
js提取指定网站内容
【知识点】HTML文档的域有关(一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-08-01 02:28
同源政策
页面中的Javascript只能读取访问同域的网页。这里需要注意的是,Javascript本身的域定义与其所在的网站无关,只与Javascript代码中嵌入的文档的域有关。如以下示例代码:
This is a webpage came from http://localhost:8000
123
console.log($('#test').text());
HTML 文档来自:8000,表示它的域是:8000(域和端口也是相关的)。虽然页面中的jquery是从加载的,但是JQuery的域只和它所在的HTML文档一样,域是相关的,这样就可以访问到HTML文档的属性,所以上面的代码就可以运行了正常。
附件:使用上述代码的原因是开发者将常用的Javascript库(如JQuery)的地址指向同一个公共URL。用户加载一次JS后,所有后续加载都会被浏览器缓存,从而加快页面加载速度。
从这个角度来说,如果提问者已知的远程指向互联网上的任何一个页面,那么你所期望的功能就无法实现;如果远程点是指您可以控制的网站,请参阅下面的放宽同源策略;
<p>放宽同源 policyDocument.domain:用于子域的情况。对于多个窗口(一个页面上有多个iframe),Javascript可以通过将document.domain的值设置为同一个域来访问外部窗口;跨域资源共享:添加Access-Control- 查看全部
【知识点】HTML文档的域有关(一)
同源政策
页面中的Javascript只能读取访问同域的网页。这里需要注意的是,Javascript本身的域定义与其所在的网站无关,只与Javascript代码中嵌入的文档的域有关。如以下示例代码:
This is a webpage came from http://localhost:8000
123
console.log($('#test').text());
HTML 文档来自:8000,表示它的域是:8000(域和端口也是相关的)。虽然页面中的jquery是从加载的,但是JQuery的域只和它所在的HTML文档一样,域是相关的,这样就可以访问到HTML文档的属性,所以上面的代码就可以运行了正常。
附件:使用上述代码的原因是开发者将常用的Javascript库(如JQuery)的地址指向同一个公共URL。用户加载一次JS后,所有后续加载都会被浏览器缓存,从而加快页面加载速度。
从这个角度来说,如果提问者已知的远程指向互联网上的任何一个页面,那么你所期望的功能就无法实现;如果远程点是指您可以控制的网站,请参阅下面的放宽同源策略;
<p>放宽同源 policyDocument.domain:用于子域的情况。对于多个窗口(一个页面上有多个iframe),Javascript可以通过将document.domain的值设置为同一个域来访问外部窗口;跨域资源共享:添加Access-Control-
,涉及JavaScript针对URL地址规则的分析与字符串的截取操作
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-07-31 21:27
,涉及JavaScript针对URL地址规则的分析与字符串的截取操作
如何通过js获取腾讯视频ID
更新时间:2016-10-03 10:20:21 作者:seoman
这次文章主要介绍js获取腾讯视频ID的方法,其中涉及到JavaScript对URL地址规则的解析以及字符串截取操作的相关操作技巧。有需要的朋友可以参考以下
本文以js获取腾讯视频ID的方法为例。分享给大家,供大家参考,如下:
使用js拦截腾讯视频ID需要知道地址规则,知道规则才能获取。
我在做项目的时候遇到了添加视频的问题,比如用户复制了腾讯视频的链接,以此为例()
现在我们需要截取.html之前和最后一个斜杠之后的内容(u0332wyg5oa);当腾讯视频点击下方分享时,会出现这样一段代码:
复制代码代码如下:
在src中找到“vid=”,里面的代码和我们要截取的视频Id是一样的。所以我总结了以下几种截取视频id的方法,方法不简单,一步步截取,欢迎朋友们提出意见或建议(手机或PC链接都可以)。
$(function(){
//腾讯视频PC端网址
var video_Pc_Tx = 'http://v.qq.com';
//腾讯视频移动端端网址
var video_Mobile_Tx = 'http://m.v.qq.com';
//点击事件
$("#video_Url").click(function(){
//获取输入框中的值
var video_Url = $("#demo").val();
var video_Url_Id = ";
if (video_Url.indexOf(video_Pc_Tx) != -1) {
//截取Pc端视频ID
var Pc_Tx_Id_w = video_Url.substr(0,video_Url.lastIndexOf('.')-1);
video_Url_Id = Pc_Tx_Id_w.substr(Pc_Tx_Id_w.lastIndexOf('/')+1,Pc_Tx_Id_w.length);
} else {
//此时有可能是移动端腾讯视频或优酷视频
if (video_Url.indexOf(video_Mobile_Tx) != -1) {
/**
* 这里是判断移动端视频链接
* GetQueryString() // 调用函数获取视频ID
*/
function GetQueryString(name){
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = video_Url.substr(1).match(reg);;
if(r!=null)return unescape(r[2]); return null;
}
//截取Pc端视频ID
video_Url_Id = GetQueryString("vid");
}
}
});
});
那么“video_Url_Id”就是视频的Id,所以你可以把它放到“src”中的“vid=”中。
也可以封装成函数,直接调用即可;
例如:
function dataVideo(Url){
//上面的代码
return video_Url_Id;
}
直接调用
video_Url_Id = dataVideo(Url);
就是这样。
更多对JavaScript相关内容感兴趣的读者可以查看本站专题:《JavaScript中json操作技巧总结》、《JavaScript切换特效及技巧总结》、《JavaScript搜索算法技巧总结》 , 《JavaScript动画特效及技巧总结、JavaScript错误及调试技巧总结、JavaScript数据结构及算法技巧总结、JavaScript遍历算法及技巧总结、JavaScript数学运算使用总结》
我希望这篇文章能帮助您进行 JavaScript 编程。 查看全部
,涉及JavaScript针对URL地址规则的分析与字符串的截取操作
如何通过js获取腾讯视频ID
更新时间:2016-10-03 10:20:21 作者:seoman
这次文章主要介绍js获取腾讯视频ID的方法,其中涉及到JavaScript对URL地址规则的解析以及字符串截取操作的相关操作技巧。有需要的朋友可以参考以下
本文以js获取腾讯视频ID的方法为例。分享给大家,供大家参考,如下:
使用js拦截腾讯视频ID需要知道地址规则,知道规则才能获取。
我在做项目的时候遇到了添加视频的问题,比如用户复制了腾讯视频的链接,以此为例()
现在我们需要截取.html之前和最后一个斜杠之后的内容(u0332wyg5oa);当腾讯视频点击下方分享时,会出现这样一段代码:
复制代码代码如下:
在src中找到“vid=”,里面的代码和我们要截取的视频Id是一样的。所以我总结了以下几种截取视频id的方法,方法不简单,一步步截取,欢迎朋友们提出意见或建议(手机或PC链接都可以)。
$(function(){
//腾讯视频PC端网址
var video_Pc_Tx = 'http://v.qq.com';
//腾讯视频移动端端网址
var video_Mobile_Tx = 'http://m.v.qq.com';
//点击事件
$("#video_Url").click(function(){
//获取输入框中的值
var video_Url = $("#demo").val();
var video_Url_Id = ";
if (video_Url.indexOf(video_Pc_Tx) != -1) {
//截取Pc端视频ID
var Pc_Tx_Id_w = video_Url.substr(0,video_Url.lastIndexOf('.')-1);
video_Url_Id = Pc_Tx_Id_w.substr(Pc_Tx_Id_w.lastIndexOf('/')+1,Pc_Tx_Id_w.length);
} else {
//此时有可能是移动端腾讯视频或优酷视频
if (video_Url.indexOf(video_Mobile_Tx) != -1) {
/**
* 这里是判断移动端视频链接
* GetQueryString() // 调用函数获取视频ID
*/
function GetQueryString(name){
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = video_Url.substr(1).match(reg);;
if(r!=null)return unescape(r[2]); return null;
}
//截取Pc端视频ID
video_Url_Id = GetQueryString("vid");
}
}
});
});
那么“video_Url_Id”就是视频的Id,所以你可以把它放到“src”中的“vid=”中。
也可以封装成函数,直接调用即可;
例如:
function dataVideo(Url){
//上面的代码
return video_Url_Id;
}
直接调用
video_Url_Id = dataVideo(Url);
就是这样。
更多对JavaScript相关内容感兴趣的读者可以查看本站专题:《JavaScript中json操作技巧总结》、《JavaScript切换特效及技巧总结》、《JavaScript搜索算法技巧总结》 , 《JavaScript动画特效及技巧总结、JavaScript错误及调试技巧总结、JavaScript数据结构及算法技巧总结、JavaScript遍历算法及技巧总结、JavaScript数学运算使用总结》
我希望这篇文章能帮助您进行 JavaScript 编程。
在js中如何获取到两个指定字符之间的字符串
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-07-31 02:24
js中如何获取两个指定字符之间的字符串?我们想到的就是用正则表达式来匹配拦截。
如果:有一个字符串abcdefghijk,我们需要截取b和j之间的字符串。使用match方法实现,代码:
var str = "abcdefghijk";
var substr = str.match(/b(\S*)j/);
console.log(substr);
返回结果为:["bcdefghij", "cdefghi"]
\S* 表达式
() 匹配所有字符串。
还有一种方法:
在高级语言中,我们将使用一个称为量词的概念:
(?=j) 这意味着前面的字符串以 j 结尾,但不包括 j
var str = "abcdefghijk";
var substr = str.match(/(\S*)(?=j)/);
console.log(substr);
返回结果为:["abcdefghi", "abcdefghi"]
(b=?) 这意味着一个以 b 开头的字符串,但不包括 b
var str = "abcdefghijk";
var substr = str.match(/(b=?)(\S*)/);
console.log(substr);
返回结果为:["bcdefghijk","b","cdefghijk"]
总结:
var str = "abcdefghijk";
var substr = str.match(/(b=?)(\S*)(?=j)/);
console.log(substr);
返回结果为:["bcdefghi","b","cdefghi"]
免责声明:如需转载请注明出处并保留原链接: 查看全部
在js中如何获取到两个指定字符之间的字符串
js中如何获取两个指定字符之间的字符串?我们想到的就是用正则表达式来匹配拦截。
如果:有一个字符串abcdefghijk,我们需要截取b和j之间的字符串。使用match方法实现,代码:
var str = "abcdefghijk";
var substr = str.match(/b(\S*)j/);
console.log(substr);
返回结果为:["bcdefghij", "cdefghi"]
\S* 表达式
() 匹配所有字符串。
还有一种方法:
在高级语言中,我们将使用一个称为量词的概念:
(?=j) 这意味着前面的字符串以 j 结尾,但不包括 j
var str = "abcdefghijk";
var substr = str.match(/(\S*)(?=j)/);
console.log(substr);
返回结果为:["abcdefghi", "abcdefghi"]
(b=?) 这意味着一个以 b 开头的字符串,但不包括 b
var str = "abcdefghijk";
var substr = str.match(/(b=?)(\S*)/);
console.log(substr);
返回结果为:["bcdefghijk","b","cdefghijk"]
总结:
var str = "abcdefghijk";
var substr = str.match(/(b=?)(\S*)(?=j)/);
console.log(substr);
返回结果为:["bcdefghi","b","cdefghi"]
免责声明:如需转载请注明出处并保留原链接:
如何采用演示视频来学习短信跳转小程序的能力?
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-07-22 21:18
写在前面
如果你想独立开发,但没有云开发经验,可以使用演示视频学习本教程:
一、能力介绍
国内非个人主体认证小程序,开启静态网站后,可发出支持不认证跳转到对应小程序的短信。短信将收录一个静态网站 链接,可以在微信内或微信外打开。打开页面后,用户可以一键跳转到你的小程序。
链接的网页使用 URL Scheme 拉起微信在外部浏览器中打开主小程序。
简而言之,短信重定向能力的实现分为“配置拉起网页”和“发送短信”两步。本教程将介绍如何进行操作来完成短信重定向小程序的能力。
如果想不写代码也能完成短信重定向小程序,可以参考无代码版教程一步步实现。
二、操作指南1、网页制作
首先我们需要构建一个基本的 Web 应用程序,在任何代码编辑器中创建一个 html 文件,并在教程中将其命名为 index.html
在这个html文件中输入以下代码,根据注释替换自己的信息:
window.onload = function(){
window.web2weapp.init({
appId: 'wx999999', //替换为自己小程序的AppID
gh_ID: 'gh_999999',//替换为自己小程序的原始ID
env_ID: 'tcb-env',//替换小程序底下云开发环境ID
function: {
name:'openMini',//提供UrlScheme服务的云函数名称
data:{} //向这个云函数中传入的自定义参数
},
path: 'pages/index/index.html' //打开小程序时的路径
})
}
上面介绍的web2weapp.js文件是微信小程序拉取教程中封装的极简应用,我们直接引用即可轻松使用。
如果想进一步学习修改一些WEB显示信息,可以到github获取源码并进行修改。
关于启动小程序的网页的更多信息,请访问官方文档
如果您只想体验短信重定向功能,请在完成上述文件创建操作后,继续以下步骤。
2、创建服务云功能
在上面创建网页的过程中,需要填写一个UrlScheme服务云函数。该云函数主要用于调用微信服务器的能力,获取对应的Scheme信息并返回给调用前端。
我们在示例中填写了命名云函数openMini。
进入微信开发者工具,找到对应的云开发环境,创建一个名为openMini的云函数。
替换云函数目录下的index.js文件,输入如下代码:
const cloud = require('wx-server-sdk')
cloud.init()
exports.main = async (event, context) => {
return cloud.openapi.urlscheme.generate({
jumpWxa: {
path: '', // 打开小程序时访问路径,为空则会进入主页
query: '',// 可以使用 event 传入的数据制作特定参数,无需求则为空
},
isExpire: true, //是否到期失效,如果为true需要填写到期时间,默认false
expire_time: Math.round(new Date().getTime()/1000) + 3600
//我们设置为当前时间3600秒后,也就是1小时后失效
//无需求可以去掉这两个参数(isExpire,expire_time)
})
}
保存代码后,右键index.js,选择增量更新文件,更新成功。
接下来,我们需要启用对云功能的无日志访问。进入小程序云开发控制台,进入设置-权限设置,发现下面没有登录,选择我们前面步骤统一操作的云开发环境(注意:配置的云开发环境和云功能环境第一步,另外,这一步的运行环境一定要一样),勾选打开未登录
接下来进入云功能控制台,点击云功能权限,最后修改安全规则,在弹出框中配置如下:
3、local 测试
我们在本地浏览器中打开第一步创建的index.html;调出控制台,如果效果如下图,说明成功!需要注意的是,如果本地开启需要HTTP协议,建议使用live server等扩展开启。不要在资源管理器中直接打开浏览器,会有跨域问题!
4、上传本地创建的index.html到static网站hosting
将本地创建的index.html上传到静态网站托管,其中静态托管需要在小程序本身的云开发环境中进行静态托管。
如果上传到其他静态主机或服务器,仍然可以使用外部浏览器拉起小程序,但是会失去在微信浏览器中拉起带有open标签的小程序的能力,并且不会享受云。开发短信发送跳转链接的能力。
如果你的目标小程序下有多个云开发环境,你不需要保证云功能和静态托管在同一个环境下,没关系。
比如你有两个环境A和B,A部署了上面的云功能,但是把index.html部署到B的静态托管环境中,这是没有问题的,满足各种能力的需求。只需确保第一步中index.html网页中的云开发环境配置为云功能所在的环境即可。
部署成功后就可以访问静态托管地址了,可以测试通过手机外部浏览器和微信内部浏览器打开小程序的能力。
5、SMS 发送云功能配置
在上面创建openMini云函数的环境中,还有一个云函数叫做sendms。
在这个云函数index.js中配置如下代码:
const cloud = require('wx-server-sdk')
cloud.init({
env: cloud.DYNAMIC_CURRENT_ENV,
})
exports.main = async (event, context) => {
try {
const config = {
env: event.env,
content: event.content ? event.content : '发布了短信跳转小程序的新能力',
path: event.path,
phoneNumberList: event.number
}
const result = await cloud.openapi.cloudbase.sendSms(config)
return result
} catch (err) {
return err
}
}
保存代码后,右键index.js,选择增量更新文件,更新成功。
6、测试短信发送能力
在小程序代码中,在app.js中初始化云开发后,调用云函数。示例代码如下:
App({
onLaunch: function () {
wx.cloud.init({
env:"tcb-env", //短信云函数所在环境ID
traceUser: true
})
wx.cloud.callFunction({
name:'sendsms',
data:{
"env": "tcb-env",//网页上传的静态托管的环境ID
"path":"/index.html",//上传的网页相对根目录的地址,如果是根目录则为/index.html
"number":[
"+8616599997777" //你要发送短信的目标手机,前面需要添加「+86」
]
},success(res){
console.log(res)
}
})
}
})
重新编译运行后,如果在控制台看到如下输出,则测试成功:
您会在发送的目标手机上收到一条短信,因为短信中收录“退订回复T”字段,可能会触发手机的自动拦截机制,需要在拦截短信中手动勾选.
注意:短信云函数和URLScheme云函数可以放置在不同的云开发环境中,但必须保证你放置的云开发环境属于你运行的小程序
另外,为了防止滥用,短信发送的云调用能力需要真正的小程序用户访问才能生效。不能使用云测试、云开发JS-SDK等非wx.cloud调用方式(微信端WEB-SDK除外),会提示如下错误:
如果想在其他地方使用这个能力,可以使用服务端API进行正常的HTTP调用,详情请访问官方文档。
7、查看短信监控图表
进入云开发控制台>运行分析>监控图表>短信监控,可以查看短信监控曲线和短信发送记录。
三、Summary 短信重定向小程序的核心是静态网站中配置的可重定向网页。外部浏览器实现了 URL Scheme。此方法不适用于微信浏览器,需要使用open标签。 URL Scheme的生成可以是云调用能力,需要在目标小程序的云开发环境的云功能中使用。并且生成的 URL Scheme 只能是自己小程序的打开链接,不能是任何小程序(任何与打开标签不一致的地方)。短信发送能力体验每个环境第一个月100条免费额度,超过额度可以去开发者工具-云开发控制台-对应的现收现付环境-资源包-短信资源打包购买。如果当前资源包不能满足需求,也可以通过云开发工单提交申请
SMS 发送也是一种云调用功能。需要真实小程序用户调用才能正常触发。其他方法报错并返回参数错误。为防止滥用,云功能和网页可以放置在不同的环境中。只要确保小程序属于同一个即可。 (需要保证对应的环境ID可以连接)如果不需要短信能力,可以忽略最后两步cms配置渠道投递,数据统计可以参考 查看全部
如何采用演示视频来学习短信跳转小程序的能力?
写在前面
如果你想独立开发,但没有云开发经验,可以使用演示视频学习本教程:
一、能力介绍
国内非个人主体认证小程序,开启静态网站后,可发出支持不认证跳转到对应小程序的短信。短信将收录一个静态网站 链接,可以在微信内或微信外打开。打开页面后,用户可以一键跳转到你的小程序。
链接的网页使用 URL Scheme 拉起微信在外部浏览器中打开主小程序。
简而言之,短信重定向能力的实现分为“配置拉起网页”和“发送短信”两步。本教程将介绍如何进行操作来完成短信重定向小程序的能力。
如果想不写代码也能完成短信重定向小程序,可以参考无代码版教程一步步实现。
二、操作指南1、网页制作
首先我们需要构建一个基本的 Web 应用程序,在任何代码编辑器中创建一个 html 文件,并在教程中将其命名为 index.html
在这个html文件中输入以下代码,根据注释替换自己的信息:
window.onload = function(){
window.web2weapp.init({
appId: 'wx999999', //替换为自己小程序的AppID
gh_ID: 'gh_999999',//替换为自己小程序的原始ID
env_ID: 'tcb-env',//替换小程序底下云开发环境ID
function: {
name:'openMini',//提供UrlScheme服务的云函数名称
data:{} //向这个云函数中传入的自定义参数
},
path: 'pages/index/index.html' //打开小程序时的路径
})
}
上面介绍的web2weapp.js文件是微信小程序拉取教程中封装的极简应用,我们直接引用即可轻松使用。
如果想进一步学习修改一些WEB显示信息,可以到github获取源码并进行修改。
关于启动小程序的网页的更多信息,请访问官方文档
如果您只想体验短信重定向功能,请在完成上述文件创建操作后,继续以下步骤。
2、创建服务云功能
在上面创建网页的过程中,需要填写一个UrlScheme服务云函数。该云函数主要用于调用微信服务器的能力,获取对应的Scheme信息并返回给调用前端。
我们在示例中填写了命名云函数openMini。
进入微信开发者工具,找到对应的云开发环境,创建一个名为openMini的云函数。
替换云函数目录下的index.js文件,输入如下代码:
const cloud = require('wx-server-sdk')
cloud.init()
exports.main = async (event, context) => {
return cloud.openapi.urlscheme.generate({
jumpWxa: {
path: '', // 打开小程序时访问路径,为空则会进入主页
query: '',// 可以使用 event 传入的数据制作特定参数,无需求则为空
},
isExpire: true, //是否到期失效,如果为true需要填写到期时间,默认false
expire_time: Math.round(new Date().getTime()/1000) + 3600
//我们设置为当前时间3600秒后,也就是1小时后失效
//无需求可以去掉这两个参数(isExpire,expire_time)
})
}
保存代码后,右键index.js,选择增量更新文件,更新成功。
接下来,我们需要启用对云功能的无日志访问。进入小程序云开发控制台,进入设置-权限设置,发现下面没有登录,选择我们前面步骤统一操作的云开发环境(注意:配置的云开发环境和云功能环境第一步,另外,这一步的运行环境一定要一样),勾选打开未登录
接下来进入云功能控制台,点击云功能权限,最后修改安全规则,在弹出框中配置如下:
3、local 测试
我们在本地浏览器中打开第一步创建的index.html;调出控制台,如果效果如下图,说明成功!需要注意的是,如果本地开启需要HTTP协议,建议使用live server等扩展开启。不要在资源管理器中直接打开浏览器,会有跨域问题!
4、上传本地创建的index.html到static网站hosting
将本地创建的index.html上传到静态网站托管,其中静态托管需要在小程序本身的云开发环境中进行静态托管。
如果上传到其他静态主机或服务器,仍然可以使用外部浏览器拉起小程序,但是会失去在微信浏览器中拉起带有open标签的小程序的能力,并且不会享受云。开发短信发送跳转链接的能力。
如果你的目标小程序下有多个云开发环境,你不需要保证云功能和静态托管在同一个环境下,没关系。
比如你有两个环境A和B,A部署了上面的云功能,但是把index.html部署到B的静态托管环境中,这是没有问题的,满足各种能力的需求。只需确保第一步中index.html网页中的云开发环境配置为云功能所在的环境即可。
部署成功后就可以访问静态托管地址了,可以测试通过手机外部浏览器和微信内部浏览器打开小程序的能力。
5、SMS 发送云功能配置
在上面创建openMini云函数的环境中,还有一个云函数叫做sendms。
在这个云函数index.js中配置如下代码:
const cloud = require('wx-server-sdk')
cloud.init({
env: cloud.DYNAMIC_CURRENT_ENV,
})
exports.main = async (event, context) => {
try {
const config = {
env: event.env,
content: event.content ? event.content : '发布了短信跳转小程序的新能力',
path: event.path,
phoneNumberList: event.number
}
const result = await cloud.openapi.cloudbase.sendSms(config)
return result
} catch (err) {
return err
}
}
保存代码后,右键index.js,选择增量更新文件,更新成功。
6、测试短信发送能力
在小程序代码中,在app.js中初始化云开发后,调用云函数。示例代码如下:
App({
onLaunch: function () {
wx.cloud.init({
env:"tcb-env", //短信云函数所在环境ID
traceUser: true
})
wx.cloud.callFunction({
name:'sendsms',
data:{
"env": "tcb-env",//网页上传的静态托管的环境ID
"path":"/index.html",//上传的网页相对根目录的地址,如果是根目录则为/index.html
"number":[
"+8616599997777" //你要发送短信的目标手机,前面需要添加「+86」
]
},success(res){
console.log(res)
}
})
}
})
重新编译运行后,如果在控制台看到如下输出,则测试成功:
您会在发送的目标手机上收到一条短信,因为短信中收录“退订回复T”字段,可能会触发手机的自动拦截机制,需要在拦截短信中手动勾选.
注意:短信云函数和URLScheme云函数可以放置在不同的云开发环境中,但必须保证你放置的云开发环境属于你运行的小程序
另外,为了防止滥用,短信发送的云调用能力需要真正的小程序用户访问才能生效。不能使用云测试、云开发JS-SDK等非wx.cloud调用方式(微信端WEB-SDK除外),会提示如下错误:
如果想在其他地方使用这个能力,可以使用服务端API进行正常的HTTP调用,详情请访问官方文档。
7、查看短信监控图表
进入云开发控制台>运行分析>监控图表>短信监控,可以查看短信监控曲线和短信发送记录。
三、Summary 短信重定向小程序的核心是静态网站中配置的可重定向网页。外部浏览器实现了 URL Scheme。此方法不适用于微信浏览器,需要使用open标签。 URL Scheme的生成可以是云调用能力,需要在目标小程序的云开发环境的云功能中使用。并且生成的 URL Scheme 只能是自己小程序的打开链接,不能是任何小程序(任何与打开标签不一致的地方)。短信发送能力体验每个环境第一个月100条免费额度,超过额度可以去开发者工具-云开发控制台-对应的现收现付环境-资源包-短信资源打包购买。如果当前资源包不能满足需求,也可以通过云开发工单提交申请
SMS 发送也是一种云调用功能。需要真实小程序用户调用才能正常触发。其他方法报错并返回参数错误。为防止滥用,云功能和网页可以放置在不同的环境中。只要确保小程序属于同一个即可。 (需要保证对应的环境ID可以连接)如果不需要短信能力,可以忽略最后两步cms配置渠道投递,数据统计可以参考
如何对网页进行爬取?(一)的使用
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-07-20 19:14
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
部分网站内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。例如,今天的头条新闻:
HTML 源代码
网页上的新闻在HTML源代码中找不到,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页?有两种方式:
1、从网页响应中查找JS脚本返回的JSON数据; 2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例说明:
1、找到JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”标签后,我们发现有很多回复。让我们过滤它们,只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,即 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
原来都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到想要的消息,所以再找一下:
有个焦点,我们点一下看看:
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看的是正常编码的数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求并解析数据接口数据
先上传完整代码:
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
# print news
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(json.dumps(title).decode("unicode-escape"))
print img_url 查看全部
如何对网页进行爬取?(一)的使用
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
部分网站内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。例如,今天的头条新闻:
HTML 源代码
网页上的新闻在HTML源代码中找不到,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页?有两种方式:
1、从网页响应中查找JS脚本返回的JSON数据; 2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例说明:
1、找到JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”标签后,我们发现有很多回复。让我们过滤它们,只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,即 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
原来都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到想要的消息,所以再找一下:
有个焦点,我们点一下看看:
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看的是正常编码的数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求并解析数据接口数据
先上传完整代码:
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
# print news
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(json.dumps(title).decode("unicode-escape"))
print img_url
java调用元素内容的动态变化及解决方案使用+PhantomJS
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-07-19 04:24
前言
现在很多网站 使用 JavaScript 或 Ajax 技术。这样,网页加载后,虽然url没有变化,但是网页的DOM元素的内容可以动态变化。如果使用python自带的requests库或urllib库处理此类网页,获取的网页内容与浏览器中网页显示的内容不一致。
解决方案
使用 Selenium+PhantomJS。这两者一起可以运行一个非常强大的爬虫,它可以处理 cookie、JavaScript、标头和任何你想做的事情。
安装第三方库
Selenium 是一个强大的网络数据采集工具,最初是为网站自动化测试开发的,它有相应的Python库;
Selenium 安装命令:
pip install selenium
安装 PhantomJS
PhantomJS 是一个基于 webkit 内核的无头浏览器,即它没有 UI 界面,即是一个浏览器,但是点击、翻页等与人相关的操作需要通过编程来实现。通过编写js程序,可以直接与webkit内核交互,在此基础上还可以结合java语言等,通过java调用js等相关操作。需要到官网下载对应平台的压缩文件;
PhantomJS(phantomjs-2.1.1-windows)下载地址:根据不同系统选择对应版本
windows系统下载PhantomJs,将解压后的可执行文件放在环境变量设置好的地方。如果不设置,后面的代码会设置,所以直接放在这里很方便;
然后勾选,在cmd窗口输入phantomjs:
如果出现这样的画面,则表示成功;
对于Mac系统,下载保存到某个路径后,可以直接保存在环境改变的路径中,也可以在环境变量路径中创建一个phantomjs的软链接
ln -s /usr/local/opt/my/phantomjs-2.1.1-macosx/bin/phantomjs /usr/local/bin
测试代码:
from selenium import webdriver
<p>driver = webdriver.PhantomJS()
driver.get('http://www.baidu.com/')
print (driver.page_source)</p>
如果能成功获取到页面元素,则说明安装成功。
示例 1:
Selenium+PhantomJS 示例代码:
from selenium import webdriver
<p>driver = webdriver.PhantomJS()
driver.get('http://www.cnblogs.com/feng0815/p/8735491.html')
#获取网页源码
data = driver.page_source
print(data)
#获取元素的html源码
tableData = driver.find_elements_by_tag_name('tableData').get_attribute('innerHTML')
#获取元素的id值
tableI = driver.find_elements_by_tag_name('tableData').get_attribute('id')
#获取元素的文本内容
tableI = driver.find_elements_by_tag_name('tableData').text
driver.quit()</p>
可以输出网页源码,说明安装成功
获取JS返回值
查看全部
java调用元素内容的动态变化及解决方案使用+PhantomJS
前言
现在很多网站 使用 JavaScript 或 Ajax 技术。这样,网页加载后,虽然url没有变化,但是网页的DOM元素的内容可以动态变化。如果使用python自带的requests库或urllib库处理此类网页,获取的网页内容与浏览器中网页显示的内容不一致。
解决方案
使用 Selenium+PhantomJS。这两者一起可以运行一个非常强大的爬虫,它可以处理 cookie、JavaScript、标头和任何你想做的事情。
安装第三方库
Selenium 是一个强大的网络数据采集工具,最初是为网站自动化测试开发的,它有相应的Python库;
Selenium 安装命令:
pip install selenium
安装 PhantomJS
PhantomJS 是一个基于 webkit 内核的无头浏览器,即它没有 UI 界面,即是一个浏览器,但是点击、翻页等与人相关的操作需要通过编程来实现。通过编写js程序,可以直接与webkit内核交互,在此基础上还可以结合java语言等,通过java调用js等相关操作。需要到官网下载对应平台的压缩文件;
PhantomJS(phantomjs-2.1.1-windows)下载地址:根据不同系统选择对应版本
windows系统下载PhantomJs,将解压后的可执行文件放在环境变量设置好的地方。如果不设置,后面的代码会设置,所以直接放在这里很方便;

然后勾选,在cmd窗口输入phantomjs:

如果出现这样的画面,则表示成功;
对于Mac系统,下载保存到某个路径后,可以直接保存在环境改变的路径中,也可以在环境变量路径中创建一个phantomjs的软链接
ln -s /usr/local/opt/my/phantomjs-2.1.1-macosx/bin/phantomjs /usr/local/bin
测试代码:
from selenium import webdriver
<p>driver = webdriver.PhantomJS()
driver.get('http://www.baidu.com/')
print (driver.page_source)</p>
如果能成功获取到页面元素,则说明安装成功。
示例 1:
Selenium+PhantomJS 示例代码:

from selenium import webdriver
<p>driver = webdriver.PhantomJS()
driver.get('http://www.cnblogs.com/feng0815/p/8735491.html')
#获取网页源码
data = driver.page_source
print(data)
#获取元素的html源码
tableData = driver.find_elements_by_tag_name('tableData').get_attribute('innerHTML')
#获取元素的id值
tableI = driver.find_elements_by_tag_name('tableData').get_attribute('id')
#获取元素的文本内容
tableI = driver.find_elements_by_tag_name('tableData').text
driver.quit()</p>
可以输出网页源码,说明安装成功
获取JS返回值
Python中的网络爬虫库获取网页的示例程序是什么?
