会解决。如果遇到一个包装好的网站,那就认命吧。.
刚开始搜索的时候,别人的博客或者论坛会给你很多网站,让你输入你的网站,就可以看到网站的核心技术,推理真的没用.
例如,我试过的一个:
操作很简单,只需要输入网址,然后看看返回什么
这就是它用来回报我的所有技巧网站,但这不是我想要的o((>ω
还有另一个问题。如果框架是ASP.NET,那么网页访问应该有相应的后缀如:.aspx、ashx等。
我只觉得这件事让我很生气...
后来,我试着用英文在google上搜索这类问题。一个告诉我靠经验来获取,就是要多了解框架,了解每个框架的特点和关键词。然后一看就知道这是哪个框架。书面。. . 说到框架,你可以看看我的另一篇博客,看看有多少前端框架;另一种是将代码贴到Github上,使用html原生函数document.querySelector()获取dom信息。主要原理和第一人称意思差不多。
归结为:不同的框架有不同的框架使用的特定关键字。比如Angular中我们使用“ng-*”作为具体的指令标识符,而React中我们使用reactid等标识符,那么你可以通过搜索这些Keyword方法来获取网站的frame(当然,这个方法不是万能的,但也是一)的有效方法
代码显示如下:
if(!!window.React ||
!!document.querySelector('[data-reactroot], [data-reactid]'))
console.log('React.js');
if(!!window.angular ||
!!document.querySelector('.ng-binding, [ng-app], [data-ng-app], [ng-controller], [data-ng-controller], [ng-repeat], [data-ng-repeat]') ||
!!document.querySelector('script[src*="angular.js"], script[src*="angular.min.js"]'))
console.log('Angular.js');
if(!!window.Backbone) console.log('Backbone.js');
if(!!window.Ember) console.log('Ember.js');
if(!!window.Vue||!!document.querySelector('[v-if],[v-for],[v-show]')) console.log('Vue.js');
if(!!window.Meteor) console.log('Meteor.js');
if(!!window.Zepto) console.log('Zepto.js');
if(!!window.jQuery) console.log('jQuery.js');
将以上代码直接注入控制台
它会直接打印出你的前端js框架,但是对于一些不工作的页面,你需要一一打开多个页面。之前测试过一个我之前做过的项目,用Angular写的,在首页测试的时候失败了,但是点击登陆页面的时候会直接显示出来。使用这种方法时必须要有一定的耐心。
当然,对于一些网站,不管测试多少,都得点击Sources阅读代码。
估计不同的框架有不同的参考文件。我还需要慢慢仔细地寻找。我找了下这个页面的登录界面,然后发现在它请求该界面的地方有调用其他框架的功能。所以我确定了这个 网站 的框架
都来了这个网站前端js框架用的是Zepto,当然这只是我的解决方案,也许大佬有更好的解决方案,请分享
总结:我觉得这个技能反正好像没什么用,但是老师做完后不能放过,所以还是做吧。 查看全部
js提取指定网站内容(吃鸡ing3杀就快决赛圈了,突然老师丢给三个网站链接)
昨天在吃鸡ing,3杀快要决赛了。突然老师丢了三个网站链接让我看看他们用的是哪个js框架。. .
说句公道话,第一次看到这个问题我头皮都麻了
怎么可能通过网页看到其他人是什么框架?大家不是都封装了吗?
写这个网站的人都是傻子吗?就让你看看核心js框架?
经过两天的试验和查资料,似乎可以看出来了。毕竟没有人是十全十美的,一百个秘密总是有隔阂的时候。
当然,这些只是我尝试过的一些方法。我的问题解决了,但不保证所有问题都会解决。如果遇到一个包装好的网站,那就认命吧。.
刚开始搜索的时候,别人的博客或者论坛会给你很多网站,让你输入你的网站,就可以看到网站的核心技术,推理真的没用.
例如,我试过的一个:
操作很简单,只需要输入网址,然后看看返回什么
这就是它用来回报我的所有技巧网站,但这不是我想要的o((>ω
还有另一个问题。如果框架是ASP.NET,那么网页访问应该有相应的后缀如:.aspx、ashx等。
我只觉得这件事让我很生气...
后来,我试着用英文在google上搜索这类问题。一个告诉我靠经验来获取,就是要多了解框架,了解每个框架的特点和关键词。然后一看就知道这是哪个框架。书面。. . 说到框架,你可以看看我的另一篇博客,看看有多少前端框架;另一种是将代码贴到Github上,使用html原生函数document.querySelector()获取dom信息。主要原理和第一人称意思差不多。
归结为:不同的框架有不同的框架使用的特定关键字。比如Angular中我们使用“ng-*”作为具体的指令标识符,而React中我们使用reactid等标识符,那么你可以通过搜索这些Keyword方法来获取网站的frame(当然,这个方法不是万能的,但也是一)的有效方法
代码显示如下:
if(!!window.React ||
!!document.querySelector('[data-reactroot], [data-reactid]'))
console.log('React.js');
if(!!window.angular ||
!!document.querySelector('.ng-binding, [ng-app], [data-ng-app], [ng-controller], [data-ng-controller], [ng-repeat], [data-ng-repeat]') ||
!!document.querySelector('script[src*="angular.js"], script[src*="angular.min.js"]'))
console.log('Angular.js');
if(!!window.Backbone) console.log('Backbone.js');
if(!!window.Ember) console.log('Ember.js');
if(!!window.Vue||!!document.querySelector('[v-if],[v-for],[v-show]')) console.log('Vue.js');
if(!!window.Meteor) console.log('Meteor.js');
if(!!window.Zepto) console.log('Zepto.js');
if(!!window.jQuery) console.log('jQuery.js');
将以上代码直接注入控制台
它会直接打印出你的前端js框架,但是对于一些不工作的页面,你需要一一打开多个页面。之前测试过一个我之前做过的项目,用Angular写的,在首页测试的时候失败了,但是点击登陆页面的时候会直接显示出来。使用这种方法时必须要有一定的耐心。
当然,对于一些网站,不管测试多少,都得点击Sources阅读代码。
估计不同的框架有不同的参考文件。我还需要慢慢仔细地寻找。我找了下这个页面的登录界面,然后发现在它请求该界面的地方有调用其他框架的功能。所以我确定了这个 网站 的框架
都来了这个网站前端js框架用的是Zepto,当然这只是我的解决方案,也许大佬有更好的解决方案,请分享
总结:我觉得这个技能反正好像没什么用,但是老师做完后不能放过,所以还是做吧。
js提取指定网站内容(实现在文本指定位置插入内容的简单,具有很好的参考价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-24 17:15
下面和大家分享一个简单的例子,JS是如何实现在文本的指定位置插入内容的。有很好的参考价值,希望对你有帮助。
示例如下:
function insertAtCursor(myField, myValue) {
//IE 浏览器
if (document.selection) {
myField.focus();
sel = document.selection.createRange();
sel.text = myValue;
sel.select();
}
//FireFox、Chrome等
else if (myField.selectionStart || myField.selectionStart == '0') {
var startPos = myField.selectionStart;
var endPos = myField.selectionEnd;
// 保存滚动条
var restoreTop = myField.scrollTop;
myField.value = myField.value.substring(0, startPos) + myValue + myField.value.substring(endPos, myField.value.length);
if (restoreTop > 0) {
myField.scrollTop = restoreTop;
}
myField.focus();
myField.selectionStart = startPos + myValue.length;
myField.selectionEnd = startPos + myValue.length;
} else {
myField.value += myValue;
myField.focus();
}
}
以上是我为你整理的,希望对你以后有帮助。
相关文章:
如何在 vue 中安装 Mint-UI
AngularJS中如何实现集合数据遍历展示
如何在 vue.js 中集成 mint-ui 中的轮播图
如何实现在Jstree中选中父节点时禁用的子节点也会被选中
关于Vue中过滤器的使用
Javascript 中的自适应处理方法
Webpack 打包配置(详细教程)
如何在 Webpack 中加载 SVG
vue-cli中如何实现移动端适配
以上就是在JS中如何在指定位置插入内容的详细内容。详情请关注其他相关php中文网站文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们 查看全部
js提取指定网站内容(实现在文本指定位置插入内容的简单,具有很好的参考价值)
下面和大家分享一个简单的例子,JS是如何实现在文本的指定位置插入内容的。有很好的参考价值,希望对你有帮助。
示例如下:
function insertAtCursor(myField, myValue) {
//IE 浏览器
if (document.selection) {
myField.focus();
sel = document.selection.createRange();
sel.text = myValue;
sel.select();
}
//FireFox、Chrome等
else if (myField.selectionStart || myField.selectionStart == '0') {
var startPos = myField.selectionStart;
var endPos = myField.selectionEnd;
// 保存滚动条
var restoreTop = myField.scrollTop;
myField.value = myField.value.substring(0, startPos) + myValue + myField.value.substring(endPos, myField.value.length);
if (restoreTop > 0) {
myField.scrollTop = restoreTop;
}
myField.focus();
myField.selectionStart = startPos + myValue.length;
myField.selectionEnd = startPos + myValue.length;
} else {
myField.value += myValue;
myField.focus();
}
}
以上是我为你整理的,希望对你以后有帮助。
相关文章:
如何在 vue 中安装 Mint-UI
AngularJS中如何实现集合数据遍历展示
如何在 vue.js 中集成 mint-ui 中的轮播图
如何实现在Jstree中选中父节点时禁用的子节点也会被选中
关于Vue中过滤器的使用
Javascript 中的自适应处理方法
Webpack 打包配置(详细教程)
如何在 Webpack 中加载 SVG
vue-cli中如何实现移动端适配
以上就是在JS中如何在指定位置插入内容的详细内容。详情请关注其他相关php中文网站文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们
js提取指定网站内容(JavaScript驾驭网页-CSS与DOM利用DOM分割HTML利用分割)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-20 20:14
JavaScript 控制网页-CSS 和 DOM
使用 DOM 拆分 HTML
使用 JavaScript 来控制 Web 内容实际上很像做饭。只是你不用清理剩菜,却没有办法享受到美味的结果。
但是,您将能够完成网页内容的 HTML 元素:更重要的是,您将拥有替换网页元素的能力。
JavaScript 可以让你随心所欲地操作网页的 HTML 代码,从而开启各种有趣的机会,这一切都是因为标准对象:DOM 的存在
getElementById
HTML标签都有一个"id"属性,第个标签的该属性都是独一无二的
可以通过id属性来获取元素
内容
var sceneDesc=document.getElementById("div2");
getElementById可以通过元素的id属性去访问标签
括号里是id的值
getElementsByTagName
也可以通过标签名来获取元素
内容
var divs=document.getElementsByTagName("div");
getElementsByTagName返回所有div标签,结果是一个数组,结果按照标签在HTML中的顺序排列
括号里是标签名
var divs=document.getElementsByTagName("div")[2];
用索引获取第三个div标签
内部HTML
innerHTML特性对所有存储在元素里的内容提供了访问管道
通过innerHTML访问元素内存储的内容:
<p id="story"> you are standing
alone in the woods.
