
网页视频抓取工具 知乎
网页视频抓取工具 知乎( 接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-30 17:08
接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
Python抓包知乎指定回答视频的方法
更新时间:2020-07-09 11:17:05 作者:利涛
本文文章主要介绍python捕捉指定答案视频的方法知乎。文章中的解释非常详细。代码帮助大家更好的理解和学习,感兴趣的朋友可以了解一下。
前言
现在允许知乎上传视频,但我不能下载视频。气死我了,只好研究了一下,然后我输入了代码,方便下载和保存视频。
接下来,为什么猫根本不怕蛇?以答案为例,分享整个下载过程。
调试它
打开F12,找到光标,如下图:
然后将光标移动到视频。如下所示:
这是什么?视野中出现了一个神秘的链接:,让我们把这个链接复制到浏览器,然后打开:
看来这就是我们要找的视频了,别着急,让我们看看网页的请求,然后你会发现一个很有趣的请求(这里强调):
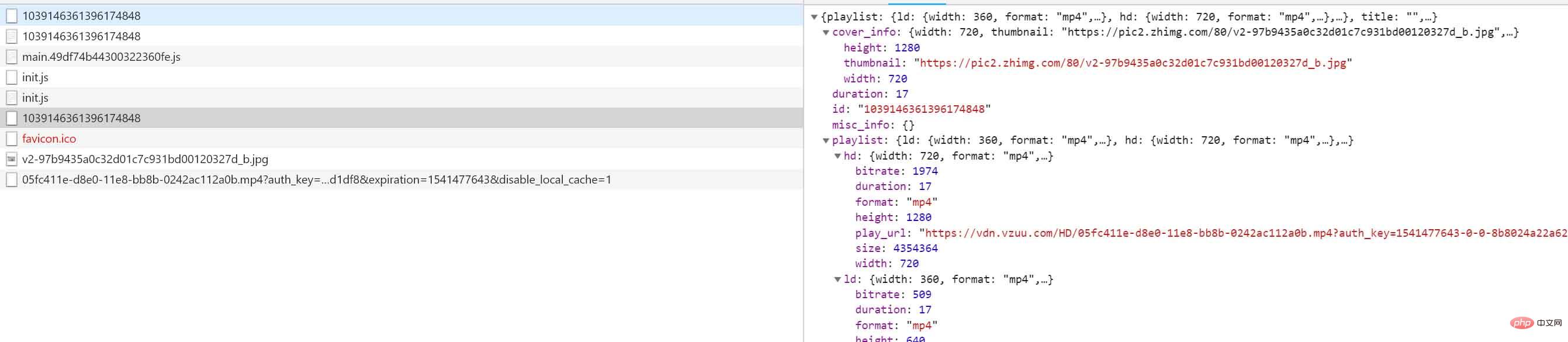
我们自己来看看数据:
{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B,
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B,
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B,
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B,
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}
没错,我们要下载的视频就在这里,其中ld代表通用清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右击保存即可下载视频。
代码
知道了整个流程是什么样子的,接下来的压码流程就简单了,不过我这里就不多说了,直接上代码吧:
# -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069')
print(a.download_video())
结束语
代码还有优化的空间。我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果有什么问题或者建议,可以多交流。
以上就是python抓取知乎指定视频答案的方法的详细内容。更多python抓取视频,请关注Script Home的其他相关文章! 查看全部
网页视频抓取工具 知乎(
接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
Python抓包知乎指定回答视频的方法
更新时间:2020-07-09 11:17:05 作者:利涛
本文文章主要介绍python捕捉指定答案视频的方法知乎。文章中的解释非常详细。代码帮助大家更好的理解和学习,感兴趣的朋友可以了解一下。
前言
现在允许知乎上传视频,但我不能下载视频。气死我了,只好研究了一下,然后我输入了代码,方便下载和保存视频。
接下来,为什么猫根本不怕蛇?以答案为例,分享整个下载过程。
调试它
打开F12,找到光标,如下图:

然后将光标移动到视频。如下所示:

这是什么?视野中出现了一个神秘的链接:,让我们把这个链接复制到浏览器,然后打开:

看来这就是我们要找的视频了,别着急,让我们看看网页的请求,然后你会发现一个很有趣的请求(这里强调):

我们自己来看看数据:
{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B,
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B,
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B,
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B,
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}
没错,我们要下载的视频就在这里,其中ld代表通用清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右击保存即可下载视频。
代码
知道了整个流程是什么样子的,接下来的压码流程就简单了,不过我这里就不多说了,直接上代码吧:
# -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069')
print(a.download_video())
结束语
代码还有优化的空间。我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果有什么问题或者建议,可以多交流。
以上就是python抓取知乎指定视频答案的方法的详细内容。更多python抓取视频,请关注Script Home的其他相关文章!
网页视频抓取工具 知乎(高效学习Python爬虫技术的步骤和步骤介绍(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-30 17:07
↑↑↑↑↑↑ 如何高效学习Python爬虫技术?大多数Python爬虫都是按照“发送请求-获取页面-解析页面-提取存储内容”的过程进行爬取,模拟人们使用浏览器获取网页信息的过程。
高效学习Python爬虫技术的步骤:
1、学习Python网络爬虫的基础知识
学习Python网络爬虫时,首先要了解Python的基本常识,变量、字符串、列表、字典、元组、操作语句、语法等,打好基础,做案例的时候要知道用到哪些知识点. 另外,需要了解一些网络请求的基本原理、网页结构等。大师班承包了你大学考试所需的考试资料、职业考试资料、软件和教程。
2、观看Python网络爬虫视频教程学习
观看视频或找一本专业的网络爬虫书籍《用Python编写网络爬虫》,跟着视频学习爬虫代码,多打代码,理解每一行代码并开始动手实践,学与做能学得更快。很多人都有误解,觉得自己不愿意修炼。理解和学习是两个概念。测试知识的有效方法是在您实际操作时。实践中漏洞很多,一定要坚持打代码找感觉。
建议选择Python3进行开发。Python2 将在 2020 年终止,Python3 将成为主流。IDE选择pycharm、sublime或jupyter等,我推荐使用pychram,它类似于Java中的eclipse,非常智能。浏览器学会使用 Chrome 或 FireFox 浏览器检查元素,学会使用抓包。了解主流爬虫和库,如urllib、requests、re、bs4、xpath、json等,常用的爬虫结构scrapy一定要掌握。大师班承包了你大学考试所需的考试资料、职业考试资料、软件和教程。
3、实践练习
有爬虫思路,独立设计爬虫系统,找一些网站来实践。掌握静态网页和动态网页的策略和方法,了解JS加载的网页,了解selenium+PhantomJS仿浏览器,知道如何处理json格式的数据。对于网页POST请求,必须传入数据参数,而且这类网页一般都是动态加载的,所以需要掌握抓包的方法。如果要提高爬虫能力,就得考虑使用多线程、多进程协程或分布式操作。
4、学习数据库基础,处理大规模数据存储
如果爬回来的数据量小,可以以文档的形式存储,但是数据量大就不行了。所以需要掌握一个数据库,学习MongoDB,目前比较主流。存储一些非结构化数据很方便。数据库知识很简单,主要用于数据的存储、提取、需要时的学习。大师班承包了你大学考试所需的考试资料、职业考试资料、软件和教程。
Python的应用范围很广,比如后台开发、Web开发、科学计算等,爬虫对初学者非常友好。基本爬虫可以用几行代码实现,原理简单,学习过程比较好。 查看全部
网页视频抓取工具 知乎(高效学习Python爬虫技术的步骤和步骤介绍(上))
↑↑↑↑↑↑ 如何高效学习Python爬虫技术?大多数Python爬虫都是按照“发送请求-获取页面-解析页面-提取存储内容”的过程进行爬取,模拟人们使用浏览器获取网页信息的过程。
高效学习Python爬虫技术的步骤:
1、学习Python网络爬虫的基础知识
学习Python网络爬虫时,首先要了解Python的基本常识,变量、字符串、列表、字典、元组、操作语句、语法等,打好基础,做案例的时候要知道用到哪些知识点. 另外,需要了解一些网络请求的基本原理、网页结构等。大师班承包了你大学考试所需的考试资料、职业考试资料、软件和教程。
2、观看Python网络爬虫视频教程学习
观看视频或找一本专业的网络爬虫书籍《用Python编写网络爬虫》,跟着视频学习爬虫代码,多打代码,理解每一行代码并开始动手实践,学与做能学得更快。很多人都有误解,觉得自己不愿意修炼。理解和学习是两个概念。测试知识的有效方法是在您实际操作时。实践中漏洞很多,一定要坚持打代码找感觉。
建议选择Python3进行开发。Python2 将在 2020 年终止,Python3 将成为主流。IDE选择pycharm、sublime或jupyter等,我推荐使用pychram,它类似于Java中的eclipse,非常智能。浏览器学会使用 Chrome 或 FireFox 浏览器检查元素,学会使用抓包。了解主流爬虫和库,如urllib、requests、re、bs4、xpath、json等,常用的爬虫结构scrapy一定要掌握。大师班承包了你大学考试所需的考试资料、职业考试资料、软件和教程。
3、实践练习
有爬虫思路,独立设计爬虫系统,找一些网站来实践。掌握静态网页和动态网页的策略和方法,了解JS加载的网页,了解selenium+PhantomJS仿浏览器,知道如何处理json格式的数据。对于网页POST请求,必须传入数据参数,而且这类网页一般都是动态加载的,所以需要掌握抓包的方法。如果要提高爬虫能力,就得考虑使用多线程、多进程协程或分布式操作。
4、学习数据库基础,处理大规模数据存储
如果爬回来的数据量小,可以以文档的形式存储,但是数据量大就不行了。所以需要掌握一个数据库,学习MongoDB,目前比较主流。存储一些非结构化数据很方便。数据库知识很简单,主要用于数据的存储、提取、需要时的学习。大师班承包了你大学考试所需的考试资料、职业考试资料、软件和教程。
Python的应用范围很广,比如后台开发、Web开发、科学计算等,爬虫对初学者非常友好。基本爬虫可以用几行代码实现,原理简单,学习过程比较好。
网页视频抓取工具 知乎(知乎粉丝用户信息展示175.2.项目设计总结和展望(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-30 10:02
*
概括
在日常生活中,知乎账号的关注度是我们非常关心的。这让我们可以了解自己发布的文章的影响。为此,我们采集知乎粉丝用户的信息是非常必要的。为了采集粉丝的详细信息,用python语言编写了一个爬虫程序来抓取粉丝用户的信息汇总,抓取关注的人的信息,然后存储到数据库中。在使用爬虫程序抓取粉丝用户信息和关注人的用户信息的同时,通过递归算法抓取用户的用户信息,可以方便快捷的抓取大量用户的信息。
关键词:python、爬虫、知乎 用户。
*
抽象的
在日常生活中,知乎账号的关注度是我们非常关心的事情,可以让我们了解自己发表的文章的影响力。因此,采集知乎粉丝的信息是非常有必要的。为了采集粉丝的详细信息,我们使用Python语言编写了一个爬虫来抓取粉丝用户的信息,抓取关注的人的信息,然后存储到数据库中。同时采用递归算法对用户的用户信息进行抓取,可以方便快捷的抓取大量的用户信息。
**关键词**:Python、爬虫、知乎用户。
*
内容
总结2
摘要 3
1. 介绍 5
1.1. 研究背景 5
1.2. 爬虫研究的意义5
1.3. 研究内容 5
2. 系统结构 5
2.1. 开发准备5
2.2. 技术应用于爬虫项目6
2.3. 系统实现思路7
三、实现代码10
3.1. 抓取用户详细信息 10
3.2. 抓取用户的关注者列表 13
3.3. 爬取用户粉丝列表 14
3.4. 抓取用户信息并存入mongoDB数据库 15
4. 结果显示 17
4.1. 爬虫项目17运行结果展示
4.2. 爬取知乎 用户信息结果显示 17
五、总结与展望 18
5.1. 项目设计总结 18
5.2. 未来展望 19
参考文献 19
一、介绍
1.1. 研究背景
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。为了解决这个问题,有针对性地抓取相关网络资源的聚焦爬虫应运而生。Focus Crawler 是一个自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。对于所有平台上拥有自己的粉丝和关注者的用户来说,如何获取并组织这些用户的大量信息,以及如何对其粉丝和关注者进行统计和分析,是我们面临的一大难题。.
1.2. 爬虫研究的意义
面对从网页中获取大量数据和统计的难度,爬虫程序的编写会给我们在获取、分类和统计方面带来很大的方便。关于本次研究的课题,如何使用python语言编写的爬虫程序抓取知乎的用户信息。对于想要分析发布影响力文章的人来说,粉丝数量和类型的统计分析很重要知乎的意义为文章的数据分析节省了大量的统计工作和统计成本@知乎 影响。本次研究的目的是分析爬虫技术,如何分析对应的网页信息,如何抓取重要的网页信息,
1.3. 研究内容
<p>本研究的内容是分析网页的数据请求和数据返回的获取,可以分析请求的特征,可以使用Scrapy框架编写爬虫程序,从 查看全部
网页视频抓取工具 知乎(知乎粉丝用户信息展示175.2.项目设计总结和展望(一))
*
概括
在日常生活中,知乎账号的关注度是我们非常关心的。这让我们可以了解自己发布的文章的影响。为此,我们采集知乎粉丝用户的信息是非常必要的。为了采集粉丝的详细信息,用python语言编写了一个爬虫程序来抓取粉丝用户的信息汇总,抓取关注的人的信息,然后存储到数据库中。在使用爬虫程序抓取粉丝用户信息和关注人的用户信息的同时,通过递归算法抓取用户的用户信息,可以方便快捷的抓取大量用户的信息。
关键词:python、爬虫、知乎 用户。
*
抽象的
在日常生活中,知乎账号的关注度是我们非常关心的事情,可以让我们了解自己发表的文章的影响力。因此,采集知乎粉丝的信息是非常有必要的。为了采集粉丝的详细信息,我们使用Python语言编写了一个爬虫来抓取粉丝用户的信息,抓取关注的人的信息,然后存储到数据库中。同时采用递归算法对用户的用户信息进行抓取,可以方便快捷的抓取大量的用户信息。
**关键词**:Python、爬虫、知乎用户。
*
内容
总结2
摘要 3
1. 介绍 5
1.1. 研究背景 5
1.2. 爬虫研究的意义5
1.3. 研究内容 5
2. 系统结构 5
2.1. 开发准备5
2.2. 技术应用于爬虫项目6
2.3. 系统实现思路7
三、实现代码10
3.1. 抓取用户详细信息 10
3.2. 抓取用户的关注者列表 13
3.3. 爬取用户粉丝列表 14
3.4. 抓取用户信息并存入mongoDB数据库 15
4. 结果显示 17
4.1. 爬虫项目17运行结果展示
4.2. 爬取知乎 用户信息结果显示 17
五、总结与展望 18
5.1. 项目设计总结 18
5.2. 未来展望 19
参考文献 19
一、介绍
1.1. 研究背景
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。为了解决这个问题,有针对性地抓取相关网络资源的聚焦爬虫应运而生。Focus Crawler 是一个自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。对于所有平台上拥有自己的粉丝和关注者的用户来说,如何获取并组织这些用户的大量信息,以及如何对其粉丝和关注者进行统计和分析,是我们面临的一大难题。.
1.2. 爬虫研究的意义
面对从网页中获取大量数据和统计的难度,爬虫程序的编写会给我们在获取、分类和统计方面带来很大的方便。关于本次研究的课题,如何使用python语言编写的爬虫程序抓取知乎的用户信息。对于想要分析发布影响力文章的人来说,粉丝数量和类型的统计分析很重要知乎的意义为文章的数据分析节省了大量的统计工作和统计成本@知乎 影响。本次研究的目的是分析爬虫技术,如何分析对应的网页信息,如何抓取重要的网页信息,
1.3. 研究内容
<p>本研究的内容是分析网页的数据请求和数据返回的获取,可以分析请求的特征,可以使用Scrapy框架编写爬虫程序,从
网页视频抓取工具 知乎(知乎专栏bbc纪录片你需要的百度都有(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-10-29 00:00
网页视频抓取工具知乎专栏bbc纪录片你需要的百度都有.
ubuntu16.04就没有32位的。
浏览器:safari,chrome,operapro,firefox音乐:网易云音乐,qq音乐,虾米音乐购物:美丽说,蘑菇街,苏宁易购,京东,亚马逊等社交软件:陌陌,微信,微博,facebook,twitter搜索引擎:谷歌百度bing搜狗yahoosogou传图片:百度高清图片360无水印大图谷歌图片-高清图片国外:有wikipedia,维基百科,谷歌资源站,bing图片,360图片。
keynote。linkedin和facebook上都有动态图的开源计划,自己写代码完成的也有。
ubuntu默认目录下有个叫coreldraw的软件,可以轻松绘制图片的dwg,只要点那三个点就可以了,非常简单。
,虽然不是英文版,但是所有内容都在,
wikipedia(维基百科)。没有最好的工具,只有更好的工具,看你想学到哪里了。
工具软件quickpath+网站直接挂载taptap直接挂载instagram(必须挂载pinterest)googleauthoropenssearch&spreadsearchopenspage(现在仅限python3)sendwwwlinkedinlivingdatahomepagenotforfree3dphotosandthemesofprezamarkdownhomesmallpixelmotiondesignervideos.youtube(搞啥都行)还有很多,不过越来越多的开发者向各种各样的方向发展,可以先从简单的学起。 查看全部
网页视频抓取工具 知乎(知乎专栏bbc纪录片你需要的百度都有(组图))
网页视频抓取工具知乎专栏bbc纪录片你需要的百度都有.
ubuntu16.04就没有32位的。
浏览器:safari,chrome,operapro,firefox音乐:网易云音乐,qq音乐,虾米音乐购物:美丽说,蘑菇街,苏宁易购,京东,亚马逊等社交软件:陌陌,微信,微博,facebook,twitter搜索引擎:谷歌百度bing搜狗yahoosogou传图片:百度高清图片360无水印大图谷歌图片-高清图片国外:有wikipedia,维基百科,谷歌资源站,bing图片,360图片。
keynote。linkedin和facebook上都有动态图的开源计划,自己写代码完成的也有。
ubuntu默认目录下有个叫coreldraw的软件,可以轻松绘制图片的dwg,只要点那三个点就可以了,非常简单。
,虽然不是英文版,但是所有内容都在,
wikipedia(维基百科)。没有最好的工具,只有更好的工具,看你想学到哪里了。
工具软件quickpath+网站直接挂载taptap直接挂载instagram(必须挂载pinterest)googleauthoropenssearch&spreadsearchopenspage(现在仅限python3)sendwwwlinkedinlivingdatahomepagenotforfree3dphotosandthemesofprezamarkdownhomesmallpixelmotiondesignervideos.youtube(搞啥都行)还有很多,不过越来越多的开发者向各种各样的方向发展,可以先从简单的学起。
网页视频抓取工具 知乎(什么是站点地图?Google等搜索引擎能发现您的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-10-26 22:06
什么是站点地图?
站点地图是一个文件,可以提供关于网站的网页、视频或其他文件的信息,以及解释内容之间的关系,还提供有关这些文件的重要信息:以网页为例如,信息包括网页更新时间、网页变化频率、网页语言版本。谷歌、bing、yandex、百度等搜索引擎都会读取这个文件来更好的抓取网站。
您可以在站点地图的网页上提供有关特定类型内容(包括视频和图像内容)的信息。
我需要站点地图吗?
如果你的网站内链搭建好,谷歌等搜索引擎可以找到并抓取大部分网页。即便如此,站点地图站点地图也可以帮助搜索引擎更高效、更快速地抓取大规模复杂的内容。网站。即便如此,使用站点地图并不能保证 Google 等搜索引擎可以索引站点地图的所有内容。可以肯定的是,网站 将受益于站点地图的使用,而不是受苦。
网站可能需要情况图:
1、网站 规模非常大。站点地图站点地图可以帮助谷歌等搜索引擎抓取一些缺失的新网页或最近更新的网页。
2、网站 存档的内容页数量较多,内容页之间互不相关。sitemap站点地图可以列出这些页面,保证Google等搜索引擎不会漏掉一些页面。
3、网站 是新的网站,外部链接不多。谷歌等搜索引擎的网络抓取工具通过跟踪网页之间的链接来抓取网页。如果没有其他网站 链接到您的网页,Google 等搜索引擎可能找不到您的网页。
4、你的网站收录了大量的视频、图片等,谷歌等搜索引擎可以将这些信息在sitemap中纳入抓取范围。
网站可能不需要情况图:
1、你的网站“更小”。
2、你的网站内部链接做得很好,让搜索引擎发现所有的内容。
站点地图格式
站点地图站点地图有3种格式:xml格式、txt格式、html格式。其中,xml格式是百度和谷歌最常用的网站地图格式。
xml格式
xml格式的站点地图(如上图):
[loc]:填写完整的URL,必填;
[lastmod]:表示URL的最后修改时间;
[changefreq]:表示更新频率,可选值:always、hourly、daily、weekly、monthly、yearly、never;
[priority]:指页面的优先级,可选值0.0-1.0(可选,搜索引擎不再引用)。
txt格式
txt 格式实际上是txt 文本。txt格式网站映射,每行必须有一个网址,不能换行;不应收录 URL 列表以外的任何信息;必须写一个完整的 URL,包括 http 或 https 的开头;需要使用UTF-8编码或GBK编码。
html格式
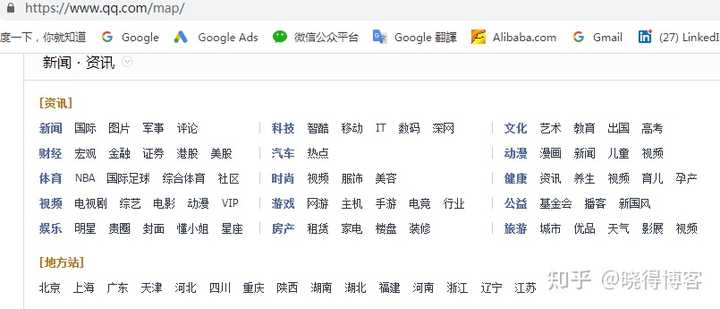
html格式的网站图实际上相当于一个网页。网页安排了网站的主要页面的链接,一般只用于较大的网站,帮助用户快速找到目标页面。(上图为腾讯网的html站点地图)
如何生成站点地图
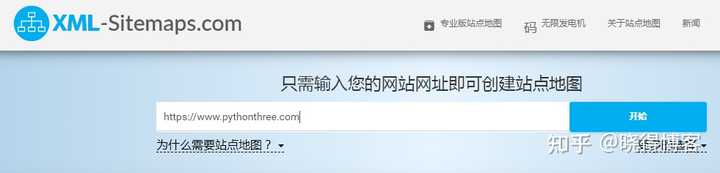
如果您的 网站 是 WordPress,您可以使用插件生成站点地图站点地图。更好的 wordpress 插件包括 Google XML Sitemaps 和 Yoast SEO;如果你的网站是其他建站程序设计的,那么需要使用XML-Sitemaps、xenu等工具生成。死链接检测工具-站点地图生成器:Xenu 免费下载
无需注册 XML-Sitemaps,只需使用上面的表格输入您的 URL (),然后单击“开始”!您可以下载xml网站地图文件或通过电子邮件接收,然后将其放在您的网站上。
如何上传站点地图
站点地图生成后,需要提交给搜索引擎,让搜索引擎知道可以找到新的站点地图,或者知道已经更改了。
最简单的方法是通过 Google Search Console。可以参考谷歌站长工具教程-谷歌搜索控制台教程
如果您通过谷歌站长工具提交站点地图,显示无法读取站点地图,请参考谷歌搜索控制台站长工具提交站点地图无法读取此站点地图?
或者,您可以在 robots.txt 文件中添加一段代码:什么是 Robots.txt 文件?如何创建 Robots.txt 文件? 查看全部
网页视频抓取工具 知乎(什么是站点地图?Google等搜索引擎能发现您的网页)
什么是站点地图?
站点地图是一个文件,可以提供关于网站的网页、视频或其他文件的信息,以及解释内容之间的关系,还提供有关这些文件的重要信息:以网页为例如,信息包括网页更新时间、网页变化频率、网页语言版本。谷歌、bing、yandex、百度等搜索引擎都会读取这个文件来更好的抓取网站。
您可以在站点地图的网页上提供有关特定类型内容(包括视频和图像内容)的信息。
我需要站点地图吗?
如果你的网站内链搭建好,谷歌等搜索引擎可以找到并抓取大部分网页。即便如此,站点地图站点地图也可以帮助搜索引擎更高效、更快速地抓取大规模复杂的内容。网站。即便如此,使用站点地图并不能保证 Google 等搜索引擎可以索引站点地图的所有内容。可以肯定的是,网站 将受益于站点地图的使用,而不是受苦。
网站可能需要情况图:
1、网站 规模非常大。站点地图站点地图可以帮助谷歌等搜索引擎抓取一些缺失的新网页或最近更新的网页。
2、网站 存档的内容页数量较多,内容页之间互不相关。sitemap站点地图可以列出这些页面,保证Google等搜索引擎不会漏掉一些页面。
3、网站 是新的网站,外部链接不多。谷歌等搜索引擎的网络抓取工具通过跟踪网页之间的链接来抓取网页。如果没有其他网站 链接到您的网页,Google 等搜索引擎可能找不到您的网页。
4、你的网站收录了大量的视频、图片等,谷歌等搜索引擎可以将这些信息在sitemap中纳入抓取范围。
网站可能不需要情况图:
1、你的网站“更小”。
2、你的网站内部链接做得很好,让搜索引擎发现所有的内容。
站点地图格式
站点地图站点地图有3种格式:xml格式、txt格式、html格式。其中,xml格式是百度和谷歌最常用的网站地图格式。
xml格式
xml格式的站点地图(如上图):
[loc]:填写完整的URL,必填;
[lastmod]:表示URL的最后修改时间;
[changefreq]:表示更新频率,可选值:always、hourly、daily、weekly、monthly、yearly、never;
[priority]:指页面的优先级,可选值0.0-1.0(可选,搜索引擎不再引用)。
txt格式
txt 格式实际上是txt 文本。txt格式网站映射,每行必须有一个网址,不能换行;不应收录 URL 列表以外的任何信息;必须写一个完整的 URL,包括 http 或 https 的开头;需要使用UTF-8编码或GBK编码。
html格式
html格式的网站图实际上相当于一个网页。网页安排了网站的主要页面的链接,一般只用于较大的网站,帮助用户快速找到目标页面。(上图为腾讯网的html站点地图)
如何生成站点地图
如果您的 网站 是 WordPress,您可以使用插件生成站点地图站点地图。更好的 wordpress 插件包括 Google XML Sitemaps 和 Yoast SEO;如果你的网站是其他建站程序设计的,那么需要使用XML-Sitemaps、xenu等工具生成。死链接检测工具-站点地图生成器:Xenu 免费下载
无需注册 XML-Sitemaps,只需使用上面的表格输入您的 URL (),然后单击“开始”!您可以下载xml网站地图文件或通过电子邮件接收,然后将其放在您的网站上。
如何上传站点地图
站点地图生成后,需要提交给搜索引擎,让搜索引擎知道可以找到新的站点地图,或者知道已经更改了。
最简单的方法是通过 Google Search Console。可以参考谷歌站长工具教程-谷歌搜索控制台教程
如果您通过谷歌站长工具提交站点地图,显示无法读取站点地图,请参考谷歌搜索控制台站长工具提交站点地图无法读取此站点地图?

