
采集文章系统
采集文章系统(快速破解网站自带的文章采集器每日文章数量多,无损加载,压缩包)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-11-12 14:15
快速破解网站内置文章采集器每日文章,无损加载,压缩包分享到个人朋友圈可公开下载,也可以转发。
文章采集器免费版-官方版-文章采集器免费版(-单树成林手机版。
文章采集器免费版快速破解网站自带大量文章优采云。
对于那些正在做网站推广和优化的人来说,可能经常需要更新一些文章,那么对于文笔不好的人来说还是有点难度的。
优采云通用文章采集器是一款可以批量下载指定关键词文章采集的工具,主要是为了帮助用户< @采集各大平台文章,也可以采集指定网站文章,非常方便快捷,适合做网站推广和优化一个不多。
《全民文章采集器免费破解版》是最简单、最智能的文章采集器,由优采云软件开发,您可以采集列表页文章、关键词新闻、微信等,以及针对采集指定的网站文章,是一个很好的文章采集器。软件功能 1.
文章采集器免费版多多快递蜘蛛是一款专业的网络采集工具;本软件采用MongoDB数据库,可以帮助用户快速获取采集文章、网站域名等信息,操作简单,功能强大,有需要的朋友,下载体验吧该软件具有特殊功能。
Universal文章采集器是一款方便易用的文章采集软件,功能强大,完全免费使用。软件操作简单,可以准确提取网页正文部分保存为文章,支持标签、链接、邮件等格式处理,只需几分钟。 查看全部
采集文章系统(快速破解网站自带的文章采集器每日文章数量多,无损加载,压缩包)
快速破解网站内置文章采集器每日文章,无损加载,压缩包分享到个人朋友圈可公开下载,也可以转发。
文章采集器免费版-官方版-文章采集器免费版(-单树成林手机版。
文章采集器免费版快速破解网站自带大量文章优采云。
对于那些正在做网站推广和优化的人来说,可能经常需要更新一些文章,那么对于文笔不好的人来说还是有点难度的。
优采云通用文章采集器是一款可以批量下载指定关键词文章采集的工具,主要是为了帮助用户< @采集各大平台文章,也可以采集指定网站文章,非常方便快捷,适合做网站推广和优化一个不多。

《全民文章采集器免费破解版》是最简单、最智能的文章采集器,由优采云软件开发,您可以采集列表页文章、关键词新闻、微信等,以及针对采集指定的网站文章,是一个很好的文章采集器。软件功能 1.
文章采集器免费版多多快递蜘蛛是一款专业的网络采集工具;本软件采用MongoDB数据库,可以帮助用户快速获取采集文章、网站域名等信息,操作简单,功能强大,有需要的朋友,下载体验吧该软件具有特殊功能。

Universal文章采集器是一款方便易用的文章采集软件,功能强大,完全免费使用。软件操作简单,可以准确提取网页正文部分保存为文章,支持标签、链接、邮件等格式处理,只需几分钟。
采集文章系统( CmsTop文章采集系统颠覆传统采集模式和流程,规则设置更简单 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-11-12 11:18
CmsTop文章采集系统颠覆传统采集模式和流程,规则设置更简单
)
5.24 文章采集
文章的采集功能是通过程序远程获取目标网页的内容,解析处理本地规则后存储到服务器的数据库中。cmsTop文章采集系统颠覆了传统的采集模式和流程,采集规则与采集界面分离,规则设置更简单,只需具备基本网页设计知识的人设置相关规则即可。编辑者无需了解太详细的技术规则,只需选择自己想要的文章列表采集,就可以像发布文章一样轻松完成采集操作,提高提高工作效率,降低人工成本。
1. 高效的采集 管理界面
自定义配置的所有采集规则都会显示在采集管理界面,根据采集的更新频率可以找到最新的文章。系统通过最新的,查看过的,文章的状态已经被标记为采集。曾经采集的文章会自动从采集列表中消失,进入采集的列表,不会重复采集。同时可以根据已经设置的采集规则快速输入网址。
图5.24‑1采集界面
管理者可以通过采集管理界面预览采集的内容,然后有选择地对需要的文章进行采集。添加任务很方便,并允许自定义目标列。
图 5.24‑2文章采集 预览
图5.24-3 编辑监控任务
图5.24‑4 自定义目标列
2. 方便简洁的采集规则配置
对于需要采集功能的网站来说,简单方便的规则配置就是易用性的体现。技术人员只需要基本的网页知识就可以自由编写采集规则。在编写规则时,可以实时显示采集的内容是否正确。通过此功能,您可以轻松测试内容的可用性。此外,它还对一些详细的采集设置提供了很好的支持,比如采集分页内容,设置是否远程图像定位等。
图5.24‑5采集 规则设置
3. 采集 规则导入导出
对于已经写入的采集规则,系统会自动将其添加到规则列表中以备后用。每个规则都可以重复使用,并且可以根据需要进行修改。同时,您还可以将您设置的采集规则导出到XML文件中,与他人共享,或导入他人共享的规则。
图5.24‑6 规则导入
4. 支持 文章 计时采集
系统内置采集功能,可以手动选择采集,也可以手动选择采集,也可以设置定时采集。提供定时采集任务切换。通过设置采集间隔、采集件数、下一次采集,系统可实现自取,无需人工干预,节省人力资源。面对系统自动完成的操作,管理员查看系统工作日志是必不可少的一环。系统增加了计时采集日志功能菜单,可以查看特定时间段内采集成功和失败的次数。文章数。您还可以一键清理采集 日志。
5. 支持过滤重复标题
采集 过程中的头衔重复是采集人员头疼的问题。无论是手动采集还是自动采集,都无法避免这个问题。提供过滤重复标题的开关,采集人员可以随时开启和关闭过滤功能。具有过滤重复标题的功能,可以直接过滤重复的标题,使其不再出现在采集列表中,从而消除采集的重复内容。
查看全部
采集文章系统(
CmsTop文章采集系统颠覆传统采集模式和流程,规则设置更简单
)
5.24 文章采集
文章的采集功能是通过程序远程获取目标网页的内容,解析处理本地规则后存储到服务器的数据库中。cmsTop文章采集系统颠覆了传统的采集模式和流程,采集规则与采集界面分离,规则设置更简单,只需具备基本网页设计知识的人设置相关规则即可。编辑者无需了解太详细的技术规则,只需选择自己想要的文章列表采集,就可以像发布文章一样轻松完成采集操作,提高提高工作效率,降低人工成本。
1. 高效的采集 管理界面
自定义配置的所有采集规则都会显示在采集管理界面,根据采集的更新频率可以找到最新的文章。系统通过最新的,查看过的,文章的状态已经被标记为采集。曾经采集的文章会自动从采集列表中消失,进入采集的列表,不会重复采集。同时可以根据已经设置的采集规则快速输入网址。

图5.24‑1采集界面
管理者可以通过采集管理界面预览采集的内容,然后有选择地对需要的文章进行采集。添加任务很方便,并允许自定义目标列。

图 5.24‑2文章采集 预览

图5.24-3 编辑监控任务

图5.24‑4 自定义目标列
2. 方便简洁的采集规则配置
对于需要采集功能的网站来说,简单方便的规则配置就是易用性的体现。技术人员只需要基本的网页知识就可以自由编写采集规则。在编写规则时,可以实时显示采集的内容是否正确。通过此功能,您可以轻松测试内容的可用性。此外,它还对一些详细的采集设置提供了很好的支持,比如采集分页内容,设置是否远程图像定位等。

图5.24‑5采集 规则设置
3. 采集 规则导入导出
对于已经写入的采集规则,系统会自动将其添加到规则列表中以备后用。每个规则都可以重复使用,并且可以根据需要进行修改。同时,您还可以将您设置的采集规则导出到XML文件中,与他人共享,或导入他人共享的规则。

图5.24‑6 规则导入
4. 支持 文章 计时采集
系统内置采集功能,可以手动选择采集,也可以手动选择采集,也可以设置定时采集。提供定时采集任务切换。通过设置采集间隔、采集件数、下一次采集,系统可实现自取,无需人工干预,节省人力资源。面对系统自动完成的操作,管理员查看系统工作日志是必不可少的一环。系统增加了计时采集日志功能菜单,可以查看特定时间段内采集成功和失败的次数。文章数。您还可以一键清理采集 日志。
5. 支持过滤重复标题
采集 过程中的头衔重复是采集人员头疼的问题。无论是手动采集还是自动采集,都无法避免这个问题。提供过滤重复标题的开关,采集人员可以随时开启和关闭过滤功能。具有过滤重复标题的功能,可以直接过滤重复的标题,使其不再出现在采集列表中,从而消除采集的重复内容。

采集文章系统(支持采集内容替换功能,支持文章内容采集、游戏简介)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-11-12 03:16
特征:
1、支持文章内容分页采集;
2、支持论坛采集
3、支持UTF-8转GB2312,但采集内容字符格式是UTF-8的目标;
4、 支持将文章的内容保存到本地;
5、支持站点+栏目管理模式,让采集管理一目了然;
6、支持替换链接、替换分页链接,破解一些JS/后台程序设置的反扒功能;
7、支持采集器设置无限过滤功能;
8、支持图片采集保存到本地,自动替换文件名避免重复;
9、支持FLASH文件采集保存到本地,自动替换文件名避免重复;
10、 支持限制PHP FOPEN和FSOCKET功能的虚拟主机;
11、 支持手动过滤采集结果,并提供“空标题空内容”的快速过滤和删除;
12、支持Flash专业网站采集,特色采集flash小游戏,可完美采集缩略图,游戏介绍;
13、 支持全站配置规则的导入导出;
14、支持栏目配置规则导入导出,提供规则复制功能,简化设置;
15、 提供引导库规则导入导出;
16、支持自定义采集间隔时间,避免被误认为DDOS攻击而拒绝响应,可以设置采集防止DDOS攻击网站;
17、支持自定义存储间隔时间,避免虚拟主机并发限制;
18、支持自定义内容写入,用户可以设置任意内容(如自己的链接、广告代码),写入采集的内容:第一个、最后一个或随机写入;需要写入的内容在浏览库时自动带在身边,无需修改WEB系统模板。
19、支持采集内容替换功能,用户可以设置替换规则随意替换;
20、支持html标签过滤,让采集接收到的内容只保留必要的html标签,甚至是纯文本,不带任何html标签;
21、支持多个cms指南库
包内收录 PHPcms V2/V3、Dedecms(织梦) V2/V3、PHP168 cms, mephpcms@ >、Mambocms、Joomlacms系统指南库规则及操作说明;
22、支持PHPWIND、Discuz论坛指南库,程序包中收录2个论坛指南库规则和操作说明;
23、自带数据库优化工具,减少频繁采集过多的数据碎片降低数据库性能。
以下特殊功能仅适用于“小蜜蜂采集器”:
1、 支持采集进程断点续传功能,不受浏览器意外关闭影响,重启后不会重复采集;
2、 支持自动比较过滤功能,不会在采集的链接系统中重复采集和存储;
以上两个功能可以大大减少采集时间,减少系统负载。
3、 支持系统每天自动创建图片存储目录,方便管理;
4、支持采集/guide间隔时间设置,避免被目标站识别为流量攻击而拒绝响应;
5、支持自定义内容写入,实现简单的反采集功能;
6、支持html标签过滤,几乎完美展现你想要的采集效果;
7、完美的内容存储解决方案,不受目标编程语言和数据库类别的限制。
以上众多强大功能免费供您使用,您可以轻松高效地安装使用体验资料采集。
v1.1115 更新:
1、添加了电骡下载格式的URL识别 查看全部
采集文章系统(支持采集内容替换功能,支持文章内容采集、游戏简介)
特征:
1、支持文章内容分页采集;
2、支持论坛采集
3、支持UTF-8转GB2312,但采集内容字符格式是UTF-8的目标;
4、 支持将文章的内容保存到本地;
5、支持站点+栏目管理模式,让采集管理一目了然;
6、支持替换链接、替换分页链接,破解一些JS/后台程序设置的反扒功能;
7、支持采集器设置无限过滤功能;
8、支持图片采集保存到本地,自动替换文件名避免重复;
9、支持FLASH文件采集保存到本地,自动替换文件名避免重复;
10、 支持限制PHP FOPEN和FSOCKET功能的虚拟主机;
11、 支持手动过滤采集结果,并提供“空标题空内容”的快速过滤和删除;
12、支持Flash专业网站采集,特色采集flash小游戏,可完美采集缩略图,游戏介绍;
13、 支持全站配置规则的导入导出;
14、支持栏目配置规则导入导出,提供规则复制功能,简化设置;
15、 提供引导库规则导入导出;
16、支持自定义采集间隔时间,避免被误认为DDOS攻击而拒绝响应,可以设置采集防止DDOS攻击网站;
17、支持自定义存储间隔时间,避免虚拟主机并发限制;
18、支持自定义内容写入,用户可以设置任意内容(如自己的链接、广告代码),写入采集的内容:第一个、最后一个或随机写入;需要写入的内容在浏览库时自动带在身边,无需修改WEB系统模板。
19、支持采集内容替换功能,用户可以设置替换规则随意替换;
20、支持html标签过滤,让采集接收到的内容只保留必要的html标签,甚至是纯文本,不带任何html标签;
21、支持多个cms指南库
包内收录 PHPcms V2/V3、Dedecms(织梦) V2/V3、PHP168 cms, mephpcms@ >、Mambocms、Joomlacms系统指南库规则及操作说明;
22、支持PHPWIND、Discuz论坛指南库,程序包中收录2个论坛指南库规则和操作说明;
23、自带数据库优化工具,减少频繁采集过多的数据碎片降低数据库性能。
以下特殊功能仅适用于“小蜜蜂采集器”:
1、 支持采集进程断点续传功能,不受浏览器意外关闭影响,重启后不会重复采集;
2、 支持自动比较过滤功能,不会在采集的链接系统中重复采集和存储;
以上两个功能可以大大减少采集时间,减少系统负载。
3、 支持系统每天自动创建图片存储目录,方便管理;
4、支持采集/guide间隔时间设置,避免被目标站识别为流量攻击而拒绝响应;
5、支持自定义内容写入,实现简单的反采集功能;
6、支持html标签过滤,几乎完美展现你想要的采集效果;
7、完美的内容存储解决方案,不受目标编程语言和数据库类别的限制。
以上众多强大功能免费供您使用,您可以轻松高效地安装使用体验资料采集。
v1.1115 更新:
1、添加了电骡下载格式的URL识别
采集文章系统(短视频行业再掀腥风血雨,这篇:采集文章系统自动生成的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-11-07 16:04
采集文章系统自动生成的,比如这篇:短视频行业再掀腥风血雨!5月上线的视频机器人抓取系统更是掀起了新一轮的轰动!视频机器人的出现是完全基于短视频的内容生产的,可以说实现了对短视频内容的整体挖掘。从去年3月起,抖音上火的鬼畜视频、搞笑视频等都逐渐成为了一种潮流,一夜成名在抖音不是一个神话,但依旧有一小部分,也有不少网红,甚至娱乐圈的不少明星,都是通过一个好的视频机器人走红的。
这个还是蛮利好的,因为这些视频机器人会根据你所播放的视频而帮你推荐,一般视频分发出去之后很快会有大量的推荐,也会有少量的掉下去。这和之前的视频推荐算法是一样的,直接让系统自己给推荐视频。那抖音短视频机器人推荐是怎么机制的呢?这个还要从整个抖音的推荐算法讲起,我这里做了个简单的说明,抖音根据你的粉丝、内容质量和账号权重等三方面,推荐一个你可能感兴趣的内容给你,你可以把这个类似打开,看看点赞量、浏览量、评论、转发等等的反馈。
短视频同样如此,根据你对这个视频的打开反馈再决定是否推荐给你更多的朋友看到。“机器人”是怎么推荐的?首先机器人会根据你所打开的反馈推荐给你一个比较大的范围,然后根据你点赞的时间、你关注的、点赞的粉丝数和关注的类型来看,来给你反馈一个总的范围,会有多少个你感兴趣的视频,推荐你多少个视频给你看。不知道抖音平台是不是还有其他的算法方法,至少我这里的机器人是基于这个思想的。
抖音的机器人推荐机制那对于一个系统来说是完全自动化的,除了开始说的抓取算法,还有后续的观看算法、下一个平台的推荐算法。其实对于所有自媒体平台来说,基本上都有一个浏览推荐的机制,比如微信推送的时候会先让你看看同类内容,看看大家的热门文章、热门评论,基本上就可以决定这篇文章是否是你感兴趣的了。抖音同样也有这个推荐机制,先是在视频或者文章里看看,如果有爆款的话,之后会有大量的流量推荐给用户。
只不过是精确的给你推荐给你感兴趣的人群而已。那对于一个机器人来说,是如何推荐视频给你的呢?具体就是当你点赞或者转发或者分享后,抖音系统会得到这个作品的信息,然后机器人就会抓取这个内容,抓取到你的信息后就可以抓取到你的喜好了,因为这个也是机器人判断你之前的内容是不是感兴趣的一个过程。之后根据你的兴趣来给你推荐更多的内容,如果你觉得不是你喜欢的,那抖音系统就会识别出来了,可能就是一个点赞,那机器人就会抓取其他机器人抓取到的喜欢的内容。这时候就是机器人推荐给你的可能性很大了。比如说你之前喜欢玩。 查看全部
采集文章系统(短视频行业再掀腥风血雨,这篇:采集文章系统自动生成的)
采集文章系统自动生成的,比如这篇:短视频行业再掀腥风血雨!5月上线的视频机器人抓取系统更是掀起了新一轮的轰动!视频机器人的出现是完全基于短视频的内容生产的,可以说实现了对短视频内容的整体挖掘。从去年3月起,抖音上火的鬼畜视频、搞笑视频等都逐渐成为了一种潮流,一夜成名在抖音不是一个神话,但依旧有一小部分,也有不少网红,甚至娱乐圈的不少明星,都是通过一个好的视频机器人走红的。
这个还是蛮利好的,因为这些视频机器人会根据你所播放的视频而帮你推荐,一般视频分发出去之后很快会有大量的推荐,也会有少量的掉下去。这和之前的视频推荐算法是一样的,直接让系统自己给推荐视频。那抖音短视频机器人推荐是怎么机制的呢?这个还要从整个抖音的推荐算法讲起,我这里做了个简单的说明,抖音根据你的粉丝、内容质量和账号权重等三方面,推荐一个你可能感兴趣的内容给你,你可以把这个类似打开,看看点赞量、浏览量、评论、转发等等的反馈。
短视频同样如此,根据你对这个视频的打开反馈再决定是否推荐给你更多的朋友看到。“机器人”是怎么推荐的?首先机器人会根据你所打开的反馈推荐给你一个比较大的范围,然后根据你点赞的时间、你关注的、点赞的粉丝数和关注的类型来看,来给你反馈一个总的范围,会有多少个你感兴趣的视频,推荐你多少个视频给你看。不知道抖音平台是不是还有其他的算法方法,至少我这里的机器人是基于这个思想的。
抖音的机器人推荐机制那对于一个系统来说是完全自动化的,除了开始说的抓取算法,还有后续的观看算法、下一个平台的推荐算法。其实对于所有自媒体平台来说,基本上都有一个浏览推荐的机制,比如微信推送的时候会先让你看看同类内容,看看大家的热门文章、热门评论,基本上就可以决定这篇文章是否是你感兴趣的了。抖音同样也有这个推荐机制,先是在视频或者文章里看看,如果有爆款的话,之后会有大量的流量推荐给用户。
只不过是精确的给你推荐给你感兴趣的人群而已。那对于一个机器人来说,是如何推荐视频给你的呢?具体就是当你点赞或者转发或者分享后,抖音系统会得到这个作品的信息,然后机器人就会抓取这个内容,抓取到你的信息后就可以抓取到你的喜好了,因为这个也是机器人判断你之前的内容是不是感兴趣的一个过程。之后根据你的兴趣来给你推荐更多的内容,如果你觉得不是你喜欢的,那抖音系统就会识别出来了,可能就是一个点赞,那机器人就会抓取其他机器人抓取到的喜欢的内容。这时候就是机器人推荐给你的可能性很大了。比如说你之前喜欢玩。
采集文章系统(一个微信公众号历史消息页面的链接地址和采集方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-11-07 07:01
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。当时批量采集特别好做,采集的入口就是公众号的历史新闻页面。这个条目现在还是一样,但是越来越难采集。采集 的方法也更新了很多版本。后来2015年html5垃圾站没做,改把采集定位到本地新闻资讯公众号,前端展示做成了app。所以一个可以自动采集的新闻应用 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证你看到的时候可以看到。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新 ==========
现在,根据不同的微信个人账号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为实际上这个链接地址还需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的一个类似 id 的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余 3 个参数与用户的 id 和 token 票证相关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量测试的ios微信客户端崩溃率采集高于Android系统。为了降低成本,我使用了Android模拟器。
2、一个微信个人账号:对于采集的内容,不仅需要一个微信客户端,还需要一个专用于采集的微信个人账号,因为这个微信账号不能做其他事情.
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众账号历史消息页面中的文章列表发送到自己的服务器。具体的安装方法后面会详细介绍。
4、文章列表分析入库系统:本人使用PHP语言编写,下篇文章将详细介绍如何分析文章列表并建立采集队列来实现批次采集内容。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、 生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
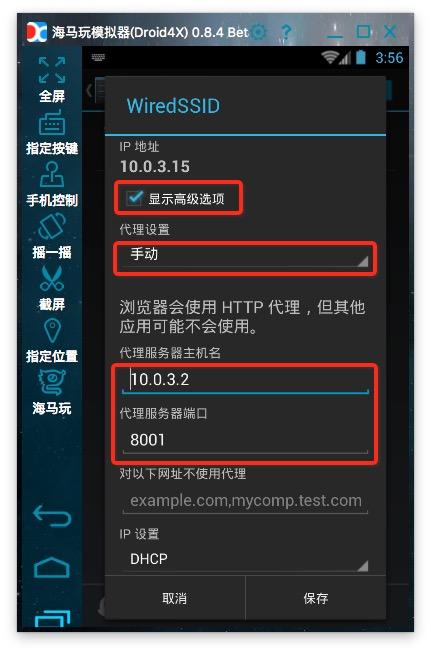
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一个公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002就可以看到anyproxy的web界面了。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,才能获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来,我们将详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p> 查看全部
采集文章系统(一个微信公众号历史消息页面的链接地址和采集方法)
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。当时批量采集特别好做,采集的入口就是公众号的历史新闻页面。这个条目现在还是一样,但是越来越难采集。采集 的方法也更新了很多版本。后来2015年html5垃圾站没做,改把采集定位到本地新闻资讯公众号,前端展示做成了app。所以一个可以自动采集的新闻应用 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证你看到的时候可以看到。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新 ==========
现在,根据不同的微信个人账号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为实际上这个链接地址还需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的一个类似 id 的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余 3 个参数与用户的 id 和 token 票证相关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量测试的ios微信客户端崩溃率采集高于Android系统。为了降低成本,我使用了Android模拟器。

