
采集文章系统
采集文章系统(采集文章系统集成的三个大方向应该不同?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-18 16:01
采集文章系统集成是百度搜索搜索技术相关的培训课程,采集系统集成是基于百度搜索、社会化网络、账号分析系统、ai等多领域解决方案的产品。采集文章系统集成是帮助用户更好地进行网站分析以及体验,帮助用户管理网站内容,并整合百度文库等第三方媒体文档的产品。采集文章系统集成网站采集、预警、统计、权限等功能。采集系统集成是基于文章推荐、网页爬虫、移动端文章源等方案的产品。
目前网站采集系统集成不断成熟,并融合人工智能、大数据、云计算等前沿科技,提供专业、全面、易用的一站式网站采集、信息数据分析等服务。
这三个都属于采集系统,应该都算是通过文章批量采集百度网页的数据。希望可以帮到你。
可能和你们需要采集的网站有关。不同的网站方向应该不同。
搜索技术,百度搜索分析,搜索算法,大数据采集.
谢邀,
分别是:大规模网站采集系统(主要是采集百度新闻、百度图片等),采集推荐系统(算法模型推荐,如最可能的关键词),站群还有采集数据、站点分析,这些领域我不太懂,只是知道这么多。
应该算利用大数据来做搜索技术改进
这里三个大方向,其实未来的发展,应该是每一块领域都有一个大项目,把技术应用到不同的领域。现在可能是ai和大数据,百度做了这两方面也算不错了,不管怎么样,上升的领域,我们也得看到。 查看全部
采集文章系统(采集文章系统集成的三个大方向应该不同?)
采集文章系统集成是百度搜索搜索技术相关的培训课程,采集系统集成是基于百度搜索、社会化网络、账号分析系统、ai等多领域解决方案的产品。采集文章系统集成是帮助用户更好地进行网站分析以及体验,帮助用户管理网站内容,并整合百度文库等第三方媒体文档的产品。采集文章系统集成网站采集、预警、统计、权限等功能。采集系统集成是基于文章推荐、网页爬虫、移动端文章源等方案的产品。
目前网站采集系统集成不断成熟,并融合人工智能、大数据、云计算等前沿科技,提供专业、全面、易用的一站式网站采集、信息数据分析等服务。
这三个都属于采集系统,应该都算是通过文章批量采集百度网页的数据。希望可以帮到你。
可能和你们需要采集的网站有关。不同的网站方向应该不同。
搜索技术,百度搜索分析,搜索算法,大数据采集.
谢邀,
分别是:大规模网站采集系统(主要是采集百度新闻、百度图片等),采集推荐系统(算法模型推荐,如最可能的关键词),站群还有采集数据、站点分析,这些领域我不太懂,只是知道这么多。
应该算利用大数据来做搜索技术改进
这里三个大方向,其实未来的发展,应该是每一块领域都有一个大项目,把技术应用到不同的领域。现在可能是ai和大数据,百度做了这两方面也算不错了,不管怎么样,上升的领域,我们也得看到。
采集文章系统(一下如何利用老Y文章管理系统采集时自动完成伪原创)
采集交流 • 优采云 发表了文章 • 0 个评论 • 244 次浏览 • 2021-09-18 04:13
作为垃圾站的站长,最可取的是"K17"能自动"K11",自动完成"K1",然后自动收钱。这真是世界上最幸福的事情,哈哈。不会讨论自动采集和自动收款。今天,我将介绍如何使用旧的y文章管理系统采集自动完成伪原创管理系统文章使用简单方便。虽然它的功能不如Dede等强大,但几乎是不正常的(当文章管理系统是用ASP语言编写时,似乎没有可比性),但有其应有的功能,而且相当简单,因此受到了很多站长的欢迎。在老Y的文章管理系统采集中,自动完成伪原创的具体方法很少被讨论。在老Y的论坛上,有些人甚至出售这种方法。我有点鄙视它。关于“K11”,我不会说太多。我相信每个人都能应付。我想介绍一下旧的y文章管理系统如何在采集的同时自动完成伪原创工作的具体方法。总体思路是利用老y文章管理系统的过滤功能,实现同义词的自动替换,从而达到伪原创的目的。例如,我想将采集文章中的所有单词“在线赚钱博客”替换为“在线赚钱日记”。具体步骤如下:第一步是进入后台。找到“采集management”-“过滤器管理”并添加新的过滤器项。我可以创建一个名为“在线赚钱博客”的项目。具体设置如图所示:“过滤名称”:填写“在线赚钱博客”或随意撰写。但是,为了便于查看,建议与替换的单词保持一致
“项目”:请根据您自己的网站选择一列网站(您必须选择一列,否则过滤后的项目将无法保存)。“过滤器对象”:选项为“标题过滤器”和“正文过滤器”。通常,您可以选择“车身过滤器”。如果你想伪原创查看标题,你可以选择“标题过滤器”。“过滤器类型”:选项为“简单更换”和“高级过滤器”。通常选择“简单替换”。如果选择了“高级过滤器”,则需要指定“开始标记”和“结束标记”,以便可以在代码级别替换采集中的内容。“使用状态”:选项为“启用”和“禁用”,无需解释。“使用范围”:选项为“公共”和“私人”。如果选择private,则过滤器仅对当前网站列有效;如果选择了public,它将对所有列有效,而不管任何列中的任何内容是采集。通常,选择“私人”。“内容”:填写“在线赚钱博客”和需要替换的词。“替换”:填写“在线赚钱日志”,这样只要采集的文章中收录“在线赚钱日志”一词,它就会自动替换为“在线赚钱日志”。其次,重复第一步的工作,直到添加所有同义词。有网友想问:我有三万多个同义词。是否要逐个手动添加它们?什么时候会添加!?无法批量添加?这是个好问题!手动添加确实是一项几乎不可能的任务。除非你有非凡的毅力,否则你可以手动添加超过30000个同义词
遗憾的是,旧的y文章管理系统没有提供批量导入功能。然而,作为真实的、有经验的、有思想的“k5”,我们应该有“k5”意识。您知道,我们刚才输入的内容存储在数据库中,旧的文章管理系统是用ASP+access编写的。MDB数据库可以轻松编辑!因此,我可以通过直接修改数据库批量导入伪原创替换规则!改进的第二步:修改数据库和批量导入规则。搜索后,我发现该数据库位于“您的管理目录\Cai\database”下。用access打开数据库并找到“过滤器”表。您会发现我们刚才添加的替换规则存储在这里。根据您的需要分批添加!接下来的工作涉及访问的操作。我不会罗嗦的。你可以自己做。解释“过滤器”表中几个字段的含义:filterid:无需输入自动生成。Itemid:column ID,当我们手动输入时,它是“item”的内容,但这里是一个数字ID。请注意以下列采集ID做好工作如果您不知道ID,可以重复第一步并进行测试。过滤器名称:过滤器名称。过滤器对象:即“过滤器对象”。填写1至“标题过滤器”,填写2至“正文过滤器”
过滤器类型:即“过滤器类型”。填写1为“简单更换”,填写2为“高级过滤”。Filtercontent:指“内容”。Fisstring:即“开始标签”,仅当设置了“高级过滤器”时才有效。如果设置了“简单过滤器”,请将其留空。Fiostring:“结束标记”,仅在设置“高级过滤器”时有效。如果设置了“简单过滤器”,请将其留空。过滤器步骤:更换。标志:即“使用状态”。True表示“已启用”,false表示“已禁用”。Publictf:即“使用范围”。真是“公开的”,假是“私人的”。最后,我们来谈谈伪原创使用过滤功能的感受:文章管理系统在使用采集时可以自动伪原创但功能不够强大。例如,我的电台有三个栏目:“第一栏”、“第二栏”和“第三栏”。我希望“第1列”将伪原创标题和文本,“第2列”将仅伪原创文本,“第3列”将仅伪原创标题。因此,我只能进行以下设置(假设我有30000条同义词规则):为“第1列”的标题伪原创创建30000条替换规则;为“第1列”的主体伪原创创建30000个替换规则;为“第2列”的文本伪原创创建30000个替换规则;为“第3列”的标题伪原创创建30000个替换规则
这造成了数据库的极大浪费。如果我的站点有几十个栏目,每个栏目的要求都不一样,那么这个数据库的大小将非常糟糕。因此,建议在旧的y文章管理系统的下一版本中对该功能进行改进:首先,增加批量导入功能。毕竟,修改数据库是危险的。其次,过滤规则不再附加到网站列,而是独立的。创建新集合项时,会添加是否使用筛选规则的判断。我相信这种修改可以大大节省数据库存储空间,使逻辑结构更加清晰。这篇文章是“我的在线赚钱日记-原创在线赚钱博客”原创. 请尊重我的劳动成果。请注明转载来源!另外,我很久没有使用旧的y文章管理系统了。如果课文中有错误或不恰当的地方,请改正!企业贸易网 查看全部
采集文章系统(一下如何利用老Y文章管理系统采集时自动完成伪原创)
作为垃圾站的站长,最可取的是"K17"能自动"K11",自动完成"K1",然后自动收钱。这真是世界上最幸福的事情,哈哈。不会讨论自动采集和自动收款。今天,我将介绍如何使用旧的y文章管理系统采集自动完成伪原创管理系统文章使用简单方便。虽然它的功能不如Dede等强大,但几乎是不正常的(当文章管理系统是用ASP语言编写时,似乎没有可比性),但有其应有的功能,而且相当简单,因此受到了很多站长的欢迎。在老Y的文章管理系统采集中,自动完成伪原创的具体方法很少被讨论。在老Y的论坛上,有些人甚至出售这种方法。我有点鄙视它。关于“K11”,我不会说太多。我相信每个人都能应付。我想介绍一下旧的y文章管理系统如何在采集的同时自动完成伪原创工作的具体方法。总体思路是利用老y文章管理系统的过滤功能,实现同义词的自动替换,从而达到伪原创的目的。例如,我想将采集文章中的所有单词“在线赚钱博客”替换为“在线赚钱日记”。具体步骤如下:第一步是进入后台。找到“采集management”-“过滤器管理”并添加新的过滤器项。我可以创建一个名为“在线赚钱博客”的项目。具体设置如图所示:“过滤名称”:填写“在线赚钱博客”或随意撰写。但是,为了便于查看,建议与替换的单词保持一致
“项目”:请根据您自己的网站选择一列网站(您必须选择一列,否则过滤后的项目将无法保存)。“过滤器对象”:选项为“标题过滤器”和“正文过滤器”。通常,您可以选择“车身过滤器”。如果你想伪原创查看标题,你可以选择“标题过滤器”。“过滤器类型”:选项为“简单更换”和“高级过滤器”。通常选择“简单替换”。如果选择了“高级过滤器”,则需要指定“开始标记”和“结束标记”,以便可以在代码级别替换采集中的内容。“使用状态”:选项为“启用”和“禁用”,无需解释。“使用范围”:选项为“公共”和“私人”。如果选择private,则过滤器仅对当前网站列有效;如果选择了public,它将对所有列有效,而不管任何列中的任何内容是采集。通常,选择“私人”。“内容”:填写“在线赚钱博客”和需要替换的词。“替换”:填写“在线赚钱日志”,这样只要采集的文章中收录“在线赚钱日志”一词,它就会自动替换为“在线赚钱日志”。其次,重复第一步的工作,直到添加所有同义词。有网友想问:我有三万多个同义词。是否要逐个手动添加它们?什么时候会添加!?无法批量添加?这是个好问题!手动添加确实是一项几乎不可能的任务。除非你有非凡的毅力,否则你可以手动添加超过30000个同义词
遗憾的是,旧的y文章管理系统没有提供批量导入功能。然而,作为真实的、有经验的、有思想的“k5”,我们应该有“k5”意识。您知道,我们刚才输入的内容存储在数据库中,旧的文章管理系统是用ASP+access编写的。MDB数据库可以轻松编辑!因此,我可以通过直接修改数据库批量导入伪原创替换规则!改进的第二步:修改数据库和批量导入规则。搜索后,我发现该数据库位于“您的管理目录\Cai\database”下。用access打开数据库并找到“过滤器”表。您会发现我们刚才添加的替换规则存储在这里。根据您的需要分批添加!接下来的工作涉及访问的操作。我不会罗嗦的。你可以自己做。解释“过滤器”表中几个字段的含义:filterid:无需输入自动生成。Itemid:column ID,当我们手动输入时,它是“item”的内容,但这里是一个数字ID。请注意以下列采集ID做好工作如果您不知道ID,可以重复第一步并进行测试。过滤器名称:过滤器名称。过滤器对象:即“过滤器对象”。填写1至“标题过滤器”,填写2至“正文过滤器”
过滤器类型:即“过滤器类型”。填写1为“简单更换”,填写2为“高级过滤”。Filtercontent:指“内容”。Fisstring:即“开始标签”,仅当设置了“高级过滤器”时才有效。如果设置了“简单过滤器”,请将其留空。Fiostring:“结束标记”,仅在设置“高级过滤器”时有效。如果设置了“简单过滤器”,请将其留空。过滤器步骤:更换。标志:即“使用状态”。True表示“已启用”,false表示“已禁用”。Publictf:即“使用范围”。真是“公开的”,假是“私人的”。最后,我们来谈谈伪原创使用过滤功能的感受:文章管理系统在使用采集时可以自动伪原创但功能不够强大。例如,我的电台有三个栏目:“第一栏”、“第二栏”和“第三栏”。我希望“第1列”将伪原创标题和文本,“第2列”将仅伪原创文本,“第3列”将仅伪原创标题。因此,我只能进行以下设置(假设我有30000条同义词规则):为“第1列”的标题伪原创创建30000条替换规则;为“第1列”的主体伪原创创建30000个替换规则;为“第2列”的文本伪原创创建30000个替换规则;为“第3列”的标题伪原创创建30000个替换规则
这造成了数据库的极大浪费。如果我的站点有几十个栏目,每个栏目的要求都不一样,那么这个数据库的大小将非常糟糕。因此,建议在旧的y文章管理系统的下一版本中对该功能进行改进:首先,增加批量导入功能。毕竟,修改数据库是危险的。其次,过滤规则不再附加到网站列,而是独立的。创建新集合项时,会添加是否使用筛选规则的判断。我相信这种修改可以大大节省数据库存储空间,使逻辑结构更加清晰。这篇文章是“我的在线赚钱日记-原创在线赚钱博客”原创. 请尊重我的劳动成果。请注明转载来源!另外,我很久没有使用旧的y文章管理系统了。如果课文中有错误或不恰当的地方,请改正!企业贸易网
采集文章系统(给站长或SEOER推荐一款免费的文章采集工具_chukang-CSDN博客)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-12 08:15
向站长或SEOER推荐一个免费的文章采集工具_chukang-CSDN博客。
Webmaster Star 是一个专业的站群 内容管理系统,它集成了文章采集、文章processing 和文章publishing。界面精美,操作简单,功能强大。 .
15个免费文章采集网站,每天更新,收录率很高!免费文章采集tools! 15个免费个人或商业文章采集网站;为了应对日渐火爆的微信公众号等自媒体平台的抄袭和洗稿,我们整理了这15个免费给大家。
如今,很多焦点新闻,文章,热点等等,都在网上不断更新。如果数量少,可以一张一张的复制采集,但是如果采集的数量太多,一张一张的复制不仅效率低下,而且会越来越烦人。所以今天给大家带来了各种款式。
3、好搜文库:类似于百度文库采集,但所有文章找到的都是免费的。 4.知网:如果你有论文,可以通过这个平台提交你的论文。
文章采集Reading 是一个用简单语言编写的简单网络文章采集 工具。不仅可以替换采集文本,还可以简单的替换一些文本,或者添加。
文章采集Reading 是一个用简单的语言编写的简单的网络文章采集 工具。不仅可以采集文字,还可以简单的替换一些文字,或者添加文字,也是SEO伪原创的好工具...
无人值守的免费自动采集器-中小网站自动更新工具!无人值守的免费采集器中小网站自动更新工具!免责声明:本软件适用于长期更新内容,非临时网站使需要对现有论坛或网站进行任何更改。 查看全部
采集文章系统(给站长或SEOER推荐一款免费的文章采集工具_chukang-CSDN博客)
向站长或SEOER推荐一个免费的文章采集工具_chukang-CSDN博客。
Webmaster Star 是一个专业的站群 内容管理系统,它集成了文章采集、文章processing 和文章publishing。界面精美,操作简单,功能强大。 .
15个免费文章采集网站,每天更新,收录率很高!免费文章采集tools! 15个免费个人或商业文章采集网站;为了应对日渐火爆的微信公众号等自媒体平台的抄袭和洗稿,我们整理了这15个免费给大家。
如今,很多焦点新闻,文章,热点等等,都在网上不断更新。如果数量少,可以一张一张的复制采集,但是如果采集的数量太多,一张一张的复制不仅效率低下,而且会越来越烦人。所以今天给大家带来了各种款式。
3、好搜文库:类似于百度文库采集,但所有文章找到的都是免费的。 4.知网:如果你有论文,可以通过这个平台提交你的论文。

文章采集Reading 是一个用简单语言编写的简单网络文章采集 工具。不仅可以替换采集文本,还可以简单的替换一些文本,或者添加。
文章采集Reading 是一个用简单的语言编写的简单的网络文章采集 工具。不仅可以采集文字,还可以简单的替换一些文字,或者添加文字,也是SEO伪原创的好工具...

无人值守的免费自动采集器-中小网站自动更新工具!无人值守的免费采集器中小网站自动更新工具!免责声明:本软件适用于长期更新内容,非临时网站使需要对现有论坛或网站进行任何更改。
采集文章系统(编辑本段文章采集系统过程相关资料功能的开发工具使用.Net)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-09-08 16:06
文章采集系统由(我的世界me采集网)开发,历时4年,在线信息采集系统基于用户自定义关键词词,从网上检索相关数据,并对数据进行合理的截取、分类、去重、过滤,并以文件或数据库的形式保存。
内容
文章采集系统进程
相关数据函数解释
展开
文章采集系统进程
相关数据函数解释
展开
编辑本段
文章采集系统进程
系统开发工具采用.Net的C#进行系统开发,数据库采用SQL Server 2000。
一、软件系统总体设计要求
1.网站搜索深度为5层,网站搜索广度为50个网页时,数据检索率达到98%。
2.网站搜索深度为5层,网站搜索广度为50个网页时,数据准确率大于97%。
3.数据存储容量:存储容量≥100G。
4.搜索单个网站时,网站搜索深度:最大5级网页; 网站search 广度:最多搜索 50 个网页。如果超过 60 秒没有结果,搜索将自动放弃。
5.并发搜索强度:10个线程可以同时并发搜索。
6.50亿汉字,平均查询时间小于3秒。
二、应用系统设计要求
1.要求系统多线程采集信息;
2.可以自动对记录进行分类和索引;
3.自动过滤重复项并自动索引记录;
三、应用系统功能详解
实时在线采集(内容抓取模块) 快速:网页抓取采用多线程并发搜索技术,可设置最大并发线程数。灵活:可同时跟踪捕捉多个网站,提供灵活的网站、栏目或频道采集策略,利用逻辑关系定位采集内容。准确:多抓取少抓取,可以自定义需要抓取的文件格式,可以抓取图片和表格信息,抓取过程成熟可靠,容错性强,可以长时间稳定运行完成初始设置后。高效自动分类 支持机检分类-可以使用预定义的关键词和规则方法来确定类别;支持自动分类——通过机器自动学习或预学习进行自动分类,准确率达到80%以上。 (这个比较麻烦,可以考虑不做)支持多种分类标准——比如按地区(华北、华南等)、内容(政治、科技、军事、教育等) .)、来源(新华网、人民日报、新浪网)等等。网页自动分析内容过滤——可以过滤掉广告、导航信息、版权等无用信息,可以剔除反动和色情内容。内容排序-对于不同的网站相同或相似的内容,可以自动识别并标记为相似。识别方法可以由用户定义的规则确定,并由内容的相似性自动确定。格式转换——自动将 HTML 格式转换为文本文件。自动索引——自动从网页中提取标题、版本、日期、作者、栏目、分类等信息。系统管理集成单一界面——系统提供基于Web的用户界面和管理员界面,满足系统管理员和用户的双重需求。浏览器可用于远程管理分类目录、用户权限,并对分类结果进行调整和强化。完善的目录维护——提供完善的分类目录添加、移动、修改、删除管理和维护权限管理,可设置管理目录和单个文件使用权限,加强安全管理。实时文件管理——可以浏览各个目录的分类结果,并进行移动、重命名等实时调整。
编辑本段
相关数据函数解释
使用文章采集系统,整个系统可以在线自动安装,后台有新版本可以自动升级;系统文件损坏可自动修复,站长无后顾之忧。
1、自动构建功能
强大的关键词管理系统
可自动批量获取关键词指定的常用相关词,轻松控制用户搜索行为
自动文章采集system四种内容
文章采集在处理过程中会自动去除重复内容,并可自由设置各类内容的聚合次数
三重过滤保证内容质量
特别是首创的任意词密度判断功能,为搜索引擎收录提供了强有力的保障
自动生成原创topic
文章采集首创以话题为内容组织形式,这是门户网站内容制胜的法宝
主题内容自动更新
话题可以自动创建和更新,各种内容的更新周期可以单独设置
原创tag 综合页面
整个网站集成了统一通用的分类标签系统,不仅使内容相关,而且原创内容页
2、个性化定制功能
原创tag 综合页面
整个网站集成了统一通用的分类标签系统,不仅使内容相关,而且原创内容页
兼容多种静态模式
不仅能有效保证收录搜索引擎的访问量,还能增加网站的持续访问量
任何顶部导航栏设置
可以随意添加或删除顶部导航栏,让网站具有高度的定制性
任意 URL 连接地址名称
不仅让你的网站独一无二,还能在一定程度上提升搜索引擎排名
支持多个模板集
采用模板编译替代技术,即使只改动一个文件,也能做出个性化的界面
任意显示数量控制
具体可以设置主题页各种内容的数量,也可以设置每个列表页的显示数量
3、内置站长工具
记录整个过程中的蜘蛛访问
智能识别搜索引擎蜘蛛99%的访问,全程控制蜘蛛爬行记录
自动创建站点地图
自动生成百度地图和google地图,可分类设置,有效提升网站content收录
一键查看排名和收录
不仅可以查看Alexa排名,还可以准确掌握网站今日收录,还可以添加网站外链
查看网站中非法的关键词
可以自动批量查看网站中是否存在国家禁止的非法内容
在线自动安装和文件修复
setup.php工具不仅可以自动获取授权,自动在线安装系统,还具有系统修复功能
后台智能自动升级
可自动判断当前需要升级的版本,并自动下载升级,让站长免去更新的烦恼
4、高效能
超高效的自动分词技术
首次使用数字分词库和双向分词验证,大大提高了中文分词的效率和准确率
高效的动态页面缓存
采用分模块页面缓存技术,有效保证系统负载能力和网站动态
代码分段调用技术
使系统每次调用最少的程序代码,减少分析时间,有效提高系统执行效率
编译模板技术
所有未改变的模板只需编译一次,减少模板解析时间,提高访问速度
最小化数据读取设计
大大降低数据库资源消耗,支持更多用户快速访问
图片缩略图保存
默认生成图片文件缩略图并保存在本地,大大降低服务器空间和带宽压力
5、全站互动功能
个人群组功能
话题可以转成群组,比论坛更自由的权限控制
外部个人主页
您可以在个人页面看到发起的话题、订阅的话题和好友
我的故乡
通过SNS功能,您可以跟踪我的话题动态和朋友的站点动态
站内好友系统
可以自由添加好友,还可以查看好友动态信息 查看全部
采集文章系统(编辑本段文章采集系统过程相关资料功能的开发工具使用.Net)
文章采集系统由(我的世界me采集网)开发,历时4年,在线信息采集系统基于用户自定义关键词词,从网上检索相关数据,并对数据进行合理的截取、分类、去重、过滤,并以文件或数据库的形式保存。
内容
文章采集系统进程
相关数据函数解释
展开
文章采集系统进程
相关数据函数解释
展开
编辑本段
文章采集系统进程
系统开发工具采用.Net的C#进行系统开发,数据库采用SQL Server 2000。
一、软件系统总体设计要求
1.网站搜索深度为5层,网站搜索广度为50个网页时,数据检索率达到98%。
2.网站搜索深度为5层,网站搜索广度为50个网页时,数据准确率大于97%。
3.数据存储容量:存储容量≥100G。
4.搜索单个网站时,网站搜索深度:最大5级网页; 网站search 广度:最多搜索 50 个网页。如果超过 60 秒没有结果,搜索将自动放弃。
5.并发搜索强度:10个线程可以同时并发搜索。
6.50亿汉字,平均查询时间小于3秒。
二、应用系统设计要求
1.要求系统多线程采集信息;
2.可以自动对记录进行分类和索引;
3.自动过滤重复项并自动索引记录;
三、应用系统功能详解
实时在线采集(内容抓取模块) 快速:网页抓取采用多线程并发搜索技术,可设置最大并发线程数。灵活:可同时跟踪捕捉多个网站,提供灵活的网站、栏目或频道采集策略,利用逻辑关系定位采集内容。准确:多抓取少抓取,可以自定义需要抓取的文件格式,可以抓取图片和表格信息,抓取过程成熟可靠,容错性强,可以长时间稳定运行完成初始设置后。高效自动分类 支持机检分类-可以使用预定义的关键词和规则方法来确定类别;支持自动分类——通过机器自动学习或预学习进行自动分类,准确率达到80%以上。 (这个比较麻烦,可以考虑不做)支持多种分类标准——比如按地区(华北、华南等)、内容(政治、科技、军事、教育等) .)、来源(新华网、人民日报、新浪网)等等。网页自动分析内容过滤——可以过滤掉广告、导航信息、版权等无用信息,可以剔除反动和色情内容。内容排序-对于不同的网站相同或相似的内容,可以自动识别并标记为相似。识别方法可以由用户定义的规则确定,并由内容的相似性自动确定。格式转换——自动将 HTML 格式转换为文本文件。自动索引——自动从网页中提取标题、版本、日期、作者、栏目、分类等信息。系统管理集成单一界面——系统提供基于Web的用户界面和管理员界面,满足系统管理员和用户的双重需求。浏览器可用于远程管理分类目录、用户权限,并对分类结果进行调整和强化。完善的目录维护——提供完善的分类目录添加、移动、修改、删除管理和维护权限管理,可设置管理目录和单个文件使用权限,加强安全管理。实时文件管理——可以浏览各个目录的分类结果,并进行移动、重命名等实时调整。
编辑本段
相关数据函数解释
使用文章采集系统,整个系统可以在线自动安装,后台有新版本可以自动升级;系统文件损坏可自动修复,站长无后顾之忧。
1、自动构建功能
强大的关键词管理系统
可自动批量获取关键词指定的常用相关词,轻松控制用户搜索行为
自动文章采集system四种内容
文章采集在处理过程中会自动去除重复内容,并可自由设置各类内容的聚合次数
三重过滤保证内容质量
特别是首创的任意词密度判断功能,为搜索引擎收录提供了强有力的保障
自动生成原创topic
文章采集首创以话题为内容组织形式,这是门户网站内容制胜的法宝
主题内容自动更新
话题可以自动创建和更新,各种内容的更新周期可以单独设置
原创tag 综合页面
整个网站集成了统一通用的分类标签系统,不仅使内容相关,而且原创内容页
2、个性化定制功能
原创tag 综合页面
整个网站集成了统一通用的分类标签系统,不仅使内容相关,而且原创内容页
兼容多种静态模式
不仅能有效保证收录搜索引擎的访问量,还能增加网站的持续访问量
任何顶部导航栏设置
可以随意添加或删除顶部导航栏,让网站具有高度的定制性
任意 URL 连接地址名称
不仅让你的网站独一无二,还能在一定程度上提升搜索引擎排名
支持多个模板集
采用模板编译替代技术,即使只改动一个文件,也能做出个性化的界面
任意显示数量控制
具体可以设置主题页各种内容的数量,也可以设置每个列表页的显示数量
3、内置站长工具
记录整个过程中的蜘蛛访问
智能识别搜索引擎蜘蛛99%的访问,全程控制蜘蛛爬行记录
自动创建站点地图
自动生成百度地图和google地图,可分类设置,有效提升网站content收录
一键查看排名和收录
不仅可以查看Alexa排名,还可以准确掌握网站今日收录,还可以添加网站外链
查看网站中非法的关键词
可以自动批量查看网站中是否存在国家禁止的非法内容
在线自动安装和文件修复
setup.php工具不仅可以自动获取授权,自动在线安装系统,还具有系统修复功能
后台智能自动升级
可自动判断当前需要升级的版本,并自动下载升级,让站长免去更新的烦恼
4、高效能
超高效的自动分词技术
首次使用数字分词库和双向分词验证,大大提高了中文分词的效率和准确率
高效的动态页面缓存
采用分模块页面缓存技术,有效保证系统负载能力和网站动态
代码分段调用技术
使系统每次调用最少的程序代码,减少分析时间,有效提高系统执行效率
编译模板技术
所有未改变的模板只需编译一次,减少模板解析时间,提高访问速度
最小化数据读取设计
大大降低数据库资源消耗,支持更多用户快速访问
图片缩略图保存
默认生成图片文件缩略图并保存在本地,大大降低服务器空间和带宽压力
5、全站互动功能
个人群组功能
话题可以转成群组,比论坛更自由的权限控制
外部个人主页
您可以在个人页面看到发起的话题、订阅的话题和好友
我的故乡
通过SNS功能,您可以跟踪我的话题动态和朋友的站点动态
站内好友系统
可以自由添加好友,还可以查看好友动态信息
采集文章系统(一个约定好该系统一个指定的栏目设置采集计划(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-05 03:08
Information采集User Manual Summary Information采集是捕捉网络数据,实现信息共享的功能模块。提供手动抓取、定时抓取、定时循环抓取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页的数据(新闻)采集传输到webplus系统中的指定栏目。步骤如下: 为指定的列做一个采集计划。在栏目管理中选择栏目,点击设置采集plan。 (例如:图一)设置采集的基本属性。包括执行方式、信息是否自动发布、采集的列类型以及页面的编码格式。(例如:图二)为此采集事先约定了@plan的执行方式是手动、定时单次或定时循环执行,如果只针对采集网页的当前数据,我们可以使用手动和定时单次采集一次;如果是采集webpage 数据会被更新,我们需要保证信息的同步,即使用定时循环采集 判断来自采集的信息是否需要发布.如果采集发来的信息不需要修改,可以直接公开到网上,选择自动发布。如果采集发来的信息需要修改、审核等,选择不自动发布.采集完成后,信息管理器会进行其他操作。 采集的umn类型如果采集的网页只是一个新闻列表,即页面的新闻采集放在指定的栏目下,则选择单栏。
如果被采集的页面有多个新闻列表,并且每个都提供了一个单独的链接进入自己的新闻列表页面,我们需要采集的所有新闻信息,那么选择多列。另外,如果采集的页面是RSS信息聚合页面,设置为对应的RSS单栏或RSS多栏。通过采集设置页面的编码 由于webplus系统使用的是UTF-8编码格式,而采集可能是其他编码格式,那么为了避免采集来的信息乱码,需要设置为采集页面的编码格式。本文来自计算机基础:设置采集plan 采集plan设置的采集规则单列(如:图三)设置“列表页起始URL”为访问路径采集页面。(必填)设置“文章页URL获取规则”,如果新闻列表是通过采集嵌入到网页中的iframe中,则需要设置规则获取链接地址list iframe 访问新闻列表。否则, no 需要制定此规则。(具体规则方法请参考下面的“采集正则表达式制定”)。如果采集的新闻列表网页有分页,则根据新闻列表的分页方式(链接和表单提交)制定分页规则,需要设置起始页码、间隔页码、采集页码。没有分页,不需要制定这个规则,如果页面被采集有多个新闻列表,并且更多新闻列表的url规则类似,但是我们只需要采集指定的一个列表,即我们需要设置规则来限制文章lists的获取。这是为了避免采集冗余数据。
否则,无需设置此规则。设置文章url获取规则,以便能够从采集页面访问特定的新闻页面,从而进行新闻采集。 (必填)设置“文章内容取法”的具体新闻页面。如果文章内容以iframe的形式嵌入到新闻页面,则需要设置规则获取文章iframe的链接地址。访问新闻内容。否则,无需制定此规则。如果新闻内容有分页,则分页规则按照文章content分页方式(链接和表单提交)制定,需要设置起始页码、间隔页码和采集分页的页码。如果文章内容没有分页,则无需制定此规则。如果新闻页面中除了新闻内容之外还有其他附加信息,那么为了在采集过程中更容易找到新闻内容,需要设置限制获取新闻内容的规则。一是避免垃圾邮件,二是降低新闻特定信息获取规则的复杂性。如果新闻页面比较简单,一般不需要设置这个规则。设置新闻属性的规则是可选的,除了标题和内容。另外,如果未设置新闻发布时间,则以当前时间作为发布时间。多列采集plan的设置(如:图五)Multicolumn采集计划) 除了在“列表页面起始URL”下设置列表页面URL规则和在“文章页URL获取”下设置列rules" 获取名称的规则与单列采集plan 中设置的规则相同。
RSS单栏采集计划的设置(如:图中四)RSS单栏的采集计划不需要设置“文章页URL获取规则”,其余与单栏采集计划一致。RSS多栏采集计划的设置(如:图六)RSS多栏采集计划需要设置列表页URL获取“列表页面起始URL”下的规则,其他与RSS单列采集计划一致。采集Rule表达式制定表达式设置和调整,以及测试表达式列表点击一个地方采集页面“获取规则设置”进入规则表达式列表页面(如:图七)此页面除了可以添加、修改、删除和调整表达式的顺序,还可以输入url、iframeurl以及设置表达式后的页面内容测试表达式规则列表 设置各种类型 表达式类型 表达式类型分为ed 分为四种类型:字符串、匹配、匹配替换和公式。其中,匹配和匹配替换需要使用java正表达式,这就需要采集计划SET人员对表达式有一定的理解。 String:直接输入字符串常量匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本S中的部分内容匹配替换:首先从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。然后用替换正则表达式替换S中匹配的内容,得到正确的内容。
公式:仅支持[pageIndex],用于获取页面地址时表示页面的页码。图标详情进入栏目管理(图一)Settings采集计划,在右侧栏目列表中选择一栏,点击Set采集计划。(图二)执行方法可以:手动(需要在列列表中点击)“立即采集”启动采集)单次(可以设置时间,到时采集会自动启动)循环(指定间隔时间) , 自动循环采集) 可以设置采集为文章 是否自动发布. 为采集的列类型:单列(采集此列下仅文章)单列RSS( 采集一RSS地址文章)多栏(采集栏和子栏下文章)多栏RSS(从一个RSS列表地址开始,采集文章在多个RSS地址下,每个RSS地址形成一个子栏)编码方式是通过采集页面采集rule单栏方式的编码设置(图片三)单栏RSS方式(图片四)这个方式不需要设置文章page URL ac查询方法,其他方法同单列法。多列方法)(图片五)该方法的起始页一般是列表页的集合。对于单列的方法,需要设置获取列表页的方法和列名规则。其他的是与单栏一致 多栏RSS(图片六)此方法) 需要设置从起始页(列表页网址)获取RSS地址,其他与单栏RSS一致。设置获取规则(图七)(图八)(图九)(图十)(图十一)))@(图10二)如上图,获取规则由多个表达式,添加多个表达式获取需要的URL,获取文章的标题内容等属性。
表达式分为4类: string:直接输入字符串常量匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式得到文本中的部分内容S。匹配替换:首先通过正则表达式从指定文本(URL、IframeURL、页面内容)中获取文本中的部分内容S。然后使用替换正则表达式替换S中匹配的内容,得到正确的内容。公式:仅支持[pageIndex],用于在获取页面地址时表示该页面的页码。此页面还可以测试设置的表达式。您可以使用表达式帮助来理解正则表达式的语法。查看采集计划的状态。回到栏目列表,可以看到如下图(图10三)采集status中的3个图标代表采集计划的运行状态(是否正在运行,是否已经运行,等))、采集方式(单列、单列RSS、多列、多列RSS)、执行方式(手动、单列、循环),点击查看采集计划的详细信息, (图10四)采集计划示例以采集新浪网站体育新闻列表网页为例,该网页的访问地址为HYPERLINK "/nba/1.shtml" /nba/ 1.shtml.采集 的内容放在一个“体育新闻”栏目下,由于这是一个测试示例,我们对采集使用手动执行方式,采集到达的信息不需要自动发布。
本网页是一个简单的新闻列表页面,编码方式为GB2312,所以我们将采集的列类型设置为“单列”,编码方式为gb2312采集。新闻不需要自动发布。如下图,由于这个页面的新闻列表内容不再在iframe中,也没有分页,所以不需要设置“在IFRAME中列出页面内容”和“列表页面分页”的获取规则方法”。并且新闻列表的内容不需要设置“限制文章list 内容”规则。设置文章url 的获取规则。由于本网页的新闻链接类似于以下网址:HYPERLINK "/k/2009-07-07shtml" /k/2009-07-07shtml,因此制定如下表达规则: 匹配内容类型:页面内容匹配表达式: /k/(\d+)-(\d+)-(\d+)/(\d+)\.shtml 匹配组:0(获取整个匹配结果) 获取采集 @Page源文件,粘贴进去页面内容,点击“测试计算-列表模式”,结果将显示所有匹配的URL列表,如下图所示。由于文章content不在iframe中,文章content没有分页,文章content不需要限制在页面中,所以“文章page内容在IFRAME中”的获取规则, 文章内容分页URL"和"limited文章页文章内容"不需要设置。 文章标题规则设置 因为新闻页面源文件中文章的标题在以下位置:休斯顿球迷期待姚明手术健康是火箭未来的希望表达规则表达类型:匹配内容type:页面内容匹配表达式:(.+?) 匹配组:1(获取匹配结果中的第一组,每个括号为一组)获取采集页面的源文件,粘贴到页面内容中,点击“测试计算-内容模式”,结果中的标题内容如下图位置:
北京时间7月7日,休斯顿新浪体育。据ESPN报道,姚明还没有决定是否接受手术来修复他的脚伤。虽然现在诊断姚明的三位主要医生都推荐手术,但姚明还在犹豫。
至于姚明现在的想法,大家都知道,姚明之所以还在犹豫,是因为他知道,如果他动了手术,下赛季他缺席也不是没有可能。 29岁的姚明不希望白费。花了一年,浪费了一年。毕竟,运动员的巅峰期就是这么一段时期。没有人能保证那个时候的姚明能保持好水平。
姚明犹豫不决,但休斯顿球迷对姚明有不同的看法。大多数球迷认为姚明应该毫不犹豫地接受手术。他们的理由是,既然有恶化的趋势,保守治疗的效果还不清楚,他们不应该做出手术的决定。毕竟,一个健康的姚明对火箭来说是最重要的。如果有必要,如果保守治疗后还需要手术,那姚明就输了。
“亲爱的姚,请你下定决心去做手术。即使你下赛季缺席,也不要犹豫,去做吧。如果保守治疗最终治愈,仍然会让我们颤抖,还有下个赛季会更多。可能有问题,最好做手术解决根本原因。你可能会输一年,但我们相信你会给休斯顿带来更健康的三年、五年,甚至更长时间。未来。”一个粉丝说。 .