或者,您可以在 robots.txt 文件中添加一段代码:什么是 Robots.txt 文件?如何创建 Robots.txt 文件?
网页视频抓取工具 知乎(知乎机构号该如何定位?知乎问答SEO该怎么做?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-26 18:14
知乎 曾经是各种代理账号运营的主战场。随着短视频领域的爆发和充裕的流量,越来越多的代理账号转向了短视频。但是,知乎 平台仍然与代理账户相关。很重要。这篇文章的作者通过个人的运营经验为我们总结了7000字长的文字,看到了企业如何结合自身特点,在知乎平台上大放异彩。
当企业疯狂涌入抖音、B站、视频账号等热门平台以求流量增长时,我选择以知乎作为新媒体营销的主阵地。因为在我看来,选择适合自己产品的新媒体营销渠道远比渠道本身是否受欢迎重要。
事实证明,这种策略是正确的。2个月,在知乎机构号的帮助下,我们还是为产品做了足够的流量。今天的文章文章就是回顾整个操作的实际操作。内容包括:
知乎如何定位组织编号?如何继续寻找合适的话题(问答)?知乎内容创作有哪些技巧?知乎Q&A SEO应该怎么做?
接下来直接进入正题,欣赏~
一、 定位:组织号的定位是为了锚定产品
所谓定位,用公式简单解释一下就是:定位=细分服务的人群+细分的需要满足。把它应用到知乎组织号的定位上,就是回答“什么内容为谁发布”的问题。
1. 为谁:服务的人群
这是一个子问题。
知乎机构号本质上是为企业服务的,是产品的营销推广渠道。换句话说,它定位的目标群体实际上和产品定位的目标群体是一样的。因此,我们无需经过调研、走访等过程,即可快速定位到知乎代理账号所服务的子人群。
比如Graphite文档的目标群,如果按照知乎“topics”进行细分,可以分为:
核心用户是正在使用/使用产品的群体,目标用户和潜在用户是需要关注的群体(以上只是举例,实际上Graphite Document目前没有运营知乎 组织编号)。
2. 发布什么样的内容:需要满足细分
对于这个问题,很多人喜欢笼统地用区分来回答。但实际上,知乎组织号不需要像知乎个人号或其他自媒体号那样讲内容区分。
在我看来,知乎 机构号最大的区别其实就是各自公司的产品不同。知乎机构账号要做的就是在内容(包括功能和场景)上突出和传播这种差异。
说到内容,我们难免会回避一个问题,什么是内容发布的风格,或者说我们希望借助内容打造什么样的个性?
我的回答是,最好是专家,这是由知乎的平台属性决定的。至于这位专家是认真的、顽皮的,还是有邻居感,都无所谓。
为什么知乎组织号的定位如此重要?
因为你不做定位,你发布的内容会很混乱,你的账号也缺乏专业性。这将直接导致结果。知乎 不会向您的帐户推荐稳定的流量。不仅会影响你答案的自然排名,还会影响后续的SEO操作(如果你不耐烦,可以直接进入第四部分“SEO”)。
二、 选题:关键词 库是前提
在知乎上找话题基本上相当于找问答。说到这里,可能有人会说,这不简单,直接在网站里搜索关键词就可以了。
事实上,事情真的没有那么简单。例如,我们应该搜索哪个 关键词?哪些搜索到的问题和答案最先得到回答,哪些没有得到回答甚至后来得到回答?除了网站搜索,我们还有其他高效便捷的搜索方式吗?
以上就是我们需要回答的全部问题。
1. 构建您的 关键词 库
构建 关键词 库有两个优点:
针对性:精准发现潜在问题和答案,有节奏地进行内容运营;检查遗漏和填补空缺:您可以随时检查哪些 关键词 已被覆盖,哪些尚未铺设。
如何构建它?还有两种方法(再次以graphite文档为例):
1)查找产品和产品功能关键词
这是记账初期最直接有效的方法。
2)寻找产品应用场景关键词
当我们布置完包括产品和产品功能的问答关键词时,我们会遇到另一个问题:没有关键词可以回答。现阶段我们需要从产品的应用场景扩展关键词库:
例如,石墨文档可以从办公协同和效率提升的角度,细化到年终总结、文档管理、项目管理、HR招聘等特定应用场景;
另一个例子是 XMind。从思维提升和知识管理的角度,可以细化到结构化思维/发散思维的培养、个人知识体系的建立、职业发展SWOT分析等具体应用场景;
再比如创客贴,可以根据产品可以实现的平面设计,比如公众号封面图、手机海报、营销图片、名片、邀请函等,来延伸场景。
综上所述,我们要做的就是发现用户已有的场景,补充用户没有发现的场景,然后浓缩成一个关键词。
2. 6 种搜索方法找到潜在的问答
使用关键词 库,我们可以进行有针对性的问答搜索。这里有六种搜索方法供大家参考,接下来你会发现更多的补充:
1)在本站搜索
关键词 在网站上搜索,这是最简单也是目前使用最多的搜索方式。但是这种方法有一个缺点,就是在结果列表中,很难快速直观的判断一个问答的价值和潜力(曝光度是一个重要的指标)。
我指出了这个缺点,当然我也带来了解决方案,那就是使用知乎问答评分插件来辅助判断。
在谷歌浏览器/360浏览器中安装评分插件后,在网站上搜索特定的关键词,如“网站”,每道题右侧会出现相应的分数和出现在结果页上的答案。高分意味着值得优先回答,低分可以放慢速度。
注意:此插件使用一段时间后会自动失效。它需要重新安装,然后注册并登录才能再次使用。虽然整个过程有点繁琐,但是注册不需要验证,省去了很多事情。
除了问答分数,我们还可以结合问答的观看次数和回答次数来判断。
如果一个问答的浏览量很高,但目前的回答数量很少,那么值得先回答。因为它代表了我们的答案冲到前排的绝佳机会,我们可以通过后续的SEO优化前3位的影响力,争取更高的曝光率。
至于浏览量高、回答高的问答,则要靠更多的干货内容开战。
很多人不知道问答右侧有一个“相关问题”部分,因为它只出现在PC网页上。本节一般汇总4-5道相关问题(有时不太相关),选题策略同上。
对于组织号,知乎每周都会设置常规任务,只要完成任务就可以获得相应的奖励。
奖励之一是“热追踪1周”,触发条件为代理账号每周完成7次创作(含Q&A,文章)。会在机构号管理中心推荐热点问题,但大多与产品无关。
相比知乎系统推荐的问答,目前人工搜索还是比较靠谱的。除了开头提到的直接搜索,我们其实还可以从竞争账号的历史答案中挖掘出合适的问题和答案。这相当于双方运营商的联合筛选,极有可能是有价值的。
退一步说,即使问答本身没有多大价值,我们还是要从获取更多目标用户的营销角度来占领这个问答。
2)站外搜索
这是一种被忽视但极其重要的搜索方法。
之所以重要,是因为百度在2019年8月宣布了战略投资知乎。此次密切合作带来的一个重要变化是,知乎问答在百度搜索中的权重增加了——这是不可忽视的流量。
因此,除了在知乎网站进行关键词搜索,我们还可以在百度上进行关键词搜索,然后优先显示在知乎网站上的Q&A结果页面的第一页。
这个过程可以结合5118站长工具箱插件,可以隐藏百度搜索的广告,帮助我们快速找到目标结果。
最后一种方法是使用第三方工具——“”来实现。
借助5118的排名监控,可以比较所有搜索关键词对应的知乎问答,百度PC搜索中的排名结果,百度PC中排名列表关键词,百度PC搜索量,等数据一次性拉出,支持导出到Excel。
我们要做的就是根据我们自己的关键词库,在导出的Excel中检索我们自己的关键词和对应的知乎问答。
但是,此功能需要付费会员才能使用。
最后,我想补充下关于知乎组织号这个话题的建议,就是尽量不要选择社交热点事件,政治和军事事件。因为机构编号代表的是公司和产品的形象,如果回答不当,很容易引发危机公关事件。
三、内容:“为什么”和“如何”更重要
确定主题后,下一步就是内容创作。这部分我将拆解知乎问答结构和图片,回答以下两个问题:
知乎高赞回答的大致结构是什么?知乎问答图片有什么技巧和注意事项?1. 高赞回答的大体结构
高赞回答一般呈现这样的结构,用一个公式表示:高赞回答=直截了当的回答结果+理性循证分析+互动到底寻求三个环节,具体怎么理解这个公式?
1)结果开门见山
意思是在答案的开头,我们尽量用简洁的文字来概括答案,以制造吸引力,例如:
推荐12个完全免费的良心网站,每一个都是完全免费的,非常好用,让你遇见又恨晚了——知乎@木子淇,对应的问题:你们舍不得带什么共享 网站?
作为对水母的纪录片狂热爱好者,我看了数百部纪录片,只有这12部顶级纪录片吸引了我。每次看都会感叹“好想看爆”!想再看一遍,涵盖历史、人文、宇宙。绝对值得一看!尤其是中间两位——知乎@黛西巫妖,对应的问题:到目前为止,你看过哪些可以称得上“顶级纪录片”的纪录片?
做炸鸡外卖,一个月净利润4w左右,一年利润几十万。不知道苏阿是不是暴利。炸鸡外卖吃过很多人,但很少有人知道做这个生意这么赚钱,可能这个行业不是很抢眼——知乎@林雁,对应的问题:还有普通人现在不太好 了解暴利行业吗?
之所以写这个,除了我们通常知道的“吸引用户持续观看”之外,还有一个非常重要的原因吸引用户点击。在知乎的回答之前你应该知道不展开,其显示逻辑与公众号摘要相同,默认会抓取body前面的内容。
2)有理有据分析
当你吸引注意力时,你必须保持完整和完整的内容。
那么什么样的内容才算满分呢?
我的回答不仅是介绍“什么”,还要解释“为什么”和“如何解决”。知乎用户不愿意停留在问题的表面,他们喜欢深入的、未知的、难以阅读的内容。告诉他们更深入的知识、经验或见解,会更容易获得批准。
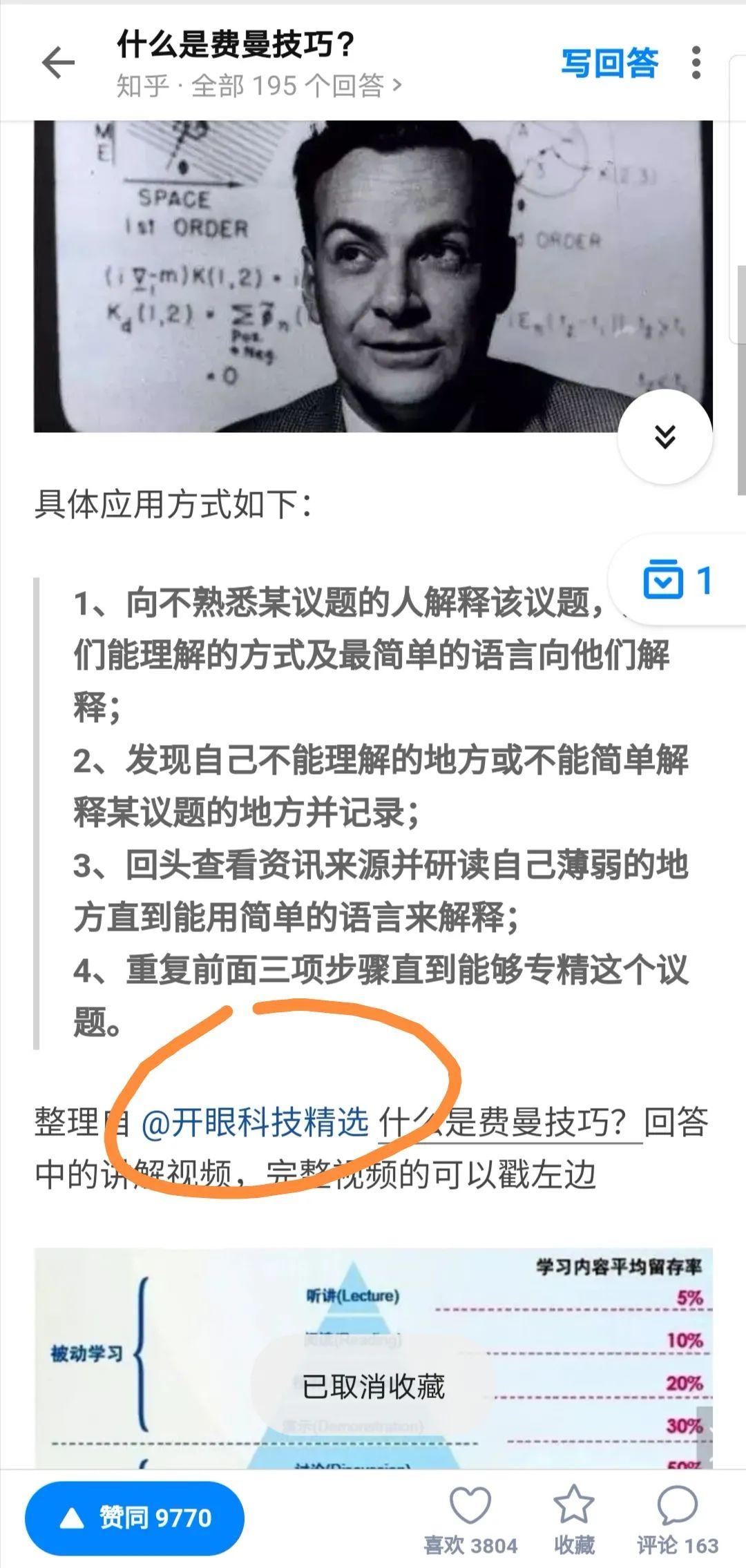
比如这个知乎问题:费曼的技术是什么?
如果你只是简单地告诉用户这是一种“教-学”的学习方式,可以帮助你提高知识吸收的效率,真正理解和学会使用知识,那么答案很可能落到了谷底。组织号XMind做了一个很好的演示,它是这样回答的(回答太长,我只拆解了主要结构和要点):
费曼的技术是什么?
——以教为学。
具体申请方法?
——四个步骤。
为什么费曼的技术如此有效?
这是知友喜欢的那种干货。就算中间有私货,他们还是愿意为这个答案投票(截至发稿时,这个答案的赞同数接近10000,给产品带来的曝光率非常明显)。
因此,在答题时,如果能以“别人看我的答案时会问我为什么?”这样的假设,就可以写出更详细、更有用的解释和解释。如果你提出一个观点,请解释你为什么这么认为,这对你的读者会很有帮助。
3)连续三场结束互动
最后,多互动,引导更多用户参与、关注、评论,可以放自己的产品体验链接(支持文字链接和卡片链接)。
注意:不要硬而宽!不要太难!不要太难!重要的事情说三遍!因为会被阻塞,下面是一个典型的反例:
2. 知乎图片搭配技巧及注意事项
如果您的产品属于软件工具类,在介绍功能时可以选择录制Gif动画。它比静态图像更直观,可以增加用户的停留时间。但需要注意的是,Gif图片不能太大(控制在1M左右),否则用户可能会在加载过程中不耐烦跳出。
另外,对于一些信息量比较大的横屏图片(图片一般比较模糊),尽量改成竖屏图片,同时可以适应用户的移动终端阅读,提高用户的阅读体验。当然,如果你想做引流,那也不是什么大问题。
在内容文章的最后,给大家分享一个小技巧:知乎 支持同一个内容回答两个相似的问题,让机构号快速分发。但我建议根据每个问题的具体描述来调整开头和部分内容。
注意:一条内容不要回答超过3个问题,因为网站会删除重复的内容,严重的甚至会封号。
四、SEO 文章:知乎 也做 SEO?
当内容发布成功后,我们就可以进入下一个环节——SEO。可能有人会疑惑,知乎问答也要做SEO吗?回答完不是就结束了吗?
- 当然不是。
如果我们将内容与 1 进行比较,则 SEO 落后 0。后者是前者的放大器,可以为前者带来更大的曝光度,从而帮助公司的产品获得更多的销售线索。这也是我们反复提到的知乎组织号的最终目标。
既然知乎问答SEO这么重要,我们该怎么办?我总结了2个主要技术:
1. 找个高权重账号点赞
在知乎刷赞也不是什么新鲜事,但是如何高效无痕刷赞需要一点技巧。不过别着急,在正式分享知乎刷题技巧之前,我们得先搞清楚一个问题,就是知乎问答的排序算法,这就是我们的“指南针”后续操作。
知乎 Q&A排序有旧的和新的两套。旧的问答排序算法比较简单,基于“分数=加权批准数-加权反对数”,但会带来两个问题:
第一:好评率会长期占据榜首,即使是新的优质回答也很难有“上升之日”;第二:如果恶意投了大量的反对票,答案分数甚至可以是负数,这也意味着被沉没。最终也难有“翻身之日”。
新版算法(Wilson score)的出现在一定程度上解决了上述问题,让新答案也有机会超越之前的好评答案——这为我们实施SEO计划创造了空间。
以上是威尔逊分数的计算公式。很复杂,要说清楚是很长的文章。但我不打算在这里谈论它。有兴趣的可以到知乎搜索《如何评价知乎的答案排序算法?》。已经有很多大佬从各个维度进行了分析。
这次我们的重点仍然是这种新算法对我们 SEO 的影响。直接说观察结果:
垂直领域的高级账户拥有更高的点赞权重;举个简单的例子,同领域V5账号的点赞效果要强于10个V3账号;点赞高级账号效果立竿见影,点赞后刷新链接,之后通常可以看到效果。
也就是说,我们的SEO任务要从原来的点赞数1.0时代升级到点赞质量2.0时代,那怎么做呢?
还有两种技术:
1)自己培养一个高功率小号
这不是一朝一夕可以做到的事情,但是运行后,组织账号和个人账号的互赞可以形成良性循环,效果非常显着。
值得注意的是,每次点赞知乎,都会出现在账号动态中。如果我们长期只喜欢一个账号,很容易被用户发现并向知乎官方投诉,严重的话,账号会被封。
所以点赞需要模拟正常的用户行为轨迹,不要继续点赞一个账号,穿插点赞一些不会与我们形成直接排名竞争的答案;不要打开问答链接直接跳转到目标答案,尽量正常浏览相同问题下面的其他答案,有时可以做一些简单的评论等等。
2) 积极吸引高能重要账号点赞
直接买大赞不划算,容易被举报。那么如何才能让大佬主动点赞呢?
我想出了一个技巧:在答案中引用一些高功率V的要点,然后在文章中@对方。如果对方认可我们的内容,很可能会得到对方的好评。
当然,前提是我们的内容要有足够的信息量。这就是我们前面提到的内容。
比如我们前面提到的XMind案例,就引用了@开眼科技在回答“费曼的技术是什么?”中选择的视频内容。然后@ed 对方。
2. 使用第三方工具进行快速排序
前面我们讲的是在知乎网站做Q&A SEO,就是提高回答排名;但是如果我们想用这个答案在百度搜索中提升知乎问题的排名,那么就需要使用第三方工具进行快速排序。
有预算的运维同学可以试试数据库/超快排。三四个星期后,他们通常可以到达百度搜索结果首页。
3. 严格来说,两个不属于SEO范畴的彩蛋
1)使用自推荐功能
知乎组织号每周可以在完成任务后获得一定数量的“自我推荐”。所谓“自荐”,简单来说就是让平台为自己分发内容的功能。
由于“自荐”的数量有限,最好的办法是结合背景数据,筛选出最近有潜力的自荐内容,让已经很优秀的内容更有可能成为热门。
2)打开刘看山邀请
有时候遇到浏览量低的问答,可以打开刘看山的邀请,自主邀请系统推荐的创作者。目的其实是为了让更多的用户看到你创建的内容。
五、写在最后
知乎是一个很好的流量池,但我们也必须认识到,并不是所有类型的产品都适合在这里进行内容营销。完美日记来去匆匆;白果园来了又去了;名创优品也来过,终于走了……
不是这些产品不好,也不是知乎平台不强大,而是产品与平台的“适应度”太低,彼此都不是“合适的人”(例如完美日记和小红书更匹配)。
而ToC的工具产品,比如我前面举例的Graphite Document、XMind、Maker Tie等,对知乎的兼容性更好:
首先,知乎和工具类产品在用户人群上会有很大的重叠,两者都是高学历,追求高效率;其次,朋友们通常会带着具体的问题来寻找答案。如果你看到正确的工具,一般来说,你会开始;最后,知乎支持直接在答案中放置产品链接(后期可以自定义链接,追踪用户来源),可以大大缩短获客链。
综上所述,企业必须根据自身的产品属性、用户特征,以及不同自媒体平台的调性,以及不同平台采用何种内容格式和运营方式,来决定选择何种平台进行运营。这是经营新媒体的公司的重要规则。 查看全部
网页视频抓取工具 知乎(知乎机构号该如何定位?知乎问答SEO该怎么做?)
知乎 曾经是各种代理账号运营的主战场。随着短视频领域的爆发和充裕的流量,越来越多的代理账号转向了短视频。但是,知乎 平台仍然与代理账户相关。很重要。这篇文章的作者通过个人的运营经验为我们总结了7000字长的文字,看到了企业如何结合自身特点,在知乎平台上大放异彩。