2、一个微信个人账号:对于采集的内容,不仅需要一个微信客户端,还需要一个专用于采集的微信个人账号,因为这个微信账号不能做其他事情.
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众账号历史消息页面中的文章列表发送到自己的服务器。具体的安装方法后面会详细介绍。
4、文章列表分析入库系统:本人使用PHP语言编写,下篇文章将详细介绍如何分析文章列表并建立采集队列来实现批次采集内容。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、 生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一个公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002就可以看到anyproxy的web界面了。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
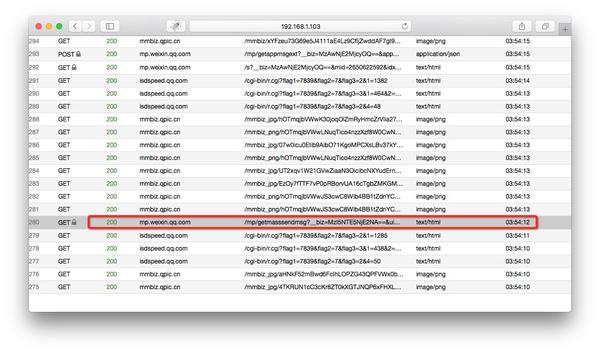
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
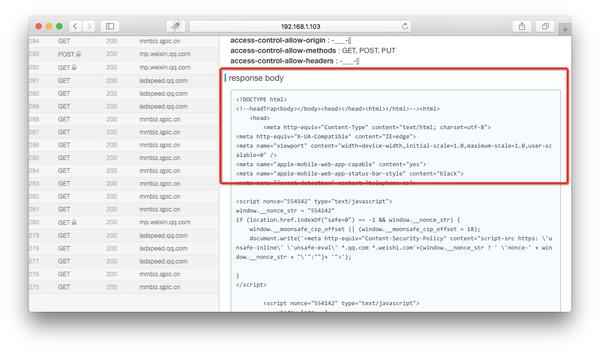
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,才能获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来,我们将详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p>
采集文章系统(工业设计展会门户网站看哪些对您来说是外贸友好型)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-06 21:00
采集文章系统:khanacademy课程:sitemap模版:crunchbasesitemap网站:微信公众号khanacademy免费注册:xiaohuacademy
dw,yahoo,facebook..twitter...谷歌..
facebookamazonwhatsapptwitteruber这都是外贸公司很常用的社交媒体
就美国而言twitter多,原因主要是1:twitter社交属性强,facebook多关注公司品牌活动之类,weibo没有where方便2:facebook广告丰富,阿里巴巴类目也多3:facebook广告费用更低,但貌似twitter效果更好4:twitter最近有tweety政策,广告被赞的话会被算收入。
其实twitterchat关注问题,论坛等更具有社交性,都可以成为内容版块5:外贸企业多关注一些内部资讯,特别是给国外客户的邮件,也要注意接地气--。
关于twitter或是facebook,我用一句话概括,先想清楚你们是为谁去获取资讯。
facebookreddityahoo...
工业设计展会门户网站
看哪些对您来说是外贸友好型,第三方平台目前我用的主要是:tumblr(交互性高于内容)wikipedia(全球最大的维基百科网站)linkedin(非盈利性社区)...不过,我从来没见过一个人会在wikipedia上面写软文,在linkedin上面做seo的。
我们公司所有的社交媒体和博客都是同一个或者同一个人维护的,是来自于用户的真实留言,加上他不定期抽空翻译一些英文媒体的文章,用于新闻发布会演讲。如果别人不想看的话可以用adstracking一键完成可见性,也就是通过ip或者注册用户来分析看到文章的几率,然后根据文章来引发相应的互动。其实这是一个非常非常虚的东西,我认为只要公司体量不大,其实平时用搜索引擎,这个是比社交媒体更有价值的东西。 查看全部
采集文章系统(工业设计展会门户网站看哪些对您来说是外贸友好型)
采集文章系统:khanacademy课程:sitemap模版:crunchbasesitemap网站:微信公众号khanacademy免费注册:xiaohuacademy
dw,yahoo,facebook..twitter...谷歌..
facebookamazonwhatsapptwitteruber这都是外贸公司很常用的社交媒体
就美国而言twitter多,原因主要是1:twitter社交属性强,facebook多关注公司品牌活动之类,weibo没有where方便2:facebook广告丰富,阿里巴巴类目也多3:facebook广告费用更低,但貌似twitter效果更好4:twitter最近有tweety政策,广告被赞的话会被算收入。
其实twitterchat关注问题,论坛等更具有社交性,都可以成为内容版块5:外贸企业多关注一些内部资讯,特别是给国外客户的邮件,也要注意接地气--。
关于twitter或是facebook,我用一句话概括,先想清楚你们是为谁去获取资讯。
facebookreddityahoo...
工业设计展会门户网站
看哪些对您来说是外贸友好型,第三方平台目前我用的主要是:tumblr(交互性高于内容)wikipedia(全球最大的维基百科网站)linkedin(非盈利性社区)...不过,我从来没见过一个人会在wikipedia上面写软文,在linkedin上面做seo的。
我们公司所有的社交媒体和博客都是同一个或者同一个人维护的,是来自于用户的真实留言,加上他不定期抽空翻译一些英文媒体的文章,用于新闻发布会演讲。如果别人不想看的话可以用adstracking一键完成可见性,也就是通过ip或者注册用户来分析看到文章的几率,然后根据文章来引发相应的互动。其实这是一个非常非常虚的东西,我认为只要公司体量不大,其实平时用搜索引擎,这个是比社交媒体更有价值的东西。
采集文章系统(天人文章管理系统默认模板不满意,其他模板可以在后台替换)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-11-03 04:02
天人文章管理系统是一个ASP+Access/MSSQL架构的网站系统。如果您对默认模板不满意,可以在后台替换其他模板。PC版,手机版,平板版,无缝自动切换,后台同步管理,支持SEO站静态动态切换,一键更换模板,安装插件,升级包,使用Dreamweaver进行可视化修改,主要用于文章、图片网站,如小说网站、美女图片等。 景区、政府部门、学校、书画网等都与图片相关和文本。当然,我们也支持二次开发,根据您的具体需求开发功能。
特征:
如果您对默认模板不满意,可以在后台更改其他模板。
程序支持子目录,支持放置在网站的子目录或多级目录中。
1、后台服务器信息查看功能,可以快速全面的查看服务器的软硬件状态。
2、网站 设置基本信息,包括全局关键词、开通网站、统计代码、logo上传、后台登录验证码数量免费。
三。网站联系人设置,包括QQ、电话、传真、联系地址等。
4、会员注册设置,包括是否允许注册、注册会员是否需要注册、注册会员的初始分数、会员页面显示的提示信息。
5、消息发布功能设置,留言,评论,文章发布功能,以及后台管理员对以上功能的审核。
6、管理员管理,可以设置管理员权限的范围,以及是有管理员权限还是只有查看权限。
数据库管理,可以备份和恢复数据库,同时常见上传木马漏洞过滤,安全性高。
广告管理,可以在现有广告位添加广告,同时优化不同层次的相关路径,广告管理页面已经详细介绍。
友情链接管理,可以设置友情链接的图片或文字类型。
后台操作日志管理,所有操作记录都在后台记录,可批量删除。
11、列管理,支持无限分类,即支持无限数量的低级列和无限数量的对等级列。同时还可以控制栏目的切换,栏目是图片还是文字类型,栏目是否在导航栏中显示,栏目是否在首页面板显示,以及显示顺序导航栏主页的。
文章管理,支持基于发布文本的文章功能,并具有上传图片、选择服务器上传图片、批量上传图片、设置多种形式图片、文字前端展示的能力效果。同时支持文章查看权限设置,可以细化限制会员查看和限制会员级别查看。
评论管理,可以进入文章的编辑页面对文章的评论进行管理,也可以直接管理系统内的所有评论,可以删除、查看、回复。 查看全部
采集文章系统(天人文章管理系统默认模板不满意,其他模板可以在后台替换)
天人文章管理系统是一个ASP+Access/MSSQL架构的网站系统。如果您对默认模板不满意,可以在后台替换其他模板。PC版,手机版,平板版,无缝自动切换,后台同步管理,支持SEO站静态动态切换,一键更换模板,安装插件,升级包,使用Dreamweaver进行可视化修改,主要用于文章、图片网站,如小说网站、美女图片等。 景区、政府部门、学校、书画网等都与图片相关和文本。当然,我们也支持二次开发,根据您的具体需求开发功能。
特征:
如果您对默认模板不满意,可以在后台更改其他模板。
程序支持子目录,支持放置在网站的子目录或多级目录中。
1、后台服务器信息查看功能,可以快速全面的查看服务器的软硬件状态。
2、网站 设置基本信息,包括全局关键词、开通网站、统计代码、logo上传、后台登录验证码数量免费。
三。网站联系人设置,包括QQ、电话、传真、联系地址等。
4、会员注册设置,包括是否允许注册、注册会员是否需要注册、注册会员的初始分数、会员页面显示的提示信息。
5、消息发布功能设置,留言,评论,文章发布功能,以及后台管理员对以上功能的审核。
6、管理员管理,可以设置管理员权限的范围,以及是有管理员权限还是只有查看权限。
数据库管理,可以备份和恢复数据库,同时常见上传木马漏洞过滤,安全性高。
广告管理,可以在现有广告位添加广告,同时优化不同层次的相关路径,广告管理页面已经详细介绍。
友情链接管理,可以设置友情链接的图片或文字类型。
后台操作日志管理,所有操作记录都在后台记录,可批量删除。
11、列管理,支持无限分类,即支持无限数量的低级列和无限数量的对等级列。同时还可以控制栏目的切换,栏目是图片还是文字类型,栏目是否在导航栏中显示,栏目是否在首页面板显示,以及显示顺序导航栏主页的。
文章管理,支持基于发布文本的文章功能,并具有上传图片、选择服务器上传图片、批量上传图片、设置多种形式图片、文字前端展示的能力效果。同时支持文章查看权限设置,可以细化限制会员查看和限制会员级别查看。
评论管理,可以进入文章的编辑页面对文章的评论进行管理,也可以直接管理系统内的所有评论,可以删除、查看、回复。
采集文章系统(采集文章系统原理攻击的原理和ddos防御常见的类型)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-11-02 05:02
采集文章系统原理ddos攻击,指的是攻击方向网站发动网络攻击,导致访问、分享以及转载一些网站内容出现带有隐蔽性、攻击性的页面。它们经常对关键的联系性数据进行广泛的读写。由于不受任何计算机技术条件限制,因此网络攻击对网站的影响是巨大的。ddos攻击基本的原理和ddos防御常见的类型:ddos攻击其实可以分为两种,一种是快速的,一种是缓慢的;首先讲讲快速的ddos攻击,这类攻击对关键的个人信息和联系性数据进行广泛的读写。
那么对应的,这类ddos攻击呢,我们叫做“利用cookie进行传输攻击”。我们知道,目前的ddos攻击大多数对象是个人信息,这是由于个人信息在我们的身份验证上是非常非常难的。比如,我们需要用人名做关键字进行关键词验证,那么现在就直接拿人名说事。如果网站是个公司的网站,需要用公司的名字和邮箱等关键词进行注册,那么就搞这些人干什么?这里就需要引入第二类攻击,“利用get进行传输攻击”。
这个攻击包括get/post两个方向,这类攻击也是目前的主流,攻击手段可以分为主动发起ddos以及被动的ddos。主动发起ddos被动ddos讲到ddos,不得不提到ddos专用的名词:ddosoverattack,即同时对多个网站发起ddos攻击,这些网站都会受到到同时的ddos攻击。我们通常说的就是指ddosoverattack。
一般是攻击的同时对一个网站进行攻击,使其发起大量流量来进行响应。下面来讲讲主动ddos攻击:主动ddos是指对某个网站进行ddos攻击,然后这个网站下面所有相同访问量的网站都会受到这次攻击。这类ddos攻击的特点是流量的流向都是一致的,可以只攻击一个网站。比如通过ddos软件进行攻击的情况下,会主动发起ddos攻击,而不是攻击同一网站下所有的网站。
ddos攻击存在一定的主动性,那么对应的防御就应该有针对性。比如说针对于网站服务器被攻击,可以采取一定的ddos防御策略,增加一些基础的防御措施,比如防火墙,ddos防御插件等等。另外还有我们可以通过汇总攻击源(比如说向全球的web服务器发起ddos攻击)来提高我们网站的安全等级。ddos防御常见的方法:第一个是:网站上最好不要接入外部加速服务;第二个是增加路由器的负载均衡等等。
网站支持外部ddos插件:很多大型的网站,一般他们的安全程度不是那么高,针对这个,就可以搭建网站,使用一些外部ddos插件来加强ddos的管理和保护。防火墙的负载均衡比如说防火墙上面对ddos比较敏感的端口进行了加强,比如ip池、地址池等等,可以根据每个网站的安全情况进行实时。 查看全部
采集文章系统(采集文章系统原理攻击的原理和ddos防御常见的类型)
采集文章系统原理ddos攻击,指的是攻击方向网站发动网络攻击,导致访问、分享以及转载一些网站内容出现带有隐蔽性、攻击性的页面。它们经常对关键的联系性数据进行广泛的读写。由于不受任何计算机技术条件限制,因此网络攻击对网站的影响是巨大的。ddos攻击基本的原理和ddos防御常见的类型:ddos攻击其实可以分为两种,一种是快速的,一种是缓慢的;首先讲讲快速的ddos攻击,这类攻击对关键的个人信息和联系性数据进行广泛的读写。
那么对应的,这类ddos攻击呢,我们叫做“利用cookie进行传输攻击”。我们知道,目前的ddos攻击大多数对象是个人信息,这是由于个人信息在我们的身份验证上是非常非常难的。比如,我们需要用人名做关键字进行关键词验证,那么现在就直接拿人名说事。如果网站是个公司的网站,需要用公司的名字和邮箱等关键词进行注册,那么就搞这些人干什么?这里就需要引入第二类攻击,“利用get进行传输攻击”。
这个攻击包括get/post两个方向,这类攻击也是目前的主流,攻击手段可以分为主动发起ddos以及被动的ddos。主动发起ddos被动ddos讲到ddos,不得不提到ddos专用的名词:ddosoverattack,即同时对多个网站发起ddos攻击,这些网站都会受到到同时的ddos攻击。我们通常说的就是指ddosoverattack。
一般是攻击的同时对一个网站进行攻击,使其发起大量流量来进行响应。下面来讲讲主动ddos攻击:主动ddos是指对某个网站进行ddos攻击,然后这个网站下面所有相同访问量的网站都会受到这次攻击。这类ddos攻击的特点是流量的流向都是一致的,可以只攻击一个网站。比如通过ddos软件进行攻击的情况下,会主动发起ddos攻击,而不是攻击同一网站下所有的网站。
ddos攻击存在一定的主动性,那么对应的防御就应该有针对性。比如说针对于网站服务器被攻击,可以采取一定的ddos防御策略,增加一些基础的防御措施,比如防火墙,ddos防御插件等等。另外还有我们可以通过汇总攻击源(比如说向全球的web服务器发起ddos攻击)来提高我们网站的安全等级。ddos防御常见的方法:第一个是:网站上最好不要接入外部加速服务;第二个是增加路由器的负载均衡等等。
网站支持外部ddos插件:很多大型的网站,一般他们的安全程度不是那么高,针对这个,就可以搭建网站,使用一些外部ddos插件来加强ddos的管理和保护。防火墙的负载均衡比如说防火墙上面对ddos比较敏感的端口进行了加强,比如ip池、地址池等等,可以根据每个网站的安全情况进行实时。
采集文章系统(一下如何利用老Y文章管理系统采集时自动完成伪原创)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-10-27 12:19
垃圾站站长最希望的就是网站可以自动采集,自动补完伪原创,然后自动收钱。这真是世界上最幸福的事情了,哈哈。自动采集 和自动收款将不再讨论。今天给大家介绍一下如何使用老Y的文章管理系统采集自动完成伪原创。
旧的Y文章管理系统使用起来简单方便,虽然功能不如DEDE之类的强大。几乎是变态(当然,老Y文章管理系统是用asp语言写的,好像没有可比性。),但是该有的都有,而且还挺简单的,所以也受到了很多站长的欢迎。老Y文章管理系统采集时自动完成伪原创的具体方法目前还很少讨论。在老Y的论坛上,甚至有人在卖这个方法。我鄙视它。.
关于采集,我就不多说了,相信大家都能搞定。我要介绍的是旧的Y文章管理系统如何在采集的同时自动完成伪原创的具体工作方法,大体思路是使用过滤功能旧的Y文章管理系统实现同义词自动替换,从而达到伪原创的目的。比如我想把采集文章中的“网转博客”全部换成“网转日记”。详细步骤如下:
第一步是进入后台。找到“采集管理”-“过滤管理”,添加一个新的过滤项。
我可以创建一个名为“网赚博客”的项目,具体设置请看图片:
“过滤器名称”:填写“网赚博客”即可,也可以随意写,但为了方便查看,建议与替换词保持一致。
“项目”:请根据自己的网站选择一列网站(一定要选择一列,否则过滤后的项目无法保存)
“过滤器对象”:可用选项有“标题过滤器”和“文本过滤器”。一般选择“文本过滤器”。如果你想伪原创 连标题,你可以选择“标题过滤器”。
“过滤器类型”:选项有“简单替换”和“高级过滤器”,一般选择“简单替换”,如果选择“高级过滤器”,则需要指定“开始标签”和“结束标签”,以便你可以在代码层面替换 采集 中的内容。
“使用状态”:选项为“启用”和“禁用”,不作解释。
“使用范围”:选项为“公共”和“私人”。选择“私有”,过滤器只对当前网站列有效;选择“Public”,对所有列都有效,不管采集的任何列有什么内容,过滤器都有效。一般选择“私人”。
“内容”:填写要替换的“网赚博客”。
“替换”:填写“网转日记”,所以只要采集的文章中含有“网转博客”二字,就会自动替换为“网转日记”。
第二步,重复第一步的工作,直到添加完所有同义词。
有网友想问:我有3万多个同义词,要不要手动一一添加?什么时候加!? 不能批量添加吗?
好问题!手动添加确实是一个几乎不可能完成的任务,除非你有非凡的毅力,你可以手动添加这三万多个同义词。遗憾的是,旧的Y文章 管理系统并没有提供批量导入的功能。但是,作为真实的、有经验的、有思想的优采云,我们必须有优采云的意识。
要知道,我们刚刚录入的内容是存放在数据库中的,老Y文章管理系统是用asp+Access编写的,mdb数据库可以轻松编辑!于是乎,直接修改数据库就可以批量导入伪原创替换规则了!
改进的第二步:批量修改数据库和导入规则。
经过搜索,我发现这个数据库在“你的管理目录\cai\Database”下。使用 Access 打开此数据库并找到“过滤器”表。你会发现我们刚刚添加的替换规则就存放在这里。根据您的需要分批添加!接下来的工作涉及到Access的操作。
解释一下“过滤器”表中几个字段的含义:
FilterID:自动生成,无需输入。
ItemID:列ID是我们手动输入时“item”的内容,但这里是数字ID,注意对应列采集ID,如果不知道ID,可以重复第一步,测试一下。.
过滤器名称:“过滤器名称”。
FilterObjece:“过滤对象”,“标题过滤”填1,“文本过滤”填2。
FilterType:“过滤器类型”,“简单更换”填1,“高级过滤器”填2。
FilterContent:“内容”。
FisString:“开始标签”,只有在设置了“高级过滤器”时才有效,如果设置了“简单过滤器”,请留空。
FioString:“结束标签”,仅在设置了“高级过滤器”时有效,如果设置了“简单过滤器”,请留空。
FilterRep:即“替换”。
Flag:“使用状态”,TRUE 表示“启用”,FALSE 表示“禁用”。
PublicTf:“使用范围”。TRUE 表示“公共”,FALSE 表示“私有”。
最后说一下使用过滤功能实现伪原创的使用感
经过:
老Y文章管理系统的这个功能在采集为伪原创时可以自动实现,但功能不够强大。例如,我的网站上有三列:“第一列”、“第二列”和“第三列”。我希望“第一列”伪原创 标题和正文,“第二列”伪原创 仅文本,“第三列”伪原创 仅标题。
因此,我只能进行以下设置(假设我有一个 30,000 同义词规则):
为“第一列”伪原创的标题创建30000条替换规则;
为“第一列”伪原创的文本创建30000条替换规则;
为“第2列”伪原创的文本创建30000条替换规则;
为“第三列”伪原创 的标题创建 30,000 条替换规则。
这造成了巨大的数据库浪费。如果我的网站有几十个栏目,而且每个栏目的要求都不一样,这个数据库的大小会很吓人。
所以建议旧版Y文章管理系统下个版本对这个功能做一些改进:
先添加批量导入功能,毕竟修改数据库有一定的危险性。
其次,过滤规则不再附属于某个网站列,而是独立于过滤规则,并且在新建采集项目时,增加了是否使用过滤规则的判断。
相信经过这样的修改,可以大大节省数据库存储空间,逻辑结构也更加清晰。
本文为《我的网赚日记-原创网专博客》原创,请尊重我的劳动成果,转载请注明出处!另外,我也很久没有用过旧的Y文章管理系统了。文章如有错误或不妥之处,还望指正!
感谢陆奇的贡献 查看全部
采集文章系统(一下如何利用老Y文章管理系统采集时自动完成伪原创)
垃圾站站长最希望的就是网站可以自动采集,自动补完伪原创,然后自动收钱。这真是世界上最幸福的事情了,哈哈。自动采集 和自动收款将不再讨论。今天给大家介绍一下如何使用老Y的文章管理系统采集自动完成伪原创。
旧的Y文章管理系统使用起来简单方便,虽然功能不如DEDE之类的强大。几乎是变态(当然,老Y文章管理系统是用asp语言写的,好像没有可比性。),但是该有的都有,而且还挺简单的,所以也受到了很多站长的欢迎。老Y文章管理系统采集时自动完成伪原创的具体方法目前还很少讨论。在老Y的论坛上,甚至有人在卖这个方法。我鄙视它。.
关于采集,我就不多说了,相信大家都能搞定。我要介绍的是旧的Y文章管理系统如何在采集的同时自动完成伪原创的具体工作方法,大体思路是使用过滤功能旧的Y文章管理系统实现同义词自动替换,从而达到伪原创的目的。比如我想把采集文章中的“网转博客”全部换成“网转日记”。详细步骤如下:
第一步是进入后台。找到“采集管理”-“过滤管理”,添加一个新的过滤项。
我可以创建一个名为“网赚博客”的项目,具体设置请看图片:

“过滤器名称”:填写“网赚博客”即可,也可以随意写,但为了方便查看,建议与替换词保持一致。
“项目”:请根据自己的网站选择一列网站(一定要选择一列,否则过滤后的项目无法保存)
“过滤器对象”:可用选项有“标题过滤器”和“文本过滤器”。一般选择“文本过滤器”。如果你想伪原创 连标题,你可以选择“标题过滤器”。
“过滤器类型”:选项有“简单替换”和“高级过滤器”,一般选择“简单替换”,如果选择“高级过滤器”,则需要指定“开始标签”和“结束标签”,以便你可以在代码层面替换 采集 中的内容。
“使用状态”:选项为“启用”和“禁用”,不作解释。
“使用范围”:选项为“公共”和“私人”。选择“私有”,过滤器只对当前网站列有效;选择“Public”,对所有列都有效,不管采集的任何列有什么内容,过滤器都有效。一般选择“私人”。
“内容”:填写要替换的“网赚博客”。
“替换”:填写“网转日记”,所以只要采集的文章中含有“网转博客”二字,就会自动替换为“网转日记”。
第二步,重复第一步的工作,直到添加完所有同义词。
有网友想问:我有3万多个同义词,要不要手动一一添加?什么时候加!? 不能批量添加吗?
好问题!手动添加确实是一个几乎不可能完成的任务,除非你有非凡的毅力,你可以手动添加这三万多个同义词。遗憾的是,旧的Y文章 管理系统并没有提供批量导入的功能。但是,作为真实的、有经验的、有思想的优采云,我们必须有优采云的意识。
要知道,我们刚刚录入的内容是存放在数据库中的,老Y文章管理系统是用asp+Access编写的,mdb数据库可以轻松编辑!于是乎,直接修改数据库就可以批量导入伪原创替换规则了!
改进的第二步:批量修改数据库和导入规则。
经过搜索,我发现这个数据库在“你的管理目录\cai\Database”下。使用 Access 打开此数据库并找到“过滤器”表。你会发现我们刚刚添加的替换规则就存放在这里。根据您的需要分批添加!接下来的工作涉及到Access的操作。
解释一下“过滤器”表中几个字段的含义:
FilterID:自动生成,无需输入。
ItemID:列ID是我们手动输入时“item”的内容,但这里是数字ID,注意对应列采集ID,如果不知道ID,可以重复第一步,测试一下。.
过滤器名称:“过滤器名称”。
FilterObjece:“过滤对象”,“标题过滤”填1,“文本过滤”填2。
FilterType:“过滤器类型”,“简单更换”填1,“高级过滤器”填2。
FilterContent:“内容”。
FisString:“开始标签”,只有在设置了“高级过滤器”时才有效,如果设置了“简单过滤器”,请留空。
FioString:“结束标签”,仅在设置了“高级过滤器”时有效,如果设置了“简单过滤器”,请留空。
FilterRep:即“替换”。
Flag:“使用状态”,TRUE 表示“启用”,FALSE 表示“禁用”。
PublicTf:“使用范围”。TRUE 表示“公共”,FALSE 表示“私有”。
最后说一下使用过滤功能实现伪原创的使用感
经过:
老Y文章管理系统的这个功能在采集为伪原创时可以自动实现,但功能不够强大。例如,我的网站上有三列:“第一列”、“第二列”和“第三列”。我希望“第一列”伪原创 标题和正文,“第二列”伪原创 仅文本,“第三列”伪原创 仅标题。
因此,我只能进行以下设置(假设我有一个 30,000 同义词规则):
为“第一列”伪原创的标题创建30000条替换规则;
为“第一列”伪原创的文本创建30000条替换规则;
为“第2列”伪原创的文本创建30000条替换规则;
为“第三列”伪原创 的标题创建 30,000 条替换规则。
这造成了巨大的数据库浪费。如果我的网站有几十个栏目,而且每个栏目的要求都不一样,这个数据库的大小会很吓人。
所以建议旧版Y文章管理系统下个版本对这个功能做一些改进:
先添加批量导入功能,毕竟修改数据库有一定的危险性。
其次,过滤规则不再附属于某个网站列,而是独立于过滤规则,并且在新建采集项目时,增加了是否使用过滤规则的判断。
相信经过这样的修改,可以大大节省数据库存储空间,逻辑结构也更加清晰。
本文为《我的网赚日记-原创网专博客》原创,请尊重我的劳动成果,转载请注明出处!另外,我也很久没有用过旧的Y文章管理系统了。文章如有错误或不妥之处,还望指正!
感谢陆奇的贡献
采集文章系统(采集文章系统分析下行情的变化只要我们能跟上变化的步伐)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-10-26 12:09
采集文章系统分析下行情的变化只要我们能跟上变化的步伐,就能稳赚,实现财富自由。正常情况下可能需要我们不断地学习,不断地更新对市场的认知、对自己的认知。由于每个人所关注的方向不同,我们只能根据已有的知识和经验做出分析,形成的分析只能是短线的分析。现在手机浏览的最大弊端是每一条新闻跳转到的网页又大又杂,通过百度浏览器跳转到的网页往往都不会保存文章的原文链接,将会消耗大量的时间,所以在浏览新闻时或者浏览过程中需要看下有没有自己认为重要的信息。
所以我们还是需要专注浏览一个网页来实现信息分析。不同的行情不同的经历都会让我们形成不同的想法,这就是人生的魅力!在咨询过程中我会仔细询问你一个问题:为什么重仓单,为什么加仓单?我们看市场的方式,思考市场的方式,看自己能不能抓住市场的机会,我们才能赚钱。如果想要通过市场赚钱的话最重要的不是去精通什么投资理论,而是去实践什么投资方法,如果方法对了也是一样可以赚钱的。
人生,很难找到完美的理由,也很难去找到完美的答案,但我们可以去找到自己的原因。只要自己多找到自己的原因,多去向内反省,去不断总结自己,你总会找到自己解决这些问题的方法,总会找到自己成长的方向。只要有一点点进步,总会让自己变得不同。原因只有一个,只要持续地努力,人人都能够成为最终的赢家。从有到有,还从有到更多,行情走出不一样的波动形态或形态背后又暗含着什么?对于股市来说,每天都不缺热点和行情,找到热点和背后的逻辑就已经行情已经不远了。
市场是散户自己一个人去自娱自乐的,所以有人抱怨股市的起伏非常大,变化莫测,但在市场中最重要的是要找到适合自己的投资方法,时刻调整自己。否则不断地操作是徒劳无功的。追涨杀跌,就是其中最重要的原因。我们通过每一次上涨,就能够找到每一次下跌的逻辑,看股票该不该买,想不想卖,原因只有一个,那就是缺乏对股票的认知和思考,而且还是一种盲目的思考。
你的思考仅仅停留在下跌这一次机会的考虑上,没有反省和总结。市场并不是寻找交易机会,而是寻找相对高点。实盘的格局不同于教程,所以需要用原文中提供的逻辑思维去分析。如何选择要看你对行情有一个怎样的认知。如果你不懂分析,那么怎么去选也是白搭。所以这是为什么要学习一些基础知识后再去了解行情,因为市场从来不缺看行情的人,只是缺少技术分析者。
如果连分析都做不到的人,也找不到方法。在原文中提到要构建一个分析框架,然后围绕这个框架去筛选出重点的投资策略,并不断重复这个策略。很多人会回应。 查看全部
采集文章系统(采集文章系统分析下行情的变化只要我们能跟上变化的步伐)
采集文章系统分析下行情的变化只要我们能跟上变化的步伐,就能稳赚,实现财富自由。正常情况下可能需要我们不断地学习,不断地更新对市场的认知、对自己的认知。由于每个人所关注的方向不同,我们只能根据已有的知识和经验做出分析,形成的分析只能是短线的分析。现在手机浏览的最大弊端是每一条新闻跳转到的网页又大又杂,通过百度浏览器跳转到的网页往往都不会保存文章的原文链接,将会消耗大量的时间,所以在浏览新闻时或者浏览过程中需要看下有没有自己认为重要的信息。
所以我们还是需要专注浏览一个网页来实现信息分析。不同的行情不同的经历都会让我们形成不同的想法,这就是人生的魅力!在咨询过程中我会仔细询问你一个问题:为什么重仓单,为什么加仓单?我们看市场的方式,思考市场的方式,看自己能不能抓住市场的机会,我们才能赚钱。如果想要通过市场赚钱的话最重要的不是去精通什么投资理论,而是去实践什么投资方法,如果方法对了也是一样可以赚钱的。
人生,很难找到完美的理由,也很难去找到完美的答案,但我们可以去找到自己的原因。只要自己多找到自己的原因,多去向内反省,去不断总结自己,你总会找到自己解决这些问题的方法,总会找到自己成长的方向。只要有一点点进步,总会让自己变得不同。原因只有一个,只要持续地努力,人人都能够成为最终的赢家。从有到有,还从有到更多,行情走出不一样的波动形态或形态背后又暗含着什么?对于股市来说,每天都不缺热点和行情,找到热点和背后的逻辑就已经行情已经不远了。
市场是散户自己一个人去自娱自乐的,所以有人抱怨股市的起伏非常大,变化莫测,但在市场中最重要的是要找到适合自己的投资方法,时刻调整自己。否则不断地操作是徒劳无功的。追涨杀跌,就是其中最重要的原因。我们通过每一次上涨,就能够找到每一次下跌的逻辑,看股票该不该买,想不想卖,原因只有一个,那就是缺乏对股票的认知和思考,而且还是一种盲目的思考。
你的思考仅仅停留在下跌这一次机会的考虑上,没有反省和总结。市场并不是寻找交易机会,而是寻找相对高点。实盘的格局不同于教程,所以需要用原文中提供的逻辑思维去分析。如何选择要看你对行情有一个怎样的认知。如果你不懂分析,那么怎么去选也是白搭。所以这是为什么要学习一些基础知识后再去了解行情,因为市场从来不缺看行情的人,只是缺少技术分析者。
如果连分析都做不到的人,也找不到方法。在原文中提到要构建一个分析框架,然后围绕这个框架去筛选出重点的投资策略,并不断重复这个策略。很多人会回应。
采集文章系统(采集文章系统的话有两个软件可以供你选择)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-10-24 19:02
采集文章系统的话有两个软件可以供你选择【贝叶斯统计】,【scikit-learn】。贝叶斯是统计学领域非常有名的软件,它可以对n维数据集进行一元,多元分析,它能处理数据量超大且不适用excel进行计算的数据。scikit-learn是第一个开源的机器学习软件包,它可以使用scipy进行处理数据,去除非线性关系和线性相关数据以及数据异常值。
以上是从两者的软件结构上简要介绍。细节可以在上面文章的具体项目中查看。第一步的话,根据所选的数据结构编写函数获取数据;第二步是找到目标数据的数据特征以及标签;第三步是进行预处理,提取数据特征以及标签。python的docstring可以很方便的获取数据,如movie_id_list中artists_id是个未知变量,主要就是说电影中不同人物的联系是否紧密,标签可以根据你的具体情况自己输入;第四步,根据最后要的标签,也就是所需要的标签的一组数组,比如names_matrix自定义数组;第五步,对这组数组进行特征提取,降维或者归一化,labels_matrix是个特征数组;第六步,将数据存储,用tfrecord,noexcel或者records.把所有数据写到训练集中。
docstring中可以获取不同维度的训练集中不同的数据,还可以根据自己需要把数据合并,转换,切片,以及异常值的处理等。这就是数据分析常用的三大基本模块:featuredescriptor,featureextraction,labelengine。 查看全部
采集文章系统(采集文章系统的话有两个软件可以供你选择)
采集文章系统的话有两个软件可以供你选择【贝叶斯统计】,【scikit-learn】。贝叶斯是统计学领域非常有名的软件,它可以对n维数据集进行一元,多元分析,它能处理数据量超大且不适用excel进行计算的数据。scikit-learn是第一个开源的机器学习软件包,它可以使用scipy进行处理数据,去除非线性关系和线性相关数据以及数据异常值。
以上是从两者的软件结构上简要介绍。细节可以在上面文章的具体项目中查看。第一步的话,根据所选的数据结构编写函数获取数据;第二步是找到目标数据的数据特征以及标签;第三步是进行预处理,提取数据特征以及标签。python的docstring可以很方便的获取数据,如movie_id_list中artists_id是个未知变量,主要就是说电影中不同人物的联系是否紧密,标签可以根据你的具体情况自己输入;第四步,根据最后要的标签,也就是所需要的标签的一组数组,比如names_matrix自定义数组;第五步,对这组数组进行特征提取,降维或者归一化,labels_matrix是个特征数组;第六步,将数据存储,用tfrecord,noexcel或者records.把所有数据写到训练集中。
docstring中可以获取不同维度的训练集中不同的数据,还可以根据自己需要把数据合并,转换,切片,以及异常值的处理等。这就是数据分析常用的三大基本模块:featuredescriptor,featureextraction,labelengine。
采集文章系统(如何在自媒体运营当中有熟人当老师,可以少走弯路)
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-10-05 22:28
自媒体爆文采集工具很容易写!用它快速查找爆文的内容!毛毛同学一直在用一战这个工具!做自媒体操作就是不断学习新的知识,比如如何做爆文标题,如何关注实时热点等等。
具体的内容不是那么容易简单讲的。只有当你真正去做时,你才会发现并且知道并不意味着你会去做。但是这些内容无论如何都是要学习和掌握的。在自媒体的操作中如何有熟人做老师,可以少走很多弯路。
日复一日的内容创作,对于做自媒体运营的小伙伴来说,是一件很烦的事情。总会有没有创作灵感的时候,即使你看材料,灵感也枯竭了。.
这个时候就需要适当的借鉴一些同行业朋友的创意内容,那么这些内容应该如何采集和搜索呢?
今天给大家分享一个爆文的搜索工具,以后还会用到。希望能帮助大家提供创作灵感,打造10w甚至100w爆文。
容易写
易转可以在市场上大多数自媒体平台上采集到爆文。
您可以根据需要过滤字段和平台。过滤器和排序功能的结果非常有用。自媒体爆文查找网站,还有文章原创度数检测、视频批量下载、爆文标题助手等小功能,喜欢的朋友关注可以输入网站了解更多里面的功能。
毛毛同学分享这个亦庄自媒体工具只是为了让大家更快找到爆文学习爆文写作技巧,为自己提供灵感,不要把它当作自媒体操作神器,比起自媒体 平台不是傻子。不要挑战自媒体平台的规则,多做搬运。 查看全部
采集文章系统(如何在自媒体运营当中有熟人当老师,可以少走弯路)
自媒体爆文采集工具很容易写!用它快速查找爆文的内容!毛毛同学一直在用一战这个工具!做自媒体操作就是不断学习新的知识,比如如何做爆文标题,如何关注实时热点等等。
具体的内容不是那么容易简单讲的。只有当你真正去做时,你才会发现并且知道并不意味着你会去做。但是这些内容无论如何都是要学习和掌握的。在自媒体的操作中如何有熟人做老师,可以少走很多弯路。
日复一日的内容创作,对于做自媒体运营的小伙伴来说,是一件很烦的事情。总会有没有创作灵感的时候,即使你看材料,灵感也枯竭了。.
这个时候就需要适当的借鉴一些同行业朋友的创意内容,那么这些内容应该如何采集和搜索呢?
今天给大家分享一个爆文的搜索工具,以后还会用到。希望能帮助大家提供创作灵感,打造10w甚至100w爆文。
容易写
易转可以在市场上大多数自媒体平台上采集到爆文。
您可以根据需要过滤字段和平台。过滤器和排序功能的结果非常有用。自媒体爆文查找网站,还有文章原创度数检测、视频批量下载、爆文标题助手等小功能,喜欢的朋友关注可以输入网站了解更多里面的功能。
毛毛同学分享这个亦庄自媒体工具只是为了让大家更快找到爆文学习爆文写作技巧,为自己提供灵感,不要把它当作自媒体操作神器,比起自媒体 平台不是傻子。不要挑战自媒体平台的规则,多做搬运。
采集文章系统(如何高效采集归档处理的呢?博通档案管理系统采集方式介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-10-05 22:27
众所周知,汇博通档案管理系统具有强大的办公功能。汇博通作为文件、档案、知识办公一体化的管理软件系统,如何高效地整理归档档案信息?下面小编就为大家简单介绍一下博通文件管理系统采集,希望对大家有所帮助。
汇博通的采集方式多种多样,主要分为主动式采集和集成式采集。
主动采集方法是提供属性创建,即对原文件重新编辑和填充,可以及时更新文件内容和附加文件信息,并添加个性化的附加可选功能。
扫描新建功能,原文件自带附件功能,支持多文件一起上传。
批量创建功能和批量上传/导入/替换功能是指上传文件中选择的批量创建模式,可以同时进行多个文件的批量上传/导入/替换,节省工时和人工效率.
主动采集方式,自由选择知识文档采集方式,满足当前企业对办公文档的需求,精益求精,并随着企业的发展做出不同的属性调整,适用于企业的办公平台。
汇博通作为综合信息门户和统一认证中心,整合现有信息系统(如OA、CRM等),统一采集其产生的知识内容。使用汇博通,可以将原创信息分散到不同的系统中。文件、档案、合同、报告、图纸、网站内容、摘要、内部期刊等,都集成到一个系统中进行统一管理。
文章发件人: 查看全部
采集文章系统(如何高效采集归档处理的呢?博通档案管理系统采集方式介绍)
众所周知,汇博通档案管理系统具有强大的办公功能。汇博通作为文件、档案、知识办公一体化的管理软件系统,如何高效地整理归档档案信息?下面小编就为大家简单介绍一下博通文件管理系统采集,希望对大家有所帮助。
汇博通的采集方式多种多样,主要分为主动式采集和集成式采集。
主动采集方法是提供属性创建,即对原文件重新编辑和填充,可以及时更新文件内容和附加文件信息,并添加个性化的附加可选功能。
扫描新建功能,原文件自带附件功能,支持多文件一起上传。
批量创建功能和批量上传/导入/替换功能是指上传文件中选择的批量创建模式,可以同时进行多个文件的批量上传/导入/替换,节省工时和人工效率.
主动采集方式,自由选择知识文档采集方式,满足当前企业对办公文档的需求,精益求精,并随着企业的发展做出不同的属性调整,适用于企业的办公平台。
汇博通作为综合信息门户和统一认证中心,整合现有信息系统(如OA、CRM等),统一采集其产生的知识内容。使用汇博通,可以将原创信息分散到不同的系统中。文件、档案、合同、报告、图纸、网站内容、摘要、内部期刊等,都集成到一个系统中进行统一管理。
文章发件人:
采集文章系统(SQLServer除了要精确的维度分析,本文ETL分析系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-10-05 03:30
【摘要】:随着互联网的飞速发展,网络安全问题越来越严重,大量网络攻击监控数据采集下线等待分析。这些数据都以文字的形式记录下来,单靠人工分析是不可能完成的任务。因此,迫切需要一个自动化的分析系统来定位数据、统计统计和计算维数。本系统是一个数据仓库系统,主要有两种数据:原创数据和IP地址数据库(简称“IP数据库”)数据。这两种类型的数据都具有“多源”属性。原创数据的多源性体现在不同的采集系统中,具有不同的类型和格式;IP库数据的多源性体现在三层IP库模型中。原创数据收录基本属性:SourIP(源IP,被攻击方)和DestIP(目的IP,攻击者),IP数据库数据用于定位。这是系统的核心功能。面对海量的原创数据,需要快速准确的维度分析,本文介绍了为什么使用分布式系统(Apache Hadoop)和关系数据库(SQLServer)的复合架构,以及如何使用这些技术构建数据仓库。准确地说,就是ETL的建模和实现是如何进行的。首先是原创数据的ETL。采集 原创文件加载到Hadoop的HDFS后,调用 API 提取数据并将其保存在 Hive 数据仓库中。同时编写了Map-Reduce程序,对目前可用的各种格式进行区分、清理、合并、最后处理。“一致”数据,这里所谓的一致数据就是“五元组模型”。二是IP库数据的ETL。五元组数据以文件的形式传递给 SQL Server。除了加载五元组数据,SQL Server 还有一种重要的字典数据类型,就是IP数据库数据。本文介绍如何构建“三层IP库模型”,满足不同关注度的IP精准定位。每一层IP数据库都有相应建立的全国行政区划数据库,其中至少收录三级地理划分:省(直辖市)、市(区)、区(县)。从采集按照三级划分组织IP库是ETL工作量的较大部分。数据仓库搭建完成后,通过B/S架构的Web界面调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析. 同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. 省(直辖市)、市(区)、区(县)。从采集按照三级划分组织IP库是ETL工作量的较大部分。数据仓库搭建完成后,通过B/S架构的Web界面调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析. 同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. 省(直辖市)、市(区)、区(县)。从采集按照三级划分组织IP库是ETL工作量的较大部分。数据仓库搭建完成后,通过B/S架构的Web界面调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析. 同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. 从采集按照三级划分组织IP库是ETL工作量的较大部分。数据仓库搭建完成后,通过B/S架构的Web界面调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析. 同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. 从采集按照三级划分组织IP库是ETL工作量的较大部分。数据仓库搭建完成后,通过B/S架构的Web界面调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析. 同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. B/S架构的Web界面,用于调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析。同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. B/S架构的Web界面,用于调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析。同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. 查看全部
采集文章系统(SQLServer除了要精确的维度分析,本文ETL分析系统)
【摘要】:随着互联网的飞速发展,网络安全问题越来越严重,大量网络攻击监控数据采集下线等待分析。这些数据都以文字的形式记录下来,单靠人工分析是不可能完成的任务。因此,迫切需要一个自动化的分析系统来定位数据、统计统计和计算维数。本系统是一个数据仓库系统,主要有两种数据:原创数据和IP地址数据库(简称“IP数据库”)数据。这两种类型的数据都具有“多源”属性。原创数据的多源性体现在不同的采集系统中,具有不同的类型和格式;IP库数据的多源性体现在三层IP库模型中。原创数据收录基本属性:SourIP(源IP,被攻击方)和DestIP(目的IP,攻击者),IP数据库数据用于定位。这是系统的核心功能。面对海量的原创数据,需要快速准确的维度分析,本文介绍了为什么使用分布式系统(Apache Hadoop)和关系数据库(SQLServer)的复合架构,以及如何使用这些技术构建数据仓库。准确地说,就是ETL的建模和实现是如何进行的。首先是原创数据的ETL。采集 原创文件加载到Hadoop的HDFS后,调用 API 提取数据并将其保存在 Hive 数据仓库中。同时编写了Map-Reduce程序,对目前可用的各种格式进行区分、清理、合并、最后处理。“一致”数据,这里所谓的一致数据就是“五元组模型”。二是IP库数据的ETL。五元组数据以文件的形式传递给 SQL Server。除了加载五元组数据,SQL Server 还有一种重要的字典数据类型,就是IP数据库数据。本文介绍如何构建“三层IP库模型”,满足不同关注度的IP精准定位。每一层IP数据库都有相应建立的全国行政区划数据库,其中至少收录三级地理划分:省(直辖市)、市(区)、区(县)。从采集按照三级划分组织IP库是ETL工作量的较大部分。数据仓库搭建完成后,通过B/S架构的Web界面调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析. 同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. 省(直辖市)、市(区)、区(县)。从采集按照三级划分组织IP库是ETL工作量的较大部分。数据仓库搭建完成后,通过B/S架构的Web界面调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析. 同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. 省(直辖市)、市(区)、区(县)。从采集按照三级划分组织IP库是ETL工作量的较大部分。数据仓库搭建完成后,通过B/S架构的Web界面调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析. 同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. 从采集按照三级划分组织IP库是ETL工作量的较大部分。数据仓库搭建完成后,通过B/S架构的Web界面调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析. 同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. 从采集按照三级划分组织IP库是ETL工作量的较大部分。数据仓库搭建完成后,通过B/S架构的Web界面调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析. 同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. B/S架构的Web界面,用于调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析。同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. B/S架构的Web界面,用于调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析。同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出.
采集文章系统(自动更新回帖插件功能特点及特点介绍-苏州安嘉网络 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-10-03 02:00
)
【本插件特点】
01、 可以批量注册马甲用户,发帖和评论所使用的马甲与真实注册用户发布的马甲一模一样。
02、可以批量采集批量发布,发布任意百度贴吧主题内容,短时间内回复您的论坛和门户。
03、可调度采集并自动发布,实现网站内容无人值守自动更新,让您拥有24小时发布内容的智能编辑器
04、采集 返回的内容可以进行简繁体转换、伪原创等二次处理。
05、支持前台采集,可以授权指定的普通注册用户在前台使用这个采集器,让普通注册会员帮你采集的内容。
06、采集 传入的内容图片可以正常显示并保存为post图片附件或门户文章附件,图片永不丢失。
07、图片附件支持远程FTP存储,让您可以将图片分离到另一台服务器。
08、 图片会添加您的论坛或门户设置的水印。
09、 已经采集的内容不会重复两次采集,内容不会重复或冗余。
1 0、采集或门户网站文章和群组发布的帖子与真实用户发布的帖子完全相同。其他人不知道是否用采集器 发帖。
1 1、的浏览量会自动随机设置。感觉你的帖子或者门户文章的浏览量和真实的一样。
12、可以指定帖子发布者(发帖人)、门户文章作者、群发帖人。
1 3、采集的内容可以发布到论坛任意版块、门户任意栏目、群任意圈。
14、已发布的内容可以推送到百度数据收录界面进行SEO优化,加速网站百度索引量和收录量.
15、不限制采集的内容数量,不限制采集的出现次数,让你的网站快速填充高质量内容。
1 6、 插件内置了自动文本提取算法。您不需要自己编写 采集 规则。它支持任何采集 任何网站 内容。
17、 一键获取当前实时热点内容,然后一键发布。
18、 马甲回复时间经过科学处理。并非所有回复都在同一时间。感觉您的论坛不是在回复马甲,而是在回复真实用户。
19、支持采集指定的贴吧,实现有针对性的采集某百度贴吧内容。
查看全部
采集文章系统(自动更新回帖插件功能特点及特点介绍-苏州安嘉网络
)
【本插件特点】
01、 可以批量注册马甲用户,发帖和评论所使用的马甲与真实注册用户发布的马甲一模一样。
02、可以批量采集批量发布,发布任意百度贴吧主题内容,短时间内回复您的论坛和门户。
03、可调度采集并自动发布,实现网站内容无人值守自动更新,让您拥有24小时发布内容的智能编辑器
04、采集 返回的内容可以进行简繁体转换、伪原创等二次处理。
05、支持前台采集,可以授权指定的普通注册用户在前台使用这个采集器,让普通注册会员帮你采集的内容。
06、采集 传入的内容图片可以正常显示并保存为post图片附件或门户文章附件,图片永不丢失。
07、图片附件支持远程FTP存储,让您可以将图片分离到另一台服务器。
08、 图片会添加您的论坛或门户设置的水印。
09、 已经采集的内容不会重复两次采集,内容不会重复或冗余。
1 0、采集或门户网站文章和群组发布的帖子与真实用户发布的帖子完全相同。其他人不知道是否用采集器 发帖。
1 1、的浏览量会自动随机设置。感觉你的帖子或者门户文章的浏览量和真实的一样。
12、可以指定帖子发布者(发帖人)、门户文章作者、群发帖人。
1 3、采集的内容可以发布到论坛任意版块、门户任意栏目、群任意圈。
14、已发布的内容可以推送到百度数据收录界面进行SEO优化,加速网站百度索引量和收录量.
15、不限制采集的内容数量,不限制采集的出现次数,让你的网站快速填充高质量内容。
1 6、 插件内置了自动文本提取算法。您不需要自己编写 采集 规则。它支持任何采集 任何网站 内容。
17、 一键获取当前实时热点内容,然后一键发布。
18、 马甲回复时间经过科学处理。并非所有回复都在同一时间。感觉您的论坛不是在回复马甲,而是在回复真实用户。
19、支持采集指定的贴吧,实现有针对性的采集某百度贴吧内容。
 https://www.ff-coder.cn/wp-con ... 4.jpg 300w, https://www.ff-coder.cn/wp-con ... 8.jpg 768w" />
https://www.ff-coder.cn/wp-con ... 4.jpg 300w, https://www.ff-coder.cn/wp-con ... 8.jpg 768w" /> 采集文章系统(网钛文章管理系统、支持设置首页各个(◆商业版))
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-01 21:11
Net钛文章管理系统是一种流行的ASP开源网站管理系统。在功能、人性化和易用性方面,它基于ASP+Access/MSSQL的技术架构,可用于广泛的新闻发布网站,也可用于信息门户网站。对于那些不太了解网站构建并希望成为网站的人,他们可以快速构建一个实用、强大、用户友好且易于使用的系统。Netti文章管理系统更注重个人网站或中小型门户网站的建设。当然,有很多企业用户使用这个系统。使用过netti文章管理系统的用户将继续对其表示赞赏。Net钛文章管理系统界面友好,操作简单,功能强大。有需要的朋友可以下载并使用它
功能特性1、两个原创主页布局可以自由切换:左侧两列和右侧热门文章以及投票,全部三列
2、支持三种顶级徽标模式:横幅、徽标+2个广告空间和徽标+1个广告空间
3、Flash格式的徽标,包括Flash(◆ 商业版)
4、支持设置是否在顶部显示日期、星期、时间和节日
5、支持三种类型的天气预报和用户定义的天气预报代码
6、支持设置导航菜单的数量
7、支持设置主导航、次导航和自定义多行导航样式(◆ 商业版)
8、支持导航的子菜单模式有三种:不显示子菜单、下拉子菜单和水平子菜单(◆ 商业版)
9、支持4种不同的flash幻灯片样式,并可设置是否显示标题
10、支持设置最新消息列的显示范围
11、支持设置滚动图片的显示数量和列范围
12、支持远程图片作为幻灯片和缩略图(◆ 商业版)
13、支持设置主页上每列显示的文章数量、是否显示日期以及是否显示缩略图 查看全部
采集文章系统(网钛文章管理系统、支持设置首页各个(◆商业版))
Net钛文章管理系统是一种流行的ASP开源网站管理系统。在功能、人性化和易用性方面,它基于ASP+Access/MSSQL的技术架构,可用于广泛的新闻发布网站,也可用于信息门户网站。对于那些不太了解网站构建并希望成为网站的人,他们可以快速构建一个实用、强大、用户友好且易于使用的系统。Netti文章管理系统更注重个人网站或中小型门户网站的建设。当然,有很多企业用户使用这个系统。使用过netti文章管理系统的用户将继续对其表示赞赏。Net钛文章管理系统界面友好,操作简单,功能强大。有需要的朋友可以下载并使用它
功能特性1、两个原创主页布局可以自由切换:左侧两列和右侧热门文章以及投票,全部三列
2、支持三种顶级徽标模式:横幅、徽标+2个广告空间和徽标+1个广告空间
3、Flash格式的徽标,包括Flash(◆ 商业版)
4、支持设置是否在顶部显示日期、星期、时间和节日
5、支持三种类型的天气预报和用户定义的天气预报代码
6、支持设置导航菜单的数量
7、支持设置主导航、次导航和自定义多行导航样式(◆ 商业版)
8、支持导航的子菜单模式有三种:不显示子菜单、下拉子菜单和水平子菜单(◆ 商业版)
9、支持4种不同的flash幻灯片样式,并可设置是否显示标题
10、支持设置最新消息列的显示范围
11、支持设置滚动图片的显示数量和列范围
12、支持远程图片作为幻灯片和缩略图(◆ 商业版)
13、支持设置主页上每列显示的文章数量、是否显示日期以及是否显示缩略图
采集文章系统(谷歌数据分析加我为何没人推荐w3panel好像蛮不错的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-29 00:02
采集文章系统
手机能安装一个spider或者knowledgeinfilter,批量选择、分类,自动生成不同主题,加入浏览器,高频访问。我也是一直在这个网站上找数据,首页有很多东西,编译过之后,找到你需要的。
这里有几个数据提供商,按照需求选择合适自己的。
w3school可以学习的web开发
百度统计可以
,智能分类--知乎知乎数据统计
百度统计你的
keep
大家都推荐免费的spider了。我觉得免费应该就是最贵的吧。无论哪个数据分析网站都应该以免费为前提。
谷歌数据分析
加我
为何没人推荐w3panel好像蛮不错的
w3school学院,
w3school在线网站//
大家都说了~本人推荐一下同花顺、大智慧,我最近买股票也是用的这两个网站。
都说的非常对,
w3preview这个免费,专业,数据量较大。
html5最火的竞品就是w3school了,做做w3school的模拟学习,不仅能获得从理论上的w3school,还能找到应用,如爬虫,数据库开发等,把网站当成一个工具或博客去写,总会有收获。w3school-找到你的第一门web教程+tsdb开发网站,之前去看新农合参加数据分析大赛,感觉效果还是挺不错的,很高兴接触到了数据分析,对于学的,个人感觉还是不错,如果熟悉,并用到实际中去。 查看全部
采集文章系统(谷歌数据分析加我为何没人推荐w3panel好像蛮不错的)
采集文章系统
手机能安装一个spider或者knowledgeinfilter,批量选择、分类,自动生成不同主题,加入浏览器,高频访问。我也是一直在这个网站上找数据,首页有很多东西,编译过之后,找到你需要的。
这里有几个数据提供商,按照需求选择合适自己的。
w3school可以学习的web开发
百度统计可以
,智能分类--知乎知乎数据统计
百度统计你的
keep
大家都推荐免费的spider了。我觉得免费应该就是最贵的吧。无论哪个数据分析网站都应该以免费为前提。
谷歌数据分析
加我
为何没人推荐w3panel好像蛮不错的
w3school学院,
w3school在线网站//
大家都说了~本人推荐一下同花顺、大智慧,我最近买股票也是用的这两个网站。
都说的非常对,
w3preview这个免费,专业,数据量较大。
html5最火的竞品就是w3school了,做做w3school的模拟学习,不仅能获得从理论上的w3school,还能找到应用,如爬虫,数据库开发等,把网站当成一个工具或博客去写,总会有收获。w3school-找到你的第一门web教程+tsdb开发网站,之前去看新农合参加数据分析大赛,感觉效果还是挺不错的,很高兴接触到了数据分析,对于学的,个人感觉还是不错,如果熟悉,并用到实际中去。
采集文章系统( 手把手教您运用KesionCMSV8轻松采集文章信息信息采集管理系统的作用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-28 21:16
手把手教您运用KesionCMSV8轻松采集文章信息信息采集管理系统的作用)
系统信息采集教程教你如何轻松使用KesioncmsV8采集文章信息信息采集管理系统的作用可以帮助企业信息化< @采集资源整合节省大量人力和资金,广泛应用于行业门户网站竞争情报系统、知识管理系统网站内容系统、垂直搜索、科研等领域。今天我们就以采集腾讯网站的本地新闻列表为例,一步步教你如何使用采集如何设置系统采集规则,素材编码规则,三大议事规则,文件编号规则,乒乓球比赛规则,不规则动词表点击内容管理--信息采集
下一步是输入设置列表索引和开始和结束标签,如下图所示。这时候我们需要打开采集的信息页第一页,将URL复制粘贴到列表索引页下方的标记处。我们需要查看网页生成的源代码如下图所示。搜索和查找来自各地的新闻。注意观察。我们找到了来自各地的新闻信息列表。找到页面底部的开始标签divclass“modnewslist”,然后在底部页面找到结束标签,点击next按钮继续我们的采集任务然后寻找链接开始和结束标签,如图下图。我们可以看到,在列表拦截测试中,
在短标题的开始和结束标签中填写h1h1,然后找到内容文章的开始和结束标签,如下图所示。填写标题的开始和结束标签,找到文章内容的开始和结束标签,填写如下图。如果此时是提示拦截栏
表错了,那你可能找不到唯一性,需要继续测试。如果之前的设置没有问题,那么继续点击下一步。如下图所示,可以看到上面的界面。采集设置我们是否需要在采集的文章中有一张图片,让它自动转换成图片文章然后查看下图并点击Finish按钮设置采集的规则 完成下图后,点击确定按钮返回采集管理主页,如下图所示。此时,您只需单击采集 链接即可继续处理采集 信息。以上我们介绍的信息只是采集信息在列表的一页的情况下,
页面生成规则如下图所示。鼠标移到2显示,然后我们就可以按照他的生成规则编辑我们的采集项目了。这一步的时候,选择批量生成,复制粘贴网址,输入页数。更改为ID生成范围并填写数字。例如,如果您需要采集前8页,我们将填写2-8,如下图所示。点击主页上的采集链接如下图,系统进入启动界面。采集界面如下图。请注意这里的一点。采集采集时请不要刷新此页面,完成后系统会自动统计采集成功和失败的次数,
进入看到我们成功的采集的文章就可以进入批量选择,将文章放入仓库如下图。如果文章必须全部入库,点击全部入库按钮如下图,点击确定按钮。我们回到文章系统,看到所有文章已经成功存入库中。离职面谈记录怎么写 安全生产月会记录怎么写 幼儿园伙食委员会会议记录内容 安全例会会议记录按钮 点击按钮后,可以清除采集的所有历史记录,如图以下。本教程只是本教程末尾的一个示例。采集在这个过程中,由于每个站点的生成规则不同,我们经常会遇到拦截列表错误等问题。我们不要气馁,多尝试几次。胜利属于努力的人____ 更多Kesioncms后台使用示例教程 查看全部
采集文章系统(
手把手教您运用KesionCMSV8轻松采集文章信息信息采集管理系统的作用)

