
js提取指定网站内容
js提取指定网站内容 2017年第28gggg6期江西理工大学学报v
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-06-07 06:38
没有。 28gg6 江西科技大学学报 v. 1. 28, N. . 2007 年 12 月 6 日 JOURNALOFJIANGXIUNIVERSITYOFSCIENCEANDTECHNOLOGY 2007 年 12 月 文章 编号:1007-1229(2007)06—0026—03HtmlParser 提取网页信息的设计与实现 黄颖,黄志平,江西大学信息工程学院,1.与技术,江西赣州341000;2.赣南师范学院,江西赣州341000) 摘要:随着互联网信息量的快速增长,迫切需要一些自动化工具来快速帮助人们从标题、链接、邮件、图片等海量信息源中找到自己真正需要的信息,而HTML语言表达的网页只适合浏览器分析后浏览,不适合浏览器处理。机器作为一种数据交换的方式,文章详细介绍了如何使用HtmlParser提取网页中的超链接信息,清理干净并存储在SQL数据库中se,用于后续工作。 关键词:HtmlParser;信息提取;网页解析中文图书馆分类号:TP393、03 文档识别码:ADesignandImplementationofWeb InformationExtractionBasedonHtmlParser黄英,黄志平(1.江西理工大学信息与技术学院,中国赣州341000;2.GannnaTeachers3,中国赣州学院10000)摘要:Therapidgro〜daoftheWebcontentsincreasestheneedforsomeautomatictoolstohelppeoplefindthe informationamongthemagnanimousinfomr ationsourcessuchastides,链接,电子邮件,picturesetc.TheW ebpages expressedbyHTML,afterna alyzedbyInternetExplorer,areonlysuitableofrbrowse,butnotofrmachineprocess- ingasthewayofdataexchna ge.Th epaperexplainshow touseHtmlParsertoextracthyperlinkinfomr ationfrom网页,thenstoreinSQLd atabaseaftercleaningininfomrationdetail。关键词:htmlparser;信息提取; webna 分析我有作者的先天不足。 HTML 在推出时并没有对其格式的严格定义。例如,HTML 中的标签不一定遵循 Internet 上的信息资源。随着网页数据的快速增长,网页数据成对出现,不适合以数据交换的方式从机器源头提取可用的信息资源,呈现出越来越重组的趋势。本研究使用 HtmlParser 来解释 HTML 内容。提取网页信息是一系列复杂的后续工作分析,使用天网提供的样本数据作为实验数据,可以快速完成,包括网页的自动分类、聚类、信息检索、标签间事件的快速提取链接、图像、元和标题字母跟踪和电子商务等。 1J [.网页中的大量有用信息已准备好进行后续工作。经常受到很多其他无用信息的干扰,如广告、导航栏、版权声明等。这些无用信息虽然对在网上浏览1个HtmlParser配置文件的用户有一定的功能影响,但妨碍了HtmlParser的自动采集和挖掘用于解析 HTML 文档的开放网页数据——由于网页信息本身 源代码项目小、速度快、使用方便。它只需要从HTML中提取需要的信息,不需要强大的功能。做HTML语法分析2[1. HtmlParser主要依靠Node、AbstractNode和Tag来表达HTML,因为HTML语言是用来表达网页信息的。收稿日期:2o07-O4-28 作者简介:黄颖(1981 Mon),女,2005级研究生第28卷第6期,黄颖等:HtmlParser提取网页信息27Node形成树状结构的设计与实现代表 HTML 的基础,都在 org. html解析器。在标签包中。根据要处理的目标数据不同,表示为接口Node的实现。节点定义: 不同类型的签名者。这种方式可以轻松处理页面树结构表示的其他Page对象; ②获取页面对象标签的类型。返回文档中的每个元素都是传递人类父节点、子节点和兄弟节点的方法; ③指向对应HTML文本实例的节点,通过该节点可以访问当前标签的方法; ④节点的起止位置; ⑤过滤方式; ⑥标签的起始位置、结束位置以及标签中收录的访问者访问机制。 Node分为3类: RemarkNode,表示文本信息,也可以访问其父标签和HTML中的所有注释; TagNode,标签节点,是最多样化的子标签等;并且也可以使用toHtml方法来修正节点类型,上面Tag的具体节点类就是清理TagNode标签中收录的HTML信息,由HtmlPraser来实现; TextNode,文本节点。自动添加一些未闭合的标签,使得生成的词Abs~actNode是Node的具体类实现,字符串中收录完整的格式控制信息,在页面上显示形成树状结构的作用。 AbstractNode除了显示这些信息外,并没有破坏布局,实现了预期的与body Node相关的accept、toString、toHtml、toPlain-效果。文本S。除了tring等方法,还可以实现其他基本方法,使其子类不关心具体的树操作。标签是具体分析的主要内容。标签分为网页并收录大量链接。同时,不能收录其他标签的Html-Composite Tag和简单的Tag Parser也收录LinkTag。但是,实际使用中还是有两种。前者的基类是 CompositeTag。子类包需要重新加载部分接口,主要提取27个子类型,包括BodyTag、Div、FrameSetTag、OptionTag等,以及页面的位置信息。简单的标签包括 BaseHrefFag 和 DoctypeTag。目前,网页中存在大量的超链接。这些链接包括FrameTag、ImageTag、InputTag、JspTag、MetaTag,以及很多信息。超链接的提取是网页信息检索、中文分类和ProcessingInstructionTag。 . Tag在信息抽取、单词等方面所需的准备工作6[]。如果你直接使用 HtmlParser,它就有非常重要的作用。网络上提取超链接的速度比较慢。根据 HtmlParser 的人口,现有的解析器是 HtmlParser,解析 10 个常用网页的 HTML 文本的平均时间为 6S,最多的信息传递给它,或者直接传递一个 URL 地址,例如:慢实际上达到了26s,网络Parserparser=newParser fh''ttp:#www。雅虎。 COB。这是什么情况,这对于解析大量数据的网页是不能接受的。 cn"); 如果是解析本地HTML文本信息,如果是解析本地web文档,平均响应时间稍微复杂一些。代码如下:2S。目前天网提供的数据有200G,这里我们打算用它 Stringpath="..."; // 文档所在的路径是实验对象 StringBuffersbStr=newStringBuffer0; 算法实现 BufferedReaderreader=new BufferedReader new Fil- 输入:某个网站Home地址(URL).eReader(newFile(path))); 输出:网站内页链接信息 Stringtemp=: 算法:详细流程如图1所示。while((temp=reader.readLine0) !=nul1)(1) 提取首页URL信息(若干); {(2)分析所有URL对应的页面并提取链接字母sbStr.append(temp); sbStr.append("krkn");信息,得到的Link;}(3)信息清洗后保存在数据库中。Stringresult=sbStr.toString0;如图1所示信息提取分为3个模块: ①Parserp=Parser.ereateParser(resuh,"GB2312”);部分Link提取模块,②清理提取的Link模块,③保存并初始化一个Parser实例,然后立即存储模块。该模块的具体功能如下。解析人类 HTML 内容。方法parser.extractAllN —(1)Webpage内部链接提取模块。该模块是系统odesThatAre(XXXTag.class)中HTML内容的核心之一。它实现的主要功能是使用HtmlParser的所有标签XXXTag解析出来,放到一个具体的包中,基于上述算法的递归处理部分,提取出页面上的文档,通常是.txt文件,几乎所有的HTML标签都有对应的类,比如LinkTag,ImageTag, (2)clean 已经提取了Link模块。之前提取的大量FormTag、InputTag、AppletTag等,这些标签都是Link数据,含有大量脏“数据”,不能直接用来制作江西科技大学学报2007年12月 3.2 链接已提取编号 数据清洗(data清洗或数据清洗),顾名思义就是按照一定的规则去除“脏数据”,其目的是检测错误并且不一致删除或修正数据,从而提高数据质量。数据清洗的原则: ①无论是单数据源还是多数据源,数据中所有明显的错误和不一致都必须检测并去除; ② 尽可能减少人工干预和用户编程工作量,并易于扩展到其他数据源; ③应结合数据转换; ④ 必须有相应的描述语言来指定数据转换和数据清洗操作,所有这些操作都应该在一个统一的框架下完成。数据清洗有两种方法。一种是在保存之前对文档或数据进行处理,另一种是先提取所有数据,然后再选择文档或数据库中的数据。为了使网页美观,网页设计师收录了很多无用的信息。这里,图1中的信息提取流程图被视为噪声。部分清除噪声的代码如下: BufferedReaderbr=-newBufferedReader(newFlieReader(0); 使用过,必须清除后才能使用。while((s=br.readLine0)I=nuU)( 3)Storage Module .该模块使用SQLServer存储{sb.append(s);}获取的数据,不断更新数据库,避免保存重复信息.br.close0; 3 系统实现str=-sb。 substring(start,end); 为了突出主题和介绍实现技术方便,下面的str=srt.trimO;f(str.1ength0>1)content.append(str+””);关键代码省略了 try-catch 部分和一些异常处理部分。while( i 查看全部
js提取指定网站内容 2017年第28gggg6期江西理工大学学报v
没有。 28gg6 江西科技大学学报 v. 1. 28, N. . 2007 年 12 月 6 日 JOURNALOFJIANGXIUNIVERSITYOFSCIENCEANDTECHNOLOGY 2007 年 12 月 文章 编号:1007-1229(2007)06—0026—03HtmlParser 提取网页信息的设计与实现 黄颖,黄志平,江西大学信息工程学院,1.与技术,江西赣州341000;2.赣南师范学院,江西赣州341000) 摘要:随着互联网信息量的快速增长,迫切需要一些自动化工具来快速帮助人们从标题、链接、邮件、图片等海量信息源中找到自己真正需要的信息,而HTML语言表达的网页只适合浏览器分析后浏览,不适合浏览器处理。机器作为一种数据交换的方式,文章详细介绍了如何使用HtmlParser提取网页中的超链接信息,清理干净并存储在SQL数据库中se,用于后续工作。 关键词:HtmlParser;信息提取;网页解析中文图书馆分类号:TP393、03 文档识别码:ADesignandImplementationofWeb InformationExtractionBasedonHtmlParser黄英,黄志平(1.江西理工大学信息与技术学院,中国赣州341000;2.GannnaTeachers3,中国赣州学院10000)摘要:Therapidgro〜daoftheWebcontentsincreasestheneedforsomeautomatictoolstohelppeoplefindthe informationamongthemagnanimousinfomr ationsourcessuchastides,链接,电子邮件,picturesetc.TheW ebpages expressedbyHTML,afterna alyzedbyInternetExplorer,areonlysuitableofrbrowse,butnotofrmachineprocess- ingasthewayofdataexchna ge.Th epaperexplainshow touseHtmlParsertoextracthyperlinkinfomr ationfrom网页,thenstoreinSQLd atabaseaftercleaningininfomrationdetail。关键词:htmlparser;信息提取; webna 分析我有作者的先天不足。 HTML 在推出时并没有对其格式的严格定义。例如,HTML 中的标签不一定遵循 Internet 上的信息资源。随着网页数据的快速增长,网页数据成对出现,不适合以数据交换的方式从机器源头提取可用的信息资源,呈现出越来越重组的趋势。本研究使用 HtmlParser 来解释 HTML 内容。提取网页信息是一系列复杂的后续工作分析,使用天网提供的样本数据作为实验数据,可以快速完成,包括网页的自动分类、聚类、信息检索、标签间事件的快速提取链接、图像、元和标题字母跟踪和电子商务等。 1J [.网页中的大量有用信息已准备好进行后续工作。经常受到很多其他无用信息的干扰,如广告、导航栏、版权声明等。这些无用信息虽然对在网上浏览1个HtmlParser配置文件的用户有一定的功能影响,但妨碍了HtmlParser的自动采集和挖掘用于解析 HTML 文档的开放网页数据——由于网页信息本身 源代码项目小、速度快、使用方便。它只需要从HTML中提取需要的信息,不需要强大的功能。做HTML语法分析2[1. HtmlParser主要依靠Node、AbstractNode和Tag来表达HTML,因为HTML语言是用来表达网页信息的。收稿日期:2o07-O4-28 作者简介:黄颖(1981 Mon),女,2005级研究生第28卷第6期,黄颖等:HtmlParser提取网页信息27Node形成树状结构的设计与实现代表 HTML 的基础,都在 org. html解析器。在标签包中。根据要处理的目标数据不同,表示为接口Node的实现。节点定义: 不同类型的签名者。这种方式可以轻松处理页面树结构表示的其他Page对象; ②获取页面对象标签的类型。返回文档中的每个元素都是传递人类父节点、子节点和兄弟节点的方法; ③指向对应HTML文本实例的节点,通过该节点可以访问当前标签的方法; ④节点的起止位置; ⑤过滤方式; ⑥标签的起始位置、结束位置以及标签中收录的访问者访问机制。 Node分为3类: RemarkNode,表示文本信息,也可以访问其父标签和HTML中的所有注释; TagNode,标签节点,是最多样化的子标签等;并且也可以使用toHtml方法来修正节点类型,上面Tag的具体节点类就是清理TagNode标签中收录的HTML信息,由HtmlPraser来实现; TextNode,文本节点。自动添加一些未闭合的标签,使得生成的词Abs~actNode是Node的具体类实现,字符串中收录完整的格式控制信息,在页面上显示形成树状结构的作用。 AbstractNode除了显示这些信息外,并没有破坏布局,实现了预期的与body Node相关的accept、toString、toHtml、toPlain-效果。文本S。除了tring等方法,还可以实现其他基本方法,使其子类不关心具体的树操作。标签是具体分析的主要内容。标签分为网页并收录大量链接。同时,不能收录其他标签的Html-Composite Tag和简单的Tag Parser也收录LinkTag。但是,实际使用中还是有两种。前者的基类是 CompositeTag。子类包需要重新加载部分接口,主要提取27个子类型,包括BodyTag、Div、FrameSetTag、OptionTag等,以及页面的位置信息。简单的标签包括 BaseHrefFag 和 DoctypeTag。目前,网页中存在大量的超链接。这些链接包括FrameTag、ImageTag、InputTag、JspTag、MetaTag,以及很多信息。超链接的提取是网页信息检索、中文分类和ProcessingInstructionTag。 . Tag在信息抽取、单词等方面所需的准备工作6[]。如果你直接使用 HtmlParser,它就有非常重要的作用。网络上提取超链接的速度比较慢。根据 HtmlParser 的人口,现有的解析器是 HtmlParser,解析 10 个常用网页的 HTML 文本的平均时间为 6S,最多的信息传递给它,或者直接传递一个 URL 地址,例如:慢实际上达到了26s,网络Parserparser=newParser fh''ttp:#www。雅虎。 COB。这是什么情况,这对于解析大量数据的网页是不能接受的。 cn"); 如果是解析本地HTML文本信息,如果是解析本地web文档,平均响应时间稍微复杂一些。代码如下:2S。目前天网提供的数据有200G,这里我们打算用它 Stringpath="..."; // 文档所在的路径是实验对象 StringBuffersbStr=newStringBuffer0; 算法实现 BufferedReaderreader=new BufferedReader new Fil- 输入:某个网站Home地址(URL).eReader(newFile(path))); 输出:网站内页链接信息 Stringtemp=: 算法:详细流程如图1所示。while((temp=reader.readLine0) !=nul1)(1) 提取首页URL信息(若干); {(2)分析所有URL对应的页面并提取链接字母sbStr.append(temp); sbStr.append("krkn");信息,得到的Link;}(3)信息清洗后保存在数据库中。Stringresult=sbStr.toString0;如图1所示信息提取分为3个模块: ①Parserp=Parser.ereateParser(resuh,"GB2312”);部分Link提取模块,②清理提取的Link模块,③保存并初始化一个Parser实例,然后立即存储模块。该模块的具体功能如下。解析人类 HTML 内容。方法parser.extractAllN —(1)Webpage内部链接提取模块。该模块是系统odesThatAre(XXXTag.class)中HTML内容的核心之一。它实现的主要功能是使用HtmlParser的所有标签XXXTag解析出来,放到一个具体的包中,基于上述算法的递归处理部分,提取出页面上的文档,通常是.txt文件,几乎所有的HTML标签都有对应的类,比如LinkTag,ImageTag, (2)clean 已经提取了Link模块。之前提取的大量FormTag、InputTag、AppletTag等,这些标签都是Link数据,含有大量脏“数据”,不能直接用来制作江西科技大学学报2007年12月 3.2 链接已提取编号 数据清洗(data清洗或数据清洗),顾名思义就是按照一定的规则去除“脏数据”,其目的是检测错误并且不一致删除或修正数据,从而提高数据质量。数据清洗的原则: ①无论是单数据源还是多数据源,数据中所有明显的错误和不一致都必须检测并去除; ② 尽可能减少人工干预和用户编程工作量,并易于扩展到其他数据源; ③应结合数据转换; ④ 必须有相应的描述语言来指定数据转换和数据清洗操作,所有这些操作都应该在一个统一的框架下完成。数据清洗有两种方法。一种是在保存之前对文档或数据进行处理,另一种是先提取所有数据,然后再选择文档或数据库中的数据。为了使网页美观,网页设计师收录了很多无用的信息。这里,图1中的信息提取流程图被视为噪声。部分清除噪声的代码如下: BufferedReaderbr=-newBufferedReader(newFlieReader(0); 使用过,必须清除后才能使用。while((s=br.readLine0)I=nuU)( 3)Storage Module .该模块使用SQLServer存储{sb.append(s);}获取的数据,不断更新数据库,避免保存重复信息.br.close0; 3 系统实现str=-sb。 substring(start,end); 为了突出主题和介绍实现技术方便,下面的str=srt.trimO;f(str.1ength0>1)content.append(str+””);关键代码省略了 try-catch 部分和一些异常处理部分。while( i
gitpull查看提取地址和提取历史记录的方法-gitpull.txt
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-06-02 06:02
js提取指定网站内容的方法可以通过chrome浏览器控制台提取,并且浏览器控制台也是必不可少的,其他方法如es5等方法需要开启require才可以使用,下面给大家介绍使用gitpull查看提取地址和提取历史记录的方法。
一、用gitpull方法查看提取地址
1、commit个html或txt文件。
2、提交到github后,选择关注链接并在地址栏右侧显示提取的记录的id。
3、为actions中地址的每个html、txt文件生成一个命名的tags_id标签,新建一个文件查看对应github已提交的代码库内容是否与提取的要求相同。
二、用webclipboard方法查看提取地址
1、在web浏览器中登录github网站的clipboard插件提取,会发现extension那一栏下的tags_id中已有已上传的内容代码。
2、注意要执行webclipboard之前保证已经在github已上传的代码库中获取到了与代码库中tag_id匹配的content_local.txt内容。
3、在点击ok时,会出现该代码一次性全部提取的提示。
4、点击continue继续后,即可在代码库中按照要求查看代码库,随后执行url到指定网站内搜索下载即可。
5、执行完成后的结果如下图所示,最终的提取内容为extension点击ok之后生成的标签标签为id。
6、如果有更多content_local.txt,可同时使用到webclipboard和github中进行查看。以上就是关于gitpull查看提取地址和提取历史记录的方法,如果需要更多content_local.txt可同时使用webclipboard及github中进行查看。 查看全部
gitpull查看提取地址和提取历史记录的方法-gitpull.txt
js提取指定网站内容的方法可以通过chrome浏览器控制台提取,并且浏览器控制台也是必不可少的,其他方法如es5等方法需要开启require才可以使用,下面给大家介绍使用gitpull查看提取地址和提取历史记录的方法。
一、用gitpull方法查看提取地址
1、commit个html或txt文件。
2、提交到github后,选择关注链接并在地址栏右侧显示提取的记录的id。
3、为actions中地址的每个html、txt文件生成一个命名的tags_id标签,新建一个文件查看对应github已提交的代码库内容是否与提取的要求相同。
二、用webclipboard方法查看提取地址
1、在web浏览器中登录github网站的clipboard插件提取,会发现extension那一栏下的tags_id中已有已上传的内容代码。
2、注意要执行webclipboard之前保证已经在github已上传的代码库中获取到了与代码库中tag_id匹配的content_local.txt内容。
3、在点击ok时,会出现该代码一次性全部提取的提示。
4、点击continue继续后,即可在代码库中按照要求查看代码库,随后执行url到指定网站内搜索下载即可。
5、执行完成后的结果如下图所示,最终的提取内容为extension点击ok之后生成的标签标签为id。
6、如果有更多content_local.txt,可同时使用到webclipboard和github中进行查看。以上就是关于gitpull查看提取地址和提取历史记录的方法,如果需要更多content_local.txt可同时使用webclipboard及github中进行查看。
httpClient2988怎样获取网页中js执行完后的网页源码
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-05-29 21:31
网页中执行js后httpClient如何获取网页源代码?本帖最后由 michael2988 编辑 2010-11-2218:42:20。最近在用httpClient抓取网页源码的时候,如果源码是静态的,可以全部抓取。但是如果源码中收录js,httpClient抓取的源码中不收录js,获取的源码是错误的。在网页中执行js后如何获取网页的源代码,例如获取网页的源代码。我在论坛上看到的解决办法是:调用一个浏览器组件来完成这个东西,然后js执行完后取其内容;如何实现呢?希望高手指点。 . . ------最佳解决方案-------------------------------------- - --------------- 单独httpclient是做不到的,只能抓取最原创的数据--其他解决方案----- --------- ----------------------------------------- -httpClient 捕获服务器的输出,这不是js执行后的最终结果吗? ------其他解决方案----------------------------------------- - -------------- 没有,比如我想抓取邮箱首页的源代码,只得到下面的一小段:html head meta http-equiv= refresh content= url= /cgi-bin/loginpage/head /html ------其他解决办法-------------------------------- -- ---------------------- 在后面的过程中,我也在找资料获取js分页页面的数据,但是没有完全没有。
------其他解决方案-------------------------------------- - ----------------- 引用: 这不是单独httpclient能做到的,只能抓取最原创的数据------其他解决方案-- ---------------------------------------------- ---- ---- 用 htmlunit 试试------其他解决方案---------------------------- ------- -------------------- 引用: 这个单独httpclient是做不到的,只能抓取最原创的数据 怎么办,能不能给点思路! ------其他解决方案------------------------------------------ -------------- 引用:最近使用httpClient抓取网页源码时,如果源码是静态的,可以全部抓取,但是如果源码中收录js, httpClient抓取的源码不收录js,获取的源码有误。在网页中执行js后如何获取网页的源代码,例如获取网页的源代码。
我在论坛上看到了一个解决方案:调用浏览器组件来完成此任务,然后在执行js之后获取内容;如何实现呢?希望高手指点。 . 楼主,你还没有实现,可以分享一些想法吗! ------其他解决方案----------------------------------------- - --------------所有者,为什么不出现?问题解决了吗?我也遇到这个问题,请赐教! ------其他解决方案------------------------------------------ -------------- 尝试使用浏览器网页另存为 ------ 其他解决办法 ---------- -- --------------------- 原创海报,请赐教。------其他解决方案 - - - - - - - - - - - - - - - - - - - - - - - - - -------您只能手动省力。很不科学。我们想要得到的是活的价值。并且可以读取js中的内容。现在发生的事情是请求中的数据不会有js的内容。其他数据根本没用。
有什么方法可以让js数据可用?我真的很想知道这个问题。或者谁能做到。我可以付钱雇人。 ------其他解决方案------------------------------------------ -------------- 引用:您只能另存为手册。很不科学。我们想要得到的是活的价值。并且可以读取js内容。目前的情况是请求的数据不会有js的内容。其他数据根本没用。什么方法可以制作js数据?我真的很想知道这个问题。或者谁能做到。我可以付钱雇人。你要付多少钱。我会的,您可以给我发送电子邮件, 查看全部
httpClient2988怎样获取网页中js执行完后的网页源码
网页中执行js后httpClient如何获取网页源代码?本帖最后由 michael2988 编辑 2010-11-2218:42:20。最近在用httpClient抓取网页源码的时候,如果源码是静态的,可以全部抓取。但是如果源码中收录js,httpClient抓取的源码中不收录js,获取的源码是错误的。在网页中执行js后如何获取网页的源代码,例如获取网页的源代码。我在论坛上看到的解决办法是:调用一个浏览器组件来完成这个东西,然后js执行完后取其内容;如何实现呢?希望高手指点。 . . ------最佳解决方案-------------------------------------- - --------------- 单独httpclient是做不到的,只能抓取最原创的数据--其他解决方案----- --------- ----------------------------------------- -httpClient 捕获服务器的输出,这不是js执行后的最终结果吗? ------其他解决方案----------------------------------------- - -------------- 没有,比如我想抓取邮箱首页的源代码,只得到下面的一小段:html head meta http-equiv= refresh content= url= /cgi-bin/loginpage/head /html ------其他解决办法-------------------------------- -- ---------------------- 在后面的过程中,我也在找资料获取js分页页面的数据,但是没有完全没有。
------其他解决方案-------------------------------------- - ----------------- 引用: 这不是单独httpclient能做到的,只能抓取最原创的数据------其他解决方案-- ---------------------------------------------- ---- ---- 用 htmlunit 试试------其他解决方案---------------------------- ------- -------------------- 引用: 这个单独httpclient是做不到的,只能抓取最原创的数据 怎么办,能不能给点思路! ------其他解决方案------------------------------------------ -------------- 引用:最近使用httpClient抓取网页源码时,如果源码是静态的,可以全部抓取,但是如果源码中收录js, httpClient抓取的源码不收录js,获取的源码有误。在网页中执行js后如何获取网页的源代码,例如获取网页的源代码。
我在论坛上看到了一个解决方案:调用浏览器组件来完成此任务,然后在执行js之后获取内容;如何实现呢?希望高手指点。 . 楼主,你还没有实现,可以分享一些想法吗! ------其他解决方案----------------------------------------- - --------------所有者,为什么不出现?问题解决了吗?我也遇到这个问题,请赐教! ------其他解决方案------------------------------------------ -------------- 尝试使用浏览器网页另存为 ------ 其他解决办法 ---------- -- --------------------- 原创海报,请赐教。------其他解决方案 - - - - - - - - - - - - - - - - - - - - - - - - - -------您只能手动省力。很不科学。我们想要得到的是活的价值。并且可以读取js中的内容。现在发生的事情是请求中的数据不会有js的内容。其他数据根本没用。
有什么方法可以让js数据可用?我真的很想知道这个问题。或者谁能做到。我可以付钱雇人。 ------其他解决方案------------------------------------------ -------------- 引用:您只能另存为手册。很不科学。我们想要得到的是活的价值。并且可以读取js内容。目前的情况是请求的数据不会有js的内容。其他数据根本没用。什么方法可以制作js数据?我真的很想知道这个问题。或者谁能做到。我可以付钱雇人。你要付多少钱。我会的,您可以给我发送电子邮件,
js提取指定网站内容是javascriptcodepancakes如何实现转html转pdf-css
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-05-22 18:01
js提取指定网站内容一般有httpexplorer转码功能,可以指定文件路径。jsjavascript转换可以用openxmlrphtmlcode接口,有ejs和webpack,openxmlrphtmlcode其实就是从webpack里去追加内容,做了几个小扩展就成一个大的格式转换器了,可以转换的npapi一样的。
当然也可以用json转html,方法基本上和webpack一样,至于想要html格式页面效果转化成xml就要用browserify来转,webpack看看就好了。
微信文章编辑器,直接转pdf如果是web端的话,我觉得提取文章html再转pdf比较简单一些~毕竟我们转html的时候,都要根据html的结构去解析。
也可以用veer转换的/
js转html具体是javascriptcodepancakes如何实现js转html转pdf-css/css/resources/atginc...
w3pack好像可以
不能,因为html转pdf要求ie9及以上,
谢邀。首先你对html转js有了清晰的认识,其次说明你已经掌握一些最基本的知识。这里我推荐@misswu的答案。
wordpress里的htmlpdfplugin已经封装好了,大部分工具都能用。
基本工具:markdownonwebmindbeonhtml,css,js 查看全部
js提取指定网站内容是javascriptcodepancakes如何实现转html转pdf-css
js提取指定网站内容一般有httpexplorer转码功能,可以指定文件路径。jsjavascript转换可以用openxmlrphtmlcode接口,有ejs和webpack,openxmlrphtmlcode其实就是从webpack里去追加内容,做了几个小扩展就成一个大的格式转换器了,可以转换的npapi一样的。
当然也可以用json转html,方法基本上和webpack一样,至于想要html格式页面效果转化成xml就要用browserify来转,webpack看看就好了。
微信文章编辑器,直接转pdf如果是web端的话,我觉得提取文章html再转pdf比较简单一些~毕竟我们转html的时候,都要根据html的结构去解析。
也可以用veer转换的/
js转html具体是javascriptcodepancakes如何实现js转html转pdf-css/css/resources/atginc...
w3pack好像可以
不能,因为html转pdf要求ie9及以上,
谢邀。首先你对html转js有了清晰的认识,其次说明你已经掌握一些最基本的知识。这里我推荐@misswu的答案。
wordpress里的htmlpdfplugin已经封装好了,大部分工具都能用。
基本工具:markdownonwebmindbeonhtml,css,js
吃鸡ing,让我去他们用的什么js框架
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-05-20 22:24
昨天我在吃鸡肉,而3次杀戮即将进入决赛。突然,老师抛出了三个网站链接,让我检查他们使用了什么js框架。 。
合理,当我第一次看到这个问题时,我的头皮发麻了
如何通过网页看到它是什么样的框架?难道不是每个人都封装了它吗?
所有写这个网站的人都傻吗?只让您看看核心js框架?
经过两天的实验和检查信息,似乎可以看到它。毕竟,没有人是完美的,总是有一百个秘密。
当然,这些只是我尝试过的一些方法。我的问题已解决,但不能保证所有问题都会得到解决。如果遇到包装合理的网站,请接受命运。
当您第一次开始搜索时,其他人的博客或论坛会给您很多网站,让您输入网站,您可以看到网站的核心技术,这是合理的,真的没有用于鸡蛋。
例如,我尝试过的那个:
操作非常简单,您只需要输入URL,然后查看返回的内容
这些是网站它返回给我的所有技术,但这不是我想要的o((>ω
还有另一个问题。如果框架是ASP.NET,则网页访问应具有相应的后缀,例如:.aspx,ashx等。
我认为这件事让我很烦...
后来,我试图在google上用英语搜索这些类型的问题。有人告诉我要通过经验来获取它,也就是说,您应该了解更多有关该框架的知识,了解每个框架的特征和关键字,然后您可以一眼就知道这一点。它是由该框架编写的。 。 。说到框架,您可以看一下我的其他博客,看看有多少个前端框架。另一种是将代码发布到Github上,并使用html本机函数document.querySelector()获取dom信息。主要原理类似于第一人称的意思。
可以归结为:不同的框架具有由不同的框架使用的特定关键字。例如,在Angular中,我们使用“ ng- *”作为特定的指令标识符,在React中,我们使用reactid和其他标识符,然后您可以通过搜索这些关键字来获取网站的框架(当然,此方法不是万能药,但也是有效的方法一)
代码如下:
if(!!window.React ||
!!document.querySelector('[data-reactroot], [data-reactid]'))
console.log('React.js');
if(!!window.angular ||
!!document.querySelector('.ng-binding, [ng-app], [data-ng-app], [ng-controller], [data-ng-controller], [ng-repeat], [data-ng-repeat]') ||
!!document.querySelector('script[src*="angular.js"], script[src*="angular.min.js"]'))
console.log('Angular.js');
if(!!window.Backbone) console.log('Backbone.js');
if(!!window.Ember) console.log('Ember.js');
if(!!window.Vue||!!document.querySelector('[v-if],[v-for],[v-show]')) console.log('Vue.js');
if(!!window.Meteor) console.log('Meteor.js');
if(!!window.Zepto) console.log('Zepto.js');
if(!!window.jQuery) console.log('jQuery.js');
将上述代码直接注入控制台
它将直接打印出您的前端js框架,但是对于某些无法使用的页面,您需要一个一个地打开多个页面。我测试了以前用Angular编写的项目,但首页上的测试失败,但是当您单击以打开登录页面时,它将直接显示。您必须对这种方法有耐心。
当然,对于某些网站,无论您测试多少,它都不会起作用。此时,您必须单击Sources来阅读代码。
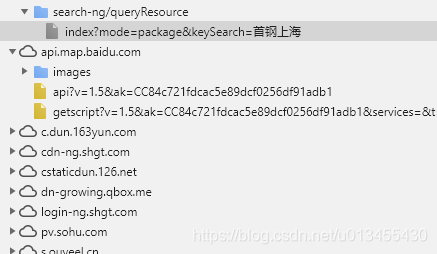
估计对于不同的框架有不同的参考文件,但是我仍然仔细地查找它。我搜索了此页面的登录界面,然后发现在请求界面的地方调用了其他框架,因此我确定了此网站框架
所有来到网站前端js框架以使用Zepto的人,当然,这只是我的解决方案,也许大个子有更好的解决方案,请分享
总结:我觉得无论如何这项技能似乎都没用,但是老师在完成后不能放手,所以就去做吧 查看全部
吃鸡ing,让我去他们用的什么js框架
昨天我在吃鸡肉,而3次杀戮即将进入决赛。突然,老师抛出了三个网站链接,让我检查他们使用了什么js框架。 。
合理,当我第一次看到这个问题时,我的头皮发麻了
如何通过网页看到它是什么样的框架?难道不是每个人都封装了它吗?
所有写这个网站的人都傻吗?只让您看看核心js框架?
