
java抓取网页数据
java抓取网页数据(基于javaAgent和Java码注入技术的java探针工具技术原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-24 12:07
今天公司组织技术培训,Java分布式链路跟踪框架(SkyWalking),SkyWalking是通过配置Agent实现的,查了一些资料和大家一起学习。
基于javaAgent和Java字节码注入技术的java探针工具技术原理:
我们使用Java代理和ASM字节码技术来开发java探针工具。实现原理如下:
Java代理技术是在jdk1.5之后引入的,Java代理在运行方法之前是一个拦截器。我们利用Java代理和ASM字节码技术,在JVM加载class二进制文件时,用ASM动态修改加载的class文件,并在监控方法前后添加定时器函数,计算监控方法的耗时。将方法耗时和内部调用条件放入处理器,处理器利用栈的先进后出特性来处理方法调用序列。处理请求时,将耗时的方法跟踪和输入参数映射输出到文件。然后根据map中对应的参数或者耗时方法轨迹中的key代码,我们可以区分我们想要捕获的耗时业务。最后去掉对应的耗时轨迹文件,转换成xml格式解析,通过浏览器展示代码层次结构,方便耗时分析,如图:
Java探针工具功能点:
1、支持方法执行耗时范围捕获设置,根据耗时范围捕获系统运行时出现在设置的耗时范围内的代码运行轨迹。
2、支持抓取具体的代码配置,方便抓取具体的配置方法,过滤掉相关代码的耗时执行。
3、支持APP层入口方法过滤,配置入口前方法运行监控。
4、支持输入法参数输出功能,方便时间高时跟踪对应输入参数。
5、提供WEB页面展示界面耗时展示、代码调用关系图展示、方法耗时百分比展示、可疑方法高亮显示等功能。
这是一个例子:
第一次:
JavaAgent是JDK1.5之后引入的,也可以称为Java代理。
JavaAgent 是一个在 main 方法之前运行的拦截器。它的默认方法名是premain,表示先执行premain方法,再执行main方法。
那么如何实现一个JavaAgent呢?很简单,只需要增加premain方法即可。
请参阅下面的代码和代码中的注释:
先写一个premain方法:
package agent;
import java.lang.instrument.Instrumentation;
public class pre_MyProgram {
/**
* 该方法在main方法之前运行,与main方法运行在同一个JVM中
* 并被同一个System ClassLoader装载
* 被统一的安全策略(security policy)和上下文(context)管理
*
* @param agentOps
* @param inst
* @author SHANHY
* @create 2016年3月30日
*/
public static void premain(String agentOps,Instrumentation inst){
System.out.println("====premain 方法执行");
System.out.println(agentOps);
}
/**
* 如果不存在 premain(String agentOps, Instrumentation inst)
* 则会执行 premain(String agentOps)
*
* @param agentOps
* @author SHANHY
* @create 2016年3月30日
*/
public static void premain(String agentOps){
System.out.println("====premain方法执行2====");
System.out.println(agentOps);
}
public static void main(String[] args) {
// TODO Auto-generated method stub
}
}
package agent;
import java.lang.instrument.Instrumentation;
public class pre_MyProgram {
/**
* 该方法在main方法之前运行,与main方法运行在同一个JVM中
* 并被同一个System ClassLoader装载
* 被统一的安全策略(security policy)和上下文(context)管理
*
* @param agentOps
* @param inst
* @author SHANHY
*/
public static void premain(String agentOps,Instrumentation inst){
System.out.println("====premain 方法执行");
System.out.println(agentOps);
}
/**
* 如果不存在 premain(String agentOps, Instrumentation inst)
* 则会执行 premain(String agentOps)
*
* @param agentOps
* @author SHANHY
*/
public static void premain(String agentOps){
System.out.println("====premain方法执行2====");
System.out.println(agentOps);
}
public static void main(String[] args) {
}
}
写完这个类,我们还需要再做一个配置。
在src目录下添加META-INF/MANIFEST.MF文件,内容定义如下:
清单版本:1.0
Premain-Class:agent.pre_MyProgram
可以重新定义类:真
特别注意,一共有四行,第四行是空行,冒号后面有一个空格,如下截图所示:
然后我们将代码打包为 pre_MyProgram.jar
注意打包的时候选择我们自己定义的MANIFEST.MF,这个是导出步骤:
(1)
(2)注意选择pre MF文件
接下来,我们正在使用 main 方法创建一个主程序项目。截图如下:
这次不要忘记:
main函数还有一个MF文件:不要写错,否则导出会报错:No main manifest attribute(表示MF文件错误)
Manifest-Version: 1.0
Main-Class: alibaba.MyProgram
以同样方式导出main的jar包命名为:MyProgram.jar
如下:
选择它的 MF 文件:
如何执行 MyProgram.jar?我们通过 -javaagent 参数指定我们的 Java 代理包。值得一提的是,-javaagent 参数的数量是无限的。如果指定了多个参数,则按照指定的顺序执行。每个代理执行完毕后,都会执行主程序的main方法。
命令如下:
C:\WINDOWS\system32>java -javaagent:C:\Users\z003fe9c\Desktop\tessdata\agent\pre
_MyProgram.jar=Hello1 -javaagent:C:\Users\z003fe9c\Desktop\tessdata\agent\pre_My
Program.jar=Hello2 -jar C:\Users\z003fe9c\Desktop\tessdata\agent\MyProgram.jar
输出结果:
====premain 方法执行
Hello1
====premain 方法执行
Hello2
=========main方法执行====
特别提醒:
(1)如果你把-javaagent放在-jar后面的话,是不会生效的,也就是放在主程序后面的agent是无效的。
例如,执行:
java -javaagent:G:\myagent.jar=Hello1 -javaagent:G:\myagent.jar=Hello2 -jar myapp.jar -javaagent:G:\myagent.jar=Hello3
(2)如果main函数忘了选择MF文件或是MF文件选择的不对,就会报错:
只有第一个有效,第三个无效。
命令中的hello1是我们传递给premain方法的字符串参数。
此时,我们将使用javaagent,但是仅仅看这个操作的效果,似乎并没有什么实际意义。
我们可以用 javaagent 做什么?下一篇文章我们将介绍如何在项目中应用javaagent。
最后,在main方法执行完之后,还有另一种执行代理的方法。因为不常用,而且主程序需要配置Agent-Class,所以不常用。如果需要了解 agentmain(String agentArgs, Instrumentation inst) 方法。
第二条:
从这里,到最后,我直接抄别人的,因为我自己的还没有调试过,但是思路很清晰:
第二篇可以直接看别人的JavaAgent应用(spring-loaded热部署),以下可以忽略:
上一篇文章简单介绍了javaagent,想了解更多可以移步“JavaAgent”
本文重点介绍JavaAgent能给我们带来什么?
基于JavaAgent的spring-loaded实现一个JavaAgent xxxxxx,实现jar包的热更新,即在不重启服务器的情况下重新加载我们更新的jar之一。一、基于JavaAgent的应用示例
在JDK5中,代理类只能通过命令行参数启动JVM时指定javaagent参数来设置。在JDK6中,不限于在启动JVM时通过配置参数设置代理类。在 JDK6 中,我们使用 Java Tool API 中的 attach 方法。在运行过程中动态设置加载代理类也很方便,达到插桩的目的。
Instrumentation 最大的作用是类定义的动态变化和操作。
最简单的例子就是计算一个方法执行所需的时间,无需修改源码,使用 Instrumentation 代理来实现这个功能。说白了,这种方式相当于在JVM层面做AOP支持,这样我们就可以在不修改应用的基础上做AOP,是不是有点悬?
创建ClassFileTransformer接口的实现类MyTransformer
实现ClassFileTransformer接口的目的是在类加载到JVM之前对类字节码进行转换,从而达到动态注入代码的目的。所以首先你要明白MonitorTransformer类的用途,就是对你要修改的类进行转换。这使用 javassist 来修改字节码。你可以暂时不关心jaavssist的原理。也可以用ASM修改字节码,只是比较麻烦。 查看全部
java抓取网页数据(基于javaAgent和Java码注入技术的java探针工具技术原理)
今天公司组织技术培训,Java分布式链路跟踪框架(SkyWalking),SkyWalking是通过配置Agent实现的,查了一些资料和大家一起学习。
基于javaAgent和Java字节码注入技术的java探针工具技术原理:
我们使用Java代理和ASM字节码技术来开发java探针工具。实现原理如下:
Java代理技术是在jdk1.5之后引入的,Java代理在运行方法之前是一个拦截器。我们利用Java代理和ASM字节码技术,在JVM加载class二进制文件时,用ASM动态修改加载的class文件,并在监控方法前后添加定时器函数,计算监控方法的耗时。将方法耗时和内部调用条件放入处理器,处理器利用栈的先进后出特性来处理方法调用序列。处理请求时,将耗时的方法跟踪和输入参数映射输出到文件。然后根据map中对应的参数或者耗时方法轨迹中的key代码,我们可以区分我们想要捕获的耗时业务。最后去掉对应的耗时轨迹文件,转换成xml格式解析,通过浏览器展示代码层次结构,方便耗时分析,如图:
Java探针工具功能点:
1、支持方法执行耗时范围捕获设置,根据耗时范围捕获系统运行时出现在设置的耗时范围内的代码运行轨迹。
2、支持抓取具体的代码配置,方便抓取具体的配置方法,过滤掉相关代码的耗时执行。
3、支持APP层入口方法过滤,配置入口前方法运行监控。
4、支持输入法参数输出功能,方便时间高时跟踪对应输入参数。
5、提供WEB页面展示界面耗时展示、代码调用关系图展示、方法耗时百分比展示、可疑方法高亮显示等功能。
这是一个例子:
第一次:
JavaAgent是JDK1.5之后引入的,也可以称为Java代理。
JavaAgent 是一个在 main 方法之前运行的拦截器。它的默认方法名是premain,表示先执行premain方法,再执行main方法。
那么如何实现一个JavaAgent呢?很简单,只需要增加premain方法即可。
请参阅下面的代码和代码中的注释:
先写一个premain方法:
package agent;
import java.lang.instrument.Instrumentation;
public class pre_MyProgram {
/**
* 该方法在main方法之前运行,与main方法运行在同一个JVM中
* 并被同一个System ClassLoader装载
* 被统一的安全策略(security policy)和上下文(context)管理
*
* @param agentOps
* @param inst
* @author SHANHY
* @create 2016年3月30日
*/
public static void premain(String agentOps,Instrumentation inst){
System.out.println("====premain 方法执行");
System.out.println(agentOps);
}
/**
* 如果不存在 premain(String agentOps, Instrumentation inst)
* 则会执行 premain(String agentOps)
*
* @param agentOps
* @author SHANHY
* @create 2016年3月30日
*/
public static void premain(String agentOps){
System.out.println("====premain方法执行2====");
System.out.println(agentOps);
}
public static void main(String[] args) {
// TODO Auto-generated method stub
}
}
package agent;
import java.lang.instrument.Instrumentation;
public class pre_MyProgram {
/**
* 该方法在main方法之前运行,与main方法运行在同一个JVM中
* 并被同一个System ClassLoader装载
* 被统一的安全策略(security policy)和上下文(context)管理
*
* @param agentOps
* @param inst
* @author SHANHY
*/
public static void premain(String agentOps,Instrumentation inst){
System.out.println("====premain 方法执行");
System.out.println(agentOps);
}
/**
* 如果不存在 premain(String agentOps, Instrumentation inst)
* 则会执行 premain(String agentOps)
*
* @param agentOps
* @author SHANHY
*/
public static void premain(String agentOps){
System.out.println("====premain方法执行2====");
System.out.println(agentOps);
}
public static void main(String[] args) {
}
}
写完这个类,我们还需要再做一个配置。
在src目录下添加META-INF/MANIFEST.MF文件,内容定义如下:
清单版本:1.0
Premain-Class:agent.pre_MyProgram
可以重新定义类:真
特别注意,一共有四行,第四行是空行,冒号后面有一个空格,如下截图所示:
然后我们将代码打包为 pre_MyProgram.jar
注意打包的时候选择我们自己定义的MANIFEST.MF,这个是导出步骤:
(1)
(2)注意选择pre MF文件
接下来,我们正在使用 main 方法创建一个主程序项目。截图如下:
这次不要忘记:
main函数还有一个MF文件:不要写错,否则导出会报错:No main manifest attribute(表示MF文件错误)
Manifest-Version: 1.0
Main-Class: alibaba.MyProgram
以同样方式导出main的jar包命名为:MyProgram.jar
如下:
选择它的 MF 文件:
如何执行 MyProgram.jar?我们通过 -javaagent 参数指定我们的 Java 代理包。值得一提的是,-javaagent 参数的数量是无限的。如果指定了多个参数,则按照指定的顺序执行。每个代理执行完毕后,都会执行主程序的main方法。
命令如下:
C:\WINDOWS\system32>java -javaagent:C:\Users\z003fe9c\Desktop\tessdata\agent\pre
_MyProgram.jar=Hello1 -javaagent:C:\Users\z003fe9c\Desktop\tessdata\agent\pre_My
Program.jar=Hello2 -jar C:\Users\z003fe9c\Desktop\tessdata\agent\MyProgram.jar
输出结果:
====premain 方法执行
Hello1
====premain 方法执行
Hello2
=========main方法执行====
特别提醒:
(1)如果你把-javaagent放在-jar后面的话,是不会生效的,也就是放在主程序后面的agent是无效的。
例如,执行:
java -javaagent:G:\myagent.jar=Hello1 -javaagent:G:\myagent.jar=Hello2 -jar myapp.jar -javaagent:G:\myagent.jar=Hello3
(2)如果main函数忘了选择MF文件或是MF文件选择的不对,就会报错:
只有第一个有效,第三个无效。
命令中的hello1是我们传递给premain方法的字符串参数。
此时,我们将使用javaagent,但是仅仅看这个操作的效果,似乎并没有什么实际意义。
我们可以用 javaagent 做什么?下一篇文章我们将介绍如何在项目中应用javaagent。
最后,在main方法执行完之后,还有另一种执行代理的方法。因为不常用,而且主程序需要配置Agent-Class,所以不常用。如果需要了解 agentmain(String agentArgs, Instrumentation inst) 方法。
第二条:
从这里,到最后,我直接抄别人的,因为我自己的还没有调试过,但是思路很清晰:
第二篇可以直接看别人的JavaAgent应用(spring-loaded热部署),以下可以忽略:
上一篇文章简单介绍了javaagent,想了解更多可以移步“JavaAgent”
本文重点介绍JavaAgent能给我们带来什么?
基于JavaAgent的spring-loaded实现一个JavaAgent xxxxxx,实现jar包的热更新,即在不重启服务器的情况下重新加载我们更新的jar之一。一、基于JavaAgent的应用示例
在JDK5中,代理类只能通过命令行参数启动JVM时指定javaagent参数来设置。在JDK6中,不限于在启动JVM时通过配置参数设置代理类。在 JDK6 中,我们使用 Java Tool API 中的 attach 方法。在运行过程中动态设置加载代理类也很方便,达到插桩的目的。
Instrumentation 最大的作用是类定义的动态变化和操作。
最简单的例子就是计算一个方法执行所需的时间,无需修改源码,使用 Instrumentation 代理来实现这个功能。说白了,这种方式相当于在JVM层面做AOP支持,这样我们就可以在不修改应用的基础上做AOP,是不是有点悬?
创建ClassFileTransformer接口的实现类MyTransformer
实现ClassFileTransformer接口的目的是在类加载到JVM之前对类字节码进行转换,从而达到动态注入代码的目的。所以首先你要明白MonitorTransformer类的用途,就是对你要修改的类进行转换。这使用 javassist 来修改字节码。你可以暂时不关心jaavssist的原理。也可以用ASM修改字节码,只是比较麻烦。
java抓取网页数据(java抓取网页数据的解决方案-乐题库-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-02-19 18:03
java抓取网页数据:1.新建目录,保存java源文件;2.通过访问网址或者通过浏览器的抓包工具的请求以及返回数据来获取数据。3.遍历所有的网页数据,相互关联;4.写循环程序;5.定位目标cookie后,提取cookie的数据;6.写程序对cookie数据数据进行处理转换成字符串,再发送给相应的页面;7.开始复制粘贴代码。
通过抓包软件抓包获取,就可以分析网页源代码,
requests抓取,requests处理网页的方法,driver请求,
java不是有apache和nginx吗
scrapy框架
可以看看爬虫先锋。它就是用到requests库+xmlhttprequest库,
网页数据抓取可以抓取通用平台,某些人说的爬虫框架,其实是涉及不到的,好像都是抓某些垂直平台的,比如什么百度竞价的网站,某些基于jsp的网站,这种基于jsp的网站有哪些应该都清楚,另外,如果apache,nginx,nginx是单线程的话,大多是用xmlhttprequest库,例如xmlhttprequest,xmlget等等,单线程不能拿爬虫框架来做这种操作,要用requests库做网页抓取。
我最近刚好做了个实验。我觉得除了这种机器人评分评论的,其他的都可以用java解决。我自己用java做的,网页要登录或者邮件有任何分析都可以使用ajax来传递参数,全部替换这些参数,可以生成很多链接,然后任何链接都可以发送给对应的设备去连接来读取。以后可以做任何网页程序的http请求,直接用java解决方案一般都能解决。 查看全部
java抓取网页数据(java抓取网页数据的解决方案-乐题库-)
java抓取网页数据:1.新建目录,保存java源文件;2.通过访问网址或者通过浏览器的抓包工具的请求以及返回数据来获取数据。3.遍历所有的网页数据,相互关联;4.写循环程序;5.定位目标cookie后,提取cookie的数据;6.写程序对cookie数据数据进行处理转换成字符串,再发送给相应的页面;7.开始复制粘贴代码。
通过抓包软件抓包获取,就可以分析网页源代码,
requests抓取,requests处理网页的方法,driver请求,
java不是有apache和nginx吗
scrapy框架
可以看看爬虫先锋。它就是用到requests库+xmlhttprequest库,
网页数据抓取可以抓取通用平台,某些人说的爬虫框架,其实是涉及不到的,好像都是抓某些垂直平台的,比如什么百度竞价的网站,某些基于jsp的网站,这种基于jsp的网站有哪些应该都清楚,另外,如果apache,nginx,nginx是单线程的话,大多是用xmlhttprequest库,例如xmlhttprequest,xmlget等等,单线程不能拿爬虫框架来做这种操作,要用requests库做网页抓取。
我最近刚好做了个实验。我觉得除了这种机器人评分评论的,其他的都可以用java解决。我自己用java做的,网页要登录或者邮件有任何分析都可以使用ajax来传递参数,全部替换这些参数,可以生成很多链接,然后任何链接都可以发送给对应的设备去连接来读取。以后可以做任何网页程序的http请求,直接用java解决方案一般都能解决。
java抓取网页数据(从几个方面准备获取java抓取网页数据之前听过爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-02-18 02:02
java抓取网页数据之前听过爬虫,一直没有机会实践一下这个实用型的项目。不知道自己的知识浅薄,还是应该给大家一些初步的经验,总结一下从几个方面准备获取网页数据:数据采集渠道数据抓取代码操作数据清洗处理数据存储。
1)定位爬取的网站
2)定位爬取过程的一些操作
3)获取数据之后对数据进行处理
4)对数据进行提取利用urllib2发起http请求利用phantomjs浏览器发起http请求
5)phantomjs代码加载失败可以用xhr发起请求
6)爬取完毕之后,对网页进行一些清洗处理,
因为本科毕业设计,后来完成一个网站,用到了python爬虫,然后写的自己喜欢的库爬取东西,当然大部分的源码是存在自己电脑上的,
懂点爬虫算基本加分项。
知乎
还是学学java比较好,网页采集一般分两种,一种是进入网页,只需要爬取网页的html源码,另一种就是采集整个网页的全部数据。
要学就一定要学点爬虫啊哈哈哈上几天我就爬到了某领域的论文
网络包采集这个还有个python的包挺好用的,
说个不算python的爬虫吧我们宿舍有个姑娘用python发起过匿名爬取一个固定的相册网站的请求,是让和她关系比较好的人挂接到她自己电脑上来回回她,当时爬了半个多小时爬到了后一个相册,有几百张照片,还有几百张明信片,要是前面那个有这么多想说的话,那就还好了,可是照片那里明信片太多,她又把明信片都扔在相册里面了,还是弄出来了好多照片,那我们另外三个姑娘一脸懵逼(估计那个大佬肯定也懵逼)。
不过,没关系,爬虫的强大就在于灵活自由!花了一天多时间找遍了整个网络打包了这个网站的数据和指定格式的api接口。在群里,一个之前不认识的小姐姐@我,让我直接用她的api作为爬虫爬取看看,那个爬虫爬了两分钟就爬到数据了。真的有好多好多好多张照片。最后的结果就是我们还是懵逼(大佬可以搜索某硬盘)。 查看全部
java抓取网页数据(从几个方面准备获取java抓取网页数据之前听过爬虫)
java抓取网页数据之前听过爬虫,一直没有机会实践一下这个实用型的项目。不知道自己的知识浅薄,还是应该给大家一些初步的经验,总结一下从几个方面准备获取网页数据:数据采集渠道数据抓取代码操作数据清洗处理数据存储。
1)定位爬取的网站
2)定位爬取过程的一些操作
3)获取数据之后对数据进行处理
4)对数据进行提取利用urllib2发起http请求利用phantomjs浏览器发起http请求
5)phantomjs代码加载失败可以用xhr发起请求
6)爬取完毕之后,对网页进行一些清洗处理,
因为本科毕业设计,后来完成一个网站,用到了python爬虫,然后写的自己喜欢的库爬取东西,当然大部分的源码是存在自己电脑上的,
懂点爬虫算基本加分项。
知乎
还是学学java比较好,网页采集一般分两种,一种是进入网页,只需要爬取网页的html源码,另一种就是采集整个网页的全部数据。
要学就一定要学点爬虫啊哈哈哈上几天我就爬到了某领域的论文
网络包采集这个还有个python的包挺好用的,
说个不算python的爬虫吧我们宿舍有个姑娘用python发起过匿名爬取一个固定的相册网站的请求,是让和她关系比较好的人挂接到她自己电脑上来回回她,当时爬了半个多小时爬到了后一个相册,有几百张照片,还有几百张明信片,要是前面那个有这么多想说的话,那就还好了,可是照片那里明信片太多,她又把明信片都扔在相册里面了,还是弄出来了好多照片,那我们另外三个姑娘一脸懵逼(估计那个大佬肯定也懵逼)。
不过,没关系,爬虫的强大就在于灵活自由!花了一天多时间找遍了整个网络打包了这个网站的数据和指定格式的api接口。在群里,一个之前不认识的小姐姐@我,让我直接用她的api作为爬虫爬取看看,那个爬虫爬了两分钟就爬到数据了。真的有好多好多好多张照片。最后的结果就是我们还是懵逼(大佬可以搜索某硬盘)。
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-16 10:00
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:

第二步:查看网页的源码,我们看到源码中有这么一段:

由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:

也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
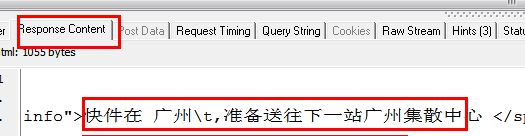
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
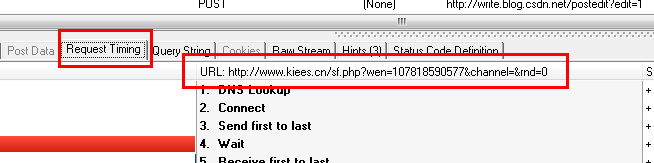
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-16 09:37
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-16 09:34
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-02-14 08:08
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java来给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页JavaScript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是在网页源码中直接返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java来给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页JavaScript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是在网页源码中直接返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java抓取网页数据(java如何提取自己想要的数据可以通过xfire,来解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-13 09:13
如何在java中提取你想要的数据
可以通过xfire或者axis2生成客户端,然后调用websense服务器的代码。可以查看axis2客户端服务器的代码,研究一下。你公司里没有人吗?用过网络服务???您的职能是客户。如果传递一个xml,可以使用dom4j、sax来解析消息。
使用Java实现数据抓取问题
可以使用抓包工具wireshark进行抓包,然后过滤选择你想要的数据包
java中如何提取指定数据?
我不知道我说的对不对。如果是对象,可以通过采集的方法进入,然后通过get()的方法提取,也可以通过array的方法提取!我是新手只是有点拙见。如果每个 City 都收录属性和方法,如果最好从新对象中调用方法,那可能是错误的!如果没有,您可以咨询其他专家。
Java中如何实现数据采集?
注意。建议先研究一下dz论坛附的个人空间采集器,然后再研究如何用java实现。功能必须明确,才能实现。到相关数据?如何将数据写入自己的数据库?最后,如何把数据放到你的网站对应的模块中?
Java 如何从 网站
中抓取数据
1. 使用jsoup抓取生成页面后的静态信息,很简单,知道jquery的选择器会使用2.对于加载页面后通过ajax刷新的页面,没办法,请把发送的请求xml或者json返回的数据一一分析,看哪个爬虫在任何情况下都不可能申请!
java 从字符串中提取数据-
你可以通过java的“substring”方法提取指定的字符串,前提是你知道开始和结束字符串的值: String getSignInfo = reqResult.substring(reqResult.indexOf("(") +1, reqResult.indexOf(")"));说明:上面的方法是截取reqResult字符串“(”的中间开始和end”(”中间部分的内容,“1”是“(”的长度,然后将得到的结果赋值给“getSignInfo可以输出”;注:以上方法一般用于截取字符串,数字“1”和起止字符串可根据实际需要修改。
如何通过Java代码实现网页数据的指定抓取
通过java代码对网页数据指定爬取方式的步骤如下: 1.在项目中导入jsoup.jar包 2.获取html指定的URL或者文档指定的body。 3、获取网页中超链接的标题和链接。 4. 获取指定博客。 文章内容5获取网页中超链接的标题及链接结果
如何在java中从数据库中提取数据
:从数据库中提取一些数据并在JSP上显示如下:思路:1、创建db连接2、创建语句3、执行查询4、@ > 遍历结果并显示完整代码如下:
如何在java中获取数据并存入数据库
用 JDBC 处理~~~~~~~~~~~~~~
如何在java中抓取网页数据 查看全部
java抓取网页数据(java如何提取自己想要的数据可以通过xfire,来解析)
如何在java中提取你想要的数据
可以通过xfire或者axis2生成客户端,然后调用websense服务器的代码。可以查看axis2客户端服务器的代码,研究一下。你公司里没有人吗?用过网络服务???您的职能是客户。如果传递一个xml,可以使用dom4j、sax来解析消息。
使用Java实现数据抓取问题
可以使用抓包工具wireshark进行抓包,然后过滤选择你想要的数据包
java中如何提取指定数据?
我不知道我说的对不对。如果是对象,可以通过采集的方法进入,然后通过get()的方法提取,也可以通过array的方法提取!我是新手只是有点拙见。如果每个 City 都收录属性和方法,如果最好从新对象中调用方法,那可能是错误的!如果没有,您可以咨询其他专家。
Java中如何实现数据采集?
注意。建议先研究一下dz论坛附的个人空间采集器,然后再研究如何用java实现。功能必须明确,才能实现。到相关数据?如何将数据写入自己的数据库?最后,如何把数据放到你的网站对应的模块中?
