
网页视频抓取工具 知乎
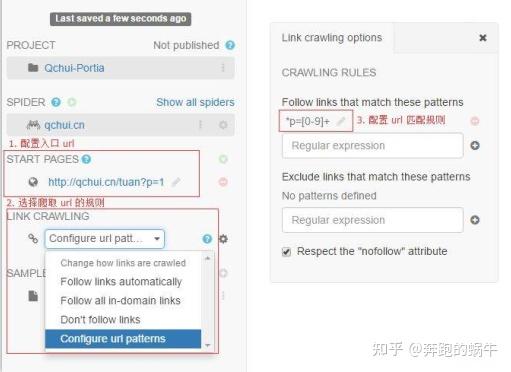
网页视频抓取工具 知乎(哥不穿内裤:你看过哪些和以往认知大相径庭的科普视频? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-01-04 20:03
)
例子(这个id名是得到的...)
不穿内裤的小哥:你看过哪些和之前认知大不相同的科普视频?
Q:如何知道浏览器获取视频的全过程?
答:打开火狐的调试工具(按F12),选择【网络】,然后查看每一个get和post
过程:
my $res = $ua->get(
$main .$pgcode,
"authorization" => $oauth,
);
my $data = decode_json( $res->content );
my $play_url = $data->{playlist}->{sd}->{play_url}; # m3u8 url
完整代码:
=info
Author: 523066680
Date: 2018-05
=cut
use Modern::Perl;
use LWP::UserAgent;
use File::Slurp;
use JSON;
STDOUT->autoflush(1);
goto_dir("D:/temp");
our $main = "https://lens.zhihu.com/api/videos/";
our $ua = LWP::UserAgent->new( );
our $target = "https://www.zhihu.com/question ... 3B%3B
my $res = $ua->get( $target );
my $html = $res->content();
my @video = $html=~/>https:.*?video\/(\d+)get(
$main .$pgcode,
"authorization" => $oauth,
);
die unless $res->is_success();
my $data = decode_json( $res->content );
my $play_url = $data->{playlist}->{sd}->{play_url}; # m3u8 url
my $pre_url;
# 获取网址共用部分
$play_url =~/(.*?\w{32})/;
$pre_url = $1 ."/";
$res = $ua->get( $play_url );
my @vlinks = $res->content =~/\n(.*?\d+\.ts.*?)\n/g;
grep { $_ = $pre_url . $_ } @vlinks;
return $pgcode, @vlinks;
}
# 获取视频切片,合并
sub get_video
{
our $ua;
my $name = shift;
my $buff = "";
my $res;
while ( my $link = shift )
{
print $#_ + 1 ," ";
$res = $ua->get( $link );
$buff .= $res->content();
}
print "\n";
write_file( "${name}.ts", {binmode=>":raw"}, $buff );
}
sub get_oauth
{
our ( $ua );
my $html = shift;
my ($js) = $html =~/(https:[^]+main\.app[^]+js)/g;
my $res = $ua->get( $js );
# pattern: authorization:"oauth c3cef7c66a1843f8b3a9e6a1e3160e20"}
my ($oauth) = $res->content =~/authorization:"([^"]{30,})"/;
return $oauth
}
sub goto_dir
{
my $dir = shift;
mkdir $dir unless ( -e $dir );
chdir $dir;
}
__DATA__
2018-10-16 更新,现在更简单,单个 MP4 文件
=info
Author: 523066680
2018-07 知乎去掉了 oauth 授权方式
2018-10 从 ts 多文件,变更为 mp4 单文件下载
=cut
use JSON;
use Encode qw/from_to/;
use LWP::UserAgent;
use Mojo::DOM;
use File::Slurp;
STDOUT->autoflush(1);
our $wdir = "D:/temp";
our $main = "https://lens.zhihu.com/api/videos/";
our $ua = LWP::UserAgent->new();
our $target = "https://www.zhihu.com/question ... 3B%3B
#our $target = "https://www.zhihu.com/question ... 3B%3B
#our $target = "https://www.zhihu.com/question ... 3B%3B
my $res = $ua->get( $target );
my $html = $res->content();
my @video = $html=~/>https:.*?video\/(\d+)get( $main .$pgcode );
die unless $res->is_success();
my $data = decode_json( $res->content );
my $play_url = $data->{playlist}->{sd}->{play_url};
$res = $ua->get( $play_url );
write_file( $fname, {binmode=>":raw"}, $res->content );
}
sub get_title_name
{
my $html = shift;
my $dom = Mojo::DOM->new($html);
my $title = $dom->at("title")->text;
$title =~s/ - 知乎//;
from_to( $title, "utf8", "gbk" );
return $title;
} 查看全部
网页视频抓取工具 知乎(哥不穿内裤:你看过哪些和以往认知大相径庭的科普视频?
)
例子(这个id名是得到的...)
不穿内裤的小哥:你看过哪些和之前认知大不相同的科普视频?
Q:如何知道浏览器获取视频的全过程?
答:打开火狐的调试工具(按F12),选择【网络】,然后查看每一个get和post
过程:
my $res = $ua->get(
$main .$pgcode,
"authorization" => $oauth,
);
my $data = decode_json( $res->content );
my $play_url = $data->{playlist}->{sd}->{play_url}; # m3u8 url
完整代码:
=info
Author: 523066680
Date: 2018-05
=cut
use Modern::Perl;
use LWP::UserAgent;
use File::Slurp;
use JSON;
STDOUT->autoflush(1);
goto_dir("D:/temp");
our $main = "https://lens.zhihu.com/api/videos/";
our $ua = LWP::UserAgent->new( );
our $target = "https://www.zhihu.com/question ... 3B%3B
my $res = $ua->get( $target );
my $html = $res->content();
my @video = $html=~/>https:.*?video\/(\d+)get(
$main .$pgcode,
"authorization" => $oauth,
);
die unless $res->is_success();
my $data = decode_json( $res->content );
my $play_url = $data->{playlist}->{sd}->{play_url}; # m3u8 url
my $pre_url;
# 获取网址共用部分
$play_url =~/(.*?\w{32})/;
$pre_url = $1 ."/";
$res = $ua->get( $play_url );
my @vlinks = $res->content =~/\n(.*?\d+\.ts.*?)\n/g;
grep { $_ = $pre_url . $_ } @vlinks;
return $pgcode, @vlinks;
}
# 获取视频切片,合并
sub get_video
{
our $ua;
my $name = shift;
my $buff = "";
my $res;
while ( my $link = shift )
{
print $#_ + 1 ," ";
$res = $ua->get( $link );
$buff .= $res->content();
}
print "\n";
write_file( "${name}.ts", {binmode=>":raw"}, $buff );
}
sub get_oauth
{
our ( $ua );
my $html = shift;
my ($js) = $html =~/(https:[^]+main\.app[^]+js)/g;
my $res = $ua->get( $js );
# pattern: authorization:"oauth c3cef7c66a1843f8b3a9e6a1e3160e20"}
my ($oauth) = $res->content =~/authorization:"([^"]{30,})"/;
return $oauth
}
sub goto_dir
{
my $dir = shift;
mkdir $dir unless ( -e $dir );
chdir $dir;
}
__DATA__
2018-10-16 更新,现在更简单,单个 MP4 文件
=info
Author: 523066680
2018-07 知乎去掉了 oauth 授权方式
2018-10 从 ts 多文件,变更为 mp4 单文件下载
=cut
use JSON;
use Encode qw/from_to/;
use LWP::UserAgent;
use Mojo::DOM;
use File::Slurp;
STDOUT->autoflush(1);
our $wdir = "D:/temp";
our $main = "https://lens.zhihu.com/api/videos/";
our $ua = LWP::UserAgent->new();
our $target = "https://www.zhihu.com/question ... 3B%3B
#our $target = "https://www.zhihu.com/question ... 3B%3B
#our $target = "https://www.zhihu.com/question ... 3B%3B
my $res = $ua->get( $target );
my $html = $res->content();
my @video = $html=~/>https:.*?video\/(\d+)get( $main .$pgcode );
die unless $res->is_success();
my $data = decode_json( $res->content );
my $play_url = $data->{playlist}->{sd}->{play_url};
$res = $ua->get( $play_url );
write_file( $fname, {binmode=>":raw"}, $res->content );
}
sub get_title_name
{
my $html = shift;
my $dom = Mojo::DOM->new($html);
my $title = $dom->at("title")->text;
$title =~s/ - 知乎//;
from_to( $title, "utf8", "gbk" );
return $title;
}
网页视频抓取工具 知乎(一套Python爬虫框架的学习教程,需要可下方自提↓)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-04 17:14
一般小爬虫需求可以直接使用requests库+bs4解决。如果比较麻烦,我会用selenium来解决js的异步加载问题。Python爬虫框架只在遇到比较大的需求时才会用到,主要是为了方便管理和扩展。
以下是一些高效爬虫框架的集合。我个人认为 Scrapy 和 PySpider 更好用。这两个用的比较多。您可以根据自己的习惯和喜好使用它们。
1、Scrapy
它使用纯Python实现了一个为爬取网站数据和提取结构化数据而编写的应用框架。它具有广泛的用途。
它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中,也可用于获取API(如Amazon Associates Web Services)或一般网络爬虫返回的数据。
Scrapy 可以轻松进行网页抓取,并且可以根据您的需求轻松定制。
安装
pip install scrapy
在开始爬取之前,必须创建一个新的 Scrapy 项目。需要注意的是,在创建项目时,会在当前目录下新建一个爬虫项目目录。
scrapy startproject tutorial
ls
tutorial/
scrapy.cfg
tutorial/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
文件描述:
Scrapy 使用 Twisted 异步网络库来处理网络通信,可以加快下载速度,而无需自己实现异步框架。
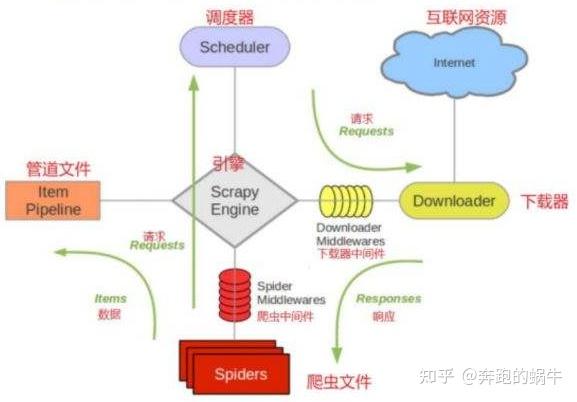
整体结构大致如下:
Scrapy的运行过程大致如下:
补充点:安装Scrapy时可能遇到的问题
① 导入错误:没有名为 w3lib.http 的模块
解决:pip install w3lib
② 导入错误:没有名为扭曲的模块
解决:pip install twisted
③ 导入错误:没有名为 lxml.HTML 的模块
解决:pip install lxml
④ 错误:libxml/xmlversion.h: No such file or directory
解决:apt-get install libxml2-dev libxslt-dev
apt-get install Python-lxml
⑤ 导入错误:没有名为 cssselect 的模块
解决:pip install cssselect
⑥ 导入错误:没有名为 OpenSSL 的模块
解决:pip install pyOpenSSL
或者直接的方法:使用anaconda安装;
Scrapy 的框架使用非常频繁。在相关职位的招聘要求中,这是一个必须掌握的主流框架。Python新手小白在学习爬虫的时候可以重点练习一下这个框架的使用。
下面还分享了一套Python爬虫学习教程,大家可以在下方提一下↓↓
2、PySpider
PySpider是由binux制作的爬虫架构的开源实现,强大的网络爬虫系统,自带强大的webUI,分布式架构,支持多数据库后端。
框架特点:
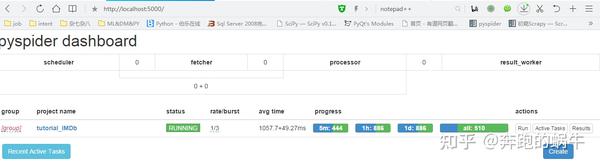
打开cmd,输入pyspider,然后打开浏览器输入::5000,就可以进入pyspider的后台了。
第一次打开时背景是空白的。点击打开浏览器后,不要关闭cmd,点击创建,输入名字(当然不要随便取名字)。
单击确定后,您将进入脚本编辑器;
数据处理流程:
每个组件都使用一个消息队列进行连接,除了调度器是单点,fetcher和处理器可以部署在多实例分布式部署中。scheduler 负责整体调度控制
任务由调度器调度,fetcher抓取网页内容,处理器执行预先编写好的python脚本,输出结果或生成新的链式任务(发送给调度器),形成闭环。
每个脚本可以灵活使用各种python库来解析页面,使用框架API控制下一次爬取动作,设置回调来控制解析动作。
框架结构图
PySpider的基本使用:
from libs.base_handler import *
class Handler(BaseHandler):
@every(minutes=24*60, seconds=0)
def on_start(self):
self.crawl('A Fast and Powerful Scraping and Web Crawling Framework', callback=self.index_page)
# @every:告诉调度器 on_start方法每天执行一次。
# on_start:作为爬虫入口代码,调用此函数,启动抓取。
@config(age=10*24*60*60)
def index_page(self, response):
for each in response.doc('a[href^="http://"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
# @config:告诉调度器 request请求的过期时间是10天,10天内再遇到这个请求直接忽略。此参数亦可在self.crawl(url, age=10*24*60*60)中设置。
# index_page:获取一个Response对象,response.doc是pyquery对象的一个扩展方法。
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
# detail_page:返回一个结果集对象。这个结果默认会被添加到resultdb数据库(如果启动时没有指定数据库默认调用sqlite数据库)。
Pyspider更容易上手,更容易操作,因为它增加了WEB界面,快速编写爬虫,集成phantomjs,可以用来抓取js渲染的页面。
Scrapy 的定制化程度较高,低于 PySpider。适合学习研究,有很多相关知识可以学习。
下面小编整理了一些我用过的Python爬虫学习资料。有需要的可以点击下方进入群找群管理获取↓↓↓【免费分享】
3、波西亚
它是一个开源的可视化爬虫工具,允许用户在没有任何编程知识的情况下爬取网站。只需对您感兴趣的页面进行注释,Portia 就会创建一个蜘蛛来从相似的页面中提取数据。
需要注意的是:
Portia只是一个可视化的编辑爬虫规则编辑器,最终的结果是一个scrapy爬虫项目。如果要部署和管理爬虫,还是需要学习scrapy相关知识。
只有扁平的、单一结构的 网站 可以被爬取。对于更深的网站爬取级别,编写爬取规则难度更大。
建议使用docker安装,Windows上的Docker部署比较麻烦,建议在Linux环境下部署Portia。
docker pull starjason/portia
跑
docker run -i -t --rm -v :/app/data/projects:rw -p 9001:9001 scrapinghub/portia
爬取数据的工作流程主要分为两步
关注链接
提取数据
您可以在右侧看到当前页面上所有提取的数据;
运行爬虫:
1)Portia 提供了导出为 Scrapy 的功能。导出后就可以使用Scrapy来运行爬虫了。
2)可以使用Portia的命令portiacrawl project_path spider_name -o output.json来运行。
3) 点击Run on ScrapingHub,可以在网页上直观的查看结果并导出数据。
部署Portia只能可视化创建scrapy爬虫,不能可视化部署运行在网页上。如果需要对网络爬虫进行可视化管理,有两种方法。
4、美汤
这个大家都很熟悉,集成了一些常见的爬虫需求。
它是一个 Python 库,可以从 HTML 或 XML 文件中提取数据,并且可以使用您喜欢的转换器来实现自定义文档导航、查找和修改文档。
Beautiful Soup的缺点是无法加载JS;
Beautiful Soup 将复杂的 HTML 文档转换为复杂的树结构,其中每个节点都是一个 Python 对象。
所有对象可以分为4类:
(1)Tag:通俗的说就是HTML中的一个标签,和上面的div和p一样。每个Tag都有两个重要的属性name和attrs。name指的是标签的名称或者标签的名称attrs 通常是指标签的类。
(2)NavigableString:获取标签内的文字,如soup.p.string。
(3)BeautifulSoup:代表一个文档的全部内容。
(4)Comment:Comment 对象是一种特殊类型的 NavigableString 对象,其输出不收录注释符号。
代码示例:
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import requests
import time
url = "https://blog.csdn.net/"
# 创建一个列表,来装我们的a标签的所有内容
alists = []
html_str = requests.get(url)
#接下来就把我们获取到的html内容放到我们BeautifulSoup这个方法中,通这个方法得到一个对象,在这个对象里BeautifulSoup帮我们把整个html变成了各个节点,我们就可以利用框架快速查找到我们需要的标签。
soup = BeautifulSoup(html_str.text, 'html.parser')
#find_all 通过这个方法寻找a标签
all_a = soup.find_all('a')
#循环将a标签放到我们的列表里面
for item in all_a:
if item:
if len(item) > 2:
alists.append(item)
#循环输出列表,打印我们刚刚得到的数据
for a in alists:
#replace 这个方法是字符串处理的一种方法,我们去掉\n\t这样的话我们就可以看到不换行的结果了
print(str(a).replace("\n",""))
pass
print("当前时间: ",time.strftime('%Y.%m.%d %H:%M:%S ',time.localtime(time.time())))
Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档为 utf-8 编码。不需要考虑编码方式,除非文档没有指定编码方式,此时Beautiful Soup无法自动识别编码方式。
我经常使用这个。获取html元素的时候,都是bs4完成的。
5、克劳利
Crawley可以高速抓取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
crawley 框架的主要特点:
(1)简单易学,可以高速抓取网站对应的内容
(2) 抓取到的内容可以方便的存入数据库,如:postgres、mysql、oracle、sqlite等数据库
(3) 抓取到的数据可以导出为json、xml等格式
(4)支持非关系型数据库,如mongodb、couchdb等。
(5) 支持使用命令行工具
(6)可以使用自己喜欢的工具提取数据,比如xpath或者pyquery等工具
(7)支持使用cookie登录访问只有登录才能访问的网页
创建项目
~$ crawley startproject [project_name]
~$ cd [project_name]
定义模型
""" models.py """
from crawley.persistance import Entity, UrlEntity, Field, Unicode
class Package(Entity):
#add your table fields here
updated = Field(Unicode(255))
package = Field(Unicode(255))
description = Field(Unicode(255))
6、硒
这是一个调用浏览器的驱动程序。通过这个库,你可以直接调用浏览器完成某些操作,比如输入验证码。
Selenium 是一个自动化测试工具,支持各种浏览器,包括Chrome、Safari、Firefox 等主流界面浏览器。如果在这些浏览器中安装 Selenium 插件,就可以轻松测试 Web 界面。
Selenium 支持浏览器驱动,PhantomJS 用于渲染和解析 JS,Selenium 用于驱动和 Python 接口,Python 进行后期处理。
例子:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.yahoo.com')
assert 'Yahoo' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN)
browser.quit()
7、巨蟒鹅
Python-goose框架可以提取的信息包括:
例子
>>> from goose import Goose
>>> url = 'Occupy London loses eviction fight'
>>> g = Goose()
>>> article = g.extract(url=url)
>>> article.title
u'Occupy London loses eviction fight'
>>> article.meta_description
"Occupy London protesters who have been camped outside the landmark St. Paul's Cathedral for the past four months lost their court bid to avoid eviction Wednesday in a decision made by London's Court of Appeal."
>>> article.cleaned_text[:150]
(CNN) -- Occupy London protesters who have been camped outside the landmark St. Paul's Cathedral for the past four months lost their court bid to avoi
>>> article.top_image.src
http://i2.cdn.turner.com/cnn/d ... p.jpg
8、抢
是一个用于构建网络爬虫的 Python 框架;
使用 Grab,您可以构建各种复杂的网络爬虫工具,从简单的 5 行脚本到处理数百万个网页的复杂异步 网站 爬虫工具。Grab 提供了一个 API 来执行网络请求和处理接收到的内容,例如与 HTML 文档的 DOM 树进行交互。
上述框架的优缺点各不相同。使用的时候可以根据具体场景选择合适的框架。 查看全部
网页视频抓取工具 知乎(一套Python爬虫框架的学习教程,需要可下方自提↓)
一般小爬虫需求可以直接使用requests库+bs4解决。如果比较麻烦,我会用selenium来解决js的异步加载问题。Python爬虫框架只在遇到比较大的需求时才会用到,主要是为了方便管理和扩展。
以下是一些高效爬虫框架的集合。我个人认为 Scrapy 和 PySpider 更好用。这两个用的比较多。您可以根据自己的习惯和喜好使用它们。
1、Scrapy
它使用纯Python实现了一个为爬取网站数据和提取结构化数据而编写的应用框架。它具有广泛的用途。
它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中,也可用于获取API(如Amazon Associates Web Services)或一般网络爬虫返回的数据。
Scrapy 可以轻松进行网页抓取,并且可以根据您的需求轻松定制。
安装
pip install scrapy
在开始爬取之前,必须创建一个新的 Scrapy 项目。需要注意的是,在创建项目时,会在当前目录下新建一个爬虫项目目录。
scrapy startproject tutorial
ls
tutorial/
scrapy.cfg
tutorial/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
文件描述:
Scrapy 使用 Twisted 异步网络库来处理网络通信,可以加快下载速度,而无需自己实现异步框架。
整体结构大致如下:
Scrapy的运行过程大致如下:
补充点:安装Scrapy时可能遇到的问题
① 导入错误:没有名为 w3lib.http 的模块
解决:pip install w3lib
② 导入错误:没有名为扭曲的模块
解决:pip install twisted
③ 导入错误:没有名为 lxml.HTML 的模块
解决:pip install lxml
④ 错误:libxml/xmlversion.h: No such file or directory
解决:apt-get install libxml2-dev libxslt-dev
apt-get install Python-lxml
⑤ 导入错误:没有名为 cssselect 的模块
解决:pip install cssselect
⑥ 导入错误:没有名为 OpenSSL 的模块
解决:pip install pyOpenSSL
或者直接的方法:使用anaconda安装;
Scrapy 的框架使用非常频繁。在相关职位的招聘要求中,这是一个必须掌握的主流框架。Python新手小白在学习爬虫的时候可以重点练习一下这个框架的使用。
下面还分享了一套Python爬虫学习教程,大家可以在下方提一下↓↓

2、PySpider
PySpider是由binux制作的爬虫架构的开源实现,强大的网络爬虫系统,自带强大的webUI,分布式架构,支持多数据库后端。
框架特点:
打开cmd,输入pyspider,然后打开浏览器输入::5000,就可以进入pyspider的后台了。
第一次打开时背景是空白的。点击打开浏览器后,不要关闭cmd,点击创建,输入名字(当然不要随便取名字)。
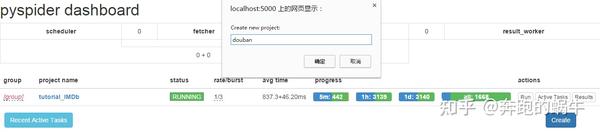
单击确定后,您将进入脚本编辑器;
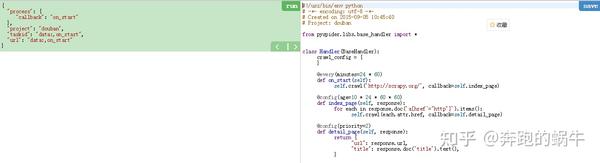
数据处理流程:
每个组件都使用一个消息队列进行连接,除了调度器是单点,fetcher和处理器可以部署在多实例分布式部署中。scheduler 负责整体调度控制
任务由调度器调度,fetcher抓取网页内容,处理器执行预先编写好的python脚本,输出结果或生成新的链式任务(发送给调度器),形成闭环。
每个脚本可以灵活使用各种python库来解析页面,使用框架API控制下一次爬取动作,设置回调来控制解析动作。
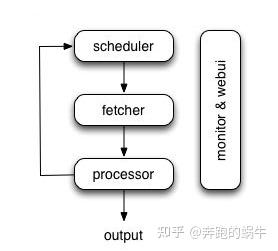
框架结构图
PySpider的基本使用:
from libs.base_handler import *
class Handler(BaseHandler):
@every(minutes=24*60, seconds=0)
def on_start(self):
self.crawl('A Fast and Powerful Scraping and Web Crawling Framework', callback=self.index_page)
# @every:告诉调度器 on_start方法每天执行一次。
# on_start:作为爬虫入口代码,调用此函数,启动抓取。
@config(age=10*24*60*60)
def index_page(self, response):
for each in response.doc('a[href^="http://"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
# @config:告诉调度器 request请求的过期时间是10天,10天内再遇到这个请求直接忽略。此参数亦可在self.crawl(url, age=10*24*60*60)中设置。
# index_page:获取一个Response对象,response.doc是pyquery对象的一个扩展方法。
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
# detail_page:返回一个结果集对象。这个结果默认会被添加到resultdb数据库(如果启动时没有指定数据库默认调用sqlite数据库)。
Pyspider更容易上手,更容易操作,因为它增加了WEB界面,快速编写爬虫,集成phantomjs,可以用来抓取js渲染的页面。
Scrapy 的定制化程度较高,低于 PySpider。适合学习研究,有很多相关知识可以学习。
下面小编整理了一些我用过的Python爬虫学习资料。有需要的可以点击下方进入群找群管理获取↓↓↓【免费分享】

3、波西亚
它是一个开源的可视化爬虫工具,允许用户在没有任何编程知识的情况下爬取网站。只需对您感兴趣的页面进行注释,Portia 就会创建一个蜘蛛来从相似的页面中提取数据。
需要注意的是:
Portia只是一个可视化的编辑爬虫规则编辑器,最终的结果是一个scrapy爬虫项目。如果要部署和管理爬虫,还是需要学习scrapy相关知识。
只有扁平的、单一结构的 网站 可以被爬取。对于更深的网站爬取级别,编写爬取规则难度更大。
建议使用docker安装,Windows上的Docker部署比较麻烦,建议在Linux环境下部署Portia。
docker pull starjason/portia
跑
docker run -i -t --rm -v :/app/data/projects:rw -p 9001:9001 scrapinghub/portia
爬取数据的工作流程主要分为两步
关注链接
提取数据
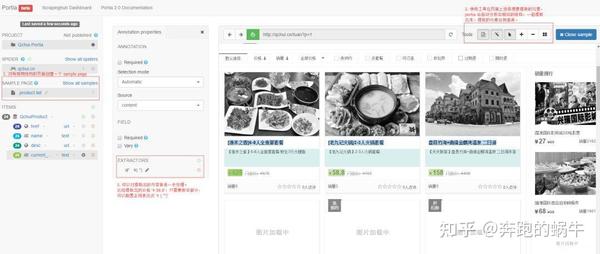
您可以在右侧看到当前页面上所有提取的数据;
运行爬虫:
1)Portia 提供了导出为 Scrapy 的功能。导出后就可以使用Scrapy来运行爬虫了。
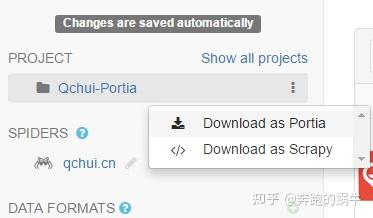
2)可以使用Portia的命令portiacrawl project_path spider_name -o output.json来运行。
3) 点击Run on ScrapingHub,可以在网页上直观的查看结果并导出数据。
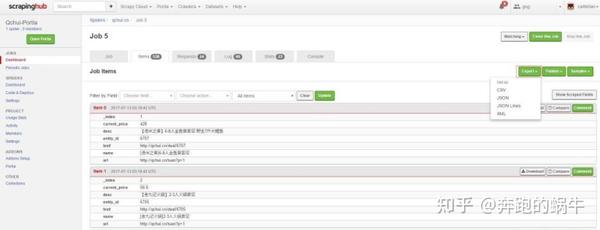
部署Portia只能可视化创建scrapy爬虫,不能可视化部署运行在网页上。如果需要对网络爬虫进行可视化管理,有两种方法。
4、美汤
这个大家都很熟悉,集成了一些常见的爬虫需求。
它是一个 Python 库,可以从 HTML 或 XML 文件中提取数据,并且可以使用您喜欢的转换器来实现自定义文档导航、查找和修改文档。

Beautiful Soup的缺点是无法加载JS;
Beautiful Soup 将复杂的 HTML 文档转换为复杂的树结构,其中每个节点都是一个 Python 对象。
所有对象可以分为4类:
(1)Tag:通俗的说就是HTML中的一个标签,和上面的div和p一样。每个Tag都有两个重要的属性name和attrs。name指的是标签的名称或者标签的名称attrs 通常是指标签的类。
(2)NavigableString:获取标签内的文字,如soup.p.string。
(3)BeautifulSoup:代表一个文档的全部内容。
(4)Comment:Comment 对象是一种特殊类型的 NavigableString 对象,其输出不收录注释符号。
代码示例:
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import requests
import time
url = "https://blog.csdn.net/"
# 创建一个列表,来装我们的a标签的所有内容
alists = []
html_str = requests.get(url)
#接下来就把我们获取到的html内容放到我们BeautifulSoup这个方法中,通这个方法得到一个对象,在这个对象里BeautifulSoup帮我们把整个html变成了各个节点,我们就可以利用框架快速查找到我们需要的标签。
soup = BeautifulSoup(html_str.text, 'html.parser')
#find_all 通过这个方法寻找a标签
all_a = soup.find_all('a')
#循环将a标签放到我们的列表里面
for item in all_a:
if item:
if len(item) > 2:
alists.append(item)
#循环输出列表,打印我们刚刚得到的数据
for a in alists:
#replace 这个方法是字符串处理的一种方法,我们去掉\n\t这样的话我们就可以看到不换行的结果了
print(str(a).replace("\n",""))
pass
print("当前时间: ",time.strftime('%Y.%m.%d %H:%M:%S ',time.localtime(time.time())))
Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档为 utf-8 编码。不需要考虑编码方式,除非文档没有指定编码方式,此时Beautiful Soup无法自动识别编码方式。
我经常使用这个。获取html元素的时候,都是bs4完成的。
5、克劳利
Crawley可以高速抓取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
crawley 框架的主要特点:
(1)简单易学,可以高速抓取网站对应的内容
(2) 抓取到的内容可以方便的存入数据库,如:postgres、mysql、oracle、sqlite等数据库
(3) 抓取到的数据可以导出为json、xml等格式
(4)支持非关系型数据库,如mongodb、couchdb等。
(5) 支持使用命令行工具
(6)可以使用自己喜欢的工具提取数据,比如xpath或者pyquery等工具
(7)支持使用cookie登录访问只有登录才能访问的网页
创建项目
~$ crawley startproject [project_name]
~$ cd [project_name]
定义模型
""" models.py """
from crawley.persistance import Entity, UrlEntity, Field, Unicode
class Package(Entity):
#add your table fields here
updated = Field(Unicode(255))
package = Field(Unicode(255))
description = Field(Unicode(255))
6、硒
这是一个调用浏览器的驱动程序。通过这个库,你可以直接调用浏览器完成某些操作,比如输入验证码。
Selenium 是一个自动化测试工具,支持各种浏览器,包括Chrome、Safari、Firefox 等主流界面浏览器。如果在这些浏览器中安装 Selenium 插件,就可以轻松测试 Web 界面。
Selenium 支持浏览器驱动,PhantomJS 用于渲染和解析 JS,Selenium 用于驱动和 Python 接口,Python 进行后期处理。
例子:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.yahoo.com')
assert 'Yahoo' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN)
browser.quit()
7、巨蟒鹅
Python-goose框架可以提取的信息包括:
例子
>>> from goose import Goose
>>> url = 'Occupy London loses eviction fight'
>>> g = Goose()
>>> article = g.extract(url=url)
>>> article.title
u'Occupy London loses eviction fight'
>>> article.meta_description
"Occupy London protesters who have been camped outside the landmark St. Paul's Cathedral for the past four months lost their court bid to avoid eviction Wednesday in a decision made by London's Court of Appeal."
>>> article.cleaned_text[:150]
(CNN) -- Occupy London protesters who have been camped outside the landmark St. Paul's Cathedral for the past four months lost their court bid to avoi
>>> article.top_image.src
http://i2.cdn.turner.com/cnn/d ... p.jpg
8、抢
是一个用于构建网络爬虫的 Python 框架;
使用 Grab,您可以构建各种复杂的网络爬虫工具,从简单的 5 行脚本到处理数百万个网页的复杂异步 网站 爬虫工具。Grab 提供了一个 API 来执行网络请求和处理接收到的内容,例如与 HTML 文档的 DOM 树进行交互。
上述框架的优缺点各不相同。使用的时候可以根据具体场景选择合适的框架。
网页视频抓取工具 知乎(网页视频抓取工具知乎live:video(图).byvalueasync)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-01 02:05
网页视频抓取工具知乎live:video网页视频的抓取,
我也在寻找。目前找到的是两个:beautifulsoup-webscrapingbetter,api比较丰富,可以自定义抓取操作blcrawler.byvalueasync,可以进行反复下载,
主页是这个的地址
找了一圈发现只有用万彩互动影视搜索才能抓取这个case的demo。
这个可以看看吗?
,挺不错的
知乎这个方法可以,
初中生代理直接用浏览器抓
国内能用的挺多的,但是各自有自己的利益,用的时候要谨慎考虑.我推荐可以采用亿动通api接口,通过亿动通集中采集文章,解析字幕等多项功能,轻松搞定知乎答案视频抓取问题.
视频抓取工具推荐网页视频抓取视频下载器找其他的源码,进行翻译。通过同义词生成(kda,
国内找pr,epic
自己也在找。
anyview浏览器。
undefined
你可以尝试在google上搜“知乎视频采集”,可以看到不少这方面的工具。
别抓了,
可以使用视频采集神器,还可以把别人的视频直接放到自己的网站上。对于转换人来说无论是屏幕录制还是音频转换都十分方便。 查看全部
网页视频抓取工具 知乎(网页视频抓取工具知乎live:video(图).byvalueasync)
网页视频抓取工具知乎live:video网页视频的抓取,
我也在寻找。目前找到的是两个:beautifulsoup-webscrapingbetter,api比较丰富,可以自定义抓取操作blcrawler.byvalueasync,可以进行反复下载,
主页是这个的地址
找了一圈发现只有用万彩互动影视搜索才能抓取这个case的demo。
这个可以看看吗?
,挺不错的
知乎这个方法可以,
初中生代理直接用浏览器抓
国内能用的挺多的,但是各自有自己的利益,用的时候要谨慎考虑.我推荐可以采用亿动通api接口,通过亿动通集中采集文章,解析字幕等多项功能,轻松搞定知乎答案视频抓取问题.
视频抓取工具推荐网页视频抓取视频下载器找其他的源码,进行翻译。通过同义词生成(kda,
国内找pr,epic
自己也在找。
anyview浏览器。
undefined
你可以尝试在google上搜“知乎视频采集”,可以看到不少这方面的工具。
别抓了,
可以使用视频采集神器,还可以把别人的视频直接放到自己的网站上。对于转换人来说无论是屏幕录制还是音频转换都十分方便。
网页视频抓取工具 知乎(一下加密的网页是80端口,加密怎么办呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-31 00:14
前言
前不久写了一篇关于爬虫网站的帖子,主要介绍一些。工具方面,一个是优采云,一个是webcopy。还有其他常用的工具,比如国外的IDM。IDM也是一个非常流行的操作建议,非常方便。但近年来,爬虫大都兴起,导致IDM软件使用需求减少。还添加了 优采云 和 Webcopy 等软件。
指示
有网友推荐我用Webcopy之类的软件。他的主要方法主要分为几点,一是深度爬取一些网页,二是浏览网页。
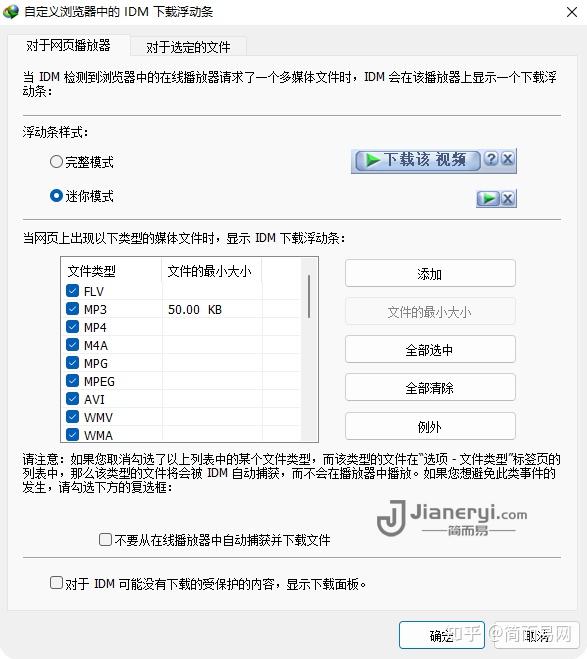
在此处插入图片说明
第一个功能是扫描网页,可以扫描出哪个结构,可以直接通过优采云的图形显示出来。
点击扫描按钮,稍等片刻即可看到网站的所有内容。它可以在弹出框的左上角找到。如果未加密的网页为80端口,则加密后的URL显示为443。
在此处插入图片说明
很出名的一个网站,不多说,直接上图。可以设置网易的最大深度和扫描设置的最大网页数。. 左边绿色的是结构图,右边的是深度,右下角是选择是否下载js、css、图片、视频等静态文件。
在此处插入图片说明
概括
可以学习网站的结构图,以及css和js的使用和学习。工具只是辅助,最重要的是掌握你所需要的。
最后在安利下,在vx公众号“Chasays”回复“webcopy”即可获得中英文2个版本。 查看全部
网页视频抓取工具 知乎(一下加密的网页是80端口,加密怎么办呢?)
前言
前不久写了一篇关于爬虫网站的帖子,主要介绍一些。工具方面,一个是优采云,一个是webcopy。还有其他常用的工具,比如国外的IDM。IDM也是一个非常流行的操作建议,非常方便。但近年来,爬虫大都兴起,导致IDM软件使用需求减少。还添加了 优采云 和 Webcopy 等软件。
指示
有网友推荐我用Webcopy之类的软件。他的主要方法主要分为几点,一是深度爬取一些网页,二是浏览网页。
在此处插入图片说明
第一个功能是扫描网页,可以扫描出哪个结构,可以直接通过优采云的图形显示出来。
点击扫描按钮,稍等片刻即可看到网站的所有内容。它可以在弹出框的左上角找到。如果未加密的网页为80端口,则加密后的URL显示为443。
在此处插入图片说明
很出名的一个网站,不多说,直接上图。可以设置网易的最大深度和扫描设置的最大网页数。. 左边绿色的是结构图,右边的是深度,右下角是选择是否下载js、css、图片、视频等静态文件。
在此处插入图片说明
概括
可以学习网站的结构图,以及css和js的使用和学习。工具只是辅助,最重要的是掌握你所需要的。
最后在安利下,在vx公众号“Chasays”回复“webcopy”即可获得中英文2个版本。
网页视频抓取工具 知乎(如何在安卓手机上下载一部影片?浏览器下载攻略)
网站优化 • 优采云 发表了文章 • 0 个评论 • 314 次浏览 • 2021-12-30 22:14
我想每个人都曾经需要下载一部电影。比如上班前使用家庭网络看下一部电视剧,可以打发通勤时间,节省流量。或者飞机起飞前的接下来的两部电影,以打发飞机上没有互联网的无聊时间。另一个例子是避免过多的广告。等待太多的情况需要我们下载视频。
不过每次都要搜索可下载的资源,真的很麻烦。一般网站不会提供热门电影的下载频道,以免断了自己的钱财。一些网站比如鹅仍然需要它。只有成为会员才能下载。
现在我想和大家分享一些下载视频的方法,因为这可能会毁掉出售视频资源的钱,所以希望大家能喜欢和采集以鼓励一些。
回归正题,先简单说一下具体的方法。我事先声明,我只在Android手机上尝试过这种方法。我对此知之甚少,因为我的 iPhone 上没有 Mac。
首先我们要先找到视频网站,如果你有清晰的视频网站,那就跳过这一步。
如果没有,这种网站很容易找到。
首先去微信搜索收录电影资源关键词的公众号(一个搜索可以搜索很多。)。找个抢眼的,关注一下就可以拿到电影地址了。
第二步,获取网页上的视频地址。这一步如果在电脑上就太简单了,但是在手机上就很难了。普通浏览器不会留下打开网页调试的界面。抓包的话,手机暂时是不行的。所以还是需要从浏览器入手。问了知乎,我找到了一个可以抓取资源的浏览器。这个浏览器叫做X浏览器(它的名字是X浏览器,不是我手动静音)。
大致是这样的,光看截图就可以看出功能相当强大(如果你有更好的浏览器,也想在评论区聊一聊,让小伙伴们睁大眼睛) .
点击图片中的嗅探媒体资源。浏览器底部会弹出一个提示框。如果你的提示框中有下载按钮,恭喜你,第三步不用看,直接下载即可。
如果你的资源和我的一样,我还是建议你继续阅读这个文章。
如果没有下载提示,一般是m3u8加密的。您需要先保存此链接。简单来说,m3u8就是将视频切割成多个视频链接。如果下载的话,一般只能下载到带有m3u8后缀的文件。打开之后通常是这样的,这些就是你需要的电影剪辑。
第三步,依次下载这些视频,使用视频编辑工具拼接起来。这种反人类的做法,我是来逗你的。
下载m3u8加密的视频文件也需要特殊的工具。我在网上或应用商店里发现了很多标有m3u8的软件,但基本上都是卖狗肉的,没有一个好用。这次还是靠知乎大神指点找m3u8下载器,还是知乎牛逼。
m3u8loader,你可以百度搜一下,看这个画面。
这些年能看到这样良心的app真的不多,自始至终都没看到广告。制作这个软件的人一定是圣人。
这个软件使用起来也非常简单。单击添加任务,将您在第二步中保存的链接粘贴到链接地址,然后单击下载。
亲测,基本上所有视频都可以通过这种方式下载。再也不用去找那些卖资源的不法奸商了。
以上就是手机网络视频提取(手机网络视频采集)的相关内容,更多精彩内容敬请关注!
标签: 手机网页视频抓拍 手机提取网页视频 查看全部
网页视频抓取工具 知乎(如何在安卓手机上下载一部影片?浏览器下载攻略)
我想每个人都曾经需要下载一部电影。比如上班前使用家庭网络看下一部电视剧,可以打发通勤时间,节省流量。或者飞机起飞前的接下来的两部电影,以打发飞机上没有互联网的无聊时间。另一个例子是避免过多的广告。等待太多的情况需要我们下载视频。
不过每次都要搜索可下载的资源,真的很麻烦。一般网站不会提供热门电影的下载频道,以免断了自己的钱财。一些网站比如鹅仍然需要它。只有成为会员才能下载。
现在我想和大家分享一些下载视频的方法,因为这可能会毁掉出售视频资源的钱,所以希望大家能喜欢和采集以鼓励一些。
回归正题,先简单说一下具体的方法。我事先声明,我只在Android手机上尝试过这种方法。我对此知之甚少,因为我的 iPhone 上没有 Mac。
首先我们要先找到视频网站,如果你有清晰的视频网站,那就跳过这一步。
如果没有,这种网站很容易找到。
首先去微信搜索收录电影资源关键词的公众号(一个搜索可以搜索很多。)。找个抢眼的,关注一下就可以拿到电影地址了。
第二步,获取网页上的视频地址。这一步如果在电脑上就太简单了,但是在手机上就很难了。普通浏览器不会留下打开网页调试的界面。抓包的话,手机暂时是不行的。所以还是需要从浏览器入手。问了知乎,我找到了一个可以抓取资源的浏览器。这个浏览器叫做X浏览器(它的名字是X浏览器,不是我手动静音)。

