
采集文章系统
采集文章系统(采集文章系统方面有免费的,没有限制的可以试试)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-12-27 00:01
采集文章系统方面有免费的,没有限制的,可以试试寻文识文,微信小程序的,随时随地想搜就搜。文章判断系统有免费的,也有收费的。你可以留言找找试试。
同问,
应该很多是不收费的。你要哪个平台的,我再推荐你个app,喜马拉雅fm,
前段时间去知乎回答了很多类似的问题
现在有啊知识星球
我也是关注很多,总觉得免费的太少。
目前有很多收费的课程不过最近人品很好还免费我觉得您可以试试用投票助手这个免费的app试试看,可以从公众号导出很多数据的,可以根据自己需要添加自己感兴趣的公众号,收入进一步了解更多知识最后,
最近更新的中信某行的培训课程()分享出来帮助你了解一下(`)想要的话可以私信我呀~如果需要直接知乎找我也可以
有一个收费的但是看起来还不错的课程收费198
真的不收费这是一个每天会发送一些链接的公众号(名字就不打了)你可以在百度上搜索关键词即可啊链接就是链接你懂的结果还挺好的我是没做免费,
我有每天一个不用付费的公众号的链接,
我在做公众号阅读的时候有一个公众号导出,能帮助你。 查看全部
采集文章系统(采集文章系统方面有免费的,没有限制的可以试试)
采集文章系统方面有免费的,没有限制的,可以试试寻文识文,微信小程序的,随时随地想搜就搜。文章判断系统有免费的,也有收费的。你可以留言找找试试。
同问,
应该很多是不收费的。你要哪个平台的,我再推荐你个app,喜马拉雅fm,
前段时间去知乎回答了很多类似的问题
现在有啊知识星球
我也是关注很多,总觉得免费的太少。
目前有很多收费的课程不过最近人品很好还免费我觉得您可以试试用投票助手这个免费的app试试看,可以从公众号导出很多数据的,可以根据自己需要添加自己感兴趣的公众号,收入进一步了解更多知识最后,
最近更新的中信某行的培训课程()分享出来帮助你了解一下(`)想要的话可以私信我呀~如果需要直接知乎找我也可以
有一个收费的但是看起来还不错的课程收费198
真的不收费这是一个每天会发送一些链接的公众号(名字就不打了)你可以在百度上搜索关键词即可啊链接就是链接你懂的结果还挺好的我是没做免费,
我有每天一个不用付费的公众号的链接,
我在做公众号阅读的时候有一个公众号导出,能帮助你。
采集文章系统(YGBOOK轻量级小说网站系统使用资料和文件的更新信息阐述 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-12-24 05:11
)
下面我们来解释一下YGBOOK小说采集System v1.4文件上YGBOOK小说采集System v1.4文件的相关使用信息和更新信息。
YGBOOK小说采集系统v1.4
YGBOOK小说内容管理系统(以下简称YGBOOK)提供了基于ThinkPHP+MySQL技术开发的轻量级小说网站解决方案。
YGBOOK是一种介于cms和小偷网站之间的新型网站系统,批量采集目标网站数据,数据存储。不仅网址完全不一样,模板也不一样,数据也是你的。它对网站管理员是完全免费的。只需设置网站,它就会自动采集+自动更新。
本软件基于SEO性能优秀的笔趣阁模板,经过多次优化,呈现给大家一个SEO优秀、外观优雅的新颖网站系统。
YGBOOK免费版提供了基本的新颖功能,包括:
1.自动采集2345导航小说数据,内置采集规则,无需自己设置管理
2.数据存储,无需担心目标站修改或挂起
3.网站 提供小说介绍和章节列表展示,章节阅读采用跳转原站模式,避免版权问题。
4. 自带伪静态功能,但不能自由定制,无手机版,无站点搜索,无站点地图,无结构化数据
YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在大多数常见的服务器上。
比如windows服务器,IIS+PHP+MYSQL,
Linux服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以发挥更大的性能优势
软件方面,PHP要求5.3或更高版本,低于5.3的版本无法运行。
硬件方面,一般配置的虚拟主机可以正常运行系统,如果有服务器就更好了。
伪静态配置参考压缩包中的txt文件,不同环境有不同的配置说明(内置.htacess文件为兼容性重新优化,解决了“没有指定输入文件”的问题。可能在 apache+nts 模式下发生)
安装步骤:
1.解压文件上传到对应目录等
2.网站 必须配置伪静态(参考上一步的配置)才能正常安装使用(第一次访问首页会自动进入安装页面,或手动输入域名.com/install)
3.同意使用协议进入下一步检查目录权限
4. 测试通过后,填写通用数据库配置项,填写正确即可完成安装。安装成功后会自动进入后台页面域名.com/admin,填写安装时输入的后台管理员和密码进行登录
5.在后台文章列表页面,可以手动采集文章,批量处理采集文章数据。初次安装后,建议采集在网站的内容中填写一些数据。网站 运行过程中会自动执行采集操作(前台访问触发,蜘蛛也可以触发采集),无需人工干预。
YGBOOK小说采集系统更新日志:
v1.4
增加百度站点地图功能
安装1.4版本后,您的站点地图地址为“您的域名/home/sitemap/baidu.xml”
将域名替换为自己的域名后,提交至百度站长平台即可
方便百度蜘蛛的抓取
v1.3
添加对 php7 的支持
查看全部
采集文章系统(YGBOOK轻量级小说网站系统使用资料和文件的更新信息阐述
)
下面我们来解释一下YGBOOK小说采集System v1.4文件上YGBOOK小说采集System v1.4文件的相关使用信息和更新信息。
YGBOOK小说采集系统v1.4
YGBOOK小说内容管理系统(以下简称YGBOOK)提供了基于ThinkPHP+MySQL技术开发的轻量级小说网站解决方案。
YGBOOK是一种介于cms和小偷网站之间的新型网站系统,批量采集目标网站数据,数据存储。不仅网址完全不一样,模板也不一样,数据也是你的。它对网站管理员是完全免费的。只需设置网站,它就会自动采集+自动更新。
本软件基于SEO性能优秀的笔趣阁模板,经过多次优化,呈现给大家一个SEO优秀、外观优雅的新颖网站系统。
YGBOOK免费版提供了基本的新颖功能,包括:
1.自动采集2345导航小说数据,内置采集规则,无需自己设置管理
2.数据存储,无需担心目标站修改或挂起
3.网站 提供小说介绍和章节列表展示,章节阅读采用跳转原站模式,避免版权问题。
4. 自带伪静态功能,但不能自由定制,无手机版,无站点搜索,无站点地图,无结构化数据
YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在大多数常见的服务器上。
比如windows服务器,IIS+PHP+MYSQL,
Linux服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以发挥更大的性能优势
软件方面,PHP要求5.3或更高版本,低于5.3的版本无法运行。
硬件方面,一般配置的虚拟主机可以正常运行系统,如果有服务器就更好了。
伪静态配置参考压缩包中的txt文件,不同环境有不同的配置说明(内置.htacess文件为兼容性重新优化,解决了“没有指定输入文件”的问题。可能在 apache+nts 模式下发生)
安装步骤:
1.解压文件上传到对应目录等
2.网站 必须配置伪静态(参考上一步的配置)才能正常安装使用(第一次访问首页会自动进入安装页面,或手动输入域名.com/install)
3.同意使用协议进入下一步检查目录权限
4. 测试通过后,填写通用数据库配置项,填写正确即可完成安装。安装成功后会自动进入后台页面域名.com/admin,填写安装时输入的后台管理员和密码进行登录
5.在后台文章列表页面,可以手动采集文章,批量处理采集文章数据。初次安装后,建议采集在网站的内容中填写一些数据。网站 运行过程中会自动执行采集操作(前台访问触发,蜘蛛也可以触发采集),无需人工干预。
YGBOOK小说采集系统更新日志:
v1.4
增加百度站点地图功能
安装1.4版本后,您的站点地图地址为“您的域名/home/sitemap/baidu.xml”
将域名替换为自己的域名后,提交至百度站长平台即可
方便百度蜘蛛的抓取
v1.3
添加对 php7 的支持

采集文章系统(采集系统操作说明(傻瓜版)插件图(1))
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-12-24 05:10
采集系统操作说明(傻瓜版)
1.准备工作
1.1 安装 FireBug 浏览器插件
图片(1):FireBug插件安装
1.2 找到需要采集网站
的目标
<p>使用以下教程示例:/main/zxnews.shtml 用于演示1.3 登录cms,进入需要的频道,进入采集系统。 查看全部
采集文章系统(采集系统操作说明(傻瓜版)插件图(1))
采集系统操作说明(傻瓜版)
1.准备工作
1.1 安装 FireBug 浏览器插件
图片(1):FireBug插件安装
1.2 找到需要采集网站
的目标
<p>使用以下教程示例:/main/zxnews.shtml 用于演示1.3 登录cms,进入需要的频道,进入采集系统。
采集文章系统( 持续更新,微信公众号文章批量采集系统的构建(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-23 13:26
持续更新,微信公众号文章批量采集系统的构建(图))
持续更新,微信公众号文章批量采集系统建设
持续更新,微信公众号文章批量采集系统建设
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。那个时候分批的采集特别好做,而采集的入口就是公众号的历史新闻页面。这个入口现在还是一样,只是越来越难采集。采集的方法也更新了很多版本。后来到了2015年,html5垃圾站就不做了。取而代之的是,采集的目标是针对本地新闻资讯公众号,将前端展示做成一个app。所以一个可以自动< @采集 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信技术的不断升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。本文文章会持续更新,保证您看到的内容在您看到时可用。首先,让'
czNjY2NA==#wechat_webview_type=1&wechat_redirect
========2017 年 1 月 11 日更新 ========== 查看全部
采集文章系统(
持续更新,微信公众号文章批量采集系统的构建(图))
持续更新,微信公众号文章批量采集系统建设
持续更新,微信公众号文章批量采集系统建设
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。那个时候分批的采集特别好做,而采集的入口就是公众号的历史新闻页面。这个入口现在还是一样,只是越来越难采集。采集的方法也更新了很多版本。后来到了2015年,html5垃圾站就不做了。取而代之的是,采集的目标是针对本地新闻资讯公众号,将前端展示做成一个app。所以一个可以自动< @采集 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信技术的不断升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。本文文章会持续更新,保证您看到的内容在您看到时可用。首先,让'
czNjY2NA==#wechat_webview_type=1&wechat_redirect
========2017 年 1 月 11 日更新 ==========
采集文章系统(优采云采集器IP:预估日均-预估:备案信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-12-22 14:08
网站说明:[优采云采集器]是一个完全在线的配置和云采集网站文章采集工具。功能强大,操作非常简单,无需安装任何客户端或插件;支持在线视觉点击;集成智能抽取引擎,自动识别数据和规则;独家第一书签一键采集;与各种cms网站、Http接口等无缝对接,是一款免费的在线网页文章采集软件。.
去网站
体重信息
搜索引擎优化信息
百度来源:51~70 IP 移动来源:30~40 IP 出站链接:8 主页内部链接:46
收录信息
百度收录:21,500360收录:-神马收录:-搜狗收录:152Google收录:-
反链接信息
百度反链:83,100,000 360 反链:-神马反链:-搜狗反链:201 谷歌反链:-
排名信息
世界排名:-国内排名:-预估日均IP:-预估日均PV:-
记录信息
备案号:粤ICP备17116157-1号性质:公司名称:审核时间:2017-09-13
域名信息
年龄:4月29日时间:2017年8月24日
服务器信息
协议类型:-页面类型:-服务器类型:-程序支持:-连接识别:-消息发送:未知GZIP检测:未启用GZIP压缩源文件大小:-压缩大小:启用GZIP估计达到0.@ > 01KB 压缩率:估计0.@>00% 最后修改时间:未知
评价网站
[优采云采集器] 网络资料采集器-免费在线网站文章采集本软件被网友主动提交给修永证券收录@ >整理收录,收录的时间是2021-12-22 10:47:09,目前已经有点击。【优采云采集器】网页资料采集器-免费在线网站文章采集 软件世界排名第一,国内排名第一No.-第一,日均IP约-,百度权重为0,百度收录有21500,百度之道约51~70个IP,备案号粤ICP备17116157-1号,域名name注册于2010年8月24日,至今已经4年3月29日,本次测评结果仅供参考,[优采云采集器]网络资料采集器-免费在线网站<
-结尾- 查看全部
采集文章系统(优采云采集器IP:预估日均-预估:备案信息)
网站说明:[优采云采集器]是一个完全在线的配置和云采集网站文章采集工具。功能强大,操作非常简单,无需安装任何客户端或插件;支持在线视觉点击;集成智能抽取引擎,自动识别数据和规则;独家第一书签一键采集;与各种cms网站、Http接口等无缝对接,是一款免费的在线网页文章采集软件。.
去网站
体重信息






搜索引擎优化信息
百度来源:51~70 IP 移动来源:30~40 IP 出站链接:8 主页内部链接:46
收录信息
百度收录:21,500360收录:-神马收录:-搜狗收录:152Google收录:-
反链接信息
百度反链:83,100,000 360 反链:-神马反链:-搜狗反链:201 谷歌反链:-
排名信息
世界排名:-国内排名:-预估日均IP:-预估日均PV:-
记录信息
备案号:粤ICP备17116157-1号性质:公司名称:审核时间:2017-09-13
域名信息
年龄:4月29日时间:2017年8月24日
服务器信息
协议类型:-页面类型:-服务器类型:-程序支持:-连接识别:-消息发送:未知GZIP检测:未启用GZIP压缩源文件大小:-压缩大小:启用GZIP估计达到0.@ > 01KB 压缩率:估计0.@>00% 最后修改时间:未知
评价网站
[优采云采集器] 网络资料采集器-免费在线网站文章采集本软件被网友主动提交给修永证券收录@ >整理收录,收录的时间是2021-12-22 10:47:09,目前已经有点击。【优采云采集器】网页资料采集器-免费在线网站文章采集 软件世界排名第一,国内排名第一No.-第一,日均IP约-,百度权重为0,百度收录有21500,百度之道约51~70个IP,备案号粤ICP备17116157-1号,域名name注册于2010年8月24日,至今已经4年3月29日,本次测评结果仅供参考,[优采云采集器]网络资料采集器-免费在线网站<
-结尾-
采集文章系统(简洁易用、永久免费的PHP文章管理系统和Access可供选择)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-12-18 07:17
Rookie 文章 管理系统是一个简单易用、永远免费的 PHP文章 管理系统;内置采集功能,Rookie官方采集每天海量数据供用户选择。系统安装时有Mysql和Access两个数据库可供选择。
后台功能介绍:
1、基本设置:基本信息、网站设置、导航管理、模块开启关闭、安全设置、管理员账号、其他设置;
2、文章管理:文章列表,发布文章,文章分类;
3、用户交互:消息管理、评论管理、友情链接;
4、文件管理:模板选择、图片管理、资源管理;
5、Data采集:采集设置、公共数据、高级数据;
6、高级应用:新频道、频道标题、后台导航管理。
安装注意事项:
1、 我们推荐的PHP版本为PHP 5.3,推荐的本地测试环境为upupw;
2、 全新安装需要将upload文件夹中的所有子目录和文件(注意在里面)上传到网站的根目录下,然后打开网站浏览器,按提示选择数据库,填写数据库信息,最后点击安装按钮完成安装;
3、 本系统默认设置为1小时内只能登录后台10次。可以在“后台-基本设置-安全设置”中修改时长和登录次数,避免调试时无法登录后台。
升级说明:
由于本版本较上一版本有较大提升,为避免升级过程中对旧版网站造成灾难性影响,本版本不提供升级程序。
预防措施:
1、本系统的Access数据库仅在部分Windows服务器上有效。建议想使用Access数据库的用户在购买主机时选择Windows主机,可能需要修改服务器配置;
2、因为本系统使用的是UTF-8编码,所以在Windows下不能使用记事本进行编辑,因为记事本会自动添加BOM头导致程序异常。建议使用专业的Dreamweaver或Notepad++的小型编辑器;
3、网站移动前请清除后台Smarty缓存,或者移动后手动删除index/compile和admin/compile目录下的所有文件,否则网站移动后可能会出错.
4、这个系统在发布前经过多次测试,一般核心功能不会出错。如果您在使用过程中遇到程序错误,请从您自己的运行环境中查找原因。请不要一遇到问题就将责任推到我们身上,甚至怀疑我们故意留下缺陷来收费。有助于解决问题和个人进步。如果您确定错误是由我们的程序引起的,您可以将问题发送到我们的邮箱,我们将在确认后免费为您提供解决方案。同时,我们非常感谢您的反馈!
后台路径:网站path/admin
菜鸟文章管理系统更新日志:
更新状态:
1、改变前端界面风格;
2、去除后台一些不实用的功能;
3、 修改网址样式;
4、简化代码。 查看全部
采集文章系统(简洁易用、永久免费的PHP文章管理系统和Access可供选择)
Rookie 文章 管理系统是一个简单易用、永远免费的 PHP文章 管理系统;内置采集功能,Rookie官方采集每天海量数据供用户选择。系统安装时有Mysql和Access两个数据库可供选择。
后台功能介绍:
1、基本设置:基本信息、网站设置、导航管理、模块开启关闭、安全设置、管理员账号、其他设置;
2、文章管理:文章列表,发布文章,文章分类;
3、用户交互:消息管理、评论管理、友情链接;
4、文件管理:模板选择、图片管理、资源管理;
5、Data采集:采集设置、公共数据、高级数据;
6、高级应用:新频道、频道标题、后台导航管理。
安装注意事项:
1、 我们推荐的PHP版本为PHP 5.3,推荐的本地测试环境为upupw;
2、 全新安装需要将upload文件夹中的所有子目录和文件(注意在里面)上传到网站的根目录下,然后打开网站浏览器,按提示选择数据库,填写数据库信息,最后点击安装按钮完成安装;
3、 本系统默认设置为1小时内只能登录后台10次。可以在“后台-基本设置-安全设置”中修改时长和登录次数,避免调试时无法登录后台。
升级说明:
由于本版本较上一版本有较大提升,为避免升级过程中对旧版网站造成灾难性影响,本版本不提供升级程序。
预防措施:
1、本系统的Access数据库仅在部分Windows服务器上有效。建议想使用Access数据库的用户在购买主机时选择Windows主机,可能需要修改服务器配置;
2、因为本系统使用的是UTF-8编码,所以在Windows下不能使用记事本进行编辑,因为记事本会自动添加BOM头导致程序异常。建议使用专业的Dreamweaver或Notepad++的小型编辑器;
3、网站移动前请清除后台Smarty缓存,或者移动后手动删除index/compile和admin/compile目录下的所有文件,否则网站移动后可能会出错.
4、这个系统在发布前经过多次测试,一般核心功能不会出错。如果您在使用过程中遇到程序错误,请从您自己的运行环境中查找原因。请不要一遇到问题就将责任推到我们身上,甚至怀疑我们故意留下缺陷来收费。有助于解决问题和个人进步。如果您确定错误是由我们的程序引起的,您可以将问题发送到我们的邮箱,我们将在确认后免费为您提供解决方案。同时,我们非常感谢您的反馈!
后台路径:网站path/admin
菜鸟文章管理系统更新日志:
更新状态:
1、改变前端界面风格;
2、去除后台一些不实用的功能;
3、 修改网址样式;
4、简化代码。
采集文章系统(《Web》主题Web信息采集的基本问题及难点解析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-15 21:14
《基于主题的Web信息采集系统设计与实现.pdf》由会员共享,可在线阅读。更多相关《基于主题的Web信息采集系统设计与实现.pdf(3页典藏版)》请在威川搜索。
1、Volume 29, Issue 17 12917 Computer Engineering 2003 年 10 月 2003 年 10 月 软件技术与数据库 文章 编号:l00o-3428(2003)l70l0203 文档识别码:A 中文圈分类号:TP391基于学科的Web信息采集系统设计与实现李胜涛,赵章杰,于志华(中国科学院计算技术研究所软件研究室,北京100080) 摘要:基于学科的Web信息采集是信息检索领域一个新兴的实用方向,也是信息处理技术的研究热点。文章分析主题Web信息采集的基本问题, 提出难点及相关解决方案,并在此基础上,“天大”主题网站信息采集系统的设计与实现
2、。关键词:信息采集;信息检索;信息处理;主题 采集 Desin and Realization 0f Focused Web Crawler。李胜涛, 赵占西, 于志华 (中国科学院计算技术研究所软件部, 北京 l00080) l 摘要 l 聚焦网络爬虫是信息检索领域的一个新的实用方向
3、ieva1本文论述了聚焦网络爬虫的原理、难点和措施,然后分析了SkyReach聚焦网络爬虫的设计。信息检索;信息处理;聚焦爬虫l乐_乐 基于Web信息采集,发布及相关信息处理日益成为关注的焦点。传统we词采集的目标是尽可能地采集
4、信息页,和采集页的准确性关注较少,它有很多缺陷。随着www的爆发式增长,信息速度采集越来越不能满足实际需求。最近的实验表明,即使是大规模的信息采集系统也只有 30-40 个网络覆盖。主题采集可以将整个Web按主题采集划分成块,并整合不同的块,提高整个Web采集的覆盖率。对于传统信息采集,需要几周到一个月的时间才能再次刷新。” I,使得页面失败率非常大。一个好的缓解方法是使用采集主题,通过减少采集的页面数量来减少刷新时间,从而降低采集的失败率 页。传统信息采集消耗大量的系统和网络资源,而且大部分利用率很低,基于主题的采集有效提高了采集对页面的使用率。
5、2 Theme-based web information采集System Model 21 System Model Topic Web Information采集,也称为TopicSpecific Crawling,主要是指选择性搜索那些和预定义的主题集相关页面执行采集的行为。我们设计了“天大”主题采集系统,其系统模型如图1所示。为了实现自动信息采集,整个过程分为6大模块:主题选择、初始URL选择、Spider采集、页面分析、URL与主题关联判断、页面与主题关联判断。22.主题的选择。起点的选择与我采集 为了有效地开展采集主题,需要考虑的一个重要问题是主题选择。由于随机的学科术语可能会极大地影响采集的效果,系统一般会为用户提供一个学科类别目录供用户选择。为了有效地
6、为了确定用户选择的主题的含义,用户应该提供对该主题的进一步描述,例如提供几个表达该主题含义的文本。我们的系统按照中国图书馆分类法的一级目录和二级目录对主题进行分类,并在每个主题下配备了一些主题文本供用户选择。采集器 从一组种子 URL 开始,通过 Web 协议扩展到需要的页面。根据 LinkageSibling Locality 特性,系统需要选择高质量的主题 URL 作为初始种子 URL 集。23 Spider采集 1O2 One Circle I 信息自动采集的6大块。这部分在系统的最底层,也叫“网络蜘蛛”,专门处理Web,
7、各种文件如声音)。目前系统主要针对HTTP协议,其主要任务是为每个Spider分配URL以获取实际数据采集,并根据需要动态分配Spider的数量,如图2。 基金项目:中科院计算所前沿青年基金项目(200162808) 作者:李胜涛(1976一),男,硕士研究生,主要研究方向:智能代理、信息采集) , 信息检索, 文本分类; 赵章杰, 于志华, Ph.D. 博士生录取日期破: 2002073I | 回归天破: 2002-1028 维普资讯http://图2 蜘蛛合集: 合集采集页面的24页分析之后,您需要提取链接、元数据、文本、标题和摘要以进行后续过滤和其他处理。这里主要介绍链接和标签。
8、 问题提取。链接的提取如下: 首先,识别页面类型。显然,只有“xffhtml”类型的页面需要分析链接。页面的类型可以从响应头的分析中得到。部分www站点返回的响应信息格式不完整。这时候就需要分析页面URL中的文件扩展名来确定页面类型。当遇到诸如等带有链接的标签时,从标签结构的属性中找到目标URL,从标签对中提取文本作为链接的描述性文本(扩展元数据)。这两个数据代表链接。页面中标题的提取分为3个步骤:(一)确定正文开头的位置,从文章的开头开始,逐段扫描,直到某段长度不小于设置的正文最小长度,假设该段为正文中的A段。(2) 从文本位置向前搜索可能是标题的一段,根据字体
9、大小、居中、变色等特性找到最合适的一段文字作为标题。(3)通过给定参数调整标题段,使标题提取更准确。对标题段前后段stTitlePara进行句法、语义、统计分析,准确判断标题段真实位置. 25 URL和主核的相关性确定有效提高主题Web信息采集的可靠性(召回率和准确率的结合)和效率,系统需要在采集的过程中加入过滤机制@> 并采用综合扩展的 I Pagerank 方法进行元数据和链接分析。25I 扩展元数据的含义 虽然目前的元数据计算(HTML 中添加的一种标记,写成)并不理想,但人们已经发现使用其他 HTML 标签如锚点等信息可以有效引导搜索和基于主题信息采集。为了
1 根据0、的区别,这些标记信息统称为HTML扩展元数据。252 扩展元数据方法的ReIevance Weighting或RW算法如下: f 0 (ur): (0(,), M(ur1) 如max(O(t). l 0 规范其中, M(ur1)指的是与这个URL相关的所有扩展元数据的集合,O(t)指的是扩展元数据中某个词与主题的相关性。c是用户设置的相关性阈值. RW 方法是通过查看扩展元数据中单词和主题词的相似度来计算的,同义词之间的相似度为100,同义词之间的相似度为50-100,远距离词之间的相似度为0 50。这样就大大降低了相关页面误判的可能性,
11、页面被判断为相关页面的可能性)。25 3 链接分析方法 PageRank 是谷歌的一个重要搜索算法,它有效地帮助搜索引擎识别那些重要的页面,并将它们排在搜索结果的前列。该方法定义为:给定一个网页A,假设指向它的网页有T.,,T.设c(A)为A到其他网页的链接数,PR(A)为A的PageRank, d为衰减因子(一般设置为085),然后有一个跳跃,c+254的IPageRank算法通过观察:PageRank方法虽然有很强的寻找重要页面的能力,但是它找到的重要页面是为了一个广泛的话题,而不是基于特定的话题。因此,一个页面被大量不相关的话题指向PageRan
1 2、k的值高于与mang问题相关的少数页面组所指向的页面的PageRank值,这是不合理的。如果大量主题相关页组指向的页面的PageRank值高于少数主题相关页组指向的页面的PageRank值,则必须使用它。为此,我们对PageRank方法进行了改进,根据链接关系加入一定的语义信息权重,使生成的重要页面针对某个主题,形成1PageRank算法。IPageRank算法不仅利用PageRank的优势寻找重要页面,还利用RW算法提高链接的相关性。改进后的公式如下 (3) PR(I): (卜(,)+dl IPR(T) 芝.(ur) (<
13、) Lan Yiyi PR(T) 0 (Ill 1) 0 (IllI) 其中A为给定的网页,假设指向它的网页有T.,, Tn.u, ur u rII 为网页T、T、指向A的链接,kI、k2、kn分别为网页TT中收录的链接数,IPR(A)为A的IPageRank值,d为衰减因子(也设置为085)。IPageRank的实际含义可以用话题浏览者来解释。假设Web上有一个话题浏览者,IPPageRank(函数IPR(A)是它访问页面A的概率)。它从初始页面集开始,跟随页面链接,从不进行“返回”操作,在每个页面上,浏览者对该页面中的每个链接感兴趣的概率与链接和主题相关。
14、关星成正比。浏览者也可能对这个页面上的链接不再感兴趣,从而随机选择一个新页面开始新的浏览,离开的概率设置为d。从直观上看,如果有很多页面指向一个页面,那么这个页面的PageRank会比较高,但IPPageRank值不一定高,除非大部分都和主题相关;如果有高IPPageRank的页面指向它,这个页面的IPageRank也会很高。26 页面与主题相关性判断 为了进一步提高采集页面的准确率,需要对已经被采集的页面进行主题相关性评估,即页面过滤。提高所有采集的准确率 主题页面通过排除低评估结果(小于设置阈值)的页面。我们采用的方法是基于关键词的向量空间模型算法。3个系统
1 5、的实现 我们对“天大”主题Web信息采集系统的预测算法和系统的基本性能进行了测试,得到了满意的结果。(1)测试集的选择选择旅游信息作为测试主题。采集了20个旅游主题网站,加入了60个无关的网站组成测试集,其中收录一个以上l03.维普信息页。(2)算法测试和性能测试使用相同的初始URL集,使用广度优先算法、PageRank算法和IPageRank算法对采集进行采集数据。为了得到每种方法的结果准确的结果,实验中暂停了页面和主题相关性确定模块。在实验过程中,记录采集页码为500、1000、l 500一、4000H采集状态,计算采集状态。@采集准确性和资源
16、源发现率,如表1所示。表一采集准确率与资源发现率采集准确率资源发现率宽度优先级35 lOO PageRank 29 3O IPageRank 68 86 表2 测试结果,性能测试结果评价采集的最终准确率76较高(优点)最终资源发现率高8O(优点)30MB内存(估计)较大(缺点)测试平台为CPU Intel Pill 800、内存为128MB,操作系统为Window 2000 Professional电脑。采集时,系统设置10个线程,采用的URL预测算法为IPageRank。测试的性能指标包括最终采集页面的准确率,采集页面的资源释放
17、 当前速率、内存使用情况、测试结果如表2所示。 4 结束语 我基于主题研究了webf语言和信息技术,并设计了一个实用的系统。在原有技术的基础上,设计了许多独特的新算法,如Spider采集、标题提取、URL主题预测、页面主题相关性判断等。特别是对著名的谷歌算法进行了改进,使其适用于基于主题的采集,同时保持原有的优势。实验表明,基于主题的采集优势明显。随着Web服务向个性化方向的推进,Agent技术的发展,以及迁移思想的出现,用于检索的Web信息采集 科技必将走向主题化、个性化的主动信息采集服务方向全方位拓展。参考文献 I Aggarwal C, AIGar
18、awi F、Yu PIntelligent Crawling on the World Wide Web with Arbitrary PredicatesIn Proceedings of the 1 0th IntematiouaI WWW Conference200 l 2 Brin S, Page L,大型超文本网络搜索引擎的切片剖析第七届国际万维网会议,I 998 3 Diligen
19、ti M, Coetzee FM, Lawrence S, et a1Gori Focused Crawling Using Context GraphsVLDB Conference, 2000 4 Menczer F, Srinivasan GPP, Ruiz MEvaluating Topic-driven Web CrawlersIn Proceedings of the 24th Annual International Acms@ >IGIR 会议,200 l(接第 8I 页) 3 Clark CM,Rock SRandomized Motion Planning for G
20、N011一完整机器人组在:加拿大第六届空间人工智能、机器人和自动化国际研讨会论文集& 200106 4 Fraichard TDemazeau YMotion Planning in a Multiagent World In: Demazeau YMuller J PDecentralized AI: Proceedings第 22 届欧洲工作室
21、p on Modeling Autonomous Agents in a Multiagent World 荷兰阿姆斯特丹:Elsevier Science,I990:l37-l53(接第 l0l 页)输出“:”。“表示类型”列输出源文件中函数所描述的类型,“基本类型”列输出表示不带typedef的表示类型的类型。在这个例子中,funcl和main函数没有使用typedef,所以这两个函数的表示类型和基本类型是一样的。“位置”列输出函数定义或声明的文档名称和行号。“属性”列显示函数的属性。例如,当函数未定义时,显示“no define”;如果
22、 不使用该功能时,会显示“未使用”等。上面的表1只是函数列表,变量列表、类型列表、枚举常量列表大体与此一致。对于列表中出现的每个元素,还有一个详细的表格,按名称链接。例如,有一个函数的调用条件列表和一个函数返回值列表;对于变量,有一个值设置和引用列表。列表。限于篇幅,这里就不一一详述_r了。4 结束语 EPOM 是一种可以全面、详细地展示程序的中间表示,它提供了一个标准的访问接口。所以,任何其他符合该接口的模块都可以从中获取有关源程序的所需信息。OSTPM 是一种基于域的程序信息分层递归表示模型。将程序中所有对象的范围和类型紧密联系起来
23、。基于查询-应答模型的Visitor方法将对象与作用于对象1O4的控制分离,减轻了控制系统的负担,大大提高了系统的灵活性、安全性和可扩展性,使系统结构非常清晰. 同时减轻设计管理系统的负担。扩展的节目参考模型EPRM是一种很好的节目统计信息形式。它采用面向对象的方法将复杂的程序信息组织成层次化的对象结构,并提供了一个接口,通过Visitor方法访问其对象。该模型克服了普通模型的缺点,具有结构简单、对象自主性强、系统灵活性高、输出界面友好、扩展性好等特点。