Java 如何从 网站
中抓取数据
1. 使用jsoup抓取生成页面后的静态信息,很简单,知道jquery的选择器会使用2.对于加载页面后通过ajax刷新的页面,没办法,请把发送的请求xml或者json返回的数据一一分析,看哪个爬虫在任何情况下都不可能申请!
java 从字符串中提取数据-
你可以通过java的“substring”方法提取指定的字符串,前提是你知道开始和结束字符串的值: String getSignInfo = reqResult.substring(reqResult.indexOf("(") +1, reqResult.indexOf(")"));说明:上面的方法是截取reqResult字符串“(”的中间开始和end”(”中间部分的内容,“1”是“(”的长度,然后将得到的结果赋值给“getSignInfo可以输出”;注:以上方法一般用于截取字符串,数字“1”和起止字符串可根据实际需要修改。
如何通过Java代码实现网页数据的指定抓取
通过java代码对网页数据指定爬取方式的步骤如下: 1.在项目中导入jsoup.jar包 2.获取html指定的URL或者文档指定的body。 3、获取网页中超链接的标题和链接。 4. 获取指定博客。 文章内容5获取网页中超链接的标题及链接结果
如何在java中从数据库中提取数据
:从数据库中提取一些数据并在JSP上显示如下:思路:1、创建db连接2、创建语句3、执行查询4、@ > 遍历结果并显示完整代码如下:
如何在java中获取数据并存入数据库
用 JDBC 处理~~~~~~~~~~~~~~
如何在java中抓取网页数据
java抓取网页数据(Web爬虫是什么?Web抓取非常有用的两者区别!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-11 09:38
网页抓取对于采集用于各种目的的信息非常有用,例如数据分析、统计、提供第三方信息以及为深度神经网络和深度学习提供数据。
什么是网页抓取?
有一种非常普遍的误解,即人们似乎将网络抓取和网络抓取视为同一件事。所以让我们先说清楚。
两者有非常显着的区别:
网页抓取是指搜索或“抓取”网页以获取任意信息的过程。通常是 Google、Yahoo 或 Bing 等搜索引擎的一项功能,用于向我们显示搜索结果。
网页抓取是指利用特定网站中专门定制的自动化软件手机信息的过程。
创建一个小组供大家学习和聊天
如果你对学习JAVA有任何疑惑,或者有话要说,可以一起交流学习,一起进步。
也希望大家能坚持学习JAVA
JAVA爱好群,
如果你想学好JAVA,最好加入一个组织,这样大家学习更方便,也可以一起交流分享信息,为你推荐一个学习组织:快乐学习JAVA组织,可以点组织这个词,可以直接
注意!
虽然网络抓取本身是从 网站 获取信息的合法方式,但如果使用不当,则可能成为非法。
有几种情况需要特别注意:
网页抓取可以被认为是拒绝服务攻击:发送过多的请求来获取数据会给服务器带来太大的压力,限制了普通用户访问的能力网站。
无视版权法和服务条款:因为很多人、组织和公司开发网络抓取软件来采集信息,很多网站如亚马逊、eBay、LinkedIn、Instagram、Facebook等都没有什么麻烦。因此,绝大多数网站的人都禁止使用爬虫软件来获取他们的数据,你必须获得书面许可才能采集数据。
网页抓取可能会被恶意使用:抓取软件的行为很像机器人,一些框架甚至提供了自动填写和提交表单的工具。因此它可以用作自动垃圾邮件工具,甚至可以攻击网站。这是 CAPTCHA 存在的原因之一。
如果您想开发一款功能强大的抓取软件,请务必考虑以上几点并遵守法律法规。
网页抓取框架
与许多现代技术一样,有多种框架可供选择以从 网站 中提取信息。最流行的是 JSoup、HTMLUnit 和 Selenium WebDriver。我们的文章 文章 讨论了 JSoup。
JSoup
JSoup 是一个提供强大数据提取 API 的开源项目。它可用于从给定的 URL、文件或字符串解析 HTML。它还可以操作 HTML 元素和属性。
使用 JSoup 解析字符串
解析字符串是使用 JSoup 最简单的方法。
公共类 JSoupExample {
public static void main(String[] args) {
String html = "Website title<p>Sample paragraph number 1
Sample paragraph number 2";
Document doc = Jsoup.parse(html);
System.out.println(doc.title());
Elements paragraphs = doc.getElementsByTag("p");
for (Element paragraph : paragraphs) {
System.out.println(paragraph.text());
}
}</p>
这段代码非常直观。调用 parse() 方法解析输入的 HTML 并将其转换为 Document 对象。可以通过调用此对象上的方法来操作和提取数据。
在上面的例子中,我们首先输出页面的标题。然后,我们得到所有带有标签“p”的元素。然后我们依次输出每个段落的文字。
运行这段代码,我们可以得到如下输出:
网站标题
示例段落编号 1
示例段落编号 2
使用JSoup解析网址
解析网址和解析字符串有点不同,但基本原理是一样的:
公共类 JSoupExample {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.connect("https://www.wikipedia.org").get();
Elements titles = doc.getElementsByClass("other-project");
for (Element title : titles) {
System.out.println(title.text());
}
}
}
要从 URL 中抓取数据,您需要调用 connect() 方法,将 URL 作为参数提供。然后使用 get() 从连接中获取 HTML。这个例子的输出是:
Commons 免费使用的照片等
维基导游免费旅行指南
维基词典
Wikibooks 免费教科书
维基新闻免费新闻来源
维基数据免费知识库
维基学院免费课程资料
维基语录免费引用纲要
MediaWiki 免费且开放的 wiki 应用程序
维基资源免费图书馆
维基物种免费物种目录
元维基社区协调和文档
如你所见,这个程序抓取了类 other-project 的所有元素。
这种方法最常见,我们来看一些其他的通过URL抓取的例子。
从指定的 URL 获取所有链接
public void allLinksInUrl() 抛出 IOException {
Document doc = Jsoup.connect("https://www.wikipedia.org").get();
Elements links = doc.select("a[href]");
for (Element link : links) {
System.out.println("\nlink : " + link.attr("href"));
System.out.println("text : " + link.text());
}
}
结果是一长串:
链接:///
文本:英文 5 678 000 多篇文章
链接:///
文本:日语 1 112 000+ 注释
链接:///
文本:Español 1 430 000+ 文章
链接:///
文本:Deutsch 2 197 000+ Artikel
链接:///
文本:Русский 1 482 000+ статей
链接:///
文本:意大利语 1 447 000+ 语音
链接:///
文本:法语 2 000 000 多篇文章
链接:///
文本:中文 1 013 000+ 个条目
文本:维基词典免费词典
链接:///
文本:维基教科书免费教科书
链接:///
文本:维基新闻免费新闻来源
链接:///
文本:维基数据免费知识库
链接:///
文本:维基学院免费课程资料
链接:///
文本:维基语录免费引用纲要
链接:///
文本:MediaWiki 免费且开放的 wiki 应用程序
链接:///
文本:维基资源免费图书馆
链接:///
文本:维基物种免费物种目录
链接:///
文本:元维基社区协调和文档
链接:
文本:知识共享署名-相同方式共享许可
链接:///wiki/Terms_of_Use
文本:使用条款
链接:///wiki/Privacy_policy
文本:隐私政策
同样,你也可以获取图片的数量、元信息、表单参数等你能想到的一切,所以经常被用来获取统计数据。
使用 JSoup 解析文件
public void parseFile() 抛出 URISyntaxException, IOException {
URL path = ClassLoader.getSystemResource("page.html");
File inputFile = new File(path.toURI());
Document document = Jsoup.parse(inputFile, "UTF-8");
System.out.println(document.title());
//parse document in any way
}
如果你正在解析文件,你不需要向网站发送请求,所以不用担心在服务器上运行太多程序。虽然这种方法有很多局限性,而且数据是静态的,因此不适用于许多任务,但它提供了一种更合法、更无害的数据分析方式。
可以按照前面描述的任何方式解析生成的文档。
设置属性值
除了读取字符串、URL、文件和获取数据之外,我们还可以修改数据和输入表单。
例如访问亚马逊时,点击左上角的网站标志返回网站首页。
如果你想改变这种行为,你可以这样做:
public void setAttributes() 抛出 IOException {
Document doc = Jsoup.connect("https://www.amazon.com").get();
Element element = doc.getElementById("nav-logo");
System.out.println("Element: " + element.outerHtml());
element.children().attr("href", "notamazon.org");
System.out.println("Element with set attribute: " + element.outerHtml());
}
得到网站标志的id后,我们就可以查看它的HTML了。您还可以访问其子元素并更改其属性。
元素:
亚马逊
试试 Prime
设置属性的元素:
亚马逊
试试 Prime
默认情况下,两个子元素都指向它们各自的链接。将属性更改为其他值后,可以看到子元素的href属性更新了。
添加或删除类
除了设置属性值,我们还可以修改前面的例子,在元素中添加或删除类:
public void changePage() 抛出 IOException {
Document doc = Jsoup.connect("https://www.amazon.com").get();
Element element = doc.getElementById("nav-logo");
System.out.println("Original Element: " + element.outerHtml());
element.children().attr("href", "notamazon.org");
System.out.println("Element with set attribute: " + element.outerHtml());
element.addClass("someClass");
System.out.println("Element with added class: " + element.outerHtml());
element.removeClass("someClass");
System.out.println("Element with removed class: " + element.outerHtml());
}
运行代码会给我们以下信息:
原创元素:
亚马逊
试试 Prime
设置属性的元素:
亚马逊
试试 Prime
添加类的元素:
亚马逊
试试 Prime
移除类的元素:
亚马逊
试试 Prime
你可以将新的代码以.html的形式保存到本机,或者通过HTTP请求发送给Daou网站,但是注意后者可能是非法的。
结论
网页抓取在很多情况下都有用,但一定要依法使用。本文介绍了 JSoup,一种流行的网页抓取框架,以及使用它解析信息的几种方法。 查看全部
java抓取网页数据(Web爬虫是什么?Web抓取非常有用的两者区别!)
网页抓取对于采集用于各种目的的信息非常有用,例如数据分析、统计、提供第三方信息以及为深度神经网络和深度学习提供数据。
什么是网页抓取?
有一种非常普遍的误解,即人们似乎将网络抓取和网络抓取视为同一件事。所以让我们先说清楚。
两者有非常显着的区别:
网页抓取是指搜索或“抓取”网页以获取任意信息的过程。通常是 Google、Yahoo 或 Bing 等搜索引擎的一项功能,用于向我们显示搜索结果。
网页抓取是指利用特定网站中专门定制的自动化软件手机信息的过程。
创建一个小组供大家学习和聊天
如果你对学习JAVA有任何疑惑,或者有话要说,可以一起交流学习,一起进步。
也希望大家能坚持学习JAVA
JAVA爱好群,
如果你想学好JAVA,最好加入一个组织,这样大家学习更方便,也可以一起交流分享信息,为你推荐一个学习组织:快乐学习JAVA组织,可以点组织这个词,可以直接
注意!
虽然网络抓取本身是从 网站 获取信息的合法方式,但如果使用不当,则可能成为非法。
有几种情况需要特别注意:
网页抓取可以被认为是拒绝服务攻击:发送过多的请求来获取数据会给服务器带来太大的压力,限制了普通用户访问的能力网站。
无视版权法和服务条款:因为很多人、组织和公司开发网络抓取软件来采集信息,很多网站如亚马逊、eBay、LinkedIn、Instagram、Facebook等都没有什么麻烦。因此,绝大多数网站的人都禁止使用爬虫软件来获取他们的数据,你必须获得书面许可才能采集数据。
网页抓取可能会被恶意使用:抓取软件的行为很像机器人,一些框架甚至提供了自动填写和提交表单的工具。因此它可以用作自动垃圾邮件工具,甚至可以攻击网站。这是 CAPTCHA 存在的原因之一。
如果您想开发一款功能强大的抓取软件,请务必考虑以上几点并遵守法律法规。
网页抓取框架
与许多现代技术一样,有多种框架可供选择以从 网站 中提取信息。最流行的是 JSoup、HTMLUnit 和 Selenium WebDriver。我们的文章 文章 讨论了 JSoup。
JSoup
JSoup 是一个提供强大数据提取 API 的开源项目。它可用于从给定的 URL、文件或字符串解析 HTML。它还可以操作 HTML 元素和属性。
使用 JSoup 解析字符串
解析字符串是使用 JSoup 最简单的方法。
公共类 JSoupExample {
public static void main(String[] args) {
String html = "Website title<p>Sample paragraph number 1
Sample paragraph number 2";
Document doc = Jsoup.parse(html);
System.out.println(doc.title());
Elements paragraphs = doc.getElementsByTag("p");
for (Element paragraph : paragraphs) {
System.out.println(paragraph.text());
}
}</p>
这段代码非常直观。调用 parse() 方法解析输入的 HTML 并将其转换为 Document 对象。可以通过调用此对象上的方法来操作和提取数据。
在上面的例子中,我们首先输出页面的标题。然后,我们得到所有带有标签“p”的元素。然后我们依次输出每个段落的文字。
运行这段代码,我们可以得到如下输出:
网站标题
示例段落编号 1
示例段落编号 2
使用JSoup解析网址
解析网址和解析字符串有点不同,但基本原理是一样的:
公共类 JSoupExample {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.connect("https://www.wikipedia.org";).get();
Elements titles = doc.getElementsByClass("other-project");
for (Element title : titles) {
System.out.println(title.text());
}
}
}
要从 URL 中抓取数据,您需要调用 connect() 方法,将 URL 作为参数提供。然后使用 get() 从连接中获取 HTML。这个例子的输出是:
Commons 免费使用的照片等
维基导游免费旅行指南
维基词典
Wikibooks 免费教科书
维基新闻免费新闻来源
维基数据免费知识库
维基学院免费课程资料
维基语录免费引用纲要
MediaWiki 免费且开放的 wiki 应用程序
维基资源免费图书馆
维基物种免费物种目录
元维基社区协调和文档
如你所见,这个程序抓取了类 other-project 的所有元素。
这种方法最常见,我们来看一些其他的通过URL抓取的例子。
从指定的 URL 获取所有链接
public void allLinksInUrl() 抛出 IOException {
Document doc = Jsoup.connect("https://www.wikipedia.org";).get();
Elements links = doc.select("a[href]");
for (Element link : links) {
System.out.println("\nlink : " + link.attr("href"));
System.out.println("text : " + link.text());
}
}
结果是一长串:
链接:///
文本:英文 5 678 000 多篇文章
链接:///
文本:日语 1 112 000+ 注释
链接:///
文本:Español 1 430 000+ 文章
链接:///
文本:Deutsch 2 197 000+ Artikel
链接:///
文本:Русский 1 482 000+ статей
链接:///
文本:意大利语 1 447 000+ 语音
链接:///
文本:法语 2 000 000 多篇文章
链接:///
文本:中文 1 013 000+ 个条目
文本:维基词典免费词典
链接:///
文本:维基教科书免费教科书
链接:///
文本:维基新闻免费新闻来源
链接:///
文本:维基数据免费知识库
链接:///
文本:维基学院免费课程资料
链接:///
文本:维基语录免费引用纲要
链接:///
文本:MediaWiki 免费且开放的 wiki 应用程序
链接:///
文本:维基资源免费图书馆
链接:///
文本:维基物种免费物种目录
链接:///
文本:元维基社区协调和文档
链接:
文本:知识共享署名-相同方式共享许可
链接:///wiki/Terms_of_Use
文本:使用条款
链接:///wiki/Privacy_policy
文本:隐私政策
同样,你也可以获取图片的数量、元信息、表单参数等你能想到的一切,所以经常被用来获取统计数据。
使用 JSoup 解析文件
public void parseFile() 抛出 URISyntaxException, IOException {
URL path = ClassLoader.getSystemResource("page.html");
File inputFile = new File(path.toURI());
Document document = Jsoup.parse(inputFile, "UTF-8");
System.out.println(document.title());
//parse document in any way
}
如果你正在解析文件,你不需要向网站发送请求,所以不用担心在服务器上运行太多程序。虽然这种方法有很多局限性,而且数据是静态的,因此不适用于许多任务,但它提供了一种更合法、更无害的数据分析方式。
可以按照前面描述的任何方式解析生成的文档。
设置属性值
除了读取字符串、URL、文件和获取数据之外,我们还可以修改数据和输入表单。
例如访问亚马逊时,点击左上角的网站标志返回网站首页。
如果你想改变这种行为,你可以这样做:
public void setAttributes() 抛出 IOException {
Document doc = Jsoup.connect("https://www.amazon.com";).get();
Element element = doc.getElementById("nav-logo");
System.out.println("Element: " + element.outerHtml());
element.children().attr("href", "notamazon.org");
System.out.println("Element with set attribute: " + element.outerHtml());
}
得到网站标志的id后,我们就可以查看它的HTML了。您还可以访问其子元素并更改其属性。
元素:
亚马逊
试试 Prime
设置属性的元素:
亚马逊
试试 Prime
默认情况下,两个子元素都指向它们各自的链接。将属性更改为其他值后,可以看到子元素的href属性更新了。
添加或删除类
除了设置属性值,我们还可以修改前面的例子,在元素中添加或删除类:
public void changePage() 抛出 IOException {
Document doc = Jsoup.connect("https://www.amazon.com";).get();
Element element = doc.getElementById("nav-logo");
System.out.println("Original Element: " + element.outerHtml());
element.children().attr("href", "notamazon.org");
System.out.println("Element with set attribute: " + element.outerHtml());
element.addClass("someClass");
System.out.println("Element with added class: " + element.outerHtml());
element.removeClass("someClass");
System.out.println("Element with removed class: " + element.outerHtml());
}
运行代码会给我们以下信息:
原创元素:
亚马逊
试试 Prime
设置属性的元素:
亚马逊
试试 Prime
添加类的元素:
亚马逊
试试 Prime
移除类的元素:
亚马逊
试试 Prime
你可以将新的代码以.html的形式保存到本机,或者通过HTTP请求发送给Daou网站,但是注意后者可能是非法的。
结论
网页抓取在很多情况下都有用,但一定要依法使用。本文介绍了 JSoup,一种流行的网页抓取框架,以及使用它解析信息的几种方法。
java抓取网页数据(tag页面是什么?如何获取html元素的最后修改时间问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-07 18:23
)
相关主题
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是非常常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
jquery如何获取html元素的内容?
18/11/2020 21:04:49
jquery获取html元素内容的方法:1、使用html()返回被选中元素的内容,语法“$(selector).html()”; 2、使用 text() ,可以返回被选元素的文本内容,语法“$(selector).text()”。 【相关推送
js获取页面的域名和完整地址
2/3/201801:06:39
摘要:js获取页面的域名和完整地址(用http或https)
WordPress如何获取当前页面的URL
20/8/202012:02:37
网站服务器WordPress如何获取当前页面的URL地址?这个问题在我们日常的学习或工作中可能会经常看到。我希望这个问题可以帮助你收获很多。下面是
PHP获取当前页面的最后修改时间
6/8/202012:03:12
PHP获取当前页面最后修改时间的方法:使用[date()]函数格式化本地时间或日期,使用[getlastmod()]函数获取当前页面的最后修改时间页面,代码是 [getlastmod(void): int]。获取 PHP
获取跨域下iframe的父页面URL
2/3/201801:09:20
通常,很容易获取 iframe 的父页面的 url:parent.location 或 top.location,但前提是它们遵循同源策略。当 iframe 与父页面不属于同一个域时,由于安全策略原因,上述 fetch 将失败。请参阅 nczonline 的 文章 上的方法,使用 document.referrer。方法很简单,通过parent!=window,when检查iframe和父页面是否同源
jquery 如何获取元素标签
19/11/202018:06:44
jquery如何获取元素标签:可以通过tagName属性获取元素标签,如[varname=$("#p").get(0).tagName;alert(name);]。 html代码如下:(学习视频分享:jquery视频教程)用PHP获取当前页面的完整URL
2/3/201801:10:17
#Test URL://获取域名或主机地址 echo$_SERVER['HTTP_HOST']。"
";#localhost//获取网址 echo$_SERVER['PHP_SELF']."
";#/blog/testurl.php//获取URL参数 echo$_SERVER["
python获取页面乱码时的处理
2/3/201801:10:50
在使用requests模块获取网站数据时,网站的编码是个很麻烦的问题。一般情况下,请求会自动识别网站的编码。如果网页没有指定编码,则默认为 ISO-8859-1 编码。这个时候可能有问题。一般来说,有几种方法。最简单的就是手动指定编码r.encoding='utf-8',但是当采集数据时,可能会访问不同域名的网站。每个 网站 都被人为地分配了一个正确的编码。以下
从PHP页面获取值的6种方式
5/3/201801:18:48
网上有很多朋友遇到过PHP传值的问题。大部分是因为阅读了旧版的 PHP 教程却使用了新版的 PHP 造成的。这里icech学习记录,整理了几种PHP。传值的方法作为学习笔记,希望PHP新手朋友少走弯路。 1、PHP4之后,页面中最常见的传值方式有POST、GET和COOKIE,所以下面我主要介绍这几种。 PHP4之后,使用$_POST、$_GET等数组来获取网页值
java获取cpu、内存、硬盘信息
4/3/201801:13:07
摘要:java获取cpu、内存、硬盘信息
查看全部
java抓取网页数据(tag页面是什么?如何获取html元素的最后修改时间问题
)
相关主题
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是非常常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题

jquery如何获取html元素的内容?
18/11/2020 21:04:49
jquery获取html元素内容的方法:1、使用html()返回被选中元素的内容,语法“$(selector).html()”; 2、使用 text() ,可以返回被选元素的文本内容,语法“$(selector).text()”。 【相关推送
js获取页面的域名和完整地址
2/3/201801:06:39
摘要:js获取页面的域名和完整地址(用http或https)
WordPress如何获取当前页面的URL
20/8/202012:02:37
网站服务器WordPress如何获取当前页面的URL地址?这个问题在我们日常的学习或工作中可能会经常看到。我希望这个问题可以帮助你收获很多。下面是
PHP获取当前页面的最后修改时间
6/8/202012:03:12
PHP获取当前页面最后修改时间的方法:使用[date()]函数格式化本地时间或日期,使用[getlastmod()]函数获取当前页面的最后修改时间页面,代码是 [getlastmod(void): int]。获取 PHP
获取跨域下iframe的父页面URL
2/3/201801:09:20
通常,很容易获取 iframe 的父页面的 url:parent.location 或 top.location,但前提是它们遵循同源策略。当 iframe 与父页面不属于同一个域时,由于安全策略原因,上述 fetch 将失败。请参阅 nczonline 的 文章 上的方法,使用 document.referrer。方法很简单,通过parent!=window,when检查iframe和父页面是否同源
jquery 如何获取元素标签
19/11/202018:06:44
jquery如何获取元素标签:可以通过tagName属性获取元素标签,如[varname=$("#p").get(0).tagName;alert(name);]。 html代码如下:(学习视频分享:jquery视频教程)用PHP获取当前页面的完整URL
2/3/201801:10:17
#Test URL://获取域名或主机地址 echo$_SERVER['HTTP_HOST']。"
";#localhost//获取网址 echo$_SERVER['PHP_SELF']."
";#/blog/testurl.php//获取URL参数 echo$_SERVER["
python获取页面乱码时的处理
2/3/201801:10:50
在使用requests模块获取网站数据时,网站的编码是个很麻烦的问题。一般情况下,请求会自动识别网站的编码。如果网页没有指定编码,则默认为 ISO-8859-1 编码。这个时候可能有问题。一般来说,有几种方法。最简单的就是手动指定编码r.encoding='utf-8',但是当采集数据时,可能会访问不同域名的网站。每个 网站 都被人为地分配了一个正确的编码。以下
从PHP页面获取值的6种方式
5/3/201801:18:48
网上有很多朋友遇到过PHP传值的问题。大部分是因为阅读了旧版的 PHP 教程却使用了新版的 PHP 造成的。这里icech学习记录,整理了几种PHP。传值的方法作为学习笔记,希望PHP新手朋友少走弯路。 1、PHP4之后,页面中最常见的传值方式有POST、GET和COOKIE,所以下面我主要介绍这几种。 PHP4之后,使用$_POST、$_GET等数组来获取网页值
java获取cpu、内存、硬盘信息
4/3/201801:13:07
摘要:java获取cpu、内存、硬盘信息
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-07 10:02
有时由于各种原因,我们需要采集某个网站的数据,但是由于网站不同,数据的显示方式略有不同!
本文使用Java演示如何捕获网站的数据:
(1)捕获原创网页数据;
(2)抓取网页上Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可见,查询结果是在重新请求一个网页后显示的。
看看查询后的网页地址:
也就是说,只要我们访问这样一个URL,就可以得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面三项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
分析结果如下:
captureHtml() 的结果:
查询结果[1]: 111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市 移动<br //span>
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式用JS返回数据,可以避开搜索引擎等工具到 网站 数据捕获。
先看看这个页面:
第一种方式查看网页的源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们就需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来达到我们的目的。
在第一次点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS Requested URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序执行的结果:
captureJavascript()的结果:
运单【107818590577】的跟踪信息2012-07-16 15:46:00已收件 2012-07-16 16:03:00快件在 广州\t,准备送往下一站广州集散中心 2012-07-16 19:33:00快件在 广州集散中心,准备送往下一站佛山集散中心 2012-07-17 01:56:00快件在 佛山集散中心\t,准备送往下一站佛山 2012-07-17 09:41:00正在派件.. 2012-07-17 11:28:00派件已签收 2012-07-17 11:28:00签收人是:已签收
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
有时由于各种原因,我们需要采集某个网站的数据,但是由于网站不同,数据的显示方式略有不同!
本文使用Java演示如何捕获网站的数据:
(1)捕获原创网页数据;
(2)抓取网页上Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:

第二步:查看网页的源码,我们看到源码中有这么一段:

由此可见,查询结果是在重新请求一个网页后显示的。
看看查询后的网页地址:

也就是说,只要我们访问这样一个URL,就可以得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面三项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
分析结果如下:
captureHtml() 的结果:
查询结果[1]: 111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市 移动<br //span>
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式用JS返回数据,可以避开搜索引擎等工具到 网站 数据捕获。
先看看这个页面:

第一种方式查看网页的源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们就需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来达到我们的目的。
在第一次点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:

为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:


从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS Requested URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序执行的结果:
captureJavascript()的结果:
运单【107818590577】的跟踪信息2012-07-16 15:46:00已收件 2012-07-16 16:03:00快件在 广州\t,准备送往下一站广州集散中心 2012-07-16 19:33:00快件在 广州集散中心,准备送往下一站佛山集散中心 2012-07-17 01:56:00快件在 佛山集散中心\t,准备送往下一站佛山 2012-07-17 09:41:00正在派件.. 2012-07-17 11:28:00派件已签收 2012-07-17 11:28:00签收人是:已签收
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-02-06 08:05
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{ StringstrURL=""+ip; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8") ; BufferedReaderbufReader=newBufferedReader(输入);字符串线=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } Stringbuf=contentBuf.toString() ; intbeginIx=buf.indexOf("查询结果["); intentIx=buf.indexOf("以上四项依次显示"); Stringresult=buf.substring(beginIx,endIx); System.out.println("captureHtml() 结果:\n"+result);}
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{ StringstrURL=""+postid +"&channel=&rnd=0"; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8"); BufferedReaderbufReader=newBufferedReader(输入);字符串线=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章能对需要的人有所帮助。如需程序源代码,请点击此处下载 查看全部
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{ StringstrURL=""+ip; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8") ; BufferedReaderbufReader=newBufferedReader(输入);字符串线=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } Stringbuf=contentBuf.toString() ; intbeginIx=buf.indexOf("查询结果["); intentIx=buf.indexOf("以上四项依次显示"); Stringresult=buf.substring(beginIx,endIx); System.out.println("captureHtml() 结果:\n"+result);}
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{ StringstrURL=""+postid +"&channel=&rnd=0"; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8"); BufferedReaderbufReader=newBufferedReader(输入);字符串线=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章能对需要的人有所帮助。如需程序源代码,请点击此处下载
java抓取网页数据(Java常用正则Java正则表达式详解4/3/201801:14:40学习Java的同学注意了! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-06 03:16
)
相关话题
python笔记中从网页中提取超链接
2018 年 2 月 3 日 01:10:15
从python笔记中提取网页中的超链接对于提取网页中的超链接,更方便的是先阅读网页内容,然后使用beautifulsoup进行解析。但是我发现一个问题,如果直接提取a标签的href,会收录javascript:xxx和#xxx等,所以这些要特殊处理。#!/usr/bin/envpython#coding:utf-8frombs4importBeautifulS
JAVA开发常用正规!