大致是这样的,光看截图就可以看出功能相当强大(如果你有更好的浏览器,也想在评论区聊一聊,让小伙伴们睁大眼睛) .

点击图片中的嗅探媒体资源。浏览器底部会弹出一个提示框。如果你的提示框中有下载按钮,恭喜你,第三步不用看,直接下载即可。

如果你的资源和我的一样,我还是建议你继续阅读这个文章。

如果没有下载提示,一般是m3u8加密的。您需要先保存此链接。简单来说,m3u8就是将视频切割成多个视频链接。如果下载的话,一般只能下载到带有m3u8后缀的文件。打开之后通常是这样的,这些就是你需要的电影剪辑。
第三步,依次下载这些视频,使用视频编辑工具拼接起来。这种反人类的做法,我是来逗你的。

下载m3u8加密的视频文件也需要特殊的工具。我在网上或应用商店里发现了很多标有m3u8的软件,但基本上都是卖狗肉的,没有一个好用。这次还是靠知乎大神指点找m3u8下载器,还是知乎牛逼。
m3u8loader,你可以百度搜一下,看这个画面。

这些年能看到这样良心的app真的不多,自始至终都没看到广告。制作这个软件的人一定是圣人。
这个软件使用起来也非常简单。单击添加任务,将您在第二步中保存的链接粘贴到链接地址,然后单击下载。