document.getElementById("story").innerHTML;
返回的内容是: you are standing alone in the woods.
innerHTML获取的是指定元素下的所有内容与标签
innerHTML也能用于设置网页内容
document.getElementById("story").innerHTML="You are not alone!";
innerHTML只用来设置可以包含文本的标签</p>
给大家介绍了很多关于JavaScript控制网页的知识——网页元素的知识,希望对大家有所帮助! 查看全部
js提取指定网站内容(JavaScript驾驭网页-CSS与DOM利用DOM分割HTML利用分割)
JavaScript 控制网页-CSS 和 DOM
使用 DOM 拆分 HTML
使用 JavaScript 来控制 Web 内容实际上很像做饭。只是你不用清理剩菜,却没有办法享受到美味的结果。
但是,您将能够完成网页内容的 HTML 元素:更重要的是,您将拥有替换网页元素的能力。
JavaScript 可以让你随心所欲地操作网页的 HTML 代码,从而开启各种有趣的机会,这一切都是因为标准对象:DOM 的存在
getElementById
HTML标签都有一个"id"属性,第个标签的该属性都是独一无二的
可以通过id属性来获取元素
内容
var sceneDesc=document.getElementById("div2");
getElementById可以通过元素的id属性去访问标签
括号里是id的值
getElementsByTagName
也可以通过标签名来获取元素
内容
var divs=document.getElementsByTagName("div");
getElementsByTagName返回所有div标签,结果是一个数组,结果按照标签在HTML中的顺序排列
括号里是标签名
var divs=document.getElementsByTagName("div")[2];
用索引获取第三个div标签
内部HTML
innerHTML特性对所有存储在元素里的内容提供了访问管道
通过innerHTML访问元素内存储的内容:
<p id="story"> you are standing
alone in the woods.
document.getElementById("story").innerHTML;
返回的内容是: you are standing alone in the woods.
innerHTML获取的是指定元素下的所有内容与标签
innerHTML也能用于设置网页内容
document.getElementById("story").innerHTML="You are not alone!";
innerHTML只用来设置可以包含文本的标签</p>
给大家介绍了很多关于JavaScript控制网页的知识——网页元素的知识,希望对大家有所帮助!
js提取指定网站内容(HTTP客户端/awaitawait//async/)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-20 00:24
HTTP 客户端是一种工具,可以向服务器发送请求,然后接收服务器的响应。下面提到的所有工具的底层都是使用一个HTTP客户端来访问你想要抓取的网站。
要求
Request 是 Javascript 生态系统中使用最广泛的 HTTP 客户端之一,但 Request 库的作者已正式声明它已被弃用。但这并不意味着它不可用,相当多的库仍在使用它,并且非常易于使用。使用 Request 发出 HTTP 请求非常简单:
1const request = require('request')
2request('https://www.reddit.com/r/progr ... 27%3B, function (
3 error,
4 response,
5 body
6) {
7 console.error('error:', error)
8 console.log('body:', body)
9})
你可以在 Github 上找到 Request 库,安装非常简单。您还可以找到弃用通知及其含义。
阿克西奥斯
Axios 是一个基于 Promise 的 HTTP 客户端,可以在浏览器和 Node.js 中运行。如果您使用 Typescript,那么 axios 将为您覆盖内置类型。通过 Axios 发起 HTTP 请求非常简单。默认情况下,它带有 Promise 支持,而不是在请求中使用回调:
1const axios = require('axios')
2
3axios
4 .get('https://www.reddit.com/r/programming.json')
5 .then((response) => {
6 console.log(response)
7 })
8 .catch((error) => {
9 console.error(error)
10 });
如果你喜欢 Promises API 的 async/await 语法糖,你也可以使用它,但由于顶级 await 仍处于第 3 阶段,我们不得不使用异步函数来代替:
1async function getForum() {
2 try {
3 const response = await axios.get(
4 'https://www.reddit.com/r/progr ... 27%3B
5 )
6 console.log(response)
7 } catch (error) {
8 console.error(error)
9 }
10}
您所要做的就是致电 getForum!可以在 Axios 库上找到。
超级代理
与 Axios 一样,Superagent 是另一个强大的 HTTP 客户端,支持 Promise 和 async/await 语法糖。它有一个类似 Axios 的相当简单的 API,但由于更多的依赖关系,Superagent 不太受欢迎。
使用 promise、async/await 或回调向 Superagent 发出 HTTP 请求如下所示:
1const superagent = require("superagent")
2const forumURL = "https://www.reddit.com/r/programming.json"
3
4// callbacks
5superagent
6 .get(forumURL)
7 .end((error, response) => {
8 console.log(response)
9 })
10
11// promises
12superagent
13 .get(forumURL)
14 .then((response) => {
15 console.log(response)
16 })
17 .catch((error) => {
18 console.error(error)
19 })
20
21// promises with async/await
22async function getForum() {
23 try {
24 const response = await superagent.get(forumURL)
25 console.log(response)
26 } catch (error) {
27 console.error(error)
28 }
29}
您可以在以下位置找到 Superagent。
正则表达式:艰难的方式
在没有任何依赖的情况下,进行网络爬虫最简单的方法是在使用 HTTP 客户端查询网页时,在接收到的 HTML 字符串上使用一堆正则表达式。正则表达式不是那么灵活,许多专业人士和业余爱好者都很难写出正确的正则表达式。
试试看,假设有一个带有用户名的标签,而我们需要那个用户名,这类似于你依赖正则表达式时必须做的
1const htmlString = 'Username: John Doe'
2const result = htmlString.match(/(.+)/)
3
4console.log(result[1], result[1].split(": ")[1])
5// Username: John Doe, John Doe
在 Javascript 中,match() 通常返回一个数组,其中收录与正则表达式匹配的所有内容。第二个元素(在索引 1 中)将找到我们想要的标记的 textContent 或 innerHTML。但结果收录一些不必要的文本(“用户名:”),必须删除。
如您所见,对于一个非常简单的用例,有许多步骤和工作要做。这就是为什么你应该依赖 HTML 解析器的原因,我们将在后面讨论。
Cheerio:用于遍历 DOM 的核心 JQuery
Cheerio 是一个高效且可移植的库,它允许您在服务器端使用 JQuery 丰富而强大的 API。如果您之前使用过 JQuery,您就会熟悉 Cheerio。它消除了 DOM 的所有不一致和浏览器相关功能,并公开了一个有效的 API 来解析和操作 DOM。
1const cheerio = require('cheerio')
2const $ = cheerio.load('Hello world')
3
4$('h2.title').text('Hello there!')