24、ts of Reusable Objectoriented SoftwareAddison Wesley Longman, Inc, l995 2 Prdn T WProgramming Languages: Design and Implementation PrenticeHall International, Inc, I 996 3 Pressman RS 软件工程从业者的研究方法(第四版)北京:机械工业出版社,1999 4 Eckel Bc+ 编程思想北京:机械工业出版社,2000 5 张杏儿计算机编译原理北京:科学出版社,I 999 6 赵阳,蔡志宇,潘金贵基于EPOM的程序可视化系统的设计与实现计算机的实现工程, 2002, 28 (cms2@>:l08Il0 7 蔡志宇, 赵阳, 潘杰, 等. 基于查询-回答模型的对象控制模型的实现. 计算机工程(已录) 维普资料 http:// 查看全部
采集文章系统(《Web》主题Web信息采集的基本问题及难点解析)
《基于主题的Web信息采集系统设计与实现.pdf》由会员共享,可在线阅读。更多相关《基于主题的Web信息采集系统设计与实现.pdf(3页典藏版)》请在威川搜索。
1、Volume 29, Issue 17 12917 Computer Engineering 2003 年 10 月 2003 年 10 月 软件技术与数据库 文章 编号:l00o-3428(2003)l70l0203 文档识别码:A 中文圈分类号:TP391基于学科的Web信息采集系统设计与实现李胜涛,赵章杰,于志华(中国科学院计算技术研究所软件研究室,北京100080) 摘要:基于学科的Web信息采集是信息检索领域一个新兴的实用方向,也是信息处理技术的研究热点。文章分析主题Web信息采集的基本问题, 提出难点及相关解决方案,并在此基础上,“天大”主题网站信息采集系统的设计与实现
2、。关键词:信息采集;信息检索;信息处理;主题 采集 Desin and Realization 0f Focused Web Crawler。李胜涛, 赵占西, 于志华 (中国科学院计算技术研究所软件部, 北京 l00080) l 摘要 l 聚焦网络爬虫是信息检索领域的一个新的实用方向
3、ieva1本文论述了聚焦网络爬虫的原理、难点和措施,然后分析了SkyReach聚焦网络爬虫的设计。信息检索;信息处理;聚焦爬虫l乐_乐 基于Web信息采集,发布及相关信息处理日益成为关注的焦点。传统we词采集的目标是尽可能地采集
4、信息页,和采集页的准确性关注较少,它有很多缺陷。随着www的爆发式增长,信息速度采集越来越不能满足实际需求。最近的实验表明,即使是大规模的信息采集系统也只有 30-40 个网络覆盖。主题采集可以将整个Web按主题采集划分成块,并整合不同的块,提高整个Web采集的覆盖率。对于传统信息采集,需要几周到一个月的时间才能再次刷新。” I,使得页面失败率非常大。一个好的缓解方法是使用采集主题,通过减少采集的页面数量来减少刷新时间,从而降低采集的失败率 页。传统信息采集消耗大量的系统和网络资源,而且大部分利用率很低,基于主题的采集有效提高了采集对页面的使用率。
5、2 Theme-based web information采集System Model 21 System Model Topic Web Information采集,也称为TopicSpecific Crawling,主要是指选择性搜索那些和预定义的主题集相关页面执行采集的行为。我们设计了“天大”主题采集系统,其系统模型如图1所示。为了实现自动信息采集,整个过程分为6大模块:主题选择、初始URL选择、Spider采集、页面分析、URL与主题关联判断、页面与主题关联判断。22.主题的选择。起点的选择与我采集 为了有效地开展采集主题,需要考虑的一个重要问题是主题选择。由于随机的学科术语可能会极大地影响采集的效果,系统一般会为用户提供一个学科类别目录供用户选择。为了有效地
6、为了确定用户选择的主题的含义,用户应该提供对该主题的进一步描述,例如提供几个表达该主题含义的文本。我们的系统按照中国图书馆分类法的一级目录和二级目录对主题进行分类,并在每个主题下配备了一些主题文本供用户选择。采集器 从一组种子 URL 开始,通过 Web 协议扩展到需要的页面。根据 LinkageSibling Locality 特性,系统需要选择高质量的主题 URL 作为初始种子 URL 集。23 Spider采集 1O2 One Circle I 信息自动采集的6大块。这部分在系统的最底层,也叫“网络蜘蛛”,专门处理Web,
7、各种文件如声音)。目前系统主要针对HTTP协议,其主要任务是为每个Spider分配URL以获取实际数据采集,并根据需要动态分配Spider的数量,如图2。 基金项目:中科院计算所前沿青年基金项目(200162808) 作者:李胜涛(1976一),男,硕士研究生,主要研究方向:智能代理、信息采集) , 信息检索, 文本分类; 赵章杰, 于志华, Ph.D. 博士生录取日期破: 2002073I | 回归天破: 2002-1028 维普资讯http://图2 蜘蛛合集: 合集采集页面的24页分析之后,您需要提取链接、元数据、文本、标题和摘要以进行后续过滤和其他处理。这里主要介绍链接和标签。
8、 问题提取。链接的提取如下: 首先,识别页面类型。显然,只有“xffhtml”类型的页面需要分析链接。页面的类型可以从响应头的分析中得到。部分www站点返回的响应信息格式不完整。这时候就需要分析页面URL中的文件扩展名来确定页面类型。当遇到诸如等带有链接的标签时,从标签结构的属性中找到目标URL,从标签对中提取文本作为链接的描述性文本(扩展元数据)。这两个数据代表链接。页面中标题的提取分为3个步骤:(一)确定正文开头的位置,从文章的开头开始,逐段扫描,直到某段长度不小于设置的正文最小长度,假设该段为正文中的A段。(2) 从文本位置向前搜索可能是标题的一段,根据字体
9、大小、居中、变色等特性找到最合适的一段文字作为标题。(3)通过给定参数调整标题段,使标题提取更准确。对标题段前后段stTitlePara进行句法、语义、统计分析,准确判断标题段真实位置. 25 URL和主核的相关性确定有效提高主题Web信息采集的可靠性(召回率和准确率的结合)和效率,系统需要在采集的过程中加入过滤机制@> 并采用综合扩展的 I Pagerank 方法进行元数据和链接分析。25I 扩展元数据的含义 虽然目前的元数据计算(HTML 中添加的一种标记,写成)并不理想,但人们已经发现使用其他 HTML 标签如锚点等信息可以有效引导搜索和基于主题信息采集。为了
1 根据0、的区别,这些标记信息统称为HTML扩展元数据。252 扩展元数据方法的ReIevance Weighting或RW算法如下: f 0 (ur): (0(,), M(ur1) 如max(O(t). l 0 规范其中, M(ur1)指的是与这个URL相关的所有扩展元数据的集合,O(t)指的是扩展元数据中某个词与主题的相关性。c是用户设置的相关性阈值. RW 方法是通过查看扩展元数据中单词和主题词的相似度来计算的,同义词之间的相似度为100,同义词之间的相似度为50-100,远距离词之间的相似度为0 50。这样就大大降低了相关页面误判的可能性,
11、页面被判断为相关页面的可能性)。25 3 链接分析方法 PageRank 是谷歌的一个重要搜索算法,它有效地帮助搜索引擎识别那些重要的页面,并将它们排在搜索结果的前列。该方法定义为:给定一个网页A,假设指向它的网页有T.,,T.设c(A)为A到其他网页的链接数,PR(A)为A的PageRank, d为衰减因子(一般设置为085),然后有一个跳跃,c+254的IPageRank算法通过观察:PageRank方法虽然有很强的寻找重要页面的能力,但是它找到的重要页面是为了一个广泛的话题,而不是基于特定的话题。因此,一个页面被大量不相关的话题指向PageRan
1 2、k的值高于与mang问题相关的少数页面组所指向的页面的PageRank值,这是不合理的。如果大量主题相关页组指向的页面的PageRank值高于少数主题相关页组指向的页面的PageRank值,则必须使用它。为此,我们对PageRank方法进行了改进,根据链接关系加入一定的语义信息权重,使生成的重要页面针对某个主题,形成1PageRank算法。IPageRank算法不仅利用PageRank的优势寻找重要页面,还利用RW算法提高链接的相关性。改进后的公式如下 (3) PR(I): (卜(,)+dl IPR(T) 芝.(ur) (<
13、) Lan Yiyi PR(T) 0 (Ill 1) 0 (IllI) 其中A为给定的网页,假设指向它的网页有T.,, Tn.u, ur u rII 为网页T、T、指向A的链接,kI、k2、kn分别为网页TT中收录的链接数,IPR(A)为A的IPageRank值,d为衰减因子(也设置为085)。IPageRank的实际含义可以用话题浏览者来解释。假设Web上有一个话题浏览者,IPPageRank(函数IPR(A)是它访问页面A的概率)。它从初始页面集开始,跟随页面链接,从不进行“返回”操作,在每个页面上,浏览者对该页面中的每个链接感兴趣的概率与链接和主题相关。
14、关星成正比。浏览者也可能对这个页面上的链接不再感兴趣,从而随机选择一个新页面开始新的浏览,离开的概率设置为d。从直观上看,如果有很多页面指向一个页面,那么这个页面的PageRank会比较高,但IPPageRank值不一定高,除非大部分都和主题相关;如果有高IPPageRank的页面指向它,这个页面的IPageRank也会很高。26 页面与主题相关性判断 为了进一步提高采集页面的准确率,需要对已经被采集的页面进行主题相关性评估,即页面过滤。提高所有采集的准确率 主题页面通过排除低评估结果(小于设置阈值)的页面。我们采用的方法是基于关键词的向量空间模型算法。3个系统
1 5、的实现 我们对“天大”主题Web信息采集系统的预测算法和系统的基本性能进行了测试,得到了满意的结果。(1)测试集的选择选择旅游信息作为测试主题。采集了20个旅游主题网站,加入了60个无关的网站组成测试集,其中收录一个以上l03.维普信息页。(2)算法测试和性能测试使用相同的初始URL集,使用广度优先算法、PageRank算法和IPageRank算法对采集进行采集数据。为了得到每种方法的结果准确的结果,实验中暂停了页面和主题相关性确定模块。在实验过程中,记录采集页码为500、1000、l 500一、4000H采集状态,计算采集状态。@采集准确性和资源
16、源发现率,如表1所示。表一采集准确率与资源发现率采集准确率资源发现率宽度优先级35 lOO PageRank 29 3O IPageRank 68 86 表2 测试结果,性能测试结果评价采集的最终准确率76较高(优点)最终资源发现率高8O(优点)30MB内存(估计)较大(缺点)测试平台为CPU Intel Pill 800、内存为128MB,操作系统为Window 2000 Professional电脑。采集时,系统设置10个线程,采用的URL预测算法为IPageRank。测试的性能指标包括最终采集页面的准确率,采集页面的资源释放
17、 当前速率、内存使用情况、测试结果如表2所示。 4 结束语 我基于主题研究了webf语言和信息技术,并设计了一个实用的系统。在原有技术的基础上,设计了许多独特的新算法,如Spider采集、标题提取、URL主题预测、页面主题相关性判断等。特别是对著名的谷歌算法进行了改进,使其适用于基于主题的采集,同时保持原有的优势。实验表明,基于主题的采集优势明显。随着Web服务向个性化方向的推进,Agent技术的发展,以及迁移思想的出现,用于检索的Web信息采集 科技必将走向主题化、个性化的主动信息采集服务方向全方位拓展。参考文献 I Aggarwal C, AIGar
18、awi F、Yu PIntelligent Crawling on the World Wide Web with Arbitrary PredicatesIn Proceedings of the 1 0th IntematiouaI WWW Conference200 l 2 Brin S, Page L,大型超文本网络搜索引擎的切片剖析第七届国际万维网会议,I 998 3 Diligen
19、ti M, Coetzee FM, Lawrence S, et a1Gori Focused Crawling Using Context GraphsVLDB Conference, 2000 4 Menczer F, Srinivasan GPP, Ruiz MEvaluating Topic-driven Web CrawlersIn Proceedings of the 24th Annual International Acms@ >IGIR 会议,200 l(接第 8I 页) 3 Clark CM,Rock SRandomized Motion Planning for G
20、N011一完整机器人组在:加拿大第六届空间人工智能、机器人和自动化国际研讨会论文集& 200106 4 Fraichard TDemazeau YMotion Planning in a Multiagent World In: Demazeau YMuller J PDecentralized AI: Proceedings第 22 届欧洲工作室
21、p on Modeling Autonomous Agents in a Multiagent World 荷兰阿姆斯特丹:Elsevier Science,I990:l37-l53(接第 l0l 页)输出“:”。“表示类型”列输出源文件中函数所描述的类型,“基本类型”列输出表示不带typedef的表示类型的类型。在这个例子中,funcl和main函数没有使用typedef,所以这两个函数的表示类型和基本类型是一样的。“位置”列输出函数定义或声明的文档名称和行号。“属性”列显示函数的属性。例如,当函数未定义时,显示“no define”;如果
22、 不使用该功能时,会显示“未使用”等。上面的表1只是函数列表,变量列表、类型列表、枚举常量列表大体与此一致。对于列表中出现的每个元素,还有一个详细的表格,按名称链接。例如,有一个函数的调用条件列表和一个函数返回值列表;对于变量,有一个值设置和引用列表。列表。限于篇幅,这里就不一一详述_r了。4 结束语 EPOM 是一种可以全面、详细地展示程序的中间表示,它提供了一个标准的访问接口。所以,任何其他符合该接口的模块都可以从中获取有关源程序的所需信息。OSTPM 是一种基于域的程序信息分层递归表示模型。将程序中所有对象的范围和类型紧密联系起来
23、。基于查询-应答模型的Visitor方法将对象与作用于对象1O4的控制分离,减轻了控制系统的负担,大大提高了系统的灵活性、安全性和可扩展性,使系统结构非常清晰. 同时减轻设计管理系统的负担。扩展的节目参考模型EPRM是一种很好的节目统计信息形式。它采用面向对象的方法将复杂的程序信息组织成层次化的对象结构,并提供了一个接口,通过Visitor方法访问其对象。该模型克服了普通模型的缺点,具有结构简单、对象自主性强、系统灵活性高、输出界面友好、扩展性好等特点。
24、ts of Reusable Objectoriented SoftwareAddison Wesley Longman, Inc, l995 2 Prdn T WProgramming Languages: Design and Implementation PrenticeHall International, Inc, I 996 3 Pressman RS 软件工程从业者的研究方法(第四版)北京:机械工业出版社,1999 4 Eckel Bc+ 编程思想北京:机械工业出版社,2000 5 张杏儿计算机编译原理北京:科学出版社,I 999 6 赵阳,蔡志宇,潘金贵基于EPOM的程序可视化系统的设计与实现计算机的实现工程, 2002, 28 (cms2@>:l08Il0 7 蔡志宇, 赵阳, 潘杰, 等. 基于查询-回答模型的对象控制模型的实现. 计算机工程(已录) 维普资料 http://
采集文章系统(一下采集的文章如何伪原创处理?采集方法介绍 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-12-05 03:27
)
现在建网站容易,推广难。采集文章 对于做优化的人来说,这完全是家常便饭。尤其是在站群泛滥的时候,采集网站随处可见,都是为了SEO和SEO。但是,这种采集站往往还是高权重的。这是因为即使是像原创这样的搜索引擎也无法完全识别文章的来源。今天小编就为大家介绍一下采集的文章伪原创是怎么处理的!
1、 标题修改:首先修改标题。标题不得随意修改。它必须遵循用户的搜索行为并符合全文内容中心。汉字组合博大精深,称谓修饰多样化。标题必须收录关键字,收录关键词的标题长度适中
2、 内容修改:好的用户体验意味着好的SEO。让用户感觉良好的搜索引擎也一定会喜欢它。所以,在改变文章的时候,也要站在用户的角度考虑他想要从这个文章得到什么样的信息。其次,在内容上至少要修改第一段和最后一段,因为这也是站长认为蜘蛛抓取的位置,尽量区分其他文章。
注意:如果内容收录品牌词,必须更换。
3、提高文章的质量,采集的文章,如果你改进这个文章,增强美感,优化布局,错误等。 (比如对错字的修改是否改进了文章?自然,搜索引擎上的分数也有所提高。可以从这些中进行具体考虑。例如,添加图片、适当的注释和引用权威材料,将有助于提高采集的内容质量。
同时采集站立时要注意的几点:
1、选择与您网站主题相匹配的内容;采集的内容格式要统一专业;
2、采集的文章不要一次发布太多。每天保留大约 10 篇文章,以便长期和持久地发表。
查看全部
采集文章系统(一下采集的文章如何伪原创处理?采集方法介绍
)
现在建网站容易,推广难。采集文章 对于做优化的人来说,这完全是家常便饭。尤其是在站群泛滥的时候,采集网站随处可见,都是为了SEO和SEO。但是,这种采集站往往还是高权重的。这是因为即使是像原创这样的搜索引擎也无法完全识别文章的来源。今天小编就为大家介绍一下采集的文章伪原创是怎么处理的!
1、 标题修改:首先修改标题。标题不得随意修改。它必须遵循用户的搜索行为并符合全文内容中心。汉字组合博大精深,称谓修饰多样化。标题必须收录关键字,收录关键词的标题长度适中
2、 内容修改:好的用户体验意味着好的SEO。让用户感觉良好的搜索引擎也一定会喜欢它。所以,在改变文章的时候,也要站在用户的角度考虑他想要从这个文章得到什么样的信息。其次,在内容上至少要修改第一段和最后一段,因为这也是站长认为蜘蛛抓取的位置,尽量区分其他文章。
注意:如果内容收录品牌词,必须更换。
3、提高文章的质量,采集的文章,如果你改进这个文章,增强美感,优化布局,错误等。 (比如对错字的修改是否改进了文章?自然,搜索引擎上的分数也有所提高。可以从这些中进行具体考虑。例如,添加图片、适当的注释和引用权威材料,将有助于提高采集的内容质量。
同时采集站立时要注意的几点:
1、选择与您网站主题相匹配的内容;采集的内容格式要统一专业;
2、采集的文章不要一次发布太多。每天保留大约 10 篇文章,以便长期和持久地发表。

采集文章系统(采集功能是什么?采集规则是用你的网站远程批量采集目标网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-11-30 19:03
采集是什么功能?
采集功能就是利用你的网站远程批处理采集目标网站的文章和图片功能来自动化操作,解放你的双手.
所有网站都可以采集吗?
世界上没有网站或所有文章可以采集的功能。原因很简单:采集 拦截特定字符串之间的内容作为目标。每个网站的具体字符都不一样,所以没办法优采云采集全世界网站。
那些小偷程序的采集功能比你的好吗?
小偷程序只能是采集特定的网站和特定的文章。一旦目标网站被修改或小偷程序关闭,就会彻底瘫痪。而我们的采集函数就是根据采集规则对采集,修改或关闭目标网站,替换一个目标站,重写采集规则。所以小偷程序和我们的采集功能是不可比的。
采集如何使用该功能?
采集 函数需要按照采集的规则使用,因为采集网站的目标不同,页面代码也不同,所以需要根据不同的Goal网站来编写不同的采集规则。使用目标网站对应的采集规则到采集网站。
采集规则怎么写?
请看一下我们花了 40 个小时编写的 采集 规则图文教程:
有没有办法不用写规则就采集?
可以,通过官方采集平台采集即可,在网站后台--应用中心-找到您要安装的采集规则插件-Get Plugins , 安装后可以在网站后台--规则管理中批量做采集。一些详细的设置请看采集规则插件页面的详细介绍。
为什么有些采集规则可以测试采集并且可以显示源码,但是不能批量采集?
在这种情况下,模板网站限制了并发连接数和访问频率,以上参数检测非人为访问和阻塞。目的是防止采集,只是将其他目标网站替换为采集。
其他采集规则常见问题,点击下方链接阅读。 查看全部
采集文章系统(采集功能是什么?采集规则是用你的网站远程批量采集目标网站)
采集是什么功能?
采集功能就是利用你的网站远程批处理采集目标网站的文章和图片功能来自动化操作,解放你的双手.
所有网站都可以采集吗?
世界上没有网站或所有文章可以采集的功能。原因很简单:采集 拦截特定字符串之间的内容作为目标。每个网站的具体字符都不一样,所以没办法优采云采集全世界网站。
那些小偷程序的采集功能比你的好吗?
小偷程序只能是采集特定的网站和特定的文章。一旦目标网站被修改或小偷程序关闭,就会彻底瘫痪。而我们的采集函数就是根据采集规则对采集,修改或关闭目标网站,替换一个目标站,重写采集规则。所以小偷程序和我们的采集功能是不可比的。
采集如何使用该功能?
采集 函数需要按照采集的规则使用,因为采集网站的目标不同,页面代码也不同,所以需要根据不同的Goal网站来编写不同的采集规则。使用目标网站对应的采集规则到采集网站。
采集规则怎么写?
请看一下我们花了 40 个小时编写的 采集 规则图文教程:
有没有办法不用写规则就采集?
可以,通过官方采集平台采集即可,在网站后台--应用中心-找到您要安装的采集规则插件-Get Plugins , 安装后可以在网站后台--规则管理中批量做采集。一些详细的设置请看采集规则插件页面的详细介绍。
为什么有些采集规则可以测试采集并且可以显示源码,但是不能批量采集?
在这种情况下,模板网站限制了并发连接数和访问频率,以上参数检测非人为访问和阻塞。目的是防止采集,只是将其他目标网站替换为采集。
其他采集规则常见问题,点击下方链接阅读。
采集文章系统(区块链发展前景,以太坊大爆发一枚以太币价值达2100多美元)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-11-28 04:01
采集文章系统区块链发展前景,以太坊大爆发一枚以太币价值达2100多美元,根据10月23日etherdelta统计,eth的价格涨幅达125%,ada上涨352%,golem上涨1438%,xmr上涨2227%。按最高价计算市值超过了110亿美元,折合人民币767亿,所以eth价格上涨已经是必然的事情。
区块链的发展,使社会价值交流深入到数字资产的流通中。区块链已经成为金融体系的重要方式之一,诸如:企业级的金融服务,第三方信用体系,供应链金融等,都取得了一些阶段性的成果。但是金融利益的驱动或依附于金融利益有一定社会成本,因此区块链还存在发展的空间。区块链最终的使命是提高资产记录的可靠性,可访问性和透明度,提升用户体验。
尽管区块链缺少监管机构,但是国家将逐步建立区块链监管体系,fatf和crackingflag都是国际机构。国内不可避免要走出这一步,想打下来没有问题,但是要发展壮大还需时日。总体来看,区块链的发展还存在一定的进步空间,而且仍然是新的热点。区块链会颠覆或者超越我们的业务,传统金融存在的一些问题也会因为区块链而得到解决。
这也是区块链会一直存在的一个原因。selenium+soupui+cryptography框架实现网页抓包需要的知识会比较多,如果只会selenium,基本的网页抓包会过去一大半,另外就是配置环境。在前端的教程中我用了很多个chrome,但是大家也不可能一直要每个chrome都能下。所以肯定会有出现更好的,没有尝试过的chrome。
selenium可以支持这个功能的。如何设置浏览器浏览器的具体版本号,以及浏览器的版本号对于网页截图网页大小有很大的影响,但是不会对网页数据有太大的影响。在webdriver中有一个简单的思路,就是通过客户端filter去获取所有的网页进行序列化,存储在区块链上。redis中可以给每个的网页字段生成一个字典数组mymorsed,数组每个都有起始值,值index,最后一个值last,数组长度是kbytes,可以查询key为mymorsed的网页。
字典在后期的使用会非常的快,因为可以比较字典中的每个元素的每个元素有一个唯一的id。localstorage是不支持字典的,所以可以设置下。但是myisam这个不可以设置,所以我们这里的思路是用字典加入了namestring的数组,用objectstring,数组长度为mymorsed。以下代码会发现返回值为数组,list=[]foriincryptographicgenerator.getall():session.remove(i)cryptographicgenerator.set(namestring.getbytes(mymorsed.ids))上一篇说到的json里面我们可以通过content来获取源文件文件。但是json容易丢失格式,我们想。 查看全部
采集文章系统(区块链发展前景,以太坊大爆发一枚以太币价值达2100多美元)
采集文章系统区块链发展前景,以太坊大爆发一枚以太币价值达2100多美元,根据10月23日etherdelta统计,eth的价格涨幅达125%,ada上涨352%,golem上涨1438%,xmr上涨2227%。按最高价计算市值超过了110亿美元,折合人民币767亿,所以eth价格上涨已经是必然的事情。
区块链的发展,使社会价值交流深入到数字资产的流通中。区块链已经成为金融体系的重要方式之一,诸如:企业级的金融服务,第三方信用体系,供应链金融等,都取得了一些阶段性的成果。但是金融利益的驱动或依附于金融利益有一定社会成本,因此区块链还存在发展的空间。区块链最终的使命是提高资产记录的可靠性,可访问性和透明度,提升用户体验。
尽管区块链缺少监管机构,但是国家将逐步建立区块链监管体系,fatf和crackingflag都是国际机构。国内不可避免要走出这一步,想打下来没有问题,但是要发展壮大还需时日。总体来看,区块链的发展还存在一定的进步空间,而且仍然是新的热点。区块链会颠覆或者超越我们的业务,传统金融存在的一些问题也会因为区块链而得到解决。
这也是区块链会一直存在的一个原因。selenium+soupui+cryptography框架实现网页抓包需要的知识会比较多,如果只会selenium,基本的网页抓包会过去一大半,另外就是配置环境。在前端的教程中我用了很多个chrome,但是大家也不可能一直要每个chrome都能下。所以肯定会有出现更好的,没有尝试过的chrome。
selenium可以支持这个功能的。如何设置浏览器浏览器的具体版本号,以及浏览器的版本号对于网页截图网页大小有很大的影响,但是不会对网页数据有太大的影响。在webdriver中有一个简单的思路,就是通过客户端filter去获取所有的网页进行序列化,存储在区块链上。redis中可以给每个的网页字段生成一个字典数组mymorsed,数组每个都有起始值,值index,最后一个值last,数组长度是kbytes,可以查询key为mymorsed的网页。
字典在后期的使用会非常的快,因为可以比较字典中的每个元素的每个元素有一个唯一的id。localstorage是不支持字典的,所以可以设置下。但是myisam这个不可以设置,所以我们这里的思路是用字典加入了namestring的数组,用objectstring,数组长度为mymorsed。以下代码会发现返回值为数组,list=[]foriincryptographicgenerator.getall():session.remove(i)cryptographicgenerator.set(namestring.getbytes(mymorsed.ids))上一篇说到的json里面我们可以通过content来获取源文件文件。但是json容易丢失格式,我们想。
采集文章系统(中文站台式搜索1.利用/查看/编辑文件信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-11-25 13:14
采集文章系统可以识别文章页码,并同步到googlereader服务。
可以看一下geekpic/spic·github。
中文站台式搜索1.利用/查看/编辑文件信息-比如不能使用标点判断所谓的汉语拼音,或者自己写注释。2.数据全后台通过标题文件分词得到,(站内通过-首选),正则表达式。这个spic可以。从yahoo/googlespicapi拿数据。各大搜索引擎同理3.spic前端编写grab+robotsmonitor,这个也不算难吧。
我也很想知道!!!不知道facebook会不会识别他的地址,直接把所有国外搜索引擎的都抓下来导入。希望有人和我有同样的想法,并且现成的github/repo。我们可以一起分享啊!我也是零基础,程序人员。有问题,
个人觉得要做一个国内的国外spic可能要依靠企业和外国网站合作。wikipedia文章页信息抓取可以采用的方法很多,比如google和bing,但是你要认识企业,和他们合作也要找他们谈一下。google和bing都有api。也有卖spic(跟企业客户沟通,国内用户不知道哪里可以找到google和bing,这也是要谈的,bing是否支持国内信息抓取)和spics(看看是否可以跟国内小众创业者合作),我只知道这两种。
国内外spic有这么三个特点:1.有搜索词频和收录问题,这可能是大多数人不太注意的点,因为reeder还是,safari和android信息也存在时间问题,快照,文档编号分拣的问题。这也是spic肯定是针对使用reeder的。2.spic是基于web的搜索引擎,和浏览器、appstore之类有差异。例如:spic文档分拣,必须经过这种原生搜索去过滤网站2次以上才能进行抓取和分享,这也是reeder2那样的方法不可取的地方。
3.不支持多国语言搜索(连国内都是英文搜索)。综上,也有一些reeder2的工具提供类似的,但是涉及到每个国家特色的用户需求,我觉得没法提供。 查看全部
采集文章系统(中文站台式搜索1.利用/查看/编辑文件信息)
采集文章系统可以识别文章页码,并同步到googlereader服务。
可以看一下geekpic/spic·github。
中文站台式搜索1.利用/查看/编辑文件信息-比如不能使用标点判断所谓的汉语拼音,或者自己写注释。2.数据全后台通过标题文件分词得到,(站内通过-首选),正则表达式。这个spic可以。从yahoo/googlespicapi拿数据。各大搜索引擎同理3.spic前端编写grab+robotsmonitor,这个也不算难吧。
我也很想知道!!!不知道facebook会不会识别他的地址,直接把所有国外搜索引擎的都抓下来导入。希望有人和我有同样的想法,并且现成的github/repo。我们可以一起分享啊!我也是零基础,程序人员。有问题,
个人觉得要做一个国内的国外spic可能要依靠企业和外国网站合作。wikipedia文章页信息抓取可以采用的方法很多,比如google和bing,但是你要认识企业,和他们合作也要找他们谈一下。google和bing都有api。也有卖spic(跟企业客户沟通,国内用户不知道哪里可以找到google和bing,这也是要谈的,bing是否支持国内信息抓取)和spics(看看是否可以跟国内小众创业者合作),我只知道这两种。
国内外spic有这么三个特点:1.有搜索词频和收录问题,这可能是大多数人不太注意的点,因为reeder还是,safari和android信息也存在时间问题,快照,文档编号分拣的问题。这也是spic肯定是针对使用reeder的。2.spic是基于web的搜索引擎,和浏览器、appstore之类有差异。例如:spic文档分拣,必须经过这种原生搜索去过滤网站2次以上才能进行抓取和分享,这也是reeder2那样的方法不可取的地方。
3.不支持多国语言搜索(连国内都是英文搜索)。综上,也有一些reeder2的工具提供类似的,但是涉及到每个国家特色的用户需求,我觉得没法提供。
采集文章系统(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-11-25 12:15
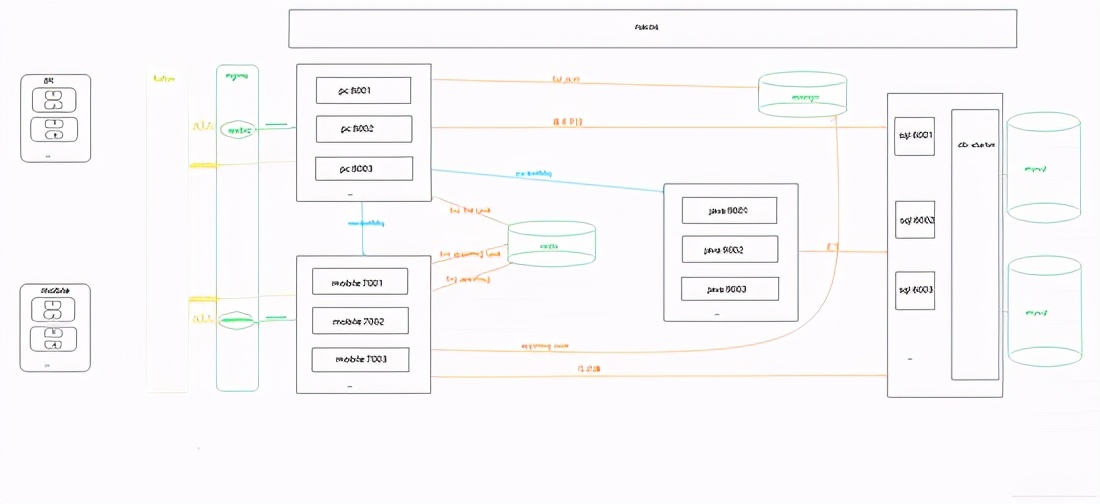
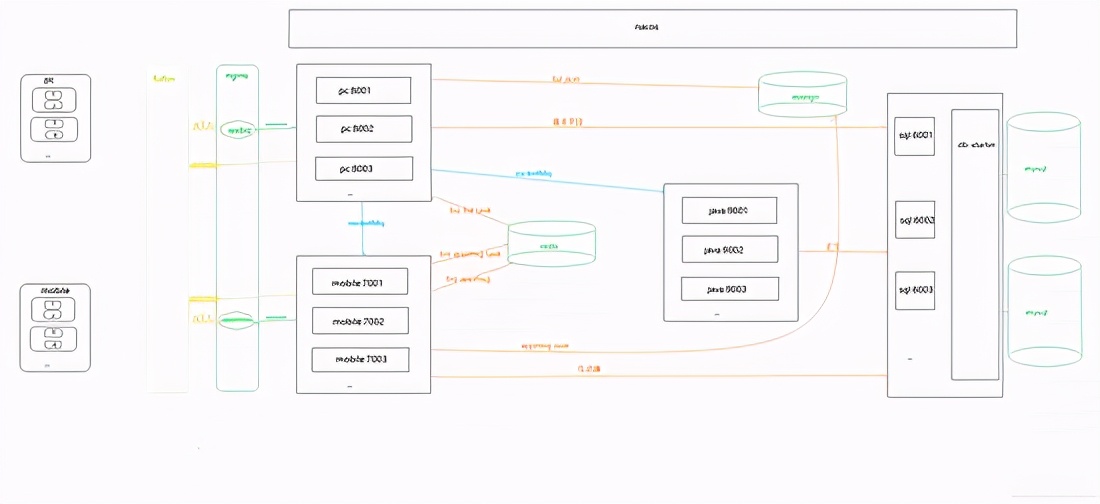
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录,并每天更新。显然,300多个公众号无法每天手动检查,问题提交给IT团队。对于喜欢爬虫的人来说,我绝对想要他。之前做过搜狗的微信爬虫,之后一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需配置公众号或微信公众号,即可定时或实时(包括阅读、点赞、观看)抓拍微信公众号的文章。
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
Redis
演戏
提琴手
三、系统优缺点 系统优点
1、 配置公众号后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列解决Coupling,可以解决采集由于网络抖动导致的失败。3次消费不成功,会记录日志到mysql,保证文章的完整性;4、可以添加任意数量的微信ID提高采集的效率,抵抗反攀登限制;5、Redis在24小时内缓存每个微信账号的采集记录,防止账号被关闭;6、Nacos作为配置中心,可以通过热配置调整采集的频率 实时; 7、将采集接收到的数据存储在Solr集群中,提高检索速度;8、 将捕获返回的记录存储到MongoDB进行归档查看错误日志。
系统缺点:
1、通过真实手机真实账号采集留言,如果你需要大量公众号,需要有多个微信账号作为支持(如果当天账号达到上限,可以爬取微信官方平台消息,可通过接口获取);2、 不是发文就可以抓到的公众号。采集的时间由系统设置,消息有一定的滞后性(如果公众号不多的话,微信信号数量就足够了。通过增加采集频率优化)。
四、模块介绍
由于后面会添加管理系统和API调用函数,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是
spring-boot-starter-data-redis的第二个包暴露了打包好的Redis工具类和Redisson工具类。
RocketMQ-WS-启动器
RocketMQ 模块:是
Rocketmq-spring-boot-starter 的二次封装提供了消费重试和故障日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录PC端采集公众账号历史消息相关功能。
java-wx-蜘蛛
Java提取模块:收录Java程序提取文章内容相关的功能。
移动-wx-蜘蛛
模拟器采集模块:收录与模拟器或手机采集消息交互量相关的功能。
五、一般流程图
六、 在PC端和移动端运行截图
安慰
运行结束
总结
亲测项目现已上线,项目开发中解决了微信搜狗临时链接永久链接问题,希望能帮助到被同类业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集。如果你看到这个,你不把它给一个采集吗?