确实,这位球迷说出了大多数休斯顿球迷不得不说的话。没有人愿意看到姚明在没有彻底治愈的情况下重返赛场。如果姚明再次受伤,相信对包括姚明在内的所有休斯顿球迷来说都是沉重的打击。
也有球迷表示姚明手术应该放心。给姚明检查确诊的医生,就是给骑士队中锋Z做手术的医生,大Z脚的伤势和姚明的伤势差不多。终于,手术后,1991年,大Z身体健康地重返赛场,接下来的几年也没有出现大的伤病,竞技状态还是比较好的。
“像哈达威一样,他们也因为伤病而急剧下滑。我认为这很难发生在姚明身上。姚明不同于希尔和哈达威。姚明是内线球员,虽然脚步移动很重要,但相对来说,弹跳并不是最重要的,姚明在内线的威慑力主要来源于他的身高和惊人的手感,足部手术不会带走姚明的身高,也不会带走他的感觉。 ”粉丝说。
总之,休斯顿人基本都希望姚明能接受手术。他们相信手术可以让姚明完全健康,而一个健康的姚明是他们最希望看到的姚明。
(小黑)
于是制定如下表达式规则表达式类型: 匹配内容类型:页面内容匹配表达式:(.+?) 匹配组:1(获取匹配结果中的第一组,每个括号为一个分组)获取源文件将采集页面粘贴到页面内容中,点击“测试计算-内容模式”,结果为文章内容如下图。 文章的其他属性这里没有设置。如有需要,请参考标题和内容的表达方式进行设置。 采集计划设置好后,选择“体育新闻”栏目,现在点击采集,稍等片刻,查看该栏目的内容管理,就会看到如下内容。另外,在“体育新闻”栏目中点击采集状态可以在栏目管理中查看采集采集的运行状态,如下图: 查看全部
采集文章系统(一个约定好该系统一个指定的栏目设置采集计划(组图))
Information采集User Manual Summary Information采集是捕捉网络数据,实现信息共享的功能模块。提供手动抓取、定时抓取、定时循环抓取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页的数据(新闻)采集传输到webplus系统中的指定栏目。步骤如下: 为指定的列做一个采集计划。在栏目管理中选择栏目,点击设置采集plan。 (例如:图一)设置采集的基本属性。包括执行方式、信息是否自动发布、采集的列类型以及页面的编码格式。(例如:图二)为此采集事先约定了@plan的执行方式是手动、定时单次或定时循环执行,如果只针对采集网页的当前数据,我们可以使用手动和定时单次采集一次;如果是采集webpage 数据会被更新,我们需要保证信息的同步,即使用定时循环采集 判断来自采集的信息是否需要发布.如果采集发来的信息不需要修改,可以直接公开到网上,选择自动发布。如果采集发来的信息需要修改、审核等,选择不自动发布.采集完成后,信息管理器会进行其他操作。 采集的umn类型如果采集的网页只是一个新闻列表,即页面的新闻采集放在指定的栏目下,则选择单栏。
如果被采集的页面有多个新闻列表,并且每个都提供了一个单独的链接进入自己的新闻列表页面,我们需要采集的所有新闻信息,那么选择多列。另外,如果采集的页面是RSS信息聚合页面,设置为对应的RSS单栏或RSS多栏。通过采集设置页面的编码 由于webplus系统使用的是UTF-8编码格式,而采集可能是其他编码格式,那么为了避免采集来的信息乱码,需要设置为采集页面的编码格式。本文来自计算机基础:设置采集plan 采集plan设置的采集规则单列(如:图三)设置“列表页起始URL”为访问路径采集页面。(必填)设置“文章页URL获取规则”,如果新闻列表是通过采集嵌入到网页中的iframe中,则需要设置规则获取链接地址list iframe 访问新闻列表。否则, no 需要制定此规则。(具体规则方法请参考下面的“采集正则表达式制定”)。如果采集的新闻列表网页有分页,则根据新闻列表的分页方式(链接和表单提交)制定分页规则,需要设置起始页码、间隔页码、采集页码。没有分页,不需要制定这个规则,如果页面被采集有多个新闻列表,并且更多新闻列表的url规则类似,但是我们只需要采集指定的一个列表,即我们需要设置规则来限制文章lists的获取。这是为了避免采集冗余数据。
否则,无需设置此规则。设置文章url获取规则,以便能够从采集页面访问特定的新闻页面,从而进行新闻采集。 (必填)设置“文章内容取法”的具体新闻页面。如果文章内容以iframe的形式嵌入到新闻页面,则需要设置规则获取文章iframe的链接地址。访问新闻内容。否则,无需制定此规则。如果新闻内容有分页,则分页规则按照文章content分页方式(链接和表单提交)制定,需要设置起始页码、间隔页码和采集分页的页码。如果文章内容没有分页,则无需制定此规则。如果新闻页面中除了新闻内容之外还有其他附加信息,那么为了在采集过程中更容易找到新闻内容,需要设置限制获取新闻内容的规则。一是避免垃圾邮件,二是降低新闻特定信息获取规则的复杂性。如果新闻页面比较简单,一般不需要设置这个规则。设置新闻属性的规则是可选的,除了标题和内容。另外,如果未设置新闻发布时间,则以当前时间作为发布时间。多列采集plan的设置(如:图五)Multicolumn采集计划) 除了在“列表页面起始URL”下设置列表页面URL规则和在“文章页URL获取”下设置列rules" 获取名称的规则与单列采集plan 中设置的规则相同。
RSS单栏采集计划的设置(如:图中四)RSS单栏的采集计划不需要设置“文章页URL获取规则”,其余与单栏采集计划一致。RSS多栏采集计划的设置(如:图六)RSS多栏采集计划需要设置列表页URL获取“列表页面起始URL”下的规则,其他与RSS单列采集计划一致。采集Rule表达式制定表达式设置和调整,以及测试表达式列表点击一个地方采集页面“获取规则设置”进入规则表达式列表页面(如:图七)此页面除了可以添加、修改、删除和调整表达式的顺序,还可以输入url、iframeurl以及设置表达式后的页面内容测试表达式规则列表 设置各种类型 表达式类型 表达式类型分为ed 分为四种类型:字符串、匹配、匹配替换和公式。其中,匹配和匹配替换需要使用java正表达式,这就需要采集计划SET人员对表达式有一定的理解。 String:直接输入字符串常量匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本S中的部分内容匹配替换:首先从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。然后用替换正则表达式替换S中匹配的内容,得到正确的内容。
公式:仅支持[pageIndex],用于获取页面地址时表示页面的页码。图标详情进入栏目管理(图一)Settings采集计划,在右侧栏目列表中选择一栏,点击Set采集计划。(图二)执行方法可以:手动(需要在列列表中点击)“立即采集”启动采集)单次(可以设置时间,到时采集会自动启动)循环(指定间隔时间) , 自动循环采集) 可以设置采集为文章 是否自动发布. 为采集的列类型:单列(采集此列下仅文章)单列RSS( 采集一RSS地址文章)多栏(采集栏和子栏下文章)多栏RSS(从一个RSS列表地址开始,采集文章在多个RSS地址下,每个RSS地址形成一个子栏)编码方式是通过采集页面采集rule单栏方式的编码设置(图片三)单栏RSS方式(图片四)这个方式不需要设置文章page URL ac查询方法,其他方法同单列法。多列方法)(图片五)该方法的起始页一般是列表页的集合。对于单列的方法,需要设置获取列表页的方法和列名规则。其他的是与单栏一致 多栏RSS(图片六)此方法) 需要设置从起始页(列表页网址)获取RSS地址,其他与单栏RSS一致。设置获取规则(图七)(图八)(图九)(图十)(图十一)))@(图10二)如上图,获取规则由多个表达式,添加多个表达式获取需要的URL,获取文章的标题内容等属性。
表达式分为4类: string:直接输入字符串常量匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式得到文本中的部分内容S。匹配替换:首先通过正则表达式从指定文本(URL、IframeURL、页面内容)中获取文本中的部分内容S。然后使用替换正则表达式替换S中匹配的内容,得到正确的内容。公式:仅支持[pageIndex],用于在获取页面地址时表示该页面的页码。此页面还可以测试设置的表达式。您可以使用表达式帮助来理解正则表达式的语法。查看采集计划的状态。回到栏目列表,可以看到如下图(图10三)采集status中的3个图标代表采集计划的运行状态(是否正在运行,是否已经运行,等))、采集方式(单列、单列RSS、多列、多列RSS)、执行方式(手动、单列、循环),点击查看采集计划的详细信息, (图10四)采集计划示例以采集新浪网站体育新闻列表网页为例,该网页的访问地址为HYPERLINK "/nba/1.shtml" /nba/ 1.shtml.采集 的内容放在一个“体育新闻”栏目下,由于这是一个测试示例,我们对采集使用手动执行方式,采集到达的信息不需要自动发布。
本网页是一个简单的新闻列表页面,编码方式为GB2312,所以我们将采集的列类型设置为“单列”,编码方式为gb2312采集。新闻不需要自动发布。如下图,由于这个页面的新闻列表内容不再在iframe中,也没有分页,所以不需要设置“在IFRAME中列出页面内容”和“列表页面分页”的获取规则方法”。并且新闻列表的内容不需要设置“限制文章list 内容”规则。设置文章url 的获取规则。由于本网页的新闻链接类似于以下网址:HYPERLINK "/k/2009-07-07shtml" /k/2009-07-07shtml,因此制定如下表达规则: 匹配内容类型:页面内容匹配表达式: /k/(\d+)-(\d+)-(\d+)/(\d+)\.shtml 匹配组:0(获取整个匹配结果) 获取采集 @Page源文件,粘贴进去页面内容,点击“测试计算-列表模式”,结果将显示所有匹配的URL列表,如下图所示。由于文章content不在iframe中,文章content没有分页,文章content不需要限制在页面中,所以“文章page内容在IFRAME中”的获取规则, 文章内容分页URL"和"limited文章页文章内容"不需要设置。 文章标题规则设置 因为新闻页面源文件中文章的标题在以下位置:休斯顿球迷期待姚明手术健康是火箭未来的希望表达规则表达类型:匹配内容type:页面内容匹配表达式:(.+?) 匹配组:1(获取匹配结果中的第一组,每个括号为一组)获取采集页面的源文件,粘贴到页面内容中,点击“测试计算-内容模式”,结果中的标题内容如下图位置:
北京时间7月7日,休斯顿新浪体育。据ESPN报道,姚明还没有决定是否接受手术来修复他的脚伤。虽然现在诊断姚明的三位主要医生都推荐手术,但姚明还在犹豫。
至于姚明现在的想法,大家都知道,姚明之所以还在犹豫,是因为他知道,如果他动了手术,下赛季他缺席也不是没有可能。 29岁的姚明不希望白费。花了一年,浪费了一年。毕竟,运动员的巅峰期就是这么一段时期。没有人能保证那个时候的姚明能保持好水平。
姚明犹豫不决,但休斯顿球迷对姚明有不同的看法。大多数球迷认为姚明应该毫不犹豫地接受手术。他们的理由是,既然有恶化的趋势,保守治疗的效果还不清楚,他们不应该做出手术的决定。毕竟,一个健康的姚明对火箭来说是最重要的。如果有必要,如果保守治疗后还需要手术,那姚明就输了。
“亲爱的姚,请你下定决心去做手术。即使你下赛季缺席,也不要犹豫,去做吧。如果保守治疗最终治愈,仍然会让我们颤抖,还有下个赛季会更多。可能有问题,最好做手术解决根本原因。你可能会输一年,但我们相信你会给休斯顿带来更健康的三年、五年,甚至更长时间。未来。”一个粉丝说。 .
确实,这位球迷说出了大多数休斯顿球迷不得不说的话。没有人愿意看到姚明在没有彻底治愈的情况下重返赛场。如果姚明再次受伤,相信对包括姚明在内的所有休斯顿球迷来说都是沉重的打击。
也有球迷表示姚明手术应该放心。给姚明检查确诊的医生,就是给骑士队中锋Z做手术的医生,大Z脚的伤势和姚明的伤势差不多。终于,手术后,1991年,大Z身体健康地重返赛场,接下来的几年也没有出现大的伤病,竞技状态还是比较好的。
“像哈达威一样,他们也因为伤病而急剧下滑。我认为这很难发生在姚明身上。姚明不同于希尔和哈达威。姚明是内线球员,虽然脚步移动很重要,但相对来说,弹跳并不是最重要的,姚明在内线的威慑力主要来源于他的身高和惊人的手感,足部手术不会带走姚明的身高,也不会带走他的感觉。 ”粉丝说。
总之,休斯顿人基本都希望姚明能接受手术。他们相信手术可以让姚明完全健康,而一个健康的姚明是他们最希望看到的姚明。
(小黑)
于是制定如下表达式规则表达式类型: 匹配内容类型:页面内容匹配表达式:(.+?) 匹配组:1(获取匹配结果中的第一组,每个括号为一个分组)获取源文件将采集页面粘贴到页面内容中,点击“测试计算-内容模式”,结果为文章内容如下图。 文章的其他属性这里没有设置。如有需要,请参考标题和内容的表达方式进行设置。 采集计划设置好后,选择“体育新闻”栏目,现在点击采集,稍等片刻,查看该栏目的内容管理,就会看到如下内容。另外,在“体育新闻”栏目中点击采集状态可以在栏目管理中查看采集采集的运行状态,如下图:
采集文章系统(新秀文章管理系统sinsiucms1.0beta7说明:安装说明)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-09-01 19:16
Xinxiu文章 管理系统是一个简单易用且永远免费的 PHP文章 管理系统;内置采集功能,新秀官方采集每天大量数据供用户选择。系统安装时有Mysql和Access两个数据库可供选择。
菜鸟文章管理系统sinsiu cms1.0 beta7 说明:
一、新秀文章管理系统是一个简单易用且永远免费的PHP文章管理系统;内置采集功能,新秀官方采集每天海量数据供用户选择,菜鸟还提供“采集customized”收费会员服务,可以帮助用户采集任何数据系统安装时,有两个数据库可供选择,Mysql和Access。
二、Background 功能介绍:
1、基本设置:基本信息、网站设置、导航管理、模块开启关闭、安全设置、静态设置、管理员账号、数据库管理等设置;
2、文章管理:文章list,发布文章,文章category;
3、用户交互:留言管理、评论管理、友情链接;
4、文件管理:选择模板、图片管理、语言设置、资源管理;
5、数据采集:采集设置、公开数据、私有定制、私有数据;
6、高级应用:新频道、频道标题、后台导航管理。
三、安装说明:
1、我们推荐的PHP版本在PHP5.2左右,我们推荐的PHP集成环境在XAMPP1.7左右;
2、新安装需要将upload文件夹中的所有子目录和文件(注意,在里面)上传到网站root目录下,然后在浏览器上打开网站,根据根据提示,填写数据库信息,最后点击安装按钮完成安装;
3、本系统默认设置为1小时内只能登录后台10次。您可以在“后台-基本设置-安全设置”中修改时长和登录次数,避免调试时无法登录后台。
四、升级说明:
1、sinsiu cms1.0 beta6 用户可以通过升级程序轻松升级到 sinsiu cms1.0 beta7,无需重新安装程序;
2、 如果您是sinsiu cms 1.0 beta6 用户,请将整个升级文件夹上传到网站root 目录,并在浏览器地址输入//网站PATH/upgrade/ bar ,然后根据提示点击升级链接;
3、如果升级后页面布局乱了,请先清除浏览器临时文件,然后重新打开网站。
五、注:
1、本系统的Access数据库只在Windows服务器上有效。建议使用Access数据库的用户选择Windows主机;
2、因为本系统使用的是UTF-8编码,所以在Windows下不能使用记事本进行编辑,因为记事本会自动添加一个BOM头导致程序异常。建议使用专业的Dreamweaver或Notepad++的小型编辑器;
3、网站移动前请先清除后台Smarty缓存,或者移动后手动删除index/compile和admin/compile目录下的所有文件,否则网站移动后可能会出错。
4、这个系统在发布前经过多次测试,核心功能基本没有错误。如果您在使用过程中遇到程序错误,请从您自己的运行环境中查找原因。请不要一遇到问题就将责任推到我们身上,甚至怀疑我们故意留下缺陷来收费。有助于解决问题和个人进步。如果您确定错误是由我们的程序引起的,您可以将问题发送到我们的邮箱,我们将在确认后免费为您提供解决方案。同时,我们非常感谢您的反馈!
六、后台路径://网站PATH/admin
七、更新状态:
1、完善“创建频道”功能并修复BUG;
2、在前台修复一些 CSS。
Rookie文章管理系统 v1.0 beta10 更新状态:
1、Improve 采集功能,取消采集customization,添加高级数据;
2、修复后台BUG。 查看全部
采集文章系统(新秀文章管理系统sinsiucms1.0beta7说明:安装说明)
Xinxiu文章 管理系统是一个简单易用且永远免费的 PHP文章 管理系统;内置采集功能,新秀官方采集每天大量数据供用户选择。系统安装时有Mysql和Access两个数据库可供选择。
菜鸟文章管理系统sinsiu cms1.0 beta7 说明:
一、新秀文章管理系统是一个简单易用且永远免费的PHP文章管理系统;内置采集功能,新秀官方采集每天海量数据供用户选择,菜鸟还提供“采集customized”收费会员服务,可以帮助用户采集任何数据系统安装时,有两个数据库可供选择,Mysql和Access。
二、Background 功能介绍:
1、基本设置:基本信息、网站设置、导航管理、模块开启关闭、安全设置、静态设置、管理员账号、数据库管理等设置;
2、文章管理:文章list,发布文章,文章category;
3、用户交互:留言管理、评论管理、友情链接;
4、文件管理:选择模板、图片管理、语言设置、资源管理;
5、数据采集:采集设置、公开数据、私有定制、私有数据;
6、高级应用:新频道、频道标题、后台导航管理。
三、安装说明:
1、我们推荐的PHP版本在PHP5.2左右,我们推荐的PHP集成环境在XAMPP1.7左右;
2、新安装需要将upload文件夹中的所有子目录和文件(注意,在里面)上传到网站root目录下,然后在浏览器上打开网站,根据根据提示,填写数据库信息,最后点击安装按钮完成安装;
3、本系统默认设置为1小时内只能登录后台10次。您可以在“后台-基本设置-安全设置”中修改时长和登录次数,避免调试时无法登录后台。
四、升级说明:
1、sinsiu cms1.0 beta6 用户可以通过升级程序轻松升级到 sinsiu cms1.0 beta7,无需重新安装程序;
2、 如果您是sinsiu cms 1.0 beta6 用户,请将整个升级文件夹上传到网站root 目录,并在浏览器地址输入//网站PATH/upgrade/ bar ,然后根据提示点击升级链接;
3、如果升级后页面布局乱了,请先清除浏览器临时文件,然后重新打开网站。
五、注:
1、本系统的Access数据库只在Windows服务器上有效。建议使用Access数据库的用户选择Windows主机;
2、因为本系统使用的是UTF-8编码,所以在Windows下不能使用记事本进行编辑,因为记事本会自动添加一个BOM头导致程序异常。建议使用专业的Dreamweaver或Notepad++的小型编辑器;
3、网站移动前请先清除后台Smarty缓存,或者移动后手动删除index/compile和admin/compile目录下的所有文件,否则网站移动后可能会出错。
4、这个系统在发布前经过多次测试,核心功能基本没有错误。如果您在使用过程中遇到程序错误,请从您自己的运行环境中查找原因。请不要一遇到问题就将责任推到我们身上,甚至怀疑我们故意留下缺陷来收费。有助于解决问题和个人进步。如果您确定错误是由我们的程序引起的,您可以将问题发送到我们的邮箱,我们将在确认后免费为您提供解决方案。同时,我们非常感谢您的反馈!
