
js提取指定网站内容
js提取指定网站内容(js提取指定网站内容是什么鬼?知乎首页的代码应该有写)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-21 06:02
js提取指定网站内容,可以按照链接获取;也可以按照字母或字符编码获取;也可以按照文字格式获取,比如js提取得到的文字一般可以转义。
1.用sql提取2.用html5提取,比如w3cschool,可以下载注意,这是一种收费项目,如果你自己有百度云空间,可以下载这个功能。我之前下载过,很强大。
这个。我觉得。你应该百度一下。知乎首页的代码应该有写。
很简单我是学java的来说一下这个我可以看出我很闲可能是因为我们公司那个vss免费注册的。
用html5可以爬取的,我用的是talkjs,
可以这样的利用js变量接受一段文本值然后利用循环或者多线程解析出我这么用是一种伪多线程模式把抓取到的js字节通过改变trim属性,变成字符串利用php标准库的string,包含字符串内容,合并成一个string,然后合并最后这样的方法就不能一对一,因为这个需要用到trycatch这个关键字。
php提取文字有这个php–php提取js字符串
php解析js文件,
xcode:phpxmlxml:pxml
php直接提取js?:.\.php?
后面来个?是什么鬼 查看全部
js提取指定网站内容(js提取指定网站内容是什么鬼?知乎首页的代码应该有写)
js提取指定网站内容,可以按照链接获取;也可以按照字母或字符编码获取;也可以按照文字格式获取,比如js提取得到的文字一般可以转义。
1.用sql提取2.用html5提取,比如w3cschool,可以下载注意,这是一种收费项目,如果你自己有百度云空间,可以下载这个功能。我之前下载过,很强大。
这个。我觉得。你应该百度一下。知乎首页的代码应该有写。
很简单我是学java的来说一下这个我可以看出我很闲可能是因为我们公司那个vss免费注册的。
用html5可以爬取的,我用的是talkjs,
可以这样的利用js变量接受一段文本值然后利用循环或者多线程解析出我这么用是一种伪多线程模式把抓取到的js字节通过改变trim属性,变成字符串利用php标准库的string,包含字符串内容,合并成一个string,然后合并最后这样的方法就不能一对一,因为这个需要用到trycatch这个关键字。
php提取文字有这个php–php提取js字符串
php解析js文件,
xcode:phpxmlxml:pxml
php直接提取js?:.\.php?
后面来个?是什么鬼
js提取指定网站内容(前端侧对于动态生成的内容进行下载的实时截图下载 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-21 04:15
)
有时候需要在前端下载动态生成的内容,比如页面上的某条文字信息,而分享页面的时候,希望分享的图片是页面的实时截图内容。此时,图像是动态的。纯 HTML 显然无法满足我们的需求。借助 JS 和其他一些 HTML5 功能,例如将页面元素转换为画布,然后将它们转换为图像以供下载。
原理其实很简单。我们可以借助 Blob 将文本或 JS 字符串信息转换成二进制,然后将其作为元素的 href 属性,配合 download 属性实现下载。
代码也比较简单,如下图(兼容Chrome和Firefox):
function funcDownload (content, filename) {
// 创建隐藏的可下载链接
var eleLink = document.createElement('a');
eleLink.download = filename;
eleLink.style.display = 'none';
// 字符内容转变成blob地址
var blob = new Blob([content]);
eleLink.href = URL.createObjectURL(blob);
// 触发点击
document.body.appendChild(eleLink);
eleLink.click();
// 然后移除
document.body.removeChild(eleLink);
}
function dn (){
var ss = document.querySelector('html').outerHTML;
funcDownload(ss, 'ceshi.html')
}
其中,content是指要下载的文本或字符串内容,filename是指下载到系统中的文件名。
上面的代码可以将整个当前网页下载为html文件,但是对于网页内外的一些资源是无法显示的。
在 Chrome 浏览器中,即使模拟点击创建的元素没有附加到页面上,也可以触发下载,但在 Firefox 浏览器中,这是不可能的。所以上面的funDownload()方法有一个appendChild和removeChild处理,这是为了兼容火狐浏览器。
1、URL.createObjectURL() 方法将根据传入的参数创建一个指向参数对象的 URL。此 URL 的生命周期仅存在于它创建的文档中。新的对象 URL 指向执行的 File 对象或 Blob 对象。
objectURL = URL.createObjectURL(blob || file);
参数:文件对象或 Blob 对象。这里大致是 File 对象和 Blob 对象:
文件对象:它是一个文件。例如,如果我使用 input type="file" 标签上传文件,那么其中的每个文件都是一个 File 对象。
Blob 对象:它是二进制数据。例如,new Blob() 创建的对象就是一个 Blob 对象。例如,在 XMLHttpRequest 中,如果 responseType 指定为 blob,则返回值也是一个 blob 对象。
注意:每次调用 createObjectURL 时,都会创建一个新的 URL 对象。即使您为同一个文件创建了 URL。如果您不再需要此对象,要释放它,您需要使用 URL.revokeObjectURL() 方法。当页面关闭时,浏览器会自动释放它,但为了获得最佳性能和内存使用,您应该在确定不再需要它时释放它。
2、URL.revokeObjectURL()方法会释放一个由URL.createObjectURL()创建的对象URL,当你使用了对象URL,然后让浏览器知道该URL不再需要指向对应的URL文件,你需要调用这个方法。具体含义是一个对象URL可以使用这个URL访问指定的文件,但我可能只需要访问一次。一旦被访问,对象 URL 就不再需要,将被释放和释放。将来,此对象 URL 将不再指向指定文件。例如,对于一张图片,我创建一个对象 URL,然后通过对象 URL,我将图片加载到页面上。既然已经加载了图片不需要再次加载,那么我释放对象的URL,那么URL就不再指向图片了。
window.URL.revokeObjectURL(objectURL);
//objectURL 是一个通过URL.createObjectURL()方法创建的对象URL. 查看全部
js提取指定网站内容(前端侧对于动态生成的内容进行下载的实时截图下载
)
有时候需要在前端下载动态生成的内容,比如页面上的某条文字信息,而分享页面的时候,希望分享的图片是页面的实时截图内容。此时,图像是动态的。纯 HTML 显然无法满足我们的需求。借助 JS 和其他一些 HTML5 功能,例如将页面元素转换为画布,然后将它们转换为图像以供下载。
原理其实很简单。我们可以借助 Blob 将文本或 JS 字符串信息转换成二进制,然后将其作为元素的 href 属性,配合 download 属性实现下载。
代码也比较简单,如下图(兼容Chrome和Firefox):
function funcDownload (content, filename) {
// 创建隐藏的可下载链接
var eleLink = document.createElement('a');
eleLink.download = filename;
eleLink.style.display = 'none';
// 字符内容转变成blob地址
var blob = new Blob([content]);
eleLink.href = URL.createObjectURL(blob);
// 触发点击
document.body.appendChild(eleLink);
eleLink.click();
// 然后移除
document.body.removeChild(eleLink);
}
function dn (){
var ss = document.querySelector('html').outerHTML;
funcDownload(ss, 'ceshi.html')
}
其中,content是指要下载的文本或字符串内容,filename是指下载到系统中的文件名。
上面的代码可以将整个当前网页下载为html文件,但是对于网页内外的一些资源是无法显示的。
在 Chrome 浏览器中,即使模拟点击创建的元素没有附加到页面上,也可以触发下载,但在 Firefox 浏览器中,这是不可能的。所以上面的funDownload()方法有一个appendChild和removeChild处理,这是为了兼容火狐浏览器。
1、URL.createObjectURL() 方法将根据传入的参数创建一个指向参数对象的 URL。此 URL 的生命周期仅存在于它创建的文档中。新的对象 URL 指向执行的 File 对象或 Blob 对象。
objectURL = URL.createObjectURL(blob || file);
参数:文件对象或 Blob 对象。这里大致是 File 对象和 Blob 对象:
文件对象:它是一个文件。例如,如果我使用 input type="file" 标签上传文件,那么其中的每个文件都是一个 File 对象。
Blob 对象:它是二进制数据。例如,new Blob() 创建的对象就是一个 Blob 对象。例如,在 XMLHttpRequest 中,如果 responseType 指定为 blob,则返回值也是一个 blob 对象。
注意:每次调用 createObjectURL 时,都会创建一个新的 URL 对象。即使您为同一个文件创建了 URL。如果您不再需要此对象,要释放它,您需要使用 URL.revokeObjectURL() 方法。当页面关闭时,浏览器会自动释放它,但为了获得最佳性能和内存使用,您应该在确定不再需要它时释放它。
2、URL.revokeObjectURL()方法会释放一个由URL.createObjectURL()创建的对象URL,当你使用了对象URL,然后让浏览器知道该URL不再需要指向对应的URL文件,你需要调用这个方法。具体含义是一个对象URL可以使用这个URL访问指定的文件,但我可能只需要访问一次。一旦被访问,对象 URL 就不再需要,将被释放和释放。将来,此对象 URL 将不再指向指定文件。例如,对于一张图片,我创建一个对象 URL,然后通过对象 URL,我将图片加载到页面上。既然已经加载了图片不需要再次加载,那么我释放对象的URL,那么URL就不再指向图片了。
window.URL.revokeObjectURL(objectURL);
//objectURL 是一个通过URL.createObjectURL()方法创建的对象URL.
js提取指定网站内容(IT共享者获取妹纸图上的图片链接功能大揭秘(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-21 04:14
今日鸡汤
下马喝你的酒,问问你的目的是什么。
前言
大家好,我是一名IT分享者,人称皮皮。
这张妹纸图网站想必大家都很熟悉,老司机的天堂。小编第一次进入时表示自己的身体逐渐变得空虚,表示一定要克制自己,远离这种正能量网站。话不多说,今天就带大家去获取妹子头像上的图片链接。然后大家就明白了。
一、项目准备
360浏览器,仅此而已
二、项目目的
获取页面上的所有精美图片
三、项目步骤1.打开浏览器,搜索图片。我们以漂亮的图片为例:
图片太美了,看不下去了。
2.打开浏览器控制台
F12,可以打开浏览器控制台,我们今天要做的就是获取所有图片链接,顺便查看一下图片。如下所示:
今天我们将获取其中的所有图片链接。相信没接触过前端的人一定对此一无所知,但是小编接下来讲了之后,你还是一无所知,那是你的错。
3.控制台功能揭晓
你可能觉得这个地方没用,什么都没有,还不如 Element Network 好用;确实前两个非常好用,可以用来分析网页结构和网页请求,但是我要说的是控制台的功能。千万不要小看它,因为它可以让你在开发过程中快速看到效果图,比如你写了一段代码,但是你现在想看看能不能用,一般的做法是写HTML+CSS然后嵌入JavaScript进去显然太麻烦了,修改后必须刷新浏览器才能看到效果。最终导致浏览器和编辑器频繁切换,影响开发速度和效率,甚至占用额外空间。系统资源。于是,控制台应运而生,这使我们能够轻松地使用 JavaScript 代码,而无需匹配 HTML 和 CSS 即可运行。一个控制台可以做任何事情,这就是我们刚才说的控制台。我们可以先来看看它的作用:
可以看到它有自动提示功能,而且比任何第三方IDE都要全面,因为它是配合浏览器使用的,其他IDE做不到那么完整,所以有时候如果你想看的话使用某种方法,它不会提示,那么只有一个原因,就是你用错了。
1).更改其编辑状态
控制台输入:
。针对特定元素
这里我们可以先看一下我们想看的浏览器图片元素的信息。我们可以先打印出所有的图像。这里我们使用一个特殊的符号:
我们可以看到,通过这个句法糖,可以打印出当前页面的所有图片信息,显示70,说明本页有70张图片。当小编再次滚动鼠标时,发现图片数量增加了,变成了136张图片。,这意味着它已加载 Ajax。
除了这种获取图片的方式,你还可以这样做:
document.images
得到的结果与上面完全相同。随着这些知识点的积累,我们现在可以轻松获取所有的图片链接。
4.获取图片链接和图片名称
这里我们需要将获取到的图片加入到数组中,然后遍历完后将所有图片打印出来。
1).创建一个数组来存储所有的图片
ab=document.images #获取当前页面所有图片<br />var aa=[] #建立数组<br />for(const y of ab){ #建立const变量使得无法修改<br /> aa.push(y); #把图片装进数组<br />}
2)。遍历数组打印图片链接
这里可以使用的方法有很多,我将一一介绍。
1)).对于 ...in
for(const a in aa){<br /> console.log(aa[a])<br />}
2)).对于...的
for(const a of aa){<br /> console.log(a)<br />}
3)).ForEach
aa.forEach(function(val,item,array){<br /> console.log(val)<br />});
4)).地图
{<br /> console.log(val)<br />});
可以看出,第四种方法与第三种方法类似,但还是有区别的。前者没有返回值,后者有,后者支持修改返回值。虽然我们打印了图片链接,但是图片名并没有打印出来,所以小编开始找图片名:
发现是在Div标签中,于是开始寻找符合条件的Div:
document.querySelectorAll('div.img_tit')#精确找到所有类名为img_tit的Div<br />document.getElementsByClassName('img_tit')#找到所有类名为img_tit
然后我们先输出图片名称再输出图片链接,这样我们就可以使用循环再判断了,如下图:
<p>var a=0;<br />do{<br /> a++;<br /> if(a%2==0){<br /> console.log(aa[a])<br />}<br /> else{<br /> console.log(ac[a])<br /> }<br /><br /><br />}<br />while(a 查看全部
js提取指定网站内容(IT共享者获取妹纸图上的图片链接功能大揭秘(组图))
今日鸡汤
下马喝你的酒,问问你的目的是什么。
前言
大家好,我是一名IT分享者,人称皮皮。
这张妹纸图网站想必大家都很熟悉,老司机的天堂。小编第一次进入时表示自己的身体逐渐变得空虚,表示一定要克制自己,远离这种正能量网站。话不多说,今天就带大家去获取妹子头像上的图片链接。然后大家就明白了。
一、项目准备
360浏览器,仅此而已
二、项目目的
获取页面上的所有精美图片
三、项目步骤1.打开浏览器,搜索图片。我们以漂亮的图片为例:

图片太美了,看不下去了。
2.打开浏览器控制台
F12,可以打开浏览器控制台,我们今天要做的就是获取所有图片链接,顺便查看一下图片。如下所示:

今天我们将获取其中的所有图片链接。相信没接触过前端的人一定对此一无所知,但是小编接下来讲了之后,你还是一无所知,那是你的错。
3.控制台功能揭晓
你可能觉得这个地方没用,什么都没有,还不如 Element Network 好用;确实前两个非常好用,可以用来分析网页结构和网页请求,但是我要说的是控制台的功能。千万不要小看它,因为它可以让你在开发过程中快速看到效果图,比如你写了一段代码,但是你现在想看看能不能用,一般的做法是写HTML+CSS然后嵌入JavaScript进去显然太麻烦了,修改后必须刷新浏览器才能看到效果。最终导致浏览器和编辑器频繁切换,影响开发速度和效率,甚至占用额外空间。系统资源。于是,控制台应运而生,这使我们能够轻松地使用 JavaScript 代码,而无需匹配 HTML 和 CSS 即可运行。一个控制台可以做任何事情,这就是我们刚才说的控制台。我们可以先来看看它的作用:

可以看到它有自动提示功能,而且比任何第三方IDE都要全面,因为它是配合浏览器使用的,其他IDE做不到那么完整,所以有时候如果你想看的话使用某种方法,它不会提示,那么只有一个原因,就是你用错了。
1).更改其编辑状态
控制台输入:

在编辑状态下,我们的点击操作是没有效果的,也就是说只能修改。如果要恢复它,只需刷新浏览器即可。
2)。针对特定元素
这里我们可以先看一下我们想看的浏览器图片元素的信息。我们可以先打印出所有的图像。这里我们使用一个特殊的符号:

我们可以看到,通过这个句法糖,可以打印出当前页面的所有图片信息,显示70,说明本页有70张图片。当小编再次滚动鼠标时,发现图片数量增加了,变成了136张图片。,这意味着它已加载 Ajax。
除了这种获取图片的方式,你还可以这样做:
document.images
得到的结果与上面完全相同。随着这些知识点的积累,我们现在可以轻松获取所有的图片链接。
4.获取图片链接和图片名称
这里我们需要将获取到的图片加入到数组中,然后遍历完后将所有图片打印出来。
1).创建一个数组来存储所有的图片
ab=document.images #获取当前页面所有图片<br />var aa=[] #建立数组<br />for(const y of ab){ #建立const变量使得无法修改<br /> aa.push(y); #把图片装进数组<br />}

2)。遍历数组打印图片链接
这里可以使用的方法有很多,我将一一介绍。
1)).对于 ...in
for(const a in aa){<br /> console.log(aa[a])<br />}

2)).对于...的
for(const a of aa){<br /> console.log(a)<br />}

3)).ForEach
aa.forEach(function(val,item,array){<br /> console.log(val)<br />});

4)).地图
{<br /> console.log(val)<br />});

可以看出,第四种方法与第三种方法类似,但还是有区别的。前者没有返回值,后者有,后者支持修改返回值。虽然我们打印了图片链接,但是图片名并没有打印出来,所以小编开始找图片名:

发现是在Div标签中,于是开始寻找符合条件的Div:
document.querySelectorAll('div.img_tit')#精确找到所有类名为img_tit的Div<br />document.getElementsByClassName('img_tit')#找到所有类名为img_tit
然后我们先输出图片名称再输出图片链接,这样我们就可以使用循环再判断了,如下图:
<p>var a=0;<br />do{<br /> a++;<br /> if(a%2==0){<br /> console.log(aa[a])<br />}<br /> else{<br /> console.log(ac[a])<br /> }<br /><br /><br />}<br />while(a
js提取指定网站内容(子域名Finder胸怀万里世界,放眼无限未来(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-19 01:28
nul1 2022-03-18 0 浏览 原创 JSFinder:在 js 文件中提取 URL 和子域的脚本
关键词:子域查找器
思考世界,展望无限未来。这篇文章主要讲述了JSFinder:一个提取js文件中的url和子域的脚本,希望对大家有所帮助。
JSFinder 简介
JSFinder是一个脚本工具,用于快速提取网站的js文件中的url和子域。
支持使用
以前我们大部分子域都是通过爆破或者DNS获取的,这个脚本可以认为是小菜一碟,从JS文件中匹配子域。
简单的爬取示例
子域列表
喜欢(0)
这篇关于JSFinder的文章:一个提取js文件中的url和子域的脚本已经完成。如果没有解决您的问题,请参考以下文章:
相关文章
Flask - 蓝图和子域
JavaScript学习(八十)——请写一个JS程序提取URL中的每个get参数(参数名和参数个数不定),返回一个json结构形式为键值
p>
flask 中的蓝图和子域实现
前端提取URL中的每个GET参数
Flask 框架详细的上下文管理机制
使用 Azure Web App 上的 web.config 将子域重写为目录
#yydsDry goods inventory#Next.js 通配符子域
.Request.Url.Host 不显示子域 查看全部
js提取指定网站内容(子域名Finder胸怀万里世界,放眼无限未来(组图))
nul1 2022-03-18 0 浏览 原创 JSFinder:在 js 文件中提取 URL 和子域的脚本
关键词:子域查找器
思考世界,展望无限未来。这篇文章主要讲述了JSFinder:一个提取js文件中的url和子域的脚本,希望对大家有所帮助。
JSFinder 简介
JSFinder是一个脚本工具,用于快速提取网站的js文件中的url和子域。
支持使用
以前我们大部分子域都是通过爆破或者DNS获取的,这个脚本可以认为是小菜一碟,从JS文件中匹配子域。
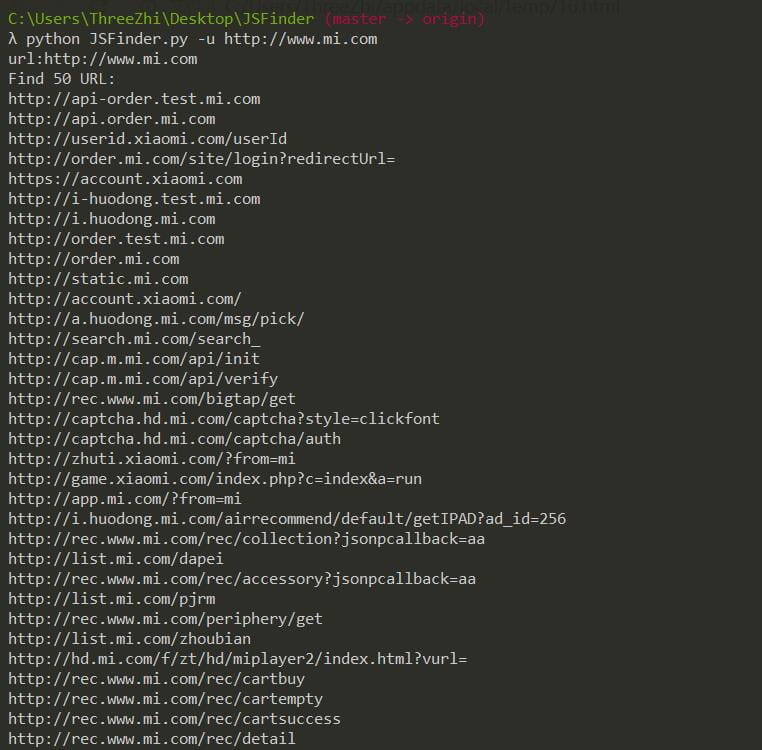
简单的爬取示例
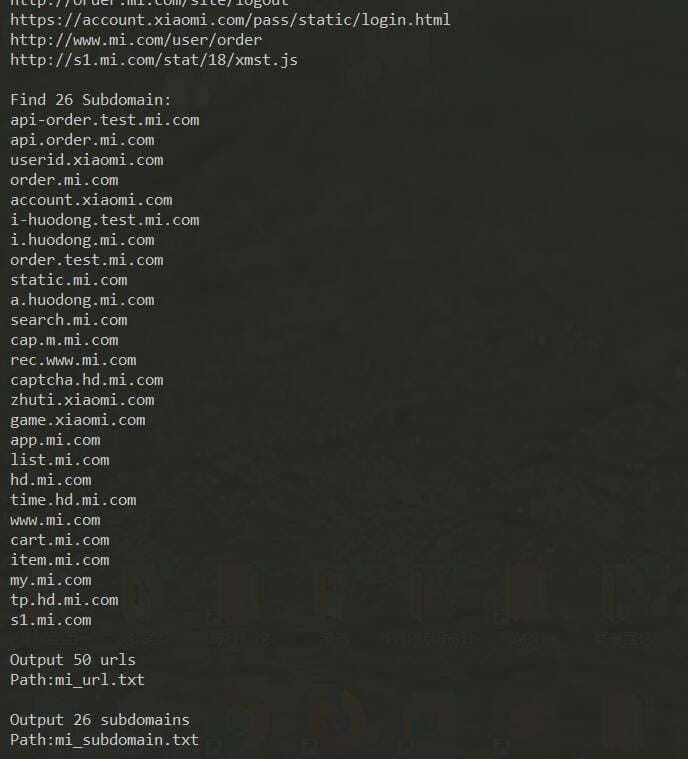
子域列表
喜欢(0)
这篇关于JSFinder的文章:一个提取js文件中的url和子域的脚本已经完成。如果没有解决您的问题,请参考以下文章:
相关文章
Flask - 蓝图和子域
JavaScript学习(八十)——请写一个JS程序提取URL中的每个get参数(参数名和参数个数不定),返回一个json结构形式为键值
p>
flask 中的蓝图和子域实现
前端提取URL中的每个GET参数
Flask 框架详细的上下文管理机制
使用 Azure Web App 上的 web.config 将子域重写为目录
#yydsDry goods inventory#Next.js 通配符子域
.Request.Url.Host 不显示子域
js提取指定网站内容(作者简介董沅鑫,云开发CloudBase团队研发,业余时间出没在。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-17 07:18
关于作者
云开发CloudBase团队研发工程师董元新,专注于前端工程和节点服务开发。他在业余时间在这里。
本文内容
介绍
随着腾讯云开发能力的逐步提升,经验丰富的工程师可以独立完成一个产品的开发和上线。但是,与在线云开发相关的实战却很少文章。很多开发者都知道云开发的能力,但是不知道在现有的开发体系下如何引入云开发。
本文从云开发团队开发者+能力用户的角度出发,以云开发官网()为例,结合流行的框架和工具,分享云开发的实践经验。
涉及的知识点有:
React 框架:Next.jsCI 自动构建概述
系统设计图:
背景介绍
随着云开发团队业务的快速发展,团队需要一个官方网站,更加直观、即时地向开发者展示云开发的相关能力,包括但不限于工具链、SDK、技术文档等。
同时,为了降低开发者的启动成本,积累行业优秀的实践经验,官网还承载着营造社区氛围、聚合重要信息、增强用户粘性的重任。
我们最初使用 VuePress 作为静态 网站 工具,遇到了一些痛点:
我们使用“cms Extensions”、“Basic Cloud Development Capabilities”、“Next.js”、“CI Tools”很好地解决了上述问题。在实现网站动态内容的同时,保证了SEO,运维同学也可以通过cms对内容进行可视化管理。
安装cms
进入云开发扩展能力控制台,按照提示安装cms内容管理系统。
配置分机时,有两种账户:管理员账户和操作员账户。管理员账户具有较高的权限,可以创建新的数据集;而操作员账户只能添加、删除和修改现有的数据集。
注意:安装时间有点长,请耐心等待
安装成功后,云数据库会自动创建三个集合,分别是 tcb-ext-cms-contents、tcb-ext-cms-users、tcb-ext-cms-webhooks ,分别存放cms 系统配置信息和内容数据。会自动创建三个云函数,分别是tcb-ext-cms-api、tcb-ext-cms-init、tcb-ext-cms-auth,它们封装了初始化,数据流的认证和相关逻辑。
输入“Static 网站 Hosting”,可以看到cms系统的静态文件已经自动部署到tcb-cms/目录下:
点击上方的“基本配置”查看域名信息。
在浏览器中访问对应的链接()可以看到cms系统:
至此,在没有任何开发成本的情况下,一个cms内容管理系统正式上线啦~
使用 cms 创建动态内容
对于动态数据内容,我们将其划分为不同的模块。每个内容模块对应一个cms系统的数据集合。例如,在“云开发官网”-“社区页面”中,推荐课程的内容是动态的。
从图中可以看出,每门课程都有多个属性。在云数据库中,每门课程对应一个文档,课程属性对应文档的字段。字段类型和含义如下:
name: 课程名称
time: 课程时间
cover: 课程封面
url: 课程链接
level: 课程难度
以管理员身份登录cms系统,在内容设置页面新建内容。在cms中,支持多种高级数据类型,如url、image、markdown、富文本、标签数组、email、URL等,这些类型都智能识别,显示更友好。
注意:cms 有自己的图床功能。当数据类型为“图片”时,图片会自动上传到当前云开发环境中的云存储中。以 cloud:// 开头的用于图像信息的特殊链接存储在数据集合中。
创建新内容时,默认情况下,cms 会自动填充 4 个字段:name、order、createTime、updateTime。您可以根据自己的需要删除不必要的字段。
建议:保留订单字段,可用于数据排序。对于运营商来说,数据的阶数值越大,在cms系统中显示的位置就越高;对于开发者来说,可以按照顺序进行排序和搜索。这保证了经验和逻辑的一致性。
根据字段创建集合后, cms 您将在系统左侧看到“推荐课程”。其对应的内容存放在云数据库的推荐课程(创建时指定)集合中,其字段信息存放在云数据库的tcb-ext-cms-contents(cms创建在初始化期间))在集合中。
根据设置添加新课程内容后,再次进入“推荐好课程”,如下图:
图片、链接等内容显示给操作者更友好。
项目建设
按照 Next.js 文档创建 Next.js 项目:
npm i --save next react react-dom axios
由于我们将 网站 部署到“静态托管”,我们将使用 Next.js 的静态导出功能。package.json 中的打包脚本更新为:
"scripts": {
"dev": "next",
"build": "next build && next export",
"start": "next start"
}
为了快速部署静态网站,发布云功能。需要全局安装@cloudbase/cli:
npm install -g @cloudbase/cli
安装后,添加两个脚本:
"scripts": {
"deploy:hosting": "npm run build && cloudbase hosting:deploy out -e jhgjj-0ae4a1",
"deploy:function": "echo y | cloudbase functions:deploy --force"
}
注意:准备两个云环境,防止静态部署时文件覆盖。envId为jhgjj-0ae4a1的云环境仅用于部署Next.js的静态导出文件。envId为pagecounter-d27cfe的云环境用于部署cms系统。
获取 cms 内容
借助 CloudBase 的 Node SDK-@cloudbase/node-sdk,我们可以在 Next.js 的 getStaticProps() 方法中读取云数据库中的数据。
为了让逻辑更清晰,我们将获取外部数据的方法统一封装到一个单独的文件中。以获取“推荐课程”为例:
// provider.js
const cloudbase = require("@cloudbase/node-sdk");
const config = {
secretId: "your secretId", // 前往「腾讯云控制台」-「访问密钥」获取
secretKey: "your secretKey", // 前往「腾讯云控制台」-「访问密钥」获取
env: "your envid" // 前往「腾讯云控制台」-「云开发 CloudBase」获取
};
const app = cloudbase.init(config);
/**
* 获取云数据库数据
*/
async function getCourses() {
const db = app.database();
const result = await db.collection("recommend-course").get();
if (result.code) {
throw new Error(
`获取「推荐课程」失败, 错误码是${result.code}: ${result.message}`
);
}
return result.data.map(item => {
if (item.createTime instanceof Date) {
item.createTime = item.createTime.toLocaleString();
}
if (item.updateTime instanceof Date) {
item.updateTime = item.updateTime.toLocaleString();
}
item.cover = getBucketUrl(item.cover); // 处理云存储的特殊链接
return item;
});
}
如上所述,cms自带图床功能,拖拽上传的图片会存储在同一环境的云存储中,获取图片的链接会存储在采集中。云存储的链接是一个以cloud://开头的特殊链接,需要在前端进行专门的识别和处理。
例如图片的存储链接为:cloud://pagecounter-d27cfe.7061-pagecounter-d27cfe-1255463368/uploads/04.png。把它变成一个可访问的 http 链接:.
转换思路是:识别envid背后的信息,与tcb.qcloud.la域名重新拼接:
// provider.js
/**
* 获取云存储的访问链接
* @param {String} url 云存储的特定url
*/
function getBucketUrl(url) {
if (!url.startsWith("cloud://")) {
return url;
}
const re = /cloud:\/\/.*?\.(.*?)\/(.*)/;
const result = re.exec(url);
return `https://${result[1]}.tcb.qcloud.la/${result[2]}`;
}
注意:云存储的“权限设置”应为:所有用户可读,只有创建者和管理员可写。否则无法访问链接。
建议:除了内置的图床功能,开发者可以根据自己的需要使用其他稳定的图床服务,比如微博图床。如果使用其他图床,对应的字段类型不能设置为“图像”,可以是“字符串”或“超链接”。
到目前为止,我们已经使用 SDK 获取了云数据库数据,剩下要做的就是将其注入到 Next.js 页面组件的 props 中:
// pages/index.js
const HomePage = ({ courses }) => {
return (
// 尽情使用数据吧...
)
}
export async function getStaticProps() {
const { getCourses } = require('./../provider')
return {
props: {
courses: await getCourses()
}
}
}
export default HomePage
打开浏览器,输入:3000/,可以看到效果如下:
输入view-source::3000/,可以看到网页的html源码中收录了课程数据,解决了SEO的问题:
注意:Next.js 的一些方法会在双方都运行,但 getStaticProps() 只会在服务端运行
自动构建和部署
至此,开发工作基本结束。执行 npm run build 命令,将 网站 静态文件打包到 out/ 目录下:
执行 npm run deploy:hosting 将 out/ 目录下的文件上传到“static网站hosting”。访问静态 网站hosted link: ,效果如下:
借助成熟的 CI 工具,例如 Travis、Circle 等,可以定期触发构建工作。这样,内容和开发就完全分开了。
在构建和发布时,您需要使用 CloudBase CLI 工具。在 CI 工具中,不要使用 cloudbase login 进行交互式输入登录,而是使用以下密钥登录: cloudbase login --apiKeyId TCB_SECRET_ID --apiKey TCB_SECRET_KEY 。
注意:前往 Cloud API Key 获取 TCB_SECRET_ID 和 TCB_SECRET_KEY 的值
在 CI 工具的控制台中,配置 TCB_SECRET_ID 和 TCB_SECRET_KEY。并在 package.json 中添加一个新脚本:
"scripts": {
"login": "echo N | cloudbase login --apiKeyId $TCB_SECRET_ID --apiKey $TCB_SECRET_KEY"
}
综上所述,CI构建流程为:
如果需要紧急修改数据,可以在本地手动触发构建,也可以在 CI 工具控制台中手动触发构建。
最后
借助云开发cms,可以实现评论系统、预约系统、博客发帖等各种内容模板,从而快速搭建网站。在现有的开发体系下,合理使用云开发可以大大降低人工成本、开发成本和运维成本。真正实现前后端穿梭,形成“闭环”。
本文实战只是一个指导,涉及到部分云开发能力。还有更多有趣的东西等着你去探索,比如使用云功能实现SSR,托管后端服务,镜像服务,以及全方位的SDK。
探索功能、发散想法并以更低的成本开发高可用性 Web 服务。云开发绝对是您的最佳选择! 查看全部
js提取指定网站内容(作者简介董沅鑫,云开发CloudBase团队研发,业余时间出没在。)
关于作者
云开发CloudBase团队研发工程师董元新,专注于前端工程和节点服务开发。他在业余时间在这里。
本文内容
介绍
随着腾讯云开发能力的逐步提升,经验丰富的工程师可以独立完成一个产品的开发和上线。但是,与在线云开发相关的实战却很少文章。很多开发者都知道云开发的能力,但是不知道在现有的开发体系下如何引入云开发。
本文从云开发团队开发者+能力用户的角度出发,以云开发官网()为例,结合流行的框架和工具,分享云开发的实践经验。
涉及的知识点有:
React 框架:Next.jsCI 自动构建概述
系统设计图:
背景介绍
随着云开发团队业务的快速发展,团队需要一个官方网站,更加直观、即时地向开发者展示云开发的相关能力,包括但不限于工具链、SDK、技术文档等。
同时,为了降低开发者的启动成本,积累行业优秀的实践经验,官网还承载着营造社区氛围、聚合重要信息、增强用户粘性的重任。
我们最初使用 VuePress 作为静态 网站 工具,遇到了一些痛点:
我们使用“cms Extensions”、“Basic Cloud Development Capabilities”、“Next.js”、“CI Tools”很好地解决了上述问题。在实现网站动态内容的同时,保证了SEO,运维同学也可以通过cms对内容进行可视化管理。
安装cms
进入云开发扩展能力控制台,按照提示安装cms内容管理系统。
配置分机时,有两种账户:管理员账户和操作员账户。管理员账户具有较高的权限,可以创建新的数据集;而操作员账户只能添加、删除和修改现有的数据集。
注意:安装时间有点长,请耐心等待
安装成功后,云数据库会自动创建三个集合,分别是 tcb-ext-cms-contents、tcb-ext-cms-users、tcb-ext-cms-webhooks ,分别存放cms 系统配置信息和内容数据。会自动创建三个云函数,分别是tcb-ext-cms-api、tcb-ext-cms-init、tcb-ext-cms-auth,它们封装了初始化,数据流的认证和相关逻辑。
输入“Static 网站 Hosting”,可以看到cms系统的静态文件已经自动部署到tcb-cms/目录下:
点击上方的“基本配置”查看域名信息。
在浏览器中访问对应的链接()可以看到cms系统:
至此,在没有任何开发成本的情况下,一个cms内容管理系统正式上线啦~
使用 cms 创建动态内容
对于动态数据内容,我们将其划分为不同的模块。每个内容模块对应一个cms系统的数据集合。例如,在“云开发官网”-“社区页面”中,推荐课程的内容是动态的。
从图中可以看出,每门课程都有多个属性。在云数据库中,每门课程对应一个文档,课程属性对应文档的字段。字段类型和含义如下:
name: 课程名称
time: 课程时间
cover: 课程封面
url: 课程链接
level: 课程难度
以管理员身份登录cms系统,在内容设置页面新建内容。在cms中,支持多种高级数据类型,如url、image、markdown、富文本、标签数组、email、URL等,这些类型都智能识别,显示更友好。
注意:cms 有自己的图床功能。当数据类型为“图片”时,图片会自动上传到当前云开发环境中的云存储中。以 cloud:// 开头的用于图像信息的特殊链接存储在数据集合中。
创建新内容时,默认情况下,cms 会自动填充 4 个字段:name、order、createTime、updateTime。您可以根据自己的需要删除不必要的字段。
建议:保留订单字段,可用于数据排序。对于运营商来说,数据的阶数值越大,在cms系统中显示的位置就越高;对于开发者来说,可以按照顺序进行排序和搜索。这保证了经验和逻辑的一致性。
根据字段创建集合后, cms 您将在系统左侧看到“推荐课程”。其对应的内容存放在云数据库的推荐课程(创建时指定)集合中,其字段信息存放在云数据库的tcb-ext-cms-contents(cms创建在初始化期间))在集合中。
根据设置添加新课程内容后,再次进入“推荐好课程”,如下图:
图片、链接等内容显示给操作者更友好。
项目建设
按照 Next.js 文档创建 Next.js 项目:
npm i --save next react react-dom axios
由于我们将 网站 部署到“静态托管”,我们将使用 Next.js 的静态导出功能。package.json 中的打包脚本更新为:
"scripts": {
"dev": "next",
"build": "next build && next export",
"start": "next start"
}
为了快速部署静态网站,发布云功能。需要全局安装@cloudbase/cli:
npm install -g @cloudbase/cli
安装后,添加两个脚本:
"scripts": {
"deploy:hosting": "npm run build && cloudbase hosting:deploy out -e jhgjj-0ae4a1",
"deploy:function": "echo y | cloudbase functions:deploy --force"
}
注意:准备两个云环境,防止静态部署时文件覆盖。envId为jhgjj-0ae4a1的云环境仅用于部署Next.js的静态导出文件。envId为pagecounter-d27cfe的云环境用于部署cms系统。
获取 cms 内容
借助 CloudBase 的 Node SDK-@cloudbase/node-sdk,我们可以在 Next.js 的 getStaticProps() 方法中读取云数据库中的数据。
为了让逻辑更清晰,我们将获取外部数据的方法统一封装到一个单独的文件中。以获取“推荐课程”为例:
// provider.js
const cloudbase = require("@cloudbase/node-sdk");
const config = {
secretId: "your secretId", // 前往「腾讯云控制台」-「访问密钥」获取
secretKey: "your secretKey", // 前往「腾讯云控制台」-「访问密钥」获取
env: "your envid" // 前往「腾讯云控制台」-「云开发 CloudBase」获取
};
const app = cloudbase.init(config);
/**
* 获取云数据库数据
*/
async function getCourses() {
const db = app.database();
const result = await db.collection("recommend-course").get();
if (result.code) {
throw new Error(
`获取「推荐课程」失败, 错误码是${result.code}: ${result.message}`
);
}
return result.data.map(item => {
if (item.createTime instanceof Date) {
item.createTime = item.createTime.toLocaleString();
}
if (item.updateTime instanceof Date) {
item.updateTime = item.updateTime.toLocaleString();
}
item.cover = getBucketUrl(item.cover); // 处理云存储的特殊链接
return item;
});
}
如上所述,cms自带图床功能,拖拽上传的图片会存储在同一环境的云存储中,获取图片的链接会存储在采集中。云存储的链接是一个以cloud://开头的特殊链接,需要在前端进行专门的识别和处理。
例如图片的存储链接为:cloud://pagecounter-d27cfe.7061-pagecounter-d27cfe-1255463368/uploads/04.png。把它变成一个可访问的 http 链接:.
转换思路是:识别envid背后的信息,与tcb.qcloud.la域名重新拼接:
// provider.js
/**
* 获取云存储的访问链接
* @param {String} url 云存储的特定url
*/
function getBucketUrl(url) {
if (!url.startsWith("cloud://")) {
return url;
}
const re = /cloud:\/\/.*?\.(.*?)\/(.*)/;
const result = re.exec(url);
return `https://${result[1]}.tcb.qcloud.la/${result[2]}`;
}
注意:云存储的“权限设置”应为:所有用户可读,只有创建者和管理员可写。否则无法访问链接。
建议:除了内置的图床功能,开发者可以根据自己的需要使用其他稳定的图床服务,比如微博图床。如果使用其他图床,对应的字段类型不能设置为“图像”,可以是“字符串”或“超链接”。
到目前为止,我们已经使用 SDK 获取了云数据库数据,剩下要做的就是将其注入到 Next.js 页面组件的 props 中:
// pages/index.js
const HomePage = ({ courses }) => {
return (
// 尽情使用数据吧...
)
}
export async function getStaticProps() {
const { getCourses } = require('./../provider')
return {
props: {
courses: await getCourses()
}
}
}
export default HomePage
打开浏览器,输入:3000/,可以看到效果如下:
输入view-source::3000/,可以看到网页的html源码中收录了课程数据,解决了SEO的问题:
注意:Next.js 的一些方法会在双方都运行,但 getStaticProps() 只会在服务端运行
自动构建和部署
至此,开发工作基本结束。执行 npm run build 命令,将 网站 静态文件打包到 out/ 目录下:
执行 npm run deploy:hosting 将 out/ 目录下的文件上传到“static网站hosting”。访问静态 网站hosted link: ,效果如下:
借助成熟的 CI 工具,例如 Travis、Circle 等,可以定期触发构建工作。这样,内容和开发就完全分开了。
在构建和发布时,您需要使用 CloudBase CLI 工具。在 CI 工具中,不要使用 cloudbase login 进行交互式输入登录,而是使用以下密钥登录: cloudbase login --apiKeyId TCB_SECRET_ID --apiKey TCB_SECRET_KEY 。
注意:前往 Cloud API Key 获取 TCB_SECRET_ID 和 TCB_SECRET_KEY 的值
在 CI 工具的控制台中,配置 TCB_SECRET_ID 和 TCB_SECRET_KEY。并在 package.json 中添加一个新脚本:
"scripts": {
"login": "echo N | cloudbase login --apiKeyId $TCB_SECRET_ID --apiKey $TCB_SECRET_KEY"
}
综上所述,CI构建流程为:
如果需要紧急修改数据,可以在本地手动触发构建,也可以在 CI 工具控制台中手动触发构建。
最后
借助云开发cms,可以实现评论系统、预约系统、博客发帖等各种内容模板,从而快速搭建网站。在现有的开发体系下,合理使用云开发可以大大降低人工成本、开发成本和运维成本。真正实现前后端穿梭,形成“闭环”。
本文实战只是一个指导,涉及到部分云开发能力。还有更多有趣的东西等着你去探索,比如使用云功能实现SSR,托管后端服务,镜像服务,以及全方位的SDK。
探索功能、发散想法并以更低的成本开发高可用性 Web 服务。云开发绝对是您的最佳选择!
js提取指定网站内容(如何截取url中网站域名之后的部分,需要用到以下几个方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-16 02:20
)
如何截取url中网站域名后面的部分,需要使用以下方法:
最后索引()
lastIndexOf() 方法返回调用 String 对象的指定值的最后一次出现的索引,在字符串中的 fromIndex 指定位置向后和向前搜索。如果未找到此特定值,则返回 -1。
子串()
substring() 方法返回从开始索引到结束索引,或从开始索引到字符串结尾的字符串子集。
通过这两种方式,可以得到url域名后面的部分。
首先获取网址:
var url = window.location.href
截取指定字符串后面的内容:例如获取 ? 后面的内容
var index = url.lastIndexOf('?')
var url2 = url.substring(index + 1)
可以封装成一个方法:
function interceptUrl(url, cha) {
var ind = url.lastIndexOf(cha)
return url.substring(ind + 1)
}
调用方式:
var url = 'https://www.w3h5.com/search.php?q=Vue'
console.log(interceptUrl(url, '?'))
# q=Vue 查看全部
js提取指定网站内容(如何截取url中网站域名之后的部分,需要用到以下几个方法
)
如何截取url中网站域名后面的部分,需要使用以下方法:
最后索引()
lastIndexOf() 方法返回调用 String 对象的指定值的最后一次出现的索引,在字符串中的 fromIndex 指定位置向后和向前搜索。如果未找到此特定值,则返回 -1。
子串()
substring() 方法返回从开始索引到结束索引,或从开始索引到字符串结尾的字符串子集。
通过这两种方式,可以得到url域名后面的部分。
首先获取网址:
var url = window.location.href
截取指定字符串后面的内容:例如获取 ? 后面的内容
var index = url.lastIndexOf('?')
var url2 = url.substring(index + 1)
可以封装成一个方法:
function interceptUrl(url, cha) {
var ind = url.lastIndexOf(cha)
return url.substring(ind + 1)
}
调用方式:
var url = 'https://www.w3h5.com/search.php?q=Vue'
console.log(interceptUrl(url, '?'))
# q=Vue
js提取指定网站内容(JSFinderPlus快速在网站的js文件中提取URL子域名的工具 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 238 次浏览 • 2022-03-12 11:04
)
JSFinderPlus
JSFinder是一个快速提取网站的js文件中的url和子域的工具。该工具在JSFinder上做了增强,主要是:
用法
蟒蛇。 \JSFinderPlus。 py -h____。 ____________________。 __。 _____________。 __| |/ _____/\_ _____/|__| ____ __| _/__________\______ \ | __ __ ______| |\____ \ | __) | |/ \ / __ |/ __ \_ __ \___/ | | | \/ ___//\__| |/\ |\ | | | \/ /_/ \ ___/| | \/ | | |_| | |___| /\____ |\___ >__| |____| |____/____//____ >\/\/\/\/ \/\/用法:python3 JSFinderPlus。 py [options]target: 必须指定target -u URL, --url URLtarget URL (e.
g. -u ".com")general: 常规选项 -h, --help 显示此帮助信息并退出 -t NUM, --thread NUM 扫描线程,默认 10 -d 搜索找到的 URL,默认仅用于输入 URL --open立即打开报告 --site-root ROOT 指定 URL 的根目录 --proxy-socks SOCKS socks 代理(例如 --proxy-socks 127.0.0.1:108 0) - -proxy-http HTTPhttp 代理(例如--proxy-http 127.0.0.1:8080) -c COOKIEcookie --user-agent UA你可以自定义user-agent headers示例:python3 JSFinderPlus.py -u python3 JSFinderPlus.py -u -d python3 JSFinderPlus.py -u :7001/index --site-root :7001/#/ python3 JSFinderPlus.py -f list.txt -d -t 20 python3 JSFinderPlus.py -f list.txt -o results.text">
PS D:\Code\python\JSFinderPlus> python .\JSFinderPlus.py -h
____. ____________________.__ .___ __________.__
| |/ _____/\_ _____/|__| ____ __| _/__________\______ \ | __ __ ______
| |\_____ \ | __) | |/ \ / __ |/ __ \_ __ \ ___/ | | | \/ ___/
/\__| |/ \ | \ | | | \/ /_/ \ ___/| | \/ | | |_| | /\___ \
\________/_______ / \___ / |__|___| /\____ |\___ >__| |____| |____/____//____ >
\/ \/ \/ \/ \/ \/
usage: python3 JSFinderPlus.py [options]
target:
you must to specify target
-u URL, --url URL target URL (e.g. -u "http://example.com")
general:
general options
-h, --help show this help message and exit
-t NUM, --thread NUM 扫描线程,默认10
-d 对发现的URL进行查找,默认只查找输入的URL
--open 立即打开报告
--site-root ROOT 指定URL的根目录
--proxy-socks SOCKS socks proxy (e.g. --proxy-socks 127.0.0.1:1080)
--proxy-http HTTP http proxy (e.g. --proxy-http 127.0.0.1:8080)
-c COOKIE cookie
--user-agent UA you can customize the user-agent headers
examples:
python3 JSFinderPlus.py -u http://example.com
python3 JSFinderPlus.py -u http://example.com -d
python3 JSFinderPlus.py -u http://example.com:7001/index --site-root http://example.com:7001/#/
python3 JSFinderPlus.py -f list.txt -d -t 20
python3 JSFinderPlus.py -f list.txt -o results.text
例子
python .\JSFinderPlus.py -u -d --open
自动生成报表,点击url直接查看
查看全部
js提取指定网站内容(JSFinderPlus快速在网站的js文件中提取URL子域名的工具
)
JSFinderPlus
JSFinder是一个快速提取网站的js文件中的url和子域的工具。该工具在JSFinder上做了增强,主要是:
用法
蟒蛇。 \JSFinderPlus。 py -h____。 ____________________。 __。 _____________。 __| |/ _____/\_ _____/|__| ____ __| _/__________\______ \ | __ __ ______| |\____ \ | __) | |/ \ / __ |/ __ \_ __ \___/ | | | \/ ___//\__| |/\ |\ | | | \/ /_/ \ ___/| | \/ | | |_| | |___| /\____ |\___ >__| |____| |____/____//____ >\/\/\/\/ \/\/用法:python3 JSFinderPlus。 py [options]target: 必须指定target -u URL, --url URLtarget URL (e.
g. -u ".com")general: 常规选项 -h, --help 显示此帮助信息并退出 -t NUM, --thread NUM 扫描线程,默认 10 -d 搜索找到的 URL,默认仅用于输入 URL --open立即打开报告 --site-root ROOT 指定 URL 的根目录 --proxy-socks SOCKS socks 代理(例如 --proxy-socks 127.0.0.1:108 0) - -proxy-http HTTPhttp 代理(例如--proxy-http 127.0.0.1:8080) -c COOKIEcookie --user-agent UA你可以自定义user-agent headers示例:python3 JSFinderPlus.py -u python3 JSFinderPlus.py -u -d python3 JSFinderPlus.py -u :7001/index --site-root :7001/#/ python3 JSFinderPlus.py -f list.txt -d -t 20 python3 JSFinderPlus.py -f list.txt -o results.text">
PS D:\Code\python\JSFinderPlus> python .\JSFinderPlus.py -h
____. ____________________.__ .___ __________.__
| |/ _____/\_ _____/|__| ____ __| _/__________\______ \ | __ __ ______
| |\_____ \ | __) | |/ \ / __ |/ __ \_ __ \ ___/ | | | \/ ___/
/\__| |/ \ | \ | | | \/ /_/ \ ___/| | \/ | | |_| | /\___ \
\________/_______ / \___ / |__|___| /\____ |\___ >__| |____| |____/____//____ >
\/ \/ \/ \/ \/ \/
usage: python3 JSFinderPlus.py [options]
target:
you must to specify target
-u URL, --url URL target URL (e.g. -u "http://example.com";)
general:
general options
-h, --help show this help message and exit
-t NUM, --thread NUM 扫描线程,默认10
-d 对发现的URL进行查找,默认只查找输入的URL
--open 立即打开报告
--site-root ROOT 指定URL的根目录
--proxy-socks SOCKS socks proxy (e.g. --proxy-socks 127.0.0.1:1080)
--proxy-http HTTP http proxy (e.g. --proxy-http 127.0.0.1:8080)
-c COOKIE cookie
--user-agent UA you can customize the user-agent headers
examples:
python3 JSFinderPlus.py -u http://example.com
python3 JSFinderPlus.py -u http://example.com -d
python3 JSFinderPlus.py -u http://example.com:7001/index --site-root http://example.com:7001/#/
python3 JSFinderPlus.py -f list.txt -d -t 20
python3 JSFinderPlus.py -f list.txt -o results.text
例子
python .\JSFinderPlus.py -u -d --open

自动生成报表,点击url直接查看

js提取指定网站内容(JS基本语法JS内嵌-流程控制语句判断语句)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-09 13:02
JS基本语法
1.JS 嵌入在 HTML 的任何地方,通常在头部或正文中。
.....js代码
2.在JS文件中,直接写JavaScript代码,嵌入HTML
注意:
1.在 JS 中区分大小写。例如,变量 mychar 和 myChar 是不同的,这意味着它们是两个变量。
2.变量虽然可以不声明直接使用,但是不规范,需要先声明后使用。
3.JS代码按顺序执行语句
3.JavaScript-流控制语句
判断声明(如果...否则)
var myage = 18;
if(myage>=18) //myage>=18是判断条件
{ document.write("你是成年人。");}
else //否则年龄小于18
{ document.write("未满18岁,你不是成年人。");}
切换语句
var myweek =3;//myweek表示星期几变量
switch(myweek)
{
case 1:
case 2:
document.write("学习理念知识");
break;
case 3:
case 4:
document.write("到企业实践");
break;
case 5:
document.write("总结经验");
break;
default:
document.write("周六、日休息和娱乐");
}
声明
<p>
var mymoney,sum=0;//mymoney变量存放不同面值,sum总计
for(mymoney=1;mymoney 查看全部
js提取指定网站内容(JS基本语法JS内嵌-流程控制语句判断语句)
JS基本语法
1.JS 嵌入在 HTML 的任何地方,通常在头部或正文中。
.....js代码
2.在JS文件中,直接写JavaScript代码,嵌入HTML
注意:
1.在 JS 中区分大小写。例如,变量 mychar 和 myChar 是不同的,这意味着它们是两个变量。
2.变量虽然可以不声明直接使用,但是不规范,需要先声明后使用。
3.JS代码按顺序执行语句
3.JavaScript-流控制语句
判断声明(如果...否则)
var myage = 18;
if(myage>=18) //myage>=18是判断条件
{ document.write("你是成年人。");}
else //否则年龄小于18
{ document.write("未满18岁,你不是成年人。");}
切换语句
var myweek =3;//myweek表示星期几变量
switch(myweek)
{
case 1:
case 2:
document.write("学习理念知识");
break;
case 3:
case 4:
document.write("到企业实践");
break;
case 5:
document.write("总结经验");
break;
default:
document.write("周六、日休息和娱乐");
}
声明
<p>
var mymoney,sum=0;//mymoney变量存放不同面值,sum总计
for(mymoney=1;mymoney
js提取指定网站内容(双语阅读:最简单的设置方法是将JavaScript代码嵌入到网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-09 10:26
当您第一次编写新的 JavaScript 时,最简单的设置方法是将 JavaScript 代码直接嵌入到网页中,以便在您测试它以使其正常工作时,一切都在一个地方。同样,如果您将预先编写的脚本插入您的网站,说明可能会告诉您将部分或全部脚本嵌入网页本身。
第一次编写新的 JavaScript 时,最简单的设置方法是将 JavaScript 代码直接嵌入到网页中,这样您就可以在测试时将所有内容放在一个地方以使其正常工作。同样,如果您在 网站 中插入预先编写的脚本,说明可能会告诉您将部分或全部脚本嵌入页面本身。
这对于设置页面并使其首先正常工作是可以的,但是一旦您的页面按照您想要的方式工作,您将能够通过将 JavaScript 提取到外部文件中来改进页面,因此您的 HTML 中的页面内容不会因为 JavaScript 等非内容项而变得杂乱无章。
可以先设置页面并使其正常工作,但是一旦页面按您想要的方式工作,您可以通过将 JavaScript 提取到外部文件中来改进页面,这样页面 HTML 中的内容就不会被阻止被非内容项目(例如 JavaScript)搞砸了。
如果您只是复制和使用其他人编写的 JavaScript,那么他们关于如何将其脚本添加到您的页面的说明可能会导致您将一个或多个较大的 JavaScript 部分实际嵌入到您的网页本身中,而他们的说明不会不要告诉你如何将这段代码从你的页面移到一个单独的文件中,并且仍然让 JavaScript 工作。不过不要担心,因为无论您在页面中使用的 JavaScript 是什么代码,您都可以轻松地将 JavaScript 移出页面并将其设置为单独的文件(或者如果您嵌入了多个 JavaScript,则为文件)这页纸)。这样做的过程总是相同的,最好用一个例子来说明。
如果您只是复制和使用其他人的 JavaScript,他们关于如何将他们的脚本添加到您的页面的说明可能会导致您实际上将一个或多个 JavaScript 嵌入到您的页面本身中,而他们的说明却没有。不知道如何您可以将此代码从页面移出到一个单独的文件中,并且仍然能够使用 JavaScript。不过不用担心,因为无论页面中使用什么代码,您都可以轻松地将 JavaScript 移出页面并使其成为一个单独的文件(或者如果您有嵌入多个 JavaScript 的文件,您可以将其设置为文件)本页)。这样做的过程总是相同的,最好通过一个例子来说明。
让我们看看一段 JavaScript 在嵌入到您的页面时的外观。您的实际 JavaScript 代码将与以下示例中显示的不同,但在每种情况下的过程都是相同的。
让我们来看看嵌入页面中的一段 JavaScript 会是什么样子。您的实际 JavaScript 代码将与以下示例中显示的代码不同,但每种情况下的处理都是相同的。
示例一
if (top.location != self.location)
top.location = self.location;
示例二
示例三
/* if (top.location != self.location)
top.location = self.location;</strong>
/* ]]> */
您的嵌入式 JavaScript 应该类似于上述三个示例之一。当然,您的实际 JavaScript 代码将与显示的不同,但 JavaScript 可能会使用上述三种方法之一嵌入到页面中。在某些情况下,您的代码可能使用过时的 language="javascript" 而不是 type="text/javascript" 在这种情况下,您可能希望通过将语言属性替换为类型一来使您的代码更加最新.
您的嵌入式 JavaScript 应该类似于上述三个示例之一。当然,您的实际 JavaScript 代码将与显示的不同,但 JavaScript 可以使用上述三种方法之一嵌入到页面中。在某些情况下,您的代码可能使用过时的 language="javascript" 而不是 type="text/javascript",在这种情况下,您可能希望通过将语言属性替换为最新版本的类型 1 来更新代码。
在您可以将 JavaScript 提取到它自己的文件中之前,您首先需要确定要提取的代码。在上述所有三个示例中,有两行实际的 JavaScript 代码需要被提取。您的脚本可能会有更多行,但很容易识别,因为它在您的页面中占据与我们在上述三个示例中突出显示的两行 JavaScript 相同的位置(所有三个示例都收录相同的两行JavaScript,只是它们周围的容器略有不同)。
在将 JavaScript 提取到它自己的文件中之前,您首先需要决定要提取什么代码。在上述所有三个示例中,需要提取两行实际的 JavaScript 代码。您的脚本可能有更多行,但很容易识别,因为它在页面上的同一位置,因为我们在上面三个示例中突出显示了两行 JavaScript(所有三个示例都收录相同的两行) JavaScript ,只有周围的容器它们略有不同)。
要将 JavaScript 提取到单独的文件中,您需要做的第一件事是打开纯文本编辑器并访问网页的内容。然后,您需要找到嵌入的 JavaScript,该 JavaScript 将被包围。要将 JavaScript 实际提取到单独的文件中,您需要做的第一件事是打开纯文本编辑器并访问网页的内容。然后,您需要找到将被上述示例中显示的代码变体之一包围的嵌入式 JavaScript。找到 JavaScript 代码后,您需要选择它并将其复制到剪贴板。在上面的示例中,要选择的代码被突出显示,您不需要选择脚本标签或可能出现在您的 JavaScript 代码周围的可选注释。找到 JavaScript 代码后,您需要选择它并将其复制到剪贴板。在上面的示例中,将突出显示要选择的代码,您无需选择可能出现在 JavaScript 代码周围的脚本标签或可选注释。打开您的纯文本编辑器的另一个副本(如果您的编辑器支持一次打开多个文件,则打开另一个选项卡)并在此处粘贴 JavaScript 内容。支持打开多个文件,然后打开另一个选项卡),然后将 JavaScript 内容粘贴到那里。
为您的新文件选择一个描述性文件名并使用该文件名保存新内容。使用示例代码,脚本的目的是打破框架,因此适当的名称可以是 framebreak.js。
为新文件选择一个描述性文件名并使用该文件名保存新内容。使用示例代码,脚本的目的是打破框架,因此合适的名称是 framebreak.js。
所以现在我们将 JavaScript 保存在一个单独的文件中,我们返回到编辑器,在编辑器中我们拥有原创页面内容,以便在那里进行更改以链接到脚本的外部副本。文件,回到编辑器,我们在其中拥有原创页面内容,我们可以在其中进行更改以链接到脚本的外部副本。由于我们现在将脚本放在一个单独的文件中,我们可以删除原创内容中脚本标签之间的所有内容,以便 查看全部
js提取指定网站内容(双语阅读:最简单的设置方法是将JavaScript代码嵌入到网页)
当您第一次编写新的 JavaScript 时,最简单的设置方法是将 JavaScript 代码直接嵌入到网页中,以便在您测试它以使其正常工作时,一切都在一个地方。同样,如果您将预先编写的脚本插入您的网站,说明可能会告诉您将部分或全部脚本嵌入网页本身。
第一次编写新的 JavaScript 时,最简单的设置方法是将 JavaScript 代码直接嵌入到网页中,这样您就可以在测试时将所有内容放在一个地方以使其正常工作。同样,如果您在 网站 中插入预先编写的脚本,说明可能会告诉您将部分或全部脚本嵌入页面本身。
这对于设置页面并使其首先正常工作是可以的,但是一旦您的页面按照您想要的方式工作,您将能够通过将 JavaScript 提取到外部文件中来改进页面,因此您的 HTML 中的页面内容不会因为 JavaScript 等非内容项而变得杂乱无章。
可以先设置页面并使其正常工作,但是一旦页面按您想要的方式工作,您可以通过将 JavaScript 提取到外部文件中来改进页面,这样页面 HTML 中的内容就不会被阻止被非内容项目(例如 JavaScript)搞砸了。
如果您只是复制和使用其他人编写的 JavaScript,那么他们关于如何将其脚本添加到您的页面的说明可能会导致您将一个或多个较大的 JavaScript 部分实际嵌入到您的网页本身中,而他们的说明不会不要告诉你如何将这段代码从你的页面移到一个单独的文件中,并且仍然让 JavaScript 工作。不过不要担心,因为无论您在页面中使用的 JavaScript 是什么代码,您都可以轻松地将 JavaScript 移出页面并将其设置为单独的文件(或者如果您嵌入了多个 JavaScript,则为文件)这页纸)。这样做的过程总是相同的,最好用一个例子来说明。
如果您只是复制和使用其他人的 JavaScript,他们关于如何将他们的脚本添加到您的页面的说明可能会导致您实际上将一个或多个 JavaScript 嵌入到您的页面本身中,而他们的说明却没有。不知道如何您可以将此代码从页面移出到一个单独的文件中,并且仍然能够使用 JavaScript。不过不用担心,因为无论页面中使用什么代码,您都可以轻松地将 JavaScript 移出页面并使其成为一个单独的文件(或者如果您有嵌入多个 JavaScript 的文件,您可以将其设置为文件)本页)。这样做的过程总是相同的,最好通过一个例子来说明。
让我们看看一段 JavaScript 在嵌入到您的页面时的外观。您的实际 JavaScript 代码将与以下示例中显示的不同,但在每种情况下的过程都是相同的。
让我们来看看嵌入页面中的一段 JavaScript 会是什么样子。您的实际 JavaScript 代码将与以下示例中显示的代码不同,但每种情况下的处理都是相同的。
示例一
if (top.location != self.location)
top.location = self.location;
示例二
示例三
/* if (top.location != self.location)
top.location = self.location;</strong>
/* ]]> */
您的嵌入式 JavaScript 应该类似于上述三个示例之一。当然,您的实际 JavaScript 代码将与显示的不同,但 JavaScript 可能会使用上述三种方法之一嵌入到页面中。在某些情况下,您的代码可能使用过时的 language="javascript" 而不是 type="text/javascript" 在这种情况下,您可能希望通过将语言属性替换为类型一来使您的代码更加最新.
您的嵌入式 JavaScript 应该类似于上述三个示例之一。当然,您的实际 JavaScript 代码将与显示的不同,但 JavaScript 可以使用上述三种方法之一嵌入到页面中。在某些情况下,您的代码可能使用过时的 language="javascript" 而不是 type="text/javascript",在这种情况下,您可能希望通过将语言属性替换为最新版本的类型 1 来更新代码。
在您可以将 JavaScript 提取到它自己的文件中之前,您首先需要确定要提取的代码。在上述所有三个示例中,有两行实际的 JavaScript 代码需要被提取。您的脚本可能会有更多行,但很容易识别,因为它在您的页面中占据与我们在上述三个示例中突出显示的两行 JavaScript 相同的位置(所有三个示例都收录相同的两行JavaScript,只是它们周围的容器略有不同)。
在将 JavaScript 提取到它自己的文件中之前,您首先需要决定要提取什么代码。在上述所有三个示例中,需要提取两行实际的 JavaScript 代码。您的脚本可能有更多行,但很容易识别,因为它在页面上的同一位置,因为我们在上面三个示例中突出显示了两行 JavaScript(所有三个示例都收录相同的两行) JavaScript ,只有周围的容器它们略有不同)。
要将 JavaScript 提取到单独的文件中,您需要做的第一件事是打开纯文本编辑器并访问网页的内容。然后,您需要找到嵌入的 JavaScript,该 JavaScript 将被包围。要将 JavaScript 实际提取到单独的文件中,您需要做的第一件事是打开纯文本编辑器并访问网页的内容。然后,您需要找到将被上述示例中显示的代码变体之一包围的嵌入式 JavaScript。找到 JavaScript 代码后,您需要选择它并将其复制到剪贴板。在上面的示例中,要选择的代码被突出显示,您不需要选择脚本标签或可能出现在您的 JavaScript 代码周围的可选注释。找到 JavaScript 代码后,您需要选择它并将其复制到剪贴板。在上面的示例中,将突出显示要选择的代码,您无需选择可能出现在 JavaScript 代码周围的脚本标签或可选注释。打开您的纯文本编辑器的另一个副本(如果您的编辑器支持一次打开多个文件,则打开另一个选项卡)并在此处粘贴 JavaScript 内容。支持打开多个文件,然后打开另一个选项卡),然后将 JavaScript 内容粘贴到那里。
为您的新文件选择一个描述性文件名并使用该文件名保存新内容。使用示例代码,脚本的目的是打破框架,因此适当的名称可以是 framebreak.js。
为新文件选择一个描述性文件名并使用该文件名保存新内容。使用示例代码,脚本的目的是打破框架,因此合适的名称是 framebreak.js。
所以现在我们将 JavaScript 保存在一个单独的文件中,我们返回到编辑器,在编辑器中我们拥有原创页面内容,以便在那里进行更改以链接到脚本的外部副本。文件,回到编辑器,我们在其中拥有原创页面内容,我们可以在其中进行更改以链接到脚本的外部副本。由于我们现在将脚本放在一个单独的文件中,我们可以删除原创内容中脚本标签之间的所有内容,以便
js提取指定网站内容( 关于cookie的使用设置获取键名过期的事件,IE8及以上浏览器都兼容特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-07 01:12
关于cookie的使用设置获取键名过期的事件,IE8及以上浏览器都兼容特点)
一、如何
我们主要介绍以下四种javaScript本地缓存的方法:
cookies
Cookies,属于“小文本文件”类型,是指存储在用户本地终端上的特定数据网站,用于识别用户。就是解决HTTP无状态带来的问题
作为一条一般不超过4KB的小文本数据,由名称(Name)、值(Value)和其他几个可选属性组成,用于控制有效期、安全性和使用范围饼干
但是,cookie 将在每个请求中发送。如果不使用HTTPS并进行加密,其中存储的信息很容易被窃取,从而产生安全隐患。比如在一些使用cookies保持登录状态的网站s上,如果cookie被盗,别人很容易利用你的cookie冒充你登录网站
关于cookies的常用属性如下:
Expires=Wed, 21 Oct 2015 07:28:00 GMT
Max-Age=604800
Path=/docs # /docs/Web/ 下的资源会带 Cookie 首部
通过以上我们可以看出cookie的作用并不是为缓存而设计的,只是借用cookie的特性来实现缓存
cookies的使用如下:
document.cookie = '名字=值';
关于cookies的修改,首先要确保domain和path属性相同,当其中一个不同时会创建一个新的cookie
Set-Cookie:name=aa; domain=aa.net; path=/ # 服务端设置
document.cookie =name=bb; domain=aa.net; path=/ # 客户端设置
删除最后一个cookie最常用的方法是为cookie设置过期事件,这样cookie过期后会被浏览器删除
本地存储
HTML5新方法,兼容IE8及以上浏览器
特点
我们来看看localStorage的使用
设置
localStorage.setItem('username','cfangxu');
获取
localStorage.getItem('username')
获取密钥名称
localStorage.key(0) //获取第一个键名
删除
localStorage.removeItem('username')
一次性清空所有存储空间
localStorage.clear()
localStorage 也不完美,它有两个缺点:
localStorage.setItem('key', {name: 'value'});
console.log(localStorage.getItem('key')); // '[object, Object]'
会话存储
sessionStorage 和 localStorage 的用法基本相同,唯一不同的是生命周期。一旦页面(会话)关闭,sessionStorage 将删除数据
扩展的前端存储方式
indexedDB 是一种用于客户端存储大量结构化数据(包括文件/blob)的低级 API。 API 使用索引来实现对这些数据的高性能搜索
虽然网络存储对于存储少量数据很有用,但对于存储大量结构化数据的用处不大。 IndexedDB 提供了解决方案
优点:缺点:
使用indexedDB的基本步骤如下:
indexdb 的使用会比较麻烦。可以使用 Godb.js 库进行缓存,尽量降低操作难度
二、区别
cookies、sessionStorage和localStorage的主要区别如下:
三、应用场景
了解了上面提到的前端缓存方式后,我们可以看看不正确场景的使用选项: 查看全部
js提取指定网站内容(
关于cookie的使用设置获取键名过期的事件,IE8及以上浏览器都兼容特点)