网站优化 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-07-13 21:17
1 什么是网络爬虫
网络爬虫是指从网站中提取数据的技术,可以将非结构化数据转化为结构化数据。
网络爬虫的目的是从网站中提取数据。提取的数据可以存储在本地文件中并保存在系统中,也可以以表格的形式存储在数据库中。网络爬虫使用 HTTP 或网络浏览器直接访问万维网 (WWW)。网络爬虫或机器人抓取网页的过程是一个自动化过程。
抓取网页的过程分为网页获取和数据提取。网络爬虫可以抓取网页,是网络爬虫的必备组件。获取网页后,需要提取网页数据。我们可以对提取的数据进行搜索、解析,并将其保存在表格中,然后重新排列格式。
2 数据提取
在本节中,我们将了解数据提取。我们可以使用 Python 的 BeautifulSoup 库进行数据提取。这里还需要 Python 库的 Requests 模块。
运行以下命令来安装 Requests 和 BeautifulSoup 库。
$ pip3 install requests
$ pip3 install beautifulsoup4
2.1Requests 库
使用请求库以易于理解的格式在 Python 脚本中使用 HTTP。在这里,使用 Python 中的 Requests 库来获取网页。 Requests 库收录不同类型的请求,这里使用 GET 请求。 GET请求用于从Web服务器获取信息,通过GET请求可以获取指定网页的HTML内容。每个请求对应一个状态码,从服务器返回。这些状态码为我们提供了相应请求执行结果的相关信息。以下是一些状态代码。
2.2BeautifulSoup 库
BeautifulSoup 也是一个 Python 库,收录简单的搜索、导航和修改方法。它只是一个从网页中提取所需数据的工具包。
要在脚本中使用 Requests 和 BeautifulSoup 模块,必须使用 import 语句导入这两个模块。现在让我们看一个用于解析网页的示例程序。在这里,我们将解析来自百度网站 的新闻网页。创建一个脚本,命名为parse_web_page.py,在里面写入如下代码。
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
print(parse_obj)
运行如下所示的脚本程序。
student@ubuntu:~/work$ python3 parse_web_page.py
Output:
var IMDbTimer={starttime: new
Date().getTime(),pt:'java'};
if (typeof uet == 'function') {
uet("bb", "LoadTitle", {wb: 1});
}
(function(t){ (t.events = t.events || {})["csm_head_pre_title"] =
new Date().getTime(); })(IMDbTimer);
Top News - IMDb
(function(t){ (t.events = t.events || {})["csm_head_post_title"] =
new Date().getTime(); })(IMDbTimer);
if (typeof uet == 'function') {
uet("be", "LoadTitle", {wb: 1});
}
if (typeof uex == 'function') {
uex("ld", "LoadTitle", {wb: 1});
}
if (typeof uet == 'function') {
uet("bb", "LoadIcons", {wb: 1});
}
上面的示例程序抓取了一个网页并使用 BeautifulSoup 对其进行了解析。首先导入requests和BeautifulSoup模块,然后使用GET请求访问URL,并将结果赋值给page_result变量,然后创建一个BeautifulSoup对象parse_obj,将requests page_result.content的返回结果作为参数,然后用 html.parser 解析了这个页面。
现在我们将从类和标签中提取数据。进入网页浏览器,右击要提取的内容向下搜索,找到“勾选”选项,点击获取类名。在程序中指定这个类名并运行脚本。创建一个脚本,将其命名为extract_from_class.py,并在其中写入以下代码。
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
top_news = parse_obj.find(class_='news-article__content')
print(top_news)
运行如下所示的脚本程序。
student@ubuntu:~/work$ python3 extract_from_class.py
Output :
Issa Rae and Laura Dern are teaming up to star in a limited
series called "The Dolls" currently in development at HBO.Inspired by true events, the
series recounts the aftermath of Christmas Eve riots in two small Arkansas
towns in 1983, riots which erupted over Cabbage Patch Dolls. The series
explores class, race, privilege and what it takes to be a "good
mother."Rae will serve as a writer and executive producer on the
series in addition to starring, with Dern also executive producing. Laura Kittrell and Amy Aniobi will also serve as writers and coexecutive
producers. Jayme Lemons of Dern’s
Jaywalker Pictures and Deniese Davis of Issa Rae Productions will also executive
produce.Both Rae and Dern currently star in HBO shows, with Dern
appearing in the acclaimed drama "Big Little
Lies" and Rae starring in and having created the hit comedy "Insecure." Dern also recently starred in the
film "The Tale,
上面的示例程序首先导入 requests 和 BeautifulSoup 模块,然后创建一个 requests 对象并为其分配一个 URL,然后创建一个 BeautifulSoup 对象 parse_obj。该对象以请求的返回结果 page_result.content 为参数,然后使用 html.parser 解析页面。最后,使用 BeautifulSoup 的 find() 方法从 news-article__content 类中获取内容。
现在让我们看一个从特定标签中提取数据的示例程序。此示例程序将从标签中提取数据。创建一个脚本,将其命名为extract_from_tag.py,并在其中写入以下代码。
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com/news')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
top_news = parse_obj.find(class_='news-article__content')
top_news_a_content = top_news.find_all('a')
print(top_news_a_content)
运行如下所示的脚本程序。
student@ubuntu:~/work$ python3 extract_from_tag.py
Output:
[Issa Rae, Laura
Dern, HBO, Laura Kittrell, Amy
Aniobi, Jayme Lemons, Jaywalker Pictures, Deniese Davis, Issa Rae Productions, Big Little Lies, Insecure, The
Tale]
上面的示例程序从标签中提取数据。这里我们使用 find_all() 方法从 news-article__content 类中提取所有标签数据。
3 从 Wikipedia网站 获取信息
在本节中,我们将学习一个示例程序,用于从维基百科网站 获取舞蹈类型列表。在这里,我们将列出所有经典的印度舞蹈。创建一个脚本,将其命名为extract_from_wikipedia.py,并在其中写入以下代码。
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://en.wikipedia.org/wiki/Portal:History')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
h_obj = parse_obj.find(class_='hlist noprint')
h_obj_a_content = h_obj.find_all('a')
print(h_obj)
print(h_obj_a_content)
运行脚本程序如下所示。
student@ubuntu:~/work$ python3 extract_from_wikipedia.py
输出如下。
Portal topics
Activities
Culture
Geography
Health
History
Mathematics
Nature
People
In the preceding example, we extracted the content from Wikipedia. In this
example also, we extracted the content from class as well as tag.
.... 查看全部
Python中的网络爬虫库获取网页的示例程序是什么?
1 什么是网络爬虫
网络爬虫是指从网站中提取数据的技术,可以将非结构化数据转化为结构化数据。
网络爬虫的目的是从网站中提取数据。提取的数据可以存储在本地文件中并保存在系统中,也可以以表格的形式存储在数据库中。网络爬虫使用 HTTP 或网络浏览器直接访问万维网 (WWW)。网络爬虫或机器人抓取网页的过程是一个自动化过程。
抓取网页的过程分为网页获取和数据提取。网络爬虫可以抓取网页,是网络爬虫的必备组件。获取网页后,需要提取网页数据。我们可以对提取的数据进行搜索、解析,并将其保存在表格中,然后重新排列格式。
2 数据提取
在本节中,我们将了解数据提取。我们可以使用 Python 的 BeautifulSoup 库进行数据提取。这里还需要 Python 库的 Requests 模块。
运行以下命令来安装 Requests 和 BeautifulSoup 库。
$ pip3 install requests
$ pip3 install beautifulsoup4
2.1Requests 库
使用请求库以易于理解的格式在 Python 脚本中使用 HTTP。在这里,使用 Python 中的 Requests 库来获取网页。 Requests 库收录不同类型的请求,这里使用 GET 请求。 GET请求用于从Web服务器获取信息,通过GET请求可以获取指定网页的HTML内容。每个请求对应一个状态码,从服务器返回。这些状态码为我们提供了相应请求执行结果的相关信息。以下是一些状态代码。
2.2BeautifulSoup 库
BeautifulSoup 也是一个 Python 库,收录简单的搜索、导航和修改方法。它只是一个从网页中提取所需数据的工具包。
要在脚本中使用 Requests 和 BeautifulSoup 模块,必须使用 import 语句导入这两个模块。现在让我们看一个用于解析网页的示例程序。在这里,我们将解析来自百度网站 的新闻网页。创建一个脚本,命名为parse_web_page.py,在里面写入如下代码。
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
print(parse_obj)
运行如下所示的脚本程序。
student@ubuntu:~/work$ python3 parse_web_page.py
Output:
var IMDbTimer={starttime: new
Date().getTime(),pt:'java'};
if (typeof uet == 'function') {
uet("bb", "LoadTitle", {wb: 1});
}
(function(t){ (t.events = t.events || {})["csm_head_pre_title"] =
new Date().getTime(); })(IMDbTimer);
Top News - IMDb
(function(t){ (t.events = t.events || {})["csm_head_post_title"] =
new Date().getTime(); })(IMDbTimer);
if (typeof uet == 'function') {
uet("be", "LoadTitle", {wb: 1});
}
if (typeof uex == 'function') {
uex("ld", "LoadTitle", {wb: 1});
}
if (typeof uet == 'function') {
uet("bb", "LoadIcons", {wb: 1});
}
上面的示例程序抓取了一个网页并使用 BeautifulSoup 对其进行了解析。首先导入requests和BeautifulSoup模块,然后使用GET请求访问URL,并将结果赋值给page_result变量,然后创建一个BeautifulSoup对象parse_obj,将requests page_result.content的返回结果作为参数,然后用 html.parser 解析了这个页面。
现在我们将从类和标签中提取数据。进入网页浏览器,右击要提取的内容向下搜索,找到“勾选”选项,点击获取类名。在程序中指定这个类名并运行脚本。创建一个脚本,将其命名为extract_from_class.py,并在其中写入以下代码。
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
top_news = parse_obj.find(class_='news-article__content')
print(top_news)
运行如下所示的脚本程序。
student@ubuntu:~/work$ python3 extract_from_class.py
Output :
Issa Rae and Laura Dern are teaming up to star in a limited
series called "The Dolls" currently in development at HBO.Inspired by true events, the
series recounts the aftermath of Christmas Eve riots in two small Arkansas
towns in 1983, riots which erupted over Cabbage Patch Dolls. The series
explores class, race, privilege and what it takes to be a "good
mother."Rae will serve as a writer and executive producer on the
series in addition to starring, with Dern also executive producing. Laura Kittrell and Amy Aniobi will also serve as writers and coexecutive
producers. Jayme Lemons of Dern’s
Jaywalker Pictures and Deniese Davis of Issa Rae Productions will also executive
produce.Both Rae and Dern currently star in HBO shows, with Dern
appearing in the acclaimed drama "Big Little
Lies" and Rae starring in and having created the hit comedy "Insecure." Dern also recently starred in the
film "The Tale,
上面的示例程序首先导入 requests 和 BeautifulSoup 模块,然后创建一个 requests 对象并为其分配一个 URL,然后创建一个 BeautifulSoup 对象 parse_obj。该对象以请求的返回结果 page_result.content 为参数,然后使用 html.parser 解析页面。最后,使用 BeautifulSoup 的 find() 方法从 news-article__content 类中获取内容。
现在让我们看一个从特定标签中提取数据的示例程序。此示例程序将从标签中提取数据。创建一个脚本,将其命名为extract_from_tag.py,并在其中写入以下代码。
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com/news')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
top_news = parse_obj.find(class_='news-article__content')
top_news_a_content = top_news.find_all('a')
print(top_news_a_content)
运行如下所示的脚本程序。
student@ubuntu:~/work$ python3 extract_from_tag.py
Output:
[Issa Rae, Laura
Dern, HBO, Laura Kittrell, Amy
Aniobi, Jayme Lemons, Jaywalker Pictures, Deniese Davis, Issa Rae Productions, Big Little Lies, Insecure, The
Tale]
上面的示例程序从标签中提取数据。这里我们使用 find_all() 方法从 news-article__content 类中提取所有标签数据。
3 从 Wikipedia网站 获取信息
在本节中,我们将学习一个示例程序,用于从维基百科网站 获取舞蹈类型列表。在这里,我们将列出所有经典的印度舞蹈。创建一个脚本,将其命名为extract_from_wikipedia.py,并在其中写入以下代码。
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://en.wikipedia.org/wiki/Portal:History')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
h_obj = parse_obj.find(class_='hlist noprint')
h_obj_a_content = h_obj.find_all('a')
print(h_obj)
print(h_obj_a_content)
运行脚本程序如下所示。
student@ubuntu:~/work$ python3 extract_from_wikipedia.py
输出如下。
Portal topics
Activities
Culture
Geography
Health
History
Mathematics
Nature
People
In the preceding example, we extracted the content from Wikipedia. In this
example also, we extracted the content from class as well as tag.
....
web.jpegJS的语法和基本对象的规范(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-07-12 20:13
web.jpegJS的语法和基本对象的规范(组图)
web.jpeg
JS 由三部分组成
ECMAscript(欧洲计算机制造商协会):描述 JS 语法和基本对象规范
DOM:处理网页(操作页面元素)的文档对象模型、方法和接口
BOM:浏览器对象模型、浏览器交互方法和界面(操作浏览器)
JS 操作 html 元素其实就是操作 DOM 文档对象。整个html文件就是一个文档。那么这个文档就被认为是一个文档对象。文档中的所有标签都可以看作一个对象。那么JS是如何操作的呢?对象呢?
1.JS 获取元素对象的方法
1. 1 根据id从整个文档中获取元素---返回的是一个元素对象
document.getElementById("id 属性值")
/*
在JS中
getElementById(元素的ID)获取元素对象
*/
//获取元素对象
var box = document.getElementById("box");
//向元素对象注册点击事件
box.onclick = function(){
this.style.backgroundColor = "红色";
//设置div里面的内容
box.innerHTML = "
这是h2标签";
}
图像.png
1.2.根据标签名称获取元素-----返回的是元素对象组成的伪数组
document.getElementsByTagName("标签名称");
1.3 这是几个兼容的访问元素
1. 根据name属性的值获取元素,返回的是一个伪数组,里面存放了多个DOM对象---> ocument.getElementsByName("name属性的值")
2. 根据类样式的名称获取元素,返回的是一个伪数组,里面存放了多个DOM对象 -->document.getElementsByClassName("类样式的名称")
3.根据选择器获取元素,返回的是一个元素对象-->document.querySelector("选择器的名字")
4.根据选择器获取元素,返回的是一个伪数组,里面存放了多个DOM对象---->document.querySelectorAll("选择器的名字")
通过JS获取元素对象的目的是修改css样式或者它们之间的交互,那么如何改变样式属性呢?
图像.png
<p>从上面的例子可以看出,如果标签有直接属性,只需要对基本标签的属性进行操作,如:src、title、alt、href、id属性、直接操作赋值 查看全部
web.jpegJS的语法和基本对象的规范(组图)
web.jpeg
JS 由三部分组成
ECMAscript(欧洲计算机制造商协会):描述 JS 语法和基本对象规范
DOM:处理网页(操作页面元素)的文档对象模型、方法和接口
BOM:浏览器对象模型、浏览器交互方法和界面(操作浏览器)
JS 操作 html 元素其实就是操作 DOM 文档对象。整个html文件就是一个文档。那么这个文档就被认为是一个文档对象。文档中的所有标签都可以看作一个对象。那么JS是如何操作的呢?对象呢?
1.JS 获取元素对象的方法
1. 1 根据id从整个文档中获取元素---返回的是一个元素对象
document.getElementById("id 属性值")
/*
在JS中
getElementById(元素的ID)获取元素对象
*/
//获取元素对象
var box = document.getElementById("box");
//向元素对象注册点击事件
box.onclick = function(){
this.style.backgroundColor = "红色";
//设置div里面的内容
box.innerHTML = "
这是h2标签";
}
图像.png
1.2.根据标签名称获取元素-----返回的是元素对象组成的伪数组
document.getElementsByTagName("标签名称");
1.3 这是几个兼容的访问元素
1. 根据name属性的值获取元素,返回的是一个伪数组,里面存放了多个DOM对象---> ocument.getElementsByName("name属性的值")
2. 根据类样式的名称获取元素,返回的是一个伪数组,里面存放了多个DOM对象 -->document.getElementsByClassName("类样式的名称")
3.根据选择器获取元素,返回的是一个元素对象-->document.querySelector("选择器的名字")
4.根据选择器获取元素,返回的是一个伪数组,里面存放了多个DOM对象---->document.querySelectorAll("选择器的名字")
通过JS获取元素对象的目的是修改css样式或者它们之间的交互,那么如何改变样式属性呢?
图像.png
<p>从上面的例子可以看出,如果标签有直接属性,只需要对基本标签的属性进行操作,如:src、title、alt、href、id属性、直接操作赋值
js提取指定网站内容,一般可以使用urllib、正则表达式等方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-07-11 19:01
js提取指定网站内容,一般可以使用urllib、正则表达式等方法。了解更多可以参考下面这个ppt:我在v2ex发过的内容提取的文章。whatisrequests?-segmentfault欢迎访问我的v2ex发现更多的干货。欢迎加我的个人微信交流wechat:fengxzhanyuan或者加入qq群:61346555交流讨论。
python2.5提供了get和post两种网页请求库,post方法还可以对图片进行提取。一.本篇教程,主要讲解post方法如何使用图片。1.明确库library(urllib2)#官方库library(fwflib)#官方库library(getips)#官方库library(base64urllib)#官方库library(phthonglib)#官方库library(mapbox)#官方库2.getimage如何使用图片库主要包括下面几个步骤1.导入库2.安装库3.自定义一个数据结构1.导入库importurllib2importfwflib2.安装库importphthongliburllib2.install_urllib2()3.自定义一个数据结构#。 查看全部
js提取指定网站内容,一般可以使用urllib、正则表达式等方法
js提取指定网站内容,一般可以使用urllib、正则表达式等方法。了解更多可以参考下面这个ppt:我在v2ex发过的内容提取的文章。whatisrequests?-segmentfault欢迎访问我的v2ex发现更多的干货。欢迎加我的个人微信交流wechat:fengxzhanyuan或者加入qq群:61346555交流讨论。
python2.5提供了get和post两种网页请求库,post方法还可以对图片进行提取。一.本篇教程,主要讲解post方法如何使用图片。1.明确库library(urllib2)#官方库library(fwflib)#官方库library(getips)#官方库library(base64urllib)#官方库library(phthonglib)#官方库library(mapbox)#官方库2.getimage如何使用图片库主要包括下面几个步骤1.导入库2.安装库3.自定义一个数据结构1.导入库importurllib2importfwflib2.安装库importphthongliburllib2.install_urllib2()3.自定义一个数据结构#。
【知识点】DOM和HTML树的定义和操作流程
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-07-10 00:08
内容
DOM 的定义
DOM 树
DOM树的定义
为什么是树状结构
根节点
节点对象
节点的三个属性
DOM 操作流程
DOM 查找
无需查找可以直接获取的元素
通过 HTML 搜索
按节点关系搜索
按选择器查找
遍历节点
DOM 搜索摘要
编辑
内容
属性
风格
添加
删除
替换
HTML DOM 常用对象
图片
选择
选项
表格
表格
DOM 的定义
用于操作 Web 内容的文档对象模型 API 标准-W3C
什么时候使用DOM
只要操作网页内容,就必须使用DOM提供的API
DOM 的分类
核心 DOM 和 HTML DOM
Core DOM:最初开发用于操作所有结构化文档的统一 API。优点:通用缺点:繁琐
HTML DOM:专门用于操作 HTML 文档的 API 优点:简洁缺点:不是万能的
总结:在实际开发中,不需要区分核心DOM和HTM LDOM。首选简单的 API。如果不能简单实现,就用复杂的补充
DOM 树
DOM树的定义
网页中的每一个内容都以树状结构存储在内存中,每一个内容(元素、文本、属性)都是树上的一个节点对象
为什么是树状结构
树结构是保存不确定层次深度的下级和下级收录关系的最佳结构
根节点
树结构有一个唯一的树根节点:文档节点。所有网页内容都是文档的子节点
节点对象
网页中的每一项都是一个节点对象,它封装了节点可用的属性和功能
节点的三个属性
nodeType:节点类型 nodeName:节点名称 nodeValue:节点值
节点类型:
功能:不同类型节点的可用属性和可执行操作不同。
包括4种类型:
文档 9
元素 1
属性 2
文本 3
问题:无法进一步区分特定元素名称
节点名称:
功能:进一步区分具体元素名称
包括4种类型:
文档#document
元素标签名称(全部大写)
attribute 属性名称
文本#文本
节点值:
功能:保存节点的值
包括4种类型:
文档为空
元素为空
attribute 属性值
文字文字内容
DOM 操作流程
增删改查+事件处理
找到触发事件的元素---->>绑定事件处理程序
找到要修改的元素---->>修改属性/样式,添加、删除
DOM 查找
1、无需寻找可以直接获取的元素
html document.documentElement
头文件.head
body document.body
2、HTML 搜索
1、通过id查找
var elem = document.getElementById("id"); //直接写id名称
强调:1、 必须与文档一起调用2、 只会返回一个元素
2、按标签名查找多个元素
var elems = document.getElementsByTagName("标签名");
重点:
1、可以在任何父元素上调用,即只查找当前父元素下的后代元素
2、不仅可以找到直接子元素,还可以找到所有后代元素
3、返回由多个元素组成的动态集合
3、按类属性搜索
var elems = document.getElementsByClassName("class");
重点:
1、 可以在任何父元素上调用
2、返回由多个元素组成的动态集合
3、只要收录指定的类名,选择要更改的元素。它不必完全匹配
4、不仅可以找到直接子元素,还可以找到所有后代元素
4、按名称属性搜索
var elems = document.getElementsByName("name");
name 属性只会在查找带有 name 属性的表单时使用
重点:
1、 只能用文档调用
2、返回由多个元素组成的动态集合
3、按节点关系搜索
何时使用:如果你已经获取了一个元素,你想找到周围的元素
1、父子关系
child.parentNode 获取节点的父节点
parent.childNodes 获取父节点下的所有直接子节点
parent.firstChild 获取父节点下的第一个子节点
parent.lastChild 获取父节点下的最后一个直接子节点
2、兄弟关系
elem.nextSibling 获取节点旁边的下一个兄弟节点
elem.previousSibling 获取与某个节点相邻的前一个兄弟节点
问题:我会被看不见的空字符打扰
解决方案:元素树
元素树:仅收录元素节点的树结构。元素树不是新树,只是节点树的部分子集
如何实现:
1、父子关系
child.parentElement 获取节点的父元素
parent.children 获取父元素下的所有直接子元素
parent.firstElementChild 获取父元素下的第一个直接子元素
parent.lastElementChild 获取父元素下的最后一个直接子元素
2、兄弟关系
elem.nextElementSibling 获取与元素相邻的下一个兄弟元素
elem.previousElementSibling 获取与元素相邻的前一个兄弟元素
4、通过选择器查找
1、只查找一个元素
var elem = parent.querySelector("selector");
2、查找多个元素
var elem = parent.querySelectorAll("selector");
重点:
1、 可以在任何父元素上调用
2、返回一个非动态集合(非动态集合:数据的实际存储,即重复访问,不会造成重复搜索DOM树)无首缓存长度的遍历
3、以当前浏览器的兼容性要求为准
5、traverse 节点
遍历节点定义:找到一个父元素下的所有后代节点
如何:
1、定义只遍历直接子节点的函数
2、 为遇到的每个子节点调用与父节点完全相同的操作
算法:深度优先(当同时有子元素和兄弟元素时,总是先遍历子元素。遍历完子元素后,返回兄弟元素)
问题:递归执行效率极低
解决方案:改用循环
操作方法:使用节点迭代器对象(NodeIterator专门按照深度优先遍历的顺序依次访问每个子元素的对象)
1、Create NodeIterator
var iterator = documnet.createNodeIterator(parent,NodeFilter.SHOW_ALL,null,false,SHOW_ELEMENT);
参数:
parent:树中要用作搜索起点的节点
NodeFilter.SHOW_ALL:显示所有类型的节点
NodeFilter.SHOW_ELEMENT:显示元素节点
NodeFilter.SHOW_TEXT:显示文本节点
NodeFilter.SHOW_COMMENT:显示评论节点
NodeFilter.SHOW_DOCUMENT:显示文档节点
2、循环调用NodeIterator的nextNode()函数
NodeIterator 的主要方法是 nextNode() 和 previousNode()
如何:
1.,返回当前节点
2.,跳转到下一个节点返回null退出
例如:
HTML 的结构:
你好
世界
遍历root下的所有元素:
var iterator = document.createNodeIterator(root, NodeFilter.SHOW_ELEMENT, null, false);
var node = iterator.nextNode();
while(节点 !== null){
console.log( node.tagName );
node = iterator.nextNode();
}
遍历root下的所有p个元素:
var filter = function(node){
返回 node.tagName.toLowerCase() =='p' ?
NodeFilter.FILTER_ACCEPT:
NodeFilter.FILTER_REJECT;
}
var iterator = document.createNodeIterator(root, NodeFilter.SHOW_ELEMENT, filter, false);
var node = iterator.nextNode();
while(节点 !== null){
console.log( node.tagName );
node = iterator.nextNode();
}
DOM 搜索摘要
1.如果已经获取到一个元素,则查找周围的元素:利用节点之间的关系来查找
2.如果传入一个条件,就可以找到你想要的元素:使用HTML搜索
3.如果搜索条件复杂:使用选择器API
按 HTML 与选择器
1.返回值:通过HTML搜索:返回动态集合
按选择器搜索:返回非动态集合
2.效率:第一次搜索通过HTML高效!
按选择器搜索有点慢!
3. 好用:按选择器搜索更简洁
HTML 搜索比较麻烦
编辑
1、content
.innerHTML .textContent .value
2、Attributes
标准属性:HTML 标准中规定的属性
1、Core DOM(4 个 API)
1、获取指定属性的值:
elem.getAttribute("属性名称")
2、修改指定属性的值:
elem.setAttribute("属性名", "值")
3、判断是否收录指定的属性:
elem.hasAttribute("属性名称")
4、去掉指定的属性:
elem.removeAttribute("属性名称")
2、HTML DOM:所有标准属性都预先封装在元素对象中,可以直接用“.”访问
1、获取指定属性的值:
elem.属性名称
2、修改指定属性的值:
elem.attribute name = "value"
3、判断是否收录指定的属性:
元素。属性名! ==""
4、去掉指定的属性:
elem.attribute name = ""
3、clas 属性
Class 是 E5 中的保留字,不能使用 DOM。使用 className 而不是 class
4、Status 属性
禁用选中选中
不能用核心 DOM 访问,只能用 HTML DOM 访问。值都是bool类型
5、自定义扩展属性(不能用HTML DOM访问自定义扩展属性)
1、核心DOM
2、HTML5:
定义属性:data-attribute name = "value"
访问:elem.dataset。属性名
3、style
1、内联
1、编辑:
elem.style.css 属性名称
css属性名必须从横线改成驼峰。优点:最高优先级,只有当前元素有自己的
2、阅读:
不能使用 style.css 属性名称。因为style只能获取内联样式,不能获取样式表中继承/级联的样式
解决方案:
以后,无论何时阅读一个样式,都必须阅读计算出的样式。 (计算样式:最终应用于元素的所有样式的合成,相对单位计算为绝对单位)
1、计算后得到所有css属性的总和:样式对象
var style = getComputedStyle(elem)
2、从样式中获取想要的css属性
style.css 属性
注意:计算出的样式是只读的,不能修改
问题:一句话只能修改一个css属性
解决方法:如何批量修改一个元素的多个属性:
1、先在css中定义多个属性为一个类
2、修改JS中元素的className为指定类
添加
1、创建一个新的空元素
var a = document.createElement("a");
2、设置密钥属性 查看全部
【知识点】DOM和HTML树的定义和操作流程
内容
DOM 的定义
DOM 树
DOM树的定义
为什么是树状结构
根节点
节点对象
节点的三个属性
DOM 操作流程
DOM 查找
无需查找可以直接获取的元素
通过 HTML 搜索
按节点关系搜索
按选择器查找
遍历节点
DOM 搜索摘要
编辑
内容
属性
风格
添加
删除
替换
HTML DOM 常用对象
图片
选择
选项
表格
表格
DOM 的定义
用于操作 Web 内容的文档对象模型 API 标准-W3C
什么时候使用DOM
只要操作网页内容,就必须使用DOM提供的API
DOM 的分类
核心 DOM 和 HTML DOM
Core DOM:最初开发用于操作所有结构化文档的统一 API。优点:通用缺点:繁琐
HTML DOM:专门用于操作 HTML 文档的 API 优点:简洁缺点:不是万能的
总结:在实际开发中,不需要区分核心DOM和HTM LDOM。首选简单的 API。如果不能简单实现,就用复杂的补充
DOM 树
DOM树的定义
网页中的每一个内容都以树状结构存储在内存中,每一个内容(元素、文本、属性)都是树上的一个节点对象
为什么是树状结构
树结构是保存不确定层次深度的下级和下级收录关系的最佳结构
根节点
树结构有一个唯一的树根节点:文档节点。所有网页内容都是文档的子节点
节点对象
网页中的每一项都是一个节点对象,它封装了节点可用的属性和功能
节点的三个属性
nodeType:节点类型 nodeName:节点名称 nodeValue:节点值
节点类型:
功能:不同类型节点的可用属性和可执行操作不同。
包括4种类型:
文档 9
元素 1
属性 2
文本 3
问题:无法进一步区分特定元素名称
节点名称:
功能:进一步区分具体元素名称
包括4种类型:
文档#document
元素标签名称(全部大写)
attribute 属性名称
文本#文本
节点值:
功能:保存节点的值
包括4种类型:
文档为空
元素为空
attribute 属性值
文字文字内容
DOM 操作流程
增删改查+事件处理
找到触发事件的元素---->>绑定事件处理程序
找到要修改的元素---->>修改属性/样式,添加、删除
DOM 查找
1、无需寻找可以直接获取的元素
html document.documentElement
头文件.head
body document.body
2、HTML 搜索
1、通过id查找
var elem = document.getElementById("id"); //直接写id名称
强调:1、 必须与文档一起调用2、 只会返回一个元素
2、按标签名查找多个元素
var elems = document.getElementsByTagName("标签名");
重点:
1、可以在任何父元素上调用,即只查找当前父元素下的后代元素
2、不仅可以找到直接子元素,还可以找到所有后代元素
3、返回由多个元素组成的动态集合
3、按类属性搜索
var elems = document.getElementsByClassName("class");
重点:
1、 可以在任何父元素上调用
2、返回由多个元素组成的动态集合
3、只要收录指定的类名,选择要更改的元素。它不必完全匹配
4、不仅可以找到直接子元素,还可以找到所有后代元素
4、按名称属性搜索
var elems = document.getElementsByName("name");
name 属性只会在查找带有 name 属性的表单时使用
重点:
1、 只能用文档调用
2、返回由多个元素组成的动态集合
3、按节点关系搜索
何时使用:如果你已经获取了一个元素,你想找到周围的元素
1、父子关系
child.parentNode 获取节点的父节点
parent.childNodes 获取父节点下的所有直接子节点
parent.firstChild 获取父节点下的第一个子节点
parent.lastChild 获取父节点下的最后一个直接子节点
2、兄弟关系
elem.nextSibling 获取节点旁边的下一个兄弟节点
elem.previousSibling 获取与某个节点相邻的前一个兄弟节点
问题:我会被看不见的空字符打扰
解决方案:元素树
元素树:仅收录元素节点的树结构。元素树不是新树,只是节点树的部分子集
如何实现:
1、父子关系
child.parentElement 获取节点的父元素
parent.children 获取父元素下的所有直接子元素
parent.firstElementChild 获取父元素下的第一个直接子元素
parent.lastElementChild 获取父元素下的最后一个直接子元素
2、兄弟关系
elem.nextElementSibling 获取与元素相邻的下一个兄弟元素
elem.previousElementSibling 获取与元素相邻的前一个兄弟元素
4、通过选择器查找
1、只查找一个元素
var elem = parent.querySelector("selector");
2、查找多个元素
var elem = parent.querySelectorAll("selector");
重点:
1、 可以在任何父元素上调用
2、返回一个非动态集合(非动态集合:数据的实际存储,即重复访问,不会造成重复搜索DOM树)无首缓存长度的遍历
3、以当前浏览器的兼容性要求为准
5、traverse 节点
遍历节点定义:找到一个父元素下的所有后代节点
如何:
1、定义只遍历直接子节点的函数
2、 为遇到的每个子节点调用与父节点完全相同的操作
算法:深度优先(当同时有子元素和兄弟元素时,总是先遍历子元素。遍历完子元素后,返回兄弟元素)
问题:递归执行效率极低
解决方案:改用循环
操作方法:使用节点迭代器对象(NodeIterator专门按照深度优先遍历的顺序依次访问每个子元素的对象)
1、Create NodeIterator
var iterator = documnet.createNodeIterator(parent,NodeFilter.SHOW_ALL,null,false,SHOW_ELEMENT);
参数:
parent:树中要用作搜索起点的节点
NodeFilter.SHOW_ALL:显示所有类型的节点
NodeFilter.SHOW_ELEMENT:显示元素节点
NodeFilter.SHOW_TEXT:显示文本节点
NodeFilter.SHOW_COMMENT:显示评论节点
NodeFilter.SHOW_DOCUMENT:显示文档节点
2、循环调用NodeIterator的nextNode()函数
NodeIterator 的主要方法是 nextNode() 和 previousNode()
如何:
1.,返回当前节点
2.,跳转到下一个节点返回null退出
例如:
HTML 的结构:
你好
世界
遍历root下的所有元素:
var iterator = document.createNodeIterator(root, NodeFilter.SHOW_ELEMENT, null, false);
var node = iterator.nextNode();
while(节点 !== null){
console.log( node.tagName );
node = iterator.nextNode();
}
遍历root下的所有p个元素:
var filter = function(node){
返回 node.tagName.toLowerCase() =='p' ?
