
网页视频抓取工具 知乎
网页视频抓取工具 知乎(Adobeanimatecc2018可以支持网页的音频、视频创作工具 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-07 20:22
)
Adobe animate cc 2018 是一款在爱尔兰开发的二维动画制作软件。Adobe animate cc 2018 可支持网页音视频创作,以及HTML5创作工具;Adobe Animate CC 可以通过扩展的架构支持任何动画格式。
一个cc2018(64位)下载地址:
链接:/s/1lMYYuCeA-GioqSeFvsB4rw
提取码:ly1b
软件对比
Adobe Animate CC 与 Flash 和 Edge Animate CC 有什么区别?
过去,Flash 是网络上的第三方插件,用于播放一些视频、音频或一些互动游戏。但是它带来了越来越多的问题,比如各种安全漏洞,黑客可以利用Flash来攻击你的电脑。如今,HTML5技术以其各方面的优势完全胜过Flash。Flash 已经成为过去式,现在 HTML5 逐渐流行起来。
Adobe 还在 2015 年宣布将 Adobe Flash Professional CC 重命名为 Adobe Animate CC,以提供对输出 HTML5 Canvas 的支持。所以,如果有任何区别,一个是新版本,另一个是旧版本。或者另一种理解方式是,一种用于 HTML 5,另一种用于 Flash。
Adobe Edge 是一种新的网络交互工具。允许设计师通过 HTML5、CSS 和 JavaScript 制作网页动画。不需要闪光灯。Adobe Edge 的目的是帮助专业设计师创建网络动画甚至简单的游戏。
查看全部
网页视频抓取工具 知乎(Adobeanimatecc2018可以支持网页的音频、视频创作工具
)
Adobe animate cc 2018 是一款在爱尔兰开发的二维动画制作软件。Adobe animate cc 2018 可支持网页音视频创作,以及HTML5创作工具;Adobe Animate CC 可以通过扩展的架构支持任何动画格式。
一个cc2018(64位)下载地址:
链接:/s/1lMYYuCeA-GioqSeFvsB4rw
提取码:ly1b
软件对比
Adobe Animate CC 与 Flash 和 Edge Animate CC 有什么区别?
过去,Flash 是网络上的第三方插件,用于播放一些视频、音频或一些互动游戏。但是它带来了越来越多的问题,比如各种安全漏洞,黑客可以利用Flash来攻击你的电脑。如今,HTML5技术以其各方面的优势完全胜过Flash。Flash 已经成为过去式,现在 HTML5 逐渐流行起来。
Adobe 还在 2015 年宣布将 Adobe Flash Professional CC 重命名为 Adobe Animate CC,以提供对输出 HTML5 Canvas 的支持。所以,如果有任何区别,一个是新版本,另一个是旧版本。或者另一种理解方式是,一种用于 HTML 5,另一种用于 Flash。
Adobe Edge 是一种新的网络交互工具。允许设计师通过 HTML5、CSS 和 JavaScript 制作网页动画。不需要闪光灯。Adobe Edge 的目的是帮助专业设计师创建网络动画甚至简单的游戏。
网页视频抓取工具 知乎( 从经典机器学习框架Scikit-learn,到深度学习慕课)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-01 04:06
从经典机器学习框架Scikit-learn,到深度学习慕课)
今天,机器学习框架在不断发展。训练人工智能模型变得越来越容易。
我还记得我上的第一门机器学习课程是吴恩达教授讲授的 Cousera MOOC。当时使用的工具是 Octave(Matlab 的开源版本)。使用起来很麻烦。即使是最简单的线性回归也需要多行代码。
但很快,我后来学到的机器学习/深度学习 MOOC,包括我自己制作的视频教程,都切换到了像 Python 这样的“开发者友好”环境。
从经典的机器学习框架 Scikit-learn 到深度学习框架 Tensorflow、Pytorch 和 fast.ai,调用 API 训练人工智能模型的方式越来越简单,步骤也越来越少。
比如我给大家演示过在fast.ai中,几行代码就可以让模型区分两个不同的卡通人物。
更进一步,你甚至不需要代码,只需让计算机自动“封装”训练任务即可。
这种工具已经存在。
我曾经在“数据科学导论,我应该怎么做?” “在文章中,我向您介绍了参观北德克萨斯大学(UNT)开放日的经历:
有一次我停在一张海报前,问学生如何获得如此高的图像识别率以及如何调整超参数?对方无法回答。但是告诉我他们使用了 Cloud AutoML。超参数调整直接在云后端完成,完全不用担心。
相比使用传统的深度学习框架如 Pytorch/Tensorflow 进行训练,AutoML 确实会帮助你减少很多流程。不过,对于普通人来说,还是有门槛的。
如果你的数据不符合系统的要求,或者训练结果不理想,你必须知道如何克服和改进。
说实话,我并没有太关注这种“低代码”/“无代码”的应用,觉得实用性不够高。
不过今天在看邵楠的《产品沉思》的时候,看到了lobe.ai的介绍。去官网看了介绍视频,感觉就两个字——惊艳。
演讲者Jake用电脑内置摄像头演示了数据采集、数据标注、模型训练、模型预测、模型迭代……直到模型导出部署成Tensorflow风格的全过程。
是的,虽然不需要写代码,但是还是可以按照主流的框架输出训练好的模型。通过这种方式,其他人可以在几分钟内将您的模型整合到他们的应用程序开发或工作流程中。
Jake 只花了几分钟就构建了一个自动识别饮酒动作的应用程序。
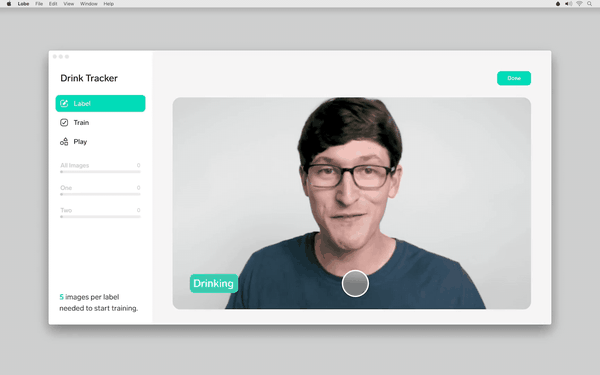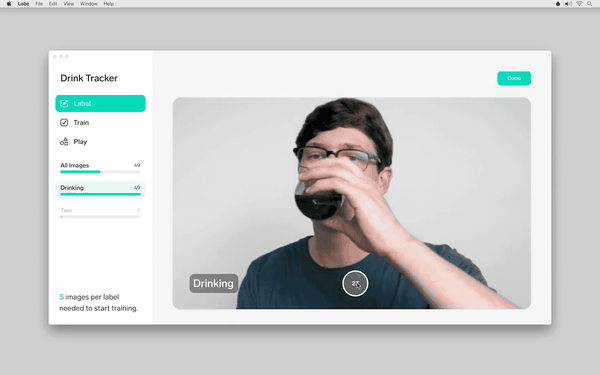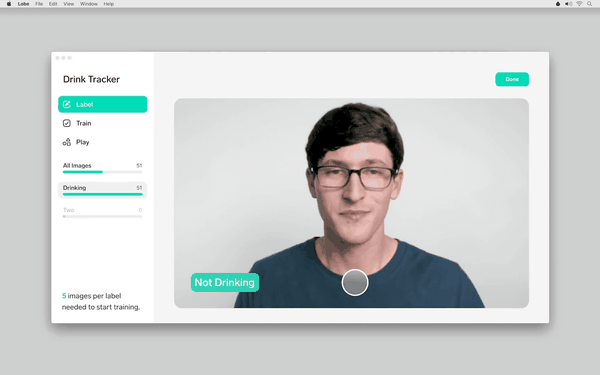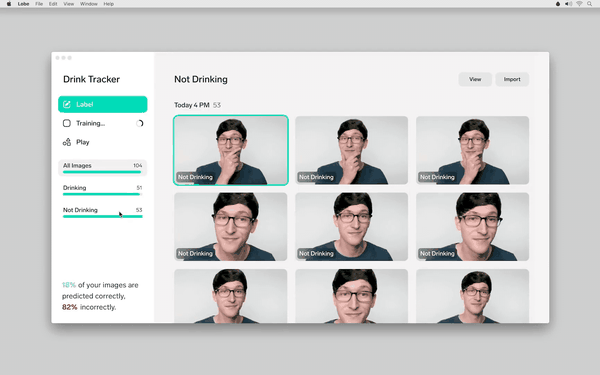
在这里的机器学习部分,你真的不需要单独写一个代码,只要按照机器学习的原创定义,并提供示例图片和相应的标记即可。
标记方法真的很简单。输入一个新的标记,然后对着相机拍一张,数据就完成了。
当然,除了像这样通过相机实时采集图片,你还可以从电脑批量选择图片文件夹,喂给模型。
想一想,如果完全不懂编程也能开发出智能模型,那应用场景就炸了。这不是“预言”。官网给出了很多例子。
这就是工具的普及给我们带来的好处。就像今天,你不必有绘画天赋,你可以用相机快速记录下你看到的一切。未来,在利用人工智能开发应用的时候,真正能限制我们的,或许只是我们的想象。
虽然这个工具目前只能服务于机器视觉任务,但相信随着迭代开发,更多类型数据的训练功能也会被整合。
即使 lobe.ai 没有这样做,其他开发者也应该注意到了这条可行的路径。
Lobe.ai 的完整介绍视频在这里。
我希望你不会满足于观看和惊叹,但你必须真正尝试这个应用程序。lobe.ai的下载地址在这里。它目前支持 Windows 和 macOS。也欢迎大家在留言区分享自己模型训练的成果,大家一起欣赏,一起交流学习。
祝(无代码)深度学习愉快! 查看全部
网页视频抓取工具 知乎(
从经典机器学习框架Scikit-learn,到深度学习慕课)

今天,机器学习框架在不断发展。训练人工智能模型变得越来越容易。
我还记得我上的第一门机器学习课程是吴恩达教授讲授的 Cousera MOOC。当时使用的工具是 Octave(Matlab 的开源版本)。使用起来很麻烦。即使是最简单的线性回归也需要多行代码。

但很快,我后来学到的机器学习/深度学习 MOOC,包括我自己制作的视频教程,都切换到了像 Python 这样的“开发者友好”环境。
从经典的机器学习框架 Scikit-learn 到深度学习框架 Tensorflow、Pytorch 和 fast.ai,调用 API 训练人工智能模型的方式越来越简单,步骤也越来越少。
比如我给大家演示过在fast.ai中,几行代码就可以让模型区分两个不同的卡通人物。
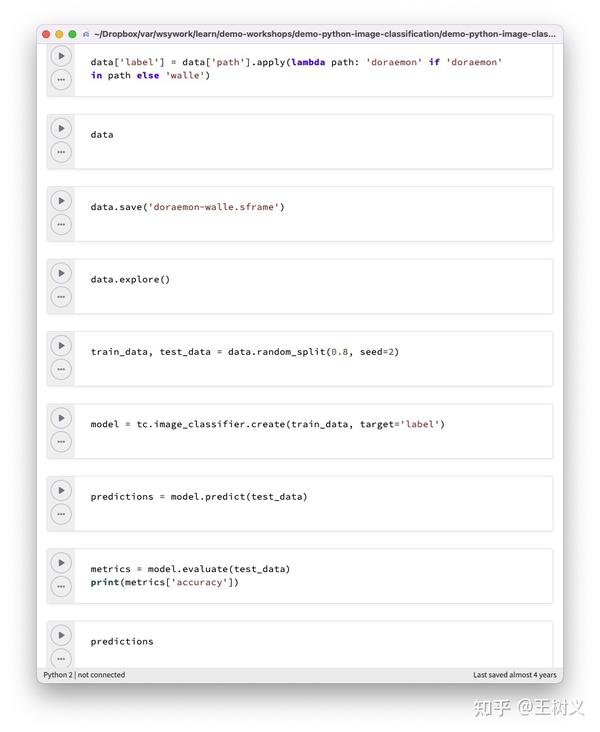
更进一步,你甚至不需要代码,只需让计算机自动“封装”训练任务即可。
这种工具已经存在。
我曾经在“数据科学导论,我应该怎么做?” “在文章中,我向您介绍了参观北德克萨斯大学(UNT)开放日的经历:
有一次我停在一张海报前,问学生如何获得如此高的图像识别率以及如何调整超参数?对方无法回答。但是告诉我他们使用了 Cloud AutoML。超参数调整直接在云后端完成,完全不用担心。
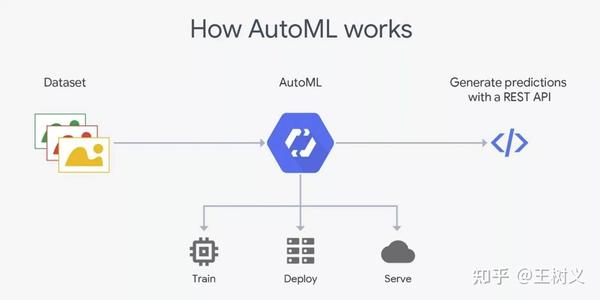
相比使用传统的深度学习框架如 Pytorch/Tensorflow 进行训练,AutoML 确实会帮助你减少很多流程。不过,对于普通人来说,还是有门槛的。
如果你的数据不符合系统的要求,或者训练结果不理想,你必须知道如何克服和改进。
说实话,我并没有太关注这种“低代码”/“无代码”的应用,觉得实用性不够高。
不过今天在看邵楠的《产品沉思》的时候,看到了lobe.ai的介绍。去官网看了介绍视频,感觉就两个字——惊艳。
演讲者Jake用电脑内置摄像头演示了数据采集、数据标注、模型训练、模型预测、模型迭代……直到模型导出部署成Tensorflow风格的全过程。
是的,虽然不需要写代码,但是还是可以按照主流的框架输出训练好的模型。通过这种方式,其他人可以在几分钟内将您的模型整合到他们的应用程序开发或工作流程中。
Jake 只花了几分钟就构建了一个自动识别饮酒动作的应用程序。
在这里的机器学习部分,你真的不需要单独写一个代码,只要按照机器学习的原创定义,并提供示例图片和相应的标记即可。
标记方法真的很简单。输入一个新的标记,然后对着相机拍一张,数据就完成了。
当然,除了像这样通过相机实时采集图片,你还可以从电脑批量选择图片文件夹,喂给模型。
想一想,如果完全不懂编程也能开发出智能模型,那应用场景就炸了。这不是“预言”。官网给出了很多例子。

这就是工具的普及给我们带来的好处。就像今天,你不必有绘画天赋,你可以用相机快速记录下你看到的一切。未来,在利用人工智能开发应用的时候,真正能限制我们的,或许只是我们的想象。
虽然这个工具目前只能服务于机器视觉任务,但相信随着迭代开发,更多类型数据的训练功能也会被整合。
即使 lobe.ai 没有这样做,其他开发者也应该注意到了这条可行的路径。
Lobe.ai 的完整介绍视频在这里。
我希望你不会满足于观看和惊叹,但你必须真正尝试这个应用程序。lobe.ai的下载地址在这里。它目前支持 Windows 和 macOS。也欢迎大家在留言区分享自己模型训练的成果,大家一起欣赏,一起交流学习。
祝(无代码)深度学习愉快!
网页视频抓取工具 知乎(如何看待Python中的各种扩展的库-Python(二) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-01 04:05
)
课程视频:
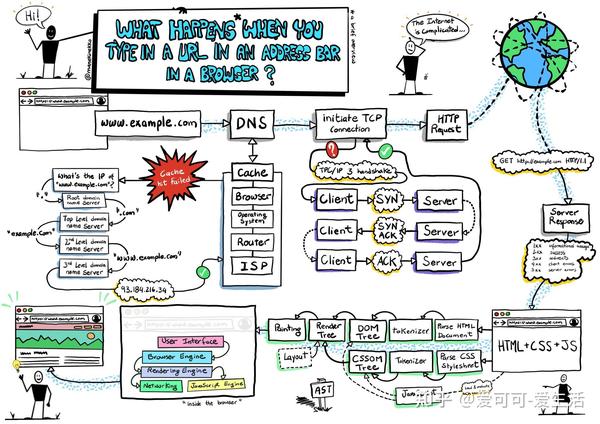
1、 当浏览器请求一个网站时,会从输入到页面显示,并描述请求过程
在课程中,我们概述了请求过程,您可以参考下图:
来源:网络| 嗨,我是法比安!全栈软件工程师 (townsend.fr)
详细过程可以参考:
2、本课爬虫可以应用于任何网站吗?
理论上是的,每个网站在细节上都会有一些差异,从内容组织到访问方式,我们会在后面的课程中讨论。
3、我对爬虫知之甚少。爬虫有什么用?我今天上课没跟上进度。
简单的说,就是一个用来获取网络信息的程序。具体可以参考wiki上的定义:
4、 无法获取网页的所有代码
一些内容是按需加载的。部分网页数据可以通过Javascript脚本和Ajax方式单独加载,可以实现页面的部分刷新。在下面的课程中,我们将通过抓取响应Json文件来获取数据的具体示例。
5、 课文中提到的“以拖拽的形式制作网页”是什么软件或者技术,是不是意味着淘汰手写css?
拖放主要用于设计内容和布局。内容显示的样式需要详细的 CSS 设置。当然,如果想省事,也可以直接使用现成的CSS框架。
6、 我们该如何看待Python中的各种扩展库,随意使用,岂不是大大提高了我们的编程能力?
在之前的问答中,我们谈到了是否要重新发明轮子的问题。从培养编程能力的角度来看,从头开始实施更多的练习是有益的,但在实际编程和构建具体项目解决方案的过程中,不一定需要自己从头开发所有模块。如果你有合适的第三方库,最好直接使用。这也是 Python 作为支持最广泛的开源社区的优势。但需要注意的是,一些第三方库可能存在一些不明显的错误甚至安全隐患,使用时要多加注意。
7、广告之类的图片怎么知道有链接?
有两种典型的实现方式,一种是直接
标签放置在标签内容中,以便图像变得可点击。另一种方法是使用 JavaScript 脚本来控制单击图像时触发的事件。单击是跳转到链接。
8、可以用爬虫复制百度文档的付费内容吗?有些内容只能预览不能复制。如果是这样,我该怎么办?
页面上无法复制的内容基本上有以下几种:一种是JavaScript脚本限制在特定区域的右键和快捷键行为,导致无法复制或弹出提示;另一种是展示图片,图片中的文字不能直接复制;然后使用特殊的编码来传输内容,在显示之前对其进行解码。理论上,只要能显示的文字是可以复制的,对于第一种情况,可以直接在网页源码中获取文字内容,对于第二种情况,可以将图片中的文字转化为OCR 文本。第三种需要分析内容的解码过程,根据解码和显示过程将传输的内容还原为原创文本。
9、“爬虫们,爬东西违法吗?如果你自己做网站,如何防止你的网站被爬”
关于爬虫的合法红线,可以参考以下文章:
我们将在后面的课程中介绍 counter-pick 策略。主要包括两个步骤:第一步是发现对方的恶意爬取行为,第二步是对该行为进行拦截或破坏。
10、 很早就听说爬虫是用来刷流量尖峰等的,很好奇
狭义的爬虫是模仿用户使用浏览器或App从网站或其他网络来源获取内容的自动化程序;广义的爬虫不限于采集数据,还可以模仿真实用户的访问行为,可以实现自动投票(刷卡排名)、自动访问(刷卡流量)、自动下单(刷卡)秒杀)等,但无论完成什么任务,本质都是一样的。尽量模仿真实用户的访问行为,避免被服务器或服务商看穿。
11、 如果网页上的数据格式不统一,比起今天豆瓣上的算法介绍,每个项目的介绍行数不统一,不均匀,我们还能不能使用连续四行不为空的条件?判断是否是标题?
当然不是。爬虫数据分析提取的核心是为每条数据找到一个共同的规律,不管是文本层面的规律还是文档结构的规律,只要规律不能用就必须调整及时。,要么修改一条适用于所有数据的规则,要么分别处理不同的情况,实现对所有待提取数据的完全覆盖。
12、request安装包在后续项目实践中有什么具体用途?
在下一课中,我们将讨论 requests 库的主要用途是用于 HTTP 访问。下载页面和提交信息(填写登录密码、提交订单等)都可以通过请求轻松实现。
13、 为什么我的txt文件是gbk编码,但是readlines不能调用
windows下默认使用gbk编码,可以参考上一课的Q&A 12:
14、 课上讲了爬虫,所以如果要修改搜索到的信息,需要权限吗?
一般情况下,除非提供相应的接口或使用黑客技术,否则无法修改服务器上的信息,但可以在本地进行修改(只影响本地显示,服务器端保持不变,刷新后恢复) . 详情请参考:
1 请求库有哪些功能?只能在爬虫中使用吗?
参考问题12。 requests库可以实现方便的HTTP访问。所有涉及HTTP访问的场景都可以使用,不限于爬虫。
16、 虚拟环境和python文件是什么关系?我的终端无法在新文件夹中配置虚拟环境
虚拟环境和您的源代码之间没有实际联系。一般为方便起见,在项目目录下创建虚拟环境相关文件,即熟悉的语句如下:
python -m venv .venv
会在当前目录下创建一个.venv子目录,虚拟环境需要的文件都会放在这个子目录下。虚拟环境激活后,所有用Python进行的操作只会影响当前虚拟环境,你代码中的import只能加载当前虚拟环境中安装的Python库。也就是说,一个虚拟环境可以对应多个实际项目,实际对应的方式可以根据需要进行调整。
17、HTML、javascript和ccs是什么关系?他们与python的嵌套相关的东西是什么?听说python也可以做前端。
HTML定义了网页要显示什么内容,要显示什么布局;CSS 一次确定每个元素的具体样式;Javvascript通过可以在牙面上运行的脚本代码为网页添加动态响应功能,比如鼠标移动到某个区域自动修改某个元素的样式,点击按钮自动弹出提示,等等。简单来说,HTML 定义页面上“有什么”,CSS 定义页面看起来像“什么”,而 Javvascript 定义“什么”。Python 程序可以下载 HTML、CSS 和 JS 文件,解析和提取内容,甚至“运行”Javvascript 脚本以获得结果。这就是爬虫的基本工作机制。Python作为前端主要是指方面。一方面,可以使用Python开发Web服务器,供客户端浏览器通过HTTP访问服务器本地的HTML、CSS、JS等文件;另一方面,你可以使用 Python 脚本来“生成” HTML 页面,就像我们类中生成的 TXT 文件一样,将内容动态写入网页中。
18、 那么xpath helper的作用就是调出代码方便爬行?
xpath helper 可以帮助我们获取页面某个元素的xPath,通过修改完整的xPath字符串,得到一个简化的xPath进行数据提取;或验证修改后的xPath 以查看匹配结果是否符合预期。
19、 想要实现爬虫,一定要学习HTML知识吗?
是的,不了解HTML在数据提取过程中会遇到很多障碍。
20、 还是不明白信息的位置和获取方式。网页上的code可以查到,老师提到的标签在网页的位置上也能看懂一点,但是说到爬行就有点糊涂了,不知道怎么抓取它进入程序,如何定期执行或在发生更改时运行它。
“采集”链接的技术,我们将在下节课介绍,主要是使用requests库通过http访问。
21、 可以用爬虫技术从书签中提取内容吗?那是什么?能不能提取特征,用python过滤信息内容?
它是指浏览器采集夹中的书签吗?当然,您可以使用爬虫下载书签对应的页面内容,也可以使用Python程序对信息进行提取过滤。
22、html中相同类型的元素一定要有相同格式的路径吗?在文件夹中新建一个文件夹,两者都创建.venv,但是vscode打开大文件,运行小文件夹中的文件时,使用大文件夹.venv。vscode只能打开小文件夹吗?使用它的 .venv
相似元素的路径不一定是相同的格式。有必要分析具体的页面。获得的路径最好使用 xpath helper 进行验证,以查看是否覆盖了所有所需的元素。如果VS Code没有自动切换到目录的虚拟环境,可以点击左下角的环境标题:
在弹出的解释器列表中选择./.venv/bin/python:
23、 能不能告诉我怎么下载名字奇怪的怪东西?浏览器处理风险,我下载完就完成了。
首先访问本网站:/s/xphelper 下载 hgimnogjllphhhkhlmebmlgjoejdpjl.rar
解压 hgimnogjllphhhkhlmebbmlgjoejdpjl.rar
打开浏览器的扩展管理界面,以Edge为例,打开左下角的“开发者模式”:
点击右上角的“加载解压后的扩展”:
选择解压后的文件夹完成安装
24、如何下载python库函数
Python标准库自带Python安装,不需要额外安装;第三方库可以直接用pip安装。以requests为例,直接运行即可:
python -m pip install requests
25、 编译的时候报错,但是在网上搜索的时候,各种说法都有。请问老师有没有更好的网站或者社区推荐的
关于异常信息的解释,大家可以关注StackOverflow上的讨论,比较有针对性,质量也比较高。搜索时,您可以添加:
site:stackoverflow.com
或者直接使用网站提供的站点搜索。
26、open和file在使用时有什么区别?为什么在使用open函数时一定要调用close函数?
Python 中没有名为 file 的标准库。使用内置函数 open() 打开文件。详情请参考文档:
close() 函数将关闭当前打开的文件并清理响应资源。关闭的好处主要有两个方面:一方面避免了在程序中其他地方访问文件时重新打开同一个文件或冲突,只要将文件写入如果模式不关闭,所有其他以读模式和写模式打开文件的请求会触发异常;另一方面,打开一个未关闭的文件会长时间占用系统资源,造成不必要的资源浪费。
27、 老师能深入讲讲Xpath吗?
不会深入,只说常用的设置。您可以参考以下快速参考表:
查看全部
网页视频抓取工具 知乎(如何看待Python中的各种扩展的库-Python(二)
)
课程视频:
1、 当浏览器请求一个网站时,会从输入到页面显示,并描述请求过程
在课程中,我们概述了请求过程,您可以参考下图:
来源:网络| 嗨,我是法比安!全栈软件工程师 (townsend.fr)
详细过程可以参考:
2、本课爬虫可以应用于任何网站吗?
理论上是的,每个网站在细节上都会有一些差异,从内容组织到访问方式,我们会在后面的课程中讨论。
3、我对爬虫知之甚少。爬虫有什么用?我今天上课没跟上进度。
简单的说,就是一个用来获取网络信息的程序。具体可以参考wiki上的定义:

4、 无法获取网页的所有代码
一些内容是按需加载的。部分网页数据可以通过Javascript脚本和Ajax方式单独加载,可以实现页面的部分刷新。在下面的课程中,我们将通过抓取响应Json文件来获取数据的具体示例。
5、 课文中提到的“以拖拽的形式制作网页”是什么软件或者技术,是不是意味着淘汰手写css?
拖放主要用于设计内容和布局。内容显示的样式需要详细的 CSS 设置。当然,如果想省事,也可以直接使用现成的CSS框架。
6、 我们该如何看待Python中的各种扩展库,随意使用,岂不是大大提高了我们的编程能力?
在之前的问答中,我们谈到了是否要重新发明轮子的问题。从培养编程能力的角度来看,从头开始实施更多的练习是有益的,但在实际编程和构建具体项目解决方案的过程中,不一定需要自己从头开发所有模块。如果你有合适的第三方库,最好直接使用。这也是 Python 作为支持最广泛的开源社区的优势。但需要注意的是,一些第三方库可能存在一些不明显的错误甚至安全隐患,使用时要多加注意。
7、广告之类的图片怎么知道有链接?
有两种典型的实现方式,一种是直接
标签放置在标签内容中,以便图像变得可点击。另一种方法是使用 JavaScript 脚本来控制单击图像时触发的事件。单击是跳转到链接。
8、可以用爬虫复制百度文档的付费内容吗?有些内容只能预览不能复制。如果是这样,我该怎么办?
页面上无法复制的内容基本上有以下几种:一种是JavaScript脚本限制在特定区域的右键和快捷键行为,导致无法复制或弹出提示;另一种是展示图片,图片中的文字不能直接复制;然后使用特殊的编码来传输内容,在显示之前对其进行解码。理论上,只要能显示的文字是可以复制的,对于第一种情况,可以直接在网页源码中获取文字内容,对于第二种情况,可以将图片中的文字转化为OCR 文本。第三种需要分析内容的解码过程,根据解码和显示过程将传输的内容还原为原创文本。
9、“爬虫们,爬东西违法吗?如果你自己做网站,如何防止你的网站被爬”
关于爬虫的合法红线,可以参考以下文章:
我们将在后面的课程中介绍 counter-pick 策略。主要包括两个步骤:第一步是发现对方的恶意爬取行为,第二步是对该行为进行拦截或破坏。
10、 很早就听说爬虫是用来刷流量尖峰等的,很好奇
狭义的爬虫是模仿用户使用浏览器或App从网站或其他网络来源获取内容的自动化程序;广义的爬虫不限于采集数据,还可以模仿真实用户的访问行为,可以实现自动投票(刷卡排名)、自动访问(刷卡流量)、自动下单(刷卡)秒杀)等,但无论完成什么任务,本质都是一样的。尽量模仿真实用户的访问行为,避免被服务器或服务商看穿。
11、 如果网页上的数据格式不统一,比起今天豆瓣上的算法介绍,每个项目的介绍行数不统一,不均匀,我们还能不能使用连续四行不为空的条件?判断是否是标题?
当然不是。爬虫数据分析提取的核心是为每条数据找到一个共同的规律,不管是文本层面的规律还是文档结构的规律,只要规律不能用就必须调整及时。,要么修改一条适用于所有数据的规则,要么分别处理不同的情况,实现对所有待提取数据的完全覆盖。
12、request安装包在后续项目实践中有什么具体用途?
在下一课中,我们将讨论 requests 库的主要用途是用于 HTTP 访问。下载页面和提交信息(填写登录密码、提交订单等)都可以通过请求轻松实现。
13、 为什么我的txt文件是gbk编码,但是readlines不能调用
windows下默认使用gbk编码,可以参考上一课的Q&A 12:
14、 课上讲了爬虫,所以如果要修改搜索到的信息,需要权限吗?
一般情况下,除非提供相应的接口或使用黑客技术,否则无法修改服务器上的信息,但可以在本地进行修改(只影响本地显示,服务器端保持不变,刷新后恢复) . 详情请参考:
1 请求库有哪些功能?只能在爬虫中使用吗?
参考问题12。 requests库可以实现方便的HTTP访问。所有涉及HTTP访问的场景都可以使用,不限于爬虫。
16、 虚拟环境和python文件是什么关系?我的终端无法在新文件夹中配置虚拟环境
虚拟环境和您的源代码之间没有实际联系。一般为方便起见,在项目目录下创建虚拟环境相关文件,即熟悉的语句如下:
python -m venv .venv
会在当前目录下创建一个.venv子目录,虚拟环境需要的文件都会放在这个子目录下。虚拟环境激活后,所有用Python进行的操作只会影响当前虚拟环境,你代码中的import只能加载当前虚拟环境中安装的Python库。也就是说,一个虚拟环境可以对应多个实际项目,实际对应的方式可以根据需要进行调整。
17、HTML、javascript和ccs是什么关系?他们与python的嵌套相关的东西是什么?听说python也可以做前端。
HTML定义了网页要显示什么内容,要显示什么布局;CSS 一次确定每个元素的具体样式;Javvascript通过可以在牙面上运行的脚本代码为网页添加动态响应功能,比如鼠标移动到某个区域自动修改某个元素的样式,点击按钮自动弹出提示,等等。简单来说,HTML 定义页面上“有什么”,CSS 定义页面看起来像“什么”,而 Javvascript 定义“什么”。Python 程序可以下载 HTML、CSS 和 JS 文件,解析和提取内容,甚至“运行”Javvascript 脚本以获得结果。这就是爬虫的基本工作机制。Python作为前端主要是指方面。一方面,可以使用Python开发Web服务器,供客户端浏览器通过HTTP访问服务器本地的HTML、CSS、JS等文件;另一方面,你可以使用 Python 脚本来“生成” HTML 页面,就像我们类中生成的 TXT 文件一样,将内容动态写入网页中。
18、 那么xpath helper的作用就是调出代码方便爬行?
xpath helper 可以帮助我们获取页面某个元素的xPath,通过修改完整的xPath字符串,得到一个简化的xPath进行数据提取;或验证修改后的xPath 以查看匹配结果是否符合预期。
19、 想要实现爬虫,一定要学习HTML知识吗?
是的,不了解HTML在数据提取过程中会遇到很多障碍。
20、 还是不明白信息的位置和获取方式。网页上的code可以查到,老师提到的标签在网页的位置上也能看懂一点,但是说到爬行就有点糊涂了,不知道怎么抓取它进入程序,如何定期执行或在发生更改时运行它。
“采集”链接的技术,我们将在下节课介绍,主要是使用requests库通过http访问。
21、 可以用爬虫技术从书签中提取内容吗?那是什么?能不能提取特征,用python过滤信息内容?
它是指浏览器采集夹中的书签吗?当然,您可以使用爬虫下载书签对应的页面内容,也可以使用Python程序对信息进行提取过滤。
22、html中相同类型的元素一定要有相同格式的路径吗?在文件夹中新建一个文件夹,两者都创建.venv,但是vscode打开大文件,运行小文件夹中的文件时,使用大文件夹.venv。vscode只能打开小文件夹吗?使用它的 .venv
相似元素的路径不一定是相同的格式。有必要分析具体的页面。获得的路径最好使用 xpath helper 进行验证,以查看是否覆盖了所有所需的元素。如果VS Code没有自动切换到目录的虚拟环境,可以点击左下角的环境标题:
在弹出的解释器列表中选择./.venv/bin/python:
23、 能不能告诉我怎么下载名字奇怪的怪东西?浏览器处理风险,我下载完就完成了。
首先访问本网站:/s/xphelper 下载 hgimnogjllphhhkhlmebmlgjoejdpjl.rar
解压 hgimnogjllphhhkhlmebbmlgjoejdpjl.rar
打开浏览器的扩展管理界面,以Edge为例,打开左下角的“开发者模式”:

点击右上角的“加载解压后的扩展”:

选择解压后的文件夹完成安装
24、如何下载python库函数
Python标准库自带Python安装,不需要额外安装;第三方库可以直接用pip安装。以requests为例,直接运行即可:
python -m pip install requests
25、 编译的时候报错,但是在网上搜索的时候,各种说法都有。请问老师有没有更好的网站或者社区推荐的
关于异常信息的解释,大家可以关注StackOverflow上的讨论,比较有针对性,质量也比较高。搜索时,您可以添加:
site:stackoverflow.com
或者直接使用网站提供的站点搜索。
26、open和file在使用时有什么区别?为什么在使用open函数时一定要调用close函数?
Python 中没有名为 file 的标准库。使用内置函数 open() 打开文件。详情请参考文档:
close() 函数将关闭当前打开的文件并清理响应资源。关闭的好处主要有两个方面:一方面避免了在程序中其他地方访问文件时重新打开同一个文件或冲突,只要将文件写入如果模式不关闭,所有其他以读模式和写模式打开文件的请求会触发异常;另一方面,打开一个未关闭的文件会长时间占用系统资源,造成不必要的资源浪费。
27、 老师能深入讲讲Xpath吗?
不会深入,只说常用的设置。您可以参考以下快速参考表:

网页视频抓取工具 知乎(研究百度蜘蛛有所来你的网站日志查看很有好处)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-30 04:07
百度蜘蛛是一个自动程序,它的英文名称是BaiduSpider。
因为百度蜘蛛是我们人类设计和制造的产品,它按照我们人类的思维方式抓取和抓取互联网上的网页、图片、视频等内容,然后根据类别建立索引数据库,以便用户可以在百度搜索搜索引擎中找到你想要的。
我们做的是网站SEO,所以研究百度蜘蛛对网站优化很有好处。
如果你想知道百度蜘蛛有没有到过你的网站,它抓取了哪些网页,状态码是什么等等,我们可以通过网站日志来查看。
网站 日志是个神奇的东西,可以看看百度蜘蛛是怎么工作的。
当然,网站的日志也能看出你的网站是哪个区的人做了坏事,比如:有人嫉妒你网站,用ddos或者CC攻击你网站,如果你的网站整天都打不开,可以从网站的日志中查看是哪个区域的IP。
实际上,Kang 很少研究网站 日志,因为Kang 使用正式的方法进行SEO,从不作弊。文章也主要是原创。简单的说,只要是网站经过我们的SEO,就不会出现降权、长时间长时间进入沙箱等严重问题。
不过经常有seo的朋友来问康如何查看网站日志中的百度蜘蛛IP段。比如,他们想知道:哪些IP段来自百度,哪些IP段来自百度。权重IP,我也想知道沙箱里有哪些IP段或者权限降低的IP段等等。
这种问题很简单。让康为您详细介绍。希望对大家学习百度蜘蛛有所帮助。
如果你的网站是123.125.68.*这个IP段的百度蜘蛛来得频繁,其他人来得少,说明你的网站可能不得不进入沙箱,或者被降级。
220.181.68.*这个IP段每天只会增加,从未减少。很有可能你已经进入沙盒或者被K站屏蔽了。
对了,说到这,康不得不告诉你什么是百度沙盒。一些SEO新手朋友还不是很明白,科普一下。
百度沙盒意味着你的网站不会马上被百度屏蔽,但不会得到好的排名。你网站有很多关键词本来排名还不错,但是有一天突然消失了,这就是典型的进沙箱。
还有一种情况会让你网站进入沙箱,也就是网页中的关键词链接,这就是你常说的锚文本。
如果你在一个网页上制作四五个关键词链接,或者制作更多的关键词链接,那么你的网站将不可避免地被百度放入沙箱。
所以大家要合理优化网站内部链接,文章一篇文章只做1-2个关键词链接。不要贪心太多。反之,网站中的文章可以随便输入,越多越好,越多越好原创。
不多说了,我们继续研究百度蜘蛛(BaiduSpider)IP段。
220.181.7.*, 123.125.66.* 代表百度蜘蛛IP访问,准备抢你网站内容。
121.14.89.* 这个IP段作为新站检查期,也就是我们刚才讲的百度沙箱。
203.208.60.*新站点出现此IP段,站点异常。
210.72.225.*该IP段连续巡视所有站点。
125.90.88.* 该IP段的区域为广东茂名电信,也属于百度蜘蛛IP段。主要原因是有更多的新在线站。有使用过站长工具,或者是SEO综合检测造成的。
220.181.108.95 这是百度抓取首页的专用IP,是百度蜘蛛的加权IP段!
如果你的网站是220.181.108.*段一直在爬,康哥可以很负责任的告诉你:你的网站我会被爬并且每天由百度蜘蛛更新,发布文章秒收录是没有问题的,不会错的。
220.181.108.92 也就是刚才提到的那个IP段。有 98% 的机会抓取您的 网站 主页,可能还有其他网页,不一定是内页。
每个人都应该注意。220.181.108*段属于百度蜘蛛权重IP段。这个IP段或者首页爬取到的文章基本上会在24小时内。给你放出来!
123.125.71.106是抓取网站内页收录,权重低,抓取本段内页文章不会很快发布,因为它不是原创文章。
220.181.108.91是综合类,主要抓取首页和内页或者其他,也属于百度蜘蛛的加权IP段,抓取文章或者主页将在24小时内发布。
220.181.108.75 专注抓取更新文章内页,抓取率可达90%,抓取首页8%,2%其他。也是百度蜘蛛的加权IP段。爬取到的文章或者首页基本上24小时内发布。
220.181.108.86专用抓取网站首页IP权重段,一般返回码为304 0 0,表示没有更新,即表示该IP段百度蜘蛛访问了您的一个网页,但发现您的网页没有更新任何内容。
123.125.71.95 这个IP段用于爬取内页收录,权重低,爬过这个内页segment文章 不会很快发布,因为不是原创文章。
123.125.71.97同理,抢内页收录,权重较低,爬上本段内页文章 no 很快就会发布,因为不是原创文章。
220.181.108.89是一个特殊的抓取主页IP权重段,一般返回码是304 0 0,表示没有更新。
220.181.108.94 专用于抓取首页IP权重段,一般返回码为304 0 0,表示未更新。
220.181.108.97 专用于抓取首页IP权重段,一般返回码为304 0 0,表示没有更新。
220.181.108.80 专用于抓取首页IP权重段,一般返回码为304 0 0,表示没有更新。
220.181.108.77 专用于抓取首页IP权重段,一般返回码为304 0 0,表示未更新。
123.125.71.117 抓取内页收录,权重低,抓取这一段文章的内页不会很快释放它,因为它不是原创文章。
220.181.108.83 专用于抓取首页IP权重段,一般返回码为304 0 0,表示没有更新。
到这里大家要注意了:其实康哥提到的百度蜘蛛IP尾数还有很多。
但是如果在网站日志中看到很多123.125.71.*IP,就说明百度蜘蛛爬取了内部页面,而收录 的权重会更低。原因是你的网站是采集文章或者拼接的文章,是百度暂时收录,但不给你说的意思待定。
220.181.108.*IP段主要用于爬取网站的首页,爬取率占80%,内页占30%。这个IP段百度蜘蛛爬取的文章或者首页肯定是24小时内发布,连夜截图。
那么今天有一个关于百度蜘蛛(BaiduSpider)IP段的研究。康哥已经跟大家解释过了。如果你的网站SEO排名不理想,站内站外都做了优化,不会发生。功能,然后快速从FTP下载网站日志,研究一下。 查看全部
网页视频抓取工具 知乎(研究百度蜘蛛有所来你的网站日志查看很有好处)
百度蜘蛛是一个自动程序,它的英文名称是BaiduSpider。
因为百度蜘蛛是我们人类设计和制造的产品,它按照我们人类的思维方式抓取和抓取互联网上的网页、图片、视频等内容,然后根据类别建立索引数据库,以便用户可以在百度搜索搜索引擎中找到你想要的。

我们做的是网站SEO,所以研究百度蜘蛛对网站优化很有好处。
如果你想知道百度蜘蛛有没有到过你的网站,它抓取了哪些网页,状态码是什么等等,我们可以通过网站日志来查看。
网站 日志是个神奇的东西,可以看看百度蜘蛛是怎么工作的。
当然,网站的日志也能看出你的网站是哪个区的人做了坏事,比如:有人嫉妒你网站,用ddos或者CC攻击你网站,如果你的网站整天都打不开,可以从网站的日志中查看是哪个区域的IP。
实际上,Kang 很少研究网站 日志,因为Kang 使用正式的方法进行SEO,从不作弊。文章也主要是原创。简单的说,只要是网站经过我们的SEO,就不会出现降权、长时间长时间进入沙箱等严重问题。
不过经常有seo的朋友来问康如何查看网站日志中的百度蜘蛛IP段。比如,他们想知道:哪些IP段来自百度,哪些IP段来自百度。权重IP,我也想知道沙箱里有哪些IP段或者权限降低的IP段等等。
这种问题很简单。让康为您详细介绍。希望对大家学习百度蜘蛛有所帮助。
如果你的网站是123.125.68.*这个IP段的百度蜘蛛来得频繁,其他人来得少,说明你的网站可能不得不进入沙箱,或者被降级。
220.181.68.*这个IP段每天只会增加,从未减少。很有可能你已经进入沙盒或者被K站屏蔽了。
对了,说到这,康不得不告诉你什么是百度沙盒。一些SEO新手朋友还不是很明白,科普一下。
百度沙盒意味着你的网站不会马上被百度屏蔽,但不会得到好的排名。你网站有很多关键词本来排名还不错,但是有一天突然消失了,这就是典型的进沙箱。
还有一种情况会让你网站进入沙箱,也就是网页中的关键词链接,这就是你常说的锚文本。
如果你在一个网页上制作四五个关键词链接,或者制作更多的关键词链接,那么你的网站将不可避免地被百度放入沙箱。
所以大家要合理优化网站内部链接,文章一篇文章只做1-2个关键词链接。不要贪心太多。反之,网站中的文章可以随便输入,越多越好,越多越好原创。
不多说了,我们继续研究百度蜘蛛(BaiduSpider)IP段。
220.181.7.*, 123.125.66.* 代表百度蜘蛛IP访问,准备抢你网站内容。
121.14.89.* 这个IP段作为新站检查期,也就是我们刚才讲的百度沙箱。
203.208.60.*新站点出现此IP段,站点异常。
210.72.225.*该IP段连续巡视所有站点。
125.90.88.* 该IP段的区域为广东茂名电信,也属于百度蜘蛛IP段。主要原因是有更多的新在线站。有使用过站长工具,或者是SEO综合检测造成的。
220.181.108.95 这是百度抓取首页的专用IP,是百度蜘蛛的加权IP段!
如果你的网站是220.181.108.*段一直在爬,康哥可以很负责任的告诉你:你的网站我会被爬并且每天由百度蜘蛛更新,发布文章秒收录是没有问题的,不会错的。
220.181.108.92 也就是刚才提到的那个IP段。有 98% 的机会抓取您的 网站 主页,可能还有其他网页,不一定是内页。
每个人都应该注意。220.181.108*段属于百度蜘蛛权重IP段。这个IP段或者首页爬取到的文章基本上会在24小时内。给你放出来!
123.125.71.106是抓取网站内页收录,权重低,抓取本段内页文章不会很快发布,因为它不是原创文章。
220.181.108.91是综合类,主要抓取首页和内页或者其他,也属于百度蜘蛛的加权IP段,抓取文章或者主页将在24小时内发布。
220.181.108.75 专注抓取更新文章内页,抓取率可达90%,抓取首页8%,2%其他。也是百度蜘蛛的加权IP段。爬取到的文章或者首页基本上24小时内发布。
220.181.108.86专用抓取网站首页IP权重段,一般返回码为304 0 0,表示没有更新,即表示该IP段百度蜘蛛访问了您的一个网页,但发现您的网页没有更新任何内容。
123.125.71.95 这个IP段用于爬取内页收录,权重低,爬过这个内页segment文章 不会很快发布,因为不是原创文章。
123.125.71.97同理,抢内页收录,权重较低,爬上本段内页文章 no 很快就会发布,因为不是原创文章。
220.181.108.89是一个特殊的抓取主页IP权重段,一般返回码是304 0 0,表示没有更新。
220.181.108.94 专用于抓取首页IP权重段,一般返回码为304 0 0,表示未更新。
220.181.108.97 专用于抓取首页IP权重段,一般返回码为304 0 0,表示没有更新。
220.181.108.80 专用于抓取首页IP权重段,一般返回码为304 0 0,表示没有更新。
220.181.108.77 专用于抓取首页IP权重段,一般返回码为304 0 0,表示未更新。
123.125.71.117 抓取内页收录,权重低,抓取这一段文章的内页不会很快释放它,因为它不是原创文章。
220.181.108.83 专用于抓取首页IP权重段,一般返回码为304 0 0,表示没有更新。
到这里大家要注意了:其实康哥提到的百度蜘蛛IP尾数还有很多。
但是如果在网站日志中看到很多123.125.71.*IP,就说明百度蜘蛛爬取了内部页面,而收录 的权重会更低。原因是你的网站是采集文章或者拼接的文章,是百度暂时收录,但不给你说的意思待定。
220.181.108.*IP段主要用于爬取网站的首页,爬取率占80%,内页占30%。这个IP段百度蜘蛛爬取的文章或者首页肯定是24小时内发布,连夜截图。
那么今天有一个关于百度蜘蛛(BaiduSpider)IP段的研究。康哥已经跟大家解释过了。如果你的网站SEO排名不理想,站内站外都做了优化,不会发生。功能,然后快速从FTP下载网站日志,研究一下。
网页视频抓取工具 知乎(前面的那个视频openwifi的2020总结以及未来展望(视频))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-22 09:04
之前的视频openwifi的2020年总结和未来前景(视频)是我使用文章openwifi的2020年总结和未来前景自动生成的,经过轻微的修改就成型了。
知乎有一个很好的文章教大家使用,这里不再赘述。简单说一些注意事项和感受。
1.它非常方便和高效,但也并不完美。
2. 只能在手机上使用。我的网页和pad都不能使用这个功能。垫子上有这个功能按钮,但是点击后没有反应。
3.只有在文章被批准并正式发布后才能使用。我的文章目前审核比较慢,经常不知什么原因需要几个小时。需要注意的一点是文章修改后,还需要审核(我猜),自动视频转换程序会提取最新版本生成,否则还是会提取旧版本文章 生成。但是文章修改后的审核在文章第一次发布的时候不会在开头给出提示。这有点棘手。判断审核是否完成,只能通过手机APP界面文章是否出现“一键生成视频”按钮来判断。
4.我发现如果文章的格式是:在句子中加一个冒号再添加图片,那么知乎默认会用那句话作为图片的副标题。所以通过这个技巧,你可以简单的控制生成的视频布局(当然,视频生成之后,你可以继续在手机上手动修改和布局)
5. 有时视频中不收录文章的个别图片。这就是我所说的不完美(也许是一个bug)。
6. 曲库因版权问题无法在海外使用。相反,哔哩哔哩没有这个问题。微信、抖音、哔哩哔哩都有自己的专属剪辑软件和音乐库,海外使用也很方便。不过知乎的高级在于自动生成,不需要这么复杂的专用编辑软件。
7.同样由于版权问题,海外只能选择默认模板(无背景音乐的基础款),其他模板无法选择。
8. 自动配音有多种选择(男孩、女孩、平静、喜悦等)。
以上。 查看全部
网页视频抓取工具 知乎(前面的那个视频openwifi的2020总结以及未来展望(视频))
之前的视频openwifi的2020年总结和未来前景(视频)是我使用文章openwifi的2020年总结和未来前景自动生成的,经过轻微的修改就成型了。
知乎有一个很好的文章教大家使用,这里不再赘述。简单说一些注意事项和感受。
1.它非常方便和高效,但也并不完美。
2. 只能在手机上使用。我的网页和pad都不能使用这个功能。垫子上有这个功能按钮,但是点击后没有反应。
3.只有在文章被批准并正式发布后才能使用。我的文章目前审核比较慢,经常不知什么原因需要几个小时。需要注意的一点是文章修改后,还需要审核(我猜),自动视频转换程序会提取最新版本生成,否则还是会提取旧版本文章 生成。但是文章修改后的审核在文章第一次发布的时候不会在开头给出提示。这有点棘手。判断审核是否完成,只能通过手机APP界面文章是否出现“一键生成视频”按钮来判断。
4.我发现如果文章的格式是:在句子中加一个冒号再添加图片,那么知乎默认会用那句话作为图片的副标题。所以通过这个技巧,你可以简单的控制生成的视频布局(当然,视频生成之后,你可以继续在手机上手动修改和布局)
5. 有时视频中不收录文章的个别图片。这就是我所说的不完美(也许是一个bug)。
6. 曲库因版权问题无法在海外使用。相反,哔哩哔哩没有这个问题。微信、抖音、哔哩哔哩都有自己的专属剪辑软件和音乐库,海外使用也很方便。不过知乎的高级在于自动生成,不需要这么复杂的专用编辑软件。
7.同样由于版权问题,海外只能选择默认模板(无背景音乐的基础款),其他模板无法选择。
8. 自动配音有多种选择(男孩、女孩、平静、喜悦等)。
以上。
网页视频抓取工具 知乎(如何鉴定一个营销人老司机,除了看日常的工作经验以外)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-22 09:00
如何辨别营销人员是不是老司机,除了看日常工作经历,还要看有没有一些厉害的私货,合理运用各种营销手段,提高工作效率。今天给大家推荐几款非常实用的安利小工具。
1.爱维帮
做新媒体的小伙伴都会遇到这样的问题。当公众号的内容过多时,对于公众号的粉丝阅读非常不方便。如果需要检索内容,只能逐页翻历史记录,非常浪费。时间,读起来很不直观。
先生推荐了一个强大的工具来解决这个问题——爱维帮的微站功能。以宇宙第一网红咪蒙公众号为例,通过爱微帮的微站功能,可以生成这样一个页面:
如果自己的公众号能生成这样的页面,粉丝阅读会更加方便直观。操作过程也很简单:
第一步:登录爱维帮官网(),点击右上角头像或昵称进入控制台。
第二步:扫描二维码,绑定自己的公众号。
第三步:在账号服务中找到微站,勾选“历史文章”。如果发现绑定的公众号中的部分文章在这里没有显示,需要把缺失的文章手动导入。
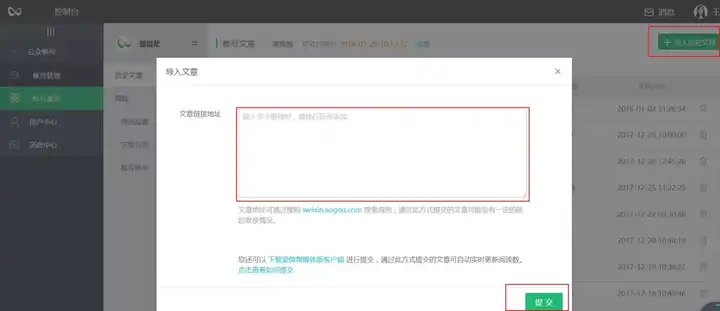
导入有两种方式:
首先是点击右上角的“导入历史文章”,在弹出的窗口中直接输入要导入的文章链接:
二是下载iWeibang媒体版客户端,从客户端导入文章。
第四步:点击“微站设置”中的“免费开通”,微站正式开通:
在这一步之后,您就可以开始个性化您自己的微型网站了。后续的设置过程也很简单,使用起来比公众号自带的模板功能简单多了!
2.简媒体
很多自媒体的朋友可能会遇到这个问题:注册的自媒体平台很多,几乎有十几个平台,每天写内容至少要花1-2个小时,关注热点,找素材,想套路,已经够累了。操作10多个平台实在是无能为力。十几套账号密码,每个文章复制粘贴十几遍,改标题,发表,看评论,看资料…………懒得去想了,就是浪费时间,可惜不发帖,浪费流量。
这里有一个小工具——Simple Media,可以一键同步十几个主流自媒体平台的文案,非常方便。
操作过程也非常简单。注册媒体后,在账号管理界面添加并绑定自己的所有账号。虽然绑定有点复杂,但这次只需要绑定即可。您可以使用标签来管理绑定的帐户。不会乱的。然后就可以在JianMedia自带的编辑器中编辑文章,文章会自动保存,不用担心丢失。文章的版面是设计师根据各个新媒体平台设计的,可以节省很多时间。编辑完文章后,选择行业,勾选原创、广告等功能按钮。最后选择你要发布的账号,也可以选择你绑定的所有账号。一键发布成功。基本上,几分钟后,所有平台都成功发布。它不仅比手动发布更快,而且布局也令人赏心悦目。文章的所有数据和链接也会显示出来,方便大家以后整理。
3.wetool
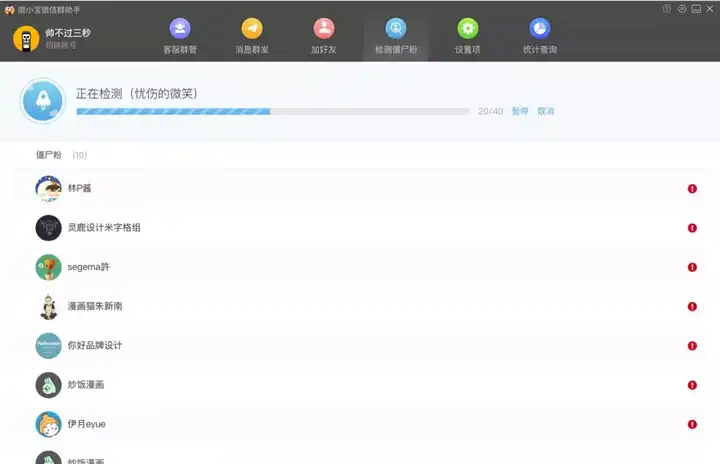
微信现在似乎构建了一个庞大的生态系统,但确实还有很多问题没有解决。例如,如何批量查找和删除您的朋友。目前的方法只能是群发消息测试或群组分组。这些方法要么粗糙,对朋友来说。对于成千上万的朋友来说,根本没有办法使用,否则会损害微信朋友的体验,面临被朋友删除的风险。
先生推荐一款免费的微信工具——wetool。本软件可以轻松解决僵尸粉丝的微信监控问题,精准检测僵尸粉丝,对真实粉丝零干扰,由你果断删除或尝试保存。算了,被对方删除或者屏蔽了会有提示,可以说是很方便了。
wetool的功能远不止这些。Wetool集成了微商伙伴喜欢使用的各种营销软件功能,稳定性和安全性更高。
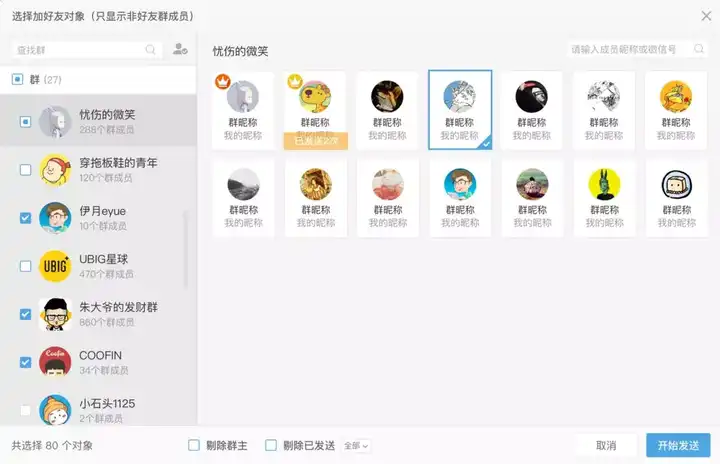
比如群好友功能可以批量向群内非好友发送好友请求,一键消除群主和发送对象,省时省心。
群管机器人功能自动通过好友验证邀请入群,新人进群发布欢迎信息,触发条件智能踢人。
可以说是做微信营销的小伙伴们必不可少的营销利器。如果你不相信,你可以去体验。可以说是非常贴心了。最重要的是免费!!!
4.你好文库
对于营销人员和自媒体人来说,他们需要参考大量的材料才能有创意并写出解决方案。百度文库是国内最大的文档资源库,涵盖了很多珍贵的参考资料,但有些文档需要大量下载 优惠券可以下载。
这里先生推荐一个文库工具——嘿文库,访问链接是47.95.226.123/wenku/,复制并输入下载的文档链接,即可一键免费下载相关文档,确实是营销人员积累信息的必备工具。
5.视频下载助手
营销人员经常需要对一些视频资源进行编辑整理,但经常会遇到这样的情况:找到了视频网页,却不知道如何下载。主流视频网站基本不支持自己的视频。本地下载。
这里推荐一个火狐浏览器插件——Video DownloadHelper。只要安装这个插件,在火狐浏览器中打开视频链接,就可以自动识别下载视频,非常方便,不仅仅是主流视频。可以下载网站的视频,甚至一些非黑非白的网站视频也可以轻松下载,可以说是非常强大了!
6.微信备忘录
现在微信已经成为每个人都离不开的工具。微信能做的,微信就能做,省去下载很多麻烦的app。但是微信便利贴的这个功能大家可能非常陌生。
其实微信有自己的笔记功能,打开采集,右上角有个+号,点击加号进入微信的笔记功能!页面非常简洁,操作非常简单。
微信内置笔记功能最大的好处就是可以搜索。微信笔记生成的笔记会保存在采集夹中。只需在微信框中搜索目标关键词即可打开,方便检索。
OK,以上就是大家分享的几个小工具。它们的功能虽小,却能大大提高工作效率和质量。我希望能帮助到大家。 查看全部
网页视频抓取工具 知乎(如何鉴定一个营销人老司机,除了看日常的工作经验以外)
如何辨别营销人员是不是老司机,除了看日常工作经历,还要看有没有一些厉害的私货,合理运用各种营销手段,提高工作效率。今天给大家推荐几款非常实用的安利小工具。
1.爱维帮
做新媒体的小伙伴都会遇到这样的问题。当公众号的内容过多时,对于公众号的粉丝阅读非常不方便。如果需要检索内容,只能逐页翻历史记录,非常浪费。时间,读起来很不直观。
先生推荐了一个强大的工具来解决这个问题——爱维帮的微站功能。以宇宙第一网红咪蒙公众号为例,通过爱微帮的微站功能,可以生成这样一个页面:

如果自己的公众号能生成这样的页面,粉丝阅读会更加方便直观。操作过程也很简单:
第一步:登录爱维帮官网(),点击右上角头像或昵称进入控制台。
第二步:扫描二维码,绑定自己的公众号。
第三步:在账号服务中找到微站,勾选“历史文章”。如果发现绑定的公众号中的部分文章在这里没有显示,需要把缺失的文章手动导入。
导入有两种方式:
首先是点击右上角的“导入历史文章”,在弹出的窗口中直接输入要导入的文章链接:
二是下载iWeibang媒体版客户端,从客户端导入文章。
第四步:点击“微站设置”中的“免费开通”,微站正式开通:
在这一步之后,您就可以开始个性化您自己的微型网站了。后续的设置过程也很简单,使用起来比公众号自带的模板功能简单多了!
2.简媒体
很多自媒体的朋友可能会遇到这个问题:注册的自媒体平台很多,几乎有十几个平台,每天写内容至少要花1-2个小时,关注热点,找素材,想套路,已经够累了。操作10多个平台实在是无能为力。十几套账号密码,每个文章复制粘贴十几遍,改标题,发表,看评论,看资料…………懒得去想了,就是浪费时间,可惜不发帖,浪费流量。
这里有一个小工具——Simple Media,可以一键同步十几个主流自媒体平台的文案,非常方便。