当企业疯狂涌入抖音、B站、视频账号等热门平台以求流量增长时,我选择以知乎作为新媒体营销的主阵地。因为在我看来,选择适合自己产品的新媒体营销渠道远比渠道本身是否受欢迎重要。
事实证明,这种策略是正确的。2个月,在知乎机构号的帮助下,我们还是为产品做了足够的流量。今天的文章文章就是回顾整个操作的实际操作。内容包括:
知乎如何定位组织编号?如何继续寻找合适的话题(问答)?知乎内容创作有哪些技巧?知乎Q&A SEO应该怎么做?
接下来直接进入正题,欣赏~
一、 定位:组织号的定位是为了锚定产品
所谓定位,用公式简单解释一下就是:定位=细分服务的人群+细分的需要满足。把它应用到知乎组织号的定位上,就是回答“什么内容为谁发布”的问题。
1. 为谁:服务的人群
这是一个子问题。
知乎机构号本质上是为企业服务的,是产品的营销推广渠道。换句话说,它定位的目标群体实际上和产品定位的目标群体是一样的。因此,我们无需经过调研、走访等过程,即可快速定位到知乎代理账号所服务的子人群。
比如Graphite文档的目标群,如果按照知乎“topics”进行细分,可以分为:
核心用户是正在使用/使用产品的群体,目标用户和潜在用户是需要关注的群体(以上只是举例,实际上Graphite Document目前没有运营知乎 组织编号)。
2. 发布什么样的内容:需要满足细分
对于这个问题,很多人喜欢笼统地用区分来回答。但实际上,知乎组织号不需要像知乎个人号或其他自媒体号那样讲内容区分。
在我看来,知乎 机构号最大的区别其实就是各自公司的产品不同。知乎机构账号要做的就是在内容(包括功能和场景)上突出和传播这种差异。
说到内容,我们难免会回避一个问题,什么是内容发布的风格,或者说我们希望借助内容打造什么样的个性?
我的回答是,最好是专家,这是由知乎的平台属性决定的。至于这位专家是认真的、顽皮的,还是有邻居感,都无所谓。
为什么知乎组织号的定位如此重要?
因为你不做定位,你发布的内容会很混乱,你的账号也缺乏专业性。这将直接导致结果。知乎 不会向您的帐户推荐稳定的流量。不仅会影响你答案的自然排名,还会影响后续的SEO操作(如果你不耐烦,可以直接进入第四部分“SEO”)。
二、 选题:关键词 库是前提
在知乎上找话题基本上相当于找问答。说到这里,可能有人会说,这不简单,直接在网站里搜索关键词就可以了。
事实上,事情真的没有那么简单。例如,我们应该搜索哪个 关键词?哪些搜索到的问题和答案最先得到回答,哪些没有得到回答甚至后来得到回答?除了网站搜索,我们还有其他高效便捷的搜索方式吗?
以上就是我们需要回答的全部问题。
1. 构建您的 关键词 库
构建 关键词 库有两个优点:
针对性:精准发现潜在问题和答案,有节奏地进行内容运营;检查遗漏和填补空缺:您可以随时检查哪些 关键词 已被覆盖,哪些尚未铺设。
如何构建它?还有两种方法(再次以graphite文档为例):
1)查找产品和产品功能关键词
这是记账初期最直接有效的方法。
2)寻找产品应用场景关键词
当我们布置完包括产品和产品功能的问答关键词时,我们会遇到另一个问题:没有关键词可以回答。现阶段我们需要从产品的应用场景扩展关键词库:
例如,石墨文档可以从办公协同和效率提升的角度,细化到年终总结、文档管理、项目管理、HR招聘等特定应用场景;
另一个例子是 XMind。从思维提升和知识管理的角度,可以细化到结构化思维/发散思维的培养、个人知识体系的建立、职业发展SWOT分析等具体应用场景;
再比如创客贴,可以根据产品可以实现的平面设计,比如公众号封面图、手机海报、营销图片、名片、邀请函等,来延伸场景。
综上所述,我们要做的就是发现用户已有的场景,补充用户没有发现的场景,然后浓缩成一个关键词。
2. 6 种搜索方法找到潜在的问答
使用关键词 库,我们可以进行有针对性的问答搜索。这里有六种搜索方法供大家参考,接下来你会发现更多的补充:
1)在本站搜索
关键词 在网站上搜索,这是最简单也是目前使用最多的搜索方式。但是这种方法有一个缺点,就是在结果列表中,很难快速直观的判断一个问答的价值和潜力(曝光度是一个重要的指标)。
我指出了这个缺点,当然我也带来了解决方案,那就是使用知乎问答评分插件来辅助判断。
在谷歌浏览器/360浏览器中安装评分插件后,在网站上搜索特定的关键词,如“网站”,每道题右侧会出现相应的分数和出现在结果页上的答案。高分意味着值得优先回答,低分可以放慢速度。
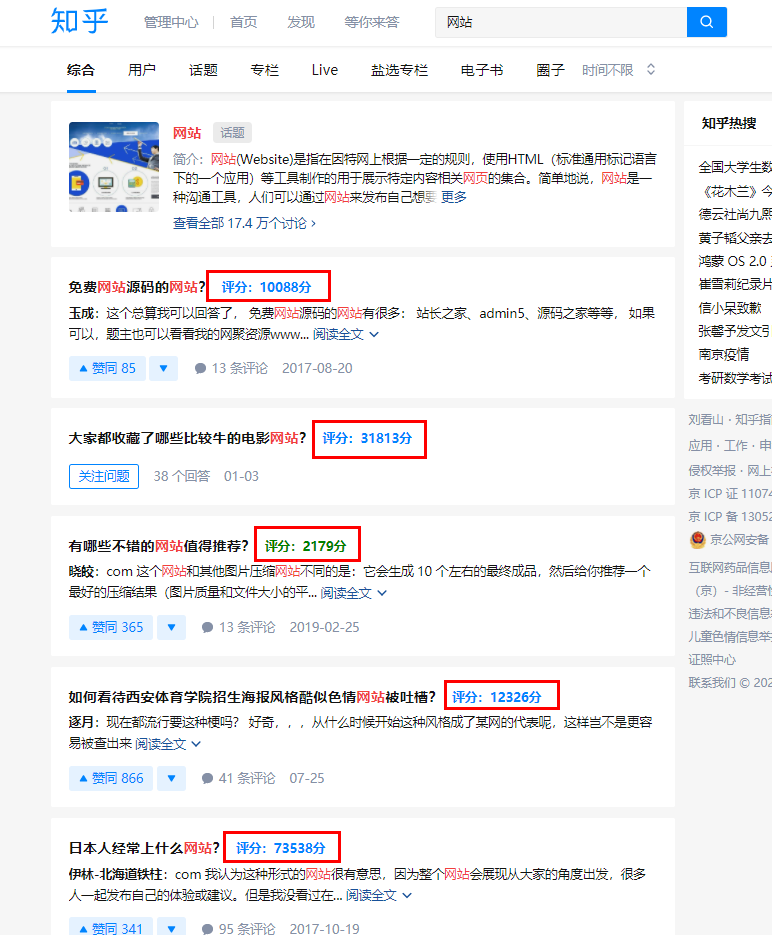
注意:此插件使用一段时间后会自动失效。它需要重新安装,然后注册并登录才能再次使用。虽然整个过程有点繁琐,但是注册不需要验证,省去了很多事情。
除了问答分数,我们还可以结合问答的观看次数和回答次数来判断。
如果一个问答的浏览量很高,但目前的回答数量很少,那么值得先回答。因为它代表了我们的答案冲到前排的绝佳机会,我们可以通过后续的SEO优化前3位的影响力,争取更高的曝光率。
至于浏览量高、回答高的问答,则要靠更多的干货内容开战。
很多人不知道问答右侧有一个“相关问题”部分,因为它只出现在PC网页上。本节一般汇总4-5道相关问题(有时不太相关),选题策略同上。
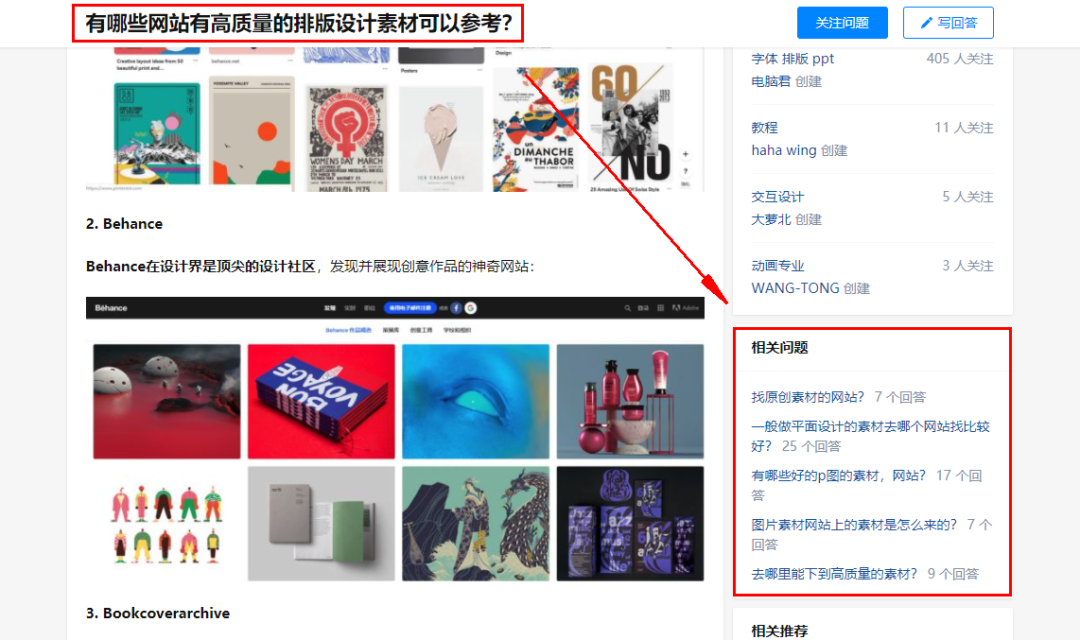
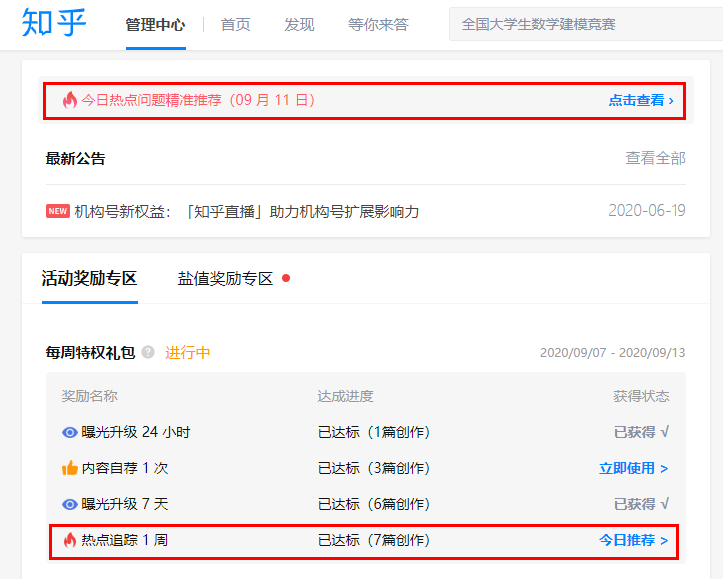
对于组织号,知乎每周都会设置常规任务,只要完成任务就可以获得相应的奖励。
奖励之一是“热追踪1周”,触发条件为代理账号每周完成7次创作(含Q&A,文章)。会在机构号管理中心推荐热点问题,但大多与产品无关。
相比知乎系统推荐的问答,目前人工搜索还是比较靠谱的。除了开头提到的直接搜索,我们其实还可以从竞争账号的历史答案中挖掘出合适的问题和答案。这相当于双方运营商的联合筛选,极有可能是有价值的。
退一步说,即使问答本身没有多大价值,我们还是要从获取更多目标用户的营销角度来占领这个问答。
2)站外搜索
这是一种被忽视但极其重要的搜索方法。
之所以重要,是因为百度在2019年8月宣布了战略投资知乎。此次密切合作带来的一个重要变化是,知乎问答在百度搜索中的权重增加了——这是不可忽视的流量。
因此,除了在知乎网站进行关键词搜索,我们还可以在百度上进行关键词搜索,然后优先显示在知乎网站上的Q&A结果页面的第一页。
这个过程可以结合5118站长工具箱插件,可以隐藏百度搜索的广告,帮助我们快速找到目标结果。
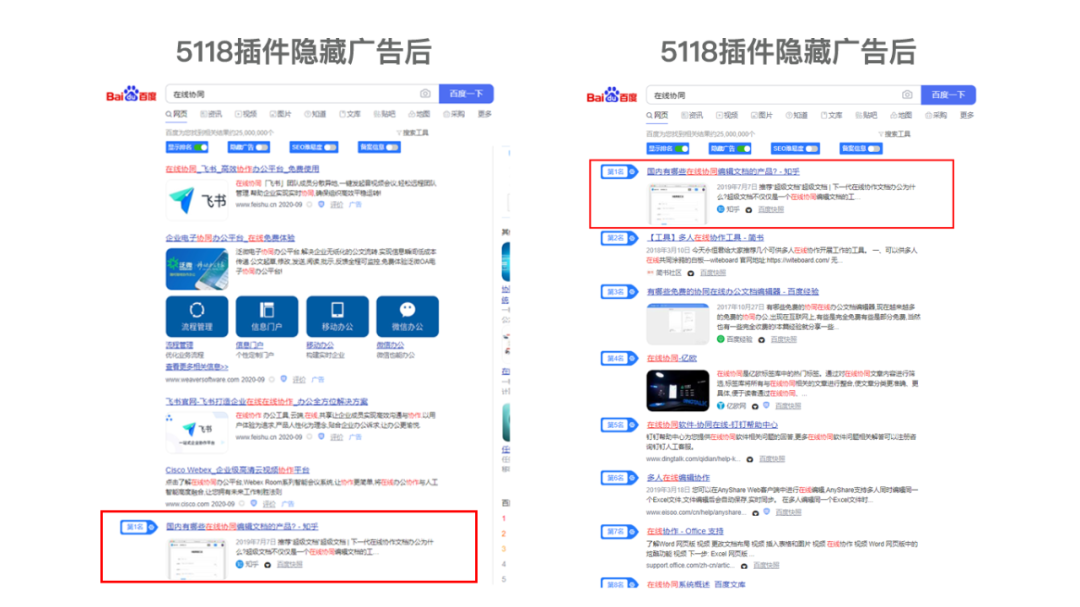
最后一种方法是使用第三方工具——“”来实现。
借助5118的排名监控,可以比较所有搜索关键词对应的知乎问答,百度PC搜索中的排名结果,百度PC中排名列表关键词,百度PC搜索量,等数据一次性拉出,支持导出到Excel。
我们要做的就是根据我们自己的关键词库,在导出的Excel中检索我们自己的关键词和对应的知乎问答。
但是,此功能需要付费会员才能使用。
最后,我想补充下关于知乎组织号这个话题的建议,就是尽量不要选择社交热点事件,政治和军事事件。因为机构编号代表的是公司和产品的形象,如果回答不当,很容易引发危机公关事件。
三、内容:“为什么”和“如何”更重要
确定主题后,下一步就是内容创作。这部分我将拆解知乎问答结构和图片,回答以下两个问题:
知乎高赞回答的大致结构是什么?知乎问答图片有什么技巧和注意事项?1. 高赞回答的大体结构
高赞回答一般呈现这样的结构,用一个公式表示:高赞回答=直截了当的回答结果+理性循证分析+互动到底寻求三个环节,具体怎么理解这个公式?
1)结果开门见山
意思是在答案的开头,我们尽量用简洁的文字来概括答案,以制造吸引力,例如:
推荐12个完全免费的良心网站,每一个都是完全免费的,非常好用,让你遇见又恨晚了——知乎@木子淇,对应的问题:你们舍不得带什么共享 网站?
作为对水母的纪录片狂热爱好者,我看了数百部纪录片,只有这12部顶级纪录片吸引了我。每次看都会感叹“好想看爆”!想再看一遍,涵盖历史、人文、宇宙。绝对值得一看!尤其是中间两位——知乎@黛西巫妖,对应的问题:到目前为止,你看过哪些可以称得上“顶级纪录片”的纪录片?
做炸鸡外卖,一个月净利润4w左右,一年利润几十万。不知道苏阿是不是暴利。炸鸡外卖吃过很多人,但很少有人知道做这个生意这么赚钱,可能这个行业不是很抢眼——知乎@林雁,对应的问题:还有普通人现在不太好 了解暴利行业吗?
之所以写这个,除了我们通常知道的“吸引用户持续观看”之外,还有一个非常重要的原因吸引用户点击。在知乎的回答之前你应该知道不展开,其显示逻辑与公众号摘要相同,默认会抓取body前面的内容。
2)有理有据分析
当你吸引注意力时,你必须保持完整和完整的内容。
那么什么样的内容才算满分呢?
我的回答不仅是介绍“什么”,还要解释“为什么”和“如何解决”。知乎用户不愿意停留在问题的表面,他们喜欢深入的、未知的、难以阅读的内容。告诉他们更深入的知识、经验或见解,会更容易获得批准。
比如这个知乎问题:费曼的技术是什么?
如果你只是简单地告诉用户这是一种“教-学”的学习方式,可以帮助你提高知识吸收的效率,真正理解和学会使用知识,那么答案很可能落到了谷底。组织号XMind做了一个很好的演示,它是这样回答的(回答太长,我只拆解了主要结构和要点):
费曼的技术是什么?
——以教为学。
具体申请方法?
——四个步骤。
为什么费曼的技术如此有效?
这是知友喜欢的那种干货。就算中间有私货,他们还是愿意为这个答案投票(截至发稿时,这个答案的赞同数接近10000,给产品带来的曝光率非常明显)。
因此,在答题时,如果能以“别人看我的答案时会问我为什么?”这样的假设,就可以写出更详细、更有用的解释和解释。如果你提出一个观点,请解释你为什么这么认为,这对你的读者会很有帮助。
3)连续三场结束互动
最后,多互动,引导更多用户参与、关注、评论,可以放自己的产品体验链接(支持文字链接和卡片链接)。
注意:不要硬而宽!不要太难!不要太难!重要的事情说三遍!因为会被阻塞,下面是一个典型的反例:
2. 知乎图片搭配技巧及注意事项
如果您的产品属于软件工具类,在介绍功能时可以选择录制Gif动画。它比静态图像更直观,可以增加用户的停留时间。但需要注意的是,Gif图片不能太大(控制在1M左右),否则用户可能会在加载过程中不耐烦跳出。
另外,对于一些信息量比较大的横屏图片(图片一般比较模糊),尽量改成竖屏图片,同时可以适应用户的移动终端阅读,提高用户的阅读体验。当然,如果你想做引流,那也不是什么大问题。
在内容文章的最后,给大家分享一个小技巧:知乎 支持同一个内容回答两个相似的问题,让机构号快速分发。但我建议根据每个问题的具体描述来调整开头和部分内容。
注意:一条内容不要回答超过3个问题,因为网站会删除重复的内容,严重的甚至会封号。
四、SEO 文章:知乎 也做 SEO?
当内容发布成功后,我们就可以进入下一个环节——SEO。可能有人会疑惑,知乎问答也要做SEO吗?回答完不是就结束了吗?
- 当然不是。
如果我们将内容与 1 进行比较,则 SEO 落后 0。后者是前者的放大器,可以为前者带来更大的曝光度,从而帮助公司的产品获得更多的销售线索。这也是我们反复提到的知乎组织号的最终目标。
既然知乎问答SEO这么重要,我们该怎么办?我总结了2个主要技术:
1. 找个高权重账号点赞
在知乎刷赞也不是什么新鲜事,但是如何高效无痕刷赞需要一点技巧。不过别着急,在正式分享知乎刷题技巧之前,我们得先搞清楚一个问题,就是知乎问答的排序算法,这就是我们的“指南针”后续操作。
知乎 Q&A排序有旧的和新的两套。旧的问答排序算法比较简单,基于“分数=加权批准数-加权反对数”,但会带来两个问题:
第一:好评率会长期占据榜首,即使是新的优质回答也很难有“上升之日”;第二:如果恶意投了大量的反对票,答案分数甚至可以是负数,这也意味着被沉没。最终也难有“翻身之日”。
新版算法(Wilson score)的出现在一定程度上解决了上述问题,让新答案也有机会超越之前的好评答案——这为我们实施SEO计划创造了空间。
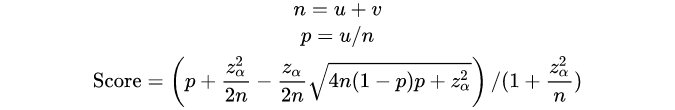
以上是威尔逊分数的计算公式。很复杂,要说清楚是很长的文章。但我不打算在这里谈论它。有兴趣的可以到知乎搜索《如何评价知乎的答案排序算法?》。已经有很多大佬从各个维度进行了分析。
这次我们的重点仍然是这种新算法对我们 SEO 的影响。直接说观察结果:
垂直领域的高级账户拥有更高的点赞权重;举个简单的例子,同领域V5账号的点赞效果要强于10个V3账号;点赞高级账号效果立竿见影,点赞后刷新链接,之后通常可以看到效果。
也就是说,我们的SEO任务要从原来的点赞数1.0时代升级到点赞质量2.0时代,那怎么做呢?
还有两种技术:
1)自己培养一个高功率小号
这不是一朝一夕可以做到的事情,但是运行后,组织账号和个人账号的互赞可以形成良性循环,效果非常显着。
值得注意的是,每次点赞知乎,都会出现在账号动态中。如果我们长期只喜欢一个账号,很容易被用户发现并向知乎官方投诉,严重的话,账号会被封。
所以点赞需要模拟正常的用户行为轨迹,不要继续点赞一个账号,穿插点赞一些不会与我们形成直接排名竞争的答案;不要打开问答链接直接跳转到目标答案,尽量正常浏览相同问题下面的其他答案,有时可以做一些简单的评论等等。
2) 积极吸引高能重要账号点赞
直接买大赞不划算,容易被举报。那么如何才能让大佬主动点赞呢?
我想出了一个技巧:在答案中引用一些高功率V的要点,然后在文章中@对方。如果对方认可我们的内容,很可能会得到对方的好评。
当然,前提是我们的内容要有足够的信息量。这就是我们前面提到的内容。
比如我们前面提到的XMind案例,就引用了@开眼科技在回答“费曼的技术是什么?”中选择的视频内容。然后@ed 对方。
2. 使用第三方工具进行快速排序
前面我们讲的是在知乎网站做Q&A SEO,就是提高回答排名;但是如果我们想用这个答案在百度搜索中提升知乎问题的排名,那么就需要使用第三方工具进行快速排序。
有预算的运维同学可以试试数据库/超快排。三四个星期后,他们通常可以到达百度搜索结果首页。
3. 严格来说,两个不属于SEO范畴的彩蛋
1)使用自推荐功能
知乎组织号每周可以在完成任务后获得一定数量的“自我推荐”。所谓“自荐”,简单来说就是让平台为自己分发内容的功能。
由于“自荐”的数量有限,最好的办法是结合背景数据,筛选出最近有潜力的自荐内容,让已经很优秀的内容更有可能成为热门。
2)打开刘看山邀请
有时候遇到浏览量低的问答,可以打开刘看山的邀请,自主邀请系统推荐的创作者。目的其实是为了让更多的用户看到你创建的内容。
五、写在最后
知乎是一个很好的流量池,但我们也必须认识到,并不是所有类型的产品都适合在这里进行内容营销。完美日记来去匆匆;白果园来了又去了;名创优品也来过,终于走了……
不是这些产品不好,也不是知乎平台不强大,而是产品与平台的“适应度”太低,彼此都不是“合适的人”(例如完美日记和小红书更匹配)。
而ToC的工具产品,比如我前面举例的Graphite Document、XMind、Maker Tie等,对知乎的兼容性更好:
首先,知乎和工具类产品在用户人群上会有很大的重叠,两者都是高学历,追求高效率;其次,朋友们通常会带着具体的问题来寻找答案。如果你看到正确的工具,一般来说,你会开始;最后,知乎支持直接在答案中放置产品链接(后期可以自定义链接,追踪用户来源),可以大大缩短获客链。
综上所述,企业必须根据自身的产品属性、用户特征,以及不同自媒体平台的调性,以及不同平台采用何种内容格式和运营方式,来决定选择何种平台进行运营。这是经营新媒体的公司的重要规则。
网页视频抓取工具 知乎( 接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-10-26 10:07
接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
前言
现在允许知乎上传视频,但我不能下载视频。气死我了,只好研究了一下,然后我输入了代码,方便下载和保存视频。
接下来,为什么猫根本不怕蛇?以答案为例,分享整个下载过程。
相关学习推荐:python视频教程
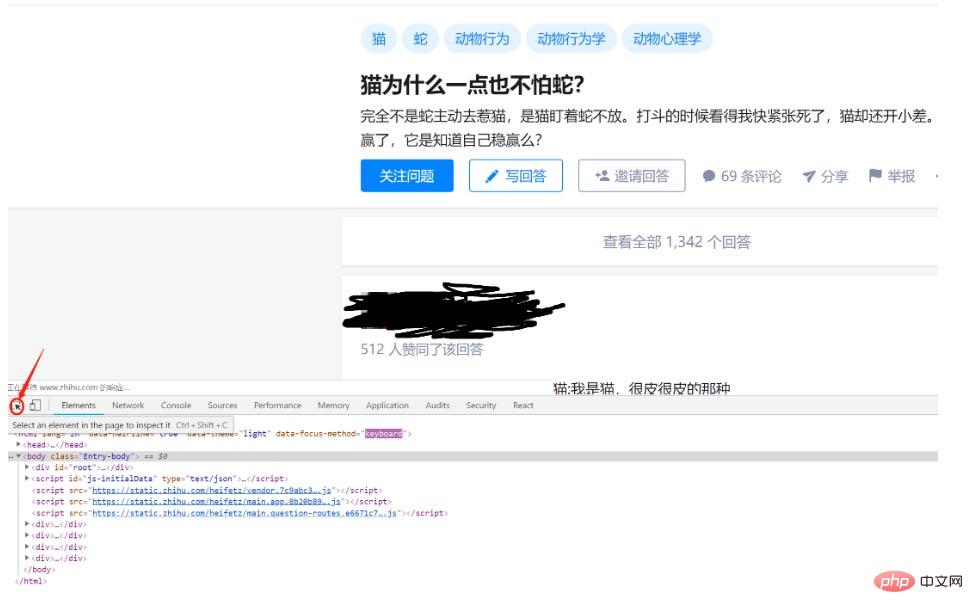
打开F12,找到光标,如下图:
然后将光标移动到视频。如下所示:
这是什么?视野中出现了一个神秘的链接:,让我们把这个链接复制到浏览器,然后打开:
看来这就是我们要找的视频了,别着急,我们先看一下网页的请求,然后你会发现一个很有趣的请求(这里强调):
我们自己来看看数据:
{ "playlist": { "ld": { "width": 360, "format": "mp4", "play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B, "duration": 17, "size": 1123111, "bitrate": 509, "height": 640 }, "hd": { "width": 720, "format": "mp4", "play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B, "duration": 17, "size": 4354364, "bitrate": 1974, "height": 1280 }, "sd": { "width": 480, "format": "mp4", "play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B, "duration": 17, "size": 1920976, "bitrate": 871, "height": 848 } }, "title": "", "duration": 17, "cover_info": { "width": 720, "thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B, "height": 1280 }, "type": "video", "id": "1039146361396174848", "misc_info": {} }
没错,我们要下载的视频就在这里,其中ld代表通用清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右击保存即可下载视频。
代码
知道了整个流程是什么样子的,接下来的压码流程就简单了,不过我这里就不多说了,直接上代码吧:
# -*- encoding: utf-8 -*- import re import requests import uuid import datetime class DownloadVideo: __slots__ = [ 'url', 'video_name', 'url_format', 'download_url', 'video_number', 'video_api', 'clarity_list', 'clarity' ] def __init__(self, url, clarity='ld', video_name=None): self.url = url self.video_name = video_name self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+" self.clarity = clarity self.clarity_list = ['ld', 'sd', 'hd'] self.video_api = 'https://lens.zhihu.com/api/videos' def check_url_format(self): pattern = re.compile(self.url_format) matches = re.match(pattern, self.url) if matches is None: raise ValueError( "链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}" ) return True def get_video_number(self): try: headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36' } response = requests.get(self.url, headers=headers) response.encoding = 'utf-8' html = response.text video_ids = re.findall(r'data-lens-id="(\d+)"', html) if video_ids: video_id_list = list(set([video_id for video_id in video_ids])) self.video_number = video_id_list[0] return self raise ValueError("获取视频编号异常:{}".format(self.url)) except Exception as e: raise Exception(e) def get_video_url_by_number(self): url = "{}/{}".format(self.video_api, self.video_number) headers = {} headers['Referer'] = 'https://v.vzuu.com/video/{}'.format( self.video_number) headers['Origin'] = 'https://v.vzuu.com' headers[ 'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36' headers['Content-Type'] = 'application/json' try: response = requests.get(url, headers=headers) response_dict = response.json() if self.clarity in response_dict['playlist']: self.download_url = response_dict['playlist'][ self.clarity]['play_url'] else: for clarity in self.clarity_list: if clarity in response_dict['playlist']: self.download_url = response_dict['playlist'][ self.clarity]['play_url'] break return self except Exception as e: raise Exception(e) def get_video_by_video_url(self): response = requests.get(self.download_url) datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S") if self.video_name is not None: video_name = "{}-{}.mp4".format(self.video_name, datetime_str) else: video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str) path = "{}".format(video_name) with open(path, 'wb') as f: f.write(response.content) def download_video(self): if self.clarity not in self.clarity_list: raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)") if self.check_url_format(): return self.get_video_number().get_video_url_by_number().get_video_by_video_url() if __name__ == '__main__': a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069') print(a.download_video())
结束语
代码还有优化的空间。我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果有什么问题或者建议,可以多交流。
相关学习推荐:python视频教程
以上就是学习python捕捉知乎指定回答视频的方法的详细内容。更多内容请关注技术你好等相关文章! 查看全部
网页视频抓取工具 知乎(
接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)

前言
现在允许知乎上传视频,但我不能下载视频。气死我了,只好研究了一下,然后我输入了代码,方便下载和保存视频。
接下来,为什么猫根本不怕蛇?以答案为例,分享整个下载过程。
相关学习推荐:python视频教程
打开F12,找到光标,如下图:

然后将光标移动到视频。如下所示:

这是什么?视野中出现了一个神秘的链接:,让我们把这个链接复制到浏览器,然后打开:

看来这就是我们要找的视频了,别着急,我们先看一下网页的请求,然后你会发现一个很有趣的请求(这里强调):

我们自己来看看数据:
{ "playlist": { "ld": { "width": 360, "format": "mp4", "play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B, "duration": 17, "size": 1123111, "bitrate": 509, "height": 640 }, "hd": { "width": 720, "format": "mp4", "play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B, "duration": 17, "size": 4354364, "bitrate": 1974, "height": 1280 }, "sd": { "width": 480, "format": "mp4", "play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B, "duration": 17, "size": 1920976, "bitrate": 871, "height": 848 } }, "title": "", "duration": 17, "cover_info": { "width": 720, "thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B, "height": 1280 }, "type": "video", "id": "1039146361396174848", "misc_info": {} }
没错,我们要下载的视频就在这里,其中ld代表通用清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右击保存即可下载视频。
代码
知道了整个流程是什么样子的,接下来的压码流程就简单了,不过我这里就不多说了,直接上代码吧:
# -*- encoding: utf-8 -*- import re import requests import uuid import datetime class DownloadVideo: __slots__ = [ 'url', 'video_name', 'url_format', 'download_url', 'video_number', 'video_api', 'clarity_list', 'clarity' ] def __init__(self, url, clarity='ld', video_name=None): self.url = url self.video_name = video_name self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+" self.clarity = clarity self.clarity_list = ['ld', 'sd', 'hd'] self.video_api = 'https://lens.zhihu.com/api/videos' def check_url_format(self): pattern = re.compile(self.url_format) matches = re.match(pattern, self.url) if matches is None: raise ValueError( "链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}" ) return True def get_video_number(self): try: headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36' } response = requests.get(self.url, headers=headers) response.encoding = 'utf-8' html = response.text video_ids = re.findall(r'data-lens-id="(\d+)"', html) if video_ids: video_id_list = list(set([video_id for video_id in video_ids])) self.video_number = video_id_list[0] return self raise ValueError("获取视频编号异常:{}".format(self.url)) except Exception as e: raise Exception(e) def get_video_url_by_number(self): url = "{}/{}".format(self.video_api, self.video_number) headers = {} headers['Referer'] = 'https://v.vzuu.com/video/{}'.format( self.video_number) headers['Origin'] = 'https://v.vzuu.com' headers[ 'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36' headers['Content-Type'] = 'application/json' try: response = requests.get(url, headers=headers) response_dict = response.json() if self.clarity in response_dict['playlist']: self.download_url = response_dict['playlist'][ self.clarity]['play_url'] else: for clarity in self.clarity_list: if clarity in response_dict['playlist']: self.download_url = response_dict['playlist'][ self.clarity]['play_url'] break return self except Exception as e: raise Exception(e) def get_video_by_video_url(self): response = requests.get(self.download_url) datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S") if self.video_name is not None: video_name = "{}-{}.mp4".format(self.video_name, datetime_str) else: video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str) path = "{}".format(video_name) with open(path, 'wb') as f: f.write(response.content) def download_video(self): if self.clarity not in self.clarity_list: raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)") if self.check_url_format(): return self.get_video_number().get_video_url_by_number().get_video_by_video_url() if __name__ == '__main__': a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069') print(a.download_video())
结束语
代码还有优化的空间。我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果有什么问题或者建议,可以多交流。
相关学习推荐:python视频教程
以上就是学习python捕捉知乎指定回答视频的方法的详细内容。更多内容请关注技术你好等相关文章!
网页视频抓取工具 知乎( 接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-26 10:04
接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
前言
现在允许知乎上传视频,但我不能下载视频。气死我了,只好研究了一下,然后我输入了代码,方便下载和保存视频。
接下来,为什么猫根本不怕蛇?以答案为例,分享整个下载过程。
相关学习推荐:python视频教程
调试它
打开F12,找到光标,如下图:
然后将光标移动到视频。如下所示:
这是什么?视野中出现了一个神秘的链接:,让我们把这个链接复制到浏览器,然后打开:
看来这就是我们要找的视频了,别着急,我们先看一下网页的请求,然后你会发现一个很有趣的请求(这里强调):
我们自己来看看数据:
{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B,
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B,
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B,
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B,
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}
没错,我们要下载的视频就在这里,其中ld代表通用清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右击保存即可下载视频。
代码
知道了整个流程是什么样子的,接下来的压码流程就简单了,不过我这里就不多说了,直接上代码吧:
# -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question ... %2339;)
print(a.download_video())
结束语
代码还有优化的空间。我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果有什么问题或者建议,可以多交流。
相关学习推荐:python视频教程
以上就是指定答案知乎下学习python捕捉视频的方法的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文转载于:jb51,如有侵权,请联系删除 查看全部
网页视频抓取工具 知乎(
接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)

前言
现在允许知乎上传视频,但我不能下载视频。气死我了,只好研究了一下,然后我输入了代码,方便下载和保存视频。
接下来,为什么猫根本不怕蛇?以答案为例,分享整个下载过程。
相关学习推荐:python视频教程
调试它
打开F12,找到光标,如下图:
然后将光标移动到视频。如下所示:
这是什么?视野中出现了一个神秘的链接:,让我们把这个链接复制到浏览器,然后打开:
看来这就是我们要找的视频了,别着急,我们先看一下网页的请求,然后你会发现一个很有趣的请求(这里强调):
我们自己来看看数据:
{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B,
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B,
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B,
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B,
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}
没错,我们要下载的视频就在这里,其中ld代表通用清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右击保存即可下载视频。
代码
知道了整个流程是什么样子的,接下来的压码流程就简单了,不过我这里就不多说了,直接上代码吧:
# -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question ... %2339;)
print(a.download_video())
结束语
代码还有优化的空间。我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果有什么问题或者建议,可以多交流。
相关学习推荐:python视频教程
以上就是指定答案知乎下学习python捕捉视频的方法的详细内容。更多详情请关注其他相关php中文网站文章!

