
网页表格抓取
网页表格抓取(《表》返回数据帧的使用方法分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-10-07 13:10
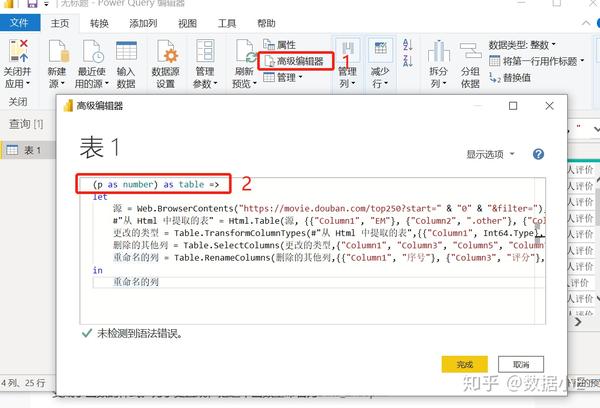
正如furas所说,您需要提取正确的表格标记(因此请接受他的解决方案)。但我也想补充,考虑使用
方法,因为它为您完成了解析表标签的繁重工作(并在引擎盖下使用了漂亮的汤)。
所以
将返回数据帧列表。我相信你想要的数据框是
, 这是第二个表(在索引位置1):
import pandas as pd
df = pd.read_html('https://www.macrotrends.net/st ... 23x27;)[1]
输出:
print(df)
Tesla Quarterly Revenue(Millions of US $) Tesla Quarterly Revenue(Millions of US $).1
0 2020-12-31 $10,744
1 2020-09-30 $8,771
2 2020-06-30 $6,036
3 2020-03-31 $5,985
4 2019-12-31 $7,384
5 2019-09-30 $6,303
6 2019-06-30 $6,350
7 2019-03-31 $4,541
8 2018-12-31 $7,226
9 2018-09-30 $6,824
10 2018-06-30 $4,002
11 2018-03-31 $3,409
12 2017-12-31 $3,288
13 2017-09-30 $2,985
14 2017-06-30 $2,790
15 2017-03-31 $2,696
16 2016-12-31 $2,285
17 2016-09-30 $2,298
18 2016-06-30 $1,270
19 2016-03-31 $1,147
20 2015-12-31 $1,214
21 2015-09-30 $937
22 2015-06-30 $955
23 2015-03-31 $940
24 2014-12-31 $957
25 2014-09-30 $852
26 2014-06-30 $769
27 2014-03-31 $621
28 2013-12-31 $615
29 2013-09-30 $431
30 2013-06-30 $405
31 2013-03-31 $562
32 2012-12-31 $306
33 2012-09-30 $50
34 2012-06-30 $27
35 2012-03-31 $30
36 2011-12-31 $39
37 2011-09-30 $58
38 2011-06-30 $58
39 2011-03-31 $49
40 2010-12-31 $36
41 2010-09-30 $31
42 2010-06-30 $28
43 2010-03-31 $21
44 2009-12-31 NaN
45 2009-09-30 $46
46 2009-06-30 $27
47 2008-12-31
NaN
CN
正如furas所说,您需要提取正确的表格标记(因此请接受他的解决方案)。但我还想补充一点,考虑如何使用它,因为它为您完成了解析表标签的繁重工作(并且在引擎盖下使用了漂亮的汤)。因此将返回数据帧列表。我相信你想要的数据框是,这是第二个表(在索引位置 1): import panda... 查看全部
网页表格抓取(《表》返回数据帧的使用方法分享)
正如furas所说,您需要提取正确的表格标记(因此请接受他的解决方案)。但我也想补充,考虑使用
方法,因为它为您完成了解析表标签的繁重工作(并在引擎盖下使用了漂亮的汤)。
所以
将返回数据帧列表。我相信你想要的数据框是
, 这是第二个表(在索引位置1):
import pandas as pd
df = pd.read_html('https://www.macrotrends.net/st ... 23x27;)[1]
输出:
print(df)
Tesla Quarterly Revenue(Millions of US $) Tesla Quarterly Revenue(Millions of US $).1
0 2020-12-31 $10,744
1 2020-09-30 $8,771
2 2020-06-30 $6,036
3 2020-03-31 $5,985
4 2019-12-31 $7,384
5 2019-09-30 $6,303
6 2019-06-30 $6,350
7 2019-03-31 $4,541
8 2018-12-31 $7,226
9 2018-09-30 $6,824
10 2018-06-30 $4,002
11 2018-03-31 $3,409
12 2017-12-31 $3,288
13 2017-09-30 $2,985
14 2017-06-30 $2,790
15 2017-03-31 $2,696
16 2016-12-31 $2,285
17 2016-09-30 $2,298
18 2016-06-30 $1,270
19 2016-03-31 $1,147
20 2015-12-31 $1,214
21 2015-09-30 $937
22 2015-06-30 $955
23 2015-03-31 $940
24 2014-12-31 $957
25 2014-09-30 $852
26 2014-06-30 $769
27 2014-03-31 $621
28 2013-12-31 $615
29 2013-09-30 $431
30 2013-06-30 $405
31 2013-03-31 $562
32 2012-12-31 $306
33 2012-09-30 $50
34 2012-06-30 $27
35 2012-03-31 $30
36 2011-12-31 $39
37 2011-09-30 $58
38 2011-06-30 $58
39 2011-03-31 $49
40 2010-12-31 $36
41 2010-09-30 $31
42 2010-06-30 $28
43 2010-03-31 $21
44 2009-12-31 NaN
45 2009-09-30 $46
46 2009-06-30 $27
47 2008-12-31
NaN
CN
正如furas所说,您需要提取正确的表格标记(因此请接受他的解决方案)。但我还想补充一点,考虑如何使用它,因为它为您完成了解析表标签的繁重工作(并且在引擎盖下使用了漂亮的汤)。因此将返回数据帧列表。我相信你想要的数据框是,这是第二个表(在索引位置 1): import panda...
网页表格抓取(如何获取表格信息之前?库怎么用方法?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-10-07 12:11
一、背景
在日常的数据分析工作中,我们经常会寻找数据来源。所以经常会看到网页表格信息,不能直接复制到excel表格中。为了快速获取网页中的表单信息,对其进行分析汇总,最后向上级汇报。所以我们需要思考如何更方便快捷地获取信息。当然,正常的网页爬取也是可行的,但是比较复杂。这里我们使用pandas库来操作,爬表很容易。
二、必备知识
在开始获取表信息之前,需要了解一些pandas的方法。pandas库的文档可以参考:
1、pandas.DataFrame.to_csv 方法:以csv格式保存数据
DataFrame.to_csv(self, path_or_buf=None, sep=', ', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression='infer', quoting=None, quotechar='"', line_terminator=None, chunksize=None, date_format=None, doublequote=True, escapechar=None, decimal='.')
2、pandas.read_html 方法:将HTML网页中的表格解析为DataFrame对象并返回列表。详情:#pandas.read_html
pandas.read_html(io, match='.+', flavor=None, header=None, index_col=None, skiprows=None, attrs=None, parse_dates=False, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None, keep_default_na=True, displayed_only=True)
三、 爬取表数据
1、分析网站
本例的网站地址为:世界大学排名网站,地址见代码。经过分析,网站的请求方式为GET,爬取难度较小。
然后,定位并获取表数据。
最后,代码实现了表格数据的爬取。
import pandas as pd
import requests
from fake_useragent import UserAgent
import random
from lxml import etree
'''请求头函数'''
def agent():
ua = UserAgent()
# 随机选择chrome、ie、firefox请求头
useragent = random.choice([ua.chrome, ua.ie, ua.firefox])
headers = {
'User-Agent': useragent,
'Referer': 'https: // cn.bing.com /'
}
return headers
'''解析网页数据'''
def parse_html(url):
try:
resp = requests.get(url, headers=agent())
# 将编码方式设置为从内容中分析出的响应内容编码方式
resp.encoding = resp.apparent_encoding
if resp.status_code == 200:
tree = etree.HTML(resp.text)
# 定位获取表格信息
tb = tree.xpath('//table[@id="rk"]')
# 将byte类型解码为str类型
tb = etree.tostring(tb[0], encoding='utf8').decode()
return tb
else:
print('爬取失败')
except Exception as e:
print(e)
def main():
url = 'http://www.compassedu.hk/qs_'
tb = parse_html(url)
# 解析表格数据
df = pd.read_html(tb, encoding='utf-8', header=0)[0]
# 转换成列表嵌套字典的格式
result = list(df.T.to_dict().values())
# 保存为csv格式
df.to_csv('university.csv', index=False)
print(result)
if __name__ == '__main__':
main()
结果显示:
四、分析表数据信息
1、编码格式转换
表格数据虽然已经保存到本地.csv文件,但是用excel打开时发现是乱码,用代码编辑器打开时显示正常。是什么原因?事实上,这非常简单。当您按下代码时,您经常会遇到编码问题。只需改变excel的编码方式,保存为excel格式的数据文件即可。
首先,创建一个 university.xlsx 文件,然后打开它。在工具栏“数据”中找到“从text/csv导入数据”,选择数据源文件,即网上爬取的university.csv数据文件。最后点击“导入”
选择文件编码方式,这里是utf-8的编码方式。这里,默认情况下,csv中的数据是用逗号分隔的,所以不需要选择。最后,点击加载。
2、数据分析
现在数据已经全部正常显示在excel表格中了,接下来点击“插入”数据透视表,或者使用快捷键ctrl+q。最后点击确定。
然后,在数据透视表中进行调整,分析数据并得出结论。
最后,对于数据量不是很大的情况,利用excel的数据透视表功能灵活处理、分析、展示数据信息也是一种非常高效的方法。 查看全部
网页表格抓取(如何获取表格信息之前?库怎么用方法?)
一、背景
在日常的数据分析工作中,我们经常会寻找数据来源。所以经常会看到网页表格信息,不能直接复制到excel表格中。为了快速获取网页中的表单信息,对其进行分析汇总,最后向上级汇报。所以我们需要思考如何更方便快捷地获取信息。当然,正常的网页爬取也是可行的,但是比较复杂。这里我们使用pandas库来操作,爬表很容易。
二、必备知识
在开始获取表信息之前,需要了解一些pandas的方法。pandas库的文档可以参考:
1、pandas.DataFrame.to_csv 方法:以csv格式保存数据
DataFrame.to_csv(self, path_or_buf=None, sep=', ', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression='infer', quoting=None, quotechar='"', line_terminator=None, chunksize=None, date_format=None, doublequote=True, escapechar=None, decimal='.')