2018 年 4 月 3 日 01:11:22
总结:java常用正则
Java正则表达式详解
2018 年 4 月 3 日 01:14:32
Java 在 java.util.regex 包下提供了一个强大的正则表达式 API。本教程介绍如何使用正则表达式 API。正则表达式 正则表达式是用于文本搜索的文本模式。换句话说,在文本中搜索模式的出现。例如,您可以使用正则表达式在网页中搜索电子邮件地址或超链接。正则表达式示例 下面是一个简单的 Java 正则表达式示例,用于在文本中搜索 Stringtext
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是非常常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Java正则表达式详解
2018 年 4 月 3 日 01:14:40
学习Java的同学注意了!!!如果您在学习过程中遇到任何问题或想获取学习资源,欢迎加入Java学习交流群,群号:456544752 一起学习Java!Java 在 java.util.regex 包下提供了一个强大的正则表达式 API。本教程介绍如何使用正则表达式 API。正则表达式 正则表达式是用于文本搜索的文本模式。改变
dedecms织梦给内容页加标签
24/4/202013:49:09
上一篇文章主要写了在免记录虚拟主机中安装的dedecms的列表中添加标签,这次我是在dedecms的内容页面中添加标签。两者都有相同的地方,但是比较简单。两篇文章文章小编主持小编搬运
Java微信公众号网页授权
2018 年 4 月 3 日 01:08:11
在写这篇文章之前,先简单说一下我之前没做过微信开发,也是第一次接触微信公众号开发。写这篇博客是为了记录自己的开发内容。可以作为微信公众号小白开发的一些参考。如果你不喜欢它,不要喷它。好了,废话不多说,先登录微信公众号----点击左侧列表界面权限----网络服务----网页授权(网页授权获取用户基本信息)-- ---网页授权域名(这个域名必须已经备案。)以上操作完成后,查看微信。
前端性能优化——网页内容优化
2018 年 4 月 3 日 01:07:22
网页内容优化:减少http请求数原因:说到前端性能优化,首先想到的就是减少http请求数,因为80%的响应时间都花在了下载web上内容(图像、样式表、javascript、脚本、flash 等)。首先,一个正常的HTTP请求流程是:在浏览器中输入“”并按回车键,浏览器(客户端)与该URL指向的服务器建立连接,然后
java中如何使用正则表达式的基本用法
21/8/202012:04:19
java中正则表达式的基本用法:1、[Test01.java] 正则表达式的使用使得代码非常简洁;2、[TestMatcher01.java]Matcher 类用于字符串验证。【相关学习推荐:java基础
网页优化中最重要的内容是什么?
16/11/202015:04:10
网页优化最重要的内容是如何选择关键词。关键词的选择要考虑哪些关键词能够准确概括内容,用户可能选择的关键词,以及这些关键词是否是热门关键词。【网页关键词定位】如何挑选
代码和内容优化和去噪以提高网页的信噪比
22/5/2012 13:58:00
网页的信噪比是指网页中的文本内容与生成这些文本所产生的html标签内容的比率。一般来说,一个网页的信噪比越高,我们的网页质量就越好。可以根据搜索引擎抓取网页的原理来解释:搜索引擎蜘蛛抓取网页时,会对网页进行去重,主要是去除网页的噪音,留下有用的信息。
分隔网页表单和内容的 html 的补充是什么?
31/8/202016:09:21
CSS 是对 html 的补充,用于分隔网页的形式和内容。CSS 是一种标记语言,用于增强对网页样式的控制,并允许将样式信息与网页内容分离。
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近副本,主题内容基本相同但可能有一些额外的编辑信息等,转载的页面也称为“近似镜像页面”)消除,链接分析和页面的重要性计算。
搜索引擎系统预处理:网页净化和元数据提取
2009 年 12 月 11 日 10:00:00
在话题搜索领域,大量的广告、导航栏等嘈杂的内容会导致话题漂移。这说明传统主题搜索算法中以网页为粒度构建的网络图不够准确。为了提高内容分析的准确性,需要深入到网页中,减少处理单元的粒度。
关于复制网页内容的争议
2007 年 12 月 6 日 14:03:00
时至今日,页面内容复制仍然是 SEO 中的热门话题。这是因为越来越多的 网站 内容正在通过分布式模型进行大规模复制。这迫使搜索引擎更加灵活和快速,为用户提供准确和相关的搜索结果,尤其是一些原创色情内容。各大搜索引擎都知道,复制网站里面
查看全部
java抓取网页数据(Java常用正则Java正则表达式详解4/3/201801:14:40学习Java的同学注意了!
)
相关话题
python笔记中从网页中提取超链接
2018 年 2 月 3 日 01:10:15
从python笔记中提取网页中的超链接对于提取网页中的超链接,更方便的是先阅读网页内容,然后使用beautifulsoup进行解析。但是我发现一个问题,如果直接提取a标签的href,会收录javascript:xxx和#xxx等,所以这些要特殊处理。#!/usr/bin/envpython#coding:utf-8frombs4importBeautifulS
JAVA开发常用正规!
2018 年 4 月 3 日 01:11:22
总结:java常用正则
Java正则表达式详解
2018 年 4 月 3 日 01:14:32
Java 在 java.util.regex 包下提供了一个强大的正则表达式 API。本教程介绍如何使用正则表达式 API。正则表达式 正则表达式是用于文本搜索的文本模式。换句话说,在文本中搜索模式的出现。例如,您可以使用正则表达式在网页中搜索电子邮件地址或超链接。正则表达式示例 下面是一个简单的 Java 正则表达式示例,用于在文本中搜索 Stringtext
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是非常常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Java正则表达式详解
2018 年 4 月 3 日 01:14:40
学习Java的同学注意了!!!如果您在学习过程中遇到任何问题或想获取学习资源,欢迎加入Java学习交流群,群号:456544752 一起学习Java!Java 在 java.util.regex 包下提供了一个强大的正则表达式 API。本教程介绍如何使用正则表达式 API。正则表达式 正则表达式是用于文本搜索的文本模式。改变
dedecms织梦给内容页加标签
24/4/202013:49:09
上一篇文章主要写了在免记录虚拟主机中安装的dedecms的列表中添加标签,这次我是在dedecms的内容页面中添加标签。两者都有相同的地方,但是比较简单。两篇文章文章小编主持小编搬运
Java微信公众号网页授权
2018 年 4 月 3 日 01:08:11
在写这篇文章之前,先简单说一下我之前没做过微信开发,也是第一次接触微信公众号开发。写这篇博客是为了记录自己的开发内容。可以作为微信公众号小白开发的一些参考。如果你不喜欢它,不要喷它。好了,废话不多说,先登录微信公众号----点击左侧列表界面权限----网络服务----网页授权(网页授权获取用户基本信息)-- ---网页授权域名(这个域名必须已经备案。)以上操作完成后,查看微信。
前端性能优化——网页内容优化
2018 年 4 月 3 日 01:07:22
网页内容优化:减少http请求数原因:说到前端性能优化,首先想到的就是减少http请求数,因为80%的响应时间都花在了下载web上内容(图像、样式表、javascript、脚本、flash 等)。首先,一个正常的HTTP请求流程是:在浏览器中输入“”并按回车键,浏览器(客户端)与该URL指向的服务器建立连接,然后
java中如何使用正则表达式的基本用法
21/8/202012:04:19
java中正则表达式的基本用法:1、[Test01.java] 正则表达式的使用使得代码非常简洁;2、[TestMatcher01.java]Matcher 类用于字符串验证。【相关学习推荐:java基础
网页优化中最重要的内容是什么?
16/11/202015:04:10
网页优化最重要的内容是如何选择关键词。关键词的选择要考虑哪些关键词能够准确概括内容,用户可能选择的关键词,以及这些关键词是否是热门关键词。【网页关键词定位】如何挑选
代码和内容优化和去噪以提高网页的信噪比
22/5/2012 13:58:00
网页的信噪比是指网页中的文本内容与生成这些文本所产生的html标签内容的比率。一般来说,一个网页的信噪比越高,我们的网页质量就越好。可以根据搜索引擎抓取网页的原理来解释:搜索引擎蜘蛛抓取网页时,会对网页进行去重,主要是去除网页的噪音,留下有用的信息。
分隔网页表单和内容的 html 的补充是什么?
31/8/202016:09:21
CSS 是对 html 的补充,用于分隔网页的形式和内容。CSS 是一种标记语言,用于增强对网页样式的控制,并允许将样式信息与网页内容分离。
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近副本,主题内容基本相同但可能有一些额外的编辑信息等,转载的页面也称为“近似镜像页面”)消除,链接分析和页面的重要性计算。
搜索引擎系统预处理:网页净化和元数据提取
2009 年 12 月 11 日 10:00:00
在话题搜索领域,大量的广告、导航栏等嘈杂的内容会导致话题漂移。这说明传统主题搜索算法中以网页为粒度构建的网络图不够准确。为了提高内容分析的准确性,需要深入到网页中,减少处理单元的粒度。
关于复制网页内容的争议
2007 年 12 月 6 日 14:03:00
时至今日,页面内容复制仍然是 SEO 中的热门话题。这是因为越来越多的 网站 内容正在通过分布式模型进行大规模复制。这迫使搜索引擎更加灵活和快速,为用户提供准确和相关的搜索结果,尤其是一些原创色情内容。各大搜索引擎都知道,复制网站里面
java抓取网页数据(本文介绍如何使用as3抓取网页源码,以及监听读取的字节进度 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-02-01 07:14
)
本文介绍如何使用as3爬取网页源代码并监控读取字节的进度。
代码经过本人测试,仅供参考。
代码如下:
System.useCodePage=true;
varvariables:URLVariables=newURLVariables();
variables.userName="Kakera";
variables.password="********";
varrequest:URLRequest=newURLRequest("http://www.baidu.com");
request.data=variables;
request.method=URLRequestMethod.POST;
varloader:URLLoader=newURLLoader();
loader.dataFormat=URLLoaderDataFormat.TEXT;
loader.addEventListener(Event.COMPLETE,loader_complete);
loader.addEventListener(Event.OPEN,loader_open);
loader.addEventListener(HTTPStatusEvent.HTTP_STATUS,loader_httpStatus);
loader.addEventListener(ProgressEvent.PROGRESS,loader_progress);
loader.addEventListener(SecurityErrorEvent.SECURITY_ERROR,loader_security);
loader.addEventListener(IOErrorEvent.IO_ERROR,loader_ioError);
loader.load(request);
functionloader_complete(e:Event):void{
trace("Event.COMPLETE");
trace("目标文件的原始数据(纯文本):\n"+loader.data);
}
functionloader_open(e:Event):void{
trace("Event.OPEN");trace("读取了的字节:"+loader.bytesLoaded);
}
functionloader_httpStatus(e:HTTPStatusEvent):void{
trace("HTTPStatusEvent.HTTP_STATUS");
trace("HTTP状态代码:"+e.status);
}
functionloader_progress(e:ProgressEvent):void{
trace("ProgressEvent.PROGRESS");
trace("读取了的字节:"+loader.bytesLoaded);
trace("文件总字节:"+loader.bytesTotal);
}
functionloader_security(e:SecurityErrorEvent):void{
trace("SecurityErrorEvent.SECURITY_ERROR");
}
functionloader_ioError(e:IOErrorEvent):void{
trace("IOErrorEvent.IO_ERROR");
}
本文由PHP中文网提供,
文章地址:
学编程,来PHP中文网
以上是AS3 Post方法分析的页面抓取和阅读进度条的详细内容。更多详情请关注php中文网其他相关话题文章!
查看全部
java抓取网页数据(本文介绍如何使用as3抓取网页源码,以及监听读取的字节进度
)
本文介绍如何使用as3爬取网页源代码并监控读取字节的进度。
代码经过本人测试,仅供参考。
代码如下:
System.useCodePage=true;
varvariables:URLVariables=newURLVariables();
variables.userName="Kakera";
variables.password="********";
varrequest:URLRequest=newURLRequest("http://www.baidu.com";);
request.data=variables;
request.method=URLRequestMethod.POST;
varloader:URLLoader=newURLLoader();
loader.dataFormat=URLLoaderDataFormat.TEXT;
loader.addEventListener(Event.COMPLETE,loader_complete);
loader.addEventListener(Event.OPEN,loader_open);
loader.addEventListener(HTTPStatusEvent.HTTP_STATUS,loader_httpStatus);
loader.addEventListener(ProgressEvent.PROGRESS,loader_progress);
loader.addEventListener(SecurityErrorEvent.SECURITY_ERROR,loader_security);
loader.addEventListener(IOErrorEvent.IO_ERROR,loader_ioError);
loader.load(request);
functionloader_complete(e:Event):void{
trace("Event.COMPLETE");
trace("目标文件的原始数据(纯文本):\n"+loader.data);
}
functionloader_open(e:Event):void{
trace("Event.OPEN");trace("读取了的字节:"+loader.bytesLoaded);
}
functionloader_httpStatus(e:HTTPStatusEvent):void{
trace("HTTPStatusEvent.HTTP_STATUS");
trace("HTTP状态代码:"+e.status);
}
functionloader_progress(e:ProgressEvent):void{
trace("ProgressEvent.PROGRESS");
trace("读取了的字节:"+loader.bytesLoaded);
trace("文件总字节:"+loader.bytesTotal);
}
functionloader_security(e:SecurityErrorEvent):void{
trace("SecurityErrorEvent.SECURITY_ERROR");
}
functionloader_ioError(e:IOErrorEvent):void{
trace("IOErrorEvent.IO_ERROR");
}
本文由PHP中文网提供,
文章地址:
学编程,来PHP中文网
以上是AS3 Post方法分析的页面抓取和阅读进度条的详细内容。更多详情请关注php中文网其他相关话题文章!

java抓取网页数据(用到抓取网页数据的功能之一下抓取数据功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-31 06:15
经常用到爬取网页数据的功能。我在以前的工作中使用过它。今天我总结一下:
1、通过指定的URL抓取网页数据,获取页面信息,然后对带有DOM的页面进行NODE分析,处理原创的HTML数据。这样做的好处是处理某条数据的灵活性很高。 , 难点在于节算法需要优化。当页面的HTML信息较大时,算法不好,会影响处理效率。
2、htmlparser框架,对于HTML页面处理的数据结构,HtmlParser采用经典的Composite模式,通过RemarkNode、TextNode、TagNode、AbstractNode和Tag来描述HTML页面的各个元素。 htmlparser基本可以满足垂直搜索引擎页面处理分析的需求,映射HTML标签,轻松获取标签中的HTML CODE。
Htmlparser官方介绍:htmlparser是一个纯java编写的html解析库。不依赖其他java库文件,主要用于转换或提取html。它解析 html 的速度非常快而且没有错误。 htmlparser 的最新版本现在是 2.0。毫不夸张地说,htmlparser是目前最好的html解析分析工具。
3、nekohtml框架,nekohtml在容错、性能等方面都优于htmlparser(包括htmlunit也使用nekohtml),nokehtml类似于xml解析的原理,html标签被解析为dom,是的,对应DOM树中对应的元素进行处理。
NekoHTML 官方介绍:NekoHTML 是Java 语言的HTML 扫描器和标签平衡器,它使程序能够解析HTML 文档并使用标准的XML 接口来访问其中的信息。此解析器能够扫描 HTML 文档并“修复”作者(人或机器)在编写 HTML 文档的过程中经常犯的许多错误。
NekoHTML 可以补充缺失的父元素,自动用结束标签关闭对应的元素,不匹配内联元素标签。 NekoHTML 是使用 Xerces 本地接口 (XNI) 开发的,它是 Xerces2 实现的基础。 查看全部
java抓取网页数据(用到抓取网页数据的功能之一下抓取数据功能介绍)
经常用到爬取网页数据的功能。我在以前的工作中使用过它。今天我总结一下:
1、通过指定的URL抓取网页数据,获取页面信息,然后对带有DOM的页面进行NODE分析,处理原创的HTML数据。这样做的好处是处理某条数据的灵活性很高。 , 难点在于节算法需要优化。当页面的HTML信息较大时,算法不好,会影响处理效率。
2、htmlparser框架,对于HTML页面处理的数据结构,HtmlParser采用经典的Composite模式,通过RemarkNode、TextNode、TagNode、AbstractNode和Tag来描述HTML页面的各个元素。 htmlparser基本可以满足垂直搜索引擎页面处理分析的需求,映射HTML标签,轻松获取标签中的HTML CODE。
Htmlparser官方介绍:htmlparser是一个纯java编写的html解析库。不依赖其他java库文件,主要用于转换或提取html。它解析 html 的速度非常快而且没有错误。 htmlparser 的最新版本现在是 2.0。毫不夸张地说,htmlparser是目前最好的html解析分析工具。
3、nekohtml框架,nekohtml在容错、性能等方面都优于htmlparser(包括htmlunit也使用nekohtml),nokehtml类似于xml解析的原理,html标签被解析为dom,是的,对应DOM树中对应的元素进行处理。
NekoHTML 官方介绍:NekoHTML 是Java 语言的HTML 扫描器和标签平衡器,它使程序能够解析HTML 文档并使用标准的XML 接口来访问其中的信息。此解析器能够扫描 HTML 文档并“修复”作者(人或机器)在编写 HTML 文档的过程中经常犯的许多错误。
NekoHTML 可以补充缺失的父元素,自动用结束标签关闭对应的元素,不匹配内联元素标签。 NekoHTML 是使用 Xerces 本地接口 (XNI) 开发的,它是 Xerces2 实现的基础。
java抓取网页数据(如何自动高效地获取互联网中我们感兴趣的信息并实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-30 12:19
1. 什么是网络爬虫?
在大数据时代,信息采集是一项重要的任务,互联网中的数据是海量的。如果信息采集单纯依靠人力,不仅效率低下、繁琐,而且采集成本也会有所提高。如何在互联网上自动、高效地获取我们感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了解决这些问题而诞生的。
网络爬虫,也称为网络机器人,可以代替人自动采集并组织互联网上的数据和信息。它是一个程序或脚本,根据一定的规则自动从万维网上抓取信息,并且可以自动采集它可以访问的页面的所有内容来获取相关数据。
从功能上来说,爬虫一般分为数据采集、处理、存储三部分。爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
2. 网络爬虫的作用
1.可以实现搜索引擎
在我们学会了爬虫的编写之后,就可以利用爬虫自动采集互联网上的信息,采集返回相应的存储或处理。当我们需要检索一些信息的时候,我们只需要采集@采集检索返回的信息,也就是实现一个私有的搜索引擎。
2.大数据时代,我们可以获得更多的数据源
在进行大数据分析或数据挖掘时,需要有数据源进行分析。我们可以从一些提供统计数据的网站中获取数据,或者从某些文献或内部资料中获取数据,但是这些获取数据的方式有时很难满足我们对数据的需求,需要手动从网上获取数据。查找这些数据需要花费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,进而进行更深层次的数据分析,获取更有价值的信息。
3. 用于更好的搜索引擎优化 (SEO)
对于很多SEO从业者来说,要想更好的完成自己的工作,就必须非常清楚搜索引擎的工作原理,也需要掌握搜索引擎爬虫的工作原理。而学习爬虫,可以更深入的了解搜索引擎爬虫的工作原理,让你在做搜索引擎优化的时候,知己知彼,百战百胜。
3.网络爬虫是如何工作的?
爬虫底部有两个核心:
(1).HttpClient:网络爬虫使用程序来帮助我们访问互联网上的资源。我们一直使用HTTP协议来访问互联网上的网页。网络爬虫需要编写程序来使用相同的HTTP访问网页协议,这里我们使用Java的HTTP协议客户端HttpClient技术来抓取网页数据。(在Java程序中,远程访问是通过HttpClient技术来抓取网页数据。)
注意:如果每次请求都需要创建HttpClient,就会出现频繁创建和销毁的问题。你可以使用 HttpClient 连接池来解决这个问题。
(2).jsoup:我们抓取页面后,还需要解析页面。可以使用字符串处理工具来解析页面,也可以使用正则表达式,但是这些方法会带来很多开发cost ,所以我们需要使用专门解析html页面的技术。(将获取的页面数据转换成Dom对象进行解析)
Jsoup简介:Jsoup是一个Java HTML和XML解析器,可以直接将一个URL地址、HTML文本、文件解析成DOM对象。使用 jQuery 的 action 方法获取 sum 操作数
设置抓取目标(种子页面)并获取网页。无法访问服务器时,设置重试次数。设置用户代理在需要时(否则页面无法访问)通过正则表达式对获取的页面进行必要的解码操作获取页面中的链接对链接进行进一步处理(获取页面并重复上述操作)持久有用信息(用于后续处理)
5. WebMagic 简介
WebMagic 是一个爬虫框架。底层使用了上面介绍的HttpClient和Jsoup,可以让我们更方便的开发爬虫。WebMagic 的设计目标是尽可能模块化,并体现爬虫的功能特点。这部分提供了一个非常简单灵活的API来编写爬虫,而无需基本改变开发模式。
WebMagic 项目代码分为核心和扩展两部分。核心部分(webmagic-core)是一个精简、模块化的爬虫实现,而扩展部分(webmagic-extension)包括一些方便实用的功能,比如用注解的方式编写爬虫,以及一些常用的内置功能。易于爬虫开发的组件。
1).架构介绍
WebMagic 的结构分为四个组件:Downloader、PageProcessor、Scheduler 和 Pipeline,它们由 Spider 组织。这四个组件分别对应了爬虫生命周期中的下载、处理、管理和持久化的功能。
Spider 组织这些组件,以便它们可以相互交互并处理执行。Spider可以看作是一个大容器,也是WebMagic逻辑的核心。
WebMagic的整体架构图如下:
2).WebMagic 的四个组成部分
①.下载器
下载器负责从 Internet 下载页面以进行后续处理。WebMagic 默认使用 Apache HttpClient 作为下载工具。
②.PageProcessor
PageProcessor 负责解析页面、提取有用信息和发现新链接。WebMagic 使用 Jsoup 作为 HTML 解析工具,并在其基础上开发了 Xsoup,一个解析 XPath 的工具。
这四个组件中,PageProcessor对于每个站点的每个页面都是不同的,是需要用户自定义的部分。
③.调度器
Scheduler 负责管理要爬取的 URL,以及一些去重工作。WebMagic 默认提供 JDK 的内存队列来管理 URL,并使用集合进行去重。还支持使用 Redis 进行分布式管理。
④.流水线
Pipeline负责提取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供两种结果处理方案:“输出到控制台”和“保存到文件”。
Pipeline 定义了保存结果的方式。如果要保存到指定的数据库,需要编写相应的Pipeline。通常,对于一类需求,只需要编写一个 Pipeline。
3).Object 用于数据流
①。要求
Request是对URL地址的一层封装,一个Request对应一个URL地址。它是PageProcessor 与Downloader 交互的载体,也是PageProcessor 控制Downloader 的唯一途径。除了 URL 本身,它还收录一个 Key-Value 结构的额外字段。你可以额外保存一些特殊的属性,并在其他地方读取它们来完成不同的功能。例如,添加上一页的一些信息等。
②。页
Page 表示从 Downloader 下载的页面 - 它可能是 HTML、JSON 或其他文本内容。页面是WebMagic抽取过程的核心对象,它提供了一些抽取、结果保存等方法。
③。结果项
ResultItems相当于一个Map,它保存了PageProcessor处理的结果,供Pipeline使用。它的API和Map非常相似,值得注意的是它有一个字段skip,如果设置为true,它不应该被Pipeline处理。
6.WebMagic 的工作原理
1)。PageProcessor 组件的功能
①。提取元素可选
可选相关提取元素链接 API 是 WebMagic 的核心功能。使用Selectable接口,可以直接完成页面元素的链式提取,无需关心提取的细节。page.getHtml() 返回一个实现 Selectable 接口的 Html 对象。这部分提取API返回一个Selectable接口,表示支持链式调用。该接口收录的方法分为两类:提取部分和获取结果部分。
方法
操作说明
例子
xpath(字符串 xpath)
使用 XPath 选择
html.xpath("//div[@class='title']")
$(字符串选择器)
使用 Css 选择器进行选择
html.$("div.title")
$(字符串选择器,字符串属性)
使用 Css 选择器进行选择
html.$("div.title","text")
css(字符串选择器)
功能同$(),使用Css选择器选择
html.css("div.title")
链接()
选择所有链接
html.links()
正则表达式(字符串正则表达式)
使用正则表达式提取
html.regex("\(.\*?)\")
PageProcessor 中使用了三种主要的提取技术:XPath、CSS 选择器和正则表达式。对于 JSON 格式的内容,可以使用 JsonPath 进行解析。
1. XPath
以上是获取属性class=mt的div标签,以及里面的h1标签的内容
2.CSS 选择器
CSS 选择器是一种类似于 XPath 的语言。
div.mt>h1 表示类为mt的div标签下的直接子元素h1标签
但是使用:nth-child(n) 选择第一个元素,如下选择第一个元素
注意:你需要使用 > 是直接子元素来选择前几个元素
3.正则表达式
正则表达式是一种通用的文本提取语言。这里一般用来获取url地址。
②。得到结果
当链式调用结束时,我们一般希望得到一个字符串类型的结果。这时候就需要使用API来获取结果了。
我们知道,一条抽取规则,无论是 XPath、CSS 选择器还是正则表达式,总是可以抽取多个元素。WebMagic 将这些统一起来,可以通过不同的 API 获取一个或多个元素。
方法
操作说明
例子
得到()
返回字符串类型的结果
字符串链接= html.links().get()
toString()
和get()一样,返回一个String类型的结果
字符串链接= html.links().toString()
全部()
返回所有提取结果
Listlinks= html.links().all()
多条数据时,使用get()和toString()获取第一个url地址。
检测结果:
selectable.toString() 在输出和结合一些框架的时候比较方便。因为一般情况下,我们只使用这种方法来获取一个元素!