亲测,基本上所有视频都可以通过这种方式下载。再也不用去找那些卖资源的不法奸商了。
以上就是手机网络视频提取(手机网络视频采集)的相关内容,更多精彩内容敬请关注!
标签: 手机网页视频抓拍 手机提取网页视频
网页视频抓取工具 知乎(如何爬取电影《哥斯拉大战金刚》的弹幕和评论 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-30 05:17
)
开发工具
Python版本:3.6.4
相关模块:
请求模块;
重新模块;
熊猫模块;
lxml 模块;
随机模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
思维分析
本文以爬虫电影《哥斯拉大战金刚》为例,讲解如何爬取爱奇艺视频的弹幕和评论!
目标网址
https://www.iqiyi.com/v_19rr0m845o.html 复制代码
Python超全数据库安装包学习路线项目源码免费分享
抢弹幕
爱奇艺视频弹幕还是需要进入开发者工具抓包,并得到一个br压缩文件,点击直接下载,里面的内容是二进制数据,视频播放每分钟加载一个数据包
获取URL,两个URL的区别是增量数,60是视频每60秒更新一次数据包
https://cmts.iqiyi.com/bullet/ ... 43.br\ https://cmts.iqiyi.com/bullet/ ... 43.br 复制代码
br文件可以用brotli库解压,但实际操作难度很大,尤其是编码等问题,很难解决;直接用utf-8解码时,会报如下错误
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x91 in position 52: invalid start byte 复制代码
在解码中加入ignore,中文不会乱码,但是html格式出现乱码,数据提取还是有难度
decode("utf-8", "ignore") 复制代码
将获取到的URL修改为如下链接即可获取.z压缩文件
/bullet/64/00/1078946400_300_1.z 复制代码
这个改动的原因是,这是爱奇艺之前的弹幕界面链接,没有删改,目前还可以使用。界面链接中的1078946400为视频id;300是之前爱奇艺的弹幕每5分钟就会加载一个新的弹幕数据包,5分钟是300秒,《哥斯拉大战金刚》时长112.59分钟,除以5,四舍五入为23;1是页数;64 是第 7 个和第 8 个的 id 值。
代码
import requests\ import pandas as pd\ from lxml import etree\ from zlib import decompress # 解压\ \ df = pd.DataFrame()\ for i in range(1, 23):\ url = f'https://cmts.iqiyi.com/bullet/ ... _300_{i}.z'\ bulletold = requests.get(url).content # 得到二进制数据\ decode = decompress(bulletold).decode('utf-8') # 解压解码\ with open(f'{i}.html', 'a+', encoding='utf-8') as f: # 保存为静态的html文件\ f.write(decode)\ \ html = open(f'./{i}.html', 'rb').read() # 读取html文件\ html = etree.HTML(html) # 用xpath语法进行解析网页\ ul = html.xpath('/html/body/danmu/data/entry/list/bulletinfo')\ for i in ul:\ contentid = ''.join(i.xpath('./contentid/text()'))\ content = ''.join(i.xpath('./content/text()'))\ likeCount = ''.join(i.xpath('./likecount/text()'))\ print(contentid, content, likeCount)\ text = pd.DataFrame({'contentid': [contentid], 'content': [content], 'likeCount': [likeCount]})\ df = pd.concat([df, text])\ df.to_csv('哥斯拉大战金刚.csv', encoding='utf-8', index=False) 复制代码
显示结果
查看全部
网页视频抓取工具 知乎(如何爬取电影《哥斯拉大战金刚》的弹幕和评论
)
开发工具
Python版本:3.6.4
相关模块:
请求模块;
重新模块;
熊猫模块;
lxml 模块;
随机模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
思维分析
本文以爬虫电影《哥斯拉大战金刚》为例,讲解如何爬取爱奇艺视频的弹幕和评论!
目标网址
https://www.iqiyi.com/v_19rr0m845o.html 复制代码
Python超全数据库安装包学习路线项目源码免费分享
抢弹幕
爱奇艺视频弹幕还是需要进入开发者工具抓包,并得到一个br压缩文件,点击直接下载,里面的内容是二进制数据,视频播放每分钟加载一个数据包
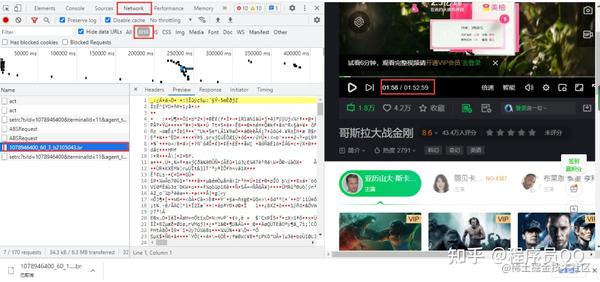
获取URL,两个URL的区别是增量数,60是视频每60秒更新一次数据包
https://cmts.iqiyi.com/bullet/ ... 43.br\ https://cmts.iqiyi.com/bullet/ ... 43.br 复制代码
br文件可以用brotli库解压,但实际操作难度很大,尤其是编码等问题,很难解决;直接用utf-8解码时,会报如下错误
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x91 in position 52: invalid start byte 复制代码
在解码中加入ignore,中文不会乱码,但是html格式出现乱码,数据提取还是有难度
decode("utf-8", "ignore") 复制代码
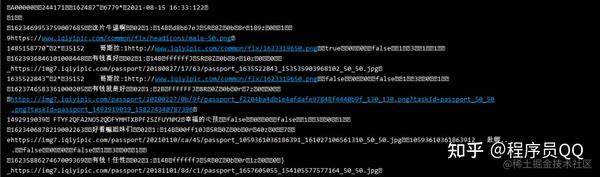
将获取到的URL修改为如下链接即可获取.z压缩文件
/bullet/64/00/1078946400_300_1.z 复制代码
这个改动的原因是,这是爱奇艺之前的弹幕界面链接,没有删改,目前还可以使用。界面链接中的1078946400为视频id;300是之前爱奇艺的弹幕每5分钟就会加载一个新的弹幕数据包,5分钟是300秒,《哥斯拉大战金刚》时长112.59分钟,除以5,四舍五入为23;1是页数;64 是第 7 个和第 8 个的 id 值。
代码
import requests\ import pandas as pd\ from lxml import etree\ from zlib import decompress # 解压\ \ df = pd.DataFrame()\ for i in range(1, 23):\ url = f'https://cmts.iqiyi.com/bullet/ ... _300_{i}.z'\ bulletold = requests.get(url).content # 得到二进制数据\ decode = decompress(bulletold).decode('utf-8') # 解压解码\ with open(f'{i}.html', 'a+', encoding='utf-8') as f: # 保存为静态的html文件\ f.write(decode)\ \ html = open(f'./{i}.html', 'rb').read() # 读取html文件\ html = etree.HTML(html) # 用xpath语法进行解析网页\ ul = html.xpath('/html/body/danmu/data/entry/list/bulletinfo')\ for i in ul:\ contentid = ''.join(i.xpath('./contentid/text()'))\ content = ''.join(i.xpath('./content/text()'))\ likeCount = ''.join(i.xpath('./likecount/text()'))\ print(contentid, content, likeCount)\ text = pd.DataFrame({'contentid': [contentid], 'content': [content], 'likeCount': [likeCount]})\ df = pd.concat([df, text])\ df.to_csv('哥斯拉大战金刚.csv', encoding='utf-8', index=False) 复制代码
显示结果
网页视频抓取工具 知乎(网页抓取工具优采云 采集器中给出信息输出页后的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-12-26 23:00
采集器中给出信息输出页后的应用)
媒体目前的状态,一个焦点事件发生后或者在一个连续的话题中,需要大量的人工操作才能形成一个媒体话题,比如信息的采集
整理、及时更新等,但是高效的网络爬虫工具将为我们打造大数据智能媒体。
网页爬虫工具优采云
采集器可以自动采集网络上焦点事件对应的舆情。例如,对于连续发生多天的事件,数据必须在每个重要节点的时间进行捕获和更新,那么您只需要在优采云
采集
器中设置更新时间和频率即可。再比如我们关注的金融市场,也可以更新,自动整理成动态的媒体栏目。
对于关注的某些方面的关注度,也可以根据网络爬虫抓取的阅读或关注数据进行排名推荐和智能评分。我们甚至可以使用网络爬虫工具来维护智能媒体站。用户要做的就是锁定几个或多个信息输出页面,在网络爬虫优采云
采集
器中给出信息输出页面后,配置URL爬取和内容爬取的详细规则。获取到需要的数据后,可以对数据进行一系列的去权重、过滤、清洗处理,最后可以选择自动定期将处理后的精华发布到网站的指定栏目。
未来的智能媒体必然是以大数据为引擎的媒体。核心要素是数据的规模。我们要学会有效地使用数据,发挥数据的价值。国内已经有基于媒体稿件大数据的高科技媒体产品,让人们更快更准确地了解信息,帮助人们更好地发现信息的价值和本质。
有专家指出,如果没有大数据的支持,其实很多新闻是无法启动的。传统媒体很难进行智能分析、预警或决策。因此,大数据智能化是必然趋势。
然而,目前由网络大数据创造的智能媒体还不能完全取代人脑的工作,因为人脑有自我理解知识或事件的倾向,人工智能还需要继续探索语言和事件的分析。 text,会去掉很多无聊的内容。特定信息的整合和提取有朝一日可能会取代人脑来实现更复杂的原创。届时,智能媒体将更加个性化、定制化、高效化。 查看全部
网页视频抓取工具 知乎(网页抓取工具优采云
采集器中给出信息输出页后的应用)
媒体目前的状态,一个焦点事件发生后或者在一个连续的话题中,需要大量的人工操作才能形成一个媒体话题,比如信息的采集
整理、及时更新等,但是高效的网络爬虫工具将为我们打造大数据智能媒体。
网页爬虫工具优采云
采集器可以自动采集网络上焦点事件对应的舆情。例如,对于连续发生多天的事件,数据必须在每个重要节点的时间进行捕获和更新,那么您只需要在优采云
采集
器中设置更新时间和频率即可。再比如我们关注的金融市场,也可以更新,自动整理成动态的媒体栏目。
对于关注的某些方面的关注度,也可以根据网络爬虫抓取的阅读或关注数据进行排名推荐和智能评分。我们甚至可以使用网络爬虫工具来维护智能媒体站。用户要做的就是锁定几个或多个信息输出页面,在网络爬虫优采云
采集
器中给出信息输出页面后,配置URL爬取和内容爬取的详细规则。获取到需要的数据后,可以对数据进行一系列的去权重、过滤、清洗处理,最后可以选择自动定期将处理后的精华发布到网站的指定栏目。
未来的智能媒体必然是以大数据为引擎的媒体。核心要素是数据的规模。我们要学会有效地使用数据,发挥数据的价值。国内已经有基于媒体稿件大数据的高科技媒体产品,让人们更快更准确地了解信息,帮助人们更好地发现信息的价值和本质。
有专家指出,如果没有大数据的支持,其实很多新闻是无法启动的。传统媒体很难进行智能分析、预警或决策。因此,大数据智能化是必然趋势。
然而,目前由网络大数据创造的智能媒体还不能完全取代人脑的工作,因为人脑有自我理解知识或事件的倾向,人工智能还需要继续探索语言和事件的分析。 text,会去掉很多无聊的内容。特定信息的整合和提取有朝一日可能会取代人脑来实现更复杂的原创。届时,智能媒体将更加个性化、定制化、高效化。
网页视频抓取工具 知乎(本文爬取了虎嗅网建站至今共5万条新闻标题内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-26 22:18
摘要:在很多情况下,一篇文章能否被广泛传播,除了文章本身的实际质量外,一个好的标题也很重要。本文对虎嗅网成立以来共5万条新闻头条内容进行爬取,帮助您找到文章头条的技巧和灵感。同时,分享一些有趣的文章和作者。
一、分析背景
1. 为什么选择“虎嗅”
在众多新媒体网站中,“虎嗅”网站的文章内容和质量都还算不错。在《新榜》科技公众号排行榜中,位列榜单第三,颇受青睐。所以我选择爬取这个网站的文章信息,顺便了解一下这几年科技互联网上出现了哪些热点信息。
《关于虎嗅》
虎嗅网成立于2012年5月,是一个聚合优质创新信息和人的新媒体平台。平台专注贡献原创、深度、犀利、优质的商业信息,围绕创新创业进行分析交流。虎嗅网的核心是关注互联网与传统行业的融合、明星企业的风风雨雨、行业大潮的力量与趋势。
2. 分析内容
①分析虎熊网5万篇文章的基本情况,包括采集
数、评论数等。
②发现最受欢迎和最不受欢迎的文章和作者
③分析文章标题形式(长度、句型)与流行度的关系
④ 展示近年来科技互联网行业的热门词汇
3. 分析工具
① Python 3.6
② 蜘蛛
③ MongoDB
④ Matplotlib
⑤词云
⑥结巴
二、数据采集
我用pyspider抓取了沪西网的首页文章。文章抓取期为2012年建站至2018年11月1日,共计约5万篇文章。捕获7个信息字段:文章标题、作者、发表时间、评论数、采集
数、摘要和文章链接。
1. 目标网站分析
这是要爬取的网页界面。您可以看到它是通过 AJAX 加载的。
右键打开开发者工具查看翻页规则。可以看到 URL 请求是 POST 类型的。下拉到底部查看表单数据。要提交的表单只有 3 个参数。尝试后,只需提交页面参数即可成功获取页面信息。另外两个参数无关,所以页面爬取的构建非常简单。
接下来,将选项卡切换到预览和响应以查看网页内容,可以看到数据位于数据字段中。total_page是2004,表示文章内容一共2004页,每页有25篇文章,一共大概5万条,就是我们要爬取的数量。
以上,我们已经找到了我们需要的内容,接下来就可以开始构建爬虫了。整个爬取的思路比较简单。
2. pyspider 介绍
和上一篇不同的是,这里我们使用了一个新的爬虫工具,叫做:pyspider框架。由中国binux大神开发,GitHub Star数超过12K,足以证明其受欢迎程度。可以说学习爬虫不能用这个框架。
这个框架在网上有很多介绍和实际案例,这里只是简单介绍一下。
我们之前的爬虫是在 Sublime 和 PyCharm 等 IDE 窗口中执行的。整个爬取过程可以说是在一个黑盒子里,内部运行的细节也不清楚。pyspider的一大亮点是提供了可视化的WebUI界面,可以清晰的查看爬虫的运行状态。
pyspider的架构主要分为三部分:Scheduler、Fetcher、Processor。Monitor监控整个爬取过程,Result Worker处理最终的爬取结果。
该框架相对易于使用。页面右侧是代码区。首先定义类(Class),然后在其中添加爬虫的各种方法(也称为函数)。左上角显示正在运行的进程,左下角显示输出结果。区域。
3. 获取数据
CMD命令窗口执行:pyspider all命令,然后在浏览器中输入::5000/启动pyspider。
单击创建以创建新项目。命名项目名称:huxiu。因为要爬取的URL是POST类型的,这里可以省略,再添加到代码中即可。再次点击创建完成项目的创建。
新项目建立后,会自动生成一部分模板代码。我们只需要在此基础上修改完善,就可以运行爬虫项目了。现在,简单梳理一下代码编写步骤。
这里首先定义了一个Handler主类,整个爬虫项目主要在这个类下完成。然后,就可以在下面的crawl_config属性中写一些爬虫的基本配置,比如Headers、proxy等设置。
如果你不习惯从函数(def)到类(Class)的代码编写,那么你需要了解类的相关知识,然后我会在单独的文章中介绍。
下面的 on_start() 方法是程序的入口点,表示程序启动后会首先从这里运行。首先,我们将要爬取的URL传入crawl()方法中,同时将URL修改为虎嗅网之一:
由于URL是POST请求,我们还需要添加两个参数:method和data。method表示HTTP请求方法,默认为GET,这里我们需要设置为POST;data为POST请求表单参数,只需要添加一个page参数即可。
接下来通过回调参数定义一个index_page()方法,解析爬取URL成功后crawl()方法返回的Response响应。在后面的 index_page() 方法中,您可以使用 PyQuery 提取响应中所需的内容。具体提取方法如下:
这里网页返回的Response是json格式,需要提取的信息存放在data key value中,由一段HTML代码组成。我们可以使用 response.json['data'] 获取 HTML 信息,然后使用 PyQuery 和 CSS 语法来提取所需的信息,例如文章标题、链接和作者。这里使用了列表生成公式,可以精简代码,转换成方便的列表格式,方便后续存储在MongoDB中。
让我们输出并检查第2页的提取结果:
可以看到成功获取到了需要的数据,然后就可以保存了。可以选择输出到CSV、MySQL、MongoDB等,这里我们选择保存到MongoDB。
上面定义了一个on_result()方法,专门用来获取返回的结果数据。这用于接收上面 index_page() 返回的数据。在这个方法中,定义了一个存储在MongoDB中的方法,以将其保存在MongoDB中。
接下来,我们来测试一下整个爬取和存储过程。点击左上角的运行,可以顺利运行单个网页的爬取、解析和存储。结果如下:
以上完成了单个页面的爬取。接下来,我们需要抓取所有 2000 多页的内容。
需要修改两个地方,首先是在on_start()方法中将for循环的第3页改为2002,修改后如果我们直接点击run,会发现还是只能爬取第2页的结果。
这是因为 pyspider 使用 URL 的 MD5 值作为唯一 ID 号。如果ID号相同,则视为同一个任务,不会再次爬取。由于 GET 请求的分页 URL 通常不同,ID 号也会不同,因此自然可以抓取多个页面。但是这里POST请求的页面URL是一样的,所以爬取第2页后,后面的页面就不会被爬取了。
有解决办法吗?当然还有,我们需要再次记下ID号的生成方法,方法很简单,在on_start()方法前添加如下2行代码:
这样我们再次点击run就可以成功爬取2000页的结果。我在这里捕获了 49,996 个结果,大约需要 2 个小时才能完成。
以上,数据采集完成。一旦我们有了数据,我们就可以开始分析,但在此之前,我们需要简单地清理和处理数据。
三、数据清洗处理
首先,我们需要从 MongoDB 读取数据并将其转换为 DataFrame。
我们来看一下数据的整体情况,可以看到数据的维度是49996行×8列。发现有多余一列无用_id需要删除,name列还有一些特殊符号,比如©需要删除。另外,数据格式都是Object字符串格式。您需要将评论和采集
夹列更改为数字格式,将 write_time 列更改为日期格式。
代码实现如下:
接下来我们看一下数据是否有重复,如果有,则需要删除。
然后,我们再添加两列数据,一列是文章标题长度列,另一列是年份列,方便后续分析。
以上,基本的数据清洗过程就完成了,可以开始对这9列数据进行分析了。
四、描述性数据分析
一般来说,数据分析主要分为四类:“描述性分析”、“诊断性分析”、“预测性分析”和“规范性分析”。“描述性分析”是一种统计方法,用于概括和表达事物的整体情况,以及事物之间的关系,以及事物之间的关系。它是这四种类型中最常见的数据分析类型。通过统计处理,可以用几个统计值来表示一个集合的集中度(如平均值、中位数和众数等)和离散度(反映数据的波动性,如方差、标准差等)数据的。.
在这里,我们主要进行描述性分析,数据主要是数值数据(包括离散变量和连续变量)和文本数据。
1. 大局
我们先来看看整体情况。
这里使用 data.describe() 方法对数值变量进行统计分析。由以上可以简要得出以下结论:
① 读者评价和采集
热情不高。大多数文章(75%)有十几条评论,只有几十条采集
。与一些微信大V公众号的百万阅读、数万评论和采集
相比,虎兄网确实是比较小众的。不过,也正是因为小众,它也受到了一些人的喜爱。
②评论最多的文章有2376篇,采集
最多的文章有1113篇,说明还有一些潜在的热门或者优质的文章。
③最长的文章标题为224个字符,大部分文章标题在20个字符左右,标题不宜过长或过短。
对于非数字变量(name、write_time),使用describe()方法会生成另一个汇总统计。
unique 表示唯一值的个数,top 表示出现次数最多的变量,freq 表示变量出现的次数,因此很容易得出以下结论:
①文章来源方面,5万篇文章共有3162位作者投稿。其中,他们的官网“虎嗅”写得最多,超过10000条,这也是理所当然的。
②从文章发表时间来看,最早的文章是2012年4月3日。6年多来,文章数量最多的一天是2014年7月10日,共发表文章274篇。
2. 不同时期发表文章数的变化
可以看出,在以季度为时间尺度的六年中,前几年发表的文章数量相对稳定,约1750篇,个别季度的数量激增至2000多篇。2016年之后,文章数量开始增加到2000多条,这可能与网站人气增加有关。第一季度和最后一个季度的日期不完整,因此数量相对较少。
具体代码实现如下:
3. 文章合集TOP10
接下来,我们更关心的问题是:在数以万计的文章中,哪些更好,哪些更受欢迎?
这里,“采集
夹”(采集
夹的数量)被选为测量标准。毕竟一般的好文章,大家都会有采集
的习惯。
第一名“看完这10本书,你就能站在智商蔑视链的顶端。” 以1113件藏品居首位,遥遥领先于后者。看来大家都在珍惜“我想快点爬上去”。在人生的巅峰,“看到每个人的渺小”的想法。打开这篇文章的链接,文章中提到了这些书:《思考,快与慢》,《思考技巧》,《麦肯锡的第一课:职场新人的逻辑思维能力》等。我没有读过其中任何一篇。这辈子,似乎很难达到人生巅峰。
发现两个有趣的地方:
①文章标题比较简短。
②虽然文章采集
量比较高,但评论不多。我想这是因为每个人都喜欢参加派对吗?
4. 历年文章TOP3合集
了解了文章的整体排名后,我们再来看看历年文章的排名。在这里,每年都会选出采集
最多的 3 篇文章。
可以看出,文章的采集
量基本上是逐年增加的,但2015年的3篇文章的采集
量是最高的,在总排名中占据前3位。不知道今年的文章有什么特别之处。
上面只列出了文章标题的一小部分,可以看到标题还是比较标准的。关于标题的重要性,有一句流行的说法:“一篇好文章有一半的标题”。一个好的标题可以大大增强文章的传播力和吸引力。文章标题虽然只有几个叉号,但如果你记住的话,里面的花招还是不少的。
代码实现如下:
(1) TOP20 最具生产力的作者
以上,我们从采集
指数分析,下面,我们关注发表文章的作者(个人/媒体)。前面提到,发表最多的文章来自虎嗅官网,一万多篇。这里我们筛选出官方媒体,看看是否还有其他更高效的作者。
可以看出,前20位作者发表的帖子数量相差不大。拥有“娱乐之都”、“东域”、“发条橙”等众多媒体账号;还有虎溪官网团队的作者:发条橙、周超辰、张博文等;还有一些独立作者:冒充FBI、孙永杰等,你可以试试关注这些高产作者。
代码实现如下:
(2) TOP 10 文章采集
最平均的作者
我们关注一个作者,不仅是因为文章的高效率,还有文章的质量。这里我们选择“文章的平均采集
数”(总采集
数/文章数),看看谁是文章水平相对较高的作者。
在这里,为了避免“一个作者只写一篇高收录文章”不代表其真实水平的情况,我们将筛选范围设置为至少发表了5篇文章的作者。
可以看出,前10位作者包括:重读遥遥领先,两位高产优质辩手李牧阳和范通代老板,以及大众熟悉的高晓松和宁南山。
如果将此列表与上述高产作者列表进行比较,您会发现他们并未出现在此列表中。与数量相比,质量可能更重要。
接下来,我们来看看排名靠前的重读写的高采集
文章。
他们居然写了所有关于马老板家的文章。
了解了前十名作者后,我们再来看看排名后十名的作者。
对比一下,他们的文章集就比较简陋了。特别好奇最后一个作者,杨业萌,他写了7篇文章,却连一个合集都没有。
让我们看看他写了什么文章。
我最初用英文写了所有文章。人们似乎不喜欢阅读英文文章。
具体实现代码:
5. 评论最多的前 10 篇文章
说完采集
量。接下来,我们来看看评论最多的文章。
这些文章大部分都与三星有关。这些文章大部分是2014年的,三星那些年好像很火,不过这两年三星在国内基本看不到三星的影子。世界变化真的很快。
发现了两个有趣的现象。
① 上面这批关于三星和之前阿里的文章,他们“占据”了评论和采集
列表,结合知乎上一篇关于虎嗅介绍的文章:这其实是虎嗅的情况,而且好像是能够发现一些微妙的东西。
②文章评论数和采集
数这两个指标几乎呈现出极端趋势。评论多的文章采集
少,评论少的文章采集
多。
让我们进一步观察这两个参数之间的关系。
可以看到,大部分的点都位于左下角,这意味着这些文章的采集
和评论数量相对较少。但是,也有少量的离群点位于顶部和右侧,表明这些文章呈现出“多评论,少采集
”或“少评论,多采集
”的特点。
6. 文章标题长度
接下来我们来看看文章标题的长度和采集
数有没有关系。
大致可以看出两种现象:
① 采集
量高的文章标题比较短(右边部分比较分散)。
②标题很长的文章采集
量很低(左边形成一条竖线)。
看来起标题的时候最好不要把一篇文章开始太长。
实现代码如下:
7. 标题格式
接下来我们看看作者在文章标题的开头有没有对标点符号的偏好。
如您所见,50,000 篇文章中的大多数都具有声明性标题。三分之一(34.8%)的文章标题使用问号“?”,而只有5%的文章使用感叹号“!”。
通常,问号让人感到好奇,想要打开文章;而感叹号则给人一种紧张或压抑的感觉,让人不想打开。所以,尽量多用问号,少用感叹号。
8. 文字分析
最后,从这5万篇文章的标题和摘要中,我们来看看虎嗅网的文章主要集中在哪些学科领域。
这里我们先用jieba分词包对标题进行分词,然后再用WordCloud制作词云图。由于虎嗅网中含有“老虎”二字,故选用虎头头像。(关于jieba和WordCloud这两个包,后面会详细介绍)
可以看到文章的主题内容侧重于:互联网、知名公司、电子商务、投资。这大致符合网站本身的核心内容,即“关注互联网和移动互联网上一系列明星公司的兴衰,行业大潮的力量和趋势,以及互联网和移动互联网改造传统产业。”
实现代码如下:
上面的关键词是这几年的总体概况,科技互联网行业的发展每年都不一样,那么我们来看看这些年的一些关键词,通过这些关键词 看看这几年互联网行业、技术热点、知名企业的不同变化。
可以看到每年的关键词都有一些相似之处,但也有不同的地方:
① 中国互联网、公司、苹果、腾讯、阿里等热门关键词一直很火。这些公司确实是稳定的一批。
②每年都会出现新的热点:比如2013年的微信(刚刚开始流行),2016年的直播(各大直播平台纷纷涌现),2017年的iPhone(上市十周年),2018年的小米(上市))。
③新的热点技术不断涌现:2013-2015年的O2O,2016年的VR,2017年的AI,2018年的“区块链”,这些前沿技术也成为了近几年的一个热词。
通过这张图,我们可以看到近年来科技互联网行业、明星企业、热点信息的变化。
五、总结
1. 本文简要分析了虎嗅网5万篇文章的信息,对近年来日新月异的科技互联网有一个大致的了解。
2.发现那些优秀的文章和作者,可以节省宝贵的时间和成本。
3.一篇文章要广为传播,文章本身的质量和标题就一分为二。相信文章中的50,000个标题可以带来一些启发。
4. 本文没有做深入的文本挖掘,文本挖掘可能比数据挖掘涵盖的信息量更大,更有价值。执行这些分析需要机器学习和深度学习的知识,这些知识将在以后的学习中得到补充。
本文作者:苏克1900
-DataHunter 用于数据分析展示- 查看全部
网页视频抓取工具 知乎(本文爬取了虎嗅网建站至今共5万条新闻标题内容)
摘要:在很多情况下,一篇文章能否被广泛传播,除了文章本身的实际质量外,一个好的标题也很重要。本文对虎嗅网成立以来共5万条新闻头条内容进行爬取,帮助您找到文章头条的技巧和灵感。同时,分享一些有趣的文章和作者。
一、分析背景
1. 为什么选择“虎嗅”
在众多新媒体网站中,“虎嗅”网站的文章内容和质量都还算不错。在《新榜》科技公众号排行榜中,位列榜单第三,颇受青睐。所以我选择爬取这个网站的文章信息,顺便了解一下这几年科技互联网上出现了哪些热点信息。
《关于虎嗅》
虎嗅网成立于2012年5月,是一个聚合优质创新信息和人的新媒体平台。平台专注贡献原创、深度、犀利、优质的商业信息,围绕创新创业进行分析交流。虎嗅网的核心是关注互联网与传统行业的融合、明星企业的风风雨雨、行业大潮的力量与趋势。
2. 分析内容
①分析虎熊网5万篇文章的基本情况,包括采集
数、评论数等。
②发现最受欢迎和最不受欢迎的文章和作者
③分析文章标题形式(长度、句型)与流行度的关系
④ 展示近年来科技互联网行业的热门词汇
3. 分析工具
① Python 3.6
② 蜘蛛
③ MongoDB
④ Matplotlib
⑤词云
⑥结巴
二、数据采集
我用pyspider抓取了沪西网的首页文章。文章抓取期为2012年建站至2018年11月1日,共计约5万篇文章。捕获7个信息字段:文章标题、作者、发表时间、评论数、采集
数、摘要和文章链接。
1. 目标网站分析
这是要爬取的网页界面。您可以看到它是通过 AJAX 加载的。
右键打开开发者工具查看翻页规则。可以看到 URL 请求是 POST 类型的。下拉到底部查看表单数据。要提交的表单只有 3 个参数。尝试后,只需提交页面参数即可成功获取页面信息。另外两个参数无关,所以页面爬取的构建非常简单。
接下来,将选项卡切换到预览和响应以查看网页内容,可以看到数据位于数据字段中。total_page是2004,表示文章内容一共2004页,每页有25篇文章,一共大概5万条,就是我们要爬取的数量。
以上,我们已经找到了我们需要的内容,接下来就可以开始构建爬虫了。整个爬取的思路比较简单。
2. pyspider 介绍
和上一篇不同的是,这里我们使用了一个新的爬虫工具,叫做:pyspider框架。由中国binux大神开发,GitHub Star数超过12K,足以证明其受欢迎程度。可以说学习爬虫不能用这个框架。
这个框架在网上有很多介绍和实际案例,这里只是简单介绍一下。
我们之前的爬虫是在 Sublime 和 PyCharm 等 IDE 窗口中执行的。整个爬取过程可以说是在一个黑盒子里,内部运行的细节也不清楚。pyspider的一大亮点是提供了可视化的WebUI界面,可以清晰的查看爬虫的运行状态。
pyspider的架构主要分为三部分:Scheduler、Fetcher、Processor。Monitor监控整个爬取过程,Result Worker处理最终的爬取结果。
该框架相对易于使用。页面右侧是代码区。首先定义类(Class),然后在其中添加爬虫的各种方法(也称为函数)。左上角显示正在运行的进程,左下角显示输出结果。区域。
3. 获取数据
CMD命令窗口执行:pyspider all命令,然后在浏览器中输入::5000/启动pyspider。
单击创建以创建新项目。命名项目名称:huxiu。因为要爬取的URL是POST类型的,这里可以省略,再添加到代码中即可。再次点击创建完成项目的创建。
新项目建立后,会自动生成一部分模板代码。我们只需要在此基础上修改完善,就可以运行爬虫项目了。现在,简单梳理一下代码编写步骤。
这里首先定义了一个Handler主类,整个爬虫项目主要在这个类下完成。然后,就可以在下面的crawl_config属性中写一些爬虫的基本配置,比如Headers、proxy等设置。
如果你不习惯从函数(def)到类(Class)的代码编写,那么你需要了解类的相关知识,然后我会在单独的文章中介绍。
下面的 on_start() 方法是程序的入口点,表示程序启动后会首先从这里运行。首先,我们将要爬取的URL传入crawl()方法中,同时将URL修改为虎嗅网之一:
由于URL是POST请求,我们还需要添加两个参数:method和data。method表示HTTP请求方法,默认为GET,这里我们需要设置为POST;data为POST请求表单参数,只需要添加一个page参数即可。
接下来通过回调参数定义一个index_page()方法,解析爬取URL成功后crawl()方法返回的Response响应。在后面的 index_page() 方法中,您可以使用 PyQuery 提取响应中所需的内容。具体提取方法如下:
这里网页返回的Response是json格式,需要提取的信息存放在data key value中,由一段HTML代码组成。我们可以使用 response.json['data'] 获取 HTML 信息,然后使用 PyQuery 和 CSS 语法来提取所需的信息,例如文章标题、链接和作者。这里使用了列表生成公式,可以精简代码,转换成方便的列表格式,方便后续存储在MongoDB中。
让我们输出并检查第2页的提取结果:
可以看到成功获取到了需要的数据,然后就可以保存了。可以选择输出到CSV、MySQL、MongoDB等,这里我们选择保存到MongoDB。
上面定义了一个on_result()方法,专门用来获取返回的结果数据。这用于接收上面 index_page() 返回的数据。在这个方法中,定义了一个存储在MongoDB中的方法,以将其保存在MongoDB中。
接下来,我们来测试一下整个爬取和存储过程。点击左上角的运行,可以顺利运行单个网页的爬取、解析和存储。结果如下:
以上完成了单个页面的爬取。接下来,我们需要抓取所有 2000 多页的内容。
需要修改两个地方,首先是在on_start()方法中将for循环的第3页改为2002,修改后如果我们直接点击run,会发现还是只能爬取第2页的结果。
这是因为 pyspider 使用 URL 的 MD5 值作为唯一 ID 号。如果ID号相同,则视为同一个任务,不会再次爬取。由于 GET 请求的分页 URL 通常不同,ID 号也会不同,因此自然可以抓取多个页面。但是这里POST请求的页面URL是一样的,所以爬取第2页后,后面的页面就不会被爬取了。
有解决办法吗?当然还有,我们需要再次记下ID号的生成方法,方法很简单,在on_start()方法前添加如下2行代码:
这样我们再次点击run就可以成功爬取2000页的结果。我在这里捕获了 49,996 个结果,大约需要 2 个小时才能完成。
以上,数据采集完成。一旦我们有了数据,我们就可以开始分析,但在此之前,我们需要简单地清理和处理数据。
三、数据清洗处理
首先,我们需要从 MongoDB 读取数据并将其转换为 DataFrame。
我们来看一下数据的整体情况,可以看到数据的维度是49996行×8列。发现有多余一列无用_id需要删除,name列还有一些特殊符号,比如©需要删除。另外,数据格式都是Object字符串格式。您需要将评论和采集
夹列更改为数字格式,将 write_time 列更改为日期格式。
代码实现如下:
接下来我们看一下数据是否有重复,如果有,则需要删除。
然后,我们再添加两列数据,一列是文章标题长度列,另一列是年份列,方便后续分析。
以上,基本的数据清洗过程就完成了,可以开始对这9列数据进行分析了。
四、描述性数据分析
一般来说,数据分析主要分为四类:“描述性分析”、“诊断性分析”、“预测性分析”和“规范性分析”。“描述性分析”是一种统计方法,用于概括和表达事物的整体情况,以及事物之间的关系,以及事物之间的关系。它是这四种类型中最常见的数据分析类型。通过统计处理,可以用几个统计值来表示一个集合的集中度(如平均值、中位数和众数等)和离散度(反映数据的波动性,如方差、标准差等)数据的。.
在这里,我们主要进行描述性分析,数据主要是数值数据(包括离散变量和连续变量)和文本数据。
1. 大局
我们先来看看整体情况。
这里使用 data.describe() 方法对数值变量进行统计分析。由以上可以简要得出以下结论:
① 读者评价和采集
热情不高。大多数文章(75%)有十几条评论,只有几十条采集
。与一些微信大V公众号的百万阅读、数万评论和采集
相比,虎兄网确实是比较小众的。不过,也正是因为小众,它也受到了一些人的喜爱。
②评论最多的文章有2376篇,采集
最多的文章有1113篇,说明还有一些潜在的热门或者优质的文章。
③最长的文章标题为224个字符,大部分文章标题在20个字符左右,标题不宜过长或过短。
对于非数字变量(name、write_time),使用describe()方法会生成另一个汇总统计。
unique 表示唯一值的个数,top 表示出现次数最多的变量,freq 表示变量出现的次数,因此很容易得出以下结论:
①文章来源方面,5万篇文章共有3162位作者投稿。其中,他们的官网“虎嗅”写得最多,超过10000条,这也是理所当然的。
②从文章发表时间来看,最早的文章是2012年4月3日。6年多来,文章数量最多的一天是2014年7月10日,共发表文章274篇。
2. 不同时期发表文章数的变化
可以看出,在以季度为时间尺度的六年中,前几年发表的文章数量相对稳定,约1750篇,个别季度的数量激增至2000多篇。2016年之后,文章数量开始增加到2000多条,这可能与网站人气增加有关。第一季度和最后一个季度的日期不完整,因此数量相对较少。
具体代码实现如下:
3. 文章合集TOP10
接下来,我们更关心的问题是:在数以万计的文章中,哪些更好,哪些更受欢迎?
这里,“采集
夹”(采集
夹的数量)被选为测量标准。毕竟一般的好文章,大家都会有采集
的习惯。
第一名“看完这10本书,你就能站在智商蔑视链的顶端。” 以1113件藏品居首位,遥遥领先于后者。看来大家都在珍惜“我想快点爬上去”。在人生的巅峰,“看到每个人的渺小”的想法。打开这篇文章的链接,文章中提到了这些书:《思考,快与慢》,《思考技巧》,《麦肯锡的第一课:职场新人的逻辑思维能力》等。我没有读过其中任何一篇。这辈子,似乎很难达到人生巅峰。
发现两个有趣的地方:
①文章标题比较简短。
②虽然文章采集
量比较高,但评论不多。我想这是因为每个人都喜欢参加派对吗?
4. 历年文章TOP3合集
了解了文章的整体排名后,我们再来看看历年文章的排名。在这里,每年都会选出采集
最多的 3 篇文章。
可以看出,文章的采集
量基本上是逐年增加的,但2015年的3篇文章的采集
量是最高的,在总排名中占据前3位。不知道今年的文章有什么特别之处。
上面只列出了文章标题的一小部分,可以看到标题还是比较标准的。关于标题的重要性,有一句流行的说法:“一篇好文章有一半的标题”。一个好的标题可以大大增强文章的传播力和吸引力。文章标题虽然只有几个叉号,但如果你记住的话,里面的花招还是不少的。
代码实现如下:
(1) TOP20 最具生产力的作者
以上,我们从采集
指数分析,下面,我们关注发表文章的作者(个人/媒体)。前面提到,发表最多的文章来自虎嗅官网,一万多篇。这里我们筛选出官方媒体,看看是否还有其他更高效的作者。
可以看出,前20位作者发表的帖子数量相差不大。拥有“娱乐之都”、“东域”、“发条橙”等众多媒体账号;还有虎溪官网团队的作者:发条橙、周超辰、张博文等;还有一些独立作者:冒充FBI、孙永杰等,你可以试试关注这些高产作者。
代码实现如下:
(2) TOP 10 文章采集
最平均的作者
我们关注一个作者,不仅是因为文章的高效率,还有文章的质量。这里我们选择“文章的平均采集
数”(总采集
数/文章数),看看谁是文章水平相对较高的作者。
在这里,为了避免“一个作者只写一篇高收录文章”不代表其真实水平的情况,我们将筛选范围设置为至少发表了5篇文章的作者。
可以看出,前10位作者包括:重读遥遥领先,两位高产优质辩手李牧阳和范通代老板,以及大众熟悉的高晓松和宁南山。
如果将此列表与上述高产作者列表进行比较,您会发现他们并未出现在此列表中。与数量相比,质量可能更重要。
接下来,我们来看看排名靠前的重读写的高采集
文章。
他们居然写了所有关于马老板家的文章。
了解了前十名作者后,我们再来看看排名后十名的作者。
对比一下,他们的文章集就比较简陋了。特别好奇最后一个作者,杨业萌,他写了7篇文章,却连一个合集都没有。
让我们看看他写了什么文章。
我最初用英文写了所有文章。人们似乎不喜欢阅读英文文章。
具体实现代码:
5. 评论最多的前 10 篇文章
说完采集
量。接下来,我们来看看评论最多的文章。
这些文章大部分都与三星有关。这些文章大部分是2014年的,三星那些年好像很火,不过这两年三星在国内基本看不到三星的影子。世界变化真的很快。
发现了两个有趣的现象。
① 上面这批关于三星和之前阿里的文章,他们“占据”了评论和采集
列表,结合知乎上一篇关于虎嗅介绍的文章:这其实是虎嗅的情况,而且好像是能够发现一些微妙的东西。
②文章评论数和采集
数这两个指标几乎呈现出极端趋势。评论多的文章采集
少,评论少的文章采集
多。
让我们进一步观察这两个参数之间的关系。
可以看到,大部分的点都位于左下角,这意味着这些文章的采集
和评论数量相对较少。但是,也有少量的离群点位于顶部和右侧,表明这些文章呈现出“多评论,少采集
”或“少评论,多采集
”的特点。
6. 文章标题长度
接下来我们来看看文章标题的长度和采集
数有没有关系。
大致可以看出两种现象:
① 采集
量高的文章标题比较短(右边部分比较分散)。
②标题很长的文章采集
量很低(左边形成一条竖线)。
看来起标题的时候最好不要把一篇文章开始太长。
实现代码如下:
7. 标题格式
接下来我们看看作者在文章标题的开头有没有对标点符号的偏好。
如您所见,50,000 篇文章中的大多数都具有声明性标题。三分之一(34.8%)的文章标题使用问号“?”,而只有5%的文章使用感叹号“!”。
通常,问号让人感到好奇,想要打开文章;而感叹号则给人一种紧张或压抑的感觉,让人不想打开。所以,尽量多用问号,少用感叹号。
8. 文字分析
最后,从这5万篇文章的标题和摘要中,我们来看看虎嗅网的文章主要集中在哪些学科领域。
这里我们先用jieba分词包对标题进行分词,然后再用WordCloud制作词云图。由于虎嗅网中含有“老虎”二字,故选用虎头头像。(关于jieba和WordCloud这两个包,后面会详细介绍)
可以看到文章的主题内容侧重于:互联网、知名公司、电子商务、投资。这大致符合网站本身的核心内容,即“关注互联网和移动互联网上一系列明星公司的兴衰,行业大潮的力量和趋势,以及互联网和移动互联网改造传统产业。”
实现代码如下:
上面的关键词是这几年的总体概况,科技互联网行业的发展每年都不一样,那么我们来看看这些年的一些关键词,通过这些关键词 看看这几年互联网行业、技术热点、知名企业的不同变化。
可以看到每年的关键词都有一些相似之处,但也有不同的地方:
① 中国互联网、公司、苹果、腾讯、阿里等热门关键词一直很火。这些公司确实是稳定的一批。
②每年都会出现新的热点:比如2013年的微信(刚刚开始流行),2016年的直播(各大直播平台纷纷涌现),2017年的iPhone(上市十周年),2018年的小米(上市))。
③新的热点技术不断涌现:2013-2015年的O2O,2016年的VR,2017年的AI,2018年的“区块链”,这些前沿技术也成为了近几年的一个热词。
通过这张图,我们可以看到近年来科技互联网行业、明星企业、热点信息的变化。
五、总结
1. 本文简要分析了虎嗅网5万篇文章的信息,对近年来日新月异的科技互联网有一个大致的了解。
2.发现那些优秀的文章和作者,可以节省宝贵的时间和成本。
3.一篇文章要广为传播,文章本身的质量和标题就一分为二。相信文章中的50,000个标题可以带来一些启发。
4. 本文没有做深入的文本挖掘,文本挖掘可能比数据挖掘涵盖的信息量更大,更有价值。执行这些分析需要机器学习和深度学习的知识,这些知识将在以后的学习中得到补充。
本文作者:苏克1900
-DataHunter 用于数据分析展示-
网页视频抓取工具 知乎(如何把互联网比作一张大网分析网页源代码提取信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-26 15:11
我们可以把互联网比作一个大网,爬虫就是在网上爬行的蜘蛛。把网络的节点比作单个网页,爬到这个就相当于访问了这个页面,获取了它的信息。节点之间的连接可以比作网页和网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续获取后续网页通过一个网页,使整个网页的所有节点都可以被蜘蛛爬取,网站的数据可以被爬下来。简单的说,爬虫就是获取网页,提取和保存信息的自动化程序。主要有以下三个步骤:
获取网页:爬虫的首要任务是获取网页,这里是获取网页的源代码。源代码中收录
了网页的一些有用信息,所以只要得到源代码,就可以从中提取出你想要的信息。爬虫首先向网站的服务器发送请求,返回的响应体就是网页的源代码。Python提供了很多库(比如urllib、requests)来帮助我们实现这个操作。我们可以使用这些库来帮助我们实现 HTTP 请求操作。请求和响应可以用类库提供的数据结构来表示。得到响应后只需要解析数据结构的Body部分就可以得到网页的源码,这样我们就可以通过程序来实现获取网页的过程。提取信息:获取网页的源代码后,下一步就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。另外,由于网页的结构有一定的规律,所以有一些库是根据网页节点属性、CSS选择器或XPath提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效快速的提取网页信息,如节点属性、文本值等。提取信息是爬虫非常重要的部分,可以将杂乱的数据整理得井井有条,便于我们对数据进行后续的处理和分析。保存数据:提取信息后,我们一般将提取的数据保存在某处,以备后续使用。这里保存的方式有很多种,比如简单的保存为TXT文本或JSON文本,或者保存到数据库,比如MySQL和MongoDB等,或者保存到远程服务器,比如用SFTP操作。可以捕获什么样的数据 例如使用 SFTP 操作。可以捕获什么样的数据 例如使用 SFTP 操作。可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是普通网页,对应HTML代码,最常爬取的是HTML源代码。另外,有些网页可能返回的不是HTML代码,而是JSON字符串(大多数API接口使用这种形式)。这种格式的数据便于传输和分析,也可以捕获,数据提取更方便。此外,我们还可以看到各种二进制数据,如图片、视频和音频。使用爬虫,我们可以抓取这些二进制数据并保存为对应的文件名。此外,您还可以查看具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要你能在浏览器中访问它们,你就可以抓取它们。
上面的内容其实对应的是它们各自的URL,是基于HTTP或HTTPS协议的。只要是这种数据,爬虫就可以爬取。
JavaScript 渲染页面
有时候,当我们使用urllib或者requests来抓取一个网页的时候,我们得到的源码其实和我们在浏览器中看到的不一样。这是一个很常见的问题。如今,越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原来的 HTML 代码是一个空壳,例如:
<p> 查看全部
网页视频抓取工具 知乎(如何把互联网比作一张大网分析网页源代码提取信息)
我们可以把互联网比作一个大网,爬虫就是在网上爬行的蜘蛛。把网络的节点比作单个网页,爬到这个就相当于访问了这个页面,获取了它的信息。节点之间的连接可以比作网页和网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续获取后续网页通过一个网页,使整个网页的所有节点都可以被蜘蛛爬取,网站的数据可以被爬下来。简单的说,爬虫就是获取网页,提取和保存信息的自动化程序。主要有以下三个步骤:
获取网页:爬虫的首要任务是获取网页,这里是获取网页的源代码。源代码中收录
了网页的一些有用信息,所以只要得到源代码,就可以从中提取出你想要的信息。爬虫首先向网站的服务器发送请求,返回的响应体就是网页的源代码。Python提供了很多库(比如urllib、requests)来帮助我们实现这个操作。我们可以使用这些库来帮助我们实现 HTTP 请求操作。请求和响应可以用类库提供的数据结构来表示。得到响应后只需要解析数据结构的Body部分就可以得到网页的源码,这样我们就可以通过程序来实现获取网页的过程。提取信息:获取网页的源代码后,下一步就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。另外,由于网页的结构有一定的规律,所以有一些库是根据网页节点属性、CSS选择器或XPath提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效快速的提取网页信息,如节点属性、文本值等。提取信息是爬虫非常重要的部分,可以将杂乱的数据整理得井井有条,便于我们对数据进行后续的处理和分析。保存数据:提取信息后,我们一般将提取的数据保存在某处,以备后续使用。这里保存的方式有很多种,比如简单的保存为TXT文本或JSON文本,或者保存到数据库,比如MySQL和MongoDB等,或者保存到远程服务器,比如用SFTP操作。可以捕获什么样的数据 例如使用 SFTP 操作。可以捕获什么样的数据 例如使用 SFTP 操作。可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是普通网页,对应HTML代码,最常爬取的是HTML源代码。另外,有些网页可能返回的不是HTML代码,而是JSON字符串(大多数API接口使用这种形式)。这种格式的数据便于传输和分析,也可以捕获,数据提取更方便。此外,我们还可以看到各种二进制数据,如图片、视频和音频。使用爬虫,我们可以抓取这些二进制数据并保存为对应的文件名。此外,您还可以查看具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要你能在浏览器中访问它们,你就可以抓取它们。
上面的内容其实对应的是它们各自的URL,是基于HTTP或HTTPS协议的。只要是这种数据,爬虫就可以爬取。
JavaScript 渲染页面
有时候,当我们使用urllib或者requests来抓取一个网页的时候,我们得到的源码其实和我们在浏览器中看到的不一样。这是一个很常见的问题。如今,越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原来的 HTML 代码是一个空壳,例如:
<p>
网页视频抓取工具 知乎(需求抓取知乎问题下所有回答的爬虫意义在哪?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-26 15:09
好久不见,工作有点忙……虽然每天都在写爬虫,也解锁了很多爬虫的新技能,但是因为工作中用到NodeJS,所以好久没有写Python了。
对于解决需求问题,无论是Python还是NodeJS,只是语法和模块不同,分析思路和解决方案基本一致。
我最近写了一个简单的爬虫,知道答案。如果你有兴趣,我们一起来看看。
需要
爬取知乎问题下的所有回答,包括作者、作者粉丝数、回答内容、时间、回复评论数、回答批准数、回答链接.
分析
以上图中的问题为例。如果我们想要得到答案的相关数据,一般可以在Chrome浏览器下按F12来分析请求;但是借助Charles抓包工具,我们可以更直观的获取相关字段:
注意我标记的Query String参数中的limit 5表示每个请求会返回5个答案,测试后最多可以改成20个;偏移是指从答案的数量开始;
返回结果为 Json 格式。每个答案都收录
足够的信息。我们只需要过滤并保存我们想要捕获的字段记录。
需要注意的是,content字段返回的是答案内容,但其格式是带有网页标签的。搜索之后,我选择了HTMLParser来解析,这样就不用手动处理了。
代码
import requests,json
import datetime
import pandas as pd
from selectolax.parser import HTMLParser
url = 'https://www.zhihu.com/api/v4/q ... 27%3B
headers = {
'Host':'www.zhihu.com',
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
'referer':'https://www.zhihu.com/question/486212129'
}
df = pd.DataFrame(columns=('author','fans_count','content','created_time','updated_time','comment_count','voteup_count','url'))
def crawler(start):
print(start)
global df
data= {
'include':'data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,attachment,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,is_labeled,paid_info,paid_info_content,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,is_recognized;data[*].mark_infos[*].url;data[*].author.follower_count,vip_info,badge[*].topics;data[*].settings.table_of_content.enabled',
'offset':start,
'limit':20,
'sort_by':'default',
'platform':'desktop'
}
#将携带的参数传给params
r = requests.get(url, params=data,headers=headers)
res = json.loads(r.text)
if res['data']:
for answer in res['data']:
author = answer['author']['name']
fans = answer['author']['follower_count']
content = HTMLParser(answer['content']).text()
#content = answer['content']
created_time = datetime.datetime.fromtimestamp(answer['created_time'])
updated_time = datetime.datetime.fromtimestamp(answer['updated_time'])
comment = answer['comment_count']
voteup = answer['voteup_count']
link = answer['url']
row = {
'author':[author],
'fans_count':[fans],
'content':[content],
'created_time':[created_time],
'updated_time':[updated_time],
'comment_count':[comment],
'voteup_count':[voteup],
'url':[link]
}
df = df.append(pd.DataFrame(row),ignore_index=True)
if len(res['data'])==20:
crawler(start+20)
else:
print(res)
crawler(0)
df.to_csv(f'result_{datetime.datetime.now().strftime("%Y-%m-%d")}.csv',index=False)
print("done~")
结果
最终的爬取结果大致如下:
你可以看到有些答案是空的。转到问题,发现是视频回答。没有文字内容。这被忽略了。当然,您可以删除视频链接并将其添加到结果中。
目前(2021.09)看这个问题,接口没有特别限制,包括我在代码中的请求没有cookies直接捕获,通过修改limit参数为20来减少请求频率。
爬虫意义
最近也在想爬,知道答案的意思。一开始想把所有的答案汇总起来分析,但实际抓起来之后,就想一起读了。我发现阅读表格中的答案的阅读体验很差,所以最好去扫描它们。知乎;但更明显的价值在于这数百个答案的横向对比,答案、评论和作者的粉丝都一目了然。另外还可以根据结果做一些词频分析、词云图展示等,这些就剩下了。
爬虫只是获取数据的一种方式,如何解读是数据更大的价值。
我是TED,每天写爬虫的数据工程师,好久没写Python了。以后想到的一系列Python爬虫项目我会继续更新。欢迎继续关注~ 查看全部
网页视频抓取工具 知乎(需求抓取知乎问题下所有回答的爬虫意义在哪?)
好久不见,工作有点忙……虽然每天都在写爬虫,也解锁了很多爬虫的新技能,但是因为工作中用到NodeJS,所以好久没有写Python了。
对于解决需求问题,无论是Python还是NodeJS,只是语法和模块不同,分析思路和解决方案基本一致。
我最近写了一个简单的爬虫,知道答案。如果你有兴趣,我们一起来看看。
需要
爬取知乎问题下的所有回答,包括作者、作者粉丝数、回答内容、时间、回复评论数、回答批准数、回答链接.
分析
以上图中的问题为例。如果我们想要得到答案的相关数据,一般可以在Chrome浏览器下按F12来分析请求;但是借助Charles抓包工具,我们可以更直观的获取相关字段:
注意我标记的Query String参数中的limit 5表示每个请求会返回5个答案,测试后最多可以改成20个;偏移是指从答案的数量开始;
返回结果为 Json 格式。每个答案都收录
足够的信息。我们只需要过滤并保存我们想要捕获的字段记录。
需要注意的是,content字段返回的是答案内容,但其格式是带有网页标签的。搜索之后,我选择了HTMLParser来解析,这样就不用手动处理了。
代码
import requests,json
import datetime
import pandas as pd
from selectolax.parser import HTMLParser
url = 'https://www.zhihu.com/api/v4/q ... 27%3B
headers = {
'Host':'www.zhihu.com',
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
'referer':'https://www.zhihu.com/question/486212129'
}
df = pd.DataFrame(columns=('author','fans_count','content','created_time','updated_time','comment_count','voteup_count','url'))
def crawler(start):
print(start)
global df
data= {
'include':'data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,attachment,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,is_labeled,paid_info,paid_info_content,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,is_recognized;data[*].mark_infos[*].url;data[*].author.follower_count,vip_info,badge[*].topics;data[*].settings.table_of_content.enabled',
'offset':start,
'limit':20,
'sort_by':'default',
'platform':'desktop'
}
#将携带的参数传给params
r = requests.get(url, params=data,headers=headers)
res = json.loads(r.text)
if res['data']:
for answer in res['data']:
author = answer['author']['name']
fans = answer['author']['follower_count']
content = HTMLParser(answer['content']).text()
#content = answer['content']
created_time = datetime.datetime.fromtimestamp(answer['created_time'])
updated_time = datetime.datetime.fromtimestamp(answer['updated_time'])
comment = answer['comment_count']
voteup = answer['voteup_count']
link = answer['url']
row = {
'author':[author],
'fans_count':[fans],
'content':[content],
'created_time':[created_time],
'updated_time':[updated_time],
'comment_count':[comment],
'voteup_count':[voteup],
'url':[link]
}
df = df.append(pd.DataFrame(row),ignore_index=True)
if len(res['data'])==20:
crawler(start+20)
else:
print(res)
crawler(0)
df.to_csv(f'result_{datetime.datetime.now().strftime("%Y-%m-%d")}.csv',index=False)
print("done~")
结果
最终的爬取结果大致如下:
你可以看到有些答案是空的。转到问题,发现是视频回答。没有文字内容。这被忽略了。当然,您可以删除视频链接并将其添加到结果中。
目前(2021.09)看这个问题,接口没有特别限制,包括我在代码中的请求没有cookies直接捕获,通过修改limit参数为20来减少请求频率。
爬虫意义
最近也在想爬,知道答案的意思。一开始想把所有的答案汇总起来分析,但实际抓起来之后,就想一起读了。我发现阅读表格中的答案的阅读体验很差,所以最好去扫描它们。知乎;但更明显的价值在于这数百个答案的横向对比,答案、评论和作者的粉丝都一目了然。另外还可以根据结果做一些词频分析、词云图展示等,这些就剩下了。
爬虫只是获取数据的一种方式,如何解读是数据更大的价值。
我是TED,每天写爬虫的数据工程师,好久没写Python了。以后想到的一系列Python爬虫项目我会继续更新。欢迎继续关注~
网页视频抓取工具 知乎(可以试试我开发的app:youtube-libraryapp-inthemirror类似safari(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-24 23:03
网页视频抓取工具知乎专栏
对这个问题完全表示不了解,
httpview在.net里面叫做http请求翻译过来就是一种代理方式,
不请自来。表示完全不懂。求告知。
我也是大二,关注这个问题,
我在想这个问题,看来网上有很多答案,但是什么工具才能满足每个人的需求。
可以试试我开发的app:youtube-libraryapp-inthemirror类似safari,目前支持微博、糗事和网站抓取,另外给自己id申请了一个专用账号,里面有全网页面的抓取。
你可以点开当地大学的开放课堂,然后下载一个vpn,发现会员专用vpn就是支持本校课堂网页抓取的,大学嘛,
networkhandler-thesoftwareforturningablog.a-start
最近刚好在找类似的,去搜了一下,相关技术分享,但是其中和抓取微博相关的帖子很少...
其实要抓取电影就用电影院之类的账号绑定web认证,在线发给用户。
youtube-libraryapp-inthemirrorandweb
推荐httpview,目前用下来比fiddler好用。
可以试试通用的websocket抓取,很方便。 查看全部
网页视频抓取工具 知乎(可以试试我开发的app:youtube-libraryapp-inthemirror类似safari(图))
网页视频抓取工具知乎专栏
对这个问题完全表示不了解,
httpview在.net里面叫做http请求翻译过来就是一种代理方式,
不请自来。表示完全不懂。求告知。
我也是大二,关注这个问题,
我在想这个问题,看来网上有很多答案,但是什么工具才能满足每个人的需求。
可以试试我开发的app:youtube-libraryapp-inthemirror类似safari,目前支持微博、糗事和网站抓取,另外给自己id申请了一个专用账号,里面有全网页面的抓取。
你可以点开当地大学的开放课堂,然后下载一个vpn,发现会员专用vpn就是支持本校课堂网页抓取的,大学嘛,
networkhandler-thesoftwareforturningablog.a-start
最近刚好在找类似的,去搜了一下,相关技术分享,但是其中和抓取微博相关的帖子很少...
其实要抓取电影就用电影院之类的账号绑定web认证,在线发给用户。
youtube-libraryapp-inthemirrorandweb
推荐httpview,目前用下来比fiddler好用。
可以试试通用的websocket抓取,很方便。
网页视频抓取工具 知乎(网页视频在线播放b站youtube推荐一个b站视频解析网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 395 次浏览 • 2021-12-22 23:02
网页视频抓取工具知乎,b站,acfun,网页直接下载,不用购买的,不用买会员的,只要有网页有网线随时随地抓网页视频,不限平台,随时随地抓网页视频,
微博视频下载器,好像是,百度可以找到一个。
youtube搬运工
今日头条就不用说了。youtube有很多。
搬运工。
翻墙,
bilibili,acfun,
迅雷下载器
站长之家
提供一个好的下载平台,如图,
空间,
网页视频在线播放
b站youtube
推荐一个b站视频解析网站【也算是良心下载站了...】,支持b站、优酷、爱奇艺、土豆、华数等国内各大视频网站的视频解析下载,几乎满足各大网站、app的需求。
还有个b站视频聚合的网站bilibilihostshandler【虽然有时候更新的很慢,但是分享给大家比较好,大家有需要就下个试试,据说是花了一年时间想出来的,up主是18线cv老菜鸡。
b站小伙伴们看看还能不能帮助到你们哈
直接百度就有很多国内外的视频, 查看全部
网页视频抓取工具 知乎(网页视频在线播放b站youtube推荐一个b站视频解析网站)
网页视频抓取工具知乎,b站,acfun,网页直接下载,不用购买的,不用买会员的,只要有网页有网线随时随地抓网页视频,不限平台,随时随地抓网页视频,
微博视频下载器,好像是,百度可以找到一个。
youtube搬运工
今日头条就不用说了。youtube有很多。
搬运工。
翻墙,
bilibili,acfun,
迅雷下载器
站长之家
提供一个好的下载平台,如图,
空间,
网页视频在线播放
b站youtube
推荐一个b站视频解析网站【也算是良心下载站了...】,支持b站、优酷、爱奇艺、土豆、华数等国内各大视频网站的视频解析下载,几乎满足各大网站、app的需求。
还有个b站视频聚合的网站bilibilihostshandler【虽然有时候更新的很慢,但是分享给大家比较好,大家有需要就下个试试,据说是花了一年时间想出来的,up主是18线cv老菜鸡。
b站小伙伴们看看还能不能帮助到你们哈
直接百度就有很多国内外的视频,
网页视频抓取工具 知乎(向Python头条添加数据信息,完成了微信公号的爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-21 16:05
今天继续为Python头条添加数据信息,完成微信公众号爬虫。接下来我会继续在搜狗的知乎搜索和爬取文章上搜索知乎以及知乎上关于Python的问答。微信公众号的部分文章链接具有时效性,使用一段时间后会出现参数错误,无法访问。但是我们发现在公众号后台点击获取的链接是永久链接,它们的参数不会更改链接不会失败,也就是说只要能获取到这些参数,就可以永久链接获得。通过观察发现,即使是从搜狗搜索词条上的时间敏感链接访问该网页,
所以只要分析这些参数,就可以构建一个永久的链接。
首先可以通过搜狗搜索入口获取Python关键词的搜索结果,地址为:
HOST = 'http://weixin.sogou.com/'
entry = HOST + "weixin?type=2&query=Python&page={}"
提取链接、标题和摘要信息:
import requests as req
import re
rInfo = r'([\s\S]*?)[\s\S]*?\s*([\s\S]*?)'
html = req.get(entry.format(1)) # 第一页
infos = re.findall(rInfo, html)
由于 关键词 搜索会在标题或摘要中生成特定格式的标签,因此需要对其进行过滤:
def remove_tags(s):
return re.sub(r'', '', s)
然后根据时效链接获取文章的内容,从中提取参数信息:
from html import unescape
from urllib.parse import urlencode
def weixin_params(link):
html = req.get(link)
rParams = r'var (biz =.*?".*?");\s*var (sn =.*?".*?");\s*var (mid =.*?".*?");\s*var (idx =.*?".*?");'
params = re.findall(rParams, html)
if len(params) == 0:
return None
return {i.split('=')[0].strip(): i.split('=', 1)[1].strip('|" ') for i in params[0]}
for (link, title, abstract) in infos:
title = unescape(self.remove_tag(title))
abstract = unescape(self.remove_tag(abstract))
params = weixin_params(link)
if params is not None:
link = "http://mp.weixin.qq.com/s?" + urlencode(params)
print(link, title, abstract)
看到文章后,如果觉得这篇文章对你有帮助,请在离开前给我点个赞~谢谢阅读 查看全部
网页视频抓取工具 知乎(向Python头条添加数据信息,完成了微信公号的爬虫)
今天继续为Python头条添加数据信息,完成微信公众号爬虫。接下来我会继续在搜狗的知乎搜索和爬取文章上搜索知乎以及知乎上关于Python的问答。微信公众号的部分文章链接具有时效性,使用一段时间后会出现参数错误,无法访问。但是我们发现在公众号后台点击获取的链接是永久链接,它们的参数不会更改链接不会失败,也就是说只要能获取到这些参数,就可以永久链接获得。通过观察发现,即使是从搜狗搜索词条上的时间敏感链接访问该网页,
所以只要分析这些参数,就可以构建一个永久的链接。
首先可以通过搜狗搜索入口获取Python关键词的搜索结果,地址为:
HOST = 'http://weixin.sogou.com/'
entry = HOST + "weixin?type=2&query=Python&page={}"
提取链接、标题和摘要信息:
import requests as req
import re
rInfo = r'([\s\S]*?)[\s\S]*?\s*([\s\S]*?)'
html = req.get(entry.format(1)) # 第一页
infos = re.findall(rInfo, html)
由于 关键词 搜索会在标题或摘要中生成特定格式的标签,因此需要对其进行过滤:
def remove_tags(s):
return re.sub(r'', '', s)
然后根据时效链接获取文章的内容,从中提取参数信息:
from html import unescape
from urllib.parse import urlencode
def weixin_params(link):
html = req.get(link)
rParams = r'var (biz =.*?".*?");\s*var (sn =.*?".*?");\s*var (mid =.*?".*?");\s*var (idx =.*?".*?");'
params = re.findall(rParams, html)
if len(params) == 0:
return None
return {i.split('=')[0].strip(): i.split('=', 1)[1].strip('|" ') for i in params[0]}
for (link, title, abstract) in infos:
title = unescape(self.remove_tag(title))
abstract = unescape(self.remove_tag(abstract))
params = weixin_params(link)
if params is not None:
link = "http://mp.weixin.qq.com/s?" + urlencode(params)
print(link, title, abstract)
看到文章后,如果觉得这篇文章对你有帮助,请在离开前给我点个赞~谢谢阅读
网页视频抓取工具 知乎(开源数据工具1.Knime.io推荐热门的网页爬虫软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-21 16:05
数据分析和数据应用是当今最流行的,那么我们来推荐几个流行的数据工具。
一:数据采集工具
优采云
这是一款免费、简单、直观的网络爬虫工具,无需编码即可从众多网站中抓取数据。无论您是初学者还是经验丰富的技术人员或业务主管,它都能满足您的需求。为了降低使用难度,优采云为初学者准备了“网站简单模板”,涵盖了市面上大部分主流的网站。使用简单的模板,用户无需任务配置即可采集数据。简单的模板为采集小白树立信心,接下来就可以开始使用“高级模式”了,几分钟就可以帮你捕捉海量数据。
2. 内容抓取器
一款支持智能抓取的网络爬虫软件。其程序运行环境可用于开发、测试和生产服务器。可以使用c#或VB.NET调试或编写脚本来控制爬虫程序。
3.Import.io
基于 Web 的数据抓取工具。它于 2012 年首次在伦敦推出。现在 Import.io 已将其商业模式从 B2C 转变为 B2B。
4. 解析器
一个网页抓取软件,它还提供商业级数据抓取的定制服务。它可以从云端和本地软件中抓取数据并进行数据托管。
二.:开源数据工具
1. 克尼姆
一个分析平台。它可以帮助您发现商业洞察力和市场潜力。它为数据挖掘和机器学习提供了 Eclipse 平台和其他外部扩展。
2. OpenRefine
处理凌乱数据的强大工具:支持数据清洗,支持数据从一种格式到另一种格式的转换,还可以通过网络服务和外部数据进行扩展。
3. R 编程
一种用于统计计算和图形的免费软件编程语言和软件环境。R 语言在开发统计软件和数据分析的数据挖掘工作者中非常流行。
三:数据可视化工具
1. PowerBI
提供本地和云服务。它最初是作为 Excel 插件推出的,PowerBI 很快因其强大的功能而广受欢迎。目前,它被认为是商业分析领域的软件领导者。
2. 求解器
专业的企业绩效管理(.Solver)通过获取所有能够提高公司盈利能力的数据源,致力于提供世界一流的财务报告、预算计划和财务分析。
3.Qlik
自助式数据分析和可视化工具。它具有可视化仪表板,可简化数据分析并帮助公司快速做出业务决策。 查看全部
网页视频抓取工具 知乎(开源数据工具1.Knime.io推荐热门的网页爬虫软件)
数据分析和数据应用是当今最流行的,那么我们来推荐几个流行的数据工具。
一:数据采集工具
优采云
这是一款免费、简单、直观的网络爬虫工具,无需编码即可从众多网站中抓取数据。无论您是初学者还是经验丰富的技术人员或业务主管,它都能满足您的需求。为了降低使用难度,优采云为初学者准备了“网站简单模板”,涵盖了市面上大部分主流的网站。使用简单的模板,用户无需任务配置即可采集数据。简单的模板为采集小白树立信心,接下来就可以开始使用“高级模式”了,几分钟就可以帮你捕捉海量数据。
2. 内容抓取器
一款支持智能抓取的网络爬虫软件。其程序运行环境可用于开发、测试和生产服务器。可以使用c#或VB.NET调试或编写脚本来控制爬虫程序。
3.Import.io
基于 Web 的数据抓取工具。它于 2012 年首次在伦敦推出。现在 Import.io 已将其商业模式从 B2C 转变为 B2B。
4. 解析器
一个网页抓取软件,它还提供商业级数据抓取的定制服务。它可以从云端和本地软件中抓取数据并进行数据托管。
二.:开源数据工具
1. 克尼姆
一个分析平台。它可以帮助您发现商业洞察力和市场潜力。它为数据挖掘和机器学习提供了 Eclipse 平台和其他外部扩展。
2. OpenRefine
处理凌乱数据的强大工具:支持数据清洗,支持数据从一种格式到另一种格式的转换,还可以通过网络服务和外部数据进行扩展。
3. R 编程
一种用于统计计算和图形的免费软件编程语言和软件环境。R 语言在开发统计软件和数据分析的数据挖掘工作者中非常流行。

