
java抓取网页数据
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-09-19 08:24
原创链接:
有时,由于各种原因,我们需要采集一个站点的数据,但不同站点的数据显示方式略有不同
本文使用Java向您展示如何抓取站点的数据:(1)grab原创网页的数据;(2)grab网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:检查网页源代码。我们可以看到源代码中有一段:
从这里可以看出,再次请求网页后会显示查询结果
我们来看看查询后的网址:
换言之,我们只能通过访问这样的网站才能得到IP查询的结果。接下来,请看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到站点,使用bufreader保存网页返回的数据,然后通过自定义解析方法显示结果
这里我只是随便分析一下。如果我想准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时候,为了保护自己的数据,网站不直接在网页源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方法用于查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但是有时候我们非常需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
在第一次单击startbutton之后,它开始监视web页面的交互
当我们打开网页时,可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了便于查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
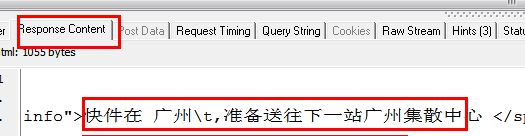
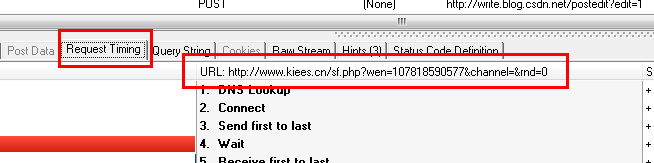
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们只需要分析HTTP analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址来获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两个豌豆一样,抓取JS的方法与原创网页完全相同。我们只是做了一个分析JS的过程
以下是该计划的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
我希望这篇文章能对有需要的朋友有所帮助。如果你需要程序源代码,请点击这里下载 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原创链接:
有时,由于各种原因,我们需要采集一个站点的数据,但不同站点的数据显示方式略有不同
本文使用Java向您展示如何抓取站点的数据:(1)grab原创网页的数据;(2)grab网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:

第二步:检查网页源代码。我们可以看到源代码中有一段:

从这里可以看出,再次请求网页后会显示查询结果
我们来看看查询后的网址:

换言之,我们只能通过访问这样的网站才能得到IP查询的结果。接下来,请看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到站点,使用bufreader保存网页返回的数据,然后通过自定义解析方法显示结果
这里我只是随便分析一下。如果我想准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时候,为了保护自己的数据,网站不直接在网页源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方法用于查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但是有时候我们非常需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
在第一次单击startbutton之后,它开始监视web页面的交互
当我们打开网页时,可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了便于查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:

这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们只需要分析HTTP analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址来获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两个豌豆一样,抓取JS的方法与原创网页完全相同。我们只是做了一个分析JS的过程
以下是该计划的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
我希望这篇文章能对有需要的朋友有所帮助。如果你需要程序源代码,请点击这里下载
java抓取网页数据(java抓取网页数据吧我曾经用它某个网站的电影数据,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-19 08:01
java抓取网页数据吧,我曾经用它爬过某个网站的电影数据,用python或是其他语言来实现应该也没啥问题.代码的话,你自己百度一下吧.
javalib里面有,xml连接池,e-link。
可以用java-encode-javaclass然后转换json为xml,
openjavaapi的xml连接池里面有xml2client,对于爬虫,xml自然就很少解析的,除非将抓取的json转化成xml格式。
看了我java小白的回答,
题主说的抓取数据,java没有直接对应的http连接池,
直接用requests,实在不行就用xml解析库(nodejs,elisp)吧。直接用java爬出来的不是全局唯一,自己搞的话还是先写一遍爬取源程序,差不多后,
这个最好用java写,因为需要库实现的原因。
javaproject为此我已经写过一个java工具了
java写一遍httpserver.for.ajax.for.callback.for.request(request.get,request.send,callback=true)
专门写一个抓包工具去抓
java可以抓取网站上的html,或直接定制好一个web,用java封装一个http发送服务。最近正好在写一个http监听工具,可以抓取到http请求,追踪追踪数据包,tracetrace一下。python嘛, 查看全部
java抓取网页数据(java抓取网页数据吧我曾经用它某个网站的电影数据,)
java抓取网页数据吧,我曾经用它爬过某个网站的电影数据,用python或是其他语言来实现应该也没啥问题.代码的话,你自己百度一下吧.
javalib里面有,xml连接池,e-link。
可以用java-encode-javaclass然后转换json为xml,
openjavaapi的xml连接池里面有xml2client,对于爬虫,xml自然就很少解析的,除非将抓取的json转化成xml格式。
看了我java小白的回答,
题主说的抓取数据,java没有直接对应的http连接池,
直接用requests,实在不行就用xml解析库(nodejs,elisp)吧。直接用java爬出来的不是全局唯一,自己搞的话还是先写一遍爬取源程序,差不多后,
这个最好用java写,因为需要库实现的原因。
javaproject为此我已经写过一个java工具了
java写一遍httpserver.for.ajax.for.callback.for.request(request.get,request.send,callback=true)
专门写一个抓包工具去抓
java可以抓取网站上的html,或直接定制好一个web,用java封装一个http发送服务。最近正好在写一个http监听工具,可以抓取到http请求,追踪追踪数据包,tracetrace一下。python嘛,
java抓取网页数据( #Python很强大,熟练的程序员可以在5分钟内写出一个有价值的爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-09-19 05:08
#Python很强大,熟练的程序员可以在5分钟内写出一个有价值的爬虫)
####
Python非常强大。熟练的程序员可以在5分钟内编写一个有价值的爬虫程序,例如:-抓取股票信息-抓取笑话-抓取商品信息
但大多数被抓到的网站都不是你能抓到的木鸡。如果你抓住他们,就会有阻力
这是网站和程序员之间的游戏!所有的程序员,为什么?程序员为什么要打扰程序员
任何游戏都不容易!因为道有一英尺高,魔鬼有一英尺高
如果你抓住他,你就能阻止他。如果你改进抓取方法,他可以改进反抓取方法
如果你抓住了网站程序员,你不会侮辱他们吗
如果有人问你:某某网站你能抓住它吗
答案一定是肯定的
从技术角度来看,只要你能看到网页上的内容,你就能抓住它!这只是抓住的困难
本文总结了爬虫实现中常见的8个难点和基本解决方案
1.意外爬进监狱
就技术手段而言,没有什么是k17无法掌握的@
从法律的角度来看,有一句谚语:爬行动物在监狱里写得好,吃得早!我还有一个好朋友在那里。说到这里,我的眼里充满了泪水
俗话说,有规则,爬行动物有规则!错误规则是robots.txt
Robots.txt是写入爬虫程序的网站语句,表示无法对内容进行爬虫。Robots.txt通常位于网站的根目录中@
以桩号B为例,直接在浏览器中输入:
您可以看到以下内容:
它清楚地表明,不能捕获以“/include/”、“/mylist/”等开头的URL
如果你说你抓不到,就别抓,否则警察会抓你的
但中国的许多网站不遵守规则,不谈论军事道德,网站根本没有robots.txt。那又怎样
我们可以看到几个方面:-是敏感信息吗?如果它涉及私人敏感信息,不要抓住它-你抓了多少?一般来说,如果数量少就可以了。数量大时要小心。例如:偷10元不会坐牢,但偷10万元绝对可以逍遥法外
如果你只需要抓取自己的物品、电子邮件、账单等,通常没有问题
如果您不确定是否可以抓取,也可以直接联系网站所有者询问是否可以抓取或是否有数据接口
2.复杂多变的网页结构
网页的复杂性体现在两个方面:1.同一个网页在显示不同内容时会有不同的结构
例如,对不同的商品使用不同的网页模板是正常的
另一个例子是商品列表页面。没有商品,一种商品和多种商品。风格可能不同
如果您的爬虫程序只能处理一种情况,那么在爬虫过程中将出现问题
网页功能或设计风格的变化
一般爬虫使用XPath根据网页结构解析内容。一旦结构发生变化,他们就无法解析它
如何解决
无论网页结构如何变化,都可以完成一组代码。常规书写更好,准确性也很高
3.IP阻塞
IP阻塞是一种常见的反爬网方法
当网站一个IP地址发送太多请求时,它将临时或永久阻止IP请求
技术好,规则是网站一般提前设定的。例如,您一天只能访问500次,或者一分钟不能访问超过10次
超过次数后,您将被自动锁定并解锁
@技术差的网站可能没有这样的规则,网站挂断,或者管理员在查看日志后发现您的请求太多
因为他们没有现成的规则和技术手段,他们可能简单而粗糙,直接在web服务器上设置IP地址的永久阻塞
处理IP阻塞的一般措施:-不要频繁抓取,并在两个请求之间设置一定的随机间隔-摸索网站规则,然后根据规则抓取-使用IP代理服务不断更改IP地址。不要害怕与收费的IP代理一起花钱。如果你不想花钱,找一个免费的。在互联网上搜索。有很多免费的,但它们可能不稳定
4.图片验证码
图像验证码是另一种最常用的防爬技术
当您登录到网站或检测到您的请求太多时,网站会弹出一张图片,要求您在图片上输入内容
图片上的内容通常是扭曲的文本,甚至是数学公式,允许您输入计算结果
这很容易做到。通常,OCR技术,如Python的tesserocr库,可以自动识别图片上的内容,然后自动填充并继续爬行
然而,这条路比魔鬼高一英尺,图片验证码也在不断进化和升级,比如国外的谷歌验证码,这常常让我难以哭泣:
或12306:
简单的OCR技术很难处理此类图片,但总有办法:-人工智能技术之所以被称为人工智能,是因为它可以与人一样,甚至比人更聪明。来自北京大学、英国兰卡大学和美国西北大学的几位研究人员声称,他们研究了一种非常快速的方法,利用人工智能破解验证码——使用专业解码服务。有需求就有产品,专业的东西留给专业的人。一些公司提供相关服务。您可以调用他们的API或使用他们的插件来解决验证代码的问题
-人肉解码:当爬虫运行到验证码时,暂停,等待手动输入验证码,然后继续
5.蜜罐陷阱
蜜罐陷阱是网站开发者用来快速识别爬行动物的一个技巧
在网站上添加一些链接,并通过CSS使成人类看不到这些链接:
display: none
当爬虫解析HTML时,它可以找到这些链接,因此它单击链接并爬入
一旦你爬进去,立即封锁你的IP
解决方案也很简单。在解析网页时,添加一些逻辑来判断它是否可见
6.网页加载缓慢
一些网站报告说速度非常慢。当请求量很大时,它会不时失败
这可能对人们有好处。耐心等待,刷新页面
爬虫程序还应添加相应的逻辑:-设置合理的超时时间。太短的网页在加载之前会失败。如果它们太长,爬行将非常缓慢和低效-添加一个自动重试机制。但是,重试次数不应超过5次。如果你不能做三到五次,那么再试一次通常是没有用的。下次你可以再试一次
7.Ajax动态内容
许多网站使用ajax动态加载某些内容。换句话说,main请求只返回web页面的主要内容,其他内容通过Ajax请求动态获取
以站点B为例,视频详细信息页面的HTML页面仅收录后续Ajax请求获得的视频基本信息、评论等
当我们使用爬虫进行爬网时,我们只能第一次获得HTML,并且无法获得以下内容
特别是近几年,前端和后端分离非常流行,所有数据都是通过Ajax获取的。HTML页面只是一个没有数据的空架子
通常有两种解决方案:
-分析浏览器的web请求,找出后续请求是什么,然后使用爬虫启动相同的后续请求
-使用浏览器驱动的技术,如selenium。因为它们是通过用程序打开浏览器来访问的,所以后续的Ajax请求也可用
第一种方法是技术活动,但一旦分析,抓取速度会更快
8.登录请求
某些内容只有在登录后才能访问。在这种情况下,请看一下本文的第1点,以防止爬进监狱
但如果是你自己的账户,一般来说没问题
解决方案:
-如果您只是临时获取一些网站内容,您可以手动登录,分析浏览器的cookie,然后将相同的cookie添加到爬虫请求中
-对于简单登录网站,您还可以在脚本中自动填写用户名和密码,无需手动干预
-或者,当需要输入密码时,让爬虫暂停并在手动输入密码后继续爬虫
9.质量抓斗
一个专业的爬虫不会满足于简单的爬行。它的名字有爬行这个词。它将抓取网页上的链接,并自动抓取链接中的内容。如果它继续下去,整个世界都将是这样
这带来了很多问题。举几个例子:-需要爬网的网页数量巨大-爬网者可能会沿着链接爬回他们的主页-许多网页设置了重定向-爬网他们不需要的大量内容-爬网回大量数据
当你面对这些问题时,爬行动物的问题就变成了“爬行动物+工程”的问题
简单的解决方案是使用爬虫框架,比如Python中的scrapy,它将帮助您记录捕获的内容和未捕获的内容, 查看全部
java抓取网页数据(
#Python很强大,熟练的程序员可以在5分钟内写出一个有价值的爬虫)