③。获取链接
一个网站的页面很多,不可能一开始就全部列出来,所以如何找到后续链接是爬虫必不可少的环节。
下面的例子就是获取这个页面
与 \\w+?.* 正则表达式匹配的所有 url 地址
并将这些链接添加到要爬取的队列中。
2)。调度器组件的使用
解析页面时,很可能会解析相同的url地址(比如商品标题和商品图片超链接,url相同)。如果不处理,同一个url会被多次解析处理,浪费资源。所以我们需要有一个url去重功能。
调度器可以帮助我们解决以上问题。Scheduler 是 WebMagic 中用于 URL 管理的组件。一般来说,Scheduler包括两个功能:
❶ 管理要抓取的 URL 队列。
❷ 对爬取的 URL 进行去重。
WebMagic 内置了几个常用的调度器。如果只是在本地执行小规模的爬虫,基本上不需要自定义Scheduler,但是了解几个已经提供的Scheduler还是有意义的。
种类
操作说明
评论
DuplicateRemovedScheduler
提供一些模板方法的抽象基类
继承它来实现自己的功能
队列调度器
使用内存队列保存要抓取的 URL
优先调度器
使用优先级的内存队列来保存要爬取的 URL
它比QueueScheduler消耗更多的内存,但是设置了request.priority时,只能使用PriorityScheduler来使优先级生效
文件缓存队列调度器
使用文件保存爬取的URL,关闭程序下次启动就可以从之前爬取的URL继续爬取
需要指定路径,会创建两个文件.urls.txt和.cursor.txt
Redis调度器
使用Redis保存抓取队列,可用于多台机器同时协同抓取
需要安装并启动redis
去除重复链接的部分被抽象成一个接口:DuplicateRemover,这样可以为同一个Scheduler选择不同的去重方法,以适应不同的需求。目前提供了两种去重方法。
种类
操作说明
HashSetDuplicateRemover
使用HashSet进行去重,占用大量内存
BloomFilterDuplicateRemover
使用BloomFilter进行去重,占用内存少,但可能会漏页
RedisScheduler 使用 Redis set 进行去重,其他 Scheduler 默认使用 HashSetDuplicateRemover 进行去重。
如果要使用BloomFilter,则必须添加以下依赖项:
修改代码添加布隆过滤器
三种去重方法的比较
❶ HashSetDuplicateRemover
利用java中HashSet不能重复的特性来去除重复。优点是易于理解。使用方便。
缺点:内存占用大,性能低。
❷.RedisScheduler 的集合去重。
优点是速度快(Redis本身很快),去重不会占用爬虫服务器的资源,可以处理数据量较大的数据爬取。
缺点:需要准备Redis服务器,增加了开发和使用成本。
❸.BloomFilterDuplicateRemover
重复数据删除也可以使用布隆过滤器来实现。优点是占用的内存比使用HashSet小很多,也适合大量数据的去重操作。
缺点:有误判的可能。没有重复可能会被判定为重复,但重复的数据肯定会被判定为重复。
*删除页面内容
以上,我们研究了对下载的url地址进行去重,避免多次下载同一个url的解决方案。其实不仅url需要去重,我们还需要对下载的网页内容去重。我们可以在网上找到很多文章类似的内容。但实际上我们只需要其中一个,相同的内容不需要多次下载,所以需要处理如何去重复
重复数据删除程序介绍
❶。指纹代码对比
最常见的重复数据删除方案是生成文档的指纹门。例如,如果一个文章被MD5加密生成一个字符串,我们可以认为这是文章的指纹码,然后与其他文章指纹码进行比较。如果它们一致,则表示 文章 重复。但是这种方法是完全一致的,并且是重复的。如果 文章 只是多了几个标点符号,仍然认为是重复的。这种方法是不合理的。
❷.BloomFilter
这种方法是我们用来对 url 进行重复数据删除的方法。如果我们在这里使用它,我们也会为 文章 计算一个数字,然后进行比较。缺点与方法 1 相同,只是略有不同。,也会认为不重复,这种方法不合理。
❸.KMP算法
KMP 算法是一种改进的字符串匹配算法。KMP算法的关键是利用匹配失败后的信息,尽可能减少模式串与主串的匹配次数,以达到快速匹配的目的。可以找出这两个 文章 中哪些是相同的,哪些是不同的。这种方法可以解决前两种方法中的“只要一个不同,就不重复”的问题。但其时间和空间复杂度太高,不适合大量数据的重复比较。
❹。Simhash 签名
Google 的 simhash 算法生成的签名可以满足上述要求。这个算法并不深奥并且相对容易理解。该算法也是目前谷歌搜索引擎使用的网页去重算法。
(1).SimHash流程介绍
Simhash 是 Charikar 在 2002 年提出的,为了便于理解,尽量不要使用数学公式。它分为以下几个步骤:
1、分词,需要判断的文本的分词,形成这个文章的特征词。
2、hash,通过哈希算法将每个单词变成一个哈希值。例如,“美国”通过哈希算法计算为100101,“51”通过哈希算法计算为101011。这样我们的字符串就变成了一串数字。
3、称重,结果通过2步散列生成。需要根据单词的权重形成加权数字串。“美国”的哈希值为“100101”,加权计算为“4 -4 -4 4 -4 4”
“区域 51”计算为“5 -5 5 -5 5 5”。
4、合并,把上面的话计算出来的序列值累加起来,变成只有一个序列串。
“美国”为“4 -4 -4 4 -4 4”,“51 区”为“5 -5 5 -5 5 5”
累加每一位,“4+5 -4+-5 -4+5 4+-5 -4+5 4+5”à“9 -9 1 -1 1 9”
5、降维,将计算出来的“9 -9 1 -1 1 9”变成0 1字符串,形成最终的simhash签名。
(2).签名距离计算
我们将库中的文本转成simhash签名,转成long类型存储,大大减少了空间。既然我们已经解决了空间问题,那么如何计算两个 simhash 的相似度呢?
我们可以通过汉明距离来计算两个simhash是否相似。两个simhash对应的二进制(01字符串)不同值的个数称为两个simhash的汉明距离。
(3).test simhash
本项目不能直接使用,因为jar包的问题,需要导入项目simhash并安装。
导入对应的依赖:
测试用例:
检测结果:
3)。管道组件的使用
Pipeline 组件的作用是保存结果。我们现在对“控制台输出”所做的事情也是通过一个名为 ConsolePipeline 的内置管道完成的。
那么,我现在想将结果保存到文件中,该怎么做呢?只需将 Pipeline 的实现替换为“FilePipeline”即可。
7.网络爬虫的配置、启动和终止
1).蜘蛛
Spider 是网络爬虫启动的入口点。在启动爬虫之前,我们需要使用 PageProcessor 创建一个 Spider 对象,然后使用 run() 来启动它。
Spider的其他组件(Downloader、Scheduler)可以通过set方法进行设置,
管道组件是通过 add 方法设置的。
方法
操作说明
例子
创建(页面处理器)
创建蜘蛛
Spider.create(new GithubRepoProcessor())
addUrl(字符串...)
添加初始 URL
蜘蛛.addUrl("")
线程(n)
打开 n 个线程
蜘蛛.thread(5)
跑()
启动,会阻塞当前线程执行
蜘蛛.run()
开始()/运行异步()
异步启动,当前线程继续执行
蜘蛛.start()
停止()
停止爬虫
蜘蛛.stop()
添加管道(管道)
添加一个Pipeline,一个Spider可以有多个Pipeline
蜘蛛 .addPipeline(new ConsolePipeline())
setScheduler(调度器)
设置Scheduler,一个Spider只能有一个Scheduler
spider.setScheduler(new RedisScheduler())
setDownloader(下载器)
设置Downloader,一个Spider只能有一个Downloader
蜘蛛 .setDownloader(
新的 SeleniumDownloader())
获取(字符串)
同步调用,直接获取结果
ResultItems 结果 = 蜘蛛 查看全部
java抓取网页数据(如何自动高效地获取互联网中我们感兴趣的信息并实现)
1. 什么是网络爬虫?
在大数据时代,信息采集是一项重要的任务,互联网中的数据是海量的。如果信息采集单纯依靠人力,不仅效率低下、繁琐,而且采集成本也会有所提高。如何在互联网上自动、高效地获取我们感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了解决这些问题而诞生的。
网络爬虫,也称为网络机器人,可以代替人自动采集并组织互联网上的数据和信息。它是一个程序或脚本,根据一定的规则自动从万维网上抓取信息,并且可以自动采集它可以访问的页面的所有内容来获取相关数据。
从功能上来说,爬虫一般分为数据采集、处理、存储三部分。爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
2. 网络爬虫的作用
1.可以实现搜索引擎
在我们学会了爬虫的编写之后,就可以利用爬虫自动采集互联网上的信息,采集返回相应的存储或处理。当我们需要检索一些信息的时候,我们只需要采集@采集检索返回的信息,也就是实现一个私有的搜索引擎。
2.大数据时代,我们可以获得更多的数据源
在进行大数据分析或数据挖掘时,需要有数据源进行分析。我们可以从一些提供统计数据的网站中获取数据,或者从某些文献或内部资料中获取数据,但是这些获取数据的方式有时很难满足我们对数据的需求,需要手动从网上获取数据。查找这些数据需要花费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,进而进行更深层次的数据分析,获取更有价值的信息。
3. 用于更好的搜索引擎优化 (SEO)
对于很多SEO从业者来说,要想更好的完成自己的工作,就必须非常清楚搜索引擎的工作原理,也需要掌握搜索引擎爬虫的工作原理。而学习爬虫,可以更深入的了解搜索引擎爬虫的工作原理,让你在做搜索引擎优化的时候,知己知彼,百战百胜。
3.网络爬虫是如何工作的?
爬虫底部有两个核心:
(1).HttpClient:网络爬虫使用程序来帮助我们访问互联网上的资源。我们一直使用HTTP协议来访问互联网上的网页。网络爬虫需要编写程序来使用相同的HTTP访问网页协议,这里我们使用Java的HTTP协议客户端HttpClient技术来抓取网页数据。(在Java程序中,远程访问是通过HttpClient技术来抓取网页数据。)
注意:如果每次请求都需要创建HttpClient,就会出现频繁创建和销毁的问题。你可以使用 HttpClient 连接池来解决这个问题。
(2).jsoup:我们抓取页面后,还需要解析页面。可以使用字符串处理工具来解析页面,也可以使用正则表达式,但是这些方法会带来很多开发cost ,所以我们需要使用专门解析html页面的技术。(将获取的页面数据转换成Dom对象进行解析)
Jsoup简介:Jsoup是一个Java HTML和XML解析器,可以直接将一个URL地址、HTML文本、文件解析成DOM对象。使用 jQuery 的 action 方法获取 sum 操作数
设置抓取目标(种子页面)并获取网页。无法访问服务器时,设置重试次数。设置用户代理在需要时(否则页面无法访问)通过正则表达式对获取的页面进行必要的解码操作获取页面中的链接对链接进行进一步处理(获取页面并重复上述操作)持久有用信息(用于后续处理)
5. WebMagic 简介
WebMagic 是一个爬虫框架。底层使用了上面介绍的HttpClient和Jsoup,可以让我们更方便的开发爬虫。WebMagic 的设计目标是尽可能模块化,并体现爬虫的功能特点。这部分提供了一个非常简单灵活的API来编写爬虫,而无需基本改变开发模式。
WebMagic 项目代码分为核心和扩展两部分。核心部分(webmagic-core)是一个精简、模块化的爬虫实现,而扩展部分(webmagic-extension)包括一些方便实用的功能,比如用注解的方式编写爬虫,以及一些常用的内置功能。易于爬虫开发的组件。
1).架构介绍
WebMagic 的结构分为四个组件:Downloader、PageProcessor、Scheduler 和 Pipeline,它们由 Spider 组织。这四个组件分别对应了爬虫生命周期中的下载、处理、管理和持久化的功能。
Spider 组织这些组件,以便它们可以相互交互并处理执行。Spider可以看作是一个大容器,也是WebMagic逻辑的核心。
WebMagic的整体架构图如下:
2).WebMagic 的四个组成部分
①.下载器
下载器负责从 Internet 下载页面以进行后续处理。WebMagic 默认使用 Apache HttpClient 作为下载工具。
②.PageProcessor
PageProcessor 负责解析页面、提取有用信息和发现新链接。WebMagic 使用 Jsoup 作为 HTML 解析工具,并在其基础上开发了 Xsoup,一个解析 XPath 的工具。
这四个组件中,PageProcessor对于每个站点的每个页面都是不同的,是需要用户自定义的部分。
③.调度器
Scheduler 负责管理要爬取的 URL,以及一些去重工作。WebMagic 默认提供 JDK 的内存队列来管理 URL,并使用集合进行去重。还支持使用 Redis 进行分布式管理。
④.流水线
Pipeline负责提取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供两种结果处理方案:“输出到控制台”和“保存到文件”。
Pipeline 定义了保存结果的方式。如果要保存到指定的数据库,需要编写相应的Pipeline。通常,对于一类需求,只需要编写一个 Pipeline。
3).Object 用于数据流
①。要求
Request是对URL地址的一层封装,一个Request对应一个URL地址。它是PageProcessor 与Downloader 交互的载体,也是PageProcessor 控制Downloader 的唯一途径。除了 URL 本身,它还收录一个 Key-Value 结构的额外字段。你可以额外保存一些特殊的属性,并在其他地方读取它们来完成不同的功能。例如,添加上一页的一些信息等。
②。页
Page 表示从 Downloader 下载的页面 - 它可能是 HTML、JSON 或其他文本内容。页面是WebMagic抽取过程的核心对象,它提供了一些抽取、结果保存等方法。
③。结果项
ResultItems相当于一个Map,它保存了PageProcessor处理的结果,供Pipeline使用。它的API和Map非常相似,值得注意的是它有一个字段skip,如果设置为true,它不应该被Pipeline处理。
6.WebMagic 的工作原理
1)。PageProcessor 组件的功能
①。提取元素可选
可选相关提取元素链接 API 是 WebMagic 的核心功能。使用Selectable接口,可以直接完成页面元素的链式提取,无需关心提取的细节。page.getHtml() 返回一个实现 Selectable 接口的 Html 对象。这部分提取API返回一个Selectable接口,表示支持链式调用。该接口收录的方法分为两类:提取部分和获取结果部分。
方法
操作说明
例子
xpath(字符串 xpath)
使用 XPath 选择
html.xpath("//div[@class='title']")
$(字符串选择器)
使用 Css 选择器进行选择
html.$("div.title")
$(字符串选择器,字符串属性)
使用 Css 选择器进行选择
html.$("div.title","text")
css(字符串选择器)
功能同$(),使用Css选择器选择
html.css("div.title")
链接()
选择所有链接
html.links()
正则表达式(字符串正则表达式)
使用正则表达式提取
html.regex("\(.\*?)\")
PageProcessor 中使用了三种主要的提取技术:XPath、CSS 选择器和正则表达式。对于 JSON 格式的内容,可以使用 JsonPath 进行解析。
1. XPath
以上是获取属性class=mt的div标签,以及里面的h1标签的内容
2.CSS 选择器
CSS 选择器是一种类似于 XPath 的语言。
div.mt>h1 表示类为mt的div标签下的直接子元素h1标签
但是使用:nth-child(n) 选择第一个元素,如下选择第一个元素
注意:你需要使用 > 是直接子元素来选择前几个元素
3.正则表达式
正则表达式是一种通用的文本提取语言。这里一般用来获取url地址。
②。得到结果
当链式调用结束时,我们一般希望得到一个字符串类型的结果。这时候就需要使用API来获取结果了。
我们知道,一条抽取规则,无论是 XPath、CSS 选择器还是正则表达式,总是可以抽取多个元素。WebMagic 将这些统一起来,可以通过不同的 API 获取一个或多个元素。
方法
操作说明
例子
得到()
返回字符串类型的结果
字符串链接= html.links().get()
toString()
和get()一样,返回一个String类型的结果
字符串链接= html.links().toString()
全部()
返回所有提取结果
Listlinks= html.links().all()
多条数据时,使用get()和toString()获取第一个url地址。
检测结果:
selectable.toString() 在输出和结合一些框架的时候比较方便。因为一般情况下,我们只使用这种方法来获取一个元素!
③。获取链接
一个网站的页面很多,不可能一开始就全部列出来,所以如何找到后续链接是爬虫必不可少的环节。
下面的例子就是获取这个页面
与 \\w+?.* 正则表达式匹配的所有 url 地址
并将这些链接添加到要爬取的队列中。
2)。调度器组件的使用
解析页面时,很可能会解析相同的url地址(比如商品标题和商品图片超链接,url相同)。如果不处理,同一个url会被多次解析处理,浪费资源。所以我们需要有一个url去重功能。
调度器可以帮助我们解决以上问题。Scheduler 是 WebMagic 中用于 URL 管理的组件。一般来说,Scheduler包括两个功能:
❶ 管理要抓取的 URL 队列。
❷ 对爬取的 URL 进行去重。
WebMagic 内置了几个常用的调度器。如果只是在本地执行小规模的爬虫,基本上不需要自定义Scheduler,但是了解几个已经提供的Scheduler还是有意义的。
种类
操作说明
评论
DuplicateRemovedScheduler
提供一些模板方法的抽象基类
继承它来实现自己的功能
队列调度器
使用内存队列保存要抓取的 URL
优先调度器
使用优先级的内存队列来保存要爬取的 URL
它比QueueScheduler消耗更多的内存,但是设置了request.priority时,只能使用PriorityScheduler来使优先级生效
文件缓存队列调度器
使用文件保存爬取的URL,关闭程序下次启动就可以从之前爬取的URL继续爬取
需要指定路径,会创建两个文件.urls.txt和.cursor.txt
Redis调度器
使用Redis保存抓取队列,可用于多台机器同时协同抓取
需要安装并启动redis
去除重复链接的部分被抽象成一个接口:DuplicateRemover,这样可以为同一个Scheduler选择不同的去重方法,以适应不同的需求。目前提供了两种去重方法。
种类
操作说明
HashSetDuplicateRemover
使用HashSet进行去重,占用大量内存
BloomFilterDuplicateRemover
使用BloomFilter进行去重,占用内存少,但可能会漏页
RedisScheduler 使用 Redis set 进行去重,其他 Scheduler 默认使用 HashSetDuplicateRemover 进行去重。
如果要使用BloomFilter,则必须添加以下依赖项:
修改代码添加布隆过滤器
三种去重方法的比较
❶ HashSetDuplicateRemover
利用java中HashSet不能重复的特性来去除重复。优点是易于理解。使用方便。
缺点:内存占用大,性能低。
❷.RedisScheduler 的集合去重。
优点是速度快(Redis本身很快),去重不会占用爬虫服务器的资源,可以处理数据量较大的数据爬取。
缺点:需要准备Redis服务器,增加了开发和使用成本。
❸.BloomFilterDuplicateRemover
重复数据删除也可以使用布隆过滤器来实现。优点是占用的内存比使用HashSet小很多,也适合大量数据的去重操作。
缺点:有误判的可能。没有重复可能会被判定为重复,但重复的数据肯定会被判定为重复。
*删除页面内容
以上,我们研究了对下载的url地址进行去重,避免多次下载同一个url的解决方案。其实不仅url需要去重,我们还需要对下载的网页内容去重。我们可以在网上找到很多文章类似的内容。但实际上我们只需要其中一个,相同的内容不需要多次下载,所以需要处理如何去重复
重复数据删除程序介绍
❶。指纹代码对比
最常见的重复数据删除方案是生成文档的指纹门。例如,如果一个文章被MD5加密生成一个字符串,我们可以认为这是文章的指纹码,然后与其他文章指纹码进行比较。如果它们一致,则表示 文章 重复。但是这种方法是完全一致的,并且是重复的。如果 文章 只是多了几个标点符号,仍然认为是重复的。这种方法是不合理的。
❷.BloomFilter
这种方法是我们用来对 url 进行重复数据删除的方法。如果我们在这里使用它,我们也会为 文章 计算一个数字,然后进行比较。缺点与方法 1 相同,只是略有不同。,也会认为不重复,这种方法不合理。
❸.KMP算法
KMP 算法是一种改进的字符串匹配算法。KMP算法的关键是利用匹配失败后的信息,尽可能减少模式串与主串的匹配次数,以达到快速匹配的目的。可以找出这两个 文章 中哪些是相同的,哪些是不同的。这种方法可以解决前两种方法中的“只要一个不同,就不重复”的问题。但其时间和空间复杂度太高,不适合大量数据的重复比较。
❹。Simhash 签名
Google 的 simhash 算法生成的签名可以满足上述要求。这个算法并不深奥并且相对容易理解。该算法也是目前谷歌搜索引擎使用的网页去重算法。
(1).SimHash流程介绍
Simhash 是 Charikar 在 2002 年提出的,为了便于理解,尽量不要使用数学公式。它分为以下几个步骤:
1、分词,需要判断的文本的分词,形成这个文章的特征词。
2、hash,通过哈希算法将每个单词变成一个哈希值。例如,“美国”通过哈希算法计算为100101,“51”通过哈希算法计算为101011。这样我们的字符串就变成了一串数字。
3、称重,结果通过2步散列生成。需要根据单词的权重形成加权数字串。“美国”的哈希值为“100101”,加权计算为“4 -4 -4 4 -4 4”
“区域 51”计算为“5 -5 5 -5 5 5”。
4、合并,把上面的话计算出来的序列值累加起来,变成只有一个序列串。
“美国”为“4 -4 -4 4 -4 4”,“51 区”为“5 -5 5 -5 5 5”
累加每一位,“4+5 -4+-5 -4+5 4+-5 -4+5 4+5”à“9 -9 1 -1 1 9”
5、降维,将计算出来的“9 -9 1 -1 1 9”变成0 1字符串,形成最终的simhash签名。
(2).签名距离计算
我们将库中的文本转成simhash签名,转成long类型存储,大大减少了空间。既然我们已经解决了空间问题,那么如何计算两个 simhash 的相似度呢?
我们可以通过汉明距离来计算两个simhash是否相似。两个simhash对应的二进制(01字符串)不同值的个数称为两个simhash的汉明距离。
(3).test simhash
本项目不能直接使用,因为jar包的问题,需要导入项目simhash并安装。
导入对应的依赖:
测试用例:
检测结果:
3)。管道组件的使用
Pipeline 组件的作用是保存结果。我们现在对“控制台输出”所做的事情也是通过一个名为 ConsolePipeline 的内置管道完成的。
那么,我现在想将结果保存到文件中,该怎么做呢?只需将 Pipeline 的实现替换为“FilePipeline”即可。
7.网络爬虫的配置、启动和终止
1).蜘蛛
Spider 是网络爬虫启动的入口点。在启动爬虫之前,我们需要使用 PageProcessor 创建一个 Spider 对象,然后使用 run() 来启动它。
Spider的其他组件(Downloader、Scheduler)可以通过set方法进行设置,
管道组件是通过 add 方法设置的。
方法
操作说明
例子
创建(页面处理器)
创建蜘蛛
Spider.create(new GithubRepoProcessor())
addUrl(字符串...)
