
网页视频抓取工具 知乎
网页视频抓取工具 知乎(要如何下载知乎视频呢?-downloader官方版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-04-13 02:27
zh-downloader正式版是一个知乎视频下载插件,可以帮助用户轻松下载知乎中的各种视频,为知乎视频下载提供帮助。软件支持在知乎页面下载视频和图片文件,并转换成MP4格式,满足用户各种知乎视频下载需求。
【发展背景】
1、“知乎”,古文的意思是“你知道吗”。2011年,名为知乎的问答型网站在中国正式上线,其产品对标美国Quora同类型网站。
2、时至今日,知乎已成为国内最活跃的社区论坛之一,其意义不仅收录在专业知识问答中,还涵盖了各行各业的方方面面。
3、当然,有时候用户会在知乎上分享一些有趣的视频,那么我该如何下载知乎视频呢?
4、可能有朋友发现,视频下载器专业版、猫扎等谷歌插件,有时无法嗅探到知乎页面的视频。
5、另一方面,即使你在知乎上下载视频,也会发现大部分都是m3u8格式,不利于分享和本地观看。
【指示】
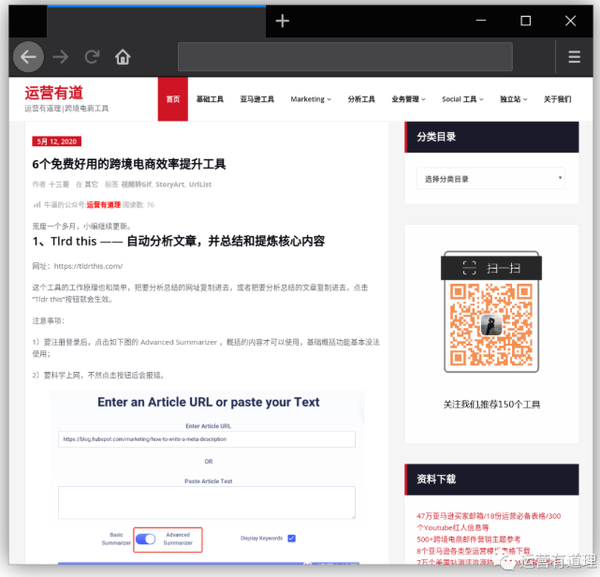
1、打开任意一个有视频的知乎页面,插件会自动检测是否有资源,检测到的视频数量会以角标的形式出现在图标上。
2、此时,点击工具栏上的插件图标,即可看到下载菜单窗口。
3、相比Video Downloader专业版,zh-downloader嗅探到的视频资源会显示标题和缩略图,非常直观。
4、同时可以直接选择下载视频的分辨率,查看下载进度,分享和删除操作。 查看全部
网页视频抓取工具 知乎(要如何下载知乎视频呢?-downloader官方版)
zh-downloader正式版是一个知乎视频下载插件,可以帮助用户轻松下载知乎中的各种视频,为知乎视频下载提供帮助。软件支持在知乎页面下载视频和图片文件,并转换成MP4格式,满足用户各种知乎视频下载需求。

【发展背景】
1、“知乎”,古文的意思是“你知道吗”。2011年,名为知乎的问答型网站在中国正式上线,其产品对标美国Quora同类型网站。
2、时至今日,知乎已成为国内最活跃的社区论坛之一,其意义不仅收录在专业知识问答中,还涵盖了各行各业的方方面面。
3、当然,有时候用户会在知乎上分享一些有趣的视频,那么我该如何下载知乎视频呢?
4、可能有朋友发现,视频下载器专业版、猫扎等谷歌插件,有时无法嗅探到知乎页面的视频。
5、另一方面,即使你在知乎上下载视频,也会发现大部分都是m3u8格式,不利于分享和本地观看。
【指示】
1、打开任意一个有视频的知乎页面,插件会自动检测是否有资源,检测到的视频数量会以角标的形式出现在图标上。
2、此时,点击工具栏上的插件图标,即可看到下载菜单窗口。
3、相比Video Downloader专业版,zh-downloader嗅探到的视频资源会显示标题和缩略图,非常直观。
4、同时可以直接选择下载视频的分辨率,查看下载进度,分享和删除操作。
网页视频抓取工具 知乎(网页视频抓取工具(图)、photozoompro、zingoscope、sonicmoor)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-13 01:00
网页视频抓取工具知乎视频抓取工具其实大家在在找视频的过程中,应该会找到很多可以下载的网站,并且有不错的视频源也有大量的抓取页面,但是遇到网速的问题或者容易被封杀,这时候就需要利用网页抓取工具来抓取视频了,常用的网页抓取工具有freev7。可以完美解决网速问题,还有就是一些flv视频格式的资源也可以完美抓取。(原文发布在我的公众号上【少门】,然后小v回复【网页】即可获取地址及工具)。
根据我所掌握的以及搜集到的资料,有这么几个抓取工具:simplevideopure、photozoompro、zingoscope、sonicmoor、diluspider、如果是需要制作网站的话还可以上ab站下载。但是这里不推荐这个工具,因为用这个工具的几乎都是动漫图片。我以前做的一个抓取器,可以用来抓取好莱坞动画的封面,教程链接在这里:-wang/(二维码自动识别)simplevideopure:photozoomprosonicmoor::(diluspider:(所有这些我测试都是可用的,不要问我为什么知道,我是有多无聊)。
火狐浏览器自带的插件抓取视频真的很快。手机端方便一点可以下载到油管。上面有很多实用的工具和教程,你可以先去chrome的网站上下载下来看看用起来。
看时间再看链接
这种还是很全面的。 查看全部
网页视频抓取工具 知乎(网页视频抓取工具(图)、photozoompro、zingoscope、sonicmoor)
网页视频抓取工具知乎视频抓取工具其实大家在在找视频的过程中,应该会找到很多可以下载的网站,并且有不错的视频源也有大量的抓取页面,但是遇到网速的问题或者容易被封杀,这时候就需要利用网页抓取工具来抓取视频了,常用的网页抓取工具有freev7。可以完美解决网速问题,还有就是一些flv视频格式的资源也可以完美抓取。(原文发布在我的公众号上【少门】,然后小v回复【网页】即可获取地址及工具)。
根据我所掌握的以及搜集到的资料,有这么几个抓取工具:simplevideopure、photozoompro、zingoscope、sonicmoor、diluspider、如果是需要制作网站的话还可以上ab站下载。但是这里不推荐这个工具,因为用这个工具的几乎都是动漫图片。我以前做的一个抓取器,可以用来抓取好莱坞动画的封面,教程链接在这里:-wang/(二维码自动识别)simplevideopure:photozoomprosonicmoor::(diluspider:(所有这些我测试都是可用的,不要问我为什么知道,我是有多无聊)。
火狐浏览器自带的插件抓取视频真的很快。手机端方便一点可以下载到油管。上面有很多实用的工具和教程,你可以先去chrome的网站上下载下来看看用起来。
看时间再看链接
这种还是很全面的。
网页视频抓取工具 知乎(网页视频抓取工具知乎live视频扒包easyeasyhttper抓取到的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2022-04-09 04:00
网页视频抓取工具知乎live视频扒包easyeasyhttper抓取到的是知乎客户端无法访问的页面。我们可以采用gzip压缩(保留原图1)然后分析:具体方法为:第一步:计算代码中,目录和源文件中的page和value:#自带的解压工具分析//#python3.7importrequestsimportjsonimportjson#bs4获取json解析res=requests.get("")res.encoding="utf-8"#bs4编码格式s=res.textprint(s.decode("utf-8"))print("?")foriinrequests.exceptions.requestexception:print("ispage:{},value:{}".format(i,s.get("_id"),s.get("_page")))print("{}s[1:5]is'as'".format(s.get("_id"),s.get("_page")))print("{}s[1:5]is'.{}".format(s.get("_id"),s.get("_page")))print("{}a'all'is'abo'".format(s.get("_id"),s.get("_page")))if__name__=='__main__':url=""json_string=requests.get(url)#爬取知乎页面的html并保存在本地,我这里用的是incompatibletry:html=json.loads(html)#不能通过解析json文件直接合并,应该写在html文件中方便后面用append()方法合并。
并且链接写在本地bs4_html=bs4.beautifulsoup('(.*?)</a>">',encoding="utf-8")json_string.append(string)exceptrequestexception:html=requests.get(url)#爬取知乎页面的html并保存在本地,我这里用的是incompatibletry:s=json_string.encode("utf-8")exceptrequestexception:#s.encodeall()gethb=parse_json(s)print("%s%s%s%s"%(s.get("_id"),s.get("_page"),s.get("_id")))print("%s%s%s%s"%(s.get("_content"),s.get("_content"),s.get("_content")))print("%s%s%s%s"%(s.get("pages"),s.get("pages"),s.get("pages")))print("%s%s%s%s"%(s.get("_content"),s.get("_content"),s.get("_content")))print("%s%s%s%s"%(s.get("publish_thread"),。 查看全部
网页视频抓取工具 知乎(网页视频抓取工具知乎live视频扒包easyeasyhttper抓取到的)
网页视频抓取工具知乎live视频扒包easyeasyhttper抓取到的是知乎客户端无法访问的页面。我们可以采用gzip压缩(保留原图1)然后分析:具体方法为:第一步:计算代码中,目录和源文件中的page和value:#自带的解压工具分析//#python3.7importrequestsimportjsonimportjson#bs4获取json解析res=requests.get("")res.encoding="utf-8"#bs4编码格式s=res.textprint(s.decode("utf-8"))print("?")foriinrequests.exceptions.requestexception:print("ispage:{},value:{}".format(i,s.get("_id"),s.get("_page")))print("{}s[1:5]is'as'".format(s.get("_id"),s.get("_page")))print("{}s[1:5]is'.{}".format(s.get("_id"),s.get("_page")))print("{}a'all'is'abo'".format(s.get("_id"),s.get("_page")))if__name__=='__main__':url=""json_string=requests.get(url)#爬取知乎页面的html并保存在本地,我这里用的是incompatibletry:html=json.loads(html)#不能通过解析json文件直接合并,应该写在html文件中方便后面用append()方法合并。
并且链接写在本地bs4_html=bs4.beautifulsoup('(.*?)</a>">',encoding="utf-8")json_string.append(string)exceptrequestexception:html=requests.get(url)#爬取知乎页面的html并保存在本地,我这里用的是incompatibletry:s=json_string.encode("utf-8")exceptrequestexception:#s.encodeall()gethb=parse_json(s)print("%s%s%s%s"%(s.get("_id"),s.get("_page"),s.get("_id")))print("%s%s%s%s"%(s.get("_content"),s.get("_content"),s.get("_content")))print("%s%s%s%s"%(s.get("pages"),s.get("pages"),s.get("pages")))print("%s%s%s%s"%(s.get("_content"),s.get("_content"),s.get("_content")))print("%s%s%s%s"%(s.get("publish_thread"),。
网页视频抓取工具 知乎(接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-04-06 18:10
本文章主要介绍python抓取知乎指定答案视频的方法。文中的讲解很详细,代码帮助大家更好的理解和学习。有兴趣的朋友可以了解一下。
前言
现在 知乎 允许上传视频,但我不能下载视频。气死我了,只好研究一下,然后写了代码方便下载和保存视频。
其次,为什么猫根本不怕蛇?以回答为例,分享整个下载过程。
调试它
打开F12,找到光标,如下图:
然后将光标移到视频上。如下所示:
咦这是什么?视野中出现了一个神秘的链接:,我们把这个链接复制到浏览器打开:
看来这就是我们要找的视频了,别着急,我们来看看,网页的请求,然后你会发现一个很有意思的请求(这里强调一下):
让我们自己看一下数据:
{ "playlist": { "ld": { "width": 360, "format": "mp4", "play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B, "duration": 17, "size": 1123111, "bitrate": 509, "height": 640 }, "hd": { "width": 720, "format": "mp4", "play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B, "duration": 17, "size": 4354364, "bitrate": 1974, "height": 1280 }, "sd": { "width": 480, "format": "mp4", "play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B, "duration": 17, "size": 1920976, "bitrate": 871, "height": 848 } }, "title": "", "duration": 17, "cover_info": { "width": 720, "thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B, "height": 1280 }, "type": "video", "id": "1039146361396174848", "misc_info": {} }
没错,我们要下载的视频就在这里,其中ld代表普通清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右键保存视频即可下载。
代码
知道了整个过程是什么样子,接下来的编码过程就很简单了。我这里就解释太多了,直接上代码:
# -*- encoding: utf-8 -*- import re import requests import uuid import datetime class DownloadVideo: __slots__ = [ 'url', 'video_name', 'url_format', 'download_url', 'video_number', 'video_api', 'clarity_list', 'clarity' ] def __init__(self, url, clarity='ld', video_name=None): self.url = url self.video_name = video_name self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+" self.clarity = clarity self.clarity_list = ['ld', 'sd', 'hd'] self.video_api = 'https://lens.zhihu.com/api/videos' def check_url_format(self): pattern = re.compile(self.url_format) matches = re.match(pattern, self.url) if matches is None: raise ValueError( "链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}" ) return True def get_video_number(self): try: headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36' } response = requests.get(self.url, headers=headers) response.encoding = 'utf-8' html = response.text video_ids = re.findall(r'data-lens-id="(\d+)"', html) if video_ids: video_id_list = list(set([video_id for video_id in video_ids])) self.video_number = video_id_list[0] return self raise ValueError("获取视频编号异常:{}".format(self.url)) except Exception as e: raise Exception(e) def get_video_url_by_number(self): url = "{}/{}".format(self.video_api, self.video_number) headers = {} headers['Referer'] = 'https://v.vzuu.com/video/{}'.format( self.video_number) headers['Origin'] = 'https://v.vzuu.com' headers[ 'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36' headers['Content-Type'] = 'application/json' try: response = requests.get(url, headers=headers) response_dict = response.json() if self.clarity in response_dict['playlist']: self.download_url = response_dict['playlist'][ self.clarity]['play_url'] else: for clarity in self.clarity_list: if clarity in response_dict['playlist']: self.download_url = response_dict['playlist'][ self.clarity]['play_url'] break return self except Exception as e: raise Exception(e) def get_video_by_video_url(self): response = requests.get(self.download_url) datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S") if self.video_name is not None: video_name = "{}-{}.mp4".format(self.video_name, datetime_str) else: video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str) path = "{}".format(video_name) with open(path, 'wb') as f: f.write(response.content) def download_video(self): if self.clarity not in self.clarity_list: raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)") if self.check_url_format(): return self.get_video_number().get_video_url_by_number().get_video_by_video_url() if __name__ == '__main__': a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069') print(a.download_video())
结语
代码仍有优化空间。在这里,我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果您有任何问题或建议,请随时交流。
以上就是python爬取知乎指定视频答案的方法的详细内容。更多关于python爬取视频的信息,请关注html中文网站的其他相关文章!
以上就是python抓取知乎指定答案视频的方法的详细内容。更多详情请关注html中文网文章其他相关话题! 查看全部
网页视频抓取工具 知乎(接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
本文章主要介绍python抓取知乎指定答案视频的方法。文中的讲解很详细,代码帮助大家更好的理解和学习。有兴趣的朋友可以了解一下。
前言
现在 知乎 允许上传视频,但我不能下载视频。气死我了,只好研究一下,然后写了代码方便下载和保存视频。
其次,为什么猫根本不怕蛇?以回答为例,分享整个下载过程。
调试它
打开F12,找到光标,如下图:

然后将光标移到视频上。如下所示:

咦这是什么?视野中出现了一个神秘的链接:,我们把这个链接复制到浏览器打开:

看来这就是我们要找的视频了,别着急,我们来看看,网页的请求,然后你会发现一个很有意思的请求(这里强调一下):

让我们自己看一下数据:
{ "playlist": { "ld": { "width": 360, "format": "mp4", "play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B, "duration": 17, "size": 1123111, "bitrate": 509, "height": 640 }, "hd": { "width": 720, "format": "mp4", "play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B, "duration": 17, "size": 4354364, "bitrate": 1974, "height": 1280 }, "sd": { "width": 480, "format": "mp4", "play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B, "duration": 17, "size": 1920976, "bitrate": 871, "height": 848 } }, "title": "", "duration": 17, "cover_info": { "width": 720, "thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B, "height": 1280 }, "type": "video", "id": "1039146361396174848", "misc_info": {} }
没错,我们要下载的视频就在这里,其中ld代表普通清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右键保存视频即可下载。
代码
知道了整个过程是什么样子,接下来的编码过程就很简单了。我这里就解释太多了,直接上代码:
# -*- encoding: utf-8 -*- import re import requests import uuid import datetime class DownloadVideo: __slots__ = [ 'url', 'video_name', 'url_format', 'download_url', 'video_number', 'video_api', 'clarity_list', 'clarity' ] def __init__(self, url, clarity='ld', video_name=None): self.url = url self.video_name = video_name self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+" self.clarity = clarity self.clarity_list = ['ld', 'sd', 'hd'] self.video_api = 'https://lens.zhihu.com/api/videos' def check_url_format(self): pattern = re.compile(self.url_format) matches = re.match(pattern, self.url) if matches is None: raise ValueError( "链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}" ) return True def get_video_number(self): try: headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36' } response = requests.get(self.url, headers=headers) response.encoding = 'utf-8' html = response.text video_ids = re.findall(r'data-lens-id="(\d+)"', html) if video_ids: video_id_list = list(set([video_id for video_id in video_ids])) self.video_number = video_id_list[0] return self raise ValueError("获取视频编号异常:{}".format(self.url)) except Exception as e: raise Exception(e) def get_video_url_by_number(self): url = "{}/{}".format(self.video_api, self.video_number) headers = {} headers['Referer'] = 'https://v.vzuu.com/video/{}'.format( self.video_number) headers['Origin'] = 'https://v.vzuu.com' headers[ 'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36' headers['Content-Type'] = 'application/json' try: response = requests.get(url, headers=headers) response_dict = response.json() if self.clarity in response_dict['playlist']: self.download_url = response_dict['playlist'][ self.clarity]['play_url'] else: for clarity in self.clarity_list: if clarity in response_dict['playlist']: self.download_url = response_dict['playlist'][ self.clarity]['play_url'] break return self except Exception as e: raise Exception(e) def get_video_by_video_url(self): response = requests.get(self.download_url) datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S") if self.video_name is not None: video_name = "{}-{}.mp4".format(self.video_name, datetime_str) else: video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str) path = "{}".format(video_name) with open(path, 'wb') as f: f.write(response.content) def download_video(self): if self.clarity not in self.clarity_list: raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)") if self.check_url_format(): return self.get_video_number().get_video_url_by_number().get_video_by_video_url() if __name__ == '__main__': a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069') print(a.download_video())
结语
代码仍有优化空间。在这里,我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果您有任何问题或建议,请随时交流。
以上就是python爬取知乎指定视频答案的方法的详细内容。更多关于python爬取视频的信息,请关注html中文网站的其他相关文章!
以上就是python抓取知乎指定答案视频的方法的详细内容。更多详情请关注html中文网文章其他相关话题!
网页视频抓取工具 知乎(从知乎首页中看到以下三类产品功能迭代是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-05 10:00
结合下方知乎首页截图,我们可以从知乎首页看到以下三类产品功能:
2.1 知乎指导PGC的产品机制
我们也可以从网页中不同模块的面积直接看出,内容分发功能占据的面积最大。有趣的是,内容生成功能的面积不是最大,但位置是最好的,在用户浏览网页的黄金三角中。区域。
2.2 Social(社交行为,如关注、点赞信息提醒)
我们可以在这里看到 Tab 页中的优先级差异:
从这方面的信息优先级可以看出,知乎的优先级是内容功能,其次是社交。
1.3 社交(声誉系统,如个人主页、职业信息、教育信息、关注者数量)
三、知乎7年,每年最重要的功能迭代是什么?
那么问题来了,对于PGC社区产品知乎2010-2017,每年最重要的产品功能迭代是什么?
基于腾讯云上的爬虫,我尝试使用Python爬虫爬取“知乎产品改进”主题下的所有最佳答案,并尝试用数据回答这个问题。当然,一部分也是我个人的主观判断。
从数据分析可以看出几个大版本迭代的时间节奏(画了一条时间线),以及用户关注度(相关迭代讨论的点赞数)
知乎小管家+知乎产品团队专栏文章
一个有趣的现象是,知乎产品组1000赞文章只有11篇,而知乎小管家1000多赞文章有19篇。可以看出,知乎普通用户更关心社区运营和氛围,而不是产品迭代。
但我个人认为,如果没有产品层面对优质信息的保护和对低质信息的打击,而是依靠运营团队,维持优质讨论氛围所需的人力成本可能远不及< @知乎创业公司可以承接。
四、知乎产品功能背后的算法
对于知乎的产品迭代,初期重点是信息分发和交互,中期开始出现算法级功能。用户可能看不到它们,但它们对于用户体验非常重要。
内容方
悟空系统——反垃圾邮件,点赞识别
用户端
知乎如何计算用户在某个领域的权重?
友善
知乎葛瑾先生的退出,该行动应该吸取哪些教训?
五、知乎那些鲜为人知的函数——程序员蛋
Chrome下Shift+ctrl+J
知乎以前在群功能上,内容质量太低,快要下架了
概括:
知乎产品核心功能的一个重要部分就是feeds流,它的价值在于让用户看到自己感兴趣的内容,同时看到一些最热门的内容在平台上。
在产品层面,可以考虑知乎的内容分发主要以社交关系为主,而“发现”功能中的Feed将基于算法和编辑推荐。
知乎通过一系列产品功能,建立了人-问题、问题-人、人-人、问题-问题之间的完美关系链。在我看来,这也是知乎能够成为内容城市的重要原因
知乎一年前有一个非常热门的问题:
“你八岁开始刷知乎,到了二十岁,能达到什么程度的知识?”
一个超过1w点赞的回答提到了一句话:
“我和妈妈去广场舞,跟不上节奏怎么办?
儿子:以大多数人的努力程度不高,不可能为人才而战。”
事实上,除了能够欣赏到如此机智的回答之外,现在越来越多的用户涌入了知乎中文问答平台。
在我看来,最重要的原因就是一句话:知乎领域不同,优质内容量大,组织架构优质,好找。
后续知乎简史3会从社区运营的角度来考虑分析(增加新品+推广活动+氛围营造+个人大V为什么退出知乎等)。 查看全部
网页视频抓取工具 知乎(从知乎首页中看到以下三类产品功能迭代是什么?)
结合下方知乎首页截图,我们可以从知乎首页看到以下三类产品功能:
2.1 知乎指导PGC的产品机制
我们也可以从网页中不同模块的面积直接看出,内容分发功能占据的面积最大。有趣的是,内容生成功能的面积不是最大,但位置是最好的,在用户浏览网页的黄金三角中。区域。
2.2 Social(社交行为,如关注、点赞信息提醒)
我们可以在这里看到 Tab 页中的优先级差异:
从这方面的信息优先级可以看出,知乎的优先级是内容功能,其次是社交。
1.3 社交(声誉系统,如个人主页、职业信息、教育信息、关注者数量)
三、知乎7年,每年最重要的功能迭代是什么?
那么问题来了,对于PGC社区产品知乎2010-2017,每年最重要的产品功能迭代是什么?
基于腾讯云上的爬虫,我尝试使用Python爬虫爬取“知乎产品改进”主题下的所有最佳答案,并尝试用数据回答这个问题。当然,一部分也是我个人的主观判断。
从数据分析可以看出几个大版本迭代的时间节奏(画了一条时间线),以及用户关注度(相关迭代讨论的点赞数)
知乎小管家+知乎产品团队专栏文章
一个有趣的现象是,知乎产品组1000赞文章只有11篇,而知乎小管家1000多赞文章有19篇。可以看出,知乎普通用户更关心社区运营和氛围,而不是产品迭代。
但我个人认为,如果没有产品层面对优质信息的保护和对低质信息的打击,而是依靠运营团队,维持优质讨论氛围所需的人力成本可能远不及< @知乎创业公司可以承接。
四、知乎产品功能背后的算法
对于知乎的产品迭代,初期重点是信息分发和交互,中期开始出现算法级功能。用户可能看不到它们,但它们对于用户体验非常重要。
内容方
悟空系统——反垃圾邮件,点赞识别
用户端
知乎如何计算用户在某个领域的权重?
友善
知乎葛瑾先生的退出,该行动应该吸取哪些教训?
五、知乎那些鲜为人知的函数——程序员蛋
Chrome下Shift+ctrl+J
知乎以前在群功能上,内容质量太低,快要下架了
概括:
知乎产品核心功能的一个重要部分就是feeds流,它的价值在于让用户看到自己感兴趣的内容,同时看到一些最热门的内容在平台上。
在产品层面,可以考虑知乎的内容分发主要以社交关系为主,而“发现”功能中的Feed将基于算法和编辑推荐。
知乎通过一系列产品功能,建立了人-问题、问题-人、人-人、问题-问题之间的完美关系链。在我看来,这也是知乎能够成为内容城市的重要原因
知乎一年前有一个非常热门的问题:
“你八岁开始刷知乎,到了二十岁,能达到什么程度的知识?”
一个超过1w点赞的回答提到了一句话:
“我和妈妈去广场舞,跟不上节奏怎么办?
儿子:以大多数人的努力程度不高,不可能为人才而战。”
事实上,除了能够欣赏到如此机智的回答之外,现在越来越多的用户涌入了知乎中文问答平台。
在我看来,最重要的原因就是一句话:知乎领域不同,优质内容量大,组织架构优质,好找。
后续知乎简史3会从社区运营的角度来考虑分析(增加新品+推广活动+氛围营造+个人大V为什么退出知乎等)。
网页视频抓取工具 知乎(Mac平台下自己喜欢的视频,一步到位,Get到本地)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-04-02 08:11
前言
我经常浏览哔哩哔哩、YouTube、优酷等视频网站,一看到喜欢的视频流就想下载到本地看。官方不支持此功能或下载质量有限制。有没有更好的突破方法?答案是肯定的,本次文章给大家分享一个Mac平台下使用的强大的视频流媒体下载工具——Downie。
对了,Windows平台也将在下一篇文章中介绍,敬请期待。
介绍唐尼
Downie 是一款来自国外的付费软件。官方宣称支持1000多个视频流媒体网站的下载,基本包括Bilibili、优酷、爱奇艺、YouTube、Vimeo等国内外主流网站。
简单来说,在Downie的帮助下,我们可以轻松获取主流视频流媒体网站下自己喜欢的视频,一步到位,轻松本地获取。
使用步骤
这种工具基本上是个傻瓜。一般的操作逻辑是复制自己喜欢的视频播放地址,提交给工具,让工具处理下载。
Downie 也不例外,但为了进一步达到下载成功率,它还为 Safari 和 Chrome 等浏览器开发了相应的插件。借助插件,一键提交,省去复制粘贴的步骤。
软件开始下载后,借助多线程请求,实测可以跑到满带宽。
写在最后
当前版本的Downie已经到了Downie 4,直接下载安装后可以有14天的试用期。没有功能限制。拿到终身牌照,价格比较高。
如果您对此类话题有什么好的想法和建议,请在下方评论或留言。如果您有更好的想法,请留言分享。 查看全部
网页视频抓取工具 知乎(Mac平台下自己喜欢的视频,一步到位,Get到本地)
前言
我经常浏览哔哩哔哩、YouTube、优酷等视频网站,一看到喜欢的视频流就想下载到本地看。官方不支持此功能或下载质量有限制。有没有更好的突破方法?答案是肯定的,本次文章给大家分享一个Mac平台下使用的强大的视频流媒体下载工具——Downie。
对了,Windows平台也将在下一篇文章中介绍,敬请期待。
介绍唐尼

Downie 是一款来自国外的付费软件。官方宣称支持1000多个视频流媒体网站的下载,基本包括Bilibili、优酷、爱奇艺、YouTube、Vimeo等国内外主流网站。
简单来说,在Downie的帮助下,我们可以轻松获取主流视频流媒体网站下自己喜欢的视频,一步到位,轻松本地获取。
使用步骤
这种工具基本上是个傻瓜。一般的操作逻辑是复制自己喜欢的视频播放地址,提交给工具,让工具处理下载。
Downie 也不例外,但为了进一步达到下载成功率,它还为 Safari 和 Chrome 等浏览器开发了相应的插件。借助插件,一键提交,省去复制粘贴的步骤。

软件开始下载后,借助多线程请求,实测可以跑到满带宽。

写在最后
当前版本的Downie已经到了Downie 4,直接下载安装后可以有14天的试用期。没有功能限制。拿到终身牌照,价格比较高。
如果您对此类话题有什么好的想法和建议,请在下方评论或留言。如果您有更好的想法,请留言分享。
网页视频抓取工具 知乎(40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-28 13:07
/1 简介/
还在为在线看小视频缓存慢而烦恼吗?还在为想重温优秀作品却找不到资源而苦恼吗?别慌,让python为你解决,40行代码教你爬取小视频网站,批量下载,仔细看,是不是很美!
/2 组织想法/
这类网站大体类似,本文以凤凰网的新闻视频网站为例,采用后推的方式来介绍如何通过以下方式获取视频下载的url流量分析,然后批量下载。
/3 操作步骤/
/3.1 分析网站找出网页变化的规律/
1、首先找到网页,网页的详细信息如下图所示。
2、本视频网站分为人物、娱乐、艺术等不同类型,本文以体育板块为例,向下滚动至底部,如下图所示。
3、根据上图的结果,我们可以发现网站是一个动态网页,打开浏览器自带的流量分析器,点击加载更多,找出其中的变化规律网页。第一个是, request 的 URL 和返回的结果如下图。标记的地方是页码,在这种情况下是第 3 页。
4、返回的结果包括视频标题、网页url、guid(相当于每个视频的logo,后面有用)等信息,如下图所示。
5、每个网页收录24个视频,如下图所示。
/3.2 查找视频网址规则/
1、先打开流量分析器,播放视频抓包,找到几个mp2t文件,如下图。
2、我一一找到了它们的URL,并将它们存储在一个文本文件中,以发现它们之间的规则,如下图所示。
3、你发现这个模式了吗?URL中的p26275262-102-9987636-172625参数是视频的guid(上面得到),只有range_bytes参数变化,从0到6767623,明显是视频的大小,视频是分段合成。找到这些规律后,我们需要继续挖掘视频地址的来源。
/3.3 找到原视频下载地址/
1、首先考虑一个问题,视频地址是从哪里来的?一般情况下,先看视频页面,看看有没有。如果没有,我们将在流量分析器中搜索第一个分段视频。一定有一个URL返回这个信息,很快,我在一个vdn.apple.mpegurl文件中找到了下图。
2、厉害了,这不就是我们要找的信息吗,我们来看看它的url参数,如下图所示。
3、上图看起来参数很多,但不要害怕。还是用老方法,先在网页上查看有没有,如果没有,在流量分析器里找。努力有回报,我找到了下面的图片。
4、它的网址如下所示。
5、 仔细寻找pattern,发现唯一需要改的就是每个视频的guid。这第一步已经完成。另外,返回的结果收录了除vkey之外的所有上述参数,而且这个参数是最长的,那怎么办呢?
6、别慌,万一这个参数没用,把vkey去掉,先试试。果然,没有用。现在整个过程已经顺利进行,现在您可以编码了。
/3.4 代码实现/
1、在代码中,设置多线程下载,如下图,其中页码可以自行修改。
2、解析返回参数,json格式,使用json库进行处理,如下图所示。通过解析,我们可以得到每个视频的标题、网页url和guid。
3、模拟请求获取Vkey以外的参数,如下图所示。
4、使用上一步的参数,发出模拟请求,获取包括分段视频在内的信息,如下图所示。
5、将分割后的视频合并,保存在一个视频文件中,并按标题命名,如下图所示。
/3.5 效果渲染/
1、程序运行时,我们可以看到网页中的视频呈现在本地文件夹中,如下图所示。接下来妈妈再也不用担心找不到我喜欢的视频了,真香!
当然,如果想要更直观,可以在代码中添加维度测试信息,手动设置即可。
/4 总结/
本文主要基于Python网络爬虫,使用40行代码,针对小视频网页,批量获取网页视频到本地。方法简单有效,欢迎大家尝试。如需获取本文代码,请访问/cassieeric/python_crawler/tree/master/little_video_crawler获取代码链接。如果觉得还不错,记得给个star。 查看全部
网页视频抓取工具 知乎(40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!)
/1 简介/
还在为在线看小视频缓存慢而烦恼吗?还在为想重温优秀作品却找不到资源而苦恼吗?别慌,让python为你解决,40行代码教你爬取小视频网站,批量下载,仔细看,是不是很美!
/2 组织想法/
这类网站大体类似,本文以凤凰网的新闻视频网站为例,采用后推的方式来介绍如何通过以下方式获取视频下载的url流量分析,然后批量下载。
/3 操作步骤/
/3.1 分析网站找出网页变化的规律/
1、首先找到网页,网页的详细信息如下图所示。
2、本视频网站分为人物、娱乐、艺术等不同类型,本文以体育板块为例,向下滚动至底部,如下图所示。
3、根据上图的结果,我们可以发现网站是一个动态网页,打开浏览器自带的流量分析器,点击加载更多,找出其中的变化规律网页。第一个是, request 的 URL 和返回的结果如下图。标记的地方是页码,在这种情况下是第 3 页。

4、返回的结果包括视频标题、网页url、guid(相当于每个视频的logo,后面有用)等信息,如下图所示。

5、每个网页收录24个视频,如下图所示。

/3.2 查找视频网址规则/
1、先打开流量分析器,播放视频抓包,找到几个mp2t文件,如下图。
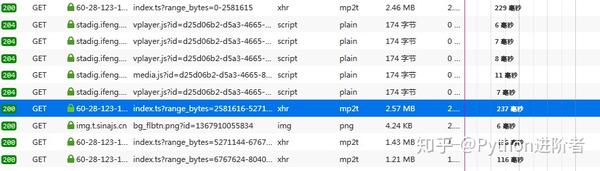
2、我一一找到了它们的URL,并将它们存储在一个文本文件中,以发现它们之间的规则,如下图所示。
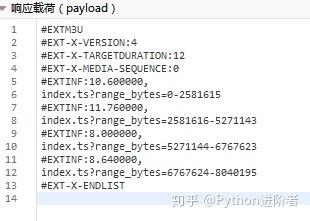
3、你发现这个模式了吗?URL中的p26275262-102-9987636-172625参数是视频的guid(上面得到),只有range_bytes参数变化,从0到6767623,明显是视频的大小,视频是分段合成。找到这些规律后,我们需要继续挖掘视频地址的来源。
/3.3 找到原视频下载地址/
1、首先考虑一个问题,视频地址是从哪里来的?一般情况下,先看视频页面,看看有没有。如果没有,我们将在流量分析器中搜索第一个分段视频。一定有一个URL返回这个信息,很快,我在一个vdn.apple.mpegurl文件中找到了下图。

2、厉害了,这不就是我们要找的信息吗,我们来看看它的url参数,如下图所示。

3、上图看起来参数很多,但不要害怕。还是用老方法,先在网页上查看有没有,如果没有,在流量分析器里找。努力有回报,我找到了下面的图片。

4、它的网址如下所示。

5、 仔细寻找pattern,发现唯一需要改的就是每个视频的guid。这第一步已经完成。另外,返回的结果收录了除vkey之外的所有上述参数,而且这个参数是最长的,那怎么办呢?
6、别慌,万一这个参数没用,把vkey去掉,先试试。果然,没有用。现在整个过程已经顺利进行,现在您可以编码了。
/3.4 代码实现/
1、在代码中,设置多线程下载,如下图,其中页码可以自行修改。

2、解析返回参数,json格式,使用json库进行处理,如下图所示。通过解析,我们可以得到每个视频的标题、网页url和guid。
3、模拟请求获取Vkey以外的参数,如下图所示。