NodeFilter.FILTER_ACCEPT:
NodeFilter.FILTER_REJECT;
}
var iterator = document.createNodeIterator(root, NodeFilter.SHOW_ELEMENT, filter, false);
var node = iterator.nextNode();
while(节点 !== null){
console.log( node.tagName );
node = iterator.nextNode();
}
DOM 搜索摘要
1.如果已经获取到一个元素,则查找周围的元素:利用节点之间的关系来查找
2.如果传入一个条件,就可以找到你想要的元素:使用HTML搜索
3.如果搜索条件复杂:使用选择器API
按 HTML 与选择器
1.返回值:通过HTML搜索:返回动态集合
按选择器搜索:返回非动态集合
2.效率:第一次搜索通过HTML高效!
按选择器搜索有点慢!
3. 好用:按选择器搜索更简洁
HTML 搜索比较麻烦
编辑
1、content
.innerHTML .textContent .value
2、Attributes
标准属性:HTML 标准中规定的属性
1、Core DOM(4 个 API)
1、获取指定属性的值:
elem.getAttribute("属性名称")
2、修改指定属性的值:
elem.setAttribute("属性名", "值")
3、判断是否收录指定的属性:
elem.hasAttribute("属性名称")
4、去掉指定的属性:
elem.removeAttribute("属性名称")
2、HTML DOM:所有标准属性都预先封装在元素对象中,可以直接用“.”访问
1、获取指定属性的值:
elem.属性名称
2、修改指定属性的值:
elem.attribute name = "value"
3、判断是否收录指定的属性:
元素。属性名! ==""
4、去掉指定的属性:
elem.attribute name = ""
3、clas 属性
Class 是 E5 中的保留字,不能使用 DOM。使用 className 而不是 class
4、Status 属性
禁用选中选中
不能用核心 DOM 访问,只能用 HTML DOM 访问。值都是bool类型
5、自定义扩展属性(不能用HTML DOM访问自定义扩展属性)
1、核心DOM
2、HTML5:
定义属性:data-attribute name = "value"
访问:elem.dataset。属性名
3、style
1、内联
1、编辑:
elem.style.css 属性名称
css属性名必须从横线改成驼峰。优点:最高优先级,只有当前元素有自己的
2、阅读:
不能使用 style.css 属性名称。因为style只能获取内联样式,不能获取样式表中继承/级联的样式
解决方案:
以后,无论何时阅读一个样式,都必须阅读计算出的样式。 (计算样式:最终应用于元素的所有样式的合成,相对单位计算为绝对单位)
1、计算后得到所有css属性的总和:样式对象
var style = getComputedStyle(elem)
2、从样式中获取想要的css属性
style.css 属性
注意:计算出的样式是只读的,不能修改
问题:一句话只能修改一个css属性
解决方法:如何批量修改一个元素的多个属性:
1、先在css中定义多个属性为一个类
2、修改JS中元素的className为指定类
添加
1、创建一个新的空元素
var a = document.createElement("a");
2、设置密钥属性
指导浏览器动作的,对服务器端完全无用
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-06-28 05:18
# 用于引导浏览器动作,在服务器端完全没用。因此,# 不收录在 HTTP 请求中。
比如访问下面这个网站,浏览器实际发送的请求是这样的:
GET /index.html HTTP/1.1
Host: www.example.com
三、#后面的字符
出现在第一个 # 之后的任何字符都将被浏览器解释为位置标识符。这意味着这些字符都不会发送到服务器。
比如下面这个网址的初衷是指定一个颜色值:,但是浏览器实际发送的请求是:
GET /?color= HTTP/1.1
Host: www.example.com
四、改#不触发网页重新加载
单次更改#后的部分,浏览器只会滚动到对应位置,不会重新加载网页。
例如,如果您将#location1 更改为#location2,浏览器将不会再次向服务器请求index.html。
五、改#会改变浏览器的访问历史
每次更改#后的部分,都会在浏览器的访问历史中添加一条记录。使用“返回”按钮返回到之前的位置。这对 ajax 应用程序特别有用。可以用不同的#值来表示不同的访问状态,然后给用户一个链接来访问某个状态。值得注意的是,以上规则对IE 6和IE 7无效,不会因为#的变化而增加历史记录。
六、window.location.hash 读取#value
属性 window.location.hash 是可读可写的。阅读时,可以用来判断网页的状态是否发生了变化;写入时会创建访问历史记录,无需重新加载网页。
七、onhashchange 事件
这是一个新的 HTML 5 事件。当#value 发生变化时,将触发此事件。 IE8+、Firefox 3.6+、Chrome 5+、Safari 4.0+ 支持此事件。
共有三种使用方式:
对于不支持onhashchange的浏览器,可以使用setInterval来监控location.hash的变化。
八、GoogleGrabber#的机制
默认情况下,Google 的网络蜘蛛会忽略 URL 的 # 部分。
不过,Google 也规定,如果希望 Ajax 生成的内容被浏览器引擎读取,可以使用“#!”在 URL 中,Google 会自动将其后面的内容转换为查询字符串 _escaped_fragment_ 的值。
比如谷歌找到了新版推特的网址:
将自动获取另一个 URL:_escaped_fragment_=/username
通过这种机制,Google 可以索引动态 Ajax 内容。
注意
AJAX= 异步 JavaScript 和 XML(标准通用标记语言的一个子集)。 AJAX 是一种用于创建快速动态网页的技术。
2.?
1)连接函数:例如
http://www.xxx.com/Show.asp%3F ... e%3D1
2)清除缓存:例如
http://www.xxxxx.com/index.html
http://www.xxxxx.com/index.html?test123123
两个url打开的页面是一样的,只是后面有个问号,表示没有调用缓存的内容,而是考虑了一个新的地址,重新读取。
3.&
不同参数的垫片
关于js获取URL信息
设置或获取对象指定的文件名或路径。
警报(window.location.pathname)
将整个 URL 设置或获取为字符串。
警报(window.location.href);
设置或获取与 URL 关联的端口号。
警报(window.location.port)
设置或获取 URL 的协议部分。
警报(window.location.protocol)
设置或获取href属性中井号“#”后的部分。
警报(window.location.hash)
设置或获取位置或 URL 的主机名和端口号。
警报(window.location.host)
设置或获取 href 属性中问号后面的部分。
警报(window.location.search)
获取变量的值(截取等号后的部分)
var url = window.location.search;
// alert(url.length);
// alert(url.lastIndexOf('='));
var loc = url.substring(url.lastIndexOf('=')+1, url.length); 查看全部
指导浏览器动作的,对服务器端完全无用
# 用于引导浏览器动作,在服务器端完全没用。因此,# 不收录在 HTTP 请求中。
比如访问下面这个网站,浏览器实际发送的请求是这样的:
GET /index.html HTTP/1.1
Host: www.example.com
三、#后面的字符
出现在第一个 # 之后的任何字符都将被浏览器解释为位置标识符。这意味着这些字符都不会发送到服务器。
比如下面这个网址的初衷是指定一个颜色值:,但是浏览器实际发送的请求是:
GET /?color= HTTP/1.1
Host: www.example.com
四、改#不触发网页重新加载
单次更改#后的部分,浏览器只会滚动到对应位置,不会重新加载网页。
例如,如果您将#location1 更改为#location2,浏览器将不会再次向服务器请求index.html。
五、改#会改变浏览器的访问历史
每次更改#后的部分,都会在浏览器的访问历史中添加一条记录。使用“返回”按钮返回到之前的位置。这对 ajax 应用程序特别有用。可以用不同的#值来表示不同的访问状态,然后给用户一个链接来访问某个状态。值得注意的是,以上规则对IE 6和IE 7无效,不会因为#的变化而增加历史记录。
六、window.location.hash 读取#value
属性 window.location.hash 是可读可写的。阅读时,可以用来判断网页的状态是否发生了变化;写入时会创建访问历史记录,无需重新加载网页。
七、onhashchange 事件
这是一个新的 HTML 5 事件。当#value 发生变化时,将触发此事件。 IE8+、Firefox 3.6+、Chrome 5+、Safari 4.0+ 支持此事件。
共有三种使用方式:
对于不支持onhashchange的浏览器,可以使用setInterval来监控location.hash的变化。
八、GoogleGrabber#的机制
默认情况下,Google 的网络蜘蛛会忽略 URL 的 # 部分。
不过,Google 也规定,如果希望 Ajax 生成的内容被浏览器引擎读取,可以使用“#!”在 URL 中,Google 会自动将其后面的内容转换为查询字符串 _escaped_fragment_ 的值。
比如谷歌找到了新版推特的网址:
将自动获取另一个 URL:_escaped_fragment_=/username
通过这种机制,Google 可以索引动态 Ajax 内容。
注意
AJAX= 异步 JavaScript 和 XML(标准通用标记语言的一个子集)。 AJAX 是一种用于创建快速动态网页的技术。
2.?
1)连接函数:例如
http://www.xxx.com/Show.asp%3F ... e%3D1
2)清除缓存:例如
http://www.xxxxx.com/index.html
http://www.xxxxx.com/index.html?test123123
两个url打开的页面是一样的,只是后面有个问号,表示没有调用缓存的内容,而是考虑了一个新的地址,重新读取。
3.&
不同参数的垫片
关于js获取URL信息
设置或获取对象指定的文件名或路径。
警报(window.location.pathname)
将整个 URL 设置或获取为字符串。
警报(window.location.href);
设置或获取与 URL 关联的端口号。
警报(window.location.port)
设置或获取 URL 的协议部分。
警报(window.location.protocol)
设置或获取href属性中井号“#”后的部分。
警报(window.location.hash)
设置或获取位置或 URL 的主机名和端口号。
警报(window.location.host)
设置或获取 href 属性中问号后面的部分。
警报(window.location.search)
获取变量的值(截取等号后的部分)
var url = window.location.search;
// alert(url.length);
// alert(url.lastIndexOf('='));
var loc = url.substring(url.lastIndexOf('=')+1, url.length);
国家地理中文网中的图片为例,演示爬虫具备的基本功能
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-06-25 00:04
本文以爬取国家地理中文网站旅游类图片为例,演示爬虫的基本功能。
给定初始地址
国家地理中文网站:
获取和分析网页内容
一个。分析网页的结构以确定所需的内容部分
打开网页,右键选择“显示网页源代码”查看网页结构,以下是我截取的部分
我们会发现image类型的数据都放在标签的scr=""里面。我们只需要找到这些标签,从中提取出我们想要的联系,就可以完成我们的期望。
B.获取网页内容
要提取内容,首先要向服务器发起获取文件的请求,然后对图片信息进行分析提取,并对数据进行整理和保存
作者使用的Python3.6,获取网页内容常用的有两种方法:requests和urllib(结合python2中的urllib和urllib2)。获取网页内容请参考这篇文章:爬虫基础:Python 获取网页内容
现在,我们定义一个方法 crawl() 来获取网页
import requests
def crawl(url, headers):
with requests.get(url=url, headers=headers) as response:
# 读取response里的内容,并转码
data = response.content.decode()
return data
调用此方法获取网页内容:
# 获取指定网页内容
url = 'http://www.ngchina.com.cn/travel/'
headers = {'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Mobile Safari/537.36'}
content = crawl(url, headers)
print(content)
写正则表达式匹配图片内容
这样我们就抓取到了给定地址中的图片信息,我们选择其中之一:
入库并进行下一轮爬取
我们抓取到指定的内容后,就可以将其保存到数据库中;如果是链接类型的抓取,我们可以创建一个URL队列,将指定URL中的新链接加入到URL队列中,然后进行轮次遍历和爬取,对于队列URL的处理,需要相应的策略通过根据具体需要完成相应的任务。更多爬虫信息可以参考:初始爬虫。
补充:
我们在写正则表达式的时候,可以使用网上的正则表达式工具快速查看匹配结果:菜鸟正则表达式工具。还有一些常用的正则表达式已经写在这个地址里了,比如电话、QQ号、网站、邮箱等,非常好用。 查看全部
国家地理中文网中的图片为例,演示爬虫具备的基本功能
本文以爬取国家地理中文网站旅游类图片为例,演示爬虫的基本功能。
给定初始地址
国家地理中文网站:
获取和分析网页内容
一个。分析网页的结构以确定所需的内容部分
打开网页,右键选择“显示网页源代码”查看网页结构,以下是我截取的部分

我们会发现image类型的数据都放在标签的scr=""里面。我们只需要找到这些标签,从中提取出我们想要的联系,就可以完成我们的期望。
B.获取网页内容
要提取内容,首先要向服务器发起获取文件的请求,然后对图片信息进行分析提取,并对数据进行整理和保存
作者使用的Python3.6,获取网页内容常用的有两种方法:requests和urllib(结合python2中的urllib和urllib2)。获取网页内容请参考这篇文章:爬虫基础:Python 获取网页内容
现在,我们定义一个方法 crawl() 来获取网页
import requests
def crawl(url, headers):
with requests.get(url=url, headers=headers) as response:
# 读取response里的内容,并转码
data = response.content.decode()
return data
调用此方法获取网页内容:
# 获取指定网页内容
url = 'http://www.ngchina.com.cn/travel/'
headers = {'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Mobile Safari/537.36'}
content = crawl(url, headers)
print(content)
写正则表达式匹配图片内容
这样我们就抓取到了给定地址中的图片信息,我们选择其中之一:

入库并进行下一轮爬取
我们抓取到指定的内容后,就可以将其保存到数据库中;如果是链接类型的抓取,我们可以创建一个URL队列,将指定URL中的新链接加入到URL队列中,然后进行轮次遍历和爬取,对于队列URL的处理,需要相应的策略通过根据具体需要完成相应的任务。更多爬虫信息可以参考:初始爬虫。
补充:
我们在写正则表达式的时候,可以使用网上的正则表达式工具快速查看匹配结果:菜鸟正则表达式工具。还有一些常用的正则表达式已经写在这个地址里了,比如电话、QQ号、网站、邮箱等,非常好用。
动用浏览器内核(PhantomJS、Selenium等)的方案
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-06-23 00:13
那些使用浏览器内核的程序(PhantomJS、Selenium等)太重了,
上面链接中的博客解释了如何通过抓取 Ajax请求采样的数据来抓取前端渲染的网页,这是“网页内容由JavaScript生成”的主题。摘录如下:
链接:http://xlzd.me/2015/12/19/python-crawler-04
来源:xlzd 杂谈
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在抓取网页时,有时会发现HTML中没有我们需要的数据。这个时候我该怎么办?
我们的目的是抓取拉勾Python类下目前全国显示的所有招聘信息。首先,在浏览器中点击查看。如果你够细心或者网速比较慢,那么你会发现在点击Python分类后跳转到的新页面上,招聘信息的出现时间晚于页框的出现时间。至此,我们几乎可以确定招聘信息不在页面的 HTML 源代码中。我们可以通过command+option+u(windows和linux的快捷键是ctrl+u)来查看网页的源码,在源码中。页面上没有显示招聘信息。
此时,我看到的大部分教程都会教使用什么库,如何模拟浏览器环境,如何完成网页的渲染,然后获取里面的信息……永远记住对于爬虫程序,模拟浏览器通常是最糟糕的事情。只有在没有其他办法的情况下才考虑模拟浏览器环境,因为那种内存开销真的很大,效率很低。
那我们怎么处理呢?经验是,在这种情况下,大多数情况是浏览器在请求解析完HTML后,会根据js的“指令”再发送一次请求,得到页面显示的内容,然后显示给浏览器通过js渲染后的界面。好消息是,此类请求的内容往往是json格式,这样既不加重爬虫任务,又可以省去解析HTML的工作量。
好吧,继续打开 Chrome 的开发者工具。我们点击“下一步”后,浏览器发送了如下请求:
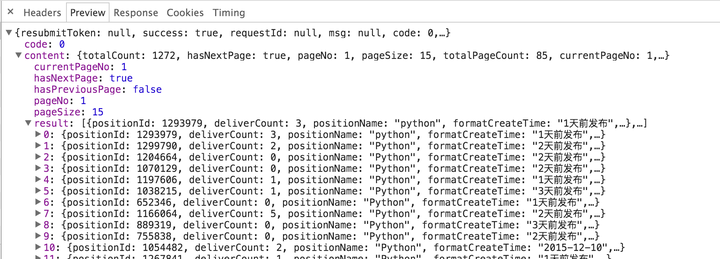
注意 positionAjax.json 请求。它的Type是xhr,它的全名是XMLHttpRequest。 XMLHttpRequest 对象可以部分更新网页,而无需将整个页面提交给服务器。所以,现在的可能性最大,我们点开后仔细观察一下:
点击后,我们在右下角找到了上面的详细信息,几个选项卡的内容表明:
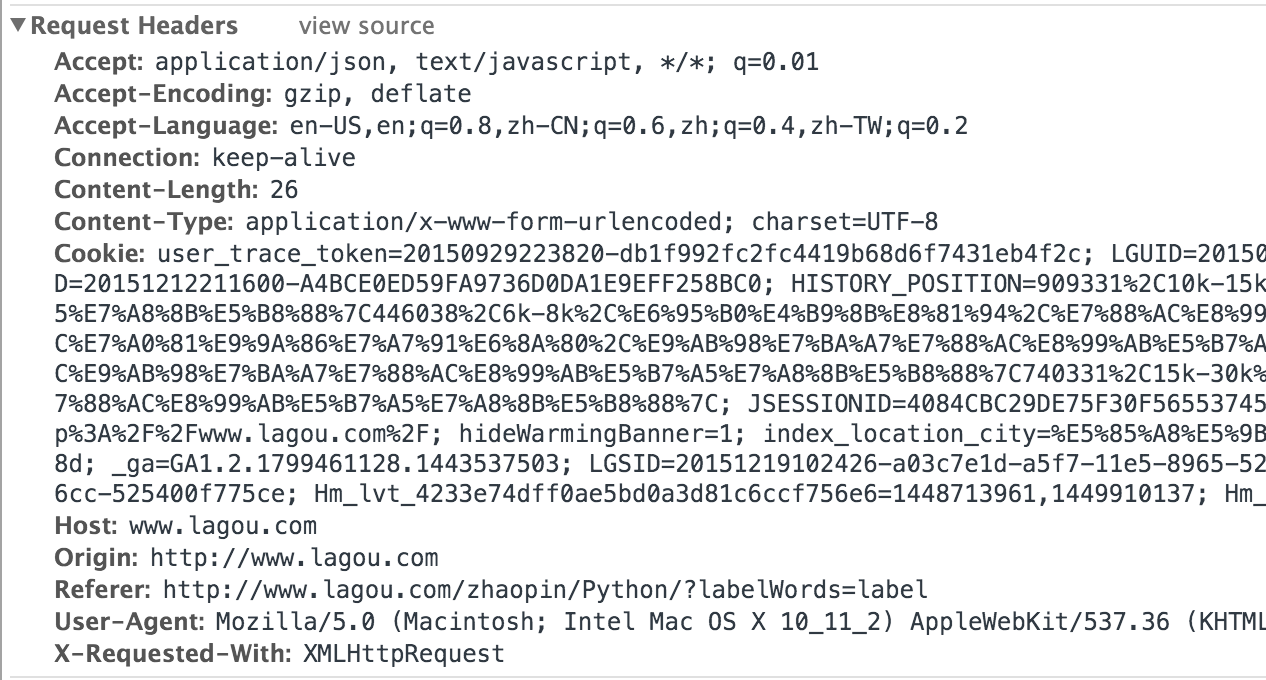
通过内容观察,返回的确实是一个json字符串,里面收录了这个页面的每一条招聘信息。至少我们这里已经说清楚了,不用解析HTML就可以获取招聘信息。那么,应该如何模拟请求呢?我们切换到Headers列,注意三个地方:
上图显示了本次请求的请求方式、请求地址等信息。
上面的截图显示了这个请求的请求头。一般来说,我们需要注意Cookie/Host/Origin/Referer/User-Agent/X-Requested-With等参数。
上面的屏幕截图显示了为此请求提交的数据。根据观察,kd代表我们查询的关键字,pn代表当前页码。
那么,我们的爬虫需要做的就是根据页码不断向这个接口发送请求,解析其中的json内容,并存储我们需要的值。这里有两个问题:什么时候结束,如何获取json中有价值的内容。
我们回去重新观察返回的json,格式化后的层次关系如下:
很容易发现content下的hasNextPage是是否有下一页,content下的结果是一个list,每一个都是一个job信息。在 Python 中,json 字符串到对象的映射可以通过 json 库来完成:
import json
json_obj = json.loads("{'key': 'value'}") # 字符串到对象
json_str = json.dumps(json_obj) # 对象到字符串
映射到Python的json字符串的“[]”类型是list,映射到Python的“{}”类型是dict。至此,分析过程完全结束,可以愉快的写代码了。具体代码这里不再给出。我希望你能自己完成。如果在写作过程中遇到问题,可以联系我寻求帮助。
总结
本篇博客介绍了在HTML源码中没有的情况下爬取一些数据的方法,适用于某些情况。 查看全部
动用浏览器内核(PhantomJS、Selenium等)的方案
那些使用浏览器内核的程序(PhantomJS、Selenium等)太重了,
上面链接中的博客解释了如何通过抓取 Ajax请求采样的数据来抓取前端渲染的网页,这是“网页内容由JavaScript生成”的主题。摘录如下:
链接:http://xlzd.me/2015/12/19/python-crawler-04
来源:xlzd 杂谈
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在抓取网页时,有时会发现HTML中没有我们需要的数据。这个时候我该怎么办?
我们的目的是抓取拉勾Python类下目前全国显示的所有招聘信息。首先,在浏览器中点击查看。如果你够细心或者网速比较慢,那么你会发现在点击Python分类后跳转到的新页面上,招聘信息的出现时间晚于页框的出现时间。至此,我们几乎可以确定招聘信息不在页面的 HTML 源代码中。我们可以通过command+option+u(windows和linux的快捷键是ctrl+u)来查看网页的源码,在源码中。页面上没有显示招聘信息。
此时,我看到的大部分教程都会教使用什么库,如何模拟浏览器环境,如何完成网页的渲染,然后获取里面的信息……永远记住对于爬虫程序,模拟浏览器通常是最糟糕的事情。只有在没有其他办法的情况下才考虑模拟浏览器环境,因为那种内存开销真的很大,效率很低。
那我们怎么处理呢?经验是,在这种情况下,大多数情况是浏览器在请求解析完HTML后,会根据js的“指令”再发送一次请求,得到页面显示的内容,然后显示给浏览器通过js渲染后的界面。好消息是,此类请求的内容往往是json格式,这样既不加重爬虫任务,又可以省去解析HTML的工作量。
好吧,继续打开 Chrome 的开发者工具。我们点击“下一步”后,浏览器发送了如下请求:
注意 positionAjax.json 请求。它的Type是xhr,它的全名是XMLHttpRequest。 XMLHttpRequest 对象可以部分更新网页,而无需将整个页面提交给服务器。所以,现在的可能性最大,我们点开后仔细观察一下:
点击后,我们在右下角找到了上面的详细信息,几个选项卡的内容表明:
通过内容观察,返回的确实是一个json字符串,里面收录了这个页面的每一条招聘信息。至少我们这里已经说清楚了,不用解析HTML就可以获取招聘信息。那么,应该如何模拟请求呢?我们切换到Headers列,注意三个地方:
上图显示了本次请求的请求方式、请求地址等信息。
上面的截图显示了这个请求的请求头。一般来说,我们需要注意Cookie/Host/Origin/Referer/User-Agent/X-Requested-With等参数。
上面的屏幕截图显示了为此请求提交的数据。根据观察,kd代表我们查询的关键字,pn代表当前页码。
那么,我们的爬虫需要做的就是根据页码不断向这个接口发送请求,解析其中的json内容,并存储我们需要的值。这里有两个问题:什么时候结束,如何获取json中有价值的内容。
我们回去重新观察返回的json,格式化后的层次关系如下:


很容易发现content下的hasNextPage是是否有下一页,content下的结果是一个list,每一个都是一个job信息。在 Python 中,json 字符串到对象的映射可以通过 json 库来完成:
import json
json_obj = json.loads("{'key': 'value'}") # 字符串到对象
json_str = json.dumps(json_obj) # 对象到字符串
映射到Python的json字符串的“[]”类型是list,映射到Python的“{}”类型是dict。至此,分析过程完全结束,可以愉快的写代码了。具体代码这里不再给出。我希望你能自己完成。如果在写作过程中遇到问题,可以联系我寻求帮助。
总结
本篇博客介绍了在HTML源码中没有的情况下爬取一些数据的方法,适用于某些情况。
什么是HTML源码网页动态生成?如何对网页进行爬取?
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-06-22 18:48
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
部分网站内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。例如,今天的头条新闻:
HTML 源代码
网页上的新闻在HTML源代码中找不到,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页?有两种方式:
1、从网页响应中查找JS脚本返回的JSON数据; 2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例说明:
1、找到JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”标签后,我们发现有很多回复。让我们过滤它们,只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
原来都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到想要的消息,所以再找一下:
有个焦点,我们点一下看看:
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看的是正常编码的数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求并解析数据接口数据
先上传完整代码:
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
# print news
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(json.dumps(title).decode("unicode-escape"))
print img_url 查看全部
什么是HTML源码网页动态生成?如何对网页进行爬取?
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
部分网站内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。例如,今天的头条新闻:
HTML 源代码
网页上的新闻在HTML源代码中找不到,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页?有两种方式:
1、从网页响应中查找JS脚本返回的JSON数据; 2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例说明:
1、找到JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”标签后,我们发现有很多回复。让我们过滤它们,只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
原来都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到想要的消息,所以再找一下:
有个焦点,我们点一下看看:
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看的是正常编码的数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求并解析数据接口数据
先上传完整代码:
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
# print news
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(json.dumps(title).decode("unicode-escape"))
print img_url
内容简而易懂,条理清晰--jQuery国际化
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-06-19 21:13
这次文章主要给大家展示了《如何使用jQuery.i18n.properties实现js国际化》,内容简单易懂,条理清晰,希望能帮到大家解惑,让小编带路大家一起研究学习《如何使用jQuery.i18n.properties实现js国际化》文章。
我们在做前端页面开发的时候,因为页面内容太多太复杂,有时候一个页面有几千行(当然这样的页面是正常的),为了减少页面的内容,我们将 page 的 js 文件解压出来,放入特定的 js 文件中,然后导入到页面中。这样,当我们需要做应用的国际化时,就需要考虑js的国际化。这里介绍使用JQuery.i18n.properties实现js的国际化。
PS:jQuery.i18n.properties 是一个轻量级的 jQuery 国际插件。类似于 Java 中的资源文件,jQuery.i18n.properties 使用 .properties 文件来国际化 JavaScript。 jQuery.i18n.properties 插件根据用户指定的(或浏览器提供的)语言和国家代码(符合ISO-639和ISO-3166)解析对应的后缀为“.properties”的资源文件标准)。
使用资源文件实现国际化是一种流行的方式。例如,Android 应用程序可以使用以语言和国家代码命名的资源文件来实现国际化。 jQuery.i18n.properties 插件中的资源文件以“.properties”为后缀,收录区域相关的键值对。我们知道Java程序也可以使用后缀为.properties的资源文件来实现国际化。因此,当我们想要在 Java 程序和前端 JavaScript 程序之间共享资源文件时,这种方法特别有用。 jQuery.i18n.properties 插件首先加载默认的资源文件(例如:strings.properties),然后加载特定语言环境的资源文件(例如:strings_zh.properties),这样可以确保当某个不提供语言翻译,默认值始终有效。开发者可以以 JavaScript 变量(或函数)或 Maps 的形式使用资源文件中的密钥。
那么如何使用jQuery.i18n.properties来实现js国际化?
第一步:创建属性资源文件。
属性资源文件的命名规则是:string_browser language shortcode.properties,例如简体中文:string_zh-CN.properties 这里需要注意下划线而不是下划线。如图,我创建了三个资源文件
js_en-US.properties(美国英语)、js_ja.properties(日语)、js_zh-CN.properties(简体中文)。
第2步:在js文件中引入jQuery.i18n.properties需要的js文件。
因为jQuery.i18n.properties依赖于Jquery框架,所以需要在js文件中收录jQuery.i18n.properties需要的js文件。
导入红色部分的js使用jQuery.i18n.properties。
第 3 步:使用 jQuery.i18n.properties API
$(document).ready(function(){
//国际化加载属性文件
jQuery.i18n.properties({
name:'js',
path:'/js/i18n/',
mode:'map',
callback: function() {// 加载成功后设置显示内容
//alert(jQuery.i18n.prop("theme_manage.js_activity"));
}
});
});
name后面的值是你定义的资源文件中语言短代码前面的字符串,因为我的资源文件是js_xxx.properties,所以这个值是js
背后的价值
path 是你的资源文件的相对路径。即相对于项目结构WebContent下的路径
mode 后面的值是加载模式; “vars”表示以JavaScript变量或函数的形式加载资源文件中的key值(默认是this),“map”表示以map值的形式加载资源文件中的key。 “都意味着这两种方法可以同时使用。”我在这里使用地图。
callback 是一个回调函数。
如何根据不同的语言环境加载不同的资源文件?其实jQuery.i18n.properties的原理就是根据名字后面的值找到对应的资源文件,加上浏览器的语言短码,加上.properties。这个过程是自动的,只需要上面的配置。
propertites中的key-value对如下:(properties文件中的中文会自动转换成对应的ASCII值,当然这里可以设置,也可以通过插件修改.反正我没这么做,是从页面复制过来的,不管),等号前的值是key,等号后的值是value(注意不同资源文件中的key必须一致和定制)。
这样,资源文件中的内容就已经加载完毕。
第四步:根据key在js文件中找到对应的值。
红色部分为取值方式,引号内的字符串对应上述资源文件中的键值。
注意事项:
上述方法可以在谷歌和火狐浏览器中实现,没有任何问题。但是IE浏览器会出现问题。问题是每次使用IE浏览器获取的语言环境是系统的语言,而不是浏览器的语言。
我一直在为这个问题苦苦挣扎。网上有一些方法可以获取浏览器的语言,但是在IE下不行。最后,我的解决方案是:在使用jQuery.i18n.properties加载资源文件之前,在请求头信息中获取浏览器语言,然后进行设置。
以上是《如何使用jQuery.i18n.properties实现js国际化》文章的全部内容,感谢阅读!相信大家都有一定的了解,希望分享的内容对大家有所帮助。想了解更多,请关注一宿云行业资讯频道! 查看全部
内容简而易懂,条理清晰--jQuery国际化
这次文章主要给大家展示了《如何使用jQuery.i18n.properties实现js国际化》,内容简单易懂,条理清晰,希望能帮到大家解惑,让小编带路大家一起研究学习《如何使用jQuery.i18n.properties实现js国际化》文章。
我们在做前端页面开发的时候,因为页面内容太多太复杂,有时候一个页面有几千行(当然这样的页面是正常的),为了减少页面的内容,我们将 page 的 js 文件解压出来,放入特定的 js 文件中,然后导入到页面中。这样,当我们需要做应用的国际化时,就需要考虑js的国际化。这里介绍使用JQuery.i18n.properties实现js的国际化。
PS:jQuery.i18n.properties 是一个轻量级的 jQuery 国际插件。类似于 Java 中的资源文件,jQuery.i18n.properties 使用 .properties 文件来国际化 JavaScript。 jQuery.i18n.properties 插件根据用户指定的(或浏览器提供的)语言和国家代码(符合ISO-639和ISO-3166)解析对应的后缀为“.properties”的资源文件标准)。
使用资源文件实现国际化是一种流行的方式。例如,Android 应用程序可以使用以语言和国家代码命名的资源文件来实现国际化。 jQuery.i18n.properties 插件中的资源文件以“.properties”为后缀,收录区域相关的键值对。我们知道Java程序也可以使用后缀为.properties的资源文件来实现国际化。因此,当我们想要在 Java 程序和前端 JavaScript 程序之间共享资源文件时,这种方法特别有用。 jQuery.i18n.properties 插件首先加载默认的资源文件(例如:strings.properties),然后加载特定语言环境的资源文件(例如:strings_zh.properties),这样可以确保当某个不提供语言翻译,默认值始终有效。开发者可以以 JavaScript 变量(或函数)或 Maps 的形式使用资源文件中的密钥。
那么如何使用jQuery.i18n.properties来实现js国际化?