系统信息采集教程教你如何轻松使用KesioncmsV8采集文章信息信息采集管理系统的作用可以帮助企业信息化< @采集资源整合节省大量人力和资金,广泛应用于行业门户网站竞争情报系统、知识管理系统网站内容系统、垂直搜索、科研等领域。今天我们就以采集腾讯网站的本地新闻列表为例,一步步教你如何使用采集如何设置系统采集规则,素材编码规则,三大议事规则,文件编号规则,乒乓球比赛规则,不规则动词表点击内容管理--信息采集

下一步是输入设置列表索引和开始和结束标签,如下图所示。这时候我们需要打开采集的信息页第一页,将URL复制粘贴到列表索引页下方的标记处。我们需要查看网页生成的源代码如下图所示。搜索和查找来自各地的新闻。注意观察。我们找到了来自各地的新闻信息列表。找到页面底部的开始标签divclass“modnewslist”,然后在底部页面找到结束标签,点击next按钮继续我们的采集任务然后寻找链接开始和结束标签,如图下图。我们可以看到,在列表拦截测试中,

在短标题的开始和结束标签中填写h1h1,然后找到内容文章的开始和结束标签,如下图所示。填写标题的开始和结束标签,找到文章内容的开始和结束标签,填写如下图。如果此时是提示拦截栏

表错了,那你可能找不到唯一性,需要继续测试。如果之前的设置没有问题,那么继续点击下一步。如下图所示,可以看到上面的界面。采集设置我们是否需要在采集的文章中有一张图片,让它自动转换成图片文章然后查看下图并点击Finish按钮设置采集的规则 完成下图后,点击确定按钮返回采集管理主页,如下图所示。此时,您只需单击采集 链接即可继续处理采集 信息。以上我们介绍的信息只是采集信息在列表的一页的情况下,

页面生成规则如下图所示。鼠标移到2显示,然后我们就可以按照他的生成规则编辑我们的采集项目了。这一步的时候,选择批量生成,复制粘贴网址,输入页数。更改为ID生成范围并填写数字。例如,如果您需要采集前8页,我们将填写2-8,如下图所示。点击主页上的采集链接如下图,系统进入启动界面。采集界面如下图。请注意这里的一点。采集采集时请不要刷新此页面,完成后系统会自动统计采集成功和失败的次数,