一、如何
我们主要介绍以下四种javaScript本地缓存的方法:
cookies
Cookies,属于“小文本文件”类型,是指存储在用户本地终端上的特定数据网站,用于识别用户。就是解决HTTP无状态带来的问题
作为一条一般不超过4KB的小文本数据,由名称(Name)、值(Value)和其他几个可选属性组成,用于控制有效期、安全性和使用范围饼干
但是,cookie 将在每个请求中发送。如果不使用HTTPS并进行加密,其中存储的信息很容易被窃取,从而产生安全隐患。比如在一些使用cookies保持登录状态的网站s上,如果cookie被盗,别人很容易利用你的cookie冒充你登录网站
关于cookies的常用属性如下:
Expires=Wed, 21 Oct 2015 07:28:00 GMT
Max-Age=604800
Path=/docs # /docs/Web/ 下的资源会带 Cookie 首部
通过以上我们可以看出cookie的作用并不是为缓存而设计的,只是借用cookie的特性来实现缓存
cookies的使用如下:
document.cookie = '名字=值';
关于cookies的修改,首先要确保domain和path属性相同,当其中一个不同时会创建一个新的cookie
Set-Cookie:name=aa; domain=aa.net; path=/ # 服务端设置
document.cookie =name=bb; domain=aa.net; path=/ # 客户端设置
删除最后一个cookie最常用的方法是为cookie设置过期事件,这样cookie过期后会被浏览器删除
本地存储
HTML5新方法,兼容IE8及以上浏览器
特点
我们来看看localStorage的使用
设置
localStorage.setItem('username','cfangxu');
获取
localStorage.getItem('username')
获取密钥名称
localStorage.key(0) //获取第一个键名
删除
localStorage.removeItem('username')
一次性清空所有存储空间
localStorage.clear()
localStorage 也不完美,它有两个缺点:
localStorage.setItem('key', {name: 'value'});
console.log(localStorage.getItem('key')); // '[object, Object]'
会话存储
sessionStorage 和 localStorage 的用法基本相同,唯一不同的是生命周期。一旦页面(会话)关闭,sessionStorage 将删除数据
扩展的前端存储方式
indexedDB 是一种用于客户端存储大量结构化数据(包括文件/blob)的低级 API。 API 使用索引来实现对这些数据的高性能搜索
虽然网络存储对于存储少量数据很有用,但对于存储大量结构化数据的用处不大。 IndexedDB 提供了解决方案
优点:缺点:
使用indexedDB的基本步骤如下:
indexdb 的使用会比较麻烦。可以使用 Godb.js 库进行缓存,尽量降低操作难度
二、区别
cookies、sessionStorage和localStorage的主要区别如下:
三、应用场景
了解了上面提到的前端缓存方式后,我们可以看看不正确场景的使用选项:
js提取指定网站内容(谷歌提取元素打印技术的基本操作流程及使用方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-03 09:17
)
方法一:提取元素并打印
步:
1、打开谷歌浏览器,按F12进入控制台:
2、在控制台输入如下JS代码回车(以打印csdn博客内容为例):
function doPrint(){
var head_str = ""; //先生成头部
var foot_str = ""; //生成尾部
var older = document.body.innerHTML;
//var new_str = document.getElementById('wrapper').innerHTML; //获取指定打印区域
var new_str = document.getElementsByClassName('blog-content-box')[0].innerHTML; //获取指定打印区域
var old_str = document.body.innerHTML; //获得原本页面的代码
document.body.innerHTML = head_str + new_str + foot_str; //构建新网页
window.print(); //打印刚才新建的网页
document.body.innerHTML = older; //将网页还原
return false;
};doPrint();
3、在弹出的打印界面中,将布局选项设置为横向(纵向布局可能不会显示行尾的内容),然后保存:
注意:建议使用谷歌浏览器,测试火狐可能会导致页面内容混乱
方法 2:隐藏而不打印元素
方法一和步骤二使用如下代码:
<p>function doPrint() {
//隐藏标题栏
$('#csdn-toolbar').css('display','none');
//隐藏评论区
document.getElementsByClassName('comment-box')[0].style.display="none";
//隐藏推荐栏
var recommends = document.getElementsByClassName('recommend-box');
for(var i=0;i 查看全部
js提取指定网站内容(谷歌提取元素打印技术的基本操作流程及使用方法
)
方法一:提取元素并打印
步:
1、打开谷歌浏览器,按F12进入控制台:

2、在控制台输入如下JS代码回车(以打印csdn博客内容为例):
function doPrint(){
var head_str = ""; //先生成头部
var foot_str = ""; //生成尾部
var older = document.body.innerHTML;
//var new_str = document.getElementById('wrapper').innerHTML; //获取指定打印区域
var new_str = document.getElementsByClassName('blog-content-box')[0].innerHTML; //获取指定打印区域
var old_str = document.body.innerHTML; //获得原本页面的代码
document.body.innerHTML = head_str + new_str + foot_str; //构建新网页
window.print(); //打印刚才新建的网页
document.body.innerHTML = older; //将网页还原
return false;
};doPrint();
3、在弹出的打印界面中,将布局选项设置为横向(纵向布局可能不会显示行尾的内容),然后保存:

注意:建议使用谷歌浏览器,测试火狐可能会导致页面内容混乱
方法 2:隐藏而不打印元素
方法一和步骤二使用如下代码:
<p>function doPrint() {
//隐藏标题栏
$('#csdn-toolbar').css('display','none');
//隐藏评论区
document.getElementsByClassName('comment-box')[0].style.display="none";
//隐藏推荐栏
var recommends = document.getElementsByClassName('recommend-box');
for(var i=0;i
js提取指定网站内容(从底层视角理解下javascript语言中表达式的“到底什么”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-02 18:00
js提取指定网站内容:提取网站内容一、关键代码识别1.1关键代码识别1.2概念及概念2.1概念2.2概念3.4图片文件识别3.5文件识别
说实话现在互联网上充斥了太多的数据,所以一般搜索引擎都已经不会像以前一样了,现在有很多语义分析技术都可以做到,特别是今年三月份以来,google推出的图片分析服务,和facebook推出的视频分析服务都体现了数据越来越多,但是语义分析技术这块很值得研究下,有很多问题可以去解决。
您好我推荐一篇公众号老师的《从底层视角理解下javascript语言中表达式的“到底什么”》希望可以对您有所帮助请点击老师公众号的内容收看获取最新javascript技术,发现新世界。推荐阅读:数据分析师工具推荐-你的福音来了?新学的公式要建立在svd和psm基础上了呢!|网课公告世界杯冷门,你猜几场?那些年我们一起跳过的坑。
我不知道知乎上javascript话题下的人大部分来自哪里,我能够知道的也就是某些公众号整天报道某个网站api的js,或者某个网站直接使用其他网站的js,还有些简单的字符串加密什么的。我不明白一个程序员能够知道甚至关注着一些小网站到什么程度,又或者它们的form里的js呢?就像我不明白一个开发者知道某个网站里会用到jquery吗?。 查看全部
js提取指定网站内容(从底层视角理解下javascript语言中表达式的“到底什么”)
js提取指定网站内容:提取网站内容一、关键代码识别1.1关键代码识别1.2概念及概念2.1概念2.2概念3.4图片文件识别3.5文件识别
说实话现在互联网上充斥了太多的数据,所以一般搜索引擎都已经不会像以前一样了,现在有很多语义分析技术都可以做到,特别是今年三月份以来,google推出的图片分析服务,和facebook推出的视频分析服务都体现了数据越来越多,但是语义分析技术这块很值得研究下,有很多问题可以去解决。
您好我推荐一篇公众号老师的《从底层视角理解下javascript语言中表达式的“到底什么”》希望可以对您有所帮助请点击老师公众号的内容收看获取最新javascript技术,发现新世界。推荐阅读:数据分析师工具推荐-你的福音来了?新学的公式要建立在svd和psm基础上了呢!|网课公告世界杯冷门,你猜几场?那些年我们一起跳过的坑。
我不知道知乎上javascript话题下的人大部分来自哪里,我能够知道的也就是某些公众号整天报道某个网站api的js,或者某个网站直接使用其他网站的js,还有些简单的字符串加密什么的。我不明白一个程序员能够知道甚至关注着一些小网站到什么程度,又或者它们的form里的js呢?就像我不明白一个开发者知道某个网站里会用到jquery吗?。
js提取指定网站内容(反(反爬虫)用不完的遍布世界的毫秒级代理IP目标网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-02 13:15
分析全球反(反爬虫)取之不尽的毫秒代理IP
目标网站:http:说实话,爬了多少个ip网站,这个网站的ip可用率很高,但同时,反爬机制也有点高端如果说是同一个IP用于频繁定向,网站会被Ban的爬取目标爬取。表面上看不明显,但实际上是js加载的动态页面,不像其他动态页面。没有后续加载,网页刷新后1秒内加载js,所以爬取的网页是没有被jsted的源码,即使解析正确,获取到的ip也是无效的,所以如果要重新更新随机使用的代理ip请调用此方法。每次调用都会随机抓取ip并将其写入文件以便下次读取尝试: for i in range(20): self.carwl_ip() cmd = input( ****** *** *是否永久保存********** 默认:临时保存为 ip.ini 文件 每次更新 ip.ini 文件都会清空并更新 1.MongoDB 2.MySQL 3.另存为.txt文件(其他key代表一行默认ip.ini配置文件,相当于每次随机改爬取的随机ip :return: 返回一个字典格式如下,可以直接放在参数{https:https
中
作为请求中的代理
160 查看全部
js提取指定网站内容(反(反爬虫)用不完的遍布世界的毫秒级代理IP目标网站)
分析全球反(反爬虫)取之不尽的毫秒代理IP
目标网站:http:说实话,爬了多少个ip网站,这个网站的ip可用率很高,但同时,反爬机制也有点高端如果说是同一个IP用于频繁定向,网站会被Ban的爬取目标爬取。表面上看不明显,但实际上是js加载的动态页面,不像其他动态页面。没有后续加载,网页刷新后1秒内加载js,所以爬取的网页是没有被jsted的源码,即使解析正确,获取到的ip也是无效的,所以如果要重新更新随机使用的代理ip请调用此方法。每次调用都会随机抓取ip并将其写入文件以便下次读取尝试: for i in range(20): self.carwl_ip() cmd = input( ****** *** *是否永久保存********** 默认:临时保存为 ip.ini 文件 每次更新 ip.ini 文件都会清空并更新 1.MongoDB 2.MySQL 3.另存为.txt文件(其他key代表一行默认ip.ini配置文件,相当于每次随机改爬取的随机ip :return: 返回一个字典格式如下,可以直接放在参数{https:https
中
作为请求中的代理
160
js提取指定网站内容( 风中蹦迪02-24:45阅读4网站SEO优化关注javascript脚本怎么运行(js编写教程))
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-24 19:13
风中蹦迪02-24:45阅读4网站SEO优化关注javascript脚本怎么运行(js编写教程))
在风中弹跳
02-24 11:45 阅读4网站SEO优化
关注
如何运行 javascript 脚本(js 脚本教程)
1 概述
本文介绍了在Java环境中执行JavaScript脚本的简单使用,包括以下内容
Java 8 内置 Nashorn Javascript 引擎介绍 Rhino JavaScript 引擎介绍和 XML 处理介绍 2 Java 8 中内置 Nashorn Javascript 引擎介绍
Nashorn 是一个内置于 Java 8 中的 JavaScript 引擎,没有任何依赖关系。
使用Nashorn的基本步骤如下
new out ScriptEngineManager 对象通过ScriptEngineManager 对象中的getEngineByName 方法获取指定的JavaScript 引擎,并返回ScriptEngine 对象。 Java 8 中默认的 JavaScript 引擎包括: [nashorn, Nashorn, , JS, JavaScript, script, ECMAScript, ecmascript] 通过 ScriptEngine 对象的 eval 方法执行 JavaScript 脚本。 2.1 通过PrintWriter对象从脚本中获取打印输出
Javascript 脚本中没有函数,也没有返回值。内容通过打印输出。这时需要通过PrintWriter获取读取脚本中的打印输出,如下
@Test
public void test_nashorn() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("Nashorn");
ScriptContext scriptContext = engine.getContext();
StringWriter stringWriter = new StringWriter();
PrintWriter printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
String jsString = "var obj=JSON.parse('{\\\"data\\\":\\\"7155\\\",\\\"sign\\\":\\\"success\\\",\\\"message\\\":null}');print(obj.sign==\"success\");";
stringWriter = new StringWriter();
printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
engine.eval(jsString);
System.out.println(String.format("1 result = %s",stringWriter.toString()));
jsString = "var obj=JSON.parse('{\\\"data\\\":\\\"7157\\\",\\\"sign\\\":\\\"success\\\",\\\"message\\\":null}');print((function getData() { return obj.data;})())";
stringWriter = new StringWriter();
printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
engine.eval(jsString);
System.out.println(String.format("2 result = %s",stringWriter.toString()));
jsString = "var obj=JSON.parse('{\\\"data\\\":\\\"7157\\\",\\\"sign\\\":\\\"success\\\",\\\"message\\\":null}');print((function getData() { return obj.data;})())";
stringWriter = new StringWriter();
printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
engine.eval(jsString);
System.out.println(String.format("3 result = %s",stringWriter.toString()));
} catch (Exception e) {
e.printStackTrace();
}
}
2.2 获取匿名函数的返回值
Javascript脚本是匿名函数,有返回值,可以通过eval函数直接访问
@Test
public void test_js_function_return() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("Nashorn");
String jsFunction = "(function(){var obj=JSON.parse('{\\\"data\\\":\\\"7155\\\",\\\"sign\\\":\\\"success\\\",\\\"message\\\":null}');return obj.sign==\"success\"})();";
Boolean result = (Boolean) engine.eval(jsFunction);
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
}
2.3调用Javascript脚本中指定的函数
Javascript脚本中有变量和多个函数,如下
@Test
public void test_invoke_js_function() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("Nashorn");
/*
var obj = JSON.parse('{\"data\":\"7155\",\"sign\":\"success\",\"message\":null}');
function checkSign() {
return obj.sign == 'success'
}
function getData() {
return obj.data
}
function calculate(a, b) {
return a + b
}
*/
String jsFunction = "var obj=JSON.parse('{\\\"data\\\":\\\"7155\\\",\\\"sign\\\":\\\"success\\\",\\\"message\\\":null}');function checkSign(){return obj.sign=='success'}function getData(){return obj.data}function calculate(a,b){return a+b}";
engine.eval(jsFunction);
Invocable invocable = (Invocable) engine;
Object result = invocable.invokeFunction("checkSign", null);
System.out.println(result);
result = invocable.invokeFunction("getData", null);
System.out.println(result);
result = invocable.invokeFunction("calculate", 2, 5);
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
}
true
7155
7.0
2.4 读取Javascript文件并执行
本例读取并执行Javascript文件,如下
@Test
public void test_invoke_js_file() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("Nashorn");
engine.eval(new FileReader(TestJSEngine.class.getResource("/test.js").getPath()));
Invocable invocable = (Invocable) engine;
Object result = invocable.invokeFunction("checkSign", null);
System.out.println(result);
result = invocable.invokeFunction("getData", null);
System.out.println(result);
result = invocable.invokeFunction("calculate", 2, 5);
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
}
文件内容同上。
3 Rhino JavaScript 引擎简介
默认的 Nashorn 引擎无法解析 xml,像 DOMParser 这样的对象是浏览器的内置组件。
这里可以依靠Rhino引擎通过Maven来处理xml。
cat.inspiracio
rhino-js-engine
1.7.10
使用的步骤与其他 JavaScript 引擎相同,引擎名称为 Rhino。
3.1 Rhino 解析xml
在这里,通过读取文件来加载和解析 JavaScript 脚本。脚本就是解析一段xml的过程。
print("----------------------------------------");
var e = new XML(' Joe20 Sue30 ');
// 获取所有的员工
print("获取所有的员工:\n" + e..name);
// 名字叫 Joe 的员工
print("名字叫 Joe 的员工:\n" + e.employee.(name == "Joe"));
// 员工的id 为 1 和 2
print("员工的id 为 1 和 2:\n" + e.employee.(@id == 1 || @id == 2));
// 员工的id 为 1
print("员工的id 为 1: " + e.employee.(@id == 1).name);
print("----------------------------------------");
@Test
public void test_rhino_file_js() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("rhino");
ScriptContext scriptContext = engine.getContext();
StringWriter stringWriter = new StringWriter();
PrintWriter printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
engine.eval(new FileReader(TestJSEngine.class.getResource("/xml.js").getPath()));
System.out.println(String.format("xml result = %s",stringWriter.toString() ));
} catch (Exception e) {
e.printStackTrace();
}
}
xml result = ----------------------------------------
All the employee names are:
Joe
Sue
The employee named Joe is:
Joe
20
Employees with ids 1 & 2:
Joe
20
Sue
30
Name of the the employee with ID=1: Joe
----------------------------------------
3.2 测试
0
操作成功!
1
7
@Test
public void test_rhino() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("rhino");
String jsString = jsString = "var obj=new XML(' 0 操作成功! 1 7 ');print(obj.Message == '操作成功!');";
ScriptContext scriptContext = engine.getContext();
StringWriter stringWriter = new StringWriter();
PrintWriter printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
engine.eval(jsString);
System.out.println(String.format("xml result = %s",stringWriter.toString() ));
} catch (Exception e) {
e.printStackTrace();
}
}
以上输出如下
xml result = true
文章类别
百科测验
文章标签
脚本
js
教程 查看全部
js提取指定网站内容(
风中蹦迪02-24:45阅读4网站SEO优化关注javascript脚本怎么运行(js编写教程))

在风中弹跳
02-24 11:45 阅读4网站SEO优化
关注
如何运行 javascript 脚本(js 脚本教程)

