
网页表格抓取
网页表格抓取(ZohoCRM的网站表单功能(免费版也帮你轻松搞定) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-11 02:21
)
有时我们浏览某个网站时,会看到网站上有在线提交信息的表格,比如“问题反馈表”、“参与申请表”等,这就是网站表格。对于企业来说,在他们的官方网站上制作这样一个在线表格,让对产品/服务感兴趣的潜在客户自己提交联系方式和其他信息是非常有用的。不用担心表单制作、发布等问题,Zoho CRM的网站表单功能(免费版也有)可以帮您轻松搞定。
1、设计表单
Zoho CRM 带有 WYSIWYG 编辑器,只需拖放表单中的必填字段即可。您还可以根据需要设置某些字段,使用隐藏字段自动填写附加信息等。您还可以请求添加验证码以过滤垃圾邮件。可以毫不夸张地说,设计可以在几分钟内完成。
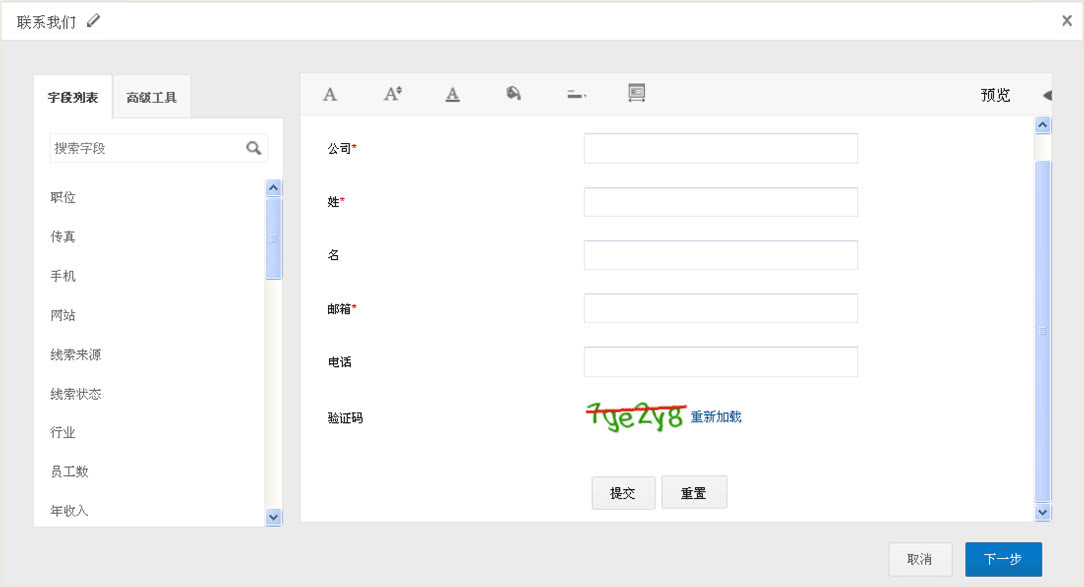
2、将表格发布到您的官网或博客等。
Zoho CRM 将自动为表单生成地址。复制并粘贴表单网站(嵌入在iFrame 源代码中)的代码以将其发布到网站。
3、设置规则并轻松分配潜在客户
如果潜在客户通过网站表单提交信息,我们希望该信息能够自动进入CRM系统,并自动分配到指定人员进行跟进。这可以在 Zoho CRM 中设置:
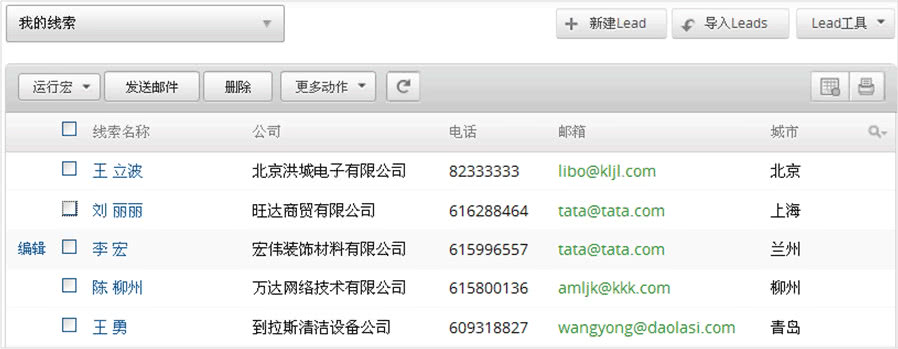
4、 采集客户信息并直接传输到CRM
设置后,在Zoho CRM中可以看到,客户通过表单填写的信息自动进入“线索”模块,CRM系统也根据之前的设置自动分配,并发送通知给销售人员跟进-向上。
查看全部
网页表格抓取(ZohoCRM的网站表单功能(免费版也帮你轻松搞定)
)
有时我们浏览某个网站时,会看到网站上有在线提交信息的表格,比如“问题反馈表”、“参与申请表”等,这就是网站表格。对于企业来说,在他们的官方网站上制作这样一个在线表格,让对产品/服务感兴趣的潜在客户自己提交联系方式和其他信息是非常有用的。不用担心表单制作、发布等问题,Zoho CRM的网站表单功能(免费版也有)可以帮您轻松搞定。

1、设计表单
Zoho CRM 带有 WYSIWYG 编辑器,只需拖放表单中的必填字段即可。您还可以根据需要设置某些字段,使用隐藏字段自动填写附加信息等。您还可以请求添加验证码以过滤垃圾邮件。可以毫不夸张地说,设计可以在几分钟内完成。
2、将表格发布到您的官网或博客等。
Zoho CRM 将自动为表单生成地址。复制并粘贴表单网站(嵌入在iFrame 源代码中)的代码以将其发布到网站。
3、设置规则并轻松分配潜在客户
如果潜在客户通过网站表单提交信息,我们希望该信息能够自动进入CRM系统,并自动分配到指定人员进行跟进。这可以在 Zoho CRM 中设置:

4、 采集客户信息并直接传输到CRM
设置后,在Zoho CRM中可以看到,客户通过表单填写的信息自动进入“线索”模块,CRM系统也根据之前的设置自动分配,并发送通知给销售人员跟进-向上。
网页表格抓取( 一个干净准确的免费在线OCR识别网站:白描网页版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-11-10 08:09
一个干净准确的免费在线OCR识别网站:白描网页版)
高效在线OCR文字识别-线描网页版
很多人都有OCR文字识别的需求,就是从图片中提取出不可编辑的文字,继续后续的处理。使用电脑上的浏览器进行在线OCR文字识别是一种非常方便的方式,无需安装额外的软件。它可以在需要时打开和使用。但是网上的OCR识别网站大多是各种满天飞的广告,识别效果参差不齐。给大家介绍一个干净准确的免费在线OCR识别网站:网页版的线描。
白妙是一款非常知名的手机识别软件。其识别率行业领先。白苗也有网页版。白妙网页版目前收录三个功能:图片文字提取、电子表格识别、扫描PDF转文字。
网页版分为两部分,左边是功能选择区,右边是识别区,可以在电脑上点击按钮选择图片,可以直接将图片拖入识别区,可以直接将图片粘贴到剪贴板中。方便的。
图片文字提取
图片文字提取是OCR文字识别功能,可以快速将图片上的文字转换成可编辑的。和手机白描App一样,可以单独识别,也可以批量识别。最多可同时支持50张图片,可一次性识别。综合所有结果,识别速度和准确率都非常好。
除了直接点击识别功能外,还有简单的图片裁剪功能和按文件名排序功能。
识别结束后,查看识别结果非常方便。左边是原图,右边是识别结果,校对超级方便!您也可以复制或直接导出 DOCX 和 TXT 文件。
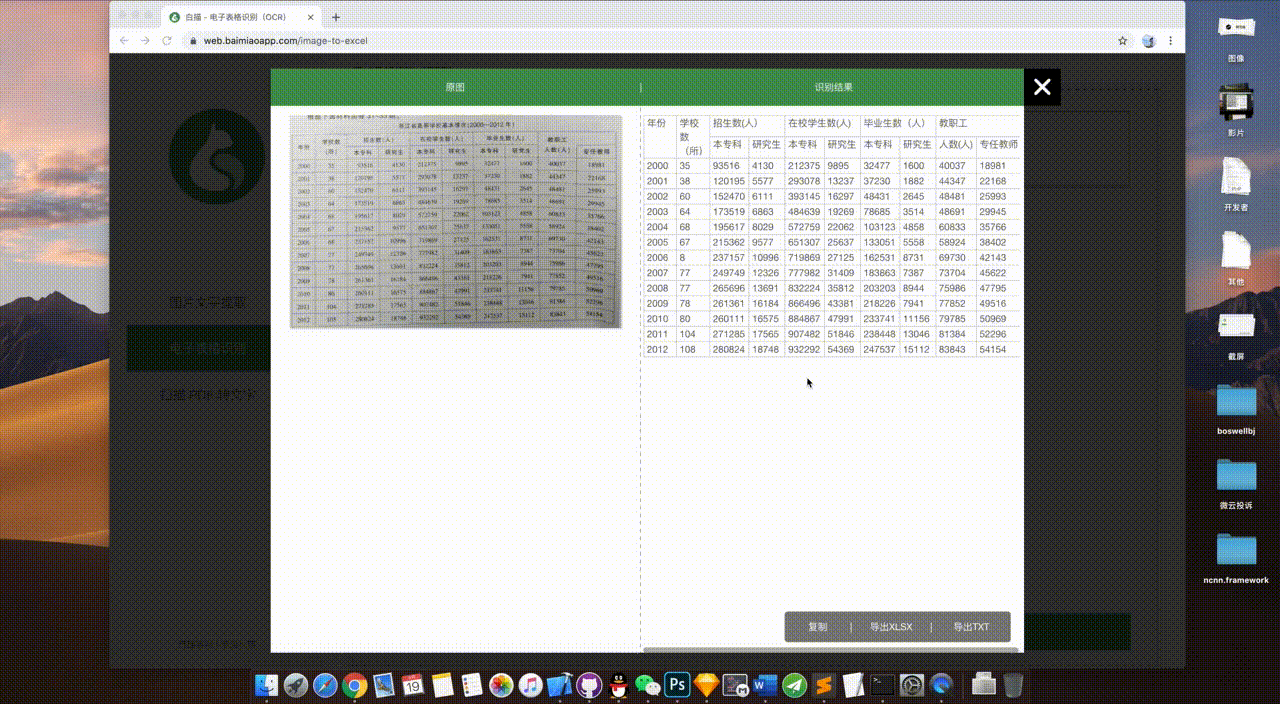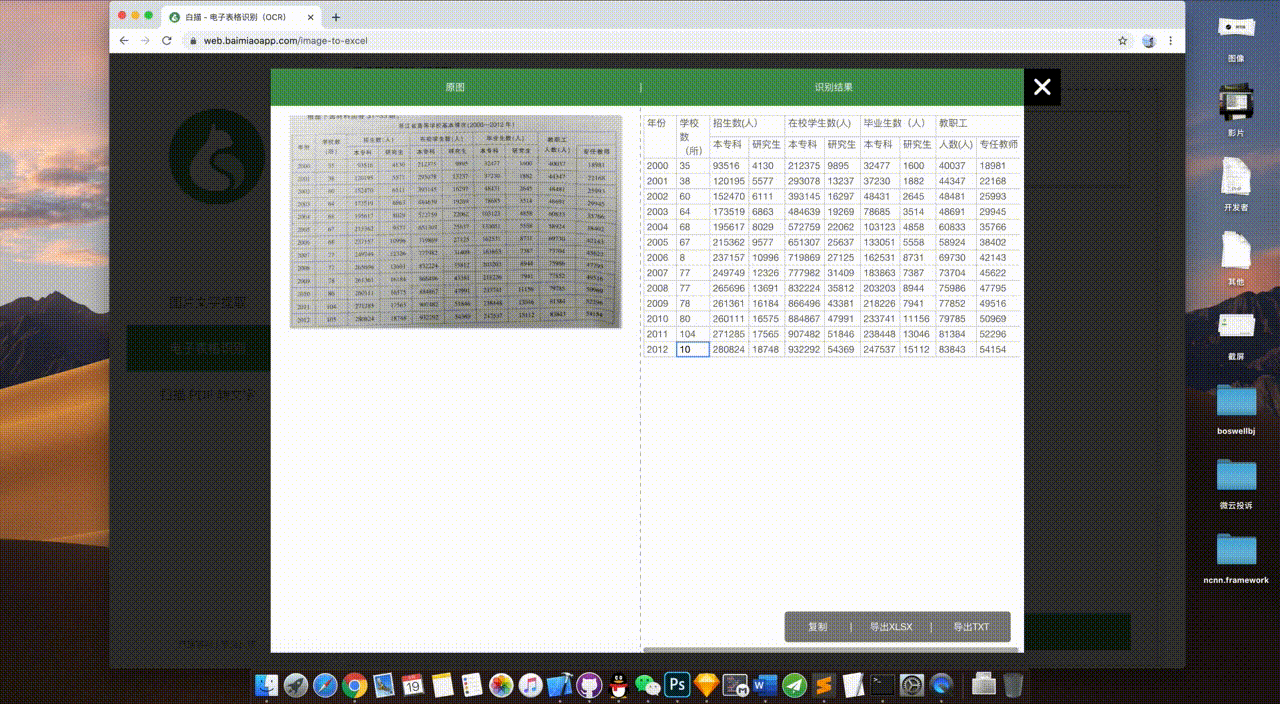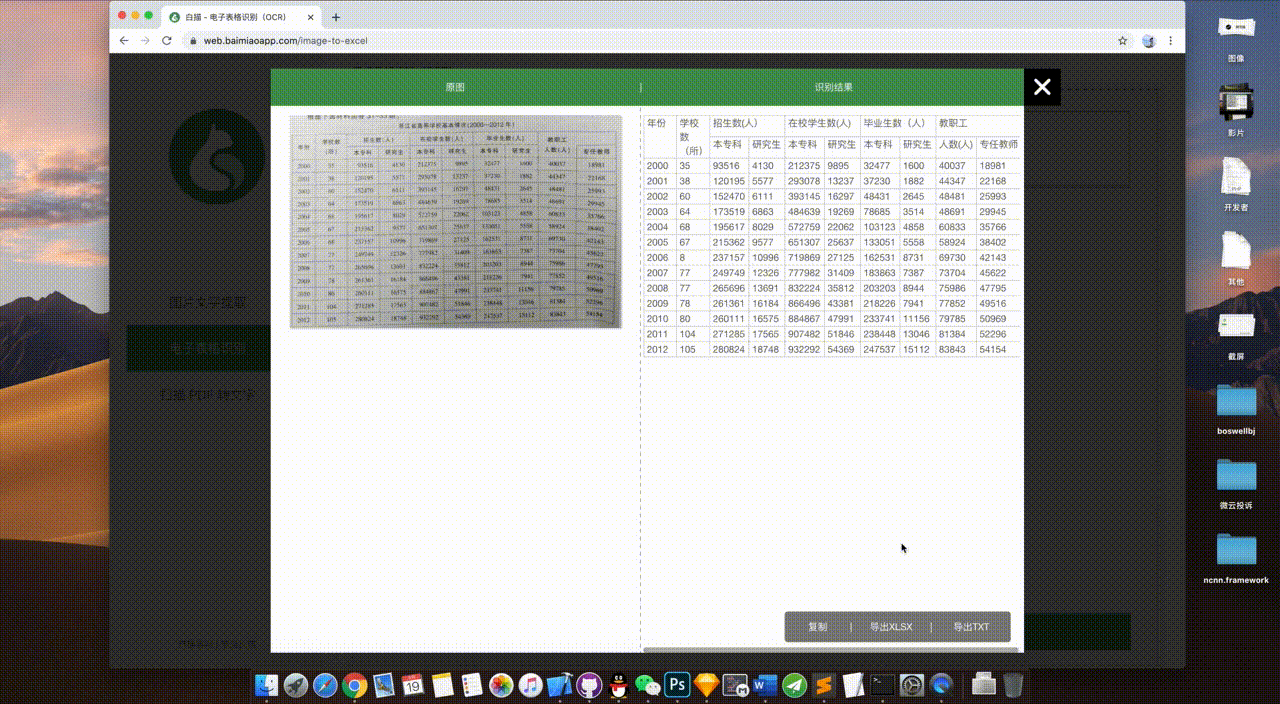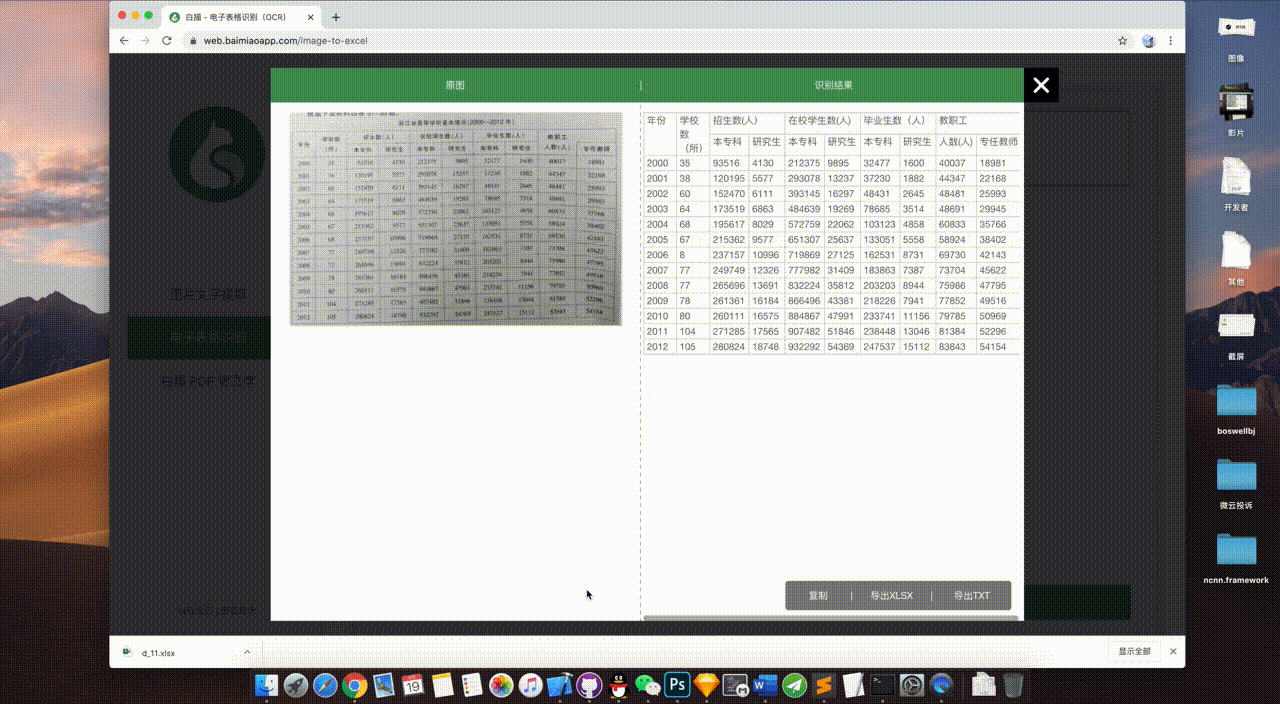
电子表格识别
电子表格识别可以轻松地将图片上的表格转换为Excel格式。
识别后,左边也是原图,右边是识别结果,识别出来的表格可以直接在网页上校对编辑。
将 PDF 扫描为文本
很多PDF文件都是由图片组成的扫描PDF文件。提取其上的所有文本非常麻烦。但是,在白线网页版中,您可以直接上传PDF文件并提取所有文本。可以说是非常大方了。
与其他网络版本相比有哪些优势
很多人也知道网上有很多OCR识别网站,画线网版有什么优势呢?
高效准确
网页版使用与画线App相同的高精度识别引擎,确保识别准确度。同时,国产服务器和大带宽也保证了识别速度,保证了高效与准确并存。
无广告
使用过一些OCR在线识别网站的用户都会知道,很多这样的网站都是各种满天飞的广告,广告面积比实际工作区大几倍。线描网页版的整个页面是一个没有任何广告的工作区。登录画线会员账号,即可享受无任何限制的识别体验。
长图识别
线描网页版支持长图识别,包括很长很长的长图。这也是画线App中长图识别的同样体验。
校对和编辑
很多在线OCR网站识别后直接扔回文件,画线App可以轻松校对和左右编辑,包括文本和表格。
与白庙App账号相同
购买一次个人资料会员后,您可以在iOS,Android和Web(以及未来的PC版本)上享受跨平台体验,这并不漂亮。当然,用的少的话,可以免费使用,每天都可以免费使用。
白线网页版地址: 查看全部
网页表格抓取(
一个干净准确的免费在线OCR识别网站:白描网页版)
高效在线OCR文字识别-线描网页版
很多人都有OCR文字识别的需求,就是从图片中提取出不可编辑的文字,继续后续的处理。使用电脑上的浏览器进行在线OCR文字识别是一种非常方便的方式,无需安装额外的软件。它可以在需要时打开和使用。但是网上的OCR识别网站大多是各种满天飞的广告,识别效果参差不齐。给大家介绍一个干净准确的免费在线OCR识别网站:网页版的线描。
白妙是一款非常知名的手机识别软件。其识别率行业领先。白苗也有网页版。白妙网页版目前收录三个功能:图片文字提取、电子表格识别、扫描PDF转文字。
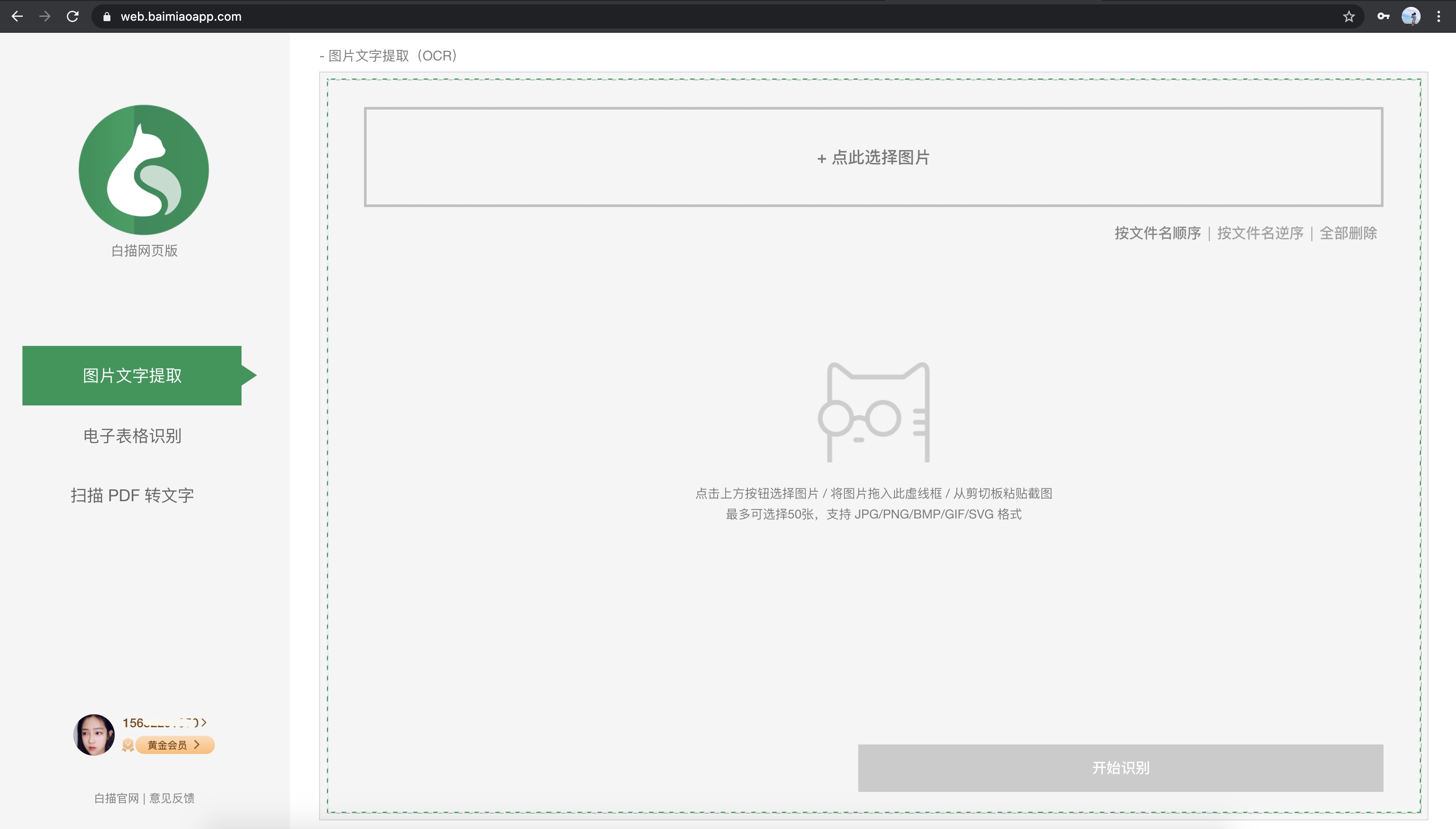
网页版分为两部分,左边是功能选择区,右边是识别区,可以在电脑上点击按钮选择图片,可以直接将图片拖入识别区,可以直接将图片粘贴到剪贴板中。方便的。
图片文字提取
图片文字提取是OCR文字识别功能,可以快速将图片上的文字转换成可编辑的。和手机白描App一样,可以单独识别,也可以批量识别。最多可同时支持50张图片,可一次性识别。综合所有结果,识别速度和准确率都非常好。
除了直接点击识别功能外,还有简单的图片裁剪功能和按文件名排序功能。
识别结束后,查看识别结果非常方便。左边是原图,右边是识别结果,校对超级方便!您也可以复制或直接导出 DOCX 和 TXT 文件。
电子表格识别
电子表格识别可以轻松地将图片上的表格转换为Excel格式。
识别后,左边也是原图,右边是识别结果,识别出来的表格可以直接在网页上校对编辑。
将 PDF 扫描为文本
很多PDF文件都是由图片组成的扫描PDF文件。提取其上的所有文本非常麻烦。但是,在白线网页版中,您可以直接上传PDF文件并提取所有文本。可以说是非常大方了。
与其他网络版本相比有哪些优势
很多人也知道网上有很多OCR识别网站,画线网版有什么优势呢?
高效准确
网页版使用与画线App相同的高精度识别引擎,确保识别准确度。同时,国产服务器和大带宽也保证了识别速度,保证了高效与准确并存。
无广告
使用过一些OCR在线识别网站的用户都会知道,很多这样的网站都是各种满天飞的广告,广告面积比实际工作区大几倍。线描网页版的整个页面是一个没有任何广告的工作区。登录画线会员账号,即可享受无任何限制的识别体验。
长图识别
线描网页版支持长图识别,包括很长很长的长图。这也是画线App中长图识别的同样体验。
校对和编辑
很多在线OCR网站识别后直接扔回文件,画线App可以轻松校对和左右编辑,包括文本和表格。
与白庙App账号相同
购买一次个人资料会员后,您可以在iOS,Android和Web(以及未来的PC版本)上享受跨平台体验,这并不漂亮。当然,用的少的话,可以免费使用,每天都可以免费使用。
白线网页版地址:
网页表格抓取(启动与使用Excalibur运行下面的命令启动:算法前一句命令)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-10 08:08
启动和使用 Excalibur
运行以下命令启动 Excalibur:算法
$ excalibur initdb
$ excalibur webserver
前一个命令是初始化数据库,后一个命令是运行服务器服务。在浏览器中输入::5050 使用平台。
进入PDF表单提取平台,首页如下:数据库
作者测试的PDF收录下表:浏览器
我们将PDF文档上传到上述平台,点击“上传PDF”按钮,然后选择对应的PDF文档和表格所在的页码。PDF上传后,表单所在页面如下图所示:bash
选择右边的Flavor中的“lattice”,用鼠标选择table所在的区域,如下图:
然后点击“查看和下载数据”按钮,获取从PDF解析表中获取的数据。下面的屏幕截图:工具
如果我们还想将这个表的解析结果保存为文件,我们可以在Download旁边的下拉框中选择一种保存格式,然后点击Download按钮。比如作者选择保存为csv文件,下载的文件如下:
"Method","Precision","Recall","F-measure"
"(S1) SP-CCG","67.5","37.2","48.0"
"(S1) SP-CFG","71.1","39.2","50.5"
"(S1) K4","70.3","26.3","38.0"
"(S2) SP-CCG","63.7","41.4","50.2"
"(S2) SP-CFG","65.5","43.8","52.5"
"(S2) K4","67.1","35.0","45.8"
"","Table 5: Extraction Performance on ACE.","",""
我们可以发现表格的分析结果还是很漂亮的。
本次分享到此结束,感谢阅读。
注:本人已开通微信公众号:Python爬虫与算法(微信ID:easy_web_scrape),欢迎关注~~ 查看全部
网页表格抓取(启动与使用Excalibur运行下面的命令启动:算法前一句命令)
启动和使用 Excalibur
运行以下命令启动 Excalibur:算法
$ excalibur initdb
$ excalibur webserver
前一个命令是初始化数据库,后一个命令是运行服务器服务。在浏览器中输入::5050 使用平台。
进入PDF表单提取平台,首页如下:数据库

作者测试的PDF收录下表:浏览器
我们将PDF文档上传到上述平台,点击“上传PDF”按钮,然后选择对应的PDF文档和表格所在的页码。PDF上传后,表单所在页面如下图所示:bash
选择右边的Flavor中的“lattice”,用鼠标选择table所在的区域,如下图:
然后点击“查看和下载数据”按钮,获取从PDF解析表中获取的数据。下面的屏幕截图:工具
如果我们还想将这个表的解析结果保存为文件,我们可以在Download旁边的下拉框中选择一种保存格式,然后点击Download按钮。比如作者选择保存为csv文件,下载的文件如下:
"Method","Precision","Recall","F-measure"
"(S1) SP-CCG","67.5","37.2","48.0"
"(S1) SP-CFG","71.1","39.2","50.5"
"(S1) K4","70.3","26.3","38.0"
"(S2) SP-CCG","63.7","41.4","50.2"
"(S2) SP-CFG","65.5","43.8","52.5"
"(S2) K4","67.1","35.0","45.8"
"","Table 5: Extraction Performance on ACE.","",""
我们可以发现表格的分析结果还是很漂亮的。
本次分享到此结束,感谢阅读。
注:本人已开通微信公众号:Python爬虫与算法(微信ID:easy_web_scrape),欢迎关注~~
网页表格抓取( 还在用收费的工具处理PDF?用Python助力冲破会员牢笼)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-09 23:21
还在用收费的工具处理PDF?用Python助力冲破会员牢笼)
作者:Seon,链接:还在使用付费工具处理 PDF?用Python帮助突破会员牢笼
大家好,我是@无欢不散,资深互联网玩家,Python技术爱好者,喜欢分享硬核技术。
欢迎关注我的专栏:
前言:害的,又要处理PDF文件了。需要的是提取表格,还得请有一定软件会员的同事来操作。没想到会员早就过期了。毕竟不常用,也没有必要给PDF文件充值。以我的码字速度,我可以在输入支付密码之前输入所有内容。但转念一想,PDF自动化的需求还有很多种,比如增删改页面,提取文字图片等等,万一哪天满足了大规模操作的需要,可能就麻烦了。自动化之王(不是)Python 有办法!让我们来看看。
我们先来看看作者遇到的问题。我要处理的是这样一个PDF文件。前几页为正文,文末附有几张表格。其中一张表格跨页分布。如何提取表格?
核心代码只需要两行。打开PDF文件和阅读表格非常方便。
import pdfplumber
pdf = pdfplumber.open("test.pdf")
for i in range(2, 4):
tables = pdf.pages[i].extract_tables()
for t in tables:
print(t)
从输出结果可以看出,它是一种嵌套列表形式,一张表展开后的部分将被识别为另一张表。
[['序列号','标题1','标题2','标题3'], ['1','内容','内容','内容'], ['2','内容', '内容','内容'], ['3','内容','内容','内容']] [['序列号','字段1','字段2','字段3','字段 4 ','字段 5'], ['1','Content','Content','Content','Content','Content'], ['2','Content','Content',' Content' ,'Content','Content'], ['3','Content','Content','Content','Content','Content'], ['4','Content','Content' , '内容','内容','内容'], ['5','content','content','content','content','content']] [['6','content','content','content','content','content'], ['7 ','Content','Content','Content','Content','Content'], ['8','Content','Content','Content','Content','Content'], [ '9','Content','Content','Content','Content','Content'], ['10','Content','Content','Content','Content','Content'] ] [ ['序列号','表头1','表头2','表头3','表头4'], ['1','content','content','content', '内容'], ['2','Content','Content','Content','Content'], ['3','Content','Content','Content','Content'], ['4','Content','content' ,'content','content'], ['5','content','content','content','content']]'Content','Content','Content','Content'], [ '9','Content','Content','Content','Content','Content'], ['10','Content','Content','Content','Content','Content'] ] [['序列号','Header 1','Header 2','Header 3','Header 4'], ['1','Content','Content','Content','Content'] , ['2','内容','内容','内容','内容'], ['3', '内容','内容','内容','内容'], ['4','内容','内容','内容','内容'], ['5','content','content','Content','content']]'Content','Content','Content','Content'], ['9','Content' ,'Content','Content','Content','Content'], ['10','Content','Content','Content','Content','Content']] [['序列号' ,'Header 1','Header 2','Header 3','Header 4'], ['1','Content','Content','Content','Content'], ['2','内容','内容','内容','内容'], ['3', '内容','内容','内容','内容'], ['4','内容','内容','内容','内容'],[' 5','content','content','Content','content']]Content','content','content']] [['序列号','表头1','表头2' ,'table header 3','table header 4'], ['1','content','content','content','content'], ['2','content','content',' content','content'], ['3','content','content', 'Content','Content'], ['4','Content','Content','Content','Content' ], ['5','内容','内容','内容','内容']]内容','内容','内容']] [['序列号','表头1','表头2','表头3','表头4 '], ['1','content','content','content','content'], ['2','content','content','content','content'], ['3 ','content','content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content', '内容','内容','内容']]内容'], ['5','内容','内容','内容','内容']]内容'],['5','内容','内容','内容','内容']]Content','Content']]Content','content','content']] [['序列号','表头1','表头2','表头3','表头4' ], ['1','content','content','content','content'], ['2','content','content','content','content'], ['3' ,'content','content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content',' Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content' ,'内容','内容','内容']]Content','Content']]Content','content','content']] [['序列号','表头1','表头2','表头3','表头4' ], ['1','content','content','content','content'], ['2','content','content','content','content'], ['3' ,'content','content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content',' Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content' ,'内容','内容','内容']],'内容']]内容','内容','内容']] [['序列号','表头1','表头2','表头3','表头4'], ['1','content','content','content','content'],['2','content','content','content','content'],['3',' content','content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content','Content' ,'Content','Content ']]Content'], ['5','content','content','content','content']]Content'], ['5','content','内容','内容','内容']],'内容']]内容','内容','内容']] [['序列号','表头1','表头2','表头3','表头4'], ['1','content','content','content','content'],['2','content','content','content','content'],['3',' content','content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content','Content' ,'Content','Content ']]Content'], ['5','content','content','content','content']]Content'], ['5','content','内容','内容','内容']]]]内容','内容','内容']] [['序列号','表头1','表头2','表头3','表头4'],['1' ,'content','content','content','content'], ['2','content','content','content','content'], ['3','content',' content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content','Content','Content' ,'Content ']]Content'], ['5','content','content','content','content']]Content'], ['5','content','content','内容','内容']]]]内容','内容','内容']] [['序列号','表头1','表头2','表头3','表头4'],['1' ,'content','content','content','content'], ['2','content','content','content','content'], ['3','content',' content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content','Content','Content' ,'Content ']]Content'], ['5','content','content','content','content']]Content'], ['5','content','content','内容','内容']]content']] [['序列号','表头1','表头2','表头3','表头4'],['1','内容','内容',' content','content'], ['2','content','content','content','content'], ['3','content','content', 'Content','Content' ], ['4','Content','Content','Content','Content'], ['5','Content','Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content','content','content','content']]content']] [['序列号','表头1','表头2','表头3','表头4'],['1','内容','内容',' content','content'], ['2','content','content','content','content'], ['3','content','content', 'Content','Content' ], ['4','Content','Content','Content','Content'], ['5','Content','Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content','content','content','content']]表头 2','表头 3','表头 4'], ['1','content','content','content','content'], ['2','content',' content','content','content'], ['3','content','content', 'Content','Content'], ['4','Content','Content','Content' ,'Content'], ['5','Content','Content','Content','Content ']]Content'], ['5','content','content','content',' content']]Content'], ['5','content','content','content','content']]表头 2','表头 3','表头 4'], ['1','content','content','content','content'], ['2','content',' content','content','content'], ['3','content','content', 'Content','Content'], ['4','Content','Content','Content' ,'Content'], ['5','Content','Content','Content','Content ']]Content'], ['5','content','content','content',' content']]Content'], ['5','content','content','content','content']]['2','content','content','content','content'],['3','content','content','Content','Content'],['4','内容','内容','内容','内容'], ['5','内容','内容','内容','内容']]内容'],['5','内容' ,'content','content','content']]Content'], ['5','content','content','content','content']]['2','content','content','content','content'],['3','content','content','Content','Content'],['4','内容','内容','内容','内容'], ['5','内容','内容','内容','内容']]内容'],['5','内容' ,'content','content','content']]Content'], ['5','content','content','content','content']]Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content' ,'内容','内容','内容']]Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content' ,'内容','内容','内容']]
那就用legend可以让EXCEL飞起来的xlwings库来写数据吧!对代码稍作修改,详情见注释。
import pdfplumber
import xlwings as xw
wb = xw.books.active # 连接到活动的工作簿
sht = wb.sheets['Sheet1'] # 连接子表1
n = 1
pdf = pdfplumber.open("test.pdf") # 打开PDF
for i in range(2, 4):
tables = pdf.pages[i].extract_tables() # 获取第3、4页的表格
for t in tables:
for row in t:
if '序号' in row and n>1:
n += 1 # 不同表格之间隔一行
sht.range(f'A{n}').value = row # 将表格的一行从A1单元格开始写入
n += 1 # 换行
果然,这种肉眼可见的效果,比其他保存表格前在内存中执行的EXCEL处理库更让人享受。您还可以使用 xlwings 为每个表格添加边框、粗体标题等。我不会在这里详细介绍。有兴趣的同学可以自行探索。本文的主角是PDF处理库。
pdfplumber 是一款基于pdfminer.six 的PDF 内容提取工具。和之前的体验一样,操作很简单。遗憾的是,它专门用于识别,不能直接修改和保存PDF。如果有比较复杂的需求,可以学习pdfminer,但是需要了解PDF文件模型,学习难度大。
官网:/jsvine/pdfplumber
PyPDF2也是著名的PDF页面级处理工具。它更擅长分割、合并、裁剪和转换页面,但缺乏提取内容的能力。
官网:/PyPDF2
让我们从常见的 PDF 操作中了解这两个!
1、插入/添加页面
让我们准备另一个 PDF 文件用于插入实验。
PyPDF2 使用阅读器来操作 PDF 文件。如果想在第一页之后插入一个页面,需要通过Reader对象的getPage方法获取该页面,然后通过Writer对象的addPage方法添加该页面,最后写入文件流。
from PyPDF2 import PdfFileWriter, PdfFileReader
output = PdfFileWriter()
input = PdfFileReader(open("test.pdf", "rb"))
insert = PdfFileReader(open("insert.pdf", "rb"))
for i in range(0, 4):
output.addPage(input.getPage(i))
if i ==0:
output.addPage(insert.getPage(0))
output.write(open("output.pdf", "wb"))
2、选择/删除页面
通过插入页面,相信大家已经可以想到一种选择/删除页面的方法,即选择需要的页面索引来添加页面。例如,在上一步中只为 output.pdf 保留了第 1 页和第 3 页。
from PyPDF2 import PdfFileWriter, PdfFileReader
new_output = PdfFileWriter()
input = PdfFileReader(open("output.pdf", "rb"))
for i in range(0, 4):
if i==0 or i==2:
new_output.addPage(input.getPage(i))
new_output.write(open("new_output.pdf", "wb"))
3、提取文本信息
不得不说pdfplumber非常精炼,用非常直观的句子就可以实现。可以通过页面对象的extract_text 方法提取文本。需要注意的是pdfplumber只能提取原生内容。如果是图片,则需要使用OCR工具。
import pdfplumber
pdf = pdfplumber.open("test.pdf")
pages = pdf.pages
for p in pages:
print(p.extract_text())
1 1 1 2 2 2 3 3 3 表1 序号标题1 标题2 标题3 1 内容内容内容2 内容内容内容3 内容内容内容表二......4、提取表单信息
之前我使用extract_tables()批量提取表。我们也可以通过extract_table()来提取指定页面上的表,然后加载到DataFrame中进行后续的分析操作。
import pdfplumber
import pandas as pd
pdf = pdfplumber.open("test.pdf")
table = pdf.pages[2].extract_table()
df = pd.DataFrame(table[1:], columns=table[0])
print(df)
但事实证明它提取了页面的第二个表。不是默认提取页面中的第一个表吗?
查阅官方资料得知extract_table()返回的是页面最大的表。如果多个表格具有相同的大小(以单元格数衡量),则返回最靠近页面顶部的表格。
5、提取图片信息
接下来,我们将为提取实验准备一个带有图片的PDF文件。
根据官方提示,如果要进行可视化操作,需要安装两个依赖工具。(另外作者发现还有其他库可以提取PDF的图像元素或者将PDF页面转换成图像,比如PyMuPDF、pdf2image等,可以扩展学习)
安装地址如下,注意选择python对应的版本。
/script/download.php#windows /download/gsdnld.html
图片参数列表可以通过页面对象的images属性获取。这里我们只有一张图片,获取其图片流数据写入文件,成功提取图片。
import pdfplumber
pdf_pic = pdfplumber.open("picture.pdf")
page = pdf_pic.pages[0]
img = page.images
data = img[0]['stream'].get_data()
with open('pic.png', 'wb') as f:
f.write(data)
同时,我们也可以验证提取图片中的文字和表格,发现是不可行的。
print(page.extract_text())
print(page.extract_table())
我是文字无6、 页面转图片
除了提取页面中的图片元素外,还可以将整个页面转换成图片输出。让我们换回原创 PDF 进行实验。page对象有to_image方法,比单个元素的操作简单。
import pdfplumber
pdf = pdfplumber.open("test.pdf")
pages = pdf.pages
for i, p in enumerate(pages):
p.to_image().save(f"第{i+1}页.png", format="PNG")
之后,我们还可以将多张图片连接到增长图表,适合移动查看。
from os import listdir
from PIL import Image
imgs = [Image.open(f) for f in listdir('.') if f.endswith('.png')] # 获取当前目录下的图像
width, height = imgs[0].size # 单幅图像尺寸
result = Image.new(imgs[0].mode, (width, height * len(imgs))) # 创建空白长图
for i, im in enumerate(imgs): # 拼接图片
result.paste(im, box=(0, i * height))
result.save('长条图.png')
本文通过一个实战案例和6个小操作演示了两个PDF库的基本功能,还有很多隐藏属性等着我们去探索,比如加水印、加解密等,还不快来自己开发一个PDF工具来收费?致富指日可待!
本文版权归原作者所有。如果您对内容的版权有任何疑问,请与我联系。本文仅供交流学习之用。
我的热门文章,也许你会感兴趣:
学好Python,这篇文章就够了(入门|基础|进阶|实战)-知乎()
神器pypandoc-实现电子书的自由-知乎()
半夜用Python爬取严选的文胸数据,发现一个惊天秘密-知乎()
为了打击不公,我用Python爬取了选中的男性内衣数据,结果...-知乎 ()
我的热门回答,也许你可以看看:
你用 Python 写过哪些有趣的脚本?-知乎 ()
哪些 Python 库让你们迟到了彼此讨厌?-知乎 ()
你们都用python做什么(全职程序员除外)?-知乎 ()
Python 新手如何快速入门?-知乎 () 查看全部
网页表格抓取(
还在用收费的工具处理PDF?用Python助力冲破会员牢笼)