进入看到我们成功的采集的文章就可以进入批量选择,将文章放入仓库如下图。如果文章必须全部入库,点击全部入库按钮如下图,点击确定按钮。我们回到文章系统,看到所有文章已经成功存入库中。离职面谈记录怎么写 安全生产月会记录怎么写 幼儿园伙食委员会会议记录内容 安全例会会议记录按钮 点击按钮后,可以清除采集的所有历史记录,如图以下。本教程只是本教程末尾的一个示例。采集在这个过程中,由于每个站点的生成规则不同,我们经常会遇到拦截列表错误等问题。我们不要气馁,多尝试几次。胜利属于努力的人____ 更多Kesioncms后台使用示例教程
采集文章系统(新秀文章管理系统sinsiucms1.0beta8说明1.0说明 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-22 18:26
)
新节目文章 @ @ 1. 0 beta8描述:一、新@ @ 文章译文是一个简单而简单,永久性的PHP 文章管理管理系统;内置采集功能,新节目官方每日采集大量采用用上选户,新节目还提供“采集自定义”收费会员服务,可以帮助用户采集任何数据;该系统具有MySQL并访问两个数据库可用。 二、后端功能:1、基本设置:基本信息,网站设置,导航管理,扇区开放,安全设置,静态设置,管理员帐户,数据库管理,其他设置; // 2、文章 @理主:文章 list,发布文章,文章 sice ;; 3、用户交互:消息管理,评论管理,友情链接; 4、文件管理:选择模板,图片管理,语言设置,资源管理; 5、 data 采集:采集设置设置,公共数据,私有定制,私人数据; 6、高级用作:新频道,频道标题,后端导航管理。 三、安装文件:1、我方推推推版本为期为为期为为; (注意,它是内部)子目录和文件上传到网站根目录,然后打开网站,按提醒选择数据库,填写数据库信息,最后单击安装按钮完成安装; 3、此系统默认设置在1小时内仅10次,您可以在“背基本设置安全设置”中修改时间长和登录号,以便在调试期间不登录后端。 四、更新说明:
1、 sinsiu cms 1. 0 beta7用户用户用户访问Sinsiu cms 1. 0 beta8,无需重新安装;
2、假,如果您是sinsiu cms 1. 0 beta7用户,请完全将升级文件夹上传到网站 root目录,输入网站path /升级/,浏览器地址栏。然后通过提醒来单击更新链接;
3、假如果更新有一个混沌文件,请清理浏览器临时文件,然后在网站 @ @。
五、 notes:1、此系统访问数据库仅在Windows Server上有效,建议使用Access数据库选择Windows主机; 2、因为此系统使用UTF-8编码,在Windows中使用记事本编辑,因为记事本将自动添加BOM头导致例外,建议使用专业的Dreamweaver或小型记事本++编辑器; 3、网站网站@ 网站网站@网站@网站@网站@ 网站网站网站@ arty手动删除索引/编译中的所有文件/移动后编译目录,否则在移动后网站可能是错误的。 4、此系统在发布之前重复测试,通常不在核心功能。如果您遇到使用过程,请首先找到自己的运行环境的原因,如果您遇到问题,请将您的责任推向我们,甚至怀疑我们的心会留下缺点,这完全无助。处理和个人进展问题。如果断开错误,则是由我们的程序引起的。您可以向我们的邮箱发送问题。我们将免费为您提供处理程序,我们的反馈谢谢! 六、后路径:网站路/ / admin 七、 upgrade:
1、添加手机支持,使用手机时自动致电手机模板;
2、改进采集函数。
查看全部
采集文章系统(新秀文章管理系统sinsiucms1.0beta8说明1.0说明
)
新节目文章 @ @ 1. 0 beta8描述:一、新@ @ 文章译文是一个简单而简单,永久性的PHP 文章管理管理系统;内置采集功能,新节目官方每日采集大量采用用上选户,新节目还提供“采集自定义”收费会员服务,可以帮助用户采集任何数据;该系统具有MySQL并访问两个数据库可用。 二、后端功能:1、基本设置:基本信息,网站设置,导航管理,扇区开放,安全设置,静态设置,管理员帐户,数据库管理,其他设置; // 2、文章 @理主:文章 list,发布文章,文章 sice ;; 3、用户交互:消息管理,评论管理,友情链接; 4、文件管理:选择模板,图片管理,语言设置,资源管理; 5、 data 采集:采集设置设置,公共数据,私有定制,私人数据; 6、高级用作:新频道,频道标题,后端导航管理。 三、安装文件:1、我方推推推版本为期为为期为为; (注意,它是内部)子目录和文件上传到网站根目录,然后打开网站,按提醒选择数据库,填写数据库信息,最后单击安装按钮完成安装; 3、此系统默认设置在1小时内仅10次,您可以在“背基本设置安全设置”中修改时间长和登录号,以便在调试期间不登录后端。 四、更新说明:
1、 sinsiu cms 1. 0 beta7用户用户用户访问Sinsiu cms 1. 0 beta8,无需重新安装;
2、假,如果您是sinsiu cms 1. 0 beta7用户,请完全将升级文件夹上传到网站 root目录,输入网站path /升级/,浏览器地址栏。然后通过提醒来单击更新链接;
3、假如果更新有一个混沌文件,请清理浏览器临时文件,然后在网站 @ @。
五、 notes:1、此系统访问数据库仅在Windows Server上有效,建议使用Access数据库选择Windows主机; 2、因为此系统使用UTF-8编码,在Windows中使用记事本编辑,因为记事本将自动添加BOM头导致例外,建议使用专业的Dreamweaver或小型记事本++编辑器; 3、网站网站@ 网站网站@网站@网站@网站@ 网站网站网站@ arty手动删除索引/编译中的所有文件/移动后编译目录,否则在移动后网站可能是错误的。 4、此系统在发布之前重复测试,通常不在核心功能。如果您遇到使用过程,请首先找到自己的运行环境的原因,如果您遇到问题,请将您的责任推向我们,甚至怀疑我们的心会留下缺点,这完全无助。处理和个人进展问题。如果断开错误,则是由我们的程序引起的。您可以向我们的邮箱发送问题。我们将免费为您提供处理程序,我们的反馈谢谢! 六、后路径:网站路/ / admin 七、 upgrade:
1、添加手机支持,使用手机时自动致电手机模板;
2、改进采集函数。
采集文章系统(【论语】采集文章系统解析《论语》中的语言框架)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-19 23:02
采集文章系统解析《论语》中的语言框架:1.字,每个字是一个概念,2.句子是以“主句”为中心,句中的“每个句子”由“字、词、词组”构成。句子中的“字、词、词组”本质上是一种关系代数数据结构,“字、词、词组”构成一个句子。所以“每个句子”和“每个词”都可以在“主句”中寻找。2.文章,每个文章是一个概念,3.每个概念由词构成,每个词又由具体的词组构成。
词可以通过迭代对“字、词、词组”有直观感受4.“字、词、词组”,直观感受直接构成文章中心内容,但是“字、词、词组”又是一个整体概念,如果我们真的通过“字、词、词组”可以不断递归迭代得到文章的一部分,那么在递归的递归中就可以用内存中的连续单位,如字、词、词组进行对比。另外,从整体性思维可以想到,每个字组是由主句单词构成,每个词组是由词组单词构成,每个词、词组也是由部分组成,当对比多个文章不断迭代递归,当文章单元最终只是一个整体之时,有用的信息也可以从多个文章单元中得到。
【整体--语言逻辑】关键词:文章意义【定理--语言逻辑--2】语言是逻辑推理的工具,使文章成为抽象描述论证和陈述观点的逻辑系统【定理--语言逻辑--3】凡是具有语言意义的陈述,都可以作为论证或陈述。本文由于主要从逻辑学角度定义语言,因此我们不会在讨论语言的性质时使用任何定义或术语。一旦谈论到语言学的观点,我们都会尽可能使用“语言论”来对其进行论述。
1.为什么一切语言都有意义?论证是一种论证者判断原来论证要说什么的过程。在这种过程中,凡能从原来论证中抽象出一个可以被说出来的独立于原来论证中描述方法的东西,即“意义”,我们就称论证有意义。那么,什么样的陈述能使一切语言成为陈述?在这里,我们要把文章也当作一种语言。2.为什么一切陈述都可以具有意义?陈述有两个特点:其一是陈述是在有意义的语言中进行。
这是很容易被人忽略的一个事实。在中国的老百姓群体中,陈述既可以不具有意义,也可以没有意义,甚至可以不具有意义。在西方人群体中,陈述就是具有意义的。不过,一些西方人认为无意义的陈述可以通过某种艺术手段具有意义。我们说的陈述是指在具有语言意义的语言中,所有陈述都可以被说出来。其二是一切陈述都可以自由组合。
也就是说,一切陈述都可以自由地进行某种意义的组合。这个特点正好符合实际上我们在每一篇论文中都会提到的“意义”这个概念。一个陈述意义的组合可以是陈述本身(每个陈述单元的构成部分)和它所对应的陈述单元,也可以是陈述的其他一切单元。 查看全部
采集文章系统(【论语】采集文章系统解析《论语》中的语言框架)
采集文章系统解析《论语》中的语言框架:1.字,每个字是一个概念,2.句子是以“主句”为中心,句中的“每个句子”由“字、词、词组”构成。句子中的“字、词、词组”本质上是一种关系代数数据结构,“字、词、词组”构成一个句子。所以“每个句子”和“每个词”都可以在“主句”中寻找。2.文章,每个文章是一个概念,3.每个概念由词构成,每个词又由具体的词组构成。
词可以通过迭代对“字、词、词组”有直观感受4.“字、词、词组”,直观感受直接构成文章中心内容,但是“字、词、词组”又是一个整体概念,如果我们真的通过“字、词、词组”可以不断递归迭代得到文章的一部分,那么在递归的递归中就可以用内存中的连续单位,如字、词、词组进行对比。另外,从整体性思维可以想到,每个字组是由主句单词构成,每个词组是由词组单词构成,每个词、词组也是由部分组成,当对比多个文章不断迭代递归,当文章单元最终只是一个整体之时,有用的信息也可以从多个文章单元中得到。
【整体--语言逻辑】关键词:文章意义【定理--语言逻辑--2】语言是逻辑推理的工具,使文章成为抽象描述论证和陈述观点的逻辑系统【定理--语言逻辑--3】凡是具有语言意义的陈述,都可以作为论证或陈述。本文由于主要从逻辑学角度定义语言,因此我们不会在讨论语言的性质时使用任何定义或术语。一旦谈论到语言学的观点,我们都会尽可能使用“语言论”来对其进行论述。
1.为什么一切语言都有意义?论证是一种论证者判断原来论证要说什么的过程。在这种过程中,凡能从原来论证中抽象出一个可以被说出来的独立于原来论证中描述方法的东西,即“意义”,我们就称论证有意义。那么,什么样的陈述能使一切语言成为陈述?在这里,我们要把文章也当作一种语言。2.为什么一切陈述都可以具有意义?陈述有两个特点:其一是陈述是在有意义的语言中进行。
这是很容易被人忽略的一个事实。在中国的老百姓群体中,陈述既可以不具有意义,也可以没有意义,甚至可以不具有意义。在西方人群体中,陈述就是具有意义的。不过,一些西方人认为无意义的陈述可以通过某种艺术手段具有意义。我们说的陈述是指在具有语言意义的语言中,所有陈述都可以被说出来。其二是一切陈述都可以自由组合。
也就是说,一切陈述都可以自由地进行某种意义的组合。这个特点正好符合实际上我们在每一篇论文中都会提到的“意义”这个概念。一个陈述意义的组合可以是陈述本身(每个陈述单元的构成部分)和它所对应的陈述单元,也可以是陈述的其他一切单元。
采集文章系统(快速破解网站自带的文章采集器每日文章数量多,无损加载,压缩包)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-11-12 14:15
快速破解网站内置文章采集器每日文章,无损加载,压缩包分享到个人朋友圈可公开下载,也可以转发。
文章采集器免费版-官方版-文章采集器免费版(-单树成林手机版。
文章采集器免费版快速破解网站自带大量文章优采云。
对于那些正在做网站推广和优化的人来说,可能经常需要更新一些文章,那么对于文笔不好的人来说还是有点难度的。
优采云通用文章采集器是一款可以批量下载指定关键词文章采集的工具,主要是为了帮助用户< @采集各大平台文章,也可以采集指定网站文章,非常方便快捷,适合做网站推广和优化一个不多。
《全民文章采集器免费破解版》是最简单、最智能的文章采集器,由优采云软件开发,您可以采集列表页文章、关键词新闻、微信等,以及针对采集指定的网站文章,是一个很好的文章采集器。软件功能 1.
文章采集器免费版多多快递蜘蛛是一款专业的网络采集工具;本软件采用MongoDB数据库,可以帮助用户快速获取采集文章、网站域名等信息,操作简单,功能强大,有需要的朋友,下载体验吧该软件具有特殊功能。
Universal文章采集器是一款方便易用的文章采集软件,功能强大,完全免费使用。软件操作简单,可以准确提取网页正文部分保存为文章,支持标签、链接、邮件等格式处理,只需几分钟。 查看全部
采集文章系统(快速破解网站自带的文章采集器每日文章数量多,无损加载,压缩包)
快速破解网站内置文章采集器每日文章,无损加载,压缩包分享到个人朋友圈可公开下载,也可以转发。
文章采集器免费版-官方版-文章采集器免费版(-单树成林手机版。
文章采集器免费版快速破解网站自带大量文章优采云。
对于那些正在做网站推广和优化的人来说,可能经常需要更新一些文章,那么对于文笔不好的人来说还是有点难度的。
优采云通用文章采集器是一款可以批量下载指定关键词文章采集的工具,主要是为了帮助用户< @采集各大平台文章,也可以采集指定网站文章,非常方便快捷,适合做网站推广和优化一个不多。
《全民文章采集器免费破解版》是最简单、最智能的文章采集器,由优采云软件开发,您可以采集列表页文章、关键词新闻、微信等,以及针对采集指定的网站文章,是一个很好的文章采集器。软件功能 1.
文章采集器免费版多多快递蜘蛛是一款专业的网络采集工具;本软件采用MongoDB数据库,可以帮助用户快速获取采集文章、网站域名等信息,操作简单,功能强大,有需要的朋友,下载体验吧该软件具有特殊功能。
Universal文章采集器是一款方便易用的文章采集软件,功能强大,完全免费使用。软件操作简单,可以准确提取网页正文部分保存为文章,支持标签、链接、邮件等格式处理,只需几分钟。
采集文章系统( CmsTop文章采集系统颠覆传统采集模式和流程,规则设置更简单 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-11-12 11:18
CmsTop文章采集系统颠覆传统采集模式和流程,规则设置更简单
)
5.24 文章采集
文章的采集功能是通过程序远程获取目标网页的内容,解析处理本地规则后存储到服务器的数据库中。cmsTop文章采集系统颠覆了传统的采集模式和流程,采集规则与采集界面分离,规则设置更简单,只需具备基本网页设计知识的人设置相关规则即可。编辑者无需了解太详细的技术规则,只需选择自己想要的文章列表采集,就可以像发布文章一样轻松完成采集操作,提高提高工作效率,降低人工成本。
1. 高效的采集 管理界面
自定义配置的所有采集规则都会显示在采集管理界面,根据采集的更新频率可以找到最新的文章。系统通过最新的,查看过的,文章的状态已经被标记为采集。曾经采集的文章会自动从采集列表中消失,进入采集的列表,不会重复采集。同时可以根据已经设置的采集规则快速输入网址。
图5.24‑1采集界面
管理者可以通过采集管理界面预览采集的内容,然后有选择地对需要的文章进行采集。添加任务很方便,并允许自定义目标列。
图 5.24‑2文章采集 预览
图5.24-3 编辑监控任务
图5.24‑4 自定义目标列
2. 方便简洁的采集规则配置
对于需要采集功能的网站来说,简单方便的规则配置就是易用性的体现。技术人员只需要基本的网页知识就可以自由编写采集规则。在编写规则时,可以实时显示采集的内容是否正确。通过此功能,您可以轻松测试内容的可用性。此外,它还对一些详细的采集设置提供了很好的支持,比如采集分页内容,设置是否远程图像定位等。
图5.24‑5采集 规则设置
3. 采集 规则导入导出
对于已经写入的采集规则,系统会自动将其添加到规则列表中以备后用。每个规则都可以重复使用,并且可以根据需要进行修改。同时,您还可以将您设置的采集规则导出到XML文件中,与他人共享,或导入他人共享的规则。
图5.24‑6 规则导入
4. 支持 文章 计时采集
系统内置采集功能,可以手动选择采集,也可以手动选择采集,也可以设置定时采集。提供定时采集任务切换。通过设置采集间隔、采集件数、下一次采集,系统可实现自取,无需人工干预,节省人力资源。面对系统自动完成的操作,管理员查看系统工作日志是必不可少的一环。系统增加了计时采集日志功能菜单,可以查看特定时间段内采集成功和失败的次数。文章数。您还可以一键清理采集 日志。
5. 支持过滤重复标题
采集 过程中的头衔重复是采集人员头疼的问题。无论是手动采集还是自动采集,都无法避免这个问题。提供过滤重复标题的开关,采集人员可以随时开启和关闭过滤功能。具有过滤重复标题的功能,可以直接过滤重复的标题,使其不再出现在采集列表中,从而消除采集的重复内容。
查看全部
采集文章系统(
CmsTop文章采集系统颠覆传统采集模式和流程,规则设置更简单
)
5.24 文章采集
文章的采集功能是通过程序远程获取目标网页的内容,解析处理本地规则后存储到服务器的数据库中。cmsTop文章采集系统颠覆了传统的采集模式和流程,采集规则与采集界面分离,规则设置更简单,只需具备基本网页设计知识的人设置相关规则即可。编辑者无需了解太详细的技术规则,只需选择自己想要的文章列表采集,就可以像发布文章一样轻松完成采集操作,提高提高工作效率,降低人工成本。
1. 高效的采集 管理界面
自定义配置的所有采集规则都会显示在采集管理界面,根据采集的更新频率可以找到最新的文章。系统通过最新的,查看过的,文章的状态已经被标记为采集。曾经采集的文章会自动从采集列表中消失,进入采集的列表,不会重复采集。同时可以根据已经设置的采集规则快速输入网址。
图5.24‑1采集界面
管理者可以通过采集管理界面预览采集的内容,然后有选择地对需要的文章进行采集。添加任务很方便,并允许自定义目标列。
图 5.24‑2文章采集 预览
图5.24-3 编辑监控任务
图5.24‑4 自定义目标列
2. 方便简洁的采集规则配置
对于需要采集功能的网站来说,简单方便的规则配置就是易用性的体现。技术人员只需要基本的网页知识就可以自由编写采集规则。在编写规则时,可以实时显示采集的内容是否正确。通过此功能,您可以轻松测试内容的可用性。此外,它还对一些详细的采集设置提供了很好的支持,比如采集分页内容,设置是否远程图像定位等。
图5.24‑5采集 规则设置
3. 采集 规则导入导出
对于已经写入的采集规则,系统会自动将其添加到规则列表中以备后用。每个规则都可以重复使用,并且可以根据需要进行修改。同时,您还可以将您设置的采集规则导出到XML文件中,与他人共享,或导入他人共享的规则。
图5.24‑6 规则导入
4. 支持 文章 计时采集
系统内置采集功能,可以手动选择采集,也可以手动选择采集,也可以设置定时采集。提供定时采集任务切换。通过设置采集间隔、采集件数、下一次采集,系统可实现自取,无需人工干预,节省人力资源。面对系统自动完成的操作,管理员查看系统工作日志是必不可少的一环。系统增加了计时采集日志功能菜单,可以查看特定时间段内采集成功和失败的次数。文章数。您还可以一键清理采集 日志。
5. 支持过滤重复标题
采集 过程中的头衔重复是采集人员头疼的问题。无论是手动采集还是自动采集,都无法避免这个问题。提供过滤重复标题的开关,采集人员可以随时开启和关闭过滤功能。具有过滤重复标题的功能,可以直接过滤重复的标题,使其不再出现在采集列表中,从而消除采集的重复内容。
采集文章系统(支持采集内容替换功能,支持文章内容采集、游戏简介)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-11-12 03:16
特征:
1、支持文章内容分页采集;
2、支持论坛采集
3、支持UTF-8转GB2312,但采集内容字符格式是UTF-8的目标;
4、 支持将文章的内容保存到本地;
5、支持站点+栏目管理模式,让采集管理一目了然;
6、支持替换链接、替换分页链接,破解一些JS/后台程序设置的反扒功能;
7、支持采集器设置无限过滤功能;
8、支持图片采集保存到本地,自动替换文件名避免重复;
9、支持FLASH文件采集保存到本地,自动替换文件名避免重复;
10、 支持限制PHP FOPEN和FSOCKET功能的虚拟主机;
11、 支持手动过滤采集结果,并提供“空标题空内容”的快速过滤和删除;
12、支持Flash专业网站采集,特色采集flash小游戏,可完美采集缩略图,游戏介绍;
13、 支持全站配置规则的导入导出;
14、支持栏目配置规则导入导出,提供规则复制功能,简化设置;
15、 提供引导库规则导入导出;
16、支持自定义采集间隔时间,避免被误认为DDOS攻击而拒绝响应,可以设置采集防止DDOS攻击网站;
17、支持自定义存储间隔时间,避免虚拟主机并发限制;
18、支持自定义内容写入,用户可以设置任意内容(如自己的链接、广告代码),写入采集的内容:第一个、最后一个或随机写入;需要写入的内容在浏览库时自动带在身边,无需修改WEB系统模板。
19、支持采集内容替换功能,用户可以设置替换规则随意替换;
20、支持html标签过滤,让采集接收到的内容只保留必要的html标签,甚至是纯文本,不带任何html标签;
21、支持多个cms指南库
包内收录 PHPcms V2/V3、Dedecms(织梦) V2/V3、PHP168 cms, mephpcms@ >、Mambocms、Joomlacms系统指南库规则及操作说明;
22、支持PHPWIND、Discuz论坛指南库,程序包中收录2个论坛指南库规则和操作说明;
23、自带数据库优化工具,减少频繁采集过多的数据碎片降低数据库性能。
以下特殊功能仅适用于“小蜜蜂采集器”:
1、 支持采集进程断点续传功能,不受浏览器意外关闭影响,重启后不会重复采集;
2、 支持自动比较过滤功能,不会在采集的链接系统中重复采集和存储;
以上两个功能可以大大减少采集时间,减少系统负载。
3、 支持系统每天自动创建图片存储目录,方便管理;
4、支持采集/guide间隔时间设置,避免被目标站识别为流量攻击而拒绝响应;
5、支持自定义内容写入,实现简单的反采集功能;
6、支持html标签过滤,几乎完美展现你想要的采集效果;
7、完美的内容存储解决方案,不受目标编程语言和数据库类别的限制。
以上众多强大功能免费供您使用,您可以轻松高效地安装使用体验资料采集。
v1.1115 更新:
1、添加了电骡下载格式的URL识别 查看全部
采集文章系统(支持采集内容替换功能,支持文章内容采集、游戏简介)
特征:
1、支持文章内容分页采集;
2、支持论坛采集
3、支持UTF-8转GB2312,但采集内容字符格式是UTF-8的目标;
4、 支持将文章的内容保存到本地;
5、支持站点+栏目管理模式,让采集管理一目了然;
6、支持替换链接、替换分页链接,破解一些JS/后台程序设置的反扒功能;
7、支持采集器设置无限过滤功能;
8、支持图片采集保存到本地,自动替换文件名避免重复;
9、支持FLASH文件采集保存到本地,自动替换文件名避免重复;
10、 支持限制PHP FOPEN和FSOCKET功能的虚拟主机;
11、 支持手动过滤采集结果,并提供“空标题空内容”的快速过滤和删除;
12、支持Flash专业网站采集,特色采集flash小游戏,可完美采集缩略图,游戏介绍;
13、 支持全站配置规则的导入导出;
14、支持栏目配置规则导入导出,提供规则复制功能,简化设置;
15、 提供引导库规则导入导出;
16、支持自定义采集间隔时间,避免被误认为DDOS攻击而拒绝响应,可以设置采集防止DDOS攻击网站;
17、支持自定义存储间隔时间,避免虚拟主机并发限制;
18、支持自定义内容写入,用户可以设置任意内容(如自己的链接、广告代码),写入采集的内容:第一个、最后一个或随机写入;需要写入的内容在浏览库时自动带在身边,无需修改WEB系统模板。
19、支持采集内容替换功能,用户可以设置替换规则随意替换;
20、支持html标签过滤,让采集接收到的内容只保留必要的html标签,甚至是纯文本,不带任何html标签;
21、支持多个cms指南库
包内收录 PHPcms V2/V3、Dedecms(织梦) V2/V3、PHP168 cms, mephpcms@ >、Mambocms、Joomlacms系统指南库规则及操作说明;
22、支持PHPWIND、Discuz论坛指南库,程序包中收录2个论坛指南库规则和操作说明;
23、自带数据库优化工具,减少频繁采集过多的数据碎片降低数据库性能。
以下特殊功能仅适用于“小蜜蜂采集器”:
1、 支持采集进程断点续传功能,不受浏览器意外关闭影响,重启后不会重复采集;
2、 支持自动比较过滤功能,不会在采集的链接系统中重复采集和存储;
以上两个功能可以大大减少采集时间,减少系统负载。
3、 支持系统每天自动创建图片存储目录,方便管理;
4、支持采集/guide间隔时间设置,避免被目标站识别为流量攻击而拒绝响应;
5、支持自定义内容写入,实现简单的反采集功能;
6、支持html标签过滤,几乎完美展现你想要的采集效果;
7、完美的内容存储解决方案,不受目标编程语言和数据库类别的限制。
以上众多强大功能免费供您使用,您可以轻松高效地安装使用体验资料采集。
v1.1115 更新:
1、添加了电骡下载格式的URL识别
采集文章系统(短视频行业再掀腥风血雨,这篇:采集文章系统自动生成的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-11-07 16:04
采集文章系统自动生成的,比如这篇:短视频行业再掀腥风血雨!5月上线的视频机器人抓取系统更是掀起了新一轮的轰动!视频机器人的出现是完全基于短视频的内容生产的,可以说实现了对短视频内容的整体挖掘。从去年3月起,抖音上火的鬼畜视频、搞笑视频等都逐渐成为了一种潮流,一夜成名在抖音不是一个神话,但依旧有一小部分,也有不少网红,甚至娱乐圈的不少明星,都是通过一个好的视频机器人走红的。
这个还是蛮利好的,因为这些视频机器人会根据你所播放的视频而帮你推荐,一般视频分发出去之后很快会有大量的推荐,也会有少量的掉下去。这和之前的视频推荐算法是一样的,直接让系统自己给推荐视频。那抖音短视频机器人推荐是怎么机制的呢?这个还要从整个抖音的推荐算法讲起,我这里做了个简单的说明,抖音根据你的粉丝、内容质量和账号权重等三方面,推荐一个你可能感兴趣的内容给你,你可以把这个类似打开,看看点赞量、浏览量、评论、转发等等的反馈。
短视频同样如此,根据你对这个视频的打开反馈再决定是否推荐给你更多的朋友看到。“机器人”是怎么推荐的?首先机器人会根据你所打开的反馈推荐给你一个比较大的范围,然后根据你点赞的时间、你关注的、点赞的粉丝数和关注的类型来看,来给你反馈一个总的范围,会有多少个你感兴趣的视频,推荐你多少个视频给你看。不知道抖音平台是不是还有其他的算法方法,至少我这里的机器人是基于这个思想的。
抖音的机器人推荐机制那对于一个系统来说是完全自动化的,除了开始说的抓取算法,还有后续的观看算法、下一个平台的推荐算法。其实对于所有自媒体平台来说,基本上都有一个浏览推荐的机制,比如微信推送的时候会先让你看看同类内容,看看大家的热门文章、热门评论,基本上就可以决定这篇文章是否是你感兴趣的了。抖音同样也有这个推荐机制,先是在视频或者文章里看看,如果有爆款的话,之后会有大量的流量推荐给用户。