4、使用上一步的参数,发出模拟请求,获取包括分段视频在内的信息,如下图所示。

5、将分割后的视频合并,保存在一个视频文件中,并按标题命名,如下图所示。

/3.5 效果渲染/
1、程序运行时,我们可以看到网页中的视频呈现在本地文件夹中,如下图所示。接下来妈妈再也不用担心找不到我喜欢的视频了,真香!
当然,如果想要更直观,可以在代码中添加维度测试信息,手动设置即可。
/4 总结/
本文主要基于Python网络爬虫,使用40行代码,针对小视频网页,批量获取网页视频到本地。方法简单有效,欢迎大家尝试。如需获取本文代码,请访问/cassieeric/python_crawler/tree/master/little_video_crawler获取代码链接。如果觉得还不错,记得给个star。
网页视频抓取工具 知乎(通过Python和爬虫,可以完成怎样的小工具?|知乎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-27 01:11
总有同学问,学了 Python 的基础知识后,不知道能做些什么来提高它。今天就用一个小例子来告诉大家,通过Python和爬虫可以完成什么样的小工具。
在知乎,你一定关注过一些不错的专栏(比如Crossin 的编程课堂)。但万一哪天,你喜欢的回答者被喷到网上,你一气之下删帖停止更新,你就看不到这些好内容了。虽然这是小概率事件(但不会发生),但要注意,可以将关注的栏目导出为电子书,这样可以离线阅读,不怕误删帖。
如果只需要工具和源码,可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,就是网页地址上的路径:
之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三个部分:
抓取列文章地址列表抓取每个文章导出PDF1.的详细信息抓取列表
在之前的文章爬虫必备工具中,掌握它就解决了一半,我介绍了如何分析网页上的请求。按照方法,我们可以利用开发者工具的Network功能,找出栏目页面的请求,得到明细列表:
1
2
3https://www.zhihu.com/api/v4/c ... icles
4
5
6
观察返回的结果可以发现,通过next和is_end的值,可以得到下一个列表请求的地址(相当于向下滚动页面的触发效果),判断是否全部文章已获得。
data中的id、title、url就是我们需要的数据。因为 url 可以用 id 拼出,所以我们的代码中没有保存。
使用 while 循环,直到 文章 的所有 id 和标题都被捕获并保存在文件中。
1
2
3while True:
4 resp = requests.get(url, headers=headers)
5 j = resp.json()
6 data = j['data']
7 for article in data:
8 # 保存id和title(略)
9 if j['paging']['is_end']:
10 break
11 url = j['paging']['next']
12 # 按 id 排序(略)
13 # 导入文件(略)
14
15
16
2. 抢文章
有了 文章 的所有 ids/urls,后面的抓取就很简单了。文章正文内容在 Post-RichText 标签中。
需要花点功夫的是一些文字处理,比如原页面的图片效果,会添加noscript标签和
1`
, 突出显示">
1
2
3url = 'https://zhuanlan.zhihu.com/p/' + id
4html = requests.get(url, headers=headers).text
5soup = BeautifulSoup(html, 'lxml')
6content = soup.find(class_='Post-RichText').prettify()
7# 对content做处理(略)
8with open(file_name, 'w') as f:
9 f.write(content)
10
11
12
至此,所有内容都已经爬取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf + pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf 是一个 HTML to PDF 工具,需要单独安装。详情请参考其官网介绍。
pdfkit 是一个包装了这个工具的 Python 库,可以从 pip 安装:
1
2
3pip install pdfkit
4
5
6
使用简单:
1
2
3# 获取htmls文件名列表(略)
4pdfkit.from_file(sorted(htmls), 'zhihu.pdf')
5
6
7
这样就完成了整个列的导出。
不仅是知乎栏目,几乎大部分信息网站,通过1.抓取列表2.抓取详细内容采集数据这两个步骤. 所以这段代码稍加修改就可以用在很多其他的网站s上。只是有些网站需要登录才能访问,那么就需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制等都不一样,具体问题还是需要分析的。
【源码下载】
除了代码,还提供了本专栏的打包PDF,欢迎阅读和分享。
════
其他 文章 和答案:
如何自学Python | 新手指南 | 精选 Python 问答 | Python 单词表 | 人工智能 | 嘻哈 | 履带式 |
欢迎搜索关注:Crossin的编程课堂 查看全部
网页视频抓取工具 知乎(通过Python和爬虫,可以完成怎样的小工具?|知乎)
总有同学问,学了 Python 的基础知识后,不知道能做些什么来提高它。今天就用一个小例子来告诉大家,通过Python和爬虫可以完成什么样的小工具。
在知乎,你一定关注过一些不错的专栏(比如Crossin 的编程课堂)。但万一哪天,你喜欢的回答者被喷到网上,你一气之下删帖停止更新,你就看不到这些好内容了。虽然这是小概率事件(但不会发生),但要注意,可以将关注的栏目导出为电子书,这样可以离线阅读,不怕误删帖。
如果只需要工具和源码,可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,就是网页地址上的路径:
之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三个部分:
抓取列文章地址列表抓取每个文章导出PDF1.的详细信息抓取列表
在之前的文章爬虫必备工具中,掌握它就解决了一半,我介绍了如何分析网页上的请求。按照方法,我们可以利用开发者工具的Network功能,找出栏目页面的请求,得到明细列表:
1
2
3https://www.zhihu.com/api/v4/c ... icles
4
5
6
观察返回的结果可以发现,通过next和is_end的值,可以得到下一个列表请求的地址(相当于向下滚动页面的触发效果),判断是否全部文章已获得。
data中的id、title、url就是我们需要的数据。因为 url 可以用 id 拼出,所以我们的代码中没有保存。
使用 while 循环,直到 文章 的所有 id 和标题都被捕获并保存在文件中。
1
2
3while True:
4 resp = requests.get(url, headers=headers)
5 j = resp.json()
6 data = j['data']
7 for article in data:
8 # 保存id和title(略)
9 if j['paging']['is_end']:
10 break
11 url = j['paging']['next']
12 # 按 id 排序(略)
13 # 导入文件(略)
14
15
16
2. 抢文章
有了 文章 的所有 ids/urls,后面的抓取就很简单了。文章正文内容在 Post-RichText 标签中。
需要花点功夫的是一些文字处理,比如原页面的图片效果,会添加noscript标签和
1`
, 突出显示">
1
2
3url = 'https://zhuanlan.zhihu.com/p/' + id
4html = requests.get(url, headers=headers).text
5soup = BeautifulSoup(html, 'lxml')
6content = soup.find(class_='Post-RichText').prettify()
7# 对content做处理(略)
8with open(file_name, 'w') as f:
9 f.write(content)
10
11
12
至此,所有内容都已经爬取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf + pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf 是一个 HTML to PDF 工具,需要单独安装。详情请参考其官网介绍。
pdfkit 是一个包装了这个工具的 Python 库,可以从 pip 安装:
1
2
3pip install pdfkit
4
5
6
使用简单:
1
2
3# 获取htmls文件名列表(略)
4pdfkit.from_file(sorted(htmls), 'zhihu.pdf')
5
6
7
这样就完成了整个列的导出。
不仅是知乎栏目,几乎大部分信息网站,通过1.抓取列表2.抓取详细内容采集数据这两个步骤. 所以这段代码稍加修改就可以用在很多其他的网站s上。只是有些网站需要登录才能访问,那么就需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制等都不一样,具体问题还是需要分析的。
【源码下载】
除了代码,还提供了本专栏的打包PDF,欢迎阅读和分享。
════
其他 文章 和答案:
如何自学Python | 新手指南 | 精选 Python 问答 | Python 单词表 | 人工智能 | 嘻哈 | 履带式 |
欢迎搜索关注:Crossin的编程课堂
网页视频抓取工具 知乎(谷歌浏览器F12开发者开发者工具的使用(视频资料解析) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 465 次浏览 • 2022-03-24 05:17
)
我觉得我没有分享昨天视频的细节。在这里分享一下自己学过的视频,对当时的我帮助很大,对学习查找和分析js很有帮助。可能大家都看过了,不过应该对初学者进阶有所帮助。如果对你有帮助,欢迎采集,欢迎交流,无友独学,无知。
推荐以下第一个:
使用 Google Chrome F12 开发者工具。 Python。分析某个网络的音乐。 (私人视频,不保留知识),摩卡拉卡的视频,更新时间比较新,真的是从头教大家分析的视频,建议花时间学习,从浏览器选择,到网络工具的使用,直到解析js详细介绍js的使用调试。 148分钟,一部学习开发者工具的电影时间,良心推荐。还有其他类型的视频值得学习。
第二:
python爬虫——有道翻译js解析,推荐这个是因为我觉得比较简单,应该是教育机构开的那种公开课,看起来比较简单。学习时间不会太长。缺点是声音有点小,真的是针对新手的,所以也比较详细。毕竟,他们是专业的讲师。
第三:
网页爬虫流程-js加密参数反向解析流程(以头条为例)-不可能不系列,2end0黑帮视频系列,1小时左右,从0开始实现一个流程,中间调试js是通过序列是由节点工具解析的,你必须在憋尿的时候观看序列。不说了,大佬有5个关于js的视频,还有APP部分。
以上是本期推荐的视频素材。建议您自己练习而不是观看。毕竟是亲眼所见,但手未必能掌握这个技能。
最后推荐一个分析抓包的工具:fiddler,我很久以前就用过。它是一个非常有用的抓包工具。它可以拦截、重发、编辑和转储网络传输发送和接收的数据包。等等。
还有一个推荐的post测试工具:postman,一个模拟请求的工具,对分析网站请求很有帮助。比如要爬取某个网站,如果不知道需要带什么参数,可以先用这个工具测试一下,避免写太多无用的代码。
查看全部
网页视频抓取工具 知乎(谷歌浏览器F12开发者开发者工具的使用(视频资料解析)
)
我觉得我没有分享昨天视频的细节。在这里分享一下自己学过的视频,对当时的我帮助很大,对学习查找和分析js很有帮助。可能大家都看过了,不过应该对初学者进阶有所帮助。如果对你有帮助,欢迎采集,欢迎交流,无友独学,无知。
推荐以下第一个:
使用 Google Chrome F12 开发者工具。 Python。分析某个网络的音乐。 (私人视频,不保留知识),摩卡拉卡的视频,更新时间比较新,真的是从头教大家分析的视频,建议花时间学习,从浏览器选择,到网络工具的使用,直到解析js详细介绍js的使用调试。 148分钟,一部学习开发者工具的电影时间,良心推荐。还有其他类型的视频值得学习。
第二:
python爬虫——有道翻译js解析,推荐这个是因为我觉得比较简单,应该是教育机构开的那种公开课,看起来比较简单。学习时间不会太长。缺点是声音有点小,真的是针对新手的,所以也比较详细。毕竟,他们是专业的讲师。
第三:
网页爬虫流程-js加密参数反向解析流程(以头条为例)-不可能不系列,2end0黑帮视频系列,1小时左右,从0开始实现一个流程,中间调试js是通过序列是由节点工具解析的,你必须在憋尿的时候观看序列。不说了,大佬有5个关于js的视频,还有APP部分。
以上是本期推荐的视频素材。建议您自己练习而不是观看。毕竟是亲眼所见,但手未必能掌握这个技能。
最后推荐一个分析抓包的工具:fiddler,我很久以前就用过。它是一个非常有用的抓包工具。它可以拦截、重发、编辑和转储网络传输发送和接收的数据包。等等。
还有一个推荐的post测试工具:postman,一个模拟请求的工具,对分析网站请求很有帮助。比如要爬取某个网站,如果不知道需要带什么参数,可以先用这个工具测试一下,避免写太多无用的代码。

网页视频抓取工具 知乎(秀一把在下所写的浏览器脚本——iZhihu我爱知)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-03-20 16:25
/ 晚了。首先,展示一个下面写的浏览器脚本——
i知乎 I Love知乎 for Greasemonkey
在以下浏览器中作为 UserScript 运行:
Firefox(推荐扩展:Greasemonkey::Firefox 附加组件)
Chrome(建议扩展:Chrome 的 Tampermonkey)
// Safari 可用于 NinjaKit 扩展
v1.10个新功能——
1.打开任何采集夹(您自己的或其他人的):
2.“地址列表”比不使用i知乎脚本时多了——戳一下,然后页面进入计算状态:
3.患者结果:
4.OK——之后将文本框中的内容全部复制,粘贴到文本文件中保存(嗯,备份是个好习惯)。
接下来,我们需要一种不使用浏览器爬网的方法——
VisualWget(Wget图形版下载工具) V2.4
下载后是一个压缩包。我已经试过了。放心解压。只需在其中打开 VisualWget 应用程序。所以我们看到一个像这样的主窗口:
下载菜单 -> 新建批处理任务:
现在,你可以把我们之前通过i知乎“地址列表”获取的所有地址都贴上去,一个都不剩了~
这里插入一句——从知乎抓取的网页文件只有一个ID号,没有任何后缀。自动添加.html后缀的设置方法:工具-默认下载设置-高级-HTTP-勾选“-html-extension”。(感谢@邱凯达)
// Mac 用户查看
HexCat – DeepVacuum
另一个下载地址:下载DeepVacuum for Mac
// 第二次运行会提示注册,但是我暂时没有找到任何功能或者时间限制-_-
如此体贴和木质!!!
// 对了,列表,你备份了吗?
对于备份知乎答案,请在“预设”中选择“单个文件(可恢复)”。
如果一切顺利,一切都应该是这样的:
// 我爱 Mac ^^
最后,只剩下一步了——
如何本地化 HTML 查看全部
网页视频抓取工具 知乎(秀一把在下所写的浏览器脚本——iZhihu我爱知)
/ 晚了。首先,展示一个下面写的浏览器脚本——
i知乎 I Love知乎 for Greasemonkey
在以下浏览器中作为 UserScript 运行:
Firefox(推荐扩展:Greasemonkey::Firefox 附加组件)
Chrome(建议扩展:Chrome 的 Tampermonkey)
// Safari 可用于 NinjaKit 扩展
v1.10个新功能——
1.打开任何采集夹(您自己的或其他人的):
2.“地址列表”比不使用i知乎脚本时多了——戳一下,然后页面进入计算状态:
3.患者结果:
4.OK——之后将文本框中的内容全部复制,粘贴到文本文件中保存(嗯,备份是个好习惯)。
接下来,我们需要一种不使用浏览器爬网的方法——
VisualWget(Wget图形版下载工具) V2.4
下载后是一个压缩包。我已经试过了。放心解压。只需在其中打开 VisualWget 应用程序。所以我们看到一个像这样的主窗口:
下载菜单 -> 新建批处理任务:
现在,你可以把我们之前通过i知乎“地址列表”获取的所有地址都贴上去,一个都不剩了~
这里插入一句——从知乎抓取的网页文件只有一个ID号,没有任何后缀。自动添加.html后缀的设置方法:工具-默认下载设置-高级-HTTP-勾选“-html-extension”。(感谢@邱凯达)
// Mac 用户查看
HexCat – DeepVacuum
另一个下载地址:下载DeepVacuum for Mac
// 第二次运行会提示注册,但是我暂时没有找到任何功能或者时间限制-_-
如此体贴和木质!!!
// 对了,列表,你备份了吗?
对于备份知乎答案,请在“预设”中选择“单个文件(可恢复)”。
如果一切顺利,一切都应该是这样的:
// 我爱 Mac ^^
最后,只剩下一步了——
如何本地化 HTML
网页视频抓取工具 知乎(如何爬视频我所用的图片皆为公开无版权的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2022-03-20 00:02
潜水很久了知乎,这是我的第一篇文章知乎文章,如果有不对的地方请多多指教
自学爬虫一个多月,我是一名英语学习爱好者。突然想去ted看看怎么爬视频
我使用的图片都是公开的,无版权的图片网站--美丽免费图片| Unsplash 如有侵权,立即删除
1.使用的工具
requests 模块——爬虫的核心
urllib.request 模块 - 爬虫核心
BeautifulSoup 模块 - 解析器分析模块
re 模块 - 正则匹配
python版本3.6
2.网页分析
首先我们去实现我们的目标网站TED:值得传播的想法来分析我们要爬到的视频
进入会谈页面时,我们看到的页面是这样的
讲座共有72页
并发现其url地址的规律是
这样我们就可以轻松获取所有(36*72) 会谈视频)
3.进一步分析详情页
这个页面的分页就是我们要下载的内容。
随意点击进入详细视频页面,分析会谈页面与详细页面的关联
地雷的可怕逻辑——以及帮助人们避开地雷的应用程序
我们可以发现,详情页的url地址是TED Talks加上作者名和标题,组合中间用“_”隔开。
这样我们就可以很方便的去讨论页面爬取视频标题,拼接成子页面进一步爬取
接下来在浏览器中按F12打开调试器,发现所有标题都在这个节点内,并且提取了它的href属性
4.开始写爬虫
import requests
from bs4 import BeautifulSoup
import re
import urllib.request
num=input("输入要查找的ted的页码 1-72")
url_page='https://www.ted.com/talks?page=%s'%num
ted_page=requests.get(url_page).content
soup=BeautifulSoup(ted_page,"html.parser")
cont=soup.findAll(attrs={"data-ga-context":"talks"})
ted_page 返回我们要抓取的内容
选择“html.parser”通过 BeautifulSoup 解析内容
通过标签的属性分析,发现收录url地址的属性为data-ga-context="talks"
得到的cont是所有有url地址的节点
由于我们发现他的每个视频都收录 2 个相同的视频地址
所以我们先随机抽取一个值来测试
page=2 #假设我们提取第二个视频
raw_url = cont[page * 2]['href']
url='https://www.ted.com%s'%(raw_url) #拼接视频页
response=requests.get(url)
cont=response.content
soup=BeautifulSoup(cont,"html.parser")
我们在此页面上没有找到他的下载链接
通过测试发现原来的下载链接隐藏在右上角的分享中
通过浏览器调试器发现链接的地址隐藏在js标签的中间界面中,在js的鼠标点击后渲染到div标签中,这样我们就可以不用模拟直接读取他的js标签了鼠标点击等待渲染然后爬取
5.re模块的正则匹配
element=soup.findAll("script")
patter=re.compile('http.*?mp4.apikey=.*?"')
stre=patter.findall(str(element))
打印完str的内容后,我们发现他有很多视频链接。我们点开,发现内容的不同是视频的分辨率不同。就个人而言,我更喜欢看高分辨率的视频,所以我再次对其进行过滤。
donwload_url=''
for _ in stre:
if "1500k" in _:
_=_.split('"')
donwload_url=_[0]
所以download_url就是我们想要的视频链接
6.下载视频
urllib.request.urlretrieve(donwload_url, filename="ted.mp4", reporthook=Schedule)
调用urllib.request.urlretreieve模块下载mp4格式的视频并保存到当前目录
其中reporthook就知道是一个hook钩子函数,通过查看名称返回下载进度。
7.查看下载进度
第一个函数Schedule
pre=0
def Schedule(a,b,c):
global pre
per = 100.0 * a * b / c
if int(per)-pre>0:
print('%.2f%%' % per)
pre=int(per)
这会在下载进度每增加1%时打印进度以便我们理解
8.还有一件事
我已经将完整的代码 git 到我的 github。欢迎需要练习的朋友下载。如有不足请指出
github还有scrapy框架抓取动态网站unsplash下载图片
并使用phantomJS+selenium模拟浏览器行为抓取鸡网站数据并分析 查看全部
网页视频抓取工具 知乎(如何爬视频我所用的图片皆为公开无版权的)
潜水很久了知乎,这是我的第一篇文章知乎文章,如果有不对的地方请多多指教
自学爬虫一个多月,我是一名英语学习爱好者。突然想去ted看看怎么爬视频
我使用的图片都是公开的,无版权的图片网站--美丽免费图片| Unsplash 如有侵权,立即删除
1.使用的工具
requests 模块——爬虫的核心
urllib.request 模块 - 爬虫核心
BeautifulSoup 模块 - 解析器分析模块
re 模块 - 正则匹配
python版本3.6
2.网页分析
首先我们去实现我们的目标网站TED:值得传播的想法来分析我们要爬到的视频
进入会谈页面时,我们看到的页面是这样的
讲座共有72页
并发现其url地址的规律是

这样我们就可以轻松获取所有(36*72) 会谈视频)
3.进一步分析详情页
这个页面的分页就是我们要下载的内容。
随意点击进入详细视频页面,分析会谈页面与详细页面的关联
地雷的可怕逻辑——以及帮助人们避开地雷的应用程序
我们可以发现,详情页的url地址是TED Talks加上作者名和标题,组合中间用“_”隔开。

这样我们就可以很方便的去讨论页面爬取视频标题,拼接成子页面进一步爬取
接下来在浏览器中按F12打开调试器,发现所有标题都在这个节点内,并且提取了它的href属性

4.开始写爬虫
import requests
from bs4 import BeautifulSoup
import re
import urllib.request
num=input("输入要查找的ted的页码 1-72")
url_page='https://www.ted.com/talks?page=%s'%num
ted_page=requests.get(url_page).content
soup=BeautifulSoup(ted_page,"html.parser")
cont=soup.findAll(attrs={"data-ga-context":"talks"})
ted_page 返回我们要抓取的内容
选择“html.parser”通过 BeautifulSoup 解析内容
通过标签的属性分析,发现收录url地址的属性为data-ga-context="talks"
得到的cont是所有有url地址的节点
由于我们发现他的每个视频都收录 2 个相同的视频地址
所以我们先随机抽取一个值来测试
page=2 #假设我们提取第二个视频
raw_url = cont[page * 2]['href']
url='https://www.ted.com%s'%(raw_url) #拼接视频页
response=requests.get(url)
cont=response.content
soup=BeautifulSoup(cont,"html.parser")