经过两天的实验和检查信息,似乎可以看到它。毕竟,没有人是完美的,总是有一百个秘密。
当然,这些只是我尝试过的一些方法。我的问题已解决,但不能保证所有问题都会得到解决。如果遇到包装合理的网站,请接受命运。
当您第一次开始搜索时,其他人的博客或论坛会给您很多网站,让您输入网站,您可以看到网站的核心技术,这是合理的,真的没有用于鸡蛋。
例如,我尝试过的那个:
操作非常简单,您只需要输入URL,然后查看返回的内容
这些是网站它返回给我的所有技术,但这不是我想要的o((>ω
还有另一个问题。如果框架是ASP.NET,则网页访问应具有相应的后缀,例如:.aspx,ashx等。
我认为这件事让我很烦...
后来,我试图在google上用英语搜索这些类型的问题。有人告诉我要通过经验来获取它,也就是说,您应该了解更多有关该框架的知识,了解每个框架的特征和关键字,然后您可以一眼就知道这一点。它是由该框架编写的。 。 。说到框架,您可以看一下我的其他博客,看看有多少个前端框架。另一种是将代码发布到Github上,并使用html本机函数document.querySelector()获取dom信息。主要原理类似于第一人称的意思。
可以归结为:不同的框架具有由不同的框架使用的特定关键字。例如,在Angular中,我们使用“ ng- *”作为特定的指令标识符,在React中,我们使用reactid和其他标识符,然后您可以通过搜索这些关键字来获取网站的框架(当然,此方法不是万能药,但也是有效的方法一)
代码如下:
if(!!window.React ||
!!document.querySelector('[data-reactroot], [data-reactid]'))
console.log('React.js');
if(!!window.angular ||
!!document.querySelector('.ng-binding, [ng-app], [data-ng-app], [ng-controller], [data-ng-controller], [ng-repeat], [data-ng-repeat]') ||
!!document.querySelector('script[src*="angular.js"], script[src*="angular.min.js"]'))
console.log('Angular.js');
if(!!window.Backbone) console.log('Backbone.js');
if(!!window.Ember) console.log('Ember.js');
if(!!window.Vue||!!document.querySelector('[v-if],[v-for],[v-show]')) console.log('Vue.js');
if(!!window.Meteor) console.log('Meteor.js');
if(!!window.Zepto) console.log('Zepto.js');
if(!!window.jQuery) console.log('jQuery.js');
将上述代码直接注入控制台

它将直接打印出您的前端js框架,但是对于某些无法使用的页面,您需要一个一个地打开多个页面。我测试了以前用Angular编写的项目,但首页上的测试失败,但是当您单击以打开登录页面时,它将直接显示。您必须对这种方法有耐心。
当然,对于某些网站,无论您测试多少,它都不会起作用。此时,您必须单击Sources来阅读代码。
估计对于不同的框架有不同的参考文件,但是我仍然仔细地查找它。我搜索了此页面的登录界面,然后发现在请求界面的地方调用了其他框架,因此我确定了此网站框架

所有来到网站前端js框架以使用Zepto的人,当然,这只是我的解决方案,也许大个子有更好的解决方案,请分享
总结:我觉得无论如何这项技能似乎都没用,但是老师在完成后不能放手,所以就去做吧
Javascript获取网页中HTML元素的集中方法分析(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-05-19 01:02
如何通过js获取HTML元素节点本文关键词:节点,元素,获取,方法,js
js方法可获取HTML元素节点。本文简介:分析通过Javascript获取网页中HTML元素的集中方法。 getElementById,getElementsByName和getElementsByTagName将引入getElementById,getElementsByName和getElementsByTagName。
如何通过js获取HTML元素的节点
使用Javascript获取网页HTML元素的集中方法分析
getElementById
getElementsByName
getElementsByTagName
关于简介
getElementById
,getElementsByName
,getElementsByTagName
最后两个是要获取一个集合,而byid只能是一个对象
getElementById
用法
例如:
网络陶艺酒吧
如何在同一页面中引用:
1、使用ID:
link 1. href,返回值为
2、使用名称:
document.all.linkname 1. href,返回值为
3、使用sourseIndex:
document.all(4) .href
//请注意,前面有HTML,HEAD,TITLE和BODY,所以它是4
4、使用链接采集:
document.anchors(0) .href
//所有集合包括全部,锚点,小程序,区域,属性,behaviorUrns,书签,boundElements,单元格,childNodes,子项,controlRange,元素,嵌入,过滤器,表单,框架,图像,导入,链接,mimeTypes,选项,插件,行,规则,脚本,styleSheets,tBodies,TextRectangle,请参阅MSDN简介。
实际上,方法3和方法4是相同的集合,只不过一个是全部,可以收录页面上的所有标签,而锚点仅收录链接。
5、 getElementById:
document.getElementById(“ link1”)。href
6、 getElementsByName:
document.getElementsByName(“ linkname1”)[0] .href
//这也是一个集合,即名称等于方法参数的所有标记的集合
7、 getElementsByTagName:
document.getElementsByTagName(“ A”)[0] .href
//这也是一个集合,所有标记名称等于该方法的参数的所有标记的集合
8、标签集合:
document.all.tags(“ A”)[0] .href
//与方法7相同,是通过标记名称获取集合
除:
event.scrElement可以获取对触发时间标签的引用;
document.elementFromPoint(x,y)可以获取元素在x和y坐标处的引用;
ponentFromPoint(event.clientX,event.clientY)可以获取对鼠标所在元素的引用;
您还可以引用元素的父子节点和同级节点的关系,例如nextSibling(当前节点的下一个节点),previousSibling(当前节点的上一个节点),childNodes,children,firstChild,lastChild ,parentElement等。对父子节点和兄弟节点的一些引用;不限于此。
以上是同一页面中的常见引用方法,也涉及到不同的页面
getElementsByName返回名称为指定值的所有元素的集合
“根据
NAME
tag属性的值获取对象的集合。 “
集合比数组宽松得多。集合中每个项目的类型可以不同。该集合只是将某些元素放在一起作为一个类别。相反,数组要严格得多。这是统一类型。
document.getElementsByName,document.getElementsByTagName,document.formName.elements
通过这种方法获得的结果都是集合。
示例:
代码
鱼
功能
get(){
var
xx = document.getElementById(“ bbs”)
alert(“标签名称:” + xx.tagName);
}
功能
getElementName(){
var
ele
=
document.getElementsByName(“ happy”);
alert(“不带元素的快乐数:” +
ele.length);
}
获取文件指定的元素
document.getElementsByName()此方法。它以相同的方式对待一个和多个,我们可以使用:
温度
=
document.getElementsByName(
开心
)引用
当只有一个Temp时,则为Temp [0]。如果有多个,则使用下标方法Temp [i]循环获取
有例外:
在即
在getElementsByName(“ test”)中,它返回id = test的对象数组,而firefox返回name =
一组测试对象。
根据w3c的规范,它应返回name =
一组测试对象。
firefox中的getElementByID与ie相同:正确获取
ID
tag属性是对指定值的第一个对象的引用。
请注意getElementsByName
里面有s
document.getElementById()可以控制某个ID的标签
document.getElementsByName(),返回的文件具有相同的
名称
不是一个特定的属性元素的集合,请注意“ s”。
和
document.getElementsByTagName()
返回的是一组相同的
标签
的集合
元素。
同一个名称可以收录多个元素,因此请使用document.getElementsByName(“ theName”)
他回来了
引用时,集合必须命名为索引
var
测试
=
document.getElementsByName(
testButton
)[0];
ID是唯一的
还应注意,类似属性没有名称属性,而其名称属性是伪属性document.getElementsByName()
这将是无效的,当然TD可以设置ID属性
JavaScript获取HTML
DOM节点元素方法概述
在Web应用程序(尤其是Web 2. 0程序)的开发中,通常需要在页面中获取一个元素,然后更新该元素的样式和内容。如何获得要更新的元素是要解决的第一个问题。好消息是,有很多方法可以使用JavaScript获取节点。这是一个简短的摘要(以下方法已在IE7和Firefox 2. 0. 0. 11中进行了测试):
1.
获取顶级文档节点:
([1)
document.getElementById(elementId):此方法可以通过节点的ID准确获取所需的元素。这是一个相对简单快捷的方法。如果页面上有多个具有相同ID的节点,则仅返回第一个节点。
如今,已经有许多JavaScript库,例如prototype和Mootools,它们提供了更方便的方法:$(id),参数仍然是节点的id。该方法可以看作是另一种编写document.getElementById()的方法,但是$()的功能更强大。有关特定用法,请参阅其各自的API文档。
([2) document.getElementsByName(elementName):此方法是根据节点名称获取节点。从名称中可以看出,此方法不返回节点元素,而是返回具有以下内容的节点数组然后,我们可以通过获取节点的某个属性来周期性地判断它是否是必需节点。
例如:在HTML中,复选框和单选框都使用相同的名称属性值来标识组中的元素。如果要立即获取选定的元素,请首先获取经过改组的元素,然后循环以确定该节点的选中属性值是否为真。
([3) document.getElementsByTagName(tagName):此方法是通过节点的标记获取节点,并且该方法还返回一个数组,例如:document.getElementsByTagName(
A
)将返回到页面上的所有超链接节点。在获取节点之前,通常会知道节点的类型,因此使用此方法相对简单。但是缺点也很明显,即返回的数组可能非常大,这将浪费大量时间。那么,这种方法没用吗?当然不是。此方法与以上两种方法不同。它不是文档节点的专有方法。也可以应用其他节点,下面将对此进行介绍。
2、通过父节点获得:
([1) parentObj.firstChild:如果该节点是已知节点(parentObj)的第一个子节点,则可以使用此方法。此属性可以递归使用,即它支持parentObj.firstChild.firstChild。 firstChild的形式为。,因此您可以获得更深的节点。
([2) parentObj.lastChild:显然,此属性用于获取已知节点的最后一个子节点(parentObj)。与firstChild一样,它也可以递归使用。
在使用中,如果将两者结合使用,将会获得更加令人兴奋的效果,即:parentObj.firstChild.lastChild.lastChild。
([3) parentObj.childNodes:获取已知节点的子节点数组,然后可以通过循环或索引找到所需的节点。
注意:经过测试,发现直接子节点的数组是在IE7上获得的,所有子节点都是在Firefox 2. 0. 0. 11上获得的,包括子节点。
([4) parentObj.children:获取已知节点的直接子节点数组。
注意:经过测试,它具有与IE7上的childNodes相同的效果,但是Firefox 2. 0. 0. 11不支持它。这就是为什么我使用与其他方法不同的样式的原因。因此,不建议这样做。
([5) parentObj.getElementsByTagName(tagName):不会重复使用该方法,它返回已知节点的所有子节点中具有指定值的子节点的数组。例如:parentObj.getElementsByTagName(
A
)返回已知子节点中的所有超链接。
3、从相邻节点获得:
([1) neighbourNode.previousSibling:获取已知节点的前一个节点(neighbourNode),此属性似乎像前一个firstChild和lastChild一样可以递归使用。
([2) neighbourNode.nextSibling:获取已知节点的下一个节点(neighbourNode),它也支持递归。
4、通过子节点获得:
([1) childNode.parentNode:获取已知节点的父节点。
上述方法只是一些基本方法。如果使用JavaScript库(例如Prototype),则还可以获取其他不同的方法,例如通过节点的类获取。但是,如果您可以灵活使用上述方法,我相信它应该能够处理大多数程序 查看全部
Javascript获取网页中HTML元素的集中方法分析(组图)
如何通过js获取HTML元素节点本文关键词:节点,元素,获取,方法,js
js方法可获取HTML元素节点。本文简介:分析通过Javascript获取网页中HTML元素的集中方法。 getElementById,getElementsByName和getElementsByTagName将引入getElementById,getElementsByName和getElementsByTagName。
如何通过js获取HTML元素的节点
使用Javascript获取网页HTML元素的集中方法分析
getElementById
getElementsByName
getElementsByTagName
关于简介
getElementById
,getElementsByName
,getElementsByTagName
最后两个是要获取一个集合,而byid只能是一个对象
getElementById
用法
例如:
网络陶艺酒吧
如何在同一页面中引用:
1、使用ID:
link 1. href,返回值为
2、使用名称:
document.all.linkname 1. href,返回值为
3、使用sourseIndex:
document.all(4) .href
//请注意,前面有HTML,HEAD,TITLE和BODY,所以它是4
4、使用链接采集:
document.anchors(0) .href
//所有集合包括全部,锚点,小程序,区域,属性,behaviorUrns,书签,boundElements,单元格,childNodes,子项,controlRange,元素,嵌入,过滤器,表单,框架,图像,导入,链接,mimeTypes,选项,插件,行,规则,脚本,styleSheets,tBodies,TextRectangle,请参阅MSDN简介。
实际上,方法3和方法4是相同的集合,只不过一个是全部,可以收录页面上的所有标签,而锚点仅收录链接。
5、 getElementById:
document.getElementById(“ link1”)。href
6、 getElementsByName:
document.getElementsByName(“ linkname1”)[0] .href
//这也是一个集合,即名称等于方法参数的所有标记的集合
7、 getElementsByTagName:
document.getElementsByTagName(“ A”)[0] .href
//这也是一个集合,所有标记名称等于该方法的参数的所有标记的集合
8、标签集合:
document.all.tags(“ A”)[0] .href
//与方法7相同,是通过标记名称获取集合
除:
event.scrElement可以获取对触发时间标签的引用;
document.elementFromPoint(x,y)可以获取元素在x和y坐标处的引用;
ponentFromPoint(event.clientX,event.clientY)可以获取对鼠标所在元素的引用;
您还可以引用元素的父子节点和同级节点的关系,例如nextSibling(当前节点的下一个节点),previousSibling(当前节点的上一个节点),childNodes,children,firstChild,lastChild ,parentElement等。对父子节点和兄弟节点的一些引用;不限于此。
以上是同一页面中的常见引用方法,也涉及到不同的页面
getElementsByName返回名称为指定值的所有元素的集合
“根据
NAME
tag属性的值获取对象的集合。 “
集合比数组宽松得多。集合中每个项目的类型可以不同。该集合只是将某些元素放在一起作为一个类别。相反,数组要严格得多。这是统一类型。
document.getElementsByName,document.getElementsByTagName,document.formName.elements
通过这种方法获得的结果都是集合。
示例:
代码
鱼
功能
get(){
var
xx = document.getElementById(“ bbs”)
alert(“标签名称:” + xx.tagName);
}
功能
getElementName(){
var
ele
=
document.getElementsByName(“ happy”);
alert(“不带元素的快乐数:” +
ele.length);
}
获取文件指定的元素
document.getElementsByName()此方法。它以相同的方式对待一个和多个,我们可以使用:
温度
=
document.getElementsByName(
开心
)引用
当只有一个Temp时,则为Temp [0]。如果有多个,则使用下标方法Temp [i]循环获取
有例外:
在即
在getElementsByName(“ test”)中,它返回id = test的对象数组,而firefox返回name =
一组测试对象。
根据w3c的规范,它应返回name =
一组测试对象。
firefox中的getElementByID与ie相同:正确获取
ID
tag属性是对指定值的第一个对象的引用。
请注意getElementsByName
里面有s
document.getElementById()可以控制某个ID的标签
document.getElementsByName(),返回的文件具有相同的
名称
不是一个特定的属性元素的集合,请注意“ s”。
和
document.getElementsByTagName()
返回的是一组相同的
标签
的集合
元素。
同一个名称可以收录多个元素,因此请使用document.getElementsByName(“ theName”)
他回来了
引用时,集合必须命名为索引
var
测试
=
document.getElementsByName(
testButton
)[0];
ID是唯一的
还应注意,类似属性没有名称属性,而其名称属性是伪属性document.getElementsByName()
这将是无效的,当然TD可以设置ID属性
JavaScript获取HTML
DOM节点元素方法概述
在Web应用程序(尤其是Web 2. 0程序)的开发中,通常需要在页面中获取一个元素,然后更新该元素的样式和内容。如何获得要更新的元素是要解决的第一个问题。好消息是,有很多方法可以使用JavaScript获取节点。这是一个简短的摘要(以下方法已在IE7和Firefox 2. 0. 0. 11中进行了测试):
1.
获取顶级文档节点:
([1)
document.getElementById(elementId):此方法可以通过节点的ID准确获取所需的元素。这是一个相对简单快捷的方法。如果页面上有多个具有相同ID的节点,则仅返回第一个节点。
如今,已经有许多JavaScript库,例如prototype和Mootools,它们提供了更方便的方法:$(id),参数仍然是节点的id。该方法可以看作是另一种编写document.getElementById()的方法,但是$()的功能更强大。有关特定用法,请参阅其各自的API文档。
([2) document.getElementsByName(elementName):此方法是根据节点名称获取节点。从名称中可以看出,此方法不返回节点元素,而是返回具有以下内容的节点数组然后,我们可以通过获取节点的某个属性来周期性地判断它是否是必需节点。
例如:在HTML中,复选框和单选框都使用相同的名称属性值来标识组中的元素。如果要立即获取选定的元素,请首先获取经过改组的元素,然后循环以确定该节点的选中属性值是否为真。
([3) document.getElementsByTagName(tagName):此方法是通过节点的标记获取节点,并且该方法还返回一个数组,例如:document.getElementsByTagName(
A
)将返回到页面上的所有超链接节点。在获取节点之前,通常会知道节点的类型,因此使用此方法相对简单。但是缺点也很明显,即返回的数组可能非常大,这将浪费大量时间。那么,这种方法没用吗?当然不是。此方法与以上两种方法不同。它不是文档节点的专有方法。也可以应用其他节点,下面将对此进行介绍。
2、通过父节点获得:
([1) parentObj.firstChild:如果该节点是已知节点(parentObj)的第一个子节点,则可以使用此方法。此属性可以递归使用,即它支持parentObj.firstChild.firstChild。 firstChild的形式为。,因此您可以获得更深的节点。
([2) parentObj.lastChild:显然,此属性用于获取已知节点的最后一个子节点(parentObj)。与firstChild一样,它也可以递归使用。
在使用中,如果将两者结合使用,将会获得更加令人兴奋的效果,即:parentObj.firstChild.lastChild.lastChild。
([3) parentObj.childNodes:获取已知节点的子节点数组,然后可以通过循环或索引找到所需的节点。
注意:经过测试,发现直接子节点的数组是在IE7上获得的,所有子节点都是在Firefox 2. 0. 0. 11上获得的,包括子节点。
([4) parentObj.children:获取已知节点的直接子节点数组。
注意:经过测试,它具有与IE7上的childNodes相同的效果,但是Firefox 2. 0. 0. 11不支持它。这就是为什么我使用与其他方法不同的样式的原因。因此,不建议这样做。
([5) parentObj.getElementsByTagName(tagName):不会重复使用该方法,它返回已知节点的所有子节点中具有指定值的子节点的数组。例如:parentObj.getElementsByTagName(
A
)返回已知子节点中的所有超链接。
3、从相邻节点获得:
([1) neighbourNode.previousSibling:获取已知节点的前一个节点(neighbourNode),此属性似乎像前一个firstChild和lastChild一样可以递归使用。
([2) neighbourNode.nextSibling:获取已知节点的下一个节点(neighbourNode),它也支持递归。
4、通过子节点获得:
([1) childNode.parentNode:获取已知节点的父节点。
上述方法只是一些基本方法。如果使用JavaScript库(例如Prototype),则还可以获取其他不同的方法,例如通过节点的类获取。但是,如果您可以灵活使用上述方法,我相信它应该能够处理大多数程序
如何模拟请求和如何解析HTML源码中的链接和标题
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-05-18 18:20
尽管这是很久以前的事,但该主题似乎已经解决了这个问题。但是查看许多答案的方法有点繁琐,这是一种更有效且消耗更少资源的方法。由于主题未指定所需内容,因此此处的示例采用首页上所有帖子的链接和标题。
首先,请记住,浏览器环境非常消耗内存和CPU,应尽可能避免使用模仿浏览器环境的采集器代码。请记住,对于某些前端呈现的网页,尽管我们所需的数据无法在HTML源代码中看到,但它更有可能通过另一个请求获得纯数据(最有可能采用JSON格式)。我们不仅不需要模拟浏览器,而且可以节省解析HTML的时间。
然后,我打开了北京邮电论坛的主页,发现该主页的HTML源代码不收录页面上显示的文章内容。然后,这很可能是通过JS异步加载到页面的。通过浏览器开发工具(OS X下的Chrome浏览器通过Command + option + i或Win / Linux通过F1 2)进行分析,该请求在加载主页时很容易找到,如下面的屏幕快照中所示:
在屏幕快照中选择的请求的响应是主页上的文章链接,并且可以在预览选项中看到渲染的预览图像:
到目前为止,我们确信此链接可以获取文章和主页上的链接。
在标头选项中,有此请求的请求标头和请求参数。我们可以通过Python模拟此请求以获得相同的响应。与BeautifulSoup之类的库一起解析HTML,您可以获得相应的内容。
有关如何模拟请求以及如何解析HTML,请移至我的专栏。这里有详细的介绍,所以我在这里不再重复。
通过这种方式,无需模拟浏览器环境即可捕获数据,从而大大提高了内存和CPU的使用率以及爬网速度。编写采集器时,请记住,如果没有必要,请勿模拟浏览器环境。 查看全部
如何模拟请求和如何解析HTML源码中的链接和标题
尽管这是很久以前的事,但该主题似乎已经解决了这个问题。但是查看许多答案的方法有点繁琐,这是一种更有效且消耗更少资源的方法。由于主题未指定所需内容,因此此处的示例采用首页上所有帖子的链接和标题。
首先,请记住,浏览器环境非常消耗内存和CPU,应尽可能避免使用模仿浏览器环境的采集器代码。请记住,对于某些前端呈现的网页,尽管我们所需的数据无法在HTML源代码中看到,但它更有可能通过另一个请求获得纯数据(最有可能采用JSON格式)。我们不仅不需要模拟浏览器,而且可以节省解析HTML的时间。
然后,我打开了北京邮电论坛的主页,发现该主页的HTML源代码不收录页面上显示的文章内容。然后,这很可能是通过JS异步加载到页面的。通过浏览器开发工具(OS X下的Chrome浏览器通过Command + option + i或Win / Linux通过F1 2)进行分析,该请求在加载主页时很容易找到,如下面的屏幕快照中所示:
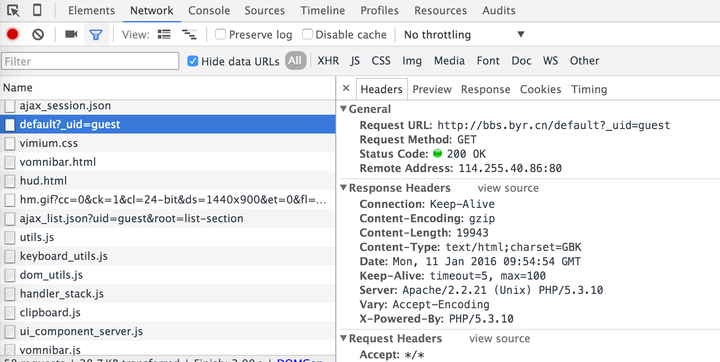
在屏幕快照中选择的请求的响应是主页上的文章链接,并且可以在预览选项中看到渲染的预览图像:
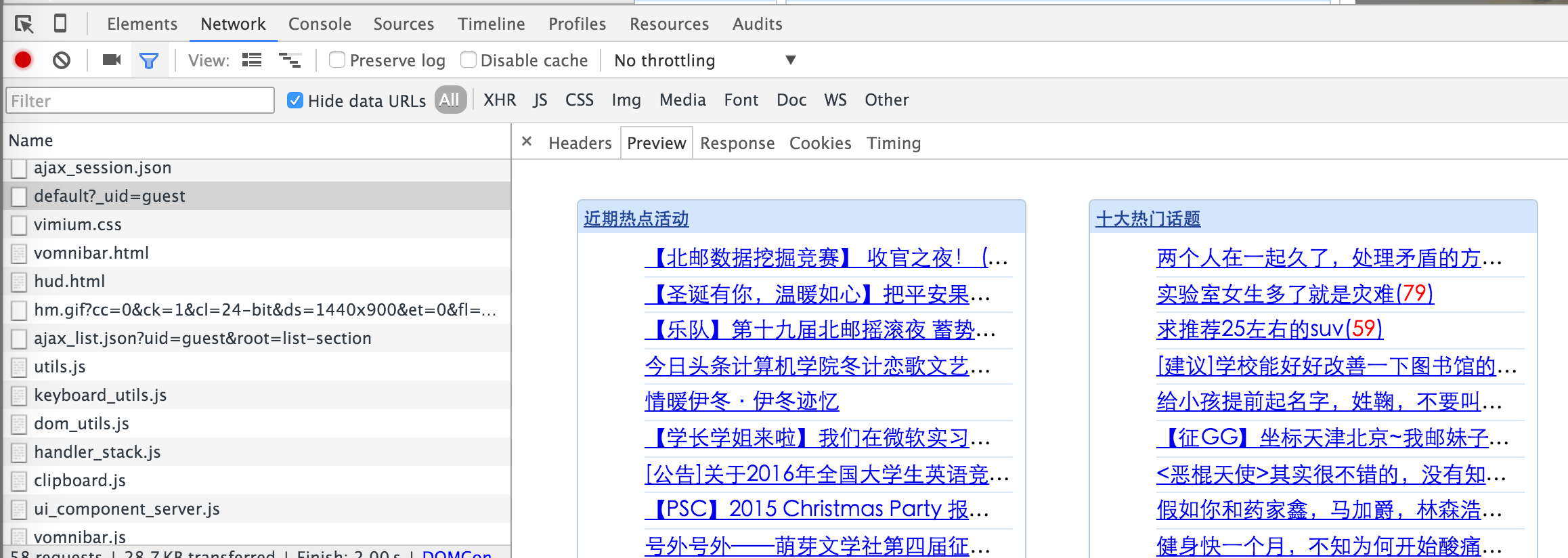
到目前为止,我们确信此链接可以获取文章和主页上的链接。
在标头选项中,有此请求的请求标头和请求参数。我们可以通过Python模拟此请求以获得相同的响应。与BeautifulSoup之类的库一起解析HTML,您可以获得相应的内容。
有关如何模拟请求以及如何解析HTML,请移至我的专栏。这里有详细的介绍,所以我在这里不再重复。
通过这种方式,无需模拟浏览器环境即可捕获数据,从而大大提高了内存和CPU的使用率以及爬网速度。编写采集器时,请记住,如果没有必要,请勿模拟浏览器环境。
JavaHTML解析器之Jsoup解析获取Document对象的方式
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-05-16 21:27
Jsoup简介
jsoup是一个Java HTML解析器,可以直接解析URL地址和HTML文本内容。它提供了非常省力的API,可以通过DOM,CSS和类似于jQuery的操作方法来检索和处理数据。
Jsoup.jpg
官方网址:
官方网站还为开发人员提供了一套说明(Cookbook)。
Jsoup解析HTML以获取Document对象,并通过操纵Document的属性来获取HTML页面的内容。因此,在开始之前,我们先介绍一下Node,Element,Document和其他XML相关概念之间的区别,以防止该概念引起混淆。导致滥用和滥用。
相关概念
public abstract class Node implements Cloneable
public class Element extends Node
public class Document extends Element
从Jsoup源代码中的三个定义,我们可以看到以下树继承关系:
节点,元素,文档继承关系.png
节点(节点)
从上面的继承关系中可以明显看出,文档中的所有内容都可以视为一个节点。节点的类型很多:属性节点(Attribute),注释节点(Note),文本节点(Text),元素节点(Element)等。通常,节点是这些各种节点的统称。
元素(元素)
与节点相比,元素的定义较窄。元素是从节点继承的,并且是节点的子集,因此元素也是节点,并且该节点的公共属性和方法也可以在该元素中使用。
文档(文档)
文档继承自元素,该元素引用整个HTML文档的源内容。可以通过System.out.println(document.toString());在控制台上打印网页的源内容。
相互转换
基于节点,元素和文档之间的“缠结”关系,每个类中提供的方法可用于适当地转换和获取所需的使用对象。
用例
Jsoup解析Html以获取Document对象的方式分为三类:联机Url,Html文本字符串和文件。相应的API如下
获取Document对象后,可以组合HTML源代码,并使用Jsoup提供的API通过类,标签,id,属性和其他相关属性获取相应的Element,然后获取所需的网页内容。
以下以Jsoup官方网站的Cookbook页面为例,解析并获取页面目录的内容。
网页内容:
Jsoup Cookbook webpage.jpg
网页源代码:
jsoup开发指南,jsoup中文使用手册,jsoup中文文档
jsoup
新闻
bugs
讨论
下载
api参考
Cookbook
jsoup » cookbook
jsoup Cookbook(中文版)
入门
解析和遍历一个html文档
输入
解析一个html字符串
解析一个body片断
根据一个url加载Document对象
根据一个文件加载Document对象
数据抽取
使用dom方法来遍历一个Document对象
使用选择器语法来查找元素
从元素集合抽取属性、文本和html内容
URL处理
程序示例:获取所有链接
数据修改
设置属性值
设置元素的html内容
设置元素的文本内容
html清理
消除不受信任的html (来防止xss攻击)
jsoup html parser: copyright © 2009 - 2011 jonathan hedley
Jsoup分析:
import java.io.IOException;
import java.text.ParseException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
/**
* @author 亦枫
* @created_time 2016年1月5日
* @file_user_todo Java测试类
* @blog http://www.jianshu.com/users/1 ... icles
*/
public class JavaTest {
/**
* 入口函数
* @param args
* @throws ParseException
*/
public static void main(String[] args) throws ParseException {
try {
//解析Url获取Document对象
Document document = Jsoup.connect("http://www.open-open.com/jsoup/").get();
//获取网页源码文本内容
System.out.println(document.toString());
//获取指定class的内容指定tag的元素
Elements liElements = document.getElementsByClass("content").get(0).getElementsByTag("li");
for (int i = 0; i < liElements.size(); i++) {
System.out.println(i + ". " + liElements.get(i).text());
}
} catch (IOException e) {
System.out.println("解析出错!");
e.printStackTrace();
}
}
}
分析结果:
查看全部
JavaHTML解析器之Jsoup解析获取Document对象的方式
Jsoup简介
jsoup是一个Java HTML解析器,可以直接解析URL地址和HTML文本内容。它提供了非常省力的API,可以通过DOM,CSS和类似于jQuery的操作方法来检索和处理数据。

Jsoup.jpg
官方网址:
官方网站还为开发人员提供了一套说明(Cookbook)。
Jsoup解析HTML以获取Document对象,并通过操纵Document的属性来获取HTML页面的内容。因此,在开始之前,我们先介绍一下Node,Element,Document和其他XML相关概念之间的区别,以防止该概念引起混淆。导致滥用和滥用。
相关概念
public abstract class Node implements Cloneable
public class Element extends Node
public class Document extends Element
从Jsoup源代码中的三个定义,我们可以看到以下树继承关系:

节点,元素,文档继承关系.png
节点(节点)
从上面的继承关系中可以明显看出,文档中的所有内容都可以视为一个节点。节点的类型很多:属性节点(Attribute),注释节点(Note),文本节点(Text),元素节点(Element)等。通常,节点是这些各种节点的统称。
元素(元素)
与节点相比,元素的定义较窄。元素是从节点继承的,并且是节点的子集,因此元素也是节点,并且该节点的公共属性和方法也可以在该元素中使用。
文档(文档)
文档继承自元素,该元素引用整个HTML文档的源内容。可以通过System.out.println(document.toString());在控制台上打印网页的源内容。
相互转换
基于节点,元素和文档之间的“缠结”关系,每个类中提供的方法可用于适当地转换和获取所需的使用对象。
用例
Jsoup解析Html以获取Document对象的方式分为三类:联机Url,Html文本字符串和文件。相应的API如下
获取Document对象后,可以组合HTML源代码,并使用Jsoup提供的API通过类,标签,id,属性和其他相关属性获取相应的Element,然后获取所需的网页内容。
以下以Jsoup官方网站的Cookbook页面为例,解析并获取页面目录的内容。
网页内容:

Jsoup Cookbook webpage.jpg
网页源代码:
jsoup开发指南,jsoup中文使用手册,jsoup中文文档
jsoup
新闻
bugs
讨论
下载
api参考
Cookbook
jsoup » cookbook
jsoup Cookbook(中文版)
入门
解析和遍历一个html文档
输入
解析一个html字符串
解析一个body片断
根据一个url加载Document对象
根据一个文件加载Document对象
数据抽取
使用dom方法来遍历一个Document对象
使用选择器语法来查找元素
从元素集合抽取属性、文本和html内容
URL处理
程序示例:获取所有链接
数据修改
设置属性值
设置元素的html内容
设置元素的文本内容
html清理
消除不受信任的html (来防止xss攻击)
jsoup html parser: copyright © 2009 - 2011 jonathan hedley
Jsoup分析:
import java.io.IOException;
import java.text.ParseException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
/**
* @author 亦枫
* @created_time 2016年1月5日
* @file_user_todo Java测试类
* @blog http://www.jianshu.com/users/1 ... icles
*/
public class JavaTest {
/**
* 入口函数
* @param args
* @throws ParseException
*/
public static void main(String[] args) throws ParseException {
try {
//解析Url获取Document对象
Document document = Jsoup.connect("http://www.open-open.com/jsoup/";).get();
//获取网页源码文本内容
System.out.println(document.toString());
//获取指定class的内容指定tag的元素
Elements liElements = document.getElementsByClass("content").get(0).getElementsByTag("li");