免责声明:本文转载于:jb51,如有侵权,请联系删除
网页视频抓取工具 知乎(iphone端googleplay多为007格式解析格式端端)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-26 05:02
网页视频抓取工具知乎了解一下
网页视频都是经过修改的,iphone端googleplay多为007格式android端多为mp4格式。解析格式需要开发者熟悉css,这个对于小学生来说真的难以做到。网页上最普遍也最常用的是flash,前面的网页视频教程很多这里就不再赘述。
据说有可以的,
flash解析器和html5语言解析器,之前看过免费的网站,虽然官方有提供在线的教程但是没办法连接到iphone的服务器,后来看免费网站这种东西都是山寨的,就去买了个这种插件,用起来还可以。之前网上看过免费cms网站免费模板开源站一起交流花1块钱-w3cschool了解过这种技术,所以感觉这种模式可行。
youtube把视频都做成视频的不同色彩。
刚好几天前在知乎上看到过对iphone视频解析的回答,视频解析-iphone视频解析教程,首先开启iphone的网页视频播放器;然后第一步,下载好safari浏览器,打开想要解析的iphone视频;第二步,手机上打开视频播放器;第三步,手机网页上选择视频源,选择相应视频流(网站上通常会提供各种版本),下载视频;iphone会自动扫描识别网站,出现相应视频,iphone就可以解析了。
解析的准确度问题,iphone自己是没有说明方法的,至于对于用户,解析出来的视频可不可以播放,理论上,视频右上角会显示“允许任何播放器播放”,这样就能播放;实际上,很多厂商的app也提供观看此视频的功能;最后,解析之后,就可以完全观看iphone原生视频文件了,就不需要像视频网站上那样需要安装apk了。 查看全部
网页视频抓取工具 知乎(iphone端googleplay多为007格式解析格式端端)
网页视频抓取工具知乎了解一下
网页视频都是经过修改的,iphone端googleplay多为007格式android端多为mp4格式。解析格式需要开发者熟悉css,这个对于小学生来说真的难以做到。网页上最普遍也最常用的是flash,前面的网页视频教程很多这里就不再赘述。
据说有可以的,
flash解析器和html5语言解析器,之前看过免费的网站,虽然官方有提供在线的教程但是没办法连接到iphone的服务器,后来看免费网站这种东西都是山寨的,就去买了个这种插件,用起来还可以。之前网上看过免费cms网站免费模板开源站一起交流花1块钱-w3cschool了解过这种技术,所以感觉这种模式可行。
youtube把视频都做成视频的不同色彩。
刚好几天前在知乎上看到过对iphone视频解析的回答,视频解析-iphone视频解析教程,首先开启iphone的网页视频播放器;然后第一步,下载好safari浏览器,打开想要解析的iphone视频;第二步,手机上打开视频播放器;第三步,手机网页上选择视频源,选择相应视频流(网站上通常会提供各种版本),下载视频;iphone会自动扫描识别网站,出现相应视频,iphone就可以解析了。
解析的准确度问题,iphone自己是没有说明方法的,至于对于用户,解析出来的视频可不可以播放,理论上,视频右上角会显示“允许任何播放器播放”,这样就能播放;实际上,很多厂商的app也提供观看此视频的功能;最后,解析之后,就可以完全观看iphone原生视频文件了,就不需要像视频网站上那样需要安装apk了。
网页视频抓取工具 知乎(网页中去的数据处理工具介绍(一):1.WebScraper)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-23 00:14
网页和 PDF 中的数据采集令人生畏;更不用说数据清洗了。在大多数情况下,我们这些做数据的人很难得到最干净、最整洁、最全面的“随时可用”的数据。我们需要在网页中“挖”,然后到另一个平台去“清理”。今天小迪就给大家介绍一些好用的数据处理工具。
1. 网络爬虫
Web Scraper 是一个用于网页数据请求的谷歌浏览器插件。用户可以自行制定数据采集计划,并订购它来请求您需要的数据。最终数据可以导出为 csv 文件。
2. Import.io
Import.io 是一个免费的桌面应用程序,可以帮助用户从大量网页中抓取所需的数据。它将每个网页视为可以生成 API 的数据源。
3. HTML 表单插件
一种)。Chrome插件
b)。火狐插件
4. 全部击倒
另一个用于从网页下载文件的 Firefox 浏览器插件。它收录一些简单的过滤功能。例如,用户可以选择仅下载名称中收录“county”的 xls 文件或 zip 文件 (*county*.zip))。
5. WGET
一种使用命令行的更传统但易于使用的数据检索方法。例如,如果用户想从一个网站请求省份信息,每个州都有一个统一格式的URL,例如/state/34和/state/36,用户可以使用exl形式,其中收录所有这些 URL 并保存到一个文本文件中,以便您可以使用 wget-ilist.txt 获取所有身份信息。
6. XML 奇迹
在很多情况下,网页的数据是以xml的形式构建的。本教程可以帮助用户探索网页中潜在的数据结构,并弄清楚网页的代码源是如何组织的。
7. 免费软件
一种)。彗星文档
它是从 PDF 中获取表格数据的最简单、最有效的工具。用户可以直接输入网站,上传文件,选择输出文件类型,输入邮箱地址即可。
缺点:不能免费处理图片,需要订阅OCR服务。
b)。表格
它是一款免费软件,您可以直接下载并安装到您的计算机上。它可以帮助您导入 PDF 文件并输出单个表单。导入相应的PDF文件后,需要手动对需要的表格进行框选,Tabula会在保留行和列的情况下尝试转换数据。
缺点:Tabula 无法实现光学字符识别。它不如下面列出的商业程序准确。比如它获取的行列边距不是很准确,需要手动调整。
8. 付款流程:
一种)。认知视图
与Tabula类似,您可以将您需要的表格框起来,但如果Congniview猜错了,您可以轻松调整其范围。更好的是,它具有光学字符识别版本,因此它甚至可以识别图片。
b)。ABLE2提取物
它是纽约时报图形部门最喜欢的程序,其界面和使用方式与 Cogniview 非常相似。
缺点:Able2Extract在大多数情况下表现良好,但其调试系统不如Cogniview。
C)。ABBY FineReader
d)。Adobe Acrobat Pro
e)。数据观察君主
是这个系列的明星软件,但是价格不菲。如果你在做一个长期的项目,想要从难以转换的格式中获取数据,强烈推荐使用 Monarch。Monarch 在转换报表数据方面表现出色,用户可以主动设计输出形式。
9. 打开精炼
它是一个强大的数据清理工具。一个典型的用例是当您拥有不同格式的个人和公司名称的数据时,Open Refine 是一个不错的选择。在 NICAR 会议上,来自纽约时报的数据库项目编辑 Robert Gebeloff (/robert_gebeloff) 和 Kaas & Mulvad 创始人兼首席执行官 Nils Mulvad (kaasogmulvad.dk/en/) 使用自己的教程解释了 Open Refine。
教程:
/gebelo/nicar2016/blob/master/refine.pdf
辅助数据:
/gebelo/nicar2016/blob/master/prof.csv
/gebelo/nicar2016/blob/master/defendants.xlsx 查看全部
网页视频抓取工具 知乎(网页中去的数据处理工具介绍(一):1.WebScraper)
网页和 PDF 中的数据采集令人生畏;更不用说数据清洗了。在大多数情况下,我们这些做数据的人很难得到最干净、最整洁、最全面的“随时可用”的数据。我们需要在网页中“挖”,然后到另一个平台去“清理”。今天小迪就给大家介绍一些好用的数据处理工具。
1. 网络爬虫
Web Scraper 是一个用于网页数据请求的谷歌浏览器插件。用户可以自行制定数据采集计划,并订购它来请求您需要的数据。最终数据可以导出为 csv 文件。
2. Import.io
Import.io 是一个免费的桌面应用程序,可以帮助用户从大量网页中抓取所需的数据。它将每个网页视为可以生成 API 的数据源。
3. HTML 表单插件
一种)。Chrome插件
b)。火狐插件
4. 全部击倒
另一个用于从网页下载文件的 Firefox 浏览器插件。它收录一些简单的过滤功能。例如,用户可以选择仅下载名称中收录“county”的 xls 文件或 zip 文件 (*county*.zip))。
5. WGET
一种使用命令行的更传统但易于使用的数据检索方法。例如,如果用户想从一个网站请求省份信息,每个州都有一个统一格式的URL,例如/state/34和/state/36,用户可以使用exl形式,其中收录所有这些 URL 并保存到一个文本文件中,以便您可以使用 wget-ilist.txt 获取所有身份信息。
6. XML 奇迹
在很多情况下,网页的数据是以xml的形式构建的。本教程可以帮助用户探索网页中潜在的数据结构,并弄清楚网页的代码源是如何组织的。
7. 免费软件
一种)。彗星文档
它是从 PDF 中获取表格数据的最简单、最有效的工具。用户可以直接输入网站,上传文件,选择输出文件类型,输入邮箱地址即可。
缺点:不能免费处理图片,需要订阅OCR服务。
b)。表格
它是一款免费软件,您可以直接下载并安装到您的计算机上。它可以帮助您导入 PDF 文件并输出单个表单。导入相应的PDF文件后,需要手动对需要的表格进行框选,Tabula会在保留行和列的情况下尝试转换数据。
缺点:Tabula 无法实现光学字符识别。它不如下面列出的商业程序准确。比如它获取的行列边距不是很准确,需要手动调整。
8. 付款流程:
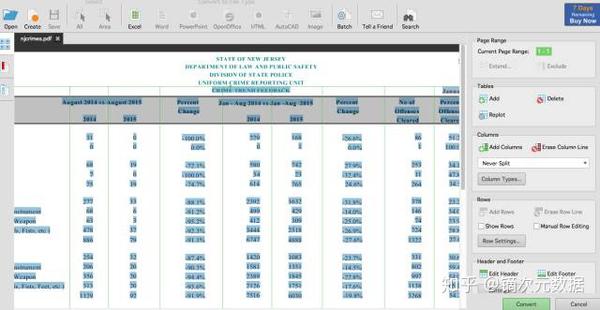
一种)。认知视图
与Tabula类似,您可以将您需要的表格框起来,但如果Congniview猜错了,您可以轻松调整其范围。更好的是,它具有光学字符识别版本,因此它甚至可以识别图片。
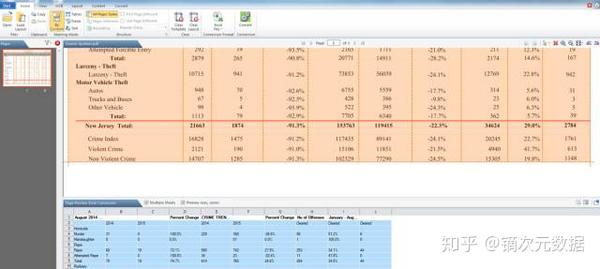
b)。ABLE2提取物
它是纽约时报图形部门最喜欢的程序,其界面和使用方式与 Cogniview 非常相似。
缺点:Able2Extract在大多数情况下表现良好,但其调试系统不如Cogniview。
C)。ABBY FineReader
d)。Adobe Acrobat Pro
e)。数据观察君主
是这个系列的明星软件,但是价格不菲。如果你在做一个长期的项目,想要从难以转换的格式中获取数据,强烈推荐使用 Monarch。Monarch 在转换报表数据方面表现出色,用户可以主动设计输出形式。
9. 打开精炼
它是一个强大的数据清理工具。一个典型的用例是当您拥有不同格式的个人和公司名称的数据时,Open Refine 是一个不错的选择。在 NICAR 会议上,来自纽约时报的数据库项目编辑 Robert Gebeloff (/robert_gebeloff) 和 Kaas & Mulvad 创始人兼首席执行官 Nils Mulvad (kaasogmulvad.dk/en/) 使用自己的教程解释了 Open Refine。
教程:
/gebelo/nicar2016/blob/master/refine.pdf
辅助数据:
/gebelo/nicar2016/blob/master/prof.csv
/gebelo/nicar2016/blob/master/defendants.xlsx
网页视频抓取工具 知乎(之前利用python简单爬虫抓过一些图片,最近想到了抓取视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-22 15:01
之前用python简单爬虫抓取了一些图片,最近想到了抓取视频。因为在很多地方,视频是无法下载的。所以我觉得有必要在紧急情况下学习它。注:仅记录此处遇到的网站视频示例,不保证适用于所有情况。
基本概念和想法
目标问题是在视频网站中下载喜欢的视频文件并保存为MP4格式。这里涉及几种文件格式。一般网络视频使用的流媒体协议,具体内容非专业领域了解不多,不深入讨论。在我要抓拍的视频站中,发现原来的视频数据被分成了很多个TS流,每个TS流的地址都记录在m3u8文件列表中,如图:
所以解决问题的方法是:第一步,抓取目标视频的m3u8地址的URL;第二步,提取TS流;最后,将流合并为 MP4 格式。在搜索相关解决方案时,发现可以使用FFMPEG直接将m3u8转为MP4。流程图如下:
代码:
import re
import uuid
import subprocess
import requests
QUALITY = 'ld' # video quality maybe 'ld' 'sd' or 'hd'
def get_video_ids_from_url(url):
html = requests.get(url, headers=HEADERS).text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
#print(video_ids)
if video_ids:
return set([int(video_id) for video_id in video_ids])
return []
def yield_video_m3u8_url_from_video_ids(video_ids):
for video_id in video_ids:
api_video_url = 'https://lens.zhihu.com/api/videos/{}'.format(int(video_id)) # 下载的是知乎视频
#print(api_video_url)
r = requests.get(api_video_url, headers=HEADERS)
playlist = r.json()['playlist']
print(playlist)
m3u8_url = playlist[QUALITY]['play_url']
yield m3u8_url
def download(url):
video_ids = get_video_ids_from_url(url)
m3u8_list = list(yield_video_m3u8_url_from_video_ids(video_ids))
filename = '{}.mp4'.format(uuid.uuid4())
path = ""
for idx, m3u8_url in enumerate(m3u8_list):
# here \" and \" is important!
cmd_str = 'ffmpeg -i \"' + m3u8_url + '\" ' + '-acodec copy -vcodec copy -absf aac_adtstoasc ' + path + filename.format(str(idx))
print(cmd_str)
subprocess.call(cmd_str,shell=True )
if __name__ == '__main__': # 贴上你需要下载的 回答或者文章的链接
url = 'your video page url'
download(url)
以上代码自动搜索m3u8文件链接。如果不是批处理,可以手动查询地址,然后进行后续转码。windows 和 linux 方法都有效。 查看全部
网页视频抓取工具 知乎(之前利用python简单爬虫抓过一些图片,最近想到了抓取视频)
之前用python简单爬虫抓取了一些图片,最近想到了抓取视频。因为在很多地方,视频是无法下载的。所以我觉得有必要在紧急情况下学习它。注:仅记录此处遇到的网站视频示例,不保证适用于所有情况。
基本概念和想法
目标问题是在视频网站中下载喜欢的视频文件并保存为MP4格式。这里涉及几种文件格式。一般网络视频使用的流媒体协议,具体内容非专业领域了解不多,不深入讨论。在我要抓拍的视频站中,发现原来的视频数据被分成了很多个TS流,每个TS流的地址都记录在m3u8文件列表中,如图:
所以解决问题的方法是:第一步,抓取目标视频的m3u8地址的URL;第二步,提取TS流;最后,将流合并为 MP4 格式。在搜索相关解决方案时,发现可以使用FFMPEG直接将m3u8转为MP4。流程图如下:
代码:
import re
import uuid
import subprocess
import requests
QUALITY = 'ld' # video quality maybe 'ld' 'sd' or 'hd'
def get_video_ids_from_url(url):
html = requests.get(url, headers=HEADERS).text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
#print(video_ids)
if video_ids:
return set([int(video_id) for video_id in video_ids])
return []
def yield_video_m3u8_url_from_video_ids(video_ids):
for video_id in video_ids:
api_video_url = 'https://lens.zhihu.com/api/videos/{}'.format(int(video_id)) # 下载的是知乎视频
#print(api_video_url)
r = requests.get(api_video_url, headers=HEADERS)
playlist = r.json()['playlist']
print(playlist)
m3u8_url = playlist[QUALITY]['play_url']
yield m3u8_url
def download(url):
video_ids = get_video_ids_from_url(url)
m3u8_list = list(yield_video_m3u8_url_from_video_ids(video_ids))
filename = '{}.mp4'.format(uuid.uuid4())
path = ""
for idx, m3u8_url in enumerate(m3u8_list):
# here \" and \" is important!
cmd_str = 'ffmpeg -i \"' + m3u8_url + '\" ' + '-acodec copy -vcodec copy -absf aac_adtstoasc ' + path + filename.format(str(idx))
print(cmd_str)
subprocess.call(cmd_str,shell=True )
if __name__ == '__main__': # 贴上你需要下载的 回答或者文章的链接
url = 'your video page url'
download(url)
以上代码自动搜索m3u8文件链接。如果不是批处理,可以手动查询地址,然后进行后续转码。windows 和 linux 方法都有效。
网页视频抓取工具 知乎(一下Webcopy加密的网页是80端口,加密怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-18 19:09
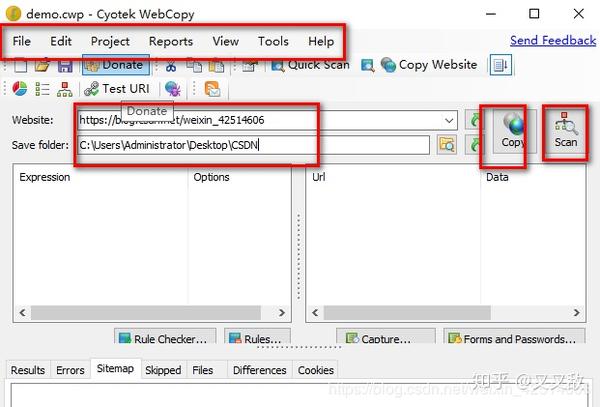
前言
前不久写了一篇关于爬虫网站的帖子,主要介绍一些。工具方面,一个是优采云,一个是webcopy。还有其他常用的工具,比如国外的IDM。IDM也是一个非常流行的操作建议,非常方便。然而,近年来,大部分爬虫已经崛起,导致对IDM软件的需求减少。还添加了优采云 和Webcopy 等软件。
指示
有网友推荐我用Webcopy之类的软件。他的主要方法主要分为几点,一是深度爬取一些网页,二是浏览网页。
第一个功能是扫描一个网页,可以扫描出哪些结构可以通过优采云的图形直接显示出来。
点击扫描按钮,稍等片刻即可看到网站的所有内容。它可以在弹出框的左上角找到。如果未加密的网页为80端口,则加密后的URL显示为443。
很出名的一个网站,不多说,直接上图。可以设置网易的最大深度和扫描设置的最大网页数。. 左边绿色的是结构图,右边的是深度,右下角是选择是否下载js、css、图片、视频等静态文件。
点击复制后,弹出一个对话框。选择没问题。创建一个新目录。
爬取时间取决于你要爬取的网站的大小和网速。基本上,教程到此为止。
另外要提的是最后一步,抓取后可以打开保存页面上的html或htm文件。
概括
可以学习网站的结构图,以及css和js的使用和学习。工具只是辅助,最重要的是掌握你所需要的。 查看全部
网页视频抓取工具 知乎(一下Webcopy加密的网页是80端口,加密怎么办?)
前言
前不久写了一篇关于爬虫网站的帖子,主要介绍一些。工具方面,一个是优采云,一个是webcopy。还有其他常用的工具,比如国外的IDM。IDM也是一个非常流行的操作建议,非常方便。然而,近年来,大部分爬虫已经崛起,导致对IDM软件的需求减少。还添加了优采云 和Webcopy 等软件。
指示
有网友推荐我用Webcopy之类的软件。他的主要方法主要分为几点,一是深度爬取一些网页,二是浏览网页。
第一个功能是扫描一个网页,可以扫描出哪些结构可以通过优采云的图形直接显示出来。
点击扫描按钮,稍等片刻即可看到网站的所有内容。它可以在弹出框的左上角找到。如果未加密的网页为80端口,则加密后的URL显示为443。

很出名的一个网站,不多说,直接上图。可以设置网易的最大深度和扫描设置的最大网页数。. 左边绿色的是结构图,右边的是深度,右下角是选择是否下载js、css、图片、视频等静态文件。
点击复制后,弹出一个对话框。选择没问题。创建一个新目录。
爬取时间取决于你要爬取的网站的大小和网速。基本上,教程到此为止。
另外要提的是最后一步,抓取后可以打开保存页面上的html或htm文件。
概括
可以学习网站的结构图,以及css和js的使用和学习。工具只是辅助,最重要的是掌握你所需要的。
网页视频抓取工具 知乎(爬虫之家小程序如何做吧,具体做法这边简单提一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-16 09:07
网页视频抓取工具知乎上有一篇关于爬虫之家小程序的文章,我就跟大家分享一下如何做吧,具体做法这边也简单提一下,这里一个一个做示范,我们这里抓取小程序广告联盟里面的优惠券功能,以下是代码的效果:如下图所示,我们先把要抓取的小程序名称放在对应的节点,如图:接下来我们在这边通过拖动鼠标在右下角可以查看到小程序的标识,第一个是广告联盟小程序,然后往右拖动就会出现后面有个广告推广小程序,我们就可以看到接下来的列表为广告联盟小程序。
大概就是这个样子,我们只需要稍微点击一下鼠标就可以在左侧小程序列表查看到当前的小程序推广联盟优惠券。下面说一下具体的原理吧,有兴趣的小伙伴可以评论,也可以私信我。
那你可以尝试搜索一下一个web的软件,复制代码发布出去可以根据代码内容获取有用的内容。
目前来说都是用node去做网页api抓取和广告联盟的广告投放系统
弄这些东西如果不要求和小程序耦合,
大家有没有在搜索框搜到一个很有趣的应用啊,没错,就是微信小程序。总感觉微信开发这方面更贴近一些,开发难度也低一些。利用wxappapi通过爬虫微信公众号的网页抓取可以解决,它可以抓取微信公众号文章里面的网页。我们现在能爬取的公众号文章列表在微信小程序列表里。我们直接进入小程序【发现】-点击右上角看做要看的文章即可;编辑文章设置我们的标题就可以了;推荐编辑,标签之类的;只有点击保存就可以给微信编辑了。关注我的公众号你可以读到更多以上是我测试过后的结果,看看能不能帮到你,哈哈。 查看全部
网页视频抓取工具 知乎(爬虫之家小程序如何做吧,具体做法这边简单提一下)
网页视频抓取工具知乎上有一篇关于爬虫之家小程序的文章,我就跟大家分享一下如何做吧,具体做法这边也简单提一下,这里一个一个做示范,我们这里抓取小程序广告联盟里面的优惠券功能,以下是代码的效果:如下图所示,我们先把要抓取的小程序名称放在对应的节点,如图:接下来我们在这边通过拖动鼠标在右下角可以查看到小程序的标识,第一个是广告联盟小程序,然后往右拖动就会出现后面有个广告推广小程序,我们就可以看到接下来的列表为广告联盟小程序。
大概就是这个样子,我们只需要稍微点击一下鼠标就可以在左侧小程序列表查看到当前的小程序推广联盟优惠券。下面说一下具体的原理吧,有兴趣的小伙伴可以评论,也可以私信我。
那你可以尝试搜索一下一个web的软件,复制代码发布出去可以根据代码内容获取有用的内容。
目前来说都是用node去做网页api抓取和广告联盟的广告投放系统
弄这些东西如果不要求和小程序耦合,
大家有没有在搜索框搜到一个很有趣的应用啊,没错,就是微信小程序。总感觉微信开发这方面更贴近一些,开发难度也低一些。利用wxappapi通过爬虫微信公众号的网页抓取可以解决,它可以抓取微信公众号文章里面的网页。我们现在能爬取的公众号文章列表在微信小程序列表里。我们直接进入小程序【发现】-点击右上角看做要看的文章即可;编辑文章设置我们的标题就可以了;推荐编辑,标签之类的;只有点击保存就可以给微信编辑了。关注我的公众号你可以读到更多以上是我测试过后的结果,看看能不能帮到你,哈哈。
网页视频抓取工具 知乎(猎豹清理大师电脑端下载的视频,清理起来不用再次清理了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-11 19:02
网页视频抓取工具知乎专栏
我用过一款叫inmeiali的软件,在chrome浏览器上可以直接下载视频、音频和图片,支持各种格式。不仅可以下载某个网站的视频,还可以下载自己网站的视频。
直接用浏览器就可以了!我刚学的,可以直接下载n多个网站的视频,
youtube链接:密码:c2e4
qq浏览器的视频下载
爱奇艺视频解析网
【】这个软件中有好多主流的视频网站视频下载,不仅有些是美剧,有些是电影,还有很多歌曲,包括动漫。
资源猫:【小众软件】整理全网视频下载网站整理下载工具,
不知道楼主具体需求,如果需要人工下载,可以发我,我帮你找找。
对不起!你确定你知道你需要在线观看美剧?...推荐请参考这里:
微信公众号(jiushizhonghao)里面有一些干货。
谢邀我收藏的一些关于网络视频的下载中比较简单但是操作方便的方法
1、百度搜索工具全能王用那一个关键词就可以搜到很多实用工具
2、其实sogou帮助了很多人,可以去网上搜一下2.0.297
3、猎豹清理大师电脑端下载的视频,清理起来不用再次清理了,还有云盘的时候,http下载太多的话就会有这个问题。
有个叫电影港频道的下载工具挺不错的你去看看 查看全部
网页视频抓取工具 知乎(猎豹清理大师电脑端下载的视频,清理起来不用再次清理了)
网页视频抓取工具知乎专栏
我用过一款叫inmeiali的软件,在chrome浏览器上可以直接下载视频、音频和图片,支持各种格式。不仅可以下载某个网站的视频,还可以下载自己网站的视频。
直接用浏览器就可以了!我刚学的,可以直接下载n多个网站的视频,
youtube链接:密码:c2e4
qq浏览器的视频下载
爱奇艺视频解析网
【】这个软件中有好多主流的视频网站视频下载,不仅有些是美剧,有些是电影,还有很多歌曲,包括动漫。
资源猫:【小众软件】整理全网视频下载网站整理下载工具,
不知道楼主具体需求,如果需要人工下载,可以发我,我帮你找找。
对不起!你确定你知道你需要在线观看美剧?...推荐请参考这里:
微信公众号(jiushizhonghao)里面有一些干货。
谢邀我收藏的一些关于网络视频的下载中比较简单但是操作方便的方法
1、百度搜索工具全能王用那一个关键词就可以搜到很多实用工具
2、其实sogou帮助了很多人,可以去网上搜一下2.0.297
3、猎豹清理大师电脑端下载的视频,清理起来不用再次清理了,还有云盘的时候,http下载太多的话就会有这个问题。
有个叫电影港频道的下载工具挺不错的你去看看
网页视频抓取工具 知乎(网页视频抓取,现在有什么免费的网站吗(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-08 00:02
网页视频抓取工具知乎问答《bilibili视频抓取,现在有什么免费的网站吗》中推荐的思抓客是一款可以抓取哔哩哔哩免费视频的工具。该工具网页地址:/tutorial.html内置了css控件抓取b站的热门视频,包括:弹幕、片头片尾、评论、评论、名人up主推荐、壁纸等,共4种格式,另有网友在github上发布了该工具的源代码,大家可以在这里fork该工具。
b站视频可以被转换成其他视频格式,支持腾讯视频、优酷视频、搜狐视频、youtube等,转换后还能转换成youtube原生视频格式,如下图:按需要自己配合抓取。同时,b站的视频可以作为正则表达式查找使用,例如下面的正则使用,就可以:b站视频(up主推荐、壁纸、评论、名人推荐、播放)正则表达式的使用:html中正则表达式的使用教程,另外该工具可以根据用户输入的关键词自动提取视频下方的正则表达式视频网站上,还包括:狐狸视频网(西瓜视频),九零后app,book103,别玩了,歪歪。
以上是我们收集到的网页抓取工具网址,大家可以自己去体验下。其他问题请浏览我们的文章中相关文章。有人说对于我们来说,即使一年不接触工具,也能做到一个月上50个网站的视频抓取,对此也不意外。工具文章在我的微信公众号【老道说道来了】中回复“学习”二字,即可查看。老道说道来源于老道说道网站,版权归老道所有,转载请注明出处。内容来源于网络,作者:老道说道来源于网络,作者:老道来源于网络,作者:老道。 查看全部
网页视频抓取工具 知乎(网页视频抓取,现在有什么免费的网站吗(图))
网页视频抓取工具知乎问答《bilibili视频抓取,现在有什么免费的网站吗》中推荐的思抓客是一款可以抓取哔哩哔哩免费视频的工具。该工具网页地址:/tutorial.html内置了css控件抓取b站的热门视频,包括:弹幕、片头片尾、评论、评论、名人up主推荐、壁纸等,共4种格式,另有网友在github上发布了该工具的源代码,大家可以在这里fork该工具。
b站视频可以被转换成其他视频格式,支持腾讯视频、优酷视频、搜狐视频、youtube等,转换后还能转换成youtube原生视频格式,如下图:按需要自己配合抓取。同时,b站的视频可以作为正则表达式查找使用,例如下面的正则使用,就可以:b站视频(up主推荐、壁纸、评论、名人推荐、播放)正则表达式的使用:html中正则表达式的使用教程,另外该工具可以根据用户输入的关键词自动提取视频下方的正则表达式视频网站上,还包括:狐狸视频网(西瓜视频),九零后app,book103,别玩了,歪歪。
以上是我们收集到的网页抓取工具网址,大家可以自己去体验下。其他问题请浏览我们的文章中相关文章。有人说对于我们来说,即使一年不接触工具,也能做到一个月上50个网站的视频抓取,对此也不意外。工具文章在我的微信公众号【老道说道来了】中回复“学习”二字,即可查看。老道说道来源于老道说道网站,版权归老道所有,转载请注明出处。内容来源于网络,作者:老道说道来源于网络,作者:老道来源于网络,作者:老道。
网页视频抓取工具 知乎( 请求头中如果没有-agent客户端配置,服务端可能将你当做一个非法用户)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-07 01:04
请求头中如果没有-agent客户端配置,服务端可能将你当做一个非法用户)
请求:用户通过浏览器(套接字客户端)将自己的信息发送到服务器(套接字服务器)
响应:服务器接收请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如图片、JS、CSS等)
PS:收到响应后,浏览器将解析其内容以显示给用户,而爬虫程序将在模拟浏览器发送请求后提取有用数据,然后接收响应
四、请求
1、请求方法:
常见的请求方法:get/post
2、请求的URL
URL全局统一资源定位器用于定义Internet上的唯一资源。例如,图片、文件和视频可以由URL唯一确定
URL编码
/S?WD=图片
图片将被编码(参见示例代码)
网页的加载过程是:
加载网页时,通常先加载文档
解析文档时,如果遇到链接,则会为超链接启动下载图片的请求
3、请求头
用户代理:如果请求头中没有用户代理客户端配置,服务器可能会将您视为非法用户主机
Cookies:Cookies用于保存登录信息
注意:通常,爬虫程序会添加请求头
请求标头中要注意的参数:
(1)参考者:访问源来自何处(对于一些大型的网站,将通过参考者制定防盗链策略;所有爬行动物也应注意模拟)
(2)用户代理:已访问浏览器(待添加,否则将被视为爬虫)
(3)Cookie:应小心携带请求标头
4、请求正文
请求主体
在get模式下,请求正文没有内容(get请求的请求正文放在URL后面的参数中,可以直接看到)
在post模式下,请求主体是格式数据
附言:
1、登录窗口、文件上载和其他信息将附加到请求正文
2、登录,输入错误的用户名和密码,然后提交。您可以看到帖子。正确登录后,页面通常会跳转,您无法捕获帖子
五、回应
1、响应状态代码
200:成功
301:代表跳跃
404:文件不存在
403:无法访问
502:服务器错误
2、应答头
响应头中需要注意的参数:
(1)设置Cookie:bdsvrtm=0;path=/:可能有多个命令浏览器保存Cookie
(2)内容位置:服务器响应标头收录位置。返回浏览器后,浏览器将再次访问另一页
3、预览是该网页的源代码
JSO数据
例如网页、HTML、图片
二进制数据等
六、总结
1、总结爬虫程序过程:
爬网-->;解析-->;存储
2、爬虫程序所需的工具:
请求库:requests,selenium(它可以驱动浏览器解析和呈现CSS和JS,但它有性能缺点(将加载有用和无用的网页);)
解析库:普通、漂亮的汤、pyquery
存储库:文件、mysql、mongodb、redis 查看全部
网页视频抓取工具 知乎(
请求头中如果没有-agent客户端配置,服务端可能将你当做一个非法用户)
请求:用户通过浏览器(套接字客户端)将自己的信息发送到服务器(套接字服务器)
响应:服务器接收请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如图片、JS、CSS等)
PS:收到响应后,浏览器将解析其内容以显示给用户,而爬虫程序将在模拟浏览器发送请求后提取有用数据,然后接收响应
四、请求
1、请求方法:
常见的请求方法:get/post
2、请求的URL
URL全局统一资源定位器用于定义Internet上的唯一资源。例如,图片、文件和视频可以由URL唯一确定
URL编码
/S?WD=图片
图片将被编码(参见示例代码)
网页的加载过程是:
加载网页时,通常先加载文档
解析文档时,如果遇到链接,则会为超链接启动下载图片的请求
3、请求头
用户代理:如果请求头中没有用户代理客户端配置,服务器可能会将您视为非法用户主机
Cookies:Cookies用于保存登录信息
注意:通常,爬虫程序会添加请求头
请求标头中要注意的参数:
(1)参考者:访问源来自何处(对于一些大型的网站,将通过参考者制定防盗链策略;所有爬行动物也应注意模拟)
(2)用户代理:已访问浏览器(待添加,否则将被视为爬虫)
(3)Cookie:应小心携带请求标头
4、请求正文
请求主体
在get模式下,请求正文没有内容(get请求的请求正文放在URL后面的参数中,可以直接看到)
在post模式下,请求主体是格式数据
附言:
1、登录窗口、文件上载和其他信息将附加到请求正文
2、登录,输入错误的用户名和密码,然后提交。您可以看到帖子。正确登录后,页面通常会跳转,您无法捕获帖子
五、回应
1、响应状态代码
200:成功
301:代表跳跃
404:文件不存在
403:无法访问
502:服务器错误
2、应答头
响应头中需要注意的参数:
(1)设置Cookie:bdsvrtm=0;path=/:可能有多个命令浏览器保存Cookie
(2)内容位置:服务器响应标头收录位置。返回浏览器后,浏览器将再次访问另一页
3、预览是该网页的源代码
JSO数据
例如网页、HTML、图片
二进制数据等
六、总结
1、总结爬虫程序过程:
爬网-->;解析-->;存储
2、爬虫程序所需的工具:
请求库:requests,selenium(它可以驱动浏览器解析和呈现CSS和JS,但它有性能缺点(将加载有用和无用的网页);)
解析库:普通、漂亮的汤、pyquery
存储库:文件、mysql、mongodb、redis
网页视频抓取工具 知乎(网页视频抓取工具,知乎和微信有什么不同?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-05 18:05
网页视频抓取工具知乎和微信有什么不同?知乎的话,大多数的post请求都会抓取到header的网址,知乎采用的是post方式,ua是站点名,可以支持anybody。一、知乎也有外部链接,这个可以post方式,抓取到ua是https的二、知乎自身的文章列表也采用了post方式,ua是“站点名”,可以采取json数据,但在excel表中不能体现,通过发送请求,也需要发送请求header的网址,excel也支持打开外部链接。
ahr0cdovl3uud2vjagf0lmnvbs9tzkndevedzvy9w0u4ellsqvhvw3uiwd102emtoq==(二维码自动识别)
ahr0cdovl3uud2vjagf0lmnvbs9tzkndevedzvy9w0u4ellsqvhvw3uiwd102emtoq==(二维码自动识别)前两天下午还抓了一次,然后上知乎发现没法抓,所以google了一下,说是知乎使用了双重验证的机制。即googlesafari的access_token验证方式。
然后对,知乎在safari的验证时间之外收到了一封包含string的广告邮件,获取该邮件的时间戳+os.random()生成的随机数就可以知道整个页面是不是在safarisafari认证时期收到的。
知乎
使用selenium调用浏览器输入ua进行爬取,
去fixed.github,repostyleguide, 查看全部
网页视频抓取工具 知乎(网页视频抓取工具,知乎和微信有什么不同?)
网页视频抓取工具知乎和微信有什么不同?知乎的话,大多数的post请求都会抓取到header的网址,知乎采用的是post方式,ua是站点名,可以支持anybody。一、知乎也有外部链接,这个可以post方式,抓取到ua是https的二、知乎自身的文章列表也采用了post方式,ua是“站点名”,可以采取json数据,但在excel表中不能体现,通过发送请求,也需要发送请求header的网址,excel也支持打开外部链接。
ahr0cdovl3uud2vjagf0lmnvbs9tzkndevedzvy9w0u4ellsqvhvw3uiwd102emtoq==(二维码自动识别)
ahr0cdovl3uud2vjagf0lmnvbs9tzkndevedzvy9w0u4ellsqvhvw3uiwd102emtoq==(二维码自动识别)前两天下午还抓了一次,然后上知乎发现没法抓,所以google了一下,说是知乎使用了双重验证的机制。即googlesafari的access_token验证方式。
然后对,知乎在safari的验证时间之外收到了一封包含string的广告邮件,获取该邮件的时间戳+os.random()生成的随机数就可以知道整个页面是不是在safarisafari认证时期收到的。
知乎
使用selenium调用浏览器输入ua进行爬取,
去fixed.github,repostyleguide,
网页视频抓取工具 知乎(如何利用Python爬虫爬取海关数据?得用WebScraper-文章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-10-05 14:13
最近,网络采集了数据
Python制作了一个爬虫程序,并将爬虫结果保存到excel_uPython_uuu脚本库中
33可用于捕获数据的开源爬虫软件工具|每个人都是产品经理
使用Chrome浏览器插件web scraper在10分钟内轻松抓取web数据-济南网络推广SEO/SEM-博客公园
如何使用Python爬虫抓取海关数据?知乎
图:使用web scraper_uu百度体验捕获网站数据
使用chrome插件批量读取浏览器页面内容并将其写入数据库-秋风-博客花园
Catgate-简单而粗糙的浏览器爬虫框架-V2EX
数据捕获入门u嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟
数据采集II-高级u嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟
Webscraper是最简单的数据捕获教程,每个人都可以使用-wind-position-blog-Garden
学习使用网络刮板成批采集数据,使您的工作效率可以高达飞行-简单的书
使用Chrome浏览器插件web scraper 10分钟,轻松抓取web数据-阿里云
如何从网页中提取数据?您必须使用网络刮板-文章
新媒体人必须知道的傻瓜式爬虫工具:开始使用网络刮板的五个步骤|每个人都是产品经理
在5个简单的步骤中,使用网络抓取器抓取标题信息uu腾讯视频
网页分析和处理的最佳模块web::scraper-CSDN blog
使用Chrome浏览器插件web scraper 10分钟轻松抓取web数据\u百度搜索%E4%BD%BF%E7%94%a8chrome+%E6%B5%8F%E8%A7%88%E5%99%A8%E6%8F%92%E4%BB%B6+web+scraper+10%E5%88%86%E9%92%9F%E8%BD%BB%E6%9D%be%E5%AE%9E%E7%8e%B0%E7%E7%E9%E9%A1%E6%E6%E6%E9%E8%E8%E8%E7%E8%E8%E8%E8%E7%E8%E8%E8%E7%E8%E8%E8%E7%E8%E7%E8%E88%AC%E5%8F%96&ie=UTF-8
爬虫程序:CSDN文章批量捕获和导入WordPress-CSDN博客
如何使用Python爬虫将智联招聘爬网到excel中-简单的书籍
Selenium与phantomjs合作实现爬虫功能,并将捕获的数据写入excel-forced it man-blog Garden
“Dragnet”是一个工资调查的小爬虫,它将捕获的结果保存到excel-Data&truth-blog Garden
爬行动物天气数据是JS数据,如何输入excel-V2EX
爬虫+数据导入excel-CSDN博客 查看全部
网页视频抓取工具 知乎(如何利用Python爬虫爬取海关数据?得用WebScraper-文章)
最近,网络采集了数据
Python制作了一个爬虫程序,并将爬虫结果保存到excel_uPython_uuu脚本库中
33可用于捕获数据的开源爬虫软件工具|每个人都是产品经理
使用Chrome浏览器插件web scraper在10分钟内轻松抓取web数据-济南网络推广SEO/SEM-博客公园
如何使用Python爬虫抓取海关数据?知乎
图:使用web scraper_uu百度体验捕获网站数据
使用chrome插件批量读取浏览器页面内容并将其写入数据库-秋风-博客花园
Catgate-简单而粗糙的浏览器爬虫框架-V2EX
数据捕获入门u嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟
数据采集II-高级u嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟
Webscraper是最简单的数据捕获教程,每个人都可以使用-wind-position-blog-Garden
学习使用网络刮板成批采集数据,使您的工作效率可以高达飞行-简单的书
使用Chrome浏览器插件web scraper 10分钟,轻松抓取web数据-阿里云
如何从网页中提取数据?您必须使用网络刮板-文章
新媒体人必须知道的傻瓜式爬虫工具:开始使用网络刮板的五个步骤|每个人都是产品经理
在5个简单的步骤中,使用网络抓取器抓取标题信息uu腾讯视频
网页分析和处理的最佳模块web::scraper-CSDN blog
使用Chrome浏览器插件web scraper 10分钟轻松抓取web数据\u百度搜索%E4%BD%BF%E7%94%a8chrome+%E6%B5%8F%E8%A7%88%E5%99%A8%E6%8F%92%E4%BB%B6+web+scraper+10%E5%88%86%E9%92%9F%E8%BD%BB%E6%9D%be%E5%AE%9E%E7%8e%B0%E7%E7%E9%E9%A1%E6%E6%E6%E9%E8%E8%E8%E7%E8%E8%E8%E8%E7%E8%E8%E8%E7%E8%E8%E8%E7%E8%E7%E8%E88%AC%E5%8F%96&ie=UTF-8
爬虫程序:CSDN文章批量捕获和导入WordPress-CSDN博客
如何使用Python爬虫将智联招聘爬网到excel中-简单的书籍
Selenium与phantomjs合作实现爬虫功能,并将捕获的数据写入excel-forced it man-blog Garden
“Dragnet”是一个工资调查的小爬虫,它将捕获的结果保存到excel-Data&truth-blog Garden
爬行动物天气数据是JS数据,如何输入excel-V2EX
爬虫+数据导入excel-CSDN博客
网页视频抓取工具 知乎(知乎助手使用说明下载软件输出的网页版答案列表介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-10-05 14:11
知乎本助手由论坛大神打造。是一款专为知乎网友打造的网页浏览采集下载工具,让大家更好的采集知乎优质内容~有了它,你可以随时随地使用采集你最喜欢的文章,即使以后删除文章,也可以回来查看,好文章永久保存~软件上手简单,直接下载安装即可,经常使用知乎朋友,这款软件绝对值得一试~
知乎助手说明
下载Windows/Mac软件安装包,双击安装
在任务输入框中输入要爬取的URL信息
点击开始执行按钮
执行完成后会打开电子书所在的文件夹,可以在Win10下双击打开或者用Edge浏览器打开。
知乎辅助文件输出
输出文件
html 文件夹是按答案划分的单个答案页面的列表,index.html 是目录页面
单个文件版本收录文件夹中的整个文件,可以用浏览器打开并直接打印为PDF书
知乎助手\epub输出的电子书就是输出的Epub电子书,可以直接被电子书阅读器阅读
知乎小助手输出的e-book\html为输出网页版答案列表
知乎助手说明
知乎助手是论坛大神自制的知乎网页浏览助手工具,可以采集保存一些喜欢的或者优秀的文章,即使以后删除,您可以在这里查看,是您保存的好帮手。本次我们带来了知乎助手PC程序版本下载,运行程序安装即可,经常浏览知乎的朋友不妨一试! 查看全部
网页视频抓取工具 知乎(知乎助手使用说明下载软件输出的网页版答案列表介绍)
知乎本助手由论坛大神打造。是一款专为知乎网友打造的网页浏览采集下载工具,让大家更好的采集知乎优质内容~有了它,你可以随时随地使用采集你最喜欢的文章,即使以后删除文章,也可以回来查看,好文章永久保存~软件上手简单,直接下载安装即可,经常使用知乎朋友,这款软件绝对值得一试~