六、后台路径://网站PATH/admin
七、更新状态:
1、完善“创建频道”功能并修复BUG;
2、在前台修复一些 CSS。
Rookie文章管理系统 v1.0 beta10 更新状态:
1、Improve 采集功能,取消采集customization,添加高级数据;
2、修复后台BUG。
采集文章系统(whatsns内容付费seo优化带采集和熊掌号运营问答系统 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-08-31 08:14
)
Whatsns内容付费seo优化带采集和熊掌号运营问答系统项目介绍
Whatsns问答系统是一个PHP开源问答系统,可以根据自身业务需求快速搭建垂直领域。内置强大的采集功能,支持云存储、图片水印设置、全文检索、站点行为监控、短信注册和通知、伪静态URL自定义、熊掌号功能、百度结构化地图(标签、问题,文章,分类,用户空间),PC和Wap模板分离,内置多套pc和wap模板,站长免费同时后台支持模板管理,模板在线编辑修改,功能强大反灌拦截过滤配置等数百项功能,深度SEO优化,适合需要SEO的站长。商业版还支持优采云采集,先进的微信公众号接口功能,支持支付宝支付、微信扫码支付、微信JSSDK支付、微信H5支付、小程序支付,以及适合不同场景的支付服务,如作为充值和呼叫奖励,回答一瞥,并咨询付费专家。
特别提示
V4免费版用户已安装,如需更新请移动V4更新地址
软件架构
基于php的CodeIgniter3.1.6开发的优雅CI框架,是国内php开发者最喜欢的MVC框架。使用速度快,重量轻,在1m带宽的虚拟主机单核cpu1g内存带宽下可以完美流畅。运行,更多框架信息可以参考CI官网
安装教程
直接把程序上传到问答的根目录即可,安装方法,上传程序后直接输入你的域名/install/
如果是二级目录安装:安装在某个域名网站下的用户,请定位到你问答的安装地址,输入你的域名/二级目录/install/
查看全部
采集文章系统(whatsns内容付费seo优化带采集和熊掌号运营问答系统
)
Whatsns内容付费seo优化带采集和熊掌号运营问答系统项目介绍
Whatsns问答系统是一个PHP开源问答系统,可以根据自身业务需求快速搭建垂直领域。内置强大的采集功能,支持云存储、图片水印设置、全文检索、站点行为监控、短信注册和通知、伪静态URL自定义、熊掌号功能、百度结构化地图(标签、问题,文章,分类,用户空间),PC和Wap模板分离,内置多套pc和wap模板,站长免费同时后台支持模板管理,模板在线编辑修改,功能强大反灌拦截过滤配置等数百项功能,深度SEO优化,适合需要SEO的站长。商业版还支持优采云采集,先进的微信公众号接口功能,支持支付宝支付、微信扫码支付、微信JSSDK支付、微信H5支付、小程序支付,以及适合不同场景的支付服务,如作为充值和呼叫奖励,回答一瞥,并咨询付费专家。
特别提示
V4免费版用户已安装,如需更新请移动V4更新地址
软件架构
基于php的CodeIgniter3.1.6开发的优雅CI框架,是国内php开发者最喜欢的MVC框架。使用速度快,重量轻,在1m带宽的虚拟主机单核cpu1g内存带宽下可以完美流畅。运行,更多框架信息可以参考CI官网
安装教程
直接把程序上传到问答的根目录即可,安装方法,上传程序后直接输入你的域名/install/
如果是二级目录安装:安装在某个域名网站下的用户,请定位到你问答的安装地址,输入你的域名/二级目录/install/

采集文章系统(优采云大数据采集网站:使用功能点:URL列表信息采集 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-08-29 22:06
)
采集网站:
使用功能点:
网址
分页列表信息采集
搜狗微信搜索:搜狗微信搜索是搜狗于2014年6月9日推出的微信公众平台。“微信搜索”支持搜索微信公众号和微信文章,可以通过关键词搜索相关微信公众号@,或文章微信公众号推送。不仅是PC端,搜狗手机搜索客户端也会推荐相关的微信公众号。
搜狗微信文章采集数据说明:本文在搜狗微信-搜索-优采云大数据的文章信息采集进行。本文仅以“搜狗微信-搜索-优采云大数据的文章信息采集”为例。实际操作中,您可以根据自己的需要,将搜狗微信的搜索词更改为执行数据采集。
搜狗微信文章采集detail采集字段说明:微信文章title、微信文章keywords、微信文章generalization、微信公众号、微信文章发布时间、微信文章地址。
第一步:创建采集task
1)进入主界面,选择“自定义模式”
2)将采集的网址复制粘贴到网站输入框中,点击“保存网址”
第 2 步:创建翻页循环
1)打开右上角的“进程”。点击页面文章搜索框,在右侧操作提示框中选择“输入文字”
2)输入要搜索的文章信息,这里以搜索“优采云大数据”为例,输入完成后点击“确定”按钮
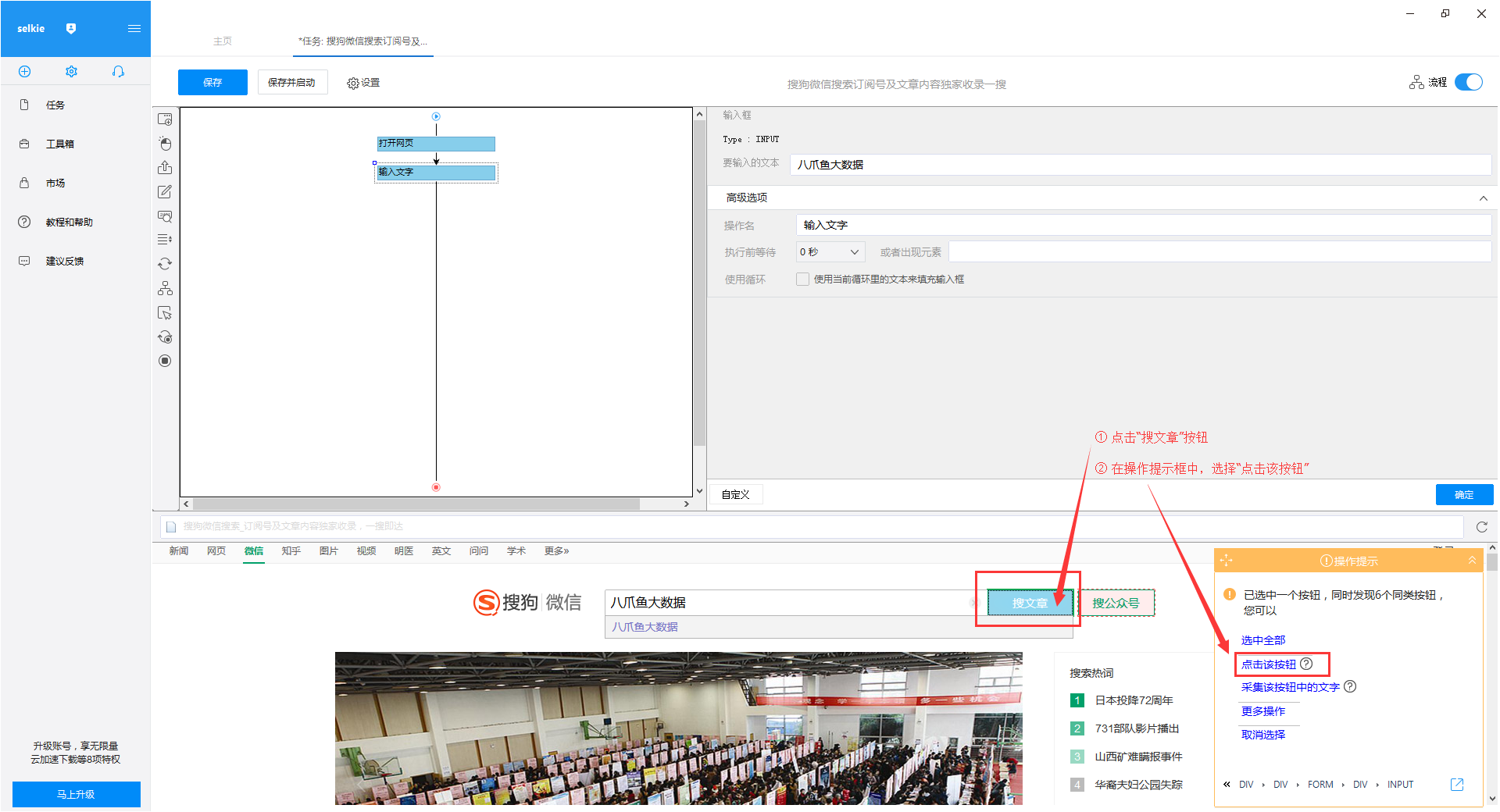
3)“优采云大数据”会自动填写搜索框,点击“search文章”按钮,在操作提示框中选择“点击此按钮”
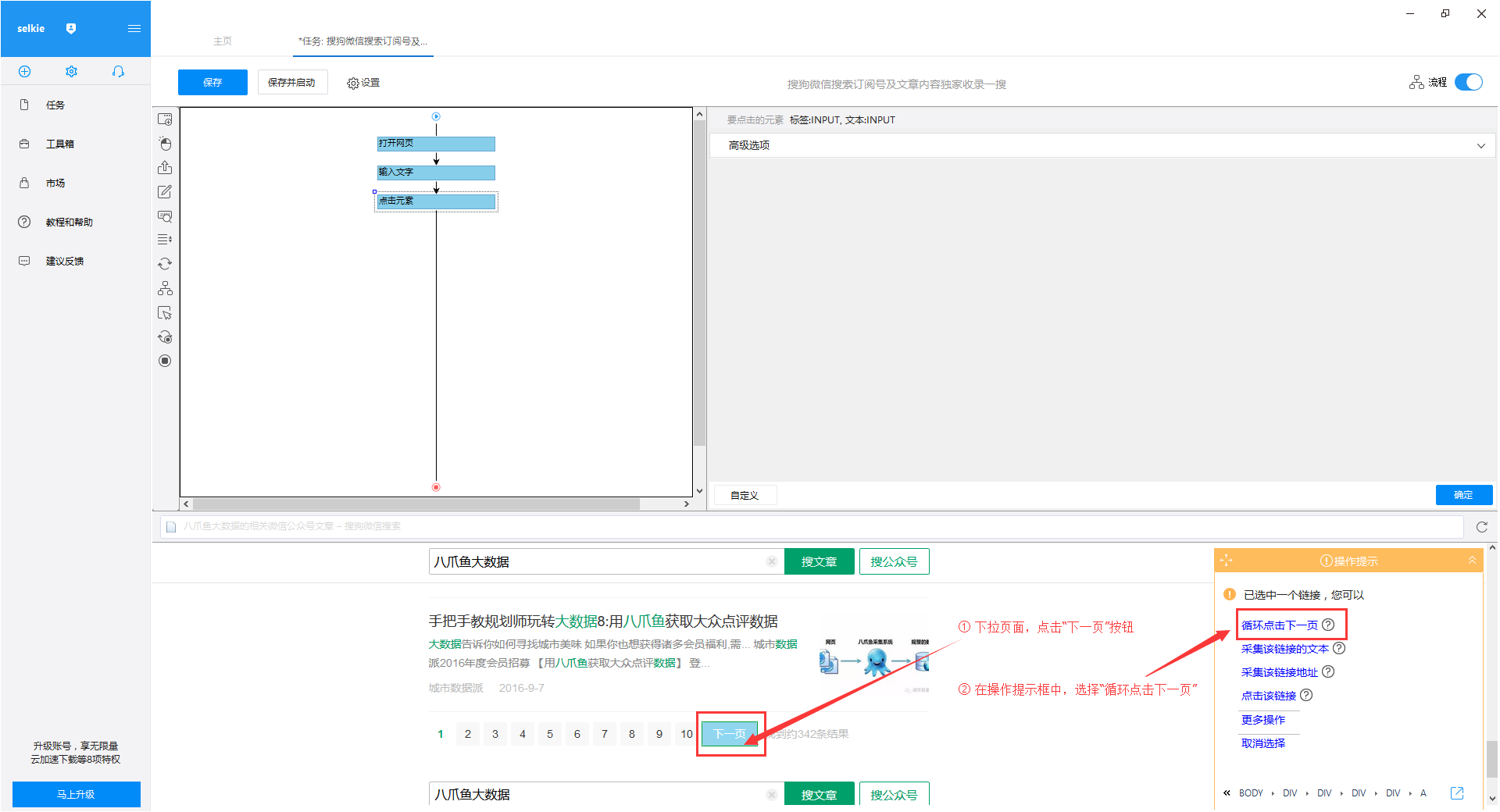
“优采云大数据”的文章搜索结果出现在4)页面上。将结果页下拉至底部,点击“下一页”按钮,在右侧操作提示框中选择“循环点击下一页”
第 3 步:创建一个列表循环并提取数据
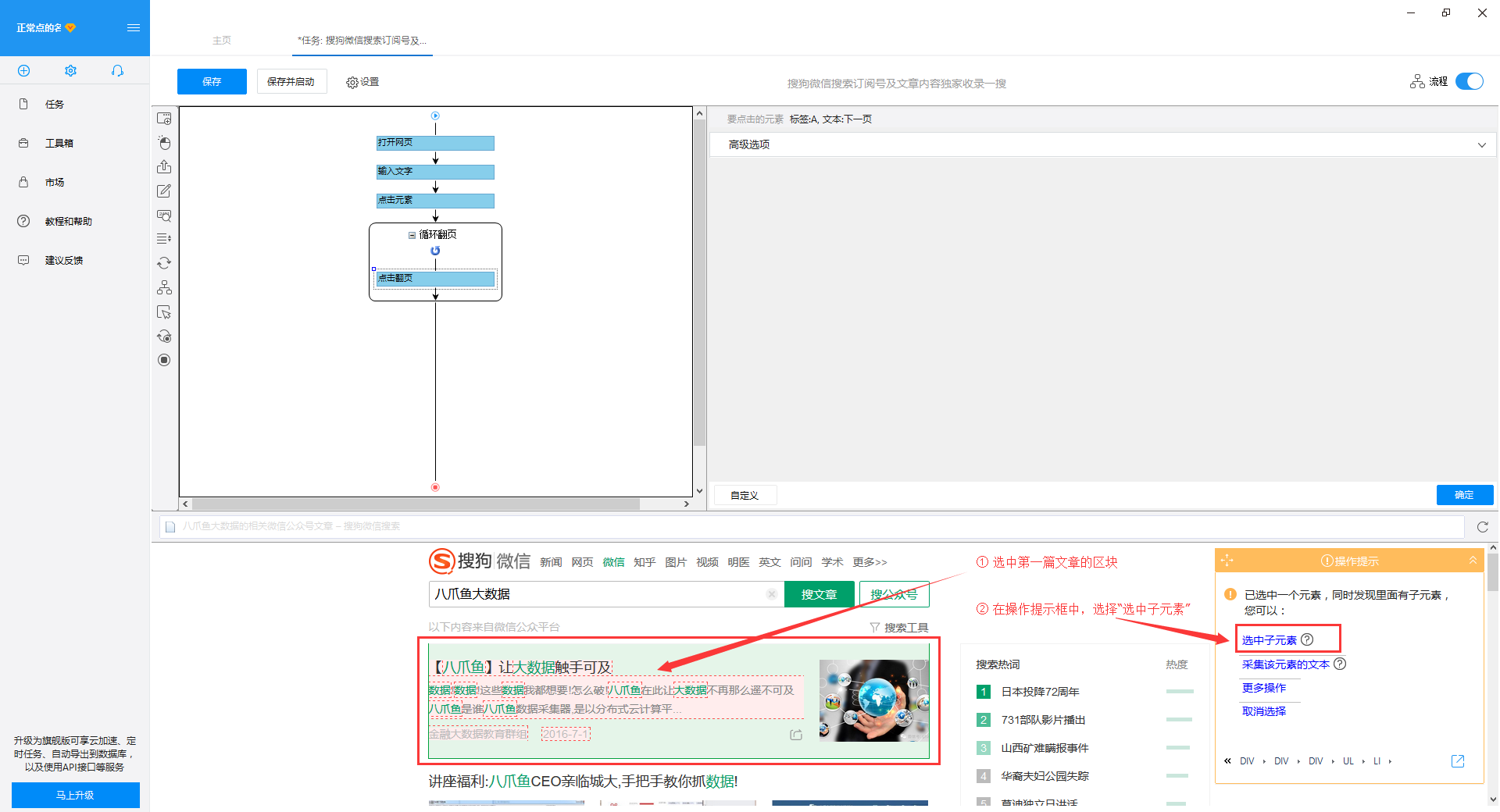
1)移动鼠标选择页面上的第一个文章块。系统将识别此块中的子元素。在操作提示框中选择“选择子元素”
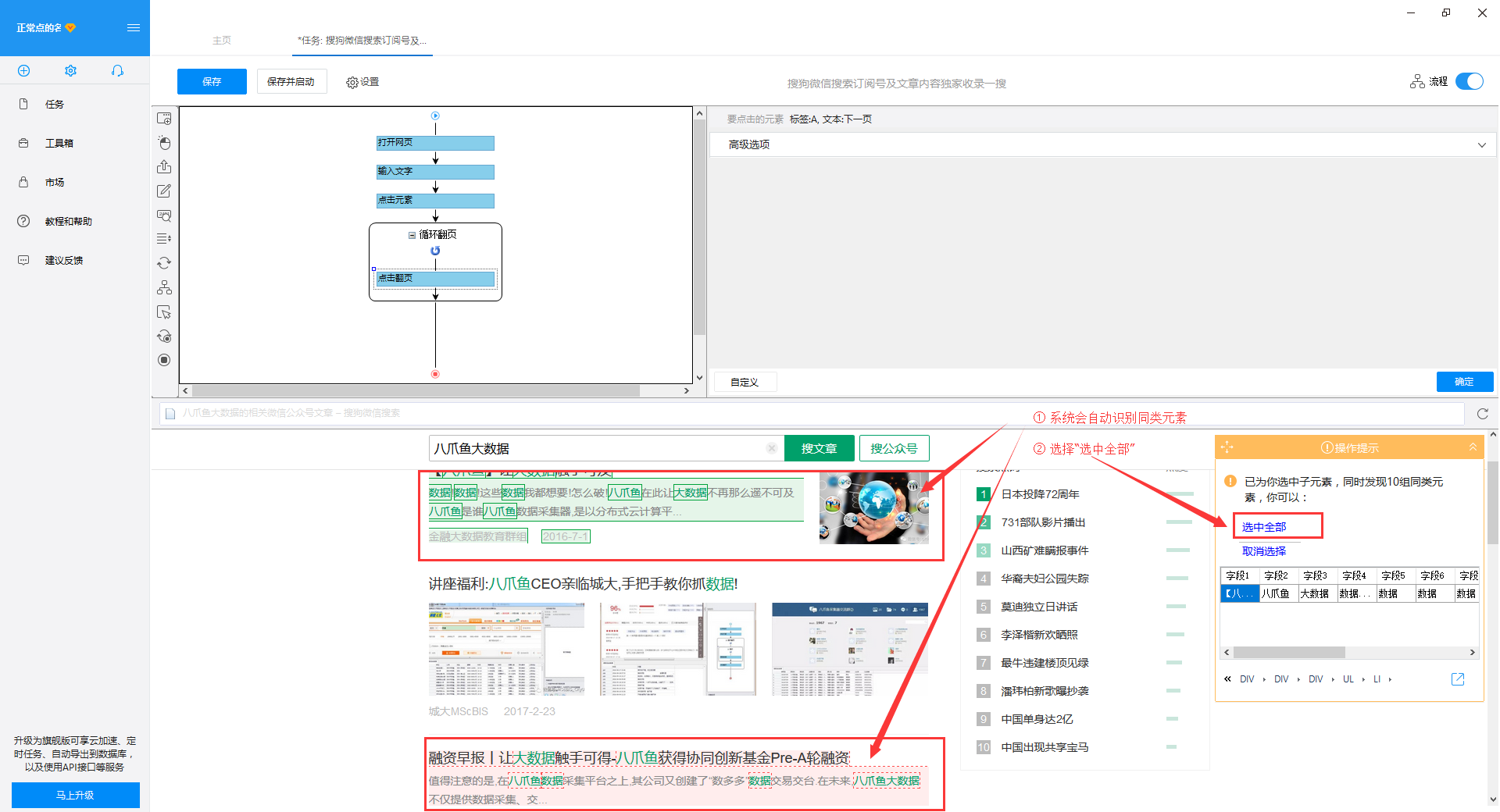
2)继续选择页面第二篇文章中的区块,系统会自动选择第二篇文章中的子元素,并识别页面上其他10组相似元素, 在操作提示框中,选择“全选”
3) 我们可以看到页面上文章块中的所有元素都被选中并变成了绿色。在右侧的操作提示框中,会出现一个字段预览表。将鼠标移动到表头并单击垃圾桶图标以删除不需要的字段。字段选择完成后,选择“采集以下数据”
4) 因为我们还想要采集 每个文章 URL,所以我们需要再提取一个字段。点击第一篇文章文章的链接,再点击第二篇文章文章的链接,系统会自动在页面上选择一组文章链接。在右侧的操作提示框中选择“采集以下链接地址”
关键词0@
关键词1@字段选择完成后,选择对应的字段,自定义字段的命名。完成后点击左上角的“保存并开始”开始采集task
关键词2@
关键词3@ 选择“启动本地采集”
关键词4@
第四步:数据采集并导出
1)采集完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,导出采集好搜狗微信文章的数据
关键词6@
2)这里我们选择excel作为导出格式,导出数据如下图
关键词8@ 查看全部
采集文章系统(优采云大数据采集网站:使用功能点:URL列表信息采集
)
采集网站:
使用功能点:
网址
分页列表信息采集
搜狗微信搜索:搜狗微信搜索是搜狗于2014年6月9日推出的微信公众平台。“微信搜索”支持搜索微信公众号和微信文章,可以通过关键词搜索相关微信公众号@,或文章微信公众号推送。不仅是PC端,搜狗手机搜索客户端也会推荐相关的微信公众号。
搜狗微信文章采集数据说明:本文在搜狗微信-搜索-优采云大数据的文章信息采集进行。本文仅以“搜狗微信-搜索-优采云大数据的文章信息采集”为例。实际操作中,您可以根据自己的需要,将搜狗微信的搜索词更改为执行数据采集。
搜狗微信文章采集detail采集字段说明:微信文章title、微信文章keywords、微信文章generalization、微信公众号、微信文章发布时间、微信文章地址。
第一步:创建采集task
1)进入主界面,选择“自定义模式”
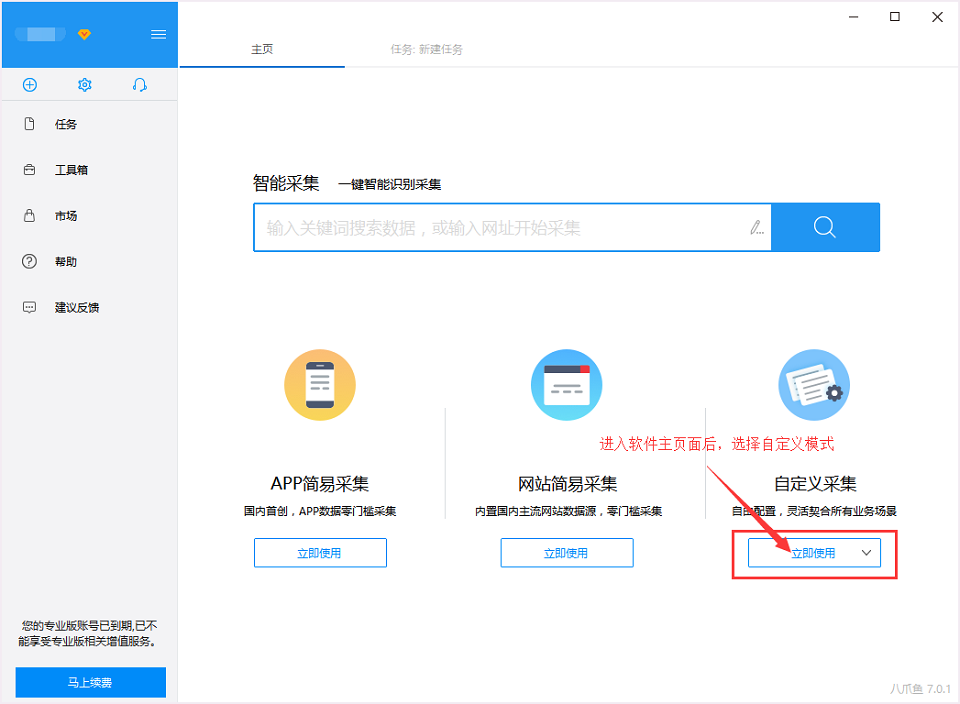
2)将采集的网址复制粘贴到网站输入框中,点击“保存网址”
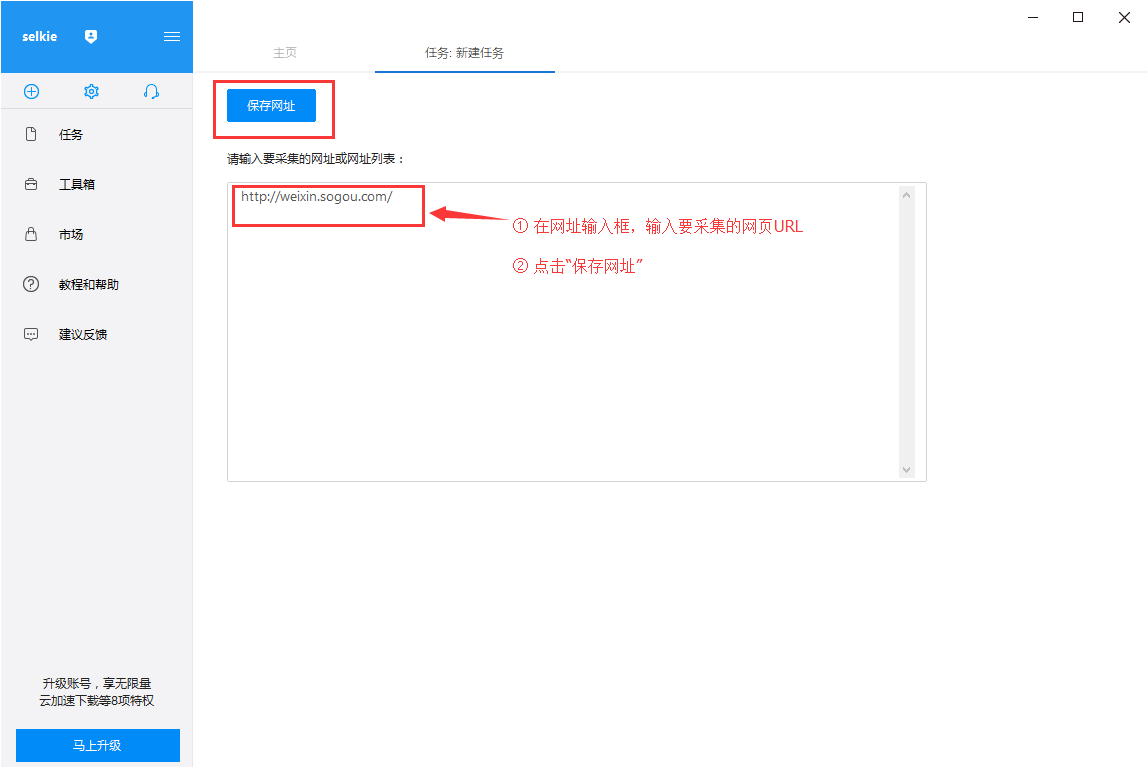
第 2 步:创建翻页循环
1)打开右上角的“进程”。点击页面文章搜索框,在右侧操作提示框中选择“输入文字”
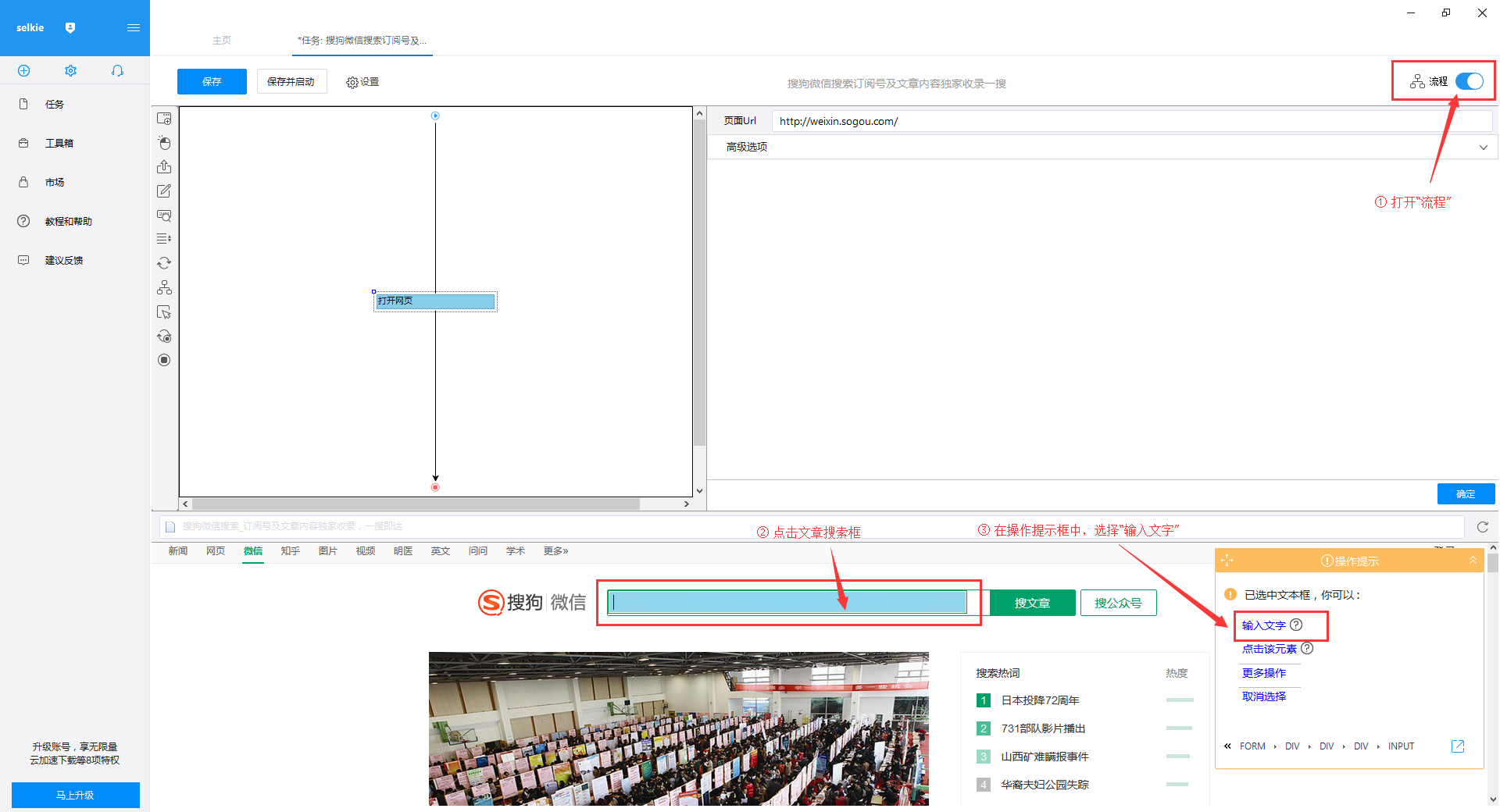
2)输入要搜索的文章信息,这里以搜索“优采云大数据”为例,输入完成后点击“确定”按钮
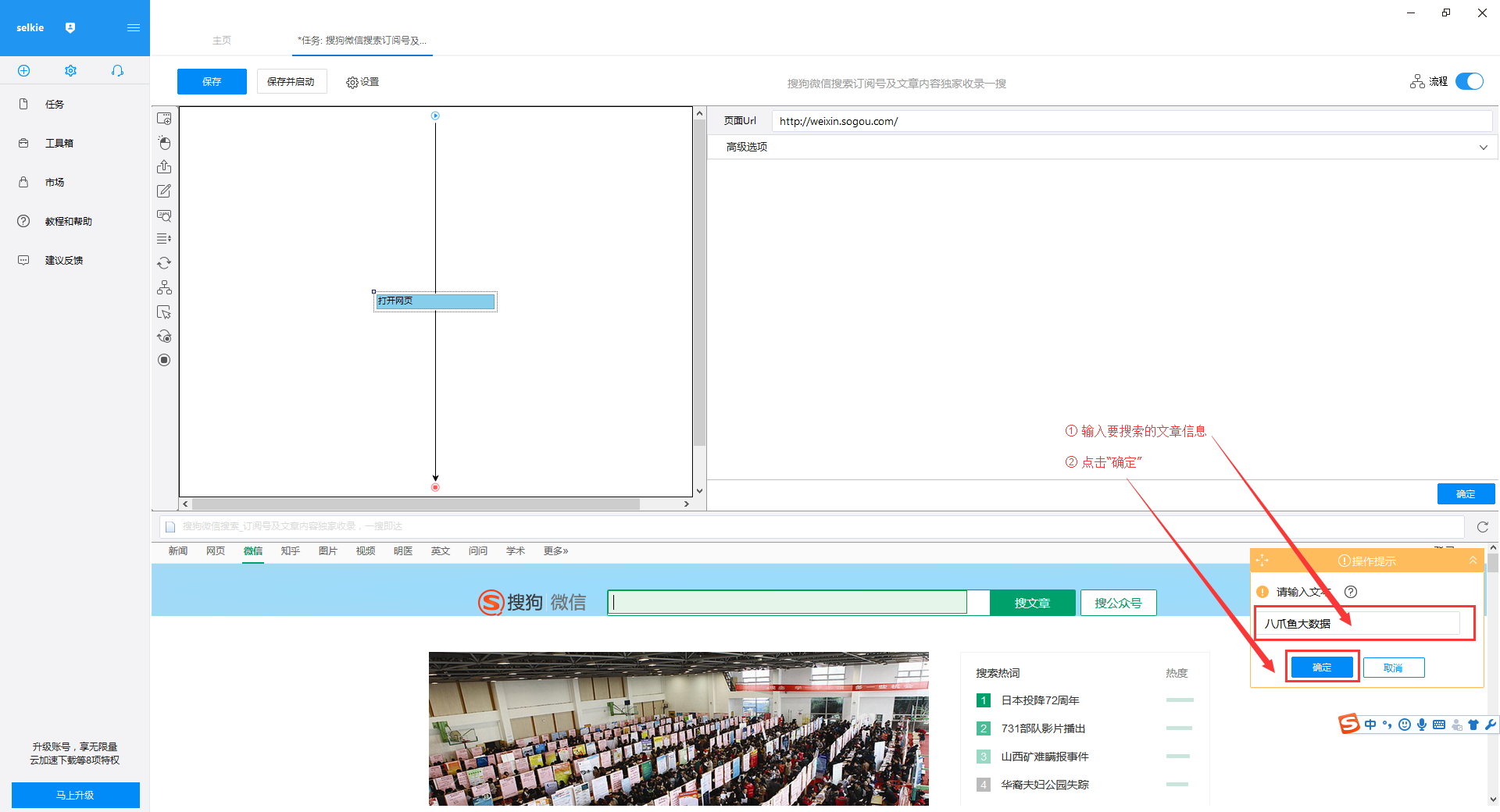
3)“优采云大数据”会自动填写搜索框,点击“search文章”按钮,在操作提示框中选择“点击此按钮”
“优采云大数据”的文章搜索结果出现在4)页面上。将结果页下拉至底部,点击“下一页”按钮,在右侧操作提示框中选择“循环点击下一页”
第 3 步:创建一个列表循环并提取数据
1)移动鼠标选择页面上的第一个文章块。系统将识别此块中的子元素。在操作提示框中选择“选择子元素”
2)继续选择页面第二篇文章中的区块,系统会自动选择第二篇文章中的子元素,并识别页面上其他10组相似元素, 在操作提示框中,选择“全选”
3) 我们可以看到页面上文章块中的所有元素都被选中并变成了绿色。在右侧的操作提示框中,会出现一个字段预览表。将鼠标移动到表头并单击垃圾桶图标以删除不需要的字段。字段选择完成后,选择“采集以下数据”
4) 因为我们还想要采集 每个文章 URL,所以我们需要再提取一个字段。点击第一篇文章文章的链接,再点击第二篇文章文章的链接,系统会自动在页面上选择一组文章链接。在右侧的操作提示框中选择“采集以下链接地址”
关键词0@
关键词1@字段选择完成后,选择对应的字段,自定义字段的命名。完成后点击左上角的“保存并开始”开始采集task
关键词2@
关键词3@ 选择“启动本地采集”
关键词4@
第四步:数据采集并导出
1)采集完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,导出采集好搜狗微信文章的数据
关键词6@
2)这里我们选择excel作为导出格式,导出数据如下图
关键词8@
史上最简单最智能文章采集器破解版.13.10.0更新日志
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-08-25 20:52
对于正在做网站推广和优化的朋友,可能经常需要更新一些文章。这对于文笔不好的人来说还是有点难度的,怎么办?你可以试试这个优采云万能文章采集器,它是一个简单实用的文章采集软件,用户可以设置搜索间隔、采集类型、时间语言等选项,并且你可以过滤采集的文章,插入关键词等,可以大大提高我们的工作效率。这是一个非常好的文章采集 工具。亲爱的站长朋友们,赶快下载一个试试吧。
ps:这里编辑的是优采云万能文章采集器破解版,附件破解文件可以成功激活软件,详细安装教程可以参考下方操作,欢迎免费下载。
软件功能
一、依托优采云software独家通用文本识别智能算法,可实现任意网页文本自动提取,准确率95%以上。
二、只需输入关键词,采集就可以进入百度新闻与网页、搜狗新闻与网页、360新闻与网页、谷歌新闻与网页、必应新闻与网页、雅虎;批量关键词AUTO采集。
三、可方向采集指定网站列列表下的所有文章,智能匹配,无需编写复杂规则。
四、文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
五、史上最简单最智能文章采集器,支持全功能试用,效果如何!
使用帮助
1、软件下载完成后,打开软件包,点击优采云·万能文章采集器Crack打开软件。软件已破解,无需二次破解。
2、打开软件后可以直接开始使用。填写采集的文章关键词你需要的关键词栏。
3、输入完成后,选择文章保存地址和保存选项。
4、设置好后点击Start采集。
更新日志
优采云万能文章采集器V2.13.10.0 更新日志(2016-10-19)
采集List页面URL函数添加高级参数(两个值之间用空格隔开,如果值为1为空,2)值会自动使用
V2.9.1.0 更新日志 (2016-05-06)
添加一些用采集处理过的网站加强采集。
V2.5.1.0 绿色版更新(2015-6-26)
添加 Yahoo采集;
其他更新。 查看全部
史上最简单最智能文章采集器破解版.13.10.0更新日志
对于正在做网站推广和优化的朋友,可能经常需要更新一些文章。这对于文笔不好的人来说还是有点难度的,怎么办?你可以试试这个优采云万能文章采集器,它是一个简单实用的文章采集软件,用户可以设置搜索间隔、采集类型、时间语言等选项,并且你可以过滤采集的文章,插入关键词等,可以大大提高我们的工作效率。这是一个非常好的文章采集 工具。亲爱的站长朋友们,赶快下载一个试试吧。
ps:这里编辑的是优采云万能文章采集器破解版,附件破解文件可以成功激活软件,详细安装教程可以参考下方操作,欢迎免费下载。

软件功能
一、依托优采云software独家通用文本识别智能算法,可实现任意网页文本自动提取,准确率95%以上。
二、只需输入关键词,采集就可以进入百度新闻与网页、搜狗新闻与网页、360新闻与网页、谷歌新闻与网页、必应新闻与网页、雅虎;批量关键词AUTO采集。
三、可方向采集指定网站列列表下的所有文章,智能匹配,无需编写复杂规则。
四、文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
五、史上最简单最智能文章采集器,支持全功能试用,效果如何!