第一步:创建属性资源文件。
属性资源文件的命名规则是:string_browser language shortcode.properties,例如简体中文:string_zh-CN.properties 这里需要注意下划线而不是下划线。如图,我创建了三个资源文件
js_en-US.properties(美国英语)、js_ja.properties(日语)、js_zh-CN.properties(简体中文)。
第2步:在js文件中引入jQuery.i18n.properties需要的js文件。
因为jQuery.i18n.properties依赖于Jquery框架,所以需要在js文件中收录jQuery.i18n.properties需要的js文件。
导入红色部分的js使用jQuery.i18n.properties。
第 3 步:使用 jQuery.i18n.properties API
$(document).ready(function(){
//国际化加载属性文件
jQuery.i18n.properties({
name:'js',
path:'/js/i18n/',
mode:'map',
callback: function() {// 加载成功后设置显示内容
//alert(jQuery.i18n.prop("theme_manage.js_activity"));
}
});
});
name后面的值是你定义的资源文件中语言短代码前面的字符串,因为我的资源文件是js_xxx.properties,所以这个值是js
背后的价值
path 是你的资源文件的相对路径。即相对于项目结构WebContent下的路径
mode 后面的值是加载模式; “vars”表示以JavaScript变量或函数的形式加载资源文件中的key值(默认是this),“map”表示以map值的形式加载资源文件中的key。 “都意味着这两种方法可以同时使用。”我在这里使用地图。
callback 是一个回调函数。
如何根据不同的语言环境加载不同的资源文件?其实jQuery.i18n.properties的原理就是根据名字后面的值找到对应的资源文件,加上浏览器的语言短码,加上.properties。这个过程是自动的,只需要上面的配置。
propertites中的key-value对如下:(properties文件中的中文会自动转换成对应的ASCII值,当然这里可以设置,也可以通过插件修改.反正我没这么做,是从页面复制过来的,不管),等号前的值是key,等号后的值是value(注意不同资源文件中的key必须一致和定制)。

这样,资源文件中的内容就已经加载完毕。
第四步:根据key在js文件中找到对应的值。
红色部分为取值方式,引号内的字符串对应上述资源文件中的键值。
注意事项:
上述方法可以在谷歌和火狐浏览器中实现,没有任何问题。但是IE浏览器会出现问题。问题是每次使用IE浏览器获取的语言环境是系统的语言,而不是浏览器的语言。
我一直在为这个问题苦苦挣扎。网上有一些方法可以获取浏览器的语言,但是在IE下不行。最后,我的解决方案是:在使用jQuery.i18n.properties加载资源文件之前,在请求头信息中获取浏览器语言,然后进行设置。
以上是《如何使用jQuery.i18n.properties实现js国际化》文章的全部内容,感谢阅读!相信大家都有一定的了解,希望分享的内容对大家有所帮助。想了解更多,请关注一宿云行业资讯频道!
从html中提取有效的文本,经常碰到2种类型
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-06-19 21:04
从html中提取有效文本,经常会遇到两种类型:
1、 提取特定网页功能的结构化信息
一个。检查网站的DOM结构:减少代码冗余,优化上一页。
B.结构化信息抽取
2、 通过网页去噪。
一个。使用比较多个网页的文本信息的方法来检测常见字符。较长的常用字符可以看到噪声信息。
B.为了提取网页模板的相似度,需要计算两个网页的结构相似度,提取同一个模板去除噪声,比如网站底部的footer部分。
c.详细页面特点:
(1)更多非锚文本
(2) 有很明显的文字段落和更多的标点符号
(3)url 结构很长,通过网站 分析,这样的网址非常规整,基本在链接结构的最底层
d。详细页面去噪特征:
(1)多以链接的形式出现,链接到其他相关页面。
(2)有很多锚文本,但标点符号很少。锚文本往往是对其他链接页面的解释。
(3)Noisy text 比如一些底部模板。
然后在从网页中提取文本之前,爬虫会首先识别网页的编码,必要时还会识别网页的语言。
如何识别网页的编码:
1、从WEB服务器返回的内容类型中提取代码。
2、 标识网页元信息中的字符编码。如果与内容类型中的编码不一致,以Meta中声明的编码为准。
3、如果真的无法确定网页的字符集,那么就需要从返回流来判断,同时必须确定网页使用的语言。
这就是为什么我们需要明确网页的编码集,以减少爬虫的判断,提高效率。
xmlns 查看全部
从html中提取有效的文本,经常碰到2种类型
从html中提取有效文本,经常会遇到两种类型:
1、 提取特定网页功能的结构化信息
一个。检查网站的DOM结构:减少代码冗余,优化上一页。
B.结构化信息抽取
2、 通过网页去噪。
一个。使用比较多个网页的文本信息的方法来检测常见字符。较长的常用字符可以看到噪声信息。
B.为了提取网页模板的相似度,需要计算两个网页的结构相似度,提取同一个模板去除噪声,比如网站底部的footer部分。
c.详细页面特点:
(1)更多非锚文本
(2) 有很明显的文字段落和更多的标点符号
(3)url 结构很长,通过网站 分析,这样的网址非常规整,基本在链接结构的最底层
d。详细页面去噪特征:
(1)多以链接的形式出现,链接到其他相关页面。
(2)有很多锚文本,但标点符号很少。锚文本往往是对其他链接页面的解释。
(3)Noisy text 比如一些底部模板。
然后在从网页中提取文本之前,爬虫会首先识别网页的编码,必要时还会识别网页的语言。
如何识别网页的编码:
1、从WEB服务器返回的内容类型中提取代码。
2、 标识网页元信息中的字符编码。如果与内容类型中的编码不一致,以Meta中声明的编码为准。
3、如果真的无法确定网页的字符集,那么就需要从返回流来判断,同时必须确定网页使用的语言。
这就是为什么我们需要明确网页的编码集,以减少爬虫的判断,提高效率。
xmlns
图片在笔记里面不能展现异常b,图片(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-06-13 07:04
直接进入主题
----------------------------------------------- -----------
1、伪协议
前期引导用户存储地址为javascript://some code的书签
2、import js
当用户点击书签时,在当前页面执行javascript:之后的代码。代码的内容大概是创建一个脚本节点并引入一个外部js资源
3、创建 iframe
加载js资源时,在当前页面创建一个iframe,并引入一个页面来引导录制和抓取操作
4、文本提取
当用户选择body而不是url时,需要提取body,主要是基于5、6步骤的原因(补充:如果body是ajax生成的或者需要权限验证等,后台没有解决方案),应该采用前端文本提取,而不是后台提取。关于文本提取的算法,请以google为例,根据文本的行高和字体大小的相似度来确定文本的位置。
5、格式预约
如果提取的文本与当前页面的css资源分离,会丢失原来的格式化格式,可读性有偏差。所以这里需要用js实时计算文本的样式(如字体、颜色、行高等),写成内联样式。 (在我们平时的复制粘贴操作中,浏览器会自动做同样的事情。如果要在后台保留格式,需要启动一个浏览器内核来计算,是不是比较复杂?)
6、图片捕捉
一般情况下,如果我们抓取的文字中有图片,就是html中的img标签。抓取云笔记后可能会出现这些问题:
a、图片所在的服务器不稳定,导致图片在备注中显示异常
b、图片服务器已经做了源码验证,图片无法在备注中显示
c、图片为内网域名,更改网络环境后无法查看
这时候我们需要做图片传输:
A 和 b 可以在捕捉时在后台传输,但 c 的情况必须取决于前景。在高端浏览器中,前端将图片转换为base64并预先存储在html中,然后在后台传输。 查看全部
图片在笔记里面不能展现异常b,图片(组图)
直接进入主题
----------------------------------------------- -----------
1、伪协议
前期引导用户存储地址为javascript://some code的书签
2、import js
当用户点击书签时,在当前页面执行javascript:之后的代码。代码的内容大概是创建一个脚本节点并引入一个外部js资源
3、创建 iframe
加载js资源时,在当前页面创建一个iframe,并引入一个页面来引导录制和抓取操作
4、文本提取
当用户选择body而不是url时,需要提取body,主要是基于5、6步骤的原因(补充:如果body是ajax生成的或者需要权限验证等,后台没有解决方案),应该采用前端文本提取,而不是后台提取。关于文本提取的算法,请以google为例,根据文本的行高和字体大小的相似度来确定文本的位置。
5、格式预约
如果提取的文本与当前页面的css资源分离,会丢失原来的格式化格式,可读性有偏差。所以这里需要用js实时计算文本的样式(如字体、颜色、行高等),写成内联样式。 (在我们平时的复制粘贴操作中,浏览器会自动做同样的事情。如果要在后台保留格式,需要启动一个浏览器内核来计算,是不是比较复杂?)
6、图片捕捉
一般情况下,如果我们抓取的文字中有图片,就是html中的img标签。抓取云笔记后可能会出现这些问题:
a、图片所在的服务器不稳定,导致图片在备注中显示异常
b、图片服务器已经做了源码验证,图片无法在备注中显示
c、图片为内网域名,更改网络环境后无法查看
这时候我们需要做图片传输:
A 和 b 可以在捕捉时在后台传输,但 c 的情况必须取决于前景。在高端浏览器中,前端将图片转换为base64并预先存储在html中,然后在后台传输。
如何使用Scrapy结合PhantomJS爬虫.py采集天猫商品内容?
网站优化 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2021-06-13 07:00
1、介绍
最近在看Scrapy爬虫框架,尝试用Scrapy框架写一个简单的小程序,可以实现网页信息采集。在尝试的过程中遇到了很多小问题,希望大家给点建议。
本文主要结合PhantomJS采集天猫品内容介绍如何使用Scrapy。文章中自定义了一个DOWNLOADER_MIDDLEWARES,使用采集动态网页内容需要加载js。看了很多关于DOWNLOADER_MIDDLEWARES的资料,总结起来,使用简单,但是会阻塞框架,所以性能不好。有资料提到自定义DOWNLOADER_HANDLER或者使用scrapyjs可以解决框架阻塞的问题。有兴趣的朋友可以去研究一下,这里就不多说了。
2、具体实现
2.1,环保要求
准备Python开发运行环境需要进行以下步骤:
以上步骤展示了两种安装方式: 1、安装本地下载的wheel包; 2、使用Python安装管理器进行远程下载安装。注意:包版本需要与python版本匹配
2.2,开发测试流程
首先找到需要采集的网页,这里简单搜索一个天猫产品,网址为/item/526449276263.htm,页面如下:
然后开始写代码,下面的代码默认在命令行界面执行
1),创建一个scrapy爬虫项目tmSpider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建一个middlewares文件夹,然后在该文件夹下创建一个middleware.py文件,代码如下:
# -*- coding: utf-8 -*-
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
import tmSpider.middlewares.downloader as downloader
class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content)
def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和PhantomJS编写一个网页内容下载器,也在上一步创建的middlewares文件夹下创建一个downloader.py文件,代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui
class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10)
def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content
def __del__(self):
self.driver.quit()
5) 创建爬虫模块
在项目目录E:\python-3.5.1\tmSpider,执行如下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
执行后会在项目目录E:\python-3.5.1\tmSpider\tmSpider\spiders下自动生成tmall.py程序文件。该程序中的解析函数处理scrapy下载器返回的网页内容。 采集网页信息的方法可以是:
# -*- coding: utf-8 -*-
import time
import scrapy
import tmSpider.gooseeker.gsextractor as gsextractor
class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/5 ... 39%3B,
)
# 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time
def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list")
result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫
在E:\python-3.5.1\tmSpider项目目录下执行命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:
提一下,上面的命令一次只能启动一个爬虫。如果你想同时启动多个爬虫怎么办?然后需要自定义一个爬虫启动模块,在spiders下创建模块文件runcrawl.py,代码如下
# -*- coding: utf-8 -*-
import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
执行runcrawl.py文件并输出结果:
3、展望
通过自定义DOWNLOADER_MIDDLEWARES调用PhantomJs实现爬虫后,一直在纠结框架阻塞的问题,一直在想解决办法。后面会研究scrapyjs、splash等调用浏览器的方式,看看能不能有效的解决这个问题。
4、相关文件
1、Python即时网络爬虫:API说明
5、汇聚GooSeeker开源代码下载源码
1、GooSeeker开源Python网络爬虫GitHub源码
6、文档修改历史
1, 2016-06-30: V1.0 查看全部
如何使用Scrapy结合PhantomJS爬虫.py采集天猫商品内容?
1、介绍
最近在看Scrapy爬虫框架,尝试用Scrapy框架写一个简单的小程序,可以实现网页信息采集。在尝试的过程中遇到了很多小问题,希望大家给点建议。
本文主要结合PhantomJS采集天猫品内容介绍如何使用Scrapy。文章中自定义了一个DOWNLOADER_MIDDLEWARES,使用采集动态网页内容需要加载js。看了很多关于DOWNLOADER_MIDDLEWARES的资料,总结起来,使用简单,但是会阻塞框架,所以性能不好。有资料提到自定义DOWNLOADER_HANDLER或者使用scrapyjs可以解决框架阻塞的问题。有兴趣的朋友可以去研究一下,这里就不多说了。
2、具体实现
2.1,环保要求
准备Python开发运行环境需要进行以下步骤:
以上步骤展示了两种安装方式: 1、安装本地下载的wheel包; 2、使用Python安装管理器进行远程下载安装。注意:包版本需要与python版本匹配
2.2,开发测试流程
首先找到需要采集的网页,这里简单搜索一个天猫产品,网址为/item/526449276263.htm,页面如下:
然后开始写代码,下面的代码默认在命令行界面执行
1),创建一个scrapy爬虫项目tmSpider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建一个middlewares文件夹,然后在该文件夹下创建一个middleware.py文件,代码如下:
# -*- coding: utf-8 -*-
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
import tmSpider.middlewares.downloader as downloader
class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content)
def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和PhantomJS编写一个网页内容下载器,也在上一步创建的middlewares文件夹下创建一个downloader.py文件,代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui
class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10)
def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content
def __del__(self):
self.driver.quit()
5) 创建爬虫模块
在项目目录E:\python-3.5.1\tmSpider,执行如下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
执行后会在项目目录E:\python-3.5.1\tmSpider\tmSpider\spiders下自动生成tmall.py程序文件。该程序中的解析函数处理scrapy下载器返回的网页内容。 采集网页信息的方法可以是:
# -*- coding: utf-8 -*-
import time
import scrapy
import tmSpider.gooseeker.gsextractor as gsextractor
class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/5 ... 39%3B,
)
# 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time
def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list")
result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫
在E:\python-3.5.1\tmSpider项目目录下执行命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:
提一下,上面的命令一次只能启动一个爬虫。如果你想同时启动多个爬虫怎么办?然后需要自定义一个爬虫启动模块,在spiders下创建模块文件runcrawl.py,代码如下
# -*- coding: utf-8 -*-
import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
执行runcrawl.py文件并输出结果:
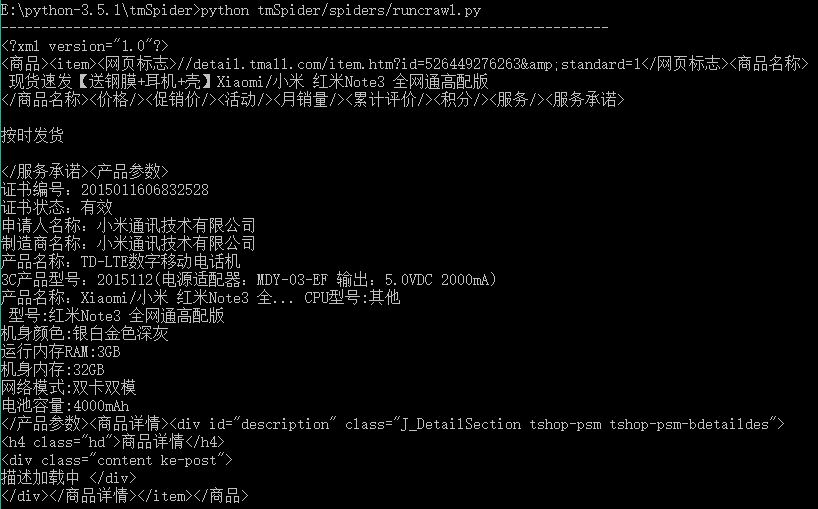
3、展望
通过自定义DOWNLOADER_MIDDLEWARES调用PhantomJs实现爬虫后,一直在纠结框架阻塞的问题,一直在想解决办法。后面会研究scrapyjs、splash等调用浏览器的方式,看看能不能有效的解决这个问题。
4、相关文件
1、Python即时网络爬虫:API说明
5、汇聚GooSeeker开源代码下载源码
1、GooSeeker开源Python网络爬虫GitHub源码
6、文档修改历史
1, 2016-06-30: V1.0
用Python获取指定网页内容提取器的定义(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-06-11 18:23
1、介绍
本文介绍了如何使用 GooSeeker API 接口下载 Java 和 JavaScript 中的内容提取器。这是一个示例程序。什么是内容提取器?为什么要使用这种方法?源自Python即时网络爬虫开源项目:通过生成内容提取器,大大节省了程序员的时间。详情请参考“内容提取器的定义”。
2、使用Java下载内容提取器
这是一系列示例程序之一。从目前的编程语言发展来看,Java提取网页内容并不合适。除了语言不够灵活方便,整个生态不够活跃,可选库增长缓慢。另外,从JavaScript动态网页中提取内容,Java也很不方便,需要JavaScript引擎。使用 JavaScript 下载内容提取器可以直接跳转到第 3 部分的内容。
具体实现
评论:
源码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回结果如下:
3、使用 JavaScript 下载内容提取器
请注意,如果本示例中的 JavaScript 代码运行在网页上,由于跨域问题,无法抓取非站点网页的内容。因此,请运行在有特权的 JavaScript 引擎上,例如浏览器扩展、自主开发的浏览器以及自己程序中的 JavaScript 引擎。
为了实验的方便,这个例子还在网页上运行。为了避免跨域问题,目标网页被保存和修改,并在其中插入JavaScript。这么多手动操作只是为了实验,正式使用时还需要考虑其他方法。
具体实现
评论:
这是源代码:
返回结果截图如下
4、展望
您也可以使用 Python 来获取指定网页的内容。感觉Python的语法更简洁。稍后我们将添加 Python 语言的示例。有兴趣的朋友可以加入一起学习。
5、相关文件
1、Python即时网络爬虫:API说明
2、内容提取器的定义
6、GooSeeker开源代码下载源码采集
1、GooSeeker开源Python网络爬虫GitHub源码
7、文档修改历史
1, 2016-06-20: V1.0
上一章 API-下载内容提取器 下一章用 Python 驱动 Firefox 查看全部
用Python获取指定网页内容提取器的定义(组图)
1、介绍
本文介绍了如何使用 GooSeeker API 接口下载 Java 和 JavaScript 中的内容提取器。这是一个示例程序。什么是内容提取器?为什么要使用这种方法?源自Python即时网络爬虫开源项目:通过生成内容提取器,大大节省了程序员的时间。详情请参考“内容提取器的定义”。
2、使用Java下载内容提取器
这是一系列示例程序之一。从目前的编程语言发展来看,Java提取网页内容并不合适。除了语言不够灵活方便,整个生态不够活跃,可选库增长缓慢。另外,从JavaScript动态网页中提取内容,Java也很不方便,需要JavaScript引擎。使用 JavaScript 下载内容提取器可以直接跳转到第 3 部分的内容。
具体实现
评论:
源码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回结果如下:


3、使用 JavaScript 下载内容提取器
请注意,如果本示例中的 JavaScript 代码运行在网页上,由于跨域问题,无法抓取非站点网页的内容。因此,请运行在有特权的 JavaScript 引擎上,例如浏览器扩展、自主开发的浏览器以及自己程序中的 JavaScript 引擎。
为了实验的方便,这个例子还在网页上运行。为了避免跨域问题,目标网页被保存和修改,并在其中插入JavaScript。这么多手动操作只是为了实验,正式使用时还需要考虑其他方法。
具体实现
评论:
这是源代码:
返回结果截图如下
4、展望
您也可以使用 Python 来获取指定网页的内容。感觉Python的语法更简洁。稍后我们将添加 Python 语言的示例。有兴趣的朋友可以加入一起学习。
5、相关文件
1、Python即时网络爬虫:API说明
2、内容提取器的定义
6、GooSeeker开源代码下载源码采集
1、GooSeeker开源Python网络爬虫GitHub源码
7、文档修改历史
1, 2016-06-20: V1.0
上一章 API-下载内容提取器 下一章用 Python 驱动 Firefox
共建,学习和探索.效果演示客户端思路先理
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-06-11 18:14
共建,学习和探索.效果演示客户端思路先理
这几年涌现了很多技术博客和技术社区,也有很多技术同仁开始创建自己的博客。我们可以将我们的博客同步到不同的技术平台,但是随着技术平台数量的增加,我们文章Sync 会花费越来越多的时间,那么有没有可以快速将博客发布到不同平台的工具?或者有没有什么工具可以直接把html转成技术平台可以直接识别的“语言”,发布怎么样?
我们都知道程序员最喜欢写博客的“语言”是makedown,而且目前大部分技术社区都支持makedown语法,所以只要有makedown,我们就可以快速同步到不同的技术平台。
也许有人会说我们不能只用makedown语法来写博客?这样确实可以满足需求,但缺点是必须在本地保存一个makedown文件。如果博客内容涉及图片,我们还是需要维护一个img目录,这样每次在不同的技术社区发布文章会很麻烦,所以总结一下,我们开发了一个自动抓取html内容的工具,一键转换成美图,让我们可以“肆无忌惮”“发了博客。
你会收获
文末附上作者github地址,感兴趣的朋友可以一起搭建、学习、探索。
效果演示
客户想法
先想想思路:
输入链接地址
获取服务器返回的html字符串,将html字符串转换为md字符串,在编辑器中同步显示预览
为什么选择夜床
客户端最重要的一步是将html转md,这里我们使用turndown。
为什么要使用调低?原因如下:
具体实现
// 引入第三方插件
import { gfm, tables, strikethrough } from 'turndown-plugin-gfm'
const turndownService = new TurndownService({ codeBlockStyle: 'fenced' })
// Use the gfm plugin
turndownService.use(gfm)
// Use the table and strikethrough plugins only
turndownService.use([tables, strikethrough])
/**
* 自定义配置(rule名不能重复)
* 这里我们指定 `pre` 标签为代码块,并在代码块的前后加个换行,防止显示异常
*/
turndownService.addRule('pre2Code', {
filter: ['pre'],
replacement (content) {
return '```\n' + content + '\n```'
}
})
额外功能
支持自动获取链接文章title,无需手动复制原文。
服务端
我们这里使用的服务端是node.js,我们使用前端框架编写服务端体验杠杆作用。
思考
首先想到一个思路:获取前端传递过来的链接地址。通过请求获取html字符串。根据不同平台的域名获取不同的dom。转换图片的相对路径并链接到绝对路径。在底部添加转载的源语句,以获得文章的标题。 * 将title和html返回给前端
获取前端传过来的链接地址的具体实现
这里我们直接使用node自己的语法,我们使用get形式传递,直接使用query
通过请求获取html字符串
这里我们正在请求请求
request({
url: qUrl
}, (error, response, body) => {
if (error) {
res.status(404).send('Url Error')
return
}
// 这里的 body 就是文章的 `html`
console.log(body)
})
根据不同的平台域名获取不同的doms
由于技术平台众多,每个平台的文章content标签、样式名称或id会有所不同,要注意兼容性。
先用js-dom模拟dom的操作,封装一个方法
/**
* 获取准确的文章内容
* @param {string} html html串
* @param {string} selector css选择器
* @return {string} htmlContent
*/
const getDom = (html, selector) => {
const dom = new JSDOM(html)
const htmlContent = dom.window.document.querySelector(selector)
return htmlContent
}
兼容不同平台并应用不同的css选择器
// 比如掘金,内容块的样式名为 .markdown-body,内容里会有 style 标签样式和一些多余的复制代码文字,通过原生 dom 操作删掉
if (qUrl.includes('juejin.cn')) {
const htmlContent = getBySelector('.markdown-body')
const extraDom = htmlContent.querySelector('style')
const extraDomArr = htmlContent.querySelectorAll('.copy-code-btn')
extraDom && extraDom.remove()
extraDomArr.length > 0 && extraDomArr.forEach((v) => { v.remove() })
return htmlContent
}
// 再比如 oschina,内容块的样式名为 .article-detail,内容里会有多余的 .ad-wrap 内容,照样删掉
if (qUrl.includes('oschina.net')) {
const htmlContent = getBySelector('.article-detail')
const extraDom = htmlContent.querySelector('.ad-wrap')
extraDom && extraDom.remove()
return htmlContent
}
// 最后匹配通用标签。优先适配 article 标签,没有再用 body 标签
const htmlArticle = getBySelector('article')
if (htmlArticle) { return htmlArticle }
const htmlBody = getBySelector('body')
if (htmlBody) { return htmlBody }
将图片和链接的相对路径转换为绝对路径,方便以后查找源路径
// 通过原生api - URL 获取链接的源域名
const qOrigin = new URL(qUrl).origin || ''
// 获取图片、链接的绝对路径。通过 URL 将 `路径+源域名` 转换为绝对路径,不熟悉的同学请自行了解
const getAbsoluteUrl = p => new URL(p, qOrigin).href
// 转换图片、链接的相对路径,不同平台的图片懒加载属性名不一样,需要做特定兼容
const changeRelativeUrl = (dom) => {
if (!dom) { return '内容出错~' }
const copyDom = dom
// 获取所有图片
const imgs = copyDom.querySelectorAll('img')
// 获取所有链接
const links = copyDom.querySelectorAll('a')
// 替换完所有路径返回新 dom
imgs.length > 0 && imgs.forEach((v) => {
/**
* 处理懒加载路径
* 简书:data-original-src
* 掘金:data-src
* segmentfault:data-src
*/
const src = v.src || v.getAttribute('data-src') || v.getAttribute('data-original-src') || ''
v.src = getAbsoluteUrl(src)
})
links.length > 0 && links.forEach((v) => {
const href = v.href || qUrl
v.href = getAbsoluteUrl(href)
})
return copyDom
}
// 在获取不同平台的文章内容 getBody 方法里,应用 changeRelativeUrl 方法
const getBody = (content) => {
...
...
return changeRelativeUrl(htmlContent)
} 查看全部
共建,学习和探索.效果演示客户端思路先理
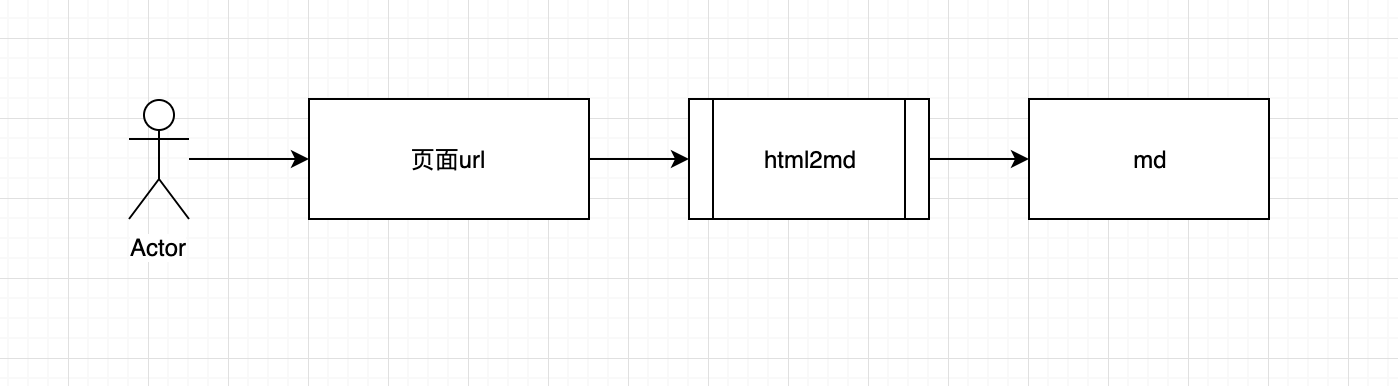
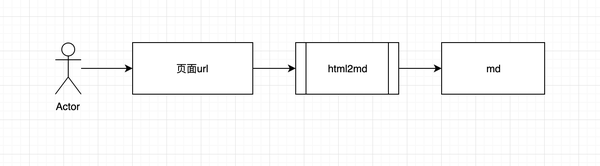
这几年涌现了很多技术博客和技术社区,也有很多技术同仁开始创建自己的博客。我们可以将我们的博客同步到不同的技术平台,但是随着技术平台数量的增加,我们文章Sync 会花费越来越多的时间,那么有没有可以快速将博客发布到不同平台的工具?或者有没有什么工具可以直接把html转成技术平台可以直接识别的“语言”,发布怎么样?