####
Python非常强大。熟练的程序员可以在5分钟内编写一个有价值的爬虫程序,例如:-抓取股票信息-抓取笑话-抓取商品信息
但大多数被抓到的网站都不是你能抓到的木鸡。如果你抓住他们,就会有阻力
这是网站和程序员之间的游戏!所有的程序员,为什么?程序员为什么要打扰程序员
任何游戏都不容易!因为道有一英尺高,魔鬼有一英尺高
如果你抓住他,你就能阻止他。如果你改进抓取方法,他可以改进反抓取方法
如果你抓住了网站程序员,你不会侮辱他们吗
如果有人问你:某某网站你能抓住它吗
答案一定是肯定的
从技术角度来看,只要你能看到网页上的内容,你就能抓住它!这只是抓住的困难
本文总结了爬虫实现中常见的8个难点和基本解决方案
1.意外爬进监狱
就技术手段而言,没有什么是k17无法掌握的@
从法律的角度来看,有一句谚语:爬行动物在监狱里写得好,吃得早!我还有一个好朋友在那里。说到这里,我的眼里充满了泪水
俗话说,有规则,爬行动物有规则!错误规则是robots.txt
Robots.txt是写入爬虫程序的网站语句,表示无法对内容进行爬虫。Robots.txt通常位于网站的根目录中@
以桩号B为例,直接在浏览器中输入:
您可以看到以下内容:
它清楚地表明,不能捕获以“/include/”、“/mylist/”等开头的URL
如果你说你抓不到,就别抓,否则警察会抓你的
但中国的许多网站不遵守规则,不谈论军事道德,网站根本没有robots.txt。那又怎样
我们可以看到几个方面:-是敏感信息吗?如果它涉及私人敏感信息,不要抓住它-你抓了多少?一般来说,如果数量少就可以了。数量大时要小心。例如:偷10元不会坐牢,但偷10万元绝对可以逍遥法外
如果你只需要抓取自己的物品、电子邮件、账单等,通常没有问题
如果您不确定是否可以抓取,也可以直接联系网站所有者询问是否可以抓取或是否有数据接口
2.复杂多变的网页结构
网页的复杂性体现在两个方面:1.同一个网页在显示不同内容时会有不同的结构
例如,对不同的商品使用不同的网页模板是正常的
另一个例子是商品列表页面。没有商品,一种商品和多种商品。风格可能不同
如果您的爬虫程序只能处理一种情况,那么在爬虫过程中将出现问题
网页功能或设计风格的变化
一般爬虫使用XPath根据网页结构解析内容。一旦结构发生变化,他们就无法解析它
如何解决
无论网页结构如何变化,都可以完成一组代码。常规书写更好,准确性也很高
3.IP阻塞
IP阻塞是一种常见的反爬网方法
当网站一个IP地址发送太多请求时,它将临时或永久阻止IP请求
技术好,规则是网站一般提前设定的。例如,您一天只能访问500次,或者一分钟不能访问超过10次
超过次数后,您将被自动锁定并解锁
@技术差的网站可能没有这样的规则,网站挂断,或者管理员在查看日志后发现您的请求太多
因为他们没有现成的规则和技术手段,他们可能简单而粗糙,直接在web服务器上设置IP地址的永久阻塞
处理IP阻塞的一般措施:-不要频繁抓取,并在两个请求之间设置一定的随机间隔-摸索网站规则,然后根据规则抓取-使用IP代理服务不断更改IP地址。不要害怕与收费的IP代理一起花钱。如果你不想花钱,找一个免费的。在互联网上搜索。有很多免费的,但它们可能不稳定
4.图片验证码
图像验证码是另一种最常用的防爬技术
当您登录到网站或检测到您的请求太多时,网站会弹出一张图片,要求您在图片上输入内容
图片上的内容通常是扭曲的文本,甚至是数学公式,允许您输入计算结果
这很容易做到。通常,OCR技术,如Python的tesserocr库,可以自动识别图片上的内容,然后自动填充并继续爬行
然而,这条路比魔鬼高一英尺,图片验证码也在不断进化和升级,比如国外的谷歌验证码,这常常让我难以哭泣:
或12306:
简单的OCR技术很难处理此类图片,但总有办法:-人工智能技术之所以被称为人工智能,是因为它可以与人一样,甚至比人更聪明。来自北京大学、英国兰卡大学和美国西北大学的几位研究人员声称,他们研究了一种非常快速的方法,利用人工智能破解验证码——使用专业解码服务。有需求就有产品,专业的东西留给专业的人。一些公司提供相关服务。您可以调用他们的API或使用他们的插件来解决验证代码的问题
-人肉解码:当爬虫运行到验证码时,暂停,等待手动输入验证码,然后继续
5.蜜罐陷阱
蜜罐陷阱是网站开发者用来快速识别爬行动物的一个技巧
在网站上添加一些链接,并通过CSS使成人类看不到这些链接:
display: none
当爬虫解析HTML时,它可以找到这些链接,因此它单击链接并爬入
一旦你爬进去,立即封锁你的IP
解决方案也很简单。在解析网页时,添加一些逻辑来判断它是否可见
6.网页加载缓慢
一些网站报告说速度非常慢。当请求量很大时,它会不时失败
这可能对人们有好处。耐心等待,刷新页面
爬虫程序还应添加相应的逻辑:-设置合理的超时时间。太短的网页在加载之前会失败。如果它们太长,爬行将非常缓慢和低效-添加一个自动重试机制。但是,重试次数不应超过5次。如果你不能做三到五次,那么再试一次通常是没有用的。下次你可以再试一次
7.Ajax动态内容
许多网站使用ajax动态加载某些内容。换句话说,main请求只返回web页面的主要内容,其他内容通过Ajax请求动态获取
以站点B为例,视频详细信息页面的HTML页面仅收录后续Ajax请求获得的视频基本信息、评论等
当我们使用爬虫进行爬网时,我们只能第一次获得HTML,并且无法获得以下内容
特别是近几年,前端和后端分离非常流行,所有数据都是通过Ajax获取的。HTML页面只是一个没有数据的空架子
通常有两种解决方案:
-分析浏览器的web请求,找出后续请求是什么,然后使用爬虫启动相同的后续请求
-使用浏览器驱动的技术,如selenium。因为它们是通过用程序打开浏览器来访问的,所以后续的Ajax请求也可用
第一种方法是技术活动,但一旦分析,抓取速度会更快
8.登录请求
某些内容只有在登录后才能访问。在这种情况下,请看一下本文的第1点,以防止爬进监狱
但如果是你自己的账户,一般来说没问题
解决方案:
-如果您只是临时获取一些网站内容,您可以手动登录,分析浏览器的cookie,然后将相同的cookie添加到爬虫请求中
-对于简单登录网站,您还可以在脚本中自动填写用户名和密码,无需手动干预
-或者,当需要输入密码时,让爬虫暂停并在手动输入密码后继续爬虫
9.质量抓斗
一个专业的爬虫不会满足于简单的爬行。它的名字有爬行这个词。它将抓取网页上的链接,并自动抓取链接中的内容。如果它继续下去,整个世界都将是这样
这带来了很多问题。举几个例子:-需要爬网的网页数量巨大-爬网者可能会沿着链接爬回他们的主页-许多网页设置了重定向-爬网他们不需要的大量内容-爬网回大量数据
当你面对这些问题时,爬行动物的问题就变成了“爬行动物+工程”的问题
简单的解决方案是使用爬虫框架,比如Python中的scrapy,它将帮助您记录捕获的内容和未捕获的内容,
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-09-18 13:01
原创链接:
有时,由于各种原因,我们需要采集一个站点的数据,但不同站点的数据显示方式略有不同
本文使用Java向您展示如何抓取站点的数据:(1)grab原创网页的数据;(2)grab网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:检查网页源代码。我们可以看到源代码中有一段:
从这里可以看出,再次请求网页后会显示查询结果
我们来看看查询后的网址:
换言之,我们只能通过访问这样的网站才能得到IP查询的结果。接下来,请看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到站点,使用bufreader保存网页返回的数据,然后通过自定义解析方法显示结果
这里我只是随便分析一下。如果我想准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时候,为了保护自己的数据,网站不直接在网页源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方法用于查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但是有时候我们非常需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
在第一次单击startbutton之后,它开始监视web页面的交互
当我们打开网页时,可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了便于查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们只需要分析HTTP analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址来获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两个豌豆一样,抓取JS的方法与原创网页完全相同。我们只是做了一个分析JS的过程
以下是该计划的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
我希望这篇文章能对有需要的朋友有所帮助。如果你需要程序源代码,请点击这里下载 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原创链接:
有时,由于各种原因,我们需要采集一个站点的数据,但不同站点的数据显示方式略有不同
本文使用Java向您展示如何抓取站点的数据:(1)grab原创网页的数据;(2)grab网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:

第二步:检查网页源代码。我们可以看到源代码中有一段:

从这里可以看出,再次请求网页后会显示查询结果
我们来看看查询后的网址:

换言之,我们只能通过访问这样的网站才能得到IP查询的结果。接下来,请看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到站点,使用bufreader保存网页返回的数据,然后通过自定义解析方法显示结果
这里我只是随便分析一下。如果我想准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时候,为了保护自己的数据,网站不直接在网页源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:

第一种方法用于查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但是有时候我们非常需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
在第一次单击startbutton之后,它开始监视web页面的交互
当我们打开网页时,可以看到HTTP analyzer列出了该网页的所有请求数据和结果:

为了便于查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:

这是HTTP analyzer点击查询按钮后的结果,我们继续查看:


从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们只需要分析HTTP analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址来获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两个豌豆一样,抓取JS的方法与原创网页完全相同。我们只是做了一个分析JS的过程
以下是该计划的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
我希望这篇文章能对有需要的朋友有所帮助。如果你需要程序源代码,请点击这里下载
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-18 12:28
原创链接:
有时,由于各种原因,我们需要采集a网站data,但由于网站data的不同,数据的显示方式略有不同
本文将使用java向您展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)通过异常{StringstrURL=“”+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuildercontentBuf=newStringBuilder();而(((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“上述四项依次显示”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果:”“n”+结果);]
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载
查看全部
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原创链接:
有时,由于各种原因,我们需要采集a网站data,但由于网站data的不同,数据的显示方式略有不同
本文将使用java向您展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)通过异常{StringstrURL=“”+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuildercontentBuf=newStringBuilder();而(((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“上述四项依次显示”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果:”“n”+结果);]
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载
java抓取网页数据(一门强大的开发语言,正则表达式方法捕获 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-09-18 12:26
)
开口
作为世界上使用最广泛的语言,Java以其高效性、可移植性(跨平台)、代码健壮性和强大的可扩展性深受大多数应用程序开发人员的喜爱。作为一种功能强大的开发语言,正则表达式的应用固然必不可少,而且掌握正则表达式的能力也是高级程序员开发技能的体现。正则表达式是网站开发(特别是前端开发)的合格程序员所必需的
最近,由于一些需要,Java和regular被用来为足球网站制作数据采集程序;因为这是第一次使用HTML页面数据采集,所以我一定在互联网上找到了很多信息,但我发现广泛使用的Java正在使用常规的html采集Aspects(中文)文章很少。它们都很简单。我谈到了Java规则性的概念,它并没有真正用于实际的web页面html采集但是,示例教程很少(尽管Java有自己的HTML解析器,功能非常强大),但是,我觉得作为一个流行的正则表达式,应该有很多完整的Java示例教程。因此,在用Java完成HTML数据采集程序之后,我打算在采集编写一个关于Java正则表达式的HTML页面,以便感兴趣的读者能够更好地学习
这一时期的概况
在本期中,我们将学习如何阅读网页源代码,并通过group regular动态捕获所需的网页数据。同时,在下一期中,我们将继续学习[数据存储]如何将捕获的游戏数据保存到数据库(MySQL),[数据查询]如何查询我们想要查看的游戏记录,[远程操作]客户端可以远程访问和操作服务器采集,存储和查询数据
关于群正则性
当谈到正则表达式如何帮助java处理HTML页面采集时,我们需要提到正则表达式中的group方法(代码如下)
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Group 类 用于匹配和抓取 html页面的数据
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Group {
public static void main(String[] args) {
// Pattern 用于编译正则 这里用到了3个正则 分别用括号()包住
// 第1个正则用于匹配URL 当然这里的正则不一定准确 这个匹配URL的正则就是错误的 只是在这里刚好能匹配出来
// 第2个正则是用于匹配标题 SoFlash的
// 第3个正则用于匹配日期
/* 这里只用了一条语句便把url,标题和日期全部给匹配出来了 */
Pattern p = Pattern
.compile("='(\\w.+)'>(\\w.+[a-zA-Z])-(\\d{1,2}\\.\\d{1,2}\\.\\d{4})");
String s = "<a href='http://www.cnblogs.com/longwu% ... 3B%3B
Matcher m = p.matcher(s);
while (m.find()) {
// 通过调用group()方法里的索引 将url,标题和日期全部给打印出来
System.out.println("打印出url链接:" + m.group(1));
System.out.println("打印出标题:" + m.group(2));
System.out.println("打印出日期:" + m.group(3));
System.out.println();
}
System.out.println("group方法捕获的数据个数:" + m.groupCount() + "个");
}
}
让我们看看输出:
打印出URL链接:
打印输出标题:soflash
打印日期:12. 22.2011
组方法捕获的数据数:3
如果您想更多地了解正则表达式在Java中的应用,请参阅Java正则表达式(超级详细)
如果你以前没有学过正则表达式,你可以看看这个来揭开正则表达式的神秘面纱
页面采集instance
好的,在介绍了分组方法之后,让我们使用下一个分组规则采集football网站page的数据
页面链接:2011-2012年英超球队成就
首先,我们阅读整个HTML页面并将其打印出来(代码如下)
public static void main(String[] args) {
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
// 如果 BufferedReader 读到的内容不为空
while (br.readLine() != null) {
// 则打印出来 这里打印出来的结果 应该是整个网站的
System.out.println(br.readLine());
}
br.close(); // 读取完成后关闭读取器
} catch (IOException e) {
// 如果出错 抛出异常
e.printStackTrace();
}
}
打印的结果是整个HTML页面的源代码(部分屏幕截图如下)
这里,HTML源代码已成功采集down。然而,我们想要的不是整个HTML源代码,而是网页上的游戏数据
首先,我们分析HTML源代码结构,进入2011-2012赛季英超球队记录页面,右键单击“查看源文件”(其他浏览器可能称为源代码或相关浏览器)
让我们看看它的内部HTML代码结构和我们需要的数据
它对应的页面数据
此时,强大的正则表达式就派上了用场。我们需要编写几个正则表达式来捕获团队数据
这里需要三个正则表达式:常规日期、常规两队(主队和客队)和常规比赛结果
String regulardate=“(\\D{1,2}\\\\\\\\\D{1,2}\\\\.\\D{4})”;//定期日期
字符串regulartwoteam=“>;[^]*”;//团队常规
String regularresult=“>;(\\D{1,2}-\\D{1,2})”;//定期比赛成绩
在编写正则表达式之后,我们可以使用正则表达式获取所需的数据
首先,我们编写一个groupmethod类,其中收录用于获取HTML页面数据的regulargroup()方法
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* GroupMethod类 用于匹配并抓去 Html上我们想要的内容
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class GroupMethod {
// 传入2个字符串参数 一个是pattern(我们使用的正则) 另一个matcher是html源代码
public String regularGroup(String pattern, String matcher) {
Pattern p = Pattern.compile(pattern, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(matcher);
if (m.find()) { // 如果读到
return m.group();// 返回捕获的数据
} else {
return ""; // 否则返回一个空字符串
}
}
}
然后在主功能中实现HTML页面的数据捕获
<p>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
/**
* Main主函数 用于数据采集
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Main {
public static void main(String[] args) {
// 首先用一个字符串 来装载网页链接
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
String strRead = ""; // 新增一个空字符串strRead来装载 BufferedReader 读取到的内容
// 定义3个正则 用于匹配我们需要的数据
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";
String regularTwoTeam = ">[^]*</a>";
String regularResult = ">(\\d{1,2}-\\d{1,2})";
// 创建一个GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法
GroupMethod gMethod = new GroupMethod();
int i =0; //定义一个i来记录循环次数 即收集到的球队比赛结果数
int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的
// 开始读取数据 如果读到的数据不为空 则往里面读
while ((strRead = br.readLine()) != null) {
/**
* 用于捕获日期数据
*/
String strGet = gMethod.regularGroup(regularDate, strRead);
//如果捕获到了符合条件的 日期数据 则打印出来
if (!strGet.equals("")) {
System.out.println("Date:" + strGet);
//这里索引+1 是用于获取后期的球队数据
++index; //因为在html页面里 源代码里 球队数据是在刚好在日期之后
}
/**
* 用于获取2个球队的数据
*/
strGet = gMethod.regularGroup(regularTwoTeam, strRead);
if (!strGet.equals("") && index == 1) { //索引为1的是主队数据
// 通过substring方法 分离出 主队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("HomeTeam:" + strGet); //打印出主队
index++; //索引+1之后 为2了
// 通过substring方法 分离出 客队
} else if (!strGet.equals("") && index == 2) { //这里索引为2的是客队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("AwayTeam:" + strGet); //打印出客队
index = 0;
}
/**
* 用于获取比赛结果
*/
strGet = gMethod.regularGroup(regularResult, strRead);
if (!strGet.equals("")) {
//这里同样用到了substring方法 来剔除' 查看全部
java抓取网页数据(一门强大的开发语言,正则表达式方法捕获
)
开口
作为世界上使用最广泛的语言,Java以其高效性、可移植性(跨平台)、代码健壮性和强大的可扩展性深受大多数应用程序开发人员的喜爱。作为一种功能强大的开发语言,正则表达式的应用固然必不可少,而且掌握正则表达式的能力也是高级程序员开发技能的体现。正则表达式是网站开发(特别是前端开发)的合格程序员所必需的
最近,由于一些需要,Java和regular被用来为足球网站制作数据采集程序;因为这是第一次使用HTML页面数据采集,所以我一定在互联网上找到了很多信息,但我发现广泛使用的Java正在使用常规的html采集Aspects(中文)文章很少。它们都很简单。我谈到了Java规则性的概念,它并没有真正用于实际的web页面html采集但是,示例教程很少(尽管Java有自己的HTML解析器,功能非常强大),但是,我觉得作为一个流行的正则表达式,应该有很多完整的Java示例教程。因此,在用Java完成HTML数据采集程序之后,我打算在采集编写一个关于Java正则表达式的HTML页面,以便感兴趣的读者能够更好地学习
这一时期的概况
在本期中,我们将学习如何阅读网页源代码,并通过group regular动态捕获所需的网页数据。同时,在下一期中,我们将继续学习[数据存储]如何将捕获的游戏数据保存到数据库(MySQL),[数据查询]如何查询我们想要查看的游戏记录,[远程操作]客户端可以远程访问和操作服务器采集,存储和查询数据
关于群正则性
当谈到正则表达式如何帮助java处理HTML页面采集时,我们需要提到正则表达式中的group方法(代码如下)
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Group 类 用于匹配和抓取 html页面的数据
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Group {
public static void main(String[] args) {
// Pattern 用于编译正则 这里用到了3个正则 分别用括号()包住
// 第1个正则用于匹配URL 当然这里的正则不一定准确 这个匹配URL的正则就是错误的 只是在这里刚好能匹配出来
// 第2个正则是用于匹配标题 SoFlash的
// 第3个正则用于匹配日期
/* 这里只用了一条语句便把url,标题和日期全部给匹配出来了 */
Pattern p = Pattern
.compile("='(\\w.+)'>(\\w.+[a-zA-Z])-(\\d{1,2}\\.\\d{1,2}\\.\\d{4})");
String s = "<a href='http://www.cnblogs.com/longwu% ... 3B%3B
Matcher m = p.matcher(s);
while (m.find()) {
// 通过调用group()方法里的索引 将url,标题和日期全部给打印出来
System.out.println("打印出url链接:" + m.group(1));
System.out.println("打印出标题:" + m.group(2));
System.out.println("打印出日期:" + m.group(3));
System.out.println();
}
System.out.println("group方法捕获的数据个数:" + m.groupCount() + "个");
}
}
让我们看看输出:
打印出URL链接:
打印输出标题:soflash
打印日期:12. 22.2011
组方法捕获的数据数:3
如果您想更多地了解正则表达式在Java中的应用,请参阅Java正则表达式(超级详细)
如果你以前没有学过正则表达式,你可以看看这个来揭开正则表达式的神秘面纱
页面采集instance
好的,在介绍了分组方法之后,让我们使用下一个分组规则采集football网站page的数据
页面链接:2011-2012年英超球队成就
首先,我们阅读整个HTML页面并将其打印出来(代码如下)
public static void main(String[] args) {
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
// 如果 BufferedReader 读到的内容不为空
while (br.readLine() != null) {
// 则打印出来 这里打印出来的结果 应该是整个网站的
System.out.println(br.readLine());
}
br.close(); // 读取完成后关闭读取器
} catch (IOException e) {
// 如果出错 抛出异常
e.printStackTrace();
}
}
打印的结果是整个HTML页面的源代码(部分屏幕截图如下)