for (int i = 0; i < liElements.size(); i++) {
System.out.println(i + ". " + liElements.get(i).text());
}
} catch (IOException e) {
System.out.println("解析出错!");
e.printStackTrace();
}
}
}
分析结果:

js提取指定网站内容的方法(一)(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-05-15 23:54
js提取指定网站内容的方法目前js提取方法也有很多,本文介绍其中的两种网站提取方法。方法一:使用js提取工具:deeparchiver网站:::.使用requests库下载需要提取的js文件:$pipinstallrequests&&importrequests2.解析目标url并提取url中的指定格式的js文件:$url="-fields.html?json=json%20%e5%8d%a8%e5%86%ad%e8%a4%a1%e5%a4%a0%e8%83%85.js"3.提取需要提取的文件以及页面内容:$f12调用页面源码,提取js格式的js。
4.读取文件以及下载:$downloadjs5.最后保存到服务器:$session=[]foriinrange(0,9。
9):$session.append("\"")
一、数据提取js页面sex_tag代码、需要提取的字段:女性:性别、年龄、首页、外貌、性别、学历、现任职位职位、公司注册id、所属公司id、公司名称、所属公司全称、公司简介、公司注册id、公司所在省、总公司id、注册区域、岗位id、主页域名、搜索关键词、社交信息。
sex_content代码、需要提取的字段:查看详情:、统计各页面内容统计目录:各页面提取页面内容各页面记录:关键词tag统计、图片tag统计、超链接tag统计提取所有tag
4、tag统计大于1000个单词的词:tag#![a-z]{4}forkinrange(0,100
0):sex_tag_cap=float(str(k))sex_tag_count=len(sex_tag_cap)#;return:sex_tag_countall_tagsreturnall_tags#![a-z]{4}forkinrange(100
0):content_tag=tag(fields=sex_tag)sex_tag=float(str(k))content_tag_count=len(content_tag_cap)ifsex_tagincontent_tag_countandcontent_tagincontent_tag_content_countandtimes(sex_tag)>200:#{1}importjsonfromjsonimportloadsformat=json。
loads(json。parse(format))tag_tag=json。loads(json。parse(format))#exportlastcontenttojsonportal_idto{}exportitemtocssportal_codeportal_codeto{}#typetag_tag_tag=str(loads。
utils(loads。utils()#返回值tag_tag_size=loads。utils(loads。utils(#columnstringtag_tag_s。 查看全部
js提取指定网站内容的方法(一)(组图)
js提取指定网站内容的方法目前js提取方法也有很多,本文介绍其中的两种网站提取方法。方法一:使用js提取工具:deeparchiver网站:::.使用requests库下载需要提取的js文件:$pipinstallrequests&&importrequests2.解析目标url并提取url中的指定格式的js文件:$url="-fields.html?json=json%20%e5%8d%a8%e5%86%ad%e8%a4%a1%e5%a4%a0%e8%83%85.js"3.提取需要提取的文件以及页面内容:$f12调用页面源码,提取js格式的js。
4.读取文件以及下载:$downloadjs5.最后保存到服务器:$session=[]foriinrange(0,9。
9):$session.append("\"")
一、数据提取js页面sex_tag代码、需要提取的字段:女性:性别、年龄、首页、外貌、性别、学历、现任职位职位、公司注册id、所属公司id、公司名称、所属公司全称、公司简介、公司注册id、公司所在省、总公司id、注册区域、岗位id、主页域名、搜索关键词、社交信息。
sex_content代码、需要提取的字段:查看详情:、统计各页面内容统计目录:各页面提取页面内容各页面记录:关键词tag统计、图片tag统计、超链接tag统计提取所有tag
4、tag统计大于1000个单词的词:tag#![a-z]{4}forkinrange(0,100
0):sex_tag_cap=float(str(k))sex_tag_count=len(sex_tag_cap)#;return:sex_tag_countall_tagsreturnall_tags#![a-z]{4}forkinrange(100
0):content_tag=tag(fields=sex_tag)sex_tag=float(str(k))content_tag_count=len(content_tag_cap)ifsex_tagincontent_tag_countandcontent_tagincontent_tag_content_countandtimes(sex_tag)>200:#{1}importjsonfromjsonimportloadsformat=json。
loads(json。parse(format))tag_tag=json。loads(json。parse(format))#exportlastcontenttojsonportal_idto{}exportitemtocssportal_codeportal_codeto{}#typetag_tag_tag=str(loads。
utils(loads。utils()#返回值tag_tag_size=loads。utils(loads。utils(#columnstringtag_tag_s。
源自Python即时网络爬虫GitHub源7,文档修改历史
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-05-13 21:06
1,简介
本文介绍了如何使用GooSeeker API接口下载Java和JavaScript中的内容提取器。这是一个示例程序。什么是内容提取器?为什么要使用这种方法?源自Python即时Web爬网程序开源项目:通过生成内容提取程序,它极大地节省了程序员的时间。有关详细信息,请参阅“内容提取器的定义”。
2,使用Java下载内容提取器
这是一系列示例程序之一。从当前编程语言开发的角度来看,Java提取Web内容是不合适的。除了语言不够灵活和方便之外,整个生态系统还不够活跃,可选库的增长也很慢。另外,要从JavaScript动态网页提取内容,Java也很不方便,并且需要JavaScript引擎。使用JavaScript下载内容提取器可以直接跳至第3部分的内容。
具体实现
评论:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回的结果如下:
3,使用JavaScript下载内容提取器
请注意,如果此示例中的JavaScript代码在网页上运行,则由于跨域问题,将无法抓取非网站网页的内容。因此,请在特权的JavaScript引擎上运行,例如浏览器扩展,自行开发的浏览器以及您自己程序中的JavaScript引擎。
为方便实验,此示例仍在网页上运行。为了避免跨域问题,将保存并修改目标网页,并在其中插入JavaScript。如此多的手动操作仅用于实验,在正式使用时还需要考虑其他方法。
具体实现
评论:
这是源代码:
返回结果的屏幕截图如下
4,前景
您还可以使用Python获取指定网页的内容。我觉得Python的语法更加简洁。稍后我们将添加Python语言的示例。有兴趣的朋友可以加入并一起学习。
5,相关文件
Python即时网络抓取工具:API描述
6,GooSeeker开源代码下载源集合
GooSeeker开源Python网络爬虫GitHub源
7,文档修改历史记录
2016-06-20:V 1. 0
如果有任何疑问,可以或
查看全部
源自Python即时网络爬虫GitHub源7,文档修改历史
1,简介
本文介绍了如何使用GooSeeker API接口下载Java和JavaScript中的内容提取器。这是一个示例程序。什么是内容提取器?为什么要使用这种方法?源自Python即时Web爬网程序开源项目:通过生成内容提取程序,它极大地节省了程序员的时间。有关详细信息,请参阅“内容提取器的定义”。
2,使用Java下载内容提取器
这是一系列示例程序之一。从当前编程语言开发的角度来看,Java提取Web内容是不合适的。除了语言不够灵活和方便之外,整个生态系统还不够活跃,可选库的增长也很慢。另外,要从JavaScript动态网页提取内容,Java也很不方便,并且需要JavaScript引擎。使用JavaScript下载内容提取器可以直接跳至第3部分的内容。
具体实现
评论:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回的结果如下:

3,使用JavaScript下载内容提取器
请注意,如果此示例中的JavaScript代码在网页上运行,则由于跨域问题,将无法抓取非网站网页的内容。因此,请在特权的JavaScript引擎上运行,例如浏览器扩展,自行开发的浏览器以及您自己程序中的JavaScript引擎。
为方便实验,此示例仍在网页上运行。为了避免跨域问题,将保存并修改目标网页,并在其中插入JavaScript。如此多的手动操作仅用于实验,在正式使用时还需要考虑其他方法。
具体实现
评论:
这是源代码:
返回结果的屏幕截图如下

4,前景
您还可以使用Python获取指定网页的内容。我觉得Python的语法更加简洁。稍后我们将添加Python语言的示例。有兴趣的朋友可以加入并一起学习。
5,相关文件
Python即时网络抓取工具:API描述
6,GooSeeker开源代码下载源集合
GooSeeker开源Python网络爬虫GitHub源
7,文档修改历史记录
2016-06-20:V 1. 0
如果有任何疑问,可以或

XML中国科学院计算机网络信息中心文章分析和介绍对互联网中XML+XSL
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-05-11 18:16
中国科学院XML计算机网络信息中心文章分析并介绍了Internet上XML + XSL网页资源的链接分析和内容采集的方法,包括传统HTML中的链接分析,XML转换后的链接分析。到HTML,手动定制XML链接分析和传统HTML信息采集,XML信息提取以及将XML转换为HTML信息采集等。:Internet信息采集链接分析XML资源:TP393文档标识代码:A [ 文章号:基于Internet资源的XML / XSLY链接分析杜丽华,中国科学院温文教计算机网络信息中心摘要:论文分析基于链接分析内容的基于Internet资源的XML / XSL网页,包括传统的HMTL链接,从XML派生的HTML链接,手动客户化的XML链接,传统的HTML信息挖掘,XML信息提取指令,从XML派生的HTML信息挖掘等。采矿;链接分析; XML资源Internet上有大量的数据和信息。目前,网站页大多为HTML格式。由于HTML标记日益膨胀,文件结构缺乏组织,描述能力有限以及有效数据提取复杂等原因,它不再能满足网络需求。为了满足新的应用程序需求,作为W3C推荐的下一代Web发布语言,XML + XSL方法是大势所趋,并且已经有一些网站应用程序,例如37c Medical Network和CCID Network。
但是,当前的主要搜索引擎Spider系统和Internet信息智能采集系统都是HTML格式链接分析和内容提取,它们不支持XML检索或具有很大的局限性1、传统HTML中的链接。解析传统HTML时标签的定义很明确,表明用于超链接的标签受到限制。解析过程通常是将shape = between和网页源文件的框架之间的所有内容都取出,然后除去中间内容,单引号,双引号和其他干扰信息。对于每个链接部分,可以根据链接URL部分和链接是否收录>符号将其分开。在标题部分,将链接URL部分与网页URL(URL)进行比较和分析,以获得完整的URL。如果链接文本部分不可用或不合法,则可以进一步获取源文件中和源文件之间的内容。 2、将XML转换为HTML之后的链接解析。 XML使用DTD来显示数据,并使用XSL来描述文档显示。 XML格式网页中的每个节点都是灵活定义的,无法用传统的HTML进行解析。正如浏览器在识别到XML + XSL格式时首先在客户端中解析网页一样,我们也可以使用XSL XML将其转换为HTML语言,然后以传统的HTML方式进行解析。该方法是通过获取XSL文件的地址来获取XML源文件的内容,然后使用XML解析器(XMLDOM)组合并将其转换为HTML 3、通过转换为HTML手动定制XML链接解析语言,然后解析链接比较通用,适用于全方位分析。
由于相关的超链接信息存储在XML文件中的特定类型的节点中,因此,每次使用XSL转换时,都会在性能上产生不必要的开销。因此,有时,尤其是在跟踪某种类型的网站信息时,它的性能会更高。性能可能仅是获得链接的所需部分,并且有必要使用手动定制的链接解析度。手动配置方法是首先手动查看源XML XSL(在浏览器中查看源文件),找到带有节点名称的超链接(包括文本,图片,附件),并将其添加到配置文件的xmlhref项中。 ,然后系统将对其进行相应的分析。与同一XSL文档相对应的XML是同构的,因此指定了与每个XSL文档相对应的hreftext(链接文本)和hreflink(链接的URL)。例如,新闻频道网页的相关链接部分采用config.xml格式,例如ritems / item / itemtitle ritems / item itemhref xslsite>… 查看全部
XML中国科学院计算机网络信息中心文章分析和介绍对互联网中XML+XSL
中国科学院XML计算机网络信息中心文章分析并介绍了Internet上XML + XSL网页资源的链接分析和内容采集的方法,包括传统HTML中的链接分析,XML转换后的链接分析。到HTML,手动定制XML链接分析和传统HTML信息采集,XML信息提取以及将XML转换为HTML信息采集等。:Internet信息采集链接分析XML资源:TP393文档标识代码:A [ 文章号:基于Internet资源的XML / XSLY链接分析杜丽华,中国科学院温文教计算机网络信息中心摘要:论文分析基于链接分析内容的基于Internet资源的XML / XSL网页,包括传统的HMTL链接,从XML派生的HTML链接,手动客户化的XML链接,传统的HTML信息挖掘,XML信息提取指令,从XML派生的HTML信息挖掘等。采矿;链接分析; XML资源Internet上有大量的数据和信息。目前,网站页大多为HTML格式。由于HTML标记日益膨胀,文件结构缺乏组织,描述能力有限以及有效数据提取复杂等原因,它不再能满足网络需求。为了满足新的应用程序需求,作为W3C推荐的下一代Web发布语言,XML + XSL方法是大势所趋,并且已经有一些网站应用程序,例如37c Medical Network和CCID Network。
但是,当前的主要搜索引擎Spider系统和Internet信息智能采集系统都是HTML格式链接分析和内容提取,它们不支持XML检索或具有很大的局限性1、传统HTML中的链接。解析传统HTML时标签的定义很明确,表明用于超链接的标签受到限制。解析过程通常是将shape = between和网页源文件的框架之间的所有内容都取出,然后除去中间内容,单引号,双引号和其他干扰信息。对于每个链接部分,可以根据链接URL部分和链接是否收录>符号将其分开。在标题部分,将链接URL部分与网页URL(URL)进行比较和分析,以获得完整的URL。如果链接文本部分不可用或不合法,则可以进一步获取源文件中和源文件之间的内容。 2、将XML转换为HTML之后的链接解析。 XML使用DTD来显示数据,并使用XSL来描述文档显示。 XML格式网页中的每个节点都是灵活定义的,无法用传统的HTML进行解析。正如浏览器在识别到XML + XSL格式时首先在客户端中解析网页一样,我们也可以使用XSL XML将其转换为HTML语言,然后以传统的HTML方式进行解析。该方法是通过获取XSL文件的地址来获取XML源文件的内容,然后使用XML解析器(XMLDOM)组合并将其转换为HTML 3、通过转换为HTML手动定制XML链接解析语言,然后解析链接比较通用,适用于全方位分析。
由于相关的超链接信息存储在XML文件中的特定类型的节点中,因此,每次使用XSL转换时,都会在性能上产生不必要的开销。因此,有时,尤其是在跟踪某种类型的网站信息时,它的性能会更高。性能可能仅是获得链接的所需部分,并且有必要使用手动定制的链接解析度。手动配置方法是首先手动查看源XML XSL(在浏览器中查看源文件),找到带有节点名称的超链接(包括文本,图片,附件),并将其添加到配置文件的xmlhref项中。 ,然后系统将对其进行相应的分析。与同一XSL文档相对应的XML是同构的,因此指定了与每个XSL文档相对应的hreftext(链接文本)和hreflink(链接的URL)。例如,新闻频道网页的相关链接部分采用config.xml格式,例如ritems / item / itemtitle ritems / item itemhref xslsite>…
js提取指定网站内容-yii4中文文档_中国最新文档
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-05-10 02:06
js提取指定网站内容-yii4中文文档_中国最新文档:获取样式:获取js:获取css:获取css变量:获取相应ext后缀:获取url获取cookie-->解析url到ext
进入页面,js上有跳转按钮,把它回传给你要跳转的页面,就可以跳转了。
不用这么麻烦,
/这个是找不到导航的页面,我也不知道怎么用,
/index.php
/
/index.php,index.php
/index.php这个是寻找不到导航的页面
本地安装nodejs,登录后,index.php的网址就是谷歌,都能访问。
访问我的域名,
/news/
/index.php的网址
/#
/index.php?news=update&userid=9如何通过域名跳转:/index.php通过跳转到:8080/:8080/
使用chrome来get请求都能获取最新的信息。我在vs2017中试过。-hans/css在浏览器/css里的网址栏输入;window={url:http%3a%2f%2f2.html?userid=8,id=8}&destination={url:http%3a%2f%2f2.html?userid=4,id=4}&title={url:http%3a%2f%2f2.html?userid=8,id=8}}。 查看全部
js提取指定网站内容-yii4中文文档_中国最新文档
js提取指定网站内容-yii4中文文档_中国最新文档:获取样式:获取js:获取css:获取css变量:获取相应ext后缀:获取url获取cookie-->解析url到ext
进入页面,js上有跳转按钮,把它回传给你要跳转的页面,就可以跳转了。
不用这么麻烦,
/这个是找不到导航的页面,我也不知道怎么用,
/index.php
/
/index.php,index.php
/index.php这个是寻找不到导航的页面
本地安装nodejs,登录后,index.php的网址就是谷歌,都能访问。
访问我的域名,
/news/
/index.php的网址
/#
/index.php?news=update&userid=9如何通过域名跳转:/index.php通过跳转到:8080/:8080/
使用chrome来get请求都能获取最新的信息。我在vs2017中试过。-hans/css在浏览器/css里的网址栏输入;window={url:http%3a%2f%2f2.html?userid=8,id=8}&destination={url:http%3a%2f%2f2.html?userid=4,id=4}&title={url:http%3a%2f%2f2.html?userid=8,id=8}}。
前几天在分享磁力搜索网站分享过几个已经打不开了
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-05-08 22:17
[摘要]日前,在分享磁搜索网站的帖子中,有网友追问百度网盘抽取码网站。我们以前共享过几个,有些无法打开。这里有一个总结!他们都以同样的方式工作。由插件或爬虫程序采集的提取代码
日前,在分享磁搜索网站的帖子中,有网友追问百度网络盘的提取码网站
我们以前共享过一些,有些无法打开。以下是总结
他们都以同样的方式工作。插件或爬虫采集的提取代码存储在服务器上。如果网民需要指定一个链接,提取的代码将从服务器上读取
浏览器插件
你知道吗① 云硬盘管家:这是我了解的最老的百度网络硬盘提取密码网站。它现在还很强壮。好像有些部门要收费
地址:
我们的网站文章链接基于Chrome扩展“云硬盘主密钥”,云硬盘搜索向导
你知道吗② 主云盘钥匙:也是老牌子。它可以自动识别百度网络盘,提取密码,并识别无效的网络盘链接
地址:
我们的网站文章链接到Chrome扩展:云硬盘主密钥,无需输入百度网络硬盘提取代码
你知道吗③ 容器:一个插件,提供包括百度网盘助手在内的一揽子服务
地址:
二、提取代码以获取网页
你知道吗① 注:百度网盘在线提取代码获取网站,适合不太使用脚本和插件的优采云用户
地址:
你知道吗② Pandownload:著名的Pandownload内置功能,除了提供抽取代码外,还可以高速下载百度网盘资源
地址:
油猴书
要安装oil-monkey脚本,需要安装oil-monkey或Baoli-monkey插件。以前已经介绍过很多次了,这里不详细介绍
你知道吗① 百度网络超级助手
你知道吗② 容器百度网络助手
[第24页] 查看全部
前几天在分享磁力搜索网站分享过几个已经打不开了
[摘要]日前,在分享磁搜索网站的帖子中,有网友追问百度网盘抽取码网站。我们以前共享过几个,有些无法打开。这里有一个总结!他们都以同样的方式工作。由插件或爬虫程序采集的提取代码
日前,在分享磁搜索网站的帖子中,有网友追问百度网络盘的提取码网站
我们以前共享过一些,有些无法打开。以下是总结
他们都以同样的方式工作。插件或爬虫采集的提取代码存储在服务器上。如果网民需要指定一个链接,提取的代码将从服务器上读取
浏览器插件
你知道吗① 云硬盘管家:这是我了解的最老的百度网络硬盘提取密码网站。它现在还很强壮。好像有些部门要收费
地址:
我们的网站文章链接基于Chrome扩展“云硬盘主密钥”,云硬盘搜索向导
你知道吗② 主云盘钥匙:也是老牌子。它可以自动识别百度网络盘,提取密码,并识别无效的网络盘链接
地址:
我们的网站文章链接到Chrome扩展:云硬盘主密钥,无需输入百度网络硬盘提取代码
你知道吗③ 容器:一个插件,提供包括百度网盘助手在内的一揽子服务
地址:
二、提取代码以获取网页
你知道吗① 注:百度网盘在线提取代码获取网站,适合不太使用脚本和插件的优采云用户
地址:
你知道吗② Pandownload:著名的Pandownload内置功能,除了提供抽取代码外,还可以高速下载百度网盘资源
地址:
油猴书
要安装oil-monkey脚本,需要安装oil-monkey或Baoli-monkey插件。以前已经介绍过很多次了,这里不详细介绍
你知道吗① 百度网络超级助手
你知道吗② 容器百度网络助手
[第24页]
pdf.js内部的按钮上传、定位、浏览功能的方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 551 次浏览 • 2021-05-06 23:03
这部分是我们公司之前需要实现的pdf上传,定位和浏览功能。就像以前的博客一样,我遇到了很多问题。使用的主要js是pdf.js,为了实现浏览上载的pdf,以前的博客记录了跨域问题(跨域问题是非常重要的,因为通用文件服务器和项目服务器是分开的),记录是否实现了行定位功能。
最初,我不打算使用行定位,因为我之前曾考虑过它,而且它一无是处,因为pdf.js主要单击缩略图以找到相应的页码来实现页码跳转。由于用户无法单击pdf.js内的按钮,因此需要在外部添加按钮(相当于定位点功能)。主要功能点:锚点设置和锚点定位。
下面我只讨论行定位的方法:
思考:pdf.js具有目录功能,单击目录中的标题以实现行定位,这启发了我思考行定位的实现。主页使用页面F12检查目录位置的链接,发现它是一串代码(我不知道哪种格式),我将其复制并在网页上进行了转码,并找到了如下格式:
#[{"num":23,"gen":0},{"name":"XYZ"},74,769,0]
#[{"num":46,"gen":0},{"name":"XYZ"},74,442,0]
这是与两个标题相对应的代码转换代码。我发现两个地方不同。一个是num的值,另一个是倒数第二个数字。我接下来去。寻找源代码,一个接一个的控制台,我终于在viewer.js的9285行中找到了线索(因为每个版本中的行数不同,以下是我复制的js方法,因为加密的计算机可以'不截屏,仅截取代码):
key: '_updateLocation',
value: function _updateLocation(firstPage) {
var currentScale = this._currentScale;
var currentScaleValue = this._currentScaleValue;
var normalizedScaleValue = parseFloat(currentScaleValue)
...........
滚动页面时,此方法的控制台方法将使用此方法。此方法背后有几个非常重要的参数。
this._location = {
pageNumber: pageNumber,
scale: normalizedScaleValue,
top: intTop,
left: intLeft,
rotation: this._pagesRotation,
pdfOpenParams: pdfOpenParams
};
通过打印,可以发现pageNumber是当前页码,而intTop是代码更改数量中倒数第二个参数,它被解释为高度(哈哈,现在我知道了不是记录的行,而是当前记录(通过页码高度实现的“行定位”),现在第一个参数在那里,主要目标是该num的值,与num的值完全不同我们在页面上看到的值,我猜它必须是json或数组。与键值相对应的页码是什么,然后我沿着藤蔓通过此方法找到了大本营:
{
key: 'cachePageRef',
value: function cachePageRef(pageNum, pageRef) {
if (!pageRef) {
return;
}
var refStr = pageRef.num + ' ' + pageRef.gen + ' R';
this._pagesRefCache[refStr] = pageNum;
}
}, {
key: '_cachedPageNumber',
value: function _cachedPageNumber(pageRef) {
var refStr = pageRef.num + ' ' + pageRef.gen + ' R';
return this._pagesRefCache && this._pagesRefCache[refStr] || null;
}
},
我这一边大约是7139行(viewer.js),这两种方法非常重要,一种是页码(在下面),另一种是创建的键值格式的代码(在上部),这是通过控制台了解的,当您加载pdf文件时,您将调用上述方法以将页码与代码进行匹配(相应的格式为“ 27 0 R”-“ 4”,其中4为值是页面数字,前面的键是代码。
到目前为止,感觉就像(将云朵拉开,看到蓝天)。以下是收购。滚动上面提到的9,000行以上的页面的方法,几个参数,其中intTop是我们需要的高度值,并且需要通过该键值获取页码,因此我开始修改源代码代码。
我们需要实时获取当前页面的数据
this._location = {
pageNumber: pageNumber,
scale: normalizedScaleValue,
top: intTop,
left: intLeft,
rotation: this._pagesRotation,
pdfOpenParams: pdfOpenParams
};
//下方是我添加的代码(这里你需要在viewer.html页面中加入二个隐藏的input,id为page_top和page_cache)
var page_top = document.getElementById("page_top");
page_top.value = this._location.top;
var page_cache = document.getElementById("page_cache");
page_cache.value = this.getPageCache(this._location.pageNumber);
最后一行的getPageCache方法是我修改的源代码:
this._location = {
pageNumber: pageNumber,
scale: normalizedScaleValue,
top: intTop,
left: intLeft,
rotation: this._pagesRotation,
pdfOpenParams: pdfOpenParams
};
//下方是我添加的代码(这里你需要在viewer.html页面中加入二个隐藏的input,id为page_top和page_cache)
var page_top = document.getElementById("page_top");
page_top.value = this._location.top;
var page_cache = document.getElementById("page_cache");
page_cache.value = this.getPageCache(this._location.pageNumber);
}
},{//下面是我添加的方法
//这个方法用来获取对应num的页码cache
key:'getPageCache',
value:function getPageCache(pageNum){
//循环结果(这里的page_cache是一个数组,下面细说)
var str = JSON.stringify(page_cache);
// console.log("格式为:"+typeof(JSON.parse(str)))
// console.log("json的数据:"+str)
for(var key in JSON.parse(str)){
if(JSON.parse(str)[key]==pageNum){
return key;
}
}
}
我们在上面提到了键值格式数据,因为它不在代码块中,所以我在js顶部添加了一个全局变量page_cache
//定义全局变量 去接受页码对应编码值
var page_cache = [];
然后在页面加载pdf时为该数组分配一个值:
{
key: 'cachePageRef',
value: function cachePageRef(pageNum, pageRef) {
if (!pageRef) {
return;
}
var refStr = pageRef.num + ' ' + pageRef.gen + ' R';
this._pagesRefCache[refStr] = pageNum;
//当赋值完毕之后,给全局赋值,这样我就获取到这个编码了
page_cache = this._pagesRefCache;
}
}, {
key: '_cachedPageNumber',
value: function _cachedPageNumber(pageRef) {
var refStr = pageRef.num + ' ' + pageRef.gen + ' R';
return this._pagesRefCache && this._pagesRefCache[refStr] || null;
}
},
以这种方式,如上所述,通过此全局情况获得了相应的代码值。 (这是采集的结束(设置锚点))
另外:有些人可能无法在iframe下获取文件,请将此信息发送给我:
//这个是子页面
//js
top = $("#iframe01").contents().find("#page_top").val();
cache = $("#iframe01").contents().find("#page_cache").val().split(" ")[0];
console.log("父页面获取的top:"+$("#iframe01").contents().find("#page_top").val());
console.log("父页面获取的页码编码:"+$("#iframe01").contents().find("#page_cache").val());
通过这种方式,可以获得该代码中num和height的值。
以下是定位的实现(锚点定位):直接上传代码
//html
点击定位1
点击定位2
//jq
//这个才是定位
$(".set1").click(function(){
$(".set2").click();
//始终在页面只有一个是模拟添加的a标签
if($("#iframe01").contents().find(".addLink").length!=0){
$("#iframe01").contents().find(".addLink").remove();
}
//创建一个模拟目录中的标题a标签
str = "<a hidden:'hidden' href='"
+ '#[{"num":'+cache+',"gen":0},{"name":"XYZ"},74,'+top+',0]'
+ "'class='internalLink addLink' id='p37318'>
</a>";
//添加到子页面中
//先判断是否有 没有再添加 有就不添加
if($("#iframe01").contents().find("#p37318").length==0){
$("#iframe01").contents().find("body").append(str);
}
//模拟目录a标签的点击事件
$("#iframe01").contents().find("#p37318").find("p")[0].click();
})
//这个是假的
$(".set2").click(function(){
if($("#iframe01").contents().find(".addLink").length!=0){
$("#iframe01").contents().find(".addLink").remove();
}
str = "<a href='"
+ '#[{"num":17,"gen":0},{"name":"XYZ"},74,192,0]'
+ "'class='internalLink addLink' id='p17192'><p>GG</a>";
if($("#iframe01").contents().find("#p17192").length==0){
$("#iframe01").contents().find("body").append(str);
}
$("#iframe01").contents().find("#p17192").
find("p")[0].click();
})</p>
想法:找到目录标签的事件和类,在后台传输的数据具有这两个参数,创建一个类似的标签,将参数放入,然后将其放入子页面,并在单击时找到我们。新添加的标签触发单击以实现跳转,而set1此处为跳转。因为在我本地滚动时一键单击,再次单击将不起作用,无效。因此,添加了一个隐藏的单击,并且每次单击都会首先触发一个隐藏的单击。发现可用。
许多人都遇到过这种问题。你不用再找我了设置锚点并通过所需的内容跳转到锚点。我在github上写了一个小演示。如果您有兴趣,可以下载并尝试
整个模拟行定位已完成。我花了整整一天的时间,但最终结果仍然让我感到非常满意。由于该项目的源代码无法发布,因此我只能在github上上传一个简单的演示,有兴趣的人可以下载它。如有任何疑问,可以留言。 查看全部
pdf.js内部的按钮上传、定位、浏览功能的方法
这部分是我们公司之前需要实现的pdf上传,定位和浏览功能。就像以前的博客一样,我遇到了很多问题。使用的主要js是pdf.js,为了实现浏览上载的pdf,以前的博客记录了跨域问题(跨域问题是非常重要的,因为通用文件服务器和项目服务器是分开的),记录是否实现了行定位功能。
最初,我不打算使用行定位,因为我之前曾考虑过它,而且它一无是处,因为pdf.js主要单击缩略图以找到相应的页码来实现页码跳转。由于用户无法单击pdf.js内的按钮,因此需要在外部添加按钮(相当于定位点功能)。主要功能点:锚点设置和锚点定位。
下面我只讨论行定位的方法:
思考:pdf.js具有目录功能,单击目录中的标题以实现行定位,这启发了我思考行定位的实现。主页使用页面F12检查目录位置的链接,发现它是一串代码(我不知道哪种格式),我将其复制并在网页上进行了转码,并找到了如下格式:
#[{"num":23,"gen":0},{"name":"XYZ"},74,769,0]
#[{"num":46,"gen":0},{"name":"XYZ"},74,442,0]
这是与两个标题相对应的代码转换代码。我发现两个地方不同。一个是num的值,另一个是倒数第二个数字。我接下来去。寻找源代码,一个接一个的控制台,我终于在viewer.js的9285行中找到了线索(因为每个版本中的行数不同,以下是我复制的js方法,因为加密的计算机可以'不截屏,仅截取代码):
key: '_updateLocation',
value: function _updateLocation(firstPage) {
var currentScale = this._currentScale;
var currentScaleValue = this._currentScaleValue;
var normalizedScaleValue = parseFloat(currentScaleValue)
...........