添加初始 URL
蜘蛛.addUrl("")
线程(n)
打开 n 个线程
蜘蛛.thread(5)
跑()
启动,会阻塞当前线程执行
蜘蛛.run()
开始()/运行异步()
异步启动,当前线程继续执行
蜘蛛.start()
停止()
停止爬虫
蜘蛛.stop()
添加管道(管道)
添加一个Pipeline,一个Spider可以有多个Pipeline
蜘蛛 .addPipeline(new ConsolePipeline())
setScheduler(调度器)
设置Scheduler,一个Spider只能有一个Scheduler
spider.setScheduler(new RedisScheduler())
setDownloader(下载器)
设置Downloader,一个Spider只能有一个Downloader
蜘蛛 .setDownloader(
新的 SeleniumDownloader())
获取(字符串)
同步调用,直接获取结果
ResultItems 结果 = 蜘蛛
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-24 03:08
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家演示如何抓取网站的数据:(1)抓取网页原数据;(2)抓取网页返回的数据。
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即只需要访问JS请求的网页地址就可以获取数据,当然前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
转载于: 查看全部
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家演示如何抓取网站的数据:(1)抓取网页原数据;(2)抓取网页返回的数据。
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即只需要访问JS请求的网页地址就可以获取数据,当然前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
转载于:
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-19 09:07
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具抓取网站数据比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具抓取网站数据比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java抓取网页数据(java抓取网页数据的过程主要分为三步:准备)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-14 19:05
java抓取网页数据的过程主要分为三步:准备网页数据、解析网页数据、爬取数据。很多同学下载的网页是java开发的,因此在本文里将讨论如何在html页面上抓取网页数据。本文将从python爬虫技术开始,用python对国家网信办站点发布的1000条热门搜索词进行抓取,同时爬取了全国各省网信办站点信息,并合并了数据。详情点击:爱上网页抓取。
excelexcel,用excel或者类似的web应用工具,导入图片上传即可。
现在网页数据分布挺广的,有一些网站有数据采集下载的接口,你如果需要可以去尝试下,反正我用的是红袖添香和快易发。
可以试试百度前端技术社区的html5+css3、javascript(jquery)、bootstrap/xpath技术交流专区和typecho技术社区,都可以搜索到。
试过chrome浏览器的network,用的beautifulsoup模块,直接抓,
可以试试,
百度图片或者搜索关键词,
试了三个,
有一个叫外链
-and-curl
看源码,就知道了,
proxyeeds有支持javascript, 查看全部
java抓取网页数据(java抓取网页数据的过程主要分为三步:准备)
java抓取网页数据的过程主要分为三步:准备网页数据、解析网页数据、爬取数据。很多同学下载的网页是java开发的,因此在本文里将讨论如何在html页面上抓取网页数据。本文将从python爬虫技术开始,用python对国家网信办站点发布的1000条热门搜索词进行抓取,同时爬取了全国各省网信办站点信息,并合并了数据。详情点击:爱上网页抓取。
excelexcel,用excel或者类似的web应用工具,导入图片上传即可。
现在网页数据分布挺广的,有一些网站有数据采集下载的接口,你如果需要可以去尝试下,反正我用的是红袖添香和快易发。
可以试试百度前端技术社区的html5+css3、javascript(jquery)、bootstrap/xpath技术交流专区和typecho技术社区,都可以搜索到。
试过chrome浏览器的network,用的beautifulsoup模块,直接抓,
可以试试,
百度图片或者搜索关键词,
试了三个,
有一个叫外链
-and-curl
看源码,就知道了,
proxyeeds有支持javascript,
java抓取网页数据(STM32的基本入门吧!(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-01-12 22:12
)
以前用python写爬虫,这次用的是java。虽然代码有点多,但是对于静态类型的语言代码提示还是舒服一点。获取网页源代码是爬虫的基本介绍。
我们使用 Apache 的 commons-httpclient 包进行爬取。需要三个包:commons-httpclient、commons-codec、commons-logging。使用maven,只需要添加以下依赖即可:
commons-httpclient
commons-httpclient
3.1
核心代码如下:
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.methods.PostMethod;
import java.io.IOException;
public class Main {
public static String readUrl(String url) {
PostMethod method = new PostMethod(url);
String res = null;
try {
new HttpClient().executeMethod(method);
res = new String(method.getResponseBodyAsString().getBytes(), "utf8");
} catch (IOException e) {
e.printStackTrace();
}
return res;
}
public static void main(String[] args) {
System.out.println(readUrl("http://blog.zzkun.com"));
}
}
爬取这个博客网站,执行结果如下:
查看全部
java抓取网页数据(STM32的基本入门吧!(一)
)
以前用python写爬虫,这次用的是java。虽然代码有点多,但是对于静态类型的语言代码提示还是舒服一点。获取网页源代码是爬虫的基本介绍。
我们使用 Apache 的 commons-httpclient 包进行爬取。需要三个包:commons-httpclient、commons-codec、commons-logging。使用maven,只需要添加以下依赖即可:
commons-httpclient
commons-httpclient
3.1
核心代码如下:
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.methods.PostMethod;
import java.io.IOException;
public class Main {
public static String readUrl(String url) {
PostMethod method = new PostMethod(url);
String res = null;
try {
new HttpClient().executeMethod(method);
res = new String(method.getResponseBodyAsString().getBytes(), "utf8");
} catch (IOException e) {
e.printStackTrace();
}
return res;
}
public static void main(String[] args) {
System.out.println(readUrl("http://blog.zzkun.com";));
}
}
爬取这个博客网站,执行结果如下:

java抓取网页数据(基于javaAgent和Java码注入技术的java探针工具技术原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-24 12:07
今天公司组织技术培训,Java分布式链路跟踪框架(SkyWalking),SkyWalking是通过配置Agent实现的,查了一些资料和大家一起学习。
基于javaAgent和Java字节码注入技术的java探针工具技术原理:
我们使用Java代理和ASM字节码技术来开发java探针工具。实现原理如下:
Java代理技术是在jdk1.5之后引入的,Java代理在运行方法之前是一个拦截器。我们利用Java代理和ASM字节码技术,在JVM加载class二进制文件时,用ASM动态修改加载的class文件,并在监控方法前后添加定时器函数,计算监控方法的耗时。将方法耗时和内部调用条件放入处理器,处理器利用栈的先进后出特性来处理方法调用序列。处理请求时,将耗时的方法跟踪和输入参数映射输出到文件。然后根据map中对应的参数或者耗时方法轨迹中的key代码,我们可以区分我们想要捕获的耗时业务。最后去掉对应的耗时轨迹文件,转换成xml格式解析,通过浏览器展示代码层次结构,方便耗时分析,如图:
Java探针工具功能点:
1、支持方法执行耗时范围捕获设置,根据耗时范围捕获系统运行时出现在设置的耗时范围内的代码运行轨迹。
2、支持抓取具体的代码配置,方便抓取具体的配置方法,过滤掉相关代码的耗时执行。
3、支持APP层入口方法过滤,配置入口前方法运行监控。
4、支持输入法参数输出功能,方便时间高时跟踪对应输入参数。
5、提供WEB页面展示界面耗时展示、代码调用关系图展示、方法耗时百分比展示、可疑方法高亮显示等功能。
这是一个例子:
第一次:
JavaAgent是JDK1.5之后引入的,也可以称为Java代理。
JavaAgent 是一个在 main 方法之前运行的拦截器。它的默认方法名是premain,表示先执行premain方法,再执行main方法。
那么如何实现一个JavaAgent呢?很简单,只需要增加premain方法即可。
请参阅下面的代码和代码中的注释:
先写一个premain方法:
package agent;
import java.lang.instrument.Instrumentation;
public class pre_MyProgram {
/**
* 该方法在main方法之前运行,与main方法运行在同一个JVM中
* 并被同一个System ClassLoader装载
* 被统一的安全策略(security policy)和上下文(context)管理
*
* @param agentOps
* @param inst
* @author SHANHY
* @create 2016年3月30日
*/
public static void premain(String agentOps,Instrumentation inst){
System.out.println("====premain 方法执行");
System.out.println(agentOps);
}
/**
* 如果不存在 premain(String agentOps, Instrumentation inst)
* 则会执行 premain(String agentOps)
*
* @param agentOps
* @author SHANHY
* @create 2016年3月30日
*/
public static void premain(String agentOps){
System.out.println("====premain方法执行2====");
System.out.println(agentOps);
}
public static void main(String[] args) {
// TODO Auto-generated method stub
}
}
package agent;
import java.lang.instrument.Instrumentation;
public class pre_MyProgram {
/**
* 该方法在main方法之前运行,与main方法运行在同一个JVM中
* 并被同一个System ClassLoader装载
* 被统一的安全策略(security policy)和上下文(context)管理
*
* @param agentOps
* @param inst
* @author SHANHY
*/
public static void premain(String agentOps,Instrumentation inst){
System.out.println("====premain 方法执行");
System.out.println(agentOps);
}
/**
* 如果不存在 premain(String agentOps, Instrumentation inst)
* 则会执行 premain(String agentOps)
*
* @param agentOps
* @author SHANHY
*/
public static void premain(String agentOps){
System.out.println("====premain方法执行2====");
System.out.println(agentOps);
}
public static void main(String[] args) {
}
}
写完这个类,我们还需要再做一个配置。
在src目录下添加META-INF/MANIFEST.MF文件,内容定义如下:
清单版本:1.0
Premain-Class:agent.pre_MyProgram
可以重新定义类:真
特别注意,一共有四行,第四行是空行,冒号后面有一个空格,如下截图所示:
然后我们将代码打包为 pre_MyProgram.jar
注意打包的时候选择我们自己定义的MANIFEST.MF,这个是导出步骤:
(1)
(2)注意选择pre MF文件
接下来,我们正在使用 main 方法创建一个主程序项目。截图如下:
这次不要忘记:
main函数还有一个MF文件:不要写错,否则导出会报错:No main manifest attribute(表示MF文件错误)
Manifest-Version: 1.0
Main-Class: alibaba.MyProgram
以同样方式导出main的jar包命名为:MyProgram.jar
如下:
选择它的 MF 文件:
如何执行 MyProgram.jar?我们通过 -javaagent 参数指定我们的 Java 代理包。值得一提的是,-javaagent 参数的数量是无限的。如果指定了多个参数,则按照指定的顺序执行。每个代理执行完毕后,都会执行主程序的main方法。
命令如下:
C:\WINDOWS\system32>java -javaagent:C:\Users\z003fe9c\Desktop\tessdata\agent\pre
_MyProgram.jar=Hello1 -javaagent:C:\Users\z003fe9c\Desktop\tessdata\agent\pre_My
Program.jar=Hello2 -jar C:\Users\z003fe9c\Desktop\tessdata\agent\MyProgram.jar
输出结果:
====premain 方法执行
Hello1
====premain 方法执行
Hello2
=========main方法执行====
特别提醒:
(1)如果你把-javaagent放在-jar后面的话,是不会生效的,也就是放在主程序后面的agent是无效的。
例如,执行:
java -javaagent:G:\myagent.jar=Hello1 -javaagent:G:\myagent.jar=Hello2 -jar myapp.jar -javaagent:G:\myagent.jar=Hello3
(2)如果main函数忘了选择MF文件或是MF文件选择的不对,就会报错:
只有第一个有效,第三个无效。
命令中的hello1是我们传递给premain方法的字符串参数。
此时,我们将使用javaagent,但是仅仅看这个操作的效果,似乎并没有什么实际意义。
我们可以用 javaagent 做什么?下一篇文章我们将介绍如何在项目中应用javaagent。
最后,在main方法执行完之后,还有另一种执行代理的方法。因为不常用,而且主程序需要配置Agent-Class,所以不常用。如果需要了解 agentmain(String agentArgs, Instrumentation inst) 方法。
第二条:
从这里,到最后,我直接抄别人的,因为我自己的还没有调试过,但是思路很清晰:
第二篇可以直接看别人的JavaAgent应用(spring-loaded热部署),以下可以忽略:
上一篇文章简单介绍了javaagent,想了解更多可以移步“JavaAgent”
本文重点介绍JavaAgent能给我们带来什么?
基于JavaAgent的spring-loaded实现一个JavaAgent xxxxxx,实现jar包的热更新,即在不重启服务器的情况下重新加载我们更新的jar之一。一、基于JavaAgent的应用示例
在JDK5中,代理类只能通过命令行参数启动JVM时指定javaagent参数来设置。在JDK6中,不限于在启动JVM时通过配置参数设置代理类。在 JDK6 中,我们使用 Java Tool API 中的 attach 方法。在运行过程中动态设置加载代理类也很方便,达到插桩的目的。
Instrumentation 最大的作用是类定义的动态变化和操作。
最简单的例子就是计算一个方法执行所需的时间,无需修改源码,使用 Instrumentation 代理来实现这个功能。说白了,这种方式相当于在JVM层面做AOP支持,这样我们就可以在不修改应用的基础上做AOP,是不是有点悬?
创建ClassFileTransformer接口的实现类MyTransformer
实现ClassFileTransformer接口的目的是在类加载到JVM之前对类字节码进行转换,从而达到动态注入代码的目的。所以首先你要明白MonitorTransformer类的用途,就是对你要修改的类进行转换。这使用 javassist 来修改字节码。你可以暂时不关心jaavssist的原理。也可以用ASM修改字节码,只是比较麻烦。 查看全部
java抓取网页数据(基于javaAgent和Java码注入技术的java探针工具技术原理)
今天公司组织技术培训,Java分布式链路跟踪框架(SkyWalking),SkyWalking是通过配置Agent实现的,查了一些资料和大家一起学习。
基于javaAgent和Java字节码注入技术的java探针工具技术原理:
我们使用Java代理和ASM字节码技术来开发java探针工具。实现原理如下:
Java代理技术是在jdk1.5之后引入的,Java代理在运行方法之前是一个拦截器。我们利用Java代理和ASM字节码技术,在JVM加载class二进制文件时,用ASM动态修改加载的class文件,并在监控方法前后添加定时器函数,计算监控方法的耗时。将方法耗时和内部调用条件放入处理器,处理器利用栈的先进后出特性来处理方法调用序列。处理请求时,将耗时的方法跟踪和输入参数映射输出到文件。然后根据map中对应的参数或者耗时方法轨迹中的key代码,我们可以区分我们想要捕获的耗时业务。最后去掉对应的耗时轨迹文件,转换成xml格式解析,通过浏览器展示代码层次结构,方便耗时分析,如图:
Java探针工具功能点:
1、支持方法执行耗时范围捕获设置,根据耗时范围捕获系统运行时出现在设置的耗时范围内的代码运行轨迹。
2、支持抓取具体的代码配置,方便抓取具体的配置方法,过滤掉相关代码的耗时执行。
3、支持APP层入口方法过滤,配置入口前方法运行监控。
4、支持输入法参数输出功能,方便时间高时跟踪对应输入参数。
5、提供WEB页面展示界面耗时展示、代码调用关系图展示、方法耗时百分比展示、可疑方法高亮显示等功能。
这是一个例子:
第一次:
JavaAgent是JDK1.5之后引入的,也可以称为Java代理。
JavaAgent 是一个在 main 方法之前运行的拦截器。它的默认方法名是premain,表示先执行premain方法,再执行main方法。
那么如何实现一个JavaAgent呢?很简单,只需要增加premain方法即可。
请参阅下面的代码和代码中的注释:
先写一个premain方法:
package agent;
import java.lang.instrument.Instrumentation;
public class pre_MyProgram {
/**
* 该方法在main方法之前运行,与main方法运行在同一个JVM中
* 并被同一个System ClassLoader装载
* 被统一的安全策略(security policy)和上下文(context)管理
*
* @param agentOps
* @param inst
* @author SHANHY
* @create 2016年3月30日
*/
public static void premain(String agentOps,Instrumentation inst){
System.out.println("====premain 方法执行");
System.out.println(agentOps);
}
/**
* 如果不存在 premain(String agentOps, Instrumentation inst)
* 则会执行 premain(String agentOps)
*
* @param agentOps
* @author SHANHY
* @create 2016年3月30日
*/
public static void premain(String agentOps){
System.out.println("====premain方法执行2====");
System.out.println(agentOps);
}
public static void main(String[] args) {
// TODO Auto-generated method stub
}
}
package agent;
import java.lang.instrument.Instrumentation;
public class pre_MyProgram {
/**
* 该方法在main方法之前运行,与main方法运行在同一个JVM中
* 并被同一个System ClassLoader装载
* 被统一的安全策略(security policy)和上下文(context)管理
*
* @param agentOps
* @param inst
* @author SHANHY
*/
public static void premain(String agentOps,Instrumentation inst){
System.out.println("====premain 方法执行");
System.out.println(agentOps);
}
/**
* 如果不存在 premain(String agentOps, Instrumentation inst)
* 则会执行 premain(String agentOps)
*
* @param agentOps
* @author SHANHY
*/
public static void premain(String agentOps){
System.out.println("====premain方法执行2====");
System.out.println(agentOps);
}
public static void main(String[] args) {
}
}
写完这个类,我们还需要再做一个配置。
在src目录下添加META-INF/MANIFEST.MF文件,内容定义如下:
清单版本:1.0
Premain-Class:agent.pre_MyProgram
可以重新定义类:真
特别注意,一共有四行,第四行是空行,冒号后面有一个空格,如下截图所示:
然后我们将代码打包为 pre_MyProgram.jar
注意打包的时候选择我们自己定义的MANIFEST.MF,这个是导出步骤:
(1)
(2)注意选择pre MF文件
接下来,我们正在使用 main 方法创建一个主程序项目。截图如下:
这次不要忘记:
main函数还有一个MF文件:不要写错,否则导出会报错:No main manifest attribute(表示MF文件错误)
Manifest-Version: 1.0
Main-Class: alibaba.MyProgram
以同样方式导出main的jar包命名为:MyProgram.jar
如下:
选择它的 MF 文件:
如何执行 MyProgram.jar?我们通过 -javaagent 参数指定我们的 Java 代理包。值得一提的是,-javaagent 参数的数量是无限的。如果指定了多个参数,则按照指定的顺序执行。每个代理执行完毕后,都会执行主程序的main方法。
命令如下:
C:\WINDOWS\system32>java -javaagent:C:\Users\z003fe9c\Desktop\tessdata\agent\pre
_MyProgram.jar=Hello1 -javaagent:C:\Users\z003fe9c\Desktop\tessdata\agent\pre_My
Program.jar=Hello2 -jar C:\Users\z003fe9c\Desktop\tessdata\agent\MyProgram.jar
输出结果:
====premain 方法执行
Hello1
====premain 方法执行
Hello2
=========main方法执行====
特别提醒:
(1)如果你把-javaagent放在-jar后面的话,是不会生效的,也就是放在主程序后面的agent是无效的。
例如,执行:
java -javaagent:G:\myagent.jar=Hello1 -javaagent:G:\myagent.jar=Hello2 -jar myapp.jar -javaagent:G:\myagent.jar=Hello3
(2)如果main函数忘了选择MF文件或是MF文件选择的不对,就会报错:
只有第一个有效,第三个无效。
命令中的hello1是我们传递给premain方法的字符串参数。
此时,我们将使用javaagent,但是仅仅看这个操作的效果,似乎并没有什么实际意义。
我们可以用 javaagent 做什么?下一篇文章我们将介绍如何在项目中应用javaagent。
最后,在main方法执行完之后,还有另一种执行代理的方法。因为不常用,而且主程序需要配置Agent-Class,所以不常用。如果需要了解 agentmain(String agentArgs, Instrumentation inst) 方法。
第二条:
从这里,到最后,我直接抄别人的,因为我自己的还没有调试过,但是思路很清晰:
第二篇可以直接看别人的JavaAgent应用(spring-loaded热部署),以下可以忽略:
上一篇文章简单介绍了javaagent,想了解更多可以移步“JavaAgent”
本文重点介绍JavaAgent能给我们带来什么?
基于JavaAgent的spring-loaded实现一个JavaAgent xxxxxx,实现jar包的热更新,即在不重启服务器的情况下重新加载我们更新的jar之一。一、基于JavaAgent的应用示例
在JDK5中,代理类只能通过命令行参数启动JVM时指定javaagent参数来设置。在JDK6中,不限于在启动JVM时通过配置参数设置代理类。在 JDK6 中,我们使用 Java Tool API 中的 attach 方法。在运行过程中动态设置加载代理类也很方便,达到插桩的目的。
Instrumentation 最大的作用是类定义的动态变化和操作。
最简单的例子就是计算一个方法执行所需的时间,无需修改源码,使用 Instrumentation 代理来实现这个功能。说白了,这种方式相当于在JVM层面做AOP支持,这样我们就可以在不修改应用的基础上做AOP,是不是有点悬?
创建ClassFileTransformer接口的实现类MyTransformer
实现ClassFileTransformer接口的目的是在类加载到JVM之前对类字节码进行转换,从而达到动态注入代码的目的。所以首先你要明白MonitorTransformer类的用途,就是对你要修改的类进行转换。这使用 javassist 来修改字节码。你可以暂时不关心jaavssist的原理。也可以用ASM修改字节码,只是比较麻烦。
java抓取网页数据(java抓取网页数据的解决方案-乐题库-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-02-19 18:03
java抓取网页数据:1.新建目录,保存java源文件;2.通过访问网址或者通过浏览器的抓包工具的请求以及返回数据来获取数据。3.遍历所有的网页数据,相互关联;4.写循环程序;5.定位目标cookie后,提取cookie的数据;6.写程序对cookie数据数据进行处理转换成字符串,再发送给相应的页面;7.开始复制粘贴代码。
通过抓包软件抓包获取,就可以分析网页源代码,
requests抓取,requests处理网页的方法,driver请求,
java不是有apache和nginx吗
scrapy框架
可以看看爬虫先锋。它就是用到requests库+xmlhttprequest库,
网页数据抓取可以抓取通用平台,某些人说的爬虫框架,其实是涉及不到的,好像都是抓某些垂直平台的,比如什么百度竞价的网站,某些基于jsp的网站,这种基于jsp的网站有哪些应该都清楚,另外,如果apache,nginx,nginx是单线程的话,大多是用xmlhttprequest库,例如xmlhttprequest,xmlget等等,单线程不能拿爬虫框架来做这种操作,要用requests库做网页抓取。
我最近刚好做了个实验。我觉得除了这种机器人评分评论的,其他的都可以用java解决。我自己用java做的,网页要登录或者邮件有任何分析都可以使用ajax来传递参数,全部替换这些参数,可以生成很多链接,然后任何链接都可以发送给对应的设备去连接来读取。以后可以做任何网页程序的http请求,直接用java解决方案一般都能解决。 查看全部
java抓取网页数据(java抓取网页数据的解决方案-乐题库-)
java抓取网页数据:1.新建目录,保存java源文件;2.通过访问网址或者通过浏览器的抓包工具的请求以及返回数据来获取数据。3.遍历所有的网页数据,相互关联;4.写循环程序;5.定位目标cookie后,提取cookie的数据;6.写程序对cookie数据数据进行处理转换成字符串,再发送给相应的页面;7.开始复制粘贴代码。
通过抓包软件抓包获取,就可以分析网页源代码,
requests抓取,requests处理网页的方法,driver请求,
java不是有apache和nginx吗
scrapy框架
可以看看爬虫先锋。它就是用到requests库+xmlhttprequest库,
网页数据抓取可以抓取通用平台,某些人说的爬虫框架,其实是涉及不到的,好像都是抓某些垂直平台的,比如什么百度竞价的网站,某些基于jsp的网站,这种基于jsp的网站有哪些应该都清楚,另外,如果apache,nginx,nginx是单线程的话,大多是用xmlhttprequest库,例如xmlhttprequest,xmlget等等,单线程不能拿爬虫框架来做这种操作,要用requests库做网页抓取。
我最近刚好做了个实验。我觉得除了这种机器人评分评论的,其他的都可以用java解决。我自己用java做的,网页要登录或者邮件有任何分析都可以使用ajax来传递参数,全部替换这些参数,可以生成很多链接,然后任何链接都可以发送给对应的设备去连接来读取。以后可以做任何网页程序的http请求,直接用java解决方案一般都能解决。
java抓取网页数据(从几个方面准备获取java抓取网页数据之前听过爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-02-18 02:02
java抓取网页数据之前听过爬虫,一直没有机会实践一下这个实用型的项目。不知道自己的知识浅薄,还是应该给大家一些初步的经验,总结一下从几个方面准备获取网页数据:数据采集渠道数据抓取代码操作数据清洗处理数据存储。
1)定位爬取的网站
2)定位爬取过程的一些操作
3)获取数据之后对数据进行处理
4)对数据进行提取利用urllib2发起http请求利用phantomjs浏览器发起http请求
5)phantomjs代码加载失败可以用xhr发起请求
6)爬取完毕之后,对网页进行一些清洗处理,
因为本科毕业设计,后来完成一个网站,用到了python爬虫,然后写的自己喜欢的库爬取东西,当然大部分的源码是存在自己电脑上的,
懂点爬虫算基本加分项。
知乎
还是学学java比较好,网页采集一般分两种,一种是进入网页,只需要爬取网页的html源码,另一种就是采集整个网页的全部数据。
要学就一定要学点爬虫啊哈哈哈上几天我就爬到了某领域的论文
网络包采集这个还有个python的包挺好用的,
说个不算python的爬虫吧我们宿舍有个姑娘用python发起过匿名爬取一个固定的相册网站的请求,是让和她关系比较好的人挂接到她自己电脑上来回回她,当时爬了半个多小时爬到了后一个相册,有几百张照片,还有几百张明信片,要是前面那个有这么多想说的话,那就还好了,可是照片那里明信片太多,她又把明信片都扔在相册里面了,还是弄出来了好多照片,那我们另外三个姑娘一脸懵逼(估计那个大佬肯定也懵逼)。
不过,没关系,爬虫的强大就在于灵活自由!花了一天多时间找遍了整个网络打包了这个网站的数据和指定格式的api接口。在群里,一个之前不认识的小姐姐@我,让我直接用她的api作为爬虫爬取看看,那个爬虫爬了两分钟就爬到数据了。真的有好多好多好多张照片。最后的结果就是我们还是懵逼(大佬可以搜索某硬盘)。 查看全部
java抓取网页数据(从几个方面准备获取java抓取网页数据之前听过爬虫)
java抓取网页数据之前听过爬虫,一直没有机会实践一下这个实用型的项目。不知道自己的知识浅薄,还是应该给大家一些初步的经验,总结一下从几个方面准备获取网页数据:数据采集渠道数据抓取代码操作数据清洗处理数据存储。
1)定位爬取的网站
2)定位爬取过程的一些操作
3)获取数据之后对数据进行处理
4)对数据进行提取利用urllib2发起http请求利用phantomjs浏览器发起http请求
5)phantomjs代码加载失败可以用xhr发起请求
6)爬取完毕之后,对网页进行一些清洗处理,
因为本科毕业设计,后来完成一个网站,用到了python爬虫,然后写的自己喜欢的库爬取东西,当然大部分的源码是存在自己电脑上的,
懂点爬虫算基本加分项。
知乎
还是学学java比较好,网页采集一般分两种,一种是进入网页,只需要爬取网页的html源码,另一种就是采集整个网页的全部数据。
要学就一定要学点爬虫啊哈哈哈上几天我就爬到了某领域的论文
网络包采集这个还有个python的包挺好用的,
说个不算python的爬虫吧我们宿舍有个姑娘用python发起过匿名爬取一个固定的相册网站的请求,是让和她关系比较好的人挂接到她自己电脑上来回回她,当时爬了半个多小时爬到了后一个相册,有几百张照片,还有几百张明信片,要是前面那个有这么多想说的话,那就还好了,可是照片那里明信片太多,她又把明信片都扔在相册里面了,还是弄出来了好多照片,那我们另外三个姑娘一脸懵逼(估计那个大佬肯定也懵逼)。
不过,没关系,爬虫的强大就在于灵活自由!花了一天多时间找遍了整个网络打包了这个网站的数据和指定格式的api接口。在群里,一个之前不认识的小姐姐@我,让我直接用她的api作为爬虫爬取看看,那个爬虫爬了两分钟就爬到数据了。真的有好多好多好多张照片。最后的结果就是我们还是懵逼(大佬可以搜索某硬盘)。
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-16 10:00
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-16 09:37
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-16 09:34
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免工具对网站数据的抓取比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-02-14 08:08
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java来给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页JavaScript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是在网页源码中直接返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java来给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页JavaScript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是在网页源码中直接返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java抓取网页数据(java如何提取自己想要的数据可以通过xfire,来解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-13 09:13
如何在java中提取你想要的数据
可以通过xfire或者axis2生成客户端,然后调用websense服务器的代码。可以查看axis2客户端服务器的代码,研究一下。你公司里没有人吗?用过网络服务???您的职能是客户。如果传递一个xml,可以使用dom4j、sax来解析消息。
使用Java实现数据抓取问题
可以使用抓包工具wireshark进行抓包,然后过滤选择你想要的数据包
java中如何提取指定数据?
我不知道我说的对不对。如果是对象,可以通过采集的方法进入,然后通过get()的方法提取,也可以通过array的方法提取!我是新手只是有点拙见。如果每个 City 都收录属性和方法,如果最好从新对象中调用方法,那可能是错误的!如果没有,您可以咨询其他专家。
Java中如何实现数据采集?
注意。建议先研究一下dz论坛附的个人空间采集器,然后再研究如何用java实现。功能必须明确,才能实现。到相关数据?如何将数据写入自己的数据库?最后,如何把数据放到你的网站对应的模块中?
Java 如何从 网站
中抓取数据
1. 使用jsoup抓取生成页面后的静态信息,很简单,知道jquery的选择器会使用2.对于加载页面后通过ajax刷新的页面,没办法,请把发送的请求xml或者json返回的数据一一分析,看哪个爬虫在任何情况下都不可能申请!
java 从字符串中提取数据-
你可以通过java的“substring”方法提取指定的字符串,前提是你知道开始和结束字符串的值: String getSignInfo = reqResult.substring(reqResult.indexOf("(") +1, reqResult.indexOf(")"));说明:上面的方法是截取reqResult字符串“(”的中间开始和end”(”中间部分的内容,“1”是“(”的长度,然后将得到的结果赋值给“getSignInfo可以输出”;注:以上方法一般用于截取字符串,数字“1”和起止字符串可根据实际需要修改。
如何通过Java代码实现网页数据的指定抓取
通过java代码对网页数据指定爬取方式的步骤如下: 1.在项目中导入jsoup.jar包 2.获取html指定的URL或者文档指定的body。 3、获取网页中超链接的标题和链接。 4. 获取指定博客。 文章内容5获取网页中超链接的标题及链接结果
如何在java中从数据库中提取数据
:从数据库中提取一些数据并在JSP上显示如下:思路:1、创建db连接2、创建语句3、执行查询4、@ > 遍历结果并显示完整代码如下:
如何在java中获取数据并存入数据库
用 JDBC 处理~~~~~~~~~~~~~~
如何在java中抓取网页数据 查看全部
java抓取网页数据(java如何提取自己想要的数据可以通过xfire,来解析)
如何在java中提取你想要的数据
可以通过xfire或者axis2生成客户端,然后调用websense服务器的代码。可以查看axis2客户端服务器的代码,研究一下。你公司里没有人吗?用过网络服务???您的职能是客户。如果传递一个xml,可以使用dom4j、sax来解析消息。
使用Java实现数据抓取问题
可以使用抓包工具wireshark进行抓包,然后过滤选择你想要的数据包
java中如何提取指定数据?
我不知道我说的对不对。如果是对象,可以通过采集的方法进入,然后通过get()的方法提取,也可以通过array的方法提取!我是新手只是有点拙见。如果每个 City 都收录属性和方法,如果最好从新对象中调用方法,那可能是错误的!如果没有,您可以咨询其他专家。
Java中如何实现数据采集?
注意。建议先研究一下dz论坛附的个人空间采集器,然后再研究如何用java实现。功能必须明确,才能实现。到相关数据?如何将数据写入自己的数据库?最后,如何把数据放到你的网站对应的模块中?