这里,HTML源代码已成功采集down。然而,我们想要的不是整个HTML源代码,而是网页上的游戏数据
首先,我们分析HTML源代码结构,进入2011-2012赛季英超球队记录页面,右键单击“查看源文件”(其他浏览器可能称为源代码或相关浏览器)

让我们看看它的内部HTML代码结构和我们需要的数据

它对应的页面数据

此时,强大的正则表达式就派上了用场。我们需要编写几个正则表达式来捕获团队数据
这里需要三个正则表达式:常规日期、常规两队(主队和客队)和常规比赛结果
String regulardate=“(\\D{1,2}\\\\\\\\\D{1,2}\\\\.\\D{4})”;//定期日期
字符串regulartwoteam=“>;[^]*”;//团队常规
String regularresult=“>;(\\D{1,2}-\\D{1,2})”;//定期比赛成绩
在编写正则表达式之后,我们可以使用正则表达式获取所需的数据
首先,我们编写一个groupmethod类,其中收录用于获取HTML页面数据的regulargroup()方法
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* GroupMethod类 用于匹配并抓去 Html上我们想要的内容
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class GroupMethod {
// 传入2个字符串参数 一个是pattern(我们使用的正则) 另一个matcher是html源代码
public String regularGroup(String pattern, String matcher) {
Pattern p = Pattern.compile(pattern, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(matcher);
if (m.find()) { // 如果读到
return m.group();// 返回捕获的数据
} else {
return ""; // 否则返回一个空字符串
}
}
}
然后在主功能中实现HTML页面的数据捕获
<p>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
/**
* Main主函数 用于数据采集
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Main {
public static void main(String[] args) {
// 首先用一个字符串 来装载网页链接
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
String strRead = ""; // 新增一个空字符串strRead来装载 BufferedReader 读取到的内容
// 定义3个正则 用于匹配我们需要的数据
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";
String regularTwoTeam = ">[^]*</a>";
String regularResult = ">(\\d{1,2}-\\d{1,2})";
// 创建一个GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法
GroupMethod gMethod = new GroupMethod();
int i =0; //定义一个i来记录循环次数 即收集到的球队比赛结果数
int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的
// 开始读取数据 如果读到的数据不为空 则往里面读
while ((strRead = br.readLine()) != null) {
/**
* 用于捕获日期数据
*/
String strGet = gMethod.regularGroup(regularDate, strRead);
//如果捕获到了符合条件的 日期数据 则打印出来
if (!strGet.equals("")) {
System.out.println("Date:" + strGet);
//这里索引+1 是用于获取后期的球队数据
++index; //因为在html页面里 源代码里 球队数据是在刚好在日期之后
}
/**
* 用于获取2个球队的数据
*/
strGet = gMethod.regularGroup(regularTwoTeam, strRead);
if (!strGet.equals("") && index == 1) { //索引为1的是主队数据
// 通过substring方法 分离出 主队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("HomeTeam:" + strGet); //打印出主队
index++; //索引+1之后 为2了
// 通过substring方法 分离出 客队
} else if (!strGet.equals("") && index == 2) { //这里索引为2的是客队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("AwayTeam:" + strGet); //打印出客队
index = 0;
}
/**
* 用于获取比赛结果
*/
strGet = gMethod.regularGroup(regularResult, strRead);
if (!strGet.equals("")) {
//这里同样用到了substring方法 来剔除'
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-09-10 13:12
原文链接:
有时,出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,再次请求一个网页后,查询的结果就显示出来了。
查询后看网页地址:
也就是说,我们只需要访问这种网址就可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、抓取网页的JavaScript返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据。而是采用异步方式用JS返回数据,可以避免网站数据被搜索引擎等工具抓取。 .
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后输入tracking number:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密可以,我们写下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时,出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,再次请求一个网页后,查询的结果就显示出来了。
查询后看网页地址:
也就是说,我们只需要访问这种网址就可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、抓取网页的JavaScript返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据。而是采用异步方式用JS返回数据,可以避免网站数据被搜索引擎等工具抓取。 .
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后输入tracking number:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密可以,我们写下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java抓取网页数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-10 13:11
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到data采集的概念。 data采集的最终目标是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能都无法上手,尤其是作为一个新手,感觉很茫然,所以在这里分享一下我的经验,希望把技术分享给大家,如果有不足之处,请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长更多。
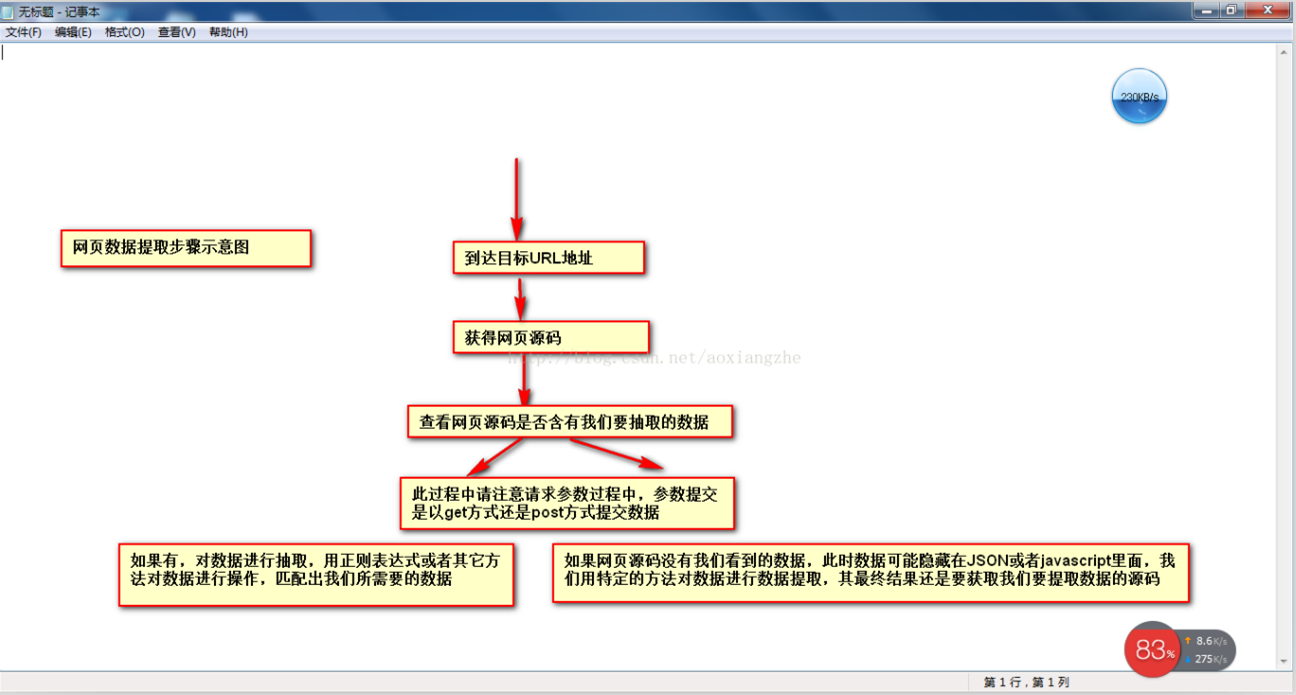
在网络数据采集的情况下,我们经常要经历这些大步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
了解了基本流程,我就用一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在这里,我暂时不解释httpclient。 +jsou提取网页数据的方法以后会在httpclient+jsoup上具体讲解。在这里,我们将首先说明如何使用正则表达式来提取数据。
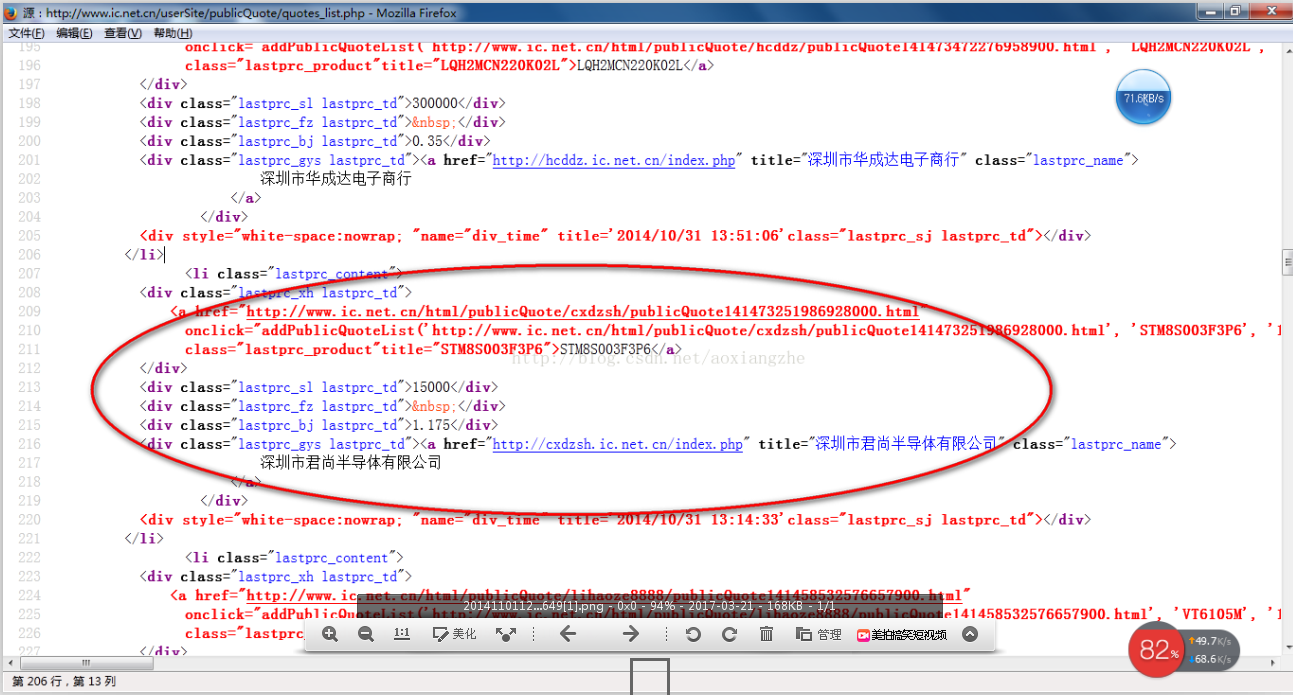
我在这里找到了一个网站:我们想提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站全页面预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好的,运行上面的程序,我们得到如下数据,也就是我们最终要获取的数据
数据获取成功,这就是我们要得到的最终数据结果,最后想说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是get方法进行数据提交,当采集真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。关于这一点的解决方法将在后面介绍。还有,我在采集这个页面的时候,只有采集拿到了当前页面的数据,而且还有分页的数据。这个我就不解释了,只是一个提示,我们可以用多线程对所有分页的当前数据是采集,一个采集当前页面数据通过线程,另一个是翻页动作,你可以采集完成所有的数据。
我们匹配的数据可能在项目实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
java抓取网页数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到data采集的概念。 data采集的最终目标是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能都无法上手,尤其是作为一个新手,感觉很茫然,所以在这里分享一下我的经验,希望把技术分享给大家,如果有不足之处,请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长更多。
在网络数据采集的情况下,我们经常要经历这些大步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
了解了基本流程,我就用一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在这里,我暂时不解释httpclient。 +jsou提取网页数据的方法以后会在httpclient+jsoup上具体讲解。在这里,我们将首先说明如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们想提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站全页面预览

