
java抓取网页数据
java抓取网页数据(SysNucleus“SysNucleusWebHarvy破解版破解版”为网页数据抓取工具介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-10-28 01:02
SysNucleus WebHarvy 破解版中文名称是网页数据抓取工具。是一款非常实用的网页数据采集软件。该软件界面简洁,没有多余的复杂功能,使用起来非常方便。广泛应用于房地产、电子商务、学术研究等强大功能,助您轻松解决所有问题。此外,它还支持多种文件格式,包括:Excel、XML、CSV、JSON、TSV 等,因此您无需担心转码。值得一提的是,今天给大家带来的是《SysNucleus WebHarvy 破解版》,此版本已经大神精心破解,文件夹附有破解补丁,可以完美激活软件,完成后免费. 使用里面的所有功能,所以不要觉得太舒服。下面我还精心准备了详细的图文安装破解教程,有需要的用户可以参考!使用此软件,您可以轻松抓取数据。不仅如此,它还可以自动提取文字、图片、网址等,非常强大。此外,它还支持从多个页面、类别和关键字中提取数据。有需要的小虎哥们还在等什么?欢迎下载体验!更多精彩有趣的事情等着你去发现!类别和关键字。有需要的小虎哥们还在等什么?欢迎下载体验!更多精彩有趣的事情等着你去发现!类别和关键字。有需要的小虎哥们还在等什么?欢迎下载体验!更多精彩有趣的事情等着你去发现!
特征
1、自动提取网站中的文字、图片、网址和邮件,并以各种格式保存内容。
2、非常好用,几分钟就可以自动找回
3、支持从多个页面/类别/关键字中提取数据
4、将提取的数据保存到文件或数据库中
5、内置调度器和代理支持
6、 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用内置浏览器浏览网页。您可以选择要单击的数据。这很简单!
7、自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据被复制,它会被自动删除。
8、可以多种格式保存从网页中提取的数据。当前版本允许您将捕获的数据导出到 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
9、通常,网页会在多个页面上显示产品列表等数据。可以从多个页面自动抓取和提取数据。只需指出“链接到下一页”,就会自动从所有页面获取数据。
软件功能
1、视觉点和点击界面
是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
2、智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据被复制,它会被自动抓取。
3、导出捕获的数据
您可以以各种格式保存从网页中提取的数据。网站 当前版本的抓取工具允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、 从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。可以自动从多个网页中抓取和提取数据。只需指出“链接到下一页,网站 抓取器将自动从所有页面抓取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字6、通过代理服务器提取
要提取匿名并防止提取网络软件被阻止的Web服务器,您必须通过{over}{filtering}选项才能访问目标网站。您可以使用单个代理服务器地址或代理服务器地址列表。
7、提取分类
网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
8、使用正则表达式提取
您可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。
SysNucleus WebHarvy 中文破解版安装教程
1、 下载并解压安装包,双击运行软件“Setup.exe”进行安装,进入安装向导,点击next进入下一步
2、同意用户协议,选择顶一个
3、设置安装目录,如果要更改,点击更改
4、确认软件安装无误后,点击安装
5、安装成功,取消勾选立即运行软件,点击完成启动安装界面
6、将破解补丁“WebHarvy.exe”替换到原安装目录,点击复制替换
ps:如果找不到位置,可以返回桌面右击图标选择位置打开文件
7、 破解成功,打开软件即可免费使用
更新日志
修复了页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源 查看全部
java抓取网页数据(SysNucleus“SysNucleusWebHarvy破解版破解版”为网页数据抓取工具介绍)
SysNucleus WebHarvy 破解版中文名称是网页数据抓取工具。是一款非常实用的网页数据采集软件。该软件界面简洁,没有多余的复杂功能,使用起来非常方便。广泛应用于房地产、电子商务、学术研究等强大功能,助您轻松解决所有问题。此外,它还支持多种文件格式,包括:Excel、XML、CSV、JSON、TSV 等,因此您无需担心转码。值得一提的是,今天给大家带来的是《SysNucleus WebHarvy 破解版》,此版本已经大神精心破解,文件夹附有破解补丁,可以完美激活软件,完成后免费. 使用里面的所有功能,所以不要觉得太舒服。下面我还精心准备了详细的图文安装破解教程,有需要的用户可以参考!使用此软件,您可以轻松抓取数据。不仅如此,它还可以自动提取文字、图片、网址等,非常强大。此外,它还支持从多个页面、类别和关键字中提取数据。有需要的小虎哥们还在等什么?欢迎下载体验!更多精彩有趣的事情等着你去发现!类别和关键字。有需要的小虎哥们还在等什么?欢迎下载体验!更多精彩有趣的事情等着你去发现!类别和关键字。有需要的小虎哥们还在等什么?欢迎下载体验!更多精彩有趣的事情等着你去发现!

特征
1、自动提取网站中的文字、图片、网址和邮件,并以各种格式保存内容。
2、非常好用,几分钟就可以自动找回
3、支持从多个页面/类别/关键字中提取数据
4、将提取的数据保存到文件或数据库中
5、内置调度器和代理支持
6、 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用内置浏览器浏览网页。您可以选择要单击的数据。这很简单!
7、自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据被复制,它会被自动删除。
8、可以多种格式保存从网页中提取的数据。当前版本允许您将捕获的数据导出到 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
9、通常,网页会在多个页面上显示产品列表等数据。可以从多个页面自动抓取和提取数据。只需指出“链接到下一页”,就会自动从所有页面获取数据。

软件功能
1、视觉点和点击界面
是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
2、智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据被复制,它会被自动抓取。
3、导出捕获的数据
您可以以各种格式保存从网页中提取的数据。网站 当前版本的抓取工具允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、 从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。可以自动从多个网页中抓取和提取数据。只需指出“链接到下一页,网站 抓取器将自动从所有页面抓取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字6、通过代理服务器提取
要提取匿名并防止提取网络软件被阻止的Web服务器,您必须通过{over}{filtering}选项才能访问目标网站。您可以使用单个代理服务器地址或代理服务器地址列表。
7、提取分类
网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
8、使用正则表达式提取
您可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。
SysNucleus WebHarvy 中文破解版安装教程
1、 下载并解压安装包,双击运行软件“Setup.exe”进行安装,进入安装向导,点击next进入下一步
2、同意用户协议,选择顶一个
3、设置安装目录,如果要更改,点击更改
4、确认软件安装无误后,点击安装
5、安装成功,取消勾选立即运行软件,点击完成启动安装界面
6、将破解补丁“WebHarvy.exe”替换到原安装目录,点击复制替换
ps:如果找不到位置,可以返回桌面右击图标选择位置打开文件
7、 破解成功,打开软件即可免费使用
更新日志
修复了页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源
java抓取网页数据(本文站点对数据的显示方式略有不同演示怎样抓取站点的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-22 03:26
有时出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示的数据略有不同。
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73。单击查询按钮。您将能够看到网页上显示的结果:
第二步:查看网页源代码。我们在源码中看到这么一段:
从这里可以看到。再次请求网页后显示查询结果。
查询后看网页地址:
换句话说。我们只想访问一个看起来像这样的网站。可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) 抛出异常 {
字符串 strURL = "
IP= = + ip;
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("以上四项依次显示");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml() 结果:\n" + result);
}使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
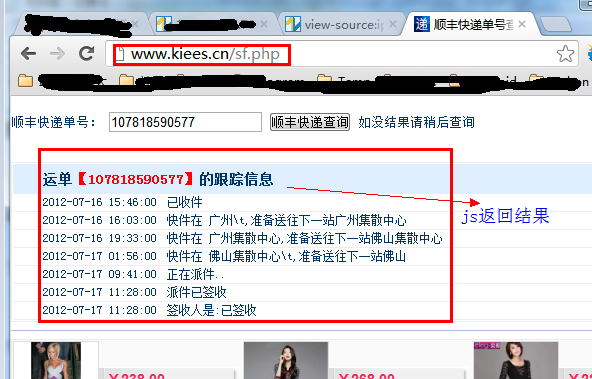
有时网站是为了保护自己的数据。网页的源代码中没有直接返回数据。而是采用异步方式用JS返回数据,避免了搜索引擎等工具对网站数据的抓取。
首先看这个页面:
使用第一种方法查看页面的源代码。但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果。我们先清除这些数据,然后输入快递号: 7.点击查询按钮,然后查看HTTP Analyzer的结果:
这是在单击查询按钮之后。HTTP Analyzer的结果,我们继续查看:
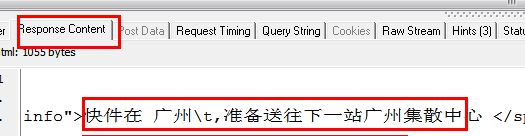
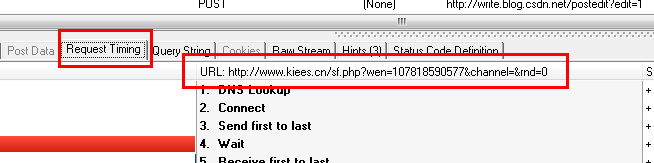
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为就可以得到数据。即我们只需要访问JS请求的网页地址即可获取数据。当然,前提是数据没有加密。我们记下JS请求的URL:
文=7&频道=&rnd=0
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) 抛出异常 {
字符串 strURL = "
文= = + postid
+ "&channel=&rnd=0";
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript():\n" + contentBuf.toString()的结果);
}你看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这能成为一个需要帮助的孩子,需要程序的源代码。点击这里下载! 查看全部
java抓取网页数据(本文站点对数据的显示方式略有不同演示怎样抓取站点的数据)
有时出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示的数据略有不同。
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73。单击查询按钮。您将能够看到网页上显示的结果:

第二步:查看网页源代码。我们在源码中看到这么一段:

从这里可以看到。再次请求网页后显示查询结果。
查询后看网页地址:

换句话说。我们只想访问一个看起来像这样的网站。可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) 抛出异常 {
字符串 strURL = "
IP= = + ip;
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("以上四项依次显示");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml() 结果:\n" + result);
}使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站是为了保护自己的数据。网页的源代码中没有直接返回数据。而是采用异步方式用JS返回数据,避免了搜索引擎等工具对网站数据的抓取。
首先看这个页面:

使用第一种方法查看页面的源代码。但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:

为了更方便的查看JS的结果。我们先清除这些数据,然后输入快递号: 7.点击查询按钮,然后查看HTTP Analyzer的结果:

这是在单击查询按钮之后。HTTP Analyzer的结果,我们继续查看:


从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为就可以得到数据。即我们只需要访问JS请求的网页地址即可获取数据。当然,前提是数据没有加密。我们记下JS请求的URL:
文=7&频道=&rnd=0
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) 抛出异常 {
字符串 strURL = "
文= = + postid
+ "&channel=&rnd=0";
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript():\n" + contentBuf.toString()的结果);
}你看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这能成为一个需要帮助的孩子,需要程序的源代码。点击这里下载!
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-20 15:14
原文链接:
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
查看平原
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义的分析方法显示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
查看平原
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原文链接:
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:

第2步:查看网页源代码,我们在源代码中看到这一段:

从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:

也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
查看平原
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义的分析方法显示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
查看平原
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载!
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-20 15:12
原文链接:
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]查看明文
publicvoidcaptureHtml(Stringip)throwsException{ StringstrURL=""+ip; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8") ; BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line);} Stringbuf=contentBuf.toString() ; intbeginIx=buf.indexOf("查询结果["); intentIx=buf.indexOf("以上四项依次显示"); Stringresult=buf.substring(beginIx,endIx); System.out.println("captureHtml()的结果:\n"+result); }
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义的分析方法显示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]查看明文
publicvoidcaptureJavascript(Stringpostid)throwsException{ StringstrURL=""+postid +"&channel=&rnd=0"; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8"); BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } System.out.println("captureJavascript():\n"+contentBuf.toString()的结果); }
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友,以及需要程序源码的朋友有所帮助! 查看全部
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原文链接:
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:

第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]查看明文
publicvoidcaptureHtml(Stringip)throwsException{ StringstrURL=""+ip; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8") ; BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line);} Stringbuf=contentBuf.toString() ; intbeginIx=buf.indexOf("查询结果["); intentIx=buf.indexOf("以上四项依次显示"); Stringresult=buf.substring(beginIx,endIx); System.out.println("captureHtml()的结果:\n"+result); }
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义的分析方法显示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]查看明文
publicvoidcaptureJavascript(Stringpostid)throwsException{ StringstrURL=""+postid +"&channel=&rnd=0"; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8"); BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } System.out.println("captureJavascript():\n"+contentBuf.toString()的结果); }
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友,以及需要程序源码的朋友有所帮助!
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-10-14 13:15
原文链接:
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{ StringstrURL=""+ip; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8") ; BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line);} Stringbuf=contentBuf.toString() ; intbeginIx=buf.indexOf("查询结果["); intentIx=buf.indexOf("以上四项依次显示"); Stringresult=buf.substring(beginIx,endIx); System.out.println("captureHtml()的结果:\n"+result); }
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义的分析方法显示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{ StringstrURL=""+postid +"&channel=&rnd=0"; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8"); BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } System.out.println("captureJavascript():\n"+contentBuf.toString()的结果); }
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了! 查看全部
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原文链接:
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{ StringstrURL=""+ip; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8") ; BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line);} Stringbuf=contentBuf.toString() ; intbeginIx=buf.indexOf("查询结果["); intentIx=buf.indexOf("以上四项依次显示"); Stringresult=buf.substring(beginIx,endIx); System.out.println("captureHtml()的结果:\n"+result); }
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义的分析方法显示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{ StringstrURL=""+postid +"&channel=&rnd=0"; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8"); BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } System.out.println("captureJavascript():\n"+contentBuf.toString()的结果); }
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
java抓取网页数据(我会不会抓网页的内容,然后把一些表格整理成excel )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-12 06:19
)
志超同志今天问我要不要抓取网页的内容,然后把一些表格整理成excel。
嗯,我不会,但我想试试,结果还是可行的。
先说他的需求,他需要把这个网站中的所有公司信息都存储在一个excel表中。
之前没用java来抓取网页内容,但是写过用过,略懂一点。
我找到了这个文章的内容:
然后,删除它的部分代码后,就可以抓取网页的源代码了。
github地址:
其他网址有相应的改编版本
下面是程序执行的第一步,抓取第一页到第22页的内容,并保存公司子页面的链接。
<p>import java.io.BufferedInputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.Reader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
public class Main {
/**
* 主函数
* @param args
*/
static public void main(String[] args){
String SrcWebSiteUrl = new String("http://www.zjex.com.cn/view/co ... 6quot;);
int WebSitePageId = 1;
ArrayList WebUrlArrayList = new ArrayList();
for (WebSitePageId = 1;WebSitePageId '){
IsBlock = false;
}
}
else{
if (TempChar == ' 查看全部
java抓取网页数据(我会不会抓网页的内容,然后把一些表格整理成excel
)
志超同志今天问我要不要抓取网页的内容,然后把一些表格整理成excel。
嗯,我不会,但我想试试,结果还是可行的。
先说他的需求,他需要把这个网站中的所有公司信息都存储在一个excel表中。
之前没用java来抓取网页内容,但是写过用过,略懂一点。
我找到了这个文章的内容:
然后,删除它的部分代码后,就可以抓取网页的源代码了。
github地址:
其他网址有相应的改编版本
下面是程序执行的第一步,抓取第一页到第22页的内容,并保存公司子页面的链接。
<p>import java.io.BufferedInputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.Reader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
public class Main {
/**
* 主函数
* @param args
*/
static public void main(String[] args){
String SrcWebSiteUrl = new String("http://www.zjex.com.cn/view/co ... 6quot;);
int WebSitePageId = 1;
ArrayList WebUrlArrayList = new ArrayList();
for (WebSitePageId = 1;WebSitePageId '){
IsBlock = false;
}
}
else{
if (TempChar == '
java抓取网页数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-09 03:01
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
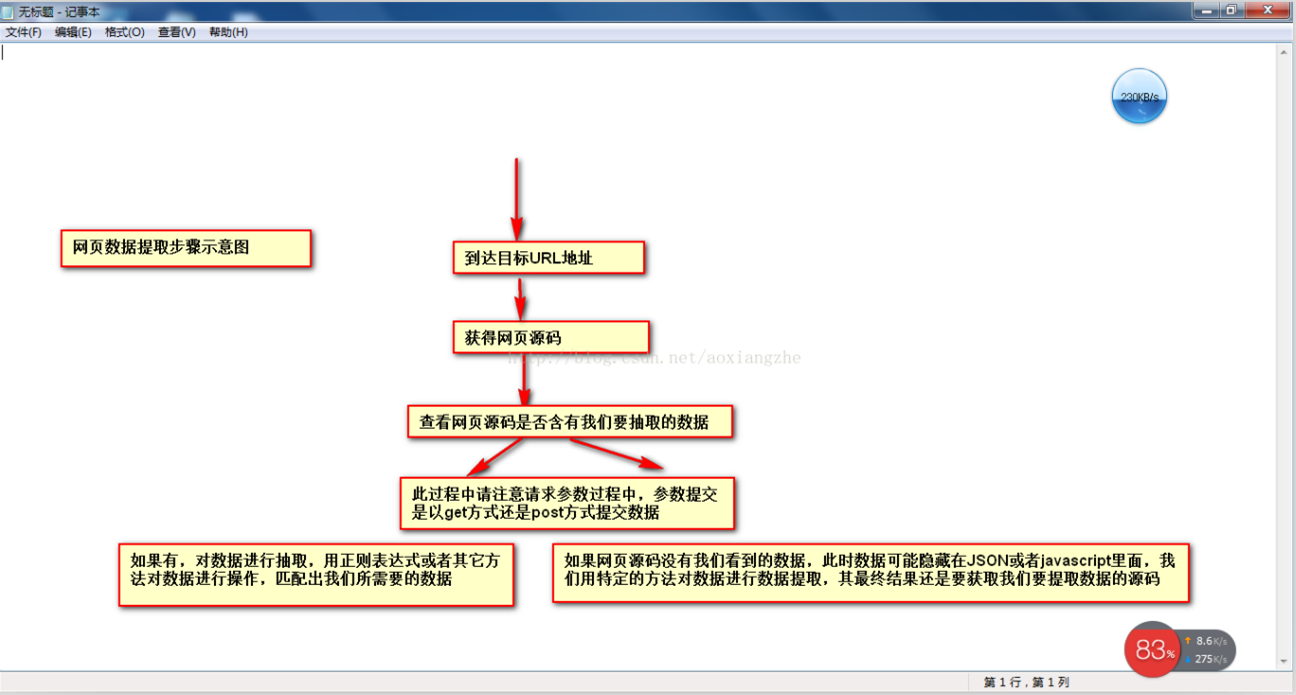
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
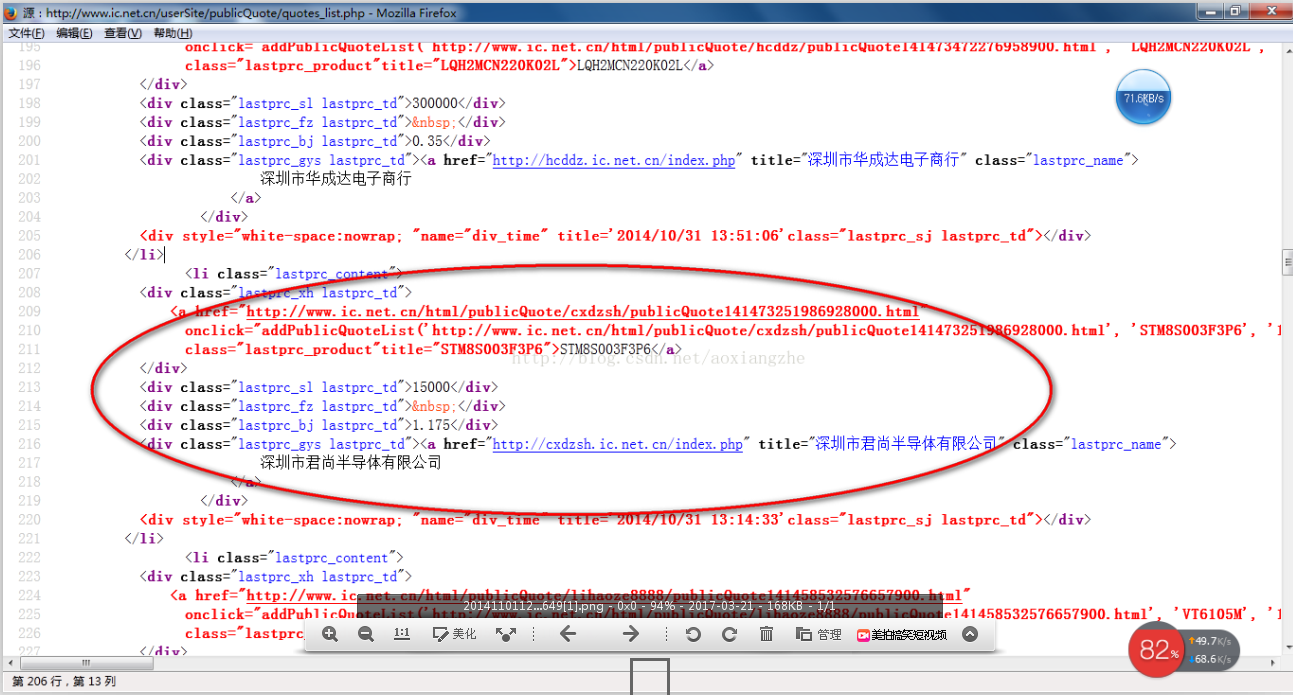
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,一个翻页动作,可以采集完成所有数据。
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
java抓取网页数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览