作者:Seon,链接:还在使用付费工具处理 PDF?用Python帮助突破会员牢笼
大家好,我是@无欢不散,资深互联网玩家,Python技术爱好者,喜欢分享硬核技术。
欢迎关注我的专栏:
前言:害的,又要处理PDF文件了。需要的是提取表格,还得请有一定软件会员的同事来操作。没想到会员早就过期了。毕竟不常用,也没有必要给PDF文件充值。以我的码字速度,我可以在输入支付密码之前输入所有内容。但转念一想,PDF自动化的需求还有很多种,比如增删改页面,提取文字图片等等,万一哪天满足了大规模操作的需要,可能就麻烦了。自动化之王(不是)Python 有办法!让我们来看看。

我们先来看看作者遇到的问题。我要处理的是这样一个PDF文件。前几页为正文,文末附有几张表格。其中一张表格跨页分布。如何提取表格?
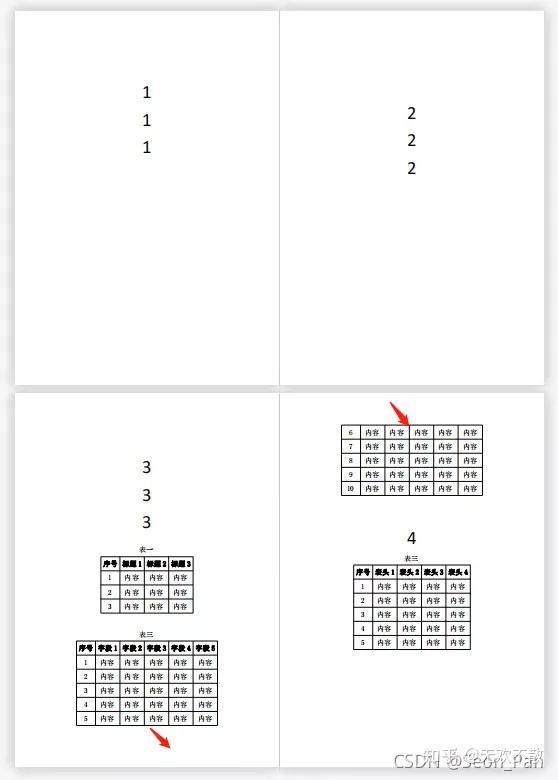
核心代码只需要两行。打开PDF文件和阅读表格非常方便。
import pdfplumber
pdf = pdfplumber.open("test.pdf")
for i in range(2, 4):
tables = pdf.pages[i].extract_tables()
for t in tables:
print(t)
从输出结果可以看出,它是一种嵌套列表形式,一张表展开后的部分将被识别为另一张表。
[['序列号','标题1','标题2','标题3'], ['1','内容','内容','内容'], ['2','内容', '内容','内容'], ['3','内容','内容','内容']] [['序列号','字段1','字段2','字段3','字段 4 ','字段 5'], ['1','Content','Content','Content','Content','Content'], ['2','Content','Content',' Content' ,'Content','Content'], ['3','Content','Content','Content','Content','Content'], ['4','Content','Content' , '内容','内容','内容'], ['5','content','content','content','content','content']] [['6','content','content','content','content','content'], ['7 ','Content','Content','Content','Content','Content'], ['8','Content','Content','Content','Content','Content'], [ '9','Content','Content','Content','Content','Content'], ['10','Content','Content','Content','Content','Content'] ] [ ['序列号','表头1','表头2','表头3','表头4'], ['1','content','content','content', '内容'], ['2','Content','Content','Content','Content'], ['3','Content','Content','Content','Content'], ['4','Content','content' ,'content','content'], ['5','content','content','content','content']]'Content','Content','Content','Content'], [ '9','Content','Content','Content','Content','Content'], ['10','Content','Content','Content','Content','Content'] ] [['序列号','Header 1','Header 2','Header 3','Header 4'], ['1','Content','Content','Content','Content'] , ['2','内容','内容','内容','内容'], ['3', '内容','内容','内容','内容'], ['4','内容','内容','内容','内容'], ['5','content','content','Content','content']]'Content','Content','Content','Content'], ['9','Content' ,'Content','Content','Content','Content'], ['10','Content','Content','Content','Content','Content']] [['序列号' ,'Header 1','Header 2','Header 3','Header 4'], ['1','Content','Content','Content','Content'], ['2','内容','内容','内容','内容'], ['3', '内容','内容','内容','内容'], ['4','内容','内容','内容','内容'],[' 5','content','content','Content','content']]Content','content','content']] [['序列号','表头1','表头2' ,'table header 3','table header 4'], ['1','content','content','content','content'], ['2','content','content',' content','content'], ['3','content','content', 'Content','Content'], ['4','Content','Content','Content','Content' ], ['5','内容','内容','内容','内容']]内容','内容','内容']] [['序列号','表头1','表头2','表头3','表头4 '], ['1','content','content','content','content'], ['2','content','content','content','content'], ['3 ','content','content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content', '内容','内容','内容']]内容'], ['5','内容','内容','内容','内容']]内容'],['5','内容','内容','内容','内容']]Content','Content']]Content','content','content']] [['序列号','表头1','表头2','表头3','表头4' ], ['1','content','content','content','content'], ['2','content','content','content','content'], ['3' ,'content','content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content',' Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content' ,'内容','内容','内容']]Content','Content']]Content','content','content']] [['序列号','表头1','表头2','表头3','表头4' ], ['1','content','content','content','content'], ['2','content','content','content','content'], ['3' ,'content','content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content',' Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content' ,'内容','内容','内容']],'内容']]内容','内容','内容']] [['序列号','表头1','表头2','表头3','表头4'], ['1','content','content','content','content'],['2','content','content','content','content'],['3',' content','content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content','Content' ,'Content','Content ']]Content'], ['5','content','content','content','content']]Content'], ['5','content','内容','内容','内容']],'内容']]内容','内容','内容']] [['序列号','表头1','表头2','表头3','表头4'], ['1','content','content','content','content'],['2','content','content','content','content'],['3',' content','content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content','Content' ,'Content','Content ']]Content'], ['5','content','content','content','content']]Content'], ['5','content','内容','内容','内容']]]]内容','内容','内容']] [['序列号','表头1','表头2','表头3','表头4'],['1' ,'content','content','content','content'], ['2','content','content','content','content'], ['3','content',' content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content','Content','Content' ,'Content ']]Content'], ['5','content','content','content','content']]Content'], ['5','content','content','内容','内容']]]]内容','内容','内容']] [['序列号','表头1','表头2','表头3','表头4'],['1' ,'content','content','content','content'], ['2','content','content','content','content'], ['3','content',' content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content','Content','Content' ,'Content ']]Content'], ['5','content','content','content','content']]Content'], ['5','content','content','内容','内容']]content']] [['序列号','表头1','表头2','表头3','表头4'],['1','内容','内容',' content','content'], ['2','content','content','content','content'], ['3','content','content', 'Content','Content' ], ['4','Content','Content','Content','Content'], ['5','Content','Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content','content','content','content']]content']] [['序列号','表头1','表头2','表头3','表头4'],['1','内容','内容',' content','content'], ['2','content','content','content','content'], ['3','content','content', 'Content','Content' ], ['4','Content','Content','Content','Content'], ['5','Content','Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content','content','content','content']]表头 2','表头 3','表头 4'], ['1','content','content','content','content'], ['2','content',' content','content','content'], ['3','content','content', 'Content','Content'], ['4','Content','Content','Content' ,'Content'], ['5','Content','Content','Content','Content ']]Content'], ['5','content','content','content',' content']]Content'], ['5','content','content','content','content']]表头 2','表头 3','表头 4'], ['1','content','content','content','content'], ['2','content',' content','content','content'], ['3','content','content', 'Content','Content'], ['4','Content','Content','Content' ,'Content'], ['5','Content','Content','Content','Content ']]Content'], ['5','content','content','content',' content']]Content'], ['5','content','content','content','content']]['2','content','content','content','content'],['3','content','content','Content','Content'],['4','内容','内容','内容','内容'], ['5','内容','内容','内容','内容']]内容'],['5','内容' ,'content','content','content']]Content'], ['5','content','content','content','content']]['2','content','content','content','content'],['3','content','content','Content','Content'],['4','内容','内容','内容','内容'], ['5','内容','内容','内容','内容']]内容'],['5','内容' ,'content','content','content']]Content'], ['5','content','content','content','content']]Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content' ,'内容','内容','内容']]Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content' ,'内容','内容','内容']]
那就用legend可以让EXCEL飞起来的xlwings库来写数据吧!对代码稍作修改,详情见注释。
import pdfplumber
import xlwings as xw
wb = xw.books.active # 连接到活动的工作簿
sht = wb.sheets['Sheet1'] # 连接子表1
n = 1
pdf = pdfplumber.open("test.pdf") # 打开PDF
for i in range(2, 4):
tables = pdf.pages[i].extract_tables() # 获取第3、4页的表格
for t in tables:
for row in t:
if '序号' in row and n>1:
n += 1 # 不同表格之间隔一行
sht.range(f'A{n}').value = row # 将表格的一行从A1单元格开始写入
n += 1 # 换行
果然,这种肉眼可见的效果,比其他保存表格前在内存中执行的EXCEL处理库更让人享受。您还可以使用 xlwings 为每个表格添加边框、粗体标题等。我不会在这里详细介绍。有兴趣的同学可以自行探索。本文的主角是PDF处理库。


pdfplumber 是一款基于pdfminer.six 的PDF 内容提取工具。和之前的体验一样,操作很简单。遗憾的是,它专门用于识别,不能直接修改和保存PDF。如果有比较复杂的需求,可以学习pdfminer,但是需要了解PDF文件模型,学习难度大。
官网:/jsvine/pdfplumber
PyPDF2也是著名的PDF页面级处理工具。它更擅长分割、合并、裁剪和转换页面,但缺乏提取内容的能力。
官网:/PyPDF2
让我们从常见的 PDF 操作中了解这两个!
1、插入/添加页面
让我们准备另一个 PDF 文件用于插入实验。

PyPDF2 使用阅读器来操作 PDF 文件。如果想在第一页之后插入一个页面,需要通过Reader对象的getPage方法获取该页面,然后通过Writer对象的addPage方法添加该页面,最后写入文件流。
from PyPDF2 import PdfFileWriter, PdfFileReader
output = PdfFileWriter()
input = PdfFileReader(open("test.pdf", "rb"))
insert = PdfFileReader(open("insert.pdf", "rb"))
for i in range(0, 4):
output.addPage(input.getPage(i))
if i ==0:
output.addPage(insert.getPage(0))
output.write(open("output.pdf", "wb"))
2、选择/删除页面
通过插入页面,相信大家已经可以想到一种选择/删除页面的方法,即选择需要的页面索引来添加页面。例如,在上一步中只为 output.pdf 保留了第 1 页和第 3 页。
from PyPDF2 import PdfFileWriter, PdfFileReader
new_output = PdfFileWriter()
input = PdfFileReader(open("output.pdf", "rb"))
for i in range(0, 4):
if i==0 or i==2:
new_output.addPage(input.getPage(i))
new_output.write(open("new_output.pdf", "wb"))

3、提取文本信息
不得不说pdfplumber非常精炼,用非常直观的句子就可以实现。可以通过页面对象的extract_text 方法提取文本。需要注意的是pdfplumber只能提取原生内容。如果是图片,则需要使用OCR工具。
import pdfplumber
pdf = pdfplumber.open("test.pdf")
pages = pdf.pages
for p in pages:
print(p.extract_text())
1 1 1 2 2 2 3 3 3 表1 序号标题1 标题2 标题3 1 内容内容内容2 内容内容内容3 内容内容内容表二......4、提取表单信息
之前我使用extract_tables()批量提取表。我们也可以通过extract_table()来提取指定页面上的表,然后加载到DataFrame中进行后续的分析操作。
import pdfplumber
import pandas as pd
pdf = pdfplumber.open("test.pdf")
table = pdf.pages[2].extract_table()
df = pd.DataFrame(table[1:], columns=table[0])
print(df)

但事实证明它提取了页面的第二个表。不是默认提取页面中的第一个表吗?
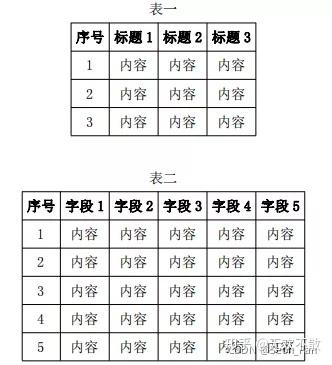
查阅官方资料得知extract_table()返回的是页面最大的表。如果多个表格具有相同的大小(以单元格数衡量),则返回最靠近页面顶部的表格。

5、提取图片信息
接下来,我们将为提取实验准备一个带有图片的PDF文件。

根据官方提示,如果要进行可视化操作,需要安装两个依赖工具。(另外作者发现还有其他库可以提取PDF的图像元素或者将PDF页面转换成图像,比如PyMuPDF、pdf2image等,可以扩展学习)

安装地址如下,注意选择python对应的版本。
/script/download.php#windows /download/gsdnld.html
图片参数列表可以通过页面对象的images属性获取。这里我们只有一张图片,获取其图片流数据写入文件,成功提取图片。
import pdfplumber
pdf_pic = pdfplumber.open("picture.pdf")
page = pdf_pic.pages[0]
img = page.images
data = img[0]['stream'].get_data()
with open('pic.png', 'wb') as f:
f.write(data)

同时,我们也可以验证提取图片中的文字和表格,发现是不可行的。
print(page.extract_text())
print(page.extract_table())
我是文字无6、 页面转图片
除了提取页面中的图片元素外,还可以将整个页面转换成图片输出。让我们换回原创 PDF 进行实验。page对象有to_image方法,比单个元素的操作简单。
import pdfplumber
pdf = pdfplumber.open("test.pdf")
pages = pdf.pages
for i, p in enumerate(pages):
p.to_image().save(f"第{i+1}页.png", format="PNG")

之后,我们还可以将多张图片连接到增长图表,适合移动查看。
from os import listdir
from PIL import Image
imgs = [Image.open(f) for f in listdir('.') if f.endswith('.png')] # 获取当前目录下的图像
width, height = imgs[0].size # 单幅图像尺寸
result = Image.new(imgs[0].mode, (width, height * len(imgs))) # 创建空白长图
for i, im in enumerate(imgs): # 拼接图片
result.paste(im, box=(0, i * height))
result.save('长条图.png')


本文通过一个实战案例和6个小操作演示了两个PDF库的基本功能,还有很多隐藏属性等着我们去探索,比如加水印、加解密等,还不快来自己开发一个PDF工具来收费?致富指日可待!
本文版权归原作者所有。如果您对内容的版权有任何疑问,请与我联系。本文仅供交流学习之用。
我的热门文章,也许你会感兴趣:
学好Python,这篇文章就够了(入门|基础|进阶|实战)-知乎()
神器pypandoc-实现电子书的自由-知乎()
半夜用Python爬取严选的文胸数据,发现一个惊天秘密-知乎()
为了打击不公,我用Python爬取了选中的男性内衣数据,结果...-知乎 ()
我的热门回答,也许你可以看看:
你用 Python 写过哪些有趣的脚本?-知乎 ()
哪些 Python 库让你们迟到了彼此讨厌?-知乎 ()
你们都用python做什么(全职程序员除外)?-知乎 ()
Python 新手如何快速入门?-知乎 ()
网页表格抓取(2017年成都会计从业资格考试:谈及pandasread_html)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-09 12:13
过去的一切都是序幕。
真正的放手不是试图强迫它,而不仅仅是不作为。
文章内容
一、简介
一般爬虫例程无非就是发送请求、获取响应、解析网页、提取数据、保存数据等步骤。 requests库主要用于构造请求,xpath和正则匹配多用于定位和提取数据。对于一个完整的爬虫来说,代码量可以从几十行到几百行不等。对于新手来说,学习成本相对较高。
说到pandas read.xxx系列的功能,常用的读取数据的方法有:pd.read_csv()和pd.read_excel(),而pd.read_html()方法很少使用,但是它的功能很强大,尤其是用来抓取Table数据的时候,简直是神器。无需掌握正则表达式或xpath等工具,只需几行代码即可快速抓取网页数据并保存到本地。
二、原理
Pandas 适用于爬取 Table 数据。首先,让我们了解一下具有 Table 数据结构的网页。示例如下:
使用Chrome浏览器查看网页的HTML结构,你会发现Table数据有一些共同点。一般网页结构如下所示。
...
...
...
...
...
...
...
...
...
网页结构如上,我们可以尝试使用pandas的pd.read_html()方法直接获取数据。
pd.read_html()的一些主要参数
三、爬行实战示例1
爬取成都2019年空气质量数据(12页数据),目标网址:
import pandas as pd
dates = pd.date_range('20190101', '20191201', freq='MS').strftime('%Y%m') # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f'http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html', encoding='gbk', header=0)[0]
if i == 0:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False) # 追加写入
i += 1
else:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False, header=False)
九行代码就搞定了,爬虫速度很快。
查看保存的数据
示例 2
抓取新浪金融基金重磅股数据(25页数据),网址:
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml?p={i}'
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv('新浪财经基金重仓股数据.csv', encoding='utf-8', index=False)
六行代码就搞定了,爬取速度非常快。
查看保存的数据:
后面爬取一些小数据的时候,只要遇到这种表数据,可以先试试pd.read_html()大法。 查看全部
网页表格抓取(2017年成都会计从业资格考试:谈及pandasread_html)
过去的一切都是序幕。
真正的放手不是试图强迫它,而不仅仅是不作为。
文章内容
一、简介
一般爬虫例程无非就是发送请求、获取响应、解析网页、提取数据、保存数据等步骤。 requests库主要用于构造请求,xpath和正则匹配多用于定位和提取数据。对于一个完整的爬虫来说,代码量可以从几十行到几百行不等。对于新手来说,学习成本相对较高。
说到pandas read.xxx系列的功能,常用的读取数据的方法有:pd.read_csv()和pd.read_excel(),而pd.read_html()方法很少使用,但是它的功能很强大,尤其是用来抓取Table数据的时候,简直是神器。无需掌握正则表达式或xpath等工具,只需几行代码即可快速抓取网页数据并保存到本地。
二、原理
Pandas 适用于爬取 Table 数据。首先,让我们了解一下具有 Table 数据结构的网页。示例如下:


使用Chrome浏览器查看网页的HTML结构,你会发现Table数据有一些共同点。一般网页结构如下所示。
...
...
...
...
...
...
...
...
...
网页结构如上,我们可以尝试使用pandas的pd.read_html()方法直接获取数据。

pd.read_html()的一些主要参数
三、爬行实战示例1
爬取成都2019年空气质量数据(12页数据),目标网址:
import pandas as pd
dates = pd.date_range('20190101', '20191201', freq='MS').strftime('%Y%m') # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f'http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html', encoding='gbk', header=0)[0]
if i == 0:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False) # 追加写入
i += 1
else:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False, header=False)
九行代码就搞定了,爬虫速度很快。
查看保存的数据

示例 2
抓取新浪金融基金重磅股数据(25页数据),网址:
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml?p={i}'
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv('新浪财经基金重仓股数据.csv', encoding='utf-8', index=False)
六行代码就搞定了,爬取速度非常快。
查看保存的数据:

后面爬取一些小数据的时候,只要遇到这种表数据,可以先试试pd.read_html()大法。
网页表格抓取(如何不使用Python去爬取网页数据?论Excel的万用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-11-09 00:12
现在很多朋友都知道可以用Python来爬取数据,但是如果你想从头开始学习Python爬虫,学Python还是需要一些时间的。但是,如果是抓取一些简单的网页表单数据,则没有必要使用Python。
今天教大家不使用Python爬取网页数据。
Excel 的通用方法之一是 Excel。Excel可以帮你实现简单网页抓取数据的功能。
先找到大家想爬的数据表。
比如今天就让我们爬取中国天气网站上的广东天气预报吧~
然后我们复制网站的链接,打开Excel,在菜单栏找到网站的数据。
然后将您刚刚复制的链接粘贴到新打开的:New Web Query 中。
点击Go打开网站,在这里预览中找到要导入的数据表,然后勾选左上角。
选择后,点击右下角的导入,将选中的表格数据导入Excel。
导入数据。
接下来就可以看到你想要的数据在Excel表格中一一呈现了~
有些朋友有疑问。这样导出的数据都是固定的。如果网页数据更新了,不需要重新导入吗?
其实不是,Excel也自带数据刷新功能。我们还是在菜单栏里找到:data-link properties 下的refresh all。
在链接属性中选择刷新条件、刷新频率、时间等,然后Excel会根据你设置的刷新属性自动更新数据~
上图是自动抓取刷新数据的Excel表格~~
当然,使用Excel表格爬取数据有利有弊。优点是使用Excel自带的功能来捕获和更新数据简单方便,不涉及编程等复杂操作。缺点是Excel网页数据抓取只能抓取表格数据,其他数据很难获取。
因此,如果你想获得更多元网页数据,不妨学习Python,这是目前爬虫类中最容易学习的。
如果想了解更多实用技巧,可以关注一下,以便下次更新及时通知W=。 查看全部
网页表格抓取(如何不使用Python去爬取网页数据?论Excel的万用方法)
现在很多朋友都知道可以用Python来爬取数据,但是如果你想从头开始学习Python爬虫,学Python还是需要一些时间的。但是,如果是抓取一些简单的网页表单数据,则没有必要使用Python。
今天教大家不使用Python爬取网页数据。

Excel 的通用方法之一是 Excel。Excel可以帮你实现简单网页抓取数据的功能。
先找到大家想爬的数据表。
比如今天就让我们爬取中国天气网站上的广东天气预报吧~

然后我们复制网站的链接,打开Excel,在菜单栏找到网站的数据。

然后将您刚刚复制的链接粘贴到新打开的:New Web Query 中。

点击Go打开网站,在这里预览中找到要导入的数据表,然后勾选左上角。

选择后,点击右下角的导入,将选中的表格数据导入Excel。
导入数据。

接下来就可以看到你想要的数据在Excel表格中一一呈现了~

有些朋友有疑问。这样导出的数据都是固定的。如果网页数据更新了,不需要重新导入吗?
其实不是,Excel也自带数据刷新功能。我们还是在菜单栏里找到:data-link properties 下的refresh all。

在链接属性中选择刷新条件、刷新频率、时间等,然后Excel会根据你设置的刷新属性自动更新数据~

上图是自动抓取刷新数据的Excel表格~~
当然,使用Excel表格爬取数据有利有弊。优点是使用Excel自带的功能来捕获和更新数据简单方便,不涉及编程等复杂操作。缺点是Excel网页数据抓取只能抓取表格数据,其他数据很难获取。

因此,如果你想获得更多元网页数据,不妨学习Python,这是目前爬虫类中最容易学习的。
如果想了解更多实用技巧,可以关注一下,以便下次更新及时通知W=。
网页表格抓取(【每日一题】法比奥布拉加托的使用和提取表格 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-07 23:02
)
法比奥布拉加托 1
为什么当我使用 .getElementsByTagName 方法提取表格时,它没有提取表格中收录的所有数据?请注意,这是向下滚动页面。
Public Sub getHistoricCotation()
Dim mainURL As String
Dim elem As Object, tRow As Object
Dim S, R, C
Dim initial_date As String, final_date As String
Dim stock As String
initial_date = DateDiff("s", "1/1/1970 00:00:00", ufHistorico.txtDtInicial) + 86400
final_date = DateDiff("s", "1/1/1970 00:00:00", ufHistorico.txtDtFinal) + 86400
stock = ufHistorico.cbAcoes.Text
mainURL = "https://finance.yahoo.com/quote/" & stock & "/history?period1=" & initial_date & "&period2=" & final_date & "&interval=1d&filter=history&frequency=1d"
With CreateObject("WinHttp.WinHttpRequest.5.1")
.Open "GET", mainURL, False
strCookie = .getAllResponseHeaders
strCookie = Split(Split(strCookie, "Cookie:")(1), ";")(0)
.Open "GET", mainURL, False
.setRequestHeader "Cookie", strCookie
.setRequestHeader "User-Agent", "Mozilla/5.0 (Windows NT 6.1; ) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36"
.send
S = .responseText
End With
With CreateObject("htmlfile")
.body.innerHTML = S
For Each elem In .getElementsByTagName("tr")
For Each tRow In elem.Cells
C = C + 1: Cells(R + 1, C) = tRow.innerText
Next tRow
C = 0: R = R + 1
Next elem
End With
End Sub
SIM卡
脚本中可以解析的部分是静态的,但不能解析的部分是动态生成的。然而,好消息是该表的所有内容都可以在页面源代码中的某些脚本标签内找到。我已经创建了一个脚本来从那里挖掘出所需的部分。您现在要做的就是使用任何 json 转换器或正则表达式来处理内容。
这是它从那里获取所有相关数据的方式:
Sub FetchHistoricalPrice()
Const mainUrl$ = "https://finance.yahoo.com/quot ... ot%3B
Dim S$, Elem As Object
With CreateObject("MSXML2.XMLHTTP")
.Open "GET", mainUrl, False
.send
S = .responseText
End With
With CreateObject("VBScript.RegExp")
.Global = True
.MultiLine = True
.Pattern = "HistoricalPriceStore[\s\S]+prices[^[]+(.*?]),"
Set Elem = .Execute(S)
If Elem.Count > 0 Then
Debug.Print Elem(0).SubMatches(0)
End If
End With
End Sub 查看全部
网页表格抓取(【每日一题】法比奥布拉加托的使用和提取表格
)
法比奥布拉加托 1
为什么当我使用 .getElementsByTagName 方法提取表格时,它没有提取表格中收录的所有数据?请注意,这是向下滚动页面。
Public Sub getHistoricCotation()
Dim mainURL As String
Dim elem As Object, tRow As Object
Dim S, R, C
Dim initial_date As String, final_date As String
Dim stock As String
initial_date = DateDiff("s", "1/1/1970 00:00:00", ufHistorico.txtDtInicial) + 86400
final_date = DateDiff("s", "1/1/1970 00:00:00", ufHistorico.txtDtFinal) + 86400
stock = ufHistorico.cbAcoes.Text
mainURL = "https://finance.yahoo.com/quote/" & stock & "/history?period1=" & initial_date & "&period2=" & final_date & "&interval=1d&filter=history&frequency=1d"
With CreateObject("WinHttp.WinHttpRequest.5.1")
.Open "GET", mainURL, False
strCookie = .getAllResponseHeaders
strCookie = Split(Split(strCookie, "Cookie:")(1), ";")(0)
.Open "GET", mainURL, False
.setRequestHeader "Cookie", strCookie
.setRequestHeader "User-Agent", "Mozilla/5.0 (Windows NT 6.1; ) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36"
.send
S = .responseText
End With
With CreateObject("htmlfile")
.body.innerHTML = S
For Each elem In .getElementsByTagName("tr")
For Each tRow In elem.Cells
C = C + 1: Cells(R + 1, C) = tRow.innerText
Next tRow
C = 0: R = R + 1
Next elem
End With
End Sub
SIM卡
脚本中可以解析的部分是静态的,但不能解析的部分是动态生成的。然而,好消息是该表的所有内容都可以在页面源代码中的某些脚本标签内找到。我已经创建了一个脚本来从那里挖掘出所需的部分。您现在要做的就是使用任何 json 转换器或正则表达式来处理内容。
这是它从那里获取所有相关数据的方式:
Sub FetchHistoricalPrice()
Const mainUrl$ = "https://finance.yahoo.com/quot ... ot%3B
Dim S$, Elem As Object
With CreateObject("MSXML2.XMLHTTP")
.Open "GET", mainUrl, False
.send
S = .responseText
End With
With CreateObject("VBScript.RegExp")
.Global = True
.MultiLine = True
.Pattern = "HistoricalPriceStore[\s\S]+prices[^[]+(.*?]),"
Set Elem = .Execute(S)
If Elem.Count > 0 Then
Debug.Print Elem(0).SubMatches(0)
End If
End With
End Sub
网页表格抓取(16款用户体验优秀的CSS价格表格样式演示及下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-05 17:04
老佐不是网页设计师,但他经常摆弄博客,修改一些他认为不好的用户体验。只限于修改一些简单的 CSS 样式。如果遇到无法解决的问题,可以搜索查阅文档。. 随着时间的推移,我们越来越意识到 CSS 样式的无限奇妙。比如我们在做表格的时候,可以简单的使用CSS样式表来修改和改变各种CSS表格样式。在页面布局和内容分享中,表格是比较常用的。有时候老左在分享评价内容的时候,为了省事,可能会直接截图,以后可能会有更多的分享风格,方便用户体验,如果信息有变化,可以修改直接截图而不是截图。
在之前的博文中,我已经分享了几篇关于 CSS 表格样式的文章:
16 个 HTML CSS 价格表单模板,具有出色的用户体验,提供演示和下载
设计师常用的8种漂亮的HTML和CSS表格样式
6 个漂亮的 HTML CSS 样式用户消息表单
今天在浏览几篇海外前端博客的时候,看到下面这7种颜色的CSS表格样式比较有条理,尤其是需要在网页中添加表格的时候,看似简单的样式,实则需要用到的时候直接copy就可以了,省很多时间。
首先:
CSS表格样式之一
CSS样式代码部分:
/* Border styles */
#table-1 thead, #table-1 tr {
border-top-width: 1px;
border-top-style: solid;
border-top-color: rgb(230, 189, 189);
}
#table-1 {
border-bottom-width: 1px;
border-bottom-style: solid;
border-bottom-color: rgb(230, 189, 189);
}
/* Padding and font style */
#table-1 td, #table-1 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
color: rgb(177, 106, 104);
}
/* Alternating background colors */
#table-1 tr:nth-child(even) {
background: rgb(238, 211, 210)
}
#table-1 tr:nth-child(odd) {
background: #FFF
}
第二种:
CSS表格样式二
CSS样式代码部分:
/* Border styles */
#table-2 thead, #table-2 tr {
border-top-width: 1px;
border-top-style: solid;
border-top-color: rgb(230, 189, 189);
}
#table-2 {
border-bottom-width: 1px;
border-bottom-style: solid;
border-bottom-color: rgb(230, 189, 189);
}
/* Padding and font style */
#table-2 td, #table-2 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
color: rgb(177, 106, 104);
}
/* Alternating background colors */
#table-2 tr:nth-child(even) {
background: rgb(238, 211, 210)
}
#table-2 tr:nth-child(odd) {
background: #FFF
}
第三种:
CSS表格样式三
CSS样式代码部分:
/* Border styles */
#table-3 thead, #table-3 tr {
border-top-width: 1px;
border-top-style: solid;
border-top-color: rgb(235, 242, 224);
}
#table-3 {
border-bottom-width: 1px;
border-bottom-style: solid;
border-bottom-color: rgb(235, 242, 224);
}
/* Padding and font style */
#table-3 td, #table-3 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
color: rgb(149, 170, 109);
}
/* Alternating background colors */
#table-3 tr:nth-child(even) {
background: rgb(230, 238, 214)
}
#table-3 tr:nth-child(odd) {
background: #FFF
}
第四种:
CSS表格样式四
CSS 代码样式部分:
/* Border styles */
#table-4 thead, #table-4 tr {
border-top-width: 1px;
border-top-style: solid;
border-top-color: rgb(211, 202, 221);
}
#table-4 {
border-bottom-width: 1px;
border-bottom-style: solid;
border-bottom-color: rgb(211, 202, 221);
}
/* Padding and font style */
#table-4 td, #table-4 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
color: rgb(95, 74, 121);
}
/* Alternating background colors */
#table-4 tr:nth-child(even) {
background: rgb(223, 216, 232)
}
#table-4 tr:nth-child(odd) {
background: #FFF
}
第五种:
CSS表格样式五
CSS 代码样式部分:
/* Table Head */
#table-5 thead th {
background-color: rgb(156, 186, 95);
color: #fff;
border-bottom-width: 0;
}
/* Column Style */
#table-5 td {
color: #000;
}
/* Heading and Column Style */
#table-5 tr, #table-5 th {
border-width: 1px;
border-style: solid;
border-color: rgb(156, 186, 95);
}
/* Padding and font style */
#table-5 td, #table-5 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
font-weight: bold;
}
第六:
CSS 表格样式六
CSS样式代码部分:
/* Table Head */
#table-6 thead th {
background-color: rgb(128, 102, 160);
color: #fff;
border-bottom-width: 0;
}
/* Column Style */
#table-6 td {
color: #000;
}
/* Heading and Column Style */
#table-6 tr, #table-6 th {
border-width: 1px;
border-style: solid;
border-color: rgb(128, 102, 160);
}
/* Padding and font style */
#table-6 td, #table-6 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
font-weight: bold;
}
第七:
CSS 表格样式七
CSS样式代码部分:
/* Table Head */
#table-7 thead th {
background-color: rgb(81, 130, 187);
color: #fff;
border-bottom-width: 0;
}
/* Column Style */
#table-7 td {
color: #000;
}
/* Heading and Column Style */
#table-7 tr, #table-7 th {
border-width: 1px;
border-style: solid;
border-color: rgb(81, 130, 187);
}
/* Padding and font style */
#table-7 td, #table-7 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
font-weight: bold;
}
以上7种颜色的CSS表格样式部分,可以根据自己的需要直接复制修改。然后将其添加到以下 TABLE 表部分:
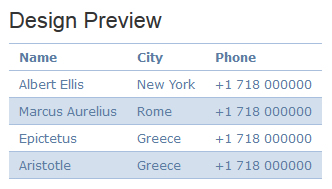
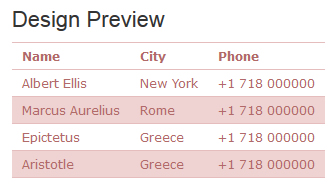
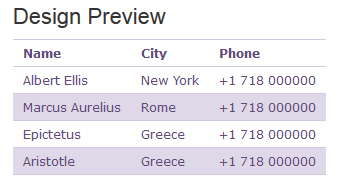
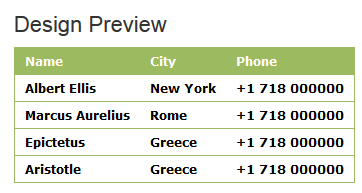
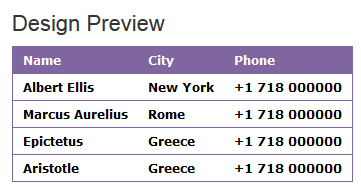
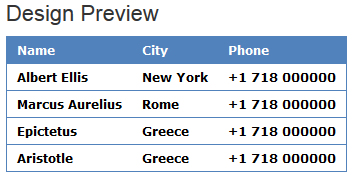
Name
City
Phone
Albert Ellis
New York
+1 718 000000
Marcus Aurelius
Rome
+1 718 000000
Epictetus
Greece
+1 718 000000
Aristotle
Greece
+1 718 000000
本文档整体框架还是采用了TABLE,比较适合文章内容中插入样式的部分。 查看全部
网页表格抓取(16款用户体验优秀的CSS价格表格样式演示及下载)
老佐不是网页设计师,但他经常摆弄博客,修改一些他认为不好的用户体验。只限于修改一些简单的 CSS 样式。如果遇到无法解决的问题,可以搜索查阅文档。. 随着时间的推移,我们越来越意识到 CSS 样式的无限奇妙。比如我们在做表格的时候,可以简单的使用CSS样式表来修改和改变各种CSS表格样式。在页面布局和内容分享中,表格是比较常用的。有时候老左在分享评价内容的时候,为了省事,可能会直接截图,以后可能会有更多的分享风格,方便用户体验,如果信息有变化,可以修改直接截图而不是截图。
在之前的博文中,我已经分享了几篇关于 CSS 表格样式的文章:
16 个 HTML CSS 价格表单模板,具有出色的用户体验,提供演示和下载
设计师常用的8种漂亮的HTML和CSS表格样式
6 个漂亮的 HTML CSS 样式用户消息表单
今天在浏览几篇海外前端博客的时候,看到下面这7种颜色的CSS表格样式比较有条理,尤其是需要在网页中添加表格的时候,看似简单的样式,实则需要用到的时候直接copy就可以了,省很多时间。
首先:
CSS表格样式之一
CSS样式代码部分:
/* Border styles */
#table-1 thead, #table-1 tr {
border-top-width: 1px;
border-top-style: solid;
border-top-color: rgb(230, 189, 189);
}
#table-1 {
border-bottom-width: 1px;
border-bottom-style: solid;
border-bottom-color: rgb(230, 189, 189);
}
/* Padding and font style */
#table-1 td, #table-1 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
color: rgb(177, 106, 104);
}
/* Alternating background colors */
#table-1 tr:nth-child(even) {
background: rgb(238, 211, 210)
}
#table-1 tr:nth-child(odd) {
background: #FFF
}
第二种:
CSS表格样式二
CSS样式代码部分:
/* Border styles */
#table-2 thead, #table-2 tr {
border-top-width: 1px;
border-top-style: solid;
border-top-color: rgb(230, 189, 189);
}
#table-2 {
border-bottom-width: 1px;
border-bottom-style: solid;
border-bottom-color: rgb(230, 189, 189);
}
/* Padding and font style */
#table-2 td, #table-2 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
color: rgb(177, 106, 104);
}
/* Alternating background colors */
#table-2 tr:nth-child(even) {
background: rgb(238, 211, 210)
}
#table-2 tr:nth-child(odd) {
background: #FFF
}
第三种:

CSS表格样式三
CSS样式代码部分:
/* Border styles */
#table-3 thead, #table-3 tr {
border-top-width: 1px;
border-top-style: solid;
border-top-color: rgb(235, 242, 224);
}
#table-3 {
border-bottom-width: 1px;
border-bottom-style: solid;
border-bottom-color: rgb(235, 242, 224);
}
/* Padding and font style */
#table-3 td, #table-3 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
color: rgb(149, 170, 109);
}
/* Alternating background colors */
#table-3 tr:nth-child(even) {
background: rgb(230, 238, 214)
}
#table-3 tr:nth-child(odd) {
background: #FFF
}
第四种:
CSS表格样式四
CSS 代码样式部分:
/* Border styles */
#table-4 thead, #table-4 tr {
border-top-width: 1px;
border-top-style: solid;
border-top-color: rgb(211, 202, 221);
}
#table-4 {
border-bottom-width: 1px;
border-bottom-style: solid;
border-bottom-color: rgb(211, 202, 221);
}
/* Padding and font style */
#table-4 td, #table-4 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
color: rgb(95, 74, 121);
}
/* Alternating background colors */
#table-4 tr:nth-child(even) {
background: rgb(223, 216, 232)
}
#table-4 tr:nth-child(odd) {
background: #FFF
}
第五种:
CSS表格样式五
CSS 代码样式部分:
/* Table Head */
#table-5 thead th {
background-color: rgb(156, 186, 95);
color: #fff;
border-bottom-width: 0;
}
/* Column Style */
#table-5 td {
color: #000;
}
/* Heading and Column Style */
#table-5 tr, #table-5 th {
border-width: 1px;
border-style: solid;
border-color: rgb(156, 186, 95);
}
/* Padding and font style */
#table-5 td, #table-5 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
font-weight: bold;
}
第六:
CSS 表格样式六
CSS样式代码部分:
/* Table Head */
#table-6 thead th {
background-color: rgb(128, 102, 160);
color: #fff;
border-bottom-width: 0;
}
/* Column Style */
#table-6 td {
color: #000;
}
/* Heading and Column Style */
#table-6 tr, #table-6 th {
border-width: 1px;
border-style: solid;
border-color: rgb(128, 102, 160);
}
/* Padding and font style */
#table-6 td, #table-6 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
font-weight: bold;
}
第七:
CSS 表格样式七
CSS样式代码部分:
/* Table Head */
#table-7 thead th {
background-color: rgb(81, 130, 187);
color: #fff;
border-bottom-width: 0;
}
/* Column Style */
#table-7 td {
color: #000;
}
/* Heading and Column Style */
#table-7 tr, #table-7 th {
border-width: 1px;
border-style: solid;
border-color: rgb(81, 130, 187);
}
/* Padding and font style */
#table-7 td, #table-7 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
font-weight: bold;
}
以上7种颜色的CSS表格样式部分,可以根据自己的需要直接复制修改。然后将其添加到以下 TABLE 表部分:
Name
City
Phone
Albert Ellis
New York
+1 718 000000
Marcus Aurelius
Rome
+1 718 000000
Epictetus
Greece
+1 718 000000
Aristotle
Greece
+1 718 000000
本文档整体框架还是采用了TABLE,比较适合文章内容中插入样式的部分。
网页表格抓取( 有你想要的精彩作者|東不归出品|Python知识学堂 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-10-30 15:02
有你想要的精彩作者|東不归出品|Python知识学堂
)
有你想要的
作者 | 东不归出品| Python知识学校
大家好,上一条推文介绍了爬虫需要注意的点,使用vscode开发环境时遇到的问题,正则表达式爬取页面信息的使用。本文主要介绍BeautifulSoup模块的使用。.
BeautifulSoup的描述
引用官方解释:
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它可以使用您喜欢的转换器来实现惯用的文档导航、查找和修改文档。
简单的说,Beautiful Soup 是一个python 库,一个可以抓取网页数据的工具。
官方文件:
BeautifulSoup 安装
pip 安装 beautifulsoup4
或者
pip 安装 beautifulsoup4
-一世
--可信主机
顺便说一句:我用的开发工具还是vscode,不知道看之前的推文。
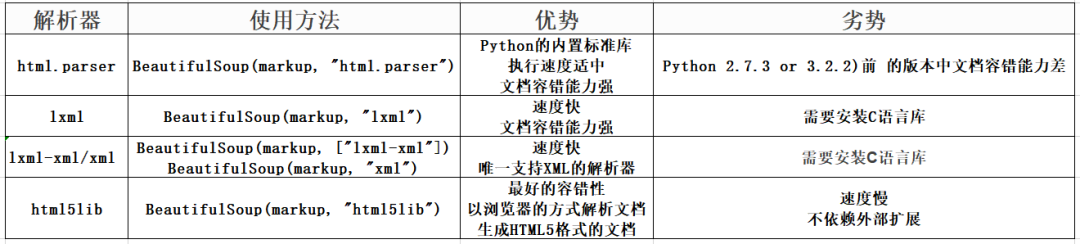
BeautifulSoup 解析器
html.parse
html.parse 是内置的,不需要安装
import requestsfrom bs4 import BeautifulSoupurl='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'html.parser')<br />print(soup.prettify())
结果
xml文件
安装 pip install lxml 需要 lxml
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'lxml')<br />print(soup)
结果
lxml-xml/xml
lxml-xml/Xm 是需要安装的pip install lxml
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'xml')<br />print(soup)
结果
html5lib
html5lib是需要安装的pip install html5lib
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'html5lib')<br />print(soup)
结果
可以看到,这些解析器解析出来的记录基本相同,但是如果一个HTML或者XML文档的格式不正确,不同解析器返回的结果可能会有所不同。什么是 HTML 或 XML 文档格式不正确?简单地说,就是缺少不必要的标签或者标签没有关闭。比如页面缺少body标签,只有a标签的开头部分缺少a标签的结尾部分(这里有一些前端知识,不明白的可以搜索一下,很简单)。
咱们试试吧
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'html.parser')
打印(“html.parser 结果:”)
打印(汤)
汤1=BeautifulSoup(html,'lxml')
打印(“lxml结果:”)
打印(汤1)
汤2=BeautifulSoup(html,'xml')
打印(“xml结果:”)
打印(汤2)
汤3=BeautifulSoup(html,'html5lib')
打印(“html5lib 结果:”)
打印(汤3)
结果
可以看到html.parser和lxml会填充标签,但是lxml会填充html标签,xml也会填充标签,还会添加xml文档的版本编码方式等信息,但不是会补全html标签,而且html5lib不仅会补全html标签,还会补全整个页面的head标签。
这验证了上表中的html5lib具有最好的容错性,但是html5lib解析器的速度并不快。如果内容较少,则速度不会有差异。因此,推荐使用lxml作为解析器,因为这样效率更高。对于 Python2.7.3 之前的版本和 Python3 中 3.2.2 之前的版本,必须安装 lxml 或 html5lib,因为这些 Python 版本具有内置的 HTML标准库中的分析方法不够稳定。
如果我们不指定解析器怎么办?
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=美丽的汤(html)
打印(“html.parser 结果:”)
打印(汤)
结果
从结果提示可以得出,如果不指定解析器,他会给出系统最好的解析器。我的系统是lxml。如果你没有在其他环境中安装 lxml,它可能是另一个解析器。总之系统会默认为你选择最好的解析器,所以你不需要指定它。这不是更用户友好。
BeautifulSoup 对象类型
Beautiful Soup 将复杂的 HTML 文档转换为复杂的树结构。每个节点都是一个 Python 对象。所有对象可以概括为 4 种类型:Tag、NavigableString、BeautifulSoup、Comment。
标签
标签中最重要的属性:名称和属性
from bs4 import BeautifulSoup<br />html="
Python知识学校
Python知识学校”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
结果
上面代码中的a标签表示一个标签,test被认为是一个标签。测试是我随便写的,所以Beautiful Soup中的html标签和自定义标签都可以看作是标签。是不是很强大?
那么什么是属性呢?看上面代码中的data-id和class一个标签,即使它们是标签中的属性;
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
打印(标签。属性)
结果:
如果要获取某个属性,可以使用 tag['data-id'] 或 tag.attrs['data-id']。
这个最有用的应该是获取a标签的链接地址和img标签的媒体文件地址。
如果里面有多个值,会返回一个列表
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'lxml')
打印(标签 ['数据 ID'])
结果:
导航字符串
标签中收录的字符串可以通过NavigableString类直接获取,也称为可遍历字符串。
from bs4 import BeautifulSoup<br />html="
”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
打印(标签。字符串)
结果:
这个比较简单,就不多说了;
美汤
BeautifulSoup 对象表示文档的全部内容。大多数时候,它可以看作是一个 Tag 对象,它支持遍历文档树和搜索文档树中描述的大部分方法。
先来了解一下,后面遍历文档和搜索文档的时候会有说明;
评论
主要是文档中的注释部分。
Comment 对象是一种特殊类型的 NavigableString 对象:
from bs4 import BeautifulSoup<br />html= "<b>"soup = BeautifulSoup(html,'lxml')<br />comment = soup.b.string<br />print(comment)
结果
但是下面的情况是不可用的
from bs4 import BeautifulSoup<br />html= "<b>我是谁?"<br />soup = BeautifulSoup(html,'lxml')<br />comment = soup.b.string<br />print(comment)
结果
可以看到返回的结果是None,所以评论的内容只能在特殊情况下才能获取;
遍历文档树
只看代码
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
上面的知识简单列举了几种获取树节点的方法,还有很多其他的方法,比如获取父节点、兄弟节点等等。有点类似于 jQuery 遍历 DOM 的概念。
搜索文档树
Beautiful Soup 定义了很多搜索方法,这里介绍两个比较常用的方法:find() 和 find_all()。其他的可以类似地使用,以此类推。
筛选
细绳
正则表达式
列表
真的
方法
from bs4 import BeautifulSoupimport re<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
找到所有()
Name:可以找到所有名称为name的标签,string对象会被自动忽略;
关键字参数:如果指定名称的参数不是内置参数名称,则搜索时将作为指定名称标签的属性进行搜索。如果它收录一个名为 id 的参数,Beautiful Soup 将搜索每个标签的“id”属性;
按CSS搜索:按CSS类名搜索标签的功能很实用,但是标识CSS类名的关键字class在Python中是保留字。使用类作为参数会导致语法错误。来自Beautiful Soup的4.< 从@1.1版本开始,可以通过class_参数搜索指定CSS类名的标签;
字符串参数:通过字符串参数,可以搜索文档中的字符串内容。与 name 参数的可选值一样,string 参数接受字符串、正则表达式、列表和 True。
limit 参数:find_all() 方法返回所有搜索结构。如果文档树很大,搜索会很慢。如果我们不需要所有的结果,我们可以使用 limit 参数来限制返回的结果数量。作用类似于SQL中的limit关键字,当搜索结果数达到limit限制时,停止搜索返回结果;
递归参数:调用标签的 find_all() 方法时,Beautiful Soup 会检索当前标签的所有后代节点。如果只想搜索标签的直接子节点,可以使用参数recursive=False。
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
请注意,只有 find_all() 和 find() 支持递归参数。
find() 方法与 find_all() 基本相同。唯一的区别是 find_all() 方法的返回结果是一个收录一个元素的列表,而 find() 方法直接返回结果。
输出
格式化输出
压缩输出
输出格式
获取文本()
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果我就不贴了,自己执行吧。
当然还有很多其他的方法,这里不再赘述,可以直接参考官方
Buaautiful汤的功能还是很强大的,这里只是简单介绍一些爬虫常用的东西。
现在就做,我们以上一篇文章获取省市为例
实例
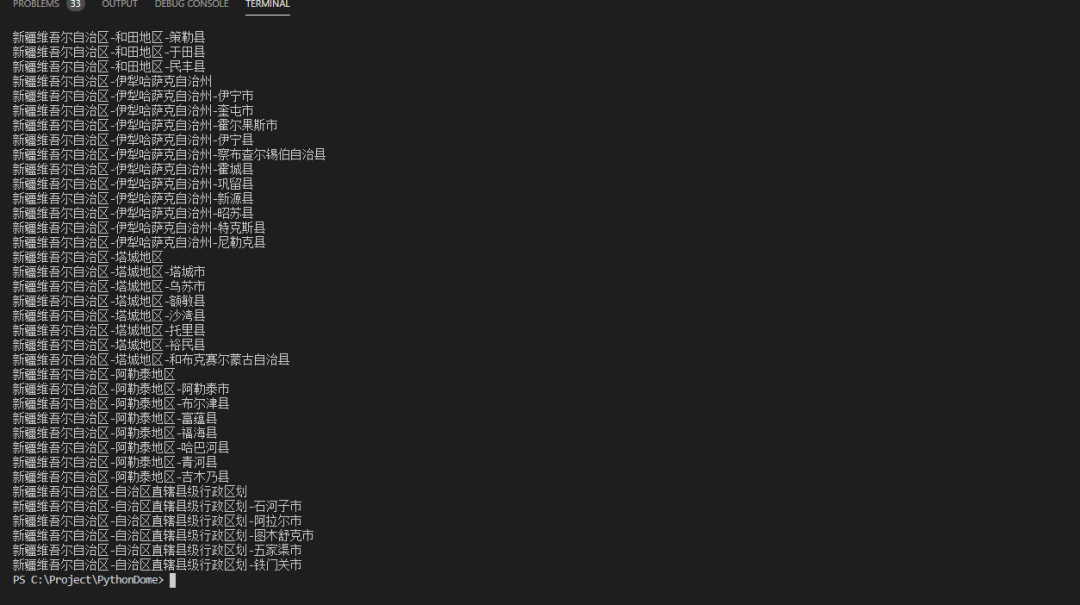
我们仍然以上一篇文章中的省市收购为例。
import requestsfrom bs4 import BeautifulSoupimport timeclass Demo():def __init__(self):try:base_url = 'http://www.stats.gov.cn/tjsj/t ... %3Bbr /> trlist = self.get_data(base_url, "provincetable",'provincetr')
结果
我直接给你看看你上一个省市的结果。请注意获取每个页面信息的时间间隔;
总结
本文文章介绍了BeautifulSoup的一些基础内容,主要是爬虫相关的,BeautifulSoup还有很多其他的功能,大家可以到官网自行学习。
再次贴出官网地址:
下一个预览
下一条推文是关于lxml模块的基本内容,但下周的推文是关于深度学习的。爬虫可能要等到下周。感谢您的支持!
过去的选择(点击查看)
Python爬虫基础教程-正则表达式爬取入门
2020-08-30
Python实战教程系列-VSCode Python开发环境搭建
2020-08-01
Python实战教程系列——异常处理
2020-07-05
喜欢就看看
查看全部
网页表格抓取(
有你想要的精彩作者|東不归出品|Python知识学堂
)

有你想要的

作者 | 东不归出品| Python知识学校
大家好,上一条推文介绍了爬虫需要注意的点,使用vscode开发环境时遇到的问题,正则表达式爬取页面信息的使用。本文主要介绍BeautifulSoup模块的使用。.
BeautifulSoup的描述
引用官方解释:
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它可以使用您喜欢的转换器来实现惯用的文档导航、查找和修改文档。
简单的说,Beautiful Soup 是一个python 库,一个可以抓取网页数据的工具。
官方文件:
BeautifulSoup 安装
pip 安装 beautifulsoup4
或者
pip 安装 beautifulsoup4
-一世
--可信主机
顺便说一句:我用的开发工具还是vscode,不知道看之前的推文。
BeautifulSoup 解析器
html.parse
html.parse 是内置的,不需要安装
import requestsfrom bs4 import BeautifulSoupurl='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'html.parser')<br />print(soup.prettify())
结果

xml文件
安装 pip install lxml 需要 lxml
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'lxml')<br />print(soup)
结果

lxml-xml/xml
lxml-xml/Xm 是需要安装的pip install lxml
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'xml')<br />print(soup)
结果
html5lib
html5lib是需要安装的pip install html5lib
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'html5lib')<br />print(soup)
结果

可以看到,这些解析器解析出来的记录基本相同,但是如果一个HTML或者XML文档的格式不正确,不同解析器返回的结果可能会有所不同。什么是 HTML 或 XML 文档格式不正确?简单地说,就是缺少不必要的标签或者标签没有关闭。比如页面缺少body标签,只有a标签的开头部分缺少a标签的结尾部分(这里有一些前端知识,不明白的可以搜索一下,很简单)。
咱们试试吧
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'html.parser')
打印(“html.parser 结果:”)
打印(汤)
汤1=BeautifulSoup(html,'lxml')
打印(“lxml结果:”)
打印(汤1)
汤2=BeautifulSoup(html,'xml')
打印(“xml结果:”)
打印(汤2)
汤3=BeautifulSoup(html,'html5lib')
打印(“html5lib 结果:”)
打印(汤3)
结果

可以看到html.parser和lxml会填充标签,但是lxml会填充html标签,xml也会填充标签,还会添加xml文档的版本编码方式等信息,但不是会补全html标签,而且html5lib不仅会补全html标签,还会补全整个页面的head标签。
这验证了上表中的html5lib具有最好的容错性,但是html5lib解析器的速度并不快。如果内容较少,则速度不会有差异。因此,推荐使用lxml作为解析器,因为这样效率更高。对于 Python2.7.3 之前的版本和 Python3 中 3.2.2 之前的版本,必须安装 lxml 或 html5lib,因为这些 Python 版本具有内置的 HTML标准库中的分析方法不够稳定。
如果我们不指定解析器怎么办?
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=美丽的汤(html)
打印(“html.parser 结果:”)
打印(汤)
结果

从结果提示可以得出,如果不指定解析器,他会给出系统最好的解析器。我的系统是lxml。如果你没有在其他环境中安装 lxml,它可能是另一个解析器。总之系统会默认为你选择最好的解析器,所以你不需要指定它。这不是更用户友好。
BeautifulSoup 对象类型
Beautiful Soup 将复杂的 HTML 文档转换为复杂的树结构。每个节点都是一个 Python 对象。所有对象可以概括为 4 种类型:Tag、NavigableString、BeautifulSoup、Comment。
标签
标签中最重要的属性:名称和属性
from bs4 import BeautifulSoup<br />html="
Python知识学校
Python知识学校”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
结果

上面代码中的a标签表示一个标签,test被认为是一个标签。测试是我随便写的,所以Beautiful Soup中的html标签和自定义标签都可以看作是标签。是不是很强大?
那么什么是属性呢?看上面代码中的data-id和class一个标签,即使它们是标签中的属性;
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
打印(标签。属性)
结果:

如果要获取某个属性,可以使用 tag['data-id'] 或 tag.attrs['data-id']。
这个最有用的应该是获取a标签的链接地址和img标签的媒体文件地址。
如果里面有多个值,会返回一个列表
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'lxml')
打印(标签 ['数据 ID'])
结果:

导航字符串
标签中收录的字符串可以通过NavigableString类直接获取,也称为可遍历字符串。
from bs4 import BeautifulSoup<br />html="
”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
打印(标签。字符串)
结果:

这个比较简单,就不多说了;
美汤
BeautifulSoup 对象表示文档的全部内容。大多数时候,它可以看作是一个 Tag 对象,它支持遍历文档树和搜索文档树中描述的大部分方法。
先来了解一下,后面遍历文档和搜索文档的时候会有说明;
评论
主要是文档中的注释部分。
Comment 对象是一种特殊类型的 NavigableString 对象:
from bs4 import BeautifulSoup<br />html= "<b>"soup = BeautifulSoup(html,'lxml')<br />comment = soup.b.string<br />print(comment)
结果

但是下面的情况是不可用的
from bs4 import BeautifulSoup<br />html= "<b>我是谁?"<br />soup = BeautifulSoup(html,'lxml')<br />comment = soup.b.string<br />print(comment)
结果

可以看到返回的结果是None,所以评论的内容只能在特殊情况下才能获取;
遍历文档树
只看代码
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:

上面的知识简单列举了几种获取树节点的方法,还有很多其他的方法,比如获取父节点、兄弟节点等等。有点类似于 jQuery 遍历 DOM 的概念。
搜索文档树
Beautiful Soup 定义了很多搜索方法,这里介绍两个比较常用的方法:find() 和 find_all()。其他的可以类似地使用,以此类推。
筛选
细绳
正则表达式
列表
真的
方法
from bs4 import BeautifulSoupimport re<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
找到所有()
Name:可以找到所有名称为name的标签,string对象会被自动忽略;
关键字参数:如果指定名称的参数不是内置参数名称,则搜索时将作为指定名称标签的属性进行搜索。如果它收录一个名为 id 的参数,Beautiful Soup 将搜索每个标签的“id”属性;
按CSS搜索:按CSS类名搜索标签的功能很实用,但是标识CSS类名的关键字class在Python中是保留字。使用类作为参数会导致语法错误。来自Beautiful Soup的4.< 从@1.1版本开始,可以通过class_参数搜索指定CSS类名的标签;
字符串参数:通过字符串参数,可以搜索文档中的字符串内容。与 name 参数的可选值一样,string 参数接受字符串、正则表达式、列表和 True。
limit 参数:find_all() 方法返回所有搜索结构。如果文档树很大,搜索会很慢。如果我们不需要所有的结果,我们可以使用 limit 参数来限制返回的结果数量。作用类似于SQL中的limit关键字,当搜索结果数达到limit限制时,停止搜索返回结果;
递归参数:调用标签的 find_all() 方法时,Beautiful Soup 会检索当前标签的所有后代节点。如果只想搜索标签的直接子节点,可以使用参数recursive=False。
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
请注意,只有 find_all() 和 find() 支持递归参数。
find() 方法与 find_all() 基本相同。唯一的区别是 find_all() 方法的返回结果是一个收录一个元素的列表,而 find() 方法直接返回结果。
输出
格式化输出
压缩输出
输出格式
获取文本()
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果我就不贴了,自己执行吧。
当然还有很多其他的方法,这里不再赘述,可以直接参考官方
Buaautiful汤的功能还是很强大的,这里只是简单介绍一些爬虫常用的东西。
现在就做,我们以上一篇文章获取省市为例
实例
我们仍然以上一篇文章中的省市收购为例。
import requestsfrom bs4 import BeautifulSoupimport timeclass Demo():def __init__(self):try:base_url = 'http://www.stats.gov.cn/tjsj/t ... %3Bbr /> trlist = self.get_data(base_url, "provincetable",'provincetr')
结果
我直接给你看看你上一个省市的结果。请注意获取每个页面信息的时间间隔;
总结
本文文章介绍了BeautifulSoup的一些基础内容,主要是爬虫相关的,BeautifulSoup还有很多其他的功能,大家可以到官网自行学习。
再次贴出官网地址:
下一个预览
下一条推文是关于lxml模块的基本内容,但下周的推文是关于深度学习的。爬虫可能要等到下周。感谢您的支持!

过去的选择(点击查看)
Python爬虫基础教程-正则表达式爬取入门
2020-08-30

Python实战教程系列-VSCode Python开发环境搭建
2020-08-01
Python实战教程系列——异常处理
2020-07-05
喜欢就看看

网页表格抓取((19)中华人民共和国国家知识产权局(12)申请(21))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-28 16:03
摘要 本发明提出了一种防止网页数据爬行的方法和系统。防止网页数据爬取的方法包括:提取网页数据;混淆网页数据;将混淆后的网页数据转换为背景图片:背景图片通过堆叠样式表显示在网页上。本发明可以实现即使恶意爬虫下载了网页采集的所有源代码和图片,并使用OCR工具进行识别,也无法获得正确的数据。并且每页的数据图片都是随机生成的,大大 摘要 本发明提出了一种防止网页数据爬行的方法和系统。防止网页数据爬取的方法包括:提取网页数据;混淆网页数据;将混淆后的网页数据转换为背景图片:背景图片通过堆叠样式表显示在网页上。本发明可以实现即使恶意爬虫下载了网页采集的所有源代码和图片,并使用OCR工具进行识别,也无法获得正确的数据。并且每页的数据图片都是随机生成的,大大 背景图片通过堆叠样式表显示在网页上。本发明可以实现即使恶意爬虫下载了网页采集的所有源代码和图片,并使用OCR工具进行识别,也无法获得正确的数据。并且每页的数据图片都是随机生成的,大大 背景图片通过堆叠样式表显示在网页上。本发明可以实现即使恶意爬虫下载了网页采集的所有源代码和图片,并使用OCR工具进行识别,也无法获得正确的数据。并且每页的数据图片都是随机生成的,大大
大大增加采集解析难度,关键数据开放互联网。法律地位 法律地位 公告日期 2017-09-29 2017-09-29 2017-10-27 法律地位 信息披露 实质审查效力 法律地位 披露实质审查效力
索赔说明书网页数据反爬取方法及系统索赔说明书内容为...请下载查看 查看全部
网页表格抓取((19)中华人民共和国国家知识产权局(12)申请(21))
摘要 本发明提出了一种防止网页数据爬行的方法和系统。防止网页数据爬取的方法包括:提取网页数据;混淆网页数据;将混淆后的网页数据转换为背景图片:背景图片通过堆叠样式表显示在网页上。本发明可以实现即使恶意爬虫下载了网页采集的所有源代码和图片,并使用OCR工具进行识别,也无法获得正确的数据。并且每页的数据图片都是随机生成的,大大 摘要 本发明提出了一种防止网页数据爬行的方法和系统。防止网页数据爬取的方法包括:提取网页数据;混淆网页数据;将混淆后的网页数据转换为背景图片:背景图片通过堆叠样式表显示在网页上。本发明可以实现即使恶意爬虫下载了网页采集的所有源代码和图片,并使用OCR工具进行识别,也无法获得正确的数据。并且每页的数据图片都是随机生成的,大大 背景图片通过堆叠样式表显示在网页上。本发明可以实现即使恶意爬虫下载了网页采集的所有源代码和图片,并使用OCR工具进行识别,也无法获得正确的数据。并且每页的数据图片都是随机生成的,大大 背景图片通过堆叠样式表显示在网页上。本发明可以实现即使恶意爬虫下载了网页采集的所有源代码和图片,并使用OCR工具进行识别,也无法获得正确的数据。并且每页的数据图片都是随机生成的,大大
大大增加采集解析难度,关键数据开放互联网。法律地位 法律地位 公告日期 2017-09-29 2017-09-29 2017-10-27 法律地位 信息披露 实质审查效力 法律地位 披露实质审查效力
索赔说明书网页数据反爬取方法及系统索赔说明书内容为...请下载查看
网页表格抓取(Matrix精选:白描App新上线了网页版文字识别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-28 01:04
矩阵精选
Matrix是一个少数民族写作社区。我们提倡分享真实的产品体验、实践经验和思考。我们会不定期地选择Matrix最好的品质文章,展现用户最真实的体验和意见。
文章代表作者个人观点,少数只对标题和版式稍作修改。
近日,画线App上线了网页版,主要是为了在大屏幕上快速高效的进行OCR文字识别。
在没有网页版之前,很多使用白图app的用户如果想在电脑上识别文字,会选择WiFi识别功能,就是将电脑浏览器和手机app通过同一个局域网连接起来,把电脑上的图片通过浏览器传给手机App识别,虽然在一定程度上也能解决电脑上识别的需求,但没那么方便。一方面取决于局域网,另一方面取决于正在运行的手机App。白色绘图网页版摆脱了这些依赖,可以在浏览器中独立运行,更好地提高工作效率。
线描网页版目前收录三大功能:图片文字提取、电子表格识别、扫描PDF转文字。您可以直接登录白庙App的账号。如果白庙App有会员,会员状态会直接同步到网页版。
白线网页版截图
网页版分为两部分,左边是功能选择区,右边是识别区,可以在电脑上点击按钮选择图片,可以直接将图片拖入识别区,可以直接将图片粘贴到剪贴板中。方便的。
图片文字提取
图片文字提取是OCR文字识别功能,可以快速将图片上的文字转换成可编辑的。和手机白描App一样,可以单独识别,也可以批量识别。最多可同时支持50张图片,可一次性识别。合并所有结果。
批量上传图片
除了直接点击识别功能外,还有简单的图片裁剪功能和按文件名排序功能。
左右校对编辑
识别结束后,查看识别结果非常方便。左边是原图,右边是识别结果,校对超级方便!您也可以复制或直接导出 DOCX 和 TXT 文件。
电子表格识别
电子表格识别可以轻松地将图片上的表格转换为Excel格式。
在线编辑表格
识别后,左边也是原图,右边是识别结果,识别出来的表格可以直接在网页上校对编辑。
将 PDF 扫描为文本
目前PDF转文本更多是针对充满图形的PDF文件的文本转换。从服务性能来看,支持的最大页数为50页。之后可以根据需要适当释放页数。
关于使用限制
当前未登录或未登录的非会员用户每天可免费使用单文识别或表单识别5次,批量识别1次。金卡会员可以无限次识别,和白庙App一样,所以如果在白庙App购买会员,可以直接同步到网页版。
与其他网络版本相比有什么优势
很多人也知道网上有很多OCR识别网站,画线网版有什么优势呢?
高效准确
网页版使用与画线App相同的高精度识别引擎,确保识别准确度。同时,国产服务器和大带宽也保证了识别速度,保证了高效与准确并存。
无广告
使用过一些OCR在线识别网站的用户都会知道,很多这样的网站都是各种满天飞的广告,广告面积比实际工作区大几倍。线描网页版的整个页面是一个没有任何广告的工作区。登录画线会员账号,即可享受无任何限制的识别体验。
长图识别
线描网页版支持长图识别,包括很长很长的长图。这也是画线App中长图识别的同样体验。
校对和编辑
很多在线OCR网站识别后直接扔回文件,画线App可以轻松校对和左右编辑,包括文本和表格。
与白庙App账号相同
购买一次个人资料会员后,您可以在iOS,Android和Web(以及未来的PC版本)上享受跨平台体验,这并不漂亮。
白图网版地址:
喜欢的话记得采集浏览器或者添加到桌面快捷方式哦~
进一步阅读: 查看全部
网页表格抓取(Matrix精选:白描App新上线了网页版文字识别)
矩阵精选
Matrix是一个少数民族写作社区。我们提倡分享真实的产品体验、实践经验和思考。我们会不定期地选择Matrix最好的品质文章,展现用户最真实的体验和意见。
文章代表作者个人观点,少数只对标题和版式稍作修改。
近日,画线App上线了网页版,主要是为了在大屏幕上快速高效的进行OCR文字识别。
在没有网页版之前,很多使用白图app的用户如果想在电脑上识别文字,会选择WiFi识别功能,就是将电脑浏览器和手机app通过同一个局域网连接起来,把电脑上的图片通过浏览器传给手机App识别,虽然在一定程度上也能解决电脑上识别的需求,但没那么方便。一方面取决于局域网,另一方面取决于正在运行的手机App。白色绘图网页版摆脱了这些依赖,可以在浏览器中独立运行,更好地提高工作效率。
线描网页版目前收录三大功能:图片文字提取、电子表格识别、扫描PDF转文字。您可以直接登录白庙App的账号。如果白庙App有会员,会员状态会直接同步到网页版。

白线网页版截图
网页版分为两部分,左边是功能选择区,右边是识别区,可以在电脑上点击按钮选择图片,可以直接将图片拖入识别区,可以直接将图片粘贴到剪贴板中。方便的。
图片文字提取
图片文字提取是OCR文字识别功能,可以快速将图片上的文字转换成可编辑的。和手机白描App一样,可以单独识别,也可以批量识别。最多可同时支持50张图片,可一次性识别。合并所有结果。

批量上传图片
除了直接点击识别功能外,还有简单的图片裁剪功能和按文件名排序功能。

左右校对编辑
识别结束后,查看识别结果非常方便。左边是原图,右边是识别结果,校对超级方便!您也可以复制或直接导出 DOCX 和 TXT 文件。
电子表格识别
电子表格识别可以轻松地将图片上的表格转换为Excel格式。