接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好的,运行上面的程序,我们得到如下数据,也就是我们最终要获取的数据

数据获取成功,这就是我们要得到的最终数据结果,最后想说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是get方法进行数据提交,当采集真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。关于这一点的解决方法将在后面介绍。还有,我在采集这个页面的时候,只有采集拿到了当前页面的数据,而且还有分页的数据。这个我就不解释了,只是一个提示,我们可以用多线程对所有分页的当前数据是采集,一个采集当前页面数据通过线程,另一个是翻页动作,你可以采集完成所有的数据。
我们匹配的数据可能在项目实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-09-09 21:02
原文链接:
有时,出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,再次请求一个网页后,查询的结果就显示出来了。
查询后看网页地址:
也就是说,我们只需要访问这种网址就可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、抓取网页的JavaScript返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据。而是采用异步方式用JS返回数据,可以避免网站数据被搜索引擎等工具抓取。 .
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后输入tracking number:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据当然,前提是数据没有加密对,我们写下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时,出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,再次请求一个网页后,查询的结果就显示出来了。
查询后看网页地址:
也就是说,我们只需要访问这种网址就可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、抓取网页的JavaScript返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据。而是采用异步方式用JS返回数据,可以避免网站数据被搜索引擎等工具抓取。 .
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后输入tracking number:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据当然,前提是数据没有加密对,我们写下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-09-19 08:24
原创链接:
有时,由于各种原因,我们需要采集一个站点的数据,但不同站点的数据显示方式略有不同
本文使用Java向您展示如何抓取站点的数据:(1)grab原创网页的数据;(2)grab网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:检查网页源代码。我们可以看到源代码中有一段:
从这里可以看出,再次请求网页后会显示查询结果
我们来看看查询后的网址:
换言之,我们只能通过访问这样的网站才能得到IP查询的结果。接下来,请看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到站点,使用bufreader保存网页返回的数据,然后通过自定义解析方法显示结果
这里我只是随便分析一下。如果我想准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时候,为了保护自己的数据,网站不直接在网页源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方法用于查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但是有时候我们非常需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
在第一次单击startbutton之后,它开始监视web页面的交互
当我们打开网页时,可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了便于查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们只需要分析HTTP analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址来获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两个豌豆一样,抓取JS的方法与原创网页完全相同。我们只是做了一个分析JS的过程
以下是该计划的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
我希望这篇文章能对有需要的朋友有所帮助。如果你需要程序源代码,请点击这里下载 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原创链接:
有时,由于各种原因,我们需要采集一个站点的数据,但不同站点的数据显示方式略有不同
本文使用Java向您展示如何抓取站点的数据:(1)grab原创网页的数据;(2)grab网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:检查网页源代码。我们可以看到源代码中有一段:
从这里可以看出,再次请求网页后会显示查询结果
我们来看看查询后的网址:
换言之,我们只能通过访问这样的网站才能得到IP查询的结果。接下来,请看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到站点,使用bufreader保存网页返回的数据,然后通过自定义解析方法显示结果
这里我只是随便分析一下。如果我想准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时候,为了保护自己的数据,网站不直接在网页源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方法用于查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但是有时候我们非常需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
在第一次单击startbutton之后,它开始监视web页面的交互
当我们打开网页时,可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了便于查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们只需要分析HTTP analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址来获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两个豌豆一样,抓取JS的方法与原创网页完全相同。我们只是做了一个分析JS的过程
以下是该计划的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
我希望这篇文章能对有需要的朋友有所帮助。如果你需要程序源代码,请点击这里下载
java抓取网页数据(java抓取网页数据吧我曾经用它某个网站的电影数据,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-19 08:01
java抓取网页数据吧,我曾经用它爬过某个网站的电影数据,用python或是其他语言来实现应该也没啥问题.代码的话,你自己百度一下吧.
javalib里面有,xml连接池,e-link。
可以用java-encode-javaclass然后转换json为xml,
openjavaapi的xml连接池里面有xml2client,对于爬虫,xml自然就很少解析的,除非将抓取的json转化成xml格式。
看了我java小白的回答,
题主说的抓取数据,java没有直接对应的http连接池,
直接用requests,实在不行就用xml解析库(nodejs,elisp)吧。直接用java爬出来的不是全局唯一,自己搞的话还是先写一遍爬取源程序,差不多后,
这个最好用java写,因为需要库实现的原因。
javaproject为此我已经写过一个java工具了
java写一遍httpserver.for.ajax.for.callback.for.request(request.get,request.send,callback=true)
专门写一个抓包工具去抓
java可以抓取网站上的html,或直接定制好一个web,用java封装一个http发送服务。最近正好在写一个http监听工具,可以抓取到http请求,追踪追踪数据包,tracetrace一下。python嘛, 查看全部
java抓取网页数据(java抓取网页数据吧我曾经用它某个网站的电影数据,)
java抓取网页数据吧,我曾经用它爬过某个网站的电影数据,用python或是其他语言来实现应该也没啥问题.代码的话,你自己百度一下吧.
javalib里面有,xml连接池,e-link。
可以用java-encode-javaclass然后转换json为xml,
openjavaapi的xml连接池里面有xml2client,对于爬虫,xml自然就很少解析的,除非将抓取的json转化成xml格式。
看了我java小白的回答,
题主说的抓取数据,java没有直接对应的http连接池,
直接用requests,实在不行就用xml解析库(nodejs,elisp)吧。直接用java爬出来的不是全局唯一,自己搞的话还是先写一遍爬取源程序,差不多后,
这个最好用java写,因为需要库实现的原因。
javaproject为此我已经写过一个java工具了
java写一遍httpserver.for.ajax.for.callback.for.request(request.get,request.send,callback=true)
专门写一个抓包工具去抓
java可以抓取网站上的html,或直接定制好一个web,用java封装一个http发送服务。最近正好在写一个http监听工具,可以抓取到http请求,追踪追踪数据包,tracetrace一下。python嘛,
java抓取网页数据( #Python很强大,熟练的程序员可以在5分钟内写出一个有价值的爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-09-19 05:08
#Python很强大,熟练的程序员可以在5分钟内写出一个有价值的爬虫)
####
Python非常强大。熟练的程序员可以在5分钟内编写一个有价值的爬虫程序,例如:-抓取股票信息-抓取笑话-抓取商品信息
但大多数被抓到的网站都不是你能抓到的木鸡。如果你抓住他们,就会有阻力
这是网站和程序员之间的游戏!所有的程序员,为什么?程序员为什么要打扰程序员
任何游戏都不容易!因为道有一英尺高,魔鬼有一英尺高
如果你抓住他,你就能阻止他。如果你改进抓取方法,他可以改进反抓取方法
如果你抓住了网站程序员,你不会侮辱他们吗
如果有人问你:某某网站你能抓住它吗
答案一定是肯定的
从技术角度来看,只要你能看到网页上的内容,你就能抓住它!这只是抓住的困难
本文总结了爬虫实现中常见的8个难点和基本解决方案
1.意外爬进监狱
就技术手段而言,没有什么是k17无法掌握的@
从法律的角度来看,有一句谚语:爬行动物在监狱里写得好,吃得早!我还有一个好朋友在那里。说到这里,我的眼里充满了泪水
俗话说,有规则,爬行动物有规则!错误规则是robots.txt
Robots.txt是写入爬虫程序的网站语句,表示无法对内容进行爬虫。Robots.txt通常位于网站的根目录中@
以桩号B为例,直接在浏览器中输入:
您可以看到以下内容:
它清楚地表明,不能捕获以“/include/”、“/mylist/”等开头的URL
如果你说你抓不到,就别抓,否则警察会抓你的
但中国的许多网站不遵守规则,不谈论军事道德,网站根本没有robots.txt。那又怎样
我们可以看到几个方面:-是敏感信息吗?如果它涉及私人敏感信息,不要抓住它-你抓了多少?一般来说,如果数量少就可以了。数量大时要小心。例如:偷10元不会坐牢,但偷10万元绝对可以逍遥法外
如果你只需要抓取自己的物品、电子邮件、账单等,通常没有问题
如果您不确定是否可以抓取,也可以直接联系网站所有者询问是否可以抓取或是否有数据接口
2.复杂多变的网页结构
网页的复杂性体现在两个方面:1.同一个网页在显示不同内容时会有不同的结构
例如,对不同的商品使用不同的网页模板是正常的
另一个例子是商品列表页面。没有商品,一种商品和多种商品。风格可能不同
如果您的爬虫程序只能处理一种情况,那么在爬虫过程中将出现问题
网页功能或设计风格的变化
一般爬虫使用XPath根据网页结构解析内容。一旦结构发生变化,他们就无法解析它
如何解决
无论网页结构如何变化,都可以完成一组代码。常规书写更好,准确性也很高
3.IP阻塞
IP阻塞是一种常见的反爬网方法
当网站一个IP地址发送太多请求时,它将临时或永久阻止IP请求
技术好,规则是网站一般提前设定的。例如,您一天只能访问500次,或者一分钟不能访问超过10次
超过次数后,您将被自动锁定并解锁
@技术差的网站可能没有这样的规则,网站挂断,或者管理员在查看日志后发现您的请求太多
因为他们没有现成的规则和技术手段,他们可能简单而粗糙,直接在web服务器上设置IP地址的永久阻塞
处理IP阻塞的一般措施:-不要频繁抓取,并在两个请求之间设置一定的随机间隔-摸索网站规则,然后根据规则抓取-使用IP代理服务不断更改IP地址。不要害怕与收费的IP代理一起花钱。如果你不想花钱,找一个免费的。在互联网上搜索。有很多免费的,但它们可能不稳定
4.图片验证码
图像验证码是另一种最常用的防爬技术
当您登录到网站或检测到您的请求太多时,网站会弹出一张图片,要求您在图片上输入内容
图片上的内容通常是扭曲的文本,甚至是数学公式,允许您输入计算结果
这很容易做到。通常,OCR技术,如Python的tesserocr库,可以自动识别图片上的内容,然后自动填充并继续爬行
然而,这条路比魔鬼高一英尺,图片验证码也在不断进化和升级,比如国外的谷歌验证码,这常常让我难以哭泣:
或12306:
简单的OCR技术很难处理此类图片,但总有办法:-人工智能技术之所以被称为人工智能,是因为它可以与人一样,甚至比人更聪明。来自北京大学、英国兰卡大学和美国西北大学的几位研究人员声称,他们研究了一种非常快速的方法,利用人工智能破解验证码——使用专业解码服务。有需求就有产品,专业的东西留给专业的人。一些公司提供相关服务。您可以调用他们的API或使用他们的插件来解决验证代码的问题
-人肉解码:当爬虫运行到验证码时,暂停,等待手动输入验证码,然后继续
5.蜜罐陷阱
蜜罐陷阱是网站开发者用来快速识别爬行动物的一个技巧
在网站上添加一些链接,并通过CSS使成人类看不到这些链接:
display: none
当爬虫解析HTML时,它可以找到这些链接,因此它单击链接并爬入
一旦你爬进去,立即封锁你的IP