接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据

成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,一个翻页动作,可以采集完成所有数据。
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据存储起来,方便我们接下来的数据查询操作。
java抓取网页数据(java抓取网页数据并解析json格式数据的整个流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-10-09 01:05
java抓取网页数据并解析json格式数据的整个流程实际上包括如下工作步骤:
1、数据存储python自带存储解析结果(json)存储库,
2、数据解析java-bson解析结果,主要读取java-jsonx(beautifulsoup)和cjs库;java-bson、cjs属于第三方库,需要依赖安装,详细说明请参考cjs-make,
3、数据存储java-jsonx数据操作,主要用于解析,支持从beautifulsoup等导入数据、mongodb、redis等;team分布式文件系统zookeeper和consul都是基于zookeeper操作json格式的。
4、运维监控可以看到系统一天内的实时运行情况:
在一般公司,可能不需要有一个java抓包工具(那太笨了),做一些实际的并发(线程、锁等)处理。但这没有什么价值,主要还是解析,只有很少的大数据量处理才需要。
解析json格式的java任务可以用第三方库java-bson或java-jsonx解析使用pymongo
首先你的一般逻辑是不可行的,你需要做到的是尽可能的减少内存占用,然后缩小体积提高性能。java这样的抓包工具,不需要自己写代码,也不需要有操作mongodb,redis,等东西的经验,有专门做这个的工具和库,比如如果是beautifulsoup或者java-xml.beautifulsoup等,不需要用自己写代码的。性能上面,专门做数据包读写,或者抓包工具自身缓存机制或者使用本地缓存,这些都能提高性能。 查看全部
java抓取网页数据(java抓取网页数据并解析json格式数据的整个流程)
java抓取网页数据并解析json格式数据的整个流程实际上包括如下工作步骤:
1、数据存储python自带存储解析结果(json)存储库,
2、数据解析java-bson解析结果,主要读取java-jsonx(beautifulsoup)和cjs库;java-bson、cjs属于第三方库,需要依赖安装,详细说明请参考cjs-make,
3、数据存储java-jsonx数据操作,主要用于解析,支持从beautifulsoup等导入数据、mongodb、redis等;team分布式文件系统zookeeper和consul都是基于zookeeper操作json格式的。
4、运维监控可以看到系统一天内的实时运行情况:
在一般公司,可能不需要有一个java抓包工具(那太笨了),做一些实际的并发(线程、锁等)处理。但这没有什么价值,主要还是解析,只有很少的大数据量处理才需要。
解析json格式的java任务可以用第三方库java-bson或java-jsonx解析使用pymongo
首先你的一般逻辑是不可行的,你需要做到的是尽可能的减少内存占用,然后缩小体积提高性能。java这样的抓包工具,不需要自己写代码,也不需要有操作mongodb,redis,等东西的经验,有专门做这个的工具和库,比如如果是beautifulsoup或者java-xml.beautifulsoup等,不需要用自己写代码的。性能上面,专门做数据包读写,或者抓包工具自身缓存机制或者使用本地缓存,这些都能提高性能。
java抓取网页数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-08 06:02
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候,可能都无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
从上面的源码中,可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好的,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们要获取的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,一个翻页动作,可以采集完成所有数据。
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
java抓取网页数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候,可能都无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解

在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览

接下来我们看一下网页的源码结构:

从上面的源码中,可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好的,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据

成功获取数据,这就是我们要获取的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,一个翻页动作,可以采集完成所有数据。
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据存储起来,方便我们接下来的数据查询操作。
java抓取网页数据(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-10-07 14:08
最近在做一个项目,有一个需求:从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,后来就稀里糊涂的打了代码(之前用的是Hadoop平台的分布式爬虫框架Nutch,用起来很方便,最后因为速度放弃了,但是生成的统计数据用在后来爬取),很快就成功下载了holder.html和finance.html页面,然后在解析了holder.html页面后,解析了finance.html,然后就郁闷的在这个页面找到了自己需要的东西数据不在 html 源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录后者)。我很高兴,终于找到了解决办法。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。当初设计的时候,不是用来服务爬虫的,但我想说的是:星盘只是有点短,你不能再进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从实际情况出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver 可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码太有限了。解析你写的js代码,js代码简单,当然WebDriver可以毫无压力的完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面用到的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml(),可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js。会启动一个带界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都免不了要解析js,这需要时间,而且对于没用的内核,js的支持程序也不一样。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身经历)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。本来以为driver解析js完成后应该可以抓到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有往前走一步,这样我们就可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。这真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会出现不同,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实如此。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好办法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log('Loading a web page');
var page = require('webpage').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码不同编译,java端一直在等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了好几天了。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后我爬网页的时候就得心应手了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过可以用Nutch和WebDirver的结合,可能爬取的结果比较稳定,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫获得的结果的稳定性有什么要说的,欢迎大家,因为我确实没有找到稳定爬虫结果的相关资料。 查看全部
java抓取网页数据(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
最近在做一个项目,有一个需求:从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,后来就稀里糊涂的打了代码(之前用的是Hadoop平台的分布式爬虫框架Nutch,用起来很方便,最后因为速度放弃了,但是生成的统计数据用在后来爬取),很快就成功下载了holder.html和finance.html页面,然后在解析了holder.html页面后,解析了finance.html,然后就郁闷的在这个页面找到了自己需要的东西数据不在 html 源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录后者)。我很高兴,终于找到了解决办法。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。当初设计的时候,不是用来服务爬虫的,但我想说的是:星盘只是有点短,你不能再进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从实际情况出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver 可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码太有限了。解析你写的js代码,js代码简单,当然WebDriver可以毫无压力的完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面用到的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml(),可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js。会启动一个带界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都免不了要解析js,这需要时间,而且对于没用的内核,js的支持程序也不一样。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身经历)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。本来以为driver解析js完成后应该可以抓到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有往前走一步,这样我们就可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。这真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会出现不同,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实如此。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好办法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log('Loading a web page');
var page = require('webpage').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码不同编译,java端一直在等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了好几天了。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后我爬网页的时候就得心应手了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过可以用Nutch和WebDirver的结合,可能爬取的结果比较稳定,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫获得的结果的稳定性有什么要说的,欢迎大家,因为我确实没有找到稳定爬虫结果的相关资料。
java抓取网页数据(VsWinForm开发系列-WebBrowser介绍(组图)介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-10-06 21:15
阿里云>云栖社区>主题图>W>winform网页爬取
推荐活动:
更多优惠>
当前主题:winform 网页抓取和添加到采集夹
相关话题:
winform网页抓取相关博客查看更多博客
C# WinForm 开发系列-WebBrowser
作者:Jack Chen 1286人浏览评论:07年前
原文:C#WinForm开发系列-WebBrowser介绍了Vs 2005中WebBrowser控件的使用以及一些疑难问题的解决方法,如如何正确显示中文、屏蔽右键菜单、设置代理等;采集到的 文章 可能还是带来了一些使用 Microsoft W 的 Asp.Net 开发
阅读全文
.NET 实现(WebBrowser Data 采集—最后一章)
作者:王庆培 772人浏览评论:010年前
它可以改进。我不明白为什么相同的 HTTP 协议用于数据 采集。能提高多少效率?在采集的过程中,我们还要经过各种高层协议到底层协议。二个人觉得WebRequest是为了实现更多的可扩展性。我的WebBrowser数据采集不是关于爬取数据的效率,而是重点说明我们
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:Jack Chen1527人浏览评论:06年前
原文:PHP 使用 QueryList 抓取网页内容,然后使用 Java Jsoup 抓取网页数据。前几天听说用PHP抓起来比较方便。今天研究了一下,主要是用QueryList来实现。QueryList 是一个基于 phpQuery 的通用列表 采集 类,简单、灵活、功能强大
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
过去,我们使用 Java Jsoup 来捕获网页数据。前几天听说用PHP抓包比较方便。今天简单研究了一下,主要是使用QueryList。
阅读全文
RDIFramework.NET框架SOA解决方案(Windows服务集、WinForm窗体和IIS窗体发布)-分布式应用
作者:科技小先锋1152人浏览评论数:03年前
RDIFramework.NET框架SOA解决方案(集合Windows服务、WinForm窗体和IIS窗体发布)——分布式应用RDIFramework.NET,基于.NET快速信息系统开发与集成框架,为用户和开发者提供最佳的.Net Framework部署方案。框架基于SOA
阅读全文
使用C#开发基于Winform的手机号码归属地查询工具
作者:xiaoqiu08172108 浏览评论人数:07年前
一、需求说明 输入正确的手机号码,查询号码归属地等相关信息。二、需求分析1、手机号码归属地查询方法01、本地数据库存储信息,查询本地数据库02、调用WebService查询03、通过Http请求Get方法从服务器获取数据2、方法解析:
阅读全文
WinForm开发中,改变TreeView控件当前选中节点的字体和颜色
作者:rdiframework920 浏览评论人数:09年前
版权声明:本文为博主原创文章所有,未经博主许可,不得转载。瞄准 T
阅读全文
玩转小型爬虫——抓取动态页面
作者:一线码农2000人浏览评论:05年前
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫爬取的只是web服务器返回给我们的html,跳过了js加载的部分,也就是说爬虫抓取到的网页不完整,不完整。您可以在下面看到博客花园主页。从首页加载可以看出,页面渲染后,还会有5个
阅读全文 查看全部
java抓取网页数据(VsWinForm开发系列-WebBrowser介绍(组图)介绍)
阿里云>云栖社区>主题图>W>winform网页爬取

推荐活动:
更多优惠>
当前主题:winform 网页抓取和添加到采集夹
相关话题:
winform网页抓取相关博客查看更多博客
C# WinForm 开发系列-WebBrowser


作者:Jack Chen 1286人浏览评论:07年前
原文:C#WinForm开发系列-WebBrowser介绍了Vs 2005中WebBrowser控件的使用以及一些疑难问题的解决方法,如如何正确显示中文、屏蔽右键菜单、设置代理等;采集到的 文章 可能还是带来了一些使用 Microsoft W 的 Asp.Net 开发
阅读全文
.NET 实现(WebBrowser Data 采集—最后一章)


作者:王庆培 772人浏览评论:010年前
它可以改进。我不明白为什么相同的 HTTP 协议用于数据 采集。能提高多少效率?在采集的过程中,我们还要经过各种高层协议到底层协议。二个人觉得WebRequest是为了实现更多的可扩展性。我的WebBrowser数据采集不是关于爬取数据的效率,而是重点说明我们
阅读全文
PHP 使用 QueryList 抓取网页内容

作者:Jack Chen1527人浏览评论:06年前
原文:PHP 使用 QueryList 抓取网页内容,然后使用 Java Jsoup 抓取网页数据。前几天听说用PHP抓起来比较方便。今天研究了一下,主要是用QueryList来实现。QueryList 是一个基于 phpQuery 的通用列表 采集 类,简单、灵活、功能强大
阅读全文
PHP 使用 QueryList 抓取网页内容


作者:thinkyoung1544 人浏览评论:06年前
过去,我们使用 Java Jsoup 来捕获网页数据。前几天听说用PHP抓包比较方便。今天简单研究了一下,主要是使用QueryList。
阅读全文
RDIFramework.NET框架SOA解决方案(Windows服务集、WinForm窗体和IIS窗体发布)-分布式应用

作者:科技小先锋1152人浏览评论数:03年前
RDIFramework.NET框架SOA解决方案(集合Windows服务、WinForm窗体和IIS窗体发布)——分布式应用RDIFramework.NET,基于.NET快速信息系统开发与集成框架,为用户和开发者提供最佳的.Net Framework部署方案。框架基于SOA
阅读全文
使用C#开发基于Winform的手机号码归属地查询工具
作者:xiaoqiu08172108 浏览评论人数:07年前
一、需求说明 输入正确的手机号码,查询号码归属地等相关信息。二、需求分析1、手机号码归属地查询方法01、本地数据库存储信息,查询本地数据库02、调用WebService查询03、通过Http请求Get方法从服务器获取数据2、方法解析:
阅读全文
WinForm开发中,改变TreeView控件当前选中节点的字体和颜色


作者:rdiframework920 浏览评论人数:09年前
版权声明:本文为博主原创文章所有,未经博主许可,不得转载。瞄准 T
阅读全文
玩转小型爬虫——抓取动态页面

作者:一线码农2000人浏览评论:05年前
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫爬取的只是web服务器返回给我们的html,跳过了js加载的部分,也就是说爬虫抓取到的网页不完整,不完整。您可以在下面看到博客花园主页。从首页加载可以看出,页面渲染后,还会有5个
阅读全文
java抓取网页数据(任务解析及提升任务)
网站优化 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2021-10-06 21:13
这个任务是:
对搜索到的网页进行聚类,并将聚类结果显示给用户。用户可以选择其中一个类别,标记焦点,以该类别的关键词为主体,用户可以跟踪该主题并了解该主题。
截止日期:11.09
任务分析:
基本任务:对网页进行聚类,按类别归档,将图片放入相应的文件夹中,将文本放入相应的文件中。
推广任务:持续跟踪网页,持续下载符合条件的文件。
编译环境总结:
如果想省事,可以直接从睿思下载Anaconda Navigator。安装后直接使用,打包即可。
话不多说,先贴上代码:
#################################################
# 网页爬虫
# Email : jtailong@163.com
#################################################
import re
import time
import urllib.request
import requests
from bs4 import BeautifulSoup
#添加网页
url = \'https://www.douban.com/\'
#将图片抓取,并打包
req = urllib.request.urlopen(url)
data = req.read().decode(\'utf-8\')
match = re.compile("data-origin=\"(.+?\.jpg)")
#j记录图片信息
f = open(\'D:\\P\图片下载记录.txt\', \'w+\')
for sj in match.findall(data):
try:
f.write(sj)
except:
print("fail")
f.write(\'\n\')
f.close()
f1 = open(\'D:\\P\Pic_information.txt\', \'r+\')
#开始抓取网页图片
x = 0
for lj in f1.readlines():
img = urllib.request.urlretrieve(lj, \'D:/P/%s.jpg\' % x)
x += 1
f1.close()
#将网页上所有的文字信息,记录到TXT文件当中
r = requests.get(url)
soup = BeautifulSoup(r.text, \'html.parser\')
content = soup.text
print (content)
file = open(\'D:\\P\网页上所有文字信息.txt\', \'w\', encoding=\'utf-8\')
file.write(content)
file.close()
编译效果对比:
上图:原网页;下图:爬取后,可以看到文件夹中的信息。
更新:
通过这个编程,我对爬虫的理解是: 查看全部
java抓取网页数据(任务解析及提升任务)
这个任务是:
对搜索到的网页进行聚类,并将聚类结果显示给用户。用户可以选择其中一个类别,标记焦点,以该类别的关键词为主体,用户可以跟踪该主题并了解该主题。
截止日期:11.09
任务分析:
基本任务:对网页进行聚类,按类别归档,将图片放入相应的文件夹中,将文本放入相应的文件中。
推广任务:持续跟踪网页,持续下载符合条件的文件。
编译环境总结:
如果想省事,可以直接从睿思下载Anaconda Navigator。安装后直接使用,打包即可。
话不多说,先贴上代码:
#################################################
# 网页爬虫
# Email : jtailong@163.com
#################################################
import re
import time
import urllib.request
import requests
from bs4 import BeautifulSoup
#添加网页
url = \'https://www.douban.com/\'
#将图片抓取,并打包
req = urllib.request.urlopen(url)
data = req.read().decode(\'utf-8\')
match = re.compile("data-origin=\"(.+?\.jpg)")
#j记录图片信息
f = open(\'D:\\P\图片下载记录.txt\', \'w+\')
for sj in match.findall(data):
try:
f.write(sj)
except:
print("fail")
f.write(\'\n\')
f.close()
f1 = open(\'D:\\P\Pic_information.txt\', \'r+\')
#开始抓取网页图片
x = 0
for lj in f1.readlines():
img = urllib.request.urlretrieve(lj, \'D:/P/%s.jpg\' % x)
x += 1
f1.close()
#将网页上所有的文字信息,记录到TXT文件当中
r = requests.get(url)
soup = BeautifulSoup(r.text, \'html.parser\')
content = soup.text
print (content)
file = open(\'D:\\P\网页上所有文字信息.txt\', \'w\', encoding=\'utf-8\')
file.write(content)
file.close()
编译效果对比:
上图:原网页;下图:爬取后,可以看到文件夹中的信息。
更新:
通过这个编程,我对爬虫的理解是:
java抓取网页数据(完整的抓取示例工程可加群250108697图 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-10-06 21:12
)
网站中的图片和网页本质上是一样的。图片和网页的获取本质上是根据URL从网站中获取网页/图片的字节数组(byte[]),浏览器根据http响应头中的content-type信息,服务器将决定是否以网页或图片的形式显示资源。
完整的抓图示例工程可以加入群250108697,在群文件中获取。
示例中的代码将美食街中的图片爬取到指定文件夹,爬取结果如下图所示:
核心代码:
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler;
import cn.edu.hfut.dmic.webcollector.plugin.net.OkHttpRequester;
import cn.edu.hfut.dmic.webcollector.util.ExceptionUtils;
import cn.edu.hfut.dmic.webcollector.util.FileUtils;
import cn.edu.hfut.dmic.webcollector.util.MD5Utils;
import java.io.File;
/**
* WebCollector抓取图片的例子
* @author hu
*/
public class DemoImageCrawler extends BreadthCrawler {
File baseDir = new File("images");
/**
* 构造一个基于伯克利DB的爬虫
* 伯克利DB文件夹为crawlPath,crawlPath中维护了历史URL等信息
* 不同任务不要使用相同的crawlPath
* 两个使用相同crawlPath的爬虫并行爬取会产生错误
*
* @param crawlPath 伯克利DB使用的文件夹
*/
public DemoImageCrawler(String crawlPath) {
super(crawlPath, true);
//只有在autoParse和autoDetectImg都为true的情况下
//爬虫才会自动解析图片链接
getConf().setAutoDetectImg(true);
//如果使用默认的Requester,需要像下面这样设置一下网页大小上限
//否则可能会获得一个不完整的页面
//下面这行将页面大小上限设置为10M
//getConf().setMaxReceiveSize(1024 * 1024 * 10);
//添加种子URL
addSeed("http://www.meishij.net/");
//限定爬取范围
addRegex("http://www.meishij.net/.*");
addRegex("http://images.meishij.net/.*");
addRegex("-.*#.*");
addRegex("-.*\\?.*");
//设置为断点爬取,否则每次开启爬虫都会重新爬取
// demoImageCrawler.setResumable(true);
setThreads(30);
}
@Override
public void visit(Page page, CrawlDatums next) {
//根据http头中的Content-Type信息来判断当前资源是网页还是图片
String contentType = page.contentType();
//根据Content-Type判断是否为图片
if(contentType!=null && contentType.startsWith("image")){
//从Content-Type中获取图片扩展名
String extensionName=contentType.split("/")[1];
try {
byte[] image = page.content();
//根据图片MD5生成文件名
String fileName = String.format("%s.%s",MD5Utils.md5(image), extensionName);
File imageFile = new File(baseDir, fileName);
FileUtils.write(imageFile, image);
System.out.println("保存图片 "+page.url()+" 到 "+ imageFile.getAbsolutePath());
} catch (Exception e) {
ExceptionUtils.fail(e);
}
}
}
public static void main(String[] args) throws Exception {
DemoImageCrawler demoImageCrawler = new DemoImageCrawler("crawl");
demoImageCrawler.setRequester(new OkHttpRequester());
//设置为断点爬取,否则每次开启爬虫都会重新爬取
demoImageCrawler.setResumable(true);
demoImageCrawler.start(3);
}
} 查看全部
java抓取网页数据(完整的抓取示例工程可加群250108697图
)
网站中的图片和网页本质上是一样的。图片和网页的获取本质上是根据URL从网站中获取网页/图片的字节数组(byte[]),浏览器根据http响应头中的content-type信息,服务器将决定是否以网页或图片的形式显示资源。
完整的抓图示例工程可以加入群250108697,在群文件中获取。
示例中的代码将美食街中的图片爬取到指定文件夹,爬取结果如下图所示:

核心代码:
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler;
import cn.edu.hfut.dmic.webcollector.plugin.net.OkHttpRequester;
import cn.edu.hfut.dmic.webcollector.util.ExceptionUtils;
import cn.edu.hfut.dmic.webcollector.util.FileUtils;
import cn.edu.hfut.dmic.webcollector.util.MD5Utils;
import java.io.File;
/**
* WebCollector抓取图片的例子
* @author hu
*/
public class DemoImageCrawler extends BreadthCrawler {
File baseDir = new File("images");
/**
* 构造一个基于伯克利DB的爬虫
* 伯克利DB文件夹为crawlPath,crawlPath中维护了历史URL等信息
* 不同任务不要使用相同的crawlPath
* 两个使用相同crawlPath的爬虫并行爬取会产生错误
*
* @param crawlPath 伯克利DB使用的文件夹
*/
public DemoImageCrawler(String crawlPath) {
super(crawlPath, true);
//只有在autoParse和autoDetectImg都为true的情况下
//爬虫才会自动解析图片链接
getConf().setAutoDetectImg(true);
//如果使用默认的Requester,需要像下面这样设置一下网页大小上限
//否则可能会获得一个不完整的页面
//下面这行将页面大小上限设置为10M
//getConf().setMaxReceiveSize(1024 * 1024 * 10);
//添加种子URL
addSeed("http://www.meishij.net/";);
//限定爬取范围
addRegex("http://www.meishij.net/.*");
addRegex("http://images.meishij.net/.*");
addRegex("-.*#.*");
addRegex("-.*\\?.*");
//设置为断点爬取,否则每次开启爬虫都会重新爬取
// demoImageCrawler.setResumable(true);
setThreads(30);
}
@Override
public void visit(Page page, CrawlDatums next) {
//根据http头中的Content-Type信息来判断当前资源是网页还是图片
String contentType = page.contentType();
//根据Content-Type判断是否为图片
if(contentType!=null && contentType.startsWith("image")){
//从Content-Type中获取图片扩展名
String extensionName=contentType.split("/")[1];
try {
byte[] image = page.content();
//根据图片MD5生成文件名
String fileName = String.format("%s.%s",MD5Utils.md5(image), extensionName);
File imageFile = new File(baseDir, fileName);
FileUtils.write(imageFile, image);
System.out.println("保存图片 "+page.url()+" 到 "+ imageFile.getAbsolutePath());
} catch (Exception e) {
ExceptionUtils.fail(e);
}
}
}
public static void main(String[] args) throws Exception {
DemoImageCrawler demoImageCrawler = new DemoImageCrawler("crawl");
demoImageCrawler.setRequester(new OkHttpRequester());
//设置为断点爬取,否则每次开启爬虫都会重新爬取
demoImageCrawler.setResumable(true);
demoImageCrawler.start(3);
}
}
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-01 22:11
原创链接:
有时由于各种原因,我们需要一些采集数据,但由于不同网站
本文使用Java向您展示如何抓取网站的数据:(1)抓取原创网页的数据;(2)抓取网页JavaScript返回的数据
一、抓取原创页面
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此网页,输入IP:111.142.55.73,然后单击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[java]查看纯拷贝
publicvoidcaptureHtml(Stringip)通过异常{StringstrURL=“”+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuildercontentBuf=newStringBuilder();而(((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“上述四项依次显示”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果:”“n”+结果);]
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111.142.55.73==>;1871591241==>;福建省漳州移动
二、在网页上抓取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这可以避免搜索引擎和其他工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[java]查看纯拷贝
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载 查看全部
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原创链接:
有时由于各种原因,我们需要一些采集数据,但由于不同网站
本文使用Java向您展示如何抓取网站的数据:(1)抓取原创网页的数据;(2)抓取网页JavaScript返回的数据
一、抓取原创页面
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此网页,输入IP:111.142.55.73,然后单击查询按钮查看网页上显示的结果:

第二步:查看web源代码。我们可以看到源代码中有一段:

从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:

换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[java]查看纯拷贝
publicvoidcaptureHtml(Stringip)通过异常{StringstrURL=“”+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuildercontentBuf=newStringBuilder();而(((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“上述四项依次显示”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果:”“n”+结果);]
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111.142.55.73==>;1871591241==>;福建省漳州移动
二、在网页上抓取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这可以避免搜索引擎和其他工具捕获网站数据
首先看一下这一页:

第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:

为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:

这是HTTP analyzer点击查询按钮后的结果,我们继续查看:


从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[java]查看纯拷贝
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载
java抓取网页数据(java爬虫网络爬虫的注释及应用详细注释)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-10-01 22:08
Java爬虫爬取网页数据一. 爬虫简介
网络爬虫,又称网络蜘蛛或网络信息采集器,是一种根据一定的规则自动抓取或下载网络信息的计算机程序或自动化脚本。它是当前搜索引擎的重要组成部分。
我的demo是基于Jsoup做一个java爬虫的简单实现
jsoup是一个Java HTML解析器,主要用于解析HTML jsoup中文官网
二. 必需的 pom.xml 依赖项
org.jsoup
jsoup
1.8.3
commons-io
commons-io
2.5
org.apache.httpcomponents
httpclient
4.5.5
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
三.java代码(附详细注释)
因为我这里是一个简单的java爬虫,所以只用了一个java
抓取图片和CSS样式并下载到本地
捕捉图像
<p>package cn.xxx.xxxx;
import org.apache.commons.io.FileUtils;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.*;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @Date 2019/11/20 14:50
* @Version 1.0
*/
public class CatchImage {
// 地址
private static final String URL = "xxxx";
// 编码
private static final String ECODING = "utf-8";
// 获取img标签正则
private static final String IMGURL_REG = "]*?>";
// 获取src路径的正则
private static final String IMGSRC_REG = "(?x)(src|SRC|background|BACKGROUND)=('|\")/?(([\\w-]+/)*([\\w-]+\\.(jpg|JPG|png|PNG|gif|GIF)))('|\")";
// img本地保存路径
private static final String SAVE_PATH = "";
/**
* @param url 要抓取的网页地址
* @param encoding 要抓取网页编码
* @return
*/
public static String getHtmlResourceByUrl(String url, String encoding) {
URL urlObj = null;
URLConnection uc = null;
InputStreamReader isr = null;
BufferedReader reader = null;
StringBuffer buffer = new StringBuffer();
// 建立网络连接
try {
urlObj = new URL(url);
// 打开网络连接
uc = urlObj.openConnection();
// 建立文件输入流
isr = new InputStreamReader(uc.getInputStream(), encoding);
// 建立缓存导入 将网页源代码下载下来
reader = new BufferedReader(isr);
// 临时
String temp = null;
while ((temp = reader.readLine()) != null) {// 一次读一行 只要不为空就说明没读完继续读
// System.out.println(temp+"\n");
buffer.append(temp + "\n");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关流
if (isr != null) {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return buffer.toString();
}
/**
* 获取网页代码保存到本地
*
* @param url 网络地址
* @param encoding 编码格式
*
*/
public static void getJobInfo(String url, String encoding) {
// 拿到网页源代码
String html = getHtmlResourceByUrl(url, encoding);
try {
File fp = new File("xxxxx");
//判断创建文件是否存在
if (fp.exists()) {
fp.mkdirs();
}
OutputStream os = new FileOutputStream(fp); //建立文件输出流
os.write(html.getBytes());
os.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 下载图片
*
* @param listImgSrc
*/
public static void Download(List listImgSrc) {
int count = 0;
try {
for (int i = 0; i 查看全部
java抓取网页数据(java爬虫网络爬虫的注释及应用详细注释)
Java爬虫爬取网页数据一. 爬虫简介
网络爬虫,又称网络蜘蛛或网络信息采集器,是一种根据一定的规则自动抓取或下载网络信息的计算机程序或自动化脚本。它是当前搜索引擎的重要组成部分。
我的demo是基于Jsoup做一个java爬虫的简单实现
jsoup是一个Java HTML解析器,主要用于解析HTML jsoup中文官网
二. 必需的 pom.xml 依赖项
org.jsoup
jsoup
1.8.3
commons-io
commons-io
2.5
org.apache.httpcomponents
httpclient
4.5.5
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
三.java代码(附详细注释)
因为我这里是一个简单的java爬虫,所以只用了一个java
抓取图片和CSS样式并下载到本地
捕捉图像
<p>package cn.xxx.xxxx;
import org.apache.commons.io.FileUtils;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.*;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @Date 2019/11/20 14:50
* @Version 1.0
*/
public class CatchImage {
// 地址
private static final String URL = "xxxx";
// 编码
private static final String ECODING = "utf-8";
// 获取img标签正则
private static final String IMGURL_REG = "]*?>";
// 获取src路径的正则
private static final String IMGSRC_REG = "(?x)(src|SRC|background|BACKGROUND)=('|\")/?(([\\w-]+/)*([\\w-]+\\.(jpg|JPG|png|PNG|gif|GIF)))('|\")";
// img本地保存路径
private static final String SAVE_PATH = "";
/**
* @param url 要抓取的网页地址
* @param encoding 要抓取网页编码
* @return
*/
public static String getHtmlResourceByUrl(String url, String encoding) {
URL urlObj = null;
URLConnection uc = null;
InputStreamReader isr = null;
BufferedReader reader = null;
StringBuffer buffer = new StringBuffer();
// 建立网络连接
try {
urlObj = new URL(url);
// 打开网络连接
uc = urlObj.openConnection();
// 建立文件输入流
isr = new InputStreamReader(uc.getInputStream(), encoding);
// 建立缓存导入 将网页源代码下载下来
reader = new BufferedReader(isr);
// 临时
String temp = null;
while ((temp = reader.readLine()) != null) {// 一次读一行 只要不为空就说明没读完继续读
// System.out.println(temp+"\n");
buffer.append(temp + "\n");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关流
if (isr != null) {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return buffer.toString();
}
/**
* 获取网页代码保存到本地
*
* @param url 网络地址
* @param encoding 编码格式
*
*/
public static void getJobInfo(String url, String encoding) {
// 拿到网页源代码
String html = getHtmlResourceByUrl(url, encoding);
try {
File fp = new File("xxxxx");
//判断创建文件是否存在
if (fp.exists()) {
fp.mkdirs();
}
OutputStream os = new FileOutputStream(fp); //建立文件输出流
os.write(html.getBytes());
os.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 下载图片
*
* @param listImgSrc
*/
public static void Download(List listImgSrc) {
int count = 0;
try {
for (int i = 0; i
java抓取网页数据(服务器判定你是ie还是chrome还是firefox?分析的请求地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-28 08:31
HttpClient 是 Apache Jakarta Common 的一个子项目,可用于提供支持 HTTP 协议的高效、最新且功能丰富的客户端编程工具包,它支持 HTTP 协议的最新版本和推荐。
3.上一页
首先模拟手机浏览器的UA。就是让我们打开的页面回到移动端的页面效果,那我们该怎么做呢?其实服务器是根据请求头中的UA来判断你是chrome还是firefox的,所以我们来找一个手机浏览器的UA。.
我们可以直接f12或者直接在浏览器中模拟移动端,然后查看请求参数:
User-Agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36
正常没问题:
那么我们如何将这句话反映到程序中呢?
简单,我们拿到get对象后直接设置:
httpGet.setHeader("User-Agent", "Mozilla/5.0
(Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36");
就可以了,然后我们就可以使用jsoup来获取我们想要的元素了。jsoup 的语法与 jq 相同。
我们直接面对页面,右键我们想要的元素,选中review元素,然后用jq选择器选中它。
你可以参考jQuery选择器
4.获得关注者
直接获取我们之前分析的请求地址
https://www.zhihu.com/api/v4/m ... mp%3B
include=data%5B%2A%5D.employments%2Ccover_url%2Callow_message%2Canswer_coun
t%2Carticles_count%2Cfavorite_count%2Cfollower_count%2Cgender%2Cis_followe
d%2Cmessage_thread_token%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer
%29%5D.topics&limit=10&offset=30
但是记得替换用户名,在请求头中添加cookie zc_0的最后一段
那么返回的请求数据就是json
{
"paging": {
"is_end": false,
"next": "https://www.zhihu.com/api/v4/m ... ot%3B,
"previous": "https://www.zhihu.com/api/v4/m ... ot%3B,
"is_start": false,
"totals": 398
},
"data": [
{
"is_followed": true,
"avatar_url_template": "https://pic1.zhimg.com/da8e974dc_{size}.jpg",
"name": "陈晓峰",
"url": "",
"type": "people",
"user_type": "people",
"answer_count": 0,
"url_token": "chen-xiao-feng-84",
"headline": "阿里巴巴,分布式数据库,",
"avatar_url": "https://pic1.zhimg.com/da8e974dc_is.jpg",
"is_following": false,
"is_org": false,
"follower_count": 14,
"badge": [],
"id": "ff02ea0544901a9ddfcb7ba60c73b673",
"articles_count": 0
}
]
}
这个数据包括下一个请求地址,最后一个请求地址,时间是开始时间,时间是结束时间,总共有多少粉丝,以及关注者的基本信息,
所以我们可以在一段时间内得到所有的粉丝:
过程:
第一次获取数据,获取is_end字段判断is_end是否为真,根据is_end判断是否继续循环。如果循环,更新is_end,更新下一个连接请求
一套后,你可以得到一个用户的所有粉丝。
我爱Java(QQ群):170936712(点击加入) 查看全部
java抓取网页数据(服务器判定你是ie还是chrome还是firefox?分析的请求地址)
HttpClient 是 Apache Jakarta Common 的一个子项目,可用于提供支持 HTTP 协议的高效、最新且功能丰富的客户端编程工具包,它支持 HTTP 协议的最新版本和推荐。
3.上一页
首先模拟手机浏览器的UA。就是让我们打开的页面回到移动端的页面效果,那我们该怎么做呢?其实服务器是根据请求头中的UA来判断你是chrome还是firefox的,所以我们来找一个手机浏览器的UA。.
我们可以直接f12或者直接在浏览器中模拟移动端,然后查看请求参数:
User-Agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36
正常没问题:
那么我们如何将这句话反映到程序中呢?
简单,我们拿到get对象后直接设置:
httpGet.setHeader("User-Agent", "Mozilla/5.0
(Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36");
就可以了,然后我们就可以使用jsoup来获取我们想要的元素了。jsoup 的语法与 jq 相同。
我们直接面对页面,右键我们想要的元素,选中review元素,然后用jq选择器选中它。
你可以参考jQuery选择器
4.获得关注者
直接获取我们之前分析的请求地址
https://www.zhihu.com/api/v4/m ... mp%3B
include=data%5B%2A%5D.employments%2Ccover_url%2Callow_message%2Canswer_coun
t%2Carticles_count%2Cfavorite_count%2Cfollower_count%2Cgender%2Cis_followe
d%2Cmessage_thread_token%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer
%29%5D.topics&limit=10&offset=30
但是记得替换用户名,在请求头中添加cookie zc_0的最后一段
那么返回的请求数据就是json
{
"paging": {
"is_end": false,
"next": "https://www.zhihu.com/api/v4/m ... ot%3B,
"previous": "https://www.zhihu.com/api/v4/m ... ot%3B,
"is_start": false,
"totals": 398
},
"data": [
{
"is_followed": true,
"avatar_url_template": "https://pic1.zhimg.com/da8e974dc_{size}.jpg",
"name": "陈晓峰",
"url": "",
"type": "people",
"user_type": "people",
"answer_count": 0,
"url_token": "chen-xiao-feng-84",
"headline": "阿里巴巴,分布式数据库,",
"avatar_url": "https://pic1.zhimg.com/da8e974dc_is.jpg",
"is_following": false,
"is_org": false,
"follower_count": 14,
"badge": [],
"id": "ff02ea0544901a9ddfcb7ba60c73b673",
"articles_count": 0
}
]
}
这个数据包括下一个请求地址,最后一个请求地址,时间是开始时间,时间是结束时间,总共有多少粉丝,以及关注者的基本信息,
所以我们可以在一段时间内得到所有的粉丝:
过程:
第一次获取数据,获取is_end字段判断is_end是否为真,根据is_end判断是否继续循环。如果循环,更新is_end,更新下一个连接请求
一套后,你可以得到一个用户的所有粉丝。
我爱Java(QQ群):170936712(点击加入)
java抓取网页数据(如何实现java抓取网页数据的数据库操作?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-25 05:01
java抓取网页数据的两种方法,第一种按照网页的格式去load也就是采用网页的数据格式实现图片的读取,但是必须要实现网页的分析这才能采用相应的数据库程序来实现数据的数据库操作。springboot是一个基于spring框架的开源框架,有很多的特点,比如动态配置web服务器;spring的无侵入式开发;完整的ioc容器;轻量级事务管理和控制器;spring支持“并发控制”(concurrenthashmap);可选择的并发数据库事务处理(java8);可选择的jdbc并发服务;spring的分页功能;等等很多,可以使用spring的特性满足大部分的需求。
谢邀。很简单的问题,不过不能用语言来回答,所以这也是一个门槛问题。关键看用什么编程语言,用什么控制器,调用的中间件,选择哪些接口,封装处理思路,等等。其实,还是看你对java怎么看待,如果只是简单的使用,java无论是自己实现网站,di还是使用javabean,都能实现。也能解决对查询,对pojo的操作。如果是做大型的java开发,性能,等等难免会有障碍。
用java,你会收获一个称之为“丰富”的世界。
网站技术现在应该不会过时吧?我感觉在中国来说,互联网大部分都是运用java技术。iphone,android等应用软件,都是java系。只要你喜欢,关键看你自己的学习成本和方向吧?如果你喜欢玩云操作,java当然是不二之选。如果你喜欢云数据库,那么sql+etl应该是不错的选择。当然,java很多都是可以模拟底层环境的。
例如springframework就会模拟mysql的应用环境。java开发web应用,应该不是问题。还有,采用自己的java程序,有很多缺点的。例如:java程序的实现难度,java线程的调度等,需要你搞清楚,应该是小问题。 查看全部
java抓取网页数据(如何实现java抓取网页数据的数据库操作?-八维教育)
java抓取网页数据的两种方法,第一种按照网页的格式去load也就是采用网页的数据格式实现图片的读取,但是必须要实现网页的分析这才能采用相应的数据库程序来实现数据的数据库操作。springboot是一个基于spring框架的开源框架,有很多的特点,比如动态配置web服务器;spring的无侵入式开发;完整的ioc容器;轻量级事务管理和控制器;spring支持“并发控制”(concurrenthashmap);可选择的并发数据库事务处理(java8);可选择的jdbc并发服务;spring的分页功能;等等很多,可以使用spring的特性满足大部分的需求。
谢邀。很简单的问题,不过不能用语言来回答,所以这也是一个门槛问题。关键看用什么编程语言,用什么控制器,调用的中间件,选择哪些接口,封装处理思路,等等。其实,还是看你对java怎么看待,如果只是简单的使用,java无论是自己实现网站,di还是使用javabean,都能实现。也能解决对查询,对pojo的操作。如果是做大型的java开发,性能,等等难免会有障碍。
用java,你会收获一个称之为“丰富”的世界。
网站技术现在应该不会过时吧?我感觉在中国来说,互联网大部分都是运用java技术。iphone,android等应用软件,都是java系。只要你喜欢,关键看你自己的学习成本和方向吧?如果你喜欢玩云操作,java当然是不二之选。如果你喜欢云数据库,那么sql+etl应该是不错的选择。当然,java很多都是可以模拟底层环境的。
例如springframework就会模拟mysql的应用环境。java开发web应用,应该不是问题。还有,采用自己的java程序,有很多缺点的。例如:java程序的实现难度,java线程的调度等,需要你搞清楚,应该是小问题。
java抓取网页数据(java抓取网页数据内存最小的大小是什么?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-24 03:00
java抓取网页数据内存最小大小是按照ua的字符集去判断的(一般是gbk,中文数据以utf-8编码,英文数据不会变换编码方式)。比如一个页面是基于gbk编码的,那么内存最小大小是256m左右。
ua是google服务器端识别的一个基本属性,如下图显示的是某一个网站打开时需要消耗的空间。而中文网站一般分为utf-8编码和gbk编码,utf-8编码ua会占用2.5m左右,而gbk编码ua又会占用32.5m。因此,有效的内存空间是打开时所占用的空间,而其是根据google服务器端的统计结果来决定的。
内存大小跟访问的网站类型相关,java只要访问的网站是google提供的,那么内存就不用计算,一般就是2^32这么大。
这个理论上取决于java要解析什么的,按照下面的来看1gbk是很小,所以内存大小如果是64m就足够了,如果是system.out.println的话需要1m,有些地方autoprint出来结果比java解析要慢很多,所以有些地方需要256m,超过256m就别放这个范围,浪费。2utf-8编码这个范围大点,所以可以部分解析。
utf-8编码的话内存大小大概就是256m。而gbk的话,内存要用1m,不然解析速度太慢。以上内容仅供参考。
没有的
1、ajax请求
2、java处理内存优化的jdk版本
3、java设计模式
4、springmvc。1m都不够的我也是手贱搜一个一个去问的,你需要其他资料直接评论我,我再看吧。 查看全部
java抓取网页数据(java抓取网页数据内存最小的大小是什么?(上))
java抓取网页数据内存最小大小是按照ua的字符集去判断的(一般是gbk,中文数据以utf-8编码,英文数据不会变换编码方式)。比如一个页面是基于gbk编码的,那么内存最小大小是256m左右。
ua是google服务器端识别的一个基本属性,如下图显示的是某一个网站打开时需要消耗的空间。而中文网站一般分为utf-8编码和gbk编码,utf-8编码ua会占用2.5m左右,而gbk编码ua又会占用32.5m。因此,有效的内存空间是打开时所占用的空间,而其是根据google服务器端的统计结果来决定的。
内存大小跟访问的网站类型相关,java只要访问的网站是google提供的,那么内存就不用计算,一般就是2^32这么大。
这个理论上取决于java要解析什么的,按照下面的来看1gbk是很小,所以内存大小如果是64m就足够了,如果是system.out.println的话需要1m,有些地方autoprint出来结果比java解析要慢很多,所以有些地方需要256m,超过256m就别放这个范围,浪费。2utf-8编码这个范围大点,所以可以部分解析。
utf-8编码的话内存大小大概就是256m。而gbk的话,内存要用1m,不然解析速度太慢。以上内容仅供参考。
没有的
1、ajax请求
2、java处理内存优化的jdk版本
3、java设计模式
4、springmvc。1m都不够的我也是手贱搜一个一个去问的,你需要其他资料直接评论我,我再看吧。
java抓取网页数据(18款Java开源Web爬虫,需要的小伙伴们赶快收藏)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-09-19 09:05
网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中更常被称为网络追踪器)是一种程序或脚本,根据特定规则自动获取万维网信息。其他不常用的名称包括蚂蚁、自动索引、模拟器或蠕虫
今天,我们将介绍18个Java开源网络爬虫。让我们快点把它们收起来
一,
赫里特里克斯
Heritrix是由Java开发的开源web爬虫程序。用户可以使用它从互联网上获取所需的资源。其最大的特点是具有良好的可扩展性,方便用户实现自己的爬网逻辑
Heritrix是一个“归档爬虫”——用于获取站点内容的完整、准确和深入复制。包括获取图像和其他非文本内容。抓取并存储相关内容。内容不会被拒绝,页面内容也不会被修改。重新爬网不会用相同的URL替换以前的URL。爬虫主要通过web用户界面启动、监控和调整,允许灵活定义URL
Heritrix是一个多线程爬虫程序。主线程将任务分配给Teo线程(处理线程),每个Teo线程一次处理一个URL。Teo线程对每个URL执行一次URL处理程序链。URL处理器链包括以下五个处理步骤
预取链:主要做一些准备工作,比如延迟和重新处理处理,拒绝后续操作
提取链:主要下载网页,进行DNS转换,填写请求和响应表单
提取链:提取完成后,提取感兴趣的HTML和Java。通常,需要抓取新的URL
写入链:存储获取结果。在此步骤中,您可以直接进行全文索引。Heritrix提供了arcbuilder处理器的实现,该处理器以arc格式保存下载结果
提交链:与此URL相关的操作的最终处理。检查哪些新提取的URL在捕获范围内,然后将这些URL提交给frontier。DNS缓存信息也会更新
Heritrix系统框架
Heritrix处理URL
二,
韦伯斯菲克斯
Webshinx是一个用于Java类包和web爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。Webshinx由两部分组成:crawler平台和Webshinx类包
Webshinx是一个用于Java类包和web爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。Webshinx由两部分组成:crawler平台和Webshinx类包
Webshinx用途:
可视显示的页面的集合
将页面下载到本地磁盘以进行脱机浏览
将所有页面拼接成一个页面,以便浏览或打印
根据特定规则从页面中提取文本字符串
用Java或Java开发自定义爬虫程序
有关详细信息,请参见~RCM/websphinx/
三,
韦布雷赫
WebLech是下载和镜像网站的强大工具。它支持根据功能需求下载网站,并尽可能模仿标准web浏览器的行为。WebLech具有功能性控制台和多线程操作
WebLech是一个强大的免费开源工具,用于下载和镜像网站。它支持根据功能需求下载网站,并尽可能模仿标准web浏览器的行为。WebLech具有功能性控制台和多线程操作
这个爬虫很简单。如果你是初学者,你可以把它作为入门参考。所以我选择用这种爬行动物开始我的研究。如果您不需要高性能的应用程序,也可以尝试。如果你想找到一个强大的,不要在WebLech上浪费时间
项目主页:
特点:
开源,免费
代码是用纯Java编写的,可以在任何支持Java的平台上使用
支持多线程下载网页
可以维护网页之间的链接信息
强大的可配置性:当以深度优先或宽度优先的方式抓取网页时,您可以自定义URL过滤器,以便根据需要抓取单个web服务器、单个目录或整个www网络。您可以设置URL的优先级,以便可以首先抓取感兴趣或重要的网页。您可以在断点处记录程序的状态,当您重新启动时,您可以继续爬网最后一次
四,
阿拉尔
Arale主要是为个人使用而设计的,而不像其他爬虫那样专注于页面索引。Arale可以下载整个网站或网站上的一些资源。Arale还可以将动态页面映射到静态页面
五,
杰斯皮德
Jspider是一个完全可配置和定制的web spider引擎。您可以使用它来检查网站错误(内部服务器错误等),检查网站内部和外部链接,分析网站结构(您可以创建网站地图),下载整个网站,并编写jspider插件来扩展您需要的功能
Spider是用Java实现的web Spider。jspider的执行格式如下:
jspider[ConfigName]
必须将协议名称添加到URL,例如:,否则将报告错误。如果省略configname,则使用默认配置
jspider的行为由配置文件专门配置。例如,在conf\[configname]\_目录中设置了使用的插件和结果存储方法。Jspider几乎没有默认的配置类型和用途。然而,jspider非常容易扩展,可以用来开发强大的网页捕获和数据分析工具。要做到这一点,您需要深入了解jspider的原理,然后根据自己的需要开发插件和编写配置文件
Jspider是:
一个高度可配置和定制的网络爬虫
根据LGPL开源许可证开发
100%纯java实现
您可以使用它来:
检查网站是否存在错误(内部服务器错误;…)
传出或内部链接检查
分析网站结构(创建站点地图;…)
下载翻新网站
通过编写jspider插件来实现任何函数
项目主页:
六,
纺锤
Spin是基于Lucene工具包构建的web索引/搜索工具。它包括一个用于创建索引的HTTP spider和一个用于搜索这些索引的搜索类。spin项目提供了一组JSP标记库,使基于JSP的站点能够在不开发任何Java类的情况下添加搜索功能
七,
蜘蛛纲
Arachnid是一个基于Java的网络蜘蛛框架。它收录一个简单的HTML解析器,可以分析收录HTML内容的输入流。通过实现arachnid的子类,它可以开发一个简单的web爬行器,并在解析web站点上的每个页面后添加几行代码调用。Arachnid的下载包收录两个spider应用程序示例来演示如何使用该框架
项目主页:
八,
云雀
Larm可以为雅加达Lucene搜索引擎框架的用户提供纯java搜索解决方案。它收录用于索引文件、数据库、表和用于索引网站的爬虫的方法
项目主页:
九,
若波
JOBO是下载整个网站的简单工具。它本质上是一个蜘蛛网。与其他下载工具相比,它的主要优点是可以自动填写表单(如自动登录)并使用cookie处理会话。JOBO还具有灵活的下载规则(如URL、大小、MIME类型等)来限制下载
十,
史努克爬行动物
它是用纯Java开发的用于网站图像捕获的工具。您可以使用配置文件中提供的URL条目来捕获浏览器可以通过get Local获取的所有网站资源,包括网页和各种类型的文件,如图片、flashmp3、Zip、rar、EXE等文件。整个网站可以完全传输到硬盘上,原创网站结构可以保持准确。只需将捕获的网站放入web服务器(如APACHE)即可实现完整的网站映像
由于在抓取过程中经常会出现一些错误的文件,而且无法正确解析很多Java控制的URL,snoics reply基本上可以通过提供接口和配置文件,自由扩展外部接口,为特殊URL注入配置文件,它可以正确解析和抓取所有网页
项目主页:
十一,
网络收获
WebHarvest是一个Java开源Web数据提取工具。它可以[url=https://www.ucaiyun.com/]采集指定的网页,并从这些网页中提取有用的数据。WebHarvest主要使用XSLT、XQuery和正则表达式等技术来操作文本/XML
WebHarvest是一个用Java编写的开源Web数据提取工具。它提供了一种从所需页面提取有用数据的方法。要实现这一点,您可能需要使用XSLT、XQuery和正则表达式等技术来操作文本/XML。WebHarvest主要关注基于HMLT/XML的页面内容,目前仍占大多数。另一方面,它可以通过编写自己的Java方法轻松地扩展其提取能力
Web harvest的主要目的是加强现有数据提取技术的应用。它的目标不是创建一种新方法,而是提供一种更好地使用和组合现有方法的方法。它提供了一组处理器来处理数据和控制数据 查看全部
java抓取网页数据(18款Java开源Web爬虫,需要的小伙伴们赶快收藏)
网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中更常被称为网络追踪器)是一种程序或脚本,根据特定规则自动获取万维网信息。其他不常用的名称包括蚂蚁、自动索引、模拟器或蠕虫
今天,我们将介绍18个Java开源网络爬虫。让我们快点把它们收起来
一,
赫里特里克斯
Heritrix是由Java开发的开源web爬虫程序。用户可以使用它从互联网上获取所需的资源。其最大的特点是具有良好的可扩展性,方便用户实现自己的爬网逻辑
Heritrix是一个“归档爬虫”——用于获取站点内容的完整、准确和深入复制。包括获取图像和其他非文本内容。抓取并存储相关内容。内容不会被拒绝,页面内容也不会被修改。重新爬网不会用相同的URL替换以前的URL。爬虫主要通过web用户界面启动、监控和调整,允许灵活定义URL
Heritrix是一个多线程爬虫程序。主线程将任务分配给Teo线程(处理线程),每个Teo线程一次处理一个URL。Teo线程对每个URL执行一次URL处理程序链。URL处理器链包括以下五个处理步骤
预取链:主要做一些准备工作,比如延迟和重新处理处理,拒绝后续操作
提取链:主要下载网页,进行DNS转换,填写请求和响应表单
提取链:提取完成后,提取感兴趣的HTML和Java。通常,需要抓取新的URL
写入链:存储获取结果。在此步骤中,您可以直接进行全文索引。Heritrix提供了arcbuilder处理器的实现,该处理器以arc格式保存下载结果
提交链:与此URL相关的操作的最终处理。检查哪些新提取的URL在捕获范围内,然后将这些URL提交给frontier。DNS缓存信息也会更新
Heritrix系统框架
Heritrix处理URL
二,
韦伯斯菲克斯
Webshinx是一个用于Java类包和web爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。Webshinx由两部分组成:crawler平台和Webshinx类包
Webshinx是一个用于Java类包和web爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。Webshinx由两部分组成:crawler平台和Webshinx类包
Webshinx用途:
可视显示的页面的集合
将页面下载到本地磁盘以进行脱机浏览
将所有页面拼接成一个页面,以便浏览或打印
根据特定规则从页面中提取文本字符串
用Java或Java开发自定义爬虫程序
有关详细信息,请参见~RCM/websphinx/
三,
韦布雷赫
WebLech是下载和镜像网站的强大工具。它支持根据功能需求下载网站,并尽可能模仿标准web浏览器的行为。WebLech具有功能性控制台和多线程操作
WebLech是一个强大的免费开源工具,用于下载和镜像网站。它支持根据功能需求下载网站,并尽可能模仿标准web浏览器的行为。WebLech具有功能性控制台和多线程操作
这个爬虫很简单。如果你是初学者,你可以把它作为入门参考。所以我选择用这种爬行动物开始我的研究。如果您不需要高性能的应用程序,也可以尝试。如果你想找到一个强大的,不要在WebLech上浪费时间
项目主页:
特点:
开源,免费
代码是用纯Java编写的,可以在任何支持Java的平台上使用
支持多线程下载网页
可以维护网页之间的链接信息
强大的可配置性:当以深度优先或宽度优先的方式抓取网页时,您可以自定义URL过滤器,以便根据需要抓取单个web服务器、单个目录或整个www网络。您可以设置URL的优先级,以便可以首先抓取感兴趣或重要的网页。您可以在断点处记录程序的状态,当您重新启动时,您可以继续爬网最后一次
四,
阿拉尔
Arale主要是为个人使用而设计的,而不像其他爬虫那样专注于页面索引。Arale可以下载整个网站或网站上的一些资源。Arale还可以将动态页面映射到静态页面
五,
杰斯皮德
Jspider是一个完全可配置和定制的web spider引擎。您可以使用它来检查网站错误(内部服务器错误等),检查网站内部和外部链接,分析网站结构(您可以创建网站地图),下载整个网站,并编写jspider插件来扩展您需要的功能
Spider是用Java实现的web Spider。jspider的执行格式如下:
jspider[ConfigName]
必须将协议名称添加到URL,例如:,否则将报告错误。如果省略configname,则使用默认配置
jspider的行为由配置文件专门配置。例如,在conf\[configname]\_目录中设置了使用的插件和结果存储方法。Jspider几乎没有默认的配置类型和用途。然而,jspider非常容易扩展,可以用来开发强大的网页捕获和数据分析工具。要做到这一点,您需要深入了解jspider的原理,然后根据自己的需要开发插件和编写配置文件
Jspider是:
一个高度可配置和定制的网络爬虫
根据LGPL开源许可证开发
100%纯java实现
您可以使用它来:
检查网站是否存在错误(内部服务器错误;…)
传出或内部链接检查
分析网站结构(创建站点地图;…)
下载翻新网站
通过编写jspider插件来实现任何函数
项目主页:
六,
纺锤
Spin是基于Lucene工具包构建的web索引/搜索工具。它包括一个用于创建索引的HTTP spider和一个用于搜索这些索引的搜索类。spin项目提供了一组JSP标记库,使基于JSP的站点能够在不开发任何Java类的情况下添加搜索功能
七,
蜘蛛纲
Arachnid是一个基于Java的网络蜘蛛框架。它收录一个简单的HTML解析器,可以分析收录HTML内容的输入流。通过实现arachnid的子类,它可以开发一个简单的web爬行器,并在解析web站点上的每个页面后添加几行代码调用。Arachnid的下载包收录两个spider应用程序示例来演示如何使用该框架
项目主页:
八,
云雀
Larm可以为雅加达Lucene搜索引擎框架的用户提供纯java搜索解决方案。它收录用于索引文件、数据库、表和用于索引网站的爬虫的方法
项目主页:
九,
若波
JOBO是下载整个网站的简单工具。它本质上是一个蜘蛛网。与其他下载工具相比,它的主要优点是可以自动填写表单(如自动登录)并使用cookie处理会话。JOBO还具有灵活的下载规则(如URL、大小、MIME类型等)来限制下载
十,
史努克爬行动物
它是用纯Java开发的用于网站图像捕获的工具。您可以使用配置文件中提供的URL条目来捕获浏览器可以通过get Local获取的所有网站资源,包括网页和各种类型的文件,如图片、flashmp3、Zip、rar、EXE等文件。整个网站可以完全传输到硬盘上,原创网站结构可以保持准确。只需将捕获的网站放入web服务器(如APACHE)即可实现完整的网站映像
由于在抓取过程中经常会出现一些错误的文件,而且无法正确解析很多Java控制的URL,snoics reply基本上可以通过提供接口和配置文件,自由扩展外部接口,为特殊URL注入配置文件,它可以正确解析和抓取所有网页
项目主页:
十一,
网络收获
WebHarvest是一个Java开源Web数据提取工具。它可以[url=https://www.ucaiyun.com/]采集指定的网页,并从这些网页中提取有用的数据。WebHarvest主要使用XSLT、XQuery和正则表达式等技术来操作文本/XML
WebHarvest是一个用Java编写的开源Web数据提取工具。它提供了一种从所需页面提取有用数据的方法。要实现这一点,您可能需要使用XSLT、XQuery和正则表达式等技术来操作文本/XML。WebHarvest主要关注基于HMLT/XML的页面内容,目前仍占大多数。另一方面,它可以通过编写自己的Java方法轻松地扩展其提取能力
Web harvest的主要目的是加强现有数据提取技术的应用。它的目标不是创建一种新方法,而是提供一种更好地使用和组合现有方法的方法。它提供了一组处理器来处理数据和控制数据
java抓取网页数据(一个-1.11.1.jarokio-3.12.0.jar-1.12.0.jar●jsoup使用文档 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 353 次浏览 • 2021-09-19 08:29
)
目录
目录
前言
最近,我想建立一个视频播放应用程序,可以播放电影和电视剧。因此,我在网上搜索了API接口,发现虽然爱奇艺和其他视频网站提供的视频接口可以使用,但注册和审核应用程序等步骤繁琐,他们的API无法在我自己的播放器中播放,但我必须使用java编写一个程序来获取网页数据,以满足我的需要。这里我记录了实施过程
前期准备
● 所需的jar包:
jsoup-1.11.1.jarokhttp -3.12.0.jarokio -@ 1.12.0.jar
● jsoup使用文档:
案例实现
public class Test {
private static final String BASE_URL="http://www.baiwanzy.com";//这里使用的是百万资源网的资源
public static void main(String[] args) {
asyncGet();
}
public static void asyncGet() {
String encode = URLEncoder.encode("雪鹰领主");//对查询的数据进行Url编码
String urlBaidu = "http://www.baiwanzy.com/index. ... de%3B
OkHttpClient okHttpClient = new OkHttpClient(); // 创建OkHttpClient对象
Request request = new Request.Builder().url(urlBaidu).build(); // 创建一个请求
okHttpClient.newCall(request).enqueue(new Callback() { // 回调
public void onResponse(Call call, Response response) throws IOException {
// 请求成功调用,该回调在子线程
getMovieList(response.body().string());
}
public void onFailure(Call call, IOException e) {
// 请求失败调用
System.out.println(e.getMessage());
}
});
}
public static void getMovieList(String datas){
Document doc = Jsoup.parse(datas);
// 根据css的后代选择器来找到相关的列表
Elements links = doc.select(".xing_vb4 a");//这里是返回的列表的类来查找相关的a标签
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
System.out.println(BASE_URL+linkHref+"==="+linkText);
}
}
} 查看全部
java抓取网页数据(一个-1.11.1.jarokio-3.12.0.jar-1.12.0.jar●jsoup使用文档
)
目录