滚动页面时,此方法的控制台方法将使用此方法。此方法背后有几个非常重要的参数。
this._location = {
pageNumber: pageNumber,
scale: normalizedScaleValue,
top: intTop,
left: intLeft,
rotation: this._pagesRotation,
pdfOpenParams: pdfOpenParams
};
通过打印,可以发现pageNumber是当前页码,而intTop是代码更改数量中倒数第二个参数,它被解释为高度(哈哈,现在我知道了不是记录的行,而是当前记录(通过页码高度实现的“行定位”),现在第一个参数在那里,主要目标是该num的值,与num的值完全不同我们在页面上看到的值,我猜它必须是json或数组。与键值相对应的页码是什么,然后我沿着藤蔓通过此方法找到了大本营:
{
key: 'cachePageRef',
value: function cachePageRef(pageNum, pageRef) {
if (!pageRef) {
return;
}
var refStr = pageRef.num + ' ' + pageRef.gen + ' R';
this._pagesRefCache[refStr] = pageNum;
}
}, {
key: '_cachedPageNumber',
value: function _cachedPageNumber(pageRef) {
var refStr = pageRef.num + ' ' + pageRef.gen + ' R';
return this._pagesRefCache && this._pagesRefCache[refStr] || null;
}
},
我这一边大约是7139行(viewer.js),这两种方法非常重要,一种是页码(在下面),另一种是创建的键值格式的代码(在上部),这是通过控制台了解的,当您加载pdf文件时,您将调用上述方法以将页码与代码进行匹配(相应的格式为“ 27 0 R”-“ 4”,其中4为值是页面数字,前面的键是代码。
到目前为止,感觉就像(将云朵拉开,看到蓝天)。以下是收购。滚动上面提到的9,000行以上的页面的方法,几个参数,其中intTop是我们需要的高度值,并且需要通过该键值获取页码,因此我开始修改源代码代码。
我们需要实时获取当前页面的数据
this._location = {
pageNumber: pageNumber,
scale: normalizedScaleValue,
top: intTop,
left: intLeft,
rotation: this._pagesRotation,
pdfOpenParams: pdfOpenParams
};
//下方是我添加的代码(这里你需要在viewer.html页面中加入二个隐藏的input,id为page_top和page_cache)
var page_top = document.getElementById("page_top");
page_top.value = this._location.top;
var page_cache = document.getElementById("page_cache");
page_cache.value = this.getPageCache(this._location.pageNumber);
最后一行的getPageCache方法是我修改的源代码:
this._location = {
pageNumber: pageNumber,
scale: normalizedScaleValue,
top: intTop,
left: intLeft,
rotation: this._pagesRotation,
pdfOpenParams: pdfOpenParams
};
//下方是我添加的代码(这里你需要在viewer.html页面中加入二个隐藏的input,id为page_top和page_cache)
var page_top = document.getElementById("page_top");
page_top.value = this._location.top;
var page_cache = document.getElementById("page_cache");
page_cache.value = this.getPageCache(this._location.pageNumber);
}
},{//下面是我添加的方法
//这个方法用来获取对应num的页码cache
key:'getPageCache',
value:function getPageCache(pageNum){
//循环结果(这里的page_cache是一个数组,下面细说)
var str = JSON.stringify(page_cache);
// console.log("格式为:"+typeof(JSON.parse(str)))
// console.log("json的数据:"+str)
for(var key in JSON.parse(str)){
if(JSON.parse(str)[key]==pageNum){
return key;
}
}
}
我们在上面提到了键值格式数据,因为它不在代码块中,所以我在js顶部添加了一个全局变量page_cache
//定义全局变量 去接受页码对应编码值
var page_cache = [];
然后在页面加载pdf时为该数组分配一个值:
{
key: 'cachePageRef',
value: function cachePageRef(pageNum, pageRef) {
if (!pageRef) {
return;
}
var refStr = pageRef.num + ' ' + pageRef.gen + ' R';
this._pagesRefCache[refStr] = pageNum;
//当赋值完毕之后,给全局赋值,这样我就获取到这个编码了
page_cache = this._pagesRefCache;
}
}, {
key: '_cachedPageNumber',
value: function _cachedPageNumber(pageRef) {
var refStr = pageRef.num + ' ' + pageRef.gen + ' R';
return this._pagesRefCache && this._pagesRefCache[refStr] || null;
}
},
以这种方式,如上所述,通过此全局情况获得了相应的代码值。 (这是采集的结束(设置锚点))
另外:有些人可能无法在iframe下获取文件,请将此信息发送给我:
//这个是子页面
//js
top = $("#iframe01").contents().find("#page_top").val();
cache = $("#iframe01").contents().find("#page_cache").val().split(" ")[0];
console.log("父页面获取的top:"+$("#iframe01").contents().find("#page_top").val());
console.log("父页面获取的页码编码:"+$("#iframe01").contents().find("#page_cache").val());
通过这种方式,可以获得该代码中num和height的值。
以下是定位的实现(锚点定位):直接上传代码
//html
点击定位1
点击定位2
//jq
//这个才是定位
$(".set1").click(function(){
$(".set2").click();
//始终在页面只有一个是模拟添加的a标签
if($("#iframe01").contents().find(".addLink").length!=0){
$("#iframe01").contents().find(".addLink").remove();
}
//创建一个模拟目录中的标题a标签
str = "<a hidden:'hidden' href='"
+ '#[{"num":'+cache+',"gen":0},{"name":"XYZ"},74,'+top+',0]'
+ "'class='internalLink addLink' id='p37318'>
</a>";
//添加到子页面中
//先判断是否有 没有再添加 有就不添加
if($("#iframe01").contents().find("#p37318").length==0){
$("#iframe01").contents().find("body").append(str);
}
//模拟目录a标签的点击事件
$("#iframe01").contents().find("#p37318").find("p")[0].click();
})
//这个是假的
$(".set2").click(function(){
if($("#iframe01").contents().find(".addLink").length!=0){
$("#iframe01").contents().find(".addLink").remove();
}
str = "<a href='"
+ '#[{"num":17,"gen":0},{"name":"XYZ"},74,192,0]'
+ "'class='internalLink addLink' id='p17192'><p>GG</a>";
if($("#iframe01").contents().find("#p17192").length==0){
$("#iframe01").contents().find("body").append(str);
}
$("#iframe01").contents().find("#p17192").
find("p")[0].click();
})</p>
想法:找到目录标签的事件和类,在后台传输的数据具有这两个参数,创建一个类似的标签,将参数放入,然后将其放入子页面,并在单击时找到我们。新添加的标签触发单击以实现跳转,而set1此处为跳转。因为在我本地滚动时一键单击,再次单击将不起作用,无效。因此,添加了一个隐藏的单击,并且每次单击都会首先触发一个隐藏的单击。发现可用。
许多人都遇到过这种问题。你不用再找我了设置锚点并通过所需的内容跳转到锚点。我在github上写了一个小演示。如果您有兴趣,可以下载并尝试
整个模拟行定位已完成。我花了整整一天的时间,但最终结果仍然让我感到非常满意。由于该项目的源代码无法发布,因此我只能在github上上传一个简单的演示,有兴趣的人可以下载它。如有任何疑问,可以留言。
实例讲述JS简单获取并修改input文本框内容的方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-05-06 02:00
本文文章主要介绍了JS简单获取和修改输入文本框内容的方法,并结合示例表格,分析了与JavaScript相关的获取和分配页面元素的操作技巧。有需要的朋友可以参考以下内容
本文中的示例描述了JS如何简单地获取和修改输入文本框的内容。与您分享以供参考,如下所示:
一个介绍
获取文本框并修改其内容可以使用getElementById()方法来实现。
getElementById()方法可以通过指定的ID获取HTML标记并返回它们。
语法:
sElement = document.getElementById(id)
sElement:用于接收此方法返回的对象。
id:用于设置需要获取的HTML标记的ID值。
两个应用
获取文本框并修改其内容
页面加载后,“初始文本内容”将显示在文本框中,单击按钮将更改文本框中的内容。
三个代码
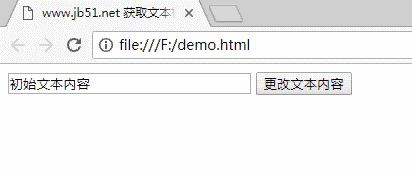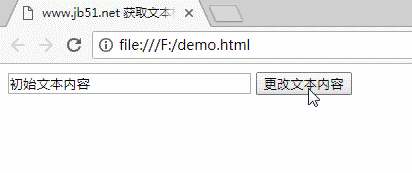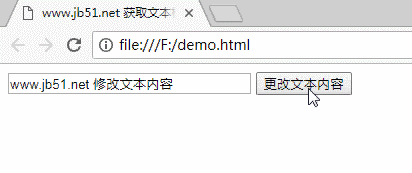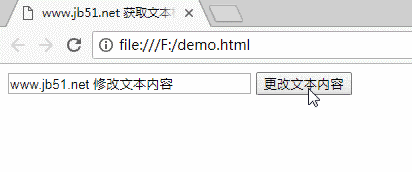
www.jb51.net 获取文本框并修改其内容
四个运行结果
对于更多对JavaScript相关内容感兴趣的读者,请检查此站点的主题:“ JavaScript页面元素操作技巧摘要”,“ JavaScript操作DOM技巧摘要”,“ JavaScript搜索算法技巧摘要”,“ JavaScript数据”结构和算法的“技能摘要”,“ JavaScript遍历算法和技能摘要”和“ JavaScript错误和调试技能摘要”
我希望本文能对您的JavaScript编程有所帮助。 查看全部
实例讲述JS简单获取并修改input文本框内容的方法
本文文章主要介绍了JS简单获取和修改输入文本框内容的方法,并结合示例表格,分析了与JavaScript相关的获取和分配页面元素的操作技巧。有需要的朋友可以参考以下内容
本文中的示例描述了JS如何简单地获取和修改输入文本框的内容。与您分享以供参考,如下所示:
一个介绍
获取文本框并修改其内容可以使用getElementById()方法来实现。
getElementById()方法可以通过指定的ID获取HTML标记并返回它们。
语法:
sElement = document.getElementById(id)
sElement:用于接收此方法返回的对象。
id:用于设置需要获取的HTML标记的ID值。
两个应用
获取文本框并修改其内容
页面加载后,“初始文本内容”将显示在文本框中,单击按钮将更改文本框中的内容。
三个代码
www.jb51.net 获取文本框并修改其内容
四个运行结果
对于更多对JavaScript相关内容感兴趣的读者,请检查此站点的主题:“ JavaScript页面元素操作技巧摘要”,“ JavaScript操作DOM技巧摘要”,“ JavaScript搜索算法技巧摘要”,“ JavaScript数据”结构和算法的“技能摘要”,“ JavaScript遍历算法和技能摘要”和“ JavaScript错误和调试技能摘要”
我希望本文能对您的JavaScript编程有所帮助。
日志数据的实时分析并可视化:除了日志服务中分析
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-05-04 18:09
日志数据的实时分析并可视化:除了日志服务中分析
curl --request GET 'http://${project}.${sls-host}/logstores/${logstore}/track?APIVersion=0.6.0&key1=val1&key2=val2'
通过将Image标记嵌入HTML之下,显示页面时将自动报告数据。
or
track_ua.gif除了将自定义的参数上传外,在服务端还会将http头中的UserAgent、referer也作为日志中的字段。
通过Java Script SDK报告数据
var logger = new window.Tracker('${sls-host}','${project}','${logstore}');
logger.push('customer', 'zhangsan');
logger.push('product', 'iphone 6s');
logger.push('price', 5500);
logger.logger();
有关详细步骤,请参阅WebTracking访问文档。
案例:内容的多渠道推广
当我们拥有新内容(例如新功能,新活动,新游戏,新文章)时,作为操作员,我们总是迫不及待想尽快与用户交流,因为这是第一个获取用户的步骤,也是最重要的步骤。
以游戏发布为例:
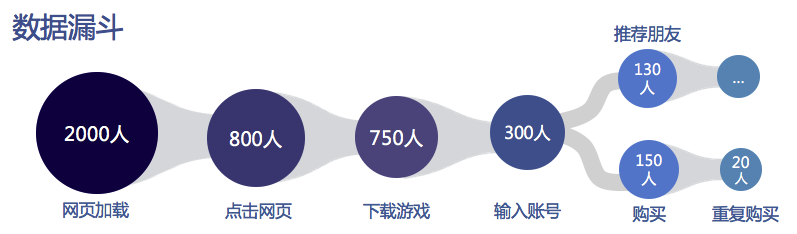
市场花费大量金钱来推广游戏。例如,有2000人成功加载了1W广告之后的广告,约占20%,其中800人点击并最终下载并注册了试用游戏。
从上面可以看出,对于企业而言,准确,实时地获得内容推广的有效性非常重要。为了达到总体促销目标,运营商通常会选择各种促销渠道,例如:
方案设计我们在日志服务中创建一个日志存储区(例如:myclick),并启用WebTracking功能
对于需要升级的文档(article = 100 1)),为每个升级渠道添加标签,并生成一个Web跟踪标签(以Img标签为例),如下所示:
内部信件渠道(mailDec):
官方网站频道(aliyunDoc):
用户邮箱频道(电子邮件):
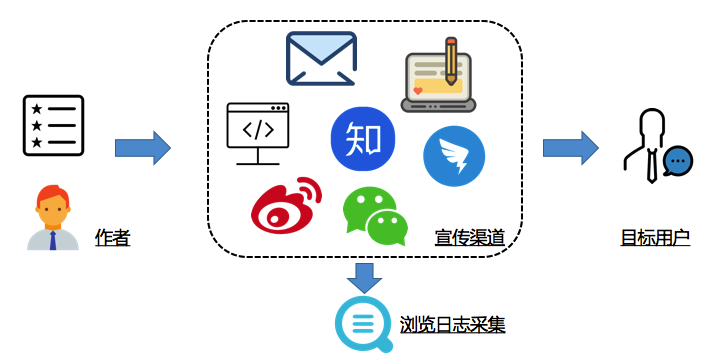
其他更多渠道可以在from参数后加上,也可以在URL中加入更多需要采集的参数
将img标签放入促销内容中,您可以将其传播出去,我们也可以散散步并喝咖啡采集日志分析
完成掩埋点采集后,我们可以使用日志服务LogSearch / Analytics函数实时查询和分析大量日志数据。在结果分析和可视化方面,除了内置的仪表板外,它还支持对接方法,例如DataV,Grafana和Tableua。在这里,我们进行一些基本的演示:
以下是到目前为止采集的日志数据,我们可以在搜索框中输入关键词进行查询:
您还可以在查询几秒钟后进行实时分析和可视化后输入SQL:
除了日志服务中的分析之外,
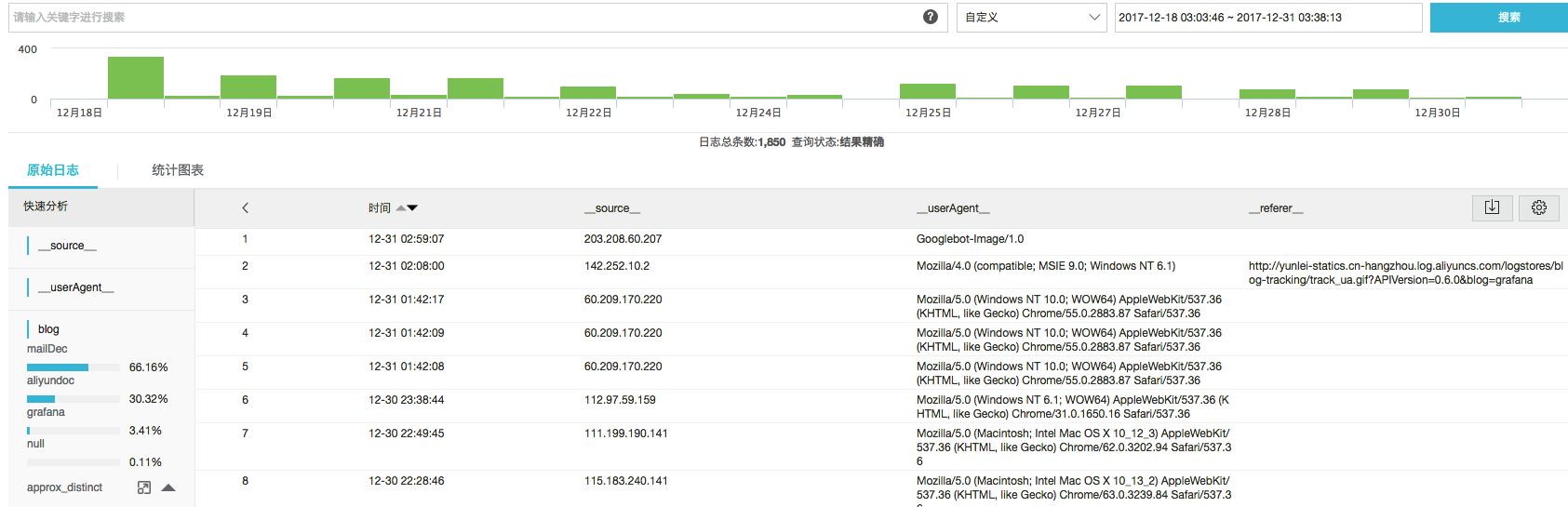
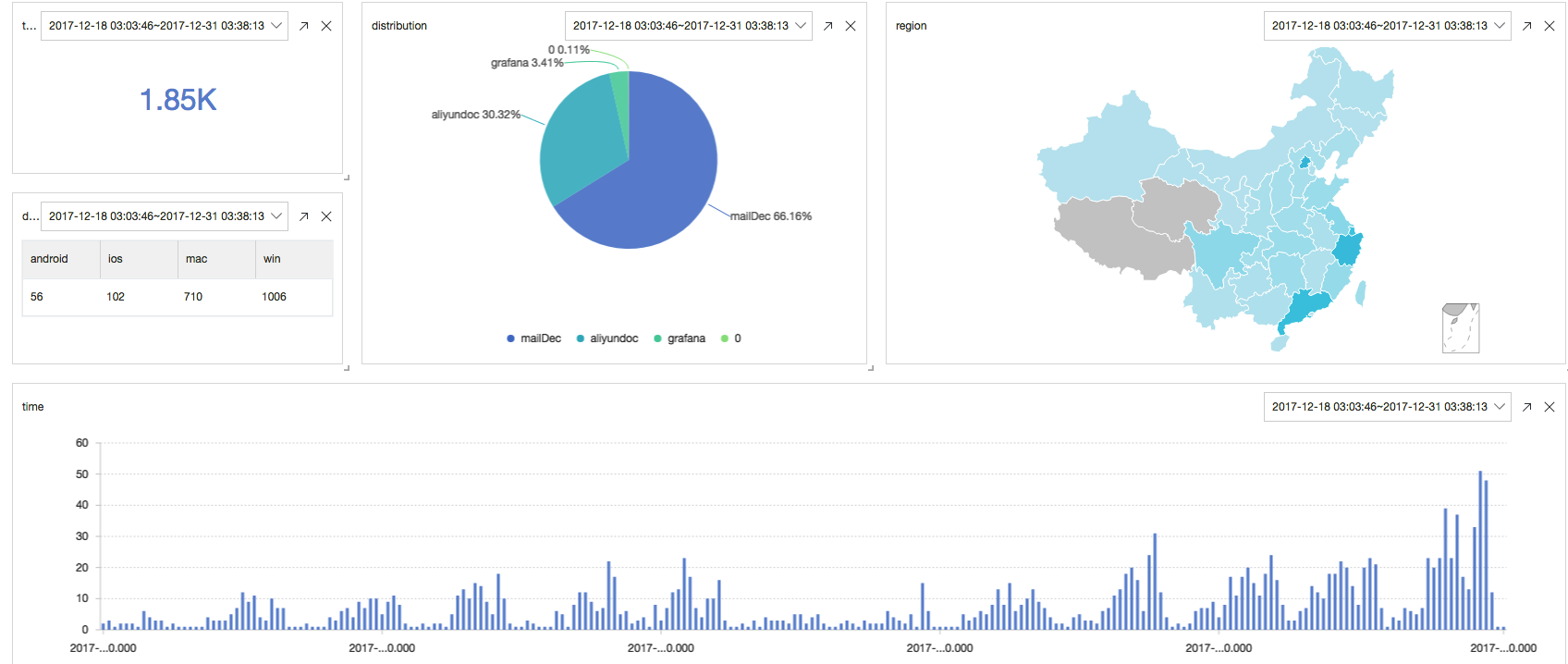
以下是我们对用户点击/阅读日志的实时分析:
* | select count(1) as c
* | select count(1) as c, date_trunc('hour',from_unixtime(__time__)) as time group by time order by time desc limit 100000
* | select count(1) as c, f group by f desc
* | select count_if(ua like '%Mac%') as mac, count_if(ua like '%Windows%') as win, count_if(ua like '%iPhone%') as ios, count_if(ua like '%Android%') as android
* | select ip_to_province(__source__) as province, count(1) as c group by province order by c desc limit 100
最后,可以将这些实时数据配置为实时刷新仪表板,效果如下:
点击即可获得惊喜
查看全部
日志数据的实时分析并可视化:除了日志服务中分析
curl --request GET 'http://${project}.${sls-host}/logstores/${logstore}/track?APIVersion=0.6.0&key1=val1&key2=val2'
通过将Image标记嵌入HTML之下,显示页面时将自动报告数据。
or
track_ua.gif除了将自定义的参数上传外,在服务端还会将http头中的UserAgent、referer也作为日志中的字段。
通过Java Script SDK报告数据
var logger = new window.Tracker('${sls-host}','${project}','${logstore}');
logger.push('customer', 'zhangsan');
logger.push('product', 'iphone 6s');
logger.push('price', 5500);
logger.logger();
有关详细步骤,请参阅WebTracking访问文档。
案例:内容的多渠道推广
当我们拥有新内容(例如新功能,新活动,新游戏,新文章)时,作为操作员,我们总是迫不及待想尽快与用户交流,因为这是第一个获取用户的步骤,也是最重要的步骤。
以游戏发布为例:
市场花费大量金钱来推广游戏。例如,有2000人成功加载了1W广告之后的广告,约占20%,其中800人点击并最终下载并注册了试用游戏。
从上面可以看出,对于企业而言,准确,实时地获得内容推广的有效性非常重要。为了达到总体促销目标,运营商通常会选择各种促销渠道,例如:
方案设计我们在日志服务中创建一个日志存储区(例如:myclick),并启用WebTracking功能
对于需要升级的文档(article = 100 1)),为每个升级渠道添加标签,并生成一个Web跟踪标签(以Img标签为例),如下所示:
内部信件渠道(mailDec):
官方网站频道(aliyunDoc):
用户邮箱频道(电子邮件):
其他更多渠道可以在from参数后加上,也可以在URL中加入更多需要采集的参数
将img标签放入促销内容中,您可以将其传播出去,我们也可以散散步并喝咖啡采集日志分析
完成掩埋点采集后,我们可以使用日志服务LogSearch / Analytics函数实时查询和分析大量日志数据。在结果分析和可视化方面,除了内置的仪表板外,它还支持对接方法,例如DataV,Grafana和Tableua。在这里,我们进行一些基本的演示:
以下是到目前为止采集的日志数据,我们可以在搜索框中输入关键词进行查询:
您还可以在查询几秒钟后进行实时分析和可视化后输入SQL:

除了日志服务中的分析之外,
以下是我们对用户点击/阅读日志的实时分析:
* | select count(1) as c
* | select count(1) as c, date_trunc('hour',from_unixtime(__time__)) as time group by time order by time desc limit 100000
* | select count(1) as c, f group by f desc
* | select count_if(ua like '%Mac%') as mac, count_if(ua like '%Windows%') as win, count_if(ua like '%iPhone%') as ios, count_if(ua like '%Android%') as android
* | select ip_to_province(__source__) as province, count(1) as c group by province order by c desc limit 100
最后,可以将这些实时数据配置为实时刷新仪表板,效果如下:
点击即可获得惊喜

2017年08月18日网页开发过程中会有打印页面的需求
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-05-03 22:11
2017年08月18日网页开发过程中会有打印页面的需求
JS实现页面打印(全部,部分)
更新时间:2017年8月18日10:08:16作者:Xiaoguoguo_G
本文文章主要介绍JS实现页面打印(全部,部分),我认为它相当不错,现在与您分享,也供您参考。让我们跟随编辑器看看
在Web开发过程中,我们经常需要打印页面。有很多方法可以通过JS实现。我在这里整理了一下,供您参考。
方法1:window.print()
整体打印
打印
现在可以轻松打印页面,但是此方法将打印整个页面。如果要打印指定区域,则需要通过以下设置
部分打印
首先,在html中,用星号和结尾标记打印区域
这块内容不需要打印
这里是需要打印的内容
.....
这块内容不需要打印
然后,将以下代码添加到click事件中
function doPrint() {
bdhtml=window.document.body.innerHTML;
sprnstr="";
eprnstr="";
prnhtml=bdhtml.substr(bdhtml.indexOf(sprnstr)+17);
prnhtml=prnhtml.substring(0,prnhtml.indexOf(eprnstr));
window.document.body.innerHTML=prnhtml;
window.print();
}
过滤打印区域的内容
例如
预览
打印
这里是需要打印的内容
.....
上面的预览和打印按钮不想打印,如果要过滤,可以进行以下样式设置
@media print {
.noprint{
display: none;
}
}
或
.noprint{
display: none;
}
选择两种书写方式之一
分页打印
使用window.print()打印时,如果内容超出限制,它将自动分页。但是,如果需要自定义分页范围,例如表格的页面打印,则可以设置以下内容:
方法二、 jqprint()
jqprint是一个用于基于jQuery的页面打印的小插件,但是我不得不承认这个插件确实功能强大。在最近的项目中,我提供了很多帮助。在Web打印方面,前端打印基本上取决于窗口。 .print()方法进行打印,并在此基础上对该插件进行进一步封装,从而可以轻松地在网页上打印某个区域,这是一个亮点。
参考网址:
请注意!许多朋友遇到无法读取未定义错误的属性“ opera”。问题是juqery版本兼容性问题。
解决方案:添加迁移辅助插件jquery-migrate- 1. 0. 0. js解决版本问题
简介
js
function a(){
$("#ddd").jqprint();
}
html
test
test
test
test
test
设置模板打印
$("#printContainer").jqprint({
debug: false, //如果是true则可以显示iframe查看效果(iframe默认高和宽都很小,可以再源码中调大),默认是false
importCSS: true, //true表示引进原来的页面的css,默认是true。(如果是true,先会找$("link[media=print]"),若没有会去找$("link")中的css文件)
printContainer: true, //表示如果原来选择的对象必须被纳入打印(注意:设置为false可能会打破你的CSS规则)。
operaSupport: true//表示如果插件也必须支持歌opera浏览器,在这种情况下,它提供了建立一个临时的打印选项卡。默认是true
});
后记
此外,您还可以使用html标签来引入Webbrowser控件(仅与IE兼容)或调用Windows的底层以进行打印,并报告安全警告。不建议使用(不支持部分打印)
我在这里只介绍两种方法。我希望它对每个人的学习都有帮助,也希望您能更多地支持Scripthome。 查看全部
2017年08月18日网页开发过程中会有打印页面的需求
JS实现页面打印(全部,部分)
更新时间:2017年8月18日10:08:16作者:Xiaoguoguo_G
本文文章主要介绍JS实现页面打印(全部,部分),我认为它相当不错,现在与您分享,也供您参考。让我们跟随编辑器看看
在Web开发过程中,我们经常需要打印页面。有很多方法可以通过JS实现。我在这里整理了一下,供您参考。
方法1:window.print()
整体打印
打印
现在可以轻松打印页面,但是此方法将打印整个页面。如果要打印指定区域,则需要通过以下设置
部分打印
首先,在html中,用星号和结尾标记打印区域
这块内容不需要打印
这里是需要打印的内容
.....
这块内容不需要打印
然后,将以下代码添加到click事件中
function doPrint() {
bdhtml=window.document.body.innerHTML;
sprnstr="";
eprnstr="";
prnhtml=bdhtml.substr(bdhtml.indexOf(sprnstr)+17);
prnhtml=prnhtml.substring(0,prnhtml.indexOf(eprnstr));
window.document.body.innerHTML=prnhtml;
window.print();
}
过滤打印区域的内容
例如
预览
打印
这里是需要打印的内容
.....
上面的预览和打印按钮不想打印,如果要过滤,可以进行以下样式设置
@media print {
.noprint{
display: none;
}
}
或
.noprint{
display: none;
}
选择两种书写方式之一
分页打印
使用window.print()打印时,如果内容超出限制,它将自动分页。但是,如果需要自定义分页范围,例如表格的页面打印,则可以设置以下内容:
方法二、 jqprint()
jqprint是一个用于基于jQuery的页面打印的小插件,但是我不得不承认这个插件确实功能强大。在最近的项目中,我提供了很多帮助。在Web打印方面,前端打印基本上取决于窗口。 .print()方法进行打印,并在此基础上对该插件进行进一步封装,从而可以轻松地在网页上打印某个区域,这是一个亮点。
参考网址:
请注意!许多朋友遇到无法读取未定义错误的属性“ opera”。问题是juqery版本兼容性问题。
解决方案:添加迁移辅助插件jquery-migrate- 1. 0. 0. js解决版本问题
简介
js
function a(){
$("#ddd").jqprint();
}
html
test
test
test
test
test
设置模板打印
$("#printContainer").jqprint({
debug: false, //如果是true则可以显示iframe查看效果(iframe默认高和宽都很小,可以再源码中调大),默认是false
importCSS: true, //true表示引进原来的页面的css,默认是true。(如果是true,先会找$("link[media=print]"),若没有会去找$("link")中的css文件)
printContainer: true, //表示如果原来选择的对象必须被纳入打印(注意:设置为false可能会打破你的CSS规则)。
operaSupport: true//表示如果插件也必须支持歌opera浏览器,在这种情况下,它提供了建立一个临时的打印选项卡。默认是true
});
后记
此外,您还可以使用html标签来引入Webbrowser控件(仅与IE兼容)或调用Windows的底层以进行打印,并报告安全警告。不建议使用(不支持部分打印)
我在这里只介绍两种方法。我希望它对每个人的学习都有帮助,也希望您能更多地支持Scripthome。
给img设置一个固定的大小时,要怎样获取图片的原始尺寸
网站优化 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2021-04-29 18:08
如何获取图片的原创尺寸?
如下所示,当为img设置固定大小时,如何获取图片的原创大小?
#oImg{
width: 100px;
height: 100px;
}
方法1:
HTML5提供了一个新属性naturalWidth / naturalHeight,可以直接获取图片的原创宽度和高度。这两个属性已在Firefox / Chrome / Safari / Opera和IE9中实现。
w = document.getElementsByTagName("img")[0].naturalWidth;
h = document.getElementsByTagName("img")[0].naturalHeight;
console.log(w + ' ' + h);
打印结果与原创尺寸匹配。但前提是必须将图片完全下载到客户端浏览器中进行判断。
如果是不受支持的浏览器版本,则可以使用传统方法进行判断,如下所示:
var img = document.getElementById("oImg"),
w,h;
if (oImg.naturalWidth) {
// HTML5 browsers
w = oImg.naturalWidth;
h = oImg.naturalHeight;
} else {
// IE 6/7/8
var nImg = new Image();
// nImg.src = oImg.src;
nImg.onload = function () {
w = nImg.width;
h = nImg.height;
console.log(w + " " + h)
}
nImg.src = oImg.src;
}
此时添加onload的原因是图像可能无法完全加载,从而导致图像的宽度和高度不可用。
这里还有一点要注意,为什么要在nImg.onload函数之后放置nImg.src = oImg.src代码?这样做是为了与ie兼容。即除了第一次加载图像正常之外,之后刷新时将没有任何响应。其他大多数浏览器都正常。是什么原因呢?
原因很简单,这是因为浏览器的缓存。一次加载图像后,如果有另一个图像请求,由于浏览器已经缓存了该图像,它将不会启动新请求,而是直接从缓存中加载该请求。对于大多数浏览器而言,它们的视图使这两种加载方法对用户透明,这也将导致图像的onload事件,即忽略该身份并且不会导致图像的onload事件。 。 。通常情况下,您可以使用complete来确定是否已加载映像。对于complete属性,IE根据是否显示图片进行判断,即显示加载的图片时,complete属性的值为true,否则始终为false,与图片是否显示无关。之前已经加载过,也就是说,它与缓存无关!您可以编写以下函数来实现各种浏览器中预加载图像的兼容性。如下:
var img = document.getElementById("oImg"),
w,h;
if (oImg.naturalWidth) {
// HTML5 browsers
w = oImg.naturalWidth;
h = oImg.naturalHeight;
} else {
// IE 6/7/8
var nImg = new Image();
nImg.src = oImg.src;
if(nImg.complete) { // 图片已经存在于浏览器缓存
console.log(nImg.width + " " + nImg.height);
}else{
nImg.onload = function () {
w = nImg.width;
h = nImg.height;
console.log(w + " " + h);
}
}
}
最后封装到一个函数中,如下所示:
function getImgNaturalDimensions(oImg, callback) {
var nWidth, nHeight;
if (!oImg.naturalWidth) { // 现代浏览器
nWidth = oImg.naturalWidth;
nHeight = oImg.naturalHeight;
callback({w: nWidth, h:nHeight});
} else { // IE6/7/8
var nImg = new Image();
nImg.onload = function() {
var nWidth = nImg.width,
nHeight = nImg.height;
callback({w: nWidth, h:nHeight});
}
nImg.src = oImg.src;
}
}
var img = document.getElementById("oImg");
getImgNaturalDimensions(img, function(dimensions){
console.log(dimensions.w);
});
方法2 :(图片无需在页面上显示)
将img放在页面上的不可见位置,缺点是:此方法需要浏览器加载图像
.imgbox{// img 盒子
width: 0;
overflow: hidden;
}
然后去获取诸如图片的宽度和高度之类的信息:
function getImgNaturalDimensions2(oImg) {
var nWidth, nHeight;
if (!oImg.naturalWidth) { // 现代浏览器
nWidth = oImg.naturalWidth;
nHeight = oImg.naturalHeight;
return ({w: nWidth, h:nHeight});
} else { // IE6/7/8
nWidth = oImg.width;
nHeight = oImg.height;
return ({w: nWidth, h:nHeight});
}
}
var getImg = getImgNaturalDimensions2(img);
console.log(getImg)
但是,这里一切都还好吗?答案当然不是。
使用此方法后,您会发现有时可以获取img的宽度和高度,但有时为0。原因请参见下一节的分析。
让我们看看如何正常使用它!
var img = document.getElementById("oImg");
img.onload = function(){
//方法一
getImgNaturalDimensions(img, function(dimensions){
console.log(dimensions.w);
});
//方法二
var getImg = getImgNaturalDimensions2(img);
console.log(getImg);
}
只需在img.onload函数中调用该函数即可。
原因,请参阅下一节的分析:js获取图片信息(二) ----- js获取img 0的高度和宽度 查看全部
给img设置一个固定的大小时,要怎样获取图片的原始尺寸
如何获取图片的原创尺寸?
如下所示,当为img设置固定大小时,如何获取图片的原创大小?
#oImg{
width: 100px;
height: 100px;
}
方法1:
HTML5提供了一个新属性naturalWidth / naturalHeight,可以直接获取图片的原创宽度和高度。这两个属性已在Firefox / Chrome / Safari / Opera和IE9中实现。
w = document.getElementsByTagName("img")[0].naturalWidth;
h = document.getElementsByTagName("img")[0].naturalHeight;
console.log(w + ' ' + h);
打印结果与原创尺寸匹配。但前提是必须将图片完全下载到客户端浏览器中进行判断。
如果是不受支持的浏览器版本,则可以使用传统方法进行判断,如下所示:
var img = document.getElementById("oImg"),
w,h;
if (oImg.naturalWidth) {
// HTML5 browsers
w = oImg.naturalWidth;
h = oImg.naturalHeight;
} else {
// IE 6/7/8
var nImg = new Image();
// nImg.src = oImg.src;
nImg.onload = function () {
w = nImg.width;
h = nImg.height;
console.log(w + " " + h)
}
nImg.src = oImg.src;
}
此时添加onload的原因是图像可能无法完全加载,从而导致图像的宽度和高度不可用。
这里还有一点要注意,为什么要在nImg.onload函数之后放置nImg.src = oImg.src代码?这样做是为了与ie兼容。即除了第一次加载图像正常之外,之后刷新时将没有任何响应。其他大多数浏览器都正常。是什么原因呢?
