
网页视频抓取工具 知乎
网页视频抓取工具 知乎(五款免费的数据工具,帮你省时又省力!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 723 次浏览 • 2022-03-01 07:18
在网络信息化时代,爬虫是采集信息不可或缺的工具。对于很多小伙伴来说,只是想用爬虫进行快速的内容爬取,并不想对爬虫研究太深。
用python写爬虫程序很酷,但是学习起来需要时间和精力。学习成本非常高。有时候仅仅为了几页数据就学了几个月的爬虫,真是让人难以忍受。
有没有什么好办法,既快又省力,当然!今天菜鸟哥今天就带领大家分享五款免费的数据采集工具,帮助大家省时省力。
01.优采云
优采云是一款比较流行的爬虫软件,即使用户不会编程也能轻松抓取数据。优采云数据采集稳定性强,配有详细的使用教程,可以快速上手。
门户网站:
我们以采集的名言为例,网址为:
打开优采云软件后,打开网页,然后点击单个文本,选择右侧的“全选”,软件会自动识别所有著名文本。接下来按照操作,选择 采集 文本,然后启动 采集 的软件。
采集完成后,选择文本导出的文件类型,点击确定即可导出数据。
2. 吉索克
Jisouke为一些流行的网站设置了快速爬虫程序,但是学习成本比优采云高。
门户网站:
我们在 知乎关键词 处抓取:。首先需要根据爬取的类别进行分类,然后输入网址,点击获取数据,开始爬取。捕获的数据如下图所示:
可以看到,极速客抓取到的信息非常丰富,但是下载数据需要消耗积分,20条数据需要消耗1积分。Jisouke会给新用户20分。
以上两款都是非常好用的国产数据采集软件。接下来菜鸟哥就介绍一下chrome浏览器下的爬虫插件。
3.网络爬虫
网络爬虫插件是一个非常好用的爬虫插件。网络爬虫的安装,可以参考之前菜鸟哥分享的文章(超棒的chrome插件,无需一行代码,轻松爬取各大网站公开信息!(附视频))。
对于简单的数据抓取,网络抓取工具可以很好地完成这项工作。我们还以名言的 URL 数据抓取为例。
通过选中多个来获取页面中的所有引号。捕获数据后,通过单击“将数据导出为 CSV”导出所有数据。
4.AnyPapa
将网页翻到评测部分,然后点击AnyPapa插件下的“本地数据”,会自动跳转到AnyPapa的数据页面。
首先,点击切换数据源,找到“京东商品评论”的数据源。此时界面会在手机评论页面显示当前所有的评论内容。点击“导出”,评论数据将以csv文件的形式下载到本地。
5.你得到
you-get 是 GitHub 上非常流行的爬虫项目。作者提供了来自网站的国内外近80个视频和图片截图,获得了40900个赞!
门户网站: 。
对于you-get的安装,可以通过命令pip install you-get来安装。
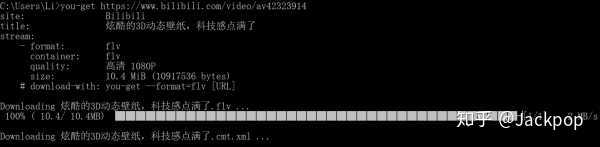
我们以B站上的视频为例,网址为:
通过命令:
1you-get -o ./ 'https://www.bilibili.com/video ... 27%3B --format=flv360
2
可以实现视频下载,其中-o是指视频下载的存储地址,--format是指视频下载的格式和定义。
6.总结
以上就是菜鸟哥今天给大家带来的五款自动提取数据的工具。如果是偶尔的爬虫,或者非常低频率的爬虫需求,完全没有必要学习爬虫技术,因为学习成本非常高。比如你只想发几张图,不用学Photoshop就可以直接用美图秀秀。
如果你对爬虫有很多定制需求,需要对采集到的数据进行分析和深度挖掘,而且频率很高,或者你想更深入地使用Python技术,通过爬虫更扎实的学习,那么可以考虑在这学习时间。爬虫。 查看全部
网页视频抓取工具 知乎(五款免费的数据工具,帮你省时又省力!)
在网络信息化时代,爬虫是采集信息不可或缺的工具。对于很多小伙伴来说,只是想用爬虫进行快速的内容爬取,并不想对爬虫研究太深。
用python写爬虫程序很酷,但是学习起来需要时间和精力。学习成本非常高。有时候仅仅为了几页数据就学了几个月的爬虫,真是让人难以忍受。
有没有什么好办法,既快又省力,当然!今天菜鸟哥今天就带领大家分享五款免费的数据采集工具,帮助大家省时省力。
01.优采云
优采云是一款比较流行的爬虫软件,即使用户不会编程也能轻松抓取数据。优采云数据采集稳定性强,配有详细的使用教程,可以快速上手。
门户网站:
我们以采集的名言为例,网址为:
打开优采云软件后,打开网页,然后点击单个文本,选择右侧的“全选”,软件会自动识别所有著名文本。接下来按照操作,选择 采集 文本,然后启动 采集 的软件。
采集完成后,选择文本导出的文件类型,点击确定即可导出数据。
2. 吉索克
Jisouke为一些流行的网站设置了快速爬虫程序,但是学习成本比优采云高。
门户网站:
我们在 知乎关键词 处抓取:。首先需要根据爬取的类别进行分类,然后输入网址,点击获取数据,开始爬取。捕获的数据如下图所示:
可以看到,极速客抓取到的信息非常丰富,但是下载数据需要消耗积分,20条数据需要消耗1积分。Jisouke会给新用户20分。
以上两款都是非常好用的国产数据采集软件。接下来菜鸟哥就介绍一下chrome浏览器下的爬虫插件。
3.网络爬虫
网络爬虫插件是一个非常好用的爬虫插件。网络爬虫的安装,可以参考之前菜鸟哥分享的文章(超棒的chrome插件,无需一行代码,轻松爬取各大网站公开信息!(附视频))。
对于简单的数据抓取,网络抓取工具可以很好地完成这项工作。我们还以名言的 URL 数据抓取为例。
通过选中多个来获取页面中的所有引号。捕获数据后,通过单击“将数据导出为 CSV”导出所有数据。
4.AnyPapa
将网页翻到评测部分,然后点击AnyPapa插件下的“本地数据”,会自动跳转到AnyPapa的数据页面。
首先,点击切换数据源,找到“京东商品评论”的数据源。此时界面会在手机评论页面显示当前所有的评论内容。点击“导出”,评论数据将以csv文件的形式下载到本地。
5.你得到
you-get 是 GitHub 上非常流行的爬虫项目。作者提供了来自网站的国内外近80个视频和图片截图,获得了40900个赞!
门户网站: 。
对于you-get的安装,可以通过命令pip install you-get来安装。
我们以B站上的视频为例,网址为:
通过命令:
1you-get -o ./ 'https://www.bilibili.com/video ... 27%3B --format=flv360
2
可以实现视频下载,其中-o是指视频下载的存储地址,--format是指视频下载的格式和定义。
6.总结
以上就是菜鸟哥今天给大家带来的五款自动提取数据的工具。如果是偶尔的爬虫,或者非常低频率的爬虫需求,完全没有必要学习爬虫技术,因为学习成本非常高。比如你只想发几张图,不用学Photoshop就可以直接用美图秀秀。
如果你对爬虫有很多定制需求,需要对采集到的数据进行分析和深度挖掘,而且频率很高,或者你想更深入地使用Python技术,通过爬虫更扎实的学习,那么可以考虑在这学习时间。爬虫。
网页视频抓取工具 知乎(注册个账号得到APIKEY来配置Workflow解决了这问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-28 13:12
)
随着 Instapaper 宣布它是免费的,我开始尝试使用该应用程序。这个app很适合我,但是爬的时候对知乎的支持不是很好。我试图用强迫症来解决它。比较有效的方法是:右上角菜单“Safari打开”——打开阅读查看器视图——发送邮件到Instapaper邮箱。不过还是有点麻烦,找了Mercury这个服务,用Workflow解决了这个问题。
注册 Mercury 的先决条件
Mercury 是一个免费的在线文本解析器网站,它允许我们提供 URL 并以 JSON 格式获取解析结果。我们需要使用他们的服务,所以我们需要注册一个账户来获取API KEY来配置Workflow来使用。
首先进入Mercury,点击右上角的“SIGN UP FOR FREE”。注册并验证您的电子邮件地址后,您将能够看到自己的 API KEY。
配置工作流程
你可以去知乎到 Instapaper 获取我写的 Workflow。
单击“GET WORKFLOW”,您应该能够将此工作流保存到您的应用程序中。
配置 Mercury API KEY 和电子邮件
我们已经拿到了KEY,我们需要的Instapaper邮箱地址可以在如何保存中找到Instapaper邮箱地址来接收邮件。
拉下脚本,找到评论,在“Text”框和“Email Address”框中分别填写KEY和Instapaper的接收邮件邮箱。
然后将脚本拉到底部,找到绿色的“运行时询问”圆圈,然后配置您的发件箱。(第一次使用Workflow的同学需要对邮箱申请进行授权。另外需要注意的是,如果邮箱服务器、用户名、密码确认无误,仍然提示错误,保存即可直接,操作无效后再修改。)
改变这三个地方后,就可以点击右上角的Done来使用了!
跑步
操作:右上角菜单-复制链接-运行Workflow
在网页中,导出菜单中的 Instapaper 图标其实只是将当前页面链接传输到后台进行爬取,但对于重视版权意识的社区 知乎 却不是很支持。此工作流脚本也可用于 知乎 列和其他 网站。这种方法相当于换了一个解析服务。对于一般的网站,建议以原生方式添加文章。@>。
下面是Workflow在iPad上得到的知乎column文章@>的效果,代码块变成了图片……
防范措施:
此方法需要重新下载网页数据并发送电子邮件。使用时请注意流量消耗;如果您找到解决方案,请写一篇博文进行分享。这也是强迫症哈哈哈(´˘`๑)
原文发表于《使用工作流保存知乎对Instapaper的回答》,内容的版权和解释权属于Mac Play Law的内容合作伙伴“猫东”。想成为我们的内容合作伙伴或提供原创文章@>?请浏览“Mac游戏内容开放计划”,我们等你加入!联系我们!
查看全部
网页视频抓取工具 知乎(注册个账号得到APIKEY来配置Workflow解决了这问题
)
随着 Instapaper 宣布它是免费的,我开始尝试使用该应用程序。这个app很适合我,但是爬的时候对知乎的支持不是很好。我试图用强迫症来解决它。比较有效的方法是:右上角菜单“Safari打开”——打开阅读查看器视图——发送邮件到Instapaper邮箱。不过还是有点麻烦,找了Mercury这个服务,用Workflow解决了这个问题。
注册 Mercury 的先决条件
Mercury 是一个免费的在线文本解析器网站,它允许我们提供 URL 并以 JSON 格式获取解析结果。我们需要使用他们的服务,所以我们需要注册一个账户来获取API KEY来配置Workflow来使用。
首先进入Mercury,点击右上角的“SIGN UP FOR FREE”。注册并验证您的电子邮件地址后,您将能够看到自己的 API KEY。
配置工作流程
你可以去知乎到 Instapaper 获取我写的 Workflow。
单击“GET WORKFLOW”,您应该能够将此工作流保存到您的应用程序中。
配置 Mercury API KEY 和电子邮件
我们已经拿到了KEY,我们需要的Instapaper邮箱地址可以在如何保存中找到Instapaper邮箱地址来接收邮件。
拉下脚本,找到评论,在“Text”框和“Email Address”框中分别填写KEY和Instapaper的接收邮件邮箱。
然后将脚本拉到底部,找到绿色的“运行时询问”圆圈,然后配置您的发件箱。(第一次使用Workflow的同学需要对邮箱申请进行授权。另外需要注意的是,如果邮箱服务器、用户名、密码确认无误,仍然提示错误,保存即可直接,操作无效后再修改。)
改变这三个地方后,就可以点击右上角的Done来使用了!
跑步

操作:右上角菜单-复制链接-运行Workflow
在网页中,导出菜单中的 Instapaper 图标其实只是将当前页面链接传输到后台进行爬取,但对于重视版权意识的社区 知乎 却不是很支持。此工作流脚本也可用于 知乎 列和其他 网站。这种方法相当于换了一个解析服务。对于一般的网站,建议以原生方式添加文章。@>。
下面是Workflow在iPad上得到的知乎column文章@>的效果,代码块变成了图片……

防范措施:
此方法需要重新下载网页数据并发送电子邮件。使用时请注意流量消耗;如果您找到解决方案,请写一篇博文进行分享。这也是强迫症哈哈哈(´˘`๑)
原文发表于《使用工作流保存知乎对Instapaper的回答》,内容的版权和解释权属于Mac Play Law的内容合作伙伴“猫东”。想成为我们的内容合作伙伴或提供原创文章@>?请浏览“Mac游戏内容开放计划”,我们等你加入!联系我们!

网页视频抓取工具 知乎(网站打开慢,如何提升网站的打开速度?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-28 07:10
网站打开很慢,如何提高网站打开速度?
1、网站代码优化
删除 网站 冗余代码,例如无用的空格、换行符、注释。网站代码也可以通过压缩工具进行压缩。
2、减少不必要的元素
尽量不要使用flash动画。如果音视频占用空间太大,可以考虑上传到第三方专用音视频网站。
3、静态页面
静态页面直接在客户端运行,无需服务器处理,加载速度更快,对 SEO 更友好。动态页面的交互效果虽然不错,但是需要服务器处理,生成html后才能在浏览器中显示。与静态页面相比,速度较慢。网站打开很慢,如何提高网站打开速度?
4、使用CSS+DIV页面结构
一些站长为了追求页面的对齐效果,在创建网页时会将页面内容加载到Table中,并以单元格划分各个部分。由于Table是等待所有内容加载完毕再分层显示,如果某个section的内容加载不出来。如果出来了,整个Table页面就不会显示出来,会导致网页加载缓慢。CSS+DIV页面结构是逐步加载的,避免了上述问题。
5、使用CDN加速网络
CDN加速网络可以根据网络流量、负载状态、用户距离、响应时间等,将用户请求信息引导至最近的服务点,使用户就近获取所需信息,提高网页加载速度。
6、大图采用延迟加载
大图像以延迟方式加载。当用户需要使用图片时,加载图片,从而减少服务器请求,提高页面加载速度。上传前压缩大图像。
网站打开很慢,如何提高网站打开速度?更多网络营销推广知识,尽在玉米俱乐部。 查看全部
网页视频抓取工具 知乎(网站打开慢,如何提升网站的打开速度?(图))
网站打开很慢,如何提高网站打开速度?
1、网站代码优化
删除 网站 冗余代码,例如无用的空格、换行符、注释。网站代码也可以通过压缩工具进行压缩。
2、减少不必要的元素
尽量不要使用flash动画。如果音视频占用空间太大,可以考虑上传到第三方专用音视频网站。
3、静态页面
静态页面直接在客户端运行,无需服务器处理,加载速度更快,对 SEO 更友好。动态页面的交互效果虽然不错,但是需要服务器处理,生成html后才能在浏览器中显示。与静态页面相比,速度较慢。网站打开很慢,如何提高网站打开速度?
4、使用CSS+DIV页面结构
一些站长为了追求页面的对齐效果,在创建网页时会将页面内容加载到Table中,并以单元格划分各个部分。由于Table是等待所有内容加载完毕再分层显示,如果某个section的内容加载不出来。如果出来了,整个Table页面就不会显示出来,会导致网页加载缓慢。CSS+DIV页面结构是逐步加载的,避免了上述问题。
5、使用CDN加速网络
CDN加速网络可以根据网络流量、负载状态、用户距离、响应时间等,将用户请求信息引导至最近的服务点,使用户就近获取所需信息,提高网页加载速度。
6、大图采用延迟加载
大图像以延迟方式加载。当用户需要使用图片时,加载图片,从而减少服务器请求,提高页面加载速度。上传前压缩大图像。
网站打开很慢,如何提高网站打开速度?更多网络营销推广知识,尽在玉米俱乐部。
网页视频抓取工具 知乎(自学爬虫两个月了,记录一下自己的爬虫学习经历 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-24 05:03
)
自学爬虫两个月,记录下我的爬虫学习心得,和大家分享一下可用的爬虫技术:
一、爬虫原理
简单介绍一下爬虫的原理。核心爬虫分为两步:
获取网页提取信息
一般来说,获取网页就是在浏览器中输入一个网址,然后获取该网址所指向的网页的所有信息。但是,通过编程,可以直接在程序中输入网址,然后获取网页。此步骤中使用的 Python 库是 urllib 和 request。
提取信息就是掌握你需要的关键信息。网页信息中收录了很多无关紧要的信息,比如“作为一个理性的消费者,你为什么要关心213青年对你的看法?” 这句话,爬下来的原创资料是:
身为一个理智的消费者,为何要在意二13青年对你的看法呢?</p>
为了提取有用信息,剔除不相关信息,需要Beautiful Soup、Pyquery等Python库。
二、知乎爬虫
在常用的网站中,比较容易爬的有知乎、微博等。首先这两个网站的信息都是公开的,与微信不同,例如,只有朋友可以被其他人查看。二是知乎,微博不用登录账号直接浏览,不像微信必须登录微信账号;最后两个可以直接用浏览器登录,不像微信,必须用app打开。
知乎爬虫使用request获取网页,使用Json和Pyquery提取信息。
废话不多说,直接放代码,库文件:
import requests
from pyquery import PyQuery as pq
#import json
import csv,codecs#解决乱码!
import os
import numpy as np
from hashlib import md5
from bs4 import BeautifulSoup
攀登知乎回答“2021年买得起的轻薄本有哪些推荐”,网址链接和头文件:
url = 'https://www.zhihu.com/question ... 39%3B
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
ajax处理获取网页:
base_url = 'https://www.zhihu.com/api/v4/q ... 39%3B
include = 'data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled'
def get_page(page):#page0就是第一页
url1 = 'include=' + include+ '&limit=5&' + 'offset=' + str(page)+ '&platform=desktop&sort_by=default'
url = base_url + url1#urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error', e.args)
好的:
def parse_page(json):
if json:
items = json.get('data')
for item in items:
zhihu = {}
zhihu['作者'] = item.get('author').get('name')
zhihu['回答'] = pq(item.get('content')).text()
zhihu['赞'] = item.get('voteup_count')
yield zhihu#生成器
主函数执行:
if __name__=='__main__':
i = 0
f = codecs.open('对于笔记本的选择,轻薄本真的被看不起吗?.csv', 'w+', 'utf_8_sig')
ftxt = open('对于笔记本的选择,轻薄本真的被看不起吗?.txt', 'w+', encoding='utf_8')
fieldnames = ['作者', '回答','赞']
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
while True:
js = get_page(5*i)
results = parse_page(js)
for res in results:
writer.writerow(res)
for detail in res.values():
ftxt.write(str(detail)+'\n')
ftxt.write('\n' + '=' * 50 + '\n')
if js.get('paging').get('is_end'):
print('finish!')
break
i+=1
f.close()
ftxt.close() 查看全部
网页视频抓取工具 知乎(自学爬虫两个月了,记录一下自己的爬虫学习经历
)
自学爬虫两个月,记录下我的爬虫学习心得,和大家分享一下可用的爬虫技术:
一、爬虫原理
简单介绍一下爬虫的原理。核心爬虫分为两步:
获取网页提取信息
一般来说,获取网页就是在浏览器中输入一个网址,然后获取该网址所指向的网页的所有信息。但是,通过编程,可以直接在程序中输入网址,然后获取网页。此步骤中使用的 Python 库是 urllib 和 request。
提取信息就是掌握你需要的关键信息。网页信息中收录了很多无关紧要的信息,比如“作为一个理性的消费者,你为什么要关心213青年对你的看法?” 这句话,爬下来的原创资料是:
身为一个理智的消费者,为何要在意二13青年对你的看法呢?</p>
为了提取有用信息,剔除不相关信息,需要Beautiful Soup、Pyquery等Python库。
二、知乎爬虫
在常用的网站中,比较容易爬的有知乎、微博等。首先这两个网站的信息都是公开的,与微信不同,例如,只有朋友可以被其他人查看。二是知乎,微博不用登录账号直接浏览,不像微信必须登录微信账号;最后两个可以直接用浏览器登录,不像微信,必须用app打开。
知乎爬虫使用request获取网页,使用Json和Pyquery提取信息。
废话不多说,直接放代码,库文件:
import requests
from pyquery import PyQuery as pq
#import json
import csv,codecs#解决乱码!
import os
import numpy as np
from hashlib import md5
from bs4 import BeautifulSoup
攀登知乎回答“2021年买得起的轻薄本有哪些推荐”,网址链接和头文件:
url = 'https://www.zhihu.com/question ... 39%3B
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
ajax处理获取网页:
base_url = 'https://www.zhihu.com/api/v4/q ... 39%3B
include = 'data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled'
def get_page(page):#page0就是第一页
url1 = 'include=' + include+ '&limit=5&' + 'offset=' + str(page)+ '&platform=desktop&sort_by=default'
url = base_url + url1#urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error', e.args)
好的:
def parse_page(json):
if json:
items = json.get('data')
for item in items:
zhihu = {}
zhihu['作者'] = item.get('author').get('name')
zhihu['回答'] = pq(item.get('content')).text()
zhihu['赞'] = item.get('voteup_count')
yield zhihu#生成器
主函数执行:
if __name__=='__main__':
i = 0
f = codecs.open('对于笔记本的选择,轻薄本真的被看不起吗?.csv', 'w+', 'utf_8_sig')
ftxt = open('对于笔记本的选择,轻薄本真的被看不起吗?.txt', 'w+', encoding='utf_8')
fieldnames = ['作者', '回答','赞']
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
while True:
js = get_page(5*i)
results = parse_page(js)
for res in results:
writer.writerow(res)
for detail in res.values():
ftxt.write(str(detail)+'\n')
ftxt.write('\n' + '=' * 50 + '\n')
if js.get('paging').get('is_end'):
print('finish!')
break
i+=1
f.close()
ftxt.close()
网页视频抓取工具 知乎(Python爬虫中爬虫的爬取数据处理流程及解决办法(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-24 05:03
)
需要salt,写了一个爬虫程序来爬取知乎网站的数据。关于知乎爬虫,我们从用户的角度和问题的角度进行爬取。挑选。
项目流程:爬虫代码(Python)→非结构化数据(Mongo)→结构化数据(MySQL)→结构化数据(Access)
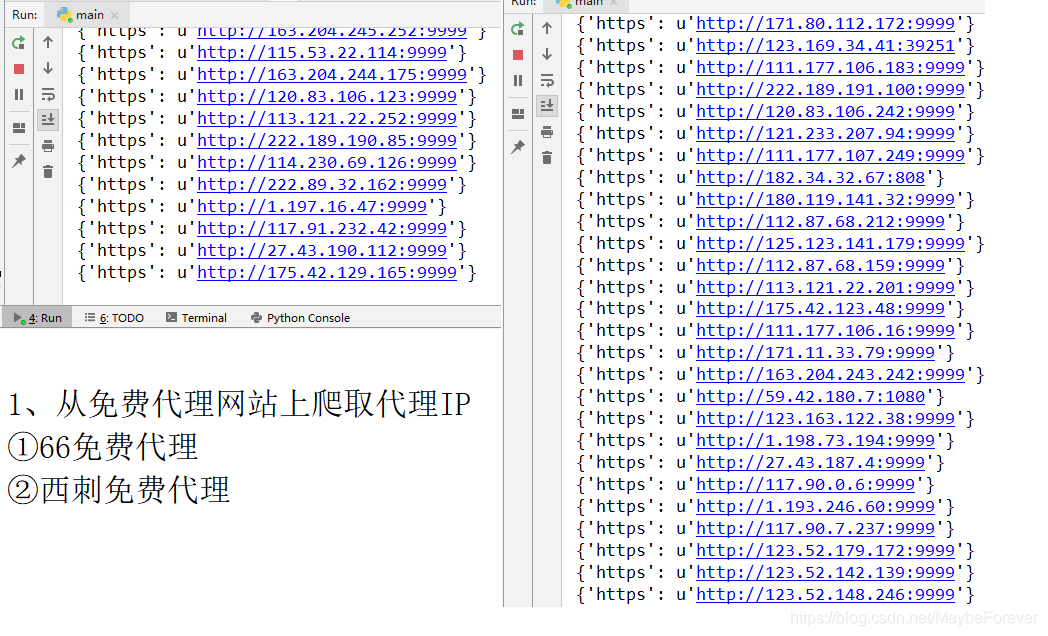
为了应对反爬机制,我们使用Python编写爬虫来爬取IP代理池。IP代理池程序的源地址为:
数据爬取以知乎主题下的内容为爬取对象。爬虫程序通过python设计实现,将知乎问答社区的数据作为研究问题分类的数据进行爬取。这些数据的来源是由浏览器获取的。浏览器获取的其实是一系列文件,包括HTML格式部分、CSS样式部分和JavaScript执行层部分。浏览器将加载并理解这些数据,并通过渲染将其显示在图表的这一侧。因此,这些文件是由爬虫获取的。通过对这些代码文件进行分析和过滤,就可以实现对图片和文字的爬取。
程序源地址:
(1)从问题的角度,对于知乎“英语学习”和“流行音乐”两个题目下的问题,我们于2018年暑期开始爬取以下内容:
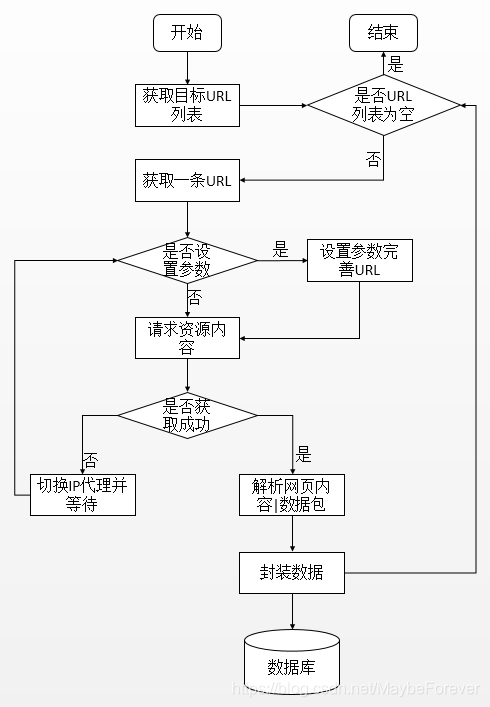
浏览器通过请求 URL 来获取资源文件。URL是一个统一的资源定位器,也称为网站,通过它可以通过特定的访问方式从互联网上查找资源的位置并获取。Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应该如何处理它的信息。Python爬虫的原理是模仿浏览器的行为,对Web服务器请求的信息和对服务器的响应进行基本的处理。本文爬虫的爬取数据处理流程如图:
网络爬虫的基本框架一般由三部分组成:网址管理模块、网页下载模块和网页解析模块。URL管理模块对要爬取的网页链接进行管理,防止重复爬取或循环指向。由于本文的数据爬取是定向的,爬虫作业基本是列表任务,所以本文爬虫程序的URL管理模块比较简单,可以直接迭代列表内容。如果动态信息请求较多,则需要对URL管理模块进行参数管理。网页下载模块是将URL对应的网页或内容下载到本地或内存中。requests 库提供了 http 的所有基本请求方法。本文爬虫程序主要通过requests模块实现信息内容的请求和下载。网页解析模块从下载的网页或内容中提取数据。由于下载的内容是 HTML 格式,因此需要的实际数据是这些标签中的文本数据。BeautifulSoup 工具是一个 python 库,可以定位数据和解析标签数据。在内容上,本文中的爬虫是通过BeautifulSoup工具和正则表达式实现的。最后,将解析后的数据保存起来,供以后处理和使用。BeautifulSoup 工具是一个 python 库,可以定位数据和解析标签数据。在内容上,本文中的爬虫是通过BeautifulSoup工具和正则表达式实现的。最后,将解析后的数据保存起来,供以后处理和使用。BeautifulSoup 工具是一个 python 库,可以定位数据和解析标签数据。在内容上,本文中的爬虫是通过BeautifulSoup工具和正则表达式实现的。最后,将解析后的数据保存起来,供以后处理和使用。
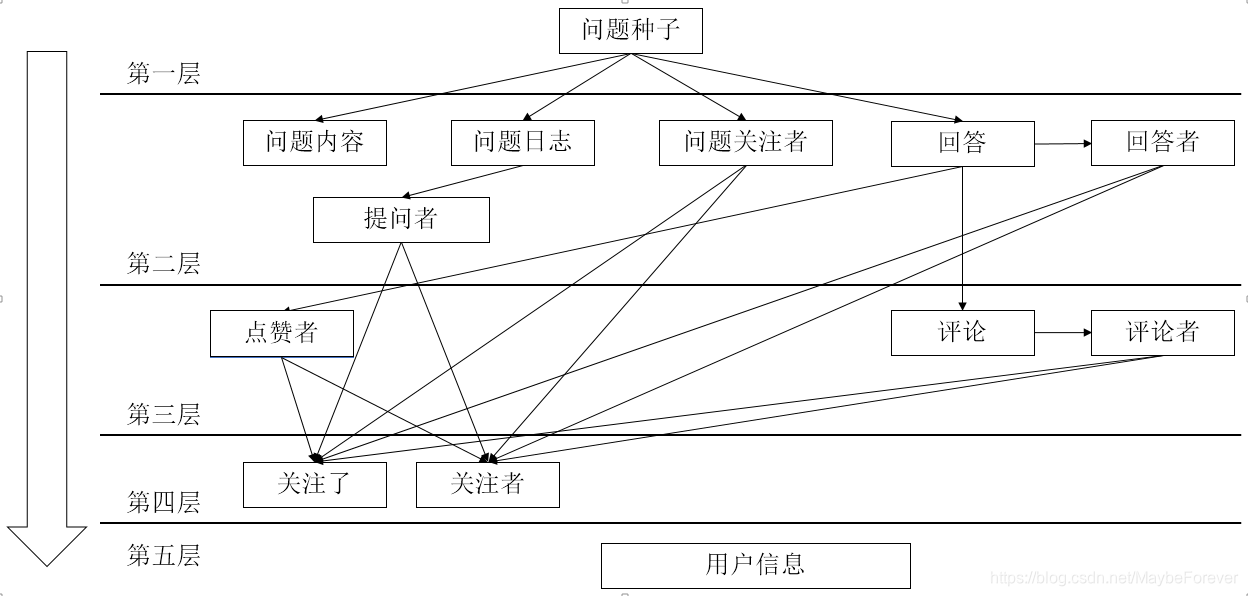
由于知乎社区的问答文本是以话题的形式组织在数据库中的,因此本文对数据的爬取是基于特定话题下的深度搜索爬取(我们爬取了英语学习和流行音乐主题)。爬取数据获取流程及数据内容如图:
在爬取过程中,程序错误状态码主要遇到以下几种情况:
200:请求成功,请求所期望的响应或数据体将与此响应一起生成。
403:服务器理解请求,但拒绝执行。(解决方法:重新登录知乎账号,更改cookie)
404:请求失败,在服务器上找不到请求的资源。(原因:网页丢失或删除)
410:请求的资源在服务器上不再可用,并且没有已知的转发地址。(原因:资源流失)
500:服务器遇到意外情况,无法完成请求的处理。一般在服务器端的源代码有错误的时候就会出现这个问题。
以上错误码中,403、410、500会导致程序中断,需要处理后重新运行。其中403表示我们的cookie过期或者因为访问太频繁被服务器拒绝了,但是我们的账号还没有被封禁,重新登录账号,更换新的cookie。410 是由于资源不可用,500 是内部服务错误,两者都是由服务器端不可知错误引起的。
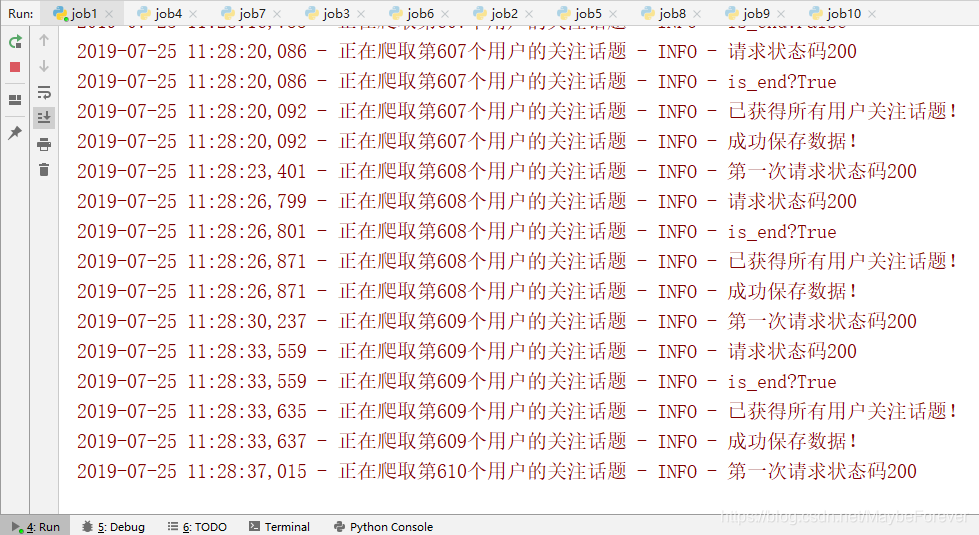
(2)从用户的角度,我们将从2018年10月到11月以及2019年夏天的时间,从知乎“英语学习”这个话题下的受访者开始抓取以下内容:
运行程序的结果如下图所示:
查看全部
网页视频抓取工具 知乎(Python爬虫中爬虫的爬取数据处理流程及解决办法(上)
)
需要salt,写了一个爬虫程序来爬取知乎网站的数据。关于知乎爬虫,我们从用户的角度和问题的角度进行爬取。挑选。
项目流程:爬虫代码(Python)→非结构化数据(Mongo)→结构化数据(MySQL)→结构化数据(Access)
为了应对反爬机制,我们使用Python编写爬虫来爬取IP代理池。IP代理池程序的源地址为:
数据爬取以知乎主题下的内容为爬取对象。爬虫程序通过python设计实现,将知乎问答社区的数据作为研究问题分类的数据进行爬取。这些数据的来源是由浏览器获取的。浏览器获取的其实是一系列文件,包括HTML格式部分、CSS样式部分和JavaScript执行层部分。浏览器将加载并理解这些数据,并通过渲染将其显示在图表的这一侧。因此,这些文件是由爬虫获取的。通过对这些代码文件进行分析和过滤,就可以实现对图片和文字的爬取。
程序源地址:
(1)从问题的角度,对于知乎“英语学习”和“流行音乐”两个题目下的问题,我们于2018年暑期开始爬取以下内容:
浏览器通过请求 URL 来获取资源文件。URL是一个统一的资源定位器,也称为网站,通过它可以通过特定的访问方式从互联网上查找资源的位置并获取。Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应该如何处理它的信息。Python爬虫的原理是模仿浏览器的行为,对Web服务器请求的信息和对服务器的响应进行基本的处理。本文爬虫的爬取数据处理流程如图:
网络爬虫的基本框架一般由三部分组成:网址管理模块、网页下载模块和网页解析模块。URL管理模块对要爬取的网页链接进行管理,防止重复爬取或循环指向。由于本文的数据爬取是定向的,爬虫作业基本是列表任务,所以本文爬虫程序的URL管理模块比较简单,可以直接迭代列表内容。如果动态信息请求较多,则需要对URL管理模块进行参数管理。网页下载模块是将URL对应的网页或内容下载到本地或内存中。requests 库提供了 http 的所有基本请求方法。本文爬虫程序主要通过requests模块实现信息内容的请求和下载。网页解析模块从下载的网页或内容中提取数据。由于下载的内容是 HTML 格式,因此需要的实际数据是这些标签中的文本数据。BeautifulSoup 工具是一个 python 库,可以定位数据和解析标签数据。在内容上,本文中的爬虫是通过BeautifulSoup工具和正则表达式实现的。最后,将解析后的数据保存起来,供以后处理和使用。BeautifulSoup 工具是一个 python 库,可以定位数据和解析标签数据。在内容上,本文中的爬虫是通过BeautifulSoup工具和正则表达式实现的。最后,将解析后的数据保存起来,供以后处理和使用。BeautifulSoup 工具是一个 python 库,可以定位数据和解析标签数据。在内容上,本文中的爬虫是通过BeautifulSoup工具和正则表达式实现的。最后,将解析后的数据保存起来,供以后处理和使用。
由于知乎社区的问答文本是以话题的形式组织在数据库中的,因此本文对数据的爬取是基于特定话题下的深度搜索爬取(我们爬取了英语学习和流行音乐主题)。爬取数据获取流程及数据内容如图:
在爬取过程中,程序错误状态码主要遇到以下几种情况:
200:请求成功,请求所期望的响应或数据体将与此响应一起生成。
403:服务器理解请求,但拒绝执行。(解决方法:重新登录知乎账号,更改cookie)
404:请求失败,在服务器上找不到请求的资源。(原因:网页丢失或删除)
410:请求的资源在服务器上不再可用,并且没有已知的转发地址。(原因:资源流失)
500:服务器遇到意外情况,无法完成请求的处理。一般在服务器端的源代码有错误的时候就会出现这个问题。
以上错误码中,403、410、500会导致程序中断,需要处理后重新运行。其中403表示我们的cookie过期或者因为访问太频繁被服务器拒绝了,但是我们的账号还没有被封禁,重新登录账号,更换新的cookie。410 是由于资源不可用,500 是内部服务错误,两者都是由服务器端不可知错误引起的。
(2)从用户的角度,我们将从2018年10月到11月以及2019年夏天的时间,从知乎“英语学习”这个话题下的受访者开始抓取以下内容:

运行程序的结果如下图所示:
网页视频抓取工具 知乎(关于链接架构的文章,你应该知道的几个问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-21 20:13
在做SEO的过程中,我们每天都面临着大量的外链建设需求。构建目标网站链接的生态,相信是每个SEO外链推广者的日常工作之一,但长期以来,很多SEO人员的操作可能是相反的,甚至是错误的,这就需要我们深刻理解网站链接结构的问题。
给大家分享一个关于链接结构的文章,虽然是基于谷歌搜索,但是对于百度SEO来说,我们认为它也会给我们一些启发。
链接架构——你如何网站内部链接——是你的网站计划的重要组成部分,并且对你的网站被搜索引擎索引的程度有重大影响。它还对 Google 机器人是否可以找到您的个人页面并从而使用户可以访问它们起着决定性作用。
确保您的核心页面距离主页只需点击几下
您可能认为用户可能更喜欢使用 网站 上的搜索框而不是目录式导航,但这样做通常会给搜索引擎爬虫造成障碍,他们几乎无法在搜索框中键入文本以进行搜索或浏览在下拉菜单中。因此,您需要确保您的重要页面可从首页点击,并让 Googlebot 轻松遍历您的 网站。你最好建立一个既便于用户浏览又便于搜索引擎抓取的链接结构。
以下是一些具体的建议:
1、人性化的导航设置
您应该尝试将自己置于“用户”的角色,并设计您的 网站 以模仿用户的习惯。例如,如果您的 网站 是关于篮球的,假设您是一位想要了解最佳运球技巧的访客。
让我们从主页开始。如果用户不使用您的网站搜索功能和下拉菜单,他们是否可以通过您提供的导航链接轻松找到他们想要的信息(例如篮球巨星的运球技巧)?
假设用户通过外部链接找到了您的 网站,但他们没有先到达主页。无论用户首先登陆哪个页面,您都希望确保他们可以轻松找到指向主页和其他相关部分的链接。换句话说,您要确保您的用户不会迷路。您的用户是否容易找到“最佳盘带技巧”?像“主页 > 提示 > Dribble”这样的导航可以帮助用户了解他们在页面上的位置。
2、为搜索引擎设置可抓取链接
文本链接很容易被搜索引擎找到。如果你特别在意自己的内容能否正常被索引,使用文本链接是一种比较安全的方法。可以想象,您还将采用一些最新技术,但无论如何,文本链接对用户更友好,更容易被搜索引擎访问。
这个文本链接很容易被搜索引擎找到。
提交 网站 地图对主要搜索引擎也很有帮助,尽管它不应该取代爬行友好的链接结构。如果您的 网站 使用了一些较新的技术,例如 AJAX,您可以参考下面的“确认 Googlebot 可以找到您的内部链接”。
3、使用描述性锚文本(anchortext-anchor text)
描述性锚文本是链接中常见的可点击词,对搜索引擎和用户来说都是一个有用的信号。Google 通过您的内容、标题、锚文本等对您的 网站 了解得越多,它返回给搜索者(可能包括您的潜在用户)的相关结果就越多。例如,如果您正在打篮球网站,并且您想通过文本链接向用户提供一些视频,许多 网站 管理员会这样设置链接:
如果您想观看我们的篮球视频,请单击此处浏览视频列表。
我们不建议使用这种通用的“单击此处”,我们建议您将锚文本替换为更具描述性的内容,例如:
欢迎收看我们的篮球视频
4、确认“Googlebot”可以找到您的内部链接
对于已经验证了网站权限的用户,网站管理工具提供了一个“链接>带有内部链接的页面”功能,这对于验证Googlebot是否已经成功找到你非常有用。关联。尤其是如果您的 网站 在导航中使用 JavaScript 之类的技术(Googlebot 通常无法正常工作并抓取它),您可能想知道您的其他内部链接是否完全被 Googlebot 成功识别。
这是指向“网站Admin Center 404 Week”的内部链接的屏幕截图。正如我们所料,我们的内部链接被成功发现。
欢迎您就内部链接的主题提出问题
这是其中的一部分...
问:我可以使用 rel="nofollow" 来最大化我们内部链接的 PageRank 流量吗?
答:我们实际上是 网站 自己在 Google 工作的管理员,您所考虑的并不是我们实际上会花时间考虑的事情。换句话说,如果你的 网站 已经有一个良好的链接结构,那么你就可以花更多的精力为你的用户提供更好的内容,而不是一直担心你的 PageRank。
MattCutts 曾经在 网站Administrator 帮助论坛上回答了“合理使用 nofollow”的问题。
问:例如,我的 网站 是关于我的两个爱好,骑自行车和露营。我应该以我的内部链接模式为主题,而不是在两者之间进行链接吗?
答:到目前为止,我们还没有看到任何 网站 管理员从故意使他们的链接模式高度主题化而受益。同时,如果访问者无法轻松访问您的网站 的各个部分,这通常意味着这种结构也是搜索引擎的障碍。
请允许我们在这里重复一遍,请尽量创建一个固定且合理的链接结构(包括符合用户习惯的导航设置和为搜索引擎设置可抓取的链接),并积极实施您的部分用户及其使用。经验是衡量利益的标准。 查看全部
网页视频抓取工具 知乎(关于链接架构的文章,你应该知道的几个问题)
在做SEO的过程中,我们每天都面临着大量的外链建设需求。构建目标网站链接的生态,相信是每个SEO外链推广者的日常工作之一,但长期以来,很多SEO人员的操作可能是相反的,甚至是错误的,这就需要我们深刻理解网站链接结构的问题。
给大家分享一个关于链接结构的文章,虽然是基于谷歌搜索,但是对于百度SEO来说,我们认为它也会给我们一些启发。

链接架构——你如何网站内部链接——是你的网站计划的重要组成部分,并且对你的网站被搜索引擎索引的程度有重大影响。它还对 Google 机器人是否可以找到您的个人页面并从而使用户可以访问它们起着决定性作用。
确保您的核心页面距离主页只需点击几下
您可能认为用户可能更喜欢使用 网站 上的搜索框而不是目录式导航,但这样做通常会给搜索引擎爬虫造成障碍,他们几乎无法在搜索框中键入文本以进行搜索或浏览在下拉菜单中。因此,您需要确保您的重要页面可从首页点击,并让 Googlebot 轻松遍历您的 网站。你最好建立一个既便于用户浏览又便于搜索引擎抓取的链接结构。
以下是一些具体的建议:
1、人性化的导航设置
您应该尝试将自己置于“用户”的角色,并设计您的 网站 以模仿用户的习惯。例如,如果您的 网站 是关于篮球的,假设您是一位想要了解最佳运球技巧的访客。
让我们从主页开始。如果用户不使用您的网站搜索功能和下拉菜单,他们是否可以通过您提供的导航链接轻松找到他们想要的信息(例如篮球巨星的运球技巧)?
假设用户通过外部链接找到了您的 网站,但他们没有先到达主页。无论用户首先登陆哪个页面,您都希望确保他们可以轻松找到指向主页和其他相关部分的链接。换句话说,您要确保您的用户不会迷路。您的用户是否容易找到“最佳盘带技巧”?像“主页 > 提示 > Dribble”这样的导航可以帮助用户了解他们在页面上的位置。
2、为搜索引擎设置可抓取链接
文本链接很容易被搜索引擎找到。如果你特别在意自己的内容能否正常被索引,使用文本链接是一种比较安全的方法。可以想象,您还将采用一些最新技术,但无论如何,文本链接对用户更友好,更容易被搜索引擎访问。
这个文本链接很容易被搜索引擎找到。
提交 网站 地图对主要搜索引擎也很有帮助,尽管它不应该取代爬行友好的链接结构。如果您的 网站 使用了一些较新的技术,例如 AJAX,您可以参考下面的“确认 Googlebot 可以找到您的内部链接”。
3、使用描述性锚文本(anchortext-anchor text)
描述性锚文本是链接中常见的可点击词,对搜索引擎和用户来说都是一个有用的信号。Google 通过您的内容、标题、锚文本等对您的 网站 了解得越多,它返回给搜索者(可能包括您的潜在用户)的相关结果就越多。例如,如果您正在打篮球网站,并且您想通过文本链接向用户提供一些视频,许多 网站 管理员会这样设置链接:
如果您想观看我们的篮球视频,请单击此处浏览视频列表。
我们不建议使用这种通用的“单击此处”,我们建议您将锚文本替换为更具描述性的内容,例如:
欢迎收看我们的篮球视频
4、确认“Googlebot”可以找到您的内部链接
对于已经验证了网站权限的用户,网站管理工具提供了一个“链接>带有内部链接的页面”功能,这对于验证Googlebot是否已经成功找到你非常有用。关联。尤其是如果您的 网站 在导航中使用 JavaScript 之类的技术(Googlebot 通常无法正常工作并抓取它),您可能想知道您的其他内部链接是否完全被 Googlebot 成功识别。
这是指向“网站Admin Center 404 Week”的内部链接的屏幕截图。正如我们所料,我们的内部链接被成功发现。
欢迎您就内部链接的主题提出问题
这是其中的一部分...
问:我可以使用 rel="nofollow" 来最大化我们内部链接的 PageRank 流量吗?
答:我们实际上是 网站 自己在 Google 工作的管理员,您所考虑的并不是我们实际上会花时间考虑的事情。换句话说,如果你的 网站 已经有一个良好的链接结构,那么你就可以花更多的精力为你的用户提供更好的内容,而不是一直担心你的 PageRank。
MattCutts 曾经在 网站Administrator 帮助论坛上回答了“合理使用 nofollow”的问题。
问:例如,我的 网站 是关于我的两个爱好,骑自行车和露营。我应该以我的内部链接模式为主题,而不是在两者之间进行链接吗?
答:到目前为止,我们还没有看到任何 网站 管理员从故意使他们的链接模式高度主题化而受益。同时,如果访问者无法轻松访问您的网站 的各个部分,这通常意味着这种结构也是搜索引擎的障碍。
请允许我们在这里重复一遍,请尽量创建一个固定且合理的链接结构(包括符合用户习惯的导航设置和为搜索引擎设置可抓取的链接),并积极实施您的部分用户及其使用。经验是衡量利益的标准。
网页视频抓取工具 知乎(Mac平台下自己喜欢的视频,一步到位,Get到本地)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-02-21 00:28
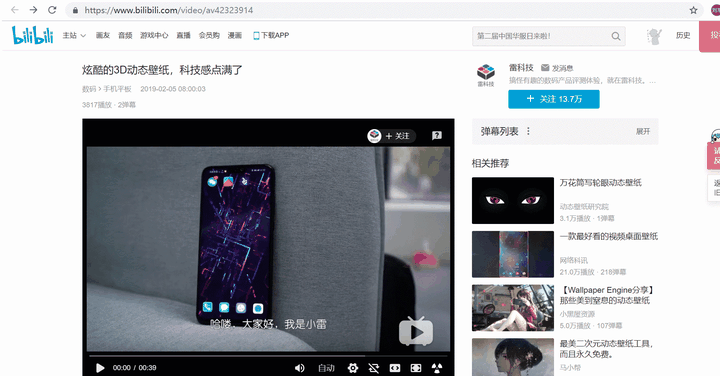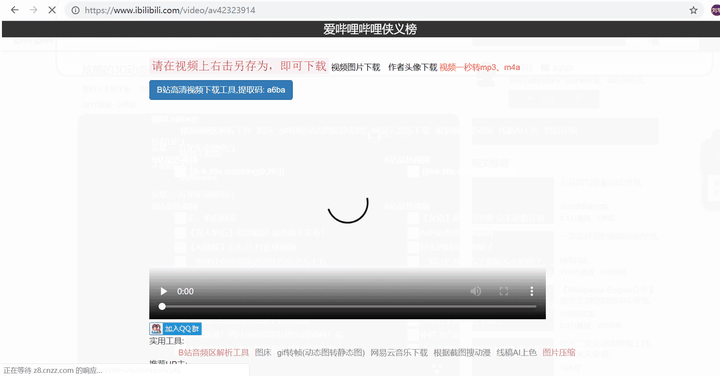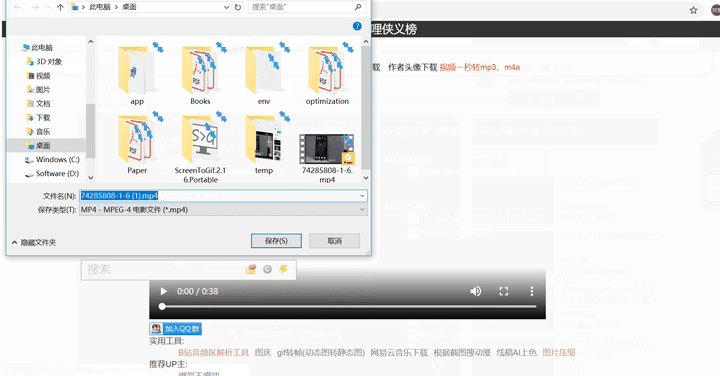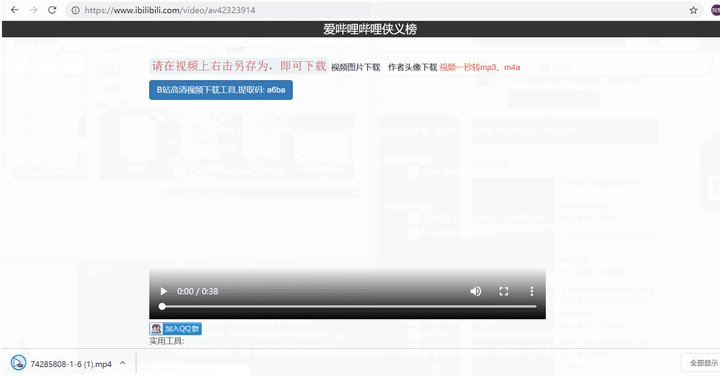
前言
我经常浏览哔哩哔哩、YouTube、优酷等视频网站,一看到喜欢的视频流就想下载到本地看。官方不支持此功能或下载质量有限制。有没有更好的突破方法?答案是肯定的,本文文章给大家分享一个Mac平台下使用的强大的视频流媒体下载工具——Downie。
对了,Windows平台也将在下一篇文章中介绍,敬请期待。
介绍唐尼
Downie 是一款来自国外的付费软件。官方宣称支持1000多个视频流媒体网站的下载,基本包括Bilibili、优酷、爱奇艺、YouTube、Vimeo等国内外主流网站。
简单来说,在Downie的帮助下,我们可以轻松获取主流视频流媒体网站下自己喜欢的视频,一步到位,轻松本地获取。
使用步骤
这种工具基本上是傻瓜式。一般的操作逻辑是复制自己喜欢的视频播放地址,提交给工具,让工具处理下载。
Downie 也不例外,但为了进一步达到下载成功率,它还为 Safari 和 Chrome 等浏览器开发了相应的插件。借助插件,一键提交,省去复制粘贴的步骤。
软件开始下载后,借助多线程请求,实测可以跑到满带宽。
写在最后
当前版本的Downie已经到了Downie 4,直接下载安装后可以有14天的试用期。没有功能限制。拿到终身牌照,价格比较高。
如果您对此类话题有什么好的想法和建议,请在下方评论或留言。如果您有更好的想法,请留言分享。 查看全部
网页视频抓取工具 知乎(Mac平台下自己喜欢的视频,一步到位,Get到本地)
前言
我经常浏览哔哩哔哩、YouTube、优酷等视频网站,一看到喜欢的视频流就想下载到本地看。官方不支持此功能或下载质量有限制。有没有更好的突破方法?答案是肯定的,本文文章给大家分享一个Mac平台下使用的强大的视频流媒体下载工具——Downie。
对了,Windows平台也将在下一篇文章中介绍,敬请期待。
介绍唐尼

Downie 是一款来自国外的付费软件。官方宣称支持1000多个视频流媒体网站的下载,基本包括Bilibili、优酷、爱奇艺、YouTube、Vimeo等国内外主流网站。
简单来说,在Downie的帮助下,我们可以轻松获取主流视频流媒体网站下自己喜欢的视频,一步到位,轻松本地获取。
使用步骤
这种工具基本上是傻瓜式。一般的操作逻辑是复制自己喜欢的视频播放地址,提交给工具,让工具处理下载。
Downie 也不例外,但为了进一步达到下载成功率,它还为 Safari 和 Chrome 等浏览器开发了相应的插件。借助插件,一键提交,省去复制粘贴的步骤。

软件开始下载后,借助多线程请求,实测可以跑到满带宽。

写在最后
当前版本的Downie已经到了Downie 4,直接下载安装后可以有14天的试用期。没有功能限制。拿到终身牌照,价格比较高。
如果您对此类话题有什么好的想法和建议,请在下方评论或留言。如果您有更好的想法,请留言分享。
网页视频抓取工具 知乎(BeautifulSoup的基础详细用法,你知道几个?(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-02-20 03:06
)
今天的朋友很聪明。只要会爬虫,都知道BeautifulSoup,但是随着知识点越来越多,很多小伙伴可能只知道如何使用这个爬虫工具,却不知道BeautifulSoup的详细使用方法。今天的文章带你了解BeautifulSoup的基本和详细用法。
什么是美汤?? ?
BeautifulSoup 是一个 Python 扩展库,可以从 HTML 或 XML 文件中提取数据。BeautifulSoup 通过合适的转换器实现文档导航、查找、修改文档等。它可以很好地处理非标准标记并生成解析树(Parse Tree);它提供导航功能(Navigating),可以简单快速地搜索和修改解析树。BeautifulSoup 技术通常用于分析网页的结构并爬取相应的网页文档。对于不规则的 HTML 文档,提供了一定的补全功能,从而为开发者节省了时间和精力。今天的文章一起来学习BeatifulSoup的详细用法吧~
环境部署
安装 BeautifulSoup
BeautifulSoup 主要通过 pip 命令安装。可以在命令提示符CMD环境中安装,也可以在PyCharm的命令行窗口中安装,即调用pip install bs4命令安装,bs4就是BeautifulSoup4。
由于我的本地环境已经安装好,显示如下:
如果还没有安装,可以直接输入命令尝试安装。如果安装好了,就可以直接上手了。
BeautifulSoup扩展包安装成功后,可以在命令行输入from bs4 import BeautifulSoup语句导入扩展包,测试是否安装成功。如果没有报异常错误,则安装成功,如下图:
BeautifulSoup解析HTML获取网页信息
BeautifulSoup 解析 HTML
BeautifulSoup解析HTML的原理是创建一个BeautifulSoup对象,然后调用BeautifulSoup包的prettify()函数对网页信息进行格式化输出。
示例如下:
from bs4 import BeautifulSoup
html = """
Hello Python
<p>BeatifulSoup 技术详解
"""
# 结果会按照标准的缩进格式的结构输出
soup = BeautifulSoup(html)
print(soup.prettify())
</p>
使用 BeautifulSoup 解析网页的输出如下:
BeatifulSoup 解析会根据 HTML 标签的缩进输出 HTML 页面的所有标签信息和内容。
当使用 BeautifulSoup 解析 HTML 文档时,它会将 HTML 文档视为 DOM 文档树。使用 prettify() 函数输出结果时,会自动补全标签。这是 BeautifulSoup 的一个优势,即使 BeautifulSoup 得到一个损坏的标签,它也会生成一个与原创文档内容尽可能一致的转换后的 DOM 树,这通常有助于更正确地采集数据。
示例如下:输入一个URL,直接用prettify()函数获取
from bs4 import BeautifulSoup
html = 'https://www.baidu.com/'
# 结果会按照标准的缩进格式的结构输出
soup = BeautifulSoup(html)
print(soup.prettify())
输出如下:
<p>
https://www.baidu.com/
</p>
输出内容自动填充标签并以 HTML 格式输出。
BeautifulSoup 获取网页标签信息
以上知识讲解了如何使用 BeautifulSoup 解析网页。解析完网页后,如果想获取某个标签的内容信息,该怎么做呢?比如获取下面超文本的标题,下面就教大家如何使用BeautifulSoup技术获取网页标签信息。获取页面标题的代码如下:
from bs4 import BeautifulSoup
# 获取标题
def get_title():
#创建本地文件soup对象
soup = BeautifulSoup(open('test.html','rb'), "html.parser")
#获取标题
title = soup.title
print('标题:', title)
if __name__ == '__main__':
get_title()
输出如下:
获取其他标签的内容也是如此,比如HTML头一个标签
# 获取a标签内容
def get_a():
#创建本地文件soup对象
soup = BeautifulSoup(open('test.html','rb'), "html.parser")
#获取a标签内容
a = soup.a
print('a标签的内容是:', a)
输出如下:
a标签的内容是: ddd
定位标签并获取内容
前面的内容简单介绍了BeautifulSoup获取title、a等标签,但是如何定位标签并获取对应标签的内容,这里需要用到BeautifulSoup的find_all()函数。详细用法如下:
def get_all():
soup = BeautifulSoup(open('test.html', 'rb'), "html.parser")
# 从文档中找到<a>的所有标签链接
for a in soup.find_all('a'):
print(a)
# 获取<a>的超链接
for link in soup.find_all('a'):
print(link.get('href'))
if __name__ == '__main__':
get_all()
输出如下:
ddd
https://www.baidu.com
ddd
以上是关于 BeautifulSoup 如何定位标签并获取内容的。
总结
本文主要讲解BeautifulSoup相关知识点中最基本的部分。下面将讲解 BeautifulSoup 的核心用法。下期见~
查看全部
网页视频抓取工具 知乎(BeautifulSoup的基础详细用法,你知道几个?(上)
)
今天的朋友很聪明。只要会爬虫,都知道BeautifulSoup,但是随着知识点越来越多,很多小伙伴可能只知道如何使用这个爬虫工具,却不知道BeautifulSoup的详细使用方法。今天的文章带你了解BeautifulSoup的基本和详细用法。
什么是美汤?? ?
BeautifulSoup 是一个 Python 扩展库,可以从 HTML 或 XML 文件中提取数据。BeautifulSoup 通过合适的转换器实现文档导航、查找、修改文档等。它可以很好地处理非标准标记并生成解析树(Parse Tree);它提供导航功能(Navigating),可以简单快速地搜索和修改解析树。BeautifulSoup 技术通常用于分析网页的结构并爬取相应的网页文档。对于不规则的 HTML 文档,提供了一定的补全功能,从而为开发者节省了时间和精力。今天的文章一起来学习BeatifulSoup的详细用法吧~
环境部署
安装 BeautifulSoup
BeautifulSoup 主要通过 pip 命令安装。可以在命令提示符CMD环境中安装,也可以在PyCharm的命令行窗口中安装,即调用pip install bs4命令安装,bs4就是BeautifulSoup4。
由于我的本地环境已经安装好,显示如下:
如果还没有安装,可以直接输入命令尝试安装。如果安装好了,就可以直接上手了。
BeautifulSoup扩展包安装成功后,可以在命令行输入from bs4 import BeautifulSoup语句导入扩展包,测试是否安装成功。如果没有报异常错误,则安装成功,如下图:
BeautifulSoup解析HTML获取网页信息
BeautifulSoup 解析 HTML
BeautifulSoup解析HTML的原理是创建一个BeautifulSoup对象,然后调用BeautifulSoup包的prettify()函数对网页信息进行格式化输出。
示例如下:
from bs4 import BeautifulSoup
html = """
Hello Python
<p>BeatifulSoup 技术详解
"""
# 结果会按照标准的缩进格式的结构输出
soup = BeautifulSoup(html)
print(soup.prettify())
</p>
使用 BeautifulSoup 解析网页的输出如下:
BeatifulSoup 解析会根据 HTML 标签的缩进输出 HTML 页面的所有标签信息和内容。
当使用 BeautifulSoup 解析 HTML 文档时,它会将 HTML 文档视为 DOM 文档树。使用 prettify() 函数输出结果时,会自动补全标签。这是 BeautifulSoup 的一个优势,即使 BeautifulSoup 得到一个损坏的标签,它也会生成一个与原创文档内容尽可能一致的转换后的 DOM 树,这通常有助于更正确地采集数据。
示例如下:输入一个URL,直接用prettify()函数获取
from bs4 import BeautifulSoup
html = 'https://www.baidu.com/'
# 结果会按照标准的缩进格式的结构输出
soup = BeautifulSoup(html)
print(soup.prettify())
输出如下:
<p>
https://www.baidu.com/
</p>
输出内容自动填充标签并以 HTML 格式输出。
BeautifulSoup 获取网页标签信息
以上知识讲解了如何使用 BeautifulSoup 解析网页。解析完网页后,如果想获取某个标签的内容信息,该怎么做呢?比如获取下面超文本的标题,下面就教大家如何使用BeautifulSoup技术获取网页标签信息。获取页面标题的代码如下:
from bs4 import BeautifulSoup
# 获取标题
def get_title():
#创建本地文件soup对象
soup = BeautifulSoup(open('test.html','rb'), "html.parser")
#获取标题
title = soup.title
print('标题:', title)
if __name__ == '__main__':
get_title()
输出如下:
获取其他标签的内容也是如此,比如HTML头一个标签
# 获取a标签内容
def get_a():
#创建本地文件soup对象
soup = BeautifulSoup(open('test.html','rb'), "html.parser")
#获取a标签内容
a = soup.a
print('a标签的内容是:', a)
输出如下:
a标签的内容是: ddd
定位标签并获取内容
前面的内容简单介绍了BeautifulSoup获取title、a等标签,但是如何定位标签并获取对应标签的内容,这里需要用到BeautifulSoup的find_all()函数。详细用法如下:
def get_all():
soup = BeautifulSoup(open('test.html', 'rb'), "html.parser")
# 从文档中找到<a>的所有标签链接
for a in soup.find_all('a'):
print(a)
# 获取<a>的超链接
for link in soup.find_all('a'):
print(link.get('href'))
if __name__ == '__main__':
get_all()
输出如下:
ddd
https://www.baidu.com
ddd
以上是关于 BeautifulSoup 如何定位标签并获取内容的。
总结
本文主要讲解BeautifulSoup相关知识点中最基本的部分。下面将讲解 BeautifulSoup 的核心用法。下期见~
网页视频抓取工具 知乎( 本篇文章抓取目标网站的链接的基础上,进一步提高难度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2022-02-16 23:12
本篇文章抓取目标网站的链接的基础上,进一步提高难度)
Java爬虫爬取视频网站下载链接
更新时间:2016-10-19 12:02:17 作者:pangfc
本文是通过JAVA获取优酷、土豆、酷6、6房的视频。小编觉得还不错。现在分享给大家,供大家参考。跟我来看看
基于本文文章抓取目标网站的链接,进一步增加难度,将目标页面上我们需要的内容抓取到数据库中。这里的测试用例使用了一个我经常使用的电影下载网站()。本来想把网站上所有电影的下载链接都抓起来,但是觉得时间太长,就改成抓2015年电影的下载链接了。
原理介绍
其实原理和第一个文章是一样的,不同的是,由于这个网站里面的分类列表太多了,如果不选中这些标签,会耗费难以想象的时间。
类别链接和标签链接都不是必需的。而不是通过这些链接爬取其他页面,只能通过页面底部所有类型电影的分页来获取其他页面上的电影列表。同时,对于电影详情页,只抓取电影片名和迅雷下载链接,不进行深度爬取。详细信息页面上的一些推荐电影和其他链接不是必需的。
最后就是将所有获取到的电影的下载链接保存在videoLinkMap集合中,通过遍历这个集合将数据保存到MySQL
两码实现
实现原理上面已经讲过了,代码中有详细的注释,这里就不多说了,代码如下:
<p>package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class VideoLinkGrab {
public static void main(String[] args) {
VideoLinkGrab videoLinkGrab = new VideoLinkGrab();
videoLinkGrab.saveData("http://www.80s.la/movie/list/-2015----p");
}
/**
* 将获取到的数据保存在数据库中
*
* @param baseUrl
* 爬虫起点
* @return null
* */
public void saveData(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLinkHost = ""; // host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); // 比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
videoLinkMap = crawlLinks(oldLinkHost, oldMap);
// 遍历,然后将数据保存在数据库中
try {
Connection connection = JDBCDemo.getConnection();
for (Map.Entry mapping : videoLinkMap.entrySet()) {
PreparedStatement pStatement = connection
.prepareStatement("insert into movie(MovieName,MovieLink) values(?,?)");
pStatement.setString(1, mapping.getKey());
pStatement.setString(2, mapping.getValue());
pStatement.executeUpdate();
pStatement.close();
// System.out.println(mapping.getKey() + " : " + mapping.getValue());
}
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 对未遍历过的新链接不断发起GET请求, 一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* 对一个链接发起请求时,对该网页用正则查找我们所需要的视频链接,找到后存入集合videoLinkMap
*
* @param oldLinkHost
* 域名,如:http://www.zifangsky.cn
* @param oldMap
* 待遍历的链接集合
*
* @return 返回所有抓取到的视频下载链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap(); // 每次循环获取到的新链接
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
// System.out.println("link:" + mapping.getKey() + "--------check:"
// + mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2500);
connection.setReadTimeout(2500);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = null;
Matcher matcher = null;
//电影详情页面,取出其中的视频下载链接,不继续深入抓取其他页面
if(isMoviePage(oldLink)){
boolean checkTitle = false;
String title = "";
while ((line = reader.readLine()) != null) {
//取出页面中的视频标题
if(!checkTitle){
pattern = Pattern.compile("([^\\s]+).*?");
matcher = pattern.matcher(line);
if(matcher.find()){
title = matcher.group(1);
checkTitle = true;
continue;
}
}
// 取出页面中的视频下载链接
pattern = Pattern
.compile("(thunder:[^\"]+).*thunder[rR]es[tT]itle=\"[^\"]*\"");
matcher = pattern.matcher(line);
if (matcher.find()) {
videoLinkMap.put(title,matcher.group(1));
System.out.println("视频名称: "
+ title + " ------ 视频链接:"
+ matcher.group(1));
break; //当前页面已经检测完毕
}
}
}
//电影列表页面
else if(checkUrl(oldLink)){
while ((line = reader.readLine()) != null) {
pattern = Pattern
.compile(" 查看全部
网页视频抓取工具 知乎(
本篇文章抓取目标网站的链接的基础上,进一步提高难度)
Java爬虫爬取视频网站下载链接
更新时间:2016-10-19 12:02:17 作者:pangfc
本文是通过JAVA获取优酷、土豆、酷6、6房的视频。小编觉得还不错。现在分享给大家,供大家参考。跟我来看看
基于本文文章抓取目标网站的链接,进一步增加难度,将目标页面上我们需要的内容抓取到数据库中。这里的测试用例使用了一个我经常使用的电影下载网站()。本来想把网站上所有电影的下载链接都抓起来,但是觉得时间太长,就改成抓2015年电影的下载链接了。
原理介绍
其实原理和第一个文章是一样的,不同的是,由于这个网站里面的分类列表太多了,如果不选中这些标签,会耗费难以想象的时间。

类别链接和标签链接都不是必需的。而不是通过这些链接爬取其他页面,只能通过页面底部所有类型电影的分页来获取其他页面上的电影列表。同时,对于电影详情页,只抓取电影片名和迅雷下载链接,不进行深度爬取。详细信息页面上的一些推荐电影和其他链接不是必需的。

最后就是将所有获取到的电影的下载链接保存在videoLinkMap集合中,通过遍历这个集合将数据保存到MySQL
两码实现
实现原理上面已经讲过了,代码中有详细的注释,这里就不多说了,代码如下:
<p>package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class VideoLinkGrab {
public static void main(String[] args) {
VideoLinkGrab videoLinkGrab = new VideoLinkGrab();
videoLinkGrab.saveData("http://www.80s.la/movie/list/-2015----p";);
}
/**
* 将获取到的数据保存在数据库中
*
* @param baseUrl
* 爬虫起点
* @return null
* */
public void saveData(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLinkHost = ""; // host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); // 比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
videoLinkMap = crawlLinks(oldLinkHost, oldMap);
// 遍历,然后将数据保存在数据库中
try {
Connection connection = JDBCDemo.getConnection();
for (Map.Entry mapping : videoLinkMap.entrySet()) {
PreparedStatement pStatement = connection
.prepareStatement("insert into movie(MovieName,MovieLink) values(?,?)");
pStatement.setString(1, mapping.getKey());
pStatement.setString(2, mapping.getValue());
pStatement.executeUpdate();
pStatement.close();
// System.out.println(mapping.getKey() + " : " + mapping.getValue());
}
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 对未遍历过的新链接不断发起GET请求, 一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* 对一个链接发起请求时,对该网页用正则查找我们所需要的视频链接,找到后存入集合videoLinkMap
*
* @param oldLinkHost
* 域名,如:http://www.zifangsky.cn
* @param oldMap
* 待遍历的链接集合
*
* @return 返回所有抓取到的视频下载链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap(); // 每次循环获取到的新链接
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
// System.out.println("link:" + mapping.getKey() + "--------check:"
// + mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2500);
connection.setReadTimeout(2500);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = null;
Matcher matcher = null;
//电影详情页面,取出其中的视频下载链接,不继续深入抓取其他页面
if(isMoviePage(oldLink)){
boolean checkTitle = false;
String title = "";
while ((line = reader.readLine()) != null) {
//取出页面中的视频标题
if(!checkTitle){
pattern = Pattern.compile("([^\\s]+).*?");
matcher = pattern.matcher(line);
if(matcher.find()){
title = matcher.group(1);
checkTitle = true;
continue;
}
}
// 取出页面中的视频下载链接
pattern = Pattern
.compile("(thunder:[^\"]+).*thunder[rR]es[tT]itle=\"[^\"]*\"");
matcher = pattern.matcher(line);
if (matcher.find()) {
videoLinkMap.put(title,matcher.group(1));
System.out.println("视频名称: "
+ title + " ------ 视频链接:"
+ matcher.group(1));
break; //当前页面已经检测完毕
}
}
}
//电影列表页面
else if(checkUrl(oldLink)){
while ((line = reader.readLine()) != null) {
pattern = Pattern
.compile("
网页视频抓取工具 知乎( 接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-16 23:08
接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
Python抓取知乎的方法指定视频的答案
更新时间:2020-07-09 11:17:05 作者:李涛
本文章主要介绍python抓取知乎指定答案视频的方法。文中的讲解很详细,代码帮助大家更好的理解和学习。有兴趣的朋友可以了解一下。
前言
现在 知乎 允许上传视频,但我不能下载视频。气死我了,只好研究一下,然后写了代码方便下载和保存视频。
其次,为什么猫根本不怕蛇?以回答为例,分享整个下载过程。
调试它
打开F12,找到光标,如下图:
然后将光标移到视频上。如下所示:
咦这是什么?视野中出现了一个神秘的链接:,我们把这个链接复制到浏览器打开:
看来这就是我们要找的视频了,别着急,我们来看看,网页的请求,然后你会发现一个很有意思的请求(这里强调一下):
让我们自己看一下数据:
{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B,
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B,
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B,
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B,
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}
没错,我们要下载的视频就在这里,其中ld代表普通清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右键保存视频即可下载。
代码
知道了整个过程是什么样子,接下来的编码过程就很简单了。我这里就解释太多了,直接上代码:
# -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069')
print(a.download_video())
结语
代码仍有优化空间。在这里,我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果您有任何问题或建议,请随时交流。
以上就是python抓取知乎指定答案视频的方法的详细内容。更多关于python抓视频的内容,请关注脚本之家文章的其他相关话题! 查看全部
网页视频抓取工具 知乎(
接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
Python抓取知乎的方法指定视频的答案
更新时间:2020-07-09 11:17:05 作者:李涛
本文章主要介绍python抓取知乎指定答案视频的方法。文中的讲解很详细,代码帮助大家更好的理解和学习。有兴趣的朋友可以了解一下。
前言
现在 知乎 允许上传视频,但我不能下载视频。气死我了,只好研究一下,然后写了代码方便下载和保存视频。
其次,为什么猫根本不怕蛇?以回答为例,分享整个下载过程。
调试它
打开F12,找到光标,如下图:

然后将光标移到视频上。如下所示:

咦这是什么?视野中出现了一个神秘的链接:,我们把这个链接复制到浏览器打开:

看来这就是我们要找的视频了,别着急,我们来看看,网页的请求,然后你会发现一个很有意思的请求(这里强调一下):

让我们自己看一下数据:
{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B,
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B,
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B,
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B,
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}
没错,我们要下载的视频就在这里,其中ld代表普通清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右键保存视频即可下载。
代码
知道了整个过程是什么样子,接下来的编码过程就很简单了。我这里就解释太多了,直接上代码:
# -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069')
print(a.download_video())
结语
代码仍有优化空间。在这里,我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果您有任何问题或建议,请随时交流。
以上就是python抓取知乎指定答案视频的方法的详细内容。更多关于python抓视频的内容,请关注脚本之家文章的其他相关话题!
网页视频抓取工具 知乎(推荐6种下载哔哩哔哩视频的方式,有不需软件的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-02-16 12:04
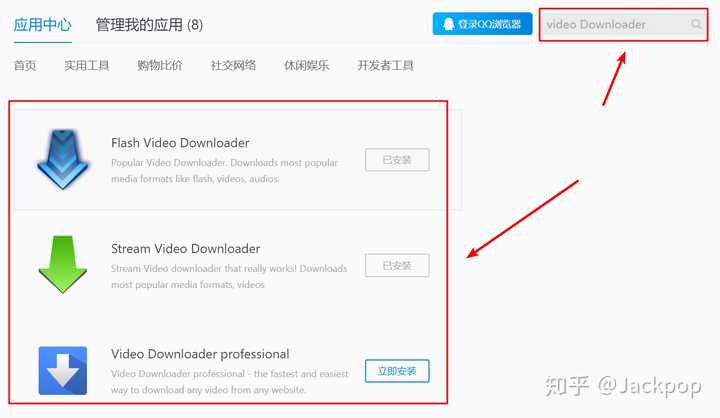
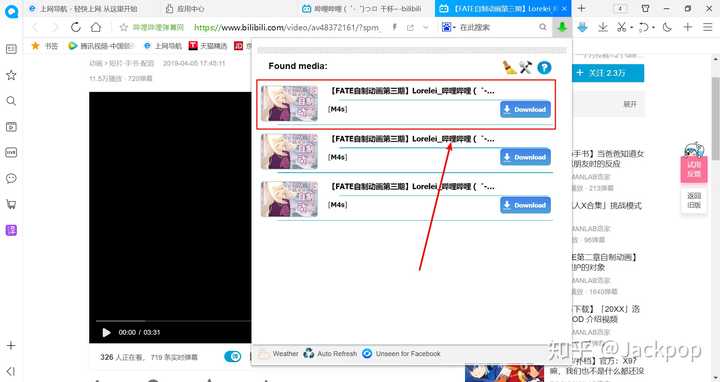
推荐6种B站视频下载方式,有的无软件,有的有软件,总有一款适合你,文末还有福利。我创建了一个知乎圈子:【平凡与诗意】,重点分享前沿技术、编程开发、实用工具等,有兴趣的可以在首页搜索【平凡与诗意】加入我的圈子,让我们一起玩吧!方法1.修改url我想很多人都会喜欢这种方法,因为太方便了,没有浏览器插件,没有Python开发环境,对于几乎所有会用电脑的人来说都是非常容易的。
指示:
例如,更改为
方法二:使用浏览器插件 使用QQ等浏览器,安装网络视频下载工具,打开视频网页。这些插件可以识别网络视频。这种方法需要配合浏览器使用,如果你已经在使用这样的浏览器,可以试试。指示:
您可以根据自己的喜好选择一个插件来使用,实测的Flash Video Downloader和Stream Video Downloader都有。
方法三:you-get比上一种更麻烦。这是一个具有一定专业性的命令行工具。安装需要使用Python的pip,或者使用Antigen,也可以克隆到本地使用,但是依赖于Python 3.2、ffmpeg 1.0环境,所以这种方式比较多适合开发者。虽然比较麻烦,但不得不说you-get真的很强大,支持YouTube、Bilibili、爱奇艺、央视、芒果TV、腾讯视频、秒拍、抖音、快手、网易等几十个< @网站视频下载。同时,you-get还可以将视频导入到自己的播放器中进行播放。
指示:
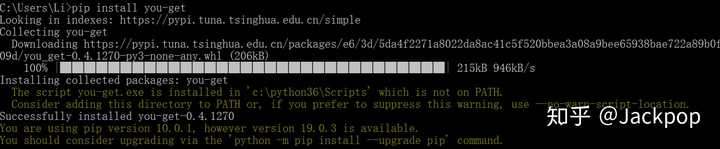
这是通过pip安装的方法
打开 cmd 或 linux 终端,输入以下命令:
pip install you-get
在终端中输入以下命令:
you-get
您还可以指定视频存储路径:
you-get -o ~/Videos -O zoo.webm 'https://www.youtube.com/watch% ... 39%3B
这会将视频保存到当前目录。
另外,如果不想下载视频,只想用指定的播放器播放对应的视频,可以使用如下命令:
you-get -p vlc 'https://www.youtube.com/watch% ... 39%3B
为什么不在网页上播放,而是使用指定的播放器播放呢?亲测,如果使用指定播放器,可以去除长广告,缓冲速度非常快。
例如下面的视频广告 75s,
指定本地播放器播放在线视频,
方法4.卫通flv
<p>一句话介绍:支持189个 查看全部
网页视频抓取工具 知乎(推荐6种下载哔哩哔哩视频的方式,有不需软件的)
推荐6种B站视频下载方式,有的无软件,有的有软件,总有一款适合你,文末还有福利。我创建了一个知乎圈子:【平凡与诗意】,重点分享前沿技术、编程开发、实用工具等,有兴趣的可以在首页搜索【平凡与诗意】加入我的圈子,让我们一起玩吧!方法1.修改url我想很多人都会喜欢这种方法,因为太方便了,没有浏览器插件,没有Python开发环境,对于几乎所有会用电脑的人来说都是非常容易的。
指示:
例如,更改为