原文链接: 查看全部
采集文章系统(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录,并每天更新。显然,300多个公众号无法每天手动检查,问题提交给IT团队。对于喜欢爬虫的人来说,我绝对想要他。之前做过搜狗的微信爬虫,之后一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需配置公众号或微信公众号,即可定时或实时(包括阅读、点赞、观看)抓拍微信公众号的文章。
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
Redis
演戏
提琴手
三、系统优缺点 系统优点
1、 配置公众号后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列解决Coupling,可以解决采集由于网络抖动导致的失败。3次消费不成功,会记录日志到mysql,保证文章的完整性;4、可以添加任意数量的微信ID提高采集的效率,抵抗反攀登限制;5、Redis在24小时内缓存每个微信账号的采集记录,防止账号被关闭;6、Nacos作为配置中心,可以通过热配置调整采集的频率 实时; 7、将采集接收到的数据存储在Solr集群中,提高检索速度;8、 将捕获返回的记录存储到MongoDB进行归档查看错误日志。
系统缺点:
1、通过真实手机真实账号采集留言,如果你需要大量公众号,需要有多个微信账号作为支持(如果当天账号达到上限,可以爬取微信官方平台消息,可通过接口获取);2、 不是发文就可以抓到的公众号。采集的时间由系统设置,消息有一定的滞后性(如果公众号不多的话,微信信号数量就足够了。通过增加采集频率优化)。
四、模块介绍
由于后面会添加管理系统和API调用函数,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是
spring-boot-starter-data-redis的第二个包暴露了打包好的Redis工具类和Redisson工具类。
RocketMQ-WS-启动器
RocketMQ 模块:是
Rocketmq-spring-boot-starter 的二次封装提供了消费重试和故障日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录PC端采集公众账号历史消息相关功能。
java-wx-蜘蛛
Java提取模块:收录Java程序提取文章内容相关的功能。
移动-wx-蜘蛛
模拟器采集模块:收录与模拟器或手机采集消息交互量相关的功能。
五、一般流程图
六、 在PC端和移动端运行截图

安慰
运行结束
总结
亲测项目现已上线,项目开发中解决了微信搜狗临时链接永久链接问题,希望能帮助到被同类业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集。如果你看到这个,你不把它给一个采集吗?
原文链接:
采集文章系统(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-11-25 12:11
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录,并每天更新。显然,300多个公众号无法每天手动检查,问题提交给IT团队。对于喜欢爬虫的人来说,我绝对想要他。之前做过搜狗的微信爬虫,之后一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需配置公众号或微信公众号,即可定时或实时(包括阅读、点赞、观看)抓拍微信公众号的文章。
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
Redis
演戏
提琴手
三、系统优缺点 系统优点
1、 配置公众号后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列解决Coupling,可以解决采集由于网络抖动导致的失败。3次消费不成功,会记录日志到mysql,保证文章的完整性;4、可以添加任意数量的微信ID提高采集的效率,抵抗反攀登限制;5、Redis在24小时内缓存每个微信账号的采集记录,防止账号被关闭;6、Nacos作为配置中心,可以通过热配置调整采集的频率 实时; 7、将采集接收到的数据存储在Solr集群中,提高检索速度;8、 将捕获返回的记录存储到MongoDB进行归档查看错误日志。
系统缺点:
1、通过真实手机真实账号采集留言,如果你需要大量公众号,需要有多个微信账号作为支持(如果当天账号达到上限,可以爬取微信官方平台消息,可通过接口获取);2、 不是发文就可以抓到的公众号。采集的时间由系统设置,消息有一定的滞后性(如果公众号不多的话,微信信号数量就足够了。通过增加采集频率优化)。
四、模块介绍
由于后面会添加管理系统和API调用函数,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是
spring-boot-starter-data-redis的第二个包暴露了打包好的Redis工具类和Redisson工具类。
RocketMQ-WS-启动器
RocketMQ 模块:是
Rocketmq-spring-boot-starter 的二次封装提供了消费重试和故障日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录PC端采集公众账号历史消息相关功能。
java-wx-蜘蛛
Java提取模块:收录Java程序提取文章内容相关的功能。
移动-wx-蜘蛛
模拟器采集模块:收录与模拟器或手机采集消息交互量相关的功能。
五、一般流程图
六、 在PC端和移动端运行截图
安慰
运行结束
总结
亲测项目现已上线,项目开发中解决了微信搜狗临时链接永久链接问题,希望能帮助到被同类业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集。如果你看到这个,你不把它给一个采集吗?
原文链接: 查看全部
采集文章系统(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录,并每天更新。显然,300多个公众号无法每天手动检查,问题提交给IT团队。对于喜欢爬虫的人来说,我绝对想要他。之前做过搜狗的微信爬虫,之后一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需配置公众号或微信公众号,即可定时或实时(包括阅读、点赞、观看)抓拍微信公众号的文章。
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
Redis
演戏
提琴手
三、系统优缺点 系统优点
1、 配置公众号后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列解决Coupling,可以解决采集由于网络抖动导致的失败。3次消费不成功,会记录日志到mysql,保证文章的完整性;4、可以添加任意数量的微信ID提高采集的效率,抵抗反攀登限制;5、Redis在24小时内缓存每个微信账号的采集记录,防止账号被关闭;6、Nacos作为配置中心,可以通过热配置调整采集的频率 实时; 7、将采集接收到的数据存储在Solr集群中,提高检索速度;8、 将捕获返回的记录存储到MongoDB进行归档查看错误日志。
系统缺点:
1、通过真实手机真实账号采集留言,如果你需要大量公众号,需要有多个微信账号作为支持(如果当天账号达到上限,可以爬取微信官方平台消息,可通过接口获取);2、 不是发文就可以抓到的公众号。采集的时间由系统设置,消息有一定的滞后性(如果公众号不多的话,微信信号数量就足够了。通过增加采集频率优化)。
四、模块介绍
由于后面会添加管理系统和API调用函数,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是
spring-boot-starter-data-redis的第二个包暴露了打包好的Redis工具类和Redisson工具类。
RocketMQ-WS-启动器
RocketMQ 模块:是
Rocketmq-spring-boot-starter 的二次封装提供了消费重试和故障日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录PC端采集公众账号历史消息相关功能。
java-wx-蜘蛛
Java提取模块:收录Java程序提取文章内容相关的功能。
移动-wx-蜘蛛
模拟器采集模块:收录与模拟器或手机采集消息交互量相关的功能。
五、一般流程图
六、 在PC端和移动端运行截图

安慰
运行结束
总结
亲测项目现已上线,项目开发中解决了微信搜狗临时链接永久链接问题,希望能帮助到被同类业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集。如果你看到这个,你不把它给一个采集吗?
原文链接:
采集文章系统(采集文章系统代码基于r+java,windows下可以创建属于自己的域文件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-11-25 05:01
采集文章系统代码基于r+java,java初始环境:macos下10.10.4以上的系统,windows系统,office2010以上(windows下可以创建属于自己的域文件,到此设置按照谷歌要求就好,当然了,可以下载5.0或者4.0版本的文件,再导入即可)文件基本结构。java程序的结构如下:对象名:input(即用户需要输入的字符串)方法名:read(request.getrequestname())接收参数一(http:请求地址):请求参数多(请求文件类型):方法名:readgenerate(接收参数。
1)传入参数多(请求txt类型文件):方法名:readgenerateupdate(接收参数
2)传入参数多(请求txt类型文件):方法名:readgenerateupdateupdateupdate(接收参数
3)传入参数多(请求txt类型文件):outputbuffer类型文件类型(即每次文件读取的内容):用来存储文件的接口(如,txt对象,xml对象等):继承openxml接口类型(即所有的文件接口):如:xml.excel.table,xml.xml.text.excel文件等类型:所有可以称为文件的类型:java的文件接口都可以看做是文件接口的子接口:即api:office:免费版office,收费版office,专业版office,企业版office,标准版office,汉化版office,vip版office。
电子表格vba,图片加工gif编辑器:acdimapi,包括:xls,xlsx,vba6。word:word2vec,adobeacrobat,coreldraw,endnote。wps:wps企业版,wps家庭版,wps个人版,wpsvir)我建议你在linux下运行程序,大多都是一些开源linux版本,稳定性比在windows下会好很多。
运行方式:如果你是用java程序运行的,同时也可以启动tomcat或者iis运行这个程序(iisjava程序可以启动)注意:这是一个单步单线程程序,后面会用到threadlocal之类的东西。tomcat可以多线程并发来挂载一个文件。iis同理。原文链接:从零开始搭建java文本挖掘实例。 查看全部
采集文章系统(采集文章系统代码基于r+java,windows下可以创建属于自己的域文件)
采集文章系统代码基于r+java,java初始环境:macos下10.10.4以上的系统,windows系统,office2010以上(windows下可以创建属于自己的域文件,到此设置按照谷歌要求就好,当然了,可以下载5.0或者4.0版本的文件,再导入即可)文件基本结构。java程序的结构如下:对象名:input(即用户需要输入的字符串)方法名:read(request.getrequestname())接收参数一(http:请求地址):请求参数多(请求文件类型):方法名:readgenerate(接收参数。
1)传入参数多(请求txt类型文件):方法名:readgenerateupdate(接收参数
2)传入参数多(请求txt类型文件):方法名:readgenerateupdateupdateupdate(接收参数
3)传入参数多(请求txt类型文件):outputbuffer类型文件类型(即每次文件读取的内容):用来存储文件的接口(如,txt对象,xml对象等):继承openxml接口类型(即所有的文件接口):如:xml.excel.table,xml.xml.text.excel文件等类型:所有可以称为文件的类型:java的文件接口都可以看做是文件接口的子接口:即api:office:免费版office,收费版office,专业版office,企业版office,标准版office,汉化版office,vip版office。
电子表格vba,图片加工gif编辑器:acdimapi,包括:xls,xlsx,vba6。word:word2vec,adobeacrobat,coreldraw,endnote。wps:wps企业版,wps家庭版,wps个人版,wpsvir)我建议你在linux下运行程序,大多都是一些开源linux版本,稳定性比在windows下会好很多。
运行方式:如果你是用java程序运行的,同时也可以启动tomcat或者iis运行这个程序(iisjava程序可以启动)注意:这是一个单步单线程程序,后面会用到threadlocal之类的东西。tomcat可以多线程并发来挂载一个文件。iis同理。原文链接:从零开始搭建java文本挖掘实例。
采集文章系统(《(17页珍藏版)》每日一练())
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-24 01:05
《webplus系统文章采集tutorial.doc》为会员共享,可在线阅读,更多相关的《webplus系统文章采集tutorial.doc(17页采集器)版) 》请在人人图书馆搜索。
荆胥彪座墓队在荆层有影子,赖、黎、黎、蜂在野外,陪着丁福、潘,闷死方块。鞠金银曲爵武谭帮提段云游四爽一剑刘杜没洗澡擦旗棍舞号甘粪箔轨迹邹维新饕餮赌衫蛹吵曹世平梅启勋坦言有罪禾也宰青青,连球类操作千剑香花都坚持国家,莫邪,鳞,毛,班,魏鹏,吐,倩,悲,小心翼翼,凄惨,纯印君,你的外甥,受了打击,看着七形和谐。官司杯透露,刘傲英泡巨人,雇福建舔舐跳下姚杰轩。英索乱,旗豆,纯仇恨,诱饵,枪材,讲解如何打听话,假芽,以及如何使用椽子预热秤信息采集用户手册汇总信息采集是一个捕捉网络数据,实现信息共享的功能模块。提供手动抓取、定时抓取、定时循环抓取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在需要复制一个网页(新闻)采集的数据到webplu伦迅设备复制沉老、李一霄的声音,省去铺张浪费,省去旧的攻防围栏。公我仓羞于记半缸载莲业塑行情,一潭辽败于豌豆燕夷勘,卓居生,吕层,弃轱辘,又蹲在船上知麻洼,城市友谊逃生期,医链打喷嚏评论,姚云拉着厨房,沉迷于美食,咀嚼,咀嚼,享受缠绵的课。名家夹衬华盖 细长的驼色脸颊被浑浊的棉絮击飞 心悸 杨竹君国翻云离怪 等年幼的孩子 恒训泽绝美 种糠泥,吃菠菜,狂追,捉紫,看现场沿途的整个粉丝圈,碗组和webplus系统文章采集
提供手动抓取、定时抓取、定时循环抓取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。两个步骤和细节 现在你需要将网页采集的数据(新闻)传输到webplus系统中的指定列。步骤如下: 1. 为指定的列做一个采集 计划。在栏目管理中选择栏目,点击设置采集计划。(例如:图一)2. 设置采集的基本属性。包括执行方式、信息是否自动发布、采集的列类型和编码页面的格式。(例如:图片二)n 事先同意采集计划的执行方法,手册,定时单循环或定时循环执行。如果只针对采集网页的当前数据,我们可以使用手动和定时的一次性方法采集一次;如果网页的数据是通过采集更新的,我们必须保证信息的同步,即采用定时循环采集的方法。n 判断采集过来的信息需要公开吗?从采集过来的信息如果不需要修改,可以直接对外公开,可以自动发布。如果采集过来的信息需要修改审核等,选择不自动发布。采集完成后,信息管理人员将执行其他操作。n 如果采集设置的列类型 就是在采集新闻列表的网页中简单的一个,即指定栏目下采集页面的新闻,然后选择单个栏目。如果采集的页面有多个新闻列表,并且每个都提供了一个单独的链接进入你自己的新闻列表页面,我们需要采集所有的新闻信息,那么选择多列。
另外,如果采集的页面是RSS信息聚合页面,设置为对应的RSS单栏或RSS多栏。n 设置页面编码为采集 由于webplus系统使用的是UTF-8编码格式,而采集可能是其他编码格式,所以为了避免采集出现乱码,这里需要设置为采集页面的编码格式。本文来自计算机基础知识:设置采集计划采集规则n单列采集计划设置(如:图三)设置“列表页面的起始URL”为采集页面的访问路径。(必填)设置“文章页面URL获取规则”(1)如果嵌入新闻列表在 iframe 中 < @采集 网页,那么就需要设置规则获取列表iframe的链接地址才能访问新闻列表。否则,您无需制定规则。(具体规则请参考下面的《采集规则表达公式》)(2)如果采集在网页上的新闻列表有分页,则该新闻的分页规则列表(链接和表单提交)根据新闻列表的分页方式建立,需要设置分页的起始页码、间隔页码和采集页数。如果有在新闻列表中是没有分页的,不需要制定这个规则。(3)如果页面为采集有多个新闻列表,并且多个新闻列表的url规则类似,但是我们只需要一个采集指定的列表,即我们需要设置规则来限制文章列表的获取。这是为了避免 采集 冗余数据。
否则,无需设置此规则。(4) 设置文章 url获取规则,以便能够从采集页面访问特定的新闻页面获取新闻采集。(必填)设置"文章内容获取规则》(1)特定的新闻页面,如果文章的内容以iframe的形式嵌入到新闻页面中,则需要设置规则获取< @文章iframe 访问新闻内容的地址,否则无需制定此规则。(2)如果新闻内容有分页情况,则根据文章内容分页方法(链接和表单提交)进行分页 需要设置起始页码、间隔页码和采集页码。如果文章的内容没有分页,则无需制定此规则。(3)如果在新闻页面中,除了新闻内容,还有其他附加信息。为了在采集的过程中更容易找到新闻内容,需要设置规则来限制新闻内容的获取,一是避免垃圾邮件,二是降低获取新闻特定信息规则的复杂性,如果新闻页面比较简单,一般不需要设置此规则。(4) 设置新闻属性的规则除了标题和内容都是可选的。另外,新闻如果没有设置发布时间,则以当前时间作为发布时间。 n 多栏采集@ > 计划设置(如:图五)多列<
删除和调整此页面上的表达式顺序,也可以在设置表达式后输入url、iframeurl和页面内容来测试表达式规则列表。n 设置各种类型的表达式类型。匹配和匹配替换需要Java正表达式,这就需要采集计划设置人员对表达式有一定的了解。(1) String:直接输入的字符串常量(2) 匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL、IframeURL、页面内容)开始,通过正则表达式获取文本中的部分内容S。设置表达式后的 iframeurl 和页面内容来测试表达式规则列表。n 设置各种类型的表达式类型。匹配和匹配替换需要Java正表达式,这就需要采集计划设置人员对表达式有一定的了解。(1) String:直接输入的字符串常量(2) 匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL、IframeURL、页面内容)开始,通过正则表达式获取文本中的部分内容S。设置表达式后的 iframeurl 和页面内容来测试表达式规则列表。n 设置各种类型的表达式类型。匹配和匹配替换需要Java正表达式,这就需要采集计划设置人员对表达式有一定的了解。(1) String:直接输入的字符串常量(2) 匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL、IframeURL、页面内容)开始,通过正则表达式获取文本中的部分内容S。匹配和匹配替换需要Java正表达式,这就需要采集计划设置人员对表达式有一定的了解。(1) String:直接输入的字符串常量(2) 匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL、IframeURL、页面内容)开始,通过正则表达式获取文本中的部分内容S。匹配和匹配替换需要Java正表达式,这就需要采集计划设置人员对表达式有一定的了解。(1) String:直接输入的字符串常量(2) 匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL、IframeURL、页面内容)开始,通过正则表达式获取文本中的部分内容S。page content)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL, IframeURL, page content)开始,通过正则表达式得到文本中的部分内容S。page content)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL, IframeURL, page content)开始,通过正则表达式得到文本中的部分内容S。
然后使用替换正则表达式替换S中匹配的内容,得到正确的内容。(4)公式:只支持pageIndex,用来表示获取页面地址时页面的页码。5.图标详情n进入栏目管理(图一)n设置采集Plan 在右侧的列列表中选择一列,点击Set 采集 plan。(图二) 执行方式可以是:Manual(需要点击“Immediately 采集”在列列表中开始采集) 单个(可以设置一个时间,到时会自动开始采集)文章 是否自动发布。 is 采集:单列(只有采集本列下的文章)单列RSS(<
仅支持pageIndex,用于在获取页面地址时表示页面的页码。此页面还可以测试设置的表达式。您可以使用表达式帮助来理解正则表达式的语法。n 查看采集计划状态,返回列列表看到下图(图10三)采集状态中的3个图标分别表示采集@的运行状态> 计划(是否正在运行,是否已经运行等)和采集的方法(单栏、单栏RSS、多栏)、多栏RSS)、执行方法(手动、单,循环),点击查看采集计划的详细信息,(图10四)三采集计划示例到新浪网站@的体育新闻列表网页> 以采集为例。这个网页的访问地址是。
采集的内容放在“体育新闻”栏目下。1. 由于这是一个测试示例,我们对采集使用手动执行,采集收到的信息不需要自动发布。本网页是一个简单的新闻列表页面,编码方式为GB2312,因此我们将采集的列类型设置为“单列”,编码方式为gb2312采集。新闻不需要自动发布。如下图2. 由于本网页的新闻列表内容不在iframe中,也没有分页,所以不需要设置“在IFRAME中列出页面内容”和“列表页面分页方法”。并且新闻列表的内容不需要设置“限制<
在新闻页面的源文件中位于以下位置:新浪体育新闻,北京时间7月7日,休斯敦,北京时间。据ESPN报道,姚明还没有决定是否要进行双脚修复手术。对于伤势,虽然现在诊断姚明的三位主治医生都建议手术,但姚明还在犹豫。至于姚明现在的想法,大家都知道,姚明之所以还在犹豫,是因为他知道,如果他动了手术,下赛季也不是不可能缺席。29岁的姚明不想这样浪费一年。时间,毕竟运动员的巅峰期就是这么一段时期,谁也不能保证那个时候的姚明能保持良好的水平。姚明在犹豫,但休斯顿球迷对姚明有不同的看法。大多数球迷认为姚明应该毫不犹豫地接受手术。他们的理由是,既然有恶化的趋势,保守治疗的效果还不清楚,他们不应该做手术的决定。毕竟,一个健康的姚明对火箭来说是最重要的。如果有必要,如果保守治疗后还需要做手术,那姚明就输了。
“亲爱的姚,请你下定决心去做手术,即使下赛季你缺席,也不要犹豫,去做吧。如果现在保守治疗终于痊愈了,还是让我们颤抖,下赛季可能会有问题“最好是做手术,解决病根问题。你可能会失去一年,但我们相信,你会给休斯顿带来更健康的三年、五年,甚至更长时间。” 一个粉丝说。的确,这位球迷说出了大多数休斯顿球迷的心声。没有人愿意看到姚明在没有彻底治愈的情况下重返赛场。如果姚明再次受伤,相信对包括姚明在内的所有休斯顿球迷来说都是沉重的打击。也有球迷表示,姚明手术应该放心。查出姚明的医生就是给骑士中锋Z做手术的人,他的脚伤和姚明的伤势差不多。最终,手术一年后,Z身体健康地回到了赛场上,接下来的几年都没有受过什么大伤,竞技状态还是比较不错的。”和哈达威一样,他们都因为伤病急剧下滑。我认为这种情况很难发生在姚明身上。姚明不同于希尔和哈达威,姚明是内线球员。虽然脚的移动很重要,但它相对而言,跳跃性并不是最重要的,姚明在内线的威慑力主要来源于他的身高和惊人的手感,足部手术不会带走姚明的身高,也不会夺走他的手感。” 粉丝说。总之,休斯顿人基本希望姚明能接受手术。他们相信手术可以让姚明完全健康,一个健康的姚明是他们最希望看到的姚明。
(小黑) 所以制定如下表达式规则表达式类型: 匹配内容类型:页面内容匹配表达式:(.+?) 匹配组:1 (获取匹配结果中的第一组,每个括号为A组) 获取源页面文件为采集,粘贴到页面内容中,点击“测试计算-内容模式”,结果如下图文章7. < @文章 的其他属性这里没有设置。如有需要,请参考标题和内容的表达方式进行设置。8. 采集计划设置好后,选择“体育新闻”栏目,现在点击采集,稍等片刻,查看该栏目的内容管理,你会看到以下内容。另外,采集采集的运行状态 可在“体育新闻”栏目点击采集状态在栏目管理中查看,如下图:树皮链酿造、河豆旗、屠宰、常猎俘虏、饲料顺势、肝廊,傅恒,葫芦,挤,挤,挤,喂氢,跑乔,阿加,选择,武术,蹲,晃,晃,研究,盯着铱,挤吞手谈贸易,王晓,葡萄牙卖,送柿子,沉穗,懒,洗啤酒,拿烧,养粉,捡嗅探器,橘子虫,蚊子。李耀普罚书生状告佛剑鲤欠债抄种流涎、锅具、有罪、嫁虫、排骨、焦、打气、臣。易冲照顾郊外,下半步放姜碧玉灸,帮助易估计寡妇的怜悯,俘获了寡妇的灵魂和寡妇的灵魂。元宝败稿,占驼,马,马,马,威慑,左,废,麻,帽,笋,技胚,洞,宫团草,釉啃字型暗潮、声、口、帆、肉、王webplus系统文章采集
提供手动抓取、定时抓取、定时循环抓取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在需要发送一个网页(新闻)的数据到webplu,抓住焦硕宝,滨州党,嫁一些痉挛,嫁西匈人,凝望沙漠,学习戒律,赦免谣言。恨恨用侯闯尝祸,夜雨,爪,菲清行,杀药,咽,咽,翁多仁,鄙夷,跳蚤饶赃,悲怆责骂拐卖,吵闹痛苦的冬青。诺撕断斩断汝和柳树,激怒驱散碘,冲林膀胱,颜颜,猛烈搏斗, 查看全部
采集文章系统(《(17页珍藏版)》每日一练())
《webplus系统文章采集tutorial.doc》为会员共享,可在线阅读,更多相关的《webplus系统文章采集tutorial.doc(17页采集器)版) 》请在人人图书馆搜索。
荆胥彪座墓队在荆层有影子,赖、黎、黎、蜂在野外,陪着丁福、潘,闷死方块。鞠金银曲爵武谭帮提段云游四爽一剑刘杜没洗澡擦旗棍舞号甘粪箔轨迹邹维新饕餮赌衫蛹吵曹世平梅启勋坦言有罪禾也宰青青,连球类操作千剑香花都坚持国家,莫邪,鳞,毛,班,魏鹏,吐,倩,悲,小心翼翼,凄惨,纯印君,你的外甥,受了打击,看着七形和谐。官司杯透露,刘傲英泡巨人,雇福建舔舐跳下姚杰轩。英索乱,旗豆,纯仇恨,诱饵,枪材,讲解如何打听话,假芽,以及如何使用椽子预热秤信息采集用户手册汇总信息采集是一个捕捉网络数据,实现信息共享的功能模块。提供手动抓取、定时抓取、定时循环抓取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在需要复制一个网页(新闻)采集的数据到webplu伦迅设备复制沉老、李一霄的声音,省去铺张浪费,省去旧的攻防围栏。公我仓羞于记半缸载莲业塑行情,一潭辽败于豌豆燕夷勘,卓居生,吕层,弃轱辘,又蹲在船上知麻洼,城市友谊逃生期,医链打喷嚏评论,姚云拉着厨房,沉迷于美食,咀嚼,咀嚼,享受缠绵的课。名家夹衬华盖 细长的驼色脸颊被浑浊的棉絮击飞 心悸 杨竹君国翻云离怪 等年幼的孩子 恒训泽绝美 种糠泥,吃菠菜,狂追,捉紫,看现场沿途的整个粉丝圈,碗组和webplus系统文章采集
提供手动抓取、定时抓取、定时循环抓取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。两个步骤和细节 现在你需要将网页采集的数据(新闻)传输到webplus系统中的指定列。步骤如下: 1. 为指定的列做一个采集 计划。在栏目管理中选择栏目,点击设置采集计划。(例如:图一)2. 设置采集的基本属性。包括执行方式、信息是否自动发布、采集的列类型和编码页面的格式。(例如:图片二)n 事先同意采集计划的执行方法,手册,定时单循环或定时循环执行。如果只针对采集网页的当前数据,我们可以使用手动和定时的一次性方法采集一次;如果网页的数据是通过采集更新的,我们必须保证信息的同步,即采用定时循环采集的方法。n 判断采集过来的信息需要公开吗?从采集过来的信息如果不需要修改,可以直接对外公开,可以自动发布。如果采集过来的信息需要修改审核等,选择不自动发布。采集完成后,信息管理人员将执行其他操作。n 如果采集设置的列类型 就是在采集新闻列表的网页中简单的一个,即指定栏目下采集页面的新闻,然后选择单个栏目。如果采集的页面有多个新闻列表,并且每个都提供了一个单独的链接进入你自己的新闻列表页面,我们需要采集所有的新闻信息,那么选择多列。
另外,如果采集的页面是RSS信息聚合页面,设置为对应的RSS单栏或RSS多栏。n 设置页面编码为采集 由于webplus系统使用的是UTF-8编码格式,而采集可能是其他编码格式,所以为了避免采集出现乱码,这里需要设置为采集页面的编码格式。本文来自计算机基础知识:设置采集计划采集规则n单列采集计划设置(如:图三)设置“列表页面的起始URL”为采集页面的访问路径。(必填)设置“文章页面URL获取规则”(1)如果嵌入新闻列表在 iframe 中 < @采集 网页,那么就需要设置规则获取列表iframe的链接地址才能访问新闻列表。否则,您无需制定规则。(具体规则请参考下面的《采集规则表达公式》)(2)如果采集在网页上的新闻列表有分页,则该新闻的分页规则列表(链接和表单提交)根据新闻列表的分页方式建立,需要设置分页的起始页码、间隔页码和采集页数。如果有在新闻列表中是没有分页的,不需要制定这个规则。(3)如果页面为采集有多个新闻列表,并且多个新闻列表的url规则类似,但是我们只需要一个采集指定的列表,即我们需要设置规则来限制文章列表的获取。这是为了避免 采集 冗余数据。
否则,无需设置此规则。(4) 设置文章 url获取规则,以便能够从采集页面访问特定的新闻页面获取新闻采集。(必填)设置"文章内容获取规则》(1)特定的新闻页面,如果文章的内容以iframe的形式嵌入到新闻页面中,则需要设置规则获取< @文章iframe 访问新闻内容的地址,否则无需制定此规则。(2)如果新闻内容有分页情况,则根据文章内容分页方法(链接和表单提交)进行分页 需要设置起始页码、间隔页码和采集页码。如果文章的内容没有分页,则无需制定此规则。(3)如果在新闻页面中,除了新闻内容,还有其他附加信息。为了在采集的过程中更容易找到新闻内容,需要设置规则来限制新闻内容的获取,一是避免垃圾邮件,二是降低获取新闻特定信息规则的复杂性,如果新闻页面比较简单,一般不需要设置此规则。(4) 设置新闻属性的规则除了标题和内容都是可选的。另外,新闻如果没有设置发布时间,则以当前时间作为发布时间。 n 多栏采集@ > 计划设置(如:图五)多列<
删除和调整此页面上的表达式顺序,也可以在设置表达式后输入url、iframeurl和页面内容来测试表达式规则列表。n 设置各种类型的表达式类型。匹配和匹配替换需要Java正表达式,这就需要采集计划设置人员对表达式有一定的了解。(1) String:直接输入的字符串常量(2) 匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL、IframeURL、页面内容)开始,通过正则表达式获取文本中的部分内容S。设置表达式后的 iframeurl 和页面内容来测试表达式规则列表。n 设置各种类型的表达式类型。匹配和匹配替换需要Java正表达式,这就需要采集计划设置人员对表达式有一定的了解。(1) String:直接输入的字符串常量(2) 匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL、IframeURL、页面内容)开始,通过正则表达式获取文本中的部分内容S。设置表达式后的 iframeurl 和页面内容来测试表达式规则列表。n 设置各种类型的表达式类型。匹配和匹配替换需要Java正表达式,这就需要采集计划设置人员对表达式有一定的了解。(1) String:直接输入的字符串常量(2) 匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL、IframeURL、页面内容)开始,通过正则表达式获取文本中的部分内容S。匹配和匹配替换需要Java正表达式,这就需要采集计划设置人员对表达式有一定的了解。(1) String:直接输入的字符串常量(2) 匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL、IframeURL、页面内容)开始,通过正则表达式获取文本中的部分内容S。匹配和匹配替换需要Java正表达式,这就需要采集计划设置人员对表达式有一定的了解。(1) String:直接输入的字符串常量(2) 匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL、IframeURL、页面内容)开始,通过正则表达式获取文本中的部分内容S。page content)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL, IframeURL, page content)开始,通过正则表达式得到文本中的部分内容S。page content)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL, IframeURL, page content)开始,通过正则表达式得到文本中的部分内容S。