1 概述
本文介绍了在Java环境中执行JavaScript脚本的简单使用,包括以下内容
Java 8 内置 Nashorn Javascript 引擎介绍 Rhino JavaScript 引擎介绍和 XML 处理介绍 2 Java 8 中内置 Nashorn Javascript 引擎介绍
Nashorn 是一个内置于 Java 8 中的 JavaScript 引擎,没有任何依赖关系。
使用Nashorn的基本步骤如下
new out ScriptEngineManager 对象通过ScriptEngineManager 对象中的getEngineByName 方法获取指定的JavaScript 引擎,并返回ScriptEngine 对象。 Java 8 中默认的 JavaScript 引擎包括: [nashorn, Nashorn, , JS, JavaScript, script, ECMAScript, ecmascript] 通过 ScriptEngine 对象的 eval 方法执行 JavaScript 脚本。 2.1 通过PrintWriter对象从脚本中获取打印输出
Javascript 脚本中没有函数,也没有返回值。内容通过打印输出。这时需要通过PrintWriter获取读取脚本中的打印输出,如下
@Test
public void test_nashorn() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("Nashorn");
ScriptContext scriptContext = engine.getContext();
StringWriter stringWriter = new StringWriter();
PrintWriter printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
String jsString = "var obj=JSON.parse('{\\\"data\\\":\\\"7155\\\",\\\"sign\\\":\\\"success\\\",\\\"message\\\":null}');print(obj.sign==\"success\");";
stringWriter = new StringWriter();
printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
engine.eval(jsString);
System.out.println(String.format("1 result = %s",stringWriter.toString()));
jsString = "var obj=JSON.parse('{\\\"data\\\":\\\"7157\\\",\\\"sign\\\":\\\"success\\\",\\\"message\\\":null}');print((function getData() { return obj.data;})())";
stringWriter = new StringWriter();
printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
engine.eval(jsString);
System.out.println(String.format("2 result = %s",stringWriter.toString()));
jsString = "var obj=JSON.parse('{\\\"data\\\":\\\"7157\\\",\\\"sign\\\":\\\"success\\\",\\\"message\\\":null}');print((function getData() { return obj.data;})())";
stringWriter = new StringWriter();
printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
engine.eval(jsString);
System.out.println(String.format("3 result = %s",stringWriter.toString()));
} catch (Exception e) {
e.printStackTrace();
}
}
2.2 获取匿名函数的返回值
Javascript脚本是匿名函数,有返回值,可以通过eval函数直接访问
@Test
public void test_js_function_return() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("Nashorn");
String jsFunction = "(function(){var obj=JSON.parse('{\\\"data\\\":\\\"7155\\\",\\\"sign\\\":\\\"success\\\",\\\"message\\\":null}');return obj.sign==\"success\"})();";
Boolean result = (Boolean) engine.eval(jsFunction);
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
}
2.3调用Javascript脚本中指定的函数
Javascript脚本中有变量和多个函数,如下
@Test
public void test_invoke_js_function() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("Nashorn");
/*
var obj = JSON.parse('{\"data\":\"7155\",\"sign\":\"success\",\"message\":null}');
function checkSign() {
return obj.sign == 'success'
}
function getData() {
return obj.data
}
function calculate(a, b) {
return a + b
}
*/
String jsFunction = "var obj=JSON.parse('{\\\"data\\\":\\\"7155\\\",\\\"sign\\\":\\\"success\\\",\\\"message\\\":null}');function checkSign(){return obj.sign=='success'}function getData(){return obj.data}function calculate(a,b){return a+b}";
engine.eval(jsFunction);
Invocable invocable = (Invocable) engine;
Object result = invocable.invokeFunction("checkSign", null);
System.out.println(result);
result = invocable.invokeFunction("getData", null);
System.out.println(result);
result = invocable.invokeFunction("calculate", 2, 5);
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
}
true
7155
7.0
2.4 读取Javascript文件并执行
本例读取并执行Javascript文件,如下
@Test
public void test_invoke_js_file() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("Nashorn");
engine.eval(new FileReader(TestJSEngine.class.getResource("/test.js").getPath()));
Invocable invocable = (Invocable) engine;
Object result = invocable.invokeFunction("checkSign", null);
System.out.println(result);
result = invocable.invokeFunction("getData", null);
System.out.println(result);
result = invocable.invokeFunction("calculate", 2, 5);
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
}
文件内容同上。
3 Rhino JavaScript 引擎简介
默认的 Nashorn 引擎无法解析 xml,像 DOMParser 这样的对象是浏览器的内置组件。
这里可以依靠Rhino引擎通过Maven来处理xml。
cat.inspiracio
rhino-js-engine
1.7.10
使用的步骤与其他 JavaScript 引擎相同,引擎名称为 Rhino。
3.1 Rhino 解析xml
在这里,通过读取文件来加载和解析 JavaScript 脚本。脚本就是解析一段xml的过程。
print("----------------------------------------");
var e = new XML(' Joe20 Sue30 ');
// 获取所有的员工
print("获取所有的员工:\n" + e..name);
// 名字叫 Joe 的员工
print("名字叫 Joe 的员工:\n" + e.employee.(name == "Joe"));
// 员工的id 为 1 和 2
print("员工的id 为 1 和 2:\n" + e.employee.(@id == 1 || @id == 2));
// 员工的id 为 1
print("员工的id 为 1: " + e.employee.(@id == 1).name);
print("----------------------------------------");
@Test
public void test_rhino_file_js() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("rhino");
ScriptContext scriptContext = engine.getContext();
StringWriter stringWriter = new StringWriter();
PrintWriter printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
engine.eval(new FileReader(TestJSEngine.class.getResource("/xml.js").getPath()));
System.out.println(String.format("xml result = %s",stringWriter.toString() ));
} catch (Exception e) {
e.printStackTrace();
}
}
xml result = ----------------------------------------
All the employee names are:
Joe
Sue
The employee named Joe is:
Joe
20
Employees with ids 1 & 2:
Joe
20
Sue
30
Name of the the employee with ID=1: Joe
----------------------------------------
3.2 测试
0
操作成功!
1
7
@Test
public void test_rhino() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("rhino");
String jsString = jsString = "var obj=new XML(' 0 操作成功! 1 7 ');print(obj.Message == '操作成功!');";
ScriptContext scriptContext = engine.getContext();
StringWriter stringWriter = new StringWriter();
PrintWriter printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
engine.eval(jsString);
System.out.println(String.format("xml result = %s",stringWriter.toString() ));
} catch (Exception e) {
e.printStackTrace();
}
}
以上输出如下
xml result = true
文章类别
百科测验
文章标签
脚本
js
教程
js提取指定网站内容(.js和puppeteer小试牛刀.newPage)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-22 18:22
如果你是技术人员,那么可以看我的下一个文章,否则请直接移到我的github仓库,看文档就行了,使用仓库地址:有文档和源码,别忘了给一星给这个需求用到的技术:Node.js和puppeteer,小测试,爬京东资源
const puppeteer = require('puppeteer'); // 引入依赖
(async () => { //使用async函数完美异步
const browser = await puppeteer.launch(); //打开新的浏览器
const page = await browser.newPage(); // 打开新的网页
await page.goto('https://www.jd.com/'); //前往里面 'url' 的网页
const result = await page.evaluate(() => { //这个result数组包含所有的图片src地址
let arr = []; //这个箭头函数内部写处理的逻辑
const imgs = document.querySelectorAll('img');
imgs.forEach(function (item) {
arr.push(item.src)
})
return arr
});
// '此时的result就是得到的爬虫数据,可以通过'fs'模块保存'
})()
复制过去 使用命令行命令 ` node 文件名 ` 就可以运行获取爬虫数据了
这个 puppeteer 的包 ,其实是替我们开启了另一个浏览器,重新去开启网页,获取它们的数据。
跳转网页中所有标题的文本内容对应 中的所有标签,最后放入一个数组中。
browser.newPage(), browser.close() 是固定的。
调用这个方法。
也就是说我们可以先进入京东网页,处理完逻辑再调用page.goto函数,
注意上面所有的逻辑都是puppeteer包帮我们在一个不可见的地方打开另一个浏览器,然后处理逻辑,所以我们最后需要调用browser.close()方法来关闭那个浏览器。
这时候我们对上一篇的代码进行优化,爬取对应的资源。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.jd.com/');
const hrefArr = await page.evaluate(() => {
let arr = [];
const aNodes = document.querySelectorAll('.cate_menu_lk');
aNodes.forEach(function (item) {
arr.push(item.href)
})
return arr
});
let arr = [];
for (let i = 0; i < hrefArr.length; i++) {
const url = hrefArr[i];
console.log(url) //这里可以打印
await page.goto(url);
const result = await page.evaluate(() => { //这个方法内部console.log无效
return $('title').text(); //返回每个界面的title文字内容
});
arr.push(result) //每次循环给数组中添加对应的值
}
console.log(arr) //得到对应的数据 可以通过Node.js的 fs 模块保存到本地
await browser.close()
})()
天坑page.evaluate函数里面的console.log不能打印,内部不能获取外部变量,只能返回return。使用的选择器在使用前必须先到相应界面的控制台测试是否可以选择DOM。比如京东就不能使用querySelector。在这里,因为京东的界面使用了jQuery,所以我们可以使用jQuery。简而言之,我们可以使用他们可以使用的所有选择器,否则我们不能。
接下来我们爬取Node.js的官网主页,直接生成PDF
本项目要求:给我们一个网页地址,爬取他的网页内容,然后输出成我们想要的PDF格式文档,请注意是高质量的PDF文档
TIPS:本项目的设计思路是一个网页和一个PDF文件,所以每次爬取单个页面,请将index.pdf复制出来,然后继续改url地址,继续爬取,生成一个新的PDF文件,当然你也可以一次爬取多个网页,通过循环编译的方式生成多个PDF文件。对于像京东首页这样开启了图片延迟加载的网页,部分爬取的内容就是处于加载状态的内容。对于有一些反爬机制的网页,爬虫也会有问题,但是大部分网站都可以
const puppeteer = require('puppeteer');
const url = require('./url');
(async () => {
const browser = await puppeteer.launch({ headless: true })
const page = await browser.newPage()
//选择要打开的网页
await page.goto(url, { waitUntil: 'networkidle0' })
//选择你要输出的那个PDF文件路径,把爬取到的内容输出到PDF中,必须是存在的PDF,可以是空内容,如果不是空的内容PDF,那么会覆盖内容
let pdfFilePath = './index.pdf';
//根据你的配置选项,我们这里选择A4纸的规格输出PDF,方便打印
await page.pdf({
path: pdfFilePath,
format: 'A4',
scale: 1,
printBackground: true,
landscape: false,
displayHeaderFooter: false
});
await browser.close()
})()
文件解构设计
在这个时代,数据非常宝贵。根据网页的设计逻辑,如果选择特定href的地址,可以直接获取对应的资源,也可以再次使用page.goto方法进入,然后调用page.evaluate( ) 处理逻辑。或者输出对应的PDF文件,当然也可以一次输出多个PDF文件~这里就不过多介绍了,毕竟Node.js可以上天,说不定以后真的可以做任何事。这么优质又短的教程,请采集或转发给您的朋友,谢谢。 查看全部
js提取指定网站内容(.js和puppeteer小试牛刀.newPage)
如果你是技术人员,那么可以看我的下一个文章,否则请直接移到我的github仓库,看文档就行了,使用仓库地址:有文档和源码,别忘了给一星给这个需求用到的技术:Node.js和puppeteer,小测试,爬京东资源
const puppeteer = require('puppeteer'); // 引入依赖
(async () => { //使用async函数完美异步
const browser = await puppeteer.launch(); //打开新的浏览器
const page = await browser.newPage(); // 打开新的网页
await page.goto('https://www.jd.com/'); //前往里面 'url' 的网页
const result = await page.evaluate(() => { //这个result数组包含所有的图片src地址
let arr = []; //这个箭头函数内部写处理的逻辑
const imgs = document.querySelectorAll('img');
imgs.forEach(function (item) {
arr.push(item.src)
})
return arr
});
// '此时的result就是得到的爬虫数据,可以通过'fs'模块保存'
})()
复制过去 使用命令行命令 ` node 文件名 ` 就可以运行获取爬虫数据了
这个 puppeteer 的包 ,其实是替我们开启了另一个浏览器,重新去开启网页,获取它们的数据。
跳转网页中所有标题的文本内容对应 中的所有标签,最后放入一个数组中。
browser.newPage(), browser.close() 是固定的。
调用这个方法。
也就是说我们可以先进入京东网页,处理完逻辑再调用page.goto函数,
注意上面所有的逻辑都是puppeteer包帮我们在一个不可见的地方打开另一个浏览器,然后处理逻辑,所以我们最后需要调用browser.close()方法来关闭那个浏览器。
这时候我们对上一篇的代码进行优化,爬取对应的资源。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.jd.com/');
const hrefArr = await page.evaluate(() => {
let arr = [];
const aNodes = document.querySelectorAll('.cate_menu_lk');
aNodes.forEach(function (item) {
arr.push(item.href)
})
return arr
});
let arr = [];
for (let i = 0; i < hrefArr.length; i++) {
const url = hrefArr[i];
console.log(url) //这里可以打印
await page.goto(url);
const result = await page.evaluate(() => { //这个方法内部console.log无效
return $('title').text(); //返回每个界面的title文字内容
});
arr.push(result) //每次循环给数组中添加对应的值
}
console.log(arr) //得到对应的数据 可以通过Node.js的 fs 模块保存到本地
await browser.close()
})()
天坑page.evaluate函数里面的console.log不能打印,内部不能获取外部变量,只能返回return。使用的选择器在使用前必须先到相应界面的控制台测试是否可以选择DOM。比如京东就不能使用querySelector。在这里,因为京东的界面使用了jQuery,所以我们可以使用jQuery。简而言之,我们可以使用他们可以使用的所有选择器,否则我们不能。
接下来我们爬取Node.js的官网主页,直接生成PDF
本项目要求:给我们一个网页地址,爬取他的网页内容,然后输出成我们想要的PDF格式文档,请注意是高质量的PDF文档
TIPS:本项目的设计思路是一个网页和一个PDF文件,所以每次爬取单个页面,请将index.pdf复制出来,然后继续改url地址,继续爬取,生成一个新的PDF文件,当然你也可以一次爬取多个网页,通过循环编译的方式生成多个PDF文件。对于像京东首页这样开启了图片延迟加载的网页,部分爬取的内容就是处于加载状态的内容。对于有一些反爬机制的网页,爬虫也会有问题,但是大部分网站都可以
const puppeteer = require('puppeteer');
const url = require('./url');
(async () => {
const browser = await puppeteer.launch({ headless: true })
const page = await browser.newPage()
//选择要打开的网页
await page.goto(url, { waitUntil: 'networkidle0' })
//选择你要输出的那个PDF文件路径,把爬取到的内容输出到PDF中,必须是存在的PDF,可以是空内容,如果不是空的内容PDF,那么会覆盖内容
let pdfFilePath = './index.pdf';
//根据你的配置选项,我们这里选择A4纸的规格输出PDF,方便打印
await page.pdf({
path: pdfFilePath,
format: 'A4',
scale: 1,
printBackground: true,
landscape: false,
displayHeaderFooter: false
});
await browser.close()
})()
文件解构设计
在这个时代,数据非常宝贵。根据网页的设计逻辑,如果选择特定href的地址,可以直接获取对应的资源,也可以再次使用page.goto方法进入,然后调用page.evaluate( ) 处理逻辑。或者输出对应的PDF文件,当然也可以一次输出多个PDF文件~这里就不过多介绍了,毕竟Node.js可以上天,说不定以后真的可以做任何事。这么优质又短的教程,请采集或转发给您的朋友,谢谢。
js提取指定网站内容(一个用jsp实现的常见的首页图片轮换效果。。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-21 08:27
最近研究的jsp实现的一个常见的首页图片旋转效果。
本来打算在网上找别人的作品,作为自己的网站项目。平时无聊的时候就去搜,结果只发现是用php做的。其他人实现的旋转效果还有很多,包括js和flash+JS,但是我还没有找到别人用jsp做的可以直接使用的组件(也是从别人的cms学习的)。,但理解起来太复杂了),所以没办法,只能想办法写个组件来实现,也方便以后使用。
主要实现思路:
文章提交时,从文章的具体内容中提取第一张图片的地址(如果有图片)和标题,在当前表中找出文章之后的最新已提交。一条数据的ID(也就是刚刚提交的文章),然后把SRC/Title/ID(或者detail.jsp?ID=ID)保存到一个XML文件中(也可以用一个数据库,但考虑到数据量不在首页,使用JS解析XML文件,提取具体数据,然后展示具体效果。
成就效果总结:
当我在考虑写这个组件的时候,我觉得这是一件很简单的事情。本来想在课后无所事事的情况下,用一整天或更长时间完成,但在实施过程中遇到了很多以前没有遇到过的问题。,经过google、百度和自己的反复测试,终于实现了这个功能。具体问题及解决方法总结如下:
1、从指定文本中提取图像
2、java对XML文件解析、节点增删操作的总结
3、JS 解析 XML
4、sql查询最后一条数据
5、XML中文乱码问题解决
6、引用转义
7、路径问题(JS读取XML,java读取XML,jsp读取XML)
8、图片上传组件 查看全部
js提取指定网站内容(一个用jsp实现的常见的首页图片轮换效果。。)
最近研究的jsp实现的一个常见的首页图片旋转效果。
本来打算在网上找别人的作品,作为自己的网站项目。平时无聊的时候就去搜,结果只发现是用php做的。其他人实现的旋转效果还有很多,包括js和flash+JS,但是我还没有找到别人用jsp做的可以直接使用的组件(也是从别人的cms学习的)。,但理解起来太复杂了),所以没办法,只能想办法写个组件来实现,也方便以后使用。
主要实现思路:
文章提交时,从文章的具体内容中提取第一张图片的地址(如果有图片)和标题,在当前表中找出文章之后的最新已提交。一条数据的ID(也就是刚刚提交的文章),然后把SRC/Title/ID(或者detail.jsp?ID=ID)保存到一个XML文件中(也可以用一个数据库,但考虑到数据量不在首页,使用JS解析XML文件,提取具体数据,然后展示具体效果。
成就效果总结:
当我在考虑写这个组件的时候,我觉得这是一件很简单的事情。本来想在课后无所事事的情况下,用一整天或更长时间完成,但在实施过程中遇到了很多以前没有遇到过的问题。,经过google、百度和自己的反复测试,终于实现了这个功能。具体问题及解决方法总结如下:
1、从指定文本中提取图像
2、java对XML文件解析、节点增删操作的总结
3、JS 解析 XML
4、sql查询最后一条数据
5、XML中文乱码问题解决
6、引用转义
7、路径问题(JS读取XML,java读取XML,jsp读取XML)
8、图片上传组件
js提取指定网站内容(js提取指定网站内容:实时抓取国内外互联网数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-19 16:04
js提取指定网站内容:实时抓取国内外互联网数据,提取大量图片、文本、视频等javascript代码,转换格式发布到社交媒体平台上,引导用户浏览时使用javascript播放实时抓取内容分析数据用户行为中的数据可提取到javascript代码数据转换文本文本的分析可以获取大量关键字,如姓名、性别、年龄等。
将这些关键字语义化,归纳内容如学习、背单词、求职等内容分析设置不同字体色标区分不同内容设置不同文件名可以统计文本中文本数据量的区别通过r语言可以很轻松的转换成不同格式的javascript代码,通过字符形式生成更加方便查看进一步的深入分析:利用函数来构建统计模型。函数有:acf,mcf,lm,jpmannagy。在javascript中构建r与python的统计模型利用tableau进行数据可视化解决实际问题:。
1、在线拉取百度、、知乎等数据并转化为可视化模型;
2、利用知乎进行数据分析,
3、通过百度指数了解目标用户的喜好和需求;
4、提取帖子内容和评论生成短图片数据可视化平台;
5、利用百度指数了解竞争对手的可投放广告库存;
6、成立一个1w亿元级别的职场平台。
7、流量变现。
8、通过百度指数收集关键字词频的内容,进行用户画像。本文内容来源于:推特官方账号:reddit官方账号:[hao123][][sc]startwith:[se.example.acf](hi)[1]thehiaccountisrewriteandenabledwhenyoucopytherequest.byrewrite,thehiaccountcannotreadthetagasrequest.accountactivatedforstartingfromthismodule,thehiclientcanreadtags.thehiaccountisrewriteandenabledwhenyoucopytherequest.accountactivatedforstartingfromthismodule,thehiclientcanreadtags.thehiaccountisrewriteandenabledwhenyoucopytherequest.copytherequestsharedbyrewritemeansthehiaccountwillautomaticallydisauthenticatethetagsuntiltheaccountissigned.byrewrite,thehiaccountcannotreadthetagsuntiltheaccountissigned.thehiaccountisrewriteandenabledwhenyoucopytherequest.dependingonthehiaccountareallowedbyrewrite.rewrite=rewrite('ccw','request')rewrite=rewrite('ccw','getjson')rewrite=rewrite('ccw','posturl')rewrite=rewrite('ccw','maxindex')rewrite。 查看全部
js提取指定网站内容(js提取指定网站内容:实时抓取国内外互联网数据)
js提取指定网站内容:实时抓取国内外互联网数据,提取大量图片、文本、视频等javascript代码,转换格式发布到社交媒体平台上,引导用户浏览时使用javascript播放实时抓取内容分析数据用户行为中的数据可提取到javascript代码数据转换文本文本的分析可以获取大量关键字,如姓名、性别、年龄等。
将这些关键字语义化,归纳内容如学习、背单词、求职等内容分析设置不同字体色标区分不同内容设置不同文件名可以统计文本中文本数据量的区别通过r语言可以很轻松的转换成不同格式的javascript代码,通过字符形式生成更加方便查看进一步的深入分析:利用函数来构建统计模型。函数有:acf,mcf,lm,jpmannagy。在javascript中构建r与python的统计模型利用tableau进行数据可视化解决实际问题:。
1、在线拉取百度、、知乎等数据并转化为可视化模型;
2、利用知乎进行数据分析,
3、通过百度指数了解目标用户的喜好和需求;
4、提取帖子内容和评论生成短图片数据可视化平台;
5、利用百度指数了解竞争对手的可投放广告库存;
6、成立一个1w亿元级别的职场平台。
7、流量变现。
8、通过百度指数收集关键字词频的内容,进行用户画像。本文内容来源于:推特官方账号:reddit官方账号:[hao123][][sc]startwith:[se.example.acf](hi)[1]thehiaccountisrewriteandenabledwhenyoucopytherequest.byrewrite,thehiaccountcannotreadthetagasrequest.accountactivatedforstartingfromthismodule,thehiclientcanreadtags.thehiaccountisrewriteandenabledwhenyoucopytherequest.accountactivatedforstartingfromthismodule,thehiclientcanreadtags.thehiaccountisrewriteandenabledwhenyoucopytherequest.copytherequestsharedbyrewritemeansthehiaccountwillautomaticallydisauthenticatethetagsuntiltheaccountissigned.byrewrite,thehiaccountcannotreadthetagsuntiltheaccountissigned.thehiaccountisrewriteandenabledwhenyoucopytherequest.dependingonthehiaccountareallowedbyrewrite.rewrite=rewrite('ccw','request')rewrite=rewrite('ccw','getjson')rewrite=rewrite('ccw','posturl')rewrite=rewrite('ccw','maxindex')rewrite。
js提取指定网站内容(《讲解开源项目》[1]系列之FilePond手痒有些)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-16 11:34
这是HelloGitHub推出的“解释开源项目”[1]系列。今天给大家推荐一款。
JavaScript 开源文件上传库项目——FilePond
一、简介
1.1 文件池
它是一个 JavaScript 文件上传库。可以拖入上传,并优化图像以加快上传速度。为用户提供出色、可见、流畅的文件上传体验。
FilePond项目地址:
1.2 特点和优势
看了效果图和功能介绍,是不是有点痒?接下来是实际操作部分。你可以跟着文章一步步使用这个库,点亮你的文件上传技能点!
实战操作
下面我们将逐步解释如何使用 FilePond 库。我们使用最简单的CDN参考方式,方便大家快速查看它的魅力(复制代码看效果),然后深入讲解各个插件的作用,最后结合几个插件写一个例子运行显示结果.
提示:解释以注释的形式显示在代码中,请仔细阅读。
2.1 快速使用(CDN)
示例代码:
FilePond from CDN
// FilePond.parse 使用类.filepond解析DOM树的给定部分,并将它们转换为FilePond元素。
FilePond.parse(document.body);
结果显示:
2.2
引入插件
看来简单的上传功能无法满足我们的需求。FilePond 库有各种强大的插件部件。您可以根据自己的需要选择和组合插件。我们先简单了解一下各个插件的作用:
现在让我介绍如何引入插件!
坑!: 使用插件前,一定要检查插件是否有CSS文件,如果有,请在标签中引入。
// 注册插件 FilePondPluginImagePreview 图像预览插件为已上传的图像呈现缩小的预览。
FilePond.registerPlugin(FilePondPluginImagePreview);
下面我们来梳理一下引入插件的步骤: 引入CSS文件(部分插件有CSS文件) 引入JS文件注册插件 配置插件(部分插件需要配置)
2.3 与插件一起使用
完整的示例代码:
FilePond from CDN
// querySelector() 方法返回文档中匹配指定 CSS 选择器的一个元素。
var inputElement = document.querySelector('input[type="file"]');
// 注册插件
// FilePondPluginImagePreview 上传时可以预览到上传的图片等
// FilePondPluginImageEdit 由于doka收费,所以编辑功能就不演示了。
// FilePondPluginFileValidateType 图片类型
// FilePondPluginImageCrop 图像裁剪
// FilePondPluginFileValidateSize 文件大小验证插件处理阻止太大的文件。
FilePond.registerPlugin(
FilePondPluginImagePreview,
FilePondPluginImageEdit,
FilePondPluginFileValidateSize,
FilePondPluginImageCrop,
FilePondPluginFileValidateType,
FilePondPluginImageExifOrientation
);
FilePond.setOptions({
// 设置单个URL是定义服务器配置的最基本形式。
server: '/upload',
// 设置图片类型只能为png才能上传
allowFileTypeValidation: false,
acceptedFileTypes: "image/jpg",
// 启用或禁用图像裁剪
allowImageCrop: true,
// 启用或禁用文件大小验证
allowFileSizeValidation: true,
maxFileSize: null,
// 启用或禁用提取EXIF信息
allowImageExifOrientation: true
});
// 使用create方法逐步增强基本文件输入到FilePond元素。
FilePond.create(inputElement)
上例展示了FilePond常用插件的方法,效果如下图:
当然还有
我不会在这里做完整的解释。有兴趣的可以自己试试这些方法。
三、总结
以上就是讲解的全部内容,FilePond是一个非常轻量级的上传插件。没有太多繁琐的配置,这里我没有一一演示每个插件的介绍,只展示常用的部分。注意上面指出的坑,掌握上面讲解的方法,其他插件可以自行学习。
FilePond 是一个值得参考和使用的 JavaScript 库。如果你想网站快速添加上传功能,不妨试试。
参考
[1] 《解释开源项目》:
[2]EXIF:
[3]FilePond官方文档:
[4]FilePond 插件列表:
关注公众号,加入交流群,一起讨论有趣的技术话题
《开源项目解读系列》——让对开源项目感兴趣的人不再害怕,让开源项目的发起者不再孤单。跟随我们的文章,您会发现编程的乐趣、易用性以及参与开源项目是多么容易。欢迎联系我(微信:xueweihan 备注:解释)加入我们,让更多人爱上开源,为开源做贡献~ 查看全部
js提取指定网站内容(《讲解开源项目》[1]系列之FilePond手痒有些)
这是HelloGitHub推出的“解释开源项目”[1]系列。今天给大家推荐一款。
JavaScript 开源文件上传库项目——FilePond
一、简介
1.1 文件池
它是一个 JavaScript 文件上传库。可以拖入上传,并优化图像以加快上传速度。为用户提供出色、可见、流畅的文件上传体验。
FilePond项目地址:
1.2 特点和优势
看了效果图和功能介绍,是不是有点痒?接下来是实际操作部分。你可以跟着文章一步步使用这个库,点亮你的文件上传技能点!
实战操作
下面我们将逐步解释如何使用 FilePond 库。我们使用最简单的CDN参考方式,方便大家快速查看它的魅力(复制代码看效果),然后深入讲解各个插件的作用,最后结合几个插件写一个例子运行显示结果.
提示:解释以注释的形式显示在代码中,请仔细阅读。
2.1 快速使用(CDN)
示例代码:
FilePond from CDN
// FilePond.parse 使用类.filepond解析DOM树的给定部分,并将它们转换为FilePond元素。
FilePond.parse(document.body);
结果显示:
2.2
引入插件
看来简单的上传功能无法满足我们的需求。FilePond 库有各种强大的插件部件。您可以根据自己的需要选择和组合插件。我们先简单了解一下各个插件的作用:
现在让我介绍如何引入插件!
坑!: 使用插件前,一定要检查插件是否有CSS文件,如果有,请在标签中引入。
// 注册插件 FilePondPluginImagePreview 图像预览插件为已上传的图像呈现缩小的预览。
FilePond.registerPlugin(FilePondPluginImagePreview);
下面我们来梳理一下引入插件的步骤: 引入CSS文件(部分插件有CSS文件) 引入JS文件注册插件 配置插件(部分插件需要配置)
2.3 与插件一起使用
完整的示例代码:
FilePond from CDN
// querySelector() 方法返回文档中匹配指定 CSS 选择器的一个元素。
var inputElement = document.querySelector('input[type="file"]');
// 注册插件
// FilePondPluginImagePreview 上传时可以预览到上传的图片等
// FilePondPluginImageEdit 由于doka收费,所以编辑功能就不演示了。
// FilePondPluginFileValidateType 图片类型
// FilePondPluginImageCrop 图像裁剪
// FilePondPluginFileValidateSize 文件大小验证插件处理阻止太大的文件。
FilePond.registerPlugin(
FilePondPluginImagePreview,
FilePondPluginImageEdit,
FilePondPluginFileValidateSize,
FilePondPluginImageCrop,
FilePondPluginFileValidateType,
FilePondPluginImageExifOrientation
);
FilePond.setOptions({
// 设置单个URL是定义服务器配置的最基本形式。
server: '/upload',
// 设置图片类型只能为png才能上传
allowFileTypeValidation: false,
acceptedFileTypes: "image/jpg",
// 启用或禁用图像裁剪
allowImageCrop: true,
// 启用或禁用文件大小验证
allowFileSizeValidation: true,
maxFileSize: null,
// 启用或禁用提取EXIF信息
allowImageExifOrientation: true
});
// 使用create方法逐步增强基本文件输入到FilePond元素。
FilePond.create(inputElement)
上例展示了FilePond常用插件的方法,效果如下图:
当然还有
我不会在这里做完整的解释。有兴趣的可以自己试试这些方法。
三、总结
以上就是讲解的全部内容,FilePond是一个非常轻量级的上传插件。没有太多繁琐的配置,这里我没有一一演示每个插件的介绍,只展示常用的部分。注意上面指出的坑,掌握上面讲解的方法,其他插件可以自行学习。
FilePond 是一个值得参考和使用的 JavaScript 库。如果你想网站快速添加上传功能,不妨试试。
参考
[1] 《解释开源项目》:
[2]EXIF:
[3]FilePond官方文档:
[4]FilePond 插件列表:
关注公众号,加入交流群,一起讨论有趣的技术话题
《开源项目解读系列》——让对开源项目感兴趣的人不再害怕,让开源项目的发起者不再孤单。跟随我们的文章,您会发现编程的乐趣、易用性以及参与开源项目是多么容易。欢迎联系我(微信:xueweihan 备注:解释)加入我们,让更多人爱上开源,为开源做贡献~
js提取指定网站内容( JavaScript语言本身的内容的演示结果[3])
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-15 23:14
JavaScript语言本身的内容的演示结果[3])
你好世界!
本教程的这一部分是关于 JavaScript 语言本身的。
但是,我们需要一个工作环境来运行我们的脚本,并且由于本教程是在线的,因此浏览器是一个不错的选择。我们将尽可能少地使用特定于浏览器的命令(如警报),因此如果您要专注于另一个环境(如 Node.js),则不必花太多时间关心这些特定命令. 在本教程的下一部分,我们将重点介绍浏览器中的 JavaScript。
首先,让我们看看如何将脚本添加到网页。对于服务器端环境(如 Node.js),您只需要使用“node my.js”之类的命令行来执行它。
“脚本”标签
JavaScript 程序可以插入到 .
有很多关于浏览器脚本以及它们与网页的关系的知识。但请记住,本教程的这一部分主要针对 JavaScript 语言本身,因此我们不应被特定于浏览器的实现分散注意力。我们将使用浏览器作为运行 JavaScript 的一种方式,这对于我们在线阅读来说非常方便,但这只是众多方式中的一种。
作业问题
1. 显示提示
重要性:⭐️⭐️⭐️⭐️⭐️
创建一个页面,然后显示一条消息“我是 JavaScript!”。
无论您是在沙盒中还是在硬盘驱动器上执行此操作,只要确保它有效即可。
您可以先在新窗口 [2] 中查看演示结果。
在微信公众号“技术讲座”后台回复1-2-1,即可获得此问题的答案。
2. 使用外部脚本显示提示
重要性:⭐️⭐️⭐️⭐️⭐️
打开问题 1 的答案。将答案中的脚本内容提取到同一文件夹中的外部 alert.js 文件中。
打开页面并确保它有效。
您可以先在新窗口 [3] 中查看演示结果。
在微信公众号“技术讲座”后台回复1-2-1,即可获得此问题的答案。
现代 JavaScript 教程:从入门到高级的开源现代 JavaScript 教程。React 官方文档推荐,一个与 MDN [4] 一起的 JavaScript 学习教程。
免费在线阅读:
参考
[1] 缓存:
[2] 新窗口中的演示结果:
[3] 新窗口中的演示结果:
[4] React官方文档推荐,与MDN并行的JavaScript学习教程:#javascript-resources 查看全部
js提取指定网站内容(
JavaScript语言本身的内容的演示结果[3])