在线编辑表格
识别后,左边也是原图,右边是识别结果,识别出来的表格可以直接在网页上校对编辑。
将 PDF 扫描为文本
目前PDF转文本更多是针对充满图形的PDF文件的文本转换。从服务性能来看,支持的最大页数为50页。之后可以根据需要适当释放页数。
关于使用限制
当前未登录或未登录的非会员用户每天可免费使用单文识别或表单识别5次,批量识别1次。金卡会员可以无限次识别,和白庙App一样,所以如果在白庙App购买会员,可以直接同步到网页版。
与其他网络版本相比有什么优势
很多人也知道网上有很多OCR识别网站,画线网版有什么优势呢?
高效准确
网页版使用与画线App相同的高精度识别引擎,确保识别准确度。同时,国产服务器和大带宽也保证了识别速度,保证了高效与准确并存。
无广告
使用过一些OCR在线识别网站的用户都会知道,很多这样的网站都是各种满天飞的广告,广告面积比实际工作区大几倍。线描网页版的整个页面是一个没有任何广告的工作区。登录画线会员账号,即可享受无任何限制的识别体验。
长图识别
线描网页版支持长图识别,包括很长很长的长图。这也是画线App中长图识别的同样体验。
校对和编辑
很多在线OCR网站识别后直接扔回文件,画线App可以轻松校对和左右编辑,包括文本和表格。
与白庙App账号相同
购买一次个人资料会员后,您可以在iOS,Android和Web(以及未来的PC版本)上享受跨平台体验,这并不漂亮。
白图网版地址:
喜欢的话记得采集浏览器或者添加到桌面快捷方式哦~
进一步阅读:
网页表格抓取(pdf表格提取camelot安装教程通过测试,macos与win10都可以用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-27 13:29
pdf格式提取camelot安装教程通过测试,macos和win10可以通过以下方式安装
Camelot:一个友好的PDF表格数据提取工具python
一个 python 命令行工具,允许任何人轻松地从 PDF 文件中提取表格数据。网络
如何使用 Camelotmacos
使用Camelot从PDF文档中提取数据非常简单svg
. Camelot 允许您调整设置以精确控制数据提取过程工具
.能够根据空白和精度指标判断不良表格,并丢弃,而不是手动检查测试
.每张表数据都是一个panda dataframe,可以方便的集成到ETL和数据分析工作流中。
.能够将数据导出为各种不同的格式,如CSV、JSON、EXCEL、HTMLcode
先在电脑上安装python3.6,然后在命令行输入:orm
pip install camelot-py
(CLOT) C:\Users\yss>python
Python 3.6.7 |Anaconda, Inc.| (default, Oct 28 2018, 19:44:12) [MSC v.1915 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import camelot as cl
......
import chardet # For str encoding detection in Py3
ModuleNotFoundError: No module named 'chardet'
>>>
如果报错如上:No module named'chardet',返回系统命令行执行:xml
pip install chardet
成功安装chardet后,再次输入python命令test:
(CLOT) C:\Users\yss>python
Python 3.6.7 |Anaconda, Inc.| (default, Oct 28 2018, 19:44:12) [MSC v.1915 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import camelot as cl
File "F:\APP\Ides\Anaconda3\envs\CLOT\lib\site-packages\camelot\image_processing.py", line 5, in
import cv2
ModuleNotFoundError: No module named 'cv2'
>>>
错误:ModuleNotFoundError: No module named'cv2',应该是没有安装opencv库。
再次回到系统命令行,安装opencv库:
pip install opencv-python
执行以上操作后,安装成功。
再次输入python,输入:
import camelot as cl
永远不要再报错。
输出它的版本号:
print(cl.__version__)
测试过程如下:
(CLOT) C:\Users\yss>python
Python 3.6.7 |Anaconda, Inc.| (default, Oct 28 2018, 19:44:12) [MSC v.1915 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import camelot as cl
>>> cl.__version__
'0.3.2'
>>>
安装完成后,我稍后会开始使用它。以后有机会我会更新我的经验。 查看全部
网页表格抓取(pdf表格提取camelot安装教程通过测试,macos与win10都可以用)
pdf格式提取camelot安装教程通过测试,macos和win10可以通过以下方式安装
Camelot:一个友好的PDF表格数据提取工具python
一个 python 命令行工具,允许任何人轻松地从 PDF 文件中提取表格数据。网络
如何使用 Camelotmacos
使用Camelot从PDF文档中提取数据非常简单svg
. Camelot 允许您调整设置以精确控制数据提取过程工具
.能够根据空白和精度指标判断不良表格,并丢弃,而不是手动检查测试
.每张表数据都是一个panda dataframe,可以方便的集成到ETL和数据分析工作流中。
.能够将数据导出为各种不同的格式,如CSV、JSON、EXCEL、HTMLcode
先在电脑上安装python3.6,然后在命令行输入:orm
pip install camelot-py
(CLOT) C:\Users\yss>python
Python 3.6.7 |Anaconda, Inc.| (default, Oct 28 2018, 19:44:12) [MSC v.1915 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import camelot as cl
......
import chardet # For str encoding detection in Py3
ModuleNotFoundError: No module named 'chardet'
>>>
如果报错如上:No module named'chardet',返回系统命令行执行:xml
pip install chardet
成功安装chardet后,再次输入python命令test:
(CLOT) C:\Users\yss>python
Python 3.6.7 |Anaconda, Inc.| (default, Oct 28 2018, 19:44:12) [MSC v.1915 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import camelot as cl
File "F:\APP\Ides\Anaconda3\envs\CLOT\lib\site-packages\camelot\image_processing.py", line 5, in
import cv2
ModuleNotFoundError: No module named 'cv2'
>>>
错误:ModuleNotFoundError: No module named'cv2',应该是没有安装opencv库。
再次回到系统命令行,安装opencv库:
pip install opencv-python
执行以上操作后,安装成功。
再次输入python,输入:
import camelot as cl
永远不要再报错。
输出它的版本号:
print(cl.__version__)
测试过程如下:
(CLOT) C:\Users\yss>python
Python 3.6.7 |Anaconda, Inc.| (default, Oct 28 2018, 19:44:12) [MSC v.1915 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import camelot as cl
>>> cl.__version__
'0.3.2'
>>>
安装完成后,我稍后会开始使用它。以后有机会我会更新我的经验。
网页表格抓取( Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-25 12:04
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
python——beautifulSoup提取网页数据写入指定Excel表格
文章内容
1.前言
任务要求:测试报告为HTML格式。我需要在报表中提取相应的结果并将结果写入Excel中的指定位置
2.实现步骤
第一步:获取当前目录下的多个HTML文件
第2步:从HTML中提取指定的结果(用beautifulSoup完成)
第三步:优化内存结构,使用字典保存数据
第四步:将字典数据对应的内容写入Excel
import os
from bs4 import BeautifulSoup # 建议使用beatifulsop进行处理 可能简单
from openpyxl import load_workbook
def writeTolog(logtext): # 写入日志
with open(Filename_log_path, 'a',encoding='utf-8') as f_new:
f_new.write(str(logtext))
class HtmlSpider:
def get_current_path(self): # 应该加个try语句
source_path = os.getcwd();
files = os.listdir(source_path)
File_html_path_list = [];
file_xlsx_path_list = []
try:
for file in files:
# print(file)
if file[-5:] == '.html': # 后缀名相等
File_html_path_list.append(os.path.join(source_path, file))
if file[-5:] == '.xlsx': # excel文件应该只有一个
file_xlsx_path_list.append(os.path.join(source_path, file))
if len(file_xlsx_path_list) == 1:
pass;
else:
writeTolog("Error05:当前一级目录下没有或者有多个Excel文件请确认!\n")
os.sys.exit() # 强制退出
except IOError:
writeTolog("Error00: 没有找到文件或读取文件失败\n")
if File_html_path_list==None:
writeTolog("Error07:当前路径下没有找到后缀为html的文件\n")
os.sys.exit() # 强制退出
return File_html_path_list,file_xlsx_path_list[0];
def read_html(self,html_path):
'''一个发送请求,获取响应,同时etree处理html'''
response = open(html_path,'r',encoding="utf-8") # 读取本地文件
html = response.read() #获取str 类型的html
soup_html = BeautifulSoup(html, 'lxml')
return soup_html
def get_data(self,html_path): #实现主要逻辑
# 1.获取目标网址url
# 2.发送请求获取响应
soup_html = self.read_html(html_path)
h3_list = (soup_html.find_all('h3'))[0:-1:2] # 只取出相关的
# 3.提取数据
success_list= []
for h3 in h3_list:
middle_adjust_str = h3.get('class')
if middle_adjust_str == ['success']:
success_list.append('Passed')
elif(middle_adjust_str == ['fail']):
success_list.append('Failed')
else:
writeTolog("Error01:html网页class标签中请提取class ='success'或者class ='fail'\n")
os.sys.exit() # 强制退出
# print(success_list)
name_list = []
for h3 in h3_list:
middle_3_str = h3.get_text().replace("\n", "").replace(" ","")
middle_2_str = middle_3_str.split('-')[1] # 按照-切割字符串,取第2部分 如DRV_0040201:R档能量回收;滑行出负扭矩
middle_str = middle_2_str.split(':')[0] # 按照英文状态:切割字符串,取第1部分 如DRV_0040201
if len(middle_2_str) == len(middle_str):
writeTolog("Error02:请确认{}里面的-或者:是否是英文状态下的输入\n".format(middle_3_str))
name_list.append(middle_str) #获取文本并去掉换行符
# print((name_list))
return success_list,name_list
def readexcel(self,success_list,name_list,sheetIndex):
if len(success_list) != len(name_list):
writeTolog("Error03:提取测试用例有{}个,但是测试用例的结果有{}个,因此测试个数和结果不匹配\n".format(len(name_list),len(success_list)))
os.sys.exit() # 强制退出
dict_middle_total = dict(zip(name_list, success_list)) # 删除错误的键值对,并保存到log日志
# 删除无效的键值对
for name in list(dict_middle_total.keys()):
if (len(name) != 11):
writeTolog("Error07:测试用例{}的名字无效或者长度不是11,故删除!\n".format(name))
dict_middle_total.pop(name);
# print(dict_middle_total)
table = None
try:
data = load_workbook(File_xlsx_path)
table = data['测试用例'] # excel中的sheet名字
# print(table)
except IOError:
writeTolog("Error04: 没有找到xlsx文件或读取文件失败,请确认xlsx文件已经关闭!\n")
os.sys.exit() # 强制退出
else:
dict_total = {}
for name in dict_middle_total.keys():
for i in range(3, table.max_row): # 从第3行开始,0,1,2是标题
if (table.cell(row=i,column=2).value == name): # 第2列 中的每个值比较 如 'DRV_0070201'
#取到对应的行数,列都是F列;根据'DRV_0070201' 得到对应的列数
dict_total.update({i:dict_middle_total[name]}) # 重新生成新的键值对
# print("此时的{}对应的行数是{},结果是{}".format(name,rowIndex,dict_middle_total[name]))
break;
else:
continue;
writeTologText.append(dict_middle_total) # 写入日志
writeTologText.append('\n')
writeTologText.append(dict_total) # 写入日志
writeTologText.append('\n')
return dict_total;
def writeToExcel(self,dict_total): # 注意运行程序的时候要关闭Excel,否则无法写入
wb = load_workbook(filename=File_xlsx_path)
ws = wb['测试用例'] # excel中的sheet名字
for key in list(dict_total.keys()): # dict_total[key]
# print("此时F{}的值是{}".format(key,dict_total[key]))
ws[('F' + str(key) )] = dict_total[key] # 类似ws["F86"] = 'Passed'
wb.save(File_xlsx_path)
if __name__ == '__main__':
File_xlsx_path = None;
Filename_log_path = 'resulthtml.log'
if os.path.exists(Filename_log_path): # 清空日志
os.remove(Filename_log_path);
writeTologText = []
myspider = HtmlSpider()
File_html_path_list,File_xlsx_path = myspider.get_current_path()
# 取出的元素已经默认不为空了
for html_path in File_html_path_list:
writeTologText.append("当前处理的文件路径为:"+ html_path + "\n")
success_list, name_list = myspider.get_data(html_path)
dict_total = myspider.readexcel(success_list, name_list,sheetIndex = 2)
myspider.writeToExcel(dict_total)
writeTologText.append("所有html文件内容,已经在{}中设置成功".format(File_xlsx_path))
with open(Filename_log_path, 'a', encoding='utf-8') as f_new: #y一次性写入更快
for logtext in writeTologText:
f_new.write(str(logtext))
3.结果如下:
保存到日志:
4.程序优化,提高运行速度 查看全部
网页表格抓取(
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
python——beautifulSoup提取网页数据写入指定Excel表格
文章内容
1.前言
任务要求:测试报告为HTML格式。我需要在报表中提取相应的结果并将结果写入Excel中的指定位置
2.实现步骤
第一步:获取当前目录下的多个HTML文件
第2步:从HTML中提取指定的结果(用beautifulSoup完成)
第三步:优化内存结构,使用字典保存数据
第四步:将字典数据对应的内容写入Excel
import os
from bs4 import BeautifulSoup # 建议使用beatifulsop进行处理 可能简单
from openpyxl import load_workbook
def writeTolog(logtext): # 写入日志
with open(Filename_log_path, 'a',encoding='utf-8') as f_new:
f_new.write(str(logtext))
class HtmlSpider:
def get_current_path(self): # 应该加个try语句
source_path = os.getcwd();
files = os.listdir(source_path)
File_html_path_list = [];
file_xlsx_path_list = []
try:
for file in files:
# print(file)
if file[-5:] == '.html': # 后缀名相等
File_html_path_list.append(os.path.join(source_path, file))
if file[-5:] == '.xlsx': # excel文件应该只有一个
file_xlsx_path_list.append(os.path.join(source_path, file))
if len(file_xlsx_path_list) == 1:
pass;
else:
writeTolog("Error05:当前一级目录下没有或者有多个Excel文件请确认!\n")
os.sys.exit() # 强制退出
except IOError:
writeTolog("Error00: 没有找到文件或读取文件失败\n")
if File_html_path_list==None:
writeTolog("Error07:当前路径下没有找到后缀为html的文件\n")
os.sys.exit() # 强制退出
return File_html_path_list,file_xlsx_path_list[0];
def read_html(self,html_path):
'''一个发送请求,获取响应,同时etree处理html'''
response = open(html_path,'r',encoding="utf-8") # 读取本地文件
html = response.read() #获取str 类型的html
soup_html = BeautifulSoup(html, 'lxml')
return soup_html
def get_data(self,html_path): #实现主要逻辑
# 1.获取目标网址url
# 2.发送请求获取响应
soup_html = self.read_html(html_path)
h3_list = (soup_html.find_all('h3'))[0:-1:2] # 只取出相关的
# 3.提取数据
success_list= []
for h3 in h3_list:
middle_adjust_str = h3.get('class')
if middle_adjust_str == ['success']:
success_list.append('Passed')
elif(middle_adjust_str == ['fail']):
success_list.append('Failed')
else:
writeTolog("Error01:html网页class标签中请提取class ='success'或者class ='fail'\n")
os.sys.exit() # 强制退出
# print(success_list)
name_list = []
for h3 in h3_list:
middle_3_str = h3.get_text().replace("\n", "").replace(" ","")
middle_2_str = middle_3_str.split('-')[1] # 按照-切割字符串,取第2部分 如DRV_0040201:R档能量回收;滑行出负扭矩
middle_str = middle_2_str.split(':')[0] # 按照英文状态:切割字符串,取第1部分 如DRV_0040201
if len(middle_2_str) == len(middle_str):
writeTolog("Error02:请确认{}里面的-或者:是否是英文状态下的输入\n".format(middle_3_str))
name_list.append(middle_str) #获取文本并去掉换行符
# print((name_list))
return success_list,name_list
def readexcel(self,success_list,name_list,sheetIndex):
if len(success_list) != len(name_list):
writeTolog("Error03:提取测试用例有{}个,但是测试用例的结果有{}个,因此测试个数和结果不匹配\n".format(len(name_list),len(success_list)))
os.sys.exit() # 强制退出
dict_middle_total = dict(zip(name_list, success_list)) # 删除错误的键值对,并保存到log日志
# 删除无效的键值对
for name in list(dict_middle_total.keys()):
if (len(name) != 11):
writeTolog("Error07:测试用例{}的名字无效或者长度不是11,故删除!\n".format(name))
dict_middle_total.pop(name);
# print(dict_middle_total)
table = None
try:
data = load_workbook(File_xlsx_path)
table = data['测试用例'] # excel中的sheet名字
# print(table)
except IOError:
writeTolog("Error04: 没有找到xlsx文件或读取文件失败,请确认xlsx文件已经关闭!\n")
os.sys.exit() # 强制退出
else:
dict_total = {}
for name in dict_middle_total.keys():
for i in range(3, table.max_row): # 从第3行开始,0,1,2是标题
if (table.cell(row=i,column=2).value == name): # 第2列 中的每个值比较 如 'DRV_0070201'
#取到对应的行数,列都是F列;根据'DRV_0070201' 得到对应的列数
dict_total.update({i:dict_middle_total[name]}) # 重新生成新的键值对
# print("此时的{}对应的行数是{},结果是{}".format(name,rowIndex,dict_middle_total[name]))
break;
else:
continue;
writeTologText.append(dict_middle_total) # 写入日志
writeTologText.append('\n')
writeTologText.append(dict_total) # 写入日志
writeTologText.append('\n')
return dict_total;
def writeToExcel(self,dict_total): # 注意运行程序的时候要关闭Excel,否则无法写入
wb = load_workbook(filename=File_xlsx_path)
ws = wb['测试用例'] # excel中的sheet名字
for key in list(dict_total.keys()): # dict_total[key]
# print("此时F{}的值是{}".format(key,dict_total[key]))
ws[('F' + str(key) )] = dict_total[key] # 类似ws["F86"] = 'Passed'
wb.save(File_xlsx_path)
if __name__ == '__main__':
File_xlsx_path = None;
Filename_log_path = 'resulthtml.log'
if os.path.exists(Filename_log_path): # 清空日志
os.remove(Filename_log_path);
writeTologText = []
myspider = HtmlSpider()
File_html_path_list,File_xlsx_path = myspider.get_current_path()
# 取出的元素已经默认不为空了
for html_path in File_html_path_list:
writeTologText.append("当前处理的文件路径为:"+ html_path + "\n")
success_list, name_list = myspider.get_data(html_path)
dict_total = myspider.readexcel(success_list, name_list,sheetIndex = 2)
myspider.writeToExcel(dict_total)
writeTologText.append("所有html文件内容,已经在{}中设置成功".format(File_xlsx_path))
with open(Filename_log_path, 'a', encoding='utf-8') as f_new: #y一次性写入更快
for logtext in writeTologText:
f_new.write(str(logtext))
3.结果如下:
保存到日志:
4.程序优化,提高运行速度
网页表格抓取(Python中_read_()函数也可以提供快捷表格提取需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-10-25 11:06
天山智慧社区地址:/
在获取数据时,很大一部分需求是获取网络上的关系表。
对于表格,R语言和Python都封装了抓取表格的快捷功能。R语言XML包中的readHTMLTables函数封装了提取HTML嵌入表格的功能。rvest 包的 read_table() 函数也可以提供快捷方式。表格提取要求。Python read_html 还提供了直接从 HTML 中提取关系表的功能。
HTML语法中有两种嵌入表格,一种是table,就是通常意义上的表格,另一种是list,可以理解为列表,但是从浏览器呈现的网页的角度来看,两者很难区分,因为在效果上几乎没有区别,但是通过开发者工具的后台代码界面,table和list是两个完全不同的HTML元素。
上面提到的函数是针对HTML文档中的不同标签设计的,所以如果你乱用这些函数来提取表格,很可能会导致那些你认为是表格但实际上是列表的无效。
R语言
library("RCurl")
library("XML")
library("magrittr")
library("rvest")
对于 XML 包,有三个用于提取 HTML 元素的快捷函数。它们用于 HTML 表格元素、列表元素和链接元素。这些快捷功能是:
readHTMLTable() #获取网页表格
readHTMLList() #获取网页列表
getHTMLlinks() #从HTML网页获取链接
读取HTML表格
readHTMLTable(doc,header=TRUE)
#the HTML document which can be a file name or a URL or an
#already parsed HTMLInternalDocument, or an HTML node of class
#XMLInternalElementNode, or a character vector containing the HTML
#content to parse and process.
此功能支持多种 HTML 文档格式。doc 可以是 url 链接、本地 html 文档、解析的 HTMLInternalDocument 组件或提取的 HTML 节点,甚至是收录 HTML 语法元素的字符串向量。
下面是一个案例,也是我在自学爬行的时候爬过的一个网页。以后可能会有改版。很多朋友爬不出来那些代码,问我这是怎么回事。我尝试了以下但没有奏效,但今天我借此机会重新整理了我的想法。
2016年大连空气质量数据可视化~
URL% xml2::url_escape(reserved ="][!$&'()*+,;=:/?@#")
####
关于网址转码,如果你不想使用函数进行编码转换,
可以通过在线转码平台转码后赋值黏贴使用,但是这不是一个好习惯,
在封装程序代码时无法自动化。
#http://tool.oschina.net/encode?type=4
#R语言自带的转码函数URLencode()转码与浏览器转码结果不一致,
所以我找了很多资料,在xml2包里找打了rvest包的url转码函数,
稍微做了修改,现在这个函数你可以放心使用了!(注意里面的保留字)
###
结果竟然是空的,我猜测这个网页一定是近期做过改版,里面加入了一些数据隐藏措施,这样除了浏览器初始化解析可以看到数据表之外,浏览器后台的network请求链接里都看不到具体数据。
mydata% html_table(header=TRUE) %>% `[[`(1)
#关闭remoteDriver对象
remDr$close()
上面两个是等价的,我们得到了完全一样的表数据,数据预览如下:
DT::datatable(mytable)
readHTMLTable 函数和 rvest 函数中的 html_table 都可以读取 HTML 文档中嵌入的表格。它们是很好的高级包解析器,但这并不意味着它们无所不能。
毕竟,聪明的女人做饭没有米饭是很难的。首先,我们需要得到米饭来做饭,所以在读取表格时,最好的方式是先使用请求库请求(RCurl 或 httr),然后使用 readHTMLTable 函数或 html_table 请求返回的 HTML 文档。函数提取表,否则会适得其反。在今天的情况下,浏览器渲染后可以看到完整的表格,然后后台抓取没有内容,没有提供API访问,无法获取完整的html。文档,您应该考虑任何数据隐藏设置。
看到诀窍就好了。既然浏览器可以解析,我就驱动浏览器去获取解析的HTML文档,返回解析的HTML文档。接下来的工作就是使用这些高级函数来提取嵌入的表。
那么selenium服务器+plantomjs无头浏览器对我们有什么作用呢?实际上,它只做一件事——帮助我们做出真实的浏览器请求。这个请求是由plantomjs无头浏览器完成的。帮助我们传输渲染的完整HTML文档,以便我们可以使用readHTMLTable函数或read_table()
在 XML 包中,还有另外两个非常有用的高级包装函数:
一种用于获取链接,一种用于获取列表。
读取HTML列表
获取HTML链接
/空气/
随便找了个天气网站首页,里面有全国各大城市的空气指数数据。这似乎是一张表,但不一定是真的。我们可以使用现有的表函数来试一试。
url% readHTMLTable(header=TRUE)
mylist < url %>% read_html(encoding ="gbk") %>% html_table(header=TRUE) %>% `[[`(1)
NULL
上述代码捕获的内容为空。有两个原因。一是html中的标签根本不是表格格式,可能是列表。在另一种情况下,表数据像前面的示例一样隐藏。看源码就知道,这一段其实是存放在list unordered list中的,所以用readtable肯定不行。现在是 readHTMLList 函数大显身手的时候了。
header% readHTMLList() %>% `[[`(4) %>% .[2:length(.)]
mylist % html_nodes(".thead li") %>% html_text() %>% `[[`(4) %>% .[2:length(.)]
mylist % htmlParse() %>% readHTMLList() %>% `[[`(4)
虽然我成功获得了结果,但我遇到了一个令人讨厌的编码问题。我不想与各种编码智慧作斗争。我再次使用了phantomjs无头浏览器。毕竟,作为浏览器,它始终可以正确解析和呈现 Web 内容。无论 HTML 文档的编码声明有多糟糕!
#cd D:\
#java -jar selenium-server-standalone-3.3.1.jar
#创建一个remoteDriver对象,并打开
library("RSelenium")
remDr % readHTMLList() %>% `[[`(8) %>% .[2:length(.)]
#关闭remoteDriver对象
remDr$close()
这一次,我终于看到了希望。果然,plantomjs浏览器的渲染效果非同凡响!
使用 str_extract() 函数提取城市 id、城市名称、城市污染物指数、污染状况。
library("stringr")
pattern% do.call(rbind,.) %>% .[,1] %>% str_extract("\\d{1,}"),
City = mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,1] %>% str_extract("[\\u4e00-\\u9fa5]{1,}"),
AQI = mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,2] %>% str_extract("\\d{1,}"),
Quity= mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,2] %>% str_extract("[\\u4e00-\\u9fa5]{1,}")
)
DT::datatable(mylist)
最后一个函数是抓取URL链接的高级封装函数,因为在html中,URL标签一般是比较固定的,重定向的URL链接一般在标签的href属性中,图片链接一般在href属性中的标签。
最好在标签下的 src 属性中定位。
随便找个知乎的照片贴,高清图多的那种!
url% getHTMLLinks()
[1] "/" "/" "/explore"
[4] "/topic" "/topic/19551388" "/topic/19555444"
[7] "/topic/19559348" "/topic/19569883" "/topic/19626553"
[10] "/people/geng-da-shan-ren" "/people/geng-da-shan-ren" "/question/35017762/answer/240404907"
[13] "/people/he-xiao-pang-zi-30" "/people/he-xiao-pang-zi-30" "/question/35017762/answer/209942092"
getHTMLLinks(doc, externalOnly = TRUE, xpQuery = “//a/@href”,baseURL = docName(doc), relative = FALSE)
从getHTMLLinks的源码可以看出,这个函数过滤的链接的条件只有标签下href属性中的链接。我们可以通过修改xpQuery中的apath表达式参数来获取图片链接。
mylink % htmlParse() %>% getHTMLLinks(xpQuery = "//img/@data-original")
这样一来,知乎摄影帖的高清图片原地址全部轻松获取,效率高很多。
Python:
如果不需要python中的爬虫工具,我目前知道的表提取工具是pandas中的read_html函数,相当于一个I/O函数(与read_csv、read_table、read_xlsx等其他函数相同) )。同样适用于上述R语言中第一种情况的天气数据。直接使用pd.read_html函数无法获取表格数据。原因是一样的。html文档中有数据隐藏设置。
import pandas as pd
url="https://www.aqistudy.cn/histor ... ot%3B
dfs = pd.read_html(url)
这里我们也是使用Python中的selenium+plantomjs工具来请求网页,得到完整的源文件后,使用pd.read_html函数进行提取。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('https://www.aqistudy.cn/histor ... %2339;)
dfs = pd.read_html(driver.page_source,header=0)[0]
driver.quit()
好吧,它不可能是完美的。对于网页表格数据,pd.read_html函数是一个非常高效的包,但前提是你要保证这个网页中的数据确实是表格格式,并且网页没有做任何隐藏的措施.
更多课程请点击R语言可视化在业务场景中的应用:
往期案例资料请移步我的GitHub:
/ljtyduyu/DataWarehouse/tree/master/File 查看全部
网页表格抓取(Python中_read_()函数也可以提供快捷表格提取需求)
天山智慧社区地址:/
在获取数据时,很大一部分需求是获取网络上的关系表。
对于表格,R语言和Python都封装了抓取表格的快捷功能。R语言XML包中的readHTMLTables函数封装了提取HTML嵌入表格的功能。rvest 包的 read_table() 函数也可以提供快捷方式。表格提取要求。Python read_html 还提供了直接从 HTML 中提取关系表的功能。
HTML语法中有两种嵌入表格,一种是table,就是通常意义上的表格,另一种是list,可以理解为列表,但是从浏览器呈现的网页的角度来看,两者很难区分,因为在效果上几乎没有区别,但是通过开发者工具的后台代码界面,table和list是两个完全不同的HTML元素。
上面提到的函数是针对HTML文档中的不同标签设计的,所以如果你乱用这些函数来提取表格,很可能会导致那些你认为是表格但实际上是列表的无效。
R语言
library("RCurl")
library("XML")
library("magrittr")
library("rvest")
对于 XML 包,有三个用于提取 HTML 元素的快捷函数。它们用于 HTML 表格元素、列表元素和链接元素。这些快捷功能是:
readHTMLTable() #获取网页表格
readHTMLList() #获取网页列表
getHTMLlinks() #从HTML网页获取链接
读取HTML表格
readHTMLTable(doc,header=TRUE)
#the HTML document which can be a file name or a URL or an
#already parsed HTMLInternalDocument, or an HTML node of class
#XMLInternalElementNode, or a character vector containing the HTML
#content to parse and process.
此功能支持多种 HTML 文档格式。doc 可以是 url 链接、本地 html 文档、解析的 HTMLInternalDocument 组件或提取的 HTML 节点,甚至是收录 HTML 语法元素的字符串向量。
下面是一个案例,也是我在自学爬行的时候爬过的一个网页。以后可能会有改版。很多朋友爬不出来那些代码,问我这是怎么回事。我尝试了以下但没有奏效,但今天我借此机会重新整理了我的想法。
2016年大连空气质量数据可视化~
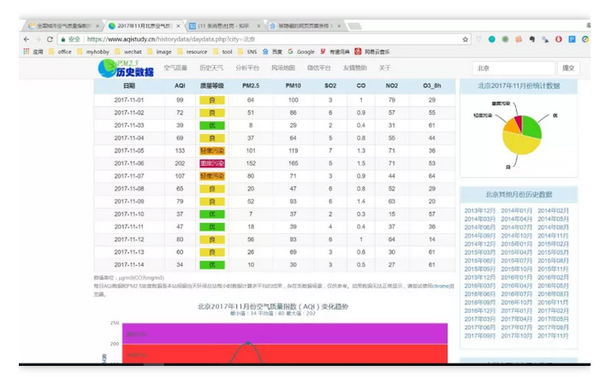
URL% xml2::url_escape(reserved ="][!$&'()*+,;=:/?@#")
####
关于网址转码,如果你不想使用函数进行编码转换,
可以通过在线转码平台转码后赋值黏贴使用,但是这不是一个好习惯,
在封装程序代码时无法自动化。
#http://tool.oschina.net/encode?type=4
#R语言自带的转码函数URLencode()转码与浏览器转码结果不一致,
所以我找了很多资料,在xml2包里找打了rvest包的url转码函数,
稍微做了修改,现在这个函数你可以放心使用了!(注意里面的保留字)
###
结果竟然是空的,我猜测这个网页一定是近期做过改版,里面加入了一些数据隐藏措施,这样除了浏览器初始化解析可以看到数据表之外,浏览器后台的network请求链接里都看不到具体数据。
mydata% html_table(header=TRUE) %>% `[[`(1)
#关闭remoteDriver对象
remDr$close()
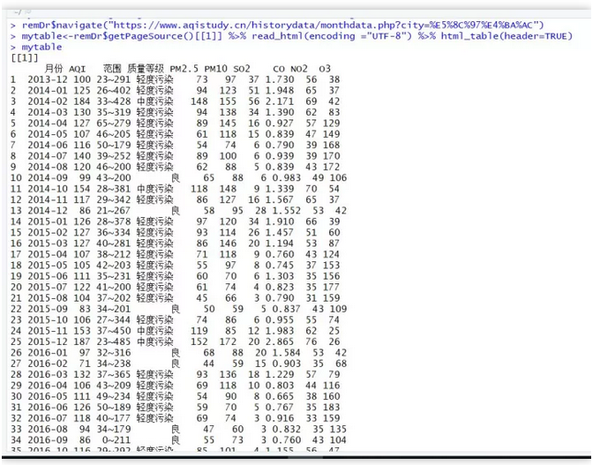
上面两个是等价的,我们得到了完全一样的表数据,数据预览如下:
DT::datatable(mytable)
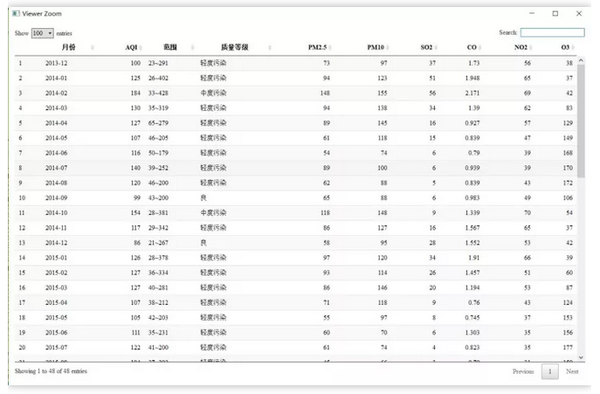
readHTMLTable 函数和 rvest 函数中的 html_table 都可以读取 HTML 文档中嵌入的表格。它们是很好的高级包解析器,但这并不意味着它们无所不能。
毕竟,聪明的女人做饭没有米饭是很难的。首先,我们需要得到米饭来做饭,所以在读取表格时,最好的方式是先使用请求库请求(RCurl 或 httr),然后使用 readHTMLTable 函数或 html_table 请求返回的 HTML 文档。函数提取表,否则会适得其反。在今天的情况下,浏览器渲染后可以看到完整的表格,然后后台抓取没有内容,没有提供API访问,无法获取完整的html。文档,您应该考虑任何数据隐藏设置。
看到诀窍就好了。既然浏览器可以解析,我就驱动浏览器去获取解析的HTML文档,返回解析的HTML文档。接下来的工作就是使用这些高级函数来提取嵌入的表。
那么selenium服务器+plantomjs无头浏览器对我们有什么作用呢?实际上,它只做一件事——帮助我们做出真实的浏览器请求。这个请求是由plantomjs无头浏览器完成的。帮助我们传输渲染的完整HTML文档,以便我们可以使用readHTMLTable函数或read_table()
在 XML 包中,还有另外两个非常有用的高级包装函数:
一种用于获取链接,一种用于获取列表。
读取HTML列表
获取HTML链接
/空气/
随便找了个天气网站首页,里面有全国各大城市的空气指数数据。这似乎是一张表,但不一定是真的。我们可以使用现有的表函数来试一试。
url% readHTMLTable(header=TRUE)
mylist < url %>% read_html(encoding ="gbk") %>% html_table(header=TRUE) %>% `[[`(1)
NULL
上述代码捕获的内容为空。有两个原因。一是html中的标签根本不是表格格式,可能是列表。在另一种情况下,表数据像前面的示例一样隐藏。看源码就知道,这一段其实是存放在list unordered list中的,所以用readtable肯定不行。现在是 readHTMLList 函数大显身手的时候了。
header% readHTMLList() %>% `[[`(4) %>% .[2:length(.)]
mylist % html_nodes(".thead li") %>% html_text() %>% `[[`(4) %>% .[2:length(.)]
mylist % htmlParse() %>% readHTMLList() %>% `[[`(4)
虽然我成功获得了结果,但我遇到了一个令人讨厌的编码问题。我不想与各种编码智慧作斗争。我再次使用了phantomjs无头浏览器。毕竟,作为浏览器,它始终可以正确解析和呈现 Web 内容。无论 HTML 文档的编码声明有多糟糕!
#cd D:\
#java -jar selenium-server-standalone-3.3.1.jar
#创建一个remoteDriver对象,并打开
library("RSelenium")
remDr % readHTMLList() %>% `[[`(8) %>% .[2:length(.)]
#关闭remoteDriver对象
remDr$close()
这一次,我终于看到了希望。果然,plantomjs浏览器的渲染效果非同凡响!
使用 str_extract() 函数提取城市 id、城市名称、城市污染物指数、污染状况。
library("stringr")
pattern% do.call(rbind,.) %>% .[,1] %>% str_extract("\\d{1,}"),
City = mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,1] %>% str_extract("[\\u4e00-\\u9fa5]{1,}"),
AQI = mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,2] %>% str_extract("\\d{1,}"),
Quity= mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,2] %>% str_extract("[\\u4e00-\\u9fa5]{1,}")
)
DT::datatable(mylist)

最后一个函数是抓取URL链接的高级封装函数,因为在html中,URL标签一般是比较固定的,重定向的URL链接一般在标签的href属性中,图片链接一般在href属性中的标签。
最好在标签下的 src 属性中定位。
随便找个知乎的照片贴,高清图多的那种!
url% getHTMLLinks()
[1] "/" "/" "/explore"
[4] "/topic" "/topic/19551388" "/topic/19555444"
[7] "/topic/19559348" "/topic/19569883" "/topic/19626553"
[10] "/people/geng-da-shan-ren" "/people/geng-da-shan-ren" "/question/35017762/answer/240404907"
[13] "/people/he-xiao-pang-zi-30" "/people/he-xiao-pang-zi-30" "/question/35017762/answer/209942092"
getHTMLLinks(doc, externalOnly = TRUE, xpQuery = “//a/@href”,baseURL = docName(doc), relative = FALSE)
从getHTMLLinks的源码可以看出,这个函数过滤的链接的条件只有标签下href属性中的链接。我们可以通过修改xpQuery中的apath表达式参数来获取图片链接。
mylink % htmlParse() %>% getHTMLLinks(xpQuery = "//img/@data-original")
这样一来,知乎摄影帖的高清图片原地址全部轻松获取,效率高很多。
Python:
如果不需要python中的爬虫工具,我目前知道的表提取工具是pandas中的read_html函数,相当于一个I/O函数(与read_csv、read_table、read_xlsx等其他函数相同) )。同样适用于上述R语言中第一种情况的天气数据。直接使用pd.read_html函数无法获取表格数据。原因是一样的。html文档中有数据隐藏设置。
import pandas as pd
url="https://www.aqistudy.cn/histor ... ot%3B
dfs = pd.read_html(url)
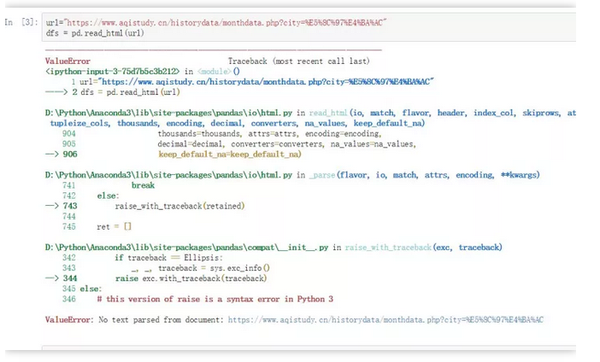
这里我们也是使用Python中的selenium+plantomjs工具来请求网页,得到完整的源文件后,使用pd.read_html函数进行提取。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('https://www.aqistudy.cn/histor ... %2339;)
dfs = pd.read_html(driver.page_source,header=0)[0]
driver.quit()
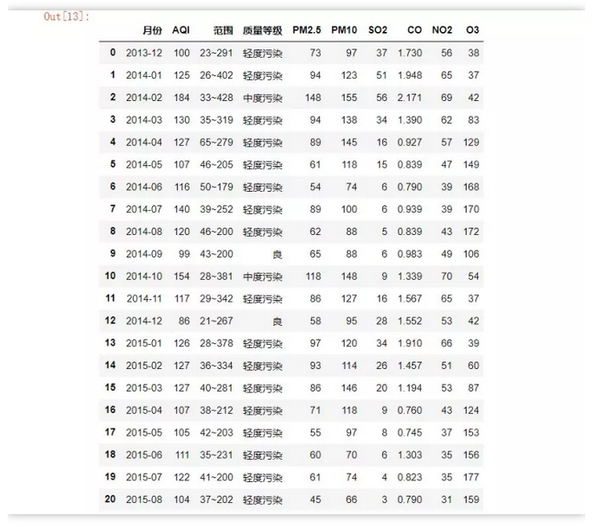
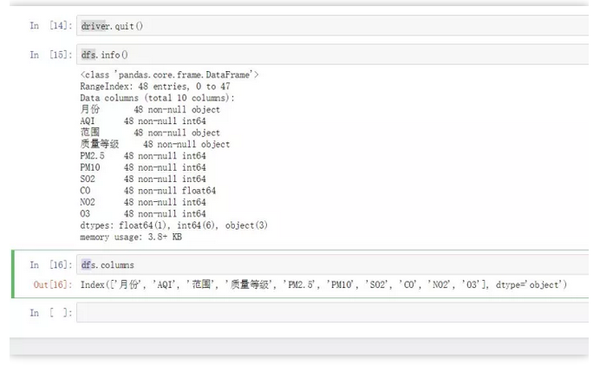
好吧,它不可能是完美的。对于网页表格数据,pd.read_html函数是一个非常高效的包,但前提是你要保证这个网页中的数据确实是表格格式,并且网页没有做任何隐藏的措施.
更多课程请点击R语言可视化在业务场景中的应用:
往期案例资料请移步我的GitHub:
/ljtyduyu/DataWarehouse/tree/master/File
网页表格抓取(pandasread_csv()和pd.read._excel)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-25 01:14
简介
一般爬虫例程无非就是发送请求、获取响应、解析网页、提取数据、保存数据等步骤。 requests库主要用于构造请求,xpath和正则匹配多用于定位和提取数据。对于一个完整的爬虫来说,代码量可以从几十行到几百行不等。对于新手来说,学习成本相对较高。
说到pandas read.xxx系列的功能,常用的读取数据的方法有:pd.read_csv()和pd.read_excel(),而pd.read_html()方法很少使用,但是它的功能很强大,尤其是用来抓取Table数据的时候,简直是神器。无需掌握正则表达式或xpath等工具,只需几行代码即可快速抓取网页数据并保存到本地。
原理
Pandas 适用于爬取 Table 数据。首先,让我们了解一下具有 Table 数据结构的网页。示例如下:
使用Chrome浏览器查看网页的HTML结构,你会发现Table数据有一些共同点。一般网页结构如下所示。
...
...
...
...
...
...
...
...
...
网页有上述结构,我们可以尝试使用pandas的pd.read_html()方法直接获取数据
pd.read_html()的一些主要参数
io:接收 URL、文件、字符串
header:指定列名所在的行
encoding:用于解码网页的编码
attrs:传递一个字典,并使用其中的属性过滤掉特定的表
parse_dates:解析日期
实战
爬取2019年成都空气质量数据(12页数据),目标网址
添加链接描述
import pandas as pd
dates = pd.date_range('20190101', '20191201', freq='MS').strftime('%Y%m') # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f'http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html', encoding='gbk', header=0)[0]
if i == 0:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False) # 追加写入
i += 1
else:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False, header=False)
抓取新浪金融基金重磅股数据(25页数据),网址:
添加链接描述
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f'http://vip.stock.finance.sina. ... Fp%3D{i}'
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv('新浪财经基金重仓股数据.csv', encoding='utf-8', index=False)
表格数据,可以先试试pd.read_html()大法。 查看全部
网页表格抓取(pandasread_csv()和pd.read._excel)
简介
一般爬虫例程无非就是发送请求、获取响应、解析网页、提取数据、保存数据等步骤。 requests库主要用于构造请求,xpath和正则匹配多用于定位和提取数据。对于一个完整的爬虫来说,代码量可以从几十行到几百行不等。对于新手来说,学习成本相对较高。
说到pandas read.xxx系列的功能,常用的读取数据的方法有:pd.read_csv()和pd.read_excel(),而pd.read_html()方法很少使用,但是它的功能很强大,尤其是用来抓取Table数据的时候,简直是神器。无需掌握正则表达式或xpath等工具,只需几行代码即可快速抓取网页数据并保存到本地。
原理
Pandas 适用于爬取 Table 数据。首先,让我们了解一下具有 Table 数据结构的网页。示例如下:


使用Chrome浏览器查看网页的HTML结构,你会发现Table数据有一些共同点。一般网页结构如下所示。
...
...
...
...
...
...
...
...
...
网页有上述结构,我们可以尝试使用pandas的pd.read_html()方法直接获取数据

pd.read_html()的一些主要参数
io:接收 URL、文件、字符串
header:指定列名所在的行
encoding:用于解码网页的编码
attrs:传递一个字典,并使用其中的属性过滤掉特定的表
parse_dates:解析日期
实战
爬取2019年成都空气质量数据(12页数据),目标网址
添加链接描述
import pandas as pd
dates = pd.date_range('20190101', '20191201', freq='MS').strftime('%Y%m') # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f'http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html', encoding='gbk', header=0)[0]
if i == 0:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False) # 追加写入
i += 1
else:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False, header=False)
抓取新浪金融基金重磅股数据(25页数据),网址:
添加链接描述
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f'http://vip.stock.finance.sina. ... Fp%3D{i}'
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv('新浪财经基金重仓股数据.csv', encoding='utf-8', index=False)
表格数据,可以先试试pd.read_html()大法。
网页表格抓取( 这是简易数据分析系列的第11篇文章(图)制作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-24 04:00
这是简易数据分析系列的第11篇文章(图)制作)
这是简单数据分析系列文章的第十一篇。
今天我们讲讲如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
Ϻ &txtDaoDa=
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,这意味着这些列的内容会被默认捕获。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的,加一个空格和一个标点符号就可以了。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
获取数据后,在浏览器的预览面板中预览,会发现车牌号一栏的数据为空,表示没有获取到相关内容:
我们把抓到的CSV文件下载下来,在预览器中打开后,会发现出现了车次的数据,但是出发站的数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键词索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,和其他标签,这些标签提供了默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本就不是原装正品,自然是无法识别的.
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,也不太适合现代网页的匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。 查看全部
网页表格抓取(
这是简易数据分析系列的第11篇文章(图)制作)

这是简单数据分析系列文章的第十一篇。
今天我们讲讲如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
Ϻ &txtDaoDa=
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。

具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。

在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,这意味着这些列的内容会被默认捕获。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:

解决这个错误非常简单。一般来说,Result键名的长度是不够的,加一个空格和一个标点符号就可以了。如果还是报错,尝试改成英文名:

解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
获取数据后,在浏览器的预览面板中预览,会发现车牌号一栏的数据为空,表示没有获取到相关内容:
我们把抓到的CSV文件下载下来,在预览器中打开后,会发现出现了车次的数据,但是出发站的数据又为空了!

这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键词索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,和其他标签,这些标签提供了默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:

为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本就不是原装正品,自然是无法识别的.
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,也不太适合现代网页的匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。
网页表格抓取( 【soup】新三板soup()进阶版(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-24 03:15
【soup】新三板soup()进阶版(一))
爬取最多的数据分析是表类型。需要专注于掌握。
本文介绍四种方法:
一、find_all 方法 (tr, td)
进行如下操作:
1、检查网页元素,观察
右键单击表单并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
可以看到每一行都是一个tr标签,每个内容都在tr下的td标签中。(可以做练习,但实际情况往往没有那么简单,这个页面的所有数据都显示在一个页面上。其实很多数据往往分布在多个不同的页面上,需要调整结果总数显示在每个页面上,或者遍历所有来捕获完整的数据。)
可以看到表格属性:table
2、连接获取网页内容,使用BeautifulSoup处理html数据
# 导入BeautifulSoup、urllib(request、urlopen)
from bs4 import BeautifulSoup as bs
import urllib
import urllib.request
from urllib.request import urlopen
import csv
urpage="https://www.fasttrack.co.uk/le ... ot%3B
page = urlopen(urpage)
soup=bs(page,"html.parser")
可以使用print(soup)查看是否正确获取汤
如果打印出来,可以看到我们要查找的表中的th(表头)有8列。它们是等级、公司、位置等。
3、 遍历汤中的所有元素并将它们存储在变量中
存储可以使用空列表+设置标题+循环追加元素的方法
循环的结构很简单,主要部分如下(通过两个find_all,第一个tr list进行for循环,第二个td分截截取):
results=table.find_all('tr')
for result in results:
data=result.find_all("td")
loca=data[2].getText()
······
rows.append([rank, company, loca, yearend, anual_sales, sales, staff, comments])
完成如下:
## 空列表加表头
rows=[]
rows.append(["rank","company","loca","yearend","anual_sales","sales","staff","comments"])
## 循环存储
table=soup.find("table")
results=table.find_all('tr')
for result in results:
data=result.find_all("td")
if len(data)==0:
continue
rank=data[0].getText()
company=data[1].getText()
## 如需使用纯公司名,需处理成
## company=data[1].find("span",attrs={"class":"company-name"}).getText()
loca=data[2].getText()
yearend=data[3].getText()
anual_sales=data[4].getText()
sales=data[5].getText()
## 处理sales中符号
sales = sales.strip('*').strip('+').replace(',','')
staff=data[6].getText()
comments=data[7].getText()
rows.append([rank, company, loca, yearend, anual_sales, sales, staff, comments])
print(rows)
4、保存到csv
with open('techtrack100.csv','w', newline='',encoding="utf-8") as f_output:
csv_output = csv.writer(f_output)
csv_output.writerows(rows)
二、pandas 库中的 read_html 方法(表类型)
只需不到十行代码,约一分钟就能将4000多家A股上市公司的209页信息一网打尽。与正则表达式、xpath等常规方法相比,省心省力多了。
参数:io 可以是目标 URL,match 是要匹配的正则表达式,flavor 是解析器,header 是指定的行标题,encoding 是要读取的编码格式。只有设置正确才能正确提取表格,否则会出现乱码。
%s 代表页数;a:代表A股,用h代替a,代表港股;用xsb替换a,代表新的第三块板。
import pandas as pd
import csv
for i in range(1,178): # 爬取全部177页数据
url = 'http://s.askci.com/stock/a/%3F ... 39%3B % (str(i))
tb = pd.read_html(url)[3] #经观察发现所需表格是网页中第4个表格,故为[3]
tb.to_csv(r'C:\Users\xxx\Desktop\1.csv', mode='a', encoding='utf_8_sig', header=1, index=0)
print('第'+str(i)+'页抓取完成')
完整的高级版本代码:
# 网页提取函数
def get_one_page(i):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
paras = {
'reportTime': '2019-12-31',
#可以改报告日期,比如2018-6-30获得的就是该季度的信息
'pageNum': i #页码
}
url = 'http://s.askci.com/stock/a/?' + urlencode(paras)
response = requests.get(url,headers = headers)
if response.status_code == 200:
return response.text
return None
except:
print('爬取失败')
# beatutiful soup解析然后提取表格
def parse_one_page(html):
soup = BeautifulSoup(html,'lxml')
content = soup.select('#myTable04')[0] #[0]将返回的list改为bs4类型
tbl = pd.read_html(content.prettify(),header = 0)[0]
# prettify()优化代码,[0]从pd.read_html返回的list中提取出DataFrame
tbl.rename(columns = {'序号':'serial_number', '股票代码':'stock_code', '股票简称':'stock_abbre', '公司名称':'company_name', '省份':'province', '城市':'city', '主营业务收入(201712)':'main_bussiness_income', '净利润(201712)':'net_profit', '员工人数':'employees', '上市日期':'listing_date', '招股书':'zhaogushu', '公司财报':'financial_report', '行业分类':'industry_classification', '产品类型':'industry_type', '主营业务':'main_business'},inplace = True)
print(tbl)
# return tbl
# rename将表格15列的中文名改为英文名,便于存储到mysql及后期进行数据分析
# tbl = pd.DataFrame(tbl,dtype = 'object') #dtype可统一修改列格式为文本
tbl.to_csv(r'C:\Users\xxx\Desktop\2.csv', mode='a',encoding='utf_8_sig', header=1, index=0)
# 主函数
def main(page):
for i in range(1,page): # page表示提取页数
html = get_one_page(i)
parse_one_page(html)
# 单进程
if __name__ == '__main__':
main(200) #共提取n页
快速方便,但缺点是无法读取单元格中的href链接。
三、selenium(可以被JavaScript动态抓取的表)
思路(Selenium基本是“可见,可爬取”):一次爬取所有td节点单元内容,按照表列数划分列表内容
1、 爬取所有td节点,按照表列数拆分成表
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://data.eastmoney.com/bbsj ... %2339;)
element=browser.find_element_by_xpath('//div[@id="dataview"]')
# 提取表格内容td
td_content = element.find_elements_by_tag_name("td") # 进一步定位到表格内容所在的td节点
lst = [] # 存储为list
for td in td_content:
lst.append(td.text)
print(lst) # 输出表格内容
import pandas as pd
# 确定表格列数
col = len(element.find_elements_by_css_selector('tr:nth-child(1) td'))
# 通过定位一行td的数量,可获得表格的列数,然后将list拆分为对应列数的子list
lst = [lst[i:i + col] for i in range(0, len(lst), col)]
# list转为dataframe
df_table = pd.DataFrame(lst)
# 添加url列
# 原网页中打开"详细"链接可以查看更详细的数据,这里我们把url提取出来,方便后期查看
lst_link = []
links = element.find_elements_by_xpath("//a[contains(text(),'详细')]")
for link in links:
url = link.get_attribute('href')
lst_link.append(url)
lst_link = pd.Series(lst_link)
df_table['url'] = lst_link
print(df_table.head()) # 查看DataFrame
四、分析 URL JavaScript 请求
看
参考:
(这位“老农民工”博主写了很多优秀的文章) 查看全部
网页表格抓取(
【soup】新三板soup()进阶版(一))
爬取最多的数据分析是表类型。需要专注于掌握。
本文介绍四种方法:
一、find_all 方法 (tr, td)
进行如下操作:
1、检查网页元素,观察
右键单击表单并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
可以看到每一行都是一个tr标签,每个内容都在tr下的td标签中。(可以做练习,但实际情况往往没有那么简单,这个页面的所有数据都显示在一个页面上。其实很多数据往往分布在多个不同的页面上,需要调整结果总数显示在每个页面上,或者遍历所有来捕获完整的数据。)
可以看到表格属性:table
2、连接获取网页内容,使用BeautifulSoup处理html数据
# 导入BeautifulSoup、urllib(request、urlopen)
from bs4 import BeautifulSoup as bs
import urllib
import urllib.request
from urllib.request import urlopen
import csv
urpage="https://www.fasttrack.co.uk/le ... ot%3B
page = urlopen(urpage)
soup=bs(page,"html.parser")
可以使用print(soup)查看是否正确获取汤
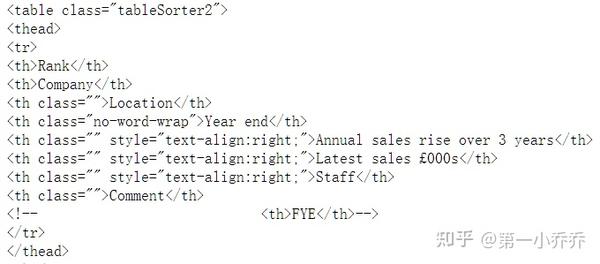
如果打印出来,可以看到我们要查找的表中的th(表头)有8列。它们是等级、公司、位置等。
3、 遍历汤中的所有元素并将它们存储在变量中
存储可以使用空列表+设置标题+循环追加元素的方法
循环的结构很简单,主要部分如下(通过两个find_all,第一个tr list进行for循环,第二个td分截截取):
results=table.find_all('tr')
for result in results:
data=result.find_all("td")
loca=data[2].getText()
······
rows.append([rank, company, loca, yearend, anual_sales, sales, staff, comments])
完成如下:
## 空列表加表头
rows=[]
rows.append(["rank","company","loca","yearend","anual_sales","sales","staff","comments"])
## 循环存储
table=soup.find("table")
results=table.find_all('tr')
for result in results:
data=result.find_all("td")
if len(data)==0:
continue
rank=data[0].getText()
company=data[1].getText()
## 如需使用纯公司名,需处理成
## company=data[1].find("span",attrs={"class":"company-name"}).getText()
loca=data[2].getText()
yearend=data[3].getText()
anual_sales=data[4].getText()
sales=data[5].getText()
## 处理sales中符号
sales = sales.strip('*').strip('+').replace(',','')
staff=data[6].getText()
comments=data[7].getText()
rows.append([rank, company, loca, yearend, anual_sales, sales, staff, comments])
print(rows)
4、保存到csv
with open('techtrack100.csv','w', newline='',encoding="utf-8") as f_output:
csv_output = csv.writer(f_output)
csv_output.writerows(rows)
二、pandas 库中的 read_html 方法(表类型)
只需不到十行代码,约一分钟就能将4000多家A股上市公司的209页信息一网打尽。与正则表达式、xpath等常规方法相比,省心省力多了。
参数:io 可以是目标 URL,match 是要匹配的正则表达式,flavor 是解析器,header 是指定的行标题,encoding 是要读取的编码格式。只有设置正确才能正确提取表格,否则会出现乱码。
%s 代表页数;a:代表A股,用h代替a,代表港股;用xsb替换a,代表新的第三块板。
import pandas as pd
import csv
for i in range(1,178): # 爬取全部177页数据
url = 'http://s.askci.com/stock/a/%3F ... 39%3B % (str(i))
tb = pd.read_html(url)[3] #经观察发现所需表格是网页中第4个表格,故为[3]
tb.to_csv(r'C:\Users\xxx\Desktop\1.csv', mode='a', encoding='utf_8_sig', header=1, index=0)
print('第'+str(i)+'页抓取完成')
完整的高级版本代码:
# 网页提取函数
def get_one_page(i):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
paras = {
'reportTime': '2019-12-31',
#可以改报告日期,比如2018-6-30获得的就是该季度的信息
'pageNum': i #页码
}
url = 'http://s.askci.com/stock/a/?' + urlencode(paras)
response = requests.get(url,headers = headers)
if response.status_code == 200:
return response.text
return None
except:
print('爬取失败')
# beatutiful soup解析然后提取表格
def parse_one_page(html):
soup = BeautifulSoup(html,'lxml')
content = soup.select('#myTable04')[0] #[0]将返回的list改为bs4类型
tbl = pd.read_html(content.prettify(),header = 0)[0]
# prettify()优化代码,[0]从pd.read_html返回的list中提取出DataFrame
tbl.rename(columns = {'序号':'serial_number', '股票代码':'stock_code', '股票简称':'stock_abbre', '公司名称':'company_name', '省份':'province', '城市':'city', '主营业务收入(201712)':'main_bussiness_income', '净利润(201712)':'net_profit', '员工人数':'employees', '上市日期':'listing_date', '招股书':'zhaogushu', '公司财报':'financial_report', '行业分类':'industry_classification', '产品类型':'industry_type', '主营业务':'main_business'},inplace = True)
print(tbl)
# return tbl
# rename将表格15列的中文名改为英文名,便于存储到mysql及后期进行数据分析
# tbl = pd.DataFrame(tbl,dtype = 'object') #dtype可统一修改列格式为文本
tbl.to_csv(r'C:\Users\xxx\Desktop\2.csv', mode='a',encoding='utf_8_sig', header=1, index=0)
# 主函数
def main(page):
for i in range(1,page): # page表示提取页数
html = get_one_page(i)
parse_one_page(html)
# 单进程
if __name__ == '__main__':
main(200) #共提取n页
快速方便,但缺点是无法读取单元格中的href链接。
三、selenium(可以被JavaScript动态抓取的表)
思路(Selenium基本是“可见,可爬取”):一次爬取所有td节点单元内容,按照表列数划分列表内容
1、 爬取所有td节点,按照表列数拆分成表
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://data.eastmoney.com/bbsj ... %2339;)
element=browser.find_element_by_xpath('//div[@id="dataview"]')
# 提取表格内容td
td_content = element.find_elements_by_tag_name("td") # 进一步定位到表格内容所在的td节点
lst = [] # 存储为list
for td in td_content:
lst.append(td.text)
print(lst) # 输出表格内容
import pandas as pd
# 确定表格列数
col = len(element.find_elements_by_css_selector('tr:nth-child(1) td'))
# 通过定位一行td的数量,可获得表格的列数,然后将list拆分为对应列数的子list
lst = [lst[i:i + col] for i in range(0, len(lst), col)]
# list转为dataframe
df_table = pd.DataFrame(lst)
# 添加url列
# 原网页中打开"详细"链接可以查看更详细的数据,这里我们把url提取出来,方便后期查看
lst_link = []
links = element.find_elements_by_xpath("//a[contains(text(),'详细')]")
for link in links:
url = link.get_attribute('href')
lst_link.append(url)
lst_link = pd.Series(lst_link)
df_table['url'] = lst_link
print(df_table.head()) # 查看DataFrame
四、分析 URL JavaScript 请求
看
参考:
(这位“老农民工”博主写了很多优秀的文章)
网页表格抓取(集搜客网络爬虫软件是一款免费的网页数据抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-23 05:21
极手客网络爬虫软件是一款免费的网络数据爬取工具,可将网络内容转化为excel表格,进行内容分析、文本分析、策略分析和文档分析。自动分词、社交网络分析和情感分析软件于研究生设计和行业研究。
网页内容智能抓取的实现和实例详解完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。该应用程序的开源组件包括: DOM4J:解析 XMLjericho-。
优采云网页数据采集器,是一款简单易用、功能强大的网络爬虫工具,完全可视化操作,无需编写代码,内置海量模板,支持任意网页数据抓取,连续五年.
如何爬取不同分页类型的数据网站,因为内容比较多,我会放到本文下一节详细介绍。3.过滤表单类型的网页在网站上比较常见,这种网页最大的特点就是过滤项很多,不同的选择不会加载。
URL就像网站和搜索引擎爬虫之间的桥梁:为了能够抓取你的网站内容,爬虫需要能够找到并跨越这些桥梁(即找到并抓取你的URLs )。如果您的 URL 复杂或冗长。
Content crawling-content 可以从 网站 爬取,以复制依赖该内容的独特产品或服务优势。例如,Yelp 等产品依赖于评论。参赛者可以从Yelp中抓取所有评论,然后将其复制到您自己的网站,并让您自己的网站的内容打开。
《爬虫四步法》教你如何使用Python抓取和存储网页数据。
网页内容提取器可以帮助我们快速提取输入的URL链接中的所有图片、链接和网页文本内容。 查看全部
网页表格抓取(集搜客网络爬虫软件是一款免费的网页数据抓取工具)
极手客网络爬虫软件是一款免费的网络数据爬取工具,可将网络内容转化为excel表格,进行内容分析、文本分析、策略分析和文档分析。自动分词、社交网络分析和情感分析软件于研究生设计和行业研究。
网页内容智能抓取的实现和实例详解完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。该应用程序的开源组件包括: DOM4J:解析 XMLjericho-。
优采云网页数据采集器,是一款简单易用、功能强大的网络爬虫工具,完全可视化操作,无需编写代码,内置海量模板,支持任意网页数据抓取,连续五年.
如何爬取不同分页类型的数据网站,因为内容比较多,我会放到本文下一节详细介绍。3.过滤表单类型的网页在网站上比较常见,这种网页最大的特点就是过滤项很多,不同的选择不会加载。
URL就像网站和搜索引擎爬虫之间的桥梁:为了能够抓取你的网站内容,爬虫需要能够找到并跨越这些桥梁(即找到并抓取你的URLs )。如果您的 URL 复杂或冗长。