我们都知道程序员最喜欢写博客的“语言”是makedown,而且目前大部分技术社区都支持makedown语法,所以只要有makedown,我们就可以快速同步到不同的技术平台。
也许有人会说我们不能只用makedown语法来写博客?这样确实可以满足需求,但缺点是必须在本地保存一个makedown文件。如果博客内容涉及图片,我们还是需要维护一个img目录,这样每次在不同的技术社区发布文章会很麻烦,所以总结一下,我们开发了一个自动抓取html内容的工具,一键转换成美图,让我们可以“肆无忌惮”“发了博客。
你会收获
文末附上作者github地址,感兴趣的朋友可以一起搭建、学习、探索。
效果演示
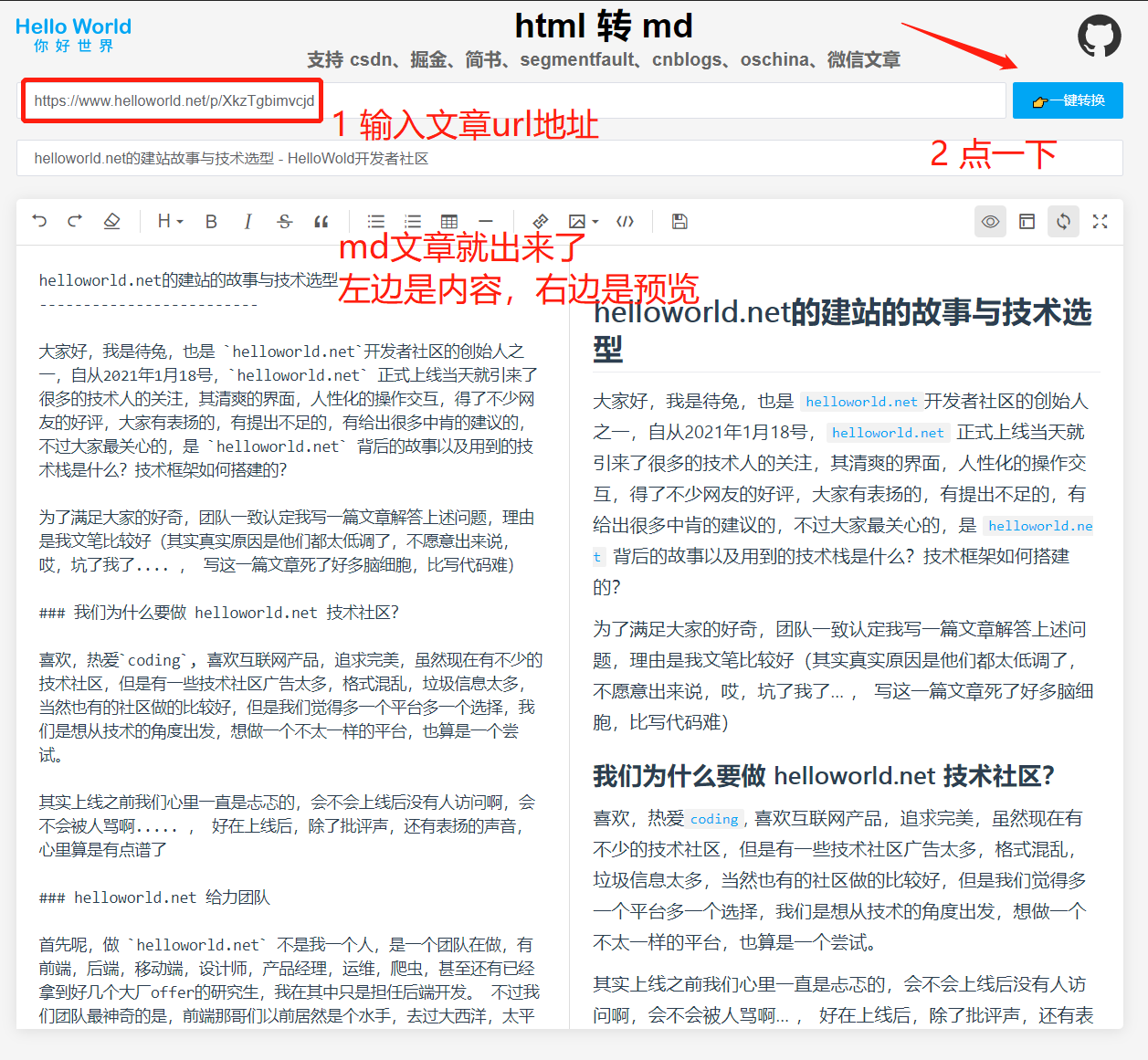
客户想法
先想想思路:
输入链接地址
获取服务器返回的html字符串,将html字符串转换为md字符串,在编辑器中同步显示预览
为什么选择夜床
客户端最重要的一步是将html转md,这里我们使用turndown。
为什么要使用调低?原因如下:
具体实现
// 引入第三方插件
import { gfm, tables, strikethrough } from 'turndown-plugin-gfm'
const turndownService = new TurndownService({ codeBlockStyle: 'fenced' })
// Use the gfm plugin
turndownService.use(gfm)
// Use the table and strikethrough plugins only
turndownService.use([tables, strikethrough])
/**
* 自定义配置(rule名不能重复)
* 这里我们指定 `pre` 标签为代码块,并在代码块的前后加个换行,防止显示异常
*/
turndownService.addRule('pre2Code', {
filter: ['pre'],
replacement (content) {
return '```\n' + content + '\n```'
}
})
额外功能
支持自动获取链接文章title,无需手动复制原文。
服务端
我们这里使用的服务端是node.js,我们使用前端框架编写服务端体验杠杆作用。
思考
首先想到一个思路:获取前端传递过来的链接地址。通过请求获取html字符串。根据不同平台的域名获取不同的dom。转换图片的相对路径并链接到绝对路径。在底部添加转载的源语句,以获得文章的标题。 * 将title和html返回给前端
获取前端传过来的链接地址的具体实现
这里我们直接使用node自己的语法,我们使用get形式传递,直接使用query
通过请求获取html字符串
这里我们正在请求请求
request({
url: qUrl
}, (error, response, body) => {
if (error) {
res.status(404).send('Url Error')
return
}
// 这里的 body 就是文章的 `html`
console.log(body)
})
根据不同的平台域名获取不同的doms
由于技术平台众多,每个平台的文章content标签、样式名称或id会有所不同,要注意兼容性。
先用js-dom模拟dom的操作,封装一个方法
/**
* 获取准确的文章内容
* @param {string} html html串
* @param {string} selector css选择器
* @return {string} htmlContent
*/
const getDom = (html, selector) => {
const dom = new JSDOM(html)
const htmlContent = dom.window.document.querySelector(selector)
return htmlContent
}
兼容不同平台并应用不同的css选择器
// 比如掘金,内容块的样式名为 .markdown-body,内容里会有 style 标签样式和一些多余的复制代码文字,通过原生 dom 操作删掉
if (qUrl.includes('juejin.cn')) {
const htmlContent = getBySelector('.markdown-body')
const extraDom = htmlContent.querySelector('style')
const extraDomArr = htmlContent.querySelectorAll('.copy-code-btn')
extraDom && extraDom.remove()
extraDomArr.length > 0 && extraDomArr.forEach((v) => { v.remove() })
return htmlContent
}
// 再比如 oschina,内容块的样式名为 .article-detail,内容里会有多余的 .ad-wrap 内容,照样删掉
if (qUrl.includes('oschina.net')) {
const htmlContent = getBySelector('.article-detail')
const extraDom = htmlContent.querySelector('.ad-wrap')
extraDom && extraDom.remove()
return htmlContent
}
// 最后匹配通用标签。优先适配 article 标签,没有再用 body 标签
const htmlArticle = getBySelector('article')
if (htmlArticle) { return htmlArticle }
const htmlBody = getBySelector('body')
if (htmlBody) { return htmlBody }
将图片和链接的相对路径转换为绝对路径,方便以后查找源路径
// 通过原生api - URL 获取链接的源域名
const qOrigin = new URL(qUrl).origin || ''
// 获取图片、链接的绝对路径。通过 URL 将 `路径+源域名` 转换为绝对路径,不熟悉的同学请自行了解
const getAbsoluteUrl = p => new URL(p, qOrigin).href
// 转换图片、链接的相对路径,不同平台的图片懒加载属性名不一样,需要做特定兼容
const changeRelativeUrl = (dom) => {
if (!dom) { return '内容出错~' }
const copyDom = dom
// 获取所有图片
const imgs = copyDom.querySelectorAll('img')
// 获取所有链接
const links = copyDom.querySelectorAll('a')
// 替换完所有路径返回新 dom
imgs.length > 0 && imgs.forEach((v) => {
/**
* 处理懒加载路径
* 简书:data-original-src
* 掘金:data-src
* segmentfault:data-src
*/
const src = v.src || v.getAttribute('data-src') || v.getAttribute('data-original-src') || ''
v.src = getAbsoluteUrl(src)
})
links.length > 0 && links.forEach((v) => {
const href = v.href || qUrl
v.href = getAbsoluteUrl(href)
})
return copyDom
}
// 在获取不同平台的文章内容 getBody 方法里,应用 changeRelativeUrl 方法
const getBody = (content) => {
...
...
return changeRelativeUrl(htmlContent)
}
【知识点】HTML文档的域有关(一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-08-01 02:28
同源政策
页面中的Javascript只能读取访问同域的网页。这里需要注意的是,Javascript本身的域定义与其所在的网站无关,只与Javascript代码中嵌入的文档的域有关。如以下示例代码:
This is a webpage came from http://localhost:8000
123
console.log($('#test').text());
HTML 文档来自:8000,表示它的域是:8000(域和端口也是相关的)。虽然页面中的jquery是从加载的,但是JQuery的域只和它所在的HTML文档一样,域是相关的,这样就可以访问到HTML文档的属性,所以上面的代码就可以运行了正常。
附件:使用上述代码的原因是开发者将常用的Javascript库(如JQuery)的地址指向同一个公共URL。用户加载一次JS后,所有后续加载都会被浏览器缓存,从而加快页面加载速度。
从这个角度来说,如果提问者已知的远程指向互联网上的任何一个页面,那么你所期望的功能就无法实现;如果远程点是指您可以控制的网站,请参阅下面的放宽同源策略;
<p>放宽同源 policyDocument.domain:用于子域的情况。对于多个窗口(一个页面上有多个iframe),Javascript可以通过将document.domain的值设置为同一个域来访问外部窗口;跨域资源共享:添加Access-Control- 查看全部
【知识点】HTML文档的域有关(一)
同源政策
页面中的Javascript只能读取访问同域的网页。这里需要注意的是,Javascript本身的域定义与其所在的网站无关,只与Javascript代码中嵌入的文档的域有关。如以下示例代码:
This is a webpage came from http://localhost:8000
123
console.log($('#test').text());
HTML 文档来自:8000,表示它的域是:8000(域和端口也是相关的)。虽然页面中的jquery是从加载的,但是JQuery的域只和它所在的HTML文档一样,域是相关的,这样就可以访问到HTML文档的属性,所以上面的代码就可以运行了正常。
附件:使用上述代码的原因是开发者将常用的Javascript库(如JQuery)的地址指向同一个公共URL。用户加载一次JS后,所有后续加载都会被浏览器缓存,从而加快页面加载速度。
从这个角度来说,如果提问者已知的远程指向互联网上的任何一个页面,那么你所期望的功能就无法实现;如果远程点是指您可以控制的网站,请参阅下面的放宽同源策略;
<p>放宽同源 policyDocument.domain:用于子域的情况。对于多个窗口(一个页面上有多个iframe),Javascript可以通过将document.domain的值设置为同一个域来访问外部窗口;跨域资源共享:添加Access-Control-
,涉及JavaScript针对URL地址规则的分析与字符串的截取操作
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-07-31 21:27
,涉及JavaScript针对URL地址规则的分析与字符串的截取操作
如何通过js获取腾讯视频ID
更新时间:2016-10-03 10:20:21 作者:seoman
这次文章主要介绍js获取腾讯视频ID的方法,其中涉及到JavaScript对URL地址规则的解析以及字符串截取操作的相关操作技巧。有需要的朋友可以参考以下
本文以js获取腾讯视频ID的方法为例。分享给大家,供大家参考,如下:
使用js拦截腾讯视频ID需要知道地址规则,知道规则才能获取。
我在做项目的时候遇到了添加视频的问题,比如用户复制了腾讯视频的链接,以此为例()
现在我们需要截取.html之前和最后一个斜杠之后的内容(u0332wyg5oa);当腾讯视频点击下方分享时,会出现这样一段代码:
复制代码代码如下:
在src中找到“vid=”,里面的代码和我们要截取的视频Id是一样的。所以我总结了以下几种截取视频id的方法,方法不简单,一步步截取,欢迎朋友们提出意见或建议(手机或PC链接都可以)。
$(function(){
//腾讯视频PC端网址
var video_Pc_Tx = 'http://v.qq.com';
//腾讯视频移动端端网址
var video_Mobile_Tx = 'http://m.v.qq.com';
//点击事件
$("#video_Url").click(function(){
//获取输入框中的值
var video_Url = $("#demo").val();
var video_Url_Id = ";
if (video_Url.indexOf(video_Pc_Tx) != -1) {
//截取Pc端视频ID
var Pc_Tx_Id_w = video_Url.substr(0,video_Url.lastIndexOf('.')-1);
video_Url_Id = Pc_Tx_Id_w.substr(Pc_Tx_Id_w.lastIndexOf('/')+1,Pc_Tx_Id_w.length);
} else {
//此时有可能是移动端腾讯视频或优酷视频
if (video_Url.indexOf(video_Mobile_Tx) != -1) {
/**
* 这里是判断移动端视频链接
* GetQueryString() // 调用函数获取视频ID
*/
function GetQueryString(name){
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = video_Url.substr(1).match(reg);;
if(r!=null)return unescape(r[2]); return null;
}
//截取Pc端视频ID
video_Url_Id = GetQueryString("vid");
}
}
});
});
那么“video_Url_Id”就是视频的Id,所以你可以把它放到“src”中的“vid=”中。
也可以封装成函数,直接调用即可;
例如:
function dataVideo(Url){
//上面的代码
return video_Url_Id;
}
直接调用
video_Url_Id = dataVideo(Url);
就是这样。
更多对JavaScript相关内容感兴趣的读者可以查看本站专题:《JavaScript中json操作技巧总结》、《JavaScript切换特效及技巧总结》、《JavaScript搜索算法技巧总结》 , 《JavaScript动画特效及技巧总结、JavaScript错误及调试技巧总结、JavaScript数据结构及算法技巧总结、JavaScript遍历算法及技巧总结、JavaScript数学运算使用总结》
我希望这篇文章能帮助您进行 JavaScript 编程。 查看全部
,涉及JavaScript针对URL地址规则的分析与字符串的截取操作
如何通过js获取腾讯视频ID
更新时间:2016-10-03 10:20:21 作者:seoman
这次文章主要介绍js获取腾讯视频ID的方法,其中涉及到JavaScript对URL地址规则的解析以及字符串截取操作的相关操作技巧。有需要的朋友可以参考以下
本文以js获取腾讯视频ID的方法为例。分享给大家,供大家参考,如下:
使用js拦截腾讯视频ID需要知道地址规则,知道规则才能获取。
我在做项目的时候遇到了添加视频的问题,比如用户复制了腾讯视频的链接,以此为例()
现在我们需要截取.html之前和最后一个斜杠之后的内容(u0332wyg5oa);当腾讯视频点击下方分享时,会出现这样一段代码:
复制代码代码如下:
在src中找到“vid=”,里面的代码和我们要截取的视频Id是一样的。所以我总结了以下几种截取视频id的方法,方法不简单,一步步截取,欢迎朋友们提出意见或建议(手机或PC链接都可以)。
$(function(){
//腾讯视频PC端网址
var video_Pc_Tx = 'http://v.qq.com';
//腾讯视频移动端端网址
var video_Mobile_Tx = 'http://m.v.qq.com';
//点击事件
$("#video_Url").click(function(){
//获取输入框中的值
var video_Url = $("#demo").val();
var video_Url_Id = ";
if (video_Url.indexOf(video_Pc_Tx) != -1) {
//截取Pc端视频ID
var Pc_Tx_Id_w = video_Url.substr(0,video_Url.lastIndexOf('.')-1);
video_Url_Id = Pc_Tx_Id_w.substr(Pc_Tx_Id_w.lastIndexOf('/')+1,Pc_Tx_Id_w.length);
} else {
//此时有可能是移动端腾讯视频或优酷视频
if (video_Url.indexOf(video_Mobile_Tx) != -1) {
/**
* 这里是判断移动端视频链接
* GetQueryString() // 调用函数获取视频ID
*/
function GetQueryString(name){
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = video_Url.substr(1).match(reg);;
if(r!=null)return unescape(r[2]); return null;
}
//截取Pc端视频ID
video_Url_Id = GetQueryString("vid");
}
}
});
});
那么“video_Url_Id”就是视频的Id,所以你可以把它放到“src”中的“vid=”中。
也可以封装成函数,直接调用即可;
例如:
function dataVideo(Url){
//上面的代码
return video_Url_Id;
}
直接调用
video_Url_Id = dataVideo(Url);
就是这样。
更多对JavaScript相关内容感兴趣的读者可以查看本站专题:《JavaScript中json操作技巧总结》、《JavaScript切换特效及技巧总结》、《JavaScript搜索算法技巧总结》 , 《JavaScript动画特效及技巧总结、JavaScript错误及调试技巧总结、JavaScript数据结构及算法技巧总结、JavaScript遍历算法及技巧总结、JavaScript数学运算使用总结》
我希望这篇文章能帮助您进行 JavaScript 编程。
在js中如何获取到两个指定字符之间的字符串
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-07-31 02:24
js中如何获取两个指定字符之间的字符串?我们想到的就是用正则表达式来匹配拦截。
如果:有一个字符串abcdefghijk,我们需要截取b和j之间的字符串。使用match方法实现,代码:
var str = "abcdefghijk";
var substr = str.match(/b(\S*)j/);
console.log(substr);
返回结果为:["bcdefghij", "cdefghi"]
\S* 表达式
() 匹配所有字符串。
还有一种方法:
在高级语言中,我们将使用一个称为量词的概念:
(?=j) 这意味着前面的字符串以 j 结尾,但不包括 j
var str = "abcdefghijk";
var substr = str.match(/(\S*)(?=j)/);
console.log(substr);
返回结果为:["abcdefghi", "abcdefghi"]
(b=?) 这意味着一个以 b 开头的字符串,但不包括 b
var str = "abcdefghijk";
var substr = str.match(/(b=?)(\S*)/);
console.log(substr);
返回结果为:["bcdefghijk","b","cdefghijk"]
总结:
var str = "abcdefghijk";
var substr = str.match(/(b=?)(\S*)(?=j)/);
console.log(substr);
返回结果为:["bcdefghi","b","cdefghi"]
免责声明:如需转载请注明出处并保留原链接: 查看全部
在js中如何获取到两个指定字符之间的字符串
js中如何获取两个指定字符之间的字符串?我们想到的就是用正则表达式来匹配拦截。
如果:有一个字符串abcdefghijk,我们需要截取b和j之间的字符串。使用match方法实现,代码:
var str = "abcdefghijk";
var substr = str.match(/b(\S*)j/);
console.log(substr);
返回结果为:["bcdefghij", "cdefghi"]
\S* 表达式
() 匹配所有字符串。
还有一种方法:
在高级语言中,我们将使用一个称为量词的概念:
(?=j) 这意味着前面的字符串以 j 结尾,但不包括 j
var str = "abcdefghijk";
var substr = str.match(/(\S*)(?=j)/);
console.log(substr);
返回结果为:["abcdefghi", "abcdefghi"]
(b=?) 这意味着一个以 b 开头的字符串,但不包括 b
var str = "abcdefghijk";
var substr = str.match(/(b=?)(\S*)/);
console.log(substr);
返回结果为:["bcdefghijk","b","cdefghijk"]
总结:
var str = "abcdefghijk";
var substr = str.match(/(b=?)(\S*)(?=j)/);
console.log(substr);
返回结果为:["bcdefghi","b","cdefghi"]
免责声明:如需转载请注明出处并保留原链接:
如何采用演示视频来学习短信跳转小程序的能力?
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-07-22 21:18
写在前面
如果你想独立开发,但没有云开发经验,可以使用演示视频学习本教程:
一、能力介绍
国内非个人主体认证小程序,开启静态网站后,可发出支持不认证跳转到对应小程序的短信。短信将收录一个静态网站 链接,可以在微信内或微信外打开。打开页面后,用户可以一键跳转到你的小程序。
链接的网页使用 URL Scheme 拉起微信在外部浏览器中打开主小程序。
简而言之,短信重定向能力的实现分为“配置拉起网页”和“发送短信”两步。本教程将介绍如何进行操作来完成短信重定向小程序的能力。
如果想不写代码也能完成短信重定向小程序,可以参考无代码版教程一步步实现。
二、操作指南1、网页制作
首先我们需要构建一个基本的 Web 应用程序,在任何代码编辑器中创建一个 html 文件,并在教程中将其命名为 index.html
在这个html文件中输入以下代码,根据注释替换自己的信息:
window.onload = function(){
window.web2weapp.init({
appId: 'wx999999', //替换为自己小程序的AppID
gh_ID: 'gh_999999',//替换为自己小程序的原始ID
env_ID: 'tcb-env',//替换小程序底下云开发环境ID
function: {
name:'openMini',//提供UrlScheme服务的云函数名称
data:{} //向这个云函数中传入的自定义参数
},
path: 'pages/index/index.html' //打开小程序时的路径
})
}
上面介绍的web2weapp.js文件是微信小程序拉取教程中封装的极简应用,我们直接引用即可轻松使用。
如果想进一步学习修改一些WEB显示信息,可以到github获取源码并进行修改。
关于启动小程序的网页的更多信息,请访问官方文档
如果您只想体验短信重定向功能,请在完成上述文件创建操作后,继续以下步骤。
2、创建服务云功能
在上面创建网页的过程中,需要填写一个UrlScheme服务云函数。该云函数主要用于调用微信服务器的能力,获取对应的Scheme信息并返回给调用前端。
我们在示例中填写了命名云函数openMini。
进入微信开发者工具,找到对应的云开发环境,创建一个名为openMini的云函数。
替换云函数目录下的index.js文件,输入如下代码:
const cloud = require('wx-server-sdk')
cloud.init()
exports.main = async (event, context) => {
return cloud.openapi.urlscheme.generate({
jumpWxa: {
path: '', // 打开小程序时访问路径,为空则会进入主页
query: '',// 可以使用 event 传入的数据制作特定参数,无需求则为空
},
isExpire: true, //是否到期失效,如果为true需要填写到期时间,默认false
expire_time: Math.round(new Date().getTime()/1000) + 3600
//我们设置为当前时间3600秒后,也就是1小时后失效
//无需求可以去掉这两个参数(isExpire,expire_time)
})
}
保存代码后,右键index.js,选择增量更新文件,更新成功。
接下来,我们需要启用对云功能的无日志访问。进入小程序云开发控制台,进入设置-权限设置,发现下面没有登录,选择我们前面步骤统一操作的云开发环境(注意:配置的云开发环境和云功能环境第一步,另外,这一步的运行环境一定要一样),勾选打开未登录
接下来进入云功能控制台,点击云功能权限,最后修改安全规则,在弹出框中配置如下:
3、local 测试
我们在本地浏览器中打开第一步创建的index.html;调出控制台,如果效果如下图,说明成功!需要注意的是,如果本地开启需要HTTP协议,建议使用live server等扩展开启。不要在资源管理器中直接打开浏览器,会有跨域问题!
4、上传本地创建的index.html到static网站hosting
将本地创建的index.html上传到静态网站托管,其中静态托管需要在小程序本身的云开发环境中进行静态托管。
如果上传到其他静态主机或服务器,仍然可以使用外部浏览器拉起小程序,但是会失去在微信浏览器中拉起带有open标签的小程序的能力,并且不会享受云。开发短信发送跳转链接的能力。
如果你的目标小程序下有多个云开发环境,你不需要保证云功能和静态托管在同一个环境下,没关系。
比如你有两个环境A和B,A部署了上面的云功能,但是把index.html部署到B的静态托管环境中,这是没有问题的,满足各种能力的需求。只需确保第一步中index.html网页中的云开发环境配置为云功能所在的环境即可。
部署成功后就可以访问静态托管地址了,可以测试通过手机外部浏览器和微信内部浏览器打开小程序的能力。
5、SMS 发送云功能配置
在上面创建openMini云函数的环境中,还有一个云函数叫做sendms。
在这个云函数index.js中配置如下代码:
const cloud = require('wx-server-sdk')
cloud.init({
env: cloud.DYNAMIC_CURRENT_ENV,
})
exports.main = async (event, context) => {
try {
const config = {
env: event.env,
content: event.content ? event.content : '发布了短信跳转小程序的新能力',
path: event.path,
phoneNumberList: event.number
}
const result = await cloud.openapi.cloudbase.sendSms(config)
return result
} catch (err) {
return err
}
}
保存代码后,右键index.js,选择增量更新文件,更新成功。
6、测试短信发送能力
在小程序代码中,在app.js中初始化云开发后,调用云函数。示例代码如下:
App({
onLaunch: function () {
wx.cloud.init({
env:"tcb-env", //短信云函数所在环境ID
traceUser: true
})
wx.cloud.callFunction({
name:'sendsms',
data:{
"env": "tcb-env",//网页上传的静态托管的环境ID
"path":"/index.html",//上传的网页相对根目录的地址,如果是根目录则为/index.html
"number":[
"+8616599997777" //你要发送短信的目标手机,前面需要添加「+86」
]
},success(res){
console.log(res)
}
})
}
})
重新编译运行后,如果在控制台看到如下输出,则测试成功:
您会在发送的目标手机上收到一条短信,因为短信中收录“退订回复T”字段,可能会触发手机的自动拦截机制,需要在拦截短信中手动勾选.
注意:短信云函数和URLScheme云函数可以放置在不同的云开发环境中,但必须保证你放置的云开发环境属于你运行的小程序
另外,为了防止滥用,短信发送的云调用能力需要真正的小程序用户访问才能生效。不能使用云测试、云开发JS-SDK等非wx.cloud调用方式(微信端WEB-SDK除外),会提示如下错误:
如果想在其他地方使用这个能力,可以使用服务端API进行正常的HTTP调用,详情请访问官方文档。
7、查看短信监控图表
进入云开发控制台>运行分析>监控图表>短信监控,可以查看短信监控曲线和短信发送记录。
三、Summary 短信重定向小程序的核心是静态网站中配置的可重定向网页。外部浏览器实现了 URL Scheme。此方法不适用于微信浏览器,需要使用open标签。 URL Scheme的生成可以是云调用能力,需要在目标小程序的云开发环境的云功能中使用。并且生成的 URL Scheme 只能是自己小程序的打开链接,不能是任何小程序(任何与打开标签不一致的地方)。短信发送能力体验每个环境第一个月100条免费额度,超过额度可以去开发者工具-云开发控制台-对应的现收现付环境-资源包-短信资源打包购买。如果当前资源包不能满足需求,也可以通过云开发工单提交申请
SMS 发送也是一种云调用功能。需要真实小程序用户调用才能正常触发。其他方法报错并返回参数错误。为防止滥用,云功能和网页可以放置在不同的环境中。只要确保小程序属于同一个即可。 (需要保证对应的环境ID可以连接)如果不需要短信能力,可以忽略最后两步cms配置渠道投递,数据统计可以参考 查看全部
如何采用演示视频来学习短信跳转小程序的能力?
写在前面
如果你想独立开发,但没有云开发经验,可以使用演示视频学习本教程:
一、能力介绍
国内非个人主体认证小程序,开启静态网站后,可发出支持不认证跳转到对应小程序的短信。短信将收录一个静态网站 链接,可以在微信内或微信外打开。打开页面后,用户可以一键跳转到你的小程序。
链接的网页使用 URL Scheme 拉起微信在外部浏览器中打开主小程序。
简而言之,短信重定向能力的实现分为“配置拉起网页”和“发送短信”两步。本教程将介绍如何进行操作来完成短信重定向小程序的能力。
如果想不写代码也能完成短信重定向小程序,可以参考无代码版教程一步步实现。
二、操作指南1、网页制作
首先我们需要构建一个基本的 Web 应用程序,在任何代码编辑器中创建一个 html 文件,并在教程中将其命名为 index.html
在这个html文件中输入以下代码,根据注释替换自己的信息:
window.onload = function(){
window.web2weapp.init({
appId: 'wx999999', //替换为自己小程序的AppID
gh_ID: 'gh_999999',//替换为自己小程序的原始ID
env_ID: 'tcb-env',//替换小程序底下云开发环境ID
function: {
name:'openMini',//提供UrlScheme服务的云函数名称
data:{} //向这个云函数中传入的自定义参数
},
path: 'pages/index/index.html' //打开小程序时的路径
})
}
上面介绍的web2weapp.js文件是微信小程序拉取教程中封装的极简应用,我们直接引用即可轻松使用。
如果想进一步学习修改一些WEB显示信息,可以到github获取源码并进行修改。
关于启动小程序的网页的更多信息,请访问官方文档
如果您只想体验短信重定向功能,请在完成上述文件创建操作后,继续以下步骤。
2、创建服务云功能
在上面创建网页的过程中,需要填写一个UrlScheme服务云函数。该云函数主要用于调用微信服务器的能力,获取对应的Scheme信息并返回给调用前端。
我们在示例中填写了命名云函数openMini。
进入微信开发者工具,找到对应的云开发环境,创建一个名为openMini的云函数。
替换云函数目录下的index.js文件,输入如下代码:
const cloud = require('wx-server-sdk')
cloud.init()
exports.main = async (event, context) => {
return cloud.openapi.urlscheme.generate({
jumpWxa: {
path: '', // 打开小程序时访问路径,为空则会进入主页
query: '',// 可以使用 event 传入的数据制作特定参数,无需求则为空
},
isExpire: true, //是否到期失效,如果为true需要填写到期时间,默认false
expire_time: Math.round(new Date().getTime()/1000) + 3600
//我们设置为当前时间3600秒后,也就是1小时后失效
//无需求可以去掉这两个参数(isExpire,expire_time)
})
}
保存代码后,右键index.js,选择增量更新文件,更新成功。
接下来,我们需要启用对云功能的无日志访问。进入小程序云开发控制台,进入设置-权限设置,发现下面没有登录,选择我们前面步骤统一操作的云开发环境(注意:配置的云开发环境和云功能环境第一步,另外,这一步的运行环境一定要一样),勾选打开未登录
接下来进入云功能控制台,点击云功能权限,最后修改安全规则,在弹出框中配置如下:
3、local 测试
我们在本地浏览器中打开第一步创建的index.html;调出控制台,如果效果如下图,说明成功!需要注意的是,如果本地开启需要HTTP协议,建议使用live server等扩展开启。不要在资源管理器中直接打开浏览器,会有跨域问题!
4、上传本地创建的index.html到static网站hosting
将本地创建的index.html上传到静态网站托管,其中静态托管需要在小程序本身的云开发环境中进行静态托管。
如果上传到其他静态主机或服务器,仍然可以使用外部浏览器拉起小程序,但是会失去在微信浏览器中拉起带有open标签的小程序的能力,并且不会享受云。开发短信发送跳转链接的能力。
如果你的目标小程序下有多个云开发环境,你不需要保证云功能和静态托管在同一个环境下,没关系。
比如你有两个环境A和B,A部署了上面的云功能,但是把index.html部署到B的静态托管环境中,这是没有问题的,满足各种能力的需求。只需确保第一步中index.html网页中的云开发环境配置为云功能所在的环境即可。
部署成功后就可以访问静态托管地址了,可以测试通过手机外部浏览器和微信内部浏览器打开小程序的能力。
5、SMS 发送云功能配置
在上面创建openMini云函数的环境中,还有一个云函数叫做sendms。
在这个云函数index.js中配置如下代码:
const cloud = require('wx-server-sdk')
cloud.init({
env: cloud.DYNAMIC_CURRENT_ENV,
})
exports.main = async (event, context) => {
try {
const config = {
env: event.env,
content: event.content ? event.content : '发布了短信跳转小程序的新能力',
path: event.path,
phoneNumberList: event.number
}
const result = await cloud.openapi.cloudbase.sendSms(config)
return result
} catch (err) {
return err
}
}
保存代码后,右键index.js,选择增量更新文件,更新成功。
6、测试短信发送能力
在小程序代码中,在app.js中初始化云开发后,调用云函数。示例代码如下:
App({
onLaunch: function () {
wx.cloud.init({
env:"tcb-env", //短信云函数所在环境ID
traceUser: true
})
wx.cloud.callFunction({
name:'sendsms',
data:{
"env": "tcb-env",//网页上传的静态托管的环境ID
"path":"/index.html",//上传的网页相对根目录的地址,如果是根目录则为/index.html
"number":[
"+8616599997777" //你要发送短信的目标手机,前面需要添加「+86」
]
},success(res){
console.log(res)
}
})
}
})
重新编译运行后,如果在控制台看到如下输出,则测试成功:
您会在发送的目标手机上收到一条短信,因为短信中收录“退订回复T”字段,可能会触发手机的自动拦截机制,需要在拦截短信中手动勾选.