Java 如何从 网站
中抓取数据
1. 使用jsoup抓取生成页面后的静态信息,很简单,知道jquery的选择器会使用2.对于加载页面后通过ajax刷新的页面,没办法,请把发送的请求xml或者json返回的数据一一分析,看哪个爬虫在任何情况下都不可能申请!
java 从字符串中提取数据-
你可以通过java的“substring”方法提取指定的字符串,前提是你知道开始和结束字符串的值: String getSignInfo = reqResult.substring(reqResult.indexOf("(") +1, reqResult.indexOf(")"));说明:上面的方法是截取reqResult字符串“(”的中间开始和end”(”中间部分的内容,“1”是“(”的长度,然后将得到的结果赋值给“getSignInfo可以输出”;注:以上方法一般用于截取字符串,数字“1”和起止字符串可根据实际需要修改。
如何通过Java代码实现网页数据的指定抓取
通过java代码对网页数据指定爬取方式的步骤如下: 1.在项目中导入jsoup.jar包 2.获取html指定的URL或者文档指定的body。 3、获取网页中超链接的标题和链接。 4. 获取指定博客。 文章内容5获取网页中超链接的标题及链接结果
如何在java中从数据库中提取数据
:从数据库中提取一些数据并在JSP上显示如下:思路:1、创建db连接2、创建语句3、执行查询4、@ > 遍历结果并显示完整代码如下:
如何在java中获取数据并存入数据库
用 JDBC 处理~~~~~~~~~~~~~~
如何在java中抓取网页数据
java抓取网页数据(Web爬虫是什么?Web抓取非常有用的两者区别!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-11 09:38
网页抓取对于采集用于各种目的的信息非常有用,例如数据分析、统计、提供第三方信息以及为深度神经网络和深度学习提供数据。
什么是网页抓取?
有一种非常普遍的误解,即人们似乎将网络抓取和网络抓取视为同一件事。所以让我们先说清楚。
两者有非常显着的区别:
网页抓取是指搜索或“抓取”网页以获取任意信息的过程。通常是 Google、Yahoo 或 Bing 等搜索引擎的一项功能,用于向我们显示搜索结果。
网页抓取是指利用特定网站中专门定制的自动化软件手机信息的过程。
创建一个小组供大家学习和聊天
如果你对学习JAVA有任何疑惑,或者有话要说,可以一起交流学习,一起进步。
也希望大家能坚持学习JAVA
JAVA爱好群,
如果你想学好JAVA,最好加入一个组织,这样大家学习更方便,也可以一起交流分享信息,为你推荐一个学习组织:快乐学习JAVA组织,可以点组织这个词,可以直接
注意!
虽然网络抓取本身是从 网站 获取信息的合法方式,但如果使用不当,则可能成为非法。
有几种情况需要特别注意:
网页抓取可以被认为是拒绝服务攻击:发送过多的请求来获取数据会给服务器带来太大的压力,限制了普通用户访问的能力网站。
无视版权法和服务条款:因为很多人、组织和公司开发网络抓取软件来采集信息,很多网站如亚马逊、eBay、LinkedIn、Instagram、Facebook等都没有什么麻烦。因此,绝大多数网站的人都禁止使用爬虫软件来获取他们的数据,你必须获得书面许可才能采集数据。
网页抓取可能会被恶意使用:抓取软件的行为很像机器人,一些框架甚至提供了自动填写和提交表单的工具。因此它可以用作自动垃圾邮件工具,甚至可以攻击网站。这是 CAPTCHA 存在的原因之一。
如果您想开发一款功能强大的抓取软件,请务必考虑以上几点并遵守法律法规。
网页抓取框架
与许多现代技术一样,有多种框架可供选择以从 网站 中提取信息。最流行的是 JSoup、HTMLUnit 和 Selenium WebDriver。我们的文章 文章 讨论了 JSoup。
JSoup
JSoup 是一个提供强大数据提取 API 的开源项目。它可用于从给定的 URL、文件或字符串解析 HTML。它还可以操作 HTML 元素和属性。
使用 JSoup 解析字符串
解析字符串是使用 JSoup 最简单的方法。
公共类 JSoupExample {
public static void main(String[] args) {
String html = "Website title<p>Sample paragraph number 1
Sample paragraph number 2";
Document doc = Jsoup.parse(html);
System.out.println(doc.title());
Elements paragraphs = doc.getElementsByTag("p");
for (Element paragraph : paragraphs) {
System.out.println(paragraph.text());
}
}</p>
这段代码非常直观。调用 parse() 方法解析输入的 HTML 并将其转换为 Document 对象。可以通过调用此对象上的方法来操作和提取数据。
在上面的例子中,我们首先输出页面的标题。然后,我们得到所有带有标签“p”的元素。然后我们依次输出每个段落的文字。
运行这段代码,我们可以得到如下输出:
网站标题
示例段落编号 1
示例段落编号 2
使用JSoup解析网址
解析网址和解析字符串有点不同,但基本原理是一样的:
公共类 JSoupExample {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.connect("https://www.wikipedia.org").get();
Elements titles = doc.getElementsByClass("other-project");
for (Element title : titles) {
System.out.println(title.text());
}
}
}
要从 URL 中抓取数据,您需要调用 connect() 方法,将 URL 作为参数提供。然后使用 get() 从连接中获取 HTML。这个例子的输出是:
Commons 免费使用的照片等
维基导游免费旅行指南
维基词典
Wikibooks 免费教科书
维基新闻免费新闻来源
维基数据免费知识库
维基学院免费课程资料
维基语录免费引用纲要
MediaWiki 免费且开放的 wiki 应用程序
维基资源免费图书馆
维基物种免费物种目录
元维基社区协调和文档
如你所见,这个程序抓取了类 other-project 的所有元素。
这种方法最常见,我们来看一些其他的通过URL抓取的例子。
从指定的 URL 获取所有链接
public void allLinksInUrl() 抛出 IOException {
Document doc = Jsoup.connect("https://www.wikipedia.org").get();
Elements links = doc.select("a[href]");
for (Element link : links) {
System.out.println("\nlink : " + link.attr("href"));
System.out.println("text : " + link.text());
}
}
结果是一长串:
链接:///
文本:英文 5 678 000 多篇文章
链接:///
文本:日语 1 112 000+ 注释
链接:///
文本:Español 1 430 000+ 文章
链接:///
文本:Deutsch 2 197 000+ Artikel
链接:///
文本:Русский 1 482 000+ статей
链接:///
文本:意大利语 1 447 000+ 语音
链接:///
文本:法语 2 000 000 多篇文章
链接:///
文本:中文 1 013 000+ 个条目
文本:维基词典免费词典
链接:///
文本:维基教科书免费教科书
链接:///
文本:维基新闻免费新闻来源
链接:///
文本:维基数据免费知识库
链接:///
文本:维基学院免费课程资料
链接:///
文本:维基语录免费引用纲要
链接:///
文本:MediaWiki 免费且开放的 wiki 应用程序
链接:///
文本:维基资源免费图书馆
链接:///
文本:维基物种免费物种目录
链接:///
文本:元维基社区协调和文档
链接:
文本:知识共享署名-相同方式共享许可
链接:///wiki/Terms_of_Use
文本:使用条款
链接:///wiki/Privacy_policy
文本:隐私政策
同样,你也可以获取图片的数量、元信息、表单参数等你能想到的一切,所以经常被用来获取统计数据。
使用 JSoup 解析文件
public void parseFile() 抛出 URISyntaxException, IOException {
URL path = ClassLoader.getSystemResource("page.html");
File inputFile = new File(path.toURI());
Document document = Jsoup.parse(inputFile, "UTF-8");
System.out.println(document.title());
//parse document in any way
}
如果你正在解析文件,你不需要向网站发送请求,所以不用担心在服务器上运行太多程序。虽然这种方法有很多局限性,而且数据是静态的,因此不适用于许多任务,但它提供了一种更合法、更无害的数据分析方式。
可以按照前面描述的任何方式解析生成的文档。
设置属性值
除了读取字符串、URL、文件和获取数据之外,我们还可以修改数据和输入表单。
例如访问亚马逊时,点击左上角的网站标志返回网站首页。
如果你想改变这种行为,你可以这样做:
public void setAttributes() 抛出 IOException {
Document doc = Jsoup.connect("https://www.amazon.com").get();
Element element = doc.getElementById("nav-logo");
System.out.println("Element: " + element.outerHtml());
element.children().attr("href", "notamazon.org");
System.out.println("Element with set attribute: " + element.outerHtml());
}
得到网站标志的id后,我们就可以查看它的HTML了。您还可以访问其子元素并更改其属性。
元素:
亚马逊
试试 Prime
设置属性的元素:
亚马逊
试试 Prime
默认情况下,两个子元素都指向它们各自的链接。将属性更改为其他值后,可以看到子元素的href属性更新了。
添加或删除类
除了设置属性值,我们还可以修改前面的例子,在元素中添加或删除类:
public void changePage() 抛出 IOException {
Document doc = Jsoup.connect("https://www.amazon.com").get();
Element element = doc.getElementById("nav-logo");
System.out.println("Original Element: " + element.outerHtml());
element.children().attr("href", "notamazon.org");
System.out.println("Element with set attribute: " + element.outerHtml());
element.addClass("someClass");
System.out.println("Element with added class: " + element.outerHtml());
element.removeClass("someClass");
System.out.println("Element with removed class: " + element.outerHtml());
}
运行代码会给我们以下信息:
原创元素:
亚马逊
试试 Prime
设置属性的元素:
亚马逊
试试 Prime
添加类的元素:
亚马逊
试试 Prime
移除类的元素:
亚马逊
试试 Prime
你可以将新的代码以.html的形式保存到本机,或者通过HTTP请求发送给Daou网站,但是注意后者可能是非法的。
结论
网页抓取在很多情况下都有用,但一定要依法使用。本文介绍了 JSoup,一种流行的网页抓取框架,以及使用它解析信息的几种方法。 查看全部
java抓取网页数据(Web爬虫是什么?Web抓取非常有用的两者区别!)
网页抓取对于采集用于各种目的的信息非常有用,例如数据分析、统计、提供第三方信息以及为深度神经网络和深度学习提供数据。
什么是网页抓取?
有一种非常普遍的误解,即人们似乎将网络抓取和网络抓取视为同一件事。所以让我们先说清楚。
两者有非常显着的区别:
网页抓取是指搜索或“抓取”网页以获取任意信息的过程。通常是 Google、Yahoo 或 Bing 等搜索引擎的一项功能,用于向我们显示搜索结果。
网页抓取是指利用特定网站中专门定制的自动化软件手机信息的过程。
创建一个小组供大家学习和聊天
如果你对学习JAVA有任何疑惑,或者有话要说,可以一起交流学习,一起进步。
也希望大家能坚持学习JAVA
JAVA爱好群,
如果你想学好JAVA,最好加入一个组织,这样大家学习更方便,也可以一起交流分享信息,为你推荐一个学习组织:快乐学习JAVA组织,可以点组织这个词,可以直接
注意!
虽然网络抓取本身是从 网站 获取信息的合法方式,但如果使用不当,则可能成为非法。
有几种情况需要特别注意:
网页抓取可以被认为是拒绝服务攻击:发送过多的请求来获取数据会给服务器带来太大的压力,限制了普通用户访问的能力网站。
无视版权法和服务条款:因为很多人、组织和公司开发网络抓取软件来采集信息,很多网站如亚马逊、eBay、LinkedIn、Instagram、Facebook等都没有什么麻烦。因此,绝大多数网站的人都禁止使用爬虫软件来获取他们的数据,你必须获得书面许可才能采集数据。
网页抓取可能会被恶意使用:抓取软件的行为很像机器人,一些框架甚至提供了自动填写和提交表单的工具。因此它可以用作自动垃圾邮件工具,甚至可以攻击网站。这是 CAPTCHA 存在的原因之一。
如果您想开发一款功能强大的抓取软件,请务必考虑以上几点并遵守法律法规。
网页抓取框架
与许多现代技术一样,有多种框架可供选择以从 网站 中提取信息。最流行的是 JSoup、HTMLUnit 和 Selenium WebDriver。我们的文章 文章 讨论了 JSoup。
JSoup
JSoup 是一个提供强大数据提取 API 的开源项目。它可用于从给定的 URL、文件或字符串解析 HTML。它还可以操作 HTML 元素和属性。
使用 JSoup 解析字符串
解析字符串是使用 JSoup 最简单的方法。
公共类 JSoupExample {
public static void main(String[] args) {
String html = "Website title<p>Sample paragraph number 1
Sample paragraph number 2";
Document doc = Jsoup.parse(html);
System.out.println(doc.title());
Elements paragraphs = doc.getElementsByTag("p");
for (Element paragraph : paragraphs) {
System.out.println(paragraph.text());
}
}</p>
这段代码非常直观。调用 parse() 方法解析输入的 HTML 并将其转换为 Document 对象。可以通过调用此对象上的方法来操作和提取数据。
在上面的例子中,我们首先输出页面的标题。然后,我们得到所有带有标签“p”的元素。然后我们依次输出每个段落的文字。
运行这段代码,我们可以得到如下输出:
网站标题
示例段落编号 1
示例段落编号 2
使用JSoup解析网址
解析网址和解析字符串有点不同,但基本原理是一样的:
公共类 JSoupExample {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.connect("https://www.wikipedia.org";).get();
Elements titles = doc.getElementsByClass("other-project");
for (Element title : titles) {
System.out.println(title.text());
}
}
}
要从 URL 中抓取数据,您需要调用 connect() 方法,将 URL 作为参数提供。然后使用 get() 从连接中获取 HTML。这个例子的输出是:
Commons 免费使用的照片等
维基导游免费旅行指南
维基词典
Wikibooks 免费教科书
维基新闻免费新闻来源
维基数据免费知识库
维基学院免费课程资料
维基语录免费引用纲要
MediaWiki 免费且开放的 wiki 应用程序
维基资源免费图书馆
维基物种免费物种目录
元维基社区协调和文档
如你所见,这个程序抓取了类 other-project 的所有元素。
这种方法最常见,我们来看一些其他的通过URL抓取的例子。
从指定的 URL 获取所有链接
public void allLinksInUrl() 抛出 IOException {
Document doc = Jsoup.connect("https://www.wikipedia.org";).get();
Elements links = doc.select("a[href]");
for (Element link : links) {
System.out.println("\nlink : " + link.attr("href"));
System.out.println("text : " + link.text());
}
}
结果是一长串:
链接:///
文本:英文 5 678 000 多篇文章
链接:///
文本:日语 1 112 000+ 注释
链接:///
文本:Español 1 430 000+ 文章
链接:///
文本:Deutsch 2 197 000+ Artikel
链接:///
文本:Русский 1 482 000+ статей
链接:///
文本:意大利语 1 447 000+ 语音
链接:///
文本:法语 2 000 000 多篇文章
链接:///
文本:中文 1 013 000+ 个条目
文本:维基词典免费词典
链接:///
文本:维基教科书免费教科书
链接:///
文本:维基新闻免费新闻来源
链接:///
文本:维基数据免费知识库
链接:///
文本:维基学院免费课程资料
链接:///
文本:维基语录免费引用纲要
链接:///
文本:MediaWiki 免费且开放的 wiki 应用程序
链接:///
文本:维基资源免费图书馆
链接:///
文本:维基物种免费物种目录
链接:///
文本:元维基社区协调和文档
链接:
文本:知识共享署名-相同方式共享许可
链接:///wiki/Terms_of_Use
文本:使用条款
链接:///wiki/Privacy_policy
文本:隐私政策
同样,你也可以获取图片的数量、元信息、表单参数等你能想到的一切,所以经常被用来获取统计数据。
使用 JSoup 解析文件
public void parseFile() 抛出 URISyntaxException, IOException {
URL path = ClassLoader.getSystemResource("page.html");
File inputFile = new File(path.toURI());
Document document = Jsoup.parse(inputFile, "UTF-8");
System.out.println(document.title());
//parse document in any way
}
如果你正在解析文件,你不需要向网站发送请求,所以不用担心在服务器上运行太多程序。虽然这种方法有很多局限性,而且数据是静态的,因此不适用于许多任务,但它提供了一种更合法、更无害的数据分析方式。
可以按照前面描述的任何方式解析生成的文档。
设置属性值
除了读取字符串、URL、文件和获取数据之外,我们还可以修改数据和输入表单。
例如访问亚马逊时,点击左上角的网站标志返回网站首页。
如果你想改变这种行为,你可以这样做:
public void setAttributes() 抛出 IOException {
Document doc = Jsoup.connect("https://www.amazon.com";).get();
Element element = doc.getElementById("nav-logo");
System.out.println("Element: " + element.outerHtml());
element.children().attr("href", "notamazon.org");
System.out.println("Element with set attribute: " + element.outerHtml());
}
得到网站标志的id后,我们就可以查看它的HTML了。您还可以访问其子元素并更改其属性。
元素:
亚马逊
试试 Prime
设置属性的元素:
亚马逊
试试 Prime
默认情况下,两个子元素都指向它们各自的链接。将属性更改为其他值后,可以看到子元素的href属性更新了。
添加或删除类
除了设置属性值,我们还可以修改前面的例子,在元素中添加或删除类:
public void changePage() 抛出 IOException {
Document doc = Jsoup.connect("https://www.amazon.com";).get();
Element element = doc.getElementById("nav-logo");
System.out.println("Original Element: " + element.outerHtml());
element.children().attr("href", "notamazon.org");
System.out.println("Element with set attribute: " + element.outerHtml());
element.addClass("someClass");
System.out.println("Element with added class: " + element.outerHtml());
element.removeClass("someClass");
System.out.println("Element with removed class: " + element.outerHtml());
}
运行代码会给我们以下信息:
原创元素:
亚马逊
试试 Prime
设置属性的元素:
亚马逊
试试 Prime
添加类的元素:
亚马逊
试试 Prime
移除类的元素:
亚马逊
试试 Prime
你可以将新的代码以.html的形式保存到本机,或者通过HTTP请求发送给Daou网站,但是注意后者可能是非法的。
结论
网页抓取在很多情况下都有用,但一定要依法使用。本文介绍了 JSoup,一种流行的网页抓取框架,以及使用它解析信息的几种方法。
java抓取网页数据(tag页面是什么?如何获取html元素的最后修改时间问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-07 18:23
)
相关主题
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是非常常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
jquery如何获取html元素的内容?
18/11/2020 21:04:49
jquery获取html元素内容的方法:1、使用html()返回被选中元素的内容,语法“$(selector).html()”; 2、使用 text() ,可以返回被选元素的文本内容,语法“$(selector).text()”。 【相关推送
js获取页面的域名和完整地址
2/3/201801:06:39
摘要:js获取页面的域名和完整地址(用http或https)
WordPress如何获取当前页面的URL
20/8/202012:02:37
网站服务器WordPress如何获取当前页面的URL地址?这个问题在我们日常的学习或工作中可能会经常看到。我希望这个问题可以帮助你收获很多。下面是
PHP获取当前页面的最后修改时间
6/8/202012:03:12
PHP获取当前页面最后修改时间的方法:使用[date()]函数格式化本地时间或日期,使用[getlastmod()]函数获取当前页面的最后修改时间页面,代码是 [getlastmod(void): int]。获取 PHP
获取跨域下iframe的父页面URL
2/3/201801:09:20
通常,很容易获取 iframe 的父页面的 url:parent.location 或 top.location,但前提是它们遵循同源策略。当 iframe 与父页面不属于同一个域时,由于安全策略原因,上述 fetch 将失败。请参阅 nczonline 的 文章 上的方法,使用 document.referrer。方法很简单,通过parent!=window,when检查iframe和父页面是否同源
jquery 如何获取元素标签
19/11/202018:06:44
jquery如何获取元素标签:可以通过tagName属性获取元素标签,如[varname=$("#p").get(0).tagName;alert(name);]。 html代码如下:(学习视频分享:jquery视频教程)用PHP获取当前页面的完整URL
2/3/201801:10:17
#Test URL://获取域名或主机地址 echo$_SERVER['HTTP_HOST']。"
";#localhost//获取网址 echo$_SERVER['PHP_SELF']."
";#/blog/testurl.php//获取URL参数 echo$_SERVER["
python获取页面乱码时的处理
2/3/201801:10:50
在使用requests模块获取网站数据时,网站的编码是个很麻烦的问题。一般情况下,请求会自动识别网站的编码。如果网页没有指定编码,则默认为 ISO-8859-1 编码。这个时候可能有问题。一般来说,有几种方法。最简单的就是手动指定编码r.encoding='utf-8',但是当采集数据时,可能会访问不同域名的网站。每个 网站 都被人为地分配了一个正确的编码。以下
从PHP页面获取值的6种方式
5/3/201801:18:48
网上有很多朋友遇到过PHP传值的问题。大部分是因为阅读了旧版的 PHP 教程却使用了新版的 PHP 造成的。这里icech学习记录,整理了几种PHP。传值的方法作为学习笔记,希望PHP新手朋友少走弯路。 1、PHP4之后,页面中最常见的传值方式有POST、GET和COOKIE,所以下面我主要介绍这几种。 PHP4之后,使用$_POST、$_GET等数组来获取网页值
java获取cpu、内存、硬盘信息
4/3/201801:13:07
摘要:java获取cpu、内存、硬盘信息
查看全部
java抓取网页数据(tag页面是什么?如何获取html元素的最后修改时间问题
)
相关主题
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是非常常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
jquery如何获取html元素的内容?
18/11/2020 21:04:49
jquery获取html元素内容的方法:1、使用html()返回被选中元素的内容,语法“$(selector).html()”; 2、使用 text() ,可以返回被选元素的文本内容,语法“$(selector).text()”。 【相关推送
js获取页面的域名和完整地址
2/3/201801:06:39
摘要:js获取页面的域名和完整地址(用http或https)
WordPress如何获取当前页面的URL
20/8/202012:02:37
网站服务器WordPress如何获取当前页面的URL地址?这个问题在我们日常的学习或工作中可能会经常看到。我希望这个问题可以帮助你收获很多。下面是
PHP获取当前页面的最后修改时间
6/8/202012:03:12
PHP获取当前页面最后修改时间的方法:使用[date()]函数格式化本地时间或日期,使用[getlastmod()]函数获取当前页面的最后修改时间页面,代码是 [getlastmod(void): int]。获取 PHP
获取跨域下iframe的父页面URL
2/3/201801:09:20
通常,很容易获取 iframe 的父页面的 url:parent.location 或 top.location,但前提是它们遵循同源策略。当 iframe 与父页面不属于同一个域时,由于安全策略原因,上述 fetch 将失败。请参阅 nczonline 的 文章 上的方法,使用 document.referrer。方法很简单,通过parent!=window,when检查iframe和父页面是否同源
jquery 如何获取元素标签
19/11/202018:06:44
jquery如何获取元素标签:可以通过tagName属性获取元素标签,如[varname=$("#p").get(0).tagName;alert(name);]。 html代码如下:(学习视频分享:jquery视频教程)用PHP获取当前页面的完整URL
2/3/201801:10:17
#Test URL://获取域名或主机地址 echo$_SERVER['HTTP_HOST']。"
";#localhost//获取网址 echo$_SERVER['PHP_SELF']."
";#/blog/testurl.php//获取URL参数 echo$_SERVER["
python获取页面乱码时的处理
2/3/201801:10:50
在使用requests模块获取网站数据时,网站的编码是个很麻烦的问题。一般情况下,请求会自动识别网站的编码。如果网页没有指定编码,则默认为 ISO-8859-1 编码。这个时候可能有问题。一般来说,有几种方法。最简单的就是手动指定编码r.encoding='utf-8',但是当采集数据时,可能会访问不同域名的网站。每个 网站 都被人为地分配了一个正确的编码。以下
从PHP页面获取值的6种方式
5/3/201801:18:48
网上有很多朋友遇到过PHP传值的问题。大部分是因为阅读了旧版的 PHP 教程却使用了新版的 PHP 造成的。这里icech学习记录,整理了几种PHP。传值的方法作为学习笔记,希望PHP新手朋友少走弯路。 1、PHP4之后,页面中最常见的传值方式有POST、GET和COOKIE,所以下面我主要介绍这几种。 PHP4之后,使用$_POST、$_GET等数组来获取网页值
java获取cpu、内存、硬盘信息
4/3/201801:13:07
摘要:java获取cpu、内存、硬盘信息
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-07 10:02
有时由于各种原因,我们需要采集某个网站的数据,但是由于网站不同,数据的显示方式略有不同!
本文使用Java演示如何捕获网站的数据:
(1)捕获原创网页数据;
(2)抓取网页上Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可见,查询结果是在重新请求一个网页后显示的。
看看查询后的网页地址:
也就是说,只要我们访问这样一个URL,就可以得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面三项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
分析结果如下:
captureHtml() 的结果:
查询结果[1]: 111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市 移动<br //span>
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式用JS返回数据,可以避开搜索引擎等工具到 网站 数据捕获。
先看看这个页面:
第一种方式查看网页的源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们就需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来达到我们的目的。
在第一次点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS Requested URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序执行的结果:
captureJavascript()的结果:
运单【107818590577】的跟踪信息2012-07-16 15:46:00已收件 2012-07-16 16:03:00快件在 广州\t,准备送往下一站广州集散中心 2012-07-16 19:33:00快件在 广州集散中心,准备送往下一站佛山集散中心 2012-07-17 01:56:00快件在 佛山集散中心\t,准备送往下一站佛山 2012-07-17 09:41:00正在派件.. 2012-07-17 11:28:00派件已签收 2012-07-17 11:28:00签收人是:已签收
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
有时由于各种原因,我们需要采集某个网站的数据,但是由于网站不同,数据的显示方式略有不同!
本文使用Java演示如何捕获网站的数据:
(1)捕获原创网页数据;
(2)抓取网页上Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可见,查询结果是在重新请求一个网页后显示的。
看看查询后的网页地址:
也就是说,只要我们访问这样一个URL,就可以得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面三项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
分析结果如下:
captureHtml() 的结果:
查询结果[1]: 111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市 移动<br //span>
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式用JS返回数据,可以避开搜索引擎等工具到 网站 数据捕获。
先看看这个页面:
第一种方式查看网页的源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们就需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来达到我们的目的。
在第一次点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS Requested URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序执行的结果:
captureJavascript()的结果:
运单【107818590577】的跟踪信息2012-07-16 15:46:00已收件 2012-07-16 16:03:00快件在 广州\t,准备送往下一站广州集散中心 2012-07-16 19:33:00快件在 广州集散中心,准备送往下一站佛山集散中心 2012-07-17 01:56:00快件在 佛山集散中心\t,准备送往下一站佛山 2012-07-17 09:41:00正在派件.. 2012-07-17 11:28:00派件已签收 2012-07-17 11:28:00签收人是:已签收
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-02-06 08:05
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{ StringstrURL=""+ip; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8") ; BufferedReaderbufReader=newBufferedReader(输入);字符串线=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } Stringbuf=contentBuf.toString() ; intbeginIx=buf.indexOf("查询结果["); intentIx=buf.indexOf("以上四项依次显示"); Stringresult=buf.substring(beginIx,endIx); System.out.println("captureHtml() 结果:\n"+result);}
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{ StringstrURL=""+postid +"&channel=&rnd=0"; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8"); BufferedReaderbufReader=newBufferedReader(输入);字符串线=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章能对需要的人有所帮助。如需程序源代码,请点击此处下载 查看全部
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{ StringstrURL=""+ip; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8") ; BufferedReaderbufReader=newBufferedReader(输入);字符串线=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } Stringbuf=contentBuf.toString() ; intbeginIx=buf.indexOf("查询结果["); intentIx=buf.indexOf("以上四项依次显示"); Stringresult=buf.substring(beginIx,endIx); System.out.println("captureHtml() 结果:\n"+result);}
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{ StringstrURL=""+postid +"&channel=&rnd=0"; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8"); BufferedReaderbufReader=newBufferedReader(输入);字符串线=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章能对需要的人有所帮助。如需程序源代码,请点击此处下载
java抓取网页数据(Java常用正则Java正则表达式详解4/3/201801:14:40学习Java的同学注意了! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-06 03:16
)
相关话题
python笔记中从网页中提取超链接
2018 年 2 月 3 日 01:10:15
从python笔记中提取网页中的超链接对于提取网页中的超链接,更方便的是先阅读网页内容,然后使用beautifulsoup进行解析。但是我发现一个问题,如果直接提取a标签的href,会收录javascript:xxx和#xxx等,所以这些要特殊处理。#!/usr/bin/envpython#coding:utf-8frombs4importBeautifulS
JAVA开发常用正规!