目录
前言
最近,我想建立一个视频播放应用程序,可以播放电影和电视剧。因此,我在网上搜索了API接口,发现虽然爱奇艺和其他视频网站提供的视频接口可以使用,但注册和审核应用程序等步骤繁琐,他们的API无法在我自己的播放器中播放,但我必须使用java编写一个程序来获取网页数据,以满足我的需要。这里我记录了实施过程
前期准备
● 所需的jar包:
jsoup-1.11.1.jarokhttp -3.12.0.jarokio -@ 1.12.0.jar
● jsoup使用文档:
案例实现
public class Test {
private static final String BASE_URL="http://www.baiwanzy.com";//这里使用的是百万资源网的资源
public static void main(String[] args) {
asyncGet();
}
public static void asyncGet() {
String encode = URLEncoder.encode("雪鹰领主");//对查询的数据进行Url编码
String urlBaidu = "http://www.baiwanzy.com/index. ... de%3B
OkHttpClient okHttpClient = new OkHttpClient(); // 创建OkHttpClient对象
Request request = new Request.Builder().url(urlBaidu).build(); // 创建一个请求
okHttpClient.newCall(request).enqueue(new Callback() { // 回调
public void onResponse(Call call, Response response) throws IOException {
// 请求成功调用,该回调在子线程
getMovieList(response.body().string());
}
public void onFailure(Call call, IOException e) {
// 请求失败调用
System.out.println(e.getMessage());
}
});
}
public static void getMovieList(String datas){
Document doc = Jsoup.parse(datas);
// 根据css的后代选择器来找到相关的列表
Elements links = doc.select(".xing_vb4 a");//这里是返回的列表的类来查找相关的a标签
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
System.out.println(BASE_URL+linkHref+"==="+linkText);
}
}
}
java抓取网页数据(SysNucleus“SysNucleusWebHarvy破解版破解版”为网页数据抓取工具介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-10-28 01:02
SysNucleus WebHarvy 破解版中文名称是网页数据抓取工具。是一款非常实用的网页数据采集软件。该软件界面简洁,没有多余的复杂功能,使用起来非常方便。广泛应用于房地产、电子商务、学术研究等强大功能,助您轻松解决所有问题。此外,它还支持多种文件格式,包括:Excel、XML、CSV、JSON、TSV 等,因此您无需担心转码。值得一提的是,今天给大家带来的是《SysNucleus WebHarvy 破解版》,此版本已经大神精心破解,文件夹附有破解补丁,可以完美激活软件,完成后免费. 使用里面的所有功能,所以不要觉得太舒服。下面我还精心准备了详细的图文安装破解教程,有需要的用户可以参考!使用此软件,您可以轻松抓取数据。不仅如此,它还可以自动提取文字、图片、网址等,非常强大。此外,它还支持从多个页面、类别和关键字中提取数据。有需要的小虎哥们还在等什么?欢迎下载体验!更多精彩有趣的事情等着你去发现!类别和关键字。有需要的小虎哥们还在等什么?欢迎下载体验!更多精彩有趣的事情等着你去发现!类别和关键字。有需要的小虎哥们还在等什么?欢迎下载体验!更多精彩有趣的事情等着你去发现!
特征
1、自动提取网站中的文字、图片、网址和邮件,并以各种格式保存内容。
2、非常好用,几分钟就可以自动找回
3、支持从多个页面/类别/关键字中提取数据
4、将提取的数据保存到文件或数据库中
5、内置调度器和代理支持
6、 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用内置浏览器浏览网页。您可以选择要单击的数据。这很简单!
7、自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据被复制,它会被自动删除。
8、可以多种格式保存从网页中提取的数据。当前版本允许您将捕获的数据导出到 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
9、通常,网页会在多个页面上显示产品列表等数据。可以从多个页面自动抓取和提取数据。只需指出“链接到下一页”,就会自动从所有页面获取数据。
软件功能
1、视觉点和点击界面
是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
2、智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据被复制,它会被自动抓取。
3、导出捕获的数据
您可以以各种格式保存从网页中提取的数据。网站 当前版本的抓取工具允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、 从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。可以自动从多个网页中抓取和提取数据。只需指出“链接到下一页,网站 抓取器将自动从所有页面抓取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字6、通过代理服务器提取
要提取匿名并防止提取网络软件被阻止的Web服务器,您必须通过{over}{filtering}选项才能访问目标网站。您可以使用单个代理服务器地址或代理服务器地址列表。
7、提取分类
网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
8、使用正则表达式提取
您可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。
SysNucleus WebHarvy 中文破解版安装教程
1、 下载并解压安装包,双击运行软件“Setup.exe”进行安装,进入安装向导,点击next进入下一步
2、同意用户协议,选择顶一个
3、设置安装目录,如果要更改,点击更改
4、确认软件安装无误后,点击安装
5、安装成功,取消勾选立即运行软件,点击完成启动安装界面
6、将破解补丁“WebHarvy.exe”替换到原安装目录,点击复制替换
ps:如果找不到位置,可以返回桌面右击图标选择位置打开文件
7、 破解成功,打开软件即可免费使用
更新日志
修复了页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源 查看全部
java抓取网页数据(SysNucleus“SysNucleusWebHarvy破解版破解版”为网页数据抓取工具介绍)
SysNucleus WebHarvy 破解版中文名称是网页数据抓取工具。是一款非常实用的网页数据采集软件。该软件界面简洁,没有多余的复杂功能,使用起来非常方便。广泛应用于房地产、电子商务、学术研究等强大功能,助您轻松解决所有问题。此外,它还支持多种文件格式,包括:Excel、XML、CSV、JSON、TSV 等,因此您无需担心转码。值得一提的是,今天给大家带来的是《SysNucleus WebHarvy 破解版》,此版本已经大神精心破解,文件夹附有破解补丁,可以完美激活软件,完成后免费. 使用里面的所有功能,所以不要觉得太舒服。下面我还精心准备了详细的图文安装破解教程,有需要的用户可以参考!使用此软件,您可以轻松抓取数据。不仅如此,它还可以自动提取文字、图片、网址等,非常强大。此外,它还支持从多个页面、类别和关键字中提取数据。有需要的小虎哥们还在等什么?欢迎下载体验!更多精彩有趣的事情等着你去发现!类别和关键字。有需要的小虎哥们还在等什么?欢迎下载体验!更多精彩有趣的事情等着你去发现!类别和关键字。有需要的小虎哥们还在等什么?欢迎下载体验!更多精彩有趣的事情等着你去发现!
特征
1、自动提取网站中的文字、图片、网址和邮件,并以各种格式保存内容。
2、非常好用,几分钟就可以自动找回
3、支持从多个页面/类别/关键字中提取数据
4、将提取的数据保存到文件或数据库中
5、内置调度器和代理支持
6、 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用内置浏览器浏览网页。您可以选择要单击的数据。这很简单!
7、自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据被复制,它会被自动删除。
8、可以多种格式保存从网页中提取的数据。当前版本允许您将捕获的数据导出到 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
9、通常,网页会在多个页面上显示产品列表等数据。可以从多个页面自动抓取和提取数据。只需指出“链接到下一页”,就会自动从所有页面获取数据。
软件功能
1、视觉点和点击界面
是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
2、智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据被复制,它会被自动抓取。
3、导出捕获的数据
您可以以各种格式保存从网页中提取的数据。网站 当前版本的抓取工具允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、 从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。可以自动从多个网页中抓取和提取数据。只需指出“链接到下一页,网站 抓取器将自动从所有页面抓取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字6、通过代理服务器提取
要提取匿名并防止提取网络软件被阻止的Web服务器,您必须通过{over}{filtering}选项才能访问目标网站。您可以使用单个代理服务器地址或代理服务器地址列表。
7、提取分类
网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
8、使用正则表达式提取
您可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。
SysNucleus WebHarvy 中文破解版安装教程
1、 下载并解压安装包,双击运行软件“Setup.exe”进行安装,进入安装向导,点击next进入下一步
2、同意用户协议,选择顶一个
3、设置安装目录,如果要更改,点击更改
4、确认软件安装无误后,点击安装
5、安装成功,取消勾选立即运行软件,点击完成启动安装界面
6、将破解补丁“WebHarvy.exe”替换到原安装目录,点击复制替换
ps:如果找不到位置,可以返回桌面右击图标选择位置打开文件
7、 破解成功,打开软件即可免费使用
更新日志
修复了页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源
java抓取网页数据(本文站点对数据的显示方式略有不同演示怎样抓取站点的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-22 03:26
有时出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示的数据略有不同。
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73。单击查询按钮。您将能够看到网页上显示的结果:
第二步:查看网页源代码。我们在源码中看到这么一段:
从这里可以看到。再次请求网页后显示查询结果。
查询后看网页地址:
换句话说。我们只想访问一个看起来像这样的网站。可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) 抛出异常 {
字符串 strURL = "
IP= = + ip;
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("以上四项依次显示");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml() 结果:\n" + result);
}使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站是为了保护自己的数据。网页的源代码中没有直接返回数据。而是采用异步方式用JS返回数据,避免了搜索引擎等工具对网站数据的抓取。
首先看这个页面:
使用第一种方法查看页面的源代码。但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果。我们先清除这些数据,然后输入快递号: 7.点击查询按钮,然后查看HTTP Analyzer的结果:
这是在单击查询按钮之后。HTTP Analyzer的结果,我们继续查看:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为就可以得到数据。即我们只需要访问JS请求的网页地址即可获取数据。当然,前提是数据没有加密。我们记下JS请求的URL:
文=7&频道=&rnd=0
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) 抛出异常 {
字符串 strURL = "
文= = + postid
+ "&channel=&rnd=0";
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript():\n" + contentBuf.toString()的结果);
}你看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这能成为一个需要帮助的孩子,需要程序的源代码。点击这里下载! 查看全部
java抓取网页数据(本文站点对数据的显示方式略有不同演示怎样抓取站点的数据)
有时出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示的数据略有不同。
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73。单击查询按钮。您将能够看到网页上显示的结果:
第二步:查看网页源代码。我们在源码中看到这么一段:
从这里可以看到。再次请求网页后显示查询结果。
查询后看网页地址:
换句话说。我们只想访问一个看起来像这样的网站。可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) 抛出异常 {
字符串 strURL = "
IP= = + ip;
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("以上四项依次显示");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml() 结果:\n" + result);
}使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站是为了保护自己的数据。网页的源代码中没有直接返回数据。而是采用异步方式用JS返回数据,避免了搜索引擎等工具对网站数据的抓取。
首先看这个页面:
使用第一种方法查看页面的源代码。但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果。我们先清除这些数据,然后输入快递号: 7.点击查询按钮,然后查看HTTP Analyzer的结果:
这是在单击查询按钮之后。HTTP Analyzer的结果,我们继续查看:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为就可以得到数据。即我们只需要访问JS请求的网页地址即可获取数据。当然,前提是数据没有加密。我们记下JS请求的URL:
文=7&频道=&rnd=0
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) 抛出异常 {
字符串 strURL = "
文= = + postid
+ "&channel=&rnd=0";
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript():\n" + contentBuf.toString()的结果);
}你看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这能成为一个需要帮助的孩子,需要程序的源代码。点击这里下载!
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-20 15:14
原文链接:
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
查看平原
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义的分析方法显示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
查看平原
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原文链接:
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
查看平原
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml()的结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义的分析方法显示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
查看平原
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript():\n"+contentBuf.toString()的结果);}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载!
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-20 15:12
原文链接:
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]查看明文
publicvoidcaptureHtml(Stringip)throwsException{ StringstrURL=""+ip; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8") ; BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line);} Stringbuf=contentBuf.toString() ; intbeginIx=buf.indexOf("查询结果["); intentIx=buf.indexOf("以上四项依次显示"); Stringresult=buf.substring(beginIx,endIx); System.out.println("captureHtml()的结果:\n"+result); }
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义的分析方法显示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]查看明文
publicvoidcaptureJavascript(Stringpostid)throwsException{ StringstrURL=""+postid +"&channel=&rnd=0"; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8"); BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } System.out.println("captureJavascript():\n"+contentBuf.toString()的结果); }
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友,以及需要程序源码的朋友有所帮助! 查看全部
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原文链接:
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]查看明文
publicvoidcaptureHtml(Stringip)throwsException{ StringstrURL=""+ip; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8") ; BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line);} Stringbuf=contentBuf.toString() ; intbeginIx=buf.indexOf("查询结果["); intentIx=buf.indexOf("以上四项依次显示"); Stringresult=buf.substring(beginIx,endIx); System.out.println("captureHtml()的结果:\n"+result); }
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义的分析方法显示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]查看明文
publicvoidcaptureJavascript(Stringpostid)throwsException{ StringstrURL=""+postid +"&channel=&rnd=0"; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8"); BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } System.out.println("captureJavascript():\n"+contentBuf.toString()的结果); }
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友,以及需要程序源码的朋友有所帮助!
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-10-14 13:15
原文链接:
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{ StringstrURL=""+ip; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8") ; BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line);} Stringbuf=contentBuf.toString() ; intbeginIx=buf.indexOf("查询结果["); intentIx=buf.indexOf("以上四项依次显示"); Stringresult=buf.substring(beginIx,endIx); System.out.println("captureHtml()的结果:\n"+result); }
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义的分析方法显示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{ StringstrURL=""+postid +"&channel=&rnd=0"; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8"); BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } System.out.println("captureJavascript():\n"+contentBuf.toString()的结果); }
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了! 查看全部
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原文链接:
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到显示的结果网页:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果。接下来看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{ StringstrURL=""+ip; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8") ; BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line);} Stringbuf=contentBuf.toString() ; intbeginIx=buf.indexOf("查询结果["); intentIx=buf.indexOf("以上四项依次显示"); Stringresult=buf.substring(beginIx,endIx); System.out.println("captureHtml()的结果:\n"+result); }
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义的分析方法显示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们不会直接在网页的源代码中返回数据。相反,他们使用 JS 以异步方式返回数据,这可以防止搜索引擎和其他工具响应网站数据捕获。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS结果,我们先清除这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{ StringstrURL=""+postid +"&channel=&rnd=0"; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8"); BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); } System.out.println("captureJavascript():\n"+contentBuf.toString()的结果); }
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
java抓取网页数据(我会不会抓网页的内容,然后把一些表格整理成excel )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-12 06:19
)
志超同志今天问我要不要抓取网页的内容,然后把一些表格整理成excel。
嗯,我不会,但我想试试,结果还是可行的。
先说他的需求,他需要把这个网站中的所有公司信息都存储在一个excel表中。
之前没用java来抓取网页内容,但是写过用过,略懂一点。
我找到了这个文章的内容:
然后,删除它的部分代码后,就可以抓取网页的源代码了。
github地址:
其他网址有相应的改编版本
下面是程序执行的第一步,抓取第一页到第22页的内容,并保存公司子页面的链接。
<p>import java.io.BufferedInputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.Reader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
public class Main {
/**
* 主函数
* @param args
*/
static public void main(String[] args){
String SrcWebSiteUrl = new String("http://www.zjex.com.cn/view/co ... 6quot;);
int WebSitePageId = 1;
ArrayList WebUrlArrayList = new ArrayList();
for (WebSitePageId = 1;WebSitePageId '){
IsBlock = false;
}
}
else{
if (TempChar == ' 查看全部
java抓取网页数据(我会不会抓网页的内容,然后把一些表格整理成excel
)
志超同志今天问我要不要抓取网页的内容,然后把一些表格整理成excel。
嗯,我不会,但我想试试,结果还是可行的。
先说他的需求,他需要把这个网站中的所有公司信息都存储在一个excel表中。
之前没用java来抓取网页内容,但是写过用过,略懂一点。
我找到了这个文章的内容:
然后,删除它的部分代码后,就可以抓取网页的源代码了。
github地址:
其他网址有相应的改编版本
下面是程序执行的第一步,抓取第一页到第22页的内容,并保存公司子页面的链接。