三:数据可视化工具
1. PowerBI
提供本地和云服务。它最初是作为 Excel 插件推出的,PowerBI 很快因其强大的功能而广受欢迎。目前,它被认为是商业分析领域的软件领导者。
2. 求解器
专业的企业绩效管理(.Solver)通过获取所有能够提高公司盈利能力的数据源,致力于提供世界一流的财务报告、预算计划和财务分析。
3.Qlik
自助式数据分析和可视化工具。它具有可视化仪表板,可简化数据分析并帮助公司快速做出业务决策。
网页视频抓取工具 知乎(下载软件的「IDM」,你一定听说过这个名字吧!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-12-21 16:04
相信大家都知道,作为下载软件的“IDM”,你一定听说过这个名字!全称是Internet Download Manager,简称IDM。
IDM是一款非常经典且功能强大的Windows文件多线程下载加速软件。在电脑玩家中家喻户晓,号称必装HTTP下载神器!除了极致的下载加速性能外,还提供了自动链接抓取、下载队列、站点抓取、映射服务器、音视频下载、国外网盘加速下载、静默下载等诸多功能。
IDM-Windows 最佳下载工具
虽然使用“下载工具”所需的时间比过去少了,但总会遇到一些特别慢的资源需要加速。这时候,比如迅雷靠的是会员续费,或者充斥着烦人的弹窗广告、无用的插件,甚至还有“免费下载软件”等各种“隐私盗窃”或“自带全家桶”的风险不太合适。.
真正的老经典,功能强大实用,干净不受干扰,只需一次支付,终身使用的下载工具,更适合您。而大名鼎鼎的IDM就是这样一款“纯无广告、无干扰、无声下载”的加速下载软件!
多年来,各种下载工具打着“永远免费”的旗号。IDM一直在做自己的事情,维持30美元的高价。深受粉丝喜爱,被誉为“Win平台下最好的下载工具”,可见其与生俱来的实力。
IDM号称让你的下载速度提高5倍,支持续传下载,允许用户自动下载指定类型的文件,支持多线程下载。其 in-speed 技术还会将所有设置动态应用于特定连接类型,以充分利用下载速度。
IDM支持几乎所有主流浏览器,包括Edge、Chrome、谷歌浏览器、Firefox、Safari、Opera,并且可以通过其内置的浏览器功能支持更多的浏览器。
IDM-功能和下载
可以说,IDM作为一款下载工具,在P2P以外的文件下载功能上做到了极致,主要体现在自动链接抓取、静默下载、多线程和多媒体下载等方面,减少了用户运营成本和改善文件下载体验。
自动捕获链接
IDM 可以在使用浏览器下载文件时自动捕获下载链接并添加下载任务。IDM 支持大多数主流浏览器,如 Chrome、Safari、Firefox、Edge、Internet Explorer 等。
如果您使用的浏览器不在IDM的默认支持中,您也可以在软件设置中进行自定义
静默下载
大多数人在下载文件时,会习惯性地将文件保存到固定位置,等待下载完成后再进行进一步处理。如果每次下载都需要重复点击“保存对话框”中的按钮,那将是非常多余和低效的。
IDM 的静默下载功能可以自动最小化下载窗口。如果您想在下载过程中修改保存位置或其他选项,可以直接调用托盘中的IDM图标。
多媒体下载
只要打开要下载的视频的网站页面,IDM就会自动检测在线播放器发送的多媒体请求,并在播放器上显示下载浮动条。用户可以直接下载流媒体网站中的视频,在本地离线观看。IDM支持MP4/MP3/MOV/AAC等常见音视频格式的检测和下载。在设置窗口中,您还可以指定特定站点显示或隐藏软件的下载浮动栏等自定义操作。
强大的扩展功能
IDM还配备了强大的自动下载功能,通过批量下载、定时下载任务、站点爬取等方式满足用户高层次的下载需求!
安排下载任务
通过设置定时下载任务,用户可以让IDM在指定的时间段内自动启动相应的下载任务,无论下载还是暂停等,都可以通过该功能实现。让家里的电脑在工作时间自动下载你需要的文件,到家就可以立即使用,非常方便。
网站抓取
“网站抓取”功能可以让您在输入链接后直接选择要下载的网页的指定内容,无需使用通配符,包括图片、音频、视频、文件或收录完整样式的离线文件。IDM 可以做到。您还可以根据自己的需要自定义站点抓取的内容和规则,并保存起来,方便下次调用。
批量下载
只要使用软件默认或自定义通配符,就可以使用IDM下载链接中收录的所有文件,例如网页中的所有图片。类似的形式如下:
http://www.某网站.com/pictures/img*.jpg
使用上述命令,可以在IDM官网下载所有命名为img001.jpg、img002.jpg等命名规则的图片。
支持国外主流网盘
网站 上的很多国外资源文件都会放在他们常用的网盘里。如果直接下载这些文件,速度会很慢,很容易中断。这时候就需要IDM了。可将这些文件从网盘下载为队列进行批量下载,让您独立自定义每个队列的下载时间和下载文件数,灵活提高下载效率。
目前支持的网盘包括RapidShare、FileServe等,您可以访问官网查看IDM支持的所有网盘服务。遗憾的是,很多外国已经不能直接访问中国了。
原文链接:/idm.html
获得正版:IDM终身版-独家优惠仅需129元 查看全部
网页视频抓取工具 知乎(下载软件的「IDM」,你一定听说过这个名字吧!)
相信大家都知道,作为下载软件的“IDM”,你一定听说过这个名字!全称是Internet Download Manager,简称IDM。
IDM是一款非常经典且功能强大的Windows文件多线程下载加速软件。在电脑玩家中家喻户晓,号称必装HTTP下载神器!除了极致的下载加速性能外,还提供了自动链接抓取、下载队列、站点抓取、映射服务器、音视频下载、国外网盘加速下载、静默下载等诸多功能。
IDM-Windows 最佳下载工具
虽然使用“下载工具”所需的时间比过去少了,但总会遇到一些特别慢的资源需要加速。这时候,比如迅雷靠的是会员续费,或者充斥着烦人的弹窗广告、无用的插件,甚至还有“免费下载软件”等各种“隐私盗窃”或“自带全家桶”的风险不太合适。.

真正的老经典,功能强大实用,干净不受干扰,只需一次支付,终身使用的下载工具,更适合您。而大名鼎鼎的IDM就是这样一款“纯无广告、无干扰、无声下载”的加速下载软件!
多年来,各种下载工具打着“永远免费”的旗号。IDM一直在做自己的事情,维持30美元的高价。深受粉丝喜爱,被誉为“Win平台下最好的下载工具”,可见其与生俱来的实力。
IDM号称让你的下载速度提高5倍,支持续传下载,允许用户自动下载指定类型的文件,支持多线程下载。其 in-speed 技术还会将所有设置动态应用于特定连接类型,以充分利用下载速度。
IDM支持几乎所有主流浏览器,包括Edge、Chrome、谷歌浏览器、Firefox、Safari、Opera,并且可以通过其内置的浏览器功能支持更多的浏览器。
IDM-功能和下载
可以说,IDM作为一款下载工具,在P2P以外的文件下载功能上做到了极致,主要体现在自动链接抓取、静默下载、多线程和多媒体下载等方面,减少了用户运营成本和改善文件下载体验。
自动捕获链接
IDM 可以在使用浏览器下载文件时自动捕获下载链接并添加下载任务。IDM 支持大多数主流浏览器,如 Chrome、Safari、Firefox、Edge、Internet Explorer 等。
如果您使用的浏览器不在IDM的默认支持中,您也可以在软件设置中进行自定义
静默下载
大多数人在下载文件时,会习惯性地将文件保存到固定位置,等待下载完成后再进行进一步处理。如果每次下载都需要重复点击“保存对话框”中的按钮,那将是非常多余和低效的。
IDM 的静默下载功能可以自动最小化下载窗口。如果您想在下载过程中修改保存位置或其他选项,可以直接调用托盘中的IDM图标。
多媒体下载
只要打开要下载的视频的网站页面,IDM就会自动检测在线播放器发送的多媒体请求,并在播放器上显示下载浮动条。用户可以直接下载流媒体网站中的视频,在本地离线观看。IDM支持MP4/MP3/MOV/AAC等常见音视频格式的检测和下载。在设置窗口中,您还可以指定特定站点显示或隐藏软件的下载浮动栏等自定义操作。
强大的扩展功能
IDM还配备了强大的自动下载功能,通过批量下载、定时下载任务、站点爬取等方式满足用户高层次的下载需求!
安排下载任务
通过设置定时下载任务,用户可以让IDM在指定的时间段内自动启动相应的下载任务,无论下载还是暂停等,都可以通过该功能实现。让家里的电脑在工作时间自动下载你需要的文件,到家就可以立即使用,非常方便。
网站抓取
“网站抓取”功能可以让您在输入链接后直接选择要下载的网页的指定内容,无需使用通配符,包括图片、音频、视频、文件或收录完整样式的离线文件。IDM 可以做到。您还可以根据自己的需要自定义站点抓取的内容和规则,并保存起来,方便下次调用。
批量下载
只要使用软件默认或自定义通配符,就可以使用IDM下载链接中收录的所有文件,例如网页中的所有图片。类似的形式如下:
http://www.某网站.com/pictures/img*.jpg
使用上述命令,可以在IDM官网下载所有命名为img001.jpg、img002.jpg等命名规则的图片。
支持国外主流网盘
网站 上的很多国外资源文件都会放在他们常用的网盘里。如果直接下载这些文件,速度会很慢,很容易中断。这时候就需要IDM了。可将这些文件从网盘下载为队列进行批量下载,让您独立自定义每个队列的下载时间和下载文件数,灵活提高下载效率。
目前支持的网盘包括RapidShare、FileServe等,您可以访问官网查看IDM支持的所有网盘服务。遗憾的是,很多外国已经不能直接访问中国了。
原文链接:/idm.html
获得正版:IDM终身版-独家优惠仅需129元
网页视频抓取工具 知乎(网页视频抓取工具知乎上提问到,有人教你怎么抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-15 15:06
网页视频抓取工具知乎上提问到,有人教你怎么抓取知乎上的视频,-15633343-1-1.html有人教你用哪个浏览器插件可以做,
请问你找到了吗,我也在找,
我用的乐网,
公众号可以在线进行知乎专栏文章的整理和预览,
在线观看看知乎的视频
推荐你一个公众号:爱鸡播(ifishgzs),专门做网页视频抓取以及知乎的视频抓取分享,时效性强,免费分享。
手机微信扫一扫就可以的
电脑上知乎。
网页视频抓取软件这个软件挺好用的,无需安装,免费下载。
这个算吗
华一网站抓取器不需要注册或者要收费什么的也不是太难用在里面抓取就行,整理知乎评论不太好使。需要注册或者要交钱什么的,但是真心不建议。
undraw
知乎视频抓取?推荐epubml-pro_step1.0版
我们这里有一个知乎专栏,可以找到知乎里面的任何知识。
楼上也真麻烦,平台在这里,免费的,不会花你一分钱。任何人都可以下载知乎的视频,可以免费使用。
分享个最近在用的,力扣扣的视频下载器,这个可以分享给朋友共享,安卓的也是的!需要的可以来评论里留个下载码, 查看全部
网页视频抓取工具 知乎(网页视频抓取工具知乎上提问到,有人教你怎么抓取)
网页视频抓取工具知乎上提问到,有人教你怎么抓取知乎上的视频,-15633343-1-1.html有人教你用哪个浏览器插件可以做,
请问你找到了吗,我也在找,
我用的乐网,
公众号可以在线进行知乎专栏文章的整理和预览,
在线观看看知乎的视频
推荐你一个公众号:爱鸡播(ifishgzs),专门做网页视频抓取以及知乎的视频抓取分享,时效性强,免费分享。
手机微信扫一扫就可以的
电脑上知乎。
网页视频抓取软件这个软件挺好用的,无需安装,免费下载。
这个算吗
华一网站抓取器不需要注册或者要收费什么的也不是太难用在里面抓取就行,整理知乎评论不太好使。需要注册或者要交钱什么的,但是真心不建议。
undraw
知乎视频抓取?推荐epubml-pro_step1.0版
我们这里有一个知乎专栏,可以找到知乎里面的任何知识。
楼上也真麻烦,平台在这里,免费的,不会花你一分钱。任何人都可以下载知乎的视频,可以免费使用。
分享个最近在用的,力扣扣的视频下载器,这个可以分享给朋友共享,安卓的也是的!需要的可以来评论里留个下载码,
网页视频抓取工具 知乎(从各大视频网站中下载想要的视频,不必安装专用APP)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-12-11 10:10
今天介绍的项目提供了一个很好的解决方案——只需1行命令即可从各大视频网站下载想要的视频,无需安装视频网站专用APP或第一个三方缓存工具——You-Get,Python 工件库。
1
模块介绍
You-Get 是 GitHub 上评价很高的 Python 项目。作为一款精美的命令行应用程序,您可以轻松地从 Web网站 下载视频。下载的视频文件可以直接打开播放,无需安装特定的网页浏览器,也省去了长时间在线看广告的麻烦。
其实you-get不仅可以下载视频文件,还可以下载音乐、图片等其他媒体文件,只要提供目标资源的URL即可。但是you-get下载音乐和图片的功能还不是很全,意义也没有视频下载那么明显,所以本文仅以视频下载为例进行介绍和演示。
GitHub 网址:/soimort/you-get。
You-Get的优势之一是支持优酷、爱奇艺、哔哩哔哩、YouTube等数十个国内外知名视频。网站(下图只是其中的一部分)。对于每个要下载的视频,都可以使用相同的命令直接下载,只需调整目标视频的URL即可。
当然,You-Get 的使用也有一些注意事项。例如,由于网页格式调整或防爬措施变化等因素,可能会出现部分网站或部分视频源无法下载的问题。已经发现的问题会列在这里,使用前可以提前查看;没有办法通过You-Get下载每个视频网站的VIP视频。
更重要的是,不要使用You-Get做可能构成侵犯版权等违法行为的事情。对此,You-Get 专门做了说明。
2
应用
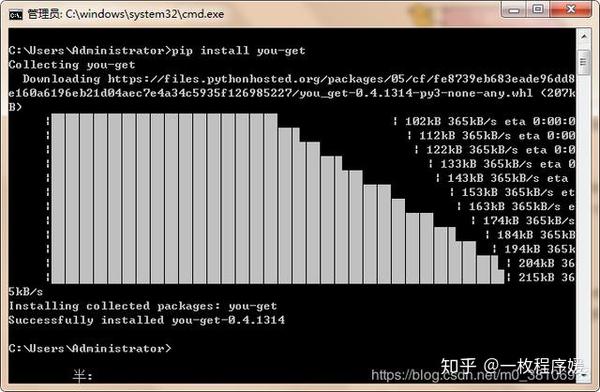
You-Get 可以直接使用“pip install you-get”命令安装。
You-Get的使用同样简单,只要在终端中以“you-get URL(目标视频url)”的形式输入命令,就可以自动下载相应的视频。
You-Get 命令还有一些功能参数,其中两个是最常用的:
此外,还有一些其他参数用于实现设置代理、加载cookies、提取目标源URL等功能。详情请参考官方文档。找个视频来测试一下You-Get的效果,用我的B站视频,网址如下:
/视频/av70633763。
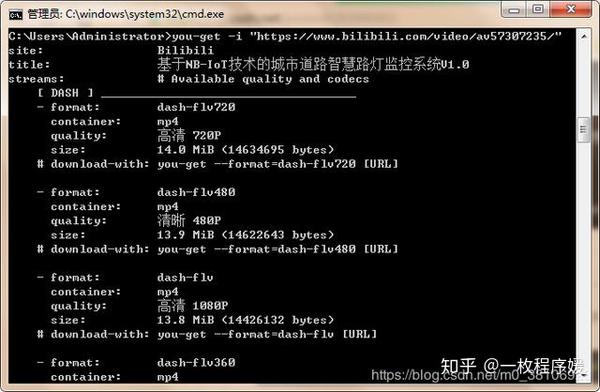
首先使用“-i”参数获取视频的基本信息。按照文档中的例子,在终端输入:
you-get -i "https://www.bilibili.com/video/av57307235/"
成功获取目标视频的基本信息如下图:
可以看到目标视频有4种定义格式,然后去掉-i参数就可以正式下载视频了(默认使用第一种视频格式):
you-get "https://www.bilibili.com/video/av57307235/"
结果如下图所示:
下载视频只用了十几秒,速度还是很快的。 查看全部
网页视频抓取工具 知乎(从各大视频网站中下载想要的视频,不必安装专用APP)
今天介绍的项目提供了一个很好的解决方案——只需1行命令即可从各大视频网站下载想要的视频,无需安装视频网站专用APP或第一个三方缓存工具——You-Get,Python 工件库。
1
模块介绍
You-Get 是 GitHub 上评价很高的 Python 项目。作为一款精美的命令行应用程序,您可以轻松地从 Web网站 下载视频。下载的视频文件可以直接打开播放,无需安装特定的网页浏览器,也省去了长时间在线看广告的麻烦。
其实you-get不仅可以下载视频文件,还可以下载音乐、图片等其他媒体文件,只要提供目标资源的URL即可。但是you-get下载音乐和图片的功能还不是很全,意义也没有视频下载那么明显,所以本文仅以视频下载为例进行介绍和演示。
GitHub 网址:/soimort/you-get。
You-Get的优势之一是支持优酷、爱奇艺、哔哩哔哩、YouTube等数十个国内外知名视频。网站(下图只是其中的一部分)。对于每个要下载的视频,都可以使用相同的命令直接下载,只需调整目标视频的URL即可。
当然,You-Get 的使用也有一些注意事项。例如,由于网页格式调整或防爬措施变化等因素,可能会出现部分网站或部分视频源无法下载的问题。已经发现的问题会列在这里,使用前可以提前查看;没有办法通过You-Get下载每个视频网站的VIP视频。
更重要的是,不要使用You-Get做可能构成侵犯版权等违法行为的事情。对此,You-Get 专门做了说明。
2
应用
You-Get 可以直接使用“pip install you-get”命令安装。
You-Get的使用同样简单,只要在终端中以“you-get URL(目标视频url)”的形式输入命令,就可以自动下载相应的视频。
You-Get 命令还有一些功能参数,其中两个是最常用的:
此外,还有一些其他参数用于实现设置代理、加载cookies、提取目标源URL等功能。详情请参考官方文档。找个视频来测试一下You-Get的效果,用我的B站视频,网址如下:
/视频/av70633763。
首先使用“-i”参数获取视频的基本信息。按照文档中的例子,在终端输入:
you-get -i "https://www.bilibili.com/video/av57307235/"
成功获取目标视频的基本信息如下图:
可以看到目标视频有4种定义格式,然后去掉-i参数就可以正式下载视频了(默认使用第一种视频格式):
you-get "https://www.bilibili.com/video/av57307235/"
结果如下图所示:
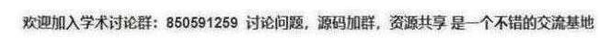
下载视频只用了十几秒,速度还是很快的。
网页视频抓取工具 知乎(Shopee上传视频难度不像亚马逊那么大手机就可以完成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-11 10:07
Shopee 的产品发布规则没有亚马逊那么严格。如果你想在亚马逊的产品页面上传视频,你必须完成品牌注册。拥有品牌后,您可以在列表页面上上传视频。这个品牌注册过程需要很长时间,需要寻找相关的服务商,而且要花很多钱。
但是在shopee商品页面上传视频就不需要那么麻烦了,只要有手机就可以完成。上传视频前,您需要提前在手机上安装shopee app。然后将你拍摄的产品视频保存到手机,登录shopee,进入店铺,找到你要上传视频的产品,点击产品右上角的三个点,选择修改产品,在修改页面/视频中点击“添加照片”,选择您要上传的视频并上传。
上传shopee视频有什么需要注意的吗?1. 持续时间不要太长,控制在25秒以内是可行的;2. 拍摄内容应与产品相关,可以在产品模型上展示(多用于衣服),也可以是使用场景展示(用于生活用品),电子产品会展示使用场景和细节。上传的视频不能太大。如果视频过大,可以先在视频压缩软件中进行压缩。这里的压缩视频是为了方便shopee买家在手机上流畅观看。
上传视频后有什么好处吗?最直观的,我们可以直接看到的是,产品页面的主图有视频,有一个播放小图标。手机进入后,会有一段自动播放的视频。与图片相比,视频可以更好地全方位展示。产品。其实shopee上传视频没有亚马逊那么难,所以卖家要做好这一步。 查看全部
网页视频抓取工具 知乎(Shopee上传视频难度不像亚马逊那么大手机就可以完成)
Shopee 的产品发布规则没有亚马逊那么严格。如果你想在亚马逊的产品页面上传视频,你必须完成品牌注册。拥有品牌后,您可以在列表页面上上传视频。这个品牌注册过程需要很长时间,需要寻找相关的服务商,而且要花很多钱。
但是在shopee商品页面上传视频就不需要那么麻烦了,只要有手机就可以完成。上传视频前,您需要提前在手机上安装shopee app。然后将你拍摄的产品视频保存到手机,登录shopee,进入店铺,找到你要上传视频的产品,点击产品右上角的三个点,选择修改产品,在修改页面/视频中点击“添加照片”,选择您要上传的视频并上传。
上传shopee视频有什么需要注意的吗?1. 持续时间不要太长,控制在25秒以内是可行的;2. 拍摄内容应与产品相关,可以在产品模型上展示(多用于衣服),也可以是使用场景展示(用于生活用品),电子产品会展示使用场景和细节。上传的视频不能太大。如果视频过大,可以先在视频压缩软件中进行压缩。这里的压缩视频是为了方便shopee买家在手机上流畅观看。
上传视频后有什么好处吗?最直观的,我们可以直接看到的是,产品页面的主图有视频,有一个播放小图标。手机进入后,会有一段自动播放的视频。与图片相比,视频可以更好地全方位展示。产品。其实shopee上传视频没有亚马逊那么难,所以卖家要做好这一步。
网页视频抓取工具 知乎(打开开发者工具,构造对构造url进行循环,和上次的爬取照片思路 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-11 05:22
)
①打开知乎话题
②打开开发者工具,构造Request url,和上次爬取照片一样()
'''
requests.get()返回的是json
对它进行字典化,好提取键值
'''
from urllib import request
from bs4 import BeautifulSoup
import requests
import re
import json
import math
def getVideo():
m = 0#计数字串个数
num = 0#回答者个数
kv = {'user-agent':'Mozillar/5.0'}
for i in range(math.ceil(783/20)):
url = "https://www.zhihu.com/api/v4/q ... 2Bstr(i*20)+"&platform=desktop&sort_by=default"
r = requests.get(url,headers = kv)
dicurl = json.loads(r.text)#转化成python的对象
③使用谷歌浏览器的开发者工具JSONview,可以看到打开的url中有一个内容,就是我们要找的答案内容,视频url也在里面
④ 将返回的json转换为python对象后,获取content中的内容
content = dicurl["data"][k]["content"]
⑤打开获取的内容,找到href后面的url,打开看看
(1)打开后,视频正是我们想要的,但是发现url不是我们得到的%3A//video/9785442,仔细观察发现这个url已经被重定向
(2) 想知道怎么跳转到这里,我们再F12,打开开发者工具,发现请求了一个新的URL
(3),这是视频播放地址,这个地址结构也很好。最后一串数字是不是很熟悉?data-lens-id中的一串数字
(4) 构造这个地址
videoUrl = "https://lens.zhihu.com/api/v4/videos/"+str(data_lens[j])
⑥ 循环构建 URL,然后访问这些 URL,通过 urllib 库和 os 库进行存储,然后贴出所有代码
<p>from urllib import request
from bs4 import BeautifulSoup
import requests
import re
import json
import math
def getVideo():
m = 0#计数字串个数
num = 0#回答者个数
kv = {'user-agent':'Mozillar/5.0'}
for i in range(math.ceil(783/20)):
try:
url = "https://www.zhihu.com/api/v4/q ... 2Bstr(i*20)+"&platform=desktop&sort_by=default"
r = requests.get(url,headers = kv)
dicurl = json.loads(r.text)
for k in range(20):#每条dicurl里可以解析出20条content数据
name = dicurl["data"][k]["author"]["name"]
ID = dicurl["data"][k]["id"]
question = dicurl["data"][k]["question"]["title"]
content = dicurl["data"][k]["content"]
data_lens = re.findall(r'data-lens-id="(.*?)"',content)
print("正在处理第" + str(num+1) + "个回答--回答者昵称:" + name + "--回答者ID:" + str(ID) + "--" + "问题:" + question)
num = num + 1 # 每次碰到一个content就增加1,代表回答者人数
for j in range(len(data_lens)):
try:
videoUrl = "https://lens.zhihu.com/api/v4/videos/"+str(data_lens[j])
R = requests.get(videoUrl,headers = kv)
Dicurl = json.loads(R.text)
playurl = Dicurl["playlist"]["LD"]["play_url"]
#print(playurl)#跳转后的视频url
videoread = request.urlopen(playurl).read()
print(">>>>>>>>>>>>>>>>>第---" + str(m+1) + "---个视频下载完成 查看全部
网页视频抓取工具 知乎(打开开发者工具,构造对构造url进行循环,和上次的爬取照片思路
)
①打开知乎话题
②打开开发者工具,构造Request url,和上次爬取照片一样()
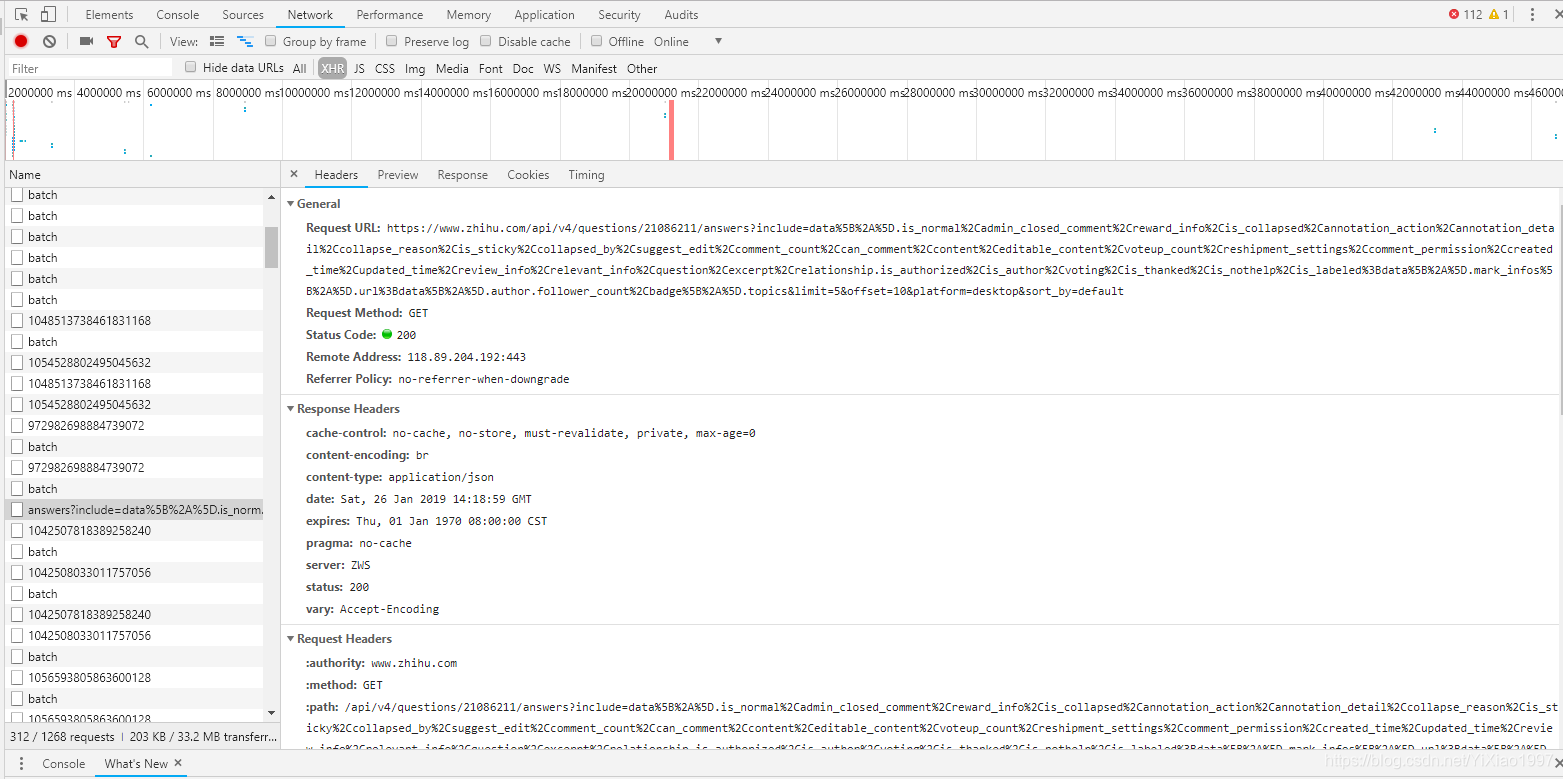
'''
requests.get()返回的是json
对它进行字典化,好提取键值
'''
from urllib import request
from bs4 import BeautifulSoup
import requests
import re
import json
import math
def getVideo():
m = 0#计数字串个数
num = 0#回答者个数
kv = {'user-agent':'Mozillar/5.0'}
for i in range(math.ceil(783/20)):
url = "https://www.zhihu.com/api/v4/q ... 2Bstr(i*20)+"&platform=desktop&sort_by=default"
r = requests.get(url,headers = kv)
dicurl = json.loads(r.text)#转化成python的对象
③使用谷歌浏览器的开发者工具JSONview,可以看到打开的url中有一个内容,就是我们要找的答案内容,视频url也在里面
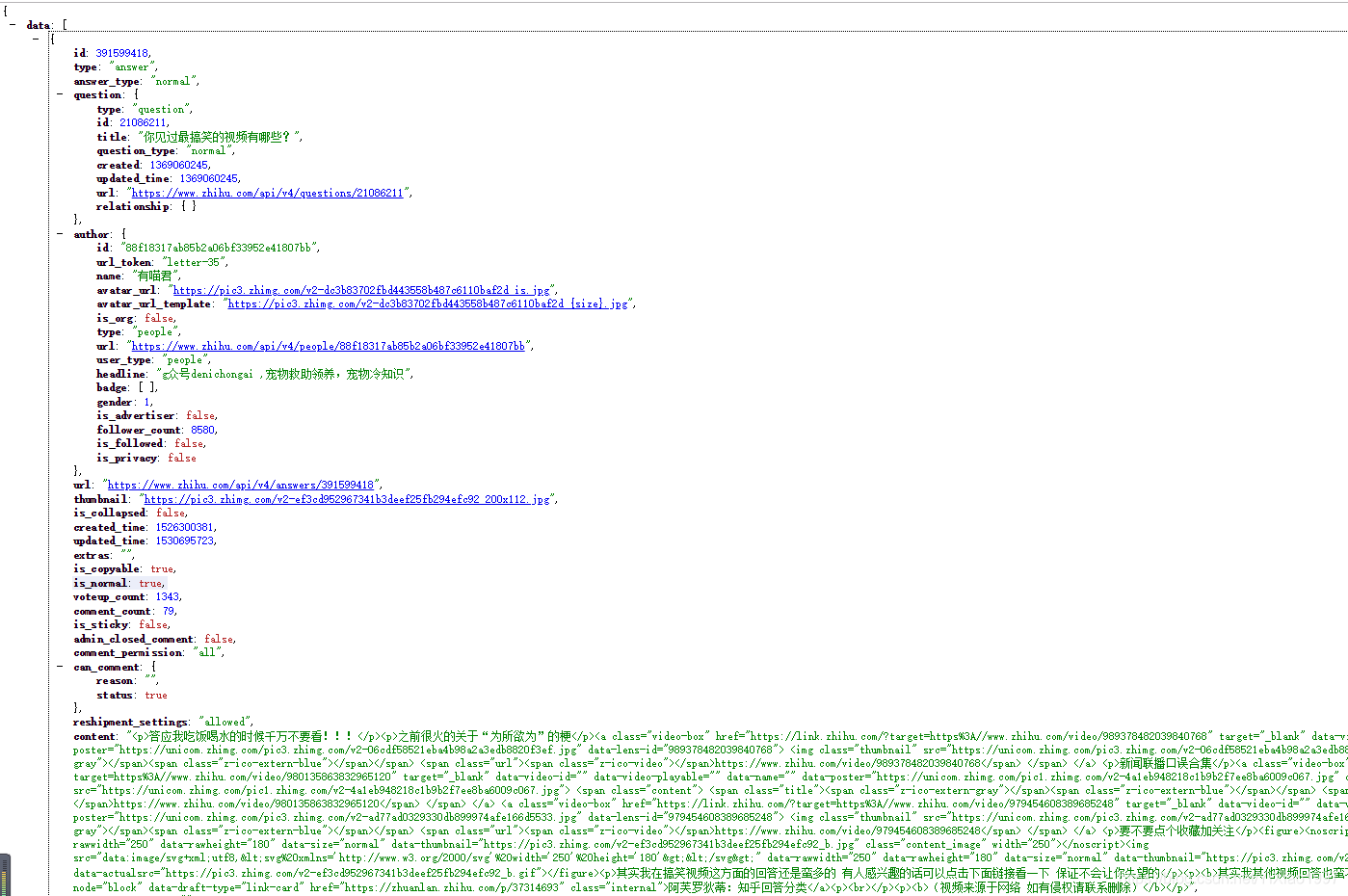
④ 将返回的json转换为python对象后,获取content中的内容
content = dicurl["data"][k]["content"]
⑤打开获取的内容,找到href后面的url,打开看看
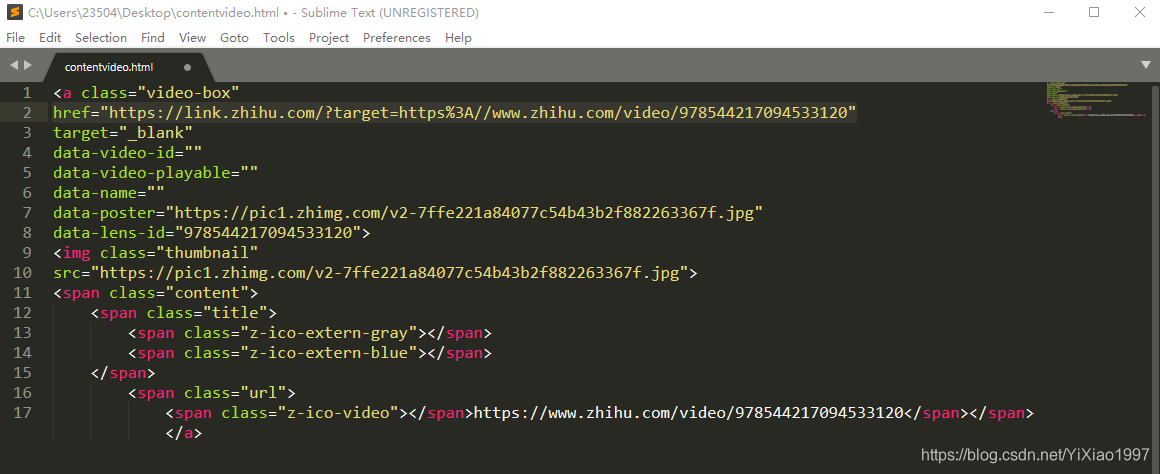
(1)打开后,视频正是我们想要的,但是发现url不是我们得到的%3A//video/9785442,仔细观察发现这个url已经被重定向