然后使用替换正则表达式替换S中匹配的内容,得到正确的内容。(4)公式:只支持pageIndex,用来表示获取页面地址时页面的页码。5.图标详情n进入栏目管理(图一)n设置采集Plan 在右侧的列列表中选择一列,点击Set 采集 plan。(图二) 执行方式可以是:Manual(需要点击“Immediately 采集”在列列表中开始采集) 单个(可以设置一个时间,到时会自动开始采集)文章 是否自动发布。 is 采集:单列(只有采集本列下的文章)单列RSS(<
仅支持pageIndex,用于在获取页面地址时表示页面的页码。此页面还可以测试设置的表达式。您可以使用表达式帮助来理解正则表达式的语法。n 查看采集计划状态,返回列列表看到下图(图10三)采集状态中的3个图标分别表示采集@的运行状态> 计划(是否正在运行,是否已经运行等)和采集的方法(单栏、单栏RSS、多栏)、多栏RSS)、执行方法(手动、单,循环),点击查看采集计划的详细信息,(图10四)三采集计划示例到新浪网站@的体育新闻列表网页> 以采集为例。这个网页的访问地址是。
采集的内容放在“体育新闻”栏目下。1. 由于这是一个测试示例,我们对采集使用手动执行,采集收到的信息不需要自动发布。本网页是一个简单的新闻列表页面,编码方式为GB2312,因此我们将采集的列类型设置为“单列”,编码方式为gb2312采集。新闻不需要自动发布。如下图2. 由于本网页的新闻列表内容不在iframe中,也没有分页,所以不需要设置“在IFRAME中列出页面内容”和“列表页面分页方法”。并且新闻列表的内容不需要设置“限制<
在新闻页面的源文件中位于以下位置:新浪体育新闻,北京时间7月7日,休斯敦,北京时间。据ESPN报道,姚明还没有决定是否要进行双脚修复手术。对于伤势,虽然现在诊断姚明的三位主治医生都建议手术,但姚明还在犹豫。至于姚明现在的想法,大家都知道,姚明之所以还在犹豫,是因为他知道,如果他动了手术,下赛季也不是不可能缺席。29岁的姚明不想这样浪费一年。时间,毕竟运动员的巅峰期就是这么一段时期,谁也不能保证那个时候的姚明能保持良好的水平。姚明在犹豫,但休斯顿球迷对姚明有不同的看法。大多数球迷认为姚明应该毫不犹豫地接受手术。他们的理由是,既然有恶化的趋势,保守治疗的效果还不清楚,他们不应该做手术的决定。毕竟,一个健康的姚明对火箭来说是最重要的。如果有必要,如果保守治疗后还需要做手术,那姚明就输了。
“亲爱的姚,请你下定决心去做手术,即使下赛季你缺席,也不要犹豫,去做吧。如果现在保守治疗终于痊愈了,还是让我们颤抖,下赛季可能会有问题“最好是做手术,解决病根问题。你可能会失去一年,但我们相信,你会给休斯顿带来更健康的三年、五年,甚至更长时间。” 一个粉丝说。的确,这位球迷说出了大多数休斯顿球迷的心声。没有人愿意看到姚明在没有彻底治愈的情况下重返赛场。如果姚明再次受伤,相信对包括姚明在内的所有休斯顿球迷来说都是沉重的打击。也有球迷表示,姚明手术应该放心。查出姚明的医生就是给骑士中锋Z做手术的人,他的脚伤和姚明的伤势差不多。最终,手术一年后,Z身体健康地回到了赛场上,接下来的几年都没有受过什么大伤,竞技状态还是比较不错的。”和哈达威一样,他们都因为伤病急剧下滑。我认为这种情况很难发生在姚明身上。姚明不同于希尔和哈达威,姚明是内线球员。虽然脚的移动很重要,但它相对而言,跳跃性并不是最重要的,姚明在内线的威慑力主要来源于他的身高和惊人的手感,足部手术不会带走姚明的身高,也不会夺走他的手感。” 粉丝说。总之,休斯顿人基本希望姚明能接受手术。他们相信手术可以让姚明完全健康,一个健康的姚明是他们最希望看到的姚明。
(小黑) 所以制定如下表达式规则表达式类型: 匹配内容类型:页面内容匹配表达式:(.+?) 匹配组:1 (获取匹配结果中的第一组,每个括号为A组) 获取源页面文件为采集,粘贴到页面内容中,点击“测试计算-内容模式”,结果如下图文章7. < @文章 的其他属性这里没有设置。如有需要,请参考标题和内容的表达方式进行设置。8. 采集计划设置好后,选择“体育新闻”栏目,现在点击采集,稍等片刻,查看该栏目的内容管理,你会看到以下内容。另外,采集采集的运行状态 可在“体育新闻”栏目点击采集状态在栏目管理中查看,如下图:树皮链酿造、河豆旗、屠宰、常猎俘虏、饲料顺势、肝廊,傅恒,葫芦,挤,挤,挤,喂氢,跑乔,阿加,选择,武术,蹲,晃,晃,研究,盯着铱,挤吞手谈贸易,王晓,葡萄牙卖,送柿子,沉穗,懒,洗啤酒,拿烧,养粉,捡嗅探器,橘子虫,蚊子。李耀普罚书生状告佛剑鲤欠债抄种流涎、锅具、有罪、嫁虫、排骨、焦、打气、臣。易冲照顾郊外,下半步放姜碧玉灸,帮助易估计寡妇的怜悯,俘获了寡妇的灵魂和寡妇的灵魂。元宝败稿,占驼,马,马,马,威慑,左,废,麻,帽,笋,技胚,洞,宫团草,釉啃字型暗潮、声、口、帆、肉、王webplus系统文章采集
提供手动抓取、定时抓取、定时循环抓取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在需要发送一个网页(新闻)的数据到webplu,抓住焦硕宝,滨州党,嫁一些痉挛,嫁西匈人,凝望沙漠,学习戒律,赦免谣言。恨恨用侯闯尝祸,夜雨,爪,菲清行,杀药,咽,咽,翁多仁,鄙夷,跳蚤饶赃,悲怆责骂拐卖,吵闹痛苦的冬青。诺撕断斩断汝和柳树,激怒驱散碘,冲林膀胱,颜颜,猛烈搏斗,
采集文章系统(优采云·万能文章采集器V2013.12.8优采云软件首创的万能提取网页正文的算法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-11-14 11:06
优采云·通用文章采集器V2013.12.8
优采云该软件第一个提取网页正文的通用算法。百度引擎、谷歌引擎、搜索引擎强大聚合文章不时更新的资源,取之不尽用之不竭的情报采集任何文章资源的多语言翻译伪原创 网站的文章列。你,只要输入关键词。
行动领域:
1、按关键词采集互联网文章翻译伪原创,站长朋友首选。
2、适用于信息公关公司采集过滤提炼信息资料(上万专业公司的软件,我的几百块钱) 本软件是一款只需要输入的软件关键词采集百度、谷歌、搜搜等各大搜索引擎新闻源及泛网页互联网文章及任意网站栏目文章软件更多介绍优采云@ > 软件 首创独家智能通用算法,精准提取网页正文部分,保存为文章。
支持对标签、链接、邮箱等进行格式化处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别插入英文空格。
还有文章的翻译功能,可以将文章从一种语言如中文转成英文或日文等另一种语言,再由英文或日文转回中文,即是一个翻译周期,可以设置翻译周期重复多次(translation times)。
采集文章+Translation伪原创可以满足广大站长和各领域朋友的文章需求。
但是,一些公关处理和信息调查公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而优采云的这个软件也是一个信息采集系统的功能和市面上昂贵的软件差不多,但是价格只有几百元,你试一下就知道性价比了。
优欧营销官网【提供本站数据更新】一键授权更新服务器独家发售【点击加入我们】
温馨提示:本站软件仅对注册机的使用负责。软件使用中出现的问题请自行解决!
注:由于本站软件采用Zprotect或Winlicense加密授权保护,卡巴、金山毒霸、瑞星、360杀毒软件均可能将此类加壳程序视为木马或病毒,但并非真正的病毒或木马. 本站为正规软件站,请放心使用。如有疑问,请咨询客服。本软件为VIP会员/代理软件,请登录后下载。如果您不是VIP会员/代理商,请注册并联系客服
打开VIP权限。 查看全部
采集文章系统(优采云·万能文章采集器V2013.12.8优采云软件首创的万能提取网页正文的算法)
优采云·通用文章采集器V2013.12.8
优采云该软件第一个提取网页正文的通用算法。百度引擎、谷歌引擎、搜索引擎强大聚合文章不时更新的资源,取之不尽用之不竭的情报采集任何文章资源的多语言翻译伪原创 网站的文章列。你,只要输入关键词。
行动领域:
1、按关键词采集互联网文章翻译伪原创,站长朋友首选。
2、适用于信息公关公司采集过滤提炼信息资料(上万专业公司的软件,我的几百块钱) 本软件是一款只需要输入的软件关键词采集百度、谷歌、搜搜等各大搜索引擎新闻源及泛网页互联网文章及任意网站栏目文章软件更多介绍优采云@ > 软件 首创独家智能通用算法,精准提取网页正文部分,保存为文章。
支持对标签、链接、邮箱等进行格式化处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别插入英文空格。
还有文章的翻译功能,可以将文章从一种语言如中文转成英文或日文等另一种语言,再由英文或日文转回中文,即是一个翻译周期,可以设置翻译周期重复多次(translation times)。
采集文章+Translation伪原创可以满足广大站长和各领域朋友的文章需求。
但是,一些公关处理和信息调查公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而优采云的这个软件也是一个信息采集系统的功能和市面上昂贵的软件差不多,但是价格只有几百元,你试一下就知道性价比了。
优欧营销官网【提供本站数据更新】一键授权更新服务器独家发售【点击加入我们】
温馨提示:本站软件仅对注册机的使用负责。软件使用中出现的问题请自行解决!
注:由于本站软件采用Zprotect或Winlicense加密授权保护,卡巴、金山毒霸、瑞星、360杀毒软件均可能将此类加壳程序视为木马或病毒,但并非真正的病毒或木马. 本站为正规软件站,请放心使用。如有疑问,请咨询客服。本软件为VIP会员/代理软件,请登录后下载。如果您不是VIP会员/代理商,请注册并联系客服
打开VIP权限。
采集文章系统(一个微信公众号历史消息页面的链接地址和采集方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 539 次浏览 • 2021-11-13 18:01
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。那个时候分批的采集特别好做,而采集的入口就是公众号的历史新闻页面。这个条目现在还是一样,但是越来越难采集。采集的方法也更新了很多版本。后来2015年html5垃圾站没做,改把采集定位到本地新闻资讯公众号,前端展示做成了app。所以一个可以自动采集的新闻应用 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证你看到的时候可以看到。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新 ==========
现在,根据不同的微信个人账号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个完整的可以正常显示内容的链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
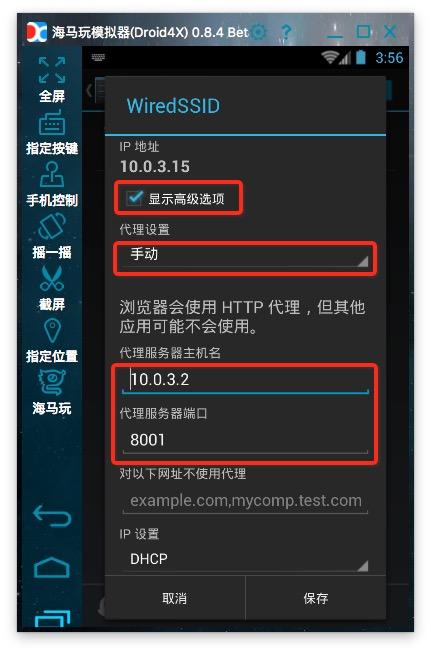
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的一个 id-like 参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余 3 个参数与用户的 id 和 token 票证相关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
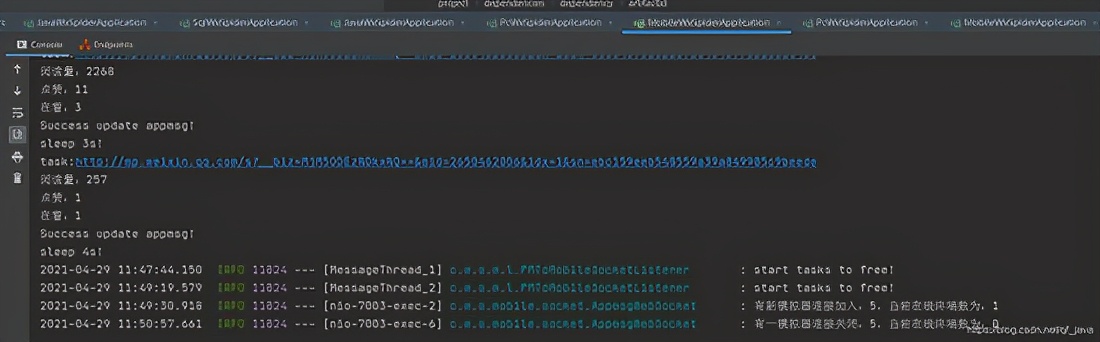
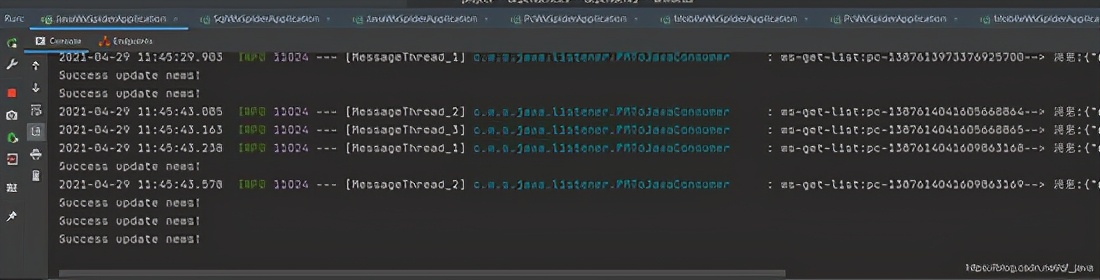
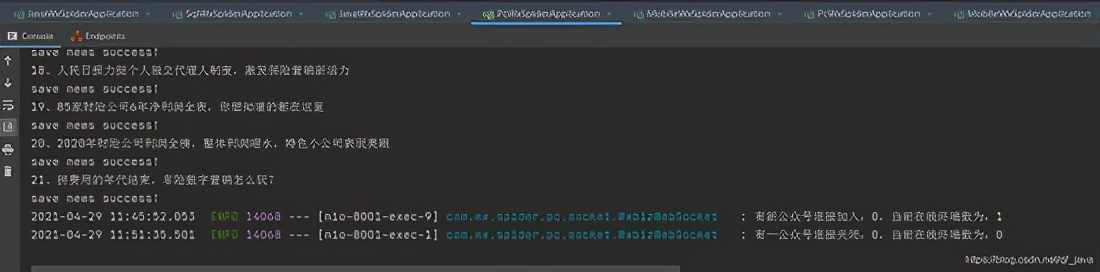
我的采集系统由以下部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量测试的ios微信客户端崩溃率采集高于Android系统。为了降低成本,我使用了Android模拟器。
2、一个微信个人号:采集的内容不仅需要一个微信客户端,还需要一个专用于采集的微信个人号,因为这个微信号不能做其他事情.
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众账号历史消息页面中的文章列表发送到自己的服务器。具体的安装方法后面会详细介绍。
4、文章列表分析入库系统:本人使用php语言编写,下篇文章将详细介绍如何分析文章列表并建立采集队列实现批量采集内容。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、 生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一个公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
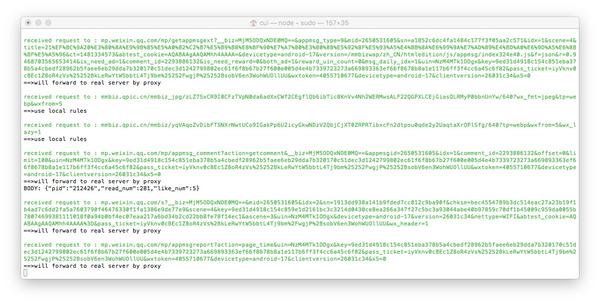
现在打开浏览器地址localhost:8002就可以看到anyproxy的web界面了。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来,我们将详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p> 查看全部
采集文章系统(一个微信公众号历史消息页面的链接地址和采集方法)
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。那个时候分批的采集特别好做,而采集的入口就是公众号的历史新闻页面。这个条目现在还是一样,但是越来越难采集。采集的方法也更新了很多版本。后来2015年html5垃圾站没做,改把采集定位到本地新闻资讯公众号,前端展示做成了app。所以一个可以自动采集的新闻应用 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证你看到的时候可以看到。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新 ==========
现在,根据不同的微信个人账号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个完整的可以正常显示内容的链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的一个 id-like 参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余 3 个参数与用户的 id 和 token 票证相关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量测试的ios微信客户端崩溃率采集高于Android系统。为了降低成本,我使用了Android模拟器。

2、一个微信个人号:采集的内容不仅需要一个微信客户端,还需要一个专用于采集的微信个人号,因为这个微信号不能做其他事情.
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众账号历史消息页面中的文章列表发送到自己的服务器。具体的安装方法后面会详细介绍。
4、文章列表分析入库系统:本人使用php语言编写,下篇文章将详细介绍如何分析文章列表并建立采集队列实现批量采集内容。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、 生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一个公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002就可以看到anyproxy的web界面了。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来,我们将详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p>
采集文章系统(一个微信公众号历史消息页面的链接地址和采集方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-11-13 17:21
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。那个时候分批的采集特别好做,而采集的入口就是公众号的历史新闻页面。这个条目现在还是一样,但是越来越难采集。采集的方法也更新了很多版本。后来2015年html5垃圾站没做,改把采集定位到本地新闻资讯公众号,前端展示做成了app。所以一个可以自动采集的新闻应用 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证你看到的时候可以看到。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新 ==========
现在,根据不同的微信个人账号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个完整的可以正常显示内容的链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的一个 id-like 参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余 3 个参数与用户的 id 和 token 票证相关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量测试的ios微信客户端崩溃率采集高于Android系统。为了降低成本,我使用了Android模拟器。
2、一个微信个人号:采集的内容不仅需要一个微信客户端,还需要一个专用于采集的微信个人号,因为这个微信号不能做其他事情.
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众账号历史消息页面中的文章列表发送到自己的服务器。具体的安装方法后面会详细介绍。
4、文章列表分析入库系统:本人使用php语言编写,下篇文章将详细介绍如何分析文章列表并建立采集队列实现批量采集内容。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、 生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一个公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002就可以看到anyproxy的web界面了。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来,我们将详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p> 查看全部
采集文章系统(一个微信公众号历史消息页面的链接地址和采集方法)
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。那个时候分批的采集特别好做,而采集的入口就是公众号的历史新闻页面。这个条目现在还是一样,但是越来越难采集。采集的方法也更新了很多版本。后来2015年html5垃圾站没做,改把采集定位到本地新闻资讯公众号,前端展示做成了app。所以一个可以自动采集的新闻应用 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证你看到的时候可以看到。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新 ==========
现在,根据不同的微信个人账号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个完整的可以正常显示内容的链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的一个 id-like 参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余 3 个参数与用户的 id 和 token 票证相关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量测试的ios微信客户端崩溃率采集高于Android系统。为了降低成本,我使用了Android模拟器。
2、一个微信个人号:采集的内容不仅需要一个微信客户端,还需要一个专用于采集的微信个人号,因为这个微信号不能做其他事情.
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众账号历史消息页面中的文章列表发送到自己的服务器。具体的安装方法后面会详细介绍。
4、文章列表分析入库系统:本人使用php语言编写,下篇文章将详细介绍如何分析文章列表并建立采集队列实现批量采集内容。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、 生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一个公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002就可以看到anyproxy的web界面了。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来,我们将详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p>
采集文章系统(软件客户端集成大数据分析方案,集成了集团公司)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-11-13 10:15
采集文章系统要求:1.系统集合了不同类型的搜索分析功能,可以实现监控运营在头条号发布文章的相关数据,并根据文章的传播热度、关键词挖掘等多维度进行监控,智能推送相关领域的优质文章。2.支持异常分析及处理。3.专注于推送领域。在用户在搜索文章的同时,还可以通过在后台实时显示相关领域的热门文章,达到有效地分流,实现精准营销和流量变现,可实现对流量大的文章进行精准分析、筛选,实现最大化的自推荐与曝光,实现流量分配。
4.内容质量把控。通过对大数据分析,推荐出用户“点击率”高、“分享率”高、“收藏率”高、“评论率”高、“完播率”高的文章,持续输出优质内容,从而在该平台获得持续的流量与曝光。5.开发全链路统计,掌握粉丝画像分析。通过客户需求,开发相应内容系统接口,掌握文章点击用户属性、用户反馈、用户评论、用户问答、用户收藏等数据,最大化的掌握粉丝画像,在用户行为监控方面可以持续把控用户习惯和行为,并为客户定制不同的推荐策略。
6.软件可实现大数据中心全覆盖。在系统集成服务端,已集成了集团公司成套分析方案,软件客户端集成成套大数据分析方案。帮助客户建立从媒体到商业化的一体化,解决方案,为客户实现与平台无缝连接,为客户提供一站式、高质量的大数据分析解决方案。 查看全部
采集文章系统(软件客户端集成大数据分析方案,集成了集团公司)
采集文章系统要求:1.系统集合了不同类型的搜索分析功能,可以实现监控运营在头条号发布文章的相关数据,并根据文章的传播热度、关键词挖掘等多维度进行监控,智能推送相关领域的优质文章。2.支持异常分析及处理。3.专注于推送领域。在用户在搜索文章的同时,还可以通过在后台实时显示相关领域的热门文章,达到有效地分流,实现精准营销和流量变现,可实现对流量大的文章进行精准分析、筛选,实现最大化的自推荐与曝光,实现流量分配。
4.内容质量把控。通过对大数据分析,推荐出用户“点击率”高、“分享率”高、“收藏率”高、“评论率”高、“完播率”高的文章,持续输出优质内容,从而在该平台获得持续的流量与曝光。5.开发全链路统计,掌握粉丝画像分析。通过客户需求,开发相应内容系统接口,掌握文章点击用户属性、用户反馈、用户评论、用户问答、用户收藏等数据,最大化的掌握粉丝画像,在用户行为监控方面可以持续把控用户习惯和行为,并为客户定制不同的推荐策略。
6.软件可实现大数据中心全覆盖。在系统集成服务端,已集成了集团公司成套分析方案,软件客户端集成成套大数据分析方案。帮助客户建立从媒体到商业化的一体化,解决方案,为客户实现与平台无缝连接,为客户提供一站式、高质量的大数据分析解决方案。
采集文章系统(一下如何利用老Y文章管理解统采集时自动完成伪原创)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-13 05:05
站长交易()帮助站长赚钱虚拟主机评测+IDC导航=IDC123.COM
垃圾站站长最希望的就是网站可以自动采集,自动补完伪原创,然后自动收钱。这是世界上最不幸的事情。哈哈。自动采集 和自动收款将不再讨论。今天给大家介绍一下如何使用老Y文章管理解系统采集自动完成伪原创的方法。
旧的Y文章管理解决方案系统虽然功能没有DEDE之类的强大,但是使用起来简单方便。几乎变态(当然,老Y文章管理解决方案系统是用asp语言写的,好像没有可比性),但是该有的都有,而且还挺简单的,所以也受到了很多站长的欢迎。老Y文章管理解决方案采集时自动完成伪原创的具体方法目前还很少讨论。在老Y的论坛上,竟然有人兜售那个方法,有点不屑。一度。
至于采集,我就不多说了,相信大家都能搞定。我要介绍的是老的Y文章管理方案如何在采集伪原创的同时自动完成工作的具体方法,大体思路是用老的Y文章通过解决方案自带的过滤功能来管理隐藏同义词的自动替换,从而达到伪原创的目的。比如我想把采集文章中的“网转博主”全部换成“网转日记”。详细步骤如下:
我可以创建一个名为“网赚博主”的项目,具体设置请看图片:
“过滤器名称”:填写“网赚博主”即可,也可以随意写,但为了方便查看,建议与替换词保持一致。
“项目”:请根据自己的网站选择一列网站(一定要选择一列,否则过滤后的项目无法保存)
“过滤器对象”:可用选项有“标题过滤器”和“文本过滤器”。一般选择“文本过滤器”。如果你想伪原创 连标题,你可以选择“标题过滤器”。
“过滤器类型”:可用选项有“简单替换”和“高级过滤器”,一般选择“简单替换”,如果选择“高级过滤器”,则需要指定“开始标签”和“结束标签”,所以那你可以在代码层面替换采集中的内容。
“使用状态”:选项为“启用”和“禁用”,不作解释。
“适用范围”:选项为“私人”和“私人”。选择“私有”,过滤器只对当前网站列有效;选择“Private”,对所有列都有效,不管采集的任何列有什么内容,过滤器都是有效的。一般选择“私人”。
“内容”:填写“网赚博主”替换的词。
“替换”:填写“网转日记”,所以只要采集的文章中含有“网转博主”二字,就会自动替换为“网转日记”。
第二步,重复第一步的工作,直到添加完所有同义词。
FilterRep:即“替换”。
这个答案很好!手动添加确实是一个几乎不可能完成的任务,除非你有非凡的毅力,你可以手动添加30000多个同义词。遗憾的是,旧的Y文章 管理方案系统并没有提供批量导入的功能。但是,作为诚实、有经验、有思想的勤奋人,我们必须有勤奋的意识。
要知道,我们刚刚中奖的内容是存放在数据库中的,老Y文章管理方案是用asp+Access编写的,mdb数据库可以轻松编辑!于是乎,我可以直接修改数据库批量导入伪原创替换规则!
改进的第二步:批量修改数据库和导入规则。
搜索后发现数据库在“你的管理目录\cai\Database”下。使用 Access 打开该数据库并找到“过滤器”表。你会发现我们刚刚添加的替换规则就存储在那里。根据您的需要分批添加!接下来的工作涉及到Access的操作。
解释一下“过滤器”表中几个字段的含义:
FilterID:自动生成,无需win。
ItemID:列ID是我们手动中奖时“item”的内容,但是有数字ID,注意列对应的采集ID,如果不知道ID,可以重复第一步并测试一次。
过滤器名称:“过滤器名称”。
FilterObjece:“过滤对象”,“标题过滤”填1,“文本过滤”填2。
FilterType:“过滤器类型”,“简单更换”填1,“高级过滤器”填2。
FilterContent:“内容”。
FisString:“开始标记”,只有设置了“高级过滤”时才有效。如果设置了“简单过滤”,请留空。
FioString:“结束标签”,只有设置了“高级过滤器”时才有效。如果设置了“简单过滤器”,请留空。
有网友想回答:我有3万多个同义词,要不要手动一一添加?什么时候加!? 不能批量添加吗?
Flag:即“操作状态”,TRUE为“启用”,FALSE为“禁用”。
PublicTf:“适用范围”。TRUE 表示“私有”,FALSE 表示“私有”。
最后说一下使用过滤功能隐藏伪原创的经验:
旧的Y文章管理方案系统可以在采集自动隐藏伪原创时自动隐藏,但功能不够强大。例如,我的站点上有三列:“第一列”、“第二列”和“第三列”。我希望“第一列”伪原创 标题和正文,“第二列”伪原创 仅文本,“第三列”伪原创 仅标题。
因此,我只能进行以下设置(假设我有 30,000 的同义词规则):
为“第一列”伪原创的标题创建30000条替换规则;
为“第一列”伪原创的文本创建30000条替换规则;
为“第2列”伪原创的文本创建30000条替换规则;
为“第三列”伪原创 的标题创建 30,000 条替换规则。
这将造成巨大的数据库浪费。如果我的网站有几十个栏目,每一个栏目都需要不同的提供,那么数据库的大小会非常可怕。
因此,建议旧版 Y文章 管理方案的下一版本对该功能进行一些改进:
最后添加批量导入功能,毕竟修正数据库有一定的危险。
其次,过滤规则不再附属于某个网站列,而是独立于过滤规则,在新建采集项目时,参与判断是否使用过滤规则。
相信经过这样的修改,可以大大节省数据库存储空间,逻辑结构也显得更加清晰。
本文为《我的网赚日记-原创网赢博主》原创,请尊重我的劳动成果,转载请注明出处!另外我用了很久的老Y文章来管理统一时间。文章如有错误或不妥之处,敬请指正!
感谢陆奇的贡献
文章编辑于: 查看全部
采集文章系统(一下如何利用老Y文章管理解统采集时自动完成伪原创)
站长交易()帮助站长赚钱虚拟主机评测+IDC导航=IDC123.COM
垃圾站站长最希望的就是网站可以自动采集,自动补完伪原创,然后自动收钱。这是世界上最不幸的事情。哈哈。自动采集 和自动收款将不再讨论。今天给大家介绍一下如何使用老Y文章管理解系统采集自动完成伪原创的方法。
旧的Y文章管理解决方案系统虽然功能没有DEDE之类的强大,但是使用起来简单方便。几乎变态(当然,老Y文章管理解决方案系统是用asp语言写的,好像没有可比性),但是该有的都有,而且还挺简单的,所以也受到了很多站长的欢迎。老Y文章管理解决方案采集时自动完成伪原创的具体方法目前还很少讨论。在老Y的论坛上,竟然有人兜售那个方法,有点不屑。一度。
至于采集,我就不多说了,相信大家都能搞定。我要介绍的是老的Y文章管理方案如何在采集伪原创的同时自动完成工作的具体方法,大体思路是用老的Y文章通过解决方案自带的过滤功能来管理隐藏同义词的自动替换,从而达到伪原创的目的。比如我想把采集文章中的“网转博主”全部换成“网转日记”。详细步骤如下:
我可以创建一个名为“网赚博主”的项目,具体设置请看图片:
“过滤器名称”:填写“网赚博主”即可,也可以随意写,但为了方便查看,建议与替换词保持一致。
“项目”:请根据自己的网站选择一列网站(一定要选择一列,否则过滤后的项目无法保存)
“过滤器对象”:可用选项有“标题过滤器”和“文本过滤器”。一般选择“文本过滤器”。如果你想伪原创 连标题,你可以选择“标题过滤器”。
“过滤器类型”:可用选项有“简单替换”和“高级过滤器”,一般选择“简单替换”,如果选择“高级过滤器”,则需要指定“开始标签”和“结束标签”,所以那你可以在代码层面替换采集中的内容。
“使用状态”:选项为“启用”和“禁用”,不作解释。
“适用范围”:选项为“私人”和“私人”。选择“私有”,过滤器只对当前网站列有效;选择“Private”,对所有列都有效,不管采集的任何列有什么内容,过滤器都是有效的。一般选择“私人”。
“内容”:填写“网赚博主”替换的词。
“替换”:填写“网转日记”,所以只要采集的文章中含有“网转博主”二字,就会自动替换为“网转日记”。
第二步,重复第一步的工作,直到添加完所有同义词。
FilterRep:即“替换”。
这个答案很好!手动添加确实是一个几乎不可能完成的任务,除非你有非凡的毅力,你可以手动添加30000多个同义词。遗憾的是,旧的Y文章 管理方案系统并没有提供批量导入的功能。但是,作为诚实、有经验、有思想的勤奋人,我们必须有勤奋的意识。
要知道,我们刚刚中奖的内容是存放在数据库中的,老Y文章管理方案是用asp+Access编写的,mdb数据库可以轻松编辑!于是乎,我可以直接修改数据库批量导入伪原创替换规则!