5$('h2').addClass('welcome')
6
7$.html()
8// Hello there!
如您所见,Cheerio 与 JQuery 非常相似。
但是,即使它的工作方式与 Web 浏览器不同,这也意味着它不能:
因此,如果您尝试抓取的网站 或 web 应用程序严重依赖 Javascript(例如“单页应用程序”),那么 Cheerio 不是最佳选择,您可能不得不依赖其他选项稍后讨论。
为了展示 Cheerio 的强大功能,我们将尝试爬取 Reddit 中的 r/programming 论坛,并尝试获取一个帖子名称列表。
首先,通过运行以下命令安装 Cheerio 和 axios:npm installcheerio axios。
然后新建一个名为crawler.js的文件,复制粘贴以下代码:
1const axios = require('axios');
2const cheerio = require('cheerio');
3
4const getPostTitles = async () => {
5 try {
6 const { data } = await axios.get(
7 'https://old.reddit.com/r/programming/'
8 );
9 const $ = cheerio.load(data);
10 const postTitles = [];
11
12 $('div > p.title > a').each((_idx, el) => {
13 const postTitle = $(el).text()
14 postTitles.push(postTitle)
15 });
16
17 return postTitles;
18 } catch (error) {
19 throw error;
20 }
21};
22
23getPostTitles()
24.then((postTitles) => console.log(postTitles));
getPostTitles() 是一个异步函数,它将抓取旧的 reddit r/编程论坛。首先通过axios HTTP客户端库使用简单的HTTP GET请求获取网站的HTML,然后使用cheerio.load()函数将html数据输入到Cheerio中。
然后在浏览器的开发工具的帮助下,你可以得到一个可以定位所有列表项的选择器。如果你用过JQuery,你一定对$('div> p.title> a')非常熟悉。这将获得所有帖子,因为您只想单独获取每个帖子的标题,因此您必须遍历每个帖子。这些操作是在 each() 函数的帮助下完成的。
要从每个标题中提取文本,您必须在 Cheerio 的帮助下获取 DOM 元素(el 指的是当前元素)。然后在每个元素上调用 text() 为您提供文本。
现在,打开终端,运行node crawler.js,你会看到一个近似titles的数组,这个数组会很长。虽然这是一个非常简单的用例,但它展示了 Cheerio 提供的 API 的简单本质。
如果您的用例需要执行 Javascript 并加载外部源,那么以下选项会有所帮助。
JSDOM:节点的 DOM
JSDOM 是 Node.js 中使用的文档对象模型的纯 Javascript 实现。如前所述,DOM 对 Node 不可用,但 JSDOM 是最接近的。它或多或少地模仿了浏览器。
因为DOM是创建的,所以你可以通过编程与web应用或者你想爬取的网站进行交互,也可以模拟点击一个按钮。如果你熟悉 DOM 操作,使用 JSDOM 会非常简单。
1const { JSDOM } = require('jsdom')
2const { document } = new JSDOM(
3 'Hello world'
4).window
5const heading = document.querySelector('.title')
6heading.textContent = 'Hello there!'
7heading.classList.add('welcome')
8
9heading.innerHTML
10// Hello there!
在代码中用JSDOM创建一个DOM,然后你就可以用和浏览器DOM一样的方法和属性来操作这个DOM了。
为了演示如何使用JSDOM与网站进行交互,我们将获取Reddit r/programming论坛的第一篇帖子并对其进行投票,然后验证该帖子是否已被投票。
首先运行以下命令安装jsdom和axios: npm install jsdom axios
然后创建一个名为 crawler.js 的文件,并复制并粘贴以下代码:
1const { JSDOM } = require("jsdom")
2const axios = require('axios')
3
4const upvoteFirstPost = async () => {
5 try {
6 const { data } = await axios.get("https://old.reddit.com/r/programming/");
7 const dom = new JSDOM(data, {
8 runScripts: "dangerously",
9 resources: "usable"
10 });
11 const { document } = dom.window;
12 const firstPost = document.querySelector("div > div.midcol > div.arrow");
13 firstPost.click();
14 const isUpvoted = firstPost.classList.contains("upmod");
15 const msg = isUpvoted
16 ? "Post has been upvoted successfully!"
17 : "The post has not been upvoted!";
18
19 return msg;
20 } catch (error) {
21 throw error;
22 }
23};
24
25upvoteFirstPost().then(msg => console.log(msg));
upvoteFirstPost() 是一个异步函数,它将获得 r/programming 中的第一篇文章,然后对其进行投票。axios 发送 HTTP GET 请求以获取指定 URL 的 HTML。然后从之前获得的 HTML 创建一个新的 DOM。JSDOM 构造函数将 HTML 作为第一个参数,将选项作为第二个参数。添加的两个选项执行以下功能:
创建DOM后,使用相同的DOM方法获取第一篇文章文章的upvote按钮,然后点击。要验证它是否真的被点击,您可以检查 classList 中是否有名为 upmod 的类。如果它存在于 classList 中,则返回一条消息。
打开终端并运行 node crawler.js,然后您将看到一个整洁的字符串,表明该帖子是否已被点赞。虽然这个例子很简单,但你可以在这个基础上构建强大的东西,例如,一个对特定用户帖子进行投票的机器人。
如果你不喜欢缺乏表达能力的 JSDOM,并且在实践中依赖很多这样的操作,或者需要重新创建很多不同的 DOM,那么下面的将是更好的选择。
Puppeteer:无头浏览器
顾名思义,Puppeteer 允许您以编程方式操纵浏览器,就像操纵木偶一样。默认情况下,它为开发人员提供了高级 API 来控制无头版本的 Chrome。
摘自 Puppeter Docs Puppeteer 比上述工具更有用,因为它允许您像真人与浏览器交互一样抓取网络。这开辟了一些以前不可用的可能性:
它还可以在网络爬虫以外的任务中发挥重要作用,例如 UI 测试、辅助性能优化等。
通常你想截取网站的截图,也许是为了了解竞争对手的产品目录,你可以使用puppeteer来做。首先运行以下命令安装puppeteer: npm install puppeteer
这将下载 Chromium 的捆绑版本,大约 180 MB 到 300 MB,具体取决于操作系统。如果要禁用此功能。
我们尝试在 Reddit 中获取 r/programming 论坛的截图和 PDF,创建一个名为 crawler.js 的新文件,并复制并粘贴以下代码:
1const puppeteer = require('puppeteer')
2
3async function getVisual() {
4 try {
5 const URL = 'https://www.reddit.com/r/programming/'
6 const browser = await puppeteer.launch()
7 const page = await browser.newPage()
8
9 await page.goto(URL)
10 await page.screenshot({ path: 'screenshot.png' })
11 await page.pdf({ path: 'page.pdf' })
12
13 await browser.close()
14 } catch (error) {
15 console.error(error)
16 }
17}
18
19getVisual()
getVisual() 是一个异步函数,它将获取 URL 变量中的 url 对应的屏幕截图和 pdf。首先通过 puppeteer.launch() 创建一个浏览器实例,然后创建一个新页面。您可以将此页面视为常规浏览器中的选项卡。然后以 URL 为参数调用 page.goto() 将之前创建的页面定向到指定的 URL。最终,浏览器实例与页面一起被销毁。
操作完成并加载页面后,将分别使用 page.screenshot() 和 page.pdf() 获取屏幕截图和pdf。也可以监听javascript的load事件,进行这些操作,生产环境中强烈推荐使用。
在终端上运行 node crawler.js。几秒钟后,您会注意到已创建两个文件,名为 screenshot.jpg 和 page.pdf。
Nightmare:Puppeteer 的替代品
Nightmare 是一个类似于 Puppeteer 的高级浏览器自动化库。该库使用 Electron,但据说它的速度是其前身 PhantomJS 的两倍。
如果您在某种程度上不喜欢 Puppeteer 或对 Chromium 包的大小感到沮丧,那么 nightmare 是一个理想的选择。首先,运行以下命令安装 nightmare 库: npm install nightmare
然后,一旦下载了 nightmare,我们将使用它通过 Google 搜索引擎找到 ScrapingBee 的 网站。创建一个名为 crawler.js 的文件,然后将以下代码复制并粘贴到其中:
1const Nightmare = require('nightmare')
2const nightmare = Nightmare()
3
4nightmare
5 .goto('https://www.google.com/')
6 .type("input[title='Search']", 'ScrapingBee')
7 .click("input[value='Google Search']")
8 .wait('#rso > div:nth-child(1) > div > div > div.r > a')
9 .evaluate(
10 () =>
11 document.querySelector(
12 '#rso > div:nth-child(1) > div > div > div.r > a'
13 ).href
14 )
15 .end()
16 .then((link) => {
17 console.log('Scraping Bee Web Link': link)
18 })
19 .catch((error) => {
20 console.error('Search failed:', error)
21 })
首先创建一个 Nightmare 实例,然后通过调用 goto() 将该实例定向到 Google 搜索引擎。加载后,使用其选择器获取搜索框,然后使用搜索框的值(输入标签)将其更改为“ScrapingBee”。完成后,单击“Google 搜索”按钮提交搜索表单。然后告诉 Nightmare 等到第一个链接加载完毕。一旦完成,它将使用 DOM 方法获取收录链接的锚标记的 href 属性的值。