2、pandas.read_html 方法:将HTML网页中的表格解析为DataFrame对象并返回列表。详情:#pandas.read_html
pandas.read_html(io, match='.+', flavor=None, header=None, index_col=None, skiprows=None, attrs=None, parse_dates=False, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None, keep_default_na=True, displayed_only=True)
三、 爬取表数据
1、分析网站
本例的网站地址为:世界大学排名网站,地址见代码。经过分析,网站的请求方式为GET,爬取难度较小。

然后,定位并获取表数据。
最后,代码实现了表格数据的爬取。
import pandas as pd
import requests
from fake_useragent import UserAgent
import random
from lxml import etree
'''请求头函数'''
def agent():
ua = UserAgent()
# 随机选择chrome、ie、firefox请求头
useragent = random.choice([ua.chrome, ua.ie, ua.firefox])
headers = {
'User-Agent': useragent,
'Referer': 'https: // cn.bing.com /'
}
return headers
'''解析网页数据'''
def parse_html(url):
try:
resp = requests.get(url, headers=agent())
# 将编码方式设置为从内容中分析出的响应内容编码方式
resp.encoding = resp.apparent_encoding
if resp.status_code == 200:
tree = etree.HTML(resp.text)
# 定位获取表格信息
tb = tree.xpath('//table[@id="rk"]')
# 将byte类型解码为str类型
tb = etree.tostring(tb[0], encoding='utf8').decode()
return tb
else:
print('爬取失败')
except Exception as e:
print(e)
def main():
url = 'http://www.compassedu.hk/qs_'
tb = parse_html(url)
# 解析表格数据
df = pd.read_html(tb, encoding='utf-8', header=0)[0]
# 转换成列表嵌套字典的格式
result = list(df.T.to_dict().values())
# 保存为csv格式
df.to_csv('university.csv', index=False)
print(result)
if __name__ == '__main__':
main()
结果显示:
四、分析表数据信息
1、编码格式转换
表格数据虽然已经保存到本地.csv文件,但是用excel打开时发现是乱码,用代码编辑器打开时显示正常。是什么原因?事实上,这非常简单。当您按下代码时,您经常会遇到编码问题。只需改变excel的编码方式,保存为excel格式的数据文件即可。
首先,创建一个 university.xlsx 文件,然后打开它。在工具栏“数据”中找到“从text/csv导入数据”,选择数据源文件,即网上爬取的university.csv数据文件。最后点击“导入”
选择文件编码方式,这里是utf-8的编码方式。这里,默认情况下,csv中的数据是用逗号分隔的,所以不需要选择。最后,点击加载。
2、数据分析
现在数据已经全部正常显示在excel表格中了,接下来点击“插入”数据透视表,或者使用快捷键ctrl+q。最后点击确定。
然后,在数据透视表中进行调整,分析数据并得出结论。
最后,对于数据量不是很大的情况,利用excel的数据透视表功能灵活处理、分析、展示数据信息也是一种非常高效的方法。
网页表格抓取(洛约拉大学(Loyola)网络研讨会演示如何无需编程即可抓取网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-02 13:26
有一些编程语言可以简化这个操作,比如 Python。这是因为 Python 提供了 Scrapy 和 BeautifulSoup 等库,它们比传统的网络爬虫更容易抓取和解析 HTML。
但是,它仍然需要适当的设计以及对编程和 网站 架构的良好理解。
假设您的团队没有编程技能。那没问题!我们团队的一名成员最近在洛约拉大学举办了一场网络研讨会,演示如何在没有编程的情况下抓取网页。相反,Google Sheets 提供了一些有用的功能,可以帮助抓取网络数据。如果您想观看我们的在线讲座视频,请点击下方。如果没有,您可以继续阅读并弄清楚如何使用 Google Sheets 来抓取 网站。
Google表格抓取功能
您可以使用 Google Sheets 进行网络抓取的功能有:
所有这些函数都将根据提供给函数 网站 的不同参数来获取。
使用 ImportFeed 进行网络抓取
ImportFeed Google Sheets 功能是更易于使用的功能之一。它只需要访问 Google 表格和 RSS 提要的 URL。这是通常与博客相关联的提要。
例如,您可以使用我们的 RSS 提要“”。
你如何使用这个功能?下面给出一个例子。
"= ImportFeed(" ")
这就是所需要的!还有其他提示和技巧可以帮助清理数据提要,因为您将拥有不止一列信息。目前,这是网络抓取的良好开端。
Google 表格导入功能会更新吗?
所有这些导入功能每 2 小时自动更新一次数据。可设置触发功能,增加更新节奏。但是,这需要更多的编程。
在这种情况下就是这样!从这里开始,这就是您的团队使用它的方式!确保设计一个可靠的数据采集系统。
上图是使用 ImportFeed 函数的示例。
使用 ImportXML 进行网络爬虫
Google 表格中的 ImportXML 函数用于使用 HTML ID 和类提取特定数据点。这需要对 HTML 和解析 XML 有一定的了解。这可能有点令人沮丧。因此,我们逐渐创建了一个 HTML 网络爬虫。
以下是 EventBrite 页面上的一些示例。
去右键单击并检查元素以找到您感兴趣的 HTML 标记。 我们正在寻找
一些文字,所以这是棘手的部分。您需要从这个 HTML 标记中提取的第一部分是类型。相似
,
,等待。您可以使用“//”,然后使用标签名称来调用第一个。例如“// div”、“// a”或“// span”。现在,如果你真的想要“这里有一些文字”,你需要调用课程。这是在步骤 5 中显示的方法中完成的。您会注意到它使用了“// div”和“[@class =“此处为类名”] 的组合。xml 字符串是“// div [@class ='list-card__body']" 你可能想要获取另一个数据值。我们想要获取所有的 URL。这种情况会涉及到想要提取第一个 HTML 标签本身内部的特定值。例如,点击这里。然后就像 step 7.xml字符串为“//a/@href”ImportXML(URL, XML string)ImportXML(“”,“//div[@class='list-card__body']”)
使用此功能的事实是它需要花费大量时间。因此,它需要规划和设计一个好的 Google 工作表,以确保您从使用中获得最大的收益。否则,您的团队最终将花时间维护它而不是研究新事物。像下面的图片
来自 xkcd
使用 ImportHTML 进行网页抓取
最后,我们将讨论 ImportHTML。这将从网页导入表格或列表。例如,如果您想从 网站 中获取收录股票价格的数据,该怎么办。
我们会用。这个页面上有一张表格,上面有过去几天的股票价格。
与过去的功能类似,您需要使用一个 URL。在 URL 的顶部,您必须提及要在页面上抓取的表格。您可以使用可能的数字来完成此操作。
例如,ImportHTML (" ",6 )。这将从上面的链接中删除股票价格。
在上面的视频中,我们还展示了如何将上述股票数据捕获结合到当天有关股市自动收录设备的新闻中。这可以以更复杂的方式使用。该团队可以创建一个算法,使用过去的股票价格和新的 文章 和 Twitter 信息来选择是买入还是卖出股票。
你有什么使用网页抓取的好主意吗?您需要有关网页抓取项目的帮助吗?让我们知道!
关于数据科学的其他精彩读物:
什么是决策树
算法如何变得不道德和有偏见
如何开发健壮的算法
数据科学家必须具备的 4 项技能
从: 查看全部
网页表格抓取(洛约拉大学(Loyola)网络研讨会演示如何无需编程即可抓取网页)
有一些编程语言可以简化这个操作,比如 Python。这是因为 Python 提供了 Scrapy 和 BeautifulSoup 等库,它们比传统的网络爬虫更容易抓取和解析 HTML。
但是,它仍然需要适当的设计以及对编程和 网站 架构的良好理解。
假设您的团队没有编程技能。那没问题!我们团队的一名成员最近在洛约拉大学举办了一场网络研讨会,演示如何在没有编程的情况下抓取网页。相反,Google Sheets 提供了一些有用的功能,可以帮助抓取网络数据。如果您想观看我们的在线讲座视频,请点击下方。如果没有,您可以继续阅读并弄清楚如何使用 Google Sheets 来抓取 网站。
Google表格抓取功能
您可以使用 Google Sheets 进行网络抓取的功能有:
所有这些函数都将根据提供给函数 网站 的不同参数来获取。
使用 ImportFeed 进行网络抓取
ImportFeed Google Sheets 功能是更易于使用的功能之一。它只需要访问 Google 表格和 RSS 提要的 URL。这是通常与博客相关联的提要。
例如,您可以使用我们的 RSS 提要“”。
你如何使用这个功能?下面给出一个例子。
"= ImportFeed(" ")
这就是所需要的!还有其他提示和技巧可以帮助清理数据提要,因为您将拥有不止一列信息。目前,这是网络抓取的良好开端。
Google 表格导入功能会更新吗?
所有这些导入功能每 2 小时自动更新一次数据。可设置触发功能,增加更新节奏。但是,这需要更多的编程。
在这种情况下就是这样!从这里开始,这就是您的团队使用它的方式!确保设计一个可靠的数据采集系统。
上图是使用 ImportFeed 函数的示例。
使用 ImportXML 进行网络爬虫
Google 表格中的 ImportXML 函数用于使用 HTML ID 和类提取特定数据点。这需要对 HTML 和解析 XML 有一定的了解。这可能有点令人沮丧。因此,我们逐渐创建了一个 HTML 网络爬虫。
以下是 EventBrite 页面上的一些示例。
去右键单击并检查元素以找到您感兴趣的 HTML 标记。 我们正在寻找
一些文字,所以这是棘手的部分。您需要从这个 HTML 标记中提取的第一部分是类型。相似
,
,等待。您可以使用“//”,然后使用标签名称来调用第一个。例如“// div”、“// a”或“// span”。现在,如果你真的想要“这里有一些文字”,你需要调用课程。这是在步骤 5 中显示的方法中完成的。您会注意到它使用了“// div”和“[@class =“此处为类名”] 的组合。xml 字符串是“// div [@class ='list-card__body']" 你可能想要获取另一个数据值。我们想要获取所有的 URL。这种情况会涉及到想要提取第一个 HTML 标签本身内部的特定值。例如,点击这里。然后就像 step 7.xml字符串为“//a/@href”ImportXML(URL, XML string)ImportXML(“”,“//div[@class='list-card__body']”)
使用此功能的事实是它需要花费大量时间。因此,它需要规划和设计一个好的 Google 工作表,以确保您从使用中获得最大的收益。否则,您的团队最终将花时间维护它而不是研究新事物。像下面的图片
来自 xkcd
使用 ImportHTML 进行网页抓取
最后,我们将讨论 ImportHTML。这将从网页导入表格或列表。例如,如果您想从 网站 中获取收录股票价格的数据,该怎么办。
我们会用。这个页面上有一张表格,上面有过去几天的股票价格。
与过去的功能类似,您需要使用一个 URL。在 URL 的顶部,您必须提及要在页面上抓取的表格。您可以使用可能的数字来完成此操作。
例如,ImportHTML (" ",6 )。这将从上面的链接中删除股票价格。
在上面的视频中,我们还展示了如何将上述股票数据捕获结合到当天有关股市自动收录设备的新闻中。这可以以更复杂的方式使用。该团队可以创建一个算法,使用过去的股票价格和新的 文章 和 Twitter 信息来选择是买入还是卖出股票。
你有什么使用网页抓取的好主意吗?您需要有关网页抓取项目的帮助吗?让我们知道!
关于数据科学的其他精彩读物:
什么是决策树
算法如何变得不道德和有偏见
如何开发健壮的算法
数据科学家必须具备的 4 项技能
从:
网页表格抓取(麒麟采集器采集东方财富网数据的方法(组图)!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 267 次浏览 • 2021-10-02 01:13
本文介绍采集使用麒麟采集器采集东方财富网的方法
采集网站:
#10
使用功能点:
lAjax翻页
l 分页信息抽取
东方财富网:东方财富网致力于打造专业、权威、用户至上的财经媒体。东方财富网网站内容涉及金融、股票、基金、期货、债券、外汇、银行、保险等众多金融资讯和财经资讯,全面覆盖金融领域,更新数十篇每天数以千计的最新数据和信息。为用户提供方便的查询。
东方财富网股票数据采集 说明:本文对东方财富网-行情中心-上涨A股股票数据进行了采集。本文仅以《东方财富网-市场中心-A股数据采集》为例。实际操作过程中,您可以根据自己的需要替换东方财富网其他内容为数据。采集。
东方财富网股票数据采集详细描述:股票编号、股票代码、股票名称、股票相关链接、股票最新价格、股票价格波动、股票振幅、股票交易量、股票交易量、股票昨天收盘, 今日开盘,股价最高,股价最低,股价5分钟内涨跌。
第一步:创建采集任务
进入主界面选择,选择自定义模式
将上述网址的网址复制粘贴到网站输入框中,点击“保存网址”
保存 URL 后,页面将在 Kylin采集器 中打开。红框内的评测信息为本次演示的内容。
第 2 步:创建翻页循环
l 找到翻页按钮,设置翻页周期
l 设置ajax翻页时间
将页面下拉到底部,找到下一页按钮,点击鼠标,在右侧的操作提示框中选择“循环点击下一页”
由于页面使用ajax加载技术,需要对点击元素和翻页步骤设置ajax延迟加载(ajax判断方法:打开流程图,找到翻页循环框,手动执行翻页,看看网站 完成加载)在右侧的高级选项框中,勾选Ajax加载数据,选择合适的超时时间,一般设置为2秒;最后点击确定
注:点击右上角“处理”按钮,显示可视化流程图。
第三步:分页表单信息采集
l 选择需要采集的字段信息,创建采集列表
l编辑采集字段名
移动鼠标选中表格中任意空白信息,点击右键,如图,框内的数据将被选中并变为绿色,点击右侧提示中的“TR”
选中数据当前行的数据将全部选中,点击“选择子元素”
在右侧操作提示框中查看提取的字段,删除不需要的字段,点击“全选”
点击“采集以下数据”
注意:提示框中的字段会出现一个“X”,点击删除该字段。
修改采集任务名称和字段名称,在下方提示中点击“保存并启动采集”
根据采集的情况,选择合适的采集方法,这里选择“启动本地采集”
注意:本地采集占用采集的当前计算机资源,如果采集有时间要求或当前计算机长时间无法执行采集你可以使用云采集功能,云采集在网络采集中进行,不需要当前电脑支持,可以关闭电脑,可以设置多个云节点共享任务。10个节点相当于10台电脑分配任务帮你采集,速度降低到原来的十分之一;采集收到的数据可以在云端存储三个月,随时可以导出。
第四步:数据采集并导出
采集 完成后会弹出提示,选择导出数据
选择合适的导出方式,导出采集好的数据 查看全部
网页表格抓取(麒麟采集器采集东方财富网数据的方法(组图)!!)