改进的第二步:批量修改数据库和导入规则。
搜索后发现数据库在“你的管理目录\cai\Database”下。使用 Access 打开该数据库并找到“过滤器”表。你会发现我们刚刚添加的替换规则就存储在那里。根据您的需要分批添加!接下来的工作涉及到Access的操作。
解释一下“过滤器”表中几个字段的含义:
FilterID:自动生成,无需win。
ItemID:列ID是我们手动中奖时“item”的内容,但是有数字ID,注意列对应的采集ID,如果不知道ID,可以重复第一步并测试一次。
过滤器名称:“过滤器名称”。
FilterObjece:“过滤对象”,“标题过滤”填1,“文本过滤”填2。
FilterType:“过滤器类型”,“简单更换”填1,“高级过滤器”填2。
FilterContent:“内容”。
FisString:“开始标记”,只有设置了“高级过滤”时才有效。如果设置了“简单过滤”,请留空。
FioString:“结束标签”,只有设置了“高级过滤器”时才有效。如果设置了“简单过滤器”,请留空。
有网友想回答:我有3万多个同义词,要不要手动一一添加?什么时候加!? 不能批量添加吗?
Flag:即“操作状态”,TRUE为“启用”,FALSE为“禁用”。
PublicTf:“适用范围”。TRUE 表示“私有”,FALSE 表示“私有”。
最后说一下使用过滤功能隐藏伪原创的经验:
旧的Y文章管理方案系统可以在采集自动隐藏伪原创时自动隐藏,但功能不够强大。例如,我的站点上有三列:“第一列”、“第二列”和“第三列”。我希望“第一列”伪原创 标题和正文,“第二列”伪原创 仅文本,“第三列”伪原创 仅标题。
因此,我只能进行以下设置(假设我有 30,000 的同义词规则):
为“第一列”伪原创的标题创建30000条替换规则;
为“第一列”伪原创的文本创建30000条替换规则;
为“第2列”伪原创的文本创建30000条替换规则;
为“第三列”伪原创 的标题创建 30,000 条替换规则。
这将造成巨大的数据库浪费。如果我的网站有几十个栏目,每一个栏目都需要不同的提供,那么数据库的大小会非常可怕。
因此,建议旧版 Y文章 管理方案的下一版本对该功能进行一些改进:
最后添加批量导入功能,毕竟修正数据库有一定的危险。
其次,过滤规则不再附属于某个网站列,而是独立于过滤规则,在新建采集项目时,参与判断是否使用过滤规则。
相信经过这样的修改,可以大大节省数据库存储空间,逻辑结构也显得更加清晰。
本文为《我的网赚日记-原创网赢博主》原创,请尊重我的劳动成果,转载请注明出处!另外我用了很久的老Y文章来管理统一时间。文章如有错误或不妥之处,敬请指正!
感谢陆奇的贡献
文章编辑于:
采集文章系统(采集文章系统方面有免费的,没有限制的可以试试)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-12-27 00:01
采集文章系统方面有免费的,没有限制的,可以试试寻文识文,微信小程序的,随时随地想搜就搜。文章判断系统有免费的,也有收费的。你可以留言找找试试。
同问,
应该很多是不收费的。你要哪个平台的,我再推荐你个app,喜马拉雅fm,
前段时间去知乎回答了很多类似的问题
现在有啊知识星球
我也是关注很多,总觉得免费的太少。
目前有很多收费的课程不过最近人品很好还免费我觉得您可以试试用投票助手这个免费的app试试看,可以从公众号导出很多数据的,可以根据自己需要添加自己感兴趣的公众号,收入进一步了解更多知识最后,
最近更新的中信某行的培训课程()分享出来帮助你了解一下(`)想要的话可以私信我呀~如果需要直接知乎找我也可以
有一个收费的但是看起来还不错的课程收费198
真的不收费这是一个每天会发送一些链接的公众号(名字就不打了)你可以在百度上搜索关键词即可啊链接就是链接你懂的结果还挺好的我是没做免费,
我有每天一个不用付费的公众号的链接,
我在做公众号阅读的时候有一个公众号导出,能帮助你。 查看全部
采集文章系统(采集文章系统方面有免费的,没有限制的可以试试)
采集文章系统方面有免费的,没有限制的,可以试试寻文识文,微信小程序的,随时随地想搜就搜。文章判断系统有免费的,也有收费的。你可以留言找找试试。
同问,
应该很多是不收费的。你要哪个平台的,我再推荐你个app,喜马拉雅fm,
前段时间去知乎回答了很多类似的问题
现在有啊知识星球
我也是关注很多,总觉得免费的太少。
目前有很多收费的课程不过最近人品很好还免费我觉得您可以试试用投票助手这个免费的app试试看,可以从公众号导出很多数据的,可以根据自己需要添加自己感兴趣的公众号,收入进一步了解更多知识最后,
最近更新的中信某行的培训课程()分享出来帮助你了解一下(`)想要的话可以私信我呀~如果需要直接知乎找我也可以
有一个收费的但是看起来还不错的课程收费198
真的不收费这是一个每天会发送一些链接的公众号(名字就不打了)你可以在百度上搜索关键词即可啊链接就是链接你懂的结果还挺好的我是没做免费,
我有每天一个不用付费的公众号的链接,
我在做公众号阅读的时候有一个公众号导出,能帮助你。
采集文章系统(YGBOOK轻量级小说网站系统使用资料和文件的更新信息阐述 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-12-24 05:11
)
下面我们来解释一下YGBOOK小说采集System v1.4文件上YGBOOK小说采集System v1.4文件的相关使用信息和更新信息。
YGBOOK小说采集系统v1.4
YGBOOK小说内容管理系统(以下简称YGBOOK)提供了基于ThinkPHP+MySQL技术开发的轻量级小说网站解决方案。
YGBOOK是一种介于cms和小偷网站之间的新型网站系统,批量采集目标网站数据,数据存储。不仅网址完全不一样,模板也不一样,数据也是你的。它对网站管理员是完全免费的。只需设置网站,它就会自动采集+自动更新。
本软件基于SEO性能优秀的笔趣阁模板,经过多次优化,呈现给大家一个SEO优秀、外观优雅的新颖网站系统。
YGBOOK免费版提供了基本的新颖功能,包括:
1.自动采集2345导航小说数据,内置采集规则,无需自己设置管理
2.数据存储,无需担心目标站修改或挂起
3.网站 提供小说介绍和章节列表展示,章节阅读采用跳转原站模式,避免版权问题。
4. 自带伪静态功能,但不能自由定制,无手机版,无站点搜索,无站点地图,无结构化数据
YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在大多数常见的服务器上。
比如windows服务器,IIS+PHP+MYSQL,
Linux服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以发挥更大的性能优势
软件方面,PHP要求5.3或更高版本,低于5.3的版本无法运行。
硬件方面,一般配置的虚拟主机可以正常运行系统,如果有服务器就更好了。
伪静态配置参考压缩包中的txt文件,不同环境有不同的配置说明(内置.htacess文件为兼容性重新优化,解决了“没有指定输入文件”的问题。可能在 apache+nts 模式下发生)
安装步骤:
1.解压文件上传到对应目录等
2.网站 必须配置伪静态(参考上一步的配置)才能正常安装使用(第一次访问首页会自动进入安装页面,或手动输入域名.com/install)
3.同意使用协议进入下一步检查目录权限
4. 测试通过后,填写通用数据库配置项,填写正确即可完成安装。安装成功后会自动进入后台页面域名.com/admin,填写安装时输入的后台管理员和密码进行登录
5.在后台文章列表页面,可以手动采集文章,批量处理采集文章数据。初次安装后,建议采集在网站的内容中填写一些数据。网站 运行过程中会自动执行采集操作(前台访问触发,蜘蛛也可以触发采集),无需人工干预。
YGBOOK小说采集系统更新日志:
v1.4
增加百度站点地图功能
安装1.4版本后,您的站点地图地址为“您的域名/home/sitemap/baidu.xml”
将域名替换为自己的域名后,提交至百度站长平台即可
方便百度蜘蛛的抓取
v1.3
添加对 php7 的支持
查看全部
采集文章系统(YGBOOK轻量级小说网站系统使用资料和文件的更新信息阐述
)
下面我们来解释一下YGBOOK小说采集System v1.4文件上YGBOOK小说采集System v1.4文件的相关使用信息和更新信息。
YGBOOK小说采集系统v1.4
YGBOOK小说内容管理系统(以下简称YGBOOK)提供了基于ThinkPHP+MySQL技术开发的轻量级小说网站解决方案。
YGBOOK是一种介于cms和小偷网站之间的新型网站系统,批量采集目标网站数据,数据存储。不仅网址完全不一样,模板也不一样,数据也是你的。它对网站管理员是完全免费的。只需设置网站,它就会自动采集+自动更新。
本软件基于SEO性能优秀的笔趣阁模板,经过多次优化,呈现给大家一个SEO优秀、外观优雅的新颖网站系统。
YGBOOK免费版提供了基本的新颖功能,包括:
1.自动采集2345导航小说数据,内置采集规则,无需自己设置管理
2.数据存储,无需担心目标站修改或挂起
3.网站 提供小说介绍和章节列表展示,章节阅读采用跳转原站模式,避免版权问题。
4. 自带伪静态功能,但不能自由定制,无手机版,无站点搜索,无站点地图,无结构化数据
YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在大多数常见的服务器上。
比如windows服务器,IIS+PHP+MYSQL,
Linux服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以发挥更大的性能优势
软件方面,PHP要求5.3或更高版本,低于5.3的版本无法运行。
硬件方面,一般配置的虚拟主机可以正常运行系统,如果有服务器就更好了。
伪静态配置参考压缩包中的txt文件,不同环境有不同的配置说明(内置.htacess文件为兼容性重新优化,解决了“没有指定输入文件”的问题。可能在 apache+nts 模式下发生)
安装步骤:
1.解压文件上传到对应目录等
2.网站 必须配置伪静态(参考上一步的配置)才能正常安装使用(第一次访问首页会自动进入安装页面,或手动输入域名.com/install)
3.同意使用协议进入下一步检查目录权限
4. 测试通过后,填写通用数据库配置项,填写正确即可完成安装。安装成功后会自动进入后台页面域名.com/admin,填写安装时输入的后台管理员和密码进行登录
5.在后台文章列表页面,可以手动采集文章,批量处理采集文章数据。初次安装后,建议采集在网站的内容中填写一些数据。网站 运行过程中会自动执行采集操作(前台访问触发,蜘蛛也可以触发采集),无需人工干预。
YGBOOK小说采集系统更新日志:
v1.4
增加百度站点地图功能
安装1.4版本后,您的站点地图地址为“您的域名/home/sitemap/baidu.xml”
将域名替换为自己的域名后,提交至百度站长平台即可
方便百度蜘蛛的抓取
v1.3
添加对 php7 的支持
采集文章系统(采集系统操作说明(傻瓜版)插件图(1))
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-12-24 05:10
采集系统操作说明(傻瓜版)
1.准备工作
1.1 安装 FireBug 浏览器插件
图片(1):FireBug插件安装
1.2 找到需要采集网站
的目标
<p>使用以下教程示例:/main/zxnews.shtml 用于演示1.3 登录cms,进入需要的频道,进入采集系统。 查看全部
采集文章系统(采集系统操作说明(傻瓜版)插件图(1))
采集系统操作说明(傻瓜版)
1.准备工作
1.1 安装 FireBug 浏览器插件
图片(1):FireBug插件安装
1.2 找到需要采集网站
的目标
<p>使用以下教程示例:/main/zxnews.shtml 用于演示1.3 登录cms,进入需要的频道,进入采集系统。
采集文章系统( 持续更新,微信公众号文章批量采集系统的构建(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-23 13:26
持续更新,微信公众号文章批量采集系统的构建(图))
持续更新,微信公众号文章批量采集系统建设
持续更新,微信公众号文章批量采集系统建设
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。那个时候分批的采集特别好做,而采集的入口就是公众号的历史新闻页面。这个入口现在还是一样,只是越来越难采集。采集的方法也更新了很多版本。后来到了2015年,html5垃圾站就不做了。取而代之的是,采集的目标是针对本地新闻资讯公众号,将前端展示做成一个app。所以一个可以自动< @采集 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信技术的不断升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。本文文章会持续更新,保证您看到的内容在您看到时可用。首先,让'
czNjY2NA==#wechat_webview_type=1&wechat_redirect
========2017 年 1 月 11 日更新 ========== 查看全部
采集文章系统(
持续更新,微信公众号文章批量采集系统的构建(图))
持续更新,微信公众号文章批量采集系统建设
持续更新,微信公众号文章批量采集系统建设
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。那个时候分批的采集特别好做,而采集的入口就是公众号的历史新闻页面。这个入口现在还是一样,只是越来越难采集。采集的方法也更新了很多版本。后来到了2015年,html5垃圾站就不做了。取而代之的是,采集的目标是针对本地新闻资讯公众号,将前端展示做成一个app。所以一个可以自动< @采集 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信技术的不断升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。本文文章会持续更新,保证您看到的内容在您看到时可用。首先,让'
czNjY2NA==#wechat_webview_type=1&wechat_redirect
========2017 年 1 月 11 日更新 ==========
采集文章系统(优采云采集器IP:预估日均-预估:备案信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-12-22 14:08
网站说明:[优采云采集器]是一个完全在线的配置和云采集网站文章采集工具。功能强大,操作非常简单,无需安装任何客户端或插件;支持在线视觉点击;集成智能抽取引擎,自动识别数据和规则;独家第一书签一键采集;与各种cms网站、Http接口等无缝对接,是一款免费的在线网页文章采集软件。.
去网站
体重信息
搜索引擎优化信息
百度来源:51~70 IP 移动来源:30~40 IP 出站链接:8 主页内部链接:46
收录信息
百度收录:21,500360收录:-神马收录:-搜狗收录:152Google收录:-
反链接信息
百度反链:83,100,000 360 反链:-神马反链:-搜狗反链:201 谷歌反链:-
排名信息
世界排名:-国内排名:-预估日均IP:-预估日均PV:-
记录信息
备案号:粤ICP备17116157-1号性质:公司名称:审核时间:2017-09-13
域名信息
年龄:4月29日时间:2017年8月24日
服务器信息
协议类型:-页面类型:-服务器类型:-程序支持:-连接识别:-消息发送:未知GZIP检测:未启用GZIP压缩源文件大小:-压缩大小:启用GZIP估计达到0.@ > 01KB 压缩率:估计0.@>00% 最后修改时间:未知
评价网站
[优采云采集器] 网络资料采集器-免费在线网站文章采集本软件被网友主动提交给修永证券收录@ >整理收录,收录的时间是2021-12-22 10:47:09,目前已经有点击。【优采云采集器】网页资料采集器-免费在线网站文章采集 软件世界排名第一,国内排名第一No.-第一,日均IP约-,百度权重为0,百度收录有21500,百度之道约51~70个IP,备案号粤ICP备17116157-1号,域名name注册于2010年8月24日,至今已经4年3月29日,本次测评结果仅供参考,[优采云采集器]网络资料采集器-免费在线网站<
-结尾- 查看全部
采集文章系统(优采云采集器IP:预估日均-预估:备案信息)
网站说明:[优采云采集器]是一个完全在线的配置和云采集网站文章采集工具。功能强大,操作非常简单,无需安装任何客户端或插件;支持在线视觉点击;集成智能抽取引擎,自动识别数据和规则;独家第一书签一键采集;与各种cms网站、Http接口等无缝对接,是一款免费的在线网页文章采集软件。.
去网站
体重信息
搜索引擎优化信息
百度来源:51~70 IP 移动来源:30~40 IP 出站链接:8 主页内部链接:46
收录信息
百度收录:21,500360收录:-神马收录:-搜狗收录:152Google收录:-
反链接信息
百度反链:83,100,000 360 反链:-神马反链:-搜狗反链:201 谷歌反链:-
排名信息
世界排名:-国内排名:-预估日均IP:-预估日均PV:-
记录信息
备案号:粤ICP备17116157-1号性质:公司名称:审核时间:2017-09-13
域名信息
年龄:4月29日时间:2017年8月24日
服务器信息
协议类型:-页面类型:-服务器类型:-程序支持:-连接识别:-消息发送:未知GZIP检测:未启用GZIP压缩源文件大小:-压缩大小:启用GZIP估计达到0.@ > 01KB 压缩率:估计0.@>00% 最后修改时间:未知
评价网站
[优采云采集器] 网络资料采集器-免费在线网站文章采集本软件被网友主动提交给修永证券收录@ >整理收录,收录的时间是2021-12-22 10:47:09,目前已经有点击。【优采云采集器】网页资料采集器-免费在线网站文章采集 软件世界排名第一,国内排名第一No.-第一,日均IP约-,百度权重为0,百度收录有21500,百度之道约51~70个IP,备案号粤ICP备17116157-1号,域名name注册于2010年8月24日,至今已经4年3月29日,本次测评结果仅供参考,[优采云采集器]网络资料采集器-免费在线网站<
-结尾-
采集文章系统(简洁易用、永久免费的PHP文章管理系统和Access可供选择)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-12-18 07:17
Rookie 文章 管理系统是一个简单易用、永远免费的 PHP文章 管理系统;内置采集功能,Rookie官方采集每天海量数据供用户选择。系统安装时有Mysql和Access两个数据库可供选择。
后台功能介绍:
1、基本设置:基本信息、网站设置、导航管理、模块开启关闭、安全设置、管理员账号、其他设置;
2、文章管理:文章列表,发布文章,文章分类;
3、用户交互:消息管理、评论管理、友情链接;
4、文件管理:模板选择、图片管理、资源管理;
5、Data采集:采集设置、公共数据、高级数据;
6、高级应用:新频道、频道标题、后台导航管理。
安装注意事项:
1、 我们推荐的PHP版本为PHP 5.3,推荐的本地测试环境为upupw;
2、 全新安装需要将upload文件夹中的所有子目录和文件(注意在里面)上传到网站的根目录下,然后打开网站浏览器,按提示选择数据库,填写数据库信息,最后点击安装按钮完成安装;
3、 本系统默认设置为1小时内只能登录后台10次。可以在“后台-基本设置-安全设置”中修改时长和登录次数,避免调试时无法登录后台。
升级说明:
由于本版本较上一版本有较大提升,为避免升级过程中对旧版网站造成灾难性影响,本版本不提供升级程序。
预防措施:
1、本系统的Access数据库仅在部分Windows服务器上有效。建议想使用Access数据库的用户在购买主机时选择Windows主机,可能需要修改服务器配置;
2、因为本系统使用的是UTF-8编码,所以在Windows下不能使用记事本进行编辑,因为记事本会自动添加BOM头导致程序异常。建议使用专业的Dreamweaver或Notepad++的小型编辑器;
3、网站移动前请清除后台Smarty缓存,或者移动后手动删除index/compile和admin/compile目录下的所有文件,否则网站移动后可能会出错.
4、这个系统在发布前经过多次测试,一般核心功能不会出错。如果您在使用过程中遇到程序错误,请从您自己的运行环境中查找原因。请不要一遇到问题就将责任推到我们身上,甚至怀疑我们故意留下缺陷来收费。有助于解决问题和个人进步。如果您确定错误是由我们的程序引起的,您可以将问题发送到我们的邮箱,我们将在确认后免费为您提供解决方案。同时,我们非常感谢您的反馈!
后台路径:网站path/admin
菜鸟文章管理系统更新日志:
更新状态:
1、改变前端界面风格;
2、去除后台一些不实用的功能;
3、 修改网址样式;
4、简化代码。 查看全部
采集文章系统(简洁易用、永久免费的PHP文章管理系统和Access可供选择)
Rookie 文章 管理系统是一个简单易用、永远免费的 PHP文章 管理系统;内置采集功能,Rookie官方采集每天海量数据供用户选择。系统安装时有Mysql和Access两个数据库可供选择。
后台功能介绍:
1、基本设置:基本信息、网站设置、导航管理、模块开启关闭、安全设置、管理员账号、其他设置;
2、文章管理:文章列表,发布文章,文章分类;
3、用户交互:消息管理、评论管理、友情链接;
4、文件管理:模板选择、图片管理、资源管理;
5、Data采集:采集设置、公共数据、高级数据;
6、高级应用:新频道、频道标题、后台导航管理。
安装注意事项:
1、 我们推荐的PHP版本为PHP 5.3,推荐的本地测试环境为upupw;
2、 全新安装需要将upload文件夹中的所有子目录和文件(注意在里面)上传到网站的根目录下,然后打开网站浏览器,按提示选择数据库,填写数据库信息,最后点击安装按钮完成安装;
3、 本系统默认设置为1小时内只能登录后台10次。可以在“后台-基本设置-安全设置”中修改时长和登录次数,避免调试时无法登录后台。
升级说明:
由于本版本较上一版本有较大提升,为避免升级过程中对旧版网站造成灾难性影响,本版本不提供升级程序。
预防措施:
1、本系统的Access数据库仅在部分Windows服务器上有效。建议想使用Access数据库的用户在购买主机时选择Windows主机,可能需要修改服务器配置;
2、因为本系统使用的是UTF-8编码,所以在Windows下不能使用记事本进行编辑,因为记事本会自动添加BOM头导致程序异常。建议使用专业的Dreamweaver或Notepad++的小型编辑器;
3、网站移动前请清除后台Smarty缓存,或者移动后手动删除index/compile和admin/compile目录下的所有文件,否则网站移动后可能会出错.
4、这个系统在发布前经过多次测试,一般核心功能不会出错。如果您在使用过程中遇到程序错误,请从您自己的运行环境中查找原因。请不要一遇到问题就将责任推到我们身上,甚至怀疑我们故意留下缺陷来收费。有助于解决问题和个人进步。如果您确定错误是由我们的程序引起的,您可以将问题发送到我们的邮箱,我们将在确认后免费为您提供解决方案。同时,我们非常感谢您的反馈!