使用帮助
1、软件下载完成后,打开软件包,点击优采云·万能文章采集器Crack打开软件。软件已破解,无需二次破解。

2、打开软件后可以直接开始使用。填写采集的文章关键词你需要的关键词栏。

3、输入完成后,选择文章保存地址和保存选项。

4、设置好后点击Start采集。
更新日志
优采云万能文章采集器V2.13.10.0 更新日志(2016-10-19)
采集List页面URL函数添加高级参数(两个值之间用空格隔开,如果值为1为空,2)值会自动使用
V2.9.1.0 更新日志 (2016-05-06)
添加一些用采集处理过的网站加强采集。
V2.5.1.0 绿色版更新(2015-6-26)
添加 Yahoo采集;
其他更新。
爬虫采集文章系统配置及同步更新的下载地址及配置
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-08-24 18:03
采集文章系统又和同步更新了,在经过数月的积累,利用爬虫来搞点小动作,初步计划实现几个类似这样的配置:拿到网页源码,自己写文章被采集的内容,如果读者觉得有用,谢谢支持哦!哈哈。1.web框架写代码就是个坑,这点坑绝对不能碰,尤其是遇到新需求的时候,不花几天弄明白怎么用爬虫,哪有办法上手写的好代码呢,可能是几个月,也可能是几个月,但是新需求还是不敢写。
所以我还是蛮遗憾没有尝试一下别的框架,除了requests还是可以写的,其他的就emmmm了,都太重量级了,虽然flask在python社区的热度还是有的,但是它的核心依然是requests,不能拿flask作为新的框架来编写。在加上模板,还是挺麻烦的。2.工具模块excel数据采集(viewer):能帮助我们方便地查看并转换各种数据格式(公式和json等),是个帮我们省去很多麻烦的利器,详细下载地址:dataviz-excelviewerforpythontablesnumpy:bigdatanumericalandnumericaldatacollectiontosolvethemathematicalessaysmodel。
pandas:importpandasaspddataframe=pd.dataframe([x1,x2,x3,x4])dataframe=pd.dataframe([[0,2,6,9],[4,3,4,8],[4,2,1,1]])pd.to_datetime(dataframe)pd.to_excel(dataframe)numpy.random.randn(。
4):用作返回4元组,返回由4个元素组成的字典pd。to_excel(dataframe)#原始的dataframedataframe=pd。dataframe([[0,2,6,9],[4,3,4,8],[4,2,1,1]])dataframe=pd。dataframe([[[0,2,6,9],[4,3,4,8],[4,2,1,1]])pd。
to_excel(dataframe)#pd文件写网页代码——网页获取代码大概会是个什么样呢:爬虫代码——excel版本首先,我得把网页所需要的excel格式转换为pdf,好吧,flask无能,只能用apowersoft自带的excel转换工具来实现,如下:importapowersoft。apowersoft。
actions。action_submit_actionsimportospath="/users/wynn/。code/gfxblog。py"#起始路径root="d:\\apowersoft"#目录路径fromexcelimportreader#读取excelx='sample\excel/like\excel/like\excel/like'#将x转换为divdiv=reader(fromroot)div。center(。
1)#左边居中div.center
1)#居中定位lookup=abs(x)#匹配xwhilelookup.next('a'):#删 查看全部
爬虫采集文章系统配置及同步更新的下载地址及配置
采集文章系统又和同步更新了,在经过数月的积累,利用爬虫来搞点小动作,初步计划实现几个类似这样的配置:拿到网页源码,自己写文章被采集的内容,如果读者觉得有用,谢谢支持哦!哈哈。1.web框架写代码就是个坑,这点坑绝对不能碰,尤其是遇到新需求的时候,不花几天弄明白怎么用爬虫,哪有办法上手写的好代码呢,可能是几个月,也可能是几个月,但是新需求还是不敢写。
所以我还是蛮遗憾没有尝试一下别的框架,除了requests还是可以写的,其他的就emmmm了,都太重量级了,虽然flask在python社区的热度还是有的,但是它的核心依然是requests,不能拿flask作为新的框架来编写。在加上模板,还是挺麻烦的。2.工具模块excel数据采集(viewer):能帮助我们方便地查看并转换各种数据格式(公式和json等),是个帮我们省去很多麻烦的利器,详细下载地址:dataviz-excelviewerforpythontablesnumpy:bigdatanumericalandnumericaldatacollectiontosolvethemathematicalessaysmodel。
pandas:importpandasaspddataframe=pd.dataframe([x1,x2,x3,x4])dataframe=pd.dataframe([[0,2,6,9],[4,3,4,8],[4,2,1,1]])pd.to_datetime(dataframe)pd.to_excel(dataframe)numpy.random.randn(。
4):用作返回4元组,返回由4个元素组成的字典pd。to_excel(dataframe)#原始的dataframedataframe=pd。dataframe([[0,2,6,9],[4,3,4,8],[4,2,1,1]])dataframe=pd。dataframe([[[0,2,6,9],[4,3,4,8],[4,2,1,1]])pd。
to_excel(dataframe)#pd文件写网页代码——网页获取代码大概会是个什么样呢:爬虫代码——excel版本首先,我得把网页所需要的excel格式转换为pdf,好吧,flask无能,只能用apowersoft自带的excel转换工具来实现,如下:importapowersoft。apowersoft。
actions。action_submit_actionsimportospath="/users/wynn/。code/gfxblog。py"#起始路径root="d:\\apowersoft"#目录路径fromexcelimportreader#读取excelx='sample\excel/like\excel/like\excel/like'#将x转换为divdiv=reader(fromroot)div。center(。
1)#左边居中div.center
1)#居中定位lookup=abs(x)#匹配xwhilelookup.next('a'):#删
大数据架构师(lamdadata)阶段的5个阶段,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-08-22 04:03
采集文章系统或资料可参考一下大数据数据采集-大数据采集平台-知乎专栏
可以去,实操技术很关键。关键看你要干什么。如果想将来工作无忧那可以去看看爬虫方面的,使用python爬虫框架或者爬虫框架的库去写爬虫。如果真的想好好学习,可以去买本相关资料学一下。
我们总说开源,就是python的开源框架很多,不管是第三方开源,还是各家公司自己研发的,这其中都会用到python的语言特性。但是,问题就来了,你总说开源框架不用担心被封,但,
1、使用官方pythonmodule,
2、使用解决方案(以及腾讯专属官方api文档)加载到数据库中,实现分析接口。
从大数据入门,爬虫,到大数据工程师,再到大数据架构师,数据分析师,数据挖掘师等等,这是大数据的5个阶段。
一、爬虫阶段
二、数据分析师(lamdadata)阶段
三、大数据架构师(hadoop)阶段
四、大数据架构师(docker)阶段
五、大数据工程师(hadoop)这就是你学习的主线。入门爬虫,那就着重讲讲爬虫吧。爬虫说白了就是一个网页,因为页面代码比较复杂,我们叫它爬虫。每个公司都有自己的爬虫部门,以用户为中心开发软件,提供爬虫的对接方式。用户访问这个网页的时候,对应的页面代码会打包发给爬虫。爬虫去执行这个网页的爬取代码。你说的核心价值在于在数据处理时,快速得到结果。
我大致给你描述一下我要爬取的数据,刚刚查的一家互联网公司,我是以xxx职位为例,主要是负责爬取公司的求职信息,一共25条,转化为数据:这25条信息主要用来产生跳槽信息,是一个跳槽的网站。详细的代码不方便展示出来。(一会打包上传)爬虫开发,你说的核心价值在于在数据处理时,快速得到结果。我给你写了一个爬虫的下载流程,以上是我要获取的爬虫代码。
这个代码说简单也不简单,说复杂也不复杂。如果你不能独立去实现,可以到我们的圈子里共同学习。在主流的爬虫工具中,tushare是国内第三方第三方的爬虫,看待爬虫,用tushare是最正确的。如果还有问题,可以加我微信。我会定期发布一些最新的爬虫技术和代码分享给大家。目前,很多python的资料很少,希望,你会喜欢和选择。
你也可以留言或者关注公众号:pythoncaixiaoyu(aaa955
5)在这里,给你无限的提升和动力。
python爬虫开发岗位快速上手过程(2019.5.1
9)给初学爬虫的同学一些建议:1.对于0基础的同学而言,什么都是你要学的,不要给自己设限,不要仅仅局限于html,css,javascript等这些初步的技术,这些很重要, 查看全部
大数据架构师(lamdadata)阶段的5个阶段,你知道吗?
采集文章系统或资料可参考一下大数据数据采集-大数据采集平台-知乎专栏
可以去,实操技术很关键。关键看你要干什么。如果想将来工作无忧那可以去看看爬虫方面的,使用python爬虫框架或者爬虫框架的库去写爬虫。如果真的想好好学习,可以去买本相关资料学一下。
我们总说开源,就是python的开源框架很多,不管是第三方开源,还是各家公司自己研发的,这其中都会用到python的语言特性。但是,问题就来了,你总说开源框架不用担心被封,但,
1、使用官方pythonmodule,
2、使用解决方案(以及腾讯专属官方api文档)加载到数据库中,实现分析接口。
从大数据入门,爬虫,到大数据工程师,再到大数据架构师,数据分析师,数据挖掘师等等,这是大数据的5个阶段。
一、爬虫阶段
二、数据分析师(lamdadata)阶段
三、大数据架构师(hadoop)阶段
四、大数据架构师(docker)阶段
五、大数据工程师(hadoop)这就是你学习的主线。入门爬虫,那就着重讲讲爬虫吧。爬虫说白了就是一个网页,因为页面代码比较复杂,我们叫它爬虫。每个公司都有自己的爬虫部门,以用户为中心开发软件,提供爬虫的对接方式。用户访问这个网页的时候,对应的页面代码会打包发给爬虫。爬虫去执行这个网页的爬取代码。你说的核心价值在于在数据处理时,快速得到结果。
我大致给你描述一下我要爬取的数据,刚刚查的一家互联网公司,我是以xxx职位为例,主要是负责爬取公司的求职信息,一共25条,转化为数据:这25条信息主要用来产生跳槽信息,是一个跳槽的网站。详细的代码不方便展示出来。(一会打包上传)爬虫开发,你说的核心价值在于在数据处理时,快速得到结果。我给你写了一个爬虫的下载流程,以上是我要获取的爬虫代码。
这个代码说简单也不简单,说复杂也不复杂。如果你不能独立去实现,可以到我们的圈子里共同学习。在主流的爬虫工具中,tushare是国内第三方第三方的爬虫,看待爬虫,用tushare是最正确的。如果还有问题,可以加我微信。我会定期发布一些最新的爬虫技术和代码分享给大家。目前,很多python的资料很少,希望,你会喜欢和选择。
你也可以留言或者关注公众号:pythoncaixiaoyu(aaa955
5)在这里,给你无限的提升和动力。
python爬虫开发岗位快速上手过程(2019.5.1
9)给初学爬虫的同学一些建议:1.对于0基础的同学而言,什么都是你要学的,不要给自己设限,不要仅仅局限于html,css,javascript等这些初步的技术,这些很重要,
某个受试者试验完成的几种常见问题,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-08-20 03:01
1 建设目的
通过构建saliva采集信息平台(APP),可以建立实时、快速的采集相关人体测试信息,提高受试者的依从性,保证测试的高质量完成。
2 功能模块要求
saliva采集信息平台主要分为以下几个模块:
受试者基本信息
Saliva采集信息
合规信息
测试的整体情况
2.1 主体基本信息采集
被选中的受试者可以在系统上创建个人登录账号,填写相关个人信息,包括:姓名、性别、年龄、身高、体重、病史等信息。
2.2 saliva采集信息
saliva采集信息主要包括:采集时间、当地PM2.5、情绪评分、饮食和运动信息、不良事件等,以上信息可以方便导出,方便后期统计分析由研究人员提供。
采集时间:受试者可以根据试验方案中的saliva采集时间点设置定时提醒功能(每个时间点包括漱口提醒和采样提醒)。您可以登录系统,点击示例采集按钮,系统会自动记录采集的时间。
PM2.5/AQP:一旦被测者点击样品采集按钮,系统会自动定位被测者的位置,并自动抓取被测者所在的最近测量点的PM@互联网。2.5浓度和AQP指数。
活动/运动量:通过来自 api采集moves 等应用的信息。
情绪得分:完成样本采集后,受试者需要选择该时段的情绪得分值。
其他信息:完成当天最后一个样本采集后,受试者还需要选择或填写当天的饮食、运动、不良事件等信息。
2.3 合规信息
系统可以以图表的形式反映所有受试者在试验过程中的样本采集情况,并根据相应的公式计算其遵守情况,根据遵守程度进行排名,并定期发布在新闻形式。
研究人员可以随时在系统上查看所有受试者的样本采集状态。如果有个别受试者在某段时间内还没有采集samples,研究人员可以向他们发送提醒信息,督促他们尽快完成这段时间的采集样本。
2.4 审判组织情况
该模块可以提供相应的图表,反映某个受试者的试验完成进度、整个试验的受试者人数、整个试验的完成进度。
以公告栏的形式发布试验中的问题,提醒受试者纠正试验中的不良行为。
有专门的操作指导模块,指导被试在实验过程中按照规定的操作标准执行样本采集。 查看全部
某个受试者试验完成的几种常见问题,你知道吗?
1 建设目的
通过构建saliva采集信息平台(APP),可以建立实时、快速的采集相关人体测试信息,提高受试者的依从性,保证测试的高质量完成。
2 功能模块要求
saliva采集信息平台主要分为以下几个模块:
受试者基本信息
Saliva采集信息
合规信息
测试的整体情况
2.1 主体基本信息采集
被选中的受试者可以在系统上创建个人登录账号,填写相关个人信息,包括:姓名、性别、年龄、身高、体重、病史等信息。
2.2 saliva采集信息
saliva采集信息主要包括:采集时间、当地PM2.5、情绪评分、饮食和运动信息、不良事件等,以上信息可以方便导出,方便后期统计分析由研究人员提供。
采集时间:受试者可以根据试验方案中的saliva采集时间点设置定时提醒功能(每个时间点包括漱口提醒和采样提醒)。您可以登录系统,点击示例采集按钮,系统会自动记录采集的时间。
PM2.5/AQP:一旦被测者点击样品采集按钮,系统会自动定位被测者的位置,并自动抓取被测者所在的最近测量点的PM@互联网。2.5浓度和AQP指数。
活动/运动量:通过来自 api采集moves 等应用的信息。
情绪得分:完成样本采集后,受试者需要选择该时段的情绪得分值。
其他信息:完成当天最后一个样本采集后,受试者还需要选择或填写当天的饮食、运动、不良事件等信息。
2.3 合规信息
系统可以以图表的形式反映所有受试者在试验过程中的样本采集情况,并根据相应的公式计算其遵守情况,根据遵守程度进行排名,并定期发布在新闻形式。
研究人员可以随时在系统上查看所有受试者的样本采集状态。如果有个别受试者在某段时间内还没有采集samples,研究人员可以向他们发送提醒信息,督促他们尽快完成这段时间的采集样本。
2.4 审判组织情况
该模块可以提供相应的图表,反映某个受试者的试验完成进度、整个试验的受试者人数、整个试验的完成进度。
以公告栏的形式发布试验中的问题,提醒受试者纠正试验中的不良行为。
有专门的操作指导模块,指导被试在实验过程中按照规定的操作标准执行样本采集。
演示站--源码简介与安装说明:【小说源码】
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-08-13 01:14
演示站-源码可根据需要修改
前端:
背景:账号:admin 密码:123456
源代码介绍和安装说明:
【小说源码】美化最新版UI+采集步骤PTcms+操作关卡+新颖自动采集系统+多条采集规则
源码大小:63.1MB
开发语言:PHP+Mysql
操作系统:Windows、Linux
源码介绍:
小说系统作者亲自操作小说系统2个月。最高IP达到每天6000+。可以看出源码模板优化的很好,适合优采云操作,因为根本不需要管理,买一些朋友链就行了。
如何赚钱:
变现的方法也很简单,就是打广告,你有上千个IP就可以打广告了。申请谷歌+百度+搜狗等联盟广告,每月留几千元。你不能赚很多钱,但你可以赚钱。少量的钱还是可以的。
测试截图:
资源下载本资源下载价格为268元,请先登录
【风险提示】付款前写:
1.全站8500+源代码,除了热门商圈几十个源代码,只要有下载按钮,终身VIP即可免费下载。
2. 本站源码多为全网各种渠道购买。 文章描述一般为渠道方测试描述转载,不代表本站观点。但是文章开头的demo源码代表本站亲自测试过,至少可以搭建,一般没有大问题,可以放心购买。
========================================
3.文章一开始没有demo站点,也就意味着我们没有时间亲自测试。源代码有缺陷风险,所以低价出售。一经购买即视为接受风险,概不退换! ! !但是,与此同时,您也可能很便宜。因为他们中的很多人已经通过了渠道的测试,但我们还没有来得及测试和确认。如果我们的测试没问题,价格会高很多倍。
========================================
4. 本站使用在线支付。支付完成后,积分将自动记入账户。
5. 充值比例:1:1。是否为VIP免费下载,需要登录后显示。
6. 所有源码默认没有安装教程。如果有的话,它们也是随机的。
7.所有源码不提供免费安装。如果您需要我们代您安装,请联系客服了解详情。
本文由(Source House@)整理,转载请注明出处:;
如果本站发布的内容侵犯了您的权益,请邮件删除,我们会及时处理!
============================================
本站下载资源大部分采集于互联网,不保证其完整性和安全性。下载后请自行测试。
本网站上的资源仅供学习和交流之用。版权属于资源的原作者。请在下载后24小时内自觉删除。
商业用途请购买正版。因未购买并付款而造成的侵权与本站无关。 查看全部
演示站--源码简介与安装说明:【小说源码】
演示站-源码可根据需要修改
前端:
背景:账号:admin 密码:123456
源代码介绍和安装说明:
【小说源码】美化最新版UI+采集步骤PTcms+操作关卡+新颖自动采集系统+多条采集规则
源码大小:63.1MB
开发语言:PHP+Mysql
操作系统:Windows、Linux
源码介绍:
小说系统作者亲自操作小说系统2个月。最高IP达到每天6000+。可以看出源码模板优化的很好,适合优采云操作,因为根本不需要管理,买一些朋友链就行了。
如何赚钱:
变现的方法也很简单,就是打广告,你有上千个IP就可以打广告了。申请谷歌+百度+搜狗等联盟广告,每月留几千元。你不能赚很多钱,但你可以赚钱。少量的钱还是可以的。
测试截图:


资源下载本资源下载价格为268元,请先登录
【风险提示】付款前写:
1.全站8500+源代码,除了热门商圈几十个源代码,只要有下载按钮,终身VIP即可免费下载。
2. 本站源码多为全网各种渠道购买。 文章描述一般为渠道方测试描述转载,不代表本站观点。但是文章开头的demo源码代表本站亲自测试过,至少可以搭建,一般没有大问题,可以放心购买。
========================================
3.文章一开始没有demo站点,也就意味着我们没有时间亲自测试。源代码有缺陷风险,所以低价出售。一经购买即视为接受风险,概不退换! ! !但是,与此同时,您也可能很便宜。因为他们中的很多人已经通过了渠道的测试,但我们还没有来得及测试和确认。如果我们的测试没问题,价格会高很多倍。
========================================
4. 本站使用在线支付。支付完成后,积分将自动记入账户。
5. 充值比例:1:1。是否为VIP免费下载,需要登录后显示。
6. 所有源码默认没有安装教程。如果有的话,它们也是随机的。
7.所有源码不提供免费安装。如果您需要我们代您安装,请联系客服了解详情。
本文由(Source House@)整理,转载请注明出处:;
如果本站发布的内容侵犯了您的权益,请邮件删除,我们会及时处理!
============================================
本站下载资源大部分采集于互联网,不保证其完整性和安全性。下载后请自行测试。
本网站上的资源仅供学习和交流之用。版权属于资源的原作者。请在下载后24小时内自觉删除。
商业用途请购买正版。因未购买并付款而造成的侵权与本站无关。
采集文章系统制作完成以后可以直接分享的多种格式
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-08-11 00:07
采集文章系统地制作完成以后可以导出成可以直接分享的多种格式。比如,以某某网站某某网站为例,
二、段落有了辅助列:段落1段落2
三、图片保存提供了很多的格式供你选择:jpgpngbmpgif
4、字体导出提供了大量的公开字体版权可以在正版电子书上使用。
你只需要下载一个word,把里面的序列号记下来,
这个真的简单。你把里面的字段记下来就好了。
最简单的方法:把jpg格式保存下来或者cad格式也可以
具体请参考图文教程:。
我做过的可以先到网站上查找目标用户群体的关键词。然后自己通过目标用户群体的习惯做出来的文章就不用愁了。
ftp格式!! 查看全部
采集文章系统的问题,可以分解成这样的话!
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-08-08 20:04
采集文章系统的问题,可以分解成这样的话:1.拍摄。拍摄的稳定性;是否有避障设置(智能跳转到应用或服务器);录像存储问题(速度及容量);镜头问题(焦距、光圈);2.app开发,文件分发;用户数据导出。
有个叫dogcombat的平台,这个平台是用来收集市面上的各类攻击,合作提供方式是跟防御机构合作,要先提供定制化服务的截图,网站的地址我就不发了,免得说我做广告。
有个应用叫dogcombat,你可以下载试试,地址是/。通过第三方应用签名收集并分析出各个应用的隐私信息,并将它们加密上传。攻击者能通过这些信息攻击你的用户账户,来获取更高额的利润。
做真实威胁模拟需要这个功能
有个防御威胁的产品你可以用下:兵锋在线_您身边的安全防护产品
谷歌appdomain可以
飞雪威胁侦测wordpress,企业网站或者小型社区都需要,可以配合其他爬虫,
谷歌appdomain就可以,
用你服务器安装上的app去检测
看你的目的了,如果是市场前景的话,有意思的文章大多数都是可以进行攻击的,这里就不点名了。 查看全部
采集文章系统的问题,可以分解成这样的话!
采集文章系统的问题,可以分解成这样的话:1.拍摄。拍摄的稳定性;是否有避障设置(智能跳转到应用或服务器);录像存储问题(速度及容量);镜头问题(焦距、光圈);2.app开发,文件分发;用户数据导出。
有个叫dogcombat的平台,这个平台是用来收集市面上的各类攻击,合作提供方式是跟防御机构合作,要先提供定制化服务的截图,网站的地址我就不发了,免得说我做广告。
有个应用叫dogcombat,你可以下载试试,地址是/。通过第三方应用签名收集并分析出各个应用的隐私信息,并将它们加密上传。攻击者能通过这些信息攻击你的用户账户,来获取更高额的利润。
做真实威胁模拟需要这个功能
有个防御威胁的产品你可以用下:兵锋在线_您身边的安全防护产品
谷歌appdomain可以
飞雪威胁侦测wordpress,企业网站或者小型社区都需要,可以配合其他爬虫,
谷歌appdomain就可以,
用你服务器安装上的app去检测
看你的目的了,如果是市场前景的话,有意思的文章大多数都是可以进行攻击的,这里就不点名了。
采集文章系统资源、更新最新行业资讯及小程序更新提示
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-08-07 07:01
采集文章系统资源、更新最新行业资讯及小程序更新提示的同学建议扫码下方二维码,关注知乎机构号:九一八商机同学wangshimengjia同学给介绍自己情况或留言,评论区备注:入行时间、所在行业、最新发布文章、自我要求等,
大家好我是转行做编程的hi,我是一名xx转行的产品狗,目前在一家小公司上班,3个月试用期,大部分都是我在写需求,但这还是不够,领导会告诉我们,最好的学习方式是看书,但是我发现一个问题,不管看什么书,后来都忘记了,就这样工作了半年后跳槽去了一家大公司,但还是对很多细节都不熟悉,经常有的时候很忙但是没办法,今天就跟大家分享下看书的问题,还有如何备考项目经理证书?想要看书我们首先要搞清楚为什么要看书?我们为什么要看书,为了提升自己,为了提升我们自己的解决问题能力,为了成为一个很牛逼的产品经理或运营?想要提升自己我们就要看书,为了提升自己,我们就要多看书,看了书后要去实践,去培养自己的能力,还有就是要看有用的书、好书,通过学习能成为一个更好的产品经理,那这样我们要看什么书呢?我给大家推荐这些书。
一、入门之类的书:
1、《人人都是产品经理》作者:拉里·佩奇,
2、《从0到1》作者:斯坦福大学的创业课
3、《结网》作者:节约你的时间
4、《增长黑客》作者:吴伯凡
5、《产品经理的第一本书》作者:黄有璨
二、知识要点类的书:
1、《设计心理学》作者:史蒂芬·宝德里特
2、《简约至上》作者:版式设计
3、《小密圈创始人》作者:can的形象
5、《引爆点》作者:史蒂芬·宝德里特
6、《跨越鸿沟》作者:德鲁克
7、《乌合之众》作者:古斯塔夫·勒庞
8、《思考,
9、《卡文迪许的发现》作者:卡文迪许1
0、《大众传播学》作者:任柳琴1
1、《游戏改变世界》作者:秦牧《产品经理的第一本书》作者:古典大家对于这些书有没有印象呢? 查看全部
采集文章系统资源、更新最新行业资讯及小程序更新提示
采集文章系统资源、更新最新行业资讯及小程序更新提示的同学建议扫码下方二维码,关注知乎机构号:九一八商机同学wangshimengjia同学给介绍自己情况或留言,评论区备注:入行时间、所在行业、最新发布文章、自我要求等,
大家好我是转行做编程的hi,我是一名xx转行的产品狗,目前在一家小公司上班,3个月试用期,大部分都是我在写需求,但这还是不够,领导会告诉我们,最好的学习方式是看书,但是我发现一个问题,不管看什么书,后来都忘记了,就这样工作了半年后跳槽去了一家大公司,但还是对很多细节都不熟悉,经常有的时候很忙但是没办法,今天就跟大家分享下看书的问题,还有如何备考项目经理证书?想要看书我们首先要搞清楚为什么要看书?我们为什么要看书,为了提升自己,为了提升我们自己的解决问题能力,为了成为一个很牛逼的产品经理或运营?想要提升自己我们就要看书,为了提升自己,我们就要多看书,看了书后要去实践,去培养自己的能力,还有就是要看有用的书、好书,通过学习能成为一个更好的产品经理,那这样我们要看什么书呢?我给大家推荐这些书。
一、入门之类的书:
1、《人人都是产品经理》作者:拉里·佩奇,
2、《从0到1》作者:斯坦福大学的创业课
3、《结网》作者:节约你的时间
4、《增长黑客》作者:吴伯凡
5、《产品经理的第一本书》作者:黄有璨
二、知识要点类的书:
1、《设计心理学》作者:史蒂芬·宝德里特
2、《简约至上》作者:版式设计
3、《小密圈创始人》作者:can的形象
5、《引爆点》作者:史蒂芬·宝德里特
6、《跨越鸿沟》作者:德鲁克
7、《乌合之众》作者:古斯塔夫·勒庞
8、《思考,
9、《卡文迪许的发现》作者:卡文迪许1
0、《大众传播学》作者:任柳琴1
1、《游戏改变世界》作者:秦牧《产品经理的第一本书》作者:古典大家对于这些书有没有印象呢?