Content crawling-content 可以从 网站 爬取,以复制依赖该内容的独特产品或服务优势。例如,Yelp 等产品依赖于评论。参赛者可以从Yelp中抓取所有评论,然后将其复制到您自己的网站,并让您自己的网站的内容打开。
《爬虫四步法》教你如何使用Python抓取和存储网页数据。

网页内容提取器可以帮助我们快速提取输入的URL链接中的所有图片、链接和网页文本内容。
网页表格抓取( 如何利用WebScraper抓取滚动到底翻页的网页?(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-18 14:14
如何利用WebScraper抓取滚动到底翻页的网页?(一)
)
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天的实践网站就是知乎数据分析模块的精髓。该网站是:
本次抓取的内容是精华帖的标题、回复者和批准数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数量控制items数量的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们按照Scrape -> Start Scraping的路径抓取数据,等了十多秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获哪些数据?怎么全都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
1. 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3. 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板,其中收录一些无法理解的彩色代码。
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑,它们是网页中的一个骨架,并提供一些排版功能。
如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树状结构:
上面这句话是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
class='ContentItem-title'/>
itemprop='知乎:question'/> 如何快速成为数据分析师?
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少名为 div 属性为 itemprop='知乎:question' 的标签!
结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题的时候,不管标题的嵌套关系如何变化,总有一个标签保持不变,也就是包裹在最外层的h2标签,属性名class='ContentItem-title' .
如果我们可以直接选择h2标签,是不是就可以完美匹配标题内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据完成的很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小规模的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。
●简单的数据分析(四):Web Scraper抓取多条内容
●简单的数据分析(二):Web Scraper尝鲜者,抢豆瓣高分电影
●简单的数据分析(一):起源,了解Web Scraper和浏览器技巧
·结尾·
图克社区
汇集精彩免费实用教程
查看全部
网页表格抓取(
如何利用WebScraper抓取滚动到底翻页的网页?(一)
)

友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。

今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天的实践网站就是知乎数据分析模块的精髓。该网站是:
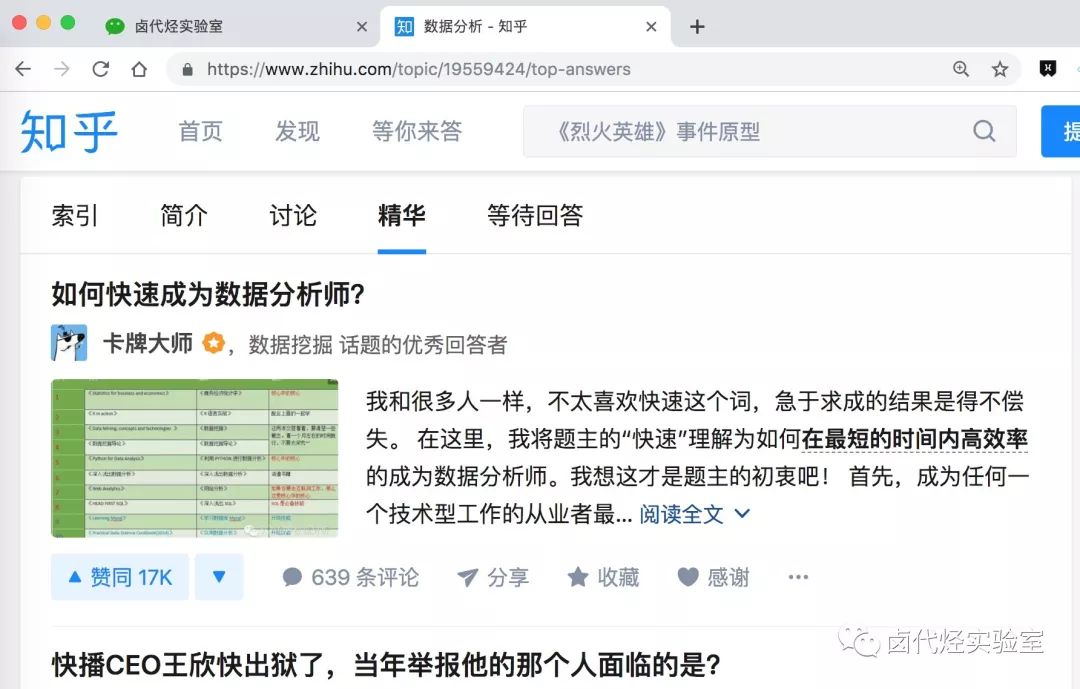
本次抓取的内容是精华帖的标题、回复者和批准数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。

在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数量控制items数量的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
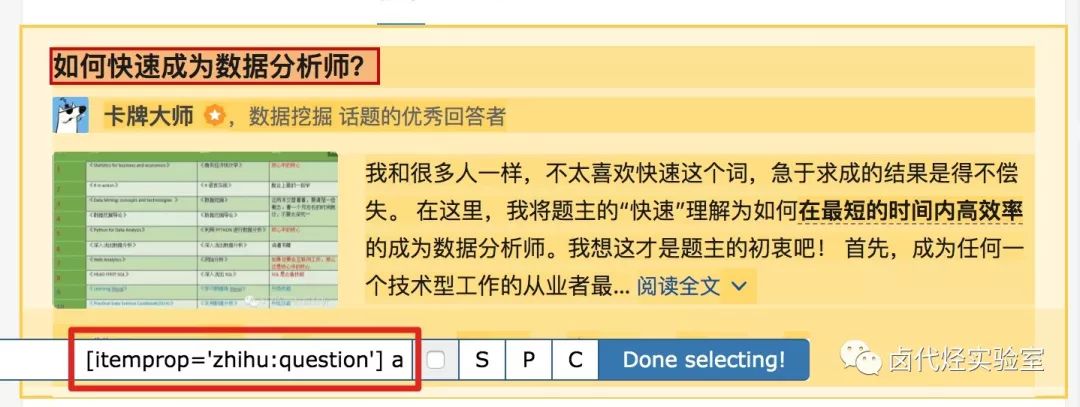
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
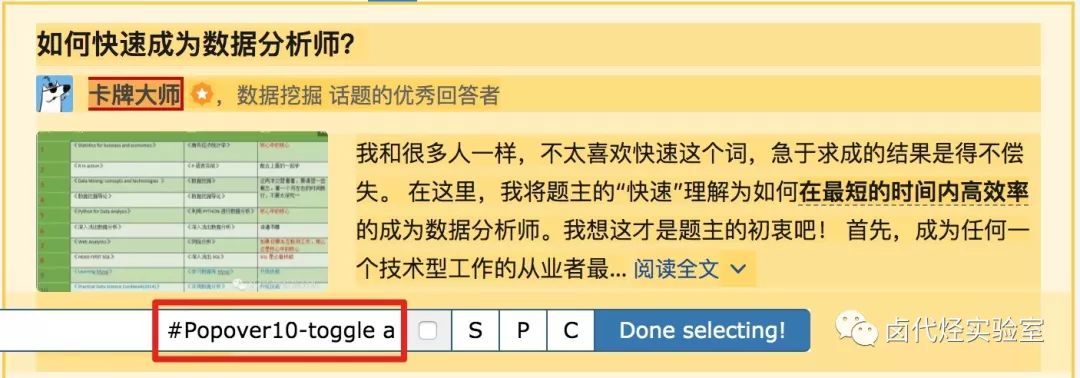

2. 爬取数据,发现问题
元素都选好了,我们按照Scrape -> Start Scraping的路径抓取数据,等了十多秒结果出来后,内容让我们目瞪口呆:

数据呢?我想捕获哪些数据?怎么全都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
1. 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3. 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板,其中收录一些无法理解的彩色代码。
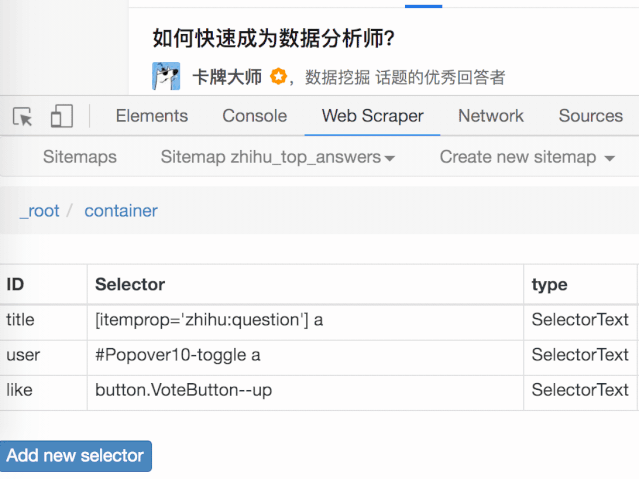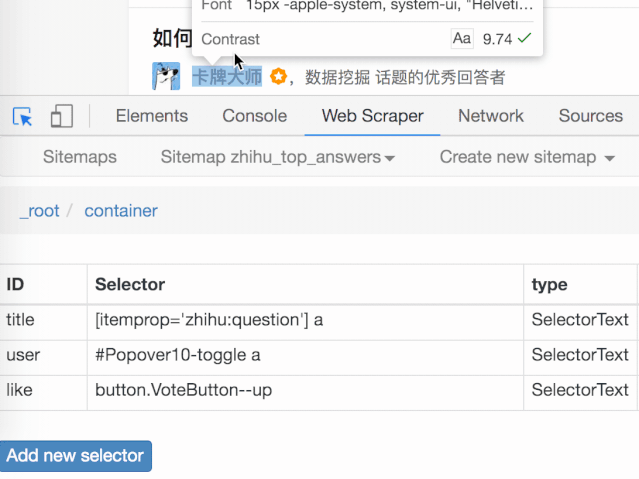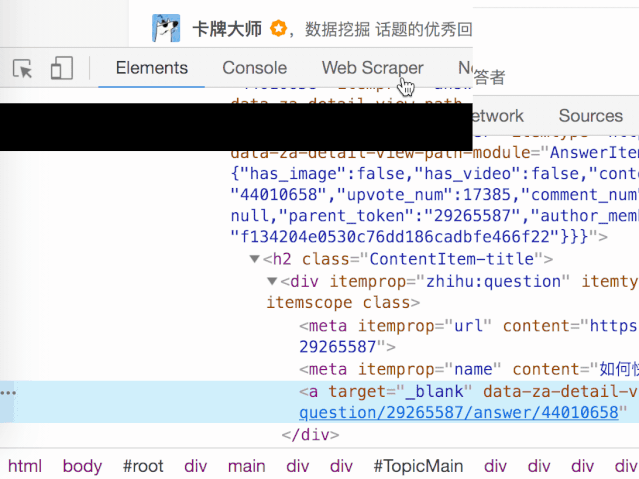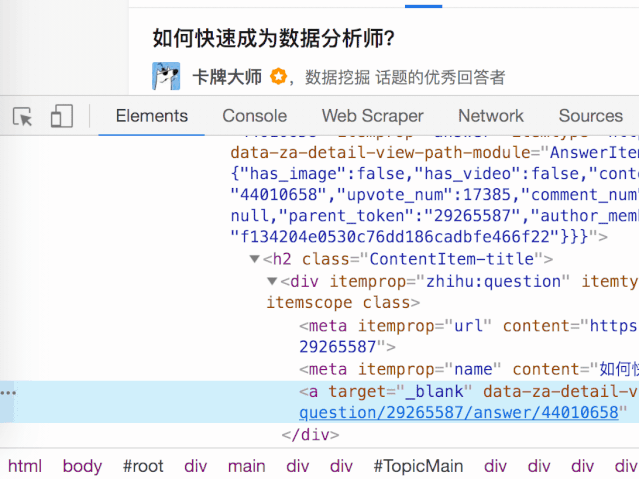
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑,它们是网页中的一个骨架,并提供一些排版功能。
如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
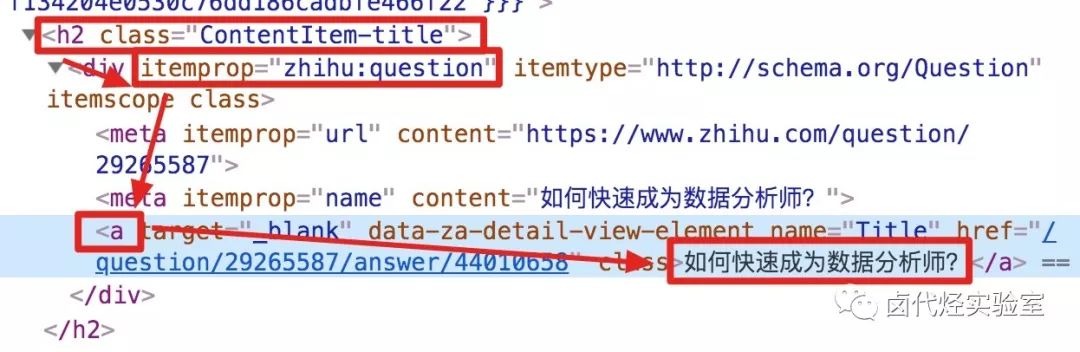
首先,这是一个树状结构:
上面这句话是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
class='ContentItem-title'/>
itemprop='知乎:question'/> 如何快速成为数据分析师?
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少名为 div 属性为 itemprop='知乎:question' 的标签!
结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题的时候,不管标题的嵌套关系如何变化,总有一个标签保持不变,也就是包裹在最外层的h2标签,属性名class='ContentItem-title' .
如果我们可以直接选择h2标签,是不是就可以完美匹配标题内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):

以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。

我的三个子内容的选择器如下,可以作为参考:

最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据完成的很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小规模的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。
●简单的数据分析(四):Web Scraper抓取多条内容
●简单的数据分析(二):Web Scraper尝鲜者,抢豆瓣高分电影
●简单的数据分析(一):起源,了解Web Scraper和浏览器技巧
·结尾·
图克社区
汇集精彩免费实用教程