本文介绍采集使用麒麟采集器采集东方财富网的方法
采集网站:
#10
使用功能点:
lAjax翻页
l 分页信息抽取
东方财富网:东方财富网致力于打造专业、权威、用户至上的财经媒体。东方财富网网站内容涉及金融、股票、基金、期货、债券、外汇、银行、保险等众多金融资讯和财经资讯,全面覆盖金融领域,更新数十篇每天数以千计的最新数据和信息。为用户提供方便的查询。
东方财富网股票数据采集 说明:本文对东方财富网-行情中心-上涨A股股票数据进行了采集。本文仅以《东方财富网-市场中心-A股数据采集》为例。实际操作过程中,您可以根据自己的需要替换东方财富网其他内容为数据。采集。
东方财富网股票数据采集详细描述:股票编号、股票代码、股票名称、股票相关链接、股票最新价格、股票价格波动、股票振幅、股票交易量、股票交易量、股票昨天收盘, 今日开盘,股价最高,股价最低,股价5分钟内涨跌。
第一步:创建采集任务
进入主界面选择,选择自定义模式
将上述网址的网址复制粘贴到网站输入框中,点击“保存网址”
保存 URL 后,页面将在 Kylin采集器 中打开。红框内的评测信息为本次演示的内容。
第 2 步:创建翻页循环
l 找到翻页按钮,设置翻页周期
l 设置ajax翻页时间
将页面下拉到底部,找到下一页按钮,点击鼠标,在右侧的操作提示框中选择“循环点击下一页”
由于页面使用ajax加载技术,需要对点击元素和翻页步骤设置ajax延迟加载(ajax判断方法:打开流程图,找到翻页循环框,手动执行翻页,看看网站 完成加载)在右侧的高级选项框中,勾选Ajax加载数据,选择合适的超时时间,一般设置为2秒;最后点击确定
注:点击右上角“处理”按钮,显示可视化流程图。
第三步:分页表单信息采集
l 选择需要采集的字段信息,创建采集列表
l编辑采集字段名
移动鼠标选中表格中任意空白信息,点击右键,如图,框内的数据将被选中并变为绿色,点击右侧提示中的“TR”
选中数据当前行的数据将全部选中,点击“选择子元素”
在右侧操作提示框中查看提取的字段,删除不需要的字段,点击“全选”
点击“采集以下数据”
注意:提示框中的字段会出现一个“X”,点击删除该字段。
修改采集任务名称和字段名称,在下方提示中点击“保存并启动采集”
根据采集的情况,选择合适的采集方法,这里选择“启动本地采集”
注意:本地采集占用采集的当前计算机资源,如果采集有时间要求或当前计算机长时间无法执行采集你可以使用云采集功能,云采集在网络采集中进行,不需要当前电脑支持,可以关闭电脑,可以设置多个云节点共享任务。10个节点相当于10台电脑分配任务帮你采集,速度降低到原来的十分之一;采集收到的数据可以在云端存储三个月,随时可以导出。
第四步:数据采集并导出
采集 完成后会弹出提示,选择导出数据
选择合适的导出方式,导出采集好的数据
网页表格抓取( 这是简易数据分析系列第11篇文章(图)Datapreview)
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-10-02 00:01
这是简易数据分析系列第11篇文章(图)Datapreview)
这是简单数据分析系列文章的第十一篇。
原文首发于博客园。
今天我们讲讲如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
%C9%CF%BA%A3&txtDaoDa=%B1%B1%BE%A9
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,这意味着这些列的内容会被默认捕获。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的,加一个空格和一个标点符号就可以了。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
我们把抓到的CSV文件下载下来,在预览器中打开后,会发现出现了车次的数据,但是出发站的数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键词索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样我们就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,和其他标签,这些标签提供了默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本就不是原装正品,自然是无法识别的.
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,也不太适合现代网页的匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。 查看全部
网页表格抓取(
这是简易数据分析系列第11篇文章(图)Datapreview)
这是简单数据分析系列文章的第十一篇。
原文首发于博客园。
今天我们讲讲如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
%C9%CF%BA%A3&txtDaoDa=%B1%B1%BE%A9
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,这意味着这些列的内容会被默认捕获。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的,加一个空格和一个标点符号就可以了。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
我们把抓到的CSV文件下载下来,在预览器中打开后,会发现出现了车次的数据,但是出发站的数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键词索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样我们就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,和其他标签,这些标签提供了默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本就不是原装正品,自然是无法识别的.
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,也不太适合现代网页的匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。
网页表格抓取( Table表格型数据网页结构?用pd._html)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-01 23:26
Table表格型数据网页结构?用pd._html)
最简单的爬虫程序:用熊猫抓取表数据
让我们承认,使用pandas爬行表数据存在一些限制
它仅适用于捕获表数据。让我们先看看什么样的网页符合条件
什么样的网页结构
当您使用浏览器打开网页并使用F12查看其HTML结构时,您会发现合格的网页结构具有一个共同的功能
如果您发现HTML结构采用下表格式,则可以直接使用pandas
...
...
...
...
...
...
...
这看起来并不直观。它开启了北京空气质量的新篇章网站
F12。左边是网页中的质量索引表。其网页结构完全符合表数据网页结构
它非常适合和熊猫一起攀爬
pd.read uhtml()
Pandas提供了read_html(),to_html()两个函数用于读取和写入html格式的文件。这两个函数非常有用。一种是容易地将复杂的数据结构(如dataframe)转换为HTML表;另一个可以在几行代码中获取表数据,而无需复杂的爬虫程序。这是人工制品![1]
特定pd.read uhtml()参数,可以查看其官方文档:
现在直接把刚才的网页打开
import pandas as pd
df = pd.read_html("http://www.air-level.com/air/beijing/", encoding='utf-8',header=0)[0]
这里只添加了几个参数。Header是指定列标题的行。对于guide包,只需要两行代码
df.head()
对比结果表明,成功地获得了表格数据
多表
在最后一个案例中,我不知道我的朋友是否注意到了
pd.read_html()[0]
对于pd.read uhtml()获得网页结果后,添加[0]。这是因为网页上可能有多个表。在这种情况下,需要使用列表的切片表[x]指定要获取的表
例如,在网站中,空气质量排名页面显然由两个表格组成
此时,如果您使用PD。阅读HTML()以获取右侧的表,只需稍加修改即可
import pandas as pd
df = pd.read_html("http://www.air-level.com/rank", encoding='utf-8',header=0)[1]
相反,您可以看到页面右侧的表已成功获取
以上是PD。阅读uhtml()以简单地抓取静态网页。但是我们使用Python的原因是为了提高效率。但是,如果只有一个网页,则鼠标更容易选择复制。因此,Python操作的最大优势将体现在批处理操作上
批量爬网
让我们向您展示如何使用pandas批量抓取Web表数据
以新浪金融机构持股汇总数据为例:
总共有47个页面,47个网页URL是通过for循环构建的,然后是pd.read uuhtml()循环爬网
df = pd.DataFrame()
for i in range(1, 48):
url = f'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jgcg/index.phtml?p={i}'
df = pd.concat([df, pd.read_html(url)[0]]) # 爬取+合并DataFrame
或者几行代码,很容易解决
共获得47页和1738条数据
通过以上小案例,相信您可以轻松掌握熊猫表数据的批量抓取 查看全部
网页表格抓取(
Table表格型数据网页结构?用pd._html)
最简单的爬虫程序:用熊猫抓取表数据
让我们承认,使用pandas爬行表数据存在一些限制
它仅适用于捕获表数据。让我们先看看什么样的网页符合条件
什么样的网页结构
当您使用浏览器打开网页并使用F12查看其HTML结构时,您会发现合格的网页结构具有一个共同的功能
如果您发现HTML结构采用下表格式,则可以直接使用pandas
...
...
...
...
...
...
...
这看起来并不直观。它开启了北京空气质量的新篇章网站
F12。左边是网页中的质量索引表。其网页结构完全符合表数据网页结构
它非常适合和熊猫一起攀爬
pd.read uhtml()
Pandas提供了read_html(),to_html()两个函数用于读取和写入html格式的文件。这两个函数非常有用。一种是容易地将复杂的数据结构(如dataframe)转换为HTML表;另一个可以在几行代码中获取表数据,而无需复杂的爬虫程序。这是人工制品![1]
特定pd.read uhtml()参数,可以查看其官方文档:
现在直接把刚才的网页打开
import pandas as pd
df = pd.read_html("http://www.air-level.com/air/beijing/", encoding='utf-8',header=0)[0]
这里只添加了几个参数。Header是指定列标题的行。对于guide包,只需要两行代码
df.head()
对比结果表明,成功地获得了表格数据
多表
在最后一个案例中,我不知道我的朋友是否注意到了
pd.read_html()[0]
对于pd.read uhtml()获得网页结果后,添加[0]。这是因为网页上可能有多个表。在这种情况下,需要使用列表的切片表[x]指定要获取的表
例如,在网站中,空气质量排名页面显然由两个表格组成
此时,如果您使用PD。阅读HTML()以获取右侧的表,只需稍加修改即可
import pandas as pd
df = pd.read_html("http://www.air-level.com/rank", encoding='utf-8',header=0)[1]
相反,您可以看到页面右侧的表已成功获取
以上是PD。阅读uhtml()以简单地抓取静态网页。但是我们使用Python的原因是为了提高效率。但是,如果只有一个网页,则鼠标更容易选择复制。因此,Python操作的最大优势将体现在批处理操作上
批量爬网
让我们向您展示如何使用pandas批量抓取Web表数据
以新浪金融机构持股汇总数据为例:
总共有47个页面,47个网页URL是通过for循环构建的,然后是pd.read uuhtml()循环爬网
df = pd.DataFrame()
for i in range(1, 48):
url = f'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jgcg/index.phtml?p={i}'
df = pd.concat([df, pd.read_html(url)[0]]) # 爬取+合并DataFrame
或者几行代码,很容易解决
共获得47页和1738条数据
通过以上小案例,相信您可以轻松掌握熊猫表数据的批量抓取
网页表格抓取( WebScraper翻页——控制链接批量数据上篇文章(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-27 18:14
WebScraper翻页——控制链接批量数据上篇文章(图)
)
这是简单数据分析系列文章的第五篇。
原文首发于博客园:Web Scraper页面翻转-控制链接批量抓取数据
在上一篇文章中,我们爬取了豆瓣电影TOP250前25部电影的数据。今天,我们将对原来的 Web Scraper 配置做一些小改动,让爬虫爬取全部 250 部电影数据。
正如我们前面所说,爬虫的本质是寻找规则。这些程序员在设计网页时,肯定会遵循一些规则。当我们找到规则时,我们就可以预测他们的行为并实现我们的目标。
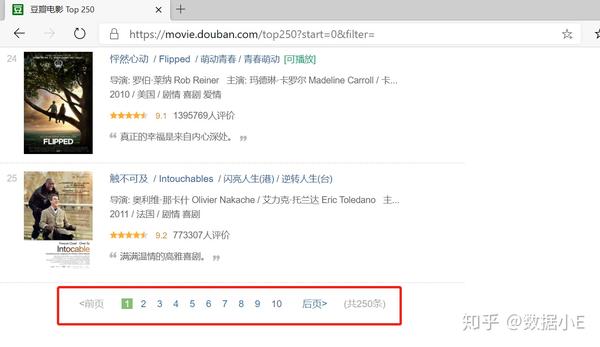
今天我们就来寻找豆瓣网站的规则,想办法把所有的数据都抓到。今天的规则始于经常被忽视的网络链接。
1.链接分析
我们先来看看第一页的豆瓣网址链接:
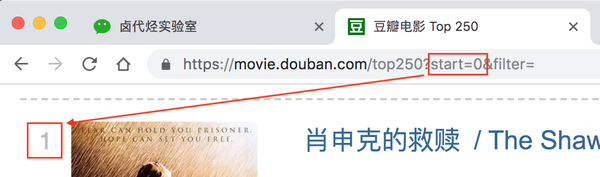
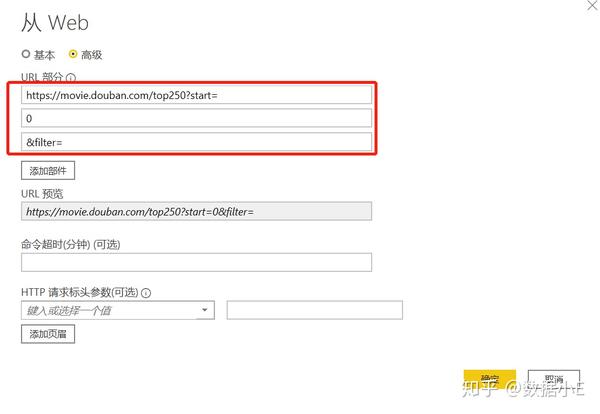
/top250?start=0&filter=
这显然是一个豆瓣电影网址。Top250,没什么好说的,就是网页的内容。豆瓣前250电影无话可说?后面有个start=0&filter=,按照英文提示,好像是filtering(filter),从0开始(start)
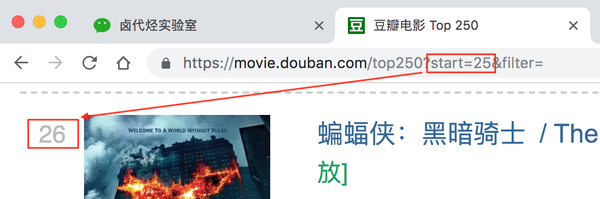
查看第二页上的 URL 链接。前面一样,只是后面的参数变了,变成start=25,从25开始;
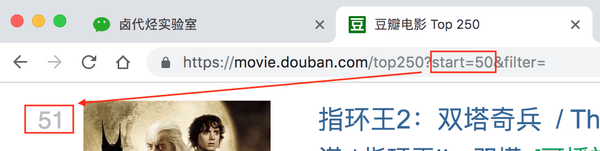
我们再看第三页的链接,参数变成start=50,从50开始;
分析这三个环节,我们可以很容易地画出一个模式:
start=0,表示从排名第一的电影开始,播放1-25部电影
start=25,表示从排名第26的电影开始,播放26-50部电影
start=50,表示从排名第51的电影开始,显示第51-75部电影
...