哪些免费的大数据可视化工具-九州云大数据交流社区
采集交流 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-08-05 04:02
采集文章系统、全网数据库资源,匹配大数据智能推荐引擎,数据是生命,有价值的资源一定能够更好的为我们服务。为方便接下来接触大数据的同学,专门收集了51cto大数据学习社区中30g的大数据相关数据库学习资源。同学们在学习的过程中,如遇问题,可以联系作者本人或者小编微信qq是1247829016希望这个资源分享能够对同学们有所帮助。数据来源:51cto大数据学习社区文档链接。
先百度有啥找啥,
需要一些基础,比如对java编程的理解,对hadoop框架的理解,做过实际项目比如在买过东西,的交易数据以及几十万条数据的hivesql,
我列的这些大数据可视化工具,都是完全免费,并且简单易用的大数据工具,所以我推荐jupyternotebook。
哪些免费的大数据可视化工具-九州云大数据可视化交流社区
转赠群里同仁,
这些都不收费的,学一下就可以了,仅供大家学习交流,
你可以看下我的三篇文章,这是数据可视化常用到的工具。(数据可视化入门简单,基本一看就懂。)(数据可视化:如何从复杂的数据中构造信息出来)(数据可视化:有效分析数据, 查看全部
哪些免费的大数据可视化工具-九州云大数据交流社区
采集文章系统、全网数据库资源,匹配大数据智能推荐引擎,数据是生命,有价值的资源一定能够更好的为我们服务。为方便接下来接触大数据的同学,专门收集了51cto大数据学习社区中30g的大数据相关数据库学习资源。同学们在学习的过程中,如遇问题,可以联系作者本人或者小编微信qq是1247829016希望这个资源分享能够对同学们有所帮助。数据来源:51cto大数据学习社区文档链接。
先百度有啥找啥,
需要一些基础,比如对java编程的理解,对hadoop框架的理解,做过实际项目比如在买过东西,的交易数据以及几十万条数据的hivesql,
我列的这些大数据可视化工具,都是完全免费,并且简单易用的大数据工具,所以我推荐jupyternotebook。
哪些免费的大数据可视化工具-九州云大数据可视化交流社区
转赠群里同仁,
这些都不收费的,学一下就可以了,仅供大家学习交流,
你可以看下我的三篇文章,这是数据可视化常用到的工具。(数据可视化入门简单,基本一看就懂。)(数据可视化:如何从复杂的数据中构造信息出来)(数据可视化:有效分析数据,
编辑本段文章采集系统过程相关资料功能的开发工具使用.Net
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-08-04 01:16
文章采集系统由(我的世界me采集网)开发,历时4年。在线信息采集系统根据用户自定义的关键词词从网上检索相关数据,对数据进行合理拦截、分类、去重、过滤,并以文件或数据库的形式保存。
内容
文章采集系统进程
相关数据函数解释
展开
文章采集系统进程
相关数据函数解释
展开
编辑本段
文章采集系统进程
系统开发工具采用.Net的C#进行系统开发,数据库采用SQL Server 2000。
一、软件系统总体设计要求
1.网站搜索深度为5层,网站搜索广度为50个网页时,数据检索率达到98%。
2.网站搜索深度为5层,网站搜索广度为50个网页时,数据准确率大于97%。
3.数据存储容量:存储容量≥100G。
4.搜索单个网站时,网站搜索深度:最大5级网页; 网站search 广度:最多搜索 50 个网页。如果超过 60 秒没有结果,搜索将自动放弃。
5.并发搜索强度:10个线程可以同时并发搜索。
6.50亿汉字,平均查询时间小于3秒。
二、应用系统设计要求
1.要求系统多线程采集信息;
2.可以自动对记录进行分类和索引;
3.自动过滤重复并自动索引记录;
三、应用系统功能详解
实时在线采集(内容抓取模块) 快速:网页抓取采用多线程并发搜索技术,可设置最大并发线程数。灵活:可同时跟踪捕捉多个网站,提供灵活的网站、栏目或频道采集策略,利用逻辑关系定位采集内容。准确:多抓取少抓取,可以自定义需要抓取的文件格式,可以抓取图片和表格信息,抓取过程成熟可靠,容错性强,可以长时间稳定运行完成初始设置后。高效自动分类 支持机检分类-可以使用预定义的关键词和规则方法来确定类别;支持自动分类——通过机器自动学习或预学习进行自动分类,准确率达到80%以上。 (这个比较麻烦,可以考虑不做)支持多种分类标准——比如按地区(华北、华南等)、内容(政治、科技、军事、教育等) )、来源(新华网、人民日报、新浪网)等等。网页自动分析内容过滤——可以过滤掉广告、导航信息、版权等无用信息,可以剔除反动和色情内容。内容排序-对于不同的网站相同或相似的内容,可以自动识别并标记为相似。识别方法可以由用户自定义规则确定,也可以根据内容的相似度自动确定。格式转换——自动将 HTML 格式转换为文本文件。自动索引——自动从网页中提取标题、版本、日期、作者、栏目、分类等信息。系统管理集成单一界面——系统提供基于Web的用户界面和管理员界面,满足系统管理员和用户的双重需求。浏览器可用于远程管理分类目录、用户权限,并对分类结果进行调整和强化。完善的目录维护——对分类目录的添加、移动、修改、删除提供完善的管理和维护权限管理,可设置管理目录和单个文件使用权限,加强安全管理。实时文件管理——可以浏览各个目录的分类结果,并进行移动、重命名等实时调整。
编辑本段
相关数据函数解释
使用文章采集系统,整个系统可以在线自动安装,后台有新版本可以自动升级;系统文件损坏可自动修复,站长无后顾之忧。
1、自动构建功能
强大的关键词管理系统
可自动批量获取关键词指定的常用相关词,轻松控制用户搜索行为
自动文章采集system四种内容
文章采集在处理过程中会自动去除重复内容,并可自由设置各类内容的聚合次数
三重过滤保证内容质量
特别是首创的任意词密度判断功能,为搜索引擎收录提供了强有力的保障
自动生成原创topic
文章采集首创以话题为内容组织形式,这是门户网站内容制胜的法宝
主题内容自动更新
话题既可以自动创建也可以更新,各种内容的更新周期可以单独设置
原创tag 综合页面
整个网站集成了统一通用的分类标签系统,不仅使内容相关,而且原创内容页
2、个性化定制功能
原创tag 综合页面
整个网站集成了统一通用的分类标签系统,不仅使内容相关,而且原创内容页
兼容多种静态模式
不仅能有效保证收录搜索引擎的访问量,还能增加网站的持续访问量
任何顶部导航栏设置
可以随意添加或删除顶部导航栏,让网站具有高度的定制性
任意 URL 连接地址名称
不仅让你的网站独一无二,还能在一定程度上提升搜索引擎排名
支持多个模板集
采用模板编译替代技术,即使只改动一个文件,也能做出个性化的界面
任意显示数量控制
具体可以设置主题页各种内容的数量,也可以设置每个列表页的显示数量
3、内置站长工具
记录整个过程中的蜘蛛访问
智能识别搜索引擎蜘蛛99%的访问,全程控制蜘蛛爬行记录
自动创建站点地图
自动生成百度地图和google地图,可分类设置,有效提升网站content收录
一键查看排名和收录
不仅可以查看Alexa排名,还可以准确掌握网站今日收录,还可以添加网站外链
查看网站中非法的关键词
可以自动批量查看网站中是否存在国家禁止的非法内容
在线自动安装和文件修复
setup.php工具不仅可以自动获取授权,自动在线安装系统,还具有系统修复功能
后台智能自动升级
可自动判断当前需要升级的版本,并自动下载升级,让站长免去更新的烦恼
4、高效能
超高效的自动分词技术
首次使用数字分词库和双向分词验证,大大提高了中文分词的效率和准确率
高效的动态页面缓存
采用分模块页面缓存技术,有效保证系统负载能力和网站动态
代码分段调用技术
使系统每次调用最少的程序代码,减少分析时间,有效提高系统执行效率
编译模板技术
所有未改变的模板只需编译一次,减少模板解析时间,提高访问速度
最小化数据读取设计
大大降低数据库资源消耗,支持更多用户快速访问
图片缩略图保存
默认生成图片文件缩略图并保存在本地,大大降低服务器空间和带宽压力
5、全站互动功能
个人群组功能
话题可以转成群组,比论坛更自由的权限控制
外部个人主页
您可以在个人页面看到发起的话题、订阅的话题和好友
我的故乡
通过SNS功能,您可以跟踪我的话题动态和朋友的站点动态
站内好友系统
可以自由添加好友,还可以查看好友动态信息 查看全部
编辑本段文章采集系统过程相关资料功能的开发工具使用.Net
文章采集系统由(我的世界me采集网)开发,历时4年。在线信息采集系统根据用户自定义的关键词词从网上检索相关数据,对数据进行合理拦截、分类、去重、过滤,并以文件或数据库的形式保存。
内容
文章采集系统进程
相关数据函数解释
展开
文章采集系统进程
相关数据函数解释
展开
编辑本段
文章采集系统进程
系统开发工具采用.Net的C#进行系统开发,数据库采用SQL Server 2000。
一、软件系统总体设计要求
1.网站搜索深度为5层,网站搜索广度为50个网页时,数据检索率达到98%。
2.网站搜索深度为5层,网站搜索广度为50个网页时,数据准确率大于97%。
3.数据存储容量:存储容量≥100G。
4.搜索单个网站时,网站搜索深度:最大5级网页; 网站search 广度:最多搜索 50 个网页。如果超过 60 秒没有结果,搜索将自动放弃。
5.并发搜索强度:10个线程可以同时并发搜索。
6.50亿汉字,平均查询时间小于3秒。
二、应用系统设计要求
1.要求系统多线程采集信息;
2.可以自动对记录进行分类和索引;
3.自动过滤重复并自动索引记录;
三、应用系统功能详解
实时在线采集(内容抓取模块) 快速:网页抓取采用多线程并发搜索技术,可设置最大并发线程数。灵活:可同时跟踪捕捉多个网站,提供灵活的网站、栏目或频道采集策略,利用逻辑关系定位采集内容。准确:多抓取少抓取,可以自定义需要抓取的文件格式,可以抓取图片和表格信息,抓取过程成熟可靠,容错性强,可以长时间稳定运行完成初始设置后。高效自动分类 支持机检分类-可以使用预定义的关键词和规则方法来确定类别;支持自动分类——通过机器自动学习或预学习进行自动分类,准确率达到80%以上。 (这个比较麻烦,可以考虑不做)支持多种分类标准——比如按地区(华北、华南等)、内容(政治、科技、军事、教育等) )、来源(新华网、人民日报、新浪网)等等。网页自动分析内容过滤——可以过滤掉广告、导航信息、版权等无用信息,可以剔除反动和色情内容。内容排序-对于不同的网站相同或相似的内容,可以自动识别并标记为相似。识别方法可以由用户自定义规则确定,也可以根据内容的相似度自动确定。格式转换——自动将 HTML 格式转换为文本文件。自动索引——自动从网页中提取标题、版本、日期、作者、栏目、分类等信息。系统管理集成单一界面——系统提供基于Web的用户界面和管理员界面,满足系统管理员和用户的双重需求。浏览器可用于远程管理分类目录、用户权限,并对分类结果进行调整和强化。完善的目录维护——对分类目录的添加、移动、修改、删除提供完善的管理和维护权限管理,可设置管理目录和单个文件使用权限,加强安全管理。实时文件管理——可以浏览各个目录的分类结果,并进行移动、重命名等实时调整。
编辑本段
相关数据函数解释
使用文章采集系统,整个系统可以在线自动安装,后台有新版本可以自动升级;系统文件损坏可自动修复,站长无后顾之忧。
1、自动构建功能
强大的关键词管理系统
可自动批量获取关键词指定的常用相关词,轻松控制用户搜索行为
自动文章采集system四种内容
文章采集在处理过程中会自动去除重复内容,并可自由设置各类内容的聚合次数
三重过滤保证内容质量
特别是首创的任意词密度判断功能,为搜索引擎收录提供了强有力的保障
自动生成原创topic
文章采集首创以话题为内容组织形式,这是门户网站内容制胜的法宝
主题内容自动更新
话题既可以自动创建也可以更新,各种内容的更新周期可以单独设置
原创tag 综合页面
整个网站集成了统一通用的分类标签系统,不仅使内容相关,而且原创内容页
2、个性化定制功能
原创tag 综合页面
整个网站集成了统一通用的分类标签系统,不仅使内容相关,而且原创内容页
兼容多种静态模式
不仅能有效保证收录搜索引擎的访问量,还能增加网站的持续访问量
任何顶部导航栏设置
可以随意添加或删除顶部导航栏,让网站具有高度的定制性
任意 URL 连接地址名称
不仅让你的网站独一无二,还能在一定程度上提升搜索引擎排名
支持多个模板集
采用模板编译替代技术,即使只改动一个文件,也能做出个性化的界面
任意显示数量控制
具体可以设置主题页各种内容的数量,也可以设置每个列表页的显示数量
3、内置站长工具
记录整个过程中的蜘蛛访问
智能识别搜索引擎蜘蛛99%的访问,全程控制蜘蛛爬行记录
自动创建站点地图
自动生成百度地图和google地图,可分类设置,有效提升网站content收录
一键查看排名和收录
不仅可以查看Alexa排名,还可以准确掌握网站今日收录,还可以添加网站外链
查看网站中非法的关键词
可以自动批量查看网站中是否存在国家禁止的非法内容
在线自动安装和文件修复
setup.php工具不仅可以自动获取授权,自动在线安装系统,还具有系统修复功能
后台智能自动升级
可自动判断当前需要升级的版本,并自动下载升级,让站长免去更新的烦恼
4、高效能
超高效的自动分词技术
首次使用数字分词库和双向分词验证,大大提高了中文分词的效率和准确率
高效的动态页面缓存
采用分模块页面缓存技术,有效保证系统负载能力和网站动态
代码分段调用技术
使系统每次调用最少的程序代码,减少分析时间,有效提高系统执行效率
编译模板技术
所有未改变的模板只需编译一次,减少模板解析时间,提高访问速度
最小化数据读取设计
大大降低数据库资源消耗,支持更多用户快速访问
图片缩略图保存
默认生成图片文件缩略图并保存在本地,大大降低服务器空间和带宽压力
5、全站互动功能
个人群组功能
话题可以转成群组,比论坛更自由的权限控制
外部个人主页
您可以在个人页面看到发起的话题、订阅的话题和好友
我的故乡
通过SNS功能,您可以跟踪我的话题动态和朋友的站点动态
站内好友系统
可以自由添加好友,还可以查看好友动态信息
如何把微信公众号文章上传到微信采集系统获取数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-07-27 02:01
采集文章系统化做的比较好的公众号比如优采云我是它的粉丝。它有企业版有个个人版专门供企业管理公众号,
用云采集器的话,是可以,最近发现一款挺不错的采集工具:zblog采集器,可以直接从微信公众号文章获取数据,然后,进行简单数据分析,分析出一些关于微信文章的走势,甚至,根据分析,
我们需要每个公众号原创转载并且获得微信认证的文章然后就是看目前这个公众号有没有关注人数可以很清楚的看到,文章转发点赞从大到小甚至更快速的看到用户数,使用百度指数看看你可以看到大概的转发率以及评论数。
目前公众号文章来源主要是:微信公众号转载,网站,自媒体平台,朋友圈,博客等。那么如何把微信公众号文章上传到微信采集系统获取数据?点击公众号文章,发送“采集文章”即可获取数据,或者在浏览器右上角点击,复制链接,然后发送给采集工具即可进行采集。ps:如果还需要在微信公众号文章里插入链接可以使用,qq群搜索:文章转载,就可以进行关键词的搜索。采集软件种类繁多,开始时可以根据自己的需求进行选择。按需分配数据即可,然后等待软件自动采集数据。
微信公众号里面一般都有原创声明,如果你也可以在公众号后台,查看自己文章的真实打开率。一般来说,如果真实打开率达到30%以上的,再谈下载下来,就不是什么难事了。当然,如果你有时间精力去调查几十万的真实转发用户群,并且原创文章质量很高的话,那也可以考虑手动采集下。本文由公众号“阿宝数据”整理发布,如需转载请注明来源。 查看全部
如何把微信公众号文章上传到微信采集系统获取数据
采集文章系统化做的比较好的公众号比如优采云我是它的粉丝。它有企业版有个个人版专门供企业管理公众号,
用云采集器的话,是可以,最近发现一款挺不错的采集工具:zblog采集器,可以直接从微信公众号文章获取数据,然后,进行简单数据分析,分析出一些关于微信文章的走势,甚至,根据分析,
我们需要每个公众号原创转载并且获得微信认证的文章然后就是看目前这个公众号有没有关注人数可以很清楚的看到,文章转发点赞从大到小甚至更快速的看到用户数,使用百度指数看看你可以看到大概的转发率以及评论数。
目前公众号文章来源主要是:微信公众号转载,网站,自媒体平台,朋友圈,博客等。那么如何把微信公众号文章上传到微信采集系统获取数据?点击公众号文章,发送“采集文章”即可获取数据,或者在浏览器右上角点击,复制链接,然后发送给采集工具即可进行采集。ps:如果还需要在微信公众号文章里插入链接可以使用,qq群搜索:文章转载,就可以进行关键词的搜索。采集软件种类繁多,开始时可以根据自己的需求进行选择。按需分配数据即可,然后等待软件自动采集数据。
微信公众号里面一般都有原创声明,如果你也可以在公众号后台,查看自己文章的真实打开率。一般来说,如果真实打开率达到30%以上的,再谈下载下来,就不是什么难事了。当然,如果你有时间精力去调查几十万的真实转发用户群,并且原创文章质量很高的话,那也可以考虑手动采集下。本文由公众号“阿宝数据”整理发布,如需转载请注明来源。
采集文章系统大,要做各种博客,博客都要用seo软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-07-21 22:00
采集文章系统大,要做各种博客,博客都要需要用seo软件,我们自己开发的二十个方案,我们自己公司就是做博客的,也有很多年的经验了,
技术大牛很多,因为需要配置很高的服务器,还需要配置独立的存储服务器,独立安全加固服务器,包括登录认证,多站群都很多,对于技术要求也比较高,普通人只能尝试下非技术大牛,建议外包寻找seo/营销方面的伙伴。
在竞争这么激烈的情况下,以市场的激烈还是有人专门做电商的,况且有天猫amazon京东这种巨无霸。刚刚在维基百科找到了美国通过立法限制seo的网站。有等,刚刚查了下也有04年13年不限的。这些电商平台还是流量很大,手机端的流量占比其实没有他们想象那么大。所以有需求。
我也有需求,
技术好是当下有价值的,我也在找,技术好会让客户信任我,觉得安全有保障,合作意愿比较强烈,目前只是基础端的开发,有找过外包,不怎么理想。希望能共同交流,共同进步。
你说的技术不好,我定义为“非技术”,都不好。技术不好,你就得开发,没错。
找个靠谱的团队:你自己看着全权负责, 查看全部
采集文章系统大,要做各种博客,博客都要用seo软件
采集文章系统大,要做各种博客,博客都要需要用seo软件,我们自己开发的二十个方案,我们自己公司就是做博客的,也有很多年的经验了,
技术大牛很多,因为需要配置很高的服务器,还需要配置独立的存储服务器,独立安全加固服务器,包括登录认证,多站群都很多,对于技术要求也比较高,普通人只能尝试下非技术大牛,建议外包寻找seo/营销方面的伙伴。
在竞争这么激烈的情况下,以市场的激烈还是有人专门做电商的,况且有天猫amazon京东这种巨无霸。刚刚在维基百科找到了美国通过立法限制seo的网站。有等,刚刚查了下也有04年13年不限的。这些电商平台还是流量很大,手机端的流量占比其实没有他们想象那么大。所以有需求。
我也有需求,
技术好是当下有价值的,我也在找,技术好会让客户信任我,觉得安全有保障,合作意愿比较强烈,目前只是基础端的开发,有找过外包,不怎么理想。希望能共同交流,共同进步。
你说的技术不好,我定义为“非技术”,都不好。技术不好,你就得开发,没错。
找个靠谱的团队:你自己看着全权负责,
采集文章系统(采集文章系统集成的三个大方向应该不同?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-18 16:01
采集文章系统集成是百度搜索搜索技术相关的培训课程,采集系统集成是基于百度搜索、社会化网络、账号分析系统、ai等多领域解决方案的产品。采集文章系统集成是帮助用户更好地进行网站分析以及体验,帮助用户管理网站内容,并整合百度文库等第三方媒体文档的产品。采集文章系统集成网站采集、预警、统计、权限等功能。采集系统集成是基于文章推荐、网页爬虫、移动端文章源等方案的产品。
目前网站采集系统集成不断成熟,并融合人工智能、大数据、云计算等前沿科技,提供专业、全面、易用的一站式网站采集、信息数据分析等服务。
这三个都属于采集系统,应该都算是通过文章批量采集百度网页的数据。希望可以帮到你。
可能和你们需要采集的网站有关。不同的网站方向应该不同。
搜索技术,百度搜索分析,搜索算法,大数据采集.
谢邀,
分别是:大规模网站采集系统(主要是采集百度新闻、百度图片等),采集推荐系统(算法模型推荐,如最可能的关键词),站群还有采集数据、站点分析,这些领域我不太懂,只是知道这么多。
应该算利用大数据来做搜索技术改进
这里三个大方向,其实未来的发展,应该是每一块领域都有一个大项目,把技术应用到不同的领域。现在可能是ai和大数据,百度做了这两方面也算不错了,不管怎么样,上升的领域,我们也得看到。 查看全部
采集文章系统(采集文章系统集成的三个大方向应该不同?)
采集文章系统集成是百度搜索搜索技术相关的培训课程,采集系统集成是基于百度搜索、社会化网络、账号分析系统、ai等多领域解决方案的产品。采集文章系统集成是帮助用户更好地进行网站分析以及体验,帮助用户管理网站内容,并整合百度文库等第三方媒体文档的产品。采集文章系统集成网站采集、预警、统计、权限等功能。采集系统集成是基于文章推荐、网页爬虫、移动端文章源等方案的产品。
目前网站采集系统集成不断成熟,并融合人工智能、大数据、云计算等前沿科技,提供专业、全面、易用的一站式网站采集、信息数据分析等服务。
这三个都属于采集系统,应该都算是通过文章批量采集百度网页的数据。希望可以帮到你。
可能和你们需要采集的网站有关。不同的网站方向应该不同。
搜索技术,百度搜索分析,搜索算法,大数据采集.
谢邀,
分别是:大规模网站采集系统(主要是采集百度新闻、百度图片等),采集推荐系统(算法模型推荐,如最可能的关键词),站群还有采集数据、站点分析,这些领域我不太懂,只是知道这么多。
应该算利用大数据来做搜索技术改进
这里三个大方向,其实未来的发展,应该是每一块领域都有一个大项目,把技术应用到不同的领域。现在可能是ai和大数据,百度做了这两方面也算不错了,不管怎么样,上升的领域,我们也得看到。
采集文章系统(一下如何利用老Y文章管理系统采集时自动完成伪原创)
采集交流 • 优采云 发表了文章 • 0 个评论 • 244 次浏览 • 2021-09-18 04:13
作为垃圾站的站长,最可取的是"K17"能自动"K11",自动完成"K1",然后自动收钱。这真是世界上最幸福的事情,哈哈。不会讨论自动采集和自动收款。今天,我将介绍如何使用旧的y文章管理系统采集自动完成伪原创管理系统文章使用简单方便。虽然它的功能不如Dede等强大,但几乎是不正常的(当文章管理系统是用ASP语言编写时,似乎没有可比性),但有其应有的功能,而且相当简单,因此受到了很多站长的欢迎。在老Y的文章管理系统采集中,自动完成伪原创的具体方法很少被讨论。在老Y的论坛上,有些人甚至出售这种方法。我有点鄙视它。关于“K11”,我不会说太多。我相信每个人都能应付。我想介绍一下旧的y文章管理系统如何在采集的同时自动完成伪原创工作的具体方法。总体思路是利用老y文章管理系统的过滤功能,实现同义词的自动替换,从而达到伪原创的目的。例如,我想将采集文章中的所有单词“在线赚钱博客”替换为“在线赚钱日记”。具体步骤如下:第一步是进入后台。找到“采集management”-“过滤器管理”并添加新的过滤器项。我可以创建一个名为“在线赚钱博客”的项目。具体设置如图所示:“过滤名称”:填写“在线赚钱博客”或随意撰写。但是,为了便于查看,建议与替换的单词保持一致
“项目”:请根据您自己的网站选择一列网站(您必须选择一列,否则过滤后的项目将无法保存)。“过滤器对象”:选项为“标题过滤器”和“正文过滤器”。通常,您可以选择“车身过滤器”。如果你想伪原创查看标题,你可以选择“标题过滤器”。“过滤器类型”:选项为“简单更换”和“高级过滤器”。通常选择“简单替换”。如果选择了“高级过滤器”,则需要指定“开始标记”和“结束标记”,以便可以在代码级别替换采集中的内容。“使用状态”:选项为“启用”和“禁用”,无需解释。“使用范围”:选项为“公共”和“私人”。如果选择private,则过滤器仅对当前网站列有效;如果选择了public,它将对所有列有效,而不管任何列中的任何内容是采集。通常,选择“私人”。“内容”:填写“在线赚钱博客”和需要替换的词。“替换”:填写“在线赚钱日志”,这样只要采集的文章中收录“在线赚钱日志”一词,它就会自动替换为“在线赚钱日志”。其次,重复第一步的工作,直到添加所有同义词。有网友想问:我有三万多个同义词。是否要逐个手动添加它们?什么时候会添加!?无法批量添加?这是个好问题!手动添加确实是一项几乎不可能的任务。除非你有非凡的毅力,否则你可以手动添加超过30000个同义词
遗憾的是,旧的y文章管理系统没有提供批量导入功能。然而,作为真实的、有经验的、有思想的“k5”,我们应该有“k5”意识。您知道,我们刚才输入的内容存储在数据库中,旧的文章管理系统是用ASP+access编写的。MDB数据库可以轻松编辑!因此,我可以通过直接修改数据库批量导入伪原创替换规则!改进的第二步:修改数据库和批量导入规则。搜索后,我发现该数据库位于“您的管理目录\Cai\database”下。用access打开数据库并找到“过滤器”表。您会发现我们刚才添加的替换规则存储在这里。根据您的需要分批添加!接下来的工作涉及访问的操作。我不会罗嗦的。你可以自己做。解释“过滤器”表中几个字段的含义:filterid:无需输入自动生成。Itemid:column ID,当我们手动输入时,它是“item”的内容,但这里是一个数字ID。请注意以下列采集ID做好工作如果您不知道ID,可以重复第一步并进行测试。过滤器名称:过滤器名称。过滤器对象:即“过滤器对象”。填写1至“标题过滤器”,填写2至“正文过滤器”
过滤器类型:即“过滤器类型”。填写1为“简单更换”,填写2为“高级过滤”。Filtercontent:指“内容”。Fisstring:即“开始标签”,仅当设置了“高级过滤器”时才有效。如果设置了“简单过滤器”,请将其留空。Fiostring:“结束标记”,仅在设置“高级过滤器”时有效。如果设置了“简单过滤器”,请将其留空。过滤器步骤:更换。标志:即“使用状态”。True表示“已启用”,false表示“已禁用”。Publictf:即“使用范围”。真是“公开的”,假是“私人的”。最后,我们来谈谈伪原创使用过滤功能的感受:文章管理系统在使用采集时可以自动伪原创但功能不够强大。例如,我的电台有三个栏目:“第一栏”、“第二栏”和“第三栏”。我希望“第1列”将伪原创标题和文本,“第2列”将仅伪原创文本,“第3列”将仅伪原创标题。因此,我只能进行以下设置(假设我有30000条同义词规则):为“第1列”的标题伪原创创建30000条替换规则;为“第1列”的主体伪原创创建30000个替换规则;为“第2列”的文本伪原创创建30000个替换规则;为“第3列”的标题伪原创创建30000个替换规则
这造成了数据库的极大浪费。如果我的站点有几十个栏目,每个栏目的要求都不一样,那么这个数据库的大小将非常糟糕。因此,建议在旧的y文章管理系统的下一版本中对该功能进行改进:首先,增加批量导入功能。毕竟,修改数据库是危险的。其次,过滤规则不再附加到网站列,而是独立的。创建新集合项时,会添加是否使用筛选规则的判断。我相信这种修改可以大大节省数据库存储空间,使逻辑结构更加清晰。这篇文章是“我的在线赚钱日记-原创在线赚钱博客”原创. 请尊重我的劳动成果。请注明转载来源!另外,我很久没有使用旧的y文章管理系统了。如果课文中有错误或不恰当的地方,请改正!企业贸易网 查看全部
采集文章系统(一下如何利用老Y文章管理系统采集时自动完成伪原创)
作为垃圾站的站长,最可取的是"K17"能自动"K11",自动完成"K1",然后自动收钱。这真是世界上最幸福的事情,哈哈。不会讨论自动采集和自动收款。今天,我将介绍如何使用旧的y文章管理系统采集自动完成伪原创管理系统文章使用简单方便。虽然它的功能不如Dede等强大,但几乎是不正常的(当文章管理系统是用ASP语言编写时,似乎没有可比性),但有其应有的功能,而且相当简单,因此受到了很多站长的欢迎。在老Y的文章管理系统采集中,自动完成伪原创的具体方法很少被讨论。在老Y的论坛上,有些人甚至出售这种方法。我有点鄙视它。关于“K11”,我不会说太多。我相信每个人都能应付。我想介绍一下旧的y文章管理系统如何在采集的同时自动完成伪原创工作的具体方法。总体思路是利用老y文章管理系统的过滤功能,实现同义词的自动替换,从而达到伪原创的目的。例如,我想将采集文章中的所有单词“在线赚钱博客”替换为“在线赚钱日记”。具体步骤如下:第一步是进入后台。找到“采集management”-“过滤器管理”并添加新的过滤器项。我可以创建一个名为“在线赚钱博客”的项目。具体设置如图所示:“过滤名称”:填写“在线赚钱博客”或随意撰写。但是,为了便于查看,建议与替换的单词保持一致
“项目”:请根据您自己的网站选择一列网站(您必须选择一列,否则过滤后的项目将无法保存)。“过滤器对象”:选项为“标题过滤器”和“正文过滤器”。通常,您可以选择“车身过滤器”。如果你想伪原创查看标题,你可以选择“标题过滤器”。“过滤器类型”:选项为“简单更换”和“高级过滤器”。通常选择“简单替换”。如果选择了“高级过滤器”,则需要指定“开始标记”和“结束标记”,以便可以在代码级别替换采集中的内容。“使用状态”:选项为“启用”和“禁用”,无需解释。“使用范围”:选项为“公共”和“私人”。如果选择private,则过滤器仅对当前网站列有效;如果选择了public,它将对所有列有效,而不管任何列中的任何内容是采集。通常,选择“私人”。“内容”:填写“在线赚钱博客”和需要替换的词。“替换”:填写“在线赚钱日志”,这样只要采集的文章中收录“在线赚钱日志”一词,它就会自动替换为“在线赚钱日志”。其次,重复第一步的工作,直到添加所有同义词。有网友想问:我有三万多个同义词。是否要逐个手动添加它们?什么时候会添加!?无法批量添加?这是个好问题!手动添加确实是一项几乎不可能的任务。除非你有非凡的毅力,否则你可以手动添加超过30000个同义词
遗憾的是,旧的y文章管理系统没有提供批量导入功能。然而,作为真实的、有经验的、有思想的“k5”,我们应该有“k5”意识。您知道,我们刚才输入的内容存储在数据库中,旧的文章管理系统是用ASP+access编写的。MDB数据库可以轻松编辑!因此,我可以通过直接修改数据库批量导入伪原创替换规则!改进的第二步:修改数据库和批量导入规则。搜索后,我发现该数据库位于“您的管理目录\Cai\database”下。用access打开数据库并找到“过滤器”表。您会发现我们刚才添加的替换规则存储在这里。根据您的需要分批添加!接下来的工作涉及访问的操作。我不会罗嗦的。你可以自己做。解释“过滤器”表中几个字段的含义:filterid:无需输入自动生成。Itemid:column ID,当我们手动输入时,它是“item”的内容,但这里是一个数字ID。请注意以下列采集ID做好工作如果您不知道ID,可以重复第一步并进行测试。过滤器名称:过滤器名称。过滤器对象:即“过滤器对象”。填写1至“标题过滤器”,填写2至“正文过滤器”
过滤器类型:即“过滤器类型”。填写1为“简单更换”,填写2为“高级过滤”。Filtercontent:指“内容”。Fisstring:即“开始标签”,仅当设置了“高级过滤器”时才有效。如果设置了“简单过滤器”,请将其留空。Fiostring:“结束标记”,仅在设置“高级过滤器”时有效。如果设置了“简单过滤器”,请将其留空。过滤器步骤:更换。标志:即“使用状态”。True表示“已启用”,false表示“已禁用”。Publictf:即“使用范围”。真是“公开的”,假是“私人的”。最后,我们来谈谈伪原创使用过滤功能的感受:文章管理系统在使用采集时可以自动伪原创但功能不够强大。例如,我的电台有三个栏目:“第一栏”、“第二栏”和“第三栏”。我希望“第1列”将伪原创标题和文本,“第2列”将仅伪原创文本,“第3列”将仅伪原创标题。因此,我只能进行以下设置(假设我有30000条同义词规则):为“第1列”的标题伪原创创建30000条替换规则;为“第1列”的主体伪原创创建30000个替换规则;为“第2列”的文本伪原创创建30000个替换规则;为“第3列”的标题伪原创创建30000个替换规则
这造成了数据库的极大浪费。如果我的站点有几十个栏目,每个栏目的要求都不一样,那么这个数据库的大小将非常糟糕。因此,建议在旧的y文章管理系统的下一版本中对该功能进行改进:首先,增加批量导入功能。毕竟,修改数据库是危险的。其次,过滤规则不再附加到网站列,而是独立的。创建新集合项时,会添加是否使用筛选规则的判断。我相信这种修改可以大大节省数据库存储空间,使逻辑结构更加清晰。这篇文章是“我的在线赚钱日记-原创在线赚钱博客”原创. 请尊重我的劳动成果。请注明转载来源!另外,我很久没有使用旧的y文章管理系统了。如果课文中有错误或不恰当的地方,请改正!企业贸易网
采集文章系统(给站长或SEOER推荐一款免费的文章采集工具_chukang-CSDN博客)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-12 08:15
向站长或SEOER推荐一个免费的文章采集工具_chukang-CSDN博客。
Webmaster Star 是一个专业的站群 内容管理系统,它集成了文章采集、文章processing 和文章publishing。界面精美,操作简单,功能强大。 .
15个免费文章采集网站,每天更新,收录率很高!免费文章采集tools! 15个免费个人或商业文章采集网站;为了应对日渐火爆的微信公众号等自媒体平台的抄袭和洗稿,我们整理了这15个免费给大家。
如今,很多焦点新闻,文章,热点等等,都在网上不断更新。如果数量少,可以一张一张的复制采集,但是如果采集的数量太多,一张一张的复制不仅效率低下,而且会越来越烦人。所以今天给大家带来了各种款式。
3、好搜文库:类似于百度文库采集,但所有文章找到的都是免费的。 4.知网:如果你有论文,可以通过这个平台提交你的论文。
文章采集Reading 是一个用简单语言编写的简单网络文章采集 工具。不仅可以替换采集文本,还可以简单的替换一些文本,或者添加。
文章采集Reading 是一个用简单的语言编写的简单的网络文章采集 工具。不仅可以采集文字,还可以简单的替换一些文字,或者添加文字,也是SEO伪原创的好工具...
无人值守的免费自动采集器-中小网站自动更新工具!无人值守的免费采集器中小网站自动更新工具!免责声明:本软件适用于长期更新内容,非临时网站使需要对现有论坛或网站进行任何更改。 查看全部
采集文章系统(给站长或SEOER推荐一款免费的文章采集工具_chukang-CSDN博客)
向站长或SEOER推荐一个免费的文章采集工具_chukang-CSDN博客。
Webmaster Star 是一个专业的站群 内容管理系统,它集成了文章采集、文章processing 和文章publishing。界面精美,操作简单,功能强大。 .
15个免费文章采集网站,每天更新,收录率很高!免费文章采集tools! 15个免费个人或商业文章采集网站;为了应对日渐火爆的微信公众号等自媒体平台的抄袭和洗稿,我们整理了这15个免费给大家。
如今,很多焦点新闻,文章,热点等等,都在网上不断更新。如果数量少,可以一张一张的复制采集,但是如果采集的数量太多,一张一张的复制不仅效率低下,而且会越来越烦人。所以今天给大家带来了各种款式。
3、好搜文库:类似于百度文库采集,但所有文章找到的都是免费的。 4.知网:如果你有论文,可以通过这个平台提交你的论文。
文章采集Reading 是一个用简单语言编写的简单网络文章采集 工具。不仅可以替换采集文本,还可以简单的替换一些文本,或者添加。
文章采集Reading 是一个用简单的语言编写的简单的网络文章采集 工具。不仅可以采集文字,还可以简单的替换一些文字,或者添加文字,也是SEO伪原创的好工具...