最后,在所有操作完成后,将链接打印到控制台。
总结 查看全部
js提取指定网站内容(HTTP客户端/awaitawait//async/)
HTTP 客户端是一种工具,可以向服务器发送请求,然后接收服务器的响应。下面提到的所有工具的底层都是使用一个HTTP客户端来访问你想要抓取的网站。
要求
Request 是 Javascript 生态系统中使用最广泛的 HTTP 客户端之一,但 Request 库的作者已正式声明它已被弃用。但这并不意味着它不可用,相当多的库仍在使用它,并且非常易于使用。使用 Request 发出 HTTP 请求非常简单:
1const request = require('request')
2request('https://www.reddit.com/r/progr ... 27%3B, function (
3 error,
4 response,
5 body
6) {
7 console.error('error:', error)
8 console.log('body:', body)
9})
你可以在 Github 上找到 Request 库,安装非常简单。您还可以找到弃用通知及其含义。
阿克西奥斯
Axios 是一个基于 Promise 的 HTTP 客户端,可以在浏览器和 Node.js 中运行。如果您使用 Typescript,那么 axios 将为您覆盖内置类型。通过 Axios 发起 HTTP 请求非常简单。默认情况下,它带有 Promise 支持,而不是在请求中使用回调:
1const axios = require('axios')
2
3axios
4 .get('https://www.reddit.com/r/programming.json')
5 .then((response) => {
6 console.log(response)
7 })
8 .catch((error) => {
9 console.error(error)
10 });
如果你喜欢 Promises API 的 async/await 语法糖,你也可以使用它,但由于顶级 await 仍处于第 3 阶段,我们不得不使用异步函数来代替:
1async function getForum() {
2 try {
3 const response = await axios.get(
4 'https://www.reddit.com/r/progr ... 27%3B
5 )
6 console.log(response)
7 } catch (error) {
8 console.error(error)
9 }
10}
您所要做的就是致电 getForum!可以在 Axios 库上找到。
超级代理
与 Axios 一样,Superagent 是另一个强大的 HTTP 客户端,支持 Promise 和 async/await 语法糖。它有一个类似 Axios 的相当简单的 API,但由于更多的依赖关系,Superagent 不太受欢迎。
使用 promise、async/await 或回调向 Superagent 发出 HTTP 请求如下所示:
1const superagent = require("superagent")
2const forumURL = "https://www.reddit.com/r/programming.json"
3
4// callbacks
5superagent
6 .get(forumURL)
7 .end((error, response) => {
8 console.log(response)
9 })
10
11// promises
12superagent
13 .get(forumURL)
14 .then((response) => {
15 console.log(response)
16 })
17 .catch((error) => {
18 console.error(error)
19 })
20
21// promises with async/await
22async function getForum() {
23 try {
24 const response = await superagent.get(forumURL)
25 console.log(response)
26 } catch (error) {
27 console.error(error)
28 }
29}
您可以在以下位置找到 Superagent。
正则表达式:艰难的方式
在没有任何依赖的情况下,进行网络爬虫最简单的方法是在使用 HTTP 客户端查询网页时,在接收到的 HTML 字符串上使用一堆正则表达式。正则表达式不是那么灵活,许多专业人士和业余爱好者都很难写出正确的正则表达式。
试试看,假设有一个带有用户名的标签,而我们需要那个用户名,这类似于你依赖正则表达式时必须做的
1const htmlString = 'Username: John Doe'
2const result = htmlString.match(/(.+)/)
3
4console.log(result[1], result[1].split(": ")[1])
5// Username: John Doe, John Doe
在 Javascript 中,match() 通常返回一个数组,其中收录与正则表达式匹配的所有内容。第二个元素(在索引 1 中)将找到我们想要的标记的 textContent 或 innerHTML。但结果收录一些不必要的文本(“用户名:”),必须删除。
如您所见,对于一个非常简单的用例,有许多步骤和工作要做。这就是为什么你应该依赖 HTML 解析器的原因,我们将在后面讨论。
Cheerio:用于遍历 DOM 的核心 JQuery
Cheerio 是一个高效且可移植的库,它允许您在服务器端使用 JQuery 丰富而强大的 API。如果您之前使用过 JQuery,您就会熟悉 Cheerio。它消除了 DOM 的所有不一致和浏览器相关功能,并公开了一个有效的 API 来解析和操作 DOM。
1const cheerio = require('cheerio')
2const $ = cheerio.load('Hello world')
3
4$('h2.title').text('Hello there!')
5$('h2').addClass('welcome')
6
7$.html()
8// Hello there!
如您所见,Cheerio 与 JQuery 非常相似。
但是,即使它的工作方式与 Web 浏览器不同,这也意味着它不能:
因此,如果您尝试抓取的网站 或 web 应用程序严重依赖 Javascript(例如“单页应用程序”),那么 Cheerio 不是最佳选择,您可能不得不依赖其他选项稍后讨论。
为了展示 Cheerio 的强大功能,我们将尝试爬取 Reddit 中的 r/programming 论坛,并尝试获取一个帖子名称列表。
首先,通过运行以下命令安装 Cheerio 和 axios:npm installcheerio axios。
然后新建一个名为crawler.js的文件,复制粘贴以下代码:
1const axios = require('axios');
2const cheerio = require('cheerio');
3
4const getPostTitles = async () => {
5 try {
6 const { data } = await axios.get(
7 'https://old.reddit.com/r/programming/'
8 );
9 const $ = cheerio.load(data);
10 const postTitles = [];
11
12 $('div > p.title > a').each((_idx, el) => {
13 const postTitle = $(el).text()
14 postTitles.push(postTitle)
15 });
16
17 return postTitles;
18 } catch (error) {
19 throw error;
20 }
21};
22
23getPostTitles()
24.then((postTitles) => console.log(postTitles));
getPostTitles() 是一个异步函数,它将抓取旧的 reddit r/编程论坛。首先通过axios HTTP客户端库使用简单的HTTP GET请求获取网站的HTML,然后使用cheerio.load()函数将html数据输入到Cheerio中。
然后在浏览器的开发工具的帮助下,你可以得到一个可以定位所有列表项的选择器。如果你用过JQuery,你一定对$('div> p.title> a')非常熟悉。这将获得所有帖子,因为您只想单独获取每个帖子的标题,因此您必须遍历每个帖子。这些操作是在 each() 函数的帮助下完成的。
要从每个标题中提取文本,您必须在 Cheerio 的帮助下获取 DOM 元素(el 指的是当前元素)。然后在每个元素上调用 text() 为您提供文本。
现在,打开终端,运行node crawler.js,你会看到一个近似titles的数组,这个数组会很长。虽然这是一个非常简单的用例,但它展示了 Cheerio 提供的 API 的简单本质。
如果您的用例需要执行 Javascript 并加载外部源,那么以下选项会有所帮助。
JSDOM:节点的 DOM
JSDOM 是 Node.js 中使用的文档对象模型的纯 Javascript 实现。如前所述,DOM 对 Node 不可用,但 JSDOM 是最接近的。它或多或少地模仿了浏览器。
因为DOM是创建的,所以你可以通过编程与web应用或者你想爬取的网站进行交互,也可以模拟点击一个按钮。如果你熟悉 DOM 操作,使用 JSDOM 会非常简单。
1const { JSDOM } = require('jsdom')
2const { document } = new JSDOM(
3 'Hello world'
4).window
5const heading = document.querySelector('.title')
6heading.textContent = 'Hello there!'
7heading.classList.add('welcome')
8
9heading.innerHTML
10// Hello there!
在代码中用JSDOM创建一个DOM,然后你就可以用和浏览器DOM一样的方法和属性来操作这个DOM了。
为了演示如何使用JSDOM与网站进行交互,我们将获取Reddit r/programming论坛的第一篇帖子并对其进行投票,然后验证该帖子是否已被投票。
首先运行以下命令安装jsdom和axios: npm install jsdom axios
然后创建一个名为 crawler.js 的文件,并复制并粘贴以下代码:
1const { JSDOM } = require("jsdom")
2const axios = require('axios')
3
4const upvoteFirstPost = async () => {
5 try {
6 const { data } = await axios.get("https://old.reddit.com/r/programming/";);
7 const dom = new JSDOM(data, {
8 runScripts: "dangerously",
9 resources: "usable"
10 });
11 const { document } = dom.window;
12 const firstPost = document.querySelector("div > div.midcol > div.arrow");
13 firstPost.click();
14 const isUpvoted = firstPost.classList.contains("upmod");
15 const msg = isUpvoted
16 ? "Post has been upvoted successfully!"