start=225,表示从排名第226的电影开始,显示226-250部电影
只要技术提供支持,很容易找到规律。深入学习,你会发现Web Scraper的操作并不难,但最重要的还是找到规律。
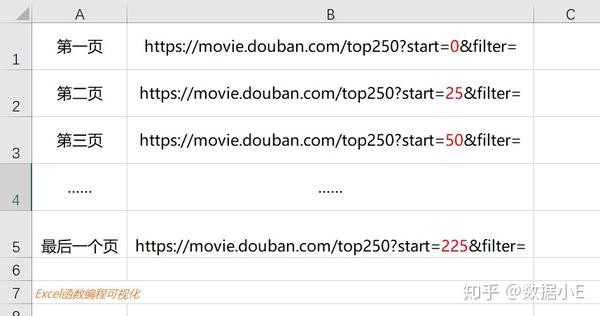
2.Web Scraper 控制链接参数翻页
Web Scraper为这种通过超链接数字分页获取分页数据的网页提供了非常方便的操作,即范围说明符。
例如,您要抓取的网页链接如下所示:
你可以写/page/[1-3],把链接改成这个,Web Scraper会自动抓取这三个网页的内容。
当然,你也可以写/page/[1-100],这样就可以爬取前100个网页。
那么我们之前分析的豆瓣网页呢?它不是从 1 增加到 100,而是 0 -> 25 -> 50 -> 75 以便它每 25 跳一次。我该怎么办?
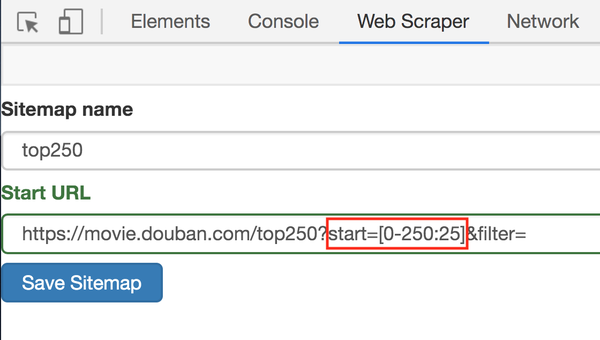
事实上,这很简单。这种情况可以用[0-100:25]来表示。每25个是一个网页,100/25=4,抓取前4个网页放到豆瓣电影场景中,我们只需要把链接改成如下即可;
/top250?start=[0-225:25]&filter=
这样,Web Scraper 将抓取 TOP250 的所有网页。
3.获取数据
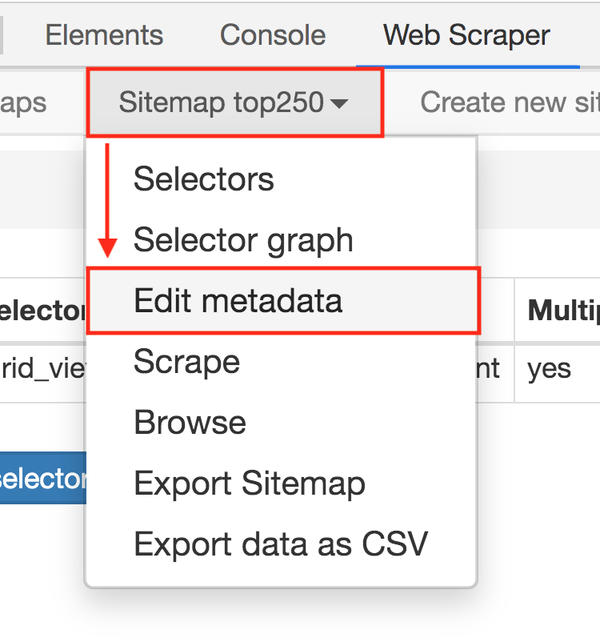
解决链接问题,下一步就是如何在Web Scraper中修改链接。很简单,鼠标点两下:
1. 点击Stiemaps,在新面板中点击ID为top250的那一列数据;
2. 进入新建面板后,找到Stiemap top250 Tab,点击,然后在下拉菜单中点击Edit metadata;
3.修改原网址,图中红框是区别:
修改超链接后,我们就可以再次抓取网页了。操作同上,这里简单重复一下:
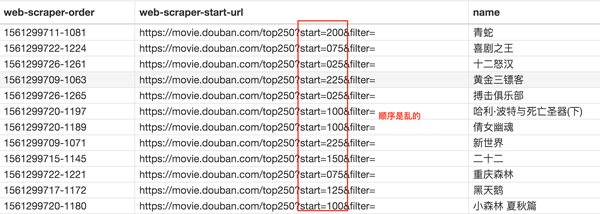
单击站点地图 top250 下拉菜单中的抓取按钮。在新操作面板的两个输入框中输入2000。单击开始抓取蓝色按钮开始抓取数据。抓取结束后,点击面板上的蓝色刷新按钮,检测我们抓取的数据。
如果到了这里抓包成功,你会发现已经抓到了所有的数据,但是顺序是乱的。
这里我们不关心顺序问题,因为这属于数据清洗的内容,我们当前的主题是数据捕获。先完成相关知识点,再攻克下一个知识点,是比较合理的学习方式。
本期讲了通过修改超链接来抓取250部电影的名字。下一期我们会讲一些简单易懂的内容来改变你的想法,说说Web Scraper如何导入别人写的爬虫文件,导出自己写的爬虫软件。
参考阅读:
简单的数据分析04 | 网络爬虫第一款抢食豆瓣高分电影
查看全部
网页表格抓取(
WebScraper翻页——控制链接批量数据上篇文章(图)
)

这是简单数据分析系列文章的第五篇。
原文首发于博客园:Web Scraper页面翻转-控制链接批量抓取数据
在上一篇文章中,我们爬取了豆瓣电影TOP250前25部电影的数据。今天,我们将对原来的 Web Scraper 配置做一些小改动,让爬虫爬取全部 250 部电影数据。
正如我们前面所说,爬虫的本质是寻找规则。这些程序员在设计网页时,肯定会遵循一些规则。当我们找到规则时,我们就可以预测他们的行为并实现我们的目标。
今天我们就来寻找豆瓣网站的规则,想办法把所有的数据都抓到。今天的规则始于经常被忽视的网络链接。
1.链接分析
我们先来看看第一页的豆瓣网址链接:
/top250?start=0&filter=
这显然是一个豆瓣电影网址。Top250,没什么好说的,就是网页的内容。豆瓣前250电影无话可说?后面有个start=0&filter=,按照英文提示,好像是filtering(filter),从0开始(start)
查看第二页上的 URL 链接。前面一样,只是后面的参数变了,变成start=25,从25开始;
我们再看第三页的链接,参数变成start=50,从50开始;
分析这三个环节,我们可以很容易地画出一个模式:
start=0,表示从排名第一的电影开始,播放1-25部电影
start=25,表示从排名第26的电影开始,播放26-50部电影
start=50,表示从排名第51的电影开始,显示第51-75部电影
...
start=225,表示从排名第226的电影开始,显示226-250部电影
只要技术提供支持,很容易找到规律。深入学习,你会发现Web Scraper的操作并不难,但最重要的还是找到规律。
2.Web Scraper 控制链接参数翻页
Web Scraper为这种通过超链接数字分页获取分页数据的网页提供了非常方便的操作,即范围说明符。
例如,您要抓取的网页链接如下所示:
你可以写/page/[1-3],把链接改成这个,Web Scraper会自动抓取这三个网页的内容。
当然,你也可以写/page/[1-100],这样就可以爬取前100个网页。
那么我们之前分析的豆瓣网页呢?它不是从 1 增加到 100,而是 0 -> 25 -> 50 -> 75 以便它每 25 跳一次。我该怎么办?
事实上,这很简单。这种情况可以用[0-100:25]来表示。每25个是一个网页,100/25=4,抓取前4个网页放到豆瓣电影场景中,我们只需要把链接改成如下即可;
/top250?start=[0-225:25]&filter=
这样,Web Scraper 将抓取 TOP250 的所有网页。
3.获取数据
解决链接问题,下一步就是如何在Web Scraper中修改链接。很简单,鼠标点两下:
1. 点击Stiemaps,在新面板中点击ID为top250的那一列数据;

2. 进入新建面板后,找到Stiemap top250 Tab,点击,然后在下拉菜单中点击Edit metadata;
3.修改原网址,图中红框是区别:
修改超链接后,我们就可以再次抓取网页了。操作同上,这里简单重复一下:
单击站点地图 top250 下拉菜单中的抓取按钮。在新操作面板的两个输入框中输入2000。单击开始抓取蓝色按钮开始抓取数据。抓取结束后,点击面板上的蓝色刷新按钮,检测我们抓取的数据。
如果到了这里抓包成功,你会发现已经抓到了所有的数据,但是顺序是乱的。
这里我们不关心顺序问题,因为这属于数据清洗的内容,我们当前的主题是数据捕获。先完成相关知识点,再攻克下一个知识点,是比较合理的学习方式。
本期讲了通过修改超链接来抓取250部电影的名字。下一期我们会讲一些简单易懂的内容来改变你的想法,说说Web Scraper如何导入别人写的爬虫文件,导出自己写的爬虫软件。
参考阅读:
简单的数据分析04 | 网络爬虫第一款抢食豆瓣高分电影

网页表格抓取(我正在尝试使用pythin从每个特定的锻炼中抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-24 14:36
我正在尝试使用 pythin 从 网站 获取一些数据。网站 收录许多不同的练习,每个练习都有自己的数据。我已经弄清楚如何从每个特定练习中获取数据,但要做到这一点,我必须在 url 中提供特定的练习 ID。主页上似乎把所有这些练习ID都列在了一个表格中,但是当我使用beautiful Soup搜索html文档时,返回的表格数据如下:
Name
Location
Instructor
Date
OT Points
Total Calories
(kCal)
{{class.class_name}}
{{class.location}}
{{class.trainer}}
{{class.class_date}} at {{class.class_time}}
{{class.points | number:0}}
{{class.CALORIES | number:0}}
如您所见,没有实际文本,但所有信息似乎都是某种变量(我的 html 知识非常有限)。看来我要的信息都是列表:
class.CLASSID
是否可以使用 python 来获取这些信息?或者它使用了一些我无法访问的 api。
任何帮助表示赞赏。 查看全部
网页表格抓取(我正在尝试使用pythin从每个特定的锻炼中抓取数据)
我正在尝试使用 pythin 从 网站 获取一些数据。网站 收录许多不同的练习,每个练习都有自己的数据。我已经弄清楚如何从每个特定练习中获取数据,但要做到这一点,我必须在 url 中提供特定的练习 ID。主页上似乎把所有这些练习ID都列在了一个表格中,但是当我使用beautiful Soup搜索html文档时,返回的表格数据如下:
Name
Location
Instructor
Date
OT Points
Total Calories
(kCal)
{{class.class_name}}
{{class.location}}
{{class.trainer}}
{{class.class_date}} at {{class.class_time}}
{{class.points | number:0}}
{{class.CALORIES | number:0}}
如您所见,没有实际文本,但所有信息似乎都是某种变量(我的 html 知识非常有限)。看来我要的信息都是列表:
class.CLASSID
是否可以使用 python 来获取这些信息?或者它使用了一些我无法访问的 api。
任何帮助表示赞赏。
网页表格抓取( 基于Web文本挖掘的“创客”热词分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-24 14:32
基于Web文本挖掘的“创客”热词分析)
《表7创客吧860网页讨论内容按频度排序的前80个词列表》
图表编号
B666
发布日期
2019.10.01
作者
夏茂森、姜玲玲
研究课题
基于Web文本挖掘的“创客”热词分析
出版单位
安徽财经大学统计与应用数学学院,安徽财经大学会计学院
下载格式
JPG、GIF(包括无水印/未压缩)
图片大小
20KB~2M(取决于下载方式)
自定义格式
Excel、Word、PDF、PPT
媒体
《表7创客吧860网讨论内容按频度排序的前80个词汇表》
预计下载时间:<2 秒图表描述和下载
在基于Web文本挖掘的“创客”热词分析中,与上述类似,基于创客吧860网页的爬取和排序,对网页讨论内容进行相应的文本分析——去除相关停靠点。词、词频统计、具体词云图和按频次排序的前80个词分别如图7和表7所示:
公告:考虑到您可能需要图表的高清原图或源文本的全套PDF,但由于获取多为付费渠道,为了大家的方便,博主会帮忙获取和分享收到相关求助信息后免费下载。五:YGMTBB
下载图表
并得到词频分布。具体词云图和按频次排序的前60个词分别如图3和表3所示...[ 研究课题:基于Web文本挖掘的“创客”热词分析2019.1< @0.01 原文格式:PDF] 《表6创客吧80字列表中860网页讨论话题Top按频率排序》 在创客吧860网页文字抓取整理的基础上,进行相应的文字分析对网页标题进行-基于去除相关停用词,进行词频数据统计,进行具体词云图,按照频度排序的前80个词如图5、@ >6 …[研究课题:基于Web文本挖掘的“创客”热词分析201< @9.10.01 原文格式:PDF] 《表1“哈萨克斯坦-2050”主要内容》 2014年1月17日,纳扎尔巴耶夫在首都阿斯塔纳独立宫发表了一份关于联盟在2050年对哈萨克斯坦的致辞。充分阐述了发展战略的具体任务和实现方法,简称“哈萨克斯坦-2050”。…[研究课题:哈萨克斯坦绿色经济发展研究——基于“丝绸之路经济带”2019.10.01 原文格式:PDF]》表5题名569其他文档 中文按频次排序前60个词的列表“通过发短信给569篇其他类型文档(包括硕士论文、国内会议、学术期刊、专利和年鉴)的标题<
上表“Table 6 Maker Bar 860 网页讨论主题”
下表“表1学术论文简介”(Swa
相关考研图 《表3 522篇特色期刊文献标题按频度排序的前60个词表》夏茂森、姜玲玲《表4 1780篇报纸文献标题按频度排序的前80个词表》夏茂森,江玲玲,“表6创客吧860网讨论话题排名前80的词汇表”夏茂森和江玲玲“表1“哈萨克斯坦-2050”的主要内容“孙欣,杨静”表1 中国知网“夏茂森、姜玲玲”与“创客”相关的文献数量统计表5 其他569篇文献“夏茂森、姜玲玲”标题中按频次排序前60位的词列表表2 2 977“夏茂森、姜玲玲”期刊文章标题前60词按频次排序表3 522篇特色期刊文章标题前60词按频次排序“夏茂森” ,蒋玲玲,《表1 各种内容生产系统特征新旧对比》 刘华强,吴以娜,《表10 不同犯罪思维水平词汇放置数量及比例》张亚辉,卢仲义吴以娜,《表10不同犯罪思维水平词汇放置数量及比例》张亚辉、陆中义吴以娜,《表10不同犯罪思维水平词汇放置数量及比例》张亚辉、陆中义 查看全部
网页表格抓取(
基于Web文本挖掘的“创客”热词分析)
《表7创客吧860网页讨论内容按频度排序的前80个词列表》
图表编号
B666
发布日期
2019.10.01
作者
夏茂森、姜玲玲
研究课题
基于Web文本挖掘的“创客”热词分析
出版单位
安徽财经大学统计与应用数学学院,安徽财经大学会计学院
下载格式
JPG、GIF(包括无水印/未压缩)
图片大小
20KB~2M(取决于下载方式)
自定义格式
Excel、Word、PDF、PPT
媒体
《表7创客吧860网讨论内容按频度排序的前80个词汇表》

预计下载时间:<2 秒图表描述和下载
在基于Web文本挖掘的“创客”热词分析中,与上述类似,基于创客吧860网页的爬取和排序,对网页讨论内容进行相应的文本分析——去除相关停靠点。词、词频统计、具体词云图和按频次排序的前80个词分别如图7和表7所示:
公告:考虑到您可能需要图表的高清原图或源文本的全套PDF,但由于获取多为付费渠道,为了大家的方便,博主会帮忙获取和分享收到相关求助信息后免费下载。五:YGMTBB
下载图表
并得到词频分布。具体词云图和按频次排序的前60个词分别如图3和表3所示...[ 研究课题:基于Web文本挖掘的“创客”热词分析2019.1< @0.01 原文格式:PDF] 《表6创客吧80字列表中860网页讨论话题Top按频率排序》 在创客吧860网页文字抓取整理的基础上,进行相应的文字分析对网页标题进行-基于去除相关停用词,进行词频数据统计,进行具体词云图,按照频度排序的前80个词如图5、@ >6 …[研究课题:基于Web文本挖掘的“创客”热词分析201< @9.10.01 原文格式:PDF] 《表1“哈萨克斯坦-2050”主要内容》 2014年1月17日,纳扎尔巴耶夫在首都阿斯塔纳独立宫发表了一份关于联盟在2050年对哈萨克斯坦的致辞。充分阐述了发展战略的具体任务和实现方法,简称“哈萨克斯坦-2050”。…[研究课题:哈萨克斯坦绿色经济发展研究——基于“丝绸之路经济带”2019.10.01 原文格式:PDF]》表5题名569其他文档 中文按频次排序前60个词的列表“通过发短信给569篇其他类型文档(包括硕士论文、国内会议、学术期刊、专利和年鉴)的标题<
上表“Table 6 Maker Bar 860 网页讨论主题”
下表“表1学术论文简介”(Swa
相关考研图 《表3 522篇特色期刊文献标题按频度排序的前60个词表》夏茂森、姜玲玲《表4 1780篇报纸文献标题按频度排序的前80个词表》夏茂森,江玲玲,“表6创客吧860网讨论话题排名前80的词汇表”夏茂森和江玲玲“表1“哈萨克斯坦-2050”的主要内容“孙欣,杨静”表1 中国知网“夏茂森、姜玲玲”与“创客”相关的文献数量统计表5 其他569篇文献“夏茂森、姜玲玲”标题中按频次排序前60位的词列表表2 2 977“夏茂森、姜玲玲”期刊文章标题前60词按频次排序表3 522篇特色期刊文章标题前60词按频次排序“夏茂森” ,蒋玲玲,《表1 各种内容生产系统特征新旧对比》 刘华强,吴以娜,《表10 不同犯罪思维水平词汇放置数量及比例》张亚辉,卢仲义吴以娜,《表10不同犯罪思维水平词汇放置数量及比例》张亚辉、陆中义吴以娜,《表10不同犯罪思维水平词汇放置数量及比例》张亚辉、陆中义
网页表格抓取(集搜客网络爬虫软件是一款免费的网页数据抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2021-09-21 17:19
内容捕获–您可以从网站捕获内容,以复制依赖于内容的独特产品或服务优势。例如,yelp等产品依赖于评论。竞争对手可以捕获yelp的所有评论,然后将其复制到他们的网站中,使其网站内容公开
Jisoke web crawler软件是一个免费的网页数据捕获工具,它将网页内容转换为excel表格,用于内容分析、文本分析、策略分析和文献分析。自动分词、社交网络分析和情感分析软件用于毕业设计和行业研究
阿里云为您提供了与网站内容捕获工具相关的8933个产品文档和常见问题解答,以及网站无法打开网页该怎么办、计算机网络技术毕业论文、键值存储kvstore、以下哪一个是数据库等云计算产品
当您打开目标文件夹TPTL时,您将获得图像或内容的网站完整数据,其中保存了HTML文件、PHP文件和JavaScript。网络
阿里云为您提供6415网站产品内容以及与免费网站内容抓取工具相关的常见问题。还有网络简单卡、支付宝API扫描码支付接口文档、it远程操作和监控、计算机网络和什么网络协议。p>
如何抓取不同页面类型的数据网站因为有很多内容,我将在本文的下一节详细介绍它。3.筛选表单网页在网站中很常见。这种网页的最大特点是有很多过滤选项,不同的选项将不会加载
获取网站太多数据或抓取太快等因素通常会导致IP被阻止的风险,但我们可以通过使用PHP构建IP地址来获取数据
爬行web内容的一个例子是通过一个程序自动读取其他网站网页上显示的信息,类似于爬行程序。例如,我们有一个 查看全部
网页表格抓取(集搜客网络爬虫软件是一款免费的网页数据抓取工具)
内容捕获–您可以从网站捕获内容,以复制依赖于内容的独特产品或服务优势。例如,yelp等产品依赖于评论。竞争对手可以捕获yelp的所有评论,然后将其复制到他们的网站中,使其网站内容公开
Jisoke web crawler软件是一个免费的网页数据捕获工具,它将网页内容转换为excel表格,用于内容分析、文本分析、策略分析和文献分析。自动分词、社交网络分析和情感分析软件用于毕业设计和行业研究
阿里云为您提供了与网站内容捕获工具相关的8933个产品文档和常见问题解答,以及网站无法打开网页该怎么办、计算机网络技术毕业论文、键值存储kvstore、以下哪一个是数据库等云计算产品
当您打开目标文件夹TPTL时,您将获得图像或内容的网站完整数据,其中保存了HTML文件、PHP文件和JavaScript。网络
阿里云为您提供6415网站产品内容以及与免费网站内容抓取工具相关的常见问题。还有网络简单卡、支付宝API扫描码支付接口文档、it远程操作和监控、计算机网络和什么网络协议。p>

如何抓取不同页面类型的数据网站因为有很多内容,我将在本文的下一节详细介绍它。3.筛选表单网页在网站中很常见。这种网页的最大特点是有很多过滤选项,不同的选项将不会加载
获取网站太多数据或抓取太快等因素通常会导致IP被阻止的风险,但我们可以通过使用PHP构建IP地址来获取数据

爬行web内容的一个例子是通过一个程序自动读取其他网站网页上显示的信息,类似于爬行程序。例如,我们有一个
网页表格抓取(鱼·云采集服务平台网站内容智能抓取实现及实例详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-17 20:00
当您打开目标文件夹TPTL时,您将获得图像或内容的网站完整数据,其中保存了HTML文件、PHP文件和JavaScript。网络
1.打开网站管理员工具,在网络信息查询中找到要抓取的模拟机器人。2.进入您的网站网站,然后单击查询。此时,您的网站将显示在下面。被捕后会发生什么事。3.在web信息查询中,单击web检测以查看您的关键词密度和网站安全性,以及关键词挖掘
阿里云为您提供了与网站内容捕获工具相关的8933个产品文档和常见问题解答,以及网站无法打开网页该怎么办、计算机网络技术毕业论文、键值存储kvstore、以下哪一个是数据库等云计算产品
Web内容智能抓取的实现和示例细节完全基于Java技术、核心技术、核心技术、XML解析、HTML解析、开源组件应用。该应用程序的开源组件包括:Dom4j:parsing xmljericho-
步骤3:提取内容。在以上两个步骤中,我们使用请求从web页面请求数据,并使用BS4解析页面。现在我们进入最关键的一步:
优采云采集器免费网络爬虫\uuuWeb大数据捕获工具
爬虫是一个自动获取网络内容的程序,如搜索引擎、谷歌、百度等。它每天运行一个巨大的爬虫系统,从网站爬到世界各地
优采云·cloud采集service platform网站内容捕获工具使用网络每天生成大量图形数据。我们如何为您和我使用这些数据,以便这些数据能够为我们的工作带来真正的价值 查看全部
网页表格抓取(鱼·云采集服务平台网站内容智能抓取实现及实例详解)
当您打开目标文件夹TPTL时,您将获得图像或内容的网站完整数据,其中保存了HTML文件、PHP文件和JavaScript。网络
1.打开网站管理员工具,在网络信息查询中找到要抓取的模拟机器人。2.进入您的网站网站,然后单击查询。此时,您的网站将显示在下面。被捕后会发生什么事。3.在web信息查询中,单击web检测以查看您的关键词密度和网站安全性,以及关键词挖掘
阿里云为您提供了与网站内容捕获工具相关的8933个产品文档和常见问题解答,以及网站无法打开网页该怎么办、计算机网络技术毕业论文、键值存储kvstore、以下哪一个是数据库等云计算产品
Web内容智能抓取的实现和示例细节完全基于Java技术、核心技术、核心技术、XML解析、HTML解析、开源组件应用。该应用程序的开源组件包括:Dom4j:parsing xmljericho-
步骤3:提取内容。在以上两个步骤中,我们使用请求从web页面请求数据,并使用BS4解析页面。现在我们进入最关键的一步:

优采云采集器免费网络爬虫\uuuWeb大数据捕获工具
爬虫是一个自动获取网络内容的程序,如搜索引擎、谷歌、百度等。它每天运行一个巨大的爬虫系统,从网站爬到世界各地

优采云·cloud采集service platform网站内容捕获工具使用网络每天生成大量图形数据。我们如何为您和我使用这些数据,以便这些数据能够为我们的工作带来真正的价值
网页表格抓取( 如何用Python快速的抓取一个网页中所有表格的爬虫3.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-13 11:13
如何用Python快速的抓取一个网页中所有表格的爬虫3.)