无人值守的免费自动采集器-中小网站自动更新工具!无人值守的免费采集器中小网站自动更新工具!免责声明:本软件适用于长期更新内容,非临时网站使需要对现有论坛或网站进行任何更改。
采集文章系统(编辑本段文章采集系统过程相关资料功能的开发工具使用.Net)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-09-08 16:06
文章采集系统由(我的世界me采集网)开发,历时4年,在线信息采集系统基于用户自定义关键词词,从网上检索相关数据,并对数据进行合理的截取、分类、去重、过滤,并以文件或数据库的形式保存。
内容
文章采集系统进程
相关数据函数解释
展开
文章采集系统进程
相关数据函数解释
展开
编辑本段
文章采集系统进程
系统开发工具采用.Net的C#进行系统开发,数据库采用SQL Server 2000。
一、软件系统总体设计要求
1.网站搜索深度为5层,网站搜索广度为50个网页时,数据检索率达到98%。
2.网站搜索深度为5层,网站搜索广度为50个网页时,数据准确率大于97%。
3.数据存储容量:存储容量≥100G。
4.搜索单个网站时,网站搜索深度:最大5级网页; 网站search 广度:最多搜索 50 个网页。如果超过 60 秒没有结果,搜索将自动放弃。
5.并发搜索强度:10个线程可以同时并发搜索。
6.50亿汉字,平均查询时间小于3秒。
二、应用系统设计要求
1.要求系统多线程采集信息;
2.可以自动对记录进行分类和索引;
3.自动过滤重复项并自动索引记录;
三、应用系统功能详解
实时在线采集(内容抓取模块) 快速:网页抓取采用多线程并发搜索技术,可设置最大并发线程数。灵活:可同时跟踪捕捉多个网站,提供灵活的网站、栏目或频道采集策略,利用逻辑关系定位采集内容。准确:多抓取少抓取,可以自定义需要抓取的文件格式,可以抓取图片和表格信息,抓取过程成熟可靠,容错性强,可以长时间稳定运行完成初始设置后。高效自动分类 支持机检分类-可以使用预定义的关键词和规则方法来确定类别;支持自动分类——通过机器自动学习或预学习进行自动分类,准确率达到80%以上。 (这个比较麻烦,可以考虑不做)支持多种分类标准——比如按地区(华北、华南等)、内容(政治、科技、军事、教育等) .)、来源(新华网、人民日报、新浪网)等等。网页自动分析内容过滤——可以过滤掉广告、导航信息、版权等无用信息,可以剔除反动和色情内容。内容排序-对于不同的网站相同或相似的内容,可以自动识别并标记为相似。识别方法可以由用户定义的规则确定,并由内容的相似性自动确定。格式转换——自动将 HTML 格式转换为文本文件。自动索引——自动从网页中提取标题、版本、日期、作者、栏目、分类等信息。系统管理集成单一界面——系统提供基于Web的用户界面和管理员界面,满足系统管理员和用户的双重需求。浏览器可用于远程管理分类目录、用户权限,并对分类结果进行调整和强化。完善的目录维护——提供完善的分类目录添加、移动、修改、删除管理和维护权限管理,可设置管理目录和单个文件使用权限,加强安全管理。实时文件管理——可以浏览各个目录的分类结果,并进行移动、重命名等实时调整。
编辑本段
相关数据函数解释
使用文章采集系统,整个系统可以在线自动安装,后台有新版本可以自动升级;系统文件损坏可自动修复,站长无后顾之忧。
1、自动构建功能
强大的关键词管理系统
可自动批量获取关键词指定的常用相关词,轻松控制用户搜索行为
自动文章采集system四种内容
文章采集在处理过程中会自动去除重复内容,并可自由设置各类内容的聚合次数
三重过滤保证内容质量
特别是首创的任意词密度判断功能,为搜索引擎收录提供了强有力的保障
自动生成原创topic
文章采集首创以话题为内容组织形式,这是门户网站内容制胜的法宝
主题内容自动更新
话题可以自动创建和更新,各种内容的更新周期可以单独设置
原创tag 综合页面
整个网站集成了统一通用的分类标签系统,不仅使内容相关,而且原创内容页
2、个性化定制功能
原创tag 综合页面
整个网站集成了统一通用的分类标签系统,不仅使内容相关,而且原创内容页
兼容多种静态模式
不仅能有效保证收录搜索引擎的访问量,还能增加网站的持续访问量
任何顶部导航栏设置
可以随意添加或删除顶部导航栏,让网站具有高度的定制性
任意 URL 连接地址名称
不仅让你的网站独一无二,还能在一定程度上提升搜索引擎排名
支持多个模板集
采用模板编译替代技术,即使只改动一个文件,也能做出个性化的界面
任意显示数量控制
具体可以设置主题页各种内容的数量,也可以设置每个列表页的显示数量
3、内置站长工具
记录整个过程中的蜘蛛访问
智能识别搜索引擎蜘蛛99%的访问,全程控制蜘蛛爬行记录
自动创建站点地图
自动生成百度地图和google地图,可分类设置,有效提升网站content收录
一键查看排名和收录
不仅可以查看Alexa排名,还可以准确掌握网站今日收录,还可以添加网站外链
查看网站中非法的关键词
可以自动批量查看网站中是否存在国家禁止的非法内容
在线自动安装和文件修复
setup.php工具不仅可以自动获取授权,自动在线安装系统,还具有系统修复功能
后台智能自动升级
可自动判断当前需要升级的版本,并自动下载升级,让站长免去更新的烦恼
4、高效能
超高效的自动分词技术
首次使用数字分词库和双向分词验证,大大提高了中文分词的效率和准确率
高效的动态页面缓存
采用分模块页面缓存技术,有效保证系统负载能力和网站动态
代码分段调用技术
使系统每次调用最少的程序代码,减少分析时间,有效提高系统执行效率
编译模板技术
所有未改变的模板只需编译一次,减少模板解析时间,提高访问速度
最小化数据读取设计
大大降低数据库资源消耗,支持更多用户快速访问
图片缩略图保存
默认生成图片文件缩略图并保存在本地,大大降低服务器空间和带宽压力
5、全站互动功能
个人群组功能
话题可以转成群组,比论坛更自由的权限控制
外部个人主页
您可以在个人页面看到发起的话题、订阅的话题和好友
我的故乡
通过SNS功能,您可以跟踪我的话题动态和朋友的站点动态
站内好友系统
可以自由添加好友,还可以查看好友动态信息 查看全部
采集文章系统(编辑本段文章采集系统过程相关资料功能的开发工具使用.Net)
文章采集系统由(我的世界me采集网)开发,历时4年,在线信息采集系统基于用户自定义关键词词,从网上检索相关数据,并对数据进行合理的截取、分类、去重、过滤,并以文件或数据库的形式保存。
内容
文章采集系统进程
相关数据函数解释
展开
文章采集系统进程
相关数据函数解释
展开
编辑本段
文章采集系统进程
系统开发工具采用.Net的C#进行系统开发,数据库采用SQL Server 2000。
一、软件系统总体设计要求
1.网站搜索深度为5层,网站搜索广度为50个网页时,数据检索率达到98%。
2.网站搜索深度为5层,网站搜索广度为50个网页时,数据准确率大于97%。
3.数据存储容量:存储容量≥100G。
4.搜索单个网站时,网站搜索深度:最大5级网页; 网站search 广度:最多搜索 50 个网页。如果超过 60 秒没有结果,搜索将自动放弃。
5.并发搜索强度:10个线程可以同时并发搜索。
6.50亿汉字,平均查询时间小于3秒。
二、应用系统设计要求
1.要求系统多线程采集信息;
2.可以自动对记录进行分类和索引;
3.自动过滤重复项并自动索引记录;
三、应用系统功能详解
实时在线采集(内容抓取模块) 快速:网页抓取采用多线程并发搜索技术,可设置最大并发线程数。灵活:可同时跟踪捕捉多个网站,提供灵活的网站、栏目或频道采集策略,利用逻辑关系定位采集内容。准确:多抓取少抓取,可以自定义需要抓取的文件格式,可以抓取图片和表格信息,抓取过程成熟可靠,容错性强,可以长时间稳定运行完成初始设置后。高效自动分类 支持机检分类-可以使用预定义的关键词和规则方法来确定类别;支持自动分类——通过机器自动学习或预学习进行自动分类,准确率达到80%以上。 (这个比较麻烦,可以考虑不做)支持多种分类标准——比如按地区(华北、华南等)、内容(政治、科技、军事、教育等) .)、来源(新华网、人民日报、新浪网)等等。网页自动分析内容过滤——可以过滤掉广告、导航信息、版权等无用信息,可以剔除反动和色情内容。内容排序-对于不同的网站相同或相似的内容,可以自动识别并标记为相似。识别方法可以由用户定义的规则确定,并由内容的相似性自动确定。格式转换——自动将 HTML 格式转换为文本文件。自动索引——自动从网页中提取标题、版本、日期、作者、栏目、分类等信息。系统管理集成单一界面——系统提供基于Web的用户界面和管理员界面,满足系统管理员和用户的双重需求。浏览器可用于远程管理分类目录、用户权限,并对分类结果进行调整和强化。完善的目录维护——提供完善的分类目录添加、移动、修改、删除管理和维护权限管理,可设置管理目录和单个文件使用权限,加强安全管理。实时文件管理——可以浏览各个目录的分类结果,并进行移动、重命名等实时调整。
编辑本段
相关数据函数解释
使用文章采集系统,整个系统可以在线自动安装,后台有新版本可以自动升级;系统文件损坏可自动修复,站长无后顾之忧。
1、自动构建功能
强大的关键词管理系统
可自动批量获取关键词指定的常用相关词,轻松控制用户搜索行为
自动文章采集system四种内容
文章采集在处理过程中会自动去除重复内容,并可自由设置各类内容的聚合次数
三重过滤保证内容质量
特别是首创的任意词密度判断功能,为搜索引擎收录提供了强有力的保障
自动生成原创topic
文章采集首创以话题为内容组织形式,这是门户网站内容制胜的法宝
主题内容自动更新
话题可以自动创建和更新,各种内容的更新周期可以单独设置
原创tag 综合页面
整个网站集成了统一通用的分类标签系统,不仅使内容相关,而且原创内容页
2、个性化定制功能
原创tag 综合页面
整个网站集成了统一通用的分类标签系统,不仅使内容相关,而且原创内容页
兼容多种静态模式
不仅能有效保证收录搜索引擎的访问量,还能增加网站的持续访问量
任何顶部导航栏设置
可以随意添加或删除顶部导航栏,让网站具有高度的定制性
任意 URL 连接地址名称
不仅让你的网站独一无二,还能在一定程度上提升搜索引擎排名
支持多个模板集
采用模板编译替代技术,即使只改动一个文件,也能做出个性化的界面
任意显示数量控制
具体可以设置主题页各种内容的数量,也可以设置每个列表页的显示数量
3、内置站长工具
记录整个过程中的蜘蛛访问
智能识别搜索引擎蜘蛛99%的访问,全程控制蜘蛛爬行记录
自动创建站点地图
自动生成百度地图和google地图,可分类设置,有效提升网站content收录
一键查看排名和收录
不仅可以查看Alexa排名,还可以准确掌握网站今日收录,还可以添加网站外链
查看网站中非法的关键词
可以自动批量查看网站中是否存在国家禁止的非法内容
在线自动安装和文件修复
setup.php工具不仅可以自动获取授权,自动在线安装系统,还具有系统修复功能
后台智能自动升级
可自动判断当前需要升级的版本,并自动下载升级,让站长免去更新的烦恼
4、高效能
超高效的自动分词技术
首次使用数字分词库和双向分词验证,大大提高了中文分词的效率和准确率
高效的动态页面缓存
采用分模块页面缓存技术,有效保证系统负载能力和网站动态
代码分段调用技术
使系统每次调用最少的程序代码,减少分析时间,有效提高系统执行效率
编译模板技术
所有未改变的模板只需编译一次,减少模板解析时间,提高访问速度
最小化数据读取设计
大大降低数据库资源消耗,支持更多用户快速访问
图片缩略图保存
默认生成图片文件缩略图并保存在本地,大大降低服务器空间和带宽压力
5、全站互动功能
个人群组功能
话题可以转成群组,比论坛更自由的权限控制
外部个人主页
您可以在个人页面看到发起的话题、订阅的话题和好友
我的故乡
通过SNS功能,您可以跟踪我的话题动态和朋友的站点动态
站内好友系统
可以自由添加好友,还可以查看好友动态信息
采集文章系统(一个约定好该系统一个指定的栏目设置采集计划(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-05 03:08
Information采集User Manual Summary Information采集是捕捉网络数据,实现信息共享的功能模块。提供手动抓取、定时抓取、定时循环抓取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页的数据(新闻)采集传输到webplus系统中的指定栏目。步骤如下: 为指定的列做一个采集计划。在栏目管理中选择栏目,点击设置采集plan。 (例如:图一)设置采集的基本属性。包括执行方式、信息是否自动发布、采集的列类型以及页面的编码格式。(例如:图二)为此采集事先约定了@plan的执行方式是手动、定时单次或定时循环执行,如果只针对采集网页的当前数据,我们可以使用手动和定时单次采集一次;如果是采集webpage 数据会被更新,我们需要保证信息的同步,即使用定时循环采集 判断来自采集的信息是否需要发布.如果采集发来的信息不需要修改,可以直接公开到网上,选择自动发布。如果采集发来的信息需要修改、审核等,选择不自动发布.采集完成后,信息管理器会进行其他操作。 采集的umn类型如果采集的网页只是一个新闻列表,即页面的新闻采集放在指定的栏目下,则选择单栏。
如果被采集的页面有多个新闻列表,并且每个都提供了一个单独的链接进入自己的新闻列表页面,我们需要采集的所有新闻信息,那么选择多列。另外,如果采集的页面是RSS信息聚合页面,设置为对应的RSS单栏或RSS多栏。通过采集设置页面的编码 由于webplus系统使用的是UTF-8编码格式,而采集可能是其他编码格式,那么为了避免采集来的信息乱码,需要设置为采集页面的编码格式。本文来自计算机基础:设置采集plan 采集plan设置的采集规则单列(如:图三)设置“列表页起始URL”为访问路径采集页面。(必填)设置“文章页URL获取规则”,如果新闻列表是通过采集嵌入到网页中的iframe中,则需要设置规则获取链接地址list iframe 访问新闻列表。否则, no 需要制定此规则。(具体规则方法请参考下面的“采集正则表达式制定”)。如果采集的新闻列表网页有分页,则根据新闻列表的分页方式(链接和表单提交)制定分页规则,需要设置起始页码、间隔页码、采集页码。没有分页,不需要制定这个规则,如果页面被采集有多个新闻列表,并且更多新闻列表的url规则类似,但是我们只需要采集指定的一个列表,即我们需要设置规则来限制文章lists的获取。这是为了避免采集冗余数据。
否则,无需设置此规则。设置文章url获取规则,以便能够从采集页面访问特定的新闻页面,从而进行新闻采集。 (必填)设置“文章内容取法”的具体新闻页面。如果文章内容以iframe的形式嵌入到新闻页面,则需要设置规则获取文章iframe的链接地址。访问新闻内容。否则,无需制定此规则。如果新闻内容有分页,则分页规则按照文章content分页方式(链接和表单提交)制定,需要设置起始页码、间隔页码和采集分页的页码。如果文章内容没有分页,则无需制定此规则。如果新闻页面中除了新闻内容之外还有其他附加信息,那么为了在采集过程中更容易找到新闻内容,需要设置限制获取新闻内容的规则。一是避免垃圾邮件,二是降低新闻特定信息获取规则的复杂性。如果新闻页面比较简单,一般不需要设置这个规则。设置新闻属性的规则是可选的,除了标题和内容。另外,如果未设置新闻发布时间,则以当前时间作为发布时间。多列采集plan的设置(如:图五)Multicolumn采集计划) 除了在“列表页面起始URL”下设置列表页面URL规则和在“文章页URL获取”下设置列rules" 获取名称的规则与单列采集plan 中设置的规则相同。
RSS单栏采集计划的设置(如:图中四)RSS单栏的采集计划不需要设置“文章页URL获取规则”,其余与单栏采集计划一致。RSS多栏采集计划的设置(如:图六)RSS多栏采集计划需要设置列表页URL获取“列表页面起始URL”下的规则,其他与RSS单列采集计划一致。采集Rule表达式制定表达式设置和调整,以及测试表达式列表点击一个地方采集页面“获取规则设置”进入规则表达式列表页面(如:图七)此页面除了可以添加、修改、删除和调整表达式的顺序,还可以输入url、iframeurl以及设置表达式后的页面内容测试表达式规则列表 设置各种类型 表达式类型 表达式类型分为ed 分为四种类型:字符串、匹配、匹配替换和公式。其中,匹配和匹配替换需要使用java正表达式,这就需要采集计划SET人员对表达式有一定的理解。 String:直接输入字符串常量匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本S中的部分内容匹配替换:首先从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。然后用替换正则表达式替换S中匹配的内容,得到正确的内容。
公式:仅支持[pageIndex],用于获取页面地址时表示页面的页码。图标详情进入栏目管理(图一)Settings采集计划,在右侧栏目列表中选择一栏,点击Set采集计划。(图二)执行方法可以:手动(需要在列列表中点击)“立即采集”启动采集)单次(可以设置时间,到时采集会自动启动)循环(指定间隔时间) , 自动循环采集) 可以设置采集为文章 是否自动发布. 为采集的列类型:单列(采集此列下仅文章)单列RSS( 采集一RSS地址文章)多栏(采集栏和子栏下文章)多栏RSS(从一个RSS列表地址开始,采集文章在多个RSS地址下,每个RSS地址形成一个子栏)编码方式是通过采集页面采集rule单栏方式的编码设置(图片三)单栏RSS方式(图片四)这个方式不需要设置文章page URL ac查询方法,其他方法同单列法。多列方法)(图片五)该方法的起始页一般是列表页的集合。对于单列的方法,需要设置获取列表页的方法和列名规则。其他的是与单栏一致 多栏RSS(图片六)此方法) 需要设置从起始页(列表页网址)获取RSS地址,其他与单栏RSS一致。设置获取规则(图七)(图八)(图九)(图十)(图十一)))@(图10二)如上图,获取规则由多个表达式,添加多个表达式获取需要的URL,获取文章的标题内容等属性。
表达式分为4类: string:直接输入字符串常量匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式得到文本中的部分内容S。匹配替换:首先通过正则表达式从指定文本(URL、IframeURL、页面内容)中获取文本中的部分内容S。然后使用替换正则表达式替换S中匹配的内容,得到正确的内容。公式:仅支持[pageIndex],用于在获取页面地址时表示该页面的页码。此页面还可以测试设置的表达式。您可以使用表达式帮助来理解正则表达式的语法。查看采集计划的状态。回到栏目列表,可以看到如下图(图10三)采集status中的3个图标代表采集计划的运行状态(是否正在运行,是否已经运行,等))、采集方式(单列、单列RSS、多列、多列RSS)、执行方式(手动、单列、循环),点击查看采集计划的详细信息, (图10四)采集计划示例以采集新浪网站体育新闻列表网页为例,该网页的访问地址为HYPERLINK "/nba/1.shtml" /nba/ 1.shtml.采集 的内容放在一个“体育新闻”栏目下,由于这是一个测试示例,我们对采集使用手动执行方式,采集到达的信息不需要自动发布。
本网页是一个简单的新闻列表页面,编码方式为GB2312,所以我们将采集的列类型设置为“单列”,编码方式为gb2312采集。新闻不需要自动发布。如下图,由于这个页面的新闻列表内容不再在iframe中,也没有分页,所以不需要设置“在IFRAME中列出页面内容”和“列表页面分页”的获取规则方法”。并且新闻列表的内容不需要设置“限制文章list 内容”规则。设置文章url 的获取规则。由于本网页的新闻链接类似于以下网址:HYPERLINK "/k/2009-07-07shtml" /k/2009-07-07shtml,因此制定如下表达规则: 匹配内容类型:页面内容匹配表达式: /k/(\d+)-(\d+)-(\d+)/(\d+)\.shtml 匹配组:0(获取整个匹配结果) 获取采集 @Page源文件,粘贴进去页面内容,点击“测试计算-列表模式”,结果将显示所有匹配的URL列表,如下图所示。由于文章content不在iframe中,文章content没有分页,文章content不需要限制在页面中,所以“文章page内容在IFRAME中”的获取规则, 文章内容分页URL"和"limited文章页文章内容"不需要设置。 文章标题规则设置 因为新闻页面源文件中文章的标题在以下位置:休斯顿球迷期待姚明手术健康是火箭未来的希望表达规则表达类型:匹配内容type:页面内容匹配表达式:(.+?) 匹配组:1(获取匹配结果中的第一组,每个括号为一组)获取采集页面的源文件,粘贴到页面内容中,点击“测试计算-内容模式”,结果中的标题内容如下图位置:
北京时间7月7日,休斯顿新浪体育。据ESPN报道,姚明还没有决定是否接受手术来修复他的脚伤。虽然现在诊断姚明的三位主要医生都推荐手术,但姚明还在犹豫。
至于姚明现在的想法,大家都知道,姚明之所以还在犹豫,是因为他知道,如果他动了手术,下赛季他缺席也不是没有可能。 29岁的姚明不希望白费。花了一年,浪费了一年。毕竟,运动员的巅峰期就是这么一段时期。没有人能保证那个时候的姚明能保持好水平。
姚明犹豫不决,但休斯顿球迷对姚明有不同的看法。大多数球迷认为姚明应该毫不犹豫地接受手术。他们的理由是,既然有恶化的趋势,保守治疗的效果还不清楚,他们不应该做出手术的决定。毕竟,一个健康的姚明对火箭来说是最重要的。如果有必要,如果保守治疗后还需要手术,那姚明就输了。
“亲爱的姚,请你下定决心去做手术。即使你下赛季缺席,也不要犹豫,去做吧。如果保守治疗最终治愈,仍然会让我们颤抖,还有下个赛季会更多。可能有问题,最好做手术解决根本原因。你可能会输一年,但我们相信你会给休斯顿带来更健康的三年、五年,甚至更长时间。未来。”一个粉丝说。 .
确实,这位球迷说出了大多数休斯顿球迷不得不说的话。没有人愿意看到姚明在没有彻底治愈的情况下重返赛场。如果姚明再次受伤,相信对包括姚明在内的所有休斯顿球迷来说都是沉重的打击。
也有球迷表示姚明手术应该放心。给姚明检查确诊的医生,就是给骑士队中锋Z做手术的医生,大Z脚的伤势和姚明的伤势差不多。终于,手术后,1991年,大Z身体健康地重返赛场,接下来的几年也没有出现大的伤病,竞技状态还是比较好的。
“像哈达威一样,他们也因为伤病而急剧下滑。我认为这很难发生在姚明身上。姚明不同于希尔和哈达威。姚明是内线球员,虽然脚步移动很重要,但相对来说,弹跳并不是最重要的,姚明在内线的威慑力主要来源于他的身高和惊人的手感,足部手术不会带走姚明的身高,也不会带走他的感觉。 ”粉丝说。
总之,休斯顿人基本都希望姚明能接受手术。他们相信手术可以让姚明完全健康,而一个健康的姚明是他们最希望看到的姚明。
(小黑)
于是制定如下表达式规则表达式类型: 匹配内容类型:页面内容匹配表达式:(.+?) 匹配组:1(获取匹配结果中的第一组,每个括号为一个分组)获取源文件将采集页面粘贴到页面内容中,点击“测试计算-内容模式”,结果为文章内容如下图。 文章的其他属性这里没有设置。如有需要,请参考标题和内容的表达方式进行设置。 采集计划设置好后,选择“体育新闻”栏目,现在点击采集,稍等片刻,查看该栏目的内容管理,就会看到如下内容。另外,在“体育新闻”栏目中点击采集状态可以在栏目管理中查看采集采集的运行状态,如下图: 查看全部
采集文章系统(一个约定好该系统一个指定的栏目设置采集计划(组图))
Information采集User Manual Summary Information采集是捕捉网络数据,实现信息共享的功能模块。提供手动抓取、定时抓取、定时循环抓取三种模式。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。步骤和细节现在需要将网页的数据(新闻)采集传输到webplus系统中的指定栏目。步骤如下: 为指定的列做一个采集计划。在栏目管理中选择栏目,点击设置采集plan。 (例如:图一)设置采集的基本属性。包括执行方式、信息是否自动发布、采集的列类型以及页面的编码格式。(例如:图二)为此采集事先约定了@plan的执行方式是手动、定时单次或定时循环执行,如果只针对采集网页的当前数据,我们可以使用手动和定时单次采集一次;如果是采集webpage 数据会被更新,我们需要保证信息的同步,即使用定时循环采集 判断来自采集的信息是否需要发布.如果采集发来的信息不需要修改,可以直接公开到网上,选择自动发布。如果采集发来的信息需要修改、审核等,选择不自动发布.采集完成后,信息管理器会进行其他操作。 采集的umn类型如果采集的网页只是一个新闻列表,即页面的新闻采集放在指定的栏目下,则选择单栏。
如果被采集的页面有多个新闻列表,并且每个都提供了一个单独的链接进入自己的新闻列表页面,我们需要采集的所有新闻信息,那么选择多列。另外,如果采集的页面是RSS信息聚合页面,设置为对应的RSS单栏或RSS多栏。通过采集设置页面的编码 由于webplus系统使用的是UTF-8编码格式,而采集可能是其他编码格式,那么为了避免采集来的信息乱码,需要设置为采集页面的编码格式。本文来自计算机基础:设置采集plan 采集plan设置的采集规则单列(如:图三)设置“列表页起始URL”为访问路径采集页面。(必填)设置“文章页URL获取规则”,如果新闻列表是通过采集嵌入到网页中的iframe中,则需要设置规则获取链接地址list iframe 访问新闻列表。否则, no 需要制定此规则。(具体规则方法请参考下面的“采集正则表达式制定”)。如果采集的新闻列表网页有分页,则根据新闻列表的分页方式(链接和表单提交)制定分页规则,需要设置起始页码、间隔页码、采集页码。没有分页,不需要制定这个规则,如果页面被采集有多个新闻列表,并且更多新闻列表的url规则类似,但是我们只需要采集指定的一个列表,即我们需要设置规则来限制文章lists的获取。这是为了避免采集冗余数据。
否则,无需设置此规则。设置文章url获取规则,以便能够从采集页面访问特定的新闻页面,从而进行新闻采集。 (必填)设置“文章内容取法”的具体新闻页面。如果文章内容以iframe的形式嵌入到新闻页面,则需要设置规则获取文章iframe的链接地址。访问新闻内容。否则,无需制定此规则。如果新闻内容有分页,则分页规则按照文章content分页方式(链接和表单提交)制定,需要设置起始页码、间隔页码和采集分页的页码。如果文章内容没有分页,则无需制定此规则。如果新闻页面中除了新闻内容之外还有其他附加信息,那么为了在采集过程中更容易找到新闻内容,需要设置限制获取新闻内容的规则。一是避免垃圾邮件,二是降低新闻特定信息获取规则的复杂性。如果新闻页面比较简单,一般不需要设置这个规则。设置新闻属性的规则是可选的,除了标题和内容。另外,如果未设置新闻发布时间,则以当前时间作为发布时间。多列采集plan的设置(如:图五)Multicolumn采集计划) 除了在“列表页面起始URL”下设置列表页面URL规则和在“文章页URL获取”下设置列rules" 获取名称的规则与单列采集plan 中设置的规则相同。
RSS单栏采集计划的设置(如:图中四)RSS单栏的采集计划不需要设置“文章页URL获取规则”,其余与单栏采集计划一致。RSS多栏采集计划的设置(如:图六)RSS多栏采集计划需要设置列表页URL获取“列表页面起始URL”下的规则,其他与RSS单列采集计划一致。采集Rule表达式制定表达式设置和调整,以及测试表达式列表点击一个地方采集页面“获取规则设置”进入规则表达式列表页面(如:图七)此页面除了可以添加、修改、删除和调整表达式的顺序,还可以输入url、iframeurl以及设置表达式后的页面内容测试表达式规则列表 设置各种类型 表达式类型 表达式类型分为ed 分为四种类型:字符串、匹配、匹配替换和公式。其中,匹配和匹配替换需要使用java正表达式,这就需要采集计划SET人员对表达式有一定的理解。 String:直接输入字符串常量匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本S中的部分内容匹配替换:首先从指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。然后用替换正则表达式替换S中匹配的内容,得到正确的内容。
公式:仅支持[pageIndex],用于获取页面地址时表示页面的页码。图标详情进入栏目管理(图一)Settings采集计划,在右侧栏目列表中选择一栏,点击Set采集计划。(图二)执行方法可以:手动(需要在列列表中点击)“立即采集”启动采集)单次(可以设置时间,到时采集会自动启动)循环(指定间隔时间) , 自动循环采集) 可以设置采集为文章 是否自动发布. 为采集的列类型:单列(采集此列下仅文章)单列RSS( 采集一RSS地址文章)多栏(采集栏和子栏下文章)多栏RSS(从一个RSS列表地址开始,采集文章在多个RSS地址下,每个RSS地址形成一个子栏)编码方式是通过采集页面采集rule单栏方式的编码设置(图片三)单栏RSS方式(图片四)这个方式不需要设置文章page URL ac查询方法,其他方法同单列法。多列方法)(图片五)该方法的起始页一般是列表页的集合。对于单列的方法,需要设置获取列表页的方法和列名规则。其他的是与单栏一致 多栏RSS(图片六)此方法) 需要设置从起始页(列表页网址)获取RSS地址,其他与单栏RSS一致。设置获取规则(图七)(图八)(图九)(图十)(图十一)))@(图10二)如上图,获取规则由多个表达式,添加多个表达式获取需要的URL,获取文章的标题内容等属性。
表达式分为4类: string:直接输入字符串常量匹配:从指定文本(URL、IframeURL、页面内容)通过正则表达式得到文本中的部分内容S。匹配替换:首先通过正则表达式从指定文本(URL、IframeURL、页面内容)中获取文本中的部分内容S。然后使用替换正则表达式替换S中匹配的内容,得到正确的内容。公式:仅支持[pageIndex],用于在获取页面地址时表示该页面的页码。此页面还可以测试设置的表达式。您可以使用表达式帮助来理解正则表达式的语法。查看采集计划的状态。回到栏目列表,可以看到如下图(图10三)采集status中的3个图标代表采集计划的运行状态(是否正在运行,是否已经运行,等))、采集方式(单列、单列RSS、多列、多列RSS)、执行方式(手动、单列、循环),点击查看采集计划的详细信息, (图10四)采集计划示例以采集新浪网站体育新闻列表网页为例,该网页的访问地址为HYPERLINK "/nba/1.shtml" /nba/ 1.shtml.采集 的内容放在一个“体育新闻”栏目下,由于这是一个测试示例,我们对采集使用手动执行方式,采集到达的信息不需要自动发布。
本网页是一个简单的新闻列表页面,编码方式为GB2312,所以我们将采集的列类型设置为“单列”,编码方式为gb2312采集。新闻不需要自动发布。如下图,由于这个页面的新闻列表内容不再在iframe中,也没有分页,所以不需要设置“在IFRAME中列出页面内容”和“列表页面分页”的获取规则方法”。并且新闻列表的内容不需要设置“限制文章list 内容”规则。设置文章url 的获取规则。由于本网页的新闻链接类似于以下网址:HYPERLINK "/k/2009-07-07shtml" /k/2009-07-07shtml,因此制定如下表达规则: 匹配内容类型:页面内容匹配表达式: /k/(\d+)-(\d+)-(\d+)/(\d+)\.shtml 匹配组:0(获取整个匹配结果) 获取采集 @Page源文件,粘贴进去页面内容,点击“测试计算-列表模式”,结果将显示所有匹配的URL列表,如下图所示。由于文章content不在iframe中,文章content没有分页,文章content不需要限制在页面中,所以“文章page内容在IFRAME中”的获取规则, 文章内容分页URL"和"limited文章页文章内容"不需要设置。 文章标题规则设置 因为新闻页面源文件中文章的标题在以下位置:休斯顿球迷期待姚明手术健康是火箭未来的希望表达规则表达类型:匹配内容type:页面内容匹配表达式:(.+?) 匹配组:1(获取匹配结果中的第一组,每个括号为一组)获取采集页面的源文件,粘贴到页面内容中,点击“测试计算-内容模式”,结果中的标题内容如下图位置:
北京时间7月7日,休斯顿新浪体育。据ESPN报道,姚明还没有决定是否接受手术来修复他的脚伤。虽然现在诊断姚明的三位主要医生都推荐手术,但姚明还在犹豫。
至于姚明现在的想法,大家都知道,姚明之所以还在犹豫,是因为他知道,如果他动了手术,下赛季他缺席也不是没有可能。 29岁的姚明不希望白费。花了一年,浪费了一年。毕竟,运动员的巅峰期就是这么一段时期。没有人能保证那个时候的姚明能保持好水平。
姚明犹豫不决,但休斯顿球迷对姚明有不同的看法。大多数球迷认为姚明应该毫不犹豫地接受手术。他们的理由是,既然有恶化的趋势,保守治疗的效果还不清楚,他们不应该做出手术的决定。毕竟,一个健康的姚明对火箭来说是最重要的。如果有必要,如果保守治疗后还需要手术,那姚明就输了。
“亲爱的姚,请你下定决心去做手术。即使你下赛季缺席,也不要犹豫,去做吧。如果保守治疗最终治愈,仍然会让我们颤抖,还有下个赛季会更多。可能有问题,最好做手术解决根本原因。你可能会输一年,但我们相信你会给休斯顿带来更健康的三年、五年,甚至更长时间。未来。”一个粉丝说。 .