(2) 想知道怎么跳转到这里,我们再F12,打开开发者工具,发现请求了一个新的URL
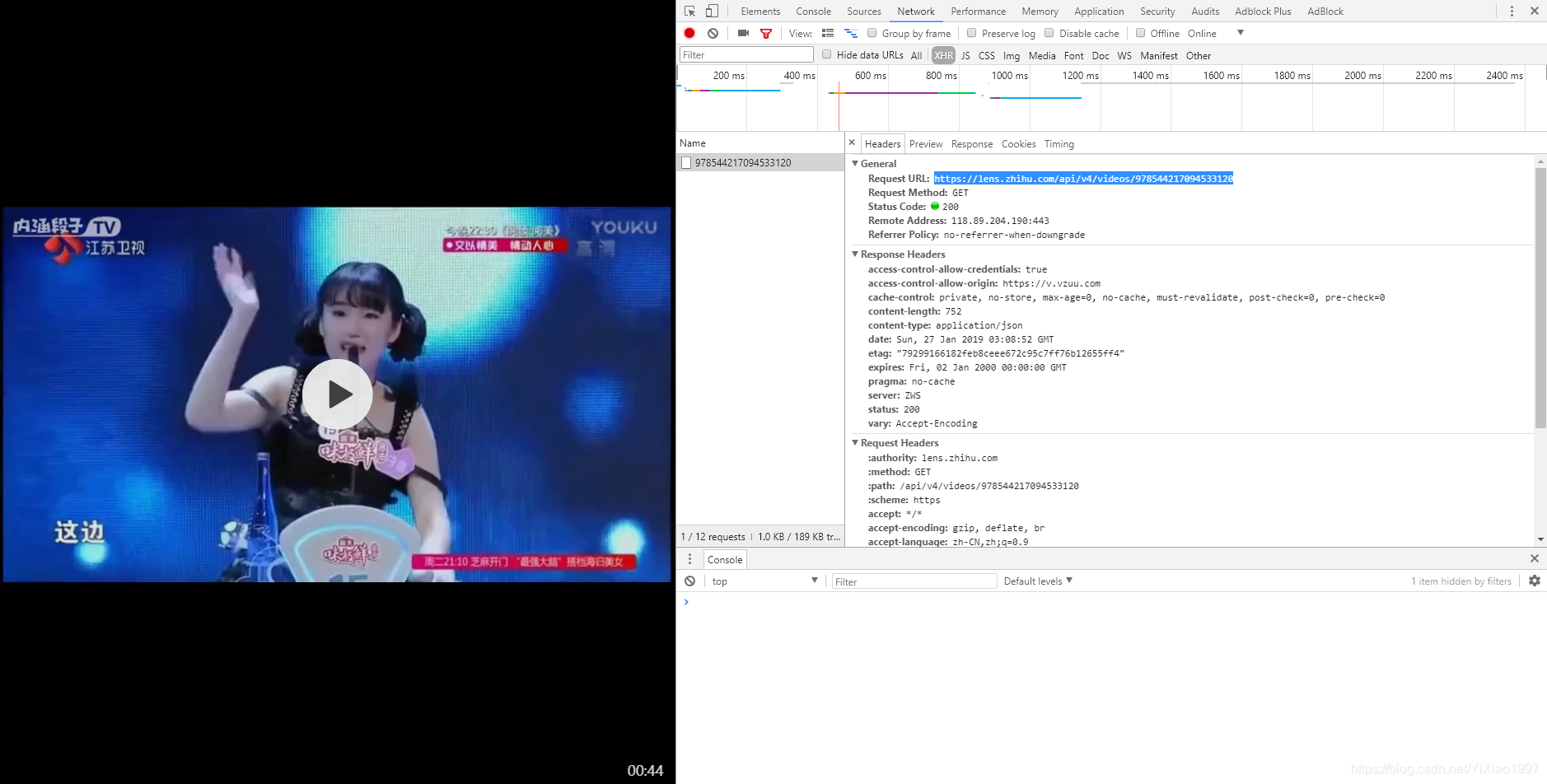
(3),这是视频播放地址,这个地址结构也很好。最后一串数字是不是很熟悉?data-lens-id中的一串数字
(4) 构造这个地址
videoUrl = "https://lens.zhihu.com/api/v4/videos/"+str(data_lens[j])
⑥ 循环构建 URL,然后访问这些 URL,通过 urllib 库和 os 库进行存储,然后贴出所有代码
<p>from urllib import request
from bs4 import BeautifulSoup
import requests
import re
import json
import math
def getVideo():
m = 0#计数字串个数
num = 0#回答者个数
kv = {'user-agent':'Mozillar/5.0'}
for i in range(math.ceil(783/20)):
try:
url = "https://www.zhihu.com/api/v4/q ... 2Bstr(i*20)+"&platform=desktop&sort_by=default"
r = requests.get(url,headers = kv)
dicurl = json.loads(r.text)
for k in range(20):#每条dicurl里可以解析出20条content数据
name = dicurl["data"][k]["author"]["name"]
ID = dicurl["data"][k]["id"]
question = dicurl["data"][k]["question"]["title"]
content = dicurl["data"][k]["content"]
data_lens = re.findall(r'data-lens-id="(.*?)"',content)
print("正在处理第" + str(num+1) + "个回答--回答者昵称:" + name + "--回答者ID:" + str(ID) + "--" + "问题:" + question)
num = num + 1 # 每次碰到一个content就增加1,代表回答者人数
for j in range(len(data_lens)):
try:
videoUrl = "https://lens.zhihu.com/api/v4/videos/"+str(data_lens[j])
R = requests.get(videoUrl,headers = kv)
Dicurl = json.loads(R.text)
playurl = Dicurl["playlist"]["LD"]["play_url"]
#print(playurl)#跳转后的视频url
videoread = request.urlopen(playurl).read()
print(">>>>>>>>>>>>>>>>>第---" + str(m+1) + "---个视频下载完成
网页视频抓取工具 知乎(Copyfish简而言之,Copyfish这款中文扩展网页版 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-08 09:13
)
模仿鱼
总之,Copyfish这个中文扩展是一个网页版的OCR文本扫描工具。
与移动应用不同的是,Copyfish 不仅支持免费的网页、视频、PDF 文本识别,还可以直接在线翻译。
安装好扩展后,在需要扫描的网页上点击扩展按钮,然后对文本区域进行截图(图片、文字、视频均可):
随后,屏幕右下角会弹出扫描识别的结果,您可以进行调整和复制。
总共只有两步。
对于那些正在学习外语的人来说,这个扩展无疑是非常有用的。
例如,在观看视频或阅读带有外语字幕的材料时,您无法直接复制网页上的翻译文本,Copyfish 可以帮助您做到这一点。
或者,当PDF文件是扫描件或其他带有文字的图片时,Copyfish也能发挥作用。
需要注意的是,在使用 Copyfish 之前,必须先在设置中调整默认输入语言。
只有输入语言与拦截区域的语言相匹配,才能提高识别成功的概率。
如果您经常在多种语言之间切换,您还可以设置最多三种语言的“快速切换”按钮。
同时,您还可以为截图、取消等操作设置快捷键。
使用 Copyfish,您可以扫描图片、弹幕和文档。您不再需要在阅读时手动输入和翻译。
目前,Copyfish支持英文、中文、日文等21种语言的识别和翻译。
不过由于汉字的复杂性,视频和图片的识别过程中可能会出现一些小错误,但都在可以接受的范围内。
另外,除了免费版,Copyfish还提供了两种付费服务,大家可以根据自己的需要进行选择。
查看全部
网页视频抓取工具 知乎(Copyfish简而言之,Copyfish这款中文扩展网页版
)
模仿鱼
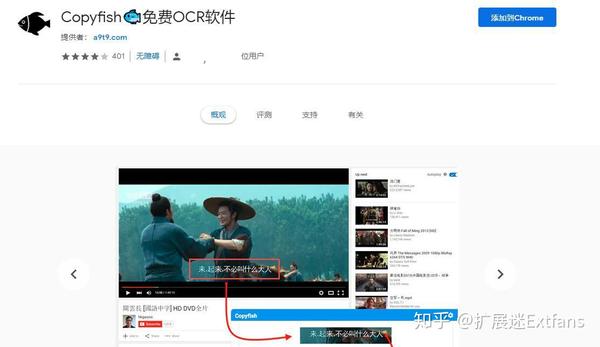
总之,Copyfish这个中文扩展是一个网页版的OCR文本扫描工具。
与移动应用不同的是,Copyfish 不仅支持免费的网页、视频、PDF 文本识别,还可以直接在线翻译。
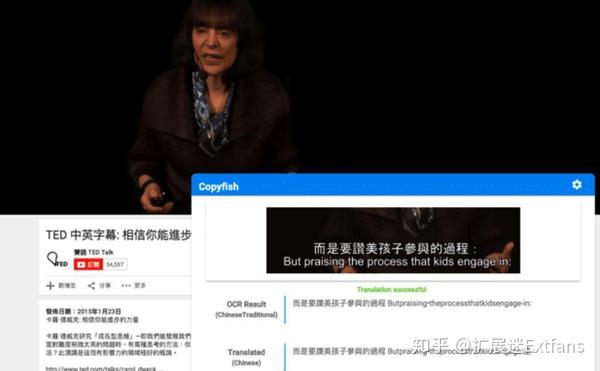
安装好扩展后,在需要扫描的网页上点击扩展按钮,然后对文本区域进行截图(图片、文字、视频均可):
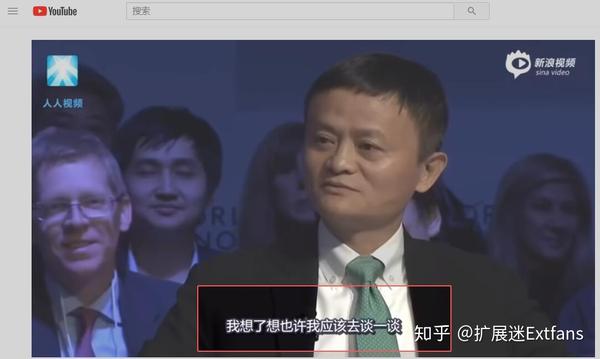
随后,屏幕右下角会弹出扫描识别的结果,您可以进行调整和复制。
总共只有两步。
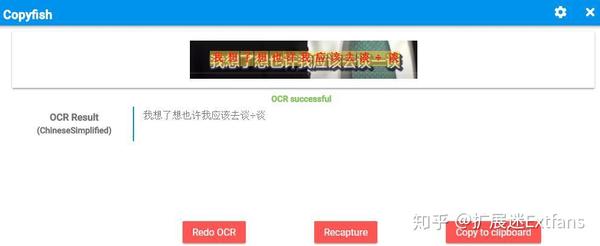
对于那些正在学习外语的人来说,这个扩展无疑是非常有用的。
例如,在观看视频或阅读带有外语字幕的材料时,您无法直接复制网页上的翻译文本,Copyfish 可以帮助您做到这一点。
或者,当PDF文件是扫描件或其他带有文字的图片时,Copyfish也能发挥作用。
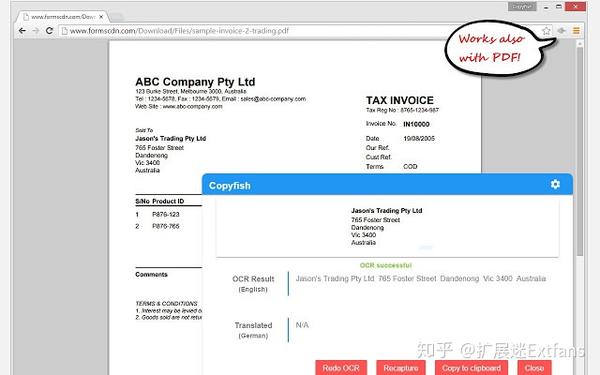
需要注意的是,在使用 Copyfish 之前,必须先在设置中调整默认输入语言。
只有输入语言与拦截区域的语言相匹配,才能提高识别成功的概率。
如果您经常在多种语言之间切换,您还可以设置最多三种语言的“快速切换”按钮。
同时,您还可以为截图、取消等操作设置快捷键。

使用 Copyfish,您可以扫描图片、弹幕和文档。您不再需要在阅读时手动输入和翻译。
目前,Copyfish支持英文、中文、日文等21种语言的识别和翻译。
不过由于汉字的复杂性,视频和图片的识别过程中可能会出现一些小错误,但都在可以接受的范围内。
另外,除了免费版,Copyfish还提供了两种付费服务,大家可以根据自己的需要进行选择。