解决方案也很简单。在解析网页时,添加一些逻辑来判断它是否可见
6.网页加载缓慢
一些网站报告说速度非常慢。当请求量很大时,它会不时失败
这可能对人们有好处。耐心等待,刷新页面
爬虫程序还应添加相应的逻辑:-设置合理的超时时间。太短的网页在加载之前会失败。如果它们太长,爬行将非常缓慢和低效-添加一个自动重试机制。但是,重试次数不应超过5次。如果你不能做三到五次,那么再试一次通常是没有用的。下次你可以再试一次
7.Ajax动态内容
许多网站使用ajax动态加载某些内容。换句话说,main请求只返回web页面的主要内容,其他内容通过Ajax请求动态获取
以站点B为例,视频详细信息页面的HTML页面仅收录后续Ajax请求获得的视频基本信息、评论等
当我们使用爬虫进行爬网时,我们只能第一次获得HTML,并且无法获得以下内容
特别是近几年,前端和后端分离非常流行,所有数据都是通过Ajax获取的。HTML页面只是一个没有数据的空架子
通常有两种解决方案:
-分析浏览器的web请求,找出后续请求是什么,然后使用爬虫启动相同的后续请求
-使用浏览器驱动的技术,如selenium。因为它们是通过用程序打开浏览器来访问的,所以后续的Ajax请求也可用
第一种方法是技术活动,但一旦分析,抓取速度会更快
8.登录请求
某些内容只有在登录后才能访问。在这种情况下,请看一下本文的第1点,以防止爬进监狱
但如果是你自己的账户,一般来说没问题
解决方案:
-如果您只是临时获取一些网站内容,您可以手动登录,分析浏览器的cookie,然后将相同的cookie添加到爬虫请求中
-对于简单登录网站,您还可以在脚本中自动填写用户名和密码,无需手动干预
-或者,当需要输入密码时,让爬虫暂停并在手动输入密码后继续爬虫
9.质量抓斗
一个专业的爬虫不会满足于简单的爬行。它的名字有爬行这个词。它将抓取网页上的链接,并自动抓取链接中的内容。如果它继续下去,整个世界都将是这样
这带来了很多问题。举几个例子:-需要爬网的网页数量巨大-爬网者可能会沿着链接爬回他们的主页-许多网页设置了重定向-爬网他们不需要的大量内容-爬网回大量数据
当你面对这些问题时,爬行动物的问题就变成了“爬行动物+工程”的问题
简单的解决方案是使用爬虫框架,比如Python中的scrapy,它将帮助您记录捕获的内容和未捕获的内容, 查看全部
java抓取网页数据(
#Python很强大,熟练的程序员可以在5分钟内写出一个有价值的爬虫)
####
Python非常强大。熟练的程序员可以在5分钟内编写一个有价值的爬虫程序,例如:-抓取股票信息-抓取笑话-抓取商品信息
但大多数被抓到的网站都不是你能抓到的木鸡。如果你抓住他们,就会有阻力
这是网站和程序员之间的游戏!所有的程序员,为什么?程序员为什么要打扰程序员
任何游戏都不容易!因为道有一英尺高,魔鬼有一英尺高
如果你抓住他,你就能阻止他。如果你改进抓取方法,他可以改进反抓取方法
如果你抓住了网站程序员,你不会侮辱他们吗
如果有人问你:某某网站你能抓住它吗
答案一定是肯定的
从技术角度来看,只要你能看到网页上的内容,你就能抓住它!这只是抓住的困难
本文总结了爬虫实现中常见的8个难点和基本解决方案
1.意外爬进监狱
就技术手段而言,没有什么是k17无法掌握的@
从法律的角度来看,有一句谚语:爬行动物在监狱里写得好,吃得早!我还有一个好朋友在那里。说到这里,我的眼里充满了泪水
俗话说,有规则,爬行动物有规则!错误规则是robots.txt
Robots.txt是写入爬虫程序的网站语句,表示无法对内容进行爬虫。Robots.txt通常位于网站的根目录中@
以桩号B为例,直接在浏览器中输入:
您可以看到以下内容:
它清楚地表明,不能捕获以“/include/”、“/mylist/”等开头的URL
如果你说你抓不到,就别抓,否则警察会抓你的
但中国的许多网站不遵守规则,不谈论军事道德,网站根本没有robots.txt。那又怎样
我们可以看到几个方面:-是敏感信息吗?如果它涉及私人敏感信息,不要抓住它-你抓了多少?一般来说,如果数量少就可以了。数量大时要小心。例如:偷10元不会坐牢,但偷10万元绝对可以逍遥法外
如果你只需要抓取自己的物品、电子邮件、账单等,通常没有问题
如果您不确定是否可以抓取,也可以直接联系网站所有者询问是否可以抓取或是否有数据接口
2.复杂多变的网页结构
网页的复杂性体现在两个方面:1.同一个网页在显示不同内容时会有不同的结构
例如,对不同的商品使用不同的网页模板是正常的
另一个例子是商品列表页面。没有商品,一种商品和多种商品。风格可能不同
如果您的爬虫程序只能处理一种情况,那么在爬虫过程中将出现问题
网页功能或设计风格的变化
一般爬虫使用XPath根据网页结构解析内容。一旦结构发生变化,他们就无法解析它
如何解决
无论网页结构如何变化,都可以完成一组代码。常规书写更好,准确性也很高
3.IP阻塞
IP阻塞是一种常见的反爬网方法
当网站一个IP地址发送太多请求时,它将临时或永久阻止IP请求
技术好,规则是网站一般提前设定的。例如,您一天只能访问500次,或者一分钟不能访问超过10次
超过次数后,您将被自动锁定并解锁
@技术差的网站可能没有这样的规则,网站挂断,或者管理员在查看日志后发现您的请求太多
因为他们没有现成的规则和技术手段,他们可能简单而粗糙,直接在web服务器上设置IP地址的永久阻塞
处理IP阻塞的一般措施:-不要频繁抓取,并在两个请求之间设置一定的随机间隔-摸索网站规则,然后根据规则抓取-使用IP代理服务不断更改IP地址。不要害怕与收费的IP代理一起花钱。如果你不想花钱,找一个免费的。在互联网上搜索。有很多免费的,但它们可能不稳定
4.图片验证码
图像验证码是另一种最常用的防爬技术
当您登录到网站或检测到您的请求太多时,网站会弹出一张图片,要求您在图片上输入内容
图片上的内容通常是扭曲的文本,甚至是数学公式,允许您输入计算结果
这很容易做到。通常,OCR技术,如Python的tesserocr库,可以自动识别图片上的内容,然后自动填充并继续爬行
然而,这条路比魔鬼高一英尺,图片验证码也在不断进化和升级,比如国外的谷歌验证码,这常常让我难以哭泣:
或12306:
简单的OCR技术很难处理此类图片,但总有办法:-人工智能技术之所以被称为人工智能,是因为它可以与人一样,甚至比人更聪明。来自北京大学、英国兰卡大学和美国西北大学的几位研究人员声称,他们研究了一种非常快速的方法,利用人工智能破解验证码——使用专业解码服务。有需求就有产品,专业的东西留给专业的人。一些公司提供相关服务。您可以调用他们的API或使用他们的插件来解决验证代码的问题
-人肉解码:当爬虫运行到验证码时,暂停,等待手动输入验证码,然后继续
5.蜜罐陷阱
蜜罐陷阱是网站开发者用来快速识别爬行动物的一个技巧
在网站上添加一些链接,并通过CSS使成人类看不到这些链接:
display: none
当爬虫解析HTML时,它可以找到这些链接,因此它单击链接并爬入
一旦你爬进去,立即封锁你的IP
解决方案也很简单。在解析网页时,添加一些逻辑来判断它是否可见
6.网页加载缓慢
一些网站报告说速度非常慢。当请求量很大时,它会不时失败
这可能对人们有好处。耐心等待,刷新页面
爬虫程序还应添加相应的逻辑:-设置合理的超时时间。太短的网页在加载之前会失败。如果它们太长,爬行将非常缓慢和低效-添加一个自动重试机制。但是,重试次数不应超过5次。如果你不能做三到五次,那么再试一次通常是没有用的。下次你可以再试一次
7.Ajax动态内容
许多网站使用ajax动态加载某些内容。换句话说,main请求只返回web页面的主要内容,其他内容通过Ajax请求动态获取
以站点B为例,视频详细信息页面的HTML页面仅收录后续Ajax请求获得的视频基本信息、评论等
当我们使用爬虫进行爬网时,我们只能第一次获得HTML,并且无法获得以下内容
特别是近几年,前端和后端分离非常流行,所有数据都是通过Ajax获取的。HTML页面只是一个没有数据的空架子
通常有两种解决方案:
-分析浏览器的web请求,找出后续请求是什么,然后使用爬虫启动相同的后续请求
-使用浏览器驱动的技术,如selenium。因为它们是通过用程序打开浏览器来访问的,所以后续的Ajax请求也可用
第一种方法是技术活动,但一旦分析,抓取速度会更快
8.登录请求
某些内容只有在登录后才能访问。在这种情况下,请看一下本文的第1点,以防止爬进监狱
但如果是你自己的账户,一般来说没问题
解决方案:
-如果您只是临时获取一些网站内容,您可以手动登录,分析浏览器的cookie,然后将相同的cookie添加到爬虫请求中
-对于简单登录网站,您还可以在脚本中自动填写用户名和密码,无需手动干预
-或者,当需要输入密码时,让爬虫暂停并在手动输入密码后继续爬虫
9.质量抓斗
一个专业的爬虫不会满足于简单的爬行。它的名字有爬行这个词。它将抓取网页上的链接,并自动抓取链接中的内容。如果它继续下去,整个世界都将是这样
这带来了很多问题。举几个例子:-需要爬网的网页数量巨大-爬网者可能会沿着链接爬回他们的主页-许多网页设置了重定向-爬网他们不需要的大量内容-爬网回大量数据
当你面对这些问题时,爬行动物的问题就变成了“爬行动物+工程”的问题
简单的解决方案是使用爬虫框架,比如Python中的scrapy,它将帮助您记录捕获的内容和未捕获的内容,
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-09-18 13:01
原创链接:
有时,由于各种原因,我们需要采集一个站点的数据,但不同站点的数据显示方式略有不同
本文使用Java向您展示如何抓取站点的数据:(1)grab原创网页的数据;(2)grab网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:检查网页源代码。我们可以看到源代码中有一段:
从这里可以看出,再次请求网页后会显示查询结果
我们来看看查询后的网址:
换言之,我们只能通过访问这样的网站才能得到IP查询的结果。接下来,请看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到站点,使用bufreader保存网页返回的数据,然后通过自定义解析方法显示结果
这里我只是随便分析一下。如果我想准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时候,为了保护自己的数据,网站不直接在网页源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方法用于查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但是有时候我们非常需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
在第一次单击startbutton之后,它开始监视web页面的交互
当我们打开网页时,可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了便于查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们只需要分析HTTP analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址来获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两个豌豆一样,抓取JS的方法与原创网页完全相同。我们只是做了一个分析JS的过程
以下是该计划的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
我希望这篇文章能对有需要的朋友有所帮助。如果你需要程序源代码,请点击这里下载 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原创链接:
有时,由于各种原因,我们需要采集一个站点的数据,但不同站点的数据显示方式略有不同
本文使用Java向您展示如何抓取站点的数据:(1)grab原创网页的数据;(2)grab网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:检查网页源代码。我们可以看到源代码中有一段:
从这里可以看出,再次请求网页后会显示查询结果
我们来看看查询后的网址:
换言之,我们只能通过访问这样的网站才能得到IP查询的结果。接下来,请看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到站点,使用bufreader保存网页返回的数据,然后通过自定义解析方法显示结果
这里我只是随便分析一下。如果我想准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时候,为了保护自己的数据,网站不直接在网页源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方法用于查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但是有时候我们非常需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
在第一次单击startbutton之后,它开始监视web页面的交互
当我们打开网页时,可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了便于查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们只需要分析HTTP analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址来获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两个豌豆一样,抓取JS的方法与原创网页完全相同。我们只是做了一个分析JS的过程
以下是该计划的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
我希望这篇文章能对有需要的朋友有所帮助。如果你需要程序源代码,请点击这里下载
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-18 12:28
原创链接:
有时,由于各种原因,我们需要采集a网站data,但由于网站data的不同,数据的显示方式略有不同
本文将使用java向您展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)通过异常{StringstrURL=“”+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuildercontentBuf=newStringBuilder();而(((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“上述四项依次显示”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果:”“n”+结果);]
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载
查看全部
java抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原创链接:
有时,由于各种原因,我们需要采集a网站data,但由于网站data的不同,数据的显示方式略有不同
本文将使用java向您展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)通过异常{StringstrURL=“”+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuildercontentBuf=newStringBuilder();而(((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“上述四项依次显示”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果:”“n”+结果);]