你好世界!
本教程的这一部分是关于 JavaScript 语言本身的。
但是,我们需要一个工作环境来运行我们的脚本,并且由于本教程是在线的,因此浏览器是一个不错的选择。我们将尽可能少地使用特定于浏览器的命令(如警报),因此如果您要专注于另一个环境(如 Node.js),则不必花太多时间关心这些特定命令. 在本教程的下一部分,我们将重点介绍浏览器中的 JavaScript。
首先,让我们看看如何将脚本添加到网页。对于服务器端环境(如 Node.js),您只需要使用“node my.js”之类的命令行来执行它。
“脚本”标签
JavaScript 程序可以插入到 .
有很多关于浏览器脚本以及它们与网页的关系的知识。但请记住,本教程的这一部分主要针对 JavaScript 语言本身,因此我们不应被特定于浏览器的实现分散注意力。我们将使用浏览器作为运行 JavaScript 的一种方式,这对于我们在线阅读来说非常方便,但这只是众多方式中的一种。
作业问题
1. 显示提示
重要性:⭐️⭐️⭐️⭐️⭐️
创建一个页面,然后显示一条消息“我是 JavaScript!”。
无论您是在沙盒中还是在硬盘驱动器上执行此操作,只要确保它有效即可。
您可以先在新窗口 [2] 中查看演示结果。
在微信公众号“技术讲座”后台回复1-2-1,即可获得此问题的答案。
2. 使用外部脚本显示提示
重要性:⭐️⭐️⭐️⭐️⭐️
打开问题 1 的答案。将答案中的脚本内容提取到同一文件夹中的外部 alert.js 文件中。
打开页面并确保它有效。
您可以先在新窗口 [3] 中查看演示结果。
在微信公众号“技术讲座”后台回复1-2-1,即可获得此问题的答案。
现代 JavaScript 教程:从入门到高级的开源现代 JavaScript 教程。React 官方文档推荐,一个与 MDN [4] 一起的 JavaScript 学习教程。
免费在线阅读:
参考
[1] 缓存:
[2] 新窗口中的演示结果:
[3] 新窗口中的演示结果:
[4] React官方文档推荐,与MDN并行的JavaScript学习教程:#javascript-resources
js提取指定网站内容(Python学习资料的PS学习方法(一)--Python )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-15 07:14
)
PS:如需Python学习资料,可点击下方链接自行获取
基本步骤和准备
调试环境:
pycharm+python3
所需库:
(http.cookiejar是后续爬虫进场时会用到的库,本项目不涉及反爬,可以省略)
如果导入过程显示上面的库不可用,可以在File→Settings→projet解释器中点击右侧的+添加(如果你使用anaconda或者python也可以直接运行这个项目,添加通过cmd→pip安装)
2.本文我们使用python来抓取、下载和存储在线短视频。基本步骤如下(可以写评论整理思路):
(1)分析页面URL和视频文件URL特征(2)获取网页源代码的HTML,解决反爬机制(3)批量下载视频存储)
分析页面 URL 和文件 URL 特征
1.分析网页 URL
通过网页URL:,我们可以找到不同页码变化的知识URL的最后一个值,这个值代表了页数,所以我们只需要把它改成固定URL+可变形式就可以得到分批建站
2.分析文件名 URL
通过分析网页中mp4的文件名,发现该文件的URL以纯文本形式显示,因此可以通过匹配re的正则性得到。
批量获取url,并从中提取视频的url
import urllib.request
import re
for page in range (1,20):
req = urllib.request.Request("http://www.budejie.com/video/%s" % page)
html = urllib.request.urlopen(req).read()
html = html.decode('UTF-8')
print(html)
1.批量抓取网页url
这里我们的page变量代表页面的代码,从这里我们暂时抓取前20页。
(1)req获取网页反馈(2)html通过函数获取网页元代码(3)恢复UTF-8编码的中文显示)源代码。
但是通过上面代码的执行,发现报错显示http Error 403,因为无法获取网页的反爬机制。
2.通过页面添加头文件
我们通过谷歌浏览器访问页面,按F12切换到Network,刷新界面观察访问过程,可以从过程文件中选择一个查看头文件,添加到代码中,(这里选择baisibudejie.js)修改代码如下,就可以正常爬取界面了。
for page in range (1,20):
req = urllib.request.Request("http://www.budejie.com/video/%s" % page)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36")
html = urllib.request.urlopen(req).read()
html = html.decode('UTF-8')
print(html)
批量下载视频并创建文件名存储
1.为批量命名创建循环结构
建立循环结构后,需要保留文件名以供下载。i.split("/")[-1]的意思是对i进行拆分,用'/'作为分隔符,保留最后一段,即MP4文件名。
2.批量下载
还是要加一条显示的输出语句来表示这个过程,这也符合程序的交互性,即在下载视频的时候显示进度,最后下载到一个mp4文件夹中。
for i in re.findall(reg, html):
filename = i.split("/")[-1] # 以‘/ ’为分割f符,保留最后一段,即MP4的文件名
print('正在下载%s视频' % filename)
urllib.request.urlretrieve(i, "mp4/%s" % filename)
1.构建一个完整的程序
作为一名合格的程序员,需要对程序进行梳理,并添加注释,方便理解和后续修改
import urllib.request
import re
def getVideo(page):
req = urllib.request.Request("http://www.budejie.com/video/%s" %page)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36")
html = urllib.request.urlopen(req).read()
html = html.decode('UTF-8')
reg = r'data-mp4="(.*?)"'
for i in re.findall(reg,html):
filename = i.split("/")[-1]#以‘/ ’为分割f符,保留最后一段,即MP4的文件名
print ('正在下载%s视频' %filename)
urllib.request.urlretrieve(i,"mp4/%s"%filename)
for i in range (1,20):
getVideo(i) 查看全部
js提取指定网站内容(Python学习资料的PS学习方法(一)--Python
)
PS:如需Python学习资料,可点击下方链接自行获取
基本步骤和准备
调试环境:
pycharm+python3
所需库:
(http.cookiejar是后续爬虫进场时会用到的库,本项目不涉及反爬,可以省略)
如果导入过程显示上面的库不可用,可以在File→Settings→projet解释器中点击右侧的+添加(如果你使用anaconda或者python也可以直接运行这个项目,添加通过cmd→pip安装)
2.本文我们使用python来抓取、下载和存储在线短视频。基本步骤如下(可以写评论整理思路):
(1)分析页面URL和视频文件URL特征(2)获取网页源代码的HTML,解决反爬机制(3)批量下载视频存储)
分析页面 URL 和文件 URL 特征
1.分析网页 URL
通过网页URL:,我们可以找到不同页码变化的知识URL的最后一个值,这个值代表了页数,所以我们只需要把它改成固定URL+可变形式就可以得到分批建站
2.分析文件名 URL
通过分析网页中mp4的文件名,发现该文件的URL以纯文本形式显示,因此可以通过匹配re的正则性得到。
批量获取url,并从中提取视频的url
import urllib.request
import re
for page in range (1,20):
req = urllib.request.Request("http://www.budejie.com/video/%s" % page)
html = urllib.request.urlopen(req).read()
html = html.decode('UTF-8')
print(html)
1.批量抓取网页url
这里我们的page变量代表页面的代码,从这里我们暂时抓取前20页。
(1)req获取网页反馈(2)html通过函数获取网页元代码(3)恢复UTF-8编码的中文显示)源代码。
但是通过上面代码的执行,发现报错显示http Error 403,因为无法获取网页的反爬机制。
2.通过页面添加头文件
我们通过谷歌浏览器访问页面,按F12切换到Network,刷新界面观察访问过程,可以从过程文件中选择一个查看头文件,添加到代码中,(这里选择baisibudejie.js)修改代码如下,就可以正常爬取界面了。
for page in range (1,20):
req = urllib.request.Request("http://www.budejie.com/video/%s" % page)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36")
html = urllib.request.urlopen(req).read()
html = html.decode('UTF-8')
print(html)
批量下载视频并创建文件名存储
1.为批量命名创建循环结构
建立循环结构后,需要保留文件名以供下载。i.split("/")[-1]的意思是对i进行拆分,用'/'作为分隔符,保留最后一段,即MP4文件名。
2.批量下载
还是要加一条显示的输出语句来表示这个过程,这也符合程序的交互性,即在下载视频的时候显示进度,最后下载到一个mp4文件夹中。
for i in re.findall(reg, html):
filename = i.split("/")[-1] # 以‘/ ’为分割f符,保留最后一段,即MP4的文件名
print('正在下载%s视频' % filename)
urllib.request.urlretrieve(i, "mp4/%s" % filename)
1.构建一个完整的程序
作为一名合格的程序员,需要对程序进行梳理,并添加注释,方便理解和后续修改
import urllib.request
import re
def getVideo(page):
req = urllib.request.Request("http://www.budejie.com/video/%s" %page)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36")
html = urllib.request.urlopen(req).read()
html = html.decode('UTF-8')
reg = r'data-mp4="(.*?)"'
for i in re.findall(reg,html):
filename = i.split("/")[-1]#以‘/ ’为分割f符,保留最后一段,即MP4的文件名
print ('正在下载%s视频' %filename)
urllib.request.urlretrieve(i,"mp4/%s"%filename)
for i in range (1,20):
getVideo(i)
js提取指定网站内容(js提取指定网站内容是什么鬼?知乎首页的代码应该有写)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-21 06:02
js提取指定网站内容,可以按照链接获取;也可以按照字母或字符编码获取;也可以按照文字格式获取,比如js提取得到的文字一般可以转义。
1.用sql提取2.用html5提取,比如w3cschool,可以下载注意,这是一种收费项目,如果你自己有百度云空间,可以下载这个功能。我之前下载过,很强大。
这个。我觉得。你应该百度一下。知乎首页的代码应该有写。
很简单我是学java的来说一下这个我可以看出我很闲可能是因为我们公司那个vss免费注册的。
用html5可以爬取的,我用的是talkjs,
可以这样的利用js变量接受一段文本值然后利用循环或者多线程解析出我这么用是一种伪多线程模式把抓取到的js字节通过改变trim属性,变成字符串利用php标准库的string,包含字符串内容,合并成一个string,然后合并最后这样的方法就不能一对一,因为这个需要用到trycatch这个关键字。
php提取文字有这个php–php提取js字符串
php解析js文件,
xcode:phpxmlxml:pxml
php直接提取js?:.\.php?
后面来个?是什么鬼 查看全部
js提取指定网站内容(js提取指定网站内容是什么鬼?知乎首页的代码应该有写)
js提取指定网站内容,可以按照链接获取;也可以按照字母或字符编码获取;也可以按照文字格式获取,比如js提取得到的文字一般可以转义。
1.用sql提取2.用html5提取,比如w3cschool,可以下载注意,这是一种收费项目,如果你自己有百度云空间,可以下载这个功能。我之前下载过,很强大。
这个。我觉得。你应该百度一下。知乎首页的代码应该有写。
很简单我是学java的来说一下这个我可以看出我很闲可能是因为我们公司那个vss免费注册的。
用html5可以爬取的,我用的是talkjs,
可以这样的利用js变量接受一段文本值然后利用循环或者多线程解析出我这么用是一种伪多线程模式把抓取到的js字节通过改变trim属性,变成字符串利用php标准库的string,包含字符串内容,合并成一个string,然后合并最后这样的方法就不能一对一,因为这个需要用到trycatch这个关键字。
php提取文字有这个php–php提取js字符串
php解析js文件,
xcode:phpxmlxml:pxml
php直接提取js?:.\.php?
后面来个?是什么鬼
js提取指定网站内容(前端侧对于动态生成的内容进行下载的实时截图下载 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-21 04:15
)
有时候需要在前端下载动态生成的内容,比如页面上的某条文字信息,而分享页面的时候,希望分享的图片是页面的实时截图内容。此时,图像是动态的。纯 HTML 显然无法满足我们的需求。借助 JS 和其他一些 HTML5 功能,例如将页面元素转换为画布,然后将它们转换为图像以供下载。
原理其实很简单。我们可以借助 Blob 将文本或 JS 字符串信息转换成二进制,然后将其作为元素的 href 属性,配合 download 属性实现下载。
代码也比较简单,如下图(兼容Chrome和Firefox):
function funcDownload (content, filename) {
// 创建隐藏的可下载链接
var eleLink = document.createElement('a');
eleLink.download = filename;
eleLink.style.display = 'none';
// 字符内容转变成blob地址
var blob = new Blob([content]);
eleLink.href = URL.createObjectURL(blob);
// 触发点击
document.body.appendChild(eleLink);
eleLink.click();
// 然后移除
document.body.removeChild(eleLink);
}
function dn (){
var ss = document.querySelector('html').outerHTML;
funcDownload(ss, 'ceshi.html')
}
其中,content是指要下载的文本或字符串内容,filename是指下载到系统中的文件名。
上面的代码可以将整个当前网页下载为html文件,但是对于网页内外的一些资源是无法显示的。
在 Chrome 浏览器中,即使模拟点击创建的元素没有附加到页面上,也可以触发下载,但在 Firefox 浏览器中,这是不可能的。所以上面的funDownload()方法有一个appendChild和removeChild处理,这是为了兼容火狐浏览器。
1、URL.createObjectURL() 方法将根据传入的参数创建一个指向参数对象的 URL。此 URL 的生命周期仅存在于它创建的文档中。新的对象 URL 指向执行的 File 对象或 Blob 对象。
objectURL = URL.createObjectURL(blob || file);
参数:文件对象或 Blob 对象。这里大致是 File 对象和 Blob 对象:
文件对象:它是一个文件。例如,如果我使用 input type="file" 标签上传文件,那么其中的每个文件都是一个 File 对象。
Blob 对象:它是二进制数据。例如,new Blob() 创建的对象就是一个 Blob 对象。例如,在 XMLHttpRequest 中,如果 responseType 指定为 blob,则返回值也是一个 blob 对象。
注意:每次调用 createObjectURL 时,都会创建一个新的 URL 对象。即使您为同一个文件创建了 URL。如果您不再需要此对象,要释放它,您需要使用 URL.revokeObjectURL() 方法。当页面关闭时,浏览器会自动释放它,但为了获得最佳性能和内存使用,您应该在确定不再需要它时释放它。
2、URL.revokeObjectURL()方法会释放一个由URL.createObjectURL()创建的对象URL,当你使用了对象URL,然后让浏览器知道该URL不再需要指向对应的URL文件,你需要调用这个方法。具体含义是一个对象URL可以使用这个URL访问指定的文件,但我可能只需要访问一次。一旦被访问,对象 URL 就不再需要,将被释放和释放。将来,此对象 URL 将不再指向指定文件。例如,对于一张图片,我创建一个对象 URL,然后通过对象 URL,我将图片加载到页面上。既然已经加载了图片不需要再次加载,那么我释放对象的URL,那么URL就不再指向图片了。
window.URL.revokeObjectURL(objectURL);
//objectURL 是一个通过URL.createObjectURL()方法创建的对象URL. 查看全部
js提取指定网站内容(前端侧对于动态生成的内容进行下载的实时截图下载
)
有时候需要在前端下载动态生成的内容,比如页面上的某条文字信息,而分享页面的时候,希望分享的图片是页面的实时截图内容。此时,图像是动态的。纯 HTML 显然无法满足我们的需求。借助 JS 和其他一些 HTML5 功能,例如将页面元素转换为画布,然后将它们转换为图像以供下载。
原理其实很简单。我们可以借助 Blob 将文本或 JS 字符串信息转换成二进制,然后将其作为元素的 href 属性,配合 download 属性实现下载。
代码也比较简单,如下图(兼容Chrome和Firefox):
function funcDownload (content, filename) {
// 创建隐藏的可下载链接
var eleLink = document.createElement('a');
eleLink.download = filename;
eleLink.style.display = 'none';
// 字符内容转变成blob地址
var blob = new Blob([content]);
eleLink.href = URL.createObjectURL(blob);
// 触发点击
document.body.appendChild(eleLink);
eleLink.click();
// 然后移除
document.body.removeChild(eleLink);
}
function dn (){
var ss = document.querySelector('html').outerHTML;
funcDownload(ss, 'ceshi.html')
}
其中,content是指要下载的文本或字符串内容,filename是指下载到系统中的文件名。
上面的代码可以将整个当前网页下载为html文件,但是对于网页内外的一些资源是无法显示的。
在 Chrome 浏览器中,即使模拟点击创建的元素没有附加到页面上,也可以触发下载,但在 Firefox 浏览器中,这是不可能的。所以上面的funDownload()方法有一个appendChild和removeChild处理,这是为了兼容火狐浏览器。
1、URL.createObjectURL() 方法将根据传入的参数创建一个指向参数对象的 URL。此 URL 的生命周期仅存在于它创建的文档中。新的对象 URL 指向执行的 File 对象或 Blob 对象。
objectURL = URL.createObjectURL(blob || file);
参数:文件对象或 Blob 对象。这里大致是 File 对象和 Blob 对象:
文件对象:它是一个文件。例如,如果我使用 input type="file" 标签上传文件,那么其中的每个文件都是一个 File 对象。
Blob 对象:它是二进制数据。例如,new Blob() 创建的对象就是一个 Blob 对象。例如,在 XMLHttpRequest 中,如果 responseType 指定为 blob,则返回值也是一个 blob 对象。
注意:每次调用 createObjectURL 时,都会创建一个新的 URL 对象。即使您为同一个文件创建了 URL。如果您不再需要此对象,要释放它,您需要使用 URL.revokeObjectURL() 方法。当页面关闭时,浏览器会自动释放它,但为了获得最佳性能和内存使用,您应该在确定不再需要它时释放它。
2、URL.revokeObjectURL()方法会释放一个由URL.createObjectURL()创建的对象URL,当你使用了对象URL,然后让浏览器知道该URL不再需要指向对应的URL文件,你需要调用这个方法。具体含义是一个对象URL可以使用这个URL访问指定的文件,但我可能只需要访问一次。一旦被访问,对象 URL 就不再需要,将被释放和释放。将来,此对象 URL 将不再指向指定文件。例如,对于一张图片,我创建一个对象 URL,然后通过对象 URL,我将图片加载到页面上。既然已经加载了图片不需要再次加载,那么我释放对象的URL,那么URL就不再指向图片了。
window.URL.revokeObjectURL(objectURL);
//objectURL 是一个通过URL.createObjectURL()方法创建的对象URL.
js提取指定网站内容(IT共享者获取妹纸图上的图片链接功能大揭秘(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-21 04:14
今日鸡汤
下马喝你的酒,问问你的目的是什么。
前言
大家好,我是一名IT分享者,人称皮皮。
这张妹纸图网站想必大家都很熟悉,老司机的天堂。小编第一次进入时表示自己的身体逐渐变得空虚,表示一定要克制自己,远离这种正能量网站。话不多说,今天就带大家去获取妹子头像上的图片链接。然后大家就明白了。
一、项目准备
360浏览器,仅此而已
二、项目目的
获取页面上的所有精美图片
三、项目步骤1.打开浏览器,搜索图片。我们以漂亮的图片为例:
图片太美了,看不下去了。
2.打开浏览器控制台
F12,可以打开浏览器控制台,我们今天要做的就是获取所有图片链接,顺便查看一下图片。如下所示:
今天我们将获取其中的所有图片链接。相信没接触过前端的人一定对此一无所知,但是小编接下来讲了之后,你还是一无所知,那是你的错。
3.控制台功能揭晓
你可能觉得这个地方没用,什么都没有,还不如 Element Network 好用;确实前两个非常好用,可以用来分析网页结构和网页请求,但是我要说的是控制台的功能。千万不要小看它,因为它可以让你在开发过程中快速看到效果图,比如你写了一段代码,但是你现在想看看能不能用,一般的做法是写HTML+CSS然后嵌入JavaScript进去显然太麻烦了,修改后必须刷新浏览器才能看到效果。最终导致浏览器和编辑器频繁切换,影响开发速度和效率,甚至占用额外空间。系统资源。于是,控制台应运而生,这使我们能够轻松地使用 JavaScript 代码,而无需匹配 HTML 和 CSS 即可运行。一个控制台可以做任何事情,这就是我们刚才说的控制台。我们可以先来看看它的作用:
可以看到它有自动提示功能,而且比任何第三方IDE都要全面,因为它是配合浏览器使用的,其他IDE做不到那么完整,所以有时候如果你想看的话使用某种方法,它不会提示,那么只有一个原因,就是你用错了。
1).更改其编辑状态
控制台输入:
。针对特定元素
这里我们可以先看一下我们想看的浏览器图片元素的信息。我们可以先打印出所有的图像。这里我们使用一个特殊的符号:
我们可以看到,通过这个句法糖,可以打印出当前页面的所有图片信息,显示70,说明本页有70张图片。当小编再次滚动鼠标时,发现图片数量增加了,变成了136张图片。,这意味着它已加载 Ajax。
除了这种获取图片的方式,你还可以这样做:
document.images
得到的结果与上面完全相同。随着这些知识点的积累,我们现在可以轻松获取所有的图片链接。
4.获取图片链接和图片名称
这里我们需要将获取到的图片加入到数组中,然后遍历完后将所有图片打印出来。
1).创建一个数组来存储所有的图片
ab=document.images #获取当前页面所有图片<br />var aa=[] #建立数组<br />for(const y of ab){ #建立const变量使得无法修改<br /> aa.push(y); #把图片装进数组<br />}
2)。遍历数组打印图片链接
这里可以使用的方法有很多,我将一一介绍。
1)).对于 ...in
for(const a in aa){<br /> console.log(aa[a])<br />}
2)).对于...的
for(const a of aa){<br /> console.log(a)<br />}
3)).ForEach
aa.forEach(function(val,item,array){<br /> console.log(val)<br />});
4)).地图
{<br /> console.log(val)<br />});
可以看出,第四种方法与第三种方法类似,但还是有区别的。前者没有返回值,后者有,后者支持修改返回值。虽然我们打印了图片链接,但是图片名并没有打印出来,所以小编开始找图片名:
发现是在Div标签中,于是开始寻找符合条件的Div:
document.querySelectorAll('div.img_tit')#精确找到所有类名为img_tit的Div<br />document.getElementsByClassName('img_tit')#找到所有类名为img_tit
然后我们先输出图片名称再输出图片链接,这样我们就可以使用循环再判断了,如下图:
<p>var a=0;<br />do{<br /> a++;<br /> if(a%2==0){<br /> console.log(aa[a])<br />}<br /> else{<br /> console.log(ac[a])<br /> }<br /><br /><br />}<br />while(a 查看全部
js提取指定网站内容(IT共享者获取妹纸图上的图片链接功能大揭秘(组图))
今日鸡汤
下马喝你的酒,问问你的目的是什么。
前言
大家好,我是一名IT分享者,人称皮皮。
这张妹纸图网站想必大家都很熟悉,老司机的天堂。小编第一次进入时表示自己的身体逐渐变得空虚,表示一定要克制自己,远离这种正能量网站。话不多说,今天就带大家去获取妹子头像上的图片链接。然后大家就明白了。
一、项目准备
360浏览器,仅此而已
二、项目目的
获取页面上的所有精美图片
三、项目步骤1.打开浏览器,搜索图片。我们以漂亮的图片为例:
图片太美了,看不下去了。
2.打开浏览器控制台
F12,可以打开浏览器控制台,我们今天要做的就是获取所有图片链接,顺便查看一下图片。如下所示:
今天我们将获取其中的所有图片链接。相信没接触过前端的人一定对此一无所知,但是小编接下来讲了之后,你还是一无所知,那是你的错。
3.控制台功能揭晓
你可能觉得这个地方没用,什么都没有,还不如 Element Network 好用;确实前两个非常好用,可以用来分析网页结构和网页请求,但是我要说的是控制台的功能。千万不要小看它,因为它可以让你在开发过程中快速看到效果图,比如你写了一段代码,但是你现在想看看能不能用,一般的做法是写HTML+CSS然后嵌入JavaScript进去显然太麻烦了,修改后必须刷新浏览器才能看到效果。最终导致浏览器和编辑器频繁切换,影响开发速度和效率,甚至占用额外空间。系统资源。于是,控制台应运而生,这使我们能够轻松地使用 JavaScript 代码,而无需匹配 HTML 和 CSS 即可运行。一个控制台可以做任何事情,这就是我们刚才说的控制台。我们可以先来看看它的作用:
可以看到它有自动提示功能,而且比任何第三方IDE都要全面,因为它是配合浏览器使用的,其他IDE做不到那么完整,所以有时候如果你想看的话使用某种方法,它不会提示,那么只有一个原因,就是你用错了。
1).更改其编辑状态
控制台输入:
。针对特定元素
这里我们可以先看一下我们想看的浏览器图片元素的信息。我们可以先打印出所有的图像。这里我们使用一个特殊的符号:
我们可以看到,通过这个句法糖,可以打印出当前页面的所有图片信息,显示70,说明本页有70张图片。当小编再次滚动鼠标时,发现图片数量增加了,变成了136张图片。,这意味着它已加载 Ajax。
除了这种获取图片的方式,你还可以这样做:
document.images
得到的结果与上面完全相同。随着这些知识点的积累,我们现在可以轻松获取所有的图片链接。
4.获取图片链接和图片名称
这里我们需要将获取到的图片加入到数组中,然后遍历完后将所有图片打印出来。
1).创建一个数组来存储所有的图片
ab=document.images #获取当前页面所有图片<br />var aa=[] #建立数组<br />for(const y of ab){ #建立const变量使得无法修改<br /> aa.push(y); #把图片装进数组<br />}
2)。遍历数组打印图片链接
这里可以使用的方法有很多,我将一一介绍。
1)).对于 ...in
for(const a in aa){<br /> console.log(aa[a])<br />}
2)).对于...的
for(const a of aa){<br /> console.log(a)<br />}
3)).ForEach
aa.forEach(function(val,item,array){<br /> console.log(val)<br />});
4)).地图
{<br /> console.log(val)<br />});
可以看出,第四种方法与第三种方法类似,但还是有区别的。前者没有返回值,后者有,后者支持修改返回值。虽然我们打印了图片链接,但是图片名并没有打印出来,所以小编开始找图片名:
发现是在Div标签中,于是开始寻找符合条件的Div:
document.querySelectorAll('div.img_tit')#精确找到所有类名为img_tit的Div<br />document.getElementsByClassName('img_tit')#找到所有类名为img_tit
然后我们先输出图片名称再输出图片链接,这样我们就可以使用循环再判断了,如下图:
<p>var a=0;<br />do{<br /> a++;<br /> if(a%2==0){<br /> console.log(aa[a])<br />}<br /> else{<br /> console.log(ac[a])<br /> }<br /><br /><br />}<br />while(a
js提取指定网站内容(子域名Finder胸怀万里世界,放眼无限未来(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-19 01:28
nul1 2022-03-18 0 浏览 原创 JSFinder:在 js 文件中提取 URL 和子域的脚本
关键词:子域查找器
思考世界,展望无限未来。这篇文章主要讲述了JSFinder:一个提取js文件中的url和子域的脚本,希望对大家有所帮助。
JSFinder 简介
JSFinder是一个脚本工具,用于快速提取网站的js文件中的url和子域。
支持使用
以前我们大部分子域都是通过爆破或者DNS获取的,这个脚本可以认为是小菜一碟,从JS文件中匹配子域。
简单的爬取示例
子域列表
喜欢(0)
这篇关于JSFinder的文章:一个提取js文件中的url和子域的脚本已经完成。如果没有解决您的问题,请参考以下文章:
相关文章
Flask - 蓝图和子域
JavaScript学习(八十)——请写一个JS程序提取URL中的每个get参数(参数名和参数个数不定),返回一个json结构形式为键值
p>
flask 中的蓝图和子域实现
前端提取URL中的每个GET参数
Flask 框架详细的上下文管理机制
使用 Azure Web App 上的 web.config 将子域重写为目录
#yydsDry goods inventory#Next.js 通配符子域
.Request.Url.Host 不显示子域 查看全部
js提取指定网站内容(子域名Finder胸怀万里世界,放眼无限未来(组图))
nul1 2022-03-18 0 浏览 原创 JSFinder:在 js 文件中提取 URL 和子域的脚本
关键词:子域查找器
思考世界,展望无限未来。这篇文章主要讲述了JSFinder:一个提取js文件中的url和子域的脚本,希望对大家有所帮助。
JSFinder 简介
JSFinder是一个脚本工具,用于快速提取网站的js文件中的url和子域。
支持使用
以前我们大部分子域都是通过爆破或者DNS获取的,这个脚本可以认为是小菜一碟,从JS文件中匹配子域。
简单的爬取示例
子域列表
喜欢(0)
这篇关于JSFinder的文章:一个提取js文件中的url和子域的脚本已经完成。如果没有解决您的问题,请参考以下文章:
相关文章
Flask - 蓝图和子域
JavaScript学习(八十)——请写一个JS程序提取URL中的每个get参数(参数名和参数个数不定),返回一个json结构形式为键值
p>
flask 中的蓝图和子域实现
前端提取URL中的每个GET参数
Flask 框架详细的上下文管理机制
使用 Azure Web App 上的 web.config 将子域重写为目录
#yydsDry goods inventory#Next.js 通配符子域
.Request.Url.Host 不显示子域
js提取指定网站内容(作者简介董沅鑫,云开发CloudBase团队研发,业余时间出没在。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-17 07:18
关于作者
云开发CloudBase团队研发工程师董元新,专注于前端工程和节点服务开发。他在业余时间在这里。
本文内容
介绍
随着腾讯云开发能力的逐步提升,经验丰富的工程师可以独立完成一个产品的开发和上线。但是,与在线云开发相关的实战却很少文章。很多开发者都知道云开发的能力,但是不知道在现有的开发体系下如何引入云开发。
本文从云开发团队开发者+能力用户的角度出发,以云开发官网()为例,结合流行的框架和工具,分享云开发的实践经验。
涉及的知识点有:
React 框架:Next.jsCI 自动构建概述
系统设计图:
背景介绍
随着云开发团队业务的快速发展,团队需要一个官方网站,更加直观、即时地向开发者展示云开发的相关能力,包括但不限于工具链、SDK、技术文档等。
同时,为了降低开发者的启动成本,积累行业优秀的实践经验,官网还承载着营造社区氛围、聚合重要信息、增强用户粘性的重任。
我们最初使用 VuePress 作为静态 网站 工具,遇到了一些痛点:
我们使用“cms Extensions”、“Basic Cloud Development Capabilities”、“Next.js”、“CI Tools”很好地解决了上述问题。在实现网站动态内容的同时,保证了SEO,运维同学也可以通过cms对内容进行可视化管理。
安装cms
进入云开发扩展能力控制台,按照提示安装cms内容管理系统。
配置分机时,有两种账户:管理员账户和操作员账户。管理员账户具有较高的权限,可以创建新的数据集;而操作员账户只能添加、删除和修改现有的数据集。
注意:安装时间有点长,请耐心等待
安装成功后,云数据库会自动创建三个集合,分别是 tcb-ext-cms-contents、tcb-ext-cms-users、tcb-ext-cms-webhooks ,分别存放cms 系统配置信息和内容数据。会自动创建三个云函数,分别是tcb-ext-cms-api、tcb-ext-cms-init、tcb-ext-cms-auth,它们封装了初始化,数据流的认证和相关逻辑。
输入“Static 网站 Hosting”,可以看到cms系统的静态文件已经自动部署到tcb-cms/目录下:
点击上方的“基本配置”查看域名信息。
在浏览器中访问对应的链接()可以看到cms系统:
至此,在没有任何开发成本的情况下,一个cms内容管理系统正式上线啦~
使用 cms 创建动态内容
对于动态数据内容,我们将其划分为不同的模块。每个内容模块对应一个cms系统的数据集合。例如,在“云开发官网”-“社区页面”中,推荐课程的内容是动态的。
从图中可以看出,每门课程都有多个属性。在云数据库中,每门课程对应一个文档,课程属性对应文档的字段。字段类型和含义如下:
name: 课程名称
time: 课程时间
cover: 课程封面
url: 课程链接
level: 课程难度
以管理员身份登录cms系统,在内容设置页面新建内容。在cms中,支持多种高级数据类型,如url、image、markdown、富文本、标签数组、email、URL等,这些类型都智能识别,显示更友好。
注意:cms 有自己的图床功能。当数据类型为“图片”时,图片会自动上传到当前云开发环境中的云存储中。以 cloud:// 开头的用于图像信息的特殊链接存储在数据集合中。
创建新内容时,默认情况下,cms 会自动填充 4 个字段:name、order、createTime、updateTime。您可以根据自己的需要删除不必要的字段。
建议:保留订单字段,可用于数据排序。对于运营商来说,数据的阶数值越大,在cms系统中显示的位置就越高;对于开发者来说,可以按照顺序进行排序和搜索。这保证了经验和逻辑的一致性。
根据字段创建集合后, cms 您将在系统左侧看到“推荐课程”。其对应的内容存放在云数据库的推荐课程(创建时指定)集合中,其字段信息存放在云数据库的tcb-ext-cms-contents(cms创建在初始化期间))在集合中。
根据设置添加新课程内容后,再次进入“推荐好课程”,如下图:
图片、链接等内容显示给操作者更友好。
项目建设
按照 Next.js 文档创建 Next.js 项目:
npm i --save next react react-dom axios
由于我们将 网站 部署到“静态托管”,我们将使用 Next.js 的静态导出功能。package.json 中的打包脚本更新为:
"scripts": {
"dev": "next",
"build": "next build && next export",
"start": "next start"
}
为了快速部署静态网站,发布云功能。需要全局安装@cloudbase/cli:
npm install -g @cloudbase/cli
安装后,添加两个脚本:
"scripts": {
"deploy:hosting": "npm run build && cloudbase hosting:deploy out -e jhgjj-0ae4a1",
"deploy:function": "echo y | cloudbase functions:deploy --force"
}
注意:准备两个云环境,防止静态部署时文件覆盖。envId为jhgjj-0ae4a1的云环境仅用于部署Next.js的静态导出文件。envId为pagecounter-d27cfe的云环境用于部署cms系统。
获取 cms 内容
借助 CloudBase 的 Node SDK-@cloudbase/node-sdk,我们可以在 Next.js 的 getStaticProps() 方法中读取云数据库中的数据。
为了让逻辑更清晰,我们将获取外部数据的方法统一封装到一个单独的文件中。以获取“推荐课程”为例:
// provider.js
const cloudbase = require("@cloudbase/node-sdk");
const config = {
secretId: "your secretId", // 前往「腾讯云控制台」-「访问密钥」获取
secretKey: "your secretKey", // 前往「腾讯云控制台」-「访问密钥」获取
env: "your envid" // 前往「腾讯云控制台」-「云开发 CloudBase」获取
};
const app = cloudbase.init(config);
/**
* 获取云数据库数据
*/
async function getCourses() {
const db = app.database();
const result = await db.collection("recommend-course").get();
if (result.code) {
throw new Error(
`获取「推荐课程」失败, 错误码是${result.code}: ${result.message}`
);
}
return result.data.map(item => {
if (item.createTime instanceof Date) {
item.createTime = item.createTime.toLocaleString();
}
if (item.updateTime instanceof Date) {
item.updateTime = item.updateTime.toLocaleString();
}
item.cover = getBucketUrl(item.cover); // 处理云存储的特殊链接
return item;
});
}
如上所述,cms自带图床功能,拖拽上传的图片会存储在同一环境的云存储中,获取图片的链接会存储在采集中。云存储的链接是一个以cloud://开头的特殊链接,需要在前端进行专门的识别和处理。
例如图片的存储链接为:cloud://pagecounter-d27cfe.7061-pagecounter-d27cfe-1255463368/uploads/04.png。把它变成一个可访问的 http 链接:.
转换思路是:识别envid背后的信息,与tcb.qcloud.la域名重新拼接:
// provider.js
/**
* 获取云存储的访问链接
* @param {String} url 云存储的特定url
*/
function getBucketUrl(url) {
if (!url.startsWith("cloud://")) {
return url;
}
const re = /cloud:\/\/.*?\.(.*?)\/(.*)/;
const result = re.exec(url);
return `https://${result[1]}.tcb.qcloud.la/${result[2]}`;
}
注意:云存储的“权限设置”应为:所有用户可读,只有创建者和管理员可写。否则无法访问链接。
建议:除了内置的图床功能,开发者可以根据自己的需要使用其他稳定的图床服务,比如微博图床。如果使用其他图床,对应的字段类型不能设置为“图像”,可以是“字符串”或“超链接”。
到目前为止,我们已经使用 SDK 获取了云数据库数据,剩下要做的就是将其注入到 Next.js 页面组件的 props 中:
// pages/index.js
const HomePage = ({ courses }) => {
return (
// 尽情使用数据吧...
)
}
export async function getStaticProps() {
const { getCourses } = require('./../provider')
return {
props: {
courses: await getCourses()
}
}
}
export default HomePage
打开浏览器,输入:3000/,可以看到效果如下:
输入view-source::3000/,可以看到网页的html源码中收录了课程数据,解决了SEO的问题:
注意:Next.js 的一些方法会在双方都运行,但 getStaticProps() 只会在服务端运行
自动构建和部署