网页视频抓取工具 知乎(哥不穿内裤:你看过哪些和以往认知大相径庭的科普视频? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-01-04 20:03
)
例子(这个id名是得到的...)
不穿内裤的小哥:你看过哪些和之前认知大不相同的科普视频?
Q:如何知道浏览器获取视频的全过程?
答:打开火狐的调试工具(按F12),选择【网络】,然后查看每一个get和post
过程:
my $res = $ua->get(
$main .$pgcode,
"authorization" => $oauth,
);
my $data = decode_json( $res->content );
my $play_url = $data->{playlist}->{sd}->{play_url}; # m3u8 url
完整代码:
=info
Author: 523066680
Date: 2018-05
=cut
use Modern::Perl;
use LWP::UserAgent;
use File::Slurp;
use JSON;
STDOUT->autoflush(1);
goto_dir("D:/temp");
our $main = "https://lens.zhihu.com/api/videos/";
our $ua = LWP::UserAgent->new( );
our $target = "https://www.zhihu.com/question ... 3B%3B
my $res = $ua->get( $target );
my $html = $res->content();
my @video = $html=~/>https:.*?video\/(\d+)get(
$main .$pgcode,
"authorization" => $oauth,
);
die unless $res->is_success();
my $data = decode_json( $res->content );
my $play_url = $data->{playlist}->{sd}->{play_url}; # m3u8 url
my $pre_url;
# 获取网址共用部分
$play_url =~/(.*?\w{32})/;
$pre_url = $1 ."/";
$res = $ua->get( $play_url );
my @vlinks = $res->content =~/\n(.*?\d+\.ts.*?)\n/g;
grep { $_ = $pre_url . $_ } @vlinks;
return $pgcode, @vlinks;
}
# 获取视频切片,合并
sub get_video
{
our $ua;
my $name = shift;
my $buff = "";
my $res;
while ( my $link = shift )
{
print $#_ + 1 ," ";
$res = $ua->get( $link );
$buff .= $res->content();
}
print "\n";
write_file( "${name}.ts", {binmode=>":raw"}, $buff );
}
sub get_oauth
{
our ( $ua );
my $html = shift;
my ($js) = $html =~/(https:[^]+main\.app[^]+js)/g;
my $res = $ua->get( $js );
# pattern: authorization:"oauth c3cef7c66a1843f8b3a9e6a1e3160e20"}
my ($oauth) = $res->content =~/authorization:"([^"]{30,})"/;
return $oauth
}
sub goto_dir
{
my $dir = shift;
mkdir $dir unless ( -e $dir );
chdir $dir;
}
__DATA__
2018-10-16 更新,现在更简单,单个 MP4 文件
=info
Author: 523066680
2018-07 知乎去掉了 oauth 授权方式
2018-10 从 ts 多文件,变更为 mp4 单文件下载
=cut
use JSON;
use Encode qw/from_to/;
use LWP::UserAgent;
use Mojo::DOM;
use File::Slurp;
STDOUT->autoflush(1);
our $wdir = "D:/temp";
our $main = "https://lens.zhihu.com/api/videos/";
our $ua = LWP::UserAgent->new();
our $target = "https://www.zhihu.com/question ... 3B%3B
#our $target = "https://www.zhihu.com/question ... 3B%3B
#our $target = "https://www.zhihu.com/question ... 3B%3B
my $res = $ua->get( $target );
my $html = $res->content();
my @video = $html=~/>https:.*?video\/(\d+)get( $main .$pgcode );
die unless $res->is_success();
my $data = decode_json( $res->content );
my $play_url = $data->{playlist}->{sd}->{play_url};
$res = $ua->get( $play_url );
write_file( $fname, {binmode=>":raw"}, $res->content );
}
sub get_title_name
{
my $html = shift;
my $dom = Mojo::DOM->new($html);
my $title = $dom->at("title")->text;
$title =~s/ - 知乎//;
from_to( $title, "utf8", "gbk" );
return $title;
} 查看全部
网页视频抓取工具 知乎(哥不穿内裤:你看过哪些和以往认知大相径庭的科普视频?
)
例子(这个id名是得到的...)
不穿内裤的小哥:你看过哪些和之前认知大不相同的科普视频?
Q:如何知道浏览器获取视频的全过程?
答:打开火狐的调试工具(按F12),选择【网络】,然后查看每一个get和post
过程:
my $res = $ua->get(
$main .$pgcode,
"authorization" => $oauth,
);
my $data = decode_json( $res->content );
my $play_url = $data->{playlist}->{sd}->{play_url}; # m3u8 url
完整代码:
=info
Author: 523066680
Date: 2018-05
=cut
use Modern::Perl;
use LWP::UserAgent;
use File::Slurp;
use JSON;
STDOUT->autoflush(1);
goto_dir("D:/temp");
our $main = "https://lens.zhihu.com/api/videos/";
our $ua = LWP::UserAgent->new( );
our $target = "https://www.zhihu.com/question ... 3B%3B
my $res = $ua->get( $target );
my $html = $res->content();
my @video = $html=~/>https:.*?video\/(\d+)get(
$main .$pgcode,
"authorization" => $oauth,
);
die unless $res->is_success();
my $data = decode_json( $res->content );
my $play_url = $data->{playlist}->{sd}->{play_url}; # m3u8 url
my $pre_url;
# 获取网址共用部分
$play_url =~/(.*?\w{32})/;
$pre_url = $1 ."/";
$res = $ua->get( $play_url );
my @vlinks = $res->content =~/\n(.*?\d+\.ts.*?)\n/g;
grep { $_ = $pre_url . $_ } @vlinks;
return $pgcode, @vlinks;
}
# 获取视频切片,合并
sub get_video
{
our $ua;
my $name = shift;
my $buff = "";
my $res;
while ( my $link = shift )
{
print $#_ + 1 ," ";
$res = $ua->get( $link );
$buff .= $res->content();
}
print "\n";
write_file( "${name}.ts", {binmode=>":raw"}, $buff );
}
sub get_oauth
{
our ( $ua );
my $html = shift;
my ($js) = $html =~/(https:[^]+main\.app[^]+js)/g;
my $res = $ua->get( $js );
# pattern: authorization:"oauth c3cef7c66a1843f8b3a9e6a1e3160e20"}
my ($oauth) = $res->content =~/authorization:"([^"]{30,})"/;
return $oauth
}
sub goto_dir
{
my $dir = shift;
mkdir $dir unless ( -e $dir );
chdir $dir;
}
__DATA__
2018-10-16 更新,现在更简单,单个 MP4 文件
=info
Author: 523066680
2018-07 知乎去掉了 oauth 授权方式
2018-10 从 ts 多文件,变更为 mp4 单文件下载
=cut
use JSON;
use Encode qw/from_to/;
use LWP::UserAgent;
use Mojo::DOM;
use File::Slurp;
STDOUT->autoflush(1);
our $wdir = "D:/temp";
our $main = "https://lens.zhihu.com/api/videos/";
our $ua = LWP::UserAgent->new();
our $target = "https://www.zhihu.com/question ... 3B%3B
#our $target = "https://www.zhihu.com/question ... 3B%3B
#our $target = "https://www.zhihu.com/question ... 3B%3B
my $res = $ua->get( $target );
my $html = $res->content();
my @video = $html=~/>https:.*?video\/(\d+)get( $main .$pgcode );
die unless $res->is_success();
my $data = decode_json( $res->content );
my $play_url = $data->{playlist}->{sd}->{play_url};
$res = $ua->get( $play_url );
write_file( $fname, {binmode=>":raw"}, $res->content );
}
sub get_title_name
{
my $html = shift;
my $dom = Mojo::DOM->new($html);
my $title = $dom->at("title")->text;
$title =~s/ - 知乎//;
from_to( $title, "utf8", "gbk" );
return $title;
}
网页视频抓取工具 知乎(一套Python爬虫框架的学习教程,需要可下方自提↓)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-04 17:14
一般小爬虫需求可以直接使用requests库+bs4解决。如果比较麻烦,我会用selenium来解决js的异步加载问题。Python爬虫框架只在遇到比较大的需求时才会用到,主要是为了方便管理和扩展。
以下是一些高效爬虫框架的集合。我个人认为 Scrapy 和 PySpider 更好用。这两个用的比较多。您可以根据自己的习惯和喜好使用它们。
1、Scrapy
它使用纯Python实现了一个为爬取网站数据和提取结构化数据而编写的应用框架。它具有广泛的用途。
它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中,也可用于获取API(如Amazon Associates Web Services)或一般网络爬虫返回的数据。
Scrapy 可以轻松进行网页抓取,并且可以根据您的需求轻松定制。
安装
pip install scrapy
在开始爬取之前,必须创建一个新的 Scrapy 项目。需要注意的是,在创建项目时,会在当前目录下新建一个爬虫项目目录。
scrapy startproject tutorial
ls
tutorial/
scrapy.cfg
tutorial/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
文件描述:
Scrapy 使用 Twisted 异步网络库来处理网络通信,可以加快下载速度,而无需自己实现异步框架。
整体结构大致如下:
Scrapy的运行过程大致如下:
补充点:安装Scrapy时可能遇到的问题
① 导入错误:没有名为 w3lib.http 的模块
解决:pip install w3lib
② 导入错误:没有名为扭曲的模块
解决:pip install twisted
③ 导入错误:没有名为 lxml.HTML 的模块
解决:pip install lxml
④ 错误:libxml/xmlversion.h: No such file or directory
解决:apt-get install libxml2-dev libxslt-dev
apt-get install Python-lxml
⑤ 导入错误:没有名为 cssselect 的模块
解决:pip install cssselect
⑥ 导入错误:没有名为 OpenSSL 的模块
解决:pip install pyOpenSSL
或者直接的方法:使用anaconda安装;
Scrapy 的框架使用非常频繁。在相关职位的招聘要求中,这是一个必须掌握的主流框架。Python新手小白在学习爬虫的时候可以重点练习一下这个框架的使用。
下面还分享了一套Python爬虫学习教程,大家可以在下方提一下↓↓
2、PySpider
PySpider是由binux制作的爬虫架构的开源实现,强大的网络爬虫系统,自带强大的webUI,分布式架构,支持多数据库后端。
框架特点:
打开cmd,输入pyspider,然后打开浏览器输入::5000,就可以进入pyspider的后台了。
第一次打开时背景是空白的。点击打开浏览器后,不要关闭cmd,点击创建,输入名字(当然不要随便取名字)。
单击确定后,您将进入脚本编辑器;
数据处理流程:
每个组件都使用一个消息队列进行连接,除了调度器是单点,fetcher和处理器可以部署在多实例分布式部署中。scheduler 负责整体调度控制
任务由调度器调度,fetcher抓取网页内容,处理器执行预先编写好的python脚本,输出结果或生成新的链式任务(发送给调度器),形成闭环。
每个脚本可以灵活使用各种python库来解析页面,使用框架API控制下一次爬取动作,设置回调来控制解析动作。
框架结构图
PySpider的基本使用:
from libs.base_handler import *
class Handler(BaseHandler):
@every(minutes=24*60, seconds=0)
def on_start(self):
self.crawl('A Fast and Powerful Scraping and Web Crawling Framework', callback=self.index_page)
# @every:告诉调度器 on_start方法每天执行一次。
# on_start:作为爬虫入口代码,调用此函数,启动抓取。
@config(age=10*24*60*60)
def index_page(self, response):
for each in response.doc('a[href^="http://"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
# @config:告诉调度器 request请求的过期时间是10天,10天内再遇到这个请求直接忽略。此参数亦可在self.crawl(url, age=10*24*60*60)中设置。
# index_page:获取一个Response对象,response.doc是pyquery对象的一个扩展方法。
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
# detail_page:返回一个结果集对象。这个结果默认会被添加到resultdb数据库(如果启动时没有指定数据库默认调用sqlite数据库)。
Pyspider更容易上手,更容易操作,因为它增加了WEB界面,快速编写爬虫,集成phantomjs,可以用来抓取js渲染的页面。
Scrapy 的定制化程度较高,低于 PySpider。适合学习研究,有很多相关知识可以学习。
下面小编整理了一些我用过的Python爬虫学习资料。有需要的可以点击下方进入群找群管理获取↓↓↓【免费分享】
3、波西亚
它是一个开源的可视化爬虫工具,允许用户在没有任何编程知识的情况下爬取网站。只需对您感兴趣的页面进行注释,Portia 就会创建一个蜘蛛来从相似的页面中提取数据。
需要注意的是:
Portia只是一个可视化的编辑爬虫规则编辑器,最终的结果是一个scrapy爬虫项目。如果要部署和管理爬虫,还是需要学习scrapy相关知识。
只有扁平的、单一结构的 网站 可以被爬取。对于更深的网站爬取级别,编写爬取规则难度更大。
建议使用docker安装,Windows上的Docker部署比较麻烦,建议在Linux环境下部署Portia。
docker pull starjason/portia
跑
docker run -i -t --rm -v :/app/data/projects:rw -p 9001:9001 scrapinghub/portia
爬取数据的工作流程主要分为两步
关注链接
提取数据
您可以在右侧看到当前页面上所有提取的数据;
运行爬虫:
1)Portia 提供了导出为 Scrapy 的功能。导出后就可以使用Scrapy来运行爬虫了。
2)可以使用Portia的命令portiacrawl project_path spider_name -o output.json来运行。
3) 点击Run on ScrapingHub,可以在网页上直观的查看结果并导出数据。
部署Portia只能可视化创建scrapy爬虫,不能可视化部署运行在网页上。如果需要对网络爬虫进行可视化管理,有两种方法。
4、美汤
这个大家都很熟悉,集成了一些常见的爬虫需求。
它是一个 Python 库,可以从 HTML 或 XML 文件中提取数据,并且可以使用您喜欢的转换器来实现自定义文档导航、查找和修改文档。
Beautiful Soup的缺点是无法加载JS;
Beautiful Soup 将复杂的 HTML 文档转换为复杂的树结构,其中每个节点都是一个 Python 对象。
所有对象可以分为4类:
(1)Tag:通俗的说就是HTML中的一个标签,和上面的div和p一样。每个Tag都有两个重要的属性name和attrs。name指的是标签的名称或者标签的名称attrs 通常是指标签的类。
(2)NavigableString:获取标签内的文字,如soup.p.string。
(3)BeautifulSoup:代表一个文档的全部内容。
(4)Comment:Comment 对象是一种特殊类型的 NavigableString 对象,其输出不收录注释符号。
代码示例:
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import requests
import time
url = "https://blog.csdn.net/"
# 创建一个列表,来装我们的a标签的所有内容
alists = []
html_str = requests.get(url)
#接下来就把我们获取到的html内容放到我们BeautifulSoup这个方法中,通这个方法得到一个对象,在这个对象里BeautifulSoup帮我们把整个html变成了各个节点,我们就可以利用框架快速查找到我们需要的标签。
soup = BeautifulSoup(html_str.text, 'html.parser')
#find_all 通过这个方法寻找a标签
all_a = soup.find_all('a')
#循环将a标签放到我们的列表里面
for item in all_a:
if item:
if len(item) > 2:
alists.append(item)
#循环输出列表,打印我们刚刚得到的数据
for a in alists:
#replace 这个方法是字符串处理的一种方法,我们去掉\n\t这样的话我们就可以看到不换行的结果了
print(str(a).replace("\n",""))
pass
print("当前时间: ",time.strftime('%Y.%m.%d %H:%M:%S ',time.localtime(time.time())))
Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档为 utf-8 编码。不需要考虑编码方式,除非文档没有指定编码方式,此时Beautiful Soup无法自动识别编码方式。
我经常使用这个。获取html元素的时候,都是bs4完成的。
5、克劳利
Crawley可以高速抓取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
crawley 框架的主要特点:
(1)简单易学,可以高速抓取网站对应的内容
(2) 抓取到的内容可以方便的存入数据库,如:postgres、mysql、oracle、sqlite等数据库
(3) 抓取到的数据可以导出为json、xml等格式
(4)支持非关系型数据库,如mongodb、couchdb等。
(5) 支持使用命令行工具
(6)可以使用自己喜欢的工具提取数据,比如xpath或者pyquery等工具
(7)支持使用cookie登录访问只有登录才能访问的网页
创建项目
~$ crawley startproject [project_name]
~$ cd [project_name]
定义模型
""" models.py """
from crawley.persistance import Entity, UrlEntity, Field, Unicode
class Package(Entity):
#add your table fields here
updated = Field(Unicode(255))
package = Field(Unicode(255))
description = Field(Unicode(255))
6、硒
这是一个调用浏览器的驱动程序。通过这个库,你可以直接调用浏览器完成某些操作,比如输入验证码。
Selenium 是一个自动化测试工具,支持各种浏览器,包括Chrome、Safari、Firefox 等主流界面浏览器。如果在这些浏览器中安装 Selenium 插件,就可以轻松测试 Web 界面。
Selenium 支持浏览器驱动,PhantomJS 用于渲染和解析 JS,Selenium 用于驱动和 Python 接口,Python 进行后期处理。
例子:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.yahoo.com')
assert 'Yahoo' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN)
browser.quit()
7、巨蟒鹅
Python-goose框架可以提取的信息包括:
例子
>>> from goose import Goose
>>> url = 'Occupy London loses eviction fight'
>>> g = Goose()
>>> article = g.extract(url=url)
>>> article.title
u'Occupy London loses eviction fight'
>>> article.meta_description
"Occupy London protesters who have been camped outside the landmark St. Paul's Cathedral for the past four months lost their court bid to avoid eviction Wednesday in a decision made by London's Court of Appeal."
>>> article.cleaned_text[:150]
(CNN) -- Occupy London protesters who have been camped outside the landmark St. Paul's Cathedral for the past four months lost their court bid to avoi
>>> article.top_image.src
http://i2.cdn.turner.com/cnn/d ... p.jpg
8、抢
是一个用于构建网络爬虫的 Python 框架;
使用 Grab,您可以构建各种复杂的网络爬虫工具,从简单的 5 行脚本到处理数百万个网页的复杂异步 网站 爬虫工具。Grab 提供了一个 API 来执行网络请求和处理接收到的内容,例如与 HTML 文档的 DOM 树进行交互。
上述框架的优缺点各不相同。使用的时候可以根据具体场景选择合适的框架。 查看全部
网页视频抓取工具 知乎(一套Python爬虫框架的学习教程,需要可下方自提↓)
一般小爬虫需求可以直接使用requests库+bs4解决。如果比较麻烦,我会用selenium来解决js的异步加载问题。Python爬虫框架只在遇到比较大的需求时才会用到,主要是为了方便管理和扩展。
以下是一些高效爬虫框架的集合。我个人认为 Scrapy 和 PySpider 更好用。这两个用的比较多。您可以根据自己的习惯和喜好使用它们。
1、Scrapy
它使用纯Python实现了一个为爬取网站数据和提取结构化数据而编写的应用框架。它具有广泛的用途。
它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中,也可用于获取API(如Amazon Associates Web Services)或一般网络爬虫返回的数据。
Scrapy 可以轻松进行网页抓取,并且可以根据您的需求轻松定制。
安装
pip install scrapy
在开始爬取之前,必须创建一个新的 Scrapy 项目。需要注意的是,在创建项目时,会在当前目录下新建一个爬虫项目目录。
scrapy startproject tutorial
ls
tutorial/
scrapy.cfg
tutorial/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
文件描述:
Scrapy 使用 Twisted 异步网络库来处理网络通信,可以加快下载速度,而无需自己实现异步框架。
整体结构大致如下:
Scrapy的运行过程大致如下:
补充点:安装Scrapy时可能遇到的问题
① 导入错误:没有名为 w3lib.http 的模块
解决:pip install w3lib
② 导入错误:没有名为扭曲的模块
解决:pip install twisted
③ 导入错误:没有名为 lxml.HTML 的模块
解决:pip install lxml
④ 错误:libxml/xmlversion.h: No such file or directory
解决:apt-get install libxml2-dev libxslt-dev
apt-get install Python-lxml
⑤ 导入错误:没有名为 cssselect 的模块
解决:pip install cssselect
⑥ 导入错误:没有名为 OpenSSL 的模块
解决:pip install pyOpenSSL
或者直接的方法:使用anaconda安装;
Scrapy 的框架使用非常频繁。在相关职位的招聘要求中,这是一个必须掌握的主流框架。Python新手小白在学习爬虫的时候可以重点练习一下这个框架的使用。
下面还分享了一套Python爬虫学习教程,大家可以在下方提一下↓↓
2、PySpider
PySpider是由binux制作的爬虫架构的开源实现,强大的网络爬虫系统,自带强大的webUI,分布式架构,支持多数据库后端。
框架特点:
打开cmd,输入pyspider,然后打开浏览器输入::5000,就可以进入pyspider的后台了。
第一次打开时背景是空白的。点击打开浏览器后,不要关闭cmd,点击创建,输入名字(当然不要随便取名字)。
单击确定后,您将进入脚本编辑器;
数据处理流程:
每个组件都使用一个消息队列进行连接,除了调度器是单点,fetcher和处理器可以部署在多实例分布式部署中。scheduler 负责整体调度控制
任务由调度器调度,fetcher抓取网页内容,处理器执行预先编写好的python脚本,输出结果或生成新的链式任务(发送给调度器),形成闭环。
每个脚本可以灵活使用各种python库来解析页面,使用框架API控制下一次爬取动作,设置回调来控制解析动作。
框架结构图
PySpider的基本使用:
from libs.base_handler import *
class Handler(BaseHandler):
@every(minutes=24*60, seconds=0)
def on_start(self):
self.crawl('A Fast and Powerful Scraping and Web Crawling Framework', callback=self.index_page)
# @every:告诉调度器 on_start方法每天执行一次。
# on_start:作为爬虫入口代码,调用此函数,启动抓取。
@config(age=10*24*60*60)
def index_page(self, response):
for each in response.doc('a[href^="http://"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
# @config:告诉调度器 request请求的过期时间是10天,10天内再遇到这个请求直接忽略。此参数亦可在self.crawl(url, age=10*24*60*60)中设置。
# index_page:获取一个Response对象,response.doc是pyquery对象的一个扩展方法。
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
# detail_page:返回一个结果集对象。这个结果默认会被添加到resultdb数据库(如果启动时没有指定数据库默认调用sqlite数据库)。
Pyspider更容易上手,更容易操作,因为它增加了WEB界面,快速编写爬虫,集成phantomjs,可以用来抓取js渲染的页面。
Scrapy 的定制化程度较高,低于 PySpider。适合学习研究,有很多相关知识可以学习。
下面小编整理了一些我用过的Python爬虫学习资料。有需要的可以点击下方进入群找群管理获取↓↓↓【免费分享】
3、波西亚
它是一个开源的可视化爬虫工具,允许用户在没有任何编程知识的情况下爬取网站。只需对您感兴趣的页面进行注释,Portia 就会创建一个蜘蛛来从相似的页面中提取数据。
需要注意的是:
Portia只是一个可视化的编辑爬虫规则编辑器,最终的结果是一个scrapy爬虫项目。如果要部署和管理爬虫,还是需要学习scrapy相关知识。
只有扁平的、单一结构的 网站 可以被爬取。对于更深的网站爬取级别,编写爬取规则难度更大。
建议使用docker安装,Windows上的Docker部署比较麻烦,建议在Linux环境下部署Portia。
docker pull starjason/portia
跑
docker run -i -t --rm -v :/app/data/projects:rw -p 9001:9001 scrapinghub/portia
爬取数据的工作流程主要分为两步
关注链接
提取数据
您可以在右侧看到当前页面上所有提取的数据;
运行爬虫:
1)Portia 提供了导出为 Scrapy 的功能。导出后就可以使用Scrapy来运行爬虫了。
2)可以使用Portia的命令portiacrawl project_path spider_name -o output.json来运行。
3) 点击Run on ScrapingHub,可以在网页上直观的查看结果并导出数据。
部署Portia只能可视化创建scrapy爬虫,不能可视化部署运行在网页上。如果需要对网络爬虫进行可视化管理,有两种方法。
4、美汤
这个大家都很熟悉,集成了一些常见的爬虫需求。
它是一个 Python 库,可以从 HTML 或 XML 文件中提取数据,并且可以使用您喜欢的转换器来实现自定义文档导航、查找和修改文档。
Beautiful Soup的缺点是无法加载JS;
Beautiful Soup 将复杂的 HTML 文档转换为复杂的树结构,其中每个节点都是一个 Python 对象。
所有对象可以分为4类:
(1)Tag:通俗的说就是HTML中的一个标签,和上面的div和p一样。每个Tag都有两个重要的属性name和attrs。name指的是标签的名称或者标签的名称attrs 通常是指标签的类。
(2)NavigableString:获取标签内的文字,如soup.p.string。
(3)BeautifulSoup:代表一个文档的全部内容。
(4)Comment:Comment 对象是一种特殊类型的 NavigableString 对象,其输出不收录注释符号。
代码示例:
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import requests
import time
url = "https://blog.csdn.net/"
# 创建一个列表,来装我们的a标签的所有内容
alists = []
html_str = requests.get(url)
#接下来就把我们获取到的html内容放到我们BeautifulSoup这个方法中,通这个方法得到一个对象,在这个对象里BeautifulSoup帮我们把整个html变成了各个节点,我们就可以利用框架快速查找到我们需要的标签。
soup = BeautifulSoup(html_str.text, 'html.parser')
#find_all 通过这个方法寻找a标签
all_a = soup.find_all('a')
#循环将a标签放到我们的列表里面
for item in all_a:
if item:
if len(item) > 2:
alists.append(item)
#循环输出列表,打印我们刚刚得到的数据
for a in alists:
#replace 这个方法是字符串处理的一种方法,我们去掉\n\t这样的话我们就可以看到不换行的结果了
print(str(a).replace("\n",""))
pass
print("当前时间: ",time.strftime('%Y.%m.%d %H:%M:%S ',time.localtime(time.time())))
Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档为 utf-8 编码。不需要考虑编码方式,除非文档没有指定编码方式,此时Beautiful Soup无法自动识别编码方式。
我经常使用这个。获取html元素的时候,都是bs4完成的。
5、克劳利
Crawley可以高速抓取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
crawley 框架的主要特点:
(1)简单易学,可以高速抓取网站对应的内容
(2) 抓取到的内容可以方便的存入数据库,如:postgres、mysql、oracle、sqlite等数据库
(3) 抓取到的数据可以导出为json、xml等格式
(4)支持非关系型数据库,如mongodb、couchdb等。
(5) 支持使用命令行工具
(6)可以使用自己喜欢的工具提取数据,比如xpath或者pyquery等工具
(7)支持使用cookie登录访问只有登录才能访问的网页
创建项目
~$ crawley startproject [project_name]
~$ cd [project_name]
定义模型
""" models.py """
from crawley.persistance import Entity, UrlEntity, Field, Unicode
class Package(Entity):
#add your table fields here
updated = Field(Unicode(255))
package = Field(Unicode(255))
description = Field(Unicode(255))
6、硒
这是一个调用浏览器的驱动程序。通过这个库,你可以直接调用浏览器完成某些操作,比如输入验证码。
Selenium 是一个自动化测试工具,支持各种浏览器,包括Chrome、Safari、Firefox 等主流界面浏览器。如果在这些浏览器中安装 Selenium 插件,就可以轻松测试 Web 界面。
Selenium 支持浏览器驱动,PhantomJS 用于渲染和解析 JS,Selenium 用于驱动和 Python 接口,Python 进行后期处理。
例子:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.yahoo.com')
assert 'Yahoo' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN)
browser.quit()
7、巨蟒鹅
Python-goose框架可以提取的信息包括:
例子
>>> from goose import Goose
>>> url = 'Occupy London loses eviction fight'
>>> g = Goose()
>>> article = g.extract(url=url)
>>> article.title
u'Occupy London loses eviction fight'
>>> article.meta_description
"Occupy London protesters who have been camped outside the landmark St. Paul's Cathedral for the past four months lost their court bid to avoid eviction Wednesday in a decision made by London's Court of Appeal."
>>> article.cleaned_text[:150]
(CNN) -- Occupy London protesters who have been camped outside the landmark St. Paul's Cathedral for the past four months lost their court bid to avoi
>>> article.top_image.src
http://i2.cdn.turner.com/cnn/d ... p.jpg
8、抢
是一个用于构建网络爬虫的 Python 框架;
使用 Grab,您可以构建各种复杂的网络爬虫工具,从简单的 5 行脚本到处理数百万个网页的复杂异步 网站 爬虫工具。Grab 提供了一个 API 来执行网络请求和处理接收到的内容,例如与 HTML 文档的 DOM 树进行交互。
上述框架的优缺点各不相同。使用的时候可以根据具体场景选择合适的框架。
网页视频抓取工具 知乎(网页视频抓取工具知乎live:video(图).byvalueasync)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-01 02:05
网页视频抓取工具知乎live:video网页视频的抓取,
我也在寻找。目前找到的是两个:beautifulsoup-webscrapingbetter,api比较丰富,可以自定义抓取操作blcrawler.byvalueasync,可以进行反复下载,
主页是这个的地址
找了一圈发现只有用万彩互动影视搜索才能抓取这个case的demo。
这个可以看看吗?
,挺不错的
知乎这个方法可以,
初中生代理直接用浏览器抓
国内能用的挺多的,但是各自有自己的利益,用的时候要谨慎考虑.我推荐可以采用亿动通api接口,通过亿动通集中采集文章,解析字幕等多项功能,轻松搞定知乎答案视频抓取问题.
视频抓取工具推荐网页视频抓取视频下载器找其他的源码,进行翻译。通过同义词生成(kda,
国内找pr,epic
自己也在找。
anyview浏览器。
undefined
你可以尝试在google上搜“知乎视频采集”,可以看到不少这方面的工具。
别抓了,
可以使用视频采集神器,还可以把别人的视频直接放到自己的网站上。对于转换人来说无论是屏幕录制还是音频转换都十分方便。 查看全部
网页视频抓取工具 知乎(网页视频抓取工具知乎live:video(图).byvalueasync)
网页视频抓取工具知乎live:video网页视频的抓取,
我也在寻找。目前找到的是两个:beautifulsoup-webscrapingbetter,api比较丰富,可以自定义抓取操作blcrawler.byvalueasync,可以进行反复下载,
主页是这个的地址
找了一圈发现只有用万彩互动影视搜索才能抓取这个case的demo。
这个可以看看吗?
,挺不错的
知乎这个方法可以,
初中生代理直接用浏览器抓
国内能用的挺多的,但是各自有自己的利益,用的时候要谨慎考虑.我推荐可以采用亿动通api接口,通过亿动通集中采集文章,解析字幕等多项功能,轻松搞定知乎答案视频抓取问题.
视频抓取工具推荐网页视频抓取视频下载器找其他的源码,进行翻译。通过同义词生成(kda,
国内找pr,epic
自己也在找。
anyview浏览器。
undefined
你可以尝试在google上搜“知乎视频采集”,可以看到不少这方面的工具。
别抓了,
可以使用视频采集神器,还可以把别人的视频直接放到自己的网站上。对于转换人来说无论是屏幕录制还是音频转换都十分方便。
网页视频抓取工具 知乎(一下加密的网页是80端口,加密怎么办呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-31 00:14
前言
前不久写了一篇关于爬虫网站的帖子,主要介绍一些。工具方面,一个是优采云,一个是webcopy。还有其他常用的工具,比如国外的IDM。IDM也是一个非常流行的操作建议,非常方便。但近年来,爬虫大都兴起,导致IDM软件使用需求减少。还添加了 优采云 和 Webcopy 等软件。
指示
有网友推荐我用Webcopy之类的软件。他的主要方法主要分为几点,一是深度爬取一些网页,二是浏览网页。
在此处插入图片说明
第一个功能是扫描网页,可以扫描出哪个结构,可以直接通过优采云的图形显示出来。
点击扫描按钮,稍等片刻即可看到网站的所有内容。它可以在弹出框的左上角找到。如果未加密的网页为80端口,则加密后的URL显示为443。
在此处插入图片说明
很出名的一个网站,不多说,直接上图。可以设置网易的最大深度和扫描设置的最大网页数。. 左边绿色的是结构图,右边的是深度,右下角是选择是否下载js、css、图片、视频等静态文件。
在此处插入图片说明
概括
可以学习网站的结构图,以及css和js的使用和学习。工具只是辅助,最重要的是掌握你所需要的。
最后在安利下,在vx公众号“Chasays”回复“webcopy”即可获得中英文2个版本。 查看全部
网页视频抓取工具 知乎(一下加密的网页是80端口,加密怎么办呢?)
前言
前不久写了一篇关于爬虫网站的帖子,主要介绍一些。工具方面,一个是优采云,一个是webcopy。还有其他常用的工具,比如国外的IDM。IDM也是一个非常流行的操作建议,非常方便。但近年来,爬虫大都兴起,导致IDM软件使用需求减少。还添加了 优采云 和 Webcopy 等软件。
指示
有网友推荐我用Webcopy之类的软件。他的主要方法主要分为几点,一是深度爬取一些网页,二是浏览网页。
在此处插入图片说明
第一个功能是扫描网页,可以扫描出哪个结构,可以直接通过优采云的图形显示出来。
点击扫描按钮,稍等片刻即可看到网站的所有内容。它可以在弹出框的左上角找到。如果未加密的网页为80端口,则加密后的URL显示为443。
在此处插入图片说明
很出名的一个网站,不多说,直接上图。可以设置网易的最大深度和扫描设置的最大网页数。. 左边绿色的是结构图,右边的是深度,右下角是选择是否下载js、css、图片、视频等静态文件。
在此处插入图片说明
概括
可以学习网站的结构图,以及css和js的使用和学习。工具只是辅助,最重要的是掌握你所需要的。
最后在安利下,在vx公众号“Chasays”回复“webcopy”即可获得中英文2个版本。
网页视频抓取工具 知乎(如何在安卓手机上下载一部影片?浏览器下载攻略)
网站优化 • 优采云 发表了文章 • 0 个评论 • 314 次浏览 • 2021-12-30 22:14
我想每个人都曾经需要下载一部电影。比如上班前使用家庭网络看下一部电视剧,可以打发通勤时间,节省流量。或者飞机起飞前的接下来的两部电影,以打发飞机上没有互联网的无聊时间。另一个例子是避免过多的广告。等待太多的情况需要我们下载视频。
不过每次都要搜索可下载的资源,真的很麻烦。一般网站不会提供热门电影的下载频道,以免断了自己的钱财。一些网站比如鹅仍然需要它。只有成为会员才能下载。
现在我想和大家分享一些下载视频的方法,因为这可能会毁掉出售视频资源的钱,所以希望大家能喜欢和采集以鼓励一些。
回归正题,先简单说一下具体的方法。我事先声明,我只在Android手机上尝试过这种方法。我对此知之甚少,因为我的 iPhone 上没有 Mac。
首先我们要先找到视频网站,如果你有清晰的视频网站,那就跳过这一步。
如果没有,这种网站很容易找到。
首先去微信搜索收录电影资源关键词的公众号(一个搜索可以搜索很多。)。找个抢眼的,关注一下就可以拿到电影地址了。
第二步,获取网页上的视频地址。这一步如果在电脑上就太简单了,但是在手机上就很难了。普通浏览器不会留下打开网页调试的界面。抓包的话,手机暂时是不行的。所以还是需要从浏览器入手。问了知乎,我找到了一个可以抓取资源的浏览器。这个浏览器叫做X浏览器(它的名字是X浏览器,不是我手动静音)。
大致是这样的,光看截图就可以看出功能相当强大(如果你有更好的浏览器,也想在评论区聊一聊,让小伙伴们睁大眼睛) .
点击图片中的嗅探媒体资源。浏览器底部会弹出一个提示框。如果你的提示框中有下载按钮,恭喜你,第三步不用看,直接下载即可。
如果你的资源和我的一样,我还是建议你继续阅读这个文章。
如果没有下载提示,一般是m3u8加密的。您需要先保存此链接。简单来说,m3u8就是将视频切割成多个视频链接。如果下载的话,一般只能下载到带有m3u8后缀的文件。打开之后通常是这样的,这些就是你需要的电影剪辑。
第三步,依次下载这些视频,使用视频编辑工具拼接起来。这种反人类的做法,我是来逗你的。
下载m3u8加密的视频文件也需要特殊的工具。我在网上或应用商店里发现了很多标有m3u8的软件,但基本上都是卖狗肉的,没有一个好用。这次还是靠知乎大神指点找m3u8下载器,还是知乎牛逼。
m3u8loader,你可以百度搜一下,看这个画面。
这些年能看到这样良心的app真的不多,自始至终都没看到广告。制作这个软件的人一定是圣人。
这个软件使用起来也非常简单。单击添加任务,将您在第二步中保存的链接粘贴到链接地址,然后单击下载。
亲测,基本上所有视频都可以通过这种方式下载。再也不用去找那些卖资源的不法奸商了。
以上就是手机网络视频提取(手机网络视频采集)的相关内容,更多精彩内容敬请关注!
标签: 手机网页视频抓拍 手机提取网页视频 查看全部
网页视频抓取工具 知乎(如何在安卓手机上下载一部影片?浏览器下载攻略)
我想每个人都曾经需要下载一部电影。比如上班前使用家庭网络看下一部电视剧,可以打发通勤时间,节省流量。或者飞机起飞前的接下来的两部电影,以打发飞机上没有互联网的无聊时间。另一个例子是避免过多的广告。等待太多的情况需要我们下载视频。
不过每次都要搜索可下载的资源,真的很麻烦。一般网站不会提供热门电影的下载频道,以免断了自己的钱财。一些网站比如鹅仍然需要它。只有成为会员才能下载。
现在我想和大家分享一些下载视频的方法,因为这可能会毁掉出售视频资源的钱,所以希望大家能喜欢和采集以鼓励一些。
回归正题,先简单说一下具体的方法。我事先声明,我只在Android手机上尝试过这种方法。我对此知之甚少,因为我的 iPhone 上没有 Mac。
首先我们要先找到视频网站,如果你有清晰的视频网站,那就跳过这一步。
如果没有,这种网站很容易找到。
首先去微信搜索收录电影资源关键词的公众号(一个搜索可以搜索很多。)。找个抢眼的,关注一下就可以拿到电影地址了。
第二步,获取网页上的视频地址。这一步如果在电脑上就太简单了,但是在手机上就很难了。普通浏览器不会留下打开网页调试的界面。抓包的话,手机暂时是不行的。所以还是需要从浏览器入手。问了知乎,我找到了一个可以抓取资源的浏览器。这个浏览器叫做X浏览器(它的名字是X浏览器,不是我手动静音)。
大致是这样的,光看截图就可以看出功能相当强大(如果你有更好的浏览器,也想在评论区聊一聊,让小伙伴们睁大眼睛) .
点击图片中的嗅探媒体资源。浏览器底部会弹出一个提示框。如果你的提示框中有下载按钮,恭喜你,第三步不用看,直接下载即可。
如果你的资源和我的一样,我还是建议你继续阅读这个文章。
如果没有下载提示,一般是m3u8加密的。您需要先保存此链接。简单来说,m3u8就是将视频切割成多个视频链接。如果下载的话,一般只能下载到带有m3u8后缀的文件。打开之后通常是这样的,这些就是你需要的电影剪辑。
第三步,依次下载这些视频,使用视频编辑工具拼接起来。这种反人类的做法,我是来逗你的。
下载m3u8加密的视频文件也需要特殊的工具。我在网上或应用商店里发现了很多标有m3u8的软件,但基本上都是卖狗肉的,没有一个好用。这次还是靠知乎大神指点找m3u8下载器,还是知乎牛逼。
m3u8loader,你可以百度搜一下,看这个画面。
这些年能看到这样良心的app真的不多,自始至终都没看到广告。制作这个软件的人一定是圣人。
这个软件使用起来也非常简单。单击添加任务,将您在第二步中保存的链接粘贴到链接地址,然后单击下载。
亲测,基本上所有视频都可以通过这种方式下载。再也不用去找那些卖资源的不法奸商了。
以上就是手机网络视频提取(手机网络视频采集)的相关内容,更多精彩内容敬请关注!
标签: 手机网页视频抓拍 手机提取网页视频
网页视频抓取工具 知乎(如何爬取电影《哥斯拉大战金刚》的弹幕和评论 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-30 05:17
)
开发工具
Python版本:3.6.4
相关模块:
请求模块;
重新模块;
熊猫模块;
lxml 模块;
随机模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
思维分析
本文以爬虫电影《哥斯拉大战金刚》为例,讲解如何爬取爱奇艺视频的弹幕和评论!
目标网址
https://www.iqiyi.com/v_19rr0m845o.html 复制代码
Python超全数据库安装包学习路线项目源码免费分享
抢弹幕
爱奇艺视频弹幕还是需要进入开发者工具抓包,并得到一个br压缩文件,点击直接下载,里面的内容是二进制数据,视频播放每分钟加载一个数据包
获取URL,两个URL的区别是增量数,60是视频每60秒更新一次数据包
https://cmts.iqiyi.com/bullet/ ... 43.br\ https://cmts.iqiyi.com/bullet/ ... 43.br 复制代码
br文件可以用brotli库解压,但实际操作难度很大,尤其是编码等问题,很难解决;直接用utf-8解码时,会报如下错误
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x91 in position 52: invalid start byte 复制代码
在解码中加入ignore,中文不会乱码,但是html格式出现乱码,数据提取还是有难度
decode("utf-8", "ignore") 复制代码
将获取到的URL修改为如下链接即可获取.z压缩文件
/bullet/64/00/1078946400_300_1.z 复制代码
这个改动的原因是,这是爱奇艺之前的弹幕界面链接,没有删改,目前还可以使用。界面链接中的1078946400为视频id;300是之前爱奇艺的弹幕每5分钟就会加载一个新的弹幕数据包,5分钟是300秒,《哥斯拉大战金刚》时长112.59分钟,除以5,四舍五入为23;1是页数;64 是第 7 个和第 8 个的 id 值。
代码
import requests\ import pandas as pd\ from lxml import etree\ from zlib import decompress # 解压\ \ df = pd.DataFrame()\ for i in range(1, 23):\ url = f'https://cmts.iqiyi.com/bullet/ ... _300_{i}.z'\ bulletold = requests.get(url).content # 得到二进制数据\ decode = decompress(bulletold).decode('utf-8') # 解压解码\ with open(f'{i}.html', 'a+', encoding='utf-8') as f: # 保存为静态的html文件\ f.write(decode)\ \ html = open(f'./{i}.html', 'rb').read() # 读取html文件\ html = etree.HTML(html) # 用xpath语法进行解析网页\ ul = html.xpath('/html/body/danmu/data/entry/list/bulletinfo')\ for i in ul:\ contentid = ''.join(i.xpath('./contentid/text()'))\ content = ''.join(i.xpath('./content/text()'))\ likeCount = ''.join(i.xpath('./likecount/text()'))\ print(contentid, content, likeCount)\ text = pd.DataFrame({'contentid': [contentid], 'content': [content], 'likeCount': [likeCount]})\ df = pd.concat([df, text])\ df.to_csv('哥斯拉大战金刚.csv', encoding='utf-8', index=False) 复制代码
显示结果
查看全部
网页视频抓取工具 知乎(如何爬取电影《哥斯拉大战金刚》的弹幕和评论
)
开发工具
Python版本:3.6.4
相关模块:
请求模块;
重新模块;
熊猫模块;
lxml 模块;
随机模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
思维分析
本文以爬虫电影《哥斯拉大战金刚》为例,讲解如何爬取爱奇艺视频的弹幕和评论!
目标网址
https://www.iqiyi.com/v_19rr0m845o.html 复制代码
Python超全数据库安装包学习路线项目源码免费分享
抢弹幕
爱奇艺视频弹幕还是需要进入开发者工具抓包,并得到一个br压缩文件,点击直接下载,里面的内容是二进制数据,视频播放每分钟加载一个数据包
获取URL,两个URL的区别是增量数,60是视频每60秒更新一次数据包
https://cmts.iqiyi.com/bullet/ ... 43.br\ https://cmts.iqiyi.com/bullet/ ... 43.br 复制代码
br文件可以用brotli库解压,但实际操作难度很大,尤其是编码等问题,很难解决;直接用utf-8解码时,会报如下错误
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x91 in position 52: invalid start byte 复制代码
在解码中加入ignore,中文不会乱码,但是html格式出现乱码,数据提取还是有难度
decode("utf-8", "ignore") 复制代码
将获取到的URL修改为如下链接即可获取.z压缩文件
/bullet/64/00/1078946400_300_1.z 复制代码
这个改动的原因是,这是爱奇艺之前的弹幕界面链接,没有删改,目前还可以使用。界面链接中的1078946400为视频id;300是之前爱奇艺的弹幕每5分钟就会加载一个新的弹幕数据包,5分钟是300秒,《哥斯拉大战金刚》时长112.59分钟,除以5,四舍五入为23;1是页数;64 是第 7 个和第 8 个的 id 值。
代码
import requests\ import pandas as pd\ from lxml import etree\ from zlib import decompress # 解压\ \ df = pd.DataFrame()\ for i in range(1, 23):\ url = f'https://cmts.iqiyi.com/bullet/ ... _300_{i}.z'\ bulletold = requests.get(url).content # 得到二进制数据\ decode = decompress(bulletold).decode('utf-8') # 解压解码\ with open(f'{i}.html', 'a+', encoding='utf-8') as f: # 保存为静态的html文件\ f.write(decode)\ \ html = open(f'./{i}.html', 'rb').read() # 读取html文件\ html = etree.HTML(html) # 用xpath语法进行解析网页\ ul = html.xpath('/html/body/danmu/data/entry/list/bulletinfo')\ for i in ul:\ contentid = ''.join(i.xpath('./contentid/text()'))\ content = ''.join(i.xpath('./content/text()'))\ likeCount = ''.join(i.xpath('./likecount/text()'))\ print(contentid, content, likeCount)\ text = pd.DataFrame({'contentid': [contentid], 'content': [content], 'likeCount': [likeCount]})\ df = pd.concat([df, text])\ df.to_csv('哥斯拉大战金刚.csv', encoding='utf-8', index=False) 复制代码
显示结果
网页视频抓取工具 知乎(网页抓取工具优采云 采集器中给出信息输出页后的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-12-26 23:00
采集器中给出信息输出页后的应用)
媒体目前的状态,一个焦点事件发生后或者在一个连续的话题中,需要大量的人工操作才能形成一个媒体话题,比如信息的采集
整理、及时更新等,但是高效的网络爬虫工具将为我们打造大数据智能媒体。
网页爬虫工具优采云
采集器可以自动采集网络上焦点事件对应的舆情。例如,对于连续发生多天的事件,数据必须在每个重要节点的时间进行捕获和更新,那么您只需要在优采云
采集
器中设置更新时间和频率即可。再比如我们关注的金融市场,也可以更新,自动整理成动态的媒体栏目。
对于关注的某些方面的关注度,也可以根据网络爬虫抓取的阅读或关注数据进行排名推荐和智能评分。我们甚至可以使用网络爬虫工具来维护智能媒体站。用户要做的就是锁定几个或多个信息输出页面,在网络爬虫优采云
采集
器中给出信息输出页面后,配置URL爬取和内容爬取的详细规则。获取到需要的数据后,可以对数据进行一系列的去权重、过滤、清洗处理,最后可以选择自动定期将处理后的精华发布到网站的指定栏目。
未来的智能媒体必然是以大数据为引擎的媒体。核心要素是数据的规模。我们要学会有效地使用数据,发挥数据的价值。国内已经有基于媒体稿件大数据的高科技媒体产品,让人们更快更准确地了解信息,帮助人们更好地发现信息的价值和本质。
有专家指出,如果没有大数据的支持,其实很多新闻是无法启动的。传统媒体很难进行智能分析、预警或决策。因此,大数据智能化是必然趋势。
然而,目前由网络大数据创造的智能媒体还不能完全取代人脑的工作,因为人脑有自我理解知识或事件的倾向,人工智能还需要继续探索语言和事件的分析。 text,会去掉很多无聊的内容。特定信息的整合和提取有朝一日可能会取代人脑来实现更复杂的原创。届时,智能媒体将更加个性化、定制化、高效化。 查看全部
网页视频抓取工具 知乎(网页抓取工具优采云
采集器中给出信息输出页后的应用)
媒体目前的状态,一个焦点事件发生后或者在一个连续的话题中,需要大量的人工操作才能形成一个媒体话题,比如信息的采集
整理、及时更新等,但是高效的网络爬虫工具将为我们打造大数据智能媒体。
网页爬虫工具优采云
采集器可以自动采集网络上焦点事件对应的舆情。例如,对于连续发生多天的事件,数据必须在每个重要节点的时间进行捕获和更新,那么您只需要在优采云
采集
器中设置更新时间和频率即可。再比如我们关注的金融市场,也可以更新,自动整理成动态的媒体栏目。
对于关注的某些方面的关注度,也可以根据网络爬虫抓取的阅读或关注数据进行排名推荐和智能评分。我们甚至可以使用网络爬虫工具来维护智能媒体站。用户要做的就是锁定几个或多个信息输出页面,在网络爬虫优采云
采集
器中给出信息输出页面后,配置URL爬取和内容爬取的详细规则。获取到需要的数据后,可以对数据进行一系列的去权重、过滤、清洗处理,最后可以选择自动定期将处理后的精华发布到网站的指定栏目。
未来的智能媒体必然是以大数据为引擎的媒体。核心要素是数据的规模。我们要学会有效地使用数据,发挥数据的价值。国内已经有基于媒体稿件大数据的高科技媒体产品,让人们更快更准确地了解信息,帮助人们更好地发现信息的价值和本质。
有专家指出,如果没有大数据的支持,其实很多新闻是无法启动的。传统媒体很难进行智能分析、预警或决策。因此,大数据智能化是必然趋势。
然而,目前由网络大数据创造的智能媒体还不能完全取代人脑的工作,因为人脑有自我理解知识或事件的倾向,人工智能还需要继续探索语言和事件的分析。 text,会去掉很多无聊的内容。特定信息的整合和提取有朝一日可能会取代人脑来实现更复杂的原创。届时,智能媒体将更加个性化、定制化、高效化。
网页视频抓取工具 知乎(本文爬取了虎嗅网建站至今共5万条新闻标题内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-26 22:18
摘要:在很多情况下,一篇文章能否被广泛传播,除了文章本身的实际质量外,一个好的标题也很重要。本文对虎嗅网成立以来共5万条新闻头条内容进行爬取,帮助您找到文章头条的技巧和灵感。同时,分享一些有趣的文章和作者。
一、分析背景
1. 为什么选择“虎嗅”
在众多新媒体网站中,“虎嗅”网站的文章内容和质量都还算不错。在《新榜》科技公众号排行榜中,位列榜单第三,颇受青睐。所以我选择爬取这个网站的文章信息,顺便了解一下这几年科技互联网上出现了哪些热点信息。
《关于虎嗅》
虎嗅网成立于2012年5月,是一个聚合优质创新信息和人的新媒体平台。平台专注贡献原创、深度、犀利、优质的商业信息,围绕创新创业进行分析交流。虎嗅网的核心是关注互联网与传统行业的融合、明星企业的风风雨雨、行业大潮的力量与趋势。
2. 分析内容
①分析虎熊网5万篇文章的基本情况,包括采集
数、评论数等。
②发现最受欢迎和最不受欢迎的文章和作者
③分析文章标题形式(长度、句型)与流行度的关系
④ 展示近年来科技互联网行业的热门词汇
3. 分析工具
① Python 3.6
② 蜘蛛
③ MongoDB
④ Matplotlib
⑤词云
⑥结巴
二、数据采集
我用pyspider抓取了沪西网的首页文章。文章抓取期为2012年建站至2018年11月1日,共计约5万篇文章。捕获7个信息字段:文章标题、作者、发表时间、评论数、采集
数、摘要和文章链接。
1. 目标网站分析
这是要爬取的网页界面。您可以看到它是通过 AJAX 加载的。
右键打开开发者工具查看翻页规则。可以看到 URL 请求是 POST 类型的。下拉到底部查看表单数据。要提交的表单只有 3 个参数。尝试后,只需提交页面参数即可成功获取页面信息。另外两个参数无关,所以页面爬取的构建非常简单。
接下来,将选项卡切换到预览和响应以查看网页内容,可以看到数据位于数据字段中。total_page是2004,表示文章内容一共2004页,每页有25篇文章,一共大概5万条,就是我们要爬取的数量。
以上,我们已经找到了我们需要的内容,接下来就可以开始构建爬虫了。整个爬取的思路比较简单。
2. pyspider 介绍
和上一篇不同的是,这里我们使用了一个新的爬虫工具,叫做:pyspider框架。由中国binux大神开发,GitHub Star数超过12K,足以证明其受欢迎程度。可以说学习爬虫不能用这个框架。
这个框架在网上有很多介绍和实际案例,这里只是简单介绍一下。
我们之前的爬虫是在 Sublime 和 PyCharm 等 IDE 窗口中执行的。整个爬取过程可以说是在一个黑盒子里,内部运行的细节也不清楚。pyspider的一大亮点是提供了可视化的WebUI界面,可以清晰的查看爬虫的运行状态。
pyspider的架构主要分为三部分:Scheduler、Fetcher、Processor。Monitor监控整个爬取过程,Result Worker处理最终的爬取结果。
该框架相对易于使用。页面右侧是代码区。首先定义类(Class),然后在其中添加爬虫的各种方法(也称为函数)。左上角显示正在运行的进程,左下角显示输出结果。区域。
3. 获取数据
CMD命令窗口执行:pyspider all命令,然后在浏览器中输入::5000/启动pyspider。
单击创建以创建新项目。命名项目名称:huxiu。因为要爬取的URL是POST类型的,这里可以省略,再添加到代码中即可。再次点击创建完成项目的创建。
新项目建立后,会自动生成一部分模板代码。我们只需要在此基础上修改完善,就可以运行爬虫项目了。现在,简单梳理一下代码编写步骤。
这里首先定义了一个Handler主类,整个爬虫项目主要在这个类下完成。然后,就可以在下面的crawl_config属性中写一些爬虫的基本配置,比如Headers、proxy等设置。
如果你不习惯从函数(def)到类(Class)的代码编写,那么你需要了解类的相关知识,然后我会在单独的文章中介绍。
下面的 on_start() 方法是程序的入口点,表示程序启动后会首先从这里运行。首先,我们将要爬取的URL传入crawl()方法中,同时将URL修改为虎嗅网之一:
由于URL是POST请求,我们还需要添加两个参数:method和data。method表示HTTP请求方法,默认为GET,这里我们需要设置为POST;data为POST请求表单参数,只需要添加一个page参数即可。
接下来通过回调参数定义一个index_page()方法,解析爬取URL成功后crawl()方法返回的Response响应。在后面的 index_page() 方法中,您可以使用 PyQuery 提取响应中所需的内容。具体提取方法如下:
这里网页返回的Response是json格式,需要提取的信息存放在data key value中,由一段HTML代码组成。我们可以使用 response.json['data'] 获取 HTML 信息,然后使用 PyQuery 和 CSS 语法来提取所需的信息,例如文章标题、链接和作者。这里使用了列表生成公式,可以精简代码,转换成方便的列表格式,方便后续存储在MongoDB中。
让我们输出并检查第2页的提取结果:
可以看到成功获取到了需要的数据,然后就可以保存了。可以选择输出到CSV、MySQL、MongoDB等,这里我们选择保存到MongoDB。
上面定义了一个on_result()方法,专门用来获取返回的结果数据。这用于接收上面 index_page() 返回的数据。在这个方法中,定义了一个存储在MongoDB中的方法,以将其保存在MongoDB中。
接下来,我们来测试一下整个爬取和存储过程。点击左上角的运行,可以顺利运行单个网页的爬取、解析和存储。结果如下:
以上完成了单个页面的爬取。接下来,我们需要抓取所有 2000 多页的内容。
需要修改两个地方,首先是在on_start()方法中将for循环的第3页改为2002,修改后如果我们直接点击run,会发现还是只能爬取第2页的结果。
这是因为 pyspider 使用 URL 的 MD5 值作为唯一 ID 号。如果ID号相同,则视为同一个任务,不会再次爬取。由于 GET 请求的分页 URL 通常不同,ID 号也会不同,因此自然可以抓取多个页面。但是这里POST请求的页面URL是一样的,所以爬取第2页后,后面的页面就不会被爬取了。
有解决办法吗?当然还有,我们需要再次记下ID号的生成方法,方法很简单,在on_start()方法前添加如下2行代码:
这样我们再次点击run就可以成功爬取2000页的结果。我在这里捕获了 49,996 个结果,大约需要 2 个小时才能完成。
以上,数据采集完成。一旦我们有了数据,我们就可以开始分析,但在此之前,我们需要简单地清理和处理数据。
三、数据清洗处理
首先,我们需要从 MongoDB 读取数据并将其转换为 DataFrame。
我们来看一下数据的整体情况,可以看到数据的维度是49996行×8列。发现有多余一列无用_id需要删除,name列还有一些特殊符号,比如©需要删除。另外,数据格式都是Object字符串格式。您需要将评论和采集
夹列更改为数字格式,将 write_time 列更改为日期格式。
代码实现如下:
接下来我们看一下数据是否有重复,如果有,则需要删除。
然后,我们再添加两列数据,一列是文章标题长度列,另一列是年份列,方便后续分析。
以上,基本的数据清洗过程就完成了,可以开始对这9列数据进行分析了。
四、描述性数据分析
一般来说,数据分析主要分为四类:“描述性分析”、“诊断性分析”、“预测性分析”和“规范性分析”。“描述性分析”是一种统计方法,用于概括和表达事物的整体情况,以及事物之间的关系,以及事物之间的关系。它是这四种类型中最常见的数据分析类型。通过统计处理,可以用几个统计值来表示一个集合的集中度(如平均值、中位数和众数等)和离散度(反映数据的波动性,如方差、标准差等)数据的。.
在这里,我们主要进行描述性分析,数据主要是数值数据(包括离散变量和连续变量)和文本数据。
1. 大局
我们先来看看整体情况。
这里使用 data.describe() 方法对数值变量进行统计分析。由以上可以简要得出以下结论:
① 读者评价和采集
热情不高。大多数文章(75%)有十几条评论,只有几十条采集
。与一些微信大V公众号的百万阅读、数万评论和采集
相比,虎兄网确实是比较小众的。不过,也正是因为小众,它也受到了一些人的喜爱。
②评论最多的文章有2376篇,采集
最多的文章有1113篇,说明还有一些潜在的热门或者优质的文章。
③最长的文章标题为224个字符,大部分文章标题在20个字符左右,标题不宜过长或过短。
对于非数字变量(name、write_time),使用describe()方法会生成另一个汇总统计。
unique 表示唯一值的个数,top 表示出现次数最多的变量,freq 表示变量出现的次数,因此很容易得出以下结论:
①文章来源方面,5万篇文章共有3162位作者投稿。其中,他们的官网“虎嗅”写得最多,超过10000条,这也是理所当然的。
②从文章发表时间来看,最早的文章是2012年4月3日。6年多来,文章数量最多的一天是2014年7月10日,共发表文章274篇。
2. 不同时期发表文章数的变化
可以看出,在以季度为时间尺度的六年中,前几年发表的文章数量相对稳定,约1750篇,个别季度的数量激增至2000多篇。2016年之后,文章数量开始增加到2000多条,这可能与网站人气增加有关。第一季度和最后一个季度的日期不完整,因此数量相对较少。
具体代码实现如下:
3. 文章合集TOP10
接下来,我们更关心的问题是:在数以万计的文章中,哪些更好,哪些更受欢迎?
这里,“采集
夹”(采集
夹的数量)被选为测量标准。毕竟一般的好文章,大家都会有采集
的习惯。
第一名“看完这10本书,你就能站在智商蔑视链的顶端。” 以1113件藏品居首位,遥遥领先于后者。看来大家都在珍惜“我想快点爬上去”。在人生的巅峰,“看到每个人的渺小”的想法。打开这篇文章的链接,文章中提到了这些书:《思考,快与慢》,《思考技巧》,《麦肯锡的第一课:职场新人的逻辑思维能力》等。我没有读过其中任何一篇。这辈子,似乎很难达到人生巅峰。
发现两个有趣的地方:
①文章标题比较简短。
②虽然文章采集
量比较高,但评论不多。我想这是因为每个人都喜欢参加派对吗?
4. 历年文章TOP3合集
了解了文章的整体排名后,我们再来看看历年文章的排名。在这里,每年都会选出采集
最多的 3 篇文章。
可以看出,文章的采集
量基本上是逐年增加的,但2015年的3篇文章的采集
量是最高的,在总排名中占据前3位。不知道今年的文章有什么特别之处。
上面只列出了文章标题的一小部分,可以看到标题还是比较标准的。关于标题的重要性,有一句流行的说法:“一篇好文章有一半的标题”。一个好的标题可以大大增强文章的传播力和吸引力。文章标题虽然只有几个叉号,但如果你记住的话,里面的花招还是不少的。
代码实现如下:
(1) TOP20 最具生产力的作者
以上,我们从采集
指数分析,下面,我们关注发表文章的作者(个人/媒体)。前面提到,发表最多的文章来自虎嗅官网,一万多篇。这里我们筛选出官方媒体,看看是否还有其他更高效的作者。
可以看出,前20位作者发表的帖子数量相差不大。拥有“娱乐之都”、“东域”、“发条橙”等众多媒体账号;还有虎溪官网团队的作者:发条橙、周超辰、张博文等;还有一些独立作者:冒充FBI、孙永杰等,你可以试试关注这些高产作者。
代码实现如下:
(2) TOP 10 文章采集
最平均的作者
我们关注一个作者,不仅是因为文章的高效率,还有文章的质量。这里我们选择“文章的平均采集
数”(总采集
数/文章数),看看谁是文章水平相对较高的作者。
在这里,为了避免“一个作者只写一篇高收录文章”不代表其真实水平的情况,我们将筛选范围设置为至少发表了5篇文章的作者。
可以看出,前10位作者包括:重读遥遥领先,两位高产优质辩手李牧阳和范通代老板,以及大众熟悉的高晓松和宁南山。
如果将此列表与上述高产作者列表进行比较,您会发现他们并未出现在此列表中。与数量相比,质量可能更重要。
接下来,我们来看看排名靠前的重读写的高采集
文章。
他们居然写了所有关于马老板家的文章。
了解了前十名作者后,我们再来看看排名后十名的作者。
对比一下,他们的文章集就比较简陋了。特别好奇最后一个作者,杨业萌,他写了7篇文章,却连一个合集都没有。
让我们看看他写了什么文章。
我最初用英文写了所有文章。人们似乎不喜欢阅读英文文章。
具体实现代码:
5. 评论最多的前 10 篇文章
说完采集
量。接下来,我们来看看评论最多的文章。
这些文章大部分都与三星有关。这些文章大部分是2014年的,三星那些年好像很火,不过这两年三星在国内基本看不到三星的影子。世界变化真的很快。
发现了两个有趣的现象。
① 上面这批关于三星和之前阿里的文章,他们“占据”了评论和采集
列表,结合知乎上一篇关于虎嗅介绍的文章:这其实是虎嗅的情况,而且好像是能够发现一些微妙的东西。
②文章评论数和采集
数这两个指标几乎呈现出极端趋势。评论多的文章采集
少,评论少的文章采集
多。
让我们进一步观察这两个参数之间的关系。
可以看到,大部分的点都位于左下角,这意味着这些文章的采集
和评论数量相对较少。但是,也有少量的离群点位于顶部和右侧,表明这些文章呈现出“多评论,少采集
”或“少评论,多采集
”的特点。
6. 文章标题长度
接下来我们来看看文章标题的长度和采集
数有没有关系。
大致可以看出两种现象:
① 采集
量高的文章标题比较短(右边部分比较分散)。
②标题很长的文章采集
量很低(左边形成一条竖线)。
看来起标题的时候最好不要把一篇文章开始太长。
实现代码如下:
7. 标题格式
接下来我们看看作者在文章标题的开头有没有对标点符号的偏好。
如您所见,50,000 篇文章中的大多数都具有声明性标题。三分之一(34.8%)的文章标题使用问号“?”,而只有5%的文章使用感叹号“!”。
通常,问号让人感到好奇,想要打开文章;而感叹号则给人一种紧张或压抑的感觉,让人不想打开。所以,尽量多用问号,少用感叹号。
8. 文字分析
最后,从这5万篇文章的标题和摘要中,我们来看看虎嗅网的文章主要集中在哪些学科领域。
这里我们先用jieba分词包对标题进行分词,然后再用WordCloud制作词云图。由于虎嗅网中含有“老虎”二字,故选用虎头头像。(关于jieba和WordCloud这两个包,后面会详细介绍)
可以看到文章的主题内容侧重于:互联网、知名公司、电子商务、投资。这大致符合网站本身的核心内容,即“关注互联网和移动互联网上一系列明星公司的兴衰,行业大潮的力量和趋势,以及互联网和移动互联网改造传统产业。”
实现代码如下:
上面的关键词是这几年的总体概况,科技互联网行业的发展每年都不一样,那么我们来看看这些年的一些关键词,通过这些关键词 看看这几年互联网行业、技术热点、知名企业的不同变化。
可以看到每年的关键词都有一些相似之处,但也有不同的地方:
① 中国互联网、公司、苹果、腾讯、阿里等热门关键词一直很火。这些公司确实是稳定的一批。
②每年都会出现新的热点:比如2013年的微信(刚刚开始流行),2016年的直播(各大直播平台纷纷涌现),2017年的iPhone(上市十周年),2018年的小米(上市))。
③新的热点技术不断涌现:2013-2015年的O2O,2016年的VR,2017年的AI,2018年的“区块链”,这些前沿技术也成为了近几年的一个热词。
通过这张图,我们可以看到近年来科技互联网行业、明星企业、热点信息的变化。
五、总结
1. 本文简要分析了虎嗅网5万篇文章的信息,对近年来日新月异的科技互联网有一个大致的了解。
2.发现那些优秀的文章和作者,可以节省宝贵的时间和成本。
3.一篇文章要广为传播,文章本身的质量和标题就一分为二。相信文章中的50,000个标题可以带来一些启发。
4. 本文没有做深入的文本挖掘,文本挖掘可能比数据挖掘涵盖的信息量更大,更有价值。执行这些分析需要机器学习和深度学习的知识,这些知识将在以后的学习中得到补充。
本文作者:苏克1900
-DataHunter 用于数据分析展示- 查看全部
网页视频抓取工具 知乎(本文爬取了虎嗅网建站至今共5万条新闻标题内容)
摘要:在很多情况下,一篇文章能否被广泛传播,除了文章本身的实际质量外,一个好的标题也很重要。本文对虎嗅网成立以来共5万条新闻头条内容进行爬取,帮助您找到文章头条的技巧和灵感。同时,分享一些有趣的文章和作者。
一、分析背景
1. 为什么选择“虎嗅”
在众多新媒体网站中,“虎嗅”网站的文章内容和质量都还算不错。在《新榜》科技公众号排行榜中,位列榜单第三,颇受青睐。所以我选择爬取这个网站的文章信息,顺便了解一下这几年科技互联网上出现了哪些热点信息。
《关于虎嗅》
虎嗅网成立于2012年5月,是一个聚合优质创新信息和人的新媒体平台。平台专注贡献原创、深度、犀利、优质的商业信息,围绕创新创业进行分析交流。虎嗅网的核心是关注互联网与传统行业的融合、明星企业的风风雨雨、行业大潮的力量与趋势。
2. 分析内容
①分析虎熊网5万篇文章的基本情况,包括采集
数、评论数等。
②发现最受欢迎和最不受欢迎的文章和作者
③分析文章标题形式(长度、句型)与流行度的关系
④ 展示近年来科技互联网行业的热门词汇
3. 分析工具
① Python 3.6
② 蜘蛛
③ MongoDB
④ Matplotlib
⑤词云
⑥结巴
二、数据采集
我用pyspider抓取了沪西网的首页文章。文章抓取期为2012年建站至2018年11月1日,共计约5万篇文章。捕获7个信息字段:文章标题、作者、发表时间、评论数、采集
数、摘要和文章链接。
1. 目标网站分析
这是要爬取的网页界面。您可以看到它是通过 AJAX 加载的。
右键打开开发者工具查看翻页规则。可以看到 URL 请求是 POST 类型的。下拉到底部查看表单数据。要提交的表单只有 3 个参数。尝试后,只需提交页面参数即可成功获取页面信息。另外两个参数无关,所以页面爬取的构建非常简单。
接下来,将选项卡切换到预览和响应以查看网页内容,可以看到数据位于数据字段中。total_page是2004,表示文章内容一共2004页,每页有25篇文章,一共大概5万条,就是我们要爬取的数量。
以上,我们已经找到了我们需要的内容,接下来就可以开始构建爬虫了。整个爬取的思路比较简单。
2. pyspider 介绍
和上一篇不同的是,这里我们使用了一个新的爬虫工具,叫做:pyspider框架。由中国binux大神开发,GitHub Star数超过12K,足以证明其受欢迎程度。可以说学习爬虫不能用这个框架。
这个框架在网上有很多介绍和实际案例,这里只是简单介绍一下。
我们之前的爬虫是在 Sublime 和 PyCharm 等 IDE 窗口中执行的。整个爬取过程可以说是在一个黑盒子里,内部运行的细节也不清楚。pyspider的一大亮点是提供了可视化的WebUI界面,可以清晰的查看爬虫的运行状态。
pyspider的架构主要分为三部分:Scheduler、Fetcher、Processor。Monitor监控整个爬取过程,Result Worker处理最终的爬取结果。
该框架相对易于使用。页面右侧是代码区。首先定义类(Class),然后在其中添加爬虫的各种方法(也称为函数)。左上角显示正在运行的进程,左下角显示输出结果。区域。
3. 获取数据
CMD命令窗口执行:pyspider all命令,然后在浏览器中输入::5000/启动pyspider。
单击创建以创建新项目。命名项目名称:huxiu。因为要爬取的URL是POST类型的,这里可以省略,再添加到代码中即可。再次点击创建完成项目的创建。
新项目建立后,会自动生成一部分模板代码。我们只需要在此基础上修改完善,就可以运行爬虫项目了。现在,简单梳理一下代码编写步骤。
这里首先定义了一个Handler主类,整个爬虫项目主要在这个类下完成。然后,就可以在下面的crawl_config属性中写一些爬虫的基本配置,比如Headers、proxy等设置。
如果你不习惯从函数(def)到类(Class)的代码编写,那么你需要了解类的相关知识,然后我会在单独的文章中介绍。
下面的 on_start() 方法是程序的入口点,表示程序启动后会首先从这里运行。首先,我们将要爬取的URL传入crawl()方法中,同时将URL修改为虎嗅网之一:
由于URL是POST请求,我们还需要添加两个参数:method和data。method表示HTTP请求方法,默认为GET,这里我们需要设置为POST;data为POST请求表单参数,只需要添加一个page参数即可。
接下来通过回调参数定义一个index_page()方法,解析爬取URL成功后crawl()方法返回的Response响应。在后面的 index_page() 方法中,您可以使用 PyQuery 提取响应中所需的内容。具体提取方法如下:
这里网页返回的Response是json格式,需要提取的信息存放在data key value中,由一段HTML代码组成。我们可以使用 response.json['data'] 获取 HTML 信息,然后使用 PyQuery 和 CSS 语法来提取所需的信息,例如文章标题、链接和作者。这里使用了列表生成公式,可以精简代码,转换成方便的列表格式,方便后续存储在MongoDB中。
让我们输出并检查第2页的提取结果:
可以看到成功获取到了需要的数据,然后就可以保存了。可以选择输出到CSV、MySQL、MongoDB等,这里我们选择保存到MongoDB。
上面定义了一个on_result()方法,专门用来获取返回的结果数据。这用于接收上面 index_page() 返回的数据。在这个方法中,定义了一个存储在MongoDB中的方法,以将其保存在MongoDB中。
接下来,我们来测试一下整个爬取和存储过程。点击左上角的运行,可以顺利运行单个网页的爬取、解析和存储。结果如下:
以上完成了单个页面的爬取。接下来,我们需要抓取所有 2000 多页的内容。
需要修改两个地方,首先是在on_start()方法中将for循环的第3页改为2002,修改后如果我们直接点击run,会发现还是只能爬取第2页的结果。
这是因为 pyspider 使用 URL 的 MD5 值作为唯一 ID 号。如果ID号相同,则视为同一个任务,不会再次爬取。由于 GET 请求的分页 URL 通常不同,ID 号也会不同,因此自然可以抓取多个页面。但是这里POST请求的页面URL是一样的,所以爬取第2页后,后面的页面就不会被爬取了。
有解决办法吗?当然还有,我们需要再次记下ID号的生成方法,方法很简单,在on_start()方法前添加如下2行代码:
这样我们再次点击run就可以成功爬取2000页的结果。我在这里捕获了 49,996 个结果,大约需要 2 个小时才能完成。
以上,数据采集完成。一旦我们有了数据,我们就可以开始分析,但在此之前,我们需要简单地清理和处理数据。
三、数据清洗处理
首先,我们需要从 MongoDB 读取数据并将其转换为 DataFrame。
我们来看一下数据的整体情况,可以看到数据的维度是49996行×8列。发现有多余一列无用_id需要删除,name列还有一些特殊符号,比如©需要删除。另外,数据格式都是Object字符串格式。您需要将评论和采集
夹列更改为数字格式,将 write_time 列更改为日期格式。
代码实现如下:
接下来我们看一下数据是否有重复,如果有,则需要删除。
然后,我们再添加两列数据,一列是文章标题长度列,另一列是年份列,方便后续分析。
以上,基本的数据清洗过程就完成了,可以开始对这9列数据进行分析了。
四、描述性数据分析
一般来说,数据分析主要分为四类:“描述性分析”、“诊断性分析”、“预测性分析”和“规范性分析”。“描述性分析”是一种统计方法,用于概括和表达事物的整体情况,以及事物之间的关系,以及事物之间的关系。它是这四种类型中最常见的数据分析类型。通过统计处理,可以用几个统计值来表示一个集合的集中度(如平均值、中位数和众数等)和离散度(反映数据的波动性,如方差、标准差等)数据的。.
在这里,我们主要进行描述性分析,数据主要是数值数据(包括离散变量和连续变量)和文本数据。
1. 大局
我们先来看看整体情况。
这里使用 data.describe() 方法对数值变量进行统计分析。由以上可以简要得出以下结论:
① 读者评价和采集
热情不高。大多数文章(75%)有十几条评论,只有几十条采集
。与一些微信大V公众号的百万阅读、数万评论和采集
相比,虎兄网确实是比较小众的。不过,也正是因为小众,它也受到了一些人的喜爱。
②评论最多的文章有2376篇,采集
最多的文章有1113篇,说明还有一些潜在的热门或者优质的文章。
③最长的文章标题为224个字符,大部分文章标题在20个字符左右,标题不宜过长或过短。
对于非数字变量(name、write_time),使用describe()方法会生成另一个汇总统计。
unique 表示唯一值的个数,top 表示出现次数最多的变量,freq 表示变量出现的次数,因此很容易得出以下结论:
①文章来源方面,5万篇文章共有3162位作者投稿。其中,他们的官网“虎嗅”写得最多,超过10000条,这也是理所当然的。
②从文章发表时间来看,最早的文章是2012年4月3日。6年多来,文章数量最多的一天是2014年7月10日,共发表文章274篇。
2. 不同时期发表文章数的变化
可以看出,在以季度为时间尺度的六年中,前几年发表的文章数量相对稳定,约1750篇,个别季度的数量激增至2000多篇。2016年之后,文章数量开始增加到2000多条,这可能与网站人气增加有关。第一季度和最后一个季度的日期不完整,因此数量相对较少。
具体代码实现如下:
3. 文章合集TOP10
接下来,我们更关心的问题是:在数以万计的文章中,哪些更好,哪些更受欢迎?
这里,“采集
夹”(采集
夹的数量)被选为测量标准。毕竟一般的好文章,大家都会有采集
的习惯。
第一名“看完这10本书,你就能站在智商蔑视链的顶端。” 以1113件藏品居首位,遥遥领先于后者。看来大家都在珍惜“我想快点爬上去”。在人生的巅峰,“看到每个人的渺小”的想法。打开这篇文章的链接,文章中提到了这些书:《思考,快与慢》,《思考技巧》,《麦肯锡的第一课:职场新人的逻辑思维能力》等。我没有读过其中任何一篇。这辈子,似乎很难达到人生巅峰。
发现两个有趣的地方:
①文章标题比较简短。
②虽然文章采集
量比较高,但评论不多。我想这是因为每个人都喜欢参加派对吗?
4. 历年文章TOP3合集
了解了文章的整体排名后,我们再来看看历年文章的排名。在这里,每年都会选出采集
最多的 3 篇文章。
可以看出,文章的采集
量基本上是逐年增加的,但2015年的3篇文章的采集
量是最高的,在总排名中占据前3位。不知道今年的文章有什么特别之处。
上面只列出了文章标题的一小部分,可以看到标题还是比较标准的。关于标题的重要性,有一句流行的说法:“一篇好文章有一半的标题”。一个好的标题可以大大增强文章的传播力和吸引力。文章标题虽然只有几个叉号,但如果你记住的话,里面的花招还是不少的。
代码实现如下:
(1) TOP20 最具生产力的作者
以上,我们从采集
指数分析,下面,我们关注发表文章的作者(个人/媒体)。前面提到,发表最多的文章来自虎嗅官网,一万多篇。这里我们筛选出官方媒体,看看是否还有其他更高效的作者。
可以看出,前20位作者发表的帖子数量相差不大。拥有“娱乐之都”、“东域”、“发条橙”等众多媒体账号;还有虎溪官网团队的作者:发条橙、周超辰、张博文等;还有一些独立作者:冒充FBI、孙永杰等,你可以试试关注这些高产作者。
代码实现如下:
(2) TOP 10 文章采集
最平均的作者
我们关注一个作者,不仅是因为文章的高效率,还有文章的质量。这里我们选择“文章的平均采集
数”(总采集
数/文章数),看看谁是文章水平相对较高的作者。
在这里,为了避免“一个作者只写一篇高收录文章”不代表其真实水平的情况,我们将筛选范围设置为至少发表了5篇文章的作者。
可以看出,前10位作者包括:重读遥遥领先,两位高产优质辩手李牧阳和范通代老板,以及大众熟悉的高晓松和宁南山。
如果将此列表与上述高产作者列表进行比较,您会发现他们并未出现在此列表中。与数量相比,质量可能更重要。
接下来,我们来看看排名靠前的重读写的高采集
文章。
他们居然写了所有关于马老板家的文章。
了解了前十名作者后,我们再来看看排名后十名的作者。
对比一下,他们的文章集就比较简陋了。特别好奇最后一个作者,杨业萌,他写了7篇文章,却连一个合集都没有。
让我们看看他写了什么文章。
我最初用英文写了所有文章。人们似乎不喜欢阅读英文文章。
具体实现代码:
5. 评论最多的前 10 篇文章
说完采集
量。接下来,我们来看看评论最多的文章。
这些文章大部分都与三星有关。这些文章大部分是2014年的,三星那些年好像很火,不过这两年三星在国内基本看不到三星的影子。世界变化真的很快。
发现了两个有趣的现象。
① 上面这批关于三星和之前阿里的文章,他们“占据”了评论和采集
列表,结合知乎上一篇关于虎嗅介绍的文章:这其实是虎嗅的情况,而且好像是能够发现一些微妙的东西。
②文章评论数和采集
数这两个指标几乎呈现出极端趋势。评论多的文章采集
少,评论少的文章采集
多。
让我们进一步观察这两个参数之间的关系。
可以看到,大部分的点都位于左下角,这意味着这些文章的采集
和评论数量相对较少。但是,也有少量的离群点位于顶部和右侧,表明这些文章呈现出“多评论,少采集
”或“少评论,多采集
”的特点。
6. 文章标题长度
接下来我们来看看文章标题的长度和采集
数有没有关系。
大致可以看出两种现象:
① 采集
量高的文章标题比较短(右边部分比较分散)。
②标题很长的文章采集
量很低(左边形成一条竖线)。
看来起标题的时候最好不要把一篇文章开始太长。
实现代码如下:
7. 标题格式
接下来我们看看作者在文章标题的开头有没有对标点符号的偏好。
如您所见,50,000 篇文章中的大多数都具有声明性标题。三分之一(34.8%)的文章标题使用问号“?”,而只有5%的文章使用感叹号“!”。
通常,问号让人感到好奇,想要打开文章;而感叹号则给人一种紧张或压抑的感觉,让人不想打开。所以,尽量多用问号,少用感叹号。
8. 文字分析
最后,从这5万篇文章的标题和摘要中,我们来看看虎嗅网的文章主要集中在哪些学科领域。
这里我们先用jieba分词包对标题进行分词,然后再用WordCloud制作词云图。由于虎嗅网中含有“老虎”二字,故选用虎头头像。(关于jieba和WordCloud这两个包,后面会详细介绍)
可以看到文章的主题内容侧重于:互联网、知名公司、电子商务、投资。这大致符合网站本身的核心内容,即“关注互联网和移动互联网上一系列明星公司的兴衰,行业大潮的力量和趋势,以及互联网和移动互联网改造传统产业。”
实现代码如下:
上面的关键词是这几年的总体概况,科技互联网行业的发展每年都不一样,那么我们来看看这些年的一些关键词,通过这些关键词 看看这几年互联网行业、技术热点、知名企业的不同变化。
可以看到每年的关键词都有一些相似之处,但也有不同的地方:
① 中国互联网、公司、苹果、腾讯、阿里等热门关键词一直很火。这些公司确实是稳定的一批。
②每年都会出现新的热点:比如2013年的微信(刚刚开始流行),2016年的直播(各大直播平台纷纷涌现),2017年的iPhone(上市十周年),2018年的小米(上市))。
③新的热点技术不断涌现:2013-2015年的O2O,2016年的VR,2017年的AI,2018年的“区块链”,这些前沿技术也成为了近几年的一个热词。
通过这张图,我们可以看到近年来科技互联网行业、明星企业、热点信息的变化。
五、总结
1. 本文简要分析了虎嗅网5万篇文章的信息,对近年来日新月异的科技互联网有一个大致的了解。
2.发现那些优秀的文章和作者,可以节省宝贵的时间和成本。
3.一篇文章要广为传播,文章本身的质量和标题就一分为二。相信文章中的50,000个标题可以带来一些启发。
4. 本文没有做深入的文本挖掘,文本挖掘可能比数据挖掘涵盖的信息量更大,更有价值。执行这些分析需要机器学习和深度学习的知识,这些知识将在以后的学习中得到补充。
本文作者:苏克1900
-DataHunter 用于数据分析展示-
网页视频抓取工具 知乎(如何把互联网比作一张大网分析网页源代码提取信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-26 15:11
我们可以把互联网比作一个大网,爬虫就是在网上爬行的蜘蛛。把网络的节点比作单个网页,爬到这个就相当于访问了这个页面,获取了它的信息。节点之间的连接可以比作网页和网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续获取后续网页通过一个网页,使整个网页的所有节点都可以被蜘蛛爬取,网站的数据可以被爬下来。简单的说,爬虫就是获取网页,提取和保存信息的自动化程序。主要有以下三个步骤:
获取网页:爬虫的首要任务是获取网页,这里是获取网页的源代码。源代码中收录
了网页的一些有用信息,所以只要得到源代码,就可以从中提取出你想要的信息。爬虫首先向网站的服务器发送请求,返回的响应体就是网页的源代码。Python提供了很多库(比如urllib、requests)来帮助我们实现这个操作。我们可以使用这些库来帮助我们实现 HTTP 请求操作。请求和响应可以用类库提供的数据结构来表示。得到响应后只需要解析数据结构的Body部分就可以得到网页的源码,这样我们就可以通过程序来实现获取网页的过程。提取信息:获取网页的源代码后,下一步就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。另外,由于网页的结构有一定的规律,所以有一些库是根据网页节点属性、CSS选择器或XPath提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效快速的提取网页信息,如节点属性、文本值等。提取信息是爬虫非常重要的部分,可以将杂乱的数据整理得井井有条,便于我们对数据进行后续的处理和分析。保存数据:提取信息后,我们一般将提取的数据保存在某处,以备后续使用。这里保存的方式有很多种,比如简单的保存为TXT文本或JSON文本,或者保存到数据库,比如MySQL和MongoDB等,或者保存到远程服务器,比如用SFTP操作。可以捕获什么样的数据 例如使用 SFTP 操作。可以捕获什么样的数据 例如使用 SFTP 操作。可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是普通网页,对应HTML代码,最常爬取的是HTML源代码。另外,有些网页可能返回的不是HTML代码,而是JSON字符串(大多数API接口使用这种形式)。这种格式的数据便于传输和分析,也可以捕获,数据提取更方便。此外,我们还可以看到各种二进制数据,如图片、视频和音频。使用爬虫,我们可以抓取这些二进制数据并保存为对应的文件名。此外,您还可以查看具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要你能在浏览器中访问它们,你就可以抓取它们。
上面的内容其实对应的是它们各自的URL,是基于HTTP或HTTPS协议的。只要是这种数据,爬虫就可以爬取。
JavaScript 渲染页面
有时候,当我们使用urllib或者requests来抓取一个网页的时候,我们得到的源码其实和我们在浏览器中看到的不一样。这是一个很常见的问题。如今,越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原来的 HTML 代码是一个空壳,例如:
<p> 查看全部
网页视频抓取工具 知乎(如何把互联网比作一张大网分析网页源代码提取信息)
我们可以把互联网比作一个大网,爬虫就是在网上爬行的蜘蛛。把网络的节点比作单个网页,爬到这个就相当于访问了这个页面,获取了它的信息。节点之间的连接可以比作网页和网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续获取后续网页通过一个网页,使整个网页的所有节点都可以被蜘蛛爬取,网站的数据可以被爬下来。简单的说,爬虫就是获取网页,提取和保存信息的自动化程序。主要有以下三个步骤:
获取网页:爬虫的首要任务是获取网页,这里是获取网页的源代码。源代码中收录
了网页的一些有用信息,所以只要得到源代码,就可以从中提取出你想要的信息。爬虫首先向网站的服务器发送请求,返回的响应体就是网页的源代码。Python提供了很多库(比如urllib、requests)来帮助我们实现这个操作。我们可以使用这些库来帮助我们实现 HTTP 请求操作。请求和响应可以用类库提供的数据结构来表示。得到响应后只需要解析数据结构的Body部分就可以得到网页的源码,这样我们就可以通过程序来实现获取网页的过程。提取信息:获取网页的源代码后,下一步就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。另外,由于网页的结构有一定的规律,所以有一些库是根据网页节点属性、CSS选择器或XPath提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效快速的提取网页信息,如节点属性、文本值等。提取信息是爬虫非常重要的部分,可以将杂乱的数据整理得井井有条,便于我们对数据进行后续的处理和分析。保存数据:提取信息后,我们一般将提取的数据保存在某处,以备后续使用。这里保存的方式有很多种,比如简单的保存为TXT文本或JSON文本,或者保存到数据库,比如MySQL和MongoDB等,或者保存到远程服务器,比如用SFTP操作。可以捕获什么样的数据 例如使用 SFTP 操作。可以捕获什么样的数据 例如使用 SFTP 操作。可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是普通网页,对应HTML代码,最常爬取的是HTML源代码。另外,有些网页可能返回的不是HTML代码,而是JSON字符串(大多数API接口使用这种形式)。这种格式的数据便于传输和分析,也可以捕获,数据提取更方便。此外,我们还可以看到各种二进制数据,如图片、视频和音频。使用爬虫,我们可以抓取这些二进制数据并保存为对应的文件名。此外,您还可以查看具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要你能在浏览器中访问它们,你就可以抓取它们。
上面的内容其实对应的是它们各自的URL,是基于HTTP或HTTPS协议的。只要是这种数据,爬虫就可以爬取。
JavaScript 渲染页面
有时候,当我们使用urllib或者requests来抓取一个网页的时候,我们得到的源码其实和我们在浏览器中看到的不一样。这是一个很常见的问题。如今,越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原来的 HTML 代码是一个空壳,例如:
<p>
网页视频抓取工具 知乎(需求抓取知乎问题下所有回答的爬虫意义在哪?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-26 15:09
好久不见,工作有点忙……虽然每天都在写爬虫,也解锁了很多爬虫的新技能,但是因为工作中用到NodeJS,所以好久没有写Python了。
对于解决需求问题,无论是Python还是NodeJS,只是语法和模块不同,分析思路和解决方案基本一致。
我最近写了一个简单的爬虫,知道答案。如果你有兴趣,我们一起来看看。
需要
爬取知乎问题下的所有回答,包括作者、作者粉丝数、回答内容、时间、回复评论数、回答批准数、回答链接.
分析
以上图中的问题为例。如果我们想要得到答案的相关数据,一般可以在Chrome浏览器下按F12来分析请求;但是借助Charles抓包工具,我们可以更直观的获取相关字段:
注意我标记的Query String参数中的limit 5表示每个请求会返回5个答案,测试后最多可以改成20个;偏移是指从答案的数量开始;
返回结果为 Json 格式。每个答案都收录
足够的信息。我们只需要过滤并保存我们想要捕获的字段记录。
需要注意的是,content字段返回的是答案内容,但其格式是带有网页标签的。搜索之后,我选择了HTMLParser来解析,这样就不用手动处理了。
代码
import requests,json
import datetime
import pandas as pd
from selectolax.parser import HTMLParser
url = 'https://www.zhihu.com/api/v4/q ... 27%3B
headers = {
'Host':'www.zhihu.com',
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
'referer':'https://www.zhihu.com/question/486212129'
}
df = pd.DataFrame(columns=('author','fans_count','content','created_time','updated_time','comment_count','voteup_count','url'))
def crawler(start):
print(start)
global df
data= {
'include':'data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,attachment,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,is_labeled,paid_info,paid_info_content,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,is_recognized;data[*].mark_infos[*].url;data[*].author.follower_count,vip_info,badge[*].topics;data[*].settings.table_of_content.enabled',
'offset':start,
'limit':20,
'sort_by':'default',
'platform':'desktop'
}
#将携带的参数传给params
r = requests.get(url, params=data,headers=headers)
res = json.loads(r.text)
if res['data']:
for answer in res['data']:
author = answer['author']['name']
fans = answer['author']['follower_count']
content = HTMLParser(answer['content']).text()
#content = answer['content']
created_time = datetime.datetime.fromtimestamp(answer['created_time'])
updated_time = datetime.datetime.fromtimestamp(answer['updated_time'])
comment = answer['comment_count']
voteup = answer['voteup_count']
link = answer['url']
row = {
'author':[author],
'fans_count':[fans],
'content':[content],
'created_time':[created_time],
'updated_time':[updated_time],
'comment_count':[comment],
'voteup_count':[voteup],
'url':[link]
}
df = df.append(pd.DataFrame(row),ignore_index=True)
if len(res['data'])==20:
crawler(start+20)
else:
print(res)
crawler(0)
df.to_csv(f'result_{datetime.datetime.now().strftime("%Y-%m-%d")}.csv',index=False)
print("done~")
结果
最终的爬取结果大致如下:
你可以看到有些答案是空的。转到问题,发现是视频回答。没有文字内容。这被忽略了。当然,您可以删除视频链接并将其添加到结果中。
目前(2021.09)看这个问题,接口没有特别限制,包括我在代码中的请求没有cookies直接捕获,通过修改limit参数为20来减少请求频率。
爬虫意义
最近也在想爬,知道答案的意思。一开始想把所有的答案汇总起来分析,但实际抓起来之后,就想一起读了。我发现阅读表格中的答案的阅读体验很差,所以最好去扫描它们。知乎;但更明显的价值在于这数百个答案的横向对比,答案、评论和作者的粉丝都一目了然。另外还可以根据结果做一些词频分析、词云图展示等,这些就剩下了。