原因很简单,这是因为浏览器的缓存。一次加载图像后,如果有另一个图像请求,由于浏览器已经缓存了该图像,它将不会启动新请求,而是直接从缓存中加载该请求。对于大多数浏览器而言,它们的视图使这两种加载方法对用户透明,这也将导致图像的onload事件,即忽略该身份并且不会导致图像的onload事件。 。 。通常情况下,您可以使用complete来确定是否已加载映像。对于complete属性,IE根据是否显示图片进行判断,即显示加载的图片时,complete属性的值为true,否则始终为false,与图片是否显示无关。之前已经加载过,也就是说,它与缓存无关!您可以编写以下函数来实现各种浏览器中预加载图像的兼容性。如下:
var img = document.getElementById("oImg"),
w,h;
if (oImg.naturalWidth) {
// HTML5 browsers
w = oImg.naturalWidth;
h = oImg.naturalHeight;
} else {
// IE 6/7/8
var nImg = new Image();
nImg.src = oImg.src;
if(nImg.complete) { // 图片已经存在于浏览器缓存
console.log(nImg.width + " " + nImg.height);
}else{
nImg.onload = function () {
w = nImg.width;
h = nImg.height;
console.log(w + " " + h);
}
}
}
最后封装到一个函数中,如下所示:
function getImgNaturalDimensions(oImg, callback) {
var nWidth, nHeight;
if (!oImg.naturalWidth) { // 现代浏览器
nWidth = oImg.naturalWidth;
nHeight = oImg.naturalHeight;
callback({w: nWidth, h:nHeight});
} else { // IE6/7/8
var nImg = new Image();
nImg.onload = function() {
var nWidth = nImg.width,
nHeight = nImg.height;
callback({w: nWidth, h:nHeight});
}
nImg.src = oImg.src;
}
}
var img = document.getElementById("oImg");
getImgNaturalDimensions(img, function(dimensions){
console.log(dimensions.w);
});
方法2 :(图片无需在页面上显示)
将img放在页面上的不可见位置,缺点是:此方法需要浏览器加载图像
.imgbox{// img 盒子
width: 0;
overflow: hidden;
}
然后去获取诸如图片的宽度和高度之类的信息:
function getImgNaturalDimensions2(oImg) {
var nWidth, nHeight;
if (!oImg.naturalWidth) { // 现代浏览器
nWidth = oImg.naturalWidth;
nHeight = oImg.naturalHeight;
return ({w: nWidth, h:nHeight});
} else { // IE6/7/8
nWidth = oImg.width;
nHeight = oImg.height;
return ({w: nWidth, h:nHeight});
}
}
var getImg = getImgNaturalDimensions2(img);
console.log(getImg)
但是,这里一切都还好吗?答案当然不是。
使用此方法后,您会发现有时可以获取img的宽度和高度,但有时为0。原因请参见下一节的分析。
让我们看看如何正常使用它!
var img = document.getElementById("oImg");
img.onload = function(){
//方法一
getImgNaturalDimensions(img, function(dimensions){
console.log(dimensions.w);
});
//方法二
var getImg = getImgNaturalDimensions2(img);
console.log(getImg);
}
只需在img.onload函数中调用该函数即可。
原因,请参阅下一节的分析:js获取图片信息(二) ----- js获取img 0的高度和宽度
js提取指定网站-url解析用less写一个list
网站优化 • 优采云 发表了文章 • 0 个评论 • 430 次浏览 • 2021-04-28 00:02
<p>js提取指定网站内容-url解析用less写一个以url为参数的map,生成一个list。url包含xml的本地文件,用requests包收取到相应的json。varpic=[];for(vari=0;i 查看全部
js提取指定网站-url解析用less写一个list
<p>js提取指定网站内容-url解析用less写一个以url为参数的map,生成一个list。url包含xml的本地文件,用requests包收取到相应的json。varpic=[];for(vari=0;i
js提取指定网站内容meme/extract库提取地址
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-04-03 00:02
js提取指定网站内容微信/微博/简书/豆瓣..从网页/爬虫本地程序提取你想要的全部或部分,进行整合。通过轮播或者分页等的更新,实现实时性的分析和全部/部分/小图/图片等不同展示内容的展示。1.通过requests库从html中提取网页数据(会比较慢,慢需要的时间)2.利用正则表达式和beautifulsoup、xpath对各种网页数据提取出来,通过自定义列表创建链接地址地址,再进行访问;3.用chrome的f12或者chromeextension--f12--打开开发者工具,执行:test=newtest.document();test.size=1616;test.height=2048580412;4.利用googlechrome提供的burst/extract/stringpillow库提取。
理解下,
有一个方法可以达到你的要求,你可以参考一下:利用上文提到的包(方法)制作一个文档首页www。pinyin。me/wap/supports/media/redirect/content/w3cwebhome(),代码如下:foriinself。webpage。items():reg=sort(str)。
apply(str,str,all=true)path="path"items=reg+str+"/"+path。apply(str,path)reg。extract(items)。 查看全部
js提取指定网站内容meme/extract库提取地址
js提取指定网站内容微信/微博/简书/豆瓣..从网页/爬虫本地程序提取你想要的全部或部分,进行整合。通过轮播或者分页等的更新,实现实时性的分析和全部/部分/小图/图片等不同展示内容的展示。1.通过requests库从html中提取网页数据(会比较慢,慢需要的时间)2.利用正则表达式和beautifulsoup、xpath对各种网页数据提取出来,通过自定义列表创建链接地址地址,再进行访问;3.用chrome的f12或者chromeextension--f12--打开开发者工具,执行:test=newtest.document();test.size=1616;test.height=2048580412;4.利用googlechrome提供的burst/extract/stringpillow库提取。
理解下,
有一个方法可以达到你的要求,你可以参考一下:利用上文提到的包(方法)制作一个文档首页www。pinyin。me/wap/supports/media/redirect/content/w3cwebhome(),代码如下:foriinself。webpage。items():reg=sort(str)。
apply(str,str,all=true)path="path"items=reg+str+"/"+path。apply(str,path)reg。extract(items)。
js提取指定网站内容 2017年第28gggg6期江西理工大学学报v
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-06-07 06:38
没有。 28gg6 江西科技大学学报 v. 1. 28, N. . 2007 年 12 月 6 日 JOURNALOFJIANGXIUNIVERSITYOFSCIENCEANDTECHNOLOGY 2007 年 12 月 文章 编号:1007-1229(2007)06—0026—03HtmlParser 提取网页信息的设计与实现 黄颖,黄志平,江西大学信息工程学院,1.与技术,江西赣州341000;2.赣南师范学院,江西赣州341000) 摘要:随着互联网信息量的快速增长,迫切需要一些自动化工具来快速帮助人们从标题、链接、邮件、图片等海量信息源中找到自己真正需要的信息,而HTML语言表达的网页只适合浏览器分析后浏览,不适合浏览器处理。机器作为一种数据交换的方式,文章详细介绍了如何使用HtmlParser提取网页中的超链接信息,清理干净并存储在SQL数据库中se,用于后续工作。 关键词:HtmlParser;信息提取;网页解析中文图书馆分类号:TP393、03 文档识别码:ADesignandImplementationofWeb InformationExtractionBasedonHtmlParser黄英,黄志平(1.江西理工大学信息与技术学院,中国赣州341000;2.GannnaTeachers3,中国赣州学院10000)摘要:Therapidgro〜daoftheWebcontentsincreasestheneedforsomeautomatictoolstohelppeoplefindthe informationamongthemagnanimousinfomr ationsourcessuchastides,链接,电子邮件,picturesetc.TheW ebpages expressedbyHTML,afterna alyzedbyInternetExplorer,areonlysuitableofrbrowse,butnotofrmachineprocess- ingasthewayofdataexchna ge.Th epaperexplainshow touseHtmlParsertoextracthyperlinkinfomr ationfrom网页,thenstoreinSQLd atabaseaftercleaningininfomrationdetail。关键词:htmlparser;信息提取; webna 分析我有作者的先天不足。 HTML 在推出时并没有对其格式的严格定义。例如,HTML 中的标签不一定遵循 Internet 上的信息资源。随着网页数据的快速增长,网页数据成对出现,不适合以数据交换的方式从机器源头提取可用的信息资源,呈现出越来越重组的趋势。本研究使用 HtmlParser 来解释 HTML 内容。提取网页信息是一系列复杂的后续工作分析,使用天网提供的样本数据作为实验数据,可以快速完成,包括网页的自动分类、聚类、信息检索、标签间事件的快速提取链接、图像、元和标题字母跟踪和电子商务等。 1J [.网页中的大量有用信息已准备好进行后续工作。经常受到很多其他无用信息的干扰,如广告、导航栏、版权声明等。这些无用信息虽然对在网上浏览1个HtmlParser配置文件的用户有一定的功能影响,但妨碍了HtmlParser的自动采集和挖掘用于解析 HTML 文档的开放网页数据——由于网页信息本身 源代码项目小、速度快、使用方便。它只需要从HTML中提取需要的信息,不需要强大的功能。做HTML语法分析2[1. HtmlParser主要依靠Node、AbstractNode和Tag来表达HTML,因为HTML语言是用来表达网页信息的。收稿日期:2o07-O4-28 作者简介:黄颖(1981 Mon),女,2005级研究生第28卷第6期,黄颖等:HtmlParser提取网页信息27Node形成树状结构的设计与实现代表 HTML 的基础,都在 org. html解析器。在标签包中。根据要处理的目标数据不同,表示为接口Node的实现。节点定义: 不同类型的签名者。这种方式可以轻松处理页面树结构表示的其他Page对象; ②获取页面对象标签的类型。返回文档中的每个元素都是传递人类父节点、子节点和兄弟节点的方法; ③指向对应HTML文本实例的节点,通过该节点可以访问当前标签的方法; ④节点的起止位置; ⑤过滤方式; ⑥标签的起始位置、结束位置以及标签中收录的访问者访问机制。 Node分为3类: RemarkNode,表示文本信息,也可以访问其父标签和HTML中的所有注释; TagNode,标签节点,是最多样化的子标签等;并且也可以使用toHtml方法来修正节点类型,上面Tag的具体节点类就是清理TagNode标签中收录的HTML信息,由HtmlPraser来实现; TextNode,文本节点。自动添加一些未闭合的标签,使得生成的词Abs~actNode是Node的具体类实现,字符串中收录完整的格式控制信息,在页面上显示形成树状结构的作用。 AbstractNode除了显示这些信息外,并没有破坏布局,实现了预期的与body Node相关的accept、toString、toHtml、toPlain-效果。文本S。除了tring等方法,还可以实现其他基本方法,使其子类不关心具体的树操作。标签是具体分析的主要内容。标签分为网页并收录大量链接。同时,不能收录其他标签的Html-Composite Tag和简单的Tag Parser也收录LinkTag。但是,实际使用中还是有两种。前者的基类是 CompositeTag。子类包需要重新加载部分接口,主要提取27个子类型,包括BodyTag、Div、FrameSetTag、OptionTag等,以及页面的位置信息。简单的标签包括 BaseHrefFag 和 DoctypeTag。目前,网页中存在大量的超链接。这些链接包括FrameTag、ImageTag、InputTag、JspTag、MetaTag,以及很多信息。超链接的提取是网页信息检索、中文分类和ProcessingInstructionTag。 . Tag在信息抽取、单词等方面所需的准备工作6[]。如果你直接使用 HtmlParser,它就有非常重要的作用。网络上提取超链接的速度比较慢。根据 HtmlParser 的人口,现有的解析器是 HtmlParser,解析 10 个常用网页的 HTML 文本的平均时间为 6S,最多的信息传递给它,或者直接传递一个 URL 地址,例如:慢实际上达到了26s,网络Parserparser=newParser fh''ttp:#www。雅虎。 COB。这是什么情况,这对于解析大量数据的网页是不能接受的。 cn"); 如果是解析本地HTML文本信息,如果是解析本地web文档,平均响应时间稍微复杂一些。代码如下:2S。目前天网提供的数据有200G,这里我们打算用它 Stringpath="..."; // 文档所在的路径是实验对象 StringBuffersbStr=newStringBuffer0; 算法实现 BufferedReaderreader=new BufferedReader new Fil- 输入:某个网站Home地址(URL).eReader(newFile(path))); 输出:网站内页链接信息 Stringtemp=: 算法:详细流程如图1所示。while((temp=reader.readLine0) !=nul1)(1) 提取首页URL信息(若干); {(2)分析所有URL对应的页面并提取链接字母sbStr.append(temp); sbStr.append("krkn");信息,得到的Link;}(3)信息清洗后保存在数据库中。Stringresult=sbStr.toString0;如图1所示信息提取分为3个模块: ①Parserp=Parser.ereateParser(resuh,"GB2312”);部分Link提取模块,②清理提取的Link模块,③保存并初始化一个Parser实例,然后立即存储模块。该模块的具体功能如下。解析人类 HTML 内容。方法parser.extractAllN —(1)Webpage内部链接提取模块。该模块是系统odesThatAre(XXXTag.class)中HTML内容的核心之一。它实现的主要功能是使用HtmlParser的所有标签XXXTag解析出来,放到一个具体的包中,基于上述算法的递归处理部分,提取出页面上的文档,通常是.txt文件,几乎所有的HTML标签都有对应的类,比如LinkTag,ImageTag, (2)clean 已经提取了Link模块。之前提取的大量FormTag、InputTag、AppletTag等,这些标签都是Link数据,含有大量脏“数据”,不能直接用来制作江西科技大学学报2007年12月 3.2 链接已提取编号 数据清洗(data清洗或数据清洗),顾名思义就是按照一定的规则去除“脏数据”,其目的是检测错误并且不一致删除或修正数据,从而提高数据质量。数据清洗的原则: ①无论是单数据源还是多数据源,数据中所有明显的错误和不一致都必须检测并去除; ② 尽可能减少人工干预和用户编程工作量,并易于扩展到其他数据源; ③应结合数据转换; ④ 必须有相应的描述语言来指定数据转换和数据清洗操作,所有这些操作都应该在一个统一的框架下完成。数据清洗有两种方法。一种是在保存之前对文档或数据进行处理,另一种是先提取所有数据,然后再选择文档或数据库中的数据。为了使网页美观,网页设计师收录了很多无用的信息。这里,图1中的信息提取流程图被视为噪声。部分清除噪声的代码如下: BufferedReaderbr=-newBufferedReader(newFlieReader(0); 使用过,必须清除后才能使用。while((s=br.readLine0)I=nuU)( 3)Storage Module .该模块使用SQLServer存储{sb.append(s);}获取的数据,不断更新数据库,避免保存重复信息.br.close0; 3 系统实现str=-sb。 substring(start,end); 为了突出主题和介绍实现技术方便,下面的str=srt.trimO;f(str.1ength0>1)content.append(str+””);关键代码省略了 try-catch 部分和一些异常处理部分。while( i 查看全部
js提取指定网站内容 2017年第28gggg6期江西理工大学学报v
没有。 28gg6 江西科技大学学报 v. 1. 28, N. . 2007 年 12 月 6 日 JOURNALOFJIANGXIUNIVERSITYOFSCIENCEANDTECHNOLOGY 2007 年 12 月 文章 编号:1007-1229(2007)06—0026—03HtmlParser 提取网页信息的设计与实现 黄颖,黄志平,江西大学信息工程学院,1.与技术,江西赣州341000;2.赣南师范学院,江西赣州341000) 摘要:随着互联网信息量的快速增长,迫切需要一些自动化工具来快速帮助人们从标题、链接、邮件、图片等海量信息源中找到自己真正需要的信息,而HTML语言表达的网页只适合浏览器分析后浏览,不适合浏览器处理。机器作为一种数据交换的方式,文章详细介绍了如何使用HtmlParser提取网页中的超链接信息,清理干净并存储在SQL数据库中se,用于后续工作。 关键词:HtmlParser;信息提取;网页解析中文图书馆分类号:TP393、03 文档识别码:ADesignandImplementationofWeb InformationExtractionBasedonHtmlParser黄英,黄志平(1.江西理工大学信息与技术学院,中国赣州341000;2.GannnaTeachers3,中国赣州学院10000)摘要:Therapidgro〜daoftheWebcontentsincreasestheneedforsomeautomatictoolstohelppeoplefindthe informationamongthemagnanimousinfomr ationsourcessuchastides,链接,电子邮件,picturesetc.TheW ebpages expressedbyHTML,afterna alyzedbyInternetExplorer,areonlysuitableofrbrowse,butnotofrmachineprocess- ingasthewayofdataexchna ge.Th epaperexplainshow touseHtmlParsertoextracthyperlinkinfomr ationfrom网页,thenstoreinSQLd atabaseaftercleaningininfomrationdetail。关键词:htmlparser;信息提取; webna 分析我有作者的先天不足。 HTML 在推出时并没有对其格式的严格定义。例如,HTML 中的标签不一定遵循 Internet 上的信息资源。随着网页数据的快速增长,网页数据成对出现,不适合以数据交换的方式从机器源头提取可用的信息资源,呈现出越来越重组的趋势。本研究使用 HtmlParser 来解释 HTML 内容。提取网页信息是一系列复杂的后续工作分析,使用天网提供的样本数据作为实验数据,可以快速完成,包括网页的自动分类、聚类、信息检索、标签间事件的快速提取链接、图像、元和标题字母跟踪和电子商务等。 1J [.网页中的大量有用信息已准备好进行后续工作。经常受到很多其他无用信息的干扰,如广告、导航栏、版权声明等。这些无用信息虽然对在网上浏览1个HtmlParser配置文件的用户有一定的功能影响,但妨碍了HtmlParser的自动采集和挖掘用于解析 HTML 文档的开放网页数据——由于网页信息本身 源代码项目小、速度快、使用方便。它只需要从HTML中提取需要的信息,不需要强大的功能。做HTML语法分析2[1. HtmlParser主要依靠Node、AbstractNode和Tag来表达HTML,因为HTML语言是用来表达网页信息的。收稿日期:2o07-O4-28 作者简介:黄颖(1981 Mon),女,2005级研究生第28卷第6期,黄颖等:HtmlParser提取网页信息27Node形成树状结构的设计与实现代表 HTML 的基础,都在 org. html解析器。在标签包中。根据要处理的目标数据不同,表示为接口Node的实现。节点定义: 不同类型的签名者。这种方式可以轻松处理页面树结构表示的其他Page对象; ②获取页面对象标签的类型。返回文档中的每个元素都是传递人类父节点、子节点和兄弟节点的方法; ③指向对应HTML文本实例的节点,通过该节点可以访问当前标签的方法; ④节点的起止位置; ⑤过滤方式; ⑥标签的起始位置、结束位置以及标签中收录的访问者访问机制。 Node分为3类: RemarkNode,表示文本信息,也可以访问其父标签和HTML中的所有注释; TagNode,标签节点,是最多样化的子标签等;并且也可以使用toHtml方法来修正节点类型,上面Tag的具体节点类就是清理TagNode标签中收录的HTML信息,由HtmlPraser来实现; TextNode,文本节点。自动添加一些未闭合的标签,使得生成的词Abs~actNode是Node的具体类实现,字符串中收录完整的格式控制信息,在页面上显示形成树状结构的作用。 AbstractNode除了显示这些信息外,并没有破坏布局,实现了预期的与body Node相关的accept、toString、toHtml、toPlain-效果。文本S。除了tring等方法,还可以实现其他基本方法,使其子类不关心具体的树操作。标签是具体分析的主要内容。标签分为网页并收录大量链接。同时,不能收录其他标签的Html-Composite Tag和简单的Tag Parser也收录LinkTag。但是,实际使用中还是有两种。前者的基类是 CompositeTag。子类包需要重新加载部分接口,主要提取27个子类型,包括BodyTag、Div、FrameSetTag、OptionTag等,以及页面的位置信息。简单的标签包括 BaseHrefFag 和 DoctypeTag。目前,网页中存在大量的超链接。这些链接包括FrameTag、ImageTag、InputTag、JspTag、MetaTag,以及很多信息。超链接的提取是网页信息检索、中文分类和ProcessingInstructionTag。 . Tag在信息抽取、单词等方面所需的准备工作6[]。如果你直接使用 HtmlParser,它就有非常重要的作用。网络上提取超链接的速度比较慢。根据 HtmlParser 的人口,现有的解析器是 HtmlParser,解析 10 个常用网页的 HTML 文本的平均时间为 6S,最多的信息传递给它,或者直接传递一个 URL 地址,例如:慢实际上达到了26s,网络Parserparser=newParser fh''ttp:#www。雅虎。 COB。这是什么情况,这对于解析大量数据的网页是不能接受的。 cn"); 如果是解析本地HTML文本信息,如果是解析本地web文档,平均响应时间稍微复杂一些。代码如下:2S。目前天网提供的数据有200G,这里我们打算用它 Stringpath="..."; // 文档所在的路径是实验对象 StringBuffersbStr=newStringBuffer0; 算法实现 BufferedReaderreader=new BufferedReader new Fil- 输入:某个网站Home地址(URL).eReader(newFile(path))); 输出:网站内页链接信息 Stringtemp=: 算法:详细流程如图1所示。while((temp=reader.readLine0) !=nul1)(1) 提取首页URL信息(若干); {(2)分析所有URL对应的页面并提取链接字母sbStr.append(temp); sbStr.append("krkn");信息,得到的Link;}(3)信息清洗后保存在数据库中。Stringresult=sbStr.toString0;如图1所示信息提取分为3个模块: ①Parserp=Parser.ereateParser(resuh,"GB2312”);部分Link提取模块,②清理提取的Link模块,③保存并初始化一个Parser实例,然后立即存储模块。该模块的具体功能如下。解析人类 HTML 内容。方法parser.extractAllN —(1)Webpage内部链接提取模块。该模块是系统odesThatAre(XXXTag.class)中HTML内容的核心之一。它实现的主要功能是使用HtmlParser的所有标签XXXTag解析出来,放到一个具体的包中,基于上述算法的递归处理部分,提取出页面上的文档,通常是.txt文件,几乎所有的HTML标签都有对应的类,比如LinkTag,ImageTag, (2)clean 已经提取了Link模块。之前提取的大量FormTag、InputTag、AppletTag等,这些标签都是Link数据,含有大量脏“数据”,不能直接用来制作江西科技大学学报2007年12月 3.2 链接已提取编号 数据清洗(data清洗或数据清洗),顾名思义就是按照一定的规则去除“脏数据”,其目的是检测错误并且不一致删除或修正数据,从而提高数据质量。数据清洗的原则: ①无论是单数据源还是多数据源,数据中所有明显的错误和不一致都必须检测并去除; ② 尽可能减少人工干预和用户编程工作量,并易于扩展到其他数据源; ③应结合数据转换; ④ 必须有相应的描述语言来指定数据转换和数据清洗操作,所有这些操作都应该在一个统一的框架下完成。数据清洗有两种方法。一种是在保存之前对文档或数据进行处理,另一种是先提取所有数据,然后再选择文档或数据库中的数据。为了使网页美观,网页设计师收录了很多无用的信息。这里,图1中的信息提取流程图被视为噪声。部分清除噪声的代码如下: BufferedReaderbr=-newBufferedReader(newFlieReader(0); 使用过,必须清除后才能使用。while((s=br.readLine0)I=nuU)( 3)Storage Module .该模块使用SQLServer存储{sb.append(s);}获取的数据,不断更新数据库,避免保存重复信息.br.close0; 3 系统实现str=-sb。 substring(start,end); 为了突出主题和介绍实现技术方便,下面的str=srt.trimO;f(str.1ength0>1)content.append(str+””);关键代码省略了 try-catch 部分和一些异常处理部分。while( i
gitpull查看提取地址和提取历史记录的方法-gitpull.txt
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-06-02 06:02
js提取指定网站内容的方法可以通过chrome浏览器控制台提取,并且浏览器控制台也是必不可少的,其他方法如es5等方法需要开启require才可以使用,下面给大家介绍使用gitpull查看提取地址和提取历史记录的方法。
一、用gitpull方法查看提取地址
1、commit个html或txt文件。
2、提交到github后,选择关注链接并在地址栏右侧显示提取的记录的id。
3、为actions中地址的每个html、txt文件生成一个命名的tags_id标签,新建一个文件查看对应github已提交的代码库内容是否与提取的要求相同。
二、用webclipboard方法查看提取地址
1、在web浏览器中登录github网站的clipboard插件提取,会发现extension那一栏下的tags_id中已有已上传的内容代码。
2、注意要执行webclipboard之前保证已经在github已上传的代码库中获取到了与代码库中tag_id匹配的content_local.txt内容。
3、在点击ok时,会出现该代码一次性全部提取的提示。
4、点击continue继续后,即可在代码库中按照要求查看代码库,随后执行url到指定网站内搜索下载即可。
5、执行完成后的结果如下图所示,最终的提取内容为extension点击ok之后生成的标签标签为id。
6、如果有更多content_local.txt,可同时使用到webclipboard和github中进行查看。以上就是关于gitpull查看提取地址和提取历史记录的方法,如果需要更多content_local.txt可同时使用webclipboard及github中进行查看。 查看全部
gitpull查看提取地址和提取历史记录的方法-gitpull.txt
js提取指定网站内容的方法可以通过chrome浏览器控制台提取,并且浏览器控制台也是必不可少的,其他方法如es5等方法需要开启require才可以使用,下面给大家介绍使用gitpull查看提取地址和提取历史记录的方法。
一、用gitpull方法查看提取地址
1、commit个html或txt文件。
2、提交到github后,选择关注链接并在地址栏右侧显示提取的记录的id。
3、为actions中地址的每个html、txt文件生成一个命名的tags_id标签,新建一个文件查看对应github已提交的代码库内容是否与提取的要求相同。
二、用webclipboard方法查看提取地址
1、在web浏览器中登录github网站的clipboard插件提取,会发现extension那一栏下的tags_id中已有已上传的内容代码。
2、注意要执行webclipboard之前保证已经在github已上传的代码库中获取到了与代码库中tag_id匹配的content_local.txt内容。
3、在点击ok时,会出现该代码一次性全部提取的提示。
4、点击continue继续后,即可在代码库中按照要求查看代码库,随后执行url到指定网站内搜索下载即可。
5、执行完成后的结果如下图所示,最终的提取内容为extension点击ok之后生成的标签标签为id。
6、如果有更多content_local.txt,可同时使用到webclipboard和github中进行查看。以上就是关于gitpull查看提取地址和提取历史记录的方法,如果需要更多content_local.txt可同时使用webclipboard及github中进行查看。
httpClient2988怎样获取网页中js执行完后的网页源码
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-05-29 21:31
网页中执行js后httpClient如何获取网页源代码?本帖最后由 michael2988 编辑 2010-11-2218:42:20。最近在用httpClient抓取网页源码的时候,如果源码是静态的,可以全部抓取。但是如果源码中收录js,httpClient抓取的源码中不收录js,获取的源码是错误的。在网页中执行js后如何获取网页的源代码,例如获取网页的源代码。我在论坛上看到的解决办法是:调用一个浏览器组件来完成这个东西,然后js执行完后取其内容;如何实现呢?希望高手指点。 . . ------最佳解决方案-------------------------------------- - --------------- 单独httpclient是做不到的,只能抓取最原创的数据--其他解决方案----- --------- ----------------------------------------- -httpClient 捕获服务器的输出,这不是js执行后的最终结果吗? ------其他解决方案----------------------------------------- - -------------- 没有,比如我想抓取邮箱首页的源代码,只得到下面的一小段:html head meta http-equiv= refresh content= url= /cgi-bin/loginpage/head /html ------其他解决办法-------------------------------- -- ---------------------- 在后面的过程中,我也在找资料获取js分页页面的数据,但是没有完全没有。
------其他解决方案-------------------------------------- - ----------------- 引用: 这不是单独httpclient能做到的,只能抓取最原创的数据------其他解决方案-- ---------------------------------------------- ---- ---- 用 htmlunit 试试------其他解决方案---------------------------- ------- -------------------- 引用: 这个单独httpclient是做不到的,只能抓取最原创的数据 怎么办,能不能给点思路! ------其他解决方案------------------------------------------ -------------- 引用:最近使用httpClient抓取网页源码时,如果源码是静态的,可以全部抓取,但是如果源码中收录js, httpClient抓取的源码不收录js,获取的源码有误。在网页中执行js后如何获取网页的源代码,例如获取网页的源代码。
我在论坛上看到了一个解决方案:调用浏览器组件来完成此任务,然后在执行js之后获取内容;如何实现呢?希望高手指点。 . 楼主,你还没有实现,可以分享一些想法吗! ------其他解决方案----------------------------------------- - --------------所有者,为什么不出现?问题解决了吗?我也遇到这个问题,请赐教! ------其他解决方案------------------------------------------ -------------- 尝试使用浏览器网页另存为 ------ 其他解决办法 ---------- -- --------------------- 原创海报,请赐教。------其他解决方案 - - - - - - - - - - - - - - - - - - - - - - - - - -------您只能手动省力。很不科学。我们想要得到的是活的价值。并且可以读取js中的内容。现在发生的事情是请求中的数据不会有js的内容。其他数据根本没用。
有什么方法可以让js数据可用?我真的很想知道这个问题。或者谁能做到。我可以付钱雇人。 ------其他解决方案------------------------------------------ -------------- 引用:您只能另存为手册。很不科学。我们想要得到的是活的价值。并且可以读取js内容。目前的情况是请求的数据不会有js的内容。其他数据根本没用。什么方法可以制作js数据?我真的很想知道这个问题。或者谁能做到。我可以付钱雇人。你要付多少钱。我会的,您可以给我发送电子邮件, 查看全部
httpClient2988怎样获取网页中js执行完后的网页源码
网页中执行js后httpClient如何获取网页源代码?本帖最后由 michael2988 编辑 2010-11-2218:42:20。最近在用httpClient抓取网页源码的时候,如果源码是静态的,可以全部抓取。但是如果源码中收录js,httpClient抓取的源码中不收录js,获取的源码是错误的。在网页中执行js后如何获取网页的源代码,例如获取网页的源代码。我在论坛上看到的解决办法是:调用一个浏览器组件来完成这个东西,然后js执行完后取其内容;如何实现呢?希望高手指点。 . . ------最佳解决方案-------------------------------------- - --------------- 单独httpclient是做不到的,只能抓取最原创的数据--其他解决方案----- --------- ----------------------------------------- -httpClient 捕获服务器的输出,这不是js执行后的最终结果吗? ------其他解决方案----------------------------------------- - -------------- 没有,比如我想抓取邮箱首页的源代码,只得到下面的一小段:html head meta http-equiv= refresh content= url= /cgi-bin/loginpage/head /html ------其他解决办法-------------------------------- -- ---------------------- 在后面的过程中,我也在找资料获取js分页页面的数据,但是没有完全没有。
------其他解决方案-------------------------------------- - ----------------- 引用: 这不是单独httpclient能做到的,只能抓取最原创的数据------其他解决方案-- ---------------------------------------------- ---- ---- 用 htmlunit 试试------其他解决方案---------------------------- ------- -------------------- 引用: 这个单独httpclient是做不到的,只能抓取最原创的数据 怎么办,能不能给点思路! ------其他解决方案------------------------------------------ -------------- 引用:最近使用httpClient抓取网页源码时,如果源码是静态的,可以全部抓取,但是如果源码中收录js, httpClient抓取的源码不收录js,获取的源码有误。在网页中执行js后如何获取网页的源代码,例如获取网页的源代码。
我在论坛上看到了一个解决方案:调用浏览器组件来完成此任务,然后在执行js之后获取内容;如何实现呢?希望高手指点。 . 楼主,你还没有实现,可以分享一些想法吗! ------其他解决方案----------------------------------------- - --------------所有者,为什么不出现?问题解决了吗?我也遇到这个问题,请赐教! ------其他解决方案------------------------------------------ -------------- 尝试使用浏览器网页另存为 ------ 其他解决办法 ---------- -- --------------------- 原创海报,请赐教。------其他解决方案 - - - - - - - - - - - - - - - - - - - - - - - - - -------您只能手动省力。很不科学。我们想要得到的是活的价值。并且可以读取js中的内容。现在发生的事情是请求中的数据不会有js的内容。其他数据根本没用。
有什么方法可以让js数据可用?我真的很想知道这个问题。或者谁能做到。我可以付钱雇人。 ------其他解决方案------------------------------------------ -------------- 引用:您只能另存为手册。很不科学。我们想要得到的是活的价值。并且可以读取js内容。目前的情况是请求的数据不会有js的内容。其他数据根本没用。什么方法可以制作js数据?我真的很想知道这个问题。或者谁能做到。我可以付钱雇人。你要付多少钱。我会的,您可以给我发送电子邮件,
js提取指定网站内容是javascriptcodepancakes如何实现转html转pdf-css
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-05-22 18:01
js提取指定网站内容一般有httpexplorer转码功能,可以指定文件路径。jsjavascript转换可以用openxmlrphtmlcode接口,有ejs和webpack,openxmlrphtmlcode其实就是从webpack里去追加内容,做了几个小扩展就成一个大的格式转换器了,可以转换的npapi一样的。
当然也可以用json转html,方法基本上和webpack一样,至于想要html格式页面效果转化成xml就要用browserify来转,webpack看看就好了。
微信文章编辑器,直接转pdf如果是web端的话,我觉得提取文章html再转pdf比较简单一些~毕竟我们转html的时候,都要根据html的结构去解析。
也可以用veer转换的/
js转html具体是javascriptcodepancakes如何实现js转html转pdf-css/css/resources/atginc...
w3pack好像可以
不能,因为html转pdf要求ie9及以上,
谢邀。首先你对html转js有了清晰的认识,其次说明你已经掌握一些最基本的知识。这里我推荐@misswu的答案。
wordpress里的htmlpdfplugin已经封装好了,大部分工具都能用。
基本工具:markdownonwebmindbeonhtml,css,js 查看全部
js提取指定网站内容是javascriptcodepancakes如何实现转html转pdf-css
js提取指定网站内容一般有httpexplorer转码功能,可以指定文件路径。jsjavascript转换可以用openxmlrphtmlcode接口,有ejs和webpack,openxmlrphtmlcode其实就是从webpack里去追加内容,做了几个小扩展就成一个大的格式转换器了,可以转换的npapi一样的。
当然也可以用json转html,方法基本上和webpack一样,至于想要html格式页面效果转化成xml就要用browserify来转,webpack看看就好了。
微信文章编辑器,直接转pdf如果是web端的话,我觉得提取文章html再转pdf比较简单一些~毕竟我们转html的时候,都要根据html的结构去解析。
也可以用veer转换的/
js转html具体是javascriptcodepancakes如何实现js转html转pdf-css/css/resources/atginc...
w3pack好像可以
不能,因为html转pdf要求ie9及以上,
谢邀。首先你对html转js有了清晰的认识,其次说明你已经掌握一些最基本的知识。这里我推荐@misswu的答案。
wordpress里的htmlpdfplugin已经封装好了,大部分工具都能用。
基本工具:markdownonwebmindbeonhtml,css,js
吃鸡ing,让我去他们用的什么js框架
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-05-20 22:24
昨天我在吃鸡肉,而3次杀戮即将进入决赛。突然,老师抛出了三个网站链接,让我检查他们使用了什么js框架。 。
合理,当我第一次看到这个问题时,我的头皮发麻了
如何通过网页看到它是什么样的框架?难道不是每个人都封装了它吗?