至此,开发工作基本结束。执行 npm run build 命令,将 网站 静态文件打包到 out/ 目录下:
执行 npm run deploy:hosting 将 out/ 目录下的文件上传到“static网站hosting”。访问静态 网站hosted link: ,效果如下:
借助成熟的 CI 工具,例如 Travis、Circle 等,可以定期触发构建工作。这样,内容和开发就完全分开了。
在构建和发布时,您需要使用 CloudBase CLI 工具。在 CI 工具中,不要使用 cloudbase login 进行交互式输入登录,而是使用以下密钥登录: cloudbase login --apiKeyId TCB_SECRET_ID --apiKey TCB_SECRET_KEY 。
注意:前往 Cloud API Key 获取 TCB_SECRET_ID 和 TCB_SECRET_KEY 的值
在 CI 工具的控制台中,配置 TCB_SECRET_ID 和 TCB_SECRET_KEY。并在 package.json 中添加一个新脚本:
"scripts": {
"login": "echo N | cloudbase login --apiKeyId $TCB_SECRET_ID --apiKey $TCB_SECRET_KEY"
}
综上所述,CI构建流程为:
如果需要紧急修改数据,可以在本地手动触发构建,也可以在 CI 工具控制台中手动触发构建。
最后
借助云开发cms,可以实现评论系统、预约系统、博客发帖等各种内容模板,从而快速搭建网站。在现有的开发体系下,合理使用云开发可以大大降低人工成本、开发成本和运维成本。真正实现前后端穿梭,形成“闭环”。
本文实战只是一个指导,涉及到部分云开发能力。还有更多有趣的东西等着你去探索,比如使用云功能实现SSR,托管后端服务,镜像服务,以及全方位的SDK。
探索功能、发散想法并以更低的成本开发高可用性 Web 服务。云开发绝对是您的最佳选择! 查看全部
js提取指定网站内容(作者简介董沅鑫,云开发CloudBase团队研发,业余时间出没在。)
关于作者
云开发CloudBase团队研发工程师董元新,专注于前端工程和节点服务开发。他在业余时间在这里。
本文内容
介绍
随着腾讯云开发能力的逐步提升,经验丰富的工程师可以独立完成一个产品的开发和上线。但是,与在线云开发相关的实战却很少文章。很多开发者都知道云开发的能力,但是不知道在现有的开发体系下如何引入云开发。
本文从云开发团队开发者+能力用户的角度出发,以云开发官网()为例,结合流行的框架和工具,分享云开发的实践经验。
涉及的知识点有:
React 框架:Next.jsCI 自动构建概述
系统设计图:
背景介绍
随着云开发团队业务的快速发展,团队需要一个官方网站,更加直观、即时地向开发者展示云开发的相关能力,包括但不限于工具链、SDK、技术文档等。
同时,为了降低开发者的启动成本,积累行业优秀的实践经验,官网还承载着营造社区氛围、聚合重要信息、增强用户粘性的重任。
我们最初使用 VuePress 作为静态 网站 工具,遇到了一些痛点:
我们使用“cms Extensions”、“Basic Cloud Development Capabilities”、“Next.js”、“CI Tools”很好地解决了上述问题。在实现网站动态内容的同时,保证了SEO,运维同学也可以通过cms对内容进行可视化管理。
安装cms
进入云开发扩展能力控制台,按照提示安装cms内容管理系统。
配置分机时,有两种账户:管理员账户和操作员账户。管理员账户具有较高的权限,可以创建新的数据集;而操作员账户只能添加、删除和修改现有的数据集。
注意:安装时间有点长,请耐心等待
安装成功后,云数据库会自动创建三个集合,分别是 tcb-ext-cms-contents、tcb-ext-cms-users、tcb-ext-cms-webhooks ,分别存放cms 系统配置信息和内容数据。会自动创建三个云函数,分别是tcb-ext-cms-api、tcb-ext-cms-init、tcb-ext-cms-auth,它们封装了初始化,数据流的认证和相关逻辑。
输入“Static 网站 Hosting”,可以看到cms系统的静态文件已经自动部署到tcb-cms/目录下:
点击上方的“基本配置”查看域名信息。
在浏览器中访问对应的链接()可以看到cms系统:
至此,在没有任何开发成本的情况下,一个cms内容管理系统正式上线啦~
使用 cms 创建动态内容
对于动态数据内容,我们将其划分为不同的模块。每个内容模块对应一个cms系统的数据集合。例如,在“云开发官网”-“社区页面”中,推荐课程的内容是动态的。
从图中可以看出,每门课程都有多个属性。在云数据库中,每门课程对应一个文档,课程属性对应文档的字段。字段类型和含义如下:
name: 课程名称
time: 课程时间
cover: 课程封面
url: 课程链接
level: 课程难度
以管理员身份登录cms系统,在内容设置页面新建内容。在cms中,支持多种高级数据类型,如url、image、markdown、富文本、标签数组、email、URL等,这些类型都智能识别,显示更友好。
注意:cms 有自己的图床功能。当数据类型为“图片”时,图片会自动上传到当前云开发环境中的云存储中。以 cloud:// 开头的用于图像信息的特殊链接存储在数据集合中。
创建新内容时,默认情况下,cms 会自动填充 4 个字段:name、order、createTime、updateTime。您可以根据自己的需要删除不必要的字段。
建议:保留订单字段,可用于数据排序。对于运营商来说,数据的阶数值越大,在cms系统中显示的位置就越高;对于开发者来说,可以按照顺序进行排序和搜索。这保证了经验和逻辑的一致性。
根据字段创建集合后, cms 您将在系统左侧看到“推荐课程”。其对应的内容存放在云数据库的推荐课程(创建时指定)集合中,其字段信息存放在云数据库的tcb-ext-cms-contents(cms创建在初始化期间))在集合中。
根据设置添加新课程内容后,再次进入“推荐好课程”,如下图:
图片、链接等内容显示给操作者更友好。
项目建设
按照 Next.js 文档创建 Next.js 项目:
npm i --save next react react-dom axios
由于我们将 网站 部署到“静态托管”,我们将使用 Next.js 的静态导出功能。package.json 中的打包脚本更新为:
"scripts": {
"dev": "next",
"build": "next build && next export",
"start": "next start"
}
为了快速部署静态网站,发布云功能。需要全局安装@cloudbase/cli:
npm install -g @cloudbase/cli
安装后,添加两个脚本:
"scripts": {
"deploy:hosting": "npm run build && cloudbase hosting:deploy out -e jhgjj-0ae4a1",
"deploy:function": "echo y | cloudbase functions:deploy --force"
}
注意:准备两个云环境,防止静态部署时文件覆盖。envId为jhgjj-0ae4a1的云环境仅用于部署Next.js的静态导出文件。envId为pagecounter-d27cfe的云环境用于部署cms系统。
获取 cms 内容
借助 CloudBase 的 Node SDK-@cloudbase/node-sdk,我们可以在 Next.js 的 getStaticProps() 方法中读取云数据库中的数据。
为了让逻辑更清晰,我们将获取外部数据的方法统一封装到一个单独的文件中。以获取“推荐课程”为例:
// provider.js
const cloudbase = require("@cloudbase/node-sdk");
const config = {
secretId: "your secretId", // 前往「腾讯云控制台」-「访问密钥」获取
secretKey: "your secretKey", // 前往「腾讯云控制台」-「访问密钥」获取
env: "your envid" // 前往「腾讯云控制台」-「云开发 CloudBase」获取
};
const app = cloudbase.init(config);
/**
* 获取云数据库数据
*/
async function getCourses() {
const db = app.database();
const result = await db.collection("recommend-course").get();
if (result.code) {
throw new Error(
`获取「推荐课程」失败, 错误码是${result.code}: ${result.message}`
);
}
return result.data.map(item => {
if (item.createTime instanceof Date) {
item.createTime = item.createTime.toLocaleString();
}
if (item.updateTime instanceof Date) {
item.updateTime = item.updateTime.toLocaleString();
}
item.cover = getBucketUrl(item.cover); // 处理云存储的特殊链接
return item;
});
}
如上所述,cms自带图床功能,拖拽上传的图片会存储在同一环境的云存储中,获取图片的链接会存储在采集中。云存储的链接是一个以cloud://开头的特殊链接,需要在前端进行专门的识别和处理。
例如图片的存储链接为:cloud://pagecounter-d27cfe.7061-pagecounter-d27cfe-1255463368/uploads/04.png。把它变成一个可访问的 http 链接:.
转换思路是:识别envid背后的信息,与tcb.qcloud.la域名重新拼接:
// provider.js
/**
* 获取云存储的访问链接
* @param {String} url 云存储的特定url
*/
function getBucketUrl(url) {
if (!url.startsWith("cloud://")) {
return url;
}
const re = /cloud:\/\/.*?\.(.*?)\/(.*)/;
const result = re.exec(url);
return `https://${result[1]}.tcb.qcloud.la/${result[2]}`;
}
注意:云存储的“权限设置”应为:所有用户可读,只有创建者和管理员可写。否则无法访问链接。
建议:除了内置的图床功能,开发者可以根据自己的需要使用其他稳定的图床服务,比如微博图床。如果使用其他图床,对应的字段类型不能设置为“图像”,可以是“字符串”或“超链接”。
到目前为止,我们已经使用 SDK 获取了云数据库数据,剩下要做的就是将其注入到 Next.js 页面组件的 props 中:
// pages/index.js
const HomePage = ({ courses }) => {
return (
// 尽情使用数据吧...
)
}
export async function getStaticProps() {
const { getCourses } = require('./../provider')
return {
props: {
courses: await getCourses()
}
}
}
export default HomePage
打开浏览器,输入:3000/,可以看到效果如下:
输入view-source::3000/,可以看到网页的html源码中收录了课程数据,解决了SEO的问题:
注意:Next.js 的一些方法会在双方都运行,但 getStaticProps() 只会在服务端运行
自动构建和部署
至此,开发工作基本结束。执行 npm run build 命令,将 网站 静态文件打包到 out/ 目录下:
执行 npm run deploy:hosting 将 out/ 目录下的文件上传到“static网站hosting”。访问静态 网站hosted link: ,效果如下:
借助成熟的 CI 工具,例如 Travis、Circle 等,可以定期触发构建工作。这样,内容和开发就完全分开了。
在构建和发布时,您需要使用 CloudBase CLI 工具。在 CI 工具中,不要使用 cloudbase login 进行交互式输入登录,而是使用以下密钥登录: cloudbase login --apiKeyId TCB_SECRET_ID --apiKey TCB_SECRET_KEY 。
注意:前往 Cloud API Key 获取 TCB_SECRET_ID 和 TCB_SECRET_KEY 的值
在 CI 工具的控制台中,配置 TCB_SECRET_ID 和 TCB_SECRET_KEY。并在 package.json 中添加一个新脚本:
"scripts": {
"login": "echo N | cloudbase login --apiKeyId $TCB_SECRET_ID --apiKey $TCB_SECRET_KEY"
}
综上所述,CI构建流程为:
如果需要紧急修改数据,可以在本地手动触发构建,也可以在 CI 工具控制台中手动触发构建。
最后
借助云开发cms,可以实现评论系统、预约系统、博客发帖等各种内容模板,从而快速搭建网站。在现有的开发体系下,合理使用云开发可以大大降低人工成本、开发成本和运维成本。真正实现前后端穿梭,形成“闭环”。
本文实战只是一个指导,涉及到部分云开发能力。还有更多有趣的东西等着你去探索,比如使用云功能实现SSR,托管后端服务,镜像服务,以及全方位的SDK。
探索功能、发散想法并以更低的成本开发高可用性 Web 服务。云开发绝对是您的最佳选择!
js提取指定网站内容(如何截取url中网站域名之后的部分,需要用到以下几个方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-16 02:20
)
如何截取url中网站域名后面的部分,需要使用以下方法:
最后索引()
lastIndexOf() 方法返回调用 String 对象的指定值的最后一次出现的索引,在字符串中的 fromIndex 指定位置向后和向前搜索。如果未找到此特定值,则返回 -1。
子串()
substring() 方法返回从开始索引到结束索引,或从开始索引到字符串结尾的字符串子集。
通过这两种方式,可以得到url域名后面的部分。
首先获取网址:
var url = window.location.href
截取指定字符串后面的内容:例如获取 ? 后面的内容
var index = url.lastIndexOf('?')
var url2 = url.substring(index + 1)
可以封装成一个方法:
function interceptUrl(url, cha) {
var ind = url.lastIndexOf(cha)
return url.substring(ind + 1)
}
调用方式:
var url = 'https://www.w3h5.com/search.php?q=Vue'
console.log(interceptUrl(url, '?'))
# q=Vue 查看全部
js提取指定网站内容(如何截取url中网站域名之后的部分,需要用到以下几个方法
)
如何截取url中网站域名后面的部分,需要使用以下方法:
最后索引()
lastIndexOf() 方法返回调用 String 对象的指定值的最后一次出现的索引,在字符串中的 fromIndex 指定位置向后和向前搜索。如果未找到此特定值,则返回 -1。
子串()
substring() 方法返回从开始索引到结束索引,或从开始索引到字符串结尾的字符串子集。
通过这两种方式,可以得到url域名后面的部分。
首先获取网址:
var url = window.location.href
截取指定字符串后面的内容:例如获取 ? 后面的内容
var index = url.lastIndexOf('?')
var url2 = url.substring(index + 1)
可以封装成一个方法:
function interceptUrl(url, cha) {
var ind = url.lastIndexOf(cha)
return url.substring(ind + 1)
}
调用方式:
var url = 'https://www.w3h5.com/search.php?q=Vue'
console.log(interceptUrl(url, '?'))
# q=Vue
js提取指定网站内容(JSFinderPlus快速在网站的js文件中提取URL子域名的工具 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 238 次浏览 • 2022-03-12 11:04
)
JSFinderPlus
JSFinder是一个快速提取网站的js文件中的url和子域的工具。该工具在JSFinder上做了增强,主要是:
用法
蟒蛇。 \JSFinderPlus。 py -h____。 ____________________。 __。 _____________。 __| |/ _____/\_ _____/|__| ____ __| _/__________\______ \ | __ __ ______| |\____ \ | __) | |/ \ / __ |/ __ \_ __ \___/ | | | \/ ___//\__| |/\ |\ | | | \/ /_/ \ ___/| | \/ | | |_| | |___| /\____ |\___ >__| |____| |____/____//____ >\/\/\/\/ \/\/用法:python3 JSFinderPlus。 py [options]target: 必须指定target -u URL, --url URLtarget URL (e.
g. -u ".com")general: 常规选项 -h, --help 显示此帮助信息并退出 -t NUM, --thread NUM 扫描线程,默认 10 -d 搜索找到的 URL,默认仅用于输入 URL --open立即打开报告 --site-root ROOT 指定 URL 的根目录 --proxy-socks SOCKS socks 代理(例如 --proxy-socks 127.0.0.1:108 0) - -proxy-http HTTPhttp 代理(例如--proxy-http 127.0.0.1:8080) -c COOKIEcookie --user-agent UA你可以自定义user-agent headers示例:python3 JSFinderPlus.py -u python3 JSFinderPlus.py -u -d python3 JSFinderPlus.py -u :7001/index --site-root :7001/#/ python3 JSFinderPlus.py -f list.txt -d -t 20 python3 JSFinderPlus.py -f list.txt -o results.text">
PS D:\Code\python\JSFinderPlus> python .\JSFinderPlus.py -h
____. ____________________.__ .___ __________.__
| |/ _____/\_ _____/|__| ____ __| _/__________\______ \ | __ __ ______
| |\_____ \ | __) | |/ \ / __ |/ __ \_ __ \ ___/ | | | \/ ___/
/\__| |/ \ | \ | | | \/ /_/ \ ___/| | \/ | | |_| | /\___ \
\________/_______ / \___ / |__|___| /\____ |\___ >__| |____| |____/____//____ >
\/ \/ \/ \/ \/ \/
usage: python3 JSFinderPlus.py [options]
target:
you must to specify target
-u URL, --url URL target URL (e.g. -u "http://example.com")
general:
general options
-h, --help show this help message and exit
-t NUM, --thread NUM 扫描线程,默认10
-d 对发现的URL进行查找,默认只查找输入的URL
--open 立即打开报告
--site-root ROOT 指定URL的根目录
--proxy-socks SOCKS socks proxy (e.g. --proxy-socks 127.0.0.1:1080)
--proxy-http HTTP http proxy (e.g. --proxy-http 127.0.0.1:8080)
-c COOKIE cookie
--user-agent UA you can customize the user-agent headers
examples:
python3 JSFinderPlus.py -u http://example.com
python3 JSFinderPlus.py -u http://example.com -d
python3 JSFinderPlus.py -u http://example.com:7001/index --site-root http://example.com:7001/#/
python3 JSFinderPlus.py -f list.txt -d -t 20
python3 JSFinderPlus.py -f list.txt -o results.text
例子
python .\JSFinderPlus.py -u -d --open
自动生成报表,点击url直接查看
查看全部
js提取指定网站内容(JSFinderPlus快速在网站的js文件中提取URL子域名的工具
)
JSFinderPlus
JSFinder是一个快速提取网站的js文件中的url和子域的工具。该工具在JSFinder上做了增强,主要是:
用法
蟒蛇。 \JSFinderPlus。 py -h____。 ____________________。 __。 _____________。 __| |/ _____/\_ _____/|__| ____ __| _/__________\______ \ | __ __ ______| |\____ \ | __) | |/ \ / __ |/ __ \_ __ \___/ | | | \/ ___//\__| |/\ |\ | | | \/ /_/ \ ___/| | \/ | | |_| | |___| /\____ |\___ >__| |____| |____/____//____ >\/\/\/\/ \/\/用法:python3 JSFinderPlus。 py [options]target: 必须指定target -u URL, --url URLtarget URL (e.
g. -u ".com")general: 常规选项 -h, --help 显示此帮助信息并退出 -t NUM, --thread NUM 扫描线程,默认 10 -d 搜索找到的 URL,默认仅用于输入 URL --open立即打开报告 --site-root ROOT 指定 URL 的根目录 --proxy-socks SOCKS socks 代理(例如 --proxy-socks 127.0.0.1:108 0) - -proxy-http HTTPhttp 代理(例如--proxy-http 127.0.0.1:8080) -c COOKIEcookie --user-agent UA你可以自定义user-agent headers示例:python3 JSFinderPlus.py -u python3 JSFinderPlus.py -u -d python3 JSFinderPlus.py -u :7001/index --site-root :7001/#/ python3 JSFinderPlus.py -f list.txt -d -t 20 python3 JSFinderPlus.py -f list.txt -o results.text">
PS D:\Code\python\JSFinderPlus> python .\JSFinderPlus.py -h
____. ____________________.__ .___ __________.__
| |/ _____/\_ _____/|__| ____ __| _/__________\______ \ | __ __ ______
| |\_____ \ | __) | |/ \ / __ |/ __ \_ __ \ ___/ | | | \/ ___/
/\__| |/ \ | \ | | | \/ /_/ \ ___/| | \/ | | |_| | /\___ \
\________/_______ / \___ / |__|___| /\____ |\___ >__| |____| |____/____//____ >
\/ \/ \/ \/ \/ \/
usage: python3 JSFinderPlus.py [options]
target:
you must to specify target
-u URL, --url URL target URL (e.g. -u "http://example.com";)
general:
general options
-h, --help show this help message and exit
-t NUM, --thread NUM 扫描线程,默认10
-d 对发现的URL进行查找,默认只查找输入的URL
--open 立即打开报告
--site-root ROOT 指定URL的根目录
--proxy-socks SOCKS socks proxy (e.g. --proxy-socks 127.0.0.1:1080)
--proxy-http HTTP http proxy (e.g. --proxy-http 127.0.0.1:8080)
-c COOKIE cookie
--user-agent UA you can customize the user-agent headers
examples:
python3 JSFinderPlus.py -u http://example.com
python3 JSFinderPlus.py -u http://example.com -d
python3 JSFinderPlus.py -u http://example.com:7001/index --site-root http://example.com:7001/#/
python3 JSFinderPlus.py -f list.txt -d -t 20
python3 JSFinderPlus.py -f list.txt -o results.text
例子
python .\JSFinderPlus.py -u -d --open
自动生成报表,点击url直接查看
js提取指定网站内容(JS基本语法JS内嵌-流程控制语句判断语句)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-09 13:02
JS基本语法
1.JS 嵌入在 HTML 的任何地方,通常在头部或正文中。
.....js代码
2.在JS文件中,直接写JavaScript代码,嵌入HTML
注意:
1.在 JS 中区分大小写。例如,变量 mychar 和 myChar 是不同的,这意味着它们是两个变量。
2.变量虽然可以不声明直接使用,但是不规范,需要先声明后使用。
3.JS代码按顺序执行语句
3.JavaScript-流控制语句
判断声明(如果...否则)
var myage = 18;
if(myage>=18) //myage>=18是判断条件
{ document.write("你是成年人。");}
else //否则年龄小于18
{ document.write("未满18岁,你不是成年人。");}
切换语句
var myweek =3;//myweek表示星期几变量
switch(myweek)
{
case 1:
case 2:
document.write("学习理念知识");
break;
case 3:
case 4:
document.write("到企业实践");
break;
case 5:
document.write("总结经验");
break;
default:
document.write("周六、日休息和娱乐");
}
声明
<p>
var mymoney,sum=0;//mymoney变量存放不同面值,sum总计
for(mymoney=1;mymoney 查看全部
js提取指定网站内容(JS基本语法JS内嵌-流程控制语句判断语句)
JS基本语法
1.JS 嵌入在 HTML 的任何地方,通常在头部或正文中。
.....js代码
2.在JS文件中,直接写JavaScript代码,嵌入HTML
注意:
1.在 JS 中区分大小写。例如,变量 mychar 和 myChar 是不同的,这意味着它们是两个变量。
2.变量虽然可以不声明直接使用,但是不规范,需要先声明后使用。
3.JS代码按顺序执行语句
3.JavaScript-流控制语句
判断声明(如果...否则)
var myage = 18;
if(myage>=18) //myage>=18是判断条件
{ document.write("你是成年人。");}
else //否则年龄小于18
{ document.write("未满18岁,你不是成年人。");}
切换语句
var myweek =3;//myweek表示星期几变量
switch(myweek)
{
case 1:
case 2:
document.write("学习理念知识");
break;
case 3:
case 4:
document.write("到企业实践");
break;
case 5:
document.write("总结经验");
break;
default:
document.write("周六、日休息和娱乐");
}
声明
<p>
var mymoney,sum=0;//mymoney变量存放不同面值,sum总计
for(mymoney=1;mymoney
js提取指定网站内容(双语阅读:最简单的设置方法是将JavaScript代码嵌入到网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-09 10:26
当您第一次编写新的 JavaScript 时,最简单的设置方法是将 JavaScript 代码直接嵌入到网页中,以便在您测试它以使其正常工作时,一切都在一个地方。同样,如果您将预先编写的脚本插入您的网站,说明可能会告诉您将部分或全部脚本嵌入网页本身。
第一次编写新的 JavaScript 时,最简单的设置方法是将 JavaScript 代码直接嵌入到网页中,这样您就可以在测试时将所有内容放在一个地方以使其正常工作。同样,如果您在 网站 中插入预先编写的脚本,说明可能会告诉您将部分或全部脚本嵌入页面本身。
这对于设置页面并使其首先正常工作是可以的,但是一旦您的页面按照您想要的方式工作,您将能够通过将 JavaScript 提取到外部文件中来改进页面,因此您的 HTML 中的页面内容不会因为 JavaScript 等非内容项而变得杂乱无章。
可以先设置页面并使其正常工作,但是一旦页面按您想要的方式工作,您可以通过将 JavaScript 提取到外部文件中来改进页面,这样页面 HTML 中的内容就不会被阻止被非内容项目(例如 JavaScript)搞砸了。
如果您只是复制和使用其他人编写的 JavaScript,那么他们关于如何将其脚本添加到您的页面的说明可能会导致您将一个或多个较大的 JavaScript 部分实际嵌入到您的网页本身中,而他们的说明不会不要告诉你如何将这段代码从你的页面移到一个单独的文件中,并且仍然让 JavaScript 工作。不过不要担心,因为无论您在页面中使用的 JavaScript 是什么代码,您都可以轻松地将 JavaScript 移出页面并将其设置为单独的文件(或者如果您嵌入了多个 JavaScript,则为文件)这页纸)。这样做的过程总是相同的,最好用一个例子来说明。
如果您只是复制和使用其他人的 JavaScript,他们关于如何将他们的脚本添加到您的页面的说明可能会导致您实际上将一个或多个 JavaScript 嵌入到您的页面本身中,而他们的说明却没有。不知道如何您可以将此代码从页面移出到一个单独的文件中,并且仍然能够使用 JavaScript。不过不用担心,因为无论页面中使用什么代码,您都可以轻松地将 JavaScript 移出页面并使其成为一个单独的文件(或者如果您有嵌入多个 JavaScript 的文件,您可以将其设置为文件)本页)。这样做的过程总是相同的,最好通过一个例子来说明。
让我们看看一段 JavaScript 在嵌入到您的页面时的外观。您的实际 JavaScript 代码将与以下示例中显示的不同,但在每种情况下的过程都是相同的。
让我们来看看嵌入页面中的一段 JavaScript 会是什么样子。您的实际 JavaScript 代码将与以下示例中显示的代码不同,但每种情况下的处理都是相同的。
示例一
if (top.location != self.location)
top.location = self.location;
示例二
示例三
/* if (top.location != self.location)
top.location = self.location;</strong>
/* ]]> */
您的嵌入式 JavaScript 应该类似于上述三个示例之一。当然,您的实际 JavaScript 代码将与显示的不同,但 JavaScript 可能会使用上述三种方法之一嵌入到页面中。在某些情况下,您的代码可能使用过时的 language="javascript" 而不是 type="text/javascript" 在这种情况下,您可能希望通过将语言属性替换为类型一来使您的代码更加最新.
您的嵌入式 JavaScript 应该类似于上述三个示例之一。当然,您的实际 JavaScript 代码将与显示的不同,但 JavaScript 可以使用上述三种方法之一嵌入到页面中。在某些情况下,您的代码可能使用过时的 language="javascript" 而不是 type="text/javascript",在这种情况下,您可能希望通过将语言属性替换为最新版本的类型 1 来更新代码。
在您可以将 JavaScript 提取到它自己的文件中之前,您首先需要确定要提取的代码。在上述所有三个示例中,有两行实际的 JavaScript 代码需要被提取。您的脚本可能会有更多行,但很容易识别,因为它在您的页面中占据与我们在上述三个示例中突出显示的两行 JavaScript 相同的位置(所有三个示例都收录相同的两行JavaScript,只是它们周围的容器略有不同)。
在将 JavaScript 提取到它自己的文件中之前,您首先需要决定要提取什么代码。在上述所有三个示例中,需要提取两行实际的 JavaScript 代码。您的脚本可能有更多行,但很容易识别,因为它在页面上的同一位置,因为我们在上面三个示例中突出显示了两行 JavaScript(所有三个示例都收录相同的两行) JavaScript ,只有周围的容器它们略有不同)。
要将 JavaScript 提取到单独的文件中,您需要做的第一件事是打开纯文本编辑器并访问网页的内容。然后,您需要找到嵌入的 JavaScript,该 JavaScript 将被包围。要将 JavaScript 实际提取到单独的文件中,您需要做的第一件事是打开纯文本编辑器并访问网页的内容。然后,您需要找到将被上述示例中显示的代码变体之一包围的嵌入式 JavaScript。找到 JavaScript 代码后,您需要选择它并将其复制到剪贴板。在上面的示例中,要选择的代码被突出显示,您不需要选择脚本标签或可能出现在您的 JavaScript 代码周围的可选注释。找到 JavaScript 代码后,您需要选择它并将其复制到剪贴板。在上面的示例中,将突出显示要选择的代码,您无需选择可能出现在 JavaScript 代码周围的脚本标签或可选注释。打开您的纯文本编辑器的另一个副本(如果您的编辑器支持一次打开多个文件,则打开另一个选项卡)并在此处粘贴 JavaScript 内容。支持打开多个文件,然后打开另一个选项卡),然后将 JavaScript 内容粘贴到那里。
为您的新文件选择一个描述性文件名并使用该文件名保存新内容。使用示例代码,脚本的目的是打破框架,因此适当的名称可以是 framebreak.js。
为新文件选择一个描述性文件名并使用该文件名保存新内容。使用示例代码,脚本的目的是打破框架,因此合适的名称是 framebreak.js。
所以现在我们将 JavaScript 保存在一个单独的文件中,我们返回到编辑器,在编辑器中我们拥有原创页面内容,以便在那里进行更改以链接到脚本的外部副本。文件,回到编辑器,我们在其中拥有原创页面内容,我们可以在其中进行更改以链接到脚本的外部副本。由于我们现在将脚本放在一个单独的文件中,我们可以删除原创内容中脚本标签之间的所有内容,以便 查看全部
js提取指定网站内容(双语阅读:最简单的设置方法是将JavaScript代码嵌入到网页)
当您第一次编写新的 JavaScript 时,最简单的设置方法是将 JavaScript 代码直接嵌入到网页中,以便在您测试它以使其正常工作时,一切都在一个地方。同样,如果您将预先编写的脚本插入您的网站,说明可能会告诉您将部分或全部脚本嵌入网页本身。
第一次编写新的 JavaScript 时,最简单的设置方法是将 JavaScript 代码直接嵌入到网页中,这样您就可以在测试时将所有内容放在一个地方以使其正常工作。同样,如果您在 网站 中插入预先编写的脚本,说明可能会告诉您将部分或全部脚本嵌入页面本身。
这对于设置页面并使其首先正常工作是可以的,但是一旦您的页面按照您想要的方式工作,您将能够通过将 JavaScript 提取到外部文件中来改进页面,因此您的 HTML 中的页面内容不会因为 JavaScript 等非内容项而变得杂乱无章。
可以先设置页面并使其正常工作,但是一旦页面按您想要的方式工作,您可以通过将 JavaScript 提取到外部文件中来改进页面,这样页面 HTML 中的内容就不会被阻止被非内容项目(例如 JavaScript)搞砸了。
如果您只是复制和使用其他人编写的 JavaScript,那么他们关于如何将其脚本添加到您的页面的说明可能会导致您将一个或多个较大的 JavaScript 部分实际嵌入到您的网页本身中,而他们的说明不会不要告诉你如何将这段代码从你的页面移到一个单独的文件中,并且仍然让 JavaScript 工作。不过不要担心,因为无论您在页面中使用的 JavaScript 是什么代码,您都可以轻松地将 JavaScript 移出页面并将其设置为单独的文件(或者如果您嵌入了多个 JavaScript,则为文件)这页纸)。这样做的过程总是相同的,最好用一个例子来说明。
如果您只是复制和使用其他人的 JavaScript,他们关于如何将他们的脚本添加到您的页面的说明可能会导致您实际上将一个或多个 JavaScript 嵌入到您的页面本身中,而他们的说明却没有。不知道如何您可以将此代码从页面移出到一个单独的文件中,并且仍然能够使用 JavaScript。不过不用担心,因为无论页面中使用什么代码,您都可以轻松地将 JavaScript 移出页面并使其成为一个单独的文件(或者如果您有嵌入多个 JavaScript 的文件,您可以将其设置为文件)本页)。这样做的过程总是相同的,最好通过一个例子来说明。
让我们看看一段 JavaScript 在嵌入到您的页面时的外观。您的实际 JavaScript 代码将与以下示例中显示的不同,但在每种情况下的过程都是相同的。
让我们来看看嵌入页面中的一段 JavaScript 会是什么样子。您的实际 JavaScript 代码将与以下示例中显示的代码不同,但每种情况下的处理都是相同的。
示例一
if (top.location != self.location)
top.location = self.location;
示例二
示例三
/* if (top.location != self.location)
top.location = self.location;</strong>
/* ]]> */
您的嵌入式 JavaScript 应该类似于上述三个示例之一。当然,您的实际 JavaScript 代码将与显示的不同,但 JavaScript 可能会使用上述三种方法之一嵌入到页面中。在某些情况下,您的代码可能使用过时的 language="javascript" 而不是 type="text/javascript" 在这种情况下,您可能希望通过将语言属性替换为类型一来使您的代码更加最新.
您的嵌入式 JavaScript 应该类似于上述三个示例之一。当然,您的实际 JavaScript 代码将与显示的不同,但 JavaScript 可以使用上述三种方法之一嵌入到页面中。在某些情况下,您的代码可能使用过时的 language="javascript" 而不是 type="text/javascript",在这种情况下,您可能希望通过将语言属性替换为最新版本的类型 1 来更新代码。
在您可以将 JavaScript 提取到它自己的文件中之前,您首先需要确定要提取的代码。在上述所有三个示例中,有两行实际的 JavaScript 代码需要被提取。您的脚本可能会有更多行,但很容易识别,因为它在您的页面中占据与我们在上述三个示例中突出显示的两行 JavaScript 相同的位置(所有三个示例都收录相同的两行JavaScript,只是它们周围的容器略有不同)。
在将 JavaScript 提取到它自己的文件中之前,您首先需要决定要提取什么代码。在上述所有三个示例中,需要提取两行实际的 JavaScript 代码。您的脚本可能有更多行,但很容易识别,因为它在页面上的同一位置,因为我们在上面三个示例中突出显示了两行 JavaScript(所有三个示例都收录相同的两行) JavaScript ,只有周围的容器它们略有不同)。
要将 JavaScript 提取到单独的文件中,您需要做的第一件事是打开纯文本编辑器并访问网页的内容。然后,您需要找到嵌入的 JavaScript,该 JavaScript 将被包围。要将 JavaScript 实际提取到单独的文件中,您需要做的第一件事是打开纯文本编辑器并访问网页的内容。然后,您需要找到将被上述示例中显示的代码变体之一包围的嵌入式 JavaScript。找到 JavaScript 代码后,您需要选择它并将其复制到剪贴板。在上面的示例中,要选择的代码被突出显示,您不需要选择脚本标签或可能出现在您的 JavaScript 代码周围的可选注释。找到 JavaScript 代码后,您需要选择它并将其复制到剪贴板。在上面的示例中,将突出显示要选择的代码,您无需选择可能出现在 JavaScript 代码周围的脚本标签或可选注释。打开您的纯文本编辑器的另一个副本(如果您的编辑器支持一次打开多个文件,则打开另一个选项卡)并在此处粘贴 JavaScript 内容。支持打开多个文件,然后打开另一个选项卡),然后将 JavaScript 内容粘贴到那里。
为您的新文件选择一个描述性文件名并使用该文件名保存新内容。使用示例代码,脚本的目的是打破框架,因此适当的名称可以是 framebreak.js。
为新文件选择一个描述性文件名并使用该文件名保存新内容。使用示例代码,脚本的目的是打破框架,因此合适的名称是 framebreak.js。
所以现在我们将 JavaScript 保存在一个单独的文件中,我们返回到编辑器,在编辑器中我们拥有原创页面内容,以便在那里进行更改以链接到脚本的外部副本。文件,回到编辑器,我们在其中拥有原创页面内容,我们可以在其中进行更改以链接到脚本的外部副本。由于我们现在将脚本放在一个单独的文件中,我们可以删除原创内容中脚本标签之间的所有内容,以便
js提取指定网站内容( 关于cookie的使用设置获取键名过期的事件,IE8及以上浏览器都兼容特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-07 01:12
关于cookie的使用设置获取键名过期的事件,IE8及以上浏览器都兼容特点)
一、如何
我们主要介绍以下四种javaScript本地缓存的方法:
cookies
Cookies,属于“小文本文件”类型,是指存储在用户本地终端上的特定数据网站,用于识别用户。就是解决HTTP无状态带来的问题
作为一条一般不超过4KB的小文本数据,由名称(Name)、值(Value)和其他几个可选属性组成,用于控制有效期、安全性和使用范围饼干
但是,cookie 将在每个请求中发送。如果不使用HTTPS并进行加密,其中存储的信息很容易被窃取,从而产生安全隐患。比如在一些使用cookies保持登录状态的网站s上,如果cookie被盗,别人很容易利用你的cookie冒充你登录网站