<p>import java.io.BufferedInputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.Reader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
public class Main {
/**
* 主函数
* @param args
*/
static public void main(String[] args){
String SrcWebSiteUrl = new String("http://www.zjex.com.cn/view/co ... 6quot;);
int WebSitePageId = 1;
ArrayList WebUrlArrayList = new ArrayList();
for (WebSitePageId = 1;WebSitePageId '){
IsBlock = false;
}
}
else{
if (TempChar == '
java抓取网页数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-09 03:01
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,一个翻页动作,可以采集完成所有数据。
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
java抓取网页数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,一个翻页动作,可以采集完成所有数据。
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据存储起来,方便我们接下来的数据查询操作。
java抓取网页数据(java抓取网页数据并解析json格式数据的整个流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-10-09 01:05
java抓取网页数据并解析json格式数据的整个流程实际上包括如下工作步骤:
1、数据存储python自带存储解析结果(json)存储库,
2、数据解析java-bson解析结果,主要读取java-jsonx(beautifulsoup)和cjs库;java-bson、cjs属于第三方库,需要依赖安装,详细说明请参考cjs-make,
3、数据存储java-jsonx数据操作,主要用于解析,支持从beautifulsoup等导入数据、mongodb、redis等;team分布式文件系统zookeeper和consul都是基于zookeeper操作json格式的。
4、运维监控可以看到系统一天内的实时运行情况:
在一般公司,可能不需要有一个java抓包工具(那太笨了),做一些实际的并发(线程、锁等)处理。但这没有什么价值,主要还是解析,只有很少的大数据量处理才需要。
解析json格式的java任务可以用第三方库java-bson或java-jsonx解析使用pymongo
首先你的一般逻辑是不可行的,你需要做到的是尽可能的减少内存占用,然后缩小体积提高性能。java这样的抓包工具,不需要自己写代码,也不需要有操作mongodb,redis,等东西的经验,有专门做这个的工具和库,比如如果是beautifulsoup或者java-xml.beautifulsoup等,不需要用自己写代码的。性能上面,专门做数据包读写,或者抓包工具自身缓存机制或者使用本地缓存,这些都能提高性能。 查看全部
java抓取网页数据(java抓取网页数据并解析json格式数据的整个流程)
java抓取网页数据并解析json格式数据的整个流程实际上包括如下工作步骤:
1、数据存储python自带存储解析结果(json)存储库,
2、数据解析java-bson解析结果,主要读取java-jsonx(beautifulsoup)和cjs库;java-bson、cjs属于第三方库,需要依赖安装,详细说明请参考cjs-make,
3、数据存储java-jsonx数据操作,主要用于解析,支持从beautifulsoup等导入数据、mongodb、redis等;team分布式文件系统zookeeper和consul都是基于zookeeper操作json格式的。
4、运维监控可以看到系统一天内的实时运行情况:
在一般公司,可能不需要有一个java抓包工具(那太笨了),做一些实际的并发(线程、锁等)处理。但这没有什么价值,主要还是解析,只有很少的大数据量处理才需要。
解析json格式的java任务可以用第三方库java-bson或java-jsonx解析使用pymongo
首先你的一般逻辑是不可行的,你需要做到的是尽可能的减少内存占用,然后缩小体积提高性能。java这样的抓包工具,不需要自己写代码,也不需要有操作mongodb,redis,等东西的经验,有专门做这个的工具和库,比如如果是beautifulsoup或者java-xml.beautifulsoup等,不需要用自己写代码的。性能上面,专门做数据包读写,或者抓包工具自身缓存机制或者使用本地缓存,这些都能提高性能。
java抓取网页数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-08 06:02
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候,可能都无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
从上面的源码中,可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好的,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们要获取的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,一个翻页动作,可以采集完成所有数据。
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
java抓取网页数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在众多行业中,需要对行业数据进行分类汇总,及时对行业数据进行分析,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候,可能都无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
从上面的源码中,可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好的,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们要获取的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只有采集当前页面的数据,还有分页的数据,这里就不解释了,只是一个提示,大家可以用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,一个翻页动作,可以采集完成所有数据。
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据存储起来,方便我们接下来的数据查询操作。
java抓取网页数据(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-10-07 14:08
最近在做一个项目,有一个需求:从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,后来就稀里糊涂的打了代码(之前用的是Hadoop平台的分布式爬虫框架Nutch,用起来很方便,最后因为速度放弃了,但是生成的统计数据用在后来爬取),很快就成功下载了holder.html和finance.html页面,然后在解析了holder.html页面后,解析了finance.html,然后就郁闷的在这个页面找到了自己需要的东西数据不在 html 源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录后者)。我很高兴,终于找到了解决办法。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。当初设计的时候,不是用来服务爬虫的,但我想说的是:星盘只是有点短,你不能再进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从实际情况出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver 可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码太有限了。解析你写的js代码,js代码简单,当然WebDriver可以毫无压力的完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面用到的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml(),可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js。会启动一个带界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都免不了要解析js,这需要时间,而且对于没用的内核,js的支持程序也不一样。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身经历)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。本来以为driver解析js完成后应该可以抓到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有往前走一步,这样我们就可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。这真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会出现不同,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实如此。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好办法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log('Loading a web page');
var page = require('webpage').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码不同编译,java端一直在等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了好几天了。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后我爬网页的时候就得心应手了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过可以用Nutch和WebDirver的结合,可能爬取的结果比较稳定,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫获得的结果的稳定性有什么要说的,欢迎大家,因为我确实没有找到稳定爬虫结果的相关资料。 查看全部
java抓取网页数据(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
最近在做一个项目,有一个需求:从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,后来就稀里糊涂的打了代码(之前用的是Hadoop平台的分布式爬虫框架Nutch,用起来很方便,最后因为速度放弃了,但是生成的统计数据用在后来爬取),很快就成功下载了holder.html和finance.html页面,然后在解析了holder.html页面后,解析了finance.html,然后就郁闷的在这个页面找到了自己需要的东西数据不在 html 源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录后者)。我很高兴,终于找到了解决办法。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。当初设计的时候,不是用来服务爬虫的,但我想说的是:星盘只是有点短,你不能再进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从实际情况出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver 可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码太有限了。解析你写的js代码,js代码简单,当然WebDriver可以毫无压力的完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面用到的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml(),可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js。会启动一个带界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都免不了要解析js,这需要时间,而且对于没用的内核,js的支持程序也不一样。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身经历)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。本来以为driver解析js完成后应该可以抓到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有往前走一步,这样我们就可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。这真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会出现不同,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实如此。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好办法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log('Loading a web page');
var page = require('webpage').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码不同编译,java端一直在等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了好几天了。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后我爬网页的时候就得心应手了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过可以用Nutch和WebDirver的结合,可能爬取的结果比较稳定,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫获得的结果的稳定性有什么要说的,欢迎大家,因为我确实没有找到稳定爬虫结果的相关资料。
java抓取网页数据(VsWinForm开发系列-WebBrowser介绍(组图)介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-10-06 21:15
阿里云>云栖社区>主题图>W>winform网页爬取
推荐活动:
更多优惠>
当前主题:winform 网页抓取和添加到采集夹
相关话题:
winform网页抓取相关博客查看更多博客
C# WinForm 开发系列-WebBrowser
作者:Jack Chen 1286人浏览评论:07年前
原文:C#WinForm开发系列-WebBrowser介绍了Vs 2005中WebBrowser控件的使用以及一些疑难问题的解决方法,如如何正确显示中文、屏蔽右键菜单、设置代理等;采集到的 文章 可能还是带来了一些使用 Microsoft W 的 Asp.Net 开发
阅读全文
.NET 实现(WebBrowser Data 采集—最后一章)
作者:王庆培 772人浏览评论:010年前
它可以改进。我不明白为什么相同的 HTTP 协议用于数据 采集。能提高多少效率?在采集的过程中,我们还要经过各种高层协议到底层协议。二个人觉得WebRequest是为了实现更多的可扩展性。我的WebBrowser数据采集不是关于爬取数据的效率,而是重点说明我们
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:Jack Chen1527人浏览评论:06年前
原文:PHP 使用 QueryList 抓取网页内容,然后使用 Java Jsoup 抓取网页数据。前几天听说用PHP抓起来比较方便。今天研究了一下,主要是用QueryList来实现。QueryList 是一个基于 phpQuery 的通用列表 采集 类,简单、灵活、功能强大
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
过去,我们使用 Java Jsoup 来捕获网页数据。前几天听说用PHP抓包比较方便。今天简单研究了一下,主要是使用QueryList。
阅读全文
RDIFramework.NET框架SOA解决方案(Windows服务集、WinForm窗体和IIS窗体发布)-分布式应用
作者:科技小先锋1152人浏览评论数:03年前
RDIFramework.NET框架SOA解决方案(集合Windows服务、WinForm窗体和IIS窗体发布)——分布式应用RDIFramework.NET,基于.NET快速信息系统开发与集成框架,为用户和开发者提供最佳的.Net Framework部署方案。框架基于SOA
阅读全文
使用C#开发基于Winform的手机号码归属地查询工具
作者:xiaoqiu08172108 浏览评论人数:07年前
一、需求说明 输入正确的手机号码,查询号码归属地等相关信息。二、需求分析1、手机号码归属地查询方法01、本地数据库存储信息,查询本地数据库02、调用WebService查询03、通过Http请求Get方法从服务器获取数据2、方法解析:
阅读全文
WinForm开发中,改变TreeView控件当前选中节点的字体和颜色
作者:rdiframework920 浏览评论人数:09年前
版权声明:本文为博主原创文章所有,未经博主许可,不得转载。瞄准 T
阅读全文
玩转小型爬虫——抓取动态页面
作者:一线码农2000人浏览评论:05年前
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫爬取的只是web服务器返回给我们的html,跳过了js加载的部分,也就是说爬虫抓取到的网页不完整,不完整。您可以在下面看到博客花园主页。从首页加载可以看出,页面渲染后,还会有5个
阅读全文 查看全部
java抓取网页数据(VsWinForm开发系列-WebBrowser介绍(组图)介绍)
阿里云>云栖社区>主题图>W>winform网页爬取
推荐活动:
更多优惠>
当前主题:winform 网页抓取和添加到采集夹
相关话题:
winform网页抓取相关博客查看更多博客
C# WinForm 开发系列-WebBrowser
作者:Jack Chen 1286人浏览评论:07年前
原文:C#WinForm开发系列-WebBrowser介绍了Vs 2005中WebBrowser控件的使用以及一些疑难问题的解决方法,如如何正确显示中文、屏蔽右键菜单、设置代理等;采集到的 文章 可能还是带来了一些使用 Microsoft W 的 Asp.Net 开发
阅读全文
.NET 实现(WebBrowser Data 采集—最后一章)
作者:王庆培 772人浏览评论:010年前
它可以改进。我不明白为什么相同的 HTTP 协议用于数据 采集。能提高多少效率?在采集的过程中,我们还要经过各种高层协议到底层协议。二个人觉得WebRequest是为了实现更多的可扩展性。我的WebBrowser数据采集不是关于爬取数据的效率,而是重点说明我们
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:Jack Chen1527人浏览评论:06年前
原文:PHP 使用 QueryList 抓取网页内容,然后使用 Java Jsoup 抓取网页数据。前几天听说用PHP抓起来比较方便。今天研究了一下,主要是用QueryList来实现。QueryList 是一个基于 phpQuery 的通用列表 采集 类,简单、灵活、功能强大
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
过去,我们使用 Java Jsoup 来捕获网页数据。前几天听说用PHP抓包比较方便。今天简单研究了一下,主要是使用QueryList。
阅读全文
RDIFramework.NET框架SOA解决方案(Windows服务集、WinForm窗体和IIS窗体发布)-分布式应用
作者:科技小先锋1152人浏览评论数:03年前
RDIFramework.NET框架SOA解决方案(集合Windows服务、WinForm窗体和IIS窗体发布)——分布式应用RDIFramework.NET,基于.NET快速信息系统开发与集成框架,为用户和开发者提供最佳的.Net Framework部署方案。框架基于SOA
阅读全文
使用C#开发基于Winform的手机号码归属地查询工具
作者:xiaoqiu08172108 浏览评论人数:07年前
一、需求说明 输入正确的手机号码,查询号码归属地等相关信息。二、需求分析1、手机号码归属地查询方法01、本地数据库存储信息,查询本地数据库02、调用WebService查询03、通过Http请求Get方法从服务器获取数据2、方法解析:
阅读全文
WinForm开发中,改变TreeView控件当前选中节点的字体和颜色
作者:rdiframework920 浏览评论人数:09年前
版权声明:本文为博主原创文章所有,未经博主许可,不得转载。瞄准 T
阅读全文
玩转小型爬虫——抓取动态页面
作者:一线码农2000人浏览评论:05年前
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫爬取的只是web服务器返回给我们的html,跳过了js加载的部分,也就是说爬虫抓取到的网页不完整,不完整。您可以在下面看到博客花园主页。从首页加载可以看出,页面渲染后,还会有5个
阅读全文
java抓取网页数据(任务解析及提升任务)
网站优化 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2021-10-06 21:13
这个任务是:
对搜索到的网页进行聚类,并将聚类结果显示给用户。用户可以选择其中一个类别,标记焦点,以该类别的关键词为主体,用户可以跟踪该主题并了解该主题。
截止日期:11.09
任务分析:
基本任务:对网页进行聚类,按类别归档,将图片放入相应的文件夹中,将文本放入相应的文件中。
推广任务:持续跟踪网页,持续下载符合条件的文件。
编译环境总结:
如果想省事,可以直接从睿思下载Anaconda Navigator。安装后直接使用,打包即可。
话不多说,先贴上代码:
#################################################
# 网页爬虫
# Email : jtailong@163.com
#################################################
import re
import time
import urllib.request
import requests
from bs4 import BeautifulSoup
#添加网页
url = \'https://www.douban.com/\'
#将图片抓取,并打包
req = urllib.request.urlopen(url)
data = req.read().decode(\'utf-8\')
match = re.compile("data-origin=\"(.+?\.jpg)")
#j记录图片信息
f = open(\'D:\\P\图片下载记录.txt\', \'w+\')
for sj in match.findall(data):
try:
f.write(sj)
except:
print("fail")
f.write(\'\n\')
f.close()
f1 = open(\'D:\\P\Pic_information.txt\', \'r+\')
#开始抓取网页图片
x = 0
for lj in f1.readlines():
img = urllib.request.urlretrieve(lj, \'D:/P/%s.jpg\' % x)
x += 1
f1.close()
#将网页上所有的文字信息,记录到TXT文件当中
r = requests.get(url)
soup = BeautifulSoup(r.text, \'html.parser\')
content = soup.text
print (content)
file = open(\'D:\\P\网页上所有文字信息.txt\', \'w\', encoding=\'utf-8\')
file.write(content)
file.close()
编译效果对比:
上图:原网页;下图:爬取后,可以看到文件夹中的信息。
更新:
通过这个编程,我对爬虫的理解是: 查看全部
java抓取网页数据(任务解析及提升任务)
这个任务是:
对搜索到的网页进行聚类,并将聚类结果显示给用户。用户可以选择其中一个类别,标记焦点,以该类别的关键词为主体,用户可以跟踪该主题并了解该主题。
截止日期:11.09
任务分析:
基本任务:对网页进行聚类,按类别归档,将图片放入相应的文件夹中,将文本放入相应的文件中。
推广任务:持续跟踪网页,持续下载符合条件的文件。
编译环境总结:
如果想省事,可以直接从睿思下载Anaconda Navigator。安装后直接使用,打包即可。
话不多说,先贴上代码:
#################################################
# 网页爬虫
# Email : jtailong@163.com
#################################################
import re
import time
import urllib.request
import requests
from bs4 import BeautifulSoup
#添加网页
url = \'https://www.douban.com/\'
#将图片抓取,并打包
req = urllib.request.urlopen(url)
data = req.read().decode(\'utf-8\')
match = re.compile("data-origin=\"(.+?\.jpg)")
#j记录图片信息
f = open(\'D:\\P\图片下载记录.txt\', \'w+\')
for sj in match.findall(data):
try:
f.write(sj)
except:
print("fail")
f.write(\'\n\')
f.close()
f1 = open(\'D:\\P\Pic_information.txt\', \'r+\')
#开始抓取网页图片
x = 0
for lj in f1.readlines():
img = urllib.request.urlretrieve(lj, \'D:/P/%s.jpg\' % x)
x += 1
f1.close()
#将网页上所有的文字信息,记录到TXT文件当中
r = requests.get(url)
soup = BeautifulSoup(r.text, \'html.parser\')
content = soup.text
print (content)
file = open(\'D:\\P\网页上所有文字信息.txt\', \'w\', encoding=\'utf-8\')
file.write(content)
file.close()
编译效果对比:
上图:原网页;下图:爬取后,可以看到文件夹中的信息。
更新:
通过这个编程,我对爬虫的理解是:
java抓取网页数据(完整的抓取示例工程可加群250108697图 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-10-06 21:12
)
网站中的图片和网页本质上是一样的。图片和网页的获取本质上是根据URL从网站中获取网页/图片的字节数组(byte[]),浏览器根据http响应头中的content-type信息,服务器将决定是否以网页或图片的形式显示资源。
完整的抓图示例工程可以加入群250108697,在群文件中获取。
示例中的代码将美食街中的图片爬取到指定文件夹,爬取结果如下图所示:
核心代码:
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler;
import cn.edu.hfut.dmic.webcollector.plugin.net.OkHttpRequester;
import cn.edu.hfut.dmic.webcollector.util.ExceptionUtils;
import cn.edu.hfut.dmic.webcollector.util.FileUtils;
import cn.edu.hfut.dmic.webcollector.util.MD5Utils;
import java.io.File;
/**
* WebCollector抓取图片的例子
* @author hu
*/
public class DemoImageCrawler extends BreadthCrawler {