17 : "The post has not been upvoted!";
18
19 return msg;
20 } catch (error) {
21 throw error;
22 }
23};
24
25upvoteFirstPost().then(msg => console.log(msg));
upvoteFirstPost() 是一个异步函数,它将获得 r/programming 中的第一篇文章,然后对其进行投票。axios 发送 HTTP GET 请求以获取指定 URL 的 HTML。然后从之前获得的 HTML 创建一个新的 DOM。JSDOM 构造函数将 HTML 作为第一个参数,将选项作为第二个参数。添加的两个选项执行以下功能:
创建DOM后,使用相同的DOM方法获取第一篇文章文章的upvote按钮,然后点击。要验证它是否真的被点击,您可以检查 classList 中是否有名为 upmod 的类。如果它存在于 classList 中,则返回一条消息。
打开终端并运行 node crawler.js,然后您将看到一个整洁的字符串,表明该帖子是否已被点赞。虽然这个例子很简单,但你可以在这个基础上构建强大的东西,例如,一个对特定用户帖子进行投票的机器人。
如果你不喜欢缺乏表达能力的 JSDOM,并且在实践中依赖很多这样的操作,或者需要重新创建很多不同的 DOM,那么下面的将是更好的选择。
Puppeteer:无头浏览器
顾名思义,Puppeteer 允许您以编程方式操纵浏览器,就像操纵木偶一样。默认情况下,它为开发人员提供了高级 API 来控制无头版本的 Chrome。
摘自 Puppeter Docs Puppeteer 比上述工具更有用,因为它允许您像真人与浏览器交互一样抓取网络。这开辟了一些以前不可用的可能性:
它还可以在网络爬虫以外的任务中发挥重要作用,例如 UI 测试、辅助性能优化等。
通常你想截取网站的截图,也许是为了了解竞争对手的产品目录,你可以使用puppeteer来做。首先运行以下命令安装puppeteer: npm install puppeteer
这将下载 Chromium 的捆绑版本,大约 180 MB 到 300 MB,具体取决于操作系统。如果要禁用此功能。
我们尝试在 Reddit 中获取 r/programming 论坛的截图和 PDF,创建一个名为 crawler.js 的新文件,并复制并粘贴以下代码:
1const puppeteer = require('puppeteer')
2
3async function getVisual() {
4 try {
5 const URL = 'https://www.reddit.com/r/programming/'
6 const browser = await puppeteer.launch()
7 const page = await browser.newPage()
8
9 await page.goto(URL)
10 await page.screenshot({ path: 'screenshot.png' })
11 await page.pdf({ path: 'page.pdf' })
12
13 await browser.close()
14 } catch (error) {
15 console.error(error)
16 }
17}
18
19getVisual()
getVisual() 是一个异步函数,它将获取 URL 变量中的 url 对应的屏幕截图和 pdf。首先通过 puppeteer.launch() 创建一个浏览器实例,然后创建一个新页面。您可以将此页面视为常规浏览器中的选项卡。然后以 URL 为参数调用 page.goto() 将之前创建的页面定向到指定的 URL。最终,浏览器实例与页面一起被销毁。
操作完成并加载页面后,将分别使用 page.screenshot() 和 page.pdf() 获取屏幕截图和pdf。也可以监听javascript的load事件,进行这些操作,生产环境中强烈推荐使用。
在终端上运行 node crawler.js。几秒钟后,您会注意到已创建两个文件,名为 screenshot.jpg 和 page.pdf。
Nightmare:Puppeteer 的替代品
Nightmare 是一个类似于 Puppeteer 的高级浏览器自动化库。该库使用 Electron,但据说它的速度是其前身 PhantomJS 的两倍。
如果您在某种程度上不喜欢 Puppeteer 或对 Chromium 包的大小感到沮丧,那么 nightmare 是一个理想的选择。首先,运行以下命令安装 nightmare 库: npm install nightmare
然后,一旦下载了 nightmare,我们将使用它通过 Google 搜索引擎找到 ScrapingBee 的 网站。创建一个名为 crawler.js 的文件,然后将以下代码复制并粘贴到其中:
1const Nightmare = require('nightmare')
2const nightmare = Nightmare()
3
4nightmare
5 .goto('https://www.google.com/')
6 .type("input[title='Search']", 'ScrapingBee')
7 .click("input[value='Google Search']")
8 .wait('#rso > div:nth-child(1) > div > div > div.r > a')
9 .evaluate(
10 () =>
11 document.querySelector(
12 '#rso > div:nth-child(1) > div > div > div.r > a'
13 ).href
14 )
15 .end()
16 .then((link) => {
17 console.log('Scraping Bee Web Link': link)
18 })
19 .catch((error) => {
20 console.error('Search failed:', error)
21 })
首先创建一个 Nightmare 实例,然后通过调用 goto() 将该实例定向到 Google 搜索引擎。加载后,使用其选择器获取搜索框,然后使用搜索框的值(输入标签)将其更改为“ScrapingBee”。完成后,单击“Google 搜索”按钮提交搜索表单。然后告诉 Nightmare 等到第一个链接加载完毕。一旦完成,它将使用 DOM 方法获取收录链接的锚标记的 href 属性的值。
最后,在所有操作完成后,将链接打印到控制台。
总结
js提取指定网站内容(如何用MSScriptControl组件执行一段数学代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-19 05:06
在抓取网页的过程中,很多网页内容都预先存储在JAVASCRIPT变量中。如果只用SUBSTRING进行拦截分析,效率低,错误率高。
我们怎样才能更好地解决它?使用 MSScriptControl
在C#中,我们也可以通过Com组件来执行一段javascript代码。
以下代码展示了如何使用 MSScriptControl 组件执行数学表达式:
MSScriptControl.ScriptControlClass sc = new MSScriptControl.ScriptControlClass();
sc.Language = "javascript";
object obj = sc.Eval(" 1 + 2 * (3 + 4)");
Console.WriteLine(obj);
要使用MSScriptControl,需要引用com组件Microsoft Script Control1.0。
上一篇文章已经详细解释了,当然代码中也有一些错误。 “MSScriptControl.IScriptControl.Timeout”和“MSScriptControl.DScriptControlSource_Event.Timeout”之间存在歧义
原创代码:
///
//// 获取或设置脚本执行时间,单位为毫秒
///
公共整数超时
{
get {return this.msc.Timeout; }
设置{this.msc.Timeout = value; }
}
修改为:
///
//// 获取或设置脚本执行时间,单位为毫秒
///
公共整数超时
{
get {return ((IScriptControl)this.msc).Timeout; }
set {((IScriptControl)this.msc).Timeout = value; }
}
是的,可以用测试,这样抓数据和介绍更方便,直接让JS输出结果即可。
结合一些技术可以做很多事情,例如:
1、ALEXA排名作弊,处理完EXE后执行POST,或者申请证书进行页面处理,数据属实。
2、一些点击或展示广告作弊,原理同上,结合ACTIVEX插件,效果不错
ActiveX 是 Microsoft 对一系列战略性面向对象编程技术和工具的名称,其中主要技术是组件对象模型 (COM)。在具有目录和其他支持的网络中,COM 已成为分布式 COM (DCOM)。创建ActiveX程序时,主要的工作是组件,一个可以运行在ActiveX网络中的自给自足的程序(目前的网络主要包括Windows和Mac)。该组件是 ActiveX Near 控件。 ActiveX 是 Microsoft 提出的,用于对抗 Sun Microsystems 的 JAVA 技术。该控件的功能类似于JAVA小程序。
如果您使用的是 Windows 操作系统,您可能会注意到一些以 OCX 结尾的文件。 OCX 代表“对象链接和嵌入控制”(OLE)。该技术是微软为混合使用桌面文件而提出的一种程序技术。现在COM的概念已经取代了一部分OLE,微软也用ActiveX控件来表示组件对象。