2018 年 4 月 3 日 01:11:22
总结:java常用正则
Java正则表达式详解
2018 年 4 月 3 日 01:14:32
Java 在 java.util.regex 包下提供了一个强大的正则表达式 API。本教程介绍如何使用正则表达式 API。正则表达式 正则表达式是用于文本搜索的文本模式。换句话说,在文本中搜索模式的出现。例如,您可以使用正则表达式在网页中搜索电子邮件地址或超链接。正则表达式示例 下面是一个简单的 Java 正则表达式示例,用于在文本中搜索 Stringtext
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是非常常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Java正则表达式详解
2018 年 4 月 3 日 01:14:40
学习Java的同学注意了!!!如果您在学习过程中遇到任何问题或想获取学习资源,欢迎加入Java学习交流群,群号:456544752 一起学习Java!Java 在 java.util.regex 包下提供了一个强大的正则表达式 API。本教程介绍如何使用正则表达式 API。正则表达式 正则表达式是用于文本搜索的文本模式。改变
dedecms织梦给内容页加标签
24/4/202013:49:09
上一篇文章主要写了在免记录虚拟主机中安装的dedecms的列表中添加标签,这次我是在dedecms的内容页面中添加标签。两者都有相同的地方,但是比较简单。两篇文章文章小编主持小编搬运
Java微信公众号网页授权
2018 年 4 月 3 日 01:08:11
在写这篇文章之前,先简单说一下我之前没做过微信开发,也是第一次接触微信公众号开发。写这篇博客是为了记录自己的开发内容。可以作为微信公众号小白开发的一些参考。如果你不喜欢它,不要喷它。好了,废话不多说,先登录微信公众号----点击左侧列表界面权限----网络服务----网页授权(网页授权获取用户基本信息)-- ---网页授权域名(这个域名必须已经备案。)以上操作完成后,查看微信。
前端性能优化——网页内容优化
2018 年 4 月 3 日 01:07:22
网页内容优化:减少http请求数原因:说到前端性能优化,首先想到的就是减少http请求数,因为80%的响应时间都花在了下载web上内容(图像、样式表、javascript、脚本、flash 等)。首先,一个正常的HTTP请求流程是:在浏览器中输入“”并按回车键,浏览器(客户端)与该URL指向的服务器建立连接,然后
java中如何使用正则表达式的基本用法
21/8/202012:04:19
java中正则表达式的基本用法:1、[Test01.java] 正则表达式的使用使得代码非常简洁;2、[TestMatcher01.java]Matcher 类用于字符串验证。【相关学习推荐:java基础
网页优化中最重要的内容是什么?
16/11/202015:04:10
网页优化最重要的内容是如何选择关键词。关键词的选择要考虑哪些关键词能够准确概括内容,用户可能选择的关键词,以及这些关键词是否是热门关键词。【网页关键词定位】如何挑选
代码和内容优化和去噪以提高网页的信噪比
22/5/2012 13:58:00
网页的信噪比是指网页中的文本内容与生成这些文本所产生的html标签内容的比率。一般来说,一个网页的信噪比越高,我们的网页质量就越好。可以根据搜索引擎抓取网页的原理来解释:搜索引擎蜘蛛抓取网页时,会对网页进行去重,主要是去除网页的噪音,留下有用的信息。
分隔网页表单和内容的 html 的补充是什么?
31/8/202016:09:21
CSS 是对 html 的补充,用于分隔网页的形式和内容。CSS 是一种标记语言,用于增强对网页样式的控制,并允许将样式信息与网页内容分离。
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近副本,主题内容基本相同但可能有一些额外的编辑信息等,转载的页面也称为“近似镜像页面”)消除,链接分析和页面的重要性计算。
搜索引擎系统预处理:网页净化和元数据提取
2009 年 12 月 11 日 10:00:00
在话题搜索领域,大量的广告、导航栏等嘈杂的内容会导致话题漂移。这说明传统主题搜索算法中以网页为粒度构建的网络图不够准确。为了提高内容分析的准确性,需要深入到网页中,减少处理单元的粒度。
关于复制网页内容的争议
2007 年 12 月 6 日 14:03:00
时至今日,页面内容复制仍然是 SEO 中的热门话题。这是因为越来越多的 网站 内容正在通过分布式模型进行大规模复制。这迫使搜索引擎更加灵活和快速,为用户提供准确和相关的搜索结果,尤其是一些原创色情内容。各大搜索引擎都知道,复制网站里面
查看全部
java抓取网页数据(Java常用正则Java正则表达式详解4/3/201801:14:40学习Java的同学注意了!
)
相关话题
python笔记中从网页中提取超链接
2018 年 2 月 3 日 01:10:15
从python笔记中提取网页中的超链接对于提取网页中的超链接,更方便的是先阅读网页内容,然后使用beautifulsoup进行解析。但是我发现一个问题,如果直接提取a标签的href,会收录javascript:xxx和#xxx等,所以这些要特殊处理。#!/usr/bin/envpython#coding:utf-8frombs4importBeautifulS
JAVA开发常用正规!
2018 年 4 月 3 日 01:11:22
总结:java常用正则
Java正则表达式详解
2018 年 4 月 3 日 01:14:32
Java 在 java.util.regex 包下提供了一个强大的正则表达式 API。本教程介绍如何使用正则表达式 API。正则表达式 正则表达式是用于文本搜索的文本模式。换句话说,在文本中搜索模式的出现。例如,您可以使用正则表达式在网页中搜索电子邮件地址或超链接。正则表达式示例 下面是一个简单的 Java 正则表达式示例,用于在文本中搜索 Stringtext
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是非常常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Java正则表达式详解
2018 年 4 月 3 日 01:14:40
学习Java的同学注意了!!!如果您在学习过程中遇到任何问题或想获取学习资源,欢迎加入Java学习交流群,群号:456544752 一起学习Java!Java 在 java.util.regex 包下提供了一个强大的正则表达式 API。本教程介绍如何使用正则表达式 API。正则表达式 正则表达式是用于文本搜索的文本模式。改变
dedecms织梦给内容页加标签
24/4/202013:49:09
上一篇文章主要写了在免记录虚拟主机中安装的dedecms的列表中添加标签,这次我是在dedecms的内容页面中添加标签。两者都有相同的地方,但是比较简单。两篇文章文章小编主持小编搬运
Java微信公众号网页授权
2018 年 4 月 3 日 01:08:11
在写这篇文章之前,先简单说一下我之前没做过微信开发,也是第一次接触微信公众号开发。写这篇博客是为了记录自己的开发内容。可以作为微信公众号小白开发的一些参考。如果你不喜欢它,不要喷它。好了,废话不多说,先登录微信公众号----点击左侧列表界面权限----网络服务----网页授权(网页授权获取用户基本信息)-- ---网页授权域名(这个域名必须已经备案。)以上操作完成后,查看微信。
前端性能优化——网页内容优化
2018 年 4 月 3 日 01:07:22
网页内容优化:减少http请求数原因:说到前端性能优化,首先想到的就是减少http请求数,因为80%的响应时间都花在了下载web上内容(图像、样式表、javascript、脚本、flash 等)。首先,一个正常的HTTP请求流程是:在浏览器中输入“”并按回车键,浏览器(客户端)与该URL指向的服务器建立连接,然后
java中如何使用正则表达式的基本用法
21/8/202012:04:19
java中正则表达式的基本用法:1、[Test01.java] 正则表达式的使用使得代码非常简洁;2、[TestMatcher01.java]Matcher 类用于字符串验证。【相关学习推荐:java基础
网页优化中最重要的内容是什么?
16/11/202015:04:10
网页优化最重要的内容是如何选择关键词。关键词的选择要考虑哪些关键词能够准确概括内容,用户可能选择的关键词,以及这些关键词是否是热门关键词。【网页关键词定位】如何挑选
代码和内容优化和去噪以提高网页的信噪比
22/5/2012 13:58:00
网页的信噪比是指网页中的文本内容与生成这些文本所产生的html标签内容的比率。一般来说,一个网页的信噪比越高,我们的网页质量就越好。可以根据搜索引擎抓取网页的原理来解释:搜索引擎蜘蛛抓取网页时,会对网页进行去重,主要是去除网页的噪音,留下有用的信息。
分隔网页表单和内容的 html 的补充是什么?
31/8/202016:09:21
CSS 是对 html 的补充,用于分隔网页的形式和内容。CSS 是一种标记语言,用于增强对网页样式的控制,并允许将样式信息与网页内容分离。
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近副本,主题内容基本相同但可能有一些额外的编辑信息等,转载的页面也称为“近似镜像页面”)消除,链接分析和页面的重要性计算。
搜索引擎系统预处理:网页净化和元数据提取
2009 年 12 月 11 日 10:00:00
在话题搜索领域,大量的广告、导航栏等嘈杂的内容会导致话题漂移。这说明传统主题搜索算法中以网页为粒度构建的网络图不够准确。为了提高内容分析的准确性,需要深入到网页中,减少处理单元的粒度。
关于复制网页内容的争议
2007 年 12 月 6 日 14:03:00
时至今日,页面内容复制仍然是 SEO 中的热门话题。这是因为越来越多的 网站 内容正在通过分布式模型进行大规模复制。这迫使搜索引擎更加灵活和快速,为用户提供准确和相关的搜索结果,尤其是一些原创色情内容。各大搜索引擎都知道,复制网站里面
java抓取网页数据(本文介绍如何使用as3抓取网页源码,以及监听读取的字节进度 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-02-01 07:14
)
本文介绍如何使用as3爬取网页源代码并监控读取字节的进度。
代码经过本人测试,仅供参考。
代码如下:
System.useCodePage=true;
varvariables:URLVariables=newURLVariables();
variables.userName="Kakera";
variables.password="********";
varrequest:URLRequest=newURLRequest("http://www.baidu.com");
request.data=variables;
request.method=URLRequestMethod.POST;
varloader:URLLoader=newURLLoader();
loader.dataFormat=URLLoaderDataFormat.TEXT;
loader.addEventListener(Event.COMPLETE,loader_complete);
loader.addEventListener(Event.OPEN,loader_open);
loader.addEventListener(HTTPStatusEvent.HTTP_STATUS,loader_httpStatus);
loader.addEventListener(ProgressEvent.PROGRESS,loader_progress);
loader.addEventListener(SecurityErrorEvent.SECURITY_ERROR,loader_security);
loader.addEventListener(IOErrorEvent.IO_ERROR,loader_ioError);
loader.load(request);
functionloader_complete(e:Event):void{
trace("Event.COMPLETE");
trace("目标文件的原始数据(纯文本):\n"+loader.data);
}
functionloader_open(e:Event):void{
trace("Event.OPEN");trace("读取了的字节:"+loader.bytesLoaded);
}
functionloader_httpStatus(e:HTTPStatusEvent):void{
trace("HTTPStatusEvent.HTTP_STATUS");
trace("HTTP状态代码:"+e.status);
}
functionloader_progress(e:ProgressEvent):void{
trace("ProgressEvent.PROGRESS");
trace("读取了的字节:"+loader.bytesLoaded);
trace("文件总字节:"+loader.bytesTotal);
}
functionloader_security(e:SecurityErrorEvent):void{
trace("SecurityErrorEvent.SECURITY_ERROR");
}
functionloader_ioError(e:IOErrorEvent):void{
trace("IOErrorEvent.IO_ERROR");
}
本文由PHP中文网提供,
文章地址:
学编程,来PHP中文网
以上是AS3 Post方法分析的页面抓取和阅读进度条的详细内容。更多详情请关注php中文网其他相关话题文章!
查看全部
java抓取网页数据(本文介绍如何使用as3抓取网页源码,以及监听读取的字节进度
)
本文介绍如何使用as3爬取网页源代码并监控读取字节的进度。
代码经过本人测试,仅供参考。
代码如下:
System.useCodePage=true;
varvariables:URLVariables=newURLVariables();
variables.userName="Kakera";
variables.password="********";
varrequest:URLRequest=newURLRequest("http://www.baidu.com";);
request.data=variables;
request.method=URLRequestMethod.POST;
varloader:URLLoader=newURLLoader();
loader.dataFormat=URLLoaderDataFormat.TEXT;
loader.addEventListener(Event.COMPLETE,loader_complete);
loader.addEventListener(Event.OPEN,loader_open);
loader.addEventListener(HTTPStatusEvent.HTTP_STATUS,loader_httpStatus);
loader.addEventListener(ProgressEvent.PROGRESS,loader_progress);
loader.addEventListener(SecurityErrorEvent.SECURITY_ERROR,loader_security);
loader.addEventListener(IOErrorEvent.IO_ERROR,loader_ioError);
loader.load(request);
functionloader_complete(e:Event):void{
trace("Event.COMPLETE");
trace("目标文件的原始数据(纯文本):\n"+loader.data);
}
functionloader_open(e:Event):void{
trace("Event.OPEN");trace("读取了的字节:"+loader.bytesLoaded);
}
functionloader_httpStatus(e:HTTPStatusEvent):void{
trace("HTTPStatusEvent.HTTP_STATUS");
trace("HTTP状态代码:"+e.status);
}
functionloader_progress(e:ProgressEvent):void{
trace("ProgressEvent.PROGRESS");
trace("读取了的字节:"+loader.bytesLoaded);
trace("文件总字节:"+loader.bytesTotal);
}
functionloader_security(e:SecurityErrorEvent):void{
trace("SecurityErrorEvent.SECURITY_ERROR");
}
functionloader_ioError(e:IOErrorEvent):void{
trace("IOErrorEvent.IO_ERROR");
}
本文由PHP中文网提供,
文章地址:
学编程,来PHP中文网
以上是AS3 Post方法分析的页面抓取和阅读进度条的详细内容。更多详情请关注php中文网其他相关话题文章!
java抓取网页数据(用到抓取网页数据的功能之一下抓取数据功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-31 06:15
经常用到爬取网页数据的功能。我在以前的工作中使用过它。今天我总结一下:
1、通过指定的URL抓取网页数据,获取页面信息,然后对带有DOM的页面进行NODE分析,处理原创的HTML数据。这样做的好处是处理某条数据的灵活性很高。 , 难点在于节算法需要优化。当页面的HTML信息较大时,算法不好,会影响处理效率。
2、htmlparser框架,对于HTML页面处理的数据结构,HtmlParser采用经典的Composite模式,通过RemarkNode、TextNode、TagNode、AbstractNode和Tag来描述HTML页面的各个元素。 htmlparser基本可以满足垂直搜索引擎页面处理分析的需求,映射HTML标签,轻松获取标签中的HTML CODE。
Htmlparser官方介绍:htmlparser是一个纯java编写的html解析库。不依赖其他java库文件,主要用于转换或提取html。它解析 html 的速度非常快而且没有错误。 htmlparser 的最新版本现在是 2.0。毫不夸张地说,htmlparser是目前最好的html解析分析工具。
3、nekohtml框架,nekohtml在容错、性能等方面都优于htmlparser(包括htmlunit也使用nekohtml),nokehtml类似于xml解析的原理,html标签被解析为dom,是的,对应DOM树中对应的元素进行处理。
NekoHTML 官方介绍:NekoHTML 是Java 语言的HTML 扫描器和标签平衡器,它使程序能够解析HTML 文档并使用标准的XML 接口来访问其中的信息。此解析器能够扫描 HTML 文档并“修复”作者(人或机器)在编写 HTML 文档的过程中经常犯的许多错误。
NekoHTML 可以补充缺失的父元素,自动用结束标签关闭对应的元素,不匹配内联元素标签。 NekoHTML 是使用 Xerces 本地接口 (XNI) 开发的,它是 Xerces2 实现的基础。 查看全部
java抓取网页数据(用到抓取网页数据的功能之一下抓取数据功能介绍)
经常用到爬取网页数据的功能。我在以前的工作中使用过它。今天我总结一下:
1、通过指定的URL抓取网页数据,获取页面信息,然后对带有DOM的页面进行NODE分析,处理原创的HTML数据。这样做的好处是处理某条数据的灵活性很高。 , 难点在于节算法需要优化。当页面的HTML信息较大时,算法不好,会影响处理效率。
2、htmlparser框架,对于HTML页面处理的数据结构,HtmlParser采用经典的Composite模式,通过RemarkNode、TextNode、TagNode、AbstractNode和Tag来描述HTML页面的各个元素。 htmlparser基本可以满足垂直搜索引擎页面处理分析的需求,映射HTML标签,轻松获取标签中的HTML CODE。
Htmlparser官方介绍:htmlparser是一个纯java编写的html解析库。不依赖其他java库文件,主要用于转换或提取html。它解析 html 的速度非常快而且没有错误。 htmlparser 的最新版本现在是 2.0。毫不夸张地说,htmlparser是目前最好的html解析分析工具。
3、nekohtml框架,nekohtml在容错、性能等方面都优于htmlparser(包括htmlunit也使用nekohtml),nokehtml类似于xml解析的原理,html标签被解析为dom,是的,对应DOM树中对应的元素进行处理。
NekoHTML 官方介绍:NekoHTML 是Java 语言的HTML 扫描器和标签平衡器,它使程序能够解析HTML 文档并使用标准的XML 接口来访问其中的信息。此解析器能够扫描 HTML 文档并“修复”作者(人或机器)在编写 HTML 文档的过程中经常犯的许多错误。
NekoHTML 可以补充缺失的父元素,自动用结束标签关闭对应的元素,不匹配内联元素标签。 NekoHTML 是使用 Xerces 本地接口 (XNI) 开发的,它是 Xerces2 实现的基础。
java抓取网页数据(如何自动高效地获取互联网中我们感兴趣的信息并实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-30 12:19
1. 什么是网络爬虫?
在大数据时代,信息采集是一项重要的任务,互联网中的数据是海量的。如果信息采集单纯依靠人力,不仅效率低下、繁琐,而且采集成本也会有所提高。如何在互联网上自动、高效地获取我们感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了解决这些问题而诞生的。
网络爬虫,也称为网络机器人,可以代替人自动采集并组织互联网上的数据和信息。它是一个程序或脚本,根据一定的规则自动从万维网上抓取信息,并且可以自动采集它可以访问的页面的所有内容来获取相关数据。
从功能上来说,爬虫一般分为数据采集、处理、存储三部分。爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
2. 网络爬虫的作用
1.可以实现搜索引擎
在我们学会了爬虫的编写之后,就可以利用爬虫自动采集互联网上的信息,采集返回相应的存储或处理。当我们需要检索一些信息的时候,我们只需要采集@采集检索返回的信息,也就是实现一个私有的搜索引擎。
2.大数据时代,我们可以获得更多的数据源
在进行大数据分析或数据挖掘时,需要有数据源进行分析。我们可以从一些提供统计数据的网站中获取数据,或者从某些文献或内部资料中获取数据,但是这些获取数据的方式有时很难满足我们对数据的需求,需要手动从网上获取数据。查找这些数据需要花费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,进而进行更深层次的数据分析,获取更有价值的信息。
3. 用于更好的搜索引擎优化 (SEO)
对于很多SEO从业者来说,要想更好的完成自己的工作,就必须非常清楚搜索引擎的工作原理,也需要掌握搜索引擎爬虫的工作原理。而学习爬虫,可以更深入的了解搜索引擎爬虫的工作原理,让你在做搜索引擎优化的时候,知己知彼,百战百胜。
3.网络爬虫是如何工作的?
爬虫底部有两个核心:
(1).HttpClient:网络爬虫使用程序来帮助我们访问互联网上的资源。我们一直使用HTTP协议来访问互联网上的网页。网络爬虫需要编写程序来使用相同的HTTP访问网页协议,这里我们使用Java的HTTP协议客户端HttpClient技术来抓取网页数据。(在Java程序中,远程访问是通过HttpClient技术来抓取网页数据。)
注意:如果每次请求都需要创建HttpClient,就会出现频繁创建和销毁的问题。你可以使用 HttpClient 连接池来解决这个问题。
(2).jsoup:我们抓取页面后,还需要解析页面。可以使用字符串处理工具来解析页面,也可以使用正则表达式,但是这些方法会带来很多开发cost ,所以我们需要使用专门解析html页面的技术。(将获取的页面数据转换成Dom对象进行解析)
Jsoup简介:Jsoup是一个Java HTML和XML解析器,可以直接将一个URL地址、HTML文本、文件解析成DOM对象。使用 jQuery 的 action 方法获取 sum 操作数
设置抓取目标(种子页面)并获取网页。无法访问服务器时,设置重试次数。设置用户代理在需要时(否则页面无法访问)通过正则表达式对获取的页面进行必要的解码操作获取页面中的链接对链接进行进一步处理(获取页面并重复上述操作)持久有用信息(用于后续处理)
5. WebMagic 简介
WebMagic 是一个爬虫框架。底层使用了上面介绍的HttpClient和Jsoup,可以让我们更方便的开发爬虫。WebMagic 的设计目标是尽可能模块化,并体现爬虫的功能特点。这部分提供了一个非常简单灵活的API来编写爬虫,而无需基本改变开发模式。
WebMagic 项目代码分为核心和扩展两部分。核心部分(webmagic-core)是一个精简、模块化的爬虫实现,而扩展部分(webmagic-extension)包括一些方便实用的功能,比如用注解的方式编写爬虫,以及一些常用的内置功能。易于爬虫开发的组件。
1).架构介绍
WebMagic 的结构分为四个组件:Downloader、PageProcessor、Scheduler 和 Pipeline,它们由 Spider 组织。这四个组件分别对应了爬虫生命周期中的下载、处理、管理和持久化的功能。
Spider 组织这些组件,以便它们可以相互交互并处理执行。Spider可以看作是一个大容器,也是WebMagic逻辑的核心。
WebMagic的整体架构图如下:
2).WebMagic 的四个组成部分
①.下载器
下载器负责从 Internet 下载页面以进行后续处理。WebMagic 默认使用 Apache HttpClient 作为下载工具。
②.PageProcessor
PageProcessor 负责解析页面、提取有用信息和发现新链接。WebMagic 使用 Jsoup 作为 HTML 解析工具,并在其基础上开发了 Xsoup,一个解析 XPath 的工具。
这四个组件中,PageProcessor对于每个站点的每个页面都是不同的,是需要用户自定义的部分。
③.调度器
Scheduler 负责管理要爬取的 URL,以及一些去重工作。WebMagic 默认提供 JDK 的内存队列来管理 URL,并使用集合进行去重。还支持使用 Redis 进行分布式管理。
④.流水线
Pipeline负责提取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供两种结果处理方案:“输出到控制台”和“保存到文件”。
Pipeline 定义了保存结果的方式。如果要保存到指定的数据库,需要编写相应的Pipeline。通常,对于一类需求,只需要编写一个 Pipeline。
3).Object 用于数据流
①。要求
Request是对URL地址的一层封装,一个Request对应一个URL地址。它是PageProcessor 与Downloader 交互的载体,也是PageProcessor 控制Downloader 的唯一途径。除了 URL 本身,它还收录一个 Key-Value 结构的额外字段。你可以额外保存一些特殊的属性,并在其他地方读取它们来完成不同的功能。例如,添加上一页的一些信息等。
②。页
Page 表示从 Downloader 下载的页面 - 它可能是 HTML、JSON 或其他文本内容。页面是WebMagic抽取过程的核心对象,它提供了一些抽取、结果保存等方法。
③。结果项
ResultItems相当于一个Map,它保存了PageProcessor处理的结果,供Pipeline使用。它的API和Map非常相似,值得注意的是它有一个字段skip,如果设置为true,它不应该被Pipeline处理。
6.WebMagic 的工作原理
1)。PageProcessor 组件的功能
①。提取元素可选
可选相关提取元素链接 API 是 WebMagic 的核心功能。使用Selectable接口,可以直接完成页面元素的链式提取,无需关心提取的细节。page.getHtml() 返回一个实现 Selectable 接口的 Html 对象。这部分提取API返回一个Selectable接口,表示支持链式调用。该接口收录的方法分为两类:提取部分和获取结果部分。
方法
操作说明
例子
xpath(字符串 xpath)
使用 XPath 选择
html.xpath("//div[@class='title']")
$(字符串选择器)
使用 Css 选择器进行选择
html.$("div.title")
$(字符串选择器,字符串属性)
使用 Css 选择器进行选择
html.$("div.title","text")
css(字符串选择器)
功能同$(),使用Css选择器选择
html.css("div.title")
链接()
选择所有链接
html.links()
正则表达式(字符串正则表达式)
使用正则表达式提取
html.regex("\(.\*?)\")
PageProcessor 中使用了三种主要的提取技术:XPath、CSS 选择器和正则表达式。对于 JSON 格式的内容,可以使用 JsonPath 进行解析。
1. XPath
以上是获取属性class=mt的div标签,以及里面的h1标签的内容
2.CSS 选择器
CSS 选择器是一种类似于 XPath 的语言。
div.mt>h1 表示类为mt的div标签下的直接子元素h1标签
但是使用:nth-child(n) 选择第一个元素,如下选择第一个元素
注意:你需要使用 > 是直接子元素来选择前几个元素
3.正则表达式
正则表达式是一种通用的文本提取语言。这里一般用来获取url地址。
②。得到结果
当链式调用结束时,我们一般希望得到一个字符串类型的结果。这时候就需要使用API来获取结果了。
我们知道,一条抽取规则,无论是 XPath、CSS 选择器还是正则表达式,总是可以抽取多个元素。WebMagic 将这些统一起来,可以通过不同的 API 获取一个或多个元素。
方法
操作说明
例子
得到()
返回字符串类型的结果
字符串链接= html.links().get()
toString()
和get()一样,返回一个String类型的结果
字符串链接= html.links().toString()
全部()
返回所有提取结果
Listlinks= html.links().all()
多条数据时,使用get()和toString()获取第一个url地址。
检测结果:
selectable.toString() 在输出和结合一些框架的时候比较方便。因为一般情况下,我们只使用这种方法来获取一个元素!