网页表格抓取(在ASP.NET中表格的显式方法利用JS来取页面表格数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-18 14:13
ASP.NET 中有多种表的显式方法。有html标签、asp服务器控件GridView、Repeater控件等,可以帮助我们在页面上显示表格信息。GridView 控件更强大,它有自己的属性和方法,可用于对显式表数据执行各种操作。但是如果使用传统的html标签或者Repeater控件来显示数据,如何获取选中行的数据呢?这里介绍一下使用JS获取页表数据的方法。
如图,我们需要对表中的数据进行编辑和删除。
以中继器控件为例:
(1)页表:定义表头,设置数据绑定(有些操作需要获取数据的主键,考虑实际情况,我们应该隐藏主键,使用隐藏属性进行对应的列就可以了)。在后台只需要将Repeater绑定到对应的数据源即可,这里我们使用class来标记按钮,这样在JS中就可以把所有同class的按钮作为一组取出. 从而在JS中监听并选择Set对应的行。
1 出货单单头:
2
3
4
5
6 ID
7 客户ID
8 出货人员
9 创建时间
10 更新时间
11 编辑
12 删除
13 新增子信息
14
15
16
17
18
19
20
21
22
23
24 编辑
25
26
27 删除
28
29
30 新增子信息
31
32
33
34
35
(2)JS部分:通过class获取对应的一组按钮并设置监听。然后通过标签名获取选中行,通过标签名获取选中行的所有列数据的集合,转换对应的数据通过DOM操作显示在前台指定位置。
1 /*编辑单头信息*/
2 var Top_Edit = document.getElementsByClassName("Top_Edit");
3
4 for (var i = 0; i < Top_Edit.length; i++) {
5
6 Top_Edit[i].index = i;
7
8 Top_Edit[i].onclick = function () {
9
10 var table = document.getElementById("Top_Table");
11
12 /*获取选中的行 */
13 var child = table.getElementsByTagName("tr")[this.index + 1];
14
15 /*获取选择行的所有列*/
16 var SZ_col = child.getElementsByTagName("td");
17
18 document.getElementById("Edit_id").value = SZ_col[0].innerHTML;
19 document.getElementById("edit_customer").value = SZ_col[1].innerHTML;
20 document.getElementById("edit_man").value = SZ_col[2].innerHTML;
21 document.getElementById("Top_Creat_Time").value = SZ_col[3].innerHTML;
22 document.getElementById("Top_Update_Time").value = SZ_col[4].innerHTML;
23
24 }
25 }
JS 只需简单几步即可获取表格数据。还有其他获取表格数据的方法,比如jQuery,大家可以多尝试,然后比较总结,这也是对程序员自己的一种改进。 查看全部
网页表格抓取(在ASP.NET中表格的显式方法利用JS来取页面表格数据)
ASP.NET 中有多种表的显式方法。有html标签、asp服务器控件GridView、Repeater控件等,可以帮助我们在页面上显示表格信息。GridView 控件更强大,它有自己的属性和方法,可用于对显式表数据执行各种操作。但是如果使用传统的html标签或者Repeater控件来显示数据,如何获取选中行的数据呢?这里介绍一下使用JS获取页表数据的方法。
如图,我们需要对表中的数据进行编辑和删除。
以中继器控件为例:
(1)页表:定义表头,设置数据绑定(有些操作需要获取数据的主键,考虑实际情况,我们应该隐藏主键,使用隐藏属性进行对应的列就可以了)。在后台只需要将Repeater绑定到对应的数据源即可,这里我们使用class来标记按钮,这样在JS中就可以把所有同class的按钮作为一组取出. 从而在JS中监听并选择Set对应的行。
1 出货单单头:
2
3
4
5
6 ID
7 客户ID
8 出货人员
9 创建时间
10 更新时间
11 编辑
12 删除
13 新增子信息
14
15
16
17
18
19
20
21
22
23
24 编辑
25
26
27 删除
28
29
30 新增子信息
31
32
33
34
35
(2)JS部分:通过class获取对应的一组按钮并设置监听。然后通过标签名获取选中行,通过标签名获取选中行的所有列数据的集合,转换对应的数据通过DOM操作显示在前台指定位置。
1 /*编辑单头信息*/
2 var Top_Edit = document.getElementsByClassName("Top_Edit");
3
4 for (var i = 0; i < Top_Edit.length; i++) {
5
6 Top_Edit[i].index = i;
7
8 Top_Edit[i].onclick = function () {
9
10 var table = document.getElementById("Top_Table");
11
12 /*获取选中的行 */
13 var child = table.getElementsByTagName("tr")[this.index + 1];
14
15 /*获取选择行的所有列*/
16 var SZ_col = child.getElementsByTagName("td");
17
18 document.getElementById("Edit_id").value = SZ_col[0].innerHTML;
19 document.getElementById("edit_customer").value = SZ_col[1].innerHTML;
20 document.getElementById("edit_man").value = SZ_col[2].innerHTML;
21 document.getElementById("Top_Creat_Time").value = SZ_col[3].innerHTML;
22 document.getElementById("Top_Update_Time").value = SZ_col[4].innerHTML;
23
24 }
25 }
JS 只需简单几步即可获取表格数据。还有其他获取表格数据的方法,比如jQuery,大家可以多尝试,然后比较总结,这也是对程序员自己的一种改进。
网页表格抓取(ZohoCRM的网站表单功能(免费版也帮你轻松搞定) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-11 02:21
)
有时我们浏览某个网站时,会看到网站上有在线提交信息的表格,比如“问题反馈表”、“参与申请表”等,这就是网站表格。对于企业来说,在他们的官方网站上制作这样一个在线表格,让对产品/服务感兴趣的潜在客户自己提交联系方式和其他信息是非常有用的。不用担心表单制作、发布等问题,Zoho CRM的网站表单功能(免费版也有)可以帮您轻松搞定。
1、设计表单
Zoho CRM 带有 WYSIWYG 编辑器,只需拖放表单中的必填字段即可。您还可以根据需要设置某些字段,使用隐藏字段自动填写附加信息等。您还可以请求添加验证码以过滤垃圾邮件。可以毫不夸张地说,设计可以在几分钟内完成。
2、将表格发布到您的官网或博客等。
Zoho CRM 将自动为表单生成地址。复制并粘贴表单网站(嵌入在iFrame 源代码中)的代码以将其发布到网站。
3、设置规则并轻松分配潜在客户
如果潜在客户通过网站表单提交信息,我们希望该信息能够自动进入CRM系统,并自动分配到指定人员进行跟进。这可以在 Zoho CRM 中设置:
4、 采集客户信息并直接传输到CRM
设置后,在Zoho CRM中可以看到,客户通过表单填写的信息自动进入“线索”模块,CRM系统也根据之前的设置自动分配,并发送通知给销售人员跟进-向上。
查看全部
网页表格抓取(ZohoCRM的网站表单功能(免费版也帮你轻松搞定)
)
有时我们浏览某个网站时,会看到网站上有在线提交信息的表格,比如“问题反馈表”、“参与申请表”等,这就是网站表格。对于企业来说,在他们的官方网站上制作这样一个在线表格,让对产品/服务感兴趣的潜在客户自己提交联系方式和其他信息是非常有用的。不用担心表单制作、发布等问题,Zoho CRM的网站表单功能(免费版也有)可以帮您轻松搞定。
1、设计表单
Zoho CRM 带有 WYSIWYG 编辑器,只需拖放表单中的必填字段即可。您还可以根据需要设置某些字段,使用隐藏字段自动填写附加信息等。您还可以请求添加验证码以过滤垃圾邮件。可以毫不夸张地说,设计可以在几分钟内完成。
2、将表格发布到您的官网或博客等。
Zoho CRM 将自动为表单生成地址。复制并粘贴表单网站(嵌入在iFrame 源代码中)的代码以将其发布到网站。
3、设置规则并轻松分配潜在客户
如果潜在客户通过网站表单提交信息,我们希望该信息能够自动进入CRM系统,并自动分配到指定人员进行跟进。这可以在 Zoho CRM 中设置:
4、 采集客户信息并直接传输到CRM
设置后,在Zoho CRM中可以看到,客户通过表单填写的信息自动进入“线索”模块,CRM系统也根据之前的设置自动分配,并发送通知给销售人员跟进-向上。
网页表格抓取( 一个干净准确的免费在线OCR识别网站:白描网页版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-11-10 08:09
一个干净准确的免费在线OCR识别网站:白描网页版)
高效在线OCR文字识别-线描网页版
很多人都有OCR文字识别的需求,就是从图片中提取出不可编辑的文字,继续后续的处理。使用电脑上的浏览器进行在线OCR文字识别是一种非常方便的方式,无需安装额外的软件。它可以在需要时打开和使用。但是网上的OCR识别网站大多是各种满天飞的广告,识别效果参差不齐。给大家介绍一个干净准确的免费在线OCR识别网站:网页版的线描。
白妙是一款非常知名的手机识别软件。其识别率行业领先。白苗也有网页版。白妙网页版目前收录三个功能:图片文字提取、电子表格识别、扫描PDF转文字。
网页版分为两部分,左边是功能选择区,右边是识别区,可以在电脑上点击按钮选择图片,可以直接将图片拖入识别区,可以直接将图片粘贴到剪贴板中。方便的。
图片文字提取
图片文字提取是OCR文字识别功能,可以快速将图片上的文字转换成可编辑的。和手机白描App一样,可以单独识别,也可以批量识别。最多可同时支持50张图片,可一次性识别。综合所有结果,识别速度和准确率都非常好。
除了直接点击识别功能外,还有简单的图片裁剪功能和按文件名排序功能。
识别结束后,查看识别结果非常方便。左边是原图,右边是识别结果,校对超级方便!您也可以复制或直接导出 DOCX 和 TXT 文件。
电子表格识别
电子表格识别可以轻松地将图片上的表格转换为Excel格式。
识别后,左边也是原图,右边是识别结果,识别出来的表格可以直接在网页上校对编辑。
将 PDF 扫描为文本
很多PDF文件都是由图片组成的扫描PDF文件。提取其上的所有文本非常麻烦。但是,在白线网页版中,您可以直接上传PDF文件并提取所有文本。可以说是非常大方了。
与其他网络版本相比有哪些优势
很多人也知道网上有很多OCR识别网站,画线网版有什么优势呢?
高效准确
网页版使用与画线App相同的高精度识别引擎,确保识别准确度。同时,国产服务器和大带宽也保证了识别速度,保证了高效与准确并存。
无广告
使用过一些OCR在线识别网站的用户都会知道,很多这样的网站都是各种满天飞的广告,广告面积比实际工作区大几倍。线描网页版的整个页面是一个没有任何广告的工作区。登录画线会员账号,即可享受无任何限制的识别体验。
长图识别
线描网页版支持长图识别,包括很长很长的长图。这也是画线App中长图识别的同样体验。
校对和编辑
很多在线OCR网站识别后直接扔回文件,画线App可以轻松校对和左右编辑,包括文本和表格。
与白庙App账号相同
购买一次个人资料会员后,您可以在iOS,Android和Web(以及未来的PC版本)上享受跨平台体验,这并不漂亮。当然,用的少的话,可以免费使用,每天都可以免费使用。
白线网页版地址: 查看全部
网页表格抓取(
一个干净准确的免费在线OCR识别网站:白描网页版)
高效在线OCR文字识别-线描网页版
很多人都有OCR文字识别的需求,就是从图片中提取出不可编辑的文字,继续后续的处理。使用电脑上的浏览器进行在线OCR文字识别是一种非常方便的方式,无需安装额外的软件。它可以在需要时打开和使用。但是网上的OCR识别网站大多是各种满天飞的广告,识别效果参差不齐。给大家介绍一个干净准确的免费在线OCR识别网站:网页版的线描。
白妙是一款非常知名的手机识别软件。其识别率行业领先。白苗也有网页版。白妙网页版目前收录三个功能:图片文字提取、电子表格识别、扫描PDF转文字。
网页版分为两部分,左边是功能选择区,右边是识别区,可以在电脑上点击按钮选择图片,可以直接将图片拖入识别区,可以直接将图片粘贴到剪贴板中。方便的。
图片文字提取
图片文字提取是OCR文字识别功能,可以快速将图片上的文字转换成可编辑的。和手机白描App一样,可以单独识别,也可以批量识别。最多可同时支持50张图片,可一次性识别。综合所有结果,识别速度和准确率都非常好。
除了直接点击识别功能外,还有简单的图片裁剪功能和按文件名排序功能。
识别结束后,查看识别结果非常方便。左边是原图,右边是识别结果,校对超级方便!您也可以复制或直接导出 DOCX 和 TXT 文件。
电子表格识别
电子表格识别可以轻松地将图片上的表格转换为Excel格式。
识别后,左边也是原图,右边是识别结果,识别出来的表格可以直接在网页上校对编辑。
将 PDF 扫描为文本
很多PDF文件都是由图片组成的扫描PDF文件。提取其上的所有文本非常麻烦。但是,在白线网页版中,您可以直接上传PDF文件并提取所有文本。可以说是非常大方了。
与其他网络版本相比有哪些优势
很多人也知道网上有很多OCR识别网站,画线网版有什么优势呢?
高效准确
网页版使用与画线App相同的高精度识别引擎,确保识别准确度。同时,国产服务器和大带宽也保证了识别速度,保证了高效与准确并存。
无广告
使用过一些OCR在线识别网站的用户都会知道,很多这样的网站都是各种满天飞的广告,广告面积比实际工作区大几倍。线描网页版的整个页面是一个没有任何广告的工作区。登录画线会员账号,即可享受无任何限制的识别体验。
长图识别
线描网页版支持长图识别,包括很长很长的长图。这也是画线App中长图识别的同样体验。
校对和编辑
很多在线OCR网站识别后直接扔回文件,画线App可以轻松校对和左右编辑,包括文本和表格。
与白庙App账号相同
购买一次个人资料会员后,您可以在iOS,Android和Web(以及未来的PC版本)上享受跨平台体验,这并不漂亮。当然,用的少的话,可以免费使用,每天都可以免费使用。
白线网页版地址:
网页表格抓取(启动与使用Excalibur运行下面的命令启动:算法前一句命令)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-10 08:08
启动和使用 Excalibur
运行以下命令启动 Excalibur:算法
$ excalibur initdb
$ excalibur webserver
前一个命令是初始化数据库,后一个命令是运行服务器服务。在浏览器中输入::5050 使用平台。
进入PDF表单提取平台,首页如下:数据库
作者测试的PDF收录下表:浏览器
我们将PDF文档上传到上述平台,点击“上传PDF”按钮,然后选择对应的PDF文档和表格所在的页码。PDF上传后,表单所在页面如下图所示:bash
选择右边的Flavor中的“lattice”,用鼠标选择table所在的区域,如下图:
然后点击“查看和下载数据”按钮,获取从PDF解析表中获取的数据。下面的屏幕截图:工具
如果我们还想将这个表的解析结果保存为文件,我们可以在Download旁边的下拉框中选择一种保存格式,然后点击Download按钮。比如作者选择保存为csv文件,下载的文件如下:
"Method","Precision","Recall","F-measure"
"(S1) SP-CCG","67.5","37.2","48.0"
"(S1) SP-CFG","71.1","39.2","50.5"
"(S1) K4","70.3","26.3","38.0"
"(S2) SP-CCG","63.7","41.4","50.2"
"(S2) SP-CFG","65.5","43.8","52.5"
"(S2) K4","67.1","35.0","45.8"
"","Table 5: Extraction Performance on ACE.","",""
我们可以发现表格的分析结果还是很漂亮的。
本次分享到此结束,感谢阅读。
注:本人已开通微信公众号:Python爬虫与算法(微信ID:easy_web_scrape),欢迎关注~~ 查看全部
网页表格抓取(启动与使用Excalibur运行下面的命令启动:算法前一句命令)
启动和使用 Excalibur
运行以下命令启动 Excalibur:算法
$ excalibur initdb
$ excalibur webserver
前一个命令是初始化数据库,后一个命令是运行服务器服务。在浏览器中输入::5050 使用平台。
进入PDF表单提取平台,首页如下:数据库
作者测试的PDF收录下表:浏览器
我们将PDF文档上传到上述平台,点击“上传PDF”按钮,然后选择对应的PDF文档和表格所在的页码。PDF上传后,表单所在页面如下图所示:bash
选择右边的Flavor中的“lattice”,用鼠标选择table所在的区域,如下图:
然后点击“查看和下载数据”按钮,获取从PDF解析表中获取的数据。下面的屏幕截图:工具
如果我们还想将这个表的解析结果保存为文件,我们可以在Download旁边的下拉框中选择一种保存格式,然后点击Download按钮。比如作者选择保存为csv文件,下载的文件如下:
"Method","Precision","Recall","F-measure"
"(S1) SP-CCG","67.5","37.2","48.0"
"(S1) SP-CFG","71.1","39.2","50.5"
"(S1) K4","70.3","26.3","38.0"
"(S2) SP-CCG","63.7","41.4","50.2"
"(S2) SP-CFG","65.5","43.8","52.5"
"(S2) K4","67.1","35.0","45.8"
"","Table 5: Extraction Performance on ACE.","",""
我们可以发现表格的分析结果还是很漂亮的。
本次分享到此结束,感谢阅读。
注:本人已开通微信公众号:Python爬虫与算法(微信ID:easy_web_scrape),欢迎关注~~
网页表格抓取( 还在用收费的工具处理PDF?用Python助力冲破会员牢笼)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-09 23:21
还在用收费的工具处理PDF?用Python助力冲破会员牢笼)
作者:Seon,链接:还在使用付费工具处理 PDF?用Python帮助突破会员牢笼
大家好,我是@无欢不散,资深互联网玩家,Python技术爱好者,喜欢分享硬核技术。
欢迎关注我的专栏:
前言:害的,又要处理PDF文件了。需要的是提取表格,还得请有一定软件会员的同事来操作。没想到会员早就过期了。毕竟不常用,也没有必要给PDF文件充值。以我的码字速度,我可以在输入支付密码之前输入所有内容。但转念一想,PDF自动化的需求还有很多种,比如增删改页面,提取文字图片等等,万一哪天满足了大规模操作的需要,可能就麻烦了。自动化之王(不是)Python 有办法!让我们来看看。
我们先来看看作者遇到的问题。我要处理的是这样一个PDF文件。前几页为正文,文末附有几张表格。其中一张表格跨页分布。如何提取表格?
核心代码只需要两行。打开PDF文件和阅读表格非常方便。
import pdfplumber
pdf = pdfplumber.open("test.pdf")
for i in range(2, 4):
tables = pdf.pages[i].extract_tables()
for t in tables:
print(t)
从输出结果可以看出,它是一种嵌套列表形式,一张表展开后的部分将被识别为另一张表。
[['序列号','标题1','标题2','标题3'], ['1','内容','内容','内容'], ['2','内容', '内容','内容'], ['3','内容','内容','内容']] [['序列号','字段1','字段2','字段3','字段 4 ','字段 5'], ['1','Content','Content','Content','Content','Content'], ['2','Content','Content',' Content' ,'Content','Content'], ['3','Content','Content','Content','Content','Content'], ['4','Content','Content' , '内容','内容','内容'], ['5','content','content','content','content','content']] [['6','content','content','content','content','content'], ['7 ','Content','Content','Content','Content','Content'], ['8','Content','Content','Content','Content','Content'], [ '9','Content','Content','Content','Content','Content'], ['10','Content','Content','Content','Content','Content'] ] [ ['序列号','表头1','表头2','表头3','表头4'], ['1','content','content','content', '内容'], ['2','Content','Content','Content','Content'], ['3','Content','Content','Content','Content'], ['4','Content','content' ,'content','content'], ['5','content','content','content','content']]'Content','Content','Content','Content'], [ '9','Content','Content','Content','Content','Content'], ['10','Content','Content','Content','Content','Content'] ] [['序列号','Header 1','Header 2','Header 3','Header 4'], ['1','Content','Content','Content','Content'] , ['2','内容','内容','内容','内容'], ['3', '内容','内容','内容','内容'], ['4','内容','内容','内容','内容'], ['5','content','content','Content','content']]'Content','Content','Content','Content'], ['9','Content' ,'Content','Content','Content','Content'], ['10','Content','Content','Content','Content','Content']] [['序列号' ,'Header 1','Header 2','Header 3','Header 4'], ['1','Content','Content','Content','Content'], ['2','内容','内容','内容','内容'], ['3', '内容','内容','内容','内容'], ['4','内容','内容','内容','内容'],[' 5','content','content','Content','content']]Content','content','content']] [['序列号','表头1','表头2' ,'table header 3','table header 4'], ['1','content','content','content','content'], ['2','content','content',' content','content'], ['3','content','content', 'Content','Content'], ['4','Content','Content','Content','Content' ], ['5','内容','内容','内容','内容']]内容','内容','内容']] [['序列号','表头1','表头2','表头3','表头4 '], ['1','content','content','content','content'], ['2','content','content','content','content'], ['3 ','content','content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content', '内容','内容','内容']]内容'], ['5','内容','内容','内容','内容']]内容'],['5','内容','内容','内容','内容']]Content','Content']]Content','content','content']] [['序列号','表头1','表头2','表头3','表头4' ], ['1','content','content','content','content'], ['2','content','content','content','content'], ['3' ,'content','content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content',' Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content' ,'内容','内容','内容']]Content','Content']]Content','content','content']] [['序列号','表头1','表头2','表头3','表头4' ], ['1','content','content','content','content'], ['2','content','content','content','content'], ['3' ,'content','content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content',' Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content' ,'内容','内容','内容']],'内容']]内容','内容','内容']] [['序列号','表头1','表头2','表头3','表头4'], ['1','content','content','content','content'],['2','content','content','content','content'],['3',' content','content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content','Content' ,'Content','Content ']]Content'], ['5','content','content','content','content']]Content'], ['5','content','内容','内容','内容']],'内容']]内容','内容','内容']] [['序列号','表头1','表头2','表头3','表头4'], ['1','content','content','content','content'],['2','content','content','content','content'],['3',' content','content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content','Content' ,'Content','Content ']]Content'], ['5','content','content','content','content']]Content'], ['5','content','内容','内容','内容']]]]内容','内容','内容']] [['序列号','表头1','表头2','表头3','表头4'],['1' ,'content','content','content','content'], ['2','content','content','content','content'], ['3','content',' content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content','Content','Content' ,'Content ']]Content'], ['5','content','content','content','content']]Content'], ['5','content','content','内容','内容']]]]内容','内容','内容']] [['序列号','表头1','表头2','表头3','表头4'],['1' ,'content','content','content','content'], ['2','content','content','content','content'], ['3','content',' content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content','Content','Content' ,'Content ']]Content'], ['5','content','content','content','content']]Content'], ['5','content','content','内容','内容']]content']] [['序列号','表头1','表头2','表头3','表头4'],['1','内容','内容',' content','content'], ['2','content','content','content','content'], ['3','content','content', 'Content','Content' ], ['4','Content','Content','Content','Content'], ['5','Content','Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content','content','content','content']]content']] [['序列号','表头1','表头2','表头3','表头4'],['1','内容','内容',' content','content'], ['2','content','content','content','content'], ['3','content','content', 'Content','Content' ], ['4','Content','Content','Content','Content'], ['5','Content','Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content','content','content','content']]表头 2','表头 3','表头 4'], ['1','content','content','content','content'], ['2','content',' content','content','content'], ['3','content','content', 'Content','Content'], ['4','Content','Content','Content' ,'Content'], ['5','Content','Content','Content','Content ']]Content'], ['5','content','content','content',' content']]Content'], ['5','content','content','content','content']]表头 2','表头 3','表头 4'], ['1','content','content','content','content'], ['2','content',' content','content','content'], ['3','content','content', 'Content','Content'], ['4','Content','Content','Content' ,'Content'], ['5','Content','Content','Content','Content ']]Content'], ['5','content','content','content',' content']]Content'], ['5','content','content','content','content']]['2','content','content','content','content'],['3','content','content','Content','Content'],['4','内容','内容','内容','内容'], ['5','内容','内容','内容','内容']]内容'],['5','内容' ,'content','content','content']]Content'], ['5','content','content','content','content']]['2','content','content','content','content'],['3','content','content','Content','Content'],['4','内容','内容','内容','内容'], ['5','内容','内容','内容','内容']]内容'],['5','内容' ,'content','content','content']]Content'], ['5','content','content','content','content']]Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content' ,'内容','内容','内容']]Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content' ,'内容','内容','内容']]
那就用legend可以让EXCEL飞起来的xlwings库来写数据吧!对代码稍作修改,详情见注释。
import pdfplumber
import xlwings as xw
wb = xw.books.active # 连接到活动的工作簿
sht = wb.sheets['Sheet1'] # 连接子表1
n = 1
pdf = pdfplumber.open("test.pdf") # 打开PDF
for i in range(2, 4):
tables = pdf.pages[i].extract_tables() # 获取第3、4页的表格
for t in tables:
for row in t:
if '序号' in row and n>1:
n += 1 # 不同表格之间隔一行
sht.range(f'A{n}').value = row # 将表格的一行从A1单元格开始写入
n += 1 # 换行
果然,这种肉眼可见的效果,比其他保存表格前在内存中执行的EXCEL处理库更让人享受。您还可以使用 xlwings 为每个表格添加边框、粗体标题等。我不会在这里详细介绍。有兴趣的同学可以自行探索。本文的主角是PDF处理库。
pdfplumber 是一款基于pdfminer.six 的PDF 内容提取工具。和之前的体验一样,操作很简单。遗憾的是,它专门用于识别,不能直接修改和保存PDF。如果有比较复杂的需求,可以学习pdfminer,但是需要了解PDF文件模型,学习难度大。
官网:/jsvine/pdfplumber
PyPDF2也是著名的PDF页面级处理工具。它更擅长分割、合并、裁剪和转换页面,但缺乏提取内容的能力。
官网:/PyPDF2
让我们从常见的 PDF 操作中了解这两个!
1、插入/添加页面
让我们准备另一个 PDF 文件用于插入实验。
PyPDF2 使用阅读器来操作 PDF 文件。如果想在第一页之后插入一个页面,需要通过Reader对象的getPage方法获取该页面,然后通过Writer对象的addPage方法添加该页面,最后写入文件流。
from PyPDF2 import PdfFileWriter, PdfFileReader
output = PdfFileWriter()
input = PdfFileReader(open("test.pdf", "rb"))
insert = PdfFileReader(open("insert.pdf", "rb"))
for i in range(0, 4):
output.addPage(input.getPage(i))
if i ==0:
output.addPage(insert.getPage(0))
output.write(open("output.pdf", "wb"))
2、选择/删除页面
通过插入页面,相信大家已经可以想到一种选择/删除页面的方法,即选择需要的页面索引来添加页面。例如,在上一步中只为 output.pdf 保留了第 1 页和第 3 页。
from PyPDF2 import PdfFileWriter, PdfFileReader
new_output = PdfFileWriter()
input = PdfFileReader(open("output.pdf", "rb"))
for i in range(0, 4):
if i==0 or i==2:
new_output.addPage(input.getPage(i))
new_output.write(open("new_output.pdf", "wb"))
3、提取文本信息
不得不说pdfplumber非常精炼,用非常直观的句子就可以实现。可以通过页面对象的extract_text 方法提取文本。需要注意的是pdfplumber只能提取原生内容。如果是图片,则需要使用OCR工具。
import pdfplumber
pdf = pdfplumber.open("test.pdf")
pages = pdf.pages
for p in pages:
print(p.extract_text())
1 1 1 2 2 2 3 3 3 表1 序号标题1 标题2 标题3 1 内容内容内容2 内容内容内容3 内容内容内容表二......4、提取表单信息
之前我使用extract_tables()批量提取表。我们也可以通过extract_table()来提取指定页面上的表,然后加载到DataFrame中进行后续的分析操作。
import pdfplumber
import pandas as pd
pdf = pdfplumber.open("test.pdf")
table = pdf.pages[2].extract_table()
df = pd.DataFrame(table[1:], columns=table[0])
print(df)
但事实证明它提取了页面的第二个表。不是默认提取页面中的第一个表吗?
查阅官方资料得知extract_table()返回的是页面最大的表。如果多个表格具有相同的大小(以单元格数衡量),则返回最靠近页面顶部的表格。
5、提取图片信息
接下来,我们将为提取实验准备一个带有图片的PDF文件。
根据官方提示,如果要进行可视化操作,需要安装两个依赖工具。(另外作者发现还有其他库可以提取PDF的图像元素或者将PDF页面转换成图像,比如PyMuPDF、pdf2image等,可以扩展学习)
安装地址如下,注意选择python对应的版本。
/script/download.php#windows /download/gsdnld.html
图片参数列表可以通过页面对象的images属性获取。这里我们只有一张图片,获取其图片流数据写入文件,成功提取图片。
import pdfplumber
pdf_pic = pdfplumber.open("picture.pdf")
page = pdf_pic.pages[0]
img = page.images
data = img[0]['stream'].get_data()
with open('pic.png', 'wb') as f:
f.write(data)
同时,我们也可以验证提取图片中的文字和表格,发现是不可行的。
print(page.extract_text())
print(page.extract_table())
我是文字无6、 页面转图片
除了提取页面中的图片元素外,还可以将整个页面转换成图片输出。让我们换回原创 PDF 进行实验。page对象有to_image方法,比单个元素的操作简单。
import pdfplumber
pdf = pdfplumber.open("test.pdf")
pages = pdf.pages
for i, p in enumerate(pages):
p.to_image().save(f"第{i+1}页.png", format="PNG")
之后,我们还可以将多张图片连接到增长图表,适合移动查看。
from os import listdir
from PIL import Image
imgs = [Image.open(f) for f in listdir('.') if f.endswith('.png')] # 获取当前目录下的图像
width, height = imgs[0].size # 单幅图像尺寸
result = Image.new(imgs[0].mode, (width, height * len(imgs))) # 创建空白长图
for i, im in enumerate(imgs): # 拼接图片
result.paste(im, box=(0, i * height))
result.save('长条图.png')
本文通过一个实战案例和6个小操作演示了两个PDF库的基本功能,还有很多隐藏属性等着我们去探索,比如加水印、加解密等,还不快来自己开发一个PDF工具来收费?致富指日可待!
本文版权归原作者所有。如果您对内容的版权有任何疑问,请与我联系。本文仅供交流学习之用。
我的热门文章,也许你会感兴趣:
学好Python,这篇文章就够了(入门|基础|进阶|实战)-知乎()
神器pypandoc-实现电子书的自由-知乎()
半夜用Python爬取严选的文胸数据,发现一个惊天秘密-知乎()
为了打击不公,我用Python爬取了选中的男性内衣数据,结果...-知乎 ()
我的热门回答,也许你可以看看:
你用 Python 写过哪些有趣的脚本?-知乎 ()
哪些 Python 库让你们迟到了彼此讨厌?-知乎 ()
你们都用python做什么(全职程序员除外)?-知乎 ()
Python 新手如何快速入门?-知乎 () 查看全部
网页表格抓取(
还在用收费的工具处理PDF?用Python助力冲破会员牢笼)
作者:Seon,链接:还在使用付费工具处理 PDF?用Python帮助突破会员牢笼
大家好,我是@无欢不散,资深互联网玩家,Python技术爱好者,喜欢分享硬核技术。
欢迎关注我的专栏:
前言:害的,又要处理PDF文件了。需要的是提取表格,还得请有一定软件会员的同事来操作。没想到会员早就过期了。毕竟不常用,也没有必要给PDF文件充值。以我的码字速度,我可以在输入支付密码之前输入所有内容。但转念一想,PDF自动化的需求还有很多种,比如增删改页面,提取文字图片等等,万一哪天满足了大规模操作的需要,可能就麻烦了。自动化之王(不是)Python 有办法!让我们来看看。
我们先来看看作者遇到的问题。我要处理的是这样一个PDF文件。前几页为正文,文末附有几张表格。其中一张表格跨页分布。如何提取表格?
核心代码只需要两行。打开PDF文件和阅读表格非常方便。
import pdfplumber
pdf = pdfplumber.open("test.pdf")
for i in range(2, 4):
tables = pdf.pages[i].extract_tables()
for t in tables:
print(t)
从输出结果可以看出,它是一种嵌套列表形式,一张表展开后的部分将被识别为另一张表。
[['序列号','标题1','标题2','标题3'], ['1','内容','内容','内容'], ['2','内容', '内容','内容'], ['3','内容','内容','内容']] [['序列号','字段1','字段2','字段3','字段 4 ','字段 5'], ['1','Content','Content','Content','Content','Content'], ['2','Content','Content',' Content' ,'Content','Content'], ['3','Content','Content','Content','Content','Content'], ['4','Content','Content' , '内容','内容','内容'], ['5','content','content','content','content','content']] [['6','content','content','content','content','content'], ['7 ','Content','Content','Content','Content','Content'], ['8','Content','Content','Content','Content','Content'], [ '9','Content','Content','Content','Content','Content'], ['10','Content','Content','Content','Content','Content'] ] [ ['序列号','表头1','表头2','表头3','表头4'], ['1','content','content','content', '内容'], ['2','Content','Content','Content','Content'], ['3','Content','Content','Content','Content'], ['4','Content','content' ,'content','content'], ['5','content','content','content','content']]'Content','Content','Content','Content'], [ '9','Content','Content','Content','Content','Content'], ['10','Content','Content','Content','Content','Content'] ] [['序列号','Header 1','Header 2','Header 3','Header 4'], ['1','Content','Content','Content','Content'] , ['2','内容','内容','内容','内容'], ['3', '内容','内容','内容','内容'], ['4','内容','内容','内容','内容'], ['5','content','content','Content','content']]'Content','Content','Content','Content'], ['9','Content' ,'Content','Content','Content','Content'], ['10','Content','Content','Content','Content','Content']] [['序列号' ,'Header 1','Header 2','Header 3','Header 4'], ['1','Content','Content','Content','Content'], ['2','内容','内容','内容','内容'], ['3', '内容','内容','内容','内容'], ['4','内容','内容','内容','内容'],[' 5','content','content','Content','content']]Content','content','content']] [['序列号','表头1','表头2' ,'table header 3','table header 4'], ['1','content','content','content','content'], ['2','content','content',' content','content'], ['3','content','content', 'Content','Content'], ['4','Content','Content','Content','Content' ], ['5','内容','内容','内容','内容']]内容','内容','内容']] [['序列号','表头1','表头2','表头3','表头4 '], ['1','content','content','content','content'], ['2','content','content','content','content'], ['3 ','content','content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content', '内容','内容','内容']]内容'], ['5','内容','内容','内容','内容']]内容'],['5','内容','内容','内容','内容']]Content','Content']]Content','content','content']] [['序列号','表头1','表头2','表头3','表头4' ], ['1','content','content','content','content'], ['2','content','content','content','content'], ['3' ,'content','content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content',' Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content' ,'内容','内容','内容']]Content','Content']]Content','content','content']] [['序列号','表头1','表头2','表头3','表头4' ], ['1','content','content','content','content'], ['2','content','content','content','content'], ['3' ,'content','content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content',' Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content' ,'内容','内容','内容']],'内容']]内容','内容','内容']] [['序列号','表头1','表头2','表头3','表头4'], ['1','content','content','content','content'],['2','content','content','content','content'],['3',' content','content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content','Content' ,'Content','Content ']]Content'], ['5','content','content','content','content']]Content'], ['5','content','内容','内容','内容']],'内容']]内容','内容','内容']] [['序列号','表头1','表头2','表头3','表头4'], ['1','content','content','content','content'],['2','content','content','content','content'],['3',' content','content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content','Content' ,'Content','Content ']]Content'], ['5','content','content','content','content']]Content'], ['5','content','内容','内容','内容']]]]内容','内容','内容']] [['序列号','表头1','表头2','表头3','表头4'],['1' ,'content','content','content','content'], ['2','content','content','content','content'], ['3','content',' content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content','Content','Content' ,'Content ']]Content'], ['5','content','content','content','content']]Content'], ['5','content','content','内容','内容']]]]内容','内容','内容']] [['序列号','表头1','表头2','表头3','表头4'],['1' ,'content','content','content','content'], ['2','content','content','content','content'], ['3','content',' content', 'Content','Content'], ['4','Content','Content','Content','Content'], ['5','Content','Content','Content' ,'Content ']]Content'], ['5','content','content','content','content']]Content'], ['5','content','content','内容','内容']]content']] [['序列号','表头1','表头2','表头3','表头4'],['1','内容','内容',' content','content'], ['2','content','content','content','content'], ['3','content','content', 'Content','Content' ], ['4','Content','Content','Content','Content'], ['5','Content','Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content','content','content','content']]content']] [['序列号','表头1','表头2','表头3','表头4'],['1','内容','内容',' content','content'], ['2','content','content','content','content'], ['3','content','content', 'Content','Content' ], ['4','Content','Content','Content','Content'], ['5','Content','Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content','content','content','content']]表头 2','表头 3','表头 4'], ['1','content','content','content','content'], ['2','content',' content','content','content'], ['3','content','content', 'Content','Content'], ['4','Content','Content','Content' ,'Content'], ['5','Content','Content','Content','Content ']]Content'], ['5','content','content','content',' content']]Content'], ['5','content','content','content','content']]表头 2','表头 3','表头 4'], ['1','content','content','content','content'], ['2','content',' content','content','content'], ['3','content','content', 'Content','Content'], ['4','Content','Content','Content' ,'Content'], ['5','Content','Content','Content','Content ']]Content'], ['5','content','content','content',' content']]Content'], ['5','content','content','content','content']]['2','content','content','content','content'],['3','content','content','Content','Content'],['4','内容','内容','内容','内容'], ['5','内容','内容','内容','内容']]内容'],['5','内容' ,'content','content','content']]Content'], ['5','content','content','content','content']]['2','content','content','content','content'],['3','content','content','Content','Content'],['4','内容','内容','内容','内容'], ['5','内容','内容','内容','内容']]内容'],['5','内容' ,'content','content','content']]Content'], ['5','content','content','content','content']]Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content' ,'内容','内容','内容']]Content','Content','Content']]Content'], ['5','content','content','content','content']]Content'], ['5','content' ,'内容','内容','内容']]
那就用legend可以让EXCEL飞起来的xlwings库来写数据吧!对代码稍作修改,详情见注释。
import pdfplumber
import xlwings as xw
wb = xw.books.active # 连接到活动的工作簿
sht = wb.sheets['Sheet1'] # 连接子表1
n = 1
pdf = pdfplumber.open("test.pdf") # 打开PDF
for i in range(2, 4):
tables = pdf.pages[i].extract_tables() # 获取第3、4页的表格
for t in tables:
for row in t:
if '序号' in row and n>1:
n += 1 # 不同表格之间隔一行
sht.range(f'A{n}').value = row # 将表格的一行从A1单元格开始写入
n += 1 # 换行
果然,这种肉眼可见的效果,比其他保存表格前在内存中执行的EXCEL处理库更让人享受。您还可以使用 xlwings 为每个表格添加边框、粗体标题等。我不会在这里详细介绍。有兴趣的同学可以自行探索。本文的主角是PDF处理库。
pdfplumber 是一款基于pdfminer.six 的PDF 内容提取工具。和之前的体验一样,操作很简单。遗憾的是,它专门用于识别,不能直接修改和保存PDF。如果有比较复杂的需求,可以学习pdfminer,但是需要了解PDF文件模型,学习难度大。
官网:/jsvine/pdfplumber
PyPDF2也是著名的PDF页面级处理工具。它更擅长分割、合并、裁剪和转换页面,但缺乏提取内容的能力。
官网:/PyPDF2
让我们从常见的 PDF 操作中了解这两个!
1、插入/添加页面
让我们准备另一个 PDF 文件用于插入实验。
PyPDF2 使用阅读器来操作 PDF 文件。如果想在第一页之后插入一个页面,需要通过Reader对象的getPage方法获取该页面,然后通过Writer对象的addPage方法添加该页面,最后写入文件流。
from PyPDF2 import PdfFileWriter, PdfFileReader
output = PdfFileWriter()
input = PdfFileReader(open("test.pdf", "rb"))
insert = PdfFileReader(open("insert.pdf", "rb"))
for i in range(0, 4):
output.addPage(input.getPage(i))
if i ==0:
output.addPage(insert.getPage(0))
output.write(open("output.pdf", "wb"))
2、选择/删除页面
通过插入页面,相信大家已经可以想到一种选择/删除页面的方法,即选择需要的页面索引来添加页面。例如,在上一步中只为 output.pdf 保留了第 1 页和第 3 页。
from PyPDF2 import PdfFileWriter, PdfFileReader
new_output = PdfFileWriter()
input = PdfFileReader(open("output.pdf", "rb"))
for i in range(0, 4):
if i==0 or i==2:
new_output.addPage(input.getPage(i))
new_output.write(open("new_output.pdf", "wb"))
3、提取文本信息
不得不说pdfplumber非常精炼,用非常直观的句子就可以实现。可以通过页面对象的extract_text 方法提取文本。需要注意的是pdfplumber只能提取原生内容。如果是图片,则需要使用OCR工具。
import pdfplumber
pdf = pdfplumber.open("test.pdf")
pages = pdf.pages
for p in pages:
print(p.extract_text())
1 1 1 2 2 2 3 3 3 表1 序号标题1 标题2 标题3 1 内容内容内容2 内容内容内容3 内容内容内容表二......4、提取表单信息
之前我使用extract_tables()批量提取表。我们也可以通过extract_table()来提取指定页面上的表,然后加载到DataFrame中进行后续的分析操作。
import pdfplumber
import pandas as pd
pdf = pdfplumber.open("test.pdf")
table = pdf.pages[2].extract_table()
df = pd.DataFrame(table[1:], columns=table[0])
print(df)
但事实证明它提取了页面的第二个表。不是默认提取页面中的第一个表吗?
查阅官方资料得知extract_table()返回的是页面最大的表。如果多个表格具有相同的大小(以单元格数衡量),则返回最靠近页面顶部的表格。
5、提取图片信息
接下来,我们将为提取实验准备一个带有图片的PDF文件。
根据官方提示,如果要进行可视化操作,需要安装两个依赖工具。(另外作者发现还有其他库可以提取PDF的图像元素或者将PDF页面转换成图像,比如PyMuPDF、pdf2image等,可以扩展学习)
安装地址如下,注意选择python对应的版本。
/script/download.php#windows /download/gsdnld.html
图片参数列表可以通过页面对象的images属性获取。这里我们只有一张图片,获取其图片流数据写入文件,成功提取图片。
import pdfplumber
pdf_pic = pdfplumber.open("picture.pdf")
page = pdf_pic.pages[0]
img = page.images
data = img[0]['stream'].get_data()
with open('pic.png', 'wb') as f:
f.write(data)
同时,我们也可以验证提取图片中的文字和表格,发现是不可行的。
print(page.extract_text())
print(page.extract_table())
我是文字无6、 页面转图片
除了提取页面中的图片元素外,还可以将整个页面转换成图片输出。让我们换回原创 PDF 进行实验。page对象有to_image方法,比单个元素的操作简单。
import pdfplumber
pdf = pdfplumber.open("test.pdf")
pages = pdf.pages
for i, p in enumerate(pages):
p.to_image().save(f"第{i+1}页.png", format="PNG")
之后,我们还可以将多张图片连接到增长图表,适合移动查看。
from os import listdir
from PIL import Image
imgs = [Image.open(f) for f in listdir('.') if f.endswith('.png')] # 获取当前目录下的图像
width, height = imgs[0].size # 单幅图像尺寸
result = Image.new(imgs[0].mode, (width, height * len(imgs))) # 创建空白长图
for i, im in enumerate(imgs): # 拼接图片
result.paste(im, box=(0, i * height))
result.save('长条图.png')
本文通过一个实战案例和6个小操作演示了两个PDF库的基本功能,还有很多隐藏属性等着我们去探索,比如加水印、加解密等,还不快来自己开发一个PDF工具来收费?致富指日可待!
本文版权归原作者所有。如果您对内容的版权有任何疑问,请与我联系。本文仅供交流学习之用。
我的热门文章,也许你会感兴趣:
学好Python,这篇文章就够了(入门|基础|进阶|实战)-知乎()
神器pypandoc-实现电子书的自由-知乎()
半夜用Python爬取严选的文胸数据,发现一个惊天秘密-知乎()
为了打击不公,我用Python爬取了选中的男性内衣数据,结果...-知乎 ()
我的热门回答,也许你可以看看:
你用 Python 写过哪些有趣的脚本?-知乎 ()
哪些 Python 库让你们迟到了彼此讨厌?-知乎 ()
你们都用python做什么(全职程序员除外)?-知乎 ()
Python 新手如何快速入门?-知乎 ()
网页表格抓取(2017年成都会计从业资格考试:谈及pandasread_html)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-09 12:13
过去的一切都是序幕。
真正的放手不是试图强迫它,而不仅仅是不作为。
文章内容
一、简介
一般爬虫例程无非就是发送请求、获取响应、解析网页、提取数据、保存数据等步骤。 requests库主要用于构造请求,xpath和正则匹配多用于定位和提取数据。对于一个完整的爬虫来说,代码量可以从几十行到几百行不等。对于新手来说,学习成本相对较高。
说到pandas read.xxx系列的功能,常用的读取数据的方法有:pd.read_csv()和pd.read_excel(),而pd.read_html()方法很少使用,但是它的功能很强大,尤其是用来抓取Table数据的时候,简直是神器。无需掌握正则表达式或xpath等工具,只需几行代码即可快速抓取网页数据并保存到本地。
二、原理
Pandas 适用于爬取 Table 数据。首先,让我们了解一下具有 Table 数据结构的网页。示例如下:
使用Chrome浏览器查看网页的HTML结构,你会发现Table数据有一些共同点。一般网页结构如下所示。
...
...
...
...
...
...
...
...
...
网页结构如上,我们可以尝试使用pandas的pd.read_html()方法直接获取数据。
pd.read_html()的一些主要参数
三、爬行实战示例1
爬取成都2019年空气质量数据(12页数据),目标网址:
import pandas as pd
dates = pd.date_range('20190101', '20191201', freq='MS').strftime('%Y%m') # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f'http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html', encoding='gbk', header=0)[0]
if i == 0:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False) # 追加写入
i += 1
else:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False, header=False)
九行代码就搞定了,爬虫速度很快。
查看保存的数据
示例 2
抓取新浪金融基金重磅股数据(25页数据),网址:
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml?p={i}'
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv('新浪财经基金重仓股数据.csv', encoding='utf-8', index=False)
六行代码就搞定了,爬取速度非常快。
查看保存的数据:
后面爬取一些小数据的时候,只要遇到这种表数据,可以先试试pd.read_html()大法。 查看全部
网页表格抓取(2017年成都会计从业资格考试:谈及pandasread_html)
过去的一切都是序幕。
真正的放手不是试图强迫它,而不仅仅是不作为。
文章内容
一、简介
一般爬虫例程无非就是发送请求、获取响应、解析网页、提取数据、保存数据等步骤。 requests库主要用于构造请求,xpath和正则匹配多用于定位和提取数据。对于一个完整的爬虫来说,代码量可以从几十行到几百行不等。对于新手来说,学习成本相对较高。
说到pandas read.xxx系列的功能,常用的读取数据的方法有:pd.read_csv()和pd.read_excel(),而pd.read_html()方法很少使用,但是它的功能很强大,尤其是用来抓取Table数据的时候,简直是神器。无需掌握正则表达式或xpath等工具,只需几行代码即可快速抓取网页数据并保存到本地。
二、原理
Pandas 适用于爬取 Table 数据。首先,让我们了解一下具有 Table 数据结构的网页。示例如下:
使用Chrome浏览器查看网页的HTML结构,你会发现Table数据有一些共同点。一般网页结构如下所示。
...
...
...
...
...
...
...
...
...
网页结构如上,我们可以尝试使用pandas的pd.read_html()方法直接获取数据。
pd.read_html()的一些主要参数
三、爬行实战示例1
爬取成都2019年空气质量数据(12页数据),目标网址:
import pandas as pd
dates = pd.date_range('20190101', '20191201', freq='MS').strftime('%Y%m') # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f'http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html', encoding='gbk', header=0)[0]
if i == 0:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False) # 追加写入
i += 1
else:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False, header=False)
九行代码就搞定了,爬虫速度很快。
查看保存的数据
示例 2
抓取新浪金融基金重磅股数据(25页数据),网址:
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml?p={i}'
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv('新浪财经基金重仓股数据.csv', encoding='utf-8', index=False)
六行代码就搞定了,爬取速度非常快。
查看保存的数据:
后面爬取一些小数据的时候,只要遇到这种表数据,可以先试试pd.read_html()大法。
网页表格抓取(如何不使用Python去爬取网页数据?论Excel的万用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-11-09 00:12
现在很多朋友都知道可以用Python来爬取数据,但是如果你想从头开始学习Python爬虫,学Python还是需要一些时间的。但是,如果是抓取一些简单的网页表单数据,则没有必要使用Python。
今天教大家不使用Python爬取网页数据。
Excel 的通用方法之一是 Excel。Excel可以帮你实现简单网页抓取数据的功能。
先找到大家想爬的数据表。
比如今天就让我们爬取中国天气网站上的广东天气预报吧~
然后我们复制网站的链接,打开Excel,在菜单栏找到网站的数据。
然后将您刚刚复制的链接粘贴到新打开的:New Web Query 中。
点击Go打开网站,在这里预览中找到要导入的数据表,然后勾选左上角。
选择后,点击右下角的导入,将选中的表格数据导入Excel。
导入数据。
接下来就可以看到你想要的数据在Excel表格中一一呈现了~
有些朋友有疑问。这样导出的数据都是固定的。如果网页数据更新了,不需要重新导入吗?
其实不是,Excel也自带数据刷新功能。我们还是在菜单栏里找到:data-link properties 下的refresh all。
在链接属性中选择刷新条件、刷新频率、时间等,然后Excel会根据你设置的刷新属性自动更新数据~
上图是自动抓取刷新数据的Excel表格~~
当然,使用Excel表格爬取数据有利有弊。优点是使用Excel自带的功能来捕获和更新数据简单方便,不涉及编程等复杂操作。缺点是Excel网页数据抓取只能抓取表格数据,其他数据很难获取。
因此,如果你想获得更多元网页数据,不妨学习Python,这是目前爬虫类中最容易学习的。
如果想了解更多实用技巧,可以关注一下,以便下次更新及时通知W=。 查看全部
网页表格抓取(如何不使用Python去爬取网页数据?论Excel的万用方法)
现在很多朋友都知道可以用Python来爬取数据,但是如果你想从头开始学习Python爬虫,学Python还是需要一些时间的。但是,如果是抓取一些简单的网页表单数据,则没有必要使用Python。
今天教大家不使用Python爬取网页数据。
Excel 的通用方法之一是 Excel。Excel可以帮你实现简单网页抓取数据的功能。
先找到大家想爬的数据表。
比如今天就让我们爬取中国天气网站上的广东天气预报吧~
然后我们复制网站的链接,打开Excel,在菜单栏找到网站的数据。
然后将您刚刚复制的链接粘贴到新打开的:New Web Query 中。
点击Go打开网站,在这里预览中找到要导入的数据表,然后勾选左上角。
选择后,点击右下角的导入,将选中的表格数据导入Excel。
导入数据。
接下来就可以看到你想要的数据在Excel表格中一一呈现了~
有些朋友有疑问。这样导出的数据都是固定的。如果网页数据更新了,不需要重新导入吗?
其实不是,Excel也自带数据刷新功能。我们还是在菜单栏里找到:data-link properties 下的refresh all。
在链接属性中选择刷新条件、刷新频率、时间等,然后Excel会根据你设置的刷新属性自动更新数据~
上图是自动抓取刷新数据的Excel表格~~
当然,使用Excel表格爬取数据有利有弊。优点是使用Excel自带的功能来捕获和更新数据简单方便,不涉及编程等复杂操作。缺点是Excel网页数据抓取只能抓取表格数据,其他数据很难获取。
因此,如果你想获得更多元网页数据,不妨学习Python,这是目前爬虫类中最容易学习的。
如果想了解更多实用技巧,可以关注一下,以便下次更新及时通知W=。
网页表格抓取(【每日一题】法比奥布拉加托的使用和提取表格 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-07 23:02
)
法比奥布拉加托 1
为什么当我使用 .getElementsByTagName 方法提取表格时,它没有提取表格中收录的所有数据?请注意,这是向下滚动页面。
Public Sub getHistoricCotation()
Dim mainURL As String
Dim elem As Object, tRow As Object
Dim S, R, C
Dim initial_date As String, final_date As String
Dim stock As String
initial_date = DateDiff("s", "1/1/1970 00:00:00", ufHistorico.txtDtInicial) + 86400