组件的优点之一是它们可以被大多数应用程序重用(这些应用程序称为组件容器)。一个COM组件(ActiveX控件)可以用不同语言的开发工具开发,包括C++和Visual Basic或PowerBuilder,甚至一些技术语言如VBScript。
目前,ActiveX 控件运行在 Windows 95/NT 和 Macintosh 上,微软也准备在 UNIX 上支持 ActiveX 控件。
转载于: 查看全部
js提取指定网站内容(如何用MSScriptControl组件执行一段数学代码)
在抓取网页的过程中,很多网页内容都预先存储在JAVASCRIPT变量中。如果只用SUBSTRING进行拦截分析,效率低,错误率高。
我们怎样才能更好地解决它?使用 MSScriptControl
在C#中,我们也可以通过Com组件来执行一段javascript代码。
以下代码展示了如何使用 MSScriptControl 组件执行数学表达式:
MSScriptControl.ScriptControlClass sc = new MSScriptControl.ScriptControlClass();
sc.Language = "javascript";
object obj = sc.Eval(" 1 + 2 * (3 + 4)");
Console.WriteLine(obj);
要使用MSScriptControl,需要引用com组件Microsoft Script Control1.0。
上一篇文章已经详细解释了,当然代码中也有一些错误。 “MSScriptControl.IScriptControl.Timeout”和“MSScriptControl.DScriptControlSource_Event.Timeout”之间存在歧义
原创代码:
///
//// 获取或设置脚本执行时间,单位为毫秒
///
公共整数超时
{
get {return this.msc.Timeout; }
设置{this.msc.Timeout = value; }
}
修改为:
///
//// 获取或设置脚本执行时间,单位为毫秒
///
公共整数超时
{
get {return ((IScriptControl)this.msc).Timeout; }
set {((IScriptControl)this.msc).Timeout = value; }
}
是的,可以用测试,这样抓数据和介绍更方便,直接让JS输出结果即可。
结合一些技术可以做很多事情,例如:
1、ALEXA排名作弊,处理完EXE后执行POST,或者申请证书进行页面处理,数据属实。
2、一些点击或展示广告作弊,原理同上,结合ACTIVEX插件,效果不错
ActiveX 是 Microsoft 对一系列战略性面向对象编程技术和工具的名称,其中主要技术是组件对象模型 (COM)。在具有目录和其他支持的网络中,COM 已成为分布式 COM (DCOM)。创建ActiveX程序时,主要的工作是组件,一个可以运行在ActiveX网络中的自给自足的程序(目前的网络主要包括Windows和Mac)。该组件是 ActiveX Near 控件。 ActiveX 是 Microsoft 提出的,用于对抗 Sun Microsystems 的 JAVA 技术。该控件的功能类似于JAVA小程序。
如果您使用的是 Windows 操作系统,您可能会注意到一些以 OCX 结尾的文件。 OCX 代表“对象链接和嵌入控制”(OLE)。该技术是微软为混合使用桌面文件而提出的一种程序技术。现在COM的概念已经取代了一部分OLE,微软也用ActiveX控件来表示组件对象。
组件的优点之一是它们可以被大多数应用程序重用(这些应用程序称为组件容器)。一个COM组件(ActiveX控件)可以用不同语言的开发工具开发,包括C++和Visual Basic或PowerBuilder,甚至一些技术语言如VBScript。
目前,ActiveX 控件运行在 Windows 95/NT 和 Macintosh 上,微软也准备在 UNIX 上支持 ActiveX 控件。
转载于:
js提取指定网站内容(使用Python爬取网页数据使用urllib.request获取网页urllib)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-17 15:02
使用 Python 抓取网页数据
使用 urllib.request 获取网页 urllib 是 Python 中内置的 HTTP 库。使用urllib可以非常简单的步骤高效地采集数据;用Beautiful等HTML伪造请求体爬取一些网站 当需要POST数据到服务器时,此时需要伪造请求体;为了实现有道词典在线翻译脚本,在Chrome中打开开发工具,找到Network下的方法为POST。注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源,大型分布式爬虫可以爬取一个站点甚至对该站点发起DDOS攻击;因此,您在使用爬虫爬取数据时,应合理安排爬取频率和时间;例如:服务器比较空闲 是时候检测网页的编码方式了 虽然大部分网页都是用UTF-8编码的,但是有时候你会遇到使用其他编码方式的网页,所以你必须知道网页的编码方式才能正确解码抓取到的页;Chardet 是python的第三方模块,用于获取跳转链接。有时一个网页的某个页面需要根据原创URL跳转一次甚至多次才能最终到达目的页面,所以需要正确处理;通过head(请求模块的))函数获取跳转链接的URL,Chardet 是python的第三方模块,用于获取跳转链接。有时一个网页的某个页面需要根据原创URL跳转一次甚至多次才能最终到达目的页面,所以需要正确处理;通过head(请求模块的))函数获取跳转链接的URL,Chardet 是python的第三方模块,用于获取跳转链接。有时一个网页的某个页面需要根据原创URL跳转一次甚至多次才能最终到达目的页面,所以需要正确处理;通过head(请求模块的))函数获取跳转链接的URL,
483 查看全部
js提取指定网站内容(使用Python爬取网页数据使用urllib.request获取网页urllib)
使用 Python 抓取网页数据
使用 urllib.request 获取网页 urllib 是 Python 中内置的 HTTP 库。使用urllib可以非常简单的步骤高效地采集数据;用Beautiful等HTML伪造请求体爬取一些网站 当需要POST数据到服务器时,此时需要伪造请求体;为了实现有道词典在线翻译脚本,在Chrome中打开开发工具,找到Network下的方法为POST。注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源,大型分布式爬虫可以爬取一个站点甚至对该站点发起DDOS攻击;因此,您在使用爬虫爬取数据时,应合理安排爬取频率和时间;例如:服务器比较空闲 是时候检测网页的编码方式了 虽然大部分网页都是用UTF-8编码的,但是有时候你会遇到使用其他编码方式的网页,所以你必须知道网页的编码方式才能正确解码抓取到的页;Chardet 是python的第三方模块,用于获取跳转链接。有时一个网页的某个页面需要根据原创URL跳转一次甚至多次才能最终到达目的页面,所以需要正确处理;通过head(请求模块的))函数获取跳转链接的URL,Chardet 是python的第三方模块,用于获取跳转链接。有时一个网页的某个页面需要根据原创URL跳转一次甚至多次才能最终到达目的页面,所以需要正确处理;通过head(请求模块的))函数获取跳转链接的URL,Chardet 是python的第三方模块,用于获取跳转链接。有时一个网页的某个页面需要根据原创URL跳转一次甚至多次才能最终到达目的页面,所以需要正确处理;通过head(请求模块的))函数获取跳转链接的URL,
483
js提取指定网站内容( 2017年12月14日14:16:47一个实例教学如何用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-15 20:14
2017年12月14日14:16:47一个实例教学如何用
)
Nodejs实现了抓取网站图片的功能
更新时间:2017年12月14日14:16:47投稿人:老张
下面是一个示例,教您如何使用nodejs实现抓取网站图片的功能。感兴趣的朋友可以采集
通过一个例子,我们将说明nodejs实现了抓取网站图片的功能。以下是全部内容:
原则:
爬虫是最明显的IO密集型应用场景。节点的使用明显减少了I/O等待开销,数据挖掘更加方便
使用express模块构建节点服务
并使用请求模块获取目标页面的HTML代码
下载cherio模块以处理HTML代码(cherio类似于jQuery语法,因此易于使用和方便)
环境配置:
(1)介绍每个模块
var http = require('http');
var request = require('request);
var cheerio = require('cheerio');
var fs = require('fs'); //用来操作文件
var url = 'https://movie.douban.com/cinema/nowplaying/beijing/' //定义要爬的页面
(2)发送请求
http.get(function(res){
var html = '';
var titles = [];
res.setEncoding('utf-8') //防止中文乱码
res.on('data',function(chunk){
html += chrunk; //监听data事件 每次取一块数据
})
res.on('end',function(){
var $ = cheerio.load(html); //获取数据完成后,解析html
//将获取的图片存到images文件夹中
$('.mod-bd img').each(function(index, item){
//获取图片属性
var imgName = $(this).parent().next().text().trimg()