③。获取链接
一个网站的页面很多,不可能一开始就全部列出来,所以如何找到后续链接是爬虫必不可少的环节。
下面的例子就是获取这个页面
与 \\w+?.* 正则表达式匹配的所有 url 地址
并将这些链接添加到要爬取的队列中。
2)。调度器组件的使用
解析页面时,很可能会解析相同的url地址(比如商品标题和商品图片超链接,url相同)。如果不处理,同一个url会被多次解析处理,浪费资源。所以我们需要有一个url去重功能。
调度器可以帮助我们解决以上问题。Scheduler 是 WebMagic 中用于 URL 管理的组件。一般来说,Scheduler包括两个功能:
❶ 管理要抓取的 URL 队列。
❷ 对爬取的 URL 进行去重。
WebMagic 内置了几个常用的调度器。如果只是在本地执行小规模的爬虫,基本上不需要自定义Scheduler,但是了解几个已经提供的Scheduler还是有意义的。
种类
操作说明
评论
DuplicateRemovedScheduler
提供一些模板方法的抽象基类
继承它来实现自己的功能
队列调度器
使用内存队列保存要抓取的 URL
优先调度器
使用优先级的内存队列来保存要爬取的 URL
它比QueueScheduler消耗更多的内存,但是设置了request.priority时,只能使用PriorityScheduler来使优先级生效
文件缓存队列调度器
使用文件保存爬取的URL,关闭程序下次启动就可以从之前爬取的URL继续爬取
需要指定路径,会创建两个文件.urls.txt和.cursor.txt
Redis调度器
使用Redis保存抓取队列,可用于多台机器同时协同抓取
需要安装并启动redis
去除重复链接的部分被抽象成一个接口:DuplicateRemover,这样可以为同一个Scheduler选择不同的去重方法,以适应不同的需求。目前提供了两种去重方法。
种类
操作说明
HashSetDuplicateRemover
使用HashSet进行去重,占用大量内存
BloomFilterDuplicateRemover
使用BloomFilter进行去重,占用内存少,但可能会漏页
RedisScheduler 使用 Redis set 进行去重,其他 Scheduler 默认使用 HashSetDuplicateRemover 进行去重。
如果要使用BloomFilter,则必须添加以下依赖项:
修改代码添加布隆过滤器
三种去重方法的比较
❶ HashSetDuplicateRemover
利用java中HashSet不能重复的特性来去除重复。优点是易于理解。使用方便。
缺点:内存占用大,性能低。
❷.RedisScheduler 的集合去重。
优点是速度快(Redis本身很快),去重不会占用爬虫服务器的资源,可以处理数据量较大的数据爬取。
缺点:需要准备Redis服务器,增加了开发和使用成本。
❸.BloomFilterDuplicateRemover
重复数据删除也可以使用布隆过滤器来实现。优点是占用的内存比使用HashSet小很多,也适合大量数据的去重操作。
缺点:有误判的可能。没有重复可能会被判定为重复,但重复的数据肯定会被判定为重复。
*删除页面内容
以上,我们研究了对下载的url地址进行去重,避免多次下载同一个url的解决方案。其实不仅url需要去重,我们还需要对下载的网页内容去重。我们可以在网上找到很多文章类似的内容。但实际上我们只需要其中一个,相同的内容不需要多次下载,所以需要处理如何去重复
重复数据删除程序介绍
❶。指纹代码对比
最常见的重复数据删除方案是生成文档的指纹门。例如,如果一个文章被MD5加密生成一个字符串,我们可以认为这是文章的指纹码,然后与其他文章指纹码进行比较。如果它们一致,则表示 文章 重复。但是这种方法是完全一致的,并且是重复的。如果 文章 只是多了几个标点符号,仍然认为是重复的。这种方法是不合理的。
❷.BloomFilter
这种方法是我们用来对 url 进行重复数据删除的方法。如果我们在这里使用它,我们也会为 文章 计算一个数字,然后进行比较。缺点与方法 1 相同,只是略有不同。,也会认为不重复,这种方法不合理。
❸.KMP算法
KMP 算法是一种改进的字符串匹配算法。KMP算法的关键是利用匹配失败后的信息,尽可能减少模式串与主串的匹配次数,以达到快速匹配的目的。可以找出这两个 文章 中哪些是相同的,哪些是不同的。这种方法可以解决前两种方法中的“只要一个不同,就不重复”的问题。但其时间和空间复杂度太高,不适合大量数据的重复比较。
❹。Simhash 签名
Google 的 simhash 算法生成的签名可以满足上述要求。这个算法并不深奥并且相对容易理解。该算法也是目前谷歌搜索引擎使用的网页去重算法。
(1).SimHash流程介绍
Simhash 是 Charikar 在 2002 年提出的,为了便于理解,尽量不要使用数学公式。它分为以下几个步骤:
1、分词,需要判断的文本的分词,形成这个文章的特征词。
2、hash,通过哈希算法将每个单词变成一个哈希值。例如,“美国”通过哈希算法计算为100101,“51”通过哈希算法计算为101011。这样我们的字符串就变成了一串数字。
3、称重,结果通过2步散列生成。需要根据单词的权重形成加权数字串。“美国”的哈希值为“100101”,加权计算为“4 -4 -4 4 -4 4”
“区域 51”计算为“5 -5 5 -5 5 5”。
4、合并,把上面的话计算出来的序列值累加起来,变成只有一个序列串。
“美国”为“4 -4 -4 4 -4 4”,“51 区”为“5 -5 5 -5 5 5”
累加每一位,“4+5 -4+-5 -4+5 4+-5 -4+5 4+5”à“9 -9 1 -1 1 9”
5、降维,将计算出来的“9 -9 1 -1 1 9”变成0 1字符串,形成最终的simhash签名。
(2).签名距离计算
我们将库中的文本转成simhash签名,转成long类型存储,大大减少了空间。既然我们已经解决了空间问题,那么如何计算两个 simhash 的相似度呢?
我们可以通过汉明距离来计算两个simhash是否相似。两个simhash对应的二进制(01字符串)不同值的个数称为两个simhash的汉明距离。
(3).test simhash
本项目不能直接使用,因为jar包的问题,需要导入项目simhash并安装。
导入对应的依赖:
测试用例:
检测结果:
3)。管道组件的使用
Pipeline 组件的作用是保存结果。我们现在对“控制台输出”所做的事情也是通过一个名为 ConsolePipeline 的内置管道完成的。
那么,我现在想将结果保存到文件中,该怎么做呢?只需将 Pipeline 的实现替换为“FilePipeline”即可。
7.网络爬虫的配置、启动和终止
1).蜘蛛
Spider 是网络爬虫启动的入口点。在启动爬虫之前,我们需要使用 PageProcessor 创建一个 Spider 对象,然后使用 run() 来启动它。
Spider的其他组件(Downloader、Scheduler)可以通过set方法进行设置,
管道组件是通过 add 方法设置的。
方法
操作说明
例子
创建(页面处理器)
创建蜘蛛
Spider.create(new GithubRepoProcessor())
addUrl(字符串...)
添加初始 URL
蜘蛛.addUrl("")
线程(n)
打开 n 个线程
蜘蛛.thread(5)
跑()
启动,会阻塞当前线程执行
蜘蛛.run()
开始()/运行异步()
异步启动,当前线程继续执行
蜘蛛.start()
停止()
停止爬虫
蜘蛛.stop()
添加管道(管道)
添加一个Pipeline,一个Spider可以有多个Pipeline
蜘蛛 .addPipeline(new ConsolePipeline())
setScheduler(调度器)
设置Scheduler,一个Spider只能有一个Scheduler
spider.setScheduler(new RedisScheduler())
setDownloader(下载器)
设置Downloader,一个Spider只能有一个Downloader
蜘蛛 .setDownloader(
新的 SeleniumDownloader())
获取(字符串)
同步调用,直接获取结果
ResultItems 结果 = 蜘蛛 查看全部
java抓取网页数据(如何自动高效地获取互联网中我们感兴趣的信息并实现)
1. 什么是网络爬虫?
在大数据时代,信息采集是一项重要的任务,互联网中的数据是海量的。如果信息采集单纯依靠人力,不仅效率低下、繁琐,而且采集成本也会有所提高。如何在互联网上自动、高效地获取我们感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了解决这些问题而诞生的。
网络爬虫,也称为网络机器人,可以代替人自动采集并组织互联网上的数据和信息。它是一个程序或脚本,根据一定的规则自动从万维网上抓取信息,并且可以自动采集它可以访问的页面的所有内容来获取相关数据。
从功能上来说,爬虫一般分为数据采集、处理、存储三部分。爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
2. 网络爬虫的作用
1.可以实现搜索引擎
在我们学会了爬虫的编写之后,就可以利用爬虫自动采集互联网上的信息,采集返回相应的存储或处理。当我们需要检索一些信息的时候,我们只需要采集@采集检索返回的信息,也就是实现一个私有的搜索引擎。
2.大数据时代,我们可以获得更多的数据源
在进行大数据分析或数据挖掘时,需要有数据源进行分析。我们可以从一些提供统计数据的网站中获取数据,或者从某些文献或内部资料中获取数据,但是这些获取数据的方式有时很难满足我们对数据的需求,需要手动从网上获取数据。查找这些数据需要花费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,进而进行更深层次的数据分析,获取更有价值的信息。
3. 用于更好的搜索引擎优化 (SEO)
对于很多SEO从业者来说,要想更好的完成自己的工作,就必须非常清楚搜索引擎的工作原理,也需要掌握搜索引擎爬虫的工作原理。而学习爬虫,可以更深入的了解搜索引擎爬虫的工作原理,让你在做搜索引擎优化的时候,知己知彼,百战百胜。
3.网络爬虫是如何工作的?
爬虫底部有两个核心:
(1).HttpClient:网络爬虫使用程序来帮助我们访问互联网上的资源。我们一直使用HTTP协议来访问互联网上的网页。网络爬虫需要编写程序来使用相同的HTTP访问网页协议,这里我们使用Java的HTTP协议客户端HttpClient技术来抓取网页数据。(在Java程序中,远程访问是通过HttpClient技术来抓取网页数据。)
注意:如果每次请求都需要创建HttpClient,就会出现频繁创建和销毁的问题。你可以使用 HttpClient 连接池来解决这个问题。
(2).jsoup:我们抓取页面后,还需要解析页面。可以使用字符串处理工具来解析页面,也可以使用正则表达式,但是这些方法会带来很多开发cost ,所以我们需要使用专门解析html页面的技术。(将获取的页面数据转换成Dom对象进行解析)
Jsoup简介:Jsoup是一个Java HTML和XML解析器,可以直接将一个URL地址、HTML文本、文件解析成DOM对象。使用 jQuery 的 action 方法获取 sum 操作数
设置抓取目标(种子页面)并获取网页。无法访问服务器时,设置重试次数。设置用户代理在需要时(否则页面无法访问)通过正则表达式对获取的页面进行必要的解码操作获取页面中的链接对链接进行进一步处理(获取页面并重复上述操作)持久有用信息(用于后续处理)
5. WebMagic 简介
WebMagic 是一个爬虫框架。底层使用了上面介绍的HttpClient和Jsoup,可以让我们更方便的开发爬虫。WebMagic 的设计目标是尽可能模块化,并体现爬虫的功能特点。这部分提供了一个非常简单灵活的API来编写爬虫,而无需基本改变开发模式。
WebMagic 项目代码分为核心和扩展两部分。核心部分(webmagic-core)是一个精简、模块化的爬虫实现,而扩展部分(webmagic-extension)包括一些方便实用的功能,比如用注解的方式编写爬虫,以及一些常用的内置功能。易于爬虫开发的组件。
1).架构介绍
WebMagic 的结构分为四个组件:Downloader、PageProcessor、Scheduler 和 Pipeline,它们由 Spider 组织。这四个组件分别对应了爬虫生命周期中的下载、处理、管理和持久化的功能。
Spider 组织这些组件,以便它们可以相互交互并处理执行。Spider可以看作是一个大容器,也是WebMagic逻辑的核心。
WebMagic的整体架构图如下:
2).WebMagic 的四个组成部分
①.下载器
下载器负责从 Internet 下载页面以进行后续处理。WebMagic 默认使用 Apache HttpClient 作为下载工具。
②.PageProcessor
PageProcessor 负责解析页面、提取有用信息和发现新链接。WebMagic 使用 Jsoup 作为 HTML 解析工具,并在其基础上开发了 Xsoup,一个解析 XPath 的工具。
这四个组件中,PageProcessor对于每个站点的每个页面都是不同的,是需要用户自定义的部分。
③.调度器
Scheduler 负责管理要爬取的 URL,以及一些去重工作。WebMagic 默认提供 JDK 的内存队列来管理 URL,并使用集合进行去重。还支持使用 Redis 进行分布式管理。
④.流水线
Pipeline负责提取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供两种结果处理方案:“输出到控制台”和“保存到文件”。
Pipeline 定义了保存结果的方式。如果要保存到指定的数据库,需要编写相应的Pipeline。通常,对于一类需求,只需要编写一个 Pipeline。
3).Object 用于数据流
①。要求
Request是对URL地址的一层封装,一个Request对应一个URL地址。它是PageProcessor 与Downloader 交互的载体,也是PageProcessor 控制Downloader 的唯一途径。除了 URL 本身,它还收录一个 Key-Value 结构的额外字段。你可以额外保存一些特殊的属性,并在其他地方读取它们来完成不同的功能。例如,添加上一页的一些信息等。
②。页
Page 表示从 Downloader 下载的页面 - 它可能是 HTML、JSON 或其他文本内容。页面是WebMagic抽取过程的核心对象,它提供了一些抽取、结果保存等方法。
③。结果项
ResultItems相当于一个Map,它保存了PageProcessor处理的结果,供Pipeline使用。它的API和Map非常相似,值得注意的是它有一个字段skip,如果设置为true,它不应该被Pipeline处理。
6.WebMagic 的工作原理
1)。PageProcessor 组件的功能
①。提取元素可选
可选相关提取元素链接 API 是 WebMagic 的核心功能。使用Selectable接口,可以直接完成页面元素的链式提取,无需关心提取的细节。page.getHtml() 返回一个实现 Selectable 接口的 Html 对象。这部分提取API返回一个Selectable接口,表示支持链式调用。该接口收录的方法分为两类:提取部分和获取结果部分。
方法
操作说明
例子
xpath(字符串 xpath)
使用 XPath 选择
html.xpath("//div[@class='title']")
$(字符串选择器)
使用 Css 选择器进行选择
html.$("div.title")
$(字符串选择器,字符串属性)
使用 Css 选择器进行选择
html.$("div.title","text")
css(字符串选择器)
功能同$(),使用Css选择器选择
html.css("div.title")
链接()
选择所有链接
html.links()
正则表达式(字符串正则表达式)
使用正则表达式提取
html.regex("\(.\*?)\")
PageProcessor 中使用了三种主要的提取技术:XPath、CSS 选择器和正则表达式。对于 JSON 格式的内容,可以使用 JsonPath 进行解析。
1. XPath
以上是获取属性class=mt的div标签,以及里面的h1标签的内容
2.CSS 选择器
CSS 选择器是一种类似于 XPath 的语言。
div.mt>h1 表示类为mt的div标签下的直接子元素h1标签
但是使用:nth-child(n) 选择第一个元素,如下选择第一个元素
注意:你需要使用 > 是直接子元素来选择前几个元素
3.正则表达式
正则表达式是一种通用的文本提取语言。这里一般用来获取url地址。
②。得到结果
当链式调用结束时,我们一般希望得到一个字符串类型的结果。这时候就需要使用API来获取结果了。
我们知道,一条抽取规则,无论是 XPath、CSS 选择器还是正则表达式,总是可以抽取多个元素。WebMagic 将这些统一起来,可以通过不同的 API 获取一个或多个元素。
方法
操作说明
例子
得到()
返回字符串类型的结果
字符串链接= html.links().get()
toString()
和get()一样,返回一个String类型的结果
字符串链接= html.links().toString()
全部()
返回所有提取结果
Listlinks= html.links().all()
多条数据时,使用get()和toString()获取第一个url地址。
检测结果:
selectable.toString() 在输出和结合一些框架的时候比较方便。因为一般情况下,我们只使用这种方法来获取一个元素!
③。获取链接
一个网站的页面很多,不可能一开始就全部列出来,所以如何找到后续链接是爬虫必不可少的环节。
下面的例子就是获取这个页面
与 \\w+?.* 正则表达式匹配的所有 url 地址
并将这些链接添加到要爬取的队列中。
2)。调度器组件的使用
解析页面时,很可能会解析相同的url地址(比如商品标题和商品图片超链接,url相同)。如果不处理,同一个url会被多次解析处理,浪费资源。所以我们需要有一个url去重功能。
调度器可以帮助我们解决以上问题。Scheduler 是 WebMagic 中用于 URL 管理的组件。一般来说,Scheduler包括两个功能:
❶ 管理要抓取的 URL 队列。
❷ 对爬取的 URL 进行去重。
WebMagic 内置了几个常用的调度器。如果只是在本地执行小规模的爬虫,基本上不需要自定义Scheduler,但是了解几个已经提供的Scheduler还是有意义的。
种类
操作说明
评论
DuplicateRemovedScheduler
提供一些模板方法的抽象基类
继承它来实现自己的功能
队列调度器
使用内存队列保存要抓取的 URL
优先调度器
使用优先级的内存队列来保存要爬取的 URL
它比QueueScheduler消耗更多的内存,但是设置了request.priority时,只能使用PriorityScheduler来使优先级生效
文件缓存队列调度器
使用文件保存爬取的URL,关闭程序下次启动就可以从之前爬取的URL继续爬取
需要指定路径,会创建两个文件.urls.txt和.cursor.txt
Redis调度器
使用Redis保存抓取队列,可用于多台机器同时协同抓取
需要安装并启动redis
去除重复链接的部分被抽象成一个接口:DuplicateRemover,这样可以为同一个Scheduler选择不同的去重方法,以适应不同的需求。目前提供了两种去重方法。
种类
操作说明
HashSetDuplicateRemover
使用HashSet进行去重,占用大量内存
BloomFilterDuplicateRemover
使用BloomFilter进行去重,占用内存少,但可能会漏页
RedisScheduler 使用 Redis set 进行去重,其他 Scheduler 默认使用 HashSetDuplicateRemover 进行去重。
如果要使用BloomFilter,则必须添加以下依赖项:
修改代码添加布隆过滤器
三种去重方法的比较
❶ HashSetDuplicateRemover
利用java中HashSet不能重复的特性来去除重复。优点是易于理解。使用方便。
缺点:内存占用大,性能低。
❷.RedisScheduler 的集合去重。
优点是速度快(Redis本身很快),去重不会占用爬虫服务器的资源,可以处理数据量较大的数据爬取。
缺点:需要准备Redis服务器,增加了开发和使用成本。
❸.BloomFilterDuplicateRemover
重复数据删除也可以使用布隆过滤器来实现。优点是占用的内存比使用HashSet小很多,也适合大量数据的去重操作。
缺点:有误判的可能。没有重复可能会被判定为重复,但重复的数据肯定会被判定为重复。
*删除页面内容
以上,我们研究了对下载的url地址进行去重,避免多次下载同一个url的解决方案。其实不仅url需要去重,我们还需要对下载的网页内容去重。我们可以在网上找到很多文章类似的内容。但实际上我们只需要其中一个,相同的内容不需要多次下载,所以需要处理如何去重复
重复数据删除程序介绍
❶。指纹代码对比
最常见的重复数据删除方案是生成文档的指纹门。例如,如果一个文章被MD5加密生成一个字符串,我们可以认为这是文章的指纹码,然后与其他文章指纹码进行比较。如果它们一致,则表示 文章 重复。但是这种方法是完全一致的,并且是重复的。如果 文章 只是多了几个标点符号,仍然认为是重复的。这种方法是不合理的。
❷.BloomFilter
这种方法是我们用来对 url 进行重复数据删除的方法。如果我们在这里使用它,我们也会为 文章 计算一个数字,然后进行比较。缺点与方法 1 相同,只是略有不同。,也会认为不重复,这种方法不合理。
❸.KMP算法
KMP 算法是一种改进的字符串匹配算法。KMP算法的关键是利用匹配失败后的信息,尽可能减少模式串与主串的匹配次数,以达到快速匹配的目的。可以找出这两个 文章 中哪些是相同的,哪些是不同的。这种方法可以解决前两种方法中的“只要一个不同,就不重复”的问题。但其时间和空间复杂度太高,不适合大量数据的重复比较。
❹。Simhash 签名
Google 的 simhash 算法生成的签名可以满足上述要求。这个算法并不深奥并且相对容易理解。该算法也是目前谷歌搜索引擎使用的网页去重算法。
(1).SimHash流程介绍
Simhash 是 Charikar 在 2002 年提出的,为了便于理解,尽量不要使用数学公式。它分为以下几个步骤:
1、分词,需要判断的文本的分词,形成这个文章的特征词。
2、hash,通过哈希算法将每个单词变成一个哈希值。例如,“美国”通过哈希算法计算为100101,“51”通过哈希算法计算为101011。这样我们的字符串就变成了一串数字。
3、称重,结果通过2步散列生成。需要根据单词的权重形成加权数字串。“美国”的哈希值为“100101”,加权计算为“4 -4 -4 4 -4 4”
“区域 51”计算为“5 -5 5 -5 5 5”。
4、合并,把上面的话计算出来的序列值累加起来,变成只有一个序列串。
“美国”为“4 -4 -4 4 -4 4”,“51 区”为“5 -5 5 -5 5 5”
累加每一位,“4+5 -4+-5 -4+5 4+-5 -4+5 4+5”à“9 -9 1 -1 1 9”
5、降维,将计算出来的“9 -9 1 -1 1 9”变成0 1字符串,形成最终的simhash签名。
(2).签名距离计算
我们将库中的文本转成simhash签名,转成long类型存储,大大减少了空间。既然我们已经解决了空间问题,那么如何计算两个 simhash 的相似度呢?
我们可以通过汉明距离来计算两个simhash是否相似。两个simhash对应的二进制(01字符串)不同值的个数称为两个simhash的汉明距离。
(3).test simhash
本项目不能直接使用,因为jar包的问题,需要导入项目simhash并安装。
导入对应的依赖:
测试用例:
检测结果:
3)。管道组件的使用
Pipeline 组件的作用是保存结果。我们现在对“控制台输出”所做的事情也是通过一个名为 ConsolePipeline 的内置管道完成的。
那么,我现在想将结果保存到文件中,该怎么做呢?只需将 Pipeline 的实现替换为“FilePipeline”即可。
7.网络爬虫的配置、启动和终止
1).蜘蛛
Spider 是网络爬虫启动的入口点。在启动爬虫之前,我们需要使用 PageProcessor 创建一个 Spider 对象,然后使用 run() 来启动它。
Spider的其他组件(Downloader、Scheduler)可以通过set方法进行设置,
管道组件是通过 add 方法设置的。
方法
操作说明
例子
创建(页面处理器)
创建蜘蛛
Spider.create(new GithubRepoProcessor())
addUrl(字符串...)
添加初始 URL
蜘蛛.addUrl("")
线程(n)
打开 n 个线程
蜘蛛.thread(5)
跑()
启动,会阻塞当前线程执行
蜘蛛.run()
开始()/运行异步()
异步启动,当前线程继续执行
蜘蛛.start()
停止()
停止爬虫
蜘蛛.stop()
添加管道(管道)
添加一个Pipeline,一个Spider可以有多个Pipeline
蜘蛛 .addPipeline(new ConsolePipeline())
setScheduler(调度器)
设置Scheduler,一个Spider只能有一个Scheduler
spider.setScheduler(new RedisScheduler())
setDownloader(下载器)
设置Downloader,一个Spider只能有一个Downloader
蜘蛛 .setDownloader(
新的 SeleniumDownloader())
获取(字符串)
同步调用,直接获取结果
ResultItems 结果 = 蜘蛛
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-24 03:08
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家演示如何抓取网站的数据:(1)抓取网页原数据;(2)抓取网页返回的数据。
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即只需要访问JS请求的网页地址就可以获取数据,当然前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
转载于: 查看全部
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家演示如何抓取网站的数据:(1)抓取网页原数据;(2)抓取网页返回的数据。
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即只需要访问JS请求的网页地址就可以获取数据,当然前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
转载于:
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-19 09:07
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具抓取网站数据比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、获取网页 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具抓取网站数据比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
java抓取网页数据(java抓取网页数据的过程主要分为三步:准备)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-14 19:05
java抓取网页数据的过程主要分为三步:准备网页数据、解析网页数据、爬取数据。很多同学下载的网页是java开发的,因此在本文里将讨论如何在html页面上抓取网页数据。本文将从python爬虫技术开始,用python对国家网信办站点发布的1000条热门搜索词进行抓取,同时爬取了全国各省网信办站点信息,并合并了数据。详情点击:爱上网页抓取。
excelexcel,用excel或者类似的web应用工具,导入图片上传即可。
现在网页数据分布挺广的,有一些网站有数据采集下载的接口,你如果需要可以去尝试下,反正我用的是红袖添香和快易发。
可以试试百度前端技术社区的html5+css3、javascript(jquery)、bootstrap/xpath技术交流专区和typecho技术社区,都可以搜索到。
试过chrome浏览器的network,用的beautifulsoup模块,直接抓,
可以试试,
百度图片或者搜索关键词,
试了三个,
有一个叫外链
-and-curl
看源码,就知道了,
proxyeeds有支持javascript, 查看全部
java抓取网页数据(java抓取网页数据的过程主要分为三步:准备)
java抓取网页数据的过程主要分为三步:准备网页数据、解析网页数据、爬取数据。很多同学下载的网页是java开发的,因此在本文里将讨论如何在html页面上抓取网页数据。本文将从python爬虫技术开始,用python对国家网信办站点发布的1000条热门搜索词进行抓取,同时爬取了全国各省网信办站点信息,并合并了数据。详情点击:爱上网页抓取。
excelexcel,用excel或者类似的web应用工具,导入图片上传即可。
现在网页数据分布挺广的,有一些网站有数据采集下载的接口,你如果需要可以去尝试下,反正我用的是红袖添香和快易发。
可以试试百度前端技术社区的html5+css3、javascript(jquery)、bootstrap/xpath技术交流专区和typecho技术社区,都可以搜索到。
试过chrome浏览器的network,用的beautifulsoup模块,直接抓,
可以试试,
百度图片或者搜索关键词,
试了三个,
有一个叫外链
-and-curl
看源码,就知道了,
proxyeeds有支持javascript,
java抓取网页数据(STM32的基本入门吧!(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-01-12 22:12
)
以前用python写爬虫,这次用的是java。虽然代码有点多,但是对于静态类型的语言代码提示还是舒服一点。获取网页源代码是爬虫的基本介绍。
我们使用 Apache 的 commons-httpclient 包进行爬取。需要三个包:commons-httpclient、commons-codec、commons-logging。使用maven,只需要添加以下依赖即可:
commons-httpclient
commons-httpclient
3.1
核心代码如下:
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.methods.PostMethod;
import java.io.IOException;
public class Main {
public static String readUrl(String url) {
PostMethod method = new PostMethod(url);
String res = null;
try {
new HttpClient().executeMethod(method);
res = new String(method.getResponseBodyAsString().getBytes(), "utf8");
} catch (IOException e) {
e.printStackTrace();
}
return res;
}
public static void main(String[] args) {
System.out.println(readUrl("http://blog.zzkun.com"));
}
}
爬取这个博客网站,执行结果如下:
查看全部
java抓取网页数据(STM32的基本入门吧!(一)
)
以前用python写爬虫,这次用的是java。虽然代码有点多,但是对于静态类型的语言代码提示还是舒服一点。获取网页源代码是爬虫的基本介绍。
我们使用 Apache 的 commons-httpclient 包进行爬取。需要三个包:commons-httpclient、commons-codec、commons-logging。使用maven,只需要添加以下依赖即可:
commons-httpclient
commons-httpclient
3.1
核心代码如下:
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.methods.PostMethod;
import java.io.IOException;
public class Main {
public static String readUrl(String url) {
PostMethod method = new PostMethod(url);
String res = null;
try {
new HttpClient().executeMethod(method);
res = new String(method.getResponseBodyAsString().getBytes(), "utf8");
} catch (IOException e) {
e.printStackTrace();
}
return res;
}
public static void main(String[] args) {
System.out.println(readUrl("http://blog.zzkun.com";));
}
}
爬取这个博客网站,执行结果如下:

