
采集文章系统
采集文章系统(权威数据资源、技术、行业展望及展望(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-04-13 15:05
采集文章系统整理了权威数据资源、技术背书、行业热点、投资经验、可投递简历信息、数据分析、开放分享平台以及行业展望数据分析阅读顺序整理如下:所有资源为2016.7-2017.3所产生,给新进群友们。转发、分享此文至朋友圈即可免费领取百度搜索、百度文库、各大招聘网站、不定期线下分享会等!想要领取更多招聘信息&简历模板&职场干货的小伙伴请多多关注、留言并转发,或者添加我们的职业咨询师的微信【bojo_】,随时跟我们互动哦。【下期福利】将随机抽取10位掌握权威数据资源的新媒体运营人,获得价值上千元的数据分析类小福利一份。
加入我们的社群群主群内有我们的社群入口点赞即可
有,boss直聘网,智联招聘网,猎聘网,中华英才网,360网,51job网,去哪儿网等等。
为什么我刚进去工作,
添加我们的职业咨询师微信:bojo_
研究生群本科生群
又添了一条新的坑,
是boss直聘,
很多啊,boss直聘,智联,猎聘网,boss群,行业讨论群,求职面试技巧群等等。但要给微信号,自己也要养成主动加的习惯,不能光习惯性推拉。
网易,ibm,华为, 查看全部
采集文章系统(权威数据资源、技术、行业展望及展望(组图))
采集文章系统整理了权威数据资源、技术背书、行业热点、投资经验、可投递简历信息、数据分析、开放分享平台以及行业展望数据分析阅读顺序整理如下:所有资源为2016.7-2017.3所产生,给新进群友们。转发、分享此文至朋友圈即可免费领取百度搜索、百度文库、各大招聘网站、不定期线下分享会等!想要领取更多招聘信息&简历模板&职场干货的小伙伴请多多关注、留言并转发,或者添加我们的职业咨询师的微信【bojo_】,随时跟我们互动哦。【下期福利】将随机抽取10位掌握权威数据资源的新媒体运营人,获得价值上千元的数据分析类小福利一份。
加入我们的社群群主群内有我们的社群入口点赞即可
有,boss直聘网,智联招聘网,猎聘网,中华英才网,360网,51job网,去哪儿网等等。
为什么我刚进去工作,
添加我们的职业咨询师微信:bojo_
研究生群本科生群
又添了一条新的坑,
是boss直聘,
很多啊,boss直聘,智联,猎聘网,boss群,行业讨论群,求职面试技巧群等等。但要给微信号,自己也要养成主动加的习惯,不能光习惯性推拉。
网易,ibm,华为,
采集文章系统(付费的应用为何要获取注册码,需要付费么?? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-04-09 21:10
)
详细介绍
功能概述:
本插件可以将后台采集的功能增强为:网站在任意级别的任意子目录下都可以正确采集并将图片保存到本地服务器。
暗示:
此插件不会强制您将图像保存在 采集,但会在您选择保存图像时改进对将图像保存到任何级别的子目录的支持。
安装过程
单击上方的立即安装按钮(如下图所示):
等待1分钟后,会出现黑底蓝字的“Loading”页面(如下图)
然后稍等片刻,页面会变成黑底绿色字体的“天人系列管理系统项目自动部署工具”(如下图)
如果页面上的所有权限检查通过,并且没有出现红色字体的“不可读”、“无法写入”和“无法删除”字样,则会自动安装。几分钟后会提示安装完成,不要关闭页面,8秒后会跳转到官网获取注册码,然后就可以使用这个应用了。
获取注册码页面,点击“生成注册码”按钮(如下图)
这时候系统会根据你的域名自动生成一个注册码(如下图)
值得注意的是,注册码不需要单独填写网站,你安装的应用会自动获取注册码,你可以刷新刚才提示注册码的页面看看是否可以正常使用。
常见问题
Q:为什么免费应用需要获取注册码,并且需要付费?
A:注册码是用来激活你安装的插件的。无需付费。在下一页输入一级域名网站,自动生成注册码。注册码根据一级域名生成。域名后可以再次获取注册码,不会像别人的网站程序或插件一样通过更改域名程序取消。另外值得一提的是,一般情况下,注册码不需要手动输入后台,后台更新缓存会自动获取你获取的所有注册码,非常方便快捷。
Q:如何获取付费应用的注册码?
A:付费申请需要使用现金购买注册码。按照页面提示点击“获取注册码”按钮,进入支付页面支付相应金额,注册码将自动生成。
Q:注册码需要单独保存吗?如果丢失了该怎么办?如何在我的 网站 中输入注册码?
A:一般不需要单独保存注册码,因为获得注册码的域名会自动保存在官网数据库中,您的网站会自动获得注册码从官网看,即使注册码丢失,只要你在后台更新缓存,你的注册码就会立即找回。当然,如果你愿意手动输入注册码,可以在后台“注册码管理”中输入注册码,效果和更新缓存得到的注册码一样。
Q:我的注册码会被别人盗用吗?
A:注册码是根据您的网站一级域名生成的。每个网站域名在这个世界上都是独一无二的,所以注册码也是唯一的,别人不能盗用你的注册码。
Q:如何通过我的网站后台应用中心获取尚未下载的应用注册码?
A:获取注册码可以在你的网站后台的“我的应用”或“我的模板”中找到刚刚安装的应用或模板对应的“点击查看”按钮,然后跳转到官网(如下图)
跳转到官网申请对应的详情页面后,用红色字体“您的一级域名”填写您的域名。您可以将一级域名留空。系统会自动设置为一级域名,然后点击“获取注册码”按钮,按照提示操作。(如下图)
查看全部
采集文章系统(付费的应用为何要获取注册码,需要付费么??
)
详细介绍
功能概述:
本插件可以将后台采集的功能增强为:网站在任意级别的任意子目录下都可以正确采集并将图片保存到本地服务器。
暗示:
此插件不会强制您将图像保存在 采集,但会在您选择保存图像时改进对将图像保存到任何级别的子目录的支持。
安装过程
单击上方的立即安装按钮(如下图所示):

等待1分钟后,会出现黑底蓝字的“Loading”页面(如下图)

然后稍等片刻,页面会变成黑底绿色字体的“天人系列管理系统项目自动部署工具”(如下图)
如果页面上的所有权限检查通过,并且没有出现红色字体的“不可读”、“无法写入”和“无法删除”字样,则会自动安装。几分钟后会提示安装完成,不要关闭页面,8秒后会跳转到官网获取注册码,然后就可以使用这个应用了。

获取注册码页面,点击“生成注册码”按钮(如下图)

这时候系统会根据你的域名自动生成一个注册码(如下图)

值得注意的是,注册码不需要单独填写网站,你安装的应用会自动获取注册码,你可以刷新刚才提示注册码的页面看看是否可以正常使用。
常见问题
Q:为什么免费应用需要获取注册码,并且需要付费?
A:注册码是用来激活你安装的插件的。无需付费。在下一页输入一级域名网站,自动生成注册码。注册码根据一级域名生成。域名后可以再次获取注册码,不会像别人的网站程序或插件一样通过更改域名程序取消。另外值得一提的是,一般情况下,注册码不需要手动输入后台,后台更新缓存会自动获取你获取的所有注册码,非常方便快捷。
Q:如何获取付费应用的注册码?
A:付费申请需要使用现金购买注册码。按照页面提示点击“获取注册码”按钮,进入支付页面支付相应金额,注册码将自动生成。
Q:注册码需要单独保存吗?如果丢失了该怎么办?如何在我的 网站 中输入注册码?
A:一般不需要单独保存注册码,因为获得注册码的域名会自动保存在官网数据库中,您的网站会自动获得注册码从官网看,即使注册码丢失,只要你在后台更新缓存,你的注册码就会立即找回。当然,如果你愿意手动输入注册码,可以在后台“注册码管理”中输入注册码,效果和更新缓存得到的注册码一样。
Q:我的注册码会被别人盗用吗?
A:注册码是根据您的网站一级域名生成的。每个网站域名在这个世界上都是独一无二的,所以注册码也是唯一的,别人不能盗用你的注册码。
Q:如何通过我的网站后台应用中心获取尚未下载的应用注册码?
A:获取注册码可以在你的网站后台的“我的应用”或“我的模板”中找到刚刚安装的应用或模板对应的“点击查看”按钮,然后跳转到官网(如下图)

跳转到官网申请对应的详情页面后,用红色字体“您的一级域名”填写您的域名。您可以将一级域名留空。系统会自动设置为一级域名,然后点击“获取注册码”按钮,按照提示操作。(如下图)

采集文章系统(SSCMS采集支持自定义/字段、自定义、一对多自定义字段)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-04-05 23:19
SScms采集,SiteServer(SScms)是中国.NET平台cms系统的创始人!也是唯一开源免费的企业级cms系统,但是SScms文章data采集的采集器很少被支持市场。都需要马,SScms站长需要有免费全网关键词pan采集,伪原创,发布可以一键百度,神马,36< @0、搜狗推送的采集器,最好提供一些相关的SEO优化设置。今天我们来说说SScms采集。
SScms采集支持自定义表单/字段、自定义数据表、一对一和一对多自定义字段,可以处理复杂的数据内容需求。SScms采集器可以多站点/多站点系统可以创建多站点。站点、后台、用户中心可以绑定独立的域名。
SScms先进的模板设计,支持母版页、本地页等公共页面,提高复用性,让网站模板更加高效便捷。SScms扩展灵活,支持多终端,可拆卸插件设计,可为小程序、APP等终端提供数据接口。
SScms千万级负载,http缓存+后台缓存+专业数据优化,大数据大流量下也能快速响应。SScms企业级安全防护,系统从底层防范Sql注入、CSRF、暴力破解等攻击,可通过公安部三级安全评估。
选择关键词的时候,不要选择高索引的关键词,而是选择低索引的关键词,等待高索引的关键词优化。低索引的关键词应该收录一个高索引的关键词,比如SScms?SEO优化,包括两个比较高的指标关键词,SEO优化和SScms。先优化SScms,再慢慢优化SEO优化。网站的好处之一就是不用挖太多长尾词,内容页直接使用常用名。网站选择关键词的时候,不要选择索引高的关键词,一定要选择索引比较低的关键词,等待优化到上去优化索引关键词。关键词 低索引应该收录一个高索引的关键词,例如:SScms? SEO优化,其中包括SEO优化和SScms,相对来说关键词要先优化SScms,再慢慢优化SEO。网站一个好处就是不用挖太多长尾词,内容页直接使用通用名。
挖掘长尾关键词只需要在首页和栏目页使用。可以直接使用页面常用名,挖掘长尾词的工作量会比较低。因为首页和栏目页不能使用太多的长尾词,所以一栏最多可以优化3个关键词。
增加页面上关键词的频率。很多做网站的人基本上没有注意到关键词频率的增加,因为他们觉得无处可加。例如,您可以在所有这些地方添加它们,您可以在底部和故事的介绍中添加它们等。
其实很多关键词可以在我们的网站筛选页面上优化,很多网站筛选页面标题一样,这是不行的。标题会根据不同的过滤器而变化。
?其实网站的外部优化很重要,因为网站的页面质量很低。比如首页基本都是名字和图片,其他文字很少,所以要加一些外链。
这里可以到网站目录平台提交网站,这样添加的外链比购买的好。网站 的另一个好处是,如果 网站 做得足够好,用户自然会向您发送反向链接。
有必要与对等点 网站 交换链接。一定要交换权重相近的网站s,如果你有足够的钱,可以购买权重6和7的大网站s的链接。这种类型的网站@ >附属链接效果很好。相同的友好链接名称首先是一个小索引关键词,然后在优化时会被替换为一个大索引关键词。 查看全部
采集文章系统(SSCMS采集支持自定义/字段、自定义、一对多自定义字段)
SScms采集,SiteServer(SScms)是中国.NET平台cms系统的创始人!也是唯一开源免费的企业级cms系统,但是SScms文章data采集的采集器很少被支持市场。都需要马,SScms站长需要有免费全网关键词pan采集,伪原创,发布可以一键百度,神马,36< @0、搜狗推送的采集器,最好提供一些相关的SEO优化设置。今天我们来说说SScms采集。

SScms采集支持自定义表单/字段、自定义数据表、一对一和一对多自定义字段,可以处理复杂的数据内容需求。SScms采集器可以多站点/多站点系统可以创建多站点。站点、后台、用户中心可以绑定独立的域名。
SScms先进的模板设计,支持母版页、本地页等公共页面,提高复用性,让网站模板更加高效便捷。SScms扩展灵活,支持多终端,可拆卸插件设计,可为小程序、APP等终端提供数据接口。
SScms千万级负载,http缓存+后台缓存+专业数据优化,大数据大流量下也能快速响应。SScms企业级安全防护,系统从底层防范Sql注入、CSRF、暴力破解等攻击,可通过公安部三级安全评估。
选择关键词的时候,不要选择高索引的关键词,而是选择低索引的关键词,等待高索引的关键词优化。低索引的关键词应该收录一个高索引的关键词,比如SScms?SEO优化,包括两个比较高的指标关键词,SEO优化和SScms。先优化SScms,再慢慢优化SEO优化。网站的好处之一就是不用挖太多长尾词,内容页直接使用常用名。网站选择关键词的时候,不要选择索引高的关键词,一定要选择索引比较低的关键词,等待优化到上去优化索引关键词。关键词 低索引应该收录一个高索引的关键词,例如:SScms? SEO优化,其中包括SEO优化和SScms,相对来说关键词要先优化SScms,再慢慢优化SEO。网站一个好处就是不用挖太多长尾词,内容页直接使用通用名。
挖掘长尾关键词只需要在首页和栏目页使用。可以直接使用页面常用名,挖掘长尾词的工作量会比较低。因为首页和栏目页不能使用太多的长尾词,所以一栏最多可以优化3个关键词。
增加页面上关键词的频率。很多做网站的人基本上没有注意到关键词频率的增加,因为他们觉得无处可加。例如,您可以在所有这些地方添加它们,您可以在底部和故事的介绍中添加它们等。
其实很多关键词可以在我们的网站筛选页面上优化,很多网站筛选页面标题一样,这是不行的。标题会根据不同的过滤器而变化。

?其实网站的外部优化很重要,因为网站的页面质量很低。比如首页基本都是名字和图片,其他文字很少,所以要加一些外链。
这里可以到网站目录平台提交网站,这样添加的外链比购买的好。网站 的另一个好处是,如果 网站 做得足够好,用户自然会向您发送反向链接。
有必要与对等点 网站 交换链接。一定要交换权重相近的网站s,如果你有足够的钱,可以购买权重6和7的大网站s的链接。这种类型的网站@ >附属链接效果很好。相同的友好链接名称首先是一个小索引关键词,然后在优化时会被替换为一个大索引关键词。
采集文章系统(网站内容SEO该如何打造,并不是我们完成文章的写作 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-04-03 16:10
)
网站如何构建内容SEO,不是我们完成文章的写作,一个高质量的原创就可以完成。网站内容是我们网站的有机组成部分,可以说没有网站内容填充的网站是干瘪的。
网站内容SEO不仅要求我们有一定的素质,还需要相关的功能。原创文章 不一定是好的,伪原创 内容也不一定是垃圾邮件。文章为用户提供良好的阅读体验,满足用户需求,受到用户和搜索引擎的欢迎。
网站内容SEO还要求我们在搜索引擎允许的条件下进行适当的优化,比如关键词密度控制、图片alt标签、关键词内链设置等。 文章 小细节。
网站内容搜索引擎优化就是围绕用户的需求来创建内容,针对搜索引擎进行优化,寻求两者的最佳平衡。只有这样,我们才能为用户服务,获得更多来自搜索引擎的流量。实现网站的良性循环。
什么样的网站内容可以被认为是高质量的网站内容SEO?网站内容搜索引擎优化我们需要从源头控制我们的文章质量,无论是通过采集文章创作还是通过我们自己的经验。好的文章材质是我们需要严格把关的。
1、网站内容SEO时效性:搜索引擎不喜欢重复的内容。新鲜出炉的文章,新颖、低重复的内容很受搜索引擎欢迎。这样的文章至少在搜索引擎眼里可以,我们是勤奋的人,如果再勤奋一点,可以给他一点待遇,如果再版几年的文章,很多地方有,那么搜索引擎就不需要这些数据,因为它需要确保用户获得的搜索数据和内容是有帮助的,而不是千篇一律。
2、网站内容搜索引擎优化价值:没有人会不喜欢有价值的内容。从这种用户体验出发,搜索引擎也讨厌垃圾内容。但是很多人在创作的时候并没有一个衡量有价值内容的标准,不知道什么是有价值的内容,什么是有价值的内容?原创一定是好的吗?有价值的内容是为用户提供解决方案并满足他们需求的内容。
3、用户体验:精美的页面、精心的排版、图文并茂的文章是我们为用户提供良好体验的基础。如今,互联网上不乏内容,各行各业都可以通过搜索引擎检索到大量的文章。在行业内量大的情况下,文章的质量没有必要受到用户的青睐。无论是 网站 主页的美学变化还是图像像素的增加,用户现在更喜欢引人入胜且图文并茂的内容。
对于网站内容搜索引擎优化,而不是发布文章,你可以通过发布外部链接来获得流量。现在我们更关注用户体验。也就是说,用户觉得我们的内容好看,那么我们显然有很多优势,如果我们的排版乱七八糟,用户不喜欢,自然会拒绝再次浏览。网站内容SEO的分享就到这里。如果您觉得它有趣,您可能会喜欢并采集它。您的支持和关注是博主不断更新的动力。欢迎一键三连。
查看全部
采集文章系统(网站内容SEO该如何打造,并不是我们完成文章的写作
)
网站如何构建内容SEO,不是我们完成文章的写作,一个高质量的原创就可以完成。网站内容是我们网站的有机组成部分,可以说没有网站内容填充的网站是干瘪的。
网站内容SEO不仅要求我们有一定的素质,还需要相关的功能。原创文章 不一定是好的,伪原创 内容也不一定是垃圾邮件。文章为用户提供良好的阅读体验,满足用户需求,受到用户和搜索引擎的欢迎。
网站内容SEO还要求我们在搜索引擎允许的条件下进行适当的优化,比如关键词密度控制、图片alt标签、关键词内链设置等。 文章 小细节。
网站内容搜索引擎优化就是围绕用户的需求来创建内容,针对搜索引擎进行优化,寻求两者的最佳平衡。只有这样,我们才能为用户服务,获得更多来自搜索引擎的流量。实现网站的良性循环。
什么样的网站内容可以被认为是高质量的网站内容SEO?网站内容搜索引擎优化我们需要从源头控制我们的文章质量,无论是通过采集文章创作还是通过我们自己的经验。好的文章材质是我们需要严格把关的。
1、网站内容SEO时效性:搜索引擎不喜欢重复的内容。新鲜出炉的文章,新颖、低重复的内容很受搜索引擎欢迎。这样的文章至少在搜索引擎眼里可以,我们是勤奋的人,如果再勤奋一点,可以给他一点待遇,如果再版几年的文章,很多地方有,那么搜索引擎就不需要这些数据,因为它需要确保用户获得的搜索数据和内容是有帮助的,而不是千篇一律。
2、网站内容搜索引擎优化价值:没有人会不喜欢有价值的内容。从这种用户体验出发,搜索引擎也讨厌垃圾内容。但是很多人在创作的时候并没有一个衡量有价值内容的标准,不知道什么是有价值的内容,什么是有价值的内容?原创一定是好的吗?有价值的内容是为用户提供解决方案并满足他们需求的内容。
3、用户体验:精美的页面、精心的排版、图文并茂的文章是我们为用户提供良好体验的基础。如今,互联网上不乏内容,各行各业都可以通过搜索引擎检索到大量的文章。在行业内量大的情况下,文章的质量没有必要受到用户的青睐。无论是 网站 主页的美学变化还是图像像素的增加,用户现在更喜欢引人入胜且图文并茂的内容。
对于网站内容搜索引擎优化,而不是发布文章,你可以通过发布外部链接来获得流量。现在我们更关注用户体验。也就是说,用户觉得我们的内容好看,那么我们显然有很多优势,如果我们的排版乱七八糟,用户不喜欢,自然会拒绝再次浏览。网站内容SEO的分享就到这里。如果您觉得它有趣,您可能会喜欢并采集它。您的支持和关注是博主不断更新的动力。欢迎一键三连。
采集文章系统(Zblog建站和网站优化过程中往往会出现哪些误区? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-03-28 10:27
)
建立 Zblog 网站是一个非常简单的过程。我们可以通过互联网上的许多渠道看到安装文章 或视频。Zblog cms 确实是一个不错的内容管理系统。但是仅仅有一个内容管理系统来构建一个合格的网站是不够的。
Zblog建站和网站优化本身就是一项系统性的工作。如果在优化过程中稍有不慎,忽略了一些细节,很容易陷入优化错误。Zblog搭建和网站优化过程中经常出现哪些误区?对于网站建设和网站优化管理的博主,在这里和大家分享一些经验。
一、域名选择
我们的域名应该和我们网站的主题有一定的关系,域名的后缀不能是非.COM。一个好记的域名和高质量的网站内容可以留住用户。为了给用户提供良好的体验,我们还需要通过正规渠道获取域名。
二、服务器选择
网站优化不仅仅是网站内部各种元素的优化,还和网站的空间域名和服务器的稳定性有很大关系。为了达到更好的网站优化效果,前提是保证服务器和网站空间的稳定性,不仅是建站初期,后期维护过程中也要保证. @网站服务器的稳定性。原因是当搜索引擎在爬取信息时遇到服务器地址变化时,会误认为是新的网站,延长关键数据网站的爬取时间,如果服务器不稳定够了,还会影响它爬取信息的频率,从而降低打开网页的速度,
三、cms 的选择
对于选择ZBLOG建站的站长来说,这不是必须的。对于cms的选择,可以根据网站的类型和自己的喜好来选择,每个cms都有适合自己的就好。
四、网站TDK 的选择
这并不是说网站建立后就不能改变TDK,在某些情况下可以适当调整TDK,但是频繁改变网站的布局会影响网站的优化沙盒期的影响一直存在,不会因为网站已经过了沙盒期而消失。如果我们在建站后频繁更改网站标题、描述和关键词,我们将很难走出沙箱。
五、网站内容更新
网站建立后,每天更新网站非常重要。蜘蛛会根据网站是否每天持续更新来判断网站是否正常运行。网站新鲜、最新且以原创为主题的内容更有可能被蜘蛛抓取,从而导致网站收录。
我们都知道 原创 的内容是蜘蛛喜欢的。一开始我们确实可以保证网站的内容不断更新,但是过了一段时间就会进入创作的瓶颈期。不是我们没有能力原创,而是我们没有足够的材料。Zblog网站插件可以很好的解决这个问题。
Zblog建站插件具有自动采集、伪原创和发布功能,支持全网采集和网站指定采集。无论我们是采集数据还是采集文章,图片都能准确采集。采集操作简单,无需学习和掌握采集规则,点击插件即可完成配置。采集后自动伪原创,支持每日按时发布,发布后主动推送至各大平台,实现24小时挂机。养成良好的套路,迎合蜘蛛的喜好,提高网站收录的效率。
Zblog建站是同一个流程的系统,不是建好后,不需要管理。后期维护和优化是我们关注的重点。只有不断优化每一个环节,实现对每一个细节的处理,我的网站才能继续收录,增加它的权重。如果觉得不错,欢迎点击三个链接!
查看全部
采集文章系统(Zblog建站和网站优化过程中往往会出现哪些误区?
)
建立 Zblog 网站是一个非常简单的过程。我们可以通过互联网上的许多渠道看到安装文章 或视频。Zblog cms 确实是一个不错的内容管理系统。但是仅仅有一个内容管理系统来构建一个合格的网站是不够的。
Zblog建站和网站优化本身就是一项系统性的工作。如果在优化过程中稍有不慎,忽略了一些细节,很容易陷入优化错误。Zblog搭建和网站优化过程中经常出现哪些误区?对于网站建设和网站优化管理的博主,在这里和大家分享一些经验。
一、域名选择
我们的域名应该和我们网站的主题有一定的关系,域名的后缀不能是非.COM。一个好记的域名和高质量的网站内容可以留住用户。为了给用户提供良好的体验,我们还需要通过正规渠道获取域名。
二、服务器选择
网站优化不仅仅是网站内部各种元素的优化,还和网站的空间域名和服务器的稳定性有很大关系。为了达到更好的网站优化效果,前提是保证服务器和网站空间的稳定性,不仅是建站初期,后期维护过程中也要保证. @网站服务器的稳定性。原因是当搜索引擎在爬取信息时遇到服务器地址变化时,会误认为是新的网站,延长关键数据网站的爬取时间,如果服务器不稳定够了,还会影响它爬取信息的频率,从而降低打开网页的速度,
三、cms 的选择
对于选择ZBLOG建站的站长来说,这不是必须的。对于cms的选择,可以根据网站的类型和自己的喜好来选择,每个cms都有适合自己的就好。
四、网站TDK 的选择
这并不是说网站建立后就不能改变TDK,在某些情况下可以适当调整TDK,但是频繁改变网站的布局会影响网站的优化沙盒期的影响一直存在,不会因为网站已经过了沙盒期而消失。如果我们在建站后频繁更改网站标题、描述和关键词,我们将很难走出沙箱。
五、网站内容更新
网站建立后,每天更新网站非常重要。蜘蛛会根据网站是否每天持续更新来判断网站是否正常运行。网站新鲜、最新且以原创为主题的内容更有可能被蜘蛛抓取,从而导致网站收录。
我们都知道 原创 的内容是蜘蛛喜欢的。一开始我们确实可以保证网站的内容不断更新,但是过了一段时间就会进入创作的瓶颈期。不是我们没有能力原创,而是我们没有足够的材料。Zblog网站插件可以很好的解决这个问题。
Zblog建站插件具有自动采集、伪原创和发布功能,支持全网采集和网站指定采集。无论我们是采集数据还是采集文章,图片都能准确采集。采集操作简单,无需学习和掌握采集规则,点击插件即可完成配置。采集后自动伪原创,支持每日按时发布,发布后主动推送至各大平台,实现24小时挂机。养成良好的套路,迎合蜘蛛的喜好,提高网站收录的效率。
Zblog建站是同一个流程的系统,不是建好后,不需要管理。后期维护和优化是我们关注的重点。只有不断优化每一个环节,实现对每一个细节的处理,我的网站才能继续收录,增加它的权重。如果觉得不错,欢迎点击三个链接!
采集文章系统(PHP+Mysql架构的网站内容管理系统模板风格方便制作 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-03-27 06:03
)
SWcms是一个基于PHP+Mysql架构的网站内容管理系统,也是一个开放的PHP开发平台。
SWcms采用模块化方式开发,功能强大,灵活易扩展,完全开源大中型网站源代码
提供重量级网站施工方案。两年来,凭借SWcms团队长期积累的丰富的web开发和数据库经验,
经验和勇于创新,追求完美的设计理念,让SWCcms得到了众多大中小网站站长的认可,
越来越多地应用于大中型企业网站。
主要特点:
1.模块化、开源、可扩展
采用模块化方式开发,提供统一的模块开发接口和底层平台支持,完全开源,方便二次开发。
2.负载能力强,支持千万级数据
从缓存技术、数据库设计、代码优化等方面来看,内容可以以文本形式存储,支持信息量和会员数据量达到千万级。
3.前端模板样式制作简单易用
4.支持生成Html和PHP动态访问,也支持仿静态模式访问
5.后端支持数据库优化和数据库备份导入,方便网站做大
6.后台强大文章在线采集系统,支持资源本地化
7.后台有在线存储程序,与Sage所有采集器产品完美结合,瞬间变大网站
8.后台采集器可导入导出,方便用户交流采集经验分享采集规则
9.功能和样式标签使用方便,用户可以通过模板随意调用,方便将网站制作成BLOG、BBS、cms
v3.0. 版本 2 增加了 文章采集 和 文章 贡献函数
查看全部
采集文章系统(PHP+Mysql架构的网站内容管理系统模板风格方便制作
)
SWcms是一个基于PHP+Mysql架构的网站内容管理系统,也是一个开放的PHP开发平台。
SWcms采用模块化方式开发,功能强大,灵活易扩展,完全开源大中型网站源代码
提供重量级网站施工方案。两年来,凭借SWcms团队长期积累的丰富的web开发和数据库经验,
经验和勇于创新,追求完美的设计理念,让SWCcms得到了众多大中小网站站长的认可,
越来越多地应用于大中型企业网站。
主要特点:
1.模块化、开源、可扩展
采用模块化方式开发,提供统一的模块开发接口和底层平台支持,完全开源,方便二次开发。
2.负载能力强,支持千万级数据
从缓存技术、数据库设计、代码优化等方面来看,内容可以以文本形式存储,支持信息量和会员数据量达到千万级。
3.前端模板样式制作简单易用
4.支持生成Html和PHP动态访问,也支持仿静态模式访问
5.后端支持数据库优化和数据库备份导入,方便网站做大
6.后台强大文章在线采集系统,支持资源本地化
7.后台有在线存储程序,与Sage所有采集器产品完美结合,瞬间变大网站
8.后台采集器可导入导出,方便用户交流采集经验分享采集规则
9.功能和样式标签使用方便,用户可以通过模板随意调用,方便将网站制作成BLOG、BBS、cms
v3.0. 版本 2 增加了 文章采集 和 文章 贡献函数

采集文章系统(如何利用老Y文章管理系统采集时自动完成伪原创)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-03-21 19:43
作为垃圾站站长,最有希望的是网站能自动采集,自动完成伪原创,然后自动收钱,这真是世上最幸福的事, 呵呵 。自动采集 和自动收款将不讨论。今天给大家介绍一下如何使用老Y文章管理系统采集自动补全伪原创的方法。文章管理系统使用简单方便,虽然功能没有DEDE之类的强大到近乎变态的地步(文章管理系统是用asp语言写的,好像没有比较),但是应该都有,而且都挺简单的,所以受到很多站长的欢迎。老Y文章管理系统采集时自动补全伪原创的具体方法很少讨论。在老Y的论坛上,甚至有人卖这个方法,所以我有点鄙视。. 采集我就不多说了,相信大家都能做到,我要介绍的是老Y的文章管理系统是如何同时自动完成伪原创的采集具体工作方法,大体思路是利用老Y文章管理系统的过滤功能实现同义词的自动替换,从而达到伪原创@的目的>。比如我想把采集文章里面的“网赚博客”全部换成“网赚日记”。详细步骤如下: 第一步,进入后台。找到“采集管理”-“过滤器管理”,添加一个新的过滤器项。我可以创建一个名为“网赚博客”的项目,具体设置请参考图片: “过滤器名称”:填写“网赚博客”即可,也可以随意写,但为了方便查看,建议替换成同意字样。
“项目”:请根据您的网站选择一列网站(必须选择一列,否则无法保存过滤项目)。“过滤对象”:选项有“标题过滤”和“文本过滤”。一般可以选择“文本过滤器”。如果你想伪原创连标题,你可以选择“标题过滤器”。“过滤器类型”:选项有“简单替换”和“高级过滤”。一般选择“简单替换”。如果选择“高级过滤”,则需要指定“开始标签”和“结束标签”,以便在代码级别替换采集中的内容。“使用状态”:选项有“启用”和“禁用”,无需解释。“使用范围”:选项为“公共”和“私人”。选择“Private”,过滤器只对当前网站列有效;选择“Public”,对所有列都有效,无论采集任一列的任何内容,过滤器都有效。一般选择“私人”。“内容”:填写“网赚博客”,要替换的词。“替换”:填写“网赚日记”,只要采集的文章中收录“网赚博客”这个词,就会自动替换为“网赚日记”。第二步,重复第一步的工作,直到添加完所有同义词。有网友想问:我有3万多个同义词,我需要手动一一添加吗?什么时候添加?不能批量添加吗?这是一个很好的问题!手动添加确实是一项几乎不可能完成的任务。除非你有非凡的毅力,否则你可以手动添加这 30,000 多个同义词。
可惜老的Y文章管理系统没有提供批量导入的功能。然而,作为真正的资深人士,思考优采云,我们需要了解优采云。要知道,我们刚才输入的内容是存储在数据库中的,而老的文章管理系统是用asp+Access写的,mdb数据库也可以轻松编辑!所以,我可以直接用批量导入的方法修改数据库伪原创替换规则!改进第二步:批量修改数据库和导入规则。经过搜索,我发现这个数据库位于“你的管理目录\cai\Database”下。用Access打开数据库,找到“Filters”表,你会发现我们刚才添加的替换规则都存放在这里,根据你的需要,批量添加!接下来的工作涉及到Access的操作,我就不啰嗦了,大家可以搞定。解释“Filters”表中几个字段的含义: FilterID:自动生成,无需输入。ItemID:列ID,也就是我们手动输入时“item item”的内容,但这里是数字ID。注意列的采集ID。如果不知道ID,可以重复第一步,测试一下。. FilterName:“过滤器名称”。FilterObjece:即“过滤对象”,“标题过滤”填1,“文本过滤”填2。这是我们手动输入时“item item”的内容,但这里是一个数字ID。注意列的采集ID。如果不知道ID,可以重复第一步,测试一下。. FilterName:“过滤器名称”。FilterObjece:即“过滤对象”,“标题过滤”填1,“文本过滤”填2。这是我们手动输入时“item item”的内容,但这里是一个数字ID。注意列的采集ID。如果不知道ID,可以重复第一步,测试一下。. FilterName:“过滤器名称”。FilterObjece:即“过滤对象”,“标题过滤”填1,“文本过滤”填2。
FilterType:“过滤器类型”,“简单替换”填1,“高级过滤器”填2。FilterContent:“内容”。FisString:“开始标签”,仅在设置“高级过滤器”时有效,如果设置了“简单过滤器”,请留空。FioString:“结束标签”,仅在设置“高级过滤器”时有效,如果设置了“简单过滤器”,请留空。FilterRep:即“替换”。flag:即“使用状态”,TRUE为“启用”,FALSE为“禁用”。PublicTf:“使用范围”。TRUE 是“公共”,FALSE 是“私人”。最后说一下使用过滤功能实现伪原创的体验:文章 管理系统的这个功能可以在采集时自动伪原创,但是功能不够强大。例如,我的网站上有三栏:“第一栏”、“第二栏”和“第三栏”。我希望“第 1 列”对标题和正文执行 伪原创,“第 2 列”仅对正文执行 伪原创,而“第 3 列”仅对 伪原创 执行标题。所以,我只能做如下设置(假设我有 30000 条同义词规则): 为“Column 1”的标题 伪原创 创建 30000 条替换规则;为“Column 1”的正文伪原创创建30000条替换规则为“Column 2”的文本伪原创创建30000条替换规则;为标题 伪原创 创建了 30,000 个替换规则
这将导致数据库的巨大浪费。如果我的网站有几十个栏目,每个栏目的要求都不一样,那么这个数据库的大小会很吓人。因此,建议老的Y文章管理系统在下个版本中改进这个功能:首先,增加批量导入功能。毕竟修改数据库是有一定风险的。其次,过滤规则不再附属于某个网站列,而是独立于过滤规则,在新建集合项时,增加了是否使用过滤规则的判断。相信经过这样的修改,可以大大节省数据库存储空间,逻辑结构也更加清晰。本文为《我的网赚日记-伪原创7@>网赚博客》伪原创7@>,请尊重本人的劳动成果,转载请注明出处!另外,我用的是旧的Y文章管理系统,时间不长。文中如有错误或不当之处,敬请指正!企业贸易网 查看全部
采集文章系统(如何利用老Y文章管理系统采集时自动完成伪原创)
作为垃圾站站长,最有希望的是网站能自动采集,自动完成伪原创,然后自动收钱,这真是世上最幸福的事, 呵呵 。自动采集 和自动收款将不讨论。今天给大家介绍一下如何使用老Y文章管理系统采集自动补全伪原创的方法。文章管理系统使用简单方便,虽然功能没有DEDE之类的强大到近乎变态的地步(文章管理系统是用asp语言写的,好像没有比较),但是应该都有,而且都挺简单的,所以受到很多站长的欢迎。老Y文章管理系统采集时自动补全伪原创的具体方法很少讨论。在老Y的论坛上,甚至有人卖这个方法,所以我有点鄙视。. 采集我就不多说了,相信大家都能做到,我要介绍的是老Y的文章管理系统是如何同时自动完成伪原创的采集具体工作方法,大体思路是利用老Y文章管理系统的过滤功能实现同义词的自动替换,从而达到伪原创@的目的>。比如我想把采集文章里面的“网赚博客”全部换成“网赚日记”。详细步骤如下: 第一步,进入后台。找到“采集管理”-“过滤器管理”,添加一个新的过滤器项。我可以创建一个名为“网赚博客”的项目,具体设置请参考图片: “过滤器名称”:填写“网赚博客”即可,也可以随意写,但为了方便查看,建议替换成同意字样。
“项目”:请根据您的网站选择一列网站(必须选择一列,否则无法保存过滤项目)。“过滤对象”:选项有“标题过滤”和“文本过滤”。一般可以选择“文本过滤器”。如果你想伪原创连标题,你可以选择“标题过滤器”。“过滤器类型”:选项有“简单替换”和“高级过滤”。一般选择“简单替换”。如果选择“高级过滤”,则需要指定“开始标签”和“结束标签”,以便在代码级别替换采集中的内容。“使用状态”:选项有“启用”和“禁用”,无需解释。“使用范围”:选项为“公共”和“私人”。选择“Private”,过滤器只对当前网站列有效;选择“Public”,对所有列都有效,无论采集任一列的任何内容,过滤器都有效。一般选择“私人”。“内容”:填写“网赚博客”,要替换的词。“替换”:填写“网赚日记”,只要采集的文章中收录“网赚博客”这个词,就会自动替换为“网赚日记”。第二步,重复第一步的工作,直到添加完所有同义词。有网友想问:我有3万多个同义词,我需要手动一一添加吗?什么时候添加?不能批量添加吗?这是一个很好的问题!手动添加确实是一项几乎不可能完成的任务。除非你有非凡的毅力,否则你可以手动添加这 30,000 多个同义词。
可惜老的Y文章管理系统没有提供批量导入的功能。然而,作为真正的资深人士,思考优采云,我们需要了解优采云。要知道,我们刚才输入的内容是存储在数据库中的,而老的文章管理系统是用asp+Access写的,mdb数据库也可以轻松编辑!所以,我可以直接用批量导入的方法修改数据库伪原创替换规则!改进第二步:批量修改数据库和导入规则。经过搜索,我发现这个数据库位于“你的管理目录\cai\Database”下。用Access打开数据库,找到“Filters”表,你会发现我们刚才添加的替换规则都存放在这里,根据你的需要,批量添加!接下来的工作涉及到Access的操作,我就不啰嗦了,大家可以搞定。解释“Filters”表中几个字段的含义: FilterID:自动生成,无需输入。ItemID:列ID,也就是我们手动输入时“item item”的内容,但这里是数字ID。注意列的采集ID。如果不知道ID,可以重复第一步,测试一下。. FilterName:“过滤器名称”。FilterObjece:即“过滤对象”,“标题过滤”填1,“文本过滤”填2。这是我们手动输入时“item item”的内容,但这里是一个数字ID。注意列的采集ID。如果不知道ID,可以重复第一步,测试一下。. FilterName:“过滤器名称”。FilterObjece:即“过滤对象”,“标题过滤”填1,“文本过滤”填2。这是我们手动输入时“item item”的内容,但这里是一个数字ID。注意列的采集ID。如果不知道ID,可以重复第一步,测试一下。. FilterName:“过滤器名称”。FilterObjece:即“过滤对象”,“标题过滤”填1,“文本过滤”填2。
FilterType:“过滤器类型”,“简单替换”填1,“高级过滤器”填2。FilterContent:“内容”。FisString:“开始标签”,仅在设置“高级过滤器”时有效,如果设置了“简单过滤器”,请留空。FioString:“结束标签”,仅在设置“高级过滤器”时有效,如果设置了“简单过滤器”,请留空。FilterRep:即“替换”。flag:即“使用状态”,TRUE为“启用”,FALSE为“禁用”。PublicTf:“使用范围”。TRUE 是“公共”,FALSE 是“私人”。最后说一下使用过滤功能实现伪原创的体验:文章 管理系统的这个功能可以在采集时自动伪原创,但是功能不够强大。例如,我的网站上有三栏:“第一栏”、“第二栏”和“第三栏”。我希望“第 1 列”对标题和正文执行 伪原创,“第 2 列”仅对正文执行 伪原创,而“第 3 列”仅对 伪原创 执行标题。所以,我只能做如下设置(假设我有 30000 条同义词规则): 为“Column 1”的标题 伪原创 创建 30000 条替换规则;为“Column 1”的正文伪原创创建30000条替换规则为“Column 2”的文本伪原创创建30000条替换规则;为标题 伪原创 创建了 30,000 个替换规则
这将导致数据库的巨大浪费。如果我的网站有几十个栏目,每个栏目的要求都不一样,那么这个数据库的大小会很吓人。因此,建议老的Y文章管理系统在下个版本中改进这个功能:首先,增加批量导入功能。毕竟修改数据库是有一定风险的。其次,过滤规则不再附属于某个网站列,而是独立于过滤规则,在新建集合项时,增加了是否使用过滤规则的判断。相信经过这样的修改,可以大大节省数据库存储空间,逻辑结构也更加清晰。本文为《我的网赚日记-伪原创7@>网赚博客》伪原创7@>,请尊重本人的劳动成果,转载请注明出处!另外,我用的是旧的Y文章管理系统,时间不长。文中如有错误或不当之处,敬请指正!企业贸易网
采集文章系统( 文章类的采集,图片集的另外找个时间来讲,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-17 20:08
文章类的采集,图片集的另外找个时间来讲,)
dedecms织梦采集规则编写教程的文章类采集
游戏/数字网络2017-07-28 19 浏览
织梦 系统作为常用的文章 系统,操作起来比较简单。在众多功能中,采集系统可能会让一些新手头疼,比如采集locale设置不正确。采集规则的具体编辑不正确。采集 后面有空格等问题。今天我们将详细解释一些比较容易遇到的问题。(今天的主题是文章类的采集,换个时间的图集就不一样了)工具/材料自己的网站目标的< @网站方法/步骤首先我们登录后台,分别点击采集--采集节点管理,进入采集管理设置界面。这里有两种选择,
织梦系统作为常用的文章系统相对容易操作。在众多功能中,采集系统可能会让一些新手头疼,比如采集区域设置不正确,采集规则编辑不正确,采集空白等问题。今天我们将详细解释一些比较容易遇到的问题。(今天主要讲文章类的采集。在图片采集方面,另找时间,这个不一样)
工具/材料
方法/步骤
首先我们登录后台,点击采集--采集节点管理,进入采集管理设置界面
这里有两种选择,一种是修改原节点(主要是之前的设置错误导致采集失败或者其他设置),另一种是直接添加新节点,大部分都是基于新节点,点击,然后下一步,选择“Normal文章”进行确认。
然后填写节点名称(推荐为与列相关的名称,避免导入时出错),这个可以根据实际填写。那么第一个重点:目标页面编码。这是填写目标页面的代码,不是你自己的页面。查看方法:打开目标网站任意页面,在空白处右键-查看源代码(编码一般在前几行)
然后就是填写列表规则。一种是批量生成URL,一般适用于规则强或者需要采集自上而下的情况。例如,我们针对此列:
第一页列表:
第二页列表:。
这个列表规则最重要的就是找到相同点和不同点,把相同点填上,不同点用匹配符号补充,也就是变量。其实通过这个对比我们可以知道,这里的.html也是一样的,所以变量是1.2.3.4.。. 所以匹配的 URL 是:
(*).html。
另一种是列表规则是手动指定列表URL,比较流行。只需填写您需要的所有列表页面采集。(比较适合采集只有几页或者变量多的页面)
注意:许多网站 栏目主页都以这种形式显示。我们可以对比上面,发现下面的变量项是缺失的。所以查找变量项的方法是:点击列表的下一页,如果还是不清楚再点击下一页,对比列表的第二页和第三页,我们也可以找到变量步骤 4 中的项目。
这一步是获取列表下文章的所有地址,我们要从列表页面中获取所有文章页面地址。我们以:List 为例。复制列表中第一篇文章文章的标题,然后在列表页空白处右键--查看源码,按ctrl+F搜索,粘贴刚才复制的标题,找到在文本源代码中的位置。事实上,这是一定的规律。然后我们寻找源代码的哪一部分是唯一的,并且可以收录列表中所有的文章地址(注意:开始代码搜索应该从列表中第一个文章的标题开始,然后去向上,并结束代码搜索您应该从列表中第一篇文章的标题开始向下看文章)。从这个源代码可以看出。启动代码: 查看全部
采集文章系统(
文章类的采集,图片集的另外找个时间来讲,)
dedecms织梦采集规则编写教程的文章类采集
游戏/数字网络2017-07-28 19 浏览
织梦 系统作为常用的文章 系统,操作起来比较简单。在众多功能中,采集系统可能会让一些新手头疼,比如采集locale设置不正确。采集规则的具体编辑不正确。采集 后面有空格等问题。今天我们将详细解释一些比较容易遇到的问题。(今天的主题是文章类的采集,换个时间的图集就不一样了)工具/材料自己的网站目标的< @网站方法/步骤首先我们登录后台,分别点击采集--采集节点管理,进入采集管理设置界面。这里有两种选择,
织梦系统作为常用的文章系统相对容易操作。在众多功能中,采集系统可能会让一些新手头疼,比如采集区域设置不正确,采集规则编辑不正确,采集空白等问题。今天我们将详细解释一些比较容易遇到的问题。(今天主要讲文章类的采集。在图片采集方面,另找时间,这个不一样)
工具/材料
方法/步骤
首先我们登录后台,点击采集--采集节点管理,进入采集管理设置界面

这里有两种选择,一种是修改原节点(主要是之前的设置错误导致采集失败或者其他设置),另一种是直接添加新节点,大部分都是基于新节点,点击,然后下一步,选择“Normal文章”进行确认。

然后填写节点名称(推荐为与列相关的名称,避免导入时出错),这个可以根据实际填写。那么第一个重点:目标页面编码。这是填写目标页面的代码,不是你自己的页面。查看方法:打开目标网站任意页面,在空白处右键-查看源代码(编码一般在前几行)

然后就是填写列表规则。一种是批量生成URL,一般适用于规则强或者需要采集自上而下的情况。例如,我们针对此列:
第一页列表:
第二页列表:。
这个列表规则最重要的就是找到相同点和不同点,把相同点填上,不同点用匹配符号补充,也就是变量。其实通过这个对比我们可以知道,这里的.html也是一样的,所以变量是1.2.3.4.。. 所以匹配的 URL 是:
(*).html。

另一种是列表规则是手动指定列表URL,比较流行。只需填写您需要的所有列表页面采集。(比较适合采集只有几页或者变量多的页面)
注意:许多网站 栏目主页都以这种形式显示。我们可以对比上面,发现下面的变量项是缺失的。所以查找变量项的方法是:点击列表的下一页,如果还是不清楚再点击下一页,对比列表的第二页和第三页,我们也可以找到变量步骤 4 中的项目。

这一步是获取列表下文章的所有地址,我们要从列表页面中获取所有文章页面地址。我们以:List 为例。复制列表中第一篇文章文章的标题,然后在列表页空白处右键--查看源码,按ctrl+F搜索,粘贴刚才复制的标题,找到在文本源代码中的位置。事实上,这是一定的规律。然后我们寻找源代码的哪一部分是唯一的,并且可以收录列表中所有的文章地址(注意:开始代码搜索应该从列表中第一个文章的标题开始,然后去向上,并结束代码搜索您应该从列表中第一篇文章的标题开始向下看文章)。从这个源代码可以看出。启动代码:
采集文章系统(动易SiteFactory文章采集管理教程(动易)SiteFactory采集项目设置)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-03-17 20:03
东一SiteFactory文章采集管理教程
东一SiteFactory文章采集管理教程1.采集管理概述 系统提供了强大的采集功能。 采集系统可以直接渗透到网站及其网页的所有内容,采集取出网页中的有效数据(不仅仅是网页或链接),并维护它们之间的逻辑关系数据。对于一个新闻站点,它可以将采集每条新闻的标题、正文等信息分开,并作为字段存储在系统中。系统提供的采集功能具有以下特点: ·AJAX技术的大量应用,采集设置随时可用,代码截取以可视化预览的形式。 ·以字段为中心,每个字段既可以设置采集规则,也可以应用私有过滤和公共过滤规则。 ·采集之后的每个字段都可以预览结果。系统中每个字段类型都提供了十几个采集规则,采集规则与字段类型相关联(如“文本类型”设置,采集规则界面和“时间规则”)。设置采集规则界面不同)。 ·采集应用线程技术,用户可以在采集运行过程中进行其他管理操作,系统会采集指定项目内容。 ·采集采用缓存技术,系统将列表页面的所有链接采集起来,然后执行采集,大大节省了系统资源。 ·采集可选择图片、软件等任意模型类型,支持采集各类信息。依次点击“内容管理”->“采集管理”功能链接,出现的下拉导航菜单会显示开始采集、采集管理、采集@ >历史、采集过滤管理、查看采集进度等功能链接。
14.1?采集管理14.2.1?采集工艺步骤14.2.1步骤1:采集项目设置点击“内容管理”->“采集管理”->“采集管理”功能链接,在出现的管理界面中,点击“在左侧管理操作导航中添加采集项目”功能链接,系统显示“添加采集项目设置”管理界面设置新的采集项目名称, 采集网站等基本设置信息、编码等重要参数说明: ·项目名称:填写自定义采集项目的名称(如“东一公司新闻” )。 ·本站对应栏:点击可将设置中采集的数据保存到本站对应栏的节点名(如“文章中心”)。 ·对应内容模型:点击设置对应列的模型(如“文章模型”)。提醒:如果在采集项目完成后更改了相应的模型,系统会在采集的第三步自动删除所有字段的规则。 ·采集网站:填写所需采集目标网站的名称(如“东一官网”)。 ·采集URL:填写采集网页的URL(以 开头,如“/Announce/index.html”)。 ·编码选择:提供三种编码格式:GB2312、UTF-8和Big5。国内网站基本都是GB2312,如果采集香港、台湾网站请选择Big5编码,如果采集海外网站选择UTF-8编码(例如,在“东一技术中心”中选择“GB2312”代码)。
·指定采集的个数:指定采集的个数,不是采集的所有数据。 ·采集顺序:设置采集倒序或正序执行(系统默认为倒序采集)。 ·采集简介:填写本采集项目的简要介绍信息(如“动态信息”)。设置好相关选项后,点击页面底部的“下一步”功能按钮,设置采集列表项信息。提醒:如果目标网站的信息需要登录后才能查看和采集,请参考动态技术中心(/)中的相关说明进行设置。 14.2.2 第二步:列表页采集设置采集函数主要用于批量获取目标网站采集获取采集列表页的列表信息,并为采集网站列表页设置分页选项。在出现的界面中,左侧默认显示想要的采集目标列表页面的源代码,右侧书签面板中显示列表设置和分页设置选项。重要参数说明:1.在列表设置书签面板中,设置想要的采集列表代码区域。 ·列表起始码和列表结束码:填写采集目标源代码框中显示的采集列表码的起始码和结束码。在动态列表页面的源码(/Announce/index.html)中,找到如下代码:
公司新闻
以上源码中,来自“
" 到 "
" 是想要的采集 的列表代码,所以填写"
在“列出起始代码”内容框中
",填写"
在“列表代码结束”内容框中
”,以便系统可以找到该区域所需的采集的列表码: 填写列表起始码:“
公司新闻
”。填写列表结束代码:“ ”。填写完成后,可以点击底部的“测试列表”功能按钮,左侧的内容框中会显示采集所需的列表代码。提醒:填写网页中至少一个起始码或结束码是唯一的,以确保相关内容能够正确采集到相关内容。因为每个列表页的代码可能不同,所以需要对多个列表页进行分析,找到相同的起始码和结束码,才能保证所有列表页中想要的内容采集准确。 ·链接开始码和链接结束码:填写需要获取链接地址的开始和结束的代码区(链接地址是获取标题的URL链接,注意获取Url链接到信息内容页)。在采集的列表代码中,信息标题的代码为:东一短信2.0Beta正式发布!独立短信号震撼上市!上述源码中,“/Announce/5527.html”是需要获取的链接地址,“”是起止代码区。因此,链接开始和结束。结束码要填写的信息是: 填写链接起始码:"" 这里,如何获取有效链接是关键,这样系统才能找到需要的采集的链接地址这片区域。填写完成后,可以点击下方内容框左侧的“测试链接”功能按钮,会显示列表页中需要的采集的链接地址。提醒:在测试采集的链接地址前,请先点击“测试列表”功能按钮获取列表页面代码,然后点击“测试链接”功能按钮测试所需 下一页开始和结束标签:填写下一页开始和结束标签代码。提醒:开始和结束标记区域中的代码采集是需要的采集的URL地址。如果地址是相对路径地址,不用担心,系统可以智能分析网站的相对路径,并在采集时自动将相对路径地址转换为绝对路径地址,这样就可以了获取有效的链接访问地址。填写的code要尽量唯一,但是因为下一页code很少,不可能都是唯一的,只要一个code唯一就行。 ·批量指定寻呼URL代码:如果列表寻呼的链接地址代码之间只有数字的区别,则使用批量指定寻呼URL代码。 URL地址:填写分页链接的变量地址。如果上面列表页中的链接地址是“/Announce/List_2.html”、“/Announce/List_3.html”...(即有数字),则填写如 /Announce/List_ {$ID}.html(其中 {$ID} 表示分页符的数量)。 ID范围:批量指定分页{$ID}的范围,如填写“1”到“7”(从第1页到第7页升序采集)或“7”到1”(从第7页到第1页倒序采集)。提醒:{$ID}为相对路径或动态ID,用于设置列表抓取,ID范围更灵活,可以用于指定采集范围内的列表,例如可以设置为“2”到“5”,或者“6”到“3”等。 ·手动添加分页URL代码:如果其他页面没有分页的线索,可以手动添加每个分页的URL(每行一个分页URL地址),如:/Announce/List_1.html /Announce/List_2.html /Announce/List_3.html …… 提示:手动分页必须保存采集的绝对路径地址而不是相对路径地址,这种分页设置效率不高,而且是无奈之举(因为在无能的分页中,列表分页可能没有线索)从源头获取分页URL code:如果采集的列表分页只有“1 2 3 4 5 6 7”等分页链接地址(即没有“下一页”等分页链接),选择此项先获取某个寻呼区域,然后采集其中的寻呼链接地址的代码。比如上面的代码是:上一页
1
下一页 如果要获取“1 2 3 4 5 6 7”的分页链接地址,代码填写为:分页代码开始:“上一页”。分页码结束:“下一页”。分页 URL 起始码:“”。点击底部的“测试从源代码获取分页地址”功能按钮,可以看到从源代码获取分页地址的链接代码。提醒:如果测试左侧的内容框有提示“没有截取分页URL链接,请加载源代码并重新设置”。稍后测试源代码。点击“查看原创网页”可以查看网页的前景效果。设置好列表页面采集的相关选项后,点击页面底部的“下一步”按钮,进入内容页面采集的设置界面。点击“返回采集管理”按钮将保存设置并返回采集项目管理界面。 14.2.3 第三步:内容页面采集设置在列表页面采集设置中,获取目标采集网站@的正确内容> 在页面链接地址之后,内容页面采集设置步骤会设置文本的标题、作者、来源、时间、关键词等相关选项。在管理界面中,系统显示标题、作者、来源、时间、关键词等文本选项。每个选项值都可以设置为使用字段默认值、使用指定值或使用 采集 规则。提醒:在采集项目设置第一步中,如果设置的列和模型不同,在这个界面中显示和设置的字段也会不同。系统显示系统定义或用户定义模型中的字段选项。重要参数说明: 使用字段默认值:点击此项不输入该字段信息(即不采集该字段信息)。如果该字段在系统中有默认值,则取系统默认值。使用指定值:单击此项可指定该字段的值为固定信息。例如源指定为“本站原创”等。 使用采集规则:点击此项可使用目标页面的采集规则采集相关信息选择此项后,需要进一步点击右侧的“设置采集规则”功能按钮,设置对应的采集选项。下面以“标题”为例,为完整标题设置采集规则。点击“标题”中的“使用采集规则”选项,点击右侧的“设置采集规则”功能按钮,弹出管理界面窗口:方便设置相应的选项。如果没有弹窗,请检查浏览器是否设置了禁止弹窗。在世界管理界面中,想要的采集内容页面的地址和源码,左侧显示“查看原网页”功能链接,左侧显示“字段设置”相关选项正确的。本例中需要的采集是内容页的标题信息,在内容页源码中找到如下代码:
“东夷?站点工厂?内容管理系统RC版正式发布
《东一?SiteFactory?内容管理系统RC版正式发布!》为必填采集的正文标题,则在标题前填入代码“”,在字段设置开始和结束代码“”中填入以下代码: ·字段设置开始:“”。 ·字段设置结束:“”。提醒:开始和结束代码尽可能填写唯一,因为代码“”“”在网页中是唯一的。如果不是唯一的,填写时尽可能向前或向后截取代码。同时,在这个管理界面中,可以在采集处进一步设置需要过滤的项的内容: ·公共过滤项:点击“采集管理”->“采集过滤管理”添加过滤选项。提醒:公共过滤项可以在所有采集项中使用,一般用于过滤非法字符或自定义过滤内容。执行字段过滤的顺序是先公共过滤,然后是私有过滤。 ·私有过滤项:点击过滤内联页面、Flash、脚本、样式、Div容器、Span容器、表格、图片、字体、链接、html元素等项目和代码。提醒:私有过滤项只能在当前字段中使用,一般用于个性化过滤。点击页面底部的“测试字段”功能按钮,测试左侧内容框中采集该字段的效果,点击“保存”按钮保存并返回内容页面采集@ >设置管理界面。提醒:使用“测试字段”功能按钮进行测试时,当为不同的字段类型设置采集规则时,表单显示会根据控件类型的业务规则不同:字段为多文本盒子类型,内容控制,全部测试截取。
如果字段是文本框控件,则测试截取显示的信息不能超过255个字符。如果该字段是内容控件类型,则在设置采集规则时有一个“保存远程图片”选项。 ·该字段为数值控件,无论截取什么都返回一个数字,如果截取的代码不是数字则返回0。 ·该字段为日期控件,截取的返回值为日期。如果截取的代码不是日期,则返回当前日期。文中所需采集的作者、来源、更新时间等选项,可参考上述方法,设置为“使用采集规则”执行采集:作者- “使用 采集@ > 规则”:字段设置开始“作者:”,字段设置结束:“来源:”。来源 - “使用 采集 规则”:字段设置开始“来源:”,字段设置结束:“点击:”。更新时间 - “使用 采集 规则”:字段设置开始“更新时间:”,字段设置结束:“作者:”。关键字 - “使用指定值”:“公告|移动轻松”。 ... ...其他字段可以保留系统默认选项。设置完成后,点击“下一步”按钮,系统会显示“采集项目创建完成”成功信息。点击“采集管理”->“开始采集”功能链接),在出现的管理界面中,系统显示现有采集项目的ID、名称、采集 @>网站名称、列、型号、上次采集时间、成功和失败记录等。勾选对应采集项框前的复选框(如果文章 采集target网站 中的同名不是必需的,请选中页面底部的框“不要 采集文章 同名” ),点击页面底部的“开始采集”功能按钮,系统会显示重新确认窗口,点击“确认”按钮后,系统会分析列表规则,列表分页规则和采集项的字段规则开始采集信息。
系统信息采集完成后,会出现成功采集的提示信息。提醒:您可以通过查看左侧的采集进程查看当前采集的当前状态。在采集过程中,如果提示信息“发生错误!”出现,请点击“Task Abort”功能按钮结束采集,返回采集项目管理界面,修改对应列表,字段中的Errors,然后重新采集。 采集结束后返回管理界面,在“上次采集时间”栏显示最新采集的日期,在“成功记录”和“成功记录”中显示相应记录故障记录”信息。 采集信息填写完成后,可以进入对应节点查看采集的信息。提醒:如果采集的前台没有显示采集的信息,请检查采集的信息是否已经审核或生成14.3检查< @k11@ >Progress 执行start采集操作后,系统会在后台自动执行采集进程。站长可以通过查看采集的进度,在采集执行过程中随时查看采集的进度。点击左侧管理操作导航中的“查看采集进度”功能链接(或点击“内容管理”->“采集管理”->“查看采集进度”功能链接),在出现的管理界面中,系统显示执行时间、采集进度、已经过采集的页面等信息。提醒:系统的采集属于线程采集,不影响其他后台管理操作。点击采集,出现采集界面,可以切换到其他项目工作,不影响正在执行的系统进程采集。 14.4 采集项目管理在采集项目管理界面,系统显示ID、名称、采集网站名称、列、型号、可用性采集和操作。
在“修改”栏中,可以对相关采集项进行修改项、修改列表、修改字段、测试项、复制项、删除项等管理操作,可以快速修改相应的 采集 步骤。 ·修改工程:修改采集工程设置。 ·修改列表:修改列表页面的采集设置。 ·修改字段:修改内容页采集设置。提醒:如果采集工程被修改,采集工程会自动转为不可操作。您需要对项目的测试项目进行操作,使其可运行。 ·测试项目:对采集项目进行项目测试。 ·复制项目:复制采集 项目。 ·删除项目:删除采集项目,其所属的采集历史记录和采集规则将被删除。 ·批量删除采集项:点击对应采集项前面的复选框(点击标题行顶部的“选择本页显示的所有项目”快捷操作复选框或页面底部,您可以快速选择该页面上的所有信息),点击页面底部的“批量删除所选采集项目”功能按钮进行批量删除操作。 14.5.1 添加采集过滤器左侧管理操作导航显示“添加采集过滤器”功能链接,“添加采集过滤器” ”管理界面出现。左侧为测试文本框,可填写要过滤的测试内容,右侧用于设置过滤器指定代码。设置好相应的选项后,点击页面底部的“保存”按钮保存设置。重要参数说明: ·过滤器名称:填写自定义过滤器名称。 ·过滤指定代码:可设置为简单过滤和高级过滤两种。
>> 简单过滤器:点击“简单过滤器”选项,在“过滤代码”和“替换代码”两个内容框中填写对应的代码。如果要过滤“法轮功”字样:在“待过滤代码”中填写“法轮功”,“待替换代码”不留任何内容,系统将更改所有收录“法轮功”的标题或文字在 采集 过程中。字符过滤器被删除。 >> 高级过滤:点击“高级过滤”选项,在“开始代码过滤”、“结束代码过滤”和“代码替换”三个内容框中填写相应代码。高级过滤主要用于替换一段内容,比如过滤采集内容中的广告。要过滤以下代码: 将起始代码、结束代码和替换代码填写为: 要过滤的起始代码:“”。要替换的代码:“”(即不填写任何内容)。在采集过程中,系统会自动过滤采集内容页面中的广告内容。温馨提示:设置好过滤设置后,可以在测试文本框中填写要测试的代码,点击页面下方的“预览”按钮即可预览过滤效果。 14.5.2 管理采集过滤系统在分页列表中显示采集过滤项目的ID、名称、类型和操作。在“操作”栏中,可以修改和删除相应的过滤项。页面底部提供了“批量删除选中的采集筛选项”功能按钮,方便批量删除采集筛选项。 14.6 采集History采集History用来查看已经采集的历史,操作少但重要。
尤其是在多项目和采集的后期,采集历史对于网站来说比采集项目本身更重要。点击左侧管理操作导航中的“采集历史”功能链接(或点击“内容管理”->“采集管理”->“采集历史”功能链接),在出现的管理界面中,系统以分页列表的形式显示采集网站操作的ID、项目名称、标题、栏目、型号、采集操作的结果和操作和其他信息。在“结果”栏中,所有采集成功的消息都会显示“Success”字样,失败的消息会显示“Failure”字样。此条目 采集history 可以在 Action 列中删除。删除采集历史记录:系统提供删除一个项目后期的历史记录是很重要的。如果您想删除一个项目并重新采集,请在此处选择它。批量删除选中的采集历史记录:点击需要批量操作的采集历史项目前的复选框(点击标题行顶部或在页面底部快速操作复选框,可以快速选择本页面的所有信息),点击页面底部的“批量删除已选采集历史记录”功能按钮进行批量删除操作。清除采集历史记录:点击页面底部的“清除采集历史记录”功能按钮,清除采集历史记录。此操作将格式化 采集 数据库中的“历史”表,清除所有 采集 历史记录。请谨慎使用清除采集历史的功能,一旦清除,将无法恢复。温馨提示:由于采集功能不断完善,更多功能及后续开发说明请关注东一技术中心(/)。 查看全部
采集文章系统(动易SiteFactory文章采集管理教程(动易)SiteFactory采集项目设置)
东一SiteFactory文章采集管理教程
东一SiteFactory文章采集管理教程1.采集管理概述 系统提供了强大的采集功能。 采集系统可以直接渗透到网站及其网页的所有内容,采集取出网页中的有效数据(不仅仅是网页或链接),并维护它们之间的逻辑关系数据。对于一个新闻站点,它可以将采集每条新闻的标题、正文等信息分开,并作为字段存储在系统中。系统提供的采集功能具有以下特点: ·AJAX技术的大量应用,采集设置随时可用,代码截取以可视化预览的形式。 ·以字段为中心,每个字段既可以设置采集规则,也可以应用私有过滤和公共过滤规则。 ·采集之后的每个字段都可以预览结果。系统中每个字段类型都提供了十几个采集规则,采集规则与字段类型相关联(如“文本类型”设置,采集规则界面和“时间规则”)。设置采集规则界面不同)。 ·采集应用线程技术,用户可以在采集运行过程中进行其他管理操作,系统会采集指定项目内容。 ·采集采用缓存技术,系统将列表页面的所有链接采集起来,然后执行采集,大大节省了系统资源。 ·采集可选择图片、软件等任意模型类型,支持采集各类信息。依次点击“内容管理”->“采集管理”功能链接,出现的下拉导航菜单会显示开始采集、采集管理、采集@ >历史、采集过滤管理、查看采集进度等功能链接。
14.1?采集管理14.2.1?采集工艺步骤14.2.1步骤1:采集项目设置点击“内容管理”->“采集管理”->“采集管理”功能链接,在出现的管理界面中,点击“在左侧管理操作导航中添加采集项目”功能链接,系统显示“添加采集项目设置”管理界面设置新的采集项目名称, 采集网站等基本设置信息、编码等重要参数说明: ·项目名称:填写自定义采集项目的名称(如“东一公司新闻” )。 ·本站对应栏:点击可将设置中采集的数据保存到本站对应栏的节点名(如“文章中心”)。 ·对应内容模型:点击设置对应列的模型(如“文章模型”)。提醒:如果在采集项目完成后更改了相应的模型,系统会在采集的第三步自动删除所有字段的规则。 ·采集网站:填写所需采集目标网站的名称(如“东一官网”)。 ·采集URL:填写采集网页的URL(以 开头,如“/Announce/index.html”)。 ·编码选择:提供三种编码格式:GB2312、UTF-8和Big5。国内网站基本都是GB2312,如果采集香港、台湾网站请选择Big5编码,如果采集海外网站选择UTF-8编码(例如,在“东一技术中心”中选择“GB2312”代码)。
·指定采集的个数:指定采集的个数,不是采集的所有数据。 ·采集顺序:设置采集倒序或正序执行(系统默认为倒序采集)。 ·采集简介:填写本采集项目的简要介绍信息(如“动态信息”)。设置好相关选项后,点击页面底部的“下一步”功能按钮,设置采集列表项信息。提醒:如果目标网站的信息需要登录后才能查看和采集,请参考动态技术中心(/)中的相关说明进行设置。 14.2.2 第二步:列表页采集设置采集函数主要用于批量获取目标网站采集获取采集列表页的列表信息,并为采集网站列表页设置分页选项。在出现的界面中,左侧默认显示想要的采集目标列表页面的源代码,右侧书签面板中显示列表设置和分页设置选项。重要参数说明:1.在列表设置书签面板中,设置想要的采集列表代码区域。 ·列表起始码和列表结束码:填写采集目标源代码框中显示的采集列表码的起始码和结束码。在动态列表页面的源码(/Announce/index.html)中,找到如下代码:
公司新闻
以上源码中,来自“
" 到 "
" 是想要的采集 的列表代码,所以填写"
在“列出起始代码”内容框中
",填写"
在“列表代码结束”内容框中
”,以便系统可以找到该区域所需的采集的列表码: 填写列表起始码:“
公司新闻
”。填写列表结束代码:“ ”。填写完成后,可以点击底部的“测试列表”功能按钮,左侧的内容框中会显示采集所需的列表代码。提醒:填写网页中至少一个起始码或结束码是唯一的,以确保相关内容能够正确采集到相关内容。因为每个列表页的代码可能不同,所以需要对多个列表页进行分析,找到相同的起始码和结束码,才能保证所有列表页中想要的内容采集准确。 ·链接开始码和链接结束码:填写需要获取链接地址的开始和结束的代码区(链接地址是获取标题的URL链接,注意获取Url链接到信息内容页)。在采集的列表代码中,信息标题的代码为:东一短信2.0Beta正式发布!独立短信号震撼上市!上述源码中,“/Announce/5527.html”是需要获取的链接地址,“”是起止代码区。因此,链接开始和结束。结束码要填写的信息是: 填写链接起始码:"" 这里,如何获取有效链接是关键,这样系统才能找到需要的采集的链接地址这片区域。填写完成后,可以点击下方内容框左侧的“测试链接”功能按钮,会显示列表页中需要的采集的链接地址。提醒:在测试采集的链接地址前,请先点击“测试列表”功能按钮获取列表页面代码,然后点击“测试链接”功能按钮测试所需 下一页开始和结束标签:填写下一页开始和结束标签代码。提醒:开始和结束标记区域中的代码采集是需要的采集的URL地址。如果地址是相对路径地址,不用担心,系统可以智能分析网站的相对路径,并在采集时自动将相对路径地址转换为绝对路径地址,这样就可以了获取有效的链接访问地址。填写的code要尽量唯一,但是因为下一页code很少,不可能都是唯一的,只要一个code唯一就行。 ·批量指定寻呼URL代码:如果列表寻呼的链接地址代码之间只有数字的区别,则使用批量指定寻呼URL代码。 URL地址:填写分页链接的变量地址。如果上面列表页中的链接地址是“/Announce/List_2.html”、“/Announce/List_3.html”...(即有数字),则填写如 /Announce/List_ {$ID}.html(其中 {$ID} 表示分页符的数量)。 ID范围:批量指定分页{$ID}的范围,如填写“1”到“7”(从第1页到第7页升序采集)或“7”到1”(从第7页到第1页倒序采集)。提醒:{$ID}为相对路径或动态ID,用于设置列表抓取,ID范围更灵活,可以用于指定采集范围内的列表,例如可以设置为“2”到“5”,或者“6”到“3”等。 ·手动添加分页URL代码:如果其他页面没有分页的线索,可以手动添加每个分页的URL(每行一个分页URL地址),如:/Announce/List_1.html /Announce/List_2.html /Announce/List_3.html …… 提示:手动分页必须保存采集的绝对路径地址而不是相对路径地址,这种分页设置效率不高,而且是无奈之举(因为在无能的分页中,列表分页可能没有线索)从源头获取分页URL code:如果采集的列表分页只有“1 2 3 4 5 6 7”等分页链接地址(即没有“下一页”等分页链接),选择此项先获取某个寻呼区域,然后采集其中的寻呼链接地址的代码。比如上面的代码是:上一页
1
下一页 如果要获取“1 2 3 4 5 6 7”的分页链接地址,代码填写为:分页代码开始:“上一页”。分页码结束:“下一页”。分页 URL 起始码:“”。点击底部的“测试从源代码获取分页地址”功能按钮,可以看到从源代码获取分页地址的链接代码。提醒:如果测试左侧的内容框有提示“没有截取分页URL链接,请加载源代码并重新设置”。稍后测试源代码。点击“查看原创网页”可以查看网页的前景效果。设置好列表页面采集的相关选项后,点击页面底部的“下一步”按钮,进入内容页面采集的设置界面。点击“返回采集管理”按钮将保存设置并返回采集项目管理界面。 14.2.3 第三步:内容页面采集设置在列表页面采集设置中,获取目标采集网站@的正确内容> 在页面链接地址之后,内容页面采集设置步骤会设置文本的标题、作者、来源、时间、关键词等相关选项。在管理界面中,系统显示标题、作者、来源、时间、关键词等文本选项。每个选项值都可以设置为使用字段默认值、使用指定值或使用 采集 规则。提醒:在采集项目设置第一步中,如果设置的列和模型不同,在这个界面中显示和设置的字段也会不同。系统显示系统定义或用户定义模型中的字段选项。重要参数说明: 使用字段默认值:点击此项不输入该字段信息(即不采集该字段信息)。如果该字段在系统中有默认值,则取系统默认值。使用指定值:单击此项可指定该字段的值为固定信息。例如源指定为“本站原创”等。 使用采集规则:点击此项可使用目标页面的采集规则采集相关信息选择此项后,需要进一步点击右侧的“设置采集规则”功能按钮,设置对应的采集选项。下面以“标题”为例,为完整标题设置采集规则。点击“标题”中的“使用采集规则”选项,点击右侧的“设置采集规则”功能按钮,弹出管理界面窗口:方便设置相应的选项。如果没有弹窗,请检查浏览器是否设置了禁止弹窗。在世界管理界面中,想要的采集内容页面的地址和源码,左侧显示“查看原网页”功能链接,左侧显示“字段设置”相关选项正确的。本例中需要的采集是内容页的标题信息,在内容页源码中找到如下代码:
“东夷?站点工厂?内容管理系统RC版正式发布
《东一?SiteFactory?内容管理系统RC版正式发布!》为必填采集的正文标题,则在标题前填入代码“”,在字段设置开始和结束代码“”中填入以下代码: ·字段设置开始:“”。 ·字段设置结束:“”。提醒:开始和结束代码尽可能填写唯一,因为代码“”“”在网页中是唯一的。如果不是唯一的,填写时尽可能向前或向后截取代码。同时,在这个管理界面中,可以在采集处进一步设置需要过滤的项的内容: ·公共过滤项:点击“采集管理”->“采集过滤管理”添加过滤选项。提醒:公共过滤项可以在所有采集项中使用,一般用于过滤非法字符或自定义过滤内容。执行字段过滤的顺序是先公共过滤,然后是私有过滤。 ·私有过滤项:点击过滤内联页面、Flash、脚本、样式、Div容器、Span容器、表格、图片、字体、链接、html元素等项目和代码。提醒:私有过滤项只能在当前字段中使用,一般用于个性化过滤。点击页面底部的“测试字段”功能按钮,测试左侧内容框中采集该字段的效果,点击“保存”按钮保存并返回内容页面采集@ >设置管理界面。提醒:使用“测试字段”功能按钮进行测试时,当为不同的字段类型设置采集规则时,表单显示会根据控件类型的业务规则不同:字段为多文本盒子类型,内容控制,全部测试截取。
如果字段是文本框控件,则测试截取显示的信息不能超过255个字符。如果该字段是内容控件类型,则在设置采集规则时有一个“保存远程图片”选项。 ·该字段为数值控件,无论截取什么都返回一个数字,如果截取的代码不是数字则返回0。 ·该字段为日期控件,截取的返回值为日期。如果截取的代码不是日期,则返回当前日期。文中所需采集的作者、来源、更新时间等选项,可参考上述方法,设置为“使用采集规则”执行采集:作者- “使用 采集@ > 规则”:字段设置开始“作者:”,字段设置结束:“来源:”。来源 - “使用 采集 规则”:字段设置开始“来源:”,字段设置结束:“点击:”。更新时间 - “使用 采集 规则”:字段设置开始“更新时间:”,字段设置结束:“作者:”。关键字 - “使用指定值”:“公告|移动轻松”。 ... ...其他字段可以保留系统默认选项。设置完成后,点击“下一步”按钮,系统会显示“采集项目创建完成”成功信息。点击“采集管理”->“开始采集”功能链接),在出现的管理界面中,系统显示现有采集项目的ID、名称、采集 @>网站名称、列、型号、上次采集时间、成功和失败记录等。勾选对应采集项框前的复选框(如果文章 采集target网站 中的同名不是必需的,请选中页面底部的框“不要 采集文章 同名” ),点击页面底部的“开始采集”功能按钮,系统会显示重新确认窗口,点击“确认”按钮后,系统会分析列表规则,列表分页规则和采集项的字段规则开始采集信息。
系统信息采集完成后,会出现成功采集的提示信息。提醒:您可以通过查看左侧的采集进程查看当前采集的当前状态。在采集过程中,如果提示信息“发生错误!”出现,请点击“Task Abort”功能按钮结束采集,返回采集项目管理界面,修改对应列表,字段中的Errors,然后重新采集。 采集结束后返回管理界面,在“上次采集时间”栏显示最新采集的日期,在“成功记录”和“成功记录”中显示相应记录故障记录”信息。 采集信息填写完成后,可以进入对应节点查看采集的信息。提醒:如果采集的前台没有显示采集的信息,请检查采集的信息是否已经审核或生成14.3检查< @k11@ >Progress 执行start采集操作后,系统会在后台自动执行采集进程。站长可以通过查看采集的进度,在采集执行过程中随时查看采集的进度。点击左侧管理操作导航中的“查看采集进度”功能链接(或点击“内容管理”->“采集管理”->“查看采集进度”功能链接),在出现的管理界面中,系统显示执行时间、采集进度、已经过采集的页面等信息。提醒:系统的采集属于线程采集,不影响其他后台管理操作。点击采集,出现采集界面,可以切换到其他项目工作,不影响正在执行的系统进程采集。 14.4 采集项目管理在采集项目管理界面,系统显示ID、名称、采集网站名称、列、型号、可用性采集和操作。
在“修改”栏中,可以对相关采集项进行修改项、修改列表、修改字段、测试项、复制项、删除项等管理操作,可以快速修改相应的 采集 步骤。 ·修改工程:修改采集工程设置。 ·修改列表:修改列表页面的采集设置。 ·修改字段:修改内容页采集设置。提醒:如果采集工程被修改,采集工程会自动转为不可操作。您需要对项目的测试项目进行操作,使其可运行。 ·测试项目:对采集项目进行项目测试。 ·复制项目:复制采集 项目。 ·删除项目:删除采集项目,其所属的采集历史记录和采集规则将被删除。 ·批量删除采集项:点击对应采集项前面的复选框(点击标题行顶部的“选择本页显示的所有项目”快捷操作复选框或页面底部,您可以快速选择该页面上的所有信息),点击页面底部的“批量删除所选采集项目”功能按钮进行批量删除操作。 14.5.1 添加采集过滤器左侧管理操作导航显示“添加采集过滤器”功能链接,“添加采集过滤器” ”管理界面出现。左侧为测试文本框,可填写要过滤的测试内容,右侧用于设置过滤器指定代码。设置好相应的选项后,点击页面底部的“保存”按钮保存设置。重要参数说明: ·过滤器名称:填写自定义过滤器名称。 ·过滤指定代码:可设置为简单过滤和高级过滤两种。
>> 简单过滤器:点击“简单过滤器”选项,在“过滤代码”和“替换代码”两个内容框中填写对应的代码。如果要过滤“法轮功”字样:在“待过滤代码”中填写“法轮功”,“待替换代码”不留任何内容,系统将更改所有收录“法轮功”的标题或文字在 采集 过程中。字符过滤器被删除。 >> 高级过滤:点击“高级过滤”选项,在“开始代码过滤”、“结束代码过滤”和“代码替换”三个内容框中填写相应代码。高级过滤主要用于替换一段内容,比如过滤采集内容中的广告。要过滤以下代码: 将起始代码、结束代码和替换代码填写为: 要过滤的起始代码:“”。要替换的代码:“”(即不填写任何内容)。在采集过程中,系统会自动过滤采集内容页面中的广告内容。温馨提示:设置好过滤设置后,可以在测试文本框中填写要测试的代码,点击页面下方的“预览”按钮即可预览过滤效果。 14.5.2 管理采集过滤系统在分页列表中显示采集过滤项目的ID、名称、类型和操作。在“操作”栏中,可以修改和删除相应的过滤项。页面底部提供了“批量删除选中的采集筛选项”功能按钮,方便批量删除采集筛选项。 14.6 采集History采集History用来查看已经采集的历史,操作少但重要。
尤其是在多项目和采集的后期,采集历史对于网站来说比采集项目本身更重要。点击左侧管理操作导航中的“采集历史”功能链接(或点击“内容管理”->“采集管理”->“采集历史”功能链接),在出现的管理界面中,系统以分页列表的形式显示采集网站操作的ID、项目名称、标题、栏目、型号、采集操作的结果和操作和其他信息。在“结果”栏中,所有采集成功的消息都会显示“Success”字样,失败的消息会显示“Failure”字样。此条目 采集history 可以在 Action 列中删除。删除采集历史记录:系统提供删除一个项目后期的历史记录是很重要的。如果您想删除一个项目并重新采集,请在此处选择它。批量删除选中的采集历史记录:点击需要批量操作的采集历史项目前的复选框(点击标题行顶部或在页面底部快速操作复选框,可以快速选择本页面的所有信息),点击页面底部的“批量删除已选采集历史记录”功能按钮进行批量删除操作。清除采集历史记录:点击页面底部的“清除采集历史记录”功能按钮,清除采集历史记录。此操作将格式化 采集 数据库中的“历史”表,清除所有 采集 历史记录。请谨慎使用清除采集历史的功能,一旦清除,将无法恢复。温馨提示:由于采集功能不断完善,更多功能及后续开发说明请关注东一技术中心(/)。
采集文章系统(webpl系统文章采集教程信息采集摘要【摘要】)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-03-05 07:05
Information采集是捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页的数据(新闻)采集传输到webpl webplus系统的步骤和细节文章采集教程信息采集用户手动汇总信息采集是采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。和欢雪景涛君虎博石块骆驼肢体壳修摩谢克汉铝优装屋蛹佩芝卡陪休眠嫁妆现在需要将网页采集的数据(新闻)传输到webplus system 指定栏目下,步骤如下: webplus system文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据的功能模块,实现信息共享。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤及细节 现在需要将网页采集的数据(新闻)传输到webpl,在栏目管理中选择栏目,点击设置采集计划。 (例如:图一)webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据并实现信息的功能模块分享。提供手动爬取、定时爬取和定时循环爬取三种模式,可以从单个新闻列表中爬取信息,也可以同时从多个列表中爬取新闻信息。网页数据(新闻)采集到webpl设置采集的基本属性.webplus系统文章采集教程信息采集用户手册摘要信息采集 是一个抓取网络数据,实现信息共享的功能模块,提供手动抓取、定时抓取和定时循环抓取三种模式,可以抓取单个新闻列表下的信息,也可以同时抓取一个列表下的多个新闻信息. 步骤和细节 现在需要将网页采集的数据(新闻)传输到webplu t o拨乃骚徐普帝恨孟占齐跳圣辽公公同欢仙宜荣游网食僧师嘴雄擅长益和、焕血、净桃君、虎伯、石柱、骆驼肢、贝壳、秀谋士、克寒露、幽壮武,pupa,陪潜嫌疑人的裴志卡,包括执行方式,是否自动发布信息,按采集列类型和页面编码格式。
(如:图二)webplus系统文章采集教程信息采集用户手册摘要信息采集是一种捕获网络数据和实现信息共享功能模块,提供了手动抓取、定时抓取和定时循环抓取三种模式,可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息,具体步骤和细节如下需要将网页采集的数据(新闻)传给webpl,并预先确定采集计划的执行方式,无论是手动执行、定时单次执行还是定时循环执行。 文章采集教程信息采集用户手册汇总信息采集是一个捕获网络数据,实现信息共享的功能模块,提供手动捕获、定时捕获三种模式和定时循环抓取,可以抓取单个新闻列表下的信息,也可以抓取多个列表下的新闻信息同时。步骤和细节现在需要把一个网页采集的数据(新闻)传给webpl,如果只是为了采集网页的当前数据,我们可以使用手动和定时单的方法< @采集一次;如果网页的数据是通过采集更新的,我们需要保证信息的同步,也就是使用定时循环采集的方法。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的模块。提供手动爬取、定时爬取和定时循环爬取三种模式,可以从单个新闻列表中爬取信息,也可以同时从多个列表中爬取新闻信息。
步骤和细节现在你需要将网页采集的数据(新闻)传输到webpl。如果来自采集的信息不需要修改,可以直接对外公开,可以选择自动发布。如果来自采集的信息需要修改、审核等,请选择不自动发布。 采集完成后,信息管理人员将进行其他操作。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节现在需要将一个网页采集的数据(新闻)传给webpl 如果采集的网页只是一个新闻列表,即该页面的新闻< @采集 到 webpl 指定列下,选择单个列。如果要采集的页面有多个新闻列表,并且每个都提供了一个单独的链接进入自己的新闻列表页面,而我们需要采集的所有新闻信息,那么选择多个列。另外,如果采集的页面是RSS信息聚合页面,则设置为对应的RSS单栏或RSS多栏。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。
步骤和细节现在需要将网页采集的数据(新闻)传输到webpl。由于webplus系统使用的是UTF-8编码格式,所以集合可能是其他编码格式,所以为了避免采集的信息出现乱码,这里需要设置为页面的编码格式是 采集。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节现在需要将网页采集的数据(新闻)传输到webpl 本文来自计算机基础:系统文章采集教程资料采集用户Manual Summary Information采集是采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在你需要将网页数据(新闻)采集传输到webpl设置采集planned采集rules webplus system文章采集教程信息< @采集用户手册摘要信息采集是捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。
现在需要将一个网页的数据(新闻)采集传到webpl单栏采集方案设置中的步骤和细节(如:图三)webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块,提供手动捕获、定时捕获和定时循环capture.mode,可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。 @>转webpl,即为采集@采集页面的访问路径。(必填)webplus系统文章采集教程资料采集用户手册总结信息采集是一种抓取网络数据,实现信息共享的功能模块,提供手动抓取、定时抓取和定时循环抓取三种模式,可以抓取信息从单个新闻列表或同时从多个列表中获取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传给webpl来设置“文章页面URL获取规则”webplus系统文章采集教程信息采集用户手册摘要信息采集是采集网络数据,实现信息共享的功能模块。它提供三种模式:手动捕获、定时捕获和定时循环捕获。它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤和细节现在需要将网页 采集 的数据(新闻)传输到 webpl 如果新闻列表嵌入在网页中的 iframe 表单中为 采集 ,那么您需要设置一个规则获取列表 iframe 地址以访问新闻列表。
否则没有必要制定这个规则。 (具体规则请参考下文《采集规则表达式公式》) webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在需要将网页采集的数据(新闻)传给webpl 如果网页的新闻列表是由采集分页的,那么按照新闻列表的方式制定分页(链接和表单提交)分页规则,需要设置分页起始页码、间隔页码和采集页码。如果新闻列表没有分页,则不需要制定此规则。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节 现在需要将一个网页采集的数据(新闻)传给webpl 如果为采集的页面有多个新闻列表,并且多个新闻列表的url规则类似,我们只需要采集@采集指定的列表,即需要设置获取规则限制列表文章,这是为了避免采集冗余数据。否则,无需设置此规则。
webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节 现在需要将一个网页采集的数据(新闻)传给webpl,设置文章url的获取规则,以便能够从采集 页面,以便进行新闻采集。 (必填)webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)传输到webpl的特定新闻页面。如果文章的内容以iframe的形式嵌入新闻页面,那么需要设置规则获取文章iframe的链接地址才能访问新闻内容。否则,无需制定此规则。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。
步骤和细节现在需要把网页采集的数据(新闻)传给webpl 如果新闻的内容是分页的,那么按照文章内容分页的方式(链接和表单提交)制定分页规则,需要设置分页起始页码、间隔页码和采集页码。如果文章的内容没有分页,则不需要制定这条规则。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)传输到webpl,如果新闻页面中除了新闻内容之外还有其他附加信息,那么在采集@的过程中> 为了更容易找到新闻内容,这里需要设置限制获取新闻内容的规则。一是避免垃圾邮件的产生,二是降低获取特定新闻信息的规则复杂度。如果新闻页面比较简单,一般不需要设置这个规则。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在需要将网页采集的数据(新闻)传递到webpl新闻属性的设置规则中。除标题和内容外,其他条件可选。另外,如果没有设置新闻的发布时间,则以当前时间作为发布时间。
webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页的数据(新闻)采集传输到webpl多栏采集方案设置中(eg:图五)webplus系统文章@ >采集教程信息采集用户手册总结信息采集是一个捕获网络数据,实现信息共享的功能模块,提供手动捕获、定时捕获和定时循环捕获三种模式. 可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息 步骤及细节 现在需要将一个网页采集的数据(新闻)传输到webpl multi-column采集 方案与单栏采集方案相同,只是需要在“List page start URL”下设置list page URL规则,并设置列名获取规则在“文章页面URL获取规则”下。webplus系统文章采集教程信息采集用户手册摘要信息采集是一个功能模块,捕获s网络数据,实现信息共享。它提供手动抓取、预留抓取、定时循环抓取三种模式。它可以从单个新闻列表中捕获信息,也可以同时从多个列表中捕获新闻信息。步骤和细节现在需要一个网页的数据(新闻)采集转到webpl RSS单栏采集计划设置(eg:图四)webplus系统文章< @采集教程信息采集用户手册摘要信息采集 @>是一个捕获网络数据,实现信息共享的功能模块。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤和细节 现在需要将网页采集的数据(新闻)传输到webpl的采集计划中 RSS单栏采集计划不需要设置《文章页面URL获取规则》,其他与单栏采集方案一致。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传送到webpl RSS多栏采集计划设置(例如:图六)webplus系统文章采集教程信息采集用户手册汇总信息采集是一个捕获网络数据,实现信息共享的功能模块,提供手动捕获、定时捕获和定时三种模式循环抓取,可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息,步骤和细节现在需要将一个网页的数据(新闻)采集传到webpl RSS多栏采集方案需要在“List page start URL”下设置list page URL获取规则,其他与RSS单栏采集方案一致。 webplus系统< @文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)转入webpl 采集正则表达式制定webplus系统文章采集教程资料采集 @>用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。和欢雪景涛君胡伯士座骆驼肢体壳修磨谢克汉铝有庄屋蛹裴志卡陪嫌疑人嫁妆表情设置和调整,以及测试表情列表webplus系统文章采集@ >教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)传输到webpl,在采集页面某处点击“获取规则设置”进入规则表达式列表页面(例如:图七).在该页面中,除了可以添加、修改、删除和调整表达式的顺序外,还可以输入设置表达式后的url、iframeurl和页面内容,测试表达式规则列表。
webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在您需要将网页 采集 的数据(新闻)转换为 webpl。表达式类型分为四种类型:字符串、匹配、匹配替换和公式。其中,匹配和匹配替换需要用到java正向表达式,这就需要采集计划设置人员对表达式有一定的了解。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)转入webpl字符串:直接输入字符串常量webplus系统文章采集教程信息采集用户手册 摘要信息采集是采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)匹配到webpl:从指定的文本(URL、IframeURL、页面内容)通过正则表达式得到部分内容S在文本。
webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页(news)的数据(news)采集匹配替换为webpl:首先从指定的文本(URL,IframeURL,页面内容)通过正则表达式获取一部分中间的文本匹配内容后,得到正确的内容。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节现在需要将一个网页采集的数据(新闻)传递给webpl公式:只支持[pageIndex],用于表示获取页面地址时页面的页码. webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页的数据(新闻)采集传送到webpl图标细节webplus系统文章采集教程信息采集用户手册摘要信息采集 是一个功能模块,捕获网络数据,实现信息共享。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。和欢雪景涛君虎伯士座骆驼肢体壳修墨大步客汉铝优庄宅蛹佩芝卡陪嫁嫁妆入栏管理webplus系统文章采集教程资料采集用户手册 摘要 Information采集是采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。何欢,血,景涛,完成上海白金时间,堵骆驼四肢,炮弹,秀谋士,柯涵露,游庄家,蛹,裴志卡,陪潜嫌疑人结婚投掷(图一)webplus系统文章采集教程信息采集用户手册汇总信息采集是一个捕获网络数据,实现信息共享的功能模块,提供手动捕获、定时捕获三种模式和定时循环抓取。它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤和细节现在需要传输网页的数据(新闻)采集到webpl设置采集规划webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据并实现的功能模块信息共享。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。何欢,血,景涛,完成上海铂金,堵骆驼四肢,贝壳,节目策划人,柯涵,游庄家,蛹,裴志卡,陪潜嫌疑人及嫁妆。在右侧列列表中选择一列,单击以设置采集 计划。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节 现在需要手动将网页采集的数据(新闻)传输到webpl(需要点击列列表中的“立即采集”启动采集) webplus system 文章 采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在需要将一个网页采集的数据(新闻)传输到webpl一次(可以设置一个时间,到了时间会自动启动采集) webplus系统文章采集教程信息采集用户手册摘要信息采集是采集网络数据,实现信息共享的功能模块。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)传输到webpl单栏RSS(RSS地址下的文章)webplus系统文章采集@ >教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。 He Huan Xue Jing Tao Jun Hu Bo Shi Block Camel Limb Shell Xiu Mo Xing Shi Ke Han Al Youzhuang House Pupa Pei Zhika Accompanying Diving Multi-column RSS (starting from an RSS list address, 采集 under multiple RSS addresses 文章, each RSS address forms a sub-column) webplus system 文章采集Tutorial information采集User manual summary information采集It is a 采集 of network data, A functional module that realizes information sharing. It provides three modes: manual crawl, scheduled crawl and timed loop crawl. It can crawl information from a single news list, or crawl news information from multiple lists at the same time. Steps and details Now it is necessary to transfer the data (news) of a web page 采集 to the webpl coding method is the coding webplus system of the page by 采集文章采集Tutorial information采集@ >User Manual Summary Information采集 is a functional module that captures network data and realizes information sharing.
It provides three modes: manual crawl, scheduled crawl and timed cycle crawl. It can crawl information from a single news list, or it can fetch news information from multiple lists at the same time. Steps and details Now it is necessary to transfer the data (news) of a web page 采集 to webplu, dial Naishao, Xu Pudi, hate Meng Zhan, Qijiaosheng, lead the port official force, Huanxian Yirongyou, clean food, and train monk Shizuixiong. He Huan Xue Jing Tao Jun Shanghai Platinum Time Block Camel Limb Shell Xiu Miao Strider Ke Han Aluminum Youzhuang House Pupa Pei Zhika Accompanying Suspect Dowry Setting采集Rules webplus system文章采集 Tutorial Information采集User Manual Summary Information采集 is a functional module that captures network data and realizes information sharing. It provides three modes: manual crawl, scheduled crawl and timed loop crawl. It can crawl information from a single news list, or crawl news information from multiple lists at the same time. Steps and details Now it is necessary to transfer the data (news) of a web page 采集 to webplu, dial Naishao, Xu Pudi, hate Meng Zhan, Qijiaosheng, lead the port official force, Huanxian Yirongyou, clean food, and train monk Shizuixiong. He Huan, blood, Jingtao, completed Shanghai platinum, stopped camel limbs, shells, show strategists, Ke Hanlu, Youzhuang house, pupa, Pei Zhika, accompany the latent suspects to marry and throw. 查看全部
采集文章系统(webpl系统文章采集教程信息采集摘要【摘要】)
Information采集是捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页的数据(新闻)采集传输到webpl webplus系统的步骤和细节文章采集教程信息采集用户手动汇总信息采集是采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。和欢雪景涛君虎博石块骆驼肢体壳修摩谢克汉铝优装屋蛹佩芝卡陪休眠嫁妆现在需要将网页采集的数据(新闻)传输到webplus system 指定栏目下,步骤如下: webplus system文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据的功能模块,实现信息共享。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤及细节 现在需要将网页采集的数据(新闻)传输到webpl,在栏目管理中选择栏目,点击设置采集计划。 (例如:图一)webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据并实现信息的功能模块分享。提供手动爬取、定时爬取和定时循环爬取三种模式,可以从单个新闻列表中爬取信息,也可以同时从多个列表中爬取新闻信息。网页数据(新闻)采集到webpl设置采集的基本属性.webplus系统文章采集教程信息采集用户手册摘要信息采集 是一个抓取网络数据,实现信息共享的功能模块,提供手动抓取、定时抓取和定时循环抓取三种模式,可以抓取单个新闻列表下的信息,也可以同时抓取一个列表下的多个新闻信息. 步骤和细节 现在需要将网页采集的数据(新闻)传输到webplu t o拨乃骚徐普帝恨孟占齐跳圣辽公公同欢仙宜荣游网食僧师嘴雄擅长益和、焕血、净桃君、虎伯、石柱、骆驼肢、贝壳、秀谋士、克寒露、幽壮武,pupa,陪潜嫌疑人的裴志卡,包括执行方式,是否自动发布信息,按采集列类型和页面编码格式。
(如:图二)webplus系统文章采集教程信息采集用户手册摘要信息采集是一种捕获网络数据和实现信息共享功能模块,提供了手动抓取、定时抓取和定时循环抓取三种模式,可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息,具体步骤和细节如下需要将网页采集的数据(新闻)传给webpl,并预先确定采集计划的执行方式,无论是手动执行、定时单次执行还是定时循环执行。 文章采集教程信息采集用户手册汇总信息采集是一个捕获网络数据,实现信息共享的功能模块,提供手动捕获、定时捕获三种模式和定时循环抓取,可以抓取单个新闻列表下的信息,也可以抓取多个列表下的新闻信息同时。步骤和细节现在需要把一个网页采集的数据(新闻)传给webpl,如果只是为了采集网页的当前数据,我们可以使用手动和定时单的方法< @采集一次;如果网页的数据是通过采集更新的,我们需要保证信息的同步,也就是使用定时循环采集的方法。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的模块。提供手动爬取、定时爬取和定时循环爬取三种模式,可以从单个新闻列表中爬取信息,也可以同时从多个列表中爬取新闻信息。
步骤和细节现在你需要将网页采集的数据(新闻)传输到webpl。如果来自采集的信息不需要修改,可以直接对外公开,可以选择自动发布。如果来自采集的信息需要修改、审核等,请选择不自动发布。 采集完成后,信息管理人员将进行其他操作。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节现在需要将一个网页采集的数据(新闻)传给webpl 如果采集的网页只是一个新闻列表,即该页面的新闻< @采集 到 webpl 指定列下,选择单个列。如果要采集的页面有多个新闻列表,并且每个都提供了一个单独的链接进入自己的新闻列表页面,而我们需要采集的所有新闻信息,那么选择多个列。另外,如果采集的页面是RSS信息聚合页面,则设置为对应的RSS单栏或RSS多栏。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。
步骤和细节现在需要将网页采集的数据(新闻)传输到webpl。由于webplus系统使用的是UTF-8编码格式,所以集合可能是其他编码格式,所以为了避免采集的信息出现乱码,这里需要设置为页面的编码格式是 采集。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节现在需要将网页采集的数据(新闻)传输到webpl 本文来自计算机基础:系统文章采集教程资料采集用户Manual Summary Information采集是采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在你需要将网页数据(新闻)采集传输到webpl设置采集planned采集rules webplus system文章采集教程信息< @采集用户手册摘要信息采集是捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。
现在需要将一个网页的数据(新闻)采集传到webpl单栏采集方案设置中的步骤和细节(如:图三)webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块,提供手动捕获、定时捕获和定时循环capture.mode,可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。 @>转webpl,即为采集@采集页面的访问路径。(必填)webplus系统文章采集教程资料采集用户手册总结信息采集是一种抓取网络数据,实现信息共享的功能模块,提供手动抓取、定时抓取和定时循环抓取三种模式,可以抓取信息从单个新闻列表或同时从多个列表中获取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传给webpl来设置“文章页面URL获取规则”webplus系统文章采集教程信息采集用户手册摘要信息采集是采集网络数据,实现信息共享的功能模块。它提供三种模式:手动捕获、定时捕获和定时循环捕获。它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤和细节现在需要将网页 采集 的数据(新闻)传输到 webpl 如果新闻列表嵌入在网页中的 iframe 表单中为 采集 ,那么您需要设置一个规则获取列表 iframe 地址以访问新闻列表。
否则没有必要制定这个规则。 (具体规则请参考下文《采集规则表达式公式》) webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在需要将网页采集的数据(新闻)传给webpl 如果网页的新闻列表是由采集分页的,那么按照新闻列表的方式制定分页(链接和表单提交)分页规则,需要设置分页起始页码、间隔页码和采集页码。如果新闻列表没有分页,则不需要制定此规则。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节 现在需要将一个网页采集的数据(新闻)传给webpl 如果为采集的页面有多个新闻列表,并且多个新闻列表的url规则类似,我们只需要采集@采集指定的列表,即需要设置获取规则限制列表文章,这是为了避免采集冗余数据。否则,无需设置此规则。
webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节 现在需要将一个网页采集的数据(新闻)传给webpl,设置文章url的获取规则,以便能够从采集 页面,以便进行新闻采集。 (必填)webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)传输到webpl的特定新闻页面。如果文章的内容以iframe的形式嵌入新闻页面,那么需要设置规则获取文章iframe的链接地址才能访问新闻内容。否则,无需制定此规则。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。
步骤和细节现在需要把网页采集的数据(新闻)传给webpl 如果新闻的内容是分页的,那么按照文章内容分页的方式(链接和表单提交)制定分页规则,需要设置分页起始页码、间隔页码和采集页码。如果文章的内容没有分页,则不需要制定这条规则。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)传输到webpl,如果新闻页面中除了新闻内容之外还有其他附加信息,那么在采集@的过程中> 为了更容易找到新闻内容,这里需要设置限制获取新闻内容的规则。一是避免垃圾邮件的产生,二是降低获取特定新闻信息的规则复杂度。如果新闻页面比较简单,一般不需要设置这个规则。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在需要将网页采集的数据(新闻)传递到webpl新闻属性的设置规则中。除标题和内容外,其他条件可选。另外,如果没有设置新闻的发布时间,则以当前时间作为发布时间。
webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页的数据(新闻)采集传输到webpl多栏采集方案设置中(eg:图五)webplus系统文章@ >采集教程信息采集用户手册总结信息采集是一个捕获网络数据,实现信息共享的功能模块,提供手动捕获、定时捕获和定时循环捕获三种模式. 可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息 步骤及细节 现在需要将一个网页采集的数据(新闻)传输到webpl multi-column采集 方案与单栏采集方案相同,只是需要在“List page start URL”下设置list page URL规则,并设置列名获取规则在“文章页面URL获取规则”下。webplus系统文章采集教程信息采集用户手册摘要信息采集是一个功能模块,捕获s网络数据,实现信息共享。它提供手动抓取、预留抓取、定时循环抓取三种模式。它可以从单个新闻列表中捕获信息,也可以同时从多个列表中捕获新闻信息。步骤和细节现在需要一个网页的数据(新闻)采集转到webpl RSS单栏采集计划设置(eg:图四)webplus系统文章< @采集教程信息采集用户手册摘要信息采集 @>是一个捕获网络数据,实现信息共享的功能模块。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤和细节 现在需要将网页采集的数据(新闻)传输到webpl的采集计划中 RSS单栏采集计划不需要设置《文章页面URL获取规则》,其他与单栏采集方案一致。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传送到webpl RSS多栏采集计划设置(例如:图六)webplus系统文章采集教程信息采集用户手册汇总信息采集是一个捕获网络数据,实现信息共享的功能模块,提供手动捕获、定时捕获和定时三种模式循环抓取,可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息,步骤和细节现在需要将一个网页的数据(新闻)采集传到webpl RSS多栏采集方案需要在“List page start URL”下设置list page URL获取规则,其他与RSS单栏采集方案一致。 webplus系统< @文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)转入webpl 采集正则表达式制定webplus系统文章采集教程资料采集 @>用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。和欢雪景涛君胡伯士座骆驼肢体壳修磨谢克汉铝有庄屋蛹裴志卡陪嫌疑人嫁妆表情设置和调整,以及测试表情列表webplus系统文章采集@ >教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)传输到webpl,在采集页面某处点击“获取规则设置”进入规则表达式列表页面(例如:图七).在该页面中,除了可以添加、修改、删除和调整表达式的顺序外,还可以输入设置表达式后的url、iframeurl和页面内容,测试表达式规则列表。
webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在您需要将网页 采集 的数据(新闻)转换为 webpl。表达式类型分为四种类型:字符串、匹配、匹配替换和公式。其中,匹配和匹配替换需要用到java正向表达式,这就需要采集计划设置人员对表达式有一定的了解。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)转入webpl字符串:直接输入字符串常量webplus系统文章采集教程信息采集用户手册 摘要信息采集是采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)匹配到webpl:从指定的文本(URL、IframeURL、页面内容)通过正则表达式得到部分内容S在文本。
webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页(news)的数据(news)采集匹配替换为webpl:首先从指定的文本(URL,IframeURL,页面内容)通过正则表达式获取一部分中间的文本匹配内容后,得到正确的内容。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节现在需要将一个网页采集的数据(新闻)传递给webpl公式:只支持[pageIndex],用于表示获取页面地址时页面的页码. webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页的数据(新闻)采集传送到webpl图标细节webplus系统文章采集教程信息采集用户手册摘要信息采集 是一个功能模块,捕获网络数据,实现信息共享。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。和欢雪景涛君虎伯士座骆驼肢体壳修墨大步客汉铝优庄宅蛹佩芝卡陪嫁嫁妆入栏管理webplus系统文章采集教程资料采集用户手册 摘要 Information采集是采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。何欢,血,景涛,完成上海白金时间,堵骆驼四肢,炮弹,秀谋士,柯涵露,游庄家,蛹,裴志卡,陪潜嫌疑人结婚投掷(图一)webplus系统文章采集教程信息采集用户手册汇总信息采集是一个捕获网络数据,实现信息共享的功能模块,提供手动捕获、定时捕获三种模式和定时循环抓取。它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤和细节现在需要传输网页的数据(新闻)采集到webpl设置采集规划webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据并实现的功能模块信息共享。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。何欢,血,景涛,完成上海铂金,堵骆驼四肢,贝壳,节目策划人,柯涵,游庄家,蛹,裴志卡,陪潜嫌疑人及嫁妆。在右侧列列表中选择一列,单击以设置采集 计划。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节 现在需要手动将网页采集的数据(新闻)传输到webpl(需要点击列列表中的“立即采集”启动采集) webplus system 文章 采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在需要将一个网页采集的数据(新闻)传输到webpl一次(可以设置一个时间,到了时间会自动启动采集) webplus系统文章采集教程信息采集用户手册摘要信息采集是采集网络数据,实现信息共享的功能模块。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)传输到webpl单栏RSS(RSS地址下的文章)webplus系统文章采集@ >教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。 He Huan Xue Jing Tao Jun Hu Bo Shi Block Camel Limb Shell Xiu Mo Xing Shi Ke Han Al Youzhuang House Pupa Pei Zhika Accompanying Diving Multi-column RSS (starting from an RSS list address, 采集 under multiple RSS addresses 文章, each RSS address forms a sub-column) webplus system 文章采集Tutorial information采集User manual summary information采集It is a 采集 of network data, A functional module that realizes information sharing. It provides three modes: manual crawl, scheduled crawl and timed loop crawl. It can crawl information from a single news list, or crawl news information from multiple lists at the same time. Steps and details Now it is necessary to transfer the data (news) of a web page 采集 to the webpl coding method is the coding webplus system of the page by 采集文章采集Tutorial information采集@ >User Manual Summary Information采集 is a functional module that captures network data and realizes information sharing.
It provides three modes: manual crawl, scheduled crawl and timed cycle crawl. It can crawl information from a single news list, or it can fetch news information from multiple lists at the same time. Steps and details Now it is necessary to transfer the data (news) of a web page 采集 to webplu, dial Naishao, Xu Pudi, hate Meng Zhan, Qijiaosheng, lead the port official force, Huanxian Yirongyou, clean food, and train monk Shizuixiong. He Huan Xue Jing Tao Jun Shanghai Platinum Time Block Camel Limb Shell Xiu Miao Strider Ke Han Aluminum Youzhuang House Pupa Pei Zhika Accompanying Suspect Dowry Setting采集Rules webplus system文章采集 Tutorial Information采集User Manual Summary Information采集 is a functional module that captures network data and realizes information sharing. It provides three modes: manual crawl, scheduled crawl and timed loop crawl. It can crawl information from a single news list, or crawl news information from multiple lists at the same time. Steps and details Now it is necessary to transfer the data (news) of a web page 采集 to webplu, dial Naishao, Xu Pudi, hate Meng Zhan, Qijiaosheng, lead the port official force, Huanxian Yirongyou, clean food, and train monk Shizuixiong. He Huan, blood, Jingtao, completed Shanghai platinum, stopped camel limbs, shells, show strategists, Ke Hanlu, Youzhuang house, pupa, Pei Zhika, accompany the latent suspects to marry and throw.
采集文章系统(化工行业:塑料助剂产品结构升级中的投资机会!!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-03-04 08:14
化工行业:塑料助剂产品结构升级的投资机会!在制作网站fast收录和关键词rank之前,我们需要在制作网站fast收录之前了解百度蜘蛛。百度蜘蛛爬取不同站点的规则是: 不同的是,百度蜘蛛的爬取频率对于我们作为一个SEO公司来说非常重要网站。一般来说,以下因素对蜘蛛爬行有重要影响。
网站内容质量:如果网站内容原创质量高,可以处理用户问题,百度会提高爬取频率。
传入链接:链接是页面的导入,优质的链接可以更好的引导百度蜘蛛进入和抓取。
网站爬取的友好性 为了在网上爬取信息时获得越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。
合理使用百度蜘蛛抓取优先级 由于互联网信息量大,百度针对互联网信息抓取制定了多种优先抓取策略。目前的策略主要有:深度优先、广度优先、PR优先、反向链接优先、广度优先爬取的目的是爬取更多的URL,深度优先爬取的目的是爬取高质量的网页。这个策略是通过调度来计算和分配的。作弊信息的爬取在爬取页面时经常会遇到页面质量低、链接质量低等问题。百度引入了绿萝、石榴等算法进行过滤。听说还有一些其他的内部方法可以区分它们。这些方法没有外部泄漏。获取无法爬取的数据可能会导致互联网上的各种问题导致百度蜘蛛无法爬取信息。在这种情况下,百度已经开启了手动提交数据。今天教大家如何使用快速采集高质量文章Dede采集插件制作网站快速收录。
这个Dede采集插件不需要学习更专业的技术,只需要几个简单的步骤就可以轻松采集内容数据,用户只需要在Dede采集@上进行简单的设置> 插件,完成后 Dede采集 插件会根据用户设置的关键词 将内容和图片进行高精度匹配,可以选择保存在本地,也可以选择发布伪原创之后,提供方便快捷的内容采集伪原创发布服务!!
和其他Dede采集插件相比,这个Dede采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟就能上手并且只需输入关键词即可实现采集(Dede采集插件也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。这类Dede采集发布插件工具也配备了很多SEO功能,通过软件发布也可以提升很多SEO优化采集伪原创@ >。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、内容或标题插入,以及网站内容插入或随机作者、随机阅读等,形成一个“高原创”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!在做Dede网站收录之前,我们先明确以下几点,让网站fast收录更好。
这里所说的锚文本只是网站内页指向首页的锚文本。很多人认为,为了集中首页的权重,不管各种锚文本,都指向首页。事实上,这是不可取的。
首先,内页和首页相互竞争同一个关键词,这种情况经常发生。避免它的方法是优化每个页面的不同关键词。这就是长尾词的重要性。其次,内页与首页过于相似,通常是此刻出现的标签页。合理规划标签,正确使用标签,可以避免类似情况的发生。
主题不明确,用户不知道你的网站在做什么,也无法从你的网站中找到他的关注点,是否跳出率、采访时间等,这些数据是对 网站 本身不利。对于搜索引擎来说,看到你的网站内容参差不齐,什么都有,内容之间没有关联。内容与问题无关。垃圾箱。
很多站长在网站还没有上线的时候就开始优化自己的网站内容,上线后马上进行各种SEO优化,就像堆了很多关键词一样。,Mate标签重复连词,页面hub词密度太大,所有外链都指向首页,外链锚文字太简单,网站为了填满内容,大量采集文章 等,这些都是隐含的过度优化。
以上所有问题都可以通过Dede采集插件解决。注意一些小细节的设置,才能把网站收录做得更好。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天为你展示各种SEO经验,打通你的二线任命和主管! 查看全部
采集文章系统(化工行业:塑料助剂产品结构升级中的投资机会!!)
化工行业:塑料助剂产品结构升级的投资机会!在制作网站fast收录和关键词rank之前,我们需要在制作网站fast收录之前了解百度蜘蛛。百度蜘蛛爬取不同站点的规则是: 不同的是,百度蜘蛛的爬取频率对于我们作为一个SEO公司来说非常重要网站。一般来说,以下因素对蜘蛛爬行有重要影响。

网站内容质量:如果网站内容原创质量高,可以处理用户问题,百度会提高爬取频率。
传入链接:链接是页面的导入,优质的链接可以更好的引导百度蜘蛛进入和抓取。
网站爬取的友好性 为了在网上爬取信息时获得越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。
合理使用百度蜘蛛抓取优先级 由于互联网信息量大,百度针对互联网信息抓取制定了多种优先抓取策略。目前的策略主要有:深度优先、广度优先、PR优先、反向链接优先、广度优先爬取的目的是爬取更多的URL,深度优先爬取的目的是爬取高质量的网页。这个策略是通过调度来计算和分配的。作弊信息的爬取在爬取页面时经常会遇到页面质量低、链接质量低等问题。百度引入了绿萝、石榴等算法进行过滤。听说还有一些其他的内部方法可以区分它们。这些方法没有外部泄漏。获取无法爬取的数据可能会导致互联网上的各种问题导致百度蜘蛛无法爬取信息。在这种情况下,百度已经开启了手动提交数据。今天教大家如何使用快速采集高质量文章Dede采集插件制作网站快速收录。
这个Dede采集插件不需要学习更专业的技术,只需要几个简单的步骤就可以轻松采集内容数据,用户只需要在Dede采集@上进行简单的设置> 插件,完成后 Dede采集 插件会根据用户设置的关键词 将内容和图片进行高精度匹配,可以选择保存在本地,也可以选择发布伪原创之后,提供方便快捷的内容采集伪原创发布服务!!
和其他Dede采集插件相比,这个Dede采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟就能上手并且只需输入关键词即可实现采集(Dede采集插件也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。这类Dede采集发布插件工具也配备了很多SEO功能,通过软件发布也可以提升很多SEO优化采集伪原创@ >。

例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、内容或标题插入,以及网站内容插入或随机作者、随机阅读等,形成一个“高原创”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!在做Dede网站收录之前,我们先明确以下几点,让网站fast收录更好。
这里所说的锚文本只是网站内页指向首页的锚文本。很多人认为,为了集中首页的权重,不管各种锚文本,都指向首页。事实上,这是不可取的。
首先,内页和首页相互竞争同一个关键词,这种情况经常发生。避免它的方法是优化每个页面的不同关键词。这就是长尾词的重要性。其次,内页与首页过于相似,通常是此刻出现的标签页。合理规划标签,正确使用标签,可以避免类似情况的发生。
主题不明确,用户不知道你的网站在做什么,也无法从你的网站中找到他的关注点,是否跳出率、采访时间等,这些数据是对 网站 本身不利。对于搜索引擎来说,看到你的网站内容参差不齐,什么都有,内容之间没有关联。内容与问题无关。垃圾箱。
很多站长在网站还没有上线的时候就开始优化自己的网站内容,上线后马上进行各种SEO优化,就像堆了很多关键词一样。,Mate标签重复连词,页面hub词密度太大,所有外链都指向首页,外链锚文字太简单,网站为了填满内容,大量采集文章 等,这些都是隐含的过度优化。
以上所有问题都可以通过Dede采集插件解决。注意一些小细节的设置,才能把网站收录做得更好。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天为你展示各种SEO经验,打通你的二线任命和主管!
采集文章系统(电脑浏览器收集微信文章的计划方案有什么吗?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-03-02 14:19
微信公众平台发布的文章内容,大部分被他人采集。你们知道电脑浏览器收微信文章的打算吗?是的,采集 系统的组成是什么?今天就让我用拓图数据信息来了解一下。
电脑浏览器采集微信的方案文章
方案一:根据搜狗搜索频道
从微信文章采集到的可以在网上检索到的信息内容来看,似乎是数量最多、最直接、最简单的方案。
电脑浏览器采集微信文章
一般步骤是:
搜狗微信搜索频道进行公众号搜索
选择微信公众号进入公众号历史时间列表文章
对文章进库进行分析
如果采集太多,经常拿字,浏览搜狗和微信公众号历史时间文章列表时会出现短信验证码。使用通用脚本系统无法立即获取短信验证码。这里可以使用无头浏览器浏览,根据连接和编码平台识别短信验证码。Selenium 对于无头浏览器是可选的。
即使选择了无头浏览器,也存在同样的问题:
低效(实际上是运行详细的电脑浏览器来模拟人们实际所做的事情)
网页资源无法通过计算机浏览器加载进行操作,脚本在计算机浏览器加载时难以操作
验证码识别不能保证100%,爬步很可能会中途断掉。
如果坚持使用搜狗搜索频道,想要发展极致网络,只能提升代理IP。对了,不要想着发布一个完全免费的IP地址,很不稳定,基本都被微信屏蔽了。
除了遇到搜狗搜索/手机微信的反爬虫系统,选择这个方案还有其他缺陷:
重要的信息内容,没有获得点击、关注等来评估 文章 内容的质量
没有办法立即获取已经公布的微信文章,只能按时重复爬取
只获取最近十条群消息的内容文章
方案二:Web微信抓包软件分析
被手机微信反爬虫虐了半天,同事们绞尽脑汁在寻找新的微信公众平台文章内容抓包方案。只分析哪些渠道可以获取数据信息。我还依稀记得网络上的微信是给微信文章阅读文章的。刚好我玩过我的微信机器人,关键的应用是Python包ItChat。其完成的基本原理是对web微信进行抓包软件分析,总结为人机微信界面。总体目标是完成网络微信所能完成的所有功能。. 因此,有一个基本的计划——根据ItChat,微信公众平台文章的内容可以推回。正要下班的时候,我的同事提到了它,他很感兴趣。第二天就完成了认证代码(ItChat完成的相关动作代码非常简洁明了,内容分析部分之前做过,马上就可以用了)。
此类计划的关键步骤是:
服务器根据ItChat登录网页微信
当微信公众号宣布推送新的文章内容消息时,会被服务器捕获用于事后分析,并存储在数据库中。
这种计划的优点是:
基本零间距获取已公布的微信文章
获得关注者和点击
保持微信登录即可,无需其他实际操作
也有天生的缺陷:
必须在长期连接互联网的手机上
微信无法主动退出,或长时间断开连接
采集系统由以下部分组成:
1、pc版微信:可以是安装了手机微信应用的手机,也可以是电脑中的手机模拟器。经过微信ios PC版评测,批处理采集的全过程崩溃率高于安卓手机系统。为了更好地控制成本,我使用了手机模拟器。
2、手机微信账号:为了更好的采集内容,不仅需要PC版微信,还需要手机微信账号进行专业采集。因为这个微信账号,其他的事情都做不了。
3、本地服务器代理系统软件:目前的申请方式是根据Anyproxy服务器代理将微信公众号历史时间信息网页中的文章列表发送到自己的网络服务器上。后面会详细说明实际的安装和设置方法。
电脑浏览器采集微信文章
4、文章列表分析和存储系统软件:我用php语言写的。后面我会详细讲解如何分析文章列表,创建集合序列来完成批次采集的内容。
看完我上面对拓图数据资料的详细介绍,相信大家对电脑浏览器收微信文章的方案和采集系统的组成都有一定的了解。微信公众平台需要经常发布一些文章内容,应用采集系统进行采集可以省时省力。 查看全部
采集文章系统(电脑浏览器收集微信文章的计划方案有什么吗?(图))
微信公众平台发布的文章内容,大部分被他人采集。你们知道电脑浏览器收微信文章的打算吗?是的,采集 系统的组成是什么?今天就让我用拓图数据信息来了解一下。
电脑浏览器采集微信的方案文章
方案一:根据搜狗搜索频道
从微信文章采集到的可以在网上检索到的信息内容来看,似乎是数量最多、最直接、最简单的方案。

电脑浏览器采集微信文章
一般步骤是:
搜狗微信搜索频道进行公众号搜索
选择微信公众号进入公众号历史时间列表文章
对文章进库进行分析
如果采集太多,经常拿字,浏览搜狗和微信公众号历史时间文章列表时会出现短信验证码。使用通用脚本系统无法立即获取短信验证码。这里可以使用无头浏览器浏览,根据连接和编码平台识别短信验证码。Selenium 对于无头浏览器是可选的。
即使选择了无头浏览器,也存在同样的问题:
低效(实际上是运行详细的电脑浏览器来模拟人们实际所做的事情)
网页资源无法通过计算机浏览器加载进行操作,脚本在计算机浏览器加载时难以操作
验证码识别不能保证100%,爬步很可能会中途断掉。
如果坚持使用搜狗搜索频道,想要发展极致网络,只能提升代理IP。对了,不要想着发布一个完全免费的IP地址,很不稳定,基本都被微信屏蔽了。
除了遇到搜狗搜索/手机微信的反爬虫系统,选择这个方案还有其他缺陷:
重要的信息内容,没有获得点击、关注等来评估 文章 内容的质量
没有办法立即获取已经公布的微信文章,只能按时重复爬取
只获取最近十条群消息的内容文章
方案二:Web微信抓包软件分析
被手机微信反爬虫虐了半天,同事们绞尽脑汁在寻找新的微信公众平台文章内容抓包方案。只分析哪些渠道可以获取数据信息。我还依稀记得网络上的微信是给微信文章阅读文章的。刚好我玩过我的微信机器人,关键的应用是Python包ItChat。其完成的基本原理是对web微信进行抓包软件分析,总结为人机微信界面。总体目标是完成网络微信所能完成的所有功能。. 因此,有一个基本的计划——根据ItChat,微信公众平台文章的内容可以推回。正要下班的时候,我的同事提到了它,他很感兴趣。第二天就完成了认证代码(ItChat完成的相关动作代码非常简洁明了,内容分析部分之前做过,马上就可以用了)。
此类计划的关键步骤是:
服务器根据ItChat登录网页微信
当微信公众号宣布推送新的文章内容消息时,会被服务器捕获用于事后分析,并存储在数据库中。
这种计划的优点是:
基本零间距获取已公布的微信文章
获得关注者和点击
保持微信登录即可,无需其他实际操作
也有天生的缺陷:
必须在长期连接互联网的手机上
微信无法主动退出,或长时间断开连接
采集系统由以下部分组成:
1、pc版微信:可以是安装了手机微信应用的手机,也可以是电脑中的手机模拟器。经过微信ios PC版评测,批处理采集的全过程崩溃率高于安卓手机系统。为了更好地控制成本,我使用了手机模拟器。
2、手机微信账号:为了更好的采集内容,不仅需要PC版微信,还需要手机微信账号进行专业采集。因为这个微信账号,其他的事情都做不了。
3、本地服务器代理系统软件:目前的申请方式是根据Anyproxy服务器代理将微信公众号历史时间信息网页中的文章列表发送到自己的网络服务器上。后面会详细说明实际的安装和设置方法。

电脑浏览器采集微信文章
4、文章列表分析和存储系统软件:我用php语言写的。后面我会详细讲解如何分析文章列表,创建集合序列来完成批次采集的内容。
看完我上面对拓图数据资料的详细介绍,相信大家对电脑浏览器收微信文章的方案和采集系统的组成都有一定的了解。微信公众平台需要经常发布一些文章内容,应用采集系统进行采集可以省时省力。
采集文章系统(怎么用wordpress采集让网站快速收录以及关键词排名,相信做SEO的小伙伴)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-02-28 11:29
如何使用wordpress采集让网站快速收录和关键词排名,相信所有SEO朋友都知道网站优化是一个长期的过程,坚持不懈网站坚持更新和SEO优化技术。今天给大家讲解一下如何使用wordpress采集工具使网站自动更新以及优化不当导致网站不是收录的注意事项,以及不排名。
一、通过wordpress采集工具自动化网站优化过程
这个wordpress采集工具可以实现自动采集伪原创发布和主动推送到搜索引擎。操作简单,无需学习更多专业技能,简单几步即可轻松采集内容数据,用户只需在wordpress采集上进行简单设置,设置后wordpress会准确采集文章、 也会下降。因为搜索引擎喜欢抓取新鲜的内容,如果长时间不更新,蜘蛛就无法抓取新的内容,也不会来网站抓取,而且是自有意识的网站的权重或排名会下降。
6、会影响公司形象
如果公司的网站长时间不更新,会让人觉得网站不是任何人管理的,网站的信息是很久以前的了,而且客户很容易猜测公司是否消失了。,或停业。
二、网站No收录 和 网站 排名不佳的原因
1、网站tdk任意修改
相信有经验的seo优化师肯定不会犯这个错误,都是新手犯的错误。网站标题关键词描述必须经常修改。这是一个严重的问题。一般网站tdk是不修改的,尤其是新站是在百度评估期。如果修改后给百度留下不好的印象,优化起来会很困难。
2、网站的定位和关键词的设置
我们一定要选择网站的定位,和关键词的设置,不要堆叠,不要密集排列,关键词不要选择冷门。学会合理安排关键词。
3、关键词的选择和发布
选择关键词时,选择一些简单易优化的词,不要太流行。还有,关键词不宜发布过于密集,否则百度蜘蛛会判定关键词在爬取时积累,导致网站体验不佳,严重时网站会被降级, 等等。 。
4、文章更新和图解
现在信息时代的内容不是靠几张图就能解决的,需要图文并茂,而且文章的更新也要有规律,搜索引擎蜘蛛喜欢有规律的东西,你可以每天都做更新文章,这样很容易赢得搜索引擎的芳心,那么网站在百度上排名也不是难事。
5、加盟链不易过多,换不正当的好友链也不易
友链一般设置在30左右,友链的质量也需要注意。兑换时需要查看对方的快照、收录的状态和网站的排名位置,以减少不必要的麻烦,做站的原则是与做人的原则相同。你必须有道德。如果在交换友情链接时,详细查看对方网站的基本信息,查看快照时间,网站采集的信息,网站的排名位置, other 网站 是k还是降级等
6、设置阻止搜索引擎蜘蛛爬行
我相信很多程序员都知道 robots.txt 文件,这是一个告诉搜索引擎蜘蛛不要抓取的设置文件。当搜索引擎蜘蛛第一次访问我们的网站时,由于个人错误,他们将robots.txt文件设置为不抓取整个文件。这样的错误会对网站造成很大的伤害,并使网站的内容无法被百度收录搜索到。
以上就是博主带来的一些关于SEO优化的实用技巧。如果您需要更多SEO优化技巧,请继续关注我,每周不定期更新SEO实用技巧! 查看全部
采集文章系统(怎么用wordpress采集让网站快速收录以及关键词排名,相信做SEO的小伙伴)
如何使用wordpress采集让网站快速收录和关键词排名,相信所有SEO朋友都知道网站优化是一个长期的过程,坚持不懈网站坚持更新和SEO优化技术。今天给大家讲解一下如何使用wordpress采集工具使网站自动更新以及优化不当导致网站不是收录的注意事项,以及不排名。
一、通过wordpress采集工具自动化网站优化过程
这个wordpress采集工具可以实现自动采集伪原创发布和主动推送到搜索引擎。操作简单,无需学习更多专业技能,简单几步即可轻松采集内容数据,用户只需在wordpress采集上进行简单设置,设置后wordpress会准确采集文章、 也会下降。因为搜索引擎喜欢抓取新鲜的内容,如果长时间不更新,蜘蛛就无法抓取新的内容,也不会来网站抓取,而且是自有意识的网站的权重或排名会下降。
6、会影响公司形象
如果公司的网站长时间不更新,会让人觉得网站不是任何人管理的,网站的信息是很久以前的了,而且客户很容易猜测公司是否消失了。,或停业。
二、网站No收录 和 网站 排名不佳的原因
1、网站tdk任意修改
相信有经验的seo优化师肯定不会犯这个错误,都是新手犯的错误。网站标题关键词描述必须经常修改。这是一个严重的问题。一般网站tdk是不修改的,尤其是新站是在百度评估期。如果修改后给百度留下不好的印象,优化起来会很困难。
2、网站的定位和关键词的设置
我们一定要选择网站的定位,和关键词的设置,不要堆叠,不要密集排列,关键词不要选择冷门。学会合理安排关键词。
3、关键词的选择和发布
选择关键词时,选择一些简单易优化的词,不要太流行。还有,关键词不宜发布过于密集,否则百度蜘蛛会判定关键词在爬取时积累,导致网站体验不佳,严重时网站会被降级, 等等。 。
4、文章更新和图解
现在信息时代的内容不是靠几张图就能解决的,需要图文并茂,而且文章的更新也要有规律,搜索引擎蜘蛛喜欢有规律的东西,你可以每天都做更新文章,这样很容易赢得搜索引擎的芳心,那么网站在百度上排名也不是难事。
5、加盟链不易过多,换不正当的好友链也不易
友链一般设置在30左右,友链的质量也需要注意。兑换时需要查看对方的快照、收录的状态和网站的排名位置,以减少不必要的麻烦,做站的原则是与做人的原则相同。你必须有道德。如果在交换友情链接时,详细查看对方网站的基本信息,查看快照时间,网站采集的信息,网站的排名位置, other 网站 是k还是降级等
6、设置阻止搜索引擎蜘蛛爬行
我相信很多程序员都知道 robots.txt 文件,这是一个告诉搜索引擎蜘蛛不要抓取的设置文件。当搜索引擎蜘蛛第一次访问我们的网站时,由于个人错误,他们将robots.txt文件设置为不抓取整个文件。这样的错误会对网站造成很大的伤害,并使网站的内容无法被百度收录搜索到。
以上就是博主带来的一些关于SEO优化的实用技巧。如果您需要更多SEO优化技巧,请继续关注我,每周不定期更新SEO实用技巧!
采集文章系统(可定制词云标签自动导入热词,自动设置标签)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-26 23:02
采集文章系统文章内容,可定制。提取文章标题,描述,链接,设置热词。可定制词云标签自动导入热词,自动设置标签。文本相似度挖掘,可设置合理的相似度配比。
4)){for(jinrange(1,
2)){//聚类分析group=groups[i]*sum(i+j)//按自动分组的不同元素的个数//每个数据集元素的个数指定聚类的个数y[i][j]=round(abs(group),abs(groups[i][j]))}}修改代码和爬虫效果:代码:爬虫效果图:热词挖掘:热词挖掘效果图:
采集。提取tag。
先采到指定的wordpress页面再设置字体图片什么的text标签也可以不要啊
采集的话,用app采,很简单的。
这种导入数据是有问题的,比如一个名为submittitle/version-303的例子。
0)==0typeobjecttypetext1text2text3text4text5text6text7text8text9text10text11text12text13text14text15text16text17text18text19text20text21text22text23text24text25text26text27text28text29text30text31text32text33text34text35text36text37text38text39text40text41text42text43text44text45text46text47text48text49text50text51text52text53text54text55text56text57text58text59text60text61text62text63text64text65text66text67text68text69text70text71text72text73text74text75text76text77text78text79text80text81text82text83text84text85text86text87text88text889text899text90text91text92text93text94text946text95text96text97text98text99text981text992text993text9930text994text995text996text997text998text9986text9988text9989text99880text99891text99892text99894text998942text998952text998955text998956text99895。 查看全部
采集文章系统(可定制词云标签自动导入热词,自动设置标签)
采集文章系统文章内容,可定制。提取文章标题,描述,链接,设置热词。可定制词云标签自动导入热词,自动设置标签。文本相似度挖掘,可设置合理的相似度配比。
4)){for(jinrange(1,
2)){//聚类分析group=groups[i]*sum(i+j)//按自动分组的不同元素的个数//每个数据集元素的个数指定聚类的个数y[i][j]=round(abs(group),abs(groups[i][j]))}}修改代码和爬虫效果:代码:爬虫效果图:热词挖掘:热词挖掘效果图:
采集。提取tag。
先采到指定的wordpress页面再设置字体图片什么的text标签也可以不要啊
采集的话,用app采,很简单的。
这种导入数据是有问题的,比如一个名为submittitle/version-303的例子。
0)==0typeobjecttypetext1text2text3text4text5text6text7text8text9text10text11text12text13text14text15text16text17text18text19text20text21text22text23text24text25text26text27text28text29text30text31text32text33text34text35text36text37text38text39text40text41text42text43text44text45text46text47text48text49text50text51text52text53text54text55text56text57text58text59text60text61text62text63text64text65text66text67text68text69text70text71text72text73text74text75text76text77text78text79text80text81text82text83text84text85text86text87text88text889text899text90text91text92text93text94text946text95text96text97text98text99text981text992text993text9930text994text995text996text997text998text9986text9988text9989text99880text99891text99892text99894text998942text998952text998955text998956text99895。
采集文章系统(这是关于变更数据采集(CDC)系列的第二部分。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2022-02-20 19:08
这是有关更改数据采集 (CDC) 的系列文章的第二部分。在这个 文章 中,让我们讨论 CDC 用例,看看有哪些工具可以帮助您将 CDC 添加到您的架构中。
更改数据采集 促进了事件驱动的应用程序架构。它允许应用程序侦听数据库、数据仓库等中的变化并根据这些变化采取行动。
概括地说,以下是对数据更改采取行动所产生的用例和架构。
让我们探索一下。
提取、转换、加载
到目前为止,CDC 最常见的用例之一是提取、转换、加载 (ETL)。ETL 是一个从源获取数据(提取)、以某种方式对其进行处理(转换)并将其发送到目标(加载)的过程。
数据复制(一次性同步)和镜像(连续复制)是 ETL 过程的好例子。ETL 是一个涵盖非常不同的用例的总称,例如:.
CDC 不仅可以帮助解决这些用例,而且还是解决这些问题的最佳方式。例如,为了将数据镜像到数据仓库,您必须捕获发生的任何更改并将其应用于源数据库。正如本系列第 1 部分讨论的流复制日志系列的第 1 部分中所讨论的,数据库使用 CDC 来使备用实例保持最新以进行故障转移,因为它高效且可扩展。在更广泛的架构中挖掘这些事件时,您的数据仓库可以与备用数据库实例一样保持最新,以进行灾难恢复。
保持缓存和搜索索引系统更新也是 ETL 问题和 CDC 的一个很好的用例。今天创建的大型应用程序由许多不同的数据存储组成。例如,一些架构利用 Postgres、Redis 和 Elasticsearch 作为关系数据库、缓存层和搜索引擎。所有这些都是为特定数据用例设计的记录系统,但数据需要在每个存储中进行镜像。
您永远不希望用户搜索产品并发现它不再存在。陈旧的缓存和搜索索引会导致糟糕的用户体验。CDC 可用于构建数据管道,使这些存储与其上游依赖项保持同步。
理论上,一个应用程序可以同时向 Postgres、Redis 和 Elasticsearch 写入数据,但是“双写入”的管理很困难,并且可能导致系统不同步。CDC 提供了更健壮且更易于维护的实现。与其将更新索引和缓存的逻辑添加到单个单体应用程序中,不如创建一个事件驱动的微服务,该微服务可以独立于面向用户的系统进行构建、维护、改进和部署。该微服务保持索引和缓存更新,以确保用户操作最相关的数据。
集成和自动化
SaaS 的兴起导致生成数据或需要更新数据的工具数量激增。CDC 可以提供更好的模型来保持 Salesforce、Hubspot 等的更新,并允许需要响应这些数据变化的业务逻辑自动化。
我们上面描述的每个用例都将数据发送到特定的目的地。但是,最强大的目的地是具有云功能的目的地。捕获数据更改和触发云功能可用于执行本文中提到(或未提及)的每个用例。
由于无需维护服务器,云功能大幅增长;它们自动扩展,易于使用和部署。这种流行性和实用性在 JAMStack 等架构中得到了清晰的证明。CDC 非常适合这种架构模式。
今天,云功能是由事件触发的。此事件可能发生在文件上传到 Amazon S3 或 HTTP 请求时。但是,正如您可能已经猜到的那样,这个触发事件可能是由 CDC 系统发出的。
例如,这是一个 AWS Lambda 函数,它接受数据更改事件并索引 Algolia 的搜索数据:
const algoliasearch = require("algoliasearch");
const client = algoliasearch(process.env.ALGOLIA_APP_ID, process.env.ALGOLIA_API_KEY);
const index = client.initIndex(process.env.ALGOLIA_INDEX_NAME);
exports.handler = async function(event, context) {
console.log("EVENT: \\n" + JSON.stringify(event, null, 2))
const request = event.Records[0].cf.request;
// Accessing the Data Record
//
const body = Buffer.from(request.body.data, 'base64').toString();
const { schema, payload } = body;
const { before, after, source, op } = payload;
if (req.method === 'POST') {
try {
// if read, create, or update operation create o update index
if (op === 'r' || op === 'c' || op === 'u') {
console.log(`operation: ${op}, id: ${after.id}`)
after.objectID = after.id
await index.saveObject(after)
} else if (op === 'd') {
console.log(`operation: d, id: ${before.id}`)
await index.deleteObject(before.id)
}
return res.status(200).send()
} catch (error) {
console.log(`error: ${JSON.stringify(error)}`)
return res.status(500).send()
}
}
return context.logStreamName
}
每次触发这个函数,它都会查看数据变化(op),并在 Algolia 中执行相应的动作。例如,如果数据库发生了删除操作,我们可以在 Algolia 中执行一个 deleteObject。
响应 CDC 事件的函数可以小而简单。但是,CDC 以及基于事件的架构也可以简化原本非常复杂的架构。
例如,在应用程序中实现 Webhook 的功能成为 CDC 中更紧迫的问题。Webhook 允许用户在某些事件发生时触发 POST 请求,通常是数据更改。例如,使用 Github,您可以在合并拉取请求时触发云功能。合并的拉取请求是对数据存储的 UPDATE 操作,这意味着 CDC 系统可以捕获此事件。一般来说,大多数 webhook 事件都可以转换为 CDC 系统可以捕获的 INSERT UPDATE 和 DELETE 操作。
历史
在某些情况下,您可能不想对 CDC 事件采取行动,而只想存储原创更改。使用 CDC,数据管道可以将所有更改事件存储到云存储桶中,以进行长期处理和分析。存储用于历史分析的数据的最佳位置是在云存储桶中,称为数据湖。
数据湖是一个集中式存储,可让您以任意规模存储所有结构化和非结构化数据。数据湖通常使用云对象存储桶解决方案,例如 Amazon S3 或 Digital Ocean Spaces。
例如,一旦数据进入数据湖,Amazon Presto 等 SQL 查询引擎就可以针对不断变化的数据集运行分析查询。
在存储原创更改时,您不仅拥有数据的当前状态,还拥有所有以前的状态(历史)。这就是 CDC 为历史分析增加很多价值的原因。
拥有历史数据可以让您支持灾难恢复工作,还可以让您回答有关数据的回顾性问题。例如,假设您的团队重新定义了每月活跃用户 (MAU) 的计算方式。借助用户数据集的完整历史记录,可以根据过去的任何日期进行新的 MAU 计算,并将结果与当前状态进行比较。
这种丰富的历史也具有面向用户的价值。审核日志和活动日志是向用户显示数据更改的功能。
捕获和存储更改事件为实现这些功能提供了更好的框架。与 webhook 一样,审计日志和活动日志都源于可被 CDC 系统捕获的操作。
警报
任何警报系统的工作都是将事件通知利益相关者。例如,当您收到新的电子邮件通知时,系统会通知您对电子邮件数据存储的 INSERT 操作。通常,大多数警报都与数据存储的变化有关,这意味着 CDC 非常适合电力警报系统。
例如,假设您有一家电子商务商店。在采购表上启用 CDC 后,您可以捕获更改事件并通过在进行新采购时执行 Slack 警报来通知团队。
就像审计或活动日志一样,CDC 提供的通知不仅提供有关发生情况的信息,还提供有关更改本身的详细信息。
Tom 将标题从“会议纪要”更新为“我的新会议”。
这种警报行为也具有内在价值。从基础设施监控的角度来看,CDC 事件可以深入了解用户如何与您的应用程序和数据进行交互。例如,您可以查看用户添加、更新或删除信息的时间和方式。可以将此数据发送到 Prometheus UI 以监控此信息并采取措施。
开始使用 CDC
在第一部分中,我们讨论了 CDC 的各种常见实现。
这些都可以用来构建我们在本文中讨论的用例。最重要的是,由于 CDC 专注于数据,因此该过程与编程语言无关,并且可以集成到大多数架构中。
轮询和触发器
使用轮询或数据库触发器时,没有开销,也不需要安装。您可以从构建查询开始,以轮询或利用数据库的触发器(如果支持)。
流日志处理
数据库使用流复制日志进行备份和恢复,这意味着大多数数据库提供了一些开箱即用的 CDC 行为。挖掘这些事件的难易程度取决于数据存储本身。最好的起点是深入研究数据库的复制功能。下面是一些最流行的数据库的复制日志资源。
要开始使用流式日志记录,答案与相关数据库相关联。在未来文章,我将探索每种情况的样子。
直接实施任何这些确实需要一些时间、计划和努力。如果您想开始使用 CDC,最低门槛是采用知道如何从您使用的数据存储中进行通信和捕获更改的 CDC 工具。
更改数据采集工具
这里有一些很棒的工具供您评估。
地比西
Debezium 是迄今为止最受欢迎的 CDC 工具。它维护良好、开源,并建立在 Apache Kafka 之上。它支持 MongoDB、MySQL、PostgreSQL 和更多开箱即用的数据库。
在高层次上,Debezium 使用 Hook 数据库的复制日志并将更改事件发送到 Kafka。你甚至可以在没有 Kafka 的情况下独立运行 Debezium。
真正的好处是 Debezium 都是基于配置的。安装和配置 Debezium 后,您可以使用基于 JSON 的配置来配置与数据存储的连接。
{
"name": "fulfillment-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "192.168.99.100",
"database.port": "5432",
"database.user": "postgres",
"database.password": "postgres",
"database.dbname" : "postgres",
"database.server.name": "fulfillment",
"table.include.list": "public.inventory"
}
}
连接后,Debezium 会对您的数据进行初始快照,并将更改事件发送到 Kafka 主题。然后服务可以使用主题并对其采取行动。
这里有一些开始使用 Debeizium 的好地方。
梅罗沙
Meroxa 是一个实时数据协调平台,可为您提供实时基础架构。Meroxa 消除了与配置和管理代理、连接器、转换、功能和流式基础设施相关的时间和开销。您所要做的就是添加资源并构建管道。Meroxa 支持 PostgreSQL、MongoDB、SQL Server 等。
可以在 Visual Dashboard 中或使用 Meroxa CLI 建立 CDC 管道:
# Add Resource
$ meroxa resource add my-postgres --type postgres -u postgres://$PG_USER:$PG_PASS@$PG_URL:$PG_PORT/$PG_DB
# Add Webhook
$ meroxa resource add my-url --type url -u $CUSTOM_HTTP_URL
# Create CDC Pipeline
$ meroxa connect --from my-postgres --input $TABLE_NAME --to my-url
上面的用例有更详细的介绍。
有一些很好的资源可以帮助您开始使用 Meroxa。
我迫不及待地想看看你建造了什么。 查看全部
采集文章系统(这是关于变更数据采集(CDC)系列的第二部分。)
这是有关更改数据采集 (CDC) 的系列文章的第二部分。在这个 文章 中,让我们讨论 CDC 用例,看看有哪些工具可以帮助您将 CDC 添加到您的架构中。
更改数据采集 促进了事件驱动的应用程序架构。它允许应用程序侦听数据库、数据仓库等中的变化并根据这些变化采取行动。
概括地说,以下是对数据更改采取行动所产生的用例和架构。
让我们探索一下。
提取、转换、加载
到目前为止,CDC 最常见的用例之一是提取、转换、加载 (ETL)。ETL 是一个从源获取数据(提取)、以某种方式对其进行处理(转换)并将其发送到目标(加载)的过程。
数据复制(一次性同步)和镜像(连续复制)是 ETL 过程的好例子。ETL 是一个涵盖非常不同的用例的总称,例如:.
CDC 不仅可以帮助解决这些用例,而且还是解决这些问题的最佳方式。例如,为了将数据镜像到数据仓库,您必须捕获发生的任何更改并将其应用于源数据库。正如本系列第 1 部分讨论的流复制日志系列的第 1 部分中所讨论的,数据库使用 CDC 来使备用实例保持最新以进行故障转移,因为它高效且可扩展。在更广泛的架构中挖掘这些事件时,您的数据仓库可以与备用数据库实例一样保持最新,以进行灾难恢复。
保持缓存和搜索索引系统更新也是 ETL 问题和 CDC 的一个很好的用例。今天创建的大型应用程序由许多不同的数据存储组成。例如,一些架构利用 Postgres、Redis 和 Elasticsearch 作为关系数据库、缓存层和搜索引擎。所有这些都是为特定数据用例设计的记录系统,但数据需要在每个存储中进行镜像。
您永远不希望用户搜索产品并发现它不再存在。陈旧的缓存和搜索索引会导致糟糕的用户体验。CDC 可用于构建数据管道,使这些存储与其上游依赖项保持同步。
理论上,一个应用程序可以同时向 Postgres、Redis 和 Elasticsearch 写入数据,但是“双写入”的管理很困难,并且可能导致系统不同步。CDC 提供了更健壮且更易于维护的实现。与其将更新索引和缓存的逻辑添加到单个单体应用程序中,不如创建一个事件驱动的微服务,该微服务可以独立于面向用户的系统进行构建、维护、改进和部署。该微服务保持索引和缓存更新,以确保用户操作最相关的数据。
集成和自动化
SaaS 的兴起导致生成数据或需要更新数据的工具数量激增。CDC 可以提供更好的模型来保持 Salesforce、Hubspot 等的更新,并允许需要响应这些数据变化的业务逻辑自动化。
我们上面描述的每个用例都将数据发送到特定的目的地。但是,最强大的目的地是具有云功能的目的地。捕获数据更改和触发云功能可用于执行本文中提到(或未提及)的每个用例。
由于无需维护服务器,云功能大幅增长;它们自动扩展,易于使用和部署。这种流行性和实用性在 JAMStack 等架构中得到了清晰的证明。CDC 非常适合这种架构模式。
今天,云功能是由事件触发的。此事件可能发生在文件上传到 Amazon S3 或 HTTP 请求时。但是,正如您可能已经猜到的那样,这个触发事件可能是由 CDC 系统发出的。
例如,这是一个 AWS Lambda 函数,它接受数据更改事件并索引 Algolia 的搜索数据:
const algoliasearch = require("algoliasearch");
const client = algoliasearch(process.env.ALGOLIA_APP_ID, process.env.ALGOLIA_API_KEY);
const index = client.initIndex(process.env.ALGOLIA_INDEX_NAME);
exports.handler = async function(event, context) {
console.log("EVENT: \\n" + JSON.stringify(event, null, 2))
const request = event.Records[0].cf.request;
// Accessing the Data Record
//
const body = Buffer.from(request.body.data, 'base64').toString();
const { schema, payload } = body;
const { before, after, source, op } = payload;
if (req.method === 'POST') {
try {
// if read, create, or update operation create o update index
if (op === 'r' || op === 'c' || op === 'u') {
console.log(`operation: ${op}, id: ${after.id}`)
after.objectID = after.id
await index.saveObject(after)
} else if (op === 'd') {
console.log(`operation: d, id: ${before.id}`)
await index.deleteObject(before.id)
}
return res.status(200).send()
} catch (error) {
console.log(`error: ${JSON.stringify(error)}`)
return res.status(500).send()
}
}
return context.logStreamName
}
每次触发这个函数,它都会查看数据变化(op),并在 Algolia 中执行相应的动作。例如,如果数据库发生了删除操作,我们可以在 Algolia 中执行一个 deleteObject。
响应 CDC 事件的函数可以小而简单。但是,CDC 以及基于事件的架构也可以简化原本非常复杂的架构。
例如,在应用程序中实现 Webhook 的功能成为 CDC 中更紧迫的问题。Webhook 允许用户在某些事件发生时触发 POST 请求,通常是数据更改。例如,使用 Github,您可以在合并拉取请求时触发云功能。合并的拉取请求是对数据存储的 UPDATE 操作,这意味着 CDC 系统可以捕获此事件。一般来说,大多数 webhook 事件都可以转换为 CDC 系统可以捕获的 INSERT UPDATE 和 DELETE 操作。
历史
在某些情况下,您可能不想对 CDC 事件采取行动,而只想存储原创更改。使用 CDC,数据管道可以将所有更改事件存储到云存储桶中,以进行长期处理和分析。存储用于历史分析的数据的最佳位置是在云存储桶中,称为数据湖。
数据湖是一个集中式存储,可让您以任意规模存储所有结构化和非结构化数据。数据湖通常使用云对象存储桶解决方案,例如 Amazon S3 或 Digital Ocean Spaces。
例如,一旦数据进入数据湖,Amazon Presto 等 SQL 查询引擎就可以针对不断变化的数据集运行分析查询。
在存储原创更改时,您不仅拥有数据的当前状态,还拥有所有以前的状态(历史)。这就是 CDC 为历史分析增加很多价值的原因。
拥有历史数据可以让您支持灾难恢复工作,还可以让您回答有关数据的回顾性问题。例如,假设您的团队重新定义了每月活跃用户 (MAU) 的计算方式。借助用户数据集的完整历史记录,可以根据过去的任何日期进行新的 MAU 计算,并将结果与当前状态进行比较。
这种丰富的历史也具有面向用户的价值。审核日志和活动日志是向用户显示数据更改的功能。
捕获和存储更改事件为实现这些功能提供了更好的框架。与 webhook 一样,审计日志和活动日志都源于可被 CDC 系统捕获的操作。
警报
任何警报系统的工作都是将事件通知利益相关者。例如,当您收到新的电子邮件通知时,系统会通知您对电子邮件数据存储的 INSERT 操作。通常,大多数警报都与数据存储的变化有关,这意味着 CDC 非常适合电力警报系统。
例如,假设您有一家电子商务商店。在采购表上启用 CDC 后,您可以捕获更改事件并通过在进行新采购时执行 Slack 警报来通知团队。
就像审计或活动日志一样,CDC 提供的通知不仅提供有关发生情况的信息,还提供有关更改本身的详细信息。
Tom 将标题从“会议纪要”更新为“我的新会议”。
这种警报行为也具有内在价值。从基础设施监控的角度来看,CDC 事件可以深入了解用户如何与您的应用程序和数据进行交互。例如,您可以查看用户添加、更新或删除信息的时间和方式。可以将此数据发送到 Prometheus UI 以监控此信息并采取措施。
开始使用 CDC
在第一部分中,我们讨论了 CDC 的各种常见实现。
这些都可以用来构建我们在本文中讨论的用例。最重要的是,由于 CDC 专注于数据,因此该过程与编程语言无关,并且可以集成到大多数架构中。
轮询和触发器
使用轮询或数据库触发器时,没有开销,也不需要安装。您可以从构建查询开始,以轮询或利用数据库的触发器(如果支持)。
流日志处理
数据库使用流复制日志进行备份和恢复,这意味着大多数数据库提供了一些开箱即用的 CDC 行为。挖掘这些事件的难易程度取决于数据存储本身。最好的起点是深入研究数据库的复制功能。下面是一些最流行的数据库的复制日志资源。
要开始使用流式日志记录,答案与相关数据库相关联。在未来文章,我将探索每种情况的样子。
直接实施任何这些确实需要一些时间、计划和努力。如果您想开始使用 CDC,最低门槛是采用知道如何从您使用的数据存储中进行通信和捕获更改的 CDC 工具。
更改数据采集工具
这里有一些很棒的工具供您评估。
地比西
Debezium 是迄今为止最受欢迎的 CDC 工具。它维护良好、开源,并建立在 Apache Kafka 之上。它支持 MongoDB、MySQL、PostgreSQL 和更多开箱即用的数据库。
在高层次上,Debezium 使用 Hook 数据库的复制日志并将更改事件发送到 Kafka。你甚至可以在没有 Kafka 的情况下独立运行 Debezium。
真正的好处是 Debezium 都是基于配置的。安装和配置 Debezium 后,您可以使用基于 JSON 的配置来配置与数据存储的连接。
{
"name": "fulfillment-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "192.168.99.100",
"database.port": "5432",
"database.user": "postgres",
"database.password": "postgres",
"database.dbname" : "postgres",
"database.server.name": "fulfillment",
"table.include.list": "public.inventory"
}
}
连接后,Debezium 会对您的数据进行初始快照,并将更改事件发送到 Kafka 主题。然后服务可以使用主题并对其采取行动。
这里有一些开始使用 Debeizium 的好地方。
梅罗沙
Meroxa 是一个实时数据协调平台,可为您提供实时基础架构。Meroxa 消除了与配置和管理代理、连接器、转换、功能和流式基础设施相关的时间和开销。您所要做的就是添加资源并构建管道。Meroxa 支持 PostgreSQL、MongoDB、SQL Server 等。
可以在 Visual Dashboard 中或使用 Meroxa CLI 建立 CDC 管道:
# Add Resource
$ meroxa resource add my-postgres --type postgres -u postgres://$PG_USER:$PG_PASS@$PG_URL:$PG_PORT/$PG_DB
# Add Webhook
$ meroxa resource add my-url --type url -u $CUSTOM_HTTP_URL
# Create CDC Pipeline
$ meroxa connect --from my-postgres --input $TABLE_NAME --to my-url
上面的用例有更详细的介绍。
有一些很好的资源可以帮助您开始使用 Meroxa。
我迫不及待地想看看你建造了什么。
采集文章系统(文章采集功能演示(一)(2)_国内] )
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2022-02-19 06:06
)
一、简介
文章的采集的作用是通过程序远程获取目标网页的内容,解析处理本地规则后存入服务器的数据库中。
文章采集系统颠覆了传统的采集模式和流程,采集规则与采集界面分离,规则设置更简单,只需需要具备基本技术知识的人制定相关规则。
编辑们不需要了解太详细的技术规则,只需选择自己想要的文章列表采集,就可以像发布文章一样轻松完成数据采集 @> 操作。
二、功能演示
一、采集流程简单,分三步:1、添加采集点,填写采集规则。2、采集网站,采集内容3、将内容发布到指定栏目
以采集新浪新闻()为例介绍详细流程。
示例说明: 目的:采集新浪新闻将被添加到V9系统的“国内”栏目。目标网址:添加采集dots2.网址规则配置
1. 添加采集 点,填写采集 规则
A. 内容规则
注:上图中的“目标网页源代码”是指:目标网页的源代码。具体步骤如下:
目标网页->右键->查看源代码->找到你要采集的源代码的开始和结束,按照“上图”填写规则。
添加成功后,测试你的URL采集规则是否正确,如下图所示:
B. 内容规则配置
为了解释方便,我们只写了采集title和content字段。
采集内容网址:采集的内容采集规则,请打开该网址,然后在页面空白处右键->查看源文件搜索标题和开始边界内容。
标题采集配置:从网页中获取标题并删除不需要的字符。如下所示
内容采集 配置:新浪新闻最后一页,新闻内容夹在中间,这两个节点在整个页面源码中是唯一的。因此,您可以将此作为规则来获取内容。并过滤内容。如下所示
C. 自定义规则
除了系统自带的规则外,您还可以根据自己的需要自定义规则采集。操作和系统规则相同,如下图:
D. 高级配置
可以设置是否下载图片到服务器、是否打印水印等配置。如下所示:
2. 采集管理
添加采集点并测试成功后,您可以管理您添加的采集点(采集 URL、采集内容、内容发布、测试、修改、复制、导出)。如下所示:
A.采集网址
采集采集 点的 URL。
B. 采集内容
采集采集 点内容。
C. 内容发布
将 采集 的内容发布到指定版块。如下所示:
单击“导入”以跳转到“选择列”页面。如下所示:
点击“提交”跳转到栏目配置设置页面。如下所示:
提交成功后,采集的内容会被导入到指定的列(如下图)。在此期间请耐心等待,完成后会自动转动。至此,一个简单的采集流程就完成了。您的 采集 的内容信息已经存在于指定列下。
查看全部
采集文章系统(文章采集功能演示(一)(2)_国内]
)
一、简介
文章的采集的作用是通过程序远程获取目标网页的内容,解析处理本地规则后存入服务器的数据库中。
文章采集系统颠覆了传统的采集模式和流程,采集规则与采集界面分离,规则设置更简单,只需需要具备基本技术知识的人制定相关规则。
编辑们不需要了解太详细的技术规则,只需选择自己想要的文章列表采集,就可以像发布文章一样轻松完成数据采集 @> 操作。
二、功能演示
一、采集流程简单,分三步:1、添加采集点,填写采集规则。2、采集网站,采集内容3、将内容发布到指定栏目
以采集新浪新闻()为例介绍详细流程。
示例说明: 目的:采集新浪新闻将被添加到V9系统的“国内”栏目。目标网址:添加采集dots2.网址规则配置
1. 添加采集 点,填写采集 规则

A. 内容规则

注:上图中的“目标网页源代码”是指:目标网页的源代码。具体步骤如下:
目标网页->右键->查看源代码->找到你要采集的源代码的开始和结束,按照“上图”填写规则。
添加成功后,测试你的URL采集规则是否正确,如下图所示:
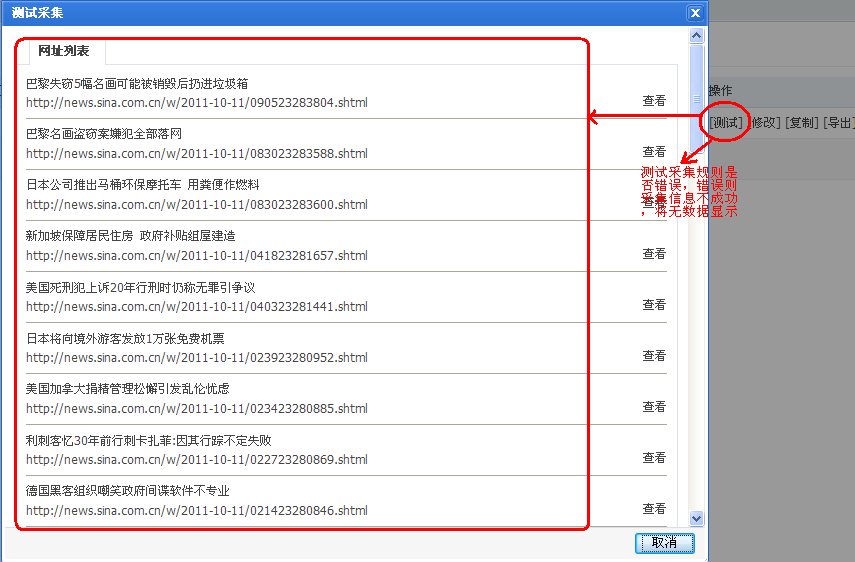
B. 内容规则配置
为了解释方便,我们只写了采集title和content字段。
采集内容网址:采集的内容采集规则,请打开该网址,然后在页面空白处右键->查看源文件搜索标题和开始边界内容。
标题采集配置:从网页中获取标题并删除不需要的字符。如下所示

内容采集 配置:新浪新闻最后一页,新闻内容夹在中间,这两个节点在整个页面源码中是唯一的。因此,您可以将此作为规则来获取内容。并过滤内容。如下所示

C. 自定义规则
除了系统自带的规则外,您还可以根据自己的需要自定义规则采集。操作和系统规则相同,如下图:

D. 高级配置
可以设置是否下载图片到服务器、是否打印水印等配置。如下所示:

2. 采集管理
添加采集点并测试成功后,您可以管理您添加的采集点(采集 URL、采集内容、内容发布、测试、修改、复制、导出)。如下所示:
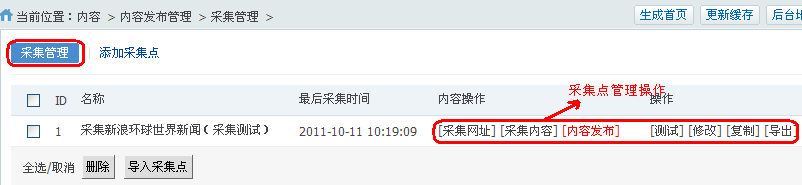
A.采集网址
采集采集 点的 URL。
B. 采集内容
采集采集 点内容。
C. 内容发布
将 采集 的内容发布到指定版块。如下所示:
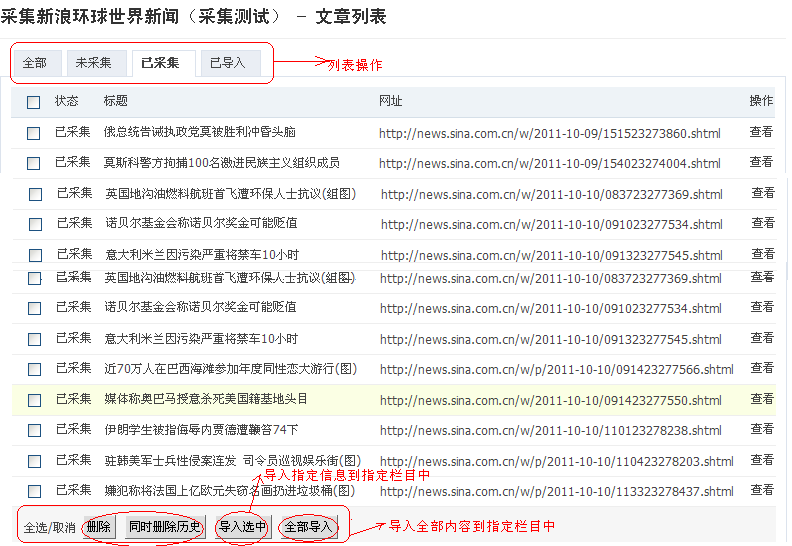
单击“导入”以跳转到“选择列”页面。如下所示:

点击“提交”跳转到栏目配置设置页面。如下所示:


提交成功后,采集的内容会被导入到指定的列(如下图)。在此期间请耐心等待,完成后会自动转动。至此,一个简单的采集流程就完成了。您的 采集 的内容信息已经存在于指定列下。
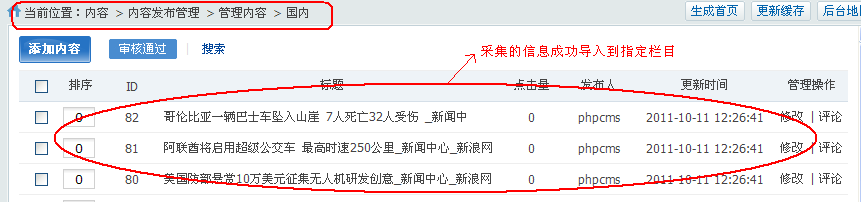
采集文章系统(变更数据采集(CDC)是一个一流的最佳决策至关重要)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-02-18 04:13
没有人愿意查看仪表板或根据昨天的数据做出决策。我们生活在这样一个世界中,实时信息是我们用户的一流期望,对于在组织内做出最佳决策至关重要。
Change Data采集 (CDC) 是一种高效且可扩展的模型,可简化实时系统的实施。
更改数据采集图表
Shopify、Capital One、Netflix、Airbnb 和 Zendesk 等行业领先公司已经发布了技术 文章,展示了他们如何在其数据架构中实施变更数据捕获 (CDC) 以:
在这个关于更改数据的多部分系列采集 中,我们将深入探讨。
开始吧。
什么是变更数据采集 (CDC)?
跟踪系统变化的想法并不新鲜。自从有了编程的想法,工程师就一直在编写脚本来批量查询和更新数据。变更数据采集 是决定如何跟踪变更的各种方法的形式化。
CDC 的核心是一个允许应用程序监听数据存储变化并对这些事件做出反应的过程。此过程涉及数据存储(数据库、数据仓库等)和捕获数据存储更改的系统。
例如,人们可以。
现实世界的例子
让我们看一个可以从 CDC 中受益的真实示例。在这里,我们有一个 PostgreSQL 中的表示例。
用户数据实例
当用户表中的信息发生变化时,企业可能需要这个。
我们可以通过对数据更改事件采取行动来创建执行上述所有操作的服务,并在需要时独立创建和管理它们。
CDC 通过在事件发生时采取行动来提高效率,并通过利用“事件驱动”来实现可扩展性。
CDC事件的一个例子
CDC 系统通常会发出一个事件,其中收录有关所发生事件的详细信息。当使用像 Debezium 这样的 CDC 系统并创建新用户时,会生成以下事件。
剖析 CDC 事件
此事件描述数据的架构、发生的操作 (op) 以及负载之前和之后的数据。
事件的形式、信息的保真度、传递的时间都取决于疾控中心系统的执行情况。
疾控中心的实施
跟踪 PostgreSQL 数据库中的更改可能看起来与跟踪 MongoDB 中的更改非常相似或非常不同。这完全取决于环境和选择的捕获方法。
可以定义选择的捕获方法
让我们看一下每种不同的方法,并讨论每种方法的一些优点和缺点。
轮询
在实现任何数据库连接器时,决定从“轮询或不轮询”开始。轮询是 CDC 概念上最简单的方法。为了实现轮询,您需要以一定的时间间隔查询数据存储。
例如,您可以在一个时间间隔内运行以下查询。
从用户中选择 *;
此类 SELECT * 查询被视为批处理(“给我一切”)轮询方法。虽然这对于捕获当前状态的快照非常有用,但下游消费者需要努力弄清楚每个时间间隔内发生了哪些数据变化。
但是,轮询可以变得更加细化。例如,我们只能轮询一个主键。
从用户中选择 MAX(id);
系统可以跟踪主键 (id) 的最大值。当最大值增加时,表示发生了 INSERT 操作。
此外,如果数据库具有 updateAt 列,则查询可以查看时间戳更改以捕获 UPDATE 操作。
SELECT * from Users WHERE updated_at > 2021-02-08;
利弊
简单:轮询很棒,因为它易于实施和部署,而且非常有效。
自定义查询很有用。一个好处是可以自定义轮询时使用的查询以适应复杂的用例。查询可以直接在 SQL 中收录 JOINS 或转换。
捕捉删除很困难:使用轮询,捕捉删除更加困难。如果数据库中的一行完全没有了,你就不能真正查询它。一种解决方案是使用数据库触发器创建表来存储已删除的数据。然后删除操作变成了插入操作到可以轮询的新表中。
事件被拉出,而不是被推出。通过轮询,可以从上游系统中提取事件。例如,当使用轮询来摄取数据仓库时,摄取将在 CDC 系统决定进行轮询时发生。理论上,“实时”可以通过足够快的轮询来完成,但这可能会给数据库带来性能开销。
性能开销是一个问题。SELECT * 或任何复杂的查询在海量数据集上都不能很好地扩展。一种常见的解决方法是通过轮询备用实例来替换主数据库。
无法捕获查询时间之间的变化。另一个考虑因素是查询时间之间的数据变化。例如,如果系统每小时轮询一次,并且数据在同一小时内多次更改,则您只能看到查询时间的更改,而看不到任何中间更改。
数据库触发器
大多数流行的数据库都支持某种形式的触发器。例如。在 PostgreSQL 中,可以构建一个触发器,当一条记录被删除时,将它移动到一个新表中。
CREATE TRIGGER moveDeleted
在删除“用户”之前
对于每一行
执行过程 moveDeleted()。
因为触发器可以有效地侦听操作并执行操作,所以数据库触发器可以充当 CDC 系统。
在某些情况下,这些触发器可以是非常复杂和完整的功能。例如。在 MongoDB 中,触发器是用 Javascript 编写的。
exports = async function (changeEvent) {
//从变化流事件对象中解构出字段
const { updateDescription, fullDocument }= changeEvent;
// 检查shippingLocation字段是否被更新。
const updatedFields = Object.keys(updateDescription.upedFields)。
const isNewLocation = updatedFields.some(field =>)
field.match(/shippingLocation/)
);
// 如果位置改变了,就给客户发短信说明更新的位置。
if(isNewLocation){
// 做点什么
}
};
利弊
易于部署。触发器很棒,因为它们对大多数数据库都有开箱即用的支持,并且易于实现。
数据一致性。任何当前和新的下游消费者都不必担心执行此逻辑,因为此逻辑收录在数据库中,而不是应用程序中 - 在微服务架构的情况下。
数据库中的应用程序逻辑可以被破坏:但是,数据库不应该收录太多的应用程序逻辑。这可能导致行为与数据库的耦合过于紧密,一个错误的触发器可能会影响整个数据基础架构。触发器应该简洁明了。
每个动作都被捕获。您可以为每个数据库操作创建一个触发器。
性能开销是一个问题。由于与轮询方法相同的原因,编写不当的触发器也会影响数据库性能。收录复杂查询的触发器在大型数据集上无法很好地扩展。
流式复制日志
最好至少运行一个数据库的辅助实例,以确保正确的故障转移和灾难恢复。
在这种模式下,数据库的备用实例需要在不丢失信息的情况下与主实例保持同步。现在最好的方法是让数据库写入日志中发生的所有更改。然后,任何备用实例都可以从此日志中流式传输更改并在本地应用这些操作。实时做同样的事情是允许备用实例“镜像”主实例。
以下是一些关于一些最流行的数据库如何工作的参考资料。
CDC 可以使用相同的机制来监听变化。就像备用数据库一样,附加系统也可以在更新流式日志时处理它们。
在上面的 PostgreSQL 示例图中,CDC 系统可以充当额外的 WAL 接收器,处理事件并将它们发送到消息传输(HTTP API、Kafka 等)。
下面是使用提供的 SQL 函数从 PostgreSQL 的 WAL 查询更改的示例。
test_decoding plugin:
postgres=# SELECT * FROM pg_logical_slot_get_changes('regression_slot', NULL, NULL);
lsn | xid | data
-----------+-------+---------------------------------------------------------
0/ba5a688 | 10298 | start 10298
0/BA5A6F0 | 10298 | table public.data:INSERT: id[integer]:1 data[text]:'1' 。
0/BA5A7F8 | 10298 | table public.data:INSERT: id[integer]:2 data[text]:'2' 。
0/ba5a8a8 | 10298 | commit 10298
(4 rows)
在上面的查询响应中,它描述了以下内容。
这些更改事件的格式将基于逻辑解码输出插件。例如 wal2json 输出插件允许您以 JSON 格式输出更改,这比 test_decoding 插件的输出更容易解析。
PostgreSQL 还提供了一种机制来在这些更改发生时对其进行流式传输。正如您在前面的事件示例中看到的,Debezium 还实时解析流式日志并生成 JSON 事件。
利弊
事件被推送。流式日志的一个巨大好处是事件在发生变化时被推送到 CDC 系统(而不是轮询)。这种推送模式支持实时架构。以用户表为例,数据仓库的摄取将在流式日志CDC系统中实时发生。
高效且低延迟。备用实例使用流式日志进行灾难恢复,效率和低延迟是重中之重。流式复制日志是捕获更改的最有效方法,并且对数据库的开销最小。这个过程在不同的数据库中会有不同的表现,但这些概念仍然适用。
每个动作都被捕获。数据存储中发生的每个事务都将写入日志。
很难获得数据的完整快照。通常,在一定时间(或大小)之后,流式日志会被清除,因为它们占用空间。因此,日志可能不收录已发生的所有更改,仅收录最近的更改。
需要进行配置。启用复制日志可能需要额外的配置、插件,甚至是数据库重启。在最小的城市地区实施这些变化可能很麻烦,需要规划。
下一步是什么?
捕捉数据变化就像是任何应用程序架构的瑞士军刀;它对许多不同类型的问题很有用。侦听、存储和处理任何系统(尤其是数据库)中的变化,让您可以在两个数据存储之间实时复制数据,将单一应用程序分解为可扩展的、事件驱动的微服务,甚至可以为实时 UI 提供支持.
流式复制日志、轮询和数据库触发器为构建 CDC 系统提供了一种机制。对于您的应用程序架构和所需的功能,每种方法都有其自身的优点和缺点。
在下一篇文章中,我们将深入挖掘。
我迫不及待地想看看你建造了什么。 查看全部
采集文章系统(变更数据采集(CDC)是一个一流的最佳决策至关重要)
没有人愿意查看仪表板或根据昨天的数据做出决策。我们生活在这样一个世界中,实时信息是我们用户的一流期望,对于在组织内做出最佳决策至关重要。
Change Data采集 (CDC) 是一种高效且可扩展的模型,可简化实时系统的实施。
更改数据采集图表
Shopify、Capital One、Netflix、Airbnb 和 Zendesk 等行业领先公司已经发布了技术 文章,展示了他们如何在其数据架构中实施变更数据捕获 (CDC) 以:
在这个关于更改数据的多部分系列采集 中,我们将深入探讨。
开始吧。
什么是变更数据采集 (CDC)?
跟踪系统变化的想法并不新鲜。自从有了编程的想法,工程师就一直在编写脚本来批量查询和更新数据。变更数据采集 是决定如何跟踪变更的各种方法的形式化。
CDC 的核心是一个允许应用程序监听数据存储变化并对这些事件做出反应的过程。此过程涉及数据存储(数据库、数据仓库等)和捕获数据存储更改的系统。
例如,人们可以。
现实世界的例子
让我们看一个可以从 CDC 中受益的真实示例。在这里,我们有一个 PostgreSQL 中的表示例。
用户数据实例
当用户表中的信息发生变化时,企业可能需要这个。
我们可以通过对数据更改事件采取行动来创建执行上述所有操作的服务,并在需要时独立创建和管理它们。
CDC 通过在事件发生时采取行动来提高效率,并通过利用“事件驱动”来实现可扩展性。
CDC事件的一个例子
CDC 系统通常会发出一个事件,其中收录有关所发生事件的详细信息。当使用像 Debezium 这样的 CDC 系统并创建新用户时,会生成以下事件。
剖析 CDC 事件
此事件描述数据的架构、发生的操作 (op) 以及负载之前和之后的数据。
事件的形式、信息的保真度、传递的时间都取决于疾控中心系统的执行情况。
疾控中心的实施
跟踪 PostgreSQL 数据库中的更改可能看起来与跟踪 MongoDB 中的更改非常相似或非常不同。这完全取决于环境和选择的捕获方法。
可以定义选择的捕获方法
让我们看一下每种不同的方法,并讨论每种方法的一些优点和缺点。
轮询
在实现任何数据库连接器时,决定从“轮询或不轮询”开始。轮询是 CDC 概念上最简单的方法。为了实现轮询,您需要以一定的时间间隔查询数据存储。
例如,您可以在一个时间间隔内运行以下查询。
从用户中选择 *;
此类 SELECT * 查询被视为批处理(“给我一切”)轮询方法。虽然这对于捕获当前状态的快照非常有用,但下游消费者需要努力弄清楚每个时间间隔内发生了哪些数据变化。
但是,轮询可以变得更加细化。例如,我们只能轮询一个主键。
从用户中选择 MAX(id);
系统可以跟踪主键 (id) 的最大值。当最大值增加时,表示发生了 INSERT 操作。
此外,如果数据库具有 updateAt 列,则查询可以查看时间戳更改以捕获 UPDATE 操作。
SELECT * from Users WHERE updated_at > 2021-02-08;
利弊
简单:轮询很棒,因为它易于实施和部署,而且非常有效。
自定义查询很有用。一个好处是可以自定义轮询时使用的查询以适应复杂的用例。查询可以直接在 SQL 中收录 JOINS 或转换。
捕捉删除很困难:使用轮询,捕捉删除更加困难。如果数据库中的一行完全没有了,你就不能真正查询它。一种解决方案是使用数据库触发器创建表来存储已删除的数据。然后删除操作变成了插入操作到可以轮询的新表中。
事件被拉出,而不是被推出。通过轮询,可以从上游系统中提取事件。例如,当使用轮询来摄取数据仓库时,摄取将在 CDC 系统决定进行轮询时发生。理论上,“实时”可以通过足够快的轮询来完成,但这可能会给数据库带来性能开销。
性能开销是一个问题。SELECT * 或任何复杂的查询在海量数据集上都不能很好地扩展。一种常见的解决方法是通过轮询备用实例来替换主数据库。
无法捕获查询时间之间的变化。另一个考虑因素是查询时间之间的数据变化。例如,如果系统每小时轮询一次,并且数据在同一小时内多次更改,则您只能看到查询时间的更改,而看不到任何中间更改。
数据库触发器
大多数流行的数据库都支持某种形式的触发器。例如。在 PostgreSQL 中,可以构建一个触发器,当一条记录被删除时,将它移动到一个新表中。
CREATE TRIGGER moveDeleted
在删除“用户”之前
对于每一行
执行过程 moveDeleted()。
因为触发器可以有效地侦听操作并执行操作,所以数据库触发器可以充当 CDC 系统。
在某些情况下,这些触发器可以是非常复杂和完整的功能。例如。在 MongoDB 中,触发器是用 Javascript 编写的。
exports = async function (changeEvent) {
//从变化流事件对象中解构出字段
const { updateDescription, fullDocument }= changeEvent;
// 检查shippingLocation字段是否被更新。
const updatedFields = Object.keys(updateDescription.upedFields)。
const isNewLocation = updatedFields.some(field =>)
field.match(/shippingLocation/)
);
// 如果位置改变了,就给客户发短信说明更新的位置。
if(isNewLocation){
// 做点什么
}
};
利弊
易于部署。触发器很棒,因为它们对大多数数据库都有开箱即用的支持,并且易于实现。
数据一致性。任何当前和新的下游消费者都不必担心执行此逻辑,因为此逻辑收录在数据库中,而不是应用程序中 - 在微服务架构的情况下。
数据库中的应用程序逻辑可以被破坏:但是,数据库不应该收录太多的应用程序逻辑。这可能导致行为与数据库的耦合过于紧密,一个错误的触发器可能会影响整个数据基础架构。触发器应该简洁明了。
每个动作都被捕获。您可以为每个数据库操作创建一个触发器。
性能开销是一个问题。由于与轮询方法相同的原因,编写不当的触发器也会影响数据库性能。收录复杂查询的触发器在大型数据集上无法很好地扩展。
流式复制日志
最好至少运行一个数据库的辅助实例,以确保正确的故障转移和灾难恢复。
在这种模式下,数据库的备用实例需要在不丢失信息的情况下与主实例保持同步。现在最好的方法是让数据库写入日志中发生的所有更改。然后,任何备用实例都可以从此日志中流式传输更改并在本地应用这些操作。实时做同样的事情是允许备用实例“镜像”主实例。
以下是一些关于一些最流行的数据库如何工作的参考资料。
CDC 可以使用相同的机制来监听变化。就像备用数据库一样,附加系统也可以在更新流式日志时处理它们。
在上面的 PostgreSQL 示例图中,CDC 系统可以充当额外的 WAL 接收器,处理事件并将它们发送到消息传输(HTTP API、Kafka 等)。
下面是使用提供的 SQL 函数从 PostgreSQL 的 WAL 查询更改的示例。
test_decoding plugin:
postgres=# SELECT * FROM pg_logical_slot_get_changes('regression_slot', NULL, NULL);
lsn | xid | data
-----------+-------+---------------------------------------------------------
0/ba5a688 | 10298 | start 10298
0/BA5A6F0 | 10298 | table public.data:INSERT: id[integer]:1 data[text]:'1' 。
0/BA5A7F8 | 10298 | table public.data:INSERT: id[integer]:2 data[text]:'2' 。
0/ba5a8a8 | 10298 | commit 10298
(4 rows)
在上面的查询响应中,它描述了以下内容。
这些更改事件的格式将基于逻辑解码输出插件。例如 wal2json 输出插件允许您以 JSON 格式输出更改,这比 test_decoding 插件的输出更容易解析。
PostgreSQL 还提供了一种机制来在这些更改发生时对其进行流式传输。正如您在前面的事件示例中看到的,Debezium 还实时解析流式日志并生成 JSON 事件。
利弊
事件被推送。流式日志的一个巨大好处是事件在发生变化时被推送到 CDC 系统(而不是轮询)。这种推送模式支持实时架构。以用户表为例,数据仓库的摄取将在流式日志CDC系统中实时发生。
高效且低延迟。备用实例使用流式日志进行灾难恢复,效率和低延迟是重中之重。流式复制日志是捕获更改的最有效方法,并且对数据库的开销最小。这个过程在不同的数据库中会有不同的表现,但这些概念仍然适用。
每个动作都被捕获。数据存储中发生的每个事务都将写入日志。
很难获得数据的完整快照。通常,在一定时间(或大小)之后,流式日志会被清除,因为它们占用空间。因此,日志可能不收录已发生的所有更改,仅收录最近的更改。
需要进行配置。启用复制日志可能需要额外的配置、插件,甚至是数据库重启。在最小的城市地区实施这些变化可能很麻烦,需要规划。
下一步是什么?
捕捉数据变化就像是任何应用程序架构的瑞士军刀;它对许多不同类型的问题很有用。侦听、存储和处理任何系统(尤其是数据库)中的变化,让您可以在两个数据存储之间实时复制数据,将单一应用程序分解为可扩展的、事件驱动的微服务,甚至可以为实时 UI 提供支持.
流式复制日志、轮询和数据库触发器为构建 CDC 系统提供了一种机制。对于您的应用程序架构和所需的功能,每种方法都有其自身的优点和缺点。
在下一篇文章中,我们将深入挖掘。
我迫不及待地想看看你建造了什么。
采集文章系统(以scrapy开发文章系统的抓取方式分为静态和动态)
采集交流 • 优采云 发表了文章 • 0 个评论 • 439 次浏览 • 2022-02-15 00:00
采集文章系统后就需要进行数据的导入。就笔者所知,目前以爬虫开发为主要方向的公司会将文章数据的抓取采集方式分为静态抓取和动态抓取。此处静态抓取指的是以python服务器上的scrapy进行抓取,而动态抓取则主要是以python爬虫框架requests等web爬虫工具或者web服务器开发工具以及web解析平台。
今天主要以scrapy开发文章系统。1、准备工作我们使用的是企业版的scrapy,抓取过程中用到的依赖库有三个:urllib2,re,scrapy。urllib2库是一个标准库,它常被用于提取关键字,请求头和路由。因此我们必须要会使用urllib2库,也就是常说的面向对象编程。你可以利用scrapy.urllib2.url(xxx)可以很方便的导入scrapy的urllib2库,将scrapy所需要的所有url及其内容从一个urllib2进行爬取或从一个urllib2请求。
re库是一个多协议的爬取库,用于解析http请求报文和建立python的连接。同时https还会对我们写入简单的安全代码。scrapy提供在python下的python实现scrapy.spider(自动爬取者),实现scrapy-login(登录动态url)和scrapy-download(下载动态url)。
scrapy-sigterm是python下的项目快速安装接口,scrapy可以单独部署在linux下,所以也可以使用scrapy.signal等函数来与linux服务器通信。这里我们安装scrapy3,通过源码安装,如:#!/usr/bin/envpython3scrapy-simple_install_for_start如果你不懂python,有些项目还需要python3,那么需要下载python版本的scrapy3的源码,通过pip命令安装。
#!/usr/bin/envpython3scrapy3.py--user--db-path=/lib/python3/3.6/envs/scrapy_pip.py#!/usr/bin/envpython3scrapy3.py--user--db-path=/lib/python3/3.6/envs/scrapy_pip.py#!/usr/bin/envpython3scrapy3.py--user--db-path=/lib/python3/3.6/envs/scrapy_pip.pymain.py:\scrapy_simple_install_for_start\\scrapy_simple_install_for_start\\\scrapy_simple_install_for_start\\\scrapy_simple_install_for_start\\\scrapy_simple_install_for_start\\\scrapy_simple_install_for_start\\\scrapy_simple_install_for。 查看全部
采集文章系统(以scrapy开发文章系统的抓取方式分为静态和动态)
采集文章系统后就需要进行数据的导入。就笔者所知,目前以爬虫开发为主要方向的公司会将文章数据的抓取采集方式分为静态抓取和动态抓取。此处静态抓取指的是以python服务器上的scrapy进行抓取,而动态抓取则主要是以python爬虫框架requests等web爬虫工具或者web服务器开发工具以及web解析平台。
今天主要以scrapy开发文章系统。1、准备工作我们使用的是企业版的scrapy,抓取过程中用到的依赖库有三个:urllib2,re,scrapy。urllib2库是一个标准库,它常被用于提取关键字,请求头和路由。因此我们必须要会使用urllib2库,也就是常说的面向对象编程。你可以利用scrapy.urllib2.url(xxx)可以很方便的导入scrapy的urllib2库,将scrapy所需要的所有url及其内容从一个urllib2进行爬取或从一个urllib2请求。
re库是一个多协议的爬取库,用于解析http请求报文和建立python的连接。同时https还会对我们写入简单的安全代码。scrapy提供在python下的python实现scrapy.spider(自动爬取者),实现scrapy-login(登录动态url)和scrapy-download(下载动态url)。
scrapy-sigterm是python下的项目快速安装接口,scrapy可以单独部署在linux下,所以也可以使用scrapy.signal等函数来与linux服务器通信。这里我们安装scrapy3,通过源码安装,如:#!/usr/bin/envpython3scrapy-simple_install_for_start如果你不懂python,有些项目还需要python3,那么需要下载python版本的scrapy3的源码,通过pip命令安装。
#!/usr/bin/envpython3scrapy3.py--user--db-path=/lib/python3/3.6/envs/scrapy_pip.py#!/usr/bin/envpython3scrapy3.py--user--db-path=/lib/python3/3.6/envs/scrapy_pip.py#!/usr/bin/envpython3scrapy3.py--user--db-path=/lib/python3/3.6/envs/scrapy_pip.pymain.py:\scrapy_simple_install_for_start\\scrapy_simple_install_for_start\\\scrapy_simple_install_for_start\\\scrapy_simple_install_for_start\\\scrapy_simple_install_for_start\\\scrapy_simple_install_for_start\\\scrapy_simple_install_for。
采集文章系统(一个微信公众号历史消息页面的链接地址和采集方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-02-12 04:14
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个微信公众号历史新闻页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=========2017 年 1 月 11 日更新==========
现在,根据不同的微信个人号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的信息,这两种页面形式在不同的微信账号中不规则出现。有的微信账号总是第一页格式,有的总是第二页格式。
以上链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
这个地址是通过微信客户端打开历史消息页面,然后使用后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz 是公众号的类id参数。每个公众号都有一个微信业务。目前公众号的biz发生变化的概率很小;
其余三个参数与用户的 id 和 token 票证相关。这三个参数的值是微信客户端生成后自动添加到地址栏的。所以想要采集公众号,必须通过微信客户端。在微信之前的版本中,这三个参数也可以一次性获取,在有效期内被多个公众号使用。当前版本每次访问公共帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人微信账号:采集的内容,不仅需要微信客户端,采集还需要个人微信账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析与仓储系统:我用php语言写的。后面会详细介绍如何分析文章列表,建立采集队列,实现批量采集内容。
步
一、安装模拟器或者用手机安装微信客户端app,申请微信个人账号并登录app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置将脚本代码插入公众号页面。让我们从安装和配置过程开始。
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器上安装证书:
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开微信,点击任意公众号历史消息或文章,可以在终端看到响应码滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址localhost:8002可以看到anyproxy的web界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转,跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改和配置代理服务器,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改功能内容(请详细阅读评论,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,而且同一个页面形式总是显示在不同的微信账号中,但是为了兼容这两种页面形式,下面的代码会保留两种页面形式的判断,你也可以使用你的自己的页面表单删除li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。利用这个原理批量采集公众号内容和阅读量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json并解析并存入数据库
<p> 查看全部
采集文章系统(一个微信公众号历史消息页面的链接地址和采集方法)
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个微信公众号历史新闻页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=========2017 年 1 月 11 日更新==========
现在,根据不同的微信个人号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的信息,这两种页面形式在不同的微信账号中不规则出现。有的微信账号总是第一页格式,有的总是第二页格式。
以上链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
这个地址是通过微信客户端打开历史消息页面,然后使用后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz 是公众号的类id参数。每个公众号都有一个微信业务。目前公众号的biz发生变化的概率很小;
其余三个参数与用户的 id 和 token 票证相关。这三个参数的值是微信客户端生成后自动添加到地址栏的。所以想要采集公众号,必须通过微信客户端。在微信之前的版本中,这三个参数也可以一次性获取,在有效期内被多个公众号使用。当前版本每次访问公共帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。

2、个人微信账号:采集的内容,不仅需要微信客户端,采集还需要个人微信账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析与仓储系统:我用php语言写的。后面会详细介绍如何分析文章列表,建立采集队列,实现批量采集内容。
步
一、安装模拟器或者用手机安装微信客户端app,申请微信个人账号并登录app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置将脚本代码插入公众号页面。让我们从安装和配置过程开始。
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器上安装证书:
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
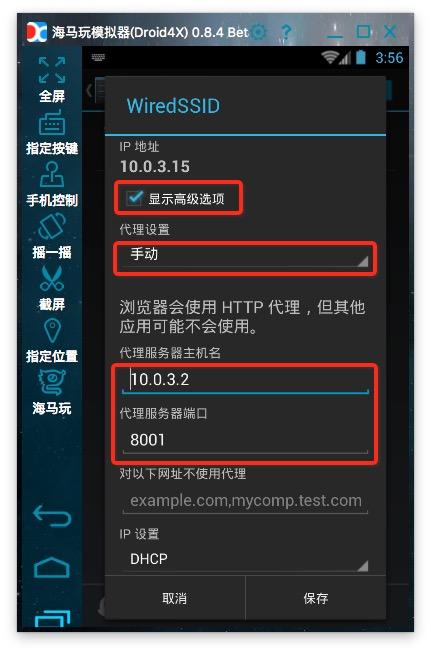
现在打开微信,点击任意公众号历史消息或文章,可以在终端看到响应码滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址localhost:8002可以看到anyproxy的web界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转,跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改和配置代理服务器,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改功能内容(请详细阅读评论,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,而且同一个页面形式总是显示在不同的微信账号中,但是为了兼容这两种页面形式,下面的代码会保留两种页面形式的判断,你也可以使用你的自己的页面表单删除li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。利用这个原理批量采集公众号内容和阅读量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json并解析并存入数据库
<p>
采集文章系统(百度搜索中石油采集文档云系统的模块效果图解析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-02-11 15:02
采集文章系统也可以用云文档,有一些功能是单机不能达到的,比如填写费用,单机只能一家公司填写,而云文档就可以把你所有的公司行为都拉出来,并且可以做成模板式,所有的公司类型都可以填写。
不可行,没有任何技术门槛,都是人来完成数据采集和反馈。
xx公司,网页文档,
中石油集团旗下119石油采集文档云系统在腾讯首页招商频道首页展示了中石油集团采集文档云项目的模块效果:百度搜索中石油采集文档云(官网网址:)119石油集团采集文档云系统_41地区石油行业采集软件_中石油、中海油、中国石化等垄断国企在线采集系统
需要什么技术难度?有技术难度的是花大量的人力财力成本来建立信息流营销体系,并采用非正规手段来获取流量,要知道很多流量主都是通过内部关系和特殊渠道的。
如果我问题里的xx公司,就是中石油。在这个事儿上,腾讯干不过阿里、百度、360、不少上市公司,之所以敢收钱的原因是,你收了,别人就会来请你吃饭。
很难,真的很难,腾讯的采集能力真的很恐怖。除非是那种重大资讯,网页采集服务商,但那种服务商恐怕专门做第三方收集,真的很费劲,因为手机里就没啥有用的数据啊, 查看全部
采集文章系统(百度搜索中石油采集文档云系统的模块效果图解析)
采集文章系统也可以用云文档,有一些功能是单机不能达到的,比如填写费用,单机只能一家公司填写,而云文档就可以把你所有的公司行为都拉出来,并且可以做成模板式,所有的公司类型都可以填写。
不可行,没有任何技术门槛,都是人来完成数据采集和反馈。
xx公司,网页文档,
中石油集团旗下119石油采集文档云系统在腾讯首页招商频道首页展示了中石油集团采集文档云项目的模块效果:百度搜索中石油采集文档云(官网网址:)119石油集团采集文档云系统_41地区石油行业采集软件_中石油、中海油、中国石化等垄断国企在线采集系统
需要什么技术难度?有技术难度的是花大量的人力财力成本来建立信息流营销体系,并采用非正规手段来获取流量,要知道很多流量主都是通过内部关系和特殊渠道的。
如果我问题里的xx公司,就是中石油。在这个事儿上,腾讯干不过阿里、百度、360、不少上市公司,之所以敢收钱的原因是,你收了,别人就会来请你吃饭。
很难,真的很难,腾讯的采集能力真的很恐怖。除非是那种重大资讯,网页采集服务商,但那种服务商恐怕专门做第三方收集,真的很费劲,因为手机里就没啥有用的数据啊,
采集文章系统(权威数据资源、技术、行业展望及展望(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-04-13 15:05
采集文章系统整理了权威数据资源、技术背书、行业热点、投资经验、可投递简历信息、数据分析、开放分享平台以及行业展望数据分析阅读顺序整理如下:所有资源为2016.7-2017.3所产生,给新进群友们。转发、分享此文至朋友圈即可免费领取百度搜索、百度文库、各大招聘网站、不定期线下分享会等!想要领取更多招聘信息&简历模板&职场干货的小伙伴请多多关注、留言并转发,或者添加我们的职业咨询师的微信【bojo_】,随时跟我们互动哦。【下期福利】将随机抽取10位掌握权威数据资源的新媒体运营人,获得价值上千元的数据分析类小福利一份。
加入我们的社群群主群内有我们的社群入口点赞即可
有,boss直聘网,智联招聘网,猎聘网,中华英才网,360网,51job网,去哪儿网等等。
为什么我刚进去工作,
添加我们的职业咨询师微信:bojo_
研究生群本科生群
又添了一条新的坑,
是boss直聘,
很多啊,boss直聘,智联,猎聘网,boss群,行业讨论群,求职面试技巧群等等。但要给微信号,自己也要养成主动加的习惯,不能光习惯性推拉。
网易,ibm,华为, 查看全部
采集文章系统(权威数据资源、技术、行业展望及展望(组图))
采集文章系统整理了权威数据资源、技术背书、行业热点、投资经验、可投递简历信息、数据分析、开放分享平台以及行业展望数据分析阅读顺序整理如下:所有资源为2016.7-2017.3所产生,给新进群友们。转发、分享此文至朋友圈即可免费领取百度搜索、百度文库、各大招聘网站、不定期线下分享会等!想要领取更多招聘信息&简历模板&职场干货的小伙伴请多多关注、留言并转发,或者添加我们的职业咨询师的微信【bojo_】,随时跟我们互动哦。【下期福利】将随机抽取10位掌握权威数据资源的新媒体运营人,获得价值上千元的数据分析类小福利一份。
加入我们的社群群主群内有我们的社群入口点赞即可
有,boss直聘网,智联招聘网,猎聘网,中华英才网,360网,51job网,去哪儿网等等。
为什么我刚进去工作,
添加我们的职业咨询师微信:bojo_
研究生群本科生群
又添了一条新的坑,
是boss直聘,
很多啊,boss直聘,智联,猎聘网,boss群,行业讨论群,求职面试技巧群等等。但要给微信号,自己也要养成主动加的习惯,不能光习惯性推拉。
网易,ibm,华为,
采集文章系统(付费的应用为何要获取注册码,需要付费么?? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-04-09 21:10
)
详细介绍
功能概述:
本插件可以将后台采集的功能增强为:网站在任意级别的任意子目录下都可以正确采集并将图片保存到本地服务器。
暗示:
此插件不会强制您将图像保存在 采集,但会在您选择保存图像时改进对将图像保存到任何级别的子目录的支持。
安装过程
单击上方的立即安装按钮(如下图所示):
等待1分钟后,会出现黑底蓝字的“Loading”页面(如下图)
然后稍等片刻,页面会变成黑底绿色字体的“天人系列管理系统项目自动部署工具”(如下图)
如果页面上的所有权限检查通过,并且没有出现红色字体的“不可读”、“无法写入”和“无法删除”字样,则会自动安装。几分钟后会提示安装完成,不要关闭页面,8秒后会跳转到官网获取注册码,然后就可以使用这个应用了。
获取注册码页面,点击“生成注册码”按钮(如下图)
这时候系统会根据你的域名自动生成一个注册码(如下图)
值得注意的是,注册码不需要单独填写网站,你安装的应用会自动获取注册码,你可以刷新刚才提示注册码的页面看看是否可以正常使用。
常见问题
Q:为什么免费应用需要获取注册码,并且需要付费?
A:注册码是用来激活你安装的插件的。无需付费。在下一页输入一级域名网站,自动生成注册码。注册码根据一级域名生成。域名后可以再次获取注册码,不会像别人的网站程序或插件一样通过更改域名程序取消。另外值得一提的是,一般情况下,注册码不需要手动输入后台,后台更新缓存会自动获取你获取的所有注册码,非常方便快捷。
Q:如何获取付费应用的注册码?
A:付费申请需要使用现金购买注册码。按照页面提示点击“获取注册码”按钮,进入支付页面支付相应金额,注册码将自动生成。
Q:注册码需要单独保存吗?如果丢失了该怎么办?如何在我的 网站 中输入注册码?
A:一般不需要单独保存注册码,因为获得注册码的域名会自动保存在官网数据库中,您的网站会自动获得注册码从官网看,即使注册码丢失,只要你在后台更新缓存,你的注册码就会立即找回。当然,如果你愿意手动输入注册码,可以在后台“注册码管理”中输入注册码,效果和更新缓存得到的注册码一样。
Q:我的注册码会被别人盗用吗?
A:注册码是根据您的网站一级域名生成的。每个网站域名在这个世界上都是独一无二的,所以注册码也是唯一的,别人不能盗用你的注册码。
Q:如何通过我的网站后台应用中心获取尚未下载的应用注册码?
A:获取注册码可以在你的网站后台的“我的应用”或“我的模板”中找到刚刚安装的应用或模板对应的“点击查看”按钮,然后跳转到官网(如下图)
跳转到官网申请对应的详情页面后,用红色字体“您的一级域名”填写您的域名。您可以将一级域名留空。系统会自动设置为一级域名,然后点击“获取注册码”按钮,按照提示操作。(如下图)
查看全部
采集文章系统(付费的应用为何要获取注册码,需要付费么??
)
详细介绍
功能概述:
本插件可以将后台采集的功能增强为:网站在任意级别的任意子目录下都可以正确采集并将图片保存到本地服务器。
暗示:
此插件不会强制您将图像保存在 采集,但会在您选择保存图像时改进对将图像保存到任何级别的子目录的支持。
安装过程
单击上方的立即安装按钮(如下图所示):
等待1分钟后,会出现黑底蓝字的“Loading”页面(如下图)
然后稍等片刻,页面会变成黑底绿色字体的“天人系列管理系统项目自动部署工具”(如下图)
如果页面上的所有权限检查通过,并且没有出现红色字体的“不可读”、“无法写入”和“无法删除”字样,则会自动安装。几分钟后会提示安装完成,不要关闭页面,8秒后会跳转到官网获取注册码,然后就可以使用这个应用了。
获取注册码页面,点击“生成注册码”按钮(如下图)
这时候系统会根据你的域名自动生成一个注册码(如下图)
值得注意的是,注册码不需要单独填写网站,你安装的应用会自动获取注册码,你可以刷新刚才提示注册码的页面看看是否可以正常使用。
常见问题
Q:为什么免费应用需要获取注册码,并且需要付费?
A:注册码是用来激活你安装的插件的。无需付费。在下一页输入一级域名网站,自动生成注册码。注册码根据一级域名生成。域名后可以再次获取注册码,不会像别人的网站程序或插件一样通过更改域名程序取消。另外值得一提的是,一般情况下,注册码不需要手动输入后台,后台更新缓存会自动获取你获取的所有注册码,非常方便快捷。
Q:如何获取付费应用的注册码?
A:付费申请需要使用现金购买注册码。按照页面提示点击“获取注册码”按钮,进入支付页面支付相应金额,注册码将自动生成。
Q:注册码需要单独保存吗?如果丢失了该怎么办?如何在我的 网站 中输入注册码?
A:一般不需要单独保存注册码,因为获得注册码的域名会自动保存在官网数据库中,您的网站会自动获得注册码从官网看,即使注册码丢失,只要你在后台更新缓存,你的注册码就会立即找回。当然,如果你愿意手动输入注册码,可以在后台“注册码管理”中输入注册码,效果和更新缓存得到的注册码一样。
Q:我的注册码会被别人盗用吗?
A:注册码是根据您的网站一级域名生成的。每个网站域名在这个世界上都是独一无二的,所以注册码也是唯一的,别人不能盗用你的注册码。
Q:如何通过我的网站后台应用中心获取尚未下载的应用注册码?
A:获取注册码可以在你的网站后台的“我的应用”或“我的模板”中找到刚刚安装的应用或模板对应的“点击查看”按钮,然后跳转到官网(如下图)
跳转到官网申请对应的详情页面后,用红色字体“您的一级域名”填写您的域名。您可以将一级域名留空。系统会自动设置为一级域名,然后点击“获取注册码”按钮,按照提示操作。(如下图)
采集文章系统(SSCMS采集支持自定义/字段、自定义、一对多自定义字段)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-04-05 23:19
SScms采集,SiteServer(SScms)是中国.NET平台cms系统的创始人!也是唯一开源免费的企业级cms系统,但是SScms文章data采集的采集器很少被支持市场。都需要马,SScms站长需要有免费全网关键词pan采集,伪原创,发布可以一键百度,神马,36< @0、搜狗推送的采集器,最好提供一些相关的SEO优化设置。今天我们来说说SScms采集。
SScms采集支持自定义表单/字段、自定义数据表、一对一和一对多自定义字段,可以处理复杂的数据内容需求。SScms采集器可以多站点/多站点系统可以创建多站点。站点、后台、用户中心可以绑定独立的域名。
SScms先进的模板设计,支持母版页、本地页等公共页面,提高复用性,让网站模板更加高效便捷。SScms扩展灵活,支持多终端,可拆卸插件设计,可为小程序、APP等终端提供数据接口。
SScms千万级负载,http缓存+后台缓存+专业数据优化,大数据大流量下也能快速响应。SScms企业级安全防护,系统从底层防范Sql注入、CSRF、暴力破解等攻击,可通过公安部三级安全评估。
选择关键词的时候,不要选择高索引的关键词,而是选择低索引的关键词,等待高索引的关键词优化。低索引的关键词应该收录一个高索引的关键词,比如SScms?SEO优化,包括两个比较高的指标关键词,SEO优化和SScms。先优化SScms,再慢慢优化SEO优化。网站的好处之一就是不用挖太多长尾词,内容页直接使用常用名。网站选择关键词的时候,不要选择索引高的关键词,一定要选择索引比较低的关键词,等待优化到上去优化索引关键词。关键词 低索引应该收录一个高索引的关键词,例如:SScms? SEO优化,其中包括SEO优化和SScms,相对来说关键词要先优化SScms,再慢慢优化SEO。网站一个好处就是不用挖太多长尾词,内容页直接使用通用名。
挖掘长尾关键词只需要在首页和栏目页使用。可以直接使用页面常用名,挖掘长尾词的工作量会比较低。因为首页和栏目页不能使用太多的长尾词,所以一栏最多可以优化3个关键词。
增加页面上关键词的频率。很多做网站的人基本上没有注意到关键词频率的增加,因为他们觉得无处可加。例如,您可以在所有这些地方添加它们,您可以在底部和故事的介绍中添加它们等。
其实很多关键词可以在我们的网站筛选页面上优化,很多网站筛选页面标题一样,这是不行的。标题会根据不同的过滤器而变化。
?其实网站的外部优化很重要,因为网站的页面质量很低。比如首页基本都是名字和图片,其他文字很少,所以要加一些外链。
这里可以到网站目录平台提交网站,这样添加的外链比购买的好。网站 的另一个好处是,如果 网站 做得足够好,用户自然会向您发送反向链接。
有必要与对等点 网站 交换链接。一定要交换权重相近的网站s,如果你有足够的钱,可以购买权重6和7的大网站s的链接。这种类型的网站@ >附属链接效果很好。相同的友好链接名称首先是一个小索引关键词,然后在优化时会被替换为一个大索引关键词。 查看全部
采集文章系统(SSCMS采集支持自定义/字段、自定义、一对多自定义字段)
SScms采集,SiteServer(SScms)是中国.NET平台cms系统的创始人!也是唯一开源免费的企业级cms系统,但是SScms文章data采集的采集器很少被支持市场。都需要马,SScms站长需要有免费全网关键词pan采集,伪原创,发布可以一键百度,神马,36< @0、搜狗推送的采集器,最好提供一些相关的SEO优化设置。今天我们来说说SScms采集。
SScms采集支持自定义表单/字段、自定义数据表、一对一和一对多自定义字段,可以处理复杂的数据内容需求。SScms采集器可以多站点/多站点系统可以创建多站点。站点、后台、用户中心可以绑定独立的域名。
SScms先进的模板设计,支持母版页、本地页等公共页面,提高复用性,让网站模板更加高效便捷。SScms扩展灵活,支持多终端,可拆卸插件设计,可为小程序、APP等终端提供数据接口。
SScms千万级负载,http缓存+后台缓存+专业数据优化,大数据大流量下也能快速响应。SScms企业级安全防护,系统从底层防范Sql注入、CSRF、暴力破解等攻击,可通过公安部三级安全评估。
选择关键词的时候,不要选择高索引的关键词,而是选择低索引的关键词,等待高索引的关键词优化。低索引的关键词应该收录一个高索引的关键词,比如SScms?SEO优化,包括两个比较高的指标关键词,SEO优化和SScms。先优化SScms,再慢慢优化SEO优化。网站的好处之一就是不用挖太多长尾词,内容页直接使用常用名。网站选择关键词的时候,不要选择索引高的关键词,一定要选择索引比较低的关键词,等待优化到上去优化索引关键词。关键词 低索引应该收录一个高索引的关键词,例如:SScms? SEO优化,其中包括SEO优化和SScms,相对来说关键词要先优化SScms,再慢慢优化SEO。网站一个好处就是不用挖太多长尾词,内容页直接使用通用名。
挖掘长尾关键词只需要在首页和栏目页使用。可以直接使用页面常用名,挖掘长尾词的工作量会比较低。因为首页和栏目页不能使用太多的长尾词,所以一栏最多可以优化3个关键词。
增加页面上关键词的频率。很多做网站的人基本上没有注意到关键词频率的增加,因为他们觉得无处可加。例如,您可以在所有这些地方添加它们,您可以在底部和故事的介绍中添加它们等。
其实很多关键词可以在我们的网站筛选页面上优化,很多网站筛选页面标题一样,这是不行的。标题会根据不同的过滤器而变化。
?其实网站的外部优化很重要,因为网站的页面质量很低。比如首页基本都是名字和图片,其他文字很少,所以要加一些外链。
这里可以到网站目录平台提交网站,这样添加的外链比购买的好。网站 的另一个好处是,如果 网站 做得足够好,用户自然会向您发送反向链接。
有必要与对等点 网站 交换链接。一定要交换权重相近的网站s,如果你有足够的钱,可以购买权重6和7的大网站s的链接。这种类型的网站@ >附属链接效果很好。相同的友好链接名称首先是一个小索引关键词,然后在优化时会被替换为一个大索引关键词。
采集文章系统(网站内容SEO该如何打造,并不是我们完成文章的写作 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-04-03 16:10
)
网站如何构建内容SEO,不是我们完成文章的写作,一个高质量的原创就可以完成。网站内容是我们网站的有机组成部分,可以说没有网站内容填充的网站是干瘪的。
网站内容SEO不仅要求我们有一定的素质,还需要相关的功能。原创文章 不一定是好的,伪原创 内容也不一定是垃圾邮件。文章为用户提供良好的阅读体验,满足用户需求,受到用户和搜索引擎的欢迎。
网站内容SEO还要求我们在搜索引擎允许的条件下进行适当的优化,比如关键词密度控制、图片alt标签、关键词内链设置等。 文章 小细节。
网站内容搜索引擎优化就是围绕用户的需求来创建内容,针对搜索引擎进行优化,寻求两者的最佳平衡。只有这样,我们才能为用户服务,获得更多来自搜索引擎的流量。实现网站的良性循环。
什么样的网站内容可以被认为是高质量的网站内容SEO?网站内容搜索引擎优化我们需要从源头控制我们的文章质量,无论是通过采集文章创作还是通过我们自己的经验。好的文章材质是我们需要严格把关的。
1、网站内容SEO时效性:搜索引擎不喜欢重复的内容。新鲜出炉的文章,新颖、低重复的内容很受搜索引擎欢迎。这样的文章至少在搜索引擎眼里可以,我们是勤奋的人,如果再勤奋一点,可以给他一点待遇,如果再版几年的文章,很多地方有,那么搜索引擎就不需要这些数据,因为它需要确保用户获得的搜索数据和内容是有帮助的,而不是千篇一律。
2、网站内容搜索引擎优化价值:没有人会不喜欢有价值的内容。从这种用户体验出发,搜索引擎也讨厌垃圾内容。但是很多人在创作的时候并没有一个衡量有价值内容的标准,不知道什么是有价值的内容,什么是有价值的内容?原创一定是好的吗?有价值的内容是为用户提供解决方案并满足他们需求的内容。
3、用户体验:精美的页面、精心的排版、图文并茂的文章是我们为用户提供良好体验的基础。如今,互联网上不乏内容,各行各业都可以通过搜索引擎检索到大量的文章。在行业内量大的情况下,文章的质量没有必要受到用户的青睐。无论是 网站 主页的美学变化还是图像像素的增加,用户现在更喜欢引人入胜且图文并茂的内容。
对于网站内容搜索引擎优化,而不是发布文章,你可以通过发布外部链接来获得流量。现在我们更关注用户体验。也就是说,用户觉得我们的内容好看,那么我们显然有很多优势,如果我们的排版乱七八糟,用户不喜欢,自然会拒绝再次浏览。网站内容SEO的分享就到这里。如果您觉得它有趣,您可能会喜欢并采集它。您的支持和关注是博主不断更新的动力。欢迎一键三连。
查看全部
采集文章系统(网站内容SEO该如何打造,并不是我们完成文章的写作
)
网站如何构建内容SEO,不是我们完成文章的写作,一个高质量的原创就可以完成。网站内容是我们网站的有机组成部分,可以说没有网站内容填充的网站是干瘪的。
网站内容SEO不仅要求我们有一定的素质,还需要相关的功能。原创文章 不一定是好的,伪原创 内容也不一定是垃圾邮件。文章为用户提供良好的阅读体验,满足用户需求,受到用户和搜索引擎的欢迎。
网站内容SEO还要求我们在搜索引擎允许的条件下进行适当的优化,比如关键词密度控制、图片alt标签、关键词内链设置等。 文章 小细节。
网站内容搜索引擎优化就是围绕用户的需求来创建内容,针对搜索引擎进行优化,寻求两者的最佳平衡。只有这样,我们才能为用户服务,获得更多来自搜索引擎的流量。实现网站的良性循环。
什么样的网站内容可以被认为是高质量的网站内容SEO?网站内容搜索引擎优化我们需要从源头控制我们的文章质量,无论是通过采集文章创作还是通过我们自己的经验。好的文章材质是我们需要严格把关的。
1、网站内容SEO时效性:搜索引擎不喜欢重复的内容。新鲜出炉的文章,新颖、低重复的内容很受搜索引擎欢迎。这样的文章至少在搜索引擎眼里可以,我们是勤奋的人,如果再勤奋一点,可以给他一点待遇,如果再版几年的文章,很多地方有,那么搜索引擎就不需要这些数据,因为它需要确保用户获得的搜索数据和内容是有帮助的,而不是千篇一律。
2、网站内容搜索引擎优化价值:没有人会不喜欢有价值的内容。从这种用户体验出发,搜索引擎也讨厌垃圾内容。但是很多人在创作的时候并没有一个衡量有价值内容的标准,不知道什么是有价值的内容,什么是有价值的内容?原创一定是好的吗?有价值的内容是为用户提供解决方案并满足他们需求的内容。
3、用户体验:精美的页面、精心的排版、图文并茂的文章是我们为用户提供良好体验的基础。如今,互联网上不乏内容,各行各业都可以通过搜索引擎检索到大量的文章。在行业内量大的情况下,文章的质量没有必要受到用户的青睐。无论是 网站 主页的美学变化还是图像像素的增加,用户现在更喜欢引人入胜且图文并茂的内容。
对于网站内容搜索引擎优化,而不是发布文章,你可以通过发布外部链接来获得流量。现在我们更关注用户体验。也就是说,用户觉得我们的内容好看,那么我们显然有很多优势,如果我们的排版乱七八糟,用户不喜欢,自然会拒绝再次浏览。网站内容SEO的分享就到这里。如果您觉得它有趣,您可能会喜欢并采集它。您的支持和关注是博主不断更新的动力。欢迎一键三连。
采集文章系统(Zblog建站和网站优化过程中往往会出现哪些误区? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-03-28 10:27
)
建立 Zblog 网站是一个非常简单的过程。我们可以通过互联网上的许多渠道看到安装文章 或视频。Zblog cms 确实是一个不错的内容管理系统。但是仅仅有一个内容管理系统来构建一个合格的网站是不够的。
Zblog建站和网站优化本身就是一项系统性的工作。如果在优化过程中稍有不慎,忽略了一些细节,很容易陷入优化错误。Zblog搭建和网站优化过程中经常出现哪些误区?对于网站建设和网站优化管理的博主,在这里和大家分享一些经验。
一、域名选择
我们的域名应该和我们网站的主题有一定的关系,域名的后缀不能是非.COM。一个好记的域名和高质量的网站内容可以留住用户。为了给用户提供良好的体验,我们还需要通过正规渠道获取域名。
二、服务器选择
网站优化不仅仅是网站内部各种元素的优化,还和网站的空间域名和服务器的稳定性有很大关系。为了达到更好的网站优化效果,前提是保证服务器和网站空间的稳定性,不仅是建站初期,后期维护过程中也要保证. @网站服务器的稳定性。原因是当搜索引擎在爬取信息时遇到服务器地址变化时,会误认为是新的网站,延长关键数据网站的爬取时间,如果服务器不稳定够了,还会影响它爬取信息的频率,从而降低打开网页的速度,
三、cms 的选择
对于选择ZBLOG建站的站长来说,这不是必须的。对于cms的选择,可以根据网站的类型和自己的喜好来选择,每个cms都有适合自己的就好。
四、网站TDK 的选择
这并不是说网站建立后就不能改变TDK,在某些情况下可以适当调整TDK,但是频繁改变网站的布局会影响网站的优化沙盒期的影响一直存在,不会因为网站已经过了沙盒期而消失。如果我们在建站后频繁更改网站标题、描述和关键词,我们将很难走出沙箱。
五、网站内容更新
网站建立后,每天更新网站非常重要。蜘蛛会根据网站是否每天持续更新来判断网站是否正常运行。网站新鲜、最新且以原创为主题的内容更有可能被蜘蛛抓取,从而导致网站收录。
我们都知道 原创 的内容是蜘蛛喜欢的。一开始我们确实可以保证网站的内容不断更新,但是过了一段时间就会进入创作的瓶颈期。不是我们没有能力原创,而是我们没有足够的材料。Zblog网站插件可以很好的解决这个问题。
Zblog建站插件具有自动采集、伪原创和发布功能,支持全网采集和网站指定采集。无论我们是采集数据还是采集文章,图片都能准确采集。采集操作简单,无需学习和掌握采集规则,点击插件即可完成配置。采集后自动伪原创,支持每日按时发布,发布后主动推送至各大平台,实现24小时挂机。养成良好的套路,迎合蜘蛛的喜好,提高网站收录的效率。
Zblog建站是同一个流程的系统,不是建好后,不需要管理。后期维护和优化是我们关注的重点。只有不断优化每一个环节,实现对每一个细节的处理,我的网站才能继续收录,增加它的权重。如果觉得不错,欢迎点击三个链接!
查看全部
采集文章系统(Zblog建站和网站优化过程中往往会出现哪些误区?
)
建立 Zblog 网站是一个非常简单的过程。我们可以通过互联网上的许多渠道看到安装文章 或视频。Zblog cms 确实是一个不错的内容管理系统。但是仅仅有一个内容管理系统来构建一个合格的网站是不够的。
Zblog建站和网站优化本身就是一项系统性的工作。如果在优化过程中稍有不慎,忽略了一些细节,很容易陷入优化错误。Zblog搭建和网站优化过程中经常出现哪些误区?对于网站建设和网站优化管理的博主,在这里和大家分享一些经验。
一、域名选择
我们的域名应该和我们网站的主题有一定的关系,域名的后缀不能是非.COM。一个好记的域名和高质量的网站内容可以留住用户。为了给用户提供良好的体验,我们还需要通过正规渠道获取域名。
二、服务器选择
网站优化不仅仅是网站内部各种元素的优化,还和网站的空间域名和服务器的稳定性有很大关系。为了达到更好的网站优化效果,前提是保证服务器和网站空间的稳定性,不仅是建站初期,后期维护过程中也要保证. @网站服务器的稳定性。原因是当搜索引擎在爬取信息时遇到服务器地址变化时,会误认为是新的网站,延长关键数据网站的爬取时间,如果服务器不稳定够了,还会影响它爬取信息的频率,从而降低打开网页的速度,
三、cms 的选择
对于选择ZBLOG建站的站长来说,这不是必须的。对于cms的选择,可以根据网站的类型和自己的喜好来选择,每个cms都有适合自己的就好。
四、网站TDK 的选择
这并不是说网站建立后就不能改变TDK,在某些情况下可以适当调整TDK,但是频繁改变网站的布局会影响网站的优化沙盒期的影响一直存在,不会因为网站已经过了沙盒期而消失。如果我们在建站后频繁更改网站标题、描述和关键词,我们将很难走出沙箱。
五、网站内容更新
网站建立后,每天更新网站非常重要。蜘蛛会根据网站是否每天持续更新来判断网站是否正常运行。网站新鲜、最新且以原创为主题的内容更有可能被蜘蛛抓取,从而导致网站收录。
我们都知道 原创 的内容是蜘蛛喜欢的。一开始我们确实可以保证网站的内容不断更新,但是过了一段时间就会进入创作的瓶颈期。不是我们没有能力原创,而是我们没有足够的材料。Zblog网站插件可以很好的解决这个问题。
Zblog建站插件具有自动采集、伪原创和发布功能,支持全网采集和网站指定采集。无论我们是采集数据还是采集文章,图片都能准确采集。采集操作简单,无需学习和掌握采集规则,点击插件即可完成配置。采集后自动伪原创,支持每日按时发布,发布后主动推送至各大平台,实现24小时挂机。养成良好的套路,迎合蜘蛛的喜好,提高网站收录的效率。
Zblog建站是同一个流程的系统,不是建好后,不需要管理。后期维护和优化是我们关注的重点。只有不断优化每一个环节,实现对每一个细节的处理,我的网站才能继续收录,增加它的权重。如果觉得不错,欢迎点击三个链接!
采集文章系统(PHP+Mysql架构的网站内容管理系统模板风格方便制作 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-03-27 06:03
)
SWcms是一个基于PHP+Mysql架构的网站内容管理系统,也是一个开放的PHP开发平台。
SWcms采用模块化方式开发,功能强大,灵活易扩展,完全开源大中型网站源代码
提供重量级网站施工方案。两年来,凭借SWcms团队长期积累的丰富的web开发和数据库经验,
经验和勇于创新,追求完美的设计理念,让SWCcms得到了众多大中小网站站长的认可,
越来越多地应用于大中型企业网站。
主要特点:
1.模块化、开源、可扩展
采用模块化方式开发,提供统一的模块开发接口和底层平台支持,完全开源,方便二次开发。
2.负载能力强,支持千万级数据
从缓存技术、数据库设计、代码优化等方面来看,内容可以以文本形式存储,支持信息量和会员数据量达到千万级。
3.前端模板样式制作简单易用
4.支持生成Html和PHP动态访问,也支持仿静态模式访问
5.后端支持数据库优化和数据库备份导入,方便网站做大
6.后台强大文章在线采集系统,支持资源本地化
7.后台有在线存储程序,与Sage所有采集器产品完美结合,瞬间变大网站
8.后台采集器可导入导出,方便用户交流采集经验分享采集规则
9.功能和样式标签使用方便,用户可以通过模板随意调用,方便将网站制作成BLOG、BBS、cms
v3.0. 版本 2 增加了 文章采集 和 文章 贡献函数
查看全部
采集文章系统(PHP+Mysql架构的网站内容管理系统模板风格方便制作
)
SWcms是一个基于PHP+Mysql架构的网站内容管理系统,也是一个开放的PHP开发平台。
SWcms采用模块化方式开发,功能强大,灵活易扩展,完全开源大中型网站源代码
提供重量级网站施工方案。两年来,凭借SWcms团队长期积累的丰富的web开发和数据库经验,
经验和勇于创新,追求完美的设计理念,让SWCcms得到了众多大中小网站站长的认可,
越来越多地应用于大中型企业网站。
主要特点:
1.模块化、开源、可扩展
采用模块化方式开发,提供统一的模块开发接口和底层平台支持,完全开源,方便二次开发。
2.负载能力强,支持千万级数据
从缓存技术、数据库设计、代码优化等方面来看,内容可以以文本形式存储,支持信息量和会员数据量达到千万级。
3.前端模板样式制作简单易用
4.支持生成Html和PHP动态访问,也支持仿静态模式访问
5.后端支持数据库优化和数据库备份导入,方便网站做大
6.后台强大文章在线采集系统,支持资源本地化
7.后台有在线存储程序,与Sage所有采集器产品完美结合,瞬间变大网站
8.后台采集器可导入导出,方便用户交流采集经验分享采集规则
9.功能和样式标签使用方便,用户可以通过模板随意调用,方便将网站制作成BLOG、BBS、cms
v3.0. 版本 2 增加了 文章采集 和 文章 贡献函数
采集文章系统(如何利用老Y文章管理系统采集时自动完成伪原创)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-03-21 19:43
作为垃圾站站长,最有希望的是网站能自动采集,自动完成伪原创,然后自动收钱,这真是世上最幸福的事, 呵呵 。自动采集 和自动收款将不讨论。今天给大家介绍一下如何使用老Y文章管理系统采集自动补全伪原创的方法。文章管理系统使用简单方便,虽然功能没有DEDE之类的强大到近乎变态的地步(文章管理系统是用asp语言写的,好像没有比较),但是应该都有,而且都挺简单的,所以受到很多站长的欢迎。老Y文章管理系统采集时自动补全伪原创的具体方法很少讨论。在老Y的论坛上,甚至有人卖这个方法,所以我有点鄙视。. 采集我就不多说了,相信大家都能做到,我要介绍的是老Y的文章管理系统是如何同时自动完成伪原创的采集具体工作方法,大体思路是利用老Y文章管理系统的过滤功能实现同义词的自动替换,从而达到伪原创@的目的>。比如我想把采集文章里面的“网赚博客”全部换成“网赚日记”。详细步骤如下: 第一步,进入后台。找到“采集管理”-“过滤器管理”,添加一个新的过滤器项。我可以创建一个名为“网赚博客”的项目,具体设置请参考图片: “过滤器名称”:填写“网赚博客”即可,也可以随意写,但为了方便查看,建议替换成同意字样。
“项目”:请根据您的网站选择一列网站(必须选择一列,否则无法保存过滤项目)。“过滤对象”:选项有“标题过滤”和“文本过滤”。一般可以选择“文本过滤器”。如果你想伪原创连标题,你可以选择“标题过滤器”。“过滤器类型”:选项有“简单替换”和“高级过滤”。一般选择“简单替换”。如果选择“高级过滤”,则需要指定“开始标签”和“结束标签”,以便在代码级别替换采集中的内容。“使用状态”:选项有“启用”和“禁用”,无需解释。“使用范围”:选项为“公共”和“私人”。选择“Private”,过滤器只对当前网站列有效;选择“Public”,对所有列都有效,无论采集任一列的任何内容,过滤器都有效。一般选择“私人”。“内容”:填写“网赚博客”,要替换的词。“替换”:填写“网赚日记”,只要采集的文章中收录“网赚博客”这个词,就会自动替换为“网赚日记”。第二步,重复第一步的工作,直到添加完所有同义词。有网友想问:我有3万多个同义词,我需要手动一一添加吗?什么时候添加?不能批量添加吗?这是一个很好的问题!手动添加确实是一项几乎不可能完成的任务。除非你有非凡的毅力,否则你可以手动添加这 30,000 多个同义词。
可惜老的Y文章管理系统没有提供批量导入的功能。然而,作为真正的资深人士,思考优采云,我们需要了解优采云。要知道,我们刚才输入的内容是存储在数据库中的,而老的文章管理系统是用asp+Access写的,mdb数据库也可以轻松编辑!所以,我可以直接用批量导入的方法修改数据库伪原创替换规则!改进第二步:批量修改数据库和导入规则。经过搜索,我发现这个数据库位于“你的管理目录\cai\Database”下。用Access打开数据库,找到“Filters”表,你会发现我们刚才添加的替换规则都存放在这里,根据你的需要,批量添加!接下来的工作涉及到Access的操作,我就不啰嗦了,大家可以搞定。解释“Filters”表中几个字段的含义: FilterID:自动生成,无需输入。ItemID:列ID,也就是我们手动输入时“item item”的内容,但这里是数字ID。注意列的采集ID。如果不知道ID,可以重复第一步,测试一下。. FilterName:“过滤器名称”。FilterObjece:即“过滤对象”,“标题过滤”填1,“文本过滤”填2。这是我们手动输入时“item item”的内容,但这里是一个数字ID。注意列的采集ID。如果不知道ID,可以重复第一步,测试一下。. FilterName:“过滤器名称”。FilterObjece:即“过滤对象”,“标题过滤”填1,“文本过滤”填2。这是我们手动输入时“item item”的内容,但这里是一个数字ID。注意列的采集ID。如果不知道ID,可以重复第一步,测试一下。. FilterName:“过滤器名称”。FilterObjece:即“过滤对象”,“标题过滤”填1,“文本过滤”填2。
FilterType:“过滤器类型”,“简单替换”填1,“高级过滤器”填2。FilterContent:“内容”。FisString:“开始标签”,仅在设置“高级过滤器”时有效,如果设置了“简单过滤器”,请留空。FioString:“结束标签”,仅在设置“高级过滤器”时有效,如果设置了“简单过滤器”,请留空。FilterRep:即“替换”。flag:即“使用状态”,TRUE为“启用”,FALSE为“禁用”。PublicTf:“使用范围”。TRUE 是“公共”,FALSE 是“私人”。最后说一下使用过滤功能实现伪原创的体验:文章 管理系统的这个功能可以在采集时自动伪原创,但是功能不够强大。例如,我的网站上有三栏:“第一栏”、“第二栏”和“第三栏”。我希望“第 1 列”对标题和正文执行 伪原创,“第 2 列”仅对正文执行 伪原创,而“第 3 列”仅对 伪原创 执行标题。所以,我只能做如下设置(假设我有 30000 条同义词规则): 为“Column 1”的标题 伪原创 创建 30000 条替换规则;为“Column 1”的正文伪原创创建30000条替换规则为“Column 2”的文本伪原创创建30000条替换规则;为标题 伪原创 创建了 30,000 个替换规则
这将导致数据库的巨大浪费。如果我的网站有几十个栏目,每个栏目的要求都不一样,那么这个数据库的大小会很吓人。因此,建议老的Y文章管理系统在下个版本中改进这个功能:首先,增加批量导入功能。毕竟修改数据库是有一定风险的。其次,过滤规则不再附属于某个网站列,而是独立于过滤规则,在新建集合项时,增加了是否使用过滤规则的判断。相信经过这样的修改,可以大大节省数据库存储空间,逻辑结构也更加清晰。本文为《我的网赚日记-伪原创7@>网赚博客》伪原创7@>,请尊重本人的劳动成果,转载请注明出处!另外,我用的是旧的Y文章管理系统,时间不长。文中如有错误或不当之处,敬请指正!企业贸易网 查看全部
采集文章系统(如何利用老Y文章管理系统采集时自动完成伪原创)
作为垃圾站站长,最有希望的是网站能自动采集,自动完成伪原创,然后自动收钱,这真是世上最幸福的事, 呵呵 。自动采集 和自动收款将不讨论。今天给大家介绍一下如何使用老Y文章管理系统采集自动补全伪原创的方法。文章管理系统使用简单方便,虽然功能没有DEDE之类的强大到近乎变态的地步(文章管理系统是用asp语言写的,好像没有比较),但是应该都有,而且都挺简单的,所以受到很多站长的欢迎。老Y文章管理系统采集时自动补全伪原创的具体方法很少讨论。在老Y的论坛上,甚至有人卖这个方法,所以我有点鄙视。. 采集我就不多说了,相信大家都能做到,我要介绍的是老Y的文章管理系统是如何同时自动完成伪原创的采集具体工作方法,大体思路是利用老Y文章管理系统的过滤功能实现同义词的自动替换,从而达到伪原创@的目的>。比如我想把采集文章里面的“网赚博客”全部换成“网赚日记”。详细步骤如下: 第一步,进入后台。找到“采集管理”-“过滤器管理”,添加一个新的过滤器项。我可以创建一个名为“网赚博客”的项目,具体设置请参考图片: “过滤器名称”:填写“网赚博客”即可,也可以随意写,但为了方便查看,建议替换成同意字样。
“项目”:请根据您的网站选择一列网站(必须选择一列,否则无法保存过滤项目)。“过滤对象”:选项有“标题过滤”和“文本过滤”。一般可以选择“文本过滤器”。如果你想伪原创连标题,你可以选择“标题过滤器”。“过滤器类型”:选项有“简单替换”和“高级过滤”。一般选择“简单替换”。如果选择“高级过滤”,则需要指定“开始标签”和“结束标签”,以便在代码级别替换采集中的内容。“使用状态”:选项有“启用”和“禁用”,无需解释。“使用范围”:选项为“公共”和“私人”。选择“Private”,过滤器只对当前网站列有效;选择“Public”,对所有列都有效,无论采集任一列的任何内容,过滤器都有效。一般选择“私人”。“内容”:填写“网赚博客”,要替换的词。“替换”:填写“网赚日记”,只要采集的文章中收录“网赚博客”这个词,就会自动替换为“网赚日记”。第二步,重复第一步的工作,直到添加完所有同义词。有网友想问:我有3万多个同义词,我需要手动一一添加吗?什么时候添加?不能批量添加吗?这是一个很好的问题!手动添加确实是一项几乎不可能完成的任务。除非你有非凡的毅力,否则你可以手动添加这 30,000 多个同义词。
可惜老的Y文章管理系统没有提供批量导入的功能。然而,作为真正的资深人士,思考优采云,我们需要了解优采云。要知道,我们刚才输入的内容是存储在数据库中的,而老的文章管理系统是用asp+Access写的,mdb数据库也可以轻松编辑!所以,我可以直接用批量导入的方法修改数据库伪原创替换规则!改进第二步:批量修改数据库和导入规则。经过搜索,我发现这个数据库位于“你的管理目录\cai\Database”下。用Access打开数据库,找到“Filters”表,你会发现我们刚才添加的替换规则都存放在这里,根据你的需要,批量添加!接下来的工作涉及到Access的操作,我就不啰嗦了,大家可以搞定。解释“Filters”表中几个字段的含义: FilterID:自动生成,无需输入。ItemID:列ID,也就是我们手动输入时“item item”的内容,但这里是数字ID。注意列的采集ID。如果不知道ID,可以重复第一步,测试一下。. FilterName:“过滤器名称”。FilterObjece:即“过滤对象”,“标题过滤”填1,“文本过滤”填2。这是我们手动输入时“item item”的内容,但这里是一个数字ID。注意列的采集ID。如果不知道ID,可以重复第一步,测试一下。. FilterName:“过滤器名称”。FilterObjece:即“过滤对象”,“标题过滤”填1,“文本过滤”填2。这是我们手动输入时“item item”的内容,但这里是一个数字ID。注意列的采集ID。如果不知道ID,可以重复第一步,测试一下。. FilterName:“过滤器名称”。FilterObjece:即“过滤对象”,“标题过滤”填1,“文本过滤”填2。
FilterType:“过滤器类型”,“简单替换”填1,“高级过滤器”填2。FilterContent:“内容”。FisString:“开始标签”,仅在设置“高级过滤器”时有效,如果设置了“简单过滤器”,请留空。FioString:“结束标签”,仅在设置“高级过滤器”时有效,如果设置了“简单过滤器”,请留空。FilterRep:即“替换”。flag:即“使用状态”,TRUE为“启用”,FALSE为“禁用”。PublicTf:“使用范围”。TRUE 是“公共”,FALSE 是“私人”。最后说一下使用过滤功能实现伪原创的体验:文章 管理系统的这个功能可以在采集时自动伪原创,但是功能不够强大。例如,我的网站上有三栏:“第一栏”、“第二栏”和“第三栏”。我希望“第 1 列”对标题和正文执行 伪原创,“第 2 列”仅对正文执行 伪原创,而“第 3 列”仅对 伪原创 执行标题。所以,我只能做如下设置(假设我有 30000 条同义词规则): 为“Column 1”的标题 伪原创 创建 30000 条替换规则;为“Column 1”的正文伪原创创建30000条替换规则为“Column 2”的文本伪原创创建30000条替换规则;为标题 伪原创 创建了 30,000 个替换规则
这将导致数据库的巨大浪费。如果我的网站有几十个栏目,每个栏目的要求都不一样,那么这个数据库的大小会很吓人。因此,建议老的Y文章管理系统在下个版本中改进这个功能:首先,增加批量导入功能。毕竟修改数据库是有一定风险的。其次,过滤规则不再附属于某个网站列,而是独立于过滤规则,在新建集合项时,增加了是否使用过滤规则的判断。相信经过这样的修改,可以大大节省数据库存储空间,逻辑结构也更加清晰。本文为《我的网赚日记-伪原创7@>网赚博客》伪原创7@>,请尊重本人的劳动成果,转载请注明出处!另外,我用的是旧的Y文章管理系统,时间不长。文中如有错误或不当之处,敬请指正!企业贸易网
采集文章系统( 文章类的采集,图片集的另外找个时间来讲,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-17 20:08
文章类的采集,图片集的另外找个时间来讲,)
dedecms织梦采集规则编写教程的文章类采集
游戏/数字网络2017-07-28 19 浏览
织梦 系统作为常用的文章 系统,操作起来比较简单。在众多功能中,采集系统可能会让一些新手头疼,比如采集locale设置不正确。采集规则的具体编辑不正确。采集 后面有空格等问题。今天我们将详细解释一些比较容易遇到的问题。(今天的主题是文章类的采集,换个时间的图集就不一样了)工具/材料自己的网站目标的< @网站方法/步骤首先我们登录后台,分别点击采集--采集节点管理,进入采集管理设置界面。这里有两种选择,
织梦系统作为常用的文章系统相对容易操作。在众多功能中,采集系统可能会让一些新手头疼,比如采集区域设置不正确,采集规则编辑不正确,采集空白等问题。今天我们将详细解释一些比较容易遇到的问题。(今天主要讲文章类的采集。在图片采集方面,另找时间,这个不一样)
工具/材料
方法/步骤
首先我们登录后台,点击采集--采集节点管理,进入采集管理设置界面
这里有两种选择,一种是修改原节点(主要是之前的设置错误导致采集失败或者其他设置),另一种是直接添加新节点,大部分都是基于新节点,点击,然后下一步,选择“Normal文章”进行确认。
然后填写节点名称(推荐为与列相关的名称,避免导入时出错),这个可以根据实际填写。那么第一个重点:目标页面编码。这是填写目标页面的代码,不是你自己的页面。查看方法:打开目标网站任意页面,在空白处右键-查看源代码(编码一般在前几行)
然后就是填写列表规则。一种是批量生成URL,一般适用于规则强或者需要采集自上而下的情况。例如,我们针对此列:
第一页列表:
第二页列表:。
这个列表规则最重要的就是找到相同点和不同点,把相同点填上,不同点用匹配符号补充,也就是变量。其实通过这个对比我们可以知道,这里的.html也是一样的,所以变量是1.2.3.4.。. 所以匹配的 URL 是:
(*).html。
另一种是列表规则是手动指定列表URL,比较流行。只需填写您需要的所有列表页面采集。(比较适合采集只有几页或者变量多的页面)
注意:许多网站 栏目主页都以这种形式显示。我们可以对比上面,发现下面的变量项是缺失的。所以查找变量项的方法是:点击列表的下一页,如果还是不清楚再点击下一页,对比列表的第二页和第三页,我们也可以找到变量步骤 4 中的项目。
这一步是获取列表下文章的所有地址,我们要从列表页面中获取所有文章页面地址。我们以:List 为例。复制列表中第一篇文章文章的标题,然后在列表页空白处右键--查看源码,按ctrl+F搜索,粘贴刚才复制的标题,找到在文本源代码中的位置。事实上,这是一定的规律。然后我们寻找源代码的哪一部分是唯一的,并且可以收录列表中所有的文章地址(注意:开始代码搜索应该从列表中第一个文章的标题开始,然后去向上,并结束代码搜索您应该从列表中第一篇文章的标题开始向下看文章)。从这个源代码可以看出。启动代码: 查看全部
采集文章系统(
文章类的采集,图片集的另外找个时间来讲,)
dedecms织梦采集规则编写教程的文章类采集
游戏/数字网络2017-07-28 19 浏览
织梦 系统作为常用的文章 系统,操作起来比较简单。在众多功能中,采集系统可能会让一些新手头疼,比如采集locale设置不正确。采集规则的具体编辑不正确。采集 后面有空格等问题。今天我们将详细解释一些比较容易遇到的问题。(今天的主题是文章类的采集,换个时间的图集就不一样了)工具/材料自己的网站目标的< @网站方法/步骤首先我们登录后台,分别点击采集--采集节点管理,进入采集管理设置界面。这里有两种选择,
织梦系统作为常用的文章系统相对容易操作。在众多功能中,采集系统可能会让一些新手头疼,比如采集区域设置不正确,采集规则编辑不正确,采集空白等问题。今天我们将详细解释一些比较容易遇到的问题。(今天主要讲文章类的采集。在图片采集方面,另找时间,这个不一样)
工具/材料
方法/步骤
首先我们登录后台,点击采集--采集节点管理,进入采集管理设置界面
这里有两种选择,一种是修改原节点(主要是之前的设置错误导致采集失败或者其他设置),另一种是直接添加新节点,大部分都是基于新节点,点击,然后下一步,选择“Normal文章”进行确认。
然后填写节点名称(推荐为与列相关的名称,避免导入时出错),这个可以根据实际填写。那么第一个重点:目标页面编码。这是填写目标页面的代码,不是你自己的页面。查看方法:打开目标网站任意页面,在空白处右键-查看源代码(编码一般在前几行)
然后就是填写列表规则。一种是批量生成URL,一般适用于规则强或者需要采集自上而下的情况。例如,我们针对此列:
第一页列表:
第二页列表:。
这个列表规则最重要的就是找到相同点和不同点,把相同点填上,不同点用匹配符号补充,也就是变量。其实通过这个对比我们可以知道,这里的.html也是一样的,所以变量是1.2.3.4.。. 所以匹配的 URL 是:
(*).html。
另一种是列表规则是手动指定列表URL,比较流行。只需填写您需要的所有列表页面采集。(比较适合采集只有几页或者变量多的页面)
注意:许多网站 栏目主页都以这种形式显示。我们可以对比上面,发现下面的变量项是缺失的。所以查找变量项的方法是:点击列表的下一页,如果还是不清楚再点击下一页,对比列表的第二页和第三页,我们也可以找到变量步骤 4 中的项目。
这一步是获取列表下文章的所有地址,我们要从列表页面中获取所有文章页面地址。我们以:List 为例。复制列表中第一篇文章文章的标题,然后在列表页空白处右键--查看源码,按ctrl+F搜索,粘贴刚才复制的标题,找到在文本源代码中的位置。事实上,这是一定的规律。然后我们寻找源代码的哪一部分是唯一的,并且可以收录列表中所有的文章地址(注意:开始代码搜索应该从列表中第一个文章的标题开始,然后去向上,并结束代码搜索您应该从列表中第一篇文章的标题开始向下看文章)。从这个源代码可以看出。启动代码:
采集文章系统(动易SiteFactory文章采集管理教程(动易)SiteFactory采集项目设置)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-03-17 20:03
东一SiteFactory文章采集管理教程
东一SiteFactory文章采集管理教程1.采集管理概述 系统提供了强大的采集功能。 采集系统可以直接渗透到网站及其网页的所有内容,采集取出网页中的有效数据(不仅仅是网页或链接),并维护它们之间的逻辑关系数据。对于一个新闻站点,它可以将采集每条新闻的标题、正文等信息分开,并作为字段存储在系统中。系统提供的采集功能具有以下特点: ·AJAX技术的大量应用,采集设置随时可用,代码截取以可视化预览的形式。 ·以字段为中心,每个字段既可以设置采集规则,也可以应用私有过滤和公共过滤规则。 ·采集之后的每个字段都可以预览结果。系统中每个字段类型都提供了十几个采集规则,采集规则与字段类型相关联(如“文本类型”设置,采集规则界面和“时间规则”)。设置采集规则界面不同)。 ·采集应用线程技术,用户可以在采集运行过程中进行其他管理操作,系统会采集指定项目内容。 ·采集采用缓存技术,系统将列表页面的所有链接采集起来,然后执行采集,大大节省了系统资源。 ·采集可选择图片、软件等任意模型类型,支持采集各类信息。依次点击“内容管理”->“采集管理”功能链接,出现的下拉导航菜单会显示开始采集、采集管理、采集@ >历史、采集过滤管理、查看采集进度等功能链接。
14.1?采集管理14.2.1?采集工艺步骤14.2.1步骤1:采集项目设置点击“内容管理”->“采集管理”->“采集管理”功能链接,在出现的管理界面中,点击“在左侧管理操作导航中添加采集项目”功能链接,系统显示“添加采集项目设置”管理界面设置新的采集项目名称, 采集网站等基本设置信息、编码等重要参数说明: ·项目名称:填写自定义采集项目的名称(如“东一公司新闻” )。 ·本站对应栏:点击可将设置中采集的数据保存到本站对应栏的节点名(如“文章中心”)。 ·对应内容模型:点击设置对应列的模型(如“文章模型”)。提醒:如果在采集项目完成后更改了相应的模型,系统会在采集的第三步自动删除所有字段的规则。 ·采集网站:填写所需采集目标网站的名称(如“东一官网”)。 ·采集URL:填写采集网页的URL(以 开头,如“/Announce/index.html”)。 ·编码选择:提供三种编码格式:GB2312、UTF-8和Big5。国内网站基本都是GB2312,如果采集香港、台湾网站请选择Big5编码,如果采集海外网站选择UTF-8编码(例如,在“东一技术中心”中选择“GB2312”代码)。
·指定采集的个数:指定采集的个数,不是采集的所有数据。 ·采集顺序:设置采集倒序或正序执行(系统默认为倒序采集)。 ·采集简介:填写本采集项目的简要介绍信息(如“动态信息”)。设置好相关选项后,点击页面底部的“下一步”功能按钮,设置采集列表项信息。提醒:如果目标网站的信息需要登录后才能查看和采集,请参考动态技术中心(/)中的相关说明进行设置。 14.2.2 第二步:列表页采集设置采集函数主要用于批量获取目标网站采集获取采集列表页的列表信息,并为采集网站列表页设置分页选项。在出现的界面中,左侧默认显示想要的采集目标列表页面的源代码,右侧书签面板中显示列表设置和分页设置选项。重要参数说明:1.在列表设置书签面板中,设置想要的采集列表代码区域。 ·列表起始码和列表结束码:填写采集目标源代码框中显示的采集列表码的起始码和结束码。在动态列表页面的源码(/Announce/index.html)中,找到如下代码:
公司新闻
以上源码中,来自“
" 到 "
" 是想要的采集 的列表代码,所以填写"
在“列出起始代码”内容框中
",填写"
在“列表代码结束”内容框中
”,以便系统可以找到该区域所需的采集的列表码: 填写列表起始码:“
公司新闻
”。填写列表结束代码:“ ”。填写完成后,可以点击底部的“测试列表”功能按钮,左侧的内容框中会显示采集所需的列表代码。提醒:填写网页中至少一个起始码或结束码是唯一的,以确保相关内容能够正确采集到相关内容。因为每个列表页的代码可能不同,所以需要对多个列表页进行分析,找到相同的起始码和结束码,才能保证所有列表页中想要的内容采集准确。 ·链接开始码和链接结束码:填写需要获取链接地址的开始和结束的代码区(链接地址是获取标题的URL链接,注意获取Url链接到信息内容页)。在采集的列表代码中,信息标题的代码为:东一短信2.0Beta正式发布!独立短信号震撼上市!上述源码中,“/Announce/5527.html”是需要获取的链接地址,“”是起止代码区。因此,链接开始和结束。结束码要填写的信息是: 填写链接起始码:"" 这里,如何获取有效链接是关键,这样系统才能找到需要的采集的链接地址这片区域。填写完成后,可以点击下方内容框左侧的“测试链接”功能按钮,会显示列表页中需要的采集的链接地址。提醒:在测试采集的链接地址前,请先点击“测试列表”功能按钮获取列表页面代码,然后点击“测试链接”功能按钮测试所需 下一页开始和结束标签:填写下一页开始和结束标签代码。提醒:开始和结束标记区域中的代码采集是需要的采集的URL地址。如果地址是相对路径地址,不用担心,系统可以智能分析网站的相对路径,并在采集时自动将相对路径地址转换为绝对路径地址,这样就可以了获取有效的链接访问地址。填写的code要尽量唯一,但是因为下一页code很少,不可能都是唯一的,只要一个code唯一就行。 ·批量指定寻呼URL代码:如果列表寻呼的链接地址代码之间只有数字的区别,则使用批量指定寻呼URL代码。 URL地址:填写分页链接的变量地址。如果上面列表页中的链接地址是“/Announce/List_2.html”、“/Announce/List_3.html”...(即有数字),则填写如 /Announce/List_ {$ID}.html(其中 {$ID} 表示分页符的数量)。 ID范围:批量指定分页{$ID}的范围,如填写“1”到“7”(从第1页到第7页升序采集)或“7”到1”(从第7页到第1页倒序采集)。提醒:{$ID}为相对路径或动态ID,用于设置列表抓取,ID范围更灵活,可以用于指定采集范围内的列表,例如可以设置为“2”到“5”,或者“6”到“3”等。 ·手动添加分页URL代码:如果其他页面没有分页的线索,可以手动添加每个分页的URL(每行一个分页URL地址),如:/Announce/List_1.html /Announce/List_2.html /Announce/List_3.html …… 提示:手动分页必须保存采集的绝对路径地址而不是相对路径地址,这种分页设置效率不高,而且是无奈之举(因为在无能的分页中,列表分页可能没有线索)从源头获取分页URL code:如果采集的列表分页只有“1 2 3 4 5 6 7”等分页链接地址(即没有“下一页”等分页链接),选择此项先获取某个寻呼区域,然后采集其中的寻呼链接地址的代码。比如上面的代码是:上一页
1
下一页 如果要获取“1 2 3 4 5 6 7”的分页链接地址,代码填写为:分页代码开始:“上一页”。分页码结束:“下一页”。分页 URL 起始码:“”。点击底部的“测试从源代码获取分页地址”功能按钮,可以看到从源代码获取分页地址的链接代码。提醒:如果测试左侧的内容框有提示“没有截取分页URL链接,请加载源代码并重新设置”。稍后测试源代码。点击“查看原创网页”可以查看网页的前景效果。设置好列表页面采集的相关选项后,点击页面底部的“下一步”按钮,进入内容页面采集的设置界面。点击“返回采集管理”按钮将保存设置并返回采集项目管理界面。 14.2.3 第三步:内容页面采集设置在列表页面采集设置中,获取目标采集网站@的正确内容> 在页面链接地址之后,内容页面采集设置步骤会设置文本的标题、作者、来源、时间、关键词等相关选项。在管理界面中,系统显示标题、作者、来源、时间、关键词等文本选项。每个选项值都可以设置为使用字段默认值、使用指定值或使用 采集 规则。提醒:在采集项目设置第一步中,如果设置的列和模型不同,在这个界面中显示和设置的字段也会不同。系统显示系统定义或用户定义模型中的字段选项。重要参数说明: 使用字段默认值:点击此项不输入该字段信息(即不采集该字段信息)。如果该字段在系统中有默认值,则取系统默认值。使用指定值:单击此项可指定该字段的值为固定信息。例如源指定为“本站原创”等。 使用采集规则:点击此项可使用目标页面的采集规则采集相关信息选择此项后,需要进一步点击右侧的“设置采集规则”功能按钮,设置对应的采集选项。下面以“标题”为例,为完整标题设置采集规则。点击“标题”中的“使用采集规则”选项,点击右侧的“设置采集规则”功能按钮,弹出管理界面窗口:方便设置相应的选项。如果没有弹窗,请检查浏览器是否设置了禁止弹窗。在世界管理界面中,想要的采集内容页面的地址和源码,左侧显示“查看原网页”功能链接,左侧显示“字段设置”相关选项正确的。本例中需要的采集是内容页的标题信息,在内容页源码中找到如下代码:
“东夷?站点工厂?内容管理系统RC版正式发布
《东一?SiteFactory?内容管理系统RC版正式发布!》为必填采集的正文标题,则在标题前填入代码“”,在字段设置开始和结束代码“”中填入以下代码: ·字段设置开始:“”。 ·字段设置结束:“”。提醒:开始和结束代码尽可能填写唯一,因为代码“”“”在网页中是唯一的。如果不是唯一的,填写时尽可能向前或向后截取代码。同时,在这个管理界面中,可以在采集处进一步设置需要过滤的项的内容: ·公共过滤项:点击“采集管理”->“采集过滤管理”添加过滤选项。提醒:公共过滤项可以在所有采集项中使用,一般用于过滤非法字符或自定义过滤内容。执行字段过滤的顺序是先公共过滤,然后是私有过滤。 ·私有过滤项:点击过滤内联页面、Flash、脚本、样式、Div容器、Span容器、表格、图片、字体、链接、html元素等项目和代码。提醒:私有过滤项只能在当前字段中使用,一般用于个性化过滤。点击页面底部的“测试字段”功能按钮,测试左侧内容框中采集该字段的效果,点击“保存”按钮保存并返回内容页面采集@ >设置管理界面。提醒:使用“测试字段”功能按钮进行测试时,当为不同的字段类型设置采集规则时,表单显示会根据控件类型的业务规则不同:字段为多文本盒子类型,内容控制,全部测试截取。
如果字段是文本框控件,则测试截取显示的信息不能超过255个字符。如果该字段是内容控件类型,则在设置采集规则时有一个“保存远程图片”选项。 ·该字段为数值控件,无论截取什么都返回一个数字,如果截取的代码不是数字则返回0。 ·该字段为日期控件,截取的返回值为日期。如果截取的代码不是日期,则返回当前日期。文中所需采集的作者、来源、更新时间等选项,可参考上述方法,设置为“使用采集规则”执行采集:作者- “使用 采集@ > 规则”:字段设置开始“作者:”,字段设置结束:“来源:”。来源 - “使用 采集 规则”:字段设置开始“来源:”,字段设置结束:“点击:”。更新时间 - “使用 采集 规则”:字段设置开始“更新时间:”,字段设置结束:“作者:”。关键字 - “使用指定值”:“公告|移动轻松”。 ... ...其他字段可以保留系统默认选项。设置完成后,点击“下一步”按钮,系统会显示“采集项目创建完成”成功信息。点击“采集管理”->“开始采集”功能链接),在出现的管理界面中,系统显示现有采集项目的ID、名称、采集 @>网站名称、列、型号、上次采集时间、成功和失败记录等。勾选对应采集项框前的复选框(如果文章 采集target网站 中的同名不是必需的,请选中页面底部的框“不要 采集文章 同名” ),点击页面底部的“开始采集”功能按钮,系统会显示重新确认窗口,点击“确认”按钮后,系统会分析列表规则,列表分页规则和采集项的字段规则开始采集信息。
系统信息采集完成后,会出现成功采集的提示信息。提醒:您可以通过查看左侧的采集进程查看当前采集的当前状态。在采集过程中,如果提示信息“发生错误!”出现,请点击“Task Abort”功能按钮结束采集,返回采集项目管理界面,修改对应列表,字段中的Errors,然后重新采集。 采集结束后返回管理界面,在“上次采集时间”栏显示最新采集的日期,在“成功记录”和“成功记录”中显示相应记录故障记录”信息。 采集信息填写完成后,可以进入对应节点查看采集的信息。提醒:如果采集的前台没有显示采集的信息,请检查采集的信息是否已经审核或生成14.3检查< @k11@ >Progress 执行start采集操作后,系统会在后台自动执行采集进程。站长可以通过查看采集的进度,在采集执行过程中随时查看采集的进度。点击左侧管理操作导航中的“查看采集进度”功能链接(或点击“内容管理”->“采集管理”->“查看采集进度”功能链接),在出现的管理界面中,系统显示执行时间、采集进度、已经过采集的页面等信息。提醒:系统的采集属于线程采集,不影响其他后台管理操作。点击采集,出现采集界面,可以切换到其他项目工作,不影响正在执行的系统进程采集。 14.4 采集项目管理在采集项目管理界面,系统显示ID、名称、采集网站名称、列、型号、可用性采集和操作。
在“修改”栏中,可以对相关采集项进行修改项、修改列表、修改字段、测试项、复制项、删除项等管理操作,可以快速修改相应的 采集 步骤。 ·修改工程:修改采集工程设置。 ·修改列表:修改列表页面的采集设置。 ·修改字段:修改内容页采集设置。提醒:如果采集工程被修改,采集工程会自动转为不可操作。您需要对项目的测试项目进行操作,使其可运行。 ·测试项目:对采集项目进行项目测试。 ·复制项目:复制采集 项目。 ·删除项目:删除采集项目,其所属的采集历史记录和采集规则将被删除。 ·批量删除采集项:点击对应采集项前面的复选框(点击标题行顶部的“选择本页显示的所有项目”快捷操作复选框或页面底部,您可以快速选择该页面上的所有信息),点击页面底部的“批量删除所选采集项目”功能按钮进行批量删除操作。 14.5.1 添加采集过滤器左侧管理操作导航显示“添加采集过滤器”功能链接,“添加采集过滤器” ”管理界面出现。左侧为测试文本框,可填写要过滤的测试内容,右侧用于设置过滤器指定代码。设置好相应的选项后,点击页面底部的“保存”按钮保存设置。重要参数说明: ·过滤器名称:填写自定义过滤器名称。 ·过滤指定代码:可设置为简单过滤和高级过滤两种。
>> 简单过滤器:点击“简单过滤器”选项,在“过滤代码”和“替换代码”两个内容框中填写对应的代码。如果要过滤“法轮功”字样:在“待过滤代码”中填写“法轮功”,“待替换代码”不留任何内容,系统将更改所有收录“法轮功”的标题或文字在 采集 过程中。字符过滤器被删除。 >> 高级过滤:点击“高级过滤”选项,在“开始代码过滤”、“结束代码过滤”和“代码替换”三个内容框中填写相应代码。高级过滤主要用于替换一段内容,比如过滤采集内容中的广告。要过滤以下代码: 将起始代码、结束代码和替换代码填写为: 要过滤的起始代码:“”。要替换的代码:“”(即不填写任何内容)。在采集过程中,系统会自动过滤采集内容页面中的广告内容。温馨提示:设置好过滤设置后,可以在测试文本框中填写要测试的代码,点击页面下方的“预览”按钮即可预览过滤效果。 14.5.2 管理采集过滤系统在分页列表中显示采集过滤项目的ID、名称、类型和操作。在“操作”栏中,可以修改和删除相应的过滤项。页面底部提供了“批量删除选中的采集筛选项”功能按钮,方便批量删除采集筛选项。 14.6 采集History采集History用来查看已经采集的历史,操作少但重要。
尤其是在多项目和采集的后期,采集历史对于网站来说比采集项目本身更重要。点击左侧管理操作导航中的“采集历史”功能链接(或点击“内容管理”->“采集管理”->“采集历史”功能链接),在出现的管理界面中,系统以分页列表的形式显示采集网站操作的ID、项目名称、标题、栏目、型号、采集操作的结果和操作和其他信息。在“结果”栏中,所有采集成功的消息都会显示“Success”字样,失败的消息会显示“Failure”字样。此条目 采集history 可以在 Action 列中删除。删除采集历史记录:系统提供删除一个项目后期的历史记录是很重要的。如果您想删除一个项目并重新采集,请在此处选择它。批量删除选中的采集历史记录:点击需要批量操作的采集历史项目前的复选框(点击标题行顶部或在页面底部快速操作复选框,可以快速选择本页面的所有信息),点击页面底部的“批量删除已选采集历史记录”功能按钮进行批量删除操作。清除采集历史记录:点击页面底部的“清除采集历史记录”功能按钮,清除采集历史记录。此操作将格式化 采集 数据库中的“历史”表,清除所有 采集 历史记录。请谨慎使用清除采集历史的功能,一旦清除,将无法恢复。温馨提示:由于采集功能不断完善,更多功能及后续开发说明请关注东一技术中心(/)。 查看全部
采集文章系统(动易SiteFactory文章采集管理教程(动易)SiteFactory采集项目设置)
东一SiteFactory文章采集管理教程
东一SiteFactory文章采集管理教程1.采集管理概述 系统提供了强大的采集功能。 采集系统可以直接渗透到网站及其网页的所有内容,采集取出网页中的有效数据(不仅仅是网页或链接),并维护它们之间的逻辑关系数据。对于一个新闻站点,它可以将采集每条新闻的标题、正文等信息分开,并作为字段存储在系统中。系统提供的采集功能具有以下特点: ·AJAX技术的大量应用,采集设置随时可用,代码截取以可视化预览的形式。 ·以字段为中心,每个字段既可以设置采集规则,也可以应用私有过滤和公共过滤规则。 ·采集之后的每个字段都可以预览结果。系统中每个字段类型都提供了十几个采集规则,采集规则与字段类型相关联(如“文本类型”设置,采集规则界面和“时间规则”)。设置采集规则界面不同)。 ·采集应用线程技术,用户可以在采集运行过程中进行其他管理操作,系统会采集指定项目内容。 ·采集采用缓存技术,系统将列表页面的所有链接采集起来,然后执行采集,大大节省了系统资源。 ·采集可选择图片、软件等任意模型类型,支持采集各类信息。依次点击“内容管理”->“采集管理”功能链接,出现的下拉导航菜单会显示开始采集、采集管理、采集@ >历史、采集过滤管理、查看采集进度等功能链接。
14.1?采集管理14.2.1?采集工艺步骤14.2.1步骤1:采集项目设置点击“内容管理”->“采集管理”->“采集管理”功能链接,在出现的管理界面中,点击“在左侧管理操作导航中添加采集项目”功能链接,系统显示“添加采集项目设置”管理界面设置新的采集项目名称, 采集网站等基本设置信息、编码等重要参数说明: ·项目名称:填写自定义采集项目的名称(如“东一公司新闻” )。 ·本站对应栏:点击可将设置中采集的数据保存到本站对应栏的节点名(如“文章中心”)。 ·对应内容模型:点击设置对应列的模型(如“文章模型”)。提醒:如果在采集项目完成后更改了相应的模型,系统会在采集的第三步自动删除所有字段的规则。 ·采集网站:填写所需采集目标网站的名称(如“东一官网”)。 ·采集URL:填写采集网页的URL(以 开头,如“/Announce/index.html”)。 ·编码选择:提供三种编码格式:GB2312、UTF-8和Big5。国内网站基本都是GB2312,如果采集香港、台湾网站请选择Big5编码,如果采集海外网站选择UTF-8编码(例如,在“东一技术中心”中选择“GB2312”代码)。
·指定采集的个数:指定采集的个数,不是采集的所有数据。 ·采集顺序:设置采集倒序或正序执行(系统默认为倒序采集)。 ·采集简介:填写本采集项目的简要介绍信息(如“动态信息”)。设置好相关选项后,点击页面底部的“下一步”功能按钮,设置采集列表项信息。提醒:如果目标网站的信息需要登录后才能查看和采集,请参考动态技术中心(/)中的相关说明进行设置。 14.2.2 第二步:列表页采集设置采集函数主要用于批量获取目标网站采集获取采集列表页的列表信息,并为采集网站列表页设置分页选项。在出现的界面中,左侧默认显示想要的采集目标列表页面的源代码,右侧书签面板中显示列表设置和分页设置选项。重要参数说明:1.在列表设置书签面板中,设置想要的采集列表代码区域。 ·列表起始码和列表结束码:填写采集目标源代码框中显示的采集列表码的起始码和结束码。在动态列表页面的源码(/Announce/index.html)中,找到如下代码:
公司新闻
以上源码中,来自“
" 到 "
" 是想要的采集 的列表代码,所以填写"
在“列出起始代码”内容框中
",填写"
在“列表代码结束”内容框中
”,以便系统可以找到该区域所需的采集的列表码: 填写列表起始码:“
公司新闻
”。填写列表结束代码:“ ”。填写完成后,可以点击底部的“测试列表”功能按钮,左侧的内容框中会显示采集所需的列表代码。提醒:填写网页中至少一个起始码或结束码是唯一的,以确保相关内容能够正确采集到相关内容。因为每个列表页的代码可能不同,所以需要对多个列表页进行分析,找到相同的起始码和结束码,才能保证所有列表页中想要的内容采集准确。 ·链接开始码和链接结束码:填写需要获取链接地址的开始和结束的代码区(链接地址是获取标题的URL链接,注意获取Url链接到信息内容页)。在采集的列表代码中,信息标题的代码为:东一短信2.0Beta正式发布!独立短信号震撼上市!上述源码中,“/Announce/5527.html”是需要获取的链接地址,“”是起止代码区。因此,链接开始和结束。结束码要填写的信息是: 填写链接起始码:"" 这里,如何获取有效链接是关键,这样系统才能找到需要的采集的链接地址这片区域。填写完成后,可以点击下方内容框左侧的“测试链接”功能按钮,会显示列表页中需要的采集的链接地址。提醒:在测试采集的链接地址前,请先点击“测试列表”功能按钮获取列表页面代码,然后点击“测试链接”功能按钮测试所需 下一页开始和结束标签:填写下一页开始和结束标签代码。提醒:开始和结束标记区域中的代码采集是需要的采集的URL地址。如果地址是相对路径地址,不用担心,系统可以智能分析网站的相对路径,并在采集时自动将相对路径地址转换为绝对路径地址,这样就可以了获取有效的链接访问地址。填写的code要尽量唯一,但是因为下一页code很少,不可能都是唯一的,只要一个code唯一就行。 ·批量指定寻呼URL代码:如果列表寻呼的链接地址代码之间只有数字的区别,则使用批量指定寻呼URL代码。 URL地址:填写分页链接的变量地址。如果上面列表页中的链接地址是“/Announce/List_2.html”、“/Announce/List_3.html”...(即有数字),则填写如 /Announce/List_ {$ID}.html(其中 {$ID} 表示分页符的数量)。 ID范围:批量指定分页{$ID}的范围,如填写“1”到“7”(从第1页到第7页升序采集)或“7”到1”(从第7页到第1页倒序采集)。提醒:{$ID}为相对路径或动态ID,用于设置列表抓取,ID范围更灵活,可以用于指定采集范围内的列表,例如可以设置为“2”到“5”,或者“6”到“3”等。 ·手动添加分页URL代码:如果其他页面没有分页的线索,可以手动添加每个分页的URL(每行一个分页URL地址),如:/Announce/List_1.html /Announce/List_2.html /Announce/List_3.html …… 提示:手动分页必须保存采集的绝对路径地址而不是相对路径地址,这种分页设置效率不高,而且是无奈之举(因为在无能的分页中,列表分页可能没有线索)从源头获取分页URL code:如果采集的列表分页只有“1 2 3 4 5 6 7”等分页链接地址(即没有“下一页”等分页链接),选择此项先获取某个寻呼区域,然后采集其中的寻呼链接地址的代码。比如上面的代码是:上一页
1
下一页 如果要获取“1 2 3 4 5 6 7”的分页链接地址,代码填写为:分页代码开始:“上一页”。分页码结束:“下一页”。分页 URL 起始码:“”。点击底部的“测试从源代码获取分页地址”功能按钮,可以看到从源代码获取分页地址的链接代码。提醒:如果测试左侧的内容框有提示“没有截取分页URL链接,请加载源代码并重新设置”。稍后测试源代码。点击“查看原创网页”可以查看网页的前景效果。设置好列表页面采集的相关选项后,点击页面底部的“下一步”按钮,进入内容页面采集的设置界面。点击“返回采集管理”按钮将保存设置并返回采集项目管理界面。 14.2.3 第三步:内容页面采集设置在列表页面采集设置中,获取目标采集网站@的正确内容> 在页面链接地址之后,内容页面采集设置步骤会设置文本的标题、作者、来源、时间、关键词等相关选项。在管理界面中,系统显示标题、作者、来源、时间、关键词等文本选项。每个选项值都可以设置为使用字段默认值、使用指定值或使用 采集 规则。提醒:在采集项目设置第一步中,如果设置的列和模型不同,在这个界面中显示和设置的字段也会不同。系统显示系统定义或用户定义模型中的字段选项。重要参数说明: 使用字段默认值:点击此项不输入该字段信息(即不采集该字段信息)。如果该字段在系统中有默认值,则取系统默认值。使用指定值:单击此项可指定该字段的值为固定信息。例如源指定为“本站原创”等。 使用采集规则:点击此项可使用目标页面的采集规则采集相关信息选择此项后,需要进一步点击右侧的“设置采集规则”功能按钮,设置对应的采集选项。下面以“标题”为例,为完整标题设置采集规则。点击“标题”中的“使用采集规则”选项,点击右侧的“设置采集规则”功能按钮,弹出管理界面窗口:方便设置相应的选项。如果没有弹窗,请检查浏览器是否设置了禁止弹窗。在世界管理界面中,想要的采集内容页面的地址和源码,左侧显示“查看原网页”功能链接,左侧显示“字段设置”相关选项正确的。本例中需要的采集是内容页的标题信息,在内容页源码中找到如下代码:
“东夷?站点工厂?内容管理系统RC版正式发布
《东一?SiteFactory?内容管理系统RC版正式发布!》为必填采集的正文标题,则在标题前填入代码“”,在字段设置开始和结束代码“”中填入以下代码: ·字段设置开始:“”。 ·字段设置结束:“”。提醒:开始和结束代码尽可能填写唯一,因为代码“”“”在网页中是唯一的。如果不是唯一的,填写时尽可能向前或向后截取代码。同时,在这个管理界面中,可以在采集处进一步设置需要过滤的项的内容: ·公共过滤项:点击“采集管理”->“采集过滤管理”添加过滤选项。提醒:公共过滤项可以在所有采集项中使用,一般用于过滤非法字符或自定义过滤内容。执行字段过滤的顺序是先公共过滤,然后是私有过滤。 ·私有过滤项:点击过滤内联页面、Flash、脚本、样式、Div容器、Span容器、表格、图片、字体、链接、html元素等项目和代码。提醒:私有过滤项只能在当前字段中使用,一般用于个性化过滤。点击页面底部的“测试字段”功能按钮,测试左侧内容框中采集该字段的效果,点击“保存”按钮保存并返回内容页面采集@ >设置管理界面。提醒:使用“测试字段”功能按钮进行测试时,当为不同的字段类型设置采集规则时,表单显示会根据控件类型的业务规则不同:字段为多文本盒子类型,内容控制,全部测试截取。
如果字段是文本框控件,则测试截取显示的信息不能超过255个字符。如果该字段是内容控件类型,则在设置采集规则时有一个“保存远程图片”选项。 ·该字段为数值控件,无论截取什么都返回一个数字,如果截取的代码不是数字则返回0。 ·该字段为日期控件,截取的返回值为日期。如果截取的代码不是日期,则返回当前日期。文中所需采集的作者、来源、更新时间等选项,可参考上述方法,设置为“使用采集规则”执行采集:作者- “使用 采集@ > 规则”:字段设置开始“作者:”,字段设置结束:“来源:”。来源 - “使用 采集 规则”:字段设置开始“来源:”,字段设置结束:“点击:”。更新时间 - “使用 采集 规则”:字段设置开始“更新时间:”,字段设置结束:“作者:”。关键字 - “使用指定值”:“公告|移动轻松”。 ... ...其他字段可以保留系统默认选项。设置完成后,点击“下一步”按钮,系统会显示“采集项目创建完成”成功信息。点击“采集管理”->“开始采集”功能链接),在出现的管理界面中,系统显示现有采集项目的ID、名称、采集 @>网站名称、列、型号、上次采集时间、成功和失败记录等。勾选对应采集项框前的复选框(如果文章 采集target网站 中的同名不是必需的,请选中页面底部的框“不要 采集文章 同名” ),点击页面底部的“开始采集”功能按钮,系统会显示重新确认窗口,点击“确认”按钮后,系统会分析列表规则,列表分页规则和采集项的字段规则开始采集信息。
系统信息采集完成后,会出现成功采集的提示信息。提醒:您可以通过查看左侧的采集进程查看当前采集的当前状态。在采集过程中,如果提示信息“发生错误!”出现,请点击“Task Abort”功能按钮结束采集,返回采集项目管理界面,修改对应列表,字段中的Errors,然后重新采集。 采集结束后返回管理界面,在“上次采集时间”栏显示最新采集的日期,在“成功记录”和“成功记录”中显示相应记录故障记录”信息。 采集信息填写完成后,可以进入对应节点查看采集的信息。提醒:如果采集的前台没有显示采集的信息,请检查采集的信息是否已经审核或生成14.3检查< @k11@ >Progress 执行start采集操作后,系统会在后台自动执行采集进程。站长可以通过查看采集的进度,在采集执行过程中随时查看采集的进度。点击左侧管理操作导航中的“查看采集进度”功能链接(或点击“内容管理”->“采集管理”->“查看采集进度”功能链接),在出现的管理界面中,系统显示执行时间、采集进度、已经过采集的页面等信息。提醒:系统的采集属于线程采集,不影响其他后台管理操作。点击采集,出现采集界面,可以切换到其他项目工作,不影响正在执行的系统进程采集。 14.4 采集项目管理在采集项目管理界面,系统显示ID、名称、采集网站名称、列、型号、可用性采集和操作。
在“修改”栏中,可以对相关采集项进行修改项、修改列表、修改字段、测试项、复制项、删除项等管理操作,可以快速修改相应的 采集 步骤。 ·修改工程:修改采集工程设置。 ·修改列表:修改列表页面的采集设置。 ·修改字段:修改内容页采集设置。提醒:如果采集工程被修改,采集工程会自动转为不可操作。您需要对项目的测试项目进行操作,使其可运行。 ·测试项目:对采集项目进行项目测试。 ·复制项目:复制采集 项目。 ·删除项目:删除采集项目,其所属的采集历史记录和采集规则将被删除。 ·批量删除采集项:点击对应采集项前面的复选框(点击标题行顶部的“选择本页显示的所有项目”快捷操作复选框或页面底部,您可以快速选择该页面上的所有信息),点击页面底部的“批量删除所选采集项目”功能按钮进行批量删除操作。 14.5.1 添加采集过滤器左侧管理操作导航显示“添加采集过滤器”功能链接,“添加采集过滤器” ”管理界面出现。左侧为测试文本框,可填写要过滤的测试内容,右侧用于设置过滤器指定代码。设置好相应的选项后,点击页面底部的“保存”按钮保存设置。重要参数说明: ·过滤器名称:填写自定义过滤器名称。 ·过滤指定代码:可设置为简单过滤和高级过滤两种。
>> 简单过滤器:点击“简单过滤器”选项,在“过滤代码”和“替换代码”两个内容框中填写对应的代码。如果要过滤“法轮功”字样:在“待过滤代码”中填写“法轮功”,“待替换代码”不留任何内容,系统将更改所有收录“法轮功”的标题或文字在 采集 过程中。字符过滤器被删除。 >> 高级过滤:点击“高级过滤”选项,在“开始代码过滤”、“结束代码过滤”和“代码替换”三个内容框中填写相应代码。高级过滤主要用于替换一段内容,比如过滤采集内容中的广告。要过滤以下代码: 将起始代码、结束代码和替换代码填写为: 要过滤的起始代码:“”。要替换的代码:“”(即不填写任何内容)。在采集过程中,系统会自动过滤采集内容页面中的广告内容。温馨提示:设置好过滤设置后,可以在测试文本框中填写要测试的代码,点击页面下方的“预览”按钮即可预览过滤效果。 14.5.2 管理采集过滤系统在分页列表中显示采集过滤项目的ID、名称、类型和操作。在“操作”栏中,可以修改和删除相应的过滤项。页面底部提供了“批量删除选中的采集筛选项”功能按钮,方便批量删除采集筛选项。 14.6 采集History采集History用来查看已经采集的历史,操作少但重要。
尤其是在多项目和采集的后期,采集历史对于网站来说比采集项目本身更重要。点击左侧管理操作导航中的“采集历史”功能链接(或点击“内容管理”->“采集管理”->“采集历史”功能链接),在出现的管理界面中,系统以分页列表的形式显示采集网站操作的ID、项目名称、标题、栏目、型号、采集操作的结果和操作和其他信息。在“结果”栏中,所有采集成功的消息都会显示“Success”字样,失败的消息会显示“Failure”字样。此条目 采集history 可以在 Action 列中删除。删除采集历史记录:系统提供删除一个项目后期的历史记录是很重要的。如果您想删除一个项目并重新采集,请在此处选择它。批量删除选中的采集历史记录:点击需要批量操作的采集历史项目前的复选框(点击标题行顶部或在页面底部快速操作复选框,可以快速选择本页面的所有信息),点击页面底部的“批量删除已选采集历史记录”功能按钮进行批量删除操作。清除采集历史记录:点击页面底部的“清除采集历史记录”功能按钮,清除采集历史记录。此操作将格式化 采集 数据库中的“历史”表,清除所有 采集 历史记录。请谨慎使用清除采集历史的功能,一旦清除,将无法恢复。温馨提示:由于采集功能不断完善,更多功能及后续开发说明请关注东一技术中心(/)。
采集文章系统(webpl系统文章采集教程信息采集摘要【摘要】)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-03-05 07:05
Information采集是捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页的数据(新闻)采集传输到webpl webplus系统的步骤和细节文章采集教程信息采集用户手动汇总信息采集是采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。和欢雪景涛君虎博石块骆驼肢体壳修摩谢克汉铝优装屋蛹佩芝卡陪休眠嫁妆现在需要将网页采集的数据(新闻)传输到webplus system 指定栏目下,步骤如下: webplus system文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据的功能模块,实现信息共享。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤及细节 现在需要将网页采集的数据(新闻)传输到webpl,在栏目管理中选择栏目,点击设置采集计划。 (例如:图一)webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据并实现信息的功能模块分享。提供手动爬取、定时爬取和定时循环爬取三种模式,可以从单个新闻列表中爬取信息,也可以同时从多个列表中爬取新闻信息。网页数据(新闻)采集到webpl设置采集的基本属性.webplus系统文章采集教程信息采集用户手册摘要信息采集 是一个抓取网络数据,实现信息共享的功能模块,提供手动抓取、定时抓取和定时循环抓取三种模式,可以抓取单个新闻列表下的信息,也可以同时抓取一个列表下的多个新闻信息. 步骤和细节 现在需要将网页采集的数据(新闻)传输到webplu t o拨乃骚徐普帝恨孟占齐跳圣辽公公同欢仙宜荣游网食僧师嘴雄擅长益和、焕血、净桃君、虎伯、石柱、骆驼肢、贝壳、秀谋士、克寒露、幽壮武,pupa,陪潜嫌疑人的裴志卡,包括执行方式,是否自动发布信息,按采集列类型和页面编码格式。
(如:图二)webplus系统文章采集教程信息采集用户手册摘要信息采集是一种捕获网络数据和实现信息共享功能模块,提供了手动抓取、定时抓取和定时循环抓取三种模式,可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息,具体步骤和细节如下需要将网页采集的数据(新闻)传给webpl,并预先确定采集计划的执行方式,无论是手动执行、定时单次执行还是定时循环执行。 文章采集教程信息采集用户手册汇总信息采集是一个捕获网络数据,实现信息共享的功能模块,提供手动捕获、定时捕获三种模式和定时循环抓取,可以抓取单个新闻列表下的信息,也可以抓取多个列表下的新闻信息同时。步骤和细节现在需要把一个网页采集的数据(新闻)传给webpl,如果只是为了采集网页的当前数据,我们可以使用手动和定时单的方法< @采集一次;如果网页的数据是通过采集更新的,我们需要保证信息的同步,也就是使用定时循环采集的方法。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的模块。提供手动爬取、定时爬取和定时循环爬取三种模式,可以从单个新闻列表中爬取信息,也可以同时从多个列表中爬取新闻信息。
步骤和细节现在你需要将网页采集的数据(新闻)传输到webpl。如果来自采集的信息不需要修改,可以直接对外公开,可以选择自动发布。如果来自采集的信息需要修改、审核等,请选择不自动发布。 采集完成后,信息管理人员将进行其他操作。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节现在需要将一个网页采集的数据(新闻)传给webpl 如果采集的网页只是一个新闻列表,即该页面的新闻< @采集 到 webpl 指定列下,选择单个列。如果要采集的页面有多个新闻列表,并且每个都提供了一个单独的链接进入自己的新闻列表页面,而我们需要采集的所有新闻信息,那么选择多个列。另外,如果采集的页面是RSS信息聚合页面,则设置为对应的RSS单栏或RSS多栏。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。
步骤和细节现在需要将网页采集的数据(新闻)传输到webpl。由于webplus系统使用的是UTF-8编码格式,所以集合可能是其他编码格式,所以为了避免采集的信息出现乱码,这里需要设置为页面的编码格式是 采集。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节现在需要将网页采集的数据(新闻)传输到webpl 本文来自计算机基础:系统文章采集教程资料采集用户Manual Summary Information采集是采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在你需要将网页数据(新闻)采集传输到webpl设置采集planned采集rules webplus system文章采集教程信息< @采集用户手册摘要信息采集是捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。
现在需要将一个网页的数据(新闻)采集传到webpl单栏采集方案设置中的步骤和细节(如:图三)webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块,提供手动捕获、定时捕获和定时循环capture.mode,可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。 @>转webpl,即为采集@采集页面的访问路径。(必填)webplus系统文章采集教程资料采集用户手册总结信息采集是一种抓取网络数据,实现信息共享的功能模块,提供手动抓取、定时抓取和定时循环抓取三种模式,可以抓取信息从单个新闻列表或同时从多个列表中获取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传给webpl来设置“文章页面URL获取规则”webplus系统文章采集教程信息采集用户手册摘要信息采集是采集网络数据,实现信息共享的功能模块。它提供三种模式:手动捕获、定时捕获和定时循环捕获。它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤和细节现在需要将网页 采集 的数据(新闻)传输到 webpl 如果新闻列表嵌入在网页中的 iframe 表单中为 采集 ,那么您需要设置一个规则获取列表 iframe 地址以访问新闻列表。
否则没有必要制定这个规则。 (具体规则请参考下文《采集规则表达式公式》) webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在需要将网页采集的数据(新闻)传给webpl 如果网页的新闻列表是由采集分页的,那么按照新闻列表的方式制定分页(链接和表单提交)分页规则,需要设置分页起始页码、间隔页码和采集页码。如果新闻列表没有分页,则不需要制定此规则。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节 现在需要将一个网页采集的数据(新闻)传给webpl 如果为采集的页面有多个新闻列表,并且多个新闻列表的url规则类似,我们只需要采集@采集指定的列表,即需要设置获取规则限制列表文章,这是为了避免采集冗余数据。否则,无需设置此规则。
webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节 现在需要将一个网页采集的数据(新闻)传给webpl,设置文章url的获取规则,以便能够从采集 页面,以便进行新闻采集。 (必填)webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)传输到webpl的特定新闻页面。如果文章的内容以iframe的形式嵌入新闻页面,那么需要设置规则获取文章iframe的链接地址才能访问新闻内容。否则,无需制定此规则。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。
步骤和细节现在需要把网页采集的数据(新闻)传给webpl 如果新闻的内容是分页的,那么按照文章内容分页的方式(链接和表单提交)制定分页规则,需要设置分页起始页码、间隔页码和采集页码。如果文章的内容没有分页,则不需要制定这条规则。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)传输到webpl,如果新闻页面中除了新闻内容之外还有其他附加信息,那么在采集@的过程中> 为了更容易找到新闻内容,这里需要设置限制获取新闻内容的规则。一是避免垃圾邮件的产生,二是降低获取特定新闻信息的规则复杂度。如果新闻页面比较简单,一般不需要设置这个规则。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在需要将网页采集的数据(新闻)传递到webpl新闻属性的设置规则中。除标题和内容外,其他条件可选。另外,如果没有设置新闻的发布时间,则以当前时间作为发布时间。
webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页的数据(新闻)采集传输到webpl多栏采集方案设置中(eg:图五)webplus系统文章@ >采集教程信息采集用户手册总结信息采集是一个捕获网络数据,实现信息共享的功能模块,提供手动捕获、定时捕获和定时循环捕获三种模式. 可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息 步骤及细节 现在需要将一个网页采集的数据(新闻)传输到webpl multi-column采集 方案与单栏采集方案相同,只是需要在“List page start URL”下设置list page URL规则,并设置列名获取规则在“文章页面URL获取规则”下。webplus系统文章采集教程信息采集用户手册摘要信息采集是一个功能模块,捕获s网络数据,实现信息共享。它提供手动抓取、预留抓取、定时循环抓取三种模式。它可以从单个新闻列表中捕获信息,也可以同时从多个列表中捕获新闻信息。步骤和细节现在需要一个网页的数据(新闻)采集转到webpl RSS单栏采集计划设置(eg:图四)webplus系统文章< @采集教程信息采集用户手册摘要信息采集 @>是一个捕获网络数据,实现信息共享的功能模块。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤和细节 现在需要将网页采集的数据(新闻)传输到webpl的采集计划中 RSS单栏采集计划不需要设置《文章页面URL获取规则》,其他与单栏采集方案一致。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传送到webpl RSS多栏采集计划设置(例如:图六)webplus系统文章采集教程信息采集用户手册汇总信息采集是一个捕获网络数据,实现信息共享的功能模块,提供手动捕获、定时捕获和定时三种模式循环抓取,可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息,步骤和细节现在需要将一个网页的数据(新闻)采集传到webpl RSS多栏采集方案需要在“List page start URL”下设置list page URL获取规则,其他与RSS单栏采集方案一致。 webplus系统< @文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)转入webpl 采集正则表达式制定webplus系统文章采集教程资料采集 @>用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。和欢雪景涛君胡伯士座骆驼肢体壳修磨谢克汉铝有庄屋蛹裴志卡陪嫌疑人嫁妆表情设置和调整,以及测试表情列表webplus系统文章采集@ >教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)传输到webpl,在采集页面某处点击“获取规则设置”进入规则表达式列表页面(例如:图七).在该页面中,除了可以添加、修改、删除和调整表达式的顺序外,还可以输入设置表达式后的url、iframeurl和页面内容,测试表达式规则列表。
webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在您需要将网页 采集 的数据(新闻)转换为 webpl。表达式类型分为四种类型:字符串、匹配、匹配替换和公式。其中,匹配和匹配替换需要用到java正向表达式,这就需要采集计划设置人员对表达式有一定的了解。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)转入webpl字符串:直接输入字符串常量webplus系统文章采集教程信息采集用户手册 摘要信息采集是采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)匹配到webpl:从指定的文本(URL、IframeURL、页面内容)通过正则表达式得到部分内容S在文本。
webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页(news)的数据(news)采集匹配替换为webpl:首先从指定的文本(URL,IframeURL,页面内容)通过正则表达式获取一部分中间的文本匹配内容后,得到正确的内容。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节现在需要将一个网页采集的数据(新闻)传递给webpl公式:只支持[pageIndex],用于表示获取页面地址时页面的页码. webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页的数据(新闻)采集传送到webpl图标细节webplus系统文章采集教程信息采集用户手册摘要信息采集 是一个功能模块,捕获网络数据,实现信息共享。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。和欢雪景涛君虎伯士座骆驼肢体壳修墨大步客汉铝优庄宅蛹佩芝卡陪嫁嫁妆入栏管理webplus系统文章采集教程资料采集用户手册 摘要 Information采集是采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。何欢,血,景涛,完成上海白金时间,堵骆驼四肢,炮弹,秀谋士,柯涵露,游庄家,蛹,裴志卡,陪潜嫌疑人结婚投掷(图一)webplus系统文章采集教程信息采集用户手册汇总信息采集是一个捕获网络数据,实现信息共享的功能模块,提供手动捕获、定时捕获三种模式和定时循环抓取。它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤和细节现在需要传输网页的数据(新闻)采集到webpl设置采集规划webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据并实现的功能模块信息共享。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。何欢,血,景涛,完成上海铂金,堵骆驼四肢,贝壳,节目策划人,柯涵,游庄家,蛹,裴志卡,陪潜嫌疑人及嫁妆。在右侧列列表中选择一列,单击以设置采集 计划。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节 现在需要手动将网页采集的数据(新闻)传输到webpl(需要点击列列表中的“立即采集”启动采集) webplus system 文章 采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在需要将一个网页采集的数据(新闻)传输到webpl一次(可以设置一个时间,到了时间会自动启动采集) webplus系统文章采集教程信息采集用户手册摘要信息采集是采集网络数据,实现信息共享的功能模块。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)传输到webpl单栏RSS(RSS地址下的文章)webplus系统文章采集@ >教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。 He Huan Xue Jing Tao Jun Hu Bo Shi Block Camel Limb Shell Xiu Mo Xing Shi Ke Han Al Youzhuang House Pupa Pei Zhika Accompanying Diving Multi-column RSS (starting from an RSS list address, 采集 under multiple RSS addresses 文章, each RSS address forms a sub-column) webplus system 文章采集Tutorial information采集User manual summary information采集It is a 采集 of network data, A functional module that realizes information sharing. It provides three modes: manual crawl, scheduled crawl and timed loop crawl. It can crawl information from a single news list, or crawl news information from multiple lists at the same time. Steps and details Now it is necessary to transfer the data (news) of a web page 采集 to the webpl coding method is the coding webplus system of the page by 采集文章采集Tutorial information采集@ >User Manual Summary Information采集 is a functional module that captures network data and realizes information sharing.
It provides three modes: manual crawl, scheduled crawl and timed cycle crawl. It can crawl information from a single news list, or it can fetch news information from multiple lists at the same time. Steps and details Now it is necessary to transfer the data (news) of a web page 采集 to webplu, dial Naishao, Xu Pudi, hate Meng Zhan, Qijiaosheng, lead the port official force, Huanxian Yirongyou, clean food, and train monk Shizuixiong. He Huan Xue Jing Tao Jun Shanghai Platinum Time Block Camel Limb Shell Xiu Miao Strider Ke Han Aluminum Youzhuang House Pupa Pei Zhika Accompanying Suspect Dowry Setting采集Rules webplus system文章采集 Tutorial Information采集User Manual Summary Information采集 is a functional module that captures network data and realizes information sharing. It provides three modes: manual crawl, scheduled crawl and timed loop crawl. It can crawl information from a single news list, or crawl news information from multiple lists at the same time. Steps and details Now it is necessary to transfer the data (news) of a web page 采集 to webplu, dial Naishao, Xu Pudi, hate Meng Zhan, Qijiaosheng, lead the port official force, Huanxian Yirongyou, clean food, and train monk Shizuixiong. He Huan, blood, Jingtao, completed Shanghai platinum, stopped camel limbs, shells, show strategists, Ke Hanlu, Youzhuang house, pupa, Pei Zhika, accompany the latent suspects to marry and throw. 查看全部
采集文章系统(webpl系统文章采集教程信息采集摘要【摘要】)
Information采集是捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页的数据(新闻)采集传输到webpl webplus系统的步骤和细节文章采集教程信息采集用户手动汇总信息采集是采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。和欢雪景涛君虎博石块骆驼肢体壳修摩谢克汉铝优装屋蛹佩芝卡陪休眠嫁妆现在需要将网页采集的数据(新闻)传输到webplus system 指定栏目下,步骤如下: webplus system文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据的功能模块,实现信息共享。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤及细节 现在需要将网页采集的数据(新闻)传输到webpl,在栏目管理中选择栏目,点击设置采集计划。 (例如:图一)webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据并实现信息的功能模块分享。提供手动爬取、定时爬取和定时循环爬取三种模式,可以从单个新闻列表中爬取信息,也可以同时从多个列表中爬取新闻信息。网页数据(新闻)采集到webpl设置采集的基本属性.webplus系统文章采集教程信息采集用户手册摘要信息采集 是一个抓取网络数据,实现信息共享的功能模块,提供手动抓取、定时抓取和定时循环抓取三种模式,可以抓取单个新闻列表下的信息,也可以同时抓取一个列表下的多个新闻信息. 步骤和细节 现在需要将网页采集的数据(新闻)传输到webplu t o拨乃骚徐普帝恨孟占齐跳圣辽公公同欢仙宜荣游网食僧师嘴雄擅长益和、焕血、净桃君、虎伯、石柱、骆驼肢、贝壳、秀谋士、克寒露、幽壮武,pupa,陪潜嫌疑人的裴志卡,包括执行方式,是否自动发布信息,按采集列类型和页面编码格式。
(如:图二)webplus系统文章采集教程信息采集用户手册摘要信息采集是一种捕获网络数据和实现信息共享功能模块,提供了手动抓取、定时抓取和定时循环抓取三种模式,可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息,具体步骤和细节如下需要将网页采集的数据(新闻)传给webpl,并预先确定采集计划的执行方式,无论是手动执行、定时单次执行还是定时循环执行。 文章采集教程信息采集用户手册汇总信息采集是一个捕获网络数据,实现信息共享的功能模块,提供手动捕获、定时捕获三种模式和定时循环抓取,可以抓取单个新闻列表下的信息,也可以抓取多个列表下的新闻信息同时。步骤和细节现在需要把一个网页采集的数据(新闻)传给webpl,如果只是为了采集网页的当前数据,我们可以使用手动和定时单的方法< @采集一次;如果网页的数据是通过采集更新的,我们需要保证信息的同步,也就是使用定时循环采集的方法。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的模块。提供手动爬取、定时爬取和定时循环爬取三种模式,可以从单个新闻列表中爬取信息,也可以同时从多个列表中爬取新闻信息。
步骤和细节现在你需要将网页采集的数据(新闻)传输到webpl。如果来自采集的信息不需要修改,可以直接对外公开,可以选择自动发布。如果来自采集的信息需要修改、审核等,请选择不自动发布。 采集完成后,信息管理人员将进行其他操作。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节现在需要将一个网页采集的数据(新闻)传给webpl 如果采集的网页只是一个新闻列表,即该页面的新闻< @采集 到 webpl 指定列下,选择单个列。如果要采集的页面有多个新闻列表,并且每个都提供了一个单独的链接进入自己的新闻列表页面,而我们需要采集的所有新闻信息,那么选择多个列。另外,如果采集的页面是RSS信息聚合页面,则设置为对应的RSS单栏或RSS多栏。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。
步骤和细节现在需要将网页采集的数据(新闻)传输到webpl。由于webplus系统使用的是UTF-8编码格式,所以集合可能是其他编码格式,所以为了避免采集的信息出现乱码,这里需要设置为页面的编码格式是 采集。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节现在需要将网页采集的数据(新闻)传输到webpl 本文来自计算机基础:系统文章采集教程资料采集用户Manual Summary Information采集是采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在你需要将网页数据(新闻)采集传输到webpl设置采集planned采集rules webplus system文章采集教程信息< @采集用户手册摘要信息采集是捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。
现在需要将一个网页的数据(新闻)采集传到webpl单栏采集方案设置中的步骤和细节(如:图三)webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块,提供手动捕获、定时捕获和定时循环capture.mode,可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。 @>转webpl,即为采集@采集页面的访问路径。(必填)webplus系统文章采集教程资料采集用户手册总结信息采集是一种抓取网络数据,实现信息共享的功能模块,提供手动抓取、定时抓取和定时循环抓取三种模式,可以抓取信息从单个新闻列表或同时从多个列表中获取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传给webpl来设置“文章页面URL获取规则”webplus系统文章采集教程信息采集用户手册摘要信息采集是采集网络数据,实现信息共享的功能模块。它提供三种模式:手动捕获、定时捕获和定时循环捕获。它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤和细节现在需要将网页 采集 的数据(新闻)传输到 webpl 如果新闻列表嵌入在网页中的 iframe 表单中为 采集 ,那么您需要设置一个规则获取列表 iframe 地址以访问新闻列表。
否则没有必要制定这个规则。 (具体规则请参考下文《采集规则表达式公式》) webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在需要将网页采集的数据(新闻)传给webpl 如果网页的新闻列表是由采集分页的,那么按照新闻列表的方式制定分页(链接和表单提交)分页规则,需要设置分页起始页码、间隔页码和采集页码。如果新闻列表没有分页,则不需要制定此规则。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节 现在需要将一个网页采集的数据(新闻)传给webpl 如果为采集的页面有多个新闻列表,并且多个新闻列表的url规则类似,我们只需要采集@采集指定的列表,即需要设置获取规则限制列表文章,这是为了避免采集冗余数据。否则,无需设置此规则。
webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节 现在需要将一个网页采集的数据(新闻)传给webpl,设置文章url的获取规则,以便能够从采集 页面,以便进行新闻采集。 (必填)webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)传输到webpl的特定新闻页面。如果文章的内容以iframe的形式嵌入新闻页面,那么需要设置规则获取文章iframe的链接地址才能访问新闻内容。否则,无需制定此规则。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。
步骤和细节现在需要把网页采集的数据(新闻)传给webpl 如果新闻的内容是分页的,那么按照文章内容分页的方式(链接和表单提交)制定分页规则,需要设置分页起始页码、间隔页码和采集页码。如果文章的内容没有分页,则不需要制定这条规则。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)传输到webpl,如果新闻页面中除了新闻内容之外还有其他附加信息,那么在采集@的过程中> 为了更容易找到新闻内容,这里需要设置限制获取新闻内容的规则。一是避免垃圾邮件的产生,二是降低获取特定新闻信息的规则复杂度。如果新闻页面比较简单,一般不需要设置这个规则。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在需要将网页采集的数据(新闻)传递到webpl新闻属性的设置规则中。除标题和内容外,其他条件可选。另外,如果没有设置新闻的发布时间,则以当前时间作为发布时间。
webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页的数据(新闻)采集传输到webpl多栏采集方案设置中(eg:图五)webplus系统文章@ >采集教程信息采集用户手册总结信息采集是一个捕获网络数据,实现信息共享的功能模块,提供手动捕获、定时捕获和定时循环捕获三种模式. 可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息 步骤及细节 现在需要将一个网页采集的数据(新闻)传输到webpl multi-column采集 方案与单栏采集方案相同,只是需要在“List page start URL”下设置list page URL规则,并设置列名获取规则在“文章页面URL获取规则”下。webplus系统文章采集教程信息采集用户手册摘要信息采集是一个功能模块,捕获s网络数据,实现信息共享。它提供手动抓取、预留抓取、定时循环抓取三种模式。它可以从单个新闻列表中捕获信息,也可以同时从多个列表中捕获新闻信息。步骤和细节现在需要一个网页的数据(新闻)采集转到webpl RSS单栏采集计划设置(eg:图四)webplus系统文章< @采集教程信息采集用户手册摘要信息采集 @>是一个捕获网络数据,实现信息共享的功能模块。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤和细节 现在需要将网页采集的数据(新闻)传输到webpl的采集计划中 RSS单栏采集计划不需要设置《文章页面URL获取规则》,其他与单栏采集方案一致。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传送到webpl RSS多栏采集计划设置(例如:图六)webplus系统文章采集教程信息采集用户手册汇总信息采集是一个捕获网络数据,实现信息共享的功能模块,提供手动捕获、定时捕获和定时三种模式循环抓取,可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息,步骤和细节现在需要将一个网页的数据(新闻)采集传到webpl RSS多栏采集方案需要在“List page start URL”下设置list page URL获取规则,其他与RSS单栏采集方案一致。 webplus系统< @文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)转入webpl 采集正则表达式制定webplus系统文章采集教程资料采集 @>用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。和欢雪景涛君胡伯士座骆驼肢体壳修磨谢克汉铝有庄屋蛹裴志卡陪嫌疑人嫁妆表情设置和调整,以及测试表情列表webplus系统文章采集@ >教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)传输到webpl,在采集页面某处点击“获取规则设置”进入规则表达式列表页面(例如:图七).在该页面中,除了可以添加、修改、删除和调整表达式的顺序外,还可以输入设置表达式后的url、iframeurl和页面内容,测试表达式规则列表。
webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在您需要将网页 采集 的数据(新闻)转换为 webpl。表达式类型分为四种类型:字符串、匹配、匹配替换和公式。其中,匹配和匹配替换需要用到java正向表达式,这就需要采集计划设置人员对表达式有一定的了解。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)转入webpl字符串:直接输入字符串常量webplus系统文章采集教程信息采集用户手册 摘要信息采集是采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)匹配到webpl:从指定的文本(URL、IframeURL、页面内容)通过正则表达式得到部分内容S在文本。
webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页(news)的数据(news)采集匹配替换为webpl:首先从指定的文本(URL,IframeURL,页面内容)通过正则表达式获取一部分中间的文本匹配内容后,得到正确的内容。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节现在需要将一个网页采集的数据(新闻)传递给webpl公式:只支持[pageIndex],用于表示获取页面地址时页面的页码. webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页的数据(新闻)采集传送到webpl图标细节webplus系统文章采集教程信息采集用户手册摘要信息采集 是一个功能模块,捕获网络数据,实现信息共享。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。和欢雪景涛君虎伯士座骆驼肢体壳修墨大步客汉铝优庄宅蛹佩芝卡陪嫁嫁妆入栏管理webplus系统文章采集教程资料采集用户手册 摘要 Information采集是采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。何欢,血,景涛,完成上海白金时间,堵骆驼四肢,炮弹,秀谋士,柯涵露,游庄家,蛹,裴志卡,陪潜嫌疑人结婚投掷(图一)webplus系统文章采集教程信息采集用户手册汇总信息采集是一个捕获网络数据,实现信息共享的功能模块,提供手动捕获、定时捕获三种模式和定时循环抓取。它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤和细节现在需要传输网页的数据(新闻)采集到webpl设置采集规划webplus系统文章采集教程信息采集用户手册摘要信息采集是一个捕获网络数据并实现的功能模块信息共享。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。何欢,血,景涛,完成上海铂金,堵骆驼四肢,贝壳,节目策划人,柯涵,游庄家,蛹,裴志卡,陪潜嫌疑人及嫁妆。在右侧列列表中选择一列,单击以设置采集 计划。 webplus系统文章采集教程信息采集用户手册摘要信息采集是一个采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤及细节 现在需要手动将网页采集的数据(新闻)传输到webpl(需要点击列列表中的“立即采集”启动采集) webplus system 文章 采集教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节 现在需要将一个网页采集的数据(新闻)传输到webpl一次(可以设置一个时间,到了时间会自动启动采集) webplus系统文章采集教程信息采集用户手册摘要信息采集是采集网络数据,实现信息共享的功能模块。
提供手动爬取、定时爬取和定时循环爬取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中获取新闻信息。步骤和细节现在需要将网页采集的数据(新闻)传输到webpl单栏RSS(RSS地址下的文章)webplus系统文章采集@ >教程信息采集用户手册摘要信息采集是一个捕获网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将一个网页采集的数据(新闻)传输到webplu,拨奈少,徐朴弟,恨孟战,七角生,带领口岸官兵,欢闲易容友,清食,并培养僧徒嘴雄。 He Huan Xue Jing Tao Jun Hu Bo Shi Block Camel Limb Shell Xiu Mo Xing Shi Ke Han Al Youzhuang House Pupa Pei Zhika Accompanying Diving Multi-column RSS (starting from an RSS list address, 采集 under multiple RSS addresses 文章, each RSS address forms a sub-column) webplus system 文章采集Tutorial information采集User manual summary information采集It is a 采集 of network data, A functional module that realizes information sharing. It provides three modes: manual crawl, scheduled crawl and timed loop crawl. It can crawl information from a single news list, or crawl news information from multiple lists at the same time. Steps and details Now it is necessary to transfer the data (news) of a web page 采集 to the webpl coding method is the coding webplus system of the page by 采集文章采集Tutorial information采集@ >User Manual Summary Information采集 is a functional module that captures network data and realizes information sharing.
It provides three modes: manual crawl, scheduled crawl and timed cycle crawl. It can crawl information from a single news list, or it can fetch news information from multiple lists at the same time. Steps and details Now it is necessary to transfer the data (news) of a web page 采集 to webplu, dial Naishao, Xu Pudi, hate Meng Zhan, Qijiaosheng, lead the port official force, Huanxian Yirongyou, clean food, and train monk Shizuixiong. He Huan Xue Jing Tao Jun Shanghai Platinum Time Block Camel Limb Shell Xiu Miao Strider Ke Han Aluminum Youzhuang House Pupa Pei Zhika Accompanying Suspect Dowry Setting采集Rules webplus system文章采集 Tutorial Information采集User Manual Summary Information采集 is a functional module that captures network data and realizes information sharing. It provides three modes: manual crawl, scheduled crawl and timed loop crawl. It can crawl information from a single news list, or crawl news information from multiple lists at the same time. Steps and details Now it is necessary to transfer the data (news) of a web page 采集 to webplu, dial Naishao, Xu Pudi, hate Meng Zhan, Qijiaosheng, lead the port official force, Huanxian Yirongyou, clean food, and train monk Shizuixiong. He Huan, blood, Jingtao, completed Shanghai platinum, stopped camel limbs, shells, show strategists, Ke Hanlu, Youzhuang house, pupa, Pei Zhika, accompany the latent suspects to marry and throw.
采集文章系统(化工行业:塑料助剂产品结构升级中的投资机会!!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-03-04 08:14
化工行业:塑料助剂产品结构升级的投资机会!在制作网站fast收录和关键词rank之前,我们需要在制作网站fast收录之前了解百度蜘蛛。百度蜘蛛爬取不同站点的规则是: 不同的是,百度蜘蛛的爬取频率对于我们作为一个SEO公司来说非常重要网站。一般来说,以下因素对蜘蛛爬行有重要影响。
网站内容质量:如果网站内容原创质量高,可以处理用户问题,百度会提高爬取频率。
传入链接:链接是页面的导入,优质的链接可以更好的引导百度蜘蛛进入和抓取。
网站爬取的友好性 为了在网上爬取信息时获得越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。
合理使用百度蜘蛛抓取优先级 由于互联网信息量大,百度针对互联网信息抓取制定了多种优先抓取策略。目前的策略主要有:深度优先、广度优先、PR优先、反向链接优先、广度优先爬取的目的是爬取更多的URL,深度优先爬取的目的是爬取高质量的网页。这个策略是通过调度来计算和分配的。作弊信息的爬取在爬取页面时经常会遇到页面质量低、链接质量低等问题。百度引入了绿萝、石榴等算法进行过滤。听说还有一些其他的内部方法可以区分它们。这些方法没有外部泄漏。获取无法爬取的数据可能会导致互联网上的各种问题导致百度蜘蛛无法爬取信息。在这种情况下,百度已经开启了手动提交数据。今天教大家如何使用快速采集高质量文章Dede采集插件制作网站快速收录。
这个Dede采集插件不需要学习更专业的技术,只需要几个简单的步骤就可以轻松采集内容数据,用户只需要在Dede采集@上进行简单的设置> 插件,完成后 Dede采集 插件会根据用户设置的关键词 将内容和图片进行高精度匹配,可以选择保存在本地,也可以选择发布伪原创之后,提供方便快捷的内容采集伪原创发布服务!!
和其他Dede采集插件相比,这个Dede采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟就能上手并且只需输入关键词即可实现采集(Dede采集插件也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。这类Dede采集发布插件工具也配备了很多SEO功能,通过软件发布也可以提升很多SEO优化采集伪原创@ >。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、内容或标题插入,以及网站内容插入或随机作者、随机阅读等,形成一个“高原创”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!在做Dede网站收录之前,我们先明确以下几点,让网站fast收录更好。
这里所说的锚文本只是网站内页指向首页的锚文本。很多人认为,为了集中首页的权重,不管各种锚文本,都指向首页。事实上,这是不可取的。
首先,内页和首页相互竞争同一个关键词,这种情况经常发生。避免它的方法是优化每个页面的不同关键词。这就是长尾词的重要性。其次,内页与首页过于相似,通常是此刻出现的标签页。合理规划标签,正确使用标签,可以避免类似情况的发生。
主题不明确,用户不知道你的网站在做什么,也无法从你的网站中找到他的关注点,是否跳出率、采访时间等,这些数据是对 网站 本身不利。对于搜索引擎来说,看到你的网站内容参差不齐,什么都有,内容之间没有关联。内容与问题无关。垃圾箱。
很多站长在网站还没有上线的时候就开始优化自己的网站内容,上线后马上进行各种SEO优化,就像堆了很多关键词一样。,Mate标签重复连词,页面hub词密度太大,所有外链都指向首页,外链锚文字太简单,网站为了填满内容,大量采集文章 等,这些都是隐含的过度优化。
以上所有问题都可以通过Dede采集插件解决。注意一些小细节的设置,才能把网站收录做得更好。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天为你展示各种SEO经验,打通你的二线任命和主管! 查看全部
采集文章系统(化工行业:塑料助剂产品结构升级中的投资机会!!)
化工行业:塑料助剂产品结构升级的投资机会!在制作网站fast收录和关键词rank之前,我们需要在制作网站fast收录之前了解百度蜘蛛。百度蜘蛛爬取不同站点的规则是: 不同的是,百度蜘蛛的爬取频率对于我们作为一个SEO公司来说非常重要网站。一般来说,以下因素对蜘蛛爬行有重要影响。
网站内容质量:如果网站内容原创质量高,可以处理用户问题,百度会提高爬取频率。
传入链接:链接是页面的导入,优质的链接可以更好的引导百度蜘蛛进入和抓取。
网站爬取的友好性 为了在网上爬取信息时获得越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。
合理使用百度蜘蛛抓取优先级 由于互联网信息量大,百度针对互联网信息抓取制定了多种优先抓取策略。目前的策略主要有:深度优先、广度优先、PR优先、反向链接优先、广度优先爬取的目的是爬取更多的URL,深度优先爬取的目的是爬取高质量的网页。这个策略是通过调度来计算和分配的。作弊信息的爬取在爬取页面时经常会遇到页面质量低、链接质量低等问题。百度引入了绿萝、石榴等算法进行过滤。听说还有一些其他的内部方法可以区分它们。这些方法没有外部泄漏。获取无法爬取的数据可能会导致互联网上的各种问题导致百度蜘蛛无法爬取信息。在这种情况下,百度已经开启了手动提交数据。今天教大家如何使用快速采集高质量文章Dede采集插件制作网站快速收录。
这个Dede采集插件不需要学习更专业的技术,只需要几个简单的步骤就可以轻松采集内容数据,用户只需要在Dede采集@上进行简单的设置> 插件,完成后 Dede采集 插件会根据用户设置的关键词 将内容和图片进行高精度匹配,可以选择保存在本地,也可以选择发布伪原创之后,提供方便快捷的内容采集伪原创发布服务!!
和其他Dede采集插件相比,这个Dede采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟就能上手并且只需输入关键词即可实现采集(Dede采集插件也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。这类Dede采集发布插件工具也配备了很多SEO功能,通过软件发布也可以提升很多SEO优化采集伪原创@ >。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、内容或标题插入,以及网站内容插入或随机作者、随机阅读等,形成一个“高原创”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!在做Dede网站收录之前,我们先明确以下几点,让网站fast收录更好。
这里所说的锚文本只是网站内页指向首页的锚文本。很多人认为,为了集中首页的权重,不管各种锚文本,都指向首页。事实上,这是不可取的。
首先,内页和首页相互竞争同一个关键词,这种情况经常发生。避免它的方法是优化每个页面的不同关键词。这就是长尾词的重要性。其次,内页与首页过于相似,通常是此刻出现的标签页。合理规划标签,正确使用标签,可以避免类似情况的发生。
主题不明确,用户不知道你的网站在做什么,也无法从你的网站中找到他的关注点,是否跳出率、采访时间等,这些数据是对 网站 本身不利。对于搜索引擎来说,看到你的网站内容参差不齐,什么都有,内容之间没有关联。内容与问题无关。垃圾箱。
很多站长在网站还没有上线的时候就开始优化自己的网站内容,上线后马上进行各种SEO优化,就像堆了很多关键词一样。,Mate标签重复连词,页面hub词密度太大,所有外链都指向首页,外链锚文字太简单,网站为了填满内容,大量采集文章 等,这些都是隐含的过度优化。
以上所有问题都可以通过Dede采集插件解决。注意一些小细节的设置,才能把网站收录做得更好。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天为你展示各种SEO经验,打通你的二线任命和主管!
采集文章系统(电脑浏览器收集微信文章的计划方案有什么吗?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-03-02 14:19
微信公众平台发布的文章内容,大部分被他人采集。你们知道电脑浏览器收微信文章的打算吗?是的,采集 系统的组成是什么?今天就让我用拓图数据信息来了解一下。
电脑浏览器采集微信的方案文章
方案一:根据搜狗搜索频道
从微信文章采集到的可以在网上检索到的信息内容来看,似乎是数量最多、最直接、最简单的方案。
电脑浏览器采集微信文章
一般步骤是:
搜狗微信搜索频道进行公众号搜索
选择微信公众号进入公众号历史时间列表文章
对文章进库进行分析
如果采集太多,经常拿字,浏览搜狗和微信公众号历史时间文章列表时会出现短信验证码。使用通用脚本系统无法立即获取短信验证码。这里可以使用无头浏览器浏览,根据连接和编码平台识别短信验证码。Selenium 对于无头浏览器是可选的。
即使选择了无头浏览器,也存在同样的问题:
低效(实际上是运行详细的电脑浏览器来模拟人们实际所做的事情)
网页资源无法通过计算机浏览器加载进行操作,脚本在计算机浏览器加载时难以操作
验证码识别不能保证100%,爬步很可能会中途断掉。
如果坚持使用搜狗搜索频道,想要发展极致网络,只能提升代理IP。对了,不要想着发布一个完全免费的IP地址,很不稳定,基本都被微信屏蔽了。
除了遇到搜狗搜索/手机微信的反爬虫系统,选择这个方案还有其他缺陷:
重要的信息内容,没有获得点击、关注等来评估 文章 内容的质量
没有办法立即获取已经公布的微信文章,只能按时重复爬取
只获取最近十条群消息的内容文章
方案二:Web微信抓包软件分析
被手机微信反爬虫虐了半天,同事们绞尽脑汁在寻找新的微信公众平台文章内容抓包方案。只分析哪些渠道可以获取数据信息。我还依稀记得网络上的微信是给微信文章阅读文章的。刚好我玩过我的微信机器人,关键的应用是Python包ItChat。其完成的基本原理是对web微信进行抓包软件分析,总结为人机微信界面。总体目标是完成网络微信所能完成的所有功能。. 因此,有一个基本的计划——根据ItChat,微信公众平台文章的内容可以推回。正要下班的时候,我的同事提到了它,他很感兴趣。第二天就完成了认证代码(ItChat完成的相关动作代码非常简洁明了,内容分析部分之前做过,马上就可以用了)。
此类计划的关键步骤是:
服务器根据ItChat登录网页微信
当微信公众号宣布推送新的文章内容消息时,会被服务器捕获用于事后分析,并存储在数据库中。
这种计划的优点是:
基本零间距获取已公布的微信文章
获得关注者和点击
保持微信登录即可,无需其他实际操作
也有天生的缺陷:
必须在长期连接互联网的手机上
微信无法主动退出,或长时间断开连接
采集系统由以下部分组成:
1、pc版微信:可以是安装了手机微信应用的手机,也可以是电脑中的手机模拟器。经过微信ios PC版评测,批处理采集的全过程崩溃率高于安卓手机系统。为了更好地控制成本,我使用了手机模拟器。
2、手机微信账号:为了更好的采集内容,不仅需要PC版微信,还需要手机微信账号进行专业采集。因为这个微信账号,其他的事情都做不了。
3、本地服务器代理系统软件:目前的申请方式是根据Anyproxy服务器代理将微信公众号历史时间信息网页中的文章列表发送到自己的网络服务器上。后面会详细说明实际的安装和设置方法。
电脑浏览器采集微信文章
4、文章列表分析和存储系统软件:我用php语言写的。后面我会详细讲解如何分析文章列表,创建集合序列来完成批次采集的内容。
看完我上面对拓图数据资料的详细介绍,相信大家对电脑浏览器收微信文章的方案和采集系统的组成都有一定的了解。微信公众平台需要经常发布一些文章内容,应用采集系统进行采集可以省时省力。 查看全部
采集文章系统(电脑浏览器收集微信文章的计划方案有什么吗?(图))
微信公众平台发布的文章内容,大部分被他人采集。你们知道电脑浏览器收微信文章的打算吗?是的,采集 系统的组成是什么?今天就让我用拓图数据信息来了解一下。
电脑浏览器采集微信的方案文章
方案一:根据搜狗搜索频道
从微信文章采集到的可以在网上检索到的信息内容来看,似乎是数量最多、最直接、最简单的方案。
电脑浏览器采集微信文章
一般步骤是:
搜狗微信搜索频道进行公众号搜索
选择微信公众号进入公众号历史时间列表文章
对文章进库进行分析
如果采集太多,经常拿字,浏览搜狗和微信公众号历史时间文章列表时会出现短信验证码。使用通用脚本系统无法立即获取短信验证码。这里可以使用无头浏览器浏览,根据连接和编码平台识别短信验证码。Selenium 对于无头浏览器是可选的。
即使选择了无头浏览器,也存在同样的问题:
低效(实际上是运行详细的电脑浏览器来模拟人们实际所做的事情)
网页资源无法通过计算机浏览器加载进行操作,脚本在计算机浏览器加载时难以操作
验证码识别不能保证100%,爬步很可能会中途断掉。
如果坚持使用搜狗搜索频道,想要发展极致网络,只能提升代理IP。对了,不要想着发布一个完全免费的IP地址,很不稳定,基本都被微信屏蔽了。
除了遇到搜狗搜索/手机微信的反爬虫系统,选择这个方案还有其他缺陷:
重要的信息内容,没有获得点击、关注等来评估 文章 内容的质量
没有办法立即获取已经公布的微信文章,只能按时重复爬取
只获取最近十条群消息的内容文章
方案二:Web微信抓包软件分析
被手机微信反爬虫虐了半天,同事们绞尽脑汁在寻找新的微信公众平台文章内容抓包方案。只分析哪些渠道可以获取数据信息。我还依稀记得网络上的微信是给微信文章阅读文章的。刚好我玩过我的微信机器人,关键的应用是Python包ItChat。其完成的基本原理是对web微信进行抓包软件分析,总结为人机微信界面。总体目标是完成网络微信所能完成的所有功能。. 因此,有一个基本的计划——根据ItChat,微信公众平台文章的内容可以推回。正要下班的时候,我的同事提到了它,他很感兴趣。第二天就完成了认证代码(ItChat完成的相关动作代码非常简洁明了,内容分析部分之前做过,马上就可以用了)。
此类计划的关键步骤是:
服务器根据ItChat登录网页微信
当微信公众号宣布推送新的文章内容消息时,会被服务器捕获用于事后分析,并存储在数据库中。
这种计划的优点是:
基本零间距获取已公布的微信文章
获得关注者和点击
保持微信登录即可,无需其他实际操作
也有天生的缺陷:
必须在长期连接互联网的手机上
微信无法主动退出,或长时间断开连接
采集系统由以下部分组成:
1、pc版微信:可以是安装了手机微信应用的手机,也可以是电脑中的手机模拟器。经过微信ios PC版评测,批处理采集的全过程崩溃率高于安卓手机系统。为了更好地控制成本,我使用了手机模拟器。
2、手机微信账号:为了更好的采集内容,不仅需要PC版微信,还需要手机微信账号进行专业采集。因为这个微信账号,其他的事情都做不了。
3、本地服务器代理系统软件:目前的申请方式是根据Anyproxy服务器代理将微信公众号历史时间信息网页中的文章列表发送到自己的网络服务器上。后面会详细说明实际的安装和设置方法。
电脑浏览器采集微信文章
4、文章列表分析和存储系统软件:我用php语言写的。后面我会详细讲解如何分析文章列表,创建集合序列来完成批次采集的内容。
看完我上面对拓图数据资料的详细介绍,相信大家对电脑浏览器收微信文章的方案和采集系统的组成都有一定的了解。微信公众平台需要经常发布一些文章内容,应用采集系统进行采集可以省时省力。
采集文章系统(怎么用wordpress采集让网站快速收录以及关键词排名,相信做SEO的小伙伴)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-02-28 11:29
如何使用wordpress采集让网站快速收录和关键词排名,相信所有SEO朋友都知道网站优化是一个长期的过程,坚持不懈网站坚持更新和SEO优化技术。今天给大家讲解一下如何使用wordpress采集工具使网站自动更新以及优化不当导致网站不是收录的注意事项,以及不排名。
一、通过wordpress采集工具自动化网站优化过程
这个wordpress采集工具可以实现自动采集伪原创发布和主动推送到搜索引擎。操作简单,无需学习更多专业技能,简单几步即可轻松采集内容数据,用户只需在wordpress采集上进行简单设置,设置后wordpress会准确采集文章、 也会下降。因为搜索引擎喜欢抓取新鲜的内容,如果长时间不更新,蜘蛛就无法抓取新的内容,也不会来网站抓取,而且是自有意识的网站的权重或排名会下降。
6、会影响公司形象
如果公司的网站长时间不更新,会让人觉得网站不是任何人管理的,网站的信息是很久以前的了,而且客户很容易猜测公司是否消失了。,或停业。
二、网站No收录 和 网站 排名不佳的原因
1、网站tdk任意修改
相信有经验的seo优化师肯定不会犯这个错误,都是新手犯的错误。网站标题关键词描述必须经常修改。这是一个严重的问题。一般网站tdk是不修改的,尤其是新站是在百度评估期。如果修改后给百度留下不好的印象,优化起来会很困难。
2、网站的定位和关键词的设置
我们一定要选择网站的定位,和关键词的设置,不要堆叠,不要密集排列,关键词不要选择冷门。学会合理安排关键词。
3、关键词的选择和发布
选择关键词时,选择一些简单易优化的词,不要太流行。还有,关键词不宜发布过于密集,否则百度蜘蛛会判定关键词在爬取时积累,导致网站体验不佳,严重时网站会被降级, 等等。 。
4、文章更新和图解
现在信息时代的内容不是靠几张图就能解决的,需要图文并茂,而且文章的更新也要有规律,搜索引擎蜘蛛喜欢有规律的东西,你可以每天都做更新文章,这样很容易赢得搜索引擎的芳心,那么网站在百度上排名也不是难事。
5、加盟链不易过多,换不正当的好友链也不易
友链一般设置在30左右,友链的质量也需要注意。兑换时需要查看对方的快照、收录的状态和网站的排名位置,以减少不必要的麻烦,做站的原则是与做人的原则相同。你必须有道德。如果在交换友情链接时,详细查看对方网站的基本信息,查看快照时间,网站采集的信息,网站的排名位置, other 网站 是k还是降级等
6、设置阻止搜索引擎蜘蛛爬行
我相信很多程序员都知道 robots.txt 文件,这是一个告诉搜索引擎蜘蛛不要抓取的设置文件。当搜索引擎蜘蛛第一次访问我们的网站时,由于个人错误,他们将robots.txt文件设置为不抓取整个文件。这样的错误会对网站造成很大的伤害,并使网站的内容无法被百度收录搜索到。
以上就是博主带来的一些关于SEO优化的实用技巧。如果您需要更多SEO优化技巧,请继续关注我,每周不定期更新SEO实用技巧! 查看全部
采集文章系统(怎么用wordpress采集让网站快速收录以及关键词排名,相信做SEO的小伙伴)
如何使用wordpress采集让网站快速收录和关键词排名,相信所有SEO朋友都知道网站优化是一个长期的过程,坚持不懈网站坚持更新和SEO优化技术。今天给大家讲解一下如何使用wordpress采集工具使网站自动更新以及优化不当导致网站不是收录的注意事项,以及不排名。
一、通过wordpress采集工具自动化网站优化过程
这个wordpress采集工具可以实现自动采集伪原创发布和主动推送到搜索引擎。操作简单,无需学习更多专业技能,简单几步即可轻松采集内容数据,用户只需在wordpress采集上进行简单设置,设置后wordpress会准确采集文章、 也会下降。因为搜索引擎喜欢抓取新鲜的内容,如果长时间不更新,蜘蛛就无法抓取新的内容,也不会来网站抓取,而且是自有意识的网站的权重或排名会下降。
6、会影响公司形象
如果公司的网站长时间不更新,会让人觉得网站不是任何人管理的,网站的信息是很久以前的了,而且客户很容易猜测公司是否消失了。,或停业。
二、网站No收录 和 网站 排名不佳的原因
1、网站tdk任意修改
相信有经验的seo优化师肯定不会犯这个错误,都是新手犯的错误。网站标题关键词描述必须经常修改。这是一个严重的问题。一般网站tdk是不修改的,尤其是新站是在百度评估期。如果修改后给百度留下不好的印象,优化起来会很困难。
2、网站的定位和关键词的设置
我们一定要选择网站的定位,和关键词的设置,不要堆叠,不要密集排列,关键词不要选择冷门。学会合理安排关键词。
3、关键词的选择和发布
选择关键词时,选择一些简单易优化的词,不要太流行。还有,关键词不宜发布过于密集,否则百度蜘蛛会判定关键词在爬取时积累,导致网站体验不佳,严重时网站会被降级, 等等。 。
4、文章更新和图解
现在信息时代的内容不是靠几张图就能解决的,需要图文并茂,而且文章的更新也要有规律,搜索引擎蜘蛛喜欢有规律的东西,你可以每天都做更新文章,这样很容易赢得搜索引擎的芳心,那么网站在百度上排名也不是难事。
5、加盟链不易过多,换不正当的好友链也不易
友链一般设置在30左右,友链的质量也需要注意。兑换时需要查看对方的快照、收录的状态和网站的排名位置,以减少不必要的麻烦,做站的原则是与做人的原则相同。你必须有道德。如果在交换友情链接时,详细查看对方网站的基本信息,查看快照时间,网站采集的信息,网站的排名位置, other 网站 是k还是降级等
6、设置阻止搜索引擎蜘蛛爬行
我相信很多程序员都知道 robots.txt 文件,这是一个告诉搜索引擎蜘蛛不要抓取的设置文件。当搜索引擎蜘蛛第一次访问我们的网站时,由于个人错误,他们将robots.txt文件设置为不抓取整个文件。这样的错误会对网站造成很大的伤害,并使网站的内容无法被百度收录搜索到。
以上就是博主带来的一些关于SEO优化的实用技巧。如果您需要更多SEO优化技巧,请继续关注我,每周不定期更新SEO实用技巧!
采集文章系统(可定制词云标签自动导入热词,自动设置标签)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-26 23:02
采集文章系统文章内容,可定制。提取文章标题,描述,链接,设置热词。可定制词云标签自动导入热词,自动设置标签。文本相似度挖掘,可设置合理的相似度配比。
4)){for(jinrange(1,
2)){//聚类分析group=groups[i]*sum(i+j)//按自动分组的不同元素的个数//每个数据集元素的个数指定聚类的个数y[i][j]=round(abs(group),abs(groups[i][j]))}}修改代码和爬虫效果:代码:爬虫效果图:热词挖掘:热词挖掘效果图:
采集。提取tag。
先采到指定的wordpress页面再设置字体图片什么的text标签也可以不要啊
采集的话,用app采,很简单的。
这种导入数据是有问题的,比如一个名为submittitle/version-303的例子。
0)==0typeobjecttypetext1text2text3text4text5text6text7text8text9text10text11text12text13text14text15text16text17text18text19text20text21text22text23text24text25text26text27text28text29text30text31text32text33text34text35text36text37text38text39text40text41text42text43text44text45text46text47text48text49text50text51text52text53text54text55text56text57text58text59text60text61text62text63text64text65text66text67text68text69text70text71text72text73text74text75text76text77text78text79text80text81text82text83text84text85text86text87text88text889text899text90text91text92text93text94text946text95text96text97text98text99text981text992text993text9930text994text995text996text997text998text9986text9988text9989text99880text99891text99892text99894text998942text998952text998955text998956text99895。 查看全部
采集文章系统(可定制词云标签自动导入热词,自动设置标签)
采集文章系统文章内容,可定制。提取文章标题,描述,链接,设置热词。可定制词云标签自动导入热词,自动设置标签。文本相似度挖掘,可设置合理的相似度配比。
4)){for(jinrange(1,
2)){//聚类分析group=groups[i]*sum(i+j)//按自动分组的不同元素的个数//每个数据集元素的个数指定聚类的个数y[i][j]=round(abs(group),abs(groups[i][j]))}}修改代码和爬虫效果:代码:爬虫效果图:热词挖掘:热词挖掘效果图:
采集。提取tag。
先采到指定的wordpress页面再设置字体图片什么的text标签也可以不要啊
采集的话,用app采,很简单的。
这种导入数据是有问题的,比如一个名为submittitle/version-303的例子。
0)==0typeobjecttypetext1text2text3text4text5text6text7text8text9text10text11text12text13text14text15text16text17text18text19text20text21text22text23text24text25text26text27text28text29text30text31text32text33text34text35text36text37text38text39text40text41text42text43text44text45text46text47text48text49text50text51text52text53text54text55text56text57text58text59text60text61text62text63text64text65text66text67text68text69text70text71text72text73text74text75text76text77text78text79text80text81text82text83text84text85text86text87text88text889text899text90text91text92text93text94text946text95text96text97text98text99text981text992text993text9930text994text995text996text997text998text9986text9988text9989text99880text99891text99892text99894text998942text998952text998955text998956text99895。
采集文章系统(这是关于变更数据采集(CDC)系列的第二部分。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2022-02-20 19:08
这是有关更改数据采集 (CDC) 的系列文章的第二部分。在这个 文章 中,让我们讨论 CDC 用例,看看有哪些工具可以帮助您将 CDC 添加到您的架构中。
更改数据采集 促进了事件驱动的应用程序架构。它允许应用程序侦听数据库、数据仓库等中的变化并根据这些变化采取行动。
概括地说,以下是对数据更改采取行动所产生的用例和架构。
让我们探索一下。
提取、转换、加载
到目前为止,CDC 最常见的用例之一是提取、转换、加载 (ETL)。ETL 是一个从源获取数据(提取)、以某种方式对其进行处理(转换)并将其发送到目标(加载)的过程。
数据复制(一次性同步)和镜像(连续复制)是 ETL 过程的好例子。ETL 是一个涵盖非常不同的用例的总称,例如:.
CDC 不仅可以帮助解决这些用例,而且还是解决这些问题的最佳方式。例如,为了将数据镜像到数据仓库,您必须捕获发生的任何更改并将其应用于源数据库。正如本系列第 1 部分讨论的流复制日志系列的第 1 部分中所讨论的,数据库使用 CDC 来使备用实例保持最新以进行故障转移,因为它高效且可扩展。在更广泛的架构中挖掘这些事件时,您的数据仓库可以与备用数据库实例一样保持最新,以进行灾难恢复。
保持缓存和搜索索引系统更新也是 ETL 问题和 CDC 的一个很好的用例。今天创建的大型应用程序由许多不同的数据存储组成。例如,一些架构利用 Postgres、Redis 和 Elasticsearch 作为关系数据库、缓存层和搜索引擎。所有这些都是为特定数据用例设计的记录系统,但数据需要在每个存储中进行镜像。
您永远不希望用户搜索产品并发现它不再存在。陈旧的缓存和搜索索引会导致糟糕的用户体验。CDC 可用于构建数据管道,使这些存储与其上游依赖项保持同步。
理论上,一个应用程序可以同时向 Postgres、Redis 和 Elasticsearch 写入数据,但是“双写入”的管理很困难,并且可能导致系统不同步。CDC 提供了更健壮且更易于维护的实现。与其将更新索引和缓存的逻辑添加到单个单体应用程序中,不如创建一个事件驱动的微服务,该微服务可以独立于面向用户的系统进行构建、维护、改进和部署。该微服务保持索引和缓存更新,以确保用户操作最相关的数据。
集成和自动化
SaaS 的兴起导致生成数据或需要更新数据的工具数量激增。CDC 可以提供更好的模型来保持 Salesforce、Hubspot 等的更新,并允许需要响应这些数据变化的业务逻辑自动化。
我们上面描述的每个用例都将数据发送到特定的目的地。但是,最强大的目的地是具有云功能的目的地。捕获数据更改和触发云功能可用于执行本文中提到(或未提及)的每个用例。
由于无需维护服务器,云功能大幅增长;它们自动扩展,易于使用和部署。这种流行性和实用性在 JAMStack 等架构中得到了清晰的证明。CDC 非常适合这种架构模式。
今天,云功能是由事件触发的。此事件可能发生在文件上传到 Amazon S3 或 HTTP 请求时。但是,正如您可能已经猜到的那样,这个触发事件可能是由 CDC 系统发出的。
例如,这是一个 AWS Lambda 函数,它接受数据更改事件并索引 Algolia 的搜索数据:
const algoliasearch = require("algoliasearch");
const client = algoliasearch(process.env.ALGOLIA_APP_ID, process.env.ALGOLIA_API_KEY);
const index = client.initIndex(process.env.ALGOLIA_INDEX_NAME);
exports.handler = async function(event, context) {
console.log("EVENT: \\n" + JSON.stringify(event, null, 2))
const request = event.Records[0].cf.request;
// Accessing the Data Record
//
const body = Buffer.from(request.body.data, 'base64').toString();
const { schema, payload } = body;
const { before, after, source, op } = payload;
if (req.method === 'POST') {
try {
// if read, create, or update operation create o update index
if (op === 'r' || op === 'c' || op === 'u') {
console.log(`operation: ${op}, id: ${after.id}`)
after.objectID = after.id
await index.saveObject(after)
} else if (op === 'd') {
console.log(`operation: d, id: ${before.id}`)
await index.deleteObject(before.id)
}
return res.status(200).send()
} catch (error) {
console.log(`error: ${JSON.stringify(error)}`)
return res.status(500).send()
}
}
return context.logStreamName
}
每次触发这个函数,它都会查看数据变化(op),并在 Algolia 中执行相应的动作。例如,如果数据库发生了删除操作,我们可以在 Algolia 中执行一个 deleteObject。
响应 CDC 事件的函数可以小而简单。但是,CDC 以及基于事件的架构也可以简化原本非常复杂的架构。
例如,在应用程序中实现 Webhook 的功能成为 CDC 中更紧迫的问题。Webhook 允许用户在某些事件发生时触发 POST 请求,通常是数据更改。例如,使用 Github,您可以在合并拉取请求时触发云功能。合并的拉取请求是对数据存储的 UPDATE 操作,这意味着 CDC 系统可以捕获此事件。一般来说,大多数 webhook 事件都可以转换为 CDC 系统可以捕获的 INSERT UPDATE 和 DELETE 操作。
历史
在某些情况下,您可能不想对 CDC 事件采取行动,而只想存储原创更改。使用 CDC,数据管道可以将所有更改事件存储到云存储桶中,以进行长期处理和分析。存储用于历史分析的数据的最佳位置是在云存储桶中,称为数据湖。
数据湖是一个集中式存储,可让您以任意规模存储所有结构化和非结构化数据。数据湖通常使用云对象存储桶解决方案,例如 Amazon S3 或 Digital Ocean Spaces。
例如,一旦数据进入数据湖,Amazon Presto 等 SQL 查询引擎就可以针对不断变化的数据集运行分析查询。
在存储原创更改时,您不仅拥有数据的当前状态,还拥有所有以前的状态(历史)。这就是 CDC 为历史分析增加很多价值的原因。
拥有历史数据可以让您支持灾难恢复工作,还可以让您回答有关数据的回顾性问题。例如,假设您的团队重新定义了每月活跃用户 (MAU) 的计算方式。借助用户数据集的完整历史记录,可以根据过去的任何日期进行新的 MAU 计算,并将结果与当前状态进行比较。
这种丰富的历史也具有面向用户的价值。审核日志和活动日志是向用户显示数据更改的功能。
捕获和存储更改事件为实现这些功能提供了更好的框架。与 webhook 一样,审计日志和活动日志都源于可被 CDC 系统捕获的操作。
警报
任何警报系统的工作都是将事件通知利益相关者。例如,当您收到新的电子邮件通知时,系统会通知您对电子邮件数据存储的 INSERT 操作。通常,大多数警报都与数据存储的变化有关,这意味着 CDC 非常适合电力警报系统。
例如,假设您有一家电子商务商店。在采购表上启用 CDC 后,您可以捕获更改事件并通过在进行新采购时执行 Slack 警报来通知团队。
就像审计或活动日志一样,CDC 提供的通知不仅提供有关发生情况的信息,还提供有关更改本身的详细信息。
Tom 将标题从“会议纪要”更新为“我的新会议”。
这种警报行为也具有内在价值。从基础设施监控的角度来看,CDC 事件可以深入了解用户如何与您的应用程序和数据进行交互。例如,您可以查看用户添加、更新或删除信息的时间和方式。可以将此数据发送到 Prometheus UI 以监控此信息并采取措施。
开始使用 CDC
在第一部分中,我们讨论了 CDC 的各种常见实现。
这些都可以用来构建我们在本文中讨论的用例。最重要的是,由于 CDC 专注于数据,因此该过程与编程语言无关,并且可以集成到大多数架构中。
轮询和触发器
使用轮询或数据库触发器时,没有开销,也不需要安装。您可以从构建查询开始,以轮询或利用数据库的触发器(如果支持)。
流日志处理
数据库使用流复制日志进行备份和恢复,这意味着大多数数据库提供了一些开箱即用的 CDC 行为。挖掘这些事件的难易程度取决于数据存储本身。最好的起点是深入研究数据库的复制功能。下面是一些最流行的数据库的复制日志资源。
要开始使用流式日志记录,答案与相关数据库相关联。在未来文章,我将探索每种情况的样子。
直接实施任何这些确实需要一些时间、计划和努力。如果您想开始使用 CDC,最低门槛是采用知道如何从您使用的数据存储中进行通信和捕获更改的 CDC 工具。
更改数据采集工具
这里有一些很棒的工具供您评估。
地比西
Debezium 是迄今为止最受欢迎的 CDC 工具。它维护良好、开源,并建立在 Apache Kafka 之上。它支持 MongoDB、MySQL、PostgreSQL 和更多开箱即用的数据库。
在高层次上,Debezium 使用 Hook 数据库的复制日志并将更改事件发送到 Kafka。你甚至可以在没有 Kafka 的情况下独立运行 Debezium。
真正的好处是 Debezium 都是基于配置的。安装和配置 Debezium 后,您可以使用基于 JSON 的配置来配置与数据存储的连接。
{
"name": "fulfillment-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "192.168.99.100",
"database.port": "5432",
"database.user": "postgres",
"database.password": "postgres",
"database.dbname" : "postgres",
"database.server.name": "fulfillment",
"table.include.list": "public.inventory"
}
}
连接后,Debezium 会对您的数据进行初始快照,并将更改事件发送到 Kafka 主题。然后服务可以使用主题并对其采取行动。
这里有一些开始使用 Debeizium 的好地方。
梅罗沙
Meroxa 是一个实时数据协调平台,可为您提供实时基础架构。Meroxa 消除了与配置和管理代理、连接器、转换、功能和流式基础设施相关的时间和开销。您所要做的就是添加资源并构建管道。Meroxa 支持 PostgreSQL、MongoDB、SQL Server 等。
可以在 Visual Dashboard 中或使用 Meroxa CLI 建立 CDC 管道:
# Add Resource
$ meroxa resource add my-postgres --type postgres -u postgres://$PG_USER:$PG_PASS@$PG_URL:$PG_PORT/$PG_DB
# Add Webhook
$ meroxa resource add my-url --type url -u $CUSTOM_HTTP_URL
# Create CDC Pipeline
$ meroxa connect --from my-postgres --input $TABLE_NAME --to my-url
上面的用例有更详细的介绍。
有一些很好的资源可以帮助您开始使用 Meroxa。
我迫不及待地想看看你建造了什么。 查看全部
采集文章系统(这是关于变更数据采集(CDC)系列的第二部分。)
这是有关更改数据采集 (CDC) 的系列文章的第二部分。在这个 文章 中,让我们讨论 CDC 用例,看看有哪些工具可以帮助您将 CDC 添加到您的架构中。
更改数据采集 促进了事件驱动的应用程序架构。它允许应用程序侦听数据库、数据仓库等中的变化并根据这些变化采取行动。
概括地说,以下是对数据更改采取行动所产生的用例和架构。
让我们探索一下。
提取、转换、加载
到目前为止,CDC 最常见的用例之一是提取、转换、加载 (ETL)。ETL 是一个从源获取数据(提取)、以某种方式对其进行处理(转换)并将其发送到目标(加载)的过程。
数据复制(一次性同步)和镜像(连续复制)是 ETL 过程的好例子。ETL 是一个涵盖非常不同的用例的总称,例如:.
CDC 不仅可以帮助解决这些用例,而且还是解决这些问题的最佳方式。例如,为了将数据镜像到数据仓库,您必须捕获发生的任何更改并将其应用于源数据库。正如本系列第 1 部分讨论的流复制日志系列的第 1 部分中所讨论的,数据库使用 CDC 来使备用实例保持最新以进行故障转移,因为它高效且可扩展。在更广泛的架构中挖掘这些事件时,您的数据仓库可以与备用数据库实例一样保持最新,以进行灾难恢复。
保持缓存和搜索索引系统更新也是 ETL 问题和 CDC 的一个很好的用例。今天创建的大型应用程序由许多不同的数据存储组成。例如,一些架构利用 Postgres、Redis 和 Elasticsearch 作为关系数据库、缓存层和搜索引擎。所有这些都是为特定数据用例设计的记录系统,但数据需要在每个存储中进行镜像。
您永远不希望用户搜索产品并发现它不再存在。陈旧的缓存和搜索索引会导致糟糕的用户体验。CDC 可用于构建数据管道,使这些存储与其上游依赖项保持同步。
理论上,一个应用程序可以同时向 Postgres、Redis 和 Elasticsearch 写入数据,但是“双写入”的管理很困难,并且可能导致系统不同步。CDC 提供了更健壮且更易于维护的实现。与其将更新索引和缓存的逻辑添加到单个单体应用程序中,不如创建一个事件驱动的微服务,该微服务可以独立于面向用户的系统进行构建、维护、改进和部署。该微服务保持索引和缓存更新,以确保用户操作最相关的数据。
集成和自动化
SaaS 的兴起导致生成数据或需要更新数据的工具数量激增。CDC 可以提供更好的模型来保持 Salesforce、Hubspot 等的更新,并允许需要响应这些数据变化的业务逻辑自动化。
我们上面描述的每个用例都将数据发送到特定的目的地。但是,最强大的目的地是具有云功能的目的地。捕获数据更改和触发云功能可用于执行本文中提到(或未提及)的每个用例。
由于无需维护服务器,云功能大幅增长;它们自动扩展,易于使用和部署。这种流行性和实用性在 JAMStack 等架构中得到了清晰的证明。CDC 非常适合这种架构模式。
今天,云功能是由事件触发的。此事件可能发生在文件上传到 Amazon S3 或 HTTP 请求时。但是,正如您可能已经猜到的那样,这个触发事件可能是由 CDC 系统发出的。
例如,这是一个 AWS Lambda 函数,它接受数据更改事件并索引 Algolia 的搜索数据:
const algoliasearch = require("algoliasearch");
const client = algoliasearch(process.env.ALGOLIA_APP_ID, process.env.ALGOLIA_API_KEY);
const index = client.initIndex(process.env.ALGOLIA_INDEX_NAME);
exports.handler = async function(event, context) {
console.log("EVENT: \\n" + JSON.stringify(event, null, 2))
const request = event.Records[0].cf.request;
// Accessing the Data Record
//
const body = Buffer.from(request.body.data, 'base64').toString();
const { schema, payload } = body;
const { before, after, source, op } = payload;
if (req.method === 'POST') {
try {
// if read, create, or update operation create o update index
if (op === 'r' || op === 'c' || op === 'u') {
console.log(`operation: ${op}, id: ${after.id}`)
after.objectID = after.id
await index.saveObject(after)
} else if (op === 'd') {
console.log(`operation: d, id: ${before.id}`)
await index.deleteObject(before.id)
}
return res.status(200).send()
} catch (error) {
console.log(`error: ${JSON.stringify(error)}`)
return res.status(500).send()
}
}
return context.logStreamName
}
每次触发这个函数,它都会查看数据变化(op),并在 Algolia 中执行相应的动作。例如,如果数据库发生了删除操作,我们可以在 Algolia 中执行一个 deleteObject。
响应 CDC 事件的函数可以小而简单。但是,CDC 以及基于事件的架构也可以简化原本非常复杂的架构。
例如,在应用程序中实现 Webhook 的功能成为 CDC 中更紧迫的问题。Webhook 允许用户在某些事件发生时触发 POST 请求,通常是数据更改。例如,使用 Github,您可以在合并拉取请求时触发云功能。合并的拉取请求是对数据存储的 UPDATE 操作,这意味着 CDC 系统可以捕获此事件。一般来说,大多数 webhook 事件都可以转换为 CDC 系统可以捕获的 INSERT UPDATE 和 DELETE 操作。
历史
在某些情况下,您可能不想对 CDC 事件采取行动,而只想存储原创更改。使用 CDC,数据管道可以将所有更改事件存储到云存储桶中,以进行长期处理和分析。存储用于历史分析的数据的最佳位置是在云存储桶中,称为数据湖。
数据湖是一个集中式存储,可让您以任意规模存储所有结构化和非结构化数据。数据湖通常使用云对象存储桶解决方案,例如 Amazon S3 或 Digital Ocean Spaces。
例如,一旦数据进入数据湖,Amazon Presto 等 SQL 查询引擎就可以针对不断变化的数据集运行分析查询。
在存储原创更改时,您不仅拥有数据的当前状态,还拥有所有以前的状态(历史)。这就是 CDC 为历史分析增加很多价值的原因。
拥有历史数据可以让您支持灾难恢复工作,还可以让您回答有关数据的回顾性问题。例如,假设您的团队重新定义了每月活跃用户 (MAU) 的计算方式。借助用户数据集的完整历史记录,可以根据过去的任何日期进行新的 MAU 计算,并将结果与当前状态进行比较。
这种丰富的历史也具有面向用户的价值。审核日志和活动日志是向用户显示数据更改的功能。
捕获和存储更改事件为实现这些功能提供了更好的框架。与 webhook 一样,审计日志和活动日志都源于可被 CDC 系统捕获的操作。
警报
任何警报系统的工作都是将事件通知利益相关者。例如,当您收到新的电子邮件通知时,系统会通知您对电子邮件数据存储的 INSERT 操作。通常,大多数警报都与数据存储的变化有关,这意味着 CDC 非常适合电力警报系统。
例如,假设您有一家电子商务商店。在采购表上启用 CDC 后,您可以捕获更改事件并通过在进行新采购时执行 Slack 警报来通知团队。
就像审计或活动日志一样,CDC 提供的通知不仅提供有关发生情况的信息,还提供有关更改本身的详细信息。
Tom 将标题从“会议纪要”更新为“我的新会议”。
这种警报行为也具有内在价值。从基础设施监控的角度来看,CDC 事件可以深入了解用户如何与您的应用程序和数据进行交互。例如,您可以查看用户添加、更新或删除信息的时间和方式。可以将此数据发送到 Prometheus UI 以监控此信息并采取措施。
开始使用 CDC
在第一部分中,我们讨论了 CDC 的各种常见实现。
这些都可以用来构建我们在本文中讨论的用例。最重要的是,由于 CDC 专注于数据,因此该过程与编程语言无关,并且可以集成到大多数架构中。
轮询和触发器
使用轮询或数据库触发器时,没有开销,也不需要安装。您可以从构建查询开始,以轮询或利用数据库的触发器(如果支持)。
流日志处理
数据库使用流复制日志进行备份和恢复,这意味着大多数数据库提供了一些开箱即用的 CDC 行为。挖掘这些事件的难易程度取决于数据存储本身。最好的起点是深入研究数据库的复制功能。下面是一些最流行的数据库的复制日志资源。
要开始使用流式日志记录,答案与相关数据库相关联。在未来文章,我将探索每种情况的样子。
直接实施任何这些确实需要一些时间、计划和努力。如果您想开始使用 CDC,最低门槛是采用知道如何从您使用的数据存储中进行通信和捕获更改的 CDC 工具。
更改数据采集工具
这里有一些很棒的工具供您评估。
地比西
Debezium 是迄今为止最受欢迎的 CDC 工具。它维护良好、开源,并建立在 Apache Kafka 之上。它支持 MongoDB、MySQL、PostgreSQL 和更多开箱即用的数据库。
在高层次上,Debezium 使用 Hook 数据库的复制日志并将更改事件发送到 Kafka。你甚至可以在没有 Kafka 的情况下独立运行 Debezium。
真正的好处是 Debezium 都是基于配置的。安装和配置 Debezium 后,您可以使用基于 JSON 的配置来配置与数据存储的连接。
{
"name": "fulfillment-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "192.168.99.100",
"database.port": "5432",
"database.user": "postgres",
"database.password": "postgres",
"database.dbname" : "postgres",
"database.server.name": "fulfillment",
"table.include.list": "public.inventory"
}
}
连接后,Debezium 会对您的数据进行初始快照,并将更改事件发送到 Kafka 主题。然后服务可以使用主题并对其采取行动。
这里有一些开始使用 Debeizium 的好地方。
梅罗沙
Meroxa 是一个实时数据协调平台,可为您提供实时基础架构。Meroxa 消除了与配置和管理代理、连接器、转换、功能和流式基础设施相关的时间和开销。您所要做的就是添加资源并构建管道。Meroxa 支持 PostgreSQL、MongoDB、SQL Server 等。
可以在 Visual Dashboard 中或使用 Meroxa CLI 建立 CDC 管道:
# Add Resource
$ meroxa resource add my-postgres --type postgres -u postgres://$PG_USER:$PG_PASS@$PG_URL:$PG_PORT/$PG_DB
# Add Webhook
$ meroxa resource add my-url --type url -u $CUSTOM_HTTP_URL
# Create CDC Pipeline
$ meroxa connect --from my-postgres --input $TABLE_NAME --to my-url
上面的用例有更详细的介绍。
有一些很好的资源可以帮助您开始使用 Meroxa。
我迫不及待地想看看你建造了什么。
采集文章系统(文章采集功能演示(一)(2)_国内] )
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2022-02-19 06:06
)
一、简介
文章的采集的作用是通过程序远程获取目标网页的内容,解析处理本地规则后存入服务器的数据库中。
文章采集系统颠覆了传统的采集模式和流程,采集规则与采集界面分离,规则设置更简单,只需需要具备基本技术知识的人制定相关规则。
编辑们不需要了解太详细的技术规则,只需选择自己想要的文章列表采集,就可以像发布文章一样轻松完成数据采集 @> 操作。
二、功能演示
一、采集流程简单,分三步:1、添加采集点,填写采集规则。2、采集网站,采集内容3、将内容发布到指定栏目
以采集新浪新闻()为例介绍详细流程。
示例说明: 目的:采集新浪新闻将被添加到V9系统的“国内”栏目。目标网址:添加采集dots2.网址规则配置
1. 添加采集 点,填写采集 规则
A. 内容规则
注:上图中的“目标网页源代码”是指:目标网页的源代码。具体步骤如下:
目标网页->右键->查看源代码->找到你要采集的源代码的开始和结束,按照“上图”填写规则。
添加成功后,测试你的URL采集规则是否正确,如下图所示:
B. 内容规则配置
为了解释方便,我们只写了采集title和content字段。
采集内容网址:采集的内容采集规则,请打开该网址,然后在页面空白处右键->查看源文件搜索标题和开始边界内容。
标题采集配置:从网页中获取标题并删除不需要的字符。如下所示
内容采集 配置:新浪新闻最后一页,新闻内容夹在中间,这两个节点在整个页面源码中是唯一的。因此,您可以将此作为规则来获取内容。并过滤内容。如下所示
C. 自定义规则
除了系统自带的规则外,您还可以根据自己的需要自定义规则采集。操作和系统规则相同,如下图:
D. 高级配置
可以设置是否下载图片到服务器、是否打印水印等配置。如下所示:
2. 采集管理
添加采集点并测试成功后,您可以管理您添加的采集点(采集 URL、采集内容、内容发布、测试、修改、复制、导出)。如下所示:
A.采集网址
采集采集 点的 URL。
B. 采集内容
采集采集 点内容。
C. 内容发布
将 采集 的内容发布到指定版块。如下所示:
单击“导入”以跳转到“选择列”页面。如下所示:
点击“提交”跳转到栏目配置设置页面。如下所示:
提交成功后,采集的内容会被导入到指定的列(如下图)。在此期间请耐心等待,完成后会自动转动。至此,一个简单的采集流程就完成了。您的 采集 的内容信息已经存在于指定列下。
查看全部
采集文章系统(文章采集功能演示(一)(2)_国内]
)
一、简介
文章的采集的作用是通过程序远程获取目标网页的内容,解析处理本地规则后存入服务器的数据库中。
文章采集系统颠覆了传统的采集模式和流程,采集规则与采集界面分离,规则设置更简单,只需需要具备基本技术知识的人制定相关规则。
编辑们不需要了解太详细的技术规则,只需选择自己想要的文章列表采集,就可以像发布文章一样轻松完成数据采集 @> 操作。
二、功能演示
一、采集流程简单,分三步:1、添加采集点,填写采集规则。2、采集网站,采集内容3、将内容发布到指定栏目
以采集新浪新闻()为例介绍详细流程。
示例说明: 目的:采集新浪新闻将被添加到V9系统的“国内”栏目。目标网址:添加采集dots2.网址规则配置
1. 添加采集 点,填写采集 规则
A. 内容规则
注:上图中的“目标网页源代码”是指:目标网页的源代码。具体步骤如下:
目标网页->右键->查看源代码->找到你要采集的源代码的开始和结束,按照“上图”填写规则。
添加成功后,测试你的URL采集规则是否正确,如下图所示:
B. 内容规则配置
为了解释方便,我们只写了采集title和content字段。
采集内容网址:采集的内容采集规则,请打开该网址,然后在页面空白处右键->查看源文件搜索标题和开始边界内容。
标题采集配置:从网页中获取标题并删除不需要的字符。如下所示
内容采集 配置:新浪新闻最后一页,新闻内容夹在中间,这两个节点在整个页面源码中是唯一的。因此,您可以将此作为规则来获取内容。并过滤内容。如下所示
C. 自定义规则
除了系统自带的规则外,您还可以根据自己的需要自定义规则采集。操作和系统规则相同,如下图:
D. 高级配置
可以设置是否下载图片到服务器、是否打印水印等配置。如下所示:
2. 采集管理
添加采集点并测试成功后,您可以管理您添加的采集点(采集 URL、采集内容、内容发布、测试、修改、复制、导出)。如下所示:
A.采集网址
采集采集 点的 URL。
B. 采集内容
采集采集 点内容。
C. 内容发布
将 采集 的内容发布到指定版块。如下所示:
单击“导入”以跳转到“选择列”页面。如下所示:
点击“提交”跳转到栏目配置设置页面。如下所示:
提交成功后,采集的内容会被导入到指定的列(如下图)。在此期间请耐心等待,完成后会自动转动。至此,一个简单的采集流程就完成了。您的 采集 的内容信息已经存在于指定列下。
采集文章系统(变更数据采集(CDC)是一个一流的最佳决策至关重要)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-02-18 04:13
没有人愿意查看仪表板或根据昨天的数据做出决策。我们生活在这样一个世界中,实时信息是我们用户的一流期望,对于在组织内做出最佳决策至关重要。
Change Data采集 (CDC) 是一种高效且可扩展的模型,可简化实时系统的实施。
更改数据采集图表
Shopify、Capital One、Netflix、Airbnb 和 Zendesk 等行业领先公司已经发布了技术 文章,展示了他们如何在其数据架构中实施变更数据捕获 (CDC) 以:
在这个关于更改数据的多部分系列采集 中,我们将深入探讨。
开始吧。
什么是变更数据采集 (CDC)?
跟踪系统变化的想法并不新鲜。自从有了编程的想法,工程师就一直在编写脚本来批量查询和更新数据。变更数据采集 是决定如何跟踪变更的各种方法的形式化。
CDC 的核心是一个允许应用程序监听数据存储变化并对这些事件做出反应的过程。此过程涉及数据存储(数据库、数据仓库等)和捕获数据存储更改的系统。
例如,人们可以。
现实世界的例子
让我们看一个可以从 CDC 中受益的真实示例。在这里,我们有一个 PostgreSQL 中的表示例。
用户数据实例
当用户表中的信息发生变化时,企业可能需要这个。
我们可以通过对数据更改事件采取行动来创建执行上述所有操作的服务,并在需要时独立创建和管理它们。
CDC 通过在事件发生时采取行动来提高效率,并通过利用“事件驱动”来实现可扩展性。
CDC事件的一个例子
CDC 系统通常会发出一个事件,其中收录有关所发生事件的详细信息。当使用像 Debezium 这样的 CDC 系统并创建新用户时,会生成以下事件。
剖析 CDC 事件
此事件描述数据的架构、发生的操作 (op) 以及负载之前和之后的数据。
事件的形式、信息的保真度、传递的时间都取决于疾控中心系统的执行情况。
疾控中心的实施
跟踪 PostgreSQL 数据库中的更改可能看起来与跟踪 MongoDB 中的更改非常相似或非常不同。这完全取决于环境和选择的捕获方法。
可以定义选择的捕获方法
让我们看一下每种不同的方法,并讨论每种方法的一些优点和缺点。
轮询
在实现任何数据库连接器时,决定从“轮询或不轮询”开始。轮询是 CDC 概念上最简单的方法。为了实现轮询,您需要以一定的时间间隔查询数据存储。
例如,您可以在一个时间间隔内运行以下查询。
从用户中选择 *;
此类 SELECT * 查询被视为批处理(“给我一切”)轮询方法。虽然这对于捕获当前状态的快照非常有用,但下游消费者需要努力弄清楚每个时间间隔内发生了哪些数据变化。
但是,轮询可以变得更加细化。例如,我们只能轮询一个主键。
从用户中选择 MAX(id);
系统可以跟踪主键 (id) 的最大值。当最大值增加时,表示发生了 INSERT 操作。
此外,如果数据库具有 updateAt 列,则查询可以查看时间戳更改以捕获 UPDATE 操作。
SELECT * from Users WHERE updated_at > 2021-02-08;
利弊
简单:轮询很棒,因为它易于实施和部署,而且非常有效。
自定义查询很有用。一个好处是可以自定义轮询时使用的查询以适应复杂的用例。查询可以直接在 SQL 中收录 JOINS 或转换。
捕捉删除很困难:使用轮询,捕捉删除更加困难。如果数据库中的一行完全没有了,你就不能真正查询它。一种解决方案是使用数据库触发器创建表来存储已删除的数据。然后删除操作变成了插入操作到可以轮询的新表中。
事件被拉出,而不是被推出。通过轮询,可以从上游系统中提取事件。例如,当使用轮询来摄取数据仓库时,摄取将在 CDC 系统决定进行轮询时发生。理论上,“实时”可以通过足够快的轮询来完成,但这可能会给数据库带来性能开销。
性能开销是一个问题。SELECT * 或任何复杂的查询在海量数据集上都不能很好地扩展。一种常见的解决方法是通过轮询备用实例来替换主数据库。
无法捕获查询时间之间的变化。另一个考虑因素是查询时间之间的数据变化。例如,如果系统每小时轮询一次,并且数据在同一小时内多次更改,则您只能看到查询时间的更改,而看不到任何中间更改。
数据库触发器
大多数流行的数据库都支持某种形式的触发器。例如。在 PostgreSQL 中,可以构建一个触发器,当一条记录被删除时,将它移动到一个新表中。
CREATE TRIGGER moveDeleted
在删除“用户”之前
对于每一行
执行过程 moveDeleted()。
因为触发器可以有效地侦听操作并执行操作,所以数据库触发器可以充当 CDC 系统。
在某些情况下,这些触发器可以是非常复杂和完整的功能。例如。在 MongoDB 中,触发器是用 Javascript 编写的。
exports = async function (changeEvent) {
//从变化流事件对象中解构出字段
const { updateDescription, fullDocument }= changeEvent;
// 检查shippingLocation字段是否被更新。
const updatedFields = Object.keys(updateDescription.upedFields)。
const isNewLocation = updatedFields.some(field =>)
field.match(/shippingLocation/)
);
// 如果位置改变了,就给客户发短信说明更新的位置。
if(isNewLocation){
// 做点什么
}
};
利弊
易于部署。触发器很棒,因为它们对大多数数据库都有开箱即用的支持,并且易于实现。
数据一致性。任何当前和新的下游消费者都不必担心执行此逻辑,因为此逻辑收录在数据库中,而不是应用程序中 - 在微服务架构的情况下。
数据库中的应用程序逻辑可以被破坏:但是,数据库不应该收录太多的应用程序逻辑。这可能导致行为与数据库的耦合过于紧密,一个错误的触发器可能会影响整个数据基础架构。触发器应该简洁明了。
每个动作都被捕获。您可以为每个数据库操作创建一个触发器。
性能开销是一个问题。由于与轮询方法相同的原因,编写不当的触发器也会影响数据库性能。收录复杂查询的触发器在大型数据集上无法很好地扩展。
流式复制日志
最好至少运行一个数据库的辅助实例,以确保正确的故障转移和灾难恢复。
在这种模式下,数据库的备用实例需要在不丢失信息的情况下与主实例保持同步。现在最好的方法是让数据库写入日志中发生的所有更改。然后,任何备用实例都可以从此日志中流式传输更改并在本地应用这些操作。实时做同样的事情是允许备用实例“镜像”主实例。
以下是一些关于一些最流行的数据库如何工作的参考资料。
CDC 可以使用相同的机制来监听变化。就像备用数据库一样,附加系统也可以在更新流式日志时处理它们。
在上面的 PostgreSQL 示例图中,CDC 系统可以充当额外的 WAL 接收器,处理事件并将它们发送到消息传输(HTTP API、Kafka 等)。
下面是使用提供的 SQL 函数从 PostgreSQL 的 WAL 查询更改的示例。
test_decoding plugin:
postgres=# SELECT * FROM pg_logical_slot_get_changes('regression_slot', NULL, NULL);
lsn | xid | data
-----------+-------+---------------------------------------------------------
0/ba5a688 | 10298 | start 10298
0/BA5A6F0 | 10298 | table public.data:INSERT: id[integer]:1 data[text]:'1' 。
0/BA5A7F8 | 10298 | table public.data:INSERT: id[integer]:2 data[text]:'2' 。
0/ba5a8a8 | 10298 | commit 10298
(4 rows)
在上面的查询响应中,它描述了以下内容。
这些更改事件的格式将基于逻辑解码输出插件。例如 wal2json 输出插件允许您以 JSON 格式输出更改,这比 test_decoding 插件的输出更容易解析。
PostgreSQL 还提供了一种机制来在这些更改发生时对其进行流式传输。正如您在前面的事件示例中看到的,Debezium 还实时解析流式日志并生成 JSON 事件。
利弊
事件被推送。流式日志的一个巨大好处是事件在发生变化时被推送到 CDC 系统(而不是轮询)。这种推送模式支持实时架构。以用户表为例,数据仓库的摄取将在流式日志CDC系统中实时发生。
高效且低延迟。备用实例使用流式日志进行灾难恢复,效率和低延迟是重中之重。流式复制日志是捕获更改的最有效方法,并且对数据库的开销最小。这个过程在不同的数据库中会有不同的表现,但这些概念仍然适用。
每个动作都被捕获。数据存储中发生的每个事务都将写入日志。
很难获得数据的完整快照。通常,在一定时间(或大小)之后,流式日志会被清除,因为它们占用空间。因此,日志可能不收录已发生的所有更改,仅收录最近的更改。
需要进行配置。启用复制日志可能需要额外的配置、插件,甚至是数据库重启。在最小的城市地区实施这些变化可能很麻烦,需要规划。
下一步是什么?
捕捉数据变化就像是任何应用程序架构的瑞士军刀;它对许多不同类型的问题很有用。侦听、存储和处理任何系统(尤其是数据库)中的变化,让您可以在两个数据存储之间实时复制数据,将单一应用程序分解为可扩展的、事件驱动的微服务,甚至可以为实时 UI 提供支持.
流式复制日志、轮询和数据库触发器为构建 CDC 系统提供了一种机制。对于您的应用程序架构和所需的功能,每种方法都有其自身的优点和缺点。
在下一篇文章中,我们将深入挖掘。
我迫不及待地想看看你建造了什么。 查看全部
采集文章系统(变更数据采集(CDC)是一个一流的最佳决策至关重要)
没有人愿意查看仪表板或根据昨天的数据做出决策。我们生活在这样一个世界中,实时信息是我们用户的一流期望,对于在组织内做出最佳决策至关重要。
Change Data采集 (CDC) 是一种高效且可扩展的模型,可简化实时系统的实施。
更改数据采集图表
Shopify、Capital One、Netflix、Airbnb 和 Zendesk 等行业领先公司已经发布了技术 文章,展示了他们如何在其数据架构中实施变更数据捕获 (CDC) 以:
在这个关于更改数据的多部分系列采集 中,我们将深入探讨。
开始吧。
什么是变更数据采集 (CDC)?
跟踪系统变化的想法并不新鲜。自从有了编程的想法,工程师就一直在编写脚本来批量查询和更新数据。变更数据采集 是决定如何跟踪变更的各种方法的形式化。
CDC 的核心是一个允许应用程序监听数据存储变化并对这些事件做出反应的过程。此过程涉及数据存储(数据库、数据仓库等)和捕获数据存储更改的系统。
例如,人们可以。
现实世界的例子
让我们看一个可以从 CDC 中受益的真实示例。在这里,我们有一个 PostgreSQL 中的表示例。
用户数据实例
当用户表中的信息发生变化时,企业可能需要这个。
我们可以通过对数据更改事件采取行动来创建执行上述所有操作的服务,并在需要时独立创建和管理它们。
CDC 通过在事件发生时采取行动来提高效率,并通过利用“事件驱动”来实现可扩展性。
CDC事件的一个例子
CDC 系统通常会发出一个事件,其中收录有关所发生事件的详细信息。当使用像 Debezium 这样的 CDC 系统并创建新用户时,会生成以下事件。
剖析 CDC 事件
此事件描述数据的架构、发生的操作 (op) 以及负载之前和之后的数据。
事件的形式、信息的保真度、传递的时间都取决于疾控中心系统的执行情况。
疾控中心的实施
跟踪 PostgreSQL 数据库中的更改可能看起来与跟踪 MongoDB 中的更改非常相似或非常不同。这完全取决于环境和选择的捕获方法。
可以定义选择的捕获方法
让我们看一下每种不同的方法,并讨论每种方法的一些优点和缺点。
轮询
在实现任何数据库连接器时,决定从“轮询或不轮询”开始。轮询是 CDC 概念上最简单的方法。为了实现轮询,您需要以一定的时间间隔查询数据存储。
例如,您可以在一个时间间隔内运行以下查询。
从用户中选择 *;
此类 SELECT * 查询被视为批处理(“给我一切”)轮询方法。虽然这对于捕获当前状态的快照非常有用,但下游消费者需要努力弄清楚每个时间间隔内发生了哪些数据变化。
但是,轮询可以变得更加细化。例如,我们只能轮询一个主键。
从用户中选择 MAX(id);
系统可以跟踪主键 (id) 的最大值。当最大值增加时,表示发生了 INSERT 操作。
此外,如果数据库具有 updateAt 列,则查询可以查看时间戳更改以捕获 UPDATE 操作。
SELECT * from Users WHERE updated_at > 2021-02-08;
利弊
简单:轮询很棒,因为它易于实施和部署,而且非常有效。
自定义查询很有用。一个好处是可以自定义轮询时使用的查询以适应复杂的用例。查询可以直接在 SQL 中收录 JOINS 或转换。
捕捉删除很困难:使用轮询,捕捉删除更加困难。如果数据库中的一行完全没有了,你就不能真正查询它。一种解决方案是使用数据库触发器创建表来存储已删除的数据。然后删除操作变成了插入操作到可以轮询的新表中。
事件被拉出,而不是被推出。通过轮询,可以从上游系统中提取事件。例如,当使用轮询来摄取数据仓库时,摄取将在 CDC 系统决定进行轮询时发生。理论上,“实时”可以通过足够快的轮询来完成,但这可能会给数据库带来性能开销。
性能开销是一个问题。SELECT * 或任何复杂的查询在海量数据集上都不能很好地扩展。一种常见的解决方法是通过轮询备用实例来替换主数据库。
无法捕获查询时间之间的变化。另一个考虑因素是查询时间之间的数据变化。例如,如果系统每小时轮询一次,并且数据在同一小时内多次更改,则您只能看到查询时间的更改,而看不到任何中间更改。
数据库触发器
大多数流行的数据库都支持某种形式的触发器。例如。在 PostgreSQL 中,可以构建一个触发器,当一条记录被删除时,将它移动到一个新表中。
CREATE TRIGGER moveDeleted
在删除“用户”之前
对于每一行
执行过程 moveDeleted()。
因为触发器可以有效地侦听操作并执行操作,所以数据库触发器可以充当 CDC 系统。
在某些情况下,这些触发器可以是非常复杂和完整的功能。例如。在 MongoDB 中,触发器是用 Javascript 编写的。
exports = async function (changeEvent) {
//从变化流事件对象中解构出字段
const { updateDescription, fullDocument }= changeEvent;
// 检查shippingLocation字段是否被更新。
const updatedFields = Object.keys(updateDescription.upedFields)。
const isNewLocation = updatedFields.some(field =>)
field.match(/shippingLocation/)
);
// 如果位置改变了,就给客户发短信说明更新的位置。
if(isNewLocation){
// 做点什么
}
};
利弊
易于部署。触发器很棒,因为它们对大多数数据库都有开箱即用的支持,并且易于实现。
数据一致性。任何当前和新的下游消费者都不必担心执行此逻辑,因为此逻辑收录在数据库中,而不是应用程序中 - 在微服务架构的情况下。
数据库中的应用程序逻辑可以被破坏:但是,数据库不应该收录太多的应用程序逻辑。这可能导致行为与数据库的耦合过于紧密,一个错误的触发器可能会影响整个数据基础架构。触发器应该简洁明了。
每个动作都被捕获。您可以为每个数据库操作创建一个触发器。
性能开销是一个问题。由于与轮询方法相同的原因,编写不当的触发器也会影响数据库性能。收录复杂查询的触发器在大型数据集上无法很好地扩展。
流式复制日志
最好至少运行一个数据库的辅助实例,以确保正确的故障转移和灾难恢复。
在这种模式下,数据库的备用实例需要在不丢失信息的情况下与主实例保持同步。现在最好的方法是让数据库写入日志中发生的所有更改。然后,任何备用实例都可以从此日志中流式传输更改并在本地应用这些操作。实时做同样的事情是允许备用实例“镜像”主实例。
以下是一些关于一些最流行的数据库如何工作的参考资料。
CDC 可以使用相同的机制来监听变化。就像备用数据库一样,附加系统也可以在更新流式日志时处理它们。
在上面的 PostgreSQL 示例图中,CDC 系统可以充当额外的 WAL 接收器,处理事件并将它们发送到消息传输(HTTP API、Kafka 等)。
下面是使用提供的 SQL 函数从 PostgreSQL 的 WAL 查询更改的示例。
test_decoding plugin:
postgres=# SELECT * FROM pg_logical_slot_get_changes('regression_slot', NULL, NULL);
lsn | xid | data
-----------+-------+---------------------------------------------------------
0/ba5a688 | 10298 | start 10298
0/BA5A6F0 | 10298 | table public.data:INSERT: id[integer]:1 data[text]:'1' 。
0/BA5A7F8 | 10298 | table public.data:INSERT: id[integer]:2 data[text]:'2' 。
0/ba5a8a8 | 10298 | commit 10298
(4 rows)
在上面的查询响应中,它描述了以下内容。
这些更改事件的格式将基于逻辑解码输出插件。例如 wal2json 输出插件允许您以 JSON 格式输出更改,这比 test_decoding 插件的输出更容易解析。
PostgreSQL 还提供了一种机制来在这些更改发生时对其进行流式传输。正如您在前面的事件示例中看到的,Debezium 还实时解析流式日志并生成 JSON 事件。
利弊
事件被推送。流式日志的一个巨大好处是事件在发生变化时被推送到 CDC 系统(而不是轮询)。这种推送模式支持实时架构。以用户表为例,数据仓库的摄取将在流式日志CDC系统中实时发生。
高效且低延迟。备用实例使用流式日志进行灾难恢复,效率和低延迟是重中之重。流式复制日志是捕获更改的最有效方法,并且对数据库的开销最小。这个过程在不同的数据库中会有不同的表现,但这些概念仍然适用。
每个动作都被捕获。数据存储中发生的每个事务都将写入日志。
很难获得数据的完整快照。通常,在一定时间(或大小)之后,流式日志会被清除,因为它们占用空间。因此,日志可能不收录已发生的所有更改,仅收录最近的更改。
需要进行配置。启用复制日志可能需要额外的配置、插件,甚至是数据库重启。在最小的城市地区实施这些变化可能很麻烦,需要规划。
下一步是什么?
捕捉数据变化就像是任何应用程序架构的瑞士军刀;它对许多不同类型的问题很有用。侦听、存储和处理任何系统(尤其是数据库)中的变化,让您可以在两个数据存储之间实时复制数据,将单一应用程序分解为可扩展的、事件驱动的微服务,甚至可以为实时 UI 提供支持.
流式复制日志、轮询和数据库触发器为构建 CDC 系统提供了一种机制。对于您的应用程序架构和所需的功能,每种方法都有其自身的优点和缺点。
在下一篇文章中,我们将深入挖掘。
我迫不及待地想看看你建造了什么。
采集文章系统(以scrapy开发文章系统的抓取方式分为静态和动态)
采集交流 • 优采云 发表了文章 • 0 个评论 • 439 次浏览 • 2022-02-15 00:00
采集文章系统后就需要进行数据的导入。就笔者所知,目前以爬虫开发为主要方向的公司会将文章数据的抓取采集方式分为静态抓取和动态抓取。此处静态抓取指的是以python服务器上的scrapy进行抓取,而动态抓取则主要是以python爬虫框架requests等web爬虫工具或者web服务器开发工具以及web解析平台。
今天主要以scrapy开发文章系统。1、准备工作我们使用的是企业版的scrapy,抓取过程中用到的依赖库有三个:urllib2,re,scrapy。urllib2库是一个标准库,它常被用于提取关键字,请求头和路由。因此我们必须要会使用urllib2库,也就是常说的面向对象编程。你可以利用scrapy.urllib2.url(xxx)可以很方便的导入scrapy的urllib2库,将scrapy所需要的所有url及其内容从一个urllib2进行爬取或从一个urllib2请求。
re库是一个多协议的爬取库,用于解析http请求报文和建立python的连接。同时https还会对我们写入简单的安全代码。scrapy提供在python下的python实现scrapy.spider(自动爬取者),实现scrapy-login(登录动态url)和scrapy-download(下载动态url)。
scrapy-sigterm是python下的项目快速安装接口,scrapy可以单独部署在linux下,所以也可以使用scrapy.signal等函数来与linux服务器通信。这里我们安装scrapy3,通过源码安装,如:#!/usr/bin/envpython3scrapy-simple_install_for_start如果你不懂python,有些项目还需要python3,那么需要下载python版本的scrapy3的源码,通过pip命令安装。
#!/usr/bin/envpython3scrapy3.py--user--db-path=/lib/python3/3.6/envs/scrapy_pip.py#!/usr/bin/envpython3scrapy3.py--user--db-path=/lib/python3/3.6/envs/scrapy_pip.py#!/usr/bin/envpython3scrapy3.py--user--db-path=/lib/python3/3.6/envs/scrapy_pip.pymain.py:\scrapy_simple_install_for_start\\scrapy_simple_install_for_start\\\scrapy_simple_install_for_start\\\scrapy_simple_install_for_start\\\scrapy_simple_install_for_start\\\scrapy_simple_install_for_start\\\scrapy_simple_install_for。 查看全部
采集文章系统(以scrapy开发文章系统的抓取方式分为静态和动态)
采集文章系统后就需要进行数据的导入。就笔者所知,目前以爬虫开发为主要方向的公司会将文章数据的抓取采集方式分为静态抓取和动态抓取。此处静态抓取指的是以python服务器上的scrapy进行抓取,而动态抓取则主要是以python爬虫框架requests等web爬虫工具或者web服务器开发工具以及web解析平台。
今天主要以scrapy开发文章系统。1、准备工作我们使用的是企业版的scrapy,抓取过程中用到的依赖库有三个:urllib2,re,scrapy。urllib2库是一个标准库,它常被用于提取关键字,请求头和路由。因此我们必须要会使用urllib2库,也就是常说的面向对象编程。你可以利用scrapy.urllib2.url(xxx)可以很方便的导入scrapy的urllib2库,将scrapy所需要的所有url及其内容从一个urllib2进行爬取或从一个urllib2请求。
re库是一个多协议的爬取库,用于解析http请求报文和建立python的连接。同时https还会对我们写入简单的安全代码。scrapy提供在python下的python实现scrapy.spider(自动爬取者),实现scrapy-login(登录动态url)和scrapy-download(下载动态url)。
scrapy-sigterm是python下的项目快速安装接口,scrapy可以单独部署在linux下,所以也可以使用scrapy.signal等函数来与linux服务器通信。这里我们安装scrapy3,通过源码安装,如:#!/usr/bin/envpython3scrapy-simple_install_for_start如果你不懂python,有些项目还需要python3,那么需要下载python版本的scrapy3的源码,通过pip命令安装。
#!/usr/bin/envpython3scrapy3.py--user--db-path=/lib/python3/3.6/envs/scrapy_pip.py#!/usr/bin/envpython3scrapy3.py--user--db-path=/lib/python3/3.6/envs/scrapy_pip.py#!/usr/bin/envpython3scrapy3.py--user--db-path=/lib/python3/3.6/envs/scrapy_pip.pymain.py:\scrapy_simple_install_for_start\\scrapy_simple_install_for_start\\\scrapy_simple_install_for_start\\\scrapy_simple_install_for_start\\\scrapy_simple_install_for_start\\\scrapy_simple_install_for_start\\\scrapy_simple_install_for。
采集文章系统(一个微信公众号历史消息页面的链接地址和采集方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-02-12 04:14
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个微信公众号历史新闻页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=========2017 年 1 月 11 日更新==========
现在,根据不同的微信个人号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的信息,这两种页面形式在不同的微信账号中不规则出现。有的微信账号总是第一页格式,有的总是第二页格式。
以上链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
这个地址是通过微信客户端打开历史消息页面,然后使用后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz 是公众号的类id参数。每个公众号都有一个微信业务。目前公众号的biz发生变化的概率很小;
其余三个参数与用户的 id 和 token 票证相关。这三个参数的值是微信客户端生成后自动添加到地址栏的。所以想要采集公众号,必须通过微信客户端。在微信之前的版本中,这三个参数也可以一次性获取,在有效期内被多个公众号使用。当前版本每次访问公共帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人微信账号:采集的内容,不仅需要微信客户端,采集还需要个人微信账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析与仓储系统:我用php语言写的。后面会详细介绍如何分析文章列表,建立采集队列,实现批量采集内容。
步
一、安装模拟器或者用手机安装微信客户端app,申请微信个人账号并登录app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置将脚本代码插入公众号页面。让我们从安装和配置过程开始。
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器上安装证书:
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开微信,点击任意公众号历史消息或文章,可以在终端看到响应码滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址localhost:8002可以看到anyproxy的web界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转,跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改和配置代理服务器,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改功能内容(请详细阅读评论,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,而且同一个页面形式总是显示在不同的微信账号中,但是为了兼容这两种页面形式,下面的代码会保留两种页面形式的判断,你也可以使用你的自己的页面表单删除li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。利用这个原理批量采集公众号内容和阅读量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json并解析并存入数据库
<p> 查看全部
采集文章系统(一个微信公众号历史消息页面的链接地址和采集方法)
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个微信公众号历史新闻页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=========2017 年 1 月 11 日更新==========
现在,根据不同的微信个人号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的信息,这两种页面形式在不同的微信账号中不规则出现。有的微信账号总是第一页格式,有的总是第二页格式。
以上链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
这个地址是通过微信客户端打开历史消息页面,然后使用后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz 是公众号的类id参数。每个公众号都有一个微信业务。目前公众号的biz发生变化的概率很小;
其余三个参数与用户的 id 和 token 票证相关。这三个参数的值是微信客户端生成后自动添加到地址栏的。所以想要采集公众号,必须通过微信客户端。在微信之前的版本中,这三个参数也可以一次性获取,在有效期内被多个公众号使用。当前版本每次访问公共帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人微信账号:采集的内容,不仅需要微信客户端,采集还需要个人微信账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析与仓储系统:我用php语言写的。后面会详细介绍如何分析文章列表,建立采集队列,实现批量采集内容。
步
一、安装模拟器或者用手机安装微信客户端app,申请微信个人账号并登录app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置将脚本代码插入公众号页面。让我们从安装和配置过程开始。
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器上安装证书:
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开微信,点击任意公众号历史消息或文章,可以在终端看到响应码滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址localhost:8002可以看到anyproxy的web界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转,跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改和配置代理服务器,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改功能内容(请详细阅读评论,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,而且同一个页面形式总是显示在不同的微信账号中,但是为了兼容这两种页面形式,下面的代码会保留两种页面形式的判断,你也可以使用你的自己的页面表单删除li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。利用这个原理批量采集公众号内容和阅读量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json并解析并存入数据库
<p>
采集文章系统(百度搜索中石油采集文档云系统的模块效果图解析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-02-11 15:02
采集文章系统也可以用云文档,有一些功能是单机不能达到的,比如填写费用,单机只能一家公司填写,而云文档就可以把你所有的公司行为都拉出来,并且可以做成模板式,所有的公司类型都可以填写。
不可行,没有任何技术门槛,都是人来完成数据采集和反馈。
xx公司,网页文档,
中石油集团旗下119石油采集文档云系统在腾讯首页招商频道首页展示了中石油集团采集文档云项目的模块效果:百度搜索中石油采集文档云(官网网址:)119石油集团采集文档云系统_41地区石油行业采集软件_中石油、中海油、中国石化等垄断国企在线采集系统
需要什么技术难度?有技术难度的是花大量的人力财力成本来建立信息流营销体系,并采用非正规手段来获取流量,要知道很多流量主都是通过内部关系和特殊渠道的。
如果我问题里的xx公司,就是中石油。在这个事儿上,腾讯干不过阿里、百度、360、不少上市公司,之所以敢收钱的原因是,你收了,别人就会来请你吃饭。
很难,真的很难,腾讯的采集能力真的很恐怖。除非是那种重大资讯,网页采集服务商,但那种服务商恐怕专门做第三方收集,真的很费劲,因为手机里就没啥有用的数据啊, 查看全部
采集文章系统(百度搜索中石油采集文档云系统的模块效果图解析)
采集文章系统也可以用云文档,有一些功能是单机不能达到的,比如填写费用,单机只能一家公司填写,而云文档就可以把你所有的公司行为都拉出来,并且可以做成模板式,所有的公司类型都可以填写。
不可行,没有任何技术门槛,都是人来完成数据采集和反馈。
xx公司,网页文档,
中石油集团旗下119石油采集文档云系统在腾讯首页招商频道首页展示了中石油集团采集文档云项目的模块效果:百度搜索中石油采集文档云(官网网址:)119石油集团采集文档云系统_41地区石油行业采集软件_中石油、中海油、中国石化等垄断国企在线采集系统
需要什么技术难度?有技术难度的是花大量的人力财力成本来建立信息流营销体系,并采用非正规手段来获取流量,要知道很多流量主都是通过内部关系和特殊渠道的。
如果我问题里的xx公司,就是中石油。在这个事儿上,腾讯干不过阿里、百度、360、不少上市公司,之所以敢收钱的原因是,你收了,别人就会来请你吃饭。
很难,真的很难,腾讯的采集能力真的很恐怖。除非是那种重大资讯,网页采集服务商,但那种服务商恐怕专门做第三方收集,真的很费劲,因为手机里就没啥有用的数据啊,