爬虫只是获取数据的一种方式,如何解读是数据更大的价值。
我是TED,每天写爬虫的数据工程师,好久没写Python了。以后想到的一系列Python爬虫项目我会继续更新。欢迎继续关注~ 查看全部
网页视频抓取工具 知乎(需求抓取知乎问题下所有回答的爬虫意义在哪?)
好久不见,工作有点忙……虽然每天都在写爬虫,也解锁了很多爬虫的新技能,但是因为工作中用到NodeJS,所以好久没有写Python了。
对于解决需求问题,无论是Python还是NodeJS,只是语法和模块不同,分析思路和解决方案基本一致。
我最近写了一个简单的爬虫,知道答案。如果你有兴趣,我们一起来看看。
需要
爬取知乎问题下的所有回答,包括作者、作者粉丝数、回答内容、时间、回复评论数、回答批准数、回答链接.
分析
以上图中的问题为例。如果我们想要得到答案的相关数据,一般可以在Chrome浏览器下按F12来分析请求;但是借助Charles抓包工具,我们可以更直观的获取相关字段:
注意我标记的Query String参数中的limit 5表示每个请求会返回5个答案,测试后最多可以改成20个;偏移是指从答案的数量开始;
返回结果为 Json 格式。每个答案都收录
足够的信息。我们只需要过滤并保存我们想要捕获的字段记录。
需要注意的是,content字段返回的是答案内容,但其格式是带有网页标签的。搜索之后,我选择了HTMLParser来解析,这样就不用手动处理了。
代码
import requests,json
import datetime
import pandas as pd
from selectolax.parser import HTMLParser
url = 'https://www.zhihu.com/api/v4/q ... 27%3B
headers = {
'Host':'www.zhihu.com',
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
'referer':'https://www.zhihu.com/question/486212129'
}
df = pd.DataFrame(columns=('author','fans_count','content','created_time','updated_time','comment_count','voteup_count','url'))
def crawler(start):
print(start)
global df
data= {
'include':'data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,attachment,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,is_labeled,paid_info,paid_info_content,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,is_recognized;data[*].mark_infos[*].url;data[*].author.follower_count,vip_info,badge[*].topics;data[*].settings.table_of_content.enabled',
'offset':start,
'limit':20,
'sort_by':'default',
'platform':'desktop'
}
#将携带的参数传给params
r = requests.get(url, params=data,headers=headers)
res = json.loads(r.text)
if res['data']:
for answer in res['data']:
author = answer['author']['name']
fans = answer['author']['follower_count']
content = HTMLParser(answer['content']).text()
#content = answer['content']
created_time = datetime.datetime.fromtimestamp(answer['created_time'])
updated_time = datetime.datetime.fromtimestamp(answer['updated_time'])
comment = answer['comment_count']
voteup = answer['voteup_count']
link = answer['url']
row = {
'author':[author],
'fans_count':[fans],
'content':[content],
'created_time':[created_time],
'updated_time':[updated_time],
'comment_count':[comment],
'voteup_count':[voteup],
'url':[link]
}
df = df.append(pd.DataFrame(row),ignore_index=True)
if len(res['data'])==20:
crawler(start+20)
else:
print(res)
crawler(0)
df.to_csv(f'result_{datetime.datetime.now().strftime("%Y-%m-%d")}.csv',index=False)
print("done~")
结果
最终的爬取结果大致如下:
你可以看到有些答案是空的。转到问题,发现是视频回答。没有文字内容。这被忽略了。当然,您可以删除视频链接并将其添加到结果中。
目前(2021.09)看这个问题,接口没有特别限制,包括我在代码中的请求没有cookies直接捕获,通过修改limit参数为20来减少请求频率。
爬虫意义
最近也在想爬,知道答案的意思。一开始想把所有的答案汇总起来分析,但实际抓起来之后,就想一起读了。我发现阅读表格中的答案的阅读体验很差,所以最好去扫描它们。知乎;但更明显的价值在于这数百个答案的横向对比,答案、评论和作者的粉丝都一目了然。另外还可以根据结果做一些词频分析、词云图展示等,这些就剩下了。
爬虫只是获取数据的一种方式,如何解读是数据更大的价值。
我是TED,每天写爬虫的数据工程师,好久没写Python了。以后想到的一系列Python爬虫项目我会继续更新。欢迎继续关注~
网页视频抓取工具 知乎(可以试试我开发的app:youtube-libraryapp-inthemirror类似safari(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-24 23:03
网页视频抓取工具知乎专栏
对这个问题完全表示不了解,
httpview在.net里面叫做http请求翻译过来就是一种代理方式,
不请自来。表示完全不懂。求告知。
我也是大二,关注这个问题,
我在想这个问题,看来网上有很多答案,但是什么工具才能满足每个人的需求。
可以试试我开发的app:youtube-libraryapp-inthemirror类似safari,目前支持微博、糗事和网站抓取,另外给自己id申请了一个专用账号,里面有全网页面的抓取。
你可以点开当地大学的开放课堂,然后下载一个vpn,发现会员专用vpn就是支持本校课堂网页抓取的,大学嘛,
networkhandler-thesoftwareforturningablog.a-start
最近刚好在找类似的,去搜了一下,相关技术分享,但是其中和抓取微博相关的帖子很少...
其实要抓取电影就用电影院之类的账号绑定web认证,在线发给用户。
youtube-libraryapp-inthemirrorandweb
推荐httpview,目前用下来比fiddler好用。
可以试试通用的websocket抓取,很方便。 查看全部
网页视频抓取工具 知乎(可以试试我开发的app:youtube-libraryapp-inthemirror类似safari(图))
网页视频抓取工具知乎专栏
对这个问题完全表示不了解,
httpview在.net里面叫做http请求翻译过来就是一种代理方式,
不请自来。表示完全不懂。求告知。
我也是大二,关注这个问题,
我在想这个问题,看来网上有很多答案,但是什么工具才能满足每个人的需求。
可以试试我开发的app:youtube-libraryapp-inthemirror类似safari,目前支持微博、糗事和网站抓取,另外给自己id申请了一个专用账号,里面有全网页面的抓取。
你可以点开当地大学的开放课堂,然后下载一个vpn,发现会员专用vpn就是支持本校课堂网页抓取的,大学嘛,
networkhandler-thesoftwareforturningablog.a-start
最近刚好在找类似的,去搜了一下,相关技术分享,但是其中和抓取微博相关的帖子很少...
其实要抓取电影就用电影院之类的账号绑定web认证,在线发给用户。
youtube-libraryapp-inthemirrorandweb
推荐httpview,目前用下来比fiddler好用。
可以试试通用的websocket抓取,很方便。
网页视频抓取工具 知乎(网页视频在线播放b站youtube推荐一个b站视频解析网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 395 次浏览 • 2021-12-22 23:02
网页视频抓取工具知乎,b站,acfun,网页直接下载,不用购买的,不用买会员的,只要有网页有网线随时随地抓网页视频,不限平台,随时随地抓网页视频,
微博视频下载器,好像是,百度可以找到一个。
youtube搬运工
今日头条就不用说了。youtube有很多。
搬运工。
翻墙,
bilibili,acfun,
迅雷下载器
站长之家
提供一个好的下载平台,如图,
空间,
网页视频在线播放
b站youtube
推荐一个b站视频解析网站【也算是良心下载站了...】,支持b站、优酷、爱奇艺、土豆、华数等国内各大视频网站的视频解析下载,几乎满足各大网站、app的需求。
还有个b站视频聚合的网站bilibilihostshandler【虽然有时候更新的很慢,但是分享给大家比较好,大家有需要就下个试试,据说是花了一年时间想出来的,up主是18线cv老菜鸡。
b站小伙伴们看看还能不能帮助到你们哈
直接百度就有很多国内外的视频, 查看全部
网页视频抓取工具 知乎(网页视频在线播放b站youtube推荐一个b站视频解析网站)
网页视频抓取工具知乎,b站,acfun,网页直接下载,不用购买的,不用买会员的,只要有网页有网线随时随地抓网页视频,不限平台,随时随地抓网页视频,
微博视频下载器,好像是,百度可以找到一个。
youtube搬运工
今日头条就不用说了。youtube有很多。
搬运工。
翻墙,
bilibili,acfun,
迅雷下载器
站长之家
提供一个好的下载平台,如图,
空间,
网页视频在线播放
b站youtube
推荐一个b站视频解析网站【也算是良心下载站了...】,支持b站、优酷、爱奇艺、土豆、华数等国内各大视频网站的视频解析下载,几乎满足各大网站、app的需求。
还有个b站视频聚合的网站bilibilihostshandler【虽然有时候更新的很慢,但是分享给大家比较好,大家有需要就下个试试,据说是花了一年时间想出来的,up主是18线cv老菜鸡。
b站小伙伴们看看还能不能帮助到你们哈
直接百度就有很多国内外的视频,
网页视频抓取工具 知乎(向Python头条添加数据信息,完成了微信公号的爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-21 16:05
今天继续为Python头条添加数据信息,完成微信公众号爬虫。接下来我会继续在搜狗的知乎搜索和爬取文章上搜索知乎以及知乎上关于Python的问答。微信公众号的部分文章链接具有时效性,使用一段时间后会出现参数错误,无法访问。但是我们发现在公众号后台点击获取的链接是永久链接,它们的参数不会更改链接不会失败,也就是说只要能获取到这些参数,就可以永久链接获得。通过观察发现,即使是从搜狗搜索词条上的时间敏感链接访问该网页,
所以只要分析这些参数,就可以构建一个永久的链接。
首先可以通过搜狗搜索入口获取Python关键词的搜索结果,地址为:
HOST = 'http://weixin.sogou.com/'
entry = HOST + "weixin?type=2&query=Python&page={}"
提取链接、标题和摘要信息:
import requests as req
import re
rInfo = r'([\s\S]*?)[\s\S]*?\s*([\s\S]*?)'
html = req.get(entry.format(1)) # 第一页
infos = re.findall(rInfo, html)
由于 关键词 搜索会在标题或摘要中生成特定格式的标签,因此需要对其进行过滤:
def remove_tags(s):
return re.sub(r'', '', s)
然后根据时效链接获取文章的内容,从中提取参数信息:
from html import unescape
from urllib.parse import urlencode
def weixin_params(link):
html = req.get(link)
rParams = r'var (biz =.*?".*?");\s*var (sn =.*?".*?");\s*var (mid =.*?".*?");\s*var (idx =.*?".*?");'
params = re.findall(rParams, html)
if len(params) == 0:
return None
return {i.split('=')[0].strip(): i.split('=', 1)[1].strip('|" ') for i in params[0]}
for (link, title, abstract) in infos:
title = unescape(self.remove_tag(title))
abstract = unescape(self.remove_tag(abstract))
params = weixin_params(link)
if params is not None:
link = "http://mp.weixin.qq.com/s?" + urlencode(params)
print(link, title, abstract)
看到文章后,如果觉得这篇文章对你有帮助,请在离开前给我点个赞~谢谢阅读 查看全部
网页视频抓取工具 知乎(向Python头条添加数据信息,完成了微信公号的爬虫)
今天继续为Python头条添加数据信息,完成微信公众号爬虫。接下来我会继续在搜狗的知乎搜索和爬取文章上搜索知乎以及知乎上关于Python的问答。微信公众号的部分文章链接具有时效性,使用一段时间后会出现参数错误,无法访问。但是我们发现在公众号后台点击获取的链接是永久链接,它们的参数不会更改链接不会失败,也就是说只要能获取到这些参数,就可以永久链接获得。通过观察发现,即使是从搜狗搜索词条上的时间敏感链接访问该网页,
所以只要分析这些参数,就可以构建一个永久的链接。
首先可以通过搜狗搜索入口获取Python关键词的搜索结果,地址为:
HOST = 'http://weixin.sogou.com/'
entry = HOST + "weixin?type=2&query=Python&page={}"
提取链接、标题和摘要信息:
import requests as req
import re
rInfo = r'([\s\S]*?)[\s\S]*?\s*([\s\S]*?)'
html = req.get(entry.format(1)) # 第一页
infos = re.findall(rInfo, html)
由于 关键词 搜索会在标题或摘要中生成特定格式的标签,因此需要对其进行过滤:
def remove_tags(s):
return re.sub(r'', '', s)
然后根据时效链接获取文章的内容,从中提取参数信息:
from html import unescape
from urllib.parse import urlencode
def weixin_params(link):
html = req.get(link)
rParams = r'var (biz =.*?".*?");\s*var (sn =.*?".*?");\s*var (mid =.*?".*?");\s*var (idx =.*?".*?");'
params = re.findall(rParams, html)
if len(params) == 0:
return None
return {i.split('=')[0].strip(): i.split('=', 1)[1].strip('|" ') for i in params[0]}
for (link, title, abstract) in infos:
title = unescape(self.remove_tag(title))
abstract = unescape(self.remove_tag(abstract))
params = weixin_params(link)
if params is not None:
link = "http://mp.weixin.qq.com/s?" + urlencode(params)
print(link, title, abstract)
看到文章后,如果觉得这篇文章对你有帮助,请在离开前给我点个赞~谢谢阅读
网页视频抓取工具 知乎(开源数据工具1.Knime.io推荐热门的网页爬虫软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-21 16:05
数据分析和数据应用是当今最流行的,那么我们来推荐几个流行的数据工具。
一:数据采集工具
优采云
这是一款免费、简单、直观的网络爬虫工具,无需编码即可从众多网站中抓取数据。无论您是初学者还是经验丰富的技术人员或业务主管,它都能满足您的需求。为了降低使用难度,优采云为初学者准备了“网站简单模板”,涵盖了市面上大部分主流的网站。使用简单的模板,用户无需任务配置即可采集数据。简单的模板为采集小白树立信心,接下来就可以开始使用“高级模式”了,几分钟就可以帮你捕捉海量数据。
2. 内容抓取器
一款支持智能抓取的网络爬虫软件。其程序运行环境可用于开发、测试和生产服务器。可以使用c#或VB.NET调试或编写脚本来控制爬虫程序。
3.Import.io
基于 Web 的数据抓取工具。它于 2012 年首次在伦敦推出。现在 Import.io 已将其商业模式从 B2C 转变为 B2B。
4. 解析器
一个网页抓取软件,它还提供商业级数据抓取的定制服务。它可以从云端和本地软件中抓取数据并进行数据托管。
二.:开源数据工具
1. 克尼姆
一个分析平台。它可以帮助您发现商业洞察力和市场潜力。它为数据挖掘和机器学习提供了 Eclipse 平台和其他外部扩展。
2. OpenRefine
处理凌乱数据的强大工具:支持数据清洗,支持数据从一种格式到另一种格式的转换,还可以通过网络服务和外部数据进行扩展。
3. R 编程
一种用于统计计算和图形的免费软件编程语言和软件环境。R 语言在开发统计软件和数据分析的数据挖掘工作者中非常流行。
三:数据可视化工具
1. PowerBI
提供本地和云服务。它最初是作为 Excel 插件推出的,PowerBI 很快因其强大的功能而广受欢迎。目前,它被认为是商业分析领域的软件领导者。
2. 求解器
专业的企业绩效管理(.Solver)通过获取所有能够提高公司盈利能力的数据源,致力于提供世界一流的财务报告、预算计划和财务分析。
3.Qlik
自助式数据分析和可视化工具。它具有可视化仪表板,可简化数据分析并帮助公司快速做出业务决策。 查看全部
网页视频抓取工具 知乎(开源数据工具1.Knime.io推荐热门的网页爬虫软件)
数据分析和数据应用是当今最流行的,那么我们来推荐几个流行的数据工具。
一:数据采集工具
优采云
这是一款免费、简单、直观的网络爬虫工具,无需编码即可从众多网站中抓取数据。无论您是初学者还是经验丰富的技术人员或业务主管,它都能满足您的需求。为了降低使用难度,优采云为初学者准备了“网站简单模板”,涵盖了市面上大部分主流的网站。使用简单的模板,用户无需任务配置即可采集数据。简单的模板为采集小白树立信心,接下来就可以开始使用“高级模式”了,几分钟就可以帮你捕捉海量数据。
2. 内容抓取器
一款支持智能抓取的网络爬虫软件。其程序运行环境可用于开发、测试和生产服务器。可以使用c#或VB.NET调试或编写脚本来控制爬虫程序。
3.Import.io
基于 Web 的数据抓取工具。它于 2012 年首次在伦敦推出。现在 Import.io 已将其商业模式从 B2C 转变为 B2B。
4. 解析器
一个网页抓取软件,它还提供商业级数据抓取的定制服务。它可以从云端和本地软件中抓取数据并进行数据托管。
二.:开源数据工具
1. 克尼姆
一个分析平台。它可以帮助您发现商业洞察力和市场潜力。它为数据挖掘和机器学习提供了 Eclipse 平台和其他外部扩展。
2. OpenRefine
处理凌乱数据的强大工具:支持数据清洗,支持数据从一种格式到另一种格式的转换,还可以通过网络服务和外部数据进行扩展。
3. R 编程
一种用于统计计算和图形的免费软件编程语言和软件环境。R 语言在开发统计软件和数据分析的数据挖掘工作者中非常流行。
三:数据可视化工具
1. PowerBI
提供本地和云服务。它最初是作为 Excel 插件推出的,PowerBI 很快因其强大的功能而广受欢迎。目前,它被认为是商业分析领域的软件领导者。
2. 求解器
专业的企业绩效管理(.Solver)通过获取所有能够提高公司盈利能力的数据源,致力于提供世界一流的财务报告、预算计划和财务分析。
3.Qlik
自助式数据分析和可视化工具。它具有可视化仪表板,可简化数据分析并帮助公司快速做出业务决策。
网页视频抓取工具 知乎(下载软件的「IDM」,你一定听说过这个名字吧!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-12-21 16:04
相信大家都知道,作为下载软件的“IDM”,你一定听说过这个名字!全称是Internet Download Manager,简称IDM。
IDM是一款非常经典且功能强大的Windows文件多线程下载加速软件。在电脑玩家中家喻户晓,号称必装HTTP下载神器!除了极致的下载加速性能外,还提供了自动链接抓取、下载队列、站点抓取、映射服务器、音视频下载、国外网盘加速下载、静默下载等诸多功能。
IDM-Windows 最佳下载工具
虽然使用“下载工具”所需的时间比过去少了,但总会遇到一些特别慢的资源需要加速。这时候,比如迅雷靠的是会员续费,或者充斥着烦人的弹窗广告、无用的插件,甚至还有“免费下载软件”等各种“隐私盗窃”或“自带全家桶”的风险不太合适。.
真正的老经典,功能强大实用,干净不受干扰,只需一次支付,终身使用的下载工具,更适合您。而大名鼎鼎的IDM就是这样一款“纯无广告、无干扰、无声下载”的加速下载软件!
多年来,各种下载工具打着“永远免费”的旗号。IDM一直在做自己的事情,维持30美元的高价。深受粉丝喜爱,被誉为“Win平台下最好的下载工具”,可见其与生俱来的实力。
IDM号称让你的下载速度提高5倍,支持续传下载,允许用户自动下载指定类型的文件,支持多线程下载。其 in-speed 技术还会将所有设置动态应用于特定连接类型,以充分利用下载速度。
IDM支持几乎所有主流浏览器,包括Edge、Chrome、谷歌浏览器、Firefox、Safari、Opera,并且可以通过其内置的浏览器功能支持更多的浏览器。
IDM-功能和下载
可以说,IDM作为一款下载工具,在P2P以外的文件下载功能上做到了极致,主要体现在自动链接抓取、静默下载、多线程和多媒体下载等方面,减少了用户运营成本和改善文件下载体验。
自动捕获链接
IDM 可以在使用浏览器下载文件时自动捕获下载链接并添加下载任务。IDM 支持大多数主流浏览器,如 Chrome、Safari、Firefox、Edge、Internet Explorer 等。
如果您使用的浏览器不在IDM的默认支持中,您也可以在软件设置中进行自定义
静默下载
大多数人在下载文件时,会习惯性地将文件保存到固定位置,等待下载完成后再进行进一步处理。如果每次下载都需要重复点击“保存对话框”中的按钮,那将是非常多余和低效的。
IDM 的静默下载功能可以自动最小化下载窗口。如果您想在下载过程中修改保存位置或其他选项,可以直接调用托盘中的IDM图标。
多媒体下载
只要打开要下载的视频的网站页面,IDM就会自动检测在线播放器发送的多媒体请求,并在播放器上显示下载浮动条。用户可以直接下载流媒体网站中的视频,在本地离线观看。IDM支持MP4/MP3/MOV/AAC等常见音视频格式的检测和下载。在设置窗口中,您还可以指定特定站点显示或隐藏软件的下载浮动栏等自定义操作。
强大的扩展功能
IDM还配备了强大的自动下载功能,通过批量下载、定时下载任务、站点爬取等方式满足用户高层次的下载需求!
安排下载任务
通过设置定时下载任务,用户可以让IDM在指定的时间段内自动启动相应的下载任务,无论下载还是暂停等,都可以通过该功能实现。让家里的电脑在工作时间自动下载你需要的文件,到家就可以立即使用,非常方便。
网站抓取
“网站抓取”功能可以让您在输入链接后直接选择要下载的网页的指定内容,无需使用通配符,包括图片、音频、视频、文件或收录完整样式的离线文件。IDM 可以做到。您还可以根据自己的需要自定义站点抓取的内容和规则,并保存起来,方便下次调用。
批量下载
只要使用软件默认或自定义通配符,就可以使用IDM下载链接中收录的所有文件,例如网页中的所有图片。类似的形式如下:
http://www.某网站.com/pictures/img*.jpg
使用上述命令,可以在IDM官网下载所有命名为img001.jpg、img002.jpg等命名规则的图片。
支持国外主流网盘
网站 上的很多国外资源文件都会放在他们常用的网盘里。如果直接下载这些文件,速度会很慢,很容易中断。这时候就需要IDM了。可将这些文件从网盘下载为队列进行批量下载,让您独立自定义每个队列的下载时间和下载文件数,灵活提高下载效率。
目前支持的网盘包括RapidShare、FileServe等,您可以访问官网查看IDM支持的所有网盘服务。遗憾的是,很多外国已经不能直接访问中国了。
原文链接:/idm.html
获得正版:IDM终身版-独家优惠仅需129元 查看全部
网页视频抓取工具 知乎(下载软件的「IDM」,你一定听说过这个名字吧!)
相信大家都知道,作为下载软件的“IDM”,你一定听说过这个名字!全称是Internet Download Manager,简称IDM。
IDM是一款非常经典且功能强大的Windows文件多线程下载加速软件。在电脑玩家中家喻户晓,号称必装HTTP下载神器!除了极致的下载加速性能外,还提供了自动链接抓取、下载队列、站点抓取、映射服务器、音视频下载、国外网盘加速下载、静默下载等诸多功能。
IDM-Windows 最佳下载工具
虽然使用“下载工具”所需的时间比过去少了,但总会遇到一些特别慢的资源需要加速。这时候,比如迅雷靠的是会员续费,或者充斥着烦人的弹窗广告、无用的插件,甚至还有“免费下载软件”等各种“隐私盗窃”或“自带全家桶”的风险不太合适。.
真正的老经典,功能强大实用,干净不受干扰,只需一次支付,终身使用的下载工具,更适合您。而大名鼎鼎的IDM就是这样一款“纯无广告、无干扰、无声下载”的加速下载软件!
多年来,各种下载工具打着“永远免费”的旗号。IDM一直在做自己的事情,维持30美元的高价。深受粉丝喜爱,被誉为“Win平台下最好的下载工具”,可见其与生俱来的实力。
IDM号称让你的下载速度提高5倍,支持续传下载,允许用户自动下载指定类型的文件,支持多线程下载。其 in-speed 技术还会将所有设置动态应用于特定连接类型,以充分利用下载速度。
IDM支持几乎所有主流浏览器,包括Edge、Chrome、谷歌浏览器、Firefox、Safari、Opera,并且可以通过其内置的浏览器功能支持更多的浏览器。
IDM-功能和下载
可以说,IDM作为一款下载工具,在P2P以外的文件下载功能上做到了极致,主要体现在自动链接抓取、静默下载、多线程和多媒体下载等方面,减少了用户运营成本和改善文件下载体验。
自动捕获链接
IDM 可以在使用浏览器下载文件时自动捕获下载链接并添加下载任务。IDM 支持大多数主流浏览器,如 Chrome、Safari、Firefox、Edge、Internet Explorer 等。
如果您使用的浏览器不在IDM的默认支持中,您也可以在软件设置中进行自定义
静默下载
大多数人在下载文件时,会习惯性地将文件保存到固定位置,等待下载完成后再进行进一步处理。如果每次下载都需要重复点击“保存对话框”中的按钮,那将是非常多余和低效的。
IDM 的静默下载功能可以自动最小化下载窗口。如果您想在下载过程中修改保存位置或其他选项,可以直接调用托盘中的IDM图标。
多媒体下载
只要打开要下载的视频的网站页面,IDM就会自动检测在线播放器发送的多媒体请求,并在播放器上显示下载浮动条。用户可以直接下载流媒体网站中的视频,在本地离线观看。IDM支持MP4/MP3/MOV/AAC等常见音视频格式的检测和下载。在设置窗口中,您还可以指定特定站点显示或隐藏软件的下载浮动栏等自定义操作。
强大的扩展功能
IDM还配备了强大的自动下载功能,通过批量下载、定时下载任务、站点爬取等方式满足用户高层次的下载需求!
安排下载任务
通过设置定时下载任务,用户可以让IDM在指定的时间段内自动启动相应的下载任务,无论下载还是暂停等,都可以通过该功能实现。让家里的电脑在工作时间自动下载你需要的文件,到家就可以立即使用,非常方便。
网站抓取
“网站抓取”功能可以让您在输入链接后直接选择要下载的网页的指定内容,无需使用通配符,包括图片、音频、视频、文件或收录完整样式的离线文件。IDM 可以做到。您还可以根据自己的需要自定义站点抓取的内容和规则,并保存起来,方便下次调用。
批量下载
只要使用软件默认或自定义通配符,就可以使用IDM下载链接中收录的所有文件,例如网页中的所有图片。类似的形式如下:
http://www.某网站.com/pictures/img*.jpg
使用上述命令,可以在IDM官网下载所有命名为img001.jpg、img002.jpg等命名规则的图片。
支持国外主流网盘
网站 上的很多国外资源文件都会放在他们常用的网盘里。如果直接下载这些文件,速度会很慢,很容易中断。这时候就需要IDM了。可将这些文件从网盘下载为队列进行批量下载,让您独立自定义每个队列的下载时间和下载文件数,灵活提高下载效率。
目前支持的网盘包括RapidShare、FileServe等,您可以访问官网查看IDM支持的所有网盘服务。遗憾的是,很多外国已经不能直接访问中国了。
原文链接:/idm.html
获得正版:IDM终身版-独家优惠仅需129元
网页视频抓取工具 知乎(网页视频抓取工具知乎上提问到,有人教你怎么抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-15 15:06
网页视频抓取工具知乎上提问到,有人教你怎么抓取知乎上的视频,-15633343-1-1.html有人教你用哪个浏览器插件可以做,
请问你找到了吗,我也在找,
我用的乐网,
公众号可以在线进行知乎专栏文章的整理和预览,
在线观看看知乎的视频
推荐你一个公众号:爱鸡播(ifishgzs),专门做网页视频抓取以及知乎的视频抓取分享,时效性强,免费分享。
手机微信扫一扫就可以的
电脑上知乎。
网页视频抓取软件这个软件挺好用的,无需安装,免费下载。
这个算吗
华一网站抓取器不需要注册或者要收费什么的也不是太难用在里面抓取就行,整理知乎评论不太好使。需要注册或者要交钱什么的,但是真心不建议。
undraw
知乎视频抓取?推荐epubml-pro_step1.0版
我们这里有一个知乎专栏,可以找到知乎里面的任何知识。
楼上也真麻烦,平台在这里,免费的,不会花你一分钱。任何人都可以下载知乎的视频,可以免费使用。
分享个最近在用的,力扣扣的视频下载器,这个可以分享给朋友共享,安卓的也是的!需要的可以来评论里留个下载码, 查看全部
网页视频抓取工具 知乎(网页视频抓取工具知乎上提问到,有人教你怎么抓取)
网页视频抓取工具知乎上提问到,有人教你怎么抓取知乎上的视频,-15633343-1-1.html有人教你用哪个浏览器插件可以做,
请问你找到了吗,我也在找,
我用的乐网,
公众号可以在线进行知乎专栏文章的整理和预览,
在线观看看知乎的视频
推荐你一个公众号:爱鸡播(ifishgzs),专门做网页视频抓取以及知乎的视频抓取分享,时效性强,免费分享。
手机微信扫一扫就可以的
电脑上知乎。
网页视频抓取软件这个软件挺好用的,无需安装,免费下载。
这个算吗
华一网站抓取器不需要注册或者要收费什么的也不是太难用在里面抓取就行,整理知乎评论不太好使。需要注册或者要交钱什么的,但是真心不建议。
undraw
知乎视频抓取?推荐epubml-pro_step1.0版
我们这里有一个知乎专栏,可以找到知乎里面的任何知识。
楼上也真麻烦,平台在这里,免费的,不会花你一分钱。任何人都可以下载知乎的视频,可以免费使用。
分享个最近在用的,力扣扣的视频下载器,这个可以分享给朋友共享,安卓的也是的!需要的可以来评论里留个下载码,
网页视频抓取工具 知乎(从各大视频网站中下载想要的视频,不必安装专用APP)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-12-11 10:10
今天介绍的项目提供了一个很好的解决方案——只需1行命令即可从各大视频网站下载想要的视频,无需安装视频网站专用APP或第一个三方缓存工具——You-Get,Python 工件库。
1
模块介绍
You-Get 是 GitHub 上评价很高的 Python 项目。作为一款精美的命令行应用程序,您可以轻松地从 Web网站 下载视频。下载的视频文件可以直接打开播放,无需安装特定的网页浏览器,也省去了长时间在线看广告的麻烦。
其实you-get不仅可以下载视频文件,还可以下载音乐、图片等其他媒体文件,只要提供目标资源的URL即可。但是you-get下载音乐和图片的功能还不是很全,意义也没有视频下载那么明显,所以本文仅以视频下载为例进行介绍和演示。
GitHub 网址:/soimort/you-get。
You-Get的优势之一是支持优酷、爱奇艺、哔哩哔哩、YouTube等数十个国内外知名视频。网站(下图只是其中的一部分)。对于每个要下载的视频,都可以使用相同的命令直接下载,只需调整目标视频的URL即可。
当然,You-Get 的使用也有一些注意事项。例如,由于网页格式调整或防爬措施变化等因素,可能会出现部分网站或部分视频源无法下载的问题。已经发现的问题会列在这里,使用前可以提前查看;没有办法通过You-Get下载每个视频网站的VIP视频。
更重要的是,不要使用You-Get做可能构成侵犯版权等违法行为的事情。对此,You-Get 专门做了说明。
2
应用
You-Get 可以直接使用“pip install you-get”命令安装。
You-Get的使用同样简单,只要在终端中以“you-get URL(目标视频url)”的形式输入命令,就可以自动下载相应的视频。
You-Get 命令还有一些功能参数,其中两个是最常用的:
此外,还有一些其他参数用于实现设置代理、加载cookies、提取目标源URL等功能。详情请参考官方文档。找个视频来测试一下You-Get的效果,用我的B站视频,网址如下:
/视频/av70633763。
首先使用“-i”参数获取视频的基本信息。按照文档中的例子,在终端输入:
you-get -i "https://www.bilibili.com/video/av57307235/"
成功获取目标视频的基本信息如下图:
可以看到目标视频有4种定义格式,然后去掉-i参数就可以正式下载视频了(默认使用第一种视频格式):
you-get "https://www.bilibili.com/video/av57307235/"
结果如下图所示:
下载视频只用了十几秒,速度还是很快的。 查看全部
网页视频抓取工具 知乎(从各大视频网站中下载想要的视频,不必安装专用APP)
今天介绍的项目提供了一个很好的解决方案——只需1行命令即可从各大视频网站下载想要的视频,无需安装视频网站专用APP或第一个三方缓存工具——You-Get,Python 工件库。
1
模块介绍
You-Get 是 GitHub 上评价很高的 Python 项目。作为一款精美的命令行应用程序,您可以轻松地从 Web网站 下载视频。下载的视频文件可以直接打开播放,无需安装特定的网页浏览器,也省去了长时间在线看广告的麻烦。
其实you-get不仅可以下载视频文件,还可以下载音乐、图片等其他媒体文件,只要提供目标资源的URL即可。但是you-get下载音乐和图片的功能还不是很全,意义也没有视频下载那么明显,所以本文仅以视频下载为例进行介绍和演示。
GitHub 网址:/soimort/you-get。
You-Get的优势之一是支持优酷、爱奇艺、哔哩哔哩、YouTube等数十个国内外知名视频。网站(下图只是其中的一部分)。对于每个要下载的视频,都可以使用相同的命令直接下载,只需调整目标视频的URL即可。
当然,You-Get 的使用也有一些注意事项。例如,由于网页格式调整或防爬措施变化等因素,可能会出现部分网站或部分视频源无法下载的问题。已经发现的问题会列在这里,使用前可以提前查看;没有办法通过You-Get下载每个视频网站的VIP视频。
更重要的是,不要使用You-Get做可能构成侵犯版权等违法行为的事情。对此,You-Get 专门做了说明。
2
应用
You-Get 可以直接使用“pip install you-get”命令安装。
You-Get的使用同样简单,只要在终端中以“you-get URL(目标视频url)”的形式输入命令,就可以自动下载相应的视频。
You-Get 命令还有一些功能参数,其中两个是最常用的:
此外,还有一些其他参数用于实现设置代理、加载cookies、提取目标源URL等功能。详情请参考官方文档。找个视频来测试一下You-Get的效果,用我的B站视频,网址如下:
/视频/av70633763。
首先使用“-i”参数获取视频的基本信息。按照文档中的例子,在终端输入:
you-get -i "https://www.bilibili.com/video/av57307235/"
成功获取目标视频的基本信息如下图:
可以看到目标视频有4种定义格式,然后去掉-i参数就可以正式下载视频了(默认使用第一种视频格式):
you-get "https://www.bilibili.com/video/av57307235/"
结果如下图所示:
下载视频只用了十几秒,速度还是很快的。
网页视频抓取工具 知乎(Shopee上传视频难度不像亚马逊那么大手机就可以完成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-11 10:07
Shopee 的产品发布规则没有亚马逊那么严格。如果你想在亚马逊的产品页面上传视频,你必须完成品牌注册。拥有品牌后,您可以在列表页面上上传视频。这个品牌注册过程需要很长时间,需要寻找相关的服务商,而且要花很多钱。
但是在shopee商品页面上传视频就不需要那么麻烦了,只要有手机就可以完成。上传视频前,您需要提前在手机上安装shopee app。然后将你拍摄的产品视频保存到手机,登录shopee,进入店铺,找到你要上传视频的产品,点击产品右上角的三个点,选择修改产品,在修改页面/视频中点击“添加照片”,选择您要上传的视频并上传。
上传shopee视频有什么需要注意的吗?1. 持续时间不要太长,控制在25秒以内是可行的;2. 拍摄内容应与产品相关,可以在产品模型上展示(多用于衣服),也可以是使用场景展示(用于生活用品),电子产品会展示使用场景和细节。上传的视频不能太大。如果视频过大,可以先在视频压缩软件中进行压缩。这里的压缩视频是为了方便shopee买家在手机上流畅观看。
上传视频后有什么好处吗?最直观的,我们可以直接看到的是,产品页面的主图有视频,有一个播放小图标。手机进入后,会有一段自动播放的视频。与图片相比,视频可以更好地全方位展示。产品。其实shopee上传视频没有亚马逊那么难,所以卖家要做好这一步。 查看全部
网页视频抓取工具 知乎(Shopee上传视频难度不像亚马逊那么大手机就可以完成)
Shopee 的产品发布规则没有亚马逊那么严格。如果你想在亚马逊的产品页面上传视频,你必须完成品牌注册。拥有品牌后,您可以在列表页面上上传视频。这个品牌注册过程需要很长时间,需要寻找相关的服务商,而且要花很多钱。
但是在shopee商品页面上传视频就不需要那么麻烦了,只要有手机就可以完成。上传视频前,您需要提前在手机上安装shopee app。然后将你拍摄的产品视频保存到手机,登录shopee,进入店铺,找到你要上传视频的产品,点击产品右上角的三个点,选择修改产品,在修改页面/视频中点击“添加照片”,选择您要上传的视频并上传。
上传shopee视频有什么需要注意的吗?1. 持续时间不要太长,控制在25秒以内是可行的;2. 拍摄内容应与产品相关,可以在产品模型上展示(多用于衣服),也可以是使用场景展示(用于生活用品),电子产品会展示使用场景和细节。上传的视频不能太大。如果视频过大,可以先在视频压缩软件中进行压缩。这里的压缩视频是为了方便shopee买家在手机上流畅观看。
上传视频后有什么好处吗?最直观的,我们可以直接看到的是,产品页面的主图有视频,有一个播放小图标。手机进入后,会有一段自动播放的视频。与图片相比,视频可以更好地全方位展示。产品。其实shopee上传视频没有亚马逊那么难,所以卖家要做好这一步。
网页视频抓取工具 知乎(打开开发者工具,构造对构造url进行循环,和上次的爬取照片思路 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-11 05:22
)
①打开知乎话题
②打开开发者工具,构造Request url,和上次爬取照片一样()
'''
requests.get()返回的是json
对它进行字典化,好提取键值
'''
from urllib import request
from bs4 import BeautifulSoup
import requests
import re
import json
import math
def getVideo():
m = 0#计数字串个数
num = 0#回答者个数
kv = {'user-agent':'Mozillar/5.0'}
for i in range(math.ceil(783/20)):
url = "https://www.zhihu.com/api/v4/q ... 2Bstr(i*20)+"&platform=desktop&sort_by=default"
r = requests.get(url,headers = kv)
dicurl = json.loads(r.text)#转化成python的对象
③使用谷歌浏览器的开发者工具JSONview,可以看到打开的url中有一个内容,就是我们要找的答案内容,视频url也在里面
④ 将返回的json转换为python对象后,获取content中的内容
content = dicurl["data"][k]["content"]
⑤打开获取的内容,找到href后面的url,打开看看
(1)打开后,视频正是我们想要的,但是发现url不是我们得到的%3A//video/9785442,仔细观察发现这个url已经被重定向
(2) 想知道怎么跳转到这里,我们再F12,打开开发者工具,发现请求了一个新的URL
(3),这是视频播放地址,这个地址结构也很好。最后一串数字是不是很熟悉?data-lens-id中的一串数字
(4) 构造这个地址
videoUrl = "https://lens.zhihu.com/api/v4/videos/"+str(data_lens[j])
⑥ 循环构建 URL,然后访问这些 URL,通过 urllib 库和 os 库进行存储,然后贴出所有代码
<p>from urllib import request
from bs4 import BeautifulSoup
import requests
import re
import json
import math
def getVideo():
m = 0#计数字串个数
num = 0#回答者个数
kv = {'user-agent':'Mozillar/5.0'}
for i in range(math.ceil(783/20)):
try:
url = "https://www.zhihu.com/api/v4/q ... 2Bstr(i*20)+"&platform=desktop&sort_by=default"
r = requests.get(url,headers = kv)
dicurl = json.loads(r.text)
for k in range(20):#每条dicurl里可以解析出20条content数据
name = dicurl["data"][k]["author"]["name"]
ID = dicurl["data"][k]["id"]
question = dicurl["data"][k]["question"]["title"]
content = dicurl["data"][k]["content"]
data_lens = re.findall(r'data-lens-id="(.*?)"',content)
print("正在处理第" + str(num+1) + "个回答--回答者昵称:" + name + "--回答者ID:" + str(ID) + "--" + "问题:" + question)
num = num + 1 # 每次碰到一个content就增加1,代表回答者人数
for j in range(len(data_lens)):
try:
videoUrl = "https://lens.zhihu.com/api/v4/videos/"+str(data_lens[j])
R = requests.get(videoUrl,headers = kv)
Dicurl = json.loads(R.text)
playurl = Dicurl["playlist"]["LD"]["play_url"]
#print(playurl)#跳转后的视频url
videoread = request.urlopen(playurl).read()
print(">>>>>>>>>>>>>>>>>第---" + str(m+1) + "---个视频下载完成 查看全部
网页视频抓取工具 知乎(打开开发者工具,构造对构造url进行循环,和上次的爬取照片思路
)
①打开知乎话题
②打开开发者工具,构造Request url,和上次爬取照片一样()
'''
requests.get()返回的是json
对它进行字典化,好提取键值
'''
from urllib import request
from bs4 import BeautifulSoup
import requests
import re
import json
import math
def getVideo():
m = 0#计数字串个数
num = 0#回答者个数
kv = {'user-agent':'Mozillar/5.0'}
for i in range(math.ceil(783/20)):
url = "https://www.zhihu.com/api/v4/q ... 2Bstr(i*20)+"&platform=desktop&sort_by=default"
r = requests.get(url,headers = kv)
dicurl = json.loads(r.text)#转化成python的对象
③使用谷歌浏览器的开发者工具JSONview,可以看到打开的url中有一个内容,就是我们要找的答案内容,视频url也在里面
④ 将返回的json转换为python对象后,获取content中的内容
content = dicurl["data"][k]["content"]
⑤打开获取的内容,找到href后面的url,打开看看
(1)打开后,视频正是我们想要的,但是发现url不是我们得到的%3A//video/9785442,仔细观察发现这个url已经被重定向
(2) 想知道怎么跳转到这里,我们再F12,打开开发者工具,发现请求了一个新的URL
(3),这是视频播放地址,这个地址结构也很好。最后一串数字是不是很熟悉?data-lens-id中的一串数字
(4) 构造这个地址
videoUrl = "https://lens.zhihu.com/api/v4/videos/"+str(data_lens[j])
⑥ 循环构建 URL,然后访问这些 URL,通过 urllib 库和 os 库进行存储,然后贴出所有代码
<p>from urllib import request
from bs4 import BeautifulSoup
import requests
import re
import json
import math
def getVideo():
m = 0#计数字串个数
num = 0#回答者个数
kv = {'user-agent':'Mozillar/5.0'}
for i in range(math.ceil(783/20)):
try:
url = "https://www.zhihu.com/api/v4/q ... 2Bstr(i*20)+"&platform=desktop&sort_by=default"
r = requests.get(url,headers = kv)
dicurl = json.loads(r.text)
for k in range(20):#每条dicurl里可以解析出20条content数据
name = dicurl["data"][k]["author"]["name"]
ID = dicurl["data"][k]["id"]
question = dicurl["data"][k]["question"]["title"]
content = dicurl["data"][k]["content"]
data_lens = re.findall(r'data-lens-id="(.*?)"',content)
print("正在处理第" + str(num+1) + "个回答--回答者昵称:" + name + "--回答者ID:" + str(ID) + "--" + "问题:" + question)
num = num + 1 # 每次碰到一个content就增加1,代表回答者人数
for j in range(len(data_lens)):
try:
videoUrl = "https://lens.zhihu.com/api/v4/videos/"+str(data_lens[j])
R = requests.get(videoUrl,headers = kv)
Dicurl = json.loads(R.text)
playurl = Dicurl["playlist"]["LD"]["play_url"]
#print(playurl)#跳转后的视频url
videoread = request.urlopen(playurl).read()
print(">>>>>>>>>>>>>>>>>第---" + str(m+1) + "---个视频下载完成
网页视频抓取工具 知乎(Copyfish简而言之,Copyfish这款中文扩展网页版 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-08 09:13
)
模仿鱼
总之,Copyfish这个中文扩展是一个网页版的OCR文本扫描工具。
与移动应用不同的是,Copyfish 不仅支持免费的网页、视频、PDF 文本识别,还可以直接在线翻译。
安装好扩展后,在需要扫描的网页上点击扩展按钮,然后对文本区域进行截图(图片、文字、视频均可):
随后,屏幕右下角会弹出扫描识别的结果,您可以进行调整和复制。
总共只有两步。
对于那些正在学习外语的人来说,这个扩展无疑是非常有用的。
例如,在观看视频或阅读带有外语字幕的材料时,您无法直接复制网页上的翻译文本,Copyfish 可以帮助您做到这一点。
或者,当PDF文件是扫描件或其他带有文字的图片时,Copyfish也能发挥作用。
需要注意的是,在使用 Copyfish 之前,必须先在设置中调整默认输入语言。
只有输入语言与拦截区域的语言相匹配,才能提高识别成功的概率。
如果您经常在多种语言之间切换,您还可以设置最多三种语言的“快速切换”按钮。
同时,您还可以为截图、取消等操作设置快捷键。
使用 Copyfish,您可以扫描图片、弹幕和文档。您不再需要在阅读时手动输入和翻译。
目前,Copyfish支持英文、中文、日文等21种语言的识别和翻译。
不过由于汉字的复杂性,视频和图片的识别过程中可能会出现一些小错误,但都在可以接受的范围内。
另外,除了免费版,Copyfish还提供了两种付费服务,大家可以根据自己的需要进行选择。
查看全部
网页视频抓取工具 知乎(Copyfish简而言之,Copyfish这款中文扩展网页版
)
模仿鱼
总之,Copyfish这个中文扩展是一个网页版的OCR文本扫描工具。
与移动应用不同的是,Copyfish 不仅支持免费的网页、视频、PDF 文本识别,还可以直接在线翻译。
安装好扩展后,在需要扫描的网页上点击扩展按钮,然后对文本区域进行截图(图片、文字、视频均可):
随后,屏幕右下角会弹出扫描识别的结果,您可以进行调整和复制。
总共只有两步。
对于那些正在学习外语的人来说,这个扩展无疑是非常有用的。
例如,在观看视频或阅读带有外语字幕的材料时,您无法直接复制网页上的翻译文本,Copyfish 可以帮助您做到这一点。
或者,当PDF文件是扫描件或其他带有文字的图片时,Copyfish也能发挥作用。
需要注意的是,在使用 Copyfish 之前,必须先在设置中调整默认输入语言。
只有输入语言与拦截区域的语言相匹配,才能提高识别成功的概率。
如果您经常在多种语言之间切换,您还可以设置最多三种语言的“快速切换”按钮。
同时,您还可以为截图、取消等操作设置快捷键。
使用 Copyfish,您可以扫描图片、弹幕和文档。您不再需要在阅读时手动输入和翻译。
目前,Copyfish支持英文、中文、日文等21种语言的识别和翻译。
不过由于汉字的复杂性,视频和图片的识别过程中可能会出现一些小错误,但都在可以接受的范围内。
另外,除了免费版,Copyfish还提供了两种付费服务,大家可以根据自己的需要进行选择。