操作过程也非常简单。注册媒体后,在账号管理界面添加并绑定自己的所有账号。虽然绑定有点复杂,但这次只需要绑定即可。您可以使用标签来管理绑定的帐户。不会乱的。然后就可以在JianMedia自带的编辑器中编辑文章,文章会自动保存,不用担心丢失。文章的版面是设计师根据各个新媒体平台设计的,可以节省很多时间。编辑完文章后,选择行业,勾选原创、广告等功能按钮。最后选择你要发布的账号,也可以选择你绑定的所有账号。一键发布成功。基本上,几分钟后,所有平台都成功发布。它不仅比手动发布更快,而且布局也令人赏心悦目。文章的所有数据和链接也会显示出来,方便大家以后整理。
3.wetool
微信现在似乎构建了一个庞大的生态系统,但确实还有很多问题没有解决。例如,如何批量查找和删除您的朋友。目前的方法只能是群发消息测试或群组分组。这些方法要么粗糙,对朋友来说。对于成千上万的朋友来说,根本没有办法使用,否则会损害微信朋友的体验,面临被朋友删除的风险。
先生推荐一款免费的微信工具——wetool。本软件可以轻松解决僵尸粉丝的微信监控问题,精准检测僵尸粉丝,对真实粉丝零干扰,由你果断删除或尝试保存。算了,被对方删除或者屏蔽了会有提示,可以说是很方便了。
wetool的功能远不止这些。Wetool集成了微商伙伴喜欢使用的各种营销软件功能,稳定性和安全性更高。
比如群好友功能可以批量向群内非好友发送好友请求,一键消除群主和发送对象,省时省心。
群管机器人功能自动通过好友验证邀请入群,新人进群发布欢迎信息,触发条件智能踢人。
可以说是做微信营销的小伙伴们必不可少的营销利器。如果你不相信,你可以去体验。可以说是非常贴心了。最重要的是免费!!!
4.你好文库
对于营销人员和自媒体人来说,他们需要参考大量的材料才能有创意并写出解决方案。百度文库是国内最大的文档资源库,涵盖了很多珍贵的参考资料,但有些文档需要大量下载 优惠券可以下载。
这里先生推荐一个文库工具——嘿文库,访问链接是47.95.226.123/wenku/,复制并输入下载的文档链接,即可一键免费下载相关文档,确实是营销人员积累信息的必备工具。
5.视频下载助手
营销人员经常需要对一些视频资源进行编辑整理,但经常会遇到这样的情况:找到了视频网页,却不知道如何下载。主流视频网站基本不支持自己的视频。本地下载。
这里推荐一个火狐浏览器插件——Video DownloadHelper。只要安装这个插件,在火狐浏览器中打开视频链接,就可以自动识别下载视频,非常方便,不仅仅是主流视频。可以下载网站的视频,甚至一些非黑非白的网站视频也可以轻松下载,可以说是非常强大了!
6.微信备忘录
现在微信已经成为每个人都离不开的工具。微信能做的,微信就能做,省去下载很多麻烦的app。但是微信便利贴的这个功能大家可能非常陌生。
其实微信有自己的笔记功能,打开采集,右上角有个+号,点击加号进入微信的笔记功能!页面非常简洁,操作非常简单。
微信内置笔记功能最大的好处就是可以搜索。微信笔记生成的笔记会保存在采集夹中。只需在微信框中搜索目标关键词即可打开,方便检索。
OK,以上就是大家分享的几个小工具。它们的功能虽小,却能大大提高工作效率和质量。我希望能帮助到大家。
网页视频抓取工具 知乎(Python开发爬虫常用的工具总结及网页抓取思路数据是否可以直接从HTML中获取?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-20 23:10
使用Python开发爬虫是一件非常轻松愉快的事情,因为相关的库很多,而且使用起来很方便,十几行代码就可以完成一个爬虫的开发;
但是在对付网站有防爬措施,网站有js动态加载,App采集,就得动脑筋了;而在分布式爬虫的开发中,高性能爬虫的时候就得精心设计。
Python开发爬虫reqeusts常用工具汇总:Python HTTP网络请求库;pyquery:Python HTML DOM结构分析库,使用类似JQuery的语法;BeautifulSoup:python HTML 和 XML 结构分析;selenium:Python自动化测试框架,可用于爬虫;Phantomjs:无头浏览器,可以配合selenium获取js动态加载的内容;re: python 内置正则表达式模块;fiddler:抓包工具,原理是一个可以抓手机包的代理服务器;anyproxy:代理服务器,可以自己编写规则来拦截请求或响应,一般用在客户端采集;celery:Python分布式计算框架,可用于开发分布式爬虫;事件:基于协程的python网络库,可用于开发高性能爬虫grequests:asynchronous requestssaio http:异步http客户端/服务器框架asyncio:python内置异步io,事件循环库uvloop:一个非常快的事件循环库, with asyncio 极其高效的并发:Python 内置用于并发任务执行scrapy 的扩展:python 爬虫框架;Splash:一个JavaScript渲染服务,相当于一个轻量级浏览器,带有lua脚本,通过他的http API解析页面;Splinter:开源自动化Python Web 测试工具pyspider:Python 爬虫系统网页 爬取思路数据能否直接从HTML 中获取?数据直接嵌套在页面的HTML结构中;数据是使用JS动态渲染到页面中的吗?数据嵌套在js代码中,然后用js加载到页面或者用ajax渲染;获取的页面使用需要认证吗?登录后可以访问该页面;可以通过API直接获取数据吗?部分数据可以通过API直接获取,省去了解析HTML的麻烦。大多数 API 以 JSON 格式返回数据;来自客户端的数据采集 怎么样?比如:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:然后用js加载到页面或者用ajax渲染;获取的页面使用需要认证吗?登录后可以访问该页面;可以通过API直接获取数据吗?部分数据可以通过API直接获取,省去了解析HTML的麻烦。大多数 API 以 JSON 格式返回数据;来自客户端的数据采集 怎么样?比如:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:然后用js加载到页面或者用ajax渲染;获取的页面使用需要认证吗?登录后可以访问该页面;可以通过API直接获取数据吗?部分数据可以通过API直接获取,省去了解析HTML的麻烦。大多数 API 以 JSON 格式返回数据;来自客户端的数据采集 怎么样?比如:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:可以通过API直接获取数据吗?部分数据可以通过API直接获取,省去了解析HTML的麻烦。大多数 API 以 JSON 格式返回数据;来自客户端的数据采集 怎么样?比如:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:可以通过API直接获取数据吗?部分数据可以通过API直接获取,省去了解析HTML的麻烦。大多数 API 以 JSON 格式返回数据;来自客户端的数据采集 怎么样?比如:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:
检查网站的cookie。在某些情况下,请求需要添加一个cookie来通过服务器上的一些验证;案例讲解静态页面解析(获取微信公众号文章)
import pyquery
import re
def weixin_article_html_parser(html):
"""
解析微信文章,返回包含文章主体的字典信息
:param html: 文章HTML源代码
:return:
"""
pq = pyquery.PyQuery(html)
article = {
"weixin_id": pq.find("#js_profile_qrcode "
".profile_inner .profile_meta").eq(0).find("span").text().strip(),
"weixin_name": pq.find("#js_profile_qrcode .profile_inner strong").text().strip(),
"account_desc": pq.find("#js_profile_qrcode .profile_inner "
".profile_meta").eq(1).find("span").text().strip(),
"article_title": pq.find("title").text().strip(),
"article_content": pq("#js_content").remove('script').text().replace(r"\r\n", ""),
"is_orig": 1 if pq("#copyright_logo").length > 0 else 0,
"article_source_url": pq("#js_sg_bar .meta_primary").attr('href') if pq(
"#js_sg_bar .meta_primary").length > 0 else '',
}
# 使用正则表达式匹配页面中js脚本中的内容
match = {
"msg_cdn_url": {"regexp": "(? a.W_texta").attr("title"))
return html
except (TimeoutException, Exception) as e:
print(e)
finally:
driver.quit()
if __name__ == '__main__':
weibo_user_search(url="http://s.weibo.com/user/%s" % parse.quote("新闻"))
# 央视新闻
# 新浪新闻
# 新闻
# 新浪新闻客户端
# 中国新闻周刊
# 中国新闻网
# 每日经济新闻
# 澎湃新闻
# 网易新闻客户端
# 凤凰新闻客户端
# 皇马新闻
# 网络新闻联播
# CCTV5体育新闻
# 曼联新闻
# 搜狐新闻客户端
# 巴萨新闻
# 新闻日日睇
# 新垣结衣新闻社
# 看看新闻KNEWS
# 央视新闻评论
使用Python模拟登录获取cookies
有的网站比较痛苦,通常需要登录才能获取数据。下面是一个简单的例子:是不是用来登录网站,获取cookie,然后可以用于其他请求
但是,这里只有在没有验证码的情况下,如果要短信验证、图片验证、邮件验证,就得单独设计;
目标网站:,日期:2017-07-03,如果网站的结构发生变化,需要修改如下代码;
#!/usr/bin/env python3
# encoding: utf-8
from time import sleep
from pprint import pprint
from selenium.common.exceptions import TimeoutException, WebDriverException
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium import webdriver
def login_newrank():
"""登录新榜,获取他的cookie信息"""
desired_capabilities = DesiredCapabilities.CHROME.copy()
desired_capabilities["phantomjs.page.settings.userAgent"] = ("Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/59.0.3071.104 Safari/537.36")
desired_capabilities["phantomjs.page.settings.loadImages"] = True
# 自定义头部
desired_capabilities["phantomjs.page.customHeaders.Upgrade-Insecure-Requests"] = 1
desired_capabilities["phantomjs.page.customHeaders.Cache-Control"] = "max-age=0"
desired_capabilities["phantomjs.page.customHeaders.Connection"] = "keep-alive"
# 填写自己的账户进行测试
user = {
"mobile": "user",
"password": "password"
}
print("login account: %s" % user["mobile"])
driver = webdriver.PhantomJS(executable_path="/usr/bin/phantomjs",
desired_capabilities=desired_capabilities,
service_log_path="ghostdriver.log", )
# 设置对象的超时时间
driver.implicitly_wait(1)
# 设置页面完全加载的超时时间,包括页面全部渲染,异步同步脚本都执行完成
driver.set_page_load_timeout(60)
# 设置异步脚本的超时时间
driver.set_script_timeout(60)
driver.maximize_window()
try:
driver.get(url="http://www.newrank.cn/public/l ... 6quot;)
driver.find_element_by_css_selector(".login-normal-tap:nth-of-type(2)").click()
sleep(0.2)
driver.find_element_by_id("account_input").send_keys(user["mobile"])
sleep(0.5)
driver.find_element_by_id("password_input").send_keys(user["password"])
sleep(0.5)
driver.find_element_by_id("pwd_confirm").click()
sleep(3)
cookies = {user["name"]: user["value"] for user in driver.get_cookies()}
pprint(cookies)
except TimeoutException as exc:
print(exc)
except WebDriverException as exc:
print(exc)
finally:
driver.quit()
if __name__ == '__main__':
login_newrank()
# login account: 15395100590
# {'CNZZDATA1253878005': '1487200824-1499071649-%7C1499071649',
# 'Hm_lpvt_a19fd7224d30e3c8a6558dcb38c4beed': '1499074715',
# 'Hm_lvt_a19fd7224d30e3c8a6558dcb38c4beed': '1499074685,1499074713',
# 'UM_distinctid': '15d07d0d4dd82b-054b56417-9383666-c0000-15d07d0d4deace',
# 'name': '15395100590',
# 'rmbuser': 'true',
# 'token': 'A7437A03346B47A9F768730BAC81C514',
# 'useLoginAccount': 'true'}
获取cookie后,可以将获取的cookie添加到后续请求中,但由于cookie有有效期,需要定期更新;
这可以通过设计cookie池,动态定期登录一批账号,获取cookie后将cookie存入数据库(redis、MySQL等)来实现。
请求时从数据库中获取一个可用的cookie,并添加到访问请求中;
尝试使用pyqt5抓取数据(PyQt 5.9.2)
import sys
import csv
import pyquery
from PyQt5.QtCore import QUrl
from PyQt5.QtWidgets import QApplication
from PyQt5.QtWebEngineWidgets import QWebEngineView
class Browser(QWebEngineView):
def __init__(self):
super(Browser, self).__init__()
self.__results = []
self.loadFinished.connect(self.__result_available)
@property
def results(self):
return self.__results
def __result_available(self):
self.page().toHtml(self.__parse_html)
def __parse_html(self, html):
pq = pyquery.PyQuery(html)
for rows in [pq.find("#table_list tr"), pq.find("#more_list tr")]:
for row in rows.items():
columns = row.find("td")
d = {
"avatar": columns.eq(1).find("img").attr("src"),
"url": columns.eq(1).find("a").attr("href"),
"name": columns.eq(1).find("a").attr("title"),
"fans_number": columns.eq(2).text(),
"view_num": columns.eq(3).text(),
"comment_num": columns.eq(4).text(),
"post_count": columns.eq(5).text(),
"newrank_index": columns.eq(6).text(),
}
self.__results.append(d)
with open("results.csv", "a+", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["name", "fans_number", "view_num", "comment_num", "post_count",
"newrank_index", "url", "avatar"])
writer.writerows(self.results)
def open(self, url: str):
self.load(QUrl(url))
if __name__ == '__main__':
app = QApplication(sys.argv)
browser = Browser()
browser.open("https://www.newrank.cn/public/ ... 6quot;)
browser.show()
app.exec_()
持续更新:
5. 使用 Fiddler 抓包分析
浏览器抓包 fiddler 手机抓包
6. 使用anyproxy 捕获客户端数据-客户端数据采集
7. 高性能爬虫开发总结
获取免费爬虫视频资料加887934385交流群 查看全部
网页视频抓取工具 知乎(Python开发爬虫常用的工具总结及网页抓取思路数据是否可以直接从HTML中获取?)
使用Python开发爬虫是一件非常轻松愉快的事情,因为相关的库很多,而且使用起来很方便,十几行代码就可以完成一个爬虫的开发;
但是在对付网站有防爬措施,网站有js动态加载,App采集,就得动脑筋了;而在分布式爬虫的开发中,高性能爬虫的时候就得精心设计。
Python开发爬虫reqeusts常用工具汇总:Python HTTP网络请求库;pyquery:Python HTML DOM结构分析库,使用类似JQuery的语法;BeautifulSoup:python HTML 和 XML 结构分析;selenium:Python自动化测试框架,可用于爬虫;Phantomjs:无头浏览器,可以配合selenium获取js动态加载的内容;re: python 内置正则表达式模块;fiddler:抓包工具,原理是一个可以抓手机包的代理服务器;anyproxy:代理服务器,可以自己编写规则来拦截请求或响应,一般用在客户端采集;celery:Python分布式计算框架,可用于开发分布式爬虫;事件:基于协程的python网络库,可用于开发高性能爬虫grequests:asynchronous requestssaio http:异步http客户端/服务器框架asyncio:python内置异步io,事件循环库uvloop:一个非常快的事件循环库, with asyncio 极其高效的并发:Python 内置用于并发任务执行scrapy 的扩展:python 爬虫框架;Splash:一个JavaScript渲染服务,相当于一个轻量级浏览器,带有lua脚本,通过他的http API解析页面;Splinter:开源自动化Python Web 测试工具pyspider:Python 爬虫系统网页 爬取思路数据能否直接从HTML 中获取?数据直接嵌套在页面的HTML结构中;数据是使用JS动态渲染到页面中的吗?数据嵌套在js代码中,然后用js加载到页面或者用ajax渲染;获取的页面使用需要认证吗?登录后可以访问该页面;可以通过API直接获取数据吗?部分数据可以通过API直接获取,省去了解析HTML的麻烦。大多数 API 以 JSON 格式返回数据;来自客户端的数据采集 怎么样?比如:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:然后用js加载到页面或者用ajax渲染;获取的页面使用需要认证吗?登录后可以访问该页面;可以通过API直接获取数据吗?部分数据可以通过API直接获取,省去了解析HTML的麻烦。大多数 API 以 JSON 格式返回数据;来自客户端的数据采集 怎么样?比如:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:然后用js加载到页面或者用ajax渲染;获取的页面使用需要认证吗?登录后可以访问该页面;可以通过API直接获取数据吗?部分数据可以通过API直接获取,省去了解析HTML的麻烦。大多数 API 以 JSON 格式返回数据;来自客户端的数据采集 怎么样?比如:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:可以通过API直接获取数据吗?部分数据可以通过API直接获取,省去了解析HTML的麻烦。大多数 API 以 JSON 格式返回数据;来自客户端的数据采集 怎么样?比如:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:可以通过API直接获取数据吗?部分数据可以通过API直接获取,省去了解析HTML的麻烦。大多数 API 以 JSON 格式返回数据;来自客户端的数据采集 怎么样?比如:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:
检查网站的cookie。在某些情况下,请求需要添加一个cookie来通过服务器上的一些验证;案例讲解静态页面解析(获取微信公众号文章)
import pyquery
import re
def weixin_article_html_parser(html):
"""
解析微信文章,返回包含文章主体的字典信息
:param html: 文章HTML源代码
:return:
"""
pq = pyquery.PyQuery(html)
article = {
"weixin_id": pq.find("#js_profile_qrcode "
".profile_inner .profile_meta").eq(0).find("span").text().strip(),
"weixin_name": pq.find("#js_profile_qrcode .profile_inner strong").text().strip(),
"account_desc": pq.find("#js_profile_qrcode .profile_inner "
".profile_meta").eq(1).find("span").text().strip(),
"article_title": pq.find("title").text().strip(),
"article_content": pq("#js_content").remove('script').text().replace(r"\r\n", ""),
"is_orig": 1 if pq("#copyright_logo").length > 0 else 0,
"article_source_url": pq("#js_sg_bar .meta_primary").attr('href') if pq(
"#js_sg_bar .meta_primary").length > 0 else '',
}
# 使用正则表达式匹配页面中js脚本中的内容
match = {
"msg_cdn_url": {"regexp": "(? a.W_texta").attr("title"))
return html
except (TimeoutException, Exception) as e:
print(e)
finally:
driver.quit()
if __name__ == '__main__':
weibo_user_search(url="http://s.weibo.com/user/%s" % parse.quote("新闻"))
# 央视新闻
# 新浪新闻
# 新闻
# 新浪新闻客户端
# 中国新闻周刊
# 中国新闻网
# 每日经济新闻
# 澎湃新闻
# 网易新闻客户端
# 凤凰新闻客户端
# 皇马新闻
# 网络新闻联播
# CCTV5体育新闻
# 曼联新闻
# 搜狐新闻客户端
# 巴萨新闻
# 新闻日日睇
# 新垣结衣新闻社
# 看看新闻KNEWS
# 央视新闻评论
使用Python模拟登录获取cookies
有的网站比较痛苦,通常需要登录才能获取数据。下面是一个简单的例子:是不是用来登录网站,获取cookie,然后可以用于其他请求
但是,这里只有在没有验证码的情况下,如果要短信验证、图片验证、邮件验证,就得单独设计;
目标网站:,日期:2017-07-03,如果网站的结构发生变化,需要修改如下代码;
#!/usr/bin/env python3
# encoding: utf-8
from time import sleep
from pprint import pprint
from selenium.common.exceptions import TimeoutException, WebDriverException
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium import webdriver
def login_newrank():
"""登录新榜,获取他的cookie信息"""
desired_capabilities = DesiredCapabilities.CHROME.copy()
desired_capabilities["phantomjs.page.settings.userAgent"] = ("Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/59.0.3071.104 Safari/537.36")
desired_capabilities["phantomjs.page.settings.loadImages"] = True
# 自定义头部
desired_capabilities["phantomjs.page.customHeaders.Upgrade-Insecure-Requests"] = 1
desired_capabilities["phantomjs.page.customHeaders.Cache-Control"] = "max-age=0"
desired_capabilities["phantomjs.page.customHeaders.Connection"] = "keep-alive"
# 填写自己的账户进行测试
user = {
"mobile": "user",
"password": "password"
}
print("login account: %s" % user["mobile"])
driver = webdriver.PhantomJS(executable_path="/usr/bin/phantomjs",
desired_capabilities=desired_capabilities,
service_log_path="ghostdriver.log", )
# 设置对象的超时时间
driver.implicitly_wait(1)
# 设置页面完全加载的超时时间,包括页面全部渲染,异步同步脚本都执行完成
driver.set_page_load_timeout(60)
# 设置异步脚本的超时时间
driver.set_script_timeout(60)
driver.maximize_window()
try:
driver.get(url="http://www.newrank.cn/public/l ... 6quot;)
driver.find_element_by_css_selector(".login-normal-tap:nth-of-type(2)").click()
sleep(0.2)
driver.find_element_by_id("account_input").send_keys(user["mobile"])
sleep(0.5)
driver.find_element_by_id("password_input").send_keys(user["password"])
sleep(0.5)
driver.find_element_by_id("pwd_confirm").click()
sleep(3)
cookies = {user["name"]: user["value"] for user in driver.get_cookies()}
pprint(cookies)
except TimeoutException as exc:
print(exc)
except WebDriverException as exc:
print(exc)
finally:
driver.quit()
if __name__ == '__main__':
login_newrank()
# login account: 15395100590
# {'CNZZDATA1253878005': '1487200824-1499071649-%7C1499071649',
# 'Hm_lpvt_a19fd7224d30e3c8a6558dcb38c4beed': '1499074715',
# 'Hm_lvt_a19fd7224d30e3c8a6558dcb38c4beed': '1499074685,1499074713',
# 'UM_distinctid': '15d07d0d4dd82b-054b56417-9383666-c0000-15d07d0d4deace',
# 'name': '15395100590',
# 'rmbuser': 'true',
# 'token': 'A7437A03346B47A9F768730BAC81C514',
# 'useLoginAccount': 'true'}
获取cookie后,可以将获取的cookie添加到后续请求中,但由于cookie有有效期,需要定期更新;
这可以通过设计cookie池,动态定期登录一批账号,获取cookie后将cookie存入数据库(redis、MySQL等)来实现。
请求时从数据库中获取一个可用的cookie,并添加到访问请求中;
尝试使用pyqt5抓取数据(PyQt 5.9.2)
import sys
import csv
import pyquery
from PyQt5.QtCore import QUrl
from PyQt5.QtWidgets import QApplication
from PyQt5.QtWebEngineWidgets import QWebEngineView
class Browser(QWebEngineView):
def __init__(self):
super(Browser, self).__init__()
self.__results = []
self.loadFinished.connect(self.__result_available)
@property
def results(self):
return self.__results
def __result_available(self):
self.page().toHtml(self.__parse_html)
def __parse_html(self, html):
pq = pyquery.PyQuery(html)
for rows in [pq.find("#table_list tr"), pq.find("#more_list tr")]:
for row in rows.items():
columns = row.find("td")
d = {
"avatar": columns.eq(1).find("img").attr("src"),
"url": columns.eq(1).find("a").attr("href"),
"name": columns.eq(1).find("a").attr("title"),
"fans_number": columns.eq(2).text(),
"view_num": columns.eq(3).text(),
"comment_num": columns.eq(4).text(),
"post_count": columns.eq(5).text(),
"newrank_index": columns.eq(6).text(),
}
self.__results.append(d)
with open("results.csv", "a+", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["name", "fans_number", "view_num", "comment_num", "post_count",
"newrank_index", "url", "avatar"])
writer.writerows(self.results)
def open(self, url: str):
self.load(QUrl(url))
if __name__ == '__main__':
app = QApplication(sys.argv)
browser = Browser()
browser.open("https://www.newrank.cn/public/ ... 6quot;)
browser.show()
app.exec_()
持续更新:
5. 使用 Fiddler 抓包分析
浏览器抓包 fiddler 手机抓包
6. 使用anyproxy 捕获客户端数据-客户端数据采集
7. 高性能爬虫开发总结
获取免费爬虫视频资料加887934385交流群
网页视频抓取工具 知乎(超强的万能视频下载器,强大到几乎支持所有下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 262 次浏览 • 2021-11-17 23:10
之前也给大家推荐过视频下载工具,但是都比较单一。一个工具解决不了多平台,也不能高效批量下载!
为了解决下载视频的问题,今天给大家分享一款超级万能的视频下载器,强大到几乎可以支持所有网站的视频下载!
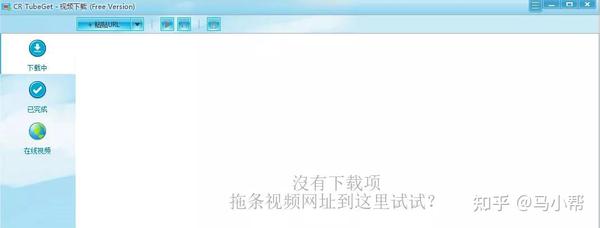
CR TubeGet
CR TubeGet是一款基于youtube-dl打包的视频下载软件。目前支持2000+网站视频下载,包括YouTube 8k下载,Mp3、M4a音频文件放不下!
这是 CR TubeGet 的简单界面。需要下载哪个网站视频,直接复制视频链接粘贴即可解析下载!实际测试了几个主流平台,比如:某某B、某某优、某某爱、某某YouTube、某某西瓜。无一例外地支持所有下载。(VIP内容除外)
软件支持aria2下载器加速下载,只要你的网络环境OK,下载速度就是这么快!
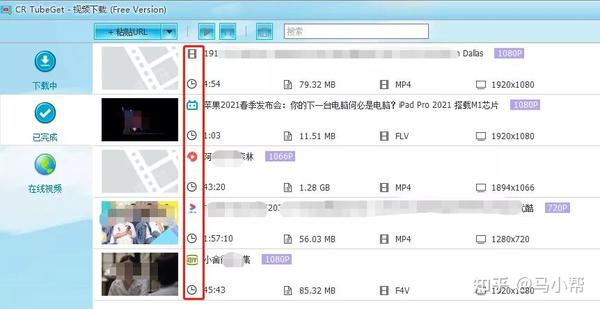
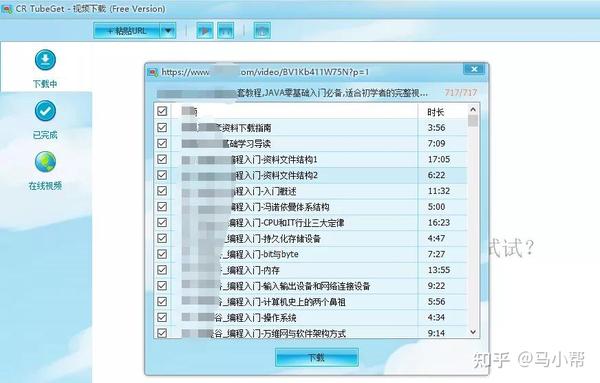
批量下载方式:
软件本身支持批量下载和列表下载。如果您复制B站列表视频中的链接,软件会自动检测列表中的所有视频并支持所有解析下载。如果你在B站看学习视频,那么这个列表下载功能真的不是太方便。
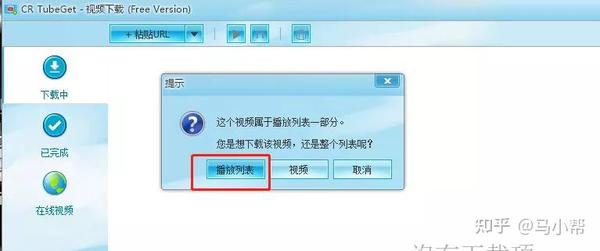
也可以直接复制多个链接到“批量下载框”,统一分析下载。
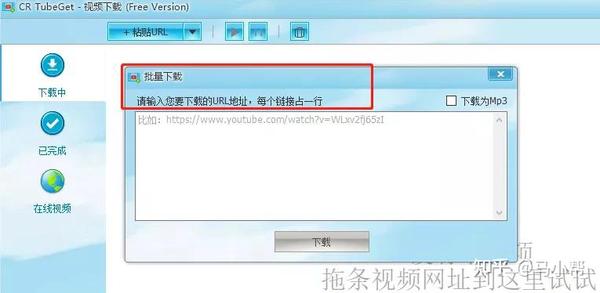
如果觉得这个批量下载不够方便,这里有一个浏览器插件:link-grabber,可以识别显示当前网页的所有链接。
比如我们想下载某个电视剧的所有视频,那么我们可以用这个插件一次性复制所有电视剧的所有链接,直接导入到CR TubeGet中进行下载。
使用谷歌浏览器(可使用谷歌内核浏览器)安装本插件,点击插件图标,即可显示当前网页的所有链接。将视频链接复制到下载工具进行批量下载。
下载:
本文首发于微信公众号马小邦(maxiaobang7),未经授权请勿转载!
一如既往,感谢大家的支持和关注 查看全部
网页视频抓取工具 知乎(超强的万能视频下载器,强大到几乎支持所有下载)
之前也给大家推荐过视频下载工具,但是都比较单一。一个工具解决不了多平台,也不能高效批量下载!
为了解决下载视频的问题,今天给大家分享一款超级万能的视频下载器,强大到几乎可以支持所有网站的视频下载!
CR TubeGet
CR TubeGet是一款基于youtube-dl打包的视频下载软件。目前支持2000+网站视频下载,包括YouTube 8k下载,Mp3、M4a音频文件放不下!
这是 CR TubeGet 的简单界面。需要下载哪个网站视频,直接复制视频链接粘贴即可解析下载!实际测试了几个主流平台,比如:某某B、某某优、某某爱、某某YouTube、某某西瓜。无一例外地支持所有下载。(VIP内容除外)
软件支持aria2下载器加速下载,只要你的网络环境OK,下载速度就是这么快!
批量下载方式:
软件本身支持批量下载和列表下载。如果您复制B站列表视频中的链接,软件会自动检测列表中的所有视频并支持所有解析下载。如果你在B站看学习视频,那么这个列表下载功能真的不是太方便。
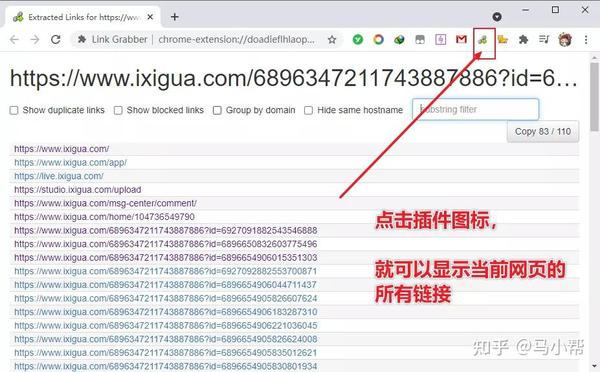
也可以直接复制多个链接到“批量下载框”,统一分析下载。
如果觉得这个批量下载不够方便,这里有一个浏览器插件:link-grabber,可以识别显示当前网页的所有链接。
比如我们想下载某个电视剧的所有视频,那么我们可以用这个插件一次性复制所有电视剧的所有链接,直接导入到CR TubeGet中进行下载。
使用谷歌浏览器(可使用谷歌内核浏览器)安装本插件,点击插件图标,即可显示当前网页的所有链接。将视频链接复制到下载工具进行批量下载。
下载:
本文首发于微信公众号马小邦(maxiaobang7),未经授权请勿转载!
一如既往,感谢大家的支持和关注
网页视频抓取工具 知乎(知乎文章下载插件是一个可以帮助用户便捷的下载知乎中的浏览插件工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-11-17 02:13
知乎文章下载插件是一款浏览器插件工具,可以帮助用户方便地在知乎下载文章。众所周知,最好的采集方式不如采集。下载到本地。很多时候打开知乎的采集夹,你会发现很多答案已经失效了。这个插件可以让你在浏览网页时一键下载文章。, 以markdown格式保存,方便大家浏览阅读。
发展背景
如果你是 知乎 用户,你应该有过这样的经历:
不久前发布的文章,或者浏览的文章,过了一会才发现被正式删除了。
这样一来,你辛苦了一个星期的人物就白费了,你想采集的好文章也可能会擦肩而过。
如果要保存知乎文章作为备份,在复制全文时不仅会遇到转载权限的限制,还可能导致部分格式丢失。
而这个chrome插件是为了防备,可以很好的解决知乎文章的备份问题。
软件功能
知乎文章下载插件,顾名思义就是下载知乎文章的文档下载工具。
支持下载所有知乎用户的文章,包括自己和其他知乎用户。您可以下载单个文章,也可以批量下载该用户的所有文章。
下载的知乎文章都是以markdown格式保存的。
使用说明
打开个人中心文章页面
需要注意的是,该插件只能在知乎用户的文章栏目页面生效。所以我们需要进入这个页面进行下载。
如下图,进入知乎用户的个人主页,然后点击切换到[文章]栏。
下载文章
然后就可以看到新增的文章下载选项,点击开始下载。
注意,如果下载按钮没有出现,只需刷新当前页面即可。 查看全部
网页视频抓取工具 知乎(知乎文章下载插件是一个可以帮助用户便捷的下载知乎中的浏览插件工具)
知乎文章下载插件是一款浏览器插件工具,可以帮助用户方便地在知乎下载文章。众所周知,最好的采集方式不如采集。下载到本地。很多时候打开知乎的采集夹,你会发现很多答案已经失效了。这个插件可以让你在浏览网页时一键下载文章。, 以markdown格式保存,方便大家浏览阅读。
发展背景
如果你是 知乎 用户,你应该有过这样的经历:
不久前发布的文章,或者浏览的文章,过了一会才发现被正式删除了。
这样一来,你辛苦了一个星期的人物就白费了,你想采集的好文章也可能会擦肩而过。
如果要保存知乎文章作为备份,在复制全文时不仅会遇到转载权限的限制,还可能导致部分格式丢失。
而这个chrome插件是为了防备,可以很好的解决知乎文章的备份问题。
软件功能
知乎文章下载插件,顾名思义就是下载知乎文章的文档下载工具。
支持下载所有知乎用户的文章,包括自己和其他知乎用户。您可以下载单个文章,也可以批量下载该用户的所有文章。
下载的知乎文章都是以markdown格式保存的。
使用说明
打开个人中心文章页面
需要注意的是,该插件只能在知乎用户的文章栏目页面生效。所以我们需要进入这个页面进行下载。
如下图,进入知乎用户的个人主页,然后点击切换到[文章]栏。
下载文章
然后就可以看到新增的文章下载选项,点击开始下载。
注意,如果下载按钮没有出现,只需刷新当前页面即可。
网页视频抓取工具 知乎(知乎助手更新日志支持单个问题/文章、文章的操作日志)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-11-17 02:12
知乎助手是专为知乎打造的网页浏览助手工具。体积小,不占内存空间,功能强大实用,支持模块xposed。不仅可以同时登录多个账号,还可以采集丰富的背景资料,抓取一些优秀的专栏文章、答案等。
知乎助手基本介绍
在知乎的帮助下,当你在访问网站时发现一些精彩的答案,就可以将它们保存到本地,制作成电子书。用户可以自定义爬取规则,过滤掉不需要的内容。
知乎辅助功能
该软件支持同时登录多个帐户。
它会自动记录您的操作日志。
您可以自定义电子书的名称。
该软件可以在 Windows 和 macOS 平台上运行。
应用可以抢专栏文章、想法、高赞回答。
知乎如何使用助手
在任务输入框中输入要爬取的URL信息。
单击开始执行按钮。
执行完成后,会打开电子书所在的文件夹。可以使用杜坎阅读或者在Win10下双击用Edge浏览器打开。
输出文件
html 文件夹是按答案划分的单个答案页面的列表,而 index.html 是目录页面。
单文件版收录文件夹内的整个文件,用浏览器打开后可直接打印为PDF书。
知乎助手输出的电子书\epub就是输出的Epub电子书,电子书阅读器可以直接阅读。
知乎助手输出的e-book\html为输出网页版答案列表。
知乎助手更新日志
支持导出单个问题/文章。
支持自动分卷。
相关教程
知乎助理评论
它会自动记录您的操作日志。
细节 查看全部
网页视频抓取工具 知乎(知乎助手更新日志支持单个问题/文章、文章的操作日志)
知乎助手是专为知乎打造的网页浏览助手工具。体积小,不占内存空间,功能强大实用,支持模块xposed。不仅可以同时登录多个账号,还可以采集丰富的背景资料,抓取一些优秀的专栏文章、答案等。

知乎助手基本介绍
在知乎的帮助下,当你在访问网站时发现一些精彩的答案,就可以将它们保存到本地,制作成电子书。用户可以自定义爬取规则,过滤掉不需要的内容。
知乎辅助功能
该软件支持同时登录多个帐户。
它会自动记录您的操作日志。
您可以自定义电子书的名称。
该软件可以在 Windows 和 macOS 平台上运行。
应用可以抢专栏文章、想法、高赞回答。
知乎如何使用助手
在任务输入框中输入要爬取的URL信息。
单击开始执行按钮。
执行完成后,会打开电子书所在的文件夹。可以使用杜坎阅读或者在Win10下双击用Edge浏览器打开。
输出文件
html 文件夹是按答案划分的单个答案页面的列表,而 index.html 是目录页面。
单文件版收录文件夹内的整个文件,用浏览器打开后可直接打印为PDF书。
知乎助手输出的电子书\epub就是输出的Epub电子书,电子书阅读器可以直接阅读。
知乎助手输出的e-book\html为输出网页版答案列表。

知乎助手更新日志
支持导出单个问题/文章。
支持自动分卷。
相关教程
知乎助理评论
它会自动记录您的操作日志。
细节
网页视频抓取工具 知乎(要如何下载知乎视频呢?-downloader插件功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-11-17 00:17
zh-downloader插件是一款不错的知乎视频分析下载工具。本软件支持在用户访问的任何知乎页面下载视频和图片文件,并能自动转换为MP4格式。有需要的朋友快来下载吧!
发展背景
“知乎”在文言文中的意思是“你知道吗”。2011年,一款名为知乎的问答式网站在中国正式上线,其产品对标美国同类网站 Quora。
时至今日,知乎已经是中国最活跃的社区论坛之一,其意义不仅包括专业知识问答,还涵盖了各行各业的方方面面。
当然,有时候用户会在知乎上分享一些有趣的视频,那么如何下载知乎的视频呢?
有朋友可能发现,经常下载Video Downloader pro、猫手等谷歌插件的视频有时无法嗅探知乎页面上的视频。
另一方面,即使你在知乎上下载视频,你也会发现大部分都是m3u8格式,不利于分享和本地观看。
特征
有没有什么工具可以嗅探知乎上的视频并在下载时自动转换成mp4格式?
答案就是这个zh-downloader插件,在商店里比较冷门。
它可以帮助我们快速检测到知乎页面上的视频。下载时还支持分辨率选择,以及分享、查看下载进度等操作。下载完成后的视频格式为mp4,无需二次转换,非常强大实用。
指示
下载视频
打开任意带有视频的知乎页面,插件会自动检测是否有资源,嗅探视频的数量会以角标的形式出现在图标上。
这时,点击工具栏上的插件图标,可以看到下载菜单窗口。
与Video Downloader Professional相比,zh-downloader嗅探的视频资源会显示标题和缩略图,非常直观。
同时,您可以直接选择下载视频的定义,查看下载进度,以及分享和删除操作。 查看全部
网页视频抓取工具 知乎(要如何下载知乎视频呢?-downloader插件功能介绍)
zh-downloader插件是一款不错的知乎视频分析下载工具。本软件支持在用户访问的任何知乎页面下载视频和图片文件,并能自动转换为MP4格式。有需要的朋友快来下载吧!

发展背景
“知乎”在文言文中的意思是“你知道吗”。2011年,一款名为知乎的问答式网站在中国正式上线,其产品对标美国同类网站 Quora。
时至今日,知乎已经是中国最活跃的社区论坛之一,其意义不仅包括专业知识问答,还涵盖了各行各业的方方面面。
当然,有时候用户会在知乎上分享一些有趣的视频,那么如何下载知乎的视频呢?
有朋友可能发现,经常下载Video Downloader pro、猫手等谷歌插件的视频有时无法嗅探知乎页面上的视频。
另一方面,即使你在知乎上下载视频,你也会发现大部分都是m3u8格式,不利于分享和本地观看。
特征
有没有什么工具可以嗅探知乎上的视频并在下载时自动转换成mp4格式?
答案就是这个zh-downloader插件,在商店里比较冷门。
它可以帮助我们快速检测到知乎页面上的视频。下载时还支持分辨率选择,以及分享、查看下载进度等操作。下载完成后的视频格式为mp4,无需二次转换,非常强大实用。
指示
下载视频
打开任意带有视频的知乎页面,插件会自动检测是否有资源,嗅探视频的数量会以角标的形式出现在图标上。
这时,点击工具栏上的插件图标,可以看到下载菜单窗口。

与Video Downloader Professional相比,zh-downloader嗅探的视频资源会显示标题和缩略图,非常直观。
同时,您可以直接选择下载视频的定义,查看下载进度,以及分享和删除操作。
网页视频抓取工具 知乎(网页视频抓取工具知乎首答(ess-zhuang-bi-gao-jing-meng/id586776958))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-13 15:01
网页视频抓取工具知乎首答-ess-zhuang-bi-gao-jing-meng/id586776958?mt=8链接地址是:;type=document&page=5
网页视频抓取你可以试试scrapy,
首先,你应该学习一下网页视频的录制方法。然后,找一个基于http的抓取工具,像百度视频全能王,先录制。然后存起来。最后,找一个录制软件。很多都可以,有文本录制,流式录制,视频录制。爬虫原理一样,都是匹配网页链接,是一个个urls,分页录制。找到目标网页的网址并解析获取,肯定有很多的url。找到目标网页的url,并且分页获取目标网页的全部url,就是有效页面url,列表页数据都是一样的。
然后就开始循环的爬取就行。一页几十条数据,一天也就是几十万的数据。如果有多个网页的页面,就多爬几层循环就行。
原理上每个网站都是通过url拿数据的,现在都是读写大数据平台,
没有。
百度搜索,搜索框某关键词,有全部的结果。不过,至少有个知乎。
以前也想问这个问题,无奈安卓端软件不开源,没法实现。后来发现可以开发一个网页视频抓取方案如下:1.1抓视频要开发一个app,配置好程序处理视频的几个逻辑(比如视频分段保存,分辨率选择以及缓存路径等),然后编写相应的程序(推荐用uibot)去抓取某个url,每个步骤可以选择性地实现。1.2抓获。上传app到百度云,app会自动抓取百度云的视频,这一步也比较简单。1.3存储。放入wiki文件夹,在mobileapp中使用文件夹访问wiki,然后下载即可。 查看全部
网页视频抓取工具 知乎(网页视频抓取工具知乎首答(ess-zhuang-bi-gao-jing-meng/id586776958))
网页视频抓取工具知乎首答-ess-zhuang-bi-gao-jing-meng/id586776958?mt=8链接地址是:;type=document&page=5
网页视频抓取你可以试试scrapy,
首先,你应该学习一下网页视频的录制方法。然后,找一个基于http的抓取工具,像百度视频全能王,先录制。然后存起来。最后,找一个录制软件。很多都可以,有文本录制,流式录制,视频录制。爬虫原理一样,都是匹配网页链接,是一个个urls,分页录制。找到目标网页的网址并解析获取,肯定有很多的url。找到目标网页的url,并且分页获取目标网页的全部url,就是有效页面url,列表页数据都是一样的。
然后就开始循环的爬取就行。一页几十条数据,一天也就是几十万的数据。如果有多个网页的页面,就多爬几层循环就行。
原理上每个网站都是通过url拿数据的,现在都是读写大数据平台,
没有。
百度搜索,搜索框某关键词,有全部的结果。不过,至少有个知乎。
以前也想问这个问题,无奈安卓端软件不开源,没法实现。后来发现可以开发一个网页视频抓取方案如下:1.1抓视频要开发一个app,配置好程序处理视频的几个逻辑(比如视频分段保存,分辨率选择以及缓存路径等),然后编写相应的程序(推荐用uibot)去抓取某个url,每个步骤可以选择性地实现。1.2抓获。上传app到百度云,app会自动抓取百度云的视频,这一步也比较简单。1.3存储。放入wiki文件夹,在mobileapp中使用文件夹访问wiki,然后下载即可。
网页视频抓取工具 知乎(如何爬取B站视频的弹幕和评论?|Python )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-10 20:09
)
开发工具
Python版本:3.6.4
相关模块:
请求模块;
重新模块;
熊猫模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
思维分析
本文以爬取视频《“这是我见过最拽的中国奥运冠军”》为例,讲解如何爬取B站视频的弹幕和评论!
目标地址
https://www.bilibili.com/video/BV1wq4y1Q7dp 复制代码
抢弹幕
网络分析
B站视频的弹幕不像腾讯视频。播放视频会触发弹幕数据包。他需要点击网页右侧的弹幕列表行展开,然后点击查看历史弹幕,可以得到视频弹幕的开始日期和结束日期。日链接:
在链接的末尾,使用oid和开始日期形成弹幕日期URL:
https://api.bilibili.com/x/v2/ ... 21-08 复制代码
在此基础上,点击任一生效日期,即可获得该日期的弹幕数据包。里面的内容目前无法读取。之所以确定是弹幕数据包,是因为日期是点击他刚加载出来的,链接和上一个链接有关系:
获取到的网址:
https://api.bilibili.com/x/v2/ ... 08-08 复制代码
URL中的oid是视频弹幕链接的id值;data参数是刚才的日期,要获取视频的所有弹幕内容,只需要修改data参数即可。data参数可以从上面弹幕日期url中获取,也可以自己构造;网页数据格式为json格式
代码
import requests\ import pandas as pd\ import re\ \ def data_resposen(url):\ headers = {\ "cookie": "你的cookie",\ "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36"\ }\ resposen = requests.get(url, headers=headers)\ return resposen\ \ def main(oid, month):\ df = pd.DataFrame()\ url = f'https://api.bilibili.com/x/v2/ ... id%3D{oid}&month={month}'\ list_data = data_resposen(url).json()['data'] # 拿到所有日期\ print(list_data)\ for data in list_data:\ urls = f'https://api.bilibili.com/x/v2/ ... id%3D{oid}&date={data}'\ text = re.findall(".*?([\u4E00-\u9FA5]+).*?", data_resposen(urls).text)\ for e in text:\ print(e)\ data = pd.DataFrame({'弹幕': [e]})\ df = pd.concat([df, data])\ df.to_csv('弹幕.csv', encoding='utf-8', index=False, mode='a+')\ \ if __name__ == '__main__':\ oid = '384801460' # 视频弹幕链接的id值\ month = '2021-08' # 开始日期\ main(oid, month) 复制代码
显示结果
查看全部
网页视频抓取工具 知乎(如何爬取B站视频的弹幕和评论?|Python
)
开发工具
Python版本:3.6.4
相关模块:
请求模块;
重新模块;
熊猫模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
思维分析
本文以爬取视频《“这是我见过最拽的中国奥运冠军”》为例,讲解如何爬取B站视频的弹幕和评论!
目标地址
https://www.bilibili.com/video/BV1wq4y1Q7dp 复制代码
抢弹幕
网络分析
B站视频的弹幕不像腾讯视频。播放视频会触发弹幕数据包。他需要点击网页右侧的弹幕列表行展开,然后点击查看历史弹幕,可以得到视频弹幕的开始日期和结束日期。日链接:
在链接的末尾,使用oid和开始日期形成弹幕日期URL:
https://api.bilibili.com/x/v2/ ... 21-08 复制代码
在此基础上,点击任一生效日期,即可获得该日期的弹幕数据包。里面的内容目前无法读取。之所以确定是弹幕数据包,是因为日期是点击他刚加载出来的,链接和上一个链接有关系:
获取到的网址:
https://api.bilibili.com/x/v2/ ... 08-08 复制代码
URL中的oid是视频弹幕链接的id值;data参数是刚才的日期,要获取视频的所有弹幕内容,只需要修改data参数即可。data参数可以从上面弹幕日期url中获取,也可以自己构造;网页数据格式为json格式
代码
import requests\ import pandas as pd\ import re\ \ def data_resposen(url):\ headers = {\ "cookie": "你的cookie",\ "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36"\ }\ resposen = requests.get(url, headers=headers)\ return resposen\ \ def main(oid, month):\ df = pd.DataFrame()\ url = f'https://api.bilibili.com/x/v2/ ... id%3D{oid}&month={month}'\ list_data = data_resposen(url).json()['data'] # 拿到所有日期\ print(list_data)\ for data in list_data:\ urls = f'https://api.bilibili.com/x/v2/ ... id%3D{oid}&date={data}'\ text = re.findall(".*?([\u4E00-\u9FA5]+).*?", data_resposen(urls).text)\ for e in text:\ print(e)\ data = pd.DataFrame({'弹幕': [e]})\ df = pd.concat([df, data])\ df.to_csv('弹幕.csv', encoding='utf-8', index=False, mode='a+')\ \ if __name__ == '__main__':\ oid = '384801460' # 视频弹幕链接的id值\ month = '2021-08' # 开始日期\ main(oid, month) 复制代码
显示结果

网页视频抓取工具 知乎(网络爬虫(webcrawler)或网络机器人()又称为)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-08 08:14
众所周知,随着计算机、互联网、物联网、云计算等网络技术的兴起,网络上的信息爆炸式增长。毫无疑问,互联网上的信息几乎涵盖了社会、文化、政治、经济、娱乐等所有话题。使用传统的数据采集机制(如问卷调查法、访谈法)获取和采集数据往往受到资金和地域范围的限制,也会由于样本量小、可靠性低 数据往往与客观事实存在偏差,局限性较大。(文末百度网盘基础视频,需要自己提)
网络爬虫使用统一资源定位器网址(Uniform ResourceLocator)寻找目标网页
用户关注的数据内容直接返回给用户,用户无需浏览网页即可获取信息,为用户节省了时间和精力,提高了数据的准确性采集@ >,让用户在海量数据中轻松搞定。
网络爬虫的最终目标是从网页中获取它们需要的信息。虽然可以使用urllib、urllib2、re等一些爬虫基础库来开发爬虫程序,获取需要的内容,但是所有爬虫程序都是这样写的,工作量太大。于是就有了爬虫框架。使用爬虫框架可以大大提高效率,缩短开发时间。
网络爬虫也称为网络蜘蛛或网络机器人。其他不常用的名称包括蚂蚁、自动索引、模拟程序或蠕虫,它也是“物联网”概念的核心之一。网络爬虫本质上是按照一定的逻辑和算法规则自动抓取和下载万维网上网页的计算机程序或脚本。它是搜索引擎的重要组成部分。
网络爬虫一般都是从预先设置的一个或几个初始网页的网址开始,然后按照一定的规则对网页进行爬取,得到初始网页上的网址列表。之后,每当网页被抓取时,抓取工具都会提取该网页。将新的URL放入未被抓取的队列中,然后循环从队列中取出一个从未抓取过的URL,然后进行新一轮的抓取,重复上述过程,直到抓取队列中的 URL。当爬虫完成或满足其他既定条件时,它就会结束。具体流程如下图所示。
随着大数据时代的到来,网络数据正在成为一种潜在的宝藏。大量的商业信息和社会信息以文本等非结构化、异构的数据格式存储在网页上。非计算机专业背景的人也可以使用机器学习、人工智能等方法进行研究。利用网络爬虫获取采集信息,不仅可以实现高效、准确、自动获取网络信息,还可以帮助企业或研究人员对采集收到的数据进行后续的挖掘和分析.
数据采集需要使用Python编程语言来设计网络爬虫,而且获得的数据中有相当比例是非结构化数据,这就需要python数据分析技术。
另外给大家分享一波基础教学视频,百度网盘,需要自己提一下!感觉有用,请关注!!
百度网盘python数据获取链接:/s/1I00b8CCAVWcZNF7ds-4EDw
提取码:in0q 查看全部
网页视频抓取工具 知乎(网络爬虫(webcrawler)或网络机器人()又称为)
众所周知,随着计算机、互联网、物联网、云计算等网络技术的兴起,网络上的信息爆炸式增长。毫无疑问,互联网上的信息几乎涵盖了社会、文化、政治、经济、娱乐等所有话题。使用传统的数据采集机制(如问卷调查法、访谈法)获取和采集数据往往受到资金和地域范围的限制,也会由于样本量小、可靠性低 数据往往与客观事实存在偏差,局限性较大。(文末百度网盘基础视频,需要自己提)

网络爬虫使用统一资源定位器网址(Uniform ResourceLocator)寻找目标网页
用户关注的数据内容直接返回给用户,用户无需浏览网页即可获取信息,为用户节省了时间和精力,提高了数据的准确性采集@ >,让用户在海量数据中轻松搞定。
网络爬虫的最终目标是从网页中获取它们需要的信息。虽然可以使用urllib、urllib2、re等一些爬虫基础库来开发爬虫程序,获取需要的内容,但是所有爬虫程序都是这样写的,工作量太大。于是就有了爬虫框架。使用爬虫框架可以大大提高效率,缩短开发时间。
网络爬虫也称为网络蜘蛛或网络机器人。其他不常用的名称包括蚂蚁、自动索引、模拟程序或蠕虫,它也是“物联网”概念的核心之一。网络爬虫本质上是按照一定的逻辑和算法规则自动抓取和下载万维网上网页的计算机程序或脚本。它是搜索引擎的重要组成部分。
网络爬虫一般都是从预先设置的一个或几个初始网页的网址开始,然后按照一定的规则对网页进行爬取,得到初始网页上的网址列表。之后,每当网页被抓取时,抓取工具都会提取该网页。将新的URL放入未被抓取的队列中,然后循环从队列中取出一个从未抓取过的URL,然后进行新一轮的抓取,重复上述过程,直到抓取队列中的 URL。当爬虫完成或满足其他既定条件时,它就会结束。具体流程如下图所示。
随着大数据时代的到来,网络数据正在成为一种潜在的宝藏。大量的商业信息和社会信息以文本等非结构化、异构的数据格式存储在网页上。非计算机专业背景的人也可以使用机器学习、人工智能等方法进行研究。利用网络爬虫获取采集信息,不仅可以实现高效、准确、自动获取网络信息,还可以帮助企业或研究人员对采集收到的数据进行后续的挖掘和分析.
数据采集需要使用Python编程语言来设计网络爬虫,而且获得的数据中有相当比例是非结构化数据,这就需要python数据分析技术。
另外给大家分享一波基础教学视频,百度网盘,需要自己提一下!感觉有用,请关注!!
百度网盘python数据获取链接:/s/1I00b8CCAVWcZNF7ds-4EDw
提取码:in0q
网页视频抓取工具 知乎(代码是最近(2021.09)新写的~需求任务需求分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-05 23:23
最近新写的代码(2021.09)~
需要
任务要求:抓取问题知乎下的所有答案,包括作者、作者粉丝数、回答内容、时间、回复评论数、回答数和回答链接.
分析
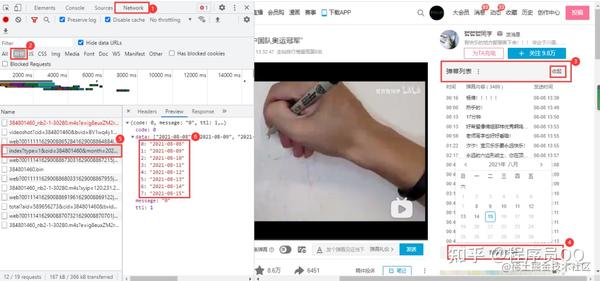
以最近关注的“大公司间链接畅通问题”为例。如果想获取答案的相关数据,可以在Chrome浏览器下按F12对请求进行分析;但是在Charles抓包工具的帮助下,你可以改变它。直观获取相关字段:
注意我标记的Query String参数中的limit 5表示每个请求会返回5个回答,测试后最多可以改成20个;偏移是指从答案的数量开始;
返回结果为 Json 格式。每个答案都收录足够的信息。我们只需要过滤并保存我们想要捕获的字段记录。
需要说明的是,content字段返回的内容为答案内容,但其格式是带有网页标签的。搜索之后,我选择了HTMLParser来解析,这样就不用手动处理了。
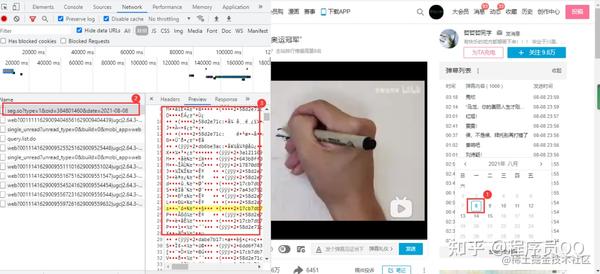
代码
import requests,json
import datetime
import pandas as pd
from selectolax.parser import HTMLParser
url = 'https://www.zhihu.com/api/v4/q ... 39%3B
headers = {
'Host':'www.zhihu.com',
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
'referer':'https://www.zhihu.com/question/486212129'
}
df = pd.DataFrame(columns=('author','fans_count','content','created_time','updated_time','comment_count','voteup_count','url'))
def crawler(start):
print(start)
global df
data= {
'include':'data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,attachment,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,is_labeled,paid_info,paid_info_content,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,is_recognized;data[*].mark_infos[*].url;data[*].author.follower_count,vip_info,badge[*].topics;data[*].settings.table_of_content.enabled',
'offset':start,
'limit':20,
'sort_by':'default',
'platform':'desktop'
}
#将携带的参数传给params
r = requests.get(url, params=data,headers=headers)
res = json.loads(r.text)
if res['data']:
for answer in res['data']:
author = answer['author']['name']
fans = answer['author']['follower_count']
content = HTMLParser(answer['content']).text()
#content = answer['content']
created_time = datetime.datetime.fromtimestamp(answer['created_time'])
updated_time = datetime.datetime.fromtimestamp(answer['updated_time'])
comment = answer['comment_count']
voteup = answer['voteup_count']
link = answer['url']
row = {
'author':[author],
'fans_count':[fans],
'content':[content],
'created_time':[created_time],
'updated_time':[updated_time],
'comment_count':[comment],
'voteup_count':[voteup],
'url':[link]
}
df = df.append(pd.DataFrame(row),ignore_index=True)
if len(res['data'])==20:
crawler(start+20)
else:
print(res)
crawler(0)
df.to_csv(f'result_{datetime.datetime.now().strftime("%Y-%m-%d")}.csv',index=False)
print("done~")
结果
得到的结果大致如下:
你可以看到有些答案是空的。转到问题并检查它是否是视频答案。没有文字内容。这被忽略了。当然,您可以删除视频链接并将其添加到结果中。
防攀登限制
目前(2021.09)看这个问题,接口没有特别限制,包括我在代码中的请求没有cookies直接捕获,通过修改limit参数为20来减少请求频率。
爬虫意义
最近也在想爬知乎答案的意义在哪里。一开始我想把所有的答案汇总起来分析,但是我真正抓住了之后,就想一起阅读了。我发现阅读表格中的答案的阅读体验很差。直接去知乎;但更明显的价值在于这数百个答案的横向比较。赞、评论、作者粉丝一目了然。另外,你还可以根据结果做一些词频分析、词云图展示等,这些都是接下来要做的事情。
爬虫只是获取数据的一种方式,如何解读是数据更大的价值。
我是TED,每天写爬虫的数据工程师,但好久没写Python了。以后想到的一系列Python爬虫项目会继续更新。欢迎继续关注~ 查看全部
网页视频抓取工具 知乎(代码是最近(2021.09)新写的~需求任务需求分析)
最近新写的代码(2021.09)~
需要
任务要求:抓取问题知乎下的所有答案,包括作者、作者粉丝数、回答内容、时间、回复评论数、回答数和回答链接.
分析
以最近关注的“大公司间链接畅通问题”为例。如果想获取答案的相关数据,可以在Chrome浏览器下按F12对请求进行分析;但是在Charles抓包工具的帮助下,你可以改变它。直观获取相关字段:

注意我标记的Query String参数中的limit 5表示每个请求会返回5个回答,测试后最多可以改成20个;偏移是指从答案的数量开始;
返回结果为 Json 格式。每个答案都收录足够的信息。我们只需要过滤并保存我们想要捕获的字段记录。
需要说明的是,content字段返回的内容为答案内容,但其格式是带有网页标签的。搜索之后,我选择了HTMLParser来解析,这样就不用手动处理了。
代码
import requests,json
import datetime
import pandas as pd
from selectolax.parser import HTMLParser
url = 'https://www.zhihu.com/api/v4/q ... 39%3B
headers = {
'Host':'www.zhihu.com',
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
'referer':'https://www.zhihu.com/question/486212129'
}
df = pd.DataFrame(columns=('author','fans_count','content','created_time','updated_time','comment_count','voteup_count','url'))
def crawler(start):
print(start)
global df
data= {
'include':'data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,attachment,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,is_labeled,paid_info,paid_info_content,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,is_recognized;data[*].mark_infos[*].url;data[*].author.follower_count,vip_info,badge[*].topics;data[*].settings.table_of_content.enabled',
'offset':start,
'limit':20,
'sort_by':'default',
'platform':'desktop'
}
#将携带的参数传给params
r = requests.get(url, params=data,headers=headers)
res = json.loads(r.text)
if res['data']:
for answer in res['data']:
author = answer['author']['name']
fans = answer['author']['follower_count']
content = HTMLParser(answer['content']).text()
#content = answer['content']
created_time = datetime.datetime.fromtimestamp(answer['created_time'])
updated_time = datetime.datetime.fromtimestamp(answer['updated_time'])
comment = answer['comment_count']
voteup = answer['voteup_count']
link = answer['url']
row = {
'author':[author],
'fans_count':[fans],
'content':[content],
'created_time':[created_time],
'updated_time':[updated_time],
'comment_count':[comment],
'voteup_count':[voteup],
'url':[link]
}
df = df.append(pd.DataFrame(row),ignore_index=True)
if len(res['data'])==20:
crawler(start+20)
else:
print(res)
crawler(0)
df.to_csv(f'result_{datetime.datetime.now().strftime("%Y-%m-%d")}.csv',index=False)
print("done~")
结果
得到的结果大致如下:

你可以看到有些答案是空的。转到问题并检查它是否是视频答案。没有文字内容。这被忽略了。当然,您可以删除视频链接并将其添加到结果中。
防攀登限制
目前(2021.09)看这个问题,接口没有特别限制,包括我在代码中的请求没有cookies直接捕获,通过修改limit参数为20来减少请求频率。
爬虫意义
最近也在想爬知乎答案的意义在哪里。一开始我想把所有的答案汇总起来分析,但是我真正抓住了之后,就想一起阅读了。我发现阅读表格中的答案的阅读体验很差。直接去知乎;但更明显的价值在于这数百个答案的横向比较。赞、评论、作者粉丝一目了然。另外,你还可以根据结果做一些词频分析、词云图展示等,这些都是接下来要做的事情。
爬虫只是获取数据的一种方式,如何解读是数据更大的价值。
我是TED,每天写爬虫的数据工程师,但好久没写Python了。以后想到的一系列Python爬虫项目会继续更新。欢迎继续关注~
网页视频抓取工具 知乎(更新日志1.修复bug2.修复已知bug优化操作体验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-05 23:20
zh-downloader 是一款非常好用的视频下载工具,它可以帮助用户下载知乎页面上的所有视频和图片,对于一些喜欢访问知乎的用户,您可以轻松帮助自己去获取你喜欢的资源。另外,该软件可以将下载的资源自动转换成MP4格式,喜欢就下载试试吧!
软件特点
有没有什么工具可以嗅探知乎上的视频并在下载时自动转换成mp4格式?
答案就是这个zh-downloader插件,在商店里比较冷门。
它可以帮助我们快速检测到知乎页面上的视频。还支持下载时选择分辨率,以及分享、查看下载进度等操作。下载完成后的视频格式为mp4,无需二次转换。,非常强大实用。
指示
打开任意带有视频的知乎页面,插件会自动检测是否有资源,嗅探视频的数量会以角标的形式出现在图标上。
这时,点击工具栏上的插件图标,可以看到下载菜单窗口。
与Video Downloader Professional相比,zh-downloader嗅探的视频资源会显示标题和缩略图,非常直观。
同时,您可以直接选择下载视频的定义,查看下载进度,以及分享和删除操作。
更新日志
1.修复已知bug
2.优化操作体验 查看全部
网页视频抓取工具 知乎(更新日志1.修复bug2.修复已知bug优化操作体验)
zh-downloader 是一款非常好用的视频下载工具,它可以帮助用户下载知乎页面上的所有视频和图片,对于一些喜欢访问知乎的用户,您可以轻松帮助自己去获取你喜欢的资源。另外,该软件可以将下载的资源自动转换成MP4格式,喜欢就下载试试吧!
软件特点
有没有什么工具可以嗅探知乎上的视频并在下载时自动转换成mp4格式?
答案就是这个zh-downloader插件,在商店里比较冷门。
它可以帮助我们快速检测到知乎页面上的视频。还支持下载时选择分辨率,以及分享、查看下载进度等操作。下载完成后的视频格式为mp4,无需二次转换。,非常强大实用。
指示
打开任意带有视频的知乎页面,插件会自动检测是否有资源,嗅探视频的数量会以角标的形式出现在图标上。
这时,点击工具栏上的插件图标,可以看到下载菜单窗口。
与Video Downloader Professional相比,zh-downloader嗅探的视频资源会显示标题和缩略图,非常直观。
同时,您可以直接选择下载视频的定义,查看下载进度,以及分享和删除操作。
更新日志
1.修复已知bug
2.优化操作体验
网页视频抓取工具 知乎(装机软件数量的繁多和平日课程、细节不足之处还望海涵 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-03 23:06
)
前言:
安装的软件很多,平日的课程,实习,考研时间紧,但还是忍不住想分享,一直想写这个答案。我会用不断的更新来补充和修改,争取在下周内完成这个答案。以下是一些已经大致介绍过的软件,不足的细节还是王海涵。
一些非常棒的Windows软件,我认为它们不应该只被少数人知道,或者随着时间的推移逐渐被埋没甚至消失。
“分割线”
————————————————————————————————————————————
以下推荐均基于Windows环境,使用十余个月后选择。安装过程中无附加软件,使用过程中无广告。内存占用小,对整机性能没有任何拖累。它是一些我认为在某些功能上非常强大和有趣的Windows软件,并为生活带来了很多乐趣。
各个程序的安装过程将在以后的主题文章中进行描述和解释。很多软件很容易混用忘记,留教程以备后患,预防痴呆。
软件分类:远程协助、录屏软件、图像处理、整机文件查询、视频下载、音频播放、分屏软件、思维导图、电脑界面修改、安卓虚拟机、360极速浏览插件等一些有趣实用的网址推荐。
1. 远程协助不得不提:TeamViewer,一款好用、专业、强大的企业级良心应用。
2. 这次所有截图使用的软件:FastStone Capture(原则上应该叫Screen Recorder,但我个人觉得它的截图功能是最强大的体现) 上面说了,功能很强大!
列出最常用的:
还有一些小功能,因为正常使用的频率不是太高,这里就不详细解释了。但也有一些实用的功能可以解决生活中的应用之痒。
归根结底,这一切都不容忽视:所有这些功能都基于一个只有几MB大小的软件,完美诠释了“小人大排量”的含义!
3. 图片查看和简单的图片处理有:ACDSee,一款专业级的图片查看软件。
总结的优点包括:
例如:前段时间,3D 打印涉及在月球表面查看和裁剪图像。单看前期1.6G原创大小的图片,证明ACDSee是当之无愧的看图王者!只有它才能在目前能遇到的涉及图片浏览的场合承担起这个重要的任务。
4. 另一个图像处理软件是:PhotoZoom
它只有一个功能,而且是经常用到的功能:
5.文件查询的最终选择是:Listary
之前用过Everything,也是很多人推荐的一款软件。但是经过长期使用,我还是觉得Listary更胜一筹。优点如下:
6.支持大部分网站视频下载软件:ShuoMo
配合我经常使用的chrome内核360极速浏览器插件,实现了主要网站规则和不规则视频的本地下载。
一般应用场景有:网站公共类视频数据下载和付费网站视频本地下载保存。
7.音频播放也是视频播放:Potplayer
没有图,也没有更详细的解释,就一句话总结:
无数视频播放软件无法解决的痒痛点。当然,在其他方面,potplayer 提供的操作也非常丰富,提供了强大而细致的视频播放设置。我不会在这里详细介绍。等待你的探索,记得回来留言分享更多使用方法和技巧。
8. 大大提高工作效率的专业级分屏软件:Dexpot
这里提供的软件有一个特点:简洁、专业。分屏软件很多,Dexpot给我留下的印象是Thinkpad:专业,很少出错。开机后会自动启动,一直运行,好像随时可以忽略一样。快捷键随时切换alt+123分屏,支持3、6、9、12分屏扩展,根据自己的需要和电脑本身的性能。解决了在同一个屏幕上打开多个程序并长时间观看导致的混乱和自我尴尬。
9.组织想法的强大工具:Mindjet Mindmanager 思维导图
应该有很多人知道和使用它,但我在综合性大学或信息技术学院,我周围的很多人对它知之甚少。一定看过思维导图做出来的成品,但是不知道是什么软件做出来的。暂时不为公众所知。
10.电脑界面改Macbook底部浮动条中的图标排序软件:来自SoftMedia Cube的Mydesk
SoftMedia's Cube安装完成后,可以在自定义安装文件夹中找到独立程序,单独选择使用,卸载之前安装的主程序。
12.安卓虚拟机:海马玩模拟器是全网最受好评的模拟器,也是支持环境最丰富的虚拟机。
13.360极速浏览插件和一些有趣有用的网站推荐。
一定有理由喜欢去某些东西,例如方便的浏览器。我选择一直使用360极速浏览器的原因很简单:
两个重要的激励措施:
查看全部
网页视频抓取工具 知乎(装机软件数量的繁多和平日课程、细节不足之处还望海涵
)
前言:
安装的软件很多,平日的课程,实习,考研时间紧,但还是忍不住想分享,一直想写这个答案。我会用不断的更新来补充和修改,争取在下周内完成这个答案。以下是一些已经大致介绍过的软件,不足的细节还是王海涵。
一些非常棒的Windows软件,我认为它们不应该只被少数人知道,或者随着时间的推移逐渐被埋没甚至消失。

“分割线”
————————————————————————————————————————————
以下推荐均基于Windows环境,使用十余个月后选择。安装过程中无附加软件,使用过程中无广告。内存占用小,对整机性能没有任何拖累。它是一些我认为在某些功能上非常强大和有趣的Windows软件,并为生活带来了很多乐趣。
各个程序的安装过程将在以后的主题文章中进行描述和解释。很多软件很容易混用忘记,留教程以备后患,预防痴呆。
软件分类:远程协助、录屏软件、图像处理、整机文件查询、视频下载、音频播放、分屏软件、思维导图、电脑界面修改、安卓虚拟机、360极速浏览插件等一些有趣实用的网址推荐。
1. 远程协助不得不提:TeamViewer,一款好用、专业、强大的企业级良心应用。
2. 这次所有截图使用的软件:FastStone Capture(原则上应该叫Screen Recorder,但我个人觉得它的截图功能是最强大的体现) 上面说了,功能很强大!
列出最常用的:
还有一些小功能,因为正常使用的频率不是太高,这里就不详细解释了。但也有一些实用的功能可以解决生活中的应用之痒。
归根结底,这一切都不容忽视:所有这些功能都基于一个只有几MB大小的软件,完美诠释了“小人大排量”的含义!
3. 图片查看和简单的图片处理有:ACDSee,一款专业级的图片查看软件。
总结的优点包括:
例如:前段时间,3D 打印涉及在月球表面查看和裁剪图像。单看前期1.6G原创大小的图片,证明ACDSee是当之无愧的看图王者!只有它才能在目前能遇到的涉及图片浏览的场合承担起这个重要的任务。
4. 另一个图像处理软件是:PhotoZoom
它只有一个功能,而且是经常用到的功能:
5.文件查询的最终选择是:Listary
之前用过Everything,也是很多人推荐的一款软件。但是经过长期使用,我还是觉得Listary更胜一筹。优点如下:
6.支持大部分网站视频下载软件:ShuoMo
配合我经常使用的chrome内核360极速浏览器插件,实现了主要网站规则和不规则视频的本地下载。
一般应用场景有:网站公共类视频数据下载和付费网站视频本地下载保存。
7.音频播放也是视频播放:Potplayer
没有图,也没有更详细的解释,就一句话总结:
无数视频播放软件无法解决的痒痛点。当然,在其他方面,potplayer 提供的操作也非常丰富,提供了强大而细致的视频播放设置。我不会在这里详细介绍。等待你的探索,记得回来留言分享更多使用方法和技巧。
8. 大大提高工作效率的专业级分屏软件:Dexpot
这里提供的软件有一个特点:简洁、专业。分屏软件很多,Dexpot给我留下的印象是Thinkpad:专业,很少出错。开机后会自动启动,一直运行,好像随时可以忽略一样。快捷键随时切换alt+123分屏,支持3、6、9、12分屏扩展,根据自己的需要和电脑本身的性能。解决了在同一个屏幕上打开多个程序并长时间观看导致的混乱和自我尴尬。
9.组织想法的强大工具:Mindjet Mindmanager 思维导图
应该有很多人知道和使用它,但我在综合性大学或信息技术学院,我周围的很多人对它知之甚少。一定看过思维导图做出来的成品,但是不知道是什么软件做出来的。暂时不为公众所知。

10.电脑界面改Macbook底部浮动条中的图标排序软件:来自SoftMedia Cube的Mydesk
SoftMedia's Cube安装完成后,可以在自定义安装文件夹中找到独立程序,单独选择使用,卸载之前安装的主程序。
12.安卓虚拟机:海马玩模拟器是全网最受好评的模拟器,也是支持环境最丰富的虚拟机。
13.360极速浏览插件和一些有趣有用的网站推荐。
一定有理由喜欢去某些东西,例如方便的浏览器。我选择一直使用360极速浏览器的原因很简单:
两个重要的激励措施:
网页视频抓取工具 知乎(Python爬虫的学习笔记(二):网络爬虫开发实战)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-03 17:16
今天给大家分享一下Python爬虫的学习笔记。我的Python爬虫从崔庆才老师的《网络爬虫开发实战》开始。学习了各种Python爬虫策略和算法,并结合实践总结。三方面解释:什么是爬虫?为什么要学习爬行?如何学习爬行?这三个问题是解决大多数问题的过程。以下分享小默的学习笔记等建议,请及时联系我
♂️1、什么是爬虫?
让我从定义开始:网络爬虫(网络蜘蛛、网络机器人)是抓取网络数据的程序。一共有三个关键词。一是爬虫是程序,就是我们用(Python等)语言写的代码,二是爬虫工具。这个过程包括主动查询、筛选和记录的过程。爬取的目标是网络数据。
总结起来就是用Python程序模仿人,进行网站访问,获取必要的网络数据。模仿的越逼真越好。
♂️2、 为什么要学爬?
直接的原因当然是为了获取数据!至于得到的数据类型,可以说有很多不同的类型。从数据结构上可以区分,包括结构化数据类型、非结构化数据类型,结构化数据有固定的格式,比如HTML、XML、JSON格式,这些格式都是与数据结构相关的数据结构。网页的语言。非结构化数据包括图片、音频、视频等,这些“数据结构”一般以二进制格式存储。
我们生活在信息和数字时代。获取这些数据可以实现我们生活和工作中的很多目标,包括自驾游策略搜索、专注信息搜索、毕业论文数据抓取等。对我来说,爬虫做量化交易中舆情策略必不可少的工具,爬通过爬虫获取投资者情绪和行业信息,这也是各大金融机构投研人员获取行情信息的手段之一!
目前,企业对各类数据的使用呈指数级增长。企业获取数据的方式包括企业自有数据,即企业日常业务过程中产生的数据。当自己的数据不能满足需求时,企业就需要从互联网上抓取数据。或者从外部平台购买数据。购买数据的平台包括数据堂、贵阳大数据交易所等近年来新兴的交易平台。这些平台的交易价格相对较高。因此,爬虫技术越来越受到企业的重视。大量相关技术人员也在招聘中,薪资理想(毕竟节省了公司购买平台数据的成本)。我正在清华一线队学习一门课程。
♂️3、如何开始和学习爬行?
经过上面的介绍,小伙伴们就知道爬虫的定义和市场定位了。下面介绍一下爬虫的流程架构,和我们日常上网流程一样,包括三个步骤:(1)发送请求(上网时输入网址,回车)---- (2)获取请求(远程服务器返回网页数据)----(3)解析请求(网页将HTML语言转换为文字、图片、视频等)。
♂️具体操作过程请期待下一篇文章。. . 小默的爬虫没了。. .
这是我2018年入职两个月后在办公室读的一本书,家里还有很多书。一种更有效的学习方式是观看视频课程。有需要材料的童鞋可以给我留言哦! 查看全部
网页视频抓取工具 知乎(Python爬虫的学习笔记(二):网络爬虫开发实战)
今天给大家分享一下Python爬虫的学习笔记。我的Python爬虫从崔庆才老师的《网络爬虫开发实战》开始。学习了各种Python爬虫策略和算法,并结合实践总结。三方面解释:什么是爬虫?为什么要学习爬行?如何学习爬行?这三个问题是解决大多数问题的过程。以下分享小默的学习笔记等建议,请及时联系我
♂️1、什么是爬虫?
让我从定义开始:网络爬虫(网络蜘蛛、网络机器人)是抓取网络数据的程序。一共有三个关键词。一是爬虫是程序,就是我们用(Python等)语言写的代码,二是爬虫工具。这个过程包括主动查询、筛选和记录的过程。爬取的目标是网络数据。
总结起来就是用Python程序模仿人,进行网站访问,获取必要的网络数据。模仿的越逼真越好。
♂️2、 为什么要学爬?
直接的原因当然是为了获取数据!至于得到的数据类型,可以说有很多不同的类型。从数据结构上可以区分,包括结构化数据类型、非结构化数据类型,结构化数据有固定的格式,比如HTML、XML、JSON格式,这些格式都是与数据结构相关的数据结构。网页的语言。非结构化数据包括图片、音频、视频等,这些“数据结构”一般以二进制格式存储。
我们生活在信息和数字时代。获取这些数据可以实现我们生活和工作中的很多目标,包括自驾游策略搜索、专注信息搜索、毕业论文数据抓取等。对我来说,爬虫做量化交易中舆情策略必不可少的工具,爬通过爬虫获取投资者情绪和行业信息,这也是各大金融机构投研人员获取行情信息的手段之一!
目前,企业对各类数据的使用呈指数级增长。企业获取数据的方式包括企业自有数据,即企业日常业务过程中产生的数据。当自己的数据不能满足需求时,企业就需要从互联网上抓取数据。或者从外部平台购买数据。购买数据的平台包括数据堂、贵阳大数据交易所等近年来新兴的交易平台。这些平台的交易价格相对较高。因此,爬虫技术越来越受到企业的重视。大量相关技术人员也在招聘中,薪资理想(毕竟节省了公司购买平台数据的成本)。我正在清华一线队学习一门课程。
♂️3、如何开始和学习爬行?
经过上面的介绍,小伙伴们就知道爬虫的定义和市场定位了。下面介绍一下爬虫的流程架构,和我们日常上网流程一样,包括三个步骤:(1)发送请求(上网时输入网址,回车)---- (2)获取请求(远程服务器返回网页数据)----(3)解析请求(网页将HTML语言转换为文字、图片、视频等)。
♂️具体操作过程请期待下一篇文章。. . 小默的爬虫没了。. .

这是我2018年入职两个月后在办公室读的一本书,家里还有很多书。一种更有效的学习方式是观看视频课程。有需要材料的童鞋可以给我留言哦!
网页视频抓取工具 知乎(B站小程序形式往公众号文章插入21个视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-03 17:13
自微信小程序诞生以来,腾讯一直在完善小程序生态。越来越多的应用厂商也开发了微信小程序。B站就是其中之一。
公众号文章是一个网页,但不像网页那样免费。不能有iframe,没有js等,视频必须从公众号资源中添加。视频数量也限制为3个,但小程序卡数量没有限制。因此,使用B站小程序是一种向公众号文章添加3个以上视频的方式。我上次嵊泗游记在文章中插入了21个视频。
无数人通过B站小程序的形式写了把视频插入公众号文章的教程,但是一个av号下却有好几个视频。昨天写游记的时候想插在文章。嵊泗VLOG视频的P2、P3找不到路。全网找不到让B站的小程序打开玩P2的教程,于是尝试了cid、p、page等各种参数,终于研究了找到方法,分享给大家,并启动全网!
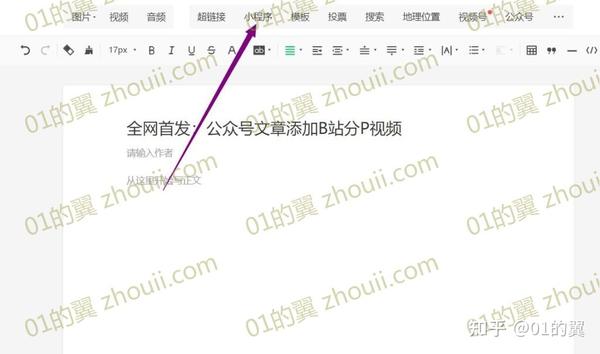
1、编辑公众号时文章,点击顶部工具栏【小程序】添加小程序
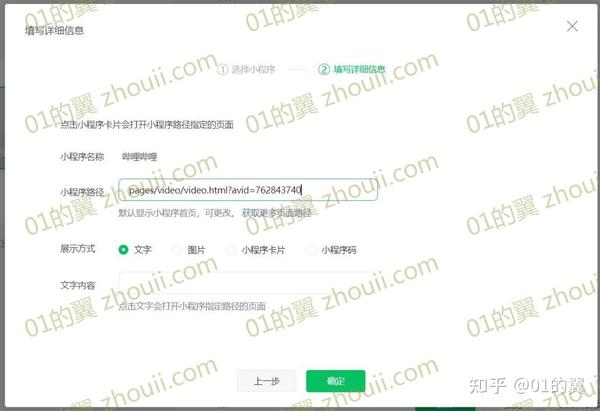
2、 在搜索框中输入【哔哔哔哔】,点击右侧搜索按钮,找到哔哔小程序后点击下一步
3、用电脑打开要插入的B站视频,将鼠标移动到视频下方的分享按钮,在右边的代码中找到[aid=]和[&bvid]之间的数字嵌入代码,比如这个视频是762843740,这是视频的av号,复制一下
(这一步只需要获取av号,如果你安装了Anti BV等脚本,只需要从地址栏复制av号即可)
4、在【小程序路径】中填写pages/video/video.html?avid=762843740,最后一个数字就是刚刚找到的视频av号
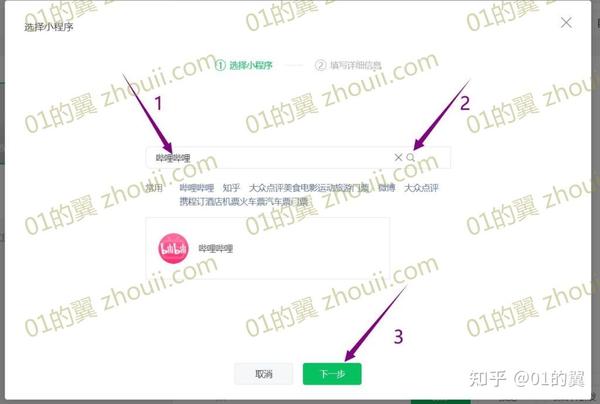
其他网上教程到此结束,所以也可以跳转到B站小程序的指定视频,但是如果是多P视频,只能跳转到第一个。以下是本教程全网重点部分。
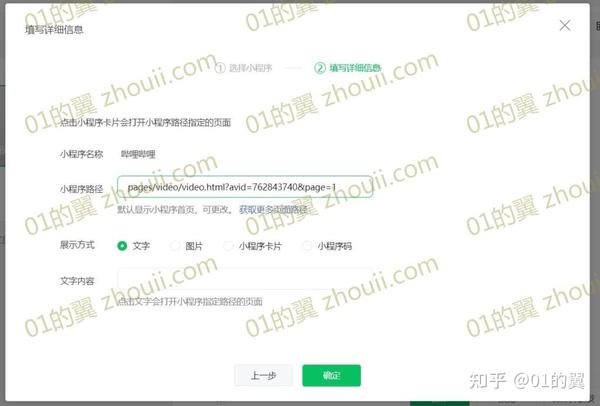
5、如果要打开多P视频,后面会P2、P3等视频,然后在小程序路径后面加上&page=number of episodes-1。例如,打开P2,在小程序路径后添加&page=1,打开P3,在小程序路径后添加&page=2。
6、最后可以根据需要选择插入文字、图片、卡片或小程序代码。
这样插入的小程序链接一打开就可以跳转到指定的剧集号,无需用户再次手动切换
允许标准转载,所有内容必须保留
原文发表于【01之翼】知乎文章 /p/423307013
本文同时发表于【01之翼】公众号/s/GvdHgMJYWrlvrrBDH7H94Q
2021 年 10 月 19 日 查看全部
网页视频抓取工具 知乎(B站小程序形式往公众号文章插入21个视频)
自微信小程序诞生以来,腾讯一直在完善小程序生态。越来越多的应用厂商也开发了微信小程序。B站就是其中之一。
公众号文章是一个网页,但不像网页那样免费。不能有iframe,没有js等,视频必须从公众号资源中添加。视频数量也限制为3个,但小程序卡数量没有限制。因此,使用B站小程序是一种向公众号文章添加3个以上视频的方式。我上次嵊泗游记在文章中插入了21个视频。
无数人通过B站小程序的形式写了把视频插入公众号文章的教程,但是一个av号下却有好几个视频。昨天写游记的时候想插在文章。嵊泗VLOG视频的P2、P3找不到路。全网找不到让B站的小程序打开玩P2的教程,于是尝试了cid、p、page等各种参数,终于研究了找到方法,分享给大家,并启动全网!
1、编辑公众号时文章,点击顶部工具栏【小程序】添加小程序
2、 在搜索框中输入【哔哔哔哔】,点击右侧搜索按钮,找到哔哔小程序后点击下一步
3、用电脑打开要插入的B站视频,将鼠标移动到视频下方的分享按钮,在右边的代码中找到[aid=]和[&bvid]之间的数字嵌入代码,比如这个视频是762843740,这是视频的av号,复制一下
(这一步只需要获取av号,如果你安装了Anti BV等脚本,只需要从地址栏复制av号即可)
4、在【小程序路径】中填写pages/video/video.html?avid=762843740,最后一个数字就是刚刚找到的视频av号
其他网上教程到此结束,所以也可以跳转到B站小程序的指定视频,但是如果是多P视频,只能跳转到第一个。以下是本教程全网重点部分。
5、如果要打开多P视频,后面会P2、P3等视频,然后在小程序路径后面加上&page=number of episodes-1。例如,打开P2,在小程序路径后添加&page=1,打开P3,在小程序路径后添加&page=2。
6、最后可以根据需要选择插入文字、图片、卡片或小程序代码。
这样插入的小程序链接一打开就可以跳转到指定的剧集号,无需用户再次手动切换
允许标准转载,所有内容必须保留
原文发表于【01之翼】知乎文章 /p/423307013
本文同时发表于【01之翼】公众号/s/GvdHgMJYWrlvrrBDH7H94Q
2021 年 10 月 19 日
网页视频抓取工具 知乎(关键词处理标题是用来告诉用户和搜索引擎这个网页的主要内容是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-03 04:08
C、添加文章Content关键词链接,链接到本站相关页面。
D. 创建站点地图。构建完整的站点地图,包括所有内容的最终页面,即站点范围的文章索引页。同时seo关键词知乎(用来告诉用户和搜索引擎这个页面的主要内容是什么,搜索引擎,标题,关键词处理),把这个链接放在首页,让搜索引擎可以找到并抓取站点地图页面;如果是大型网站seo关键字知乎,可以按照栏目列出主要类别。
E. 写一个总结文章 或设置一个主题。一般来说,可以简单介绍一下这个月写的文章,并链接到具体内容页面。或者将同一主题的内容合并为一个文章。
F、alt标签可以让用户在图片无法以较慢的速度显示的情况下了解图片所传达的信息,也可以让搜索引擎了解图片的内容。
四、标题,关键词处理
标题是用来告诉用户和搜索引擎这个页面的主要内容是什么。当搜索引擎确定网页内容的权重时,标题是主要参考信息之一。每个网页都应该有一个唯一的标题。
关键词 非常重要。它们需要准确定位,不应随意修改。可以设置多个关键词,但不要太多,适当就好,不要重置积累的关键词,对搜索引擎不友好。关键字应以逗号分隔。
首页栏目页频道页第一句收录页面标题+第二句描述关键词+第三句摘要内容页:文章适当加长尾的介绍关键词@ >
五、 检查 404
子墨SEO前的这篇文章告诉你如何找到404以及如何解决
六、 定期定量发表文章
百度对新版网站有审核期。即使百度收录有你的内容网站,也不会立即发布。只要你定期、每天发布原创的内容,审核期很快就会过去,收录的页面会逐步发布。出来。
定期发布新内容,让网站形成持续稳定的更新模式,让蜘蛛发现这种模式,实现定时爬取。这是百度第二个收录的一个非常关键的因素。这就像在固定的时间和约会吃饭。这样的更新模式形成后,蜘蛛该来的时候就会来。二是定量释放。每天保持一个恒定的数字。今天避免一个文章,明天避免十个文章。搜索引擎会认为你的网站不稳定且善变,避免被降级和沙盒化。
网页越丰富,网站中的网页越多,这样的网站对用户浏览的吸引力就越大。现在搜索引擎越来越注重用户体验。如果用户体验好,搜索引擎自然可以更好地对你的网站进行更好的排名。内容更新是网站生存的基础。一个网站想要活跃、丰富、足够长以吸引和留住人,就必须掌握网站的更新频率。
七、 外链建设
新的网站上线了。如果想收录快照,可以每天定时添加外链,引导搜索引擎抓取网站。不要过度构建外部链接。慢慢来。新网站上线时,不要过于激进地发布外部链接。信权重低,容易被百度判断为作弊,容易出现网站的问题:首页不再第一,关键词的排名消失。所以大家还是比较关注内容的。外链通过审核期后,每天会定期添加外链。不要让外链随波逐流!不要突然增加,否则就是k。
外链构建方法:
1、友情链接
2、 网站 有自己的特点和独特的功能来获取他人的活跃链接
3、发送给第三方,发送新闻,其他网站转载seo关键词知乎,获取链接
4、去其他论坛和博客,留言内容里有链接 查看全部
网页视频抓取工具 知乎(关键词处理标题是用来告诉用户和搜索引擎这个网页的主要内容是什么)
C、添加文章Content关键词链接,链接到本站相关页面。
D. 创建站点地图。构建完整的站点地图,包括所有内容的最终页面,即站点范围的文章索引页。同时seo关键词知乎(用来告诉用户和搜索引擎这个页面的主要内容是什么,搜索引擎,标题,关键词处理),把这个链接放在首页,让搜索引擎可以找到并抓取站点地图页面;如果是大型网站seo关键字知乎,可以按照栏目列出主要类别。
E. 写一个总结文章 或设置一个主题。一般来说,可以简单介绍一下这个月写的文章,并链接到具体内容页面。或者将同一主题的内容合并为一个文章。
F、alt标签可以让用户在图片无法以较慢的速度显示的情况下了解图片所传达的信息,也可以让搜索引擎了解图片的内容。
四、标题,关键词处理
标题是用来告诉用户和搜索引擎这个页面的主要内容是什么。当搜索引擎确定网页内容的权重时,标题是主要参考信息之一。每个网页都应该有一个唯一的标题。
关键词 非常重要。它们需要准确定位,不应随意修改。可以设置多个关键词,但不要太多,适当就好,不要重置积累的关键词,对搜索引擎不友好。关键字应以逗号分隔。
首页栏目页频道页第一句收录页面标题+第二句描述关键词+第三句摘要内容页:文章适当加长尾的介绍关键词@ >
五、 检查 404
子墨SEO前的这篇文章告诉你如何找到404以及如何解决
六、 定期定量发表文章
百度对新版网站有审核期。即使百度收录有你的内容网站,也不会立即发布。只要你定期、每天发布原创的内容,审核期很快就会过去,收录的页面会逐步发布。出来。
定期发布新内容,让网站形成持续稳定的更新模式,让蜘蛛发现这种模式,实现定时爬取。这是百度第二个收录的一个非常关键的因素。这就像在固定的时间和约会吃饭。这样的更新模式形成后,蜘蛛该来的时候就会来。二是定量释放。每天保持一个恒定的数字。今天避免一个文章,明天避免十个文章。搜索引擎会认为你的网站不稳定且善变,避免被降级和沙盒化。

网页越丰富,网站中的网页越多,这样的网站对用户浏览的吸引力就越大。现在搜索引擎越来越注重用户体验。如果用户体验好,搜索引擎自然可以更好地对你的网站进行更好的排名。内容更新是网站生存的基础。一个网站想要活跃、丰富、足够长以吸引和留住人,就必须掌握网站的更新频率。
七、 外链建设
新的网站上线了。如果想收录快照,可以每天定时添加外链,引导搜索引擎抓取网站。不要过度构建外部链接。慢慢来。新网站上线时,不要过于激进地发布外部链接。信权重低,容易被百度判断为作弊,容易出现网站的问题:首页不再第一,关键词的排名消失。所以大家还是比较关注内容的。外链通过审核期后,每天会定期添加外链。不要让外链随波逐流!不要突然增加,否则就是k。
外链构建方法:
1、友情链接
2、 网站 有自己的特点和独特的功能来获取他人的活跃链接
3、发送给第三方,发送新闻,其他网站转载seo关键词知乎,获取链接
4、去其他论坛和博客,留言内容里有链接
网页视频抓取工具 知乎(Adobeanimatecc2018可以支持网页的音频、视频创作工具 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-07 20:22
)
Adobe animate cc 2018 是一款在爱尔兰开发的二维动画制作软件。Adobe animate cc 2018 可支持网页音视频创作,以及HTML5创作工具;Adobe Animate CC 可以通过扩展的架构支持任何动画格式。
一个cc2018(64位)下载地址:
链接:/s/1lMYYuCeA-GioqSeFvsB4rw
提取码:ly1b
软件对比
Adobe Animate CC 与 Flash 和 Edge Animate CC 有什么区别?
过去,Flash 是网络上的第三方插件,用于播放一些视频、音频或一些互动游戏。但是它带来了越来越多的问题,比如各种安全漏洞,黑客可以利用Flash来攻击你的电脑。如今,HTML5技术以其各方面的优势完全胜过Flash。Flash 已经成为过去式,现在 HTML5 逐渐流行起来。
Adobe 还在 2015 年宣布将 Adobe Flash Professional CC 重命名为 Adobe Animate CC,以提供对输出 HTML5 Canvas 的支持。所以,如果有任何区别,一个是新版本,另一个是旧版本。或者另一种理解方式是,一种用于 HTML 5,另一种用于 Flash。
Adobe Edge 是一种新的网络交互工具。允许设计师通过 HTML5、CSS 和 JavaScript 制作网页动画。不需要闪光灯。Adobe Edge 的目的是帮助专业设计师创建网络动画甚至简单的游戏。
查看全部
网页视频抓取工具 知乎(Adobeanimatecc2018可以支持网页的音频、视频创作工具
)
Adobe animate cc 2018 是一款在爱尔兰开发的二维动画制作软件。Adobe animate cc 2018 可支持网页音视频创作,以及HTML5创作工具;Adobe Animate CC 可以通过扩展的架构支持任何动画格式。
一个cc2018(64位)下载地址:
链接:/s/1lMYYuCeA-GioqSeFvsB4rw
提取码:ly1b
软件对比
Adobe Animate CC 与 Flash 和 Edge Animate CC 有什么区别?
过去,Flash 是网络上的第三方插件,用于播放一些视频、音频或一些互动游戏。但是它带来了越来越多的问题,比如各种安全漏洞,黑客可以利用Flash来攻击你的电脑。如今,HTML5技术以其各方面的优势完全胜过Flash。Flash 已经成为过去式,现在 HTML5 逐渐流行起来。
Adobe 还在 2015 年宣布将 Adobe Flash Professional CC 重命名为 Adobe Animate CC,以提供对输出 HTML5 Canvas 的支持。所以,如果有任何区别,一个是新版本,另一个是旧版本。或者另一种理解方式是,一种用于 HTML 5,另一种用于 Flash。
Adobe Edge 是一种新的网络交互工具。允许设计师通过 HTML5、CSS 和 JavaScript 制作网页动画。不需要闪光灯。Adobe Edge 的目的是帮助专业设计师创建网络动画甚至简单的游戏。
网页视频抓取工具 知乎( 从经典机器学习框架Scikit-learn,到深度学习慕课)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-01 04:06
从经典机器学习框架Scikit-learn,到深度学习慕课)
今天,机器学习框架在不断发展。训练人工智能模型变得越来越容易。
我还记得我上的第一门机器学习课程是吴恩达教授讲授的 Cousera MOOC。当时使用的工具是 Octave(Matlab 的开源版本)。使用起来很麻烦。即使是最简单的线性回归也需要多行代码。
但很快,我后来学到的机器学习/深度学习 MOOC,包括我自己制作的视频教程,都切换到了像 Python 这样的“开发者友好”环境。
从经典的机器学习框架 Scikit-learn 到深度学习框架 Tensorflow、Pytorch 和 fast.ai,调用 API 训练人工智能模型的方式越来越简单,步骤也越来越少。
比如我给大家演示过在fast.ai中,几行代码就可以让模型区分两个不同的卡通人物。
更进一步,你甚至不需要代码,只需让计算机自动“封装”训练任务即可。
这种工具已经存在。
我曾经在“数据科学导论,我应该怎么做?” “在文章中,我向您介绍了参观北德克萨斯大学(UNT)开放日的经历:
有一次我停在一张海报前,问学生如何获得如此高的图像识别率以及如何调整超参数?对方无法回答。但是告诉我他们使用了 Cloud AutoML。超参数调整直接在云后端完成,完全不用担心。
相比使用传统的深度学习框架如 Pytorch/Tensorflow 进行训练,AutoML 确实会帮助你减少很多流程。不过,对于普通人来说,还是有门槛的。
如果你的数据不符合系统的要求,或者训练结果不理想,你必须知道如何克服和改进。
说实话,我并没有太关注这种“低代码”/“无代码”的应用,觉得实用性不够高。
不过今天在看邵楠的《产品沉思》的时候,看到了lobe.ai的介绍。去官网看了介绍视频,感觉就两个字——惊艳。
演讲者Jake用电脑内置摄像头演示了数据采集、数据标注、模型训练、模型预测、模型迭代……直到模型导出部署成Tensorflow风格的全过程。
是的,虽然不需要写代码,但是还是可以按照主流的框架输出训练好的模型。通过这种方式,其他人可以在几分钟内将您的模型整合到他们的应用程序开发或工作流程中。
Jake 只花了几分钟就构建了一个自动识别饮酒动作的应用程序。
在这里的机器学习部分,你真的不需要单独写一个代码,只要按照机器学习的原创定义,并提供示例图片和相应的标记即可。
标记方法真的很简单。输入一个新的标记,然后对着相机拍一张,数据就完成了。
当然,除了像这样通过相机实时采集图片,你还可以从电脑批量选择图片文件夹,喂给模型。
想一想,如果完全不懂编程也能开发出智能模型,那应用场景就炸了。这不是“预言”。官网给出了很多例子。
这就是工具的普及给我们带来的好处。就像今天,你不必有绘画天赋,你可以用相机快速记录下你看到的一切。未来,在利用人工智能开发应用的时候,真正能限制我们的,或许只是我们的想象。
虽然这个工具目前只能服务于机器视觉任务,但相信随着迭代开发,更多类型数据的训练功能也会被整合。
即使 lobe.ai 没有这样做,其他开发者也应该注意到了这条可行的路径。
Lobe.ai 的完整介绍视频在这里。
我希望你不会满足于观看和惊叹,但你必须真正尝试这个应用程序。lobe.ai的下载地址在这里。它目前支持 Windows 和 macOS。也欢迎大家在留言区分享自己模型训练的成果,大家一起欣赏,一起交流学习。
祝(无代码)深度学习愉快! 查看全部
网页视频抓取工具 知乎(
从经典机器学习框架Scikit-learn,到深度学习慕课)
今天,机器学习框架在不断发展。训练人工智能模型变得越来越容易。
我还记得我上的第一门机器学习课程是吴恩达教授讲授的 Cousera MOOC。当时使用的工具是 Octave(Matlab 的开源版本)。使用起来很麻烦。即使是最简单的线性回归也需要多行代码。
但很快,我后来学到的机器学习/深度学习 MOOC,包括我自己制作的视频教程,都切换到了像 Python 这样的“开发者友好”环境。
从经典的机器学习框架 Scikit-learn 到深度学习框架 Tensorflow、Pytorch 和 fast.ai,调用 API 训练人工智能模型的方式越来越简单,步骤也越来越少。
比如我给大家演示过在fast.ai中,几行代码就可以让模型区分两个不同的卡通人物。
更进一步,你甚至不需要代码,只需让计算机自动“封装”训练任务即可。
这种工具已经存在。
我曾经在“数据科学导论,我应该怎么做?” “在文章中,我向您介绍了参观北德克萨斯大学(UNT)开放日的经历:
有一次我停在一张海报前,问学生如何获得如此高的图像识别率以及如何调整超参数?对方无法回答。但是告诉我他们使用了 Cloud AutoML。超参数调整直接在云后端完成,完全不用担心。
相比使用传统的深度学习框架如 Pytorch/Tensorflow 进行训练,AutoML 确实会帮助你减少很多流程。不过,对于普通人来说,还是有门槛的。
如果你的数据不符合系统的要求,或者训练结果不理想,你必须知道如何克服和改进。
说实话,我并没有太关注这种“低代码”/“无代码”的应用,觉得实用性不够高。
不过今天在看邵楠的《产品沉思》的时候,看到了lobe.ai的介绍。去官网看了介绍视频,感觉就两个字——惊艳。
演讲者Jake用电脑内置摄像头演示了数据采集、数据标注、模型训练、模型预测、模型迭代……直到模型导出部署成Tensorflow风格的全过程。
是的,虽然不需要写代码,但是还是可以按照主流的框架输出训练好的模型。通过这种方式,其他人可以在几分钟内将您的模型整合到他们的应用程序开发或工作流程中。
Jake 只花了几分钟就构建了一个自动识别饮酒动作的应用程序。
在这里的机器学习部分,你真的不需要单独写一个代码,只要按照机器学习的原创定义,并提供示例图片和相应的标记即可。
标记方法真的很简单。输入一个新的标记,然后对着相机拍一张,数据就完成了。
当然,除了像这样通过相机实时采集图片,你还可以从电脑批量选择图片文件夹,喂给模型。
想一想,如果完全不懂编程也能开发出智能模型,那应用场景就炸了。这不是“预言”。官网给出了很多例子。
这就是工具的普及给我们带来的好处。就像今天,你不必有绘画天赋,你可以用相机快速记录下你看到的一切。未来,在利用人工智能开发应用的时候,真正能限制我们的,或许只是我们的想象。
虽然这个工具目前只能服务于机器视觉任务,但相信随着迭代开发,更多类型数据的训练功能也会被整合。
即使 lobe.ai 没有这样做,其他开发者也应该注意到了这条可行的路径。
Lobe.ai 的完整介绍视频在这里。
我希望你不会满足于观看和惊叹,但你必须真正尝试这个应用程序。lobe.ai的下载地址在这里。它目前支持 Windows 和 macOS。也欢迎大家在留言区分享自己模型训练的成果,大家一起欣赏,一起交流学习。
祝(无代码)深度学习愉快!
网页视频抓取工具 知乎(如何看待Python中的各种扩展的库-Python(二) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-01 04:05
)
课程视频:
1、 当浏览器请求一个网站时,会从输入到页面显示,并描述请求过程
在课程中,我们概述了请求过程,您可以参考下图:
来源:网络| 嗨,我是法比安!全栈软件工程师 (townsend.fr)
详细过程可以参考:
2、本课爬虫可以应用于任何网站吗?
理论上是的,每个网站在细节上都会有一些差异,从内容组织到访问方式,我们会在后面的课程中讨论。
3、我对爬虫知之甚少。爬虫有什么用?我今天上课没跟上进度。
简单的说,就是一个用来获取网络信息的程序。具体可以参考wiki上的定义:
4、 无法获取网页的所有代码
一些内容是按需加载的。部分网页数据可以通过Javascript脚本和Ajax方式单独加载,可以实现页面的部分刷新。在下面的课程中,我们将通过抓取响应Json文件来获取数据的具体示例。
5、 课文中提到的“以拖拽的形式制作网页”是什么软件或者技术,是不是意味着淘汰手写css?
拖放主要用于设计内容和布局。内容显示的样式需要详细的 CSS 设置。当然,如果想省事,也可以直接使用现成的CSS框架。
6、 我们该如何看待Python中的各种扩展库,随意使用,岂不是大大提高了我们的编程能力?
在之前的问答中,我们谈到了是否要重新发明轮子的问题。从培养编程能力的角度来看,从头开始实施更多的练习是有益的,但在实际编程和构建具体项目解决方案的过程中,不一定需要自己从头开发所有模块。如果你有合适的第三方库,最好直接使用。这也是 Python 作为支持最广泛的开源社区的优势。但需要注意的是,一些第三方库可能存在一些不明显的错误甚至安全隐患,使用时要多加注意。
7、广告之类的图片怎么知道有链接?
有两种典型的实现方式,一种是直接
标签放置在标签内容中,以便图像变得可点击。另一种方法是使用 JavaScript 脚本来控制单击图像时触发的事件。单击是跳转到链接。
8、可以用爬虫复制百度文档的付费内容吗?有些内容只能预览不能复制。如果是这样,我该怎么办?
页面上无法复制的内容基本上有以下几种:一种是JavaScript脚本限制在特定区域的右键和快捷键行为,导致无法复制或弹出提示;另一种是展示图片,图片中的文字不能直接复制;然后使用特殊的编码来传输内容,在显示之前对其进行解码。理论上,只要能显示的文字是可以复制的,对于第一种情况,可以直接在网页源码中获取文字内容,对于第二种情况,可以将图片中的文字转化为OCR 文本。第三种需要分析内容的解码过程,根据解码和显示过程将传输的内容还原为原创文本。
9、“爬虫们,爬东西违法吗?如果你自己做网站,如何防止你的网站被爬”
关于爬虫的合法红线,可以参考以下文章:
我们将在后面的课程中介绍 counter-pick 策略。主要包括两个步骤:第一步是发现对方的恶意爬取行为,第二步是对该行为进行拦截或破坏。
10、 很早就听说爬虫是用来刷流量尖峰等的,很好奇
狭义的爬虫是模仿用户使用浏览器或App从网站或其他网络来源获取内容的自动化程序;广义的爬虫不限于采集数据,还可以模仿真实用户的访问行为,可以实现自动投票(刷卡排名)、自动访问(刷卡流量)、自动下单(刷卡)秒杀)等,但无论完成什么任务,本质都是一样的。尽量模仿真实用户的访问行为,避免被服务器或服务商看穿。
11、 如果网页上的数据格式不统一,比起今天豆瓣上的算法介绍,每个项目的介绍行数不统一,不均匀,我们还能不能使用连续四行不为空的条件?判断是否是标题?
当然不是。爬虫数据分析提取的核心是为每条数据找到一个共同的规律,不管是文本层面的规律还是文档结构的规律,只要规律不能用就必须调整及时。,要么修改一条适用于所有数据的规则,要么分别处理不同的情况,实现对所有待提取数据的完全覆盖。
12、request安装包在后续项目实践中有什么具体用途?
在下一课中,我们将讨论 requests 库的主要用途是用于 HTTP 访问。下载页面和提交信息(填写登录密码、提交订单等)都可以通过请求轻松实现。
13、 为什么我的txt文件是gbk编码,但是readlines不能调用
windows下默认使用gbk编码,可以参考上一课的Q&A 12:
14、 课上讲了爬虫,所以如果要修改搜索到的信息,需要权限吗?
一般情况下,除非提供相应的接口或使用黑客技术,否则无法修改服务器上的信息,但可以在本地进行修改(只影响本地显示,服务器端保持不变,刷新后恢复) . 详情请参考:
1 请求库有哪些功能?只能在爬虫中使用吗?
参考问题12。 requests库可以实现方便的HTTP访问。所有涉及HTTP访问的场景都可以使用,不限于爬虫。
16、 虚拟环境和python文件是什么关系?我的终端无法在新文件夹中配置虚拟环境
虚拟环境和您的源代码之间没有实际联系。一般为方便起见,在项目目录下创建虚拟环境相关文件,即熟悉的语句如下:
python -m venv .venv
会在当前目录下创建一个.venv子目录,虚拟环境需要的文件都会放在这个子目录下。虚拟环境激活后,所有用Python进行的操作只会影响当前虚拟环境,你代码中的import只能加载当前虚拟环境中安装的Python库。也就是说,一个虚拟环境可以对应多个实际项目,实际对应的方式可以根据需要进行调整。
17、HTML、javascript和ccs是什么关系?他们与python的嵌套相关的东西是什么?听说python也可以做前端。
HTML定义了网页要显示什么内容,要显示什么布局;CSS 一次确定每个元素的具体样式;Javvascript通过可以在牙面上运行的脚本代码为网页添加动态响应功能,比如鼠标移动到某个区域自动修改某个元素的样式,点击按钮自动弹出提示,等等。简单来说,HTML 定义页面上“有什么”,CSS 定义页面看起来像“什么”,而 Javvascript 定义“什么”。Python 程序可以下载 HTML、CSS 和 JS 文件,解析和提取内容,甚至“运行”Javvascript 脚本以获得结果。这就是爬虫的基本工作机制。Python作为前端主要是指方面。一方面,可以使用Python开发Web服务器,供客户端浏览器通过HTTP访问服务器本地的HTML、CSS、JS等文件;另一方面,你可以使用 Python 脚本来“生成” HTML 页面,就像我们类中生成的 TXT 文件一样,将内容动态写入网页中。
18、 那么xpath helper的作用就是调出代码方便爬行?
xpath helper 可以帮助我们获取页面某个元素的xPath,通过修改完整的xPath字符串,得到一个简化的xPath进行数据提取;或验证修改后的xPath 以查看匹配结果是否符合预期。
19、 想要实现爬虫,一定要学习HTML知识吗?
是的,不了解HTML在数据提取过程中会遇到很多障碍。
20、 还是不明白信息的位置和获取方式。网页上的code可以查到,老师提到的标签在网页的位置上也能看懂一点,但是说到爬行就有点糊涂了,不知道怎么抓取它进入程序,如何定期执行或在发生更改时运行它。
“采集”链接的技术,我们将在下节课介绍,主要是使用requests库通过http访问。
21、 可以用爬虫技术从书签中提取内容吗?那是什么?能不能提取特征,用python过滤信息内容?
它是指浏览器采集夹中的书签吗?当然,您可以使用爬虫下载书签对应的页面内容,也可以使用Python程序对信息进行提取过滤。
22、html中相同类型的元素一定要有相同格式的路径吗?在文件夹中新建一个文件夹,两者都创建.venv,但是vscode打开大文件,运行小文件夹中的文件时,使用大文件夹.venv。vscode只能打开小文件夹吗?使用它的 .venv
相似元素的路径不一定是相同的格式。有必要分析具体的页面。获得的路径最好使用 xpath helper 进行验证,以查看是否覆盖了所有所需的元素。如果VS Code没有自动切换到目录的虚拟环境,可以点击左下角的环境标题:
在弹出的解释器列表中选择./.venv/bin/python:
23、 能不能告诉我怎么下载名字奇怪的怪东西?浏览器处理风险,我下载完就完成了。
首先访问本网站:/s/xphelper 下载 hgimnogjllphhhkhlmebmlgjoejdpjl.rar
解压 hgimnogjllphhhkhlmebbmlgjoejdpjl.rar
打开浏览器的扩展管理界面,以Edge为例,打开左下角的“开发者模式”:
点击右上角的“加载解压后的扩展”:
选择解压后的文件夹完成安装
24、如何下载python库函数
Python标准库自带Python安装,不需要额外安装;第三方库可以直接用pip安装。以requests为例,直接运行即可:
python -m pip install requests
25、 编译的时候报错,但是在网上搜索的时候,各种说法都有。请问老师有没有更好的网站或者社区推荐的
关于异常信息的解释,大家可以关注StackOverflow上的讨论,比较有针对性,质量也比较高。搜索时,您可以添加:
site:stackoverflow.com
或者直接使用网站提供的站点搜索。
26、open和file在使用时有什么区别?为什么在使用open函数时一定要调用close函数?
Python 中没有名为 file 的标准库。使用内置函数 open() 打开文件。详情请参考文档:
close() 函数将关闭当前打开的文件并清理响应资源。关闭的好处主要有两个方面:一方面避免了在程序中其他地方访问文件时重新打开同一个文件或冲突,只要将文件写入如果模式不关闭,所有其他以读模式和写模式打开文件的请求会触发异常;另一方面,打开一个未关闭的文件会长时间占用系统资源,造成不必要的资源浪费。
27、 老师能深入讲讲Xpath吗?
不会深入,只说常用的设置。您可以参考以下快速参考表:
查看全部
网页视频抓取工具 知乎(如何看待Python中的各种扩展的库-Python(二)
)
课程视频:
1、 当浏览器请求一个网站时,会从输入到页面显示,并描述请求过程
在课程中,我们概述了请求过程,您可以参考下图:
来源:网络| 嗨,我是法比安!全栈软件工程师 (townsend.fr)
详细过程可以参考:
2、本课爬虫可以应用于任何网站吗?
理论上是的,每个网站在细节上都会有一些差异,从内容组织到访问方式,我们会在后面的课程中讨论。
3、我对爬虫知之甚少。爬虫有什么用?我今天上课没跟上进度。
简单的说,就是一个用来获取网络信息的程序。具体可以参考wiki上的定义:
4、 无法获取网页的所有代码
一些内容是按需加载的。部分网页数据可以通过Javascript脚本和Ajax方式单独加载,可以实现页面的部分刷新。在下面的课程中,我们将通过抓取响应Json文件来获取数据的具体示例。
5、 课文中提到的“以拖拽的形式制作网页”是什么软件或者技术,是不是意味着淘汰手写css?
拖放主要用于设计内容和布局。内容显示的样式需要详细的 CSS 设置。当然,如果想省事,也可以直接使用现成的CSS框架。
6、 我们该如何看待Python中的各种扩展库,随意使用,岂不是大大提高了我们的编程能力?
在之前的问答中,我们谈到了是否要重新发明轮子的问题。从培养编程能力的角度来看,从头开始实施更多的练习是有益的,但在实际编程和构建具体项目解决方案的过程中,不一定需要自己从头开发所有模块。如果你有合适的第三方库,最好直接使用。这也是 Python 作为支持最广泛的开源社区的优势。但需要注意的是,一些第三方库可能存在一些不明显的错误甚至安全隐患,使用时要多加注意。
7、广告之类的图片怎么知道有链接?
有两种典型的实现方式,一种是直接
标签放置在标签内容中,以便图像变得可点击。另一种方法是使用 JavaScript 脚本来控制单击图像时触发的事件。单击是跳转到链接。
8、可以用爬虫复制百度文档的付费内容吗?有些内容只能预览不能复制。如果是这样,我该怎么办?
页面上无法复制的内容基本上有以下几种:一种是JavaScript脚本限制在特定区域的右键和快捷键行为,导致无法复制或弹出提示;另一种是展示图片,图片中的文字不能直接复制;然后使用特殊的编码来传输内容,在显示之前对其进行解码。理论上,只要能显示的文字是可以复制的,对于第一种情况,可以直接在网页源码中获取文字内容,对于第二种情况,可以将图片中的文字转化为OCR 文本。第三种需要分析内容的解码过程,根据解码和显示过程将传输的内容还原为原创文本。
9、“爬虫们,爬东西违法吗?如果你自己做网站,如何防止你的网站被爬”
关于爬虫的合法红线,可以参考以下文章:
我们将在后面的课程中介绍 counter-pick 策略。主要包括两个步骤:第一步是发现对方的恶意爬取行为,第二步是对该行为进行拦截或破坏。
10、 很早就听说爬虫是用来刷流量尖峰等的,很好奇
狭义的爬虫是模仿用户使用浏览器或App从网站或其他网络来源获取内容的自动化程序;广义的爬虫不限于采集数据,还可以模仿真实用户的访问行为,可以实现自动投票(刷卡排名)、自动访问(刷卡流量)、自动下单(刷卡)秒杀)等,但无论完成什么任务,本质都是一样的。尽量模仿真实用户的访问行为,避免被服务器或服务商看穿。
11、 如果网页上的数据格式不统一,比起今天豆瓣上的算法介绍,每个项目的介绍行数不统一,不均匀,我们还能不能使用连续四行不为空的条件?判断是否是标题?
当然不是。爬虫数据分析提取的核心是为每条数据找到一个共同的规律,不管是文本层面的规律还是文档结构的规律,只要规律不能用就必须调整及时。,要么修改一条适用于所有数据的规则,要么分别处理不同的情况,实现对所有待提取数据的完全覆盖。
12、request安装包在后续项目实践中有什么具体用途?
在下一课中,我们将讨论 requests 库的主要用途是用于 HTTP 访问。下载页面和提交信息(填写登录密码、提交订单等)都可以通过请求轻松实现。
13、 为什么我的txt文件是gbk编码,但是readlines不能调用
windows下默认使用gbk编码,可以参考上一课的Q&A 12:
14、 课上讲了爬虫,所以如果要修改搜索到的信息,需要权限吗?
一般情况下,除非提供相应的接口或使用黑客技术,否则无法修改服务器上的信息,但可以在本地进行修改(只影响本地显示,服务器端保持不变,刷新后恢复) . 详情请参考:
1 请求库有哪些功能?只能在爬虫中使用吗?
参考问题12。 requests库可以实现方便的HTTP访问。所有涉及HTTP访问的场景都可以使用,不限于爬虫。
16、 虚拟环境和python文件是什么关系?我的终端无法在新文件夹中配置虚拟环境
虚拟环境和您的源代码之间没有实际联系。一般为方便起见,在项目目录下创建虚拟环境相关文件,即熟悉的语句如下:
python -m venv .venv
会在当前目录下创建一个.venv子目录,虚拟环境需要的文件都会放在这个子目录下。虚拟环境激活后,所有用Python进行的操作只会影响当前虚拟环境,你代码中的import只能加载当前虚拟环境中安装的Python库。也就是说,一个虚拟环境可以对应多个实际项目,实际对应的方式可以根据需要进行调整。
17、HTML、javascript和ccs是什么关系?他们与python的嵌套相关的东西是什么?听说python也可以做前端。
HTML定义了网页要显示什么内容,要显示什么布局;CSS 一次确定每个元素的具体样式;Javvascript通过可以在牙面上运行的脚本代码为网页添加动态响应功能,比如鼠标移动到某个区域自动修改某个元素的样式,点击按钮自动弹出提示,等等。简单来说,HTML 定义页面上“有什么”,CSS 定义页面看起来像“什么”,而 Javvascript 定义“什么”。Python 程序可以下载 HTML、CSS 和 JS 文件,解析和提取内容,甚至“运行”Javvascript 脚本以获得结果。这就是爬虫的基本工作机制。Python作为前端主要是指方面。一方面,可以使用Python开发Web服务器,供客户端浏览器通过HTTP访问服务器本地的HTML、CSS、JS等文件;另一方面,你可以使用 Python 脚本来“生成” HTML 页面,就像我们类中生成的 TXT 文件一样,将内容动态写入网页中。
18、 那么xpath helper的作用就是调出代码方便爬行?
xpath helper 可以帮助我们获取页面某个元素的xPath,通过修改完整的xPath字符串,得到一个简化的xPath进行数据提取;或验证修改后的xPath 以查看匹配结果是否符合预期。
19、 想要实现爬虫,一定要学习HTML知识吗?
是的,不了解HTML在数据提取过程中会遇到很多障碍。
20、 还是不明白信息的位置和获取方式。网页上的code可以查到,老师提到的标签在网页的位置上也能看懂一点,但是说到爬行就有点糊涂了,不知道怎么抓取它进入程序,如何定期执行或在发生更改时运行它。
“采集”链接的技术,我们将在下节课介绍,主要是使用requests库通过http访问。
21、 可以用爬虫技术从书签中提取内容吗?那是什么?能不能提取特征,用python过滤信息内容?
它是指浏览器采集夹中的书签吗?当然,您可以使用爬虫下载书签对应的页面内容,也可以使用Python程序对信息进行提取过滤。
22、html中相同类型的元素一定要有相同格式的路径吗?在文件夹中新建一个文件夹,两者都创建.venv,但是vscode打开大文件,运行小文件夹中的文件时,使用大文件夹.venv。vscode只能打开小文件夹吗?使用它的 .venv
相似元素的路径不一定是相同的格式。有必要分析具体的页面。获得的路径最好使用 xpath helper 进行验证,以查看是否覆盖了所有所需的元素。如果VS Code没有自动切换到目录的虚拟环境,可以点击左下角的环境标题:
在弹出的解释器列表中选择./.venv/bin/python:
23、 能不能告诉我怎么下载名字奇怪的怪东西?浏览器处理风险,我下载完就完成了。
首先访问本网站:/s/xphelper 下载 hgimnogjllphhhkhlmebmlgjoejdpjl.rar
解压 hgimnogjllphhhkhlmebbmlgjoejdpjl.rar
打开浏览器的扩展管理界面,以Edge为例,打开左下角的“开发者模式”:
点击右上角的“加载解压后的扩展”:
选择解压后的文件夹完成安装
24、如何下载python库函数
Python标准库自带Python安装,不需要额外安装;第三方库可以直接用pip安装。以requests为例,直接运行即可:
python -m pip install requests
25、 编译的时候报错,但是在网上搜索的时候,各种说法都有。请问老师有没有更好的网站或者社区推荐的
关于异常信息的解释,大家可以关注StackOverflow上的讨论,比较有针对性,质量也比较高。搜索时,您可以添加:
site:stackoverflow.com
或者直接使用网站提供的站点搜索。
26、open和file在使用时有什么区别?为什么在使用open函数时一定要调用close函数?
Python 中没有名为 file 的标准库。使用内置函数 open() 打开文件。详情请参考文档:
close() 函数将关闭当前打开的文件并清理响应资源。关闭的好处主要有两个方面:一方面避免了在程序中其他地方访问文件时重新打开同一个文件或冲突,只要将文件写入如果模式不关闭,所有其他以读模式和写模式打开文件的请求会触发异常;另一方面,打开一个未关闭的文件会长时间占用系统资源,造成不必要的资源浪费。
27、 老师能深入讲讲Xpath吗?
不会深入,只说常用的设置。您可以参考以下快速参考表:
网页视频抓取工具 知乎(研究百度蜘蛛有所来你的网站日志查看很有好处)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-30 04:07
百度蜘蛛是一个自动程序,它的英文名称是BaiduSpider。
因为百度蜘蛛是我们人类设计和制造的产品,它按照我们人类的思维方式抓取和抓取互联网上的网页、图片、视频等内容,然后根据类别建立索引数据库,以便用户可以在百度搜索搜索引擎中找到你想要的。
我们做的是网站SEO,所以研究百度蜘蛛对网站优化很有好处。
如果你想知道百度蜘蛛有没有到过你的网站,它抓取了哪些网页,状态码是什么等等,我们可以通过网站日志来查看。
网站 日志是个神奇的东西,可以看看百度蜘蛛是怎么工作的。
当然,网站的日志也能看出你的网站是哪个区的人做了坏事,比如:有人嫉妒你网站,用ddos或者CC攻击你网站,如果你的网站整天都打不开,可以从网站的日志中查看是哪个区域的IP。
实际上,Kang 很少研究网站 日志,因为Kang 使用正式的方法进行SEO,从不作弊。文章也主要是原创。简单的说,只要是网站经过我们的SEO,就不会出现降权、长时间长时间进入沙箱等严重问题。
不过经常有seo的朋友来问康如何查看网站日志中的百度蜘蛛IP段。比如,他们想知道:哪些IP段来自百度,哪些IP段来自百度。权重IP,我也想知道沙箱里有哪些IP段或者权限降低的IP段等等。
这种问题很简单。让康为您详细介绍。希望对大家学习百度蜘蛛有所帮助。
如果你的网站是123.125.68.*这个IP段的百度蜘蛛来得频繁,其他人来得少,说明你的网站可能不得不进入沙箱,或者被降级。
220.181.68.*这个IP段每天只会增加,从未减少。很有可能你已经进入沙盒或者被K站屏蔽了。
对了,说到这,康不得不告诉你什么是百度沙盒。一些SEO新手朋友还不是很明白,科普一下。
百度沙盒意味着你的网站不会马上被百度屏蔽,但不会得到好的排名。你网站有很多关键词本来排名还不错,但是有一天突然消失了,这就是典型的进沙箱。
还有一种情况会让你网站进入沙箱,也就是网页中的关键词链接,这就是你常说的锚文本。
如果你在一个网页上制作四五个关键词链接,或者制作更多的关键词链接,那么你的网站将不可避免地被百度放入沙箱。
所以大家要合理优化网站内部链接,文章一篇文章只做1-2个关键词链接。不要贪心太多。反之,网站中的文章可以随便输入,越多越好,越多越好原创。
不多说了,我们继续研究百度蜘蛛(BaiduSpider)IP段。
220.181.7.*, 123.125.66.* 代表百度蜘蛛IP访问,准备抢你网站内容。
121.14.89.* 这个IP段作为新站检查期,也就是我们刚才讲的百度沙箱。
203.208.60.*新站点出现此IP段,站点异常。
210.72.225.*该IP段连续巡视所有站点。
125.90.88.* 该IP段的区域为广东茂名电信,也属于百度蜘蛛IP段。主要原因是有更多的新在线站。有使用过站长工具,或者是SEO综合检测造成的。
220.181.108.95 这是百度抓取首页的专用IP,是百度蜘蛛的加权IP段!
如果你的网站是220.181.108.*段一直在爬,康哥可以很负责任的告诉你:你的网站我会被爬并且每天由百度蜘蛛更新,发布文章秒收录是没有问题的,不会错的。
220.181.108.92 也就是刚才提到的那个IP段。有 98% 的机会抓取您的 网站 主页,可能还有其他网页,不一定是内页。
每个人都应该注意。220.181.108*段属于百度蜘蛛权重IP段。这个IP段或者首页爬取到的文章基本上会在24小时内。给你放出来!
123.125.71.106是抓取网站内页收录,权重低,抓取本段内页文章不会很快发布,因为它不是原创文章。
220.181.108.91是综合类,主要抓取首页和内页或者其他,也属于百度蜘蛛的加权IP段,抓取文章或者主页将在24小时内发布。
220.181.108.75 专注抓取更新文章内页,抓取率可达90%,抓取首页8%,2%其他。也是百度蜘蛛的加权IP段。爬取到的文章或者首页基本上24小时内发布。
220.181.108.86专用抓取网站首页IP权重段,一般返回码为304 0 0,表示没有更新,即表示该IP段百度蜘蛛访问了您的一个网页,但发现您的网页没有更新任何内容。
123.125.71.95 这个IP段用于爬取内页收录,权重低,爬过这个内页segment文章 不会很快发布,因为不是原创文章。
123.125.71.97同理,抢内页收录,权重较低,爬上本段内页文章 no 很快就会发布,因为不是原创文章。
220.181.108.89是一个特殊的抓取主页IP权重段,一般返回码是304 0 0,表示没有更新。
220.181.108.94 专用于抓取首页IP权重段,一般返回码为304 0 0,表示未更新。
220.181.108.97 专用于抓取首页IP权重段,一般返回码为304 0 0,表示没有更新。
220.181.108.80 专用于抓取首页IP权重段,一般返回码为304 0 0,表示没有更新。
220.181.108.77 专用于抓取首页IP权重段,一般返回码为304 0 0,表示未更新。
123.125.71.117 抓取内页收录,权重低,抓取这一段文章的内页不会很快释放它,因为它不是原创文章。
220.181.108.83 专用于抓取首页IP权重段,一般返回码为304 0 0,表示没有更新。
到这里大家要注意了:其实康哥提到的百度蜘蛛IP尾数还有很多。
但是如果在网站日志中看到很多123.125.71.*IP,就说明百度蜘蛛爬取了内部页面,而收录 的权重会更低。原因是你的网站是采集文章或者拼接的文章,是百度暂时收录,但不给你说的意思待定。
220.181.108.*IP段主要用于爬取网站的首页,爬取率占80%,内页占30%。这个IP段百度蜘蛛爬取的文章或者首页肯定是24小时内发布,连夜截图。
那么今天有一个关于百度蜘蛛(BaiduSpider)IP段的研究。康哥已经跟大家解释过了。如果你的网站SEO排名不理想,站内站外都做了优化,不会发生。功能,然后快速从FTP下载网站日志,研究一下。 查看全部
网页视频抓取工具 知乎(研究百度蜘蛛有所来你的网站日志查看很有好处)
百度蜘蛛是一个自动程序,它的英文名称是BaiduSpider。
因为百度蜘蛛是我们人类设计和制造的产品,它按照我们人类的思维方式抓取和抓取互联网上的网页、图片、视频等内容,然后根据类别建立索引数据库,以便用户可以在百度搜索搜索引擎中找到你想要的。
我们做的是网站SEO,所以研究百度蜘蛛对网站优化很有好处。
如果你想知道百度蜘蛛有没有到过你的网站,它抓取了哪些网页,状态码是什么等等,我们可以通过网站日志来查看。
网站 日志是个神奇的东西,可以看看百度蜘蛛是怎么工作的。
当然,网站的日志也能看出你的网站是哪个区的人做了坏事,比如:有人嫉妒你网站,用ddos或者CC攻击你网站,如果你的网站整天都打不开,可以从网站的日志中查看是哪个区域的IP。
实际上,Kang 很少研究网站 日志,因为Kang 使用正式的方法进行SEO,从不作弊。文章也主要是原创。简单的说,只要是网站经过我们的SEO,就不会出现降权、长时间长时间进入沙箱等严重问题。
不过经常有seo的朋友来问康如何查看网站日志中的百度蜘蛛IP段。比如,他们想知道:哪些IP段来自百度,哪些IP段来自百度。权重IP,我也想知道沙箱里有哪些IP段或者权限降低的IP段等等。
这种问题很简单。让康为您详细介绍。希望对大家学习百度蜘蛛有所帮助。
如果你的网站是123.125.68.*这个IP段的百度蜘蛛来得频繁,其他人来得少,说明你的网站可能不得不进入沙箱,或者被降级。
220.181.68.*这个IP段每天只会增加,从未减少。很有可能你已经进入沙盒或者被K站屏蔽了。
对了,说到这,康不得不告诉你什么是百度沙盒。一些SEO新手朋友还不是很明白,科普一下。
百度沙盒意味着你的网站不会马上被百度屏蔽,但不会得到好的排名。你网站有很多关键词本来排名还不错,但是有一天突然消失了,这就是典型的进沙箱。
还有一种情况会让你网站进入沙箱,也就是网页中的关键词链接,这就是你常说的锚文本。
如果你在一个网页上制作四五个关键词链接,或者制作更多的关键词链接,那么你的网站将不可避免地被百度放入沙箱。
所以大家要合理优化网站内部链接,文章一篇文章只做1-2个关键词链接。不要贪心太多。反之,网站中的文章可以随便输入,越多越好,越多越好原创。
不多说了,我们继续研究百度蜘蛛(BaiduSpider)IP段。
220.181.7.*, 123.125.66.* 代表百度蜘蛛IP访问,准备抢你网站内容。
121.14.89.* 这个IP段作为新站检查期,也就是我们刚才讲的百度沙箱。
203.208.60.*新站点出现此IP段,站点异常。
210.72.225.*该IP段连续巡视所有站点。
125.90.88.* 该IP段的区域为广东茂名电信,也属于百度蜘蛛IP段。主要原因是有更多的新在线站。有使用过站长工具,或者是SEO综合检测造成的。
220.181.108.95 这是百度抓取首页的专用IP,是百度蜘蛛的加权IP段!
如果你的网站是220.181.108.*段一直在爬,康哥可以很负责任的告诉你:你的网站我会被爬并且每天由百度蜘蛛更新,发布文章秒收录是没有问题的,不会错的。
220.181.108.92 也就是刚才提到的那个IP段。有 98% 的机会抓取您的 网站 主页,可能还有其他网页,不一定是内页。
每个人都应该注意。220.181.108*段属于百度蜘蛛权重IP段。这个IP段或者首页爬取到的文章基本上会在24小时内。给你放出来!
123.125.71.106是抓取网站内页收录,权重低,抓取本段内页文章不会很快发布,因为它不是原创文章。
220.181.108.91是综合类,主要抓取首页和内页或者其他,也属于百度蜘蛛的加权IP段,抓取文章或者主页将在24小时内发布。
220.181.108.75 专注抓取更新文章内页,抓取率可达90%,抓取首页8%,2%其他。也是百度蜘蛛的加权IP段。爬取到的文章或者首页基本上24小时内发布。
220.181.108.86专用抓取网站首页IP权重段,一般返回码为304 0 0,表示没有更新,即表示该IP段百度蜘蛛访问了您的一个网页,但发现您的网页没有更新任何内容。
123.125.71.95 这个IP段用于爬取内页收录,权重低,爬过这个内页segment文章 不会很快发布,因为不是原创文章。
123.125.71.97同理,抢内页收录,权重较低,爬上本段内页文章 no 很快就会发布,因为不是原创文章。
220.181.108.89是一个特殊的抓取主页IP权重段,一般返回码是304 0 0,表示没有更新。
220.181.108.94 专用于抓取首页IP权重段,一般返回码为304 0 0,表示未更新。
220.181.108.97 专用于抓取首页IP权重段,一般返回码为304 0 0,表示没有更新。
220.181.108.80 专用于抓取首页IP权重段,一般返回码为304 0 0,表示没有更新。
220.181.108.77 专用于抓取首页IP权重段,一般返回码为304 0 0,表示未更新。
123.125.71.117 抓取内页收录,权重低,抓取这一段文章的内页不会很快释放它,因为它不是原创文章。
220.181.108.83 专用于抓取首页IP权重段,一般返回码为304 0 0,表示没有更新。
到这里大家要注意了:其实康哥提到的百度蜘蛛IP尾数还有很多。
但是如果在网站日志中看到很多123.125.71.*IP,就说明百度蜘蛛爬取了内部页面,而收录 的权重会更低。原因是你的网站是采集文章或者拼接的文章,是百度暂时收录,但不给你说的意思待定。
220.181.108.*IP段主要用于爬取网站的首页,爬取率占80%,内页占30%。这个IP段百度蜘蛛爬取的文章或者首页肯定是24小时内发布,连夜截图。
那么今天有一个关于百度蜘蛛(BaiduSpider)IP段的研究。康哥已经跟大家解释过了。如果你的网站SEO排名不理想,站内站外都做了优化,不会发生。功能,然后快速从FTP下载网站日志,研究一下。
网页视频抓取工具 知乎(前面的那个视频openwifi的2020总结以及未来展望(视频))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-22 09:04
之前的视频openwifi的2020年总结和未来前景(视频)是我使用文章openwifi的2020年总结和未来前景自动生成的,经过轻微的修改就成型了。
知乎有一个很好的文章教大家使用,这里不再赘述。简单说一些注意事项和感受。
1.它非常方便和高效,但也并不完美。
2. 只能在手机上使用。我的网页和pad都不能使用这个功能。垫子上有这个功能按钮,但是点击后没有反应。
3.只有在文章被批准并正式发布后才能使用。我的文章目前审核比较慢,经常不知什么原因需要几个小时。需要注意的一点是文章修改后,还需要审核(我猜),自动视频转换程序会提取最新版本生成,否则还是会提取旧版本文章 生成。但是文章修改后的审核在文章第一次发布的时候不会在开头给出提示。这有点棘手。判断审核是否完成,只能通过手机APP界面文章是否出现“一键生成视频”按钮来判断。
4.我发现如果文章的格式是:在句子中加一个冒号再添加图片,那么知乎默认会用那句话作为图片的副标题。所以通过这个技巧,你可以简单的控制生成的视频布局(当然,视频生成之后,你可以继续在手机上手动修改和布局)
5. 有时视频中不收录文章的个别图片。这就是我所说的不完美(也许是一个bug)。
6. 曲库因版权问题无法在海外使用。相反,哔哩哔哩没有这个问题。微信、抖音、哔哩哔哩都有自己的专属剪辑软件和音乐库,海外使用也很方便。不过知乎的高级在于自动生成,不需要这么复杂的专用编辑软件。
7.同样由于版权问题,海外只能选择默认模板(无背景音乐的基础款),其他模板无法选择。
8. 自动配音有多种选择(男孩、女孩、平静、喜悦等)。
以上。 查看全部
网页视频抓取工具 知乎(前面的那个视频openwifi的2020总结以及未来展望(视频))
之前的视频openwifi的2020年总结和未来前景(视频)是我使用文章openwifi的2020年总结和未来前景自动生成的,经过轻微的修改就成型了。
知乎有一个很好的文章教大家使用,这里不再赘述。简单说一些注意事项和感受。
1.它非常方便和高效,但也并不完美。
2. 只能在手机上使用。我的网页和pad都不能使用这个功能。垫子上有这个功能按钮,但是点击后没有反应。
3.只有在文章被批准并正式发布后才能使用。我的文章目前审核比较慢,经常不知什么原因需要几个小时。需要注意的一点是文章修改后,还需要审核(我猜),自动视频转换程序会提取最新版本生成,否则还是会提取旧版本文章 生成。但是文章修改后的审核在文章第一次发布的时候不会在开头给出提示。这有点棘手。判断审核是否完成,只能通过手机APP界面文章是否出现“一键生成视频”按钮来判断。
4.我发现如果文章的格式是:在句子中加一个冒号再添加图片,那么知乎默认会用那句话作为图片的副标题。所以通过这个技巧,你可以简单的控制生成的视频布局(当然,视频生成之后,你可以继续在手机上手动修改和布局)
5. 有时视频中不收录文章的个别图片。这就是我所说的不完美(也许是一个bug)。
6. 曲库因版权问题无法在海外使用。相反,哔哩哔哩没有这个问题。微信、抖音、哔哩哔哩都有自己的专属剪辑软件和音乐库,海外使用也很方便。不过知乎的高级在于自动生成,不需要这么复杂的专用编辑软件。
7.同样由于版权问题,海外只能选择默认模板(无背景音乐的基础款),其他模板无法选择。
8. 自动配音有多种选择(男孩、女孩、平静、喜悦等)。
以上。
网页视频抓取工具 知乎(如何鉴定一个营销人老司机,除了看日常的工作经验以外)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-22 09:00
如何辨别营销人员是不是老司机,除了看日常工作经历,还要看有没有一些厉害的私货,合理运用各种营销手段,提高工作效率。今天给大家推荐几款非常实用的安利小工具。
1.爱维帮
做新媒体的小伙伴都会遇到这样的问题。当公众号的内容过多时,对于公众号的粉丝阅读非常不方便。如果需要检索内容,只能逐页翻历史记录,非常浪费。时间,读起来很不直观。
先生推荐了一个强大的工具来解决这个问题——爱维帮的微站功能。以宇宙第一网红咪蒙公众号为例,通过爱微帮的微站功能,可以生成这样一个页面:
如果自己的公众号能生成这样的页面,粉丝阅读会更加方便直观。操作过程也很简单:
第一步:登录爱维帮官网(),点击右上角头像或昵称进入控制台。
第二步:扫描二维码,绑定自己的公众号。
第三步:在账号服务中找到微站,勾选“历史文章”。如果发现绑定的公众号中的部分文章在这里没有显示,需要把缺失的文章手动导入。
导入有两种方式:
首先是点击右上角的“导入历史文章”,在弹出的窗口中直接输入要导入的文章链接:
二是下载iWeibang媒体版客户端,从客户端导入文章。
第四步:点击“微站设置”中的“免费开通”,微站正式开通:
在这一步之后,您就可以开始个性化您自己的微型网站了。后续的设置过程也很简单,使用起来比公众号自带的模板功能简单多了!
2.简媒体
很多自媒体的朋友可能会遇到这个问题:注册的自媒体平台很多,几乎有十几个平台,每天写内容至少要花1-2个小时,关注热点,找素材,想套路,已经够累了。操作10多个平台实在是无能为力。十几套账号密码,每个文章复制粘贴十几遍,改标题,发表,看评论,看资料…………懒得去想了,就是浪费时间,可惜不发帖,浪费流量。
这里有一个小工具——Simple Media,可以一键同步十几个主流自媒体平台的文案,非常方便。
操作过程也非常简单。注册媒体后,在账号管理界面添加并绑定自己的所有账号。虽然绑定有点复杂,但这次只需要绑定即可。您可以使用标签来管理绑定的帐户。不会乱的。然后就可以在JianMedia自带的编辑器中编辑文章,文章会自动保存,不用担心丢失。文章的版面是设计师根据各个新媒体平台设计的,可以节省很多时间。编辑完文章后,选择行业,勾选原创、广告等功能按钮。最后选择你要发布的账号,也可以选择你绑定的所有账号。一键发布成功。基本上,几分钟后,所有平台都成功发布。它不仅比手动发布更快,而且布局也令人赏心悦目。文章的所有数据和链接也会显示出来,方便大家以后整理。
3.wetool
微信现在似乎构建了一个庞大的生态系统,但确实还有很多问题没有解决。例如,如何批量查找和删除您的朋友。目前的方法只能是群发消息测试或群组分组。这些方法要么粗糙,对朋友来说。对于成千上万的朋友来说,根本没有办法使用,否则会损害微信朋友的体验,面临被朋友删除的风险。
先生推荐一款免费的微信工具——wetool。本软件可以轻松解决僵尸粉丝的微信监控问题,精准检测僵尸粉丝,对真实粉丝零干扰,由你果断删除或尝试保存。算了,被对方删除或者屏蔽了会有提示,可以说是很方便了。
wetool的功能远不止这些。Wetool集成了微商伙伴喜欢使用的各种营销软件功能,稳定性和安全性更高。
比如群好友功能可以批量向群内非好友发送好友请求,一键消除群主和发送对象,省时省心。
群管机器人功能自动通过好友验证邀请入群,新人进群发布欢迎信息,触发条件智能踢人。
可以说是做微信营销的小伙伴们必不可少的营销利器。如果你不相信,你可以去体验。可以说是非常贴心了。最重要的是免费!!!
4.你好文库
对于营销人员和自媒体人来说,他们需要参考大量的材料才能有创意并写出解决方案。百度文库是国内最大的文档资源库,涵盖了很多珍贵的参考资料,但有些文档需要大量下载 优惠券可以下载。
这里先生推荐一个文库工具——嘿文库,访问链接是47.95.226.123/wenku/,复制并输入下载的文档链接,即可一键免费下载相关文档,确实是营销人员积累信息的必备工具。
5.视频下载助手
营销人员经常需要对一些视频资源进行编辑整理,但经常会遇到这样的情况:找到了视频网页,却不知道如何下载。主流视频网站基本不支持自己的视频。本地下载。
这里推荐一个火狐浏览器插件——Video DownloadHelper。只要安装这个插件,在火狐浏览器中打开视频链接,就可以自动识别下载视频,非常方便,不仅仅是主流视频。可以下载网站的视频,甚至一些非黑非白的网站视频也可以轻松下载,可以说是非常强大了!
6.微信备忘录
现在微信已经成为每个人都离不开的工具。微信能做的,微信就能做,省去下载很多麻烦的app。但是微信便利贴的这个功能大家可能非常陌生。
其实微信有自己的笔记功能,打开采集,右上角有个+号,点击加号进入微信的笔记功能!页面非常简洁,操作非常简单。
微信内置笔记功能最大的好处就是可以搜索。微信笔记生成的笔记会保存在采集夹中。只需在微信框中搜索目标关键词即可打开,方便检索。
OK,以上就是大家分享的几个小工具。它们的功能虽小,却能大大提高工作效率和质量。我希望能帮助到大家。 查看全部
网页视频抓取工具 知乎(如何鉴定一个营销人老司机,除了看日常的工作经验以外)
如何辨别营销人员是不是老司机,除了看日常工作经历,还要看有没有一些厉害的私货,合理运用各种营销手段,提高工作效率。今天给大家推荐几款非常实用的安利小工具。
1.爱维帮
做新媒体的小伙伴都会遇到这样的问题。当公众号的内容过多时,对于公众号的粉丝阅读非常不方便。如果需要检索内容,只能逐页翻历史记录,非常浪费。时间,读起来很不直观。
先生推荐了一个强大的工具来解决这个问题——爱维帮的微站功能。以宇宙第一网红咪蒙公众号为例,通过爱微帮的微站功能,可以生成这样一个页面:
如果自己的公众号能生成这样的页面,粉丝阅读会更加方便直观。操作过程也很简单:
第一步:登录爱维帮官网(),点击右上角头像或昵称进入控制台。
第二步:扫描二维码,绑定自己的公众号。
第三步:在账号服务中找到微站,勾选“历史文章”。如果发现绑定的公众号中的部分文章在这里没有显示,需要把缺失的文章手动导入。
导入有两种方式:
首先是点击右上角的“导入历史文章”,在弹出的窗口中直接输入要导入的文章链接:
二是下载iWeibang媒体版客户端,从客户端导入文章。
第四步:点击“微站设置”中的“免费开通”,微站正式开通:
在这一步之后,您就可以开始个性化您自己的微型网站了。后续的设置过程也很简单,使用起来比公众号自带的模板功能简单多了!
2.简媒体
很多自媒体的朋友可能会遇到这个问题:注册的自媒体平台很多,几乎有十几个平台,每天写内容至少要花1-2个小时,关注热点,找素材,想套路,已经够累了。操作10多个平台实在是无能为力。十几套账号密码,每个文章复制粘贴十几遍,改标题,发表,看评论,看资料…………懒得去想了,就是浪费时间,可惜不发帖,浪费流量。
这里有一个小工具——Simple Media,可以一键同步十几个主流自媒体平台的文案,非常方便。
操作过程也非常简单。注册媒体后,在账号管理界面添加并绑定自己的所有账号。虽然绑定有点复杂,但这次只需要绑定即可。您可以使用标签来管理绑定的帐户。不会乱的。然后就可以在JianMedia自带的编辑器中编辑文章,文章会自动保存,不用担心丢失。文章的版面是设计师根据各个新媒体平台设计的,可以节省很多时间。编辑完文章后,选择行业,勾选原创、广告等功能按钮。最后选择你要发布的账号,也可以选择你绑定的所有账号。一键发布成功。基本上,几分钟后,所有平台都成功发布。它不仅比手动发布更快,而且布局也令人赏心悦目。文章的所有数据和链接也会显示出来,方便大家以后整理。
3.wetool
微信现在似乎构建了一个庞大的生态系统,但确实还有很多问题没有解决。例如,如何批量查找和删除您的朋友。目前的方法只能是群发消息测试或群组分组。这些方法要么粗糙,对朋友来说。对于成千上万的朋友来说,根本没有办法使用,否则会损害微信朋友的体验,面临被朋友删除的风险。
先生推荐一款免费的微信工具——wetool。本软件可以轻松解决僵尸粉丝的微信监控问题,精准检测僵尸粉丝,对真实粉丝零干扰,由你果断删除或尝试保存。算了,被对方删除或者屏蔽了会有提示,可以说是很方便了。
wetool的功能远不止这些。Wetool集成了微商伙伴喜欢使用的各种营销软件功能,稳定性和安全性更高。
比如群好友功能可以批量向群内非好友发送好友请求,一键消除群主和发送对象,省时省心。
群管机器人功能自动通过好友验证邀请入群,新人进群发布欢迎信息,触发条件智能踢人。
可以说是做微信营销的小伙伴们必不可少的营销利器。如果你不相信,你可以去体验。可以说是非常贴心了。最重要的是免费!!!
4.你好文库
对于营销人员和自媒体人来说,他们需要参考大量的材料才能有创意并写出解决方案。百度文库是国内最大的文档资源库,涵盖了很多珍贵的参考资料,但有些文档需要大量下载 优惠券可以下载。
这里先生推荐一个文库工具——嘿文库,访问链接是47.95.226.123/wenku/,复制并输入下载的文档链接,即可一键免费下载相关文档,确实是营销人员积累信息的必备工具。
5.视频下载助手
营销人员经常需要对一些视频资源进行编辑整理,但经常会遇到这样的情况:找到了视频网页,却不知道如何下载。主流视频网站基本不支持自己的视频。本地下载。
这里推荐一个火狐浏览器插件——Video DownloadHelper。只要安装这个插件,在火狐浏览器中打开视频链接,就可以自动识别下载视频,非常方便,不仅仅是主流视频。可以下载网站的视频,甚至一些非黑非白的网站视频也可以轻松下载,可以说是非常强大了!
6.微信备忘录
现在微信已经成为每个人都离不开的工具。微信能做的,微信就能做,省去下载很多麻烦的app。但是微信便利贴的这个功能大家可能非常陌生。
其实微信有自己的笔记功能,打开采集,右上角有个+号,点击加号进入微信的笔记功能!页面非常简洁,操作非常简单。
微信内置笔记功能最大的好处就是可以搜索。微信笔记生成的笔记会保存在采集夹中。只需在微信框中搜索目标关键词即可打开,方便检索。
OK,以上就是大家分享的几个小工具。它们的功能虽小,却能大大提高工作效率和质量。我希望能帮助到大家。
网页视频抓取工具 知乎(Python开发爬虫常用的工具总结及网页抓取思路数据是否可以直接从HTML中获取?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-20 23:10
使用Python开发爬虫是一件非常轻松愉快的事情,因为相关的库很多,而且使用起来很方便,十几行代码就可以完成一个爬虫的开发;
但是在对付网站有防爬措施,网站有js动态加载,App采集,就得动脑筋了;而在分布式爬虫的开发中,高性能爬虫的时候就得精心设计。
Python开发爬虫reqeusts常用工具汇总:Python HTTP网络请求库;pyquery:Python HTML DOM结构分析库,使用类似JQuery的语法;BeautifulSoup:python HTML 和 XML 结构分析;selenium:Python自动化测试框架,可用于爬虫;Phantomjs:无头浏览器,可以配合selenium获取js动态加载的内容;re: python 内置正则表达式模块;fiddler:抓包工具,原理是一个可以抓手机包的代理服务器;anyproxy:代理服务器,可以自己编写规则来拦截请求或响应,一般用在客户端采集;celery:Python分布式计算框架,可用于开发分布式爬虫;事件:基于协程的python网络库,可用于开发高性能爬虫grequests:asynchronous requestssaio http:异步http客户端/服务器框架asyncio:python内置异步io,事件循环库uvloop:一个非常快的事件循环库, with asyncio 极其高效的并发:Python 内置用于并发任务执行scrapy 的扩展:python 爬虫框架;Splash:一个JavaScript渲染服务,相当于一个轻量级浏览器,带有lua脚本,通过他的http API解析页面;Splinter:开源自动化Python Web 测试工具pyspider:Python 爬虫系统网页 爬取思路数据能否直接从HTML 中获取?数据直接嵌套在页面的HTML结构中;数据是使用JS动态渲染到页面中的吗?数据嵌套在js代码中,然后用js加载到页面或者用ajax渲染;获取的页面使用需要认证吗?登录后可以访问该页面;可以通过API直接获取数据吗?部分数据可以通过API直接获取,省去了解析HTML的麻烦。大多数 API 以 JSON 格式返回数据;来自客户端的数据采集 怎么样?比如:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:然后用js加载到页面或者用ajax渲染;获取的页面使用需要认证吗?登录后可以访问该页面;可以通过API直接获取数据吗?部分数据可以通过API直接获取,省去了解析HTML的麻烦。大多数 API 以 JSON 格式返回数据;来自客户端的数据采集 怎么样?比如:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:然后用js加载到页面或者用ajax渲染;获取的页面使用需要认证吗?登录后可以访问该页面;可以通过API直接获取数据吗?部分数据可以通过API直接获取,省去了解析HTML的麻烦。大多数 API 以 JSON 格式返回数据;来自客户端的数据采集 怎么样?比如:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:可以通过API直接获取数据吗?部分数据可以通过API直接获取,省去了解析HTML的麻烦。大多数 API 以 JSON 格式返回数据;来自客户端的数据采集 怎么样?比如:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:可以通过API直接获取数据吗?部分数据可以通过API直接获取,省去了解析HTML的麻烦。大多数 API 以 JSON 格式返回数据;来自客户端的数据采集 怎么样?比如:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:
检查网站的cookie。在某些情况下,请求需要添加一个cookie来通过服务器上的一些验证;案例讲解静态页面解析(获取微信公众号文章)
import pyquery
import re
def weixin_article_html_parser(html):
"""
解析微信文章,返回包含文章主体的字典信息
:param html: 文章HTML源代码
:return:
"""
pq = pyquery.PyQuery(html)
article = {
"weixin_id": pq.find("#js_profile_qrcode "
".profile_inner .profile_meta").eq(0).find("span").text().strip(),
"weixin_name": pq.find("#js_profile_qrcode .profile_inner strong").text().strip(),
"account_desc": pq.find("#js_profile_qrcode .profile_inner "
".profile_meta").eq(1).find("span").text().strip(),
"article_title": pq.find("title").text().strip(),
"article_content": pq("#js_content").remove('script').text().replace(r"\r\n", ""),
"is_orig": 1 if pq("#copyright_logo").length > 0 else 0,
"article_source_url": pq("#js_sg_bar .meta_primary").attr('href') if pq(
"#js_sg_bar .meta_primary").length > 0 else '',
}
# 使用正则表达式匹配页面中js脚本中的内容
match = {
"msg_cdn_url": {"regexp": "(? a.W_texta").attr("title"))
return html
except (TimeoutException, Exception) as e:
print(e)
finally:
driver.quit()
if __name__ == '__main__':
weibo_user_search(url="http://s.weibo.com/user/%s" % parse.quote("新闻"))
# 央视新闻
# 新浪新闻
# 新闻
# 新浪新闻客户端
# 中国新闻周刊
# 中国新闻网
# 每日经济新闻
# 澎湃新闻
# 网易新闻客户端
# 凤凰新闻客户端
# 皇马新闻
# 网络新闻联播
# CCTV5体育新闻
# 曼联新闻
# 搜狐新闻客户端
# 巴萨新闻
# 新闻日日睇
# 新垣结衣新闻社
# 看看新闻KNEWS
# 央视新闻评论
使用Python模拟登录获取cookies
有的网站比较痛苦,通常需要登录才能获取数据。下面是一个简单的例子:是不是用来登录网站,获取cookie,然后可以用于其他请求
但是,这里只有在没有验证码的情况下,如果要短信验证、图片验证、邮件验证,就得单独设计;
目标网站:,日期:2017-07-03,如果网站的结构发生变化,需要修改如下代码;
#!/usr/bin/env python3
# encoding: utf-8
from time import sleep
from pprint import pprint
from selenium.common.exceptions import TimeoutException, WebDriverException
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium import webdriver
def login_newrank():
"""登录新榜,获取他的cookie信息"""
desired_capabilities = DesiredCapabilities.CHROME.copy()
desired_capabilities["phantomjs.page.settings.userAgent"] = ("Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/59.0.3071.104 Safari/537.36")
desired_capabilities["phantomjs.page.settings.loadImages"] = True
# 自定义头部
desired_capabilities["phantomjs.page.customHeaders.Upgrade-Insecure-Requests"] = 1
desired_capabilities["phantomjs.page.customHeaders.Cache-Control"] = "max-age=0"
desired_capabilities["phantomjs.page.customHeaders.Connection"] = "keep-alive"
# 填写自己的账户进行测试
user = {
"mobile": "user",
"password": "password"
}
print("login account: %s" % user["mobile"])
driver = webdriver.PhantomJS(executable_path="/usr/bin/phantomjs",
desired_capabilities=desired_capabilities,
service_log_path="ghostdriver.log", )
# 设置对象的超时时间
driver.implicitly_wait(1)
# 设置页面完全加载的超时时间,包括页面全部渲染,异步同步脚本都执行完成
driver.set_page_load_timeout(60)
# 设置异步脚本的超时时间
driver.set_script_timeout(60)
driver.maximize_window()
try:
driver.get(url="http://www.newrank.cn/public/l ... 6quot;)
driver.find_element_by_css_selector(".login-normal-tap:nth-of-type(2)").click()
sleep(0.2)
driver.find_element_by_id("account_input").send_keys(user["mobile"])
sleep(0.5)
driver.find_element_by_id("password_input").send_keys(user["password"])
sleep(0.5)
driver.find_element_by_id("pwd_confirm").click()
sleep(3)
cookies = {user["name"]: user["value"] for user in driver.get_cookies()}
pprint(cookies)
except TimeoutException as exc:
print(exc)
except WebDriverException as exc:
print(exc)
finally:
driver.quit()
if __name__ == '__main__':
login_newrank()
# login account: 15395100590
# {'CNZZDATA1253878005': '1487200824-1499071649-%7C1499071649',
# 'Hm_lpvt_a19fd7224d30e3c8a6558dcb38c4beed': '1499074715',
# 'Hm_lvt_a19fd7224d30e3c8a6558dcb38c4beed': '1499074685,1499074713',
# 'UM_distinctid': '15d07d0d4dd82b-054b56417-9383666-c0000-15d07d0d4deace',
# 'name': '15395100590',
# 'rmbuser': 'true',
# 'token': 'A7437A03346B47A9F768730BAC81C514',
# 'useLoginAccount': 'true'}
获取cookie后,可以将获取的cookie添加到后续请求中,但由于cookie有有效期,需要定期更新;
这可以通过设计cookie池,动态定期登录一批账号,获取cookie后将cookie存入数据库(redis、MySQL等)来实现。
请求时从数据库中获取一个可用的cookie,并添加到访问请求中;
尝试使用pyqt5抓取数据(PyQt 5.9.2)
import sys
import csv
import pyquery
from PyQt5.QtCore import QUrl
from PyQt5.QtWidgets import QApplication
from PyQt5.QtWebEngineWidgets import QWebEngineView
class Browser(QWebEngineView):
def __init__(self):
super(Browser, self).__init__()
self.__results = []
self.loadFinished.connect(self.__result_available)
@property
def results(self):
return self.__results
def __result_available(self):
self.page().toHtml(self.__parse_html)
def __parse_html(self, html):
pq = pyquery.PyQuery(html)
for rows in [pq.find("#table_list tr"), pq.find("#more_list tr")]:
for row in rows.items():
columns = row.find("td")
d = {
"avatar": columns.eq(1).find("img").attr("src"),
"url": columns.eq(1).find("a").attr("href"),
"name": columns.eq(1).find("a").attr("title"),
"fans_number": columns.eq(2).text(),
"view_num": columns.eq(3).text(),
"comment_num": columns.eq(4).text(),
"post_count": columns.eq(5).text(),
"newrank_index": columns.eq(6).text(),
}
self.__results.append(d)
with open("results.csv", "a+", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["name", "fans_number", "view_num", "comment_num", "post_count",
"newrank_index", "url", "avatar"])
writer.writerows(self.results)
def open(self, url: str):
self.load(QUrl(url))
if __name__ == '__main__':
app = QApplication(sys.argv)
browser = Browser()
browser.open("https://www.newrank.cn/public/ ... 6quot;)
browser.show()
app.exec_()
持续更新:
5. 使用 Fiddler 抓包分析
浏览器抓包 fiddler 手机抓包
6. 使用anyproxy 捕获客户端数据-客户端数据采集
7. 高性能爬虫开发总结
获取免费爬虫视频资料加887934385交流群 查看全部
网页视频抓取工具 知乎(Python开发爬虫常用的工具总结及网页抓取思路数据是否可以直接从HTML中获取?)
使用Python开发爬虫是一件非常轻松愉快的事情,因为相关的库很多,而且使用起来很方便,十几行代码就可以完成一个爬虫的开发;
但是在对付网站有防爬措施,网站有js动态加载,App采集,就得动脑筋了;而在分布式爬虫的开发中,高性能爬虫的时候就得精心设计。
Python开发爬虫reqeusts常用工具汇总:Python HTTP网络请求库;pyquery:Python HTML DOM结构分析库,使用类似JQuery的语法;BeautifulSoup:python HTML 和 XML 结构分析;selenium:Python自动化测试框架,可用于爬虫;Phantomjs:无头浏览器,可以配合selenium获取js动态加载的内容;re: python 内置正则表达式模块;fiddler:抓包工具,原理是一个可以抓手机包的代理服务器;anyproxy:代理服务器,可以自己编写规则来拦截请求或响应,一般用在客户端采集;celery:Python分布式计算框架,可用于开发分布式爬虫;事件:基于协程的python网络库,可用于开发高性能爬虫grequests:asynchronous requestssaio http:异步http客户端/服务器框架asyncio:python内置异步io,事件循环库uvloop:一个非常快的事件循环库, with asyncio 极其高效的并发:Python 内置用于并发任务执行scrapy 的扩展:python 爬虫框架;Splash:一个JavaScript渲染服务,相当于一个轻量级浏览器,带有lua脚本,通过他的http API解析页面;Splinter:开源自动化Python Web 测试工具pyspider:Python 爬虫系统网页 爬取思路数据能否直接从HTML 中获取?数据直接嵌套在页面的HTML结构中;数据是使用JS动态渲染到页面中的吗?数据嵌套在js代码中,然后用js加载到页面或者用ajax渲染;获取的页面使用需要认证吗?登录后可以访问该页面;可以通过API直接获取数据吗?部分数据可以通过API直接获取,省去了解析HTML的麻烦。大多数 API 以 JSON 格式返回数据;来自客户端的数据采集 怎么样?比如:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:然后用js加载到页面或者用ajax渲染;获取的页面使用需要认证吗?登录后可以访问该页面;可以通过API直接获取数据吗?部分数据可以通过API直接获取,省去了解析HTML的麻烦。大多数 API 以 JSON 格式返回数据;来自客户端的数据采集 怎么样?比如:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:然后用js加载到页面或者用ajax渲染;获取的页面使用需要认证吗?登录后可以访问该页面;可以通过API直接获取数据吗?部分数据可以通过API直接获取,省去了解析HTML的麻烦。大多数 API 以 JSON 格式返回数据;来自客户端的数据采集 怎么样?比如:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:可以通过API直接获取数据吗?部分数据可以通过API直接获取,省去了解析HTML的麻烦。大多数 API 以 JSON 格式返回数据;来自客户端的数据采集 怎么样?比如:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:可以通过API直接获取数据吗?部分数据可以通过API直接获取,省去了解析HTML的麻烦。大多数 API 以 JSON 格式返回数据;来自客户端的数据采集 怎么样?比如:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:微信APP和微信客户端怎么应对反爬的不要太多,控制爬虫的速度,不要把人打倒,你会两败俱伤;使用代理隐藏真实IP,实现防爬;使爬虫看起来像人类用户,可选择设置以下 HTTP 标头:
检查网站的cookie。在某些情况下,请求需要添加一个cookie来通过服务器上的一些验证;案例讲解静态页面解析(获取微信公众号文章)
import pyquery
import re
def weixin_article_html_parser(html):
"""
解析微信文章,返回包含文章主体的字典信息
:param html: 文章HTML源代码
:return:
"""
pq = pyquery.PyQuery(html)
article = {
"weixin_id": pq.find("#js_profile_qrcode "
".profile_inner .profile_meta").eq(0).find("span").text().strip(),
"weixin_name": pq.find("#js_profile_qrcode .profile_inner strong").text().strip(),
"account_desc": pq.find("#js_profile_qrcode .profile_inner "
".profile_meta").eq(1).find("span").text().strip(),
"article_title": pq.find("title").text().strip(),
"article_content": pq("#js_content").remove('script').text().replace(r"\r\n", ""),
"is_orig": 1 if pq("#copyright_logo").length > 0 else 0,
"article_source_url": pq("#js_sg_bar .meta_primary").attr('href') if pq(
"#js_sg_bar .meta_primary").length > 0 else '',
}
# 使用正则表达式匹配页面中js脚本中的内容
match = {
"msg_cdn_url": {"regexp": "(? a.W_texta").attr("title"))
return html
except (TimeoutException, Exception) as e:
print(e)
finally:
driver.quit()
if __name__ == '__main__':
weibo_user_search(url="http://s.weibo.com/user/%s" % parse.quote("新闻"))
# 央视新闻
# 新浪新闻
# 新闻
# 新浪新闻客户端
# 中国新闻周刊
# 中国新闻网
# 每日经济新闻
# 澎湃新闻
# 网易新闻客户端
# 凤凰新闻客户端
# 皇马新闻
# 网络新闻联播
# CCTV5体育新闻
# 曼联新闻
# 搜狐新闻客户端
# 巴萨新闻
# 新闻日日睇
# 新垣结衣新闻社
# 看看新闻KNEWS
# 央视新闻评论
使用Python模拟登录获取cookies
有的网站比较痛苦,通常需要登录才能获取数据。下面是一个简单的例子:是不是用来登录网站,获取cookie,然后可以用于其他请求
但是,这里只有在没有验证码的情况下,如果要短信验证、图片验证、邮件验证,就得单独设计;
目标网站:,日期:2017-07-03,如果网站的结构发生变化,需要修改如下代码;
#!/usr/bin/env python3
# encoding: utf-8
from time import sleep
from pprint import pprint
from selenium.common.exceptions import TimeoutException, WebDriverException
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium import webdriver
def login_newrank():
"""登录新榜,获取他的cookie信息"""
desired_capabilities = DesiredCapabilities.CHROME.copy()
desired_capabilities["phantomjs.page.settings.userAgent"] = ("Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/59.0.3071.104 Safari/537.36")
desired_capabilities["phantomjs.page.settings.loadImages"] = True
# 自定义头部
desired_capabilities["phantomjs.page.customHeaders.Upgrade-Insecure-Requests"] = 1
desired_capabilities["phantomjs.page.customHeaders.Cache-Control"] = "max-age=0"
desired_capabilities["phantomjs.page.customHeaders.Connection"] = "keep-alive"
# 填写自己的账户进行测试
user = {
"mobile": "user",
"password": "password"
}
print("login account: %s" % user["mobile"])
driver = webdriver.PhantomJS(executable_path="/usr/bin/phantomjs",
desired_capabilities=desired_capabilities,
service_log_path="ghostdriver.log", )
# 设置对象的超时时间
driver.implicitly_wait(1)
# 设置页面完全加载的超时时间,包括页面全部渲染,异步同步脚本都执行完成
driver.set_page_load_timeout(60)
# 设置异步脚本的超时时间
driver.set_script_timeout(60)
driver.maximize_window()
try:
driver.get(url="http://www.newrank.cn/public/l ... 6quot;)
driver.find_element_by_css_selector(".login-normal-tap:nth-of-type(2)").click()
sleep(0.2)
driver.find_element_by_id("account_input").send_keys(user["mobile"])
sleep(0.5)
driver.find_element_by_id("password_input").send_keys(user["password"])
sleep(0.5)
driver.find_element_by_id("pwd_confirm").click()
sleep(3)
cookies = {user["name"]: user["value"] for user in driver.get_cookies()}
pprint(cookies)
except TimeoutException as exc:
print(exc)
except WebDriverException as exc:
print(exc)
finally:
driver.quit()
if __name__ == '__main__':
login_newrank()
# login account: 15395100590
# {'CNZZDATA1253878005': '1487200824-1499071649-%7C1499071649',
# 'Hm_lpvt_a19fd7224d30e3c8a6558dcb38c4beed': '1499074715',
# 'Hm_lvt_a19fd7224d30e3c8a6558dcb38c4beed': '1499074685,1499074713',
# 'UM_distinctid': '15d07d0d4dd82b-054b56417-9383666-c0000-15d07d0d4deace',
# 'name': '15395100590',
# 'rmbuser': 'true',
# 'token': 'A7437A03346B47A9F768730BAC81C514',
# 'useLoginAccount': 'true'}
获取cookie后,可以将获取的cookie添加到后续请求中,但由于cookie有有效期,需要定期更新;
这可以通过设计cookie池,动态定期登录一批账号,获取cookie后将cookie存入数据库(redis、MySQL等)来实现。
请求时从数据库中获取一个可用的cookie,并添加到访问请求中;
尝试使用pyqt5抓取数据(PyQt 5.9.2)
import sys
import csv
import pyquery
from PyQt5.QtCore import QUrl
from PyQt5.QtWidgets import QApplication
from PyQt5.QtWebEngineWidgets import QWebEngineView
class Browser(QWebEngineView):
def __init__(self):
super(Browser, self).__init__()
self.__results = []
self.loadFinished.connect(self.__result_available)
@property
def results(self):
return self.__results
def __result_available(self):
self.page().toHtml(self.__parse_html)
def __parse_html(self, html):
pq = pyquery.PyQuery(html)
for rows in [pq.find("#table_list tr"), pq.find("#more_list tr")]:
for row in rows.items():
columns = row.find("td")
d = {
"avatar": columns.eq(1).find("img").attr("src"),
"url": columns.eq(1).find("a").attr("href"),
"name": columns.eq(1).find("a").attr("title"),
"fans_number": columns.eq(2).text(),
"view_num": columns.eq(3).text(),
"comment_num": columns.eq(4).text(),
"post_count": columns.eq(5).text(),
"newrank_index": columns.eq(6).text(),
}
self.__results.append(d)
with open("results.csv", "a+", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["name", "fans_number", "view_num", "comment_num", "post_count",
"newrank_index", "url", "avatar"])
writer.writerows(self.results)
def open(self, url: str):
self.load(QUrl(url))
if __name__ == '__main__':
app = QApplication(sys.argv)
browser = Browser()
browser.open("https://www.newrank.cn/public/ ... 6quot;)
browser.show()
app.exec_()
持续更新:
5. 使用 Fiddler 抓包分析
浏览器抓包 fiddler 手机抓包
6. 使用anyproxy 捕获客户端数据-客户端数据采集
7. 高性能爬虫开发总结
获取免费爬虫视频资料加887934385交流群
网页视频抓取工具 知乎(超强的万能视频下载器,强大到几乎支持所有下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 262 次浏览 • 2021-11-17 23:10
之前也给大家推荐过视频下载工具,但是都比较单一。一个工具解决不了多平台,也不能高效批量下载!
为了解决下载视频的问题,今天给大家分享一款超级万能的视频下载器,强大到几乎可以支持所有网站的视频下载!
CR TubeGet
CR TubeGet是一款基于youtube-dl打包的视频下载软件。目前支持2000+网站视频下载,包括YouTube 8k下载,Mp3、M4a音频文件放不下!
这是 CR TubeGet 的简单界面。需要下载哪个网站视频,直接复制视频链接粘贴即可解析下载!实际测试了几个主流平台,比如:某某B、某某优、某某爱、某某YouTube、某某西瓜。无一例外地支持所有下载。(VIP内容除外)
软件支持aria2下载器加速下载,只要你的网络环境OK,下载速度就是这么快!
批量下载方式:
软件本身支持批量下载和列表下载。如果您复制B站列表视频中的链接,软件会自动检测列表中的所有视频并支持所有解析下载。如果你在B站看学习视频,那么这个列表下载功能真的不是太方便。
也可以直接复制多个链接到“批量下载框”,统一分析下载。
如果觉得这个批量下载不够方便,这里有一个浏览器插件:link-grabber,可以识别显示当前网页的所有链接。
比如我们想下载某个电视剧的所有视频,那么我们可以用这个插件一次性复制所有电视剧的所有链接,直接导入到CR TubeGet中进行下载。
使用谷歌浏览器(可使用谷歌内核浏览器)安装本插件,点击插件图标,即可显示当前网页的所有链接。将视频链接复制到下载工具进行批量下载。
下载:
本文首发于微信公众号马小邦(maxiaobang7),未经授权请勿转载!
一如既往,感谢大家的支持和关注 查看全部
网页视频抓取工具 知乎(超强的万能视频下载器,强大到几乎支持所有下载)
之前也给大家推荐过视频下载工具,但是都比较单一。一个工具解决不了多平台,也不能高效批量下载!
为了解决下载视频的问题,今天给大家分享一款超级万能的视频下载器,强大到几乎可以支持所有网站的视频下载!
CR TubeGet
CR TubeGet是一款基于youtube-dl打包的视频下载软件。目前支持2000+网站视频下载,包括YouTube 8k下载,Mp3、M4a音频文件放不下!
这是 CR TubeGet 的简单界面。需要下载哪个网站视频,直接复制视频链接粘贴即可解析下载!实际测试了几个主流平台,比如:某某B、某某优、某某爱、某某YouTube、某某西瓜。无一例外地支持所有下载。(VIP内容除外)
软件支持aria2下载器加速下载,只要你的网络环境OK,下载速度就是这么快!
批量下载方式:
软件本身支持批量下载和列表下载。如果您复制B站列表视频中的链接,软件会自动检测列表中的所有视频并支持所有解析下载。如果你在B站看学习视频,那么这个列表下载功能真的不是太方便。
也可以直接复制多个链接到“批量下载框”,统一分析下载。
如果觉得这个批量下载不够方便,这里有一个浏览器插件:link-grabber,可以识别显示当前网页的所有链接。
比如我们想下载某个电视剧的所有视频,那么我们可以用这个插件一次性复制所有电视剧的所有链接,直接导入到CR TubeGet中进行下载。
使用谷歌浏览器(可使用谷歌内核浏览器)安装本插件,点击插件图标,即可显示当前网页的所有链接。将视频链接复制到下载工具进行批量下载。
下载:
本文首发于微信公众号马小邦(maxiaobang7),未经授权请勿转载!
一如既往,感谢大家的支持和关注
网页视频抓取工具 知乎(知乎文章下载插件是一个可以帮助用户便捷的下载知乎中的浏览插件工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-11-17 02:13
知乎文章下载插件是一款浏览器插件工具,可以帮助用户方便地在知乎下载文章。众所周知,最好的采集方式不如采集。下载到本地。很多时候打开知乎的采集夹,你会发现很多答案已经失效了。这个插件可以让你在浏览网页时一键下载文章。, 以markdown格式保存,方便大家浏览阅读。
发展背景
如果你是 知乎 用户,你应该有过这样的经历:
不久前发布的文章,或者浏览的文章,过了一会才发现被正式删除了。
这样一来,你辛苦了一个星期的人物就白费了,你想采集的好文章也可能会擦肩而过。
如果要保存知乎文章作为备份,在复制全文时不仅会遇到转载权限的限制,还可能导致部分格式丢失。
而这个chrome插件是为了防备,可以很好的解决知乎文章的备份问题。
软件功能
知乎文章下载插件,顾名思义就是下载知乎文章的文档下载工具。
支持下载所有知乎用户的文章,包括自己和其他知乎用户。您可以下载单个文章,也可以批量下载该用户的所有文章。
下载的知乎文章都是以markdown格式保存的。
使用说明
打开个人中心文章页面
需要注意的是,该插件只能在知乎用户的文章栏目页面生效。所以我们需要进入这个页面进行下载。
如下图,进入知乎用户的个人主页,然后点击切换到[文章]栏。
下载文章
然后就可以看到新增的文章下载选项,点击开始下载。
注意,如果下载按钮没有出现,只需刷新当前页面即可。 查看全部
网页视频抓取工具 知乎(知乎文章下载插件是一个可以帮助用户便捷的下载知乎中的浏览插件工具)
知乎文章下载插件是一款浏览器插件工具,可以帮助用户方便地在知乎下载文章。众所周知,最好的采集方式不如采集。下载到本地。很多时候打开知乎的采集夹,你会发现很多答案已经失效了。这个插件可以让你在浏览网页时一键下载文章。, 以markdown格式保存,方便大家浏览阅读。
发展背景
如果你是 知乎 用户,你应该有过这样的经历:
不久前发布的文章,或者浏览的文章,过了一会才发现被正式删除了。
这样一来,你辛苦了一个星期的人物就白费了,你想采集的好文章也可能会擦肩而过。
如果要保存知乎文章作为备份,在复制全文时不仅会遇到转载权限的限制,还可能导致部分格式丢失。
而这个chrome插件是为了防备,可以很好的解决知乎文章的备份问题。
软件功能
知乎文章下载插件,顾名思义就是下载知乎文章的文档下载工具。
支持下载所有知乎用户的文章,包括自己和其他知乎用户。您可以下载单个文章,也可以批量下载该用户的所有文章。
下载的知乎文章都是以markdown格式保存的。
使用说明
打开个人中心文章页面
需要注意的是,该插件只能在知乎用户的文章栏目页面生效。所以我们需要进入这个页面进行下载。
如下图,进入知乎用户的个人主页,然后点击切换到[文章]栏。
下载文章
然后就可以看到新增的文章下载选项,点击开始下载。
注意,如果下载按钮没有出现,只需刷新当前页面即可。
网页视频抓取工具 知乎(知乎助手更新日志支持单个问题/文章、文章的操作日志)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-11-17 02:12
知乎助手是专为知乎打造的网页浏览助手工具。体积小,不占内存空间,功能强大实用,支持模块xposed。不仅可以同时登录多个账号,还可以采集丰富的背景资料,抓取一些优秀的专栏文章、答案等。
知乎助手基本介绍
在知乎的帮助下,当你在访问网站时发现一些精彩的答案,就可以将它们保存到本地,制作成电子书。用户可以自定义爬取规则,过滤掉不需要的内容。
知乎辅助功能
该软件支持同时登录多个帐户。
它会自动记录您的操作日志。
您可以自定义电子书的名称。
该软件可以在 Windows 和 macOS 平台上运行。
应用可以抢专栏文章、想法、高赞回答。
知乎如何使用助手
在任务输入框中输入要爬取的URL信息。
单击开始执行按钮。
执行完成后,会打开电子书所在的文件夹。可以使用杜坎阅读或者在Win10下双击用Edge浏览器打开。
输出文件
html 文件夹是按答案划分的单个答案页面的列表,而 index.html 是目录页面。
单文件版收录文件夹内的整个文件,用浏览器打开后可直接打印为PDF书。
知乎助手输出的电子书\epub就是输出的Epub电子书,电子书阅读器可以直接阅读。
知乎助手输出的e-book\html为输出网页版答案列表。
知乎助手更新日志
支持导出单个问题/文章。
支持自动分卷。
相关教程
知乎助理评论
它会自动记录您的操作日志。
细节 查看全部
网页视频抓取工具 知乎(知乎助手更新日志支持单个问题/文章、文章的操作日志)
知乎助手是专为知乎打造的网页浏览助手工具。体积小,不占内存空间,功能强大实用,支持模块xposed。不仅可以同时登录多个账号,还可以采集丰富的背景资料,抓取一些优秀的专栏文章、答案等。
知乎助手基本介绍
在知乎的帮助下,当你在访问网站时发现一些精彩的答案,就可以将它们保存到本地,制作成电子书。用户可以自定义爬取规则,过滤掉不需要的内容。
知乎辅助功能
该软件支持同时登录多个帐户。
它会自动记录您的操作日志。
您可以自定义电子书的名称。
该软件可以在 Windows 和 macOS 平台上运行。
应用可以抢专栏文章、想法、高赞回答。
知乎如何使用助手
在任务输入框中输入要爬取的URL信息。
单击开始执行按钮。
执行完成后,会打开电子书所在的文件夹。可以使用杜坎阅读或者在Win10下双击用Edge浏览器打开。
输出文件
html 文件夹是按答案划分的单个答案页面的列表,而 index.html 是目录页面。
单文件版收录文件夹内的整个文件,用浏览器打开后可直接打印为PDF书。
知乎助手输出的电子书\epub就是输出的Epub电子书,电子书阅读器可以直接阅读。
知乎助手输出的e-book\html为输出网页版答案列表。
知乎助手更新日志
支持导出单个问题/文章。
支持自动分卷。
相关教程
知乎助理评论
它会自动记录您的操作日志。
细节
网页视频抓取工具 知乎(要如何下载知乎视频呢?-downloader插件功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-11-17 00:17
zh-downloader插件是一款不错的知乎视频分析下载工具。本软件支持在用户访问的任何知乎页面下载视频和图片文件,并能自动转换为MP4格式。有需要的朋友快来下载吧!
发展背景
“知乎”在文言文中的意思是“你知道吗”。2011年,一款名为知乎的问答式网站在中国正式上线,其产品对标美国同类网站 Quora。
时至今日,知乎已经是中国最活跃的社区论坛之一,其意义不仅包括专业知识问答,还涵盖了各行各业的方方面面。
当然,有时候用户会在知乎上分享一些有趣的视频,那么如何下载知乎的视频呢?
有朋友可能发现,经常下载Video Downloader pro、猫手等谷歌插件的视频有时无法嗅探知乎页面上的视频。
另一方面,即使你在知乎上下载视频,你也会发现大部分都是m3u8格式,不利于分享和本地观看。
特征
有没有什么工具可以嗅探知乎上的视频并在下载时自动转换成mp4格式?
答案就是这个zh-downloader插件,在商店里比较冷门。
它可以帮助我们快速检测到知乎页面上的视频。下载时还支持分辨率选择,以及分享、查看下载进度等操作。下载完成后的视频格式为mp4,无需二次转换,非常强大实用。
指示
下载视频
打开任意带有视频的知乎页面,插件会自动检测是否有资源,嗅探视频的数量会以角标的形式出现在图标上。
这时,点击工具栏上的插件图标,可以看到下载菜单窗口。
与Video Downloader Professional相比,zh-downloader嗅探的视频资源会显示标题和缩略图,非常直观。
同时,您可以直接选择下载视频的定义,查看下载进度,以及分享和删除操作。 查看全部
网页视频抓取工具 知乎(要如何下载知乎视频呢?-downloader插件功能介绍)
zh-downloader插件是一款不错的知乎视频分析下载工具。本软件支持在用户访问的任何知乎页面下载视频和图片文件,并能自动转换为MP4格式。有需要的朋友快来下载吧!
发展背景
“知乎”在文言文中的意思是“你知道吗”。2011年,一款名为知乎的问答式网站在中国正式上线,其产品对标美国同类网站 Quora。
时至今日,知乎已经是中国最活跃的社区论坛之一,其意义不仅包括专业知识问答,还涵盖了各行各业的方方面面。
当然,有时候用户会在知乎上分享一些有趣的视频,那么如何下载知乎的视频呢?
有朋友可能发现,经常下载Video Downloader pro、猫手等谷歌插件的视频有时无法嗅探知乎页面上的视频。
另一方面,即使你在知乎上下载视频,你也会发现大部分都是m3u8格式,不利于分享和本地观看。
特征
有没有什么工具可以嗅探知乎上的视频并在下载时自动转换成mp4格式?
答案就是这个zh-downloader插件,在商店里比较冷门。
它可以帮助我们快速检测到知乎页面上的视频。下载时还支持分辨率选择,以及分享、查看下载进度等操作。下载完成后的视频格式为mp4,无需二次转换,非常强大实用。
指示
下载视频
打开任意带有视频的知乎页面,插件会自动检测是否有资源,嗅探视频的数量会以角标的形式出现在图标上。
这时,点击工具栏上的插件图标,可以看到下载菜单窗口。
与Video Downloader Professional相比,zh-downloader嗅探的视频资源会显示标题和缩略图,非常直观。
同时,您可以直接选择下载视频的定义,查看下载进度,以及分享和删除操作。
网页视频抓取工具 知乎(网页视频抓取工具知乎首答(ess-zhuang-bi-gao-jing-meng/id586776958))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-13 15:01
网页视频抓取工具知乎首答-ess-zhuang-bi-gao-jing-meng/id586776958?mt=8链接地址是:;type=document&page=5
网页视频抓取你可以试试scrapy,
首先,你应该学习一下网页视频的录制方法。然后,找一个基于http的抓取工具,像百度视频全能王,先录制。然后存起来。最后,找一个录制软件。很多都可以,有文本录制,流式录制,视频录制。爬虫原理一样,都是匹配网页链接,是一个个urls,分页录制。找到目标网页的网址并解析获取,肯定有很多的url。找到目标网页的url,并且分页获取目标网页的全部url,就是有效页面url,列表页数据都是一样的。
然后就开始循环的爬取就行。一页几十条数据,一天也就是几十万的数据。如果有多个网页的页面,就多爬几层循环就行。
原理上每个网站都是通过url拿数据的,现在都是读写大数据平台,
没有。
百度搜索,搜索框某关键词,有全部的结果。不过,至少有个知乎。
以前也想问这个问题,无奈安卓端软件不开源,没法实现。后来发现可以开发一个网页视频抓取方案如下:1.1抓视频要开发一个app,配置好程序处理视频的几个逻辑(比如视频分段保存,分辨率选择以及缓存路径等),然后编写相应的程序(推荐用uibot)去抓取某个url,每个步骤可以选择性地实现。1.2抓获。上传app到百度云,app会自动抓取百度云的视频,这一步也比较简单。1.3存储。放入wiki文件夹,在mobileapp中使用文件夹访问wiki,然后下载即可。 查看全部
网页视频抓取工具 知乎(网页视频抓取工具知乎首答(ess-zhuang-bi-gao-jing-meng/id586776958))
网页视频抓取工具知乎首答-ess-zhuang-bi-gao-jing-meng/id586776958?mt=8链接地址是:;type=document&page=5
网页视频抓取你可以试试scrapy,
首先,你应该学习一下网页视频的录制方法。然后,找一个基于http的抓取工具,像百度视频全能王,先录制。然后存起来。最后,找一个录制软件。很多都可以,有文本录制,流式录制,视频录制。爬虫原理一样,都是匹配网页链接,是一个个urls,分页录制。找到目标网页的网址并解析获取,肯定有很多的url。找到目标网页的url,并且分页获取目标网页的全部url,就是有效页面url,列表页数据都是一样的。
然后就开始循环的爬取就行。一页几十条数据,一天也就是几十万的数据。如果有多个网页的页面,就多爬几层循环就行。
原理上每个网站都是通过url拿数据的,现在都是读写大数据平台,
没有。
百度搜索,搜索框某关键词,有全部的结果。不过,至少有个知乎。
以前也想问这个问题,无奈安卓端软件不开源,没法实现。后来发现可以开发一个网页视频抓取方案如下:1.1抓视频要开发一个app,配置好程序处理视频的几个逻辑(比如视频分段保存,分辨率选择以及缓存路径等),然后编写相应的程序(推荐用uibot)去抓取某个url,每个步骤可以选择性地实现。1.2抓获。上传app到百度云,app会自动抓取百度云的视频,这一步也比较简单。1.3存储。放入wiki文件夹,在mobileapp中使用文件夹访问wiki,然后下载即可。
网页视频抓取工具 知乎(如何爬取B站视频的弹幕和评论?|Python )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-10 20:09
)
开发工具
Python版本:3.6.4
相关模块:
请求模块;
重新模块;
熊猫模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
思维分析
本文以爬取视频《“这是我见过最拽的中国奥运冠军”》为例,讲解如何爬取B站视频的弹幕和评论!
目标地址
https://www.bilibili.com/video/BV1wq4y1Q7dp 复制代码
抢弹幕
网络分析
B站视频的弹幕不像腾讯视频。播放视频会触发弹幕数据包。他需要点击网页右侧的弹幕列表行展开,然后点击查看历史弹幕,可以得到视频弹幕的开始日期和结束日期。日链接:
在链接的末尾,使用oid和开始日期形成弹幕日期URL:
https://api.bilibili.com/x/v2/ ... 21-08 复制代码
在此基础上,点击任一生效日期,即可获得该日期的弹幕数据包。里面的内容目前无法读取。之所以确定是弹幕数据包,是因为日期是点击他刚加载出来的,链接和上一个链接有关系:
获取到的网址:
https://api.bilibili.com/x/v2/ ... 08-08 复制代码
URL中的oid是视频弹幕链接的id值;data参数是刚才的日期,要获取视频的所有弹幕内容,只需要修改data参数即可。data参数可以从上面弹幕日期url中获取,也可以自己构造;网页数据格式为json格式
代码
import requests\ import pandas as pd\ import re\ \ def data_resposen(url):\ headers = {\ "cookie": "你的cookie",\ "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36"\ }\ resposen = requests.get(url, headers=headers)\ return resposen\ \ def main(oid, month):\ df = pd.DataFrame()\ url = f'https://api.bilibili.com/x/v2/ ... id%3D{oid}&month={month}'\ list_data = data_resposen(url).json()['data'] # 拿到所有日期\ print(list_data)\ for data in list_data:\ urls = f'https://api.bilibili.com/x/v2/ ... id%3D{oid}&date={data}'\ text = re.findall(".*?([\u4E00-\u9FA5]+).*?", data_resposen(urls).text)\ for e in text:\ print(e)\ data = pd.DataFrame({'弹幕': [e]})\ df = pd.concat([df, data])\ df.to_csv('弹幕.csv', encoding='utf-8', index=False, mode='a+')\ \ if __name__ == '__main__':\ oid = '384801460' # 视频弹幕链接的id值\ month = '2021-08' # 开始日期\ main(oid, month) 复制代码
显示结果
查看全部
网页视频抓取工具 知乎(如何爬取B站视频的弹幕和评论?|Python
)
开发工具
Python版本:3.6.4
相关模块:
请求模块;
重新模块;
熊猫模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
思维分析
本文以爬取视频《“这是我见过最拽的中国奥运冠军”》为例,讲解如何爬取B站视频的弹幕和评论!
目标地址
https://www.bilibili.com/video/BV1wq4y1Q7dp 复制代码
抢弹幕
网络分析
B站视频的弹幕不像腾讯视频。播放视频会触发弹幕数据包。他需要点击网页右侧的弹幕列表行展开,然后点击查看历史弹幕,可以得到视频弹幕的开始日期和结束日期。日链接:
在链接的末尾,使用oid和开始日期形成弹幕日期URL:
https://api.bilibili.com/x/v2/ ... 21-08 复制代码
在此基础上,点击任一生效日期,即可获得该日期的弹幕数据包。里面的内容目前无法读取。之所以确定是弹幕数据包,是因为日期是点击他刚加载出来的,链接和上一个链接有关系:
获取到的网址:
https://api.bilibili.com/x/v2/ ... 08-08 复制代码
URL中的oid是视频弹幕链接的id值;data参数是刚才的日期,要获取视频的所有弹幕内容,只需要修改data参数即可。data参数可以从上面弹幕日期url中获取,也可以自己构造;网页数据格式为json格式
代码
import requests\ import pandas as pd\ import re\ \ def data_resposen(url):\ headers = {\ "cookie": "你的cookie",\ "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36"\ }\ resposen = requests.get(url, headers=headers)\ return resposen\ \ def main(oid, month):\ df = pd.DataFrame()\ url = f'https://api.bilibili.com/x/v2/ ... id%3D{oid}&month={month}'\ list_data = data_resposen(url).json()['data'] # 拿到所有日期\ print(list_data)\ for data in list_data:\ urls = f'https://api.bilibili.com/x/v2/ ... id%3D{oid}&date={data}'\ text = re.findall(".*?([\u4E00-\u9FA5]+).*?", data_resposen(urls).text)\ for e in text:\ print(e)\ data = pd.DataFrame({'弹幕': [e]})\ df = pd.concat([df, data])\ df.to_csv('弹幕.csv', encoding='utf-8', index=False, mode='a+')\ \ if __name__ == '__main__':\ oid = '384801460' # 视频弹幕链接的id值\ month = '2021-08' # 开始日期\ main(oid, month) 复制代码
显示结果
网页视频抓取工具 知乎(网络爬虫(webcrawler)或网络机器人()又称为)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-08 08:14
众所周知,随着计算机、互联网、物联网、云计算等网络技术的兴起,网络上的信息爆炸式增长。毫无疑问,互联网上的信息几乎涵盖了社会、文化、政治、经济、娱乐等所有话题。使用传统的数据采集机制(如问卷调查法、访谈法)获取和采集数据往往受到资金和地域范围的限制,也会由于样本量小、可靠性低 数据往往与客观事实存在偏差,局限性较大。(文末百度网盘基础视频,需要自己提)
网络爬虫使用统一资源定位器网址(Uniform ResourceLocator)寻找目标网页
用户关注的数据内容直接返回给用户,用户无需浏览网页即可获取信息,为用户节省了时间和精力,提高了数据的准确性采集@ >,让用户在海量数据中轻松搞定。
网络爬虫的最终目标是从网页中获取它们需要的信息。虽然可以使用urllib、urllib2、re等一些爬虫基础库来开发爬虫程序,获取需要的内容,但是所有爬虫程序都是这样写的,工作量太大。于是就有了爬虫框架。使用爬虫框架可以大大提高效率,缩短开发时间。
网络爬虫也称为网络蜘蛛或网络机器人。其他不常用的名称包括蚂蚁、自动索引、模拟程序或蠕虫,它也是“物联网”概念的核心之一。网络爬虫本质上是按照一定的逻辑和算法规则自动抓取和下载万维网上网页的计算机程序或脚本。它是搜索引擎的重要组成部分。
网络爬虫一般都是从预先设置的一个或几个初始网页的网址开始,然后按照一定的规则对网页进行爬取,得到初始网页上的网址列表。之后,每当网页被抓取时,抓取工具都会提取该网页。将新的URL放入未被抓取的队列中,然后循环从队列中取出一个从未抓取过的URL,然后进行新一轮的抓取,重复上述过程,直到抓取队列中的 URL。当爬虫完成或满足其他既定条件时,它就会结束。具体流程如下图所示。
随着大数据时代的到来,网络数据正在成为一种潜在的宝藏。大量的商业信息和社会信息以文本等非结构化、异构的数据格式存储在网页上。非计算机专业背景的人也可以使用机器学习、人工智能等方法进行研究。利用网络爬虫获取采集信息,不仅可以实现高效、准确、自动获取网络信息,还可以帮助企业或研究人员对采集收到的数据进行后续的挖掘和分析.
数据采集需要使用Python编程语言来设计网络爬虫,而且获得的数据中有相当比例是非结构化数据,这就需要python数据分析技术。
另外给大家分享一波基础教学视频,百度网盘,需要自己提一下!感觉有用,请关注!!
百度网盘python数据获取链接:/s/1I00b8CCAVWcZNF7ds-4EDw
提取码:in0q 查看全部
网页视频抓取工具 知乎(网络爬虫(webcrawler)或网络机器人()又称为)
众所周知,随着计算机、互联网、物联网、云计算等网络技术的兴起,网络上的信息爆炸式增长。毫无疑问,互联网上的信息几乎涵盖了社会、文化、政治、经济、娱乐等所有话题。使用传统的数据采集机制(如问卷调查法、访谈法)获取和采集数据往往受到资金和地域范围的限制,也会由于样本量小、可靠性低 数据往往与客观事实存在偏差,局限性较大。(文末百度网盘基础视频,需要自己提)
网络爬虫使用统一资源定位器网址(Uniform ResourceLocator)寻找目标网页
用户关注的数据内容直接返回给用户,用户无需浏览网页即可获取信息,为用户节省了时间和精力,提高了数据的准确性采集@ >,让用户在海量数据中轻松搞定。
网络爬虫的最终目标是从网页中获取它们需要的信息。虽然可以使用urllib、urllib2、re等一些爬虫基础库来开发爬虫程序,获取需要的内容,但是所有爬虫程序都是这样写的,工作量太大。于是就有了爬虫框架。使用爬虫框架可以大大提高效率,缩短开发时间。
网络爬虫也称为网络蜘蛛或网络机器人。其他不常用的名称包括蚂蚁、自动索引、模拟程序或蠕虫,它也是“物联网”概念的核心之一。网络爬虫本质上是按照一定的逻辑和算法规则自动抓取和下载万维网上网页的计算机程序或脚本。它是搜索引擎的重要组成部分。
网络爬虫一般都是从预先设置的一个或几个初始网页的网址开始,然后按照一定的规则对网页进行爬取,得到初始网页上的网址列表。之后,每当网页被抓取时,抓取工具都会提取该网页。将新的URL放入未被抓取的队列中,然后循环从队列中取出一个从未抓取过的URL,然后进行新一轮的抓取,重复上述过程,直到抓取队列中的 URL。当爬虫完成或满足其他既定条件时,它就会结束。具体流程如下图所示。
随着大数据时代的到来,网络数据正在成为一种潜在的宝藏。大量的商业信息和社会信息以文本等非结构化、异构的数据格式存储在网页上。非计算机专业背景的人也可以使用机器学习、人工智能等方法进行研究。利用网络爬虫获取采集信息,不仅可以实现高效、准确、自动获取网络信息,还可以帮助企业或研究人员对采集收到的数据进行后续的挖掘和分析.
数据采集需要使用Python编程语言来设计网络爬虫,而且获得的数据中有相当比例是非结构化数据,这就需要python数据分析技术。
另外给大家分享一波基础教学视频,百度网盘,需要自己提一下!感觉有用,请关注!!
百度网盘python数据获取链接:/s/1I00b8CCAVWcZNF7ds-4EDw
提取码:in0q
网页视频抓取工具 知乎(代码是最近(2021.09)新写的~需求任务需求分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-05 23:23
最近新写的代码(2021.09)~
需要
任务要求:抓取问题知乎下的所有答案,包括作者、作者粉丝数、回答内容、时间、回复评论数、回答数和回答链接.
分析
以最近关注的“大公司间链接畅通问题”为例。如果想获取答案的相关数据,可以在Chrome浏览器下按F12对请求进行分析;但是在Charles抓包工具的帮助下,你可以改变它。直观获取相关字段:
注意我标记的Query String参数中的limit 5表示每个请求会返回5个回答,测试后最多可以改成20个;偏移是指从答案的数量开始;
返回结果为 Json 格式。每个答案都收录足够的信息。我们只需要过滤并保存我们想要捕获的字段记录。
需要说明的是,content字段返回的内容为答案内容,但其格式是带有网页标签的。搜索之后,我选择了HTMLParser来解析,这样就不用手动处理了。
代码
import requests,json
import datetime
import pandas as pd
from selectolax.parser import HTMLParser
url = 'https://www.zhihu.com/api/v4/q ... 39%3B
headers = {
'Host':'www.zhihu.com',
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
'referer':'https://www.zhihu.com/question/486212129'
}
df = pd.DataFrame(columns=('author','fans_count','content','created_time','updated_time','comment_count','voteup_count','url'))
def crawler(start):
print(start)
global df
data= {
'include':'data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,attachment,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,is_labeled,paid_info,paid_info_content,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,is_recognized;data[*].mark_infos[*].url;data[*].author.follower_count,vip_info,badge[*].topics;data[*].settings.table_of_content.enabled',
'offset':start,
'limit':20,
'sort_by':'default',
'platform':'desktop'
}
#将携带的参数传给params
r = requests.get(url, params=data,headers=headers)
res = json.loads(r.text)
if res['data']:
for answer in res['data']:
author = answer['author']['name']
fans = answer['author']['follower_count']
content = HTMLParser(answer['content']).text()
#content = answer['content']
created_time = datetime.datetime.fromtimestamp(answer['created_time'])
updated_time = datetime.datetime.fromtimestamp(answer['updated_time'])
comment = answer['comment_count']
voteup = answer['voteup_count']
link = answer['url']
row = {
'author':[author],
'fans_count':[fans],
'content':[content],
'created_time':[created_time],
'updated_time':[updated_time],
'comment_count':[comment],
'voteup_count':[voteup],
'url':[link]
}
df = df.append(pd.DataFrame(row),ignore_index=True)
if len(res['data'])==20:
crawler(start+20)
else:
print(res)
crawler(0)
df.to_csv(f'result_{datetime.datetime.now().strftime("%Y-%m-%d")}.csv',index=False)
print("done~")
结果
得到的结果大致如下:
你可以看到有些答案是空的。转到问题并检查它是否是视频答案。没有文字内容。这被忽略了。当然,您可以删除视频链接并将其添加到结果中。
防攀登限制
目前(2021.09)看这个问题,接口没有特别限制,包括我在代码中的请求没有cookies直接捕获,通过修改limit参数为20来减少请求频率。
爬虫意义
最近也在想爬知乎答案的意义在哪里。一开始我想把所有的答案汇总起来分析,但是我真正抓住了之后,就想一起阅读了。我发现阅读表格中的答案的阅读体验很差。直接去知乎;但更明显的价值在于这数百个答案的横向比较。赞、评论、作者粉丝一目了然。另外,你还可以根据结果做一些词频分析、词云图展示等,这些都是接下来要做的事情。
爬虫只是获取数据的一种方式,如何解读是数据更大的价值。
我是TED,每天写爬虫的数据工程师,但好久没写Python了。以后想到的一系列Python爬虫项目会继续更新。欢迎继续关注~ 查看全部
网页视频抓取工具 知乎(代码是最近(2021.09)新写的~需求任务需求分析)
最近新写的代码(2021.09)~
需要
任务要求:抓取问题知乎下的所有答案,包括作者、作者粉丝数、回答内容、时间、回复评论数、回答数和回答链接.
分析
以最近关注的“大公司间链接畅通问题”为例。如果想获取答案的相关数据,可以在Chrome浏览器下按F12对请求进行分析;但是在Charles抓包工具的帮助下,你可以改变它。直观获取相关字段:
注意我标记的Query String参数中的limit 5表示每个请求会返回5个回答,测试后最多可以改成20个;偏移是指从答案的数量开始;
返回结果为 Json 格式。每个答案都收录足够的信息。我们只需要过滤并保存我们想要捕获的字段记录。
需要说明的是,content字段返回的内容为答案内容,但其格式是带有网页标签的。搜索之后,我选择了HTMLParser来解析,这样就不用手动处理了。
代码
import requests,json
import datetime
import pandas as pd
from selectolax.parser import HTMLParser
url = 'https://www.zhihu.com/api/v4/q ... 39%3B
headers = {
'Host':'www.zhihu.com',
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
'referer':'https://www.zhihu.com/question/486212129'
}
df = pd.DataFrame(columns=('author','fans_count','content','created_time','updated_time','comment_count','voteup_count','url'))
def crawler(start):
print(start)
global df
data= {
'include':'data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,attachment,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,is_labeled,paid_info,paid_info_content,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,is_recognized;data[*].mark_infos[*].url;data[*].author.follower_count,vip_info,badge[*].topics;data[*].settings.table_of_content.enabled',
'offset':start,
'limit':20,
'sort_by':'default',
'platform':'desktop'
}
#将携带的参数传给params
r = requests.get(url, params=data,headers=headers)
res = json.loads(r.text)
if res['data']:
for answer in res['data']:
author = answer['author']['name']
fans = answer['author']['follower_count']
content = HTMLParser(answer['content']).text()
#content = answer['content']
created_time = datetime.datetime.fromtimestamp(answer['created_time'])
updated_time = datetime.datetime.fromtimestamp(answer['updated_time'])
comment = answer['comment_count']
voteup = answer['voteup_count']
link = answer['url']
row = {
'author':[author],
'fans_count':[fans],
'content':[content],
'created_time':[created_time],
'updated_time':[updated_time],
'comment_count':[comment],
'voteup_count':[voteup],
'url':[link]
}
df = df.append(pd.DataFrame(row),ignore_index=True)
if len(res['data'])==20:
crawler(start+20)
else:
print(res)
crawler(0)
df.to_csv(f'result_{datetime.datetime.now().strftime("%Y-%m-%d")}.csv',index=False)
print("done~")
结果
得到的结果大致如下:
你可以看到有些答案是空的。转到问题并检查它是否是视频答案。没有文字内容。这被忽略了。当然,您可以删除视频链接并将其添加到结果中。
防攀登限制
目前(2021.09)看这个问题,接口没有特别限制,包括我在代码中的请求没有cookies直接捕获,通过修改limit参数为20来减少请求频率。
爬虫意义
最近也在想爬知乎答案的意义在哪里。一开始我想把所有的答案汇总起来分析,但是我真正抓住了之后,就想一起阅读了。我发现阅读表格中的答案的阅读体验很差。直接去知乎;但更明显的价值在于这数百个答案的横向比较。赞、评论、作者粉丝一目了然。另外,你还可以根据结果做一些词频分析、词云图展示等,这些都是接下来要做的事情。
爬虫只是获取数据的一种方式,如何解读是数据更大的价值。
我是TED,每天写爬虫的数据工程师,但好久没写Python了。以后想到的一系列Python爬虫项目会继续更新。欢迎继续关注~
网页视频抓取工具 知乎(更新日志1.修复bug2.修复已知bug优化操作体验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-05 23:20
zh-downloader 是一款非常好用的视频下载工具,它可以帮助用户下载知乎页面上的所有视频和图片,对于一些喜欢访问知乎的用户,您可以轻松帮助自己去获取你喜欢的资源。另外,该软件可以将下载的资源自动转换成MP4格式,喜欢就下载试试吧!
软件特点
有没有什么工具可以嗅探知乎上的视频并在下载时自动转换成mp4格式?
答案就是这个zh-downloader插件,在商店里比较冷门。
它可以帮助我们快速检测到知乎页面上的视频。还支持下载时选择分辨率,以及分享、查看下载进度等操作。下载完成后的视频格式为mp4,无需二次转换。,非常强大实用。
指示
打开任意带有视频的知乎页面,插件会自动检测是否有资源,嗅探视频的数量会以角标的形式出现在图标上。
这时,点击工具栏上的插件图标,可以看到下载菜单窗口。
与Video Downloader Professional相比,zh-downloader嗅探的视频资源会显示标题和缩略图,非常直观。
同时,您可以直接选择下载视频的定义,查看下载进度,以及分享和删除操作。
更新日志
1.修复已知bug
2.优化操作体验 查看全部
网页视频抓取工具 知乎(更新日志1.修复bug2.修复已知bug优化操作体验)
zh-downloader 是一款非常好用的视频下载工具,它可以帮助用户下载知乎页面上的所有视频和图片,对于一些喜欢访问知乎的用户,您可以轻松帮助自己去获取你喜欢的资源。另外,该软件可以将下载的资源自动转换成MP4格式,喜欢就下载试试吧!
软件特点
有没有什么工具可以嗅探知乎上的视频并在下载时自动转换成mp4格式?
答案就是这个zh-downloader插件,在商店里比较冷门。
它可以帮助我们快速检测到知乎页面上的视频。还支持下载时选择分辨率,以及分享、查看下载进度等操作。下载完成后的视频格式为mp4,无需二次转换。,非常强大实用。
指示
打开任意带有视频的知乎页面,插件会自动检测是否有资源,嗅探视频的数量会以角标的形式出现在图标上。
这时,点击工具栏上的插件图标,可以看到下载菜单窗口。
与Video Downloader Professional相比,zh-downloader嗅探的视频资源会显示标题和缩略图,非常直观。
同时,您可以直接选择下载视频的定义,查看下载进度,以及分享和删除操作。
更新日志
1.修复已知bug
2.优化操作体验
网页视频抓取工具 知乎(装机软件数量的繁多和平日课程、细节不足之处还望海涵 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-03 23:06
)
前言:
安装的软件很多,平日的课程,实习,考研时间紧,但还是忍不住想分享,一直想写这个答案。我会用不断的更新来补充和修改,争取在下周内完成这个答案。以下是一些已经大致介绍过的软件,不足的细节还是王海涵。
一些非常棒的Windows软件,我认为它们不应该只被少数人知道,或者随着时间的推移逐渐被埋没甚至消失。
“分割线”
————————————————————————————————————————————
以下推荐均基于Windows环境,使用十余个月后选择。安装过程中无附加软件,使用过程中无广告。内存占用小,对整机性能没有任何拖累。它是一些我认为在某些功能上非常强大和有趣的Windows软件,并为生活带来了很多乐趣。
各个程序的安装过程将在以后的主题文章中进行描述和解释。很多软件很容易混用忘记,留教程以备后患,预防痴呆。
软件分类:远程协助、录屏软件、图像处理、整机文件查询、视频下载、音频播放、分屏软件、思维导图、电脑界面修改、安卓虚拟机、360极速浏览插件等一些有趣实用的网址推荐。
1. 远程协助不得不提:TeamViewer,一款好用、专业、强大的企业级良心应用。
2. 这次所有截图使用的软件:FastStone Capture(原则上应该叫Screen Recorder,但我个人觉得它的截图功能是最强大的体现) 上面说了,功能很强大!
列出最常用的:
还有一些小功能,因为正常使用的频率不是太高,这里就不详细解释了。但也有一些实用的功能可以解决生活中的应用之痒。
归根结底,这一切都不容忽视:所有这些功能都基于一个只有几MB大小的软件,完美诠释了“小人大排量”的含义!
3. 图片查看和简单的图片处理有:ACDSee,一款专业级的图片查看软件。
总结的优点包括:
例如:前段时间,3D 打印涉及在月球表面查看和裁剪图像。单看前期1.6G原创大小的图片,证明ACDSee是当之无愧的看图王者!只有它才能在目前能遇到的涉及图片浏览的场合承担起这个重要的任务。
4. 另一个图像处理软件是:PhotoZoom
它只有一个功能,而且是经常用到的功能:
5.文件查询的最终选择是:Listary
之前用过Everything,也是很多人推荐的一款软件。但是经过长期使用,我还是觉得Listary更胜一筹。优点如下:
6.支持大部分网站视频下载软件:ShuoMo
配合我经常使用的chrome内核360极速浏览器插件,实现了主要网站规则和不规则视频的本地下载。
一般应用场景有:网站公共类视频数据下载和付费网站视频本地下载保存。
7.音频播放也是视频播放:Potplayer
没有图,也没有更详细的解释,就一句话总结:
无数视频播放软件无法解决的痒痛点。当然,在其他方面,potplayer 提供的操作也非常丰富,提供了强大而细致的视频播放设置。我不会在这里详细介绍。等待你的探索,记得回来留言分享更多使用方法和技巧。
8. 大大提高工作效率的专业级分屏软件:Dexpot
这里提供的软件有一个特点:简洁、专业。分屏软件很多,Dexpot给我留下的印象是Thinkpad:专业,很少出错。开机后会自动启动,一直运行,好像随时可以忽略一样。快捷键随时切换alt+123分屏,支持3、6、9、12分屏扩展,根据自己的需要和电脑本身的性能。解决了在同一个屏幕上打开多个程序并长时间观看导致的混乱和自我尴尬。
9.组织想法的强大工具:Mindjet Mindmanager 思维导图
应该有很多人知道和使用它,但我在综合性大学或信息技术学院,我周围的很多人对它知之甚少。一定看过思维导图做出来的成品,但是不知道是什么软件做出来的。暂时不为公众所知。
10.电脑界面改Macbook底部浮动条中的图标排序软件:来自SoftMedia Cube的Mydesk
SoftMedia's Cube安装完成后,可以在自定义安装文件夹中找到独立程序,单独选择使用,卸载之前安装的主程序。
12.安卓虚拟机:海马玩模拟器是全网最受好评的模拟器,也是支持环境最丰富的虚拟机。
13.360极速浏览插件和一些有趣有用的网站推荐。
一定有理由喜欢去某些东西,例如方便的浏览器。我选择一直使用360极速浏览器的原因很简单:
两个重要的激励措施:
查看全部
网页视频抓取工具 知乎(装机软件数量的繁多和平日课程、细节不足之处还望海涵
)
前言:
安装的软件很多,平日的课程,实习,考研时间紧,但还是忍不住想分享,一直想写这个答案。我会用不断的更新来补充和修改,争取在下周内完成这个答案。以下是一些已经大致介绍过的软件,不足的细节还是王海涵。
一些非常棒的Windows软件,我认为它们不应该只被少数人知道,或者随着时间的推移逐渐被埋没甚至消失。
“分割线”
————————————————————————————————————————————
以下推荐均基于Windows环境,使用十余个月后选择。安装过程中无附加软件,使用过程中无广告。内存占用小,对整机性能没有任何拖累。它是一些我认为在某些功能上非常强大和有趣的Windows软件,并为生活带来了很多乐趣。
各个程序的安装过程将在以后的主题文章中进行描述和解释。很多软件很容易混用忘记,留教程以备后患,预防痴呆。
软件分类:远程协助、录屏软件、图像处理、整机文件查询、视频下载、音频播放、分屏软件、思维导图、电脑界面修改、安卓虚拟机、360极速浏览插件等一些有趣实用的网址推荐。
1. 远程协助不得不提:TeamViewer,一款好用、专业、强大的企业级良心应用。
2. 这次所有截图使用的软件:FastStone Capture(原则上应该叫Screen Recorder,但我个人觉得它的截图功能是最强大的体现) 上面说了,功能很强大!
列出最常用的:
还有一些小功能,因为正常使用的频率不是太高,这里就不详细解释了。但也有一些实用的功能可以解决生活中的应用之痒。
归根结底,这一切都不容忽视:所有这些功能都基于一个只有几MB大小的软件,完美诠释了“小人大排量”的含义!
3. 图片查看和简单的图片处理有:ACDSee,一款专业级的图片查看软件。
总结的优点包括:
例如:前段时间,3D 打印涉及在月球表面查看和裁剪图像。单看前期1.6G原创大小的图片,证明ACDSee是当之无愧的看图王者!只有它才能在目前能遇到的涉及图片浏览的场合承担起这个重要的任务。
4. 另一个图像处理软件是:PhotoZoom
它只有一个功能,而且是经常用到的功能:
5.文件查询的最终选择是:Listary
之前用过Everything,也是很多人推荐的一款软件。但是经过长期使用,我还是觉得Listary更胜一筹。优点如下:
6.支持大部分网站视频下载软件:ShuoMo
配合我经常使用的chrome内核360极速浏览器插件,实现了主要网站规则和不规则视频的本地下载。
一般应用场景有:网站公共类视频数据下载和付费网站视频本地下载保存。
7.音频播放也是视频播放:Potplayer
没有图,也没有更详细的解释,就一句话总结:
无数视频播放软件无法解决的痒痛点。当然,在其他方面,potplayer 提供的操作也非常丰富,提供了强大而细致的视频播放设置。我不会在这里详细介绍。等待你的探索,记得回来留言分享更多使用方法和技巧。
8. 大大提高工作效率的专业级分屏软件:Dexpot
这里提供的软件有一个特点:简洁、专业。分屏软件很多,Dexpot给我留下的印象是Thinkpad:专业,很少出错。开机后会自动启动,一直运行,好像随时可以忽略一样。快捷键随时切换alt+123分屏,支持3、6、9、12分屏扩展,根据自己的需要和电脑本身的性能。解决了在同一个屏幕上打开多个程序并长时间观看导致的混乱和自我尴尬。
9.组织想法的强大工具:Mindjet Mindmanager 思维导图
应该有很多人知道和使用它,但我在综合性大学或信息技术学院,我周围的很多人对它知之甚少。一定看过思维导图做出来的成品,但是不知道是什么软件做出来的。暂时不为公众所知。
10.电脑界面改Macbook底部浮动条中的图标排序软件:来自SoftMedia Cube的Mydesk
SoftMedia's Cube安装完成后,可以在自定义安装文件夹中找到独立程序,单独选择使用,卸载之前安装的主程序。
12.安卓虚拟机:海马玩模拟器是全网最受好评的模拟器,也是支持环境最丰富的虚拟机。
13.360极速浏览插件和一些有趣有用的网站推荐。
一定有理由喜欢去某些东西,例如方便的浏览器。我选择一直使用360极速浏览器的原因很简单:
两个重要的激励措施:
网页视频抓取工具 知乎(Python爬虫的学习笔记(二):网络爬虫开发实战)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-03 17:16
今天给大家分享一下Python爬虫的学习笔记。我的Python爬虫从崔庆才老师的《网络爬虫开发实战》开始。学习了各种Python爬虫策略和算法,并结合实践总结。三方面解释:什么是爬虫?为什么要学习爬行?如何学习爬行?这三个问题是解决大多数问题的过程。以下分享小默的学习笔记等建议,请及时联系我
♂️1、什么是爬虫?
让我从定义开始:网络爬虫(网络蜘蛛、网络机器人)是抓取网络数据的程序。一共有三个关键词。一是爬虫是程序,就是我们用(Python等)语言写的代码,二是爬虫工具。这个过程包括主动查询、筛选和记录的过程。爬取的目标是网络数据。
总结起来就是用Python程序模仿人,进行网站访问,获取必要的网络数据。模仿的越逼真越好。
♂️2、 为什么要学爬?
直接的原因当然是为了获取数据!至于得到的数据类型,可以说有很多不同的类型。从数据结构上可以区分,包括结构化数据类型、非结构化数据类型,结构化数据有固定的格式,比如HTML、XML、JSON格式,这些格式都是与数据结构相关的数据结构。网页的语言。非结构化数据包括图片、音频、视频等,这些“数据结构”一般以二进制格式存储。
我们生活在信息和数字时代。获取这些数据可以实现我们生活和工作中的很多目标,包括自驾游策略搜索、专注信息搜索、毕业论文数据抓取等。对我来说,爬虫做量化交易中舆情策略必不可少的工具,爬通过爬虫获取投资者情绪和行业信息,这也是各大金融机构投研人员获取行情信息的手段之一!
目前,企业对各类数据的使用呈指数级增长。企业获取数据的方式包括企业自有数据,即企业日常业务过程中产生的数据。当自己的数据不能满足需求时,企业就需要从互联网上抓取数据。或者从外部平台购买数据。购买数据的平台包括数据堂、贵阳大数据交易所等近年来新兴的交易平台。这些平台的交易价格相对较高。因此,爬虫技术越来越受到企业的重视。大量相关技术人员也在招聘中,薪资理想(毕竟节省了公司购买平台数据的成本)。我正在清华一线队学习一门课程。
♂️3、如何开始和学习爬行?
经过上面的介绍,小伙伴们就知道爬虫的定义和市场定位了。下面介绍一下爬虫的流程架构,和我们日常上网流程一样,包括三个步骤:(1)发送请求(上网时输入网址,回车)---- (2)获取请求(远程服务器返回网页数据)----(3)解析请求(网页将HTML语言转换为文字、图片、视频等)。
♂️具体操作过程请期待下一篇文章。. . 小默的爬虫没了。. .
这是我2018年入职两个月后在办公室读的一本书,家里还有很多书。一种更有效的学习方式是观看视频课程。有需要材料的童鞋可以给我留言哦! 查看全部
网页视频抓取工具 知乎(Python爬虫的学习笔记(二):网络爬虫开发实战)
今天给大家分享一下Python爬虫的学习笔记。我的Python爬虫从崔庆才老师的《网络爬虫开发实战》开始。学习了各种Python爬虫策略和算法,并结合实践总结。三方面解释:什么是爬虫?为什么要学习爬行?如何学习爬行?这三个问题是解决大多数问题的过程。以下分享小默的学习笔记等建议,请及时联系我
♂️1、什么是爬虫?
让我从定义开始:网络爬虫(网络蜘蛛、网络机器人)是抓取网络数据的程序。一共有三个关键词。一是爬虫是程序,就是我们用(Python等)语言写的代码,二是爬虫工具。这个过程包括主动查询、筛选和记录的过程。爬取的目标是网络数据。
总结起来就是用Python程序模仿人,进行网站访问,获取必要的网络数据。模仿的越逼真越好。
♂️2、 为什么要学爬?
直接的原因当然是为了获取数据!至于得到的数据类型,可以说有很多不同的类型。从数据结构上可以区分,包括结构化数据类型、非结构化数据类型,结构化数据有固定的格式,比如HTML、XML、JSON格式,这些格式都是与数据结构相关的数据结构。网页的语言。非结构化数据包括图片、音频、视频等,这些“数据结构”一般以二进制格式存储。
我们生活在信息和数字时代。获取这些数据可以实现我们生活和工作中的很多目标,包括自驾游策略搜索、专注信息搜索、毕业论文数据抓取等。对我来说,爬虫做量化交易中舆情策略必不可少的工具,爬通过爬虫获取投资者情绪和行业信息,这也是各大金融机构投研人员获取行情信息的手段之一!
目前,企业对各类数据的使用呈指数级增长。企业获取数据的方式包括企业自有数据,即企业日常业务过程中产生的数据。当自己的数据不能满足需求时,企业就需要从互联网上抓取数据。或者从外部平台购买数据。购买数据的平台包括数据堂、贵阳大数据交易所等近年来新兴的交易平台。这些平台的交易价格相对较高。因此,爬虫技术越来越受到企业的重视。大量相关技术人员也在招聘中,薪资理想(毕竟节省了公司购买平台数据的成本)。我正在清华一线队学习一门课程。
♂️3、如何开始和学习爬行?
经过上面的介绍,小伙伴们就知道爬虫的定义和市场定位了。下面介绍一下爬虫的流程架构,和我们日常上网流程一样,包括三个步骤:(1)发送请求(上网时输入网址,回车)---- (2)获取请求(远程服务器返回网页数据)----(3)解析请求(网页将HTML语言转换为文字、图片、视频等)。
♂️具体操作过程请期待下一篇文章。. . 小默的爬虫没了。. .
这是我2018年入职两个月后在办公室读的一本书,家里还有很多书。一种更有效的学习方式是观看视频课程。有需要材料的童鞋可以给我留言哦!
网页视频抓取工具 知乎(B站小程序形式往公众号文章插入21个视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-03 17:13
自微信小程序诞生以来,腾讯一直在完善小程序生态。越来越多的应用厂商也开发了微信小程序。B站就是其中之一。
公众号文章是一个网页,但不像网页那样免费。不能有iframe,没有js等,视频必须从公众号资源中添加。视频数量也限制为3个,但小程序卡数量没有限制。因此,使用B站小程序是一种向公众号文章添加3个以上视频的方式。我上次嵊泗游记在文章中插入了21个视频。
无数人通过B站小程序的形式写了把视频插入公众号文章的教程,但是一个av号下却有好几个视频。昨天写游记的时候想插在文章。嵊泗VLOG视频的P2、P3找不到路。全网找不到让B站的小程序打开玩P2的教程,于是尝试了cid、p、page等各种参数,终于研究了找到方法,分享给大家,并启动全网!
1、编辑公众号时文章,点击顶部工具栏【小程序】添加小程序
2、 在搜索框中输入【哔哔哔哔】,点击右侧搜索按钮,找到哔哔小程序后点击下一步
3、用电脑打开要插入的B站视频,将鼠标移动到视频下方的分享按钮,在右边的代码中找到[aid=]和[&bvid]之间的数字嵌入代码,比如这个视频是762843740,这是视频的av号,复制一下
(这一步只需要获取av号,如果你安装了Anti BV等脚本,只需要从地址栏复制av号即可)
4、在【小程序路径】中填写pages/video/video.html?avid=762843740,最后一个数字就是刚刚找到的视频av号
其他网上教程到此结束,所以也可以跳转到B站小程序的指定视频,但是如果是多P视频,只能跳转到第一个。以下是本教程全网重点部分。
5、如果要打开多P视频,后面会P2、P3等视频,然后在小程序路径后面加上&page=number of episodes-1。例如,打开P2,在小程序路径后添加&page=1,打开P3,在小程序路径后添加&page=2。
6、最后可以根据需要选择插入文字、图片、卡片或小程序代码。
这样插入的小程序链接一打开就可以跳转到指定的剧集号,无需用户再次手动切换
允许标准转载,所有内容必须保留
原文发表于【01之翼】知乎文章 /p/423307013
本文同时发表于【01之翼】公众号/s/GvdHgMJYWrlvrrBDH7H94Q
2021 年 10 月 19 日 查看全部
网页视频抓取工具 知乎(B站小程序形式往公众号文章插入21个视频)
自微信小程序诞生以来,腾讯一直在完善小程序生态。越来越多的应用厂商也开发了微信小程序。B站就是其中之一。
公众号文章是一个网页,但不像网页那样免费。不能有iframe,没有js等,视频必须从公众号资源中添加。视频数量也限制为3个,但小程序卡数量没有限制。因此,使用B站小程序是一种向公众号文章添加3个以上视频的方式。我上次嵊泗游记在文章中插入了21个视频。
无数人通过B站小程序的形式写了把视频插入公众号文章的教程,但是一个av号下却有好几个视频。昨天写游记的时候想插在文章。嵊泗VLOG视频的P2、P3找不到路。全网找不到让B站的小程序打开玩P2的教程,于是尝试了cid、p、page等各种参数,终于研究了找到方法,分享给大家,并启动全网!
1、编辑公众号时文章,点击顶部工具栏【小程序】添加小程序
2、 在搜索框中输入【哔哔哔哔】,点击右侧搜索按钮,找到哔哔小程序后点击下一步
3、用电脑打开要插入的B站视频,将鼠标移动到视频下方的分享按钮,在右边的代码中找到[aid=]和[&bvid]之间的数字嵌入代码,比如这个视频是762843740,这是视频的av号,复制一下
(这一步只需要获取av号,如果你安装了Anti BV等脚本,只需要从地址栏复制av号即可)
4、在【小程序路径】中填写pages/video/video.html?avid=762843740,最后一个数字就是刚刚找到的视频av号
其他网上教程到此结束,所以也可以跳转到B站小程序的指定视频,但是如果是多P视频,只能跳转到第一个。以下是本教程全网重点部分。
5、如果要打开多P视频,后面会P2、P3等视频,然后在小程序路径后面加上&page=number of episodes-1。例如,打开P2,在小程序路径后添加&page=1,打开P3,在小程序路径后添加&page=2。
6、最后可以根据需要选择插入文字、图片、卡片或小程序代码。
这样插入的小程序链接一打开就可以跳转到指定的剧集号,无需用户再次手动切换
允许标准转载,所有内容必须保留
原文发表于【01之翼】知乎文章 /p/423307013
本文同时发表于【01之翼】公众号/s/GvdHgMJYWrlvrrBDH7H94Q
2021 年 10 月 19 日
网页视频抓取工具 知乎(关键词处理标题是用来告诉用户和搜索引擎这个网页的主要内容是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-03 04:08
C、添加文章Content关键词链接,链接到本站相关页面。
D. 创建站点地图。构建完整的站点地图,包括所有内容的最终页面,即站点范围的文章索引页。同时seo关键词知乎(用来告诉用户和搜索引擎这个页面的主要内容是什么,搜索引擎,标题,关键词处理),把这个链接放在首页,让搜索引擎可以找到并抓取站点地图页面;如果是大型网站seo关键字知乎,可以按照栏目列出主要类别。
E. 写一个总结文章 或设置一个主题。一般来说,可以简单介绍一下这个月写的文章,并链接到具体内容页面。或者将同一主题的内容合并为一个文章。
F、alt标签可以让用户在图片无法以较慢的速度显示的情况下了解图片所传达的信息,也可以让搜索引擎了解图片的内容。
四、标题,关键词处理
标题是用来告诉用户和搜索引擎这个页面的主要内容是什么。当搜索引擎确定网页内容的权重时,标题是主要参考信息之一。每个网页都应该有一个唯一的标题。
关键词 非常重要。它们需要准确定位,不应随意修改。可以设置多个关键词,但不要太多,适当就好,不要重置积累的关键词,对搜索引擎不友好。关键字应以逗号分隔。
首页栏目页频道页第一句收录页面标题+第二句描述关键词+第三句摘要内容页:文章适当加长尾的介绍关键词@ >
五、 检查 404
子墨SEO前的这篇文章告诉你如何找到404以及如何解决
六、 定期定量发表文章
百度对新版网站有审核期。即使百度收录有你的内容网站,也不会立即发布。只要你定期、每天发布原创的内容,审核期很快就会过去,收录的页面会逐步发布。出来。
定期发布新内容,让网站形成持续稳定的更新模式,让蜘蛛发现这种模式,实现定时爬取。这是百度第二个收录的一个非常关键的因素。这就像在固定的时间和约会吃饭。这样的更新模式形成后,蜘蛛该来的时候就会来。二是定量释放。每天保持一个恒定的数字。今天避免一个文章,明天避免十个文章。搜索引擎会认为你的网站不稳定且善变,避免被降级和沙盒化。
网页越丰富,网站中的网页越多,这样的网站对用户浏览的吸引力就越大。现在搜索引擎越来越注重用户体验。如果用户体验好,搜索引擎自然可以更好地对你的网站进行更好的排名。内容更新是网站生存的基础。一个网站想要活跃、丰富、足够长以吸引和留住人,就必须掌握网站的更新频率。
七、 外链建设
新的网站上线了。如果想收录快照,可以每天定时添加外链,引导搜索引擎抓取网站。不要过度构建外部链接。慢慢来。新网站上线时,不要过于激进地发布外部链接。信权重低,容易被百度判断为作弊,容易出现网站的问题:首页不再第一,关键词的排名消失。所以大家还是比较关注内容的。外链通过审核期后,每天会定期添加外链。不要让外链随波逐流!不要突然增加,否则就是k。
外链构建方法:
1、友情链接
2、 网站 有自己的特点和独特的功能来获取他人的活跃链接
3、发送给第三方,发送新闻,其他网站转载seo关键词知乎,获取链接
4、去其他论坛和博客,留言内容里有链接 查看全部
网页视频抓取工具 知乎(关键词处理标题是用来告诉用户和搜索引擎这个网页的主要内容是什么)
C、添加文章Content关键词链接,链接到本站相关页面。
D. 创建站点地图。构建完整的站点地图,包括所有内容的最终页面,即站点范围的文章索引页。同时seo关键词知乎(用来告诉用户和搜索引擎这个页面的主要内容是什么,搜索引擎,标题,关键词处理),把这个链接放在首页,让搜索引擎可以找到并抓取站点地图页面;如果是大型网站seo关键字知乎,可以按照栏目列出主要类别。
E. 写一个总结文章 或设置一个主题。一般来说,可以简单介绍一下这个月写的文章,并链接到具体内容页面。或者将同一主题的内容合并为一个文章。
F、alt标签可以让用户在图片无法以较慢的速度显示的情况下了解图片所传达的信息,也可以让搜索引擎了解图片的内容。
四、标题,关键词处理
标题是用来告诉用户和搜索引擎这个页面的主要内容是什么。当搜索引擎确定网页内容的权重时,标题是主要参考信息之一。每个网页都应该有一个唯一的标题。
关键词 非常重要。它们需要准确定位,不应随意修改。可以设置多个关键词,但不要太多,适当就好,不要重置积累的关键词,对搜索引擎不友好。关键字应以逗号分隔。
首页栏目页频道页第一句收录页面标题+第二句描述关键词+第三句摘要内容页:文章适当加长尾的介绍关键词@ >
五、 检查 404
子墨SEO前的这篇文章告诉你如何找到404以及如何解决
六、 定期定量发表文章
百度对新版网站有审核期。即使百度收录有你的内容网站,也不会立即发布。只要你定期、每天发布原创的内容,审核期很快就会过去,收录的页面会逐步发布。出来。
定期发布新内容,让网站形成持续稳定的更新模式,让蜘蛛发现这种模式,实现定时爬取。这是百度第二个收录的一个非常关键的因素。这就像在固定的时间和约会吃饭。这样的更新模式形成后,蜘蛛该来的时候就会来。二是定量释放。每天保持一个恒定的数字。今天避免一个文章,明天避免十个文章。搜索引擎会认为你的网站不稳定且善变,避免被降级和沙盒化。
网页越丰富,网站中的网页越多,这样的网站对用户浏览的吸引力就越大。现在搜索引擎越来越注重用户体验。如果用户体验好,搜索引擎自然可以更好地对你的网站进行更好的排名。内容更新是网站生存的基础。一个网站想要活跃、丰富、足够长以吸引和留住人,就必须掌握网站的更新频率。
七、 外链建设
新的网站上线了。如果想收录快照,可以每天定时添加外链,引导搜索引擎抓取网站。不要过度构建外部链接。慢慢来。新网站上线时,不要过于激进地发布外部链接。信权重低,容易被百度判断为作弊,容易出现网站的问题:首页不再第一,关键词的排名消失。所以大家还是比较关注内容的。外链通过审核期后,每天会定期添加外链。不要让外链随波逐流!不要突然增加,否则就是k。
外链构建方法:
1、友情链接
2、 网站 有自己的特点和独特的功能来获取他人的活跃链接
3、发送给第三方,发送新闻,其他网站转载seo关键词知乎,获取链接
4、去其他论坛和博客,留言内容里有链接