var imgfile = imgName + '.jpeg';
var imgSrc = $(this).attr('src')
//采用request模块,向服务器发起请求 获取图片资源
request.head(imgSrc, function(error, res,body){
if(error){
console.log('失败了')
}
});
//通过管道的方式用fs模块将图片写到本地的images文件下
request(imgSrc).pipe.(fs.createWriteStream('./images/' + imgfile));
})
})
}) 查看全部
js提取指定网站内容(
2017年12月14日14:16:47一个实例教学如何用
)
Nodejs实现了抓取网站图片的功能
更新时间:2017年12月14日14:16:47投稿人:老张
下面是一个示例,教您如何使用nodejs实现抓取网站图片的功能。感兴趣的朋友可以采集
通过一个例子,我们将说明nodejs实现了抓取网站图片的功能。以下是全部内容:
原则:
爬虫是最明显的IO密集型应用场景。节点的使用明显减少了I/O等待开销,数据挖掘更加方便
使用express模块构建节点服务
并使用请求模块获取目标页面的HTML代码
下载cherio模块以处理HTML代码(cherio类似于jQuery语法,因此易于使用和方便)
环境配置:
(1)介绍每个模块
var http = require('http');
var request = require('request);
var cheerio = require('cheerio');
var fs = require('fs'); //用来操作文件
var url = 'https://movie.douban.com/cinema/nowplaying/beijing/' //定义要爬的页面
(2)发送请求
http.get(function(res){
var html = '';
var titles = [];
res.setEncoding('utf-8') //防止中文乱码
res.on('data',function(chunk){
html += chrunk; //监听data事件 每次取一块数据
})
res.on('end',function(){
var $ = cheerio.load(html); //获取数据完成后,解析html
//将获取的图片存到images文件夹中
$('.mod-bd img').each(function(index, item){
//获取图片属性
var imgName = $(this).parent().next().text().trimg()
var imgfile = imgName + '.jpeg';
var imgSrc = $(this).attr('src')
//采用request模块,向服务器发起请求 获取图片资源
request.head(imgSrc, function(error, res,body){
if(error){
console.log('失败了')
}
});
//通过管道的方式用fs模块将图片写到本地的images文件下
request(imgSrc).pipe.(fs.createWriteStream('./images/' + imgfile));
})
})
})
js提取指定网站内容(如何用JS在网页中常用的webserver(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-15 13:17
1、首先要懂js,然后用iframe加载原网页,然后调用js
2、js很简单,写成一个网页,用winform加载网页,nodejs比较复杂,首先得让用户在windows上安装nodejs(我没试过),然后调用nodejs环境, linux下使用nodejs服务器,与windows程序不兼容。
尽管有可能,但 nodejs 通常不会直接用作 Web 服务器。node js中常用的web服务器是express。在express中,可以使用req.param('key')来获取post返回的参数。
通过设置formData使用请求模块发送。关于 formData,请参阅此处了解有关如何使用它的详细信息:
支持者都是市场上最新最热的知识点。名师录的高清视频应该可以帮到你。
尽管有可能,但 nodejs 通常不会直接用作 Web 服务器。node js中常用的web服务器是express。在express中,可以使用req.param('key')来获取post返回的参数。
如何使用JS在一个网页中引用另一个网页的内容
------ 使用javascript和AJAX非常方便的传输html文档。
JQuery很好的封装了AJAX,使用起来非常方便。
最简单的方便就是使用jQuery的load方法,可以很方便的加载包括html在内的文档。
例如:
$('#result').load('ajax/test.html', function() {
alert('加载完成。');
});
如果导入了jQuery,并且指定的html文档也存在,系统会将test.html中的内容导入#result元素中。
我可以在别人的 网站 上嵌入 js 代码吗?具体怎么做,没有恶意,就是想采集一些资料。
------ 至少你得有FTP控制吧?而且js采集信息涉及到跨域等问题!
如何把自己写的javascript脚本放到别人的网页中——
------ 只有这样才能搞定:登录应用服务器,把你的JS脚本放到服务器上,嵌入到那个页面中,这样就可以了,不然就别想了。想想看,如果你登录银行网站,如果写的外部js可以...
如何在一个 js 中使用另一种 js 方法-
------ 我们知道在html中,两个引入的js是不能互相调用的。那么如何解决呢?当然,你可以把代码全部复制过来,也许你不喜欢这样。例如有这样一个...
如何在Javascript中调用另一个JS文件中的网页-
------ 哈哈,使用js调用:注意这种方式js其实是普通文本,没有指定页面语言,如果指定了就用
如何使用JS弹出另一个网站页面?
------ 如果window.open 不起作用,就没有其他办法了。用360安全浏览器可以看到它的拦截程序导致弹窗无效,但是你可以尝试用框架直接放到你的页面上。种类
如何让多个网页共享javascript效果-
------ 将js代码另存为.js文件,这样引用
如何使用 JavaScript 读取另一个网页的源代码-
------ 考虑到目前浏览器的安全问题,javascript只能读取知岛子网页的内容,无法读取内兄弟网页和父网页的内容,可以使用javascript的window.open方法进行另一个网页 打开弹出窗口,然后您可以阅读另一个网页的源代码。
如何将别人的代码应用到自己的网站-
------ 只需在需要的地方添加代码即可。如果您的 CSS 文件不可用,只需将其 CSS 代码添加到您的 CSS 文件中。
js 文件,任何 网站 调用 js-
------ script标签本来是支持跨域的,你可以直接在script标签的src属性里写你的js URL地址。
视频链接:\\\\\\JavaWeb视频教程_380-JSP-介绍案例-使用JSP显示动态数据\\06.处理JS分页加载的网页_recv \\JS教程10.@ >讲解网页日历的开发过程\\JS网页制作实例实现导航高亮方法\\\\ 查看全部
js提取指定网站内容(如何用JS在网页中常用的webserver(图))
1、首先要懂js,然后用iframe加载原网页,然后调用js
2、js很简单,写成一个网页,用winform加载网页,nodejs比较复杂,首先得让用户在windows上安装nodejs(我没试过),然后调用nodejs环境, linux下使用nodejs服务器,与windows程序不兼容。
尽管有可能,但 nodejs 通常不会直接用作 Web 服务器。node js中常用的web服务器是express。在express中,可以使用req.param('key')来获取post返回的参数。
通过设置formData使用请求模块发送。关于 formData,请参阅此处了解有关如何使用它的详细信息:
支持者都是市场上最新最热的知识点。名师录的高清视频应该可以帮到你。
尽管有可能,但 nodejs 通常不会直接用作 Web 服务器。node js中常用的web服务器是express。在express中,可以使用req.param('key')来获取post返回的参数。
如何使用JS在一个网页中引用另一个网页的内容
------ 使用javascript和AJAX非常方便的传输html文档。
JQuery很好的封装了AJAX,使用起来非常方便。
最简单的方便就是使用jQuery的load方法,可以很方便的加载包括html在内的文档。
例如:
$('#result').load('ajax/test.html', function() {
alert('加载完成。');
});
如果导入了jQuery,并且指定的html文档也存在,系统会将test.html中的内容导入#result元素中。
我可以在别人的 网站 上嵌入 js 代码吗?具体怎么做,没有恶意,就是想采集一些资料。
------ 至少你得有FTP控制吧?而且js采集信息涉及到跨域等问题!
如何把自己写的javascript脚本放到别人的网页中——
------ 只有这样才能搞定:登录应用服务器,把你的JS脚本放到服务器上,嵌入到那个页面中,这样就可以了,不然就别想了。想想看,如果你登录银行网站,如果写的外部js可以...
如何在一个 js 中使用另一种 js 方法-
------ 我们知道在html中,两个引入的js是不能互相调用的。那么如何解决呢?当然,你可以把代码全部复制过来,也许你不喜欢这样。例如有这样一个...
如何在Javascript中调用另一个JS文件中的网页-
------ 哈哈,使用js调用:注意这种方式js其实是普通文本,没有指定页面语言,如果指定了就用
如何使用JS弹出另一个网站页面?