之前在搜索vscode的快捷键时,发现一个页面以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学了Python爬虫,就形成了惯性思维。当我在网页中看到什么更好,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面简单介绍一下我的一些抢表思路和方法。
1.IE浏览器直接导出EXCLE
微软的设计还是很人性化的。以这种方式访问网页上表格中呈现的内容特别方便。我们只需要在页面上右击选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
2.使用Python从网页中抓取表格
接下来就是本文的重点了,我们先直接上代码。
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'https://segmentfault.com/a/1190000007688656'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
tables = soup.select('table')
df_list = []
for table in tables:
df_list.append(pd.concat(pd.read_html(table.prettify())))
df = pd.concat(df_list)
df.to_excel('vscode快捷键大全.xlsx')
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。我以前这样做过,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址即可。
下面简单介绍一下代码的含义:
这样就完成了一个简单的爬虫,爬取一个网页中的所有表格
3.关于选择方法的建议
最后,我想强调的是,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格最好的方法就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样我们就可以把精力集中在学习vscode快捷键上,而不是获取这种形式。
如果,在另一种场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也很重要。
所以,关键是我们要明确自己的目标,根据相应的目标选择最合适的方法。
下一期:下一篇文章我将介绍使用正则表达式从本地统计公报中抓取结构化数据 查看全部
网页表格抓取(
如何用Python快速的抓取一个网页中所有表格的爬虫3.)
之前在搜索vscode的快捷键时,发现一个页面以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学了Python爬虫,就形成了惯性思维。当我在网页中看到什么更好,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面简单介绍一下我的一些抢表思路和方法。
1.IE浏览器直接导出EXCLE
微软的设计还是很人性化的。以这种方式访问网页上表格中呈现的内容特别方便。我们只需要在页面上右击选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
2.使用Python从网页中抓取表格
接下来就是本文的重点了,我们先直接上代码。
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'https://segmentfault.com/a/1190000007688656'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
tables = soup.select('table')
df_list = []
for table in tables:
df_list.append(pd.concat(pd.read_html(table.prettify())))
df = pd.concat(df_list)
df.to_excel('vscode快捷键大全.xlsx')
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。我以前这样做过,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址即可。
下面简单介绍一下代码的含义:
这样就完成了一个简单的爬虫,爬取一个网页中的所有表格
3.关于选择方法的建议
最后,我想强调的是,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格最好的方法就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样我们就可以把精力集中在学习vscode快捷键上,而不是获取这种形式。
如果,在另一种场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也很重要。
所以,关键是我们要明确自己的目标,根据相应的目标选择最合适的方法。
下一期:下一篇文章我将介绍使用正则表达式从本地统计公报中抓取结构化数据
网页表格抓取(爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-11 05:09
)
爬虫是 Python 的一个重要应用。使用 Python 爬虫,我们可以轻松地从互联网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍 Python爬虫的基本流程。如果您还处于初始爬虫阶段或不了解爬虫的具体工作流程,那么您应该仔细阅读本文!
第一步:尝试请求
首先进入b站首页,点击排行榜复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动 Jupyter notebook 并运行以下代码
import requests
url = 'https://www.bilibili.com/ranki ... 39%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第 2 步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换为Web页面结构化数据,因此您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的。