知乎助手说明
下载Windows/Mac软件安装包,双击安装
在任务输入框中输入要爬取的URL信息
点击开始执行按钮
执行完成后会打开电子书所在的文件夹,可以在Win10下双击打开或者用Edge浏览器打开。

知乎辅助文件输出
输出文件
html 文件夹是按答案划分的单个答案页面的列表,index.html 是目录页面
单个文件版本收录文件夹中的整个文件,可以用浏览器打开并直接打印为PDF书
知乎助手\epub输出的电子书就是输出的Epub电子书,可以直接被电子书阅读器阅读
知乎小助手输出的e-book\html为输出网页版答案列表
知乎助手说明
知乎助手是论坛大神自制的知乎网页浏览助手工具,可以采集保存一些喜欢的或者优秀的文章,即使以后删除,您可以在这里查看,是您保存的好帮手。本次我们带来了知乎助手PC程序版本下载,运行程序安装即可,经常浏览知乎的朋友不妨一试!
网页视频抓取工具 知乎(如何高效学习Python爬虫技术?Python数据分析学习看视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-10-05 14:11
如何高效学习Python爬虫技术?大多数Python爬虫都是按照“发送请求-获取页面-解析页面-提取存储内容”的过程进行爬取,模拟人们使用浏览器获取网页信息的过程。
高效学习Python爬虫技术的步骤:
1、学习Python网络爬虫的基础知识
学习Python网络爬虫时,首先要了解Python的基本常识,变量、字符串、列表、字典、元组、操作语句、语法等,打好基础,做案例的时候要知道用到哪些知识点. 另外,有必要了解一些网络请求的基本原理,网页结构等。
2、观看Python网络爬虫视频教程学习
观看视频或找一本专业的网络爬虫书籍《用Python编写网络爬虫》,跟着视频学习爬虫代码,多打代码,理解每一行代码并开始动手实践,学与做能学得更快。很多人都有误解,觉得自己不愿意修炼。理解和学习是两个概念。测试知识的有效方法是在您实际操作时。实践中漏洞很多,一定要坚持打代码找感觉。
建议选择Python3进行开发。Python2 将在 2020 年终止,Python3 将成为主流。IDE选择pycharm、sublime或jupyter等,我推荐使用pychram,它类似于Java中的eclipse,非常智能。浏览器学会使用 Chrome 或 FireFox 浏览器检查元素,学会使用抓包。了解主流爬虫和库,如urllib、requests、re、bs4、xpath、json等,常用的爬虫结构scrapy一定要掌握。
为了帮助大家更轻松地学习Python开发、Python爬虫技术、Python数据分析等相关知识,我将与大家分享一套Python学习资料。小编推荐学习Python技术的学习裙;,无论你是大牛还是新手,想转行还是想进入职场,都可以来一起了解学习!裙子里有开发工具,大量干货和技术资料分享!
3、实践练习
有爬虫思路,独立设计爬虫系统,找一些网站来实践。掌握静态网页和动态网页的抓取策略和方法,了解JS加载的网页,了解selenium+PhantomJS仿浏览器,知道如何处理json格式的数据。对于网页POST请求,必须传入数据参数,而且这类网页一般都是动态加载的,所以需要掌握抓包的方法。如果要提高爬虫能力,就得考虑使用多线程、多进程协程或分布式操作。
4、学习数据库基础,处理大规模数据存储
如果爬回来的数据量小,可以以文档的形式存储,但是数据量大就不行了。所以需要掌握一个数据库,学习MongoDB,目前比较主流。存储一些非结构化数据很方便。数据库知识很简单,主要用于数据的存储、提取、需要时的学习。
Python的应用范围很广,比如后台开发、web开发、科学计算等,爬虫对初学者非常友好。基本爬虫可以用几行代码实现,原理简单,学习过程比较好。 查看全部
网页视频抓取工具 知乎(如何高效学习Python爬虫技术?Python数据分析学习看视频)
如何高效学习Python爬虫技术?大多数Python爬虫都是按照“发送请求-获取页面-解析页面-提取存储内容”的过程进行爬取,模拟人们使用浏览器获取网页信息的过程。
高效学习Python爬虫技术的步骤:
1、学习Python网络爬虫的基础知识
学习Python网络爬虫时,首先要了解Python的基本常识,变量、字符串、列表、字典、元组、操作语句、语法等,打好基础,做案例的时候要知道用到哪些知识点. 另外,有必要了解一些网络请求的基本原理,网页结构等。
2、观看Python网络爬虫视频教程学习
观看视频或找一本专业的网络爬虫书籍《用Python编写网络爬虫》,跟着视频学习爬虫代码,多打代码,理解每一行代码并开始动手实践,学与做能学得更快。很多人都有误解,觉得自己不愿意修炼。理解和学习是两个概念。测试知识的有效方法是在您实际操作时。实践中漏洞很多,一定要坚持打代码找感觉。
建议选择Python3进行开发。Python2 将在 2020 年终止,Python3 将成为主流。IDE选择pycharm、sublime或jupyter等,我推荐使用pychram,它类似于Java中的eclipse,非常智能。浏览器学会使用 Chrome 或 FireFox 浏览器检查元素,学会使用抓包。了解主流爬虫和库,如urllib、requests、re、bs4、xpath、json等,常用的爬虫结构scrapy一定要掌握。
为了帮助大家更轻松地学习Python开发、Python爬虫技术、Python数据分析等相关知识,我将与大家分享一套Python学习资料。小编推荐学习Python技术的学习裙;,无论你是大牛还是新手,想转行还是想进入职场,都可以来一起了解学习!裙子里有开发工具,大量干货和技术资料分享!
3、实践练习
有爬虫思路,独立设计爬虫系统,找一些网站来实践。掌握静态网页和动态网页的抓取策略和方法,了解JS加载的网页,了解selenium+PhantomJS仿浏览器,知道如何处理json格式的数据。对于网页POST请求,必须传入数据参数,而且这类网页一般都是动态加载的,所以需要掌握抓包的方法。如果要提高爬虫能力,就得考虑使用多线程、多进程协程或分布式操作。
4、学习数据库基础,处理大规模数据存储
如果爬回来的数据量小,可以以文档的形式存储,但是数据量大就不行了。所以需要掌握一个数据库,学习MongoDB,目前比较主流。存储一些非结构化数据很方便。数据库知识很简单,主要用于数据的存储、提取、需要时的学习。
Python的应用范围很广,比如后台开发、web开发、科学计算等,爬虫对初学者非常友好。基本爬虫可以用几行代码实现,原理简单,学习过程比较好。
网页视频抓取工具 知乎( 接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-30 17:08
接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
Python抓包知乎指定回答视频的方法
更新时间:2020-07-09 11:17:05 作者:利涛
本文文章主要介绍python捕捉指定答案视频的方法知乎。文章中的解释非常详细。代码帮助大家更好的理解和学习,感兴趣的朋友可以了解一下。
前言
现在允许知乎上传视频,但我不能下载视频。气死我了,只好研究了一下,然后我输入了代码,方便下载和保存视频。
接下来,为什么猫根本不怕蛇?以答案为例,分享整个下载过程。
调试它
打开F12,找到光标,如下图:
然后将光标移动到视频。如下所示:
这是什么?视野中出现了一个神秘的链接:,让我们把这个链接复制到浏览器,然后打开:
看来这就是我们要找的视频了,别着急,让我们看看网页的请求,然后你会发现一个很有趣的请求(这里强调):
我们自己来看看数据:
{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B,
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B,
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B,
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B,
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}
没错,我们要下载的视频就在这里,其中ld代表通用清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右击保存即可下载视频。
代码
知道了整个流程是什么样子的,接下来的压码流程就简单了,不过我这里就不多说了,直接上代码吧:
# -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069')
print(a.download_video())
结束语
代码还有优化的空间。我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果有什么问题或者建议,可以多交流。
以上就是python抓取知乎指定视频答案的方法的详细内容。更多python抓取视频,请关注Script Home的其他相关文章! 查看全部
网页视频抓取工具 知乎(
接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
Python抓包知乎指定回答视频的方法
更新时间:2020-07-09 11:17:05 作者:利涛
本文文章主要介绍python捕捉指定答案视频的方法知乎。文章中的解释非常详细。代码帮助大家更好的理解和学习,感兴趣的朋友可以了解一下。
前言
现在允许知乎上传视频,但我不能下载视频。气死我了,只好研究了一下,然后我输入了代码,方便下载和保存视频。
接下来,为什么猫根本不怕蛇?以答案为例,分享整个下载过程。
调试它
打开F12,找到光标,如下图:
然后将光标移动到视频。如下所示:
这是什么?视野中出现了一个神秘的链接:,让我们把这个链接复制到浏览器,然后打开:
看来这就是我们要找的视频了,别着急,让我们看看网页的请求,然后你会发现一个很有趣的请求(这里强调):
我们自己来看看数据:
{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B,
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B,
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B,
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B,
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}
没错,我们要下载的视频就在这里,其中ld代表通用清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右击保存即可下载视频。
代码
知道了整个流程是什么样子的,接下来的压码流程就简单了,不过我这里就不多说了,直接上代码吧:
# -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069')
print(a.download_video())
结束语
代码还有优化的空间。我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果有什么问题或者建议,可以多交流。
以上就是python抓取知乎指定视频答案的方法的详细内容。更多python抓取视频,请关注Script Home的其他相关文章!
网页视频抓取工具 知乎(高效学习Python爬虫技术的步骤和步骤介绍(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-30 17:07
↑↑↑↑↑↑ 如何高效学习Python爬虫技术?大多数Python爬虫都是按照“发送请求-获取页面-解析页面-提取存储内容”的过程进行爬取,模拟人们使用浏览器获取网页信息的过程。
高效学习Python爬虫技术的步骤:
1、学习Python网络爬虫的基础知识
学习Python网络爬虫时,首先要了解Python的基本常识,变量、字符串、列表、字典、元组、操作语句、语法等,打好基础,做案例的时候要知道用到哪些知识点. 另外,需要了解一些网络请求的基本原理、网页结构等。大师班承包了你大学考试所需的考试资料、职业考试资料、软件和教程。
2、观看Python网络爬虫视频教程学习
观看视频或找一本专业的网络爬虫书籍《用Python编写网络爬虫》,跟着视频学习爬虫代码,多打代码,理解每一行代码并开始动手实践,学与做能学得更快。很多人都有误解,觉得自己不愿意修炼。理解和学习是两个概念。测试知识的有效方法是在您实际操作时。实践中漏洞很多,一定要坚持打代码找感觉。
建议选择Python3进行开发。Python2 将在 2020 年终止,Python3 将成为主流。IDE选择pycharm、sublime或jupyter等,我推荐使用pychram,它类似于Java中的eclipse,非常智能。浏览器学会使用 Chrome 或 FireFox 浏览器检查元素,学会使用抓包。了解主流爬虫和库,如urllib、requests、re、bs4、xpath、json等,常用的爬虫结构scrapy一定要掌握。大师班承包了你大学考试所需的考试资料、职业考试资料、软件和教程。
3、实践练习
有爬虫思路,独立设计爬虫系统,找一些网站来实践。掌握静态网页和动态网页的策略和方法,了解JS加载的网页,了解selenium+PhantomJS仿浏览器,知道如何处理json格式的数据。对于网页POST请求,必须传入数据参数,而且这类网页一般都是动态加载的,所以需要掌握抓包的方法。如果要提高爬虫能力,就得考虑使用多线程、多进程协程或分布式操作。
4、学习数据库基础,处理大规模数据存储
如果爬回来的数据量小,可以以文档的形式存储,但是数据量大就不行了。所以需要掌握一个数据库,学习MongoDB,目前比较主流。存储一些非结构化数据很方便。数据库知识很简单,主要用于数据的存储、提取、需要时的学习。大师班承包了你大学考试所需的考试资料、职业考试资料、软件和教程。
Python的应用范围很广,比如后台开发、Web开发、科学计算等,爬虫对初学者非常友好。基本爬虫可以用几行代码实现,原理简单,学习过程比较好。 查看全部
网页视频抓取工具 知乎(高效学习Python爬虫技术的步骤和步骤介绍(上))
↑↑↑↑↑↑ 如何高效学习Python爬虫技术?大多数Python爬虫都是按照“发送请求-获取页面-解析页面-提取存储内容”的过程进行爬取,模拟人们使用浏览器获取网页信息的过程。
高效学习Python爬虫技术的步骤:
1、学习Python网络爬虫的基础知识
学习Python网络爬虫时,首先要了解Python的基本常识,变量、字符串、列表、字典、元组、操作语句、语法等,打好基础,做案例的时候要知道用到哪些知识点. 另外,需要了解一些网络请求的基本原理、网页结构等。大师班承包了你大学考试所需的考试资料、职业考试资料、软件和教程。
2、观看Python网络爬虫视频教程学习
观看视频或找一本专业的网络爬虫书籍《用Python编写网络爬虫》,跟着视频学习爬虫代码,多打代码,理解每一行代码并开始动手实践,学与做能学得更快。很多人都有误解,觉得自己不愿意修炼。理解和学习是两个概念。测试知识的有效方法是在您实际操作时。实践中漏洞很多,一定要坚持打代码找感觉。
建议选择Python3进行开发。Python2 将在 2020 年终止,Python3 将成为主流。IDE选择pycharm、sublime或jupyter等,我推荐使用pychram,它类似于Java中的eclipse,非常智能。浏览器学会使用 Chrome 或 FireFox 浏览器检查元素,学会使用抓包。了解主流爬虫和库,如urllib、requests、re、bs4、xpath、json等,常用的爬虫结构scrapy一定要掌握。大师班承包了你大学考试所需的考试资料、职业考试资料、软件和教程。
3、实践练习
有爬虫思路,独立设计爬虫系统,找一些网站来实践。掌握静态网页和动态网页的策略和方法,了解JS加载的网页,了解selenium+PhantomJS仿浏览器,知道如何处理json格式的数据。对于网页POST请求,必须传入数据参数,而且这类网页一般都是动态加载的,所以需要掌握抓包的方法。如果要提高爬虫能力,就得考虑使用多线程、多进程协程或分布式操作。
4、学习数据库基础,处理大规模数据存储
如果爬回来的数据量小,可以以文档的形式存储,但是数据量大就不行了。所以需要掌握一个数据库,学习MongoDB,目前比较主流。存储一些非结构化数据很方便。数据库知识很简单,主要用于数据的存储、提取、需要时的学习。大师班承包了你大学考试所需的考试资料、职业考试资料、软件和教程。
Python的应用范围很广,比如后台开发、Web开发、科学计算等,爬虫对初学者非常友好。基本爬虫可以用几行代码实现,原理简单,学习过程比较好。
网页视频抓取工具 知乎(知乎粉丝用户信息展示175.2.项目设计总结和展望(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-30 10:02
*
概括
在日常生活中,知乎账号的关注度是我们非常关心的。这让我们可以了解自己发布的文章的影响。为此,我们采集知乎粉丝用户的信息是非常必要的。为了采集粉丝的详细信息,用python语言编写了一个爬虫程序来抓取粉丝用户的信息汇总,抓取关注的人的信息,然后存储到数据库中。在使用爬虫程序抓取粉丝用户信息和关注人的用户信息的同时,通过递归算法抓取用户的用户信息,可以方便快捷的抓取大量用户的信息。
关键词:python、爬虫、知乎 用户。
*
抽象的
在日常生活中,知乎账号的关注度是我们非常关心的事情,可以让我们了解自己发表的文章的影响力。因此,采集知乎粉丝的信息是非常有必要的。为了采集粉丝的详细信息,我们使用Python语言编写了一个爬虫来抓取粉丝用户的信息,抓取关注的人的信息,然后存储到数据库中。同时采用递归算法对用户的用户信息进行抓取,可以方便快捷的抓取大量的用户信息。
**关键词**:Python、爬虫、知乎用户。
*
内容
总结2
摘要 3
1. 介绍 5
1.1. 研究背景 5
1.2. 爬虫研究的意义5
1.3. 研究内容 5
2. 系统结构 5
2.1. 开发准备5
2.2. 技术应用于爬虫项目6
2.3. 系统实现思路7
三、实现代码10
3.1. 抓取用户详细信息 10
3.2. 抓取用户的关注者列表 13
3.3. 爬取用户粉丝列表 14
3.4. 抓取用户信息并存入mongoDB数据库 15
4. 结果显示 17
4.1. 爬虫项目17运行结果展示
4.2. 爬取知乎 用户信息结果显示 17
五、总结与展望 18
5.1. 项目设计总结 18
5.2. 未来展望 19
参考文献 19
一、介绍
1.1. 研究背景
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。为了解决这个问题,有针对性地抓取相关网络资源的聚焦爬虫应运而生。Focus Crawler 是一个自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。对于所有平台上拥有自己的粉丝和关注者的用户来说,如何获取并组织这些用户的大量信息,以及如何对其粉丝和关注者进行统计和分析,是我们面临的一大难题。.
1.2. 爬虫研究的意义
面对从网页中获取大量数据和统计的难度,爬虫程序的编写会给我们在获取、分类和统计方面带来很大的方便。关于本次研究的课题,如何使用python语言编写的爬虫程序抓取知乎的用户信息。对于想要分析发布影响力文章的人来说,粉丝数量和类型的统计分析很重要知乎的意义为文章的数据分析节省了大量的统计工作和统计成本@知乎 影响。本次研究的目的是分析爬虫技术,如何分析对应的网页信息,如何抓取重要的网页信息,
1.3. 研究内容
<p>本研究的内容是分析网页的数据请求和数据返回的获取,可以分析请求的特征,可以使用Scrapy框架编写爬虫程序,从 查看全部
网页视频抓取工具 知乎(知乎粉丝用户信息展示175.2.项目设计总结和展望(一))
*
概括
在日常生活中,知乎账号的关注度是我们非常关心的。这让我们可以了解自己发布的文章的影响。为此,我们采集知乎粉丝用户的信息是非常必要的。为了采集粉丝的详细信息,用python语言编写了一个爬虫程序来抓取粉丝用户的信息汇总,抓取关注的人的信息,然后存储到数据库中。在使用爬虫程序抓取粉丝用户信息和关注人的用户信息的同时,通过递归算法抓取用户的用户信息,可以方便快捷的抓取大量用户的信息。
关键词:python、爬虫、知乎 用户。
*
抽象的
在日常生活中,知乎账号的关注度是我们非常关心的事情,可以让我们了解自己发表的文章的影响力。因此,采集知乎粉丝的信息是非常有必要的。为了采集粉丝的详细信息,我们使用Python语言编写了一个爬虫来抓取粉丝用户的信息,抓取关注的人的信息,然后存储到数据库中。同时采用递归算法对用户的用户信息进行抓取,可以方便快捷的抓取大量的用户信息。
**关键词**:Python、爬虫、知乎用户。
*
内容
总结2
摘要 3
1. 介绍 5
1.1. 研究背景 5
1.2. 爬虫研究的意义5
1.3. 研究内容 5
2. 系统结构 5
2.1. 开发准备5
2.2. 技术应用于爬虫项目6
2.3. 系统实现思路7
三、实现代码10
3.1. 抓取用户详细信息 10
3.2. 抓取用户的关注者列表 13
3.3. 爬取用户粉丝列表 14
3.4. 抓取用户信息并存入mongoDB数据库 15
4. 结果显示 17
4.1. 爬虫项目17运行结果展示
4.2. 爬取知乎 用户信息结果显示 17
五、总结与展望 18
5.1. 项目设计总结 18
5.2. 未来展望 19
参考文献 19
一、介绍
1.1. 研究背景
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。为了解决这个问题,有针对性地抓取相关网络资源的聚焦爬虫应运而生。Focus Crawler 是一个自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。对于所有平台上拥有自己的粉丝和关注者的用户来说,如何获取并组织这些用户的大量信息,以及如何对其粉丝和关注者进行统计和分析,是我们面临的一大难题。.
1.2. 爬虫研究的意义
面对从网页中获取大量数据和统计的难度,爬虫程序的编写会给我们在获取、分类和统计方面带来很大的方便。关于本次研究的课题,如何使用python语言编写的爬虫程序抓取知乎的用户信息。对于想要分析发布影响力文章的人来说,粉丝数量和类型的统计分析很重要知乎的意义为文章的数据分析节省了大量的统计工作和统计成本@知乎 影响。本次研究的目的是分析爬虫技术,如何分析对应的网页信息,如何抓取重要的网页信息,
1.3. 研究内容
<p>本研究的内容是分析网页的数据请求和数据返回的获取,可以分析请求的特征,可以使用Scrapy框架编写爬虫程序,从
网页视频抓取工具 知乎(知乎专栏bbc纪录片你需要的百度都有(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-10-29 00:00
网页视频抓取工具知乎专栏bbc纪录片你需要的百度都有.
ubuntu16.04就没有32位的。
浏览器:safari,chrome,operapro,firefox音乐:网易云音乐,qq音乐,虾米音乐购物:美丽说,蘑菇街,苏宁易购,京东,亚马逊等社交软件:陌陌,微信,微博,facebook,twitter搜索引擎:谷歌百度bing搜狗yahoosogou传图片:百度高清图片360无水印大图谷歌图片-高清图片国外:有wikipedia,维基百科,谷歌资源站,bing图片,360图片。
keynote。linkedin和facebook上都有动态图的开源计划,自己写代码完成的也有。
ubuntu默认目录下有个叫coreldraw的软件,可以轻松绘制图片的dwg,只要点那三个点就可以了,非常简单。
,虽然不是英文版,但是所有内容都在,
wikipedia(维基百科)。没有最好的工具,只有更好的工具,看你想学到哪里了。
工具软件quickpath+网站直接挂载taptap直接挂载instagram(必须挂载pinterest)googleauthoropenssearch&spreadsearchopenspage(现在仅限python3)sendwwwlinkedinlivingdatahomepagenotforfree3dphotosandthemesofprezamarkdownhomesmallpixelmotiondesignervideos.youtube(搞啥都行)还有很多,不过越来越多的开发者向各种各样的方向发展,可以先从简单的学起。 查看全部
网页视频抓取工具 知乎(知乎专栏bbc纪录片你需要的百度都有(组图))
网页视频抓取工具知乎专栏bbc纪录片你需要的百度都有.
ubuntu16.04就没有32位的。
浏览器:safari,chrome,operapro,firefox音乐:网易云音乐,qq音乐,虾米音乐购物:美丽说,蘑菇街,苏宁易购,京东,亚马逊等社交软件:陌陌,微信,微博,facebook,twitter搜索引擎:谷歌百度bing搜狗yahoosogou传图片:百度高清图片360无水印大图谷歌图片-高清图片国外:有wikipedia,维基百科,谷歌资源站,bing图片,360图片。
keynote。linkedin和facebook上都有动态图的开源计划,自己写代码完成的也有。
ubuntu默认目录下有个叫coreldraw的软件,可以轻松绘制图片的dwg,只要点那三个点就可以了,非常简单。
,虽然不是英文版,但是所有内容都在,
wikipedia(维基百科)。没有最好的工具,只有更好的工具,看你想学到哪里了。
工具软件quickpath+网站直接挂载taptap直接挂载instagram(必须挂载pinterest)googleauthoropenssearch&spreadsearchopenspage(现在仅限python3)sendwwwlinkedinlivingdatahomepagenotforfree3dphotosandthemesofprezamarkdownhomesmallpixelmotiondesignervideos.youtube(搞啥都行)还有很多,不过越来越多的开发者向各种各样的方向发展,可以先从简单的学起。
网页视频抓取工具 知乎(什么是站点地图?Google等搜索引擎能发现您的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-10-26 22:06
什么是站点地图?
站点地图是一个文件,可以提供关于网站的网页、视频或其他文件的信息,以及解释内容之间的关系,还提供有关这些文件的重要信息:以网页为例如,信息包括网页更新时间、网页变化频率、网页语言版本。谷歌、bing、yandex、百度等搜索引擎都会读取这个文件来更好的抓取网站。
您可以在站点地图的网页上提供有关特定类型内容(包括视频和图像内容)的信息。
我需要站点地图吗?
如果你的网站内链搭建好,谷歌等搜索引擎可以找到并抓取大部分网页。即便如此,站点地图站点地图也可以帮助搜索引擎更高效、更快速地抓取大规模复杂的内容。网站。即便如此,使用站点地图并不能保证 Google 等搜索引擎可以索引站点地图的所有内容。可以肯定的是,网站 将受益于站点地图的使用,而不是受苦。
网站可能需要情况图:
1、网站 规模非常大。站点地图站点地图可以帮助谷歌等搜索引擎抓取一些缺失的新网页或最近更新的网页。
2、网站 存档的内容页数量较多,内容页之间互不相关。sitemap站点地图可以列出这些页面,保证Google等搜索引擎不会漏掉一些页面。
3、网站 是新的网站,外部链接不多。谷歌等搜索引擎的网络抓取工具通过跟踪网页之间的链接来抓取网页。如果没有其他网站 链接到您的网页,Google 等搜索引擎可能找不到您的网页。
4、你的网站收录了大量的视频、图片等,谷歌等搜索引擎可以将这些信息在sitemap中纳入抓取范围。
网站可能不需要情况图:
1、你的网站“更小”。
2、你的网站内部链接做得很好,让搜索引擎发现所有的内容。
站点地图格式
站点地图站点地图有3种格式:xml格式、txt格式、html格式。其中,xml格式是百度和谷歌最常用的网站地图格式。
xml格式
xml格式的站点地图(如上图):
[loc]:填写完整的URL,必填;
[lastmod]:表示URL的最后修改时间;
[changefreq]:表示更新频率,可选值:always、hourly、daily、weekly、monthly、yearly、never;
[priority]:指页面的优先级,可选值0.0-1.0(可选,搜索引擎不再引用)。
txt格式
txt 格式实际上是txt 文本。txt格式网站映射,每行必须有一个网址,不能换行;不应收录 URL 列表以外的任何信息;必须写一个完整的 URL,包括 http 或 https 的开头;需要使用UTF-8编码或GBK编码。
html格式
html格式的网站图实际上相当于一个网页。网页安排了网站的主要页面的链接,一般只用于较大的网站,帮助用户快速找到目标页面。(上图为腾讯网的html站点地图)
如何生成站点地图
如果您的 网站 是 WordPress,您可以使用插件生成站点地图站点地图。更好的 wordpress 插件包括 Google XML Sitemaps 和 Yoast SEO;如果你的网站是其他建站程序设计的,那么需要使用XML-Sitemaps、xenu等工具生成。死链接检测工具-站点地图生成器:Xenu 免费下载
无需注册 XML-Sitemaps,只需使用上面的表格输入您的 URL (),然后单击“开始”!您可以下载xml网站地图文件或通过电子邮件接收,然后将其放在您的网站上。
如何上传站点地图
站点地图生成后,需要提交给搜索引擎,让搜索引擎知道可以找到新的站点地图,或者知道已经更改了。
最简单的方法是通过 Google Search Console。可以参考谷歌站长工具教程-谷歌搜索控制台教程
如果您通过谷歌站长工具提交站点地图,显示无法读取站点地图,请参考谷歌搜索控制台站长工具提交站点地图无法读取此站点地图?
或者,您可以在 robots.txt 文件中添加一段代码:什么是 Robots.txt 文件?如何创建 Robots.txt 文件? 查看全部
网页视频抓取工具 知乎(什么是站点地图?Google等搜索引擎能发现您的网页)
什么是站点地图?
站点地图是一个文件,可以提供关于网站的网页、视频或其他文件的信息,以及解释内容之间的关系,还提供有关这些文件的重要信息:以网页为例如,信息包括网页更新时间、网页变化频率、网页语言版本。谷歌、bing、yandex、百度等搜索引擎都会读取这个文件来更好的抓取网站。
您可以在站点地图的网页上提供有关特定类型内容(包括视频和图像内容)的信息。
我需要站点地图吗?
如果你的网站内链搭建好,谷歌等搜索引擎可以找到并抓取大部分网页。即便如此,站点地图站点地图也可以帮助搜索引擎更高效、更快速地抓取大规模复杂的内容。网站。即便如此,使用站点地图并不能保证 Google 等搜索引擎可以索引站点地图的所有内容。可以肯定的是,网站 将受益于站点地图的使用,而不是受苦。
网站可能需要情况图:
1、网站 规模非常大。站点地图站点地图可以帮助谷歌等搜索引擎抓取一些缺失的新网页或最近更新的网页。
2、网站 存档的内容页数量较多,内容页之间互不相关。sitemap站点地图可以列出这些页面,保证Google等搜索引擎不会漏掉一些页面。
3、网站 是新的网站,外部链接不多。谷歌等搜索引擎的网络抓取工具通过跟踪网页之间的链接来抓取网页。如果没有其他网站 链接到您的网页,Google 等搜索引擎可能找不到您的网页。
4、你的网站收录了大量的视频、图片等,谷歌等搜索引擎可以将这些信息在sitemap中纳入抓取范围。
网站可能不需要情况图:
1、你的网站“更小”。
2、你的网站内部链接做得很好,让搜索引擎发现所有的内容。
站点地图格式
站点地图站点地图有3种格式:xml格式、txt格式、html格式。其中,xml格式是百度和谷歌最常用的网站地图格式。
xml格式
xml格式的站点地图(如上图):
[loc]:填写完整的URL,必填;
[lastmod]:表示URL的最后修改时间;
[changefreq]:表示更新频率,可选值:always、hourly、daily、weekly、monthly、yearly、never;
[priority]:指页面的优先级,可选值0.0-1.0(可选,搜索引擎不再引用)。
txt格式
txt 格式实际上是txt 文本。txt格式网站映射,每行必须有一个网址,不能换行;不应收录 URL 列表以外的任何信息;必须写一个完整的 URL,包括 http 或 https 的开头;需要使用UTF-8编码或GBK编码。
html格式
html格式的网站图实际上相当于一个网页。网页安排了网站的主要页面的链接,一般只用于较大的网站,帮助用户快速找到目标页面。(上图为腾讯网的html站点地图)
如何生成站点地图
如果您的 网站 是 WordPress,您可以使用插件生成站点地图站点地图。更好的 wordpress 插件包括 Google XML Sitemaps 和 Yoast SEO;如果你的网站是其他建站程序设计的,那么需要使用XML-Sitemaps、xenu等工具生成。死链接检测工具-站点地图生成器:Xenu 免费下载
无需注册 XML-Sitemaps,只需使用上面的表格输入您的 URL (),然后单击“开始”!您可以下载xml网站地图文件或通过电子邮件接收,然后将其放在您的网站上。
如何上传站点地图
站点地图生成后,需要提交给搜索引擎,让搜索引擎知道可以找到新的站点地图,或者知道已经更改了。
最简单的方法是通过 Google Search Console。可以参考谷歌站长工具教程-谷歌搜索控制台教程
如果您通过谷歌站长工具提交站点地图,显示无法读取站点地图,请参考谷歌搜索控制台站长工具提交站点地图无法读取此站点地图?
或者,您可以在 robots.txt 文件中添加一段代码:什么是 Robots.txt 文件?如何创建 Robots.txt 文件?
网页视频抓取工具 知乎(知乎机构号该如何定位?知乎问答SEO该怎么做?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-26 18:14
知乎 曾经是各种代理账号运营的主战场。随着短视频领域的爆发和充裕的流量,越来越多的代理账号转向了短视频。但是,知乎 平台仍然与代理账户相关。很重要。这篇文章的作者通过个人的运营经验为我们总结了7000字长的文字,看到了企业如何结合自身特点,在知乎平台上大放异彩。
当企业疯狂涌入抖音、B站、视频账号等热门平台以求流量增长时,我选择以知乎作为新媒体营销的主阵地。因为在我看来,选择适合自己产品的新媒体营销渠道远比渠道本身是否受欢迎重要。
事实证明,这种策略是正确的。2个月,在知乎机构号的帮助下,我们还是为产品做了足够的流量。今天的文章文章就是回顾整个操作的实际操作。内容包括:
知乎如何定位组织编号?如何继续寻找合适的话题(问答)?知乎内容创作有哪些技巧?知乎Q&A SEO应该怎么做?
接下来直接进入正题,欣赏~
一、 定位:组织号的定位是为了锚定产品
所谓定位,用公式简单解释一下就是:定位=细分服务的人群+细分的需要满足。把它应用到知乎组织号的定位上,就是回答“什么内容为谁发布”的问题。