final_date = DateDiff("s", "1/1/1970 00:00:00", ufHistorico.txtDtFinal) + 86400
stock = ufHistorico.cbAcoes.Text
mainURL = "https://finance.yahoo.com/quote/" & stock & "/history?period1=" & initial_date & "&period2=" & final_date & "&interval=1d&filter=history&frequency=1d"
With CreateObject("WinHttp.WinHttpRequest.5.1")
.Open "GET", mainURL, False
strCookie = .getAllResponseHeaders
strCookie = Split(Split(strCookie, "Cookie:")(1), ";")(0)
.Open "GET", mainURL, False
.setRequestHeader "Cookie", strCookie
.setRequestHeader "User-Agent", "Mozilla/5.0 (Windows NT 6.1; ) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36"
.send
S = .responseText
End With
With CreateObject("htmlfile")
.body.innerHTML = S
For Each elem In .getElementsByTagName("tr")
For Each tRow In elem.Cells
C = C + 1: Cells(R + 1, C) = tRow.innerText
Next tRow
C = 0: R = R + 1
Next elem
End With
End Sub
SIM卡
脚本中可以解析的部分是静态的,但不能解析的部分是动态生成的。然而,好消息是该表的所有内容都可以在页面源代码中的某些脚本标签内找到。我已经创建了一个脚本来从那里挖掘出所需的部分。您现在要做的就是使用任何 json 转换器或正则表达式来处理内容。
这是它从那里获取所有相关数据的方式:
Sub FetchHistoricalPrice()
Const mainUrl$ = "https://finance.yahoo.com/quot ... ot%3B
Dim S$, Elem As Object
With CreateObject("MSXML2.XMLHTTP")
.Open "GET", mainUrl, False
.send
S = .responseText
End With
With CreateObject("VBScript.RegExp")
.Global = True
.MultiLine = True
.Pattern = "HistoricalPriceStore[\s\S]+prices[^[]+(.*?]),"
Set Elem = .Execute(S)
If Elem.Count > 0 Then
Debug.Print Elem(0).SubMatches(0)
End If
End With
End Sub 查看全部
网页表格抓取(【每日一题】法比奥布拉加托的使用和提取表格
)
法比奥布拉加托 1
为什么当我使用 .getElementsByTagName 方法提取表格时,它没有提取表格中收录的所有数据?请注意,这是向下滚动页面。
Public Sub getHistoricCotation()
Dim mainURL As String
Dim elem As Object, tRow As Object
Dim S, R, C
Dim initial_date As String, final_date As String
Dim stock As String
initial_date = DateDiff("s", "1/1/1970 00:00:00", ufHistorico.txtDtInicial) + 86400
final_date = DateDiff("s", "1/1/1970 00:00:00", ufHistorico.txtDtFinal) + 86400
stock = ufHistorico.cbAcoes.Text
mainURL = "https://finance.yahoo.com/quote/" & stock & "/history?period1=" & initial_date & "&period2=" & final_date & "&interval=1d&filter=history&frequency=1d"
With CreateObject("WinHttp.WinHttpRequest.5.1")
.Open "GET", mainURL, False
strCookie = .getAllResponseHeaders
strCookie = Split(Split(strCookie, "Cookie:")(1), ";")(0)
.Open "GET", mainURL, False
.setRequestHeader "Cookie", strCookie
.setRequestHeader "User-Agent", "Mozilla/5.0 (Windows NT 6.1; ) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36"
.send
S = .responseText
End With
With CreateObject("htmlfile")
.body.innerHTML = S
For Each elem In .getElementsByTagName("tr")
For Each tRow In elem.Cells
C = C + 1: Cells(R + 1, C) = tRow.innerText
Next tRow
C = 0: R = R + 1
Next elem
End With
End Sub
SIM卡
脚本中可以解析的部分是静态的,但不能解析的部分是动态生成的。然而,好消息是该表的所有内容都可以在页面源代码中的某些脚本标签内找到。我已经创建了一个脚本来从那里挖掘出所需的部分。您现在要做的就是使用任何 json 转换器或正则表达式来处理内容。
这是它从那里获取所有相关数据的方式:
Sub FetchHistoricalPrice()
Const mainUrl$ = "https://finance.yahoo.com/quot ... ot%3B
Dim S$, Elem As Object
With CreateObject("MSXML2.XMLHTTP")
.Open "GET", mainUrl, False
.send
S = .responseText
End With
With CreateObject("VBScript.RegExp")
.Global = True
.MultiLine = True
.Pattern = "HistoricalPriceStore[\s\S]+prices[^[]+(.*?]),"
Set Elem = .Execute(S)
If Elem.Count > 0 Then
Debug.Print Elem(0).SubMatches(0)
End If
End With
End Sub
网页表格抓取(16款用户体验优秀的CSS价格表格样式演示及下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-05 17:04
老佐不是网页设计师,但他经常摆弄博客,修改一些他认为不好的用户体验。只限于修改一些简单的 CSS 样式。如果遇到无法解决的问题,可以搜索查阅文档。. 随着时间的推移,我们越来越意识到 CSS 样式的无限奇妙。比如我们在做表格的时候,可以简单的使用CSS样式表来修改和改变各种CSS表格样式。在页面布局和内容分享中,表格是比较常用的。有时候老左在分享评价内容的时候,为了省事,可能会直接截图,以后可能会有更多的分享风格,方便用户体验,如果信息有变化,可以修改直接截图而不是截图。
在之前的博文中,我已经分享了几篇关于 CSS 表格样式的文章:
16 个 HTML CSS 价格表单模板,具有出色的用户体验,提供演示和下载
设计师常用的8种漂亮的HTML和CSS表格样式
6 个漂亮的 HTML CSS 样式用户消息表单
今天在浏览几篇海外前端博客的时候,看到下面这7种颜色的CSS表格样式比较有条理,尤其是需要在网页中添加表格的时候,看似简单的样式,实则需要用到的时候直接copy就可以了,省很多时间。
首先:
CSS表格样式之一
CSS样式代码部分:
/* Border styles */
#table-1 thead, #table-1 tr {
border-top-width: 1px;
border-top-style: solid;
border-top-color: rgb(230, 189, 189);
}
#table-1 {
border-bottom-width: 1px;
border-bottom-style: solid;
border-bottom-color: rgb(230, 189, 189);
}
/* Padding and font style */
#table-1 td, #table-1 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
color: rgb(177, 106, 104);
}
/* Alternating background colors */
#table-1 tr:nth-child(even) {
background: rgb(238, 211, 210)
}
#table-1 tr:nth-child(odd) {
background: #FFF
}
第二种:
CSS表格样式二
CSS样式代码部分:
/* Border styles */
#table-2 thead, #table-2 tr {
border-top-width: 1px;
border-top-style: solid;
border-top-color: rgb(230, 189, 189);
}
#table-2 {
border-bottom-width: 1px;
border-bottom-style: solid;
border-bottom-color: rgb(230, 189, 189);
}
/* Padding and font style */
#table-2 td, #table-2 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
color: rgb(177, 106, 104);
}
/* Alternating background colors */
#table-2 tr:nth-child(even) {
background: rgb(238, 211, 210)
}
#table-2 tr:nth-child(odd) {
background: #FFF
}
第三种:
CSS表格样式三
CSS样式代码部分:
/* Border styles */
#table-3 thead, #table-3 tr {
border-top-width: 1px;
border-top-style: solid;
border-top-color: rgb(235, 242, 224);
}
#table-3 {
border-bottom-width: 1px;
border-bottom-style: solid;
border-bottom-color: rgb(235, 242, 224);
}
/* Padding and font style */
#table-3 td, #table-3 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
color: rgb(149, 170, 109);
}
/* Alternating background colors */
#table-3 tr:nth-child(even) {
background: rgb(230, 238, 214)
}
#table-3 tr:nth-child(odd) {
background: #FFF
}
第四种:
CSS表格样式四
CSS 代码样式部分:
/* Border styles */
#table-4 thead, #table-4 tr {
border-top-width: 1px;
border-top-style: solid;
border-top-color: rgb(211, 202, 221);
}
#table-4 {
border-bottom-width: 1px;
border-bottom-style: solid;
border-bottom-color: rgb(211, 202, 221);
}
/* Padding and font style */
#table-4 td, #table-4 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
color: rgb(95, 74, 121);
}
/* Alternating background colors */
#table-4 tr:nth-child(even) {
background: rgb(223, 216, 232)
}
#table-4 tr:nth-child(odd) {
background: #FFF
}
第五种:
CSS表格样式五
CSS 代码样式部分:
/* Table Head */
#table-5 thead th {
background-color: rgb(156, 186, 95);
color: #fff;
border-bottom-width: 0;
}
/* Column Style */
#table-5 td {
color: #000;
}
/* Heading and Column Style */
#table-5 tr, #table-5 th {
border-width: 1px;
border-style: solid;
border-color: rgb(156, 186, 95);
}
/* Padding and font style */
#table-5 td, #table-5 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
font-weight: bold;
}
第六:
CSS 表格样式六
CSS样式代码部分:
/* Table Head */
#table-6 thead th {
background-color: rgb(128, 102, 160);
color: #fff;
border-bottom-width: 0;
}
/* Column Style */
#table-6 td {
color: #000;
}
/* Heading and Column Style */
#table-6 tr, #table-6 th {
border-width: 1px;
border-style: solid;
border-color: rgb(128, 102, 160);
}
/* Padding and font style */
#table-6 td, #table-6 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
font-weight: bold;
}
第七:
CSS 表格样式七
CSS样式代码部分:
/* Table Head */
#table-7 thead th {
background-color: rgb(81, 130, 187);
color: #fff;
border-bottom-width: 0;
}
/* Column Style */
#table-7 td {
color: #000;
}
/* Heading and Column Style */
#table-7 tr, #table-7 th {
border-width: 1px;
border-style: solid;
border-color: rgb(81, 130, 187);
}
/* Padding and font style */
#table-7 td, #table-7 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
font-weight: bold;
}
以上7种颜色的CSS表格样式部分,可以根据自己的需要直接复制修改。然后将其添加到以下 TABLE 表部分:
Name
City
Phone
Albert Ellis
New York
+1 718 000000
Marcus Aurelius
Rome
+1 718 000000
Epictetus
Greece
+1 718 000000
Aristotle
Greece
+1 718 000000
本文档整体框架还是采用了TABLE,比较适合文章内容中插入样式的部分。 查看全部
网页表格抓取(16款用户体验优秀的CSS价格表格样式演示及下载)
老佐不是网页设计师,但他经常摆弄博客,修改一些他认为不好的用户体验。只限于修改一些简单的 CSS 样式。如果遇到无法解决的问题,可以搜索查阅文档。. 随着时间的推移,我们越来越意识到 CSS 样式的无限奇妙。比如我们在做表格的时候,可以简单的使用CSS样式表来修改和改变各种CSS表格样式。在页面布局和内容分享中,表格是比较常用的。有时候老左在分享评价内容的时候,为了省事,可能会直接截图,以后可能会有更多的分享风格,方便用户体验,如果信息有变化,可以修改直接截图而不是截图。
在之前的博文中,我已经分享了几篇关于 CSS 表格样式的文章:
16 个 HTML CSS 价格表单模板,具有出色的用户体验,提供演示和下载
设计师常用的8种漂亮的HTML和CSS表格样式
6 个漂亮的 HTML CSS 样式用户消息表单
今天在浏览几篇海外前端博客的时候,看到下面这7种颜色的CSS表格样式比较有条理,尤其是需要在网页中添加表格的时候,看似简单的样式,实则需要用到的时候直接copy就可以了,省很多时间。
首先:
CSS表格样式之一
CSS样式代码部分:
/* Border styles */
#table-1 thead, #table-1 tr {
border-top-width: 1px;
border-top-style: solid;
border-top-color: rgb(230, 189, 189);
}
#table-1 {
border-bottom-width: 1px;
border-bottom-style: solid;
border-bottom-color: rgb(230, 189, 189);
}
/* Padding and font style */
#table-1 td, #table-1 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
color: rgb(177, 106, 104);
}
/* Alternating background colors */
#table-1 tr:nth-child(even) {
background: rgb(238, 211, 210)
}
#table-1 tr:nth-child(odd) {
background: #FFF
}
第二种:
CSS表格样式二
CSS样式代码部分:
/* Border styles */
#table-2 thead, #table-2 tr {
border-top-width: 1px;
border-top-style: solid;
border-top-color: rgb(230, 189, 189);
}
#table-2 {
border-bottom-width: 1px;
border-bottom-style: solid;
border-bottom-color: rgb(230, 189, 189);
}
/* Padding and font style */
#table-2 td, #table-2 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
color: rgb(177, 106, 104);
}
/* Alternating background colors */
#table-2 tr:nth-child(even) {
background: rgb(238, 211, 210)
}
#table-2 tr:nth-child(odd) {
background: #FFF
}
第三种:
CSS表格样式三
CSS样式代码部分:
/* Border styles */
#table-3 thead, #table-3 tr {
border-top-width: 1px;
border-top-style: solid;
border-top-color: rgb(235, 242, 224);
}
#table-3 {
border-bottom-width: 1px;
border-bottom-style: solid;
border-bottom-color: rgb(235, 242, 224);
}
/* Padding and font style */
#table-3 td, #table-3 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
color: rgb(149, 170, 109);
}
/* Alternating background colors */
#table-3 tr:nth-child(even) {
background: rgb(230, 238, 214)
}
#table-3 tr:nth-child(odd) {
background: #FFF
}
第四种:
CSS表格样式四
CSS 代码样式部分:
/* Border styles */
#table-4 thead, #table-4 tr {
border-top-width: 1px;
border-top-style: solid;
border-top-color: rgb(211, 202, 221);
}
#table-4 {
border-bottom-width: 1px;
border-bottom-style: solid;
border-bottom-color: rgb(211, 202, 221);
}
/* Padding and font style */
#table-4 td, #table-4 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
color: rgb(95, 74, 121);
}
/* Alternating background colors */
#table-4 tr:nth-child(even) {
background: rgb(223, 216, 232)
}
#table-4 tr:nth-child(odd) {
background: #FFF
}
第五种:
CSS表格样式五
CSS 代码样式部分:
/* Table Head */
#table-5 thead th {
background-color: rgb(156, 186, 95);
color: #fff;
border-bottom-width: 0;
}
/* Column Style */
#table-5 td {
color: #000;
}
/* Heading and Column Style */
#table-5 tr, #table-5 th {
border-width: 1px;
border-style: solid;
border-color: rgb(156, 186, 95);
}
/* Padding and font style */
#table-5 td, #table-5 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
font-weight: bold;
}
第六:
CSS 表格样式六
CSS样式代码部分:
/* Table Head */
#table-6 thead th {
background-color: rgb(128, 102, 160);
color: #fff;
border-bottom-width: 0;
}
/* Column Style */
#table-6 td {
color: #000;
}
/* Heading and Column Style */
#table-6 tr, #table-6 th {
border-width: 1px;
border-style: solid;
border-color: rgb(128, 102, 160);
}
/* Padding and font style */
#table-6 td, #table-6 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
font-weight: bold;
}
第七:
CSS 表格样式七
CSS样式代码部分:
/* Table Head */
#table-7 thead th {
background-color: rgb(81, 130, 187);
color: #fff;
border-bottom-width: 0;
}
/* Column Style */
#table-7 td {
color: #000;
}
/* Heading and Column Style */
#table-7 tr, #table-7 th {
border-width: 1px;
border-style: solid;
border-color: rgb(81, 130, 187);
}
/* Padding and font style */
#table-7 td, #table-7 th {
padding: 5px 10px;
font-size: 12px;
font-family: Verdana;
font-weight: bold;
}
以上7种颜色的CSS表格样式部分,可以根据自己的需要直接复制修改。然后将其添加到以下 TABLE 表部分:
Name
City
Phone
Albert Ellis
New York
+1 718 000000
Marcus Aurelius
Rome
+1 718 000000
Epictetus
Greece
+1 718 000000
Aristotle
Greece
+1 718 000000
本文档整体框架还是采用了TABLE,比较适合文章内容中插入样式的部分。
网页表格抓取( 有你想要的精彩作者|東不归出品|Python知识学堂 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-10-30 15:02
有你想要的精彩作者|東不归出品|Python知识学堂
)
有你想要的
作者 | 东不归出品| Python知识学校
大家好,上一条推文介绍了爬虫需要注意的点,使用vscode开发环境时遇到的问题,正则表达式爬取页面信息的使用。本文主要介绍BeautifulSoup模块的使用。.
BeautifulSoup的描述
引用官方解释:
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它可以使用您喜欢的转换器来实现惯用的文档导航、查找和修改文档。
简单的说,Beautiful Soup 是一个python 库,一个可以抓取网页数据的工具。
官方文件:
BeautifulSoup 安装
pip 安装 beautifulsoup4
或者
pip 安装 beautifulsoup4
-一世
--可信主机
顺便说一句:我用的开发工具还是vscode,不知道看之前的推文。
BeautifulSoup 解析器
html.parse
html.parse 是内置的,不需要安装
import requestsfrom bs4 import BeautifulSoupurl='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'html.parser')<br />print(soup.prettify())
结果
xml文件
安装 pip install lxml 需要 lxml
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'lxml')<br />print(soup)
结果
lxml-xml/xml
lxml-xml/Xm 是需要安装的pip install lxml
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'xml')<br />print(soup)
结果
html5lib
html5lib是需要安装的pip install html5lib
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'html5lib')<br />print(soup)
结果
可以看到,这些解析器解析出来的记录基本相同,但是如果一个HTML或者XML文档的格式不正确,不同解析器返回的结果可能会有所不同。什么是 HTML 或 XML 文档格式不正确?简单地说,就是缺少不必要的标签或者标签没有关闭。比如页面缺少body标签,只有a标签的开头部分缺少a标签的结尾部分(这里有一些前端知识,不明白的可以搜索一下,很简单)。
咱们试试吧
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'html.parser')
打印(“html.parser 结果:”)
打印(汤)
汤1=BeautifulSoup(html,'lxml')
打印(“lxml结果:”)
打印(汤1)
汤2=BeautifulSoup(html,'xml')
打印(“xml结果:”)
打印(汤2)
汤3=BeautifulSoup(html,'html5lib')
打印(“html5lib 结果:”)
打印(汤3)
结果
可以看到html.parser和lxml会填充标签,但是lxml会填充html标签,xml也会填充标签,还会添加xml文档的版本编码方式等信息,但不是会补全html标签,而且html5lib不仅会补全html标签,还会补全整个页面的head标签。
这验证了上表中的html5lib具有最好的容错性,但是html5lib解析器的速度并不快。如果内容较少,则速度不会有差异。因此,推荐使用lxml作为解析器,因为这样效率更高。对于 Python2.7.3 之前的版本和 Python3 中 3.2.2 之前的版本,必须安装 lxml 或 html5lib,因为这些 Python 版本具有内置的 HTML标准库中的分析方法不够稳定。
如果我们不指定解析器怎么办?
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=美丽的汤(html)
打印(“html.parser 结果:”)
打印(汤)
结果
从结果提示可以得出,如果不指定解析器,他会给出系统最好的解析器。我的系统是lxml。如果你没有在其他环境中安装 lxml,它可能是另一个解析器。总之系统会默认为你选择最好的解析器,所以你不需要指定它。这不是更用户友好。
BeautifulSoup 对象类型
Beautiful Soup 将复杂的 HTML 文档转换为复杂的树结构。每个节点都是一个 Python 对象。所有对象可以概括为 4 种类型:Tag、NavigableString、BeautifulSoup、Comment。
标签
标签中最重要的属性:名称和属性
from bs4 import BeautifulSoup<br />html="
Python知识学校
Python知识学校”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
结果
上面代码中的a标签表示一个标签,test被认为是一个标签。测试是我随便写的,所以Beautiful Soup中的html标签和自定义标签都可以看作是标签。是不是很强大?
那么什么是属性呢?看上面代码中的data-id和class一个标签,即使它们是标签中的属性;
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
打印(标签。属性)
结果:
如果要获取某个属性,可以使用 tag['data-id'] 或 tag.attrs['data-id']。
这个最有用的应该是获取a标签的链接地址和img标签的媒体文件地址。
如果里面有多个值,会返回一个列表
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'lxml')
打印(标签 ['数据 ID'])
结果:
导航字符串
标签中收录的字符串可以通过NavigableString类直接获取,也称为可遍历字符串。
from bs4 import BeautifulSoup<br />html="
”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
打印(标签。字符串)
结果:
这个比较简单,就不多说了;
美汤
BeautifulSoup 对象表示文档的全部内容。大多数时候,它可以看作是一个 Tag 对象,它支持遍历文档树和搜索文档树中描述的大部分方法。
先来了解一下,后面遍历文档和搜索文档的时候会有说明;
评论
主要是文档中的注释部分。
Comment 对象是一种特殊类型的 NavigableString 对象:
from bs4 import BeautifulSoup<br />html= "<b>"soup = BeautifulSoup(html,'lxml')<br />comment = soup.b.string<br />print(comment)
结果
但是下面的情况是不可用的
from bs4 import BeautifulSoup<br />html= "<b>我是谁?"<br />soup = BeautifulSoup(html,'lxml')<br />comment = soup.b.string<br />print(comment)
结果
可以看到返回的结果是None,所以评论的内容只能在特殊情况下才能获取;
遍历文档树
只看代码
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
上面的知识简单列举了几种获取树节点的方法,还有很多其他的方法,比如获取父节点、兄弟节点等等。有点类似于 jQuery 遍历 DOM 的概念。
搜索文档树
Beautiful Soup 定义了很多搜索方法,这里介绍两个比较常用的方法:find() 和 find_all()。其他的可以类似地使用,以此类推。
筛选
细绳
正则表达式
列表
真的
方法
from bs4 import BeautifulSoupimport re<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
找到所有()
Name:可以找到所有名称为name的标签,string对象会被自动忽略;
关键字参数:如果指定名称的参数不是内置参数名称,则搜索时将作为指定名称标签的属性进行搜索。如果它收录一个名为 id 的参数,Beautiful Soup 将搜索每个标签的“id”属性;
按CSS搜索:按CSS类名搜索标签的功能很实用,但是标识CSS类名的关键字class在Python中是保留字。使用类作为参数会导致语法错误。来自Beautiful Soup的4.< 从@1.1版本开始,可以通过class_参数搜索指定CSS类名的标签;
字符串参数:通过字符串参数,可以搜索文档中的字符串内容。与 name 参数的可选值一样,string 参数接受字符串、正则表达式、列表和 True。
limit 参数:find_all() 方法返回所有搜索结构。如果文档树很大,搜索会很慢。如果我们不需要所有的结果,我们可以使用 limit 参数来限制返回的结果数量。作用类似于SQL中的limit关键字,当搜索结果数达到limit限制时,停止搜索返回结果;
递归参数:调用标签的 find_all() 方法时,Beautiful Soup 会检索当前标签的所有后代节点。如果只想搜索标签的直接子节点,可以使用参数recursive=False。
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
请注意,只有 find_all() 和 find() 支持递归参数。
find() 方法与 find_all() 基本相同。唯一的区别是 find_all() 方法的返回结果是一个收录一个元素的列表,而 find() 方法直接返回结果。
输出
格式化输出
压缩输出
输出格式
获取文本()
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果我就不贴了,自己执行吧。
当然还有很多其他的方法,这里不再赘述,可以直接参考官方
Buaautiful汤的功能还是很强大的,这里只是简单介绍一些爬虫常用的东西。
现在就做,我们以上一篇文章获取省市为例
实例
我们仍然以上一篇文章中的省市收购为例。
import requestsfrom bs4 import BeautifulSoupimport timeclass Demo():def __init__(self):try:base_url = 'http://www.stats.gov.cn/tjsj/t ... %3Bbr /> trlist = self.get_data(base_url, "provincetable",'provincetr')
结果
我直接给你看看你上一个省市的结果。请注意获取每个页面信息的时间间隔;
总结
本文文章介绍了BeautifulSoup的一些基础内容,主要是爬虫相关的,BeautifulSoup还有很多其他的功能,大家可以到官网自行学习。
再次贴出官网地址:
下一个预览
下一条推文是关于lxml模块的基本内容,但下周的推文是关于深度学习的。爬虫可能要等到下周。感谢您的支持!
过去的选择(点击查看)
Python爬虫基础教程-正则表达式爬取入门
2020-08-30
Python实战教程系列-VSCode Python开发环境搭建
2020-08-01
Python实战教程系列——异常处理
2020-07-05
喜欢就看看
查看全部
网页表格抓取(
有你想要的精彩作者|東不归出品|Python知识学堂
)
有你想要的
作者 | 东不归出品| Python知识学校
大家好,上一条推文介绍了爬虫需要注意的点,使用vscode开发环境时遇到的问题,正则表达式爬取页面信息的使用。本文主要介绍BeautifulSoup模块的使用。.
BeautifulSoup的描述
引用官方解释:
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它可以使用您喜欢的转换器来实现惯用的文档导航、查找和修改文档。
简单的说,Beautiful Soup 是一个python 库,一个可以抓取网页数据的工具。
官方文件:
BeautifulSoup 安装
pip 安装 beautifulsoup4
或者
pip 安装 beautifulsoup4
-一世
--可信主机
顺便说一句:我用的开发工具还是vscode,不知道看之前的推文。
BeautifulSoup 解析器
html.parse
html.parse 是内置的,不需要安装
import requestsfrom bs4 import BeautifulSoupurl='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'html.parser')<br />print(soup.prettify())
结果
xml文件
安装 pip install lxml 需要 lxml
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'lxml')<br />print(soup)
结果
lxml-xml/xml
lxml-xml/Xm 是需要安装的pip install lxml
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'xml')<br />print(soup)
结果
html5lib
html5lib是需要安装的pip install html5lib
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'html5lib')<br />print(soup)
结果
可以看到,这些解析器解析出来的记录基本相同,但是如果一个HTML或者XML文档的格式不正确,不同解析器返回的结果可能会有所不同。什么是 HTML 或 XML 文档格式不正确?简单地说,就是缺少不必要的标签或者标签没有关闭。比如页面缺少body标签,只有a标签的开头部分缺少a标签的结尾部分(这里有一些前端知识,不明白的可以搜索一下,很简单)。
咱们试试吧
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'html.parser')
打印(“html.parser 结果:”)
打印(汤)
汤1=BeautifulSoup(html,'lxml')
打印(“lxml结果:”)
打印(汤1)
汤2=BeautifulSoup(html,'xml')
打印(“xml结果:”)
打印(汤2)
汤3=BeautifulSoup(html,'html5lib')
打印(“html5lib 结果:”)
打印(汤3)
结果
可以看到html.parser和lxml会填充标签,但是lxml会填充html标签,xml也会填充标签,还会添加xml文档的版本编码方式等信息,但不是会补全html标签,而且html5lib不仅会补全html标签,还会补全整个页面的head标签。
这验证了上表中的html5lib具有最好的容错性,但是html5lib解析器的速度并不快。如果内容较少,则速度不会有差异。因此,推荐使用lxml作为解析器,因为这样效率更高。对于 Python2.7.3 之前的版本和 Python3 中 3.2.2 之前的版本,必须安装 lxml 或 html5lib,因为这些 Python 版本具有内置的 HTML标准库中的分析方法不够稳定。
如果我们不指定解析器怎么办?
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=美丽的汤(html)
打印(“html.parser 结果:”)
打印(汤)
结果
从结果提示可以得出,如果不指定解析器,他会给出系统最好的解析器。我的系统是lxml。如果你没有在其他环境中安装 lxml,它可能是另一个解析器。总之系统会默认为你选择最好的解析器,所以你不需要指定它。这不是更用户友好。
BeautifulSoup 对象类型
Beautiful Soup 将复杂的 HTML 文档转换为复杂的树结构。每个节点都是一个 Python 对象。所有对象可以概括为 4 种类型:Tag、NavigableString、BeautifulSoup、Comment。
标签
标签中最重要的属性:名称和属性
from bs4 import BeautifulSoup<br />html="
Python知识学校
Python知识学校”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
结果
上面代码中的a标签表示一个标签,test被认为是一个标签。测试是我随便写的,所以Beautiful Soup中的html标签和自定义标签都可以看作是标签。是不是很强大?
那么什么是属性呢?看上面代码中的data-id和class一个标签,即使它们是标签中的属性;
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
打印(标签。属性)
结果:
如果要获取某个属性,可以使用 tag['data-id'] 或 tag.attrs['data-id']。
这个最有用的应该是获取a标签的链接地址和img标签的媒体文件地址。
如果里面有多个值,会返回一个列表
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'lxml')
打印(标签 ['数据 ID'])
结果:
导航字符串
标签中收录的字符串可以通过NavigableString类直接获取,也称为可遍历字符串。
from bs4 import BeautifulSoup<br />html="
”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
打印(标签。字符串)
结果:
这个比较简单,就不多说了;
美汤
BeautifulSoup 对象表示文档的全部内容。大多数时候,它可以看作是一个 Tag 对象,它支持遍历文档树和搜索文档树中描述的大部分方法。
先来了解一下,后面遍历文档和搜索文档的时候会有说明;
评论
主要是文档中的注释部分。
Comment 对象是一种特殊类型的 NavigableString 对象:
from bs4 import BeautifulSoup<br />html= "<b>"soup = BeautifulSoup(html,'lxml')<br />comment = soup.b.string<br />print(comment)
结果
但是下面的情况是不可用的
from bs4 import BeautifulSoup<br />html= "<b>我是谁?"<br />soup = BeautifulSoup(html,'lxml')<br />comment = soup.b.string<br />print(comment)
结果
可以看到返回的结果是None,所以评论的内容只能在特殊情况下才能获取;
遍历文档树
只看代码
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
上面的知识简单列举了几种获取树节点的方法,还有很多其他的方法,比如获取父节点、兄弟节点等等。有点类似于 jQuery 遍历 DOM 的概念。
搜索文档树
Beautiful Soup 定义了很多搜索方法,这里介绍两个比较常用的方法:find() 和 find_all()。其他的可以类似地使用,以此类推。
筛选
细绳
正则表达式
列表
真的
方法
from bs4 import BeautifulSoupimport re<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
找到所有()
Name:可以找到所有名称为name的标签,string对象会被自动忽略;
关键字参数:如果指定名称的参数不是内置参数名称,则搜索时将作为指定名称标签的属性进行搜索。如果它收录一个名为 id 的参数,Beautiful Soup 将搜索每个标签的“id”属性;
按CSS搜索:按CSS类名搜索标签的功能很实用,但是标识CSS类名的关键字class在Python中是保留字。使用类作为参数会导致语法错误。来自Beautiful Soup的4.< 从@1.1版本开始,可以通过class_参数搜索指定CSS类名的标签;
字符串参数:通过字符串参数,可以搜索文档中的字符串内容。与 name 参数的可选值一样,string 参数接受字符串、正则表达式、列表和 True。
limit 参数:find_all() 方法返回所有搜索结构。如果文档树很大,搜索会很慢。如果我们不需要所有的结果,我们可以使用 limit 参数来限制返回的结果数量。作用类似于SQL中的limit关键字,当搜索结果数达到limit限制时,停止搜索返回结果;
递归参数:调用标签的 find_all() 方法时,Beautiful Soup 会检索当前标签的所有后代节点。如果只想搜索标签的直接子节点,可以使用参数recursive=False。
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
请注意,只有 find_all() 和 find() 支持递归参数。
find() 方法与 find_all() 基本相同。唯一的区别是 find_all() 方法的返回结果是一个收录一个元素的列表,而 find() 方法直接返回结果。
输出
格式化输出
压缩输出
输出格式
获取文本()
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果我就不贴了,自己执行吧。
当然还有很多其他的方法,这里不再赘述,可以直接参考官方
Buaautiful汤的功能还是很强大的,这里只是简单介绍一些爬虫常用的东西。
现在就做,我们以上一篇文章获取省市为例
实例
我们仍然以上一篇文章中的省市收购为例。
import requestsfrom bs4 import BeautifulSoupimport timeclass Demo():def __init__(self):try:base_url = 'http://www.stats.gov.cn/tjsj/t ... %3Bbr /> trlist = self.get_data(base_url, "provincetable",'provincetr')
结果
我直接给你看看你上一个省市的结果。请注意获取每个页面信息的时间间隔;
总结
本文文章介绍了BeautifulSoup的一些基础内容,主要是爬虫相关的,BeautifulSoup还有很多其他的功能,大家可以到官网自行学习。
再次贴出官网地址:
下一个预览
下一条推文是关于lxml模块的基本内容,但下周的推文是关于深度学习的。爬虫可能要等到下周。感谢您的支持!
过去的选择(点击查看)
Python爬虫基础教程-正则表达式爬取入门
2020-08-30
Python实战教程系列-VSCode Python开发环境搭建
2020-08-01
Python实战教程系列——异常处理
2020-07-05
喜欢就看看
网页表格抓取((19)中华人民共和国国家知识产权局(12)申请(21))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-28 16:03
摘要 本发明提出了一种防止网页数据爬行的方法和系统。防止网页数据爬取的方法包括:提取网页数据;混淆网页数据;将混淆后的网页数据转换为背景图片:背景图片通过堆叠样式表显示在网页上。本发明可以实现即使恶意爬虫下载了网页采集的所有源代码和图片,并使用OCR工具进行识别,也无法获得正确的数据。并且每页的数据图片都是随机生成的,大大 摘要 本发明提出了一种防止网页数据爬行的方法和系统。防止网页数据爬取的方法包括:提取网页数据;混淆网页数据;将混淆后的网页数据转换为背景图片:背景图片通过堆叠样式表显示在网页上。本发明可以实现即使恶意爬虫下载了网页采集的所有源代码和图片,并使用OCR工具进行识别,也无法获得正确的数据。并且每页的数据图片都是随机生成的,大大 背景图片通过堆叠样式表显示在网页上。本发明可以实现即使恶意爬虫下载了网页采集的所有源代码和图片,并使用OCR工具进行识别,也无法获得正确的数据。并且每页的数据图片都是随机生成的,大大 背景图片通过堆叠样式表显示在网页上。本发明可以实现即使恶意爬虫下载了网页采集的所有源代码和图片,并使用OCR工具进行识别,也无法获得正确的数据。并且每页的数据图片都是随机生成的,大大
大大增加采集解析难度,关键数据开放互联网。法律地位 法律地位 公告日期 2017-09-29 2017-09-29 2017-10-27 法律地位 信息披露 实质审查效力 法律地位 披露实质审查效力
索赔说明书网页数据反爬取方法及系统索赔说明书内容为...请下载查看 查看全部
网页表格抓取((19)中华人民共和国国家知识产权局(12)申请(21))
摘要 本发明提出了一种防止网页数据爬行的方法和系统。防止网页数据爬取的方法包括:提取网页数据;混淆网页数据;将混淆后的网页数据转换为背景图片:背景图片通过堆叠样式表显示在网页上。本发明可以实现即使恶意爬虫下载了网页采集的所有源代码和图片,并使用OCR工具进行识别,也无法获得正确的数据。并且每页的数据图片都是随机生成的,大大 摘要 本发明提出了一种防止网页数据爬行的方法和系统。防止网页数据爬取的方法包括:提取网页数据;混淆网页数据;将混淆后的网页数据转换为背景图片:背景图片通过堆叠样式表显示在网页上。本发明可以实现即使恶意爬虫下载了网页采集的所有源代码和图片,并使用OCR工具进行识别,也无法获得正确的数据。并且每页的数据图片都是随机生成的,大大 背景图片通过堆叠样式表显示在网页上。本发明可以实现即使恶意爬虫下载了网页采集的所有源代码和图片,并使用OCR工具进行识别,也无法获得正确的数据。并且每页的数据图片都是随机生成的,大大 背景图片通过堆叠样式表显示在网页上。本发明可以实现即使恶意爬虫下载了网页采集的所有源代码和图片,并使用OCR工具进行识别,也无法获得正确的数据。并且每页的数据图片都是随机生成的,大大
大大增加采集解析难度,关键数据开放互联网。法律地位 法律地位 公告日期 2017-09-29 2017-09-29 2017-10-27 法律地位 信息披露 实质审查效力 法律地位 披露实质审查效力
索赔说明书网页数据反爬取方法及系统索赔说明书内容为...请下载查看
网页表格抓取(Matrix精选:白描App新上线了网页版文字识别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-28 01:04
矩阵精选
Matrix是一个少数民族写作社区。我们提倡分享真实的产品体验、实践经验和思考。我们会不定期地选择Matrix最好的品质文章,展现用户最真实的体验和意见。
文章代表作者个人观点,少数只对标题和版式稍作修改。
近日,画线App上线了网页版,主要是为了在大屏幕上快速高效的进行OCR文字识别。
在没有网页版之前,很多使用白图app的用户如果想在电脑上识别文字,会选择WiFi识别功能,就是将电脑浏览器和手机app通过同一个局域网连接起来,把电脑上的图片通过浏览器传给手机App识别,虽然在一定程度上也能解决电脑上识别的需求,但没那么方便。一方面取决于局域网,另一方面取决于正在运行的手机App。白色绘图网页版摆脱了这些依赖,可以在浏览器中独立运行,更好地提高工作效率。
线描网页版目前收录三大功能:图片文字提取、电子表格识别、扫描PDF转文字。您可以直接登录白庙App的账号。如果白庙App有会员,会员状态会直接同步到网页版。
白线网页版截图
网页版分为两部分,左边是功能选择区,右边是识别区,可以在电脑上点击按钮选择图片,可以直接将图片拖入识别区,可以直接将图片粘贴到剪贴板中。方便的。
图片文字提取
图片文字提取是OCR文字识别功能,可以快速将图片上的文字转换成可编辑的。和手机白描App一样,可以单独识别,也可以批量识别。最多可同时支持50张图片,可一次性识别。合并所有结果。
批量上传图片
除了直接点击识别功能外,还有简单的图片裁剪功能和按文件名排序功能。
左右校对编辑
识别结束后,查看识别结果非常方便。左边是原图,右边是识别结果,校对超级方便!您也可以复制或直接导出 DOCX 和 TXT 文件。
电子表格识别
电子表格识别可以轻松地将图片上的表格转换为Excel格式。
在线编辑表格
识别后,左边也是原图,右边是识别结果,识别出来的表格可以直接在网页上校对编辑。
将 PDF 扫描为文本
目前PDF转文本更多是针对充满图形的PDF文件的文本转换。从服务性能来看,支持的最大页数为50页。之后可以根据需要适当释放页数。
关于使用限制
当前未登录或未登录的非会员用户每天可免费使用单文识别或表单识别5次,批量识别1次。金卡会员可以无限次识别,和白庙App一样,所以如果在白庙App购买会员,可以直接同步到网页版。
与其他网络版本相比有什么优势
很多人也知道网上有很多OCR识别网站,画线网版有什么优势呢?
高效准确
网页版使用与画线App相同的高精度识别引擎,确保识别准确度。同时,国产服务器和大带宽也保证了识别速度,保证了高效与准确并存。
无广告
使用过一些OCR在线识别网站的用户都会知道,很多这样的网站都是各种满天飞的广告,广告面积比实际工作区大几倍。线描网页版的整个页面是一个没有任何广告的工作区。登录画线会员账号,即可享受无任何限制的识别体验。
长图识别
线描网页版支持长图识别,包括很长很长的长图。这也是画线App中长图识别的同样体验。
校对和编辑
很多在线OCR网站识别后直接扔回文件,画线App可以轻松校对和左右编辑,包括文本和表格。
与白庙App账号相同
购买一次个人资料会员后,您可以在iOS,Android和Web(以及未来的PC版本)上享受跨平台体验,这并不漂亮。
白图网版地址:
喜欢的话记得采集浏览器或者添加到桌面快捷方式哦~
进一步阅读: 查看全部
网页表格抓取(Matrix精选:白描App新上线了网页版文字识别)
矩阵精选
Matrix是一个少数民族写作社区。我们提倡分享真实的产品体验、实践经验和思考。我们会不定期地选择Matrix最好的品质文章,展现用户最真实的体验和意见。
文章代表作者个人观点,少数只对标题和版式稍作修改。
近日,画线App上线了网页版,主要是为了在大屏幕上快速高效的进行OCR文字识别。
在没有网页版之前,很多使用白图app的用户如果想在电脑上识别文字,会选择WiFi识别功能,就是将电脑浏览器和手机app通过同一个局域网连接起来,把电脑上的图片通过浏览器传给手机App识别,虽然在一定程度上也能解决电脑上识别的需求,但没那么方便。一方面取决于局域网,另一方面取决于正在运行的手机App。白色绘图网页版摆脱了这些依赖,可以在浏览器中独立运行,更好地提高工作效率。
线描网页版目前收录三大功能:图片文字提取、电子表格识别、扫描PDF转文字。您可以直接登录白庙App的账号。如果白庙App有会员,会员状态会直接同步到网页版。
白线网页版截图
网页版分为两部分,左边是功能选择区,右边是识别区,可以在电脑上点击按钮选择图片,可以直接将图片拖入识别区,可以直接将图片粘贴到剪贴板中。方便的。
图片文字提取
图片文字提取是OCR文字识别功能,可以快速将图片上的文字转换成可编辑的。和手机白描App一样,可以单独识别,也可以批量识别。最多可同时支持50张图片,可一次性识别。合并所有结果。
批量上传图片
除了直接点击识别功能外,还有简单的图片裁剪功能和按文件名排序功能。
左右校对编辑
识别结束后,查看识别结果非常方便。左边是原图,右边是识别结果,校对超级方便!您也可以复制或直接导出 DOCX 和 TXT 文件。
电子表格识别
电子表格识别可以轻松地将图片上的表格转换为Excel格式。
在线编辑表格
识别后,左边也是原图,右边是识别结果,识别出来的表格可以直接在网页上校对编辑。
将 PDF 扫描为文本
目前PDF转文本更多是针对充满图形的PDF文件的文本转换。从服务性能来看,支持的最大页数为50页。之后可以根据需要适当释放页数。
关于使用限制
当前未登录或未登录的非会员用户每天可免费使用单文识别或表单识别5次,批量识别1次。金卡会员可以无限次识别,和白庙App一样,所以如果在白庙App购买会员,可以直接同步到网页版。
与其他网络版本相比有什么优势
很多人也知道网上有很多OCR识别网站,画线网版有什么优势呢?
高效准确
网页版使用与画线App相同的高精度识别引擎,确保识别准确度。同时,国产服务器和大带宽也保证了识别速度,保证了高效与准确并存。
无广告
使用过一些OCR在线识别网站的用户都会知道,很多这样的网站都是各种满天飞的广告,广告面积比实际工作区大几倍。线描网页版的整个页面是一个没有任何广告的工作区。登录画线会员账号,即可享受无任何限制的识别体验。
长图识别
线描网页版支持长图识别,包括很长很长的长图。这也是画线App中长图识别的同样体验。
校对和编辑
很多在线OCR网站识别后直接扔回文件,画线App可以轻松校对和左右编辑,包括文本和表格。
与白庙App账号相同
购买一次个人资料会员后,您可以在iOS,Android和Web(以及未来的PC版本)上享受跨平台体验,这并不漂亮。
白图网版地址:
喜欢的话记得采集浏览器或者添加到桌面快捷方式哦~
进一步阅读:
网页表格抓取(pdf表格提取camelot安装教程通过测试,macos与win10都可以用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-27 13:29
pdf格式提取camelot安装教程通过测试,macos和win10可以通过以下方式安装
Camelot:一个友好的PDF表格数据提取工具python
一个 python 命令行工具,允许任何人轻松地从 PDF 文件中提取表格数据。网络
如何使用 Camelotmacos
使用Camelot从PDF文档中提取数据非常简单svg
. Camelot 允许您调整设置以精确控制数据提取过程工具
.能够根据空白和精度指标判断不良表格,并丢弃,而不是手动检查测试
.每张表数据都是一个panda dataframe,可以方便的集成到ETL和数据分析工作流中。
.能够将数据导出为各种不同的格式,如CSV、JSON、EXCEL、HTMLcode
先在电脑上安装python3.6,然后在命令行输入:orm
pip install camelot-py
(CLOT) C:\Users\yss>python
Python 3.6.7 |Anaconda, Inc.| (default, Oct 28 2018, 19:44:12) [MSC v.1915 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import camelot as cl
......
import chardet # For str encoding detection in Py3
ModuleNotFoundError: No module named 'chardet'
>>>
如果报错如上:No module named'chardet',返回系统命令行执行:xml
pip install chardet
成功安装chardet后,再次输入python命令test:
(CLOT) C:\Users\yss>python
Python 3.6.7 |Anaconda, Inc.| (default, Oct 28 2018, 19:44:12) [MSC v.1915 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import camelot as cl
File "F:\APP\Ides\Anaconda3\envs\CLOT\lib\site-packages\camelot\image_processing.py", line 5, in
import cv2
ModuleNotFoundError: No module named 'cv2'
>>>
错误:ModuleNotFoundError: No module named'cv2',应该是没有安装opencv库。
再次回到系统命令行,安装opencv库:
pip install opencv-python
执行以上操作后,安装成功。
再次输入python,输入:
import camelot as cl
永远不要再报错。
输出它的版本号:
print(cl.__version__)
测试过程如下:
(CLOT) C:\Users\yss>python
Python 3.6.7 |Anaconda, Inc.| (default, Oct 28 2018, 19:44:12) [MSC v.1915 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import camelot as cl
>>> cl.__version__
'0.3.2'
>>>
安装完成后,我稍后会开始使用它。以后有机会我会更新我的经验。 查看全部
网页表格抓取(pdf表格提取camelot安装教程通过测试,macos与win10都可以用)
pdf格式提取camelot安装教程通过测试,macos和win10可以通过以下方式安装
Camelot:一个友好的PDF表格数据提取工具python
一个 python 命令行工具,允许任何人轻松地从 PDF 文件中提取表格数据。网络
如何使用 Camelotmacos
使用Camelot从PDF文档中提取数据非常简单svg
. Camelot 允许您调整设置以精确控制数据提取过程工具
.能够根据空白和精度指标判断不良表格,并丢弃,而不是手动检查测试
.每张表数据都是一个panda dataframe,可以方便的集成到ETL和数据分析工作流中。
.能够将数据导出为各种不同的格式,如CSV、JSON、EXCEL、HTMLcode
先在电脑上安装python3.6,然后在命令行输入:orm
pip install camelot-py
(CLOT) C:\Users\yss>python
Python 3.6.7 |Anaconda, Inc.| (default, Oct 28 2018, 19:44:12) [MSC v.1915 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import camelot as cl
......
import chardet # For str encoding detection in Py3
ModuleNotFoundError: No module named 'chardet'
>>>
如果报错如上:No module named'chardet',返回系统命令行执行:xml
pip install chardet
成功安装chardet后,再次输入python命令test:
(CLOT) C:\Users\yss>python
Python 3.6.7 |Anaconda, Inc.| (default, Oct 28 2018, 19:44:12) [MSC v.1915 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import camelot as cl
File "F:\APP\Ides\Anaconda3\envs\CLOT\lib\site-packages\camelot\image_processing.py", line 5, in
import cv2
ModuleNotFoundError: No module named 'cv2'
>>>
错误:ModuleNotFoundError: No module named'cv2',应该是没有安装opencv库。
再次回到系统命令行,安装opencv库:
pip install opencv-python
执行以上操作后,安装成功。
再次输入python,输入:
import camelot as cl
永远不要再报错。
输出它的版本号:
print(cl.__version__)
测试过程如下:
(CLOT) C:\Users\yss>python
Python 3.6.7 |Anaconda, Inc.| (default, Oct 28 2018, 19:44:12) [MSC v.1915 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import camelot as cl
>>> cl.__version__
'0.3.2'
>>>
安装完成后,我稍后会开始使用它。以后有机会我会更新我的经验。
网页表格抓取( Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-25 12:04
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
python——beautifulSoup提取网页数据写入指定Excel表格
文章内容
1.前言
任务要求:测试报告为HTML格式。我需要在报表中提取相应的结果并将结果写入Excel中的指定位置
2.实现步骤
第一步:获取当前目录下的多个HTML文件
第2步:从HTML中提取指定的结果(用beautifulSoup完成)
第三步:优化内存结构,使用字典保存数据
第四步:将字典数据对应的内容写入Excel
import os
from bs4 import BeautifulSoup # 建议使用beatifulsop进行处理 可能简单
from openpyxl import load_workbook
def writeTolog(logtext): # 写入日志
with open(Filename_log_path, 'a',encoding='utf-8') as f_new:
f_new.write(str(logtext))
class HtmlSpider:
def get_current_path(self): # 应该加个try语句
source_path = os.getcwd();
files = os.listdir(source_path)
File_html_path_list = [];
file_xlsx_path_list = []
try:
for file in files:
# print(file)
if file[-5:] == '.html': # 后缀名相等
File_html_path_list.append(os.path.join(source_path, file))
if file[-5:] == '.xlsx': # excel文件应该只有一个
file_xlsx_path_list.append(os.path.join(source_path, file))
if len(file_xlsx_path_list) == 1:
pass;
else:
writeTolog("Error05:当前一级目录下没有或者有多个Excel文件请确认!\n")
os.sys.exit() # 强制退出
except IOError:
writeTolog("Error00: 没有找到文件或读取文件失败\n")
if File_html_path_list==None:
writeTolog("Error07:当前路径下没有找到后缀为html的文件\n")
os.sys.exit() # 强制退出
return File_html_path_list,file_xlsx_path_list[0];
def read_html(self,html_path):
'''一个发送请求,获取响应,同时etree处理html'''
response = open(html_path,'r',encoding="utf-8") # 读取本地文件
html = response.read() #获取str 类型的html
soup_html = BeautifulSoup(html, 'lxml')
return soup_html
def get_data(self,html_path): #实现主要逻辑
# 1.获取目标网址url
# 2.发送请求获取响应
soup_html = self.read_html(html_path)
h3_list = (soup_html.find_all('h3'))[0:-1:2] # 只取出相关的
# 3.提取数据
success_list= []
for h3 in h3_list:
middle_adjust_str = h3.get('class')
if middle_adjust_str == ['success']:
success_list.append('Passed')
elif(middle_adjust_str == ['fail']):
success_list.append('Failed')
else:
writeTolog("Error01:html网页class标签中请提取class ='success'或者class ='fail'\n")
os.sys.exit() # 强制退出
# print(success_list)
name_list = []
for h3 in h3_list:
middle_3_str = h3.get_text().replace("\n", "").replace(" ","")
middle_2_str = middle_3_str.split('-')[1] # 按照-切割字符串,取第2部分 如DRV_0040201:R档能量回收;滑行出负扭矩
middle_str = middle_2_str.split(':')[0] # 按照英文状态:切割字符串,取第1部分 如DRV_0040201
if len(middle_2_str) == len(middle_str):
writeTolog("Error02:请确认{}里面的-或者:是否是英文状态下的输入\n".format(middle_3_str))
name_list.append(middle_str) #获取文本并去掉换行符
# print((name_list))
return success_list,name_list
def readexcel(self,success_list,name_list,sheetIndex):
if len(success_list) != len(name_list):
writeTolog("Error03:提取测试用例有{}个,但是测试用例的结果有{}个,因此测试个数和结果不匹配\n".format(len(name_list),len(success_list)))
os.sys.exit() # 强制退出
dict_middle_total = dict(zip(name_list, success_list)) # 删除错误的键值对,并保存到log日志
# 删除无效的键值对
for name in list(dict_middle_total.keys()):
if (len(name) != 11):
writeTolog("Error07:测试用例{}的名字无效或者长度不是11,故删除!\n".format(name))
dict_middle_total.pop(name);
# print(dict_middle_total)
table = None
try:
data = load_workbook(File_xlsx_path)
table = data['测试用例'] # excel中的sheet名字
# print(table)
except IOError:
writeTolog("Error04: 没有找到xlsx文件或读取文件失败,请确认xlsx文件已经关闭!\n")
os.sys.exit() # 强制退出
else:
dict_total = {}
for name in dict_middle_total.keys():
for i in range(3, table.max_row): # 从第3行开始,0,1,2是标题
if (table.cell(row=i,column=2).value == name): # 第2列 中的每个值比较 如 'DRV_0070201'
#取到对应的行数,列都是F列;根据'DRV_0070201' 得到对应的列数
dict_total.update({i:dict_middle_total[name]}) # 重新生成新的键值对
# print("此时的{}对应的行数是{},结果是{}".format(name,rowIndex,dict_middle_total[name]))
break;
else:
continue;
writeTologText.append(dict_middle_total) # 写入日志
writeTologText.append('\n')
writeTologText.append(dict_total) # 写入日志
writeTologText.append('\n')
return dict_total;
def writeToExcel(self,dict_total): # 注意运行程序的时候要关闭Excel,否则无法写入
wb = load_workbook(filename=File_xlsx_path)
ws = wb['测试用例'] # excel中的sheet名字
for key in list(dict_total.keys()): # dict_total[key]
# print("此时F{}的值是{}".format(key,dict_total[key]))
ws[('F' + str(key) )] = dict_total[key] # 类似ws["F86"] = 'Passed'
wb.save(File_xlsx_path)
if __name__ == '__main__':
File_xlsx_path = None;
Filename_log_path = 'resulthtml.log'
if os.path.exists(Filename_log_path): # 清空日志
os.remove(Filename_log_path);
writeTologText = []
myspider = HtmlSpider()
File_html_path_list,File_xlsx_path = myspider.get_current_path()
# 取出的元素已经默认不为空了
for html_path in File_html_path_list:
writeTologText.append("当前处理的文件路径为:"+ html_path + "\n")
success_list, name_list = myspider.get_data(html_path)
dict_total = myspider.readexcel(success_list, name_list,sheetIndex = 2)
myspider.writeToExcel(dict_total)
writeTologText.append("所有html文件内容,已经在{}中设置成功".format(File_xlsx_path))
with open(Filename_log_path, 'a', encoding='utf-8') as f_new: #y一次性写入更快
for logtext in writeTologText:
f_new.write(str(logtext))
3.结果如下:
保存到日志:
4.程序优化,提高运行速度 查看全部
网页表格抓取(
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
python——beautifulSoup提取网页数据写入指定Excel表格
文章内容
1.前言
任务要求:测试报告为HTML格式。我需要在报表中提取相应的结果并将结果写入Excel中的指定位置
2.实现步骤
第一步:获取当前目录下的多个HTML文件
第2步:从HTML中提取指定的结果(用beautifulSoup完成)
第三步:优化内存结构,使用字典保存数据
第四步:将字典数据对应的内容写入Excel
import os
from bs4 import BeautifulSoup # 建议使用beatifulsop进行处理 可能简单
from openpyxl import load_workbook
def writeTolog(logtext): # 写入日志
with open(Filename_log_path, 'a',encoding='utf-8') as f_new:
f_new.write(str(logtext))
class HtmlSpider:
def get_current_path(self): # 应该加个try语句
source_path = os.getcwd();
files = os.listdir(source_path)
File_html_path_list = [];
file_xlsx_path_list = []
try:
for file in files:
# print(file)
if file[-5:] == '.html': # 后缀名相等