File baseDir = new File("images");
/**
* 构造一个基于伯克利DB的爬虫
* 伯克利DB文件夹为crawlPath,crawlPath中维护了历史URL等信息
* 不同任务不要使用相同的crawlPath
* 两个使用相同crawlPath的爬虫并行爬取会产生错误
*
* @param crawlPath 伯克利DB使用的文件夹
*/
public DemoImageCrawler(String crawlPath) {
super(crawlPath, true);
//只有在autoParse和autoDetectImg都为true的情况下
//爬虫才会自动解析图片链接
getConf().setAutoDetectImg(true);
//如果使用默认的Requester,需要像下面这样设置一下网页大小上限
//否则可能会获得一个不完整的页面
//下面这行将页面大小上限设置为10M
//getConf().setMaxReceiveSize(1024 * 1024 * 10);
//添加种子URL
addSeed("http://www.meishij.net/");
//限定爬取范围
addRegex("http://www.meishij.net/.*");
addRegex("http://images.meishij.net/.*");
addRegex("-.*#.*");
addRegex("-.*\\?.*");
//设置为断点爬取,否则每次开启爬虫都会重新爬取
// demoImageCrawler.setResumable(true);
setThreads(30);
}
@Override
public void visit(Page page, CrawlDatums next) {
//根据http头中的Content-Type信息来判断当前资源是网页还是图片
String contentType = page.contentType();
//根据Content-Type判断是否为图片
if(contentType!=null && contentType.startsWith("image")){
//从Content-Type中获取图片扩展名
String extensionName=contentType.split("/")[1];
try {
byte[] image = page.content();
//根据图片MD5生成文件名
String fileName = String.format("%s.%s",MD5Utils.md5(image), extensionName);
File imageFile = new File(baseDir, fileName);
FileUtils.write(imageFile, image);
System.out.println("保存图片 "+page.url()+" 到 "+ imageFile.getAbsolutePath());
} catch (Exception e) {
ExceptionUtils.fail(e);
}
}
}
public static void main(String[] args) throws Exception {
DemoImageCrawler demoImageCrawler = new DemoImageCrawler("crawl");
demoImageCrawler.setRequester(new OkHttpRequester());
//设置为断点爬取,否则每次开启爬虫都会重新爬取
demoImageCrawler.setResumable(true);
demoImageCrawler.start(3);
}
} 查看全部
java抓取网页数据(完整的抓取示例工程可加群250108697图
)
网站中的图片和网页本质上是一样的。图片和网页的获取本质上是根据URL从网站中获取网页/图片的字节数组(byte[]),浏览器根据http响应头中的content-type信息,服务器将决定是否以网页或图片的形式显示资源。
完整的抓图示例工程可以加入群250108697,在群文件中获取。
示例中的代码将美食街中的图片爬取到指定文件夹,爬取结果如下图所示:
核心代码:
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler;
import cn.edu.hfut.dmic.webcollector.plugin.net.OkHttpRequester;
import cn.edu.hfut.dmic.webcollector.util.ExceptionUtils;
import cn.edu.hfut.dmic.webcollector.util.FileUtils;
import cn.edu.hfut.dmic.webcollector.util.MD5Utils;
import java.io.File;
/**
* WebCollector抓取图片的例子
* @author hu
*/
public class DemoImageCrawler extends BreadthCrawler {
File baseDir = new File("images");
/**
* 构造一个基于伯克利DB的爬虫
* 伯克利DB文件夹为crawlPath,crawlPath中维护了历史URL等信息
* 不同任务不要使用相同的crawlPath
* 两个使用相同crawlPath的爬虫并行爬取会产生错误
*
* @param crawlPath 伯克利DB使用的文件夹
*/
public DemoImageCrawler(String crawlPath) {
super(crawlPath, true);
//只有在autoParse和autoDetectImg都为true的情况下
//爬虫才会自动解析图片链接
getConf().setAutoDetectImg(true);
//如果使用默认的Requester,需要像下面这样设置一下网页大小上限
//否则可能会获得一个不完整的页面
//下面这行将页面大小上限设置为10M
//getConf().setMaxReceiveSize(1024 * 1024 * 10);
//添加种子URL
addSeed("http://www.meishij.net/";);
//限定爬取范围
addRegex("http://www.meishij.net/.*");
addRegex("http://images.meishij.net/.*");
addRegex("-.*#.*");
addRegex("-.*\\?.*");
//设置为断点爬取,否则每次开启爬虫都会重新爬取
// demoImageCrawler.setResumable(true);
setThreads(30);
}
@Override
public void visit(Page page, CrawlDatums next) {
//根据http头中的Content-Type信息来判断当前资源是网页还是图片
String contentType = page.contentType();
//根据Content-Type判断是否为图片
if(contentType!=null && contentType.startsWith("image")){
//从Content-Type中获取图片扩展名
String extensionName=contentType.split("/")[1];
try {
byte[] image = page.content();
//根据图片MD5生成文件名
String fileName = String.format("%s.%s",MD5Utils.md5(image), extensionName);
File imageFile = new File(baseDir, fileName);
FileUtils.write(imageFile, image);
System.out.println("保存图片 "+page.url()+" 到 "+ imageFile.getAbsolutePath());
} catch (Exception e) {
ExceptionUtils.fail(e);
}
}
}
public static void main(String[] args) throws Exception {
DemoImageCrawler demoImageCrawler = new DemoImageCrawler("crawl");
demoImageCrawler.setRequester(new OkHttpRequester());
//设置为断点爬取,否则每次开启爬虫都会重新爬取
demoImageCrawler.setResumable(true);
demoImageCrawler.start(3);
}
}
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-01 22:11
原创链接:
有时由于各种原因,我们需要一些采集数据,但由于不同网站
本文使用Java向您展示如何抓取网站的数据:(1)抓取原创网页的数据;(2)抓取网页JavaScript返回的数据
一、抓取原创页面
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此网页,输入IP:111.142.55.73,然后单击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[java]查看纯拷贝
publicvoidcaptureHtml(Stringip)通过异常{StringstrURL=“”+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuildercontentBuf=newStringBuilder();而(((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“上述四项依次显示”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果:”“n”+结果);]
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111.142.55.73==>;1871591241==>;福建省漳州移动
二、在网页上抓取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这可以避免搜索引擎和其他工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[java]查看纯拷贝
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载 查看全部
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原创链接:
有时由于各种原因,我们需要一些采集数据,但由于不同网站
本文使用Java向您展示如何抓取网站的数据:(1)抓取原创网页的数据;(2)抓取网页JavaScript返回的数据
一、抓取原创页面
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此网页,输入IP:111.142.55.73,然后单击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[java]查看纯拷贝
publicvoidcaptureHtml(Stringip)通过异常{StringstrURL=“”+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuildercontentBuf=newStringBuilder();而(((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“上述四项依次显示”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果:”“n”+结果);]
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111.142.55.73==>;1871591241==>;福建省漳州移动
二、在网页上抓取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这可以避免搜索引擎和其他工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[java]查看纯拷贝
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载
java抓取网页数据(java爬虫网络爬虫的注释及应用详细注释)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-10-01 22:08
Java爬虫爬取网页数据一. 爬虫简介
网络爬虫,又称网络蜘蛛或网络信息采集器,是一种根据一定的规则自动抓取或下载网络信息的计算机程序或自动化脚本。它是当前搜索引擎的重要组成部分。
我的demo是基于Jsoup做一个java爬虫的简单实现
jsoup是一个Java HTML解析器,主要用于解析HTML jsoup中文官网
二. 必需的 pom.xml 依赖项
org.jsoup
jsoup
1.8.3
commons-io
commons-io
2.5
org.apache.httpcomponents
httpclient
4.5.5
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
三.java代码(附详细注释)
因为我这里是一个简单的java爬虫,所以只用了一个java
抓取图片和CSS样式并下载到本地
捕捉图像
<p>package cn.xxx.xxxx;
import org.apache.commons.io.FileUtils;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.*;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @Date 2019/11/20 14:50
* @Version 1.0
*/
public class CatchImage {
// 地址
private static final String URL = "xxxx";
// 编码
private static final String ECODING = "utf-8";
// 获取img标签正则
private static final String IMGURL_REG = "]*?>";
// 获取src路径的正则
private static final String IMGSRC_REG = "(?x)(src|SRC|background|BACKGROUND)=('|\")/?(([\\w-]+/)*([\\w-]+\\.(jpg|JPG|png|PNG|gif|GIF)))('|\")";
// img本地保存路径
private static final String SAVE_PATH = "";
/**
* @param url 要抓取的网页地址
* @param encoding 要抓取网页编码
* @return
*/
public static String getHtmlResourceByUrl(String url, String encoding) {
URL urlObj = null;
URLConnection uc = null;
InputStreamReader isr = null;
BufferedReader reader = null;
StringBuffer buffer = new StringBuffer();
// 建立网络连接
try {
urlObj = new URL(url);
// 打开网络连接
uc = urlObj.openConnection();
// 建立文件输入流
isr = new InputStreamReader(uc.getInputStream(), encoding);
// 建立缓存导入 将网页源代码下载下来
reader = new BufferedReader(isr);
// 临时
String temp = null;
while ((temp = reader.readLine()) != null) {// 一次读一行 只要不为空就说明没读完继续读
// System.out.println(temp+"\n");
buffer.append(temp + "\n");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关流
if (isr != null) {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return buffer.toString();
}
/**
* 获取网页代码保存到本地
*
* @param url 网络地址
* @param encoding 编码格式
*
*/
public static void getJobInfo(String url, String encoding) {
// 拿到网页源代码
String html = getHtmlResourceByUrl(url, encoding);
try {
File fp = new File("xxxxx");
//判断创建文件是否存在
if (fp.exists()) {
fp.mkdirs();
}
OutputStream os = new FileOutputStream(fp); //建立文件输出流
os.write(html.getBytes());
os.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 下载图片
*
* @param listImgSrc
*/
public static void Download(List listImgSrc) {
int count = 0;
try {
for (int i = 0; i 查看全部
java抓取网页数据(java爬虫网络爬虫的注释及应用详细注释)
Java爬虫爬取网页数据一. 爬虫简介
网络爬虫,又称网络蜘蛛或网络信息采集器,是一种根据一定的规则自动抓取或下载网络信息的计算机程序或自动化脚本。它是当前搜索引擎的重要组成部分。
我的demo是基于Jsoup做一个java爬虫的简单实现
jsoup是一个Java HTML解析器,主要用于解析HTML jsoup中文官网
二. 必需的 pom.xml 依赖项
org.jsoup
jsoup
1.8.3
commons-io
commons-io
2.5
org.apache.httpcomponents
httpclient
4.5.5
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
三.java代码(附详细注释)
因为我这里是一个简单的java爬虫,所以只用了一个java
抓取图片和CSS样式并下载到本地
捕捉图像
<p>package cn.xxx.xxxx;
import org.apache.commons.io.FileUtils;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.*;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @Date 2019/11/20 14:50
* @Version 1.0
*/
public class CatchImage {
// 地址
private static final String URL = "xxxx";
// 编码
private static final String ECODING = "utf-8";
// 获取img标签正则
private static final String IMGURL_REG = "]*?>";
// 获取src路径的正则
private static final String IMGSRC_REG = "(?x)(src|SRC|background|BACKGROUND)=('|\")/?(([\\w-]+/)*([\\w-]+\\.(jpg|JPG|png|PNG|gif|GIF)))('|\")";
// img本地保存路径
private static final String SAVE_PATH = "";
/**
* @param url 要抓取的网页地址
* @param encoding 要抓取网页编码
* @return
*/
public static String getHtmlResourceByUrl(String url, String encoding) {
URL urlObj = null;
URLConnection uc = null;
InputStreamReader isr = null;
BufferedReader reader = null;
StringBuffer buffer = new StringBuffer();
// 建立网络连接
try {
urlObj = new URL(url);
// 打开网络连接
uc = urlObj.openConnection();
// 建立文件输入流
isr = new InputStreamReader(uc.getInputStream(), encoding);
// 建立缓存导入 将网页源代码下载下来
reader = new BufferedReader(isr);
// 临时
String temp = null;
while ((temp = reader.readLine()) != null) {// 一次读一行 只要不为空就说明没读完继续读
// System.out.println(temp+"\n");
buffer.append(temp + "\n");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关流
if (isr != null) {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return buffer.toString();
}
/**
* 获取网页代码保存到本地
*
* @param url 网络地址
* @param encoding 编码格式
*
*/
public static void getJobInfo(String url, String encoding) {
// 拿到网页源代码
String html = getHtmlResourceByUrl(url, encoding);
try {
File fp = new File("xxxxx");
//判断创建文件是否存在
if (fp.exists()) {
fp.mkdirs();
}
OutputStream os = new FileOutputStream(fp); //建立文件输出流
os.write(html.getBytes());
os.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 下载图片
*
* @param listImgSrc
*/
public static void Download(List listImgSrc) {
int count = 0;
try {
for (int i = 0; i
java抓取网页数据(服务器判定你是ie还是chrome还是firefox?分析的请求地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-28 08:31
HttpClient 是 Apache Jakarta Common 的一个子项目,可用于提供支持 HTTP 协议的高效、最新且功能丰富的客户端编程工具包,它支持 HTTP 协议的最新版本和推荐。
3.上一页
首先模拟手机浏览器的UA。就是让我们打开的页面回到移动端的页面效果,那我们该怎么做呢?其实服务器是根据请求头中的UA来判断你是chrome还是firefox的,所以我们来找一个手机浏览器的UA。.
我们可以直接f12或者直接在浏览器中模拟移动端,然后查看请求参数:
User-Agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36
正常没问题:
那么我们如何将这句话反映到程序中呢?
简单,我们拿到get对象后直接设置:
httpGet.setHeader("User-Agent", "Mozilla/5.0
(Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36");
就可以了,然后我们就可以使用jsoup来获取我们想要的元素了。jsoup 的语法与 jq 相同。
我们直接面对页面,右键我们想要的元素,选中review元素,然后用jq选择器选中它。
你可以参考jQuery选择器
4.获得关注者
直接获取我们之前分析的请求地址
https://www.zhihu.com/api/v4/m ... mp%3B
include=data%5B%2A%5D.employments%2Ccover_url%2Callow_message%2Canswer_coun
t%2Carticles_count%2Cfavorite_count%2Cfollower_count%2Cgender%2Cis_followe
d%2Cmessage_thread_token%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer
%29%5D.topics&limit=10&offset=30
但是记得替换用户名,在请求头中添加cookie zc_0的最后一段
那么返回的请求数据就是json
{
"paging": {
"is_end": false,
"next": "https://www.zhihu.com/api/v4/m ... ot%3B,
"previous": "https://www.zhihu.com/api/v4/m ... ot%3B,
"is_start": false,
"totals": 398
},
"data": [
{
"is_followed": true,
"avatar_url_template": "https://pic1.zhimg.com/da8e974dc_{size}.jpg",
"name": "陈晓峰",
"url": "",
"type": "people",
"user_type": "people",
"answer_count": 0,
"url_token": "chen-xiao-feng-84",
"headline": "阿里巴巴,分布式数据库,",
"avatar_url": "https://pic1.zhimg.com/da8e974dc_is.jpg",
"is_following": false,
"is_org": false,
"follower_count": 14,
"badge": [],
"id": "ff02ea0544901a9ddfcb7ba60c73b673",
"articles_count": 0
}
]
}
这个数据包括下一个请求地址,最后一个请求地址,时间是开始时间,时间是结束时间,总共有多少粉丝,以及关注者的基本信息,
所以我们可以在一段时间内得到所有的粉丝:
过程:
第一次获取数据,获取is_end字段判断is_end是否为真,根据is_end判断是否继续循环。如果循环,更新is_end,更新下一个连接请求
一套后,你可以得到一个用户的所有粉丝。
我爱Java(QQ群):170936712(点击加入) 查看全部
java抓取网页数据(服务器判定你是ie还是chrome还是firefox?分析的请求地址)
HttpClient 是 Apache Jakarta Common 的一个子项目,可用于提供支持 HTTP 协议的高效、最新且功能丰富的客户端编程工具包,它支持 HTTP 协议的最新版本和推荐。
3.上一页
首先模拟手机浏览器的UA。就是让我们打开的页面回到移动端的页面效果,那我们该怎么做呢?其实服务器是根据请求头中的UA来判断你是chrome还是firefox的,所以我们来找一个手机浏览器的UA。.
我们可以直接f12或者直接在浏览器中模拟移动端,然后查看请求参数:
User-Agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36
正常没问题:
那么我们如何将这句话反映到程序中呢?
简单,我们拿到get对象后直接设置:
httpGet.setHeader("User-Agent", "Mozilla/5.0
(Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36");
就可以了,然后我们就可以使用jsoup来获取我们想要的元素了。jsoup 的语法与 jq 相同。
我们直接面对页面,右键我们想要的元素,选中review元素,然后用jq选择器选中它。
你可以参考jQuery选择器
4.获得关注者
直接获取我们之前分析的请求地址
https://www.zhihu.com/api/v4/m ... mp%3B
include=data%5B%2A%5D.employments%2Ccover_url%2Callow_message%2Canswer_coun
t%2Carticles_count%2Cfavorite_count%2Cfollower_count%2Cgender%2Cis_followe
d%2Cmessage_thread_token%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer
%29%5D.topics&limit=10&offset=30
但是记得替换用户名,在请求头中添加cookie zc_0的最后一段
那么返回的请求数据就是json
{
"paging": {
"is_end": false,
"next": "https://www.zhihu.com/api/v4/m ... ot%3B,
"previous": "https://www.zhihu.com/api/v4/m ... ot%3B,
"is_start": false,
"totals": 398
},
"data": [
{
"is_followed": true,
"avatar_url_template": "https://pic1.zhimg.com/da8e974dc_{size}.jpg",
"name": "陈晓峰",
"url": "",
"type": "people",
"user_type": "people",
"answer_count": 0,
"url_token": "chen-xiao-feng-84",
"headline": "阿里巴巴,分布式数据库,",
"avatar_url": "https://pic1.zhimg.com/da8e974dc_is.jpg",
"is_following": false,
"is_org": false,
"follower_count": 14,
"badge": [],
"id": "ff02ea0544901a9ddfcb7ba60c73b673",
"articles_count": 0
}
]
}
这个数据包括下一个请求地址,最后一个请求地址,时间是开始时间,时间是结束时间,总共有多少粉丝,以及关注者的基本信息,
所以我们可以在一段时间内得到所有的粉丝:
过程:
第一次获取数据,获取is_end字段判断is_end是否为真,根据is_end判断是否继续循环。如果循环,更新is_end,更新下一个连接请求
一套后,你可以得到一个用户的所有粉丝。
我爱Java(QQ群):170936712(点击加入)
java抓取网页数据(如何实现java抓取网页数据的数据库操作?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-25 05:01
java抓取网页数据的两种方法,第一种按照网页的格式去load也就是采用网页的数据格式实现图片的读取,但是必须要实现网页的分析这才能采用相应的数据库程序来实现数据的数据库操作。springboot是一个基于spring框架的开源框架,有很多的特点,比如动态配置web服务器;spring的无侵入式开发;完整的ioc容器;轻量级事务管理和控制器;spring支持“并发控制”(concurrenthashmap);可选择的并发数据库事务处理(java8);可选择的jdbc并发服务;spring的分页功能;等等很多,可以使用spring的特性满足大部分的需求。
谢邀。很简单的问题,不过不能用语言来回答,所以这也是一个门槛问题。关键看用什么编程语言,用什么控制器,调用的中间件,选择哪些接口,封装处理思路,等等。其实,还是看你对java怎么看待,如果只是简单的使用,java无论是自己实现网站,di还是使用javabean,都能实现。也能解决对查询,对pojo的操作。如果是做大型的java开发,性能,等等难免会有障碍。
用java,你会收获一个称之为“丰富”的世界。
网站技术现在应该不会过时吧?我感觉在中国来说,互联网大部分都是运用java技术。iphone,android等应用软件,都是java系。只要你喜欢,关键看你自己的学习成本和方向吧?如果你喜欢玩云操作,java当然是不二之选。如果你喜欢云数据库,那么sql+etl应该是不错的选择。当然,java很多都是可以模拟底层环境的。
例如springframework就会模拟mysql的应用环境。java开发web应用,应该不是问题。还有,采用自己的java程序,有很多缺点的。例如:java程序的实现难度,java线程的调度等,需要你搞清楚,应该是小问题。 查看全部
java抓取网页数据(如何实现java抓取网页数据的数据库操作?-八维教育)
java抓取网页数据的两种方法,第一种按照网页的格式去load也就是采用网页的数据格式实现图片的读取,但是必须要实现网页的分析这才能采用相应的数据库程序来实现数据的数据库操作。springboot是一个基于spring框架的开源框架,有很多的特点,比如动态配置web服务器;spring的无侵入式开发;完整的ioc容器;轻量级事务管理和控制器;spring支持“并发控制”(concurrenthashmap);可选择的并发数据库事务处理(java8);可选择的jdbc并发服务;spring的分页功能;等等很多,可以使用spring的特性满足大部分的需求。
谢邀。很简单的问题,不过不能用语言来回答,所以这也是一个门槛问题。关键看用什么编程语言,用什么控制器,调用的中间件,选择哪些接口,封装处理思路,等等。其实,还是看你对java怎么看待,如果只是简单的使用,java无论是自己实现网站,di还是使用javabean,都能实现。也能解决对查询,对pojo的操作。如果是做大型的java开发,性能,等等难免会有障碍。
用java,你会收获一个称之为“丰富”的世界。
网站技术现在应该不会过时吧?我感觉在中国来说,互联网大部分都是运用java技术。iphone,android等应用软件,都是java系。只要你喜欢,关键看你自己的学习成本和方向吧?如果你喜欢玩云操作,java当然是不二之选。如果你喜欢云数据库,那么sql+etl应该是不错的选择。当然,java很多都是可以模拟底层环境的。
例如springframework就会模拟mysql的应用环境。java开发web应用,应该不是问题。还有,采用自己的java程序,有很多缺点的。例如:java程序的实现难度,java线程的调度等,需要你搞清楚,应该是小问题。
java抓取网页数据(java抓取网页数据内存最小的大小是什么?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-24 03:00
java抓取网页数据内存最小大小是按照ua的字符集去判断的(一般是gbk,中文数据以utf-8编码,英文数据不会变换编码方式)。比如一个页面是基于gbk编码的,那么内存最小大小是256m左右。
ua是google服务器端识别的一个基本属性,如下图显示的是某一个网站打开时需要消耗的空间。而中文网站一般分为utf-8编码和gbk编码,utf-8编码ua会占用2.5m左右,而gbk编码ua又会占用32.5m。因此,有效的内存空间是打开时所占用的空间,而其是根据google服务器端的统计结果来决定的。
内存大小跟访问的网站类型相关,java只要访问的网站是google提供的,那么内存就不用计算,一般就是2^32这么大。
这个理论上取决于java要解析什么的,按照下面的来看1gbk是很小,所以内存大小如果是64m就足够了,如果是system.out.println的话需要1m,有些地方autoprint出来结果比java解析要慢很多,所以有些地方需要256m,超过256m就别放这个范围,浪费。2utf-8编码这个范围大点,所以可以部分解析。
utf-8编码的话内存大小大概就是256m。而gbk的话,内存要用1m,不然解析速度太慢。以上内容仅供参考。
没有的
1、ajax请求
2、java处理内存优化的jdk版本
3、java设计模式
4、springmvc。1m都不够的我也是手贱搜一个一个去问的,你需要其他资料直接评论我,我再看吧。 查看全部
java抓取网页数据(java抓取网页数据内存最小的大小是什么?(上))
java抓取网页数据内存最小大小是按照ua的字符集去判断的(一般是gbk,中文数据以utf-8编码,英文数据不会变换编码方式)。比如一个页面是基于gbk编码的,那么内存最小大小是256m左右。
ua是google服务器端识别的一个基本属性,如下图显示的是某一个网站打开时需要消耗的空间。而中文网站一般分为utf-8编码和gbk编码,utf-8编码ua会占用2.5m左右,而gbk编码ua又会占用32.5m。因此,有效的内存空间是打开时所占用的空间,而其是根据google服务器端的统计结果来决定的。
内存大小跟访问的网站类型相关,java只要访问的网站是google提供的,那么内存就不用计算,一般就是2^32这么大。
这个理论上取决于java要解析什么的,按照下面的来看1gbk是很小,所以内存大小如果是64m就足够了,如果是system.out.println的话需要1m,有些地方autoprint出来结果比java解析要慢很多,所以有些地方需要256m,超过256m就别放这个范围,浪费。2utf-8编码这个范围大点,所以可以部分解析。
utf-8编码的话内存大小大概就是256m。而gbk的话,内存要用1m,不然解析速度太慢。以上内容仅供参考。
没有的
1、ajax请求
2、java处理内存优化的jdk版本
3、java设计模式
4、springmvc。1m都不够的我也是手贱搜一个一个去问的,你需要其他资料直接评论我,我再看吧。
java抓取网页数据(18款Java开源Web爬虫,需要的小伙伴们赶快收藏)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-09-19 09:05
网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中更常被称为网络追踪器)是一种程序或脚本,根据特定规则自动获取万维网信息。其他不常用的名称包括蚂蚁、自动索引、模拟器或蠕虫
今天,我们将介绍18个Java开源网络爬虫。让我们快点把它们收起来
一,
赫里特里克斯
Heritrix是由Java开发的开源web爬虫程序。用户可以使用它从互联网上获取所需的资源。其最大的特点是具有良好的可扩展性,方便用户实现自己的爬网逻辑
Heritrix是一个“归档爬虫”——用于获取站点内容的完整、准确和深入复制。包括获取图像和其他非文本内容。抓取并存储相关内容。内容不会被拒绝,页面内容也不会被修改。重新爬网不会用相同的URL替换以前的URL。爬虫主要通过web用户界面启动、监控和调整,允许灵活定义URL
Heritrix是一个多线程爬虫程序。主线程将任务分配给Teo线程(处理线程),每个Teo线程一次处理一个URL。Teo线程对每个URL执行一次URL处理程序链。URL处理器链包括以下五个处理步骤
预取链:主要做一些准备工作,比如延迟和重新处理处理,拒绝后续操作
提取链:主要下载网页,进行DNS转换,填写请求和响应表单
提取链:提取完成后,提取感兴趣的HTML和Java。通常,需要抓取新的URL
写入链:存储获取结果。在此步骤中,您可以直接进行全文索引。Heritrix提供了arcbuilder处理器的实现,该处理器以arc格式保存下载结果
提交链:与此URL相关的操作的最终处理。检查哪些新提取的URL在捕获范围内,然后将这些URL提交给frontier。DNS缓存信息也会更新
Heritrix系统框架
Heritrix处理URL
二,
韦伯斯菲克斯
Webshinx是一个用于Java类包和web爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。Webshinx由两部分组成:crawler平台和Webshinx类包
Webshinx是一个用于Java类包和web爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。Webshinx由两部分组成:crawler平台和Webshinx类包
Webshinx用途:
可视显示的页面的集合
将页面下载到本地磁盘以进行脱机浏览
将所有页面拼接成一个页面,以便浏览或打印
根据特定规则从页面中提取文本字符串
用Java或Java开发自定义爬虫程序
有关详细信息,请参见~RCM/websphinx/
三,
韦布雷赫
WebLech是下载和镜像网站的强大工具。它支持根据功能需求下载网站,并尽可能模仿标准web浏览器的行为。WebLech具有功能性控制台和多线程操作
WebLech是一个强大的免费开源工具,用于下载和镜像网站。它支持根据功能需求下载网站,并尽可能模仿标准web浏览器的行为。WebLech具有功能性控制台和多线程操作
这个爬虫很简单。如果你是初学者,你可以把它作为入门参考。所以我选择用这种爬行动物开始我的研究。如果您不需要高性能的应用程序,也可以尝试。如果你想找到一个强大的,不要在WebLech上浪费时间
项目主页:
特点:
开源,免费
代码是用纯Java编写的,可以在任何支持Java的平台上使用
支持多线程下载网页
可以维护网页之间的链接信息
强大的可配置性:当以深度优先或宽度优先的方式抓取网页时,您可以自定义URL过滤器,以便根据需要抓取单个web服务器、单个目录或整个www网络。您可以设置URL的优先级,以便可以首先抓取感兴趣或重要的网页。您可以在断点处记录程序的状态,当您重新启动时,您可以继续爬网最后一次
四,
阿拉尔
Arale主要是为个人使用而设计的,而不像其他爬虫那样专注于页面索引。Arale可以下载整个网站或网站上的一些资源。Arale还可以将动态页面映射到静态页面
五,
杰斯皮德
Jspider是一个完全可配置和定制的web spider引擎。您可以使用它来检查网站错误(内部服务器错误等),检查网站内部和外部链接,分析网站结构(您可以创建网站地图),下载整个网站,并编写jspider插件来扩展您需要的功能
Spider是用Java实现的web Spider。jspider的执行格式如下:
jspider[ConfigName]
必须将协议名称添加到URL,例如:,否则将报告错误。如果省略configname,则使用默认配置
jspider的行为由配置文件专门配置。例如,在conf\[configname]\_目录中设置了使用的插件和结果存储方法。Jspider几乎没有默认的配置类型和用途。然而,jspider非常容易扩展,可以用来开发强大的网页捕获和数据分析工具。要做到这一点,您需要深入了解jspider的原理,然后根据自己的需要开发插件和编写配置文件
Jspider是:
一个高度可配置和定制的网络爬虫
根据LGPL开源许可证开发
100%纯java实现
您可以使用它来:
检查网站是否存在错误(内部服务器错误;…)
传出或内部链接检查
分析网站结构(创建站点地图;…)
下载翻新网站
通过编写jspider插件来实现任何函数
项目主页:
六,
纺锤
Spin是基于Lucene工具包构建的web索引/搜索工具。它包括一个用于创建索引的HTTP spider和一个用于搜索这些索引的搜索类。spin项目提供了一组JSP标记库,使基于JSP的站点能够在不开发任何Java类的情况下添加搜索功能
七,
蜘蛛纲
Arachnid是一个基于Java的网络蜘蛛框架。它收录一个简单的HTML解析器,可以分析收录HTML内容的输入流。通过实现arachnid的子类,它可以开发一个简单的web爬行器,并在解析web站点上的每个页面后添加几行代码调用。Arachnid的下载包收录两个spider应用程序示例来演示如何使用该框架
项目主页:
八,
云雀
Larm可以为雅加达Lucene搜索引擎框架的用户提供纯java搜索解决方案。它收录用于索引文件、数据库、表和用于索引网站的爬虫的方法
项目主页:
九,
若波
JOBO是下载整个网站的简单工具。它本质上是一个蜘蛛网。与其他下载工具相比,它的主要优点是可以自动填写表单(如自动登录)并使用cookie处理会话。JOBO还具有灵活的下载规则(如URL、大小、MIME类型等)来限制下载
十,
史努克爬行动物
它是用纯Java开发的用于网站图像捕获的工具。您可以使用配置文件中提供的URL条目来捕获浏览器可以通过get Local获取的所有网站资源,包括网页和各种类型的文件,如图片、flashmp3、Zip、rar、EXE等文件。整个网站可以完全传输到硬盘上,原创网站结构可以保持准确。只需将捕获的网站放入web服务器(如APACHE)即可实现完整的网站映像
由于在抓取过程中经常会出现一些错误的文件,而且无法正确解析很多Java控制的URL,snoics reply基本上可以通过提供接口和配置文件,自由扩展外部接口,为特殊URL注入配置文件,它可以正确解析和抓取所有网页
项目主页:
十一,
网络收获
WebHarvest是一个Java开源Web数据提取工具。它可以[url=https://www.ucaiyun.com/]采集指定的网页,并从这些网页中提取有用的数据。WebHarvest主要使用XSLT、XQuery和正则表达式等技术来操作文本/XML
WebHarvest是一个用Java编写的开源Web数据提取工具。它提供了一种从所需页面提取有用数据的方法。要实现这一点,您可能需要使用XSLT、XQuery和正则表达式等技术来操作文本/XML。WebHarvest主要关注基于HMLT/XML的页面内容,目前仍占大多数。另一方面,它可以通过编写自己的Java方法轻松地扩展其提取能力
Web harvest的主要目的是加强现有数据提取技术的应用。它的目标不是创建一种新方法,而是提供一种更好地使用和组合现有方法的方法。它提供了一组处理器来处理数据和控制数据 查看全部
java抓取网页数据(18款Java开源Web爬虫,需要的小伙伴们赶快收藏)
网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中更常被称为网络追踪器)是一种程序或脚本,根据特定规则自动获取万维网信息。其他不常用的名称包括蚂蚁、自动索引、模拟器或蠕虫
今天,我们将介绍18个Java开源网络爬虫。让我们快点把它们收起来
一,
赫里特里克斯
Heritrix是由Java开发的开源web爬虫程序。用户可以使用它从互联网上获取所需的资源。其最大的特点是具有良好的可扩展性,方便用户实现自己的爬网逻辑
Heritrix是一个“归档爬虫”——用于获取站点内容的完整、准确和深入复制。包括获取图像和其他非文本内容。抓取并存储相关内容。内容不会被拒绝,页面内容也不会被修改。重新爬网不会用相同的URL替换以前的URL。爬虫主要通过web用户界面启动、监控和调整,允许灵活定义URL
Heritrix是一个多线程爬虫程序。主线程将任务分配给Teo线程(处理线程),每个Teo线程一次处理一个URL。Teo线程对每个URL执行一次URL处理程序链。URL处理器链包括以下五个处理步骤
预取链:主要做一些准备工作,比如延迟和重新处理处理,拒绝后续操作
提取链:主要下载网页,进行DNS转换,填写请求和响应表单
提取链:提取完成后,提取感兴趣的HTML和Java。通常,需要抓取新的URL
写入链:存储获取结果。在此步骤中,您可以直接进行全文索引。Heritrix提供了arcbuilder处理器的实现,该处理器以arc格式保存下载结果
提交链:与此URL相关的操作的最终处理。检查哪些新提取的URL在捕获范围内,然后将这些URL提交给frontier。DNS缓存信息也会更新
Heritrix系统框架
Heritrix处理URL
二,
韦伯斯菲克斯
Webshinx是一个用于Java类包和web爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。Webshinx由两部分组成:crawler平台和Webshinx类包
Webshinx是一个用于Java类包和web爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。Webshinx由两部分组成:crawler平台和Webshinx类包
Webshinx用途:
可视显示的页面的集合
将页面下载到本地磁盘以进行脱机浏览
将所有页面拼接成一个页面,以便浏览或打印
根据特定规则从页面中提取文本字符串
用Java或Java开发自定义爬虫程序
有关详细信息,请参见~RCM/websphinx/
三,
韦布雷赫
WebLech是下载和镜像网站的强大工具。它支持根据功能需求下载网站,并尽可能模仿标准web浏览器的行为。WebLech具有功能性控制台和多线程操作
WebLech是一个强大的免费开源工具,用于下载和镜像网站。它支持根据功能需求下载网站,并尽可能模仿标准web浏览器的行为。WebLech具有功能性控制台和多线程操作
这个爬虫很简单。如果你是初学者,你可以把它作为入门参考。所以我选择用这种爬行动物开始我的研究。如果您不需要高性能的应用程序,也可以尝试。如果你想找到一个强大的,不要在WebLech上浪费时间
项目主页:
特点:
开源,免费
代码是用纯Java编写的,可以在任何支持Java的平台上使用
支持多线程下载网页
可以维护网页之间的链接信息
强大的可配置性:当以深度优先或宽度优先的方式抓取网页时,您可以自定义URL过滤器,以便根据需要抓取单个web服务器、单个目录或整个www网络。您可以设置URL的优先级,以便可以首先抓取感兴趣或重要的网页。您可以在断点处记录程序的状态,当您重新启动时,您可以继续爬网最后一次
四,
阿拉尔
Arale主要是为个人使用而设计的,而不像其他爬虫那样专注于页面索引。Arale可以下载整个网站或网站上的一些资源。Arale还可以将动态页面映射到静态页面
五,
杰斯皮德
Jspider是一个完全可配置和定制的web spider引擎。您可以使用它来检查网站错误(内部服务器错误等),检查网站内部和外部链接,分析网站结构(您可以创建网站地图),下载整个网站,并编写jspider插件来扩展您需要的功能
Spider是用Java实现的web Spider。jspider的执行格式如下:
jspider[ConfigName]
必须将协议名称添加到URL,例如:,否则将报告错误。如果省略configname,则使用默认配置
jspider的行为由配置文件专门配置。例如,在conf\[configname]\_目录中设置了使用的插件和结果存储方法。Jspider几乎没有默认的配置类型和用途。然而,jspider非常容易扩展,可以用来开发强大的网页捕获和数据分析工具。要做到这一点,您需要深入了解jspider的原理,然后根据自己的需要开发插件和编写配置文件
Jspider是:
一个高度可配置和定制的网络爬虫
根据LGPL开源许可证开发
100%纯java实现
您可以使用它来:
检查网站是否存在错误(内部服务器错误;…)
传出或内部链接检查
分析网站结构(创建站点地图;…)
下载翻新网站
通过编写jspider插件来实现任何函数
项目主页:
六,
纺锤
Spin是基于Lucene工具包构建的web索引/搜索工具。它包括一个用于创建索引的HTTP spider和一个用于搜索这些索引的搜索类。spin项目提供了一组JSP标记库,使基于JSP的站点能够在不开发任何Java类的情况下添加搜索功能
七,
蜘蛛纲
Arachnid是一个基于Java的网络蜘蛛框架。它收录一个简单的HTML解析器,可以分析收录HTML内容的输入流。通过实现arachnid的子类,它可以开发一个简单的web爬行器,并在解析web站点上的每个页面后添加几行代码调用。Arachnid的下载包收录两个spider应用程序示例来演示如何使用该框架
项目主页:
八,
云雀
Larm可以为雅加达Lucene搜索引擎框架的用户提供纯java搜索解决方案。它收录用于索引文件、数据库、表和用于索引网站的爬虫的方法
项目主页:
九,
若波
JOBO是下载整个网站的简单工具。它本质上是一个蜘蛛网。与其他下载工具相比,它的主要优点是可以自动填写表单(如自动登录)并使用cookie处理会话。JOBO还具有灵活的下载规则(如URL、大小、MIME类型等)来限制下载
十,
史努克爬行动物
它是用纯Java开发的用于网站图像捕获的工具。您可以使用配置文件中提供的URL条目来捕获浏览器可以通过get Local获取的所有网站资源,包括网页和各种类型的文件,如图片、flashmp3、Zip、rar、EXE等文件。整个网站可以完全传输到硬盘上,原创网站结构可以保持准确。只需将捕获的网站放入web服务器(如APACHE)即可实现完整的网站映像
由于在抓取过程中经常会出现一些错误的文件,而且无法正确解析很多Java控制的URL,snoics reply基本上可以通过提供接口和配置文件,自由扩展外部接口,为特殊URL注入配置文件,它可以正确解析和抓取所有网页
项目主页:
十一,
网络收获
WebHarvest是一个Java开源Web数据提取工具。它可以[url=https://www.ucaiyun.com/]采集指定的网页,并从这些网页中提取有用的数据。WebHarvest主要使用XSLT、XQuery和正则表达式等技术来操作文本/XML
WebHarvest是一个用Java编写的开源Web数据提取工具。它提供了一种从所需页面提取有用数据的方法。要实现这一点,您可能需要使用XSLT、XQuery和正则表达式等技术来操作文本/XML。WebHarvest主要关注基于HMLT/XML的页面内容,目前仍占大多数。另一方面,它可以通过编写自己的Java方法轻松地扩展其提取能力
Web harvest的主要目的是加强现有数据提取技术的应用。它的目标不是创建一种新方法,而是提供一种更好地使用和组合现有方法的方法。它提供了一组处理器来处理数据和控制数据
java抓取网页数据(一个-1.11.1.jarokio-3.12.0.jar-1.12.0.jar●jsoup使用文档 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 353 次浏览 • 2021-09-19 08:29
)
目录
目录
前言
最近,我想建立一个视频播放应用程序,可以播放电影和电视剧。因此,我在网上搜索了API接口,发现虽然爱奇艺和其他视频网站提供的视频接口可以使用,但注册和审核应用程序等步骤繁琐,他们的API无法在我自己的播放器中播放,但我必须使用java编写一个程序来获取网页数据,以满足我的需要。这里我记录了实施过程
前期准备
● 所需的jar包:
jsoup-1.11.1.jarokhttp -3.12.0.jarokio -@ 1.12.0.jar
● jsoup使用文档:
案例实现
public class Test {
private static final String BASE_URL="http://www.baiwanzy.com";//这里使用的是百万资源网的资源
public static void main(String[] args) {
asyncGet();
}
public static void asyncGet() {
String encode = URLEncoder.encode("雪鹰领主");//对查询的数据进行Url编码
String urlBaidu = "http://www.baiwanzy.com/index. ... de%3B
OkHttpClient okHttpClient = new OkHttpClient(); // 创建OkHttpClient对象
Request request = new Request.Builder().url(urlBaidu).build(); // 创建一个请求
okHttpClient.newCall(request).enqueue(new Callback() { // 回调
public void onResponse(Call call, Response response) throws IOException {
// 请求成功调用,该回调在子线程
getMovieList(response.body().string());
}
public void onFailure(Call call, IOException e) {
// 请求失败调用
System.out.println(e.getMessage());
}
});
}
public static void getMovieList(String datas){
Document doc = Jsoup.parse(datas);
// 根据css的后代选择器来找到相关的列表
Elements links = doc.select(".xing_vb4 a");//这里是返回的列表的类来查找相关的a标签
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
System.out.println(BASE_URL+linkHref+"==="+linkText);
}
}
} 查看全部
java抓取网页数据(一个-1.11.1.jarokio-3.12.0.jar-1.12.0.jar●jsoup使用文档
)
目录
目录
前言
最近,我想建立一个视频播放应用程序,可以播放电影和电视剧。因此,我在网上搜索了API接口,发现虽然爱奇艺和其他视频网站提供的视频接口可以使用,但注册和审核应用程序等步骤繁琐,他们的API无法在我自己的播放器中播放,但我必须使用java编写一个程序来获取网页数据,以满足我的需要。这里我记录了实施过程
前期准备
● 所需的jar包:
jsoup-1.11.1.jarokhttp -3.12.0.jarokio -@ 1.12.0.jar
● jsoup使用文档:
案例实现
public class Test {
private static final String BASE_URL="http://www.baiwanzy.com";//这里使用的是百万资源网的资源
public static void main(String[] args) {
asyncGet();
}
public static void asyncGet() {
String encode = URLEncoder.encode("雪鹰领主");//对查询的数据进行Url编码
String urlBaidu = "http://www.baiwanzy.com/index. ... de%3B
OkHttpClient okHttpClient = new OkHttpClient(); // 创建OkHttpClient对象
Request request = new Request.Builder().url(urlBaidu).build(); // 创建一个请求
okHttpClient.newCall(request).enqueue(new Callback() { // 回调
public void onResponse(Call call, Response response) throws IOException {
// 请求成功调用,该回调在子线程
getMovieList(response.body().string());
}
public void onFailure(Call call, IOException e) {
// 请求失败调用
System.out.println(e.getMessage());
}
});
}
public static void getMovieList(String datas){
Document doc = Jsoup.parse(datas);
// 根据css的后代选择器来找到相关的列表
Elements links = doc.select(".xing_vb4 a");//这里是返回的列表的类来查找相关的a标签
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
System.out.println(BASE_URL+linkHref+"==="+linkText);
}
}
}