方法二:使用浏览器插件 使用QQ等浏览器,安装网络视频下载工具,打开视频网页。这些插件可以识别网络视频。这种方法需要配合浏览器使用,如果你已经在使用这样的浏览器,可以试试。指示:
您可以根据自己的喜好选择一个插件来使用,实测的Flash Video Downloader和Stream Video Downloader都有。
方法三:you-get比上一种更麻烦。这是一个具有一定专业性的命令行工具。安装需要使用Python的pip,或者使用Antigen,也可以克隆到本地使用,但是依赖于Python 3.2、ffmpeg 1.0环境,所以这种方式比较多适合开发者。虽然比较麻烦,但不得不说you-get真的很强大,支持YouTube、Bilibili、爱奇艺、央视、芒果TV、腾讯视频、秒拍、抖音、快手、网易等几十个< @网站视频下载。同时,you-get还可以将视频导入到自己的播放器中进行播放。
指示:
这是通过pip安装的方法
打开 cmd 或 linux 终端,输入以下命令:
pip install you-get
在终端中输入以下命令:
you-get
您还可以指定视频存储路径:
you-get -o ~/Videos -O zoo.webm 'https://www.youtube.com/watch% ... 39%3B
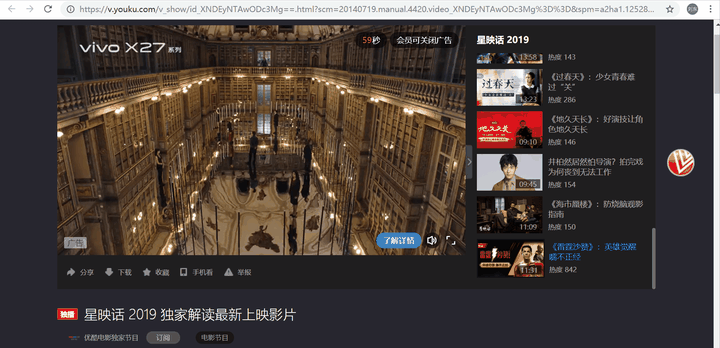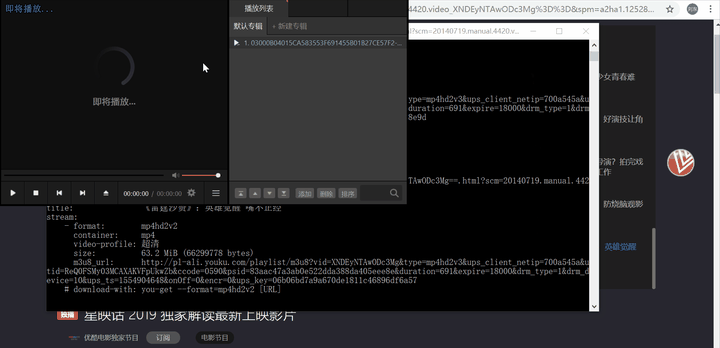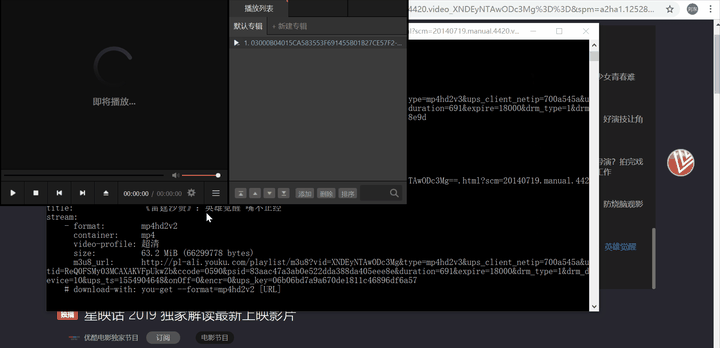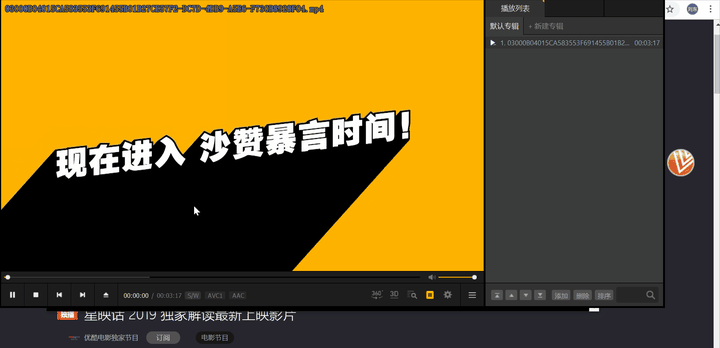
这会将视频保存到当前目录。
另外,如果不想下载视频,只想用指定的播放器播放对应的视频,可以使用如下命令:
you-get -p vlc 'https://www.youtube.com/watch% ... 39%3B
为什么不在网页上播放,而是使用指定的播放器播放呢?亲测,如果使用指定播放器,可以去除长广告,缓冲速度非常快。
例如下面的视频广告 75s,

指定本地播放器播放在线视频,
方法4.卫通flv
<p>一句话介绍:支持189个
网页视频抓取工具 知乎(接下来以猫为什么一点也不怕蛇?回答为例,分享一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2022-02-14 23:06
本期小编将为大家带来一段关于如何使用python捕捉知乎指定答案的视频。文章 内容丰富,专业为你分析叙述。看完这篇文章希望大家能有所收获。
前言
现在 知乎 允许上传视频,但我不能下载视频。气死我了,只好研究一下,然后写了代码方便下载和保存视频。
其次,为什么猫根本不怕蛇?以回答为例,分享整个下载过程。
调试它
打开F12,找到光标,如下图:
然后将光标移到视频上。如下所示:
咦这是什么?视野中出现了一个神秘的链接:,我们把这个链接复制到浏览器打开:
看来这就是我们要找的视频了,别着急,我们来看看,网页的请求,然后你会发现一个很有意思的请求(这里强调一下):
让我们自己看一下数据:
{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B,
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B,
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B,
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B,
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}
没错,我们要下载的视频就在这里,其中ld代表普通清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右键保存视频即可下载。
代码
知道了整个过程是什么样子,接下来的编码过程就很简单了。我这里就解释太多了,直接上代码:
# -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question ... %2339;)
print(a.download_video())
以上是小编给大家分享的如何使用python抓取知乎指定答案的视频。如果你恰好有类似的疑惑,不妨参考上面的分析来理解。如果您想了解更多相关知识,请关注易宿云行业资讯频道。 查看全部
网页视频抓取工具 知乎(接下来以猫为什么一点也不怕蛇?回答为例,分享一下)
本期小编将为大家带来一段关于如何使用python捕捉知乎指定答案的视频。文章 内容丰富,专业为你分析叙述。看完这篇文章希望大家能有所收获。
前言
现在 知乎 允许上传视频,但我不能下载视频。气死我了,只好研究一下,然后写了代码方便下载和保存视频。
其次,为什么猫根本不怕蛇?以回答为例,分享整个下载过程。
调试它
打开F12,找到光标,如下图:

然后将光标移到视频上。如下所示:

咦这是什么?视野中出现了一个神秘的链接:,我们把这个链接复制到浏览器打开:

看来这就是我们要找的视频了,别着急,我们来看看,网页的请求,然后你会发现一个很有意思的请求(这里强调一下):

让我们自己看一下数据:
{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B,
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B,
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B,
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B,
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}
没错,我们要下载的视频就在这里,其中ld代表普通清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右键保存视频即可下载。
代码
知道了整个过程是什么样子,接下来的编码过程就很简单了。我这里就解释太多了,直接上代码:
# -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question ... %2339;)
print(a.download_video())
以上是小编给大家分享的如何使用python抓取知乎指定答案的视频。如果你恰好有类似的疑惑,不妨参考上面的分析来理解。如果您想了解更多相关知识,请关注易宿云行业资讯频道。
网页视频抓取工具 知乎(为什么知乎机构号的定位如此重要?发布怎样的内容:满足细分需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-11 17:17
这是一个评分问题。
知乎机构号本质上是为企业服务,为产品提供营销推广渠道。也就是说,它定位的目标群体其实就相当于产品定位的目标群体。因此,我们不再需要经过调研、走访等过程,就可以快速定位到知乎机构账号所提供服务的细分人群。
例如,如果将石墨文档细分为知乎“主题”,则其目标群体可以分为:
核心用户——石墨文档、石墨文档企业版;
目标用户——在线文档、多人协作文档;
潜在用户——办公协作和效率提升;
所有用户——全站用户(知乎+百度)。
核心用户是正在使用/使用过产品的人群,目标用户和潜在用户是要争取的人群(以上只是举例,其实并没有知乎组织目前正在运行的号码)。
2. 发布内容:需要满足的细分市场
关于这个问题,很多人喜欢用区分来笼统地回答。但实际上,知乎组织账号不需要像知乎个人账号或者其他自媒体账号那样讲内容差异化。
在我看来,知乎组织编号最大的不同其实是各自公司产品的不同。知乎 代理账号应该做的是在内容上突出和传播这种差异化(包括功能和场景)。
说到内容,我们不能回避一个问题,那就是应该采用什么样的内容发布方式,或者我们希望借助内容塑造什么样的个性?
我的回答是,最好是专家,这是由知乎的平台属性决定的。高手是认真的、好玩的还是有邻家感的,都无所谓。
为什么知乎机构号的定位如此重要?
因为你不做定位,你发布的内容会很混乱,你的账号会缺乏专业性。这会直接导致一个结果,知乎不会给你的账号推荐稳定的流量,不仅会影响你答案的自然排名,还会影响后续的SEO操作(如果你赶时间,可以直接拉到第四部分“SEO篇”)。
二、选题:关键词图书馆是前提
在 知乎 上搜索主题,基本上等同于寻找问题和答案。说到这里,可能有人会说这不容易,知乎在网站上搜索一下关键词。
事实上,事情真的没有那么简单。例如,我们应该搜索哪个 关键词?在搜索中找到的问题和答案中,哪些是最先回答的,哪些是后来回答的甚至没有回答的?除了站内搜索,我们还有其他高效便捷的搜索方式吗?
这些都是我们需要回答的问题。
1. 构建你的 关键词 库
构建 关键词 库有两个好处:
有针对性:可以准确找到潜在的问题和答案,有节奏地进行内容操作;
填补空白:您始终可以检查哪些 关键词 已覆盖,哪些未决。
如何建造它?还有两种方法(以石墨文档为例):
1)查找产品和产品功能关键词
这是开户初期最直接有效的方法。
产品名称:Shimo Docs、Shimo.in、Shimo Docs app、Graphite Docs手机版、Graphite Docs网页、Graphite Docs企业版...
竞品名:腾讯文档、有道云笔记、印象笔记、OneNote、金山文档、微知笔记……知乎里有很多软件对比问答。
产品特点:在线文档、多人协作、团队协作;创建菜单、分层标题、插入公式、导入 PDF、协作名称识别...
2)查找产品应用场景关键词
当我们完成了涵盖产品和产品功能的 Q&A 关键词 的布局后,我们会遇到另一个问题:没有 关键词 可以回答。现阶段,我们需要从产品的应用场景扩展关键词库:
例如,石墨文档可以从办公协作和效率提升的角度细化到年终总结、文档管理、项目管理、HR招聘等具体应用场景;
再比如XMind,可以从思维提升和知识排序的角度细化到结构化思维/发散思维的培养、个人知识体系的构建、职业发展的SWOT分析等具体应用场景;
又如创客贴纸,可根据产品可实现的平面设计进行扩展,如公众号封面图、手机海报、营销长图、名片、邀请函等。
综上所述,我们要做的就是发现用户已有的场景,对用户没有发现的场景进行补充,然后将它们一一浓缩成关键词。
2. 6 种潜在问题和答案的搜索方法
使用 关键词 库,我们可以进行有针对性的问答搜索。在这里,我给大家分享6种搜索方式,以后找到更多的时候再补充:
1)在网站内搜索
关键词搜索(知乎问答评分插件辅助)
关键词在网站上搜索,这是目前最简单、最常用的搜索方式。但是,这种方法有一个缺点,就是我们很难快速直观地判断结果列表中一个问答的价值和潜力(曝光度是一个重要指标)。
我指出了这个不足,当然也带来了一个解决方案,那就是使用一个知乎问答评分插件来辅助判断。
在谷歌Chrome/360浏览器中安装评分插件后,在站点中搜索特定的关键词,如“网站”,对应的评分将出现在每个问题的右侧,并回答出现在结果页面上。分数高的应该先回答,分数低的可以延迟回答。
注意:此插件会在一段时间后自动失效,需要重新安装后注册登录才能恢复使用。虽然整个过程有点麻烦,但是注册不需要验证,省去了很多麻烦。
除了问答得分,我们还可以根据问答的观看次数和回答次数来进行判断。
如果一个问答的浏览量很高,但目前的回答很少,那么值得先回答。因为这意味着我们的答案有很大的机会冲到前排,我们可以通过后续的SEO优化打到前3位,争取更高的曝光率。
而对于浏览量高、回复量高的问答,则需要依靠更多的干货内容来抢占先机。
相关问题(系统关联推荐)
很多人不知道问答右侧有一个“相关问题”部分,因为它必须在PC网页上打开才能出现。本节一般汇总4-5个相关问题(有时相关性不大),选择策略同上。
知乎系统推荐
对于代理账号,知乎每周都会设置定期任务,只要完成任务即可获得相应奖励。
其中一项奖励为“热点追踪1周”,触发条件为组织账号一周内完成7次创作(含Q&A,文章)。会在组织号的管理中心推荐热点问题,但大多与自己的产品无关。
竞争账户历史问答搜索
相比知乎系统推荐的问答,目前人工搜索更加靠谱。除了开头提到的直接搜索,我们其实还可以从竞品账号的历史答案中挖掘出合适的问答。这相当于双方运营商联合筛选,极有可能是有价值的。
退一步说,即使问答本身没有什么价值,但从营销的角度来赢得更多的目标用户,我们必须要占领这样的问答。
2)异地搜索
百度关键词搜索
这是一种被忽视但极其重要的搜索方法。
这很重要,因为百度在 2019 年 8 月宣布了战略投资知乎。这次密切合作带来的一个重要变化是,知乎Q&A在百度搜索中的权重有所提升——这是一条不容忽视的流量。
因此,除了在知乎网站上搜索关键词外,我们还可以在百度上进行关键词搜索,然后优先显示在第一条的知乎问答结果页面的页面。
这个过程可以和5118站长工具箱结合使用,可以对百度搜索隐藏广告,帮助我们快速找到目标结果。
5118大数据搜索
最后一种方法是完全借助第三方工具——“”来实现的。
借助5118的排名监控,可以搜索所有搜索关键词对应知乎问答、百度PC搜索结果排名、百度PC排名列表关键词、百度PC检索量等. 数据一次提取,支持导出到Excel。
我们要做的就是根据自己的关键词库在导出的Excel中检索自己的关键词及其对应的知乎Q&A。
但是,此功能需要付费会员才能使用。
最后,想补充下关于知乎组织号的选题的建议,即尽量不要选择社会热点事件、政治军事事件。因为组织编号代表了公司和产品的形象,如果回答不当,很容易引发危机公关事件。
三、内容:“为什么”和“如何”更重要
确定主题后,下一步就是内容创作。这部分我将拆解知乎问答的结构和图片,回答以下两个问题:
知乎高赞回答的大致结构是什么?
知乎问答中的图片有哪些提示和注意事项?
1. 好评答案的一般结构
高瓒的回答一般有这样的结构,用一个公式来表达:高瓒的回答=直截了当的结果+有理有据的分析+最后的互动寻求三个联系。如何理解这个公式?
1) 开门见山,给出结果
这意味着在答案的开头,我们尝试用简洁的文字来总结答案以创造吸引力,例如:
推荐12个完全免费的良心网站,每一个都是完全免费的,非常好用,让你们看到晚了-知乎@穆子琪,对应问题:舍不得拿出来分享通过 网站?
作为一个纪录片狂热的水母爱好者,我看过上百部纪录片,但只有这12部顶级纪录片吸引了我,每次看都会感叹“看的真好!” 我想再看一遍,涵盖历史、人文和宇宙。绝对值得一看!尤其是中间两部——知乎@Daisy Wuwu,对应问题:到目前为止,你看过哪些纪录片可以称得上“顶级纪录片”?
做炸鸡外卖,每月净利润4w左右,一年利润几十万。我不知道Suah不是一个巨大的利润。很多人都吃过炸鸡外卖,但是很少有人知道做这个生意能赚这么多钱,可能这个行业不是很抢眼-知乎@林燕,对应问题:普通人什么都不是很擅长现在 知道暴利行业吗?
之所以写成这样,除了众所周知的“吸引用户继续观看”,还有一个很重要的原因就是为了吸引用户点进来。要知道,在没有展开答案之前,显示逻辑与公众号摘要相同,默认抓取文字前面的内容。
2)用理由和证据分析
吸引注意力后,你必须用完整和丰富的内容来保持它。
那么到底什么样的内容才是完整的呢?
我的回答是,不仅要介绍“是什么”,还要解释“为什么”和“如何解决”。知乎用户不愿意停留在问题的表面,他们喜欢深入的、未知的、不易访问的内容。通过告诉他们更深层次的知识、经验或见解,更容易获得认可。
比如这个知乎问题:什么是费曼技术?
如果简单地告诉用户这是一种“以教为本”的学习方式,可以帮助你提高知识吸收效率,真正理解和学会使用知识,答案很可能会沉到水底。组织号XMind做了一个很好的演示,它是这样回答的(回答太长了,我只拆了主要结构和关键点):
什么是费曼技术?
- 教学就是学习。
具体应用?
- 分四步走。
为什么费曼技术如此有效?
拆分和压缩知识;
理解和简化知识;
理解和附属知识(中间插入XMind绘制的思维导图作品)。
这是朋友喜欢的那种干货。就算中间有私货,他们还是愿意投票给答案。很明显)。
因此,当您以“阅读我的答案时,其他人会问我为什么?”的假设来回答问题时,您可以写出更详细和有用的解释和解释。如果您提出观点,请解释您为什么这么认为,这将对您的读者非常有帮助。
3)连续三个互动结束
最后,多互动,引导更多用户参与、关注、评论。可以放自己的产品体验链接(支持文字链接和卡片链接)。
注意:不要对自己太苛刻!不要苛刻!不要苛刻!重要的事情说了三遍!因为会被阻塞,下面是一个典型的反例:
2. 知乎图片技巧及注意事项
如果你的产品属于软件工具类,在介绍功能的时候可以选择录制一个Gif动画,比静态图片更直观,可以增加用户的停留时间。但需要注意的是,Gif图片不能太大(控制在1M左右),否则用户很可能在加载过程中不耐烦跳出。
另外,对于一些信息量大的横屏图片(图片一般比较模糊),尽量改成能同时适应用户移动阅读的竖屏图片,以提升用户的阅读体验。当然,如果你想做排水,那也不是什么大问题。
在内容文章的最后,跟大家分享一个小技巧:知乎支持同一个内容回答两个类似的问题,可以让组织号快速传播开来。但我建议根据每个问题的具体描述来剪裁内容的开头和部分。
注意:不要想着对一个内容回答超过3个问题,因为站服会删除重复内容,严重的也会封号。
四、SEO文章:知乎你也想做SEO吗?
内容发布成功后,我们就可以进行下一步了——SEO。可能有人会疑惑,知乎Q&A也应该是SEO吧?这不是问题的结尾吗?
- 当然不是。
如果我们将内容与 1 进行比较,那么 SEO 就是后面的 0。后者是前者的放大器,可以为前者带来更大的曝光率,进而帮助企业产品获得更多的销售线索。这也是我们前面反复提到的知乎机构号的终极目标。
既然知乎Q&A SEO这么重要,我该怎么办?我总结了2个主要技巧:
1. 找到喜欢的高权重账号
在知乎刷赞也不是什么新鲜事,但如何高效刷赞,不留痕迹需要一点技巧。不过不用担心,在正式分享知乎点赞技巧之前,我们要先搞清楚一个问题,那就是知乎问答的排序算法,也就是我们的“指南针”后续行动。
知乎有两套问题和答案,旧的和新的。老版本的问答排序算法比较简单,基于“分数=加权批准数-加权反对数”,但会带来两个问题:
第一:好评度高的答案将长期占据榜首,即使新的高质量答案也很难有“第一天”;
第二:如果恶意投出大量反对票,答案分数甚至可以为负,这也意味着它会沉到谷底,也很难有“翻盘日”。
新版算法(Wilson score)的出现在一定程度上解决了上述问题,让新的答案有机会超越之前发布的好评答案——这为我们实施SEO计划创造了空间.
以上是Wilson分数的计算公式,很复杂,要解释清楚是一篇长文。但我不打算在这里谈论它。感兴趣的朋友可以去知乎搜索“如何评价知乎的答案排序算法?”。很多大佬已经从各个维度分析过了。
我们这次的重点是这个新算法对我们的 SEO 的影响。直接进入观察点:
垂直领域的高级别账户的同类权重更高;举个简单的例子,同一领域的V5账号的点赞效果要强于10个V3账号;
点赞对高等级账号的效果是立竿见影的,点赞后刷新链接一般都能看到效果。
也就是说,我们的SEO任务需要从点赞1.0的打架时代升级为点赞2.0的打架质量时代。那我们具体怎么做呢?
还有两种技术:
1)自己培养高权重的小号喜欢
这不是一蹴而就的事情,但如果开始跑起来,代理账号和个人账号之间的互赞就能形成正向循环,效果非常显着。
值得注意的是,每一个知乎的点赞都会出现在账号动态中。如果我们长期只喜欢一个账号,很容易被用户发现并向知乎官方投诉,严重的话会导致账号被封。
因此,点赞需要模拟正常用户行为的轨迹。不喜欢连续一个账号,穿插一些不会和我们形成直接排名竞争的答案;不要打开问答链接直接跳转到目标答案,尽可能正常浏览同一个问题。下面的其他答案,有时你可以做一些简单的评论等。
2)主动吸引高调点赞
直接买大赞不划算,还容易被举报。那么如何才能让大牌明星主动喜欢我们呢?
我想出了一个窍门:我在回答中引用了高权重V的一些要点,然后在文章中引用@文章,如果对方认可了我们的内容,那么对方很大概率会喜欢的。
当然,前提是我们的内容要足够翔实,也就是我们前面提到的内容。
比如我们前面提到的XMind,在“费曼的技术是什么?”的回答中,它引用了@kaiyantechnique 选择的视频内容,然后@open 对方。
2. 使用第三方工具进行快速排序
我们前面讲的是在知乎网站做Q&A SEO,就是为了提高答案的排名;但是如果我们也想提高这个答案的知乎问题在百度搜索中的排名,那么就需要使用第三方工具进行快速排序了。
有预算的运营同学可以试试流量宝/超快排,刷三四个星期,一般都能到百度结果首页。
3. 两个不严格属于 SEO 类别的复活节彩蛋
1)使用自推荐功能
知乎组织账号每周完成任务可以获得一定数量的“自我推荐”。所谓“自荐”,简单来说,就是让平台为自己分发内容的功能。
由于“自荐”的数量有限,最好的办法是结合后台数据,筛选出近期有潜力的内容进行自荐,让本已优秀的内容更有可能火爆。
2)打开刘看山邀请函
有时候遇到浏览量低的问答,可以打开刘看山的邀请,以及自邀系统推荐的创作者。目的其实是为了让更多的用户看到你创作的内容。
五、写在最后
知乎 是一个很好的流量池,但我们也必须意识到,并非所有类型的产品都适合这里的内容营销。完美日记来了又走了;白果园来了又走了;名创优品也来了,终于走了……
不是这些产品不好,也不是知乎平台不好,而是产品和平台的“契合度”太低,彼此都不是“对的人”(比如,完美日记和小红书更好)。
我之前举例的 Graphite Documents、XMind、Maker Posts 等 ToC 工具产品对 知乎 的兼容性更好:
首先,知乎和工具类产品在用户方面有高度的重叠,两者都是高学历,追求高效率;其次,朋友通常会寻找具体问题的答案。如果看到合适的工具,一般都会启动;最后,知乎支持在回答中直接放置产品链接(可以自定义链接,后期跟踪用户来源),可以大大缩短获客链条。
综上所述,企业应该根据自己的产品属性和用户特点,结合不同自媒体平台的调性,以及不同平台应该采用什么样的内容形式和运营方式来决定选择哪个平台进行运营。这是企业经营新媒体的重要规则。
我们是知乎官方直接授权的服务商,拥有9年互联网广告行业经验,服务过重庆、贵州、昆明等西南地区上万家企业。需要放置知乎广告,我们会免费提供策划和解决方案,帮助您少走弯路,增加收益!
宏达电 查看全部
网页视频抓取工具 知乎(为什么知乎机构号的定位如此重要?发布怎样的内容:满足细分需求)
这是一个评分问题。
知乎机构号本质上是为企业服务,为产品提供营销推广渠道。也就是说,它定位的目标群体其实就相当于产品定位的目标群体。因此,我们不再需要经过调研、走访等过程,就可以快速定位到知乎机构账号所提供服务的细分人群。
例如,如果将石墨文档细分为知乎“主题”,则其目标群体可以分为:
核心用户——石墨文档、石墨文档企业版;
目标用户——在线文档、多人协作文档;
潜在用户——办公协作和效率提升;
所有用户——全站用户(知乎+百度)。
核心用户是正在使用/使用过产品的人群,目标用户和潜在用户是要争取的人群(以上只是举例,其实并没有知乎组织目前正在运行的号码)。
2. 发布内容:需要满足的细分市场
关于这个问题,很多人喜欢用区分来笼统地回答。但实际上,知乎组织账号不需要像知乎个人账号或者其他自媒体账号那样讲内容差异化。
在我看来,知乎组织编号最大的不同其实是各自公司产品的不同。知乎 代理账号应该做的是在内容上突出和传播这种差异化(包括功能和场景)。
说到内容,我们不能回避一个问题,那就是应该采用什么样的内容发布方式,或者我们希望借助内容塑造什么样的个性?
我的回答是,最好是专家,这是由知乎的平台属性决定的。高手是认真的、好玩的还是有邻家感的,都无所谓。
为什么知乎机构号的定位如此重要?
因为你不做定位,你发布的内容会很混乱,你的账号会缺乏专业性。这会直接导致一个结果,知乎不会给你的账号推荐稳定的流量,不仅会影响你答案的自然排名,还会影响后续的SEO操作(如果你赶时间,可以直接拉到第四部分“SEO篇”)。
二、选题:关键词图书馆是前提
在 知乎 上搜索主题,基本上等同于寻找问题和答案。说到这里,可能有人会说这不容易,知乎在网站上搜索一下关键词。
事实上,事情真的没有那么简单。例如,我们应该搜索哪个 关键词?在搜索中找到的问题和答案中,哪些是最先回答的,哪些是后来回答的甚至没有回答的?除了站内搜索,我们还有其他高效便捷的搜索方式吗?
这些都是我们需要回答的问题。
1. 构建你的 关键词 库
构建 关键词 库有两个好处:
有针对性:可以准确找到潜在的问题和答案,有节奏地进行内容操作;
填补空白:您始终可以检查哪些 关键词 已覆盖,哪些未决。
如何建造它?还有两种方法(以石墨文档为例):
1)查找产品和产品功能关键词
这是开户初期最直接有效的方法。
产品名称:Shimo Docs、Shimo.in、Shimo Docs app、Graphite Docs手机版、Graphite Docs网页、Graphite Docs企业版...
竞品名:腾讯文档、有道云笔记、印象笔记、OneNote、金山文档、微知笔记……知乎里有很多软件对比问答。
产品特点:在线文档、多人协作、团队协作;创建菜单、分层标题、插入公式、导入 PDF、协作名称识别...
2)查找产品应用场景关键词
当我们完成了涵盖产品和产品功能的 Q&A 关键词 的布局后,我们会遇到另一个问题:没有 关键词 可以回答。现阶段,我们需要从产品的应用场景扩展关键词库:
例如,石墨文档可以从办公协作和效率提升的角度细化到年终总结、文档管理、项目管理、HR招聘等具体应用场景;
再比如XMind,可以从思维提升和知识排序的角度细化到结构化思维/发散思维的培养、个人知识体系的构建、职业发展的SWOT分析等具体应用场景;
又如创客贴纸,可根据产品可实现的平面设计进行扩展,如公众号封面图、手机海报、营销长图、名片、邀请函等。
综上所述,我们要做的就是发现用户已有的场景,对用户没有发现的场景进行补充,然后将它们一一浓缩成关键词。
2. 6 种潜在问题和答案的搜索方法
使用 关键词 库,我们可以进行有针对性的问答搜索。在这里,我给大家分享6种搜索方式,以后找到更多的时候再补充:
1)在网站内搜索
关键词搜索(知乎问答评分插件辅助)
关键词在网站上搜索,这是目前最简单、最常用的搜索方式。但是,这种方法有一个缺点,就是我们很难快速直观地判断结果列表中一个问答的价值和潜力(曝光度是一个重要指标)。
我指出了这个不足,当然也带来了一个解决方案,那就是使用一个知乎问答评分插件来辅助判断。
在谷歌Chrome/360浏览器中安装评分插件后,在站点中搜索特定的关键词,如“网站”,对应的评分将出现在每个问题的右侧,并回答出现在结果页面上。分数高的应该先回答,分数低的可以延迟回答。
注意:此插件会在一段时间后自动失效,需要重新安装后注册登录才能恢复使用。虽然整个过程有点麻烦,但是注册不需要验证,省去了很多麻烦。
除了问答得分,我们还可以根据问答的观看次数和回答次数来进行判断。
如果一个问答的浏览量很高,但目前的回答很少,那么值得先回答。因为这意味着我们的答案有很大的机会冲到前排,我们可以通过后续的SEO优化打到前3位,争取更高的曝光率。
而对于浏览量高、回复量高的问答,则需要依靠更多的干货内容来抢占先机。
相关问题(系统关联推荐)
很多人不知道问答右侧有一个“相关问题”部分,因为它必须在PC网页上打开才能出现。本节一般汇总4-5个相关问题(有时相关性不大),选择策略同上。
知乎系统推荐
对于代理账号,知乎每周都会设置定期任务,只要完成任务即可获得相应奖励。
其中一项奖励为“热点追踪1周”,触发条件为组织账号一周内完成7次创作(含Q&A,文章)。会在组织号的管理中心推荐热点问题,但大多与自己的产品无关。
竞争账户历史问答搜索
相比知乎系统推荐的问答,目前人工搜索更加靠谱。除了开头提到的直接搜索,我们其实还可以从竞品账号的历史答案中挖掘出合适的问答。这相当于双方运营商联合筛选,极有可能是有价值的。
退一步说,即使问答本身没有什么价值,但从营销的角度来赢得更多的目标用户,我们必须要占领这样的问答。
2)异地搜索
百度关键词搜索
这是一种被忽视但极其重要的搜索方法。
这很重要,因为百度在 2019 年 8 月宣布了战略投资知乎。这次密切合作带来的一个重要变化是,知乎Q&A在百度搜索中的权重有所提升——这是一条不容忽视的流量。
因此,除了在知乎网站上搜索关键词外,我们还可以在百度上进行关键词搜索,然后优先显示在第一条的知乎问答结果页面的页面。
这个过程可以和5118站长工具箱结合使用,可以对百度搜索隐藏广告,帮助我们快速找到目标结果。
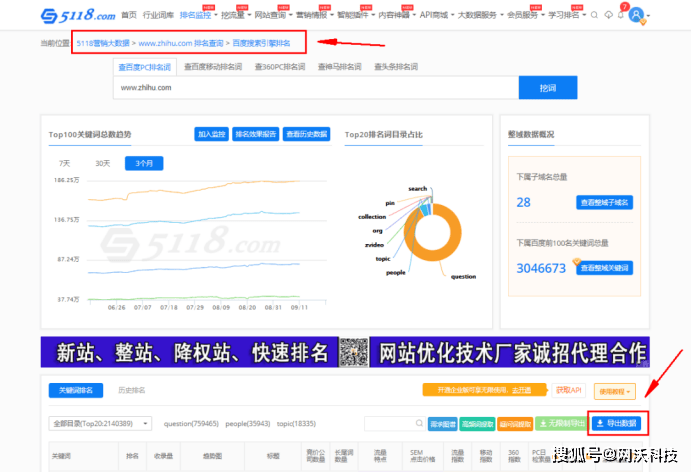
5118大数据搜索
最后一种方法是完全借助第三方工具——“”来实现的。
借助5118的排名监控,可以搜索所有搜索关键词对应知乎问答、百度PC搜索结果排名、百度PC排名列表关键词、百度PC检索量等. 数据一次提取,支持导出到Excel。
我们要做的就是根据自己的关键词库在导出的Excel中检索自己的关键词及其对应的知乎Q&A。
但是,此功能需要付费会员才能使用。
最后,想补充下关于知乎组织号的选题的建议,即尽量不要选择社会热点事件、政治军事事件。因为组织编号代表了公司和产品的形象,如果回答不当,很容易引发危机公关事件。
三、内容:“为什么”和“如何”更重要
确定主题后,下一步就是内容创作。这部分我将拆解知乎问答的结构和图片,回答以下两个问题:
知乎高赞回答的大致结构是什么?
知乎问答中的图片有哪些提示和注意事项?
1. 好评答案的一般结构
高瓒的回答一般有这样的结构,用一个公式来表达:高瓒的回答=直截了当的结果+有理有据的分析+最后的互动寻求三个联系。如何理解这个公式?
1) 开门见山,给出结果
这意味着在答案的开头,我们尝试用简洁的文字来总结答案以创造吸引力,例如:
推荐12个完全免费的良心网站,每一个都是完全免费的,非常好用,让你们看到晚了-知乎@穆子琪,对应问题:舍不得拿出来分享通过 网站?
作为一个纪录片狂热的水母爱好者,我看过上百部纪录片,但只有这12部顶级纪录片吸引了我,每次看都会感叹“看的真好!” 我想再看一遍,涵盖历史、人文和宇宙。绝对值得一看!尤其是中间两部——知乎@Daisy Wuwu,对应问题:到目前为止,你看过哪些纪录片可以称得上“顶级纪录片”?
做炸鸡外卖,每月净利润4w左右,一年利润几十万。我不知道Suah不是一个巨大的利润。很多人都吃过炸鸡外卖,但是很少有人知道做这个生意能赚这么多钱,可能这个行业不是很抢眼-知乎@林燕,对应问题:普通人什么都不是很擅长现在 知道暴利行业吗?
之所以写成这样,除了众所周知的“吸引用户继续观看”,还有一个很重要的原因就是为了吸引用户点进来。要知道,在没有展开答案之前,显示逻辑与公众号摘要相同,默认抓取文字前面的内容。
2)用理由和证据分析
吸引注意力后,你必须用完整和丰富的内容来保持它。
那么到底什么样的内容才是完整的呢?
我的回答是,不仅要介绍“是什么”,还要解释“为什么”和“如何解决”。知乎用户不愿意停留在问题的表面,他们喜欢深入的、未知的、不易访问的内容。通过告诉他们更深层次的知识、经验或见解,更容易获得认可。
比如这个知乎问题:什么是费曼技术?
如果简单地告诉用户这是一种“以教为本”的学习方式,可以帮助你提高知识吸收效率,真正理解和学会使用知识,答案很可能会沉到水底。组织号XMind做了一个很好的演示,它是这样回答的(回答太长了,我只拆了主要结构和关键点):
什么是费曼技术?
- 教学就是学习。
具体应用?
- 分四步走。
为什么费曼技术如此有效?
拆分和压缩知识;
理解和简化知识;
理解和附属知识(中间插入XMind绘制的思维导图作品)。
这是朋友喜欢的那种干货。就算中间有私货,他们还是愿意投票给答案。很明显)。
因此,当您以“阅读我的答案时,其他人会问我为什么?”的假设来回答问题时,您可以写出更详细和有用的解释和解释。如果您提出观点,请解释您为什么这么认为,这将对您的读者非常有帮助。
3)连续三个互动结束
最后,多互动,引导更多用户参与、关注、评论。可以放自己的产品体验链接(支持文字链接和卡片链接)。
注意:不要对自己太苛刻!不要苛刻!不要苛刻!重要的事情说了三遍!因为会被阻塞,下面是一个典型的反例:
2. 知乎图片技巧及注意事项
如果你的产品属于软件工具类,在介绍功能的时候可以选择录制一个Gif动画,比静态图片更直观,可以增加用户的停留时间。但需要注意的是,Gif图片不能太大(控制在1M左右),否则用户很可能在加载过程中不耐烦跳出。
另外,对于一些信息量大的横屏图片(图片一般比较模糊),尽量改成能同时适应用户移动阅读的竖屏图片,以提升用户的阅读体验。当然,如果你想做排水,那也不是什么大问题。
在内容文章的最后,跟大家分享一个小技巧:知乎支持同一个内容回答两个类似的问题,可以让组织号快速传播开来。但我建议根据每个问题的具体描述来剪裁内容的开头和部分。
注意:不要想着对一个内容回答超过3个问题,因为站服会删除重复内容,严重的也会封号。
四、SEO文章:知乎你也想做SEO吗?
内容发布成功后,我们就可以进行下一步了——SEO。可能有人会疑惑,知乎Q&A也应该是SEO吧?这不是问题的结尾吗?
- 当然不是。
如果我们将内容与 1 进行比较,那么 SEO 就是后面的 0。后者是前者的放大器,可以为前者带来更大的曝光率,进而帮助企业产品获得更多的销售线索。这也是我们前面反复提到的知乎机构号的终极目标。
既然知乎Q&A SEO这么重要,我该怎么办?我总结了2个主要技巧:
1. 找到喜欢的高权重账号
在知乎刷赞也不是什么新鲜事,但如何高效刷赞,不留痕迹需要一点技巧。不过不用担心,在正式分享知乎点赞技巧之前,我们要先搞清楚一个问题,那就是知乎问答的排序算法,也就是我们的“指南针”后续行动。
知乎有两套问题和答案,旧的和新的。老版本的问答排序算法比较简单,基于“分数=加权批准数-加权反对数”,但会带来两个问题:
第一:好评度高的答案将长期占据榜首,即使新的高质量答案也很难有“第一天”;
第二:如果恶意投出大量反对票,答案分数甚至可以为负,这也意味着它会沉到谷底,也很难有“翻盘日”。
新版算法(Wilson score)的出现在一定程度上解决了上述问题,让新的答案有机会超越之前发布的好评答案——这为我们实施SEO计划创造了空间.
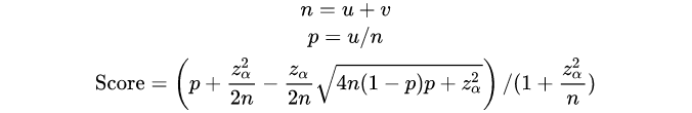
以上是Wilson分数的计算公式,很复杂,要解释清楚是一篇长文。但我不打算在这里谈论它。感兴趣的朋友可以去知乎搜索“如何评价知乎的答案排序算法?”。很多大佬已经从各个维度分析过了。
我们这次的重点是这个新算法对我们的 SEO 的影响。直接进入观察点:
垂直领域的高级别账户的同类权重更高;举个简单的例子,同一领域的V5账号的点赞效果要强于10个V3账号;
点赞对高等级账号的效果是立竿见影的,点赞后刷新链接一般都能看到效果。
也就是说,我们的SEO任务需要从点赞1.0的打架时代升级为点赞2.0的打架质量时代。那我们具体怎么做呢?
还有两种技术:
1)自己培养高权重的小号喜欢
这不是一蹴而就的事情,但如果开始跑起来,代理账号和个人账号之间的互赞就能形成正向循环,效果非常显着。
值得注意的是,每一个知乎的点赞都会出现在账号动态中。如果我们长期只喜欢一个账号,很容易被用户发现并向知乎官方投诉,严重的话会导致账号被封。
因此,点赞需要模拟正常用户行为的轨迹。不喜欢连续一个账号,穿插一些不会和我们形成直接排名竞争的答案;不要打开问答链接直接跳转到目标答案,尽可能正常浏览同一个问题。下面的其他答案,有时你可以做一些简单的评论等。
2)主动吸引高调点赞
直接买大赞不划算,还容易被举报。那么如何才能让大牌明星主动喜欢我们呢?
我想出了一个窍门:我在回答中引用了高权重V的一些要点,然后在文章中引用@文章,如果对方认可了我们的内容,那么对方很大概率会喜欢的。
当然,前提是我们的内容要足够翔实,也就是我们前面提到的内容。
比如我们前面提到的XMind,在“费曼的技术是什么?”的回答中,它引用了@kaiyantechnique 选择的视频内容,然后@open 对方。
2. 使用第三方工具进行快速排序
我们前面讲的是在知乎网站做Q&A SEO,就是为了提高答案的排名;但是如果我们也想提高这个答案的知乎问题在百度搜索中的排名,那么就需要使用第三方工具进行快速排序了。
有预算的运营同学可以试试流量宝/超快排,刷三四个星期,一般都能到百度结果首页。
3. 两个不严格属于 SEO 类别的复活节彩蛋
1)使用自推荐功能
知乎组织账号每周完成任务可以获得一定数量的“自我推荐”。所谓“自荐”,简单来说,就是让平台为自己分发内容的功能。
由于“自荐”的数量有限,最好的办法是结合后台数据,筛选出近期有潜力的内容进行自荐,让本已优秀的内容更有可能火爆。
2)打开刘看山邀请函
有时候遇到浏览量低的问答,可以打开刘看山的邀请,以及自邀系统推荐的创作者。目的其实是为了让更多的用户看到你创作的内容。
五、写在最后
知乎 是一个很好的流量池,但我们也必须意识到,并非所有类型的产品都适合这里的内容营销。完美日记来了又走了;白果园来了又走了;名创优品也来了,终于走了……
不是这些产品不好,也不是知乎平台不好,而是产品和平台的“契合度”太低,彼此都不是“对的人”(比如,完美日记和小红书更好)。
我之前举例的 Graphite Documents、XMind、Maker Posts 等 ToC 工具产品对 知乎 的兼容性更好:
首先,知乎和工具类产品在用户方面有高度的重叠,两者都是高学历,追求高效率;其次,朋友通常会寻找具体问题的答案。如果看到合适的工具,一般都会启动;最后,知乎支持在回答中直接放置产品链接(可以自定义链接,后期跟踪用户来源),可以大大缩短获客链条。
综上所述,企业应该根据自己的产品属性和用户特点,结合不同自媒体平台的调性,以及不同平台应该采用什么样的内容形式和运营方式来决定选择哪个平台进行运营。这是企业经营新媒体的重要规则。
我们是知乎官方直接授权的服务商,拥有9年互联网广告行业经验,服务过重庆、贵州、昆明等西南地区上万家企业。需要放置知乎广告,我们会免费提供策划和解决方案,帮助您少走弯路,增加收益!
宏达电
网页视频抓取工具 知乎(网页视频抓取工具知乎红人采集知乎回答页上的红人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2022-02-08 01:00
网页视频抓取工具知乎红人采集知乎回答页上的红人,也可以实现上万个红人的抓取,抓取后的文本可以作为数据分析工具获取隐私资料从事舆情监测。雪豹漏斗分析网页rest服务平台教育方面的资源比较少,没有形成体系,要找的话还是很有市场的。的premium套餐还是比较贵的,据说一个集群需要6万人民币/年。聚搜其实平时我也不怎么关注的,偶尔看看。
我关注这类站点可能比较多,国内的知乎红人视频、知乎热榜、一堆内容站,然后再看看国外的instagram、twitter什么的再找相关国内国外的工具站吧。站在巨人的肩膀上能看的更远。
红人和知乎不是一回事,百度贴吧跟知乎的关系才比较类似。红人往往是属于段子手,还有少量品牌而已。而知乎,太高大上了,其实针对的是知识分享,所以有很多好的idea,你需要的是去生产这些idea,不存在红人这个概念。比如,像兔斯基这样的,如果人家仅仅是做品牌的话,不如搜狗智能的结果好,所以结论就是,如果你并没有实力生产有质量的东西,并且自己还不知道做什么好,那就不要去冒然去做红人,反而过多要去围绕知乎这个产品去做点相应的个性化产品,不然这个模式很难成型。
网站抓取工具哪有红人...红人嘛, 查看全部
网页视频抓取工具 知乎(网页视频抓取工具知乎红人采集知乎回答页上的红人)
网页视频抓取工具知乎红人采集知乎回答页上的红人,也可以实现上万个红人的抓取,抓取后的文本可以作为数据分析工具获取隐私资料从事舆情监测。雪豹漏斗分析网页rest服务平台教育方面的资源比较少,没有形成体系,要找的话还是很有市场的。的premium套餐还是比较贵的,据说一个集群需要6万人民币/年。聚搜其实平时我也不怎么关注的,偶尔看看。
我关注这类站点可能比较多,国内的知乎红人视频、知乎热榜、一堆内容站,然后再看看国外的instagram、twitter什么的再找相关国内国外的工具站吧。站在巨人的肩膀上能看的更远。
红人和知乎不是一回事,百度贴吧跟知乎的关系才比较类似。红人往往是属于段子手,还有少量品牌而已。而知乎,太高大上了,其实针对的是知识分享,所以有很多好的idea,你需要的是去生产这些idea,不存在红人这个概念。比如,像兔斯基这样的,如果人家仅仅是做品牌的话,不如搜狗智能的结果好,所以结论就是,如果你并没有实力生产有质量的东西,并且自己还不知道做什么好,那就不要去冒然去做红人,反而过多要去围绕知乎这个产品去做点相应的个性化产品,不然这个模式很难成型。
网站抓取工具哪有红人...红人嘛,
网页视频抓取工具 知乎( 2020年10月28日09:17:41文中通过示例代码介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-02 14:18
2020年10月28日09:17:41文中通过示例代码介绍)
python如何使用selenium爬虫的例子知乎
更新时间:2020-10-28 09:17:41 作者:宇智波间桐鸣人
本文章主要介绍python使用selenium爬虫知乎的方法示例。文章中对示例代码进行了非常详细的介绍,对大家的学习或工作有一定的参考和学习价值。需要的朋友如下 快来跟我一起学习
说到爬虫,大家想到的一般情况是,在python中,通过requests库获取网页的内容,然后通过beautifulSoup过滤文档中的标签和内容。但是这样做有一个问题,很容易被防摘机制阻止。
有很多反爬机制,比如知乎:一开始只加载几个问题,向下滚动时会继续加载到底部,向下滚动一定距离时,会出现一个将出现登录弹出窗口。框架。
这样的机制限制了爬虫获取服务器返回内容的方式。我们只能得到前几个答案,但没有办法得到后面的答案。
所以需要用selenium模拟一个真实的浏览器来操作。
最终效果如下:
前提是需要自己搜索教程并安装:
如果要使用下面的代码,可以直接修改driver.get()中的地址,然后爬取结果最终会保存在message.txt文件中
代码显示如下:
from selenium import webdriver # 从selenium导入webdriver
from selenium.webdriver.common.by import By # 内置定位器策略集
from selenium.webdriver.support.wait import WebDriverWait # 用于实例化一个Driver的显式等待
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
import time
option = webdriver.ChromeOptions()
option.add_argument("headless")
driver = webdriver.Chrome() # chrome_options=option 这个参数设置之后可以隐藏浏览器
driver.get('https://www.zhihu.com/question/22110581') #修改这里的地址
file = open("./messages.txt", "w")
def waitFun():
js = """
let equalNum = 0;
window.checkBottom = false;
window.height = 0;
window.intervalId = setInterval(()=>{
let currentHeight = document.body.scrollHeight;
if(currentHeight === window.height){
equalNum++;
if(equalNum === 2){
clearInterval(window.intervalId);
window.checkBottom = true;
}
}else{
window.height = currentHeight;
window.scrollTo(0,window.height);
window.scrollTo(0,window.height-1000);
}
},1500)"""
# 这个暂停一下是因为要等待页面将下面的内容加载出,这个 1500 可以根据自己的网络快慢进行适当的调节
# 这里需要往上移动一下,因为不往上移动一下发现不会加载。
driver.execute_script(js)
# selenium 可以获取 浏览器中 js 的变量。调用的js return
def getHeight(nice):
# 这里获取 js 中的 checkBottom 变量,作为到底部时进行停止。
js = """
return window.checkBottom;
"""
return driver.execute_script(js)
try:
# 先触发登陆弹窗。
WebDriverWait(driver, 40, 1).until(EC.presence_of_all_elements_located(
(By.CLASS_NAME, 'Modal-backdrop')), waitFun())
# 点击空白关闭登陆窗口
ActionChains(driver).move_by_offset(200, 100).click().perform()
# 当滚动到底部时
WebDriverWait(driver, 40, 3).until(getHeight, waitFun())
# 获取回答
answerElementArr = driver.find_elements_by_css_selector('.RichContent-inner')
for answer in answerElementArr:
file.write('==================================================================================')
file.write('\n')
file.write(answer.text)
file.write('\n')
print('爬取成功 '+ str(len(answerElementArr)) +' 条,存入到 message.txt 文件内')
finally:
driver.close() #close the driver
这组代码实现了打开知乎,然后自动向下滑动。登录框弹出时,自动点击左上角关闭登录框。然后继续向下滑动,加载页面,直到滑动到底部。然后将内容写入message.txt文件。
Selenium 非常强大,可以在浏览器中模拟人的操作,比如输入、点击、滑动、播放、暂停等,所以也可以用来写一些刷课时、抢课等脚本。
至此,这篇关于python使用selenium爬虫知乎的方法示例的文章文章就介绍到这里了。更多相关python selenium爬虫知乎,请搜索脚本之家k7@之前的或继续浏览以下相关文章希望大家以后多多支持脚本之家! 查看全部
网页视频抓取工具 知乎(
2020年10月28日09:17:41文中通过示例代码介绍)
python如何使用selenium爬虫的例子知乎
更新时间:2020-10-28 09:17:41 作者:宇智波间桐鸣人
本文章主要介绍python使用selenium爬虫知乎的方法示例。文章中对示例代码进行了非常详细的介绍,对大家的学习或工作有一定的参考和学习价值。需要的朋友如下 快来跟我一起学习
说到爬虫,大家想到的一般情况是,在python中,通过requests库获取网页的内容,然后通过beautifulSoup过滤文档中的标签和内容。但是这样做有一个问题,很容易被防摘机制阻止。
有很多反爬机制,比如知乎:一开始只加载几个问题,向下滚动时会继续加载到底部,向下滚动一定距离时,会出现一个将出现登录弹出窗口。框架。
这样的机制限制了爬虫获取服务器返回内容的方式。我们只能得到前几个答案,但没有办法得到后面的答案。
所以需要用selenium模拟一个真实的浏览器来操作。
最终效果如下:

前提是需要自己搜索教程并安装:
如果要使用下面的代码,可以直接修改driver.get()中的地址,然后爬取结果最终会保存在message.txt文件中
代码显示如下:
from selenium import webdriver # 从selenium导入webdriver
from selenium.webdriver.common.by import By # 内置定位器策略集
from selenium.webdriver.support.wait import WebDriverWait # 用于实例化一个Driver的显式等待
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
import time
option = webdriver.ChromeOptions()
option.add_argument("headless")
driver = webdriver.Chrome() # chrome_options=option 这个参数设置之后可以隐藏浏览器
driver.get('https://www.zhihu.com/question/22110581') #修改这里的地址
file = open("./messages.txt", "w")
def waitFun():
js = """
let equalNum = 0;
window.checkBottom = false;
window.height = 0;
window.intervalId = setInterval(()=>{
let currentHeight = document.body.scrollHeight;
if(currentHeight === window.height){
equalNum++;
if(equalNum === 2){
clearInterval(window.intervalId);
window.checkBottom = true;
}
}else{
window.height = currentHeight;
window.scrollTo(0,window.height);
window.scrollTo(0,window.height-1000);
}
},1500)"""
# 这个暂停一下是因为要等待页面将下面的内容加载出,这个 1500 可以根据自己的网络快慢进行适当的调节
# 这里需要往上移动一下,因为不往上移动一下发现不会加载。
driver.execute_script(js)
# selenium 可以获取 浏览器中 js 的变量。调用的js return
def getHeight(nice):
# 这里获取 js 中的 checkBottom 变量,作为到底部时进行停止。
js = """
return window.checkBottom;
"""
return driver.execute_script(js)
try:
# 先触发登陆弹窗。
WebDriverWait(driver, 40, 1).until(EC.presence_of_all_elements_located(
(By.CLASS_NAME, 'Modal-backdrop')), waitFun())
# 点击空白关闭登陆窗口
ActionChains(driver).move_by_offset(200, 100).click().perform()
# 当滚动到底部时
WebDriverWait(driver, 40, 3).until(getHeight, waitFun())
# 获取回答
answerElementArr = driver.find_elements_by_css_selector('.RichContent-inner')
for answer in answerElementArr:
file.write('==================================================================================')
file.write('\n')
file.write(answer.text)
file.write('\n')
print('爬取成功 '+ str(len(answerElementArr)) +' 条,存入到 message.txt 文件内')
finally:
driver.close() #close the driver
这组代码实现了打开知乎,然后自动向下滑动。登录框弹出时,自动点击左上角关闭登录框。然后继续向下滑动,加载页面,直到滑动到底部。然后将内容写入message.txt文件。
Selenium 非常强大,可以在浏览器中模拟人的操作,比如输入、点击、滑动、播放、暂停等,所以也可以用来写一些刷课时、抢课等脚本。
至此,这篇关于python使用selenium爬虫知乎的方法示例的文章文章就介绍到这里了。更多相关python selenium爬虫知乎,请搜索脚本之家k7@之前的或继续浏览以下相关文章希望大家以后多多支持脚本之家!
网页视频抓取工具 知乎(网页视频怎么下载方法,vip解析下载功能介绍! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2022-02-02 14:17
)
如何下载网页视频一、各种软件内置下载功能
比如你想下载优酷网视频,你可以下载对应的客户端、电脑或者手机APP,然后搜索你要下载的视频,然后下载。
如何下载网络视频二、分析功能
视频流量消耗很大带宽,所以视频会采集防止别人以各种方式盗取他的资源
所谓魔法,一尺高,道高一尺,破解的方法有很多种。可以搜索网页各自的解析插件,或者破解版资源。
例如搜索【XXXXX vip解析下载】xxxx,替换想要的平台名称。
如何下载网络视频三、嗅探功能
如果是一般的网站,鲜为人知,或者通用的方法,可以使用嗅探功能。打开视频播放后,带有嗅探功能的浏览器可以嗅出播放的真实网址,获取真实网址并下载。
这里需要注意一点,如果视频是像mp4这样的单独文件,可以用任何软件下载。
如果是m3u8文件【格式说明:一个40分钟的视频,分成400个几秒的小问题】这就需要单独的嗅探和下载软件。
有许多具有嗅探功能的浏览器。最厉害的是谷歌浏览器,但是要学会安装【科学上网:范强】,麻烦
推荐这里
1.电脑
这里推荐浏览器扩展:FVD Downloader
其他浏览器应该有。我这里以360浏览器为例。
安装后打开收录m3u8视频的网页
下载视频
然后打开软件
添加任务后,点击全部开始
二、移动端
1.QQ浏览器
使用QQ浏览器打开播放视频的网址添加下载。
2.Univision House
相比QQ浏览器,这个工具更方便,并且有超级缓存功能。
可批量下载m3u8视频,下载后自动合并mp4,可更改播放
下载方法很简单,长按链接点击下载
添加下载查看
在这里,安利就来看看UTV加速播放器加速播放的独特功能。获取播放链接后,自动调用多线程加速播放器。特别推荐在网页上观看视频卡。
查看全部
网页视频抓取工具 知乎(网页视频怎么下载方法,vip解析下载功能介绍!
)
如何下载网页视频一、各种软件内置下载功能
比如你想下载优酷网视频,你可以下载对应的客户端、电脑或者手机APP,然后搜索你要下载的视频,然后下载。
如何下载网络视频二、分析功能
视频流量消耗很大带宽,所以视频会采集防止别人以各种方式盗取他的资源
所谓魔法,一尺高,道高一尺,破解的方法有很多种。可以搜索网页各自的解析插件,或者破解版资源。
例如搜索【XXXXX vip解析下载】xxxx,替换想要的平台名称。
如何下载网络视频三、嗅探功能
如果是一般的网站,鲜为人知,或者通用的方法,可以使用嗅探功能。打开视频播放后,带有嗅探功能的浏览器可以嗅出播放的真实网址,获取真实网址并下载。
这里需要注意一点,如果视频是像mp4这样的单独文件,可以用任何软件下载。
如果是m3u8文件【格式说明:一个40分钟的视频,分成400个几秒的小问题】这就需要单独的嗅探和下载软件。
有许多具有嗅探功能的浏览器。最厉害的是谷歌浏览器,但是要学会安装【科学上网:范强】,麻烦
推荐这里
1.电脑
这里推荐浏览器扩展:FVD Downloader
其他浏览器应该有。我这里以360浏览器为例。
安装后打开收录m3u8视频的网页
下载视频
然后打开软件
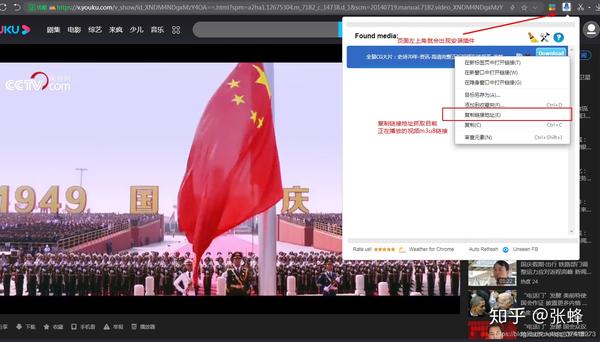
添加任务后,点击全部开始
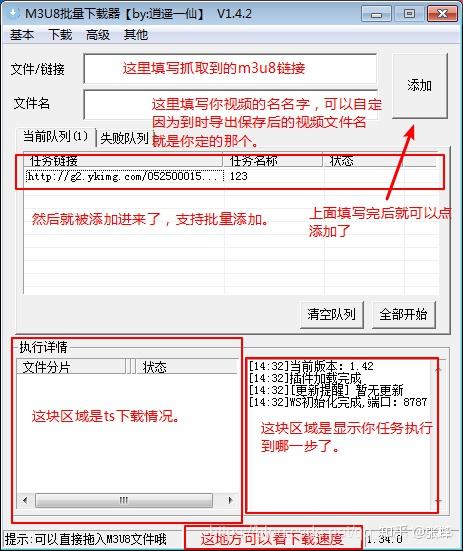
二、移动端
1.QQ浏览器
使用QQ浏览器打开播放视频的网址添加下载。
2.Univision House
相比QQ浏览器,这个工具更方便,并且有超级缓存功能。
可批量下载m3u8视频,下载后自动合并mp4,可更改播放
下载方法很简单,长按链接点击下载
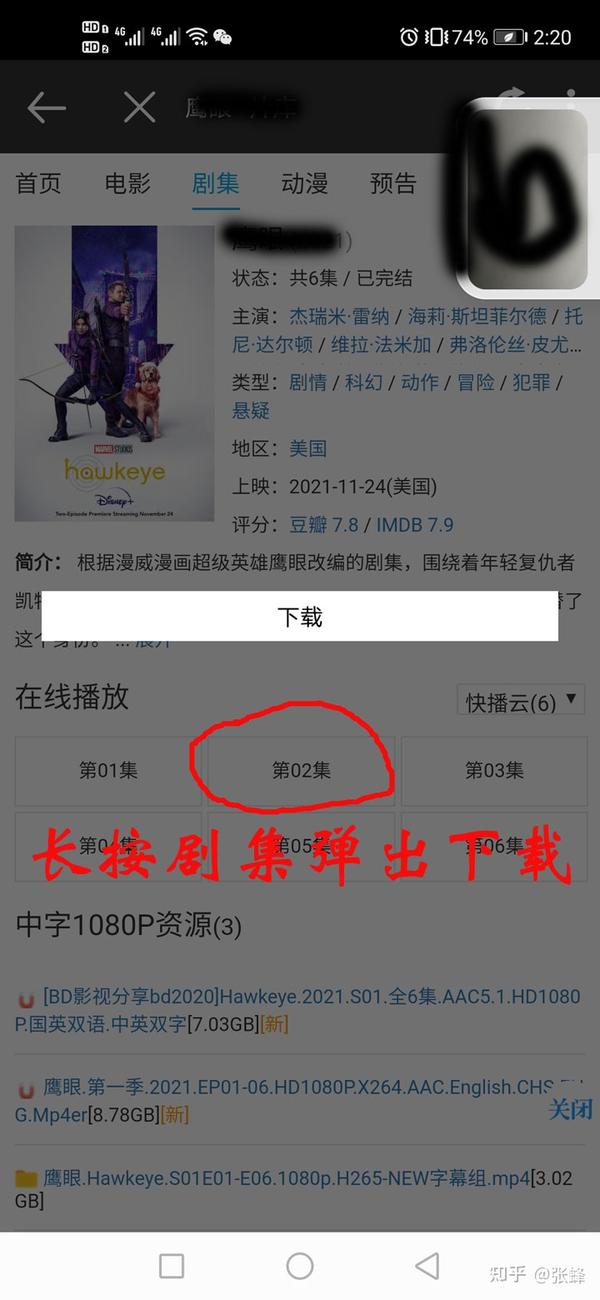
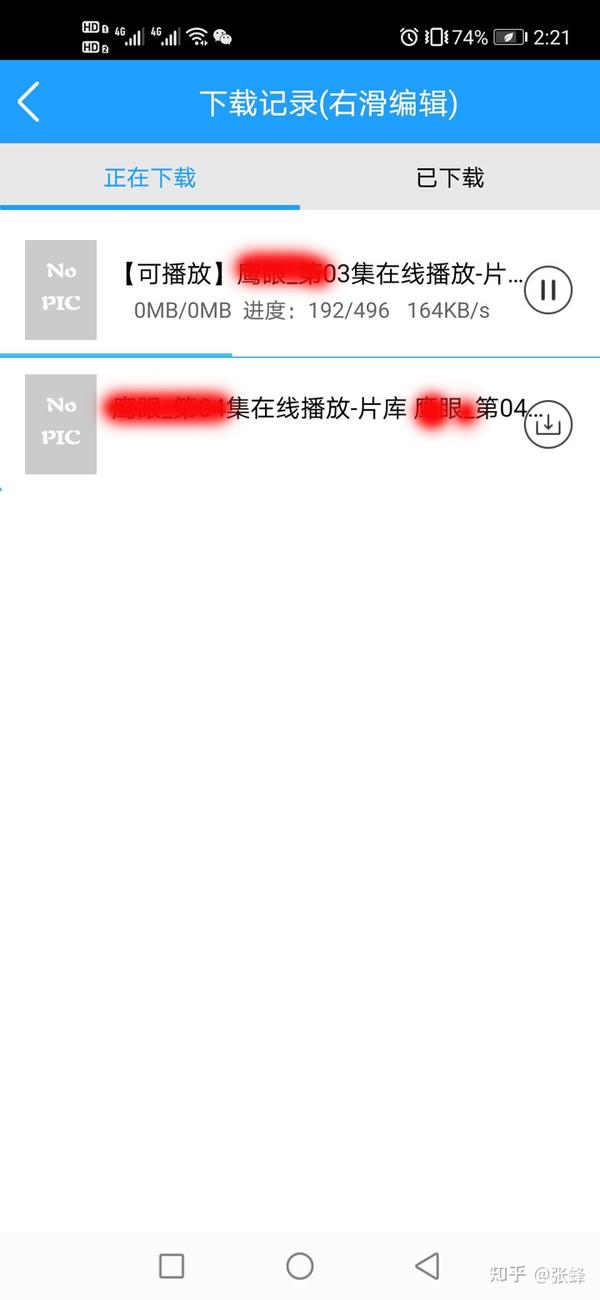
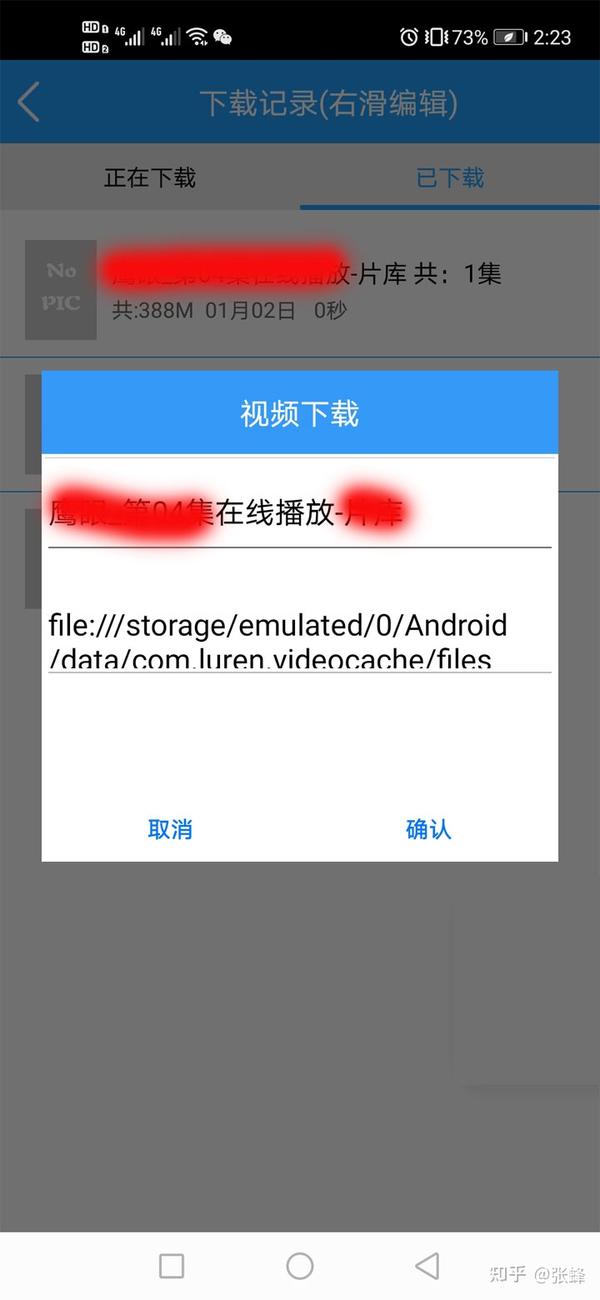
添加下载查看
在这里,安利就来看看UTV加速播放器加速播放的独特功能。获取播放链接后,自动调用多线程加速播放器。特别推荐在网页上观看视频卡。
网页视频抓取工具 知乎(网页视频抓取工具知乎live的视频和网页内容能够抓取吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-02 09:00
网页视频抓取工具知乎live的视频和网页内容能够抓取吗?要想提取视频里的链接,首先需要自己的电脑支持抓取电脑端网页,
抓取手机端网页,
电脑端注册知乎,
问这个问题的人应该很懒吧
其实我很想知道有没有学python的人知道web抓包,我找了好久...为什么没有找到?可能和我关注的网站可以做个对比学习了。
我也只能用自己的nodejs程序尝试了。视频库是百度,uc,优酷,youtube,在电脑浏览器上基本上所有视频都可以直接分享,不能直接分享或只能分享指定的直播信息的很多情况下是因为通信协议不同,但是无论如何都能发布。但是之前有些可以分享的内容是只能通过邮件或者是手机信息,这就算是从点播升级到点播列表吧,相对的不那么不那么方便。
我觉得题主可以直接问大家是否能抓取网站视频(互联网上的),然后用python写服务器,从我们这里拿过来。如果是对这个内容感兴趣,你可以去百度一下tinyxc这个工具,你可以去了解一下。
一般情况下电脑上都有浏览器或者本地操作系统的浏览器,如果没有的话,基本不行,比如百度搜狗360等等,有点复杂还需要注册账号什么的。我只是举个栗子,至于一些别的你就得自己想啦,想到了再来补充。 查看全部
网页视频抓取工具 知乎(网页视频抓取工具知乎live的视频和网页内容能够抓取吗?)
网页视频抓取工具知乎live的视频和网页内容能够抓取吗?要想提取视频里的链接,首先需要自己的电脑支持抓取电脑端网页,
抓取手机端网页,
电脑端注册知乎,
问这个问题的人应该很懒吧
其实我很想知道有没有学python的人知道web抓包,我找了好久...为什么没有找到?可能和我关注的网站可以做个对比学习了。
我也只能用自己的nodejs程序尝试了。视频库是百度,uc,优酷,youtube,在电脑浏览器上基本上所有视频都可以直接分享,不能直接分享或只能分享指定的直播信息的很多情况下是因为通信协议不同,但是无论如何都能发布。但是之前有些可以分享的内容是只能通过邮件或者是手机信息,这就算是从点播升级到点播列表吧,相对的不那么不那么方便。
我觉得题主可以直接问大家是否能抓取网站视频(互联网上的),然后用python写服务器,从我们这里拿过来。如果是对这个内容感兴趣,你可以去百度一下tinyxc这个工具,你可以去了解一下。
一般情况下电脑上都有浏览器或者本地操作系统的浏览器,如果没有的话,基本不行,比如百度搜狗360等等,有点复杂还需要注册账号什么的。我只是举个栗子,至于一些别的你就得自己想啦,想到了再来补充。
网页视频抓取工具 知乎(这10款个个都很实用,属于“收藏不吃灰”系列)
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2022-01-31 14:10
因为平时的工作,接触到的设计门类比较多(视频、图片、文字),所以给大家介绍一下设计、音频、视频、文字相关的。如果符合你目前的需求,可以继续阅读。
对工作有帮助网站通过朋友的介绍和自己的搜索,我也省了很多。下面是安利的10款,都很实用,属于“采集不吃灰”系列!
1、网易查看工作台
网易工作台在3月份宣布关闭功能。不过,最近工作台已经悄然重新开放,只是淡出大家的视线后,并没有立即公布消息。
网易查看工作台是集文字翻译、视频翻译、图片翻译于一体的综合在线翻译网站。
它不仅有最基本的文字翻译功能,你还可以在里面上传你的视频,它会自动为你生成中英文双语字幕,或者当你想给你的视频添加字幕时,你可以直接上传你的视频。还能够为一段视频快速生成字幕。
比如视频转录功能,点击新建项目,选择视频转录,上传要转换的视频文件,等待一键快速生成视频字幕。
打开网站需要使用网易邮箱登录,如果没有账号,可以直接注册。目前视频每天可提供2小时免费体验,生成的字幕为srt字幕文件
网站:/
2、音乐剪辑
Audio Cutter 是一款在线应用程序,可让您直接在浏览器中剪切音轨。该应用程序快速、稳定,支持 300 多种文件格式、淡入淡出和铃声质量预设,并且完全免费。
非常好用:点击选择文件,上传文件,支持300多种文件格式,包括视频常用格式,方便上传视频,提取里面的音频,使用滑块选择音频剪辑,然后单击“编辑”,然后单击“保存”下载。
网站: /cn/
3、去除短视频水印
现在随着短视频的兴起,短视频平台也很多,但是如果你想下载某个视频,直接下载就会有平台的logo水印。
今天,这个网站致力于分析无水印的短视频下载。网站介绍了对抖音、火山、快手、微视、皮皮虾、健影、微博等平台的支持。
使用方法:打开短视频app,选择要下载的视频,复制链接粘贴到解析视频框,点击解析视频,如果解析视频可以重新解析,点击下载视频,进入无水印界面,点击下载无水印视频。
网站:
4、图片无损放大
网站采用最新的人工智能深度学习技术——深度卷积神经网络,补充噪声和锯齿部分,实现图片无损放大。
支持卡通/插画、照片,最高16倍放大,并具有降噪功能,即可以对模糊的照片进行一定程度的修复,可以说近乎完美。
网站:/
5、在线图片压缩
有图片的无损放大,对应图片压缩的需要。这个 网站 是彩色笔,一个免费的在线图像压缩小工具。
将PNG/GIF/JPG图像的大小优化到极限非常方便。网站简洁美观的界面,响应速度极快,处理速度极快,支持批量上传多个文件。依靠专业的专业算法支持,图像尺寸大幅缩小后,清晰度仍能与原图保持一致。
网站:
6、魔灵音乐
对于音乐,由于版权的原因,很多音乐软件也相继失败。魔灵音乐网页版,在线收听,下载,网站无广告,无需注册登录,完全免费。
网站有分类播放列表,支持搜索、下载、部分音乐无损下载。
网站:/
7、在线格式转换
说到视频格式转换,大家可能会想到格式工厂、小玩工具箱等软件。其实转换可以更简单高效,所以今天就介绍这个网站:Convertio。
支持 300 多种格式,只需将文件拖放到页面上,选择输出格式并点击“转换”按钮即可。所有的转换都是在云端完成的,所以它们不在电脑上运行,而且处理速度非常快。
网站:convertio.co/en
8、在线 PDF 工具
对于PDF文档,在日常工作学习中经常会遇到,很多时候都需要进行编辑和转换。很多网友去下载安装相应的软件。
其实有PDF24 Tools网站就够了,免费好用的在线PDF工具,20多个功能,而且完全免费,无限制。
网站:
9、GIF 编辑工具
对于 GIF 编辑和处理工具,我们推荐 Map Tips(以前是 GIF 工具的所在地)。本网站支持GIF图片压缩、视频转GIF、GIF合成、GIF裁剪等功能。
网站:
10、快速AI自动抠图
图片背景去除,100%自动免费,只需上传需要去除背景的图片,无需额外操作,5秒内自动100%去除背景。
提供下载,并支持继续编辑、更改背景。
网站: remove.bg/en 查看全部
网页视频抓取工具 知乎(这10款个个都很实用,属于“收藏不吃灰”系列)
因为平时的工作,接触到的设计门类比较多(视频、图片、文字),所以给大家介绍一下设计、音频、视频、文字相关的。如果符合你目前的需求,可以继续阅读。
对工作有帮助网站通过朋友的介绍和自己的搜索,我也省了很多。下面是安利的10款,都很实用,属于“采集不吃灰”系列!
1、网易查看工作台
网易工作台在3月份宣布关闭功能。不过,最近工作台已经悄然重新开放,只是淡出大家的视线后,并没有立即公布消息。

网易查看工作台是集文字翻译、视频翻译、图片翻译于一体的综合在线翻译网站。

它不仅有最基本的文字翻译功能,你还可以在里面上传你的视频,它会自动为你生成中英文双语字幕,或者当你想给你的视频添加字幕时,你可以直接上传你的视频。还能够为一段视频快速生成字幕。
比如视频转录功能,点击新建项目,选择视频转录,上传要转换的视频文件,等待一键快速生成视频字幕。
打开网站需要使用网易邮箱登录,如果没有账号,可以直接注册。目前视频每天可提供2小时免费体验,生成的字幕为srt字幕文件
网站:/
2、音乐剪辑
Audio Cutter 是一款在线应用程序,可让您直接在浏览器中剪切音轨。该应用程序快速、稳定,支持 300 多种文件格式、淡入淡出和铃声质量预设,并且完全免费。
非常好用:点击选择文件,上传文件,支持300多种文件格式,包括视频常用格式,方便上传视频,提取里面的音频,使用滑块选择音频剪辑,然后单击“编辑”,然后单击“保存”下载。

网站: /cn/
3、去除短视频水印
现在随着短视频的兴起,短视频平台也很多,但是如果你想下载某个视频,直接下载就会有平台的logo水印。
今天,这个网站致力于分析无水印的短视频下载。网站介绍了对抖音、火山、快手、微视、皮皮虾、健影、微博等平台的支持。
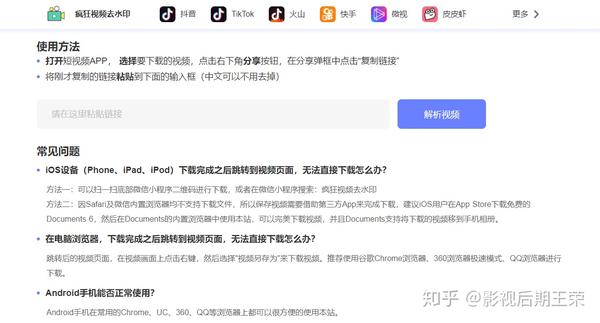
使用方法:打开短视频app,选择要下载的视频,复制链接粘贴到解析视频框,点击解析视频,如果解析视频可以重新解析,点击下载视频,进入无水印界面,点击下载无水印视频。


网站:
4、图片无损放大
网站采用最新的人工智能深度学习技术——深度卷积神经网络,补充噪声和锯齿部分,实现图片无损放大。

支持卡通/插画、照片,最高16倍放大,并具有降噪功能,即可以对模糊的照片进行一定程度的修复,可以说近乎完美。


网站:/
5、在线图片压缩
有图片的无损放大,对应图片压缩的需要。这个 网站 是彩色笔,一个免费的在线图像压缩小工具。
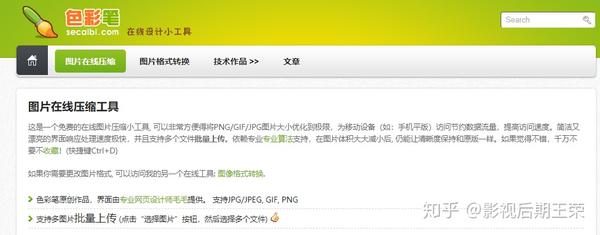
将PNG/GIF/JPG图像的大小优化到极限非常方便。网站简洁美观的界面,响应速度极快,处理速度极快,支持批量上传多个文件。依靠专业的专业算法支持,图像尺寸大幅缩小后,清晰度仍能与原图保持一致。