只不过是精确的给你推荐给你感兴趣的人群而已。那对于一个机器人来说,是如何推荐视频给你的呢?具体就是当你点赞或者转发或者分享后,抖音系统会得到这个作品的信息,然后机器人就会抓取这个内容,抓取到你的信息后就可以抓取到你的喜好了,因为这个也是机器人判断你之前的内容是不是感兴趣的一个过程。之后根据你的兴趣来给你推荐更多的内容,如果你觉得不是你喜欢的,那抖音系统就会识别出来了,可能就是一个点赞,那机器人就会抓取其他机器人抓取到的喜欢的内容。这时候就是机器人推荐给你的可能性很大了。比如说你之前喜欢玩。 查看全部
采集文章系统(短视频行业再掀腥风血雨,这篇:采集文章系统自动生成的)
采集文章系统自动生成的,比如这篇:短视频行业再掀腥风血雨!5月上线的视频机器人抓取系统更是掀起了新一轮的轰动!视频机器人的出现是完全基于短视频的内容生产的,可以说实现了对短视频内容的整体挖掘。从去年3月起,抖音上火的鬼畜视频、搞笑视频等都逐渐成为了一种潮流,一夜成名在抖音不是一个神话,但依旧有一小部分,也有不少网红,甚至娱乐圈的不少明星,都是通过一个好的视频机器人走红的。
这个还是蛮利好的,因为这些视频机器人会根据你所播放的视频而帮你推荐,一般视频分发出去之后很快会有大量的推荐,也会有少量的掉下去。这和之前的视频推荐算法是一样的,直接让系统自己给推荐视频。那抖音短视频机器人推荐是怎么机制的呢?这个还要从整个抖音的推荐算法讲起,我这里做了个简单的说明,抖音根据你的粉丝、内容质量和账号权重等三方面,推荐一个你可能感兴趣的内容给你,你可以把这个类似打开,看看点赞量、浏览量、评论、转发等等的反馈。
短视频同样如此,根据你对这个视频的打开反馈再决定是否推荐给你更多的朋友看到。“机器人”是怎么推荐的?首先机器人会根据你所打开的反馈推荐给你一个比较大的范围,然后根据你点赞的时间、你关注的、点赞的粉丝数和关注的类型来看,来给你反馈一个总的范围,会有多少个你感兴趣的视频,推荐你多少个视频给你看。不知道抖音平台是不是还有其他的算法方法,至少我这里的机器人是基于这个思想的。
抖音的机器人推荐机制那对于一个系统来说是完全自动化的,除了开始说的抓取算法,还有后续的观看算法、下一个平台的推荐算法。其实对于所有自媒体平台来说,基本上都有一个浏览推荐的机制,比如微信推送的时候会先让你看看同类内容,看看大家的热门文章、热门评论,基本上就可以决定这篇文章是否是你感兴趣的了。抖音同样也有这个推荐机制,先是在视频或者文章里看看,如果有爆款的话,之后会有大量的流量推荐给用户。
只不过是精确的给你推荐给你感兴趣的人群而已。那对于一个机器人来说,是如何推荐视频给你的呢?具体就是当你点赞或者转发或者分享后,抖音系统会得到这个作品的信息,然后机器人就会抓取这个内容,抓取到你的信息后就可以抓取到你的喜好了,因为这个也是机器人判断你之前的内容是不是感兴趣的一个过程。之后根据你的兴趣来给你推荐更多的内容,如果你觉得不是你喜欢的,那抖音系统就会识别出来了,可能就是一个点赞,那机器人就会抓取其他机器人抓取到的喜欢的内容。这时候就是机器人推荐给你的可能性很大了。比如说你之前喜欢玩。
采集文章系统(一个微信公众号历史消息页面的链接地址和采集方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-11-07 07:01
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。当时批量采集特别好做,采集的入口就是公众号的历史新闻页面。这个条目现在还是一样,但是越来越难采集。采集 的方法也更新了很多版本。后来2015年html5垃圾站没做,改把采集定位到本地新闻资讯公众号,前端展示做成了app。所以一个可以自动采集的新闻应用 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证你看到的时候可以看到。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新 ==========
现在,根据不同的微信个人账号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为实际上这个链接地址还需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的一个类似 id 的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余 3 个参数与用户的 id 和 token 票证相关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量测试的ios微信客户端崩溃率采集高于Android系统。为了降低成本,我使用了Android模拟器。
2、一个微信个人账号:对于采集的内容,不仅需要一个微信客户端,还需要一个专用于采集的微信个人账号,因为这个微信账号不能做其他事情.
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众账号历史消息页面中的文章列表发送到自己的服务器。具体的安装方法后面会详细介绍。
4、文章列表分析入库系统:本人使用PHP语言编写,下篇文章将详细介绍如何分析文章列表并建立采集队列来实现批次采集内容。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、 生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一个公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002就可以看到anyproxy的web界面了。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,才能获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来,我们将详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p> 查看全部
采集文章系统(一个微信公众号历史消息页面的链接地址和采集方法)
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。当时批量采集特别好做,采集的入口就是公众号的历史新闻页面。这个条目现在还是一样,但是越来越难采集。采集 的方法也更新了很多版本。后来2015年html5垃圾站没做,改把采集定位到本地新闻资讯公众号,前端展示做成了app。所以一个可以自动采集的新闻应用 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证你看到的时候可以看到。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新 ==========
现在,根据不同的微信个人账号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为实际上这个链接地址还需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的一个类似 id 的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余 3 个参数与用户的 id 和 token 票证相关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量测试的ios微信客户端崩溃率采集高于Android系统。为了降低成本,我使用了Android模拟器。
2、一个微信个人账号:对于采集的内容,不仅需要一个微信客户端,还需要一个专用于采集的微信个人账号,因为这个微信账号不能做其他事情.
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众账号历史消息页面中的文章列表发送到自己的服务器。具体的安装方法后面会详细介绍。
4、文章列表分析入库系统:本人使用PHP语言编写,下篇文章将详细介绍如何分析文章列表并建立采集队列来实现批次采集内容。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、 生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一个公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002就可以看到anyproxy的web界面了。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,才能获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来,我们将详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p>
采集文章系统(工业设计展会门户网站看哪些对您来说是外贸友好型)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-06 21:00
采集文章系统:khanacademy课程:sitemap模版:crunchbasesitemap网站:微信公众号khanacademy免费注册:xiaohuacademy
dw,yahoo,facebook..twitter...谷歌..
facebookamazonwhatsapptwitteruber这都是外贸公司很常用的社交媒体
就美国而言twitter多,原因主要是1:twitter社交属性强,facebook多关注公司品牌活动之类,weibo没有where方便2:facebook广告丰富,阿里巴巴类目也多3:facebook广告费用更低,但貌似twitter效果更好4:twitter最近有tweety政策,广告被赞的话会被算收入。
其实twitterchat关注问题,论坛等更具有社交性,都可以成为内容版块5:外贸企业多关注一些内部资讯,特别是给国外客户的邮件,也要注意接地气--。
关于twitter或是facebook,我用一句话概括,先想清楚你们是为谁去获取资讯。
facebookreddityahoo...
工业设计展会门户网站
看哪些对您来说是外贸友好型,第三方平台目前我用的主要是:tumblr(交互性高于内容)wikipedia(全球最大的维基百科网站)linkedin(非盈利性社区)...不过,我从来没见过一个人会在wikipedia上面写软文,在linkedin上面做seo的。
我们公司所有的社交媒体和博客都是同一个或者同一个人维护的,是来自于用户的真实留言,加上他不定期抽空翻译一些英文媒体的文章,用于新闻发布会演讲。如果别人不想看的话可以用adstracking一键完成可见性,也就是通过ip或者注册用户来分析看到文章的几率,然后根据文章来引发相应的互动。其实这是一个非常非常虚的东西,我认为只要公司体量不大,其实平时用搜索引擎,这个是比社交媒体更有价值的东西。 查看全部
采集文章系统(工业设计展会门户网站看哪些对您来说是外贸友好型)
采集文章系统:khanacademy课程:sitemap模版:crunchbasesitemap网站:微信公众号khanacademy免费注册:xiaohuacademy
dw,yahoo,facebook..twitter...谷歌..
facebookamazonwhatsapptwitteruber这都是外贸公司很常用的社交媒体
就美国而言twitter多,原因主要是1:twitter社交属性强,facebook多关注公司品牌活动之类,weibo没有where方便2:facebook广告丰富,阿里巴巴类目也多3:facebook广告费用更低,但貌似twitter效果更好4:twitter最近有tweety政策,广告被赞的话会被算收入。
其实twitterchat关注问题,论坛等更具有社交性,都可以成为内容版块5:外贸企业多关注一些内部资讯,特别是给国外客户的邮件,也要注意接地气--。
关于twitter或是facebook,我用一句话概括,先想清楚你们是为谁去获取资讯。
facebookreddityahoo...
工业设计展会门户网站
看哪些对您来说是外贸友好型,第三方平台目前我用的主要是:tumblr(交互性高于内容)wikipedia(全球最大的维基百科网站)linkedin(非盈利性社区)...不过,我从来没见过一个人会在wikipedia上面写软文,在linkedin上面做seo的。
我们公司所有的社交媒体和博客都是同一个或者同一个人维护的,是来自于用户的真实留言,加上他不定期抽空翻译一些英文媒体的文章,用于新闻发布会演讲。如果别人不想看的话可以用adstracking一键完成可见性,也就是通过ip或者注册用户来分析看到文章的几率,然后根据文章来引发相应的互动。其实这是一个非常非常虚的东西,我认为只要公司体量不大,其实平时用搜索引擎,这个是比社交媒体更有价值的东西。
采集文章系统(天人文章管理系统默认模板不满意,其他模板可以在后台替换)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-11-03 04:02
天人文章管理系统是一个ASP+Access/MSSQL架构的网站系统。如果您对默认模板不满意,可以在后台替换其他模板。PC版,手机版,平板版,无缝自动切换,后台同步管理,支持SEO站静态动态切换,一键更换模板,安装插件,升级包,使用Dreamweaver进行可视化修改,主要用于文章、图片网站,如小说网站、美女图片等。 景区、政府部门、学校、书画网等都与图片相关和文本。当然,我们也支持二次开发,根据您的具体需求开发功能。
特征:
如果您对默认模板不满意,可以在后台更改其他模板。
程序支持子目录,支持放置在网站的子目录或多级目录中。
1、后台服务器信息查看功能,可以快速全面的查看服务器的软硬件状态。
2、网站 设置基本信息,包括全局关键词、开通网站、统计代码、logo上传、后台登录验证码数量免费。
三。网站联系人设置,包括QQ、电话、传真、联系地址等。
4、会员注册设置,包括是否允许注册、注册会员是否需要注册、注册会员的初始分数、会员页面显示的提示信息。
5、消息发布功能设置,留言,评论,文章发布功能,以及后台管理员对以上功能的审核。
6、管理员管理,可以设置管理员权限的范围,以及是有管理员权限还是只有查看权限。
数据库管理,可以备份和恢复数据库,同时常见上传木马漏洞过滤,安全性高。
广告管理,可以在现有广告位添加广告,同时优化不同层次的相关路径,广告管理页面已经详细介绍。
友情链接管理,可以设置友情链接的图片或文字类型。
后台操作日志管理,所有操作记录都在后台记录,可批量删除。
11、列管理,支持无限分类,即支持无限数量的低级列和无限数量的对等级列。同时还可以控制栏目的切换,栏目是图片还是文字类型,栏目是否在导航栏中显示,栏目是否在首页面板显示,以及显示顺序导航栏主页的。
文章管理,支持基于发布文本的文章功能,并具有上传图片、选择服务器上传图片、批量上传图片、设置多种形式图片、文字前端展示的能力效果。同时支持文章查看权限设置,可以细化限制会员查看和限制会员级别查看。
评论管理,可以进入文章的编辑页面对文章的评论进行管理,也可以直接管理系统内的所有评论,可以删除、查看、回复。 查看全部
采集文章系统(天人文章管理系统默认模板不满意,其他模板可以在后台替换)
天人文章管理系统是一个ASP+Access/MSSQL架构的网站系统。如果您对默认模板不满意,可以在后台替换其他模板。PC版,手机版,平板版,无缝自动切换,后台同步管理,支持SEO站静态动态切换,一键更换模板,安装插件,升级包,使用Dreamweaver进行可视化修改,主要用于文章、图片网站,如小说网站、美女图片等。 景区、政府部门、学校、书画网等都与图片相关和文本。当然,我们也支持二次开发,根据您的具体需求开发功能。
特征:
如果您对默认模板不满意,可以在后台更改其他模板。
程序支持子目录,支持放置在网站的子目录或多级目录中。
1、后台服务器信息查看功能,可以快速全面的查看服务器的软硬件状态。
2、网站 设置基本信息,包括全局关键词、开通网站、统计代码、logo上传、后台登录验证码数量免费。
三。网站联系人设置,包括QQ、电话、传真、联系地址等。
4、会员注册设置,包括是否允许注册、注册会员是否需要注册、注册会员的初始分数、会员页面显示的提示信息。
5、消息发布功能设置,留言,评论,文章发布功能,以及后台管理员对以上功能的审核。
6、管理员管理,可以设置管理员权限的范围,以及是有管理员权限还是只有查看权限。
数据库管理,可以备份和恢复数据库,同时常见上传木马漏洞过滤,安全性高。
广告管理,可以在现有广告位添加广告,同时优化不同层次的相关路径,广告管理页面已经详细介绍。
友情链接管理,可以设置友情链接的图片或文字类型。
后台操作日志管理,所有操作记录都在后台记录,可批量删除。
11、列管理,支持无限分类,即支持无限数量的低级列和无限数量的对等级列。同时还可以控制栏目的切换,栏目是图片还是文字类型,栏目是否在导航栏中显示,栏目是否在首页面板显示,以及显示顺序导航栏主页的。
文章管理,支持基于发布文本的文章功能,并具有上传图片、选择服务器上传图片、批量上传图片、设置多种形式图片、文字前端展示的能力效果。同时支持文章查看权限设置,可以细化限制会员查看和限制会员级别查看。
评论管理,可以进入文章的编辑页面对文章的评论进行管理,也可以直接管理系统内的所有评论,可以删除、查看、回复。
采集文章系统(采集文章系统原理攻击的原理和ddos防御常见的类型)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-11-02 05:02
采集文章系统原理ddos攻击,指的是攻击方向网站发动网络攻击,导致访问、分享以及转载一些网站内容出现带有隐蔽性、攻击性的页面。它们经常对关键的联系性数据进行广泛的读写。由于不受任何计算机技术条件限制,因此网络攻击对网站的影响是巨大的。ddos攻击基本的原理和ddos防御常见的类型:ddos攻击其实可以分为两种,一种是快速的,一种是缓慢的;首先讲讲快速的ddos攻击,这类攻击对关键的个人信息和联系性数据进行广泛的读写。
那么对应的,这类ddos攻击呢,我们叫做“利用cookie进行传输攻击”。我们知道,目前的ddos攻击大多数对象是个人信息,这是由于个人信息在我们的身份验证上是非常非常难的。比如,我们需要用人名做关键字进行关键词验证,那么现在就直接拿人名说事。如果网站是个公司的网站,需要用公司的名字和邮箱等关键词进行注册,那么就搞这些人干什么?这里就需要引入第二类攻击,“利用get进行传输攻击”。
这个攻击包括get/post两个方向,这类攻击也是目前的主流,攻击手段可以分为主动发起ddos以及被动的ddos。主动发起ddos被动ddos讲到ddos,不得不提到ddos专用的名词:ddosoverattack,即同时对多个网站发起ddos攻击,这些网站都会受到到同时的ddos攻击。我们通常说的就是指ddosoverattack。
一般是攻击的同时对一个网站进行攻击,使其发起大量流量来进行响应。下面来讲讲主动ddos攻击:主动ddos是指对某个网站进行ddos攻击,然后这个网站下面所有相同访问量的网站都会受到这次攻击。这类ddos攻击的特点是流量的流向都是一致的,可以只攻击一个网站。比如通过ddos软件进行攻击的情况下,会主动发起ddos攻击,而不是攻击同一网站下所有的网站。
ddos攻击存在一定的主动性,那么对应的防御就应该有针对性。比如说针对于网站服务器被攻击,可以采取一定的ddos防御策略,增加一些基础的防御措施,比如防火墙,ddos防御插件等等。另外还有我们可以通过汇总攻击源(比如说向全球的web服务器发起ddos攻击)来提高我们网站的安全等级。ddos防御常见的方法:第一个是:网站上最好不要接入外部加速服务;第二个是增加路由器的负载均衡等等。
网站支持外部ddos插件:很多大型的网站,一般他们的安全程度不是那么高,针对这个,就可以搭建网站,使用一些外部ddos插件来加强ddos的管理和保护。防火墙的负载均衡比如说防火墙上面对ddos比较敏感的端口进行了加强,比如ip池、地址池等等,可以根据每个网站的安全情况进行实时。 查看全部
采集文章系统(采集文章系统原理攻击的原理和ddos防御常见的类型)
采集文章系统原理ddos攻击,指的是攻击方向网站发动网络攻击,导致访问、分享以及转载一些网站内容出现带有隐蔽性、攻击性的页面。它们经常对关键的联系性数据进行广泛的读写。由于不受任何计算机技术条件限制,因此网络攻击对网站的影响是巨大的。ddos攻击基本的原理和ddos防御常见的类型:ddos攻击其实可以分为两种,一种是快速的,一种是缓慢的;首先讲讲快速的ddos攻击,这类攻击对关键的个人信息和联系性数据进行广泛的读写。
那么对应的,这类ddos攻击呢,我们叫做“利用cookie进行传输攻击”。我们知道,目前的ddos攻击大多数对象是个人信息,这是由于个人信息在我们的身份验证上是非常非常难的。比如,我们需要用人名做关键字进行关键词验证,那么现在就直接拿人名说事。如果网站是个公司的网站,需要用公司的名字和邮箱等关键词进行注册,那么就搞这些人干什么?这里就需要引入第二类攻击,“利用get进行传输攻击”。
这个攻击包括get/post两个方向,这类攻击也是目前的主流,攻击手段可以分为主动发起ddos以及被动的ddos。主动发起ddos被动ddos讲到ddos,不得不提到ddos专用的名词:ddosoverattack,即同时对多个网站发起ddos攻击,这些网站都会受到到同时的ddos攻击。我们通常说的就是指ddosoverattack。
一般是攻击的同时对一个网站进行攻击,使其发起大量流量来进行响应。下面来讲讲主动ddos攻击:主动ddos是指对某个网站进行ddos攻击,然后这个网站下面所有相同访问量的网站都会受到这次攻击。这类ddos攻击的特点是流量的流向都是一致的,可以只攻击一个网站。比如通过ddos软件进行攻击的情况下,会主动发起ddos攻击,而不是攻击同一网站下所有的网站。
ddos攻击存在一定的主动性,那么对应的防御就应该有针对性。比如说针对于网站服务器被攻击,可以采取一定的ddos防御策略,增加一些基础的防御措施,比如防火墙,ddos防御插件等等。另外还有我们可以通过汇总攻击源(比如说向全球的web服务器发起ddos攻击)来提高我们网站的安全等级。ddos防御常见的方法:第一个是:网站上最好不要接入外部加速服务;第二个是增加路由器的负载均衡等等。
网站支持外部ddos插件:很多大型的网站,一般他们的安全程度不是那么高,针对这个,就可以搭建网站,使用一些外部ddos插件来加强ddos的管理和保护。防火墙的负载均衡比如说防火墙上面对ddos比较敏感的端口进行了加强,比如ip池、地址池等等,可以根据每个网站的安全情况进行实时。
采集文章系统(一下如何利用老Y文章管理系统采集时自动完成伪原创)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-10-27 12:19
垃圾站站长最希望的就是网站可以自动采集,自动补完伪原创,然后自动收钱。这真是世界上最幸福的事情了,哈哈。自动采集 和自动收款将不再讨论。今天给大家介绍一下如何使用老Y的文章管理系统采集自动完成伪原创。
旧的Y文章管理系统使用起来简单方便,虽然功能不如DEDE之类的强大。几乎是变态(当然,老Y文章管理系统是用asp语言写的,好像没有可比性。),但是该有的都有,而且还挺简单的,所以也受到了很多站长的欢迎。老Y文章管理系统采集时自动完成伪原创的具体方法目前还很少讨论。在老Y的论坛上,甚至有人在卖这个方法。我鄙视它。.
关于采集,我就不多说了,相信大家都能搞定。我要介绍的是旧的Y文章管理系统如何在采集的同时自动完成伪原创的具体工作方法,大体思路是使用过滤功能旧的Y文章管理系统实现同义词自动替换,从而达到伪原创的目的。比如我想把采集文章中的“网转博客”全部换成“网转日记”。详细步骤如下:
第一步是进入后台。找到“采集管理”-“过滤管理”,添加一个新的过滤项。
我可以创建一个名为“网赚博客”的项目,具体设置请看图片:
“过滤器名称”:填写“网赚博客”即可,也可以随意写,但为了方便查看,建议与替换词保持一致。
“项目”:请根据自己的网站选择一列网站(一定要选择一列,否则过滤后的项目无法保存)
“过滤器对象”:可用选项有“标题过滤器”和“文本过滤器”。一般选择“文本过滤器”。如果你想伪原创 连标题,你可以选择“标题过滤器”。
“过滤器类型”:选项有“简单替换”和“高级过滤器”,一般选择“简单替换”,如果选择“高级过滤器”,则需要指定“开始标签”和“结束标签”,以便你可以在代码层面替换 采集 中的内容。
“使用状态”:选项为“启用”和“禁用”,不作解释。
“使用范围”:选项为“公共”和“私人”。选择“私有”,过滤器只对当前网站列有效;选择“Public”,对所有列都有效,不管采集的任何列有什么内容,过滤器都有效。一般选择“私人”。
“内容”:填写要替换的“网赚博客”。
“替换”:填写“网转日记”,所以只要采集的文章中含有“网转博客”二字,就会自动替换为“网转日记”。
第二步,重复第一步的工作,直到添加完所有同义词。
有网友想问:我有3万多个同义词,要不要手动一一添加?什么时候加!? 不能批量添加吗?
好问题!手动添加确实是一个几乎不可能完成的任务,除非你有非凡的毅力,你可以手动添加这三万多个同义词。遗憾的是,旧的Y文章 管理系统并没有提供批量导入的功能。但是,作为真实的、有经验的、有思想的优采云,我们必须有优采云的意识。
要知道,我们刚刚录入的内容是存放在数据库中的,老Y文章管理系统是用asp+Access编写的,mdb数据库可以轻松编辑!于是乎,直接修改数据库就可以批量导入伪原创替换规则了!
改进的第二步:批量修改数据库和导入规则。
经过搜索,我发现这个数据库在“你的管理目录\cai\Database”下。使用 Access 打开此数据库并找到“过滤器”表。你会发现我们刚刚添加的替换规则就存放在这里。根据您的需要分批添加!接下来的工作涉及到Access的操作。
解释一下“过滤器”表中几个字段的含义:
FilterID:自动生成,无需输入。
ItemID:列ID是我们手动输入时“item”的内容,但这里是数字ID,注意对应列采集ID,如果不知道ID,可以重复第一步,测试一下。.
过滤器名称:“过滤器名称”。
FilterObjece:“过滤对象”,“标题过滤”填1,“文本过滤”填2。
FilterType:“过滤器类型”,“简单更换”填1,“高级过滤器”填2。
FilterContent:“内容”。
FisString:“开始标签”,只有在设置了“高级过滤器”时才有效,如果设置了“简单过滤器”,请留空。
FioString:“结束标签”,仅在设置了“高级过滤器”时有效,如果设置了“简单过滤器”,请留空。
FilterRep:即“替换”。
Flag:“使用状态”,TRUE 表示“启用”,FALSE 表示“禁用”。
PublicTf:“使用范围”。TRUE 表示“公共”,FALSE 表示“私有”。
最后说一下使用过滤功能实现伪原创的使用感
经过:
老Y文章管理系统的这个功能在采集为伪原创时可以自动实现,但功能不够强大。例如,我的网站上有三列:“第一列”、“第二列”和“第三列”。我希望“第一列”伪原创 标题和正文,“第二列”伪原创 仅文本,“第三列”伪原创 仅标题。
因此,我只能进行以下设置(假设我有一个 30,000 同义词规则):
为“第一列”伪原创的标题创建30000条替换规则;
为“第一列”伪原创的文本创建30000条替换规则;
为“第2列”伪原创的文本创建30000条替换规则;
为“第三列”伪原创 的标题创建 30,000 条替换规则。
这造成了巨大的数据库浪费。如果我的网站有几十个栏目,而且每个栏目的要求都不一样,这个数据库的大小会很吓人。