确实,这位球迷说出了大多数休斯顿球迷不得不说的话。没有人愿意看到姚明在没有彻底治愈的情况下重返赛场。如果姚明再次受伤,相信对包括姚明在内的所有休斯顿球迷来说都是沉重的打击。
也有球迷表示姚明手术应该放心。给姚明检查确诊的医生,就是给骑士队中锋Z做手术的医生,大Z脚的伤势和姚明的伤势差不多。终于,手术后,1991年,大Z身体健康地重返赛场,接下来的几年也没有出现大的伤病,竞技状态还是比较好的。
“像哈达威一样,他们也因为伤病而急剧下滑。我认为这很难发生在姚明身上。姚明不同于希尔和哈达威。姚明是内线球员,虽然脚步移动很重要,但相对来说,弹跳并不是最重要的,姚明在内线的威慑力主要来源于他的身高和惊人的手感,足部手术不会带走姚明的身高,也不会带走他的感觉。 ”粉丝说。
总之,休斯顿人基本都希望姚明能接受手术。他们相信手术可以让姚明完全健康,而一个健康的姚明是他们最希望看到的姚明。
(小黑)
于是制定如下表达式规则表达式类型: 匹配内容类型:页面内容匹配表达式:(.+?) 匹配组:1(获取匹配结果中的第一组,每个括号为一个分组)获取源文件将采集页面粘贴到页面内容中,点击“测试计算-内容模式”,结果为文章内容如下图。 文章的其他属性这里没有设置。如有需要,请参考标题和内容的表达方式进行设置。 采集计划设置好后,选择“体育新闻”栏目,现在点击采集,稍等片刻,查看该栏目的内容管理,就会看到如下内容。另外,在“体育新闻”栏目中点击采集状态可以在栏目管理中查看采集采集的运行状态,如下图:
采集文章系统(新秀文章管理系统sinsiucms1.0beta7说明:安装说明)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-09-01 19:16
Xinxiu文章 管理系统是一个简单易用且永远免费的 PHP文章 管理系统;内置采集功能,新秀官方采集每天大量数据供用户选择。系统安装时有Mysql和Access两个数据库可供选择。
菜鸟文章管理系统sinsiu cms1.0 beta7 说明:
一、新秀文章管理系统是一个简单易用且永远免费的PHP文章管理系统;内置采集功能,新秀官方采集每天海量数据供用户选择,菜鸟还提供“采集customized”收费会员服务,可以帮助用户采集任何数据系统安装时,有两个数据库可供选择,Mysql和Access。
二、Background 功能介绍:
1、基本设置:基本信息、网站设置、导航管理、模块开启关闭、安全设置、静态设置、管理员账号、数据库管理等设置;
2、文章管理:文章list,发布文章,文章category;
3、用户交互:留言管理、评论管理、友情链接;
4、文件管理:选择模板、图片管理、语言设置、资源管理;
5、数据采集:采集设置、公开数据、私有定制、私有数据;
6、高级应用:新频道、频道标题、后台导航管理。
三、安装说明:
1、我们推荐的PHP版本在PHP5.2左右,我们推荐的PHP集成环境在XAMPP1.7左右;
2、新安装需要将upload文件夹中的所有子目录和文件(注意,在里面)上传到网站root目录下,然后在浏览器上打开网站,根据根据提示,填写数据库信息,最后点击安装按钮完成安装;
3、本系统默认设置为1小时内只能登录后台10次。您可以在“后台-基本设置-安全设置”中修改时长和登录次数,避免调试时无法登录后台。
四、升级说明:
1、sinsiu cms1.0 beta6 用户可以通过升级程序轻松升级到 sinsiu cms1.0 beta7,无需重新安装程序;
2、 如果您是sinsiu cms 1.0 beta6 用户,请将整个升级文件夹上传到网站root 目录,并在浏览器地址输入//网站PATH/upgrade/ bar ,然后根据提示点击升级链接;
3、如果升级后页面布局乱了,请先清除浏览器临时文件,然后重新打开网站。
五、注:
1、本系统的Access数据库只在Windows服务器上有效。建议使用Access数据库的用户选择Windows主机;
2、因为本系统使用的是UTF-8编码,所以在Windows下不能使用记事本进行编辑,因为记事本会自动添加一个BOM头导致程序异常。建议使用专业的Dreamweaver或Notepad++的小型编辑器;
3、网站移动前请先清除后台Smarty缓存,或者移动后手动删除index/compile和admin/compile目录下的所有文件,否则网站移动后可能会出错。
4、这个系统在发布前经过多次测试,核心功能基本没有错误。如果您在使用过程中遇到程序错误,请从您自己的运行环境中查找原因。请不要一遇到问题就将责任推到我们身上,甚至怀疑我们故意留下缺陷来收费。有助于解决问题和个人进步。如果您确定错误是由我们的程序引起的,您可以将问题发送到我们的邮箱,我们将在确认后免费为您提供解决方案。同时,我们非常感谢您的反馈!
六、后台路径://网站PATH/admin
七、更新状态:
1、完善“创建频道”功能并修复BUG;
2、在前台修复一些 CSS。
Rookie文章管理系统 v1.0 beta10 更新状态:
1、Improve 采集功能,取消采集customization,添加高级数据;
2、修复后台BUG。 查看全部
采集文章系统(新秀文章管理系统sinsiucms1.0beta7说明:安装说明)
Xinxiu文章 管理系统是一个简单易用且永远免费的 PHP文章 管理系统;内置采集功能,新秀官方采集每天大量数据供用户选择。系统安装时有Mysql和Access两个数据库可供选择。
菜鸟文章管理系统sinsiu cms1.0 beta7 说明:
一、新秀文章管理系统是一个简单易用且永远免费的PHP文章管理系统;内置采集功能,新秀官方采集每天海量数据供用户选择,菜鸟还提供“采集customized”收费会员服务,可以帮助用户采集任何数据系统安装时,有两个数据库可供选择,Mysql和Access。
二、Background 功能介绍:
1、基本设置:基本信息、网站设置、导航管理、模块开启关闭、安全设置、静态设置、管理员账号、数据库管理等设置;
2、文章管理:文章list,发布文章,文章category;
3、用户交互:留言管理、评论管理、友情链接;
4、文件管理:选择模板、图片管理、语言设置、资源管理;
5、数据采集:采集设置、公开数据、私有定制、私有数据;
6、高级应用:新频道、频道标题、后台导航管理。
三、安装说明:
1、我们推荐的PHP版本在PHP5.2左右,我们推荐的PHP集成环境在XAMPP1.7左右;
2、新安装需要将upload文件夹中的所有子目录和文件(注意,在里面)上传到网站root目录下,然后在浏览器上打开网站,根据根据提示,填写数据库信息,最后点击安装按钮完成安装;
3、本系统默认设置为1小时内只能登录后台10次。您可以在“后台-基本设置-安全设置”中修改时长和登录次数,避免调试时无法登录后台。
四、升级说明:
1、sinsiu cms1.0 beta6 用户可以通过升级程序轻松升级到 sinsiu cms1.0 beta7,无需重新安装程序;
2、 如果您是sinsiu cms 1.0 beta6 用户,请将整个升级文件夹上传到网站root 目录,并在浏览器地址输入//网站PATH/upgrade/ bar ,然后根据提示点击升级链接;
3、如果升级后页面布局乱了,请先清除浏览器临时文件,然后重新打开网站。
五、注:
1、本系统的Access数据库只在Windows服务器上有效。建议使用Access数据库的用户选择Windows主机;
2、因为本系统使用的是UTF-8编码,所以在Windows下不能使用记事本进行编辑,因为记事本会自动添加一个BOM头导致程序异常。建议使用专业的Dreamweaver或Notepad++的小型编辑器;
3、网站移动前请先清除后台Smarty缓存,或者移动后手动删除index/compile和admin/compile目录下的所有文件,否则网站移动后可能会出错。
4、这个系统在发布前经过多次测试,核心功能基本没有错误。如果您在使用过程中遇到程序错误,请从您自己的运行环境中查找原因。请不要一遇到问题就将责任推到我们身上,甚至怀疑我们故意留下缺陷来收费。有助于解决问题和个人进步。如果您确定错误是由我们的程序引起的,您可以将问题发送到我们的邮箱,我们将在确认后免费为您提供解决方案。同时,我们非常感谢您的反馈!
六、后台路径://网站PATH/admin
七、更新状态:
1、完善“创建频道”功能并修复BUG;
2、在前台修复一些 CSS。
Rookie文章管理系统 v1.0 beta10 更新状态:
1、Improve 采集功能,取消采集customization,添加高级数据;
2、修复后台BUG。
采集文章系统(whatsns内容付费seo优化带采集和熊掌号运营问答系统 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-08-31 08:14
)
Whatsns内容付费seo优化带采集和熊掌号运营问答系统项目介绍
Whatsns问答系统是一个PHP开源问答系统,可以根据自身业务需求快速搭建垂直领域。内置强大的采集功能,支持云存储、图片水印设置、全文检索、站点行为监控、短信注册和通知、伪静态URL自定义、熊掌号功能、百度结构化地图(标签、问题,文章,分类,用户空间),PC和Wap模板分离,内置多套pc和wap模板,站长免费同时后台支持模板管理,模板在线编辑修改,功能强大反灌拦截过滤配置等数百项功能,深度SEO优化,适合需要SEO的站长。商业版还支持优采云采集,先进的微信公众号接口功能,支持支付宝支付、微信扫码支付、微信JSSDK支付、微信H5支付、小程序支付,以及适合不同场景的支付服务,如作为充值和呼叫奖励,回答一瞥,并咨询付费专家。
特别提示
V4免费版用户已安装,如需更新请移动V4更新地址
软件架构
基于php的CodeIgniter3.1.6开发的优雅CI框架,是国内php开发者最喜欢的MVC框架。使用速度快,重量轻,在1m带宽的虚拟主机单核cpu1g内存带宽下可以完美流畅。运行,更多框架信息可以参考CI官网
安装教程
直接把程序上传到问答的根目录即可,安装方法,上传程序后直接输入你的域名/install/
如果是二级目录安装:安装在某个域名网站下的用户,请定位到你问答的安装地址,输入你的域名/二级目录/install/
查看全部
采集文章系统(whatsns内容付费seo优化带采集和熊掌号运营问答系统
)
Whatsns内容付费seo优化带采集和熊掌号运营问答系统项目介绍
Whatsns问答系统是一个PHP开源问答系统,可以根据自身业务需求快速搭建垂直领域。内置强大的采集功能,支持云存储、图片水印设置、全文检索、站点行为监控、短信注册和通知、伪静态URL自定义、熊掌号功能、百度结构化地图(标签、问题,文章,分类,用户空间),PC和Wap模板分离,内置多套pc和wap模板,站长免费同时后台支持模板管理,模板在线编辑修改,功能强大反灌拦截过滤配置等数百项功能,深度SEO优化,适合需要SEO的站长。商业版还支持优采云采集,先进的微信公众号接口功能,支持支付宝支付、微信扫码支付、微信JSSDK支付、微信H5支付、小程序支付,以及适合不同场景的支付服务,如作为充值和呼叫奖励,回答一瞥,并咨询付费专家。
特别提示
V4免费版用户已安装,如需更新请移动V4更新地址
软件架构
基于php的CodeIgniter3.1.6开发的优雅CI框架,是国内php开发者最喜欢的MVC框架。使用速度快,重量轻,在1m带宽的虚拟主机单核cpu1g内存带宽下可以完美流畅。运行,更多框架信息可以参考CI官网
安装教程
直接把程序上传到问答的根目录即可,安装方法,上传程序后直接输入你的域名/install/
如果是二级目录安装:安装在某个域名网站下的用户,请定位到你问答的安装地址,输入你的域名/二级目录/install/
采集文章系统(优采云大数据采集网站:使用功能点:URL列表信息采集 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-08-29 22:06
)
采集网站:
使用功能点:
网址
分页列表信息采集
搜狗微信搜索:搜狗微信搜索是搜狗于2014年6月9日推出的微信公众平台。“微信搜索”支持搜索微信公众号和微信文章,可以通过关键词搜索相关微信公众号@,或文章微信公众号推送。不仅是PC端,搜狗手机搜索客户端也会推荐相关的微信公众号。
搜狗微信文章采集数据说明:本文在搜狗微信-搜索-优采云大数据的文章信息采集进行。本文仅以“搜狗微信-搜索-优采云大数据的文章信息采集”为例。实际操作中,您可以根据自己的需要,将搜狗微信的搜索词更改为执行数据采集。
搜狗微信文章采集detail采集字段说明:微信文章title、微信文章keywords、微信文章generalization、微信公众号、微信文章发布时间、微信文章地址。
第一步:创建采集task
1)进入主界面,选择“自定义模式”
2)将采集的网址复制粘贴到网站输入框中,点击“保存网址”
第 2 步:创建翻页循环
1)打开右上角的“进程”。点击页面文章搜索框,在右侧操作提示框中选择“输入文字”
2)输入要搜索的文章信息,这里以搜索“优采云大数据”为例,输入完成后点击“确定”按钮
3)“优采云大数据”会自动填写搜索框,点击“search文章”按钮,在操作提示框中选择“点击此按钮”
“优采云大数据”的文章搜索结果出现在4)页面上。将结果页下拉至底部,点击“下一页”按钮,在右侧操作提示框中选择“循环点击下一页”
第 3 步:创建一个列表循环并提取数据
1)移动鼠标选择页面上的第一个文章块。系统将识别此块中的子元素。在操作提示框中选择“选择子元素”
2)继续选择页面第二篇文章中的区块,系统会自动选择第二篇文章中的子元素,并识别页面上其他10组相似元素, 在操作提示框中,选择“全选”
3) 我们可以看到页面上文章块中的所有元素都被选中并变成了绿色。在右侧的操作提示框中,会出现一个字段预览表。将鼠标移动到表头并单击垃圾桶图标以删除不需要的字段。字段选择完成后,选择“采集以下数据”
4) 因为我们还想要采集 每个文章 URL,所以我们需要再提取一个字段。点击第一篇文章文章的链接,再点击第二篇文章文章的链接,系统会自动在页面上选择一组文章链接。在右侧的操作提示框中选择“采集以下链接地址”
关键词0@
关键词1@字段选择完成后,选择对应的字段,自定义字段的命名。完成后点击左上角的“保存并开始”开始采集task
关键词2@
关键词3@ 选择“启动本地采集”
关键词4@
第四步:数据采集并导出
1)采集完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,导出采集好搜狗微信文章的数据
关键词6@
2)这里我们选择excel作为导出格式,导出数据如下图
关键词8@ 查看全部
采集文章系统(优采云大数据采集网站:使用功能点:URL列表信息采集
)
采集网站:
使用功能点:
网址
分页列表信息采集
搜狗微信搜索:搜狗微信搜索是搜狗于2014年6月9日推出的微信公众平台。“微信搜索”支持搜索微信公众号和微信文章,可以通过关键词搜索相关微信公众号@,或文章微信公众号推送。不仅是PC端,搜狗手机搜索客户端也会推荐相关的微信公众号。
搜狗微信文章采集数据说明:本文在搜狗微信-搜索-优采云大数据的文章信息采集进行。本文仅以“搜狗微信-搜索-优采云大数据的文章信息采集”为例。实际操作中,您可以根据自己的需要,将搜狗微信的搜索词更改为执行数据采集。
搜狗微信文章采集detail采集字段说明:微信文章title、微信文章keywords、微信文章generalization、微信公众号、微信文章发布时间、微信文章地址。
第一步:创建采集task
1)进入主界面,选择“自定义模式”
2)将采集的网址复制粘贴到网站输入框中,点击“保存网址”
第 2 步:创建翻页循环
1)打开右上角的“进程”。点击页面文章搜索框,在右侧操作提示框中选择“输入文字”
2)输入要搜索的文章信息,这里以搜索“优采云大数据”为例,输入完成后点击“确定”按钮
3)“优采云大数据”会自动填写搜索框,点击“search文章”按钮,在操作提示框中选择“点击此按钮”
“优采云大数据”的文章搜索结果出现在4)页面上。将结果页下拉至底部,点击“下一页”按钮,在右侧操作提示框中选择“循环点击下一页”
第 3 步:创建一个列表循环并提取数据
1)移动鼠标选择页面上的第一个文章块。系统将识别此块中的子元素。在操作提示框中选择“选择子元素”
2)继续选择页面第二篇文章中的区块,系统会自动选择第二篇文章中的子元素,并识别页面上其他10组相似元素, 在操作提示框中,选择“全选”
3) 我们可以看到页面上文章块中的所有元素都被选中并变成了绿色。在右侧的操作提示框中,会出现一个字段预览表。将鼠标移动到表头并单击垃圾桶图标以删除不需要的字段。字段选择完成后,选择“采集以下数据”
4) 因为我们还想要采集 每个文章 URL,所以我们需要再提取一个字段。点击第一篇文章文章的链接,再点击第二篇文章文章的链接,系统会自动在页面上选择一组文章链接。在右侧的操作提示框中选择“采集以下链接地址”
关键词0@
关键词1@字段选择完成后,选择对应的字段,自定义字段的命名。完成后点击左上角的“保存并开始”开始采集task
关键词2@
关键词3@ 选择“启动本地采集”
关键词4@
第四步:数据采集并导出
1)采集完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,导出采集好搜狗微信文章的数据
关键词6@
2)这里我们选择excel作为导出格式,导出数据如下图
关键词8@
史上最简单最智能文章采集器破解版.13.10.0更新日志
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-08-25 20:52
对于正在做网站推广和优化的朋友,可能经常需要更新一些文章。这对于文笔不好的人来说还是有点难度的,怎么办?你可以试试这个优采云万能文章采集器,它是一个简单实用的文章采集软件,用户可以设置搜索间隔、采集类型、时间语言等选项,并且你可以过滤采集的文章,插入关键词等,可以大大提高我们的工作效率。这是一个非常好的文章采集 工具。亲爱的站长朋友们,赶快下载一个试试吧。
ps:这里编辑的是优采云万能文章采集器破解版,附件破解文件可以成功激活软件,详细安装教程可以参考下方操作,欢迎免费下载。
软件功能
一、依托优采云software独家通用文本识别智能算法,可实现任意网页文本自动提取,准确率95%以上。
二、只需输入关键词,采集就可以进入百度新闻与网页、搜狗新闻与网页、360新闻与网页、谷歌新闻与网页、必应新闻与网页、雅虎;批量关键词AUTO采集。
三、可方向采集指定网站列列表下的所有文章,智能匹配,无需编写复杂规则。
四、文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
五、史上最简单最智能文章采集器,支持全功能试用,效果如何!
使用帮助
1、软件下载完成后,打开软件包,点击优采云·万能文章采集器Crack打开软件。软件已破解,无需二次破解。
2、打开软件后可以直接开始使用。填写采集的文章关键词你需要的关键词栏。
3、输入完成后,选择文章保存地址和保存选项。
4、设置好后点击Start采集。
更新日志
优采云万能文章采集器V2.13.10.0 更新日志(2016-10-19)
采集List页面URL函数添加高级参数(两个值之间用空格隔开,如果值为1为空,2)值会自动使用
V2.9.1.0 更新日志 (2016-05-06)
添加一些用采集处理过的网站加强采集。
V2.5.1.0 绿色版更新(2015-6-26)
添加 Yahoo采集;
其他更新。 查看全部
史上最简单最智能文章采集器破解版.13.10.0更新日志
对于正在做网站推广和优化的朋友,可能经常需要更新一些文章。这对于文笔不好的人来说还是有点难度的,怎么办?你可以试试这个优采云万能文章采集器,它是一个简单实用的文章采集软件,用户可以设置搜索间隔、采集类型、时间语言等选项,并且你可以过滤采集的文章,插入关键词等,可以大大提高我们的工作效率。这是一个非常好的文章采集 工具。亲爱的站长朋友们,赶快下载一个试试吧。
ps:这里编辑的是优采云万能文章采集器破解版,附件破解文件可以成功激活软件,详细安装教程可以参考下方操作,欢迎免费下载。
软件功能
一、依托优采云software独家通用文本识别智能算法,可实现任意网页文本自动提取,准确率95%以上。
二、只需输入关键词,采集就可以进入百度新闻与网页、搜狗新闻与网页、360新闻与网页、谷歌新闻与网页、必应新闻与网页、雅虎;批量关键词AUTO采集。
三、可方向采集指定网站列列表下的所有文章,智能匹配,无需编写复杂规则。
四、文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
五、史上最简单最智能文章采集器,支持全功能试用,效果如何!
使用帮助
1、软件下载完成后,打开软件包,点击优采云·万能文章采集器Crack打开软件。软件已破解,无需二次破解。
2、打开软件后可以直接开始使用。填写采集的文章关键词你需要的关键词栏。
3、输入完成后,选择文章保存地址和保存选项。
4、设置好后点击Start采集。
更新日志
优采云万能文章采集器V2.13.10.0 更新日志(2016-10-19)
采集List页面URL函数添加高级参数(两个值之间用空格隔开,如果值为1为空,2)值会自动使用
V2.9.1.0 更新日志 (2016-05-06)
添加一些用采集处理过的网站加强采集。
V2.5.1.0 绿色版更新(2015-6-26)
添加 Yahoo采集;
其他更新。
爬虫采集文章系统配置及同步更新的下载地址及配置
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-08-24 18:03
采集文章系统又和同步更新了,在经过数月的积累,利用爬虫来搞点小动作,初步计划实现几个类似这样的配置:拿到网页源码,自己写文章被采集的内容,如果读者觉得有用,谢谢支持哦!哈哈。1.web框架写代码就是个坑,这点坑绝对不能碰,尤其是遇到新需求的时候,不花几天弄明白怎么用爬虫,哪有办法上手写的好代码呢,可能是几个月,也可能是几个月,但是新需求还是不敢写。
所以我还是蛮遗憾没有尝试一下别的框架,除了requests还是可以写的,其他的就emmmm了,都太重量级了,虽然flask在python社区的热度还是有的,但是它的核心依然是requests,不能拿flask作为新的框架来编写。在加上模板,还是挺麻烦的。2.工具模块excel数据采集(viewer):能帮助我们方便地查看并转换各种数据格式(公式和json等),是个帮我们省去很多麻烦的利器,详细下载地址:dataviz-excelviewerforpythontablesnumpy:bigdatanumericalandnumericaldatacollectiontosolvethemathematicalessaysmodel。
pandas:importpandasaspddataframe=pd.dataframe([x1,x2,x3,x4])dataframe=pd.dataframe([[0,2,6,9],[4,3,4,8],[4,2,1,1]])pd.to_datetime(dataframe)pd.to_excel(dataframe)numpy.random.randn(。
4):用作返回4元组,返回由4个元素组成的字典pd。to_excel(dataframe)#原始的dataframedataframe=pd。dataframe([[0,2,6,9],[4,3,4,8],[4,2,1,1]])dataframe=pd。dataframe([[[0,2,6,9],[4,3,4,8],[4,2,1,1]])pd。
to_excel(dataframe)#pd文件写网页代码——网页获取代码大概会是个什么样呢:爬虫代码——excel版本首先,我得把网页所需要的excel格式转换为pdf,好吧,flask无能,只能用apowersoft自带的excel转换工具来实现,如下:importapowersoft。apowersoft。
actions。action_submit_actionsimportospath="/users/wynn/。code/gfxblog。py"#起始路径root="d:\\apowersoft"#目录路径fromexcelimportreader#读取excelx='sample\excel/like\excel/like\excel/like'#将x转换为divdiv=reader(fromroot)div。center(。
1)#左边居中div.center
1)#居中定位lookup=abs(x)#匹配xwhilelookup.next('a'):#删 查看全部
爬虫采集文章系统配置及同步更新的下载地址及配置
采集文章系统又和同步更新了,在经过数月的积累,利用爬虫来搞点小动作,初步计划实现几个类似这样的配置:拿到网页源码,自己写文章被采集的内容,如果读者觉得有用,谢谢支持哦!哈哈。1.web框架写代码就是个坑,这点坑绝对不能碰,尤其是遇到新需求的时候,不花几天弄明白怎么用爬虫,哪有办法上手写的好代码呢,可能是几个月,也可能是几个月,但是新需求还是不敢写。
所以我还是蛮遗憾没有尝试一下别的框架,除了requests还是可以写的,其他的就emmmm了,都太重量级了,虽然flask在python社区的热度还是有的,但是它的核心依然是requests,不能拿flask作为新的框架来编写。在加上模板,还是挺麻烦的。2.工具模块excel数据采集(viewer):能帮助我们方便地查看并转换各种数据格式(公式和json等),是个帮我们省去很多麻烦的利器,详细下载地址:dataviz-excelviewerforpythontablesnumpy:bigdatanumericalandnumericaldatacollectiontosolvethemathematicalessaysmodel。
pandas:importpandasaspddataframe=pd.dataframe([x1,x2,x3,x4])dataframe=pd.dataframe([[0,2,6,9],[4,3,4,8],[4,2,1,1]])pd.to_datetime(dataframe)pd.to_excel(dataframe)numpy.random.randn(。
4):用作返回4元组,返回由4个元素组成的字典pd。to_excel(dataframe)#原始的dataframedataframe=pd。dataframe([[0,2,6,9],[4,3,4,8],[4,2,1,1]])dataframe=pd。dataframe([[[0,2,6,9],[4,3,4,8],[4,2,1,1]])pd。
to_excel(dataframe)#pd文件写网页代码——网页获取代码大概会是个什么样呢:爬虫代码——excel版本首先,我得把网页所需要的excel格式转换为pdf,好吧,flask无能,只能用apowersoft自带的excel转换工具来实现,如下:importapowersoft。apowersoft。
actions。action_submit_actionsimportospath="/users/wynn/。code/gfxblog。py"#起始路径root="d:\\apowersoft"#目录路径fromexcelimportreader#读取excelx='sample\excel/like\excel/like\excel/like'#将x转换为divdiv=reader(fromroot)div。center(。
1)#左边居中div.center
1)#居中定位lookup=abs(x)#匹配xwhilelookup.next('a'):#删
大数据架构师(lamdadata)阶段的5个阶段,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-08-22 04:03
采集文章系统或资料可参考一下大数据数据采集-大数据采集平台-知乎专栏
可以去,实操技术很关键。关键看你要干什么。如果想将来工作无忧那可以去看看爬虫方面的,使用python爬虫框架或者爬虫框架的库去写爬虫。如果真的想好好学习,可以去买本相关资料学一下。
我们总说开源,就是python的开源框架很多,不管是第三方开源,还是各家公司自己研发的,这其中都会用到python的语言特性。但是,问题就来了,你总说开源框架不用担心被封,但,
1、使用官方pythonmodule,
2、使用解决方案(以及腾讯专属官方api文档)加载到数据库中,实现分析接口。
从大数据入门,爬虫,到大数据工程师,再到大数据架构师,数据分析师,数据挖掘师等等,这是大数据的5个阶段。
一、爬虫阶段
二、数据分析师(lamdadata)阶段
三、大数据架构师(hadoop)阶段
四、大数据架构师(docker)阶段
五、大数据工程师(hadoop)这就是你学习的主线。入门爬虫,那就着重讲讲爬虫吧。爬虫说白了就是一个网页,因为页面代码比较复杂,我们叫它爬虫。每个公司都有自己的爬虫部门,以用户为中心开发软件,提供爬虫的对接方式。用户访问这个网页的时候,对应的页面代码会打包发给爬虫。爬虫去执行这个网页的爬取代码。你说的核心价值在于在数据处理时,快速得到结果。
我大致给你描述一下我要爬取的数据,刚刚查的一家互联网公司,我是以xxx职位为例,主要是负责爬取公司的求职信息,一共25条,转化为数据:这25条信息主要用来产生跳槽信息,是一个跳槽的网站。详细的代码不方便展示出来。(一会打包上传)爬虫开发,你说的核心价值在于在数据处理时,快速得到结果。我给你写了一个爬虫的下载流程,以上是我要获取的爬虫代码。
这个代码说简单也不简单,说复杂也不复杂。如果你不能独立去实现,可以到我们的圈子里共同学习。在主流的爬虫工具中,tushare是国内第三方第三方的爬虫,看待爬虫,用tushare是最正确的。如果还有问题,可以加我微信。我会定期发布一些最新的爬虫技术和代码分享给大家。目前,很多python的资料很少,希望,你会喜欢和选择。
你也可以留言或者关注公众号:pythoncaixiaoyu(aaa955
5)在这里,给你无限的提升和动力。
python爬虫开发岗位快速上手过程(2019.5.1
9)给初学爬虫的同学一些建议:1.对于0基础的同学而言,什么都是你要学的,不要给自己设限,不要仅仅局限于html,css,javascript等这些初步的技术,这些很重要, 查看全部
大数据架构师(lamdadata)阶段的5个阶段,你知道吗?
采集文章系统或资料可参考一下大数据数据采集-大数据采集平台-知乎专栏
可以去,实操技术很关键。关键看你要干什么。如果想将来工作无忧那可以去看看爬虫方面的,使用python爬虫框架或者爬虫框架的库去写爬虫。如果真的想好好学习,可以去买本相关资料学一下。
我们总说开源,就是python的开源框架很多,不管是第三方开源,还是各家公司自己研发的,这其中都会用到python的语言特性。但是,问题就来了,你总说开源框架不用担心被封,但,
1、使用官方pythonmodule,
2、使用解决方案(以及腾讯专属官方api文档)加载到数据库中,实现分析接口。
从大数据入门,爬虫,到大数据工程师,再到大数据架构师,数据分析师,数据挖掘师等等,这是大数据的5个阶段。
一、爬虫阶段
二、数据分析师(lamdadata)阶段
三、大数据架构师(hadoop)阶段
四、大数据架构师(docker)阶段
五、大数据工程师(hadoop)这就是你学习的主线。入门爬虫,那就着重讲讲爬虫吧。爬虫说白了就是一个网页,因为页面代码比较复杂,我们叫它爬虫。每个公司都有自己的爬虫部门,以用户为中心开发软件,提供爬虫的对接方式。用户访问这个网页的时候,对应的页面代码会打包发给爬虫。爬虫去执行这个网页的爬取代码。你说的核心价值在于在数据处理时,快速得到结果。
我大致给你描述一下我要爬取的数据,刚刚查的一家互联网公司,我是以xxx职位为例,主要是负责爬取公司的求职信息,一共25条,转化为数据:这25条信息主要用来产生跳槽信息,是一个跳槽的网站。详细的代码不方便展示出来。(一会打包上传)爬虫开发,你说的核心价值在于在数据处理时,快速得到结果。我给你写了一个爬虫的下载流程,以上是我要获取的爬虫代码。
这个代码说简单也不简单,说复杂也不复杂。如果你不能独立去实现,可以到我们的圈子里共同学习。在主流的爬虫工具中,tushare是国内第三方第三方的爬虫,看待爬虫,用tushare是最正确的。如果还有问题,可以加我微信。我会定期发布一些最新的爬虫技术和代码分享给大家。目前,很多python的资料很少,希望,你会喜欢和选择。
你也可以留言或者关注公众号:pythoncaixiaoyu(aaa955
5)在这里,给你无限的提升和动力。
python爬虫开发岗位快速上手过程(2019.5.1
9)给初学爬虫的同学一些建议:1.对于0基础的同学而言,什么都是你要学的,不要给自己设限,不要仅仅局限于html,css,javascript等这些初步的技术,这些很重要,
某个受试者试验完成的几种常见问题,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-08-20 03:01
1 建设目的
通过构建saliva采集信息平台(APP),可以建立实时、快速的采集相关人体测试信息,提高受试者的依从性,保证测试的高质量完成。
2 功能模块要求
saliva采集信息平台主要分为以下几个模块:
受试者基本信息
Saliva采集信息
合规信息
测试的整体情况
2.1 主体基本信息采集
被选中的受试者可以在系统上创建个人登录账号,填写相关个人信息,包括:姓名、性别、年龄、身高、体重、病史等信息。
2.2 saliva采集信息
saliva采集信息主要包括:采集时间、当地PM2.5、情绪评分、饮食和运动信息、不良事件等,以上信息可以方便导出,方便后期统计分析由研究人员提供。
采集时间:受试者可以根据试验方案中的saliva采集时间点设置定时提醒功能(每个时间点包括漱口提醒和采样提醒)。您可以登录系统,点击示例采集按钮,系统会自动记录采集的时间。
PM2.5/AQP:一旦被测者点击样品采集按钮,系统会自动定位被测者的位置,并自动抓取被测者所在的最近测量点的PM@互联网。2.5浓度和AQP指数。
活动/运动量:通过来自 api采集moves 等应用的信息。
情绪得分:完成样本采集后,受试者需要选择该时段的情绪得分值。
其他信息:完成当天最后一个样本采集后,受试者还需要选择或填写当天的饮食、运动、不良事件等信息。
2.3 合规信息
系统可以以图表的形式反映所有受试者在试验过程中的样本采集情况,并根据相应的公式计算其遵守情况,根据遵守程度进行排名,并定期发布在新闻形式。
研究人员可以随时在系统上查看所有受试者的样本采集状态。如果有个别受试者在某段时间内还没有采集samples,研究人员可以向他们发送提醒信息,督促他们尽快完成这段时间的采集样本。
2.4 审判组织情况
该模块可以提供相应的图表,反映某个受试者的试验完成进度、整个试验的受试者人数、整个试验的完成进度。
以公告栏的形式发布试验中的问题,提醒受试者纠正试验中的不良行为。
有专门的操作指导模块,指导被试在实验过程中按照规定的操作标准执行样本采集。 查看全部
某个受试者试验完成的几种常见问题,你知道吗?