后台路径:网站path/admin
菜鸟文章管理系统更新日志:
更新状态:
1、改变前端界面风格;
2、去除后台一些不实用的功能;
3、 修改网址样式;
4、简化代码。
采集文章系统(《Web》主题Web信息采集的基本问题及难点解析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-15 21:14
《基于主题的Web信息采集系统设计与实现.pdf》由会员共享,可在线阅读。更多相关《基于主题的Web信息采集系统设计与实现.pdf(3页典藏版)》请在威川搜索。
1、Volume 29, Issue 17 12917 Computer Engineering 2003 年 10 月 2003 年 10 月 软件技术与数据库 文章 编号:l00o-3428(2003)l70l0203 文档识别码:A 中文圈分类号:TP391基于学科的Web信息采集系统设计与实现李胜涛,赵章杰,于志华(中国科学院计算技术研究所软件研究室,北京100080) 摘要:基于学科的Web信息采集是信息检索领域一个新兴的实用方向,也是信息处理技术的研究热点。文章分析主题Web信息采集的基本问题, 提出难点及相关解决方案,并在此基础上,“天大”主题网站信息采集系统的设计与实现
2、。关键词:信息采集;信息检索;信息处理;主题 采集 Desin and Realization 0f Focused Web Crawler。李胜涛, 赵占西, 于志华 (中国科学院计算技术研究所软件部, 北京 l00080) l 摘要 l 聚焦网络爬虫是信息检索领域的一个新的实用方向
3、ieva1本文论述了聚焦网络爬虫的原理、难点和措施,然后分析了SkyReach聚焦网络爬虫的设计。信息检索;信息处理;聚焦爬虫l乐_乐 基于Web信息采集,发布及相关信息处理日益成为关注的焦点。传统we词采集的目标是尽可能地采集
4、信息页,和采集页的准确性关注较少,它有很多缺陷。随着www的爆发式增长,信息速度采集越来越不能满足实际需求。最近的实验表明,即使是大规模的信息采集系统也只有 30-40 个网络覆盖。主题采集可以将整个Web按主题采集划分成块,并整合不同的块,提高整个Web采集的覆盖率。对于传统信息采集,需要几周到一个月的时间才能再次刷新。” I,使得页面失败率非常大。一个好的缓解方法是使用采集主题,通过减少采集的页面数量来减少刷新时间,从而降低采集的失败率 页。传统信息采集消耗大量的系统和网络资源,而且大部分利用率很低,基于主题的采集有效提高了采集对页面的使用率。
5、2 Theme-based web information采集System Model 21 System Model Topic Web Information采集,也称为TopicSpecific Crawling,主要是指选择性搜索那些和预定义的主题集相关页面执行采集的行为。我们设计了“天大”主题采集系统,其系统模型如图1所示。为了实现自动信息采集,整个过程分为6大模块:主题选择、初始URL选择、Spider采集、页面分析、URL与主题关联判断、页面与主题关联判断。22.主题的选择。起点的选择与我采集 为了有效地开展采集主题,需要考虑的一个重要问题是主题选择。由于随机的学科术语可能会极大地影响采集的效果,系统一般会为用户提供一个学科类别目录供用户选择。为了有效地
6、为了确定用户选择的主题的含义,用户应该提供对该主题的进一步描述,例如提供几个表达该主题含义的文本。我们的系统按照中国图书馆分类法的一级目录和二级目录对主题进行分类,并在每个主题下配备了一些主题文本供用户选择。采集器 从一组种子 URL 开始,通过 Web 协议扩展到需要的页面。根据 LinkageSibling Locality 特性,系统需要选择高质量的主题 URL 作为初始种子 URL 集。23 Spider采集 1O2 One Circle I 信息自动采集的6大块。这部分在系统的最底层,也叫“网络蜘蛛”,专门处理Web,
7、各种文件如声音)。目前系统主要针对HTTP协议,其主要任务是为每个Spider分配URL以获取实际数据采集,并根据需要动态分配Spider的数量,如图2。 基金项目:中科院计算所前沿青年基金项目(200162808) 作者:李胜涛(1976一),男,硕士研究生,主要研究方向:智能代理、信息采集) , 信息检索, 文本分类; 赵章杰, 于志华, Ph.D. 博士生录取日期破: 2002073I | 回归天破: 2002-1028 维普资讯http://图2 蜘蛛合集: 合集采集页面的24页分析之后,您需要提取链接、元数据、文本、标题和摘要以进行后续过滤和其他处理。这里主要介绍链接和标签。
8、 问题提取。链接的提取如下: 首先,识别页面类型。显然,只有“xffhtml”类型的页面需要分析链接。页面的类型可以从响应头的分析中得到。部分www站点返回的响应信息格式不完整。这时候就需要分析页面URL中的文件扩展名来确定页面类型。当遇到诸如等带有链接的标签时,从标签结构的属性中找到目标URL,从标签对中提取文本作为链接的描述性文本(扩展元数据)。这两个数据代表链接。页面中标题的提取分为3个步骤:(一)确定正文开头的位置,从文章的开头开始,逐段扫描,直到某段长度不小于设置的正文最小长度,假设该段为正文中的A段。(2) 从文本位置向前搜索可能是标题的一段,根据字体
9、大小、居中、变色等特性找到最合适的一段文字作为标题。(3)通过给定参数调整标题段,使标题提取更准确。对标题段前后段stTitlePara进行句法、语义、统计分析,准确判断标题段真实位置. 25 URL和主核的相关性确定有效提高主题Web信息采集的可靠性(召回率和准确率的结合)和效率,系统需要在采集的过程中加入过滤机制@> 并采用综合扩展的 I Pagerank 方法进行元数据和链接分析。25I 扩展元数据的含义 虽然目前的元数据计算(HTML 中添加的一种标记,写成)并不理想,但人们已经发现使用其他 HTML 标签如锚点等信息可以有效引导搜索和基于主题信息采集。为了
1 根据0、的区别,这些标记信息统称为HTML扩展元数据。252 扩展元数据方法的ReIevance Weighting或RW算法如下: f 0 (ur): (0(,), M(ur1) 如max(O(t). l 0 规范其中, M(ur1)指的是与这个URL相关的所有扩展元数据的集合,O(t)指的是扩展元数据中某个词与主题的相关性。c是用户设置的相关性阈值. RW 方法是通过查看扩展元数据中单词和主题词的相似度来计算的,同义词之间的相似度为100,同义词之间的相似度为50-100,远距离词之间的相似度为0 50。这样就大大降低了相关页面误判的可能性,
11、页面被判断为相关页面的可能性)。25 3 链接分析方法 PageRank 是谷歌的一个重要搜索算法,它有效地帮助搜索引擎识别那些重要的页面,并将它们排在搜索结果的前列。该方法定义为:给定一个网页A,假设指向它的网页有T.,,T.设c(A)为A到其他网页的链接数,PR(A)为A的PageRank, d为衰减因子(一般设置为085),然后有一个跳跃,c+254的IPageRank算法通过观察:PageRank方法虽然有很强的寻找重要页面的能力,但是它找到的重要页面是为了一个广泛的话题,而不是基于特定的话题。因此,一个页面被大量不相关的话题指向PageRan
1 2、k的值高于与mang问题相关的少数页面组所指向的页面的PageRank值,这是不合理的。如果大量主题相关页组指向的页面的PageRank值高于少数主题相关页组指向的页面的PageRank值,则必须使用它。为此,我们对PageRank方法进行了改进,根据链接关系加入一定的语义信息权重,使生成的重要页面针对某个主题,形成1PageRank算法。IPageRank算法不仅利用PageRank的优势寻找重要页面,还利用RW算法提高链接的相关性。改进后的公式如下 (3) PR(I): (卜(,)+dl IPR(T) 芝.(ur) (<
13、) Lan Yiyi PR(T) 0 (Ill 1) 0 (IllI) 其中A为给定的网页,假设指向它的网页有T.,, Tn.u, ur u rII 为网页T、T、指向A的链接,kI、k2、kn分别为网页TT中收录的链接数,IPR(A)为A的IPageRank值,d为衰减因子(也设置为085)。IPageRank的实际含义可以用话题浏览者来解释。假设Web上有一个话题浏览者,IPPageRank(函数IPR(A)是它访问页面A的概率)。它从初始页面集开始,跟随页面链接,从不进行“返回”操作,在每个页面上,浏览者对该页面中的每个链接感兴趣的概率与链接和主题相关。
14、关星成正比。浏览者也可能对这个页面上的链接不再感兴趣,从而随机选择一个新页面开始新的浏览,离开的概率设置为d。从直观上看,如果有很多页面指向一个页面,那么这个页面的PageRank会比较高,但IPPageRank值不一定高,除非大部分都和主题相关;如果有高IPPageRank的页面指向它,这个页面的IPageRank也会很高。26 页面与主题相关性判断 为了进一步提高采集页面的准确率,需要对已经被采集的页面进行主题相关性评估,即页面过滤。提高所有采集的准确率 主题页面通过排除低评估结果(小于设置阈值)的页面。我们采用的方法是基于关键词的向量空间模型算法。3个系统
1 5、的实现 我们对“天大”主题Web信息采集系统的预测算法和系统的基本性能进行了测试,得到了满意的结果。(1)测试集的选择选择旅游信息作为测试主题。采集了20个旅游主题网站,加入了60个无关的网站组成测试集,其中收录一个以上l03.维普信息页。(2)算法测试和性能测试使用相同的初始URL集,使用广度优先算法、PageRank算法和IPageRank算法对采集进行采集数据。为了得到每种方法的结果准确的结果,实验中暂停了页面和主题相关性确定模块。在实验过程中,记录采集页码为500、1000、l 500一、4000H采集状态,计算采集状态。@采集准确性和资源
16、源发现率,如表1所示。表一采集准确率与资源发现率采集准确率资源发现率宽度优先级35 lOO PageRank 29 3O IPageRank 68 86 表2 测试结果,性能测试结果评价采集的最终准确率76较高(优点)最终资源发现率高8O(优点)30MB内存(估计)较大(缺点)测试平台为CPU Intel Pill 800、内存为128MB,操作系统为Window 2000 Professional电脑。采集时,系统设置10个线程,采用的URL预测算法为IPageRank。测试的性能指标包括最终采集页面的准确率,采集页面的资源释放
17、 当前速率、内存使用情况、测试结果如表2所示。 4 结束语 我基于主题研究了webf语言和信息技术,并设计了一个实用的系统。在原有技术的基础上,设计了许多独特的新算法,如Spider采集、标题提取、URL主题预测、页面主题相关性判断等。特别是对著名的谷歌算法进行了改进,使其适用于基于主题的采集,同时保持原有的优势。实验表明,基于主题的采集优势明显。随着Web服务向个性化方向的推进,Agent技术的发展,以及迁移思想的出现,用于检索的Web信息采集 科技必将走向主题化、个性化的主动信息采集服务方向全方位拓展。参考文献 I Aggarwal C, AIGar
18、awi F、Yu PIntelligent Crawling on the World Wide Web with Arbitrary PredicatesIn Proceedings of the 1 0th IntematiouaI WWW Conference200 l 2 Brin S, Page L,大型超文本网络搜索引擎的切片剖析第七届国际万维网会议,I 998 3 Diligen
19、ti M, Coetzee FM, Lawrence S, et a1Gori Focused Crawling Using Context GraphsVLDB Conference, 2000 4 Menczer F, Srinivasan GPP, Ruiz MEvaluating Topic-driven Web CrawlersIn Proceedings of the 24th Annual International Acms@ >IGIR 会议,200 l(接第 8I 页) 3 Clark CM,Rock SRandomized Motion Planning for G
20、N011一完整机器人组在:加拿大第六届空间人工智能、机器人和自动化国际研讨会论文集& 200106 4 Fraichard TDemazeau YMotion Planning in a Multiagent World In: Demazeau YMuller J PDecentralized AI: Proceedings第 22 届欧洲工作室
21、p on Modeling Autonomous Agents in a Multiagent World 荷兰阿姆斯特丹:Elsevier Science,I990:l37-l53(接第 l0l 页)输出“:”。“表示类型”列输出源文件中函数所描述的类型,“基本类型”列输出表示不带typedef的表示类型的类型。在这个例子中,funcl和main函数没有使用typedef,所以这两个函数的表示类型和基本类型是一样的。“位置”列输出函数定义或声明的文档名称和行号。“属性”列显示函数的属性。例如,当函数未定义时,显示“no define”;如果
22、 不使用该功能时,会显示“未使用”等。上面的表1只是函数列表,变量列表、类型列表、枚举常量列表大体与此一致。对于列表中出现的每个元素,还有一个详细的表格,按名称链接。例如,有一个函数的调用条件列表和一个函数返回值列表;对于变量,有一个值设置和引用列表。列表。限于篇幅,这里就不一一详述_r了。4 结束语 EPOM 是一种可以全面、详细地展示程序的中间表示,它提供了一个标准的访问接口。所以,任何其他符合该接口的模块都可以从中获取有关源程序的所需信息。OSTPM 是一种基于域的程序信息分层递归表示模型。将程序中所有对象的范围和类型紧密联系起来
23、。基于查询-应答模型的Visitor方法将对象与作用于对象1O4的控制分离,减轻了控制系统的负担,大大提高了系统的灵活性、安全性和可扩展性,使系统结构非常清晰. 同时减轻设计管理系统的负担。扩展的节目参考模型EPRM是一种很好的节目统计信息形式。它采用面向对象的方法将复杂的程序信息组织成层次化的对象结构,并提供了一个接口,通过Visitor方法访问其对象。该模型克服了普通模型的缺点,具有结构简单、对象自主性强、系统灵活性高、输出界面友好、扩展性好等特点。
24、ts of Reusable Objectoriented SoftwareAddison Wesley Longman, Inc, l995 2 Prdn T WProgramming Languages: Design and Implementation PrenticeHall International, Inc, I 996 3 Pressman RS 软件工程从业者的研究方法(第四版)北京:机械工业出版社,1999 4 Eckel Bc+ 编程思想北京:机械工业出版社,2000 5 张杏儿计算机编译原理北京:科学出版社,I 999 6 赵阳,蔡志宇,潘金贵基于EPOM的程序可视化系统的设计与实现计算机的实现工程, 2002, 28 (cms2@>:l08Il0 7 蔡志宇, 赵阳, 潘杰, 等. 基于查询-回答模型的对象控制模型的实现. 计算机工程(已录) 维普资料 http:// 查看全部
采集文章系统(《Web》主题Web信息采集的基本问题及难点解析)
《基于主题的Web信息采集系统设计与实现.pdf》由会员共享,可在线阅读。更多相关《基于主题的Web信息采集系统设计与实现.pdf(3页典藏版)》请在威川搜索。
1、Volume 29, Issue 17 12917 Computer Engineering 2003 年 10 月 2003 年 10 月 软件技术与数据库 文章 编号:l00o-3428(2003)l70l0203 文档识别码:A 中文圈分类号:TP391基于学科的Web信息采集系统设计与实现李胜涛,赵章杰,于志华(中国科学院计算技术研究所软件研究室,北京100080) 摘要:基于学科的Web信息采集是信息检索领域一个新兴的实用方向,也是信息处理技术的研究热点。文章分析主题Web信息采集的基本问题, 提出难点及相关解决方案,并在此基础上,“天大”主题网站信息采集系统的设计与实现
2、。关键词:信息采集;信息检索;信息处理;主题 采集 Desin and Realization 0f Focused Web Crawler。李胜涛, 赵占西, 于志华 (中国科学院计算技术研究所软件部, 北京 l00080) l 摘要 l 聚焦网络爬虫是信息检索领域的一个新的实用方向
3、ieva1本文论述了聚焦网络爬虫的原理、难点和措施,然后分析了SkyReach聚焦网络爬虫的设计。信息检索;信息处理;聚焦爬虫l乐_乐 基于Web信息采集,发布及相关信息处理日益成为关注的焦点。传统we词采集的目标是尽可能地采集
4、信息页,和采集页的准确性关注较少,它有很多缺陷。随着www的爆发式增长,信息速度采集越来越不能满足实际需求。最近的实验表明,即使是大规模的信息采集系统也只有 30-40 个网络覆盖。主题采集可以将整个Web按主题采集划分成块,并整合不同的块,提高整个Web采集的覆盖率。对于传统信息采集,需要几周到一个月的时间才能再次刷新。” I,使得页面失败率非常大。一个好的缓解方法是使用采集主题,通过减少采集的页面数量来减少刷新时间,从而降低采集的失败率 页。传统信息采集消耗大量的系统和网络资源,而且大部分利用率很低,基于主题的采集有效提高了采集对页面的使用率。
5、2 Theme-based web information采集System Model 21 System Model Topic Web Information采集,也称为TopicSpecific Crawling,主要是指选择性搜索那些和预定义的主题集相关页面执行采集的行为。我们设计了“天大”主题采集系统,其系统模型如图1所示。为了实现自动信息采集,整个过程分为6大模块:主题选择、初始URL选择、Spider采集、页面分析、URL与主题关联判断、页面与主题关联判断。22.主题的选择。起点的选择与我采集 为了有效地开展采集主题,需要考虑的一个重要问题是主题选择。由于随机的学科术语可能会极大地影响采集的效果,系统一般会为用户提供一个学科类别目录供用户选择。为了有效地
6、为了确定用户选择的主题的含义,用户应该提供对该主题的进一步描述,例如提供几个表达该主题含义的文本。我们的系统按照中国图书馆分类法的一级目录和二级目录对主题进行分类,并在每个主题下配备了一些主题文本供用户选择。采集器 从一组种子 URL 开始,通过 Web 协议扩展到需要的页面。根据 LinkageSibling Locality 特性,系统需要选择高质量的主题 URL 作为初始种子 URL 集。23 Spider采集 1O2 One Circle I 信息自动采集的6大块。这部分在系统的最底层,也叫“网络蜘蛛”,专门处理Web,
7、各种文件如声音)。目前系统主要针对HTTP协议,其主要任务是为每个Spider分配URL以获取实际数据采集,并根据需要动态分配Spider的数量,如图2。 基金项目:中科院计算所前沿青年基金项目(200162808) 作者:李胜涛(1976一),男,硕士研究生,主要研究方向:智能代理、信息采集) , 信息检索, 文本分类; 赵章杰, 于志华, Ph.D. 博士生录取日期破: 2002073I | 回归天破: 2002-1028 维普资讯http://图2 蜘蛛合集: 合集采集页面的24页分析之后,您需要提取链接、元数据、文本、标题和摘要以进行后续过滤和其他处理。这里主要介绍链接和标签。
8、 问题提取。链接的提取如下: 首先,识别页面类型。显然,只有“xffhtml”类型的页面需要分析链接。页面的类型可以从响应头的分析中得到。部分www站点返回的响应信息格式不完整。这时候就需要分析页面URL中的文件扩展名来确定页面类型。当遇到诸如等带有链接的标签时,从标签结构的属性中找到目标URL,从标签对中提取文本作为链接的描述性文本(扩展元数据)。这两个数据代表链接。页面中标题的提取分为3个步骤:(一)确定正文开头的位置,从文章的开头开始,逐段扫描,直到某段长度不小于设置的正文最小长度,假设该段为正文中的A段。(2) 从文本位置向前搜索可能是标题的一段,根据字体
9、大小、居中、变色等特性找到最合适的一段文字作为标题。(3)通过给定参数调整标题段,使标题提取更准确。对标题段前后段stTitlePara进行句法、语义、统计分析,准确判断标题段真实位置. 25 URL和主核的相关性确定有效提高主题Web信息采集的可靠性(召回率和准确率的结合)和效率,系统需要在采集的过程中加入过滤机制@> 并采用综合扩展的 I Pagerank 方法进行元数据和链接分析。25I 扩展元数据的含义 虽然目前的元数据计算(HTML 中添加的一种标记,写成)并不理想,但人们已经发现使用其他 HTML 标签如锚点等信息可以有效引导搜索和基于主题信息采集。为了
1 根据0、的区别,这些标记信息统称为HTML扩展元数据。252 扩展元数据方法的ReIevance Weighting或RW算法如下: f 0 (ur): (0(,), M(ur1) 如max(O(t). l 0 规范其中, M(ur1)指的是与这个URL相关的所有扩展元数据的集合,O(t)指的是扩展元数据中某个词与主题的相关性。c是用户设置的相关性阈值. RW 方法是通过查看扩展元数据中单词和主题词的相似度来计算的,同义词之间的相似度为100,同义词之间的相似度为50-100,远距离词之间的相似度为0 50。这样就大大降低了相关页面误判的可能性,
11、页面被判断为相关页面的可能性)。25 3 链接分析方法 PageRank 是谷歌的一个重要搜索算法,它有效地帮助搜索引擎识别那些重要的页面,并将它们排在搜索结果的前列。该方法定义为:给定一个网页A,假设指向它的网页有T.,,T.设c(A)为A到其他网页的链接数,PR(A)为A的PageRank, d为衰减因子(一般设置为085),然后有一个跳跃,c+254的IPageRank算法通过观察:PageRank方法虽然有很强的寻找重要页面的能力,但是它找到的重要页面是为了一个广泛的话题,而不是基于特定的话题。因此,一个页面被大量不相关的话题指向PageRan
1 2、k的值高于与mang问题相关的少数页面组所指向的页面的PageRank值,这是不合理的。如果大量主题相关页组指向的页面的PageRank值高于少数主题相关页组指向的页面的PageRank值,则必须使用它。为此,我们对PageRank方法进行了改进,根据链接关系加入一定的语义信息权重,使生成的重要页面针对某个主题,形成1PageRank算法。IPageRank算法不仅利用PageRank的优势寻找重要页面,还利用RW算法提高链接的相关性。改进后的公式如下 (3) PR(I): (卜(,)+dl IPR(T) 芝.(ur) (<
13、) Lan Yiyi PR(T) 0 (Ill 1) 0 (IllI) 其中A为给定的网页,假设指向它的网页有T.,, Tn.u, ur u rII 为网页T、T、指向A的链接,kI、k2、kn分别为网页TT中收录的链接数,IPR(A)为A的IPageRank值,d为衰减因子(也设置为085)。IPageRank的实际含义可以用话题浏览者来解释。假设Web上有一个话题浏览者,IPPageRank(函数IPR(A)是它访问页面A的概率)。它从初始页面集开始,跟随页面链接,从不进行“返回”操作,在每个页面上,浏览者对该页面中的每个链接感兴趣的概率与链接和主题相关。
14、关星成正比。浏览者也可能对这个页面上的链接不再感兴趣,从而随机选择一个新页面开始新的浏览,离开的概率设置为d。从直观上看,如果有很多页面指向一个页面,那么这个页面的PageRank会比较高,但IPPageRank值不一定高,除非大部分都和主题相关;如果有高IPPageRank的页面指向它,这个页面的IPageRank也会很高。26 页面与主题相关性判断 为了进一步提高采集页面的准确率,需要对已经被采集的页面进行主题相关性评估,即页面过滤。提高所有采集的准确率 主题页面通过排除低评估结果(小于设置阈值)的页面。我们采用的方法是基于关键词的向量空间模型算法。3个系统
1 5、的实现 我们对“天大”主题Web信息采集系统的预测算法和系统的基本性能进行了测试,得到了满意的结果。(1)测试集的选择选择旅游信息作为测试主题。采集了20个旅游主题网站,加入了60个无关的网站组成测试集,其中收录一个以上l03.维普信息页。(2)算法测试和性能测试使用相同的初始URL集,使用广度优先算法、PageRank算法和IPageRank算法对采集进行采集数据。为了得到每种方法的结果准确的结果,实验中暂停了页面和主题相关性确定模块。在实验过程中,记录采集页码为500、1000、l 500一、4000H采集状态,计算采集状态。@采集准确性和资源
16、源发现率,如表1所示。表一采集准确率与资源发现率采集准确率资源发现率宽度优先级35 lOO PageRank 29 3O IPageRank 68 86 表2 测试结果,性能测试结果评价采集的最终准确率76较高(优点)最终资源发现率高8O(优点)30MB内存(估计)较大(缺点)测试平台为CPU Intel Pill 800、内存为128MB,操作系统为Window 2000 Professional电脑。采集时,系统设置10个线程,采用的URL预测算法为IPageRank。测试的性能指标包括最终采集页面的准确率,采集页面的资源释放
17、 当前速率、内存使用情况、测试结果如表2所示。 4 结束语 我基于主题研究了webf语言和信息技术,并设计了一个实用的系统。在原有技术的基础上,设计了许多独特的新算法,如Spider采集、标题提取、URL主题预测、页面主题相关性判断等。特别是对著名的谷歌算法进行了改进,使其适用于基于主题的采集,同时保持原有的优势。实验表明,基于主题的采集优势明显。随着Web服务向个性化方向的推进,Agent技术的发展,以及迁移思想的出现,用于检索的Web信息采集 科技必将走向主题化、个性化的主动信息采集服务方向全方位拓展。参考文献 I Aggarwal C, AIGar
18、awi F、Yu PIntelligent Crawling on the World Wide Web with Arbitrary PredicatesIn Proceedings of the 1 0th IntematiouaI WWW Conference200 l 2 Brin S, Page L,大型超文本网络搜索引擎的切片剖析第七届国际万维网会议,I 998 3 Diligen
19、ti M, Coetzee FM, Lawrence S, et a1Gori Focused Crawling Using Context GraphsVLDB Conference, 2000 4 Menczer F, Srinivasan GPP, Ruiz MEvaluating Topic-driven Web CrawlersIn Proceedings of the 24th Annual International Acms@ >IGIR 会议,200 l(接第 8I 页) 3 Clark CM,Rock SRandomized Motion Planning for G
20、N011一完整机器人组在:加拿大第六届空间人工智能、机器人和自动化国际研讨会论文集& 200106 4 Fraichard TDemazeau YMotion Planning in a Multiagent World In: Demazeau YMuller J PDecentralized AI: Proceedings第 22 届欧洲工作室
21、p on Modeling Autonomous Agents in a Multiagent World 荷兰阿姆斯特丹:Elsevier Science,I990:l37-l53(接第 l0l 页)输出“:”。“表示类型”列输出源文件中函数所描述的类型,“基本类型”列输出表示不带typedef的表示类型的类型。在这个例子中,funcl和main函数没有使用typedef,所以这两个函数的表示类型和基本类型是一样的。“位置”列输出函数定义或声明的文档名称和行号。“属性”列显示函数的属性。例如,当函数未定义时,显示“no define”;如果
22、 不使用该功能时,会显示“未使用”等。上面的表1只是函数列表,变量列表、类型列表、枚举常量列表大体与此一致。对于列表中出现的每个元素,还有一个详细的表格,按名称链接。例如,有一个函数的调用条件列表和一个函数返回值列表;对于变量,有一个值设置和引用列表。列表。限于篇幅,这里就不一一详述_r了。4 结束语 EPOM 是一种可以全面、详细地展示程序的中间表示,它提供了一个标准的访问接口。所以,任何其他符合该接口的模块都可以从中获取有关源程序的所需信息。OSTPM 是一种基于域的程序信息分层递归表示模型。将程序中所有对象的范围和类型紧密联系起来
23、。基于查询-应答模型的Visitor方法将对象与作用于对象1O4的控制分离,减轻了控制系统的负担,大大提高了系统的灵活性、安全性和可扩展性,使系统结构非常清晰. 同时减轻设计管理系统的负担。扩展的节目参考模型EPRM是一种很好的节目统计信息形式。它采用面向对象的方法将复杂的程序信息组织成层次化的对象结构,并提供了一个接口,通过Visitor方法访问其对象。该模型克服了普通模型的缺点,具有结构简单、对象自主性强、系统灵活性高、输出界面友好、扩展性好等特点。
24、ts of Reusable Objectoriented SoftwareAddison Wesley Longman, Inc, l995 2 Prdn T WProgramming Languages: Design and Implementation PrenticeHall International, Inc, I 996 3 Pressman RS 软件工程从业者的研究方法(第四版)北京:机械工业出版社,1999 4 Eckel Bc+ 编程思想北京:机械工业出版社,2000 5 张杏儿计算机编译原理北京:科学出版社,I 999 6 赵阳,蔡志宇,潘金贵基于EPOM的程序可视化系统的设计与实现计算机的实现工程, 2002, 28 (cms2@>:l08Il0 7 蔡志宇, 赵阳, 潘杰, 等. 基于查询-回答模型的对象控制模型的实现. 计算机工程(已录) 维普资料 http://
采集文章系统(一下采集的文章如何伪原创处理?采集方法介绍 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-12-05 03:27
)
现在建网站容易,推广难。采集文章 对于做优化的人来说,这完全是家常便饭。尤其是在站群泛滥的时候,采集网站随处可见,都是为了SEO和SEO。但是,这种采集站往往还是高权重的。这是因为即使是像原创这样的搜索引擎也无法完全识别文章的来源。今天小编就为大家介绍一下采集的文章伪原创是怎么处理的!
1、 标题修改:首先修改标题。标题不得随意修改。它必须遵循用户的搜索行为并符合全文内容中心。汉字组合博大精深,称谓修饰多样化。标题必须收录关键字,收录关键词的标题长度适中
2、 内容修改:好的用户体验意味着好的SEO。让用户感觉良好的搜索引擎也一定会喜欢它。所以,在改变文章的时候,也要站在用户的角度考虑他想要从这个文章得到什么样的信息。其次,在内容上至少要修改第一段和最后一段,因为这也是站长认为蜘蛛抓取的位置,尽量区分其他文章。
注意:如果内容收录品牌词,必须更换。
3、提高文章的质量,采集的文章,如果你改进这个文章,增强美感,优化布局,错误等。 (比如对错字的修改是否改进了文章?自然,搜索引擎上的分数也有所提高。可以从这些中进行具体考虑。例如,添加图片、适当的注释和引用权威材料,将有助于提高采集的内容质量。
同时采集站立时要注意的几点:
1、选择与您网站主题相匹配的内容;采集的内容格式要统一专业;
2、采集的文章不要一次发布太多。每天保留大约 10 篇文章,以便长期和持久地发表。
查看全部
采集文章系统(一下采集的文章如何伪原创处理?采集方法介绍
)
现在建网站容易,推广难。采集文章 对于做优化的人来说,这完全是家常便饭。尤其是在站群泛滥的时候,采集网站随处可见,都是为了SEO和SEO。但是,这种采集站往往还是高权重的。这是因为即使是像原创这样的搜索引擎也无法完全识别文章的来源。今天小编就为大家介绍一下采集的文章伪原创是怎么处理的!
1、 标题修改:首先修改标题。标题不得随意修改。它必须遵循用户的搜索行为并符合全文内容中心。汉字组合博大精深,称谓修饰多样化。标题必须收录关键字,收录关键词的标题长度适中
2、 内容修改:好的用户体验意味着好的SEO。让用户感觉良好的搜索引擎也一定会喜欢它。所以,在改变文章的时候,也要站在用户的角度考虑他想要从这个文章得到什么样的信息。其次,在内容上至少要修改第一段和最后一段,因为这也是站长认为蜘蛛抓取的位置,尽量区分其他文章。
注意:如果内容收录品牌词,必须更换。
3、提高文章的质量,采集的文章,如果你改进这个文章,增强美感,优化布局,错误等。 (比如对错字的修改是否改进了文章?自然,搜索引擎上的分数也有所提高。可以从这些中进行具体考虑。例如,添加图片、适当的注释和引用权威材料,将有助于提高采集的内容质量。
同时采集站立时要注意的几点:
1、选择与您网站主题相匹配的内容;采集的内容格式要统一专业;
2、采集的文章不要一次发布太多。每天保留大约 10 篇文章,以便长期和持久地发表。
采集文章系统(采集功能是什么?采集规则是用你的网站远程批量采集目标网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-11-30 19:03
采集是什么功能?
采集功能就是利用你的网站远程批处理采集目标网站的文章和图片功能来自动化操作,解放你的双手.
所有网站都可以采集吗?
世界上没有网站或所有文章可以采集的功能。原因很简单:采集 拦截特定字符串之间的内容作为目标。每个网站的具体字符都不一样,所以没办法优采云采集全世界网站。
那些小偷程序的采集功能比你的好吗?
小偷程序只能是采集特定的网站和特定的文章。一旦目标网站被修改或小偷程序关闭,就会彻底瘫痪。而我们的采集函数就是根据采集规则对采集,修改或关闭目标网站,替换一个目标站,重写采集规则。所以小偷程序和我们的采集功能是不可比的。
采集如何使用该功能?
采集 函数需要按照采集的规则使用,因为采集网站的目标不同,页面代码也不同,所以需要根据不同的Goal网站来编写不同的采集规则。使用目标网站对应的采集规则到采集网站。
采集规则怎么写?
请看一下我们花了 40 个小时编写的 采集 规则图文教程:
有没有办法不用写规则就采集?
可以,通过官方采集平台采集即可,在网站后台--应用中心-找到您要安装的采集规则插件-Get Plugins , 安装后可以在网站后台--规则管理中批量做采集。一些详细的设置请看采集规则插件页面的详细介绍。
为什么有些采集规则可以测试采集并且可以显示源码,但是不能批量采集?
在这种情况下,模板网站限制了并发连接数和访问频率,以上参数检测非人为访问和阻塞。目的是防止采集,只是将其他目标网站替换为采集。
其他采集规则常见问题,点击下方链接阅读。 查看全部
采集文章系统(采集功能是什么?采集规则是用你的网站远程批量采集目标网站)
采集是什么功能?
采集功能就是利用你的网站远程批处理采集目标网站的文章和图片功能来自动化操作,解放你的双手.
所有网站都可以采集吗?
世界上没有网站或所有文章可以采集的功能。原因很简单:采集 拦截特定字符串之间的内容作为目标。每个网站的具体字符都不一样,所以没办法优采云采集全世界网站。
那些小偷程序的采集功能比你的好吗?
小偷程序只能是采集特定的网站和特定的文章。一旦目标网站被修改或小偷程序关闭,就会彻底瘫痪。而我们的采集函数就是根据采集规则对采集,修改或关闭目标网站,替换一个目标站,重写采集规则。所以小偷程序和我们的采集功能是不可比的。
采集如何使用该功能?
采集 函数需要按照采集的规则使用,因为采集网站的目标不同,页面代码也不同,所以需要根据不同的Goal网站来编写不同的采集规则。使用目标网站对应的采集规则到采集网站。
采集规则怎么写?
请看一下我们花了 40 个小时编写的 采集 规则图文教程:
有没有办法不用写规则就采集?
可以,通过官方采集平台采集即可,在网站后台--应用中心-找到您要安装的采集规则插件-Get Plugins , 安装后可以在网站后台--规则管理中批量做采集。一些详细的设置请看采集规则插件页面的详细介绍。
为什么有些采集规则可以测试采集并且可以显示源码,但是不能批量采集?
在这种情况下,模板网站限制了并发连接数和访问频率,以上参数检测非人为访问和阻塞。目的是防止采集,只是将其他目标网站替换为采集。
其他采集规则常见问题,点击下方链接阅读。
采集文章系统(区块链发展前景,以太坊大爆发一枚以太币价值达2100多美元)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-11-28 04:01
采集文章系统区块链发展前景,以太坊大爆发一枚以太币价值达2100多美元,根据10月23日etherdelta统计,eth的价格涨幅达125%,ada上涨352%,golem上涨1438%,xmr上涨2227%。按最高价计算市值超过了110亿美元,折合人民币767亿,所以eth价格上涨已经是必然的事情。
区块链的发展,使社会价值交流深入到数字资产的流通中。区块链已经成为金融体系的重要方式之一,诸如:企业级的金融服务,第三方信用体系,供应链金融等,都取得了一些阶段性的成果。但是金融利益的驱动或依附于金融利益有一定社会成本,因此区块链还存在发展的空间。区块链最终的使命是提高资产记录的可靠性,可访问性和透明度,提升用户体验。
尽管区块链缺少监管机构,但是国家将逐步建立区块链监管体系,fatf和crackingflag都是国际机构。国内不可避免要走出这一步,想打下来没有问题,但是要发展壮大还需时日。总体来看,区块链的发展还存在一定的进步空间,而且仍然是新的热点。区块链会颠覆或者超越我们的业务,传统金融存在的一些问题也会因为区块链而得到解决。
这也是区块链会一直存在的一个原因。selenium+soupui+cryptography框架实现网页抓包需要的知识会比较多,如果只会selenium,基本的网页抓包会过去一大半,另外就是配置环境。在前端的教程中我用了很多个chrome,但是大家也不可能一直要每个chrome都能下。所以肯定会有出现更好的,没有尝试过的chrome。
selenium可以支持这个功能的。如何设置浏览器浏览器的具体版本号,以及浏览器的版本号对于网页截图网页大小有很大的影响,但是不会对网页数据有太大的影响。在webdriver中有一个简单的思路,就是通过客户端filter去获取所有的网页进行序列化,存储在区块链上。redis中可以给每个的网页字段生成一个字典数组mymorsed,数组每个都有起始值,值index,最后一个值last,数组长度是kbytes,可以查询key为mymorsed的网页。
字典在后期的使用会非常的快,因为可以比较字典中的每个元素的每个元素有一个唯一的id。localstorage是不支持字典的,所以可以设置下。但是myisam这个不可以设置,所以我们这里的思路是用字典加入了namestring的数组,用objectstring,数组长度为mymorsed。以下代码会发现返回值为数组,list=[]foriincryptographicgenerator.getall():session.remove(i)cryptographicgenerator.set(namestring.getbytes(mymorsed.ids))上一篇说到的json里面我们可以通过content来获取源文件文件。但是json容易丢失格式,我们想。 查看全部
采集文章系统(区块链发展前景,以太坊大爆发一枚以太币价值达2100多美元)
采集文章系统区块链发展前景,以太坊大爆发一枚以太币价值达2100多美元,根据10月23日etherdelta统计,eth的价格涨幅达125%,ada上涨352%,golem上涨1438%,xmr上涨2227%。按最高价计算市值超过了110亿美元,折合人民币767亿,所以eth价格上涨已经是必然的事情。
区块链的发展,使社会价值交流深入到数字资产的流通中。区块链已经成为金融体系的重要方式之一,诸如:企业级的金融服务,第三方信用体系,供应链金融等,都取得了一些阶段性的成果。但是金融利益的驱动或依附于金融利益有一定社会成本,因此区块链还存在发展的空间。区块链最终的使命是提高资产记录的可靠性,可访问性和透明度,提升用户体验。
尽管区块链缺少监管机构,但是国家将逐步建立区块链监管体系,fatf和crackingflag都是国际机构。国内不可避免要走出这一步,想打下来没有问题,但是要发展壮大还需时日。总体来看,区块链的发展还存在一定的进步空间,而且仍然是新的热点。区块链会颠覆或者超越我们的业务,传统金融存在的一些问题也会因为区块链而得到解决。
这也是区块链会一直存在的一个原因。selenium+soupui+cryptography框架实现网页抓包需要的知识会比较多,如果只会selenium,基本的网页抓包会过去一大半,另外就是配置环境。在前端的教程中我用了很多个chrome,但是大家也不可能一直要每个chrome都能下。所以肯定会有出现更好的,没有尝试过的chrome。
selenium可以支持这个功能的。如何设置浏览器浏览器的具体版本号,以及浏览器的版本号对于网页截图网页大小有很大的影响,但是不会对网页数据有太大的影响。在webdriver中有一个简单的思路,就是通过客户端filter去获取所有的网页进行序列化,存储在区块链上。redis中可以给每个的网页字段生成一个字典数组mymorsed,数组每个都有起始值,值index,最后一个值last,数组长度是kbytes,可以查询key为mymorsed的网页。
字典在后期的使用会非常的快,因为可以比较字典中的每个元素的每个元素有一个唯一的id。localstorage是不支持字典的,所以可以设置下。但是myisam这个不可以设置,所以我们这里的思路是用字典加入了namestring的数组,用objectstring,数组长度为mymorsed。以下代码会发现返回值为数组,list=[]foriincryptographicgenerator.getall():session.remove(i)cryptographicgenerator.set(namestring.getbytes(mymorsed.ids))上一篇说到的json里面我们可以通过content来获取源文件文件。但是json容易丢失格式,我们想。
采集文章系统(中文站台式搜索1.利用/查看/编辑文件信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-11-25 13:14
采集文章系统可以识别文章页码,并同步到googlereader服务。
可以看一下geekpic/spic·github。
中文站台式搜索1.利用/查看/编辑文件信息-比如不能使用标点判断所谓的汉语拼音,或者自己写注释。2.数据全后台通过标题文件分词得到,(站内通过-首选),正则表达式。这个spic可以。从yahoo/googlespicapi拿数据。各大搜索引擎同理3.spic前端编写grab+robotsmonitor,这个也不算难吧。
我也很想知道!!!不知道facebook会不会识别他的地址,直接把所有国外搜索引擎的都抓下来导入。希望有人和我有同样的想法,并且现成的github/repo。我们可以一起分享啊!我也是零基础,程序人员。有问题,
个人觉得要做一个国内的国外spic可能要依靠企业和外国网站合作。wikipedia文章页信息抓取可以采用的方法很多,比如google和bing,但是你要认识企业,和他们合作也要找他们谈一下。google和bing都有api。也有卖spic(跟企业客户沟通,国内用户不知道哪里可以找到google和bing,这也是要谈的,bing是否支持国内信息抓取)和spics(看看是否可以跟国内小众创业者合作),我只知道这两种。
国内外spic有这么三个特点:1.有搜索词频和收录问题,这可能是大多数人不太注意的点,因为reeder还是,safari和android信息也存在时间问题,快照,文档编号分拣的问题。这也是spic肯定是针对使用reeder的。2.spic是基于web的搜索引擎,和浏览器、appstore之类有差异。例如:spic文档分拣,必须经过这种原生搜索去过滤网站2次以上才能进行抓取和分享,这也是reeder2那样的方法不可取的地方。
3.不支持多国语言搜索(连国内都是英文搜索)。综上,也有一些reeder2的工具提供类似的,但是涉及到每个国家特色的用户需求,我觉得没法提供。 查看全部
采集文章系统(中文站台式搜索1.利用/查看/编辑文件信息)
采集文章系统可以识别文章页码,并同步到googlereader服务。
可以看一下geekpic/spic·github。
中文站台式搜索1.利用/查看/编辑文件信息-比如不能使用标点判断所谓的汉语拼音,或者自己写注释。2.数据全后台通过标题文件分词得到,(站内通过-首选),正则表达式。这个spic可以。从yahoo/googlespicapi拿数据。各大搜索引擎同理3.spic前端编写grab+robotsmonitor,这个也不算难吧。
我也很想知道!!!不知道facebook会不会识别他的地址,直接把所有国外搜索引擎的都抓下来导入。希望有人和我有同样的想法,并且现成的github/repo。我们可以一起分享啊!我也是零基础,程序人员。有问题,
个人觉得要做一个国内的国外spic可能要依靠企业和外国网站合作。wikipedia文章页信息抓取可以采用的方法很多,比如google和bing,但是你要认识企业,和他们合作也要找他们谈一下。google和bing都有api。也有卖spic(跟企业客户沟通,国内用户不知道哪里可以找到google和bing,这也是要谈的,bing是否支持国内信息抓取)和spics(看看是否可以跟国内小众创业者合作),我只知道这两种。
国内外spic有这么三个特点:1.有搜索词频和收录问题,这可能是大多数人不太注意的点,因为reeder还是,safari和android信息也存在时间问题,快照,文档编号分拣的问题。这也是spic肯定是针对使用reeder的。2.spic是基于web的搜索引擎,和浏览器、appstore之类有差异。例如:spic文档分拣,必须经过这种原生搜索去过滤网站2次以上才能进行抓取和分享,这也是reeder2那样的方法不可取的地方。
3.不支持多国语言搜索(连国内都是英文搜索)。综上,也有一些reeder2的工具提供类似的,但是涉及到每个国家特色的用户需求,我觉得没法提供。
采集文章系统(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-11-25 12:15
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录,并每天更新。显然,300多个公众号无法每天手动检查,问题提交给IT团队。对于喜欢爬虫的人来说,我绝对想要他。之前做过搜狗的微信爬虫,之后一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需配置公众号或微信公众号,即可定时或实时(包括阅读、点赞、观看)抓拍微信公众号的文章。
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
Redis
演戏
提琴手
三、系统优缺点 系统优点
1、 配置公众号后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列解决Coupling,可以解决采集由于网络抖动导致的失败。3次消费不成功,会记录日志到mysql,保证文章的完整性;4、可以添加任意数量的微信ID提高采集的效率,抵抗反攀登限制;5、Redis在24小时内缓存每个微信账号的采集记录,防止账号被关闭;6、Nacos作为配置中心,可以通过热配置调整采集的频率 实时; 7、将采集接收到的数据存储在Solr集群中,提高检索速度;8、 将捕获返回的记录存储到MongoDB进行归档查看错误日志。
系统缺点:
1、通过真实手机真实账号采集留言,如果你需要大量公众号,需要有多个微信账号作为支持(如果当天账号达到上限,可以爬取微信官方平台消息,可通过接口获取);2、 不是发文就可以抓到的公众号。采集的时间由系统设置,消息有一定的滞后性(如果公众号不多的话,微信信号数量就足够了。通过增加采集频率优化)。
四、模块介绍
由于后面会添加管理系统和API调用函数,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是
spring-boot-starter-data-redis的第二个包暴露了打包好的Redis工具类和Redisson工具类。
RocketMQ-WS-启动器
RocketMQ 模块:是
Rocketmq-spring-boot-starter 的二次封装提供了消费重试和故障日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录PC端采集公众账号历史消息相关功能。
java-wx-蜘蛛
Java提取模块:收录Java程序提取文章内容相关的功能。
移动-wx-蜘蛛
模拟器采集模块:收录与模拟器或手机采集消息交互量相关的功能。
五、一般流程图
六、 在PC端和移动端运行截图
安慰
运行结束
总结
亲测项目现已上线,项目开发中解决了微信搜狗临时链接永久链接问题,希望能帮助到被同类业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集。如果你看到这个,你不把它给一个采集吗?
原文链接: 查看全部
采集文章系统(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录,并每天更新。显然,300多个公众号无法每天手动检查,问题提交给IT团队。对于喜欢爬虫的人来说,我绝对想要他。之前做过搜狗的微信爬虫,之后一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需配置公众号或微信公众号,即可定时或实时(包括阅读、点赞、观看)抓拍微信公众号的文章。
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
Redis
演戏
提琴手
三、系统优缺点 系统优点
1、 配置公众号后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列解决Coupling,可以解决采集由于网络抖动导致的失败。3次消费不成功,会记录日志到mysql,保证文章的完整性;4、可以添加任意数量的微信ID提高采集的效率,抵抗反攀登限制;5、Redis在24小时内缓存每个微信账号的采集记录,防止账号被关闭;6、Nacos作为配置中心,可以通过热配置调整采集的频率 实时; 7、将采集接收到的数据存储在Solr集群中,提高检索速度;8、 将捕获返回的记录存储到MongoDB进行归档查看错误日志。
系统缺点:
1、通过真实手机真实账号采集留言,如果你需要大量公众号,需要有多个微信账号作为支持(如果当天账号达到上限,可以爬取微信官方平台消息,可通过接口获取);2、 不是发文就可以抓到的公众号。采集的时间由系统设置,消息有一定的滞后性(如果公众号不多的话,微信信号数量就足够了。通过增加采集频率优化)。
四、模块介绍
由于后面会添加管理系统和API调用函数,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是
spring-boot-starter-data-redis的第二个包暴露了打包好的Redis工具类和Redisson工具类。
RocketMQ-WS-启动器
RocketMQ 模块:是
Rocketmq-spring-boot-starter 的二次封装提供了消费重试和故障日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录PC端采集公众账号历史消息相关功能。
java-wx-蜘蛛
Java提取模块:收录Java程序提取文章内容相关的功能。
移动-wx-蜘蛛
模拟器采集模块:收录与模拟器或手机采集消息交互量相关的功能。
五、一般流程图
六、 在PC端和移动端运行截图
安慰
运行结束
总结
亲测项目现已上线,项目开发中解决了微信搜狗临时链接永久链接问题,希望能帮助到被同类业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集。如果你看到这个,你不把它给一个采集吗?
原文链接:
采集文章系统(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-11-25 12:11
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录,并每天更新。显然,300多个公众号无法每天手动检查,问题提交给IT团队。对于喜欢爬虫的人来说,我绝对想要他。之前做过搜狗的微信爬虫,之后一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需配置公众号或微信公众号,即可定时或实时(包括阅读、点赞、观看)抓拍微信公众号的文章。
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
Redis
演戏
提琴手
三、系统优缺点 系统优点
1、 配置公众号后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列解决Coupling,可以解决采集由于网络抖动导致的失败。3次消费不成功,会记录日志到mysql,保证文章的完整性;4、可以添加任意数量的微信ID提高采集的效率,抵抗反攀登限制;5、Redis在24小时内缓存每个微信账号的采集记录,防止账号被关闭;6、Nacos作为配置中心,可以通过热配置调整采集的频率 实时; 7、将采集接收到的数据存储在Solr集群中,提高检索速度;8、 将捕获返回的记录存储到MongoDB进行归档查看错误日志。
系统缺点:
1、通过真实手机真实账号采集留言,如果你需要大量公众号,需要有多个微信账号作为支持(如果当天账号达到上限,可以爬取微信官方平台消息,可通过接口获取);2、 不是发文就可以抓到的公众号。采集的时间由系统设置,消息有一定的滞后性(如果公众号不多的话,微信信号数量就足够了。通过增加采集频率优化)。
四、模块介绍
由于后面会添加管理系统和API调用函数,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是
spring-boot-starter-data-redis的第二个包暴露了打包好的Redis工具类和Redisson工具类。
RocketMQ-WS-启动器
RocketMQ 模块:是
Rocketmq-spring-boot-starter 的二次封装提供了消费重试和故障日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录PC端采集公众账号历史消息相关功能。
java-wx-蜘蛛
Java提取模块:收录Java程序提取文章内容相关的功能。
移动-wx-蜘蛛
模拟器采集模块:收录与模拟器或手机采集消息交互量相关的功能。
五、一般流程图
六、 在PC端和移动端运行截图
安慰
运行结束
总结
亲测项目现已上线,项目开发中解决了微信搜狗临时链接永久链接问题,希望能帮助到被同类业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集。如果你看到这个,你不把它给一个采集吗?
原文链接: 查看全部
采集文章系统(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录,并每天更新。显然,300多个公众号无法每天手动检查,问题提交给IT团队。对于喜欢爬虫的人来说,我绝对想要他。之前做过搜狗的微信爬虫,之后一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需配置公众号或微信公众号,即可定时或实时(包括阅读、点赞、观看)抓拍微信公众号的文章。
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
Redis
演戏
提琴手
三、系统优缺点 系统优点
1、 配置公众号后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列解决Coupling,可以解决采集由于网络抖动导致的失败。3次消费不成功,会记录日志到mysql,保证文章的完整性;4、可以添加任意数量的微信ID提高采集的效率,抵抗反攀登限制;5、Redis在24小时内缓存每个微信账号的采集记录,防止账号被关闭;6、Nacos作为配置中心,可以通过热配置调整采集的频率 实时; 7、将采集接收到的数据存储在Solr集群中,提高检索速度;8、 将捕获返回的记录存储到MongoDB进行归档查看错误日志。
系统缺点:
1、通过真实手机真实账号采集留言,如果你需要大量公众号,需要有多个微信账号作为支持(如果当天账号达到上限,可以爬取微信官方平台消息,可通过接口获取);2、 不是发文就可以抓到的公众号。采集的时间由系统设置,消息有一定的滞后性(如果公众号不多的话,微信信号数量就足够了。通过增加采集频率优化)。
四、模块介绍
由于后面会添加管理系统和API调用函数,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是
spring-boot-starter-data-redis的第二个包暴露了打包好的Redis工具类和Redisson工具类。
RocketMQ-WS-启动器
RocketMQ 模块:是
Rocketmq-spring-boot-starter 的二次封装提供了消费重试和故障日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录PC端采集公众账号历史消息相关功能。
java-wx-蜘蛛
Java提取模块:收录Java程序提取文章内容相关的功能。
移动-wx-蜘蛛
模拟器采集模块:收录与模拟器或手机采集消息交互量相关的功能。
五、一般流程图
六、 在PC端和移动端运行截图
安慰
运行结束
总结
亲测项目现已上线,项目开发中解决了微信搜狗临时链接永久链接问题,希望能帮助到被同类业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集。如果你看到这个,你不把它给一个采集吗?
原文链接:
采集文章系统(采集文章系统代码基于r+java,windows下可以创建属于自己的域文件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-11-25 05:01
采集文章系统代码基于r+java,java初始环境:macos下10.10.4以上的系统,windows系统,office2010以上(windows下可以创建属于自己的域文件,到此设置按照谷歌要求就好,当然了,可以下载5.0或者4.0版本的文件,再导入即可)文件基本结构。java程序的结构如下:对象名:input(即用户需要输入的字符串)方法名:read(request.getrequestname())接收参数一(http:请求地址):请求参数多(请求文件类型):方法名:readgenerate(接收参数。
1)传入参数多(请求txt类型文件):方法名:readgenerateupdate(接收参数
2)传入参数多(请求txt类型文件):方法名:readgenerateupdateupdateupdate(接收参数
3)传入参数多(请求txt类型文件):outputbuffer类型文件类型(即每次文件读取的内容):用来存储文件的接口(如,txt对象,xml对象等):继承openxml接口类型(即所有的文件接口):如:xml.excel.table,xml.xml.text.excel文件等类型:所有可以称为文件的类型:java的文件接口都可以看做是文件接口的子接口:即api:office:免费版office,收费版office,专业版office,企业版office,标准版office,汉化版office,vip版office。
电子表格vba,图片加工gif编辑器:acdimapi,包括:xls,xlsx,vba6。word:word2vec,adobeacrobat,coreldraw,endnote。wps:wps企业版,wps家庭版,wps个人版,wpsvir)我建议你在linux下运行程序,大多都是一些开源linux版本,稳定性比在windows下会好很多。
运行方式:如果你是用java程序运行的,同时也可以启动tomcat或者iis运行这个程序(iisjava程序可以启动)注意:这是一个单步单线程程序,后面会用到threadlocal之类的东西。tomcat可以多线程并发来挂载一个文件。iis同理。原文链接:从零开始搭建java文本挖掘实例。 查看全部
采集文章系统(采集文章系统代码基于r+java,windows下可以创建属于自己的域文件)
采集文章系统代码基于r+java,java初始环境:macos下10.10.4以上的系统,windows系统,office2010以上(windows下可以创建属于自己的域文件,到此设置按照谷歌要求就好,当然了,可以下载5.0或者4.0版本的文件,再导入即可)文件基本结构。java程序的结构如下:对象名:input(即用户需要输入的字符串)方法名:read(request.getrequestname())接收参数一(http:请求地址):请求参数多(请求文件类型):方法名:readgenerate(接收参数。
1)传入参数多(请求txt类型文件):方法名:readgenerateupdate(接收参数
2)传入参数多(请求txt类型文件):方法名:readgenerateupdateupdateupdate(接收参数
3)传入参数多(请求txt类型文件):outputbuffer类型文件类型(即每次文件读取的内容):用来存储文件的接口(如,txt对象,xml对象等):继承openxml接口类型(即所有的文件接口):如:xml.excel.table,xml.xml.text.excel文件等类型:所有可以称为文件的类型:java的文件接口都可以看做是文件接口的子接口:即api:office:免费版office,收费版office,专业版office,企业版office,标准版office,汉化版office,vip版office。
电子表格vba,图片加工gif编辑器:acdimapi,包括:xls,xlsx,vba6。word:word2vec,adobeacrobat,coreldraw,endnote。wps:wps企业版,wps家庭版,wps个人版,wpsvir)我建议你在linux下运行程序,大多都是一些开源linux版本,稳定性比在windows下会好很多。
运行方式:如果你是用java程序运行的,同时也可以启动tomcat或者iis运行这个程序(iisjava程序可以启动)注意:这是一个单步单线程程序,后面会用到threadlocal之类的东西。tomcat可以多线程并发来挂载一个文件。iis同理。原文链接:从零开始搭建java文本挖掘实例。
采集文章系统(《(17页珍藏版)》每日一练())
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-24 01:05
《webplus系统文章采集tutorial.doc》为会员共享,可在线阅读,更多相关的《webplus系统文章采集tutorial.doc(17页采集器)版) 》请在人人图书馆搜索。
荆胥彪座墓队在荆层有影子,赖、黎、黎、蜂在野外,陪着丁福、潘,闷死方块。鞠金银曲爵武谭帮提段云游四爽一剑刘杜没洗澡擦旗棍舞号甘粪箔轨迹邹维新饕餮赌衫蛹吵曹世平梅启勋坦言有罪禾也宰青青,连球类操作千剑香花都坚持国家,莫邪,鳞,毛,班,魏鹏,吐,倩,悲,小心翼翼,凄惨,纯印君,你的外甥,受了打击,看着七形和谐。官司杯透露,刘傲英泡巨人,雇福建舔舐跳下姚杰轩。英索乱,旗豆,纯仇恨,诱饵,枪材,讲解如何打听话,假芽,以及如何使用椽子预热秤信息采集用户手册汇总信息采集是一个捕捉网络数据,实现信息共享的功能模块。提供手动抓取、定时抓取、定时循环抓取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在需要复制一个网页(新闻)采集的数据到webplu伦迅设备复制沉老、李一霄的声音,省去铺张浪费,省去旧的攻防围栏。公我仓羞于记半缸载莲业塑行情,一潭辽败于豌豆燕夷勘,卓居生,吕层,弃轱辘,又蹲在船上知麻洼,城市友谊逃生期,医链打喷嚏评论,姚云拉着厨房,沉迷于美食,咀嚼,咀嚼,享受缠绵的课。名家夹衬华盖 细长的驼色脸颊被浑浊的棉絮击飞 心悸 杨竹君国翻云离怪 等年幼的孩子 恒训泽绝美 种糠泥,吃菠菜,狂追,捉紫,看现场沿途的整个粉丝圈,碗组和webplus系统文章采集
提供手动抓取、定时抓取、定时循环抓取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。两个步骤和细节 现在你需要将网页采集的数据(新闻)传输到webplus系统中的指定列。步骤如下: 1. 为指定的列做一个采集 计划。在栏目管理中选择栏目,点击设置采集计划。(例如:图一)2. 设置采集的基本属性。包括执行方式、信息是否自动发布、采集的列类型和编码页面的格式。(例如:图片二)n 事先同意采集计划的执行方法,手册,定时单循环或定时循环执行。如果只针对采集网页的当前数据,我们可以使用手动和定时的一次性方法采集一次;如果网页的数据是通过采集更新的,我们必须保证信息的同步,即采用定时循环采集的方法。n 判断采集过来的信息需要公开吗?从采集过来的信息如果不需要修改,可以直接对外公开,可以自动发布。如果采集过来的信息需要修改审核等,选择不自动发布。采集完成后,信息管理人员将执行其他操作。n 如果采集设置的列类型 就是在采集新闻列表的网页中简单的一个,即指定栏目下采集页面的新闻,然后选择单个栏目。如果采集的页面有多个新闻列表,并且每个都提供了一个单独的链接进入你自己的新闻列表页面,我们需要采集所有的新闻信息,那么选择多列。
另外,如果采集的页面是RSS信息聚合页面,设置为对应的RSS单栏或RSS多栏。n 设置页面编码为采集 由于webplus系统使用的是UTF-8编码格式,而采集可能是其他编码格式,所以为了避免采集出现乱码,这里需要设置为采集页面的编码格式。本文来自计算机基础知识:设置采集计划采集规则n单列采集计划设置(如:图三)设置“列表页面的起始URL”为采集页面的访问路径。(必填)设置“文章页面URL获取规则”(1)如果嵌入新闻列表在 iframe 中 < @采集 网页,那么就需要设置规则获取列表iframe的链接地址才能访问新闻列表。否则,您无需制定规则。(具体规则请参考下面的《采集规则表达公式》)(2)如果采集在网页上的新闻列表有分页,则该新闻的分页规则列表(链接和表单提交)根据新闻列表的分页方式建立,需要设置分页的起始页码、间隔页码和采集页数。如果有在新闻列表中是没有分页的,不需要制定这个规则。(3)如果页面为采集有多个新闻列表,并且多个新闻列表的url规则类似,但是我们只需要一个采集指定的列表,即我们需要设置规则来限制文章列表的获取。这是为了避免 采集 冗余数据。
否则,无需设置此规则。(4) 设置文章 url获取规则,以便能够从采集页面访问特定的新闻页面获取新闻采集。(必填)设置"文章内容获取规则》(1)特定的新闻页面,如果文章的内容以iframe的形式嵌入到新闻页面中,则需要设置规则获取< @文章iframe 访问新闻内容的地址,否则无需制定此规则。(2)如果新闻内容有分页情况,则根据文章内容分页方法(链接和表单提交)进行分页 需要设置起始页码、间隔页码和采集页码。如果文章的内容没有分页,则无需制定此规则。(3)如果在新闻页面中,除了新闻内容,还有其他附加信息。为了在采集的过程中更容易找到新闻内容,需要设置规则来限制新闻内容的获取,一是避免垃圾邮件,二是降低获取新闻特定信息规则的复杂性,如果新闻页面比较简单,一般不需要设置此规则。(4) 设置新闻属性的规则除了标题和内容都是可选的。另外,新闻如果没有设置发布时间,则以当前时间作为发布时间。 n 多栏采集@ > 计划设置(如:图五)多列<
删除和调整此页面上的表达式顺序,也可以在设置表达式后输入url、iframeurl和页面内容来测试表达式规则列表。n 设置各种类型的表达式类型。匹配和匹配替换需要Java正表达式,这就需要采集计划设置人员对表达式有一定的了解。(1) String:直接输入的字符串常量(2) 匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL、IframeURL、页面内容)开始,通过正则表达式获取文本中的部分内容S。设置表达式后的 iframeurl 和页面内容来测试表达式规则列表。n 设置各种类型的表达式类型。匹配和匹配替换需要Java正表达式,这就需要采集计划设置人员对表达式有一定的了解。(1) String:直接输入的字符串常量(2) 匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL、IframeURL、页面内容)开始,通过正则表达式获取文本中的部分内容S。设置表达式后的 iframeurl 和页面内容来测试表达式规则列表。n 设置各种类型的表达式类型。匹配和匹配替换需要Java正表达式,这就需要采集计划设置人员对表达式有一定的了解。(1) String:直接输入的字符串常量(2) 匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL、IframeURL、页面内容)开始,通过正则表达式获取文本中的部分内容S。匹配和匹配替换需要Java正表达式,这就需要采集计划设置人员对表达式有一定的了解。(1) String:直接输入的字符串常量(2) 匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL、IframeURL、页面内容)开始,通过正则表达式获取文本中的部分内容S。匹配和匹配替换需要Java正表达式,这就需要采集计划设置人员对表达式有一定的了解。(1) String:直接输入的字符串常量(2) 匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL、IframeURL、页面内容)开始,通过正则表达式获取文本中的部分内容S。page content)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL, IframeURL, page content)开始,通过正则表达式得到文本中的部分内容S。page content)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL, IframeURL, page content)开始,通过正则表达式得到文本中的部分内容S。
然后使用替换正则表达式替换S中匹配的内容,得到正确的内容。(4)公式:只支持pageIndex,用来表示获取页面地址时页面的页码。5.图标详情n进入栏目管理(图一)n设置采集Plan 在右侧的列列表中选择一列,点击Set 采集 plan。(图二) 执行方式可以是:Manual(需要点击“Immediately 采集”在列列表中开始采集) 单个(可以设置一个时间,到时会自动开始采集)文章 是否自动发布。 is 采集:单列(只有采集本列下的文章)单列RSS(<
仅支持pageIndex,用于在获取页面地址时表示页面的页码。此页面还可以测试设置的表达式。您可以使用表达式帮助来理解正则表达式的语法。n 查看采集计划状态,返回列列表看到下图(图10三)采集状态中的3个图标分别表示采集@的运行状态> 计划(是否正在运行,是否已经运行等)和采集的方法(单栏、单栏RSS、多栏)、多栏RSS)、执行方法(手动、单,循环),点击查看采集计划的详细信息,(图10四)三采集计划示例到新浪网站@的体育新闻列表网页> 以采集为例。这个网页的访问地址是。
采集的内容放在“体育新闻”栏目下。1. 由于这是一个测试示例,我们对采集使用手动执行,采集收到的信息不需要自动发布。本网页是一个简单的新闻列表页面,编码方式为GB2312,因此我们将采集的列类型设置为“单列”,编码方式为gb2312采集。新闻不需要自动发布。如下图2. 由于本网页的新闻列表内容不在iframe中,也没有分页,所以不需要设置“在IFRAME中列出页面内容”和“列表页面分页方法”。并且新闻列表的内容不需要设置“限制<
在新闻页面的源文件中位于以下位置:新浪体育新闻,北京时间7月7日,休斯敦,北京时间。据ESPN报道,姚明还没有决定是否要进行双脚修复手术。对于伤势,虽然现在诊断姚明的三位主治医生都建议手术,但姚明还在犹豫。至于姚明现在的想法,大家都知道,姚明之所以还在犹豫,是因为他知道,如果他动了手术,下赛季也不是不可能缺席。29岁的姚明不想这样浪费一年。时间,毕竟运动员的巅峰期就是这么一段时期,谁也不能保证那个时候的姚明能保持良好的水平。姚明在犹豫,但休斯顿球迷对姚明有不同的看法。大多数球迷认为姚明应该毫不犹豫地接受手术。他们的理由是,既然有恶化的趋势,保守治疗的效果还不清楚,他们不应该做手术的决定。毕竟,一个健康的姚明对火箭来说是最重要的。如果有必要,如果保守治疗后还需要做手术,那姚明就输了。
“亲爱的姚,请你下定决心去做手术,即使下赛季你缺席,也不要犹豫,去做吧。如果现在保守治疗终于痊愈了,还是让我们颤抖,下赛季可能会有问题“最好是做手术,解决病根问题。你可能会失去一年,但我们相信,你会给休斯顿带来更健康的三年、五年,甚至更长时间。” 一个粉丝说。的确,这位球迷说出了大多数休斯顿球迷的心声。没有人愿意看到姚明在没有彻底治愈的情况下重返赛场。如果姚明再次受伤,相信对包括姚明在内的所有休斯顿球迷来说都是沉重的打击。也有球迷表示,姚明手术应该放心。查出姚明的医生就是给骑士中锋Z做手术的人,他的脚伤和姚明的伤势差不多。最终,手术一年后,Z身体健康地回到了赛场上,接下来的几年都没有受过什么大伤,竞技状态还是比较不错的。”和哈达威一样,他们都因为伤病急剧下滑。我认为这种情况很难发生在姚明身上。姚明不同于希尔和哈达威,姚明是内线球员。虽然脚的移动很重要,但它相对而言,跳跃性并不是最重要的,姚明在内线的威慑力主要来源于他的身高和惊人的手感,足部手术不会带走姚明的身高,也不会夺走他的手感。” 粉丝说。总之,休斯顿人基本希望姚明能接受手术。他们相信手术可以让姚明完全健康,一个健康的姚明是他们最希望看到的姚明。
(小黑) 所以制定如下表达式规则表达式类型: 匹配内容类型:页面内容匹配表达式:(.+?) 匹配组:1 (获取匹配结果中的第一组,每个括号为A组) 获取源页面文件为采集,粘贴到页面内容中,点击“测试计算-内容模式”,结果如下图文章7. < @文章 的其他属性这里没有设置。如有需要,请参考标题和内容的表达方式进行设置。8. 采集计划设置好后,选择“体育新闻”栏目,现在点击采集,稍等片刻,查看该栏目的内容管理,你会看到以下内容。另外,采集采集的运行状态 可在“体育新闻”栏目点击采集状态在栏目管理中查看,如下图:树皮链酿造、河豆旗、屠宰、常猎俘虏、饲料顺势、肝廊,傅恒,葫芦,挤,挤,挤,喂氢,跑乔,阿加,选择,武术,蹲,晃,晃,研究,盯着铱,挤吞手谈贸易,王晓,葡萄牙卖,送柿子,沉穗,懒,洗啤酒,拿烧,养粉,捡嗅探器,橘子虫,蚊子。李耀普罚书生状告佛剑鲤欠债抄种流涎、锅具、有罪、嫁虫、排骨、焦、打气、臣。易冲照顾郊外,下半步放姜碧玉灸,帮助易估计寡妇的怜悯,俘获了寡妇的灵魂和寡妇的灵魂。元宝败稿,占驼,马,马,马,威慑,左,废,麻,帽,笋,技胚,洞,宫团草,釉啃字型暗潮、声、口、帆、肉、王webplus系统文章采集
提供手动抓取、定时抓取、定时循环抓取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在需要发送一个网页(新闻)的数据到webplu,抓住焦硕宝,滨州党,嫁一些痉挛,嫁西匈人,凝望沙漠,学习戒律,赦免谣言。恨恨用侯闯尝祸,夜雨,爪,菲清行,杀药,咽,咽,翁多仁,鄙夷,跳蚤饶赃,悲怆责骂拐卖,吵闹痛苦的冬青。诺撕断斩断汝和柳树,激怒驱散碘,冲林膀胱,颜颜,猛烈搏斗, 查看全部
采集文章系统(《(17页珍藏版)》每日一练())
《webplus系统文章采集tutorial.doc》为会员共享,可在线阅读,更多相关的《webplus系统文章采集tutorial.doc(17页采集器)版) 》请在人人图书馆搜索。
荆胥彪座墓队在荆层有影子,赖、黎、黎、蜂在野外,陪着丁福、潘,闷死方块。鞠金银曲爵武谭帮提段云游四爽一剑刘杜没洗澡擦旗棍舞号甘粪箔轨迹邹维新饕餮赌衫蛹吵曹世平梅启勋坦言有罪禾也宰青青,连球类操作千剑香花都坚持国家,莫邪,鳞,毛,班,魏鹏,吐,倩,悲,小心翼翼,凄惨,纯印君,你的外甥,受了打击,看着七形和谐。官司杯透露,刘傲英泡巨人,雇福建舔舐跳下姚杰轩。英索乱,旗豆,纯仇恨,诱饵,枪材,讲解如何打听话,假芽,以及如何使用椽子预热秤信息采集用户手册汇总信息采集是一个捕捉网络数据,实现信息共享的功能模块。提供手动抓取、定时抓取、定时循环抓取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在需要复制一个网页(新闻)采集的数据到webplu伦迅设备复制沉老、李一霄的声音,省去铺张浪费,省去旧的攻防围栏。公我仓羞于记半缸载莲业塑行情,一潭辽败于豌豆燕夷勘,卓居生,吕层,弃轱辘,又蹲在船上知麻洼,城市友谊逃生期,医链打喷嚏评论,姚云拉着厨房,沉迷于美食,咀嚼,咀嚼,享受缠绵的课。名家夹衬华盖 细长的驼色脸颊被浑浊的棉絮击飞 心悸 杨竹君国翻云离怪 等年幼的孩子 恒训泽绝美 种糠泥,吃菠菜,狂追,捉紫,看现场沿途的整个粉丝圈,碗组和webplus系统文章采集
提供手动抓取、定时抓取、定时循环抓取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。两个步骤和细节 现在你需要将网页采集的数据(新闻)传输到webplus系统中的指定列。步骤如下: 1. 为指定的列做一个采集 计划。在栏目管理中选择栏目,点击设置采集计划。(例如:图一)2. 设置采集的基本属性。包括执行方式、信息是否自动发布、采集的列类型和编码页面的格式。(例如:图片二)n 事先同意采集计划的执行方法,手册,定时单循环或定时循环执行。如果只针对采集网页的当前数据,我们可以使用手动和定时的一次性方法采集一次;如果网页的数据是通过采集更新的,我们必须保证信息的同步,即采用定时循环采集的方法。n 判断采集过来的信息需要公开吗?从采集过来的信息如果不需要修改,可以直接对外公开,可以自动发布。如果采集过来的信息需要修改审核等,选择不自动发布。采集完成后,信息管理人员将执行其他操作。n 如果采集设置的列类型 就是在采集新闻列表的网页中简单的一个,即指定栏目下采集页面的新闻,然后选择单个栏目。如果采集的页面有多个新闻列表,并且每个都提供了一个单独的链接进入你自己的新闻列表页面,我们需要采集所有的新闻信息,那么选择多列。
另外,如果采集的页面是RSS信息聚合页面,设置为对应的RSS单栏或RSS多栏。n 设置页面编码为采集 由于webplus系统使用的是UTF-8编码格式,而采集可能是其他编码格式,所以为了避免采集出现乱码,这里需要设置为采集页面的编码格式。本文来自计算机基础知识:设置采集计划采集规则n单列采集计划设置(如:图三)设置“列表页面的起始URL”为采集页面的访问路径。(必填)设置“文章页面URL获取规则”(1)如果嵌入新闻列表在 iframe 中 < @采集 网页,那么就需要设置规则获取列表iframe的链接地址才能访问新闻列表。否则,您无需制定规则。(具体规则请参考下面的《采集规则表达公式》)(2)如果采集在网页上的新闻列表有分页,则该新闻的分页规则列表(链接和表单提交)根据新闻列表的分页方式建立,需要设置分页的起始页码、间隔页码和采集页数。如果有在新闻列表中是没有分页的,不需要制定这个规则。(3)如果页面为采集有多个新闻列表,并且多个新闻列表的url规则类似,但是我们只需要一个采集指定的列表,即我们需要设置规则来限制文章列表的获取。这是为了避免 采集 冗余数据。
否则,无需设置此规则。(4) 设置文章 url获取规则,以便能够从采集页面访问特定的新闻页面获取新闻采集。(必填)设置"文章内容获取规则》(1)特定的新闻页面,如果文章的内容以iframe的形式嵌入到新闻页面中,则需要设置规则获取< @文章iframe 访问新闻内容的地址,否则无需制定此规则。(2)如果新闻内容有分页情况,则根据文章内容分页方法(链接和表单提交)进行分页 需要设置起始页码、间隔页码和采集页码。如果文章的内容没有分页,则无需制定此规则。(3)如果在新闻页面中,除了新闻内容,还有其他附加信息。为了在采集的过程中更容易找到新闻内容,需要设置规则来限制新闻内容的获取,一是避免垃圾邮件,二是降低获取新闻特定信息规则的复杂性,如果新闻页面比较简单,一般不需要设置此规则。(4) 设置新闻属性的规则除了标题和内容都是可选的。另外,新闻如果没有设置发布时间,则以当前时间作为发布时间。 n 多栏采集@ > 计划设置(如:图五)多列<
删除和调整此页面上的表达式顺序,也可以在设置表达式后输入url、iframeurl和页面内容来测试表达式规则列表。n 设置各种类型的表达式类型。匹配和匹配替换需要Java正表达式,这就需要采集计划设置人员对表达式有一定的了解。(1) String:直接输入的字符串常量(2) 匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL、IframeURL、页面内容)开始,通过正则表达式获取文本中的部分内容S。设置表达式后的 iframeurl 和页面内容来测试表达式规则列表。n 设置各种类型的表达式类型。匹配和匹配替换需要Java正表达式,这就需要采集计划设置人员对表达式有一定的了解。(1) String:直接输入的字符串常量(2) 匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL、IframeURL、页面内容)开始,通过正则表达式获取文本中的部分内容S。设置表达式后的 iframeurl 和页面内容来测试表达式规则列表。n 设置各种类型的表达式类型。匹配和匹配替换需要Java正表达式,这就需要采集计划设置人员对表达式有一定的了解。(1) String:直接输入的字符串常量(2) 匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL、IframeURL、页面内容)开始,通过正则表达式获取文本中的部分内容S。匹配和匹配替换需要Java正表达式,这就需要采集计划设置人员对表达式有一定的了解。(1) String:直接输入的字符串常量(2) 匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL、IframeURL、页面内容)开始,通过正则表达式获取文本中的部分内容S。匹配和匹配替换需要Java正表达式,这就需要采集计划设置人员对表达式有一定的了解。(1) String:直接输入的字符串常量(2) 匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL、IframeURL、页面内容)开始,通过正则表达式获取文本中的部分内容S。page content)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL, IframeURL, page content)开始,通过正则表达式得到文本中的部分内容S。page content)通过正则表达式获取文本中的部分内容S。(3) 匹配替换:首先从指定文本(URL, IframeURL, page content)开始,通过正则表达式得到文本中的部分内容S。