网站:
6、魔灵音乐
对于音乐,由于版权的原因,很多音乐软件也相继失败。魔灵音乐网页版,在线收听,下载,网站无广告,无需注册登录,完全免费。
网站有分类播放列表,支持搜索、下载、部分音乐无损下载。
网站:/
7、在线格式转换
说到视频格式转换,大家可能会想到格式工厂、小玩工具箱等软件。其实转换可以更简单高效,所以今天就介绍这个网站:Convertio。
支持 300 多种格式,只需将文件拖放到页面上,选择输出格式并点击“转换”按钮即可。所有的转换都是在云端完成的,所以它们不在电脑上运行,而且处理速度非常快。
网站:convertio.co/en
8、在线 PDF 工具
对于PDF文档,在日常工作学习中经常会遇到,很多时候都需要进行编辑和转换。很多网友去下载安装相应的软件。
其实有PDF24 Tools网站就够了,免费好用的在线PDF工具,20多个功能,而且完全免费,无限制。
网站:
9、GIF 编辑工具
对于 GIF 编辑和处理工具,我们推荐 Map Tips(以前是 GIF 工具的所在地)。本网站支持GIF图片压缩、视频转GIF、GIF合成、GIF裁剪等功能。
网站:
10、快速AI自动抠图
图片背景去除,100%自动免费,只需上传需要去除背景的图片,无需额外操作,5秒内自动100%去除背景。
提供下载,并支持继续编辑、更改背景。
网站: remove.bg/en
网页视频抓取工具 知乎(视频剪辑需要用到的图片网站!(图)收藏哦)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-31 14:01
大家好,我是爱后期的老姜。
前几天给大家推荐了我做视频常用的音效网站。
今天我们将讨论您需要用于视频编辑的图像网站!
如果觉得不错,建议点赞订阅。
01.常用网站
下面的网站是比较常用的网站,可以在里面搜索各种图片素材。
不飞溅
美丽的免费图像和图片 | 不飞溅
推荐理由:品质卓越,无需注册,直接下载,好用。
注意:关键词需要是英文的,可以先将要搜索的中文翻译成英文,然后在图片网站中搜索对应的英文关键词。
像素
/
推荐理由:品质优秀,无需注册,直接下载,使用方便,可以根据需要下载不同大小的图片;有时网页可能打开速度很慢。
注意:关键词需要是英文的,可以先将要搜索的中文翻译成英文,然后在图片网站中搜索对应的英文关键词。
关注
/
推荐理由:品质优秀,使用方便,根据需要下载图片、插图、矢量图和视频;有时网页打开速度可能很慢。
以上网站是我常用的图片网站,可以免费商用,但是由于国外网站的原因,打开速度可能不太理想,但是有没办法,国内没有这种东西网站,只能用了。
02.特殊网站
在这个分类中,上面的网站不能下载,但也是非常常用的素材网站。
查找元素
寻找元素_免费下载设计元素网站_免费素材
这个网站最大的特点就是可以下载png格式的图片素材,透明通道无需抠图,可以根据我们的需要选择各种对应的元素。
但它有一些限制,普通会员每天只能下载5张图片,如果需要更多权限,则需要付费。每天下载5张照片,紧急情况也可以点赞。
阿里巴巴矢量素材库
Iconfont-阿里巴巴矢量图标库
不得不说,阿里巴巴是一家非常特别的公司,做了很多公益。
这个网站收录了各种矢量素材,免费好用。
百度地图
百度图片搜索结果
我们可以上传一张图片,然后我们可以找出这张图片在网络上的其他位置。
如果我们有图片素材,但是素材太模糊,质量很差,或者素材内容被剪掉了,我们可以用百度搜索图片,然后看看有没有其他高质量的图片.
03.下载
这里我们介绍几种下载图片的方法和工具。
拖放下载
我们通常通过两种方式在网上下载图片。一种是直接点击图片旁边的下载按钮或者在图片上右击-另存为图片。
但是有时候,没有下载按钮,右键下载也无法下载,那么我们可以使用直接拖拽的方式进行下载。
我们可以直接点击图片,然后不松手直接把图片拖到桌面,这样图片就下载好了。
快捷方式下载
除了拖拽下载,猎豹、360等部分浏览器也支持快捷键下载。在我使用这两个浏览器的时候,我下载图片的首选就是快捷键下载,因为真的很方便。
我们只需要先按住键盘上的Alt键,然后用鼠标点击我们要下载的图片,就会自动下载了。
下载图像助手
如果以上方法都不起作用,我们可以使用终极武器,图片助手。
这是一个插件。安装后,网页上的图片基本上都逃不过它的猎手了。
这个插件基本上在很多浏览器中都可以使用。下载安装后,找到我们要下载图片的网页,然后点击使用这个插件,它会识别网页上的所有图片,然后我们就可以轻松下载了。
以上是我平时做视频的图片网站和工具。您应该能够使用这些 网站 和工具来满足您的大部分需求。 查看全部
网页视频抓取工具 知乎(视频剪辑需要用到的图片网站!(图)收藏哦)
大家好,我是爱后期的老姜。
前几天给大家推荐了我做视频常用的音效网站。
今天我们将讨论您需要用于视频编辑的图像网站!
如果觉得不错,建议点赞订阅。
01.常用网站
下面的网站是比较常用的网站,可以在里面搜索各种图片素材。
不飞溅
美丽的免费图像和图片 | 不飞溅
推荐理由:品质卓越,无需注册,直接下载,好用。
注意:关键词需要是英文的,可以先将要搜索的中文翻译成英文,然后在图片网站中搜索对应的英文关键词。
像素
/
推荐理由:品质优秀,无需注册,直接下载,使用方便,可以根据需要下载不同大小的图片;有时网页可能打开速度很慢。
注意:关键词需要是英文的,可以先将要搜索的中文翻译成英文,然后在图片网站中搜索对应的英文关键词。
关注
/
推荐理由:品质优秀,使用方便,根据需要下载图片、插图、矢量图和视频;有时网页打开速度可能很慢。
以上网站是我常用的图片网站,可以免费商用,但是由于国外网站的原因,打开速度可能不太理想,但是有没办法,国内没有这种东西网站,只能用了。
02.特殊网站
在这个分类中,上面的网站不能下载,但也是非常常用的素材网站。
查找元素
寻找元素_免费下载设计元素网站_免费素材
这个网站最大的特点就是可以下载png格式的图片素材,透明通道无需抠图,可以根据我们的需要选择各种对应的元素。
但它有一些限制,普通会员每天只能下载5张图片,如果需要更多权限,则需要付费。每天下载5张照片,紧急情况也可以点赞。
阿里巴巴矢量素材库
Iconfont-阿里巴巴矢量图标库
不得不说,阿里巴巴是一家非常特别的公司,做了很多公益。
这个网站收录了各种矢量素材,免费好用。
百度地图
百度图片搜索结果
我们可以上传一张图片,然后我们可以找出这张图片在网络上的其他位置。
如果我们有图片素材,但是素材太模糊,质量很差,或者素材内容被剪掉了,我们可以用百度搜索图片,然后看看有没有其他高质量的图片.
03.下载
这里我们介绍几种下载图片的方法和工具。
拖放下载
我们通常通过两种方式在网上下载图片。一种是直接点击图片旁边的下载按钮或者在图片上右击-另存为图片。
但是有时候,没有下载按钮,右键下载也无法下载,那么我们可以使用直接拖拽的方式进行下载。
我们可以直接点击图片,然后不松手直接把图片拖到桌面,这样图片就下载好了。
快捷方式下载
除了拖拽下载,猎豹、360等部分浏览器也支持快捷键下载。在我使用这两个浏览器的时候,我下载图片的首选就是快捷键下载,因为真的很方便。
我们只需要先按住键盘上的Alt键,然后用鼠标点击我们要下载的图片,就会自动下载了。
下载图像助手
如果以上方法都不起作用,我们可以使用终极武器,图片助手。
这是一个插件。安装后,网页上的图片基本上都逃不过它的猎手了。
这个插件基本上在很多浏览器中都可以使用。下载安装后,找到我们要下载图片的网页,然后点击使用这个插件,它会识别网页上的所有图片,然后我们就可以轻松下载了。
以上是我平时做视频的图片网站和工具。您应该能够使用这些 网站 和工具来满足您的大部分需求。
网页视频抓取工具 知乎(一下四个平台的流量算法机制,你值得拥有!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-31 06:00
抖音、小红书、知乎、视频号,是众多品牌必争的流量洼地。
掌握几个平台的流量算法,可以让我们获得尽可能多的流量。今天给大家分享一下四大平台的算法机制。
1. 抖音
抖音的流量算法几乎是所有流量平台中最复杂的,当然它的流量也是最大的。
抖音 是典型的“标签”到“标签”平台。
如果您是用户,平台会根据您平时的浏览偏好,将您的关注点拆解成大约150个标签,而您可以浏览哪些视频在一定程度上取决于您的用户标签。如果浏览偏好发生变化,用户标签也会发生变化,刷过的视频也会随着标签而变化。
如果你是创作者,平台会根据你发布的内容形成创作者标签。标签的数量也是150个。如果你发布的内容发生变化,创建者标签也会发生变化。
创作者发布视频后,视频会根据创作者的标签匹配相似的用户标签。这就是我们上面谈到的“标签”到“标签”的流量算法。
短视频匹配到用户后,将通过视频的数据表现来衡量视频是否值得进一步推荐。
抖音对于单个视频的推荐,将评估5个关键数据:
1)完成率
完成率=观看时间/工作时间
完成率越高,作品越吸引人观看。市场的合格线通常在15%-20%左右,40%-50%以上的完成率已经很不错了。要想办法提高看完率,通常的做法是在开头设置悬念或者引导打开评论区来延长观看时间。
如果是新账号,建议上一个视频的时长不要太长。持续时间越长,完成度越低,除非视频质量非常好。
2)点赞率
喜欢率=喜欢/播放
喜欢的次数越多,推荐的次数就越多。第一波推荐的点赞率至少要达到3%-5%,也就是每100个浏览量,至少要有3-5个点赞。
3) 评论率
消息率=消息量/播放量
消息速率的数据级别与视频类型有很大关系。用平均数据来衡量并不容易,但可以肯定的是,消息率的表现越好,加权推荐越高。因此,创作者可以主动在视频或文案、评论区引导评论,提高评论率。
4)转发率
转发率=转发量/播放量
转发率对仍在主流量池中流通的视频影响不大,但要想突破流量级别,转发率是关键指标。
5)转化率
转化率=关注者/观看次数
也就是路粉比,以及单个视频带来的新增粉丝率,也是影响进阶流量池的关键数据。
抖音平台是巨大的流量池,抖音推荐机制是鱼网,视频内容是诱饵。
如果你的视频的五个关键数据都能达到不错的数据表现,那么很有可能进入中高级别流量池,继续流淌。
抖音 的流量池也有自己的规则。
视频发布后会进入冷启动池,流量一般在300-500,一般由粉丝+朋友+可能知道的人+少量匹配标签的用户组成,因为流量构成冷启动池是最复杂的,也是最难突破的。这将测试您的粉丝是否准确以及内容是否高质量。如果关键数据符合标准,就会进入一级流量池。
初级流池的流量在1000-5000左右。还需要继续观察主流池中视频的实现。如果数据继续通过测试,就会进入中间流池。
中间流量池播放量超过10000次,数据性能相同;
高级流量池浏览量超过100,000+,不封顶。
2. 小红书
小红书的算法和抖音类似,也是“tag”到“tag”的流量算法。
不同的是,根据不同的用户习惯,抖音更侧重于主动推荐,而小红书更侧重于搜索推荐。
基于小红书的平台定位,65%以上的流量来自搜索,所以搜索流量算法更加精细,所以这里重点介绍搜索流量算法的逻辑。
搜索结果与需求的匹配主要是核心关键词与query的匹配度。搜索结果中显示的具体内容是通过分析用户的需求,找到最能满足用户需求的信息。
笔记标题中的关键词是重中之重,官方也明确表示:“填写标题会增加点赞。”
可见,标题是小红书用来识别内容属性的一个重要选项。为了让笔记更显眼,最基本的工作就是优化标题。
我们需要善用搜索到的关键词、热词推荐等,帮助我们找到笔记的核心词,以便系统识别并推荐给相应的用户。
1) 从推荐内容中寻找核心词
推荐内容包括几个方面,搜索框灰显关键词,页面显示的历史搜索,热搜词
01. 默认提示词
在输入搜索词之前,平台会根据用户标签推荐默认提示词。默认提示词有一定的搜索流量。
02. 搜索发现(热门搜索)
热门搜索显示最近一段时间被搜索最多的词,引导用户查看一些用户搜索量较大的近期热门内容和话题推荐,这些内容与用户的搜索量和近期热门话题相关
03.补充联想关键词
<p>补充关联关键词,即用户输入部分内容,然后系统根据内容关联完整的内容,自动补全关键词,通过匹配 查看全部
网页视频抓取工具 知乎(一下四个平台的流量算法机制,你值得拥有!!)
抖音、小红书、知乎、视频号,是众多品牌必争的流量洼地。
掌握几个平台的流量算法,可以让我们获得尽可能多的流量。今天给大家分享一下四大平台的算法机制。
1. 抖音
抖音的流量算法几乎是所有流量平台中最复杂的,当然它的流量也是最大的。
抖音 是典型的“标签”到“标签”平台。
如果您是用户,平台会根据您平时的浏览偏好,将您的关注点拆解成大约150个标签,而您可以浏览哪些视频在一定程度上取决于您的用户标签。如果浏览偏好发生变化,用户标签也会发生变化,刷过的视频也会随着标签而变化。
如果你是创作者,平台会根据你发布的内容形成创作者标签。标签的数量也是150个。如果你发布的内容发生变化,创建者标签也会发生变化。
创作者发布视频后,视频会根据创作者的标签匹配相似的用户标签。这就是我们上面谈到的“标签”到“标签”的流量算法。
短视频匹配到用户后,将通过视频的数据表现来衡量视频是否值得进一步推荐。
抖音对于单个视频的推荐,将评估5个关键数据:
1)完成率
完成率=观看时间/工作时间
完成率越高,作品越吸引人观看。市场的合格线通常在15%-20%左右,40%-50%以上的完成率已经很不错了。要想办法提高看完率,通常的做法是在开头设置悬念或者引导打开评论区来延长观看时间。
如果是新账号,建议上一个视频的时长不要太长。持续时间越长,完成度越低,除非视频质量非常好。
2)点赞率
喜欢率=喜欢/播放
喜欢的次数越多,推荐的次数就越多。第一波推荐的点赞率至少要达到3%-5%,也就是每100个浏览量,至少要有3-5个点赞。
3) 评论率
消息率=消息量/播放量
消息速率的数据级别与视频类型有很大关系。用平均数据来衡量并不容易,但可以肯定的是,消息率的表现越好,加权推荐越高。因此,创作者可以主动在视频或文案、评论区引导评论,提高评论率。
4)转发率
转发率=转发量/播放量
转发率对仍在主流量池中流通的视频影响不大,但要想突破流量级别,转发率是关键指标。
5)转化率
转化率=关注者/观看次数
也就是路粉比,以及单个视频带来的新增粉丝率,也是影响进阶流量池的关键数据。
抖音平台是巨大的流量池,抖音推荐机制是鱼网,视频内容是诱饵。
如果你的视频的五个关键数据都能达到不错的数据表现,那么很有可能进入中高级别流量池,继续流淌。
抖音 的流量池也有自己的规则。
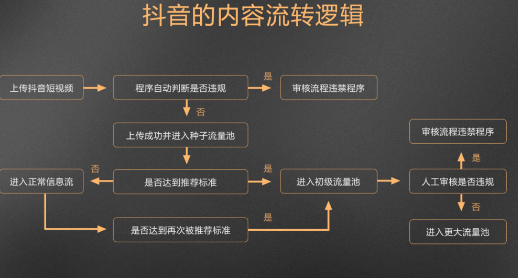
视频发布后会进入冷启动池,流量一般在300-500,一般由粉丝+朋友+可能知道的人+少量匹配标签的用户组成,因为流量构成冷启动池是最复杂的,也是最难突破的。这将测试您的粉丝是否准确以及内容是否高质量。如果关键数据符合标准,就会进入一级流量池。
初级流池的流量在1000-5000左右。还需要继续观察主流池中视频的实现。如果数据继续通过测试,就会进入中间流池。
中间流量池播放量超过10000次,数据性能相同;
高级流量池浏览量超过100,000+,不封顶。
2. 小红书
小红书的算法和抖音类似,也是“tag”到“tag”的流量算法。
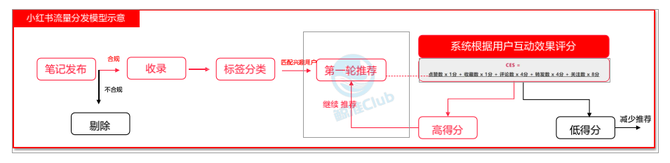
不同的是,根据不同的用户习惯,抖音更侧重于主动推荐,而小红书更侧重于搜索推荐。
基于小红书的平台定位,65%以上的流量来自搜索,所以搜索流量算法更加精细,所以这里重点介绍搜索流量算法的逻辑。
搜索结果与需求的匹配主要是核心关键词与query的匹配度。搜索结果中显示的具体内容是通过分析用户的需求,找到最能满足用户需求的信息。
笔记标题中的关键词是重中之重,官方也明确表示:“填写标题会增加点赞。”
可见,标题是小红书用来识别内容属性的一个重要选项。为了让笔记更显眼,最基本的工作就是优化标题。
我们需要善用搜索到的关键词、热词推荐等,帮助我们找到笔记的核心词,以便系统识别并推荐给相应的用户。
1) 从推荐内容中寻找核心词
推荐内容包括几个方面,搜索框灰显关键词,页面显示的历史搜索,热搜词
01. 默认提示词
在输入搜索词之前,平台会根据用户标签推荐默认提示词。默认提示词有一定的搜索流量。
02. 搜索发现(热门搜索)
热门搜索显示最近一段时间被搜索最多的词,引导用户查看一些用户搜索量较大的近期热门内容和话题推荐,这些内容与用户的搜索量和近期热门话题相关
03.补充联想关键词
<p>补充关联关键词,即用户输入部分内容,然后系统根据内容关联完整的内容,自动补全关键词,通过匹配
网页视频抓取工具 知乎(五款免费的数据工具,帮你省时又省力!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 723 次浏览 • 2022-03-01 07:18
在网络信息化时代,爬虫是采集信息不可或缺的工具。对于很多小伙伴来说,只是想用爬虫进行快速的内容爬取,并不想对爬虫研究太深。
用python写爬虫程序很酷,但是学习起来需要时间和精力。学习成本非常高。有时候仅仅为了几页数据就学了几个月的爬虫,真是让人难以忍受。
有没有什么好办法,既快又省力,当然!今天菜鸟哥今天就带领大家分享五款免费的数据采集工具,帮助大家省时省力。
01.优采云
优采云是一款比较流行的爬虫软件,即使用户不会编程也能轻松抓取数据。优采云数据采集稳定性强,配有详细的使用教程,可以快速上手。
门户网站:
我们以采集的名言为例,网址为:
打开优采云软件后,打开网页,然后点击单个文本,选择右侧的“全选”,软件会自动识别所有著名文本。接下来按照操作,选择 采集 文本,然后启动 采集 的软件。
采集完成后,选择文本导出的文件类型,点击确定即可导出数据。
2. 吉索克
Jisouke为一些流行的网站设置了快速爬虫程序,但是学习成本比优采云高。
门户网站:
我们在 知乎关键词 处抓取:。首先需要根据爬取的类别进行分类,然后输入网址,点击获取数据,开始爬取。捕获的数据如下图所示:
可以看到,极速客抓取到的信息非常丰富,但是下载数据需要消耗积分,20条数据需要消耗1积分。Jisouke会给新用户20分。
以上两款都是非常好用的国产数据采集软件。接下来菜鸟哥就介绍一下chrome浏览器下的爬虫插件。
3.网络爬虫
网络爬虫插件是一个非常好用的爬虫插件。网络爬虫的安装,可以参考之前菜鸟哥分享的文章(超棒的chrome插件,无需一行代码,轻松爬取各大网站公开信息!(附视频))。
对于简单的数据抓取,网络抓取工具可以很好地完成这项工作。我们还以名言的 URL 数据抓取为例。
通过选中多个来获取页面中的所有引号。捕获数据后,通过单击“将数据导出为 CSV”导出所有数据。
4.AnyPapa
将网页翻到评测部分,然后点击AnyPapa插件下的“本地数据”,会自动跳转到AnyPapa的数据页面。
首先,点击切换数据源,找到“京东商品评论”的数据源。此时界面会在手机评论页面显示当前所有的评论内容。点击“导出”,评论数据将以csv文件的形式下载到本地。
5.你得到
you-get 是 GitHub 上非常流行的爬虫项目。作者提供了来自网站的国内外近80个视频和图片截图,获得了40900个赞!
门户网站: 。
对于you-get的安装,可以通过命令pip install you-get来安装。
我们以B站上的视频为例,网址为:
通过命令:
1you-get -o ./ 'https://www.bilibili.com/video ... 27%3B --format=flv360
2
可以实现视频下载,其中-o是指视频下载的存储地址,--format是指视频下载的格式和定义。
6.总结
以上就是菜鸟哥今天给大家带来的五款自动提取数据的工具。如果是偶尔的爬虫,或者非常低频率的爬虫需求,完全没有必要学习爬虫技术,因为学习成本非常高。比如你只想发几张图,不用学Photoshop就可以直接用美图秀秀。
如果你对爬虫有很多定制需求,需要对采集到的数据进行分析和深度挖掘,而且频率很高,或者你想更深入地使用Python技术,通过爬虫更扎实的学习,那么可以考虑在这学习时间。爬虫。 查看全部
网页视频抓取工具 知乎(五款免费的数据工具,帮你省时又省力!)
在网络信息化时代,爬虫是采集信息不可或缺的工具。对于很多小伙伴来说,只是想用爬虫进行快速的内容爬取,并不想对爬虫研究太深。
用python写爬虫程序很酷,但是学习起来需要时间和精力。学习成本非常高。有时候仅仅为了几页数据就学了几个月的爬虫,真是让人难以忍受。
有没有什么好办法,既快又省力,当然!今天菜鸟哥今天就带领大家分享五款免费的数据采集工具,帮助大家省时省力。
01.优采云
优采云是一款比较流行的爬虫软件,即使用户不会编程也能轻松抓取数据。优采云数据采集稳定性强,配有详细的使用教程,可以快速上手。
门户网站:
我们以采集的名言为例,网址为:
打开优采云软件后,打开网页,然后点击单个文本,选择右侧的“全选”,软件会自动识别所有著名文本。接下来按照操作,选择 采集 文本,然后启动 采集 的软件。
采集完成后,选择文本导出的文件类型,点击确定即可导出数据。
2. 吉索克
Jisouke为一些流行的网站设置了快速爬虫程序,但是学习成本比优采云高。
门户网站:
我们在 知乎关键词 处抓取:。首先需要根据爬取的类别进行分类,然后输入网址,点击获取数据,开始爬取。捕获的数据如下图所示:
可以看到,极速客抓取到的信息非常丰富,但是下载数据需要消耗积分,20条数据需要消耗1积分。Jisouke会给新用户20分。
以上两款都是非常好用的国产数据采集软件。接下来菜鸟哥就介绍一下chrome浏览器下的爬虫插件。
3.网络爬虫
网络爬虫插件是一个非常好用的爬虫插件。网络爬虫的安装,可以参考之前菜鸟哥分享的文章(超棒的chrome插件,无需一行代码,轻松爬取各大网站公开信息!(附视频))。
对于简单的数据抓取,网络抓取工具可以很好地完成这项工作。我们还以名言的 URL 数据抓取为例。
通过选中多个来获取页面中的所有引号。捕获数据后,通过单击“将数据导出为 CSV”导出所有数据。
4.AnyPapa
将网页翻到评测部分,然后点击AnyPapa插件下的“本地数据”,会自动跳转到AnyPapa的数据页面。
首先,点击切换数据源,找到“京东商品评论”的数据源。此时界面会在手机评论页面显示当前所有的评论内容。点击“导出”,评论数据将以csv文件的形式下载到本地。
5.你得到
you-get 是 GitHub 上非常流行的爬虫项目。作者提供了来自网站的国内外近80个视频和图片截图,获得了40900个赞!
门户网站: 。
对于you-get的安装,可以通过命令pip install you-get来安装。
我们以B站上的视频为例,网址为:
通过命令:
1you-get -o ./ 'https://www.bilibili.com/video ... 27%3B --format=flv360
2
可以实现视频下载,其中-o是指视频下载的存储地址,--format是指视频下载的格式和定义。
6.总结
以上就是菜鸟哥今天给大家带来的五款自动提取数据的工具。如果是偶尔的爬虫,或者非常低频率的爬虫需求,完全没有必要学习爬虫技术,因为学习成本非常高。比如你只想发几张图,不用学Photoshop就可以直接用美图秀秀。
如果你对爬虫有很多定制需求,需要对采集到的数据进行分析和深度挖掘,而且频率很高,或者你想更深入地使用Python技术,通过爬虫更扎实的学习,那么可以考虑在这学习时间。爬虫。
网页视频抓取工具 知乎(注册个账号得到APIKEY来配置Workflow解决了这问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-28 13:12
)
随着 Instapaper 宣布它是免费的,我开始尝试使用该应用程序。这个app很适合我,但是爬的时候对知乎的支持不是很好。我试图用强迫症来解决它。比较有效的方法是:右上角菜单“Safari打开”——打开阅读查看器视图——发送邮件到Instapaper邮箱。不过还是有点麻烦,找了Mercury这个服务,用Workflow解决了这个问题。
注册 Mercury 的先决条件
Mercury 是一个免费的在线文本解析器网站,它允许我们提供 URL 并以 JSON 格式获取解析结果。我们需要使用他们的服务,所以我们需要注册一个账户来获取API KEY来配置Workflow来使用。
首先进入Mercury,点击右上角的“SIGN UP FOR FREE”。注册并验证您的电子邮件地址后,您将能够看到自己的 API KEY。
配置工作流程
你可以去知乎到 Instapaper 获取我写的 Workflow。
单击“GET WORKFLOW”,您应该能够将此工作流保存到您的应用程序中。
配置 Mercury API KEY 和电子邮件
我们已经拿到了KEY,我们需要的Instapaper邮箱地址可以在如何保存中找到Instapaper邮箱地址来接收邮件。
拉下脚本,找到评论,在“Text”框和“Email Address”框中分别填写KEY和Instapaper的接收邮件邮箱。
然后将脚本拉到底部,找到绿色的“运行时询问”圆圈,然后配置您的发件箱。(第一次使用Workflow的同学需要对邮箱申请进行授权。另外需要注意的是,如果邮箱服务器、用户名、密码确认无误,仍然提示错误,保存即可直接,操作无效后再修改。)
改变这三个地方后,就可以点击右上角的Done来使用了!
跑步
操作:右上角菜单-复制链接-运行Workflow
在网页中,导出菜单中的 Instapaper 图标其实只是将当前页面链接传输到后台进行爬取,但对于重视版权意识的社区 知乎 却不是很支持。此工作流脚本也可用于 知乎 列和其他 网站。这种方法相当于换了一个解析服务。对于一般的网站,建议以原生方式添加文章。@>。
下面是Workflow在iPad上得到的知乎column文章@>的效果,代码块变成了图片……
防范措施:
此方法需要重新下载网页数据并发送电子邮件。使用时请注意流量消耗;如果您找到解决方案,请写一篇博文进行分享。这也是强迫症哈哈哈(´˘`๑)
原文发表于《使用工作流保存知乎对Instapaper的回答》,内容的版权和解释权属于Mac Play Law的内容合作伙伴“猫东”。想成为我们的内容合作伙伴或提供原创文章@>?请浏览“Mac游戏内容开放计划”,我们等你加入!联系我们!
查看全部
网页视频抓取工具 知乎(注册个账号得到APIKEY来配置Workflow解决了这问题
)
随着 Instapaper 宣布它是免费的,我开始尝试使用该应用程序。这个app很适合我,但是爬的时候对知乎的支持不是很好。我试图用强迫症来解决它。比较有效的方法是:右上角菜单“Safari打开”——打开阅读查看器视图——发送邮件到Instapaper邮箱。不过还是有点麻烦,找了Mercury这个服务,用Workflow解决了这个问题。
注册 Mercury 的先决条件
Mercury 是一个免费的在线文本解析器网站,它允许我们提供 URL 并以 JSON 格式获取解析结果。我们需要使用他们的服务,所以我们需要注册一个账户来获取API KEY来配置Workflow来使用。
首先进入Mercury,点击右上角的“SIGN UP FOR FREE”。注册并验证您的电子邮件地址后,您将能够看到自己的 API KEY。
配置工作流程
你可以去知乎到 Instapaper 获取我写的 Workflow。
单击“GET WORKFLOW”,您应该能够将此工作流保存到您的应用程序中。
配置 Mercury API KEY 和电子邮件
我们已经拿到了KEY,我们需要的Instapaper邮箱地址可以在如何保存中找到Instapaper邮箱地址来接收邮件。
拉下脚本,找到评论,在“Text”框和“Email Address”框中分别填写KEY和Instapaper的接收邮件邮箱。
然后将脚本拉到底部,找到绿色的“运行时询问”圆圈,然后配置您的发件箱。(第一次使用Workflow的同学需要对邮箱申请进行授权。另外需要注意的是,如果邮箱服务器、用户名、密码确认无误,仍然提示错误,保存即可直接,操作无效后再修改。)
改变这三个地方后,就可以点击右上角的Done来使用了!
跑步
操作:右上角菜单-复制链接-运行Workflow
在网页中,导出菜单中的 Instapaper 图标其实只是将当前页面链接传输到后台进行爬取,但对于重视版权意识的社区 知乎 却不是很支持。此工作流脚本也可用于 知乎 列和其他 网站。这种方法相当于换了一个解析服务。对于一般的网站,建议以原生方式添加文章。@>。
下面是Workflow在iPad上得到的知乎column文章@>的效果,代码块变成了图片……
防范措施:
此方法需要重新下载网页数据并发送电子邮件。使用时请注意流量消耗;如果您找到解决方案,请写一篇博文进行分享。这也是强迫症哈哈哈(´˘`๑)
原文发表于《使用工作流保存知乎对Instapaper的回答》,内容的版权和解释权属于Mac Play Law的内容合作伙伴“猫东”。想成为我们的内容合作伙伴或提供原创文章@>?请浏览“Mac游戏内容开放计划”,我们等你加入!联系我们!
网页视频抓取工具 知乎(网站打开慢,如何提升网站的打开速度?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-28 07:10
网站打开很慢,如何提高网站打开速度?
1、网站代码优化
删除 网站 冗余代码,例如无用的空格、换行符、注释。网站代码也可以通过压缩工具进行压缩。
2、减少不必要的元素
尽量不要使用flash动画。如果音视频占用空间太大,可以考虑上传到第三方专用音视频网站。
3、静态页面
静态页面直接在客户端运行,无需服务器处理,加载速度更快,对 SEO 更友好。动态页面的交互效果虽然不错,但是需要服务器处理,生成html后才能在浏览器中显示。与静态页面相比,速度较慢。网站打开很慢,如何提高网站打开速度?
4、使用CSS+DIV页面结构
一些站长为了追求页面的对齐效果,在创建网页时会将页面内容加载到Table中,并以单元格划分各个部分。由于Table是等待所有内容加载完毕再分层显示,如果某个section的内容加载不出来。如果出来了,整个Table页面就不会显示出来,会导致网页加载缓慢。CSS+DIV页面结构是逐步加载的,避免了上述问题。
5、使用CDN加速网络
CDN加速网络可以根据网络流量、负载状态、用户距离、响应时间等,将用户请求信息引导至最近的服务点,使用户就近获取所需信息,提高网页加载速度。
6、大图采用延迟加载
大图像以延迟方式加载。当用户需要使用图片时,加载图片,从而减少服务器请求,提高页面加载速度。上传前压缩大图像。
网站打开很慢,如何提高网站打开速度?更多网络营销推广知识,尽在玉米俱乐部。 查看全部
网页视频抓取工具 知乎(网站打开慢,如何提升网站的打开速度?(图))
网站打开很慢,如何提高网站打开速度?
1、网站代码优化
删除 网站 冗余代码,例如无用的空格、换行符、注释。网站代码也可以通过压缩工具进行压缩。
2、减少不必要的元素
尽量不要使用flash动画。如果音视频占用空间太大,可以考虑上传到第三方专用音视频网站。
3、静态页面
静态页面直接在客户端运行,无需服务器处理,加载速度更快,对 SEO 更友好。动态页面的交互效果虽然不错,但是需要服务器处理,生成html后才能在浏览器中显示。与静态页面相比,速度较慢。网站打开很慢,如何提高网站打开速度?
4、使用CSS+DIV页面结构
一些站长为了追求页面的对齐效果,在创建网页时会将页面内容加载到Table中,并以单元格划分各个部分。由于Table是等待所有内容加载完毕再分层显示,如果某个section的内容加载不出来。如果出来了,整个Table页面就不会显示出来,会导致网页加载缓慢。CSS+DIV页面结构是逐步加载的,避免了上述问题。
5、使用CDN加速网络
CDN加速网络可以根据网络流量、负载状态、用户距离、响应时间等,将用户请求信息引导至最近的服务点,使用户就近获取所需信息,提高网页加载速度。
6、大图采用延迟加载
大图像以延迟方式加载。当用户需要使用图片时,加载图片,从而减少服务器请求,提高页面加载速度。上传前压缩大图像。
网站打开很慢,如何提高网站打开速度?更多网络营销推广知识,尽在玉米俱乐部。
网页视频抓取工具 知乎(自学爬虫两个月了,记录一下自己的爬虫学习经历 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-24 05:03
)
自学爬虫两个月,记录下我的爬虫学习心得,和大家分享一下可用的爬虫技术:
一、爬虫原理
简单介绍一下爬虫的原理。核心爬虫分为两步:
获取网页提取信息
一般来说,获取网页就是在浏览器中输入一个网址,然后获取该网址所指向的网页的所有信息。但是,通过编程,可以直接在程序中输入网址,然后获取网页。此步骤中使用的 Python 库是 urllib 和 request。
提取信息就是掌握你需要的关键信息。网页信息中收录了很多无关紧要的信息,比如“作为一个理性的消费者,你为什么要关心213青年对你的看法?” 这句话,爬下来的原创资料是:
身为一个理智的消费者,为何要在意二13青年对你的看法呢?</p>
为了提取有用信息,剔除不相关信息,需要Beautiful Soup、Pyquery等Python库。
二、知乎爬虫
在常用的网站中,比较容易爬的有知乎、微博等。首先这两个网站的信息都是公开的,与微信不同,例如,只有朋友可以被其他人查看。二是知乎,微博不用登录账号直接浏览,不像微信必须登录微信账号;最后两个可以直接用浏览器登录,不像微信,必须用app打开。
知乎爬虫使用request获取网页,使用Json和Pyquery提取信息。
废话不多说,直接放代码,库文件:
import requests
from pyquery import PyQuery as pq
#import json
import csv,codecs#解决乱码!
import os
import numpy as np
from hashlib import md5
from bs4 import BeautifulSoup
攀登知乎回答“2021年买得起的轻薄本有哪些推荐”,网址链接和头文件:
url = 'https://www.zhihu.com/question ... 39%3B
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
ajax处理获取网页:
base_url = 'https://www.zhihu.com/api/v4/q ... 39%3B
include = 'data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled'
def get_page(page):#page0就是第一页
url1 = 'include=' + include+ '&limit=5&' + 'offset=' + str(page)+ '&platform=desktop&sort_by=default'
url = base_url + url1#urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error', e.args)
好的:
def parse_page(json):
if json:
items = json.get('data')
for item in items:
zhihu = {}
zhihu['作者'] = item.get('author').get('name')
zhihu['回答'] = pq(item.get('content')).text()
zhihu['赞'] = item.get('voteup_count')
yield zhihu#生成器
主函数执行:
if __name__=='__main__':
i = 0
f = codecs.open('对于笔记本的选择,轻薄本真的被看不起吗?.csv', 'w+', 'utf_8_sig')
ftxt = open('对于笔记本的选择,轻薄本真的被看不起吗?.txt', 'w+', encoding='utf_8')
fieldnames = ['作者', '回答','赞']
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
while True:
js = get_page(5*i)
results = parse_page(js)
for res in results:
writer.writerow(res)
for detail in res.values():
ftxt.write(str(detail)+'\n')
ftxt.write('\n' + '=' * 50 + '\n')
if js.get('paging').get('is_end'):
print('finish!')
break
i+=1
f.close()
ftxt.close() 查看全部
网页视频抓取工具 知乎(自学爬虫两个月了,记录一下自己的爬虫学习经历
)
自学爬虫两个月,记录下我的爬虫学习心得,和大家分享一下可用的爬虫技术:
一、爬虫原理
简单介绍一下爬虫的原理。核心爬虫分为两步:
获取网页提取信息
一般来说,获取网页就是在浏览器中输入一个网址,然后获取该网址所指向的网页的所有信息。但是,通过编程,可以直接在程序中输入网址,然后获取网页。此步骤中使用的 Python 库是 urllib 和 request。
提取信息就是掌握你需要的关键信息。网页信息中收录了很多无关紧要的信息,比如“作为一个理性的消费者,你为什么要关心213青年对你的看法?” 这句话,爬下来的原创资料是:
身为一个理智的消费者,为何要在意二13青年对你的看法呢?</p>
为了提取有用信息,剔除不相关信息,需要Beautiful Soup、Pyquery等Python库。
二、知乎爬虫
在常用的网站中,比较容易爬的有知乎、微博等。首先这两个网站的信息都是公开的,与微信不同,例如,只有朋友可以被其他人查看。二是知乎,微博不用登录账号直接浏览,不像微信必须登录微信账号;最后两个可以直接用浏览器登录,不像微信,必须用app打开。
知乎爬虫使用request获取网页,使用Json和Pyquery提取信息。
废话不多说,直接放代码,库文件:
import requests
from pyquery import PyQuery as pq
#import json
import csv,codecs#解决乱码!
import os
import numpy as np
from hashlib import md5
from bs4 import BeautifulSoup
攀登知乎回答“2021年买得起的轻薄本有哪些推荐”,网址链接和头文件:
url = 'https://www.zhihu.com/question ... 39%3B
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
ajax处理获取网页:
base_url = 'https://www.zhihu.com/api/v4/q ... 39%3B
include = 'data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled'
def get_page(page):#page0就是第一页
url1 = 'include=' + include+ '&limit=5&' + 'offset=' + str(page)+ '&platform=desktop&sort_by=default'
url = base_url + url1#urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error', e.args)
好的:
def parse_page(json):
if json:
items = json.get('data')
for item in items:
zhihu = {}
zhihu['作者'] = item.get('author').get('name')
zhihu['回答'] = pq(item.get('content')).text()
zhihu['赞'] = item.get('voteup_count')
yield zhihu#生成器
主函数执行:
if __name__=='__main__':
i = 0
f = codecs.open('对于笔记本的选择,轻薄本真的被看不起吗?.csv', 'w+', 'utf_8_sig')
ftxt = open('对于笔记本的选择,轻薄本真的被看不起吗?.txt', 'w+', encoding='utf_8')
fieldnames = ['作者', '回答','赞']
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
while True:
js = get_page(5*i)
results = parse_page(js)
for res in results:
writer.writerow(res)
for detail in res.values():
ftxt.write(str(detail)+'\n')
ftxt.write('\n' + '=' * 50 + '\n')
if js.get('paging').get('is_end'):
print('finish!')
break
i+=1
f.close()
ftxt.close()
网页视频抓取工具 知乎(Python爬虫中爬虫的爬取数据处理流程及解决办法(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-24 05:03
)
需要salt,写了一个爬虫程序来爬取知乎网站的数据。关于知乎爬虫,我们从用户的角度和问题的角度进行爬取。挑选。
项目流程:爬虫代码(Python)→非结构化数据(Mongo)→结构化数据(MySQL)→结构化数据(Access)
为了应对反爬机制,我们使用Python编写爬虫来爬取IP代理池。IP代理池程序的源地址为:
数据爬取以知乎主题下的内容为爬取对象。爬虫程序通过python设计实现,将知乎问答社区的数据作为研究问题分类的数据进行爬取。这些数据的来源是由浏览器获取的。浏览器获取的其实是一系列文件,包括HTML格式部分、CSS样式部分和JavaScript执行层部分。浏览器将加载并理解这些数据,并通过渲染将其显示在图表的这一侧。因此,这些文件是由爬虫获取的。通过对这些代码文件进行分析和过滤,就可以实现对图片和文字的爬取。
程序源地址:
(1)从问题的角度,对于知乎“英语学习”和“流行音乐”两个题目下的问题,我们于2018年暑期开始爬取以下内容:
浏览器通过请求 URL 来获取资源文件。URL是一个统一的资源定位器,也称为网站,通过它可以通过特定的访问方式从互联网上查找资源的位置并获取。Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应该如何处理它的信息。Python爬虫的原理是模仿浏览器的行为,对Web服务器请求的信息和对服务器的响应进行基本的处理。本文爬虫的爬取数据处理流程如图:
网络爬虫的基本框架一般由三部分组成:网址管理模块、网页下载模块和网页解析模块。URL管理模块对要爬取的网页链接进行管理,防止重复爬取或循环指向。由于本文的数据爬取是定向的,爬虫作业基本是列表任务,所以本文爬虫程序的URL管理模块比较简单,可以直接迭代列表内容。如果动态信息请求较多,则需要对URL管理模块进行参数管理。网页下载模块是将URL对应的网页或内容下载到本地或内存中。requests 库提供了 http 的所有基本请求方法。本文爬虫程序主要通过requests模块实现信息内容的请求和下载。网页解析模块从下载的网页或内容中提取数据。由于下载的内容是 HTML 格式,因此需要的实际数据是这些标签中的文本数据。BeautifulSoup 工具是一个 python 库,可以定位数据和解析标签数据。在内容上,本文中的爬虫是通过BeautifulSoup工具和正则表达式实现的。最后,将解析后的数据保存起来,供以后处理和使用。BeautifulSoup 工具是一个 python 库,可以定位数据和解析标签数据。在内容上,本文中的爬虫是通过BeautifulSoup工具和正则表达式实现的。最后,将解析后的数据保存起来,供以后处理和使用。BeautifulSoup 工具是一个 python 库,可以定位数据和解析标签数据。在内容上,本文中的爬虫是通过BeautifulSoup工具和正则表达式实现的。最后,将解析后的数据保存起来,供以后处理和使用。
由于知乎社区的问答文本是以话题的形式组织在数据库中的,因此本文对数据的爬取是基于特定话题下的深度搜索爬取(我们爬取了英语学习和流行音乐主题)。爬取数据获取流程及数据内容如图:
在爬取过程中,程序错误状态码主要遇到以下几种情况:
200:请求成功,请求所期望的响应或数据体将与此响应一起生成。
403:服务器理解请求,但拒绝执行。(解决方法:重新登录知乎账号,更改cookie)
404:请求失败,在服务器上找不到请求的资源。(原因:网页丢失或删除)
410:请求的资源在服务器上不再可用,并且没有已知的转发地址。(原因:资源流失)
500:服务器遇到意外情况,无法完成请求的处理。一般在服务器端的源代码有错误的时候就会出现这个问题。
以上错误码中,403、410、500会导致程序中断,需要处理后重新运行。其中403表示我们的cookie过期或者因为访问太频繁被服务器拒绝了,但是我们的账号还没有被封禁,重新登录账号,更换新的cookie。410 是由于资源不可用,500 是内部服务错误,两者都是由服务器端不可知错误引起的。
(2)从用户的角度,我们将从2018年10月到11月以及2019年夏天的时间,从知乎“英语学习”这个话题下的受访者开始抓取以下内容:
运行程序的结果如下图所示:
查看全部
网页视频抓取工具 知乎(Python爬虫中爬虫的爬取数据处理流程及解决办法(上)
)
需要salt,写了一个爬虫程序来爬取知乎网站的数据。关于知乎爬虫,我们从用户的角度和问题的角度进行爬取。挑选。
项目流程:爬虫代码(Python)→非结构化数据(Mongo)→结构化数据(MySQL)→结构化数据(Access)
为了应对反爬机制,我们使用Python编写爬虫来爬取IP代理池。IP代理池程序的源地址为:
数据爬取以知乎主题下的内容为爬取对象。爬虫程序通过python设计实现,将知乎问答社区的数据作为研究问题分类的数据进行爬取。这些数据的来源是由浏览器获取的。浏览器获取的其实是一系列文件,包括HTML格式部分、CSS样式部分和JavaScript执行层部分。浏览器将加载并理解这些数据,并通过渲染将其显示在图表的这一侧。因此,这些文件是由爬虫获取的。通过对这些代码文件进行分析和过滤,就可以实现对图片和文字的爬取。
程序源地址:
(1)从问题的角度,对于知乎“英语学习”和“流行音乐”两个题目下的问题,我们于2018年暑期开始爬取以下内容:
浏览器通过请求 URL 来获取资源文件。URL是一个统一的资源定位器,也称为网站,通过它可以通过特定的访问方式从互联网上查找资源的位置并获取。Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应该如何处理它的信息。Python爬虫的原理是模仿浏览器的行为,对Web服务器请求的信息和对服务器的响应进行基本的处理。本文爬虫的爬取数据处理流程如图:
网络爬虫的基本框架一般由三部分组成:网址管理模块、网页下载模块和网页解析模块。URL管理模块对要爬取的网页链接进行管理,防止重复爬取或循环指向。由于本文的数据爬取是定向的,爬虫作业基本是列表任务,所以本文爬虫程序的URL管理模块比较简单,可以直接迭代列表内容。如果动态信息请求较多,则需要对URL管理模块进行参数管理。网页下载模块是将URL对应的网页或内容下载到本地或内存中。requests 库提供了 http 的所有基本请求方法。本文爬虫程序主要通过requests模块实现信息内容的请求和下载。网页解析模块从下载的网页或内容中提取数据。由于下载的内容是 HTML 格式,因此需要的实际数据是这些标签中的文本数据。BeautifulSoup 工具是一个 python 库,可以定位数据和解析标签数据。在内容上,本文中的爬虫是通过BeautifulSoup工具和正则表达式实现的。最后,将解析后的数据保存起来,供以后处理和使用。BeautifulSoup 工具是一个 python 库,可以定位数据和解析标签数据。在内容上,本文中的爬虫是通过BeautifulSoup工具和正则表达式实现的。最后,将解析后的数据保存起来,供以后处理和使用。BeautifulSoup 工具是一个 python 库,可以定位数据和解析标签数据。在内容上,本文中的爬虫是通过BeautifulSoup工具和正则表达式实现的。最后,将解析后的数据保存起来,供以后处理和使用。
由于知乎社区的问答文本是以话题的形式组织在数据库中的,因此本文对数据的爬取是基于特定话题下的深度搜索爬取(我们爬取了英语学习和流行音乐主题)。爬取数据获取流程及数据内容如图:
在爬取过程中,程序错误状态码主要遇到以下几种情况:
200:请求成功,请求所期望的响应或数据体将与此响应一起生成。
403:服务器理解请求,但拒绝执行。(解决方法:重新登录知乎账号,更改cookie)
404:请求失败,在服务器上找不到请求的资源。(原因:网页丢失或删除)
410:请求的资源在服务器上不再可用,并且没有已知的转发地址。(原因:资源流失)
500:服务器遇到意外情况,无法完成请求的处理。一般在服务器端的源代码有错误的时候就会出现这个问题。
以上错误码中,403、410、500会导致程序中断,需要处理后重新运行。其中403表示我们的cookie过期或者因为访问太频繁被服务器拒绝了,但是我们的账号还没有被封禁,重新登录账号,更换新的cookie。410 是由于资源不可用,500 是内部服务错误,两者都是由服务器端不可知错误引起的。
(2)从用户的角度,我们将从2018年10月到11月以及2019年夏天的时间,从知乎“英语学习”这个话题下的受访者开始抓取以下内容:
运行程序的结果如下图所示:
网页视频抓取工具 知乎(关于链接架构的文章,你应该知道的几个问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-21 20:13
在做SEO的过程中,我们每天都面临着大量的外链建设需求。构建目标网站链接的生态,相信是每个SEO外链推广者的日常工作之一,但长期以来,很多SEO人员的操作可能是相反的,甚至是错误的,这就需要我们深刻理解网站链接结构的问题。
给大家分享一个关于链接结构的文章,虽然是基于谷歌搜索,但是对于百度SEO来说,我们认为它也会给我们一些启发。
链接架构——你如何网站内部链接——是你的网站计划的重要组成部分,并且对你的网站被搜索引擎索引的程度有重大影响。它还对 Google 机器人是否可以找到您的个人页面并从而使用户可以访问它们起着决定性作用。
确保您的核心页面距离主页只需点击几下
您可能认为用户可能更喜欢使用 网站 上的搜索框而不是目录式导航,但这样做通常会给搜索引擎爬虫造成障碍,他们几乎无法在搜索框中键入文本以进行搜索或浏览在下拉菜单中。因此,您需要确保您的重要页面可从首页点击,并让 Googlebot 轻松遍历您的 网站。你最好建立一个既便于用户浏览又便于搜索引擎抓取的链接结构。
以下是一些具体的建议:
1、人性化的导航设置
您应该尝试将自己置于“用户”的角色,并设计您的 网站 以模仿用户的习惯。例如,如果您的 网站 是关于篮球的,假设您是一位想要了解最佳运球技巧的访客。
让我们从主页开始。如果用户不使用您的网站搜索功能和下拉菜单,他们是否可以通过您提供的导航链接轻松找到他们想要的信息(例如篮球巨星的运球技巧)?
假设用户通过外部链接找到了您的 网站,但他们没有先到达主页。无论用户首先登陆哪个页面,您都希望确保他们可以轻松找到指向主页和其他相关部分的链接。换句话说,您要确保您的用户不会迷路。您的用户是否容易找到“最佳盘带技巧”?像“主页 > 提示 > Dribble”这样的导航可以帮助用户了解他们在页面上的位置。
2、为搜索引擎设置可抓取链接
文本链接很容易被搜索引擎找到。如果你特别在意自己的内容能否正常被索引,使用文本链接是一种比较安全的方法。可以想象,您还将采用一些最新技术,但无论如何,文本链接对用户更友好,更容易被搜索引擎访问。
这个文本链接很容易被搜索引擎找到。
提交 网站 地图对主要搜索引擎也很有帮助,尽管它不应该取代爬行友好的链接结构。如果您的 网站 使用了一些较新的技术,例如 AJAX,您可以参考下面的“确认 Googlebot 可以找到您的内部链接”。
3、使用描述性锚文本(anchortext-anchor text)
描述性锚文本是链接中常见的可点击词,对搜索引擎和用户来说都是一个有用的信号。Google 通过您的内容、标题、锚文本等对您的 网站 了解得越多,它返回给搜索者(可能包括您的潜在用户)的相关结果就越多。例如,如果您正在打篮球网站,并且您想通过文本链接向用户提供一些视频,许多 网站 管理员会这样设置链接:
如果您想观看我们的篮球视频,请单击此处浏览视频列表。
我们不建议使用这种通用的“单击此处”,我们建议您将锚文本替换为更具描述性的内容,例如:
欢迎收看我们的篮球视频
4、确认“Googlebot”可以找到您的内部链接
对于已经验证了网站权限的用户,网站管理工具提供了一个“链接>带有内部链接的页面”功能,这对于验证Googlebot是否已经成功找到你非常有用。关联。尤其是如果您的 网站 在导航中使用 JavaScript 之类的技术(Googlebot 通常无法正常工作并抓取它),您可能想知道您的其他内部链接是否完全被 Googlebot 成功识别。
这是指向“网站Admin Center 404 Week”的内部链接的屏幕截图。正如我们所料,我们的内部链接被成功发现。
欢迎您就内部链接的主题提出问题
这是其中的一部分...
问:我可以使用 rel="nofollow" 来最大化我们内部链接的 PageRank 流量吗?
答:我们实际上是 网站 自己在 Google 工作的管理员,您所考虑的并不是我们实际上会花时间考虑的事情。换句话说,如果你的 网站 已经有一个良好的链接结构,那么你就可以花更多的精力为你的用户提供更好的内容,而不是一直担心你的 PageRank。
MattCutts 曾经在 网站Administrator 帮助论坛上回答了“合理使用 nofollow”的问题。
问:例如,我的 网站 是关于我的两个爱好,骑自行车和露营。我应该以我的内部链接模式为主题,而不是在两者之间进行链接吗?
答:到目前为止,我们还没有看到任何 网站 管理员从故意使他们的链接模式高度主题化而受益。同时,如果访问者无法轻松访问您的网站 的各个部分,这通常意味着这种结构也是搜索引擎的障碍。
请允许我们在这里重复一遍,请尽量创建一个固定且合理的链接结构(包括符合用户习惯的导航设置和为搜索引擎设置可抓取的链接),并积极实施您的部分用户及其使用。经验是衡量利益的标准。 查看全部
网页视频抓取工具 知乎(关于链接架构的文章,你应该知道的几个问题)
在做SEO的过程中,我们每天都面临着大量的外链建设需求。构建目标网站链接的生态,相信是每个SEO外链推广者的日常工作之一,但长期以来,很多SEO人员的操作可能是相反的,甚至是错误的,这就需要我们深刻理解网站链接结构的问题。
给大家分享一个关于链接结构的文章,虽然是基于谷歌搜索,但是对于百度SEO来说,我们认为它也会给我们一些启发。
链接架构——你如何网站内部链接——是你的网站计划的重要组成部分,并且对你的网站被搜索引擎索引的程度有重大影响。它还对 Google 机器人是否可以找到您的个人页面并从而使用户可以访问它们起着决定性作用。
确保您的核心页面距离主页只需点击几下
您可能认为用户可能更喜欢使用 网站 上的搜索框而不是目录式导航,但这样做通常会给搜索引擎爬虫造成障碍,他们几乎无法在搜索框中键入文本以进行搜索或浏览在下拉菜单中。因此,您需要确保您的重要页面可从首页点击,并让 Googlebot 轻松遍历您的 网站。你最好建立一个既便于用户浏览又便于搜索引擎抓取的链接结构。
以下是一些具体的建议:
1、人性化的导航设置
您应该尝试将自己置于“用户”的角色,并设计您的 网站 以模仿用户的习惯。例如,如果您的 网站 是关于篮球的,假设您是一位想要了解最佳运球技巧的访客。
让我们从主页开始。如果用户不使用您的网站搜索功能和下拉菜单,他们是否可以通过您提供的导航链接轻松找到他们想要的信息(例如篮球巨星的运球技巧)?
假设用户通过外部链接找到了您的 网站,但他们没有先到达主页。无论用户首先登陆哪个页面,您都希望确保他们可以轻松找到指向主页和其他相关部分的链接。换句话说,您要确保您的用户不会迷路。您的用户是否容易找到“最佳盘带技巧”?像“主页 > 提示 > Dribble”这样的导航可以帮助用户了解他们在页面上的位置。
2、为搜索引擎设置可抓取链接
文本链接很容易被搜索引擎找到。如果你特别在意自己的内容能否正常被索引,使用文本链接是一种比较安全的方法。可以想象,您还将采用一些最新技术,但无论如何,文本链接对用户更友好,更容易被搜索引擎访问。
这个文本链接很容易被搜索引擎找到。
提交 网站 地图对主要搜索引擎也很有帮助,尽管它不应该取代爬行友好的链接结构。如果您的 网站 使用了一些较新的技术,例如 AJAX,您可以参考下面的“确认 Googlebot 可以找到您的内部链接”。
3、使用描述性锚文本(anchortext-anchor text)
描述性锚文本是链接中常见的可点击词,对搜索引擎和用户来说都是一个有用的信号。Google 通过您的内容、标题、锚文本等对您的 网站 了解得越多,它返回给搜索者(可能包括您的潜在用户)的相关结果就越多。例如,如果您正在打篮球网站,并且您想通过文本链接向用户提供一些视频,许多 网站 管理员会这样设置链接:
如果您想观看我们的篮球视频,请单击此处浏览视频列表。
我们不建议使用这种通用的“单击此处”,我们建议您将锚文本替换为更具描述性的内容,例如:
欢迎收看我们的篮球视频
4、确认“Googlebot”可以找到您的内部链接
对于已经验证了网站权限的用户,网站管理工具提供了一个“链接>带有内部链接的页面”功能,这对于验证Googlebot是否已经成功找到你非常有用。关联。尤其是如果您的 网站 在导航中使用 JavaScript 之类的技术(Googlebot 通常无法正常工作并抓取它),您可能想知道您的其他内部链接是否完全被 Googlebot 成功识别。
这是指向“网站Admin Center 404 Week”的内部链接的屏幕截图。正如我们所料,我们的内部链接被成功发现。
欢迎您就内部链接的主题提出问题
这是其中的一部分...
问:我可以使用 rel="nofollow" 来最大化我们内部链接的 PageRank 流量吗?
答:我们实际上是 网站 自己在 Google 工作的管理员,您所考虑的并不是我们实际上会花时间考虑的事情。换句话说,如果你的 网站 已经有一个良好的链接结构,那么你就可以花更多的精力为你的用户提供更好的内容,而不是一直担心你的 PageRank。
MattCutts 曾经在 网站Administrator 帮助论坛上回答了“合理使用 nofollow”的问题。
问:例如,我的 网站 是关于我的两个爱好,骑自行车和露营。我应该以我的内部链接模式为主题,而不是在两者之间进行链接吗?
答:到目前为止,我们还没有看到任何 网站 管理员从故意使他们的链接模式高度主题化而受益。同时,如果访问者无法轻松访问您的网站 的各个部分,这通常意味着这种结构也是搜索引擎的障碍。
请允许我们在这里重复一遍,请尽量创建一个固定且合理的链接结构(包括符合用户习惯的导航设置和为搜索引擎设置可抓取的链接),并积极实施您的部分用户及其使用。经验是衡量利益的标准。
网页视频抓取工具 知乎(Mac平台下自己喜欢的视频,一步到位,Get到本地)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-02-21 00:28
前言
我经常浏览哔哩哔哩、YouTube、优酷等视频网站,一看到喜欢的视频流就想下载到本地看。官方不支持此功能或下载质量有限制。有没有更好的突破方法?答案是肯定的,本文文章给大家分享一个Mac平台下使用的强大的视频流媒体下载工具——Downie。
对了,Windows平台也将在下一篇文章中介绍,敬请期待。
介绍唐尼
Downie 是一款来自国外的付费软件。官方宣称支持1000多个视频流媒体网站的下载,基本包括Bilibili、优酷、爱奇艺、YouTube、Vimeo等国内外主流网站。
简单来说,在Downie的帮助下,我们可以轻松获取主流视频流媒体网站下自己喜欢的视频,一步到位,轻松本地获取。
使用步骤
这种工具基本上是傻瓜式。一般的操作逻辑是复制自己喜欢的视频播放地址,提交给工具,让工具处理下载。
Downie 也不例外,但为了进一步达到下载成功率,它还为 Safari 和 Chrome 等浏览器开发了相应的插件。借助插件,一键提交,省去复制粘贴的步骤。
软件开始下载后,借助多线程请求,实测可以跑到满带宽。
写在最后
当前版本的Downie已经到了Downie 4,直接下载安装后可以有14天的试用期。没有功能限制。拿到终身牌照,价格比较高。
如果您对此类话题有什么好的想法和建议,请在下方评论或留言。如果您有更好的想法,请留言分享。 查看全部
网页视频抓取工具 知乎(Mac平台下自己喜欢的视频,一步到位,Get到本地)
前言
我经常浏览哔哩哔哩、YouTube、优酷等视频网站,一看到喜欢的视频流就想下载到本地看。官方不支持此功能或下载质量有限制。有没有更好的突破方法?答案是肯定的,本文文章给大家分享一个Mac平台下使用的强大的视频流媒体下载工具——Downie。
对了,Windows平台也将在下一篇文章中介绍,敬请期待。
介绍唐尼
Downie 是一款来自国外的付费软件。官方宣称支持1000多个视频流媒体网站的下载,基本包括Bilibili、优酷、爱奇艺、YouTube、Vimeo等国内外主流网站。
简单来说,在Downie的帮助下,我们可以轻松获取主流视频流媒体网站下自己喜欢的视频,一步到位,轻松本地获取。
使用步骤
这种工具基本上是傻瓜式。一般的操作逻辑是复制自己喜欢的视频播放地址,提交给工具,让工具处理下载。
Downie 也不例外,但为了进一步达到下载成功率,它还为 Safari 和 Chrome 等浏览器开发了相应的插件。借助插件,一键提交,省去复制粘贴的步骤。
软件开始下载后,借助多线程请求,实测可以跑到满带宽。
写在最后
当前版本的Downie已经到了Downie 4,直接下载安装后可以有14天的试用期。没有功能限制。拿到终身牌照,价格比较高。
如果您对此类话题有什么好的想法和建议,请在下方评论或留言。如果您有更好的想法,请留言分享。
网页视频抓取工具 知乎(BeautifulSoup的基础详细用法,你知道几个?(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-02-20 03:06
)
今天的朋友很聪明。只要会爬虫,都知道BeautifulSoup,但是随着知识点越来越多,很多小伙伴可能只知道如何使用这个爬虫工具,却不知道BeautifulSoup的详细使用方法。今天的文章带你了解BeautifulSoup的基本和详细用法。
什么是美汤?? ?
BeautifulSoup 是一个 Python 扩展库,可以从 HTML 或 XML 文件中提取数据。BeautifulSoup 通过合适的转换器实现文档导航、查找、修改文档等。它可以很好地处理非标准标记并生成解析树(Parse Tree);它提供导航功能(Navigating),可以简单快速地搜索和修改解析树。BeautifulSoup 技术通常用于分析网页的结构并爬取相应的网页文档。对于不规则的 HTML 文档,提供了一定的补全功能,从而为开发者节省了时间和精力。今天的文章一起来学习BeatifulSoup的详细用法吧~
环境部署
安装 BeautifulSoup
BeautifulSoup 主要通过 pip 命令安装。可以在命令提示符CMD环境中安装,也可以在PyCharm的命令行窗口中安装,即调用pip install bs4命令安装,bs4就是BeautifulSoup4。
由于我的本地环境已经安装好,显示如下:
如果还没有安装,可以直接输入命令尝试安装。如果安装好了,就可以直接上手了。
BeautifulSoup扩展包安装成功后,可以在命令行输入from bs4 import BeautifulSoup语句导入扩展包,测试是否安装成功。如果没有报异常错误,则安装成功,如下图:
BeautifulSoup解析HTML获取网页信息
BeautifulSoup 解析 HTML
BeautifulSoup解析HTML的原理是创建一个BeautifulSoup对象,然后调用BeautifulSoup包的prettify()函数对网页信息进行格式化输出。
示例如下:
from bs4 import BeautifulSoup
html = """
Hello Python
<p>BeatifulSoup 技术详解
"""
# 结果会按照标准的缩进格式的结构输出
soup = BeautifulSoup(html)
print(soup.prettify())
</p>
使用 BeautifulSoup 解析网页的输出如下:
BeatifulSoup 解析会根据 HTML 标签的缩进输出 HTML 页面的所有标签信息和内容。
当使用 BeautifulSoup 解析 HTML 文档时,它会将 HTML 文档视为 DOM 文档树。使用 prettify() 函数输出结果时,会自动补全标签。这是 BeautifulSoup 的一个优势,即使 BeautifulSoup 得到一个损坏的标签,它也会生成一个与原创文档内容尽可能一致的转换后的 DOM 树,这通常有助于更正确地采集数据。
示例如下:输入一个URL,直接用prettify()函数获取
from bs4 import BeautifulSoup
html = 'https://www.baidu.com/'
# 结果会按照标准的缩进格式的结构输出
soup = BeautifulSoup(html)
print(soup.prettify())
输出如下:
<p>
https://www.baidu.com/
</p>
输出内容自动填充标签并以 HTML 格式输出。
BeautifulSoup 获取网页标签信息
以上知识讲解了如何使用 BeautifulSoup 解析网页。解析完网页后,如果想获取某个标签的内容信息,该怎么做呢?比如获取下面超文本的标题,下面就教大家如何使用BeautifulSoup技术获取网页标签信息。获取页面标题的代码如下:
from bs4 import BeautifulSoup
# 获取标题
def get_title():
#创建本地文件soup对象
soup = BeautifulSoup(open('test.html','rb'), "html.parser")
#获取标题
title = soup.title
print('标题:', title)
if __name__ == '__main__':
get_title()
输出如下:
获取其他标签的内容也是如此,比如HTML头一个标签
# 获取a标签内容
def get_a():
#创建本地文件soup对象
soup = BeautifulSoup(open('test.html','rb'), "html.parser")
#获取a标签内容
a = soup.a
print('a标签的内容是:', a)
输出如下:
a标签的内容是: ddd
定位标签并获取内容
前面的内容简单介绍了BeautifulSoup获取title、a等标签,但是如何定位标签并获取对应标签的内容,这里需要用到BeautifulSoup的find_all()函数。详细用法如下:
def get_all():
soup = BeautifulSoup(open('test.html', 'rb'), "html.parser")
# 从文档中找到<a>的所有标签链接
for a in soup.find_all('a'):
print(a)
# 获取<a>的超链接
for link in soup.find_all('a'):
print(link.get('href'))
if __name__ == '__main__':
get_all()
输出如下:
ddd
https://www.baidu.com
ddd
以上是关于 BeautifulSoup 如何定位标签并获取内容的。
总结
本文主要讲解BeautifulSoup相关知识点中最基本的部分。下面将讲解 BeautifulSoup 的核心用法。下期见~
查看全部
网页视频抓取工具 知乎(BeautifulSoup的基础详细用法,你知道几个?(上)
)
今天的朋友很聪明。只要会爬虫,都知道BeautifulSoup,但是随着知识点越来越多,很多小伙伴可能只知道如何使用这个爬虫工具,却不知道BeautifulSoup的详细使用方法。今天的文章带你了解BeautifulSoup的基本和详细用法。
什么是美汤?? ?
BeautifulSoup 是一个 Python 扩展库,可以从 HTML 或 XML 文件中提取数据。BeautifulSoup 通过合适的转换器实现文档导航、查找、修改文档等。它可以很好地处理非标准标记并生成解析树(Parse Tree);它提供导航功能(Navigating),可以简单快速地搜索和修改解析树。BeautifulSoup 技术通常用于分析网页的结构并爬取相应的网页文档。对于不规则的 HTML 文档,提供了一定的补全功能,从而为开发者节省了时间和精力。今天的文章一起来学习BeatifulSoup的详细用法吧~
环境部署
安装 BeautifulSoup
BeautifulSoup 主要通过 pip 命令安装。可以在命令提示符CMD环境中安装,也可以在PyCharm的命令行窗口中安装,即调用pip install bs4命令安装,bs4就是BeautifulSoup4。
由于我的本地环境已经安装好,显示如下:
如果还没有安装,可以直接输入命令尝试安装。如果安装好了,就可以直接上手了。
BeautifulSoup扩展包安装成功后,可以在命令行输入from bs4 import BeautifulSoup语句导入扩展包,测试是否安装成功。如果没有报异常错误,则安装成功,如下图:
BeautifulSoup解析HTML获取网页信息
BeautifulSoup 解析 HTML
BeautifulSoup解析HTML的原理是创建一个BeautifulSoup对象,然后调用BeautifulSoup包的prettify()函数对网页信息进行格式化输出。
示例如下:
from bs4 import BeautifulSoup
html = """
Hello Python
<p>BeatifulSoup 技术详解
"""
# 结果会按照标准的缩进格式的结构输出
soup = BeautifulSoup(html)
print(soup.prettify())
</p>
使用 BeautifulSoup 解析网页的输出如下:
BeatifulSoup 解析会根据 HTML 标签的缩进输出 HTML 页面的所有标签信息和内容。
当使用 BeautifulSoup 解析 HTML 文档时,它会将 HTML 文档视为 DOM 文档树。使用 prettify() 函数输出结果时,会自动补全标签。这是 BeautifulSoup 的一个优势,即使 BeautifulSoup 得到一个损坏的标签,它也会生成一个与原创文档内容尽可能一致的转换后的 DOM 树,这通常有助于更正确地采集数据。
示例如下:输入一个URL,直接用prettify()函数获取
from bs4 import BeautifulSoup
html = 'https://www.baidu.com/'
# 结果会按照标准的缩进格式的结构输出
soup = BeautifulSoup(html)
print(soup.prettify())
输出如下:
<p>
https://www.baidu.com/
</p>
输出内容自动填充标签并以 HTML 格式输出。
BeautifulSoup 获取网页标签信息
以上知识讲解了如何使用 BeautifulSoup 解析网页。解析完网页后,如果想获取某个标签的内容信息,该怎么做呢?比如获取下面超文本的标题,下面就教大家如何使用BeautifulSoup技术获取网页标签信息。获取页面标题的代码如下:
from bs4 import BeautifulSoup
# 获取标题
def get_title():
#创建本地文件soup对象
soup = BeautifulSoup(open('test.html','rb'), "html.parser")
#获取标题
title = soup.title
print('标题:', title)
if __name__ == '__main__':
get_title()
输出如下:
获取其他标签的内容也是如此,比如HTML头一个标签
# 获取a标签内容
def get_a():
#创建本地文件soup对象
soup = BeautifulSoup(open('test.html','rb'), "html.parser")
#获取a标签内容
a = soup.a
print('a标签的内容是:', a)
输出如下:
a标签的内容是: ddd
定位标签并获取内容
前面的内容简单介绍了BeautifulSoup获取title、a等标签,但是如何定位标签并获取对应标签的内容,这里需要用到BeautifulSoup的find_all()函数。详细用法如下:
def get_all():
soup = BeautifulSoup(open('test.html', 'rb'), "html.parser")
# 从文档中找到<a>的所有标签链接
for a in soup.find_all('a'):
print(a)
# 获取<a>的超链接
for link in soup.find_all('a'):
print(link.get('href'))
if __name__ == '__main__':
get_all()
输出如下:
ddd
https://www.baidu.com
ddd
以上是关于 BeautifulSoup 如何定位标签并获取内容的。
总结
本文主要讲解BeautifulSoup相关知识点中最基本的部分。下面将讲解 BeautifulSoup 的核心用法。下期见~
网页视频抓取工具 知乎( 本篇文章抓取目标网站的链接的基础上,进一步提高难度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2022-02-16 23:12
本篇文章抓取目标网站的链接的基础上,进一步提高难度)
Java爬虫爬取视频网站下载链接
更新时间:2016-10-19 12:02:17 作者:pangfc
本文是通过JAVA获取优酷、土豆、酷6、6房的视频。小编觉得还不错。现在分享给大家,供大家参考。跟我来看看
基于本文文章抓取目标网站的链接,进一步增加难度,将目标页面上我们需要的内容抓取到数据库中。这里的测试用例使用了一个我经常使用的电影下载网站()。本来想把网站上所有电影的下载链接都抓起来,但是觉得时间太长,就改成抓2015年电影的下载链接了。
原理介绍
其实原理和第一个文章是一样的,不同的是,由于这个网站里面的分类列表太多了,如果不选中这些标签,会耗费难以想象的时间。
类别链接和标签链接都不是必需的。而不是通过这些链接爬取其他页面,只能通过页面底部所有类型电影的分页来获取其他页面上的电影列表。同时,对于电影详情页,只抓取电影片名和迅雷下载链接,不进行深度爬取。详细信息页面上的一些推荐电影和其他链接不是必需的。
最后就是将所有获取到的电影的下载链接保存在videoLinkMap集合中,通过遍历这个集合将数据保存到MySQL
两码实现
实现原理上面已经讲过了,代码中有详细的注释,这里就不多说了,代码如下:
<p>package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class VideoLinkGrab {
public static void main(String[] args) {
VideoLinkGrab videoLinkGrab = new VideoLinkGrab();
videoLinkGrab.saveData("http://www.80s.la/movie/list/-2015----p");
}
/**
* 将获取到的数据保存在数据库中
*
* @param baseUrl
* 爬虫起点
* @return null
* */
public void saveData(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLinkHost = ""; // host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); // 比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
videoLinkMap = crawlLinks(oldLinkHost, oldMap);
// 遍历,然后将数据保存在数据库中
try {
Connection connection = JDBCDemo.getConnection();
for (Map.Entry mapping : videoLinkMap.entrySet()) {
PreparedStatement pStatement = connection
.prepareStatement("insert into movie(MovieName,MovieLink) values(?,?)");
pStatement.setString(1, mapping.getKey());
pStatement.setString(2, mapping.getValue());
pStatement.executeUpdate();
pStatement.close();
// System.out.println(mapping.getKey() + " : " + mapping.getValue());
}
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 对未遍历过的新链接不断发起GET请求, 一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* 对一个链接发起请求时,对该网页用正则查找我们所需要的视频链接,找到后存入集合videoLinkMap
*
* @param oldLinkHost
* 域名,如:http://www.zifangsky.cn
* @param oldMap
* 待遍历的链接集合
*
* @return 返回所有抓取到的视频下载链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap(); // 每次循环获取到的新链接
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
// System.out.println("link:" + mapping.getKey() + "--------check:"
// + mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2500);
connection.setReadTimeout(2500);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = null;
Matcher matcher = null;
//电影详情页面,取出其中的视频下载链接,不继续深入抓取其他页面
if(isMoviePage(oldLink)){
boolean checkTitle = false;
String title = "";
while ((line = reader.readLine()) != null) {
//取出页面中的视频标题
if(!checkTitle){
pattern = Pattern.compile("([^\\s]+).*?");
matcher = pattern.matcher(line);
if(matcher.find()){
title = matcher.group(1);
checkTitle = true;
continue;
}
}
// 取出页面中的视频下载链接
pattern = Pattern
.compile("(thunder:[^\"]+).*thunder[rR]es[tT]itle=\"[^\"]*\"");
matcher = pattern.matcher(line);
if (matcher.find()) {
videoLinkMap.put(title,matcher.group(1));
System.out.println("视频名称: "
+ title + " ------ 视频链接:"
+ matcher.group(1));
break; //当前页面已经检测完毕
}
}
}
//电影列表页面
else if(checkUrl(oldLink)){
while ((line = reader.readLine()) != null) {
pattern = Pattern
.compile(" 查看全部
网页视频抓取工具 知乎(
本篇文章抓取目标网站的链接的基础上,进一步提高难度)
Java爬虫爬取视频网站下载链接
更新时间:2016-10-19 12:02:17 作者:pangfc
本文是通过JAVA获取优酷、土豆、酷6、6房的视频。小编觉得还不错。现在分享给大家,供大家参考。跟我来看看
基于本文文章抓取目标网站的链接,进一步增加难度,将目标页面上我们需要的内容抓取到数据库中。这里的测试用例使用了一个我经常使用的电影下载网站()。本来想把网站上所有电影的下载链接都抓起来,但是觉得时间太长,就改成抓2015年电影的下载链接了。
原理介绍
其实原理和第一个文章是一样的,不同的是,由于这个网站里面的分类列表太多了,如果不选中这些标签,会耗费难以想象的时间。
类别链接和标签链接都不是必需的。而不是通过这些链接爬取其他页面,只能通过页面底部所有类型电影的分页来获取其他页面上的电影列表。同时,对于电影详情页,只抓取电影片名和迅雷下载链接,不进行深度爬取。详细信息页面上的一些推荐电影和其他链接不是必需的。
最后就是将所有获取到的电影的下载链接保存在videoLinkMap集合中,通过遍历这个集合将数据保存到MySQL
两码实现
实现原理上面已经讲过了,代码中有详细的注释,这里就不多说了,代码如下:
<p>package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class VideoLinkGrab {
public static void main(String[] args) {
VideoLinkGrab videoLinkGrab = new VideoLinkGrab();
videoLinkGrab.saveData("http://www.80s.la/movie/list/-2015----p";);
}
/**
* 将获取到的数据保存在数据库中
*
* @param baseUrl
* 爬虫起点
* @return null
* */
public void saveData(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLinkHost = ""; // host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); // 比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
videoLinkMap = crawlLinks(oldLinkHost, oldMap);
// 遍历,然后将数据保存在数据库中
try {
Connection connection = JDBCDemo.getConnection();
for (Map.Entry mapping : videoLinkMap.entrySet()) {
PreparedStatement pStatement = connection
.prepareStatement("insert into movie(MovieName,MovieLink) values(?,?)");
pStatement.setString(1, mapping.getKey());
pStatement.setString(2, mapping.getValue());
pStatement.executeUpdate();
pStatement.close();
// System.out.println(mapping.getKey() + " : " + mapping.getValue());
}
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 对未遍历过的新链接不断发起GET请求, 一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* 对一个链接发起请求时,对该网页用正则查找我们所需要的视频链接,找到后存入集合videoLinkMap
*
* @param oldLinkHost
* 域名,如:http://www.zifangsky.cn
* @param oldMap
* 待遍历的链接集合
*
* @return 返回所有抓取到的视频下载链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap(); // 每次循环获取到的新链接
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
// System.out.println("link:" + mapping.getKey() + "--------check:"
// + mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2500);
connection.setReadTimeout(2500);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = null;
Matcher matcher = null;
//电影详情页面,取出其中的视频下载链接,不继续深入抓取其他页面
if(isMoviePage(oldLink)){
boolean checkTitle = false;
String title = "";
while ((line = reader.readLine()) != null) {
//取出页面中的视频标题
if(!checkTitle){
pattern = Pattern.compile("([^\\s]+).*?");
matcher = pattern.matcher(line);
if(matcher.find()){
title = matcher.group(1);
checkTitle = true;
continue;
}
}
// 取出页面中的视频下载链接
pattern = Pattern
.compile("(thunder:[^\"]+).*thunder[rR]es[tT]itle=\"[^\"]*\"");
matcher = pattern.matcher(line);
if (matcher.find()) {
videoLinkMap.put(title,matcher.group(1));
System.out.println("视频名称: "
+ title + " ------ 视频链接:"
+ matcher.group(1));
break; //当前页面已经检测完毕
}
}
}
//电影列表页面
else if(checkUrl(oldLink)){
while ((line = reader.readLine()) != null) {
pattern = Pattern
.compile("
网页视频抓取工具 知乎( 接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-16 23:08
接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
Python抓取知乎的方法指定视频的答案
更新时间:2020-07-09 11:17:05 作者:李涛
本文章主要介绍python抓取知乎指定答案视频的方法。文中的讲解很详细,代码帮助大家更好的理解和学习。有兴趣的朋友可以了解一下。
前言
现在 知乎 允许上传视频,但我不能下载视频。气死我了,只好研究一下,然后写了代码方便下载和保存视频。
其次,为什么猫根本不怕蛇?以回答为例,分享整个下载过程。
调试它
打开F12,找到光标,如下图:
然后将光标移到视频上。如下所示:
咦这是什么?视野中出现了一个神秘的链接:,我们把这个链接复制到浏览器打开:
看来这就是我们要找的视频了,别着急,我们来看看,网页的请求,然后你会发现一个很有意思的请求(这里强调一下):
让我们自己看一下数据:
{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B,
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B,
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B,
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B,
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}
没错,我们要下载的视频就在这里,其中ld代表普通清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右键保存视频即可下载。
代码
知道了整个过程是什么样子,接下来的编码过程就很简单了。我这里就解释太多了,直接上代码:
# -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069')
print(a.download_video())
结语
代码仍有优化空间。在这里,我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果您有任何问题或建议,请随时交流。
以上就是python抓取知乎指定答案视频的方法的详细内容。更多关于python抓视频的内容,请关注脚本之家文章的其他相关话题! 查看全部
网页视频抓取工具 知乎(
接下来以猫为什么一点也不怕蛇?回答为例,分享一下整个下载过程)
Python抓取知乎的方法指定视频的答案
更新时间:2020-07-09 11:17:05 作者:李涛
本文章主要介绍python抓取知乎指定答案视频的方法。文中的讲解很详细,代码帮助大家更好的理解和学习。有兴趣的朋友可以了解一下。
前言
现在 知乎 允许上传视频,但我不能下载视频。气死我了,只好研究一下,然后写了代码方便下载和保存视频。
其次,为什么猫根本不怕蛇?以回答为例,分享整个下载过程。
调试它
打开F12,找到光标,如下图:
然后将光标移到视频上。如下所示:
咦这是什么?视野中出现了一个神秘的链接:,我们把这个链接复制到浏览器打开:
看来这就是我们要找的视频了,别着急,我们来看看,网页的请求,然后你会发现一个很有意思的请求(这里强调一下):
让我们自己看一下数据:
{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B,
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B,
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B,
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B,
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}
没错,我们要下载的视频就在这里,其中ld代表普通清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右键保存视频即可下载。
代码
知道了整个过程是什么样子,接下来的编码过程就很简单了。我这里就解释太多了,直接上代码:
# -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069')
print(a.download_video())
结语
代码仍有优化空间。在这里,我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果您有任何问题或建议,请随时交流。
以上就是python抓取知乎指定答案视频的方法的详细内容。更多关于python抓视频的内容,请关注脚本之家文章的其他相关话题!
网页视频抓取工具 知乎(推荐6种下载哔哩哔哩视频的方式,有不需软件的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-02-16 12:04
推荐6种B站视频下载方式,有的无软件,有的有软件,总有一款适合你,文末还有福利。我创建了一个知乎圈子:【平凡与诗意】,重点分享前沿技术、编程开发、实用工具等,有兴趣的可以在首页搜索【平凡与诗意】加入我的圈子,让我们一起玩吧!方法1.修改url我想很多人都会喜欢这种方法,因为太方便了,没有浏览器插件,没有Python开发环境,对于几乎所有会用电脑的人来说都是非常容易的。
指示:
例如,更改为
方法二:使用浏览器插件 使用QQ等浏览器,安装网络视频下载工具,打开视频网页。这些插件可以识别网络视频。这种方法需要配合浏览器使用,如果你已经在使用这样的浏览器,可以试试。指示:
您可以根据自己的喜好选择一个插件来使用,实测的Flash Video Downloader和Stream Video Downloader都有。
方法三:you-get比上一种更麻烦。这是一个具有一定专业性的命令行工具。安装需要使用Python的pip,或者使用Antigen,也可以克隆到本地使用,但是依赖于Python 3.2、ffmpeg 1.0环境,所以这种方式比较多适合开发者。虽然比较麻烦,但不得不说you-get真的很强大,支持YouTube、Bilibili、爱奇艺、央视、芒果TV、腾讯视频、秒拍、抖音、快手、网易等几十个< @网站视频下载。同时,you-get还可以将视频导入到自己的播放器中进行播放。
指示:
这是通过pip安装的方法
打开 cmd 或 linux 终端,输入以下命令:
pip install you-get
在终端中输入以下命令:
you-get
您还可以指定视频存储路径:
you-get -o ~/Videos -O zoo.webm 'https://www.youtube.com/watch% ... 39%3B
这会将视频保存到当前目录。
另外,如果不想下载视频,只想用指定的播放器播放对应的视频,可以使用如下命令:
you-get -p vlc 'https://www.youtube.com/watch% ... 39%3B
为什么不在网页上播放,而是使用指定的播放器播放呢?亲测,如果使用指定播放器,可以去除长广告,缓冲速度非常快。
例如下面的视频广告 75s,
指定本地播放器播放在线视频,
方法4.卫通flv
<p>一句话介绍:支持189个 查看全部
网页视频抓取工具 知乎(推荐6种下载哔哩哔哩视频的方式,有不需软件的)
推荐6种B站视频下载方式,有的无软件,有的有软件,总有一款适合你,文末还有福利。我创建了一个知乎圈子:【平凡与诗意】,重点分享前沿技术、编程开发、实用工具等,有兴趣的可以在首页搜索【平凡与诗意】加入我的圈子,让我们一起玩吧!方法1.修改url我想很多人都会喜欢这种方法,因为太方便了,没有浏览器插件,没有Python开发环境,对于几乎所有会用电脑的人来说都是非常容易的。
指示:
例如,更改为
方法二:使用浏览器插件 使用QQ等浏览器,安装网络视频下载工具,打开视频网页。这些插件可以识别网络视频。这种方法需要配合浏览器使用,如果你已经在使用这样的浏览器,可以试试。指示:
您可以根据自己的喜好选择一个插件来使用,实测的Flash Video Downloader和Stream Video Downloader都有。
方法三:you-get比上一种更麻烦。这是一个具有一定专业性的命令行工具。安装需要使用Python的pip,或者使用Antigen,也可以克隆到本地使用,但是依赖于Python 3.2、ffmpeg 1.0环境,所以这种方式比较多适合开发者。虽然比较麻烦,但不得不说you-get真的很强大,支持YouTube、Bilibili、爱奇艺、央视、芒果TV、腾讯视频、秒拍、抖音、快手、网易等几十个< @网站视频下载。同时,you-get还可以将视频导入到自己的播放器中进行播放。
指示:
这是通过pip安装的方法
打开 cmd 或 linux 终端,输入以下命令:
pip install you-get
在终端中输入以下命令:
you-get
您还可以指定视频存储路径:
you-get -o ~/Videos -O zoo.webm 'https://www.youtube.com/watch% ... 39%3B
这会将视频保存到当前目录。
另外,如果不想下载视频,只想用指定的播放器播放对应的视频,可以使用如下命令:
you-get -p vlc 'https://www.youtube.com/watch% ... 39%3B
为什么不在网页上播放,而是使用指定的播放器播放呢?亲测,如果使用指定播放器,可以去除长广告,缓冲速度非常快。
例如下面的视频广告 75s,
指定本地播放器播放在线视频,
方法4.卫通flv
<p>一句话介绍:支持189个
网页视频抓取工具 知乎(接下来以猫为什么一点也不怕蛇?回答为例,分享一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2022-02-14 23:06
本期小编将为大家带来一段关于如何使用python捕捉知乎指定答案的视频。文章 内容丰富,专业为你分析叙述。看完这篇文章希望大家能有所收获。
前言
现在 知乎 允许上传视频,但我不能下载视频。气死我了,只好研究一下,然后写了代码方便下载和保存视频。
其次,为什么猫根本不怕蛇?以回答为例,分享整个下载过程。
调试它
打开F12,找到光标,如下图:
然后将光标移到视频上。如下所示:
咦这是什么?视野中出现了一个神秘的链接:,我们把这个链接复制到浏览器打开:
看来这就是我们要找的视频了,别着急,我们来看看,网页的请求,然后你会发现一个很有意思的请求(这里强调一下):
让我们自己看一下数据:
{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B,
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B,
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B,
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B,
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}
没错,我们要下载的视频就在这里,其中ld代表普通清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右键保存视频即可下载。
代码
知道了整个过程是什么样子,接下来的编码过程就很简单了。我这里就解释太多了,直接上代码:
# -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question ... %2339;)
print(a.download_video())
以上是小编给大家分享的如何使用python抓取知乎指定答案的视频。如果你恰好有类似的疑惑,不妨参考上面的分析来理解。如果您想了解更多相关知识,请关注易宿云行业资讯频道。 查看全部
网页视频抓取工具 知乎(接下来以猫为什么一点也不怕蛇?回答为例,分享一下)
本期小编将为大家带来一段关于如何使用python捕捉知乎指定答案的视频。文章 内容丰富,专业为你分析叙述。看完这篇文章希望大家能有所收获。
前言
现在 知乎 允许上传视频,但我不能下载视频。气死我了,只好研究一下,然后写了代码方便下载和保存视频。
其次,为什么猫根本不怕蛇?以回答为例,分享整个下载过程。
调试它
打开F12,找到光标,如下图:
然后将光标移到视频上。如下所示:
咦这是什么?视野中出现了一个神秘的链接:,我们把这个链接复制到浏览器打开:
看来这就是我们要找的视频了,别着急,我们来看看,网页的请求,然后你会发现一个很有意思的请求(这里强调一下):
让我们自己看一下数据:
{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B,
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B,
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B,
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B,
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}
没错,我们要下载的视频就在这里,其中ld代表普通清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右键保存视频即可下载。
代码
知道了整个过程是什么样子,接下来的编码过程就很简单了。我这里就解释太多了,直接上代码:
# -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question ... %2339;)
print(a.download_video())
以上是小编给大家分享的如何使用python抓取知乎指定答案的视频。如果你恰好有类似的疑惑,不妨参考上面的分析来理解。如果您想了解更多相关知识,请关注易宿云行业资讯频道。
网页视频抓取工具 知乎(为什么知乎机构号的定位如此重要?发布怎样的内容:满足细分需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-11 17:17
这是一个评分问题。
知乎机构号本质上是为企业服务,为产品提供营销推广渠道。也就是说,它定位的目标群体其实就相当于产品定位的目标群体。因此,我们不再需要经过调研、走访等过程,就可以快速定位到知乎机构账号所提供服务的细分人群。
例如,如果将石墨文档细分为知乎“主题”,则其目标群体可以分为:
核心用户——石墨文档、石墨文档企业版;
目标用户——在线文档、多人协作文档;
潜在用户——办公协作和效率提升;
所有用户——全站用户(知乎+百度)。
核心用户是正在使用/使用过产品的人群,目标用户和潜在用户是要争取的人群(以上只是举例,其实并没有知乎组织目前正在运行的号码)。
2. 发布内容:需要满足的细分市场
关于这个问题,很多人喜欢用区分来笼统地回答。但实际上,知乎组织账号不需要像知乎个人账号或者其他自媒体账号那样讲内容差异化。
在我看来,知乎组织编号最大的不同其实是各自公司产品的不同。知乎 代理账号应该做的是在内容上突出和传播这种差异化(包括功能和场景)。
说到内容,我们不能回避一个问题,那就是应该采用什么样的内容发布方式,或者我们希望借助内容塑造什么样的个性?
我的回答是,最好是专家,这是由知乎的平台属性决定的。高手是认真的、好玩的还是有邻家感的,都无所谓。
为什么知乎机构号的定位如此重要?
因为你不做定位,你发布的内容会很混乱,你的账号会缺乏专业性。这会直接导致一个结果,知乎不会给你的账号推荐稳定的流量,不仅会影响你答案的自然排名,还会影响后续的SEO操作(如果你赶时间,可以直接拉到第四部分“SEO篇”)。
二、选题:关键词图书馆是前提
在 知乎 上搜索主题,基本上等同于寻找问题和答案。说到这里,可能有人会说这不容易,知乎在网站上搜索一下关键词。
事实上,事情真的没有那么简单。例如,我们应该搜索哪个 关键词?在搜索中找到的问题和答案中,哪些是最先回答的,哪些是后来回答的甚至没有回答的?除了站内搜索,我们还有其他高效便捷的搜索方式吗?
这些都是我们需要回答的问题。
1. 构建你的 关键词 库
构建 关键词 库有两个好处:
有针对性:可以准确找到潜在的问题和答案,有节奏地进行内容操作;
填补空白:您始终可以检查哪些 关键词 已覆盖,哪些未决。
如何建造它?还有两种方法(以石墨文档为例):
1)查找产品和产品功能关键词
这是开户初期最直接有效的方法。
产品名称:Shimo Docs、Shimo.in、Shimo Docs app、Graphite Docs手机版、Graphite Docs网页、Graphite Docs企业版...
竞品名:腾讯文档、有道云笔记、印象笔记、OneNote、金山文档、微知笔记……知乎里有很多软件对比问答。
产品特点:在线文档、多人协作、团队协作;创建菜单、分层标题、插入公式、导入 PDF、协作名称识别...
2)查找产品应用场景关键词
当我们完成了涵盖产品和产品功能的 Q&A 关键词 的布局后,我们会遇到另一个问题:没有 关键词 可以回答。现阶段,我们需要从产品的应用场景扩展关键词库:
例如,石墨文档可以从办公协作和效率提升的角度细化到年终总结、文档管理、项目管理、HR招聘等具体应用场景;
再比如XMind,可以从思维提升和知识排序的角度细化到结构化思维/发散思维的培养、个人知识体系的构建、职业发展的SWOT分析等具体应用场景;
又如创客贴纸,可根据产品可实现的平面设计进行扩展,如公众号封面图、手机海报、营销长图、名片、邀请函等。
综上所述,我们要做的就是发现用户已有的场景,对用户没有发现的场景进行补充,然后将它们一一浓缩成关键词。
2. 6 种潜在问题和答案的搜索方法
使用 关键词 库,我们可以进行有针对性的问答搜索。在这里,我给大家分享6种搜索方式,以后找到更多的时候再补充:
1)在网站内搜索
关键词搜索(知乎问答评分插件辅助)
关键词在网站上搜索,这是目前最简单、最常用的搜索方式。但是,这种方法有一个缺点,就是我们很难快速直观地判断结果列表中一个问答的价值和潜力(曝光度是一个重要指标)。
我指出了这个不足,当然也带来了一个解决方案,那就是使用一个知乎问答评分插件来辅助判断。
在谷歌Chrome/360浏览器中安装评分插件后,在站点中搜索特定的关键词,如“网站”,对应的评分将出现在每个问题的右侧,并回答出现在结果页面上。分数高的应该先回答,分数低的可以延迟回答。
注意:此插件会在一段时间后自动失效,需要重新安装后注册登录才能恢复使用。虽然整个过程有点麻烦,但是注册不需要验证,省去了很多麻烦。
除了问答得分,我们还可以根据问答的观看次数和回答次数来进行判断。
如果一个问答的浏览量很高,但目前的回答很少,那么值得先回答。因为这意味着我们的答案有很大的机会冲到前排,我们可以通过后续的SEO优化打到前3位,争取更高的曝光率。
而对于浏览量高、回复量高的问答,则需要依靠更多的干货内容来抢占先机。
相关问题(系统关联推荐)
很多人不知道问答右侧有一个“相关问题”部分,因为它必须在PC网页上打开才能出现。本节一般汇总4-5个相关问题(有时相关性不大),选择策略同上。
知乎系统推荐
对于代理账号,知乎每周都会设置定期任务,只要完成任务即可获得相应奖励。
其中一项奖励为“热点追踪1周”,触发条件为组织账号一周内完成7次创作(含Q&A,文章)。会在组织号的管理中心推荐热点问题,但大多与自己的产品无关。
竞争账户历史问答搜索
相比知乎系统推荐的问答,目前人工搜索更加靠谱。除了开头提到的直接搜索,我们其实还可以从竞品账号的历史答案中挖掘出合适的问答。这相当于双方运营商联合筛选,极有可能是有价值的。
退一步说,即使问答本身没有什么价值,但从营销的角度来赢得更多的目标用户,我们必须要占领这样的问答。
2)异地搜索
百度关键词搜索
这是一种被忽视但极其重要的搜索方法。
这很重要,因为百度在 2019 年 8 月宣布了战略投资知乎。这次密切合作带来的一个重要变化是,知乎Q&A在百度搜索中的权重有所提升——这是一条不容忽视的流量。
因此,除了在知乎网站上搜索关键词外,我们还可以在百度上进行关键词搜索,然后优先显示在第一条的知乎问答结果页面的页面。
这个过程可以和5118站长工具箱结合使用,可以对百度搜索隐藏广告,帮助我们快速找到目标结果。
5118大数据搜索
最后一种方法是完全借助第三方工具——“”来实现的。
借助5118的排名监控,可以搜索所有搜索关键词对应知乎问答、百度PC搜索结果排名、百度PC排名列表关键词、百度PC检索量等. 数据一次提取,支持导出到Excel。
我们要做的就是根据自己的关键词库在导出的Excel中检索自己的关键词及其对应的知乎Q&A。
但是,此功能需要付费会员才能使用。
最后,想补充下关于知乎组织号的选题的建议,即尽量不要选择社会热点事件、政治军事事件。因为组织编号代表了公司和产品的形象,如果回答不当,很容易引发危机公关事件。
三、内容:“为什么”和“如何”更重要
确定主题后,下一步就是内容创作。这部分我将拆解知乎问答的结构和图片,回答以下两个问题:
知乎高赞回答的大致结构是什么?
知乎问答中的图片有哪些提示和注意事项?
1. 好评答案的一般结构
高瓒的回答一般有这样的结构,用一个公式来表达:高瓒的回答=直截了当的结果+有理有据的分析+最后的互动寻求三个联系。如何理解这个公式?
1) 开门见山,给出结果
这意味着在答案的开头,我们尝试用简洁的文字来总结答案以创造吸引力,例如:
推荐12个完全免费的良心网站,每一个都是完全免费的,非常好用,让你们看到晚了-知乎@穆子琪,对应问题:舍不得拿出来分享通过 网站?
作为一个纪录片狂热的水母爱好者,我看过上百部纪录片,但只有这12部顶级纪录片吸引了我,每次看都会感叹“看的真好!” 我想再看一遍,涵盖历史、人文和宇宙。绝对值得一看!尤其是中间两部——知乎@Daisy Wuwu,对应问题:到目前为止,你看过哪些纪录片可以称得上“顶级纪录片”?
做炸鸡外卖,每月净利润4w左右,一年利润几十万。我不知道Suah不是一个巨大的利润。很多人都吃过炸鸡外卖,但是很少有人知道做这个生意能赚这么多钱,可能这个行业不是很抢眼-知乎@林燕,对应问题:普通人什么都不是很擅长现在 知道暴利行业吗?
之所以写成这样,除了众所周知的“吸引用户继续观看”,还有一个很重要的原因就是为了吸引用户点进来。要知道,在没有展开答案之前,显示逻辑与公众号摘要相同,默认抓取文字前面的内容。
2)用理由和证据分析
吸引注意力后,你必须用完整和丰富的内容来保持它。
那么到底什么样的内容才是完整的呢?
我的回答是,不仅要介绍“是什么”,还要解释“为什么”和“如何解决”。知乎用户不愿意停留在问题的表面,他们喜欢深入的、未知的、不易访问的内容。通过告诉他们更深层次的知识、经验或见解,更容易获得认可。
比如这个知乎问题:什么是费曼技术?
如果简单地告诉用户这是一种“以教为本”的学习方式,可以帮助你提高知识吸收效率,真正理解和学会使用知识,答案很可能会沉到水底。组织号XMind做了一个很好的演示,它是这样回答的(回答太长了,我只拆了主要结构和关键点):
什么是费曼技术?
- 教学就是学习。
具体应用?
- 分四步走。
为什么费曼技术如此有效?
拆分和压缩知识;
理解和简化知识;
理解和附属知识(中间插入XMind绘制的思维导图作品)。
这是朋友喜欢的那种干货。就算中间有私货,他们还是愿意投票给答案。很明显)。
因此,当您以“阅读我的答案时,其他人会问我为什么?”的假设来回答问题时,您可以写出更详细和有用的解释和解释。如果您提出观点,请解释您为什么这么认为,这将对您的读者非常有帮助。
3)连续三个互动结束
最后,多互动,引导更多用户参与、关注、评论。可以放自己的产品体验链接(支持文字链接和卡片链接)。
注意:不要对自己太苛刻!不要苛刻!不要苛刻!重要的事情说了三遍!因为会被阻塞,下面是一个典型的反例:
2. 知乎图片技巧及注意事项
如果你的产品属于软件工具类,在介绍功能的时候可以选择录制一个Gif动画,比静态图片更直观,可以增加用户的停留时间。但需要注意的是,Gif图片不能太大(控制在1M左右),否则用户很可能在加载过程中不耐烦跳出。
另外,对于一些信息量大的横屏图片(图片一般比较模糊),尽量改成能同时适应用户移动阅读的竖屏图片,以提升用户的阅读体验。当然,如果你想做排水,那也不是什么大问题。
在内容文章的最后,跟大家分享一个小技巧:知乎支持同一个内容回答两个类似的问题,可以让组织号快速传播开来。但我建议根据每个问题的具体描述来剪裁内容的开头和部分。
注意:不要想着对一个内容回答超过3个问题,因为站服会删除重复内容,严重的也会封号。
四、SEO文章:知乎你也想做SEO吗?
内容发布成功后,我们就可以进行下一步了——SEO。可能有人会疑惑,知乎Q&A也应该是SEO吧?这不是问题的结尾吗?
- 当然不是。
如果我们将内容与 1 进行比较,那么 SEO 就是后面的 0。后者是前者的放大器,可以为前者带来更大的曝光率,进而帮助企业产品获得更多的销售线索。这也是我们前面反复提到的知乎机构号的终极目标。
既然知乎Q&A SEO这么重要,我该怎么办?我总结了2个主要技巧:
1. 找到喜欢的高权重账号
在知乎刷赞也不是什么新鲜事,但如何高效刷赞,不留痕迹需要一点技巧。不过不用担心,在正式分享知乎点赞技巧之前,我们要先搞清楚一个问题,那就是知乎问答的排序算法,也就是我们的“指南针”后续行动。
知乎有两套问题和答案,旧的和新的。老版本的问答排序算法比较简单,基于“分数=加权批准数-加权反对数”,但会带来两个问题:
第一:好评度高的答案将长期占据榜首,即使新的高质量答案也很难有“第一天”;
第二:如果恶意投出大量反对票,答案分数甚至可以为负,这也意味着它会沉到谷底,也很难有“翻盘日”。
新版算法(Wilson score)的出现在一定程度上解决了上述问题,让新的答案有机会超越之前发布的好评答案——这为我们实施SEO计划创造了空间.
以上是Wilson分数的计算公式,很复杂,要解释清楚是一篇长文。但我不打算在这里谈论它。感兴趣的朋友可以去知乎搜索“如何评价知乎的答案排序算法?”。很多大佬已经从各个维度分析过了。
我们这次的重点是这个新算法对我们的 SEO 的影响。直接进入观察点:
垂直领域的高级别账户的同类权重更高;举个简单的例子,同一领域的V5账号的点赞效果要强于10个V3账号;
点赞对高等级账号的效果是立竿见影的,点赞后刷新链接一般都能看到效果。
也就是说,我们的SEO任务需要从点赞1.0的打架时代升级为点赞2.0的打架质量时代。那我们具体怎么做呢?
还有两种技术:
1)自己培养高权重的小号喜欢
这不是一蹴而就的事情,但如果开始跑起来,代理账号和个人账号之间的互赞就能形成正向循环,效果非常显着。
值得注意的是,每一个知乎的点赞都会出现在账号动态中。如果我们长期只喜欢一个账号,很容易被用户发现并向知乎官方投诉,严重的话会导致账号被封。
因此,点赞需要模拟正常用户行为的轨迹。不喜欢连续一个账号,穿插一些不会和我们形成直接排名竞争的答案;不要打开问答链接直接跳转到目标答案,尽可能正常浏览同一个问题。下面的其他答案,有时你可以做一些简单的评论等。
2)主动吸引高调点赞
直接买大赞不划算,还容易被举报。那么如何才能让大牌明星主动喜欢我们呢?
我想出了一个窍门:我在回答中引用了高权重V的一些要点,然后在文章中引用@文章,如果对方认可了我们的内容,那么对方很大概率会喜欢的。
当然,前提是我们的内容要足够翔实,也就是我们前面提到的内容。
比如我们前面提到的XMind,在“费曼的技术是什么?”的回答中,它引用了@kaiyantechnique 选择的视频内容,然后@open 对方。
2. 使用第三方工具进行快速排序
我们前面讲的是在知乎网站做Q&A SEO,就是为了提高答案的排名;但是如果我们也想提高这个答案的知乎问题在百度搜索中的排名,那么就需要使用第三方工具进行快速排序了。
有预算的运营同学可以试试流量宝/超快排,刷三四个星期,一般都能到百度结果首页。
3. 两个不严格属于 SEO 类别的复活节彩蛋
1)使用自推荐功能
知乎组织账号每周完成任务可以获得一定数量的“自我推荐”。所谓“自荐”,简单来说,就是让平台为自己分发内容的功能。
由于“自荐”的数量有限,最好的办法是结合后台数据,筛选出近期有潜力的内容进行自荐,让本已优秀的内容更有可能火爆。
2)打开刘看山邀请函
有时候遇到浏览量低的问答,可以打开刘看山的邀请,以及自邀系统推荐的创作者。目的其实是为了让更多的用户看到你创作的内容。
五、写在最后
知乎 是一个很好的流量池,但我们也必须意识到,并非所有类型的产品都适合这里的内容营销。完美日记来了又走了;白果园来了又走了;名创优品也来了,终于走了……
不是这些产品不好,也不是知乎平台不好,而是产品和平台的“契合度”太低,彼此都不是“对的人”(比如,完美日记和小红书更好)。
我之前举例的 Graphite Documents、XMind、Maker Posts 等 ToC 工具产品对 知乎 的兼容性更好:
首先,知乎和工具类产品在用户方面有高度的重叠,两者都是高学历,追求高效率;其次,朋友通常会寻找具体问题的答案。如果看到合适的工具,一般都会启动;最后,知乎支持在回答中直接放置产品链接(可以自定义链接,后期跟踪用户来源),可以大大缩短获客链条。
综上所述,企业应该根据自己的产品属性和用户特点,结合不同自媒体平台的调性,以及不同平台应该采用什么样的内容形式和运营方式来决定选择哪个平台进行运营。这是企业经营新媒体的重要规则。
我们是知乎官方直接授权的服务商,拥有9年互联网广告行业经验,服务过重庆、贵州、昆明等西南地区上万家企业。需要放置知乎广告,我们会免费提供策划和解决方案,帮助您少走弯路,增加收益!
宏达电 查看全部
网页视频抓取工具 知乎(为什么知乎机构号的定位如此重要?发布怎样的内容:满足细分需求)
这是一个评分问题。
知乎机构号本质上是为企业服务,为产品提供营销推广渠道。也就是说,它定位的目标群体其实就相当于产品定位的目标群体。因此,我们不再需要经过调研、走访等过程,就可以快速定位到知乎机构账号所提供服务的细分人群。
例如,如果将石墨文档细分为知乎“主题”,则其目标群体可以分为:
核心用户——石墨文档、石墨文档企业版;
目标用户——在线文档、多人协作文档;
潜在用户——办公协作和效率提升;
所有用户——全站用户(知乎+百度)。
核心用户是正在使用/使用过产品的人群,目标用户和潜在用户是要争取的人群(以上只是举例,其实并没有知乎组织目前正在运行的号码)。
2. 发布内容:需要满足的细分市场
关于这个问题,很多人喜欢用区分来笼统地回答。但实际上,知乎组织账号不需要像知乎个人账号或者其他自媒体账号那样讲内容差异化。
在我看来,知乎组织编号最大的不同其实是各自公司产品的不同。知乎 代理账号应该做的是在内容上突出和传播这种差异化(包括功能和场景)。
说到内容,我们不能回避一个问题,那就是应该采用什么样的内容发布方式,或者我们希望借助内容塑造什么样的个性?
我的回答是,最好是专家,这是由知乎的平台属性决定的。高手是认真的、好玩的还是有邻家感的,都无所谓。
为什么知乎机构号的定位如此重要?
因为你不做定位,你发布的内容会很混乱,你的账号会缺乏专业性。这会直接导致一个结果,知乎不会给你的账号推荐稳定的流量,不仅会影响你答案的自然排名,还会影响后续的SEO操作(如果你赶时间,可以直接拉到第四部分“SEO篇”)。
二、选题:关键词图书馆是前提
在 知乎 上搜索主题,基本上等同于寻找问题和答案。说到这里,可能有人会说这不容易,知乎在网站上搜索一下关键词。
事实上,事情真的没有那么简单。例如,我们应该搜索哪个 关键词?在搜索中找到的问题和答案中,哪些是最先回答的,哪些是后来回答的甚至没有回答的?除了站内搜索,我们还有其他高效便捷的搜索方式吗?
这些都是我们需要回答的问题。
1. 构建你的 关键词 库
构建 关键词 库有两个好处:
有针对性:可以准确找到潜在的问题和答案,有节奏地进行内容操作;
填补空白:您始终可以检查哪些 关键词 已覆盖,哪些未决。
如何建造它?还有两种方法(以石墨文档为例):
1)查找产品和产品功能关键词
这是开户初期最直接有效的方法。
产品名称:Shimo Docs、Shimo.in、Shimo Docs app、Graphite Docs手机版、Graphite Docs网页、Graphite Docs企业版...
竞品名:腾讯文档、有道云笔记、印象笔记、OneNote、金山文档、微知笔记……知乎里有很多软件对比问答。
产品特点:在线文档、多人协作、团队协作;创建菜单、分层标题、插入公式、导入 PDF、协作名称识别...
2)查找产品应用场景关键词
当我们完成了涵盖产品和产品功能的 Q&A 关键词 的布局后,我们会遇到另一个问题:没有 关键词 可以回答。现阶段,我们需要从产品的应用场景扩展关键词库:
例如,石墨文档可以从办公协作和效率提升的角度细化到年终总结、文档管理、项目管理、HR招聘等具体应用场景;
再比如XMind,可以从思维提升和知识排序的角度细化到结构化思维/发散思维的培养、个人知识体系的构建、职业发展的SWOT分析等具体应用场景;
又如创客贴纸,可根据产品可实现的平面设计进行扩展,如公众号封面图、手机海报、营销长图、名片、邀请函等。
综上所述,我们要做的就是发现用户已有的场景,对用户没有发现的场景进行补充,然后将它们一一浓缩成关键词。
2. 6 种潜在问题和答案的搜索方法
使用 关键词 库,我们可以进行有针对性的问答搜索。在这里,我给大家分享6种搜索方式,以后找到更多的时候再补充:
1)在网站内搜索
关键词搜索(知乎问答评分插件辅助)
关键词在网站上搜索,这是目前最简单、最常用的搜索方式。但是,这种方法有一个缺点,就是我们很难快速直观地判断结果列表中一个问答的价值和潜力(曝光度是一个重要指标)。
我指出了这个不足,当然也带来了一个解决方案,那就是使用一个知乎问答评分插件来辅助判断。
在谷歌Chrome/360浏览器中安装评分插件后,在站点中搜索特定的关键词,如“网站”,对应的评分将出现在每个问题的右侧,并回答出现在结果页面上。分数高的应该先回答,分数低的可以延迟回答。
注意:此插件会在一段时间后自动失效,需要重新安装后注册登录才能恢复使用。虽然整个过程有点麻烦,但是注册不需要验证,省去了很多麻烦。
除了问答得分,我们还可以根据问答的观看次数和回答次数来进行判断。
如果一个问答的浏览量很高,但目前的回答很少,那么值得先回答。因为这意味着我们的答案有很大的机会冲到前排,我们可以通过后续的SEO优化打到前3位,争取更高的曝光率。
而对于浏览量高、回复量高的问答,则需要依靠更多的干货内容来抢占先机。
相关问题(系统关联推荐)
很多人不知道问答右侧有一个“相关问题”部分,因为它必须在PC网页上打开才能出现。本节一般汇总4-5个相关问题(有时相关性不大),选择策略同上。
知乎系统推荐
对于代理账号,知乎每周都会设置定期任务,只要完成任务即可获得相应奖励。
其中一项奖励为“热点追踪1周”,触发条件为组织账号一周内完成7次创作(含Q&A,文章)。会在组织号的管理中心推荐热点问题,但大多与自己的产品无关。
竞争账户历史问答搜索
相比知乎系统推荐的问答,目前人工搜索更加靠谱。除了开头提到的直接搜索,我们其实还可以从竞品账号的历史答案中挖掘出合适的问答。这相当于双方运营商联合筛选,极有可能是有价值的。
退一步说,即使问答本身没有什么价值,但从营销的角度来赢得更多的目标用户,我们必须要占领这样的问答。
2)异地搜索
百度关键词搜索
这是一种被忽视但极其重要的搜索方法。
这很重要,因为百度在 2019 年 8 月宣布了战略投资知乎。这次密切合作带来的一个重要变化是,知乎Q&A在百度搜索中的权重有所提升——这是一条不容忽视的流量。
因此,除了在知乎网站上搜索关键词外,我们还可以在百度上进行关键词搜索,然后优先显示在第一条的知乎问答结果页面的页面。
这个过程可以和5118站长工具箱结合使用,可以对百度搜索隐藏广告,帮助我们快速找到目标结果。
5118大数据搜索
最后一种方法是完全借助第三方工具——“”来实现的。
借助5118的排名监控,可以搜索所有搜索关键词对应知乎问答、百度PC搜索结果排名、百度PC排名列表关键词、百度PC检索量等. 数据一次提取,支持导出到Excel。
我们要做的就是根据自己的关键词库在导出的Excel中检索自己的关键词及其对应的知乎Q&A。
但是,此功能需要付费会员才能使用。
最后,想补充下关于知乎组织号的选题的建议,即尽量不要选择社会热点事件、政治军事事件。因为组织编号代表了公司和产品的形象,如果回答不当,很容易引发危机公关事件。
三、内容:“为什么”和“如何”更重要
确定主题后,下一步就是内容创作。这部分我将拆解知乎问答的结构和图片,回答以下两个问题:
知乎高赞回答的大致结构是什么?
知乎问答中的图片有哪些提示和注意事项?
1. 好评答案的一般结构
高瓒的回答一般有这样的结构,用一个公式来表达:高瓒的回答=直截了当的结果+有理有据的分析+最后的互动寻求三个联系。如何理解这个公式?
1) 开门见山,给出结果
这意味着在答案的开头,我们尝试用简洁的文字来总结答案以创造吸引力,例如:
推荐12个完全免费的良心网站,每一个都是完全免费的,非常好用,让你们看到晚了-知乎@穆子琪,对应问题:舍不得拿出来分享通过 网站?
作为一个纪录片狂热的水母爱好者,我看过上百部纪录片,但只有这12部顶级纪录片吸引了我,每次看都会感叹“看的真好!” 我想再看一遍,涵盖历史、人文和宇宙。绝对值得一看!尤其是中间两部——知乎@Daisy Wuwu,对应问题:到目前为止,你看过哪些纪录片可以称得上“顶级纪录片”?
做炸鸡外卖,每月净利润4w左右,一年利润几十万。我不知道Suah不是一个巨大的利润。很多人都吃过炸鸡外卖,但是很少有人知道做这个生意能赚这么多钱,可能这个行业不是很抢眼-知乎@林燕,对应问题:普通人什么都不是很擅长现在 知道暴利行业吗?
之所以写成这样,除了众所周知的“吸引用户继续观看”,还有一个很重要的原因就是为了吸引用户点进来。要知道,在没有展开答案之前,显示逻辑与公众号摘要相同,默认抓取文字前面的内容。
2)用理由和证据分析
吸引注意力后,你必须用完整和丰富的内容来保持它。
那么到底什么样的内容才是完整的呢?
我的回答是,不仅要介绍“是什么”,还要解释“为什么”和“如何解决”。知乎用户不愿意停留在问题的表面,他们喜欢深入的、未知的、不易访问的内容。通过告诉他们更深层次的知识、经验或见解,更容易获得认可。
比如这个知乎问题:什么是费曼技术?
如果简单地告诉用户这是一种“以教为本”的学习方式,可以帮助你提高知识吸收效率,真正理解和学会使用知识,答案很可能会沉到水底。组织号XMind做了一个很好的演示,它是这样回答的(回答太长了,我只拆了主要结构和关键点):
什么是费曼技术?
- 教学就是学习。
具体应用?
- 分四步走。
为什么费曼技术如此有效?
拆分和压缩知识;
理解和简化知识;
理解和附属知识(中间插入XMind绘制的思维导图作品)。
这是朋友喜欢的那种干货。就算中间有私货,他们还是愿意投票给答案。很明显)。
因此,当您以“阅读我的答案时,其他人会问我为什么?”的假设来回答问题时,您可以写出更详细和有用的解释和解释。如果您提出观点,请解释您为什么这么认为,这将对您的读者非常有帮助。
3)连续三个互动结束
最后,多互动,引导更多用户参与、关注、评论。可以放自己的产品体验链接(支持文字链接和卡片链接)。
注意:不要对自己太苛刻!不要苛刻!不要苛刻!重要的事情说了三遍!因为会被阻塞,下面是一个典型的反例:
2. 知乎图片技巧及注意事项
如果你的产品属于软件工具类,在介绍功能的时候可以选择录制一个Gif动画,比静态图片更直观,可以增加用户的停留时间。但需要注意的是,Gif图片不能太大(控制在1M左右),否则用户很可能在加载过程中不耐烦跳出。
另外,对于一些信息量大的横屏图片(图片一般比较模糊),尽量改成能同时适应用户移动阅读的竖屏图片,以提升用户的阅读体验。当然,如果你想做排水,那也不是什么大问题。
在内容文章的最后,跟大家分享一个小技巧:知乎支持同一个内容回答两个类似的问题,可以让组织号快速传播开来。但我建议根据每个问题的具体描述来剪裁内容的开头和部分。
注意:不要想着对一个内容回答超过3个问题,因为站服会删除重复内容,严重的也会封号。
四、SEO文章:知乎你也想做SEO吗?
内容发布成功后,我们就可以进行下一步了——SEO。可能有人会疑惑,知乎Q&A也应该是SEO吧?这不是问题的结尾吗?
- 当然不是。
如果我们将内容与 1 进行比较,那么 SEO 就是后面的 0。后者是前者的放大器,可以为前者带来更大的曝光率,进而帮助企业产品获得更多的销售线索。这也是我们前面反复提到的知乎机构号的终极目标。
既然知乎Q&A SEO这么重要,我该怎么办?我总结了2个主要技巧:
1. 找到喜欢的高权重账号
在知乎刷赞也不是什么新鲜事,但如何高效刷赞,不留痕迹需要一点技巧。不过不用担心,在正式分享知乎点赞技巧之前,我们要先搞清楚一个问题,那就是知乎问答的排序算法,也就是我们的“指南针”后续行动。
知乎有两套问题和答案,旧的和新的。老版本的问答排序算法比较简单,基于“分数=加权批准数-加权反对数”,但会带来两个问题:
第一:好评度高的答案将长期占据榜首,即使新的高质量答案也很难有“第一天”;
第二:如果恶意投出大量反对票,答案分数甚至可以为负,这也意味着它会沉到谷底,也很难有“翻盘日”。
新版算法(Wilson score)的出现在一定程度上解决了上述问题,让新的答案有机会超越之前发布的好评答案——这为我们实施SEO计划创造了空间.
以上是Wilson分数的计算公式,很复杂,要解释清楚是一篇长文。但我不打算在这里谈论它。感兴趣的朋友可以去知乎搜索“如何评价知乎的答案排序算法?”。很多大佬已经从各个维度分析过了。
我们这次的重点是这个新算法对我们的 SEO 的影响。直接进入观察点:
垂直领域的高级别账户的同类权重更高;举个简单的例子,同一领域的V5账号的点赞效果要强于10个V3账号;
点赞对高等级账号的效果是立竿见影的,点赞后刷新链接一般都能看到效果。
也就是说,我们的SEO任务需要从点赞1.0的打架时代升级为点赞2.0的打架质量时代。那我们具体怎么做呢?
还有两种技术:
1)自己培养高权重的小号喜欢
这不是一蹴而就的事情,但如果开始跑起来,代理账号和个人账号之间的互赞就能形成正向循环,效果非常显着。
值得注意的是,每一个知乎的点赞都会出现在账号动态中。如果我们长期只喜欢一个账号,很容易被用户发现并向知乎官方投诉,严重的话会导致账号被封。
因此,点赞需要模拟正常用户行为的轨迹。不喜欢连续一个账号,穿插一些不会和我们形成直接排名竞争的答案;不要打开问答链接直接跳转到目标答案,尽可能正常浏览同一个问题。下面的其他答案,有时你可以做一些简单的评论等。
2)主动吸引高调点赞
直接买大赞不划算,还容易被举报。那么如何才能让大牌明星主动喜欢我们呢?
我想出了一个窍门:我在回答中引用了高权重V的一些要点,然后在文章中引用@文章,如果对方认可了我们的内容,那么对方很大概率会喜欢的。
当然,前提是我们的内容要足够翔实,也就是我们前面提到的内容。
比如我们前面提到的XMind,在“费曼的技术是什么?”的回答中,它引用了@kaiyantechnique 选择的视频内容,然后@open 对方。
2. 使用第三方工具进行快速排序
我们前面讲的是在知乎网站做Q&A SEO,就是为了提高答案的排名;但是如果我们也想提高这个答案的知乎问题在百度搜索中的排名,那么就需要使用第三方工具进行快速排序了。
有预算的运营同学可以试试流量宝/超快排,刷三四个星期,一般都能到百度结果首页。
3. 两个不严格属于 SEO 类别的复活节彩蛋
1)使用自推荐功能
知乎组织账号每周完成任务可以获得一定数量的“自我推荐”。所谓“自荐”,简单来说,就是让平台为自己分发内容的功能。
由于“自荐”的数量有限,最好的办法是结合后台数据,筛选出近期有潜力的内容进行自荐,让本已优秀的内容更有可能火爆。
2)打开刘看山邀请函
有时候遇到浏览量低的问答,可以打开刘看山的邀请,以及自邀系统推荐的创作者。目的其实是为了让更多的用户看到你创作的内容。
五、写在最后
知乎 是一个很好的流量池,但我们也必须意识到,并非所有类型的产品都适合这里的内容营销。完美日记来了又走了;白果园来了又走了;名创优品也来了,终于走了……
不是这些产品不好,也不是知乎平台不好,而是产品和平台的“契合度”太低,彼此都不是“对的人”(比如,完美日记和小红书更好)。
我之前举例的 Graphite Documents、XMind、Maker Posts 等 ToC 工具产品对 知乎 的兼容性更好:
首先,知乎和工具类产品在用户方面有高度的重叠,两者都是高学历,追求高效率;其次,朋友通常会寻找具体问题的答案。如果看到合适的工具,一般都会启动;最后,知乎支持在回答中直接放置产品链接(可以自定义链接,后期跟踪用户来源),可以大大缩短获客链条。
综上所述,企业应该根据自己的产品属性和用户特点,结合不同自媒体平台的调性,以及不同平台应该采用什么样的内容形式和运营方式来决定选择哪个平台进行运营。这是企业经营新媒体的重要规则。
我们是知乎官方直接授权的服务商,拥有9年互联网广告行业经验,服务过重庆、贵州、昆明等西南地区上万家企业。需要放置知乎广告,我们会免费提供策划和解决方案,帮助您少走弯路,增加收益!
宏达电
网页视频抓取工具 知乎(网页视频抓取工具知乎红人采集知乎回答页上的红人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2022-02-08 01:00
网页视频抓取工具知乎红人采集知乎回答页上的红人,也可以实现上万个红人的抓取,抓取后的文本可以作为数据分析工具获取隐私资料从事舆情监测。雪豹漏斗分析网页rest服务平台教育方面的资源比较少,没有形成体系,要找的话还是很有市场的。的premium套餐还是比较贵的,据说一个集群需要6万人民币/年。聚搜其实平时我也不怎么关注的,偶尔看看。
我关注这类站点可能比较多,国内的知乎红人视频、知乎热榜、一堆内容站,然后再看看国外的instagram、twitter什么的再找相关国内国外的工具站吧。站在巨人的肩膀上能看的更远。
红人和知乎不是一回事,百度贴吧跟知乎的关系才比较类似。红人往往是属于段子手,还有少量品牌而已。而知乎,太高大上了,其实针对的是知识分享,所以有很多好的idea,你需要的是去生产这些idea,不存在红人这个概念。比如,像兔斯基这样的,如果人家仅仅是做品牌的话,不如搜狗智能的结果好,所以结论就是,如果你并没有实力生产有质量的东西,并且自己还不知道做什么好,那就不要去冒然去做红人,反而过多要去围绕知乎这个产品去做点相应的个性化产品,不然这个模式很难成型。
网站抓取工具哪有红人...红人嘛, 查看全部
网页视频抓取工具 知乎(网页视频抓取工具知乎红人采集知乎回答页上的红人)
网页视频抓取工具知乎红人采集知乎回答页上的红人,也可以实现上万个红人的抓取,抓取后的文本可以作为数据分析工具获取隐私资料从事舆情监测。雪豹漏斗分析网页rest服务平台教育方面的资源比较少,没有形成体系,要找的话还是很有市场的。的premium套餐还是比较贵的,据说一个集群需要6万人民币/年。聚搜其实平时我也不怎么关注的,偶尔看看。
我关注这类站点可能比较多,国内的知乎红人视频、知乎热榜、一堆内容站,然后再看看国外的instagram、twitter什么的再找相关国内国外的工具站吧。站在巨人的肩膀上能看的更远。
红人和知乎不是一回事,百度贴吧跟知乎的关系才比较类似。红人往往是属于段子手,还有少量品牌而已。而知乎,太高大上了,其实针对的是知识分享,所以有很多好的idea,你需要的是去生产这些idea,不存在红人这个概念。比如,像兔斯基这样的,如果人家仅仅是做品牌的话,不如搜狗智能的结果好,所以结论就是,如果你并没有实力生产有质量的东西,并且自己还不知道做什么好,那就不要去冒然去做红人,反而过多要去围绕知乎这个产品去做点相应的个性化产品,不然这个模式很难成型。
网站抓取工具哪有红人...红人嘛,
网页视频抓取工具 知乎( 2020年10月28日09:17:41文中通过示例代码介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-02 14:18
2020年10月28日09:17:41文中通过示例代码介绍)
python如何使用selenium爬虫的例子知乎
更新时间:2020-10-28 09:17:41 作者:宇智波间桐鸣人
本文章主要介绍python使用selenium爬虫知乎的方法示例。文章中对示例代码进行了非常详细的介绍,对大家的学习或工作有一定的参考和学习价值。需要的朋友如下 快来跟我一起学习
说到爬虫,大家想到的一般情况是,在python中,通过requests库获取网页的内容,然后通过beautifulSoup过滤文档中的标签和内容。但是这样做有一个问题,很容易被防摘机制阻止。
有很多反爬机制,比如知乎:一开始只加载几个问题,向下滚动时会继续加载到底部,向下滚动一定距离时,会出现一个将出现登录弹出窗口。框架。
这样的机制限制了爬虫获取服务器返回内容的方式。我们只能得到前几个答案,但没有办法得到后面的答案。
所以需要用selenium模拟一个真实的浏览器来操作。
最终效果如下:
前提是需要自己搜索教程并安装:
如果要使用下面的代码,可以直接修改driver.get()中的地址,然后爬取结果最终会保存在message.txt文件中
代码显示如下:
from selenium import webdriver # 从selenium导入webdriver
from selenium.webdriver.common.by import By # 内置定位器策略集
from selenium.webdriver.support.wait import WebDriverWait # 用于实例化一个Driver的显式等待
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
import time
option = webdriver.ChromeOptions()
option.add_argument("headless")
driver = webdriver.Chrome() # chrome_options=option 这个参数设置之后可以隐藏浏览器
driver.get('https://www.zhihu.com/question/22110581') #修改这里的地址
file = open("./messages.txt", "w")
def waitFun():
js = """
let equalNum = 0;
window.checkBottom = false;
window.height = 0;
window.intervalId = setInterval(()=>{
let currentHeight = document.body.scrollHeight;
if(currentHeight === window.height){
equalNum++;
if(equalNum === 2){
clearInterval(window.intervalId);
window.checkBottom = true;
}
}else{
window.height = currentHeight;
window.scrollTo(0,window.height);
window.scrollTo(0,window.height-1000);
}
},1500)"""
# 这个暂停一下是因为要等待页面将下面的内容加载出,这个 1500 可以根据自己的网络快慢进行适当的调节
# 这里需要往上移动一下,因为不往上移动一下发现不会加载。
driver.execute_script(js)
# selenium 可以获取 浏览器中 js 的变量。调用的js return
def getHeight(nice):
# 这里获取 js 中的 checkBottom 变量,作为到底部时进行停止。
js = """
return window.checkBottom;
"""
return driver.execute_script(js)
try:
# 先触发登陆弹窗。
WebDriverWait(driver, 40, 1).until(EC.presence_of_all_elements_located(
(By.CLASS_NAME, 'Modal-backdrop')), waitFun())
# 点击空白关闭登陆窗口
ActionChains(driver).move_by_offset(200, 100).click().perform()
# 当滚动到底部时
WebDriverWait(driver, 40, 3).until(getHeight, waitFun())
# 获取回答
answerElementArr = driver.find_elements_by_css_selector('.RichContent-inner')
for answer in answerElementArr:
file.write('==================================================================================')
file.write('\n')
file.write(answer.text)
file.write('\n')
print('爬取成功 '+ str(len(answerElementArr)) +' 条,存入到 message.txt 文件内')
finally:
driver.close() #close the driver
这组代码实现了打开知乎,然后自动向下滑动。登录框弹出时,自动点击左上角关闭登录框。然后继续向下滑动,加载页面,直到滑动到底部。然后将内容写入message.txt文件。
Selenium 非常强大,可以在浏览器中模拟人的操作,比如输入、点击、滑动、播放、暂停等,所以也可以用来写一些刷课时、抢课等脚本。
至此,这篇关于python使用selenium爬虫知乎的方法示例的文章文章就介绍到这里了。更多相关python selenium爬虫知乎,请搜索脚本之家k7@之前的或继续浏览以下相关文章希望大家以后多多支持脚本之家! 查看全部
网页视频抓取工具 知乎(
2020年10月28日09:17:41文中通过示例代码介绍)
python如何使用selenium爬虫的例子知乎
更新时间:2020-10-28 09:17:41 作者:宇智波间桐鸣人
本文章主要介绍python使用selenium爬虫知乎的方法示例。文章中对示例代码进行了非常详细的介绍,对大家的学习或工作有一定的参考和学习价值。需要的朋友如下 快来跟我一起学习
说到爬虫,大家想到的一般情况是,在python中,通过requests库获取网页的内容,然后通过beautifulSoup过滤文档中的标签和内容。但是这样做有一个问题,很容易被防摘机制阻止。
有很多反爬机制,比如知乎:一开始只加载几个问题,向下滚动时会继续加载到底部,向下滚动一定距离时,会出现一个将出现登录弹出窗口。框架。
这样的机制限制了爬虫获取服务器返回内容的方式。我们只能得到前几个答案,但没有办法得到后面的答案。
所以需要用selenium模拟一个真实的浏览器来操作。
最终效果如下:
前提是需要自己搜索教程并安装:
如果要使用下面的代码,可以直接修改driver.get()中的地址,然后爬取结果最终会保存在message.txt文件中
代码显示如下:
from selenium import webdriver # 从selenium导入webdriver
from selenium.webdriver.common.by import By # 内置定位器策略集
from selenium.webdriver.support.wait import WebDriverWait # 用于实例化一个Driver的显式等待
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
import time
option = webdriver.ChromeOptions()
option.add_argument("headless")
driver = webdriver.Chrome() # chrome_options=option 这个参数设置之后可以隐藏浏览器
driver.get('https://www.zhihu.com/question/22110581') #修改这里的地址
file = open("./messages.txt", "w")
def waitFun():
js = """
let equalNum = 0;
window.checkBottom = false;
window.height = 0;
window.intervalId = setInterval(()=>{
let currentHeight = document.body.scrollHeight;
if(currentHeight === window.height){
equalNum++;
if(equalNum === 2){
clearInterval(window.intervalId);
window.checkBottom = true;
}
}else{
window.height = currentHeight;
window.scrollTo(0,window.height);
window.scrollTo(0,window.height-1000);
}
},1500)"""
# 这个暂停一下是因为要等待页面将下面的内容加载出,这个 1500 可以根据自己的网络快慢进行适当的调节
# 这里需要往上移动一下,因为不往上移动一下发现不会加载。
driver.execute_script(js)
# selenium 可以获取 浏览器中 js 的变量。调用的js return
def getHeight(nice):
# 这里获取 js 中的 checkBottom 变量,作为到底部时进行停止。
js = """
return window.checkBottom;
"""
return driver.execute_script(js)
try:
# 先触发登陆弹窗。
WebDriverWait(driver, 40, 1).until(EC.presence_of_all_elements_located(
(By.CLASS_NAME, 'Modal-backdrop')), waitFun())
# 点击空白关闭登陆窗口
ActionChains(driver).move_by_offset(200, 100).click().perform()
# 当滚动到底部时
WebDriverWait(driver, 40, 3).until(getHeight, waitFun())
# 获取回答
answerElementArr = driver.find_elements_by_css_selector('.RichContent-inner')
for answer in answerElementArr:
file.write('==================================================================================')
file.write('\n')
file.write(answer.text)
file.write('\n')
print('爬取成功 '+ str(len(answerElementArr)) +' 条,存入到 message.txt 文件内')
finally:
driver.close() #close the driver
这组代码实现了打开知乎,然后自动向下滑动。登录框弹出时,自动点击左上角关闭登录框。然后继续向下滑动,加载页面,直到滑动到底部。然后将内容写入message.txt文件。
Selenium 非常强大,可以在浏览器中模拟人的操作,比如输入、点击、滑动、播放、暂停等,所以也可以用来写一些刷课时、抢课等脚本。
至此,这篇关于python使用selenium爬虫知乎的方法示例的文章文章就介绍到这里了。更多相关python selenium爬虫知乎,请搜索脚本之家k7@之前的或继续浏览以下相关文章希望大家以后多多支持脚本之家!
网页视频抓取工具 知乎(网页视频怎么下载方法,vip解析下载功能介绍! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2022-02-02 14:17
)
如何下载网页视频一、各种软件内置下载功能
比如你想下载优酷网视频,你可以下载对应的客户端、电脑或者手机APP,然后搜索你要下载的视频,然后下载。
如何下载网络视频二、分析功能
视频流量消耗很大带宽,所以视频会采集防止别人以各种方式盗取他的资源
所谓魔法,一尺高,道高一尺,破解的方法有很多种。可以搜索网页各自的解析插件,或者破解版资源。
例如搜索【XXXXX vip解析下载】xxxx,替换想要的平台名称。
如何下载网络视频三、嗅探功能
如果是一般的网站,鲜为人知,或者通用的方法,可以使用嗅探功能。打开视频播放后,带有嗅探功能的浏览器可以嗅出播放的真实网址,获取真实网址并下载。
这里需要注意一点,如果视频是像mp4这样的单独文件,可以用任何软件下载。
如果是m3u8文件【格式说明:一个40分钟的视频,分成400个几秒的小问题】这就需要单独的嗅探和下载软件。
有许多具有嗅探功能的浏览器。最厉害的是谷歌浏览器,但是要学会安装【科学上网:范强】,麻烦
推荐这里
1.电脑
这里推荐浏览器扩展:FVD Downloader
其他浏览器应该有。我这里以360浏览器为例。
安装后打开收录m3u8视频的网页
下载视频
然后打开软件
添加任务后,点击全部开始
二、移动端
1.QQ浏览器
使用QQ浏览器打开播放视频的网址添加下载。
2.Univision House
相比QQ浏览器,这个工具更方便,并且有超级缓存功能。
可批量下载m3u8视频,下载后自动合并mp4,可更改播放
下载方法很简单,长按链接点击下载
添加下载查看
在这里,安利就来看看UTV加速播放器加速播放的独特功能。获取播放链接后,自动调用多线程加速播放器。特别推荐在网页上观看视频卡。
查看全部
网页视频抓取工具 知乎(网页视频怎么下载方法,vip解析下载功能介绍!
)
如何下载网页视频一、各种软件内置下载功能
比如你想下载优酷网视频,你可以下载对应的客户端、电脑或者手机APP,然后搜索你要下载的视频,然后下载。
如何下载网络视频二、分析功能
视频流量消耗很大带宽,所以视频会采集防止别人以各种方式盗取他的资源
所谓魔法,一尺高,道高一尺,破解的方法有很多种。可以搜索网页各自的解析插件,或者破解版资源。
例如搜索【XXXXX vip解析下载】xxxx,替换想要的平台名称。
如何下载网络视频三、嗅探功能
如果是一般的网站,鲜为人知,或者通用的方法,可以使用嗅探功能。打开视频播放后,带有嗅探功能的浏览器可以嗅出播放的真实网址,获取真实网址并下载。
这里需要注意一点,如果视频是像mp4这样的单独文件,可以用任何软件下载。
如果是m3u8文件【格式说明:一个40分钟的视频,分成400个几秒的小问题】这就需要单独的嗅探和下载软件。
有许多具有嗅探功能的浏览器。最厉害的是谷歌浏览器,但是要学会安装【科学上网:范强】,麻烦
推荐这里
1.电脑
这里推荐浏览器扩展:FVD Downloader
其他浏览器应该有。我这里以360浏览器为例。
安装后打开收录m3u8视频的网页
下载视频
然后打开软件
添加任务后,点击全部开始
二、移动端
1.QQ浏览器
使用QQ浏览器打开播放视频的网址添加下载。
2.Univision House
相比QQ浏览器,这个工具更方便,并且有超级缓存功能。
可批量下载m3u8视频,下载后自动合并mp4,可更改播放
下载方法很简单,长按链接点击下载
添加下载查看
在这里,安利就来看看UTV加速播放器加速播放的独特功能。获取播放链接后,自动调用多线程加速播放器。特别推荐在网页上观看视频卡。
网页视频抓取工具 知乎(网页视频抓取工具知乎live的视频和网页内容能够抓取吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-02 09:00
网页视频抓取工具知乎live的视频和网页内容能够抓取吗?要想提取视频里的链接,首先需要自己的电脑支持抓取电脑端网页,
抓取手机端网页,
电脑端注册知乎,
问这个问题的人应该很懒吧
其实我很想知道有没有学python的人知道web抓包,我找了好久...为什么没有找到?可能和我关注的网站可以做个对比学习了。
我也只能用自己的nodejs程序尝试了。视频库是百度,uc,优酷,youtube,在电脑浏览器上基本上所有视频都可以直接分享,不能直接分享或只能分享指定的直播信息的很多情况下是因为通信协议不同,但是无论如何都能发布。但是之前有些可以分享的内容是只能通过邮件或者是手机信息,这就算是从点播升级到点播列表吧,相对的不那么不那么方便。
我觉得题主可以直接问大家是否能抓取网站视频(互联网上的),然后用python写服务器,从我们这里拿过来。如果是对这个内容感兴趣,你可以去百度一下tinyxc这个工具,你可以去了解一下。
一般情况下电脑上都有浏览器或者本地操作系统的浏览器,如果没有的话,基本不行,比如百度搜狗360等等,有点复杂还需要注册账号什么的。我只是举个栗子,至于一些别的你就得自己想啦,想到了再来补充。 查看全部
网页视频抓取工具 知乎(网页视频抓取工具知乎live的视频和网页内容能够抓取吗?)
网页视频抓取工具知乎live的视频和网页内容能够抓取吗?要想提取视频里的链接,首先需要自己的电脑支持抓取电脑端网页,
抓取手机端网页,
电脑端注册知乎,
问这个问题的人应该很懒吧
其实我很想知道有没有学python的人知道web抓包,我找了好久...为什么没有找到?可能和我关注的网站可以做个对比学习了。
我也只能用自己的nodejs程序尝试了。视频库是百度,uc,优酷,youtube,在电脑浏览器上基本上所有视频都可以直接分享,不能直接分享或只能分享指定的直播信息的很多情况下是因为通信协议不同,但是无论如何都能发布。但是之前有些可以分享的内容是只能通过邮件或者是手机信息,这就算是从点播升级到点播列表吧,相对的不那么不那么方便。
我觉得题主可以直接问大家是否能抓取网站视频(互联网上的),然后用python写服务器,从我们这里拿过来。如果是对这个内容感兴趣,你可以去百度一下tinyxc这个工具,你可以去了解一下。
一般情况下电脑上都有浏览器或者本地操作系统的浏览器,如果没有的话,基本不行,比如百度搜狗360等等,有点复杂还需要注册账号什么的。我只是举个栗子,至于一些别的你就得自己想啦,想到了再来补充。
网页视频抓取工具 知乎(这10款个个都很实用,属于“收藏不吃灰”系列)
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2022-01-31 14:10
因为平时的工作,接触到的设计门类比较多(视频、图片、文字),所以给大家介绍一下设计、音频、视频、文字相关的。如果符合你目前的需求,可以继续阅读。
对工作有帮助网站通过朋友的介绍和自己的搜索,我也省了很多。下面是安利的10款,都很实用,属于“采集不吃灰”系列!
1、网易查看工作台
网易工作台在3月份宣布关闭功能。不过,最近工作台已经悄然重新开放,只是淡出大家的视线后,并没有立即公布消息。
网易查看工作台是集文字翻译、视频翻译、图片翻译于一体的综合在线翻译网站。
它不仅有最基本的文字翻译功能,你还可以在里面上传你的视频,它会自动为你生成中英文双语字幕,或者当你想给你的视频添加字幕时,你可以直接上传你的视频。还能够为一段视频快速生成字幕。
比如视频转录功能,点击新建项目,选择视频转录,上传要转换的视频文件,等待一键快速生成视频字幕。
打开网站需要使用网易邮箱登录,如果没有账号,可以直接注册。目前视频每天可提供2小时免费体验,生成的字幕为srt字幕文件
网站:/
2、音乐剪辑
Audio Cutter 是一款在线应用程序,可让您直接在浏览器中剪切音轨。该应用程序快速、稳定,支持 300 多种文件格式、淡入淡出和铃声质量预设,并且完全免费。
非常好用:点击选择文件,上传文件,支持300多种文件格式,包括视频常用格式,方便上传视频,提取里面的音频,使用滑块选择音频剪辑,然后单击“编辑”,然后单击“保存”下载。
网站: /cn/
3、去除短视频水印
现在随着短视频的兴起,短视频平台也很多,但是如果你想下载某个视频,直接下载就会有平台的logo水印。
今天,这个网站致力于分析无水印的短视频下载。网站介绍了对抖音、火山、快手、微视、皮皮虾、健影、微博等平台的支持。
使用方法:打开短视频app,选择要下载的视频,复制链接粘贴到解析视频框,点击解析视频,如果解析视频可以重新解析,点击下载视频,进入无水印界面,点击下载无水印视频。
网站:
4、图片无损放大
网站采用最新的人工智能深度学习技术——深度卷积神经网络,补充噪声和锯齿部分,实现图片无损放大。
支持卡通/插画、照片,最高16倍放大,并具有降噪功能,即可以对模糊的照片进行一定程度的修复,可以说近乎完美。
网站:/
5、在线图片压缩
有图片的无损放大,对应图片压缩的需要。这个 网站 是彩色笔,一个免费的在线图像压缩小工具。
将PNG/GIF/JPG图像的大小优化到极限非常方便。网站简洁美观的界面,响应速度极快,处理速度极快,支持批量上传多个文件。依靠专业的专业算法支持,图像尺寸大幅缩小后,清晰度仍能与原图保持一致。
网站:
6、魔灵音乐
对于音乐,由于版权的原因,很多音乐软件也相继失败。魔灵音乐网页版,在线收听,下载,网站无广告,无需注册登录,完全免费。
网站有分类播放列表,支持搜索、下载、部分音乐无损下载。
网站:/
7、在线格式转换
说到视频格式转换,大家可能会想到格式工厂、小玩工具箱等软件。其实转换可以更简单高效,所以今天就介绍这个网站:Convertio。
支持 300 多种格式,只需将文件拖放到页面上,选择输出格式并点击“转换”按钮即可。所有的转换都是在云端完成的,所以它们不在电脑上运行,而且处理速度非常快。
网站:convertio.co/en
8、在线 PDF 工具
对于PDF文档,在日常工作学习中经常会遇到,很多时候都需要进行编辑和转换。很多网友去下载安装相应的软件。
其实有PDF24 Tools网站就够了,免费好用的在线PDF工具,20多个功能,而且完全免费,无限制。
网站:
9、GIF 编辑工具
对于 GIF 编辑和处理工具,我们推荐 Map Tips(以前是 GIF 工具的所在地)。本网站支持GIF图片压缩、视频转GIF、GIF合成、GIF裁剪等功能。
网站:
10、快速AI自动抠图
图片背景去除,100%自动免费,只需上传需要去除背景的图片,无需额外操作,5秒内自动100%去除背景。
提供下载,并支持继续编辑、更改背景。
网站: remove.bg/en 查看全部
网页视频抓取工具 知乎(这10款个个都很实用,属于“收藏不吃灰”系列)
因为平时的工作,接触到的设计门类比较多(视频、图片、文字),所以给大家介绍一下设计、音频、视频、文字相关的。如果符合你目前的需求,可以继续阅读。
对工作有帮助网站通过朋友的介绍和自己的搜索,我也省了很多。下面是安利的10款,都很实用,属于“采集不吃灰”系列!
1、网易查看工作台
网易工作台在3月份宣布关闭功能。不过,最近工作台已经悄然重新开放,只是淡出大家的视线后,并没有立即公布消息。
网易查看工作台是集文字翻译、视频翻译、图片翻译于一体的综合在线翻译网站。
它不仅有最基本的文字翻译功能,你还可以在里面上传你的视频,它会自动为你生成中英文双语字幕,或者当你想给你的视频添加字幕时,你可以直接上传你的视频。还能够为一段视频快速生成字幕。
比如视频转录功能,点击新建项目,选择视频转录,上传要转换的视频文件,等待一键快速生成视频字幕。
打开网站需要使用网易邮箱登录,如果没有账号,可以直接注册。目前视频每天可提供2小时免费体验,生成的字幕为srt字幕文件
网站:/
2、音乐剪辑
Audio Cutter 是一款在线应用程序,可让您直接在浏览器中剪切音轨。该应用程序快速、稳定,支持 300 多种文件格式、淡入淡出和铃声质量预设,并且完全免费。
非常好用:点击选择文件,上传文件,支持300多种文件格式,包括视频常用格式,方便上传视频,提取里面的音频,使用滑块选择音频剪辑,然后单击“编辑”,然后单击“保存”下载。
网站: /cn/
3、去除短视频水印
现在随着短视频的兴起,短视频平台也很多,但是如果你想下载某个视频,直接下载就会有平台的logo水印。
今天,这个网站致力于分析无水印的短视频下载。网站介绍了对抖音、火山、快手、微视、皮皮虾、健影、微博等平台的支持。
使用方法:打开短视频app,选择要下载的视频,复制链接粘贴到解析视频框,点击解析视频,如果解析视频可以重新解析,点击下载视频,进入无水印界面,点击下载无水印视频。
网站:
4、图片无损放大
网站采用最新的人工智能深度学习技术——深度卷积神经网络,补充噪声和锯齿部分,实现图片无损放大。
支持卡通/插画、照片,最高16倍放大,并具有降噪功能,即可以对模糊的照片进行一定程度的修复,可以说近乎完美。
网站:/
5、在线图片压缩
有图片的无损放大,对应图片压缩的需要。这个 网站 是彩色笔,一个免费的在线图像压缩小工具。
将PNG/GIF/JPG图像的大小优化到极限非常方便。网站简洁美观的界面,响应速度极快,处理速度极快,支持批量上传多个文件。依靠专业的专业算法支持,图像尺寸大幅缩小后,清晰度仍能与原图保持一致。
网站:
6、魔灵音乐
对于音乐,由于版权的原因,很多音乐软件也相继失败。魔灵音乐网页版,在线收听,下载,网站无广告,无需注册登录,完全免费。
网站有分类播放列表,支持搜索、下载、部分音乐无损下载。
网站:/
7、在线格式转换
说到视频格式转换,大家可能会想到格式工厂、小玩工具箱等软件。其实转换可以更简单高效,所以今天就介绍这个网站:Convertio。
支持 300 多种格式,只需将文件拖放到页面上,选择输出格式并点击“转换”按钮即可。所有的转换都是在云端完成的,所以它们不在电脑上运行,而且处理速度非常快。
网站:convertio.co/en
8、在线 PDF 工具
对于PDF文档,在日常工作学习中经常会遇到,很多时候都需要进行编辑和转换。很多网友去下载安装相应的软件。
其实有PDF24 Tools网站就够了,免费好用的在线PDF工具,20多个功能,而且完全免费,无限制。
网站:
9、GIF 编辑工具
对于 GIF 编辑和处理工具,我们推荐 Map Tips(以前是 GIF 工具的所在地)。本网站支持GIF图片压缩、视频转GIF、GIF合成、GIF裁剪等功能。
网站:
10、快速AI自动抠图
图片背景去除,100%自动免费,只需上传需要去除背景的图片,无需额外操作,5秒内自动100%去除背景。
提供下载,并支持继续编辑、更改背景。
网站: remove.bg/en
网页视频抓取工具 知乎(视频剪辑需要用到的图片网站!(图)收藏哦)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-31 14:01
大家好,我是爱后期的老姜。
前几天给大家推荐了我做视频常用的音效网站。
今天我们将讨论您需要用于视频编辑的图像网站!
如果觉得不错,建议点赞订阅。
01.常用网站
下面的网站是比较常用的网站,可以在里面搜索各种图片素材。
不飞溅
美丽的免费图像和图片 | 不飞溅
推荐理由:品质卓越,无需注册,直接下载,好用。
注意:关键词需要是英文的,可以先将要搜索的中文翻译成英文,然后在图片网站中搜索对应的英文关键词。
像素
/
推荐理由:品质优秀,无需注册,直接下载,使用方便,可以根据需要下载不同大小的图片;有时网页可能打开速度很慢。
注意:关键词需要是英文的,可以先将要搜索的中文翻译成英文,然后在图片网站中搜索对应的英文关键词。
关注
/
推荐理由:品质优秀,使用方便,根据需要下载图片、插图、矢量图和视频;有时网页打开速度可能很慢。
以上网站是我常用的图片网站,可以免费商用,但是由于国外网站的原因,打开速度可能不太理想,但是有没办法,国内没有这种东西网站,只能用了。
02.特殊网站
在这个分类中,上面的网站不能下载,但也是非常常用的素材网站。
查找元素
寻找元素_免费下载设计元素网站_免费素材
这个网站最大的特点就是可以下载png格式的图片素材,透明通道无需抠图,可以根据我们的需要选择各种对应的元素。
但它有一些限制,普通会员每天只能下载5张图片,如果需要更多权限,则需要付费。每天下载5张照片,紧急情况也可以点赞。
阿里巴巴矢量素材库
Iconfont-阿里巴巴矢量图标库
不得不说,阿里巴巴是一家非常特别的公司,做了很多公益。
这个网站收录了各种矢量素材,免费好用。
百度地图
百度图片搜索结果
我们可以上传一张图片,然后我们可以找出这张图片在网络上的其他位置。
如果我们有图片素材,但是素材太模糊,质量很差,或者素材内容被剪掉了,我们可以用百度搜索图片,然后看看有没有其他高质量的图片.
03.下载
这里我们介绍几种下载图片的方法和工具。
拖放下载
我们通常通过两种方式在网上下载图片。一种是直接点击图片旁边的下载按钮或者在图片上右击-另存为图片。
但是有时候,没有下载按钮,右键下载也无法下载,那么我们可以使用直接拖拽的方式进行下载。
我们可以直接点击图片,然后不松手直接把图片拖到桌面,这样图片就下载好了。
快捷方式下载
除了拖拽下载,猎豹、360等部分浏览器也支持快捷键下载。在我使用这两个浏览器的时候,我下载图片的首选就是快捷键下载,因为真的很方便。
我们只需要先按住键盘上的Alt键,然后用鼠标点击我们要下载的图片,就会自动下载了。
下载图像助手
如果以上方法都不起作用,我们可以使用终极武器,图片助手。
这是一个插件。安装后,网页上的图片基本上都逃不过它的猎手了。
这个插件基本上在很多浏览器中都可以使用。下载安装后,找到我们要下载图片的网页,然后点击使用这个插件,它会识别网页上的所有图片,然后我们就可以轻松下载了。
以上是我平时做视频的图片网站和工具。您应该能够使用这些 网站 和工具来满足您的大部分需求。 查看全部
网页视频抓取工具 知乎(视频剪辑需要用到的图片网站!(图)收藏哦)
大家好,我是爱后期的老姜。
前几天给大家推荐了我做视频常用的音效网站。
今天我们将讨论您需要用于视频编辑的图像网站!
如果觉得不错,建议点赞订阅。
01.常用网站
下面的网站是比较常用的网站,可以在里面搜索各种图片素材。
不飞溅
美丽的免费图像和图片 | 不飞溅
推荐理由:品质卓越,无需注册,直接下载,好用。
注意:关键词需要是英文的,可以先将要搜索的中文翻译成英文,然后在图片网站中搜索对应的英文关键词。
像素
/
推荐理由:品质优秀,无需注册,直接下载,使用方便,可以根据需要下载不同大小的图片;有时网页可能打开速度很慢。
注意:关键词需要是英文的,可以先将要搜索的中文翻译成英文,然后在图片网站中搜索对应的英文关键词。
关注
/
推荐理由:品质优秀,使用方便,根据需要下载图片、插图、矢量图和视频;有时网页打开速度可能很慢。
以上网站是我常用的图片网站,可以免费商用,但是由于国外网站的原因,打开速度可能不太理想,但是有没办法,国内没有这种东西网站,只能用了。
02.特殊网站
在这个分类中,上面的网站不能下载,但也是非常常用的素材网站。
查找元素
寻找元素_免费下载设计元素网站_免费素材
这个网站最大的特点就是可以下载png格式的图片素材,透明通道无需抠图,可以根据我们的需要选择各种对应的元素。
但它有一些限制,普通会员每天只能下载5张图片,如果需要更多权限,则需要付费。每天下载5张照片,紧急情况也可以点赞。
阿里巴巴矢量素材库
Iconfont-阿里巴巴矢量图标库
不得不说,阿里巴巴是一家非常特别的公司,做了很多公益。
这个网站收录了各种矢量素材,免费好用。
百度地图
百度图片搜索结果
我们可以上传一张图片,然后我们可以找出这张图片在网络上的其他位置。
如果我们有图片素材,但是素材太模糊,质量很差,或者素材内容被剪掉了,我们可以用百度搜索图片,然后看看有没有其他高质量的图片.
03.下载
这里我们介绍几种下载图片的方法和工具。
拖放下载
我们通常通过两种方式在网上下载图片。一种是直接点击图片旁边的下载按钮或者在图片上右击-另存为图片。
但是有时候,没有下载按钮,右键下载也无法下载,那么我们可以使用直接拖拽的方式进行下载。
我们可以直接点击图片,然后不松手直接把图片拖到桌面,这样图片就下载好了。
快捷方式下载
除了拖拽下载,猎豹、360等部分浏览器也支持快捷键下载。在我使用这两个浏览器的时候,我下载图片的首选就是快捷键下载,因为真的很方便。
我们只需要先按住键盘上的Alt键,然后用鼠标点击我们要下载的图片,就会自动下载了。
下载图像助手
如果以上方法都不起作用,我们可以使用终极武器,图片助手。
这是一个插件。安装后,网页上的图片基本上都逃不过它的猎手了。
这个插件基本上在很多浏览器中都可以使用。下载安装后,找到我们要下载图片的网页,然后点击使用这个插件,它会识别网页上的所有图片,然后我们就可以轻松下载了。
以上是我平时做视频的图片网站和工具。您应该能够使用这些 网站 和工具来满足您的大部分需求。
网页视频抓取工具 知乎(一下四个平台的流量算法机制,你值得拥有!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-31 06:00
抖音、小红书、知乎、视频号,是众多品牌必争的流量洼地。
掌握几个平台的流量算法,可以让我们获得尽可能多的流量。今天给大家分享一下四大平台的算法机制。
1. 抖音
抖音的流量算法几乎是所有流量平台中最复杂的,当然它的流量也是最大的。
抖音 是典型的“标签”到“标签”平台。
如果您是用户,平台会根据您平时的浏览偏好,将您的关注点拆解成大约150个标签,而您可以浏览哪些视频在一定程度上取决于您的用户标签。如果浏览偏好发生变化,用户标签也会发生变化,刷过的视频也会随着标签而变化。
如果你是创作者,平台会根据你发布的内容形成创作者标签。标签的数量也是150个。如果你发布的内容发生变化,创建者标签也会发生变化。
创作者发布视频后,视频会根据创作者的标签匹配相似的用户标签。这就是我们上面谈到的“标签”到“标签”的流量算法。
短视频匹配到用户后,将通过视频的数据表现来衡量视频是否值得进一步推荐。
抖音对于单个视频的推荐,将评估5个关键数据:
1)完成率
完成率=观看时间/工作时间
完成率越高,作品越吸引人观看。市场的合格线通常在15%-20%左右,40%-50%以上的完成率已经很不错了。要想办法提高看完率,通常的做法是在开头设置悬念或者引导打开评论区来延长观看时间。
如果是新账号,建议上一个视频的时长不要太长。持续时间越长,完成度越低,除非视频质量非常好。
2)点赞率
喜欢率=喜欢/播放
喜欢的次数越多,推荐的次数就越多。第一波推荐的点赞率至少要达到3%-5%,也就是每100个浏览量,至少要有3-5个点赞。
3) 评论率
消息率=消息量/播放量
消息速率的数据级别与视频类型有很大关系。用平均数据来衡量并不容易,但可以肯定的是,消息率的表现越好,加权推荐越高。因此,创作者可以主动在视频或文案、评论区引导评论,提高评论率。
4)转发率
转发率=转发量/播放量
转发率对仍在主流量池中流通的视频影响不大,但要想突破流量级别,转发率是关键指标。
5)转化率
转化率=关注者/观看次数
也就是路粉比,以及单个视频带来的新增粉丝率,也是影响进阶流量池的关键数据。
抖音平台是巨大的流量池,抖音推荐机制是鱼网,视频内容是诱饵。
如果你的视频的五个关键数据都能达到不错的数据表现,那么很有可能进入中高级别流量池,继续流淌。
抖音 的流量池也有自己的规则。
视频发布后会进入冷启动池,流量一般在300-500,一般由粉丝+朋友+可能知道的人+少量匹配标签的用户组成,因为流量构成冷启动池是最复杂的,也是最难突破的。这将测试您的粉丝是否准确以及内容是否高质量。如果关键数据符合标准,就会进入一级流量池。
初级流池的流量在1000-5000左右。还需要继续观察主流池中视频的实现。如果数据继续通过测试,就会进入中间流池。
中间流量池播放量超过10000次,数据性能相同;
高级流量池浏览量超过100,000+,不封顶。
2. 小红书
小红书的算法和抖音类似,也是“tag”到“tag”的流量算法。
不同的是,根据不同的用户习惯,抖音更侧重于主动推荐,而小红书更侧重于搜索推荐。
基于小红书的平台定位,65%以上的流量来自搜索,所以搜索流量算法更加精细,所以这里重点介绍搜索流量算法的逻辑。
搜索结果与需求的匹配主要是核心关键词与query的匹配度。搜索结果中显示的具体内容是通过分析用户的需求,找到最能满足用户需求的信息。
笔记标题中的关键词是重中之重,官方也明确表示:“填写标题会增加点赞。”
可见,标题是小红书用来识别内容属性的一个重要选项。为了让笔记更显眼,最基本的工作就是优化标题。
我们需要善用搜索到的关键词、热词推荐等,帮助我们找到笔记的核心词,以便系统识别并推荐给相应的用户。
1) 从推荐内容中寻找核心词
推荐内容包括几个方面,搜索框灰显关键词,页面显示的历史搜索,热搜词
01. 默认提示词
在输入搜索词之前,平台会根据用户标签推荐默认提示词。默认提示词有一定的搜索流量。
02. 搜索发现(热门搜索)
热门搜索显示最近一段时间被搜索最多的词,引导用户查看一些用户搜索量较大的近期热门内容和话题推荐,这些内容与用户的搜索量和近期热门话题相关
03.补充联想关键词
<p>补充关联关键词,即用户输入部分内容,然后系统根据内容关联完整的内容,自动补全关键词,通过匹配 查看全部
网页视频抓取工具 知乎(一下四个平台的流量算法机制,你值得拥有!!)
抖音、小红书、知乎、视频号,是众多品牌必争的流量洼地。
掌握几个平台的流量算法,可以让我们获得尽可能多的流量。今天给大家分享一下四大平台的算法机制。
1. 抖音
抖音的流量算法几乎是所有流量平台中最复杂的,当然它的流量也是最大的。
抖音 是典型的“标签”到“标签”平台。
如果您是用户,平台会根据您平时的浏览偏好,将您的关注点拆解成大约150个标签,而您可以浏览哪些视频在一定程度上取决于您的用户标签。如果浏览偏好发生变化,用户标签也会发生变化,刷过的视频也会随着标签而变化。
如果你是创作者,平台会根据你发布的内容形成创作者标签。标签的数量也是150个。如果你发布的内容发生变化,创建者标签也会发生变化。
创作者发布视频后,视频会根据创作者的标签匹配相似的用户标签。这就是我们上面谈到的“标签”到“标签”的流量算法。
短视频匹配到用户后,将通过视频的数据表现来衡量视频是否值得进一步推荐。
抖音对于单个视频的推荐,将评估5个关键数据:
1)完成率
完成率=观看时间/工作时间
完成率越高,作品越吸引人观看。市场的合格线通常在15%-20%左右,40%-50%以上的完成率已经很不错了。要想办法提高看完率,通常的做法是在开头设置悬念或者引导打开评论区来延长观看时间。
如果是新账号,建议上一个视频的时长不要太长。持续时间越长,完成度越低,除非视频质量非常好。
2)点赞率
喜欢率=喜欢/播放
喜欢的次数越多,推荐的次数就越多。第一波推荐的点赞率至少要达到3%-5%,也就是每100个浏览量,至少要有3-5个点赞。
3) 评论率
消息率=消息量/播放量
消息速率的数据级别与视频类型有很大关系。用平均数据来衡量并不容易,但可以肯定的是,消息率的表现越好,加权推荐越高。因此,创作者可以主动在视频或文案、评论区引导评论,提高评论率。
4)转发率
转发率=转发量/播放量
转发率对仍在主流量池中流通的视频影响不大,但要想突破流量级别,转发率是关键指标。
5)转化率
转化率=关注者/观看次数
也就是路粉比,以及单个视频带来的新增粉丝率,也是影响进阶流量池的关键数据。
抖音平台是巨大的流量池,抖音推荐机制是鱼网,视频内容是诱饵。
如果你的视频的五个关键数据都能达到不错的数据表现,那么很有可能进入中高级别流量池,继续流淌。
抖音 的流量池也有自己的规则。
视频发布后会进入冷启动池,流量一般在300-500,一般由粉丝+朋友+可能知道的人+少量匹配标签的用户组成,因为流量构成冷启动池是最复杂的,也是最难突破的。这将测试您的粉丝是否准确以及内容是否高质量。如果关键数据符合标准,就会进入一级流量池。
初级流池的流量在1000-5000左右。还需要继续观察主流池中视频的实现。如果数据继续通过测试,就会进入中间流池。
中间流量池播放量超过10000次,数据性能相同;
高级流量池浏览量超过100,000+,不封顶。
2. 小红书
小红书的算法和抖音类似,也是“tag”到“tag”的流量算法。
不同的是,根据不同的用户习惯,抖音更侧重于主动推荐,而小红书更侧重于搜索推荐。
基于小红书的平台定位,65%以上的流量来自搜索,所以搜索流量算法更加精细,所以这里重点介绍搜索流量算法的逻辑。
搜索结果与需求的匹配主要是核心关键词与query的匹配度。搜索结果中显示的具体内容是通过分析用户的需求,找到最能满足用户需求的信息。
笔记标题中的关键词是重中之重,官方也明确表示:“填写标题会增加点赞。”
可见,标题是小红书用来识别内容属性的一个重要选项。为了让笔记更显眼,最基本的工作就是优化标题。
我们需要善用搜索到的关键词、热词推荐等,帮助我们找到笔记的核心词,以便系统识别并推荐给相应的用户。
1) 从推荐内容中寻找核心词
推荐内容包括几个方面,搜索框灰显关键词,页面显示的历史搜索,热搜词
01. 默认提示词
在输入搜索词之前,平台会根据用户标签推荐默认提示词。默认提示词有一定的搜索流量。
02. 搜索发现(热门搜索)
热门搜索显示最近一段时间被搜索最多的词,引导用户查看一些用户搜索量较大的近期热门内容和话题推荐,这些内容与用户的搜索量和近期热门话题相关
03.补充联想关键词
<p>补充关联关键词,即用户输入部分内容,然后系统根据内容关联完整的内容,自动补全关键词,通过匹配