1 建设目的
通过构建saliva采集信息平台(APP),可以建立实时、快速的采集相关人体测试信息,提高受试者的依从性,保证测试的高质量完成。
2 功能模块要求
saliva采集信息平台主要分为以下几个模块:
受试者基本信息
Saliva采集信息
合规信息
测试的整体情况
2.1 主体基本信息采集
被选中的受试者可以在系统上创建个人登录账号,填写相关个人信息,包括:姓名、性别、年龄、身高、体重、病史等信息。
2.2 saliva采集信息
saliva采集信息主要包括:采集时间、当地PM2.5、情绪评分、饮食和运动信息、不良事件等,以上信息可以方便导出,方便后期统计分析由研究人员提供。
采集时间:受试者可以根据试验方案中的saliva采集时间点设置定时提醒功能(每个时间点包括漱口提醒和采样提醒)。您可以登录系统,点击示例采集按钮,系统会自动记录采集的时间。
PM2.5/AQP:一旦被测者点击样品采集按钮,系统会自动定位被测者的位置,并自动抓取被测者所在的最近测量点的PM@互联网。2.5浓度和AQP指数。
活动/运动量:通过来自 api采集moves 等应用的信息。
情绪得分:完成样本采集后,受试者需要选择该时段的情绪得分值。
其他信息:完成当天最后一个样本采集后,受试者还需要选择或填写当天的饮食、运动、不良事件等信息。
2.3 合规信息
系统可以以图表的形式反映所有受试者在试验过程中的样本采集情况,并根据相应的公式计算其遵守情况,根据遵守程度进行排名,并定期发布在新闻形式。
研究人员可以随时在系统上查看所有受试者的样本采集状态。如果有个别受试者在某段时间内还没有采集samples,研究人员可以向他们发送提醒信息,督促他们尽快完成这段时间的采集样本。
2.4 审判组织情况
该模块可以提供相应的图表,反映某个受试者的试验完成进度、整个试验的受试者人数、整个试验的完成进度。
以公告栏的形式发布试验中的问题,提醒受试者纠正试验中的不良行为。
有专门的操作指导模块,指导被试在实验过程中按照规定的操作标准执行样本采集。
演示站--源码简介与安装说明:【小说源码】
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-08-13 01:14
演示站-源码可根据需要修改
前端:
背景:账号:admin 密码:123456
源代码介绍和安装说明:
【小说源码】美化最新版UI+采集步骤PTcms+操作关卡+新颖自动采集系统+多条采集规则
源码大小:63.1MB
开发语言:PHP+Mysql
操作系统:Windows、Linux
源码介绍:
小说系统作者亲自操作小说系统2个月。最高IP达到每天6000+。可以看出源码模板优化的很好,适合优采云操作,因为根本不需要管理,买一些朋友链就行了。
如何赚钱:
变现的方法也很简单,就是打广告,你有上千个IP就可以打广告了。申请谷歌+百度+搜狗等联盟广告,每月留几千元。你不能赚很多钱,但你可以赚钱。少量的钱还是可以的。
测试截图:
资源下载本资源下载价格为268元,请先登录
【风险提示】付款前写:
1.全站8500+源代码,除了热门商圈几十个源代码,只要有下载按钮,终身VIP即可免费下载。
2. 本站源码多为全网各种渠道购买。 文章描述一般为渠道方测试描述转载,不代表本站观点。但是文章开头的demo源码代表本站亲自测试过,至少可以搭建,一般没有大问题,可以放心购买。
========================================
3.文章一开始没有demo站点,也就意味着我们没有时间亲自测试。源代码有缺陷风险,所以低价出售。一经购买即视为接受风险,概不退换! ! !但是,与此同时,您也可能很便宜。因为他们中的很多人已经通过了渠道的测试,但我们还没有来得及测试和确认。如果我们的测试没问题,价格会高很多倍。
========================================
4. 本站使用在线支付。支付完成后,积分将自动记入账户。
5. 充值比例:1:1。是否为VIP免费下载,需要登录后显示。
6. 所有源码默认没有安装教程。如果有的话,它们也是随机的。
7.所有源码不提供免费安装。如果您需要我们代您安装,请联系客服了解详情。
本文由(Source House@)整理,转载请注明出处:;
如果本站发布的内容侵犯了您的权益,请邮件删除,我们会及时处理!
============================================
本站下载资源大部分采集于互联网,不保证其完整性和安全性。下载后请自行测试。
本网站上的资源仅供学习和交流之用。版权属于资源的原作者。请在下载后24小时内自觉删除。
商业用途请购买正版。因未购买并付款而造成的侵权与本站无关。 查看全部
演示站--源码简介与安装说明:【小说源码】
演示站-源码可根据需要修改
前端:
背景:账号:admin 密码:123456
源代码介绍和安装说明:
【小说源码】美化最新版UI+采集步骤PTcms+操作关卡+新颖自动采集系统+多条采集规则
源码大小:63.1MB
开发语言:PHP+Mysql
操作系统:Windows、Linux
源码介绍:
小说系统作者亲自操作小说系统2个月。最高IP达到每天6000+。可以看出源码模板优化的很好,适合优采云操作,因为根本不需要管理,买一些朋友链就行了。
如何赚钱:
变现的方法也很简单,就是打广告,你有上千个IP就可以打广告了。申请谷歌+百度+搜狗等联盟广告,每月留几千元。你不能赚很多钱,但你可以赚钱。少量的钱还是可以的。
测试截图:
资源下载本资源下载价格为268元,请先登录
【风险提示】付款前写:
1.全站8500+源代码,除了热门商圈几十个源代码,只要有下载按钮,终身VIP即可免费下载。
2. 本站源码多为全网各种渠道购买。 文章描述一般为渠道方测试描述转载,不代表本站观点。但是文章开头的demo源码代表本站亲自测试过,至少可以搭建,一般没有大问题,可以放心购买。
========================================
3.文章一开始没有demo站点,也就意味着我们没有时间亲自测试。源代码有缺陷风险,所以低价出售。一经购买即视为接受风险,概不退换! ! !但是,与此同时,您也可能很便宜。因为他们中的很多人已经通过了渠道的测试,但我们还没有来得及测试和确认。如果我们的测试没问题,价格会高很多倍。
========================================
4. 本站使用在线支付。支付完成后,积分将自动记入账户。
5. 充值比例:1:1。是否为VIP免费下载,需要登录后显示。
6. 所有源码默认没有安装教程。如果有的话,它们也是随机的。
7.所有源码不提供免费安装。如果您需要我们代您安装,请联系客服了解详情。
本文由(Source House@)整理,转载请注明出处:;
如果本站发布的内容侵犯了您的权益,请邮件删除,我们会及时处理!
============================================
本站下载资源大部分采集于互联网,不保证其完整性和安全性。下载后请自行测试。
本网站上的资源仅供学习和交流之用。版权属于资源的原作者。请在下载后24小时内自觉删除。
商业用途请购买正版。因未购买并付款而造成的侵权与本站无关。
采集文章系统制作完成以后可以直接分享的多种格式
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-08-11 00:07
采集文章系统地制作完成以后可以导出成可以直接分享的多种格式。比如,以某某网站某某网站为例,
二、段落有了辅助列:段落1段落2
三、图片保存提供了很多的格式供你选择:jpgpngbmpgif
4、字体导出提供了大量的公开字体版权可以在正版电子书上使用。
你只需要下载一个word,把里面的序列号记下来,
这个真的简单。你把里面的字段记下来就好了。
最简单的方法:把jpg格式保存下来或者cad格式也可以
具体请参考图文教程:。
我做过的可以先到网站上查找目标用户群体的关键词。然后自己通过目标用户群体的习惯做出来的文章就不用愁了。
ftp格式!! 查看全部
采集文章系统的问题,可以分解成这样的话!
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-08-08 20:04
采集文章系统的问题,可以分解成这样的话:1.拍摄。拍摄的稳定性;是否有避障设置(智能跳转到应用或服务器);录像存储问题(速度及容量);镜头问题(焦距、光圈);2.app开发,文件分发;用户数据导出。
有个叫dogcombat的平台,这个平台是用来收集市面上的各类攻击,合作提供方式是跟防御机构合作,要先提供定制化服务的截图,网站的地址我就不发了,免得说我做广告。
有个应用叫dogcombat,你可以下载试试,地址是/。通过第三方应用签名收集并分析出各个应用的隐私信息,并将它们加密上传。攻击者能通过这些信息攻击你的用户账户,来获取更高额的利润。
做真实威胁模拟需要这个功能
有个防御威胁的产品你可以用下:兵锋在线_您身边的安全防护产品
谷歌appdomain可以
飞雪威胁侦测wordpress,企业网站或者小型社区都需要,可以配合其他爬虫,
谷歌appdomain就可以,
用你服务器安装上的app去检测
看你的目的了,如果是市场前景的话,有意思的文章大多数都是可以进行攻击的,这里就不点名了。 查看全部
采集文章系统的问题,可以分解成这样的话!
采集文章系统的问题,可以分解成这样的话:1.拍摄。拍摄的稳定性;是否有避障设置(智能跳转到应用或服务器);录像存储问题(速度及容量);镜头问题(焦距、光圈);2.app开发,文件分发;用户数据导出。
有个叫dogcombat的平台,这个平台是用来收集市面上的各类攻击,合作提供方式是跟防御机构合作,要先提供定制化服务的截图,网站的地址我就不发了,免得说我做广告。
有个应用叫dogcombat,你可以下载试试,地址是/。通过第三方应用签名收集并分析出各个应用的隐私信息,并将它们加密上传。攻击者能通过这些信息攻击你的用户账户,来获取更高额的利润。
做真实威胁模拟需要这个功能
有个防御威胁的产品你可以用下:兵锋在线_您身边的安全防护产品
谷歌appdomain可以
飞雪威胁侦测wordpress,企业网站或者小型社区都需要,可以配合其他爬虫,
谷歌appdomain就可以,
用你服务器安装上的app去检测
看你的目的了,如果是市场前景的话,有意思的文章大多数都是可以进行攻击的,这里就不点名了。
采集文章系统资源、更新最新行业资讯及小程序更新提示
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-08-07 07:01
采集文章系统资源、更新最新行业资讯及小程序更新提示的同学建议扫码下方二维码,关注知乎机构号:九一八商机同学wangshimengjia同学给介绍自己情况或留言,评论区备注:入行时间、所在行业、最新发布文章、自我要求等,
大家好我是转行做编程的hi,我是一名xx转行的产品狗,目前在一家小公司上班,3个月试用期,大部分都是我在写需求,但这还是不够,领导会告诉我们,最好的学习方式是看书,但是我发现一个问题,不管看什么书,后来都忘记了,就这样工作了半年后跳槽去了一家大公司,但还是对很多细节都不熟悉,经常有的时候很忙但是没办法,今天就跟大家分享下看书的问题,还有如何备考项目经理证书?想要看书我们首先要搞清楚为什么要看书?我们为什么要看书,为了提升自己,为了提升我们自己的解决问题能力,为了成为一个很牛逼的产品经理或运营?想要提升自己我们就要看书,为了提升自己,我们就要多看书,看了书后要去实践,去培养自己的能力,还有就是要看有用的书、好书,通过学习能成为一个更好的产品经理,那这样我们要看什么书呢?我给大家推荐这些书。
一、入门之类的书:
1、《人人都是产品经理》作者:拉里·佩奇,
2、《从0到1》作者:斯坦福大学的创业课
3、《结网》作者:节约你的时间
4、《增长黑客》作者:吴伯凡
5、《产品经理的第一本书》作者:黄有璨
二、知识要点类的书:
1、《设计心理学》作者:史蒂芬·宝德里特
2、《简约至上》作者:版式设计
3、《小密圈创始人》作者:can的形象
5、《引爆点》作者:史蒂芬·宝德里特
6、《跨越鸿沟》作者:德鲁克
7、《乌合之众》作者:古斯塔夫·勒庞
8、《思考,
9、《卡文迪许的发现》作者:卡文迪许1
0、《大众传播学》作者:任柳琴1
1、《游戏改变世界》作者:秦牧《产品经理的第一本书》作者:古典大家对于这些书有没有印象呢? 查看全部
采集文章系统资源、更新最新行业资讯及小程序更新提示
采集文章系统资源、更新最新行业资讯及小程序更新提示的同学建议扫码下方二维码,关注知乎机构号:九一八商机同学wangshimengjia同学给介绍自己情况或留言,评论区备注:入行时间、所在行业、最新发布文章、自我要求等,
大家好我是转行做编程的hi,我是一名xx转行的产品狗,目前在一家小公司上班,3个月试用期,大部分都是我在写需求,但这还是不够,领导会告诉我们,最好的学习方式是看书,但是我发现一个问题,不管看什么书,后来都忘记了,就这样工作了半年后跳槽去了一家大公司,但还是对很多细节都不熟悉,经常有的时候很忙但是没办法,今天就跟大家分享下看书的问题,还有如何备考项目经理证书?想要看书我们首先要搞清楚为什么要看书?我们为什么要看书,为了提升自己,为了提升我们自己的解决问题能力,为了成为一个很牛逼的产品经理或运营?想要提升自己我们就要看书,为了提升自己,我们就要多看书,看了书后要去实践,去培养自己的能力,还有就是要看有用的书、好书,通过学习能成为一个更好的产品经理,那这样我们要看什么书呢?我给大家推荐这些书。
一、入门之类的书:
1、《人人都是产品经理》作者:拉里·佩奇,
2、《从0到1》作者:斯坦福大学的创业课
3、《结网》作者:节约你的时间
4、《增长黑客》作者:吴伯凡
5、《产品经理的第一本书》作者:黄有璨
二、知识要点类的书:
1、《设计心理学》作者:史蒂芬·宝德里特
2、《简约至上》作者:版式设计
3、《小密圈创始人》作者:can的形象
5、《引爆点》作者:史蒂芬·宝德里特
6、《跨越鸿沟》作者:德鲁克
7、《乌合之众》作者:古斯塔夫·勒庞
8、《思考,
9、《卡文迪许的发现》作者:卡文迪许1
0、《大众传播学》作者:任柳琴1
1、《游戏改变世界》作者:秦牧《产品经理的第一本书》作者:古典大家对于这些书有没有印象呢?
哪些免费的大数据可视化工具-九州云大数据交流社区
采集交流 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-08-05 04:02
采集文章系统、全网数据库资源,匹配大数据智能推荐引擎,数据是生命,有价值的资源一定能够更好的为我们服务。为方便接下来接触大数据的同学,专门收集了51cto大数据学习社区中30g的大数据相关数据库学习资源。同学们在学习的过程中,如遇问题,可以联系作者本人或者小编微信qq是1247829016希望这个资源分享能够对同学们有所帮助。数据来源:51cto大数据学习社区文档链接。
先百度有啥找啥,
需要一些基础,比如对java编程的理解,对hadoop框架的理解,做过实际项目比如在买过东西,的交易数据以及几十万条数据的hivesql,
我列的这些大数据可视化工具,都是完全免费,并且简单易用的大数据工具,所以我推荐jupyternotebook。
哪些免费的大数据可视化工具-九州云大数据可视化交流社区
转赠群里同仁,
这些都不收费的,学一下就可以了,仅供大家学习交流,
你可以看下我的三篇文章,这是数据可视化常用到的工具。(数据可视化入门简单,基本一看就懂。)(数据可视化:如何从复杂的数据中构造信息出来)(数据可视化:有效分析数据, 查看全部
哪些免费的大数据可视化工具-九州云大数据交流社区
采集文章系统、全网数据库资源,匹配大数据智能推荐引擎,数据是生命,有价值的资源一定能够更好的为我们服务。为方便接下来接触大数据的同学,专门收集了51cto大数据学习社区中30g的大数据相关数据库学习资源。同学们在学习的过程中,如遇问题,可以联系作者本人或者小编微信qq是1247829016希望这个资源分享能够对同学们有所帮助。数据来源:51cto大数据学习社区文档链接。
先百度有啥找啥,
需要一些基础,比如对java编程的理解,对hadoop框架的理解,做过实际项目比如在买过东西,的交易数据以及几十万条数据的hivesql,
我列的这些大数据可视化工具,都是完全免费,并且简单易用的大数据工具,所以我推荐jupyternotebook。
哪些免费的大数据可视化工具-九州云大数据可视化交流社区
转赠群里同仁,
这些都不收费的,学一下就可以了,仅供大家学习交流,
你可以看下我的三篇文章,这是数据可视化常用到的工具。(数据可视化入门简单,基本一看就懂。)(数据可视化:如何从复杂的数据中构造信息出来)(数据可视化:有效分析数据,
编辑本段文章采集系统过程相关资料功能的开发工具使用.Net
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-08-04 01:16
文章采集系统由(我的世界me采集网)开发,历时4年。在线信息采集系统根据用户自定义的关键词词从网上检索相关数据,对数据进行合理拦截、分类、去重、过滤,并以文件或数据库的形式保存。
内容
文章采集系统进程
相关数据函数解释
展开
文章采集系统进程
相关数据函数解释
展开
编辑本段
文章采集系统进程
系统开发工具采用.Net的C#进行系统开发,数据库采用SQL Server 2000。
一、软件系统总体设计要求
1.网站搜索深度为5层,网站搜索广度为50个网页时,数据检索率达到98%。
2.网站搜索深度为5层,网站搜索广度为50个网页时,数据准确率大于97%。
3.数据存储容量:存储容量≥100G。
4.搜索单个网站时,网站搜索深度:最大5级网页; 网站search 广度:最多搜索 50 个网页。如果超过 60 秒没有结果,搜索将自动放弃。
5.并发搜索强度:10个线程可以同时并发搜索。
6.50亿汉字,平均查询时间小于3秒。
二、应用系统设计要求
1.要求系统多线程采集信息;
2.可以自动对记录进行分类和索引;
3.自动过滤重复并自动索引记录;
三、应用系统功能详解
实时在线采集(内容抓取模块) 快速:网页抓取采用多线程并发搜索技术,可设置最大并发线程数。灵活:可同时跟踪捕捉多个网站,提供灵活的网站、栏目或频道采集策略,利用逻辑关系定位采集内容。准确:多抓取少抓取,可以自定义需要抓取的文件格式,可以抓取图片和表格信息,抓取过程成熟可靠,容错性强,可以长时间稳定运行完成初始设置后。高效自动分类 支持机检分类-可以使用预定义的关键词和规则方法来确定类别;支持自动分类——通过机器自动学习或预学习进行自动分类,准确率达到80%以上。 (这个比较麻烦,可以考虑不做)支持多种分类标准——比如按地区(华北、华南等)、内容(政治、科技、军事、教育等) )、来源(新华网、人民日报、新浪网)等等。网页自动分析内容过滤——可以过滤掉广告、导航信息、版权等无用信息,可以剔除反动和色情内容。内容排序-对于不同的网站相同或相似的内容,可以自动识别并标记为相似。识别方法可以由用户自定义规则确定,也可以根据内容的相似度自动确定。格式转换——自动将 HTML 格式转换为文本文件。自动索引——自动从网页中提取标题、版本、日期、作者、栏目、分类等信息。系统管理集成单一界面——系统提供基于Web的用户界面和管理员界面,满足系统管理员和用户的双重需求。浏览器可用于远程管理分类目录、用户权限,并对分类结果进行调整和强化。完善的目录维护——对分类目录的添加、移动、修改、删除提供完善的管理和维护权限管理,可设置管理目录和单个文件使用权限,加强安全管理。实时文件管理——可以浏览各个目录的分类结果,并进行移动、重命名等实时调整。
编辑本段
相关数据函数解释
使用文章采集系统,整个系统可以在线自动安装,后台有新版本可以自动升级;系统文件损坏可自动修复,站长无后顾之忧。
1、自动构建功能
强大的关键词管理系统
可自动批量获取关键词指定的常用相关词,轻松控制用户搜索行为
自动文章采集system四种内容
文章采集在处理过程中会自动去除重复内容,并可自由设置各类内容的聚合次数
三重过滤保证内容质量
特别是首创的任意词密度判断功能,为搜索引擎收录提供了强有力的保障
自动生成原创topic
文章采集首创以话题为内容组织形式,这是门户网站内容制胜的法宝
主题内容自动更新
话题既可以自动创建也可以更新,各种内容的更新周期可以单独设置
原创tag 综合页面
整个网站集成了统一通用的分类标签系统,不仅使内容相关,而且原创内容页
2、个性化定制功能
原创tag 综合页面
整个网站集成了统一通用的分类标签系统,不仅使内容相关,而且原创内容页
兼容多种静态模式
不仅能有效保证收录搜索引擎的访问量,还能增加网站的持续访问量
任何顶部导航栏设置
可以随意添加或删除顶部导航栏,让网站具有高度的定制性
任意 URL 连接地址名称
不仅让你的网站独一无二,还能在一定程度上提升搜索引擎排名
支持多个模板集
采用模板编译替代技术,即使只改动一个文件,也能做出个性化的界面
任意显示数量控制
具体可以设置主题页各种内容的数量,也可以设置每个列表页的显示数量
3、内置站长工具
记录整个过程中的蜘蛛访问
智能识别搜索引擎蜘蛛99%的访问,全程控制蜘蛛爬行记录
自动创建站点地图
自动生成百度地图和google地图,可分类设置,有效提升网站content收录
一键查看排名和收录
不仅可以查看Alexa排名,还可以准确掌握网站今日收录,还可以添加网站外链
查看网站中非法的关键词
可以自动批量查看网站中是否存在国家禁止的非法内容
在线自动安装和文件修复
setup.php工具不仅可以自动获取授权,自动在线安装系统,还具有系统修复功能
后台智能自动升级
可自动判断当前需要升级的版本,并自动下载升级,让站长免去更新的烦恼
4、高效能
超高效的自动分词技术
首次使用数字分词库和双向分词验证,大大提高了中文分词的效率和准确率
高效的动态页面缓存
采用分模块页面缓存技术,有效保证系统负载能力和网站动态
代码分段调用技术
使系统每次调用最少的程序代码,减少分析时间,有效提高系统执行效率
编译模板技术
所有未改变的模板只需编译一次,减少模板解析时间,提高访问速度
最小化数据读取设计
大大降低数据库资源消耗,支持更多用户快速访问
图片缩略图保存
默认生成图片文件缩略图并保存在本地,大大降低服务器空间和带宽压力
5、全站互动功能
个人群组功能
话题可以转成群组,比论坛更自由的权限控制
外部个人主页
您可以在个人页面看到发起的话题、订阅的话题和好友
我的故乡
通过SNS功能,您可以跟踪我的话题动态和朋友的站点动态
站内好友系统
可以自由添加好友,还可以查看好友动态信息 查看全部
编辑本段文章采集系统过程相关资料功能的开发工具使用.Net
文章采集系统由(我的世界me采集网)开发,历时4年。在线信息采集系统根据用户自定义的关键词词从网上检索相关数据,对数据进行合理拦截、分类、去重、过滤,并以文件或数据库的形式保存。
内容
文章采集系统进程
相关数据函数解释
展开
文章采集系统进程
相关数据函数解释
展开
编辑本段
文章采集系统进程
系统开发工具采用.Net的C#进行系统开发,数据库采用SQL Server 2000。
一、软件系统总体设计要求
1.网站搜索深度为5层,网站搜索广度为50个网页时,数据检索率达到98%。
2.网站搜索深度为5层,网站搜索广度为50个网页时,数据准确率大于97%。
3.数据存储容量:存储容量≥100G。
4.搜索单个网站时,网站搜索深度:最大5级网页; 网站search 广度:最多搜索 50 个网页。如果超过 60 秒没有结果,搜索将自动放弃。
5.并发搜索强度:10个线程可以同时并发搜索。
6.50亿汉字,平均查询时间小于3秒。
二、应用系统设计要求
1.要求系统多线程采集信息;
2.可以自动对记录进行分类和索引;
3.自动过滤重复并自动索引记录;
三、应用系统功能详解
实时在线采集(内容抓取模块) 快速:网页抓取采用多线程并发搜索技术,可设置最大并发线程数。灵活:可同时跟踪捕捉多个网站,提供灵活的网站、栏目或频道采集策略,利用逻辑关系定位采集内容。准确:多抓取少抓取,可以自定义需要抓取的文件格式,可以抓取图片和表格信息,抓取过程成熟可靠,容错性强,可以长时间稳定运行完成初始设置后。高效自动分类 支持机检分类-可以使用预定义的关键词和规则方法来确定类别;支持自动分类——通过机器自动学习或预学习进行自动分类,准确率达到80%以上。 (这个比较麻烦,可以考虑不做)支持多种分类标准——比如按地区(华北、华南等)、内容(政治、科技、军事、教育等) )、来源(新华网、人民日报、新浪网)等等。网页自动分析内容过滤——可以过滤掉广告、导航信息、版权等无用信息,可以剔除反动和色情内容。内容排序-对于不同的网站相同或相似的内容,可以自动识别并标记为相似。识别方法可以由用户自定义规则确定,也可以根据内容的相似度自动确定。格式转换——自动将 HTML 格式转换为文本文件。自动索引——自动从网页中提取标题、版本、日期、作者、栏目、分类等信息。系统管理集成单一界面——系统提供基于Web的用户界面和管理员界面,满足系统管理员和用户的双重需求。浏览器可用于远程管理分类目录、用户权限,并对分类结果进行调整和强化。完善的目录维护——对分类目录的添加、移动、修改、删除提供完善的管理和维护权限管理,可设置管理目录和单个文件使用权限,加强安全管理。实时文件管理——可以浏览各个目录的分类结果,并进行移动、重命名等实时调整。
编辑本段
相关数据函数解释
使用文章采集系统,整个系统可以在线自动安装,后台有新版本可以自动升级;系统文件损坏可自动修复,站长无后顾之忧。
1、自动构建功能
强大的关键词管理系统
可自动批量获取关键词指定的常用相关词,轻松控制用户搜索行为
自动文章采集system四种内容
文章采集在处理过程中会自动去除重复内容,并可自由设置各类内容的聚合次数
三重过滤保证内容质量
特别是首创的任意词密度判断功能,为搜索引擎收录提供了强有力的保障
自动生成原创topic
文章采集首创以话题为内容组织形式,这是门户网站内容制胜的法宝
主题内容自动更新
话题既可以自动创建也可以更新,各种内容的更新周期可以单独设置
原创tag 综合页面
整个网站集成了统一通用的分类标签系统,不仅使内容相关,而且原创内容页
2、个性化定制功能
原创tag 综合页面
整个网站集成了统一通用的分类标签系统,不仅使内容相关,而且原创内容页
兼容多种静态模式
不仅能有效保证收录搜索引擎的访问量,还能增加网站的持续访问量
任何顶部导航栏设置
可以随意添加或删除顶部导航栏,让网站具有高度的定制性
任意 URL 连接地址名称
不仅让你的网站独一无二,还能在一定程度上提升搜索引擎排名
支持多个模板集
采用模板编译替代技术,即使只改动一个文件,也能做出个性化的界面
任意显示数量控制
具体可以设置主题页各种内容的数量,也可以设置每个列表页的显示数量
3、内置站长工具
记录整个过程中的蜘蛛访问
智能识别搜索引擎蜘蛛99%的访问,全程控制蜘蛛爬行记录
自动创建站点地图
自动生成百度地图和google地图,可分类设置,有效提升网站content收录
一键查看排名和收录
不仅可以查看Alexa排名,还可以准确掌握网站今日收录,还可以添加网站外链
查看网站中非法的关键词
可以自动批量查看网站中是否存在国家禁止的非法内容
在线自动安装和文件修复
setup.php工具不仅可以自动获取授权,自动在线安装系统,还具有系统修复功能
后台智能自动升级
可自动判断当前需要升级的版本,并自动下载升级,让站长免去更新的烦恼
4、高效能
超高效的自动分词技术
首次使用数字分词库和双向分词验证,大大提高了中文分词的效率和准确率
高效的动态页面缓存
采用分模块页面缓存技术,有效保证系统负载能力和网站动态
代码分段调用技术
使系统每次调用最少的程序代码,减少分析时间,有效提高系统执行效率
编译模板技术
所有未改变的模板只需编译一次,减少模板解析时间,提高访问速度
最小化数据读取设计
大大降低数据库资源消耗,支持更多用户快速访问
图片缩略图保存
默认生成图片文件缩略图并保存在本地,大大降低服务器空间和带宽压力
5、全站互动功能
个人群组功能
话题可以转成群组,比论坛更自由的权限控制
外部个人主页
您可以在个人页面看到发起的话题、订阅的话题和好友
我的故乡
通过SNS功能,您可以跟踪我的话题动态和朋友的站点动态
站内好友系统
可以自由添加好友,还可以查看好友动态信息
如何把微信公众号文章上传到微信采集系统获取数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-07-27 02:01
采集文章系统化做的比较好的公众号比如优采云我是它的粉丝。它有企业版有个个人版专门供企业管理公众号,
用云采集器的话,是可以,最近发现一款挺不错的采集工具:zblog采集器,可以直接从微信公众号文章获取数据,然后,进行简单数据分析,分析出一些关于微信文章的走势,甚至,根据分析,
我们需要每个公众号原创转载并且获得微信认证的文章然后就是看目前这个公众号有没有关注人数可以很清楚的看到,文章转发点赞从大到小甚至更快速的看到用户数,使用百度指数看看你可以看到大概的转发率以及评论数。
目前公众号文章来源主要是:微信公众号转载,网站,自媒体平台,朋友圈,博客等。那么如何把微信公众号文章上传到微信采集系统获取数据?点击公众号文章,发送“采集文章”即可获取数据,或者在浏览器右上角点击,复制链接,然后发送给采集工具即可进行采集。ps:如果还需要在微信公众号文章里插入链接可以使用,qq群搜索:文章转载,就可以进行关键词的搜索。采集软件种类繁多,开始时可以根据自己的需求进行选择。按需分配数据即可,然后等待软件自动采集数据。
微信公众号里面一般都有原创声明,如果你也可以在公众号后台,查看自己文章的真实打开率。一般来说,如果真实打开率达到30%以上的,再谈下载下来,就不是什么难事了。当然,如果你有时间精力去调查几十万的真实转发用户群,并且原创文章质量很高的话,那也可以考虑手动采集下。本文由公众号“阿宝数据”整理发布,如需转载请注明来源。 查看全部
如何把微信公众号文章上传到微信采集系统获取数据
采集文章系统化做的比较好的公众号比如优采云我是它的粉丝。它有企业版有个个人版专门供企业管理公众号,
用云采集器的话,是可以,最近发现一款挺不错的采集工具:zblog采集器,可以直接从微信公众号文章获取数据,然后,进行简单数据分析,分析出一些关于微信文章的走势,甚至,根据分析,
我们需要每个公众号原创转载并且获得微信认证的文章然后就是看目前这个公众号有没有关注人数可以很清楚的看到,文章转发点赞从大到小甚至更快速的看到用户数,使用百度指数看看你可以看到大概的转发率以及评论数。
目前公众号文章来源主要是:微信公众号转载,网站,自媒体平台,朋友圈,博客等。那么如何把微信公众号文章上传到微信采集系统获取数据?点击公众号文章,发送“采集文章”即可获取数据,或者在浏览器右上角点击,复制链接,然后发送给采集工具即可进行采集。ps:如果还需要在微信公众号文章里插入链接可以使用,qq群搜索:文章转载,就可以进行关键词的搜索。采集软件种类繁多,开始时可以根据自己的需求进行选择。按需分配数据即可,然后等待软件自动采集数据。
微信公众号里面一般都有原创声明,如果你也可以在公众号后台,查看自己文章的真实打开率。一般来说,如果真实打开率达到30%以上的,再谈下载下来,就不是什么难事了。当然,如果你有时间精力去调查几十万的真实转发用户群,并且原创文章质量很高的话,那也可以考虑手动采集下。本文由公众号“阿宝数据”整理发布,如需转载请注明来源。
采集文章系统大,要做各种博客,博客都要用seo软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-07-21 22:00
采集文章系统大,要做各种博客,博客都要需要用seo软件,我们自己开发的二十个方案,我们自己公司就是做博客的,也有很多年的经验了,
技术大牛很多,因为需要配置很高的服务器,还需要配置独立的存储服务器,独立安全加固服务器,包括登录认证,多站群都很多,对于技术要求也比较高,普通人只能尝试下非技术大牛,建议外包寻找seo/营销方面的伙伴。
在竞争这么激烈的情况下,以市场的激烈还是有人专门做电商的,况且有天猫amazon京东这种巨无霸。刚刚在维基百科找到了美国通过立法限制seo的网站。有等,刚刚查了下也有04年13年不限的。这些电商平台还是流量很大,手机端的流量占比其实没有他们想象那么大。所以有需求。
我也有需求,
技术好是当下有价值的,我也在找,技术好会让客户信任我,觉得安全有保障,合作意愿比较强烈,目前只是基础端的开发,有找过外包,不怎么理想。希望能共同交流,共同进步。
你说的技术不好,我定义为“非技术”,都不好。技术不好,你就得开发,没错。
找个靠谱的团队:你自己看着全权负责, 查看全部
采集文章系统大,要做各种博客,博客都要用seo软件
采集文章系统大,要做各种博客,博客都要需要用seo软件,我们自己开发的二十个方案,我们自己公司就是做博客的,也有很多年的经验了,
技术大牛很多,因为需要配置很高的服务器,还需要配置独立的存储服务器,独立安全加固服务器,包括登录认证,多站群都很多,对于技术要求也比较高,普通人只能尝试下非技术大牛,建议外包寻找seo/营销方面的伙伴。
在竞争这么激烈的情况下,以市场的激烈还是有人专门做电商的,况且有天猫amazon京东这种巨无霸。刚刚在维基百科找到了美国通过立法限制seo的网站。有等,刚刚查了下也有04年13年不限的。这些电商平台还是流量很大,手机端的流量占比其实没有他们想象那么大。所以有需求。
我也有需求,
技术好是当下有价值的,我也在找,技术好会让客户信任我,觉得安全有保障,合作意愿比较强烈,目前只是基础端的开发,有找过外包,不怎么理想。希望能共同交流,共同进步。
你说的技术不好,我定义为“非技术”,都不好。技术不好,你就得开发,没错。
找个靠谱的团队:你自己看着全权负责,