File_html_path_list.append(os.path.join(source_path, file))
if file[-5:] == '.xlsx': # excel文件应该只有一个
file_xlsx_path_list.append(os.path.join(source_path, file))
if len(file_xlsx_path_list) == 1:
pass;
else:
writeTolog("Error05:当前一级目录下没有或者有多个Excel文件请确认!\n")
os.sys.exit() # 强制退出
except IOError:
writeTolog("Error00: 没有找到文件或读取文件失败\n")
if File_html_path_list==None:
writeTolog("Error07:当前路径下没有找到后缀为html的文件\n")
os.sys.exit() # 强制退出
return File_html_path_list,file_xlsx_path_list[0];
def read_html(self,html_path):
'''一个发送请求,获取响应,同时etree处理html'''
response = open(html_path,'r',encoding="utf-8") # 读取本地文件
html = response.read() #获取str 类型的html
soup_html = BeautifulSoup(html, 'lxml')
return soup_html
def get_data(self,html_path): #实现主要逻辑
# 1.获取目标网址url
# 2.发送请求获取响应
soup_html = self.read_html(html_path)
h3_list = (soup_html.find_all('h3'))[0:-1:2] # 只取出相关的
# 3.提取数据
success_list= []
for h3 in h3_list:
middle_adjust_str = h3.get('class')
if middle_adjust_str == ['success']:
success_list.append('Passed')
elif(middle_adjust_str == ['fail']):
success_list.append('Failed')
else:
writeTolog("Error01:html网页class标签中请提取class ='success'或者class ='fail'\n")
os.sys.exit() # 强制退出
# print(success_list)
name_list = []
for h3 in h3_list:
middle_3_str = h3.get_text().replace("\n", "").replace(" ","")
middle_2_str = middle_3_str.split('-')[1] # 按照-切割字符串,取第2部分 如DRV_0040201:R档能量回收;滑行出负扭矩
middle_str = middle_2_str.split(':')[0] # 按照英文状态:切割字符串,取第1部分 如DRV_0040201
if len(middle_2_str) == len(middle_str):
writeTolog("Error02:请确认{}里面的-或者:是否是英文状态下的输入\n".format(middle_3_str))
name_list.append(middle_str) #获取文本并去掉换行符
# print((name_list))
return success_list,name_list
def readexcel(self,success_list,name_list,sheetIndex):
if len(success_list) != len(name_list):
writeTolog("Error03:提取测试用例有{}个,但是测试用例的结果有{}个,因此测试个数和结果不匹配\n".format(len(name_list),len(success_list)))
os.sys.exit() # 强制退出
dict_middle_total = dict(zip(name_list, success_list)) # 删除错误的键值对,并保存到log日志
# 删除无效的键值对
for name in list(dict_middle_total.keys()):
if (len(name) != 11):
writeTolog("Error07:测试用例{}的名字无效或者长度不是11,故删除!\n".format(name))
dict_middle_total.pop(name);
# print(dict_middle_total)
table = None
try:
data = load_workbook(File_xlsx_path)
table = data['测试用例'] # excel中的sheet名字
# print(table)
except IOError:
writeTolog("Error04: 没有找到xlsx文件或读取文件失败,请确认xlsx文件已经关闭!\n")
os.sys.exit() # 强制退出
else:
dict_total = {}
for name in dict_middle_total.keys():
for i in range(3, table.max_row): # 从第3行开始,0,1,2是标题
if (table.cell(row=i,column=2).value == name): # 第2列 中的每个值比较 如 'DRV_0070201'
#取到对应的行数,列都是F列;根据'DRV_0070201' 得到对应的列数
dict_total.update({i:dict_middle_total[name]}) # 重新生成新的键值对
# print("此时的{}对应的行数是{},结果是{}".format(name,rowIndex,dict_middle_total[name]))
break;
else:
continue;
writeTologText.append(dict_middle_total) # 写入日志
writeTologText.append('\n')
writeTologText.append(dict_total) # 写入日志
writeTologText.append('\n')
return dict_total;
def writeToExcel(self,dict_total): # 注意运行程序的时候要关闭Excel,否则无法写入
wb = load_workbook(filename=File_xlsx_path)
ws = wb['测试用例'] # excel中的sheet名字
for key in list(dict_total.keys()): # dict_total[key]
# print("此时F{}的值是{}".format(key,dict_total[key]))
ws[('F' + str(key) )] = dict_total[key] # 类似ws["F86"] = 'Passed'
wb.save(File_xlsx_path)
if __name__ == '__main__':
File_xlsx_path = None;
Filename_log_path = 'resulthtml.log'
if os.path.exists(Filename_log_path): # 清空日志
os.remove(Filename_log_path);
writeTologText = []
myspider = HtmlSpider()
File_html_path_list,File_xlsx_path = myspider.get_current_path()
# 取出的元素已经默认不为空了
for html_path in File_html_path_list:
writeTologText.append("当前处理的文件路径为:"+ html_path + "\n")
success_list, name_list = myspider.get_data(html_path)
dict_total = myspider.readexcel(success_list, name_list,sheetIndex = 2)
myspider.writeToExcel(dict_total)
writeTologText.append("所有html文件内容,已经在{}中设置成功".format(File_xlsx_path))
with open(Filename_log_path, 'a', encoding='utf-8') as f_new: #y一次性写入更快
for logtext in writeTologText:
f_new.write(str(logtext))
3.结果如下:
保存到日志:
4.程序优化,提高运行速度
网页表格抓取(Python中_read_()函数也可以提供快捷表格提取需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-10-25 11:06
天山智慧社区地址:/
在获取数据时,很大一部分需求是获取网络上的关系表。
对于表格,R语言和Python都封装了抓取表格的快捷功能。R语言XML包中的readHTMLTables函数封装了提取HTML嵌入表格的功能。rvest 包的 read_table() 函数也可以提供快捷方式。表格提取要求。Python read_html 还提供了直接从 HTML 中提取关系表的功能。
HTML语法中有两种嵌入表格,一种是table,就是通常意义上的表格,另一种是list,可以理解为列表,但是从浏览器呈现的网页的角度来看,两者很难区分,因为在效果上几乎没有区别,但是通过开发者工具的后台代码界面,table和list是两个完全不同的HTML元素。
上面提到的函数是针对HTML文档中的不同标签设计的,所以如果你乱用这些函数来提取表格,很可能会导致那些你认为是表格但实际上是列表的无效。
R语言
library("RCurl")
library("XML")
library("magrittr")
library("rvest")
对于 XML 包,有三个用于提取 HTML 元素的快捷函数。它们用于 HTML 表格元素、列表元素和链接元素。这些快捷功能是:
readHTMLTable() #获取网页表格
readHTMLList() #获取网页列表
getHTMLlinks() #从HTML网页获取链接
读取HTML表格
readHTMLTable(doc,header=TRUE)
#the HTML document which can be a file name or a URL or an
#already parsed HTMLInternalDocument, or an HTML node of class
#XMLInternalElementNode, or a character vector containing the HTML
#content to parse and process.
此功能支持多种 HTML 文档格式。doc 可以是 url 链接、本地 html 文档、解析的 HTMLInternalDocument 组件或提取的 HTML 节点,甚至是收录 HTML 语法元素的字符串向量。
下面是一个案例,也是我在自学爬行的时候爬过的一个网页。以后可能会有改版。很多朋友爬不出来那些代码,问我这是怎么回事。我尝试了以下但没有奏效,但今天我借此机会重新整理了我的想法。
2016年大连空气质量数据可视化~
URL% xml2::url_escape(reserved ="][!$&'()*+,;=:/?@#")
####
关于网址转码,如果你不想使用函数进行编码转换,
可以通过在线转码平台转码后赋值黏贴使用,但是这不是一个好习惯,
在封装程序代码时无法自动化。
#http://tool.oschina.net/encode?type=4
#R语言自带的转码函数URLencode()转码与浏览器转码结果不一致,
所以我找了很多资料,在xml2包里找打了rvest包的url转码函数,
稍微做了修改,现在这个函数你可以放心使用了!(注意里面的保留字)
###
结果竟然是空的,我猜测这个网页一定是近期做过改版,里面加入了一些数据隐藏措施,这样除了浏览器初始化解析可以看到数据表之外,浏览器后台的network请求链接里都看不到具体数据。
mydata% html_table(header=TRUE) %>% `[[`(1)
#关闭remoteDriver对象
remDr$close()
上面两个是等价的,我们得到了完全一样的表数据,数据预览如下:
DT::datatable(mytable)
readHTMLTable 函数和 rvest 函数中的 html_table 都可以读取 HTML 文档中嵌入的表格。它们是很好的高级包解析器,但这并不意味着它们无所不能。
毕竟,聪明的女人做饭没有米饭是很难的。首先,我们需要得到米饭来做饭,所以在读取表格时,最好的方式是先使用请求库请求(RCurl 或 httr),然后使用 readHTMLTable 函数或 html_table 请求返回的 HTML 文档。函数提取表,否则会适得其反。在今天的情况下,浏览器渲染后可以看到完整的表格,然后后台抓取没有内容,没有提供API访问,无法获取完整的html。文档,您应该考虑任何数据隐藏设置。
看到诀窍就好了。既然浏览器可以解析,我就驱动浏览器去获取解析的HTML文档,返回解析的HTML文档。接下来的工作就是使用这些高级函数来提取嵌入的表。
那么selenium服务器+plantomjs无头浏览器对我们有什么作用呢?实际上,它只做一件事——帮助我们做出真实的浏览器请求。这个请求是由plantomjs无头浏览器完成的。帮助我们传输渲染的完整HTML文档,以便我们可以使用readHTMLTable函数或read_table()
在 XML 包中,还有另外两个非常有用的高级包装函数:
一种用于获取链接,一种用于获取列表。
读取HTML列表
获取HTML链接
/空气/
随便找了个天气网站首页,里面有全国各大城市的空气指数数据。这似乎是一张表,但不一定是真的。我们可以使用现有的表函数来试一试。
url% readHTMLTable(header=TRUE)
mylist < url %>% read_html(encoding ="gbk") %>% html_table(header=TRUE) %>% `[[`(1)
NULL
上述代码捕获的内容为空。有两个原因。一是html中的标签根本不是表格格式,可能是列表。在另一种情况下,表数据像前面的示例一样隐藏。看源码就知道,这一段其实是存放在list unordered list中的,所以用readtable肯定不行。现在是 readHTMLList 函数大显身手的时候了。
header% readHTMLList() %>% `[[`(4) %>% .[2:length(.)]
mylist % html_nodes(".thead li") %>% html_text() %>% `[[`(4) %>% .[2:length(.)]
mylist % htmlParse() %>% readHTMLList() %>% `[[`(4)
虽然我成功获得了结果,但我遇到了一个令人讨厌的编码问题。我不想与各种编码智慧作斗争。我再次使用了phantomjs无头浏览器。毕竟,作为浏览器,它始终可以正确解析和呈现 Web 内容。无论 HTML 文档的编码声明有多糟糕!
#cd D:\
#java -jar selenium-server-standalone-3.3.1.jar
#创建一个remoteDriver对象,并打开
library("RSelenium")
remDr % readHTMLList() %>% `[[`(8) %>% .[2:length(.)]
#关闭remoteDriver对象
remDr$close()
这一次,我终于看到了希望。果然,plantomjs浏览器的渲染效果非同凡响!
使用 str_extract() 函数提取城市 id、城市名称、城市污染物指数、污染状况。
library("stringr")
pattern% do.call(rbind,.) %>% .[,1] %>% str_extract("\\d{1,}"),
City = mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,1] %>% str_extract("[\\u4e00-\\u9fa5]{1,}"),
AQI = mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,2] %>% str_extract("\\d{1,}"),
Quity= mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,2] %>% str_extract("[\\u4e00-\\u9fa5]{1,}")
)
DT::datatable(mylist)
最后一个函数是抓取URL链接的高级封装函数,因为在html中,URL标签一般是比较固定的,重定向的URL链接一般在标签的href属性中,图片链接一般在href属性中的标签。
最好在标签下的 src 属性中定位。
随便找个知乎的照片贴,高清图多的那种!
url% getHTMLLinks()
[1] "/" "/" "/explore"
[4] "/topic" "/topic/19551388" "/topic/19555444"
[7] "/topic/19559348" "/topic/19569883" "/topic/19626553"
[10] "/people/geng-da-shan-ren" "/people/geng-da-shan-ren" "/question/35017762/answer/240404907"
[13] "/people/he-xiao-pang-zi-30" "/people/he-xiao-pang-zi-30" "/question/35017762/answer/209942092"
getHTMLLinks(doc, externalOnly = TRUE, xpQuery = “//a/@href”,baseURL = docName(doc), relative = FALSE)
从getHTMLLinks的源码可以看出,这个函数过滤的链接的条件只有标签下href属性中的链接。我们可以通过修改xpQuery中的apath表达式参数来获取图片链接。
mylink % htmlParse() %>% getHTMLLinks(xpQuery = "//img/@data-original")
这样一来,知乎摄影帖的高清图片原地址全部轻松获取,效率高很多。
Python:
如果不需要python中的爬虫工具,我目前知道的表提取工具是pandas中的read_html函数,相当于一个I/O函数(与read_csv、read_table、read_xlsx等其他函数相同) )。同样适用于上述R语言中第一种情况的天气数据。直接使用pd.read_html函数无法获取表格数据。原因是一样的。html文档中有数据隐藏设置。
import pandas as pd
url="https://www.aqistudy.cn/histor ... ot%3B
dfs = pd.read_html(url)
这里我们也是使用Python中的selenium+plantomjs工具来请求网页,得到完整的源文件后,使用pd.read_html函数进行提取。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('https://www.aqistudy.cn/histor ... %2339;)
dfs = pd.read_html(driver.page_source,header=0)[0]
driver.quit()
好吧,它不可能是完美的。对于网页表格数据,pd.read_html函数是一个非常高效的包,但前提是你要保证这个网页中的数据确实是表格格式,并且网页没有做任何隐藏的措施.
更多课程请点击R语言可视化在业务场景中的应用:
往期案例资料请移步我的GitHub:
/ljtyduyu/DataWarehouse/tree/master/File 查看全部
网页表格抓取(Python中_read_()函数也可以提供快捷表格提取需求)
天山智慧社区地址:/
在获取数据时,很大一部分需求是获取网络上的关系表。
对于表格,R语言和Python都封装了抓取表格的快捷功能。R语言XML包中的readHTMLTables函数封装了提取HTML嵌入表格的功能。rvest 包的 read_table() 函数也可以提供快捷方式。表格提取要求。Python read_html 还提供了直接从 HTML 中提取关系表的功能。
HTML语法中有两种嵌入表格,一种是table,就是通常意义上的表格,另一种是list,可以理解为列表,但是从浏览器呈现的网页的角度来看,两者很难区分,因为在效果上几乎没有区别,但是通过开发者工具的后台代码界面,table和list是两个完全不同的HTML元素。
上面提到的函数是针对HTML文档中的不同标签设计的,所以如果你乱用这些函数来提取表格,很可能会导致那些你认为是表格但实际上是列表的无效。
R语言
library("RCurl")
library("XML")
library("magrittr")
library("rvest")
对于 XML 包,有三个用于提取 HTML 元素的快捷函数。它们用于 HTML 表格元素、列表元素和链接元素。这些快捷功能是:
readHTMLTable() #获取网页表格
readHTMLList() #获取网页列表
getHTMLlinks() #从HTML网页获取链接
读取HTML表格
readHTMLTable(doc,header=TRUE)
#the HTML document which can be a file name or a URL or an
#already parsed HTMLInternalDocument, or an HTML node of class
#XMLInternalElementNode, or a character vector containing the HTML
#content to parse and process.
此功能支持多种 HTML 文档格式。doc 可以是 url 链接、本地 html 文档、解析的 HTMLInternalDocument 组件或提取的 HTML 节点,甚至是收录 HTML 语法元素的字符串向量。
下面是一个案例,也是我在自学爬行的时候爬过的一个网页。以后可能会有改版。很多朋友爬不出来那些代码,问我这是怎么回事。我尝试了以下但没有奏效,但今天我借此机会重新整理了我的想法。
2016年大连空气质量数据可视化~
URL% xml2::url_escape(reserved ="][!$&'()*+,;=:/?@#")
####
关于网址转码,如果你不想使用函数进行编码转换,
可以通过在线转码平台转码后赋值黏贴使用,但是这不是一个好习惯,
在封装程序代码时无法自动化。
#http://tool.oschina.net/encode?type=4
#R语言自带的转码函数URLencode()转码与浏览器转码结果不一致,
所以我找了很多资料,在xml2包里找打了rvest包的url转码函数,
稍微做了修改,现在这个函数你可以放心使用了!(注意里面的保留字)
###
结果竟然是空的,我猜测这个网页一定是近期做过改版,里面加入了一些数据隐藏措施,这样除了浏览器初始化解析可以看到数据表之外,浏览器后台的network请求链接里都看不到具体数据。
mydata% html_table(header=TRUE) %>% `[[`(1)
#关闭remoteDriver对象
remDr$close()
上面两个是等价的,我们得到了完全一样的表数据,数据预览如下:
DT::datatable(mytable)
readHTMLTable 函数和 rvest 函数中的 html_table 都可以读取 HTML 文档中嵌入的表格。它们是很好的高级包解析器,但这并不意味着它们无所不能。
毕竟,聪明的女人做饭没有米饭是很难的。首先,我们需要得到米饭来做饭,所以在读取表格时,最好的方式是先使用请求库请求(RCurl 或 httr),然后使用 readHTMLTable 函数或 html_table 请求返回的 HTML 文档。函数提取表,否则会适得其反。在今天的情况下,浏览器渲染后可以看到完整的表格,然后后台抓取没有内容,没有提供API访问,无法获取完整的html。文档,您应该考虑任何数据隐藏设置。
看到诀窍就好了。既然浏览器可以解析,我就驱动浏览器去获取解析的HTML文档,返回解析的HTML文档。接下来的工作就是使用这些高级函数来提取嵌入的表。
那么selenium服务器+plantomjs无头浏览器对我们有什么作用呢?实际上,它只做一件事——帮助我们做出真实的浏览器请求。这个请求是由plantomjs无头浏览器完成的。帮助我们传输渲染的完整HTML文档,以便我们可以使用readHTMLTable函数或read_table()
在 XML 包中,还有另外两个非常有用的高级包装函数:
一种用于获取链接,一种用于获取列表。
读取HTML列表
获取HTML链接
/空气/
随便找了个天气网站首页,里面有全国各大城市的空气指数数据。这似乎是一张表,但不一定是真的。我们可以使用现有的表函数来试一试。
url% readHTMLTable(header=TRUE)
mylist < url %>% read_html(encoding ="gbk") %>% html_table(header=TRUE) %>% `[[`(1)
NULL
上述代码捕获的内容为空。有两个原因。一是html中的标签根本不是表格格式,可能是列表。在另一种情况下,表数据像前面的示例一样隐藏。看源码就知道,这一段其实是存放在list unordered list中的,所以用readtable肯定不行。现在是 readHTMLList 函数大显身手的时候了。
header% readHTMLList() %>% `[[`(4) %>% .[2:length(.)]
mylist % html_nodes(".thead li") %>% html_text() %>% `[[`(4) %>% .[2:length(.)]
mylist % htmlParse() %>% readHTMLList() %>% `[[`(4)
虽然我成功获得了结果,但我遇到了一个令人讨厌的编码问题。我不想与各种编码智慧作斗争。我再次使用了phantomjs无头浏览器。毕竟,作为浏览器,它始终可以正确解析和呈现 Web 内容。无论 HTML 文档的编码声明有多糟糕!
#cd D:\
#java -jar selenium-server-standalone-3.3.1.jar
#创建一个remoteDriver对象,并打开
library("RSelenium")
remDr % readHTMLList() %>% `[[`(8) %>% .[2:length(.)]
#关闭remoteDriver对象
remDr$close()
这一次,我终于看到了希望。果然,plantomjs浏览器的渲染效果非同凡响!
使用 str_extract() 函数提取城市 id、城市名称、城市污染物指数、污染状况。
library("stringr")
pattern% do.call(rbind,.) %>% .[,1] %>% str_extract("\\d{1,}"),
City = mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,1] %>% str_extract("[\\u4e00-\\u9fa5]{1,}"),
AQI = mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,2] %>% str_extract("\\d{1,}"),
Quity= mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,2] %>% str_extract("[\\u4e00-\\u9fa5]{1,}")
)
DT::datatable(mylist)
最后一个函数是抓取URL链接的高级封装函数,因为在html中,URL标签一般是比较固定的,重定向的URL链接一般在标签的href属性中,图片链接一般在href属性中的标签。
最好在标签下的 src 属性中定位。
随便找个知乎的照片贴,高清图多的那种!
url% getHTMLLinks()
[1] "/" "/" "/explore"
[4] "/topic" "/topic/19551388" "/topic/19555444"
[7] "/topic/19559348" "/topic/19569883" "/topic/19626553"
[10] "/people/geng-da-shan-ren" "/people/geng-da-shan-ren" "/question/35017762/answer/240404907"
[13] "/people/he-xiao-pang-zi-30" "/people/he-xiao-pang-zi-30" "/question/35017762/answer/209942092"
getHTMLLinks(doc, externalOnly = TRUE, xpQuery = “//a/@href”,baseURL = docName(doc), relative = FALSE)
从getHTMLLinks的源码可以看出,这个函数过滤的链接的条件只有标签下href属性中的链接。我们可以通过修改xpQuery中的apath表达式参数来获取图片链接。
mylink % htmlParse() %>% getHTMLLinks(xpQuery = "//img/@data-original")
这样一来,知乎摄影帖的高清图片原地址全部轻松获取,效率高很多。
Python:
如果不需要python中的爬虫工具,我目前知道的表提取工具是pandas中的read_html函数,相当于一个I/O函数(与read_csv、read_table、read_xlsx等其他函数相同) )。同样适用于上述R语言中第一种情况的天气数据。直接使用pd.read_html函数无法获取表格数据。原因是一样的。html文档中有数据隐藏设置。
import pandas as pd
url="https://www.aqistudy.cn/histor ... ot%3B
dfs = pd.read_html(url)
这里我们也是使用Python中的selenium+plantomjs工具来请求网页,得到完整的源文件后,使用pd.read_html函数进行提取。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('https://www.aqistudy.cn/histor ... %2339;)
dfs = pd.read_html(driver.page_source,header=0)[0]
driver.quit()
好吧,它不可能是完美的。对于网页表格数据,pd.read_html函数是一个非常高效的包,但前提是你要保证这个网页中的数据确实是表格格式,并且网页没有做任何隐藏的措施.
更多课程请点击R语言可视化在业务场景中的应用:
往期案例资料请移步我的GitHub:
/ljtyduyu/DataWarehouse/tree/master/File
网页表格抓取(pandasread_csv()和pd.read._excel)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-25 01:14
简介
一般爬虫例程无非就是发送请求、获取响应、解析网页、提取数据、保存数据等步骤。 requests库主要用于构造请求,xpath和正则匹配多用于定位和提取数据。对于一个完整的爬虫来说,代码量可以从几十行到几百行不等。对于新手来说,学习成本相对较高。
说到pandas read.xxx系列的功能,常用的读取数据的方法有:pd.read_csv()和pd.read_excel(),而pd.read_html()方法很少使用,但是它的功能很强大,尤其是用来抓取Table数据的时候,简直是神器。无需掌握正则表达式或xpath等工具,只需几行代码即可快速抓取网页数据并保存到本地。
原理
Pandas 适用于爬取 Table 数据。首先,让我们了解一下具有 Table 数据结构的网页。示例如下:
使用Chrome浏览器查看网页的HTML结构,你会发现Table数据有一些共同点。一般网页结构如下所示。
...
...
...
...
...
...
...
...
...
网页有上述结构,我们可以尝试使用pandas的pd.read_html()方法直接获取数据
pd.read_html()的一些主要参数
io:接收 URL、文件、字符串
header:指定列名所在的行
encoding:用于解码网页的编码
attrs:传递一个字典,并使用其中的属性过滤掉特定的表
parse_dates:解析日期
实战
爬取2019年成都空气质量数据(12页数据),目标网址
添加链接描述
import pandas as pd
dates = pd.date_range('20190101', '20191201', freq='MS').strftime('%Y%m') # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f'http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html', encoding='gbk', header=0)[0]
if i == 0:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False) # 追加写入
i += 1
else:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False, header=False)
抓取新浪金融基金重磅股数据(25页数据),网址:
添加链接描述
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f'http://vip.stock.finance.sina. ... Fp%3D{i}'
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv('新浪财经基金重仓股数据.csv', encoding='utf-8', index=False)
表格数据,可以先试试pd.read_html()大法。 查看全部
网页表格抓取(pandasread_csv()和pd.read._excel)
简介
一般爬虫例程无非就是发送请求、获取响应、解析网页、提取数据、保存数据等步骤。 requests库主要用于构造请求,xpath和正则匹配多用于定位和提取数据。对于一个完整的爬虫来说,代码量可以从几十行到几百行不等。对于新手来说,学习成本相对较高。
说到pandas read.xxx系列的功能,常用的读取数据的方法有:pd.read_csv()和pd.read_excel(),而pd.read_html()方法很少使用,但是它的功能很强大,尤其是用来抓取Table数据的时候,简直是神器。无需掌握正则表达式或xpath等工具,只需几行代码即可快速抓取网页数据并保存到本地。
原理
Pandas 适用于爬取 Table 数据。首先,让我们了解一下具有 Table 数据结构的网页。示例如下:
使用Chrome浏览器查看网页的HTML结构,你会发现Table数据有一些共同点。一般网页结构如下所示。
...
...
...
...
...
...
...
...
...
网页有上述结构,我们可以尝试使用pandas的pd.read_html()方法直接获取数据
pd.read_html()的一些主要参数
io:接收 URL、文件、字符串
header:指定列名所在的行
encoding:用于解码网页的编码
attrs:传递一个字典,并使用其中的属性过滤掉特定的表
parse_dates:解析日期
实战
爬取2019年成都空气质量数据(12页数据),目标网址
添加链接描述
import pandas as pd
dates = pd.date_range('20190101', '20191201', freq='MS').strftime('%Y%m') # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f'http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html', encoding='gbk', header=0)[0]
if i == 0:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False) # 追加写入
i += 1
else:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False, header=False)
抓取新浪金融基金重磅股数据(25页数据),网址:
添加链接描述
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f'http://vip.stock.finance.sina. ... Fp%3D{i}'
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv('新浪财经基金重仓股数据.csv', encoding='utf-8', index=False)
表格数据,可以先试试pd.read_html()大法。
网页表格抓取( 这是简易数据分析系列的第11篇文章(图)制作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-24 04:00
这是简易数据分析系列的第11篇文章(图)制作)
这是简单数据分析系列文章的第十一篇。
今天我们讲讲如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
Ϻ &txtDaoDa=
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,这意味着这些列的内容会被默认捕获。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的,加一个空格和一个标点符号就可以了。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
获取数据后,在浏览器的预览面板中预览,会发现车牌号一栏的数据为空,表示没有获取到相关内容:
我们把抓到的CSV文件下载下来,在预览器中打开后,会发现出现了车次的数据,但是出发站的数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键词索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,和其他标签,这些标签提供了默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本就不是原装正品,自然是无法识别的.
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,也不太适合现代网页的匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。 查看全部
网页表格抓取(
这是简易数据分析系列的第11篇文章(图)制作)
这是简单数据分析系列文章的第十一篇。
今天我们讲讲如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
Ϻ &txtDaoDa=
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,这意味着这些列的内容会被默认捕获。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的,加一个空格和一个标点符号就可以了。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
获取数据后,在浏览器的预览面板中预览,会发现车牌号一栏的数据为空,表示没有获取到相关内容:
我们把抓到的CSV文件下载下来,在预览器中打开后,会发现出现了车次的数据,但是出发站的数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键词索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,和其他标签,这些标签提供了默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本就不是原装正品,自然是无法识别的.
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,也不太适合现代网页的匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。
网页表格抓取( 【soup】新三板soup()进阶版(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-24 03:15
【soup】新三板soup()进阶版(一))
爬取最多的数据分析是表类型。需要专注于掌握。
本文介绍四种方法:
一、find_all 方法 (tr, td)
进行如下操作:
1、检查网页元素,观察
右键单击表单并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
可以看到每一行都是一个tr标签,每个内容都在tr下的td标签中。(可以做练习,但实际情况往往没有那么简单,这个页面的所有数据都显示在一个页面上。其实很多数据往往分布在多个不同的页面上,需要调整结果总数显示在每个页面上,或者遍历所有来捕获完整的数据。)
可以看到表格属性:table
2、连接获取网页内容,使用BeautifulSoup处理html数据
# 导入BeautifulSoup、urllib(request、urlopen)
from bs4 import BeautifulSoup as bs
import urllib
import urllib.request
from urllib.request import urlopen
import csv
urpage="https://www.fasttrack.co.uk/le ... ot%3B
page = urlopen(urpage)
soup=bs(page,"html.parser")
可以使用print(soup)查看是否正确获取汤
如果打印出来,可以看到我们要查找的表中的th(表头)有8列。它们是等级、公司、位置等。
3、 遍历汤中的所有元素并将它们存储在变量中
存储可以使用空列表+设置标题+循环追加元素的方法
循环的结构很简单,主要部分如下(通过两个find_all,第一个tr list进行for循环,第二个td分截截取):
results=table.find_all('tr')
for result in results:
data=result.find_all("td")
loca=data[2].getText()
······
rows.append([rank, company, loca, yearend, anual_sales, sales, staff, comments])
完成如下:
## 空列表加表头
rows=[]
rows.append(["rank","company","loca","yearend","anual_sales","sales","staff","comments"])
## 循环存储
table=soup.find("table")
results=table.find_all('tr')
for result in results:
data=result.find_all("td")
if len(data)==0:
continue
rank=data[0].getText()
company=data[1].getText()
## 如需使用纯公司名,需处理成
## company=data[1].find("span",attrs={"class":"company-name"}).getText()
loca=data[2].getText()
yearend=data[3].getText()
anual_sales=data[4].getText()
sales=data[5].getText()
## 处理sales中符号
sales = sales.strip('*').strip('+').replace(',','')
staff=data[6].getText()
comments=data[7].getText()
rows.append([rank, company, loca, yearend, anual_sales, sales, staff, comments])
print(rows)
4、保存到csv
with open('techtrack100.csv','w', newline='',encoding="utf-8") as f_output:
csv_output = csv.writer(f_output)
csv_output.writerows(rows)
二、pandas 库中的 read_html 方法(表类型)
只需不到十行代码,约一分钟就能将4000多家A股上市公司的209页信息一网打尽。与正则表达式、xpath等常规方法相比,省心省力多了。
参数:io 可以是目标 URL,match 是要匹配的正则表达式,flavor 是解析器,header 是指定的行标题,encoding 是要读取的编码格式。只有设置正确才能正确提取表格,否则会出现乱码。
%s 代表页数;a:代表A股,用h代替a,代表港股;用xsb替换a,代表新的第三块板。
import pandas as pd
import csv
for i in range(1,178): # 爬取全部177页数据
url = 'http://s.askci.com/stock/a/%3F ... 39%3B % (str(i))
tb = pd.read_html(url)[3] #经观察发现所需表格是网页中第4个表格,故为[3]
tb.to_csv(r'C:\Users\xxx\Desktop\1.csv', mode='a', encoding='utf_8_sig', header=1, index=0)
print('第'+str(i)+'页抓取完成')
完整的高级版本代码:
# 网页提取函数
def get_one_page(i):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
paras = {
'reportTime': '2019-12-31',
#可以改报告日期,比如2018-6-30获得的就是该季度的信息
'pageNum': i #页码
}
url = 'http://s.askci.com/stock/a/?' + urlencode(paras)
response = requests.get(url,headers = headers)
if response.status_code == 200:
return response.text
return None
except:
print('爬取失败')
# beatutiful soup解析然后提取表格
def parse_one_page(html):
soup = BeautifulSoup(html,'lxml')
content = soup.select('#myTable04')[0] #[0]将返回的list改为bs4类型
tbl = pd.read_html(content.prettify(),header = 0)[0]
# prettify()优化代码,[0]从pd.read_html返回的list中提取出DataFrame
tbl.rename(columns = {'序号':'serial_number', '股票代码':'stock_code', '股票简称':'stock_abbre', '公司名称':'company_name', '省份':'province', '城市':'city', '主营业务收入(201712)':'main_bussiness_income', '净利润(201712)':'net_profit', '员工人数':'employees', '上市日期':'listing_date', '招股书':'zhaogushu', '公司财报':'financial_report', '行业分类':'industry_classification', '产品类型':'industry_type', '主营业务':'main_business'},inplace = True)
print(tbl)
# return tbl
# rename将表格15列的中文名改为英文名,便于存储到mysql及后期进行数据分析
# tbl = pd.DataFrame(tbl,dtype = 'object') #dtype可统一修改列格式为文本
tbl.to_csv(r'C:\Users\xxx\Desktop\2.csv', mode='a',encoding='utf_8_sig', header=1, index=0)
# 主函数
def main(page):
for i in range(1,page): # page表示提取页数
html = get_one_page(i)
parse_one_page(html)
# 单进程
if __name__ == '__main__':
main(200) #共提取n页
快速方便,但缺点是无法读取单元格中的href链接。
三、selenium(可以被JavaScript动态抓取的表)
思路(Selenium基本是“可见,可爬取”):一次爬取所有td节点单元内容,按照表列数划分列表内容
1、 爬取所有td节点,按照表列数拆分成表
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://data.eastmoney.com/bbsj ... %2339;)
element=browser.find_element_by_xpath('//div[@id="dataview"]')
# 提取表格内容td
td_content = element.find_elements_by_tag_name("td") # 进一步定位到表格内容所在的td节点
lst = [] # 存储为list
for td in td_content:
lst.append(td.text)
print(lst) # 输出表格内容
import pandas as pd
# 确定表格列数
col = len(element.find_elements_by_css_selector('tr:nth-child(1) td'))
# 通过定位一行td的数量,可获得表格的列数,然后将list拆分为对应列数的子list
lst = [lst[i:i + col] for i in range(0, len(lst), col)]
# list转为dataframe
df_table = pd.DataFrame(lst)
# 添加url列
# 原网页中打开"详细"链接可以查看更详细的数据,这里我们把url提取出来,方便后期查看
lst_link = []
links = element.find_elements_by_xpath("//a[contains(text(),'详细')]")
for link in links:
url = link.get_attribute('href')
lst_link.append(url)
lst_link = pd.Series(lst_link)
df_table['url'] = lst_link
print(df_table.head()) # 查看DataFrame
四、分析 URL JavaScript 请求
看
参考:
(这位“老农民工”博主写了很多优秀的文章) 查看全部
网页表格抓取(
【soup】新三板soup()进阶版(一))
爬取最多的数据分析是表类型。需要专注于掌握。
本文介绍四种方法:
一、find_all 方法 (tr, td)
进行如下操作:
1、检查网页元素,观察
右键单击表单并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
可以看到每一行都是一个tr标签,每个内容都在tr下的td标签中。(可以做练习,但实际情况往往没有那么简单,这个页面的所有数据都显示在一个页面上。其实很多数据往往分布在多个不同的页面上,需要调整结果总数显示在每个页面上,或者遍历所有来捕获完整的数据。)
可以看到表格属性:table
2、连接获取网页内容,使用BeautifulSoup处理html数据
# 导入BeautifulSoup、urllib(request、urlopen)
from bs4 import BeautifulSoup as bs
import urllib
import urllib.request
from urllib.request import urlopen
import csv
urpage="https://www.fasttrack.co.uk/le ... ot%3B
page = urlopen(urpage)
soup=bs(page,"html.parser")
可以使用print(soup)查看是否正确获取汤
如果打印出来,可以看到我们要查找的表中的th(表头)有8列。它们是等级、公司、位置等。
3、 遍历汤中的所有元素并将它们存储在变量中
存储可以使用空列表+设置标题+循环追加元素的方法
循环的结构很简单,主要部分如下(通过两个find_all,第一个tr list进行for循环,第二个td分截截取):
results=table.find_all('tr')
for result in results:
data=result.find_all("td")
loca=data[2].getText()
······
rows.append([rank, company, loca, yearend, anual_sales, sales, staff, comments])
完成如下:
## 空列表加表头
rows=[]
rows.append(["rank","company","loca","yearend","anual_sales","sales","staff","comments"])
## 循环存储
table=soup.find("table")
results=table.find_all('tr')
for result in results:
data=result.find_all("td")
if len(data)==0:
continue
rank=data[0].getText()
company=data[1].getText()
## 如需使用纯公司名,需处理成
## company=data[1].find("span",attrs={"class":"company-name"}).getText()
loca=data[2].getText()
yearend=data[3].getText()
anual_sales=data[4].getText()
sales=data[5].getText()
## 处理sales中符号
sales = sales.strip('*').strip('+').replace(',','')
staff=data[6].getText()
comments=data[7].getText()
rows.append([rank, company, loca, yearend, anual_sales, sales, staff, comments])
print(rows)
4、保存到csv
with open('techtrack100.csv','w', newline='',encoding="utf-8") as f_output:
csv_output = csv.writer(f_output)
csv_output.writerows(rows)
二、pandas 库中的 read_html 方法(表类型)
只需不到十行代码,约一分钟就能将4000多家A股上市公司的209页信息一网打尽。与正则表达式、xpath等常规方法相比,省心省力多了。
参数:io 可以是目标 URL,match 是要匹配的正则表达式,flavor 是解析器,header 是指定的行标题,encoding 是要读取的编码格式。只有设置正确才能正确提取表格,否则会出现乱码。
%s 代表页数;a:代表A股,用h代替a,代表港股;用xsb替换a,代表新的第三块板。
import pandas as pd
import csv
for i in range(1,178): # 爬取全部177页数据
url = 'http://s.askci.com/stock/a/%3F ... 39%3B % (str(i))
tb = pd.read_html(url)[3] #经观察发现所需表格是网页中第4个表格,故为[3]
tb.to_csv(r'C:\Users\xxx\Desktop\1.csv', mode='a', encoding='utf_8_sig', header=1, index=0)
print('第'+str(i)+'页抓取完成')
完整的高级版本代码:
# 网页提取函数
def get_one_page(i):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
paras = {
'reportTime': '2019-12-31',
#可以改报告日期,比如2018-6-30获得的就是该季度的信息
'pageNum': i #页码
}
url = 'http://s.askci.com/stock/a/?' + urlencode(paras)
response = requests.get(url,headers = headers)
if response.status_code == 200:
return response.text
return None
except:
print('爬取失败')
# beatutiful soup解析然后提取表格
def parse_one_page(html):
soup = BeautifulSoup(html,'lxml')
content = soup.select('#myTable04')[0] #[0]将返回的list改为bs4类型
tbl = pd.read_html(content.prettify(),header = 0)[0]
# prettify()优化代码,[0]从pd.read_html返回的list中提取出DataFrame
tbl.rename(columns = {'序号':'serial_number', '股票代码':'stock_code', '股票简称':'stock_abbre', '公司名称':'company_name', '省份':'province', '城市':'city', '主营业务收入(201712)':'main_bussiness_income', '净利润(201712)':'net_profit', '员工人数':'employees', '上市日期':'listing_date', '招股书':'zhaogushu', '公司财报':'financial_report', '行业分类':'industry_classification', '产品类型':'industry_type', '主营业务':'main_business'},inplace = True)
print(tbl)
# return tbl
# rename将表格15列的中文名改为英文名,便于存储到mysql及后期进行数据分析
# tbl = pd.DataFrame(tbl,dtype = 'object') #dtype可统一修改列格式为文本
tbl.to_csv(r'C:\Users\xxx\Desktop\2.csv', mode='a',encoding='utf_8_sig', header=1, index=0)
# 主函数
def main(page):
for i in range(1,page): # page表示提取页数
html = get_one_page(i)
parse_one_page(html)
# 单进程
if __name__ == '__main__':
main(200) #共提取n页
快速方便,但缺点是无法读取单元格中的href链接。
三、selenium(可以被JavaScript动态抓取的表)
思路(Selenium基本是“可见,可爬取”):一次爬取所有td节点单元内容,按照表列数划分列表内容
1、 爬取所有td节点,按照表列数拆分成表
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://data.eastmoney.com/bbsj ... %2339;)
element=browser.find_element_by_xpath('//div[@id="dataview"]')
# 提取表格内容td
td_content = element.find_elements_by_tag_name("td") # 进一步定位到表格内容所在的td节点
lst = [] # 存储为list
for td in td_content:
lst.append(td.text)
print(lst) # 输出表格内容
import pandas as pd
# 确定表格列数
col = len(element.find_elements_by_css_selector('tr:nth-child(1) td'))
# 通过定位一行td的数量,可获得表格的列数,然后将list拆分为对应列数的子list
lst = [lst[i:i + col] for i in range(0, len(lst), col)]
# list转为dataframe
df_table = pd.DataFrame(lst)
# 添加url列
# 原网页中打开"详细"链接可以查看更详细的数据,这里我们把url提取出来,方便后期查看
lst_link = []
links = element.find_elements_by_xpath("//a[contains(text(),'详细')]")
for link in links:
url = link.get_attribute('href')
lst_link.append(url)
lst_link = pd.Series(lst_link)
df_table['url'] = lst_link
print(df_table.head()) # 查看DataFrame
四、分析 URL JavaScript 请求
看
参考:
(这位“老农民工”博主写了很多优秀的文章)
网页表格抓取(集搜客网络爬虫软件是一款免费的网页数据抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-23 05:21
极手客网络爬虫软件是一款免费的网络数据爬取工具,可将网络内容转化为excel表格,进行内容分析、文本分析、策略分析和文档分析。自动分词、社交网络分析和情感分析软件于研究生设计和行业研究。
网页内容智能抓取的实现和实例详解完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。该应用程序的开源组件包括: DOM4J:解析 XMLjericho-。
优采云网页数据采集器,是一款简单易用、功能强大的网络爬虫工具,完全可视化操作,无需编写代码,内置海量模板,支持任意网页数据抓取,连续五年.
如何爬取不同分页类型的数据网站,因为内容比较多,我会放到本文下一节详细介绍。3.过滤表单类型的网页在网站上比较常见,这种网页最大的特点就是过滤项很多,不同的选择不会加载。
URL就像网站和搜索引擎爬虫之间的桥梁:为了能够抓取你的网站内容,爬虫需要能够找到并跨越这些桥梁(即找到并抓取你的URLs )。如果您的 URL 复杂或冗长。
Content crawling-content 可以从 网站 爬取,以复制依赖该内容的独特产品或服务优势。例如,Yelp 等产品依赖于评论。参赛者可以从Yelp中抓取所有评论,然后将其复制到您自己的网站,并让您自己的网站的内容打开。
《爬虫四步法》教你如何使用Python抓取和存储网页数据。
网页内容提取器可以帮助我们快速提取输入的URL链接中的所有图片、链接和网页文本内容。 查看全部
网页表格抓取(集搜客网络爬虫软件是一款免费的网页数据抓取工具)
极手客网络爬虫软件是一款免费的网络数据爬取工具,可将网络内容转化为excel表格,进行内容分析、文本分析、策略分析和文档分析。自动分词、社交网络分析和情感分析软件于研究生设计和行业研究。
网页内容智能抓取的实现和实例详解完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。该应用程序的开源组件包括: DOM4J:解析 XMLjericho-。
优采云网页数据采集器,是一款简单易用、功能强大的网络爬虫工具,完全可视化操作,无需编写代码,内置海量模板,支持任意网页数据抓取,连续五年.
如何爬取不同分页类型的数据网站,因为内容比较多,我会放到本文下一节详细介绍。3.过滤表单类型的网页在网站上比较常见,这种网页最大的特点就是过滤项很多,不同的选择不会加载。
URL就像网站和搜索引擎爬虫之间的桥梁:为了能够抓取你的网站内容,爬虫需要能够找到并跨越这些桥梁(即找到并抓取你的URLs )。如果您的 URL 复杂或冗长。
Content crawling-content 可以从 网站 爬取,以复制依赖该内容的独特产品或服务优势。例如,Yelp 等产品依赖于评论。参赛者可以从Yelp中抓取所有评论,然后将其复制到您自己的网站,并让您自己的网站的内容打开。
《爬虫四步法》教你如何使用Python抓取和存储网页数据。
网页内容提取器可以帮助我们快速提取输入的URL链接中的所有图片、链接和网页文本内容。
网页表格抓取( 如何利用WebScraper抓取滚动到底翻页的网页?(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-18 14:14
如何利用WebScraper抓取滚动到底翻页的网页?(一)
)
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天的实践网站就是知乎数据分析模块的精髓。该网站是:
本次抓取的内容是精华帖的标题、回复者和批准数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数量控制items数量的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们按照Scrape -> Start Scraping的路径抓取数据,等了十多秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获哪些数据?怎么全都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
1. 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3. 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板,其中收录一些无法理解的彩色代码。
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑,它们是网页中的一个骨架,并提供一些排版功能。
如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树状结构:
上面这句话是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
class='ContentItem-title'/>
itemprop='知乎:question'/> 如何快速成为数据分析师?
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少名为 div 属性为 itemprop='知乎:question' 的标签!
结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题的时候,不管标题的嵌套关系如何变化,总有一个标签保持不变,也就是包裹在最外层的h2标签,属性名class='ContentItem-title' .
如果我们可以直接选择h2标签,是不是就可以完美匹配标题内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据完成的很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小规模的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。
●简单的数据分析(四):Web Scraper抓取多条内容
●简单的数据分析(二):Web Scraper尝鲜者,抢豆瓣高分电影
●简单的数据分析(一):起源,了解Web Scraper和浏览器技巧
·结尾·
图克社区
汇集精彩免费实用教程
查看全部
网页表格抓取(
如何利用WebScraper抓取滚动到底翻页的网页?(一)
)
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天的实践网站就是知乎数据分析模块的精髓。该网站是:
本次抓取的内容是精华帖的标题、回复者和批准数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数量控制items数量的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们按照Scrape -> Start Scraping的路径抓取数据,等了十多秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获哪些数据?怎么全都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
1. 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3. 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板,其中收录一些无法理解的彩色代码。
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑,它们是网页中的一个骨架,并提供一些排版功能。
如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树状结构:
上面这句话是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
class='ContentItem-title'/>
itemprop='知乎:question'/> 如何快速成为数据分析师?
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少名为 div 属性为 itemprop='知乎:question' 的标签!
结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题的时候,不管标题的嵌套关系如何变化,总有一个标签保持不变,也就是包裹在最外层的h2标签,属性名class='ContentItem-title' .
如果我们可以直接选择h2标签,是不是就可以完美匹配标题内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据完成的很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小规模的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。
●简单的数据分析(四):Web Scraper抓取多条内容
●简单的数据分析(二):Web Scraper尝鲜者,抢豆瓣高分电影
●简单的数据分析(一):起源,了解Web Scraper和浏览器技巧
·结尾·
图克社区
汇集精彩免费实用教程
网页表格抓取(在ASP.NET中表格的显式方法利用JS来取页面表格数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-18 14:13
ASP.NET 中有多种表的显式方法。有html标签、asp服务器控件GridView、Repeater控件等,可以帮助我们在页面上显示表格信息。GridView 控件更强大,它有自己的属性和方法,可用于对显式表数据执行各种操作。但是如果使用传统的html标签或者Repeater控件来显示数据,如何获取选中行的数据呢?这里介绍一下使用JS获取页表数据的方法。
如图,我们需要对表中的数据进行编辑和删除。
以中继器控件为例:
(1)页表:定义表头,设置数据绑定(有些操作需要获取数据的主键,考虑实际情况,我们应该隐藏主键,使用隐藏属性进行对应的列就可以了)。在后台只需要将Repeater绑定到对应的数据源即可,这里我们使用class来标记按钮,这样在JS中就可以把所有同class的按钮作为一组取出. 从而在JS中监听并选择Set对应的行。
1 出货单单头:
2
3
4
5
6 ID
7 客户ID
8 出货人员
9 创建时间
10 更新时间
11 编辑
12 删除
13 新增子信息
14
15
16
17
18
19
20
21
22
23
24 编辑
25
26
27 删除
28
29
30 新增子信息
31
32
33
34
35
(2)JS部分:通过class获取对应的一组按钮并设置监听。然后通过标签名获取选中行,通过标签名获取选中行的所有列数据的集合,转换对应的数据通过DOM操作显示在前台指定位置。
1 /*编辑单头信息*/
2 var Top_Edit = document.getElementsByClassName("Top_Edit");
3
4 for (var i = 0; i < Top_Edit.length; i++) {
5
6 Top_Edit[i].index = i;
7
8 Top_Edit[i].onclick = function () {
9
10 var table = document.getElementById("Top_Table");
11
12 /*获取选中的行 */
13 var child = table.getElementsByTagName("tr")[this.index + 1];
14
15 /*获取选择行的所有列*/
16 var SZ_col = child.getElementsByTagName("td");
17
18 document.getElementById("Edit_id").value = SZ_col[0].innerHTML;
19 document.getElementById("edit_customer").value = SZ_col[1].innerHTML;
20 document.getElementById("edit_man").value = SZ_col[2].innerHTML;
21 document.getElementById("Top_Creat_Time").value = SZ_col[3].innerHTML;
22 document.getElementById("Top_Update_Time").value = SZ_col[4].innerHTML;
23
24 }
25 }
JS 只需简单几步即可获取表格数据。还有其他获取表格数据的方法,比如jQuery,大家可以多尝试,然后比较总结,这也是对程序员自己的一种改进。 查看全部
网页表格抓取(在ASP.NET中表格的显式方法利用JS来取页面表格数据)
ASP.NET 中有多种表的显式方法。有html标签、asp服务器控件GridView、Repeater控件等,可以帮助我们在页面上显示表格信息。GridView 控件更强大,它有自己的属性和方法,可用于对显式表数据执行各种操作。但是如果使用传统的html标签或者Repeater控件来显示数据,如何获取选中行的数据呢?这里介绍一下使用JS获取页表数据的方法。
如图,我们需要对表中的数据进行编辑和删除。
以中继器控件为例:
(1)页表:定义表头,设置数据绑定(有些操作需要获取数据的主键,考虑实际情况,我们应该隐藏主键,使用隐藏属性进行对应的列就可以了)。在后台只需要将Repeater绑定到对应的数据源即可,这里我们使用class来标记按钮,这样在JS中就可以把所有同class的按钮作为一组取出. 从而在JS中监听并选择Set对应的行。
1 出货单单头:
2
3
4
5
6 ID
7 客户ID
8 出货人员
9 创建时间
10 更新时间
11 编辑
12 删除
13 新增子信息
14
15
16
17
18
19
20
21
22
23
24 编辑
25
26
27 删除
28
29
30 新增子信息
31
32
33
34
35
(2)JS部分:通过class获取对应的一组按钮并设置监听。然后通过标签名获取选中行,通过标签名获取选中行的所有列数据的集合,转换对应的数据通过DOM操作显示在前台指定位置。
1 /*编辑单头信息*/
2 var Top_Edit = document.getElementsByClassName("Top_Edit");
3
4 for (var i = 0; i < Top_Edit.length; i++) {
5
6 Top_Edit[i].index = i;
7
8 Top_Edit[i].onclick = function () {
9
10 var table = document.getElementById("Top_Table");
11
12 /*获取选中的行 */
13 var child = table.getElementsByTagName("tr")[this.index + 1];
14
15 /*获取选择行的所有列*/
16 var SZ_col = child.getElementsByTagName("td");
17
18 document.getElementById("Edit_id").value = SZ_col[0].innerHTML;
19 document.getElementById("edit_customer").value = SZ_col[1].innerHTML;
20 document.getElementById("edit_man").value = SZ_col[2].innerHTML;
21 document.getElementById("Top_Creat_Time").value = SZ_col[3].innerHTML;
22 document.getElementById("Top_Update_Time").value = SZ_col[4].innerHTML;
23
24 }
25 }
JS 只需简单几步即可获取表格数据。还有其他获取表格数据的方法,比如jQuery,大家可以多尝试,然后比较总结,这也是对程序员自己的一种改进。