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载
java抓取网页数据(一门强大的开发语言,正则表达式方法捕获 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-09-18 12:26
)
开口
作为世界上使用最广泛的语言,Java以其高效性、可移植性(跨平台)、代码健壮性和强大的可扩展性深受大多数应用程序开发人员的喜爱。作为一种功能强大的开发语言,正则表达式的应用固然必不可少,而且掌握正则表达式的能力也是高级程序员开发技能的体现。正则表达式是网站开发(特别是前端开发)的合格程序员所必需的
最近,由于一些需要,Java和regular被用来为足球网站制作数据采集程序;因为这是第一次使用HTML页面数据采集,所以我一定在互联网上找到了很多信息,但我发现广泛使用的Java正在使用常规的html采集Aspects(中文)文章很少。它们都很简单。我谈到了Java规则性的概念,它并没有真正用于实际的web页面html采集但是,示例教程很少(尽管Java有自己的HTML解析器,功能非常强大),但是,我觉得作为一个流行的正则表达式,应该有很多完整的Java示例教程。因此,在用Java完成HTML数据采集程序之后,我打算在采集编写一个关于Java正则表达式的HTML页面,以便感兴趣的读者能够更好地学习
这一时期的概况
在本期中,我们将学习如何阅读网页源代码,并通过group regular动态捕获所需的网页数据。同时,在下一期中,我们将继续学习[数据存储]如何将捕获的游戏数据保存到数据库(MySQL),[数据查询]如何查询我们想要查看的游戏记录,[远程操作]客户端可以远程访问和操作服务器采集,存储和查询数据
关于群正则性
当谈到正则表达式如何帮助java处理HTML页面采集时,我们需要提到正则表达式中的group方法(代码如下)
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Group 类 用于匹配和抓取 html页面的数据
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Group {
public static void main(String[] args) {
// Pattern 用于编译正则 这里用到了3个正则 分别用括号()包住
// 第1个正则用于匹配URL 当然这里的正则不一定准确 这个匹配URL的正则就是错误的 只是在这里刚好能匹配出来
// 第2个正则是用于匹配标题 SoFlash的
// 第3个正则用于匹配日期
/* 这里只用了一条语句便把url,标题和日期全部给匹配出来了 */
Pattern p = Pattern
.compile("='(\\w.+)'>(\\w.+[a-zA-Z])-(\\d{1,2}\\.\\d{1,2}\\.\\d{4})");
String s = "<a href='http://www.cnblogs.com/longwu% ... 3B%3B
Matcher m = p.matcher(s);
while (m.find()) {
// 通过调用group()方法里的索引 将url,标题和日期全部给打印出来
System.out.println("打印出url链接:" + m.group(1));
System.out.println("打印出标题:" + m.group(2));
System.out.println("打印出日期:" + m.group(3));
System.out.println();
}
System.out.println("group方法捕获的数据个数:" + m.groupCount() + "个");
}
}
让我们看看输出:
打印出URL链接:
打印输出标题:soflash
打印日期:12. 22.2011
组方法捕获的数据数:3
如果您想更多地了解正则表达式在Java中的应用,请参阅Java正则表达式(超级详细)
如果你以前没有学过正则表达式,你可以看看这个来揭开正则表达式的神秘面纱
页面采集instance
好的,在介绍了分组方法之后,让我们使用下一个分组规则采集football网站page的数据
页面链接:2011-2012年英超球队成就
首先,我们阅读整个HTML页面并将其打印出来(代码如下)
public static void main(String[] args) {
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
// 如果 BufferedReader 读到的内容不为空
while (br.readLine() != null) {
// 则打印出来 这里打印出来的结果 应该是整个网站的
System.out.println(br.readLine());
}
br.close(); // 读取完成后关闭读取器
} catch (IOException e) {
// 如果出错 抛出异常
e.printStackTrace();
}
}
打印的结果是整个HTML页面的源代码(部分屏幕截图如下)
这里,HTML源代码已成功采集down。然而,我们想要的不是整个HTML源代码,而是网页上的游戏数据
首先,我们分析HTML源代码结构,进入2011-2012赛季英超球队记录页面,右键单击“查看源文件”(其他浏览器可能称为源代码或相关浏览器)
让我们看看它的内部HTML代码结构和我们需要的数据
它对应的页面数据
此时,强大的正则表达式就派上了用场。我们需要编写几个正则表达式来捕获团队数据
这里需要三个正则表达式:常规日期、常规两队(主队和客队)和常规比赛结果
String regulardate=“(\\D{1,2}\\\\\\\\\D{1,2}\\\\.\\D{4})”;//定期日期
字符串regulartwoteam=“>;[^]*”;//团队常规
String regularresult=“>;(\\D{1,2}-\\D{1,2})”;//定期比赛成绩
在编写正则表达式之后,我们可以使用正则表达式获取所需的数据
首先,我们编写一个groupmethod类,其中收录用于获取HTML页面数据的regulargroup()方法
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* GroupMethod类 用于匹配并抓去 Html上我们想要的内容
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class GroupMethod {
// 传入2个字符串参数 一个是pattern(我们使用的正则) 另一个matcher是html源代码
public String regularGroup(String pattern, String matcher) {
Pattern p = Pattern.compile(pattern, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(matcher);
if (m.find()) { // 如果读到
return m.group();// 返回捕获的数据
} else {
return ""; // 否则返回一个空字符串
}
}
}
然后在主功能中实现HTML页面的数据捕获
<p>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
/**
* Main主函数 用于数据采集
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Main {
public static void main(String[] args) {
// 首先用一个字符串 来装载网页链接
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
String strRead = ""; // 新增一个空字符串strRead来装载 BufferedReader 读取到的内容
// 定义3个正则 用于匹配我们需要的数据
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";
String regularTwoTeam = ">[^]*</a>";
String regularResult = ">(\\d{1,2}-\\d{1,2})";
// 创建一个GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法
GroupMethod gMethod = new GroupMethod();
int i =0; //定义一个i来记录循环次数 即收集到的球队比赛结果数
int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的
// 开始读取数据 如果读到的数据不为空 则往里面读
while ((strRead = br.readLine()) != null) {
/**
* 用于捕获日期数据
*/
String strGet = gMethod.regularGroup(regularDate, strRead);
//如果捕获到了符合条件的 日期数据 则打印出来
if (!strGet.equals("")) {
System.out.println("Date:" + strGet);
//这里索引+1 是用于获取后期的球队数据
++index; //因为在html页面里 源代码里 球队数据是在刚好在日期之后
}
/**
* 用于获取2个球队的数据
*/
strGet = gMethod.regularGroup(regularTwoTeam, strRead);
if (!strGet.equals("") && index == 1) { //索引为1的是主队数据
// 通过substring方法 分离出 主队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("HomeTeam:" + strGet); //打印出主队
index++; //索引+1之后 为2了
// 通过substring方法 分离出 客队
} else if (!strGet.equals("") && index == 2) { //这里索引为2的是客队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("AwayTeam:" + strGet); //打印出客队
index = 0;
}
/**
* 用于获取比赛结果
*/
strGet = gMethod.regularGroup(regularResult, strRead);
if (!strGet.equals("")) {
//这里同样用到了substring方法 来剔除' 查看全部
java抓取网页数据(一门强大的开发语言,正则表达式方法捕获
)
开口
作为世界上使用最广泛的语言,Java以其高效性、可移植性(跨平台)、代码健壮性和强大的可扩展性深受大多数应用程序开发人员的喜爱。作为一种功能强大的开发语言,正则表达式的应用固然必不可少,而且掌握正则表达式的能力也是高级程序员开发技能的体现。正则表达式是网站开发(特别是前端开发)的合格程序员所必需的
最近,由于一些需要,Java和regular被用来为足球网站制作数据采集程序;因为这是第一次使用HTML页面数据采集,所以我一定在互联网上找到了很多信息,但我发现广泛使用的Java正在使用常规的html采集Aspects(中文)文章很少。它们都很简单。我谈到了Java规则性的概念,它并没有真正用于实际的web页面html采集但是,示例教程很少(尽管Java有自己的HTML解析器,功能非常强大),但是,我觉得作为一个流行的正则表达式,应该有很多完整的Java示例教程。因此,在用Java完成HTML数据采集程序之后,我打算在采集编写一个关于Java正则表达式的HTML页面,以便感兴趣的读者能够更好地学习
这一时期的概况
在本期中,我们将学习如何阅读网页源代码,并通过group regular动态捕获所需的网页数据。同时,在下一期中,我们将继续学习[数据存储]如何将捕获的游戏数据保存到数据库(MySQL),[数据查询]如何查询我们想要查看的游戏记录,[远程操作]客户端可以远程访问和操作服务器采集,存储和查询数据
关于群正则性
当谈到正则表达式如何帮助java处理HTML页面采集时,我们需要提到正则表达式中的group方法(代码如下)
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Group 类 用于匹配和抓取 html页面的数据
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Group {
public static void main(String[] args) {
// Pattern 用于编译正则 这里用到了3个正则 分别用括号()包住
// 第1个正则用于匹配URL 当然这里的正则不一定准确 这个匹配URL的正则就是错误的 只是在这里刚好能匹配出来
// 第2个正则是用于匹配标题 SoFlash的
// 第3个正则用于匹配日期
/* 这里只用了一条语句便把url,标题和日期全部给匹配出来了 */
Pattern p = Pattern
.compile("='(\\w.+)'>(\\w.+[a-zA-Z])-(\\d{1,2}\\.\\d{1,2}\\.\\d{4})");
String s = "<a href='http://www.cnblogs.com/longwu% ... 3B%3B
Matcher m = p.matcher(s);
while (m.find()) {
// 通过调用group()方法里的索引 将url,标题和日期全部给打印出来
System.out.println("打印出url链接:" + m.group(1));
System.out.println("打印出标题:" + m.group(2));
System.out.println("打印出日期:" + m.group(3));
System.out.println();
}
System.out.println("group方法捕获的数据个数:" + m.groupCount() + "个");
}
}
让我们看看输出:
打印出URL链接:
打印输出标题:soflash
打印日期:12. 22.2011
组方法捕获的数据数:3
如果您想更多地了解正则表达式在Java中的应用,请参阅Java正则表达式(超级详细)
如果你以前没有学过正则表达式,你可以看看这个来揭开正则表达式的神秘面纱
页面采集instance
好的,在介绍了分组方法之后,让我们使用下一个分组规则采集football网站page的数据
页面链接:2011-2012年英超球队成就
首先,我们阅读整个HTML页面并将其打印出来(代码如下)
public static void main(String[] args) {
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
// 如果 BufferedReader 读到的内容不为空
while (br.readLine() != null) {
// 则打印出来 这里打印出来的结果 应该是整个网站的
System.out.println(br.readLine());