所以建议旧版Y文章管理系统下个版本对这个功能做一些改进:
先添加批量导入功能,毕竟修改数据库有一定的危险性。
其次,过滤规则不再附属于某个网站列,而是独立于过滤规则,并且在新建采集项目时,增加了是否使用过滤规则的判断。
相信经过这样的修改,可以大大节省数据库存储空间,逻辑结构也更加清晰。
本文为《我的网赚日记-原创网专博客》原创,请尊重我的劳动成果,转载请注明出处!另外,我也很久没有用过旧的Y文章管理系统了。文章如有错误或不妥之处,还望指正!
感谢陆奇的贡献 查看全部
采集文章系统(一下如何利用老Y文章管理系统采集时自动完成伪原创)
垃圾站站长最希望的就是网站可以自动采集,自动补完伪原创,然后自动收钱。这真是世界上最幸福的事情了,哈哈。自动采集 和自动收款将不再讨论。今天给大家介绍一下如何使用老Y的文章管理系统采集自动完成伪原创。
旧的Y文章管理系统使用起来简单方便,虽然功能不如DEDE之类的强大。几乎是变态(当然,老Y文章管理系统是用asp语言写的,好像没有可比性。),但是该有的都有,而且还挺简单的,所以也受到了很多站长的欢迎。老Y文章管理系统采集时自动完成伪原创的具体方法目前还很少讨论。在老Y的论坛上,甚至有人在卖这个方法。我鄙视它。.
关于采集,我就不多说了,相信大家都能搞定。我要介绍的是旧的Y文章管理系统如何在采集的同时自动完成伪原创的具体工作方法,大体思路是使用过滤功能旧的Y文章管理系统实现同义词自动替换,从而达到伪原创的目的。比如我想把采集文章中的“网转博客”全部换成“网转日记”。详细步骤如下:
第一步是进入后台。找到“采集管理”-“过滤管理”,添加一个新的过滤项。
我可以创建一个名为“网赚博客”的项目,具体设置请看图片:
“过滤器名称”:填写“网赚博客”即可,也可以随意写,但为了方便查看,建议与替换词保持一致。
“项目”:请根据自己的网站选择一列网站(一定要选择一列,否则过滤后的项目无法保存)
“过滤器对象”:可用选项有“标题过滤器”和“文本过滤器”。一般选择“文本过滤器”。如果你想伪原创 连标题,你可以选择“标题过滤器”。
“过滤器类型”:选项有“简单替换”和“高级过滤器”,一般选择“简单替换”,如果选择“高级过滤器”,则需要指定“开始标签”和“结束标签”,以便你可以在代码层面替换 采集 中的内容。
“使用状态”:选项为“启用”和“禁用”,不作解释。
“使用范围”:选项为“公共”和“私人”。选择“私有”,过滤器只对当前网站列有效;选择“Public”,对所有列都有效,不管采集的任何列有什么内容,过滤器都有效。一般选择“私人”。
“内容”:填写要替换的“网赚博客”。
“替换”:填写“网转日记”,所以只要采集的文章中含有“网转博客”二字,就会自动替换为“网转日记”。
第二步,重复第一步的工作,直到添加完所有同义词。
有网友想问:我有3万多个同义词,要不要手动一一添加?什么时候加!? 不能批量添加吗?
好问题!手动添加确实是一个几乎不可能完成的任务,除非你有非凡的毅力,你可以手动添加这三万多个同义词。遗憾的是,旧的Y文章 管理系统并没有提供批量导入的功能。但是,作为真实的、有经验的、有思想的优采云,我们必须有优采云的意识。
要知道,我们刚刚录入的内容是存放在数据库中的,老Y文章管理系统是用asp+Access编写的,mdb数据库可以轻松编辑!于是乎,直接修改数据库就可以批量导入伪原创替换规则了!
改进的第二步:批量修改数据库和导入规则。
经过搜索,我发现这个数据库在“你的管理目录\cai\Database”下。使用 Access 打开此数据库并找到“过滤器”表。你会发现我们刚刚添加的替换规则就存放在这里。根据您的需要分批添加!接下来的工作涉及到Access的操作。
解释一下“过滤器”表中几个字段的含义:
FilterID:自动生成,无需输入。
ItemID:列ID是我们手动输入时“item”的内容,但这里是数字ID,注意对应列采集ID,如果不知道ID,可以重复第一步,测试一下。.
过滤器名称:“过滤器名称”。
FilterObjece:“过滤对象”,“标题过滤”填1,“文本过滤”填2。
FilterType:“过滤器类型”,“简单更换”填1,“高级过滤器”填2。
FilterContent:“内容”。
FisString:“开始标签”,只有在设置了“高级过滤器”时才有效,如果设置了“简单过滤器”,请留空。
FioString:“结束标签”,仅在设置了“高级过滤器”时有效,如果设置了“简单过滤器”,请留空。
FilterRep:即“替换”。
Flag:“使用状态”,TRUE 表示“启用”,FALSE 表示“禁用”。
PublicTf:“使用范围”。TRUE 表示“公共”,FALSE 表示“私有”。
最后说一下使用过滤功能实现伪原创的使用感
经过:
老Y文章管理系统的这个功能在采集为伪原创时可以自动实现,但功能不够强大。例如,我的网站上有三列:“第一列”、“第二列”和“第三列”。我希望“第一列”伪原创 标题和正文,“第二列”伪原创 仅文本,“第三列”伪原创 仅标题。
因此,我只能进行以下设置(假设我有一个 30,000 同义词规则):
为“第一列”伪原创的标题创建30000条替换规则;
为“第一列”伪原创的文本创建30000条替换规则;
为“第2列”伪原创的文本创建30000条替换规则;
为“第三列”伪原创 的标题创建 30,000 条替换规则。
这造成了巨大的数据库浪费。如果我的网站有几十个栏目,而且每个栏目的要求都不一样,这个数据库的大小会很吓人。
所以建议旧版Y文章管理系统下个版本对这个功能做一些改进:
先添加批量导入功能,毕竟修改数据库有一定的危险性。
其次,过滤规则不再附属于某个网站列,而是独立于过滤规则,并且在新建采集项目时,增加了是否使用过滤规则的判断。
相信经过这样的修改,可以大大节省数据库存储空间,逻辑结构也更加清晰。
本文为《我的网赚日记-原创网专博客》原创,请尊重我的劳动成果,转载请注明出处!另外,我也很久没有用过旧的Y文章管理系统了。文章如有错误或不妥之处,还望指正!
感谢陆奇的贡献
采集文章系统(采集文章系统分析下行情的变化只要我们能跟上变化的步伐)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-10-26 12:09
采集文章系统分析下行情的变化只要我们能跟上变化的步伐,就能稳赚,实现财富自由。正常情况下可能需要我们不断地学习,不断地更新对市场的认知、对自己的认知。由于每个人所关注的方向不同,我们只能根据已有的知识和经验做出分析,形成的分析只能是短线的分析。现在手机浏览的最大弊端是每一条新闻跳转到的网页又大又杂,通过百度浏览器跳转到的网页往往都不会保存文章的原文链接,将会消耗大量的时间,所以在浏览新闻时或者浏览过程中需要看下有没有自己认为重要的信息。
所以我们还是需要专注浏览一个网页来实现信息分析。不同的行情不同的经历都会让我们形成不同的想法,这就是人生的魅力!在咨询过程中我会仔细询问你一个问题:为什么重仓单,为什么加仓单?我们看市场的方式,思考市场的方式,看自己能不能抓住市场的机会,我们才能赚钱。如果想要通过市场赚钱的话最重要的不是去精通什么投资理论,而是去实践什么投资方法,如果方法对了也是一样可以赚钱的。
人生,很难找到完美的理由,也很难去找到完美的答案,但我们可以去找到自己的原因。只要自己多找到自己的原因,多去向内反省,去不断总结自己,你总会找到自己解决这些问题的方法,总会找到自己成长的方向。只要有一点点进步,总会让自己变得不同。原因只有一个,只要持续地努力,人人都能够成为最终的赢家。从有到有,还从有到更多,行情走出不一样的波动形态或形态背后又暗含着什么?对于股市来说,每天都不缺热点和行情,找到热点和背后的逻辑就已经行情已经不远了。
市场是散户自己一个人去自娱自乐的,所以有人抱怨股市的起伏非常大,变化莫测,但在市场中最重要的是要找到适合自己的投资方法,时刻调整自己。否则不断地操作是徒劳无功的。追涨杀跌,就是其中最重要的原因。我们通过每一次上涨,就能够找到每一次下跌的逻辑,看股票该不该买,想不想卖,原因只有一个,那就是缺乏对股票的认知和思考,而且还是一种盲目的思考。
你的思考仅仅停留在下跌这一次机会的考虑上,没有反省和总结。市场并不是寻找交易机会,而是寻找相对高点。实盘的格局不同于教程,所以需要用原文中提供的逻辑思维去分析。如何选择要看你对行情有一个怎样的认知。如果你不懂分析,那么怎么去选也是白搭。所以这是为什么要学习一些基础知识后再去了解行情,因为市场从来不缺看行情的人,只是缺少技术分析者。
如果连分析都做不到的人,也找不到方法。在原文中提到要构建一个分析框架,然后围绕这个框架去筛选出重点的投资策略,并不断重复这个策略。很多人会回应。 查看全部
采集文章系统(采集文章系统分析下行情的变化只要我们能跟上变化的步伐)
采集文章系统分析下行情的变化只要我们能跟上变化的步伐,就能稳赚,实现财富自由。正常情况下可能需要我们不断地学习,不断地更新对市场的认知、对自己的认知。由于每个人所关注的方向不同,我们只能根据已有的知识和经验做出分析,形成的分析只能是短线的分析。现在手机浏览的最大弊端是每一条新闻跳转到的网页又大又杂,通过百度浏览器跳转到的网页往往都不会保存文章的原文链接,将会消耗大量的时间,所以在浏览新闻时或者浏览过程中需要看下有没有自己认为重要的信息。
所以我们还是需要专注浏览一个网页来实现信息分析。不同的行情不同的经历都会让我们形成不同的想法,这就是人生的魅力!在咨询过程中我会仔细询问你一个问题:为什么重仓单,为什么加仓单?我们看市场的方式,思考市场的方式,看自己能不能抓住市场的机会,我们才能赚钱。如果想要通过市场赚钱的话最重要的不是去精通什么投资理论,而是去实践什么投资方法,如果方法对了也是一样可以赚钱的。
人生,很难找到完美的理由,也很难去找到完美的答案,但我们可以去找到自己的原因。只要自己多找到自己的原因,多去向内反省,去不断总结自己,你总会找到自己解决这些问题的方法,总会找到自己成长的方向。只要有一点点进步,总会让自己变得不同。原因只有一个,只要持续地努力,人人都能够成为最终的赢家。从有到有,还从有到更多,行情走出不一样的波动形态或形态背后又暗含着什么?对于股市来说,每天都不缺热点和行情,找到热点和背后的逻辑就已经行情已经不远了。
市场是散户自己一个人去自娱自乐的,所以有人抱怨股市的起伏非常大,变化莫测,但在市场中最重要的是要找到适合自己的投资方法,时刻调整自己。否则不断地操作是徒劳无功的。追涨杀跌,就是其中最重要的原因。我们通过每一次上涨,就能够找到每一次下跌的逻辑,看股票该不该买,想不想卖,原因只有一个,那就是缺乏对股票的认知和思考,而且还是一种盲目的思考。
你的思考仅仅停留在下跌这一次机会的考虑上,没有反省和总结。市场并不是寻找交易机会,而是寻找相对高点。实盘的格局不同于教程,所以需要用原文中提供的逻辑思维去分析。如何选择要看你对行情有一个怎样的认知。如果你不懂分析,那么怎么去选也是白搭。所以这是为什么要学习一些基础知识后再去了解行情,因为市场从来不缺看行情的人,只是缺少技术分析者。
如果连分析都做不到的人,也找不到方法。在原文中提到要构建一个分析框架,然后围绕这个框架去筛选出重点的投资策略,并不断重复这个策略。很多人会回应。
采集文章系统(采集文章系统的话有两个软件可以供你选择)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-10-24 19:02
采集文章系统的话有两个软件可以供你选择【贝叶斯统计】,【scikit-learn】。贝叶斯是统计学领域非常有名的软件,它可以对n维数据集进行一元,多元分析,它能处理数据量超大且不适用excel进行计算的数据。scikit-learn是第一个开源的机器学习软件包,它可以使用scipy进行处理数据,去除非线性关系和线性相关数据以及数据异常值。
以上是从两者的软件结构上简要介绍。细节可以在上面文章的具体项目中查看。第一步的话,根据所选的数据结构编写函数获取数据;第二步是找到目标数据的数据特征以及标签;第三步是进行预处理,提取数据特征以及标签。python的docstring可以很方便的获取数据,如movie_id_list中artists_id是个未知变量,主要就是说电影中不同人物的联系是否紧密,标签可以根据你的具体情况自己输入;第四步,根据最后要的标签,也就是所需要的标签的一组数组,比如names_matrix自定义数组;第五步,对这组数组进行特征提取,降维或者归一化,labels_matrix是个特征数组;第六步,将数据存储,用tfrecord,noexcel或者records.把所有数据写到训练集中。
docstring中可以获取不同维度的训练集中不同的数据,还可以根据自己需要把数据合并,转换,切片,以及异常值的处理等。这就是数据分析常用的三大基本模块:featuredescriptor,featureextraction,labelengine。 查看全部
采集文章系统(采集文章系统的话有两个软件可以供你选择)
采集文章系统的话有两个软件可以供你选择【贝叶斯统计】,【scikit-learn】。贝叶斯是统计学领域非常有名的软件,它可以对n维数据集进行一元,多元分析,它能处理数据量超大且不适用excel进行计算的数据。scikit-learn是第一个开源的机器学习软件包,它可以使用scipy进行处理数据,去除非线性关系和线性相关数据以及数据异常值。
以上是从两者的软件结构上简要介绍。细节可以在上面文章的具体项目中查看。第一步的话,根据所选的数据结构编写函数获取数据;第二步是找到目标数据的数据特征以及标签;第三步是进行预处理,提取数据特征以及标签。python的docstring可以很方便的获取数据,如movie_id_list中artists_id是个未知变量,主要就是说电影中不同人物的联系是否紧密,标签可以根据你的具体情况自己输入;第四步,根据最后要的标签,也就是所需要的标签的一组数组,比如names_matrix自定义数组;第五步,对这组数组进行特征提取,降维或者归一化,labels_matrix是个特征数组;第六步,将数据存储,用tfrecord,noexcel或者records.把所有数据写到训练集中。
docstring中可以获取不同维度的训练集中不同的数据,还可以根据自己需要把数据合并,转换,切片,以及异常值的处理等。这就是数据分析常用的三大基本模块:featuredescriptor,featureextraction,labelengine。
采集文章系统(如何在自媒体运营当中有熟人当老师,可以少走弯路)
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-10-05 22:28
自媒体爆文采集工具很容易写!用它快速查找爆文的内容!毛毛同学一直在用一战这个工具!做自媒体操作就是不断学习新的知识,比如如何做爆文标题,如何关注实时热点等等。
具体的内容不是那么容易简单讲的。只有当你真正去做时,你才会发现并且知道并不意味着你会去做。但是这些内容无论如何都是要学习和掌握的。在自媒体的操作中如何有熟人做老师,可以少走很多弯路。
日复一日的内容创作,对于做自媒体运营的小伙伴来说,是一件很烦的事情。总会有没有创作灵感的时候,即使你看材料,灵感也枯竭了。.
这个时候就需要适当的借鉴一些同行业朋友的创意内容,那么这些内容应该如何采集和搜索呢?
今天给大家分享一个爆文的搜索工具,以后还会用到。希望能帮助大家提供创作灵感,打造10w甚至100w爆文。
容易写
易转可以在市场上大多数自媒体平台上采集到爆文。
您可以根据需要过滤字段和平台。过滤器和排序功能的结果非常有用。自媒体爆文查找网站,还有文章原创度数检测、视频批量下载、爆文标题助手等小功能,喜欢的朋友关注可以输入网站了解更多里面的功能。
毛毛同学分享这个亦庄自媒体工具只是为了让大家更快找到爆文学习爆文写作技巧,为自己提供灵感,不要把它当作自媒体操作神器,比起自媒体 平台不是傻子。不要挑战自媒体平台的规则,多做搬运。 查看全部
采集文章系统(如何在自媒体运营当中有熟人当老师,可以少走弯路)
自媒体爆文采集工具很容易写!用它快速查找爆文的内容!毛毛同学一直在用一战这个工具!做自媒体操作就是不断学习新的知识,比如如何做爆文标题,如何关注实时热点等等。
具体的内容不是那么容易简单讲的。只有当你真正去做时,你才会发现并且知道并不意味着你会去做。但是这些内容无论如何都是要学习和掌握的。在自媒体的操作中如何有熟人做老师,可以少走很多弯路。
日复一日的内容创作,对于做自媒体运营的小伙伴来说,是一件很烦的事情。总会有没有创作灵感的时候,即使你看材料,灵感也枯竭了。.
这个时候就需要适当的借鉴一些同行业朋友的创意内容,那么这些内容应该如何采集和搜索呢?
今天给大家分享一个爆文的搜索工具,以后还会用到。希望能帮助大家提供创作灵感,打造10w甚至100w爆文。
容易写
易转可以在市场上大多数自媒体平台上采集到爆文。
您可以根据需要过滤字段和平台。过滤器和排序功能的结果非常有用。自媒体爆文查找网站,还有文章原创度数检测、视频批量下载、爆文标题助手等小功能,喜欢的朋友关注可以输入网站了解更多里面的功能。
毛毛同学分享这个亦庄自媒体工具只是为了让大家更快找到爆文学习爆文写作技巧,为自己提供灵感,不要把它当作自媒体操作神器,比起自媒体 平台不是傻子。不要挑战自媒体平台的规则,多做搬运。
采集文章系统(如何高效采集归档处理的呢?博通档案管理系统采集方式介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-10-05 22:27
众所周知,汇博通档案管理系统具有强大的办公功能。汇博通作为文件、档案、知识办公一体化的管理软件系统,如何高效地整理归档档案信息?下面小编就为大家简单介绍一下博通文件管理系统采集,希望对大家有所帮助。
汇博通的采集方式多种多样,主要分为主动式采集和集成式采集。
主动采集方法是提供属性创建,即对原文件重新编辑和填充,可以及时更新文件内容和附加文件信息,并添加个性化的附加可选功能。
扫描新建功能,原文件自带附件功能,支持多文件一起上传。
批量创建功能和批量上传/导入/替换功能是指上传文件中选择的批量创建模式,可以同时进行多个文件的批量上传/导入/替换,节省工时和人工效率.
主动采集方式,自由选择知识文档采集方式,满足当前企业对办公文档的需求,精益求精,并随着企业的发展做出不同的属性调整,适用于企业的办公平台。
汇博通作为综合信息门户和统一认证中心,整合现有信息系统(如OA、CRM等),统一采集其产生的知识内容。使用汇博通,可以将原创信息分散到不同的系统中。文件、档案、合同、报告、图纸、网站内容、摘要、内部期刊等,都集成到一个系统中进行统一管理。
文章发件人: 查看全部
采集文章系统(如何高效采集归档处理的呢?博通档案管理系统采集方式介绍)
众所周知,汇博通档案管理系统具有强大的办公功能。汇博通作为文件、档案、知识办公一体化的管理软件系统,如何高效地整理归档档案信息?下面小编就为大家简单介绍一下博通文件管理系统采集,希望对大家有所帮助。
汇博通的采集方式多种多样,主要分为主动式采集和集成式采集。
主动采集方法是提供属性创建,即对原文件重新编辑和填充,可以及时更新文件内容和附加文件信息,并添加个性化的附加可选功能。
扫描新建功能,原文件自带附件功能,支持多文件一起上传。
批量创建功能和批量上传/导入/替换功能是指上传文件中选择的批量创建模式,可以同时进行多个文件的批量上传/导入/替换,节省工时和人工效率.
主动采集方式,自由选择知识文档采集方式,满足当前企业对办公文档的需求,精益求精,并随着企业的发展做出不同的属性调整,适用于企业的办公平台。
汇博通作为综合信息门户和统一认证中心,整合现有信息系统(如OA、CRM等),统一采集其产生的知识内容。使用汇博通,可以将原创信息分散到不同的系统中。文件、档案、合同、报告、图纸、网站内容、摘要、内部期刊等,都集成到一个系统中进行统一管理。
文章发件人:
采集文章系统(SQLServer除了要精确的维度分析,本文ETL分析系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-10-05 03:30
【摘要】:随着互联网的飞速发展,网络安全问题越来越严重,大量网络攻击监控数据采集下线等待分析。这些数据都以文字的形式记录下来,单靠人工分析是不可能完成的任务。因此,迫切需要一个自动化的分析系统来定位数据、统计统计和计算维数。本系统是一个数据仓库系统,主要有两种数据:原创数据和IP地址数据库(简称“IP数据库”)数据。这两种类型的数据都具有“多源”属性。原创数据的多源性体现在不同的采集系统中,具有不同的类型和格式;IP库数据的多源性体现在三层IP库模型中。原创数据收录基本属性:SourIP(源IP,被攻击方)和DestIP(目的IP,攻击者),IP数据库数据用于定位。这是系统的核心功能。面对海量的原创数据,需要快速准确的维度分析,本文介绍了为什么使用分布式系统(Apache Hadoop)和关系数据库(SQLServer)的复合架构,以及如何使用这些技术构建数据仓库。准确地说,就是ETL的建模和实现是如何进行的。首先是原创数据的ETL。采集 原创文件加载到Hadoop的HDFS后,调用 API 提取数据并将其保存在 Hive 数据仓库中。同时编写了Map-Reduce程序,对目前可用的各种格式进行区分、清理、合并、最后处理。“一致”数据,这里所谓的一致数据就是“五元组模型”。二是IP库数据的ETL。五元组数据以文件的形式传递给 SQL Server。除了加载五元组数据,SQL Server 还有一种重要的字典数据类型,就是IP数据库数据。本文介绍如何构建“三层IP库模型”,满足不同关注度的IP精准定位。每一层IP数据库都有相应建立的全国行政区划数据库,其中至少收录三级地理划分:省(直辖市)、市(区)、区(县)。从采集按照三级划分组织IP库是ETL工作量的较大部分。数据仓库搭建完成后,通过B/S架构的Web界面调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析. 同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. 省(直辖市)、市(区)、区(县)。从采集按照三级划分组织IP库是ETL工作量的较大部分。数据仓库搭建完成后,通过B/S架构的Web界面调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析. 同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. 省(直辖市)、市(区)、区(县)。从采集按照三级划分组织IP库是ETL工作量的较大部分。数据仓库搭建完成后,通过B/S架构的Web界面调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析. 同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. 从采集按照三级划分组织IP库是ETL工作量的较大部分。数据仓库搭建完成后,通过B/S架构的Web界面调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析. 同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. 从采集按照三级划分组织IP库是ETL工作量的较大部分。数据仓库搭建完成后,通过B/S架构的Web界面调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析. 同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. B/S架构的Web界面,用于调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析。同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. B/S架构的Web界面,用于调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析。同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. 查看全部
采集文章系统(SQLServer除了要精确的维度分析,本文ETL分析系统)
【摘要】:随着互联网的飞速发展,网络安全问题越来越严重,大量网络攻击监控数据采集下线等待分析。这些数据都以文字的形式记录下来,单靠人工分析是不可能完成的任务。因此,迫切需要一个自动化的分析系统来定位数据、统计统计和计算维数。本系统是一个数据仓库系统,主要有两种数据:原创数据和IP地址数据库(简称“IP数据库”)数据。这两种类型的数据都具有“多源”属性。原创数据的多源性体现在不同的采集系统中,具有不同的类型和格式;IP库数据的多源性体现在三层IP库模型中。原创数据收录基本属性:SourIP(源IP,被攻击方)和DestIP(目的IP,攻击者),IP数据库数据用于定位。这是系统的核心功能。面对海量的原创数据,需要快速准确的维度分析,本文介绍了为什么使用分布式系统(Apache Hadoop)和关系数据库(SQLServer)的复合架构,以及如何使用这些技术构建数据仓库。准确地说,就是ETL的建模和实现是如何进行的。首先是原创数据的ETL。采集 原创文件加载到Hadoop的HDFS后,调用 API 提取数据并将其保存在 Hive 数据仓库中。同时编写了Map-Reduce程序,对目前可用的各种格式进行区分、清理、合并、最后处理。“一致”数据,这里所谓的一致数据就是“五元组模型”。二是IP库数据的ETL。五元组数据以文件的形式传递给 SQL Server。除了加载五元组数据,SQL Server 还有一种重要的字典数据类型,就是IP数据库数据。本文介绍如何构建“三层IP库模型”,满足不同关注度的IP精准定位。每一层IP数据库都有相应建立的全国行政区划数据库,其中至少收录三级地理划分:省(直辖市)、市(区)、区(县)。从采集按照三级划分组织IP库是ETL工作量的较大部分。数据仓库搭建完成后,通过B/S架构的Web界面调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析. 同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. 省(直辖市)、市(区)、区(县)。从采集按照三级划分组织IP库是ETL工作量的较大部分。数据仓库搭建完成后,通过B/S架构的Web界面调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析. 同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. 省(直辖市)、市(区)、区(县)。从采集按照三级划分组织IP库是ETL工作量的较大部分。数据仓库搭建完成后,通过B/S架构的Web界面调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析. 同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. 从采集按照三级划分组织IP库是ETL工作量的较大部分。数据仓库搭建完成后,通过B/S架构的Web界面调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析. 同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. 从采集按照三级划分组织IP库是ETL工作量的较大部分。数据仓库搭建完成后,通过B/S架构的Web界面调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析. 同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. B/S架构的Web界面,用于调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析。同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出. B/S架构的Web界面,用于调用T-SQL(SQL Server提供的基于SQL的编程语言)存储过程对数据仓库中的内容进行维度查询和分析。同时完成业务系统的功能:用户操作、用户权限、用户管理、数据可视化等。提供即席查询和必要检索,提供趋势、统计、图表等数据展示,提供报表制作和输出.