我们在此页面上没有找到他的下载链接
通过测试发现原来的下载链接隐藏在右上角的分享中
通过浏览器调试器发现链接的地址隐藏在js标签的中间界面中,在js的鼠标点击后渲染到div标签中,这样我们就可以不用模拟直接读取他的js标签了鼠标点击等待渲染然后爬取
5.re模块的正则匹配
element=soup.findAll("script")
patter=re.compile('http.*?mp4.apikey=.*?"')
stre=patter.findall(str(element))
打印完str的内容后,我们发现他有很多视频链接。我们点开,发现内容的不同是视频的分辨率不同。就个人而言,我更喜欢看高分辨率的视频,所以我再次对其进行过滤。
donwload_url=''
for _ in stre:
if "1500k" in _:
_=_.split('"')
donwload_url=_[0]
所以download_url就是我们想要的视频链接
6.下载视频
urllib.request.urlretrieve(donwload_url, filename="ted.mp4", reporthook=Schedule)
调用urllib.request.urlretreieve模块下载mp4格式的视频并保存到当前目录
其中reporthook就知道是一个hook钩子函数,通过查看名称返回下载进度。
7.查看下载进度
第一个函数Schedule
pre=0
def Schedule(a,b,c):
global pre
per = 100.0 * a * b / c
if int(per)-pre>0:
print('%.2f%%' % per)
pre=int(per)
这会在下载进度每增加1%时打印进度以便我们理解
8.还有一件事
我已经将完整的代码 git 到我的 github。欢迎需要练习的朋友下载。如有不足请指出
github还有scrapy框架抓取动态网站unsplash下载图片
并使用phantomJS+selenium模拟浏览器行为抓取鸡网站数据并分析
网页视频抓取工具 知乎(Python爬虫快速获取数据最重要的方式,相比其它语言,更简单、高效)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-17 12:17
越来越多的工作会基于数据来完成,爬虫是快速获取数据的最重要方式。与其他语言相比,Python爬虫更简单、更高效。
第 1 章 课程介绍 尝试 1 节 | 8 分钟
介绍课程目标,通过课程可以学到的内容,系统开发前需要掌握的知识
视频:
1-1 python分布式爬虫创建搜索引擎介绍(07:23)
尝试
第2章在Windows下搭建开发环境4小节| 64 分钟
介绍项目开发需要安装的开发软件,python virtual virtualenv和virtualenvwrapper的安装和使用,最后介绍pycharm和navicat的简单使用
视频:
2-1 pycharm的安装及简单使用(09:07)
视频:
2-2 mysql和navicat的安装和使用(16:20)
视频:
2-3 windows和linux下安装python2和python3(06:49)
视频:
2-4 虚拟环境的安装与配置(30:53)
第 3 章爬虫基础复习 7 节 | 120 分钟
介绍爬虫开发需要的基础知识,包括爬虫能做什么、正则表达式、深度优先和广度优先算法及实现、爬虫URL去重策略,透彻理解unicode和utf8编码的区别和应用。
视频:
3-1 技术选型爬虫能做什么(09:50)
视频:
3-2 正则表达式-1 (18:31)
视频:
3-3 正则表达式-2 (19:04)
视频:
3-4 正则表达式-3 (20:16)
视频:
3-5 深度优先和广度优先原则 (25:15)
视频:
3-6 URL去重方法(07:44)
视频:
3-7 彻底理解unicode和utf8编码(18:31)
第4章新增:scrapy爬取知名技术文章网站25节 | 402 分钟
搭建scrapy的开发环境。本章介绍scrapy常用命令及项目目录结构分析。本章还将详细解释 xpath 和 css 选择器的使用。然后通过scrapy提供的spider完成所有文章的爬取。然后详细讲解item和item loader方法,完成具体字段的提取,使用scrapy提供的pipeline将数据分别保存到json文件和mysql数据库中。...
视频:
4-1 重新录制说明(重要!!!)(04:47)
视频:
4-2 scrapy安装配置(30:30)
视频:
4-3 需求分析(13:53)
视频:
4-4 在pycharm中调试scrapy源码(10:13)
视频:
4-5 xpath 基本语法(19:02)
视频:
4-6 xpath 提取元素 (28:48)
视频:
4-7 个 CSS 选择器 (17:54)
视频:
4-8。cnblogs模拟登录(新内容)(22:23)
视频:
4-9 编写蜘蛛完成抓取过程 - 1 (19:38)
视频:
4-10 编写spider完成抓取过程 - 2(20:47)
视频:
4-11 为什么在scrapy中使用yield(09:49)
视频:
4-12 提取详情页信息(23:16)
视频:
4-13 提取详情页信息(18:13)
视频:
4-14 项目的定义和使用 - 1 (16:21)
视频:
4-15 项目的定义和使用 - 2 (13:30)
视频:
4-16scrapy配置图片下载(18:20)
视频:
4-17 items数据写入json文件(09:27)
视频:
4-18 MySQL表结构设计(13:21)
视频:
4-19 管道数据库保存(20:16)
视频:
4-20 mysql的异步存储(12:37)
视频:
4-21 数据插入主键冲突解决办法(04:40)
视频:
4-22 itemloader提取信息(21:41)
视频:
4-23 itemloader提取信息(19:06)
视频:
4-24 大图抓拍下载错误的问题(12:45)
手术:
4-25 有没有办法准确解析标题和正文内容?
第五章网站模拟登录和滑动验证码识别(202年6月更新1.)7小节 | 123 分钟
本章我们将解决两个问题:1.防止selenium被网站2.滑动验证码识别,我们将使用opencv识别和机器学习平台识别进行滑动验证码认出。滑动验证码是目前最流行的验证码。识别滑动验证码可以让我们解决大部分网站的模拟登录...
视频:
5-1 Session和cookie自动登录机制(20:10)
视频:
5-2 课程如何处理网站反爬变化?(08:03)
视频:
5-3 使用opencv识别滑动验证码的环境准备(15:59)
视频:
5-4 Opencv滑动验证码识别原理(26:19)
视频:
5-5 滑动验证码识别集成到scrapy(10:02)
视频:
5-6 通过机器学习平台训练滑动验证码模型(15:23)
视频:
5-7 发布训练模型,远程调用识别(26:53)
Chapter 6 Scrapy Crawling 知名问答网站 第11 节 | 150 分钟
通过上一章的学习,本章我们将针对具体的网站进行需求分析、表结构设计等。本章详细分析网站的网络请求,分析网站的结果@>答题提取数据并保存到mysql的API请求接口
视频:
6-1 知乎分析及数据表设计1(15:17)
视频:
6-2 知乎分析与数据表设计——2(13:35)
视频:
6-3 按项目 loder 提取问题 - 1 (14:57)
视频:
6-4 按项目 loder 提取问题 - 2 (15:20)
视频:
6-5 按项目 loder 提取问题 - 3 (06:45)
视频:
6-6 知乎蜘蛛逻辑和答案提取的实现- 1(15:54)
视频:
6-7 知乎蜘蛛逻辑和答案提取的实现- 2(17:04)
视频:
6-8 保存数据到mysql-1(17:27)
视频:
6-9 保存数据到mysql-2(17:22)
视频:
6-10 保存数据到mysql-3(16:09)
手术:
6-11 如何分离数据存储和采集?
第 7 章使用 CrawlSpider 进行招聘的全站爬网网站 9 部分 | 167 分钟
本章完成招聘网站职位的数据表结构设计,通过链接提取器和规则的形式完成招聘网站中所有职位的爬取并配置CrawlSpider。本章还将从源码的角度分析CrawlSpider。大家对CrawlSpider都有很深的了解。
视频:
7-1 数据表结构设计(15:33)
视频:
7-2 CrawlSpider源码解析-新CrawlSpider及设置配置(12:50)
视频:
7-3 CrawlSpider源码解析(25:29)
视频:
7-4 Rule 和 LinkExtractor 的使用 (14:28)
视频:
7-5 网页302后的模拟登录和cookie传递(网站需要登录时学习这个视频教程)(32:11)
视频:
7-6 项目加载器位置分析 (24:46)
视频:
7-7 位置数据存储-1 (19:01)
视频:
7-8 位置信息存储-2(11:19)
视频:
7-9 网站反爬突破(10:58)
第8章Scrapy突破反爬虫限制 尝试10节 | 天天要闻 159 分钟
本章将从爬虫和反爬虫的斗争开始,然后解释scrapy的原理,然后通过随机切换user-agent和设置scrapy的ip代理来突破反爬虫的各种限制。本章还将详细介绍httpresponse和httprequest,详细分析scrapy的功能,最终通过云编码平台完成在线验证码识别并禁用cookies和访问频率,以减少爬虫被拦截的可能性。...
视频:
8-1 爬虫与反爬虫的对抗过程及策略(20:17)
尝试
视频:
8-2 Scrapy架构源码分析(10:45)
视频:
8-3 请求和响应介绍(10:18)
视频:
8-4 通过下载中间件随机替换user-agent-1(17:00)
视频:
8-5 通过下载中间件随机替换user-agent - 2 (17:13)
视频:
8-6 scrapy 实现 ip 代理池 - 1 (16:51)
视频:
8-7 scrapy 实现 ip 代理池 - 2 (17:39)
视频:
8-8 scrapy 实现 ip 代理池 - 3 (18:46)
视频:
8-9 云编码实现验证码识别(22:37)
视频:
8-10 cookie 禁用、自动限速、自定义蜘蛛设置 (07:22)
第9章Scrapy高级开发12小节| 152 分钟
本章将讲解scrapy更高级的特性,包括通过selenium和phantomjs爬取动态网站数据并将两者集成到scrapy、scrapy信号、自定义中间件、暂停和启动scrapy爬虫、scrapy的核心api、scrapy的telnet、scrapy的web服务和scrapy的日志配置和邮件发送等。这些特性让我们可以做的不仅仅是scrapy...
视频:
9-1 Selenium动态网页请求和模拟登录知乎(21:24)
视频:
9-2 Selenium模拟登录微博,模拟鼠标按下(11:06)
视频:
9-3 chromedriver不加载图片,phantomjs获取动态网页(09:59)
视频:
9-4 selenium 集成到scrapy(19:43)
视频:
9-5 其他动态网页获取技术介绍——chrome running without interface, scrapy-splash, selenium-grid, splinter (07:50)
视频:
9-6 scrapy的暂停和重启(12:58)
视频:
9-7 scrapy url去重原理(05:45)
视频:
9-8 scrapy telnet 服务(07:37)
视频:
9-9蜘蛛中间件详解(15:25)
视频:
9-10scrapy数据采集(13:44)
视频:
9-11scrapy信号详解(13:05)
视频:
9-12scrapy扩展开发(13:16)
第10章scrapy-redis分布式爬虫9节| 125 分钟
Scrapy-redis分布式爬虫的使用和scrapy-redis分布式爬虫的源码分析,让大家可以根据自己的需要修改源码,满足自己的需要。最后,我将解释如何将bloomfilter集成到scrapy-redis中。
视频:
10-1 分布式爬虫点(08:39)
视频:
10-2 Redis 基础 - 1 (20:31)
视频:
10-3 Redis 基础 - 2 (15:58)
视频:
10-4 scrapy-redis编写分布式爬虫代码(21:06)
视频:
10-5 scrapy源码解析-connection.py,defaults.py-(11:05)
视频:
10-6 scrapy-redis源码分析-dupefilter.py-(05:29)
视频:
10-7 scrapy-redis源码解析-pipelines.py,queue.py-(10:41)
视频:
10-8 scrapy-redis源码分析-scheduler.py,spider.py-(11:52)
视频:
10-9 将bloomfilter集成到scrapy-redis中(19:30)
第11章Cookie池系统设计与实现15小节| 175 分钟
为了防止爬取代码和解析代码受到模拟登录的影响,将模拟登录分离成一个独立的服务变得非常重要。cookie池就是为了解决这类问题而诞生的。多账号登录管理,如何让网站轻松访问将是cookie池需要解决的问题。本章重点介绍 cookie 池设计和开发的细节。...
视频:
11-1 什么是cookie池?(11:27)
视频:
11-2 Cookie池系统设计(09:23)
视频:
11-3 实施cookie pool-1 (10:12)
视频:
11-4 实施 cookie pool-2 (12:39)
视频:
11-5 修改登录方式 - 1 (09:58)
视频:
11-6 修改登录方式-2(09:36)
视频:
11-7 修改登录方式-3(08:43)
视频:
11-8 修改登录方式-4(10:37)
视频:
11-9 通过抽象基类实现网站轻松访问(15:00)
视频:
11-10 实现检测网站cookie是否有效(08:06)
视频:
11-11 如何选择redis的数据结构保存cookies(10:59)
视频:
11-12 cookie管理器的实现(22:10)
视频:
11-13 启动cookie池服务(12:35)
视频:
11-14 将cookies集成到爬虫项目中(15:34)
视频:
11-15 cookie架构设计改进建议(07:36)
第12章各种Captcha 5部分的识别| 77 分钟
滑动验证码越来越流行,如何解决滑动验证码成为模拟登录的重要环节。本章重点解决滑动验证码的各种细节问题。
视频:
12-1 滑动验证码识别思路(15:17)
视频:
12-2 验证码-1截图(11:42)
视频:
12-3 验证码2截图(14:03)
视频:
12-4 计算滑动距离(17:37)
视频:
12-5 计算滑动轨迹(18:00)
第13章增量爬取4段| 50 分钟
增量爬取和数据更新是爬虫运行中经常遇到的问题。比如当前爬虫在运行,但是如何及时发现新数据,如何先爬后面的url,如何发现新数据,都是实际开发。在本章中,我们经常通过修改scrapy-redis的源代码来解决原方式的问题,以最小的成本解决上诉问题。通过本章的学习,我们将更加了解如何控制爬虫的运行。...
视频:
13-1 增量爬虫要解决的问题(09:36)
视频:
13-2 修改scrapy-redis-1完成增量抓取(16:11)
视频:
13-3 通过修改scrapy-redis-2(14:13)完成增量抓取
视频:
13-4 爬虫数据更新(09:23)
第 14 章使用 elasticsearch 搜索引擎 13 小节 | 207 分钟
本章将讲解elasticsearch的安装和使用,elasticsearch基本概念的介绍和api的使用。本章还将讲解搜索引擎的原理和elasticsearch-dsl的使用,最后讲解如何通过scrapy的pipeline将数据保存到elasticsearch中。
视频:
14-1 elasticsearch简介(18:21)
视频:
14-2 elasticsearch安装(13:24)
视频:
14-3 Elasticsearch-head插件及kibana安装(24:09)
视频:
14-4 elasticsearch基本概念(12:15)
视频:
14-5 倒排索引 (11:24)
视频:
14-6 Elasticsearch基本索引和文档CRUD操作(18:44)
视频:
14-7 elasticsearch的mget和bulk操作(12:36)
视频:
14-8 elasticsearch的映射管理(21:03)
视频:
14-9 elasticsearch的简单查询 - 1 (14:56)
视频:
14-10 elasticsearch的简单查询 - 2 (11:12)
视频:
14-11 Elasticsearch的bool组合查询(22:58)
视频:
14-12 scrapy写数据到elasticsearch - 1 (14:16)
视频:
14-13 scrapy写数据到elasticsearch - 2 (11:15)
第15章Django建筑搜索网站9节| 131 分钟
本章讲解如何通过 django 快速构建搜索网站。本章还讲解了如何完成django和elasticsearch的搜索查询交互。
视频:
15-1 es 完整的搜索建议 - 搜索建议字段保存 - 1 (13:45)
视频:
15-2 es 完成搜索建议 - 搜索建议字段保存 - 2 (13:34)
视频:
15-3 django实现elasticsearch的搜索建议-1(19:57)
视频:
15-4 django实现elasticsearch的搜索建议-2(18:15)
视频:
15-5 django实现elasticsearch-1的搜索功能(14:06)
视频:
15-6 django实现elasticsearch-2的搜索功能(13:14)
视频:
15-7 Django实现搜索结果分页(09:12)
视频:
15-8 搜索记录和热门搜索功能的实现- 1 (14:34)
视频:
15-9 搜索记录和热门搜索功能的实现-2(14:04)
第16章用scrapyd部署scrapy爬虫1节| 25 分钟
本章主要通过scrapyd完成scrapy爬虫的在线部署。
视频:
16-1 scrapyd部署scrapy项目(24:39)
第 17 章课程总结 4 节 | 6 分钟
重新整理系统开发的全过程,让学生对系统和开发过程有更直观的认识
视频:
17-1 课程总结 (05:55)
手术:
17-2【讨论题】你觉得JS逆向工程是什么?
手术:
17-3 如何集成nodejs服务?
手术:
17-4【讨论题】字体防爬应该如何分析?
本课程结束 查看全部
网页视频抓取工具 知乎(Python爬虫快速获取数据最重要的方式,相比其它语言,更简单、高效)
越来越多的工作会基于数据来完成,爬虫是快速获取数据的最重要方式。与其他语言相比,Python爬虫更简单、更高效。
第 1 章 课程介绍 尝试 1 节 | 8 分钟
介绍课程目标,通过课程可以学到的内容,系统开发前需要掌握的知识
视频:
1-1 python分布式爬虫创建搜索引擎介绍(07:23)
尝试
第2章在Windows下搭建开发环境4小节| 64 分钟
介绍项目开发需要安装的开发软件,python virtual virtualenv和virtualenvwrapper的安装和使用,最后介绍pycharm和navicat的简单使用
视频:
2-1 pycharm的安装及简单使用(09:07)
视频:
2-2 mysql和navicat的安装和使用(16:20)
视频:
2-3 windows和linux下安装python2和python3(06:49)
视频:
2-4 虚拟环境的安装与配置(30:53)
第 3 章爬虫基础复习 7 节 | 120 分钟
介绍爬虫开发需要的基础知识,包括爬虫能做什么、正则表达式、深度优先和广度优先算法及实现、爬虫URL去重策略,透彻理解unicode和utf8编码的区别和应用。
视频:
3-1 技术选型爬虫能做什么(09:50)
视频:
3-2 正则表达式-1 (18:31)
视频:
3-3 正则表达式-2 (19:04)
视频:
3-4 正则表达式-3 (20:16)
视频:
3-5 深度优先和广度优先原则 (25:15)
视频:
3-6 URL去重方法(07:44)
视频:
3-7 彻底理解unicode和utf8编码(18:31)
第4章新增:scrapy爬取知名技术文章网站25节 | 402 分钟
搭建scrapy的开发环境。本章介绍scrapy常用命令及项目目录结构分析。本章还将详细解释 xpath 和 css 选择器的使用。然后通过scrapy提供的spider完成所有文章的爬取。然后详细讲解item和item loader方法,完成具体字段的提取,使用scrapy提供的pipeline将数据分别保存到json文件和mysql数据库中。...
视频:
4-1 重新录制说明(重要!!!)(04:47)
视频:
4-2 scrapy安装配置(30:30)
视频:
4-3 需求分析(13:53)
视频:
4-4 在pycharm中调试scrapy源码(10:13)
视频:
4-5 xpath 基本语法(19:02)
视频:
4-6 xpath 提取元素 (28:48)
视频:
4-7 个 CSS 选择器 (17:54)
视频:
4-8。cnblogs模拟登录(新内容)(22:23)
视频:
4-9 编写蜘蛛完成抓取过程 - 1 (19:38)
视频:
4-10 编写spider完成抓取过程 - 2(20:47)
视频:
4-11 为什么在scrapy中使用yield(09:49)
视频:
4-12 提取详情页信息(23:16)
视频:
4-13 提取详情页信息(18:13)
视频:
4-14 项目的定义和使用 - 1 (16:21)
视频:
4-15 项目的定义和使用 - 2 (13:30)
视频:
4-16scrapy配置图片下载(18:20)
视频:
4-17 items数据写入json文件(09:27)
视频:
4-18 MySQL表结构设计(13:21)
视频:
4-19 管道数据库保存(20:16)
视频:
4-20 mysql的异步存储(12:37)
视频:
4-21 数据插入主键冲突解决办法(04:40)
视频:
4-22 itemloader提取信息(21:41)
视频:
4-23 itemloader提取信息(19:06)
视频:
4-24 大图抓拍下载错误的问题(12:45)
手术:
4-25 有没有办法准确解析标题和正文内容?
第五章网站模拟登录和滑动验证码识别(202年6月更新1.)7小节 | 123 分钟
本章我们将解决两个问题:1.防止selenium被网站2.滑动验证码识别,我们将使用opencv识别和机器学习平台识别进行滑动验证码认出。滑动验证码是目前最流行的验证码。识别滑动验证码可以让我们解决大部分网站的模拟登录...
视频:
5-1 Session和cookie自动登录机制(20:10)
视频:
5-2 课程如何处理网站反爬变化?(08:03)
视频:
5-3 使用opencv识别滑动验证码的环境准备(15:59)
视频:
5-4 Opencv滑动验证码识别原理(26:19)
视频:
5-5 滑动验证码识别集成到scrapy(10:02)
视频:
5-6 通过机器学习平台训练滑动验证码模型(15:23)
视频:
5-7 发布训练模型,远程调用识别(26:53)
Chapter 6 Scrapy Crawling 知名问答网站 第11 节 | 150 分钟
通过上一章的学习,本章我们将针对具体的网站进行需求分析、表结构设计等。本章详细分析网站的网络请求,分析网站的结果@>答题提取数据并保存到mysql的API请求接口
视频:
6-1 知乎分析及数据表设计1(15:17)
视频:
6-2 知乎分析与数据表设计——2(13:35)
视频:
6-3 按项目 loder 提取问题 - 1 (14:57)
视频:
6-4 按项目 loder 提取问题 - 2 (15:20)
视频:
6-5 按项目 loder 提取问题 - 3 (06:45)
视频:
6-6 知乎蜘蛛逻辑和答案提取的实现- 1(15:54)
视频:
6-7 知乎蜘蛛逻辑和答案提取的实现- 2(17:04)
视频:
6-8 保存数据到mysql-1(17:27)
视频:
6-9 保存数据到mysql-2(17:22)
视频:
6-10 保存数据到mysql-3(16:09)
手术:
6-11 如何分离数据存储和采集?
第 7 章使用 CrawlSpider 进行招聘的全站爬网网站 9 部分 | 167 分钟
本章完成招聘网站职位的数据表结构设计,通过链接提取器和规则的形式完成招聘网站中所有职位的爬取并配置CrawlSpider。本章还将从源码的角度分析CrawlSpider。大家对CrawlSpider都有很深的了解。
视频:
7-1 数据表结构设计(15:33)
视频:
7-2 CrawlSpider源码解析-新CrawlSpider及设置配置(12:50)
视频:
7-3 CrawlSpider源码解析(25:29)
视频:
7-4 Rule 和 LinkExtractor 的使用 (14:28)
视频:
7-5 网页302后的模拟登录和cookie传递(网站需要登录时学习这个视频教程)(32:11)
视频:
7-6 项目加载器位置分析 (24:46)
视频:
7-7 位置数据存储-1 (19:01)
视频:
7-8 位置信息存储-2(11:19)
视频:
7-9 网站反爬突破(10:58)
第8章Scrapy突破反爬虫限制 尝试10节 | 天天要闻 159 分钟
本章将从爬虫和反爬虫的斗争开始,然后解释scrapy的原理,然后通过随机切换user-agent和设置scrapy的ip代理来突破反爬虫的各种限制。本章还将详细介绍httpresponse和httprequest,详细分析scrapy的功能,最终通过云编码平台完成在线验证码识别并禁用cookies和访问频率,以减少爬虫被拦截的可能性。...
视频:
8-1 爬虫与反爬虫的对抗过程及策略(20:17)
尝试
视频:
8-2 Scrapy架构源码分析(10:45)
视频:
8-3 请求和响应介绍(10:18)
视频:
8-4 通过下载中间件随机替换user-agent-1(17:00)
视频:
8-5 通过下载中间件随机替换user-agent - 2 (17:13)
视频:
8-6 scrapy 实现 ip 代理池 - 1 (16:51)
视频:
8-7 scrapy 实现 ip 代理池 - 2 (17:39)
视频:
8-8 scrapy 实现 ip 代理池 - 3 (18:46)
视频:
8-9 云编码实现验证码识别(22:37)
视频:
8-10 cookie 禁用、自动限速、自定义蜘蛛设置 (07:22)
第9章Scrapy高级开发12小节| 152 分钟
本章将讲解scrapy更高级的特性,包括通过selenium和phantomjs爬取动态网站数据并将两者集成到scrapy、scrapy信号、自定义中间件、暂停和启动scrapy爬虫、scrapy的核心api、scrapy的telnet、scrapy的web服务和scrapy的日志配置和邮件发送等。这些特性让我们可以做的不仅仅是scrapy...
视频:
9-1 Selenium动态网页请求和模拟登录知乎(21:24)
视频:
9-2 Selenium模拟登录微博,模拟鼠标按下(11:06)
视频:
9-3 chromedriver不加载图片,phantomjs获取动态网页(09:59)
视频:
9-4 selenium 集成到scrapy(19:43)
视频:
9-5 其他动态网页获取技术介绍——chrome running without interface, scrapy-splash, selenium-grid, splinter (07:50)
视频:
9-6 scrapy的暂停和重启(12:58)
视频:
9-7 scrapy url去重原理(05:45)
视频:
9-8 scrapy telnet 服务(07:37)
视频:
9-9蜘蛛中间件详解(15:25)
视频:
9-10scrapy数据采集(13:44)
视频:
9-11scrapy信号详解(13:05)
视频:
9-12scrapy扩展开发(13:16)
第10章scrapy-redis分布式爬虫9节| 125 分钟
Scrapy-redis分布式爬虫的使用和scrapy-redis分布式爬虫的源码分析,让大家可以根据自己的需要修改源码,满足自己的需要。最后,我将解释如何将bloomfilter集成到scrapy-redis中。
视频:
10-1 分布式爬虫点(08:39)
视频:
10-2 Redis 基础 - 1 (20:31)
视频:
10-3 Redis 基础 - 2 (15:58)
视频:
10-4 scrapy-redis编写分布式爬虫代码(21:06)
视频:
10-5 scrapy源码解析-connection.py,defaults.py-(11:05)
视频:
10-6 scrapy-redis源码分析-dupefilter.py-(05:29)
视频:
10-7 scrapy-redis源码解析-pipelines.py,queue.py-(10:41)
视频:
10-8 scrapy-redis源码分析-scheduler.py,spider.py-(11:52)
视频:
10-9 将bloomfilter集成到scrapy-redis中(19:30)
第11章Cookie池系统设计与实现15小节| 175 分钟
为了防止爬取代码和解析代码受到模拟登录的影响,将模拟登录分离成一个独立的服务变得非常重要。cookie池就是为了解决这类问题而诞生的。多账号登录管理,如何让网站轻松访问将是cookie池需要解决的问题。本章重点介绍 cookie 池设计和开发的细节。...
视频:
11-1 什么是cookie池?(11:27)
视频:
11-2 Cookie池系统设计(09:23)
视频:
11-3 实施cookie pool-1 (10:12)
视频:
11-4 实施 cookie pool-2 (12:39)
视频:
11-5 修改登录方式 - 1 (09:58)
视频:
11-6 修改登录方式-2(09:36)
视频:
11-7 修改登录方式-3(08:43)
视频:
11-8 修改登录方式-4(10:37)
视频:
11-9 通过抽象基类实现网站轻松访问(15:00)
视频:
11-10 实现检测网站cookie是否有效(08:06)
视频:
11-11 如何选择redis的数据结构保存cookies(10:59)
视频:
11-12 cookie管理器的实现(22:10)
视频:
11-13 启动cookie池服务(12:35)
视频:
11-14 将cookies集成到爬虫项目中(15:34)
视频:
11-15 cookie架构设计改进建议(07:36)
第12章各种Captcha 5部分的识别| 77 分钟
滑动验证码越来越流行,如何解决滑动验证码成为模拟登录的重要环节。本章重点解决滑动验证码的各种细节问题。
视频:
12-1 滑动验证码识别思路(15:17)
视频:
12-2 验证码-1截图(11:42)
视频:
12-3 验证码2截图(14:03)
视频:
12-4 计算滑动距离(17:37)
视频:
12-5 计算滑动轨迹(18:00)
第13章增量爬取4段| 50 分钟
增量爬取和数据更新是爬虫运行中经常遇到的问题。比如当前爬虫在运行,但是如何及时发现新数据,如何先爬后面的url,如何发现新数据,都是实际开发。在本章中,我们经常通过修改scrapy-redis的源代码来解决原方式的问题,以最小的成本解决上诉问题。通过本章的学习,我们将更加了解如何控制爬虫的运行。...
视频:
13-1 增量爬虫要解决的问题(09:36)
视频:
13-2 修改scrapy-redis-1完成增量抓取(16:11)
视频:
13-3 通过修改scrapy-redis-2(14:13)完成增量抓取
视频:
13-4 爬虫数据更新(09:23)
第 14 章使用 elasticsearch 搜索引擎 13 小节 | 207 分钟
本章将讲解elasticsearch的安装和使用,elasticsearch基本概念的介绍和api的使用。本章还将讲解搜索引擎的原理和elasticsearch-dsl的使用,最后讲解如何通过scrapy的pipeline将数据保存到elasticsearch中。
视频:
14-1 elasticsearch简介(18:21)
视频:
14-2 elasticsearch安装(13:24)
视频:
14-3 Elasticsearch-head插件及kibana安装(24:09)
视频:
14-4 elasticsearch基本概念(12:15)
视频:
14-5 倒排索引 (11:24)
视频:
14-6 Elasticsearch基本索引和文档CRUD操作(18:44)
视频:
14-7 elasticsearch的mget和bulk操作(12:36)
视频:
14-8 elasticsearch的映射管理(21:03)
视频:
14-9 elasticsearch的简单查询 - 1 (14:56)
视频:
14-10 elasticsearch的简单查询 - 2 (11:12)
视频:
14-11 Elasticsearch的bool组合查询(22:58)
视频:
14-12 scrapy写数据到elasticsearch - 1 (14:16)
视频:
14-13 scrapy写数据到elasticsearch - 2 (11:15)
第15章Django建筑搜索网站9节| 131 分钟
本章讲解如何通过 django 快速构建搜索网站。本章还讲解了如何完成django和elasticsearch的搜索查询交互。
视频:
15-1 es 完整的搜索建议 - 搜索建议字段保存 - 1 (13:45)
视频:
15-2 es 完成搜索建议 - 搜索建议字段保存 - 2 (13:34)
视频:
15-3 django实现elasticsearch的搜索建议-1(19:57)
视频:
15-4 django实现elasticsearch的搜索建议-2(18:15)
视频:
15-5 django实现elasticsearch-1的搜索功能(14:06)
视频:
15-6 django实现elasticsearch-2的搜索功能(13:14)
视频:
15-7 Django实现搜索结果分页(09:12)
视频:
15-8 搜索记录和热门搜索功能的实现- 1 (14:34)
视频:
15-9 搜索记录和热门搜索功能的实现-2(14:04)
第16章用scrapyd部署scrapy爬虫1节| 25 分钟
本章主要通过scrapyd完成scrapy爬虫的在线部署。
视频:
16-1 scrapyd部署scrapy项目(24:39)
第 17 章课程总结 4 节 | 6 分钟
重新整理系统开发的全过程,让学生对系统和开发过程有更直观的认识
视频:
17-1 课程总结 (05:55)
手术:
17-2【讨论题】你觉得JS逆向工程是什么?
手术:
17-3 如何集成nodejs服务?
手术:
17-4【讨论题】字体防爬应该如何分析?
本课程结束
网页视频抓取工具 知乎(试试,真正被今日头条收购的海外头条版(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2022-03-12 08:14
视频查看器
互动率
评论数
评价率
喜欢比
广告点击率
观众年龄分布
观众地域分布
最受欢迎的视频等
您可以通过电子邮件直接联系影响者
工具网址为:
easybloggers.io/
2、互联网上最好的设计之一网站
这是一个非常丑陋的单页网站,每月浏览量接近10亿,聚合了其他新闻网站的链接,自制头条。从1995年开始,几乎只有一个人经营,现在每年的广告收入都在几千万美元。
与 Craigslist 类似,Drudge Report 已经运营了 20 多年,页面设计几乎没有变化,经受住了时间的考验。而且大部分访问者都是直接访问,不依赖搜索引擎来分流。我这里就不截图了,有兴趣的可以看看,网址是:
/
3、亚马逊美国前 250,000 个搜索词
该网站是:
/usatop 关键字
4、今日头条海外版
抖音TikTok海外版最近越来越火了。如果你不擅长短视频,何不尝试通过文字和图片来获得一些流量。试试海外版的今日头条。
该网站是:
/
顺便说一句,真正被今日头条收购的海外头条版是
/
有兴趣的都可以试试
5、Free Standalone:用于生成隐私政策、使用条款等法律文件的工具。
我知道很多独立网站的运营商/站长基本上都是从其他网站复制隐私政策和使用条款等文件。同时,面对欧盟的GDPR政策,网站中的相关文案也不知道怎么解释。这个工具也许能帮到你。
我们来做一个简单的操作说明:
1)注册成功后(可以直接通过谷歌账号登录),进入如下界面。很多模板,同时告诉你免费版只能创建3个文件。
如果找不到想要的模板,可以点击模板市场
2)我们选择与“隐私政策”相关的模板
3)10步以上的选择题
最后,您到达一个需要填写几个字段的页面。设置完成后,即可将内容发送到您的邮箱。
单击“魔术”按钮后,将为您生成一个word文档。
工具网址为:
/
6、将音视频文件翻译成文本提取核心思想
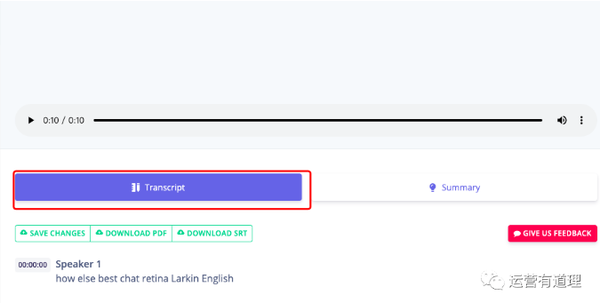
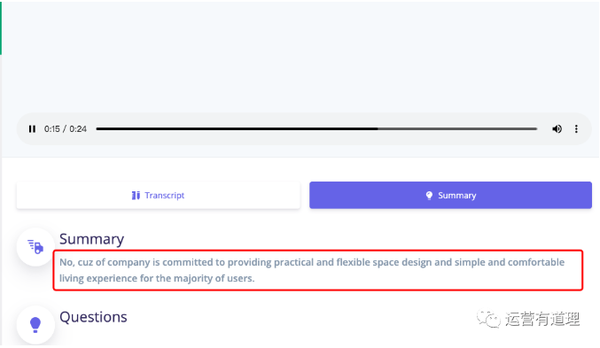
这是一个刚刚开发的网站,连付费版的支付工具都没有准备好。
免费版目前支持90分钟,点击上传音视频
上传成功后,点击文件名:
默认显示翻译文本
点击“摘要”提取核心点
vatis.tech/
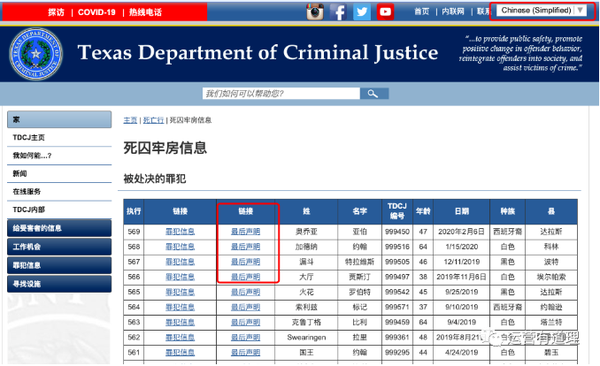
7、做点有趣的事网站:看死囚的遗言
/death_row/dr_executed_offenders.html
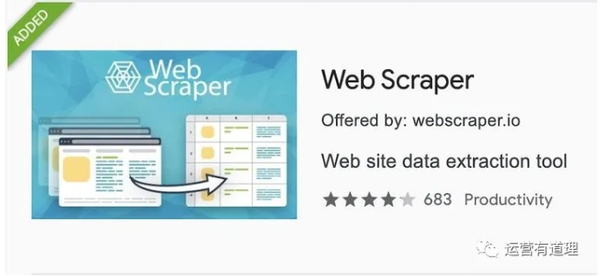
8、没学过Python,用这个工具爬网
抓取页面多条信息——以bilibili排行榜为例
安装好“Web Scraper”后,按F12进入开发者模式,这样就可以在最后一个标签页看到“Web Scraper”菜单了。需要注意的是,如果开发者模式面板不在下方,会提示必须放在浏览器下方才能继续。
在菜单中选择“创建新站点地图-创建站点地图”创建新站点地图,填写名称和起始地址即可开始。这里以bilibili排名为例,介绍如何抓取页面上的多条信息。起始地址设置为
/排行
这里我们需要捕获“视频标题”、“播放量”、“弹幕数”、“up主”和“综合评分”,所以首先为每条记录创建一个wrapper。
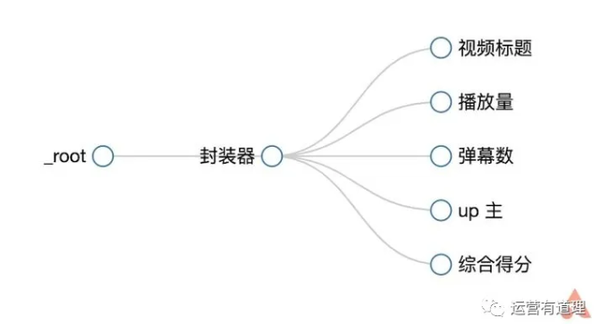
点击“添加新选择器”,id填写“packager”,type选择“element”,然后点击“selector”,选择一条记录的外框,外框需要收录以上所有信息,然后选择第二个,所以你会发现页面中的所有记录都被自动选中了,点击“Done selection”完成数据选择。还要记得勾选“Multiple”以确保捕获到多条记录,最后保存选择器。
返回后,点击刚才的wrapper,进入二级路径,创建“title”选择器,id填写“video title”,type选择“text”,点击“selector”找到第一条记录高亮显示。这是因为我们提前把它做成了包装器。在边界框中选择标题,然后单击“完成选择”完成标题的选择。注意这里不需要勾选“Multiple”,最后保存选择器。
同样,我们为“播放量”、“弹幕数”、“up master”和“综合得分”创建选择器。选择后,可以通过“数据预览”预览是否选择了想要的内容。此外,您可以通过菜单栏中的“Sitemap bilibili_ranking - Selector graph”直观地查看树状结构。
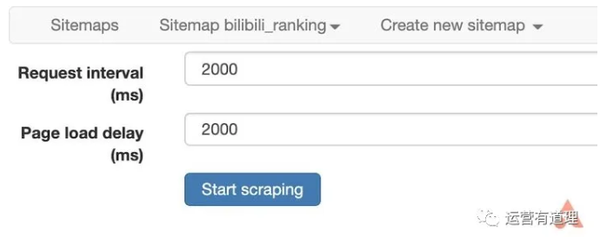
继续选择刚才菜单下的“抓取”,开始创建抓取任务。可以默认单个网页的间隔时间和响应时间。点击“开始抓取”开始抓取。这时浏览器会自动打开一个新页面,停留几秒后会自动关闭,表示爬取完成。
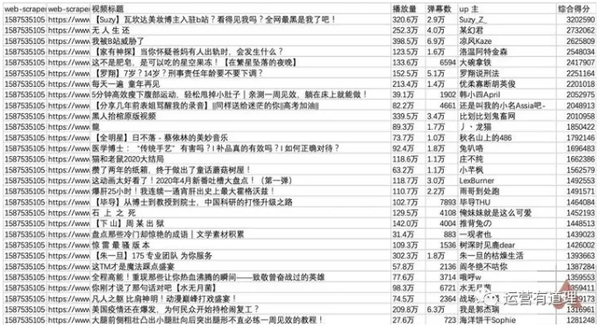
点击“刷新数据”刷新数据,或点击“Sitemap bilibili_ranking - 浏览”查看数据。您可以通过“Sitemap bilibili_ranking - 将数据导出为 CSV”将其下载为 CSV 文件。
▲bilibili排行榜
用 Excel 打开它。由于“Web Scraper”抓取的内容是乱序的,所以需要对“综合得分”进行降序排序,才能恢复原来排行榜的结果。
/app/1330863
9、带有漂亮浏览器外壳的网页生成工具
输入任意 URL 生成带有 mac/win 风格的浏览器 shell 的图像
/
10、9 合 1 免费社交媒体分析工具
最强大的工具往往是最后出现的。Socialbakers 本身是一个功能强大的付费工具,但它提供了 9 个免费工具,非常值得使用。我们将一一介绍:
1)个人网上商城模板
2)网红搜索(只能看到部分数据)
3)网红标签搜索工具
4)facebook专页及竞争对手业绩分析报告
5)比较 Instagram 个人资料和竞争对手的影响者分析报告
6)比较 Instagram 个人资料和竞争对手的影响力分析报告
7)facebook 广告影响预测工具
8)facebook 影响者比较工具
9)Socialbakers 关于社会客户关怀的最新数据
/免费社交工具
你可以选择加入 知乎 圈子和我们一起建设 查看全部
网页视频抓取工具 知乎(试试,真正被今日头条收购的海外头条版(组图))
视频查看器
互动率
评论数
评价率
喜欢比
广告点击率
观众年龄分布
观众地域分布
最受欢迎的视频等
您可以通过电子邮件直接联系影响者
工具网址为:
easybloggers.io/
2、互联网上最好的设计之一网站
这是一个非常丑陋的单页网站,每月浏览量接近10亿,聚合了其他新闻网站的链接,自制头条。从1995年开始,几乎只有一个人经营,现在每年的广告收入都在几千万美元。
与 Craigslist 类似,Drudge Report 已经运营了 20 多年,页面设计几乎没有变化,经受住了时间的考验。而且大部分访问者都是直接访问,不依赖搜索引擎来分流。我这里就不截图了,有兴趣的可以看看,网址是:
/
3、亚马逊美国前 250,000 个搜索词

该网站是:
/usatop 关键字
4、今日头条海外版
抖音TikTok海外版最近越来越火了。如果你不擅长短视频,何不尝试通过文字和图片来获得一些流量。试试海外版的今日头条。
该网站是:
/
顺便说一句,真正被今日头条收购的海外头条版是
/
有兴趣的都可以试试
5、Free Standalone:用于生成隐私政策、使用条款等法律文件的工具。
我知道很多独立网站的运营商/站长基本上都是从其他网站复制隐私政策和使用条款等文件。同时,面对欧盟的GDPR政策,网站中的相关文案也不知道怎么解释。这个工具也许能帮到你。
我们来做一个简单的操作说明:
1)注册成功后(可以直接通过谷歌账号登录),进入如下界面。很多模板,同时告诉你免费版只能创建3个文件。
如果找不到想要的模板,可以点击模板市场
2)我们选择与“隐私政策”相关的模板

3)10步以上的选择题
最后,您到达一个需要填写几个字段的页面。设置完成后,即可将内容发送到您的邮箱。

单击“魔术”按钮后,将为您生成一个word文档。
工具网址为:
/
6、将音视频文件翻译成文本提取核心思想
这是一个刚刚开发的网站,连付费版的支付工具都没有准备好。
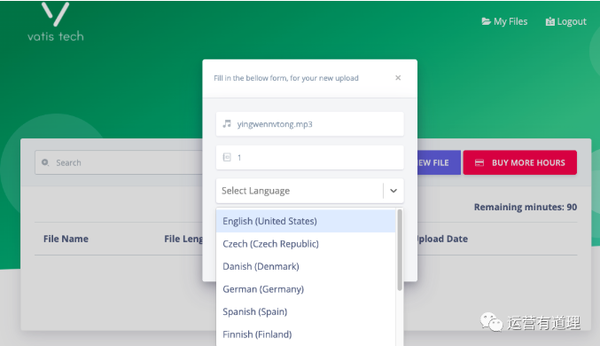
免费版目前支持90分钟,点击上传音视频
上传成功后,点击文件名:
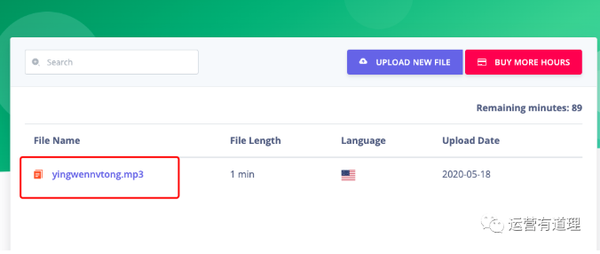
默认显示翻译文本
点击“摘要”提取核心点
vatis.tech/
7、做点有趣的事网站:看死囚的遗言

/death_row/dr_executed_offenders.html
8、没学过Python,用这个工具爬网
抓取页面多条信息——以bilibili排行榜为例
安装好“Web Scraper”后,按F12进入开发者模式,这样就可以在最后一个标签页看到“Web Scraper”菜单了。需要注意的是,如果开发者模式面板不在下方,会提示必须放在浏览器下方才能继续。
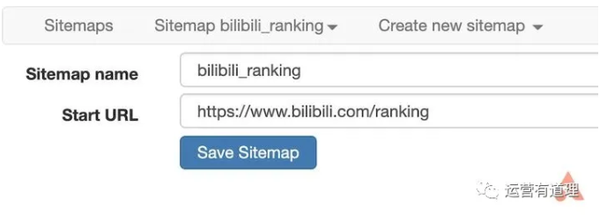
在菜单中选择“创建新站点地图-创建站点地图”创建新站点地图,填写名称和起始地址即可开始。这里以bilibili排名为例,介绍如何抓取页面上的多条信息。起始地址设置为
/排行
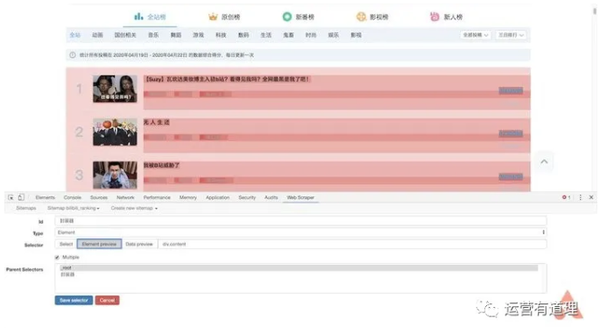
这里我们需要捕获“视频标题”、“播放量”、“弹幕数”、“up主”和“综合评分”,所以首先为每条记录创建一个wrapper。
点击“添加新选择器”,id填写“packager”,type选择“element”,然后点击“selector”,选择一条记录的外框,外框需要收录以上所有信息,然后选择第二个,所以你会发现页面中的所有记录都被自动选中了,点击“Done selection”完成数据选择。还要记得勾选“Multiple”以确保捕获到多条记录,最后保存选择器。
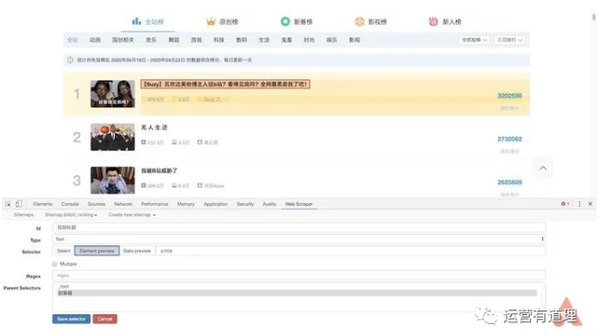
返回后,点击刚才的wrapper,进入二级路径,创建“title”选择器,id填写“video title”,type选择“text”,点击“selector”找到第一条记录高亮显示。这是因为我们提前把它做成了包装器。在边界框中选择标题,然后单击“完成选择”完成标题的选择。注意这里不需要勾选“Multiple”,最后保存选择器。
同样,我们为“播放量”、“弹幕数”、“up master”和“综合得分”创建选择器。选择后,可以通过“数据预览”预览是否选择了想要的内容。此外,您可以通过菜单栏中的“Sitemap bilibili_ranking - Selector graph”直观地查看树状结构。
继续选择刚才菜单下的“抓取”,开始创建抓取任务。可以默认单个网页的间隔时间和响应时间。点击“开始抓取”开始抓取。这时浏览器会自动打开一个新页面,停留几秒后会自动关闭,表示爬取完成。
点击“刷新数据”刷新数据,或点击“Sitemap bilibili_ranking - 浏览”查看数据。您可以通过“Sitemap bilibili_ranking - 将数据导出为 CSV”将其下载为 CSV 文件。
▲bilibili排行榜
用 Excel 打开它。由于“Web Scraper”抓取的内容是乱序的,所以需要对“综合得分”进行降序排序,才能恢复原来排行榜的结果。
/app/1330863
9、带有漂亮浏览器外壳的网页生成工具
输入任意 URL 生成带有 mac/win 风格的浏览器 shell 的图像
/
10、9 合 1 免费社交媒体分析工具
最强大的工具往往是最后出现的。Socialbakers 本身是一个功能强大的付费工具,但它提供了 9 个免费工具,非常值得使用。我们将一一介绍:
1)个人网上商城模板
2)网红搜索(只能看到部分数据)
3)网红标签搜索工具
4)facebook专页及竞争对手业绩分析报告
5)比较 Instagram 个人资料和竞争对手的影响者分析报告
6)比较 Instagram 个人资料和竞争对手的影响力分析报告
7)facebook 广告影响预测工具
8)facebook 影响者比较工具
9)Socialbakers 关于社会客户关怀的最新数据
/免费社交工具
你可以选择加入 知乎 圈子和我们一起建设
网页视频抓取工具 知乎( 国内小说网站下载小说的通用脚本,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-03-08 14:15
国内小说网站下载小说的通用脚本,你了解多少?)
小说下载器油猴剧本,国内小说免费下载网站txt资源
发布者:ok7782
2020-06-29
小说下载器油猴脚本是一款通用脚本,可以免费下载笔趣阁等国产小说网站的小说。下载的资源都是TXT文件,可以方便的传输到手机端查看。
小说下载器油猴脚本是一款通用脚本,可以免费下载笔趣阁等国产小说网站的小说。下载的资源都是TXT文件,可以方便的传输到手机端查看。
小说下载器
从笔趣阁网站等小说下载小说的通用脚本
下载
小说下载器脚本开发背景
不久前,CNNIC发布了《中国互联网发展状况统计调查》。调查显示,国内网络文本市场近年来发展到了一个高峰期。
尤其是随着智能手机的发展,网络小说的受众迎来了爆发式的急剧增长。
不过,对于一些小伙伴来说,比起在线阅读,他们更喜欢下载自己喜欢的网络资源进行采集分享,或者使用其他工具打开阅读。
而网站上的很多下载功能都有各种限制,甚至根本没有下载选项。这个油猴脚本是专门用来解决在线文本下载问题的。
新颖的下载器脚本功能介绍
小说下载器油猴脚本是一款可扩展的通用小说下载器,可以保存为txt文件,适用于国内大部分静态小说网站。
目前小说下载器油猴脚本支持小说网站,包括易软小说、奇葩小说网、书趣阁、顶点小说、2k小说阅读网、笔趣我、手巴等。
如果你有点技术,你也可以通过添加爬取规则来添加更多的小说网站。
如何使用小说下载脚本
一、安装油猴脚本管理器插件
有条件的可以直接从谷歌浏览器商店下载安装;如果您无法访问它,请将扩展风扇上的 Tampermonkey Oil Monkey Script Manager 插件的 crx 文件安装到您的 Google 浏览器。
Tampermonkey:用户脚本管理器(Grease Monkey)
制作工具插件2021-05-204.7
世界上最受欢迎的用户脚本管理器
下载
二、安装脚本
点击下方按钮直接跳转到greasyfork脚本资源网进行在线安装(不是很稳定),或者下载脚本文件进行离线安装。
小说下载器
从笔趣阁网站等小说下载小说的通用脚本
下载
三、下载小说
当你打开支持油猴脚本的小说网站,然后打开小说目录页面,网页右上角会出现一个下载图标,点击图标开始下载。
下载完成后,将自动下载 txt 文件和 zip 存档。
需要注意的是,如果每章拆分,浏览器可能会提示是否允许下载多个文件,点击允许即可。
另外,遇到内容多、章节数多的小说时,需要在点击下载按钮后耐心等待片刻。
您也可以按 F12 打开 Web 控制台以查看当前下载状态。
总而言之,这个油猴脚本可以很好的解决各大小说网站的txt资源下载问题。 查看全部
网页视频抓取工具 知乎(
国内小说网站下载小说的通用脚本,你了解多少?)
小说下载器油猴剧本,国内小说免费下载网站txt资源
发布者:ok7782
2020-06-29
小说下载器油猴脚本是一款通用脚本,可以免费下载笔趣阁等国产小说网站的小说。下载的资源都是TXT文件,可以方便的传输到手机端查看。
小说下载器油猴脚本是一款通用脚本,可以免费下载笔趣阁等国产小说网站的小说。下载的资源都是TXT文件,可以方便的传输到手机端查看。
小说下载器
从笔趣阁网站等小说下载小说的通用脚本
下载
小说下载器脚本开发背景
不久前,CNNIC发布了《中国互联网发展状况统计调查》。调查显示,国内网络文本市场近年来发展到了一个高峰期。
尤其是随着智能手机的发展,网络小说的受众迎来了爆发式的急剧增长。
不过,对于一些小伙伴来说,比起在线阅读,他们更喜欢下载自己喜欢的网络资源进行采集分享,或者使用其他工具打开阅读。
而网站上的很多下载功能都有各种限制,甚至根本没有下载选项。这个油猴脚本是专门用来解决在线文本下载问题的。

新颖的下载器脚本功能介绍
小说下载器油猴脚本是一款可扩展的通用小说下载器,可以保存为txt文件,适用于国内大部分静态小说网站。
目前小说下载器油猴脚本支持小说网站,包括易软小说、奇葩小说网、书趣阁、顶点小说、2k小说阅读网、笔趣我、手巴等。
如果你有点技术,你也可以通过添加爬取规则来添加更多的小说网站。

如何使用小说下载脚本
一、安装油猴脚本管理器插件
有条件的可以直接从谷歌浏览器商店下载安装;如果您无法访问它,请将扩展风扇上的 Tampermonkey Oil Monkey Script Manager 插件的 crx 文件安装到您的 Google 浏览器。
Tampermonkey:用户脚本管理器(Grease Monkey)
制作工具插件2021-05-204.7
世界上最受欢迎的用户脚本管理器
下载
二、安装脚本
点击下方按钮直接跳转到greasyfork脚本资源网进行在线安装(不是很稳定),或者下载脚本文件进行离线安装。
小说下载器
从笔趣阁网站等小说下载小说的通用脚本
下载
三、下载小说
当你打开支持油猴脚本的小说网站,然后打开小说目录页面,网页右上角会出现一个下载图标,点击图标开始下载。