1. 为谁:服务的人群
这是一个子问题。
知乎机构号本质上是为企业服务的,是产品的营销推广渠道。换句话说,它定位的目标群体实际上和产品定位的目标群体是一样的。因此,我们无需经过调研、走访等过程,即可快速定位到知乎代理账号所服务的子人群。
比如Graphite文档的目标群,如果按照知乎“topics”进行细分,可以分为:
核心用户是正在使用/使用产品的群体,目标用户和潜在用户是需要关注的群体(以上只是举例,实际上Graphite Document目前没有运营知乎 组织编号)。
2. 发布什么样的内容:需要满足细分
对于这个问题,很多人喜欢笼统地用区分来回答。但实际上,知乎组织号不需要像知乎个人号或其他自媒体号那样讲内容区分。
在我看来,知乎 机构号最大的区别其实就是各自公司的产品不同。知乎机构账号要做的就是在内容(包括功能和场景)上突出和传播这种差异。
说到内容,我们难免会回避一个问题,什么是内容发布的风格,或者说我们希望借助内容打造什么样的个性?
我的回答是,最好是专家,这是由知乎的平台属性决定的。至于这位专家是认真的、顽皮的,还是有邻居感,都无所谓。
为什么知乎组织号的定位如此重要?
因为你不做定位,你发布的内容会很混乱,你的账号也缺乏专业性。这将直接导致结果。知乎 不会向您的帐户推荐稳定的流量。不仅会影响你答案的自然排名,还会影响后续的SEO操作(如果你不耐烦,可以直接进入第四部分“SEO”)。
二、 选题:关键词 库是前提
在知乎上找话题基本上相当于找问答。说到这里,可能有人会说,这不简单,直接在网站里搜索关键词就可以了。
事实上,事情真的没有那么简单。例如,我们应该搜索哪个 关键词?哪些搜索到的问题和答案最先得到回答,哪些没有得到回答甚至后来得到回答?除了网站搜索,我们还有其他高效便捷的搜索方式吗?
以上就是我们需要回答的全部问题。
1. 构建您的 关键词 库
构建 关键词 库有两个优点:
针对性:精准发现潜在问题和答案,有节奏地进行内容运营;检查遗漏和填补空缺:您可以随时检查哪些 关键词 已被覆盖,哪些尚未铺设。
如何构建它?还有两种方法(再次以graphite文档为例):
1)查找产品和产品功能关键词
这是记账初期最直接有效的方法。
2)寻找产品应用场景关键词
当我们布置完包括产品和产品功能的问答关键词时,我们会遇到另一个问题:没有关键词可以回答。现阶段我们需要从产品的应用场景扩展关键词库:
例如,石墨文档可以从办公协同和效率提升的角度,细化到年终总结、文档管理、项目管理、HR招聘等特定应用场景;
另一个例子是 XMind。从思维提升和知识管理的角度,可以细化到结构化思维/发散思维的培养、个人知识体系的建立、职业发展SWOT分析等具体应用场景;
再比如创客贴,可以根据产品可以实现的平面设计,比如公众号封面图、手机海报、营销图片、名片、邀请函等,来延伸场景。
综上所述,我们要做的就是发现用户已有的场景,补充用户没有发现的场景,然后浓缩成一个关键词。
2. 6 种搜索方法找到潜在的问答
使用关键词 库,我们可以进行有针对性的问答搜索。这里有六种搜索方法供大家参考,接下来你会发现更多的补充:
1)在本站搜索
关键词 在网站上搜索,这是最简单也是目前使用最多的搜索方式。但是这种方法有一个缺点,就是在结果列表中,很难快速直观的判断一个问答的价值和潜力(曝光度是一个重要的指标)。
我指出了这个缺点,当然我也带来了解决方案,那就是使用知乎问答评分插件来辅助判断。
在谷歌浏览器/360浏览器中安装评分插件后,在网站上搜索特定的关键词,如“网站”,每道题右侧会出现相应的分数和出现在结果页上的答案。高分意味着值得优先回答,低分可以放慢速度。
注意:此插件使用一段时间后会自动失效。它需要重新安装,然后注册并登录才能再次使用。虽然整个过程有点繁琐,但是注册不需要验证,省去了很多事情。
除了问答分数,我们还可以结合问答的观看次数和回答次数来判断。
如果一个问答的浏览量很高,但目前的回答数量很少,那么值得先回答。因为它代表了我们的答案冲到前排的绝佳机会,我们可以通过后续的SEO优化前3位的影响力,争取更高的曝光率。
至于浏览量高、回答高的问答,则要靠更多的干货内容开战。
很多人不知道问答右侧有一个“相关问题”部分,因为它只出现在PC网页上。本节一般汇总4-5道相关问题(有时不太相关),选题策略同上。
对于组织号,知乎每周都会设置常规任务,只要完成任务就可以获得相应的奖励。
奖励之一是“热追踪1周”,触发条件为代理账号每周完成7次创作(含Q&A,文章)。会在机构号管理中心推荐热点问题,但大多与产品无关。
相比知乎系统推荐的问答,目前人工搜索还是比较靠谱的。除了开头提到的直接搜索,我们其实还可以从竞争账号的历史答案中挖掘出合适的问题和答案。这相当于双方运营商的联合筛选,极有可能是有价值的。
退一步说,即使问答本身没有多大价值,我们还是要从获取更多目标用户的营销角度来占领这个问答。
2)站外搜索
这是一种被忽视但极其重要的搜索方法。
之所以重要,是因为百度在2019年8月宣布了战略投资知乎。此次密切合作带来的一个重要变化是,知乎问答在百度搜索中的权重增加了——这是不可忽视的流量。
因此,除了在知乎网站进行关键词搜索,我们还可以在百度上进行关键词搜索,然后优先显示在知乎网站上的Q&A结果页面的第一页。
这个过程可以结合5118站长工具箱插件,可以隐藏百度搜索的广告,帮助我们快速找到目标结果。
最后一种方法是使用第三方工具——“”来实现。
借助5118的排名监控,可以比较所有搜索关键词对应的知乎问答,百度PC搜索中的排名结果,百度PC中排名列表关键词,百度PC搜索量,等数据一次性拉出,支持导出到Excel。
我们要做的就是根据我们自己的关键词库,在导出的Excel中检索我们自己的关键词和对应的知乎问答。
但是,此功能需要付费会员才能使用。
最后,我想补充下关于知乎组织号这个话题的建议,就是尽量不要选择社交热点事件,政治和军事事件。因为机构编号代表的是公司和产品的形象,如果回答不当,很容易引发危机公关事件。
三、内容:“为什么”和“如何”更重要
确定主题后,下一步就是内容创作。这部分我将拆解知乎问答结构和图片,回答以下两个问题:
知乎高赞回答的大致结构是什么?知乎问答图片有什么技巧和注意事项?1. 高赞回答的大体结构
高赞回答一般呈现这样的结构,用一个公式表示:高赞回答=直截了当的回答结果+理性循证分析+互动到底寻求三个环节,具体怎么理解这个公式?
1)结果开门见山
意思是在答案的开头,我们尽量用简洁的文字来概括答案,以制造吸引力,例如:
推荐12个完全免费的良心网站,每一个都是完全免费的,非常好用,让你遇见又恨晚了——知乎@木子淇,对应的问题:你们舍不得带什么共享 网站?
作为对水母的纪录片狂热爱好者,我看了数百部纪录片,只有这12部顶级纪录片吸引了我。每次看都会感叹“好想看爆”!想再看一遍,涵盖历史、人文、宇宙。绝对值得一看!尤其是中间两位——知乎@黛西巫妖,对应的问题:到目前为止,你看过哪些可以称得上“顶级纪录片”的纪录片?
做炸鸡外卖,一个月净利润4w左右,一年利润几十万。不知道苏阿是不是暴利。炸鸡外卖吃过很多人,但很少有人知道做这个生意这么赚钱,可能这个行业不是很抢眼——知乎@林雁,对应的问题:还有普通人现在不太好 了解暴利行业吗?
之所以写这个,除了我们通常知道的“吸引用户持续观看”之外,还有一个非常重要的原因吸引用户点击。在知乎的回答之前你应该知道不展开,其显示逻辑与公众号摘要相同,默认会抓取body前面的内容。
2)有理有据分析
当你吸引注意力时,你必须保持完整和完整的内容。
那么什么样的内容才算满分呢?
我的回答不仅是介绍“什么”,还要解释“为什么”和“如何解决”。知乎用户不愿意停留在问题的表面,他们喜欢深入的、未知的、难以阅读的内容。告诉他们更深入的知识、经验或见解,会更容易获得批准。
比如这个知乎问题:费曼的技术是什么?
如果你只是简单地告诉用户这是一种“教-学”的学习方式,可以帮助你提高知识吸收的效率,真正理解和学会使用知识,那么答案很可能落到了谷底。组织号XMind做了一个很好的演示,它是这样回答的(回答太长,我只拆解了主要结构和要点):
费曼的技术是什么?
——以教为学。
具体申请方法?
——四个步骤。
为什么费曼的技术如此有效?
这是知友喜欢的那种干货。就算中间有私货,他们还是愿意为这个答案投票(截至发稿时,这个答案的赞同数接近10000,给产品带来的曝光率非常明显)。
因此,在答题时,如果能以“别人看我的答案时会问我为什么?”这样的假设,就可以写出更详细、更有用的解释和解释。如果你提出一个观点,请解释你为什么这么认为,这对你的读者会很有帮助。
3)连续三场结束互动
最后,多互动,引导更多用户参与、关注、评论,可以放自己的产品体验链接(支持文字链接和卡片链接)。
注意:不要硬而宽!不要太难!不要太难!重要的事情说三遍!因为会被阻塞,下面是一个典型的反例:
2. 知乎图片搭配技巧及注意事项
如果您的产品属于软件工具类,在介绍功能时可以选择录制Gif动画。它比静态图像更直观,可以增加用户的停留时间。但需要注意的是,Gif图片不能太大(控制在1M左右),否则用户可能会在加载过程中不耐烦跳出。
另外,对于一些信息量比较大的横屏图片(图片一般比较模糊),尽量改成竖屏图片,同时可以适应用户的移动终端阅读,提高用户的阅读体验。当然,如果你想做引流,那也不是什么大问题。
在内容文章的最后,给大家分享一个小技巧:知乎 支持同一个内容回答两个相似的问题,让机构号快速分发。但我建议根据每个问题的具体描述来调整开头和部分内容。
注意:一条内容不要回答超过3个问题,因为网站会删除重复的内容,严重的甚至会封号。
四、SEO 文章:知乎 也做 SEO?
当内容发布成功后,我们就可以进入下一个环节——SEO。可能有人会疑惑,知乎问答也要做SEO吗?回答完不是就结束了吗?
- 当然不是。
如果我们将内容与 1 进行比较,则 SEO 落后 0。后者是前者的放大器,可以为前者带来更大的曝光度,从而帮助公司的产品获得更多的销售线索。这也是我们反复提到的知乎组织号的最终目标。
既然知乎问答SEO这么重要,我们该怎么办?我总结了2个主要技术:
1. 找个高权重账号点赞
在知乎刷赞也不是什么新鲜事,但是如何高效无痕刷赞需要一点技巧。不过别着急,在正式分享知乎刷题技巧之前,我们得先搞清楚一个问题,就是知乎问答的排序算法,这就是我们的“指南针”后续操作。
知乎 Q&A排序有旧的和新的两套。旧的问答排序算法比较简单,基于“分数=加权批准数-加权反对数”,但会带来两个问题:
第一:好评率会长期占据榜首,即使是新的优质回答也很难有“上升之日”;第二:如果恶意投了大量的反对票,答案分数甚至可以是负数,这也意味着被沉没。最终也难有“翻身之日”。
新版算法(Wilson score)的出现在一定程度上解决了上述问题,让新答案也有机会超越之前的好评答案——这为我们实施SEO计划创造了空间。
以上是威尔逊分数的计算公式。很复杂,要说清楚是很长的文章。但我不打算在这里谈论它。有兴趣的可以到知乎搜索《如何评价知乎的答案排序算法?》。已经有很多大佬从各个维度进行了分析。
这次我们的重点仍然是这种新算法对我们 SEO 的影响。直接说观察结果:
垂直领域的高级账户拥有更高的点赞权重;举个简单的例子,同领域V5账号的点赞效果要强于10个V3账号;点赞高级账号效果立竿见影,点赞后刷新链接,之后通常可以看到效果。
也就是说,我们的SEO任务要从原来的点赞数1.0时代升级到点赞质量2.0时代,那怎么做呢?
还有两种技术:
1)自己培养一个高功率小号
这不是一朝一夕可以做到的事情,但是运行后,组织账号和个人账号的互赞可以形成良性循环,效果非常显着。
值得注意的是,每次点赞知乎,都会出现在账号动态中。如果我们长期只喜欢一个账号,很容易被用户发现并向知乎官方投诉,严重的话,账号会被封。
所以点赞需要模拟正常的用户行为轨迹,不要继续点赞一个账号,穿插点赞一些不会与我们形成直接排名竞争的答案;不要打开问答链接直接跳转到目标答案,尽量正常浏览相同问题下面的其他答案,有时可以做一些简单的评论等等。
2) 积极吸引高能重要账号点赞
直接买大赞不划算,容易被举报。那么如何才能让大佬主动点赞呢?
我想出了一个技巧:在答案中引用一些高功率V的要点,然后在文章中@对方。如果对方认可我们的内容,很可能会得到对方的好评。
当然,前提是我们的内容要有足够的信息量。这就是我们前面提到的内容。
比如我们前面提到的XMind案例,就引用了@开眼科技在回答“费曼的技术是什么?”中选择的视频内容。然后@ed 对方。
2. 使用第三方工具进行快速排序
前面我们讲的是在知乎网站做Q&A SEO,就是提高回答排名;但是如果我们想用这个答案在百度搜索中提升知乎问题的排名,那么就需要使用第三方工具进行快速排序。
有预算的运维同学可以试试数据库/超快排。三四个星期后,他们通常可以到达百度搜索结果首页。
3. 严格来说,两个不属于SEO范畴的彩蛋
1)使用自推荐功能
知乎组织号每周可以在完成任务后获得一定数量的“自我推荐”。所谓“自荐”,简单来说就是让平台为自己分发内容的功能。
由于“自荐”的数量有限,最好的办法是结合背景数据,筛选出最近有潜力的自荐内容,让已经很优秀的内容更有可能成为热门。
2)打开刘看山邀请
有时候遇到浏览量低的问答,可以打开刘看山的邀请,自主邀请系统推荐的创作者。目的其实是为了让更多的用户看到你创建的内容。
五、写在最后
知乎是一个很好的流量池,但我们也必须认识到,并不是所有类型的产品都适合在这里进行内容营销。完美日记来去匆匆;白果园来了又去了;名创优品也来过,终于走了……
不是这些产品不好,也不是知乎平台不强大,而是产品与平台的“适应度”太低,彼此都不是“合适的人”(例如完美日记和小红书更匹配)。
而ToC的工具产品,比如我前面举例的Graphite Document、XMind、Maker Tie等,对知乎的兼容性更好:
首先,知乎和工具类产品在用户人群上会有很大的重叠,两者都是高学历,追求高效率;其次,朋友们通常会带着具体的问题来寻找答案。如果你看到正确的工具,一般来说,你会开始;最后,知乎支持直接在答案中放置产品链接(后期可以自定义链接,追踪用户来源),可以大大缩短获客链。
综上所述,企业必须根据自身的产品属性、用户特征,以及不同自媒体平台的调性,以及不同平台采用何种内容格式和运营方式,来决定选择何种平台进行运营。这是经营新媒体的公司的重要规则。 查看全部
网页视频抓取工具 知乎(知乎机构号该如何定位?知乎问答SEO该怎么做?)
知乎 曾经是各种代理账号运营的主战场。随着短视频领域的爆发和充裕的流量,越来越多的代理账号转向了短视频。但是,知乎 平台仍然与代理账户相关。很重要。这篇文章的作者通过个人的运营经验为我们总结了7000字长的文字,看到了企业如何结合自身特点,在知乎平台上大放异彩。
当企业疯狂涌入抖音、B站、视频账号等热门平台以求流量增长时,我选择以知乎作为新媒体营销的主阵地。因为在我看来,选择适合自己产品的新媒体营销渠道远比渠道本身是否受欢迎重要。
事实证明,这种策略是正确的。2个月,在知乎机构号的帮助下,我们还是为产品做了足够的流量。今天的文章文章就是回顾整个操作的实际操作。内容包括:
知乎如何定位组织编号?如何继续寻找合适的话题(问答)?知乎内容创作有哪些技巧?知乎Q&A SEO应该怎么做?
接下来直接进入正题,欣赏~
一、 定位:组织号的定位是为了锚定产品
所谓定位,用公式简单解释一下就是:定位=细分服务的人群+细分的需要满足。把它应用到知乎组织号的定位上,就是回答“什么内容为谁发布”的问题。
1. 为谁:服务的人群
这是一个子问题。
知乎机构号本质上是为企业服务的,是产品的营销推广渠道。换句话说,它定位的目标群体实际上和产品定位的目标群体是一样的。因此,我们无需经过调研、走访等过程,即可快速定位到知乎代理账号所服务的子人群。
比如Graphite文档的目标群,如果按照知乎“topics”进行细分,可以分为:
核心用户是正在使用/使用产品的群体,目标用户和潜在用户是需要关注的群体(以上只是举例,实际上Graphite Document目前没有运营知乎 组织编号)。
2. 发布什么样的内容:需要满足细分
对于这个问题,很多人喜欢笼统地用区分来回答。但实际上,知乎组织号不需要像知乎个人号或其他自媒体号那样讲内容区分。
在我看来,知乎 机构号最大的区别其实就是各自公司的产品不同。知乎机构账号要做的就是在内容(包括功能和场景)上突出和传播这种差异。
说到内容,我们难免会回避一个问题,什么是内容发布的风格,或者说我们希望借助内容打造什么样的个性?
我的回答是,最好是专家,这是由知乎的平台属性决定的。至于这位专家是认真的、顽皮的,还是有邻居感,都无所谓。
为什么知乎组织号的定位如此重要?
因为你不做定位,你发布的内容会很混乱,你的账号也缺乏专业性。这将直接导致结果。知乎 不会向您的帐户推荐稳定的流量。不仅会影响你答案的自然排名,还会影响后续的SEO操作(如果你不耐烦,可以直接进入第四部分“SEO”)。
二、 选题:关键词 库是前提
在知乎上找话题基本上相当于找问答。说到这里,可能有人会说,这不简单,直接在网站里搜索关键词就可以了。
事实上,事情真的没有那么简单。例如,我们应该搜索哪个 关键词?哪些搜索到的问题和答案最先得到回答,哪些没有得到回答甚至后来得到回答?除了网站搜索,我们还有其他高效便捷的搜索方式吗?
以上就是我们需要回答的全部问题。
1. 构建您的 关键词 库
构建 关键词 库有两个优点:
针对性:精准发现潜在问题和答案,有节奏地进行内容运营;检查遗漏和填补空缺:您可以随时检查哪些 关键词 已被覆盖,哪些尚未铺设。
如何构建它?还有两种方法(再次以graphite文档为例):
1)查找产品和产品功能关键词
这是记账初期最直接有效的方法。
2)寻找产品应用场景关键词
当我们布置完包括产品和产品功能的问答关键词时,我们会遇到另一个问题:没有关键词可以回答。现阶段我们需要从产品的应用场景扩展关键词库:
例如,石墨文档可以从办公协同和效率提升的角度,细化到年终总结、文档管理、项目管理、HR招聘等特定应用场景;
另一个例子是 XMind。从思维提升和知识管理的角度,可以细化到结构化思维/发散思维的培养、个人知识体系的建立、职业发展SWOT分析等具体应用场景;
再比如创客贴,可以根据产品可以实现的平面设计,比如公众号封面图、手机海报、营销图片、名片、邀请函等,来延伸场景。
综上所述,我们要做的就是发现用户已有的场景,补充用户没有发现的场景,然后浓缩成一个关键词。
2. 6 种搜索方法找到潜在的问答
使用关键词 库,我们可以进行有针对性的问答搜索。这里有六种搜索方法供大家参考,接下来你会发现更多的补充:
1)在本站搜索
关键词 在网站上搜索,这是最简单也是目前使用最多的搜索方式。但是这种方法有一个缺点,就是在结果列表中,很难快速直观的判断一个问答的价值和潜力(曝光度是一个重要的指标)。
我指出了这个缺点,当然我也带来了解决方案,那就是使用知乎问答评分插件来辅助判断。
在谷歌浏览器/360浏览器中安装评分插件后,在网站上搜索特定的关键词,如“网站”,每道题右侧会出现相应的分数和出现在结果页上的答案。高分意味着值得优先回答,低分可以放慢速度。
注意:此插件使用一段时间后会自动失效。它需要重新安装,然后注册并登录才能再次使用。虽然整个过程有点繁琐,但是注册不需要验证,省去了很多事情。
除了问答分数,我们还可以结合问答的观看次数和回答次数来判断。
如果一个问答的浏览量很高,但目前的回答数量很少,那么值得先回答。因为它代表了我们的答案冲到前排的绝佳机会,我们可以通过后续的SEO优化前3位的影响力,争取更高的曝光率。
至于浏览量高、回答高的问答,则要靠更多的干货内容开战。
很多人不知道问答右侧有一个“相关问题”部分,因为它只出现在PC网页上。本节一般汇总4-5道相关问题(有时不太相关),选题策略同上。
对于组织号,知乎每周都会设置常规任务,只要完成任务就可以获得相应的奖励。
奖励之一是“热追踪1周”,触发条件为代理账号每周完成7次创作(含Q&A,文章)。会在机构号管理中心推荐热点问题,但大多与产品无关。
相比知乎系统推荐的问答,目前人工搜索还是比较靠谱的。除了开头提到的直接搜索,我们其实还可以从竞争账号的历史答案中挖掘出合适的问题和答案。这相当于双方运营商的联合筛选,极有可能是有价值的。
退一步说,即使问答本身没有多大价值,我们还是要从获取更多目标用户的营销角度来占领这个问答。
2)站外搜索
这是一种被忽视但极其重要的搜索方法。
之所以重要,是因为百度在2019年8月宣布了战略投资知乎。此次密切合作带来的一个重要变化是,知乎问答在百度搜索中的权重增加了——这是不可忽视的流量。
因此,除了在知乎网站进行关键词搜索,我们还可以在百度上进行关键词搜索,然后优先显示在知乎网站上的Q&A结果页面的第一页。
这个过程可以结合5118站长工具箱插件,可以隐藏百度搜索的广告,帮助我们快速找到目标结果。
最后一种方法是使用第三方工具——“”来实现。
借助5118的排名监控,可以比较所有搜索关键词对应的知乎问答,百度PC搜索中的排名结果,百度PC中排名列表关键词,百度PC搜索量,等数据一次性拉出,支持导出到Excel。
我们要做的就是根据我们自己的关键词库,在导出的Excel中检索我们自己的关键词和对应的知乎问答。
但是,此功能需要付费会员才能使用。
最后,我想补充下关于知乎组织号这个话题的建议,就是尽量不要选择社交热点事件,政治和军事事件。因为机构编号代表的是公司和产品的形象,如果回答不当,很容易引发危机公关事件。
三、内容:“为什么”和“如何”更重要
确定主题后,下一步就是内容创作。这部分我将拆解知乎问答结构和图片,回答以下两个问题:
知乎高赞回答的大致结构是什么?知乎问答图片有什么技巧和注意事项?1. 高赞回答的大体结构
高赞回答一般呈现这样的结构,用一个公式表示:高赞回答=直截了当的回答结果+理性循证分析+互动到底寻求三个环节,具体怎么理解这个公式?
1)结果开门见山
意思是在答案的开头,我们尽量用简洁的文字来概括答案,以制造吸引力,例如:
推荐12个完全免费的良心网站,每一个都是完全免费的,非常好用,让你遇见又恨晚了——知乎@木子淇,对应的问题:你们舍不得带什么共享 网站?
作为对水母的纪录片狂热爱好者,我看了数百部纪录片,只有这12部顶级纪录片吸引了我。每次看都会感叹“好想看爆”!想再看一遍,涵盖历史、人文、宇宙。绝对值得一看!尤其是中间两位——知乎@黛西巫妖,对应的问题:到目前为止,你看过哪些可以称得上“顶级纪录片”的纪录片?
做炸鸡外卖,一个月净利润4w左右,一年利润几十万。不知道苏阿是不是暴利。炸鸡外卖吃过很多人,但很少有人知道做这个生意这么赚钱,可能这个行业不是很抢眼——知乎@林雁,对应的问题:还有普通人现在不太好 了解暴利行业吗?
之所以写这个,除了我们通常知道的“吸引用户持续观看”之外,还有一个非常重要的原因吸引用户点击。在知乎的回答之前你应该知道不展开,其显示逻辑与公众号摘要相同,默认会抓取body前面的内容。
2)有理有据分析
当你吸引注意力时,你必须保持完整和完整的内容。
那么什么样的内容才算满分呢?
我的回答不仅是介绍“什么”,还要解释“为什么”和“如何解决”。知乎用户不愿意停留在问题的表面,他们喜欢深入的、未知的、难以阅读的内容。告诉他们更深入的知识、经验或见解,会更容易获得批准。
比如这个知乎问题:费曼的技术是什么?
如果你只是简单地告诉用户这是一种“教-学”的学习方式,可以帮助你提高知识吸收的效率,真正理解和学会使用知识,那么答案很可能落到了谷底。组织号XMind做了一个很好的演示,它是这样回答的(回答太长,我只拆解了主要结构和要点):
费曼的技术是什么?
——以教为学。
具体申请方法?
——四个步骤。
为什么费曼的技术如此有效?
这是知友喜欢的那种干货。就算中间有私货,他们还是愿意为这个答案投票(截至发稿时,这个答案的赞同数接近10000,给产品带来的曝光率非常明显)。
因此,在答题时,如果能以“别人看我的答案时会问我为什么?”这样的假设,就可以写出更详细、更有用的解释和解释。如果你提出一个观点,请解释你为什么这么认为,这对你的读者会很有帮助。
3)连续三场结束互动
最后,多互动,引导更多用户参与、关注、评论,可以放自己的产品体验链接(支持文字链接和卡片链接)。
注意:不要硬而宽!不要太难!不要太难!重要的事情说三遍!因为会被阻塞,下面是一个典型的反例:
2. 知乎图片搭配技巧及注意事项
如果您的产品属于软件工具类,在介绍功能时可以选择录制Gif动画。它比静态图像更直观,可以增加用户的停留时间。但需要注意的是,Gif图片不能太大(控制在1M左右),否则用户可能会在加载过程中不耐烦跳出。
另外,对于一些信息量比较大的横屏图片(图片一般比较模糊),尽量改成竖屏图片,同时可以适应用户的移动终端阅读,提高用户的阅读体验。当然,如果你想做引流,那也不是什么大问题。
在内容文章的最后,给大家分享一个小技巧:知乎 支持同一个内容回答两个相似的问题,让机构号快速分发。但我建议根据每个问题的具体描述来调整开头和部分内容。
注意:一条内容不要回答超过3个问题,因为网站会删除重复的内容,严重的甚至会封号。
四、SEO 文章:知乎 也做 SEO?
当内容发布成功后,我们就可以进入下一个环节——SEO。可能有人会疑惑,知乎问答也要做SEO吗?回答完不是就结束了吗?
- 当然不是。
如果我们将内容与 1 进行比较,则 SEO 落后 0。后者是前者的放大器,可以为前者带来更大的曝光度,从而帮助公司的产品获得更多的销售线索。这也是我们反复提到的知乎组织号的最终目标。
既然知乎问答SEO这么重要,我们该怎么办?我总结了2个主要技术:
1. 找个高权重账号点赞
在知乎刷赞也不是什么新鲜事,但是如何高效无痕刷赞需要一点技巧。不过别着急,在正式分享知乎刷题技巧之前,我们得先搞清楚一个问题,就是知乎问答的排序算法,这就是我们的“指南针”后续操作。
知乎 Q&A排序有旧的和新的两套。旧的问答排序算法比较简单,基于“分数=加权批准数-加权反对数”,但会带来两个问题:
第一:好评率会长期占据榜首,即使是新的优质回答也很难有“上升之日”;第二:如果恶意投了大量的反对票,答案分数甚至可以是负数,这也意味着被沉没。最终也难有“翻身之日”。
新版算法(Wilson score)的出现在一定程度上解决了上述问题,让新答案也有机会超越之前的好评答案——这为我们实施SEO计划创造了空间。
以上是威尔逊分数的计算公式。很复杂,要说清楚是很长的文章。但我不打算在这里谈论它。有兴趣的可以到知乎搜索《如何评价知乎的答案排序算法?》。已经有很多大佬从各个维度进行了分析。
这次我们的重点仍然是这种新算法对我们 SEO 的影响。直接说观察结果:
垂直领域的高级账户拥有更高的点赞权重;举个简单的例子,同领域V5账号的点赞效果要强于10个V3账号;点赞高级账号效果立竿见影,点赞后刷新链接,之后通常可以看到效果。
也就是说,我们的SEO任务要从原来的点赞数1.0时代升级到点赞质量2.0时代,那怎么做呢?
还有两种技术:
1)自己培养一个高功率小号
这不是一朝一夕可以做到的事情,但是运行后,组织账号和个人账号的互赞可以形成良性循环,效果非常显着。
值得注意的是,每次点赞知乎,都会出现在账号动态中。如果我们长期只喜欢一个账号,很容易被用户发现并向知乎官方投诉,严重的话,账号会被封。
所以点赞需要模拟正常的用户行为轨迹,不要继续点赞一个账号,穿插点赞一些不会与我们形成直接排名竞争的答案;不要打开问答链接直接跳转到目标答案,尽量正常浏览相同问题下面的其他答案,有时可以做一些简单的评论等等。
2) 积极吸引高能重要账号点赞
直接买大赞不划算,容易被举报。那么如何才能让大佬主动点赞呢?
我想出了一个技巧:在答案中引用一些高功率V的要点,然后在文章中@对方。如果对方认可我们的内容,很可能会得到对方的好评。
当然,前提是我们的内容要有足够的信息量。这就是我们前面提到的内容。
比如我们前面提到的XMind案例,就引用了@开眼科技在回答“费曼的技术是什么?”中选择的视频内容。然后@ed 对方。
2. 使用第三方工具进行快速排序
前面我们讲的是在知乎网站做Q&A SEO,就是提高回答排名;但是如果我们想用这个答案在百度搜索中提升知乎问题的排名,那么就需要使用第三方工具进行快速排序。
有预算的运维同学可以试试数据库/超快排。三四个星期后,他们通常可以到达百度搜索结果首页。
3. 严格来说,两个不属于SEO范畴的彩蛋
1)使用自推荐功能
知乎组织号每周可以在完成任务后获得一定数量的“自我推荐”。所谓“自荐”,简单来说就是让平台为自己分发内容的功能。
由于“自荐”的数量有限,最好的办法是结合背景数据,筛选出最近有潜力的自荐内容,让已经很优秀的内容更有可能成为热门。
2)打开刘看山邀请
有时候遇到浏览量低的问答,可以打开刘看山的邀请,自主邀请系统推荐的创作者。目的其实是为了让更多的用户看到你创建的内容。
五、写在最后
知乎是一个很好的流量池,但我们也必须认识到,并不是所有类型的产品都适合在这里进行内容营销。完美日记来去匆匆;白果园来了又去了;名创优品也来过,终于走了……
不是这些产品不好,也不是知乎平台不强大,而是产品与平台的“适应度”太低,彼此都不是“合适的人”(例如完美日记和小红书更匹配)。
而ToC的工具产品,比如我前面举例的Graphite Document、XMind、Maker Tie等,对知乎的兼容性更好:
首先,知乎和工具类产品在用户人群上会有很大的重叠,两者都是高学历,追求高效率;其次,朋友们通常会带着具体的问题来寻找答案。如果你看到正确的工具,一般来说,你会开始;最后,知乎支持直接在答案中放置产品链接(后期可以自定义链接,追踪用户来源),可以大大缩短获客链。
综上所述,企业必须根据自身的产品属性、用户特征,以及不同自媒体平台的调性,以及不同平台采用何种内容格式和运营方式,来决定选择何种平台进行运营。这是经营新媒体的公司的重要规则。
网页视频抓取工具 知乎( 接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-10-26 10:07
接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
前言
现在允许知乎上传视频,但我不能下载视频。气死我了,只好研究了一下,然后我输入了代码,方便下载和保存视频。
接下来,为什么猫根本不怕蛇?以答案为例,分享整个下载过程。
相关学习推荐:python视频教程
打开F12,找到光标,如下图:
然后将光标移动到视频。如下所示:
这是什么?视野中出现了一个神秘的链接:,让我们把这个链接复制到浏览器,然后打开:
看来这就是我们要找的视频了,别着急,我们先看一下网页的请求,然后你会发现一个很有趣的请求(这里强调):
我们自己来看看数据:
{ "playlist": { "ld": { "width": 360, "format": "mp4", "play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B, "duration": 17, "size": 1123111, "bitrate": 509, "height": 640 }, "hd": { "width": 720, "format": "mp4", "play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B, "duration": 17, "size": 4354364, "bitrate": 1974, "height": 1280 }, "sd": { "width": 480, "format": "mp4", "play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B, "duration": 17, "size": 1920976, "bitrate": 871, "height": 848 } }, "title": "", "duration": 17, "cover_info": { "width": 720, "thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B, "height": 1280 }, "type": "video", "id": "1039146361396174848", "misc_info": {} }
没错,我们要下载的视频就在这里,其中ld代表通用清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右击保存即可下载视频。
代码
知道了整个流程是什么样子的,接下来的压码流程就简单了,不过我这里就不多说了,直接上代码吧:
# -*- encoding: utf-8 -*- import re import requests import uuid import datetime class DownloadVideo: __slots__ = [ 'url', 'video_name', 'url_format', 'download_url', 'video_number', 'video_api', 'clarity_list', 'clarity' ] def __init__(self, url, clarity='ld', video_name=None): self.url = url self.video_name = video_name self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+" self.clarity = clarity self.clarity_list = ['ld', 'sd', 'hd'] self.video_api = 'https://lens.zhihu.com/api/videos' def check_url_format(self): pattern = re.compile(self.url_format) matches = re.match(pattern, self.url) if matches is None: raise ValueError( "链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}" ) return True def get_video_number(self): try: headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36' } response = requests.get(self.url, headers=headers) response.encoding = 'utf-8' html = response.text video_ids = re.findall(r'data-lens-id="(\d+)"', html) if video_ids: video_id_list = list(set([video_id for video_id in video_ids])) self.video_number = video_id_list[0] return self raise ValueError("获取视频编号异常:{}".format(self.url)) except Exception as e: raise Exception(e) def get_video_url_by_number(self): url = "{}/{}".format(self.video_api, self.video_number) headers = {} headers['Referer'] = 'https://v.vzuu.com/video/{}'.format( self.video_number) headers['Origin'] = 'https://v.vzuu.com' headers[ 'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36' headers['Content-Type'] = 'application/json' try: response = requests.get(url, headers=headers) response_dict = response.json() if self.clarity in response_dict['playlist']: self.download_url = response_dict['playlist'][ self.clarity]['play_url'] else: for clarity in self.clarity_list: if clarity in response_dict['playlist']: self.download_url = response_dict['playlist'][ self.clarity]['play_url'] break return self except Exception as e: raise Exception(e) def get_video_by_video_url(self): response = requests.get(self.download_url) datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S") if self.video_name is not None: video_name = "{}-{}.mp4".format(self.video_name, datetime_str) else: video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str) path = "{}".format(video_name) with open(path, 'wb') as f: f.write(response.content) def download_video(self): if self.clarity not in self.clarity_list: raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)") if self.check_url_format(): return self.get_video_number().get_video_url_by_number().get_video_by_video_url() if __name__ == '__main__': a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069') print(a.download_video())
结束语