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用时需要开发一个解析器,这里使用的是html.parser。
然后您可以获得结构化元素之一及其属性。例如,您可以使用soup.title.text 来获取页面标题。你也可以使用soup.body、soup.p等来获取任何需要的元素。
第 3 步:提取内容
在上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
现在我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下面的说明找到
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码就可以这样写了
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
在上面的代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取字段信息我们想要的是以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了encoding='utf-8-sig',否则会出现中文乱码的问题。
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码。
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
总结
到此我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都遵循以上四个步骤。
虽然看起来很简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有各种形式的反爬、加密,以及后续的数据分析、提取甚至存储。许多需要进一步探索和学习。
本文之所以选择B站视频热榜,正是因为它足够简单。希望通过这个案例,大家能够了解爬虫的基本过程,最后附上完整的代码。
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranki ... 39%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig') 查看全部
网页表格抓取(爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取
)
爬虫是 Python 的一个重要应用。使用 Python 爬虫,我们可以轻松地从互联网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍 Python爬虫的基本流程。如果您还处于初始爬虫阶段或不了解爬虫的具体工作流程,那么您应该仔细阅读本文!
第一步:尝试请求
首先进入b站首页,点击排行榜复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动 Jupyter notebook 并运行以下代码
import requests
url = 'https://www.bilibili.com/ranki ... 39%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第 2 步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容

可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换为Web页面结构化数据,因此您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的。
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用时需要开发一个解析器,这里使用的是html.parser。
然后您可以获得结构化元素之一及其属性。例如,您可以使用soup.title.text 来获取页面标题。你也可以使用soup.body、soup.p等来获取任何需要的元素。
第 3 步:提取内容
在上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
现在我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下面的说明找到
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码就可以这样写了
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
在上面的代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取字段信息我们想要的是以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了encoding='utf-8-sig',否则会出现中文乱码的问题。
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码。
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
总结
到此我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都遵循以上四个步骤。
虽然看起来很简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有各种形式的反爬、加密,以及后续的数据分析、提取甚至存储。许多需要进一步探索和学习。
本文之所以选择B站视频热榜,正是因为它足够简单。希望通过这个案例,大家能够了解爬虫的基本过程,最后附上完整的代码。
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranki ... 39%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
网页表格抓取(Python批量爬取网页数据的文章,让我们一起看看吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-09-11 05:07