所有写这个网站的人都傻吗?只让您看看核心js框架?
经过两天的实验和检查信息,似乎可以看到它。毕竟,没有人是完美的,总是有一百个秘密。
当然,这些只是我尝试过的一些方法。我的问题已解决,但不能保证所有问题都会得到解决。如果遇到包装合理的网站,请接受命运。
当您第一次开始搜索时,其他人的博客或论坛会给您很多网站,让您输入网站,您可以看到网站的核心技术,这是合理的,真的没有用于鸡蛋。
例如,我尝试过的那个:
操作非常简单,您只需要输入URL,然后查看返回的内容
这些是网站它返回给我的所有技术,但这不是我想要的o((>ω
还有另一个问题。如果框架是ASP.NET,则网页访问应具有相应的后缀,例如:.aspx,ashx等。
我认为这件事让我很烦...
后来,我试图在google上用英语搜索这些类型的问题。有人告诉我要通过经验来获取它,也就是说,您应该了解更多有关该框架的知识,了解每个框架的特征和关键字,然后您可以一眼就知道这一点。它是由该框架编写的。 。 。说到框架,您可以看一下我的其他博客,看看有多少个前端框架。另一种是将代码发布到Github上,并使用html本机函数document.querySelector()获取dom信息。主要原理类似于第一人称的意思。
可以归结为:不同的框架具有由不同的框架使用的特定关键字。例如,在Angular中,我们使用“ ng- *”作为特定的指令标识符,在React中,我们使用reactid和其他标识符,然后您可以通过搜索这些关键字来获取网站的框架(当然,此方法不是万能药,但也是有效的方法一)
代码如下:
if(!!window.React ||
!!document.querySelector('[data-reactroot], [data-reactid]'))
console.log('React.js');
if(!!window.angular ||
!!document.querySelector('.ng-binding, [ng-app], [data-ng-app], [ng-controller], [data-ng-controller], [ng-repeat], [data-ng-repeat]') ||
!!document.querySelector('script[src*="angular.js"], script[src*="angular.min.js"]'))
console.log('Angular.js');
if(!!window.Backbone) console.log('Backbone.js');
if(!!window.Ember) console.log('Ember.js');
if(!!window.Vue||!!document.querySelector('[v-if],[v-for],[v-show]')) console.log('Vue.js');
if(!!window.Meteor) console.log('Meteor.js');
if(!!window.Zepto) console.log('Zepto.js');
if(!!window.jQuery) console.log('jQuery.js');
将上述代码直接注入控制台
它将直接打印出您的前端js框架,但是对于某些无法使用的页面,您需要一个一个地打开多个页面。我测试了以前用Angular编写的项目,但首页上的测试失败,但是当您单击以打开登录页面时,它将直接显示。您必须对这种方法有耐心。
当然,对于某些网站,无论您测试多少,它都不会起作用。此时,您必须单击Sources来阅读代码。
估计对于不同的框架有不同的参考文件,但是我仍然仔细地查找它。我搜索了此页面的登录界面,然后发现在请求界面的地方调用了其他框架,因此我确定了此网站框架
所有来到网站前端js框架以使用Zepto的人,当然,这只是我的解决方案,也许大个子有更好的解决方案,请分享
总结:我觉得无论如何这项技能似乎都没用,但是老师在完成后不能放手,所以就去做吧 查看全部
吃鸡ing,让我去他们用的什么js框架
昨天我在吃鸡肉,而3次杀戮即将进入决赛。突然,老师抛出了三个网站链接,让我检查他们使用了什么js框架。 。
合理,当我第一次看到这个问题时,我的头皮发麻了
如何通过网页看到它是什么样的框架?难道不是每个人都封装了它吗?
所有写这个网站的人都傻吗?只让您看看核心js框架?
经过两天的实验和检查信息,似乎可以看到它。毕竟,没有人是完美的,总是有一百个秘密。
当然,这些只是我尝试过的一些方法。我的问题已解决,但不能保证所有问题都会得到解决。如果遇到包装合理的网站,请接受命运。
当您第一次开始搜索时,其他人的博客或论坛会给您很多网站,让您输入网站,您可以看到网站的核心技术,这是合理的,真的没有用于鸡蛋。
例如,我尝试过的那个:
操作非常简单,您只需要输入URL,然后查看返回的内容
这些是网站它返回给我的所有技术,但这不是我想要的o((>ω
还有另一个问题。如果框架是ASP.NET,则网页访问应具有相应的后缀,例如:.aspx,ashx等。
我认为这件事让我很烦...
后来,我试图在google上用英语搜索这些类型的问题。有人告诉我要通过经验来获取它,也就是说,您应该了解更多有关该框架的知识,了解每个框架的特征和关键字,然后您可以一眼就知道这一点。它是由该框架编写的。 。 。说到框架,您可以看一下我的其他博客,看看有多少个前端框架。另一种是将代码发布到Github上,并使用html本机函数document.querySelector()获取dom信息。主要原理类似于第一人称的意思。
可以归结为:不同的框架具有由不同的框架使用的特定关键字。例如,在Angular中,我们使用“ ng- *”作为特定的指令标识符,在React中,我们使用reactid和其他标识符,然后您可以通过搜索这些关键字来获取网站的框架(当然,此方法不是万能药,但也是有效的方法一)
代码如下:
if(!!window.React ||
!!document.querySelector('[data-reactroot], [data-reactid]'))
console.log('React.js');
if(!!window.angular ||
!!document.querySelector('.ng-binding, [ng-app], [data-ng-app], [ng-controller], [data-ng-controller], [ng-repeat], [data-ng-repeat]') ||
!!document.querySelector('script[src*="angular.js"], script[src*="angular.min.js"]'))
console.log('Angular.js');
if(!!window.Backbone) console.log('Backbone.js');
if(!!window.Ember) console.log('Ember.js');
if(!!window.Vue||!!document.querySelector('[v-if],[v-for],[v-show]')) console.log('Vue.js');
if(!!window.Meteor) console.log('Meteor.js');
if(!!window.Zepto) console.log('Zepto.js');
if(!!window.jQuery) console.log('jQuery.js');
将上述代码直接注入控制台
它将直接打印出您的前端js框架,但是对于某些无法使用的页面,您需要一个一个地打开多个页面。我测试了以前用Angular编写的项目,但首页上的测试失败,但是当您单击以打开登录页面时,它将直接显示。您必须对这种方法有耐心。
当然,对于某些网站,无论您测试多少,它都不会起作用。此时,您必须单击Sources来阅读代码。
估计对于不同的框架有不同的参考文件,但是我仍然仔细地查找它。我搜索了此页面的登录界面,然后发现在请求界面的地方调用了其他框架,因此我确定了此网站框架
所有来到网站前端js框架以使用Zepto的人,当然,这只是我的解决方案,也许大个子有更好的解决方案,请分享
总结:我觉得无论如何这项技能似乎都没用,但是老师在完成后不能放手,所以就去做吧
Javascript获取网页中HTML元素的集中方法分析(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-05-19 01:02
如何通过js获取HTML元素节点本文关键词:节点,元素,获取,方法,js
js方法可获取HTML元素节点。本文简介:分析通过Javascript获取网页中HTML元素的集中方法。 getElementById,getElementsByName和getElementsByTagName将引入getElementById,getElementsByName和getElementsByTagName。
如何通过js获取HTML元素的节点
使用Javascript获取网页HTML元素的集中方法分析
getElementById
getElementsByName
getElementsByTagName
关于简介
getElementById
,getElementsByName
,getElementsByTagName
最后两个是要获取一个集合,而byid只能是一个对象
getElementById
用法
例如:
网络陶艺酒吧
如何在同一页面中引用:
1、使用ID:
link 1. href,返回值为
2、使用名称:
document.all.linkname 1. href,返回值为
3、使用sourseIndex:
document.all(4) .href
//请注意,前面有HTML,HEAD,TITLE和BODY,所以它是4
4、使用链接采集:
document.anchors(0) .href
//所有集合包括全部,锚点,小程序,区域,属性,behaviorUrns,书签,boundElements,单元格,childNodes,子项,controlRange,元素,嵌入,过滤器,表单,框架,图像,导入,链接,mimeTypes,选项,插件,行,规则,脚本,styleSheets,tBodies,TextRectangle,请参阅MSDN简介。
实际上,方法3和方法4是相同的集合,只不过一个是全部,可以收录页面上的所有标签,而锚点仅收录链接。
5、 getElementById:
document.getElementById(“ link1”)。href
6、 getElementsByName:
document.getElementsByName(“ linkname1”)[0] .href
//这也是一个集合,即名称等于方法参数的所有标记的集合
7、 getElementsByTagName:
document.getElementsByTagName(“ A”)[0] .href
//这也是一个集合,所有标记名称等于该方法的参数的所有标记的集合
8、标签集合:
document.all.tags(“ A”)[0] .href
//与方法7相同,是通过标记名称获取集合
除:
event.scrElement可以获取对触发时间标签的引用;
document.elementFromPoint(x,y)可以获取元素在x和y坐标处的引用;
ponentFromPoint(event.clientX,event.clientY)可以获取对鼠标所在元素的引用;
您还可以引用元素的父子节点和同级节点的关系,例如nextSibling(当前节点的下一个节点),previousSibling(当前节点的上一个节点),childNodes,children,firstChild,lastChild ,parentElement等。对父子节点和兄弟节点的一些引用;不限于此。
以上是同一页面中的常见引用方法,也涉及到不同的页面
getElementsByName返回名称为指定值的所有元素的集合
“根据
NAME
tag属性的值获取对象的集合。 “
集合比数组宽松得多。集合中每个项目的类型可以不同。该集合只是将某些元素放在一起作为一个类别。相反,数组要严格得多。这是统一类型。
document.getElementsByName,document.getElementsByTagName,document.formName.elements
通过这种方法获得的结果都是集合。
示例:
代码
鱼
功能
get(){
var
xx = document.getElementById(“ bbs”)
alert(“标签名称:” + xx.tagName);
}
功能
getElementName(){
var
ele
=
document.getElementsByName(“ happy”);
alert(“不带元素的快乐数:” +
ele.length);
}
获取文件指定的元素
document.getElementsByName()此方法。它以相同的方式对待一个和多个,我们可以使用:
温度
=
document.getElementsByName(
开心
)引用
当只有一个Temp时,则为Temp [0]。如果有多个,则使用下标方法Temp [i]循环获取
有例外:
在即
在getElementsByName(“ test”)中,它返回id = test的对象数组,而firefox返回name =
一组测试对象。
根据w3c的规范,它应返回name =
一组测试对象。
firefox中的getElementByID与ie相同:正确获取
ID
tag属性是对指定值的第一个对象的引用。
请注意getElementsByName
里面有s
document.getElementById()可以控制某个ID的标签
document.getElementsByName(),返回的文件具有相同的
名称
不是一个特定的属性元素的集合,请注意“ s”。
和
document.getElementsByTagName()
返回的是一组相同的
标签
的集合
元素。
同一个名称可以收录多个元素,因此请使用document.getElementsByName(“ theName”)
他回来了
引用时,集合必须命名为索引
var
测试
=
document.getElementsByName(
testButton
)[0];
ID是唯一的
还应注意,类似属性没有名称属性,而其名称属性是伪属性document.getElementsByName()
这将是无效的,当然TD可以设置ID属性
JavaScript获取HTML
DOM节点元素方法概述
在Web应用程序(尤其是Web 2. 0程序)的开发中,通常需要在页面中获取一个元素,然后更新该元素的样式和内容。如何获得要更新的元素是要解决的第一个问题。好消息是,有很多方法可以使用JavaScript获取节点。这是一个简短的摘要(以下方法已在IE7和Firefox 2. 0. 0. 11中进行了测试):
1.
获取顶级文档节点:
([1)
document.getElementById(elementId):此方法可以通过节点的ID准确获取所需的元素。这是一个相对简单快捷的方法。如果页面上有多个具有相同ID的节点,则仅返回第一个节点。
如今,已经有许多JavaScript库,例如prototype和Mootools,它们提供了更方便的方法:$(id),参数仍然是节点的id。该方法可以看作是另一种编写document.getElementById()的方法,但是$()的功能更强大。有关特定用法,请参阅其各自的API文档。
([2) document.getElementsByName(elementName):此方法是根据节点名称获取节点。从名称中可以看出,此方法不返回节点元素,而是返回具有以下内容的节点数组然后,我们可以通过获取节点的某个属性来周期性地判断它是否是必需节点。
例如:在HTML中,复选框和单选框都使用相同的名称属性值来标识组中的元素。如果要立即获取选定的元素,请首先获取经过改组的元素,然后循环以确定该节点的选中属性值是否为真。
([3) document.getElementsByTagName(tagName):此方法是通过节点的标记获取节点,并且该方法还返回一个数组,例如:document.getElementsByTagName(
A
)将返回到页面上的所有超链接节点。在获取节点之前,通常会知道节点的类型,因此使用此方法相对简单。但是缺点也很明显,即返回的数组可能非常大,这将浪费大量时间。那么,这种方法没用吗?当然不是。此方法与以上两种方法不同。它不是文档节点的专有方法。也可以应用其他节点,下面将对此进行介绍。
2、通过父节点获得:
([1) parentObj.firstChild:如果该节点是已知节点(parentObj)的第一个子节点,则可以使用此方法。此属性可以递归使用,即它支持parentObj.firstChild.firstChild。 firstChild的形式为。,因此您可以获得更深的节点。
([2) parentObj.lastChild:显然,此属性用于获取已知节点的最后一个子节点(parentObj)。与firstChild一样,它也可以递归使用。
在使用中,如果将两者结合使用,将会获得更加令人兴奋的效果,即:parentObj.firstChild.lastChild.lastChild。
([3) parentObj.childNodes:获取已知节点的子节点数组,然后可以通过循环或索引找到所需的节点。
注意:经过测试,发现直接子节点的数组是在IE7上获得的,所有子节点都是在Firefox 2. 0. 0. 11上获得的,包括子节点。
([4) parentObj.children:获取已知节点的直接子节点数组。
注意:经过测试,它具有与IE7上的childNodes相同的效果,但是Firefox 2. 0. 0. 11不支持它。这就是为什么我使用与其他方法不同的样式的原因。因此,不建议这样做。
([5) parentObj.getElementsByTagName(tagName):不会重复使用该方法,它返回已知节点的所有子节点中具有指定值的子节点的数组。例如:parentObj.getElementsByTagName(
A
)返回已知子节点中的所有超链接。
3、从相邻节点获得:
([1) neighbourNode.previousSibling:获取已知节点的前一个节点(neighbourNode),此属性似乎像前一个firstChild和lastChild一样可以递归使用。
([2) neighbourNode.nextSibling:获取已知节点的下一个节点(neighbourNode),它也支持递归。
4、通过子节点获得:
([1) childNode.parentNode:获取已知节点的父节点。
上述方法只是一些基本方法。如果使用JavaScript库(例如Prototype),则还可以获取其他不同的方法,例如通过节点的类获取。但是,如果您可以灵活使用上述方法,我相信它应该能够处理大多数程序 查看全部
Javascript获取网页中HTML元素的集中方法分析(组图)
如何通过js获取HTML元素节点本文关键词:节点,元素,获取,方法,js
js方法可获取HTML元素节点。本文简介:分析通过Javascript获取网页中HTML元素的集中方法。 getElementById,getElementsByName和getElementsByTagName将引入getElementById,getElementsByName和getElementsByTagName。
如何通过js获取HTML元素的节点
使用Javascript获取网页HTML元素的集中方法分析
getElementById
getElementsByName
getElementsByTagName
关于简介
getElementById
,getElementsByName
,getElementsByTagName
最后两个是要获取一个集合,而byid只能是一个对象
getElementById
用法
例如:
网络陶艺酒吧
如何在同一页面中引用:
1、使用ID:
link 1. href,返回值为
2、使用名称:
document.all.linkname 1. href,返回值为
3、使用sourseIndex:
document.all(4) .href
//请注意,前面有HTML,HEAD,TITLE和BODY,所以它是4
4、使用链接采集:
document.anchors(0) .href
//所有集合包括全部,锚点,小程序,区域,属性,behaviorUrns,书签,boundElements,单元格,childNodes,子项,controlRange,元素,嵌入,过滤器,表单,框架,图像,导入,链接,mimeTypes,选项,插件,行,规则,脚本,styleSheets,tBodies,TextRectangle,请参阅MSDN简介。
实际上,方法3和方法4是相同的集合,只不过一个是全部,可以收录页面上的所有标签,而锚点仅收录链接。
5、 getElementById:
document.getElementById(“ link1”)。href
6、 getElementsByName:
document.getElementsByName(“ linkname1”)[0] .href
//这也是一个集合,即名称等于方法参数的所有标记的集合
7、 getElementsByTagName:
document.getElementsByTagName(“ A”)[0] .href
//这也是一个集合,所有标记名称等于该方法的参数的所有标记的集合
8、标签集合:
document.all.tags(“ A”)[0] .href
//与方法7相同,是通过标记名称获取集合
除:
event.scrElement可以获取对触发时间标签的引用;
document.elementFromPoint(x,y)可以获取元素在x和y坐标处的引用;
ponentFromPoint(event.clientX,event.clientY)可以获取对鼠标所在元素的引用;
您还可以引用元素的父子节点和同级节点的关系,例如nextSibling(当前节点的下一个节点),previousSibling(当前节点的上一个节点),childNodes,children,firstChild,lastChild ,parentElement等。对父子节点和兄弟节点的一些引用;不限于此。
以上是同一页面中的常见引用方法,也涉及到不同的页面
getElementsByName返回名称为指定值的所有元素的集合
“根据
NAME
tag属性的值获取对象的集合。 “
集合比数组宽松得多。集合中每个项目的类型可以不同。该集合只是将某些元素放在一起作为一个类别。相反,数组要严格得多。这是统一类型。
document.getElementsByName,document.getElementsByTagName,document.formName.elements
通过这种方法获得的结果都是集合。
示例:
代码
鱼
功能
get(){
var
xx = document.getElementById(“ bbs”)
alert(“标签名称:” + xx.tagName);
}
功能
getElementName(){
var
ele
=
document.getElementsByName(“ happy”);
alert(“不带元素的快乐数:” +
ele.length);
}
获取文件指定的元素
document.getElementsByName()此方法。它以相同的方式对待一个和多个,我们可以使用:
温度
=
document.getElementsByName(
开心
)引用
当只有一个Temp时,则为Temp [0]。如果有多个,则使用下标方法Temp [i]循环获取
有例外:
在即
在getElementsByName(“ test”)中,它返回id = test的对象数组,而firefox返回name =
一组测试对象。
根据w3c的规范,它应返回name =
一组测试对象。
firefox中的getElementByID与ie相同:正确获取
ID
tag属性是对指定值的第一个对象的引用。
请注意getElementsByName
里面有s
document.getElementById()可以控制某个ID的标签
document.getElementsByName(),返回的文件具有相同的
名称
不是一个特定的属性元素的集合,请注意“ s”。
和
document.getElementsByTagName()
返回的是一组相同的
标签
的集合
元素。
同一个名称可以收录多个元素,因此请使用document.getElementsByName(“ theName”)
他回来了
引用时,集合必须命名为索引
var
测试
=
document.getElementsByName(
testButton
)[0];
ID是唯一的
还应注意,类似属性没有名称属性,而其名称属性是伪属性document.getElementsByName()
这将是无效的,当然TD可以设置ID属性
JavaScript获取HTML
DOM节点元素方法概述
在Web应用程序(尤其是Web 2. 0程序)的开发中,通常需要在页面中获取一个元素,然后更新该元素的样式和内容。如何获得要更新的元素是要解决的第一个问题。好消息是,有很多方法可以使用JavaScript获取节点。这是一个简短的摘要(以下方法已在IE7和Firefox 2. 0. 0. 11中进行了测试):
1.
获取顶级文档节点:
([1)
document.getElementById(elementId):此方法可以通过节点的ID准确获取所需的元素。这是一个相对简单快捷的方法。如果页面上有多个具有相同ID的节点,则仅返回第一个节点。
如今,已经有许多JavaScript库,例如prototype和Mootools,它们提供了更方便的方法:$(id),参数仍然是节点的id。该方法可以看作是另一种编写document.getElementById()的方法,但是$()的功能更强大。有关特定用法,请参阅其各自的API文档。
([2) document.getElementsByName(elementName):此方法是根据节点名称获取节点。从名称中可以看出,此方法不返回节点元素,而是返回具有以下内容的节点数组然后,我们可以通过获取节点的某个属性来周期性地判断它是否是必需节点。
例如:在HTML中,复选框和单选框都使用相同的名称属性值来标识组中的元素。如果要立即获取选定的元素,请首先获取经过改组的元素,然后循环以确定该节点的选中属性值是否为真。
([3) document.getElementsByTagName(tagName):此方法是通过节点的标记获取节点,并且该方法还返回一个数组,例如:document.getElementsByTagName(
A
)将返回到页面上的所有超链接节点。在获取节点之前,通常会知道节点的类型,因此使用此方法相对简单。但是缺点也很明显,即返回的数组可能非常大,这将浪费大量时间。那么,这种方法没用吗?当然不是。此方法与以上两种方法不同。它不是文档节点的专有方法。也可以应用其他节点,下面将对此进行介绍。
2、通过父节点获得:
([1) parentObj.firstChild:如果该节点是已知节点(parentObj)的第一个子节点,则可以使用此方法。此属性可以递归使用,即它支持parentObj.firstChild.firstChild。 firstChild的形式为。,因此您可以获得更深的节点。
([2) parentObj.lastChild:显然,此属性用于获取已知节点的最后一个子节点(parentObj)。与firstChild一样,它也可以递归使用。
在使用中,如果将两者结合使用,将会获得更加令人兴奋的效果,即:parentObj.firstChild.lastChild.lastChild。
([3) parentObj.childNodes:获取已知节点的子节点数组,然后可以通过循环或索引找到所需的节点。
注意:经过测试,发现直接子节点的数组是在IE7上获得的,所有子节点都是在Firefox 2. 0. 0. 11上获得的,包括子节点。
([4) parentObj.children:获取已知节点的直接子节点数组。
注意:经过测试,它具有与IE7上的childNodes相同的效果,但是Firefox 2. 0. 0. 11不支持它。这就是为什么我使用与其他方法不同的样式的原因。因此,不建议这样做。
([5) parentObj.getElementsByTagName(tagName):不会重复使用该方法,它返回已知节点的所有子节点中具有指定值的子节点的数组。例如:parentObj.getElementsByTagName(
A
)返回已知子节点中的所有超链接。
3、从相邻节点获得:
([1) neighbourNode.previousSibling:获取已知节点的前一个节点(neighbourNode),此属性似乎像前一个firstChild和lastChild一样可以递归使用。
([2) neighbourNode.nextSibling:获取已知节点的下一个节点(neighbourNode),它也支持递归。
4、通过子节点获得:
([1) childNode.parentNode:获取已知节点的父节点。
上述方法只是一些基本方法。如果使用JavaScript库(例如Prototype),则还可以获取其他不同的方法,例如通过节点的类获取。但是,如果您可以灵活使用上述方法,我相信它应该能够处理大多数程序
如何模拟请求和如何解析HTML源码中的链接和标题
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-05-18 18:20
尽管这是很久以前的事,但该主题似乎已经解决了这个问题。但是查看许多答案的方法有点繁琐,这是一种更有效且消耗更少资源的方法。由于主题未指定所需内容,因此此处的示例采用首页上所有帖子的链接和标题。
首先,请记住,浏览器环境非常消耗内存和CPU,应尽可能避免使用模仿浏览器环境的采集器代码。请记住,对于某些前端呈现的网页,尽管我们所需的数据无法在HTML源代码中看到,但它更有可能通过另一个请求获得纯数据(最有可能采用JSON格式)。我们不仅不需要模拟浏览器,而且可以节省解析HTML的时间。
然后,我打开了北京邮电论坛的主页,发现该主页的HTML源代码不收录页面上显示的文章内容。然后,这很可能是通过JS异步加载到页面的。通过浏览器开发工具(OS X下的Chrome浏览器通过Command + option + i或Win / Linux通过F1 2)进行分析,该请求在加载主页时很容易找到,如下面的屏幕快照中所示:
在屏幕快照中选择的请求的响应是主页上的文章链接,并且可以在预览选项中看到渲染的预览图像:
到目前为止,我们确信此链接可以获取文章和主页上的链接。
在标头选项中,有此请求的请求标头和请求参数。我们可以通过Python模拟此请求以获得相同的响应。与BeautifulSoup之类的库一起解析HTML,您可以获得相应的内容。
有关如何模拟请求以及如何解析HTML,请移至我的专栏。这里有详细的介绍,所以我在这里不再重复。
通过这种方式,无需模拟浏览器环境即可捕获数据,从而大大提高了内存和CPU的使用率以及爬网速度。编写采集器时,请记住,如果没有必要,请勿模拟浏览器环境。 查看全部
如何模拟请求和如何解析HTML源码中的链接和标题
尽管这是很久以前的事,但该主题似乎已经解决了这个问题。但是查看许多答案的方法有点繁琐,这是一种更有效且消耗更少资源的方法。由于主题未指定所需内容,因此此处的示例采用首页上所有帖子的链接和标题。
首先,请记住,浏览器环境非常消耗内存和CPU,应尽可能避免使用模仿浏览器环境的采集器代码。请记住,对于某些前端呈现的网页,尽管我们所需的数据无法在HTML源代码中看到,但它更有可能通过另一个请求获得纯数据(最有可能采用JSON格式)。我们不仅不需要模拟浏览器,而且可以节省解析HTML的时间。
然后,我打开了北京邮电论坛的主页,发现该主页的HTML源代码不收录页面上显示的文章内容。然后,这很可能是通过JS异步加载到页面的。通过浏览器开发工具(OS X下的Chrome浏览器通过Command + option + i或Win / Linux通过F1 2)进行分析,该请求在加载主页时很容易找到,如下面的屏幕快照中所示:
在屏幕快照中选择的请求的响应是主页上的文章链接,并且可以在预览选项中看到渲染的预览图像:
到目前为止,我们确信此链接可以获取文章和主页上的链接。
在标头选项中,有此请求的请求标头和请求参数。我们可以通过Python模拟此请求以获得相同的响应。与BeautifulSoup之类的库一起解析HTML,您可以获得相应的内容。
有关如何模拟请求以及如何解析HTML,请移至我的专栏。这里有详细的介绍,所以我在这里不再重复。
通过这种方式,无需模拟浏览器环境即可捕获数据,从而大大提高了内存和CPU的使用率以及爬网速度。编写采集器时,请记住,如果没有必要,请勿模拟浏览器环境。
JavaHTML解析器之Jsoup解析获取Document对象的方式
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-05-16 21:27
Jsoup简介
jsoup是一个Java HTML解析器,可以直接解析URL地址和HTML文本内容。它提供了非常省力的API,可以通过DOM,CSS和类似于jQuery的操作方法来检索和处理数据。
Jsoup.jpg
官方网址:
官方网站还为开发人员提供了一套说明(Cookbook)。
Jsoup解析HTML以获取Document对象,并通过操纵Document的属性来获取HTML页面的内容。因此,在开始之前,我们先介绍一下Node,Element,Document和其他XML相关概念之间的区别,以防止该概念引起混淆。导致滥用和滥用。
相关概念
public abstract class Node implements Cloneable
public class Element extends Node
public class Document extends Element
从Jsoup源代码中的三个定义,我们可以看到以下树继承关系:
节点,元素,文档继承关系.png
节点(节点)
从上面的继承关系中可以明显看出,文档中的所有内容都可以视为一个节点。节点的类型很多:属性节点(Attribute),注释节点(Note),文本节点(Text),元素节点(Element)等。通常,节点是这些各种节点的统称。
元素(元素)
与节点相比,元素的定义较窄。元素是从节点继承的,并且是节点的子集,因此元素也是节点,并且该节点的公共属性和方法也可以在该元素中使用。
文档(文档)
文档继承自元素,该元素引用整个HTML文档的源内容。可以通过System.out.println(document.toString());在控制台上打印网页的源内容。
相互转换
基于节点,元素和文档之间的“缠结”关系,每个类中提供的方法可用于适当地转换和获取所需的使用对象。
用例
Jsoup解析Html以获取Document对象的方式分为三类:联机Url,Html文本字符串和文件。相应的API如下
获取Document对象后,可以组合HTML源代码,并使用Jsoup提供的API通过类,标签,id,属性和其他相关属性获取相应的Element,然后获取所需的网页内容。
以下以Jsoup官方网站的Cookbook页面为例,解析并获取页面目录的内容。
网页内容:
Jsoup Cookbook webpage.jpg
网页源代码:
jsoup开发指南,jsoup中文使用手册,jsoup中文文档
jsoup
新闻
bugs
讨论
下载
api参考
Cookbook
jsoup » cookbook
jsoup Cookbook(中文版)
入门
解析和遍历一个html文档
输入
解析一个html字符串
解析一个body片断
根据一个url加载Document对象
根据一个文件加载Document对象
数据抽取
使用dom方法来遍历一个Document对象
使用选择器语法来查找元素
从元素集合抽取属性、文本和html内容
URL处理
程序示例:获取所有链接
数据修改
设置属性值
设置元素的html内容
设置元素的文本内容
html清理
消除不受信任的html (来防止xss攻击)
jsoup html parser: copyright © 2009 - 2011 jonathan hedley
Jsoup分析:
import java.io.IOException;
import java.text.ParseException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
/**
* @author 亦枫
* @created_time 2016年1月5日
* @file_user_todo Java测试类
* @blog http://www.jianshu.com/users/1 ... icles
*/
public class JavaTest {
/**
* 入口函数
* @param args
* @throws ParseException
*/
public static void main(String[] args) throws ParseException {
try {
//解析Url获取Document对象
Document document = Jsoup.connect("http://www.open-open.com/jsoup/").get();
//获取网页源码文本内容
System.out.println(document.toString());
//获取指定class的内容指定tag的元素
Elements liElements = document.getElementsByClass("content").get(0).getElementsByTag("li");
for (int i = 0; i < liElements.size(); i++) {
System.out.println(i + ". " + liElements.get(i).text());
}
} catch (IOException e) {
System.out.println("解析出错!");
e.printStackTrace();
}
}
}
分析结果:
查看全部
JavaHTML解析器之Jsoup解析获取Document对象的方式
Jsoup简介
jsoup是一个Java HTML解析器,可以直接解析URL地址和HTML文本内容。它提供了非常省力的API,可以通过DOM,CSS和类似于jQuery的操作方法来检索和处理数据。
Jsoup.jpg
官方网址:
官方网站还为开发人员提供了一套说明(Cookbook)。
Jsoup解析HTML以获取Document对象,并通过操纵Document的属性来获取HTML页面的内容。因此,在开始之前,我们先介绍一下Node,Element,Document和其他XML相关概念之间的区别,以防止该概念引起混淆。导致滥用和滥用。
相关概念
public abstract class Node implements Cloneable
public class Element extends Node
public class Document extends Element
从Jsoup源代码中的三个定义,我们可以看到以下树继承关系:
节点,元素,文档继承关系.png
节点(节点)
从上面的继承关系中可以明显看出,文档中的所有内容都可以视为一个节点。节点的类型很多:属性节点(Attribute),注释节点(Note),文本节点(Text),元素节点(Element)等。通常,节点是这些各种节点的统称。
元素(元素)
与节点相比,元素的定义较窄。元素是从节点继承的,并且是节点的子集,因此元素也是节点,并且该节点的公共属性和方法也可以在该元素中使用。
文档(文档)
文档继承自元素,该元素引用整个HTML文档的源内容。可以通过System.out.println(document.toString());在控制台上打印网页的源内容。
相互转换
基于节点,元素和文档之间的“缠结”关系,每个类中提供的方法可用于适当地转换和获取所需的使用对象。
用例
Jsoup解析Html以获取Document对象的方式分为三类:联机Url,Html文本字符串和文件。相应的API如下
获取Document对象后,可以组合HTML源代码,并使用Jsoup提供的API通过类,标签,id,属性和其他相关属性获取相应的Element,然后获取所需的网页内容。
以下以Jsoup官方网站的Cookbook页面为例,解析并获取页面目录的内容。
网页内容:
Jsoup Cookbook webpage.jpg
网页源代码:
jsoup开发指南,jsoup中文使用手册,jsoup中文文档
jsoup
新闻
bugs
讨论
下载
api参考
Cookbook
jsoup » cookbook
jsoup Cookbook(中文版)
入门
解析和遍历一个html文档
输入