采集文章系统(自动更新回帖插件功能特点及特点介绍-苏州安嘉网络 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-10-03 02:00
)
【本插件特点】
01、 可以批量注册马甲用户,发帖和评论所使用的马甲与真实注册用户发布的马甲一模一样。
02、可以批量采集批量发布,发布任意百度贴吧主题内容,短时间内回复您的论坛和门户。
03、可调度采集并自动发布,实现网站内容无人值守自动更新,让您拥有24小时发布内容的智能编辑器
04、采集 返回的内容可以进行简繁体转换、伪原创等二次处理。
05、支持前台采集,可以授权指定的普通注册用户在前台使用这个采集器,让普通注册会员帮你采集的内容。
06、采集 传入的内容图片可以正常显示并保存为post图片附件或门户文章附件,图片永不丢失。
07、图片附件支持远程FTP存储,让您可以将图片分离到另一台服务器。
08、 图片会添加您的论坛或门户设置的水印。
09、 已经采集的内容不会重复两次采集,内容不会重复或冗余。
1 0、采集或门户网站文章和群组发布的帖子与真实用户发布的帖子完全相同。其他人不知道是否用采集器 发帖。
1 1、的浏览量会自动随机设置。感觉你的帖子或者门户文章的浏览量和真实的一样。
12、可以指定帖子发布者(发帖人)、门户文章作者、群发帖人。
1 3、采集的内容可以发布到论坛任意版块、门户任意栏目、群任意圈。
14、已发布的内容可以推送到百度数据收录界面进行SEO优化,加速网站百度索引量和收录量.
15、不限制采集的内容数量,不限制采集的出现次数,让你的网站快速填充高质量内容。
1 6、 插件内置了自动文本提取算法。您不需要自己编写 采集 规则。它支持任何采集 任何网站 内容。
17、 一键获取当前实时热点内容,然后一键发布。
18、 马甲回复时间经过科学处理。并非所有回复都在同一时间。感觉您的论坛不是在回复马甲,而是在回复真实用户。
19、支持采集指定的贴吧,实现有针对性的采集某百度贴吧内容。
查看全部
采集文章系统(自动更新回帖插件功能特点及特点介绍-苏州安嘉网络
)
【本插件特点】
01、 可以批量注册马甲用户,发帖和评论所使用的马甲与真实注册用户发布的马甲一模一样。
02、可以批量采集批量发布,发布任意百度贴吧主题内容,短时间内回复您的论坛和门户。
03、可调度采集并自动发布,实现网站内容无人值守自动更新,让您拥有24小时发布内容的智能编辑器
04、采集 返回的内容可以进行简繁体转换、伪原创等二次处理。
05、支持前台采集,可以授权指定的普通注册用户在前台使用这个采集器,让普通注册会员帮你采集的内容。
06、采集 传入的内容图片可以正常显示并保存为post图片附件或门户文章附件,图片永不丢失。
07、图片附件支持远程FTP存储,让您可以将图片分离到另一台服务器。
08、 图片会添加您的论坛或门户设置的水印。
09、 已经采集的内容不会重复两次采集,内容不会重复或冗余。
1 0、采集或门户网站文章和群组发布的帖子与真实用户发布的帖子完全相同。其他人不知道是否用采集器 发帖。
1 1、的浏览量会自动随机设置。感觉你的帖子或者门户文章的浏览量和真实的一样。
12、可以指定帖子发布者(发帖人)、门户文章作者、群发帖人。
1 3、采集的内容可以发布到论坛任意版块、门户任意栏目、群任意圈。
14、已发布的内容可以推送到百度数据收录界面进行SEO优化,加速网站百度索引量和收录量.
15、不限制采集的内容数量,不限制采集的出现次数,让你的网站快速填充高质量内容。
1 6、 插件内置了自动文本提取算法。您不需要自己编写 采集 规则。它支持任何采集 任何网站 内容。
17、 一键获取当前实时热点内容,然后一键发布。
18、 马甲回复时间经过科学处理。并非所有回复都在同一时间。感觉您的论坛不是在回复马甲,而是在回复真实用户。
19、支持采集指定的贴吧,实现有针对性的采集某百度贴吧内容。
https://www.ff-coder.cn/wp-con ... 4.jpg 300w, https://www.ff-coder.cn/wp-con ... 8.jpg 768w" /> 采集文章系统(网钛文章管理系统、支持设置首页各个(◆商业版))
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-01 21:11
Net钛文章管理系统是一种流行的ASP开源网站管理系统。在功能、人性化和易用性方面,它基于ASP+Access/MSSQL的技术架构,可用于广泛的新闻发布网站,也可用于信息门户网站。对于那些不太了解网站构建并希望成为网站的人,他们可以快速构建一个实用、强大、用户友好且易于使用的系统。Netti文章管理系统更注重个人网站或中小型门户网站的建设。当然,有很多企业用户使用这个系统。使用过netti文章管理系统的用户将继续对其表示赞赏。Net钛文章管理系统界面友好,操作简单,功能强大。有需要的朋友可以下载并使用它
功能特性1、两个原创主页布局可以自由切换:左侧两列和右侧热门文章以及投票,全部三列
2、支持三种顶级徽标模式:横幅、徽标+2个广告空间和徽标+1个广告空间
3、Flash格式的徽标,包括Flash(◆ 商业版)
4、支持设置是否在顶部显示日期、星期、时间和节日
5、支持三种类型的天气预报和用户定义的天气预报代码
6、支持设置导航菜单的数量
7、支持设置主导航、次导航和自定义多行导航样式(◆ 商业版)
8、支持导航的子菜单模式有三种:不显示子菜单、下拉子菜单和水平子菜单(◆ 商业版)
9、支持4种不同的flash幻灯片样式,并可设置是否显示标题
10、支持设置最新消息列的显示范围
11、支持设置滚动图片的显示数量和列范围
12、支持远程图片作为幻灯片和缩略图(◆ 商业版)
13、支持设置主页上每列显示的文章数量、是否显示日期以及是否显示缩略图 查看全部
采集文章系统(网钛文章管理系统、支持设置首页各个(◆商业版))
Net钛文章管理系统是一种流行的ASP开源网站管理系统。在功能、人性化和易用性方面,它基于ASP+Access/MSSQL的技术架构,可用于广泛的新闻发布网站,也可用于信息门户网站。对于那些不太了解网站构建并希望成为网站的人,他们可以快速构建一个实用、强大、用户友好且易于使用的系统。Netti文章管理系统更注重个人网站或中小型门户网站的建设。当然,有很多企业用户使用这个系统。使用过netti文章管理系统的用户将继续对其表示赞赏。Net钛文章管理系统界面友好,操作简单,功能强大。有需要的朋友可以下载并使用它
功能特性1、两个原创主页布局可以自由切换:左侧两列和右侧热门文章以及投票,全部三列
2、支持三种顶级徽标模式:横幅、徽标+2个广告空间和徽标+1个广告空间
3、Flash格式的徽标,包括Flash(◆ 商业版)
4、支持设置是否在顶部显示日期、星期、时间和节日
5、支持三种类型的天气预报和用户定义的天气预报代码
6、支持设置导航菜单的数量
7、支持设置主导航、次导航和自定义多行导航样式(◆ 商业版)
8、支持导航的子菜单模式有三种:不显示子菜单、下拉子菜单和水平子菜单(◆ 商业版)
9、支持4种不同的flash幻灯片样式,并可设置是否显示标题
10、支持设置最新消息列的显示范围
11、支持设置滚动图片的显示数量和列范围
12、支持远程图片作为幻灯片和缩略图(◆ 商业版)
13、支持设置主页上每列显示的文章数量、是否显示日期以及是否显示缩略图
采集文章系统(谷歌数据分析加我为何没人推荐w3panel好像蛮不错的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-29 00:02
采集文章系统
手机能安装一个spider或者knowledgeinfilter,批量选择、分类,自动生成不同主题,加入浏览器,高频访问。我也是一直在这个网站上找数据,首页有很多东西,编译过之后,找到你需要的。
这里有几个数据提供商,按照需求选择合适自己的。
w3school可以学习的web开发
百度统计可以
,智能分类--知乎知乎数据统计
百度统计你的
keep
大家都推荐免费的spider了。我觉得免费应该就是最贵的吧。无论哪个数据分析网站都应该以免费为前提。
谷歌数据分析
加我
为何没人推荐w3panel好像蛮不错的
w3school学院,
w3school在线网站//
大家都说了~本人推荐一下同花顺、大智慧,我最近买股票也是用的这两个网站。
都说的非常对,
w3preview这个免费,专业,数据量较大。
html5最火的竞品就是w3school了,做做w3school的模拟学习,不仅能获得从理论上的w3school,还能找到应用,如爬虫,数据库开发等,把网站当成一个工具或博客去写,总会有收获。w3school-找到你的第一门web教程+tsdb开发网站,之前去看新农合参加数据分析大赛,感觉效果还是挺不错的,很高兴接触到了数据分析,对于学的,个人感觉还是不错,如果熟悉,并用到实际中去。 查看全部
采集文章系统(谷歌数据分析加我为何没人推荐w3panel好像蛮不错的)
采集文章系统
手机能安装一个spider或者knowledgeinfilter,批量选择、分类,自动生成不同主题,加入浏览器,高频访问。我也是一直在这个网站上找数据,首页有很多东西,编译过之后,找到你需要的。
这里有几个数据提供商,按照需求选择合适自己的。
w3school可以学习的web开发
百度统计可以
,智能分类--知乎知乎数据统计
百度统计你的
keep
大家都推荐免费的spider了。我觉得免费应该就是最贵的吧。无论哪个数据分析网站都应该以免费为前提。
谷歌数据分析
加我
为何没人推荐w3panel好像蛮不错的
w3school学院,
w3school在线网站//
大家都说了~本人推荐一下同花顺、大智慧,我最近买股票也是用的这两个网站。
都说的非常对,
w3preview这个免费,专业,数据量较大。
html5最火的竞品就是w3school了,做做w3school的模拟学习,不仅能获得从理论上的w3school,还能找到应用,如爬虫,数据库开发等,把网站当成一个工具或博客去写,总会有收获。w3school-找到你的第一门web教程+tsdb开发网站,之前去看新农合参加数据分析大赛,感觉效果还是挺不错的,很高兴接触到了数据分析,对于学的,个人感觉还是不错,如果熟悉,并用到实际中去。
采集文章系统( 手把手教您运用KesionCMSV8轻松采集文章信息信息采集管理系统的作用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-28 21:16
手把手教您运用KesionCMSV8轻松采集文章信息信息采集管理系统的作用)
系统信息采集教程教你如何轻松使用KesioncmsV8采集文章信息信息采集管理系统的作用可以帮助企业信息化< @采集资源整合节省大量人力和资金,广泛应用于行业门户网站竞争情报系统、知识管理系统网站内容系统、垂直搜索、科研等领域。今天我们就以采集腾讯网站的本地新闻列表为例,一步步教你如何使用采集如何设置系统采集规则,素材编码规则,三大议事规则,文件编号规则,乒乓球比赛规则,不规则动词表点击内容管理--信息采集
下一步是输入设置列表索引和开始和结束标签,如下图所示。这时候我们需要打开采集的信息页第一页,将URL复制粘贴到列表索引页下方的标记处。我们需要查看网页生成的源代码如下图所示。搜索和查找来自各地的新闻。注意观察。我们找到了来自各地的新闻信息列表。找到页面底部的开始标签divclass“modnewslist”,然后在底部页面找到结束标签,点击next按钮继续我们的采集任务然后寻找链接开始和结束标签,如图下图。我们可以看到,在列表拦截测试中,
在短标题的开始和结束标签中填写h1h1,然后找到内容文章的开始和结束标签,如下图所示。填写标题的开始和结束标签,找到文章内容的开始和结束标签,填写如下图。如果此时是提示拦截栏
表错了,那你可能找不到唯一性,需要继续测试。如果之前的设置没有问题,那么继续点击下一步。如下图所示,可以看到上面的界面。采集设置我们是否需要在采集的文章中有一张图片,让它自动转换成图片文章然后查看下图并点击Finish按钮设置采集的规则 完成下图后,点击确定按钮返回采集管理主页,如下图所示。此时,您只需单击采集 链接即可继续处理采集 信息。以上我们介绍的信息只是采集信息在列表的一页的情况下,
页面生成规则如下图所示。鼠标移到2显示,然后我们就可以按照他的生成规则编辑我们的采集项目了。这一步的时候,选择批量生成,复制粘贴网址,输入页数。更改为ID生成范围并填写数字。例如,如果您需要采集前8页,我们将填写2-8,如下图所示。点击主页上的采集链接如下图,系统进入启动界面。采集界面如下图。请注意这里的一点。采集采集时请不要刷新此页面,完成后系统会自动统计采集成功和失败的次数,
进入看到我们成功的采集的文章就可以进入批量选择,将文章放入仓库如下图。如果文章必须全部入库,点击全部入库按钮如下图,点击确定按钮。我们回到文章系统,看到所有文章已经成功存入库中。离职面谈记录怎么写 安全生产月会记录怎么写 幼儿园伙食委员会会议记录内容 安全例会会议记录按钮 点击按钮后,可以清除采集的所有历史记录,如图以下。本教程只是本教程末尾的一个示例。采集在这个过程中,由于每个站点的生成规则不同,我们经常会遇到拦截列表错误等问题。我们不要气馁,多尝试几次。胜利属于努力的人____ 更多Kesioncms后台使用示例教程 查看全部
采集文章系统(
手把手教您运用KesionCMSV8轻松采集文章信息信息采集管理系统的作用)
系统信息采集教程教你如何轻松使用KesioncmsV8采集文章信息信息采集管理系统的作用可以帮助企业信息化< @采集资源整合节省大量人力和资金,广泛应用于行业门户网站竞争情报系统、知识管理系统网站内容系统、垂直搜索、科研等领域。今天我们就以采集腾讯网站的本地新闻列表为例,一步步教你如何使用采集如何设置系统采集规则,素材编码规则,三大议事规则,文件编号规则,乒乓球比赛规则,不规则动词表点击内容管理--信息采集
下一步是输入设置列表索引和开始和结束标签,如下图所示。这时候我们需要打开采集的信息页第一页,将URL复制粘贴到列表索引页下方的标记处。我们需要查看网页生成的源代码如下图所示。搜索和查找来自各地的新闻。注意观察。我们找到了来自各地的新闻信息列表。找到页面底部的开始标签divclass“modnewslist”,然后在底部页面找到结束标签,点击next按钮继续我们的采集任务然后寻找链接开始和结束标签,如图下图。我们可以看到,在列表拦截测试中,
在短标题的开始和结束标签中填写h1h1,然后找到内容文章的开始和结束标签,如下图所示。填写标题的开始和结束标签,找到文章内容的开始和结束标签,填写如下图。如果此时是提示拦截栏
表错了,那你可能找不到唯一性,需要继续测试。如果之前的设置没有问题,那么继续点击下一步。如下图所示,可以看到上面的界面。采集设置我们是否需要在采集的文章中有一张图片,让它自动转换成图片文章然后查看下图并点击Finish按钮设置采集的规则 完成下图后,点击确定按钮返回采集管理主页,如下图所示。此时,您只需单击采集 链接即可继续处理采集 信息。以上我们介绍的信息只是采集信息在列表的一页的情况下,
页面生成规则如下图所示。鼠标移到2显示,然后我们就可以按照他的生成规则编辑我们的采集项目了。这一步的时候,选择批量生成,复制粘贴网址,输入页数。更改为ID生成范围并填写数字。例如,如果您需要采集前8页,我们将填写2-8,如下图所示。点击主页上的采集链接如下图,系统进入启动界面。采集界面如下图。请注意这里的一点。采集采集时请不要刷新此页面,完成后系统会自动统计采集成功和失败的次数,
进入看到我们成功的采集的文章就可以进入批量选择,将文章放入仓库如下图。如果文章必须全部入库,点击全部入库按钮如下图,点击确定按钮。我们回到文章系统,看到所有文章已经成功存入库中。离职面谈记录怎么写 安全生产月会记录怎么写 幼儿园伙食委员会会议记录内容 安全例会会议记录按钮 点击按钮后,可以清除采集的所有历史记录,如图以下。本教程只是本教程末尾的一个示例。采集在这个过程中,由于每个站点的生成规则不同,我们经常会遇到拦截列表错误等问题。我们不要气馁,多尝试几次。胜利属于努力的人____ 更多Kesioncms后台使用示例教程
采集文章系统(新秀文章管理系统sinsiucms1.0beta8说明1.0说明 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-22 18:26
)
新节目文章 @ @ 1. 0 beta8描述:一、新@ @ 文章译文是一个简单而简单,永久性的PHP 文章管理管理系统;内置采集功能,新节目官方每日采集大量采用用上选户,新节目还提供“采集自定义”收费会员服务,可以帮助用户采集任何数据;该系统具有MySQL并访问两个数据库可用。 二、后端功能:1、基本设置:基本信息,网站设置,导航管理,扇区开放,安全设置,静态设置,管理员帐户,数据库管理,其他设置; // 2、文章 @理主:文章 list,发布文章,文章 sice ;; 3、用户交互:消息管理,评论管理,友情链接; 4、文件管理:选择模板,图片管理,语言设置,资源管理; 5、 data 采集:采集设置设置,公共数据,私有定制,私人数据; 6、高级用作:新频道,频道标题,后端导航管理。 三、安装文件:1、我方推推推版本为期为为期为为; (注意,它是内部)子目录和文件上传到网站根目录,然后打开网站,按提醒选择数据库,填写数据库信息,最后单击安装按钮完成安装; 3、此系统默认设置在1小时内仅10次,您可以在“背基本设置安全设置”中修改时间长和登录号,以便在调试期间不登录后端。 四、更新说明:
1、 sinsiu cms 1. 0 beta7用户用户用户访问Sinsiu cms 1. 0 beta8,无需重新安装;
2、假,如果您是sinsiu cms 1. 0 beta7用户,请完全将升级文件夹上传到网站 root目录,输入网站path /升级/,浏览器地址栏。然后通过提醒来单击更新链接;
3、假如果更新有一个混沌文件,请清理浏览器临时文件,然后在网站 @ @。
五、 notes:1、此系统访问数据库仅在Windows Server上有效,建议使用Access数据库选择Windows主机; 2、因为此系统使用UTF-8编码,在Windows中使用记事本编辑,因为记事本将自动添加BOM头导致例外,建议使用专业的Dreamweaver或小型记事本++编辑器; 3、网站网站@ 网站网站@网站@网站@网站@ 网站网站网站@ arty手动删除索引/编译中的所有文件/移动后编译目录,否则在移动后网站可能是错误的。 4、此系统在发布之前重复测试,通常不在核心功能。如果您遇到使用过程,请首先找到自己的运行环境的原因,如果您遇到问题,请将您的责任推向我们,甚至怀疑我们的心会留下缺点,这完全无助。处理和个人进展问题。如果断开错误,则是由我们的程序引起的。您可以向我们的邮箱发送问题。我们将免费为您提供处理程序,我们的反馈谢谢! 六、后路径:网站路/ / admin 七、 upgrade:
1、添加手机支持,使用手机时自动致电手机模板;
2、改进采集函数。
查看全部
采集文章系统(新秀文章管理系统sinsiucms1.0beta8说明1.0说明
)
新节目文章 @ @ 1. 0 beta8描述:一、新@ @ 文章译文是一个简单而简单,永久性的PHP 文章管理管理系统;内置采集功能,新节目官方每日采集大量采用用上选户,新节目还提供“采集自定义”收费会员服务,可以帮助用户采集任何数据;该系统具有MySQL并访问两个数据库可用。 二、后端功能:1、基本设置:基本信息,网站设置,导航管理,扇区开放,安全设置,静态设置,管理员帐户,数据库管理,其他设置; // 2、文章 @理主:文章 list,发布文章,文章 sice ;; 3、用户交互:消息管理,评论管理,友情链接; 4、文件管理:选择模板,图片管理,语言设置,资源管理; 5、 data 采集:采集设置设置,公共数据,私有定制,私人数据; 6、高级用作:新频道,频道标题,后端导航管理。 三、安装文件:1、我方推推推版本为期为为期为为; (注意,它是内部)子目录和文件上传到网站根目录,然后打开网站,按提醒选择数据库,填写数据库信息,最后单击安装按钮完成安装; 3、此系统默认设置在1小时内仅10次,您可以在“背基本设置安全设置”中修改时间长和登录号,以便在调试期间不登录后端。 四、更新说明:
1、 sinsiu cms 1. 0 beta7用户用户用户访问Sinsiu cms 1. 0 beta8,无需重新安装;
2、假,如果您是sinsiu cms 1. 0 beta7用户,请完全将升级文件夹上传到网站 root目录,输入网站path /升级/,浏览器地址栏。然后通过提醒来单击更新链接;
3、假如果更新有一个混沌文件,请清理浏览器临时文件,然后在网站 @ @。
五、 notes:1、此系统访问数据库仅在Windows Server上有效,建议使用Access数据库选择Windows主机; 2、因为此系统使用UTF-8编码,在Windows中使用记事本编辑,因为记事本将自动添加BOM头导致例外,建议使用专业的Dreamweaver或小型记事本++编辑器; 3、网站网站@ 网站网站@网站@网站@网站@ 网站网站网站@ arty手动删除索引/编译中的所有文件/移动后编译目录,否则在移动后网站可能是错误的。 4、此系统在发布之前重复测试,通常不在核心功能。如果您遇到使用过程,请首先找到自己的运行环境的原因,如果您遇到问题,请将您的责任推向我们,甚至怀疑我们的心会留下缺点,这完全无助。处理和个人进展问题。如果断开错误,则是由我们的程序引起的。您可以向我们的邮箱发送问题。我们将免费为您提供处理程序,我们的反馈谢谢! 六、后路径:网站路/ / admin 七、 upgrade:
1、添加手机支持,使用手机时自动致电手机模板;
2、改进采集函数。
采集文章系统(【论语】采集文章系统解析《论语》中的语言框架)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-19 23:02
采集文章系统解析《论语》中的语言框架:1.字,每个字是一个概念,2.句子是以“主句”为中心,句中的“每个句子”由“字、词、词组”构成。句子中的“字、词、词组”本质上是一种关系代数数据结构,“字、词、词组”构成一个句子。所以“每个句子”和“每个词”都可以在“主句”中寻找。2.文章,每个文章是一个概念,3.每个概念由词构成,每个词又由具体的词组构成。
词可以通过迭代对“字、词、词组”有直观感受4.“字、词、词组”,直观感受直接构成文章中心内容,但是“字、词、词组”又是一个整体概念,如果我们真的通过“字、词、词组”可以不断递归迭代得到文章的一部分,那么在递归的递归中就可以用内存中的连续单位,如字、词、词组进行对比。另外,从整体性思维可以想到,每个字组是由主句单词构成,每个词组是由词组单词构成,每个词、词组也是由部分组成,当对比多个文章不断迭代递归,当文章单元最终只是一个整体之时,有用的信息也可以从多个文章单元中得到。
【整体--语言逻辑】关键词:文章意义【定理--语言逻辑--2】语言是逻辑推理的工具,使文章成为抽象描述论证和陈述观点的逻辑系统【定理--语言逻辑--3】凡是具有语言意义的陈述,都可以作为论证或陈述。本文由于主要从逻辑学角度定义语言,因此我们不会在讨论语言的性质时使用任何定义或术语。一旦谈论到语言学的观点,我们都会尽可能使用“语言论”来对其进行论述。
1.为什么一切语言都有意义?论证是一种论证者判断原来论证要说什么的过程。在这种过程中,凡能从原来论证中抽象出一个可以被说出来的独立于原来论证中描述方法的东西,即“意义”,我们就称论证有意义。那么,什么样的陈述能使一切语言成为陈述?在这里,我们要把文章也当作一种语言。2.为什么一切陈述都可以具有意义?陈述有两个特点:其一是陈述是在有意义的语言中进行。
这是很容易被人忽略的一个事实。在中国的老百姓群体中,陈述既可以不具有意义,也可以没有意义,甚至可以不具有意义。在西方人群体中,陈述就是具有意义的。不过,一些西方人认为无意义的陈述可以通过某种艺术手段具有意义。我们说的陈述是指在具有语言意义的语言中,所有陈述都可以被说出来。其二是一切陈述都可以自由组合。
也就是说,一切陈述都可以自由地进行某种意义的组合。这个特点正好符合实际上我们在每一篇论文中都会提到的“意义”这个概念。一个陈述意义的组合可以是陈述本身(每个陈述单元的构成部分)和它所对应的陈述单元,也可以是陈述的其他一切单元。 查看全部
采集文章系统(【论语】采集文章系统解析《论语》中的语言框架)
采集文章系统解析《论语》中的语言框架:1.字,每个字是一个概念,2.句子是以“主句”为中心,句中的“每个句子”由“字、词、词组”构成。句子中的“字、词、词组”本质上是一种关系代数数据结构,“字、词、词组”构成一个句子。所以“每个句子”和“每个词”都可以在“主句”中寻找。2.文章,每个文章是一个概念,3.每个概念由词构成,每个词又由具体的词组构成。
词可以通过迭代对“字、词、词组”有直观感受4.“字、词、词组”,直观感受直接构成文章中心内容,但是“字、词、词组”又是一个整体概念,如果我们真的通过“字、词、词组”可以不断递归迭代得到文章的一部分,那么在递归的递归中就可以用内存中的连续单位,如字、词、词组进行对比。另外,从整体性思维可以想到,每个字组是由主句单词构成,每个词组是由词组单词构成,每个词、词组也是由部分组成,当对比多个文章不断迭代递归,当文章单元最终只是一个整体之时,有用的信息也可以从多个文章单元中得到。
【整体--语言逻辑】关键词:文章意义【定理--语言逻辑--2】语言是逻辑推理的工具,使文章成为抽象描述论证和陈述观点的逻辑系统【定理--语言逻辑--3】凡是具有语言意义的陈述,都可以作为论证或陈述。本文由于主要从逻辑学角度定义语言,因此我们不会在讨论语言的性质时使用任何定义或术语。一旦谈论到语言学的观点,我们都会尽可能使用“语言论”来对其进行论述。
1.为什么一切语言都有意义?论证是一种论证者判断原来论证要说什么的过程。在这种过程中,凡能从原来论证中抽象出一个可以被说出来的独立于原来论证中描述方法的东西,即“意义”,我们就称论证有意义。那么,什么样的陈述能使一切语言成为陈述?在这里,我们要把文章也当作一种语言。2.为什么一切陈述都可以具有意义?陈述有两个特点:其一是陈述是在有意义的语言中进行。
这是很容易被人忽略的一个事实。在中国的老百姓群体中,陈述既可以不具有意义,也可以没有意义,甚至可以不具有意义。在西方人群体中,陈述就是具有意义的。不过,一些西方人认为无意义的陈述可以通过某种艺术手段具有意义。我们说的陈述是指在具有语言意义的语言中,所有陈述都可以被说出来。其二是一切陈述都可以自由组合。
也就是说,一切陈述都可以自由地进行某种意义的组合。这个特点正好符合实际上我们在每一篇论文中都会提到的“意义”这个概念。一个陈述意义的组合可以是陈述本身(每个陈述单元的构成部分)和它所对应的陈述单元,也可以是陈述的其他一切单元。