代码还有优化的空间。我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果有什么问题或者建议,可以多交流。
相关学习推荐:python视频教程
以上就是学习python捕捉知乎指定回答视频的方法的详细内容。更多内容请关注技术你好等相关文章! 查看全部
网页视频抓取工具 知乎(
接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
前言
现在允许知乎上传视频,但我不能下载视频。气死我了,只好研究了一下,然后我输入了代码,方便下载和保存视频。
接下来,为什么猫根本不怕蛇?以答案为例,分享整个下载过程。
相关学习推荐:python视频教程
打开F12,找到光标,如下图:
然后将光标移动到视频。如下所示:
这是什么?视野中出现了一个神秘的链接:,让我们把这个链接复制到浏览器,然后打开:
看来这就是我们要找的视频了,别着急,我们先看一下网页的请求,然后你会发现一个很有趣的请求(这里强调):
我们自己来看看数据:
{ "playlist": { "ld": { "width": 360, "format": "mp4", "play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B, "duration": 17, "size": 1123111, "bitrate": 509, "height": 640 }, "hd": { "width": 720, "format": "mp4", "play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B, "duration": 17, "size": 4354364, "bitrate": 1974, "height": 1280 }, "sd": { "width": 480, "format": "mp4", "play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B, "duration": 17, "size": 1920976, "bitrate": 871, "height": 848 } }, "title": "", "duration": 17, "cover_info": { "width": 720, "thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B, "height": 1280 }, "type": "video", "id": "1039146361396174848", "misc_info": {} }
没错,我们要下载的视频就在这里,其中ld代表通用清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右击保存即可下载视频。
代码
知道了整个流程是什么样子的,接下来的压码流程就简单了,不过我这里就不多说了,直接上代码吧:
# -*- encoding: utf-8 -*- import re import requests import uuid import datetime class DownloadVideo: __slots__ = [ 'url', 'video_name', 'url_format', 'download_url', 'video_number', 'video_api', 'clarity_list', 'clarity' ] def __init__(self, url, clarity='ld', video_name=None): self.url = url self.video_name = video_name self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+" self.clarity = clarity self.clarity_list = ['ld', 'sd', 'hd'] self.video_api = 'https://lens.zhihu.com/api/videos' def check_url_format(self): pattern = re.compile(self.url_format) matches = re.match(pattern, self.url) if matches is None: raise ValueError( "链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}" ) return True def get_video_number(self): try: headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36' } response = requests.get(self.url, headers=headers) response.encoding = 'utf-8' html = response.text video_ids = re.findall(r'data-lens-id="(\d+)"', html) if video_ids: video_id_list = list(set([video_id for video_id in video_ids])) self.video_number = video_id_list[0] return self raise ValueError("获取视频编号异常:{}".format(self.url)) except Exception as e: raise Exception(e) def get_video_url_by_number(self): url = "{}/{}".format(self.video_api, self.video_number) headers = {} headers['Referer'] = 'https://v.vzuu.com/video/{}'.format( self.video_number) headers['Origin'] = 'https://v.vzuu.com' headers[ 'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36' headers['Content-Type'] = 'application/json' try: response = requests.get(url, headers=headers) response_dict = response.json() if self.clarity in response_dict['playlist']: self.download_url = response_dict['playlist'][ self.clarity]['play_url'] else: for clarity in self.clarity_list: if clarity in response_dict['playlist']: self.download_url = response_dict['playlist'][ self.clarity]['play_url'] break return self except Exception as e: raise Exception(e) def get_video_by_video_url(self): response = requests.get(self.download_url) datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S") if self.video_name is not None: video_name = "{}-{}.mp4".format(self.video_name, datetime_str) else: video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str) path = "{}".format(video_name) with open(path, 'wb') as f: f.write(response.content) def download_video(self): if self.clarity not in self.clarity_list: raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)") if self.check_url_format(): return self.get_video_number().get_video_url_by_number().get_video_by_video_url() if __name__ == '__main__': a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069') print(a.download_video())
结束语
代码还有优化的空间。我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果有什么问题或者建议,可以多交流。
相关学习推荐:python视频教程
以上就是学习python捕捉知乎指定回答视频的方法的详细内容。更多内容请关注技术你好等相关文章!
网页视频抓取工具 知乎( 接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-26 10:04
接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
前言
现在允许知乎上传视频,但我不能下载视频。气死我了,只好研究了一下,然后我输入了代码,方便下载和保存视频。
接下来,为什么猫根本不怕蛇?以答案为例,分享整个下载过程。
相关学习推荐:python视频教程
调试它
打开F12,找到光标,如下图:
然后将光标移动到视频。如下所示:
这是什么?视野中出现了一个神秘的链接:,让我们把这个链接复制到浏览器,然后打开:
看来这就是我们要找的视频了,别着急,我们先看一下网页的请求,然后你会发现一个很有趣的请求(这里强调):
我们自己来看看数据:
{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B,
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B,
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B,
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B,
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}
没错,我们要下载的视频就在这里,其中ld代表通用清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右击保存即可下载视频。
代码
知道了整个流程是什么样子的,接下来的压码流程就简单了,不过我这里就不多说了,直接上代码吧:
# -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question ... %2339;)
print(a.download_video())
结束语
代码还有优化的空间。我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果有什么问题或者建议,可以多交流。
相关学习推荐:python视频教程
以上就是指定答案知乎下学习python捕捉视频的方法的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文转载于:jb51,如有侵权,请联系删除 查看全部
网页视频抓取工具 知乎(
接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
前言
现在允许知乎上传视频,但我不能下载视频。气死我了,只好研究了一下,然后我输入了代码,方便下载和保存视频。
接下来,为什么猫根本不怕蛇?以答案为例,分享整个下载过程。
相关学习推荐:python视频教程
调试它
打开F12,找到光标,如下图:
然后将光标移动到视频。如下所示:
这是什么?视野中出现了一个神秘的链接:,让我们把这个链接复制到浏览器,然后打开:
看来这就是我们要找的视频了,别着急,我们先看一下网页的请求,然后你会发现一个很有趣的请求(这里强调):
我们自己来看看数据:
{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B,
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B,
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B,
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B,
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}
没错,我们要下载的视频就在这里,其中ld代表通用清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右击保存即可下载视频。
代码
知道了整个流程是什么样子的,接下来的压码流程就简单了,不过我这里就不多说了,直接上代码吧:
# -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question ... %2339;)
print(a.download_video())
结束语
代码还有优化的空间。我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果有什么问题或者建议,可以多交流。
相关学习推荐:python视频教程
以上就是指定答案知乎下学习python捕捉视频的方法的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文转载于:jb51,如有侵权,请联系删除
网页视频抓取工具 知乎(iphone端googleplay多为007格式解析格式端端)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-26 05:02
网页视频抓取工具知乎了解一下
网页视频都是经过修改的,iphone端googleplay多为007格式android端多为mp4格式。解析格式需要开发者熟悉css,这个对于小学生来说真的难以做到。网页上最普遍也最常用的是flash,前面的网页视频教程很多这里就不再赘述。
据说有可以的,
flash解析器和html5语言解析器,之前看过免费的网站,虽然官方有提供在线的教程但是没办法连接到iphone的服务器,后来看免费网站这种东西都是山寨的,就去买了个这种插件,用起来还可以。之前网上看过免费cms网站免费模板开源站一起交流花1块钱-w3cschool了解过这种技术,所以感觉这种模式可行。
youtube把视频都做成视频的不同色彩。
刚好几天前在知乎上看到过对iphone视频解析的回答,视频解析-iphone视频解析教程,首先开启iphone的网页视频播放器;然后第一步,下载好safari浏览器,打开想要解析的iphone视频;第二步,手机上打开视频播放器;第三步,手机网页上选择视频源,选择相应视频流(网站上通常会提供各种版本),下载视频;iphone会自动扫描识别网站,出现相应视频,iphone就可以解析了。
解析的准确度问题,iphone自己是没有说明方法的,至于对于用户,解析出来的视频可不可以播放,理论上,视频右上角会显示“允许任何播放器播放”,这样就能播放;实际上,很多厂商的app也提供观看此视频的功能;最后,解析之后,就可以完全观看iphone原生视频文件了,就不需要像视频网站上那样需要安装apk了。 查看全部
网页视频抓取工具 知乎(iphone端googleplay多为007格式解析格式端端)
网页视频抓取工具知乎了解一下
网页视频都是经过修改的,iphone端googleplay多为007格式android端多为mp4格式。解析格式需要开发者熟悉css,这个对于小学生来说真的难以做到。网页上最普遍也最常用的是flash,前面的网页视频教程很多这里就不再赘述。
据说有可以的,
flash解析器和html5语言解析器,之前看过免费的网站,虽然官方有提供在线的教程但是没办法连接到iphone的服务器,后来看免费网站这种东西都是山寨的,就去买了个这种插件,用起来还可以。之前网上看过免费cms网站免费模板开源站一起交流花1块钱-w3cschool了解过这种技术,所以感觉这种模式可行。
youtube把视频都做成视频的不同色彩。
刚好几天前在知乎上看到过对iphone视频解析的回答,视频解析-iphone视频解析教程,首先开启iphone的网页视频播放器;然后第一步,下载好safari浏览器,打开想要解析的iphone视频;第二步,手机上打开视频播放器;第三步,手机网页上选择视频源,选择相应视频流(网站上通常会提供各种版本),下载视频;iphone会自动扫描识别网站,出现相应视频,iphone就可以解析了。
解析的准确度问题,iphone自己是没有说明方法的,至于对于用户,解析出来的视频可不可以播放,理论上,视频右上角会显示“允许任何播放器播放”,这样就能播放;实际上,很多厂商的app也提供观看此视频的功能;最后,解析之后,就可以完全观看iphone原生视频文件了,就不需要像视频网站上那样需要安装apk了。
网页视频抓取工具 知乎(网页中去的数据处理工具介绍(一):1.WebScraper)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-23 00:14
网页和 PDF 中的数据采集令人生畏;更不用说数据清洗了。在大多数情况下,我们这些做数据的人很难得到最干净、最整洁、最全面的“随时可用”的数据。我们需要在网页中“挖”,然后到另一个平台去“清理”。今天小迪就给大家介绍一些好用的数据处理工具。
1. 网络爬虫
Web Scraper 是一个用于网页数据请求的谷歌浏览器插件。用户可以自行制定数据采集计划,并订购它来请求您需要的数据。最终数据可以导出为 csv 文件。
2. Import.io
Import.io 是一个免费的桌面应用程序,可以帮助用户从大量网页中抓取所需的数据。它将每个网页视为可以生成 API 的数据源。
3. HTML 表单插件
一种)。Chrome插件
b)。火狐插件
4. 全部击倒
另一个用于从网页下载文件的 Firefox 浏览器插件。它收录一些简单的过滤功能。例如,用户可以选择仅下载名称中收录“county”的 xls 文件或 zip 文件 (*county*.zip))。
5. WGET
一种使用命令行的更传统但易于使用的数据检索方法。例如,如果用户想从一个网站请求省份信息,每个州都有一个统一格式的URL,例如/state/34和/state/36,用户可以使用exl形式,其中收录所有这些 URL 并保存到一个文本文件中,以便您可以使用 wget-ilist.txt 获取所有身份信息。
6. XML 奇迹
在很多情况下,网页的数据是以xml的形式构建的。本教程可以帮助用户探索网页中潜在的数据结构,并弄清楚网页的代码源是如何组织的。
7. 免费软件
一种)。彗星文档
它是从 PDF 中获取表格数据的最简单、最有效的工具。用户可以直接输入网站,上传文件,选择输出文件类型,输入邮箱地址即可。
缺点:不能免费处理图片,需要订阅OCR服务。
b)。表格
它是一款免费软件,您可以直接下载并安装到您的计算机上。它可以帮助您导入 PDF 文件并输出单个表单。导入相应的PDF文件后,需要手动对需要的表格进行框选,Tabula会在保留行和列的情况下尝试转换数据。
缺点:Tabula 无法实现光学字符识别。它不如下面列出的商业程序准确。比如它获取的行列边距不是很准确,需要手动调整。
8. 付款流程:
一种)。认知视图
与Tabula类似,您可以将您需要的表格框起来,但如果Congniview猜错了,您可以轻松调整其范围。更好的是,它具有光学字符识别版本,因此它甚至可以识别图片。
b)。ABLE2提取物
它是纽约时报图形部门最喜欢的程序,其界面和使用方式与 Cogniview 非常相似。
缺点:Able2Extract在大多数情况下表现良好,但其调试系统不如Cogniview。
C)。ABBY FineReader
d)。Adobe Acrobat Pro
e)。数据观察君主
是这个系列的明星软件,但是价格不菲。如果你在做一个长期的项目,想要从难以转换的格式中获取数据,强烈推荐使用 Monarch。Monarch 在转换报表数据方面表现出色,用户可以主动设计输出形式。
9. 打开精炼
它是一个强大的数据清理工具。一个典型的用例是当您拥有不同格式的个人和公司名称的数据时,Open Refine 是一个不错的选择。在 NICAR 会议上,来自纽约时报的数据库项目编辑 Robert Gebeloff (/robert_gebeloff) 和 Kaas & Mulvad 创始人兼首席执行官 Nils Mulvad (kaasogmulvad.dk/en/) 使用自己的教程解释了 Open Refine。
教程:
/gebelo/nicar2016/blob/master/refine.pdf
辅助数据:
/gebelo/nicar2016/blob/master/prof.csv
/gebelo/nicar2016/blob/master/defendants.xlsx 查看全部
网页视频抓取工具 知乎(网页中去的数据处理工具介绍(一):1.WebScraper)
网页和 PDF 中的数据采集令人生畏;更不用说数据清洗了。在大多数情况下,我们这些做数据的人很难得到最干净、最整洁、最全面的“随时可用”的数据。我们需要在网页中“挖”,然后到另一个平台去“清理”。今天小迪就给大家介绍一些好用的数据处理工具。
1. 网络爬虫
Web Scraper 是一个用于网页数据请求的谷歌浏览器插件。用户可以自行制定数据采集计划,并订购它来请求您需要的数据。最终数据可以导出为 csv 文件。
2. Import.io
Import.io 是一个免费的桌面应用程序,可以帮助用户从大量网页中抓取所需的数据。它将每个网页视为可以生成 API 的数据源。
3. HTML 表单插件
一种)。Chrome插件
b)。火狐插件
4. 全部击倒
另一个用于从网页下载文件的 Firefox 浏览器插件。它收录一些简单的过滤功能。例如,用户可以选择仅下载名称中收录“county”的 xls 文件或 zip 文件 (*county*.zip))。
5. WGET
一种使用命令行的更传统但易于使用的数据检索方法。例如,如果用户想从一个网站请求省份信息,每个州都有一个统一格式的URL,例如/state/34和/state/36,用户可以使用exl形式,其中收录所有这些 URL 并保存到一个文本文件中,以便您可以使用 wget-ilist.txt 获取所有身份信息。
6. XML 奇迹
在很多情况下,网页的数据是以xml的形式构建的。本教程可以帮助用户探索网页中潜在的数据结构,并弄清楚网页的代码源是如何组织的。
7. 免费软件
一种)。彗星文档
它是从 PDF 中获取表格数据的最简单、最有效的工具。用户可以直接输入网站,上传文件,选择输出文件类型,输入邮箱地址即可。
缺点:不能免费处理图片,需要订阅OCR服务。
b)。表格
它是一款免费软件,您可以直接下载并安装到您的计算机上。它可以帮助您导入 PDF 文件并输出单个表单。导入相应的PDF文件后,需要手动对需要的表格进行框选,Tabula会在保留行和列的情况下尝试转换数据。
缺点:Tabula 无法实现光学字符识别。它不如下面列出的商业程序准确。比如它获取的行列边距不是很准确,需要手动调整。
8. 付款流程:
一种)。认知视图
与Tabula类似,您可以将您需要的表格框起来,但如果Congniview猜错了,您可以轻松调整其范围。更好的是,它具有光学字符识别版本,因此它甚至可以识别图片。
b)。ABLE2提取物
它是纽约时报图形部门最喜欢的程序,其界面和使用方式与 Cogniview 非常相似。
缺点:Able2Extract在大多数情况下表现良好,但其调试系统不如Cogniview。
C)。ABBY FineReader
d)。Adobe Acrobat Pro
e)。数据观察君主
是这个系列的明星软件,但是价格不菲。如果你在做一个长期的项目,想要从难以转换的格式中获取数据,强烈推荐使用 Monarch。Monarch 在转换报表数据方面表现出色,用户可以主动设计输出形式。
9. 打开精炼
它是一个强大的数据清理工具。一个典型的用例是当您拥有不同格式的个人和公司名称的数据时,Open Refine 是一个不错的选择。在 NICAR 会议上,来自纽约时报的数据库项目编辑 Robert Gebeloff (/robert_gebeloff) 和 Kaas & Mulvad 创始人兼首席执行官 Nils Mulvad (kaasogmulvad.dk/en/) 使用自己的教程解释了 Open Refine。
教程:
/gebelo/nicar2016/blob/master/refine.pdf
辅助数据:
/gebelo/nicar2016/blob/master/prof.csv
/gebelo/nicar2016/blob/master/defendants.xlsx
网页视频抓取工具 知乎(之前利用python简单爬虫抓过一些图片,最近想到了抓取视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-22 15:01
之前用python简单爬虫抓取了一些图片,最近想到了抓取视频。因为在很多地方,视频是无法下载的。所以我觉得有必要在紧急情况下学习它。注:仅记录此处遇到的网站视频示例,不保证适用于所有情况。
基本概念和想法
目标问题是在视频网站中下载喜欢的视频文件并保存为MP4格式。这里涉及几种文件格式。一般网络视频使用的流媒体协议,具体内容非专业领域了解不多,不深入讨论。在我要抓拍的视频站中,发现原来的视频数据被分成了很多个TS流,每个TS流的地址都记录在m3u8文件列表中,如图:
所以解决问题的方法是:第一步,抓取目标视频的m3u8地址的URL;第二步,提取TS流;最后,将流合并为 MP4 格式。在搜索相关解决方案时,发现可以使用FFMPEG直接将m3u8转为MP4。流程图如下:
代码:
import re
import uuid
import subprocess
import requests
QUALITY = 'ld' # video quality maybe 'ld' 'sd' or 'hd'
def get_video_ids_from_url(url):
html = requests.get(url, headers=HEADERS).text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
#print(video_ids)
if video_ids:
return set([int(video_id) for video_id in video_ids])
return []
def yield_video_m3u8_url_from_video_ids(video_ids):
for video_id in video_ids:
api_video_url = 'https://lens.zhihu.com/api/videos/{}'.format(int(video_id)) # 下载的是知乎视频
#print(api_video_url)
r = requests.get(api_video_url, headers=HEADERS)
playlist = r.json()['playlist']
print(playlist)
m3u8_url = playlist[QUALITY]['play_url']
yield m3u8_url
def download(url):
video_ids = get_video_ids_from_url(url)
m3u8_list = list(yield_video_m3u8_url_from_video_ids(video_ids))
filename = '{}.mp4'.format(uuid.uuid4())
path = ""
for idx, m3u8_url in enumerate(m3u8_list):
# here \" and \" is important!
cmd_str = 'ffmpeg -i \"' + m3u8_url + '\" ' + '-acodec copy -vcodec copy -absf aac_adtstoasc ' + path + filename.format(str(idx))
print(cmd_str)
subprocess.call(cmd_str,shell=True )
if __name__ == '__main__': # 贴上你需要下载的 回答或者文章的链接
url = 'your video page url'
download(url)
以上代码自动搜索m3u8文件链接。如果不是批处理,可以手动查询地址,然后进行后续转码。windows 和 linux 方法都有效。 查看全部
网页视频抓取工具 知乎(之前利用python简单爬虫抓过一些图片,最近想到了抓取视频)
之前用python简单爬虫抓取了一些图片,最近想到了抓取视频。因为在很多地方,视频是无法下载的。所以我觉得有必要在紧急情况下学习它。注:仅记录此处遇到的网站视频示例,不保证适用于所有情况。
基本概念和想法
目标问题是在视频网站中下载喜欢的视频文件并保存为MP4格式。这里涉及几种文件格式。一般网络视频使用的流媒体协议,具体内容非专业领域了解不多,不深入讨论。在我要抓拍的视频站中,发现原来的视频数据被分成了很多个TS流,每个TS流的地址都记录在m3u8文件列表中,如图:
所以解决问题的方法是:第一步,抓取目标视频的m3u8地址的URL;第二步,提取TS流;最后,将流合并为 MP4 格式。在搜索相关解决方案时,发现可以使用FFMPEG直接将m3u8转为MP4。流程图如下:
代码:
import re
import uuid
import subprocess
import requests
QUALITY = 'ld' # video quality maybe 'ld' 'sd' or 'hd'
def get_video_ids_from_url(url):
html = requests.get(url, headers=HEADERS).text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
#print(video_ids)
if video_ids:
return set([int(video_id) for video_id in video_ids])
return []
def yield_video_m3u8_url_from_video_ids(video_ids):
for video_id in video_ids:
api_video_url = 'https://lens.zhihu.com/api/videos/{}'.format(int(video_id)) # 下载的是知乎视频
#print(api_video_url)
r = requests.get(api_video_url, headers=HEADERS)
playlist = r.json()['playlist']
print(playlist)
m3u8_url = playlist[QUALITY]['play_url']
yield m3u8_url
def download(url):
video_ids = get_video_ids_from_url(url)
m3u8_list = list(yield_video_m3u8_url_from_video_ids(video_ids))
filename = '{}.mp4'.format(uuid.uuid4())
path = ""
for idx, m3u8_url in enumerate(m3u8_list):