注意:短信云函数和URLScheme云函数可以放置在不同的云开发环境中,但必须保证你放置的云开发环境属于你运行的小程序
另外,为了防止滥用,短信发送的云调用能力需要真正的小程序用户访问才能生效。不能使用云测试、云开发JS-SDK等非wx.cloud调用方式(微信端WEB-SDK除外),会提示如下错误:
如果想在其他地方使用这个能力,可以使用服务端API进行正常的HTTP调用,详情请访问官方文档。
7、查看短信监控图表
进入云开发控制台>运行分析>监控图表>短信监控,可以查看短信监控曲线和短信发送记录。
三、Summary 短信重定向小程序的核心是静态网站中配置的可重定向网页。外部浏览器实现了 URL Scheme。此方法不适用于微信浏览器,需要使用open标签。 URL Scheme的生成可以是云调用能力,需要在目标小程序的云开发环境的云功能中使用。并且生成的 URL Scheme 只能是自己小程序的打开链接,不能是任何小程序(任何与打开标签不一致的地方)。短信发送能力体验每个环境第一个月100条免费额度,超过额度可以去开发者工具-云开发控制台-对应的现收现付环境-资源包-短信资源打包购买。如果当前资源包不能满足需求,也可以通过云开发工单提交申请
SMS 发送也是一种云调用功能。需要真实小程序用户调用才能正常触发。其他方法报错并返回参数错误。为防止滥用,云功能和网页可以放置在不同的环境中。只要确保小程序属于同一个即可。 (需要保证对应的环境ID可以连接)如果不需要短信能力,可以忽略最后两步cms配置渠道投递,数据统计可以参考
如何对网页进行爬取?(一)的使用
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-07-20 19:14
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
部分网站内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。例如,今天的头条新闻:
HTML 源代码
网页上的新闻在HTML源代码中找不到,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页?有两种方式:
1、从网页响应中查找JS脚本返回的JSON数据; 2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例说明:
1、找到JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”标签后,我们发现有很多回复。让我们过滤它们,只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,即 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
原来都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到想要的消息,所以再找一下:
有个焦点,我们点一下看看:
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看的是正常编码的数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求并解析数据接口数据
先上传完整代码:
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
# print news
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(json.dumps(title).decode("unicode-escape"))
print img_url 查看全部
如何对网页进行爬取?(一)的使用
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
部分网站内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。例如,今天的头条新闻:
HTML 源代码
网页上的新闻在HTML源代码中找不到,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页?有两种方式:
1、从网页响应中查找JS脚本返回的JSON数据; 2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例说明:
1、找到JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”标签后,我们发现有很多回复。让我们过滤它们,只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,即 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
原来都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到想要的消息,所以再找一下:
有个焦点,我们点一下看看:
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看的是正常编码的数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求并解析数据接口数据
先上传完整代码:
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
# print news
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(json.dumps(title).decode("unicode-escape"))
print img_url
java调用元素内容的动态变化及解决方案使用+PhantomJS
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-07-19 04:24
前言
现在很多网站 使用 JavaScript 或 Ajax 技术。这样,网页加载后,虽然url没有变化,但是网页的DOM元素的内容可以动态变化。如果使用python自带的requests库或urllib库处理此类网页,获取的网页内容与浏览器中网页显示的内容不一致。
解决方案
使用 Selenium+PhantomJS。这两者一起可以运行一个非常强大的爬虫,它可以处理 cookie、JavaScript、标头和任何你想做的事情。
安装第三方库
Selenium 是一个强大的网络数据采集工具,最初是为网站自动化测试开发的,它有相应的Python库;
Selenium 安装命令:
pip install selenium
安装 PhantomJS
PhantomJS 是一个基于 webkit 内核的无头浏览器,即它没有 UI 界面,即是一个浏览器,但是点击、翻页等与人相关的操作需要通过编程来实现。通过编写js程序,可以直接与webkit内核交互,在此基础上还可以结合java语言等,通过java调用js等相关操作。需要到官网下载对应平台的压缩文件;
PhantomJS(phantomjs-2.1.1-windows)下载地址:根据不同系统选择对应版本
windows系统下载PhantomJs,将解压后的可执行文件放在环境变量设置好的地方。如果不设置,后面的代码会设置,所以直接放在这里很方便;
然后勾选,在cmd窗口输入phantomjs:
如果出现这样的画面,则表示成功;
对于Mac系统,下载保存到某个路径后,可以直接保存在环境改变的路径中,也可以在环境变量路径中创建一个phantomjs的软链接
ln -s /usr/local/opt/my/phantomjs-2.1.1-macosx/bin/phantomjs /usr/local/bin
测试代码:
from selenium import webdriver
<p>driver = webdriver.PhantomJS()
driver.get('http://www.baidu.com/')
print (driver.page_source)</p>
如果能成功获取到页面元素,则说明安装成功。
示例 1:
Selenium+PhantomJS 示例代码:
from selenium import webdriver
<p>driver = webdriver.PhantomJS()
driver.get('http://www.cnblogs.com/feng0815/p/8735491.html')
#获取网页源码
data = driver.page_source
print(data)
#获取元素的html源码
tableData = driver.find_elements_by_tag_name('tableData').get_attribute('innerHTML')
#获取元素的id值
tableI = driver.find_elements_by_tag_name('tableData').get_attribute('id')
#获取元素的文本内容
tableI = driver.find_elements_by_tag_name('tableData').text
driver.quit()</p>
可以输出网页源码,说明安装成功
获取JS返回值
查看全部
java调用元素内容的动态变化及解决方案使用+PhantomJS
前言
现在很多网站 使用 JavaScript 或 Ajax 技术。这样,网页加载后,虽然url没有变化,但是网页的DOM元素的内容可以动态变化。如果使用python自带的requests库或urllib库处理此类网页,获取的网页内容与浏览器中网页显示的内容不一致。
解决方案
使用 Selenium+PhantomJS。这两者一起可以运行一个非常强大的爬虫,它可以处理 cookie、JavaScript、标头和任何你想做的事情。
安装第三方库
Selenium 是一个强大的网络数据采集工具,最初是为网站自动化测试开发的,它有相应的Python库;
Selenium 安装命令:
pip install selenium
安装 PhantomJS
PhantomJS 是一个基于 webkit 内核的无头浏览器,即它没有 UI 界面,即是一个浏览器,但是点击、翻页等与人相关的操作需要通过编程来实现。通过编写js程序,可以直接与webkit内核交互,在此基础上还可以结合java语言等,通过java调用js等相关操作。需要到官网下载对应平台的压缩文件;
PhantomJS(phantomjs-2.1.1-windows)下载地址:根据不同系统选择对应版本
windows系统下载PhantomJs,将解压后的可执行文件放在环境变量设置好的地方。如果不设置,后面的代码会设置,所以直接放在这里很方便;
然后勾选,在cmd窗口输入phantomjs:
如果出现这样的画面,则表示成功;
对于Mac系统,下载保存到某个路径后,可以直接保存在环境改变的路径中,也可以在环境变量路径中创建一个phantomjs的软链接
ln -s /usr/local/opt/my/phantomjs-2.1.1-macosx/bin/phantomjs /usr/local/bin
测试代码:
from selenium import webdriver
<p>driver = webdriver.PhantomJS()
driver.get('http://www.baidu.com/')
print (driver.page_source)</p>
如果能成功获取到页面元素,则说明安装成功。
示例 1:
Selenium+PhantomJS 示例代码:
from selenium import webdriver
<p>driver = webdriver.PhantomJS()
driver.get('http://www.cnblogs.com/feng0815/p/8735491.html')
#获取网页源码
data = driver.page_source
print(data)
#获取元素的html源码
tableData = driver.find_elements_by_tag_name('tableData').get_attribute('innerHTML')
#获取元素的id值
tableI = driver.find_elements_by_tag_name('tableData').get_attribute('id')
#获取元素的文本内容
tableI = driver.find_elements_by_tag_name('tableData').text
driver.quit()</p>
可以输出网页源码,说明安装成功
获取JS返回值
Python中的网络爬虫库获取网页的示例程序是什么?
网站优化 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-07-13 21:17
1 什么是网络爬虫
网络爬虫是指从网站中提取数据的技术,可以将非结构化数据转化为结构化数据。
网络爬虫的目的是从网站中提取数据。提取的数据可以存储在本地文件中并保存在系统中,也可以以表格的形式存储在数据库中。网络爬虫使用 HTTP 或网络浏览器直接访问万维网 (WWW)。网络爬虫或机器人抓取网页的过程是一个自动化过程。
抓取网页的过程分为网页获取和数据提取。网络爬虫可以抓取网页,是网络爬虫的必备组件。获取网页后,需要提取网页数据。我们可以对提取的数据进行搜索、解析,并将其保存在表格中,然后重新排列格式。
2 数据提取
在本节中,我们将了解数据提取。我们可以使用 Python 的 BeautifulSoup 库进行数据提取。这里还需要 Python 库的 Requests 模块。
运行以下命令来安装 Requests 和 BeautifulSoup 库。
$ pip3 install requests
$ pip3 install beautifulsoup4
2.1Requests 库
使用请求库以易于理解的格式在 Python 脚本中使用 HTTP。在这里,使用 Python 中的 Requests 库来获取网页。 Requests 库收录不同类型的请求,这里使用 GET 请求。 GET请求用于从Web服务器获取信息,通过GET请求可以获取指定网页的HTML内容。每个请求对应一个状态码,从服务器返回。这些状态码为我们提供了相应请求执行结果的相关信息。以下是一些状态代码。
2.2BeautifulSoup 库
BeautifulSoup 也是一个 Python 库,收录简单的搜索、导航和修改方法。它只是一个从网页中提取所需数据的工具包。
要在脚本中使用 Requests 和 BeautifulSoup 模块,必须使用 import 语句导入这两个模块。现在让我们看一个用于解析网页的示例程序。在这里,我们将解析来自百度网站 的新闻网页。创建一个脚本,命名为parse_web_page.py,在里面写入如下代码。
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
print(parse_obj)
运行如下所示的脚本程序。
student@ubuntu:~/work$ python3 parse_web_page.py
Output:
var IMDbTimer={starttime: new
Date().getTime(),pt:'java'};
if (typeof uet == 'function') {
uet("bb", "LoadTitle", {wb: 1});
}
(function(t){ (t.events = t.events || {})["csm_head_pre_title"] =
new Date().getTime(); })(IMDbTimer);
Top News - IMDb
(function(t){ (t.events = t.events || {})["csm_head_post_title"] =
new Date().getTime(); })(IMDbTimer);
if (typeof uet == 'function') {
uet("be", "LoadTitle", {wb: 1});
}
if (typeof uex == 'function') {
uex("ld", "LoadTitle", {wb: 1});
}
if (typeof uet == 'function') {
uet("bb", "LoadIcons", {wb: 1});
}
上面的示例程序抓取了一个网页并使用 BeautifulSoup 对其进行了解析。首先导入requests和BeautifulSoup模块,然后使用GET请求访问URL,并将结果赋值给page_result变量,然后创建一个BeautifulSoup对象parse_obj,将requests page_result.content的返回结果作为参数,然后用 html.parser 解析了这个页面。
现在我们将从类和标签中提取数据。进入网页浏览器,右击要提取的内容向下搜索,找到“勾选”选项,点击获取类名。在程序中指定这个类名并运行脚本。创建一个脚本,将其命名为extract_from_class.py,并在其中写入以下代码。
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
top_news = parse_obj.find(class_='news-article__content')
print(top_news)
运行如下所示的脚本程序。
student@ubuntu:~/work$ python3 extract_from_class.py
Output :
Issa Rae and Laura Dern are teaming up to star in a limited
series called "The Dolls" currently in development at HBO.Inspired by true events, the
series recounts the aftermath of Christmas Eve riots in two small Arkansas
towns in 1983, riots which erupted over Cabbage Patch Dolls. The series
explores class, race, privilege and what it takes to be a "good
mother."Rae will serve as a writer and executive producer on the
series in addition to starring, with Dern also executive producing. Laura Kittrell and Amy Aniobi will also serve as writers and coexecutive
producers. Jayme Lemons of Dern’s
Jaywalker Pictures and Deniese Davis of Issa Rae Productions will also executive
produce.Both Rae and Dern currently star in HBO shows, with Dern
appearing in the acclaimed drama "Big Little
Lies" and Rae starring in and having created the hit comedy "Insecure." Dern also recently starred in the
film "The Tale,
上面的示例程序首先导入 requests 和 BeautifulSoup 模块,然后创建一个 requests 对象并为其分配一个 URL,然后创建一个 BeautifulSoup 对象 parse_obj。该对象以请求的返回结果 page_result.content 为参数,然后使用 html.parser 解析页面。最后,使用 BeautifulSoup 的 find() 方法从 news-article__content 类中获取内容。
现在让我们看一个从特定标签中提取数据的示例程序。此示例程序将从标签中提取数据。创建一个脚本,将其命名为extract_from_tag.py,并在其中写入以下代码。
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com/news')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
top_news = parse_obj.find(class_='news-article__content')
top_news_a_content = top_news.find_all('a')
print(top_news_a_content)
运行如下所示的脚本程序。
student@ubuntu:~/work$ python3 extract_from_tag.py
Output:
[Issa Rae, Laura
Dern, HBO, Laura Kittrell, Amy
Aniobi, Jayme Lemons, Jaywalker Pictures, Deniese Davis, Issa Rae Productions, Big Little Lies, Insecure, The
Tale]
上面的示例程序从标签中提取数据。这里我们使用 find_all() 方法从 news-article__content 类中提取所有标签数据。
3 从 Wikipedia网站 获取信息
在本节中,我们将学习一个示例程序,用于从维基百科网站 获取舞蹈类型列表。在这里,我们将列出所有经典的印度舞蹈。创建一个脚本,将其命名为extract_from_wikipedia.py,并在其中写入以下代码。
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://en.wikipedia.org/wiki/Portal:History')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
h_obj = parse_obj.find(class_='hlist noprint')
h_obj_a_content = h_obj.find_all('a')
print(h_obj)
print(h_obj_a_content)
运行脚本程序如下所示。
student@ubuntu:~/work$ python3 extract_from_wikipedia.py
输出如下。
Portal topics
Activities
Culture
Geography
Health
History
Mathematics
Nature
People
In the preceding example, we extracted the content from Wikipedia. In this
example also, we extracted the content from class as well as tag.
.... 查看全部
Python中的网络爬虫库获取网页的示例程序是什么?
1 什么是网络爬虫
网络爬虫是指从网站中提取数据的技术,可以将非结构化数据转化为结构化数据。
网络爬虫的目的是从网站中提取数据。提取的数据可以存储在本地文件中并保存在系统中,也可以以表格的形式存储在数据库中。网络爬虫使用 HTTP 或网络浏览器直接访问万维网 (WWW)。网络爬虫或机器人抓取网页的过程是一个自动化过程。
抓取网页的过程分为网页获取和数据提取。网络爬虫可以抓取网页,是网络爬虫的必备组件。获取网页后,需要提取网页数据。我们可以对提取的数据进行搜索、解析,并将其保存在表格中,然后重新排列格式。
2 数据提取
在本节中,我们将了解数据提取。我们可以使用 Python 的 BeautifulSoup 库进行数据提取。这里还需要 Python 库的 Requests 模块。
运行以下命令来安装 Requests 和 BeautifulSoup 库。
$ pip3 install requests
$ pip3 install beautifulsoup4
2.1Requests 库
使用请求库以易于理解的格式在 Python 脚本中使用 HTTP。在这里,使用 Python 中的 Requests 库来获取网页。 Requests 库收录不同类型的请求,这里使用 GET 请求。 GET请求用于从Web服务器获取信息,通过GET请求可以获取指定网页的HTML内容。每个请求对应一个状态码,从服务器返回。这些状态码为我们提供了相应请求执行结果的相关信息。以下是一些状态代码。
2.2BeautifulSoup 库
BeautifulSoup 也是一个 Python 库,收录简单的搜索、导航和修改方法。它只是一个从网页中提取所需数据的工具包。
要在脚本中使用 Requests 和 BeautifulSoup 模块,必须使用 import 语句导入这两个模块。现在让我们看一个用于解析网页的示例程序。在这里,我们将解析来自百度网站 的新闻网页。创建一个脚本,命名为parse_web_page.py,在里面写入如下代码。
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
print(parse_obj)
运行如下所示的脚本程序。
student@ubuntu:~/work$ python3 parse_web_page.py
Output:
var IMDbTimer={starttime: new
Date().getTime(),pt:'java'};
if (typeof uet == 'function') {
uet("bb", "LoadTitle", {wb: 1});
}
(function(t){ (t.events = t.events || {})["csm_head_pre_title"] =
new Date().getTime(); })(IMDbTimer);
Top News - IMDb
(function(t){ (t.events = t.events || {})["csm_head_post_title"] =
new Date().getTime(); })(IMDbTimer);
if (typeof uet == 'function') {
uet("be", "LoadTitle", {wb: 1});
}
if (typeof uex == 'function') {
uex("ld", "LoadTitle", {wb: 1});
}
if (typeof uet == 'function') {
uet("bb", "LoadIcons", {wb: 1});
}
上面的示例程序抓取了一个网页并使用 BeautifulSoup 对其进行了解析。首先导入requests和BeautifulSoup模块,然后使用GET请求访问URL,并将结果赋值给page_result变量,然后创建一个BeautifulSoup对象parse_obj,将requests page_result.content的返回结果作为参数,然后用 html.parser 解析了这个页面。
现在我们将从类和标签中提取数据。进入网页浏览器,右击要提取的内容向下搜索,找到“勾选”选项,点击获取类名。在程序中指定这个类名并运行脚本。创建一个脚本,将其命名为extract_from_class.py,并在其中写入以下代码。
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
top_news = parse_obj.find(class_='news-article__content')
print(top_news)
运行如下所示的脚本程序。
student@ubuntu:~/work$ python3 extract_from_class.py
Output :
Issa Rae and Laura Dern are teaming up to star in a limited
series called "The Dolls" currently in development at HBO.Inspired by true events, the
series recounts the aftermath of Christmas Eve riots in two small Arkansas
towns in 1983, riots which erupted over Cabbage Patch Dolls. The series
explores class, race, privilege and what it takes to be a "good
mother."Rae will serve as a writer and executive producer on the
series in addition to starring, with Dern also executive producing. Laura Kittrell and Amy Aniobi will also serve as writers and coexecutive
producers. Jayme Lemons of Dern’s
Jaywalker Pictures and Deniese Davis of Issa Rae Productions will also executive
produce.Both Rae and Dern currently star in HBO shows, with Dern
appearing in the acclaimed drama "Big Little
Lies" and Rae starring in and having created the hit comedy "Insecure." Dern also recently starred in the
film "The Tale,
上面的示例程序首先导入 requests 和 BeautifulSoup 模块,然后创建一个 requests 对象并为其分配一个 URL,然后创建一个 BeautifulSoup 对象 parse_obj。该对象以请求的返回结果 page_result.content 为参数,然后使用 html.parser 解析页面。最后,使用 BeautifulSoup 的 find() 方法从 news-article__content 类中获取内容。
现在让我们看一个从特定标签中提取数据的示例程序。此示例程序将从标签中提取数据。创建一个脚本,将其命名为extract_from_tag.py,并在其中写入以下代码。
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com/news')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
top_news = parse_obj.find(class_='news-article__content')
top_news_a_content = top_news.find_all('a')
print(top_news_a_content)
运行如下所示的脚本程序。
student@ubuntu:~/work$ python3 extract_from_tag.py
Output:
[Issa Rae, Laura
Dern, HBO, Laura Kittrell, Amy
Aniobi, Jayme Lemons, Jaywalker Pictures, Deniese Davis, Issa Rae Productions, Big Little Lies, Insecure, The
Tale]
上面的示例程序从标签中提取数据。这里我们使用 find_all() 方法从 news-article__content 类中提取所有标签数据。
3 从 Wikipedia网站 获取信息
在本节中,我们将学习一个示例程序,用于从维基百科网站 获取舞蹈类型列表。在这里,我们将列出所有经典的印度舞蹈。创建一个脚本,将其命名为extract_from_wikipedia.py,并在其中写入以下代码。
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://en.wikipedia.org/wiki/Portal:History')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
h_obj = parse_obj.find(class_='hlist noprint')
h_obj_a_content = h_obj.find_all('a')
print(h_obj)
print(h_obj_a_content)
运行脚本程序如下所示。
student@ubuntu:~/work$ python3 extract_from_wikipedia.py
输出如下。
Portal topics
Activities
Culture
Geography
Health
History
Mathematics
Nature
People
In the preceding example, we extracted the content from Wikipedia. In this
example also, we extracted the content from class as well as tag.
....
web.jpegJS的语法和基本对象的规范(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-07-12 20:13
web.jpegJS的语法和基本对象的规范(组图)
web.jpeg
JS 由三部分组成
ECMAscript(欧洲计算机制造商协会):描述 JS 语法和基本对象规范
DOM:处理网页(操作页面元素)的文档对象模型、方法和接口
BOM:浏览器对象模型、浏览器交互方法和界面(操作浏览器)
JS 操作 html 元素其实就是操作 DOM 文档对象。整个html文件就是一个文档。那么这个文档就被认为是一个文档对象。文档中的所有标签都可以看作一个对象。那么JS是如何操作的呢?对象呢?
1.JS 获取元素对象的方法
1. 1 根据id从整个文档中获取元素---返回的是一个元素对象
document.getElementById("id 属性值")
/*
在JS中
getElementById(元素的ID)获取元素对象
*/
//获取元素对象
var box = document.getElementById("box");
//向元素对象注册点击事件
box.onclick = function(){
this.style.backgroundColor = "红色";
//设置div里面的内容
box.innerHTML = "
这是h2标签";
}
图像.png
1.2.根据标签名称获取元素-----返回的是元素对象组成的伪数组
document.getElementsByTagName("标签名称");
1.3 这是几个兼容的访问元素
1. 根据name属性的值获取元素,返回的是一个伪数组,里面存放了多个DOM对象---> ocument.getElementsByName("name属性的值")
2. 根据类样式的名称获取元素,返回的是一个伪数组,里面存放了多个DOM对象 -->document.getElementsByClassName("类样式的名称")
3.根据选择器获取元素,返回的是一个元素对象-->document.querySelector("选择器的名字")
4.根据选择器获取元素,返回的是一个伪数组,里面存放了多个DOM对象---->document.querySelectorAll("选择器的名字")
通过JS获取元素对象的目的是修改css样式或者它们之间的交互,那么如何改变样式属性呢?
图像.png
<p>从上面的例子可以看出,如果标签有直接属性,只需要对基本标签的属性进行操作,如:src、title、alt、href、id属性、直接操作赋值 查看全部
web.jpegJS的语法和基本对象的规范(组图)
web.jpeg
JS 由三部分组成
ECMAscript(欧洲计算机制造商协会):描述 JS 语法和基本对象规范
DOM:处理网页(操作页面元素)的文档对象模型、方法和接口
BOM:浏览器对象模型、浏览器交互方法和界面(操作浏览器)
JS 操作 html 元素其实就是操作 DOM 文档对象。整个html文件就是一个文档。那么这个文档就被认为是一个文档对象。文档中的所有标签都可以看作一个对象。那么JS是如何操作的呢?对象呢?
1.JS 获取元素对象的方法
1. 1 根据id从整个文档中获取元素---返回的是一个元素对象
document.getElementById("id 属性值")
/*
在JS中
getElementById(元素的ID)获取元素对象
*/
//获取元素对象
var box = document.getElementById("box");
//向元素对象注册点击事件
box.onclick = function(){
this.style.backgroundColor = "红色";
//设置div里面的内容
box.innerHTML = "
这是h2标签";
}
图像.png
1.2.根据标签名称获取元素-----返回的是元素对象组成的伪数组
document.getElementsByTagName("标签名称");
1.3 这是几个兼容的访问元素
1. 根据name属性的值获取元素,返回的是一个伪数组,里面存放了多个DOM对象---> ocument.getElementsByName("name属性的值")
2. 根据类样式的名称获取元素,返回的是一个伪数组,里面存放了多个DOM对象 -->document.getElementsByClassName("类样式的名称")
3.根据选择器获取元素,返回的是一个元素对象-->document.querySelector("选择器的名字")
4.根据选择器获取元素,返回的是一个伪数组,里面存放了多个DOM对象---->document.querySelectorAll("选择器的名字")
通过JS获取元素对象的目的是修改css样式或者它们之间的交互,那么如何改变样式属性呢?
图像.png
<p>从上面的例子可以看出,如果标签有直接属性,只需要对基本标签的属性进行操作,如:src、title、alt、href、id属性、直接操作赋值
js提取指定网站内容,一般可以使用urllib、正则表达式等方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-07-11 19:01
js提取指定网站内容,一般可以使用urllib、正则表达式等方法。了解更多可以参考下面这个ppt:我在v2ex发过的内容提取的文章。whatisrequests?-segmentfault欢迎访问我的v2ex发现更多的干货。欢迎加我的个人微信交流wechat:fengxzhanyuan或者加入qq群:61346555交流讨论。
python2.5提供了get和post两种网页请求库,post方法还可以对图片进行提取。一.本篇教程,主要讲解post方法如何使用图片。1.明确库library(urllib2)#官方库library(fwflib)#官方库library(getips)#官方库library(base64urllib)#官方库library(phthonglib)#官方库library(mapbox)#官方库2.getimage如何使用图片库主要包括下面几个步骤1.导入库2.安装库3.自定义一个数据结构1.导入库importurllib2importfwflib2.安装库importphthongliburllib2.install_urllib2()3.自定义一个数据结构#。 查看全部
js提取指定网站内容,一般可以使用urllib、正则表达式等方法
js提取指定网站内容,一般可以使用urllib、正则表达式等方法。了解更多可以参考下面这个ppt:我在v2ex发过的内容提取的文章。whatisrequests?-segmentfault欢迎访问我的v2ex发现更多的干货。欢迎加我的个人微信交流wechat:fengxzhanyuan或者加入qq群:61346555交流讨论。
python2.5提供了get和post两种网页请求库,post方法还可以对图片进行提取。一.本篇教程,主要讲解post方法如何使用图片。1.明确库library(urllib2)#官方库library(fwflib)#官方库library(getips)#官方库library(base64urllib)#官方库library(phthonglib)#官方库library(mapbox)#官方库2.getimage如何使用图片库主要包括下面几个步骤1.导入库2.安装库3.自定义一个数据结构1.导入库importurllib2importfwflib2.安装库importphthongliburllib2.install_urllib2()3.自定义一个数据结构#。
【知识点】DOM和HTML树的定义和操作流程
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-07-10 00:08
内容
DOM 的定义
DOM 树
DOM树的定义
为什么是树状结构
根节点
节点对象
节点的三个属性
DOM 操作流程
DOM 查找
无需查找可以直接获取的元素
通过 HTML 搜索
按节点关系搜索
按选择器查找
遍历节点
DOM 搜索摘要
编辑
内容
属性
风格
添加
删除
替换
HTML DOM 常用对象
图片
选择
选项
表格
表格
DOM 的定义
用于操作 Web 内容的文档对象模型 API 标准-W3C
什么时候使用DOM
只要操作网页内容,就必须使用DOM提供的API
DOM 的分类
核心 DOM 和 HTML DOM
Core DOM:最初开发用于操作所有结构化文档的统一 API。优点:通用缺点:繁琐
HTML DOM:专门用于操作 HTML 文档的 API 优点:简洁缺点:不是万能的
总结:在实际开发中,不需要区分核心DOM和HTM LDOM。首选简单的 API。如果不能简单实现,就用复杂的补充
DOM 树
DOM树的定义
网页中的每一个内容都以树状结构存储在内存中,每一个内容(元素、文本、属性)都是树上的一个节点对象
为什么是树状结构
树结构是保存不确定层次深度的下级和下级收录关系的最佳结构
根节点
树结构有一个唯一的树根节点:文档节点。所有网页内容都是文档的子节点
节点对象
网页中的每一项都是一个节点对象,它封装了节点可用的属性和功能
节点的三个属性
nodeType:节点类型 nodeName:节点名称 nodeValue:节点值
节点类型:
功能:不同类型节点的可用属性和可执行操作不同。
包括4种类型:
文档 9
元素 1
属性 2
文本 3
问题:无法进一步区分特定元素名称
节点名称:
功能:进一步区分具体元素名称
包括4种类型:
文档#document
元素标签名称(全部大写)
attribute 属性名称
文本#文本
节点值:
功能:保存节点的值
包括4种类型:
文档为空
元素为空
attribute 属性值
文字文字内容
DOM 操作流程
增删改查+事件处理
找到触发事件的元素---->>绑定事件处理程序
找到要修改的元素---->>修改属性/样式,添加、删除
DOM 查找
1、无需寻找可以直接获取的元素
html document.documentElement
头文件.head
body document.body
2、HTML 搜索
1、通过id查找
var elem = document.getElementById("id"); //直接写id名称
强调:1、 必须与文档一起调用2、 只会返回一个元素
2、按标签名查找多个元素
var elems = document.getElementsByTagName("标签名");
重点:
1、可以在任何父元素上调用,即只查找当前父元素下的后代元素
2、不仅可以找到直接子元素,还可以找到所有后代元素
3、返回由多个元素组成的动态集合
3、按类属性搜索
var elems = document.getElementsByClassName("class");
重点:
1、 可以在任何父元素上调用
2、返回由多个元素组成的动态集合
3、只要收录指定的类名,选择要更改的元素。它不必完全匹配
4、不仅可以找到直接子元素,还可以找到所有后代元素
4、按名称属性搜索
var elems = document.getElementsByName("name");
name 属性只会在查找带有 name 属性的表单时使用
重点:
1、 只能用文档调用
2、返回由多个元素组成的动态集合
3、按节点关系搜索
何时使用:如果你已经获取了一个元素,你想找到周围的元素
1、父子关系
child.parentNode 获取节点的父节点
parent.childNodes 获取父节点下的所有直接子节点
parent.firstChild 获取父节点下的第一个子节点
parent.lastChild 获取父节点下的最后一个直接子节点
2、兄弟关系
elem.nextSibling 获取节点旁边的下一个兄弟节点
elem.previousSibling 获取与某个节点相邻的前一个兄弟节点
问题:我会被看不见的空字符打扰
解决方案:元素树
元素树:仅收录元素节点的树结构。元素树不是新树,只是节点树的部分子集
如何实现:
1、父子关系
child.parentElement 获取节点的父元素
parent.children 获取父元素下的所有直接子元素
parent.firstElementChild 获取父元素下的第一个直接子元素
parent.lastElementChild 获取父元素下的最后一个直接子元素
2、兄弟关系
elem.nextElementSibling 获取与元素相邻的下一个兄弟元素
elem.previousElementSibling 获取与元素相邻的前一个兄弟元素
4、通过选择器查找
1、只查找一个元素
var elem = parent.querySelector("selector");
2、查找多个元素
var elem = parent.querySelectorAll("selector");
重点:
1、 可以在任何父元素上调用
2、返回一个非动态集合(非动态集合:数据的实际存储,即重复访问,不会造成重复搜索DOM树)无首缓存长度的遍历
3、以当前浏览器的兼容性要求为准
5、traverse 节点
遍历节点定义:找到一个父元素下的所有后代节点
如何:
1、定义只遍历直接子节点的函数
2、 为遇到的每个子节点调用与父节点完全相同的操作
算法:深度优先(当同时有子元素和兄弟元素时,总是先遍历子元素。遍历完子元素后,返回兄弟元素)
问题:递归执行效率极低
解决方案:改用循环
操作方法:使用节点迭代器对象(NodeIterator专门按照深度优先遍历的顺序依次访问每个子元素的对象)
1、Create NodeIterator
var iterator = documnet.createNodeIterator(parent,NodeFilter.SHOW_ALL,null,false,SHOW_ELEMENT);
参数:
parent:树中要用作搜索起点的节点
NodeFilter.SHOW_ALL:显示所有类型的节点
NodeFilter.SHOW_ELEMENT:显示元素节点
NodeFilter.SHOW_TEXT:显示文本节点
NodeFilter.SHOW_COMMENT:显示评论节点
NodeFilter.SHOW_DOCUMENT:显示文档节点
2、循环调用NodeIterator的nextNode()函数
NodeIterator 的主要方法是 nextNode() 和 previousNode()
如何:
1.,返回当前节点
2.,跳转到下一个节点返回null退出
例如:
HTML 的结构:
你好
世界
遍历root下的所有元素:
var iterator = document.createNodeIterator(root, NodeFilter.SHOW_ELEMENT, null, false);
var node = iterator.nextNode();
while(节点 !== null){
console.log( node.tagName );
node = iterator.nextNode();
}
遍历root下的所有p个元素:
var filter = function(node){
返回 node.tagName.toLowerCase() =='p' ?
NodeFilter.FILTER_ACCEPT:
NodeFilter.FILTER_REJECT;
}
var iterator = document.createNodeIterator(root, NodeFilter.SHOW_ELEMENT, filter, false);
var node = iterator.nextNode();
while(节点 !== null){
console.log( node.tagName );
node = iterator.nextNode();
}
DOM 搜索摘要
1.如果已经获取到一个元素,则查找周围的元素:利用节点之间的关系来查找
2.如果传入一个条件,就可以找到你想要的元素:使用HTML搜索
3.如果搜索条件复杂:使用选择器API
按 HTML 与选择器
1.返回值:通过HTML搜索:返回动态集合
按选择器搜索:返回非动态集合
2.效率:第一次搜索通过HTML高效!
按选择器搜索有点慢!