}
br.close(); // 读取完成后关闭读取器
} catch (IOException e) {
// 如果出错 抛出异常
e.printStackTrace();
}
}
打印的结果是整个HTML页面的源代码(部分屏幕截图如下)
这里,HTML源代码已成功采集down。然而,我们想要的不是整个HTML源代码,而是网页上的游戏数据
首先,我们分析HTML源代码结构,进入2011-2012赛季英超球队记录页面,右键单击“查看源文件”(其他浏览器可能称为源代码或相关浏览器)
让我们看看它的内部HTML代码结构和我们需要的数据
它对应的页面数据
此时,强大的正则表达式就派上了用场。我们需要编写几个正则表达式来捕获团队数据
这里需要三个正则表达式:常规日期、常规两队(主队和客队)和常规比赛结果
String regulardate=“(\\D{1,2}\\\\\\\\\D{1,2}\\\\.\\D{4})”;//定期日期
字符串regulartwoteam=“>;[^]*”;//团队常规
String regularresult=“>;(\\D{1,2}-\\D{1,2})”;//定期比赛成绩
在编写正则表达式之后,我们可以使用正则表达式获取所需的数据
首先,我们编写一个groupmethod类,其中收录用于获取HTML页面数据的regulargroup()方法
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* GroupMethod类 用于匹配并抓去 Html上我们想要的内容
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class GroupMethod {
// 传入2个字符串参数 一个是pattern(我们使用的正则) 另一个matcher是html源代码
public String regularGroup(String pattern, String matcher) {
Pattern p = Pattern.compile(pattern, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(matcher);
if (m.find()) { // 如果读到
return m.group();// 返回捕获的数据
} else {
return ""; // 否则返回一个空字符串
}
}
}
然后在主功能中实现HTML页面的数据捕获
<p>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
/**
* Main主函数 用于数据采集
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Main {
public static void main(String[] args) {
// 首先用一个字符串 来装载网页链接
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
String strRead = ""; // 新增一个空字符串strRead来装载 BufferedReader 读取到的内容
// 定义3个正则 用于匹配我们需要的数据
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";
String regularTwoTeam = ">[^]*</a>";
String regularResult = ">(\\d{1,2}-\\d{1,2})";
// 创建一个GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法
GroupMethod gMethod = new GroupMethod();
int i =0; //定义一个i来记录循环次数 即收集到的球队比赛结果数
int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的
// 开始读取数据 如果读到的数据不为空 则往里面读
while ((strRead = br.readLine()) != null) {
/**
* 用于捕获日期数据
*/
String strGet = gMethod.regularGroup(regularDate, strRead);
//如果捕获到了符合条件的 日期数据 则打印出来
if (!strGet.equals("")) {
System.out.println("Date:" + strGet);
//这里索引+1 是用于获取后期的球队数据
++index; //因为在html页面里 源代码里 球队数据是在刚好在日期之后
}
/**
* 用于获取2个球队的数据
*/
strGet = gMethod.regularGroup(regularTwoTeam, strRead);
if (!strGet.equals("") && index == 1) { //索引为1的是主队数据
// 通过substring方法 分离出 主队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("HomeTeam:" + strGet); //打印出主队
index++; //索引+1之后 为2了
// 通过substring方法 分离出 客队
} else if (!strGet.equals("") && index == 2) { //这里索引为2的是客队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("AwayTeam:" + strGet); //打印出客队
index = 0;
}
/**
* 用于获取比赛结果
*/
strGet = gMethod.regularGroup(regularResult, strRead);
if (!strGet.equals("")) {
//这里同样用到了substring方法 来剔除'
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-09-10 13:12
原文链接:
有时,出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,再次请求一个网页后,查询的结果就显示出来了。
查询后看网页地址:
也就是说,我们只需要访问这种网址就可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、抓取网页的JavaScript返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据。而是采用异步方式用JS返回数据,可以避免网站数据被搜索引擎等工具抓取。 .
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后输入tracking number:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密可以,我们写下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时,出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,再次请求一个网页后,查询的结果就显示出来了。
查询后看网页地址:
也就是说,我们只需要访问这种网址就可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、抓取网页的JavaScript返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据。而是采用异步方式用JS返回数据,可以避免网站数据被搜索引擎等工具抓取。 .
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后输入tracking number:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密可以,我们写下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java抓取网页数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-10 13:11
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到data采集的概念。 data采集的最终目标是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能都无法上手,尤其是作为一个新手,感觉很茫然,所以在这里分享一下我的经验,希望把技术分享给大家,如果有不足之处,请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长更多。
在网络数据采集的情况下,我们经常要经历这些大步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
了解了基本流程,我就用一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在这里,我暂时不解释httpclient。 +jsou提取网页数据的方法以后会在httpclient+jsoup上具体讲解。在这里,我们将首先说明如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们想提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站全页面预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好的,运行上面的程序,我们得到如下数据,也就是我们最终要获取的数据
数据获取成功,这就是我们要得到的最终数据结果,最后想说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是get方法进行数据提交,当采集真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。关于这一点的解决方法将在后面介绍。还有,我在采集这个页面的时候,只有采集拿到了当前页面的数据,而且还有分页的数据。这个我就不解释了,只是一个提示,我们可以用多线程对所有分页的当前数据是采集,一个采集当前页面数据通过线程,另一个是翻页动作,你可以采集完成所有的数据。
我们匹配的数据可能在项目实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
java抓取网页数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到data采集的概念。 data采集的最终目标是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能都无法上手,尤其是作为一个新手,感觉很茫然,所以在这里分享一下我的经验,希望把技术分享给大家,如果有不足之处,请指正。写这篇的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长更多。
在网络数据采集的情况下,我们经常要经历这些大步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
了解了基本流程,我就用一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在这里,我暂时不解释httpclient。 +jsou提取网页数据的方法以后会在httpclient+jsoup上具体讲解。在这里,我们将首先说明如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们想提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站全页面预览
接下来我们看一下网页的源码结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好的,运行上面的程序,我们得到如下数据,也就是我们最终要获取的数据
数据获取成功,这就是我们要得到的最终数据结果,最后想说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是get方法进行数据提交,当采集真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。关于这一点的解决方法将在后面介绍。还有,我在采集这个页面的时候,只有采集拿到了当前页面的数据,而且还有分页的数据。这个我就不解释了,只是一个提示,我们可以用多线程对所有分页的当前数据是采集,一个采集当前页面数据通过线程,另一个是翻页动作,你可以采集完成所有的数据。
我们匹配的数据可能在项目实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-09-09 21:02
原文链接:
有时,出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,再次请求一个网页后,查询的结果就显示出来了。
查询后看网页地址:
也就是说,我们只需要访问这种网址就可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、抓取网页的JavaScript返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据。而是采用异步方式用JS返回数据,可以避免网站数据被搜索引擎等工具抓取。 .
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后输入tracking number:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据当然,前提是数据没有加密对,我们写下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时,出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,再次请求一个网页后,查询的结果就显示出来了。
查询后看网页地址:
也就是说,我们只需要访问这种网址就可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、抓取网页的JavaScript返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据。而是采用异步方式用JS返回数据,可以避免网站数据被搜索引擎等工具抓取。 .
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候该怎么办?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到我们的目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后输入tracking number:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据当然,前提是数据没有加密对,我们写下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
以下是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!