解析一个html字符串
解析一个body片断
根据一个url加载Document对象
根据一个文件加载Document对象
数据抽取
使用dom方法来遍历一个Document对象
使用选择器语法来查找元素
从元素集合抽取属性、文本和html内容
URL处理
程序示例:获取所有链接
数据修改
设置属性值
设置元素的html内容
设置元素的文本内容
html清理
消除不受信任的html (来防止xss攻击)
jsoup html parser: copyright © 2009 - 2011 jonathan hedley
Jsoup分析:
import java.io.IOException;
import java.text.ParseException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
/**
* @author 亦枫
* @created_time 2016年1月5日
* @file_user_todo Java测试类
* @blog http://www.jianshu.com/users/1 ... icles
*/
public class JavaTest {
/**
* 入口函数
* @param args
* @throws ParseException
*/
public static void main(String[] args) throws ParseException {
try {
//解析Url获取Document对象
Document document = Jsoup.connect("http://www.open-open.com/jsoup/";).get();
//获取网页源码文本内容
System.out.println(document.toString());
//获取指定class的内容指定tag的元素
Elements liElements = document.getElementsByClass("content").get(0).getElementsByTag("li");
for (int i = 0; i < liElements.size(); i++) {
System.out.println(i + ". " + liElements.get(i).text());
}
} catch (IOException e) {
System.out.println("解析出错!");
e.printStackTrace();
}
}
}
分析结果:
js提取指定网站内容的方法(一)(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-05-15 23:54
js提取指定网站内容的方法目前js提取方法也有很多,本文介绍其中的两种网站提取方法。方法一:使用js提取工具:deeparchiver网站:::.使用requests库下载需要提取的js文件:$pipinstallrequests&&importrequests2.解析目标url并提取url中的指定格式的js文件:$url="-fields.html?json=json%20%e5%8d%a8%e5%86%ad%e8%a4%a1%e5%a4%a0%e8%83%85.js"3.提取需要提取的文件以及页面内容:$f12调用页面源码,提取js格式的js。
4.读取文件以及下载:$downloadjs5.最后保存到服务器:$session=[]foriinrange(0,9。
9):$session.append("\"")
一、数据提取js页面sex_tag代码、需要提取的字段:女性:性别、年龄、首页、外貌、性别、学历、现任职位职位、公司注册id、所属公司id、公司名称、所属公司全称、公司简介、公司注册id、公司所在省、总公司id、注册区域、岗位id、主页域名、搜索关键词、社交信息。
sex_content代码、需要提取的字段:查看详情:、统计各页面内容统计目录:各页面提取页面内容各页面记录:关键词tag统计、图片tag统计、超链接tag统计提取所有tag
4、tag统计大于1000个单词的词:tag#![a-z]{4}forkinrange(0,100
0):sex_tag_cap=float(str(k))sex_tag_count=len(sex_tag_cap)#;return:sex_tag_countall_tagsreturnall_tags#![a-z]{4}forkinrange(100
0):content_tag=tag(fields=sex_tag)sex_tag=float(str(k))content_tag_count=len(content_tag_cap)ifsex_tagincontent_tag_countandcontent_tagincontent_tag_content_countandtimes(sex_tag)>200:#{1}importjsonfromjsonimportloadsformat=json。
loads(json。parse(format))tag_tag=json。loads(json。parse(format))#exportlastcontenttojsonportal_idto{}exportitemtocssportal_codeportal_codeto{}#typetag_tag_tag=str(loads。
utils(loads。utils()#返回值tag_tag_size=loads。utils(loads。utils(#columnstringtag_tag_s。 查看全部
js提取指定网站内容的方法(一)(组图)
js提取指定网站内容的方法目前js提取方法也有很多,本文介绍其中的两种网站提取方法。方法一:使用js提取工具:deeparchiver网站:::.使用requests库下载需要提取的js文件:$pipinstallrequests&&importrequests2.解析目标url并提取url中的指定格式的js文件:$url="-fields.html?json=json%20%e5%8d%a8%e5%86%ad%e8%a4%a1%e5%a4%a0%e8%83%85.js"3.提取需要提取的文件以及页面内容:$f12调用页面源码,提取js格式的js。
4.读取文件以及下载:$downloadjs5.最后保存到服务器:$session=[]foriinrange(0,9。
9):$session.append("\"")
一、数据提取js页面sex_tag代码、需要提取的字段:女性:性别、年龄、首页、外貌、性别、学历、现任职位职位、公司注册id、所属公司id、公司名称、所属公司全称、公司简介、公司注册id、公司所在省、总公司id、注册区域、岗位id、主页域名、搜索关键词、社交信息。
sex_content代码、需要提取的字段:查看详情:、统计各页面内容统计目录:各页面提取页面内容各页面记录:关键词tag统计、图片tag统计、超链接tag统计提取所有tag
4、tag统计大于1000个单词的词:tag#![a-z]{4}forkinrange(0,100
0):sex_tag_cap=float(str(k))sex_tag_count=len(sex_tag_cap)#;return:sex_tag_countall_tagsreturnall_tags#![a-z]{4}forkinrange(100
0):content_tag=tag(fields=sex_tag)sex_tag=float(str(k))content_tag_count=len(content_tag_cap)ifsex_tagincontent_tag_countandcontent_tagincontent_tag_content_countandtimes(sex_tag)>200:#{1}importjsonfromjsonimportloadsformat=json。
loads(json。parse(format))tag_tag=json。loads(json。parse(format))#exportlastcontenttojsonportal_idto{}exportitemtocssportal_codeportal_codeto{}#typetag_tag_tag=str(loads。
utils(loads。utils()#返回值tag_tag_size=loads。utils(loads。utils(#columnstringtag_tag_s。
源自Python即时网络爬虫GitHub源7,文档修改历史
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-05-13 21:06
1,简介
本文介绍了如何使用GooSeeker API接口下载Java和JavaScript中的内容提取器。这是一个示例程序。什么是内容提取器?为什么要使用这种方法?源自Python即时Web爬网程序开源项目:通过生成内容提取程序,它极大地节省了程序员的时间。有关详细信息,请参阅“内容提取器的定义”。
2,使用Java下载内容提取器
这是一系列示例程序之一。从当前编程语言开发的角度来看,Java提取Web内容是不合适的。除了语言不够灵活和方便之外,整个生态系统还不够活跃,可选库的增长也很慢。另外,要从JavaScript动态网页提取内容,Java也很不方便,并且需要JavaScript引擎。使用JavaScript下载内容提取器可以直接跳至第3部分的内容。
具体实现
评论:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回的结果如下:
3,使用JavaScript下载内容提取器
请注意,如果此示例中的JavaScript代码在网页上运行,则由于跨域问题,将无法抓取非网站网页的内容。因此,请在特权的JavaScript引擎上运行,例如浏览器扩展,自行开发的浏览器以及您自己程序中的JavaScript引擎。
为方便实验,此示例仍在网页上运行。为了避免跨域问题,将保存并修改目标网页,并在其中插入JavaScript。如此多的手动操作仅用于实验,在正式使用时还需要考虑其他方法。
具体实现
评论:
这是源代码:
返回结果的屏幕截图如下
4,前景
您还可以使用Python获取指定网页的内容。我觉得Python的语法更加简洁。稍后我们将添加Python语言的示例。有兴趣的朋友可以加入并一起学习。
5,相关文件
Python即时网络抓取工具:API描述
6,GooSeeker开源代码下载源集合
GooSeeker开源Python网络爬虫GitHub源
7,文档修改历史记录
2016-06-20:V 1. 0
如果有任何疑问,可以或
查看全部
源自Python即时网络爬虫GitHub源7,文档修改历史
1,简介
本文介绍了如何使用GooSeeker API接口下载Java和JavaScript中的内容提取器。这是一个示例程序。什么是内容提取器?为什么要使用这种方法?源自Python即时Web爬网程序开源项目:通过生成内容提取程序,它极大地节省了程序员的时间。有关详细信息,请参阅“内容提取器的定义”。
2,使用Java下载内容提取器
这是一系列示例程序之一。从当前编程语言开发的角度来看,Java提取Web内容是不合适的。除了语言不够灵活和方便之外,整个生态系统还不够活跃,可选库的增长也很慢。另外,要从JavaScript动态网页提取内容,Java也很不方便,并且需要JavaScript引擎。使用JavaScript下载内容提取器可以直接跳至第3部分的内容。
具体实现
评论:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回的结果如下:
3,使用JavaScript下载内容提取器
请注意,如果此示例中的JavaScript代码在网页上运行,则由于跨域问题,将无法抓取非网站网页的内容。因此,请在特权的JavaScript引擎上运行,例如浏览器扩展,自行开发的浏览器以及您自己程序中的JavaScript引擎。
为方便实验,此示例仍在网页上运行。为了避免跨域问题,将保存并修改目标网页,并在其中插入JavaScript。如此多的手动操作仅用于实验,在正式使用时还需要考虑其他方法。
具体实现
评论:
这是源代码:
返回结果的屏幕截图如下
4,前景
您还可以使用Python获取指定网页的内容。我觉得Python的语法更加简洁。稍后我们将添加Python语言的示例。有兴趣的朋友可以加入并一起学习。
5,相关文件
Python即时网络抓取工具:API描述
6,GooSeeker开源代码下载源集合
GooSeeker开源Python网络爬虫GitHub源
7,文档修改历史记录
2016-06-20:V 1. 0
如果有任何疑问,可以或
XML中国科学院计算机网络信息中心文章分析和介绍对互联网中XML+XSL
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-05-11 18:16
中国科学院XML计算机网络信息中心文章分析并介绍了Internet上XML + XSL网页资源的链接分析和内容采集的方法,包括传统HTML中的链接分析,XML转换后的链接分析。到HTML,手动定制XML链接分析和传统HTML信息采集,XML信息提取以及将XML转换为HTML信息采集等。:Internet信息采集链接分析XML资源:TP393文档标识代码:A [ 文章号:基于Internet资源的XML / XSLY链接分析杜丽华,中国科学院温文教计算机网络信息中心摘要:论文分析基于链接分析内容的基于Internet资源的XML / XSL网页,包括传统的HMTL链接,从XML派生的HTML链接,手动客户化的XML链接,传统的HTML信息挖掘,XML信息提取指令,从XML派生的HTML信息挖掘等。采矿;链接分析; XML资源Internet上有大量的数据和信息。目前,网站页大多为HTML格式。由于HTML标记日益膨胀,文件结构缺乏组织,描述能力有限以及有效数据提取复杂等原因,它不再能满足网络需求。为了满足新的应用程序需求,作为W3C推荐的下一代Web发布语言,XML + XSL方法是大势所趋,并且已经有一些网站应用程序,例如37c Medical Network和CCID Network。
但是,当前的主要搜索引擎Spider系统和Internet信息智能采集系统都是HTML格式链接分析和内容提取,它们不支持XML检索或具有很大的局限性1、传统HTML中的链接。解析传统HTML时标签的定义很明确,表明用于超链接的标签受到限制。解析过程通常是将shape = between和网页源文件的框架之间的所有内容都取出,然后除去中间内容,单引号,双引号和其他干扰信息。对于每个链接部分,可以根据链接URL部分和链接是否收录>符号将其分开。在标题部分,将链接URL部分与网页URL(URL)进行比较和分析,以获得完整的URL。如果链接文本部分不可用或不合法,则可以进一步获取源文件中和源文件之间的内容。 2、将XML转换为HTML之后的链接解析。 XML使用DTD来显示数据,并使用XSL来描述文档显示。 XML格式网页中的每个节点都是灵活定义的,无法用传统的HTML进行解析。正如浏览器在识别到XML + XSL格式时首先在客户端中解析网页一样,我们也可以使用XSL XML将其转换为HTML语言,然后以传统的HTML方式进行解析。该方法是通过获取XSL文件的地址来获取XML源文件的内容,然后使用XML解析器(XMLDOM)组合并将其转换为HTML 3、通过转换为HTML手动定制XML链接解析语言,然后解析链接比较通用,适用于全方位分析。
由于相关的超链接信息存储在XML文件中的特定类型的节点中,因此,每次使用XSL转换时,都会在性能上产生不必要的开销。因此,有时,尤其是在跟踪某种类型的网站信息时,它的性能会更高。性能可能仅是获得链接的所需部分,并且有必要使用手动定制的链接解析度。手动配置方法是首先手动查看源XML XSL(在浏览器中查看源文件),找到带有节点名称的超链接(包括文本,图片,附件),并将其添加到配置文件的xmlhref项中。 ,然后系统将对其进行相应的分析。与同一XSL文档相对应的XML是同构的,因此指定了与每个XSL文档相对应的hreftext(链接文本)和hreflink(链接的URL)。例如,新闻频道网页的相关链接部分采用config.xml格式,例如ritems / item / itemtitle ritems / item itemhref xslsite>… 查看全部
XML中国科学院计算机网络信息中心文章分析和介绍对互联网中XML+XSL
中国科学院XML计算机网络信息中心文章分析并介绍了Internet上XML + XSL网页资源的链接分析和内容采集的方法,包括传统HTML中的链接分析,XML转换后的链接分析。到HTML,手动定制XML链接分析和传统HTML信息采集,XML信息提取以及将XML转换为HTML信息采集等。:Internet信息采集链接分析XML资源:TP393文档标识代码:A [ 文章号:基于Internet资源的XML / XSLY链接分析杜丽华,中国科学院温文教计算机网络信息中心摘要:论文分析基于链接分析内容的基于Internet资源的XML / XSL网页,包括传统的HMTL链接,从XML派生的HTML链接,手动客户化的XML链接,传统的HTML信息挖掘,XML信息提取指令,从XML派生的HTML信息挖掘等。采矿;链接分析; XML资源Internet上有大量的数据和信息。目前,网站页大多为HTML格式。由于HTML标记日益膨胀,文件结构缺乏组织,描述能力有限以及有效数据提取复杂等原因,它不再能满足网络需求。为了满足新的应用程序需求,作为W3C推荐的下一代Web发布语言,XML + XSL方法是大势所趋,并且已经有一些网站应用程序,例如37c Medical Network和CCID Network。
但是,当前的主要搜索引擎Spider系统和Internet信息智能采集系统都是HTML格式链接分析和内容提取,它们不支持XML检索或具有很大的局限性1、传统HTML中的链接。解析传统HTML时标签的定义很明确,表明用于超链接的标签受到限制。解析过程通常是将shape = between和网页源文件的框架之间的所有内容都取出,然后除去中间内容,单引号,双引号和其他干扰信息。对于每个链接部分,可以根据链接URL部分和链接是否收录>符号将其分开。在标题部分,将链接URL部分与网页URL(URL)进行比较和分析,以获得完整的URL。如果链接文本部分不可用或不合法,则可以进一步获取源文件中和源文件之间的内容。 2、将XML转换为HTML之后的链接解析。 XML使用DTD来显示数据,并使用XSL来描述文档显示。 XML格式网页中的每个节点都是灵活定义的,无法用传统的HTML进行解析。正如浏览器在识别到XML + XSL格式时首先在客户端中解析网页一样,我们也可以使用XSL XML将其转换为HTML语言,然后以传统的HTML方式进行解析。该方法是通过获取XSL文件的地址来获取XML源文件的内容,然后使用XML解析器(XMLDOM)组合并将其转换为HTML 3、通过转换为HTML手动定制XML链接解析语言,然后解析链接比较通用,适用于全方位分析。
由于相关的超链接信息存储在XML文件中的特定类型的节点中,因此,每次使用XSL转换时,都会在性能上产生不必要的开销。因此,有时,尤其是在跟踪某种类型的网站信息时,它的性能会更高。性能可能仅是获得链接的所需部分,并且有必要使用手动定制的链接解析度。手动配置方法是首先手动查看源XML XSL(在浏览器中查看源文件),找到带有节点名称的超链接(包括文本,图片,附件),并将其添加到配置文件的xmlhref项中。 ,然后系统将对其进行相应的分析。与同一XSL文档相对应的XML是同构的,因此指定了与每个XSL文档相对应的hreftext(链接文本)和hreflink(链接的URL)。例如,新闻频道网页的相关链接部分采用config.xml格式,例如ritems / item / itemtitle ritems / item itemhref xslsite>…
js提取指定网站内容-yii4中文文档_中国最新文档
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-05-10 02:06
js提取指定网站内容-yii4中文文档_中国最新文档:获取样式:获取js:获取css:获取css变量:获取相应ext后缀:获取url获取cookie-->解析url到ext
进入页面,js上有跳转按钮,把它回传给你要跳转的页面,就可以跳转了。
不用这么麻烦,
/这个是找不到导航的页面,我也不知道怎么用,
/index.php
/
/index.php,index.php
/index.php这个是寻找不到导航的页面
本地安装nodejs,登录后,index.php的网址就是谷歌,都能访问。
访问我的域名,
/news/
/index.php的网址
/#
/index.php?news=update&userid=9如何通过域名跳转:/index.php通过跳转到:8080/:8080/
使用chrome来get请求都能获取最新的信息。我在vs2017中试过。-hans/css在浏览器/css里的网址栏输入;window={url:http%3a%2f%2f2.html?userid=8,id=8}&destination={url:http%3a%2f%2f2.html?userid=4,id=4}&title={url:http%3a%2f%2f2.html?userid=8,id=8}}。 查看全部
js提取指定网站内容-yii4中文文档_中国最新文档
js提取指定网站内容-yii4中文文档_中国最新文档:获取样式:获取js:获取css:获取css变量:获取相应ext后缀:获取url获取cookie-->解析url到ext
进入页面,js上有跳转按钮,把它回传给你要跳转的页面,就可以跳转了。
不用这么麻烦,
/这个是找不到导航的页面,我也不知道怎么用,
/index.php
/
/index.php,index.php
/index.php这个是寻找不到导航的页面
本地安装nodejs,登录后,index.php的网址就是谷歌,都能访问。
访问我的域名,
/news/
/index.php的网址
/#
/index.php?news=update&userid=9如何通过域名跳转:/index.php通过跳转到:8080/:8080/
使用chrome来get请求都能获取最新的信息。我在vs2017中试过。-hans/css在浏览器/css里的网址栏输入;window={url:http%3a%2f%2f2.html?userid=8,id=8}&destination={url:http%3a%2f%2f2.html?userid=4,id=4}&title={url:http%3a%2f%2f2.html?userid=8,id=8}}。
前几天在分享磁力搜索网站分享过几个已经打不开了
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-05-08 22:17
[摘要]日前,在分享磁搜索网站的帖子中,有网友追问百度网盘抽取码网站。我们以前共享过几个,有些无法打开。这里有一个总结!他们都以同样的方式工作。由插件或爬虫程序采集的提取代码
日前,在分享磁搜索网站的帖子中,有网友追问百度网络盘的提取码网站
我们以前共享过一些,有些无法打开。以下是总结
他们都以同样的方式工作。插件或爬虫采集的提取代码存储在服务器上。如果网民需要指定一个链接,提取的代码将从服务器上读取
浏览器插件
你知道吗① 云硬盘管家:这是我了解的最老的百度网络硬盘提取密码网站。它现在还很强壮。好像有些部门要收费
地址:
我们的网站文章链接基于Chrome扩展“云硬盘主密钥”,云硬盘搜索向导
你知道吗② 主云盘钥匙:也是老牌子。它可以自动识别百度网络盘,提取密码,并识别无效的网络盘链接
地址:
我们的网站文章链接到Chrome扩展:云硬盘主密钥,无需输入百度网络硬盘提取代码
你知道吗③ 容器:一个插件,提供包括百度网盘助手在内的一揽子服务
地址:
二、提取代码以获取网页
你知道吗① 注:百度网盘在线提取代码获取网站,适合不太使用脚本和插件的优采云用户
地址:
你知道吗② Pandownload:著名的Pandownload内置功能,除了提供抽取代码外,还可以高速下载百度网盘资源
地址:
油猴书
要安装oil-monkey脚本,需要安装oil-monkey或Baoli-monkey插件。以前已经介绍过很多次了,这里不详细介绍
你知道吗① 百度网络超级助手
你知道吗② 容器百度网络助手
[第24页] 查看全部
前几天在分享磁力搜索网站分享过几个已经打不开了
[摘要]日前,在分享磁搜索网站的帖子中,有网友追问百度网盘抽取码网站。我们以前共享过几个,有些无法打开。这里有一个总结!他们都以同样的方式工作。由插件或爬虫程序采集的提取代码
日前,在分享磁搜索网站的帖子中,有网友追问百度网络盘的提取码网站
我们以前共享过一些,有些无法打开。以下是总结
他们都以同样的方式工作。插件或爬虫采集的提取代码存储在服务器上。如果网民需要指定一个链接,提取的代码将从服务器上读取
浏览器插件
你知道吗① 云硬盘管家:这是我了解的最老的百度网络硬盘提取密码网站。它现在还很强壮。好像有些部门要收费
地址:
我们的网站文章链接基于Chrome扩展“云硬盘主密钥”,云硬盘搜索向导
你知道吗② 主云盘钥匙:也是老牌子。它可以自动识别百度网络盘,提取密码,并识别无效的网络盘链接
地址:
我们的网站文章链接到Chrome扩展:云硬盘主密钥,无需输入百度网络硬盘提取代码
你知道吗③ 容器:一个插件,提供包括百度网盘助手在内的一揽子服务
地址:
二、提取代码以获取网页
你知道吗① 注:百度网盘在线提取代码获取网站,适合不太使用脚本和插件的优采云用户
地址:
你知道吗② Pandownload:著名的Pandownload内置功能,除了提供抽取代码外,还可以高速下载百度网盘资源
地址:
油猴书
要安装oil-monkey脚本,需要安装oil-monkey或Baoli-monkey插件。以前已经介绍过很多次了,这里不详细介绍
你知道吗① 百度网络超级助手
你知道吗② 容器百度网络助手
[第24页]
pdf.js内部的按钮上传、定位、浏览功能的方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 551 次浏览 • 2021-05-06 23:03
这部分是我们公司之前需要实现的pdf上传,定位和浏览功能。就像以前的博客一样,我遇到了很多问题。使用的主要js是pdf.js,为了实现浏览上载的pdf,以前的博客记录了跨域问题(跨域问题是非常重要的,因为通用文件服务器和项目服务器是分开的),记录是否实现了行定位功能。
最初,我不打算使用行定位,因为我之前曾考虑过它,而且它一无是处,因为pdf.js主要单击缩略图以找到相应的页码来实现页码跳转。由于用户无法单击pdf.js内的按钮,因此需要在外部添加按钮(相当于定位点功能)。主要功能点:锚点设置和锚点定位。
下面我只讨论行定位的方法:
思考:pdf.js具有目录功能,单击目录中的标题以实现行定位,这启发了我思考行定位的实现。主页使用页面F12检查目录位置的链接,发现它是一串代码(我不知道哪种格式),我将其复制并在网页上进行了转码,并找到了如下格式:
#[{"num":23,"gen":0},{"name":"XYZ"},74,769,0]
#[{"num":46,"gen":0},{"name":"XYZ"},74,442,0]
这是与两个标题相对应的代码转换代码。我发现两个地方不同。一个是num的值,另一个是倒数第二个数字。我接下来去。寻找源代码,一个接一个的控制台,我终于在viewer.js的9285行中找到了线索(因为每个版本中的行数不同,以下是我复制的js方法,因为加密的计算机可以'不截屏,仅截取代码):
key: '_updateLocation',
value: function _updateLocation(firstPage) {
var currentScale = this._currentScale;
var currentScaleValue = this._currentScaleValue;
var normalizedScaleValue = parseFloat(currentScaleValue)
...........
滚动页面时,此方法的控制台方法将使用此方法。此方法背后有几个非常重要的参数。
this._location = {
pageNumber: pageNumber,
scale: normalizedScaleValue,
top: intTop,
left: intLeft,
rotation: this._pagesRotation,
pdfOpenParams: pdfOpenParams
};
通过打印,可以发现pageNumber是当前页码,而intTop是代码更改数量中倒数第二个参数,它被解释为高度(哈哈,现在我知道了不是记录的行,而是当前记录(通过页码高度实现的“行定位”),现在第一个参数在那里,主要目标是该num的值,与num的值完全不同我们在页面上看到的值,我猜它必须是json或数组。与键值相对应的页码是什么,然后我沿着藤蔓通过此方法找到了大本营:
{
key: 'cachePageRef',
value: function cachePageRef(pageNum, pageRef) {
if (!pageRef) {
return;
}
var refStr = pageRef.num + ' ' + pageRef.gen + ' R';
this._pagesRefCache[refStr] = pageNum;
}
}, {
key: '_cachedPageNumber',
value: function _cachedPageNumber(pageRef) {
var refStr = pageRef.num + ' ' + pageRef.gen + ' R';
return this._pagesRefCache && this._pagesRefCache[refStr] || null;
}
},
我这一边大约是7139行(viewer.js),这两种方法非常重要,一种是页码(在下面),另一种是创建的键值格式的代码(在上部),这是通过控制台了解的,当您加载pdf文件时,您将调用上述方法以将页码与代码进行匹配(相应的格式为“ 27 0 R”-“ 4”,其中4为值是页面数字,前面的键是代码。
到目前为止,感觉就像(将云朵拉开,看到蓝天)。以下是收购。滚动上面提到的9,000行以上的页面的方法,几个参数,其中intTop是我们需要的高度值,并且需要通过该键值获取页码,因此我开始修改源代码代码。
我们需要实时获取当前页面的数据
this._location = {
pageNumber: pageNumber,
scale: normalizedScaleValue,
top: intTop,
left: intLeft,
rotation: this._pagesRotation,
pdfOpenParams: pdfOpenParams
};
//下方是我添加的代码(这里你需要在viewer.html页面中加入二个隐藏的input,id为page_top和page_cache)
var page_top = document.getElementById("page_top");
page_top.value = this._location.top;
var page_cache = document.getElementById("page_cache");
page_cache.value = this.getPageCache(this._location.pageNumber);
最后一行的getPageCache方法是我修改的源代码:
this._location = {
pageNumber: pageNumber,
scale: normalizedScaleValue,
top: intTop,
left: intLeft,
rotation: this._pagesRotation,
pdfOpenParams: pdfOpenParams
};
//下方是我添加的代码(这里你需要在viewer.html页面中加入二个隐藏的input,id为page_top和page_cache)
var page_top = document.getElementById("page_top");
page_top.value = this._location.top;
var page_cache = document.getElementById("page_cache");
page_cache.value = this.getPageCache(this._location.pageNumber);
}
},{//下面是我添加的方法
//这个方法用来获取对应num的页码cache
key:'getPageCache',
value:function getPageCache(pageNum){
//循环结果(这里的page_cache是一个数组,下面细说)
var str = JSON.stringify(page_cache);
// console.log("格式为:"+typeof(JSON.parse(str)))
// console.log("json的数据:"+str)
for(var key in JSON.parse(str)){
if(JSON.parse(str)[key]==pageNum){
return key;
}
}
}
我们在上面提到了键值格式数据,因为它不在代码块中,所以我在js顶部添加了一个全局变量page_cache
//定义全局变量 去接受页码对应编码值
var page_cache = [];
然后在页面加载pdf时为该数组分配一个值:
{
key: 'cachePageRef',
value: function cachePageRef(pageNum, pageRef) {
if (!pageRef) {
return;
}
var refStr = pageRef.num + ' ' + pageRef.gen + ' R';
this._pagesRefCache[refStr] = pageNum;
//当赋值完毕之后,给全局赋值,这样我就获取到这个编码了
page_cache = this._pagesRefCache;
}
}, {
key: '_cachedPageNumber',
value: function _cachedPageNumber(pageRef) {
var refStr = pageRef.num + ' ' + pageRef.gen + ' R';
return this._pagesRefCache && this._pagesRefCache[refStr] || null;
}
},
以这种方式,如上所述,通过此全局情况获得了相应的代码值。 (这是采集的结束(设置锚点))
另外:有些人可能无法在iframe下获取文件,请将此信息发送给我:
//这个是子页面
//js
top = $("#iframe01").contents().find("#page_top").val();
cache = $("#iframe01").contents().find("#page_cache").val().split(" ")[0];
console.log("父页面获取的top:"+$("#iframe01").contents().find("#page_top").val());
console.log("父页面获取的页码编码:"+$("#iframe01").contents().find("#page_cache").val());
通过这种方式,可以获得该代码中num和height的值。
以下是定位的实现(锚点定位):直接上传代码
//html
点击定位1
点击定位2
//jq
//这个才是定位
$(".set1").click(function(){
$(".set2").click();
//始终在页面只有一个是模拟添加的a标签
if($("#iframe01").contents().find(".addLink").length!=0){
$("#iframe01").contents().find(".addLink").remove();
}
//创建一个模拟目录中的标题a标签
str = "<a hidden:'hidden' href='"
+ '#[{"num":'+cache+',"gen":0},{"name":"XYZ"},74,'+top+',0]'
+ "'class='internalLink addLink' id='p37318'>
</a>";
//添加到子页面中
//先判断是否有 没有再添加 有就不添加
if($("#iframe01").contents().find("#p37318").length==0){
$("#iframe01").contents().find("body").append(str);
}
//模拟目录a标签的点击事件
$("#iframe01").contents().find("#p37318").find("p")[0].click();
})
//这个是假的
$(".set2").click(function(){
if($("#iframe01").contents().find(".addLink").length!=0){
$("#iframe01").contents().find(".addLink").remove();
}
str = "<a href='"
+ '#[{"num":17,"gen":0},{"name":"XYZ"},74,192,0]'
+ "'class='internalLink addLink' id='p17192'><p>GG</a>";
if($("#iframe01").contents().find("#p17192").length==0){
$("#iframe01").contents().find("body").append(str);
}
$("#iframe01").contents().find("#p17192").
find("p")[0].click();
})</p>
想法:找到目录标签的事件和类,在后台传输的数据具有这两个参数,创建一个类似的标签,将参数放入,然后将其放入子页面,并在单击时找到我们。新添加的标签触发单击以实现跳转,而set1此处为跳转。因为在我本地滚动时一键单击,再次单击将不起作用,无效。因此,添加了一个隐藏的单击,并且每次单击都会首先触发一个隐藏的单击。发现可用。
许多人都遇到过这种问题。你不用再找我了设置锚点并通过所需的内容跳转到锚点。我在github上写了一个小演示。如果您有兴趣,可以下载并尝试
整个模拟行定位已完成。我花了整整一天的时间,但最终结果仍然让我感到非常满意。由于该项目的源代码无法发布,因此我只能在github上上传一个简单的演示,有兴趣的人可以下载它。如有任何疑问,可以留言。 查看全部
pdf.js内部的按钮上传、定位、浏览功能的方法
这部分是我们公司之前需要实现的pdf上传,定位和浏览功能。就像以前的博客一样,我遇到了很多问题。使用的主要js是pdf.js,为了实现浏览上载的pdf,以前的博客记录了跨域问题(跨域问题是非常重要的,因为通用文件服务器和项目服务器是分开的),记录是否实现了行定位功能。
最初,我不打算使用行定位,因为我之前曾考虑过它,而且它一无是处,因为pdf.js主要单击缩略图以找到相应的页码来实现页码跳转。由于用户无法单击pdf.js内的按钮,因此需要在外部添加按钮(相当于定位点功能)。主要功能点:锚点设置和锚点定位。
下面我只讨论行定位的方法:
思考:pdf.js具有目录功能,单击目录中的标题以实现行定位,这启发了我思考行定位的实现。主页使用页面F12检查目录位置的链接,发现它是一串代码(我不知道哪种格式),我将其复制并在网页上进行了转码,并找到了如下格式:
#[{"num":23,"gen":0},{"name":"XYZ"},74,769,0]
#[{"num":46,"gen":0},{"name":"XYZ"},74,442,0]
这是与两个标题相对应的代码转换代码。我发现两个地方不同。一个是num的值,另一个是倒数第二个数字。我接下来去。寻找源代码,一个接一个的控制台,我终于在viewer.js的9285行中找到了线索(因为每个版本中的行数不同,以下是我复制的js方法,因为加密的计算机可以'不截屏,仅截取代码):
key: '_updateLocation',
value: function _updateLocation(firstPage) {
var currentScale = this._currentScale;
var currentScaleValue = this._currentScaleValue;
var normalizedScaleValue = parseFloat(currentScaleValue)
...........