------ 如果window.open 不起作用,就没有其他办法了。用360安全浏览器可以看到它的拦截程序导致弹窗无效,但是你可以尝试用框架直接放到你的页面上。种类
如何让多个网页共享javascript效果-
------ 将js代码另存为.js文件,这样引用
如何使用 JavaScript 读取另一个网页的源代码-
------ 考虑到目前浏览器的安全问题,javascript只能读取知岛子网页的内容,无法读取内兄弟网页和父网页的内容,可以使用javascript的window.open方法进行另一个网页 打开弹出窗口,然后您可以阅读另一个网页的源代码。
如何将别人的代码应用到自己的网站-
------ 只需在需要的地方添加代码即可。如果您的 CSS 文件不可用,只需将其 CSS 代码添加到您的 CSS 文件中。
js 文件,任何 网站 调用 js-
------ script标签本来是支持跨域的,你可以直接在script标签的src属性里写你的js URL地址。
视频链接:\\\\\\JavaWeb视频教程_380-JSP-介绍案例-使用JSP显示动态数据\\06.处理JS分页加载的网页_recv \\JS教程10.@ >讲解网页日历的开发过程\\JS网页制作实例实现导航高亮方法\\\\
js提取指定网站内容(京东资源复制过去使用命令行.js和puppeteer小试牛刀`)
网站优化 • 优采云 发表了文章 • 0 个评论 • 39 次浏览 • 2021-12-15 13:10
需要:
如果你是技术员,那可以看我下一个文章,否则请直接移到我的github仓库看文档直接使用
仓库地址:附文件和源代码
此要求中使用的技术:Node.js 和 puppeteer
做个小测试,爬取京东资源
const puppeteer = require('puppeteer'); // 引入依赖
(async () => { //使用async函数完美异步
const browser = await puppeteer.launch(); //打开新的浏览器
const page = await browser.newPage(); // 打开新的网页
await page.goto('https://www.jd.com/'); //前往里面 'url' 的网页
const result = await page.evaluate(() => { //这个result数组包含所有的图片src地址
let arr = []; //这个箭头函数内部写处理的逻辑
const imgs = document.querySelectorAll('img');
imgs.forEach(function (item) {
arr.push(item.src)
})
return arr
});
// '此时的result就是得到的爬虫数据,可以通过'fs'模块保存'
})()
复制过去,使用命令行命令`node file name`运行获取爬虫数据。这个 puppeteer 包实际上为我们打开了另一个浏览器,重新打开了网页,并获取了他们的数据。
注意上面所有的逻辑都是puppeteer包帮助我们在不可见的地方打开另一个浏览器,然后处理逻辑,所以我们最后调用browser.close()方法关闭那个浏览器。
这时候我们优化了上一篇的代码,爬取了相应的资源。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.jd.com/');
const hrefArr = await page.evaluate(() => {
let arr = [];
const aNodes = document.querySelectorAll('.cate_menu_lk');
aNodes.forEach(function (item) {
arr.push(item.href)
})
return arr
});
let arr = [];
for (let i = 0; i < hrefArr.length; i++) {
const url = hrefArr[i];
console.log(url) //这里可以打印
await page.goto(url);
const result = await page.evaluate(() => { //这个方法内部console.log无效
return $('title').text(); //返回每个界面的title文字内容
});
arr.push(result) //每次循环给数组中添加对应的值
}
console.log(arr) //得到对应的数据 可以通过Node.js的 fs 模块保存到本地
await browser.close()
})()
有一个天坑page.evaluate函数。内部console.log无法打印,内部无法获取外部变量,只能使用return。
要使用选择器,必须先到对应界面的控制台测试是否可以选择DOM,然后才能使用。比如京东就不能使用querySelector。这里因为
京东的界面使用了jQuery,所以我们可以使用jQuery。简而言之,他们可以开发任何可以使用的选择器。我们可以使用它们,否则我们不能。
接下来直接爬取Node.js的官网首页,直接生成PDF
无论您是否了解 Node.js 和 puppeteer 爬虫,您都可以做到。请仔细阅读本文档并按顺序执行每个步骤。
本项目的实现需求:给我们一个网页地址,抓取他的网页内容,然后输出成我们想要的PDF格式文档,请注意是高质量的PDF文档
TIPS:本项目的设计思路是每个网页一个PDF文件,所以每次爬取单个页面时,请复制index.pdf,然后继续更改URL地址,继续爬取,生成一个新的PDF 文件。当然,你也可以通过循环编译等方式一次抓取多个网页生成多个PDF文件。
对应京东首页这种图片懒加载的网页,爬取的部分内容是处于加载状态的内容。对于有一些反爬虫机制的网页,爬虫也会有问题,但是绝大多数网站都是有可能的
const puppeteer = require('puppeteer');
const url = require('./url');
(async () => {
const browser = await puppeteer.launch({ headless: true })
const page = await browser.newPage()
//选择要打开的网页
await page.goto(url, { waitUntil: 'networkidle0' })
//选择你要输出的那个PDF文件路径,把爬取到的内容输出到PDF中,必须是存在的PDF,可以是空内容,如果不是空的内容PDF,那么会覆盖内容
let pdfFilePath = './index.pdf';
//根据你的配置选项,我们这里选择A4纸的规格输出PDF,方便打印
await page.pdf({
path: pdfFilePath,
format: 'A4',
scale: 1,
printBackground: true,
landscape: false,
displayHeaderFooter: false
});
await browser.close()
})()
文件解构设计
数据在这个时代非常宝贵。根据网页的设计逻辑,通过选择特定href的地址,可以直接先获取对应的资源,也可以再次使用page.goto方法进入,然后调用page.evaluate( ) 处理逻辑。或者输出对应的PDF文件,当然也可以一次输出多个PDF文件~
这里就不过多介绍了,毕竟Node.js可以上天堂,说不定以后真的什么都可以了。这么高质量的短教程,请采集
或者转发给你的朋友,谢谢。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持面圈教程。 查看全部
js提取指定网站内容(京东资源复制过去使用命令行.js和puppeteer小试牛刀`)
需要:
如果你是技术员,那可以看我下一个文章,否则请直接移到我的github仓库看文档直接使用
仓库地址:附文件和源代码
此要求中使用的技术:Node.js 和 puppeteer
做个小测试,爬取京东资源
const puppeteer = require('puppeteer'); // 引入依赖
(async () => { //使用async函数完美异步
const browser = await puppeteer.launch(); //打开新的浏览器
const page = await browser.newPage(); // 打开新的网页
await page.goto('https://www.jd.com/'); //前往里面 'url' 的网页
const result = await page.evaluate(() => { //这个result数组包含所有的图片src地址
let arr = []; //这个箭头函数内部写处理的逻辑
const imgs = document.querySelectorAll('img');
imgs.forEach(function (item) {
arr.push(item.src)
})
return arr
});
// '此时的result就是得到的爬虫数据,可以通过'fs'模块保存'
})()
复制过去,使用命令行命令`node file name`运行获取爬虫数据。这个 puppeteer 包实际上为我们打开了另一个浏览器,重新打开了网页,并获取了他们的数据。
注意上面所有的逻辑都是puppeteer包帮助我们在不可见的地方打开另一个浏览器,然后处理逻辑,所以我们最后调用browser.close()方法关闭那个浏览器。
这时候我们优化了上一篇的代码,爬取了相应的资源。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.jd.com/');
const hrefArr = await page.evaluate(() => {
let arr = [];
const aNodes = document.querySelectorAll('.cate_menu_lk');
aNodes.forEach(function (item) {
arr.push(item.href)
})
return arr
});
let arr = [];
for (let i = 0; i < hrefArr.length; i++) {
const url = hrefArr[i];
console.log(url) //这里可以打印
await page.goto(url);
const result = await page.evaluate(() => { //这个方法内部console.log无效
return $('title').text(); //返回每个界面的title文字内容
});
arr.push(result) //每次循环给数组中添加对应的值
}
console.log(arr) //得到对应的数据 可以通过Node.js的 fs 模块保存到本地
await browser.close()
})()
有一个天坑page.evaluate函数。内部console.log无法打印,内部无法获取外部变量,只能使用return。
要使用选择器,必须先到对应界面的控制台测试是否可以选择DOM,然后才能使用。比如京东就不能使用querySelector。这里因为
京东的界面使用了jQuery,所以我们可以使用jQuery。简而言之,他们可以开发任何可以使用的选择器。我们可以使用它们,否则我们不能。
接下来直接爬取Node.js的官网首页,直接生成PDF
无论您是否了解 Node.js 和 puppeteer 爬虫,您都可以做到。请仔细阅读本文档并按顺序执行每个步骤。
本项目的实现需求:给我们一个网页地址,抓取他的网页内容,然后输出成我们想要的PDF格式文档,请注意是高质量的PDF文档
TIPS:本项目的设计思路是每个网页一个PDF文件,所以每次爬取单个页面时,请复制index.pdf,然后继续更改URL地址,继续爬取,生成一个新的PDF 文件。当然,你也可以通过循环编译等方式一次抓取多个网页生成多个PDF文件。
对应京东首页这种图片懒加载的网页,爬取的部分内容是处于加载状态的内容。对于有一些反爬虫机制的网页,爬虫也会有问题,但是绝大多数网站都是有可能的
const puppeteer = require('puppeteer');
const url = require('./url');
(async () => {
const browser = await puppeteer.launch({ headless: true })
const page = await browser.newPage()
//选择要打开的网页
await page.goto(url, { waitUntil: 'networkidle0' })
//选择你要输出的那个PDF文件路径,把爬取到的内容输出到PDF中,必须是存在的PDF,可以是空内容,如果不是空的内容PDF,那么会覆盖内容
let pdfFilePath = './index.pdf';
//根据你的配置选项,我们这里选择A4纸的规格输出PDF,方便打印
await page.pdf({
path: pdfFilePath,
format: 'A4',
scale: 1,
printBackground: true,
landscape: false,
displayHeaderFooter: false
});
await browser.close()
})()
文件解构设计
数据在这个时代非常宝贵。根据网页的设计逻辑,通过选择特定href的地址,可以直接先获取对应的资源,也可以再次使用page.goto方法进入,然后调用page.evaluate( ) 处理逻辑。或者输出对应的PDF文件,当然也可以一次输出多个PDF文件~
这里就不过多介绍了,毕竟Node.js可以上天堂,说不定以后真的什么都可以了。这么高质量的短教程,请采集
或者转发给你的朋友,谢谢。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持面圈教程。