关于cookies的常用属性如下:
Expires=Wed, 21 Oct 2015 07:28:00 GMT
Max-Age=604800
Path=/docs # /docs/Web/ 下的资源会带 Cookie 首部
通过以上我们可以看出cookie的作用并不是为缓存而设计的,只是借用cookie的特性来实现缓存
cookies的使用如下:
document.cookie = '名字=值';
关于cookies的修改,首先要确保domain和path属性相同,当其中一个不同时会创建一个新的cookie
Set-Cookie:name=aa; domain=aa.net; path=/ # 服务端设置
document.cookie =name=bb; domain=aa.net; path=/ # 客户端设置
删除最后一个cookie最常用的方法是为cookie设置过期事件,这样cookie过期后会被浏览器删除
本地存储
HTML5新方法,兼容IE8及以上浏览器
特点
我们来看看localStorage的使用
设置
localStorage.setItem('username','cfangxu');
获取
localStorage.getItem('username')
获取密钥名称
localStorage.key(0) //获取第一个键名
删除
localStorage.removeItem('username')
一次性清空所有存储空间
localStorage.clear()
localStorage 也不完美,它有两个缺点:
localStorage.setItem('key', {name: 'value'});
console.log(localStorage.getItem('key')); // '[object, Object]'
会话存储
sessionStorage 和 localStorage 的用法基本相同,唯一不同的是生命周期。一旦页面(会话)关闭,sessionStorage 将删除数据
扩展的前端存储方式
indexedDB 是一种用于客户端存储大量结构化数据(包括文件/blob)的低级 API。 API 使用索引来实现对这些数据的高性能搜索
虽然网络存储对于存储少量数据很有用,但对于存储大量结构化数据的用处不大。 IndexedDB 提供了解决方案
优点:缺点:
使用indexedDB的基本步骤如下:
indexdb 的使用会比较麻烦。可以使用 Godb.js 库进行缓存,尽量降低操作难度
二、区别
cookies、sessionStorage和localStorage的主要区别如下:
三、应用场景
了解了上面提到的前端缓存方式后,我们可以看看不正确场景的使用选项: 查看全部
js提取指定网站内容(
关于cookie的使用设置获取键名过期的事件,IE8及以上浏览器都兼容特点)
一、如何
我们主要介绍以下四种javaScript本地缓存的方法:
cookies
Cookies,属于“小文本文件”类型,是指存储在用户本地终端上的特定数据网站,用于识别用户。就是解决HTTP无状态带来的问题
作为一条一般不超过4KB的小文本数据,由名称(Name)、值(Value)和其他几个可选属性组成,用于控制有效期、安全性和使用范围饼干
但是,cookie 将在每个请求中发送。如果不使用HTTPS并进行加密,其中存储的信息很容易被窃取,从而产生安全隐患。比如在一些使用cookies保持登录状态的网站s上,如果cookie被盗,别人很容易利用你的cookie冒充你登录网站
关于cookies的常用属性如下:
Expires=Wed, 21 Oct 2015 07:28:00 GMT
Max-Age=604800
Path=/docs # /docs/Web/ 下的资源会带 Cookie 首部
通过以上我们可以看出cookie的作用并不是为缓存而设计的,只是借用cookie的特性来实现缓存
cookies的使用如下:
document.cookie = '名字=值';
关于cookies的修改,首先要确保domain和path属性相同,当其中一个不同时会创建一个新的cookie
Set-Cookie:name=aa; domain=aa.net; path=/ # 服务端设置
document.cookie =name=bb; domain=aa.net; path=/ # 客户端设置
删除最后一个cookie最常用的方法是为cookie设置过期事件,这样cookie过期后会被浏览器删除
本地存储
HTML5新方法,兼容IE8及以上浏览器
特点
我们来看看localStorage的使用
设置
localStorage.setItem('username','cfangxu');
获取
localStorage.getItem('username')
获取密钥名称
localStorage.key(0) //获取第一个键名
删除
localStorage.removeItem('username')
一次性清空所有存储空间
localStorage.clear()
localStorage 也不完美,它有两个缺点:
localStorage.setItem('key', {name: 'value'});
console.log(localStorage.getItem('key')); // '[object, Object]'
会话存储
sessionStorage 和 localStorage 的用法基本相同,唯一不同的是生命周期。一旦页面(会话)关闭,sessionStorage 将删除数据
扩展的前端存储方式
indexedDB 是一种用于客户端存储大量结构化数据(包括文件/blob)的低级 API。 API 使用索引来实现对这些数据的高性能搜索
虽然网络存储对于存储少量数据很有用,但对于存储大量结构化数据的用处不大。 IndexedDB 提供了解决方案
优点:缺点:
使用indexedDB的基本步骤如下:
indexdb 的使用会比较麻烦。可以使用 Godb.js 库进行缓存,尽量降低操作难度
二、区别
cookies、sessionStorage和localStorage的主要区别如下:
三、应用场景
了解了上面提到的前端缓存方式后,我们可以看看不正确场景的使用选项:
js提取指定网站内容(谷歌提取元素打印技术的基本操作流程及使用方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-03 09:17
)
方法一:提取元素并打印
步:
1、打开谷歌浏览器,按F12进入控制台:
2、在控制台输入如下JS代码回车(以打印csdn博客内容为例):
function doPrint(){
var head_str = ""; //先生成头部
var foot_str = ""; //生成尾部
var older = document.body.innerHTML;
//var new_str = document.getElementById('wrapper').innerHTML; //获取指定打印区域
var new_str = document.getElementsByClassName('blog-content-box')[0].innerHTML; //获取指定打印区域
var old_str = document.body.innerHTML; //获得原本页面的代码
document.body.innerHTML = head_str + new_str + foot_str; //构建新网页
window.print(); //打印刚才新建的网页
document.body.innerHTML = older; //将网页还原
return false;
};doPrint();
3、在弹出的打印界面中,将布局选项设置为横向(纵向布局可能不会显示行尾的内容),然后保存:
注意:建议使用谷歌浏览器,测试火狐可能会导致页面内容混乱
方法 2:隐藏而不打印元素
方法一和步骤二使用如下代码:
<p>function doPrint() {
//隐藏标题栏
$('#csdn-toolbar').css('display','none');
//隐藏评论区
document.getElementsByClassName('comment-box')[0].style.display="none";
//隐藏推荐栏
var recommends = document.getElementsByClassName('recommend-box');
for(var i=0;i 查看全部
js提取指定网站内容(谷歌提取元素打印技术的基本操作流程及使用方法
)
方法一:提取元素并打印
步:
1、打开谷歌浏览器,按F12进入控制台:
2、在控制台输入如下JS代码回车(以打印csdn博客内容为例):
function doPrint(){
var head_str = ""; //先生成头部
var foot_str = ""; //生成尾部
var older = document.body.innerHTML;
//var new_str = document.getElementById('wrapper').innerHTML; //获取指定打印区域
var new_str = document.getElementsByClassName('blog-content-box')[0].innerHTML; //获取指定打印区域
var old_str = document.body.innerHTML; //获得原本页面的代码
document.body.innerHTML = head_str + new_str + foot_str; //构建新网页
window.print(); //打印刚才新建的网页
document.body.innerHTML = older; //将网页还原
return false;
};doPrint();
3、在弹出的打印界面中,将布局选项设置为横向(纵向布局可能不会显示行尾的内容),然后保存:
注意:建议使用谷歌浏览器,测试火狐可能会导致页面内容混乱
方法 2:隐藏而不打印元素
方法一和步骤二使用如下代码:
<p>function doPrint() {
//隐藏标题栏
$('#csdn-toolbar').css('display','none');
//隐藏评论区
document.getElementsByClassName('comment-box')[0].style.display="none";
//隐藏推荐栏
var recommends = document.getElementsByClassName('recommend-box');
for(var i=0;i
js提取指定网站内容(从底层视角理解下javascript语言中表达式的“到底什么”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-02 18:00
js提取指定网站内容:提取网站内容一、关键代码识别1.1关键代码识别1.2概念及概念2.1概念2.2概念3.4图片文件识别3.5文件识别
说实话现在互联网上充斥了太多的数据,所以一般搜索引擎都已经不会像以前一样了,现在有很多语义分析技术都可以做到,特别是今年三月份以来,google推出的图片分析服务,和facebook推出的视频分析服务都体现了数据越来越多,但是语义分析技术这块很值得研究下,有很多问题可以去解决。
您好我推荐一篇公众号老师的《从底层视角理解下javascript语言中表达式的“到底什么”》希望可以对您有所帮助请点击老师公众号的内容收看获取最新javascript技术,发现新世界。推荐阅读:数据分析师工具推荐-你的福音来了?新学的公式要建立在svd和psm基础上了呢!|网课公告世界杯冷门,你猜几场?那些年我们一起跳过的坑。
我不知道知乎上javascript话题下的人大部分来自哪里,我能够知道的也就是某些公众号整天报道某个网站api的js,或者某个网站直接使用其他网站的js,还有些简单的字符串加密什么的。我不明白一个程序员能够知道甚至关注着一些小网站到什么程度,又或者它们的form里的js呢?就像我不明白一个开发者知道某个网站里会用到jquery吗?。 查看全部
js提取指定网站内容(从底层视角理解下javascript语言中表达式的“到底什么”)
js提取指定网站内容:提取网站内容一、关键代码识别1.1关键代码识别1.2概念及概念2.1概念2.2概念3.4图片文件识别3.5文件识别
说实话现在互联网上充斥了太多的数据,所以一般搜索引擎都已经不会像以前一样了,现在有很多语义分析技术都可以做到,特别是今年三月份以来,google推出的图片分析服务,和facebook推出的视频分析服务都体现了数据越来越多,但是语义分析技术这块很值得研究下,有很多问题可以去解决。
您好我推荐一篇公众号老师的《从底层视角理解下javascript语言中表达式的“到底什么”》希望可以对您有所帮助请点击老师公众号的内容收看获取最新javascript技术,发现新世界。推荐阅读:数据分析师工具推荐-你的福音来了?新学的公式要建立在svd和psm基础上了呢!|网课公告世界杯冷门,你猜几场?那些年我们一起跳过的坑。
我不知道知乎上javascript话题下的人大部分来自哪里,我能够知道的也就是某些公众号整天报道某个网站api的js,或者某个网站直接使用其他网站的js,还有些简单的字符串加密什么的。我不明白一个程序员能够知道甚至关注着一些小网站到什么程度,又或者它们的form里的js呢?就像我不明白一个开发者知道某个网站里会用到jquery吗?。
js提取指定网站内容(反(反爬虫)用不完的遍布世界的毫秒级代理IP目标网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-02 13:15
分析全球反(反爬虫)取之不尽的毫秒代理IP
目标网站:http:说实话,爬了多少个ip网站,这个网站的ip可用率很高,但同时,反爬机制也有点高端如果说是同一个IP用于频繁定向,网站会被Ban的爬取目标爬取。表面上看不明显,但实际上是js加载的动态页面,不像其他动态页面。没有后续加载,网页刷新后1秒内加载js,所以爬取的网页是没有被jsted的源码,即使解析正确,获取到的ip也是无效的,所以如果要重新更新随机使用的代理ip请调用此方法。每次调用都会随机抓取ip并将其写入文件以便下次读取尝试: for i in range(20): self.carwl_ip() cmd = input( ****** *** *是否永久保存********** 默认:临时保存为 ip.ini 文件 每次更新 ip.ini 文件都会清空并更新 1.MongoDB 2.MySQL 3.另存为.txt文件(其他key代表一行默认ip.ini配置文件,相当于每次随机改爬取的随机ip :return: 返回一个字典格式如下,可以直接放在参数{https:https
中
作为请求中的代理
160 查看全部
js提取指定网站内容(反(反爬虫)用不完的遍布世界的毫秒级代理IP目标网站)
分析全球反(反爬虫)取之不尽的毫秒代理IP
目标网站:http:说实话,爬了多少个ip网站,这个网站的ip可用率很高,但同时,反爬机制也有点高端如果说是同一个IP用于频繁定向,网站会被Ban的爬取目标爬取。表面上看不明显,但实际上是js加载的动态页面,不像其他动态页面。没有后续加载,网页刷新后1秒内加载js,所以爬取的网页是没有被jsted的源码,即使解析正确,获取到的ip也是无效的,所以如果要重新更新随机使用的代理ip请调用此方法。每次调用都会随机抓取ip并将其写入文件以便下次读取尝试: for i in range(20): self.carwl_ip() cmd = input( ****** *** *是否永久保存********** 默认:临时保存为 ip.ini 文件 每次更新 ip.ini 文件都会清空并更新 1.MongoDB 2.MySQL 3.另存为.txt文件(其他key代表一行默认ip.ini配置文件,相当于每次随机改爬取的随机ip :return: 返回一个字典格式如下,可以直接放在参数{https:https
中
作为请求中的代理
160
js提取指定网站内容( 风中蹦迪02-24:45阅读4网站SEO优化关注javascript脚本怎么运行(js编写教程))
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-24 19:13
风中蹦迪02-24:45阅读4网站SEO优化关注javascript脚本怎么运行(js编写教程))
在风中弹跳
02-24 11:45 阅读4网站SEO优化
关注
如何运行 javascript 脚本(js 脚本教程)
1 概述
本文介绍了在Java环境中执行JavaScript脚本的简单使用,包括以下内容
Java 8 内置 Nashorn Javascript 引擎介绍 Rhino JavaScript 引擎介绍和 XML 处理介绍 2 Java 8 中内置 Nashorn Javascript 引擎介绍
Nashorn 是一个内置于 Java 8 中的 JavaScript 引擎,没有任何依赖关系。
使用Nashorn的基本步骤如下
new out ScriptEngineManager 对象通过ScriptEngineManager 对象中的getEngineByName 方法获取指定的JavaScript 引擎,并返回ScriptEngine 对象。 Java 8 中默认的 JavaScript 引擎包括: [nashorn, Nashorn, , JS, JavaScript, script, ECMAScript, ecmascript] 通过 ScriptEngine 对象的 eval 方法执行 JavaScript 脚本。 2.1 通过PrintWriter对象从脚本中获取打印输出
Javascript 脚本中没有函数,也没有返回值。内容通过打印输出。这时需要通过PrintWriter获取读取脚本中的打印输出,如下
@Test
public void test_nashorn() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("Nashorn");
ScriptContext scriptContext = engine.getContext();
StringWriter stringWriter = new StringWriter();
PrintWriter printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
String jsString = "var obj=JSON.parse('{\\\"data\\\":\\\"7155\\\",\\\"sign\\\":\\\"success\\\",\\\"message\\\":null}');print(obj.sign==\"success\");";
stringWriter = new StringWriter();
printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
engine.eval(jsString);
System.out.println(String.format("1 result = %s",stringWriter.toString()));
jsString = "var obj=JSON.parse('{\\\"data\\\":\\\"7157\\\",\\\"sign\\\":\\\"success\\\",\\\"message\\\":null}');print((function getData() { return obj.data;})())";
stringWriter = new StringWriter();
printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
engine.eval(jsString);
System.out.println(String.format("2 result = %s",stringWriter.toString()));
jsString = "var obj=JSON.parse('{\\\"data\\\":\\\"7157\\\",\\\"sign\\\":\\\"success\\\",\\\"message\\\":null}');print((function getData() { return obj.data;})())";
stringWriter = new StringWriter();
printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
engine.eval(jsString);
System.out.println(String.format("3 result = %s",stringWriter.toString()));
} catch (Exception e) {
e.printStackTrace();
}
}
2.2 获取匿名函数的返回值
Javascript脚本是匿名函数,有返回值,可以通过eval函数直接访问
@Test
public void test_js_function_return() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("Nashorn");
String jsFunction = "(function(){var obj=JSON.parse('{\\\"data\\\":\\\"7155\\\",\\\"sign\\\":\\\"success\\\",\\\"message\\\":null}');return obj.sign==\"success\"})();";
Boolean result = (Boolean) engine.eval(jsFunction);
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
}
2.3调用Javascript脚本中指定的函数
Javascript脚本中有变量和多个函数,如下
@Test
public void test_invoke_js_function() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("Nashorn");
/*
var obj = JSON.parse('{\"data\":\"7155\",\"sign\":\"success\",\"message\":null}');
function checkSign() {
return obj.sign == 'success'
}
function getData() {
return obj.data
}
function calculate(a, b) {
return a + b
}
*/
String jsFunction = "var obj=JSON.parse('{\\\"data\\\":\\\"7155\\\",\\\"sign\\\":\\\"success\\\",\\\"message\\\":null}');function checkSign(){return obj.sign=='success'}function getData(){return obj.data}function calculate(a,b){return a+b}";
engine.eval(jsFunction);
Invocable invocable = (Invocable) engine;
Object result = invocable.invokeFunction("checkSign", null);
System.out.println(result);
result = invocable.invokeFunction("getData", null);
System.out.println(result);
result = invocable.invokeFunction("calculate", 2, 5);
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
}
true
7155
7.0
2.4 读取Javascript文件并执行
本例读取并执行Javascript文件,如下
@Test
public void test_invoke_js_file() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("Nashorn");
engine.eval(new FileReader(TestJSEngine.class.getResource("/test.js").getPath()));
Invocable invocable = (Invocable) engine;
Object result = invocable.invokeFunction("checkSign", null);
System.out.println(result);
result = invocable.invokeFunction("getData", null);
System.out.println(result);
result = invocable.invokeFunction("calculate", 2, 5);
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
}
文件内容同上。
3 Rhino JavaScript 引擎简介
默认的 Nashorn 引擎无法解析 xml,像 DOMParser 这样的对象是浏览器的内置组件。
这里可以依靠Rhino引擎通过Maven来处理xml。
cat.inspiracio
rhino-js-engine
1.7.10
使用的步骤与其他 JavaScript 引擎相同,引擎名称为 Rhino。
3.1 Rhino 解析xml
在这里,通过读取文件来加载和解析 JavaScript 脚本。脚本就是解析一段xml的过程。
print("----------------------------------------");
var e = new XML(' Joe20 Sue30 ');
// 获取所有的员工
print("获取所有的员工:\n" + e..name);
// 名字叫 Joe 的员工
print("名字叫 Joe 的员工:\n" + e.employee.(name == "Joe"));
// 员工的id 为 1 和 2
print("员工的id 为 1 和 2:\n" + e.employee.(@id == 1 || @id == 2));
// 员工的id 为 1
print("员工的id 为 1: " + e.employee.(@id == 1).name);
print("----------------------------------------");
@Test
public void test_rhino_file_js() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("rhino");
ScriptContext scriptContext = engine.getContext();
StringWriter stringWriter = new StringWriter();
PrintWriter printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
engine.eval(new FileReader(TestJSEngine.class.getResource("/xml.js").getPath()));
System.out.println(String.format("xml result = %s",stringWriter.toString() ));
} catch (Exception e) {
e.printStackTrace();
}
}
xml result = ----------------------------------------
All the employee names are:
Joe
Sue
The employee named Joe is:
Joe
20
Employees with ids 1 & 2:
Joe
20
Sue
30
Name of the the employee with ID=1: Joe
----------------------------------------
3.2 测试
0
操作成功!
1
7
@Test
public void test_rhino() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("rhino");
String jsString = jsString = "var obj=new XML(' 0 操作成功! 1 7 ');print(obj.Message == '操作成功!');";
ScriptContext scriptContext = engine.getContext();
StringWriter stringWriter = new StringWriter();
PrintWriter printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
engine.eval(jsString);
System.out.println(String.format("xml result = %s",stringWriter.toString() ));
} catch (Exception e) {
e.printStackTrace();
}
}
以上输出如下
xml result = true
文章类别
百科测验
文章标签
脚本
js
教程 查看全部
js提取指定网站内容(
风中蹦迪02-24:45阅读4网站SEO优化关注javascript脚本怎么运行(js编写教程))
在风中弹跳
02-24 11:45 阅读4网站SEO优化
关注
如何运行 javascript 脚本(js 脚本教程)
1 概述
本文介绍了在Java环境中执行JavaScript脚本的简单使用,包括以下内容
Java 8 内置 Nashorn Javascript 引擎介绍 Rhino JavaScript 引擎介绍和 XML 处理介绍 2 Java 8 中内置 Nashorn Javascript 引擎介绍
Nashorn 是一个内置于 Java 8 中的 JavaScript 引擎,没有任何依赖关系。
使用Nashorn的基本步骤如下
new out ScriptEngineManager 对象通过ScriptEngineManager 对象中的getEngineByName 方法获取指定的JavaScript 引擎,并返回ScriptEngine 对象。 Java 8 中默认的 JavaScript 引擎包括: [nashorn, Nashorn, , JS, JavaScript, script, ECMAScript, ecmascript] 通过 ScriptEngine 对象的 eval 方法执行 JavaScript 脚本。 2.1 通过PrintWriter对象从脚本中获取打印输出
Javascript 脚本中没有函数,也没有返回值。内容通过打印输出。这时需要通过PrintWriter获取读取脚本中的打印输出,如下
@Test
public void test_nashorn() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("Nashorn");
ScriptContext scriptContext = engine.getContext();
StringWriter stringWriter = new StringWriter();
PrintWriter printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
String jsString = "var obj=JSON.parse('{\\\"data\\\":\\\"7155\\\",\\\"sign\\\":\\\"success\\\",\\\"message\\\":null}');print(obj.sign==\"success\");";
stringWriter = new StringWriter();
printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
engine.eval(jsString);
System.out.println(String.format("1 result = %s",stringWriter.toString()));
jsString = "var obj=JSON.parse('{\\\"data\\\":\\\"7157\\\",\\\"sign\\\":\\\"success\\\",\\\"message\\\":null}');print((function getData() { return obj.data;})())";
stringWriter = new StringWriter();
printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
engine.eval(jsString);
System.out.println(String.format("2 result = %s",stringWriter.toString()));
jsString = "var obj=JSON.parse('{\\\"data\\\":\\\"7157\\\",\\\"sign\\\":\\\"success\\\",\\\"message\\\":null}');print((function getData() { return obj.data;})())";
stringWriter = new StringWriter();
printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
engine.eval(jsString);
System.out.println(String.format("3 result = %s",stringWriter.toString()));
} catch (Exception e) {
e.printStackTrace();
}
}
2.2 获取匿名函数的返回值
Javascript脚本是匿名函数,有返回值,可以通过eval函数直接访问
@Test
public void test_js_function_return() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("Nashorn");
String jsFunction = "(function(){var obj=JSON.parse('{\\\"data\\\":\\\"7155\\\",\\\"sign\\\":\\\"success\\\",\\\"message\\\":null}');return obj.sign==\"success\"})();";
Boolean result = (Boolean) engine.eval(jsFunction);
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
}
2.3调用Javascript脚本中指定的函数
Javascript脚本中有变量和多个函数,如下
@Test
public void test_invoke_js_function() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("Nashorn");
/*
var obj = JSON.parse('{\"data\":\"7155\",\"sign\":\"success\",\"message\":null}');
function checkSign() {
return obj.sign == 'success'
}
function getData() {
return obj.data
}
function calculate(a, b) {
return a + b
}
*/
String jsFunction = "var obj=JSON.parse('{\\\"data\\\":\\\"7155\\\",\\\"sign\\\":\\\"success\\\",\\\"message\\\":null}');function checkSign(){return obj.sign=='success'}function getData(){return obj.data}function calculate(a,b){return a+b}";
engine.eval(jsFunction);
Invocable invocable = (Invocable) engine;
Object result = invocable.invokeFunction("checkSign", null);
System.out.println(result);
result = invocable.invokeFunction("getData", null);
System.out.println(result);
result = invocable.invokeFunction("calculate", 2, 5);
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
}
true
7155
7.0
2.4 读取Javascript文件并执行
本例读取并执行Javascript文件,如下
@Test
public void test_invoke_js_file() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("Nashorn");
engine.eval(new FileReader(TestJSEngine.class.getResource("/test.js").getPath()));
Invocable invocable = (Invocable) engine;
Object result = invocable.invokeFunction("checkSign", null);
System.out.println(result);
result = invocable.invokeFunction("getData", null);
System.out.println(result);
result = invocable.invokeFunction("calculate", 2, 5);
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
}
文件内容同上。
3 Rhino JavaScript 引擎简介
默认的 Nashorn 引擎无法解析 xml,像 DOMParser 这样的对象是浏览器的内置组件。
这里可以依靠Rhino引擎通过Maven来处理xml。
cat.inspiracio
rhino-js-engine
1.7.10
使用的步骤与其他 JavaScript 引擎相同,引擎名称为 Rhino。
3.1 Rhino 解析xml
在这里,通过读取文件来加载和解析 JavaScript 脚本。脚本就是解析一段xml的过程。
print("----------------------------------------");
var e = new XML(' Joe20 Sue30 ');
// 获取所有的员工
print("获取所有的员工:\n" + e..name);
// 名字叫 Joe 的员工
print("名字叫 Joe 的员工:\n" + e.employee.(name == "Joe"));
// 员工的id 为 1 和 2
print("员工的id 为 1 和 2:\n" + e.employee.(@id == 1 || @id == 2));
// 员工的id 为 1
print("员工的id 为 1: " + e.employee.(@id == 1).name);
print("----------------------------------------");
@Test
public void test_rhino_file_js() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("rhino");
ScriptContext scriptContext = engine.getContext();
StringWriter stringWriter = new StringWriter();
PrintWriter printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
engine.eval(new FileReader(TestJSEngine.class.getResource("/xml.js").getPath()));
System.out.println(String.format("xml result = %s",stringWriter.toString() ));
} catch (Exception e) {
e.printStackTrace();
}
}
xml result = ----------------------------------------
All the employee names are:
Joe
Sue
The employee named Joe is:
Joe
20
Employees with ids 1 & 2:
Joe
20
Sue
30
Name of the the employee with ID=1: Joe
----------------------------------------
3.2 测试
0
操作成功!
1
7
@Test
public void test_rhino() {
try {
ScriptEngine engine = new ScriptEngineManager().getEngineByName("rhino");
String jsString = jsString = "var obj=new XML(' 0 操作成功! 1 7 ');print(obj.Message == '操作成功!');";
ScriptContext scriptContext = engine.getContext();
StringWriter stringWriter = new StringWriter();
PrintWriter printWriter = new PrintWriter(stringWriter);
scriptContext.setWriter(printWriter);
engine.eval(jsString);
System.out.println(String.format("xml result = %s",stringWriter.toString() ));
} catch (Exception e) {
e.printStackTrace();
}
}
以上输出如下
xml result = true
文章类别
百科测验
文章标签
脚本
js
教程
js提取指定网站内容(.js和puppeteer小试牛刀.newPage)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-22 18:22
如果你是技术人员,那么可以看我的下一个文章,否则请直接移到我的github仓库,看文档就行了,使用仓库地址:有文档和源码,别忘了给一星给这个需求用到的技术:Node.js和puppeteer,小测试,爬京东资源
const puppeteer = require('puppeteer'); // 引入依赖
(async () => { //使用async函数完美异步
const browser = await puppeteer.launch(); //打开新的浏览器
const page = await browser.newPage(); // 打开新的网页
await page.goto('https://www.jd.com/'); //前往里面 'url' 的网页
const result = await page.evaluate(() => { //这个result数组包含所有的图片src地址
let arr = []; //这个箭头函数内部写处理的逻辑
const imgs = document.querySelectorAll('img');
imgs.forEach(function (item) {
arr.push(item.src)
})
return arr
});
// '此时的result就是得到的爬虫数据,可以通过'fs'模块保存'
})()
复制过去 使用命令行命令 ` node 文件名 ` 就可以运行获取爬虫数据了
这个 puppeteer 的包 ,其实是替我们开启了另一个浏览器,重新去开启网页,获取它们的数据。
跳转网页中所有标题的文本内容对应 中的所有标签,最后放入一个数组中。
browser.newPage(), browser.close() 是固定的。
调用这个方法。
也就是说我们可以先进入京东网页,处理完逻辑再调用page.goto函数,
注意上面所有的逻辑都是puppeteer包帮我们在一个不可见的地方打开另一个浏览器,然后处理逻辑,所以我们最后需要调用browser.close()方法来关闭那个浏览器。
这时候我们对上一篇的代码进行优化,爬取对应的资源。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.jd.com/');
const hrefArr = await page.evaluate(() => {
let arr = [];
const aNodes = document.querySelectorAll('.cate_menu_lk');
aNodes.forEach(function (item) {
arr.push(item.href)
})
return arr
});
let arr = [];
for (let i = 0; i < hrefArr.length; i++) {
const url = hrefArr[i];
console.log(url) //这里可以打印
await page.goto(url);
const result = await page.evaluate(() => { //这个方法内部console.log无效
return $('title').text(); //返回每个界面的title文字内容
});
arr.push(result) //每次循环给数组中添加对应的值
}
console.log(arr) //得到对应的数据 可以通过Node.js的 fs 模块保存到本地
await browser.close()
})()
天坑page.evaluate函数里面的console.log不能打印,内部不能获取外部变量,只能返回return。使用的选择器在使用前必须先到相应界面的控制台测试是否可以选择DOM。比如京东就不能使用querySelector。在这里,因为京东的界面使用了jQuery,所以我们可以使用jQuery。简而言之,我们可以使用他们可以使用的所有选择器,否则我们不能。
接下来我们爬取Node.js的官网主页,直接生成PDF
本项目要求:给我们一个网页地址,爬取他的网页内容,然后输出成我们想要的PDF格式文档,请注意是高质量的PDF文档
TIPS:本项目的设计思路是一个网页和一个PDF文件,所以每次爬取单个页面,请将index.pdf复制出来,然后继续改url地址,继续爬取,生成一个新的PDF文件,当然你也可以一次爬取多个网页,通过循环编译的方式生成多个PDF文件。对于像京东首页这样开启了图片延迟加载的网页,部分爬取的内容就是处于加载状态的内容。对于有一些反爬机制的网页,爬虫也会有问题,但是大部分网站都可以
const puppeteer = require('puppeteer');
const url = require('./url');
(async () => {
const browser = await puppeteer.launch({ headless: true })
const page = await browser.newPage()
//选择要打开的网页
await page.goto(url, { waitUntil: 'networkidle0' })
//选择你要输出的那个PDF文件路径,把爬取到的内容输出到PDF中,必须是存在的PDF,可以是空内容,如果不是空的内容PDF,那么会覆盖内容
let pdfFilePath = './index.pdf';
//根据你的配置选项,我们这里选择A4纸的规格输出PDF,方便打印
await page.pdf({
path: pdfFilePath,
format: 'A4',
scale: 1,
printBackground: true,
landscape: false,
displayHeaderFooter: false
});
await browser.close()
})()
文件解构设计
在这个时代,数据非常宝贵。根据网页的设计逻辑,如果选择特定href的地址,可以直接获取对应的资源,也可以再次使用page.goto方法进入,然后调用page.evaluate( ) 处理逻辑。或者输出对应的PDF文件,当然也可以一次输出多个PDF文件~这里就不过多介绍了,毕竟Node.js可以上天,说不定以后真的可以做任何事。这么优质又短的教程,请采集或转发给您的朋友,谢谢。 查看全部
js提取指定网站内容(.js和puppeteer小试牛刀.newPage)
如果你是技术人员,那么可以看我的下一个文章,否则请直接移到我的github仓库,看文档就行了,使用仓库地址:有文档和源码,别忘了给一星给这个需求用到的技术:Node.js和puppeteer,小测试,爬京东资源
const puppeteer = require('puppeteer'); // 引入依赖
(async () => { //使用async函数完美异步
const browser = await puppeteer.launch(); //打开新的浏览器
const page = await browser.newPage(); // 打开新的网页
await page.goto('https://www.jd.com/'); //前往里面 'url' 的网页
const result = await page.evaluate(() => { //这个result数组包含所有的图片src地址
let arr = []; //这个箭头函数内部写处理的逻辑
const imgs = document.querySelectorAll('img');
imgs.forEach(function (item) {
arr.push(item.src)
})
return arr
});
// '此时的result就是得到的爬虫数据,可以通过'fs'模块保存'
})()
复制过去 使用命令行命令 ` node 文件名 ` 就可以运行获取爬虫数据了
这个 puppeteer 的包 ,其实是替我们开启了另一个浏览器,重新去开启网页,获取它们的数据。
跳转网页中所有标题的文本内容对应 中的所有标签,最后放入一个数组中。
browser.newPage(), browser.close() 是固定的。
调用这个方法。
也就是说我们可以先进入京东网页,处理完逻辑再调用page.goto函数,
注意上面所有的逻辑都是puppeteer包帮我们在一个不可见的地方打开另一个浏览器,然后处理逻辑,所以我们最后需要调用browser.close()方法来关闭那个浏览器。
这时候我们对上一篇的代码进行优化,爬取对应的资源。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.jd.com/');
const hrefArr = await page.evaluate(() => {
let arr = [];
const aNodes = document.querySelectorAll('.cate_menu_lk');
aNodes.forEach(function (item) {
arr.push(item.href)
})
return arr
});
let arr = [];
for (let i = 0; i < hrefArr.length; i++) {
const url = hrefArr[i];
console.log(url) //这里可以打印
await page.goto(url);
const result = await page.evaluate(() => { //这个方法内部console.log无效
return $('title').text(); //返回每个界面的title文字内容
});
arr.push(result) //每次循环给数组中添加对应的值
}
console.log(arr) //得到对应的数据 可以通过Node.js的 fs 模块保存到本地
await browser.close()
})()
天坑page.evaluate函数里面的console.log不能打印,内部不能获取外部变量,只能返回return。使用的选择器在使用前必须先到相应界面的控制台测试是否可以选择DOM。比如京东就不能使用querySelector。在这里,因为京东的界面使用了jQuery,所以我们可以使用jQuery。简而言之,我们可以使用他们可以使用的所有选择器,否则我们不能。
接下来我们爬取Node.js的官网主页,直接生成PDF
本项目要求:给我们一个网页地址,爬取他的网页内容,然后输出成我们想要的PDF格式文档,请注意是高质量的PDF文档
TIPS:本项目的设计思路是一个网页和一个PDF文件,所以每次爬取单个页面,请将index.pdf复制出来,然后继续改url地址,继续爬取,生成一个新的PDF文件,当然你也可以一次爬取多个网页,通过循环编译的方式生成多个PDF文件。对于像京东首页这样开启了图片延迟加载的网页,部分爬取的内容就是处于加载状态的内容。对于有一些反爬机制的网页,爬虫也会有问题,但是大部分网站都可以
const puppeteer = require('puppeteer');
const url = require('./url');
(async () => {
const browser = await puppeteer.launch({ headless: true })
const page = await browser.newPage()
//选择要打开的网页
await page.goto(url, { waitUntil: 'networkidle0' })
//选择你要输出的那个PDF文件路径,把爬取到的内容输出到PDF中,必须是存在的PDF,可以是空内容,如果不是空的内容PDF,那么会覆盖内容
let pdfFilePath = './index.pdf';
//根据你的配置选项,我们这里选择A4纸的规格输出PDF,方便打印
await page.pdf({
path: pdfFilePath,
format: 'A4',
scale: 1,
printBackground: true,
landscape: false,
displayHeaderFooter: false
});
await browser.close()
})()
文件解构设计
在这个时代,数据非常宝贵。根据网页的设计逻辑,如果选择特定href的地址,可以直接获取对应的资源,也可以再次使用page.goto方法进入,然后调用page.evaluate( ) 处理逻辑。或者输出对应的PDF文件,当然也可以一次输出多个PDF文件~这里就不过多介绍了,毕竟Node.js可以上天,说不定以后真的可以做任何事。这么优质又短的教程,请采集或转发给您的朋友,谢谢。
js提取指定网站内容(一个用jsp实现的常见的首页图片轮换效果。。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-21 08:27
最近研究的jsp实现的一个常见的首页图片旋转效果。
本来打算在网上找别人的作品,作为自己的网站项目。平时无聊的时候就去搜,结果只发现是用php做的。其他人实现的旋转效果还有很多,包括js和flash+JS,但是我还没有找到别人用jsp做的可以直接使用的组件(也是从别人的cms学习的)。,但理解起来太复杂了),所以没办法,只能想办法写个组件来实现,也方便以后使用。
主要实现思路:
文章提交时,从文章的具体内容中提取第一张图片的地址(如果有图片)和标题,在当前表中找出文章之后的最新已提交。一条数据的ID(也就是刚刚提交的文章),然后把SRC/Title/ID(或者detail.jsp?ID=ID)保存到一个XML文件中(也可以用一个数据库,但考虑到数据量不在首页,使用JS解析XML文件,提取具体数据,然后展示具体效果。
成就效果总结:
当我在考虑写这个组件的时候,我觉得这是一件很简单的事情。本来想在课后无所事事的情况下,用一整天或更长时间完成,但在实施过程中遇到了很多以前没有遇到过的问题。,经过google、百度和自己的反复测试,终于实现了这个功能。具体问题及解决方法总结如下:
1、从指定文本中提取图像
2、java对XML文件解析、节点增删操作的总结
3、JS 解析 XML
4、sql查询最后一条数据
5、XML中文乱码问题解决
6、引用转义
7、路径问题(JS读取XML,java读取XML,jsp读取XML)
8、图片上传组件 查看全部
js提取指定网站内容(一个用jsp实现的常见的首页图片轮换效果。。)
最近研究的jsp实现的一个常见的首页图片旋转效果。
本来打算在网上找别人的作品,作为自己的网站项目。平时无聊的时候就去搜,结果只发现是用php做的。其他人实现的旋转效果还有很多,包括js和flash+JS,但是我还没有找到别人用jsp做的可以直接使用的组件(也是从别人的cms学习的)。,但理解起来太复杂了),所以没办法,只能想办法写个组件来实现,也方便以后使用。
主要实现思路:
文章提交时,从文章的具体内容中提取第一张图片的地址(如果有图片)和标题,在当前表中找出文章之后的最新已提交。一条数据的ID(也就是刚刚提交的文章),然后把SRC/Title/ID(或者detail.jsp?ID=ID)保存到一个XML文件中(也可以用一个数据库,但考虑到数据量不在首页,使用JS解析XML文件,提取具体数据,然后展示具体效果。
成就效果总结:
当我在考虑写这个组件的时候,我觉得这是一件很简单的事情。本来想在课后无所事事的情况下,用一整天或更长时间完成,但在实施过程中遇到了很多以前没有遇到过的问题。,经过google、百度和自己的反复测试,终于实现了这个功能。具体问题及解决方法总结如下:
1、从指定文本中提取图像
2、java对XML文件解析、节点增删操作的总结
3、JS 解析 XML
4、sql查询最后一条数据
5、XML中文乱码问题解决
6、引用转义
7、路径问题(JS读取XML,java读取XML,jsp读取XML)
8、图片上传组件
js提取指定网站内容(js提取指定网站内容:实时抓取国内外互联网数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-19 16:04
js提取指定网站内容:实时抓取国内外互联网数据,提取大量图片、文本、视频等javascript代码,转换格式发布到社交媒体平台上,引导用户浏览时使用javascript播放实时抓取内容分析数据用户行为中的数据可提取到javascript代码数据转换文本文本的分析可以获取大量关键字,如姓名、性别、年龄等。
将这些关键字语义化,归纳内容如学习、背单词、求职等内容分析设置不同字体色标区分不同内容设置不同文件名可以统计文本中文本数据量的区别通过r语言可以很轻松的转换成不同格式的javascript代码,通过字符形式生成更加方便查看进一步的深入分析:利用函数来构建统计模型。函数有:acf,mcf,lm,jpmannagy。在javascript中构建r与python的统计模型利用tableau进行数据可视化解决实际问题:。
1、在线拉取百度、、知乎等数据并转化为可视化模型;
2、利用知乎进行数据分析,
3、通过百度指数了解目标用户的喜好和需求;
4、提取帖子内容和评论生成短图片数据可视化平台;
5、利用百度指数了解竞争对手的可投放广告库存;
6、成立一个1w亿元级别的职场平台。
7、流量变现。
8、通过百度指数收集关键字词频的内容,进行用户画像。本文内容来源于:推特官方账号:reddit官方账号:[hao123][][sc]startwith:[se.example.acf](hi)[1]thehiaccountisrewriteandenabledwhenyoucopytherequest.byrewrite,thehiaccountcannotreadthetagasrequest.accountactivatedforstartingfromthismodule,thehiclientcanreadtags.thehiaccountisrewriteandenabledwhenyoucopytherequest.accountactivatedforstartingfromthismodule,thehiclientcanreadtags.thehiaccountisrewriteandenabledwhenyoucopytherequest.copytherequestsharedbyrewritemeansthehiaccountwillautomaticallydisauthenticatethetagsuntiltheaccountissigned.byrewrite,thehiaccountcannotreadthetagsuntiltheaccountissigned.thehiaccountisrewriteandenabledwhenyoucopytherequest.dependingonthehiaccountareallowedbyrewrite.rewrite=rewrite('ccw','request')rewrite=rewrite('ccw','getjson')rewrite=rewrite('ccw','posturl')rewrite=rewrite('ccw','maxindex')rewrite。 查看全部
js提取指定网站内容(js提取指定网站内容:实时抓取国内外互联网数据)
js提取指定网站内容:实时抓取国内外互联网数据,提取大量图片、文本、视频等javascript代码,转换格式发布到社交媒体平台上,引导用户浏览时使用javascript播放实时抓取内容分析数据用户行为中的数据可提取到javascript代码数据转换文本文本的分析可以获取大量关键字,如姓名、性别、年龄等。
将这些关键字语义化,归纳内容如学习、背单词、求职等内容分析设置不同字体色标区分不同内容设置不同文件名可以统计文本中文本数据量的区别通过r语言可以很轻松的转换成不同格式的javascript代码,通过字符形式生成更加方便查看进一步的深入分析:利用函数来构建统计模型。函数有:acf,mcf,lm,jpmannagy。在javascript中构建r与python的统计模型利用tableau进行数据可视化解决实际问题:。
1、在线拉取百度、、知乎等数据并转化为可视化模型;
2、利用知乎进行数据分析,
3、通过百度指数了解目标用户的喜好和需求;
4、提取帖子内容和评论生成短图片数据可视化平台;
5、利用百度指数了解竞争对手的可投放广告库存;
6、成立一个1w亿元级别的职场平台。
7、流量变现。
8、通过百度指数收集关键字词频的内容,进行用户画像。本文内容来源于:推特官方账号:reddit官方账号:[hao123][][sc]startwith:[se.example.acf](hi)[1]thehiaccountisrewriteandenabledwhenyoucopytherequest.byrewrite,thehiaccountcannotreadthetagasrequest.accountactivatedforstartingfromthismodule,thehiclientcanreadtags.thehiaccountisrewriteandenabledwhenyoucopytherequest.accountactivatedforstartingfromthismodule,thehiclientcanreadtags.thehiaccountisrewriteandenabledwhenyoucopytherequest.copytherequestsharedbyrewritemeansthehiaccountwillautomaticallydisauthenticatethetagsuntiltheaccountissigned.byrewrite,thehiaccountcannotreadthetagsuntiltheaccountissigned.thehiaccountisrewriteandenabledwhenyoucopytherequest.dependingonthehiaccountareallowedbyrewrite.rewrite=rewrite('ccw','request')rewrite=rewrite('ccw','getjson')rewrite=rewrite('ccw','posturl')rewrite=rewrite('ccw','maxindex')rewrite。
js提取指定网站内容(《讲解开源项目》[1]系列之FilePond手痒有些)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-16 11:34
这是HelloGitHub推出的“解释开源项目”[1]系列。今天给大家推荐一款。
JavaScript 开源文件上传库项目——FilePond
一、简介
1.1 文件池
它是一个 JavaScript 文件上传库。可以拖入上传,并优化图像以加快上传速度。为用户提供出色、可见、流畅的文件上传体验。
FilePond项目地址:
1.2 特点和优势
看了效果图和功能介绍,是不是有点痒?接下来是实际操作部分。你可以跟着文章一步步使用这个库,点亮你的文件上传技能点!
实战操作
下面我们将逐步解释如何使用 FilePond 库。我们使用最简单的CDN参考方式,方便大家快速查看它的魅力(复制代码看效果),然后深入讲解各个插件的作用,最后结合几个插件写一个例子运行显示结果.
提示:解释以注释的形式显示在代码中,请仔细阅读。
2.1 快速使用(CDN)
示例代码:
FilePond from CDN
// FilePond.parse 使用类.filepond解析DOM树的给定部分,并将它们转换为FilePond元素。
FilePond.parse(document.body);
结果显示:
2.2
引入插件
看来简单的上传功能无法满足我们的需求。FilePond 库有各种强大的插件部件。您可以根据自己的需要选择和组合插件。我们先简单了解一下各个插件的作用:
现在让我介绍如何引入插件!
坑!: 使用插件前,一定要检查插件是否有CSS文件,如果有,请在标签中引入。
// 注册插件 FilePondPluginImagePreview 图像预览插件为已上传的图像呈现缩小的预览。
FilePond.registerPlugin(FilePondPluginImagePreview);
下面我们来梳理一下引入插件的步骤: 引入CSS文件(部分插件有CSS文件) 引入JS文件注册插件 配置插件(部分插件需要配置)
2.3 与插件一起使用
完整的示例代码:
FilePond from CDN
// querySelector() 方法返回文档中匹配指定 CSS 选择器的一个元素。
var inputElement = document.querySelector('input[type="file"]');
// 注册插件
// FilePondPluginImagePreview 上传时可以预览到上传的图片等
// FilePondPluginImageEdit 由于doka收费,所以编辑功能就不演示了。
// FilePondPluginFileValidateType 图片类型
// FilePondPluginImageCrop 图像裁剪
// FilePondPluginFileValidateSize 文件大小验证插件处理阻止太大的文件。
FilePond.registerPlugin(
FilePondPluginImagePreview,
FilePondPluginImageEdit,
FilePondPluginFileValidateSize,
FilePondPluginImageCrop,
FilePondPluginFileValidateType,
FilePondPluginImageExifOrientation
);
FilePond.setOptions({
// 设置单个URL是定义服务器配置的最基本形式。
server: '/upload',
// 设置图片类型只能为png才能上传
allowFileTypeValidation: false,
acceptedFileTypes: "image/jpg",
// 启用或禁用图像裁剪
allowImageCrop: true,
// 启用或禁用文件大小验证
allowFileSizeValidation: true,
maxFileSize: null,
// 启用或禁用提取EXIF信息
allowImageExifOrientation: true
});
// 使用create方法逐步增强基本文件输入到FilePond元素。
FilePond.create(inputElement)
上例展示了FilePond常用插件的方法,效果如下图:
当然还有
我不会在这里做完整的解释。有兴趣的可以自己试试这些方法。
三、总结
以上就是讲解的全部内容,FilePond是一个非常轻量级的上传插件。没有太多繁琐的配置,这里我没有一一演示每个插件的介绍,只展示常用的部分。注意上面指出的坑,掌握上面讲解的方法,其他插件可以自行学习。
FilePond 是一个值得参考和使用的 JavaScript 库。如果你想网站快速添加上传功能,不妨试试。
参考
[1] 《解释开源项目》:
[2]EXIF:
[3]FilePond官方文档:
[4]FilePond 插件列表:
关注公众号,加入交流群,一起讨论有趣的技术话题
《开源项目解读系列》——让对开源项目感兴趣的人不再害怕,让开源项目的发起者不再孤单。跟随我们的文章,您会发现编程的乐趣、易用性以及参与开源项目是多么容易。欢迎联系我(微信:xueweihan 备注:解释)加入我们,让更多人爱上开源,为开源做贡献~ 查看全部
js提取指定网站内容(《讲解开源项目》[1]系列之FilePond手痒有些)
这是HelloGitHub推出的“解释开源项目”[1]系列。今天给大家推荐一款。
JavaScript 开源文件上传库项目——FilePond
一、简介
1.1 文件池
它是一个 JavaScript 文件上传库。可以拖入上传,并优化图像以加快上传速度。为用户提供出色、可见、流畅的文件上传体验。
FilePond项目地址:
1.2 特点和优势
看了效果图和功能介绍,是不是有点痒?接下来是实际操作部分。你可以跟着文章一步步使用这个库,点亮你的文件上传技能点!
实战操作
下面我们将逐步解释如何使用 FilePond 库。我们使用最简单的CDN参考方式,方便大家快速查看它的魅力(复制代码看效果),然后深入讲解各个插件的作用,最后结合几个插件写一个例子运行显示结果.
提示:解释以注释的形式显示在代码中,请仔细阅读。
2.1 快速使用(CDN)
示例代码:
FilePond from CDN
// FilePond.parse 使用类.filepond解析DOM树的给定部分,并将它们转换为FilePond元素。
FilePond.parse(document.body);
结果显示:
2.2
引入插件
看来简单的上传功能无法满足我们的需求。FilePond 库有各种强大的插件部件。您可以根据自己的需要选择和组合插件。我们先简单了解一下各个插件的作用:
现在让我介绍如何引入插件!
坑!: 使用插件前,一定要检查插件是否有CSS文件,如果有,请在标签中引入。
// 注册插件 FilePondPluginImagePreview 图像预览插件为已上传的图像呈现缩小的预览。
FilePond.registerPlugin(FilePondPluginImagePreview);
下面我们来梳理一下引入插件的步骤: 引入CSS文件(部分插件有CSS文件) 引入JS文件注册插件 配置插件(部分插件需要配置)
2.3 与插件一起使用
完整的示例代码:
FilePond from CDN
// querySelector() 方法返回文档中匹配指定 CSS 选择器的一个元素。
var inputElement = document.querySelector('input[type="file"]');
// 注册插件
// FilePondPluginImagePreview 上传时可以预览到上传的图片等
// FilePondPluginImageEdit 由于doka收费,所以编辑功能就不演示了。
// FilePondPluginFileValidateType 图片类型
// FilePondPluginImageCrop 图像裁剪
// FilePondPluginFileValidateSize 文件大小验证插件处理阻止太大的文件。
FilePond.registerPlugin(
FilePondPluginImagePreview,
FilePondPluginImageEdit,
FilePondPluginFileValidateSize,
FilePondPluginImageCrop,
FilePondPluginFileValidateType,
FilePondPluginImageExifOrientation
);
FilePond.setOptions({
// 设置单个URL是定义服务器配置的最基本形式。
server: '/upload',
// 设置图片类型只能为png才能上传
allowFileTypeValidation: false,
acceptedFileTypes: "image/jpg",
// 启用或禁用图像裁剪
allowImageCrop: true,
// 启用或禁用文件大小验证
allowFileSizeValidation: true,
maxFileSize: null,
// 启用或禁用提取EXIF信息
allowImageExifOrientation: true
});
// 使用create方法逐步增强基本文件输入到FilePond元素。
FilePond.create(inputElement)
上例展示了FilePond常用插件的方法,效果如下图:
当然还有
我不会在这里做完整的解释。有兴趣的可以自己试试这些方法。
三、总结
以上就是讲解的全部内容,FilePond是一个非常轻量级的上传插件。没有太多繁琐的配置,这里我没有一一演示每个插件的介绍,只展示常用的部分。注意上面指出的坑,掌握上面讲解的方法,其他插件可以自行学习。
FilePond 是一个值得参考和使用的 JavaScript 库。如果你想网站快速添加上传功能,不妨试试。
参考
[1] 《解释开源项目》:
[2]EXIF:
[3]FilePond官方文档:
[4]FilePond 插件列表:
关注公众号,加入交流群,一起讨论有趣的技术话题
《开源项目解读系列》——让对开源项目感兴趣的人不再害怕,让开源项目的发起者不再孤单。跟随我们的文章,您会发现编程的乐趣、易用性以及参与开源项目是多么容易。欢迎联系我(微信:xueweihan 备注:解释)加入我们,让更多人爱上开源,为开源做贡献~
js提取指定网站内容( JavaScript语言本身的内容的演示结果[3])
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-15 23:14
JavaScript语言本身的内容的演示结果[3])
你好世界!
本教程的这一部分是关于 JavaScript 语言本身的。
但是,我们需要一个工作环境来运行我们的脚本,并且由于本教程是在线的,因此浏览器是一个不错的选择。我们将尽可能少地使用特定于浏览器的命令(如警报),因此如果您要专注于另一个环境(如 Node.js),则不必花太多时间关心这些特定命令. 在本教程的下一部分,我们将重点介绍浏览器中的 JavaScript。
首先,让我们看看如何将脚本添加到网页。对于服务器端环境(如 Node.js),您只需要使用“node my.js”之类的命令行来执行它。
“脚本”标签
JavaScript 程序可以插入到 .
有很多关于浏览器脚本以及它们与网页的关系的知识。但请记住,本教程的这一部分主要针对 JavaScript 语言本身,因此我们不应被特定于浏览器的实现分散注意力。我们将使用浏览器作为运行 JavaScript 的一种方式,这对于我们在线阅读来说非常方便,但这只是众多方式中的一种。
作业问题
1. 显示提示
重要性:⭐️⭐️⭐️⭐️⭐️
创建一个页面,然后显示一条消息“我是 JavaScript!”。
无论您是在沙盒中还是在硬盘驱动器上执行此操作,只要确保它有效即可。
您可以先在新窗口 [2] 中查看演示结果。
在微信公众号“技术讲座”后台回复1-2-1,即可获得此问题的答案。
2. 使用外部脚本显示提示
重要性:⭐️⭐️⭐️⭐️⭐️
打开问题 1 的答案。将答案中的脚本内容提取到同一文件夹中的外部 alert.js 文件中。
打开页面并确保它有效。
您可以先在新窗口 [3] 中查看演示结果。
在微信公众号“技术讲座”后台回复1-2-1,即可获得此问题的答案。
现代 JavaScript 教程:从入门到高级的开源现代 JavaScript 教程。React 官方文档推荐,一个与 MDN [4] 一起的 JavaScript 学习教程。
免费在线阅读:
参考
[1] 缓存:
[2] 新窗口中的演示结果:
[3] 新窗口中的演示结果:
[4] React官方文档推荐,与MDN并行的JavaScript学习教程:#javascript-resources 查看全部
js提取指定网站内容(
JavaScript语言本身的内容的演示结果[3])
你好世界!
本教程的这一部分是关于 JavaScript 语言本身的。
但是,我们需要一个工作环境来运行我们的脚本,并且由于本教程是在线的,因此浏览器是一个不错的选择。我们将尽可能少地使用特定于浏览器的命令(如警报),因此如果您要专注于另一个环境(如 Node.js),则不必花太多时间关心这些特定命令. 在本教程的下一部分,我们将重点介绍浏览器中的 JavaScript。
首先,让我们看看如何将脚本添加到网页。对于服务器端环境(如 Node.js),您只需要使用“node my.js”之类的命令行来执行它。
“脚本”标签
JavaScript 程序可以插入到 .
有很多关于浏览器脚本以及它们与网页的关系的知识。但请记住,本教程的这一部分主要针对 JavaScript 语言本身,因此我们不应被特定于浏览器的实现分散注意力。我们将使用浏览器作为运行 JavaScript 的一种方式,这对于我们在线阅读来说非常方便,但这只是众多方式中的一种。
作业问题
1. 显示提示
重要性:⭐️⭐️⭐️⭐️⭐️
创建一个页面,然后显示一条消息“我是 JavaScript!”。
无论您是在沙盒中还是在硬盘驱动器上执行此操作,只要确保它有效即可。
您可以先在新窗口 [2] 中查看演示结果。
在微信公众号“技术讲座”后台回复1-2-1,即可获得此问题的答案。
2. 使用外部脚本显示提示
重要性:⭐️⭐️⭐️⭐️⭐️
打开问题 1 的答案。将答案中的脚本内容提取到同一文件夹中的外部 alert.js 文件中。
打开页面并确保它有效。
您可以先在新窗口 [3] 中查看演示结果。
在微信公众号“技术讲座”后台回复1-2-1,即可获得此问题的答案。
现代 JavaScript 教程:从入门到高级的开源现代 JavaScript 教程。React 官方文档推荐,一个与 MDN [4] 一起的 JavaScript 学习教程。
免费在线阅读:
参考
[1] 缓存:
[2] 新窗口中的演示结果:
[3] 新窗口中的演示结果:
[4] React官方文档推荐,与MDN并行的JavaScript学习教程:#javascript-resources
js提取指定网站内容(Python学习资料的PS学习方法(一)--Python )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-15 07:14
)
PS:如需Python学习资料,可点击下方链接自行获取
基本步骤和准备
调试环境:
pycharm+python3
所需库:
(http.cookiejar是后续爬虫进场时会用到的库,本项目不涉及反爬,可以省略)
如果导入过程显示上面的库不可用,可以在File→Settings→projet解释器中点击右侧的+添加(如果你使用anaconda或者python也可以直接运行这个项目,添加通过cmd→pip安装)
2.本文我们使用python来抓取、下载和存储在线短视频。基本步骤如下(可以写评论整理思路):
(1)分析页面URL和视频文件URL特征(2)获取网页源代码的HTML,解决反爬机制(3)批量下载视频存储)
分析页面 URL 和文件 URL 特征
1.分析网页 URL
通过网页URL:,我们可以找到不同页码变化的知识URL的最后一个值,这个值代表了页数,所以我们只需要把它改成固定URL+可变形式就可以得到分批建站
2.分析文件名 URL
通过分析网页中mp4的文件名,发现该文件的URL以纯文本形式显示,因此可以通过匹配re的正则性得到。
批量获取url,并从中提取视频的url
import urllib.request
import re
for page in range (1,20):
req = urllib.request.Request("http://www.budejie.com/video/%s" % page)
html = urllib.request.urlopen(req).read()
html = html.decode('UTF-8')
print(html)
1.批量抓取网页url
这里我们的page变量代表页面的代码,从这里我们暂时抓取前20页。
(1)req获取网页反馈(2)html通过函数获取网页元代码(3)恢复UTF-8编码的中文显示)源代码。
但是通过上面代码的执行,发现报错显示http Error 403,因为无法获取网页的反爬机制。
2.通过页面添加头文件
我们通过谷歌浏览器访问页面,按F12切换到Network,刷新界面观察访问过程,可以从过程文件中选择一个查看头文件,添加到代码中,(这里选择baisibudejie.js)修改代码如下,就可以正常爬取界面了。
for page in range (1,20):
req = urllib.request.Request("http://www.budejie.com/video/%s" % page)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36")
html = urllib.request.urlopen(req).read()
html = html.decode('UTF-8')
print(html)
批量下载视频并创建文件名存储
1.为批量命名创建循环结构
建立循环结构后,需要保留文件名以供下载。i.split("/")[-1]的意思是对i进行拆分,用'/'作为分隔符,保留最后一段,即MP4文件名。
2.批量下载
还是要加一条显示的输出语句来表示这个过程,这也符合程序的交互性,即在下载视频的时候显示进度,最后下载到一个mp4文件夹中。
for i in re.findall(reg, html):
filename = i.split("/")[-1] # 以‘/ ’为分割f符,保留最后一段,即MP4的文件名
print('正在下载%s视频' % filename)
urllib.request.urlretrieve(i, "mp4/%s" % filename)
1.构建一个完整的程序
作为一名合格的程序员,需要对程序进行梳理,并添加注释,方便理解和后续修改
import urllib.request
import re
def getVideo(page):
req = urllib.request.Request("http://www.budejie.com/video/%s" %page)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36")
html = urllib.request.urlopen(req).read()
html = html.decode('UTF-8')
reg = r'data-mp4="(.*?)"'
for i in re.findall(reg,html):
filename = i.split("/")[-1]#以‘/ ’为分割f符,保留最后一段,即MP4的文件名
print ('正在下载%s视频' %filename)
urllib.request.urlretrieve(i,"mp4/%s"%filename)
for i in range (1,20):
getVideo(i) 查看全部
js提取指定网站内容(Python学习资料的PS学习方法(一)--Python
)
PS:如需Python学习资料,可点击下方链接自行获取
基本步骤和准备
调试环境:
pycharm+python3
所需库:
(http.cookiejar是后续爬虫进场时会用到的库,本项目不涉及反爬,可以省略)
如果导入过程显示上面的库不可用,可以在File→Settings→projet解释器中点击右侧的+添加(如果你使用anaconda或者python也可以直接运行这个项目,添加通过cmd→pip安装)
2.本文我们使用python来抓取、下载和存储在线短视频。基本步骤如下(可以写评论整理思路):
(1)分析页面URL和视频文件URL特征(2)获取网页源代码的HTML,解决反爬机制(3)批量下载视频存储)
分析页面 URL 和文件 URL 特征
1.分析网页 URL
通过网页URL:,我们可以找到不同页码变化的知识URL的最后一个值,这个值代表了页数,所以我们只需要把它改成固定URL+可变形式就可以得到分批建站
2.分析文件名 URL
通过分析网页中mp4的文件名,发现该文件的URL以纯文本形式显示,因此可以通过匹配re的正则性得到。
批量获取url,并从中提取视频的url
import urllib.request
import re
for page in range (1,20):
req = urllib.request.Request("http://www.budejie.com/video/%s" % page)
html = urllib.request.urlopen(req).read()
html = html.decode('UTF-8')
print(html)
1.批量抓取网页url
这里我们的page变量代表页面的代码,从这里我们暂时抓取前20页。
(1)req获取网页反馈(2)html通过函数获取网页元代码(3)恢复UTF-8编码的中文显示)源代码。
但是通过上面代码的执行,发现报错显示http Error 403,因为无法获取网页的反爬机制。
2.通过页面添加头文件
我们通过谷歌浏览器访问页面,按F12切换到Network,刷新界面观察访问过程,可以从过程文件中选择一个查看头文件,添加到代码中,(这里选择baisibudejie.js)修改代码如下,就可以正常爬取界面了。
for page in range (1,20):
req = urllib.request.Request("http://www.budejie.com/video/%s" % page)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36")
html = urllib.request.urlopen(req).read()
html = html.decode('UTF-8')
print(html)
批量下载视频并创建文件名存储
1.为批量命名创建循环结构
建立循环结构后,需要保留文件名以供下载。i.split("/")[-1]的意思是对i进行拆分,用'/'作为分隔符,保留最后一段,即MP4文件名。
2.批量下载
还是要加一条显示的输出语句来表示这个过程,这也符合程序的交互性,即在下载视频的时候显示进度,最后下载到一个mp4文件夹中。
for i in re.findall(reg, html):
filename = i.split("/")[-1] # 以‘/ ’为分割f符,保留最后一段,即MP4的文件名
print('正在下载%s视频' % filename)
urllib.request.urlretrieve(i, "mp4/%s" % filename)
1.构建一个完整的程序
作为一名合格的程序员,需要对程序进行梳理,并添加注释,方便理解和后续修改
import urllib.request
import re
def getVideo(page):
req = urllib.request.Request("http://www.budejie.com/video/%s" %page)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36")
html = urllib.request.urlopen(req).read()
html = html.decode('UTF-8')
reg = r'data-mp4="(.*?)"'
for i in re.findall(reg,html):
filename = i.split("/")[-1]#以‘/ ’为分割f符,保留最后一段,即MP4的文件名
print ('正在下载%s视频' %filename)
urllib.request.urlretrieve(i,"mp4/%s"%filename)
for i in range (1,20):
getVideo(i)