滚动页面时,此方法的控制台方法将使用此方法。此方法背后有几个非常重要的参数。
this._location = {
pageNumber: pageNumber,
scale: normalizedScaleValue,
top: intTop,
left: intLeft,
rotation: this._pagesRotation,
pdfOpenParams: pdfOpenParams
};
通过打印,可以发现pageNumber是当前页码,而intTop是代码更改数量中倒数第二个参数,它被解释为高度(哈哈,现在我知道了不是记录的行,而是当前记录(通过页码高度实现的“行定位”),现在第一个参数在那里,主要目标是该num的值,与num的值完全不同我们在页面上看到的值,我猜它必须是json或数组。与键值相对应的页码是什么,然后我沿着藤蔓通过此方法找到了大本营:
{
key: 'cachePageRef',
value: function cachePageRef(pageNum, pageRef) {
if (!pageRef) {
return;
}
var refStr = pageRef.num + ' ' + pageRef.gen + ' R';
this._pagesRefCache[refStr] = pageNum;
}
}, {
key: '_cachedPageNumber',
value: function _cachedPageNumber(pageRef) {
var refStr = pageRef.num + ' ' + pageRef.gen + ' R';
return this._pagesRefCache && this._pagesRefCache[refStr] || null;
}
},
我这一边大约是7139行(viewer.js),这两种方法非常重要,一种是页码(在下面),另一种是创建的键值格式的代码(在上部),这是通过控制台了解的,当您加载pdf文件时,您将调用上述方法以将页码与代码进行匹配(相应的格式为“ 27 0 R”-“ 4”,其中4为值是页面数字,前面的键是代码。
到目前为止,感觉就像(将云朵拉开,看到蓝天)。以下是收购。滚动上面提到的9,000行以上的页面的方法,几个参数,其中intTop是我们需要的高度值,并且需要通过该键值获取页码,因此我开始修改源代码代码。
我们需要实时获取当前页面的数据
this._location = {
pageNumber: pageNumber,
scale: normalizedScaleValue,
top: intTop,
left: intLeft,
rotation: this._pagesRotation,
pdfOpenParams: pdfOpenParams
};
//下方是我添加的代码(这里你需要在viewer.html页面中加入二个隐藏的input,id为page_top和page_cache)
var page_top = document.getElementById("page_top");
page_top.value = this._location.top;
var page_cache = document.getElementById("page_cache");
page_cache.value = this.getPageCache(this._location.pageNumber);
最后一行的getPageCache方法是我修改的源代码:
this._location = {
pageNumber: pageNumber,
scale: normalizedScaleValue,
top: intTop,
left: intLeft,
rotation: this._pagesRotation,
pdfOpenParams: pdfOpenParams
};
//下方是我添加的代码(这里你需要在viewer.html页面中加入二个隐藏的input,id为page_top和page_cache)
var page_top = document.getElementById("page_top");
page_top.value = this._location.top;
var page_cache = document.getElementById("page_cache");
page_cache.value = this.getPageCache(this._location.pageNumber);
}
},{//下面是我添加的方法
//这个方法用来获取对应num的页码cache
key:'getPageCache',
value:function getPageCache(pageNum){
//循环结果(这里的page_cache是一个数组,下面细说)
var str = JSON.stringify(page_cache);
// console.log("格式为:"+typeof(JSON.parse(str)))
// console.log("json的数据:"+str)
for(var key in JSON.parse(str)){
if(JSON.parse(str)[key]==pageNum){
return key;
}
}
}
我们在上面提到了键值格式数据,因为它不在代码块中,所以我在js顶部添加了一个全局变量page_cache
//定义全局变量 去接受页码对应编码值
var page_cache = [];
然后在页面加载pdf时为该数组分配一个值:
{
key: 'cachePageRef',
value: function cachePageRef(pageNum, pageRef) {
if (!pageRef) {
return;
}
var refStr = pageRef.num + ' ' + pageRef.gen + ' R';
this._pagesRefCache[refStr] = pageNum;
//当赋值完毕之后,给全局赋值,这样我就获取到这个编码了
page_cache = this._pagesRefCache;
}
}, {
key: '_cachedPageNumber',
value: function _cachedPageNumber(pageRef) {
var refStr = pageRef.num + ' ' + pageRef.gen + ' R';
return this._pagesRefCache && this._pagesRefCache[refStr] || null;
}
},
以这种方式,如上所述,通过此全局情况获得了相应的代码值。 (这是采集的结束(设置锚点))
另外:有些人可能无法在iframe下获取文件,请将此信息发送给我:
//这个是子页面
//js
top = $("#iframe01").contents().find("#page_top").val();
cache = $("#iframe01").contents().find("#page_cache").val().split(" ")[0];
console.log("父页面获取的top:"+$("#iframe01").contents().find("#page_top").val());
console.log("父页面获取的页码编码:"+$("#iframe01").contents().find("#page_cache").val());
通过这种方式,可以获得该代码中num和height的值。
以下是定位的实现(锚点定位):直接上传代码
//html
点击定位1
点击定位2
//jq
//这个才是定位
$(".set1").click(function(){
$(".set2").click();
//始终在页面只有一个是模拟添加的a标签
if($("#iframe01").contents().find(".addLink").length!=0){
$("#iframe01").contents().find(".addLink").remove();
}
//创建一个模拟目录中的标题a标签
str = "<a hidden:'hidden' href='"
+ '#[{"num":'+cache+',"gen":0},{"name":"XYZ"},74,'+top+',0]'
+ "'class='internalLink addLink' id='p37318'>
</a>";
//添加到子页面中
//先判断是否有 没有再添加 有就不添加
if($("#iframe01").contents().find("#p37318").length==0){
$("#iframe01").contents().find("body").append(str);
}
//模拟目录a标签的点击事件
$("#iframe01").contents().find("#p37318").find("p")[0].click();
})
//这个是假的
$(".set2").click(function(){
if($("#iframe01").contents().find(".addLink").length!=0){
$("#iframe01").contents().find(".addLink").remove();
}
str = "<a href='"
+ '#[{"num":17,"gen":0},{"name":"XYZ"},74,192,0]'
+ "'class='internalLink addLink' id='p17192'><p>GG</a>";
if($("#iframe01").contents().find("#p17192").length==0){
$("#iframe01").contents().find("body").append(str);
}
$("#iframe01").contents().find("#p17192").
find("p")[0].click();
})</p>
想法:找到目录标签的事件和类,在后台传输的数据具有这两个参数,创建一个类似的标签,将参数放入,然后将其放入子页面,并在单击时找到我们。新添加的标签触发单击以实现跳转,而set1此处为跳转。因为在我本地滚动时一键单击,再次单击将不起作用,无效。因此,添加了一个隐藏的单击,并且每次单击都会首先触发一个隐藏的单击。发现可用。
许多人都遇到过这种问题。你不用再找我了设置锚点并通过所需的内容跳转到锚点。我在github上写了一个小演示。如果您有兴趣,可以下载并尝试
整个模拟行定位已完成。我花了整整一天的时间,但最终结果仍然让我感到非常满意。由于该项目的源代码无法发布,因此我只能在github上上传一个简单的演示,有兴趣的人可以下载它。如有任何疑问,可以留言。
实例讲述JS简单获取并修改input文本框内容的方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-05-06 02:00
本文文章主要介绍了JS简单获取和修改输入文本框内容的方法,并结合示例表格,分析了与JavaScript相关的获取和分配页面元素的操作技巧。有需要的朋友可以参考以下内容
本文中的示例描述了JS如何简单地获取和修改输入文本框的内容。与您分享以供参考,如下所示:
一个介绍
获取文本框并修改其内容可以使用getElementById()方法来实现。
getElementById()方法可以通过指定的ID获取HTML标记并返回它们。
语法:
sElement = document.getElementById(id)
sElement:用于接收此方法返回的对象。
id:用于设置需要获取的HTML标记的ID值。
两个应用
获取文本框并修改其内容
页面加载后,“初始文本内容”将显示在文本框中,单击按钮将更改文本框中的内容。
三个代码
www.jb51.net 获取文本框并修改其内容
四个运行结果
对于更多对JavaScript相关内容感兴趣的读者,请检查此站点的主题:“ JavaScript页面元素操作技巧摘要”,“ JavaScript操作DOM技巧摘要”,“ JavaScript搜索算法技巧摘要”,“ JavaScript数据”结构和算法的“技能摘要”,“ JavaScript遍历算法和技能摘要”和“ JavaScript错误和调试技能摘要”
我希望本文能对您的JavaScript编程有所帮助。 查看全部
实例讲述JS简单获取并修改input文本框内容的方法
本文文章主要介绍了JS简单获取和修改输入文本框内容的方法,并结合示例表格,分析了与JavaScript相关的获取和分配页面元素的操作技巧。有需要的朋友可以参考以下内容
本文中的示例描述了JS如何简单地获取和修改输入文本框的内容。与您分享以供参考,如下所示:
一个介绍
获取文本框并修改其内容可以使用getElementById()方法来实现。
getElementById()方法可以通过指定的ID获取HTML标记并返回它们。
语法:
sElement = document.getElementById(id)
sElement:用于接收此方法返回的对象。
id:用于设置需要获取的HTML标记的ID值。
两个应用
获取文本框并修改其内容
页面加载后,“初始文本内容”将显示在文本框中,单击按钮将更改文本框中的内容。
三个代码
www.jb51.net 获取文本框并修改其内容
四个运行结果
对于更多对JavaScript相关内容感兴趣的读者,请检查此站点的主题:“ JavaScript页面元素操作技巧摘要”,“ JavaScript操作DOM技巧摘要”,“ JavaScript搜索算法技巧摘要”,“ JavaScript数据”结构和算法的“技能摘要”,“ JavaScript遍历算法和技能摘要”和“ JavaScript错误和调试技能摘要”
我希望本文能对您的JavaScript编程有所帮助。
日志数据的实时分析并可视化:除了日志服务中分析
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-05-04 18:09
日志数据的实时分析并可视化:除了日志服务中分析
curl --request GET 'http://${project}.${sls-host}/logstores/${logstore}/track?APIVersion=0.6.0&key1=val1&key2=val2'
通过将Image标记嵌入HTML之下,显示页面时将自动报告数据。
or
track_ua.gif除了将自定义的参数上传外,在服务端还会将http头中的UserAgent、referer也作为日志中的字段。
通过Java Script SDK报告数据
var logger = new window.Tracker('${sls-host}','${project}','${logstore}');
logger.push('customer', 'zhangsan');
logger.push('product', 'iphone 6s');
logger.push('price', 5500);
logger.logger();
有关详细步骤,请参阅WebTracking访问文档。
案例:内容的多渠道推广
当我们拥有新内容(例如新功能,新活动,新游戏,新文章)时,作为操作员,我们总是迫不及待想尽快与用户交流,因为这是第一个获取用户的步骤,也是最重要的步骤。
以游戏发布为例:
市场花费大量金钱来推广游戏。例如,有2000人成功加载了1W广告之后的广告,约占20%,其中800人点击并最终下载并注册了试用游戏。
从上面可以看出,对于企业而言,准确,实时地获得内容推广的有效性非常重要。为了达到总体促销目标,运营商通常会选择各种促销渠道,例如:
方案设计我们在日志服务中创建一个日志存储区(例如:myclick),并启用WebTracking功能
对于需要升级的文档(article = 100 1)),为每个升级渠道添加标签,并生成一个Web跟踪标签(以Img标签为例),如下所示:
内部信件渠道(mailDec):
官方网站频道(aliyunDoc):
用户邮箱频道(电子邮件):
其他更多渠道可以在from参数后加上,也可以在URL中加入更多需要采集的参数
将img标签放入促销内容中,您可以将其传播出去,我们也可以散散步并喝咖啡采集日志分析
完成掩埋点采集后,我们可以使用日志服务LogSearch / Analytics函数实时查询和分析大量日志数据。在结果分析和可视化方面,除了内置的仪表板外,它还支持对接方法,例如DataV,Grafana和Tableua。在这里,我们进行一些基本的演示:
以下是到目前为止采集的日志数据,我们可以在搜索框中输入关键词进行查询:
您还可以在查询几秒钟后进行实时分析和可视化后输入SQL:
除了日志服务中的分析之外,
以下是我们对用户点击/阅读日志的实时分析:
* | select count(1) as c
* | select count(1) as c, date_trunc('hour',from_unixtime(__time__)) as time group by time order by time desc limit 100000
* | select count(1) as c, f group by f desc
* | select count_if(ua like '%Mac%') as mac, count_if(ua like '%Windows%') as win, count_if(ua like '%iPhone%') as ios, count_if(ua like '%Android%') as android
* | select ip_to_province(__source__) as province, count(1) as c group by province order by c desc limit 100
最后,可以将这些实时数据配置为实时刷新仪表板,效果如下:
点击即可获得惊喜
查看全部
日志数据的实时分析并可视化:除了日志服务中分析
curl --request GET 'http://${project}.${sls-host}/logstores/${logstore}/track?APIVersion=0.6.0&key1=val1&key2=val2'
通过将Image标记嵌入HTML之下,显示页面时将自动报告数据。
or
track_ua.gif除了将自定义的参数上传外,在服务端还会将http头中的UserAgent、referer也作为日志中的字段。
通过Java Script SDK报告数据
var logger = new window.Tracker('${sls-host}','${project}','${logstore}');
logger.push('customer', 'zhangsan');
logger.push('product', 'iphone 6s');
logger.push('price', 5500);
logger.logger();
有关详细步骤,请参阅WebTracking访问文档。
案例:内容的多渠道推广
当我们拥有新内容(例如新功能,新活动,新游戏,新文章)时,作为操作员,我们总是迫不及待想尽快与用户交流,因为这是第一个获取用户的步骤,也是最重要的步骤。
以游戏发布为例:
市场花费大量金钱来推广游戏。例如,有2000人成功加载了1W广告之后的广告,约占20%,其中800人点击并最终下载并注册了试用游戏。
从上面可以看出,对于企业而言,准确,实时地获得内容推广的有效性非常重要。为了达到总体促销目标,运营商通常会选择各种促销渠道,例如:
方案设计我们在日志服务中创建一个日志存储区(例如:myclick),并启用WebTracking功能
对于需要升级的文档(article = 100 1)),为每个升级渠道添加标签,并生成一个Web跟踪标签(以Img标签为例),如下所示:
内部信件渠道(mailDec):
官方网站频道(aliyunDoc):
用户邮箱频道(电子邮件):
其他更多渠道可以在from参数后加上,也可以在URL中加入更多需要采集的参数
将img标签放入促销内容中,您可以将其传播出去,我们也可以散散步并喝咖啡采集日志分析
完成掩埋点采集后,我们可以使用日志服务LogSearch / Analytics函数实时查询和分析大量日志数据。在结果分析和可视化方面,除了内置的仪表板外,它还支持对接方法,例如DataV,Grafana和Tableua。在这里,我们进行一些基本的演示:
以下是到目前为止采集的日志数据,我们可以在搜索框中输入关键词进行查询:
您还可以在查询几秒钟后进行实时分析和可视化后输入SQL:
除了日志服务中的分析之外,
以下是我们对用户点击/阅读日志的实时分析:
* | select count(1) as c
* | select count(1) as c, date_trunc('hour',from_unixtime(__time__)) as time group by time order by time desc limit 100000
* | select count(1) as c, f group by f desc
* | select count_if(ua like '%Mac%') as mac, count_if(ua like '%Windows%') as win, count_if(ua like '%iPhone%') as ios, count_if(ua like '%Android%') as android
* | select ip_to_province(__source__) as province, count(1) as c group by province order by c desc limit 100
最后,可以将这些实时数据配置为实时刷新仪表板,效果如下:
点击即可获得惊喜
2017年08月18日网页开发过程中会有打印页面的需求
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-05-03 22:11
2017年08月18日网页开发过程中会有打印页面的需求
JS实现页面打印(全部,部分)
更新时间:2017年8月18日10:08:16作者:Xiaoguoguo_G
本文文章主要介绍JS实现页面打印(全部,部分),我认为它相当不错,现在与您分享,也供您参考。让我们跟随编辑器看看
在Web开发过程中,我们经常需要打印页面。有很多方法可以通过JS实现。我在这里整理了一下,供您参考。
方法1:window.print()
整体打印
打印
现在可以轻松打印页面,但是此方法将打印整个页面。如果要打印指定区域,则需要通过以下设置
部分打印
首先,在html中,用星号和结尾标记打印区域
这块内容不需要打印
这里是需要打印的内容
.....
这块内容不需要打印
然后,将以下代码添加到click事件中
function doPrint() {
bdhtml=window.document.body.innerHTML;
sprnstr="";
eprnstr="";
prnhtml=bdhtml.substr(bdhtml.indexOf(sprnstr)+17);
prnhtml=prnhtml.substring(0,prnhtml.indexOf(eprnstr));
window.document.body.innerHTML=prnhtml;
window.print();
}
过滤打印区域的内容
例如
预览
打印
这里是需要打印的内容
.....
上面的预览和打印按钮不想打印,如果要过滤,可以进行以下样式设置
@media print {
.noprint{
display: none;
}
}
或
.noprint{
display: none;
}
选择两种书写方式之一
分页打印
使用window.print()打印时,如果内容超出限制,它将自动分页。但是,如果需要自定义分页范围,例如表格的页面打印,则可以设置以下内容:
方法二、 jqprint()
jqprint是一个用于基于jQuery的页面打印的小插件,但是我不得不承认这个插件确实功能强大。在最近的项目中,我提供了很多帮助。在Web打印方面,前端打印基本上取决于窗口。 .print()方法进行打印,并在此基础上对该插件进行进一步封装,从而可以轻松地在网页上打印某个区域,这是一个亮点。
参考网址:
请注意!许多朋友遇到无法读取未定义错误的属性“ opera”。问题是juqery版本兼容性问题。
解决方案:添加迁移辅助插件jquery-migrate- 1. 0. 0. js解决版本问题
简介
js
function a(){
$("#ddd").jqprint();
}
html
test
test
test
test
test
设置模板打印
$("#printContainer").jqprint({
debug: false, //如果是true则可以显示iframe查看效果(iframe默认高和宽都很小,可以再源码中调大),默认是false
importCSS: true, //true表示引进原来的页面的css,默认是true。(如果是true,先会找$("link[media=print]"),若没有会去找$("link")中的css文件)
printContainer: true, //表示如果原来选择的对象必须被纳入打印(注意:设置为false可能会打破你的CSS规则)。
operaSupport: true//表示如果插件也必须支持歌opera浏览器,在这种情况下,它提供了建立一个临时的打印选项卡。默认是true
});
后记
此外,您还可以使用html标签来引入Webbrowser控件(仅与IE兼容)或调用Windows的底层以进行打印,并报告安全警告。不建议使用(不支持部分打印)
我在这里只介绍两种方法。我希望它对每个人的学习都有帮助,也希望您能更多地支持Scripthome。 查看全部
2017年08月18日网页开发过程中会有打印页面的需求
JS实现页面打印(全部,部分)
更新时间:2017年8月18日10:08:16作者:Xiaoguoguo_G
本文文章主要介绍JS实现页面打印(全部,部分),我认为它相当不错,现在与您分享,也供您参考。让我们跟随编辑器看看
在Web开发过程中,我们经常需要打印页面。有很多方法可以通过JS实现。我在这里整理了一下,供您参考。
方法1:window.print()
整体打印
打印
现在可以轻松打印页面,但是此方法将打印整个页面。如果要打印指定区域,则需要通过以下设置
部分打印
首先,在html中,用星号和结尾标记打印区域
这块内容不需要打印
这里是需要打印的内容
.....
这块内容不需要打印
然后,将以下代码添加到click事件中
function doPrint() {
bdhtml=window.document.body.innerHTML;
sprnstr="";
eprnstr="";
prnhtml=bdhtml.substr(bdhtml.indexOf(sprnstr)+17);
prnhtml=prnhtml.substring(0,prnhtml.indexOf(eprnstr));
window.document.body.innerHTML=prnhtml;
window.print();
}
过滤打印区域的内容
例如
预览
打印
这里是需要打印的内容
.....
上面的预览和打印按钮不想打印,如果要过滤,可以进行以下样式设置
@media print {
.noprint{
display: none;
}
}
或
.noprint{
display: none;
}
选择两种书写方式之一
分页打印
使用window.print()打印时,如果内容超出限制,它将自动分页。但是,如果需要自定义分页范围,例如表格的页面打印,则可以设置以下内容:
方法二、 jqprint()
jqprint是一个用于基于jQuery的页面打印的小插件,但是我不得不承认这个插件确实功能强大。在最近的项目中,我提供了很多帮助。在Web打印方面,前端打印基本上取决于窗口。 .print()方法进行打印,并在此基础上对该插件进行进一步封装,从而可以轻松地在网页上打印某个区域,这是一个亮点。
参考网址:
请注意!许多朋友遇到无法读取未定义错误的属性“ opera”。问题是juqery版本兼容性问题。
解决方案:添加迁移辅助插件jquery-migrate- 1. 0. 0. js解决版本问题
简介
js
function a(){
$("#ddd").jqprint();
}
html
test
test
test
test
test
设置模板打印
$("#printContainer").jqprint({
debug: false, //如果是true则可以显示iframe查看效果(iframe默认高和宽都很小,可以再源码中调大),默认是false
importCSS: true, //true表示引进原来的页面的css,默认是true。(如果是true,先会找$("link[media=print]"),若没有会去找$("link")中的css文件)
printContainer: true, //表示如果原来选择的对象必须被纳入打印(注意:设置为false可能会打破你的CSS规则)。
operaSupport: true//表示如果插件也必须支持歌opera浏览器,在这种情况下,它提供了建立一个临时的打印选项卡。默认是true
});
后记
此外,您还可以使用html标签来引入Webbrowser控件(仅与IE兼容)或调用Windows的底层以进行打印,并报告安全警告。不建议使用(不支持部分打印)
我在这里只介绍两种方法。我希望它对每个人的学习都有帮助,也希望您能更多地支持Scripthome。
给img设置一个固定的大小时,要怎样获取图片的原始尺寸
网站优化 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2021-04-29 18:08
如何获取图片的原创尺寸?
如下所示,当为img设置固定大小时,如何获取图片的原创大小?
#oImg{
width: 100px;
height: 100px;
}
方法1:
HTML5提供了一个新属性naturalWidth / naturalHeight,可以直接获取图片的原创宽度和高度。这两个属性已在Firefox / Chrome / Safari / Opera和IE9中实现。
w = document.getElementsByTagName("img")[0].naturalWidth;
h = document.getElementsByTagName("img")[0].naturalHeight;
console.log(w + ' ' + h);
打印结果与原创尺寸匹配。但前提是必须将图片完全下载到客户端浏览器中进行判断。
如果是不受支持的浏览器版本,则可以使用传统方法进行判断,如下所示:
var img = document.getElementById("oImg"),
w,h;
if (oImg.naturalWidth) {
// HTML5 browsers
w = oImg.naturalWidth;
h = oImg.naturalHeight;
} else {
// IE 6/7/8
var nImg = new Image();
// nImg.src = oImg.src;
nImg.onload = function () {
w = nImg.width;
h = nImg.height;
console.log(w + " " + h)
}
nImg.src = oImg.src;
}
此时添加onload的原因是图像可能无法完全加载,从而导致图像的宽度和高度不可用。
这里还有一点要注意,为什么要在nImg.onload函数之后放置nImg.src = oImg.src代码?这样做是为了与ie兼容。即除了第一次加载图像正常之外,之后刷新时将没有任何响应。其他大多数浏览器都正常。是什么原因呢?
原因很简单,这是因为浏览器的缓存。一次加载图像后,如果有另一个图像请求,由于浏览器已经缓存了该图像,它将不会启动新请求,而是直接从缓存中加载该请求。对于大多数浏览器而言,它们的视图使这两种加载方法对用户透明,这也将导致图像的onload事件,即忽略该身份并且不会导致图像的onload事件。 。 。通常情况下,您可以使用complete来确定是否已加载映像。对于complete属性,IE根据是否显示图片进行判断,即显示加载的图片时,complete属性的值为true,否则始终为false,与图片是否显示无关。之前已经加载过,也就是说,它与缓存无关!您可以编写以下函数来实现各种浏览器中预加载图像的兼容性。如下:
var img = document.getElementById("oImg"),
w,h;
if (oImg.naturalWidth) {
// HTML5 browsers
w = oImg.naturalWidth;
h = oImg.naturalHeight;
} else {
// IE 6/7/8
var nImg = new Image();
nImg.src = oImg.src;
if(nImg.complete) { // 图片已经存在于浏览器缓存
console.log(nImg.width + " " + nImg.height);
}else{
nImg.onload = function () {
w = nImg.width;
h = nImg.height;
console.log(w + " " + h);
}
}
}
最后封装到一个函数中,如下所示:
function getImgNaturalDimensions(oImg, callback) {
var nWidth, nHeight;
if (!oImg.naturalWidth) { // 现代浏览器
nWidth = oImg.naturalWidth;
nHeight = oImg.naturalHeight;
callback({w: nWidth, h:nHeight});
} else { // IE6/7/8
var nImg = new Image();
nImg.onload = function() {
var nWidth = nImg.width,
nHeight = nImg.height;
callback({w: nWidth, h:nHeight});
}
nImg.src = oImg.src;
}
}
var img = document.getElementById("oImg");
getImgNaturalDimensions(img, function(dimensions){
console.log(dimensions.w);
});
方法2 :(图片无需在页面上显示)
将img放在页面上的不可见位置,缺点是:此方法需要浏览器加载图像
.imgbox{// img 盒子
width: 0;
overflow: hidden;
}
然后去获取诸如图片的宽度和高度之类的信息:
function getImgNaturalDimensions2(oImg) {
var nWidth, nHeight;
if (!oImg.naturalWidth) { // 现代浏览器
nWidth = oImg.naturalWidth;
nHeight = oImg.naturalHeight;
return ({w: nWidth, h:nHeight});
} else { // IE6/7/8
nWidth = oImg.width;
nHeight = oImg.height;
return ({w: nWidth, h:nHeight});
}
}
var getImg = getImgNaturalDimensions2(img);
console.log(getImg)
但是,这里一切都还好吗?答案当然不是。
使用此方法后,您会发现有时可以获取img的宽度和高度,但有时为0。原因请参见下一节的分析。
让我们看看如何正常使用它!
var img = document.getElementById("oImg");
img.onload = function(){
//方法一
getImgNaturalDimensions(img, function(dimensions){
console.log(dimensions.w);
});
//方法二
var getImg = getImgNaturalDimensions2(img);
console.log(getImg);
}
只需在img.onload函数中调用该函数即可。
原因,请参阅下一节的分析:js获取图片信息(二) ----- js获取img 0的高度和宽度 查看全部
给img设置一个固定的大小时,要怎样获取图片的原始尺寸
如何获取图片的原创尺寸?
如下所示,当为img设置固定大小时,如何获取图片的原创大小?
#oImg{
width: 100px;
height: 100px;
}
方法1:
HTML5提供了一个新属性naturalWidth / naturalHeight,可以直接获取图片的原创宽度和高度。这两个属性已在Firefox / Chrome / Safari / Opera和IE9中实现。
w = document.getElementsByTagName("img")[0].naturalWidth;
h = document.getElementsByTagName("img")[0].naturalHeight;
console.log(w + ' ' + h);
打印结果与原创尺寸匹配。但前提是必须将图片完全下载到客户端浏览器中进行判断。
如果是不受支持的浏览器版本,则可以使用传统方法进行判断,如下所示:
var img = document.getElementById("oImg"),
w,h;
if (oImg.naturalWidth) {
// HTML5 browsers
w = oImg.naturalWidth;
h = oImg.naturalHeight;
} else {
// IE 6/7/8
var nImg = new Image();
// nImg.src = oImg.src;
nImg.onload = function () {
w = nImg.width;
h = nImg.height;
console.log(w + " " + h)
}
nImg.src = oImg.src;
}
此时添加onload的原因是图像可能无法完全加载,从而导致图像的宽度和高度不可用。
这里还有一点要注意,为什么要在nImg.onload函数之后放置nImg.src = oImg.src代码?这样做是为了与ie兼容。即除了第一次加载图像正常之外,之后刷新时将没有任何响应。其他大多数浏览器都正常。是什么原因呢?
原因很简单,这是因为浏览器的缓存。一次加载图像后,如果有另一个图像请求,由于浏览器已经缓存了该图像,它将不会启动新请求,而是直接从缓存中加载该请求。对于大多数浏览器而言,它们的视图使这两种加载方法对用户透明,这也将导致图像的onload事件,即忽略该身份并且不会导致图像的onload事件。 。 。通常情况下,您可以使用complete来确定是否已加载映像。对于complete属性,IE根据是否显示图片进行判断,即显示加载的图片时,complete属性的值为true,否则始终为false,与图片是否显示无关。之前已经加载过,也就是说,它与缓存无关!您可以编写以下函数来实现各种浏览器中预加载图像的兼容性。如下:
var img = document.getElementById("oImg"),
w,h;
if (oImg.naturalWidth) {
// HTML5 browsers
w = oImg.naturalWidth;
h = oImg.naturalHeight;
} else {
// IE 6/7/8
var nImg = new Image();
nImg.src = oImg.src;
if(nImg.complete) { // 图片已经存在于浏览器缓存
console.log(nImg.width + " " + nImg.height);
}else{
nImg.onload = function () {
w = nImg.width;
h = nImg.height;
console.log(w + " " + h);
}
}
}
最后封装到一个函数中,如下所示:
function getImgNaturalDimensions(oImg, callback) {
var nWidth, nHeight;
if (!oImg.naturalWidth) { // 现代浏览器
nWidth = oImg.naturalWidth;
nHeight = oImg.naturalHeight;
callback({w: nWidth, h:nHeight});
} else { // IE6/7/8
var nImg = new Image();
nImg.onload = function() {
var nWidth = nImg.width,
nHeight = nImg.height;
callback({w: nWidth, h:nHeight});
}
nImg.src = oImg.src;
}
}
var img = document.getElementById("oImg");
getImgNaturalDimensions(img, function(dimensions){
console.log(dimensions.w);
});
方法2 :(图片无需在页面上显示)
将img放在页面上的不可见位置,缺点是:此方法需要浏览器加载图像
.imgbox{// img 盒子
width: 0;
overflow: hidden;
}
然后去获取诸如图片的宽度和高度之类的信息:
function getImgNaturalDimensions2(oImg) {
var nWidth, nHeight;
if (!oImg.naturalWidth) { // 现代浏览器
nWidth = oImg.naturalWidth;
nHeight = oImg.naturalHeight;
return ({w: nWidth, h:nHeight});
} else { // IE6/7/8
nWidth = oImg.width;
nHeight = oImg.height;
return ({w: nWidth, h:nHeight});
}
}
var getImg = getImgNaturalDimensions2(img);
console.log(getImg)
但是,这里一切都还好吗?答案当然不是。
使用此方法后,您会发现有时可以获取img的宽度和高度,但有时为0。原因请参见下一节的分析。
让我们看看如何正常使用它!
var img = document.getElementById("oImg");
img.onload = function(){
//方法一
getImgNaturalDimensions(img, function(dimensions){
console.log(dimensions.w);
});
//方法二
var getImg = getImgNaturalDimensions2(img);
console.log(getImg);
}
只需在img.onload函数中调用该函数即可。
原因,请参阅下一节的分析:js获取图片信息(二) ----- js获取img 0的高度和宽度
js提取指定网站-url解析用less写一个list
网站优化 • 优采云 发表了文章 • 0 个评论 • 430 次浏览 • 2021-04-28 00:02
<p>js提取指定网站内容-url解析用less写一个以url为参数的map,生成一个list。url包含xml的本地文件,用requests包收取到相应的json。varpic=[];for(vari=0;i 查看全部
js提取指定网站-url解析用less写一个list
<p>js提取指定网站内容-url解析用less写一个以url为参数的map,生成一个list。url包含xml的本地文件,用requests包收取到相应的json。varpic=[];for(vari=0;i
js提取指定网站内容meme/extract库提取地址
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-04-03 00:02
js提取指定网站内容微信/微博/简书/豆瓣..从网页/爬虫本地程序提取你想要的全部或部分,进行整合。通过轮播或者分页等的更新,实现实时性的分析和全部/部分/小图/图片等不同展示内容的展示。1.通过requests库从html中提取网页数据(会比较慢,慢需要的时间)2.利用正则表达式和beautifulsoup、xpath对各种网页数据提取出来,通过自定义列表创建链接地址地址,再进行访问;3.用chrome的f12或者chromeextension--f12--打开开发者工具,执行:test=newtest.document();test.size=1616;test.height=2048580412;4.利用googlechrome提供的burst/extract/stringpillow库提取。
理解下,
有一个方法可以达到你的要求,你可以参考一下:利用上文提到的包(方法)制作一个文档首页www。pinyin。me/wap/supports/media/redirect/content/w3cwebhome(),代码如下:foriinself。webpage。items():reg=sort(str)。
apply(str,str,all=true)path="path"items=reg+str+"/"+path。apply(str,path)reg。extract(items)。 查看全部
js提取指定网站内容meme/extract库提取地址
js提取指定网站内容微信/微博/简书/豆瓣..从网页/爬虫本地程序提取你想要的全部或部分,进行整合。通过轮播或者分页等的更新,实现实时性的分析和全部/部分/小图/图片等不同展示内容的展示。1.通过requests库从html中提取网页数据(会比较慢,慢需要的时间)2.利用正则表达式和beautifulsoup、xpath对各种网页数据提取出来,通过自定义列表创建链接地址地址,再进行访问;3.用chrome的f12或者chromeextension--f12--打开开发者工具,执行:test=newtest.document();test.size=1616;test.height=2048580412;4.利用googlechrome提供的burst/extract/stringpillow库提取。
理解下,
有一个方法可以达到你的要求,你可以参考一下:利用上文提到的包(方法)制作一个文档首页www。pinyin。me/wap/supports/media/redirect/content/w3cwebhome(),代码如下:foriinself。webpage。items():reg=sort(str)。
apply(str,str,all=true)path="path"items=reg+str+"/"+path。apply(str,path)reg。extract(items)。