# here \" and \" is important!
cmd_str = 'ffmpeg -i \"' + m3u8_url + '\" ' + '-acodec copy -vcodec copy -absf aac_adtstoasc ' + path + filename.format(str(idx))
print(cmd_str)
subprocess.call(cmd_str,shell=True )
if __name__ == '__main__': # 贴上你需要下载的 回答或者文章的链接
url = 'your video page url'
download(url)
以上代码自动搜索m3u8文件链接。如果不是批处理,可以手动查询地址,然后进行后续转码。windows 和 linux 方法都有效。
网页视频抓取工具 知乎(一下Webcopy加密的网页是80端口,加密怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-18 19:09
前言
前不久写了一篇关于爬虫网站的帖子,主要介绍一些。工具方面,一个是优采云,一个是webcopy。还有其他常用的工具,比如国外的IDM。IDM也是一个非常流行的操作建议,非常方便。然而,近年来,大部分爬虫已经崛起,导致对IDM软件的需求减少。还添加了优采云 和Webcopy 等软件。
指示
有网友推荐我用Webcopy之类的软件。他的主要方法主要分为几点,一是深度爬取一些网页,二是浏览网页。
第一个功能是扫描一个网页,可以扫描出哪些结构可以通过优采云的图形直接显示出来。
点击扫描按钮,稍等片刻即可看到网站的所有内容。它可以在弹出框的左上角找到。如果未加密的网页为80端口,则加密后的URL显示为443。
很出名的一个网站,不多说,直接上图。可以设置网易的最大深度和扫描设置的最大网页数。. 左边绿色的是结构图,右边的是深度,右下角是选择是否下载js、css、图片、视频等静态文件。
点击复制后,弹出一个对话框。选择没问题。创建一个新目录。
爬取时间取决于你要爬取的网站的大小和网速。基本上,教程到此为止。
另外要提的是最后一步,抓取后可以打开保存页面上的html或htm文件。
概括
可以学习网站的结构图,以及css和js的使用和学习。工具只是辅助,最重要的是掌握你所需要的。 查看全部
网页视频抓取工具 知乎(一下Webcopy加密的网页是80端口,加密怎么办?)
前言
前不久写了一篇关于爬虫网站的帖子,主要介绍一些。工具方面,一个是优采云,一个是webcopy。还有其他常用的工具,比如国外的IDM。IDM也是一个非常流行的操作建议,非常方便。然而,近年来,大部分爬虫已经崛起,导致对IDM软件的需求减少。还添加了优采云 和Webcopy 等软件。
指示
有网友推荐我用Webcopy之类的软件。他的主要方法主要分为几点,一是深度爬取一些网页,二是浏览网页。
第一个功能是扫描一个网页,可以扫描出哪些结构可以通过优采云的图形直接显示出来。
点击扫描按钮,稍等片刻即可看到网站的所有内容。它可以在弹出框的左上角找到。如果未加密的网页为80端口,则加密后的URL显示为443。
很出名的一个网站,不多说,直接上图。可以设置网易的最大深度和扫描设置的最大网页数。. 左边绿色的是结构图,右边的是深度,右下角是选择是否下载js、css、图片、视频等静态文件。
点击复制后,弹出一个对话框。选择没问题。创建一个新目录。
爬取时间取决于你要爬取的网站的大小和网速。基本上,教程到此为止。
另外要提的是最后一步,抓取后可以打开保存页面上的html或htm文件。
概括
可以学习网站的结构图,以及css和js的使用和学习。工具只是辅助,最重要的是掌握你所需要的。
网页视频抓取工具 知乎(爬虫之家小程序如何做吧,具体做法这边简单提一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-16 09:07
网页视频抓取工具知乎上有一篇关于爬虫之家小程序的文章,我就跟大家分享一下如何做吧,具体做法这边也简单提一下,这里一个一个做示范,我们这里抓取小程序广告联盟里面的优惠券功能,以下是代码的效果:如下图所示,我们先把要抓取的小程序名称放在对应的节点,如图:接下来我们在这边通过拖动鼠标在右下角可以查看到小程序的标识,第一个是广告联盟小程序,然后往右拖动就会出现后面有个广告推广小程序,我们就可以看到接下来的列表为广告联盟小程序。
大概就是这个样子,我们只需要稍微点击一下鼠标就可以在左侧小程序列表查看到当前的小程序推广联盟优惠券。下面说一下具体的原理吧,有兴趣的小伙伴可以评论,也可以私信我。
那你可以尝试搜索一下一个web的软件,复制代码发布出去可以根据代码内容获取有用的内容。
目前来说都是用node去做网页api抓取和广告联盟的广告投放系统
弄这些东西如果不要求和小程序耦合,
大家有没有在搜索框搜到一个很有趣的应用啊,没错,就是微信小程序。总感觉微信开发这方面更贴近一些,开发难度也低一些。利用wxappapi通过爬虫微信公众号的网页抓取可以解决,它可以抓取微信公众号文章里面的网页。我们现在能爬取的公众号文章列表在微信小程序列表里。我们直接进入小程序【发现】-点击右上角看做要看的文章即可;编辑文章设置我们的标题就可以了;推荐编辑,标签之类的;只有点击保存就可以给微信编辑了。关注我的公众号你可以读到更多以上是我测试过后的结果,看看能不能帮到你,哈哈。 查看全部
网页视频抓取工具 知乎(爬虫之家小程序如何做吧,具体做法这边简单提一下)
网页视频抓取工具知乎上有一篇关于爬虫之家小程序的文章,我就跟大家分享一下如何做吧,具体做法这边也简单提一下,这里一个一个做示范,我们这里抓取小程序广告联盟里面的优惠券功能,以下是代码的效果:如下图所示,我们先把要抓取的小程序名称放在对应的节点,如图:接下来我们在这边通过拖动鼠标在右下角可以查看到小程序的标识,第一个是广告联盟小程序,然后往右拖动就会出现后面有个广告推广小程序,我们就可以看到接下来的列表为广告联盟小程序。
大概就是这个样子,我们只需要稍微点击一下鼠标就可以在左侧小程序列表查看到当前的小程序推广联盟优惠券。下面说一下具体的原理吧,有兴趣的小伙伴可以评论,也可以私信我。
那你可以尝试搜索一下一个web的软件,复制代码发布出去可以根据代码内容获取有用的内容。
目前来说都是用node去做网页api抓取和广告联盟的广告投放系统
弄这些东西如果不要求和小程序耦合,
大家有没有在搜索框搜到一个很有趣的应用啊,没错,就是微信小程序。总感觉微信开发这方面更贴近一些,开发难度也低一些。利用wxappapi通过爬虫微信公众号的网页抓取可以解决,它可以抓取微信公众号文章里面的网页。我们现在能爬取的公众号文章列表在微信小程序列表里。我们直接进入小程序【发现】-点击右上角看做要看的文章即可;编辑文章设置我们的标题就可以了;推荐编辑,标签之类的;只有点击保存就可以给微信编辑了。关注我的公众号你可以读到更多以上是我测试过后的结果,看看能不能帮到你,哈哈。
网页视频抓取工具 知乎(猎豹清理大师电脑端下载的视频,清理起来不用再次清理了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-11 19:02
网页视频抓取工具知乎专栏
我用过一款叫inmeiali的软件,在chrome浏览器上可以直接下载视频、音频和图片,支持各种格式。不仅可以下载某个网站的视频,还可以下载自己网站的视频。
直接用浏览器就可以了!我刚学的,可以直接下载n多个网站的视频,
youtube链接:密码:c2e4
qq浏览器的视频下载
爱奇艺视频解析网
【】这个软件中有好多主流的视频网站视频下载,不仅有些是美剧,有些是电影,还有很多歌曲,包括动漫。
资源猫:【小众软件】整理全网视频下载网站整理下载工具,
不知道楼主具体需求,如果需要人工下载,可以发我,我帮你找找。
对不起!你确定你知道你需要在线观看美剧?...推荐请参考这里:
微信公众号(jiushizhonghao)里面有一些干货。
谢邀我收藏的一些关于网络视频的下载中比较简单但是操作方便的方法
1、百度搜索工具全能王用那一个关键词就可以搜到很多实用工具
2、其实sogou帮助了很多人,可以去网上搜一下2.0.297
3、猎豹清理大师电脑端下载的视频,清理起来不用再次清理了,还有云盘的时候,http下载太多的话就会有这个问题。
有个叫电影港频道的下载工具挺不错的你去看看 查看全部
网页视频抓取工具 知乎(猎豹清理大师电脑端下载的视频,清理起来不用再次清理了)
网页视频抓取工具知乎专栏
我用过一款叫inmeiali的软件,在chrome浏览器上可以直接下载视频、音频和图片,支持各种格式。不仅可以下载某个网站的视频,还可以下载自己网站的视频。
直接用浏览器就可以了!我刚学的,可以直接下载n多个网站的视频,
youtube链接:密码:c2e4
qq浏览器的视频下载
爱奇艺视频解析网
【】这个软件中有好多主流的视频网站视频下载,不仅有些是美剧,有些是电影,还有很多歌曲,包括动漫。
资源猫:【小众软件】整理全网视频下载网站整理下载工具,
不知道楼主具体需求,如果需要人工下载,可以发我,我帮你找找。
对不起!你确定你知道你需要在线观看美剧?...推荐请参考这里:
微信公众号(jiushizhonghao)里面有一些干货。
谢邀我收藏的一些关于网络视频的下载中比较简单但是操作方便的方法
1、百度搜索工具全能王用那一个关键词就可以搜到很多实用工具
2、其实sogou帮助了很多人,可以去网上搜一下2.0.297
3、猎豹清理大师电脑端下载的视频,清理起来不用再次清理了,还有云盘的时候,http下载太多的话就会有这个问题。
有个叫电影港频道的下载工具挺不错的你去看看
网页视频抓取工具 知乎(网页视频抓取,现在有什么免费的网站吗(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-08 00:02
网页视频抓取工具知乎问答《bilibili视频抓取,现在有什么免费的网站吗》中推荐的思抓客是一款可以抓取哔哩哔哩免费视频的工具。该工具网页地址:/tutorial.html内置了css控件抓取b站的热门视频,包括:弹幕、片头片尾、评论、评论、名人up主推荐、壁纸等,共4种格式,另有网友在github上发布了该工具的源代码,大家可以在这里fork该工具。
b站视频可以被转换成其他视频格式,支持腾讯视频、优酷视频、搜狐视频、youtube等,转换后还能转换成youtube原生视频格式,如下图:按需要自己配合抓取。同时,b站的视频可以作为正则表达式查找使用,例如下面的正则使用,就可以:b站视频(up主推荐、壁纸、评论、名人推荐、播放)正则表达式的使用:html中正则表达式的使用教程,另外该工具可以根据用户输入的关键词自动提取视频下方的正则表达式视频网站上,还包括:狐狸视频网(西瓜视频),九零后app,book103,别玩了,歪歪。
以上是我们收集到的网页抓取工具网址,大家可以自己去体验下。其他问题请浏览我们的文章中相关文章。有人说对于我们来说,即使一年不接触工具,也能做到一个月上50个网站的视频抓取,对此也不意外。工具文章在我的微信公众号【老道说道来了】中回复“学习”二字,即可查看。老道说道来源于老道说道网站,版权归老道所有,转载请注明出处。内容来源于网络,作者:老道说道来源于网络,作者:老道来源于网络,作者:老道。 查看全部
网页视频抓取工具 知乎(网页视频抓取,现在有什么免费的网站吗(图))
网页视频抓取工具知乎问答《bilibili视频抓取,现在有什么免费的网站吗》中推荐的思抓客是一款可以抓取哔哩哔哩免费视频的工具。该工具网页地址:/tutorial.html内置了css控件抓取b站的热门视频,包括:弹幕、片头片尾、评论、评论、名人up主推荐、壁纸等,共4种格式,另有网友在github上发布了该工具的源代码,大家可以在这里fork该工具。
b站视频可以被转换成其他视频格式,支持腾讯视频、优酷视频、搜狐视频、youtube等,转换后还能转换成youtube原生视频格式,如下图:按需要自己配合抓取。同时,b站的视频可以作为正则表达式查找使用,例如下面的正则使用,就可以:b站视频(up主推荐、壁纸、评论、名人推荐、播放)正则表达式的使用:html中正则表达式的使用教程,另外该工具可以根据用户输入的关键词自动提取视频下方的正则表达式视频网站上,还包括:狐狸视频网(西瓜视频),九零后app,book103,别玩了,歪歪。
以上是我们收集到的网页抓取工具网址,大家可以自己去体验下。其他问题请浏览我们的文章中相关文章。有人说对于我们来说,即使一年不接触工具,也能做到一个月上50个网站的视频抓取,对此也不意外。工具文章在我的微信公众号【老道说道来了】中回复“学习”二字,即可查看。老道说道来源于老道说道网站,版权归老道所有,转载请注明出处。内容来源于网络,作者:老道说道来源于网络,作者:老道来源于网络,作者:老道。
网页视频抓取工具 知乎( 请求头中如果没有-agent客户端配置,服务端可能将你当做一个非法用户)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-07 01:04
请求头中如果没有-agent客户端配置,服务端可能将你当做一个非法用户)
请求:用户通过浏览器(套接字客户端)将自己的信息发送到服务器(套接字服务器)
响应:服务器接收请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如图片、JS、CSS等)
PS:收到响应后,浏览器将解析其内容以显示给用户,而爬虫程序将在模拟浏览器发送请求后提取有用数据,然后接收响应
四、请求
1、请求方法:
常见的请求方法:get/post
2、请求的URL
URL全局统一资源定位器用于定义Internet上的唯一资源。例如,图片、文件和视频可以由URL唯一确定
URL编码
/S?WD=图片
图片将被编码(参见示例代码)
网页的加载过程是:
加载网页时,通常先加载文档
解析文档时,如果遇到链接,则会为超链接启动下载图片的请求
3、请求头
用户代理:如果请求头中没有用户代理客户端配置,服务器可能会将您视为非法用户主机
Cookies:Cookies用于保存登录信息
注意:通常,爬虫程序会添加请求头
请求标头中要注意的参数:
(1)参考者:访问源来自何处(对于一些大型的网站,将通过参考者制定防盗链策略;所有爬行动物也应注意模拟)
(2)用户代理:已访问浏览器(待添加,否则将被视为爬虫)
(3)Cookie:应小心携带请求标头
4、请求正文
请求主体
在get模式下,请求正文没有内容(get请求的请求正文放在URL后面的参数中,可以直接看到)
在post模式下,请求主体是格式数据
附言:
1、登录窗口、文件上载和其他信息将附加到请求正文
2、登录,输入错误的用户名和密码,然后提交。您可以看到帖子。正确登录后,页面通常会跳转,您无法捕获帖子
五、回应
1、响应状态代码
200:成功
301:代表跳跃
404:文件不存在
403:无法访问
502:服务器错误
2、应答头
响应头中需要注意的参数:
(1)设置Cookie:bdsvrtm=0;path=/:可能有多个命令浏览器保存Cookie
(2)内容位置:服务器响应标头收录位置。返回浏览器后,浏览器将再次访问另一页
3、预览是该网页的源代码
JSO数据
例如网页、HTML、图片
二进制数据等
六、总结
1、总结爬虫程序过程:
爬网-->;解析-->;存储
2、爬虫程序所需的工具:
请求库:requests,selenium(它可以驱动浏览器解析和呈现CSS和JS,但它有性能缺点(将加载有用和无用的网页);)
解析库:普通、漂亮的汤、pyquery
存储库:文件、mysql、mongodb、redis 查看全部
网页视频抓取工具 知乎(
请求头中如果没有-agent客户端配置,服务端可能将你当做一个非法用户)
请求:用户通过浏览器(套接字客户端)将自己的信息发送到服务器(套接字服务器)
响应:服务器接收请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如图片、JS、CSS等)
PS:收到响应后,浏览器将解析其内容以显示给用户,而爬虫程序将在模拟浏览器发送请求后提取有用数据,然后接收响应
四、请求
1、请求方法:
常见的请求方法:get/post
2、请求的URL
URL全局统一资源定位器用于定义Internet上的唯一资源。例如,图片、文件和视频可以由URL唯一确定
URL编码
/S?WD=图片
图片将被编码(参见示例代码)
网页的加载过程是:
加载网页时,通常先加载文档
解析文档时,如果遇到链接,则会为超链接启动下载图片的请求
3、请求头
用户代理:如果请求头中没有用户代理客户端配置,服务器可能会将您视为非法用户主机
Cookies:Cookies用于保存登录信息
注意:通常,爬虫程序会添加请求头
请求标头中要注意的参数:
(1)参考者:访问源来自何处(对于一些大型的网站,将通过参考者制定防盗链策略;所有爬行动物也应注意模拟)
(2)用户代理:已访问浏览器(待添加,否则将被视为爬虫)
(3)Cookie:应小心携带请求标头
4、请求正文
请求主体
在get模式下,请求正文没有内容(get请求的请求正文放在URL后面的参数中,可以直接看到)
在post模式下,请求主体是格式数据
附言:
1、登录窗口、文件上载和其他信息将附加到请求正文
2、登录,输入错误的用户名和密码,然后提交。您可以看到帖子。正确登录后,页面通常会跳转,您无法捕获帖子
五、回应
1、响应状态代码
200:成功
301:代表跳跃
404:文件不存在
403:无法访问
502:服务器错误
2、应答头
响应头中需要注意的参数:
(1)设置Cookie:bdsvrtm=0;path=/:可能有多个命令浏览器保存Cookie
(2)内容位置:服务器响应标头收录位置。返回浏览器后,浏览器将再次访问另一页
3、预览是该网页的源代码
JSO数据
例如网页、HTML、图片
二进制数据等
六、总结
1、总结爬虫程序过程:
爬网-->;解析-->;存储
2、爬虫程序所需的工具:
请求库:requests,selenium(它可以驱动浏览器解析和呈现CSS和JS,但它有性能缺点(将加载有用和无用的网页);)
解析库:普通、漂亮的汤、pyquery
存储库:文件、mysql、mongodb、redis
网页视频抓取工具 知乎(网页视频抓取工具,知乎和微信有什么不同?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-05 18:05
网页视频抓取工具知乎和微信有什么不同?知乎的话,大多数的post请求都会抓取到header的网址,知乎采用的是post方式,ua是站点名,可以支持anybody。一、知乎也有外部链接,这个可以post方式,抓取到ua是https的二、知乎自身的文章列表也采用了post方式,ua是“站点名”,可以采取json数据,但在excel表中不能体现,通过发送请求,也需要发送请求header的网址,excel也支持打开外部链接。
ahr0cdovl3uud2vjagf0lmnvbs9tzkndevedzvy9w0u4ellsqvhvw3uiwd102emtoq==(二维码自动识别)
ahr0cdovl3uud2vjagf0lmnvbs9tzkndevedzvy9w0u4ellsqvhvw3uiwd102emtoq==(二维码自动识别)前两天下午还抓了一次,然后上知乎发现没法抓,所以google了一下,说是知乎使用了双重验证的机制。即googlesafari的access_token验证方式。
然后对,知乎在safari的验证时间之外收到了一封包含string的广告邮件,获取该邮件的时间戳+os.random()生成的随机数就可以知道整个页面是不是在safarisafari认证时期收到的。
知乎
使用selenium调用浏览器输入ua进行爬取,
去fixed.github,repostyleguide, 查看全部
网页视频抓取工具 知乎(网页视频抓取工具,知乎和微信有什么不同?)
网页视频抓取工具知乎和微信有什么不同?知乎的话,大多数的post请求都会抓取到header的网址,知乎采用的是post方式,ua是站点名,可以支持anybody。一、知乎也有外部链接,这个可以post方式,抓取到ua是https的二、知乎自身的文章列表也采用了post方式,ua是“站点名”,可以采取json数据,但在excel表中不能体现,通过发送请求,也需要发送请求header的网址,excel也支持打开外部链接。
ahr0cdovl3uud2vjagf0lmnvbs9tzkndevedzvy9w0u4ellsqvhvw3uiwd102emtoq==(二维码自动识别)
ahr0cdovl3uud2vjagf0lmnvbs9tzkndevedzvy9w0u4ellsqvhvw3uiwd102emtoq==(二维码自动识别)前两天下午还抓了一次,然后上知乎发现没法抓,所以google了一下,说是知乎使用了双重验证的机制。即googlesafari的access_token验证方式。
然后对,知乎在safari的验证时间之外收到了一封包含string的广告邮件,获取该邮件的时间戳+os.random()生成的随机数就可以知道整个页面是不是在safarisafari认证时期收到的。
知乎
使用selenium调用浏览器输入ua进行爬取,
去fixed.github,repostyleguide,
网页视频抓取工具 知乎(如何利用Python爬虫爬取海关数据?得用WebScraper-文章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-10-05 14:13
最近,网络采集了数据
Python制作了一个爬虫程序,并将爬虫结果保存到excel_uPython_uuu脚本库中
33可用于捕获数据的开源爬虫软件工具|每个人都是产品经理
使用Chrome浏览器插件web scraper在10分钟内轻松抓取web数据-济南网络推广SEO/SEM-博客公园
如何使用Python爬虫抓取海关数据?知乎
图:使用web scraper_uu百度体验捕获网站数据
使用chrome插件批量读取浏览器页面内容并将其写入数据库-秋风-博客花园
Catgate-简单而粗糙的浏览器爬虫框架-V2EX
数据捕获入门u嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟
数据采集II-高级u嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟
Webscraper是最简单的数据捕获教程,每个人都可以使用-wind-position-blog-Garden
学习使用网络刮板成批采集数据,使您的工作效率可以高达飞行-简单的书
使用Chrome浏览器插件web scraper 10分钟,轻松抓取web数据-阿里云
如何从网页中提取数据?您必须使用网络刮板-文章
新媒体人必须知道的傻瓜式爬虫工具:开始使用网络刮板的五个步骤|每个人都是产品经理
在5个简单的步骤中,使用网络抓取器抓取标题信息uu腾讯视频
网页分析和处理的最佳模块web::scraper-CSDN blog
使用Chrome浏览器插件web scraper 10分钟轻松抓取web数据\u百度搜索%E4%BD%BF%E7%94%a8chrome+%E6%B5%8F%E8%A7%88%E5%99%A8%E6%8F%92%E4%BB%B6+web+scraper+10%E5%88%86%E9%92%9F%E8%BD%BB%E6%9D%be%E5%AE%9E%E7%8e%B0%E7%E7%E9%E9%A1%E6%E6%E6%E9%E8%E8%E8%E7%E8%E8%E8%E8%E7%E8%E8%E8%E7%E8%E8%E8%E7%E8%E7%E8%E88%AC%E5%8F%96&ie=UTF-8
爬虫程序:CSDN文章批量捕获和导入WordPress-CSDN博客
如何使用Python爬虫将智联招聘爬网到excel中-简单的书籍
Selenium与phantomjs合作实现爬虫功能,并将捕获的数据写入excel-forced it man-blog Garden
“Dragnet”是一个工资调查的小爬虫,它将捕获的结果保存到excel-Data&truth-blog Garden
爬行动物天气数据是JS数据,如何输入excel-V2EX
爬虫+数据导入excel-CSDN博客 查看全部
网页视频抓取工具 知乎(如何利用Python爬虫爬取海关数据?得用WebScraper-文章)
最近,网络采集了数据
Python制作了一个爬虫程序,并将爬虫结果保存到excel_uPython_uuu脚本库中
33可用于捕获数据的开源爬虫软件工具|每个人都是产品经理
使用Chrome浏览器插件web scraper在10分钟内轻松抓取web数据-济南网络推广SEO/SEM-博客公园
如何使用Python爬虫抓取海关数据?知乎
图:使用web scraper_uu百度体验捕获网站数据
使用chrome插件批量读取浏览器页面内容并将其写入数据库-秋风-博客花园
Catgate-简单而粗糙的浏览器爬虫框架-V2EX
数据捕获入门u嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟
数据采集II-高级u嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟嘟
Webscraper是最简单的数据捕获教程,每个人都可以使用-wind-position-blog-Garden
学习使用网络刮板成批采集数据,使您的工作效率可以高达飞行-简单的书
使用Chrome浏览器插件web scraper 10分钟,轻松抓取web数据-阿里云
如何从网页中提取数据?您必须使用网络刮板-文章
新媒体人必须知道的傻瓜式爬虫工具:开始使用网络刮板的五个步骤|每个人都是产品经理
在5个简单的步骤中,使用网络抓取器抓取标题信息uu腾讯视频
网页分析和处理的最佳模块web::scraper-CSDN blog
使用Chrome浏览器插件web scraper 10分钟轻松抓取web数据\u百度搜索%E4%BD%BF%E7%94%a8chrome+%E6%B5%8F%E8%A7%88%E5%99%A8%E6%8F%92%E4%BB%B6+web+scraper+10%E5%88%86%E9%92%9F%E8%BD%BB%E6%9D%be%E5%AE%9E%E7%8e%B0%E7%E7%E9%E9%A1%E6%E6%E6%E9%E8%E8%E8%E7%E8%E8%E8%E8%E7%E8%E8%E8%E7%E8%E8%E8%E7%E8%E7%E8%E88%AC%E5%8F%96&ie=UTF-8
爬虫程序:CSDN文章批量捕获和导入WordPress-CSDN博客
如何使用Python爬虫将智联招聘爬网到excel中-简单的书籍
Selenium与phantomjs合作实现爬虫功能,并将捕获的数据写入excel-forced it man-blog Garden
“Dragnet”是一个工资调查的小爬虫,它将捕获的结果保存到excel-Data&truth-blog Garden
爬行动物天气数据是JS数据,如何输入excel-V2EX
爬虫+数据导入excel-CSDN博客
网页视频抓取工具 知乎(知乎助手使用说明下载软件输出的网页版答案列表介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-10-05 14:11
知乎本助手由论坛大神打造。是一款专为知乎网友打造的网页浏览采集下载工具,让大家更好的采集知乎优质内容~有了它,你可以随时随地使用采集你最喜欢的文章,即使以后删除文章,也可以回来查看,好文章永久保存~软件上手简单,直接下载安装即可,经常使用知乎朋友,这款软件绝对值得一试~
知乎助手说明
下载Windows/Mac软件安装包,双击安装
在任务输入框中输入要爬取的URL信息
点击开始执行按钮
执行完成后会打开电子书所在的文件夹,可以在Win10下双击打开或者用Edge浏览器打开。
知乎辅助文件输出
输出文件
html 文件夹是按答案划分的单个答案页面的列表,index.html 是目录页面
单个文件版本收录文件夹中的整个文件,可以用浏览器打开并直接打印为PDF书
知乎助手\epub输出的电子书就是输出的Epub电子书,可以直接被电子书阅读器阅读
知乎小助手输出的e-book\html为输出网页版答案列表
知乎助手说明
知乎助手是论坛大神自制的知乎网页浏览助手工具,可以采集保存一些喜欢的或者优秀的文章,即使以后删除,您可以在这里查看,是您保存的好帮手。本次我们带来了知乎助手PC程序版本下载,运行程序安装即可,经常浏览知乎的朋友不妨一试! 查看全部
网页视频抓取工具 知乎(知乎助手使用说明下载软件输出的网页版答案列表介绍)
知乎本助手由论坛大神打造。是一款专为知乎网友打造的网页浏览采集下载工具,让大家更好的采集知乎优质内容~有了它,你可以随时随地使用采集你最喜欢的文章,即使以后删除文章,也可以回来查看,好文章永久保存~软件上手简单,直接下载安装即可,经常使用知乎朋友,这款软件绝对值得一试~
知乎助手说明
下载Windows/Mac软件安装包,双击安装
在任务输入框中输入要爬取的URL信息
点击开始执行按钮
执行完成后会打开电子书所在的文件夹,可以在Win10下双击打开或者用Edge浏览器打开。
知乎辅助文件输出
输出文件
html 文件夹是按答案划分的单个答案页面的列表,index.html 是目录页面
单个文件版本收录文件夹中的整个文件,可以用浏览器打开并直接打印为PDF书
知乎助手\epub输出的电子书就是输出的Epub电子书,可以直接被电子书阅读器阅读
知乎小助手输出的e-book\html为输出网页版答案列表
知乎助手说明
知乎助手是论坛大神自制的知乎网页浏览助手工具,可以采集保存一些喜欢的或者优秀的文章,即使以后删除,您可以在这里查看,是您保存的好帮手。本次我们带来了知乎助手PC程序版本下载,运行程序安装即可,经常浏览知乎的朋友不妨一试!
网页视频抓取工具 知乎(如何高效学习Python爬虫技术?Python数据分析学习看视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-10-05 14:11
如何高效学习Python爬虫技术?大多数Python爬虫都是按照“发送请求-获取页面-解析页面-提取存储内容”的过程进行爬取,模拟人们使用浏览器获取网页信息的过程。
高效学习Python爬虫技术的步骤:
1、学习Python网络爬虫的基础知识
学习Python网络爬虫时,首先要了解Python的基本常识,变量、字符串、列表、字典、元组、操作语句、语法等,打好基础,做案例的时候要知道用到哪些知识点. 另外,有必要了解一些网络请求的基本原理,网页结构等。
2、观看Python网络爬虫视频教程学习
观看视频或找一本专业的网络爬虫书籍《用Python编写网络爬虫》,跟着视频学习爬虫代码,多打代码,理解每一行代码并开始动手实践,学与做能学得更快。很多人都有误解,觉得自己不愿意修炼。理解和学习是两个概念。测试知识的有效方法是在您实际操作时。实践中漏洞很多,一定要坚持打代码找感觉。
建议选择Python3进行开发。Python2 将在 2020 年终止,Python3 将成为主流。IDE选择pycharm、sublime或jupyter等,我推荐使用pychram,它类似于Java中的eclipse,非常智能。浏览器学会使用 Chrome 或 FireFox 浏览器检查元素,学会使用抓包。了解主流爬虫和库,如urllib、requests、re、bs4、xpath、json等,常用的爬虫结构scrapy一定要掌握。
为了帮助大家更轻松地学习Python开发、Python爬虫技术、Python数据分析等相关知识,我将与大家分享一套Python学习资料。小编推荐学习Python技术的学习裙;,无论你是大牛还是新手,想转行还是想进入职场,都可以来一起了解学习!裙子里有开发工具,大量干货和技术资料分享!
3、实践练习
有爬虫思路,独立设计爬虫系统,找一些网站来实践。掌握静态网页和动态网页的抓取策略和方法,了解JS加载的网页,了解selenium+PhantomJS仿浏览器,知道如何处理json格式的数据。对于网页POST请求,必须传入数据参数,而且这类网页一般都是动态加载的,所以需要掌握抓包的方法。如果要提高爬虫能力,就得考虑使用多线程、多进程协程或分布式操作。
4、学习数据库基础,处理大规模数据存储
如果爬回来的数据量小,可以以文档的形式存储,但是数据量大就不行了。所以需要掌握一个数据库,学习MongoDB,目前比较主流。存储一些非结构化数据很方便。数据库知识很简单,主要用于数据的存储、提取、需要时的学习。
Python的应用范围很广,比如后台开发、web开发、科学计算等,爬虫对初学者非常友好。基本爬虫可以用几行代码实现,原理简单,学习过程比较好。 查看全部
网页视频抓取工具 知乎(如何高效学习Python爬虫技术?Python数据分析学习看视频)
如何高效学习Python爬虫技术?大多数Python爬虫都是按照“发送请求-获取页面-解析页面-提取存储内容”的过程进行爬取,模拟人们使用浏览器获取网页信息的过程。
高效学习Python爬虫技术的步骤:
1、学习Python网络爬虫的基础知识
学习Python网络爬虫时,首先要了解Python的基本常识,变量、字符串、列表、字典、元组、操作语句、语法等,打好基础,做案例的时候要知道用到哪些知识点. 另外,有必要了解一些网络请求的基本原理,网页结构等。
2、观看Python网络爬虫视频教程学习
观看视频或找一本专业的网络爬虫书籍《用Python编写网络爬虫》,跟着视频学习爬虫代码,多打代码,理解每一行代码并开始动手实践,学与做能学得更快。很多人都有误解,觉得自己不愿意修炼。理解和学习是两个概念。测试知识的有效方法是在您实际操作时。实践中漏洞很多,一定要坚持打代码找感觉。
建议选择Python3进行开发。Python2 将在 2020 年终止,Python3 将成为主流。IDE选择pycharm、sublime或jupyter等,我推荐使用pychram,它类似于Java中的eclipse,非常智能。浏览器学会使用 Chrome 或 FireFox 浏览器检查元素,学会使用抓包。了解主流爬虫和库,如urllib、requests、re、bs4、xpath、json等,常用的爬虫结构scrapy一定要掌握。
为了帮助大家更轻松地学习Python开发、Python爬虫技术、Python数据分析等相关知识,我将与大家分享一套Python学习资料。小编推荐学习Python技术的学习裙;,无论你是大牛还是新手,想转行还是想进入职场,都可以来一起了解学习!裙子里有开发工具,大量干货和技术资料分享!
3、实践练习
有爬虫思路,独立设计爬虫系统,找一些网站来实践。掌握静态网页和动态网页的抓取策略和方法,了解JS加载的网页,了解selenium+PhantomJS仿浏览器,知道如何处理json格式的数据。对于网页POST请求,必须传入数据参数,而且这类网页一般都是动态加载的,所以需要掌握抓包的方法。如果要提高爬虫能力,就得考虑使用多线程、多进程协程或分布式操作。
4、学习数据库基础,处理大规模数据存储
如果爬回来的数据量小,可以以文档的形式存储,但是数据量大就不行了。所以需要掌握一个数据库,学习MongoDB,目前比较主流。存储一些非结构化数据很方便。数据库知识很简单,主要用于数据的存储、提取、需要时的学习。
Python的应用范围很广,比如后台开发、web开发、科学计算等,爬虫对初学者非常友好。基本爬虫可以用几行代码实现,原理简单,学习过程比较好。