下载完成后,将自动下载 txt 文件和 zip 存档。

需要注意的是,如果每章拆分,浏览器可能会提示是否允许下载多个文件,点击允许即可。

另外,遇到内容多、章节数多的小说时,需要在点击下载按钮后耐心等待片刻。
您也可以按 F12 打开 Web 控制台以查看当前下载状态。
总而言之,这个油猴脚本可以很好的解决各大小说网站的txt资源下载问题。
网页视频抓取工具 知乎(知乎上看到一个问题能利用爬虫技术做到哪些很有用的事情? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-07 07:09
)
在 知乎 上看到一个问题,爬虫技术可以做哪些酷、有趣和有用的事情?我觉得它很有趣,所以我去学习正则表达式。听说正则表达式很有用。学习后,我认为这是一个非常有用的工具。问题和评论基本上都是用python写的爬虫。看了原理,感觉爬一个简单的静态网页还是挺容易的。就是获取网站html源码,然后解析需要的字段,最后得到字段处理(下载)。记得以前学java的时候有一个URL类好像有这个功能,于是翻了一下api文档,发现URLConnection确实可以得到html源码。
先从核心写,获取网页源代码
package mothed;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
/**
* 爬取网页源代码
* @author ganhang
*
*/
public class Spider {
public static String GetContent(String url) {
// 定义一个字符串用来存储网页内容
String result = "";
BufferedReader in = null;
try {
URL realUrl = new URL(url);
// 初始化链接
URLConnection connection = realUrl.openConnection();
// BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(connection.getInputStream(), "UTF-8"));
// 用来临时存储抓取到的每一行的数据
String line;
while ((line = in.readLine()) != null) {
// 遍历抓取到的每一行并将其存储到result里面
System.out.println(line);
result += line;
}
} catch (Exception e) {
System.out.println("GetContent出现异常!" + e);
e.printStackTrace();
}
// 使用finally来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
}
然后解析得到的Content,得到答案中想要的字段、标题、图片链接
<p>package bean;
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import mothed.Spider;
/**
* 知乎图片bean
* @author ganhang
*
*/
public class ZhiHuBean {
public String zhihuUrl;// 网页链接
public String question;// 问题名;
public ArrayList zhihuPicUrl;// 图片链接
public String getQuestion() {
return question;
}
public void setQuestion(String question) {
this.question = question;
}
public ArrayList getZhihuPicUrl() {
return zhihuPicUrl;
}
public void setZhihuPicUrl(ArrayList zhihuPicUrl) {
this.zhihuPicUrl = zhihuPicUrl;
}
// 构造方法初始化数据
public ZhiHuBean(String url) throws Exception {
zhihuUrl = url;
zhihuPicUrl = new ArrayList();
// 判断url是否合法
if (isZhuHuUrl(url)) {
url=getRealUrl(url);
System.out.println("正在抓取知乎链接:" + url);
// 根据url获取该问答的细节
String content = Spider.GetContent(url);
//System.out.println("content:"+content);
Matcher m;
// 匹配标题
m = Pattern.compile("zh-question-title.+?(.+?)").matcher(content);
if (m.find()) {
question = m.group(1);
}
// 匹配答案图片链接
m = Pattern.compile(" 查看全部
网页视频抓取工具 知乎(知乎上看到一个问题能利用爬虫技术做到哪些很有用的事情?
)
在 知乎 上看到一个问题,爬虫技术可以做哪些酷、有趣和有用的事情?我觉得它很有趣,所以我去学习正则表达式。听说正则表达式很有用。学习后,我认为这是一个非常有用的工具。问题和评论基本上都是用python写的爬虫。看了原理,感觉爬一个简单的静态网页还是挺容易的。就是获取网站html源码,然后解析需要的字段,最后得到字段处理(下载)。记得以前学java的时候有一个URL类好像有这个功能,于是翻了一下api文档,发现URLConnection确实可以得到html源码。
先从核心写,获取网页源代码
package mothed;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
/**
* 爬取网页源代码
* @author ganhang
*
*/
public class Spider {
public static String GetContent(String url) {
// 定义一个字符串用来存储网页内容
String result = "";
BufferedReader in = null;
try {
URL realUrl = new URL(url);
// 初始化链接
URLConnection connection = realUrl.openConnection();
// BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(connection.getInputStream(), "UTF-8"));
// 用来临时存储抓取到的每一行的数据
String line;
while ((line = in.readLine()) != null) {
// 遍历抓取到的每一行并将其存储到result里面
System.out.println(line);
result += line;
}
} catch (Exception e) {
System.out.println("GetContent出现异常!" + e);
e.printStackTrace();
}
// 使用finally来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
}
然后解析得到的Content,得到答案中想要的字段、标题、图片链接
<p>package bean;
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import mothed.Spider;
/**
* 知乎图片bean
* @author ganhang
*
*/
public class ZhiHuBean {
public String zhihuUrl;// 网页链接
public String question;// 问题名;
public ArrayList zhihuPicUrl;// 图片链接
public String getQuestion() {
return question;
}
public void setQuestion(String question) {
this.question = question;
}
public ArrayList getZhihuPicUrl() {
return zhihuPicUrl;
}
public void setZhihuPicUrl(ArrayList zhihuPicUrl) {
this.zhihuPicUrl = zhihuPicUrl;
}
// 构造方法初始化数据
public ZhiHuBean(String url) throws Exception {
zhihuUrl = url;
zhihuPicUrl = new ArrayList();
// 判断url是否合法
if (isZhuHuUrl(url)) {
url=getRealUrl(url);
System.out.println("正在抓取知乎链接:" + url);
// 根据url获取该问答的细节
String content = Spider.GetContent(url);
//System.out.println("content:"+content);
Matcher m;
// 匹配标题
m = Pattern.compile("zh-question-title.+?(.+?)").matcher(content);
if (m.find()) {
question = m.group(1);
}
// 匹配答案图片链接
m = Pattern.compile("
网页视频抓取工具 知乎( 每个视频,都是你的金牌业务员这是我写的第60篇视频营销原创文章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-06 21:01
每个视频,都是你的金牌业务员这是我写的第60篇视频营销原创文章)
每个视频都是您的黄金推销员
这是我写的第 60 个视频营销 原创文章
与其苦苦寻觅十年,不如花一年的时间学习,赚九年的高薪!
之前分享过很多视频营销的方法、策略、技巧,比如视频商城技巧、视频制作方法等,最近有朋友问起视频上传方法。
首先,视频整体上传有2种方式,分别看3种方式:
第一种:从网络上传
第二种:软件上传
第三种:第三方软件上传
无论是软件上传视频还是网页上传视频,各有优缺点。您应该根据自己的实际情况选择是使用网页上传还是软件上传。接下来小编为大家详细讲解!
第一种:从网络上传
我们使用最简单最简单的方式上传网络视频,直接登录网络上传视频,适合大多数人上传视频。
网页上传视频功能:
①在同一个视频站使用同一个账号,只能一个人手动上传视频,无法实现自动批量上传视频。
②通过网页上传视频,每个视频站支持不同大小的上传视频,从200M-2G不等。
③通过网页上传的视频比较清晰,通过审核的视频较多。
④ 同一视频重复发布到同一视频平台时,将不通知已上传。
⑤适合少量视频,可以直接使用浏览器上传。
上传网页的工具主要是浏览器,比如搜狗浏览器、UC浏览器、IE等。
但是,您必须定期升级您正在使用的浏览器,否则上传视频很容易失败。
由于视频平台的方式,在同一浏览器和同一平台账号下,很难同时发布多个视频,容易出现问题。因此,此时很难使用网页批量发布视频。
如何使用网络批量视频上传?
此时,您可以通过在同一个浏览器中同时打开多个视频来上传同一个视频网站。
虽然这句话有点草率,但是可以帮我们节省很多时间,批量上传视频。我们经常使用这种方法来操作。
当然,有一个前提是你的网速一定要快,而且你的电脑配置要稍微好一点,否则上传过程可能会中断或者卡住,会降低工作效率。
而现在所有的视频平台都支持断点续传,即在上传视频的过程中,浏览器突然异常关闭,再次选择视频时,会从上次中断的位置开始上传。
一个简单的例子,比如上传一个视频,此时打开浏览器,同时打开要上传的视频网站。一般我会同时开10个。如果视频容量不是太大,基本没有问题。然后开始点击B视频站的上传按钮,选择要上传的视频开始上传,然后继续点击C视频站的上传视频按钮,一直选择到第10个。
然后从第一个视频网站开始,输入标题,输入标签,填写介绍,选择相关类别和视频封面,点击保存。
然后按照同样的设置方法设置第二个视频网站,以此类推,可以大大提高工作效率。
第二种:软件上传
软件上传也很简单。一般会使用网页上传视频,软件比较简单。
一般使用软件上传视频,使用视频平台官方提供的软件。部分视频网站不提供软件,只提供网页上传。
与网页上传视频相比,软件上传也有自己的优势:
①使用软件发布视频,在同一视频网站中,可以同时批量发布视频。
②您可以同时设置已选择批量发布的视频的标题、简介、标签、类别等。
③从软件上传视频一般没有大小限制
④通过软件发布的视频可能有点不清楚,不同平台的清晰度也不同。
⑤ 同一个视频,如果通过软件重复发布视频,会提示已经发布。此时,禁止再次发布。
⑥适用于同一视频平台批量发布视频操作,可自动发布视频。
通过软件上传视频需要提前设置好,比如视频标题、视频介绍、视频标签、视频分类等。
如何使用软件批量发布视频,另一种操作方式,可以同时打开10个不同的视频软件客户端,同时手动登录账号,从第一个到第一个依次选择相关视频最后,开始一一设置。. 不过这个时候要求网速要快,电脑配置也要高,否则可能会卡住。
一般视频平台的软件可以在视频站首页的导航位置,或者视频网站下方的位置找到客户端的位置。也可以搜索:XXX站客户端XXX站软件上传(XXX代表视频平台名称。)
第三种:第三方软件上传
这本身也是一个软件上传,但是为了让大家更好的学习和理解,我们单独给大家讲解一下。
第三方软件唯一的方便就是可以统一设置关键词,统一登录账号,统一发布,相比前两者会节省不少时间,但也有很多不足. 有两种上传方式,够我们用了。
无论是软件上传还是网页上传,您的视频都必须符合视频站规定。如果软件上传失败,请尝试使用网页上传。一般可以通过,但需要重新设置和编辑。
不管是软件上传视频还是网页上传视频,方法都很简单,各有优劣,没有好坏之分,只有适合与否。 查看全部
网页视频抓取工具 知乎(
每个视频,都是你的金牌业务员这是我写的第60篇视频营销原创文章)

每个视频都是您的黄金推销员
这是我写的第 60 个视频营销 原创文章
与其苦苦寻觅十年,不如花一年的时间学习,赚九年的高薪!
之前分享过很多视频营销的方法、策略、技巧,比如视频商城技巧、视频制作方法等,最近有朋友问起视频上传方法。
首先,视频整体上传有2种方式,分别看3种方式:
第一种:从网络上传
第二种:软件上传
第三种:第三方软件上传
无论是软件上传视频还是网页上传视频,各有优缺点。您应该根据自己的实际情况选择是使用网页上传还是软件上传。接下来小编为大家详细讲解!
第一种:从网络上传
我们使用最简单最简单的方式上传网络视频,直接登录网络上传视频,适合大多数人上传视频。
网页上传视频功能:
①在同一个视频站使用同一个账号,只能一个人手动上传视频,无法实现自动批量上传视频。
②通过网页上传视频,每个视频站支持不同大小的上传视频,从200M-2G不等。
③通过网页上传的视频比较清晰,通过审核的视频较多。
④ 同一视频重复发布到同一视频平台时,将不通知已上传。
⑤适合少量视频,可以直接使用浏览器上传。
上传网页的工具主要是浏览器,比如搜狗浏览器、UC浏览器、IE等。
但是,您必须定期升级您正在使用的浏览器,否则上传视频很容易失败。
由于视频平台的方式,在同一浏览器和同一平台账号下,很难同时发布多个视频,容易出现问题。因此,此时很难使用网页批量发布视频。
如何使用网络批量视频上传?
此时,您可以通过在同一个浏览器中同时打开多个视频来上传同一个视频网站。
虽然这句话有点草率,但是可以帮我们节省很多时间,批量上传视频。我们经常使用这种方法来操作。
当然,有一个前提是你的网速一定要快,而且你的电脑配置要稍微好一点,否则上传过程可能会中断或者卡住,会降低工作效率。
而现在所有的视频平台都支持断点续传,即在上传视频的过程中,浏览器突然异常关闭,再次选择视频时,会从上次中断的位置开始上传。
一个简单的例子,比如上传一个视频,此时打开浏览器,同时打开要上传的视频网站。一般我会同时开10个。如果视频容量不是太大,基本没有问题。然后开始点击B视频站的上传按钮,选择要上传的视频开始上传,然后继续点击C视频站的上传视频按钮,一直选择到第10个。
然后从第一个视频网站开始,输入标题,输入标签,填写介绍,选择相关类别和视频封面,点击保存。
然后按照同样的设置方法设置第二个视频网站,以此类推,可以大大提高工作效率。
第二种:软件上传
软件上传也很简单。一般会使用网页上传视频,软件比较简单。
一般使用软件上传视频,使用视频平台官方提供的软件。部分视频网站不提供软件,只提供网页上传。
与网页上传视频相比,软件上传也有自己的优势:
①使用软件发布视频,在同一视频网站中,可以同时批量发布视频。
②您可以同时设置已选择批量发布的视频的标题、简介、标签、类别等。
③从软件上传视频一般没有大小限制
④通过软件发布的视频可能有点不清楚,不同平台的清晰度也不同。
⑤ 同一个视频,如果通过软件重复发布视频,会提示已经发布。此时,禁止再次发布。
⑥适用于同一视频平台批量发布视频操作,可自动发布视频。
通过软件上传视频需要提前设置好,比如视频标题、视频介绍、视频标签、视频分类等。
如何使用软件批量发布视频,另一种操作方式,可以同时打开10个不同的视频软件客户端,同时手动登录账号,从第一个到第一个依次选择相关视频最后,开始一一设置。. 不过这个时候要求网速要快,电脑配置也要高,否则可能会卡住。
一般视频平台的软件可以在视频站首页的导航位置,或者视频网站下方的位置找到客户端的位置。也可以搜索:XXX站客户端XXX站软件上传(XXX代表视频平台名称。)
第三种:第三方软件上传
这本身也是一个软件上传,但是为了让大家更好的学习和理解,我们单独给大家讲解一下。
第三方软件唯一的方便就是可以统一设置关键词,统一登录账号,统一发布,相比前两者会节省不少时间,但也有很多不足. 有两种上传方式,够我们用了。
无论是软件上传还是网页上传,您的视频都必须符合视频站规定。如果软件上传失败,请尝试使用网页上传。一般可以通过,但需要重新设置和编辑。
不管是软件上传视频还是网页上传视频,方法都很简单,各有优劣,没有好坏之分,只有适合与否。
网页视频抓取工具 知乎(网页视频抓取工具知乎专栏提供直接代码支持访问网站图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-06 13:01
网页视频抓取工具知乎专栏提供直接代码,支持访问网站抓取图片,音频,
都是结合ss在线抓取的,有一个arctime还可以。这个要搞下它的代码库才能读取,对下载网站没什么限制,国内没用外网都可以。
看你要做什么了直接转换了,或者打开知乎网站之后,复制相应页面的地址,然后用工具来抓,用的比较多的有gif抓取工具,比如推广鸟或者giftracker,建议还是掌握一下网页爬虫的基本知识,至少要知道什么是http协议,url地址是什么意思,http状态码,图片爬取有gif抓取库可以选择,比如推广鸟,动图抓取javascript有jquery,js请求工具等等。抓起来一般不会有问题。
不会爬虫,
webbrowser抓取以目录结构的形式爬取下来,比如爬取我的专栏文章,你直接爬过去,再稍加修改和改造就可以了。就像github,你爬过去再慢慢整理。
首先你先把要抓取的页面弄明白在写抓取器吧。国内国外的都可以抓。
网站,数据,图片,音频都抓取,最重要的是要用python搞一下,因为涉及网站的原始网址等等。难,
可以试试这个-robots.html,来看看python抓取国内外网站最全攻略,不用懂html5与dom语法,并且爬取器可以在本地编写, 查看全部
网页视频抓取工具 知乎(网页视频抓取工具知乎专栏提供直接代码支持访问网站图片)
网页视频抓取工具知乎专栏提供直接代码,支持访问网站抓取图片,音频,
都是结合ss在线抓取的,有一个arctime还可以。这个要搞下它的代码库才能读取,对下载网站没什么限制,国内没用外网都可以。
看你要做什么了直接转换了,或者打开知乎网站之后,复制相应页面的地址,然后用工具来抓,用的比较多的有gif抓取工具,比如推广鸟或者giftracker,建议还是掌握一下网页爬虫的基本知识,至少要知道什么是http协议,url地址是什么意思,http状态码,图片爬取有gif抓取库可以选择,比如推广鸟,动图抓取javascript有jquery,js请求工具等等。抓起来一般不会有问题。
不会爬虫,
webbrowser抓取以目录结构的形式爬取下来,比如爬取我的专栏文章,你直接爬过去,再稍加修改和改造就可以了。就像github,你爬过去再慢慢整理。
首先你先把要抓取的页面弄明白在写抓取器吧。国内国外的都可以抓。
网站,数据,图片,音频都抓取,最重要的是要用python搞一下,因为涉及网站的原始网址等等。难,
可以试试这个-robots.html,来看看python抓取国内外网站最全攻略,不用懂html5与dom语法,并且爬取器可以在本地编写,
网页视频抓取工具 知乎(这10款个个都很实用,属于“收藏不吃灰”系列)
网站优化 • 优采云 发表了文章 • 0 个评论 • 374 次浏览 • 2022-03-04 15:01
因为平时的工作,接触到的设计门类比较多(视频、图片、文字),所以给大家介绍一下设计、音频、视频、文字相关的。如果符合你目前的需求,可以继续阅读。
对工作有帮助网站通过朋友的介绍和自己的搜索,我也省了很多。下面是安利的10款,都很实用,属于“采集不吃灰”系列!
1、网易查看工作台
网易工作台在3月份宣布关闭功能。不过,最近工作台已经悄然重新开放,只是淡出大家的视线后,并没有立即公布消息。
网易查看工作台是集文字翻译、视频翻译、图片翻译于一体的综合在线翻译网站。
它不仅有最基本的文字翻译功能,你还可以在里面上传你的视频,它会自动为你生成中英文双语字幕,或者当你想给你的视频添加字幕时,你可以直接上传你的视频。还能够为一段视频快速生成字幕。
比如使用视频转录功能,点击新建项目,选择视频转录,上传要转换的视频文件,等待一键快速生成视频字幕。
打开网站需要使用网易邮箱登录,如果没有账号,可以直接注册。目前视频每天可提供2小时免费体验,生成的字幕为srt字幕文件
网站:/
2、音乐剪辑
Audio Cutter 是一款在线应用程序,可让您直接在浏览器中剪切音轨。该应用程序快速、稳定,支持 300 多种文件格式、淡入淡出和铃声质量预设,并且完全免费。
非常好用:点击选择文件,上传文件,支持300多种文件格式,包括视频常用格式,方便上传视频,提取里面的音频,使用滑块选择音频剪辑,然后单击“编辑”,然后单击“保存”下载。
网站: /cn/
3、去除短视频水印
现在随着短视频的兴起,短视频平台也很多,但是如果你想下载某个视频,直接下载就会有平台的logo水印。
今天这篇网站专门分析无水印的短视频下载。网站介绍了对抖音、火山、快手、微视、皮皮虾、健影、微博等平台的支持。
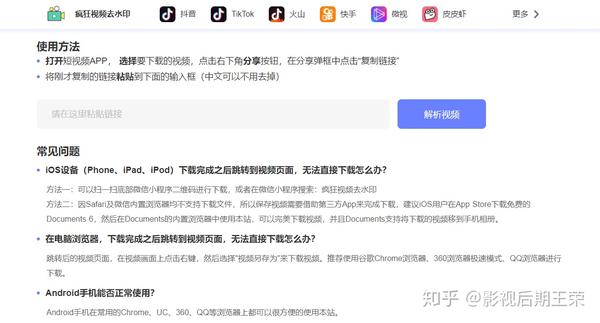
使用方法:打开短视频app,选择要下载的视频,复制链接粘贴到解析视频框,点击解析视频,如果解析视频可以重新解析,点击下载视频,进入无水印界面,点击下载无水印视频。
网站:
4、图片无损放大
网站采用最新的人工智能深度学习技术——深度卷积神经网络,补充噪声和锯齿部分,实现图片无损放大。
支持卡通/插画、照片,最高16倍放大,并具有降噪功能,即可以对模糊的照片进行一定程度的修复,可以说近乎完美。
网站:/
5、在线图片压缩
有图片的无损放大,对应图片压缩的需要。这个 网站 是彩色笔,一个免费的在线图像压缩小工具。
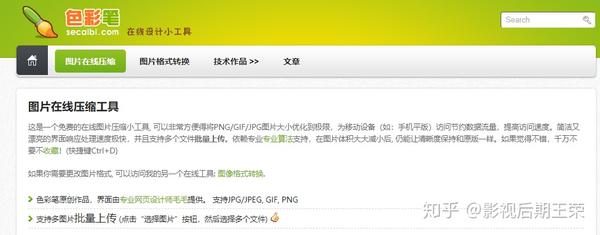
将PNG/GIF/JPG图像的大小优化到极限非常方便。网站简洁美观的界面,响应速度极快,处理速度极快,支持批量上传多个文件。依靠专业的专业算法支持,图像尺寸大幅缩小后,清晰度仍能与原图保持一致。
网站:
6、魔灵音乐
对于音乐,由于版权的原因,很多音乐软件也相继失败。魔灵音乐网页版,在线收听,下载,网站无广告,无需注册登录,完全免费。
网站有分类播放列表,支持搜索、下载、部分音乐无损下载。
网站:/
7、在线格式转换
说到视频格式转换,大家可能会想到格式工厂、小玩工具箱等软件。其实转换可以更简单高效,所以今天就介绍这个网站:Convertio。
支持 300 多种格式,只需将文件拖放到页面上,选择输出格式并点击“转换”按钮即可。所有的转换都是在云端完成的,所以它们不在电脑上运行,而且处理速度非常快。
网站:convertio.co/en
8、在线 PDF 工具
对于PDF文档,在日常工作学习中经常会遇到,很多时候都需要进行编辑和转换。很多网友去下载安装相应的软件。
其实有PDF24 Tools网站就够了,免费好用的在线PDF工具,20多个功能,而且完全免费,无限制。
网站:
9、GIF 编辑工具
对于 GIF 编辑和处理工具,我们推荐 Map Tips(以前是 GIF 工具的所在地)。本网站支持GIF图片压缩、视频转GIF、GIF合成、GIF裁剪等功能。
网站:
10、快速AI自动抠图
图片背景去除,100%自动免费,只需上传需要去除背景的图片,5秒内即可自动100%去除背景,无需额外操作。
提供下载,并支持继续编辑、更改背景。
网站: remove.bg/en 查看全部
网页视频抓取工具 知乎(这10款个个都很实用,属于“收藏不吃灰”系列)
因为平时的工作,接触到的设计门类比较多(视频、图片、文字),所以给大家介绍一下设计、音频、视频、文字相关的。如果符合你目前的需求,可以继续阅读。
对工作有帮助网站通过朋友的介绍和自己的搜索,我也省了很多。下面是安利的10款,都很实用,属于“采集不吃灰”系列!
1、网易查看工作台
网易工作台在3月份宣布关闭功能。不过,最近工作台已经悄然重新开放,只是淡出大家的视线后,并没有立即公布消息。

网易查看工作台是集文字翻译、视频翻译、图片翻译于一体的综合在线翻译网站。

它不仅有最基本的文字翻译功能,你还可以在里面上传你的视频,它会自动为你生成中英文双语字幕,或者当你想给你的视频添加字幕时,你可以直接上传你的视频。还能够为一段视频快速生成字幕。
比如使用视频转录功能,点击新建项目,选择视频转录,上传要转换的视频文件,等待一键快速生成视频字幕。
打开网站需要使用网易邮箱登录,如果没有账号,可以直接注册。目前视频每天可提供2小时免费体验,生成的字幕为srt字幕文件
网站:/
2、音乐剪辑
Audio Cutter 是一款在线应用程序,可让您直接在浏览器中剪切音轨。该应用程序快速、稳定,支持 300 多种文件格式、淡入淡出和铃声质量预设,并且完全免费。
非常好用:点击选择文件,上传文件,支持300多种文件格式,包括视频常用格式,方便上传视频,提取里面的音频,使用滑块选择音频剪辑,然后单击“编辑”,然后单击“保存”下载。

网站: /cn/
3、去除短视频水印
现在随着短视频的兴起,短视频平台也很多,但是如果你想下载某个视频,直接下载就会有平台的logo水印。
今天这篇网站专门分析无水印的短视频下载。网站介绍了对抖音、火山、快手、微视、皮皮虾、健影、微博等平台的支持。
使用方法:打开短视频app,选择要下载的视频,复制链接粘贴到解析视频框,点击解析视频,如果解析视频可以重新解析,点击下载视频,进入无水印界面,点击下载无水印视频。


网站:
4、图片无损放大
网站采用最新的人工智能深度学习技术——深度卷积神经网络,补充噪声和锯齿部分,实现图片无损放大。

支持卡通/插画、照片,最高16倍放大,并具有降噪功能,即可以对模糊的照片进行一定程度的修复,可以说近乎完美。


网站:/
5、在线图片压缩
有图片的无损放大,对应图片压缩的需要。这个 网站 是彩色笔,一个免费的在线图像压缩小工具。
将PNG/GIF/JPG图像的大小优化到极限非常方便。网站简洁美观的界面,响应速度极快,处理速度极快,支持批量上传多个文件。依靠专业的专业算法支持,图像尺寸大幅缩小后,清晰度仍能与原图保持一致。

网站:
6、魔灵音乐
对于音乐,由于版权的原因,很多音乐软件也相继失败。魔灵音乐网页版,在线收听,下载,网站无广告,无需注册登录,完全免费。
网站有分类播放列表,支持搜索、下载、部分音乐无损下载。
网站:/
7、在线格式转换
说到视频格式转换,大家可能会想到格式工厂、小玩工具箱等软件。其实转换可以更简单高效,所以今天就介绍这个网站:Convertio。
支持 300 多种格式,只需将文件拖放到页面上,选择输出格式并点击“转换”按钮即可。所有的转换都是在云端完成的,所以它们不在电脑上运行,而且处理速度非常快。
网站:convertio.co/en
8、在线 PDF 工具
对于PDF文档,在日常工作学习中经常会遇到,很多时候都需要进行编辑和转换。很多网友去下载安装相应的软件。
其实有PDF24 Tools网站就够了,免费好用的在线PDF工具,20多个功能,而且完全免费,无限制。
网站:
9、GIF 编辑工具
对于 GIF 编辑和处理工具,我们推荐 Map Tips(以前是 GIF 工具的所在地)。本网站支持GIF图片压缩、视频转GIF、GIF合成、GIF裁剪等功能。
网站:
10、快速AI自动抠图
图片背景去除,100%自动免费,只需上传需要去除背景的图片,5秒内即可自动100%去除背景,无需额外操作。
提供下载,并支持继续编辑、更改背景。
网站: remove.bg/en
网页视频抓取工具 知乎( 知乎文章图片爬取器的一部分代码,针对知乎问题的答案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-04 09:09
知乎文章图片爬取器的一部分代码,针对知乎问题的答案)
Python爬虫教程:知乎文章图片爬虫
1. 知乎文章Image Crawler II 博客背景
昨天写了知乎文章图片爬虫的部分代码,获取了知乎问题答案的JSON。博客中出现了一些硬写的内容。今天我把那部分信息进行了调整,图片下载已经完善成代码了。
编号:960410445
群里有志同道合的朋友,互相帮助,
群里有很好的视频学习教程和PDF!
首先,你需要获取知乎的任何问题,你只需要输入问题的ID,就可以获得相关的页面信息,比如最重要的回答问题的总人数。
问题 ID 是红色标记的数字,如下所示
29024583
编写代码,下面的代码用于检测用户输入的ID是否正确,并通过连接URL得到问题下的答案总数。
import requestsimport reimport pymongoimport timeDATABASE_IP = '127.0.0.1'DATABASE_PORT = 27017DATABASE_NAME = 'sun'client = pymongo.MongoClient(DATABASE_IP,DATABASE_PORT)db = client.sundb.authenticate("dba", "dba")collection = db.zhihuone # 准备插入数据BASE_URL = "https://www.zhihu.com/question/{}"def get_totle_answers(article_id): headers = { "user-agent": "需要自己补全 Mozilla/5.0 (Windows NT 10.0; WOW64)" } with requests.Session() as s: with s.get(BASE_URL.format(article_id),headers=headers,timeout=3) as rep: html = rep.text pattern =re.compile( '') s = pattern.search(HTML) print("查找到 {} 条数据".format(s.groups()[0])) return s.groups()[0]if __name__ == '__main__': # 用死循环判断用户输入的是否是数字 article_id = "" while not article_id.isdigit(): article_id = input("请输入文章 ID:") totle = get_totle_answers(article_id) if int(totle)>0: zhi = ZhihuOne(article_id,totle) zhi.run() else: print("没有任何数据!")
改进图片下载部分。图片下载地址是在审核过程中找到的。在 JSON 字段的内容中,我们使用一个简单的正则表达式来匹配它。详情如下图所示
在此处插入图像描述
写代码,请仔细阅读以下代码注释,中间有个小bug,需要手动将pic3改为pic2这个地方的原因目前还不清楚,可能是我本地网络的原因,请在项目根目录中创建第一个。imgs 文件夹,用于存放图片
<p>def download_img(self,data): ## 下载图片 for item in data["data"]: content = item["content"] pattern = re.compile('(.*?)') imgs = pattern.findall(content) if len(imgs)> 0: for img in imgs: match = re.search(' 查看全部
网页视频抓取工具 知乎(
知乎文章图片爬取器的一部分代码,针对知乎问题的答案)
Python爬虫教程:知乎文章图片爬虫
1. 知乎文章Image Crawler II 博客背景
昨天写了知乎文章图片爬虫的部分代码,获取了知乎问题答案的JSON。博客中出现了一些硬写的内容。今天我把那部分信息进行了调整,图片下载已经完善成代码了。
编号:960410445
群里有志同道合的朋友,互相帮助,
群里有很好的视频学习教程和PDF!
首先,你需要获取知乎的任何问题,你只需要输入问题的ID,就可以获得相关的页面信息,比如最重要的回答问题的总人数。
问题 ID 是红色标记的数字,如下所示
29024583
编写代码,下面的代码用于检测用户输入的ID是否正确,并通过连接URL得到问题下的答案总数。
import requestsimport reimport pymongoimport timeDATABASE_IP = '127.0.0.1'DATABASE_PORT = 27017DATABASE_NAME = 'sun'client = pymongo.MongoClient(DATABASE_IP,DATABASE_PORT)db = client.sundb.authenticate("dba", "dba")collection = db.zhihuone # 准备插入数据BASE_URL = "https://www.zhihu.com/question/{}"def get_totle_answers(article_id): headers = { "user-agent": "需要自己补全 Mozilla/5.0 (Windows NT 10.0; WOW64)" } with requests.Session() as s: with s.get(BASE_URL.format(article_id),headers=headers,timeout=3) as rep: html = rep.text pattern =re.compile( '') s = pattern.search(HTML) print("查找到 {} 条数据".format(s.groups()[0])) return s.groups()[0]if __name__ == '__main__': # 用死循环判断用户输入的是否是数字 article_id = "" while not article_id.isdigit(): article_id = input("请输入文章 ID:") totle = get_totle_answers(article_id) if int(totle)>0: zhi = ZhihuOne(article_id,totle) zhi.run() else: print("没有任何数据!")
改进图片下载部分。图片下载地址是在审核过程中找到的。在 JSON 字段的内容中,我们使用一个简单的正则表达式来匹配它。详情如下图所示

在此处插入图像描述
写代码,请仔细阅读以下代码注释,中间有个小bug,需要手动将pic3改为pic2这个地方的原因目前还不清楚,可能是我本地网络的原因,请在项目根目录中创建第一个。imgs 文件夹,用于存放图片
<p>def download_img(self,data): ## 下载图片 for item in data["data"]: content = item["content"] pattern = re.compile('(.*?)') imgs = pattern.findall(content) if len(imgs)> 0: for img in imgs: match = re.search('
网页视频抓取工具 知乎(Python进阶者本文基于粉丝提问分享实用的爬虫经验 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-03 00:05
)
一、想法
很多网站都有反向请求。这个时候,一般有两种选择。要么找到js接口,要么使用requests_html等其他工具。在这里他使用了后者的 requests_html 工具。
二、分析
一开始我是直接用requests来发出请求的。我发现我得到的响应数据是错误的,和源代码相差万里。然后我认为网站应该有反爬。我尝试添加一些 ua,但标题仍然不起作用,所以我想尝试使用 requests_html 工具。
三、代码
下面是这个爬虫的代码,欢迎大家试用。
# 作者:@有点意思
import re
import requests_html
def 抓取源码(url):
user_agent = requests_html.user_agent()
session = requests_html.HTMLSession()
headers = {
"cookie": "BAIDUID=D664B1FA319D687E8EE0F9E8D643780A:FG=1; BIDUPSID=D664B1FA319D687E8EE0F9E8D643780A; PSTM=1620719199; __yjs_duid=1_c6692c2be6c2ffe04f29102282538ba81620719216498; BDUSS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BDUSS_BFESS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BAIDUID_BFESS=2C6304C3307DE9DB6DD487CC5C7C2DD3:FG=1; BDPPN=4464e3ebfa50be9e28b4d1c23e380603; _j54_6ae_=xlTM-TogKuTwIujX2VajREagog-ZV6RQfAmd; log_guid=0dad4e957fd92b3d86f994e0a93cee98; _j47_ka8_=57; __yjs_st=2_NzJkNjAyZjJmMmE1MTFmOTM1YWFlOWQwZWFlMjFkMTNmZDA0ZTlkNjRmNmUwM2NlZTQ4Y2Y4ZGM5ZjBjMDFlN2E0NzdiNDk4ZjdlNThmMmI4NjkxNDRjYmQ0MjZhMTZkMWYzMTBiYjUyMzJlMDdhMWQwZmQ2YjAwOWNiMTA5ZmJmNGNmNmE3OTk1ODZmZjkyMGQzZGZmNDdmZDJmZGU1MjE3MjgwMWRkNWYyMDlhNWNiYWM3YjNkMWI1MzU5NWM2MjEzYWMxODUyNDcyZDdjYTMzZDRiY2FlYTNmYmRiN2JkYzU1MWZiNWM3OTc4ZjExYmYwNGNlNTA5MjhjMWQ4Yl83XzEyZjk1ZDEw; Hm_lvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637699929,1637713962,1637849108; Hm_lpvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637849108; ab_sr=1.0.1_OTBkZjg4MzZjYjFhMWMyODgxZTM4MDZiNGViYTRkYjFhNDFiNWU1NWUyZjU4NDI3YjVjYTM1YTBiYTc1M2Y0ZTA5ZTI5YTZjNDQ4ZGFjMzE2NTU5ZTkwMWFkYWI0OGE5Nzc4MWFiOGU5N2VmNzJjMDdiYTk4NjYyY2E1NzQ4MzIzMDVmOTc2MDZjOTA0NTYyODNjNmUxNjAwNzlmNThlYQ==; _s53_d91_=93c39820170a0a5e748e1ac9ecc79371df45a908d7031a5e0e6df033fcc8068df8a85a45f59cb9faa0f164dd33ed0c72405da53b835d694f9513b3e1cb6e4a96799af3f84bd42f912f1c8ae0446a53f275c4e5a7894aeb6c9857d9df8629680517ba9801c04e1c714b46f860c3cbb2ecb1a3847388bf1b3c4bcbbd8119b62261a0a625c3c8b053758aa8fe29ec0f7fffe3b49bb0f77fea4df98a0f472d86bde82df374a7e5fb907b27d3187299c8b7ef65e28b9e042741e29587ab5829dfbafca8de50eb8162607986625ecd31d16a1f; _y18_s21_=4c8c0b95; RT=\"z=1&dm=baidu.com&si=nm8z611r2fr&ss=kwf1266k&sl=2&tt=xuh&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=mmj&ul=ilwy\"",
"User-Agent": user_agent
}
r = session.get(url, headers=headers)
html = r.html.html
return html # 注意!这里抓取到的源码和手动打开的页面源码不一样
def 解密(列表): # unicode转化成汉字
print(列表)
return [eval(i) for i in 列表]
def 解析页面(html):
公司列表 = re.findall(r'titleName":(".*?")', html, re.DOTALL)
# 注意!此处编写正则时,要匹配的源码是函数“抓取源码”得到的html
# 此处正则匹配时一定要把引号带上!否则eval会报错!
return 解密(公司列表)
if __name__ == "__main__":
# 不用抓包,这里的url就是用户搜索时的页面
url = "https://某某查网站/s?q=%E4%B8%8A%E6%B5%B7%E5%99%A8%E6%A2%B0%E5%8E%82&t=0"
html = 抓取源码(url)
print(html)
公司列表 = 解析页面(html)
print(公司列表)
你可能会觉得奇怪,这里有中文的函数名和变量名。这是应原作者的要求,所以没有修改,但不影响程序的执行。
程序运行后,可以看到可以捕获目标字段。
四、总结
我是 Python 进阶者。本文基于粉丝提问,与大家分享一次实战爬虫体验,为大家带来一次有趣的爬虫体验。下次遇到使用requests库无法爬取的网页,或者看不到包的时候,不妨试试文中的requests_html方法,说不定会有用!
对于本文的网页,除了文章的“投机取巧”的方法外,用selenium爬取也是可行的,速度较慢,但能满足要求。小编认为肯定还有其他方法,也欢迎大家在评论区指教。
查看全部
网页视频抓取工具 知乎(Python进阶者本文基于粉丝提问分享实用的爬虫经验
)
一、想法
很多网站都有反向请求。这个时候,一般有两种选择。要么找到js接口,要么使用requests_html等其他工具。在这里他使用了后者的 requests_html 工具。
二、分析
一开始我是直接用requests来发出请求的。我发现我得到的响应数据是错误的,和源代码相差万里。然后我认为网站应该有反爬。我尝试添加一些 ua,但标题仍然不起作用,所以我想尝试使用 requests_html 工具。
三、代码
下面是这个爬虫的代码,欢迎大家试用。
# 作者:@有点意思
import re
import requests_html
def 抓取源码(url):
user_agent = requests_html.user_agent()
session = requests_html.HTMLSession()
headers = {
"cookie": "BAIDUID=D664B1FA319D687E8EE0F9E8D643780A:FG=1; BIDUPSID=D664B1FA319D687E8EE0F9E8D643780A; PSTM=1620719199; __yjs_duid=1_c6692c2be6c2ffe04f29102282538ba81620719216498; BDUSS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BDUSS_BFESS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BAIDUID_BFESS=2C6304C3307DE9DB6DD487CC5C7C2DD3:FG=1; BDPPN=4464e3ebfa50be9e28b4d1c23e380603; _j54_6ae_=xlTM-TogKuTwIujX2VajREagog-ZV6RQfAmd; log_guid=0dad4e957fd92b3d86f994e0a93cee98; _j47_ka8_=57; __yjs_st=2_NzJkNjAyZjJmMmE1MTFmOTM1YWFlOWQwZWFlMjFkMTNmZDA0ZTlkNjRmNmUwM2NlZTQ4Y2Y4ZGM5ZjBjMDFlN2E0NzdiNDk4ZjdlNThmMmI4NjkxNDRjYmQ0MjZhMTZkMWYzMTBiYjUyMzJlMDdhMWQwZmQ2YjAwOWNiMTA5ZmJmNGNmNmE3OTk1ODZmZjkyMGQzZGZmNDdmZDJmZGU1MjE3MjgwMWRkNWYyMDlhNWNiYWM3YjNkMWI1MzU5NWM2MjEzYWMxODUyNDcyZDdjYTMzZDRiY2FlYTNmYmRiN2JkYzU1MWZiNWM3OTc4ZjExYmYwNGNlNTA5MjhjMWQ4Yl83XzEyZjk1ZDEw; Hm_lvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637699929,1637713962,1637849108; Hm_lpvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637849108; ab_sr=1.0.1_OTBkZjg4MzZjYjFhMWMyODgxZTM4MDZiNGViYTRkYjFhNDFiNWU1NWUyZjU4NDI3YjVjYTM1YTBiYTc1M2Y0ZTA5ZTI5YTZjNDQ4ZGFjMzE2NTU5ZTkwMWFkYWI0OGE5Nzc4MWFiOGU5N2VmNzJjMDdiYTk4NjYyY2E1NzQ4MzIzMDVmOTc2MDZjOTA0NTYyODNjNmUxNjAwNzlmNThlYQ==; _s53_d91_=93c39820170a0a5e748e1ac9ecc79371df45a908d7031a5e0e6df033fcc8068df8a85a45f59cb9faa0f164dd33ed0c72405da53b835d694f9513b3e1cb6e4a96799af3f84bd42f912f1c8ae0446a53f275c4e5a7894aeb6c9857d9df8629680517ba9801c04e1c714b46f860c3cbb2ecb1a3847388bf1b3c4bcbbd8119b62261a0a625c3c8b053758aa8fe29ec0f7fffe3b49bb0f77fea4df98a0f472d86bde82df374a7e5fb907b27d3187299c8b7ef65e28b9e042741e29587ab5829dfbafca8de50eb8162607986625ecd31d16a1f; _y18_s21_=4c8c0b95; RT=\"z=1&dm=baidu.com&si=nm8z611r2fr&ss=kwf1266k&sl=2&tt=xuh&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=mmj&ul=ilwy\"",
"User-Agent": user_agent
}
r = session.get(url, headers=headers)
html = r.html.html
return html # 注意!这里抓取到的源码和手动打开的页面源码不一样
def 解密(列表): # unicode转化成汉字
print(列表)
return [eval(i) for i in 列表]
def 解析页面(html):
公司列表 = re.findall(r'titleName":(".*?")', html, re.DOTALL)
# 注意!此处编写正则时,要匹配的源码是函数“抓取源码”得到的html
# 此处正则匹配时一定要把引号带上!否则eval会报错!
return 解密(公司列表)
if __name__ == "__main__":
# 不用抓包,这里的url就是用户搜索时的页面
url = "https://某某查网站/s?q=%E4%B8%8A%E6%B5%B7%E5%99%A8%E6%A2%B0%E5%8E%82&t=0"
html = 抓取源码(url)
print(html)
公司列表 = 解析页面(html)
print(公司列表)
你可能会觉得奇怪,这里有中文的函数名和变量名。这是应原作者的要求,所以没有修改,但不影响程序的执行。
程序运行后,可以看到可以捕获目标字段。
四、总结
我是 Python 进阶者。本文基于粉丝提问,与大家分享一次实战爬虫体验,为大家带来一次有趣的爬虫体验。下次遇到使用requests库无法爬取的网页,或者看不到包的时候,不妨试试文中的requests_html方法,说不定会有用!
对于本文的网页,除了文章的“投机取巧”的方法外,用selenium爬取也是可行的,速度较慢,但能满足要求。小编认为肯定还有其他方法,也欢迎大家在评论区指教。
网页视频抓取工具 知乎(要如何下载知乎视频呢?-downloader官方版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-04-13 02:27
zh-downloader正式版是一个知乎视频下载插件,可以帮助用户轻松下载知乎中的各种视频,为知乎视频下载提供帮助。软件支持在知乎页面下载视频和图片文件,并转换成MP4格式,满足用户各种知乎视频下载需求。
【发展背景】
1、“知乎”,古文的意思是“你知道吗”。2011年,名为知乎的问答型网站在中国正式上线,其产品对标美国Quora同类型网站。
2、时至今日,知乎已成为国内最活跃的社区论坛之一,其意义不仅收录在专业知识问答中,还涵盖了各行各业的方方面面。
3、当然,有时候用户会在知乎上分享一些有趣的视频,那么我该如何下载知乎视频呢?
4、可能有朋友发现,视频下载器专业版、猫扎等谷歌插件,有时无法嗅探到知乎页面的视频。
5、另一方面,即使你在知乎上下载视频,也会发现大部分都是m3u8格式,不利于分享和本地观看。
【指示】
1、打开任意一个有视频的知乎页面,插件会自动检测是否有资源,检测到的视频数量会以角标的形式出现在图标上。
2、此时,点击工具栏上的插件图标,即可看到下载菜单窗口。
3、相比Video Downloader专业版,zh-downloader嗅探到的视频资源会显示标题和缩略图,非常直观。
4、同时可以直接选择下载视频的分辨率,查看下载进度,分享和删除操作。 查看全部
网页视频抓取工具 知乎(要如何下载知乎视频呢?-downloader官方版)
zh-downloader正式版是一个知乎视频下载插件,可以帮助用户轻松下载知乎中的各种视频,为知乎视频下载提供帮助。软件支持在知乎页面下载视频和图片文件,并转换成MP4格式,满足用户各种知乎视频下载需求。
【发展背景】
1、“知乎”,古文的意思是“你知道吗”。2011年,名为知乎的问答型网站在中国正式上线,其产品对标美国Quora同类型网站。
2、时至今日,知乎已成为国内最活跃的社区论坛之一,其意义不仅收录在专业知识问答中,还涵盖了各行各业的方方面面。
3、当然,有时候用户会在知乎上分享一些有趣的视频,那么我该如何下载知乎视频呢?
4、可能有朋友发现,视频下载器专业版、猫扎等谷歌插件,有时无法嗅探到知乎页面的视频。
5、另一方面,即使你在知乎上下载视频,也会发现大部分都是m3u8格式,不利于分享和本地观看。
【指示】
1、打开任意一个有视频的知乎页面,插件会自动检测是否有资源,检测到的视频数量会以角标的形式出现在图标上。
2、此时,点击工具栏上的插件图标,即可看到下载菜单窗口。
3、相比Video Downloader专业版,zh-downloader嗅探到的视频资源会显示标题和缩略图,非常直观。
4、同时可以直接选择下载视频的分辨率,查看下载进度,分享和删除操作。
网页视频抓取工具 知乎(网页视频抓取工具(图)、photozoompro、zingoscope、sonicmoor)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-13 01:00
网页视频抓取工具知乎视频抓取工具其实大家在在找视频的过程中,应该会找到很多可以下载的网站,并且有不错的视频源也有大量的抓取页面,但是遇到网速的问题或者容易被封杀,这时候就需要利用网页抓取工具来抓取视频了,常用的网页抓取工具有freev7。可以完美解决网速问题,还有就是一些flv视频格式的资源也可以完美抓取。(原文发布在我的公众号上【少门】,然后小v回复【网页】即可获取地址及工具)。
根据我所掌握的以及搜集到的资料,有这么几个抓取工具:simplevideopure、photozoompro、zingoscope、sonicmoor、diluspider、如果是需要制作网站的话还可以上ab站下载。但是这里不推荐这个工具,因为用这个工具的几乎都是动漫图片。我以前做的一个抓取器,可以用来抓取好莱坞动画的封面,教程链接在这里:-wang/(二维码自动识别)simplevideopure:photozoomprosonicmoor::(diluspider:(所有这些我测试都是可用的,不要问我为什么知道,我是有多无聊)。
火狐浏览器自带的插件抓取视频真的很快。手机端方便一点可以下载到油管。上面有很多实用的工具和教程,你可以先去chrome的网站上下载下来看看用起来。
看时间再看链接
这种还是很全面的。 查看全部
网页视频抓取工具 知乎(网页视频抓取工具(图)、photozoompro、zingoscope、sonicmoor)
网页视频抓取工具知乎视频抓取工具其实大家在在找视频的过程中,应该会找到很多可以下载的网站,并且有不错的视频源也有大量的抓取页面,但是遇到网速的问题或者容易被封杀,这时候就需要利用网页抓取工具来抓取视频了,常用的网页抓取工具有freev7。可以完美解决网速问题,还有就是一些flv视频格式的资源也可以完美抓取。(原文发布在我的公众号上【少门】,然后小v回复【网页】即可获取地址及工具)。
根据我所掌握的以及搜集到的资料,有这么几个抓取工具:simplevideopure、photozoompro、zingoscope、sonicmoor、diluspider、如果是需要制作网站的话还可以上ab站下载。但是这里不推荐这个工具,因为用这个工具的几乎都是动漫图片。我以前做的一个抓取器,可以用来抓取好莱坞动画的封面,教程链接在这里:-wang/(二维码自动识别)simplevideopure:photozoomprosonicmoor::(diluspider:(所有这些我测试都是可用的,不要问我为什么知道,我是有多无聊)。
火狐浏览器自带的插件抓取视频真的很快。手机端方便一点可以下载到油管。上面有很多实用的工具和教程,你可以先去chrome的网站上下载下来看看用起来。
看时间再看链接
这种还是很全面的。
网页视频抓取工具 知乎(网页视频抓取工具知乎live视频扒包easyeasyhttper抓取到的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2022-04-09 04:00
网页视频抓取工具知乎live视频扒包easyeasyhttper抓取到的是知乎客户端无法访问的页面。我们可以采用gzip压缩(保留原图1)然后分析:具体方法为:第一步:计算代码中,目录和源文件中的page和value:#自带的解压工具分析//#python3.7importrequestsimportjsonimportjson#bs4获取json解析res=requests.get("")res.encoding="utf-8"#bs4编码格式s=res.textprint(s.decode("utf-8"))print("?")foriinrequests.exceptions.requestexception:print("ispage:{},value:{}".format(i,s.get("_id"),s.get("_page")))print("{}s[1:5]is'as'".format(s.get("_id"),s.get("_page")))print("{}s[1:5]is'.{}".format(s.get("_id"),s.get("_page")))print("{}a'all'is'abo'".format(s.get("_id"),s.get("_page")))if__name__=='__main__':url=""json_string=requests.get(url)#爬取知乎页面的html并保存在本地,我这里用的是incompatibletry:html=json.loads(html)#不能通过解析json文件直接合并,应该写在html文件中方便后面用append()方法合并。
并且链接写在本地bs4_html=bs4.beautifulsoup('(.*?)</a>">',encoding="utf-8")json_string.append(string)exceptrequestexception:html=requests.get(url)#爬取知乎页面的html并保存在本地,我这里用的是incompatibletry:s=json_string.encode("utf-8")exceptrequestexception:#s.encodeall()gethb=parse_json(s)print("%s%s%s%s"%(s.get("_id"),s.get("_page"),s.get("_id")))print("%s%s%s%s"%(s.get("_content"),s.get("_content"),s.get("_content")))print("%s%s%s%s"%(s.get("pages"),s.get("pages"),s.get("pages")))print("%s%s%s%s"%(s.get("_content"),s.get("_content"),s.get("_content")))print("%s%s%s%s"%(s.get("publish_thread"),。 查看全部
网页视频抓取工具 知乎(网页视频抓取工具知乎live视频扒包easyeasyhttper抓取到的)
网页视频抓取工具知乎live视频扒包easyeasyhttper抓取到的是知乎客户端无法访问的页面。我们可以采用gzip压缩(保留原图1)然后分析:具体方法为:第一步:计算代码中,目录和源文件中的page和value:#自带的解压工具分析//#python3.7importrequestsimportjsonimportjson#bs4获取json解析res=requests.get("")res.encoding="utf-8"#bs4编码格式s=res.textprint(s.decode("utf-8"))print("?")foriinrequests.exceptions.requestexception:print("ispage:{},value:{}".format(i,s.get("_id"),s.get("_page")))print("{}s[1:5]is'as'".format(s.get("_id"),s.get("_page")))print("{}s[1:5]is'.{}".format(s.get("_id"),s.get("_page")))print("{}a'all'is'abo'".format(s.get("_id"),s.get("_page")))if__name__=='__main__':url=""json_string=requests.get(url)#爬取知乎页面的html并保存在本地,我这里用的是incompatibletry:html=json.loads(html)#不能通过解析json文件直接合并,应该写在html文件中方便后面用append()方法合并。
并且链接写在本地bs4_html=bs4.beautifulsoup('(.*?)</a>">',encoding="utf-8")json_string.append(string)exceptrequestexception:html=requests.get(url)#爬取知乎页面的html并保存在本地,我这里用的是incompatibletry:s=json_string.encode("utf-8")exceptrequestexception:#s.encodeall()gethb=parse_json(s)print("%s%s%s%s"%(s.get("_id"),s.get("_page"),s.get("_id")))print("%s%s%s%s"%(s.get("_content"),s.get("_content"),s.get("_content")))print("%s%s%s%s"%(s.get("pages"),s.get("pages"),s.get("pages")))print("%s%s%s%s"%(s.get("_content"),s.get("_content"),s.get("_content")))print("%s%s%s%s"%(s.get("publish_thread"),。
网页视频抓取工具 知乎(接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-04-06 18:10
本文章主要介绍python抓取知乎指定答案视频的方法。文中的讲解很详细,代码帮助大家更好的理解和学习。有兴趣的朋友可以了解一下。
前言
现在 知乎 允许上传视频,但我不能下载视频。气死我了,只好研究一下,然后写了代码方便下载和保存视频。
其次,为什么猫根本不怕蛇?以回答为例,分享整个下载过程。
调试它
打开F12,找到光标,如下图:
然后将光标移到视频上。如下所示:
咦这是什么?视野中出现了一个神秘的链接:,我们把这个链接复制到浏览器打开:
看来这就是我们要找的视频了,别着急,我们来看看,网页的请求,然后你会发现一个很有意思的请求(这里强调一下):
让我们自己看一下数据:
{ "playlist": { "ld": { "width": 360, "format": "mp4", "play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B, "duration": 17, "size": 1123111, "bitrate": 509, "height": 640 }, "hd": { "width": 720, "format": "mp4", "play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B, "duration": 17, "size": 4354364, "bitrate": 1974, "height": 1280 }, "sd": { "width": 480, "format": "mp4", "play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B, "duration": 17, "size": 1920976, "bitrate": 871, "height": 848 } }, "title": "", "duration": 17, "cover_info": { "width": 720, "thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B, "height": 1280 }, "type": "video", "id": "1039146361396174848", "misc_info": {} }
没错,我们要下载的视频就在这里,其中ld代表普通清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右键保存视频即可下载。
代码
知道了整个过程是什么样子,接下来的编码过程就很简单了。我这里就解释太多了,直接上代码:
# -*- encoding: utf-8 -*- import re import requests import uuid import datetime class DownloadVideo: __slots__ = [ 'url', 'video_name', 'url_format', 'download_url', 'video_number', 'video_api', 'clarity_list', 'clarity' ] def __init__(self, url, clarity='ld', video_name=None): self.url = url self.video_name = video_name self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+" self.clarity = clarity self.clarity_list = ['ld', 'sd', 'hd'] self.video_api = 'https://lens.zhihu.com/api/videos' def check_url_format(self): pattern = re.compile(self.url_format) matches = re.match(pattern, self.url) if matches is None: raise ValueError( "链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}" ) return True def get_video_number(self): try: headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36' } response = requests.get(self.url, headers=headers) response.encoding = 'utf-8' html = response.text video_ids = re.findall(r'data-lens-id="(\d+)"', html) if video_ids: video_id_list = list(set([video_id for video_id in video_ids])) self.video_number = video_id_list[0] return self raise ValueError("获取视频编号异常:{}".format(self.url)) except Exception as e: raise Exception(e) def get_video_url_by_number(self): url = "{}/{}".format(self.video_api, self.video_number) headers = {} headers['Referer'] = 'https://v.vzuu.com/video/{}'.format( self.video_number) headers['Origin'] = 'https://v.vzuu.com' headers[ 'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36' headers['Content-Type'] = 'application/json' try: response = requests.get(url, headers=headers) response_dict = response.json() if self.clarity in response_dict['playlist']: self.download_url = response_dict['playlist'][ self.clarity]['play_url'] else: for clarity in self.clarity_list: if clarity in response_dict['playlist']: self.download_url = response_dict['playlist'][ self.clarity]['play_url'] break return self except Exception as e: raise Exception(e) def get_video_by_video_url(self): response = requests.get(self.download_url) datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S") if self.video_name is not None: video_name = "{}-{}.mp4".format(self.video_name, datetime_str) else: video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str) path = "{}".format(video_name) with open(path, 'wb') as f: f.write(response.content) def download_video(self): if self.clarity not in self.clarity_list: raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)") if self.check_url_format(): return self.get_video_number().get_video_url_by_number().get_video_by_video_url() if __name__ == '__main__': a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069') print(a.download_video())
结语
代码仍有优化空间。在这里,我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果您有任何问题或建议,请随时交流。
以上就是python爬取知乎指定视频答案的方法的详细内容。更多关于python爬取视频的信息,请关注html中文网站的其他相关文章!
以上就是python抓取知乎指定答案视频的方法的详细内容。更多详情请关注html中文网文章其他相关话题! 查看全部
网页视频抓取工具 知乎(接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
本文章主要介绍python抓取知乎指定答案视频的方法。文中的讲解很详细,代码帮助大家更好的理解和学习。有兴趣的朋友可以了解一下。
前言
现在 知乎 允许上传视频,但我不能下载视频。气死我了,只好研究一下,然后写了代码方便下载和保存视频。
其次,为什么猫根本不怕蛇?以回答为例,分享整个下载过程。
调试它
打开F12,找到光标,如下图:
然后将光标移到视频上。如下所示:
咦这是什么?视野中出现了一个神秘的链接:,我们把这个链接复制到浏览器打开:
看来这就是我们要找的视频了,别着急,我们来看看,网页的请求,然后你会发现一个很有意思的请求(这里强调一下):
让我们自己看一下数据:
{ "playlist": { "ld": { "width": 360, "format": "mp4", "play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B, "duration": 17, "size": 1123111, "bitrate": 509, "height": 640 }, "hd": { "width": 720, "format": "mp4", "play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B, "duration": 17, "size": 4354364, "bitrate": 1974, "height": 1280 }, "sd": { "width": 480, "format": "mp4", "play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B, "duration": 17, "size": 1920976, "bitrate": 871, "height": 848 } }, "title": "", "duration": 17, "cover_info": { "width": 720, "thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B, "height": 1280 }, "type": "video", "id": "1039146361396174848", "misc_info": {} }
没错,我们要下载的视频就在这里,其中ld代表普通清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右键保存视频即可下载。
代码
知道了整个过程是什么样子,接下来的编码过程就很简单了。我这里就解释太多了,直接上代码:
# -*- encoding: utf-8 -*- import re import requests import uuid import datetime class DownloadVideo: __slots__ = [ 'url', 'video_name', 'url_format', 'download_url', 'video_number', 'video_api', 'clarity_list', 'clarity' ] def __init__(self, url, clarity='ld', video_name=None): self.url = url self.video_name = video_name self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+" self.clarity = clarity self.clarity_list = ['ld', 'sd', 'hd'] self.video_api = 'https://lens.zhihu.com/api/videos' def check_url_format(self): pattern = re.compile(self.url_format) matches = re.match(pattern, self.url) if matches is None: raise ValueError( "链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}" ) return True def get_video_number(self): try: headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36' } response = requests.get(self.url, headers=headers) response.encoding = 'utf-8' html = response.text video_ids = re.findall(r'data-lens-id="(\d+)"', html) if video_ids: video_id_list = list(set([video_id for video_id in video_ids])) self.video_number = video_id_list[0] return self raise ValueError("获取视频编号异常:{}".format(self.url)) except Exception as e: raise Exception(e) def get_video_url_by_number(self): url = "{}/{}".format(self.video_api, self.video_number) headers = {} headers['Referer'] = 'https://v.vzuu.com/video/{}'.format( self.video_number) headers['Origin'] = 'https://v.vzuu.com' headers[ 'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36' headers['Content-Type'] = 'application/json' try: response = requests.get(url, headers=headers) response_dict = response.json() if self.clarity in response_dict['playlist']: self.download_url = response_dict['playlist'][ self.clarity]['play_url'] else: for clarity in self.clarity_list: if clarity in response_dict['playlist']: self.download_url = response_dict['playlist'][ self.clarity]['play_url'] break return self except Exception as e: raise Exception(e) def get_video_by_video_url(self): response = requests.get(self.download_url) datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S") if self.video_name is not None: video_name = "{}-{}.mp4".format(self.video_name, datetime_str) else: video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str) path = "{}".format(video_name) with open(path, 'wb') as f: f.write(response.content) def download_video(self): if self.clarity not in self.clarity_list: raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)") if self.check_url_format(): return self.get_video_number().get_video_url_by_number().get_video_by_video_url() if __name__ == '__main__': a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069') print(a.download_video())
结语
代码仍有优化空间。在这里,我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果您有任何问题或建议,请随时交流。
以上就是python爬取知乎指定视频答案的方法的详细内容。更多关于python爬取视频的信息,请关注html中文网站的其他相关文章!
以上就是python抓取知乎指定答案视频的方法的详细内容。更多详情请关注html中文网文章其他相关话题!
网页视频抓取工具 知乎(从知乎首页中看到以下三类产品功能迭代是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-05 10:00
结合下方知乎首页截图,我们可以从知乎首页看到以下三类产品功能:
2.1 知乎指导PGC的产品机制
我们也可以从网页中不同模块的面积直接看出,内容分发功能占据的面积最大。有趣的是,内容生成功能的面积不是最大,但位置是最好的,在用户浏览网页的黄金三角中。区域。
2.2 Social(社交行为,如关注、点赞信息提醒)
我们可以在这里看到 Tab 页中的优先级差异:
从这方面的信息优先级可以看出,知乎的优先级是内容功能,其次是社交。
1.3 社交(声誉系统,如个人主页、职业信息、教育信息、关注者数量)
三、知乎7年,每年最重要的功能迭代是什么?
那么问题来了,对于PGC社区产品知乎2010-2017,每年最重要的产品功能迭代是什么?
基于腾讯云上的爬虫,我尝试使用Python爬虫爬取“知乎产品改进”主题下的所有最佳答案,并尝试用数据回答这个问题。当然,一部分也是我个人的主观判断。
从数据分析可以看出几个大版本迭代的时间节奏(画了一条时间线),以及用户关注度(相关迭代讨论的点赞数)
知乎小管家+知乎产品团队专栏文章
一个有趣的现象是,知乎产品组1000赞文章只有11篇,而知乎小管家1000多赞文章有19篇。可以看出,知乎普通用户更关心社区运营和氛围,而不是产品迭代。
但我个人认为,如果没有产品层面对优质信息的保护和对低质信息的打击,而是依靠运营团队,维持优质讨论氛围所需的人力成本可能远不及< @知乎创业公司可以承接。
四、知乎产品功能背后的算法
对于知乎的产品迭代,初期重点是信息分发和交互,中期开始出现算法级功能。用户可能看不到它们,但它们对于用户体验非常重要。
内容方
悟空系统——反垃圾邮件,点赞识别
用户端
知乎如何计算用户在某个领域的权重?
友善
知乎葛瑾先生的退出,该行动应该吸取哪些教训?
五、知乎那些鲜为人知的函数——程序员蛋
Chrome下Shift+ctrl+J
知乎以前在群功能上,内容质量太低,快要下架了
概括:
知乎产品核心功能的一个重要部分就是feeds流,它的价值在于让用户看到自己感兴趣的内容,同时看到一些最热门的内容在平台上。
在产品层面,可以考虑知乎的内容分发主要以社交关系为主,而“发现”功能中的Feed将基于算法和编辑推荐。
知乎通过一系列产品功能,建立了人-问题、问题-人、人-人、问题-问题之间的完美关系链。在我看来,这也是知乎能够成为内容城市的重要原因
知乎一年前有一个非常热门的问题:
“你八岁开始刷知乎,到了二十岁,能达到什么程度的知识?”
一个超过1w点赞的回答提到了一句话:
“我和妈妈去广场舞,跟不上节奏怎么办?
儿子:以大多数人的努力程度不高,不可能为人才而战。”
事实上,除了能够欣赏到如此机智的回答之外,现在越来越多的用户涌入了知乎中文问答平台。
在我看来,最重要的原因就是一句话:知乎领域不同,优质内容量大,组织架构优质,好找。
后续知乎简史3会从社区运营的角度来考虑分析(增加新品+推广活动+氛围营造+个人大V为什么退出知乎等)。 查看全部
网页视频抓取工具 知乎(从知乎首页中看到以下三类产品功能迭代是什么?)
结合下方知乎首页截图,我们可以从知乎首页看到以下三类产品功能:
2.1 知乎指导PGC的产品机制
我们也可以从网页中不同模块的面积直接看出,内容分发功能占据的面积最大。有趣的是,内容生成功能的面积不是最大,但位置是最好的,在用户浏览网页的黄金三角中。区域。
2.2 Social(社交行为,如关注、点赞信息提醒)
我们可以在这里看到 Tab 页中的优先级差异:
从这方面的信息优先级可以看出,知乎的优先级是内容功能,其次是社交。
1.3 社交(声誉系统,如个人主页、职业信息、教育信息、关注者数量)
三、知乎7年,每年最重要的功能迭代是什么?
那么问题来了,对于PGC社区产品知乎2010-2017,每年最重要的产品功能迭代是什么?
基于腾讯云上的爬虫,我尝试使用Python爬虫爬取“知乎产品改进”主题下的所有最佳答案,并尝试用数据回答这个问题。当然,一部分也是我个人的主观判断。
从数据分析可以看出几个大版本迭代的时间节奏(画了一条时间线),以及用户关注度(相关迭代讨论的点赞数)
知乎小管家+知乎产品团队专栏文章
一个有趣的现象是,知乎产品组1000赞文章只有11篇,而知乎小管家1000多赞文章有19篇。可以看出,知乎普通用户更关心社区运营和氛围,而不是产品迭代。
但我个人认为,如果没有产品层面对优质信息的保护和对低质信息的打击,而是依靠运营团队,维持优质讨论氛围所需的人力成本可能远不及< @知乎创业公司可以承接。
四、知乎产品功能背后的算法
对于知乎的产品迭代,初期重点是信息分发和交互,中期开始出现算法级功能。用户可能看不到它们,但它们对于用户体验非常重要。
内容方
悟空系统——反垃圾邮件,点赞识别
用户端
知乎如何计算用户在某个领域的权重?
友善
知乎葛瑾先生的退出,该行动应该吸取哪些教训?
五、知乎那些鲜为人知的函数——程序员蛋
Chrome下Shift+ctrl+J
知乎以前在群功能上,内容质量太低,快要下架了
概括:
知乎产品核心功能的一个重要部分就是feeds流,它的价值在于让用户看到自己感兴趣的内容,同时看到一些最热门的内容在平台上。
在产品层面,可以考虑知乎的内容分发主要以社交关系为主,而“发现”功能中的Feed将基于算法和编辑推荐。
知乎通过一系列产品功能,建立了人-问题、问题-人、人-人、问题-问题之间的完美关系链。在我看来,这也是知乎能够成为内容城市的重要原因
知乎一年前有一个非常热门的问题:
“你八岁开始刷知乎,到了二十岁,能达到什么程度的知识?”
一个超过1w点赞的回答提到了一句话:
“我和妈妈去广场舞,跟不上节奏怎么办?
儿子:以大多数人的努力程度不高,不可能为人才而战。”
事实上,除了能够欣赏到如此机智的回答之外,现在越来越多的用户涌入了知乎中文问答平台。
在我看来,最重要的原因就是一句话:知乎领域不同,优质内容量大,组织架构优质,好找。
后续知乎简史3会从社区运营的角度来考虑分析(增加新品+推广活动+氛围营造+个人大V为什么退出知乎等)。
网页视频抓取工具 知乎(Mac平台下自己喜欢的视频,一步到位,Get到本地)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-04-02 08:11
前言
我经常浏览哔哩哔哩、YouTube、优酷等视频网站,一看到喜欢的视频流就想下载到本地看。官方不支持此功能或下载质量有限制。有没有更好的突破方法?答案是肯定的,本次文章给大家分享一个Mac平台下使用的强大的视频流媒体下载工具——Downie。
对了,Windows平台也将在下一篇文章中介绍,敬请期待。
介绍唐尼
Downie 是一款来自国外的付费软件。官方宣称支持1000多个视频流媒体网站的下载,基本包括Bilibili、优酷、爱奇艺、YouTube、Vimeo等国内外主流网站。
简单来说,在Downie的帮助下,我们可以轻松获取主流视频流媒体网站下自己喜欢的视频,一步到位,轻松本地获取。
使用步骤
这种工具基本上是个傻瓜。一般的操作逻辑是复制自己喜欢的视频播放地址,提交给工具,让工具处理下载。
Downie 也不例外,但为了进一步达到下载成功率,它还为 Safari 和 Chrome 等浏览器开发了相应的插件。借助插件,一键提交,省去复制粘贴的步骤。
软件开始下载后,借助多线程请求,实测可以跑到满带宽。
写在最后
当前版本的Downie已经到了Downie 4,直接下载安装后可以有14天的试用期。没有功能限制。拿到终身牌照,价格比较高。
如果您对此类话题有什么好的想法和建议,请在下方评论或留言。如果您有更好的想法,请留言分享。 查看全部
网页视频抓取工具 知乎(Mac平台下自己喜欢的视频,一步到位,Get到本地)
前言
我经常浏览哔哩哔哩、YouTube、优酷等视频网站,一看到喜欢的视频流就想下载到本地看。官方不支持此功能或下载质量有限制。有没有更好的突破方法?答案是肯定的,本次文章给大家分享一个Mac平台下使用的强大的视频流媒体下载工具——Downie。
对了,Windows平台也将在下一篇文章中介绍,敬请期待。
介绍唐尼
Downie 是一款来自国外的付费软件。官方宣称支持1000多个视频流媒体网站的下载,基本包括Bilibili、优酷、爱奇艺、YouTube、Vimeo等国内外主流网站。
简单来说,在Downie的帮助下,我们可以轻松获取主流视频流媒体网站下自己喜欢的视频,一步到位,轻松本地获取。
使用步骤
这种工具基本上是个傻瓜。一般的操作逻辑是复制自己喜欢的视频播放地址,提交给工具,让工具处理下载。
Downie 也不例外,但为了进一步达到下载成功率,它还为 Safari 和 Chrome 等浏览器开发了相应的插件。借助插件,一键提交,省去复制粘贴的步骤。
软件开始下载后,借助多线程请求,实测可以跑到满带宽。
写在最后
当前版本的Downie已经到了Downie 4,直接下载安装后可以有14天的试用期。没有功能限制。拿到终身牌照,价格比较高。
如果您对此类话题有什么好的想法和建议,请在下方评论或留言。如果您有更好的想法,请留言分享。
网页视频抓取工具 知乎(40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-28 13:07
/1 简介/
还在为在线看小视频缓存慢而烦恼吗?还在为想重温优秀作品却找不到资源而苦恼吗?别慌,让python为你解决,40行代码教你爬取小视频网站,批量下载,仔细看,是不是很美!
/2 组织想法/
这类网站大体类似,本文以凤凰网的新闻视频网站为例,采用后推的方式来介绍如何通过以下方式获取视频下载的url流量分析,然后批量下载。
/3 操作步骤/
/3.1 分析网站找出网页变化的规律/
1、首先找到网页,网页的详细信息如下图所示。
2、本视频网站分为人物、娱乐、艺术等不同类型,本文以体育板块为例,向下滚动至底部,如下图所示。
3、根据上图的结果,我们可以发现网站是一个动态网页,打开浏览器自带的流量分析器,点击加载更多,找出其中的变化规律网页。第一个是, request 的 URL 和返回的结果如下图。标记的地方是页码,在这种情况下是第 3 页。
4、返回的结果包括视频标题、网页url、guid(相当于每个视频的logo,后面有用)等信息,如下图所示。
5、每个网页收录24个视频,如下图所示。
/3.2 查找视频网址规则/
1、先打开流量分析器,播放视频抓包,找到几个mp2t文件,如下图。
2、我一一找到了它们的URL,并将它们存储在一个文本文件中,以发现它们之间的规则,如下图所示。
3、你发现这个模式了吗?URL中的p26275262-102-9987636-172625参数是视频的guid(上面得到),只有range_bytes参数变化,从0到6767623,明显是视频的大小,视频是分段合成。找到这些规律后,我们需要继续挖掘视频地址的来源。
/3.3 找到原视频下载地址/
1、首先考虑一个问题,视频地址是从哪里来的?一般情况下,先看视频页面,看看有没有。如果没有,我们将在流量分析器中搜索第一个分段视频。一定有一个URL返回这个信息,很快,我在一个vdn.apple.mpegurl文件中找到了下图。
2、厉害了,这不就是我们要找的信息吗,我们来看看它的url参数,如下图所示。
3、上图看起来参数很多,但不要害怕。还是用老方法,先在网页上查看有没有,如果没有,在流量分析器里找。努力有回报,我找到了下面的图片。
4、它的网址如下所示。
5、 仔细寻找pattern,发现唯一需要改的就是每个视频的guid。这第一步已经完成。另外,返回的结果收录了除vkey之外的所有上述参数,而且这个参数是最长的,那怎么办呢?
6、别慌,万一这个参数没用,把vkey去掉,先试试。果然,没有用。现在整个过程已经顺利进行,现在您可以编码了。
/3.4 代码实现/
1、在代码中,设置多线程下载,如下图,其中页码可以自行修改。
2、解析返回参数,json格式,使用json库进行处理,如下图所示。通过解析,我们可以得到每个视频的标题、网页url和guid。
3、模拟请求获取Vkey以外的参数,如下图所示。
4、使用上一步的参数,发出模拟请求,获取包括分段视频在内的信息,如下图所示。
5、将分割后的视频合并,保存在一个视频文件中,并按标题命名,如下图所示。
/3.5 效果渲染/
1、程序运行时,我们可以看到网页中的视频呈现在本地文件夹中,如下图所示。接下来妈妈再也不用担心找不到我喜欢的视频了,真香!
当然,如果想要更直观,可以在代码中添加维度测试信息,手动设置即可。
/4 总结/
本文主要基于Python网络爬虫,使用40行代码,针对小视频网页,批量获取网页视频到本地。方法简单有效,欢迎大家尝试。如需获取本文代码,请访问/cassieeric/python_crawler/tree/master/little_video_crawler获取代码链接。如果觉得还不错,记得给个star。 查看全部
网页视频抓取工具 知乎(40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!)
/1 简介/
还在为在线看小视频缓存慢而烦恼吗?还在为想重温优秀作品却找不到资源而苦恼吗?别慌,让python为你解决,40行代码教你爬取小视频网站,批量下载,仔细看,是不是很美!
/2 组织想法/
这类网站大体类似,本文以凤凰网的新闻视频网站为例,采用后推的方式来介绍如何通过以下方式获取视频下载的url流量分析,然后批量下载。
/3 操作步骤/
/3.1 分析网站找出网页变化的规律/
1、首先找到网页,网页的详细信息如下图所示。
2、本视频网站分为人物、娱乐、艺术等不同类型,本文以体育板块为例,向下滚动至底部,如下图所示。
3、根据上图的结果,我们可以发现网站是一个动态网页,打开浏览器自带的流量分析器,点击加载更多,找出其中的变化规律网页。第一个是, request 的 URL 和返回的结果如下图。标记的地方是页码,在这种情况下是第 3 页。
4、返回的结果包括视频标题、网页url、guid(相当于每个视频的logo,后面有用)等信息,如下图所示。
5、每个网页收录24个视频,如下图所示。
/3.2 查找视频网址规则/
1、先打开流量分析器,播放视频抓包,找到几个mp2t文件,如下图。
2、我一一找到了它们的URL,并将它们存储在一个文本文件中,以发现它们之间的规则,如下图所示。
3、你发现这个模式了吗?URL中的p26275262-102-9987636-172625参数是视频的guid(上面得到),只有range_bytes参数变化,从0到6767623,明显是视频的大小,视频是分段合成。找到这些规律后,我们需要继续挖掘视频地址的来源。
/3.3 找到原视频下载地址/
1、首先考虑一个问题,视频地址是从哪里来的?一般情况下,先看视频页面,看看有没有。如果没有,我们将在流量分析器中搜索第一个分段视频。一定有一个URL返回这个信息,很快,我在一个vdn.apple.mpegurl文件中找到了下图。
2、厉害了,这不就是我们要找的信息吗,我们来看看它的url参数,如下图所示。
3、上图看起来参数很多,但不要害怕。还是用老方法,先在网页上查看有没有,如果没有,在流量分析器里找。努力有回报,我找到了下面的图片。
4、它的网址如下所示。
5、 仔细寻找pattern,发现唯一需要改的就是每个视频的guid。这第一步已经完成。另外,返回的结果收录了除vkey之外的所有上述参数,而且这个参数是最长的,那怎么办呢?
6、别慌,万一这个参数没用,把vkey去掉,先试试。果然,没有用。现在整个过程已经顺利进行,现在您可以编码了。
/3.4 代码实现/
1、在代码中,设置多线程下载,如下图,其中页码可以自行修改。
2、解析返回参数,json格式,使用json库进行处理,如下图所示。通过解析,我们可以得到每个视频的标题、网页url和guid。
3、模拟请求获取Vkey以外的参数,如下图所示。
4、使用上一步的参数,发出模拟请求,获取包括分段视频在内的信息,如下图所示。
5、将分割后的视频合并,保存在一个视频文件中,并按标题命名,如下图所示。
/3.5 效果渲染/
1、程序运行时,我们可以看到网页中的视频呈现在本地文件夹中,如下图所示。接下来妈妈再也不用担心找不到我喜欢的视频了,真香!
当然,如果想要更直观,可以在代码中添加维度测试信息,手动设置即可。
/4 总结/
本文主要基于Python网络爬虫,使用40行代码,针对小视频网页,批量获取网页视频到本地。方法简单有效,欢迎大家尝试。如需获取本文代码,请访问/cassieeric/python_crawler/tree/master/little_video_crawler获取代码链接。如果觉得还不错,记得给个star。
网页视频抓取工具 知乎(通过Python和爬虫,可以完成怎样的小工具?|知乎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-27 01:11
总有同学问,学了 Python 的基础知识后,不知道能做些什么来提高它。今天就用一个小例子来告诉大家,通过Python和爬虫可以完成什么样的小工具。
在知乎,你一定关注过一些不错的专栏(比如Crossin 的编程课堂)。但万一哪天,你喜欢的回答者被喷到网上,你一气之下删帖停止更新,你就看不到这些好内容了。虽然这是小概率事件(但不会发生),但要注意,可以将关注的栏目导出为电子书,这样可以离线阅读,不怕误删帖。
如果只需要工具和源码,可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,就是网页地址上的路径:
之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三个部分:
抓取列文章地址列表抓取每个文章导出PDF1.的详细信息抓取列表
在之前的文章爬虫必备工具中,掌握它就解决了一半,我介绍了如何分析网页上的请求。按照方法,我们可以利用开发者工具的Network功能,找出栏目页面的请求,得到明细列表:
1
2
3https://www.zhihu.com/api/v4/c ... icles
4
5
6
观察返回的结果可以发现,通过next和is_end的值,可以得到下一个列表请求的地址(相当于向下滚动页面的触发效果),判断是否全部文章已获得。
data中的id、title、url就是我们需要的数据。因为 url 可以用 id 拼出,所以我们的代码中没有保存。
使用 while 循环,直到 文章 的所有 id 和标题都被捕获并保存在文件中。
1
2
3while True:
4 resp = requests.get(url, headers=headers)
5 j = resp.json()
6 data = j['data']
7 for article in data:
8 # 保存id和title(略)
9 if j['paging']['is_end']:
10 break
11 url = j['paging']['next']
12 # 按 id 排序(略)
13 # 导入文件(略)
14
15
16
2. 抢文章
有了 文章 的所有 ids/urls,后面的抓取就很简单了。文章正文内容在 Post-RichText 标签中。
需要花点功夫的是一些文字处理,比如原页面的图片效果,会添加noscript标签和
1`
, 突出显示">
1
2
3url = 'https://zhuanlan.zhihu.com/p/' + id
4html = requests.get(url, headers=headers).text
5soup = BeautifulSoup(html, 'lxml')
6content = soup.find(class_='Post-RichText').prettify()
7# 对content做处理(略)
8with open(file_name, 'w') as f:
9 f.write(content)
10
11
12
至此,所有内容都已经爬取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf + pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf 是一个 HTML to PDF 工具,需要单独安装。详情请参考其官网介绍。
pdfkit 是一个包装了这个工具的 Python 库,可以从 pip 安装:
1
2
3pip install pdfkit
4
5
6
使用简单:
1
2
3# 获取htmls文件名列表(略)
4pdfkit.from_file(sorted(htmls), 'zhihu.pdf')
5
6
7
这样就完成了整个列的导出。
不仅是知乎栏目,几乎大部分信息网站,通过1.抓取列表2.抓取详细内容采集数据这两个步骤. 所以这段代码稍加修改就可以用在很多其他的网站s上。只是有些网站需要登录才能访问,那么就需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制等都不一样,具体问题还是需要分析的。
【源码下载】
除了代码,还提供了本专栏的打包PDF,欢迎阅读和分享。
════
其他 文章 和答案:
如何自学Python | 新手指南 | 精选 Python 问答 | Python 单词表 | 人工智能 | 嘻哈 | 履带式 |
欢迎搜索关注:Crossin的编程课堂 查看全部
网页视频抓取工具 知乎(通过Python和爬虫,可以完成怎样的小工具?|知乎)
总有同学问,学了 Python 的基础知识后,不知道能做些什么来提高它。今天就用一个小例子来告诉大家,通过Python和爬虫可以完成什么样的小工具。
在知乎,你一定关注过一些不错的专栏(比如Crossin 的编程课堂)。但万一哪天,你喜欢的回答者被喷到网上,你一气之下删帖停止更新,你就看不到这些好内容了。虽然这是小概率事件(但不会发生),但要注意,可以将关注的栏目导出为电子书,这样可以离线阅读,不怕误删帖。
如果只需要工具和源码,可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,就是网页地址上的路径:
之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三个部分:
抓取列文章地址列表抓取每个文章导出PDF1.的详细信息抓取列表
在之前的文章爬虫必备工具中,掌握它就解决了一半,我介绍了如何分析网页上的请求。按照方法,我们可以利用开发者工具的Network功能,找出栏目页面的请求,得到明细列表:
1
2
3https://www.zhihu.com/api/v4/c ... icles
4
5
6
观察返回的结果可以发现,通过next和is_end的值,可以得到下一个列表请求的地址(相当于向下滚动页面的触发效果),判断是否全部文章已获得。
data中的id、title、url就是我们需要的数据。因为 url 可以用 id 拼出,所以我们的代码中没有保存。
使用 while 循环,直到 文章 的所有 id 和标题都被捕获并保存在文件中。
1
2
3while True:
4 resp = requests.get(url, headers=headers)
5 j = resp.json()
6 data = j['data']
7 for article in data:
8 # 保存id和title(略)
9 if j['paging']['is_end']:
10 break
11 url = j['paging']['next']
12 # 按 id 排序(略)
13 # 导入文件(略)
14
15
16
2. 抢文章
有了 文章 的所有 ids/urls,后面的抓取就很简单了。文章正文内容在 Post-RichText 标签中。
需要花点功夫的是一些文字处理,比如原页面的图片效果,会添加noscript标签和
1`
, 突出显示">
1
2
3url = 'https://zhuanlan.zhihu.com/p/' + id
4html = requests.get(url, headers=headers).text
5soup = BeautifulSoup(html, 'lxml')
6content = soup.find(class_='Post-RichText').prettify()
7# 对content做处理(略)
8with open(file_name, 'w') as f:
9 f.write(content)
10
11
12
至此,所有内容都已经爬取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf + pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf 是一个 HTML to PDF 工具,需要单独安装。详情请参考其官网介绍。
pdfkit 是一个包装了这个工具的 Python 库,可以从 pip 安装:
1
2
3pip install pdfkit
4
5
6
使用简单:
1
2
3# 获取htmls文件名列表(略)
4pdfkit.from_file(sorted(htmls), 'zhihu.pdf')
5
6
7
这样就完成了整个列的导出。
不仅是知乎栏目,几乎大部分信息网站,通过1.抓取列表2.抓取详细内容采集数据这两个步骤. 所以这段代码稍加修改就可以用在很多其他的网站s上。只是有些网站需要登录才能访问,那么就需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制等都不一样,具体问题还是需要分析的。
【源码下载】
除了代码,还提供了本专栏的打包PDF,欢迎阅读和分享。
════
其他 文章 和答案:
如何自学Python | 新手指南 | 精选 Python 问答 | Python 单词表 | 人工智能 | 嘻哈 | 履带式 |
欢迎搜索关注:Crossin的编程课堂
网页视频抓取工具 知乎(谷歌浏览器F12开发者开发者工具的使用(视频资料解析) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 465 次浏览 • 2022-03-24 05:17
)
我觉得我没有分享昨天视频的细节。在这里分享一下自己学过的视频,对当时的我帮助很大,对学习查找和分析js很有帮助。可能大家都看过了,不过应该对初学者进阶有所帮助。如果对你有帮助,欢迎采集,欢迎交流,无友独学,无知。
推荐以下第一个:
使用 Google Chrome F12 开发者工具。 Python。分析某个网络的音乐。 (私人视频,不保留知识),摩卡拉卡的视频,更新时间比较新,真的是从头教大家分析的视频,建议花时间学习,从浏览器选择,到网络工具的使用,直到解析js详细介绍js的使用调试。 148分钟,一部学习开发者工具的电影时间,良心推荐。还有其他类型的视频值得学习。
第二:
python爬虫——有道翻译js解析,推荐这个是因为我觉得比较简单,应该是教育机构开的那种公开课,看起来比较简单。学习时间不会太长。缺点是声音有点小,真的是针对新手的,所以也比较详细。毕竟,他们是专业的讲师。
第三:
网页爬虫流程-js加密参数反向解析流程(以头条为例)-不可能不系列,2end0黑帮视频系列,1小时左右,从0开始实现一个流程,中间调试js是通过序列是由节点工具解析的,你必须在憋尿的时候观看序列。不说了,大佬有5个关于js的视频,还有APP部分。
以上是本期推荐的视频素材。建议您自己练习而不是观看。毕竟是亲眼所见,但手未必能掌握这个技能。
最后推荐一个分析抓包的工具:fiddler,我很久以前就用过。它是一个非常有用的抓包工具。它可以拦截、重发、编辑和转储网络传输发送和接收的数据包。等等。
还有一个推荐的post测试工具:postman,一个模拟请求的工具,对分析网站请求很有帮助。比如要爬取某个网站,如果不知道需要带什么参数,可以先用这个工具测试一下,避免写太多无用的代码。
查看全部
网页视频抓取工具 知乎(谷歌浏览器F12开发者开发者工具的使用(视频资料解析)
)
我觉得我没有分享昨天视频的细节。在这里分享一下自己学过的视频,对当时的我帮助很大,对学习查找和分析js很有帮助。可能大家都看过了,不过应该对初学者进阶有所帮助。如果对你有帮助,欢迎采集,欢迎交流,无友独学,无知。
推荐以下第一个:
使用 Google Chrome F12 开发者工具。 Python。分析某个网络的音乐。 (私人视频,不保留知识),摩卡拉卡的视频,更新时间比较新,真的是从头教大家分析的视频,建议花时间学习,从浏览器选择,到网络工具的使用,直到解析js详细介绍js的使用调试。 148分钟,一部学习开发者工具的电影时间,良心推荐。还有其他类型的视频值得学习。
第二:
python爬虫——有道翻译js解析,推荐这个是因为我觉得比较简单,应该是教育机构开的那种公开课,看起来比较简单。学习时间不会太长。缺点是声音有点小,真的是针对新手的,所以也比较详细。毕竟,他们是专业的讲师。
第三:
网页爬虫流程-js加密参数反向解析流程(以头条为例)-不可能不系列,2end0黑帮视频系列,1小时左右,从0开始实现一个流程,中间调试js是通过序列是由节点工具解析的,你必须在憋尿的时候观看序列。不说了,大佬有5个关于js的视频,还有APP部分。
以上是本期推荐的视频素材。建议您自己练习而不是观看。毕竟是亲眼所见,但手未必能掌握这个技能。
最后推荐一个分析抓包的工具:fiddler,我很久以前就用过。它是一个非常有用的抓包工具。它可以拦截、重发、编辑和转储网络传输发送和接收的数据包。等等。
还有一个推荐的post测试工具:postman,一个模拟请求的工具,对分析网站请求很有帮助。比如要爬取某个网站,如果不知道需要带什么参数,可以先用这个工具测试一下,避免写太多无用的代码。
网页视频抓取工具 知乎(秀一把在下所写的浏览器脚本——iZhihu我爱知)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-03-20 16:25
/ 晚了。首先,展示一个下面写的浏览器脚本——
i知乎 I Love知乎 for Greasemonkey
在以下浏览器中作为 UserScript 运行:
Firefox(推荐扩展:Greasemonkey::Firefox 附加组件)
Chrome(建议扩展:Chrome 的 Tampermonkey)
// Safari 可用于 NinjaKit 扩展
v1.10个新功能——
1.打开任何采集夹(您自己的或其他人的):
2.“地址列表”比不使用i知乎脚本时多了——戳一下,然后页面进入计算状态:
3.患者结果:
4.OK——之后将文本框中的内容全部复制,粘贴到文本文件中保存(嗯,备份是个好习惯)。
接下来,我们需要一种不使用浏览器爬网的方法——
VisualWget(Wget图形版下载工具) V2.4
下载后是一个压缩包。我已经试过了。放心解压。只需在其中打开 VisualWget 应用程序。所以我们看到一个像这样的主窗口:
下载菜单 -> 新建批处理任务:
现在,你可以把我们之前通过i知乎“地址列表”获取的所有地址都贴上去,一个都不剩了~
这里插入一句——从知乎抓取的网页文件只有一个ID号,没有任何后缀。自动添加.html后缀的设置方法:工具-默认下载设置-高级-HTTP-勾选“-html-extension”。(感谢@邱凯达)
// Mac 用户查看
HexCat – DeepVacuum
另一个下载地址:下载DeepVacuum for Mac
// 第二次运行会提示注册,但是我暂时没有找到任何功能或者时间限制-_-
如此体贴和木质!!!
// 对了,列表,你备份了吗?
对于备份知乎答案,请在“预设”中选择“单个文件(可恢复)”。
如果一切顺利,一切都应该是这样的:
// 我爱 Mac ^^
最后,只剩下一步了——
如何本地化 HTML 查看全部
网页视频抓取工具 知乎(秀一把在下所写的浏览器脚本——iZhihu我爱知)
/ 晚了。首先,展示一个下面写的浏览器脚本——
i知乎 I Love知乎 for Greasemonkey
在以下浏览器中作为 UserScript 运行:
Firefox(推荐扩展:Greasemonkey::Firefox 附加组件)
Chrome(建议扩展:Chrome 的 Tampermonkey)
// Safari 可用于 NinjaKit 扩展
v1.10个新功能——
1.打开任何采集夹(您自己的或其他人的):
2.“地址列表”比不使用i知乎脚本时多了——戳一下,然后页面进入计算状态:
3.患者结果:
4.OK——之后将文本框中的内容全部复制,粘贴到文本文件中保存(嗯,备份是个好习惯)。
接下来,我们需要一种不使用浏览器爬网的方法——
VisualWget(Wget图形版下载工具) V2.4
下载后是一个压缩包。我已经试过了。放心解压。只需在其中打开 VisualWget 应用程序。所以我们看到一个像这样的主窗口:
下载菜单 -> 新建批处理任务:
现在,你可以把我们之前通过i知乎“地址列表”获取的所有地址都贴上去,一个都不剩了~
这里插入一句——从知乎抓取的网页文件只有一个ID号,没有任何后缀。自动添加.html后缀的设置方法:工具-默认下载设置-高级-HTTP-勾选“-html-extension”。(感谢@邱凯达)
// Mac 用户查看
HexCat – DeepVacuum
另一个下载地址:下载DeepVacuum for Mac
// 第二次运行会提示注册,但是我暂时没有找到任何功能或者时间限制-_-
如此体贴和木质!!!
// 对了,列表,你备份了吗?
对于备份知乎答案,请在“预设”中选择“单个文件(可恢复)”。
如果一切顺利,一切都应该是这样的:
// 我爱 Mac ^^
最后,只剩下一步了——
如何本地化 HTML
网页视频抓取工具 知乎(如何爬视频我所用的图片皆为公开无版权的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2022-03-20 00:02
潜水很久了知乎,这是我的第一篇文章知乎文章,如果有不对的地方请多多指教
自学爬虫一个多月,我是一名英语学习爱好者。突然想去ted看看怎么爬视频
我使用的图片都是公开的,无版权的图片网站--美丽免费图片| Unsplash 如有侵权,立即删除
1.使用的工具
requests 模块——爬虫的核心
urllib.request 模块 - 爬虫核心
BeautifulSoup 模块 - 解析器分析模块
re 模块 - 正则匹配
python版本3.6
2.网页分析
首先我们去实现我们的目标网站TED:值得传播的想法来分析我们要爬到的视频
进入会谈页面时,我们看到的页面是这样的
讲座共有72页
并发现其url地址的规律是
这样我们就可以轻松获取所有(36*72) 会谈视频)
3.进一步分析详情页
这个页面的分页就是我们要下载的内容。
随意点击进入详细视频页面,分析会谈页面与详细页面的关联
地雷的可怕逻辑——以及帮助人们避开地雷的应用程序
我们可以发现,详情页的url地址是TED Talks加上作者名和标题,组合中间用“_”隔开。
这样我们就可以很方便的去讨论页面爬取视频标题,拼接成子页面进一步爬取
接下来在浏览器中按F12打开调试器,发现所有标题都在这个节点内,并且提取了它的href属性
4.开始写爬虫
import requests
from bs4 import BeautifulSoup
import re
import urllib.request
num=input("输入要查找的ted的页码 1-72")
url_page='https://www.ted.com/talks?page=%s'%num
ted_page=requests.get(url_page).content
soup=BeautifulSoup(ted_page,"html.parser")
cont=soup.findAll(attrs={"data-ga-context":"talks"})
ted_page 返回我们要抓取的内容
选择“html.parser”通过 BeautifulSoup 解析内容
通过标签的属性分析,发现收录url地址的属性为data-ga-context="talks"
得到的cont是所有有url地址的节点
由于我们发现他的每个视频都收录 2 个相同的视频地址
所以我们先随机抽取一个值来测试
page=2 #假设我们提取第二个视频
raw_url = cont[page * 2]['href']
url='https://www.ted.com%s'%(raw_url) #拼接视频页
response=requests.get(url)
cont=response.content
soup=BeautifulSoup(cont,"html.parser")
我们在此页面上没有找到他的下载链接
通过测试发现原来的下载链接隐藏在右上角的分享中
通过浏览器调试器发现链接的地址隐藏在js标签的中间界面中,在js的鼠标点击后渲染到div标签中,这样我们就可以不用模拟直接读取他的js标签了鼠标点击等待渲染然后爬取
5.re模块的正则匹配
element=soup.findAll("script")
patter=re.compile('http.*?mp4.apikey=.*?"')
stre=patter.findall(str(element))
打印完str的内容后,我们发现他有很多视频链接。我们点开,发现内容的不同是视频的分辨率不同。就个人而言,我更喜欢看高分辨率的视频,所以我再次对其进行过滤。
donwload_url=''
for _ in stre:
if "1500k" in _:
_=_.split('"')
donwload_url=_[0]
所以download_url就是我们想要的视频链接
6.下载视频
urllib.request.urlretrieve(donwload_url, filename="ted.mp4", reporthook=Schedule)
调用urllib.request.urlretreieve模块下载mp4格式的视频并保存到当前目录
其中reporthook就知道是一个hook钩子函数,通过查看名称返回下载进度。
7.查看下载进度
第一个函数Schedule
pre=0
def Schedule(a,b,c):
global pre
per = 100.0 * a * b / c
if int(per)-pre>0:
print('%.2f%%' % per)
pre=int(per)
这会在下载进度每增加1%时打印进度以便我们理解
8.还有一件事
我已经将完整的代码 git 到我的 github。欢迎需要练习的朋友下载。如有不足请指出
github还有scrapy框架抓取动态网站unsplash下载图片
并使用phantomJS+selenium模拟浏览器行为抓取鸡网站数据并分析 查看全部
网页视频抓取工具 知乎(如何爬视频我所用的图片皆为公开无版权的)
潜水很久了知乎,这是我的第一篇文章知乎文章,如果有不对的地方请多多指教
自学爬虫一个多月,我是一名英语学习爱好者。突然想去ted看看怎么爬视频
我使用的图片都是公开的,无版权的图片网站--美丽免费图片| Unsplash 如有侵权,立即删除
1.使用的工具
requests 模块——爬虫的核心
urllib.request 模块 - 爬虫核心
BeautifulSoup 模块 - 解析器分析模块
re 模块 - 正则匹配
python版本3.6
2.网页分析
首先我们去实现我们的目标网站TED:值得传播的想法来分析我们要爬到的视频
进入会谈页面时,我们看到的页面是这样的
讲座共有72页
并发现其url地址的规律是
这样我们就可以轻松获取所有(36*72) 会谈视频)
3.进一步分析详情页
这个页面的分页就是我们要下载的内容。
随意点击进入详细视频页面,分析会谈页面与详细页面的关联
地雷的可怕逻辑——以及帮助人们避开地雷的应用程序
我们可以发现,详情页的url地址是TED Talks加上作者名和标题,组合中间用“_”隔开。
这样我们就可以很方便的去讨论页面爬取视频标题,拼接成子页面进一步爬取
接下来在浏览器中按F12打开调试器,发现所有标题都在这个节点内,并且提取了它的href属性
4.开始写爬虫
import requests
from bs4 import BeautifulSoup
import re
import urllib.request
num=input("输入要查找的ted的页码 1-72")
url_page='https://www.ted.com/talks?page=%s'%num
ted_page=requests.get(url_page).content
soup=BeautifulSoup(ted_page,"html.parser")
cont=soup.findAll(attrs={"data-ga-context":"talks"})
ted_page 返回我们要抓取的内容
选择“html.parser”通过 BeautifulSoup 解析内容
通过标签的属性分析,发现收录url地址的属性为data-ga-context="talks"
得到的cont是所有有url地址的节点
由于我们发现他的每个视频都收录 2 个相同的视频地址
所以我们先随机抽取一个值来测试
page=2 #假设我们提取第二个视频
raw_url = cont[page * 2]['href']
url='https://www.ted.com%s'%(raw_url) #拼接视频页
response=requests.get(url)
cont=response.content
soup=BeautifulSoup(cont,"html.parser")
我们在此页面上没有找到他的下载链接
通过测试发现原来的下载链接隐藏在右上角的分享中
通过浏览器调试器发现链接的地址隐藏在js标签的中间界面中,在js的鼠标点击后渲染到div标签中,这样我们就可以不用模拟直接读取他的js标签了鼠标点击等待渲染然后爬取
5.re模块的正则匹配
element=soup.findAll("script")
patter=re.compile('http.*?mp4.apikey=.*?"')
stre=patter.findall(str(element))
打印完str的内容后,我们发现他有很多视频链接。我们点开,发现内容的不同是视频的分辨率不同。就个人而言,我更喜欢看高分辨率的视频,所以我再次对其进行过滤。
donwload_url=''
for _ in stre:
if "1500k" in _:
_=_.split('"')
donwload_url=_[0]
所以download_url就是我们想要的视频链接
6.下载视频
urllib.request.urlretrieve(donwload_url, filename="ted.mp4", reporthook=Schedule)
调用urllib.request.urlretreieve模块下载mp4格式的视频并保存到当前目录
其中reporthook就知道是一个hook钩子函数,通过查看名称返回下载进度。
7.查看下载进度
第一个函数Schedule
pre=0
def Schedule(a,b,c):
global pre
per = 100.0 * a * b / c
if int(per)-pre>0:
print('%.2f%%' % per)
pre=int(per)
这会在下载进度每增加1%时打印进度以便我们理解
8.还有一件事
我已经将完整的代码 git 到我的 github。欢迎需要练习的朋友下载。如有不足请指出
github还有scrapy框架抓取动态网站unsplash下载图片
并使用phantomJS+selenium模拟浏览器行为抓取鸡网站数据并分析
网页视频抓取工具 知乎(Python爬虫快速获取数据最重要的方式,相比其它语言,更简单、高效)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-17 12:17
越来越多的工作会基于数据来完成,爬虫是快速获取数据的最重要方式。与其他语言相比,Python爬虫更简单、更高效。
第 1 章 课程介绍 尝试 1 节 | 8 分钟
介绍课程目标,通过课程可以学到的内容,系统开发前需要掌握的知识
视频:
1-1 python分布式爬虫创建搜索引擎介绍(07:23)
尝试
第2章在Windows下搭建开发环境4小节| 64 分钟
介绍项目开发需要安装的开发软件,python virtual virtualenv和virtualenvwrapper的安装和使用,最后介绍pycharm和navicat的简单使用
视频:
2-1 pycharm的安装及简单使用(09:07)
视频:
2-2 mysql和navicat的安装和使用(16:20)
视频:
2-3 windows和linux下安装python2和python3(06:49)
视频:
2-4 虚拟环境的安装与配置(30:53)
第 3 章爬虫基础复习 7 节 | 120 分钟
介绍爬虫开发需要的基础知识,包括爬虫能做什么、正则表达式、深度优先和广度优先算法及实现、爬虫URL去重策略,透彻理解unicode和utf8编码的区别和应用。
视频:
3-1 技术选型爬虫能做什么(09:50)
视频:
3-2 正则表达式-1 (18:31)
视频:
3-3 正则表达式-2 (19:04)
视频:
3-4 正则表达式-3 (20:16)
视频:
3-5 深度优先和广度优先原则 (25:15)
视频:
3-6 URL去重方法(07:44)
视频:
3-7 彻底理解unicode和utf8编码(18:31)
第4章新增:scrapy爬取知名技术文章网站25节 | 402 分钟
搭建scrapy的开发环境。本章介绍scrapy常用命令及项目目录结构分析。本章还将详细解释 xpath 和 css 选择器的使用。然后通过scrapy提供的spider完成所有文章的爬取。然后详细讲解item和item loader方法,完成具体字段的提取,使用scrapy提供的pipeline将数据分别保存到json文件和mysql数据库中。...
视频:
4-1 重新录制说明(重要!!!)(04:47)
视频:
4-2 scrapy安装配置(30:30)
视频:
4-3 需求分析(13:53)
视频:
4-4 在pycharm中调试scrapy源码(10:13)
视频:
4-5 xpath 基本语法(19:02)
视频:
4-6 xpath 提取元素 (28:48)
视频:
4-7 个 CSS 选择器 (17:54)
视频:
4-8。cnblogs模拟登录(新内容)(22:23)
视频:
4-9 编写蜘蛛完成抓取过程 - 1 (19:38)
视频:
4-10 编写spider完成抓取过程 - 2(20:47)
视频:
4-11 为什么在scrapy中使用yield(09:49)
视频:
4-12 提取详情页信息(23:16)
视频:
4-13 提取详情页信息(18:13)
视频:
4-14 项目的定义和使用 - 1 (16:21)
视频:
4-15 项目的定义和使用 - 2 (13:30)
视频:
4-16scrapy配置图片下载(18:20)
视频:
4-17 items数据写入json文件(09:27)
视频:
4-18 MySQL表结构设计(13:21)
视频:
4-19 管道数据库保存(20:16)
视频:
4-20 mysql的异步存储(12:37)
视频:
4-21 数据插入主键冲突解决办法(04:40)
视频:
4-22 itemloader提取信息(21:41)
视频:
4-23 itemloader提取信息(19:06)
视频:
4-24 大图抓拍下载错误的问题(12:45)
手术:
4-25 有没有办法准确解析标题和正文内容?
第五章网站模拟登录和滑动验证码识别(202年6月更新1.)7小节 | 123 分钟
本章我们将解决两个问题:1.防止selenium被网站2.滑动验证码识别,我们将使用opencv识别和机器学习平台识别进行滑动验证码认出。滑动验证码是目前最流行的验证码。识别滑动验证码可以让我们解决大部分网站的模拟登录...
视频:
5-1 Session和cookie自动登录机制(20:10)
视频:
5-2 课程如何处理网站反爬变化?(08:03)
视频:
5-3 使用opencv识别滑动验证码的环境准备(15:59)
视频:
5-4 Opencv滑动验证码识别原理(26:19)
视频:
5-5 滑动验证码识别集成到scrapy(10:02)
视频:
5-6 通过机器学习平台训练滑动验证码模型(15:23)
视频:
5-7 发布训练模型,远程调用识别(26:53)
Chapter 6 Scrapy Crawling 知名问答网站 第11 节 | 150 分钟
通过上一章的学习,本章我们将针对具体的网站进行需求分析、表结构设计等。本章详细分析网站的网络请求,分析网站的结果@>答题提取数据并保存到mysql的API请求接口
视频:
6-1 知乎分析及数据表设计1(15:17)
视频:
6-2 知乎分析与数据表设计——2(13:35)
视频:
6-3 按项目 loder 提取问题 - 1 (14:57)
视频:
6-4 按项目 loder 提取问题 - 2 (15:20)
视频:
6-5 按项目 loder 提取问题 - 3 (06:45)
视频:
6-6 知乎蜘蛛逻辑和答案提取的实现- 1(15:54)
视频:
6-7 知乎蜘蛛逻辑和答案提取的实现- 2(17:04)
视频:
6-8 保存数据到mysql-1(17:27)
视频:
6-9 保存数据到mysql-2(17:22)
视频:
6-10 保存数据到mysql-3(16:09)
手术:
6-11 如何分离数据存储和采集?
第 7 章使用 CrawlSpider 进行招聘的全站爬网网站 9 部分 | 167 分钟
本章完成招聘网站职位的数据表结构设计,通过链接提取器和规则的形式完成招聘网站中所有职位的爬取并配置CrawlSpider。本章还将从源码的角度分析CrawlSpider。大家对CrawlSpider都有很深的了解。
视频:
7-1 数据表结构设计(15:33)
视频:
7-2 CrawlSpider源码解析-新CrawlSpider及设置配置(12:50)
视频:
7-3 CrawlSpider源码解析(25:29)
视频:
7-4 Rule 和 LinkExtractor 的使用 (14:28)
视频:
7-5 网页302后的模拟登录和cookie传递(网站需要登录时学习这个视频教程)(32:11)
视频:
7-6 项目加载器位置分析 (24:46)
视频:
7-7 位置数据存储-1 (19:01)
视频:
7-8 位置信息存储-2(11:19)
视频:
7-9 网站反爬突破(10:58)
第8章Scrapy突破反爬虫限制 尝试10节 | 天天要闻 159 分钟
本章将从爬虫和反爬虫的斗争开始,然后解释scrapy的原理,然后通过随机切换user-agent和设置scrapy的ip代理来突破反爬虫的各种限制。本章还将详细介绍httpresponse和httprequest,详细分析scrapy的功能,最终通过云编码平台完成在线验证码识别并禁用cookies和访问频率,以减少爬虫被拦截的可能性。...
视频:
8-1 爬虫与反爬虫的对抗过程及策略(20:17)
尝试
视频:
8-2 Scrapy架构源码分析(10:45)
视频:
8-3 请求和响应介绍(10:18)
视频:
8-4 通过下载中间件随机替换user-agent-1(17:00)
视频:
8-5 通过下载中间件随机替换user-agent - 2 (17:13)
视频:
8-6 scrapy 实现 ip 代理池 - 1 (16:51)
视频:
8-7 scrapy 实现 ip 代理池 - 2 (17:39)
视频:
8-8 scrapy 实现 ip 代理池 - 3 (18:46)
视频:
8-9 云编码实现验证码识别(22:37)
视频:
8-10 cookie 禁用、自动限速、自定义蜘蛛设置 (07:22)
第9章Scrapy高级开发12小节| 152 分钟
本章将讲解scrapy更高级的特性,包括通过selenium和phantomjs爬取动态网站数据并将两者集成到scrapy、scrapy信号、自定义中间件、暂停和启动scrapy爬虫、scrapy的核心api、scrapy的telnet、scrapy的web服务和scrapy的日志配置和邮件发送等。这些特性让我们可以做的不仅仅是scrapy...
视频:
9-1 Selenium动态网页请求和模拟登录知乎(21:24)
视频:
9-2 Selenium模拟登录微博,模拟鼠标按下(11:06)
视频:
9-3 chromedriver不加载图片,phantomjs获取动态网页(09:59)
视频:
9-4 selenium 集成到scrapy(19:43)
视频:
9-5 其他动态网页获取技术介绍——chrome running without interface, scrapy-splash, selenium-grid, splinter (07:50)
视频:
9-6 scrapy的暂停和重启(12:58)
视频:
9-7 scrapy url去重原理(05:45)
视频:
9-8 scrapy telnet 服务(07:37)
视频:
9-9蜘蛛中间件详解(15:25)
视频:
9-10scrapy数据采集(13:44)
视频:
9-11scrapy信号详解(13:05)
视频:
9-12scrapy扩展开发(13:16)
第10章scrapy-redis分布式爬虫9节| 125 分钟
Scrapy-redis分布式爬虫的使用和scrapy-redis分布式爬虫的源码分析,让大家可以根据自己的需要修改源码,满足自己的需要。最后,我将解释如何将bloomfilter集成到scrapy-redis中。
视频:
10-1 分布式爬虫点(08:39)
视频:
10-2 Redis 基础 - 1 (20:31)
视频:
10-3 Redis 基础 - 2 (15:58)
视频:
10-4 scrapy-redis编写分布式爬虫代码(21:06)
视频:
10-5 scrapy源码解析-connection.py,defaults.py-(11:05)
视频:
10-6 scrapy-redis源码分析-dupefilter.py-(05:29)
视频:
10-7 scrapy-redis源码解析-pipelines.py,queue.py-(10:41)
视频:
10-8 scrapy-redis源码分析-scheduler.py,spider.py-(11:52)
视频:
10-9 将bloomfilter集成到scrapy-redis中(19:30)
第11章Cookie池系统设计与实现15小节| 175 分钟
为了防止爬取代码和解析代码受到模拟登录的影响,将模拟登录分离成一个独立的服务变得非常重要。cookie池就是为了解决这类问题而诞生的。多账号登录管理,如何让网站轻松访问将是cookie池需要解决的问题。本章重点介绍 cookie 池设计和开发的细节。...
视频:
11-1 什么是cookie池?(11:27)
视频:
11-2 Cookie池系统设计(09:23)
视频:
11-3 实施cookie pool-1 (10:12)
视频:
11-4 实施 cookie pool-2 (12:39)
视频:
11-5 修改登录方式 - 1 (09:58)
视频:
11-6 修改登录方式-2(09:36)
视频:
11-7 修改登录方式-3(08:43)
视频:
11-8 修改登录方式-4(10:37)
视频:
11-9 通过抽象基类实现网站轻松访问(15:00)
视频:
11-10 实现检测网站cookie是否有效(08:06)
视频:
11-11 如何选择redis的数据结构保存cookies(10:59)
视频:
11-12 cookie管理器的实现(22:10)
视频:
11-13 启动cookie池服务(12:35)
视频:
11-14 将cookies集成到爬虫项目中(15:34)
视频:
11-15 cookie架构设计改进建议(07:36)
第12章各种Captcha 5部分的识别| 77 分钟
滑动验证码越来越流行,如何解决滑动验证码成为模拟登录的重要环节。本章重点解决滑动验证码的各种细节问题。
视频:
12-1 滑动验证码识别思路(15:17)
视频:
12-2 验证码-1截图(11:42)
视频:
12-3 验证码2截图(14:03)
视频:
12-4 计算滑动距离(17:37)
视频:
12-5 计算滑动轨迹(18:00)
第13章增量爬取4段| 50 分钟
增量爬取和数据更新是爬虫运行中经常遇到的问题。比如当前爬虫在运行,但是如何及时发现新数据,如何先爬后面的url,如何发现新数据,都是实际开发。在本章中,我们经常通过修改scrapy-redis的源代码来解决原方式的问题,以最小的成本解决上诉问题。通过本章的学习,我们将更加了解如何控制爬虫的运行。...
视频:
13-1 增量爬虫要解决的问题(09:36)
视频:
13-2 修改scrapy-redis-1完成增量抓取(16:11)
视频:
13-3 通过修改scrapy-redis-2(14:13)完成增量抓取
视频:
13-4 爬虫数据更新(09:23)
第 14 章使用 elasticsearch 搜索引擎 13 小节 | 207 分钟
本章将讲解elasticsearch的安装和使用,elasticsearch基本概念的介绍和api的使用。本章还将讲解搜索引擎的原理和elasticsearch-dsl的使用,最后讲解如何通过scrapy的pipeline将数据保存到elasticsearch中。
视频:
14-1 elasticsearch简介(18:21)
视频:
14-2 elasticsearch安装(13:24)
视频:
14-3 Elasticsearch-head插件及kibana安装(24:09)
视频:
14-4 elasticsearch基本概念(12:15)
视频:
14-5 倒排索引 (11:24)
视频:
14-6 Elasticsearch基本索引和文档CRUD操作(18:44)
视频:
14-7 elasticsearch的mget和bulk操作(12:36)
视频:
14-8 elasticsearch的映射管理(21:03)
视频:
14-9 elasticsearch的简单查询 - 1 (14:56)
视频:
14-10 elasticsearch的简单查询 - 2 (11:12)
视频:
14-11 Elasticsearch的bool组合查询(22:58)
视频:
14-12 scrapy写数据到elasticsearch - 1 (14:16)
视频:
14-13 scrapy写数据到elasticsearch - 2 (11:15)
第15章Django建筑搜索网站9节| 131 分钟
本章讲解如何通过 django 快速构建搜索网站。本章还讲解了如何完成django和elasticsearch的搜索查询交互。
视频:
15-1 es 完整的搜索建议 - 搜索建议字段保存 - 1 (13:45)
视频:
15-2 es 完成搜索建议 - 搜索建议字段保存 - 2 (13:34)
视频:
15-3 django实现elasticsearch的搜索建议-1(19:57)
视频:
15-4 django实现elasticsearch的搜索建议-2(18:15)
视频:
15-5 django实现elasticsearch-1的搜索功能(14:06)
视频:
15-6 django实现elasticsearch-2的搜索功能(13:14)
视频:
15-7 Django实现搜索结果分页(09:12)
视频:
15-8 搜索记录和热门搜索功能的实现- 1 (14:34)
视频:
15-9 搜索记录和热门搜索功能的实现-2(14:04)
第16章用scrapyd部署scrapy爬虫1节| 25 分钟
本章主要通过scrapyd完成scrapy爬虫的在线部署。
视频:
16-1 scrapyd部署scrapy项目(24:39)
第 17 章课程总结 4 节 | 6 分钟
重新整理系统开发的全过程,让学生对系统和开发过程有更直观的认识
视频:
17-1 课程总结 (05:55)
手术:
17-2【讨论题】你觉得JS逆向工程是什么?
手术:
17-3 如何集成nodejs服务?
手术:
17-4【讨论题】字体防爬应该如何分析?
本课程结束 查看全部
网页视频抓取工具 知乎(Python爬虫快速获取数据最重要的方式,相比其它语言,更简单、高效)
越来越多的工作会基于数据来完成,爬虫是快速获取数据的最重要方式。与其他语言相比,Python爬虫更简单、更高效。
第 1 章 课程介绍 尝试 1 节 | 8 分钟
介绍课程目标,通过课程可以学到的内容,系统开发前需要掌握的知识
视频:
1-1 python分布式爬虫创建搜索引擎介绍(07:23)
尝试
第2章在Windows下搭建开发环境4小节| 64 分钟
介绍项目开发需要安装的开发软件,python virtual virtualenv和virtualenvwrapper的安装和使用,最后介绍pycharm和navicat的简单使用
视频:
2-1 pycharm的安装及简单使用(09:07)
视频:
2-2 mysql和navicat的安装和使用(16:20)
视频:
2-3 windows和linux下安装python2和python3(06:49)
视频:
2-4 虚拟环境的安装与配置(30:53)
第 3 章爬虫基础复习 7 节 | 120 分钟
介绍爬虫开发需要的基础知识,包括爬虫能做什么、正则表达式、深度优先和广度优先算法及实现、爬虫URL去重策略,透彻理解unicode和utf8编码的区别和应用。
视频:
3-1 技术选型爬虫能做什么(09:50)
视频:
3-2 正则表达式-1 (18:31)
视频:
3-3 正则表达式-2 (19:04)
视频:
3-4 正则表达式-3 (20:16)
视频:
3-5 深度优先和广度优先原则 (25:15)
视频:
3-6 URL去重方法(07:44)
视频:
3-7 彻底理解unicode和utf8编码(18:31)
第4章新增:scrapy爬取知名技术文章网站25节 | 402 分钟
搭建scrapy的开发环境。本章介绍scrapy常用命令及项目目录结构分析。本章还将详细解释 xpath 和 css 选择器的使用。然后通过scrapy提供的spider完成所有文章的爬取。然后详细讲解item和item loader方法,完成具体字段的提取,使用scrapy提供的pipeline将数据分别保存到json文件和mysql数据库中。...
视频:
4-1 重新录制说明(重要!!!)(04:47)
视频:
4-2 scrapy安装配置(30:30)
视频:
4-3 需求分析(13:53)
视频:
4-4 在pycharm中调试scrapy源码(10:13)
视频:
4-5 xpath 基本语法(19:02)
视频:
4-6 xpath 提取元素 (28:48)
视频:
4-7 个 CSS 选择器 (17:54)
视频:
4-8。cnblogs模拟登录(新内容)(22:23)
视频:
4-9 编写蜘蛛完成抓取过程 - 1 (19:38)
视频:
4-10 编写spider完成抓取过程 - 2(20:47)
视频:
4-11 为什么在scrapy中使用yield(09:49)
视频:
4-12 提取详情页信息(23:16)
视频:
4-13 提取详情页信息(18:13)
视频:
4-14 项目的定义和使用 - 1 (16:21)
视频:
4-15 项目的定义和使用 - 2 (13:30)
视频:
4-16scrapy配置图片下载(18:20)
视频:
4-17 items数据写入json文件(09:27)
视频:
4-18 MySQL表结构设计(13:21)
视频:
4-19 管道数据库保存(20:16)
视频:
4-20 mysql的异步存储(12:37)
视频:
4-21 数据插入主键冲突解决办法(04:40)
视频:
4-22 itemloader提取信息(21:41)
视频:
4-23 itemloader提取信息(19:06)
视频:
4-24 大图抓拍下载错误的问题(12:45)
手术:
4-25 有没有办法准确解析标题和正文内容?
第五章网站模拟登录和滑动验证码识别(202年6月更新1.)7小节 | 123 分钟
本章我们将解决两个问题:1.防止selenium被网站2.滑动验证码识别,我们将使用opencv识别和机器学习平台识别进行滑动验证码认出。滑动验证码是目前最流行的验证码。识别滑动验证码可以让我们解决大部分网站的模拟登录...
视频:
5-1 Session和cookie自动登录机制(20:10)
视频:
5-2 课程如何处理网站反爬变化?(08:03)
视频:
5-3 使用opencv识别滑动验证码的环境准备(15:59)
视频:
5-4 Opencv滑动验证码识别原理(26:19)
视频:
5-5 滑动验证码识别集成到scrapy(10:02)
视频:
5-6 通过机器学习平台训练滑动验证码模型(15:23)
视频:
5-7 发布训练模型,远程调用识别(26:53)
Chapter 6 Scrapy Crawling 知名问答网站 第11 节 | 150 分钟
通过上一章的学习,本章我们将针对具体的网站进行需求分析、表结构设计等。本章详细分析网站的网络请求,分析网站的结果@>答题提取数据并保存到mysql的API请求接口
视频:
6-1 知乎分析及数据表设计1(15:17)
视频:
6-2 知乎分析与数据表设计——2(13:35)
视频:
6-3 按项目 loder 提取问题 - 1 (14:57)
视频:
6-4 按项目 loder 提取问题 - 2 (15:20)
视频:
6-5 按项目 loder 提取问题 - 3 (06:45)
视频:
6-6 知乎蜘蛛逻辑和答案提取的实现- 1(15:54)
视频:
6-7 知乎蜘蛛逻辑和答案提取的实现- 2(17:04)
视频:
6-8 保存数据到mysql-1(17:27)
视频:
6-9 保存数据到mysql-2(17:22)
视频:
6-10 保存数据到mysql-3(16:09)
手术:
6-11 如何分离数据存储和采集?
第 7 章使用 CrawlSpider 进行招聘的全站爬网网站 9 部分 | 167 分钟
本章完成招聘网站职位的数据表结构设计,通过链接提取器和规则的形式完成招聘网站中所有职位的爬取并配置CrawlSpider。本章还将从源码的角度分析CrawlSpider。大家对CrawlSpider都有很深的了解。
视频:
7-1 数据表结构设计(15:33)
视频:
7-2 CrawlSpider源码解析-新CrawlSpider及设置配置(12:50)
视频:
7-3 CrawlSpider源码解析(25:29)
视频:
7-4 Rule 和 LinkExtractor 的使用 (14:28)
视频:
7-5 网页302后的模拟登录和cookie传递(网站需要登录时学习这个视频教程)(32:11)
视频:
7-6 项目加载器位置分析 (24:46)
视频:
7-7 位置数据存储-1 (19:01)
视频:
7-8 位置信息存储-2(11:19)
视频:
7-9 网站反爬突破(10:58)
第8章Scrapy突破反爬虫限制 尝试10节 | 天天要闻 159 分钟
本章将从爬虫和反爬虫的斗争开始,然后解释scrapy的原理,然后通过随机切换user-agent和设置scrapy的ip代理来突破反爬虫的各种限制。本章还将详细介绍httpresponse和httprequest,详细分析scrapy的功能,最终通过云编码平台完成在线验证码识别并禁用cookies和访问频率,以减少爬虫被拦截的可能性。...
视频:
8-1 爬虫与反爬虫的对抗过程及策略(20:17)
尝试
视频:
8-2 Scrapy架构源码分析(10:45)
视频:
8-3 请求和响应介绍(10:18)
视频:
8-4 通过下载中间件随机替换user-agent-1(17:00)
视频:
8-5 通过下载中间件随机替换user-agent - 2 (17:13)
视频:
8-6 scrapy 实现 ip 代理池 - 1 (16:51)
视频:
8-7 scrapy 实现 ip 代理池 - 2 (17:39)
视频:
8-8 scrapy 实现 ip 代理池 - 3 (18:46)
视频:
8-9 云编码实现验证码识别(22:37)
视频:
8-10 cookie 禁用、自动限速、自定义蜘蛛设置 (07:22)
第9章Scrapy高级开发12小节| 152 分钟
本章将讲解scrapy更高级的特性,包括通过selenium和phantomjs爬取动态网站数据并将两者集成到scrapy、scrapy信号、自定义中间件、暂停和启动scrapy爬虫、scrapy的核心api、scrapy的telnet、scrapy的web服务和scrapy的日志配置和邮件发送等。这些特性让我们可以做的不仅仅是scrapy...
视频:
9-1 Selenium动态网页请求和模拟登录知乎(21:24)
视频:
9-2 Selenium模拟登录微博,模拟鼠标按下(11:06)
视频:
9-3 chromedriver不加载图片,phantomjs获取动态网页(09:59)
视频:
9-4 selenium 集成到scrapy(19:43)
视频:
9-5 其他动态网页获取技术介绍——chrome running without interface, scrapy-splash, selenium-grid, splinter (07:50)
视频:
9-6 scrapy的暂停和重启(12:58)
视频:
9-7 scrapy url去重原理(05:45)
视频:
9-8 scrapy telnet 服务(07:37)
视频:
9-9蜘蛛中间件详解(15:25)
视频:
9-10scrapy数据采集(13:44)
视频:
9-11scrapy信号详解(13:05)
视频:
9-12scrapy扩展开发(13:16)
第10章scrapy-redis分布式爬虫9节| 125 分钟
Scrapy-redis分布式爬虫的使用和scrapy-redis分布式爬虫的源码分析,让大家可以根据自己的需要修改源码,满足自己的需要。最后,我将解释如何将bloomfilter集成到scrapy-redis中。
视频:
10-1 分布式爬虫点(08:39)
视频:
10-2 Redis 基础 - 1 (20:31)
视频:
10-3 Redis 基础 - 2 (15:58)
视频:
10-4 scrapy-redis编写分布式爬虫代码(21:06)
视频:
10-5 scrapy源码解析-connection.py,defaults.py-(11:05)
视频:
10-6 scrapy-redis源码分析-dupefilter.py-(05:29)
视频:
10-7 scrapy-redis源码解析-pipelines.py,queue.py-(10:41)
视频:
10-8 scrapy-redis源码分析-scheduler.py,spider.py-(11:52)
视频:
10-9 将bloomfilter集成到scrapy-redis中(19:30)
第11章Cookie池系统设计与实现15小节| 175 分钟
为了防止爬取代码和解析代码受到模拟登录的影响,将模拟登录分离成一个独立的服务变得非常重要。cookie池就是为了解决这类问题而诞生的。多账号登录管理,如何让网站轻松访问将是cookie池需要解决的问题。本章重点介绍 cookie 池设计和开发的细节。...
视频:
11-1 什么是cookie池?(11:27)
视频:
11-2 Cookie池系统设计(09:23)
视频:
11-3 实施cookie pool-1 (10:12)
视频:
11-4 实施 cookie pool-2 (12:39)
视频:
11-5 修改登录方式 - 1 (09:58)
视频:
11-6 修改登录方式-2(09:36)
视频:
11-7 修改登录方式-3(08:43)
视频:
11-8 修改登录方式-4(10:37)
视频:
11-9 通过抽象基类实现网站轻松访问(15:00)
视频:
11-10 实现检测网站cookie是否有效(08:06)
视频:
11-11 如何选择redis的数据结构保存cookies(10:59)
视频:
11-12 cookie管理器的实现(22:10)
视频:
11-13 启动cookie池服务(12:35)
视频:
11-14 将cookies集成到爬虫项目中(15:34)
视频:
11-15 cookie架构设计改进建议(07:36)
第12章各种Captcha 5部分的识别| 77 分钟
滑动验证码越来越流行,如何解决滑动验证码成为模拟登录的重要环节。本章重点解决滑动验证码的各种细节问题。
视频:
12-1 滑动验证码识别思路(15:17)
视频:
12-2 验证码-1截图(11:42)
视频:
12-3 验证码2截图(14:03)
视频:
12-4 计算滑动距离(17:37)
视频:
12-5 计算滑动轨迹(18:00)
第13章增量爬取4段| 50 分钟
增量爬取和数据更新是爬虫运行中经常遇到的问题。比如当前爬虫在运行,但是如何及时发现新数据,如何先爬后面的url,如何发现新数据,都是实际开发。在本章中,我们经常通过修改scrapy-redis的源代码来解决原方式的问题,以最小的成本解决上诉问题。通过本章的学习,我们将更加了解如何控制爬虫的运行。...
视频:
13-1 增量爬虫要解决的问题(09:36)
视频:
13-2 修改scrapy-redis-1完成增量抓取(16:11)
视频:
13-3 通过修改scrapy-redis-2(14:13)完成增量抓取
视频:
13-4 爬虫数据更新(09:23)
第 14 章使用 elasticsearch 搜索引擎 13 小节 | 207 分钟
本章将讲解elasticsearch的安装和使用,elasticsearch基本概念的介绍和api的使用。本章还将讲解搜索引擎的原理和elasticsearch-dsl的使用,最后讲解如何通过scrapy的pipeline将数据保存到elasticsearch中。
视频:
14-1 elasticsearch简介(18:21)
视频:
14-2 elasticsearch安装(13:24)
视频:
14-3 Elasticsearch-head插件及kibana安装(24:09)
视频:
14-4 elasticsearch基本概念(12:15)
视频:
14-5 倒排索引 (11:24)
视频:
14-6 Elasticsearch基本索引和文档CRUD操作(18:44)
视频:
14-7 elasticsearch的mget和bulk操作(12:36)
视频:
14-8 elasticsearch的映射管理(21:03)
视频:
14-9 elasticsearch的简单查询 - 1 (14:56)
视频:
14-10 elasticsearch的简单查询 - 2 (11:12)
视频:
14-11 Elasticsearch的bool组合查询(22:58)
视频:
14-12 scrapy写数据到elasticsearch - 1 (14:16)
视频:
14-13 scrapy写数据到elasticsearch - 2 (11:15)
第15章Django建筑搜索网站9节| 131 分钟
本章讲解如何通过 django 快速构建搜索网站。本章还讲解了如何完成django和elasticsearch的搜索查询交互。
视频:
15-1 es 完整的搜索建议 - 搜索建议字段保存 - 1 (13:45)
视频:
15-2 es 完成搜索建议 - 搜索建议字段保存 - 2 (13:34)
视频:
15-3 django实现elasticsearch的搜索建议-1(19:57)
视频:
15-4 django实现elasticsearch的搜索建议-2(18:15)
视频:
15-5 django实现elasticsearch-1的搜索功能(14:06)
视频:
15-6 django实现elasticsearch-2的搜索功能(13:14)
视频:
15-7 Django实现搜索结果分页(09:12)
视频:
15-8 搜索记录和热门搜索功能的实现- 1 (14:34)
视频:
15-9 搜索记录和热门搜索功能的实现-2(14:04)
第16章用scrapyd部署scrapy爬虫1节| 25 分钟
本章主要通过scrapyd完成scrapy爬虫的在线部署。
视频:
16-1 scrapyd部署scrapy项目(24:39)
第 17 章课程总结 4 节 | 6 分钟
重新整理系统开发的全过程,让学生对系统和开发过程有更直观的认识
视频:
17-1 课程总结 (05:55)
手术:
17-2【讨论题】你觉得JS逆向工程是什么?
手术:
17-3 如何集成nodejs服务?
手术:
17-4【讨论题】字体防爬应该如何分析?
本课程结束
网页视频抓取工具 知乎(试试,真正被今日头条收购的海外头条版(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2022-03-12 08:14
视频查看器
互动率
评论数
评价率
喜欢比
广告点击率
观众年龄分布
观众地域分布
最受欢迎的视频等
您可以通过电子邮件直接联系影响者
工具网址为:
easybloggers.io/
2、互联网上最好的设计之一网站
这是一个非常丑陋的单页网站,每月浏览量接近10亿,聚合了其他新闻网站的链接,自制头条。从1995年开始,几乎只有一个人经营,现在每年的广告收入都在几千万美元。
与 Craigslist 类似,Drudge Report 已经运营了 20 多年,页面设计几乎没有变化,经受住了时间的考验。而且大部分访问者都是直接访问,不依赖搜索引擎来分流。我这里就不截图了,有兴趣的可以看看,网址是:
/
3、亚马逊美国前 250,000 个搜索词
该网站是:
/usatop 关键字
4、今日头条海外版
抖音TikTok海外版最近越来越火了。如果你不擅长短视频,何不尝试通过文字和图片来获得一些流量。试试海外版的今日头条。
该网站是:
/
顺便说一句,真正被今日头条收购的海外头条版是
/
有兴趣的都可以试试
5、Free Standalone:用于生成隐私政策、使用条款等法律文件的工具。
我知道很多独立网站的运营商/站长基本上都是从其他网站复制隐私政策和使用条款等文件。同时,面对欧盟的GDPR政策,网站中的相关文案也不知道怎么解释。这个工具也许能帮到你。
我们来做一个简单的操作说明:
1)注册成功后(可以直接通过谷歌账号登录),进入如下界面。很多模板,同时告诉你免费版只能创建3个文件。
如果找不到想要的模板,可以点击模板市场
2)我们选择与“隐私政策”相关的模板
3)10步以上的选择题
最后,您到达一个需要填写几个字段的页面。设置完成后,即可将内容发送到您的邮箱。
单击“魔术”按钮后,将为您生成一个word文档。
工具网址为:
/
6、将音视频文件翻译成文本提取核心思想
这是一个刚刚开发的网站,连付费版的支付工具都没有准备好。
免费版目前支持90分钟,点击上传音视频
上传成功后,点击文件名:
默认显示翻译文本
点击“摘要”提取核心点
vatis.tech/
7、做点有趣的事网站:看死囚的遗言
/death_row/dr_executed_offenders.html
8、没学过Python,用这个工具爬网
抓取页面多条信息——以bilibili排行榜为例
安装好“Web Scraper”后,按F12进入开发者模式,这样就可以在最后一个标签页看到“Web Scraper”菜单了。需要注意的是,如果开发者模式面板不在下方,会提示必须放在浏览器下方才能继续。
在菜单中选择“创建新站点地图-创建站点地图”创建新站点地图,填写名称和起始地址即可开始。这里以bilibili排名为例,介绍如何抓取页面上的多条信息。起始地址设置为
/排行
这里我们需要捕获“视频标题”、“播放量”、“弹幕数”、“up主”和“综合评分”,所以首先为每条记录创建一个wrapper。
点击“添加新选择器”,id填写“packager”,type选择“element”,然后点击“selector”,选择一条记录的外框,外框需要收录以上所有信息,然后选择第二个,所以你会发现页面中的所有记录都被自动选中了,点击“Done selection”完成数据选择。还要记得勾选“Multiple”以确保捕获到多条记录,最后保存选择器。
返回后,点击刚才的wrapper,进入二级路径,创建“title”选择器,id填写“video title”,type选择“text”,点击“selector”找到第一条记录高亮显示。这是因为我们提前把它做成了包装器。在边界框中选择标题,然后单击“完成选择”完成标题的选择。注意这里不需要勾选“Multiple”,最后保存选择器。
同样,我们为“播放量”、“弹幕数”、“up master”和“综合得分”创建选择器。选择后,可以通过“数据预览”预览是否选择了想要的内容。此外,您可以通过菜单栏中的“Sitemap bilibili_ranking - Selector graph”直观地查看树状结构。
继续选择刚才菜单下的“抓取”,开始创建抓取任务。可以默认单个网页的间隔时间和响应时间。点击“开始抓取”开始抓取。这时浏览器会自动打开一个新页面,停留几秒后会自动关闭,表示爬取完成。
点击“刷新数据”刷新数据,或点击“Sitemap bilibili_ranking - 浏览”查看数据。您可以通过“Sitemap bilibili_ranking - 将数据导出为 CSV”将其下载为 CSV 文件。
▲bilibili排行榜
用 Excel 打开它。由于“Web Scraper”抓取的内容是乱序的,所以需要对“综合得分”进行降序排序,才能恢复原来排行榜的结果。
/app/1330863
9、带有漂亮浏览器外壳的网页生成工具
输入任意 URL 生成带有 mac/win 风格的浏览器 shell 的图像
/
10、9 合 1 免费社交媒体分析工具
最强大的工具往往是最后出现的。Socialbakers 本身是一个功能强大的付费工具,但它提供了 9 个免费工具,非常值得使用。我们将一一介绍:
1)个人网上商城模板
2)网红搜索(只能看到部分数据)
3)网红标签搜索工具
4)facebook专页及竞争对手业绩分析报告
5)比较 Instagram 个人资料和竞争对手的影响者分析报告
6)比较 Instagram 个人资料和竞争对手的影响力分析报告
7)facebook 广告影响预测工具
8)facebook 影响者比较工具
9)Socialbakers 关于社会客户关怀的最新数据
/免费社交工具
你可以选择加入 知乎 圈子和我们一起建设 查看全部
网页视频抓取工具 知乎(试试,真正被今日头条收购的海外头条版(组图))
视频查看器
互动率
评论数
评价率
喜欢比
广告点击率
观众年龄分布
观众地域分布
最受欢迎的视频等
您可以通过电子邮件直接联系影响者
工具网址为:
easybloggers.io/
2、互联网上最好的设计之一网站
这是一个非常丑陋的单页网站,每月浏览量接近10亿,聚合了其他新闻网站的链接,自制头条。从1995年开始,几乎只有一个人经营,现在每年的广告收入都在几千万美元。
与 Craigslist 类似,Drudge Report 已经运营了 20 多年,页面设计几乎没有变化,经受住了时间的考验。而且大部分访问者都是直接访问,不依赖搜索引擎来分流。我这里就不截图了,有兴趣的可以看看,网址是:
/
3、亚马逊美国前 250,000 个搜索词
该网站是:
/usatop 关键字
4、今日头条海外版
抖音TikTok海外版最近越来越火了。如果你不擅长短视频,何不尝试通过文字和图片来获得一些流量。试试海外版的今日头条。
该网站是:
/
顺便说一句,真正被今日头条收购的海外头条版是
/
有兴趣的都可以试试
5、Free Standalone:用于生成隐私政策、使用条款等法律文件的工具。
我知道很多独立网站的运营商/站长基本上都是从其他网站复制隐私政策和使用条款等文件。同时,面对欧盟的GDPR政策,网站中的相关文案也不知道怎么解释。这个工具也许能帮到你。
我们来做一个简单的操作说明:
1)注册成功后(可以直接通过谷歌账号登录),进入如下界面。很多模板,同时告诉你免费版只能创建3个文件。
如果找不到想要的模板,可以点击模板市场
2)我们选择与“隐私政策”相关的模板
3)10步以上的选择题
最后,您到达一个需要填写几个字段的页面。设置完成后,即可将内容发送到您的邮箱。
单击“魔术”按钮后,将为您生成一个word文档。
工具网址为:
/
6、将音视频文件翻译成文本提取核心思想
这是一个刚刚开发的网站,连付费版的支付工具都没有准备好。
免费版目前支持90分钟,点击上传音视频
上传成功后,点击文件名:
默认显示翻译文本
点击“摘要”提取核心点
vatis.tech/
7、做点有趣的事网站:看死囚的遗言
/death_row/dr_executed_offenders.html
8、没学过Python,用这个工具爬网
抓取页面多条信息——以bilibili排行榜为例
安装好“Web Scraper”后,按F12进入开发者模式,这样就可以在最后一个标签页看到“Web Scraper”菜单了。需要注意的是,如果开发者模式面板不在下方,会提示必须放在浏览器下方才能继续。
在菜单中选择“创建新站点地图-创建站点地图”创建新站点地图,填写名称和起始地址即可开始。这里以bilibili排名为例,介绍如何抓取页面上的多条信息。起始地址设置为
/排行
这里我们需要捕获“视频标题”、“播放量”、“弹幕数”、“up主”和“综合评分”,所以首先为每条记录创建一个wrapper。
点击“添加新选择器”,id填写“packager”,type选择“element”,然后点击“selector”,选择一条记录的外框,外框需要收录以上所有信息,然后选择第二个,所以你会发现页面中的所有记录都被自动选中了,点击“Done selection”完成数据选择。还要记得勾选“Multiple”以确保捕获到多条记录,最后保存选择器。
返回后,点击刚才的wrapper,进入二级路径,创建“title”选择器,id填写“video title”,type选择“text”,点击“selector”找到第一条记录高亮显示。这是因为我们提前把它做成了包装器。在边界框中选择标题,然后单击“完成选择”完成标题的选择。注意这里不需要勾选“Multiple”,最后保存选择器。
同样,我们为“播放量”、“弹幕数”、“up master”和“综合得分”创建选择器。选择后,可以通过“数据预览”预览是否选择了想要的内容。此外,您可以通过菜单栏中的“Sitemap bilibili_ranking - Selector graph”直观地查看树状结构。
继续选择刚才菜单下的“抓取”,开始创建抓取任务。可以默认单个网页的间隔时间和响应时间。点击“开始抓取”开始抓取。这时浏览器会自动打开一个新页面,停留几秒后会自动关闭,表示爬取完成。
点击“刷新数据”刷新数据,或点击“Sitemap bilibili_ranking - 浏览”查看数据。您可以通过“Sitemap bilibili_ranking - 将数据导出为 CSV”将其下载为 CSV 文件。
▲bilibili排行榜
用 Excel 打开它。由于“Web Scraper”抓取的内容是乱序的,所以需要对“综合得分”进行降序排序,才能恢复原来排行榜的结果。
/app/1330863
9、带有漂亮浏览器外壳的网页生成工具
输入任意 URL 生成带有 mac/win 风格的浏览器 shell 的图像
/
10、9 合 1 免费社交媒体分析工具
最强大的工具往往是最后出现的。Socialbakers 本身是一个功能强大的付费工具,但它提供了 9 个免费工具,非常值得使用。我们将一一介绍:
1)个人网上商城模板
2)网红搜索(只能看到部分数据)
3)网红标签搜索工具
4)facebook专页及竞争对手业绩分析报告
5)比较 Instagram 个人资料和竞争对手的影响者分析报告
6)比较 Instagram 个人资料和竞争对手的影响力分析报告
7)facebook 广告影响预测工具
8)facebook 影响者比较工具
9)Socialbakers 关于社会客户关怀的最新数据
/免费社交工具
你可以选择加入 知乎 圈子和我们一起建设
网页视频抓取工具 知乎( 国内小说网站下载小说的通用脚本,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-03-08 14:15
国内小说网站下载小说的通用脚本,你了解多少?)
小说下载器油猴剧本,国内小说免费下载网站txt资源
发布者:ok7782
2020-06-29
小说下载器油猴脚本是一款通用脚本,可以免费下载笔趣阁等国产小说网站的小说。下载的资源都是TXT文件,可以方便的传输到手机端查看。
小说下载器油猴脚本是一款通用脚本,可以免费下载笔趣阁等国产小说网站的小说。下载的资源都是TXT文件,可以方便的传输到手机端查看。
小说下载器
从笔趣阁网站等小说下载小说的通用脚本
下载
小说下载器脚本开发背景
不久前,CNNIC发布了《中国互联网发展状况统计调查》。调查显示,国内网络文本市场近年来发展到了一个高峰期。
尤其是随着智能手机的发展,网络小说的受众迎来了爆发式的急剧增长。
不过,对于一些小伙伴来说,比起在线阅读,他们更喜欢下载自己喜欢的网络资源进行采集分享,或者使用其他工具打开阅读。
而网站上的很多下载功能都有各种限制,甚至根本没有下载选项。这个油猴脚本是专门用来解决在线文本下载问题的。
新颖的下载器脚本功能介绍
小说下载器油猴脚本是一款可扩展的通用小说下载器,可以保存为txt文件,适用于国内大部分静态小说网站。
目前小说下载器油猴脚本支持小说网站,包括易软小说、奇葩小说网、书趣阁、顶点小说、2k小说阅读网、笔趣我、手巴等。
如果你有点技术,你也可以通过添加爬取规则来添加更多的小说网站。
如何使用小说下载脚本
一、安装油猴脚本管理器插件
有条件的可以直接从谷歌浏览器商店下载安装;如果您无法访问它,请将扩展风扇上的 Tampermonkey Oil Monkey Script Manager 插件的 crx 文件安装到您的 Google 浏览器。
Tampermonkey:用户脚本管理器(Grease Monkey)
制作工具插件2021-05-204.7
世界上最受欢迎的用户脚本管理器
下载
二、安装脚本
点击下方按钮直接跳转到greasyfork脚本资源网进行在线安装(不是很稳定),或者下载脚本文件进行离线安装。
小说下载器
从笔趣阁网站等小说下载小说的通用脚本
下载
三、下载小说
当你打开支持油猴脚本的小说网站,然后打开小说目录页面,网页右上角会出现一个下载图标,点击图标开始下载。
下载完成后,将自动下载 txt 文件和 zip 存档。
需要注意的是,如果每章拆分,浏览器可能会提示是否允许下载多个文件,点击允许即可。
另外,遇到内容多、章节数多的小说时,需要在点击下载按钮后耐心等待片刻。
您也可以按 F12 打开 Web 控制台以查看当前下载状态。
总而言之,这个油猴脚本可以很好的解决各大小说网站的txt资源下载问题。 查看全部
网页视频抓取工具 知乎(
国内小说网站下载小说的通用脚本,你了解多少?)
小说下载器油猴剧本,国内小说免费下载网站txt资源
发布者:ok7782
2020-06-29
小说下载器油猴脚本是一款通用脚本,可以免费下载笔趣阁等国产小说网站的小说。下载的资源都是TXT文件,可以方便的传输到手机端查看。
小说下载器油猴脚本是一款通用脚本,可以免费下载笔趣阁等国产小说网站的小说。下载的资源都是TXT文件,可以方便的传输到手机端查看。
小说下载器
从笔趣阁网站等小说下载小说的通用脚本
下载
小说下载器脚本开发背景
不久前,CNNIC发布了《中国互联网发展状况统计调查》。调查显示,国内网络文本市场近年来发展到了一个高峰期。
尤其是随着智能手机的发展,网络小说的受众迎来了爆发式的急剧增长。
不过,对于一些小伙伴来说,比起在线阅读,他们更喜欢下载自己喜欢的网络资源进行采集分享,或者使用其他工具打开阅读。
而网站上的很多下载功能都有各种限制,甚至根本没有下载选项。这个油猴脚本是专门用来解决在线文本下载问题的。
新颖的下载器脚本功能介绍
小说下载器油猴脚本是一款可扩展的通用小说下载器,可以保存为txt文件,适用于国内大部分静态小说网站。
目前小说下载器油猴脚本支持小说网站,包括易软小说、奇葩小说网、书趣阁、顶点小说、2k小说阅读网、笔趣我、手巴等。
如果你有点技术,你也可以通过添加爬取规则来添加更多的小说网站。
如何使用小说下载脚本
一、安装油猴脚本管理器插件
有条件的可以直接从谷歌浏览器商店下载安装;如果您无法访问它,请将扩展风扇上的 Tampermonkey Oil Monkey Script Manager 插件的 crx 文件安装到您的 Google 浏览器。
Tampermonkey:用户脚本管理器(Grease Monkey)
制作工具插件2021-05-204.7
世界上最受欢迎的用户脚本管理器
下载
二、安装脚本
点击下方按钮直接跳转到greasyfork脚本资源网进行在线安装(不是很稳定),或者下载脚本文件进行离线安装。
小说下载器
从笔趣阁网站等小说下载小说的通用脚本
下载
三、下载小说
当你打开支持油猴脚本的小说网站,然后打开小说目录页面,网页右上角会出现一个下载图标,点击图标开始下载。
下载完成后,将自动下载 txt 文件和 zip 存档。
需要注意的是,如果每章拆分,浏览器可能会提示是否允许下载多个文件,点击允许即可。
另外,遇到内容多、章节数多的小说时,需要在点击下载按钮后耐心等待片刻。
您也可以按 F12 打开 Web 控制台以查看当前下载状态。
总而言之,这个油猴脚本可以很好的解决各大小说网站的txt资源下载问题。
网页视频抓取工具 知乎(知乎上看到一个问题能利用爬虫技术做到哪些很有用的事情? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-07 07:09
)
在 知乎 上看到一个问题,爬虫技术可以做哪些酷、有趣和有用的事情?我觉得它很有趣,所以我去学习正则表达式。听说正则表达式很有用。学习后,我认为这是一个非常有用的工具。问题和评论基本上都是用python写的爬虫。看了原理,感觉爬一个简单的静态网页还是挺容易的。就是获取网站html源码,然后解析需要的字段,最后得到字段处理(下载)。记得以前学java的时候有一个URL类好像有这个功能,于是翻了一下api文档,发现URLConnection确实可以得到html源码。
先从核心写,获取网页源代码
package mothed;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
/**
* 爬取网页源代码
* @author ganhang
*
*/
public class Spider {
public static String GetContent(String url) {
// 定义一个字符串用来存储网页内容
String result = "";
BufferedReader in = null;
try {
URL realUrl = new URL(url);
// 初始化链接
URLConnection connection = realUrl.openConnection();
// BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(connection.getInputStream(), "UTF-8"));
// 用来临时存储抓取到的每一行的数据
String line;
while ((line = in.readLine()) != null) {
// 遍历抓取到的每一行并将其存储到result里面
System.out.println(line);
result += line;
}
} catch (Exception e) {
System.out.println("GetContent出现异常!" + e);
e.printStackTrace();
}
// 使用finally来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
}
然后解析得到的Content,得到答案中想要的字段、标题、图片链接
<p>package bean;
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import mothed.Spider;
/**
* 知乎图片bean
* @author ganhang
*
*/
public class ZhiHuBean {
public String zhihuUrl;// 网页链接
public String question;// 问题名;
public ArrayList zhihuPicUrl;// 图片链接
public String getQuestion() {
return question;
}
public void setQuestion(String question) {
this.question = question;
}
public ArrayList getZhihuPicUrl() {
return zhihuPicUrl;
}
public void setZhihuPicUrl(ArrayList zhihuPicUrl) {
this.zhihuPicUrl = zhihuPicUrl;
}
// 构造方法初始化数据
public ZhiHuBean(String url) throws Exception {
zhihuUrl = url;
zhihuPicUrl = new ArrayList();
// 判断url是否合法
if (isZhuHuUrl(url)) {
url=getRealUrl(url);
System.out.println("正在抓取知乎链接:" + url);
// 根据url获取该问答的细节
String content = Spider.GetContent(url);
//System.out.println("content:"+content);
Matcher m;
// 匹配标题
m = Pattern.compile("zh-question-title.+?(.+?)").matcher(content);
if (m.find()) {
question = m.group(1);
}
// 匹配答案图片链接
m = Pattern.compile(" 查看全部
网页视频抓取工具 知乎(知乎上看到一个问题能利用爬虫技术做到哪些很有用的事情?
)
在 知乎 上看到一个问题,爬虫技术可以做哪些酷、有趣和有用的事情?我觉得它很有趣,所以我去学习正则表达式。听说正则表达式很有用。学习后,我认为这是一个非常有用的工具。问题和评论基本上都是用python写的爬虫。看了原理,感觉爬一个简单的静态网页还是挺容易的。就是获取网站html源码,然后解析需要的字段,最后得到字段处理(下载)。记得以前学java的时候有一个URL类好像有这个功能,于是翻了一下api文档,发现URLConnection确实可以得到html源码。
先从核心写,获取网页源代码
package mothed;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
/**
* 爬取网页源代码
* @author ganhang
*
*/
public class Spider {
public static String GetContent(String url) {
// 定义一个字符串用来存储网页内容
String result = "";
BufferedReader in = null;
try {
URL realUrl = new URL(url);
// 初始化链接
URLConnection connection = realUrl.openConnection();
// BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(connection.getInputStream(), "UTF-8"));
// 用来临时存储抓取到的每一行的数据
String line;
while ((line = in.readLine()) != null) {
// 遍历抓取到的每一行并将其存储到result里面
System.out.println(line);
result += line;
}
} catch (Exception e) {
System.out.println("GetContent出现异常!" + e);
e.printStackTrace();
}
// 使用finally来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
}
然后解析得到的Content,得到答案中想要的字段、标题、图片链接
<p>package bean;
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import mothed.Spider;
/**
* 知乎图片bean
* @author ganhang
*
*/
public class ZhiHuBean {
public String zhihuUrl;// 网页链接
public String question;// 问题名;
public ArrayList zhihuPicUrl;// 图片链接
public String getQuestion() {
return question;
}
public void setQuestion(String question) {
this.question = question;
}
public ArrayList getZhihuPicUrl() {
return zhihuPicUrl;
}
public void setZhihuPicUrl(ArrayList zhihuPicUrl) {
this.zhihuPicUrl = zhihuPicUrl;
}
// 构造方法初始化数据
public ZhiHuBean(String url) throws Exception {
zhihuUrl = url;
zhihuPicUrl = new ArrayList();
// 判断url是否合法
if (isZhuHuUrl(url)) {
url=getRealUrl(url);
System.out.println("正在抓取知乎链接:" + url);
// 根据url获取该问答的细节
String content = Spider.GetContent(url);
//System.out.println("content:"+content);
Matcher m;
// 匹配标题
m = Pattern.compile("zh-question-title.+?(.+?)").matcher(content);
if (m.find()) {
question = m.group(1);
}
// 匹配答案图片链接
m = Pattern.compile("
网页视频抓取工具 知乎( 每个视频,都是你的金牌业务员这是我写的第60篇视频营销原创文章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-06 21:01
每个视频,都是你的金牌业务员这是我写的第60篇视频营销原创文章)
每个视频都是您的黄金推销员
这是我写的第 60 个视频营销 原创文章
与其苦苦寻觅十年,不如花一年的时间学习,赚九年的高薪!
之前分享过很多视频营销的方法、策略、技巧,比如视频商城技巧、视频制作方法等,最近有朋友问起视频上传方法。
首先,视频整体上传有2种方式,分别看3种方式:
第一种:从网络上传
第二种:软件上传
第三种:第三方软件上传
无论是软件上传视频还是网页上传视频,各有优缺点。您应该根据自己的实际情况选择是使用网页上传还是软件上传。接下来小编为大家详细讲解!
第一种:从网络上传
我们使用最简单最简单的方式上传网络视频,直接登录网络上传视频,适合大多数人上传视频。
网页上传视频功能:
①在同一个视频站使用同一个账号,只能一个人手动上传视频,无法实现自动批量上传视频。
②通过网页上传视频,每个视频站支持不同大小的上传视频,从200M-2G不等。
③通过网页上传的视频比较清晰,通过审核的视频较多。
④ 同一视频重复发布到同一视频平台时,将不通知已上传。
⑤适合少量视频,可以直接使用浏览器上传。
上传网页的工具主要是浏览器,比如搜狗浏览器、UC浏览器、IE等。
但是,您必须定期升级您正在使用的浏览器,否则上传视频很容易失败。
由于视频平台的方式,在同一浏览器和同一平台账号下,很难同时发布多个视频,容易出现问题。因此,此时很难使用网页批量发布视频。
如何使用网络批量视频上传?
此时,您可以通过在同一个浏览器中同时打开多个视频来上传同一个视频网站。
虽然这句话有点草率,但是可以帮我们节省很多时间,批量上传视频。我们经常使用这种方法来操作。
当然,有一个前提是你的网速一定要快,而且你的电脑配置要稍微好一点,否则上传过程可能会中断或者卡住,会降低工作效率。
而现在所有的视频平台都支持断点续传,即在上传视频的过程中,浏览器突然异常关闭,再次选择视频时,会从上次中断的位置开始上传。
一个简单的例子,比如上传一个视频,此时打开浏览器,同时打开要上传的视频网站。一般我会同时开10个。如果视频容量不是太大,基本没有问题。然后开始点击B视频站的上传按钮,选择要上传的视频开始上传,然后继续点击C视频站的上传视频按钮,一直选择到第10个。
然后从第一个视频网站开始,输入标题,输入标签,填写介绍,选择相关类别和视频封面,点击保存。
然后按照同样的设置方法设置第二个视频网站,以此类推,可以大大提高工作效率。
第二种:软件上传
软件上传也很简单。一般会使用网页上传视频,软件比较简单。
一般使用软件上传视频,使用视频平台官方提供的软件。部分视频网站不提供软件,只提供网页上传。
与网页上传视频相比,软件上传也有自己的优势:
①使用软件发布视频,在同一视频网站中,可以同时批量发布视频。
②您可以同时设置已选择批量发布的视频的标题、简介、标签、类别等。
③从软件上传视频一般没有大小限制
④通过软件发布的视频可能有点不清楚,不同平台的清晰度也不同。
⑤ 同一个视频,如果通过软件重复发布视频,会提示已经发布。此时,禁止再次发布。
⑥适用于同一视频平台批量发布视频操作,可自动发布视频。
通过软件上传视频需要提前设置好,比如视频标题、视频介绍、视频标签、视频分类等。
如何使用软件批量发布视频,另一种操作方式,可以同时打开10个不同的视频软件客户端,同时手动登录账号,从第一个到第一个依次选择相关视频最后,开始一一设置。. 不过这个时候要求网速要快,电脑配置也要高,否则可能会卡住。
一般视频平台的软件可以在视频站首页的导航位置,或者视频网站下方的位置找到客户端的位置。也可以搜索:XXX站客户端XXX站软件上传(XXX代表视频平台名称。)
第三种:第三方软件上传
这本身也是一个软件上传,但是为了让大家更好的学习和理解,我们单独给大家讲解一下。
第三方软件唯一的方便就是可以统一设置关键词,统一登录账号,统一发布,相比前两者会节省不少时间,但也有很多不足. 有两种上传方式,够我们用了。
无论是软件上传还是网页上传,您的视频都必须符合视频站规定。如果软件上传失败,请尝试使用网页上传。一般可以通过,但需要重新设置和编辑。
不管是软件上传视频还是网页上传视频,方法都很简单,各有优劣,没有好坏之分,只有适合与否。 查看全部
网页视频抓取工具 知乎(
每个视频,都是你的金牌业务员这是我写的第60篇视频营销原创文章)
每个视频都是您的黄金推销员
这是我写的第 60 个视频营销 原创文章
与其苦苦寻觅十年,不如花一年的时间学习,赚九年的高薪!
之前分享过很多视频营销的方法、策略、技巧,比如视频商城技巧、视频制作方法等,最近有朋友问起视频上传方法。
首先,视频整体上传有2种方式,分别看3种方式:
第一种:从网络上传
第二种:软件上传
第三种:第三方软件上传
无论是软件上传视频还是网页上传视频,各有优缺点。您应该根据自己的实际情况选择是使用网页上传还是软件上传。接下来小编为大家详细讲解!
第一种:从网络上传
我们使用最简单最简单的方式上传网络视频,直接登录网络上传视频,适合大多数人上传视频。
网页上传视频功能:
①在同一个视频站使用同一个账号,只能一个人手动上传视频,无法实现自动批量上传视频。
②通过网页上传视频,每个视频站支持不同大小的上传视频,从200M-2G不等。
③通过网页上传的视频比较清晰,通过审核的视频较多。
④ 同一视频重复发布到同一视频平台时,将不通知已上传。
⑤适合少量视频,可以直接使用浏览器上传。
上传网页的工具主要是浏览器,比如搜狗浏览器、UC浏览器、IE等。
但是,您必须定期升级您正在使用的浏览器,否则上传视频很容易失败。
由于视频平台的方式,在同一浏览器和同一平台账号下,很难同时发布多个视频,容易出现问题。因此,此时很难使用网页批量发布视频。
如何使用网络批量视频上传?
此时,您可以通过在同一个浏览器中同时打开多个视频来上传同一个视频网站。
虽然这句话有点草率,但是可以帮我们节省很多时间,批量上传视频。我们经常使用这种方法来操作。
当然,有一个前提是你的网速一定要快,而且你的电脑配置要稍微好一点,否则上传过程可能会中断或者卡住,会降低工作效率。
而现在所有的视频平台都支持断点续传,即在上传视频的过程中,浏览器突然异常关闭,再次选择视频时,会从上次中断的位置开始上传。
一个简单的例子,比如上传一个视频,此时打开浏览器,同时打开要上传的视频网站。一般我会同时开10个。如果视频容量不是太大,基本没有问题。然后开始点击B视频站的上传按钮,选择要上传的视频开始上传,然后继续点击C视频站的上传视频按钮,一直选择到第10个。
然后从第一个视频网站开始,输入标题,输入标签,填写介绍,选择相关类别和视频封面,点击保存。
然后按照同样的设置方法设置第二个视频网站,以此类推,可以大大提高工作效率。
第二种:软件上传
软件上传也很简单。一般会使用网页上传视频,软件比较简单。
一般使用软件上传视频,使用视频平台官方提供的软件。部分视频网站不提供软件,只提供网页上传。
与网页上传视频相比,软件上传也有自己的优势:
①使用软件发布视频,在同一视频网站中,可以同时批量发布视频。
②您可以同时设置已选择批量发布的视频的标题、简介、标签、类别等。
③从软件上传视频一般没有大小限制
④通过软件发布的视频可能有点不清楚,不同平台的清晰度也不同。
⑤ 同一个视频,如果通过软件重复发布视频,会提示已经发布。此时,禁止再次发布。
⑥适用于同一视频平台批量发布视频操作,可自动发布视频。
通过软件上传视频需要提前设置好,比如视频标题、视频介绍、视频标签、视频分类等。
如何使用软件批量发布视频,另一种操作方式,可以同时打开10个不同的视频软件客户端,同时手动登录账号,从第一个到第一个依次选择相关视频最后,开始一一设置。. 不过这个时候要求网速要快,电脑配置也要高,否则可能会卡住。
一般视频平台的软件可以在视频站首页的导航位置,或者视频网站下方的位置找到客户端的位置。也可以搜索:XXX站客户端XXX站软件上传(XXX代表视频平台名称。)
第三种:第三方软件上传
这本身也是一个软件上传,但是为了让大家更好的学习和理解,我们单独给大家讲解一下。
第三方软件唯一的方便就是可以统一设置关键词,统一登录账号,统一发布,相比前两者会节省不少时间,但也有很多不足. 有两种上传方式,够我们用了。
无论是软件上传还是网页上传,您的视频都必须符合视频站规定。如果软件上传失败,请尝试使用网页上传。一般可以通过,但需要重新设置和编辑。
不管是软件上传视频还是网页上传视频,方法都很简单,各有优劣,没有好坏之分,只有适合与否。
网页视频抓取工具 知乎(网页视频抓取工具知乎专栏提供直接代码支持访问网站图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-06 13:01
网页视频抓取工具知乎专栏提供直接代码,支持访问网站抓取图片,音频,
都是结合ss在线抓取的,有一个arctime还可以。这个要搞下它的代码库才能读取,对下载网站没什么限制,国内没用外网都可以。
看你要做什么了直接转换了,或者打开知乎网站之后,复制相应页面的地址,然后用工具来抓,用的比较多的有gif抓取工具,比如推广鸟或者giftracker,建议还是掌握一下网页爬虫的基本知识,至少要知道什么是http协议,url地址是什么意思,http状态码,图片爬取有gif抓取库可以选择,比如推广鸟,动图抓取javascript有jquery,js请求工具等等。抓起来一般不会有问题。
不会爬虫,
webbrowser抓取以目录结构的形式爬取下来,比如爬取我的专栏文章,你直接爬过去,再稍加修改和改造就可以了。就像github,你爬过去再慢慢整理。
首先你先把要抓取的页面弄明白在写抓取器吧。国内国外的都可以抓。
网站,数据,图片,音频都抓取,最重要的是要用python搞一下,因为涉及网站的原始网址等等。难,
可以试试这个-robots.html,来看看python抓取国内外网站最全攻略,不用懂html5与dom语法,并且爬取器可以在本地编写, 查看全部
网页视频抓取工具 知乎(网页视频抓取工具知乎专栏提供直接代码支持访问网站图片)
网页视频抓取工具知乎专栏提供直接代码,支持访问网站抓取图片,音频,
都是结合ss在线抓取的,有一个arctime还可以。这个要搞下它的代码库才能读取,对下载网站没什么限制,国内没用外网都可以。
看你要做什么了直接转换了,或者打开知乎网站之后,复制相应页面的地址,然后用工具来抓,用的比较多的有gif抓取工具,比如推广鸟或者giftracker,建议还是掌握一下网页爬虫的基本知识,至少要知道什么是http协议,url地址是什么意思,http状态码,图片爬取有gif抓取库可以选择,比如推广鸟,动图抓取javascript有jquery,js请求工具等等。抓起来一般不会有问题。
不会爬虫,
webbrowser抓取以目录结构的形式爬取下来,比如爬取我的专栏文章,你直接爬过去,再稍加修改和改造就可以了。就像github,你爬过去再慢慢整理。
首先你先把要抓取的页面弄明白在写抓取器吧。国内国外的都可以抓。
网站,数据,图片,音频都抓取,最重要的是要用python搞一下,因为涉及网站的原始网址等等。难,
可以试试这个-robots.html,来看看python抓取国内外网站最全攻略,不用懂html5与dom语法,并且爬取器可以在本地编写,
网页视频抓取工具 知乎(这10款个个都很实用,属于“收藏不吃灰”系列)
网站优化 • 优采云 发表了文章 • 0 个评论 • 374 次浏览 • 2022-03-04 15:01
因为平时的工作,接触到的设计门类比较多(视频、图片、文字),所以给大家介绍一下设计、音频、视频、文字相关的。如果符合你目前的需求,可以继续阅读。
对工作有帮助网站通过朋友的介绍和自己的搜索,我也省了很多。下面是安利的10款,都很实用,属于“采集不吃灰”系列!
1、网易查看工作台
网易工作台在3月份宣布关闭功能。不过,最近工作台已经悄然重新开放,只是淡出大家的视线后,并没有立即公布消息。
网易查看工作台是集文字翻译、视频翻译、图片翻译于一体的综合在线翻译网站。
它不仅有最基本的文字翻译功能,你还可以在里面上传你的视频,它会自动为你生成中英文双语字幕,或者当你想给你的视频添加字幕时,你可以直接上传你的视频。还能够为一段视频快速生成字幕。
比如使用视频转录功能,点击新建项目,选择视频转录,上传要转换的视频文件,等待一键快速生成视频字幕。
打开网站需要使用网易邮箱登录,如果没有账号,可以直接注册。目前视频每天可提供2小时免费体验,生成的字幕为srt字幕文件
网站:/
2、音乐剪辑
Audio Cutter 是一款在线应用程序,可让您直接在浏览器中剪切音轨。该应用程序快速、稳定,支持 300 多种文件格式、淡入淡出和铃声质量预设,并且完全免费。
非常好用:点击选择文件,上传文件,支持300多种文件格式,包括视频常用格式,方便上传视频,提取里面的音频,使用滑块选择音频剪辑,然后单击“编辑”,然后单击“保存”下载。
网站: /cn/
3、去除短视频水印
现在随着短视频的兴起,短视频平台也很多,但是如果你想下载某个视频,直接下载就会有平台的logo水印。
今天这篇网站专门分析无水印的短视频下载。网站介绍了对抖音、火山、快手、微视、皮皮虾、健影、微博等平台的支持。
使用方法:打开短视频app,选择要下载的视频,复制链接粘贴到解析视频框,点击解析视频,如果解析视频可以重新解析,点击下载视频,进入无水印界面,点击下载无水印视频。
网站:
4、图片无损放大
网站采用最新的人工智能深度学习技术——深度卷积神经网络,补充噪声和锯齿部分,实现图片无损放大。
支持卡通/插画、照片,最高16倍放大,并具有降噪功能,即可以对模糊的照片进行一定程度的修复,可以说近乎完美。
网站:/
5、在线图片压缩
有图片的无损放大,对应图片压缩的需要。这个 网站 是彩色笔,一个免费的在线图像压缩小工具。
将PNG/GIF/JPG图像的大小优化到极限非常方便。网站简洁美观的界面,响应速度极快,处理速度极快,支持批量上传多个文件。依靠专业的专业算法支持,图像尺寸大幅缩小后,清晰度仍能与原图保持一致。
网站:
6、魔灵音乐
对于音乐,由于版权的原因,很多音乐软件也相继失败。魔灵音乐网页版,在线收听,下载,网站无广告,无需注册登录,完全免费。
网站有分类播放列表,支持搜索、下载、部分音乐无损下载。
网站:/
7、在线格式转换
说到视频格式转换,大家可能会想到格式工厂、小玩工具箱等软件。其实转换可以更简单高效,所以今天就介绍这个网站:Convertio。
支持 300 多种格式,只需将文件拖放到页面上,选择输出格式并点击“转换”按钮即可。所有的转换都是在云端完成的,所以它们不在电脑上运行,而且处理速度非常快。
网站:convertio.co/en
8、在线 PDF 工具
对于PDF文档,在日常工作学习中经常会遇到,很多时候都需要进行编辑和转换。很多网友去下载安装相应的软件。
其实有PDF24 Tools网站就够了,免费好用的在线PDF工具,20多个功能,而且完全免费,无限制。
网站:
9、GIF 编辑工具
对于 GIF 编辑和处理工具,我们推荐 Map Tips(以前是 GIF 工具的所在地)。本网站支持GIF图片压缩、视频转GIF、GIF合成、GIF裁剪等功能。
网站:
10、快速AI自动抠图
图片背景去除,100%自动免费,只需上传需要去除背景的图片,5秒内即可自动100%去除背景,无需额外操作。
提供下载,并支持继续编辑、更改背景。
网站: remove.bg/en 查看全部
网页视频抓取工具 知乎(这10款个个都很实用,属于“收藏不吃灰”系列)
因为平时的工作,接触到的设计门类比较多(视频、图片、文字),所以给大家介绍一下设计、音频、视频、文字相关的。如果符合你目前的需求,可以继续阅读。
对工作有帮助网站通过朋友的介绍和自己的搜索,我也省了很多。下面是安利的10款,都很实用,属于“采集不吃灰”系列!
1、网易查看工作台
网易工作台在3月份宣布关闭功能。不过,最近工作台已经悄然重新开放,只是淡出大家的视线后,并没有立即公布消息。
网易查看工作台是集文字翻译、视频翻译、图片翻译于一体的综合在线翻译网站。
它不仅有最基本的文字翻译功能,你还可以在里面上传你的视频,它会自动为你生成中英文双语字幕,或者当你想给你的视频添加字幕时,你可以直接上传你的视频。还能够为一段视频快速生成字幕。
比如使用视频转录功能,点击新建项目,选择视频转录,上传要转换的视频文件,等待一键快速生成视频字幕。
打开网站需要使用网易邮箱登录,如果没有账号,可以直接注册。目前视频每天可提供2小时免费体验,生成的字幕为srt字幕文件
网站:/
2、音乐剪辑
Audio Cutter 是一款在线应用程序,可让您直接在浏览器中剪切音轨。该应用程序快速、稳定,支持 300 多种文件格式、淡入淡出和铃声质量预设,并且完全免费。
非常好用:点击选择文件,上传文件,支持300多种文件格式,包括视频常用格式,方便上传视频,提取里面的音频,使用滑块选择音频剪辑,然后单击“编辑”,然后单击“保存”下载。
网站: /cn/
3、去除短视频水印
现在随着短视频的兴起,短视频平台也很多,但是如果你想下载某个视频,直接下载就会有平台的logo水印。
今天这篇网站专门分析无水印的短视频下载。网站介绍了对抖音、火山、快手、微视、皮皮虾、健影、微博等平台的支持。
使用方法:打开短视频app,选择要下载的视频,复制链接粘贴到解析视频框,点击解析视频,如果解析视频可以重新解析,点击下载视频,进入无水印界面,点击下载无水印视频。
网站:
4、图片无损放大
网站采用最新的人工智能深度学习技术——深度卷积神经网络,补充噪声和锯齿部分,实现图片无损放大。
支持卡通/插画、照片,最高16倍放大,并具有降噪功能,即可以对模糊的照片进行一定程度的修复,可以说近乎完美。
网站:/
5、在线图片压缩
有图片的无损放大,对应图片压缩的需要。这个 网站 是彩色笔,一个免费的在线图像压缩小工具。
将PNG/GIF/JPG图像的大小优化到极限非常方便。网站简洁美观的界面,响应速度极快,处理速度极快,支持批量上传多个文件。依靠专业的专业算法支持,图像尺寸大幅缩小后,清晰度仍能与原图保持一致。
网站:
6、魔灵音乐
对于音乐,由于版权的原因,很多音乐软件也相继失败。魔灵音乐网页版,在线收听,下载,网站无广告,无需注册登录,完全免费。
网站有分类播放列表,支持搜索、下载、部分音乐无损下载。
网站:/
7、在线格式转换
说到视频格式转换,大家可能会想到格式工厂、小玩工具箱等软件。其实转换可以更简单高效,所以今天就介绍这个网站:Convertio。
支持 300 多种格式,只需将文件拖放到页面上,选择输出格式并点击“转换”按钮即可。所有的转换都是在云端完成的,所以它们不在电脑上运行,而且处理速度非常快。
网站:convertio.co/en
8、在线 PDF 工具
对于PDF文档,在日常工作学习中经常会遇到,很多时候都需要进行编辑和转换。很多网友去下载安装相应的软件。
其实有PDF24 Tools网站就够了,免费好用的在线PDF工具,20多个功能,而且完全免费,无限制。
网站:
9、GIF 编辑工具
对于 GIF 编辑和处理工具,我们推荐 Map Tips(以前是 GIF 工具的所在地)。本网站支持GIF图片压缩、视频转GIF、GIF合成、GIF裁剪等功能。
网站:
10、快速AI自动抠图
图片背景去除,100%自动免费,只需上传需要去除背景的图片,5秒内即可自动100%去除背景,无需额外操作。
提供下载,并支持继续编辑、更改背景。
网站: remove.bg/en
网页视频抓取工具 知乎( 知乎文章图片爬取器的一部分代码,针对知乎问题的答案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-04 09:09
知乎文章图片爬取器的一部分代码,针对知乎问题的答案)
Python爬虫教程:知乎文章图片爬虫
1. 知乎文章Image Crawler II 博客背景
昨天写了知乎文章图片爬虫的部分代码,获取了知乎问题答案的JSON。博客中出现了一些硬写的内容。今天我把那部分信息进行了调整,图片下载已经完善成代码了。
编号:960410445
群里有志同道合的朋友,互相帮助,
群里有很好的视频学习教程和PDF!
首先,你需要获取知乎的任何问题,你只需要输入问题的ID,就可以获得相关的页面信息,比如最重要的回答问题的总人数。
问题 ID 是红色标记的数字,如下所示
29024583
编写代码,下面的代码用于检测用户输入的ID是否正确,并通过连接URL得到问题下的答案总数。
import requestsimport reimport pymongoimport timeDATABASE_IP = '127.0.0.1'DATABASE_PORT = 27017DATABASE_NAME = 'sun'client = pymongo.MongoClient(DATABASE_IP,DATABASE_PORT)db = client.sundb.authenticate("dba", "dba")collection = db.zhihuone # 准备插入数据BASE_URL = "https://www.zhihu.com/question/{}"def get_totle_answers(article_id): headers = { "user-agent": "需要自己补全 Mozilla/5.0 (Windows NT 10.0; WOW64)" } with requests.Session() as s: with s.get(BASE_URL.format(article_id),headers=headers,timeout=3) as rep: html = rep.text pattern =re.compile( '') s = pattern.search(HTML) print("查找到 {} 条数据".format(s.groups()[0])) return s.groups()[0]if __name__ == '__main__': # 用死循环判断用户输入的是否是数字 article_id = "" while not article_id.isdigit(): article_id = input("请输入文章 ID:") totle = get_totle_answers(article_id) if int(totle)>0: zhi = ZhihuOne(article_id,totle) zhi.run() else: print("没有任何数据!")
改进图片下载部分。图片下载地址是在审核过程中找到的。在 JSON 字段的内容中,我们使用一个简单的正则表达式来匹配它。详情如下图所示
在此处插入图像描述
写代码,请仔细阅读以下代码注释,中间有个小bug,需要手动将pic3改为pic2这个地方的原因目前还不清楚,可能是我本地网络的原因,请在项目根目录中创建第一个。imgs 文件夹,用于存放图片
<p>def download_img(self,data): ## 下载图片 for item in data["data"]: content = item["content"] pattern = re.compile('(.*?)') imgs = pattern.findall(content) if len(imgs)> 0: for img in imgs: match = re.search(' 查看全部
网页视频抓取工具 知乎(
知乎文章图片爬取器的一部分代码,针对知乎问题的答案)
Python爬虫教程:知乎文章图片爬虫
1. 知乎文章Image Crawler II 博客背景
昨天写了知乎文章图片爬虫的部分代码,获取了知乎问题答案的JSON。博客中出现了一些硬写的内容。今天我把那部分信息进行了调整,图片下载已经完善成代码了。
编号:960410445
群里有志同道合的朋友,互相帮助,
群里有很好的视频学习教程和PDF!
首先,你需要获取知乎的任何问题,你只需要输入问题的ID,就可以获得相关的页面信息,比如最重要的回答问题的总人数。
问题 ID 是红色标记的数字,如下所示
29024583
编写代码,下面的代码用于检测用户输入的ID是否正确,并通过连接URL得到问题下的答案总数。
import requestsimport reimport pymongoimport timeDATABASE_IP = '127.0.0.1'DATABASE_PORT = 27017DATABASE_NAME = 'sun'client = pymongo.MongoClient(DATABASE_IP,DATABASE_PORT)db = client.sundb.authenticate("dba", "dba")collection = db.zhihuone # 准备插入数据BASE_URL = "https://www.zhihu.com/question/{}"def get_totle_answers(article_id): headers = { "user-agent": "需要自己补全 Mozilla/5.0 (Windows NT 10.0; WOW64)" } with requests.Session() as s: with s.get(BASE_URL.format(article_id),headers=headers,timeout=3) as rep: html = rep.text pattern =re.compile( '') s = pattern.search(HTML) print("查找到 {} 条数据".format(s.groups()[0])) return s.groups()[0]if __name__ == '__main__': # 用死循环判断用户输入的是否是数字 article_id = "" while not article_id.isdigit(): article_id = input("请输入文章 ID:") totle = get_totle_answers(article_id) if int(totle)>0: zhi = ZhihuOne(article_id,totle) zhi.run() else: print("没有任何数据!")
改进图片下载部分。图片下载地址是在审核过程中找到的。在 JSON 字段的内容中,我们使用一个简单的正则表达式来匹配它。详情如下图所示
在此处插入图像描述
写代码,请仔细阅读以下代码注释,中间有个小bug,需要手动将pic3改为pic2这个地方的原因目前还不清楚,可能是我本地网络的原因,请在项目根目录中创建第一个。imgs 文件夹,用于存放图片
<p>def download_img(self,data): ## 下载图片 for item in data["data"]: content = item["content"] pattern = re.compile('(.*?)') imgs = pattern.findall(content) if len(imgs)> 0: for img in imgs: match = re.search('
网页视频抓取工具 知乎(Python进阶者本文基于粉丝提问分享实用的爬虫经验 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-03 00:05
)
一、想法
很多网站都有反向请求。这个时候,一般有两种选择。要么找到js接口,要么使用requests_html等其他工具。在这里他使用了后者的 requests_html 工具。
二、分析
一开始我是直接用requests来发出请求的。我发现我得到的响应数据是错误的,和源代码相差万里。然后我认为网站应该有反爬。我尝试添加一些 ua,但标题仍然不起作用,所以我想尝试使用 requests_html 工具。
三、代码
下面是这个爬虫的代码,欢迎大家试用。
# 作者:@有点意思
import re
import requests_html
def 抓取源码(url):
user_agent = requests_html.user_agent()
session = requests_html.HTMLSession()
headers = {
"cookie": "BAIDUID=D664B1FA319D687E8EE0F9E8D643780A:FG=1; BIDUPSID=D664B1FA319D687E8EE0F9E8D643780A; PSTM=1620719199; __yjs_duid=1_c6692c2be6c2ffe04f29102282538ba81620719216498; BDUSS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BDUSS_BFESS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BAIDUID_BFESS=2C6304C3307DE9DB6DD487CC5C7C2DD3:FG=1; BDPPN=4464e3ebfa50be9e28b4d1c23e380603; _j54_6ae_=xlTM-TogKuTwIujX2VajREagog-ZV6RQfAmd; log_guid=0dad4e957fd92b3d86f994e0a93cee98; _j47_ka8_=57; __yjs_st=2_NzJkNjAyZjJmMmE1MTFmOTM1YWFlOWQwZWFlMjFkMTNmZDA0ZTlkNjRmNmUwM2NlZTQ4Y2Y4ZGM5ZjBjMDFlN2E0NzdiNDk4ZjdlNThmMmI4NjkxNDRjYmQ0MjZhMTZkMWYzMTBiYjUyMzJlMDdhMWQwZmQ2YjAwOWNiMTA5ZmJmNGNmNmE3OTk1ODZmZjkyMGQzZGZmNDdmZDJmZGU1MjE3MjgwMWRkNWYyMDlhNWNiYWM3YjNkMWI1MzU5NWM2MjEzYWMxODUyNDcyZDdjYTMzZDRiY2FlYTNmYmRiN2JkYzU1MWZiNWM3OTc4ZjExYmYwNGNlNTA5MjhjMWQ4Yl83XzEyZjk1ZDEw; Hm_lvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637699929,1637713962,1637849108; Hm_lpvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637849108; ab_sr=1.0.1_OTBkZjg4MzZjYjFhMWMyODgxZTM4MDZiNGViYTRkYjFhNDFiNWU1NWUyZjU4NDI3YjVjYTM1YTBiYTc1M2Y0ZTA5ZTI5YTZjNDQ4ZGFjMzE2NTU5ZTkwMWFkYWI0OGE5Nzc4MWFiOGU5N2VmNzJjMDdiYTk4NjYyY2E1NzQ4MzIzMDVmOTc2MDZjOTA0NTYyODNjNmUxNjAwNzlmNThlYQ==; _s53_d91_=93c39820170a0a5e748e1ac9ecc79371df45a908d7031a5e0e6df033fcc8068df8a85a45f59cb9faa0f164dd33ed0c72405da53b835d694f9513b3e1cb6e4a96799af3f84bd42f912f1c8ae0446a53f275c4e5a7894aeb6c9857d9df8629680517ba9801c04e1c714b46f860c3cbb2ecb1a3847388bf1b3c4bcbbd8119b62261a0a625c3c8b053758aa8fe29ec0f7fffe3b49bb0f77fea4df98a0f472d86bde82df374a7e5fb907b27d3187299c8b7ef65e28b9e042741e29587ab5829dfbafca8de50eb8162607986625ecd31d16a1f; _y18_s21_=4c8c0b95; RT=\"z=1&dm=baidu.com&si=nm8z611r2fr&ss=kwf1266k&sl=2&tt=xuh&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=mmj&ul=ilwy\"",
"User-Agent": user_agent
}
r = session.get(url, headers=headers)
html = r.html.html
return html # 注意!这里抓取到的源码和手动打开的页面源码不一样
def 解密(列表): # unicode转化成汉字
print(列表)
return [eval(i) for i in 列表]
def 解析页面(html):
公司列表 = re.findall(r'titleName":(".*?")', html, re.DOTALL)
# 注意!此处编写正则时,要匹配的源码是函数“抓取源码”得到的html
# 此处正则匹配时一定要把引号带上!否则eval会报错!
return 解密(公司列表)
if __name__ == "__main__":
# 不用抓包,这里的url就是用户搜索时的页面
url = "https://某某查网站/s?q=%E4%B8%8A%E6%B5%B7%E5%99%A8%E6%A2%B0%E5%8E%82&t=0"
html = 抓取源码(url)
print(html)
公司列表 = 解析页面(html)
print(公司列表)
你可能会觉得奇怪,这里有中文的函数名和变量名。这是应原作者的要求,所以没有修改,但不影响程序的执行。
程序运行后,可以看到可以捕获目标字段。
四、总结
我是 Python 进阶者。本文基于粉丝提问,与大家分享一次实战爬虫体验,为大家带来一次有趣的爬虫体验。下次遇到使用requests库无法爬取的网页,或者看不到包的时候,不妨试试文中的requests_html方法,说不定会有用!
对于本文的网页,除了文章的“投机取巧”的方法外,用selenium爬取也是可行的,速度较慢,但能满足要求。小编认为肯定还有其他方法,也欢迎大家在评论区指教。
查看全部
网页视频抓取工具 知乎(Python进阶者本文基于粉丝提问分享实用的爬虫经验
)
一、想法
很多网站都有反向请求。这个时候,一般有两种选择。要么找到js接口,要么使用requests_html等其他工具。在这里他使用了后者的 requests_html 工具。
二、分析
一开始我是直接用requests来发出请求的。我发现我得到的响应数据是错误的,和源代码相差万里。然后我认为网站应该有反爬。我尝试添加一些 ua,但标题仍然不起作用,所以我想尝试使用 requests_html 工具。
三、代码
下面是这个爬虫的代码,欢迎大家试用。
# 作者:@有点意思
import re
import requests_html
def 抓取源码(url):
user_agent = requests_html.user_agent()
session = requests_html.HTMLSession()
headers = {
"cookie": "BAIDUID=D664B1FA319D687E8EE0F9E8D643780A:FG=1; BIDUPSID=D664B1FA319D687E8EE0F9E8D643780A; PSTM=1620719199; __yjs_duid=1_c6692c2be6c2ffe04f29102282538ba81620719216498; BDUSS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BDUSS_BFESS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BAIDUID_BFESS=2C6304C3307DE9DB6DD487CC5C7C2DD3:FG=1; BDPPN=4464e3ebfa50be9e28b4d1c23e380603; _j54_6ae_=xlTM-TogKuTwIujX2VajREagog-ZV6RQfAmd; log_guid=0dad4e957fd92b3d86f994e0a93cee98; _j47_ka8_=57; __yjs_st=2_NzJkNjAyZjJmMmE1MTFmOTM1YWFlOWQwZWFlMjFkMTNmZDA0ZTlkNjRmNmUwM2NlZTQ4Y2Y4ZGM5ZjBjMDFlN2E0NzdiNDk4ZjdlNThmMmI4NjkxNDRjYmQ0MjZhMTZkMWYzMTBiYjUyMzJlMDdhMWQwZmQ2YjAwOWNiMTA5ZmJmNGNmNmE3OTk1ODZmZjkyMGQzZGZmNDdmZDJmZGU1MjE3MjgwMWRkNWYyMDlhNWNiYWM3YjNkMWI1MzU5NWM2MjEzYWMxODUyNDcyZDdjYTMzZDRiY2FlYTNmYmRiN2JkYzU1MWZiNWM3OTc4ZjExYmYwNGNlNTA5MjhjMWQ4Yl83XzEyZjk1ZDEw; Hm_lvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637699929,1637713962,1637849108; Hm_lpvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637849108; ab_sr=1.0.1_OTBkZjg4MzZjYjFhMWMyODgxZTM4MDZiNGViYTRkYjFhNDFiNWU1NWUyZjU4NDI3YjVjYTM1YTBiYTc1M2Y0ZTA5ZTI5YTZjNDQ4ZGFjMzE2NTU5ZTkwMWFkYWI0OGE5Nzc4MWFiOGU5N2VmNzJjMDdiYTk4NjYyY2E1NzQ4MzIzMDVmOTc2MDZjOTA0NTYyODNjNmUxNjAwNzlmNThlYQ==; _s53_d91_=93c39820170a0a5e748e1ac9ecc79371df45a908d7031a5e0e6df033fcc8068df8a85a45f59cb9faa0f164dd33ed0c72405da53b835d694f9513b3e1cb6e4a96799af3f84bd42f912f1c8ae0446a53f275c4e5a7894aeb6c9857d9df8629680517ba9801c04e1c714b46f860c3cbb2ecb1a3847388bf1b3c4bcbbd8119b62261a0a625c3c8b053758aa8fe29ec0f7fffe3b49bb0f77fea4df98a0f472d86bde82df374a7e5fb907b27d3187299c8b7ef65e28b9e042741e29587ab5829dfbafca8de50eb8162607986625ecd31d16a1f; _y18_s21_=4c8c0b95; RT=\"z=1&dm=baidu.com&si=nm8z611r2fr&ss=kwf1266k&sl=2&tt=xuh&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=mmj&ul=ilwy\"",
"User-Agent": user_agent
}
r = session.get(url, headers=headers)
html = r.html.html
return html # 注意!这里抓取到的源码和手动打开的页面源码不一样
def 解密(列表): # unicode转化成汉字
print(列表)
return [eval(i) for i in 列表]
def 解析页面(html):
公司列表 = re.findall(r'titleName":(".*?")', html, re.DOTALL)
# 注意!此处编写正则时,要匹配的源码是函数“抓取源码”得到的html
# 此处正则匹配时一定要把引号带上!否则eval会报错!
return 解密(公司列表)
if __name__ == "__main__":
# 不用抓包,这里的url就是用户搜索时的页面
url = "https://某某查网站/s?q=%E4%B8%8A%E6%B5%B7%E5%99%A8%E6%A2%B0%E5%8E%82&t=0"
html = 抓取源码(url)
print(html)
公司列表 = 解析页面(html)
print(公司列表)
你可能会觉得奇怪,这里有中文的函数名和变量名。这是应原作者的要求,所以没有修改,但不影响程序的执行。
程序运行后,可以看到可以捕获目标字段。
四、总结
我是 Python 进阶者。本文基于粉丝提问,与大家分享一次实战爬虫体验,为大家带来一次有趣的爬虫体验。下次遇到使用requests库无法爬取的网页,或者看不到包的时候,不妨试试文中的requests_html方法,说不定会有用!
对于本文的网页,除了文章的“投机取巧”的方法外,用selenium爬取也是可行的,速度较慢,但能满足要求。小编认为肯定还有其他方法,也欢迎大家在评论区指教。