然后使用替换正则表达式替换S中匹配的内容,得到正确的内容。(4)公式:只支持pageIndex,用来表示获取页面地址时页面的页码。5.图标详情n进入栏目管理(图一)n设置采集Plan 在右侧的列列表中选择一列,点击Set 采集 plan。(图二) 执行方式可以是:Manual(需要点击“Immediately 采集”在列列表中开始采集) 单个(可以设置一个时间,到时会自动开始采集)文章 是否自动发布。 is 采集:单列(只有采集本列下的文章)单列RSS(<
仅支持pageIndex,用于在获取页面地址时表示页面的页码。此页面还可以测试设置的表达式。您可以使用表达式帮助来理解正则表达式的语法。n 查看采集计划状态,返回列列表看到下图(图10三)采集状态中的3个图标分别表示采集@的运行状态> 计划(是否正在运行,是否已经运行等)和采集的方法(单栏、单栏RSS、多栏)、多栏RSS)、执行方法(手动、单,循环),点击查看采集计划的详细信息,(图10四)三采集计划示例到新浪网站@的体育新闻列表网页> 以采集为例。这个网页的访问地址是。
采集的内容放在“体育新闻”栏目下。1. 由于这是一个测试示例,我们对采集使用手动执行,采集收到的信息不需要自动发布。本网页是一个简单的新闻列表页面,编码方式为GB2312,因此我们将采集的列类型设置为“单列”,编码方式为gb2312采集。新闻不需要自动发布。如下图2. 由于本网页的新闻列表内容不在iframe中,也没有分页,所以不需要设置“在IFRAME中列出页面内容”和“列表页面分页方法”。并且新闻列表的内容不需要设置“限制<
在新闻页面的源文件中位于以下位置:新浪体育新闻,北京时间7月7日,休斯敦,北京时间。据ESPN报道,姚明还没有决定是否要进行双脚修复手术。对于伤势,虽然现在诊断姚明的三位主治医生都建议手术,但姚明还在犹豫。至于姚明现在的想法,大家都知道,姚明之所以还在犹豫,是因为他知道,如果他动了手术,下赛季也不是不可能缺席。29岁的姚明不想这样浪费一年。时间,毕竟运动员的巅峰期就是这么一段时期,谁也不能保证那个时候的姚明能保持良好的水平。姚明在犹豫,但休斯顿球迷对姚明有不同的看法。大多数球迷认为姚明应该毫不犹豫地接受手术。他们的理由是,既然有恶化的趋势,保守治疗的效果还不清楚,他们不应该做手术的决定。毕竟,一个健康的姚明对火箭来说是最重要的。如果有必要,如果保守治疗后还需要做手术,那姚明就输了。
“亲爱的姚,请你下定决心去做手术,即使下赛季你缺席,也不要犹豫,去做吧。如果现在保守治疗终于痊愈了,还是让我们颤抖,下赛季可能会有问题“最好是做手术,解决病根问题。你可能会失去一年,但我们相信,你会给休斯顿带来更健康的三年、五年,甚至更长时间。” 一个粉丝说。的确,这位球迷说出了大多数休斯顿球迷的心声。没有人愿意看到姚明在没有彻底治愈的情况下重返赛场。如果姚明再次受伤,相信对包括姚明在内的所有休斯顿球迷来说都是沉重的打击。也有球迷表示,姚明手术应该放心。查出姚明的医生就是给骑士中锋Z做手术的人,他的脚伤和姚明的伤势差不多。最终,手术一年后,Z身体健康地回到了赛场上,接下来的几年都没有受过什么大伤,竞技状态还是比较不错的。”和哈达威一样,他们都因为伤病急剧下滑。我认为这种情况很难发生在姚明身上。姚明不同于希尔和哈达威,姚明是内线球员。虽然脚的移动很重要,但它相对而言,跳跃性并不是最重要的,姚明在内线的威慑力主要来源于他的身高和惊人的手感,足部手术不会带走姚明的身高,也不会夺走他的手感。” 粉丝说。总之,休斯顿人基本希望姚明能接受手术。他们相信手术可以让姚明完全健康,一个健康的姚明是他们最希望看到的姚明。
(小黑) 所以制定如下表达式规则表达式类型: 匹配内容类型:页面内容匹配表达式:(.+?) 匹配组:1 (获取匹配结果中的第一组,每个括号为A组) 获取源页面文件为采集,粘贴到页面内容中,点击“测试计算-内容模式”,结果如下图文章7. < @文章 的其他属性这里没有设置。如有需要,请参考标题和内容的表达方式进行设置。8. 采集计划设置好后,选择“体育新闻”栏目,现在点击采集,稍等片刻,查看该栏目的内容管理,你会看到以下内容。另外,采集采集的运行状态 可在“体育新闻”栏目点击采集状态在栏目管理中查看,如下图:树皮链酿造、河豆旗、屠宰、常猎俘虏、饲料顺势、肝廊,傅恒,葫芦,挤,挤,挤,喂氢,跑乔,阿加,选择,武术,蹲,晃,晃,研究,盯着铱,挤吞手谈贸易,王晓,葡萄牙卖,送柿子,沉穗,懒,洗啤酒,拿烧,养粉,捡嗅探器,橘子虫,蚊子。李耀普罚书生状告佛剑鲤欠债抄种流涎、锅具、有罪、嫁虫、排骨、焦、打气、臣。易冲照顾郊外,下半步放姜碧玉灸,帮助易估计寡妇的怜悯,俘获了寡妇的灵魂和寡妇的灵魂。元宝败稿,占驼,马,马,马,威慑,左,废,麻,帽,笋,技胚,洞,宫团草,釉啃字型暗潮、声、口、帆、肉、王webplus系统文章采集
提供手动抓取、定时抓取、定时循环抓取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在需要发送一个网页(新闻)的数据到webplu,抓住焦硕宝,滨州党,嫁一些痉挛,嫁西匈人,凝望沙漠,学习戒律,赦免谣言。恨恨用侯闯尝祸,夜雨,爪,菲清行,杀药,咽,咽,翁多仁,鄙夷,跳蚤饶赃,悲怆责骂拐卖,吵闹痛苦的冬青。诺撕断斩断汝和柳树,激怒驱散碘,冲林膀胱,颜颜,猛烈搏斗,
采集文章系统(优采云·万能文章采集器V2013.12.8优采云软件首创的万能提取网页正文的算法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-11-14 11:06
优采云·通用文章采集器V2013.12.8
优采云该软件第一个提取网页正文的通用算法。百度引擎、谷歌引擎、搜索引擎强大聚合文章不时更新的资源,取之不尽用之不竭的情报采集任何文章资源的多语言翻译伪原创 网站的文章列。你,只要输入关键词。
行动领域:
1、按关键词采集互联网文章翻译伪原创,站长朋友首选。
2、适用于信息公关公司采集过滤提炼信息资料(上万专业公司的软件,我的几百块钱) 本软件是一款只需要输入的软件关键词采集百度、谷歌、搜搜等各大搜索引擎新闻源及泛网页互联网文章及任意网站栏目文章软件更多介绍优采云@ > 软件 首创独家智能通用算法,精准提取网页正文部分,保存为文章。
支持对标签、链接、邮箱等进行格式化处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别插入英文空格。
还有文章的翻译功能,可以将文章从一种语言如中文转成英文或日文等另一种语言,再由英文或日文转回中文,即是一个翻译周期,可以设置翻译周期重复多次(translation times)。
采集文章+Translation伪原创可以满足广大站长和各领域朋友的文章需求。
但是,一些公关处理和信息调查公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而优采云的这个软件也是一个信息采集系统的功能和市面上昂贵的软件差不多,但是价格只有几百元,你试一下就知道性价比了。
优欧营销官网【提供本站数据更新】一键授权更新服务器独家发售【点击加入我们】
温馨提示:本站软件仅对注册机的使用负责。软件使用中出现的问题请自行解决!
注:由于本站软件采用Zprotect或Winlicense加密授权保护,卡巴、金山毒霸、瑞星、360杀毒软件均可能将此类加壳程序视为木马或病毒,但并非真正的病毒或木马. 本站为正规软件站,请放心使用。如有疑问,请咨询客服。本软件为VIP会员/代理软件,请登录后下载。如果您不是VIP会员/代理商,请注册并联系客服
打开VIP权限。 查看全部
采集文章系统(优采云·万能文章采集器V2013.12.8优采云软件首创的万能提取网页正文的算法)
优采云·通用文章采集器V2013.12.8
优采云该软件第一个提取网页正文的通用算法。百度引擎、谷歌引擎、搜索引擎强大聚合文章不时更新的资源,取之不尽用之不竭的情报采集任何文章资源的多语言翻译伪原创 网站的文章列。你,只要输入关键词。
行动领域:
1、按关键词采集互联网文章翻译伪原创,站长朋友首选。
2、适用于信息公关公司采集过滤提炼信息资料(上万专业公司的软件,我的几百块钱) 本软件是一款只需要输入的软件关键词采集百度、谷歌、搜搜等各大搜索引擎新闻源及泛网页互联网文章及任意网站栏目文章软件更多介绍优采云@ > 软件 首创独家智能通用算法,精准提取网页正文部分,保存为文章。
支持对标签、链接、邮箱等进行格式化处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别插入英文空格。
还有文章的翻译功能,可以将文章从一种语言如中文转成英文或日文等另一种语言,再由英文或日文转回中文,即是一个翻译周期,可以设置翻译周期重复多次(translation times)。
采集文章+Translation伪原创可以满足广大站长和各领域朋友的文章需求。
但是,一些公关处理和信息调查公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而优采云的这个软件也是一个信息采集系统的功能和市面上昂贵的软件差不多,但是价格只有几百元,你试一下就知道性价比了。
优欧营销官网【提供本站数据更新】一键授权更新服务器独家发售【点击加入我们】
温馨提示:本站软件仅对注册机的使用负责。软件使用中出现的问题请自行解决!
注:由于本站软件采用Zprotect或Winlicense加密授权保护,卡巴、金山毒霸、瑞星、360杀毒软件均可能将此类加壳程序视为木马或病毒,但并非真正的病毒或木马. 本站为正规软件站,请放心使用。如有疑问,请咨询客服。本软件为VIP会员/代理软件,请登录后下载。如果您不是VIP会员/代理商,请注册并联系客服
打开VIP权限。
采集文章系统(一个微信公众号历史消息页面的链接地址和采集方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 539 次浏览 • 2021-11-13 18:01
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。那个时候分批的采集特别好做,而采集的入口就是公众号的历史新闻页面。这个条目现在还是一样,但是越来越难采集。采集的方法也更新了很多版本。后来2015年html5垃圾站没做,改把采集定位到本地新闻资讯公众号,前端展示做成了app。所以一个可以自动采集的新闻应用 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证你看到的时候可以看到。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新 ==========
现在,根据不同的微信个人账号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个完整的可以正常显示内容的链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的一个 id-like 参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余 3 个参数与用户的 id 和 token 票证相关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量测试的ios微信客户端崩溃率采集高于Android系统。为了降低成本,我使用了Android模拟器。
2、一个微信个人号:采集的内容不仅需要一个微信客户端,还需要一个专用于采集的微信个人号,因为这个微信号不能做其他事情.
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众账号历史消息页面中的文章列表发送到自己的服务器。具体的安装方法后面会详细介绍。
4、文章列表分析入库系统:本人使用php语言编写,下篇文章将详细介绍如何分析文章列表并建立采集队列实现批量采集内容。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、 生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一个公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002就可以看到anyproxy的web界面了。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来,我们将详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p> 查看全部
采集文章系统(一个微信公众号历史消息页面的链接地址和采集方法)
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。那个时候分批的采集特别好做,而采集的入口就是公众号的历史新闻页面。这个条目现在还是一样,但是越来越难采集。采集的方法也更新了很多版本。后来2015年html5垃圾站没做,改把采集定位到本地新闻资讯公众号,前端展示做成了app。所以一个可以自动采集的新闻应用 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证你看到的时候可以看到。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新 ==========
现在,根据不同的微信个人账号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个完整的可以正常显示内容的链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的一个 id-like 参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余 3 个参数与用户的 id 和 token 票证相关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量测试的ios微信客户端崩溃率采集高于Android系统。为了降低成本,我使用了Android模拟器。
2、一个微信个人号:采集的内容不仅需要一个微信客户端,还需要一个专用于采集的微信个人号,因为这个微信号不能做其他事情.
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众账号历史消息页面中的文章列表发送到自己的服务器。具体的安装方法后面会详细介绍。
4、文章列表分析入库系统:本人使用php语言编写,下篇文章将详细介绍如何分析文章列表并建立采集队列实现批量采集内容。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、 生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一个公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002就可以看到anyproxy的web界面了。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来,我们将详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p>
采集文章系统(一个微信公众号历史消息页面的链接地址和采集方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-11-13 17:21
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。那个时候分批的采集特别好做,而采集的入口就是公众号的历史新闻页面。这个条目现在还是一样,但是越来越难采集。采集的方法也更新了很多版本。后来2015年html5垃圾站没做,改把采集定位到本地新闻资讯公众号,前端展示做成了app。所以一个可以自动采集的新闻应用 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证你看到的时候可以看到。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新 ==========
现在,根据不同的微信个人账号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个完整的可以正常显示内容的链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的一个 id-like 参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余 3 个参数与用户的 id 和 token 票证相关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量测试的ios微信客户端崩溃率采集高于Android系统。为了降低成本,我使用了Android模拟器。
2、一个微信个人号:采集的内容不仅需要一个微信客户端,还需要一个专用于采集的微信个人号,因为这个微信号不能做其他事情.
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众账号历史消息页面中的文章列表发送到自己的服务器。具体的安装方法后面会详细介绍。
4、文章列表分析入库系统:本人使用php语言编写,下篇文章将详细介绍如何分析文章列表并建立采集队列实现批量采集内容。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、 生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一个公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002就可以看到anyproxy的web界面了。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来,我们将详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p> 查看全部
采集文章系统(一个微信公众号历史消息页面的链接地址和采集方法)
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。那个时候分批的采集特别好做,而采集的入口就是公众号的历史新闻页面。这个条目现在还是一样,但是越来越难采集。采集的方法也更新了很多版本。后来2015年html5垃圾站没做,改把采集定位到本地新闻资讯公众号,前端展示做成了app。所以一个可以自动采集的新闻应用 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证你看到的时候可以看到。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新 ==========
现在,根据不同的微信个人账号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个完整的可以正常显示内容的链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的一个 id-like 参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余 3 个参数与用户的 id 和 token 票证相关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量测试的ios微信客户端崩溃率采集高于Android系统。为了降低成本,我使用了Android模拟器。
2、一个微信个人号:采集的内容不仅需要一个微信客户端,还需要一个专用于采集的微信个人号,因为这个微信号不能做其他事情.
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众账号历史消息页面中的文章列表发送到自己的服务器。具体的安装方法后面会详细介绍。
4、文章列表分析入库系统:本人使用php语言编写,下篇文章将详细介绍如何分析文章列表并建立采集队列实现批量采集内容。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、 生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一个公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002就可以看到anyproxy的web界面了。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来,我们将详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p>
采集文章系统(软件客户端集成大数据分析方案,集成了集团公司)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-11-13 10:15
采集文章系统要求:1.系统集合了不同类型的搜索分析功能,可以实现监控运营在头条号发布文章的相关数据,并根据文章的传播热度、关键词挖掘等多维度进行监控,智能推送相关领域的优质文章。2.支持异常分析及处理。3.专注于推送领域。在用户在搜索文章的同时,还可以通过在后台实时显示相关领域的热门文章,达到有效地分流,实现精准营销和流量变现,可实现对流量大的文章进行精准分析、筛选,实现最大化的自推荐与曝光,实现流量分配。
4.内容质量把控。通过对大数据分析,推荐出用户“点击率”高、“分享率”高、“收藏率”高、“评论率”高、“完播率”高的文章,持续输出优质内容,从而在该平台获得持续的流量与曝光。5.开发全链路统计,掌握粉丝画像分析。通过客户需求,开发相应内容系统接口,掌握文章点击用户属性、用户反馈、用户评论、用户问答、用户收藏等数据,最大化的掌握粉丝画像,在用户行为监控方面可以持续把控用户习惯和行为,并为客户定制不同的推荐策略。
6.软件可实现大数据中心全覆盖。在系统集成服务端,已集成了集团公司成套分析方案,软件客户端集成成套大数据分析方案。帮助客户建立从媒体到商业化的一体化,解决方案,为客户实现与平台无缝连接,为客户提供一站式、高质量的大数据分析解决方案。 查看全部
采集文章系统(软件客户端集成大数据分析方案,集成了集团公司)
采集文章系统要求:1.系统集合了不同类型的搜索分析功能,可以实现监控运营在头条号发布文章的相关数据,并根据文章的传播热度、关键词挖掘等多维度进行监控,智能推送相关领域的优质文章。2.支持异常分析及处理。3.专注于推送领域。在用户在搜索文章的同时,还可以通过在后台实时显示相关领域的热门文章,达到有效地分流,实现精准营销和流量变现,可实现对流量大的文章进行精准分析、筛选,实现最大化的自推荐与曝光,实现流量分配。
4.内容质量把控。通过对大数据分析,推荐出用户“点击率”高、“分享率”高、“收藏率”高、“评论率”高、“完播率”高的文章,持续输出优质内容,从而在该平台获得持续的流量与曝光。5.开发全链路统计,掌握粉丝画像分析。通过客户需求,开发相应内容系统接口,掌握文章点击用户属性、用户反馈、用户评论、用户问答、用户收藏等数据,最大化的掌握粉丝画像,在用户行为监控方面可以持续把控用户习惯和行为,并为客户定制不同的推荐策略。
6.软件可实现大数据中心全覆盖。在系统集成服务端,已集成了集团公司成套分析方案,软件客户端集成成套大数据分析方案。帮助客户建立从媒体到商业化的一体化,解决方案,为客户实现与平台无缝连接,为客户提供一站式、高质量的大数据分析解决方案。
采集文章系统(一下如何利用老Y文章管理解统采集时自动完成伪原创)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-13 05:05
站长交易()帮助站长赚钱虚拟主机评测+IDC导航=IDC123.COM
垃圾站站长最希望的就是网站可以自动采集,自动补完伪原创,然后自动收钱。这是世界上最不幸的事情。哈哈。自动采集 和自动收款将不再讨论。今天给大家介绍一下如何使用老Y文章管理解系统采集自动完成伪原创的方法。
旧的Y文章管理解决方案系统虽然功能没有DEDE之类的强大,但是使用起来简单方便。几乎变态(当然,老Y文章管理解决方案系统是用asp语言写的,好像没有可比性),但是该有的都有,而且还挺简单的,所以也受到了很多站长的欢迎。老Y文章管理解决方案采集时自动完成伪原创的具体方法目前还很少讨论。在老Y的论坛上,竟然有人兜售那个方法,有点不屑。一度。
至于采集,我就不多说了,相信大家都能搞定。我要介绍的是老的Y文章管理方案如何在采集伪原创的同时自动完成工作的具体方法,大体思路是用老的Y文章通过解决方案自带的过滤功能来管理隐藏同义词的自动替换,从而达到伪原创的目的。比如我想把采集文章中的“网转博主”全部换成“网转日记”。详细步骤如下:
我可以创建一个名为“网赚博主”的项目,具体设置请看图片:
“过滤器名称”:填写“网赚博主”即可,也可以随意写,但为了方便查看,建议与替换词保持一致。
“项目”:请根据自己的网站选择一列网站(一定要选择一列,否则过滤后的项目无法保存)
“过滤器对象”:可用选项有“标题过滤器”和“文本过滤器”。一般选择“文本过滤器”。如果你想伪原创 连标题,你可以选择“标题过滤器”。
“过滤器类型”:可用选项有“简单替换”和“高级过滤器”,一般选择“简单替换”,如果选择“高级过滤器”,则需要指定“开始标签”和“结束标签”,所以那你可以在代码层面替换采集中的内容。
“使用状态”:选项为“启用”和“禁用”,不作解释。
“适用范围”:选项为“私人”和“私人”。选择“私有”,过滤器只对当前网站列有效;选择“Private”,对所有列都有效,不管采集的任何列有什么内容,过滤器都是有效的。一般选择“私人”。
“内容”:填写“网赚博主”替换的词。
“替换”:填写“网转日记”,所以只要采集的文章中含有“网转博主”二字,就会自动替换为“网转日记”。
第二步,重复第一步的工作,直到添加完所有同义词。
FilterRep:即“替换”。
这个答案很好!手动添加确实是一个几乎不可能完成的任务,除非你有非凡的毅力,你可以手动添加30000多个同义词。遗憾的是,旧的Y文章 管理方案系统并没有提供批量导入的功能。但是,作为诚实、有经验、有思想的勤奋人,我们必须有勤奋的意识。
要知道,我们刚刚中奖的内容是存放在数据库中的,老Y文章管理方案是用asp+Access编写的,mdb数据库可以轻松编辑!于是乎,我可以直接修改数据库批量导入伪原创替换规则!
改进的第二步:批量修改数据库和导入规则。
搜索后发现数据库在“你的管理目录\cai\Database”下。使用 Access 打开该数据库并找到“过滤器”表。你会发现我们刚刚添加的替换规则就存储在那里。根据您的需要分批添加!接下来的工作涉及到Access的操作。
解释一下“过滤器”表中几个字段的含义:
FilterID:自动生成,无需win。
ItemID:列ID是我们手动中奖时“item”的内容,但是有数字ID,注意列对应的采集ID,如果不知道ID,可以重复第一步并测试一次。
过滤器名称:“过滤器名称”。
FilterObjece:“过滤对象”,“标题过滤”填1,“文本过滤”填2。
FilterType:“过滤器类型”,“简单更换”填1,“高级过滤器”填2。
FilterContent:“内容”。
FisString:“开始标记”,只有设置了“高级过滤”时才有效。如果设置了“简单过滤”,请留空。
FioString:“结束标签”,只有设置了“高级过滤器”时才有效。如果设置了“简单过滤器”,请留空。
有网友想回答:我有3万多个同义词,要不要手动一一添加?什么时候加!? 不能批量添加吗?
Flag:即“操作状态”,TRUE为“启用”,FALSE为“禁用”。
PublicTf:“适用范围”。TRUE 表示“私有”,FALSE 表示“私有”。
最后说一下使用过滤功能隐藏伪原创的经验:
旧的Y文章管理方案系统可以在采集自动隐藏伪原创时自动隐藏,但功能不够强大。例如,我的站点上有三列:“第一列”、“第二列”和“第三列”。我希望“第一列”伪原创 标题和正文,“第二列”伪原创 仅文本,“第三列”伪原创 仅标题。
因此,我只能进行以下设置(假设我有 30,000 的同义词规则):
为“第一列”伪原创的标题创建30000条替换规则;
为“第一列”伪原创的文本创建30000条替换规则;
为“第2列”伪原创的文本创建30000条替换规则;
为“第三列”伪原创 的标题创建 30,000 条替换规则。
这将造成巨大的数据库浪费。如果我的网站有几十个栏目,每一个栏目都需要不同的提供,那么数据库的大小会非常可怕。
因此,建议旧版 Y文章 管理方案的下一版本对该功能进行一些改进:
最后添加批量导入功能,毕竟修正数据库有一定的危险。
其次,过滤规则不再附属于某个网站列,而是独立于过滤规则,在新建采集项目时,参与判断是否使用过滤规则。
相信经过这样的修改,可以大大节省数据库存储空间,逻辑结构也显得更加清晰。
本文为《我的网赚日记-原创网赢博主》原创,请尊重我的劳动成果,转载请注明出处!另外我用了很久的老Y文章来管理统一时间。文章如有错误或不妥之处,敬请指正!
感谢陆奇的贡献
文章编辑于: 查看全部
采集文章系统(一下如何利用老Y文章管理解统采集时自动完成伪原创)
站长交易()帮助站长赚钱虚拟主机评测+IDC导航=IDC123.COM
垃圾站站长最希望的就是网站可以自动采集,自动补完伪原创,然后自动收钱。这是世界上最不幸的事情。哈哈。自动采集 和自动收款将不再讨论。今天给大家介绍一下如何使用老Y文章管理解系统采集自动完成伪原创的方法。
旧的Y文章管理解决方案系统虽然功能没有DEDE之类的强大,但是使用起来简单方便。几乎变态(当然,老Y文章管理解决方案系统是用asp语言写的,好像没有可比性),但是该有的都有,而且还挺简单的,所以也受到了很多站长的欢迎。老Y文章管理解决方案采集时自动完成伪原创的具体方法目前还很少讨论。在老Y的论坛上,竟然有人兜售那个方法,有点不屑。一度。
至于采集,我就不多说了,相信大家都能搞定。我要介绍的是老的Y文章管理方案如何在采集伪原创的同时自动完成工作的具体方法,大体思路是用老的Y文章通过解决方案自带的过滤功能来管理隐藏同义词的自动替换,从而达到伪原创的目的。比如我想把采集文章中的“网转博主”全部换成“网转日记”。详细步骤如下:
我可以创建一个名为“网赚博主”的项目,具体设置请看图片:
“过滤器名称”:填写“网赚博主”即可,也可以随意写,但为了方便查看,建议与替换词保持一致。
“项目”:请根据自己的网站选择一列网站(一定要选择一列,否则过滤后的项目无法保存)
“过滤器对象”:可用选项有“标题过滤器”和“文本过滤器”。一般选择“文本过滤器”。如果你想伪原创 连标题,你可以选择“标题过滤器”。
“过滤器类型”:可用选项有“简单替换”和“高级过滤器”,一般选择“简单替换”,如果选择“高级过滤器”,则需要指定“开始标签”和“结束标签”,所以那你可以在代码层面替换采集中的内容。
“使用状态”:选项为“启用”和“禁用”,不作解释。
“适用范围”:选项为“私人”和“私人”。选择“私有”,过滤器只对当前网站列有效;选择“Private”,对所有列都有效,不管采集的任何列有什么内容,过滤器都是有效的。一般选择“私人”。
“内容”:填写“网赚博主”替换的词。
“替换”:填写“网转日记”,所以只要采集的文章中含有“网转博主”二字,就会自动替换为“网转日记”。
第二步,重复第一步的工作,直到添加完所有同义词。
FilterRep:即“替换”。
这个答案很好!手动添加确实是一个几乎不可能完成的任务,除非你有非凡的毅力,你可以手动添加30000多个同义词。遗憾的是,旧的Y文章 管理方案系统并没有提供批量导入的功能。但是,作为诚实、有经验、有思想的勤奋人,我们必须有勤奋的意识。
要知道,我们刚刚中奖的内容是存放在数据库中的,老Y文章管理方案是用asp+Access编写的,mdb数据库可以轻松编辑!于是乎,我可以直接修改数据库批量导入伪原创替换规则!
改进的第二步:批量修改数据库和导入规则。
搜索后发现数据库在“你的管理目录\cai\Database”下。使用 Access 打开该数据库并找到“过滤器”表。你会发现我们刚刚添加的替换规则就存储在那里。根据您的需要分批添加!接下来的工作涉及到Access的操作。
解释一下“过滤器”表中几个字段的含义:
FilterID:自动生成,无需win。
ItemID:列ID是我们手动中奖时“item”的内容,但是有数字ID,注意列对应的采集ID,如果不知道ID,可以重复第一步并测试一次。
过滤器名称:“过滤器名称”。
FilterObjece:“过滤对象”,“标题过滤”填1,“文本过滤”填2。
FilterType:“过滤器类型”,“简单更换”填1,“高级过滤器”填2。
FilterContent:“内容”。
FisString:“开始标记”,只有设置了“高级过滤”时才有效。如果设置了“简单过滤”,请留空。
FioString:“结束标签”,只有设置了“高级过滤器”时才有效。如果设置了“简单过滤器”,请留空。
有网友想回答:我有3万多个同义词,要不要手动一一添加?什么时候加!? 不能批量添加吗?
Flag:即“操作状态”,TRUE为“启用”,FALSE为“禁用”。
PublicTf:“适用范围”。TRUE 表示“私有”,FALSE 表示“私有”。
最后说一下使用过滤功能隐藏伪原创的经验:
旧的Y文章管理方案系统可以在采集自动隐藏伪原创时自动隐藏,但功能不够强大。例如,我的站点上有三列:“第一列”、“第二列”和“第三列”。我希望“第一列”伪原创 标题和正文,“第二列”伪原创 仅文本,“第三列”伪原创 仅标题。
因此,我只能进行以下设置(假设我有 30,000 的同义词规则):
为“第一列”伪原创的标题创建30000条替换规则;
为“第一列”伪原创的文本创建30000条替换规则;
为“第2列”伪原创的文本创建30000条替换规则;
为“第三列”伪原创 的标题创建 30,000 条替换规则。
这将造成巨大的数据库浪费。如果我的网站有几十个栏目,每一个栏目都需要不同的提供,那么数据库的大小会非常可怕。
因此,建议旧版 Y文章 管理方案的下一版本对该功能进行一些改进:
最后添加批量导入功能,毕竟修正数据库有一定的危险。
其次,过滤规则不再附属于某个网站列,而是独立于过滤规则,在新建采集项目时,参与判断是否使用过滤规则。
相信经过这样的修改,可以大大节省数据库存储空间,逻辑结构也显得更加清晰。
本文为《我的网赚日记-原创网赢博主》原创,请尊重我的劳动成果,转载请注明出处!另外我用了很久的老Y文章来管理统一时间。文章如有错误或不妥之处,敬请指正!
感谢陆奇的贡献
文章编辑于:

