
网页表格抓取
网页表格抓取(基于MSHTML设计开发的原理、程序结构和网页元素属性表格化显示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-01-16 16:27
罗进才
【摘要】介绍了基于MSHTML设计开发的网页信息表格提取程序的原理、程序结构和工作流程。使用网页信息提取、网页元素分析、采集配置管理三个功能模块,提取网页信息。其内部相关信息的提取、解析、排序和表格展示,创新性地采用二进制检查机制确认网页属性值和树形路径值,可以实现对指定信息的准确提取。本文还说明了程序的操作步骤和实际效果。
【关键词】MSHTML信息自动提取网页元素属性并以表格形式展示
[CLC 编号] G64 [文档识别码] A [文章 编号] 2095-3089 (2017)10-0229-02
介绍
当今是网络飞速发展、信息量迅速膨胀的信息时代。人们通过信息相互交流,了解世界。信息中有很多有价值的信息元素,这些有价值的信息元素大多以网页的形式存在,其内容和格式差异很大。通过浏览器浏览阅读是没有问题的,但是如果需要保存和整理某类感兴趣的信息及其内部相关信息,常用的工具一般都有一些不足,比如网络蜘蛛等爬虫工具. 无法实现内部相关信息的提取。因此笔者使用MSHTML语言设计了一个网页内部表格抽取自动程序,
1.程序设计思路
1.1 采集原理
众所周知,网页是用 HTML 语言描述的。采集网页信息的本质是从网页的HTML代码中提取出我们需要的信息。如果直接从代码中提取,就只能使用正则表达式等文本匹配的方式来采集。这会导致以下问题:一是使用不方便。用户不仅需要了解 HTML,还需要了解正则表达式。另外,他们需要在大量的 HTML 代码中找到需要的信息,然后再考虑如何匹配;二是容错性差。,如果代码稍有偏差,会导致文本匹配失败,比如遇到制表符、回车、空格等。
经过长期研究,作者发现MSHTML可以有效解决这些问题。MSHTML是微软公司的一个COM组件,它将所有元素及其属性封装在HTML语言中,可以通过它提供的标准接口访问指定网页的所有元素。
MSHTML 提供丰富的 HTML 文档接口,包括 7 种 IHTMLDocument、IHTMLDocument2、…、IHTMLDocument7 等。其中,IHTMLDocument只有一个Script属性,用于管理页面脚本; IHTMLDocument2接口与C#的HtmlDocument类非常相似(即直接通过Web Browser控件获取的Document属性); IHTMLDocument3 与 Visual Basic 6.0 相同。一个类似于文档对象的接口,基本上可以使用的方法都在里面。 MSHTML 还提供了 IHTMLElement 接口,封装了 HTML 元素的完整操作。通过IHTMLElement可以准确判断HTML元素节点的类型,获取HTML元素节点的所有属性。
1.2 二进制校验机制
通过比较元素属性值,基本可以判断一个元素节点是否为采集的节点。由于网络中网页信息属性值相同的元素节点比例较高,相同属性值不能唯一指定节点为采集,还需要其他约束。通过分析发现,MSHTML还提供了访问当前节点的父节点的功能。我们可以通过回溯父节点来获取该节点在 HTML 文档树中的路径。这样,通过同时比较网页元素的属性值和树形路径值,就可以准确判断该节点是否为需要采集的节点。
使用属性值和树路径值进行元素验证的双重检查机制是作者的创新。该技术不仅可以大大提高采集节点的准确率,保证程序运行的效果,而且由于程序中使用了智能判断语句,保证了程序的运行效率,同时考虑到用户具有良好的用户体验。
1.3主要功能设计
网页信息列表提取程序可以实现网页信息的可配置采集,并将信息列表保存。程序主要分为三个功能模块:
1.网页信息提取功能模块。提供信息提取功能的主界面,输入采集网址,采集页码,启动采集。
2.网页元素分析功能模块。将html代码解析成网页元素列表,自动生成采集项的DOM树路径,方便脚本编写。
3.采集配置管理功能模块。用于管理采集配置,提供添加、编辑、删除等功能。
3.程序的主要功能实现方法
3.1采集配置管理
采集配置信息存储在数据库中,主要由一对主从表记录。主表记录了对应的网站采集配置名、域名、翻页设置、加载等待设置等信息。记录 采集 项的名称、ID、ClassName、TagName 和表格中网页元素的 DOM 树路径。
3.2 网页元素分析
该函数的目标是将网页的 HTML 代码解析为 HTML DOM 网页元素,并列出它们的各种属性值。通过遍历网页的元素,找出想要的采集数据项和下一页的web元素,记录在采集配置表中,同时添加DOM树采集 项的路径自动记录在配置表中。
3.2 自动提取网页信息
该函数将网页中需要采集的数据项采集转换成数据表,最后以XML文档的形式保存。该程序的工作原理如下:
Step1:遍历网页中的所有元素,count变量记录网页元素的个数。
Step2:将每个元素与采集配置中的采集项配置进行比较,判断该元素是否为采集元素。tab_item是一个adotable变量,记录了当前页面的采集配置,webbro.OleObject.document.all.item(i)变量是网页元素,itembyscript()函数会判断是否网页元素需要采集。
Step3:如果元素需要采集元素,进一步判断数据列缓存行中是否有采集项的数据。如果没有,则将采集 中的数据存入行,如果有,则通过addrec() 函数将采集 中的数据行存入XML 文档。
4.运行测试
4.1 读页
本示例将使用厦门本地知名论坛小鱼社区的帖子进行测试。网页中的html代码会被解析成网页元素列表,并显示在“元素”页面中。
图1 读取页面信息
4.2 配置采集
将操作界面切换到“元素”页面,可以看到网页元素列表,在列表中找到需要采集的网页元素。setup采集 配置如下:
(1) 翻页。首先找到“下一页”链接的网页元素,其tagname属性值为“A”,innertext属性值为“下一页”。设置为“下一页” 采集 项。
(2)作者。所属的网页元素,classname属性值为“readName b”,tagname属性值为“DIV”。
(3)Body.所属页面元素,classname属性值为“tpc_content”,tagname属性值为“DIV”。
(4)DOM树路径。DOM路径是通过网页元素列表自动生成的。
4.3查看采集结果
图 2 采集 结果的表格显示
5.结束语
随着互联网的快速发展,人们对网页元素的需求越来越转向个性化分类和精准提取。之前对所有内容的粗暴的采集方法已经不能满足现在的需求。研究是积极的。
网页信息表格提取程序通过网页信息提取、网页元素分析、采集 配置管理。克服了以往网页信息爬取工具无法提取内部相关网页信息的缺点,使程序的适用性和扩展性显着提高,程序创新性地采用了二进制校验机制来确认网页属性值和树路径值。可以实现对指定信息的准确提取,大大提高了程序结果的准确性。
网页信息表格提取程序虽然在准确性、适用性和可扩展性方面取得了进步,但仍存在一些不足,希望以后能找到更好的解决方案。
1.部分操作界面的用户自动化程序不足,操作比较复杂。
2.海量数据不兼容,处理效率低。由于程序的采集页面使用了WebBrowser技术,采集的效率较低,在处理大数据时会出现效率低的问题。有必要寻找更好的技术方法进行优化。
参考:
[1] 方勇,李寅生. 一种基于DOM状态转移的隐藏网页信息提取算法[J]. 计算机应用与软件, 2015, (09): 17-21.
[2] 张建英,王家梅,棠雪,胡刚。易文网络信息采集技术研究[J]. 网络安全技术与应用, 2014, (12): 6-8.@ >
[3] 孙宝华. 企业社交媒体主题信息抽取算法研究[J]. 煤炭, 2014, (01): 72-76.
[4] 金涛.网络爬虫在网页信息提取中的应用研究[J]. 现代计算机(专业版),2012,(01):16-18.@>
[5]朱志宁,黄庆松.快速中文网页分类方法的实现[J].山西电子科技, 2008, (04):7-9.
[6] 高军,王腾蛟,杨冬青,唐世伟。基于Ontology的Web内容两阶段半自动提取方法[J]. 中国计算机学报, 2004, (03): 310-318.@> 查看全部
网页表格抓取(基于MSHTML设计开发的原理、程序结构和网页元素属性表格化显示)
罗进才
【摘要】介绍了基于MSHTML设计开发的网页信息表格提取程序的原理、程序结构和工作流程。使用网页信息提取、网页元素分析、采集配置管理三个功能模块,提取网页信息。其内部相关信息的提取、解析、排序和表格展示,创新性地采用二进制检查机制确认网页属性值和树形路径值,可以实现对指定信息的准确提取。本文还说明了程序的操作步骤和实际效果。
【关键词】MSHTML信息自动提取网页元素属性并以表格形式展示
[CLC 编号] G64 [文档识别码] A [文章 编号] 2095-3089 (2017)10-0229-02
介绍
当今是网络飞速发展、信息量迅速膨胀的信息时代。人们通过信息相互交流,了解世界。信息中有很多有价值的信息元素,这些有价值的信息元素大多以网页的形式存在,其内容和格式差异很大。通过浏览器浏览阅读是没有问题的,但是如果需要保存和整理某类感兴趣的信息及其内部相关信息,常用的工具一般都有一些不足,比如网络蜘蛛等爬虫工具. 无法实现内部相关信息的提取。因此笔者使用MSHTML语言设计了一个网页内部表格抽取自动程序,
1.程序设计思路
1.1 采集原理
众所周知,网页是用 HTML 语言描述的。采集网页信息的本质是从网页的HTML代码中提取出我们需要的信息。如果直接从代码中提取,就只能使用正则表达式等文本匹配的方式来采集。这会导致以下问题:一是使用不方便。用户不仅需要了解 HTML,还需要了解正则表达式。另外,他们需要在大量的 HTML 代码中找到需要的信息,然后再考虑如何匹配;二是容错性差。,如果代码稍有偏差,会导致文本匹配失败,比如遇到制表符、回车、空格等。
经过长期研究,作者发现MSHTML可以有效解决这些问题。MSHTML是微软公司的一个COM组件,它将所有元素及其属性封装在HTML语言中,可以通过它提供的标准接口访问指定网页的所有元素。
MSHTML 提供丰富的 HTML 文档接口,包括 7 种 IHTMLDocument、IHTMLDocument2、…、IHTMLDocument7 等。其中,IHTMLDocument只有一个Script属性,用于管理页面脚本; IHTMLDocument2接口与C#的HtmlDocument类非常相似(即直接通过Web Browser控件获取的Document属性); IHTMLDocument3 与 Visual Basic 6.0 相同。一个类似于文档对象的接口,基本上可以使用的方法都在里面。 MSHTML 还提供了 IHTMLElement 接口,封装了 HTML 元素的完整操作。通过IHTMLElement可以准确判断HTML元素节点的类型,获取HTML元素节点的所有属性。
1.2 二进制校验机制
通过比较元素属性值,基本可以判断一个元素节点是否为采集的节点。由于网络中网页信息属性值相同的元素节点比例较高,相同属性值不能唯一指定节点为采集,还需要其他约束。通过分析发现,MSHTML还提供了访问当前节点的父节点的功能。我们可以通过回溯父节点来获取该节点在 HTML 文档树中的路径。这样,通过同时比较网页元素的属性值和树形路径值,就可以准确判断该节点是否为需要采集的节点。
使用属性值和树路径值进行元素验证的双重检查机制是作者的创新。该技术不仅可以大大提高采集节点的准确率,保证程序运行的效果,而且由于程序中使用了智能判断语句,保证了程序的运行效率,同时考虑到用户具有良好的用户体验。
1.3主要功能设计
网页信息列表提取程序可以实现网页信息的可配置采集,并将信息列表保存。程序主要分为三个功能模块:
1.网页信息提取功能模块。提供信息提取功能的主界面,输入采集网址,采集页码,启动采集。
2.网页元素分析功能模块。将html代码解析成网页元素列表,自动生成采集项的DOM树路径,方便脚本编写。
3.采集配置管理功能模块。用于管理采集配置,提供添加、编辑、删除等功能。
3.程序的主要功能实现方法
3.1采集配置管理
采集配置信息存储在数据库中,主要由一对主从表记录。主表记录了对应的网站采集配置名、域名、翻页设置、加载等待设置等信息。记录 采集 项的名称、ID、ClassName、TagName 和表格中网页元素的 DOM 树路径。
3.2 网页元素分析
该函数的目标是将网页的 HTML 代码解析为 HTML DOM 网页元素,并列出它们的各种属性值。通过遍历网页的元素,找出想要的采集数据项和下一页的web元素,记录在采集配置表中,同时添加DOM树采集 项的路径自动记录在配置表中。
3.2 自动提取网页信息
该函数将网页中需要采集的数据项采集转换成数据表,最后以XML文档的形式保存。该程序的工作原理如下:
Step1:遍历网页中的所有元素,count变量记录网页元素的个数。
Step2:将每个元素与采集配置中的采集项配置进行比较,判断该元素是否为采集元素。tab_item是一个adotable变量,记录了当前页面的采集配置,webbro.OleObject.document.all.item(i)变量是网页元素,itembyscript()函数会判断是否网页元素需要采集。
Step3:如果元素需要采集元素,进一步判断数据列缓存行中是否有采集项的数据。如果没有,则将采集 中的数据存入行,如果有,则通过addrec() 函数将采集 中的数据行存入XML 文档。
4.运行测试
4.1 读页
本示例将使用厦门本地知名论坛小鱼社区的帖子进行测试。网页中的html代码会被解析成网页元素列表,并显示在“元素”页面中。
图1 读取页面信息
4.2 配置采集
将操作界面切换到“元素”页面,可以看到网页元素列表,在列表中找到需要采集的网页元素。setup采集 配置如下:
(1) 翻页。首先找到“下一页”链接的网页元素,其tagname属性值为“A”,innertext属性值为“下一页”。设置为“下一页” 采集 项。
(2)作者。所属的网页元素,classname属性值为“readName b”,tagname属性值为“DIV”。
(3)Body.所属页面元素,classname属性值为“tpc_content”,tagname属性值为“DIV”。
(4)DOM树路径。DOM路径是通过网页元素列表自动生成的。
4.3查看采集结果
图 2 采集 结果的表格显示
5.结束语
随着互联网的快速发展,人们对网页元素的需求越来越转向个性化分类和精准提取。之前对所有内容的粗暴的采集方法已经不能满足现在的需求。研究是积极的。
网页信息表格提取程序通过网页信息提取、网页元素分析、采集 配置管理。克服了以往网页信息爬取工具无法提取内部相关网页信息的缺点,使程序的适用性和扩展性显着提高,程序创新性地采用了二进制校验机制来确认网页属性值和树路径值。可以实现对指定信息的准确提取,大大提高了程序结果的准确性。
网页信息表格提取程序虽然在准确性、适用性和可扩展性方面取得了进步,但仍存在一些不足,希望以后能找到更好的解决方案。
1.部分操作界面的用户自动化程序不足,操作比较复杂。
2.海量数据不兼容,处理效率低。由于程序的采集页面使用了WebBrowser技术,采集的效率较低,在处理大数据时会出现效率低的问题。有必要寻找更好的技术方法进行优化。
参考:
[1] 方勇,李寅生. 一种基于DOM状态转移的隐藏网页信息提取算法[J]. 计算机应用与软件, 2015, (09): 17-21.
[2] 张建英,王家梅,棠雪,胡刚。易文网络信息采集技术研究[J]. 网络安全技术与应用, 2014, (12): 6-8.@ >
[3] 孙宝华. 企业社交媒体主题信息抽取算法研究[J]. 煤炭, 2014, (01): 72-76.
[4] 金涛.网络爬虫在网页信息提取中的应用研究[J]. 现代计算机(专业版),2012,(01):16-18.@>
[5]朱志宁,黄庆松.快速中文网页分类方法的实现[J].山西电子科技, 2008, (04):7-9.
[6] 高军,王腾蛟,杨冬青,唐世伟。基于Ontology的Web内容两阶段半自动提取方法[J]. 中国计算机学报, 2004, (03): 310-318.@>
网页表格抓取(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-01-13 12:09
Excel 2013及以后版本提供WEBSERVICE和FILTERXML函数,可用于网页数据采集,但只能采集XML格式的数据。现在很多网站网页或者界面返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天笔者就以豆瓣图书的基本信息为例,介绍如何使用Excel API网络函数库抓取JSON格式的网页数据。
1 第一步是在豆瓣上查找书籍的基本信息。豆瓣网图书信息的网址是n/:9787111529385,网址最后一串数字是图书的IN号。在火狐浏览器下,这个URL会返回如下信息,都是标准的JSON格式。蓝色字体为属性名称,红色字体为对应的属性值。
2第二步,安装ExcelAPI网络函数库。访问ExcelAPI网络函数库官网,根据帮助页面安装函数库。或者参考百度经验《Excel生成条码》
3 第三步,使用函数抓取JSON数据。首先,使用函数 GetJs o e(url, "UTF-8") 返回 JSON 原创数据。
4 然后,使用GetJsonByPropertyName(json_so e, property_name)函数返回图书的基本信息。使用GetJs o e() 函数可以一次抓取所有数据,然后按需抓取。这样做的目的是提高抓取速度。毕竟,访问网页需要时间。
必须安装 Excel API 网络函数库 查看全部
网页表格抓取(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据?)
Excel 2013及以后版本提供WEBSERVICE和FILTERXML函数,可用于网页数据采集,但只能采集XML格式的数据。现在很多网站网页或者界面返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天笔者就以豆瓣图书的基本信息为例,介绍如何使用Excel API网络函数库抓取JSON格式的网页数据。
1 第一步是在豆瓣上查找书籍的基本信息。豆瓣网图书信息的网址是n/:9787111529385,网址最后一串数字是图书的IN号。在火狐浏览器下,这个URL会返回如下信息,都是标准的JSON格式。蓝色字体为属性名称,红色字体为对应的属性值。

2第二步,安装ExcelAPI网络函数库。访问ExcelAPI网络函数库官网,根据帮助页面安装函数库。或者参考百度经验《Excel生成条码》

3 第三步,使用函数抓取JSON数据。首先,使用函数 GetJs o e(url, "UTF-8") 返回 JSON 原创数据。
4 然后,使用GetJsonByPropertyName(json_so e, property_name)函数返回图书的基本信息。使用GetJs o e() 函数可以一次抓取所有数据,然后按需抓取。这样做的目的是提高抓取速度。毕竟,访问网页需要时间。

必须安装 Excel API 网络函数库
网页表格抓取(Python中的表格分为图片型和文本型库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 263 次浏览 • 2022-01-10 10:19
内容
大家好,从PDF中提取信息是办公场景中经常用到的操作,也是读者经常在后台询问的操作。
如果内容不多,我们可以手动复制粘贴,但是如果需要批量提取,可以考虑使用Python。之前也转载了相关的文章,提到主要是使用pdfplumber库。今天我们再举一个例子。
通常,PDF中的表格分为图像类型和文本类型。文本类型分为简单型和复杂型。本文提供了这三个部分的示例。
使用的模块主要有
本文出现的PDF资料为从巨超信息官网下载的公开PDF文件。题目是关于财务管理的。相关发布信息及其他信息如下:
内容一共6页,后面会给出例子。
一、简单文本类型数据
简单的文本类型表格是指一个PDF页面中只有一个表格,表格的内容可以完全复制。比如我们选择的内容是PDF中的第四页,内容如下:
如您所见,此页面上只有一个表。接下来,我们将这张表写入Excel,先放代码。
import pdfplumber as pr
import pandas as pd
pdf = pr.open('关于使用自有资金购买银行理财产品的进展公告.PDF')
ps = pdf.pages
pg = ps[3]
tables = pg.extract_tables()
table = tables[0]
print(table)
df = pd.DataFrame(table[1:],columns = table[0])
for i in range(len(table)):
for j in range(len(table[i])):
table[i][j] = table[i][j].replace('\n','')
df1 = pd.DataFrame(table[1:],columns = table[0])
df1.to_excel('page2.xlsx')
得到的结果如下:
与PDF上的原创表格相比,内容完全相同。唯一不同的是,主要业务内容较多,展示不全面。现在让我们谈谈这段代码。
首先导入要使用的两个库。在pdfplumber中,open()函数用于打开PDF文件,代码使用相对路径。.open().pages是获取PDF的页数,打印ps值可以如下获取
pg = ps[3] 代表我们选择的第三页。
pg.extract_tables():可以输出页面中的所有表格,并返回一个结构层次为table→row→cell的嵌套列表。此时将页面上的整个表格放入一个大列表中,原创表格中的每一行形成大列表中的每个子列表。如果要输出单个外部列表元素,则得到的是由原创表的同一行中的元素组成的列表。
与此类似的是 pg.extract_table( ):返回多个独立的列表,其结构级别为 row→cell。如果页面中有多个行数相同的表,则默认输出最上面的表;否则,只输出行数最多的表。此时将表格的每一行作为一个单独的列表,列表中的每个元素都是原表格每个单元格的内容。
由于此页面中只有一个表格,因此我们需要表格集合中的第一个元素。打印表格值如下:
可以看出,上面有个不必要的字符\n,它的作用其实是换行但是我们在Excel中不需要它。所以需要去掉它,使用代码中的for循环和replace函数将控件替换为空格(即删除\n)。观察该表是一个收录 2 个元素的列表。
最后,df1 = pd.DataFrame(table[1:],columns = table[0])的作用就是创建一个数据框,把内容放到对应的行和列中。
此代码只是将数据保存到 Excel。如果需要进一步调整样式,可以使用openpyxl等模块进行修改。
二、复杂表提取
复杂表格是指表格样式不统一或一页有多个表格。以PDF的第五页为例:
可以看到这个页面有两个大表,仔细看其实有四个表。按照简单的表格类型提取方法,效果如下:
可以看到,所有的表格文本只是提取出来的,但实际上第一个表格被细分为两个表格,所以我们需要进一步修改,再次拆分这个表格!例如,将代码的上半部分提取如下:
import pdfplumber as pr
import pandas as pd
pdf = pr.open('关于使用自有资金购买银行理财产品的进展公告.PDF')
ps = pdf.pages
pg = ps[4]
tables = pg.extract_tables()
table = tables[0]
print(table)
df = pd.DataFrame(table[1:],columns = table[0])
for i in range(len(table)):
for j in range(len(table[i])):
table[i][j] = table[i][j].replace('\n','')
df1 = pd.DataFrame(table[1:],columns = table[0])
df2 = df1.iloc[2:,:]
df2 = df2.rename(columns = {"2019年12月31日":"2019年1-12月","2020年9月30日":"2020年1-9月"})
df2 = df2.loc[3:,:]
df1 = df1.loc[:1,:]
with pd.ExcelWriter('公司影响.xlsx') as i:
df1.to_excel(i,sheet_name='资产', index=False, header=True) #放入资产数据
df2.to_excel(i,sheet_name='营业',index=False, header=True) #放入营业数据
这段代码是在简单表格抽取的基础上修改的。第十四行代码的作用是提取另一个表头的信息,赋值给df2,然后重命名df2(使用rename函数)。)。
打印df2显示列名和第一行信息重复,所以我们需要重复刚才的步骤,使用loc()函数对数据框进行切割。
请注意,我们使用罕见的 pandas.Excelwriter 函数来覆盖 for 循环。这是为了避免直接写入导致最终数据覆盖原创数据。有兴趣的可以试试不带withopen的结果。最终结果如下:
如您所见,此表现在单独显示在两个工作表中。当然,也可以放在一张表中进行比较。
毕竟复杂形式的主观性很大,需要根据不同的情况进行不同的处理。写一个一劳永逸的方法更难!
三、图片表提取
最后也是最难处理的是图像类型的表单。人们经常问如何提取图像类型PDF中的表格/文本和其他信息。
其实本质上就是提取图片,如何进一步处理图片提取信息与Python提取PDF表格的话题关系不大!
这里我们也简单介绍一下,即先提取图片再进行OCR识别提取表格。Tesseract库可以在Python中使用,需要先安装pip。
pip install pytesseract
在 Python 中安装此库后,我们需要安装要在后面的代码中使用的 exe 文件。
http://digi.bib.uni-mannheim.d ... v.exe
只需下载并安装它。注意,如果按照正常步骤安装,是不会识别中文的,所以需要安装简体中文语言包。下载地址是,放在Tesseract-OCR的tessdata目录下。
接下来我们使用一个简单的图片类型pdf如下:
第一步是提取图片。这里使用GUI办公自动化系列中的图片提取软件对PDF中的图片进行提取,得到如下图片:
然后执行以下代码识别图片内容
import pytesseract
from PIL import Image
import pandas as pd
pytesseract.pytesseract.tesseract_cmd = 'C://Program Files (x86)/Tesseract-OCR/tesseract.exe'
tiqu = pytesseract.image_to_string(Image.open('图片型.jpg'))
print(tiqu)
tiqu = tiqu.split('\n')
while '' in tiqu: #不能使用for
tiqu.remove('')
first = tiqu[:6]
second = tiqu[6:12]
third = tiqu[12:]
df = pd.DataFrame()
df[first[0]] = first[1:]
df[second[0]] = second[1:]
df[third[0]] = third[1:]
#df.to_excel('图片型表格.xlsx') #转为xlsx文件
我们的想法是使用 Tesseract-OCR 解析图像,得到一个字符串,然后在字符串上使用 split 函数将字符串变成一个列表并删除 \n。
然后你可以发现我们的列表中还有空格。这时候,我们使用一个while循环来删除这些空字符。注意这里不能使用for循环,因为每次删除一个,列表中的元素都会前移一个,不会删除。完全地。最后就是使用pandas将这些转换成数据框形式。最终结果如下:
可以看到图片表格的内容被完美的解析处理了!当然,之所以能轻松搞定,也和这张表的简单性有关。真实场景中的图片可能会有更复杂的干扰因素,这就需要大家在处理的时候找到最合适的方法!
以上就是用Python提取PDF表格的方法的详细内容。更多关于Python提取PDF表格的内容,请关注脚本之家文章的其他相关话题! 查看全部
网页表格抓取(Python中的表格分为图片型和文本型库)
内容
大家好,从PDF中提取信息是办公场景中经常用到的操作,也是读者经常在后台询问的操作。
如果内容不多,我们可以手动复制粘贴,但是如果需要批量提取,可以考虑使用Python。之前也转载了相关的文章,提到主要是使用pdfplumber库。今天我们再举一个例子。
通常,PDF中的表格分为图像类型和文本类型。文本类型分为简单型和复杂型。本文提供了这三个部分的示例。

使用的模块主要有
本文出现的PDF资料为从巨超信息官网下载的公开PDF文件。题目是关于财务管理的。相关发布信息及其他信息如下:

内容一共6页,后面会给出例子。
一、简单文本类型数据
简单的文本类型表格是指一个PDF页面中只有一个表格,表格的内容可以完全复制。比如我们选择的内容是PDF中的第四页,内容如下:

如您所见,此页面上只有一个表。接下来,我们将这张表写入Excel,先放代码。
import pdfplumber as pr
import pandas as pd
pdf = pr.open('关于使用自有资金购买银行理财产品的进展公告.PDF')
ps = pdf.pages
pg = ps[3]
tables = pg.extract_tables()
table = tables[0]
print(table)
df = pd.DataFrame(table[1:],columns = table[0])
for i in range(len(table)):
for j in range(len(table[i])):
table[i][j] = table[i][j].replace('\n','')
df1 = pd.DataFrame(table[1:],columns = table[0])
df1.to_excel('page2.xlsx')
得到的结果如下:

与PDF上的原创表格相比,内容完全相同。唯一不同的是,主要业务内容较多,展示不全面。现在让我们谈谈这段代码。
首先导入要使用的两个库。在pdfplumber中,open()函数用于打开PDF文件,代码使用相对路径。.open().pages是获取PDF的页数,打印ps值可以如下获取

pg = ps[3] 代表我们选择的第三页。
pg.extract_tables():可以输出页面中的所有表格,并返回一个结构层次为table→row→cell的嵌套列表。此时将页面上的整个表格放入一个大列表中,原创表格中的每一行形成大列表中的每个子列表。如果要输出单个外部列表元素,则得到的是由原创表的同一行中的元素组成的列表。
与此类似的是 pg.extract_table( ):返回多个独立的列表,其结构级别为 row→cell。如果页面中有多个行数相同的表,则默认输出最上面的表;否则,只输出行数最多的表。此时将表格的每一行作为一个单独的列表,列表中的每个元素都是原表格每个单元格的内容。
由于此页面中只有一个表格,因此我们需要表格集合中的第一个元素。打印表格值如下:

可以看出,上面有个不必要的字符\n,它的作用其实是换行但是我们在Excel中不需要它。所以需要去掉它,使用代码中的for循环和replace函数将控件替换为空格(即删除\n)。观察该表是一个收录 2 个元素的列表。
最后,df1 = pd.DataFrame(table[1:],columns = table[0])的作用就是创建一个数据框,把内容放到对应的行和列中。
此代码只是将数据保存到 Excel。如果需要进一步调整样式,可以使用openpyxl等模块进行修改。
二、复杂表提取
复杂表格是指表格样式不统一或一页有多个表格。以PDF的第五页为例:

可以看到这个页面有两个大表,仔细看其实有四个表。按照简单的表格类型提取方法,效果如下:

可以看到,所有的表格文本只是提取出来的,但实际上第一个表格被细分为两个表格,所以我们需要进一步修改,再次拆分这个表格!例如,将代码的上半部分提取如下:
import pdfplumber as pr
import pandas as pd
pdf = pr.open('关于使用自有资金购买银行理财产品的进展公告.PDF')
ps = pdf.pages
pg = ps[4]
tables = pg.extract_tables()
table = tables[0]
print(table)
df = pd.DataFrame(table[1:],columns = table[0])
for i in range(len(table)):
for j in range(len(table[i])):
table[i][j] = table[i][j].replace('\n','')
df1 = pd.DataFrame(table[1:],columns = table[0])
df2 = df1.iloc[2:,:]
df2 = df2.rename(columns = {"2019年12月31日":"2019年1-12月","2020年9月30日":"2020年1-9月"})
df2 = df2.loc[3:,:]
df1 = df1.loc[:1,:]
with pd.ExcelWriter('公司影响.xlsx') as i:
df1.to_excel(i,sheet_name='资产', index=False, header=True) #放入资产数据
df2.to_excel(i,sheet_name='营业',index=False, header=True) #放入营业数据
这段代码是在简单表格抽取的基础上修改的。第十四行代码的作用是提取另一个表头的信息,赋值给df2,然后重命名df2(使用rename函数)。)。
打印df2显示列名和第一行信息重复,所以我们需要重复刚才的步骤,使用loc()函数对数据框进行切割。
请注意,我们使用罕见的 pandas.Excelwriter 函数来覆盖 for 循环。这是为了避免直接写入导致最终数据覆盖原创数据。有兴趣的可以试试不带withopen的结果。最终结果如下:


如您所见,此表现在单独显示在两个工作表中。当然,也可以放在一张表中进行比较。

毕竟复杂形式的主观性很大,需要根据不同的情况进行不同的处理。写一个一劳永逸的方法更难!
三、图片表提取
最后也是最难处理的是图像类型的表单。人们经常问如何提取图像类型PDF中的表格/文本和其他信息。
其实本质上就是提取图片,如何进一步处理图片提取信息与Python提取PDF表格的话题关系不大!
这里我们也简单介绍一下,即先提取图片再进行OCR识别提取表格。Tesseract库可以在Python中使用,需要先安装pip。
pip install pytesseract
在 Python 中安装此库后,我们需要安装要在后面的代码中使用的 exe 文件。
http://digi.bib.uni-mannheim.d ... v.exe
只需下载并安装它。注意,如果按照正常步骤安装,是不会识别中文的,所以需要安装简体中文语言包。下载地址是,放在Tesseract-OCR的tessdata目录下。
接下来我们使用一个简单的图片类型pdf如下:

第一步是提取图片。这里使用GUI办公自动化系列中的图片提取软件对PDF中的图片进行提取,得到如下图片:

然后执行以下代码识别图片内容
import pytesseract
from PIL import Image
import pandas as pd
pytesseract.pytesseract.tesseract_cmd = 'C://Program Files (x86)/Tesseract-OCR/tesseract.exe'
tiqu = pytesseract.image_to_string(Image.open('图片型.jpg'))
print(tiqu)
tiqu = tiqu.split('\n')
while '' in tiqu: #不能使用for
tiqu.remove('')
first = tiqu[:6]
second = tiqu[6:12]
third = tiqu[12:]
df = pd.DataFrame()
df[first[0]] = first[1:]
df[second[0]] = second[1:]
df[third[0]] = third[1:]
#df.to_excel('图片型表格.xlsx') #转为xlsx文件
我们的想法是使用 Tesseract-OCR 解析图像,得到一个字符串,然后在字符串上使用 split 函数将字符串变成一个列表并删除 \n。
然后你可以发现我们的列表中还有空格。这时候,我们使用一个while循环来删除这些空字符。注意这里不能使用for循环,因为每次删除一个,列表中的元素都会前移一个,不会删除。完全地。最后就是使用pandas将这些转换成数据框形式。最终结果如下:

可以看到图片表格的内容被完美的解析处理了!当然,之所以能轻松搞定,也和这张表的简单性有关。真实场景中的图片可能会有更复杂的干扰因素,这就需要大家在处理的时候找到最合适的方法!
以上就是用Python提取PDF表格的方法的详细内容。更多关于Python提取PDF表格的内容,请关注脚本之家文章的其他相关话题!
网页表格抓取(WebDataMiner是一款网页数据挖掘工具,帮你轻松挖掘网页中的各种数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-10 09:02
Web Data Miner 是一个 Web 数据挖掘工具。该软件可以帮助您轻松挖掘网页中的各种数据。软件可以将挖掘出来的数据以表格的形式呈现。可以智能地帮助用户从网站中提取准确的数据在不同的布局中,例如购物、分类、基于产品和其他网站。
软件介绍
此数据抓取器将从打开的网页中抓取点击的项目或类似项目。在这个工具中有两个选项“自动保存”和“自动暂停”。自动保存消除了数据丢失的风险,而自动暂停消除了某些 网站 阻止 IP 地址的风险。
网站数据挖掘工具可以从一个网站内的多个网页中挖掘数据。用户可以配置“设置下一页链接”以从所有网页中提取相似数据。用户可以选择定义数量的页面来提取数据,否则它将从所有网页中挖掘数据。该软件的独特和最强大的功能之一是调度。
用户可以设置时间和日期,并提供配置文件。它将在用户定义的时间自动启动数据挖掘过程。挖掘数据后,它会自动关闭并将配置文件保存在用户定义的位置。
软件功能
以表格形式从网页中提取数据。
从不同布局的 网站 中提取数据。
从网页中提取文本、html、图像、链接和 URL。
从外部和自定义链接中提取数据。
自动跟踪页面以提取数据。
保存提取的数据,消除数据丢失的风险。
自动暂停以防止被某些 网站 阻止。 查看全部
网页表格抓取(WebDataMiner是一款网页数据挖掘工具,帮你轻松挖掘网页中的各种数据)
Web Data Miner 是一个 Web 数据挖掘工具。该软件可以帮助您轻松挖掘网页中的各种数据。软件可以将挖掘出来的数据以表格的形式呈现。可以智能地帮助用户从网站中提取准确的数据在不同的布局中,例如购物、分类、基于产品和其他网站。
软件介绍
此数据抓取器将从打开的网页中抓取点击的项目或类似项目。在这个工具中有两个选项“自动保存”和“自动暂停”。自动保存消除了数据丢失的风险,而自动暂停消除了某些 网站 阻止 IP 地址的风险。
网站数据挖掘工具可以从一个网站内的多个网页中挖掘数据。用户可以配置“设置下一页链接”以从所有网页中提取相似数据。用户可以选择定义数量的页面来提取数据,否则它将从所有网页中挖掘数据。该软件的独特和最强大的功能之一是调度。
用户可以设置时间和日期,并提供配置文件。它将在用户定义的时间自动启动数据挖掘过程。挖掘数据后,它会自动关闭并将配置文件保存在用户定义的位置。
软件功能
以表格形式从网页中提取数据。
从不同布局的 网站 中提取数据。
从网页中提取文本、html、图像、链接和 URL。
从外部和自定义链接中提取数据。
自动跟踪页面以提取数据。
保存提取的数据,消除数据丢失的风险。
自动暂停以防止被某些 网站 阻止。
网页表格抓取(在ASP.NET中表格的显式方法利用JS来取页面表格数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-01-09 21:13
ASP.NET中有各种显式的表格方法,例如html标签、asp服务器控件GridView、Repeater控件等,都可以帮助我们在页面上显示表格信息。GridView控件更强大,它有自己的属性和方法,可以用来对显式表数据进行各种操作。但是如果使用传统的html标签或者Repeater控件来展示数据,那么如何获取选中行的数据呢?这里我们将介绍使用JS获取页表数据的方法。
如图所示,我们需要对表中的数据进行编辑、删除等操作。
下面是一个Repeater控件的例子:
(1)页表:定义表头,设置数据绑定(有些操作需要获取数据的主键,考虑实际情况,我们应该隐藏主键,对应列使用隐藏属性) )这就够了)。在后台,只需要将Repeater绑定到对应的数据源即可。这里我们使用class来标记按钮,这样在JS中就可以将所有具有相同class的按钮作为一个组取出来。因此,我们可以在 JS 中监控和选择按钮。设置相应的行。
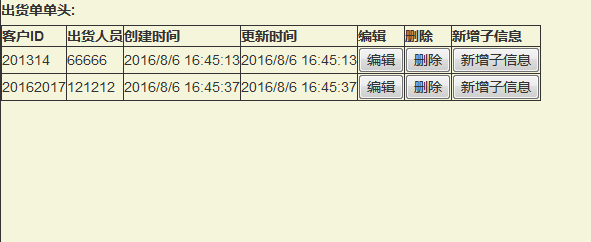
1 出货单单头:
2
3
4
5
6 ID
7 客户ID
8 出货人员
9 创建时间
10 更新时间
11 编辑
12 删除
13 新增子信息
14
15
16
17
18
19
20
21
22
23
24 编辑
25
26
27 删除
28
29
30 新增子信息
31
32
33
34
35
(2)JS部分:通过class获取对应的一组按钮并设置监控。然后通过标签名获取选中行,通过标签名获取选中行所有列数据的集合,并进行转换对应的数据通过 DOM 操作显示在前台的指定位置。
1 /*编辑单头信息*/
2 var Top_Edit = document.getElementsByClassName("Top_Edit");
3
4 for (var i = 0; i < Top_Edit.length; i++) {
5
6 Top_Edit[i].index = i;
7
8 Top_Edit[i].onclick = function () {
9
10 var table = document.getElementById("Top_Table");
11
12 /*获取选中的行 */
13 var child = table.getElementsByTagName("tr")[this.index + 1];
14
15 /*获取选择行的所有列*/
16 var SZ_col = child.getElementsByTagName("td");
17
18 document.getElementById("Edit_id").value = SZ_col[0].innerHTML;
19 document.getElementById("edit_customer").value = SZ_col[1].innerHTML;
20 document.getElementById("edit_man").value = SZ_col[2].innerHTML;
21 document.getElementById("Top_Creat_Time").value = SZ_col[3].innerHTML;
22 document.getElementById("Top_Update_Time").value = SZ_col[4].innerHTML;
23
24 }
25 }
在JS中获取表格数据只是几个简单的步骤。还有其他方法,例如 jQuery 来获取表格数据。你可以多尝试,然后比较总结,这也是对程序员自身的一种提升。 查看全部
网页表格抓取(在ASP.NET中表格的显式方法利用JS来取页面表格数据)
ASP.NET中有各种显式的表格方法,例如html标签、asp服务器控件GridView、Repeater控件等,都可以帮助我们在页面上显示表格信息。GridView控件更强大,它有自己的属性和方法,可以用来对显式表数据进行各种操作。但是如果使用传统的html标签或者Repeater控件来展示数据,那么如何获取选中行的数据呢?这里我们将介绍使用JS获取页表数据的方法。
如图所示,我们需要对表中的数据进行编辑、删除等操作。
下面是一个Repeater控件的例子:
(1)页表:定义表头,设置数据绑定(有些操作需要获取数据的主键,考虑实际情况,我们应该隐藏主键,对应列使用隐藏属性) )这就够了)。在后台,只需要将Repeater绑定到对应的数据源即可。这里我们使用class来标记按钮,这样在JS中就可以将所有具有相同class的按钮作为一个组取出来。因此,我们可以在 JS 中监控和选择按钮。设置相应的行。
1 出货单单头:
2
3
4
5
6 ID
7 客户ID
8 出货人员
9 创建时间
10 更新时间
11 编辑
12 删除
13 新增子信息
14
15
16
17
18
19
20
21
22
23
24 编辑
25
26
27 删除
28
29
30 新增子信息
31
32
33
34
35
(2)JS部分:通过class获取对应的一组按钮并设置监控。然后通过标签名获取选中行,通过标签名获取选中行所有列数据的集合,并进行转换对应的数据通过 DOM 操作显示在前台的指定位置。
1 /*编辑单头信息*/
2 var Top_Edit = document.getElementsByClassName("Top_Edit");
3
4 for (var i = 0; i < Top_Edit.length; i++) {
5
6 Top_Edit[i].index = i;
7
8 Top_Edit[i].onclick = function () {
9
10 var table = document.getElementById("Top_Table");
11
12 /*获取选中的行 */
13 var child = table.getElementsByTagName("tr")[this.index + 1];
14
15 /*获取选择行的所有列*/
16 var SZ_col = child.getElementsByTagName("td");
17
18 document.getElementById("Edit_id").value = SZ_col[0].innerHTML;
19 document.getElementById("edit_customer").value = SZ_col[1].innerHTML;
20 document.getElementById("edit_man").value = SZ_col[2].innerHTML;
21 document.getElementById("Top_Creat_Time").value = SZ_col[3].innerHTML;
22 document.getElementById("Top_Update_Time").value = SZ_col[4].innerHTML;
23
24 }
25 }
在JS中获取表格数据只是几个简单的步骤。还有其他方法,例如 jQuery 来获取表格数据。你可以多尝试,然后比较总结,这也是对程序员自身的一种提升。
网页表格抓取( Python抓取动态网页信息的相关操作、网上教程编写出)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-09 21:11
Python抓取动态网页信息的相关操作、网上教程编写出)
5月1日假期学习了Python爬取动态网页信息相关的操作,结合封面上的参考书和在线教程,编写了能满足自己需求的代码。由于最初是python的介入,所以过程中有很多曲折。为了避免以后出现问题,我找不到相关资料来创建这篇文章。
准备工具:
Python 3.8Google Chrome Googledriver
测试网站:
1.想法 (#cb)
考试前准备:
1.配置python运行的环境变量,参考link()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json分析的方式;另一种是硒的方式。requests方法速度快,但是有些元素的链接信息抓不到;selenium 方法通过模拟打开浏览器来捕获数据。由于需要打开浏览器,所以速度比较慢,但是能抓取到的信息比较全面。
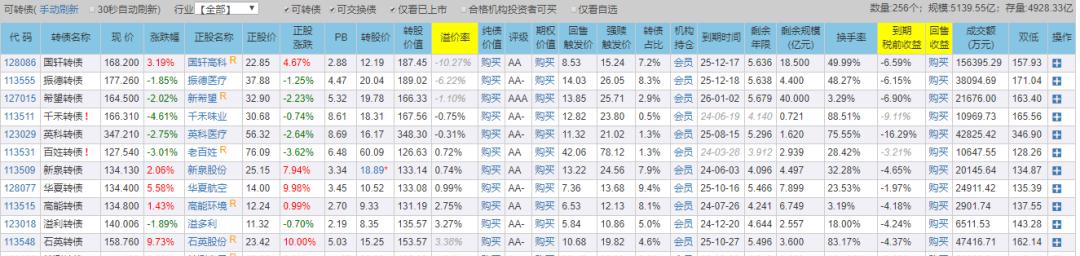
主要抓取内容如下:(网站中部分可转债数据)
获取网站信息的请求方法:
Python需要安装的相关脚本:Requests
安装方法:以管理员身份运行cmd;输入 pip install requests 命令,安装成功后会有提示。如果一次安装不成功,多安装几次。
(前提是相关端口没有关闭)。如果 pip 版本不是最新的,它会提醒你更新 pip 版本,pip 环境变量也要设置。设置方法参考python设置方法。
请求抓取代码如下:
import requestsimport jsonurl='https://www.jisilu.cn/data/cbn ... _data = requests.get(url,verify = False)js=return_data.json()for i in js['rows']: print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的网址:chrome open brainstorming网站(#cb)。点击F12键,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5键刷新。在名称栏中一一点击,找到所需的 XHR。通过预览我们可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
JSON转换请求的数据格式,方便数据搜索。转换成json格式后,requests的数据格式和preview的数据格式一样。如果要定位“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考请求安装)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。把它放在安装chrome的文件夹中,并设置环境变量。
selenium 抓取代码如下:
from selenium import webdriverimport timedriver=webdriver.Chrome()url1='https://www.jisilu.cn/data/cbn ... r.get(url1)time.sleep(5) #增加延时命令,等待元素加载driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elementsfor tr in table_tr_list: if len(tr.get_attribute('id'))>0: print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)driver.quit()
结果如下:
注意三点:
1、添加延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(NoSuchElementException)
2、使用find_element_by_xpath时,可以在网页开发者中右键copy xpath来确认元素的路径。
3、发送ID时,将字符转换为数值,注意去掉空字符
捕获的数据也可以通过python保存到excel中。 查看全部
网页表格抓取(
Python抓取动态网页信息的相关操作、网上教程编写出)

5月1日假期学习了Python爬取动态网页信息相关的操作,结合封面上的参考书和在线教程,编写了能满足自己需求的代码。由于最初是python的介入,所以过程中有很多曲折。为了避免以后出现问题,我找不到相关资料来创建这篇文章。
准备工具:
Python 3.8Google Chrome Googledriver
测试网站:
1.想法 (#cb)
考试前准备:
1.配置python运行的环境变量,参考link()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json分析的方式;另一种是硒的方式。requests方法速度快,但是有些元素的链接信息抓不到;selenium 方法通过模拟打开浏览器来捕获数据。由于需要打开浏览器,所以速度比较慢,但是能抓取到的信息比较全面。
主要抓取内容如下:(网站中部分可转债数据)
获取网站信息的请求方法:
Python需要安装的相关脚本:Requests
安装方法:以管理员身份运行cmd;输入 pip install requests 命令,安装成功后会有提示。如果一次安装不成功,多安装几次。
(前提是相关端口没有关闭)。如果 pip 版本不是最新的,它会提醒你更新 pip 版本,pip 环境变量也要设置。设置方法参考python设置方法。
请求抓取代码如下:
import requestsimport jsonurl='https://www.jisilu.cn/data/cbn ... _data = requests.get(url,verify = False)js=return_data.json()for i in js['rows']: print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的网址:chrome open brainstorming网站(#cb)。点击F12键,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5键刷新。在名称栏中一一点击,找到所需的 XHR。通过预览我们可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
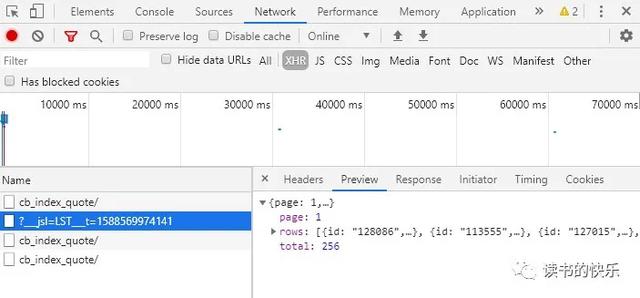
JSON转换请求的数据格式,方便数据搜索。转换成json格式后,requests的数据格式和preview的数据格式一样。如果要定位“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考请求安装)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。把它放在安装chrome的文件夹中,并设置环境变量。
selenium 抓取代码如下:
from selenium import webdriverimport timedriver=webdriver.Chrome()url1='https://www.jisilu.cn/data/cbn ... r.get(url1)time.sleep(5) #增加延时命令,等待元素加载driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elementsfor tr in table_tr_list: if len(tr.get_attribute('id'))>0: print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)driver.quit()
结果如下:

注意三点:
1、添加延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(NoSuchElementException)
2、使用find_element_by_xpath时,可以在网页开发者中右键copy xpath来确认元素的路径。
3、发送ID时,将字符转换为数值,注意去掉空字符
捕获的数据也可以通过python保存到excel中。
网页表格抓取(不同时间段的网络表格数据节点获取需要注意的事项!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-09 20:06
(1)数据URL获取
网易财经和新浪财经等网站数据可以免费获取,我们可以使用爬虫方式(通过rvest包)抓取对应的网站表数据,我们先在网易财经抓取600550例如,2019年第三季度的数据,其URL为:
,
可以看出,不同时间段的网址是有规律的,只需要更改里面的股票代码、年份、季节,就可以循环爬取多只股票的网页。
(2)网络表单数据节点获取
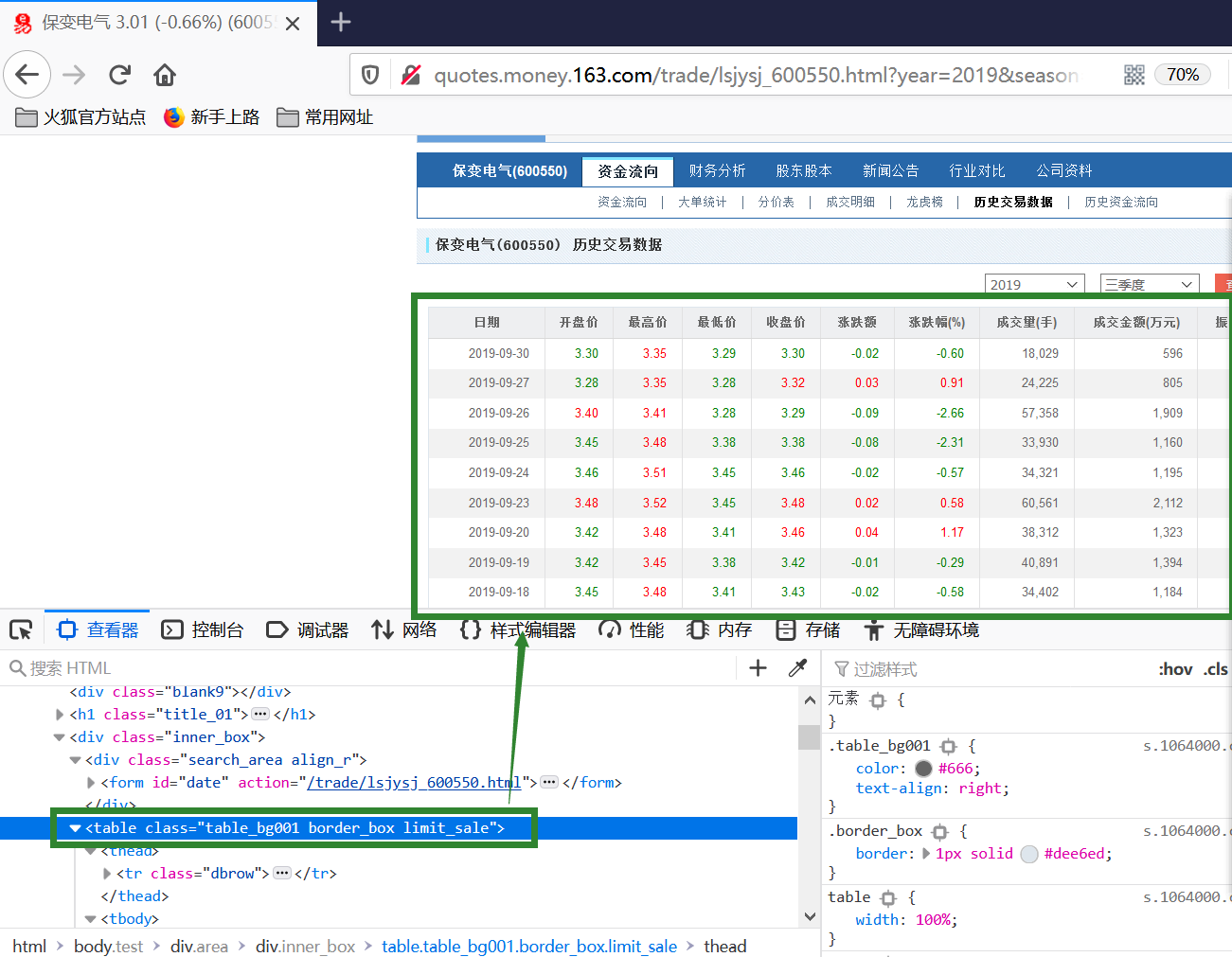
我们需要解析网页表数据的节点。除了系统地掌握网页设计的原理和基本结构外,我们还可以通过FireFox(Firebug插件)和Chrome浏览器对网页结构进行解析,得到相应的分支结构点。这里我们使用火狐浏览器,找到我们需要的表位置后(如何找到表位置请自行探索),右键复制XPath路径。
表格部分的 XPath 是 /html/body/div[2]/div[4]/table[1]。
(3)获取单只股票的单页数据
library(rvest)
symbol=600550
year=2019
season=3
url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
此时的web.table就是爬取的数据
(4)获取单个股票的多页数据并合并
library(lubridate)
symbol=600550
from="2001-05-28"
from=as.Date(from)
to=Sys.Date()
time.index=seq(from=from,to=to,by="quarter")#生成以季度为开始的时间序列
year.id=year(time.index)#获取年份
quarter.id=quarter(time.index)#获取季度
price=list()
for(t in 1:length(time.index)){
year=year.id[t]
season=quarter.id[t]
url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
web.table=web.table[[1]][-1,]
price[[t]]=web.table
}
(5)抓取多只股票的多页数据并将它们合并
get.wangyi.stock=function(symbol,from,to){
from=as.Date(from)
to=as.Date(to)
if(mday(from==1)){
from=from-1
}
time.index=seq(from=from,to=to,by="quarter")
year.id=year(time.index)
quarter.id=quarter(time.index)
prices=list()
for(t in 1:length(time.index)){
year=year.id[t]
season=quarter.id[t] url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
web.table=web.table[[1]][-1,]
prices[[t]]=web.table
}
}
to=Sys.Date()
stock.index=matrix(nrow=6,ncol=2)
stock.index[,1]=c("600550.ss","600192.ss","600152.ss","600644.ss","600885.ss","600151.ss")
stock.index[,2]=c("2017-05-28","2017-05-28","2017-05-28","2017-05-28","2017-05-28","2017-05-28")
for(i in nrow(stock.index)){
symbol=stock.index[i,1]
from=stock.index[i,2]
prices=get.wangyi.stock(symbol,from,to)
filenames=paste0("D://dataset//",symbol,".csv")
}
(6)读取所有A股数据
我们还可以将所有A股代码整理成一个文件,读取后可以实现所有A股股票数据的实时更新。这种方法可以用来建立我们自己的数据库进行实时分析。同时,通过网络爬虫,我们还可以爬取大量有意义的数据并实时更新。 查看全部
网页表格抓取(不同时间段的网络表格数据节点获取需要注意的事项!)
(1)数据URL获取
网易财经和新浪财经等网站数据可以免费获取,我们可以使用爬虫方式(通过rvest包)抓取对应的网站表数据,我们先在网易财经抓取600550例如,2019年第三季度的数据,其URL为:
,
可以看出,不同时间段的网址是有规律的,只需要更改里面的股票代码、年份、季节,就可以循环爬取多只股票的网页。
(2)网络表单数据节点获取
我们需要解析网页表数据的节点。除了系统地掌握网页设计的原理和基本结构外,我们还可以通过FireFox(Firebug插件)和Chrome浏览器对网页结构进行解析,得到相应的分支结构点。这里我们使用火狐浏览器,找到我们需要的表位置后(如何找到表位置请自行探索),右键复制XPath路径。
表格部分的 XPath 是 /html/body/div[2]/div[4]/table[1]。
(3)获取单只股票的单页数据
library(rvest)
symbol=600550
year=2019
season=3
url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
此时的web.table就是爬取的数据
(4)获取单个股票的多页数据并合并
library(lubridate)
symbol=600550
from="2001-05-28"
from=as.Date(from)
to=Sys.Date()
time.index=seq(from=from,to=to,by="quarter")#生成以季度为开始的时间序列
year.id=year(time.index)#获取年份
quarter.id=quarter(time.index)#获取季度
price=list()
for(t in 1:length(time.index)){
year=year.id[t]
season=quarter.id[t]
url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
web.table=web.table[[1]][-1,]
price[[t]]=web.table
}
(5)抓取多只股票的多页数据并将它们合并
get.wangyi.stock=function(symbol,from,to){
from=as.Date(from)
to=as.Date(to)
if(mday(from==1)){
from=from-1
}
time.index=seq(from=from,to=to,by="quarter")
year.id=year(time.index)
quarter.id=quarter(time.index)
prices=list()
for(t in 1:length(time.index)){
year=year.id[t]
season=quarter.id[t] url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
web.table=web.table[[1]][-1,]
prices[[t]]=web.table
}
}
to=Sys.Date()
stock.index=matrix(nrow=6,ncol=2)
stock.index[,1]=c("600550.ss","600192.ss","600152.ss","600644.ss","600885.ss","600151.ss")
stock.index[,2]=c("2017-05-28","2017-05-28","2017-05-28","2017-05-28","2017-05-28","2017-05-28")
for(i in nrow(stock.index)){
symbol=stock.index[i,1]
from=stock.index[i,2]
prices=get.wangyi.stock(symbol,from,to)
filenames=paste0("D://dataset//",symbol,".csv")
}
(6)读取所有A股数据
我们还可以将所有A股代码整理成一个文件,读取后可以实现所有A股股票数据的实时更新。这种方法可以用来建立我们自己的数据库进行实时分析。同时,通过网络爬虫,我们还可以爬取大量有意义的数据并实时更新。
网页表格抓取(WebDataMiner是一款网页数据挖掘工具,帮你轻松挖掘网页中的各种数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-01-09 12:01
Web Data Miner 是一个 Web 数据挖掘工具。该软件可以帮助您轻松挖掘网页中的各种数据。软件可以将挖掘出来的数据以表格的形式呈现。可以智能地帮助用户从网站中提取准确的数据,在不同的布局中,例如购物、分类、基于产品和其他网站。
软件介绍
此数据抓取器将从打开的网页中抓取点击的项目或类似项目。在这个工具中有两个选项“自动保存”和“自动暂停”。自动保存消除了数据丢失的风险,而自动暂停消除了某些 网站 阻止 IP 地址的风险。
网站数据挖掘工具可以从一个网站内的多个网页中挖掘数据。用户可以配置“设置下一页链接”以从所有网页中提取相似数据。用户可以选择定义数量的页面来提取数据,否则它将从所有网页中挖掘数据。该软件的独特和最强大的功能之一是调度。
用户可以设置时间和日期,并提供配置文件。它将在用户定义的时间自动启动数据挖掘过程。挖掘数据后,它会自动关闭并将配置文件保存在用户定义的位置。
软件功能
以表格形式从网页中提取数据。
从不同布局的 网站 中提取数据。
从网页中提取文本、html、图像、链接和 URL。
从外部和自定义链接中提取数据。
自动跟踪页面以提取数据。
保存提取的数据,消除数据丢失的风险。
自动暂停以防止被某些 网站 阻止。 查看全部
网页表格抓取(WebDataMiner是一款网页数据挖掘工具,帮你轻松挖掘网页中的各种数据)
Web Data Miner 是一个 Web 数据挖掘工具。该软件可以帮助您轻松挖掘网页中的各种数据。软件可以将挖掘出来的数据以表格的形式呈现。可以智能地帮助用户从网站中提取准确的数据,在不同的布局中,例如购物、分类、基于产品和其他网站。
软件介绍
此数据抓取器将从打开的网页中抓取点击的项目或类似项目。在这个工具中有两个选项“自动保存”和“自动暂停”。自动保存消除了数据丢失的风险,而自动暂停消除了某些 网站 阻止 IP 地址的风险。
网站数据挖掘工具可以从一个网站内的多个网页中挖掘数据。用户可以配置“设置下一页链接”以从所有网页中提取相似数据。用户可以选择定义数量的页面来提取数据,否则它将从所有网页中挖掘数据。该软件的独特和最强大的功能之一是调度。
用户可以设置时间和日期,并提供配置文件。它将在用户定义的时间自动启动数据挖掘过程。挖掘数据后,它会自动关闭并将配置文件保存在用户定义的位置。
软件功能
以表格形式从网页中提取数据。
从不同布局的 网站 中提取数据。
从网页中提取文本、html、图像、链接和 URL。
从外部和自定义链接中提取数据。
自动跟踪页面以提取数据。
保存提取的数据,消除数据丢失的风险。
自动暂停以防止被某些 网站 阻止。
网页表格抓取(第5步中显示的方法中完成的显示方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-06 20:09
,
,等待。您可以使用“//”,然后使用标签名称来调用第一个。例如“// div”、“// a”或“// span”。现在,如果你真的想得到“Some Text Here”,你需要调用课程。这是在步骤 5 中显示的方法中完成的。您会注意到它使用了“// div”和“[@class =“这里是类名”] 的组合。xml 字符串是“// div [@class ='list-card__body']" 你可能想要获取另一个数据值。我们想要获取所有的 URL。这种情况会涉及到想要提取第一个 HTML 标签本身内部的特定值。例如,点击这里。然后就像 step 7.xml字符串为“//a/@href”ImportXML(URL, XML string)ImportXML(“”,“//div[@class='list-card__body']”)
使用此功能的事实是它需要花费大量时间。因此,它需要规划和设计一个好的谷歌工作表,以确保您从使用中获得最大的收益。否则,您的团队最终将花时间维护它而不是研究新事物。像下面的图片
来自 xkcd
使用 ImportHTML 进行网页抓取
最后,我们将讨论 ImportHTML。这将从网页导入表格或列表。例如,如果您想从 网站 获取收录股票价格的数据,该怎么办。
我们会用。此页面上有一张表格,其中收录过去几天的股票价格。
与过去的功能类似,您需要使用一个 URL。在 URL 的顶部,您必须提及要在页面上抓取的表格。您可以使用可能的数字来完成此操作。
例如,ImportHTML (" ",6 )。这将从上面的链接中删除股票价格。
在上面的视频中,我们还展示了如何将上述股票数据捕获结合到当天有关股市自动收录设备的新闻中。这可以以更复杂的方式使用。该团队可以创建一个算法,使用过去的股票价格和新的 文章 和 Twitter 信息来选择是买入还是卖出股票。
你有什么使用网页抓取的好主意吗?您需要有关网页抓取项目的帮助吗?让我们知道!
关于数据科学的其他精彩读物:
什么是决策树
算法如何变得不道德和有偏见
如何开发健壮的算法
数据科学家必须具备的 4 项技能
翻译自:
网页抓取表单 查看全部
网页表格抓取(第5步中显示的方法中完成的显示方法介绍)
,
,等待。您可以使用“//”,然后使用标签名称来调用第一个。例如“// div”、“// a”或“// span”。现在,如果你真的想得到“Some Text Here”,你需要调用课程。这是在步骤 5 中显示的方法中完成的。您会注意到它使用了“// div”和“[@class =“这里是类名”] 的组合。xml 字符串是“// div [@class ='list-card__body']" 你可能想要获取另一个数据值。我们想要获取所有的 URL。这种情况会涉及到想要提取第一个 HTML 标签本身内部的特定值。例如,点击这里。然后就像 step 7.xml字符串为“//a/@href”ImportXML(URL, XML string)ImportXML(“”,“//div[@class='list-card__body']”)
使用此功能的事实是它需要花费大量时间。因此,它需要规划和设计一个好的谷歌工作表,以确保您从使用中获得最大的收益。否则,您的团队最终将花时间维护它而不是研究新事物。像下面的图片
来自 xkcd
使用 ImportHTML 进行网页抓取
最后,我们将讨论 ImportHTML。这将从网页导入表格或列表。例如,如果您想从 网站 获取收录股票价格的数据,该怎么办。
我们会用。此页面上有一张表格,其中收录过去几天的股票价格。
与过去的功能类似,您需要使用一个 URL。在 URL 的顶部,您必须提及要在页面上抓取的表格。您可以使用可能的数字来完成此操作。
例如,ImportHTML (" ",6 )。这将从上面的链接中删除股票价格。
在上面的视频中,我们还展示了如何将上述股票数据捕获结合到当天有关股市自动收录设备的新闻中。这可以以更复杂的方式使用。该团队可以创建一个算法,使用过去的股票价格和新的 文章 和 Twitter 信息来选择是买入还是卖出股票。
你有什么使用网页抓取的好主意吗?您需要有关网页抓取项目的帮助吗?让我们知道!
关于数据科学的其他精彩读物:
什么是决策树
算法如何变得不道德和有偏见
如何开发健壮的算法
数据科学家必须具备的 4 项技能
翻译自:
网页抓取表单
网页表格抓取(网页上只有一个表格的数据如何获取?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-05 21:22
首先下载jsoup的jar包,自己在网上搜索这个,有很多,然后导入到程序中方便使用。
接下来先获取你想要获取的网页内容,Document doc = Jsoup.connect(url).timeout(5000).get();
这里的网址就是你要爬取的网址。timeout(5000) 设置你抓取网页的最长时间,超过时间后不再尝试。一般网站不需要设置,只需要Document doc = Jsoup.connect(url).get(); 获取网页内容并转换为文档格式。
下一步是找到您想要获取的数据。这里我们主要讲一下如何获取网页表格中的数据。其他类似。
你需要了解你想要获取的网页的html标签的结构,按F12进入开发者模式,寻找你想要获取的数据信息。
如果网页上只有一张表格,很简单: Elements elements1 = doc.select("table").select("tr"); 这行代码获取网页上表格中的行,返回的元素是表格有多少行。如果是多个表,那么select()就是表的标签,比如它的class和其他属性,来决定你选择哪个表。
for (int i = 0; i <elements1.size()-1; i++) {
//获取每一行的列
元素 tds = 元素1.get(i).select("td");
{
//处理每一行你需要的一些列
//获取第i行第j列的值
字符串 oldClose = tds.get(j).text()
//接下来,继续你的操作
………………
}
} 查看全部
网页表格抓取(网页上只有一个表格的数据如何获取?(一))
首先下载jsoup的jar包,自己在网上搜索这个,有很多,然后导入到程序中方便使用。
接下来先获取你想要获取的网页内容,Document doc = Jsoup.connect(url).timeout(5000).get();
这里的网址就是你要爬取的网址。timeout(5000) 设置你抓取网页的最长时间,超过时间后不再尝试。一般网站不需要设置,只需要Document doc = Jsoup.connect(url).get(); 获取网页内容并转换为文档格式。
下一步是找到您想要获取的数据。这里我们主要讲一下如何获取网页表格中的数据。其他类似。
你需要了解你想要获取的网页的html标签的结构,按F12进入开发者模式,寻找你想要获取的数据信息。
如果网页上只有一张表格,很简单: Elements elements1 = doc.select("table").select("tr"); 这行代码获取网页上表格中的行,返回的元素是表格有多少行。如果是多个表,那么select()就是表的标签,比如它的class和其他属性,来决定你选择哪个表。
for (int i = 0; i <elements1.size()-1; i++) {
//获取每一行的列
元素 tds = 元素1.get(i).select("td");
{
//处理每一行你需要的一些列
//获取第i行第j列的值
字符串 oldClose = tds.get(j).text()
//接下来,继续你的操作
………………
}
}
网页表格抓取( Python中如何使用Pandas_html方法从HTML中获取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-04 14:11
Python中如何使用Pandas_html方法从HTML中获取数据
)
在本 Pandas 教程中,我们将详细介绍如何使用 Pandas 的 read_html 方法从 HTML 中获取数据。首先,在最简单的示例中,我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例使用 Pandas read_html 从维基百科表格中获取数据。在上一篇文章(Python中的探索性数据分析)中,我们也使用了Pandas从HTML表格中读取数据。
在 Python 中导入数据
在开始学习Python和Pandas的时候,为了进行数据分析和可视化,我们通常会从导入数据的实践开始。在前面的文章中,我们已经了解到我们可以直接在Python中输入值(例如,从Python字典创建一个Pandas数据框)。但是,通过从可用来源导入数据来获取数据当然更为常见。这通常通过从 CSV 文件或 Excel 文件中读取数据来完成。例如,要从 .csv 文件导入数据,我们可以使用 Pandas read_csv 方法。这是如何使用此方法的快速示例,但请务必查看主题 文章 的博客以获取更多信息。
现在,上述方法仅在我们已经拥有合适格式(例如 csv 或 JSON)的数据时才有用(请参阅 文章 了解如何使用 Python 和 Pandas 解析 JSON 文件)。
我们大多数人都会使用维基百科来了解我们感兴趣的话题。此外,这些 Wikipedia文章 通常收录 HTML 表格。
要使用pandas在Python中获取这些表格,我们可以将它们剪切并粘贴到电子表格中,然后例如使用read_excel将它们读入Python。现在,这个任务当然可以用更少的步骤完成:我们可以通过网络抓取来自动化它。一定要检查什么是网页抓取。
先决条件
当然,这个 Pandas 阅读 HTML 教程需要我们安装 Pandas 及其依赖项。例如,我们可以使用 pip 安装 Python 包,例如 Pandas,或安装 Python 发行版(例如,Anaconda、ActivePython)。以下是使用 pip 安装 Pandas 的方法:pip install pandas。
请注意,如果出现一条消息说有新版本的 pip 可用,请查看此 文章 以了解如何升级 pip。请注意,我们还需要安装 lxml 或 BeautifulSoup4。当然,这些包也可以使用 pip 安装:pip install lxml。
熊猫 read_html 语法
以下是如何使用 Pandas read_html 从 HTML 表中获取数据的最简单语法:
现在我们知道了使用 Pandas 读取 HTML 表格的简单语法,我们可以看看 read_html 的一些例子。
熊猫 read_html 示例 1:
第一个例子是关于如何使用 Pandas read_html 方法。我们将从一个字符串中读取一个 HTML 表格。
现在,我们得到的结果不是 Pandas DataFrame,而是 Python 列表。换句话说,如果我们使用 type 函数,我们可以看到:
如果我们想要得到表,我们可以使用列表的第一个索引(0)
熊猫 read_html 示例 2:
在第二个 Pandas read_html 示例中,我们将从维基百科中抓取数据。其实我们会得到python(也叫python)的HTML表格。
现在,我们有一个收录 7 个表的列表 (len(df))。如果我们转到维基百科页面,我们可以看到第一个表格是右边的表格。然而,在这个例子中,我们可能对第二个表更感兴趣。
熊猫 read_html 示例 3:
在第三个示例中,我们将从瑞典的 covid-19 案例中读取 HTML 表格。在这里,我们将使用 read_html 方法的一些附加参数。具体来说,我们将使用 match 参数。在此之后,我们仍然需要清理数据,最后我们将进行一些简单的数据可视化操作。
使用 Pandas read_html 和匹配参数抓取数据:
如上图所示,表格的标题是:“瑞典各县的新 COVID-19 病例”。现在,我们可以使用 match 参数并将其作为字符串输入:
这样,我们只得到了这张表,但它仍然是一个dataframes的列表。现在,如上图所示,在底部,我们需要删除三行。因此,我们要删除最后三行。
使用 Pandas iloc 删除最后一行
现在,我们将使用 Pandas iloc 删除最后 3 行。请注意,我们使用 -3 作为第二个参数(确保您查看此 Panda iloc 教程以获取更多信息)。最后,我们还创建了此数据框的副本。
在下一节中,我们将学习如何将多索引列名更改为单索引。
将多个索引更改为单个索引并删除不需要的字符
现在,我们要删除多索引列。换句话说,我们将把 2 列索引(名称)变成一个唯一的列名。在这里,我们将使用 DataFrame.columns 和 DataFrame.columns,get_level_values:
最后,正如您在“日期”列中看到的,我们使用 Pandas read_html 从 WikiPedia 表中抓取了一些评论。接下来,我们将使用 str.replace 方法和正则表达式来删除它们:
使用 Pandas set_index 更改索引
现在,我们继续使用 Pandas set_index 将日期列变成索引。这样,我们以后就可以轻松创建时间序列图了。
现在,为了能够画出这个时间序列图,我们需要用0填充缺失值,并将这些列的数据类型改为数值型。这里我们也使用了apply方法。最后,我们使用 cumsum 方法获取列中每个新值的累加值:
HTML 表格中的时间序列图
在上一个例子中,我们使用 Pandas read_html 来获取我们爬取的数据并创建了一个时间序列图。现在,我们还导入了 matplotlib,以便我们可以更改 Pandas 图例标题的位置:
结论:如何将 HTML 读入 Pandas DataFrame
在本 Pandas 教程中,我们学习了如何使用 Pandas read_html 方法从 HTML 中抓取数据。此外,我们使用来自维基百科文章 的数据来创建时间序列图。最后,我们还可以使用 Pandas read_html 通过参数 index_col 将 'Date' 列设置为索引列。
英文原文:
译者:片刻
查看全部
网页表格抓取(
Python中如何使用Pandas_html方法从HTML中获取数据
)
在本 Pandas 教程中,我们将详细介绍如何使用 Pandas 的 read_html 方法从 HTML 中获取数据。首先,在最简单的示例中,我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例使用 Pandas read_html 从维基百科表格中获取数据。在上一篇文章(Python中的探索性数据分析)中,我们也使用了Pandas从HTML表格中读取数据。
在 Python 中导入数据
在开始学习Python和Pandas的时候,为了进行数据分析和可视化,我们通常会从导入数据的实践开始。在前面的文章中,我们已经了解到我们可以直接在Python中输入值(例如,从Python字典创建一个Pandas数据框)。但是,通过从可用来源导入数据来获取数据当然更为常见。这通常通过从 CSV 文件或 Excel 文件中读取数据来完成。例如,要从 .csv 文件导入数据,我们可以使用 Pandas read_csv 方法。这是如何使用此方法的快速示例,但请务必查看主题 文章 的博客以获取更多信息。
现在,上述方法仅在我们已经拥有合适格式(例如 csv 或 JSON)的数据时才有用(请参阅 文章 了解如何使用 Python 和 Pandas 解析 JSON 文件)。
我们大多数人都会使用维基百科来了解我们感兴趣的话题。此外,这些 Wikipedia文章 通常收录 HTML 表格。
要使用pandas在Python中获取这些表格,我们可以将它们剪切并粘贴到电子表格中,然后例如使用read_excel将它们读入Python。现在,这个任务当然可以用更少的步骤完成:我们可以通过网络抓取来自动化它。一定要检查什么是网页抓取。
先决条件
当然,这个 Pandas 阅读 HTML 教程需要我们安装 Pandas 及其依赖项。例如,我们可以使用 pip 安装 Python 包,例如 Pandas,或安装 Python 发行版(例如,Anaconda、ActivePython)。以下是使用 pip 安装 Pandas 的方法:pip install pandas。
请注意,如果出现一条消息说有新版本的 pip 可用,请查看此 文章 以了解如何升级 pip。请注意,我们还需要安装 lxml 或 BeautifulSoup4。当然,这些包也可以使用 pip 安装:pip install lxml。
熊猫 read_html 语法
以下是如何使用 Pandas read_html 从 HTML 表中获取数据的最简单语法:
现在我们知道了使用 Pandas 读取 HTML 表格的简单语法,我们可以看看 read_html 的一些例子。
熊猫 read_html 示例 1:
第一个例子是关于如何使用 Pandas read_html 方法。我们将从一个字符串中读取一个 HTML 表格。
现在,我们得到的结果不是 Pandas DataFrame,而是 Python 列表。换句话说,如果我们使用 type 函数,我们可以看到:
如果我们想要得到表,我们可以使用列表的第一个索引(0)
熊猫 read_html 示例 2:
在第二个 Pandas read_html 示例中,我们将从维基百科中抓取数据。其实我们会得到python(也叫python)的HTML表格。
现在,我们有一个收录 7 个表的列表 (len(df))。如果我们转到维基百科页面,我们可以看到第一个表格是右边的表格。然而,在这个例子中,我们可能对第二个表更感兴趣。
熊猫 read_html 示例 3:
在第三个示例中,我们将从瑞典的 covid-19 案例中读取 HTML 表格。在这里,我们将使用 read_html 方法的一些附加参数。具体来说,我们将使用 match 参数。在此之后,我们仍然需要清理数据,最后我们将进行一些简单的数据可视化操作。
使用 Pandas read_html 和匹配参数抓取数据:
如上图所示,表格的标题是:“瑞典各县的新 COVID-19 病例”。现在,我们可以使用 match 参数并将其作为字符串输入:
这样,我们只得到了这张表,但它仍然是一个dataframes的列表。现在,如上图所示,在底部,我们需要删除三行。因此,我们要删除最后三行。
使用 Pandas iloc 删除最后一行
现在,我们将使用 Pandas iloc 删除最后 3 行。请注意,我们使用 -3 作为第二个参数(确保您查看此 Panda iloc 教程以获取更多信息)。最后,我们还创建了此数据框的副本。
在下一节中,我们将学习如何将多索引列名更改为单索引。
将多个索引更改为单个索引并删除不需要的字符
现在,我们要删除多索引列。换句话说,我们将把 2 列索引(名称)变成一个唯一的列名。在这里,我们将使用 DataFrame.columns 和 DataFrame.columns,get_level_values:
最后,正如您在“日期”列中看到的,我们使用 Pandas read_html 从 WikiPedia 表中抓取了一些评论。接下来,我们将使用 str.replace 方法和正则表达式来删除它们:
使用 Pandas set_index 更改索引
现在,我们继续使用 Pandas set_index 将日期列变成索引。这样,我们以后就可以轻松创建时间序列图了。
现在,为了能够画出这个时间序列图,我们需要用0填充缺失值,并将这些列的数据类型改为数值型。这里我们也使用了apply方法。最后,我们使用 cumsum 方法获取列中每个新值的累加值:
HTML 表格中的时间序列图
在上一个例子中,我们使用 Pandas read_html 来获取我们爬取的数据并创建了一个时间序列图。现在,我们还导入了 matplotlib,以便我们可以更改 Pandas 图例标题的位置:
结论:如何将 HTML 读入 Pandas DataFrame
在本 Pandas 教程中,我们学习了如何使用 Pandas read_html 方法从 HTML 中抓取数据。此外,我们使用来自维基百科文章 的数据来创建时间序列图。最后,我们还可以使用 Pandas read_html 通过参数 index_col 将 'Date' 列设置为索引列。
英文原文:
译者:片刻
网页表格抓取(怎么处理这类网页的网页?表格中的两个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-04 07:09
想爬取一个网站1-n页面的内容,url构造为”,其中?它指的是第n页。假设是58095,url是“(需要登录才能看到详细信息,可以填写我的账号,密码123b45),那么如果我爬下公司名称和公司注册号,等可以用panyname,panyid等存储,这些比较简单,问题是后面的融资信息,如果我用item.invest来存储,那么这个变量其实就是一张没有详细展开的表,需要后面处理,所以如果我Expand的话,需要的变量太多了,而且每个公司融资的数量不同,也就是说对于不同的页面,html标签tr的数量是不确定的,包括以下业务更改记录也是这样,那么我的问题是:
1. 这种行数不定的表信息怎么保存,因为之前用了item.name等item变量,相当于建表了,那怎么保存融资在这张桌子上?不确定嵌入的表信息的行数?后端的数据库是不是一般都存放在类似于json格式的字典中?
2. 如果以保存业务变更记录的形式添加信息,如上,是不是相当于在一个表单中嵌套了两个表单?感觉好复杂啊想着把融资信息和业务变更记录信息分别创建一个itemi()和itemc(),爬上去后再合并。
由于网页的复杂性,不知道大神们平时是怎么处理这样的网页的? 查看全部
网页表格抓取(怎么处理这类网页的网页?表格中的两个)
想爬取一个网站1-n页面的内容,url构造为”,其中?它指的是第n页。假设是58095,url是“(需要登录才能看到详细信息,可以填写我的账号,密码123b45),那么如果我爬下公司名称和公司注册号,等可以用panyname,panyid等存储,这些比较简单,问题是后面的融资信息,如果我用item.invest来存储,那么这个变量其实就是一张没有详细展开的表,需要后面处理,所以如果我Expand的话,需要的变量太多了,而且每个公司融资的数量不同,也就是说对于不同的页面,html标签tr的数量是不确定的,包括以下业务更改记录也是这样,那么我的问题是:
1. 这种行数不定的表信息怎么保存,因为之前用了item.name等item变量,相当于建表了,那怎么保存融资在这张桌子上?不确定嵌入的表信息的行数?后端的数据库是不是一般都存放在类似于json格式的字典中?
2. 如果以保存业务变更记录的形式添加信息,如上,是不是相当于在一个表单中嵌套了两个表单?感觉好复杂啊想着把融资信息和业务变更记录信息分别创建一个itemi()和itemc(),爬上去后再合并。
由于网页的复杂性,不知道大神们平时是怎么处理这样的网页的?
网页表格抓取()
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-03 19:12
问题描述
伙计们!我又向你申请了。我可以使用标记来抓取简单的 网站,但我最近遇到了一个非常复杂的 网站 收录 JavaScript。因此,我想使用表格(csv)的格式获取页面底部的所有估计值。类似于用户“,收入估算”,“EPS估算”。
伙计们!我再次向你申请。我可以用标签抓取简单的网站,但最近我遇到了一个相当复杂的网站,它有 JavaScript。因此,我想以表格 (csv) 的格式获取页面底部的所有估计值。像“用户”、“收入估算”、“每股收益估算”。
我希望自己解决这个问题,但我还是失败了。
我希望自己解决,但有点失败。
这是我的代码:
from urllib import urlopen
from bs4 import BeautifulSoup
html = urlopen("https://www.estimize.com/jpm/f ... 6quot;)
soup = BeautifulSoup(html.read(), "html.parser")
print(soup.findAll('script')[11].string.encode('utf8'))
输出格式很奇怪,我不知道如何以正确的格式提取数据。我将不胜感激!
输出格式奇怪,我不知道如何以适当的形式提取数据。我将不胜感激!
推荐答案
您要提取的数据看起来像是在数据模型中,这意味着它是 JSON。如果您使用以下进行少量分析:
看起来您尝试提取的数据位于数据模型中,这意味着它是 JSON 格式。如果您使用以下内容进行少量解析:
import json
import re
data_string = soup.findAll('script')[11].string.encode('utf8')
data_string = data_string.split("DataModel.parse(")[1]
data_string = data_string.split(");")[0]
// parse out erroneous html
while re.search('\]*\>', datastring):
data_string = ''.join(datastring.split(re.search('\]*\>', datastring).group(0)))
// parse out other function parameters, leaving you with the json
data_you_want = json.loads(data_string.split(re.search('\}[^",\}\]]+,', data_string).group(0))[0]+'}')
print(data_you_want["estimate"])
>>> {'shares': {'shares_hash': {'twitter': None, 'stocktwits': None, 'linkedin': None}}, 'lastRevised': None, 'id': None, 'revenue_points': None, 'sector': 'financials', 'persisted': False, 'points': None, 'instrumentSlug': 'jpm', 'wallstreetRevenue': 23972, 'revenue': 23972, 'createdAt': None, 'username': None, 'isBlind': False, 'releaseSlug': 'fq3-2016', 'statement': '', 'errorRanges': {'revenue': {'low': 21247.3532016398, 'high': 26820.423240734}, 'eps': {'low': 1.02460526459765, 'high': 1.81359679579922}}, 'eps_points': None, 'rank': None, 'instrumentId': 981, 'eps': 1.4, 'season': '2016-fall', 'releaseId': 52773}
DataModel.parse 是一个 javascript 方法,这意味着它以括号和冒号结尾。该函数的参数是所需的 JSON 对象。通过将其加载到 json.loads 中,您可以将其作为字典访问。
DataModel.parse 是一个 javascript 方法,这意味着它以括号和冒号结尾。该函数的参数是您想要的 JSON 对象。通过将其加载到 json.loads 中,您可以像访问字典一样访问它。
从那里,您可以将数据重新映射为您想要的 CSV 格式。
从那里您将数据重新映射到您希望它在 csv 中使用的形式。 查看全部
网页表格抓取()
问题描述
伙计们!我又向你申请了。我可以使用标记来抓取简单的 网站,但我最近遇到了一个非常复杂的 网站 收录 JavaScript。因此,我想使用表格(csv)的格式获取页面底部的所有估计值。类似于用户“,收入估算”,“EPS估算”。
伙计们!我再次向你申请。我可以用标签抓取简单的网站,但最近我遇到了一个相当复杂的网站,它有 JavaScript。因此,我想以表格 (csv) 的格式获取页面底部的所有估计值。像“用户”、“收入估算”、“每股收益估算”。
我希望自己解决这个问题,但我还是失败了。
我希望自己解决,但有点失败。
这是我的代码:
from urllib import urlopen
from bs4 import BeautifulSoup
html = urlopen("https://www.estimize.com/jpm/f ... 6quot;)
soup = BeautifulSoup(html.read(), "html.parser")
print(soup.findAll('script')[11].string.encode('utf8'))
输出格式很奇怪,我不知道如何以正确的格式提取数据。我将不胜感激!
输出格式奇怪,我不知道如何以适当的形式提取数据。我将不胜感激!
推荐答案
您要提取的数据看起来像是在数据模型中,这意味着它是 JSON。如果您使用以下进行少量分析:
看起来您尝试提取的数据位于数据模型中,这意味着它是 JSON 格式。如果您使用以下内容进行少量解析:
import json
import re
data_string = soup.findAll('script')[11].string.encode('utf8')
data_string = data_string.split("DataModel.parse(")[1]
data_string = data_string.split(");")[0]
// parse out erroneous html
while re.search('\]*\>', datastring):
data_string = ''.join(datastring.split(re.search('\]*\>', datastring).group(0)))
// parse out other function parameters, leaving you with the json
data_you_want = json.loads(data_string.split(re.search('\}[^",\}\]]+,', data_string).group(0))[0]+'}')
print(data_you_want["estimate"])
>>> {'shares': {'shares_hash': {'twitter': None, 'stocktwits': None, 'linkedin': None}}, 'lastRevised': None, 'id': None, 'revenue_points': None, 'sector': 'financials', 'persisted': False, 'points': None, 'instrumentSlug': 'jpm', 'wallstreetRevenue': 23972, 'revenue': 23972, 'createdAt': None, 'username': None, 'isBlind': False, 'releaseSlug': 'fq3-2016', 'statement': '', 'errorRanges': {'revenue': {'low': 21247.3532016398, 'high': 26820.423240734}, 'eps': {'low': 1.02460526459765, 'high': 1.81359679579922}}, 'eps_points': None, 'rank': None, 'instrumentId': 981, 'eps': 1.4, 'season': '2016-fall', 'releaseId': 52773}
DataModel.parse 是一个 javascript 方法,这意味着它以括号和冒号结尾。该函数的参数是所需的 JSON 对象。通过将其加载到 json.loads 中,您可以将其作为字典访问。
DataModel.parse 是一个 javascript 方法,这意味着它以括号和冒号结尾。该函数的参数是您想要的 JSON 对象。通过将其加载到 json.loads 中,您可以像访问字典一样访问它。
从那里,您可以将数据重新映射为您想要的 CSV 格式。
从那里您将数据重新映射到您希望它在 csv 中使用的形式。
网页表格抓取(如何使用Python和pandas库从web页面获取表数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-03 14:02
如今,人们可以随时随地连接到 Internet。 Internet 可能是最大的公共数据库。学习如何从互联网上获取数据是非常重要的。因此,有必要了解如何使用Python和pandas库从网页中获取表格数据。另外,如果你已经在使用Excel PowerQuery,这相当于“从Web获取数据”的功能,只不过这里的功能强大100倍。
从网站获取数据(网络爬虫)
HTML 是每个 网站 背后的语言。当我们访问一个网站时,发生的事情是这样的:
1.在浏览器地址栏中输入地址(URL),浏览器会向目标网站的服务器发送请求。
2. 服务器接收到请求,并返回构成网页的 HTML 代码。
3.浏览器接收HTML代码,动态运行,创建一个网页供我们查看。
网页抓取基本上是指我们可以不用浏览器,而是使用Python向网站服务器发送请求,接收HTML代码,然后提取所需数据。
这里不会涉及太多HTML,只介绍一些关键点,让我们对网站和网页抓取的工作原理有一个基本的了解。 HTML 元素或“HTML 标签”被特定的关键字包围。比如下面的HTML代码就是网页的标题,将鼠标悬停在网页中的标签上,浏览器会看到相同的标题。请注意,大多数 HTML 元素都需要一个开始标记(例如,)和相应的结束标记(例如,)。
Python pandas获取网页中的表格数据(网络爬虫)
同理,下面的代码会在浏览器上绘制一个表格,你可以尝试复制粘贴到记事本中,然后保存为“table example.html”文件,应该可以在浏览器中显示浏览器 打开它。简要说明如下:
用户姓名
国家
城市
性别
年龄
Forrest Gump
USA
New York
M>
50
Mary Jane
CANADA
Toronto
F
30
使用pandas进行网络爬虫的要求
学习了 网站 的基本构建块以及如何解释 HTML(至少是表格部分!)。这里之所以只介绍HTML表格,是因为大多数时候,我们尝试从网站中获取数据时,都是表格形式的。 pandas 是从 网站 获取表格格式数据的完美工具!
因此,使用pandas从网站获取数据的唯一要求是数据必须存储在表格中,或者用HTML术语存储在...标签中。 pandas 将能够使用我们刚刚介绍的 HTML 标签提取表格、标题和数据行。
如果您尝试使用 pandas 从不收录任何表格(...标签)的网页中“提取数据”,您将无法获取任何数据。对于那些没有存储在表中的数据,我们需要其他方法来抓取网站。
网页抓取示例
我们之前的大多数示例都是带有少量数据点的小表,让我们使用稍大一些的数据进行处理。
我们将从百度百科获取最新的世界500强企业名称及相关信息:
%E4%B8%96%E7%95%8C500%E5%BC%BA/640042?fr=阿拉丁
图1(如果有错误按照错误提示处理,我电脑没有安装lxml,安装后正常)
上面的df其实是一个列表,很有意思……列表里好像有3个项目。让我们看看pandas为我们采集了哪些数据...
图二
第一个数据框df[0]似乎无关紧要,但是爬到了这个页面的第一个表。查看网页,可以知道这张表是在中国举办的财富全球论坛。
图 3
第二个数据框 df[1] 是本页的另一个表格。请注意,在它的末尾,这意味着有 [500 行 x 6 列]。这张表是世界500强排名表。
图 4
第三个数据框 df[2] 是页面上的第三个表格,最后是 [110 行 x 5 列]。本表为上榜中国企业名单。
注意,总是检查pd.read_html()返回的内容,一个网页可能收录多个表格,所以你会得到一个数据框列表而不是单个数据框!
注:本文借鉴自。
欢迎在下方留言完善本文内容,让更多人学习到更完善的知识。 查看全部
网页表格抓取(如何使用Python和pandas库从web页面获取表数据?)
如今,人们可以随时随地连接到 Internet。 Internet 可能是最大的公共数据库。学习如何从互联网上获取数据是非常重要的。因此,有必要了解如何使用Python和pandas库从网页中获取表格数据。另外,如果你已经在使用Excel PowerQuery,这相当于“从Web获取数据”的功能,只不过这里的功能强大100倍。
从网站获取数据(网络爬虫)
HTML 是每个 网站 背后的语言。当我们访问一个网站时,发生的事情是这样的:
1.在浏览器地址栏中输入地址(URL),浏览器会向目标网站的服务器发送请求。
2. 服务器接收到请求,并返回构成网页的 HTML 代码。
3.浏览器接收HTML代码,动态运行,创建一个网页供我们查看。
网页抓取基本上是指我们可以不用浏览器,而是使用Python向网站服务器发送请求,接收HTML代码,然后提取所需数据。
这里不会涉及太多HTML,只介绍一些关键点,让我们对网站和网页抓取的工作原理有一个基本的了解。 HTML 元素或“HTML 标签”被特定的关键字包围。比如下面的HTML代码就是网页的标题,将鼠标悬停在网页中的标签上,浏览器会看到相同的标题。请注意,大多数 HTML 元素都需要一个开始标记(例如,)和相应的结束标记(例如,)。
Python pandas获取网页中的表格数据(网络爬虫)
同理,下面的代码会在浏览器上绘制一个表格,你可以尝试复制粘贴到记事本中,然后保存为“table example.html”文件,应该可以在浏览器中显示浏览器 打开它。简要说明如下:
用户姓名
国家
城市
性别
年龄
Forrest Gump
USA
New York
M>
50
Mary Jane
CANADA
Toronto
F
30
使用pandas进行网络爬虫的要求
学习了 网站 的基本构建块以及如何解释 HTML(至少是表格部分!)。这里之所以只介绍HTML表格,是因为大多数时候,我们尝试从网站中获取数据时,都是表格形式的。 pandas 是从 网站 获取表格格式数据的完美工具!
因此,使用pandas从网站获取数据的唯一要求是数据必须存储在表格中,或者用HTML术语存储在...标签中。 pandas 将能够使用我们刚刚介绍的 HTML 标签提取表格、标题和数据行。
如果您尝试使用 pandas 从不收录任何表格(...标签)的网页中“提取数据”,您将无法获取任何数据。对于那些没有存储在表中的数据,我们需要其他方法来抓取网站。
网页抓取示例
我们之前的大多数示例都是带有少量数据点的小表,让我们使用稍大一些的数据进行处理。
我们将从百度百科获取最新的世界500强企业名称及相关信息:
%E4%B8%96%E7%95%8C500%E5%BC%BA/640042?fr=阿拉丁
图1(如果有错误按照错误提示处理,我电脑没有安装lxml,安装后正常)
上面的df其实是一个列表,很有意思……列表里好像有3个项目。让我们看看pandas为我们采集了哪些数据...
图二
第一个数据框df[0]似乎无关紧要,但是爬到了这个页面的第一个表。查看网页,可以知道这张表是在中国举办的财富全球论坛。
图 3
第二个数据框 df[1] 是本页的另一个表格。请注意,在它的末尾,这意味着有 [500 行 x 6 列]。这张表是世界500强排名表。
图 4
第三个数据框 df[2] 是页面上的第三个表格,最后是 [110 行 x 5 列]。本表为上榜中国企业名单。
注意,总是检查pd.read_html()返回的内容,一个网页可能收录多个表格,所以你会得到一个数据框列表而不是单个数据框!
注:本文借鉴自。
欢迎在下方留言完善本文内容,让更多人学习到更完善的知识。
网页表格抓取( 如何用Python快速的抓取一个网页中所有表格的爬虫3.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-30 19:11
如何用Python快速的抓取一个网页中所有表格的爬虫3.)
之前在搜索vscode的快捷键时,发现有一个页面,以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学习了Python爬虫,就形成了惯性思维。当我在网页上看到更好的东西,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面简单介绍一下我的一些抢表的思路和方法。
1.在IE浏览器中直接使用export EXCLE
微软的这种设计还是很人性化的,通过这种方式访问网页表格中呈现的内容特别方便。我们只需要在页面上右击,选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
2. 使用Python从网页中抓取表格
接下来就是本文的重点了,直接上代码先。
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'https://segmentfault.com/a/1190000007688656'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
tables = soup.select('table')
df_list = []
for table in tables:
df_list.append(pd.concat(pd.read_html(table.prettify())))
df = pd.concat(df_list)
df.to_excel('vscode快捷键大全.xlsx')
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。我以前这样做过,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址。
下面简单介绍一下代码的含义:
这样就完成了一个简单的爬虫,爬取一个网页中的所有表
3.关于选择方法的建议
最后,我想强调,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格最好的方法就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样,我们就可以把精力集中在学习vscode快捷键的操作上,而不是学习这张表的获取方法。
如果,在另一个场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也是非常重要的。
因此,关键是我们要明确自己的目标,并根据相应的目标选择最合适的方法。
下一篇预告:在下一篇文章中,我将介绍使用正则表达式从本地统计公报中捕获结构化数据 查看全部
网页表格抓取(
如何用Python快速的抓取一个网页中所有表格的爬虫3.)

之前在搜索vscode的快捷键时,发现有一个页面,以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学习了Python爬虫,就形成了惯性思维。当我在网页上看到更好的东西,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面简单介绍一下我的一些抢表的思路和方法。
1.在IE浏览器中直接使用export EXCLE
微软的这种设计还是很人性化的,通过这种方式访问网页表格中呈现的内容特别方便。我们只需要在页面上右击,选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
2. 使用Python从网页中抓取表格
接下来就是本文的重点了,直接上代码先。
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'https://segmentfault.com/a/1190000007688656'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
tables = soup.select('table')
df_list = []
for table in tables:
df_list.append(pd.concat(pd.read_html(table.prettify())))
df = pd.concat(df_list)
df.to_excel('vscode快捷键大全.xlsx')
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。我以前这样做过,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址。
下面简单介绍一下代码的含义:
这样就完成了一个简单的爬虫,爬取一个网页中的所有表
3.关于选择方法的建议
最后,我想强调,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格最好的方法就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样,我们就可以把精力集中在学习vscode快捷键的操作上,而不是学习这张表的获取方法。
如果,在另一个场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也是非常重要的。
因此,关键是我们要明确自己的目标,并根据相应的目标选择最合适的方法。
下一篇预告:在下一篇文章中,我将介绍使用正则表达式从本地统计公报中捕获结构化数据
网页表格抓取(PowerBI汉字的地名来作图,经常出现的精度要求并不高)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-12-25 13:19
在Power BI Desktop做数据地图的时候,因为BING地图中国数据不是那么准确,如果只用汉字中的地名做地图,经常会出现莫名其妙的情况。明明是国内地址,会出国。所以最准确的方法是通过经纬度定位。
互联网上有各种各样的数据。搜索后,有很多网站提供经纬度查询。我们的映射不需要高纬度和经度精度。我找到了一个可以查询全国所有省市县经纬度的网站:
找上海,随便找个区查一下:果然
检查网页上的连接地址。它的结构非常简单,应该可以直接抓取:
具有这种结构的网页通常通过指向子页面的链接来查找内容。它不是现成的数据表。页面上只有三个有用的数据:地名、经度和纬度。所以我们需要用文本打开,然后过滤出我们需要的内容,然后进行整理。
但是我们无法手动一个一个地添加这么多子页面。如果您从任何页面进入,都会有到其他区域的链接,我们会通过此链接自动添加它们。
第一部分获取所有链接地址
首先,修改此源的设置。注意一定要设置GB2312编码,否则汉字乱码。
保留行,从109行开始,共19行
接下来是提取内容:各区名和连接地址:
这提取了>分隔符之间的文本,非常好用。在高级设置中,跳过 1 个字符。观察到这个“”中的“>”是第一个开始符号,我们需要的内容在第二个开始符号之后,所以跳过第一个开始符号。
获取连接地址的方法也是一样的,但是可以直接获取,不用跳过:
第二部分爬行
自定义列:仍然可以使用Web.Contents根据链接地址进行查询。
查询的结果是一个二进制文件,点击合并后会出现警告,点击编辑
点击编辑后,会弹出一个对话框,这里还是要选择文本文件:
接下来就是合并文件的操作了,还是要注意选择GB2312编码:
Power Query在合并文件的时候会像我一样自动生成一个自定义函数,并引用这个自定义函数来合并所有的页面。为方便后续操作,我们在右边的步骤中退一步,查找并删除其他的。列,在这里您可以检索自动删除的区域的名称。如果您不检索它们,则稍后需要再次检索它们。
最终的结果是这样的:第二部分的工作完成了。
第三部分整理资料
这么多行,只有19行对我们有用
我们要过滤掉这19行:通过观察,只要同时收录
这两个关键字的行就是我们需要的内容,世界一下子就刷新了。
需要再次使用Extraction>Separator之间的文本,这次不需要转换文本,使用添加列中的提取保存复制列。首先提取经度:
然后提取纬度:
最后,修改以下名称和数据类型,大功告成:
我们在每个区模拟一列销售数据,然后使用每个区的名称为索引列建立表关系:
您可以在BI中制作图片:
最好将本地从网络捕获的数据保存为存档。无需每次都在网络上刷新。可以直接在 Power BI Desktop 的表格模式下复制表格,然后粘贴到 Excel 中。向上。
如果在 Excel 中从 Power Query 中抓取数据,则更简单,只需将其加载到表中并复制即可。 查看全部
网页表格抓取(PowerBI汉字的地名来作图,经常出现的精度要求并不高)
在Power BI Desktop做数据地图的时候,因为BING地图中国数据不是那么准确,如果只用汉字中的地名做地图,经常会出现莫名其妙的情况。明明是国内地址,会出国。所以最准确的方法是通过经纬度定位。
互联网上有各种各样的数据。搜索后,有很多网站提供经纬度查询。我们的映射不需要高纬度和经度精度。我找到了一个可以查询全国所有省市县经纬度的网站:
找上海,随便找个区查一下:果然
检查网页上的连接地址。它的结构非常简单,应该可以直接抓取:
具有这种结构的网页通常通过指向子页面的链接来查找内容。它不是现成的数据表。页面上只有三个有用的数据:地名、经度和纬度。所以我们需要用文本打开,然后过滤出我们需要的内容,然后进行整理。
但是我们无法手动一个一个地添加这么多子页面。如果您从任何页面进入,都会有到其他区域的链接,我们会通过此链接自动添加它们。
第一部分获取所有链接地址
首先,修改此源的设置。注意一定要设置GB2312编码,否则汉字乱码。
保留行,从109行开始,共19行
接下来是提取内容:各区名和连接地址:
这提取了>分隔符之间的文本,非常好用。在高级设置中,跳过 1 个字符。观察到这个“”中的“>”是第一个开始符号,我们需要的内容在第二个开始符号之后,所以跳过第一个开始符号。
获取连接地址的方法也是一样的,但是可以直接获取,不用跳过:
第二部分爬行
自定义列:仍然可以使用Web.Contents根据链接地址进行查询。
查询的结果是一个二进制文件,点击合并后会出现警告,点击编辑
点击编辑后,会弹出一个对话框,这里还是要选择文本文件:
接下来就是合并文件的操作了,还是要注意选择GB2312编码:
Power Query在合并文件的时候会像我一样自动生成一个自定义函数,并引用这个自定义函数来合并所有的页面。为方便后续操作,我们在右边的步骤中退一步,查找并删除其他的。列,在这里您可以检索自动删除的区域的名称。如果您不检索它们,则稍后需要再次检索它们。
最终的结果是这样的:第二部分的工作完成了。
第三部分整理资料
这么多行,只有19行对我们有用
我们要过滤掉这19行:通过观察,只要同时收录
这两个关键字的行就是我们需要的内容,世界一下子就刷新了。
需要再次使用Extraction>Separator之间的文本,这次不需要转换文本,使用添加列中的提取保存复制列。首先提取经度:
然后提取纬度:
最后,修改以下名称和数据类型,大功告成:
我们在每个区模拟一列销售数据,然后使用每个区的名称为索引列建立表关系:
您可以在BI中制作图片:
最好将本地从网络捕获的数据保存为存档。无需每次都在网络上刷新。可以直接在 Power BI Desktop 的表格模式下复制表格,然后粘贴到 Excel 中。向上。
如果在 Excel 中从 Power Query 中抓取数据,则更简单,只需将其加载到表中并复制即可。
网页表格抓取(Excel,R,Python和BI,作为开始数据分析的基础)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-25 13:17
数据分析时代已经到来。从国家、政府、公司到个人,大数据和数据分析已经成为大家耳熟能详的趋势。但是你可能没有数据分析和编程方面的专业知识,或者你已经了解了很多数据分析的理论,但你仍然无法实践。在这里,我将比较数据分析师最流行的四种工具,Excel、R、Python 和 BI,作为开始数据分析的基础。
1. Excel
1.1使用场景
1.2 优点
1.3 缺点
2. R
2.1使用场景
R 的功能几乎涵盖了任何需要数据的领域。就我们一般的数据分析或学术数据分析而言,R能做的主要有以下几个方面。
2.2 R 好学吗?
在我看来,R 入门非常简单。10天的强化学习,足以掌握基本用法、基本数据结构、数据导入导出、简单数据可视化。有了这些基础,当你遇到实际问题的时候,就可以找到你需要用到的R包了。通过阅读 R 的帮助文件和互联网上的信息,您可以相对较快地解决特定问题。
3. Python
3.1使用场景
3.2 R 和 Python
R 和 Python 都是需要编程的数据分析工具。不同的是R只用在数据分析领域,而科学计算和数据分析只是Python的应用分支。Python还可以用于开发网页、开发游戏、开发系统后端,以及执行一些运维任务。
目前的趋势是Python在数据分析领域正在追赶R。在某些方面,它已经超越了 R,例如机器学习和文本挖掘。但R在统计领域仍然保持优势。Python在数据分析方面的发展在很多地方模拟了R的一些特性。所以,如果你还是新手,还没有开始学习,我建议你从Python开始。
Python 和 R 都很容易学习。但是如果同时研究两者,就会很混乱,因为它们在很多地方都非常相似。所以建议不要同时学习。等到你掌握了其中一个,然后开始学习另一个。
3.3 选择 R 还是 Python?
如果因为时间有限只能选择其中之一学习,我推荐使用Python。但我仍然建议你看看两者。在某些地方,您可能会听说 Python 在工作中更常用,但解决问题是最重要的。如果你能用R有效解决问题,那就用R吧。其实Python模仿了R的很多功能,比如Pandas库中的DataFrames。正在开发的可视化包ggplot模仿了R中非常有名的ggplot2。
双
数据分析中有一句话:文字不如表格,表格不如图表。数据可视化是数据分析的主要方向之一。Excel图表可以满足基本的图形要求,但这只是基础。高级可视化需要编程。除了学习R、Python等编程语言,还可以选择简单易用的BI工具。有关 BI 的介绍,您可以阅读我的另一篇文章,我应该学习哪些数据分析工具才能开始我的数据分析师职业?
商业智能诞生于数据分析,它诞生于一个非常高的起点。目标是缩短从业务数据到业务决策的时间。它是关于如何使用数据来影响决策。
BI 的优势在于其在交互和报告方面的优势。擅长解读历史数据和实时数据。可以大大解放数据分析师的工作,增强整个公司的数据意识,提高数据导入的效率。市场上有许多BI产品。他们的原理是通过连接和钻孔维度来构建仪表板以获得可视化分析。 查看全部
网页表格抓取(Excel,R,Python和BI,作为开始数据分析的基础)
数据分析时代已经到来。从国家、政府、公司到个人,大数据和数据分析已经成为大家耳熟能详的趋势。但是你可能没有数据分析和编程方面的专业知识,或者你已经了解了很多数据分析的理论,但你仍然无法实践。在这里,我将比较数据分析师最流行的四种工具,Excel、R、Python 和 BI,作为开始数据分析的基础。
1. Excel
1.1使用场景
1.2 优点
1.3 缺点
2. R
2.1使用场景
R 的功能几乎涵盖了任何需要数据的领域。就我们一般的数据分析或学术数据分析而言,R能做的主要有以下几个方面。
2.2 R 好学吗?
在我看来,R 入门非常简单。10天的强化学习,足以掌握基本用法、基本数据结构、数据导入导出、简单数据可视化。有了这些基础,当你遇到实际问题的时候,就可以找到你需要用到的R包了。通过阅读 R 的帮助文件和互联网上的信息,您可以相对较快地解决特定问题。
3. Python
3.1使用场景
3.2 R 和 Python
R 和 Python 都是需要编程的数据分析工具。不同的是R只用在数据分析领域,而科学计算和数据分析只是Python的应用分支。Python还可以用于开发网页、开发游戏、开发系统后端,以及执行一些运维任务。
目前的趋势是Python在数据分析领域正在追赶R。在某些方面,它已经超越了 R,例如机器学习和文本挖掘。但R在统计领域仍然保持优势。Python在数据分析方面的发展在很多地方模拟了R的一些特性。所以,如果你还是新手,还没有开始学习,我建议你从Python开始。
Python 和 R 都很容易学习。但是如果同时研究两者,就会很混乱,因为它们在很多地方都非常相似。所以建议不要同时学习。等到你掌握了其中一个,然后开始学习另一个。
3.3 选择 R 还是 Python?
如果因为时间有限只能选择其中之一学习,我推荐使用Python。但我仍然建议你看看两者。在某些地方,您可能会听说 Python 在工作中更常用,但解决问题是最重要的。如果你能用R有效解决问题,那就用R吧。其实Python模仿了R的很多功能,比如Pandas库中的DataFrames。正在开发的可视化包ggplot模仿了R中非常有名的ggplot2。
双
数据分析中有一句话:文字不如表格,表格不如图表。数据可视化是数据分析的主要方向之一。Excel图表可以满足基本的图形要求,但这只是基础。高级可视化需要编程。除了学习R、Python等编程语言,还可以选择简单易用的BI工具。有关 BI 的介绍,您可以阅读我的另一篇文章,我应该学习哪些数据分析工具才能开始我的数据分析师职业?
商业智能诞生于数据分析,它诞生于一个非常高的起点。目标是缩短从业务数据到业务决策的时间。它是关于如何使用数据来影响决策。
BI 的优势在于其在交互和报告方面的优势。擅长解读历史数据和实时数据。可以大大解放数据分析师的工作,增强整个公司的数据意识,提高数据导入的效率。市场上有许多BI产品。他们的原理是通过连接和钻孔维度来构建仪表板以获得可视化分析。
网页表格抓取(如何采集网页中的表格数据采集助手(网页表格采集器))
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-12-23 18:05
网页表单数据采集助手(Web Form采集器)是一款绿色简单的网页表单数据采集工具。如何在网页中采集表单?网页表单数据采集助手(网页表单采集器)为您快速采集。一些网页上的表格很多,只是复制格式容易出错,麻烦,所以这个软件可以快速帮你采集这些表格,并且保留表格的原创表格,非常方便。
软件说明:
网上资料采集的工作最麻烦的就是从网页上复制数据表很枯燥,复制之后还要做很多修改,不仅麻烦而且浪费时间和工作效率。它非常低。对于少量简单的表格,我们或许可以借助微软EXCEL软件进行导入,但是如果要复制网页上的表格,则必须将其保存为原创文本格式,或者同时保存时间采集某一个网站连续几十页甚至上百页,我觉得你要停止做饭了,现在好了,我们有了这个通用的网页表单数据采集器软件不仅可以采集单页规则和不规则表格,还可以自动连续采集 指定网站的形式,可以指定采集 required 字段的内容,采集之后的内容可以保存为EXCEL软件可以读取的文件格式,或者作为保留原创形式的纯文本形式。绝对简单、方便、快捷、纯绿色。
使用说明:
1、首先在地址栏中输入采集的网页地址。如果采集的网页已经在IE浏览器中打开过,这个地址会自动添加到软件的网址列表中。
2、 然后点击爬虫测试按钮,可以看到网页的源代码和网页收录的表数。网页的源代码显示在软件下方的文本框中。网页中收录的表格和标题信息的数量在软件中。显示在左上角的列表框中。
3、从表数列表中选择要抓取的表。此时,软件窗体左上角的内容输入框中将显示窗体左上角的第一个文本。表单中收录的字段(列)将显示在软件左侧的中间列表中。
4、 然后选择你要采集的表数据的字段(列),如果不选择,都是采集。
5、选择是否要抓取表格的标题行以及保存时是否显示表格行。如果web表单的某个字段中有链接,可以选择是否收录链接地址,如果是并且需要采集其链接地址,则不能同时选择收录标题行时间。
6、 如果你想让采集的表单数据只有一个网页,那么现在可以直接点击抓取表单。如果之前不选择收录表单行,表单数据将保存为 CVS 格式。这种格式可以直接用微软EXCEL软件打开,转换成EXCEL格式。如果选择在前面收录表格行,表格数据将以TXT格式保存。可以用记事本软件打开查看。表线直接可用,也很清晰。
7、如果要采集表数据有多个连续页,并且要采集向下,那么请重新设置程序采集下一页和跟随页面的方式可以是根据链接名称打开下一个页面。几乎大多数页面的链接名称都是“下一页”。您可以查看页面,找到后输入。如果页面没有下一页的链接,但URL收录页码,那么您也可以根据URL中的页数选择打开。可以选择从前到后,比如从第1页到第10页,或者从后到前,比如从第10页到第1页,在页码里输入就行了,但是此时的位置URL中的页码应替换为“(*)”,
8、 然后选择定时采集或者等待网页打开加载采集后立即加载,定时采集是程序根据设定的小时间间隔判断打开如果页面中有你想要的表单,可以采集,页面加载后,采集只要采集的页面已经打开,程序就会马上着手采集,两者各有特点,看需要选择。
9、最后,您只需单击“抓取表单”按钮,即可制作一杯咖啡!
10、如果你已经熟悉了要采集的网页信息,并且想要采集指定表单中的所有字段,也可以输入一些信息需要不经过爬取测试等操作,直接点击爬取表。 查看全部
网页表格抓取(如何采集网页中的表格数据采集助手(网页表格采集器))
网页表单数据采集助手(Web Form采集器)是一款绿色简单的网页表单数据采集工具。如何在网页中采集表单?网页表单数据采集助手(网页表单采集器)为您快速采集。一些网页上的表格很多,只是复制格式容易出错,麻烦,所以这个软件可以快速帮你采集这些表格,并且保留表格的原创表格,非常方便。
软件说明:
网上资料采集的工作最麻烦的就是从网页上复制数据表很枯燥,复制之后还要做很多修改,不仅麻烦而且浪费时间和工作效率。它非常低。对于少量简单的表格,我们或许可以借助微软EXCEL软件进行导入,但是如果要复制网页上的表格,则必须将其保存为原创文本格式,或者同时保存时间采集某一个网站连续几十页甚至上百页,我觉得你要停止做饭了,现在好了,我们有了这个通用的网页表单数据采集器软件不仅可以采集单页规则和不规则表格,还可以自动连续采集 指定网站的形式,可以指定采集 required 字段的内容,采集之后的内容可以保存为EXCEL软件可以读取的文件格式,或者作为保留原创形式的纯文本形式。绝对简单、方便、快捷、纯绿色。

使用说明:
1、首先在地址栏中输入采集的网页地址。如果采集的网页已经在IE浏览器中打开过,这个地址会自动添加到软件的网址列表中。
2、 然后点击爬虫测试按钮,可以看到网页的源代码和网页收录的表数。网页的源代码显示在软件下方的文本框中。网页中收录的表格和标题信息的数量在软件中。显示在左上角的列表框中。
3、从表数列表中选择要抓取的表。此时,软件窗体左上角的内容输入框中将显示窗体左上角的第一个文本。表单中收录的字段(列)将显示在软件左侧的中间列表中。
4、 然后选择你要采集的表数据的字段(列),如果不选择,都是采集。
5、选择是否要抓取表格的标题行以及保存时是否显示表格行。如果web表单的某个字段中有链接,可以选择是否收录链接地址,如果是并且需要采集其链接地址,则不能同时选择收录标题行时间。
6、 如果你想让采集的表单数据只有一个网页,那么现在可以直接点击抓取表单。如果之前不选择收录表单行,表单数据将保存为 CVS 格式。这种格式可以直接用微软EXCEL软件打开,转换成EXCEL格式。如果选择在前面收录表格行,表格数据将以TXT格式保存。可以用记事本软件打开查看。表线直接可用,也很清晰。
7、如果要采集表数据有多个连续页,并且要采集向下,那么请重新设置程序采集下一页和跟随页面的方式可以是根据链接名称打开下一个页面。几乎大多数页面的链接名称都是“下一页”。您可以查看页面,找到后输入。如果页面没有下一页的链接,但URL收录页码,那么您也可以根据URL中的页数选择打开。可以选择从前到后,比如从第1页到第10页,或者从后到前,比如从第10页到第1页,在页码里输入就行了,但是此时的位置URL中的页码应替换为“(*)”,
8、 然后选择定时采集或者等待网页打开加载采集后立即加载,定时采集是程序根据设定的小时间间隔判断打开如果页面中有你想要的表单,可以采集,页面加载后,采集只要采集的页面已经打开,程序就会马上着手采集,两者各有特点,看需要选择。
9、最后,您只需单击“抓取表单”按钮,即可制作一杯咖啡!
10、如果你已经熟悉了要采集的网页信息,并且想要采集指定表单中的所有字段,也可以输入一些信息需要不经过爬取测试等操作,直接点击爬取表。
网页表格抓取(网页表格数据采集器软件可立刻解决你的问题呢? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-12-14 23:06
)
亲,你有很多网页表单数据要复制吗,采集,抓紧吗?您是否正在为如何复制这些数百、数千甚至数万页的表数据而烦恼?是不是觉得键盘打字、鼠标点击、效率低下太累太难了?重复枯燥的工作太让人抓狂了
, 有没有可以立即解决您的问题的软件?当你读到这些话的时候,我想告诉你,你已经看到了曙光,没错,就是这个页面给你介绍的软件——网页表单数据采集器。
web表单数据采集器软件支持在一个网站上连续无限页面批量采集相同表单数据,支持采集@指定表单数据在一个采集 page>,也支持采集一个页面中具有通用数据的多个表数据,采集可以根据网页上的“下一页”等链接的后续页面进行无限采集@ >,也可以根据网址采集中的页数来指定连续页中的表格数据,或者根据您自己指定的网址列表。可以采集,并且可以自动过滤隐藏的干扰码,采集的结果可以显示为文本表格,另存为文本,
下面是我们的软件界面截图,软件下载地址如下
支持单数据链路采集
仅支持采集指定的字段
该软件可以连续或定期采集指定与网站正面和背面相关联的标准二维表,操作非常简单方便。连续批量需要采集的网页文章,请选择本店其他软件-Web文采集Master。
网页表单数据采集器软件现已更新至V2.38版。最新版本下载地址如下,请复制地址用浏览器或其他下载工具下载。
关于本软件的更多信息,请查看软件官网论坛
web表单数据采集软件的使用也很简单。熟悉的话,表单采集 一键搞定。以下是使用该软件的简单步骤:
1、首先在地址栏中输入网页地址为采集。如果要采集的网页已经在IE浏览器中打开了,那么这个地址会自动添加到软件的网址列表中。
2、 然后点击爬取测试按钮,网页中收录的表数和页眉信息会自动显示在软件左上角的列表框中,同时自动识别您可能想要抓取并选择此表。如果网页表单是多页连续的,并且网页中有“下一页”链接,程序会自动在“根据链接或按钮关键字打开下一页”的输入框中输入“下一页”。
3、从表号列表中选择要抓取的表。此时,表格左上角第一个格子或三个格子中的文字会显示在软件的“表格中收录的字段(列)会显示在软件左侧的中间列表中(注意,也可以点击“表格第一行的第一部分”的标签,输入会变成“表格中每一行的部分”来判断表格是否收录某个字符串使用来识别网页中的表单,也可以输入为“所有表单中的序号”,输入表单列表框中显示的表单序号,确定网页中识别表单的标记)。
4、 然后选择你想要采集的表数据的字段(列),如果不选择,设置表采集的所有列。
5、选择是否要抓取表格的标题行以及保存时是否显示表格行。如果web表单的字段中有链接,可以选择是否收录链接地址,如果有并且需要采集它的链接地址,那么就不能选择在页眉行收录同时。
6、 如果想让采集的表单数据只有一个网页,那么可以直接点击抓取表格来抓取。如果之前不选择收录表格行,表格数据将保存为 CVS 格式。这种格式可以直接用微软EXCEL软件打开,转换成EXCEL格式。如果选择在前面收录表格行,表格数据将以TXT格式保存。可以用记事本软件打开查看。表线直接可用,也很清晰。
7、如果想让采集的表单数据有多个连续的页面,并且想要采集向下,那么请重新设置程序采集下一页并跟随页面的方式可以是根据链接名称打开下一页。几乎大多数页面的链接名称都是“下一页”。您可以查看页面,找到后输入。如果页面没有下一页的链接,但URL收录页码,那么您也可以根据URL中的页数选择打开。可以选择从前到后,比如从第1页到第10页,或者从后到前,比如从第10页到第1页,在页码里输入就行了,但是此时的位置URL中的页码应替换为“(*)”,
8、 然后选择定时采集或者等待网页打开加载采集后立即加载,定时采集是程序根据设定的小时间间隔判断打开如果页面中有你想要的表单,可以采集,页面加载后,采集只要采集的页面已经打开,程序就会马上着手采集,两者各有特点,看需要选择。
9、最后,你只需要点击抢表按钮,就可以泡一杯咖啡了!
10、如果你已经熟悉了要采集的网页信息,并且想要采集指定表单中的所有字段,也可以输入需要的信息不经过爬取测试等操作,直接点击爬取表格。
时间,一寸光阴,一寸金。寸金难买寸光阴。我们不能把有限的时间浪费在一些重复而枯燥的工作上。有现成的软件。为什么不使用该软件。再说,现在的30块钱,你在菜市场买不到任何菜。这么便宜的价格,你不能再犹豫了。如果您需要,请尽快开始。
下单时请在备注栏中填写邮箱地址和软件打开后显示的机器码。购买后,我们将向您发送正式版。如果需要,我们还可以为您进行远程演示操作。
如果现有方案不能满足您的需求,我们也可以支持方案定制。如果需要,请先增加费用。
406
客户的评论和不断的好评。尤其是这款软件还可以持续捕捉店铺评论和评论,以及宝贝销售记录。如果您需要采集已售出的婴儿数据,它带有一个已售出的婴儿数据管理器:
感谢您的好评,您的好评是对我不断升级完善本软件的最大支持
另外,购买本软件后,如果想要treeView和ListView数据采集器,也可以向楼主索取
查看全部
网页表格抓取(网页表格数据采集器软件可立刻解决你的问题呢?
)
亲,你有很多网页表单数据要复制吗,采集,抓紧吗?您是否正在为如何复制这些数百、数千甚至数万页的表数据而烦恼?是不是觉得键盘打字、鼠标点击、效率低下太累太难了?重复枯燥的工作太让人抓狂了

, 有没有可以立即解决您的问题的软件?当你读到这些话的时候,我想告诉你,你已经看到了曙光,没错,就是这个页面给你介绍的软件——网页表单数据采集器。
web表单数据采集器软件支持在一个网站上连续无限页面批量采集相同表单数据,支持采集@指定表单数据在一个采集 page>,也支持采集一个页面中具有通用数据的多个表数据,采集可以根据网页上的“下一页”等链接的后续页面进行无限采集@ >,也可以根据网址采集中的页数来指定连续页中的表格数据,或者根据您自己指定的网址列表。可以采集,并且可以自动过滤隐藏的干扰码,采集的结果可以显示为文本表格,另存为文本,
下面是我们的软件界面截图,软件下载地址如下

支持单数据链路采集

仅支持采集指定的字段
该软件可以连续或定期采集指定与网站正面和背面相关联的标准二维表,操作非常简单方便。连续批量需要采集的网页文章,请选择本店其他软件-Web文采集Master。
网页表单数据采集器软件现已更新至V2.38版。最新版本下载地址如下,请复制地址用浏览器或其他下载工具下载。
关于本软件的更多信息,请查看软件官网论坛
web表单数据采集软件的使用也很简单。熟悉的话,表单采集 一键搞定。以下是使用该软件的简单步骤:
1、首先在地址栏中输入网页地址为采集。如果要采集的网页已经在IE浏览器中打开了,那么这个地址会自动添加到软件的网址列表中。
2、 然后点击爬取测试按钮,网页中收录的表数和页眉信息会自动显示在软件左上角的列表框中,同时自动识别您可能想要抓取并选择此表。如果网页表单是多页连续的,并且网页中有“下一页”链接,程序会自动在“根据链接或按钮关键字打开下一页”的输入框中输入“下一页”。
3、从表号列表中选择要抓取的表。此时,表格左上角第一个格子或三个格子中的文字会显示在软件的“表格中收录的字段(列)会显示在软件左侧的中间列表中(注意,也可以点击“表格第一行的第一部分”的标签,输入会变成“表格中每一行的部分”来判断表格是否收录某个字符串使用来识别网页中的表单,也可以输入为“所有表单中的序号”,输入表单列表框中显示的表单序号,确定网页中识别表单的标记)。
4、 然后选择你想要采集的表数据的字段(列),如果不选择,设置表采集的所有列。
5、选择是否要抓取表格的标题行以及保存时是否显示表格行。如果web表单的字段中有链接,可以选择是否收录链接地址,如果有并且需要采集它的链接地址,那么就不能选择在页眉行收录同时。
6、 如果想让采集的表单数据只有一个网页,那么可以直接点击抓取表格来抓取。如果之前不选择收录表格行,表格数据将保存为 CVS 格式。这种格式可以直接用微软EXCEL软件打开,转换成EXCEL格式。如果选择在前面收录表格行,表格数据将以TXT格式保存。可以用记事本软件打开查看。表线直接可用,也很清晰。
7、如果想让采集的表单数据有多个连续的页面,并且想要采集向下,那么请重新设置程序采集下一页并跟随页面的方式可以是根据链接名称打开下一页。几乎大多数页面的链接名称都是“下一页”。您可以查看页面,找到后输入。如果页面没有下一页的链接,但URL收录页码,那么您也可以根据URL中的页数选择打开。可以选择从前到后,比如从第1页到第10页,或者从后到前,比如从第10页到第1页,在页码里输入就行了,但是此时的位置URL中的页码应替换为“(*)”,
8、 然后选择定时采集或者等待网页打开加载采集后立即加载,定时采集是程序根据设定的小时间间隔判断打开如果页面中有你想要的表单,可以采集,页面加载后,采集只要采集的页面已经打开,程序就会马上着手采集,两者各有特点,看需要选择。
9、最后,你只需要点击抢表按钮,就可以泡一杯咖啡了!
10、如果你已经熟悉了要采集的网页信息,并且想要采集指定表单中的所有字段,也可以输入需要的信息不经过爬取测试等操作,直接点击爬取表格。
时间,一寸光阴,一寸金。寸金难买寸光阴。我们不能把有限的时间浪费在一些重复而枯燥的工作上。有现成的软件。为什么不使用该软件。再说,现在的30块钱,你在菜市场买不到任何菜。这么便宜的价格,你不能再犹豫了。如果您需要,请尽快开始。
下单时请在备注栏中填写邮箱地址和软件打开后显示的机器码。购买后,我们将向您发送正式版。如果需要,我们还可以为您进行远程演示操作。
如果现有方案不能满足您的需求,我们也可以支持方案定制。如果需要,请先增加费用。
406

客户的评论和不断的好评。尤其是这款软件还可以持续捕捉店铺评论和评论,以及宝贝销售记录。如果您需要采集已售出的婴儿数据,它带有一个已售出的婴儿数据管理器:

感谢您的好评,您的好评是对我不断升级完善本软件的最大支持

另外,购买本软件后,如果想要treeView和ListView数据采集器,也可以向楼主索取

网页表格抓取(小五书接上文,让你的网页满足条件read_html)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-11 06:03
大家好,我是小吴?
书在上面,我们可以,文末我说对应的read_html()也是神器!
PS:大家也都很好,我点了30个赞,小吴赶紧安排了
最简单的爬虫:用Pandas爬取表数据
有一点不得不承认,使用Pandas爬取表格数据有一定的局限性。
只适合抓取Table数据,那么我们先看看什么样的网页符合条件?
什么样的网页结构?
用浏览器打开网页,F12查看HTML结构,你会发现符合条件的网页结构有一个共同特征。
如果你发现 HTML 结构是下面的 Table 格式,你可以直接使用 Pandas 上手。
...
...
...
...
...
...
...
这看起来不直观。开启北京空气质量网站。
F12,左边是网页质量指标表,其网页结构与Table表格数据网页结构完美匹配。
非常适合使用pandas爬取。
pd.read_html()
Pandas 提供了两个函数:read_html() 和 to_html() 用于读写 html 格式的文件。这两个功能非常有用。可以轻松地将复杂的数据结构(例如 DataFrame)转换为 HTML 表格;另一个不需要复杂的爬虫,几行代码就可以抓取Table表数据,简直就是神器! [1]
具体的pd.read_html()参数可以查看官方文档:
我们把刚才的网页打开看看吧!
import pandas as pd
df = pd.read_html("http://www.air-level.com/air/beijing/", encoding='utf-8',header=0)[0]
这里只添加了几个参数,header就是指定列标题的那一行。使用guide包,只需要两行代码。
df.head()
对比结果,可以看到已经成功获取到表数据。
多表
之前的情况,不知道有没有人注意到
pd.read_html()[0]
对于pd.read_html(),在得到网页结果后,还要加上一个[0]。这是因为网页上可能有多个表格。这时候就需要通过列表的分片tables[x]来指定获取哪个表。
比如刚才的网站,空气质量排名网页明显是由两张表组成的。
此时如果使用pd.read_html()得到右边的表格,只需稍微修改即可。
import pandas as pd
df = pd.read_html("http://www.air-level.com/rank", encoding='utf-8',header=0)[1]
相反,可以看到页面右侧的表格已经成功获取。
以上就是简单的使用pd.read_html()抓取静态网页。但是我们之所以使用Python,其实是为了提高效率。但是如果只有一个网页,用鼠标选择复制不是更容易吗?所以Python操作的最大优势会体现在批量操作上。
批量抓取
给大家演示一下如何使用Pandas批量抓取网络表格数据?
以新浪金融机构持股汇总数据为例:
一共47个页面,47个网页网址通过一个for循环构造,然后通过pd.read_html()循环抓取。
df = pd.DataFrame()
for i in range(1, 48):
url = f'http://vip.stock.finance.sina. ... Fp%3D{i}'
df = pd.concat([df, pd.read_html(url)[0]]) # 爬取+合并DataFrame
几行代码,轻松解决。
共获取47页1738条数据。
通过上面的小案例,相信你可以轻松掌握Pandas对表数据的批量抓取了吗? 查看全部
网页表格抓取(小五书接上文,让你的网页满足条件read_html)
大家好,我是小吴?
书在上面,我们可以,文末我说对应的read_html()也是神器!
PS:大家也都很好,我点了30个赞,小吴赶紧安排了
最简单的爬虫:用Pandas爬取表数据
有一点不得不承认,使用Pandas爬取表格数据有一定的局限性。
只适合抓取Table数据,那么我们先看看什么样的网页符合条件?
什么样的网页结构?
用浏览器打开网页,F12查看HTML结构,你会发现符合条件的网页结构有一个共同特征。
如果你发现 HTML 结构是下面的 Table 格式,你可以直接使用 Pandas 上手。
...
...
...
...
...
...
...
这看起来不直观。开启北京空气质量网站。
F12,左边是网页质量指标表,其网页结构与Table表格数据网页结构完美匹配。
非常适合使用pandas爬取。
pd.read_html()
Pandas 提供了两个函数:read_html() 和 to_html() 用于读写 html 格式的文件。这两个功能非常有用。可以轻松地将复杂的数据结构(例如 DataFrame)转换为 HTML 表格;另一个不需要复杂的爬虫,几行代码就可以抓取Table表数据,简直就是神器! [1]
具体的pd.read_html()参数可以查看官方文档:
我们把刚才的网页打开看看吧!
import pandas as pd
df = pd.read_html("http://www.air-level.com/air/beijing/", encoding='utf-8',header=0)[0]
这里只添加了几个参数,header就是指定列标题的那一行。使用guide包,只需要两行代码。
df.head()
对比结果,可以看到已经成功获取到表数据。
多表
之前的情况,不知道有没有人注意到
pd.read_html()[0]
对于pd.read_html(),在得到网页结果后,还要加上一个[0]。这是因为网页上可能有多个表格。这时候就需要通过列表的分片tables[x]来指定获取哪个表。
比如刚才的网站,空气质量排名网页明显是由两张表组成的。
此时如果使用pd.read_html()得到右边的表格,只需稍微修改即可。
import pandas as pd
df = pd.read_html("http://www.air-level.com/rank", encoding='utf-8',header=0)[1]
相反,可以看到页面右侧的表格已经成功获取。
以上就是简单的使用pd.read_html()抓取静态网页。但是我们之所以使用Python,其实是为了提高效率。但是如果只有一个网页,用鼠标选择复制不是更容易吗?所以Python操作的最大优势会体现在批量操作上。
批量抓取
给大家演示一下如何使用Pandas批量抓取网络表格数据?
以新浪金融机构持股汇总数据为例:
一共47个页面,47个网页网址通过一个for循环构造,然后通过pd.read_html()循环抓取。
df = pd.DataFrame()
for i in range(1, 48):
url = f'http://vip.stock.finance.sina. ... Fp%3D{i}'
df = pd.concat([df, pd.read_html(url)[0]]) # 爬取+合并DataFrame
几行代码,轻松解决。
共获取47页1738条数据。
通过上面的小案例,相信你可以轻松掌握Pandas对表数据的批量抓取了吗?
网页表格抓取(基于MSHTML设计开发的原理、程序结构和网页元素属性表格化显示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-01-16 16:27
罗进才
【摘要】介绍了基于MSHTML设计开发的网页信息表格提取程序的原理、程序结构和工作流程。使用网页信息提取、网页元素分析、采集配置管理三个功能模块,提取网页信息。其内部相关信息的提取、解析、排序和表格展示,创新性地采用二进制检查机制确认网页属性值和树形路径值,可以实现对指定信息的准确提取。本文还说明了程序的操作步骤和实际效果。
【关键词】MSHTML信息自动提取网页元素属性并以表格形式展示
[CLC 编号] G64 [文档识别码] A [文章 编号] 2095-3089 (2017)10-0229-02
介绍
当今是网络飞速发展、信息量迅速膨胀的信息时代。人们通过信息相互交流,了解世界。信息中有很多有价值的信息元素,这些有价值的信息元素大多以网页的形式存在,其内容和格式差异很大。通过浏览器浏览阅读是没有问题的,但是如果需要保存和整理某类感兴趣的信息及其内部相关信息,常用的工具一般都有一些不足,比如网络蜘蛛等爬虫工具. 无法实现内部相关信息的提取。因此笔者使用MSHTML语言设计了一个网页内部表格抽取自动程序,
1.程序设计思路
1.1 采集原理
众所周知,网页是用 HTML 语言描述的。采集网页信息的本质是从网页的HTML代码中提取出我们需要的信息。如果直接从代码中提取,就只能使用正则表达式等文本匹配的方式来采集。这会导致以下问题:一是使用不方便。用户不仅需要了解 HTML,还需要了解正则表达式。另外,他们需要在大量的 HTML 代码中找到需要的信息,然后再考虑如何匹配;二是容错性差。,如果代码稍有偏差,会导致文本匹配失败,比如遇到制表符、回车、空格等。
经过长期研究,作者发现MSHTML可以有效解决这些问题。MSHTML是微软公司的一个COM组件,它将所有元素及其属性封装在HTML语言中,可以通过它提供的标准接口访问指定网页的所有元素。
MSHTML 提供丰富的 HTML 文档接口,包括 7 种 IHTMLDocument、IHTMLDocument2、…、IHTMLDocument7 等。其中,IHTMLDocument只有一个Script属性,用于管理页面脚本; IHTMLDocument2接口与C#的HtmlDocument类非常相似(即直接通过Web Browser控件获取的Document属性); IHTMLDocument3 与 Visual Basic 6.0 相同。一个类似于文档对象的接口,基本上可以使用的方法都在里面。 MSHTML 还提供了 IHTMLElement 接口,封装了 HTML 元素的完整操作。通过IHTMLElement可以准确判断HTML元素节点的类型,获取HTML元素节点的所有属性。
1.2 二进制校验机制
通过比较元素属性值,基本可以判断一个元素节点是否为采集的节点。由于网络中网页信息属性值相同的元素节点比例较高,相同属性值不能唯一指定节点为采集,还需要其他约束。通过分析发现,MSHTML还提供了访问当前节点的父节点的功能。我们可以通过回溯父节点来获取该节点在 HTML 文档树中的路径。这样,通过同时比较网页元素的属性值和树形路径值,就可以准确判断该节点是否为需要采集的节点。
使用属性值和树路径值进行元素验证的双重检查机制是作者的创新。该技术不仅可以大大提高采集节点的准确率,保证程序运行的效果,而且由于程序中使用了智能判断语句,保证了程序的运行效率,同时考虑到用户具有良好的用户体验。
1.3主要功能设计
网页信息列表提取程序可以实现网页信息的可配置采集,并将信息列表保存。程序主要分为三个功能模块:
1.网页信息提取功能模块。提供信息提取功能的主界面,输入采集网址,采集页码,启动采集。
2.网页元素分析功能模块。将html代码解析成网页元素列表,自动生成采集项的DOM树路径,方便脚本编写。
3.采集配置管理功能模块。用于管理采集配置,提供添加、编辑、删除等功能。
3.程序的主要功能实现方法
3.1采集配置管理
采集配置信息存储在数据库中,主要由一对主从表记录。主表记录了对应的网站采集配置名、域名、翻页设置、加载等待设置等信息。记录 采集 项的名称、ID、ClassName、TagName 和表格中网页元素的 DOM 树路径。
3.2 网页元素分析
该函数的目标是将网页的 HTML 代码解析为 HTML DOM 网页元素,并列出它们的各种属性值。通过遍历网页的元素,找出想要的采集数据项和下一页的web元素,记录在采集配置表中,同时添加DOM树采集 项的路径自动记录在配置表中。
3.2 自动提取网页信息
该函数将网页中需要采集的数据项采集转换成数据表,最后以XML文档的形式保存。该程序的工作原理如下:
Step1:遍历网页中的所有元素,count变量记录网页元素的个数。
Step2:将每个元素与采集配置中的采集项配置进行比较,判断该元素是否为采集元素。tab_item是一个adotable变量,记录了当前页面的采集配置,webbro.OleObject.document.all.item(i)变量是网页元素,itembyscript()函数会判断是否网页元素需要采集。
Step3:如果元素需要采集元素,进一步判断数据列缓存行中是否有采集项的数据。如果没有,则将采集 中的数据存入行,如果有,则通过addrec() 函数将采集 中的数据行存入XML 文档。
4.运行测试
4.1 读页
本示例将使用厦门本地知名论坛小鱼社区的帖子进行测试。网页中的html代码会被解析成网页元素列表,并显示在“元素”页面中。
图1 读取页面信息
4.2 配置采集
将操作界面切换到“元素”页面,可以看到网页元素列表,在列表中找到需要采集的网页元素。setup采集 配置如下:
(1) 翻页。首先找到“下一页”链接的网页元素,其tagname属性值为“A”,innertext属性值为“下一页”。设置为“下一页” 采集 项。
(2)作者。所属的网页元素,classname属性值为“readName b”,tagname属性值为“DIV”。
(3)Body.所属页面元素,classname属性值为“tpc_content”,tagname属性值为“DIV”。
(4)DOM树路径。DOM路径是通过网页元素列表自动生成的。
4.3查看采集结果
图 2 采集 结果的表格显示
5.结束语
随着互联网的快速发展,人们对网页元素的需求越来越转向个性化分类和精准提取。之前对所有内容的粗暴的采集方法已经不能满足现在的需求。研究是积极的。
网页信息表格提取程序通过网页信息提取、网页元素分析、采集 配置管理。克服了以往网页信息爬取工具无法提取内部相关网页信息的缺点,使程序的适用性和扩展性显着提高,程序创新性地采用了二进制校验机制来确认网页属性值和树路径值。可以实现对指定信息的准确提取,大大提高了程序结果的准确性。
网页信息表格提取程序虽然在准确性、适用性和可扩展性方面取得了进步,但仍存在一些不足,希望以后能找到更好的解决方案。
1.部分操作界面的用户自动化程序不足,操作比较复杂。
2.海量数据不兼容,处理效率低。由于程序的采集页面使用了WebBrowser技术,采集的效率较低,在处理大数据时会出现效率低的问题。有必要寻找更好的技术方法进行优化。
参考:
[1] 方勇,李寅生. 一种基于DOM状态转移的隐藏网页信息提取算法[J]. 计算机应用与软件, 2015, (09): 17-21.
[2] 张建英,王家梅,棠雪,胡刚。易文网络信息采集技术研究[J]. 网络安全技术与应用, 2014, (12): 6-8.@ >
[3] 孙宝华. 企业社交媒体主题信息抽取算法研究[J]. 煤炭, 2014, (01): 72-76.
[4] 金涛.网络爬虫在网页信息提取中的应用研究[J]. 现代计算机(专业版),2012,(01):16-18.@>
[5]朱志宁,黄庆松.快速中文网页分类方法的实现[J].山西电子科技, 2008, (04):7-9.
[6] 高军,王腾蛟,杨冬青,唐世伟。基于Ontology的Web内容两阶段半自动提取方法[J]. 中国计算机学报, 2004, (03): 310-318.@> 查看全部
网页表格抓取(基于MSHTML设计开发的原理、程序结构和网页元素属性表格化显示)
罗进才
【摘要】介绍了基于MSHTML设计开发的网页信息表格提取程序的原理、程序结构和工作流程。使用网页信息提取、网页元素分析、采集配置管理三个功能模块,提取网页信息。其内部相关信息的提取、解析、排序和表格展示,创新性地采用二进制检查机制确认网页属性值和树形路径值,可以实现对指定信息的准确提取。本文还说明了程序的操作步骤和实际效果。
【关键词】MSHTML信息自动提取网页元素属性并以表格形式展示
[CLC 编号] G64 [文档识别码] A [文章 编号] 2095-3089 (2017)10-0229-02
介绍
当今是网络飞速发展、信息量迅速膨胀的信息时代。人们通过信息相互交流,了解世界。信息中有很多有价值的信息元素,这些有价值的信息元素大多以网页的形式存在,其内容和格式差异很大。通过浏览器浏览阅读是没有问题的,但是如果需要保存和整理某类感兴趣的信息及其内部相关信息,常用的工具一般都有一些不足,比如网络蜘蛛等爬虫工具. 无法实现内部相关信息的提取。因此笔者使用MSHTML语言设计了一个网页内部表格抽取自动程序,
1.程序设计思路
1.1 采集原理
众所周知,网页是用 HTML 语言描述的。采集网页信息的本质是从网页的HTML代码中提取出我们需要的信息。如果直接从代码中提取,就只能使用正则表达式等文本匹配的方式来采集。这会导致以下问题:一是使用不方便。用户不仅需要了解 HTML,还需要了解正则表达式。另外,他们需要在大量的 HTML 代码中找到需要的信息,然后再考虑如何匹配;二是容错性差。,如果代码稍有偏差,会导致文本匹配失败,比如遇到制表符、回车、空格等。
经过长期研究,作者发现MSHTML可以有效解决这些问题。MSHTML是微软公司的一个COM组件,它将所有元素及其属性封装在HTML语言中,可以通过它提供的标准接口访问指定网页的所有元素。
MSHTML 提供丰富的 HTML 文档接口,包括 7 种 IHTMLDocument、IHTMLDocument2、…、IHTMLDocument7 等。其中,IHTMLDocument只有一个Script属性,用于管理页面脚本; IHTMLDocument2接口与C#的HtmlDocument类非常相似(即直接通过Web Browser控件获取的Document属性); IHTMLDocument3 与 Visual Basic 6.0 相同。一个类似于文档对象的接口,基本上可以使用的方法都在里面。 MSHTML 还提供了 IHTMLElement 接口,封装了 HTML 元素的完整操作。通过IHTMLElement可以准确判断HTML元素节点的类型,获取HTML元素节点的所有属性。
1.2 二进制校验机制
通过比较元素属性值,基本可以判断一个元素节点是否为采集的节点。由于网络中网页信息属性值相同的元素节点比例较高,相同属性值不能唯一指定节点为采集,还需要其他约束。通过分析发现,MSHTML还提供了访问当前节点的父节点的功能。我们可以通过回溯父节点来获取该节点在 HTML 文档树中的路径。这样,通过同时比较网页元素的属性值和树形路径值,就可以准确判断该节点是否为需要采集的节点。
使用属性值和树路径值进行元素验证的双重检查机制是作者的创新。该技术不仅可以大大提高采集节点的准确率,保证程序运行的效果,而且由于程序中使用了智能判断语句,保证了程序的运行效率,同时考虑到用户具有良好的用户体验。
1.3主要功能设计
网页信息列表提取程序可以实现网页信息的可配置采集,并将信息列表保存。程序主要分为三个功能模块:
1.网页信息提取功能模块。提供信息提取功能的主界面,输入采集网址,采集页码,启动采集。
2.网页元素分析功能模块。将html代码解析成网页元素列表,自动生成采集项的DOM树路径,方便脚本编写。
3.采集配置管理功能模块。用于管理采集配置,提供添加、编辑、删除等功能。
3.程序的主要功能实现方法
3.1采集配置管理
采集配置信息存储在数据库中,主要由一对主从表记录。主表记录了对应的网站采集配置名、域名、翻页设置、加载等待设置等信息。记录 采集 项的名称、ID、ClassName、TagName 和表格中网页元素的 DOM 树路径。
3.2 网页元素分析
该函数的目标是将网页的 HTML 代码解析为 HTML DOM 网页元素,并列出它们的各种属性值。通过遍历网页的元素,找出想要的采集数据项和下一页的web元素,记录在采集配置表中,同时添加DOM树采集 项的路径自动记录在配置表中。
3.2 自动提取网页信息
该函数将网页中需要采集的数据项采集转换成数据表,最后以XML文档的形式保存。该程序的工作原理如下:
Step1:遍历网页中的所有元素,count变量记录网页元素的个数。
Step2:将每个元素与采集配置中的采集项配置进行比较,判断该元素是否为采集元素。tab_item是一个adotable变量,记录了当前页面的采集配置,webbro.OleObject.document.all.item(i)变量是网页元素,itembyscript()函数会判断是否网页元素需要采集。
Step3:如果元素需要采集元素,进一步判断数据列缓存行中是否有采集项的数据。如果没有,则将采集 中的数据存入行,如果有,则通过addrec() 函数将采集 中的数据行存入XML 文档。
4.运行测试
4.1 读页
本示例将使用厦门本地知名论坛小鱼社区的帖子进行测试。网页中的html代码会被解析成网页元素列表,并显示在“元素”页面中。
图1 读取页面信息
4.2 配置采集
将操作界面切换到“元素”页面,可以看到网页元素列表,在列表中找到需要采集的网页元素。setup采集 配置如下:
(1) 翻页。首先找到“下一页”链接的网页元素,其tagname属性值为“A”,innertext属性值为“下一页”。设置为“下一页” 采集 项。
(2)作者。所属的网页元素,classname属性值为“readName b”,tagname属性值为“DIV”。
(3)Body.所属页面元素,classname属性值为“tpc_content”,tagname属性值为“DIV”。
(4)DOM树路径。DOM路径是通过网页元素列表自动生成的。
4.3查看采集结果
图 2 采集 结果的表格显示
5.结束语
随着互联网的快速发展,人们对网页元素的需求越来越转向个性化分类和精准提取。之前对所有内容的粗暴的采集方法已经不能满足现在的需求。研究是积极的。
网页信息表格提取程序通过网页信息提取、网页元素分析、采集 配置管理。克服了以往网页信息爬取工具无法提取内部相关网页信息的缺点,使程序的适用性和扩展性显着提高,程序创新性地采用了二进制校验机制来确认网页属性值和树路径值。可以实现对指定信息的准确提取,大大提高了程序结果的准确性。
网页信息表格提取程序虽然在准确性、适用性和可扩展性方面取得了进步,但仍存在一些不足,希望以后能找到更好的解决方案。
1.部分操作界面的用户自动化程序不足,操作比较复杂。
2.海量数据不兼容,处理效率低。由于程序的采集页面使用了WebBrowser技术,采集的效率较低,在处理大数据时会出现效率低的问题。有必要寻找更好的技术方法进行优化。
参考:
[1] 方勇,李寅生. 一种基于DOM状态转移的隐藏网页信息提取算法[J]. 计算机应用与软件, 2015, (09): 17-21.
[2] 张建英,王家梅,棠雪,胡刚。易文网络信息采集技术研究[J]. 网络安全技术与应用, 2014, (12): 6-8.@ >
[3] 孙宝华. 企业社交媒体主题信息抽取算法研究[J]. 煤炭, 2014, (01): 72-76.
[4] 金涛.网络爬虫在网页信息提取中的应用研究[J]. 现代计算机(专业版),2012,(01):16-18.@>
[5]朱志宁,黄庆松.快速中文网页分类方法的实现[J].山西电子科技, 2008, (04):7-9.
[6] 高军,王腾蛟,杨冬青,唐世伟。基于Ontology的Web内容两阶段半自动提取方法[J]. 中国计算机学报, 2004, (03): 310-318.@>
网页表格抓取(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-01-13 12:09
Excel 2013及以后版本提供WEBSERVICE和FILTERXML函数,可用于网页数据采集,但只能采集XML格式的数据。现在很多网站网页或者界面返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天笔者就以豆瓣图书的基本信息为例,介绍如何使用Excel API网络函数库抓取JSON格式的网页数据。
1 第一步是在豆瓣上查找书籍的基本信息。豆瓣网图书信息的网址是n/:9787111529385,网址最后一串数字是图书的IN号。在火狐浏览器下,这个URL会返回如下信息,都是标准的JSON格式。蓝色字体为属性名称,红色字体为对应的属性值。
2第二步,安装ExcelAPI网络函数库。访问ExcelAPI网络函数库官网,根据帮助页面安装函数库。或者参考百度经验《Excel生成条码》
3 第三步,使用函数抓取JSON数据。首先,使用函数 GetJs o e(url, "UTF-8") 返回 JSON 原创数据。
4 然后,使用GetJsonByPropertyName(json_so e, property_name)函数返回图书的基本信息。使用GetJs o e() 函数可以一次抓取所有数据,然后按需抓取。这样做的目的是提高抓取速度。毕竟,访问网页需要时间。
必须安装 Excel API 网络函数库 查看全部
网页表格抓取(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据?)
Excel 2013及以后版本提供WEBSERVICE和FILTERXML函数,可用于网页数据采集,但只能采集XML格式的数据。现在很多网站网页或者界面返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天笔者就以豆瓣图书的基本信息为例,介绍如何使用Excel API网络函数库抓取JSON格式的网页数据。
1 第一步是在豆瓣上查找书籍的基本信息。豆瓣网图书信息的网址是n/:9787111529385,网址最后一串数字是图书的IN号。在火狐浏览器下,这个URL会返回如下信息,都是标准的JSON格式。蓝色字体为属性名称,红色字体为对应的属性值。
2第二步,安装ExcelAPI网络函数库。访问ExcelAPI网络函数库官网,根据帮助页面安装函数库。或者参考百度经验《Excel生成条码》
3 第三步,使用函数抓取JSON数据。首先,使用函数 GetJs o e(url, "UTF-8") 返回 JSON 原创数据。
4 然后,使用GetJsonByPropertyName(json_so e, property_name)函数返回图书的基本信息。使用GetJs o e() 函数可以一次抓取所有数据,然后按需抓取。这样做的目的是提高抓取速度。毕竟,访问网页需要时间。
必须安装 Excel API 网络函数库
网页表格抓取(Python中的表格分为图片型和文本型库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 263 次浏览 • 2022-01-10 10:19
内容
大家好,从PDF中提取信息是办公场景中经常用到的操作,也是读者经常在后台询问的操作。
如果内容不多,我们可以手动复制粘贴,但是如果需要批量提取,可以考虑使用Python。之前也转载了相关的文章,提到主要是使用pdfplumber库。今天我们再举一个例子。
通常,PDF中的表格分为图像类型和文本类型。文本类型分为简单型和复杂型。本文提供了这三个部分的示例。
使用的模块主要有
本文出现的PDF资料为从巨超信息官网下载的公开PDF文件。题目是关于财务管理的。相关发布信息及其他信息如下:
内容一共6页,后面会给出例子。
一、简单文本类型数据
简单的文本类型表格是指一个PDF页面中只有一个表格,表格的内容可以完全复制。比如我们选择的内容是PDF中的第四页,内容如下:
如您所见,此页面上只有一个表。接下来,我们将这张表写入Excel,先放代码。
import pdfplumber as pr
import pandas as pd
pdf = pr.open('关于使用自有资金购买银行理财产品的进展公告.PDF')
ps = pdf.pages
pg = ps[3]
tables = pg.extract_tables()
table = tables[0]
print(table)
df = pd.DataFrame(table[1:],columns = table[0])
for i in range(len(table)):
for j in range(len(table[i])):
table[i][j] = table[i][j].replace('\n','')
df1 = pd.DataFrame(table[1:],columns = table[0])
df1.to_excel('page2.xlsx')
得到的结果如下:
与PDF上的原创表格相比,内容完全相同。唯一不同的是,主要业务内容较多,展示不全面。现在让我们谈谈这段代码。
首先导入要使用的两个库。在pdfplumber中,open()函数用于打开PDF文件,代码使用相对路径。.open().pages是获取PDF的页数,打印ps值可以如下获取
pg = ps[3] 代表我们选择的第三页。
pg.extract_tables():可以输出页面中的所有表格,并返回一个结构层次为table→row→cell的嵌套列表。此时将页面上的整个表格放入一个大列表中,原创表格中的每一行形成大列表中的每个子列表。如果要输出单个外部列表元素,则得到的是由原创表的同一行中的元素组成的列表。
与此类似的是 pg.extract_table( ):返回多个独立的列表,其结构级别为 row→cell。如果页面中有多个行数相同的表,则默认输出最上面的表;否则,只输出行数最多的表。此时将表格的每一行作为一个单独的列表,列表中的每个元素都是原表格每个单元格的内容。
由于此页面中只有一个表格,因此我们需要表格集合中的第一个元素。打印表格值如下:
可以看出,上面有个不必要的字符\n,它的作用其实是换行但是我们在Excel中不需要它。所以需要去掉它,使用代码中的for循环和replace函数将控件替换为空格(即删除\n)。观察该表是一个收录 2 个元素的列表。
最后,df1 = pd.DataFrame(table[1:],columns = table[0])的作用就是创建一个数据框,把内容放到对应的行和列中。
此代码只是将数据保存到 Excel。如果需要进一步调整样式,可以使用openpyxl等模块进行修改。
二、复杂表提取
复杂表格是指表格样式不统一或一页有多个表格。以PDF的第五页为例:
可以看到这个页面有两个大表,仔细看其实有四个表。按照简单的表格类型提取方法,效果如下:
可以看到,所有的表格文本只是提取出来的,但实际上第一个表格被细分为两个表格,所以我们需要进一步修改,再次拆分这个表格!例如,将代码的上半部分提取如下:
import pdfplumber as pr
import pandas as pd
pdf = pr.open('关于使用自有资金购买银行理财产品的进展公告.PDF')
ps = pdf.pages
pg = ps[4]
tables = pg.extract_tables()
table = tables[0]
print(table)
df = pd.DataFrame(table[1:],columns = table[0])
for i in range(len(table)):
for j in range(len(table[i])):
table[i][j] = table[i][j].replace('\n','')
df1 = pd.DataFrame(table[1:],columns = table[0])
df2 = df1.iloc[2:,:]
df2 = df2.rename(columns = {"2019年12月31日":"2019年1-12月","2020年9月30日":"2020年1-9月"})
df2 = df2.loc[3:,:]
df1 = df1.loc[:1,:]
with pd.ExcelWriter('公司影响.xlsx') as i:
df1.to_excel(i,sheet_name='资产', index=False, header=True) #放入资产数据
df2.to_excel(i,sheet_name='营业',index=False, header=True) #放入营业数据
这段代码是在简单表格抽取的基础上修改的。第十四行代码的作用是提取另一个表头的信息,赋值给df2,然后重命名df2(使用rename函数)。)。
打印df2显示列名和第一行信息重复,所以我们需要重复刚才的步骤,使用loc()函数对数据框进行切割。
请注意,我们使用罕见的 pandas.Excelwriter 函数来覆盖 for 循环。这是为了避免直接写入导致最终数据覆盖原创数据。有兴趣的可以试试不带withopen的结果。最终结果如下:
如您所见,此表现在单独显示在两个工作表中。当然,也可以放在一张表中进行比较。
毕竟复杂形式的主观性很大,需要根据不同的情况进行不同的处理。写一个一劳永逸的方法更难!
三、图片表提取
最后也是最难处理的是图像类型的表单。人们经常问如何提取图像类型PDF中的表格/文本和其他信息。
其实本质上就是提取图片,如何进一步处理图片提取信息与Python提取PDF表格的话题关系不大!
这里我们也简单介绍一下,即先提取图片再进行OCR识别提取表格。Tesseract库可以在Python中使用,需要先安装pip。
pip install pytesseract
在 Python 中安装此库后,我们需要安装要在后面的代码中使用的 exe 文件。
http://digi.bib.uni-mannheim.d ... v.exe
只需下载并安装它。注意,如果按照正常步骤安装,是不会识别中文的,所以需要安装简体中文语言包。下载地址是,放在Tesseract-OCR的tessdata目录下。
接下来我们使用一个简单的图片类型pdf如下:
第一步是提取图片。这里使用GUI办公自动化系列中的图片提取软件对PDF中的图片进行提取,得到如下图片:
然后执行以下代码识别图片内容
import pytesseract
from PIL import Image
import pandas as pd
pytesseract.pytesseract.tesseract_cmd = 'C://Program Files (x86)/Tesseract-OCR/tesseract.exe'
tiqu = pytesseract.image_to_string(Image.open('图片型.jpg'))
print(tiqu)
tiqu = tiqu.split('\n')
while '' in tiqu: #不能使用for
tiqu.remove('')
first = tiqu[:6]
second = tiqu[6:12]
third = tiqu[12:]
df = pd.DataFrame()
df[first[0]] = first[1:]
df[second[0]] = second[1:]
df[third[0]] = third[1:]
#df.to_excel('图片型表格.xlsx') #转为xlsx文件
我们的想法是使用 Tesseract-OCR 解析图像,得到一个字符串,然后在字符串上使用 split 函数将字符串变成一个列表并删除 \n。
然后你可以发现我们的列表中还有空格。这时候,我们使用一个while循环来删除这些空字符。注意这里不能使用for循环,因为每次删除一个,列表中的元素都会前移一个,不会删除。完全地。最后就是使用pandas将这些转换成数据框形式。最终结果如下:
可以看到图片表格的内容被完美的解析处理了!当然,之所以能轻松搞定,也和这张表的简单性有关。真实场景中的图片可能会有更复杂的干扰因素,这就需要大家在处理的时候找到最合适的方法!
以上就是用Python提取PDF表格的方法的详细内容。更多关于Python提取PDF表格的内容,请关注脚本之家文章的其他相关话题! 查看全部
网页表格抓取(Python中的表格分为图片型和文本型库)
内容
大家好,从PDF中提取信息是办公场景中经常用到的操作,也是读者经常在后台询问的操作。
如果内容不多,我们可以手动复制粘贴,但是如果需要批量提取,可以考虑使用Python。之前也转载了相关的文章,提到主要是使用pdfplumber库。今天我们再举一个例子。
通常,PDF中的表格分为图像类型和文本类型。文本类型分为简单型和复杂型。本文提供了这三个部分的示例。
使用的模块主要有
本文出现的PDF资料为从巨超信息官网下载的公开PDF文件。题目是关于财务管理的。相关发布信息及其他信息如下:
内容一共6页,后面会给出例子。
一、简单文本类型数据
简单的文本类型表格是指一个PDF页面中只有一个表格,表格的内容可以完全复制。比如我们选择的内容是PDF中的第四页,内容如下:
如您所见,此页面上只有一个表。接下来,我们将这张表写入Excel,先放代码。
import pdfplumber as pr
import pandas as pd
pdf = pr.open('关于使用自有资金购买银行理财产品的进展公告.PDF')
ps = pdf.pages
pg = ps[3]
tables = pg.extract_tables()
table = tables[0]
print(table)
df = pd.DataFrame(table[1:],columns = table[0])
for i in range(len(table)):
for j in range(len(table[i])):
table[i][j] = table[i][j].replace('\n','')
df1 = pd.DataFrame(table[1:],columns = table[0])
df1.to_excel('page2.xlsx')
得到的结果如下:
与PDF上的原创表格相比,内容完全相同。唯一不同的是,主要业务内容较多,展示不全面。现在让我们谈谈这段代码。
首先导入要使用的两个库。在pdfplumber中,open()函数用于打开PDF文件,代码使用相对路径。.open().pages是获取PDF的页数,打印ps值可以如下获取
pg = ps[3] 代表我们选择的第三页。
pg.extract_tables():可以输出页面中的所有表格,并返回一个结构层次为table→row→cell的嵌套列表。此时将页面上的整个表格放入一个大列表中,原创表格中的每一行形成大列表中的每个子列表。如果要输出单个外部列表元素,则得到的是由原创表的同一行中的元素组成的列表。
与此类似的是 pg.extract_table( ):返回多个独立的列表,其结构级别为 row→cell。如果页面中有多个行数相同的表,则默认输出最上面的表;否则,只输出行数最多的表。此时将表格的每一行作为一个单独的列表,列表中的每个元素都是原表格每个单元格的内容。
由于此页面中只有一个表格,因此我们需要表格集合中的第一个元素。打印表格值如下:
可以看出,上面有个不必要的字符\n,它的作用其实是换行但是我们在Excel中不需要它。所以需要去掉它,使用代码中的for循环和replace函数将控件替换为空格(即删除\n)。观察该表是一个收录 2 个元素的列表。
最后,df1 = pd.DataFrame(table[1:],columns = table[0])的作用就是创建一个数据框,把内容放到对应的行和列中。
此代码只是将数据保存到 Excel。如果需要进一步调整样式,可以使用openpyxl等模块进行修改。
二、复杂表提取
复杂表格是指表格样式不统一或一页有多个表格。以PDF的第五页为例:
可以看到这个页面有两个大表,仔细看其实有四个表。按照简单的表格类型提取方法,效果如下:
可以看到,所有的表格文本只是提取出来的,但实际上第一个表格被细分为两个表格,所以我们需要进一步修改,再次拆分这个表格!例如,将代码的上半部分提取如下:
import pdfplumber as pr
import pandas as pd
pdf = pr.open('关于使用自有资金购买银行理财产品的进展公告.PDF')
ps = pdf.pages
pg = ps[4]
tables = pg.extract_tables()
table = tables[0]
print(table)
df = pd.DataFrame(table[1:],columns = table[0])
for i in range(len(table)):
for j in range(len(table[i])):
table[i][j] = table[i][j].replace('\n','')
df1 = pd.DataFrame(table[1:],columns = table[0])
df2 = df1.iloc[2:,:]
df2 = df2.rename(columns = {"2019年12月31日":"2019年1-12月","2020年9月30日":"2020年1-9月"})
df2 = df2.loc[3:,:]
df1 = df1.loc[:1,:]
with pd.ExcelWriter('公司影响.xlsx') as i:
df1.to_excel(i,sheet_name='资产', index=False, header=True) #放入资产数据
df2.to_excel(i,sheet_name='营业',index=False, header=True) #放入营业数据
这段代码是在简单表格抽取的基础上修改的。第十四行代码的作用是提取另一个表头的信息,赋值给df2,然后重命名df2(使用rename函数)。)。
打印df2显示列名和第一行信息重复,所以我们需要重复刚才的步骤,使用loc()函数对数据框进行切割。
请注意,我们使用罕见的 pandas.Excelwriter 函数来覆盖 for 循环。这是为了避免直接写入导致最终数据覆盖原创数据。有兴趣的可以试试不带withopen的结果。最终结果如下:
如您所见,此表现在单独显示在两个工作表中。当然,也可以放在一张表中进行比较。
毕竟复杂形式的主观性很大,需要根据不同的情况进行不同的处理。写一个一劳永逸的方法更难!
三、图片表提取
最后也是最难处理的是图像类型的表单。人们经常问如何提取图像类型PDF中的表格/文本和其他信息。
其实本质上就是提取图片,如何进一步处理图片提取信息与Python提取PDF表格的话题关系不大!
这里我们也简单介绍一下,即先提取图片再进行OCR识别提取表格。Tesseract库可以在Python中使用,需要先安装pip。
pip install pytesseract
在 Python 中安装此库后,我们需要安装要在后面的代码中使用的 exe 文件。
http://digi.bib.uni-mannheim.d ... v.exe
只需下载并安装它。注意,如果按照正常步骤安装,是不会识别中文的,所以需要安装简体中文语言包。下载地址是,放在Tesseract-OCR的tessdata目录下。
接下来我们使用一个简单的图片类型pdf如下:
第一步是提取图片。这里使用GUI办公自动化系列中的图片提取软件对PDF中的图片进行提取,得到如下图片:
然后执行以下代码识别图片内容
import pytesseract
from PIL import Image
import pandas as pd
pytesseract.pytesseract.tesseract_cmd = 'C://Program Files (x86)/Tesseract-OCR/tesseract.exe'
tiqu = pytesseract.image_to_string(Image.open('图片型.jpg'))
print(tiqu)
tiqu = tiqu.split('\n')
while '' in tiqu: #不能使用for
tiqu.remove('')
first = tiqu[:6]
second = tiqu[6:12]
third = tiqu[12:]
df = pd.DataFrame()
df[first[0]] = first[1:]
df[second[0]] = second[1:]
df[third[0]] = third[1:]
#df.to_excel('图片型表格.xlsx') #转为xlsx文件
我们的想法是使用 Tesseract-OCR 解析图像,得到一个字符串,然后在字符串上使用 split 函数将字符串变成一个列表并删除 \n。
然后你可以发现我们的列表中还有空格。这时候,我们使用一个while循环来删除这些空字符。注意这里不能使用for循环,因为每次删除一个,列表中的元素都会前移一个,不会删除。完全地。最后就是使用pandas将这些转换成数据框形式。最终结果如下:
可以看到图片表格的内容被完美的解析处理了!当然,之所以能轻松搞定,也和这张表的简单性有关。真实场景中的图片可能会有更复杂的干扰因素,这就需要大家在处理的时候找到最合适的方法!
以上就是用Python提取PDF表格的方法的详细内容。更多关于Python提取PDF表格的内容,请关注脚本之家文章的其他相关话题!
网页表格抓取(WebDataMiner是一款网页数据挖掘工具,帮你轻松挖掘网页中的各种数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-10 09:02
Web Data Miner 是一个 Web 数据挖掘工具。该软件可以帮助您轻松挖掘网页中的各种数据。软件可以将挖掘出来的数据以表格的形式呈现。可以智能地帮助用户从网站中提取准确的数据在不同的布局中,例如购物、分类、基于产品和其他网站。
软件介绍
此数据抓取器将从打开的网页中抓取点击的项目或类似项目。在这个工具中有两个选项“自动保存”和“自动暂停”。自动保存消除了数据丢失的风险,而自动暂停消除了某些 网站 阻止 IP 地址的风险。
网站数据挖掘工具可以从一个网站内的多个网页中挖掘数据。用户可以配置“设置下一页链接”以从所有网页中提取相似数据。用户可以选择定义数量的页面来提取数据,否则它将从所有网页中挖掘数据。该软件的独特和最强大的功能之一是调度。
用户可以设置时间和日期,并提供配置文件。它将在用户定义的时间自动启动数据挖掘过程。挖掘数据后,它会自动关闭并将配置文件保存在用户定义的位置。
软件功能
以表格形式从网页中提取数据。
从不同布局的 网站 中提取数据。
从网页中提取文本、html、图像、链接和 URL。
从外部和自定义链接中提取数据。
自动跟踪页面以提取数据。
保存提取的数据,消除数据丢失的风险。
自动暂停以防止被某些 网站 阻止。 查看全部
网页表格抓取(WebDataMiner是一款网页数据挖掘工具,帮你轻松挖掘网页中的各种数据)
Web Data Miner 是一个 Web 数据挖掘工具。该软件可以帮助您轻松挖掘网页中的各种数据。软件可以将挖掘出来的数据以表格的形式呈现。可以智能地帮助用户从网站中提取准确的数据在不同的布局中,例如购物、分类、基于产品和其他网站。
软件介绍
此数据抓取器将从打开的网页中抓取点击的项目或类似项目。在这个工具中有两个选项“自动保存”和“自动暂停”。自动保存消除了数据丢失的风险,而自动暂停消除了某些 网站 阻止 IP 地址的风险。
网站数据挖掘工具可以从一个网站内的多个网页中挖掘数据。用户可以配置“设置下一页链接”以从所有网页中提取相似数据。用户可以选择定义数量的页面来提取数据,否则它将从所有网页中挖掘数据。该软件的独特和最强大的功能之一是调度。
用户可以设置时间和日期,并提供配置文件。它将在用户定义的时间自动启动数据挖掘过程。挖掘数据后,它会自动关闭并将配置文件保存在用户定义的位置。
软件功能
以表格形式从网页中提取数据。
从不同布局的 网站 中提取数据。
从网页中提取文本、html、图像、链接和 URL。
从外部和自定义链接中提取数据。
自动跟踪页面以提取数据。
保存提取的数据,消除数据丢失的风险。
自动暂停以防止被某些 网站 阻止。
网页表格抓取(在ASP.NET中表格的显式方法利用JS来取页面表格数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-01-09 21:13
ASP.NET中有各种显式的表格方法,例如html标签、asp服务器控件GridView、Repeater控件等,都可以帮助我们在页面上显示表格信息。GridView控件更强大,它有自己的属性和方法,可以用来对显式表数据进行各种操作。但是如果使用传统的html标签或者Repeater控件来展示数据,那么如何获取选中行的数据呢?这里我们将介绍使用JS获取页表数据的方法。
如图所示,我们需要对表中的数据进行编辑、删除等操作。
下面是一个Repeater控件的例子:
(1)页表:定义表头,设置数据绑定(有些操作需要获取数据的主键,考虑实际情况,我们应该隐藏主键,对应列使用隐藏属性) )这就够了)。在后台,只需要将Repeater绑定到对应的数据源即可。这里我们使用class来标记按钮,这样在JS中就可以将所有具有相同class的按钮作为一个组取出来。因此,我们可以在 JS 中监控和选择按钮。设置相应的行。
1 出货单单头:
2
3
4
5
6 ID
7 客户ID
8 出货人员
9 创建时间
10 更新时间
11 编辑
12 删除
13 新增子信息
14
15
16
17
18
19
20
21
22
23
24 编辑
25
26
27 删除
28
29
30 新增子信息
31
32
33
34
35
(2)JS部分:通过class获取对应的一组按钮并设置监控。然后通过标签名获取选中行,通过标签名获取选中行所有列数据的集合,并进行转换对应的数据通过 DOM 操作显示在前台的指定位置。
1 /*编辑单头信息*/
2 var Top_Edit = document.getElementsByClassName("Top_Edit");
3
4 for (var i = 0; i < Top_Edit.length; i++) {
5
6 Top_Edit[i].index = i;
7
8 Top_Edit[i].onclick = function () {
9
10 var table = document.getElementById("Top_Table");
11
12 /*获取选中的行 */
13 var child = table.getElementsByTagName("tr")[this.index + 1];
14
15 /*获取选择行的所有列*/
16 var SZ_col = child.getElementsByTagName("td");
17
18 document.getElementById("Edit_id").value = SZ_col[0].innerHTML;
19 document.getElementById("edit_customer").value = SZ_col[1].innerHTML;
20 document.getElementById("edit_man").value = SZ_col[2].innerHTML;
21 document.getElementById("Top_Creat_Time").value = SZ_col[3].innerHTML;
22 document.getElementById("Top_Update_Time").value = SZ_col[4].innerHTML;
23
24 }
25 }
在JS中获取表格数据只是几个简单的步骤。还有其他方法,例如 jQuery 来获取表格数据。你可以多尝试,然后比较总结,这也是对程序员自身的一种提升。 查看全部
网页表格抓取(在ASP.NET中表格的显式方法利用JS来取页面表格数据)
ASP.NET中有各种显式的表格方法,例如html标签、asp服务器控件GridView、Repeater控件等,都可以帮助我们在页面上显示表格信息。GridView控件更强大,它有自己的属性和方法,可以用来对显式表数据进行各种操作。但是如果使用传统的html标签或者Repeater控件来展示数据,那么如何获取选中行的数据呢?这里我们将介绍使用JS获取页表数据的方法。
如图所示,我们需要对表中的数据进行编辑、删除等操作。
下面是一个Repeater控件的例子:
(1)页表:定义表头,设置数据绑定(有些操作需要获取数据的主键,考虑实际情况,我们应该隐藏主键,对应列使用隐藏属性) )这就够了)。在后台,只需要将Repeater绑定到对应的数据源即可。这里我们使用class来标记按钮,这样在JS中就可以将所有具有相同class的按钮作为一个组取出来。因此,我们可以在 JS 中监控和选择按钮。设置相应的行。
1 出货单单头:
2
3
4
5
6 ID
7 客户ID
8 出货人员
9 创建时间
10 更新时间
11 编辑
12 删除
13 新增子信息
14
15
16
17
18
19
20
21
22
23
24 编辑
25
26
27 删除
28
29
30 新增子信息
31
32
33
34
35
(2)JS部分:通过class获取对应的一组按钮并设置监控。然后通过标签名获取选中行,通过标签名获取选中行所有列数据的集合,并进行转换对应的数据通过 DOM 操作显示在前台的指定位置。
1 /*编辑单头信息*/
2 var Top_Edit = document.getElementsByClassName("Top_Edit");
3
4 for (var i = 0; i < Top_Edit.length; i++) {
5
6 Top_Edit[i].index = i;
7
8 Top_Edit[i].onclick = function () {
9
10 var table = document.getElementById("Top_Table");
11
12 /*获取选中的行 */
13 var child = table.getElementsByTagName("tr")[this.index + 1];
14
15 /*获取选择行的所有列*/
16 var SZ_col = child.getElementsByTagName("td");
17
18 document.getElementById("Edit_id").value = SZ_col[0].innerHTML;
19 document.getElementById("edit_customer").value = SZ_col[1].innerHTML;
20 document.getElementById("edit_man").value = SZ_col[2].innerHTML;
21 document.getElementById("Top_Creat_Time").value = SZ_col[3].innerHTML;
22 document.getElementById("Top_Update_Time").value = SZ_col[4].innerHTML;
23
24 }
25 }
在JS中获取表格数据只是几个简单的步骤。还有其他方法,例如 jQuery 来获取表格数据。你可以多尝试,然后比较总结,这也是对程序员自身的一种提升。
网页表格抓取( Python抓取动态网页信息的相关操作、网上教程编写出)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-09 21:11
Python抓取动态网页信息的相关操作、网上教程编写出)
5月1日假期学习了Python爬取动态网页信息相关的操作,结合封面上的参考书和在线教程,编写了能满足自己需求的代码。由于最初是python的介入,所以过程中有很多曲折。为了避免以后出现问题,我找不到相关资料来创建这篇文章。
准备工具:
Python 3.8Google Chrome Googledriver
测试网站:
1.想法 (#cb)
考试前准备:
1.配置python运行的环境变量,参考link()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json分析的方式;另一种是硒的方式。requests方法速度快,但是有些元素的链接信息抓不到;selenium 方法通过模拟打开浏览器来捕获数据。由于需要打开浏览器,所以速度比较慢,但是能抓取到的信息比较全面。
主要抓取内容如下:(网站中部分可转债数据)
获取网站信息的请求方法:
Python需要安装的相关脚本:Requests
安装方法:以管理员身份运行cmd;输入 pip install requests 命令,安装成功后会有提示。如果一次安装不成功,多安装几次。
(前提是相关端口没有关闭)。如果 pip 版本不是最新的,它会提醒你更新 pip 版本,pip 环境变量也要设置。设置方法参考python设置方法。
请求抓取代码如下:
import requestsimport jsonurl='https://www.jisilu.cn/data/cbn ... _data = requests.get(url,verify = False)js=return_data.json()for i in js['rows']: print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的网址:chrome open brainstorming网站(#cb)。点击F12键,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5键刷新。在名称栏中一一点击,找到所需的 XHR。通过预览我们可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
JSON转换请求的数据格式,方便数据搜索。转换成json格式后,requests的数据格式和preview的数据格式一样。如果要定位“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考请求安装)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。把它放在安装chrome的文件夹中,并设置环境变量。
selenium 抓取代码如下:
from selenium import webdriverimport timedriver=webdriver.Chrome()url1='https://www.jisilu.cn/data/cbn ... r.get(url1)time.sleep(5) #增加延时命令,等待元素加载driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elementsfor tr in table_tr_list: if len(tr.get_attribute('id'))>0: print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)driver.quit()
结果如下:
注意三点:
1、添加延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(NoSuchElementException)
2、使用find_element_by_xpath时,可以在网页开发者中右键copy xpath来确认元素的路径。
3、发送ID时,将字符转换为数值,注意去掉空字符
捕获的数据也可以通过python保存到excel中。 查看全部
网页表格抓取(
Python抓取动态网页信息的相关操作、网上教程编写出)
5月1日假期学习了Python爬取动态网页信息相关的操作,结合封面上的参考书和在线教程,编写了能满足自己需求的代码。由于最初是python的介入,所以过程中有很多曲折。为了避免以后出现问题,我找不到相关资料来创建这篇文章。
准备工具:
Python 3.8Google Chrome Googledriver
测试网站:
1.想法 (#cb)
考试前准备:
1.配置python运行的环境变量,参考link()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json分析的方式;另一种是硒的方式。requests方法速度快,但是有些元素的链接信息抓不到;selenium 方法通过模拟打开浏览器来捕获数据。由于需要打开浏览器,所以速度比较慢,但是能抓取到的信息比较全面。
主要抓取内容如下:(网站中部分可转债数据)
获取网站信息的请求方法:
Python需要安装的相关脚本:Requests
安装方法:以管理员身份运行cmd;输入 pip install requests 命令,安装成功后会有提示。如果一次安装不成功,多安装几次。
(前提是相关端口没有关闭)。如果 pip 版本不是最新的,它会提醒你更新 pip 版本,pip 环境变量也要设置。设置方法参考python设置方法。
请求抓取代码如下:
import requestsimport jsonurl='https://www.jisilu.cn/data/cbn ... _data = requests.get(url,verify = False)js=return_data.json()for i in js['rows']: print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的网址:chrome open brainstorming网站(#cb)。点击F12键,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5键刷新。在名称栏中一一点击,找到所需的 XHR。通过预览我们可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
JSON转换请求的数据格式,方便数据搜索。转换成json格式后,requests的数据格式和preview的数据格式一样。如果要定位“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考请求安装)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。把它放在安装chrome的文件夹中,并设置环境变量。
selenium 抓取代码如下:
from selenium import webdriverimport timedriver=webdriver.Chrome()url1='https://www.jisilu.cn/data/cbn ... r.get(url1)time.sleep(5) #增加延时命令,等待元素加载driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elementsfor tr in table_tr_list: if len(tr.get_attribute('id'))>0: print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)driver.quit()
结果如下:
注意三点:
1、添加延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(NoSuchElementException)
2、使用find_element_by_xpath时,可以在网页开发者中右键copy xpath来确认元素的路径。
3、发送ID时,将字符转换为数值,注意去掉空字符
捕获的数据也可以通过python保存到excel中。
网页表格抓取(不同时间段的网络表格数据节点获取需要注意的事项!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-09 20:06
(1)数据URL获取
网易财经和新浪财经等网站数据可以免费获取,我们可以使用爬虫方式(通过rvest包)抓取对应的网站表数据,我们先在网易财经抓取600550例如,2019年第三季度的数据,其URL为:
,
可以看出,不同时间段的网址是有规律的,只需要更改里面的股票代码、年份、季节,就可以循环爬取多只股票的网页。
(2)网络表单数据节点获取
我们需要解析网页表数据的节点。除了系统地掌握网页设计的原理和基本结构外,我们还可以通过FireFox(Firebug插件)和Chrome浏览器对网页结构进行解析,得到相应的分支结构点。这里我们使用火狐浏览器,找到我们需要的表位置后(如何找到表位置请自行探索),右键复制XPath路径。
表格部分的 XPath 是 /html/body/div[2]/div[4]/table[1]。
(3)获取单只股票的单页数据
library(rvest)
symbol=600550
year=2019
season=3
url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
此时的web.table就是爬取的数据
(4)获取单个股票的多页数据并合并
library(lubridate)
symbol=600550
from="2001-05-28"
from=as.Date(from)
to=Sys.Date()
time.index=seq(from=from,to=to,by="quarter")#生成以季度为开始的时间序列
year.id=year(time.index)#获取年份
quarter.id=quarter(time.index)#获取季度
price=list()
for(t in 1:length(time.index)){
year=year.id[t]
season=quarter.id[t]
url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
web.table=web.table[[1]][-1,]
price[[t]]=web.table
}
(5)抓取多只股票的多页数据并将它们合并
get.wangyi.stock=function(symbol,from,to){
from=as.Date(from)
to=as.Date(to)
if(mday(from==1)){
from=from-1
}
time.index=seq(from=from,to=to,by="quarter")
year.id=year(time.index)
quarter.id=quarter(time.index)
prices=list()
for(t in 1:length(time.index)){
year=year.id[t]
season=quarter.id[t] url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
web.table=web.table[[1]][-1,]
prices[[t]]=web.table
}
}
to=Sys.Date()
stock.index=matrix(nrow=6,ncol=2)
stock.index[,1]=c("600550.ss","600192.ss","600152.ss","600644.ss","600885.ss","600151.ss")
stock.index[,2]=c("2017-05-28","2017-05-28","2017-05-28","2017-05-28","2017-05-28","2017-05-28")
for(i in nrow(stock.index)){
symbol=stock.index[i,1]
from=stock.index[i,2]
prices=get.wangyi.stock(symbol,from,to)
filenames=paste0("D://dataset//",symbol,".csv")
}
(6)读取所有A股数据
我们还可以将所有A股代码整理成一个文件,读取后可以实现所有A股股票数据的实时更新。这种方法可以用来建立我们自己的数据库进行实时分析。同时,通过网络爬虫,我们还可以爬取大量有意义的数据并实时更新。 查看全部
网页表格抓取(不同时间段的网络表格数据节点获取需要注意的事项!)
(1)数据URL获取
网易财经和新浪财经等网站数据可以免费获取,我们可以使用爬虫方式(通过rvest包)抓取对应的网站表数据,我们先在网易财经抓取600550例如,2019年第三季度的数据,其URL为:
,
可以看出,不同时间段的网址是有规律的,只需要更改里面的股票代码、年份、季节,就可以循环爬取多只股票的网页。
(2)网络表单数据节点获取
我们需要解析网页表数据的节点。除了系统地掌握网页设计的原理和基本结构外,我们还可以通过FireFox(Firebug插件)和Chrome浏览器对网页结构进行解析,得到相应的分支结构点。这里我们使用火狐浏览器,找到我们需要的表位置后(如何找到表位置请自行探索),右键复制XPath路径。
表格部分的 XPath 是 /html/body/div[2]/div[4]/table[1]。
(3)获取单只股票的单页数据
library(rvest)
symbol=600550
year=2019
season=3
url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
此时的web.table就是爬取的数据
(4)获取单个股票的多页数据并合并
library(lubridate)
symbol=600550
from="2001-05-28"
from=as.Date(from)
to=Sys.Date()
time.index=seq(from=from,to=to,by="quarter")#生成以季度为开始的时间序列
year.id=year(time.index)#获取年份
quarter.id=quarter(time.index)#获取季度
price=list()
for(t in 1:length(time.index)){
year=year.id[t]
season=quarter.id[t]
url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
web.table=web.table[[1]][-1,]
price[[t]]=web.table
}
(5)抓取多只股票的多页数据并将它们合并
get.wangyi.stock=function(symbol,from,to){
from=as.Date(from)
to=as.Date(to)
if(mday(from==1)){
from=from-1
}
time.index=seq(from=from,to=to,by="quarter")
year.id=year(time.index)
quarter.id=quarter(time.index)
prices=list()
for(t in 1:length(time.index)){
year=year.id[t]
season=quarter.id[t] url=paste0("http://quotes.money.163.com/trade/lsjysj_",symbol,".html?year=",year,"&season=",season)
web=read_html(url)
xpath="/html/body/div[2]/div[4]/table[1]"
web.table=web%>%html_nodes(xpath=xpath)%>%html_table()
web.table=web.table[[1]][-1,]
prices[[t]]=web.table
}
}
to=Sys.Date()
stock.index=matrix(nrow=6,ncol=2)
stock.index[,1]=c("600550.ss","600192.ss","600152.ss","600644.ss","600885.ss","600151.ss")
stock.index[,2]=c("2017-05-28","2017-05-28","2017-05-28","2017-05-28","2017-05-28","2017-05-28")
for(i in nrow(stock.index)){
symbol=stock.index[i,1]
from=stock.index[i,2]
prices=get.wangyi.stock(symbol,from,to)
filenames=paste0("D://dataset//",symbol,".csv")
}
(6)读取所有A股数据
我们还可以将所有A股代码整理成一个文件,读取后可以实现所有A股股票数据的实时更新。这种方法可以用来建立我们自己的数据库进行实时分析。同时,通过网络爬虫,我们还可以爬取大量有意义的数据并实时更新。
网页表格抓取(WebDataMiner是一款网页数据挖掘工具,帮你轻松挖掘网页中的各种数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-01-09 12:01
Web Data Miner 是一个 Web 数据挖掘工具。该软件可以帮助您轻松挖掘网页中的各种数据。软件可以将挖掘出来的数据以表格的形式呈现。可以智能地帮助用户从网站中提取准确的数据,在不同的布局中,例如购物、分类、基于产品和其他网站。
软件介绍
此数据抓取器将从打开的网页中抓取点击的项目或类似项目。在这个工具中有两个选项“自动保存”和“自动暂停”。自动保存消除了数据丢失的风险,而自动暂停消除了某些 网站 阻止 IP 地址的风险。
网站数据挖掘工具可以从一个网站内的多个网页中挖掘数据。用户可以配置“设置下一页链接”以从所有网页中提取相似数据。用户可以选择定义数量的页面来提取数据,否则它将从所有网页中挖掘数据。该软件的独特和最强大的功能之一是调度。
用户可以设置时间和日期,并提供配置文件。它将在用户定义的时间自动启动数据挖掘过程。挖掘数据后,它会自动关闭并将配置文件保存在用户定义的位置。
软件功能
以表格形式从网页中提取数据。
从不同布局的 网站 中提取数据。
从网页中提取文本、html、图像、链接和 URL。
从外部和自定义链接中提取数据。
自动跟踪页面以提取数据。
保存提取的数据,消除数据丢失的风险。
自动暂停以防止被某些 网站 阻止。 查看全部
网页表格抓取(WebDataMiner是一款网页数据挖掘工具,帮你轻松挖掘网页中的各种数据)
Web Data Miner 是一个 Web 数据挖掘工具。该软件可以帮助您轻松挖掘网页中的各种数据。软件可以将挖掘出来的数据以表格的形式呈现。可以智能地帮助用户从网站中提取准确的数据,在不同的布局中,例如购物、分类、基于产品和其他网站。
软件介绍
此数据抓取器将从打开的网页中抓取点击的项目或类似项目。在这个工具中有两个选项“自动保存”和“自动暂停”。自动保存消除了数据丢失的风险,而自动暂停消除了某些 网站 阻止 IP 地址的风险。
网站数据挖掘工具可以从一个网站内的多个网页中挖掘数据。用户可以配置“设置下一页链接”以从所有网页中提取相似数据。用户可以选择定义数量的页面来提取数据,否则它将从所有网页中挖掘数据。该软件的独特和最强大的功能之一是调度。
用户可以设置时间和日期,并提供配置文件。它将在用户定义的时间自动启动数据挖掘过程。挖掘数据后,它会自动关闭并将配置文件保存在用户定义的位置。
软件功能
以表格形式从网页中提取数据。
从不同布局的 网站 中提取数据。
从网页中提取文本、html、图像、链接和 URL。
从外部和自定义链接中提取数据。
自动跟踪页面以提取数据。
保存提取的数据,消除数据丢失的风险。
自动暂停以防止被某些 网站 阻止。
网页表格抓取(第5步中显示的方法中完成的显示方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-06 20:09
,
,等待。您可以使用“//”,然后使用标签名称来调用第一个。例如“// div”、“// a”或“// span”。现在,如果你真的想得到“Some Text Here”,你需要调用课程。这是在步骤 5 中显示的方法中完成的。您会注意到它使用了“// div”和“[@class =“这里是类名”] 的组合。xml 字符串是“// div [@class ='list-card__body']" 你可能想要获取另一个数据值。我们想要获取所有的 URL。这种情况会涉及到想要提取第一个 HTML 标签本身内部的特定值。例如,点击这里。然后就像 step 7.xml字符串为“//a/@href”ImportXML(URL, XML string)ImportXML(“”,“//div[@class='list-card__body']”)
使用此功能的事实是它需要花费大量时间。因此,它需要规划和设计一个好的谷歌工作表,以确保您从使用中获得最大的收益。否则,您的团队最终将花时间维护它而不是研究新事物。像下面的图片
来自 xkcd
使用 ImportHTML 进行网页抓取
最后,我们将讨论 ImportHTML。这将从网页导入表格或列表。例如,如果您想从 网站 获取收录股票价格的数据,该怎么办。
我们会用。此页面上有一张表格,其中收录过去几天的股票价格。
与过去的功能类似,您需要使用一个 URL。在 URL 的顶部,您必须提及要在页面上抓取的表格。您可以使用可能的数字来完成此操作。
例如,ImportHTML (" ",6 )。这将从上面的链接中删除股票价格。
在上面的视频中,我们还展示了如何将上述股票数据捕获结合到当天有关股市自动收录设备的新闻中。这可以以更复杂的方式使用。该团队可以创建一个算法,使用过去的股票价格和新的 文章 和 Twitter 信息来选择是买入还是卖出股票。
你有什么使用网页抓取的好主意吗?您需要有关网页抓取项目的帮助吗?让我们知道!
关于数据科学的其他精彩读物:
什么是决策树
算法如何变得不道德和有偏见
如何开发健壮的算法
数据科学家必须具备的 4 项技能
翻译自:
网页抓取表单 查看全部
网页表格抓取(第5步中显示的方法中完成的显示方法介绍)
,
,等待。您可以使用“//”,然后使用标签名称来调用第一个。例如“// div”、“// a”或“// span”。现在,如果你真的想得到“Some Text Here”,你需要调用课程。这是在步骤 5 中显示的方法中完成的。您会注意到它使用了“// div”和“[@class =“这里是类名”] 的组合。xml 字符串是“// div [@class ='list-card__body']" 你可能想要获取另一个数据值。我们想要获取所有的 URL。这种情况会涉及到想要提取第一个 HTML 标签本身内部的特定值。例如,点击这里。然后就像 step 7.xml字符串为“//a/@href”ImportXML(URL, XML string)ImportXML(“”,“//div[@class='list-card__body']”)
使用此功能的事实是它需要花费大量时间。因此,它需要规划和设计一个好的谷歌工作表,以确保您从使用中获得最大的收益。否则,您的团队最终将花时间维护它而不是研究新事物。像下面的图片
来自 xkcd
使用 ImportHTML 进行网页抓取
最后,我们将讨论 ImportHTML。这将从网页导入表格或列表。例如,如果您想从 网站 获取收录股票价格的数据,该怎么办。
我们会用。此页面上有一张表格,其中收录过去几天的股票价格。
与过去的功能类似,您需要使用一个 URL。在 URL 的顶部,您必须提及要在页面上抓取的表格。您可以使用可能的数字来完成此操作。
例如,ImportHTML (" ",6 )。这将从上面的链接中删除股票价格。
在上面的视频中,我们还展示了如何将上述股票数据捕获结合到当天有关股市自动收录设备的新闻中。这可以以更复杂的方式使用。该团队可以创建一个算法,使用过去的股票价格和新的 文章 和 Twitter 信息来选择是买入还是卖出股票。
你有什么使用网页抓取的好主意吗?您需要有关网页抓取项目的帮助吗?让我们知道!
关于数据科学的其他精彩读物:
什么是决策树
算法如何变得不道德和有偏见
如何开发健壮的算法
数据科学家必须具备的 4 项技能
翻译自:
网页抓取表单
网页表格抓取(网页上只有一个表格的数据如何获取?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-05 21:22
首先下载jsoup的jar包,自己在网上搜索这个,有很多,然后导入到程序中方便使用。
接下来先获取你想要获取的网页内容,Document doc = Jsoup.connect(url).timeout(5000).get();
这里的网址就是你要爬取的网址。timeout(5000) 设置你抓取网页的最长时间,超过时间后不再尝试。一般网站不需要设置,只需要Document doc = Jsoup.connect(url).get(); 获取网页内容并转换为文档格式。
下一步是找到您想要获取的数据。这里我们主要讲一下如何获取网页表格中的数据。其他类似。
你需要了解你想要获取的网页的html标签的结构,按F12进入开发者模式,寻找你想要获取的数据信息。
如果网页上只有一张表格,很简单: Elements elements1 = doc.select("table").select("tr"); 这行代码获取网页上表格中的行,返回的元素是表格有多少行。如果是多个表,那么select()就是表的标签,比如它的class和其他属性,来决定你选择哪个表。
for (int i = 0; i <elements1.size()-1; i++) {
//获取每一行的列
元素 tds = 元素1.get(i).select("td");
{
//处理每一行你需要的一些列
//获取第i行第j列的值
字符串 oldClose = tds.get(j).text()
//接下来,继续你的操作
………………
}
} 查看全部
网页表格抓取(网页上只有一个表格的数据如何获取?(一))
首先下载jsoup的jar包,自己在网上搜索这个,有很多,然后导入到程序中方便使用。
接下来先获取你想要获取的网页内容,Document doc = Jsoup.connect(url).timeout(5000).get();
这里的网址就是你要爬取的网址。timeout(5000) 设置你抓取网页的最长时间,超过时间后不再尝试。一般网站不需要设置,只需要Document doc = Jsoup.connect(url).get(); 获取网页内容并转换为文档格式。
下一步是找到您想要获取的数据。这里我们主要讲一下如何获取网页表格中的数据。其他类似。
你需要了解你想要获取的网页的html标签的结构,按F12进入开发者模式,寻找你想要获取的数据信息。
如果网页上只有一张表格,很简单: Elements elements1 = doc.select("table").select("tr"); 这行代码获取网页上表格中的行,返回的元素是表格有多少行。如果是多个表,那么select()就是表的标签,比如它的class和其他属性,来决定你选择哪个表。
for (int i = 0; i <elements1.size()-1; i++) {
//获取每一行的列
元素 tds = 元素1.get(i).select("td");
{
//处理每一行你需要的一些列
//获取第i行第j列的值
字符串 oldClose = tds.get(j).text()
//接下来,继续你的操作
………………
}
}
网页表格抓取( Python中如何使用Pandas_html方法从HTML中获取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-04 14:11
Python中如何使用Pandas_html方法从HTML中获取数据
)
在本 Pandas 教程中,我们将详细介绍如何使用 Pandas 的 read_html 方法从 HTML 中获取数据。首先,在最简单的示例中,我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例使用 Pandas read_html 从维基百科表格中获取数据。在上一篇文章(Python中的探索性数据分析)中,我们也使用了Pandas从HTML表格中读取数据。
在 Python 中导入数据
在开始学习Python和Pandas的时候,为了进行数据分析和可视化,我们通常会从导入数据的实践开始。在前面的文章中,我们已经了解到我们可以直接在Python中输入值(例如,从Python字典创建一个Pandas数据框)。但是,通过从可用来源导入数据来获取数据当然更为常见。这通常通过从 CSV 文件或 Excel 文件中读取数据来完成。例如,要从 .csv 文件导入数据,我们可以使用 Pandas read_csv 方法。这是如何使用此方法的快速示例,但请务必查看主题 文章 的博客以获取更多信息。
现在,上述方法仅在我们已经拥有合适格式(例如 csv 或 JSON)的数据时才有用(请参阅 文章 了解如何使用 Python 和 Pandas 解析 JSON 文件)。
我们大多数人都会使用维基百科来了解我们感兴趣的话题。此外,这些 Wikipedia文章 通常收录 HTML 表格。
要使用pandas在Python中获取这些表格,我们可以将它们剪切并粘贴到电子表格中,然后例如使用read_excel将它们读入Python。现在,这个任务当然可以用更少的步骤完成:我们可以通过网络抓取来自动化它。一定要检查什么是网页抓取。
先决条件
当然,这个 Pandas 阅读 HTML 教程需要我们安装 Pandas 及其依赖项。例如,我们可以使用 pip 安装 Python 包,例如 Pandas,或安装 Python 发行版(例如,Anaconda、ActivePython)。以下是使用 pip 安装 Pandas 的方法:pip install pandas。
请注意,如果出现一条消息说有新版本的 pip 可用,请查看此 文章 以了解如何升级 pip。请注意,我们还需要安装 lxml 或 BeautifulSoup4。当然,这些包也可以使用 pip 安装:pip install lxml。
熊猫 read_html 语法
以下是如何使用 Pandas read_html 从 HTML 表中获取数据的最简单语法:
现在我们知道了使用 Pandas 读取 HTML 表格的简单语法,我们可以看看 read_html 的一些例子。
熊猫 read_html 示例 1:
第一个例子是关于如何使用 Pandas read_html 方法。我们将从一个字符串中读取一个 HTML 表格。
现在,我们得到的结果不是 Pandas DataFrame,而是 Python 列表。换句话说,如果我们使用 type 函数,我们可以看到:
如果我们想要得到表,我们可以使用列表的第一个索引(0)
熊猫 read_html 示例 2:
在第二个 Pandas read_html 示例中,我们将从维基百科中抓取数据。其实我们会得到python(也叫python)的HTML表格。
现在,我们有一个收录 7 个表的列表 (len(df))。如果我们转到维基百科页面,我们可以看到第一个表格是右边的表格。然而,在这个例子中,我们可能对第二个表更感兴趣。
熊猫 read_html 示例 3:
在第三个示例中,我们将从瑞典的 covid-19 案例中读取 HTML 表格。在这里,我们将使用 read_html 方法的一些附加参数。具体来说,我们将使用 match 参数。在此之后,我们仍然需要清理数据,最后我们将进行一些简单的数据可视化操作。
使用 Pandas read_html 和匹配参数抓取数据:
如上图所示,表格的标题是:“瑞典各县的新 COVID-19 病例”。现在,我们可以使用 match 参数并将其作为字符串输入:
这样,我们只得到了这张表,但它仍然是一个dataframes的列表。现在,如上图所示,在底部,我们需要删除三行。因此,我们要删除最后三行。
使用 Pandas iloc 删除最后一行
现在,我们将使用 Pandas iloc 删除最后 3 行。请注意,我们使用 -3 作为第二个参数(确保您查看此 Panda iloc 教程以获取更多信息)。最后,我们还创建了此数据框的副本。
在下一节中,我们将学习如何将多索引列名更改为单索引。
将多个索引更改为单个索引并删除不需要的字符
现在,我们要删除多索引列。换句话说,我们将把 2 列索引(名称)变成一个唯一的列名。在这里,我们将使用 DataFrame.columns 和 DataFrame.columns,get_level_values:
最后,正如您在“日期”列中看到的,我们使用 Pandas read_html 从 WikiPedia 表中抓取了一些评论。接下来,我们将使用 str.replace 方法和正则表达式来删除它们:
使用 Pandas set_index 更改索引
现在,我们继续使用 Pandas set_index 将日期列变成索引。这样,我们以后就可以轻松创建时间序列图了。
现在,为了能够画出这个时间序列图,我们需要用0填充缺失值,并将这些列的数据类型改为数值型。这里我们也使用了apply方法。最后,我们使用 cumsum 方法获取列中每个新值的累加值:
HTML 表格中的时间序列图
在上一个例子中,我们使用 Pandas read_html 来获取我们爬取的数据并创建了一个时间序列图。现在,我们还导入了 matplotlib,以便我们可以更改 Pandas 图例标题的位置:
结论:如何将 HTML 读入 Pandas DataFrame
在本 Pandas 教程中,我们学习了如何使用 Pandas read_html 方法从 HTML 中抓取数据。此外,我们使用来自维基百科文章 的数据来创建时间序列图。最后,我们还可以使用 Pandas read_html 通过参数 index_col 将 'Date' 列设置为索引列。
英文原文:
译者:片刻
查看全部
网页表格抓取(
Python中如何使用Pandas_html方法从HTML中获取数据
)
在本 Pandas 教程中,我们将详细介绍如何使用 Pandas 的 read_html 方法从 HTML 中获取数据。首先,在最简单的示例中,我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例使用 Pandas read_html 从维基百科表格中获取数据。在上一篇文章(Python中的探索性数据分析)中,我们也使用了Pandas从HTML表格中读取数据。
在 Python 中导入数据
在开始学习Python和Pandas的时候,为了进行数据分析和可视化,我们通常会从导入数据的实践开始。在前面的文章中,我们已经了解到我们可以直接在Python中输入值(例如,从Python字典创建一个Pandas数据框)。但是,通过从可用来源导入数据来获取数据当然更为常见。这通常通过从 CSV 文件或 Excel 文件中读取数据来完成。例如,要从 .csv 文件导入数据,我们可以使用 Pandas read_csv 方法。这是如何使用此方法的快速示例,但请务必查看主题 文章 的博客以获取更多信息。
现在,上述方法仅在我们已经拥有合适格式(例如 csv 或 JSON)的数据时才有用(请参阅 文章 了解如何使用 Python 和 Pandas 解析 JSON 文件)。
我们大多数人都会使用维基百科来了解我们感兴趣的话题。此外,这些 Wikipedia文章 通常收录 HTML 表格。
要使用pandas在Python中获取这些表格,我们可以将它们剪切并粘贴到电子表格中,然后例如使用read_excel将它们读入Python。现在,这个任务当然可以用更少的步骤完成:我们可以通过网络抓取来自动化它。一定要检查什么是网页抓取。
先决条件
当然,这个 Pandas 阅读 HTML 教程需要我们安装 Pandas 及其依赖项。例如,我们可以使用 pip 安装 Python 包,例如 Pandas,或安装 Python 发行版(例如,Anaconda、ActivePython)。以下是使用 pip 安装 Pandas 的方法:pip install pandas。
请注意,如果出现一条消息说有新版本的 pip 可用,请查看此 文章 以了解如何升级 pip。请注意,我们还需要安装 lxml 或 BeautifulSoup4。当然,这些包也可以使用 pip 安装:pip install lxml。
熊猫 read_html 语法
以下是如何使用 Pandas read_html 从 HTML 表中获取数据的最简单语法:
现在我们知道了使用 Pandas 读取 HTML 表格的简单语法,我们可以看看 read_html 的一些例子。
熊猫 read_html 示例 1:
第一个例子是关于如何使用 Pandas read_html 方法。我们将从一个字符串中读取一个 HTML 表格。
现在,我们得到的结果不是 Pandas DataFrame,而是 Python 列表。换句话说,如果我们使用 type 函数,我们可以看到:
如果我们想要得到表,我们可以使用列表的第一个索引(0)
熊猫 read_html 示例 2:
在第二个 Pandas read_html 示例中,我们将从维基百科中抓取数据。其实我们会得到python(也叫python)的HTML表格。
现在,我们有一个收录 7 个表的列表 (len(df))。如果我们转到维基百科页面,我们可以看到第一个表格是右边的表格。然而,在这个例子中,我们可能对第二个表更感兴趣。
熊猫 read_html 示例 3:
在第三个示例中,我们将从瑞典的 covid-19 案例中读取 HTML 表格。在这里,我们将使用 read_html 方法的一些附加参数。具体来说,我们将使用 match 参数。在此之后,我们仍然需要清理数据,最后我们将进行一些简单的数据可视化操作。
使用 Pandas read_html 和匹配参数抓取数据:
如上图所示,表格的标题是:“瑞典各县的新 COVID-19 病例”。现在,我们可以使用 match 参数并将其作为字符串输入:
这样,我们只得到了这张表,但它仍然是一个dataframes的列表。现在,如上图所示,在底部,我们需要删除三行。因此,我们要删除最后三行。
使用 Pandas iloc 删除最后一行
现在,我们将使用 Pandas iloc 删除最后 3 行。请注意,我们使用 -3 作为第二个参数(确保您查看此 Panda iloc 教程以获取更多信息)。最后,我们还创建了此数据框的副本。
在下一节中,我们将学习如何将多索引列名更改为单索引。
将多个索引更改为单个索引并删除不需要的字符
现在,我们要删除多索引列。换句话说,我们将把 2 列索引(名称)变成一个唯一的列名。在这里,我们将使用 DataFrame.columns 和 DataFrame.columns,get_level_values:
最后,正如您在“日期”列中看到的,我们使用 Pandas read_html 从 WikiPedia 表中抓取了一些评论。接下来,我们将使用 str.replace 方法和正则表达式来删除它们:
使用 Pandas set_index 更改索引
现在,我们继续使用 Pandas set_index 将日期列变成索引。这样,我们以后就可以轻松创建时间序列图了。
现在,为了能够画出这个时间序列图,我们需要用0填充缺失值,并将这些列的数据类型改为数值型。这里我们也使用了apply方法。最后,我们使用 cumsum 方法获取列中每个新值的累加值:
HTML 表格中的时间序列图
在上一个例子中,我们使用 Pandas read_html 来获取我们爬取的数据并创建了一个时间序列图。现在,我们还导入了 matplotlib,以便我们可以更改 Pandas 图例标题的位置:
结论:如何将 HTML 读入 Pandas DataFrame
在本 Pandas 教程中,我们学习了如何使用 Pandas read_html 方法从 HTML 中抓取数据。此外,我们使用来自维基百科文章 的数据来创建时间序列图。最后,我们还可以使用 Pandas read_html 通过参数 index_col 将 'Date' 列设置为索引列。
英文原文:
译者:片刻
网页表格抓取(怎么处理这类网页的网页?表格中的两个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-04 07:09
想爬取一个网站1-n页面的内容,url构造为”,其中?它指的是第n页。假设是58095,url是“(需要登录才能看到详细信息,可以填写我的账号,密码123b45),那么如果我爬下公司名称和公司注册号,等可以用panyname,panyid等存储,这些比较简单,问题是后面的融资信息,如果我用item.invest来存储,那么这个变量其实就是一张没有详细展开的表,需要后面处理,所以如果我Expand的话,需要的变量太多了,而且每个公司融资的数量不同,也就是说对于不同的页面,html标签tr的数量是不确定的,包括以下业务更改记录也是这样,那么我的问题是:
1. 这种行数不定的表信息怎么保存,因为之前用了item.name等item变量,相当于建表了,那怎么保存融资在这张桌子上?不确定嵌入的表信息的行数?后端的数据库是不是一般都存放在类似于json格式的字典中?
2. 如果以保存业务变更记录的形式添加信息,如上,是不是相当于在一个表单中嵌套了两个表单?感觉好复杂啊想着把融资信息和业务变更记录信息分别创建一个itemi()和itemc(),爬上去后再合并。
由于网页的复杂性,不知道大神们平时是怎么处理这样的网页的? 查看全部
网页表格抓取(怎么处理这类网页的网页?表格中的两个)
想爬取一个网站1-n页面的内容,url构造为”,其中?它指的是第n页。假设是58095,url是“(需要登录才能看到详细信息,可以填写我的账号,密码123b45),那么如果我爬下公司名称和公司注册号,等可以用panyname,panyid等存储,这些比较简单,问题是后面的融资信息,如果我用item.invest来存储,那么这个变量其实就是一张没有详细展开的表,需要后面处理,所以如果我Expand的话,需要的变量太多了,而且每个公司融资的数量不同,也就是说对于不同的页面,html标签tr的数量是不确定的,包括以下业务更改记录也是这样,那么我的问题是:
1. 这种行数不定的表信息怎么保存,因为之前用了item.name等item变量,相当于建表了,那怎么保存融资在这张桌子上?不确定嵌入的表信息的行数?后端的数据库是不是一般都存放在类似于json格式的字典中?
2. 如果以保存业务变更记录的形式添加信息,如上,是不是相当于在一个表单中嵌套了两个表单?感觉好复杂啊想着把融资信息和业务变更记录信息分别创建一个itemi()和itemc(),爬上去后再合并。
由于网页的复杂性,不知道大神们平时是怎么处理这样的网页的?
网页表格抓取()
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-03 19:12
问题描述
伙计们!我又向你申请了。我可以使用标记来抓取简单的 网站,但我最近遇到了一个非常复杂的 网站 收录 JavaScript。因此,我想使用表格(csv)的格式获取页面底部的所有估计值。类似于用户“,收入估算”,“EPS估算”。
伙计们!我再次向你申请。我可以用标签抓取简单的网站,但最近我遇到了一个相当复杂的网站,它有 JavaScript。因此,我想以表格 (csv) 的格式获取页面底部的所有估计值。像“用户”、“收入估算”、“每股收益估算”。
我希望自己解决这个问题,但我还是失败了。
我希望自己解决,但有点失败。
这是我的代码:
from urllib import urlopen
from bs4 import BeautifulSoup
html = urlopen("https://www.estimize.com/jpm/f ... 6quot;)
soup = BeautifulSoup(html.read(), "html.parser")
print(soup.findAll('script')[11].string.encode('utf8'))
输出格式很奇怪,我不知道如何以正确的格式提取数据。我将不胜感激!
输出格式奇怪,我不知道如何以适当的形式提取数据。我将不胜感激!
推荐答案
您要提取的数据看起来像是在数据模型中,这意味着它是 JSON。如果您使用以下进行少量分析:
看起来您尝试提取的数据位于数据模型中,这意味着它是 JSON 格式。如果您使用以下内容进行少量解析:
import json
import re
data_string = soup.findAll('script')[11].string.encode('utf8')
data_string = data_string.split("DataModel.parse(")[1]
data_string = data_string.split(");")[0]
// parse out erroneous html
while re.search('\]*\>', datastring):
data_string = ''.join(datastring.split(re.search('\]*\>', datastring).group(0)))
// parse out other function parameters, leaving you with the json
data_you_want = json.loads(data_string.split(re.search('\}[^",\}\]]+,', data_string).group(0))[0]+'}')
print(data_you_want["estimate"])
>>> {'shares': {'shares_hash': {'twitter': None, 'stocktwits': None, 'linkedin': None}}, 'lastRevised': None, 'id': None, 'revenue_points': None, 'sector': 'financials', 'persisted': False, 'points': None, 'instrumentSlug': 'jpm', 'wallstreetRevenue': 23972, 'revenue': 23972, 'createdAt': None, 'username': None, 'isBlind': False, 'releaseSlug': 'fq3-2016', 'statement': '', 'errorRanges': {'revenue': {'low': 21247.3532016398, 'high': 26820.423240734}, 'eps': {'low': 1.02460526459765, 'high': 1.81359679579922}}, 'eps_points': None, 'rank': None, 'instrumentId': 981, 'eps': 1.4, 'season': '2016-fall', 'releaseId': 52773}
DataModel.parse 是一个 javascript 方法,这意味着它以括号和冒号结尾。该函数的参数是所需的 JSON 对象。通过将其加载到 json.loads 中,您可以将其作为字典访问。
DataModel.parse 是一个 javascript 方法,这意味着它以括号和冒号结尾。该函数的参数是您想要的 JSON 对象。通过将其加载到 json.loads 中,您可以像访问字典一样访问它。
从那里,您可以将数据重新映射为您想要的 CSV 格式。
从那里您将数据重新映射到您希望它在 csv 中使用的形式。 查看全部
网页表格抓取()
问题描述
伙计们!我又向你申请了。我可以使用标记来抓取简单的 网站,但我最近遇到了一个非常复杂的 网站 收录 JavaScript。因此,我想使用表格(csv)的格式获取页面底部的所有估计值。类似于用户“,收入估算”,“EPS估算”。
伙计们!我再次向你申请。我可以用标签抓取简单的网站,但最近我遇到了一个相当复杂的网站,它有 JavaScript。因此,我想以表格 (csv) 的格式获取页面底部的所有估计值。像“用户”、“收入估算”、“每股收益估算”。
我希望自己解决这个问题,但我还是失败了。
我希望自己解决,但有点失败。
这是我的代码:
from urllib import urlopen
from bs4 import BeautifulSoup
html = urlopen("https://www.estimize.com/jpm/f ... 6quot;)
soup = BeautifulSoup(html.read(), "html.parser")
print(soup.findAll('script')[11].string.encode('utf8'))
输出格式很奇怪,我不知道如何以正确的格式提取数据。我将不胜感激!
输出格式奇怪,我不知道如何以适当的形式提取数据。我将不胜感激!
推荐答案
您要提取的数据看起来像是在数据模型中,这意味着它是 JSON。如果您使用以下进行少量分析:
看起来您尝试提取的数据位于数据模型中,这意味着它是 JSON 格式。如果您使用以下内容进行少量解析:
import json
import re
data_string = soup.findAll('script')[11].string.encode('utf8')
data_string = data_string.split("DataModel.parse(")[1]
data_string = data_string.split(");")[0]
// parse out erroneous html
while re.search('\]*\>', datastring):
data_string = ''.join(datastring.split(re.search('\]*\>', datastring).group(0)))
// parse out other function parameters, leaving you with the json
data_you_want = json.loads(data_string.split(re.search('\}[^",\}\]]+,', data_string).group(0))[0]+'}')
print(data_you_want["estimate"])
>>> {'shares': {'shares_hash': {'twitter': None, 'stocktwits': None, 'linkedin': None}}, 'lastRevised': None, 'id': None, 'revenue_points': None, 'sector': 'financials', 'persisted': False, 'points': None, 'instrumentSlug': 'jpm', 'wallstreetRevenue': 23972, 'revenue': 23972, 'createdAt': None, 'username': None, 'isBlind': False, 'releaseSlug': 'fq3-2016', 'statement': '', 'errorRanges': {'revenue': {'low': 21247.3532016398, 'high': 26820.423240734}, 'eps': {'low': 1.02460526459765, 'high': 1.81359679579922}}, 'eps_points': None, 'rank': None, 'instrumentId': 981, 'eps': 1.4, 'season': '2016-fall', 'releaseId': 52773}
DataModel.parse 是一个 javascript 方法,这意味着它以括号和冒号结尾。该函数的参数是所需的 JSON 对象。通过将其加载到 json.loads 中,您可以将其作为字典访问。
DataModel.parse 是一个 javascript 方法,这意味着它以括号和冒号结尾。该函数的参数是您想要的 JSON 对象。通过将其加载到 json.loads 中,您可以像访问字典一样访问它。
从那里,您可以将数据重新映射为您想要的 CSV 格式。
从那里您将数据重新映射到您希望它在 csv 中使用的形式。
网页表格抓取(如何使用Python和pandas库从web页面获取表数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-03 14:02
如今,人们可以随时随地连接到 Internet。 Internet 可能是最大的公共数据库。学习如何从互联网上获取数据是非常重要的。因此,有必要了解如何使用Python和pandas库从网页中获取表格数据。另外,如果你已经在使用Excel PowerQuery,这相当于“从Web获取数据”的功能,只不过这里的功能强大100倍。
从网站获取数据(网络爬虫)
HTML 是每个 网站 背后的语言。当我们访问一个网站时,发生的事情是这样的:
1.在浏览器地址栏中输入地址(URL),浏览器会向目标网站的服务器发送请求。
2. 服务器接收到请求,并返回构成网页的 HTML 代码。
3.浏览器接收HTML代码,动态运行,创建一个网页供我们查看。
网页抓取基本上是指我们可以不用浏览器,而是使用Python向网站服务器发送请求,接收HTML代码,然后提取所需数据。
这里不会涉及太多HTML,只介绍一些关键点,让我们对网站和网页抓取的工作原理有一个基本的了解。 HTML 元素或“HTML 标签”被特定的关键字包围。比如下面的HTML代码就是网页的标题,将鼠标悬停在网页中的标签上,浏览器会看到相同的标题。请注意,大多数 HTML 元素都需要一个开始标记(例如,)和相应的结束标记(例如,)。
Python pandas获取网页中的表格数据(网络爬虫)
同理,下面的代码会在浏览器上绘制一个表格,你可以尝试复制粘贴到记事本中,然后保存为“table example.html”文件,应该可以在浏览器中显示浏览器 打开它。简要说明如下:
用户姓名
国家
城市
性别
年龄
Forrest Gump
USA
New York
M>
50
Mary Jane
CANADA
Toronto
F
30
使用pandas进行网络爬虫的要求
学习了 网站 的基本构建块以及如何解释 HTML(至少是表格部分!)。这里之所以只介绍HTML表格,是因为大多数时候,我们尝试从网站中获取数据时,都是表格形式的。 pandas 是从 网站 获取表格格式数据的完美工具!
因此,使用pandas从网站获取数据的唯一要求是数据必须存储在表格中,或者用HTML术语存储在...标签中。 pandas 将能够使用我们刚刚介绍的 HTML 标签提取表格、标题和数据行。
如果您尝试使用 pandas 从不收录任何表格(...标签)的网页中“提取数据”,您将无法获取任何数据。对于那些没有存储在表中的数据,我们需要其他方法来抓取网站。
网页抓取示例
我们之前的大多数示例都是带有少量数据点的小表,让我们使用稍大一些的数据进行处理。
我们将从百度百科获取最新的世界500强企业名称及相关信息:
%E4%B8%96%E7%95%8C500%E5%BC%BA/640042?fr=阿拉丁
图1(如果有错误按照错误提示处理,我电脑没有安装lxml,安装后正常)
上面的df其实是一个列表,很有意思……列表里好像有3个项目。让我们看看pandas为我们采集了哪些数据...
图二
第一个数据框df[0]似乎无关紧要,但是爬到了这个页面的第一个表。查看网页,可以知道这张表是在中国举办的财富全球论坛。
图 3
第二个数据框 df[1] 是本页的另一个表格。请注意,在它的末尾,这意味着有 [500 行 x 6 列]。这张表是世界500强排名表。
图 4
第三个数据框 df[2] 是页面上的第三个表格,最后是 [110 行 x 5 列]。本表为上榜中国企业名单。
注意,总是检查pd.read_html()返回的内容,一个网页可能收录多个表格,所以你会得到一个数据框列表而不是单个数据框!
注:本文借鉴自。
欢迎在下方留言完善本文内容,让更多人学习到更完善的知识。 查看全部
网页表格抓取(如何使用Python和pandas库从web页面获取表数据?)
如今,人们可以随时随地连接到 Internet。 Internet 可能是最大的公共数据库。学习如何从互联网上获取数据是非常重要的。因此,有必要了解如何使用Python和pandas库从网页中获取表格数据。另外,如果你已经在使用Excel PowerQuery,这相当于“从Web获取数据”的功能,只不过这里的功能强大100倍。
从网站获取数据(网络爬虫)
HTML 是每个 网站 背后的语言。当我们访问一个网站时,发生的事情是这样的:
1.在浏览器地址栏中输入地址(URL),浏览器会向目标网站的服务器发送请求。
2. 服务器接收到请求,并返回构成网页的 HTML 代码。
3.浏览器接收HTML代码,动态运行,创建一个网页供我们查看。
网页抓取基本上是指我们可以不用浏览器,而是使用Python向网站服务器发送请求,接收HTML代码,然后提取所需数据。
这里不会涉及太多HTML,只介绍一些关键点,让我们对网站和网页抓取的工作原理有一个基本的了解。 HTML 元素或“HTML 标签”被特定的关键字包围。比如下面的HTML代码就是网页的标题,将鼠标悬停在网页中的标签上,浏览器会看到相同的标题。请注意,大多数 HTML 元素都需要一个开始标记(例如,)和相应的结束标记(例如,)。
Python pandas获取网页中的表格数据(网络爬虫)
同理,下面的代码会在浏览器上绘制一个表格,你可以尝试复制粘贴到记事本中,然后保存为“table example.html”文件,应该可以在浏览器中显示浏览器 打开它。简要说明如下:
用户姓名
国家
城市
性别
年龄
Forrest Gump
USA
New York
M>
50
Mary Jane
CANADA
Toronto
F
30
使用pandas进行网络爬虫的要求
学习了 网站 的基本构建块以及如何解释 HTML(至少是表格部分!)。这里之所以只介绍HTML表格,是因为大多数时候,我们尝试从网站中获取数据时,都是表格形式的。 pandas 是从 网站 获取表格格式数据的完美工具!
因此,使用pandas从网站获取数据的唯一要求是数据必须存储在表格中,或者用HTML术语存储在...标签中。 pandas 将能够使用我们刚刚介绍的 HTML 标签提取表格、标题和数据行。
如果您尝试使用 pandas 从不收录任何表格(...标签)的网页中“提取数据”,您将无法获取任何数据。对于那些没有存储在表中的数据,我们需要其他方法来抓取网站。
网页抓取示例
我们之前的大多数示例都是带有少量数据点的小表,让我们使用稍大一些的数据进行处理。
我们将从百度百科获取最新的世界500强企业名称及相关信息:
%E4%B8%96%E7%95%8C500%E5%BC%BA/640042?fr=阿拉丁
图1(如果有错误按照错误提示处理,我电脑没有安装lxml,安装后正常)
上面的df其实是一个列表,很有意思……列表里好像有3个项目。让我们看看pandas为我们采集了哪些数据...
图二
第一个数据框df[0]似乎无关紧要,但是爬到了这个页面的第一个表。查看网页,可以知道这张表是在中国举办的财富全球论坛。
图 3
第二个数据框 df[1] 是本页的另一个表格。请注意,在它的末尾,这意味着有 [500 行 x 6 列]。这张表是世界500强排名表。
图 4
第三个数据框 df[2] 是页面上的第三个表格,最后是 [110 行 x 5 列]。本表为上榜中国企业名单。
注意,总是检查pd.read_html()返回的内容,一个网页可能收录多个表格,所以你会得到一个数据框列表而不是单个数据框!
注:本文借鉴自。
欢迎在下方留言完善本文内容,让更多人学习到更完善的知识。
网页表格抓取( 如何用Python快速的抓取一个网页中所有表格的爬虫3.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-30 19:11
如何用Python快速的抓取一个网页中所有表格的爬虫3.)
之前在搜索vscode的快捷键时,发现有一个页面,以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学习了Python爬虫,就形成了惯性思维。当我在网页上看到更好的东西,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面简单介绍一下我的一些抢表的思路和方法。
1.在IE浏览器中直接使用export EXCLE
微软的这种设计还是很人性化的,通过这种方式访问网页表格中呈现的内容特别方便。我们只需要在页面上右击,选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
2. 使用Python从网页中抓取表格
接下来就是本文的重点了,直接上代码先。
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'https://segmentfault.com/a/1190000007688656'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
tables = soup.select('table')
df_list = []
for table in tables:
df_list.append(pd.concat(pd.read_html(table.prettify())))
df = pd.concat(df_list)
df.to_excel('vscode快捷键大全.xlsx')
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。我以前这样做过,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址。
下面简单介绍一下代码的含义:
这样就完成了一个简单的爬虫,爬取一个网页中的所有表
3.关于选择方法的建议
最后,我想强调,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格最好的方法就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样,我们就可以把精力集中在学习vscode快捷键的操作上,而不是学习这张表的获取方法。
如果,在另一个场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也是非常重要的。
因此,关键是我们要明确自己的目标,并根据相应的目标选择最合适的方法。
下一篇预告:在下一篇文章中,我将介绍使用正则表达式从本地统计公报中捕获结构化数据 查看全部
网页表格抓取(
如何用Python快速的抓取一个网页中所有表格的爬虫3.)
之前在搜索vscode的快捷键时,发现有一个页面,以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学习了Python爬虫,就形成了惯性思维。当我在网页上看到更好的东西,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面简单介绍一下我的一些抢表的思路和方法。
1.在IE浏览器中直接使用export EXCLE
微软的这种设计还是很人性化的,通过这种方式访问网页表格中呈现的内容特别方便。我们只需要在页面上右击,选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
2. 使用Python从网页中抓取表格
接下来就是本文的重点了,直接上代码先。
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'https://segmentfault.com/a/1190000007688656'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
tables = soup.select('table')
df_list = []
for table in tables:
df_list.append(pd.concat(pd.read_html(table.prettify())))
df = pd.concat(df_list)
df.to_excel('vscode快捷键大全.xlsx')
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。我以前这样做过,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址。
下面简单介绍一下代码的含义:
这样就完成了一个简单的爬虫,爬取一个网页中的所有表
3.关于选择方法的建议
最后,我想强调,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格最好的方法就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样,我们就可以把精力集中在学习vscode快捷键的操作上,而不是学习这张表的获取方法。
如果,在另一个场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也是非常重要的。
因此,关键是我们要明确自己的目标,并根据相应的目标选择最合适的方法。
下一篇预告:在下一篇文章中,我将介绍使用正则表达式从本地统计公报中捕获结构化数据
网页表格抓取(PowerBI汉字的地名来作图,经常出现的精度要求并不高)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-12-25 13:19
在Power BI Desktop做数据地图的时候,因为BING地图中国数据不是那么准确,如果只用汉字中的地名做地图,经常会出现莫名其妙的情况。明明是国内地址,会出国。所以最准确的方法是通过经纬度定位。
互联网上有各种各样的数据。搜索后,有很多网站提供经纬度查询。我们的映射不需要高纬度和经度精度。我找到了一个可以查询全国所有省市县经纬度的网站:
找上海,随便找个区查一下:果然
检查网页上的连接地址。它的结构非常简单,应该可以直接抓取:
具有这种结构的网页通常通过指向子页面的链接来查找内容。它不是现成的数据表。页面上只有三个有用的数据:地名、经度和纬度。所以我们需要用文本打开,然后过滤出我们需要的内容,然后进行整理。
但是我们无法手动一个一个地添加这么多子页面。如果您从任何页面进入,都会有到其他区域的链接,我们会通过此链接自动添加它们。
第一部分获取所有链接地址
首先,修改此源的设置。注意一定要设置GB2312编码,否则汉字乱码。
保留行,从109行开始,共19行
接下来是提取内容:各区名和连接地址:
这提取了>分隔符之间的文本,非常好用。在高级设置中,跳过 1 个字符。观察到这个“”中的“>”是第一个开始符号,我们需要的内容在第二个开始符号之后,所以跳过第一个开始符号。
获取连接地址的方法也是一样的,但是可以直接获取,不用跳过:
第二部分爬行
自定义列:仍然可以使用Web.Contents根据链接地址进行查询。
查询的结果是一个二进制文件,点击合并后会出现警告,点击编辑
点击编辑后,会弹出一个对话框,这里还是要选择文本文件:
接下来就是合并文件的操作了,还是要注意选择GB2312编码:
Power Query在合并文件的时候会像我一样自动生成一个自定义函数,并引用这个自定义函数来合并所有的页面。为方便后续操作,我们在右边的步骤中退一步,查找并删除其他的。列,在这里您可以检索自动删除的区域的名称。如果您不检索它们,则稍后需要再次检索它们。
最终的结果是这样的:第二部分的工作完成了。
第三部分整理资料
这么多行,只有19行对我们有用
我们要过滤掉这19行:通过观察,只要同时收录
这两个关键字的行就是我们需要的内容,世界一下子就刷新了。
需要再次使用Extraction>Separator之间的文本,这次不需要转换文本,使用添加列中的提取保存复制列。首先提取经度:
然后提取纬度:
最后,修改以下名称和数据类型,大功告成:
我们在每个区模拟一列销售数据,然后使用每个区的名称为索引列建立表关系:
您可以在BI中制作图片:
最好将本地从网络捕获的数据保存为存档。无需每次都在网络上刷新。可以直接在 Power BI Desktop 的表格模式下复制表格,然后粘贴到 Excel 中。向上。
如果在 Excel 中从 Power Query 中抓取数据,则更简单,只需将其加载到表中并复制即可。 查看全部
网页表格抓取(PowerBI汉字的地名来作图,经常出现的精度要求并不高)
在Power BI Desktop做数据地图的时候,因为BING地图中国数据不是那么准确,如果只用汉字中的地名做地图,经常会出现莫名其妙的情况。明明是国内地址,会出国。所以最准确的方法是通过经纬度定位。
互联网上有各种各样的数据。搜索后,有很多网站提供经纬度查询。我们的映射不需要高纬度和经度精度。我找到了一个可以查询全国所有省市县经纬度的网站:
找上海,随便找个区查一下:果然
检查网页上的连接地址。它的结构非常简单,应该可以直接抓取:
具有这种结构的网页通常通过指向子页面的链接来查找内容。它不是现成的数据表。页面上只有三个有用的数据:地名、经度和纬度。所以我们需要用文本打开,然后过滤出我们需要的内容,然后进行整理。
但是我们无法手动一个一个地添加这么多子页面。如果您从任何页面进入,都会有到其他区域的链接,我们会通过此链接自动添加它们。
第一部分获取所有链接地址
首先,修改此源的设置。注意一定要设置GB2312编码,否则汉字乱码。
保留行,从109行开始,共19行
接下来是提取内容:各区名和连接地址:
这提取了>分隔符之间的文本,非常好用。在高级设置中,跳过 1 个字符。观察到这个“”中的“>”是第一个开始符号,我们需要的内容在第二个开始符号之后,所以跳过第一个开始符号。
获取连接地址的方法也是一样的,但是可以直接获取,不用跳过:
第二部分爬行
自定义列:仍然可以使用Web.Contents根据链接地址进行查询。
查询的结果是一个二进制文件,点击合并后会出现警告,点击编辑
点击编辑后,会弹出一个对话框,这里还是要选择文本文件:
接下来就是合并文件的操作了,还是要注意选择GB2312编码:
Power Query在合并文件的时候会像我一样自动生成一个自定义函数,并引用这个自定义函数来合并所有的页面。为方便后续操作,我们在右边的步骤中退一步,查找并删除其他的。列,在这里您可以检索自动删除的区域的名称。如果您不检索它们,则稍后需要再次检索它们。
最终的结果是这样的:第二部分的工作完成了。
第三部分整理资料
这么多行,只有19行对我们有用
我们要过滤掉这19行:通过观察,只要同时收录
这两个关键字的行就是我们需要的内容,世界一下子就刷新了。
需要再次使用Extraction>Separator之间的文本,这次不需要转换文本,使用添加列中的提取保存复制列。首先提取经度:
然后提取纬度:
最后,修改以下名称和数据类型,大功告成:
我们在每个区模拟一列销售数据,然后使用每个区的名称为索引列建立表关系:
您可以在BI中制作图片:
最好将本地从网络捕获的数据保存为存档。无需每次都在网络上刷新。可以直接在 Power BI Desktop 的表格模式下复制表格,然后粘贴到 Excel 中。向上。
如果在 Excel 中从 Power Query 中抓取数据,则更简单,只需将其加载到表中并复制即可。
网页表格抓取(Excel,R,Python和BI,作为开始数据分析的基础)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-25 13:17
数据分析时代已经到来。从国家、政府、公司到个人,大数据和数据分析已经成为大家耳熟能详的趋势。但是你可能没有数据分析和编程方面的专业知识,或者你已经了解了很多数据分析的理论,但你仍然无法实践。在这里,我将比较数据分析师最流行的四种工具,Excel、R、Python 和 BI,作为开始数据分析的基础。
1. Excel
1.1使用场景
1.2 优点
1.3 缺点
2. R
2.1使用场景
R 的功能几乎涵盖了任何需要数据的领域。就我们一般的数据分析或学术数据分析而言,R能做的主要有以下几个方面。
2.2 R 好学吗?
在我看来,R 入门非常简单。10天的强化学习,足以掌握基本用法、基本数据结构、数据导入导出、简单数据可视化。有了这些基础,当你遇到实际问题的时候,就可以找到你需要用到的R包了。通过阅读 R 的帮助文件和互联网上的信息,您可以相对较快地解决特定问题。
3. Python
3.1使用场景
3.2 R 和 Python
R 和 Python 都是需要编程的数据分析工具。不同的是R只用在数据分析领域,而科学计算和数据分析只是Python的应用分支。Python还可以用于开发网页、开发游戏、开发系统后端,以及执行一些运维任务。
目前的趋势是Python在数据分析领域正在追赶R。在某些方面,它已经超越了 R,例如机器学习和文本挖掘。但R在统计领域仍然保持优势。Python在数据分析方面的发展在很多地方模拟了R的一些特性。所以,如果你还是新手,还没有开始学习,我建议你从Python开始。
Python 和 R 都很容易学习。但是如果同时研究两者,就会很混乱,因为它们在很多地方都非常相似。所以建议不要同时学习。等到你掌握了其中一个,然后开始学习另一个。
3.3 选择 R 还是 Python?
如果因为时间有限只能选择其中之一学习,我推荐使用Python。但我仍然建议你看看两者。在某些地方,您可能会听说 Python 在工作中更常用,但解决问题是最重要的。如果你能用R有效解决问题,那就用R吧。其实Python模仿了R的很多功能,比如Pandas库中的DataFrames。正在开发的可视化包ggplot模仿了R中非常有名的ggplot2。
双
数据分析中有一句话:文字不如表格,表格不如图表。数据可视化是数据分析的主要方向之一。Excel图表可以满足基本的图形要求,但这只是基础。高级可视化需要编程。除了学习R、Python等编程语言,还可以选择简单易用的BI工具。有关 BI 的介绍,您可以阅读我的另一篇文章,我应该学习哪些数据分析工具才能开始我的数据分析师职业?
商业智能诞生于数据分析,它诞生于一个非常高的起点。目标是缩短从业务数据到业务决策的时间。它是关于如何使用数据来影响决策。
BI 的优势在于其在交互和报告方面的优势。擅长解读历史数据和实时数据。可以大大解放数据分析师的工作,增强整个公司的数据意识,提高数据导入的效率。市场上有许多BI产品。他们的原理是通过连接和钻孔维度来构建仪表板以获得可视化分析。 查看全部
网页表格抓取(Excel,R,Python和BI,作为开始数据分析的基础)
数据分析时代已经到来。从国家、政府、公司到个人,大数据和数据分析已经成为大家耳熟能详的趋势。但是你可能没有数据分析和编程方面的专业知识,或者你已经了解了很多数据分析的理论,但你仍然无法实践。在这里,我将比较数据分析师最流行的四种工具,Excel、R、Python 和 BI,作为开始数据分析的基础。
1. Excel
1.1使用场景
1.2 优点
1.3 缺点
2. R
2.1使用场景
R 的功能几乎涵盖了任何需要数据的领域。就我们一般的数据分析或学术数据分析而言,R能做的主要有以下几个方面。
2.2 R 好学吗?
在我看来,R 入门非常简单。10天的强化学习,足以掌握基本用法、基本数据结构、数据导入导出、简单数据可视化。有了这些基础,当你遇到实际问题的时候,就可以找到你需要用到的R包了。通过阅读 R 的帮助文件和互联网上的信息,您可以相对较快地解决特定问题。
3. Python
3.1使用场景
3.2 R 和 Python
R 和 Python 都是需要编程的数据分析工具。不同的是R只用在数据分析领域,而科学计算和数据分析只是Python的应用分支。Python还可以用于开发网页、开发游戏、开发系统后端,以及执行一些运维任务。
目前的趋势是Python在数据分析领域正在追赶R。在某些方面,它已经超越了 R,例如机器学习和文本挖掘。但R在统计领域仍然保持优势。Python在数据分析方面的发展在很多地方模拟了R的一些特性。所以,如果你还是新手,还没有开始学习,我建议你从Python开始。
Python 和 R 都很容易学习。但是如果同时研究两者,就会很混乱,因为它们在很多地方都非常相似。所以建议不要同时学习。等到你掌握了其中一个,然后开始学习另一个。
3.3 选择 R 还是 Python?
如果因为时间有限只能选择其中之一学习,我推荐使用Python。但我仍然建议你看看两者。在某些地方,您可能会听说 Python 在工作中更常用,但解决问题是最重要的。如果你能用R有效解决问题,那就用R吧。其实Python模仿了R的很多功能,比如Pandas库中的DataFrames。正在开发的可视化包ggplot模仿了R中非常有名的ggplot2。
双
数据分析中有一句话:文字不如表格,表格不如图表。数据可视化是数据分析的主要方向之一。Excel图表可以满足基本的图形要求,但这只是基础。高级可视化需要编程。除了学习R、Python等编程语言,还可以选择简单易用的BI工具。有关 BI 的介绍,您可以阅读我的另一篇文章,我应该学习哪些数据分析工具才能开始我的数据分析师职业?
商业智能诞生于数据分析,它诞生于一个非常高的起点。目标是缩短从业务数据到业务决策的时间。它是关于如何使用数据来影响决策。
BI 的优势在于其在交互和报告方面的优势。擅长解读历史数据和实时数据。可以大大解放数据分析师的工作,增强整个公司的数据意识,提高数据导入的效率。市场上有许多BI产品。他们的原理是通过连接和钻孔维度来构建仪表板以获得可视化分析。
网页表格抓取(如何采集网页中的表格数据采集助手(网页表格采集器))
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-12-23 18:05
网页表单数据采集助手(Web Form采集器)是一款绿色简单的网页表单数据采集工具。如何在网页中采集表单?网页表单数据采集助手(网页表单采集器)为您快速采集。一些网页上的表格很多,只是复制格式容易出错,麻烦,所以这个软件可以快速帮你采集这些表格,并且保留表格的原创表格,非常方便。
软件说明:
网上资料采集的工作最麻烦的就是从网页上复制数据表很枯燥,复制之后还要做很多修改,不仅麻烦而且浪费时间和工作效率。它非常低。对于少量简单的表格,我们或许可以借助微软EXCEL软件进行导入,但是如果要复制网页上的表格,则必须将其保存为原创文本格式,或者同时保存时间采集某一个网站连续几十页甚至上百页,我觉得你要停止做饭了,现在好了,我们有了这个通用的网页表单数据采集器软件不仅可以采集单页规则和不规则表格,还可以自动连续采集 指定网站的形式,可以指定采集 required 字段的内容,采集之后的内容可以保存为EXCEL软件可以读取的文件格式,或者作为保留原创形式的纯文本形式。绝对简单、方便、快捷、纯绿色。
使用说明:
1、首先在地址栏中输入采集的网页地址。如果采集的网页已经在IE浏览器中打开过,这个地址会自动添加到软件的网址列表中。
2、 然后点击爬虫测试按钮,可以看到网页的源代码和网页收录的表数。网页的源代码显示在软件下方的文本框中。网页中收录的表格和标题信息的数量在软件中。显示在左上角的列表框中。
3、从表数列表中选择要抓取的表。此时,软件窗体左上角的内容输入框中将显示窗体左上角的第一个文本。表单中收录的字段(列)将显示在软件左侧的中间列表中。
4、 然后选择你要采集的表数据的字段(列),如果不选择,都是采集。
5、选择是否要抓取表格的标题行以及保存时是否显示表格行。如果web表单的某个字段中有链接,可以选择是否收录链接地址,如果是并且需要采集其链接地址,则不能同时选择收录标题行时间。
6、 如果你想让采集的表单数据只有一个网页,那么现在可以直接点击抓取表单。如果之前不选择收录表单行,表单数据将保存为 CVS 格式。这种格式可以直接用微软EXCEL软件打开,转换成EXCEL格式。如果选择在前面收录表格行,表格数据将以TXT格式保存。可以用记事本软件打开查看。表线直接可用,也很清晰。
7、如果要采集表数据有多个连续页,并且要采集向下,那么请重新设置程序采集下一页和跟随页面的方式可以是根据链接名称打开下一个页面。几乎大多数页面的链接名称都是“下一页”。您可以查看页面,找到后输入。如果页面没有下一页的链接,但URL收录页码,那么您也可以根据URL中的页数选择打开。可以选择从前到后,比如从第1页到第10页,或者从后到前,比如从第10页到第1页,在页码里输入就行了,但是此时的位置URL中的页码应替换为“(*)”,
8、 然后选择定时采集或者等待网页打开加载采集后立即加载,定时采集是程序根据设定的小时间间隔判断打开如果页面中有你想要的表单,可以采集,页面加载后,采集只要采集的页面已经打开,程序就会马上着手采集,两者各有特点,看需要选择。
9、最后,您只需单击“抓取表单”按钮,即可制作一杯咖啡!
10、如果你已经熟悉了要采集的网页信息,并且想要采集指定表单中的所有字段,也可以输入一些信息需要不经过爬取测试等操作,直接点击爬取表。 查看全部
网页表格抓取(如何采集网页中的表格数据采集助手(网页表格采集器))
网页表单数据采集助手(Web Form采集器)是一款绿色简单的网页表单数据采集工具。如何在网页中采集表单?网页表单数据采集助手(网页表单采集器)为您快速采集。一些网页上的表格很多,只是复制格式容易出错,麻烦,所以这个软件可以快速帮你采集这些表格,并且保留表格的原创表格,非常方便。
软件说明:
网上资料采集的工作最麻烦的就是从网页上复制数据表很枯燥,复制之后还要做很多修改,不仅麻烦而且浪费时间和工作效率。它非常低。对于少量简单的表格,我们或许可以借助微软EXCEL软件进行导入,但是如果要复制网页上的表格,则必须将其保存为原创文本格式,或者同时保存时间采集某一个网站连续几十页甚至上百页,我觉得你要停止做饭了,现在好了,我们有了这个通用的网页表单数据采集器软件不仅可以采集单页规则和不规则表格,还可以自动连续采集 指定网站的形式,可以指定采集 required 字段的内容,采集之后的内容可以保存为EXCEL软件可以读取的文件格式,或者作为保留原创形式的纯文本形式。绝对简单、方便、快捷、纯绿色。
使用说明:
1、首先在地址栏中输入采集的网页地址。如果采集的网页已经在IE浏览器中打开过,这个地址会自动添加到软件的网址列表中。
2、 然后点击爬虫测试按钮,可以看到网页的源代码和网页收录的表数。网页的源代码显示在软件下方的文本框中。网页中收录的表格和标题信息的数量在软件中。显示在左上角的列表框中。
3、从表数列表中选择要抓取的表。此时,软件窗体左上角的内容输入框中将显示窗体左上角的第一个文本。表单中收录的字段(列)将显示在软件左侧的中间列表中。
4、 然后选择你要采集的表数据的字段(列),如果不选择,都是采集。
5、选择是否要抓取表格的标题行以及保存时是否显示表格行。如果web表单的某个字段中有链接,可以选择是否收录链接地址,如果是并且需要采集其链接地址,则不能同时选择收录标题行时间。
6、 如果你想让采集的表单数据只有一个网页,那么现在可以直接点击抓取表单。如果之前不选择收录表单行,表单数据将保存为 CVS 格式。这种格式可以直接用微软EXCEL软件打开,转换成EXCEL格式。如果选择在前面收录表格行,表格数据将以TXT格式保存。可以用记事本软件打开查看。表线直接可用,也很清晰。
7、如果要采集表数据有多个连续页,并且要采集向下,那么请重新设置程序采集下一页和跟随页面的方式可以是根据链接名称打开下一个页面。几乎大多数页面的链接名称都是“下一页”。您可以查看页面,找到后输入。如果页面没有下一页的链接,但URL收录页码,那么您也可以根据URL中的页数选择打开。可以选择从前到后,比如从第1页到第10页,或者从后到前,比如从第10页到第1页,在页码里输入就行了,但是此时的位置URL中的页码应替换为“(*)”,
8、 然后选择定时采集或者等待网页打开加载采集后立即加载,定时采集是程序根据设定的小时间间隔判断打开如果页面中有你想要的表单,可以采集,页面加载后,采集只要采集的页面已经打开,程序就会马上着手采集,两者各有特点,看需要选择。
9、最后,您只需单击“抓取表单”按钮,即可制作一杯咖啡!
10、如果你已经熟悉了要采集的网页信息,并且想要采集指定表单中的所有字段,也可以输入一些信息需要不经过爬取测试等操作,直接点击爬取表。
网页表格抓取(网页表格数据采集器软件可立刻解决你的问题呢? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-12-14 23:06
)
亲,你有很多网页表单数据要复制吗,采集,抓紧吗?您是否正在为如何复制这些数百、数千甚至数万页的表数据而烦恼?是不是觉得键盘打字、鼠标点击、效率低下太累太难了?重复枯燥的工作太让人抓狂了
, 有没有可以立即解决您的问题的软件?当你读到这些话的时候,我想告诉你,你已经看到了曙光,没错,就是这个页面给你介绍的软件——网页表单数据采集器。
web表单数据采集器软件支持在一个网站上连续无限页面批量采集相同表单数据,支持采集@指定表单数据在一个采集 page>,也支持采集一个页面中具有通用数据的多个表数据,采集可以根据网页上的“下一页”等链接的后续页面进行无限采集@ >,也可以根据网址采集中的页数来指定连续页中的表格数据,或者根据您自己指定的网址列表。可以采集,并且可以自动过滤隐藏的干扰码,采集的结果可以显示为文本表格,另存为文本,
下面是我们的软件界面截图,软件下载地址如下
支持单数据链路采集
仅支持采集指定的字段
该软件可以连续或定期采集指定与网站正面和背面相关联的标准二维表,操作非常简单方便。连续批量需要采集的网页文章,请选择本店其他软件-Web文采集Master。
网页表单数据采集器软件现已更新至V2.38版。最新版本下载地址如下,请复制地址用浏览器或其他下载工具下载。
关于本软件的更多信息,请查看软件官网论坛
web表单数据采集软件的使用也很简单。熟悉的话,表单采集 一键搞定。以下是使用该软件的简单步骤:
1、首先在地址栏中输入网页地址为采集。如果要采集的网页已经在IE浏览器中打开了,那么这个地址会自动添加到软件的网址列表中。
2、 然后点击爬取测试按钮,网页中收录的表数和页眉信息会自动显示在软件左上角的列表框中,同时自动识别您可能想要抓取并选择此表。如果网页表单是多页连续的,并且网页中有“下一页”链接,程序会自动在“根据链接或按钮关键字打开下一页”的输入框中输入“下一页”。
3、从表号列表中选择要抓取的表。此时,表格左上角第一个格子或三个格子中的文字会显示在软件的“表格中收录的字段(列)会显示在软件左侧的中间列表中(注意,也可以点击“表格第一行的第一部分”的标签,输入会变成“表格中每一行的部分”来判断表格是否收录某个字符串使用来识别网页中的表单,也可以输入为“所有表单中的序号”,输入表单列表框中显示的表单序号,确定网页中识别表单的标记)。
4、 然后选择你想要采集的表数据的字段(列),如果不选择,设置表采集的所有列。
5、选择是否要抓取表格的标题行以及保存时是否显示表格行。如果web表单的字段中有链接,可以选择是否收录链接地址,如果有并且需要采集它的链接地址,那么就不能选择在页眉行收录同时。
6、 如果想让采集的表单数据只有一个网页,那么可以直接点击抓取表格来抓取。如果之前不选择收录表格行,表格数据将保存为 CVS 格式。这种格式可以直接用微软EXCEL软件打开,转换成EXCEL格式。如果选择在前面收录表格行,表格数据将以TXT格式保存。可以用记事本软件打开查看。表线直接可用,也很清晰。
7、如果想让采集的表单数据有多个连续的页面,并且想要采集向下,那么请重新设置程序采集下一页并跟随页面的方式可以是根据链接名称打开下一页。几乎大多数页面的链接名称都是“下一页”。您可以查看页面,找到后输入。如果页面没有下一页的链接,但URL收录页码,那么您也可以根据URL中的页数选择打开。可以选择从前到后,比如从第1页到第10页,或者从后到前,比如从第10页到第1页,在页码里输入就行了,但是此时的位置URL中的页码应替换为“(*)”,
8、 然后选择定时采集或者等待网页打开加载采集后立即加载,定时采集是程序根据设定的小时间间隔判断打开如果页面中有你想要的表单,可以采集,页面加载后,采集只要采集的页面已经打开,程序就会马上着手采集,两者各有特点,看需要选择。
9、最后,你只需要点击抢表按钮,就可以泡一杯咖啡了!
10、如果你已经熟悉了要采集的网页信息,并且想要采集指定表单中的所有字段,也可以输入需要的信息不经过爬取测试等操作,直接点击爬取表格。
时间,一寸光阴,一寸金。寸金难买寸光阴。我们不能把有限的时间浪费在一些重复而枯燥的工作上。有现成的软件。为什么不使用该软件。再说,现在的30块钱,你在菜市场买不到任何菜。这么便宜的价格,你不能再犹豫了。如果您需要,请尽快开始。
下单时请在备注栏中填写邮箱地址和软件打开后显示的机器码。购买后,我们将向您发送正式版。如果需要,我们还可以为您进行远程演示操作。
如果现有方案不能满足您的需求,我们也可以支持方案定制。如果需要,请先增加费用。
406
客户的评论和不断的好评。尤其是这款软件还可以持续捕捉店铺评论和评论,以及宝贝销售记录。如果您需要采集已售出的婴儿数据,它带有一个已售出的婴儿数据管理器:
感谢您的好评,您的好评是对我不断升级完善本软件的最大支持
另外,购买本软件后,如果想要treeView和ListView数据采集器,也可以向楼主索取
查看全部
网页表格抓取(网页表格数据采集器软件可立刻解决你的问题呢?
)
亲,你有很多网页表单数据要复制吗,采集,抓紧吗?您是否正在为如何复制这些数百、数千甚至数万页的表数据而烦恼?是不是觉得键盘打字、鼠标点击、效率低下太累太难了?重复枯燥的工作太让人抓狂了
, 有没有可以立即解决您的问题的软件?当你读到这些话的时候,我想告诉你,你已经看到了曙光,没错,就是这个页面给你介绍的软件——网页表单数据采集器。
web表单数据采集器软件支持在一个网站上连续无限页面批量采集相同表单数据,支持采集@指定表单数据在一个采集 page>,也支持采集一个页面中具有通用数据的多个表数据,采集可以根据网页上的“下一页”等链接的后续页面进行无限采集@ >,也可以根据网址采集中的页数来指定连续页中的表格数据,或者根据您自己指定的网址列表。可以采集,并且可以自动过滤隐藏的干扰码,采集的结果可以显示为文本表格,另存为文本,
下面是我们的软件界面截图,软件下载地址如下
支持单数据链路采集
仅支持采集指定的字段
该软件可以连续或定期采集指定与网站正面和背面相关联的标准二维表,操作非常简单方便。连续批量需要采集的网页文章,请选择本店其他软件-Web文采集Master。
网页表单数据采集器软件现已更新至V2.38版。最新版本下载地址如下,请复制地址用浏览器或其他下载工具下载。
关于本软件的更多信息,请查看软件官网论坛
web表单数据采集软件的使用也很简单。熟悉的话,表单采集 一键搞定。以下是使用该软件的简单步骤:
1、首先在地址栏中输入网页地址为采集。如果要采集的网页已经在IE浏览器中打开了,那么这个地址会自动添加到软件的网址列表中。
2、 然后点击爬取测试按钮,网页中收录的表数和页眉信息会自动显示在软件左上角的列表框中,同时自动识别您可能想要抓取并选择此表。如果网页表单是多页连续的,并且网页中有“下一页”链接,程序会自动在“根据链接或按钮关键字打开下一页”的输入框中输入“下一页”。
3、从表号列表中选择要抓取的表。此时,表格左上角第一个格子或三个格子中的文字会显示在软件的“表格中收录的字段(列)会显示在软件左侧的中间列表中(注意,也可以点击“表格第一行的第一部分”的标签,输入会变成“表格中每一行的部分”来判断表格是否收录某个字符串使用来识别网页中的表单,也可以输入为“所有表单中的序号”,输入表单列表框中显示的表单序号,确定网页中识别表单的标记)。
4、 然后选择你想要采集的表数据的字段(列),如果不选择,设置表采集的所有列。
5、选择是否要抓取表格的标题行以及保存时是否显示表格行。如果web表单的字段中有链接,可以选择是否收录链接地址,如果有并且需要采集它的链接地址,那么就不能选择在页眉行收录同时。
6、 如果想让采集的表单数据只有一个网页,那么可以直接点击抓取表格来抓取。如果之前不选择收录表格行,表格数据将保存为 CVS 格式。这种格式可以直接用微软EXCEL软件打开,转换成EXCEL格式。如果选择在前面收录表格行,表格数据将以TXT格式保存。可以用记事本软件打开查看。表线直接可用,也很清晰。
7、如果想让采集的表单数据有多个连续的页面,并且想要采集向下,那么请重新设置程序采集下一页并跟随页面的方式可以是根据链接名称打开下一页。几乎大多数页面的链接名称都是“下一页”。您可以查看页面,找到后输入。如果页面没有下一页的链接,但URL收录页码,那么您也可以根据URL中的页数选择打开。可以选择从前到后,比如从第1页到第10页,或者从后到前,比如从第10页到第1页,在页码里输入就行了,但是此时的位置URL中的页码应替换为“(*)”,
8、 然后选择定时采集或者等待网页打开加载采集后立即加载,定时采集是程序根据设定的小时间间隔判断打开如果页面中有你想要的表单,可以采集,页面加载后,采集只要采集的页面已经打开,程序就会马上着手采集,两者各有特点,看需要选择。
9、最后,你只需要点击抢表按钮,就可以泡一杯咖啡了!
10、如果你已经熟悉了要采集的网页信息,并且想要采集指定表单中的所有字段,也可以输入需要的信息不经过爬取测试等操作,直接点击爬取表格。
时间,一寸光阴,一寸金。寸金难买寸光阴。我们不能把有限的时间浪费在一些重复而枯燥的工作上。有现成的软件。为什么不使用该软件。再说,现在的30块钱,你在菜市场买不到任何菜。这么便宜的价格,你不能再犹豫了。如果您需要,请尽快开始。
下单时请在备注栏中填写邮箱地址和软件打开后显示的机器码。购买后,我们将向您发送正式版。如果需要,我们还可以为您进行远程演示操作。
如果现有方案不能满足您的需求,我们也可以支持方案定制。如果需要,请先增加费用。
406
客户的评论和不断的好评。尤其是这款软件还可以持续捕捉店铺评论和评论,以及宝贝销售记录。如果您需要采集已售出的婴儿数据,它带有一个已售出的婴儿数据管理器:
感谢您的好评,您的好评是对我不断升级完善本软件的最大支持
另外,购买本软件后,如果想要treeView和ListView数据采集器,也可以向楼主索取
网页表格抓取(小五书接上文,让你的网页满足条件read_html)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-11 06:03
大家好,我是小吴?
书在上面,我们可以,文末我说对应的read_html()也是神器!
PS:大家也都很好,我点了30个赞,小吴赶紧安排了
最简单的爬虫:用Pandas爬取表数据
有一点不得不承认,使用Pandas爬取表格数据有一定的局限性。
只适合抓取Table数据,那么我们先看看什么样的网页符合条件?
什么样的网页结构?
用浏览器打开网页,F12查看HTML结构,你会发现符合条件的网页结构有一个共同特征。
如果你发现 HTML 结构是下面的 Table 格式,你可以直接使用 Pandas 上手。
...
...
...
...
...
...
...
这看起来不直观。开启北京空气质量网站。
F12,左边是网页质量指标表,其网页结构与Table表格数据网页结构完美匹配。
非常适合使用pandas爬取。
pd.read_html()
Pandas 提供了两个函数:read_html() 和 to_html() 用于读写 html 格式的文件。这两个功能非常有用。可以轻松地将复杂的数据结构(例如 DataFrame)转换为 HTML 表格;另一个不需要复杂的爬虫,几行代码就可以抓取Table表数据,简直就是神器! [1]
具体的pd.read_html()参数可以查看官方文档:
我们把刚才的网页打开看看吧!
import pandas as pd
df = pd.read_html("http://www.air-level.com/air/beijing/", encoding='utf-8',header=0)[0]
这里只添加了几个参数,header就是指定列标题的那一行。使用guide包,只需要两行代码。
df.head()
对比结果,可以看到已经成功获取到表数据。
多表
之前的情况,不知道有没有人注意到
pd.read_html()[0]
对于pd.read_html(),在得到网页结果后,还要加上一个[0]。这是因为网页上可能有多个表格。这时候就需要通过列表的分片tables[x]来指定获取哪个表。
比如刚才的网站,空气质量排名网页明显是由两张表组成的。
此时如果使用pd.read_html()得到右边的表格,只需稍微修改即可。
import pandas as pd
df = pd.read_html("http://www.air-level.com/rank", encoding='utf-8',header=0)[1]
相反,可以看到页面右侧的表格已经成功获取。
以上就是简单的使用pd.read_html()抓取静态网页。但是我们之所以使用Python,其实是为了提高效率。但是如果只有一个网页,用鼠标选择复制不是更容易吗?所以Python操作的最大优势会体现在批量操作上。
批量抓取
给大家演示一下如何使用Pandas批量抓取网络表格数据?
以新浪金融机构持股汇总数据为例:
一共47个页面,47个网页网址通过一个for循环构造,然后通过pd.read_html()循环抓取。
df = pd.DataFrame()
for i in range(1, 48):
url = f'http://vip.stock.finance.sina. ... Fp%3D{i}'
df = pd.concat([df, pd.read_html(url)[0]]) # 爬取+合并DataFrame
几行代码,轻松解决。
共获取47页1738条数据。
通过上面的小案例,相信你可以轻松掌握Pandas对表数据的批量抓取了吗? 查看全部
网页表格抓取(小五书接上文,让你的网页满足条件read_html)
大家好,我是小吴?
书在上面,我们可以,文末我说对应的read_html()也是神器!
PS:大家也都很好,我点了30个赞,小吴赶紧安排了
最简单的爬虫:用Pandas爬取表数据
有一点不得不承认,使用Pandas爬取表格数据有一定的局限性。
只适合抓取Table数据,那么我们先看看什么样的网页符合条件?
什么样的网页结构?
用浏览器打开网页,F12查看HTML结构,你会发现符合条件的网页结构有一个共同特征。
如果你发现 HTML 结构是下面的 Table 格式,你可以直接使用 Pandas 上手。
...
...
...
...
...
...
...
这看起来不直观。开启北京空气质量网站。
F12,左边是网页质量指标表,其网页结构与Table表格数据网页结构完美匹配。
非常适合使用pandas爬取。
pd.read_html()
Pandas 提供了两个函数:read_html() 和 to_html() 用于读写 html 格式的文件。这两个功能非常有用。可以轻松地将复杂的数据结构(例如 DataFrame)转换为 HTML 表格;另一个不需要复杂的爬虫,几行代码就可以抓取Table表数据,简直就是神器! [1]
具体的pd.read_html()参数可以查看官方文档:
我们把刚才的网页打开看看吧!
import pandas as pd
df = pd.read_html("http://www.air-level.com/air/beijing/", encoding='utf-8',header=0)[0]
这里只添加了几个参数,header就是指定列标题的那一行。使用guide包,只需要两行代码。
df.head()
对比结果,可以看到已经成功获取到表数据。
多表
之前的情况,不知道有没有人注意到
pd.read_html()[0]
对于pd.read_html(),在得到网页结果后,还要加上一个[0]。这是因为网页上可能有多个表格。这时候就需要通过列表的分片tables[x]来指定获取哪个表。
比如刚才的网站,空气质量排名网页明显是由两张表组成的。
此时如果使用pd.read_html()得到右边的表格,只需稍微修改即可。
import pandas as pd
df = pd.read_html("http://www.air-level.com/rank", encoding='utf-8',header=0)[1]
相反,可以看到页面右侧的表格已经成功获取。
以上就是简单的使用pd.read_html()抓取静态网页。但是我们之所以使用Python,其实是为了提高效率。但是如果只有一个网页,用鼠标选择复制不是更容易吗?所以Python操作的最大优势会体现在批量操作上。
批量抓取
给大家演示一下如何使用Pandas批量抓取网络表格数据?
以新浪金融机构持股汇总数据为例:
一共47个页面,47个网页网址通过一个for循环构造,然后通过pd.read_html()循环抓取。
df = pd.DataFrame()
for i in range(1, 48):
url = f'http://vip.stock.finance.sina. ... Fp%3D{i}'
df = pd.concat([df, pd.read_html(url)[0]]) # 爬取+合并DataFrame
几行代码,轻松解决。
共获取47页1738条数据。
通过上面的小案例,相信你可以轻松掌握Pandas对表数据的批量抓取了吗?