3. 好用:按选择器搜索更简洁
HTML 搜索比较麻烦
编辑
1、content
.innerHTML .textContent .value
2、Attributes
标准属性:HTML 标准中规定的属性
1、Core DOM(4 个 API)
1、获取指定属性的值:
elem.getAttribute("属性名称")
2、修改指定属性的值:
elem.setAttribute("属性名", "值")
3、判断是否收录指定的属性:
elem.hasAttribute("属性名称")
4、去掉指定的属性:
elem.removeAttribute("属性名称")
2、HTML DOM:所有标准属性都预先封装在元素对象中,可以直接用“.”访问
1、获取指定属性的值:
elem.属性名称
2、修改指定属性的值:
elem.attribute name = "value"
3、判断是否收录指定的属性:
元素。属性名! ==""
4、去掉指定的属性:
elem.attribute name = ""
3、clas 属性
Class 是 E5 中的保留字,不能使用 DOM。使用 className 而不是 class
4、Status 属性
禁用选中选中
不能用核心 DOM 访问,只能用 HTML DOM 访问。值都是bool类型
5、自定义扩展属性(不能用HTML DOM访问自定义扩展属性)
1、核心DOM
2、HTML5:
定义属性:data-attribute name = "value"
访问:elem.dataset。属性名
3、style
1、内联
1、编辑:
elem.style.css 属性名称
css属性名必须从横线改成驼峰。优点:最高优先级,只有当前元素有自己的
2、阅读:
不能使用 style.css 属性名称。因为style只能获取内联样式,不能获取样式表中继承/级联的样式
解决方案:
以后,无论何时阅读一个样式,都必须阅读计算出的样式。 (计算样式:最终应用于元素的所有样式的合成,相对单位计算为绝对单位)
1、计算后得到所有css属性的总和:样式对象
var style = getComputedStyle(elem)
2、从样式中获取想要的css属性
style.css 属性
注意:计算出的样式是只读的,不能修改
问题:一句话只能修改一个css属性
解决方法:如何批量修改一个元素的多个属性:
1、先在css中定义多个属性为一个类
2、修改JS中元素的className为指定类
添加
1、创建一个新的空元素
var a = document.createElement("a");
2、设置密钥属性 查看全部
【知识点】DOM和HTML树的定义和操作流程
内容
DOM 的定义
DOM 树
DOM树的定义
为什么是树状结构
根节点
节点对象
节点的三个属性
DOM 操作流程
DOM 查找
无需查找可以直接获取的元素
通过 HTML 搜索
按节点关系搜索
按选择器查找
遍历节点
DOM 搜索摘要
编辑
内容
属性
风格
添加
删除
替换
HTML DOM 常用对象
图片
选择
选项
表格
表格
DOM 的定义
用于操作 Web 内容的文档对象模型 API 标准-W3C
什么时候使用DOM
只要操作网页内容,就必须使用DOM提供的API
DOM 的分类
核心 DOM 和 HTML DOM
Core DOM:最初开发用于操作所有结构化文档的统一 API。优点:通用缺点:繁琐
HTML DOM:专门用于操作 HTML 文档的 API 优点:简洁缺点:不是万能的
总结:在实际开发中,不需要区分核心DOM和HTM LDOM。首选简单的 API。如果不能简单实现,就用复杂的补充
DOM 树
DOM树的定义
网页中的每一个内容都以树状结构存储在内存中,每一个内容(元素、文本、属性)都是树上的一个节点对象
为什么是树状结构
树结构是保存不确定层次深度的下级和下级收录关系的最佳结构
根节点
树结构有一个唯一的树根节点:文档节点。所有网页内容都是文档的子节点
节点对象
网页中的每一项都是一个节点对象,它封装了节点可用的属性和功能
节点的三个属性
nodeType:节点类型 nodeName:节点名称 nodeValue:节点值
节点类型:
功能:不同类型节点的可用属性和可执行操作不同。
包括4种类型:
文档 9
元素 1
属性 2
文本 3
问题:无法进一步区分特定元素名称
节点名称:
功能:进一步区分具体元素名称
包括4种类型:
文档#document
元素标签名称(全部大写)
attribute 属性名称
文本#文本
节点值:
功能:保存节点的值
包括4种类型:
文档为空
元素为空
attribute 属性值
文字文字内容
DOM 操作流程
增删改查+事件处理
找到触发事件的元素---->>绑定事件处理程序
找到要修改的元素---->>修改属性/样式,添加、删除
DOM 查找
1、无需寻找可以直接获取的元素
html document.documentElement
头文件.head
body document.body
2、HTML 搜索
1、通过id查找
var elem = document.getElementById("id"); //直接写id名称
强调:1、 必须与文档一起调用2、 只会返回一个元素
2、按标签名查找多个元素
var elems = document.getElementsByTagName("标签名");
重点:
1、可以在任何父元素上调用,即只查找当前父元素下的后代元素
2、不仅可以找到直接子元素,还可以找到所有后代元素
3、返回由多个元素组成的动态集合
3、按类属性搜索
var elems = document.getElementsByClassName("class");
重点:
1、 可以在任何父元素上调用
2、返回由多个元素组成的动态集合
3、只要收录指定的类名,选择要更改的元素。它不必完全匹配
4、不仅可以找到直接子元素,还可以找到所有后代元素
4、按名称属性搜索
var elems = document.getElementsByName("name");
name 属性只会在查找带有 name 属性的表单时使用
重点:
1、 只能用文档调用
2、返回由多个元素组成的动态集合
3、按节点关系搜索
何时使用:如果你已经获取了一个元素,你想找到周围的元素
1、父子关系
child.parentNode 获取节点的父节点
parent.childNodes 获取父节点下的所有直接子节点
parent.firstChild 获取父节点下的第一个子节点
parent.lastChild 获取父节点下的最后一个直接子节点
2、兄弟关系
elem.nextSibling 获取节点旁边的下一个兄弟节点
elem.previousSibling 获取与某个节点相邻的前一个兄弟节点
问题:我会被看不见的空字符打扰
解决方案:元素树
元素树:仅收录元素节点的树结构。元素树不是新树,只是节点树的部分子集
如何实现:
1、父子关系
child.parentElement 获取节点的父元素
parent.children 获取父元素下的所有直接子元素
parent.firstElementChild 获取父元素下的第一个直接子元素
parent.lastElementChild 获取父元素下的最后一个直接子元素
2、兄弟关系
elem.nextElementSibling 获取与元素相邻的下一个兄弟元素
elem.previousElementSibling 获取与元素相邻的前一个兄弟元素
4、通过选择器查找
1、只查找一个元素
var elem = parent.querySelector("selector");
2、查找多个元素
var elem = parent.querySelectorAll("selector");
重点:
1、 可以在任何父元素上调用
2、返回一个非动态集合(非动态集合:数据的实际存储,即重复访问,不会造成重复搜索DOM树)无首缓存长度的遍历
3、以当前浏览器的兼容性要求为准
5、traverse 节点
遍历节点定义:找到一个父元素下的所有后代节点
如何:
1、定义只遍历直接子节点的函数
2、 为遇到的每个子节点调用与父节点完全相同的操作
算法:深度优先(当同时有子元素和兄弟元素时,总是先遍历子元素。遍历完子元素后,返回兄弟元素)
问题:递归执行效率极低
解决方案:改用循环
操作方法:使用节点迭代器对象(NodeIterator专门按照深度优先遍历的顺序依次访问每个子元素的对象)
1、Create NodeIterator
var iterator = documnet.createNodeIterator(parent,NodeFilter.SHOW_ALL,null,false,SHOW_ELEMENT);
参数:
parent:树中要用作搜索起点的节点
NodeFilter.SHOW_ALL:显示所有类型的节点
NodeFilter.SHOW_ELEMENT:显示元素节点
NodeFilter.SHOW_TEXT:显示文本节点
NodeFilter.SHOW_COMMENT:显示评论节点
NodeFilter.SHOW_DOCUMENT:显示文档节点
2、循环调用NodeIterator的nextNode()函数
NodeIterator 的主要方法是 nextNode() 和 previousNode()
如何:
1.,返回当前节点
2.,跳转到下一个节点返回null退出
例如:
HTML 的结构:
你好
世界
遍历root下的所有元素:
var iterator = document.createNodeIterator(root, NodeFilter.SHOW_ELEMENT, null, false);
var node = iterator.nextNode();
while(节点 !== null){
console.log( node.tagName );
node = iterator.nextNode();
}
遍历root下的所有p个元素:
var filter = function(node){
返回 node.tagName.toLowerCase() =='p' ?
NodeFilter.FILTER_ACCEPT:
NodeFilter.FILTER_REJECT;
}
var iterator = document.createNodeIterator(root, NodeFilter.SHOW_ELEMENT, filter, false);
var node = iterator.nextNode();
while(节点 !== null){
console.log( node.tagName );
node = iterator.nextNode();
}
DOM 搜索摘要
1.如果已经获取到一个元素,则查找周围的元素:利用节点之间的关系来查找
2.如果传入一个条件,就可以找到你想要的元素:使用HTML搜索
3.如果搜索条件复杂:使用选择器API
按 HTML 与选择器
1.返回值:通过HTML搜索:返回动态集合
按选择器搜索:返回非动态集合
2.效率:第一次搜索通过HTML高效!
按选择器搜索有点慢!
3. 好用:按选择器搜索更简洁
HTML 搜索比较麻烦
编辑
1、content
.innerHTML .textContent .value
2、Attributes
标准属性:HTML 标准中规定的属性
1、Core DOM(4 个 API)
1、获取指定属性的值:
elem.getAttribute("属性名称")
2、修改指定属性的值:
elem.setAttribute("属性名", "值")
3、判断是否收录指定的属性:
elem.hasAttribute("属性名称")
4、去掉指定的属性:
elem.removeAttribute("属性名称")
2、HTML DOM:所有标准属性都预先封装在元素对象中,可以直接用“.”访问
1、获取指定属性的值:
elem.属性名称
2、修改指定属性的值:
elem.attribute name = "value"
3、判断是否收录指定的属性:
元素。属性名! ==""
4、去掉指定的属性:
elem.attribute name = ""
3、clas 属性
Class 是 E5 中的保留字,不能使用 DOM。使用 className 而不是 class
4、Status 属性
禁用选中选中
不能用核心 DOM 访问,只能用 HTML DOM 访问。值都是bool类型
5、自定义扩展属性(不能用HTML DOM访问自定义扩展属性)
1、核心DOM
2、HTML5:
定义属性:data-attribute name = "value"
访问:elem.dataset。属性名
3、style
1、内联
1、编辑:
elem.style.css 属性名称
css属性名必须从横线改成驼峰。优点:最高优先级,只有当前元素有自己的
2、阅读:
不能使用 style.css 属性名称。因为style只能获取内联样式,不能获取样式表中继承/级联的样式
解决方案:
以后,无论何时阅读一个样式,都必须阅读计算出的样式。 (计算样式:最终应用于元素的所有样式的合成,相对单位计算为绝对单位)
1、计算后得到所有css属性的总和:样式对象
var style = getComputedStyle(elem)
2、从样式中获取想要的css属性
style.css 属性
注意:计算出的样式是只读的,不能修改
问题:一句话只能修改一个css属性
解决方法:如何批量修改一个元素的多个属性:
1、先在css中定义多个属性为一个类
2、修改JS中元素的className为指定类
添加
1、创建一个新的空元素
var a = document.createElement("a");
2、设置密钥属性
指导浏览器动作的,对服务器端完全无用
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-06-28 05:18
# 用于引导浏览器动作,在服务器端完全没用。因此,# 不收录在 HTTP 请求中。
比如访问下面这个网站,浏览器实际发送的请求是这样的:
GET /index.html HTTP/1.1
Host: www.example.com
三、#后面的字符
出现在第一个 # 之后的任何字符都将被浏览器解释为位置标识符。这意味着这些字符都不会发送到服务器。
比如下面这个网址的初衷是指定一个颜色值:,但是浏览器实际发送的请求是:
GET /?color= HTTP/1.1
Host: www.example.com
四、改#不触发网页重新加载
单次更改#后的部分,浏览器只会滚动到对应位置,不会重新加载网页。
例如,如果您将#location1 更改为#location2,浏览器将不会再次向服务器请求index.html。
五、改#会改变浏览器的访问历史
每次更改#后的部分,都会在浏览器的访问历史中添加一条记录。使用“返回”按钮返回到之前的位置。这对 ajax 应用程序特别有用。可以用不同的#值来表示不同的访问状态,然后给用户一个链接来访问某个状态。值得注意的是,以上规则对IE 6和IE 7无效,不会因为#的变化而增加历史记录。
六、window.location.hash 读取#value
属性 window.location.hash 是可读可写的。阅读时,可以用来判断网页的状态是否发生了变化;写入时会创建访问历史记录,无需重新加载网页。
七、onhashchange 事件
这是一个新的 HTML 5 事件。当#value 发生变化时,将触发此事件。 IE8+、Firefox 3.6+、Chrome 5+、Safari 4.0+ 支持此事件。
共有三种使用方式:
对于不支持onhashchange的浏览器,可以使用setInterval来监控location.hash的变化。
八、GoogleGrabber#的机制
默认情况下,Google 的网络蜘蛛会忽略 URL 的 # 部分。
不过,Google 也规定,如果希望 Ajax 生成的内容被浏览器引擎读取,可以使用“#!”在 URL 中,Google 会自动将其后面的内容转换为查询字符串 _escaped_fragment_ 的值。
比如谷歌找到了新版推特的网址:
将自动获取另一个 URL:_escaped_fragment_=/username
通过这种机制,Google 可以索引动态 Ajax 内容。
注意
AJAX= 异步 JavaScript 和 XML(标准通用标记语言的一个子集)。 AJAX 是一种用于创建快速动态网页的技术。
2.?
1)连接函数:例如
http://www.xxx.com/Show.asp%3F ... e%3D1
2)清除缓存:例如
http://www.xxxxx.com/index.html
http://www.xxxxx.com/index.html?test123123
两个url打开的页面是一样的,只是后面有个问号,表示没有调用缓存的内容,而是考虑了一个新的地址,重新读取。
3.&
不同参数的垫片
关于js获取URL信息
设置或获取对象指定的文件名或路径。
警报(window.location.pathname)
将整个 URL 设置或获取为字符串。
警报(window.location.href);
设置或获取与 URL 关联的端口号。
警报(window.location.port)
设置或获取 URL 的协议部分。
警报(window.location.protocol)
设置或获取href属性中井号“#”后的部分。
警报(window.location.hash)
设置或获取位置或 URL 的主机名和端口号。
警报(window.location.host)
设置或获取 href 属性中问号后面的部分。
警报(window.location.search)
获取变量的值(截取等号后的部分)
var url = window.location.search;
// alert(url.length);
// alert(url.lastIndexOf('='));
var loc = url.substring(url.lastIndexOf('=')+1, url.length); 查看全部
指导浏览器动作的,对服务器端完全无用
# 用于引导浏览器动作,在服务器端完全没用。因此,# 不收录在 HTTP 请求中。
比如访问下面这个网站,浏览器实际发送的请求是这样的:
GET /index.html HTTP/1.1
Host: www.example.com
三、#后面的字符
出现在第一个 # 之后的任何字符都将被浏览器解释为位置标识符。这意味着这些字符都不会发送到服务器。
比如下面这个网址的初衷是指定一个颜色值:,但是浏览器实际发送的请求是:
GET /?color= HTTP/1.1
Host: www.example.com
四、改#不触发网页重新加载
单次更改#后的部分,浏览器只会滚动到对应位置,不会重新加载网页。
例如,如果您将#location1 更改为#location2,浏览器将不会再次向服务器请求index.html。
五、改#会改变浏览器的访问历史
每次更改#后的部分,都会在浏览器的访问历史中添加一条记录。使用“返回”按钮返回到之前的位置。这对 ajax 应用程序特别有用。可以用不同的#值来表示不同的访问状态,然后给用户一个链接来访问某个状态。值得注意的是,以上规则对IE 6和IE 7无效,不会因为#的变化而增加历史记录。
六、window.location.hash 读取#value
属性 window.location.hash 是可读可写的。阅读时,可以用来判断网页的状态是否发生了变化;写入时会创建访问历史记录,无需重新加载网页。
七、onhashchange 事件
这是一个新的 HTML 5 事件。当#value 发生变化时,将触发此事件。 IE8+、Firefox 3.6+、Chrome 5+、Safari 4.0+ 支持此事件。
共有三种使用方式:
对于不支持onhashchange的浏览器,可以使用setInterval来监控location.hash的变化。
八、GoogleGrabber#的机制
默认情况下,Google 的网络蜘蛛会忽略 URL 的 # 部分。
不过,Google 也规定,如果希望 Ajax 生成的内容被浏览器引擎读取,可以使用“#!”在 URL 中,Google 会自动将其后面的内容转换为查询字符串 _escaped_fragment_ 的值。
比如谷歌找到了新版推特的网址:
将自动获取另一个 URL:_escaped_fragment_=/username
通过这种机制,Google 可以索引动态 Ajax 内容。
注意
AJAX= 异步 JavaScript 和 XML(标准通用标记语言的一个子集)。 AJAX 是一种用于创建快速动态网页的技术。
2.?
1)连接函数:例如
http://www.xxx.com/Show.asp%3F ... e%3D1
2)清除缓存:例如
http://www.xxxxx.com/index.html
http://www.xxxxx.com/index.html?test123123
两个url打开的页面是一样的,只是后面有个问号,表示没有调用缓存的内容,而是考虑了一个新的地址,重新读取。
3.&
不同参数的垫片
关于js获取URL信息
设置或获取对象指定的文件名或路径。
警报(window.location.pathname)
将整个 URL 设置或获取为字符串。
警报(window.location.href);
设置或获取与 URL 关联的端口号。
警报(window.location.port)
设置或获取 URL 的协议部分。
警报(window.location.protocol)
设置或获取href属性中井号“#”后的部分。
警报(window.location.hash)
设置或获取位置或 URL 的主机名和端口号。
警报(window.location.host)
设置或获取 href 属性中问号后面的部分。
警报(window.location.search)
获取变量的值(截取等号后的部分)
var url = window.location.search;
// alert(url.length);
// alert(url.lastIndexOf('='));
var loc = url.substring(url.lastIndexOf('=')+1, url.length);
国家地理中文网中的图片为例,演示爬虫具备的基本功能
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-06-25 00:04
本文以爬取国家地理中文网站旅游类图片为例,演示爬虫的基本功能。
给定初始地址
国家地理中文网站:
获取和分析网页内容
一个。分析网页的结构以确定所需的内容部分
打开网页,右键选择“显示网页源代码”查看网页结构,以下是我截取的部分
我们会发现image类型的数据都放在标签的scr=""里面。我们只需要找到这些标签,从中提取出我们想要的联系,就可以完成我们的期望。
B.获取网页内容
要提取内容,首先要向服务器发起获取文件的请求,然后对图片信息进行分析提取,并对数据进行整理和保存
作者使用的Python3.6,获取网页内容常用的有两种方法:requests和urllib(结合python2中的urllib和urllib2)。获取网页内容请参考这篇文章:爬虫基础:Python 获取网页内容
现在,我们定义一个方法 crawl() 来获取网页
import requests
def crawl(url, headers):
with requests.get(url=url, headers=headers) as response:
# 读取response里的内容,并转码
data = response.content.decode()
return data
调用此方法获取网页内容:
# 获取指定网页内容
url = 'http://www.ngchina.com.cn/travel/'
headers = {'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Mobile Safari/537.36'}
content = crawl(url, headers)
print(content)
写正则表达式匹配图片内容
这样我们就抓取到了给定地址中的图片信息,我们选择其中之一:
入库并进行下一轮爬取
我们抓取到指定的内容后,就可以将其保存到数据库中;如果是链接类型的抓取,我们可以创建一个URL队列,将指定URL中的新链接加入到URL队列中,然后进行轮次遍历和爬取,对于队列URL的处理,需要相应的策略通过根据具体需要完成相应的任务。更多爬虫信息可以参考:初始爬虫。
补充:
我们在写正则表达式的时候,可以使用网上的正则表达式工具快速查看匹配结果:菜鸟正则表达式工具。还有一些常用的正则表达式已经写在这个地址里了,比如电话、QQ号、网站、邮箱等,非常好用。 查看全部
国家地理中文网中的图片为例,演示爬虫具备的基本功能
本文以爬取国家地理中文网站旅游类图片为例,演示爬虫的基本功能。
给定初始地址
国家地理中文网站:
获取和分析网页内容
一个。分析网页的结构以确定所需的内容部分
打开网页,右键选择“显示网页源代码”查看网页结构,以下是我截取的部分
我们会发现image类型的数据都放在标签的scr=""里面。我们只需要找到这些标签,从中提取出我们想要的联系,就可以完成我们的期望。
B.获取网页内容
要提取内容,首先要向服务器发起获取文件的请求,然后对图片信息进行分析提取,并对数据进行整理和保存
作者使用的Python3.6,获取网页内容常用的有两种方法:requests和urllib(结合python2中的urllib和urllib2)。获取网页内容请参考这篇文章:爬虫基础:Python 获取网页内容
现在,我们定义一个方法 crawl() 来获取网页
import requests
def crawl(url, headers):
with requests.get(url=url, headers=headers) as response:
# 读取response里的内容,并转码
data = response.content.decode()
return data
调用此方法获取网页内容:
# 获取指定网页内容
url = 'http://www.ngchina.com.cn/travel/'
headers = {'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Mobile Safari/537.36'}
content = crawl(url, headers)
print(content)
写正则表达式匹配图片内容
这样我们就抓取到了给定地址中的图片信息,我们选择其中之一:
入库并进行下一轮爬取
我们抓取到指定的内容后,就可以将其保存到数据库中;如果是链接类型的抓取,我们可以创建一个URL队列,将指定URL中的新链接加入到URL队列中,然后进行轮次遍历和爬取,对于队列URL的处理,需要相应的策略通过根据具体需要完成相应的任务。更多爬虫信息可以参考:初始爬虫。
补充:
我们在写正则表达式的时候,可以使用网上的正则表达式工具快速查看匹配结果:菜鸟正则表达式工具。还有一些常用的正则表达式已经写在这个地址里了,比如电话、QQ号、网站、邮箱等,非常好用。
动用浏览器内核(PhantomJS、Selenium等)的方案
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-06-23 00:13
那些使用浏览器内核的程序(PhantomJS、Selenium等)太重了,
上面链接中的博客解释了如何通过抓取 Ajax请求采样的数据来抓取前端渲染的网页,这是“网页内容由JavaScript生成”的主题。摘录如下:
链接:http://xlzd.me/2015/12/19/python-crawler-04
来源:xlzd 杂谈
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在抓取网页时,有时会发现HTML中没有我们需要的数据。这个时候我该怎么办?
我们的目的是抓取拉勾Python类下目前全国显示的所有招聘信息。首先,在浏览器中点击查看。如果你够细心或者网速比较慢,那么你会发现在点击Python分类后跳转到的新页面上,招聘信息的出现时间晚于页框的出现时间。至此,我们几乎可以确定招聘信息不在页面的 HTML 源代码中。我们可以通过command+option+u(windows和linux的快捷键是ctrl+u)来查看网页的源码,在源码中。页面上没有显示招聘信息。
此时,我看到的大部分教程都会教使用什么库,如何模拟浏览器环境,如何完成网页的渲染,然后获取里面的信息……永远记住对于爬虫程序,模拟浏览器通常是最糟糕的事情。只有在没有其他办法的情况下才考虑模拟浏览器环境,因为那种内存开销真的很大,效率很低。
那我们怎么处理呢?经验是,在这种情况下,大多数情况是浏览器在请求解析完HTML后,会根据js的“指令”再发送一次请求,得到页面显示的内容,然后显示给浏览器通过js渲染后的界面。好消息是,此类请求的内容往往是json格式,这样既不加重爬虫任务,又可以省去解析HTML的工作量。
好吧,继续打开 Chrome 的开发者工具。我们点击“下一步”后,浏览器发送了如下请求:
注意 positionAjax.json 请求。它的Type是xhr,它的全名是XMLHttpRequest。 XMLHttpRequest 对象可以部分更新网页,而无需将整个页面提交给服务器。所以,现在的可能性最大,我们点开后仔细观察一下:
点击后,我们在右下角找到了上面的详细信息,几个选项卡的内容表明:
通过内容观察,返回的确实是一个json字符串,里面收录了这个页面的每一条招聘信息。至少我们这里已经说清楚了,不用解析HTML就可以获取招聘信息。那么,应该如何模拟请求呢?我们切换到Headers列,注意三个地方:
上图显示了本次请求的请求方式、请求地址等信息。
上面的截图显示了这个请求的请求头。一般来说,我们需要注意Cookie/Host/Origin/Referer/User-Agent/X-Requested-With等参数。
上面的屏幕截图显示了为此请求提交的数据。根据观察,kd代表我们查询的关键字,pn代表当前页码。
那么,我们的爬虫需要做的就是根据页码不断向这个接口发送请求,解析其中的json内容,并存储我们需要的值。这里有两个问题:什么时候结束,如何获取json中有价值的内容。
我们回去重新观察返回的json,格式化后的层次关系如下:
很容易发现content下的hasNextPage是是否有下一页,content下的结果是一个list,每一个都是一个job信息。在 Python 中,json 字符串到对象的映射可以通过 json 库来完成:
import json
json_obj = json.loads("{'key': 'value'}") # 字符串到对象
json_str = json.dumps(json_obj) # 对象到字符串
映射到Python的json字符串的“[]”类型是list,映射到Python的“{}”类型是dict。至此,分析过程完全结束,可以愉快的写代码了。具体代码这里不再给出。我希望你能自己完成。如果在写作过程中遇到问题,可以联系我寻求帮助。
总结
本篇博客介绍了在HTML源码中没有的情况下爬取一些数据的方法,适用于某些情况。 查看全部
动用浏览器内核(PhantomJS、Selenium等)的方案
那些使用浏览器内核的程序(PhantomJS、Selenium等)太重了,
上面链接中的博客解释了如何通过抓取 Ajax请求采样的数据来抓取前端渲染的网页,这是“网页内容由JavaScript生成”的主题。摘录如下:
链接:http://xlzd.me/2015/12/19/python-crawler-04
来源:xlzd 杂谈
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在抓取网页时,有时会发现HTML中没有我们需要的数据。这个时候我该怎么办?
我们的目的是抓取拉勾Python类下目前全国显示的所有招聘信息。首先,在浏览器中点击查看。如果你够细心或者网速比较慢,那么你会发现在点击Python分类后跳转到的新页面上,招聘信息的出现时间晚于页框的出现时间。至此,我们几乎可以确定招聘信息不在页面的 HTML 源代码中。我们可以通过command+option+u(windows和linux的快捷键是ctrl+u)来查看网页的源码,在源码中。页面上没有显示招聘信息。
此时,我看到的大部分教程都会教使用什么库,如何模拟浏览器环境,如何完成网页的渲染,然后获取里面的信息……永远记住对于爬虫程序,模拟浏览器通常是最糟糕的事情。只有在没有其他办法的情况下才考虑模拟浏览器环境,因为那种内存开销真的很大,效率很低。
那我们怎么处理呢?经验是,在这种情况下,大多数情况是浏览器在请求解析完HTML后,会根据js的“指令”再发送一次请求,得到页面显示的内容,然后显示给浏览器通过js渲染后的界面。好消息是,此类请求的内容往往是json格式,这样既不加重爬虫任务,又可以省去解析HTML的工作量。
好吧,继续打开 Chrome 的开发者工具。我们点击“下一步”后,浏览器发送了如下请求:
注意 positionAjax.json 请求。它的Type是xhr,它的全名是XMLHttpRequest。 XMLHttpRequest 对象可以部分更新网页,而无需将整个页面提交给服务器。所以,现在的可能性最大,我们点开后仔细观察一下:
点击后,我们在右下角找到了上面的详细信息,几个选项卡的内容表明:
通过内容观察,返回的确实是一个json字符串,里面收录了这个页面的每一条招聘信息。至少我们这里已经说清楚了,不用解析HTML就可以获取招聘信息。那么,应该如何模拟请求呢?我们切换到Headers列,注意三个地方:
上图显示了本次请求的请求方式、请求地址等信息。
上面的截图显示了这个请求的请求头。一般来说,我们需要注意Cookie/Host/Origin/Referer/User-Agent/X-Requested-With等参数。
上面的屏幕截图显示了为此请求提交的数据。根据观察,kd代表我们查询的关键字,pn代表当前页码。
那么,我们的爬虫需要做的就是根据页码不断向这个接口发送请求,解析其中的json内容,并存储我们需要的值。这里有两个问题:什么时候结束,如何获取json中有价值的内容。
我们回去重新观察返回的json,格式化后的层次关系如下:
很容易发现content下的hasNextPage是是否有下一页,content下的结果是一个list,每一个都是一个job信息。在 Python 中,json 字符串到对象的映射可以通过 json 库来完成:
import json
json_obj = json.loads("{'key': 'value'}") # 字符串到对象
json_str = json.dumps(json_obj) # 对象到字符串
映射到Python的json字符串的“[]”类型是list,映射到Python的“{}”类型是dict。至此,分析过程完全结束,可以愉快的写代码了。具体代码这里不再给出。我希望你能自己完成。如果在写作过程中遇到问题,可以联系我寻求帮助。
总结
本篇博客介绍了在HTML源码中没有的情况下爬取一些数据的方法,适用于某些情况。
什么是HTML源码网页动态生成?如何对网页进行爬取?
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-06-22 18:48
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
部分网站内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。例如,今天的头条新闻:
HTML 源代码
网页上的新闻在HTML源代码中找不到,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页?有两种方式:
1、从网页响应中查找JS脚本返回的JSON数据; 2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例说明:
1、找到JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”标签后,我们发现有很多回复。让我们过滤它们,只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
原来都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到想要的消息,所以再找一下:
有个焦点,我们点一下看看:
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看的是正常编码的数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求并解析数据接口数据
先上传完整代码:
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
# print news
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(json.dumps(title).decode("unicode-escape"))
print img_url 查看全部
什么是HTML源码网页动态生成?如何对网页进行爬取?
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
部分网站内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。例如,今天的头条新闻:
HTML 源代码
网页上的新闻在HTML源代码中找不到,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页?有两种方式:
1、从网页响应中查找JS脚本返回的JSON数据; 2、使用Selenium模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例说明:
1、找到JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”标签后,我们发现有很多回复。让我们过滤它们,只查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
原来都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到想要的消息,所以再找一下:
有个焦点,我们点一下看看:
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看的是正常编码的数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求并解析数据接口数据
先上传完整代码:
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
# print news
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(json.dumps(title).decode("unicode-escape"))
print img_url
内容简而易懂,条理清晰--jQuery国际化
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-06-19 21:13
这次文章主要给大家展示了《如何使用jQuery.i18n.properties实现js国际化》,内容简单易懂,条理清晰,希望能帮到大家解惑,让小编带路大家一起研究学习《如何使用jQuery.i18n.properties实现js国际化》文章。
我们在做前端页面开发的时候,因为页面内容太多太复杂,有时候一个页面有几千行(当然这样的页面是正常的),为了减少页面的内容,我们将 page 的 js 文件解压出来,放入特定的 js 文件中,然后导入到页面中。这样,当我们需要做应用的国际化时,就需要考虑js的国际化。这里介绍使用JQuery.i18n.properties实现js的国际化。
PS:jQuery.i18n.properties 是一个轻量级的 jQuery 国际插件。类似于 Java 中的资源文件,jQuery.i18n.properties 使用 .properties 文件来国际化 JavaScript。 jQuery.i18n.properties 插件根据用户指定的(或浏览器提供的)语言和国家代码(符合ISO-639和ISO-3166)解析对应的后缀为“.properties”的资源文件标准)。
使用资源文件实现国际化是一种流行的方式。例如,Android 应用程序可以使用以语言和国家代码命名的资源文件来实现国际化。 jQuery.i18n.properties 插件中的资源文件以“.properties”为后缀,收录区域相关的键值对。我们知道Java程序也可以使用后缀为.properties的资源文件来实现国际化。因此,当我们想要在 Java 程序和前端 JavaScript 程序之间共享资源文件时,这种方法特别有用。 jQuery.i18n.properties 插件首先加载默认的资源文件(例如:strings.properties),然后加载特定语言环境的资源文件(例如:strings_zh.properties),这样可以确保当某个不提供语言翻译,默认值始终有效。开发者可以以 JavaScript 变量(或函数)或 Maps 的形式使用资源文件中的密钥。
那么如何使用jQuery.i18n.properties来实现js国际化?
第一步:创建属性资源文件。
属性资源文件的命名规则是:string_browser language shortcode.properties,例如简体中文:string_zh-CN.properties 这里需要注意下划线而不是下划线。如图,我创建了三个资源文件
js_en-US.properties(美国英语)、js_ja.properties(日语)、js_zh-CN.properties(简体中文)。
第2步:在js文件中引入jQuery.i18n.properties需要的js文件。
因为jQuery.i18n.properties依赖于Jquery框架,所以需要在js文件中收录jQuery.i18n.properties需要的js文件。
导入红色部分的js使用jQuery.i18n.properties。
第 3 步:使用 jQuery.i18n.properties API
$(document).ready(function(){
//国际化加载属性文件
jQuery.i18n.properties({
name:'js',
path:'/js/i18n/',
mode:'map',
callback: function() {// 加载成功后设置显示内容
//alert(jQuery.i18n.prop("theme_manage.js_activity"));
}
});
});
name后面的值是你定义的资源文件中语言短代码前面的字符串,因为我的资源文件是js_xxx.properties,所以这个值是js
背后的价值
path 是你的资源文件的相对路径。即相对于项目结构WebContent下的路径
mode 后面的值是加载模式; “vars”表示以JavaScript变量或函数的形式加载资源文件中的key值(默认是this),“map”表示以map值的形式加载资源文件中的key。 “都意味着这两种方法可以同时使用。”我在这里使用地图。
callback 是一个回调函数。
如何根据不同的语言环境加载不同的资源文件?其实jQuery.i18n.properties的原理就是根据名字后面的值找到对应的资源文件,加上浏览器的语言短码,加上.properties。这个过程是自动的,只需要上面的配置。
propertites中的key-value对如下:(properties文件中的中文会自动转换成对应的ASCII值,当然这里可以设置,也可以通过插件修改.反正我没这么做,是从页面复制过来的,不管),等号前的值是key,等号后的值是value(注意不同资源文件中的key必须一致和定制)。
这样,资源文件中的内容就已经加载完毕。
第四步:根据key在js文件中找到对应的值。
红色部分为取值方式,引号内的字符串对应上述资源文件中的键值。
注意事项:
上述方法可以在谷歌和火狐浏览器中实现,没有任何问题。但是IE浏览器会出现问题。问题是每次使用IE浏览器获取的语言环境是系统的语言,而不是浏览器的语言。
我一直在为这个问题苦苦挣扎。网上有一些方法可以获取浏览器的语言,但是在IE下不行。最后,我的解决方案是:在使用jQuery.i18n.properties加载资源文件之前,在请求头信息中获取浏览器语言,然后进行设置。
以上是《如何使用jQuery.i18n.properties实现js国际化》文章的全部内容,感谢阅读!相信大家都有一定的了解,希望分享的内容对大家有所帮助。想了解更多,请关注一宿云行业资讯频道! 查看全部
内容简而易懂,条理清晰--jQuery国际化
这次文章主要给大家展示了《如何使用jQuery.i18n.properties实现js国际化》,内容简单易懂,条理清晰,希望能帮到大家解惑,让小编带路大家一起研究学习《如何使用jQuery.i18n.properties实现js国际化》文章。
我们在做前端页面开发的时候,因为页面内容太多太复杂,有时候一个页面有几千行(当然这样的页面是正常的),为了减少页面的内容,我们将 page 的 js 文件解压出来,放入特定的 js 文件中,然后导入到页面中。这样,当我们需要做应用的国际化时,就需要考虑js的国际化。这里介绍使用JQuery.i18n.properties实现js的国际化。
PS:jQuery.i18n.properties 是一个轻量级的 jQuery 国际插件。类似于 Java 中的资源文件,jQuery.i18n.properties 使用 .properties 文件来国际化 JavaScript。 jQuery.i18n.properties 插件根据用户指定的(或浏览器提供的)语言和国家代码(符合ISO-639和ISO-3166)解析对应的后缀为“.properties”的资源文件标准)。
使用资源文件实现国际化是一种流行的方式。例如,Android 应用程序可以使用以语言和国家代码命名的资源文件来实现国际化。 jQuery.i18n.properties 插件中的资源文件以“.properties”为后缀,收录区域相关的键值对。我们知道Java程序也可以使用后缀为.properties的资源文件来实现国际化。因此,当我们想要在 Java 程序和前端 JavaScript 程序之间共享资源文件时,这种方法特别有用。 jQuery.i18n.properties 插件首先加载默认的资源文件(例如:strings.properties),然后加载特定语言环境的资源文件(例如:strings_zh.properties),这样可以确保当某个不提供语言翻译,默认值始终有效。开发者可以以 JavaScript 变量(或函数)或 Maps 的形式使用资源文件中的密钥。
那么如何使用jQuery.i18n.properties来实现js国际化?
第一步:创建属性资源文件。
属性资源文件的命名规则是:string_browser language shortcode.properties,例如简体中文:string_zh-CN.properties 这里需要注意下划线而不是下划线。如图,我创建了三个资源文件
js_en-US.properties(美国英语)、js_ja.properties(日语)、js_zh-CN.properties(简体中文)。
第2步:在js文件中引入jQuery.i18n.properties需要的js文件。
因为jQuery.i18n.properties依赖于Jquery框架,所以需要在js文件中收录jQuery.i18n.properties需要的js文件。
导入红色部分的js使用jQuery.i18n.properties。
第 3 步:使用 jQuery.i18n.properties API
$(document).ready(function(){
//国际化加载属性文件
jQuery.i18n.properties({
name:'js',
path:'/js/i18n/',
mode:'map',
callback: function() {// 加载成功后设置显示内容
//alert(jQuery.i18n.prop("theme_manage.js_activity"));
}
});
});
name后面的值是你定义的资源文件中语言短代码前面的字符串,因为我的资源文件是js_xxx.properties,所以这个值是js
背后的价值
path 是你的资源文件的相对路径。即相对于项目结构WebContent下的路径
mode 后面的值是加载模式; “vars”表示以JavaScript变量或函数的形式加载资源文件中的key值(默认是this),“map”表示以map值的形式加载资源文件中的key。 “都意味着这两种方法可以同时使用。”我在这里使用地图。
callback 是一个回调函数。
如何根据不同的语言环境加载不同的资源文件?其实jQuery.i18n.properties的原理就是根据名字后面的值找到对应的资源文件,加上浏览器的语言短码,加上.properties。这个过程是自动的,只需要上面的配置。
propertites中的key-value对如下:(properties文件中的中文会自动转换成对应的ASCII值,当然这里可以设置,也可以通过插件修改.反正我没这么做,是从页面复制过来的,不管),等号前的值是key,等号后的值是value(注意不同资源文件中的key必须一致和定制)。
这样,资源文件中的内容就已经加载完毕。
第四步:根据key在js文件中找到对应的值。
红色部分为取值方式,引号内的字符串对应上述资源文件中的键值。
注意事项:
上述方法可以在谷歌和火狐浏览器中实现,没有任何问题。但是IE浏览器会出现问题。问题是每次使用IE浏览器获取的语言环境是系统的语言,而不是浏览器的语言。
我一直在为这个问题苦苦挣扎。网上有一些方法可以获取浏览器的语言,但是在IE下不行。最后,我的解决方案是:在使用jQuery.i18n.properties加载资源文件之前,在请求头信息中获取浏览器语言,然后进行设置。
以上是《如何使用jQuery.i18n.properties实现js国际化》文章的全部内容,感谢阅读!相信大家都有一定的了解,希望分享的内容对大家有所帮助。想了解更多,请关注一宿云行业资讯频道!
从html中提取有效的文本,经常碰到2种类型
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-06-19 21:04
从html中提取有效文本,经常会遇到两种类型:
1、 提取特定网页功能的结构化信息
一个。检查网站的DOM结构:减少代码冗余,优化上一页。
B.结构化信息抽取
2、 通过网页去噪。
一个。使用比较多个网页的文本信息的方法来检测常见字符。较长的常用字符可以看到噪声信息。
B.为了提取网页模板的相似度,需要计算两个网页的结构相似度,提取同一个模板去除噪声,比如网站底部的footer部分。
c.详细页面特点:
(1)更多非锚文本
(2) 有很明显的文字段落和更多的标点符号
(3)url 结构很长,通过网站 分析,这样的网址非常规整,基本在链接结构的最底层
d。详细页面去噪特征:
(1)多以链接的形式出现,链接到其他相关页面。
(2)有很多锚文本,但标点符号很少。锚文本往往是对其他链接页面的解释。
(3)Noisy text 比如一些底部模板。
然后在从网页中提取文本之前,爬虫会首先识别网页的编码,必要时还会识别网页的语言。
如何识别网页的编码:
1、从WEB服务器返回的内容类型中提取代码。
2、 标识网页元信息中的字符编码。如果与内容类型中的编码不一致,以Meta中声明的编码为准。
3、如果真的无法确定网页的字符集,那么就需要从返回流来判断,同时必须确定网页使用的语言。
这就是为什么我们需要明确网页的编码集,以减少爬虫的判断,提高效率。
xmlns 查看全部
从html中提取有效的文本,经常碰到2种类型
从html中提取有效文本,经常会遇到两种类型:
1、 提取特定网页功能的结构化信息
一个。检查网站的DOM结构:减少代码冗余,优化上一页。
B.结构化信息抽取
2、 通过网页去噪。
一个。使用比较多个网页的文本信息的方法来检测常见字符。较长的常用字符可以看到噪声信息。
B.为了提取网页模板的相似度,需要计算两个网页的结构相似度,提取同一个模板去除噪声,比如网站底部的footer部分。
c.详细页面特点:
(1)更多非锚文本
(2) 有很明显的文字段落和更多的标点符号
(3)url 结构很长,通过网站 分析,这样的网址非常规整,基本在链接结构的最底层
d。详细页面去噪特征:
(1)多以链接的形式出现,链接到其他相关页面。
(2)有很多锚文本,但标点符号很少。锚文本往往是对其他链接页面的解释。
(3)Noisy text 比如一些底部模板。
然后在从网页中提取文本之前,爬虫会首先识别网页的编码,必要时还会识别网页的语言。
如何识别网页的编码:
1、从WEB服务器返回的内容类型中提取代码。
2、 标识网页元信息中的字符编码。如果与内容类型中的编码不一致,以Meta中声明的编码为准。
3、如果真的无法确定网页的字符集,那么就需要从返回流来判断,同时必须确定网页使用的语言。
这就是为什么我们需要明确网页的编码集,以减少爬虫的判断,提高效率。
xmlns
图片在笔记里面不能展现异常b,图片(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-06-13 07:04
直接进入主题
----------------------------------------------- -----------
1、伪协议
前期引导用户存储地址为javascript://some code的书签
2、import js
当用户点击书签时,在当前页面执行javascript:之后的代码。代码的内容大概是创建一个脚本节点并引入一个外部js资源
3、创建 iframe
加载js资源时,在当前页面创建一个iframe,并引入一个页面来引导录制和抓取操作
4、文本提取
当用户选择body而不是url时,需要提取body,主要是基于5、6步骤的原因(补充:如果body是ajax生成的或者需要权限验证等,后台没有解决方案),应该采用前端文本提取,而不是后台提取。关于文本提取的算法,请以google为例,根据文本的行高和字体大小的相似度来确定文本的位置。
5、格式预约
如果提取的文本与当前页面的css资源分离,会丢失原来的格式化格式,可读性有偏差。所以这里需要用js实时计算文本的样式(如字体、颜色、行高等),写成内联样式。 (在我们平时的复制粘贴操作中,浏览器会自动做同样的事情。如果要在后台保留格式,需要启动一个浏览器内核来计算,是不是比较复杂?)
6、图片捕捉
一般情况下,如果我们抓取的文字中有图片,就是html中的img标签。抓取云笔记后可能会出现这些问题:
a、图片所在的服务器不稳定,导致图片在备注中显示异常
b、图片服务器已经做了源码验证,图片无法在备注中显示
c、图片为内网域名,更改网络环境后无法查看
这时候我们需要做图片传输:
A 和 b 可以在捕捉时在后台传输,但 c 的情况必须取决于前景。在高端浏览器中,前端将图片转换为base64并预先存储在html中,然后在后台传输。 查看全部
图片在笔记里面不能展现异常b,图片(组图)
直接进入主题
----------------------------------------------- -----------
1、伪协议
前期引导用户存储地址为javascript://some code的书签
2、import js
当用户点击书签时,在当前页面执行javascript:之后的代码。代码的内容大概是创建一个脚本节点并引入一个外部js资源
3、创建 iframe
加载js资源时,在当前页面创建一个iframe,并引入一个页面来引导录制和抓取操作
4、文本提取
当用户选择body而不是url时,需要提取body,主要是基于5、6步骤的原因(补充:如果body是ajax生成的或者需要权限验证等,后台没有解决方案),应该采用前端文本提取,而不是后台提取。关于文本提取的算法,请以google为例,根据文本的行高和字体大小的相似度来确定文本的位置。
5、格式预约
如果提取的文本与当前页面的css资源分离,会丢失原来的格式化格式,可读性有偏差。所以这里需要用js实时计算文本的样式(如字体、颜色、行高等),写成内联样式。 (在我们平时的复制粘贴操作中,浏览器会自动做同样的事情。如果要在后台保留格式,需要启动一个浏览器内核来计算,是不是比较复杂?)
6、图片捕捉
一般情况下,如果我们抓取的文字中有图片,就是html中的img标签。抓取云笔记后可能会出现这些问题:
a、图片所在的服务器不稳定,导致图片在备注中显示异常
b、图片服务器已经做了源码验证,图片无法在备注中显示
c、图片为内网域名,更改网络环境后无法查看
这时候我们需要做图片传输:
A 和 b 可以在捕捉时在后台传输,但 c 的情况必须取决于前景。在高端浏览器中,前端将图片转换为base64并预先存储在html中,然后在后台传输。
如何使用Scrapy结合PhantomJS爬虫.py采集天猫商品内容?
网站优化 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2021-06-13 07:00
1、介绍
最近在看Scrapy爬虫框架,尝试用Scrapy框架写一个简单的小程序,可以实现网页信息采集。在尝试的过程中遇到了很多小问题,希望大家给点建议。
本文主要结合PhantomJS采集天猫品内容介绍如何使用Scrapy。文章中自定义了一个DOWNLOADER_MIDDLEWARES,使用采集动态网页内容需要加载js。看了很多关于DOWNLOADER_MIDDLEWARES的资料,总结起来,使用简单,但是会阻塞框架,所以性能不好。有资料提到自定义DOWNLOADER_HANDLER或者使用scrapyjs可以解决框架阻塞的问题。有兴趣的朋友可以去研究一下,这里就不多说了。
2、具体实现
2.1,环保要求
准备Python开发运行环境需要进行以下步骤:
以上步骤展示了两种安装方式: 1、安装本地下载的wheel包; 2、使用Python安装管理器进行远程下载安装。注意:包版本需要与python版本匹配
2.2,开发测试流程
首先找到需要采集的网页,这里简单搜索一个天猫产品,网址为/item/526449276263.htm,页面如下:
然后开始写代码,下面的代码默认在命令行界面执行
1),创建一个scrapy爬虫项目tmSpider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建一个middlewares文件夹,然后在该文件夹下创建一个middleware.py文件,代码如下:
# -*- coding: utf-8 -*-
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
import tmSpider.middlewares.downloader as downloader
class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content)
def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和PhantomJS编写一个网页内容下载器,也在上一步创建的middlewares文件夹下创建一个downloader.py文件,代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui
class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10)
def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content
def __del__(self):
self.driver.quit()
5) 创建爬虫模块
在项目目录E:\python-3.5.1\tmSpider,执行如下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
执行后会在项目目录E:\python-3.5.1\tmSpider\tmSpider\spiders下自动生成tmall.py程序文件。该程序中的解析函数处理scrapy下载器返回的网页内容。 采集网页信息的方法可以是:
# -*- coding: utf-8 -*-
import time
import scrapy
import tmSpider.gooseeker.gsextractor as gsextractor
class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/5 ... 39%3B,
)
# 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time
def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list")
result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫
在E:\python-3.5.1\tmSpider项目目录下执行命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:
提一下,上面的命令一次只能启动一个爬虫。如果你想同时启动多个爬虫怎么办?然后需要自定义一个爬虫启动模块,在spiders下创建模块文件runcrawl.py,代码如下
# -*- coding: utf-8 -*-
import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
执行runcrawl.py文件并输出结果:
3、展望
通过自定义DOWNLOADER_MIDDLEWARES调用PhantomJs实现爬虫后,一直在纠结框架阻塞的问题,一直在想解决办法。后面会研究scrapyjs、splash等调用浏览器的方式,看看能不能有效的解决这个问题。
4、相关文件
1、Python即时网络爬虫:API说明
5、汇聚GooSeeker开源代码下载源码
1、GooSeeker开源Python网络爬虫GitHub源码
6、文档修改历史
1, 2016-06-30: V1.0 查看全部
如何使用Scrapy结合PhantomJS爬虫.py采集天猫商品内容?
1、介绍
最近在看Scrapy爬虫框架,尝试用Scrapy框架写一个简单的小程序,可以实现网页信息采集。在尝试的过程中遇到了很多小问题,希望大家给点建议。
本文主要结合PhantomJS采集天猫品内容介绍如何使用Scrapy。文章中自定义了一个DOWNLOADER_MIDDLEWARES,使用采集动态网页内容需要加载js。看了很多关于DOWNLOADER_MIDDLEWARES的资料,总结起来,使用简单,但是会阻塞框架,所以性能不好。有资料提到自定义DOWNLOADER_HANDLER或者使用scrapyjs可以解决框架阻塞的问题。有兴趣的朋友可以去研究一下,这里就不多说了。
2、具体实现
2.1,环保要求
准备Python开发运行环境需要进行以下步骤:
以上步骤展示了两种安装方式: 1、安装本地下载的wheel包; 2、使用Python安装管理器进行远程下载安装。注意:包版本需要与python版本匹配
2.2,开发测试流程
首先找到需要采集的网页,这里简单搜索一个天猫产品,网址为/item/526449276263.htm,页面如下:
然后开始写代码,下面的代码默认在命令行界面执行
1),创建一个scrapy爬虫项目tmSpider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建一个middlewares文件夹,然后在该文件夹下创建一个middleware.py文件,代码如下:
# -*- coding: utf-8 -*-
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
import tmSpider.middlewares.downloader as downloader
class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content)
def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和PhantomJS编写一个网页内容下载器,也在上一步创建的middlewares文件夹下创建一个downloader.py文件,代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui
class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10)
def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content
def __del__(self):
self.driver.quit()
5) 创建爬虫模块
在项目目录E:\python-3.5.1\tmSpider,执行如下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
执行后会在项目目录E:\python-3.5.1\tmSpider\tmSpider\spiders下自动生成tmall.py程序文件。该程序中的解析函数处理scrapy下载器返回的网页内容。 采集网页信息的方法可以是:
# -*- coding: utf-8 -*-
import time
import scrapy
import tmSpider.gooseeker.gsextractor as gsextractor
class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/5 ... 39%3B,
)
# 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time
def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list")
result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫
在E:\python-3.5.1\tmSpider项目目录下执行命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:
提一下,上面的命令一次只能启动一个爬虫。如果你想同时启动多个爬虫怎么办?然后需要自定义一个爬虫启动模块,在spiders下创建模块文件runcrawl.py,代码如下
# -*- coding: utf-8 -*-
import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
执行runcrawl.py文件并输出结果:
3、展望
通过自定义DOWNLOADER_MIDDLEWARES调用PhantomJs实现爬虫后,一直在纠结框架阻塞的问题,一直在想解决办法。后面会研究scrapyjs、splash等调用浏览器的方式,看看能不能有效的解决这个问题。
4、相关文件
1、Python即时网络爬虫:API说明
5、汇聚GooSeeker开源代码下载源码
1、GooSeeker开源Python网络爬虫GitHub源码
6、文档修改历史
1, 2016-06-30: V1.0
用Python获取指定网页内容提取器的定义(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-06-11 18:23
1、介绍
本文介绍了如何使用 GooSeeker API 接口下载 Java 和 JavaScript 中的内容提取器。这是一个示例程序。什么是内容提取器?为什么要使用这种方法?源自Python即时网络爬虫开源项目:通过生成内容提取器,大大节省了程序员的时间。详情请参考“内容提取器的定义”。
2、使用Java下载内容提取器
这是一系列示例程序之一。从目前的编程语言发展来看,Java提取网页内容并不合适。除了语言不够灵活方便,整个生态不够活跃,可选库增长缓慢。另外,从JavaScript动态网页中提取内容,Java也很不方便,需要JavaScript引擎。使用 JavaScript 下载内容提取器可以直接跳转到第 3 部分的内容。
具体实现
评论:
源码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回结果如下:
3、使用 JavaScript 下载内容提取器
请注意,如果本示例中的 JavaScript 代码运行在网页上,由于跨域问题,无法抓取非站点网页的内容。因此,请运行在有特权的 JavaScript 引擎上,例如浏览器扩展、自主开发的浏览器以及自己程序中的 JavaScript 引擎。
为了实验的方便,这个例子还在网页上运行。为了避免跨域问题,目标网页被保存和修改,并在其中插入JavaScript。这么多手动操作只是为了实验,正式使用时还需要考虑其他方法。
具体实现
评论:
这是源代码:
返回结果截图如下
4、展望
您也可以使用 Python 来获取指定网页的内容。感觉Python的语法更简洁。稍后我们将添加 Python 语言的示例。有兴趣的朋友可以加入一起学习。
5、相关文件
1、Python即时网络爬虫:API说明
2、内容提取器的定义
6、GooSeeker开源代码下载源码采集
1、GooSeeker开源Python网络爬虫GitHub源码
7、文档修改历史
1, 2016-06-20: V1.0
上一章 API-下载内容提取器 下一章用 Python 驱动 Firefox 查看全部
用Python获取指定网页内容提取器的定义(组图)
1、介绍
本文介绍了如何使用 GooSeeker API 接口下载 Java 和 JavaScript 中的内容提取器。这是一个示例程序。什么是内容提取器?为什么要使用这种方法?源自Python即时网络爬虫开源项目:通过生成内容提取器,大大节省了程序员的时间。详情请参考“内容提取器的定义”。
2、使用Java下载内容提取器
这是一系列示例程序之一。从目前的编程语言发展来看,Java提取网页内容并不合适。除了语言不够灵活方便,整个生态不够活跃,可选库增长缓慢。另外,从JavaScript动态网页中提取内容,Java也很不方便,需要JavaScript引擎。使用 JavaScript 下载内容提取器可以直接跳转到第 3 部分的内容。
具体实现
评论:
源码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回结果如下:
3、使用 JavaScript 下载内容提取器
请注意,如果本示例中的 JavaScript 代码运行在网页上,由于跨域问题,无法抓取非站点网页的内容。因此,请运行在有特权的 JavaScript 引擎上,例如浏览器扩展、自主开发的浏览器以及自己程序中的 JavaScript 引擎。
为了实验的方便,这个例子还在网页上运行。为了避免跨域问题,目标网页被保存和修改,并在其中插入JavaScript。这么多手动操作只是为了实验,正式使用时还需要考虑其他方法。
具体实现
评论:
这是源代码:
返回结果截图如下
4、展望
您也可以使用 Python 来获取指定网页的内容。感觉Python的语法更简洁。稍后我们将添加 Python 语言的示例。有兴趣的朋友可以加入一起学习。
5、相关文件
1、Python即时网络爬虫:API说明
2、内容提取器的定义
6、GooSeeker开源代码下载源码采集
1、GooSeeker开源Python网络爬虫GitHub源码
7、文档修改历史
1, 2016-06-20: V1.0
上一章 API-下载内容提取器 下一章用 Python 驱动 Firefox
共建,学习和探索.效果演示客户端思路先理
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-06-11 18:14
共建,学习和探索.效果演示客户端思路先理
这几年涌现了很多技术博客和技术社区,也有很多技术同仁开始创建自己的博客。我们可以将我们的博客同步到不同的技术平台,但是随着技术平台数量的增加,我们文章Sync 会花费越来越多的时间,那么有没有可以快速将博客发布到不同平台的工具?或者有没有什么工具可以直接把html转成技术平台可以直接识别的“语言”,发布怎么样?
我们都知道程序员最喜欢写博客的“语言”是makedown,而且目前大部分技术社区都支持makedown语法,所以只要有makedown,我们就可以快速同步到不同的技术平台。
也许有人会说我们不能只用makedown语法来写博客?这样确实可以满足需求,但缺点是必须在本地保存一个makedown文件。如果博客内容涉及图片,我们还是需要维护一个img目录,这样每次在不同的技术社区发布文章会很麻烦,所以总结一下,我们开发了一个自动抓取html内容的工具,一键转换成美图,让我们可以“肆无忌惮”“发了博客。
你会收获
文末附上作者github地址,感兴趣的朋友可以一起搭建、学习、探索。
效果演示
客户想法
先想想思路:
输入链接地址
获取服务器返回的html字符串,将html字符串转换为md字符串,在编辑器中同步显示预览
为什么选择夜床
客户端最重要的一步是将html转md,这里我们使用turndown。
为什么要使用调低?原因如下:
具体实现
// 引入第三方插件
import { gfm, tables, strikethrough } from 'turndown-plugin-gfm'
const turndownService = new TurndownService({ codeBlockStyle: 'fenced' })
// Use the gfm plugin
turndownService.use(gfm)
// Use the table and strikethrough plugins only
turndownService.use([tables, strikethrough])
/**
* 自定义配置(rule名不能重复)
* 这里我们指定 `pre` 标签为代码块,并在代码块的前后加个换行,防止显示异常
*/
turndownService.addRule('pre2Code', {
filter: ['pre'],
replacement (content) {
return '```\n' + content + '\n```'
}
})
额外功能
支持自动获取链接文章title,无需手动复制原文。
服务端
我们这里使用的服务端是node.js,我们使用前端框架编写服务端体验杠杆作用。
思考
首先想到一个思路:获取前端传递过来的链接地址。通过请求获取html字符串。根据不同平台的域名获取不同的dom。转换图片的相对路径并链接到绝对路径。在底部添加转载的源语句,以获得文章的标题。 * 将title和html返回给前端
获取前端传过来的链接地址的具体实现
这里我们直接使用node自己的语法,我们使用get形式传递,直接使用query
通过请求获取html字符串
这里我们正在请求请求
request({
url: qUrl
}, (error, response, body) => {
if (error) {
res.status(404).send('Url Error')
return
}
// 这里的 body 就是文章的 `html`
console.log(body)
})
根据不同的平台域名获取不同的doms
由于技术平台众多,每个平台的文章content标签、样式名称或id会有所不同,要注意兼容性。
先用js-dom模拟dom的操作,封装一个方法
/**
* 获取准确的文章内容
* @param {string} html html串
* @param {string} selector css选择器
* @return {string} htmlContent
*/
const getDom = (html, selector) => {
const dom = new JSDOM(html)
const htmlContent = dom.window.document.querySelector(selector)
return htmlContent
}
兼容不同平台并应用不同的css选择器
// 比如掘金,内容块的样式名为 .markdown-body,内容里会有 style 标签样式和一些多余的复制代码文字,通过原生 dom 操作删掉
if (qUrl.includes('juejin.cn')) {
const htmlContent = getBySelector('.markdown-body')
const extraDom = htmlContent.querySelector('style')
const extraDomArr = htmlContent.querySelectorAll('.copy-code-btn')
extraDom && extraDom.remove()
extraDomArr.length > 0 && extraDomArr.forEach((v) => { v.remove() })
return htmlContent
}
// 再比如 oschina,内容块的样式名为 .article-detail,内容里会有多余的 .ad-wrap 内容,照样删掉
if (qUrl.includes('oschina.net')) {
const htmlContent = getBySelector('.article-detail')
const extraDom = htmlContent.querySelector('.ad-wrap')
extraDom && extraDom.remove()
return htmlContent
}
// 最后匹配通用标签。优先适配 article 标签,没有再用 body 标签
const htmlArticle = getBySelector('article')
if (htmlArticle) { return htmlArticle }
const htmlBody = getBySelector('body')
if (htmlBody) { return htmlBody }
将图片和链接的相对路径转换为绝对路径,方便以后查找源路径
// 通过原生api - URL 获取链接的源域名
const qOrigin = new URL(qUrl).origin || ''
// 获取图片、链接的绝对路径。通过 URL 将 `路径+源域名` 转换为绝对路径,不熟悉的同学请自行了解
const getAbsoluteUrl = p => new URL(p, qOrigin).href
// 转换图片、链接的相对路径,不同平台的图片懒加载属性名不一样,需要做特定兼容
const changeRelativeUrl = (dom) => {
if (!dom) { return '内容出错~' }
const copyDom = dom
// 获取所有图片
const imgs = copyDom.querySelectorAll('img')
// 获取所有链接
const links = copyDom.querySelectorAll('a')
// 替换完所有路径返回新 dom
imgs.length > 0 && imgs.forEach((v) => {
/**
* 处理懒加载路径
* 简书:data-original-src
* 掘金:data-src
* segmentfault:data-src
*/
const src = v.src || v.getAttribute('data-src') || v.getAttribute('data-original-src') || ''
v.src = getAbsoluteUrl(src)
})
links.length > 0 && links.forEach((v) => {
const href = v.href || qUrl
v.href = getAbsoluteUrl(href)
})
return copyDom
}
// 在获取不同平台的文章内容 getBody 方法里,应用 changeRelativeUrl 方法
const getBody = (content) => {
...
...
return changeRelativeUrl(htmlContent)
} 查看全部
共建,学习和探索.效果演示客户端思路先理
这几年涌现了很多技术博客和技术社区,也有很多技术同仁开始创建自己的博客。我们可以将我们的博客同步到不同的技术平台,但是随着技术平台数量的增加,我们文章Sync 会花费越来越多的时间,那么有没有可以快速将博客发布到不同平台的工具?或者有没有什么工具可以直接把html转成技术平台可以直接识别的“语言”,发布怎么样?
我们都知道程序员最喜欢写博客的“语言”是makedown,而且目前大部分技术社区都支持makedown语法,所以只要有makedown,我们就可以快速同步到不同的技术平台。
也许有人会说我们不能只用makedown语法来写博客?这样确实可以满足需求,但缺点是必须在本地保存一个makedown文件。如果博客内容涉及图片,我们还是需要维护一个img目录,这样每次在不同的技术社区发布文章会很麻烦,所以总结一下,我们开发了一个自动抓取html内容的工具,一键转换成美图,让我们可以“肆无忌惮”“发了博客。
你会收获
文末附上作者github地址,感兴趣的朋友可以一起搭建、学习、探索。
效果演示
客户想法
先想想思路:
输入链接地址
获取服务器返回的html字符串,将html字符串转换为md字符串,在编辑器中同步显示预览
为什么选择夜床
客户端最重要的一步是将html转md,这里我们使用turndown。
为什么要使用调低?原因如下:
具体实现
// 引入第三方插件
import { gfm, tables, strikethrough } from 'turndown-plugin-gfm'
const turndownService = new TurndownService({ codeBlockStyle: 'fenced' })
// Use the gfm plugin
turndownService.use(gfm)
// Use the table and strikethrough plugins only
turndownService.use([tables, strikethrough])
/**
* 自定义配置(rule名不能重复)
* 这里我们指定 `pre` 标签为代码块,并在代码块的前后加个换行,防止显示异常
*/
turndownService.addRule('pre2Code', {
filter: ['pre'],
replacement (content) {
return '```\n' + content + '\n```'
}
})
额外功能
支持自动获取链接文章title,无需手动复制原文。
服务端
我们这里使用的服务端是node.js,我们使用前端框架编写服务端体验杠杆作用。
思考
首先想到一个思路:获取前端传递过来的链接地址。通过请求获取html字符串。根据不同平台的域名获取不同的dom。转换图片的相对路径并链接到绝对路径。在底部添加转载的源语句,以获得文章的标题。 * 将title和html返回给前端
获取前端传过来的链接地址的具体实现
这里我们直接使用node自己的语法,我们使用get形式传递,直接使用query
通过请求获取html字符串
这里我们正在请求请求
request({
url: qUrl
}, (error, response, body) => {
if (error) {
res.status(404).send('Url Error')
return
}
// 这里的 body 就是文章的 `html`
console.log(body)
})
根据不同的平台域名获取不同的doms
由于技术平台众多,每个平台的文章content标签、样式名称或id会有所不同,要注意兼容性。
先用js-dom模拟dom的操作,封装一个方法
/**
* 获取准确的文章内容
* @param {string} html html串
* @param {string} selector css选择器
* @return {string} htmlContent
*/
const getDom = (html, selector) => {
const dom = new JSDOM(html)
const htmlContent = dom.window.document.querySelector(selector)
return htmlContent
}
兼容不同平台并应用不同的css选择器
// 比如掘金,内容块的样式名为 .markdown-body,内容里会有 style 标签样式和一些多余的复制代码文字,通过原生 dom 操作删掉
if (qUrl.includes('juejin.cn')) {
const htmlContent = getBySelector('.markdown-body')
const extraDom = htmlContent.querySelector('style')
const extraDomArr = htmlContent.querySelectorAll('.copy-code-btn')
extraDom && extraDom.remove()
extraDomArr.length > 0 && extraDomArr.forEach((v) => { v.remove() })
return htmlContent
}
// 再比如 oschina,内容块的样式名为 .article-detail,内容里会有多余的 .ad-wrap 内容,照样删掉
if (qUrl.includes('oschina.net')) {
const htmlContent = getBySelector('.article-detail')
const extraDom = htmlContent.querySelector('.ad-wrap')
extraDom && extraDom.remove()
return htmlContent
}
// 最后匹配通用标签。优先适配 article 标签,没有再用 body 标签
const htmlArticle = getBySelector('article')
if (htmlArticle) { return htmlArticle }
const htmlBody = getBySelector('body')
if (htmlBody) { return htmlBody }
将图片和链接的相对路径转换为绝对路径,方便以后查找源路径
// 通过原生api - URL 获取链接的源域名
const qOrigin = new URL(qUrl).origin || ''
// 获取图片、链接的绝对路径。通过 URL 将 `路径+源域名` 转换为绝对路径,不熟悉的同学请自行了解
const getAbsoluteUrl = p => new URL(p, qOrigin).href
// 转换图片、链接的相对路径,不同平台的图片懒加载属性名不一样,需要做特定兼容
const changeRelativeUrl = (dom) => {
if (!dom) { return '内容出错~' }
const copyDom = dom
// 获取所有图片
const imgs = copyDom.querySelectorAll('img')
// 获取所有链接
const links = copyDom.querySelectorAll('a')
// 替换完所有路径返回新 dom
imgs.length > 0 && imgs.forEach((v) => {
/**
* 处理懒加载路径
* 简书:data-original-src
* 掘金:data-src
* segmentfault:data-src
*/
const src = v.src || v.getAttribute('data-src') || v.getAttribute('data-original-src') || ''
v.src = getAbsoluteUrl(src)
})
links.length > 0 && links.forEach((v) => {
const href = v.href || qUrl
v.href = getAbsoluteUrl(href)
})
return copyDom
}
// 在获取不同平台的文章内容 getBody 方法里,应用 changeRelativeUrl 方法
const getBody = (content) => {
...
...
return changeRelativeUrl(htmlContent)
}