我写过一篇关于Python批量抓取网页数据的文章文章。后来发现随着版本的迭代,Excel已经全面支持多页爬取数据了。您无需编码,只需点击几下鼠标即可抓取数据。一起来看看吧~
网页分析
在抓取数据之前,先对网页进行分析。下图是豆瓣TOP250的初始页面。到最底部,一共10页,每页25部电影,一共250部电影。
我们可以依次获取前三个页面的URL,找出它们之间的规则。除了中间的数字外,每个 URL 都相同。编号从 0/25/50 到 25 递增(每页电影的数量),共 10 页。
发现规律后,我们将10页之间的数字存入一个表格中以备将来使用,如下图A列所示,保存以备将来使用。
数据采集
Excel2016及以上版本内嵌网络批量抓取功能(“数据”-“新建查询”-“其他来源”-“来自网络”),案例演示版本未到,所以我下载了A Power BI Desktop(Excel扩展产品),免安装免使用,效果和Excel一样,不用担心不会用,用Excel来操作就可以了。
打开 Power BI Desktop 或 Excel,点击【获取数据】-【网页】(对于 Excel 2016 及以上版本,在“数据”-“新建查询”-“来自其他来源”-“来自网页”)
界面设置:
点击高级后,在 URL 部分,点击“添加组件”。一共有三个盒子。豆瓣TOP250首页网址以数字0分隔,分为三段,分别放在三个框中,如下图:
你会发现在URL预览框中会自动显示完整的URL。点击确定完成设置。
导航界面
之后程序会进入抓数据状态,稍等片刻,跳出“导航”界面。左侧有一个表“表 1”。查看后,右侧显示屏显示了详细数据,在首页首页可以发现是豆瓣TOP250 25部电影;
一共抓取了9个字段,包括序列号、电影名称、评分、评论数量、电影介绍等信息,部分栏目不需要,我们进入Power Query界面删除,以及点击底部的“数据转换”进入Power Query界面。
Power Query 数据编辑
进入Power Query界面后,只会保留序号、评分、电影名称、评论次数四列,其余列将被删除。删除后,四列数据将被重命名。动画显示如下:
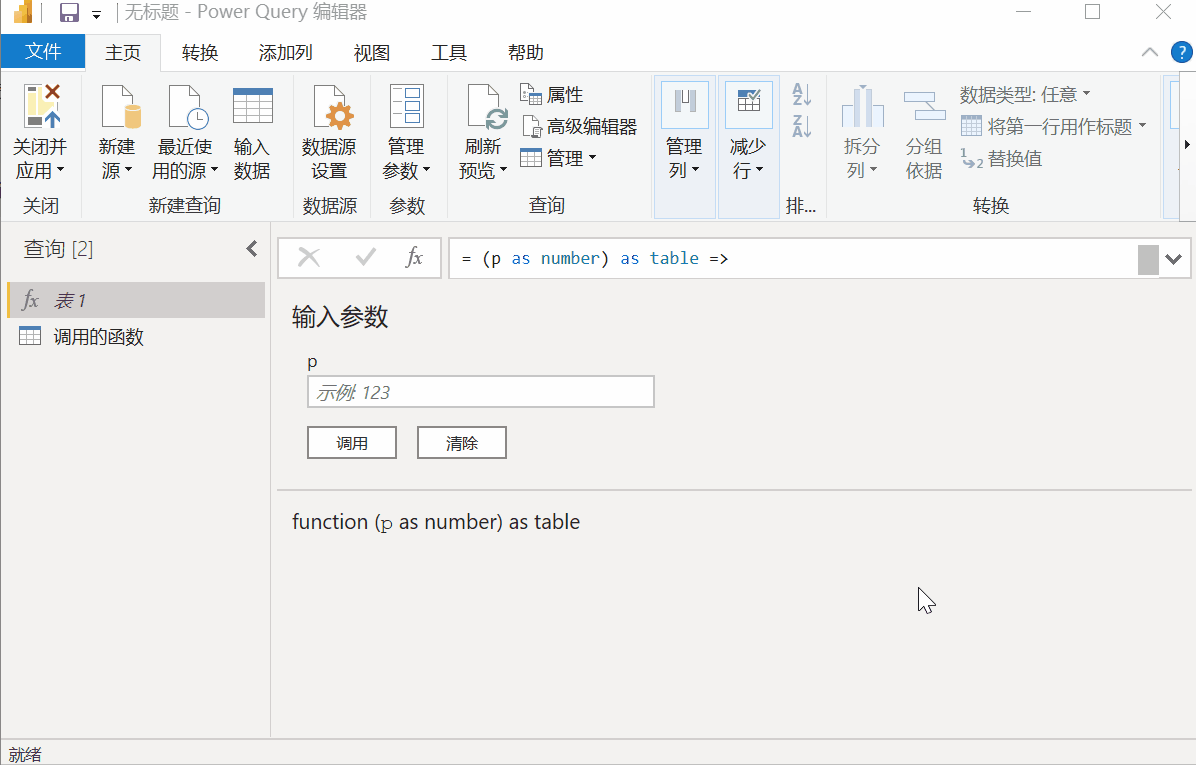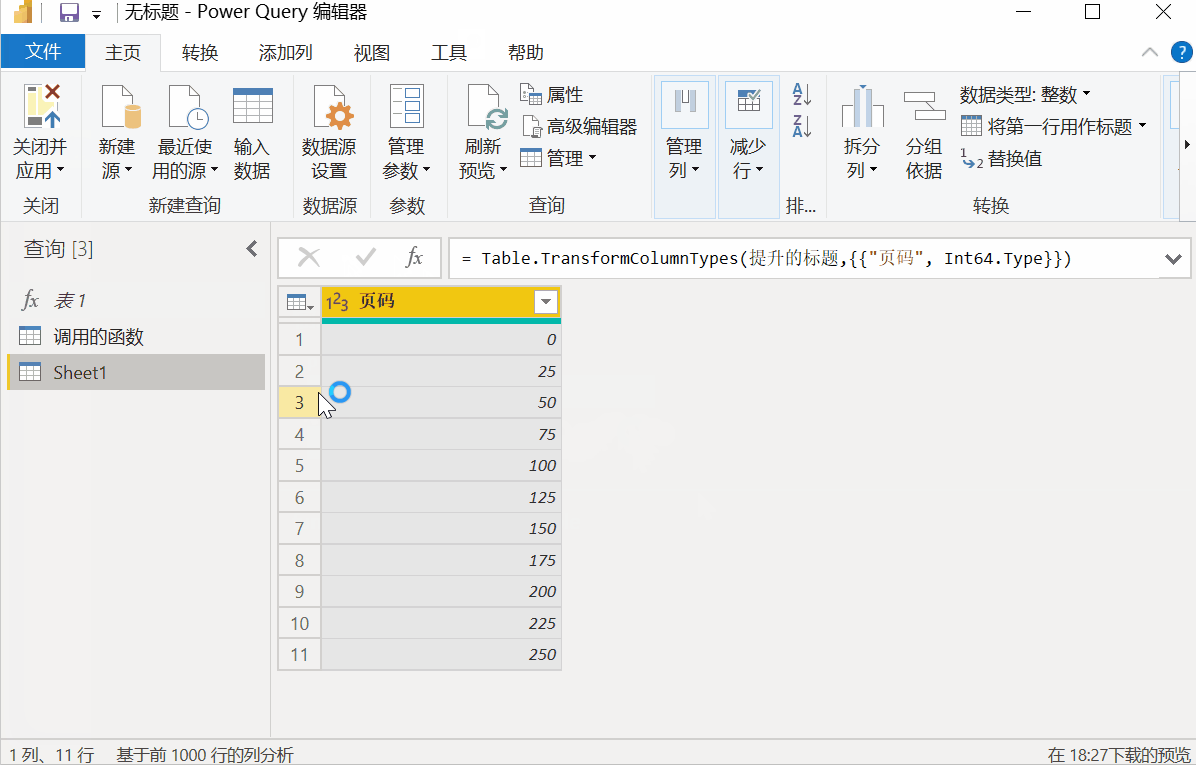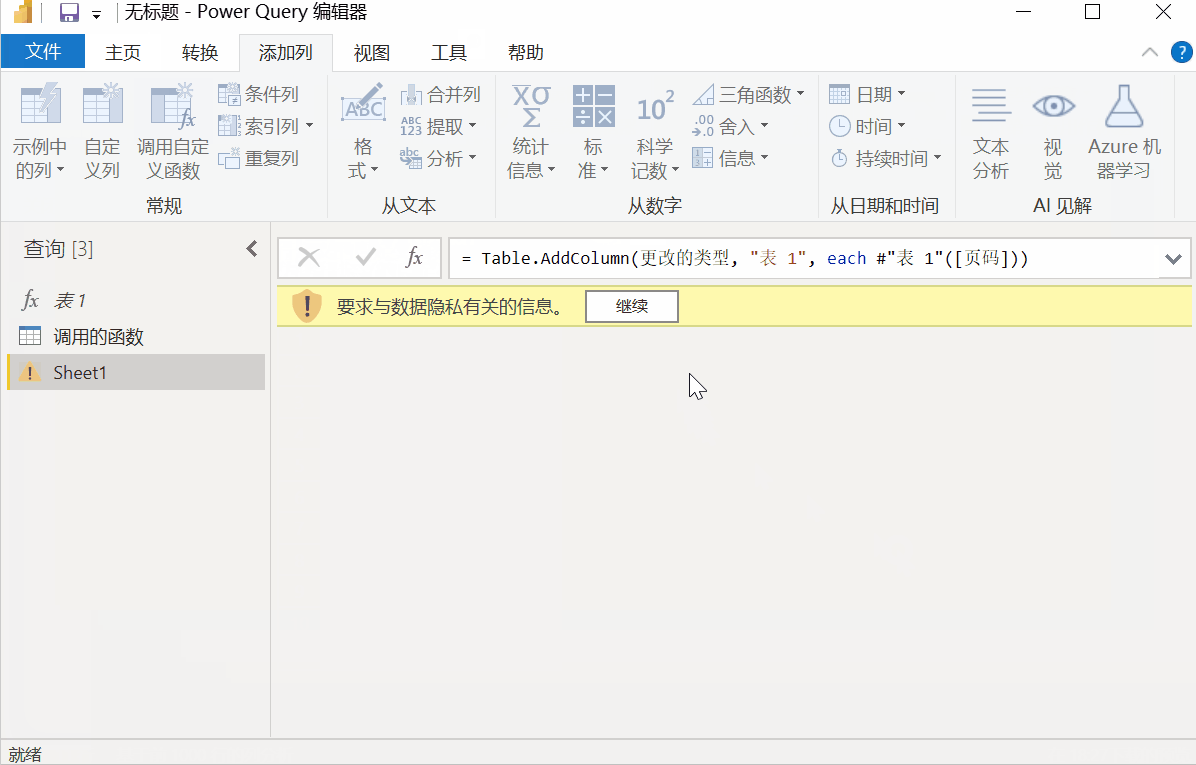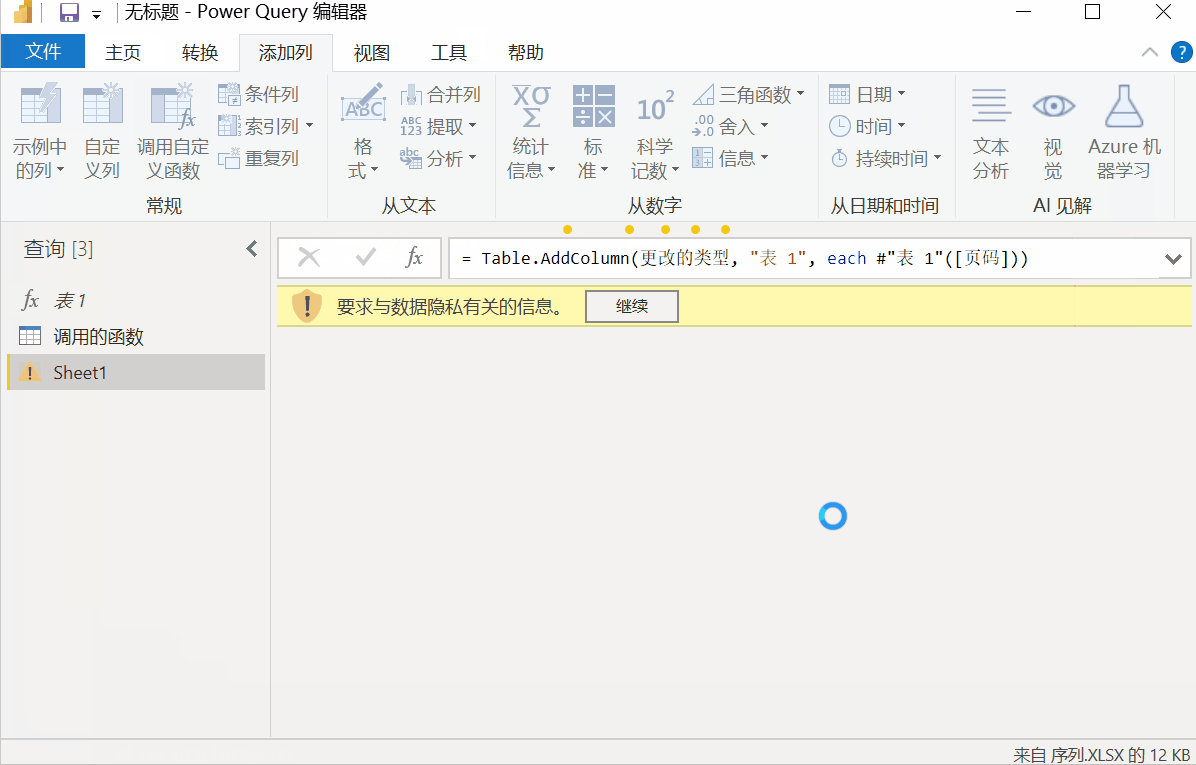
设置自定义函数
依次点击【首页】-【高级编辑器】,在弹出的界面中,在字母“let”前输入如下代码:
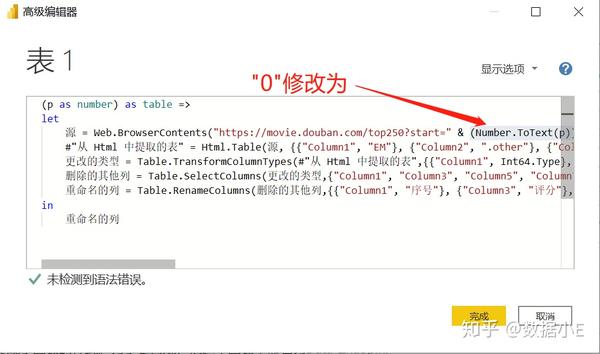
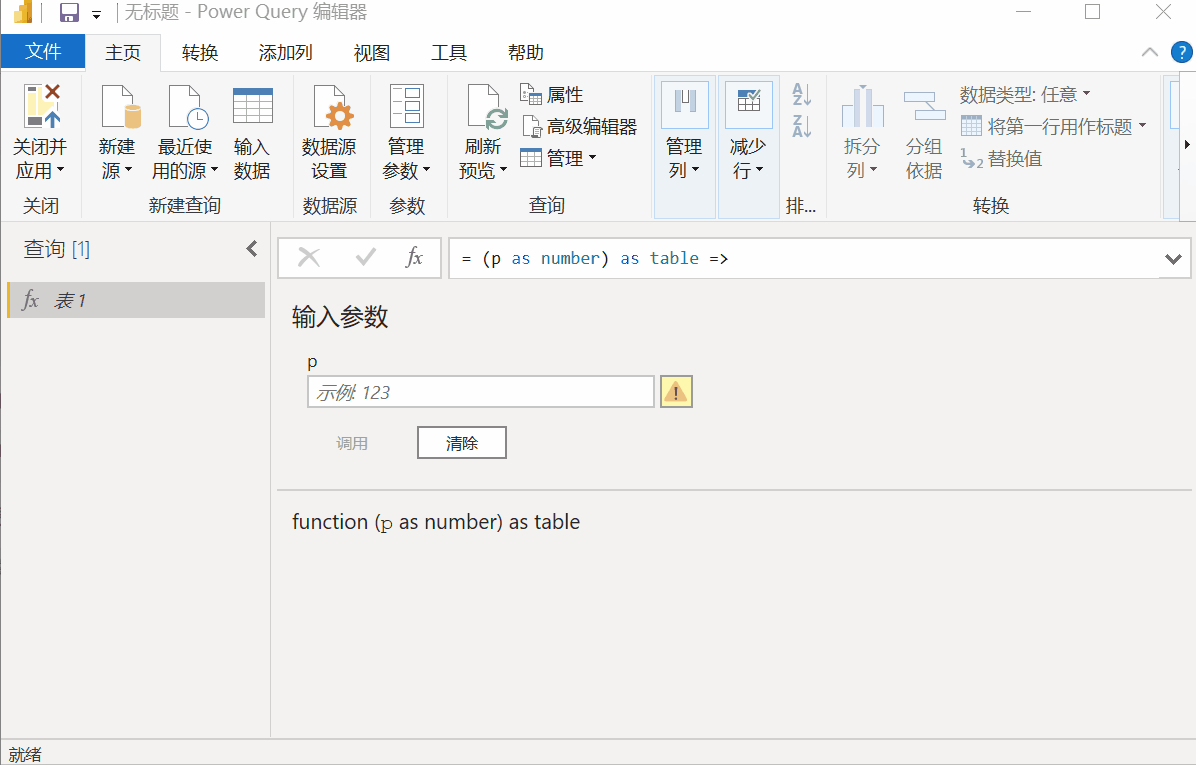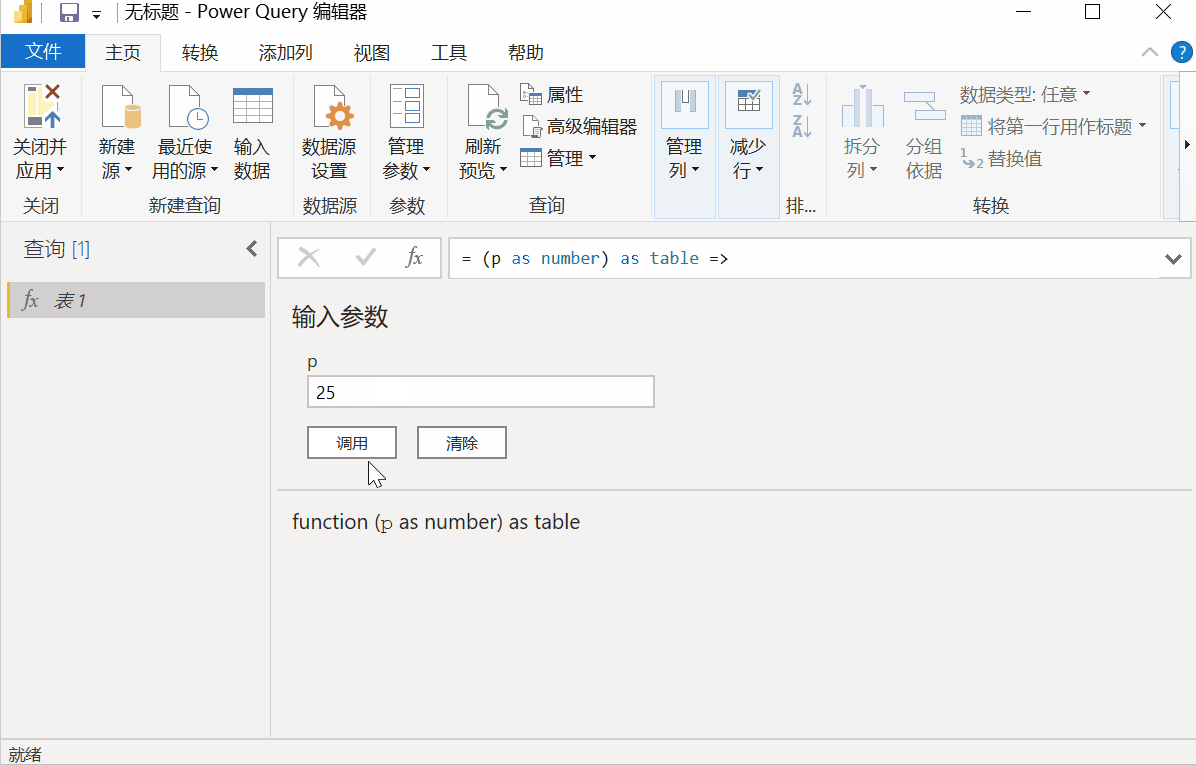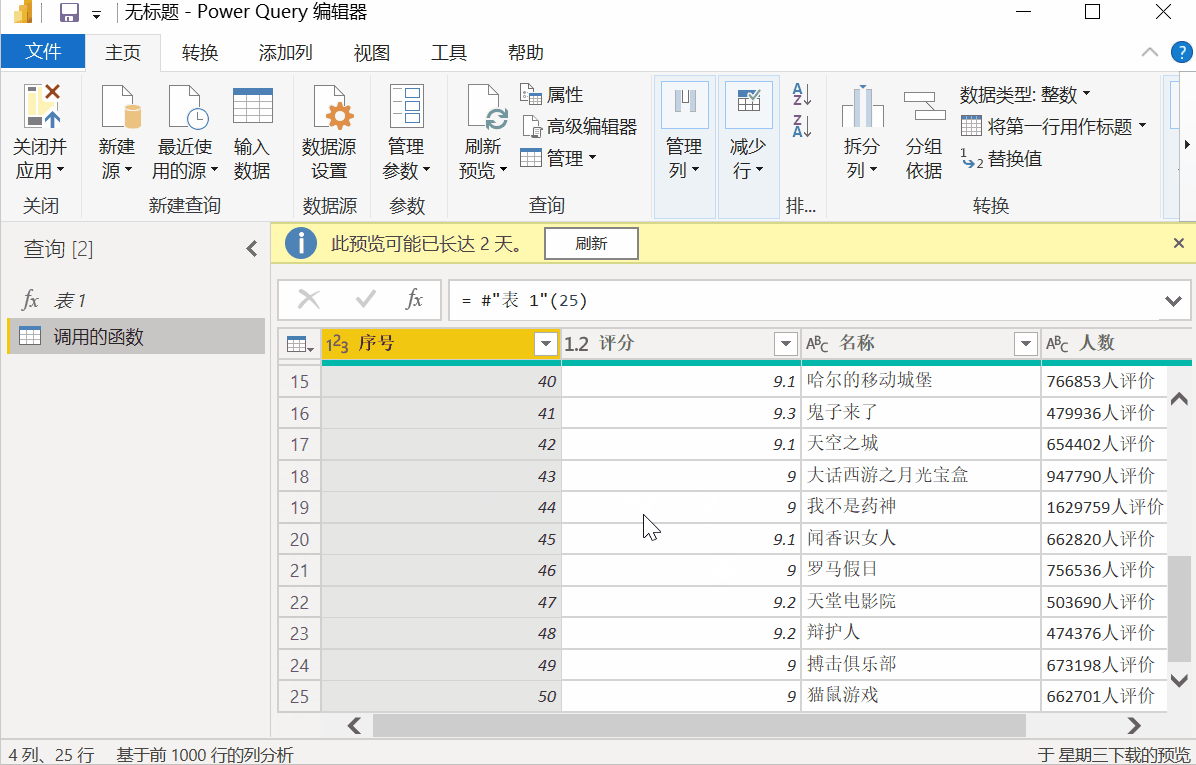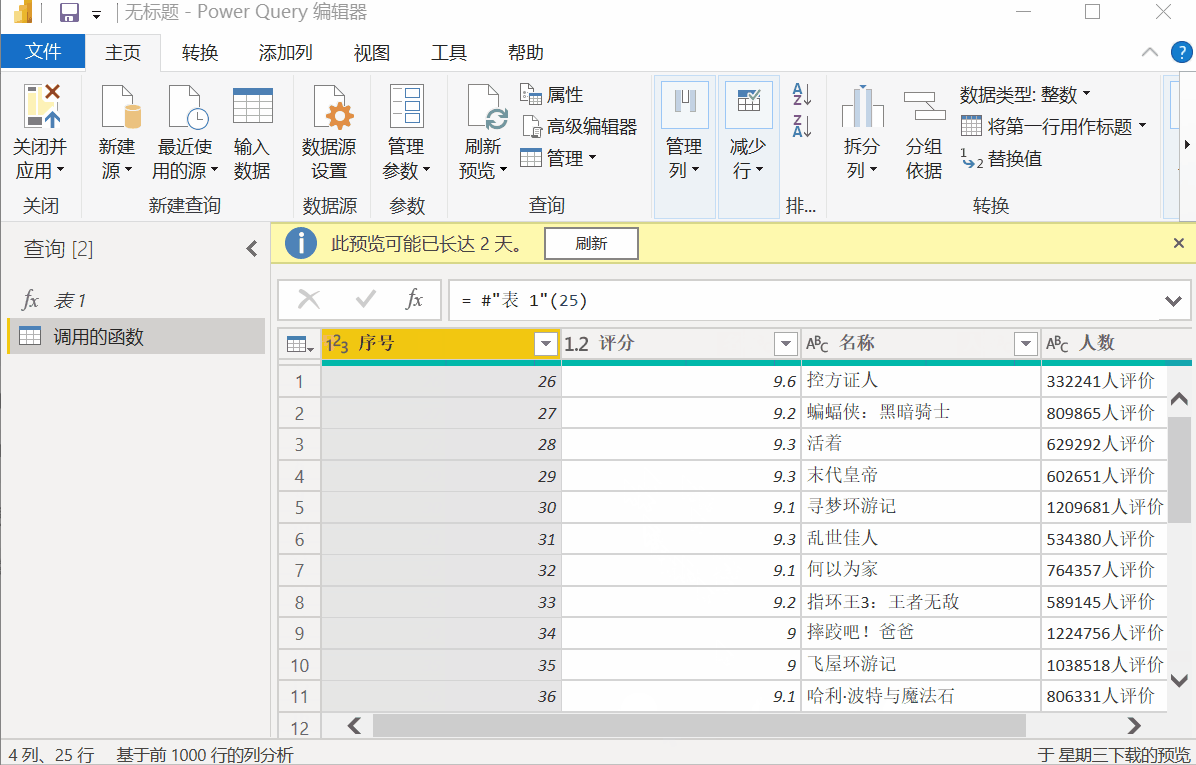
(p as number) as table =>
然后将第三行代码中的数字["0"]替换为[(Number.ToText(p))],如下图:
(Number.ToText(p))
完成以上两步设置后,点击“确定”,可以发现原来的表1变成了函数样式,fx表1,其中p是函数参数,控件页码,如输入25、可以得到TOP250两页电影列表的数据。
批量调用,批量抓取数据
然后点击【新建源】-【Excel】,选择第一步保存备用Excel表格,导入后点击【添加列】-【调用自定义函数】,下拉函数查询选择【表1】 ,点击确定。
界面会弹出警告框【需要与数据隐私相关的信息】,点击【继续】,勾选【忽略此文件的隐私级别检查】。 ...],点击【保存】后,程序进入页面抓取阶段。
由于爬取的页面较多,程序需要运行一段时间。十多秒后,数据采集完成。总共十页存储在 10 个表中。点击字段【表格1】,勾选【展开】,TOP250信息显示在表格中。
此时数据还在Power Query中,点击【开始】-【关闭并上传】将数据加载到Excel中,完成数据爬取。
总结
我们这些不会编码的人,曾经害怕数据爬行。随着ExcelBI工具的丰富,数据爬取会变得更简单,快来试试吧~
如果您没有更高版本的 Excel,不妨尝试安装 Power BI Desktop。这很方便。您无需注册,只需打开并使用它。您可以从应用商店的 Microsoft 商店下载 Power BI Desktop。 查看全部
网页表格抓取(Python批量爬取网页数据的文章,让我们一起看看吧)
我写过一篇关于Python批量抓取网页数据的文章文章。后来发现随着版本的迭代,Excel已经全面支持多页爬取数据了。您无需编码,只需点击几下鼠标即可抓取数据。一起来看看吧~
网页分析
在抓取数据之前,先对网页进行分析。下图是豆瓣TOP250的初始页面。到最底部,一共10页,每页25部电影,一共250部电影。
我们可以依次获取前三个页面的URL,找出它们之间的规则。除了中间的数字外,每个 URL 都相同。编号从 0/25/50 到 25 递增(每页电影的数量),共 10 页。
发现规律后,我们将10页之间的数字存入一个表格中以备将来使用,如下图A列所示,保存以备将来使用。
数据采集
Excel2016及以上版本内嵌网络批量抓取功能(“数据”-“新建查询”-“其他来源”-“来自网络”),案例演示版本未到,所以我下载了A Power BI Desktop(Excel扩展产品),免安装免使用,效果和Excel一样,不用担心不会用,用Excel来操作就可以了。

打开 Power BI Desktop 或 Excel,点击【获取数据】-【网页】(对于 Excel 2016 及以上版本,在“数据”-“新建查询”-“来自其他来源”-“来自网页”)
界面设置:
点击高级后,在 URL 部分,点击“添加组件”。一共有三个盒子。豆瓣TOP250首页网址以数字0分隔,分为三段,分别放在三个框中,如下图:
你会发现在URL预览框中会自动显示完整的URL。点击确定完成设置。
导航界面
之后程序会进入抓数据状态,稍等片刻,跳出“导航”界面。左侧有一个表“表 1”。查看后,右侧显示屏显示了详细数据,在首页首页可以发现是豆瓣TOP250 25部电影;
一共抓取了9个字段,包括序列号、电影名称、评分、评论数量、电影介绍等信息,部分栏目不需要,我们进入Power Query界面删除,以及点击底部的“数据转换”进入Power Query界面。
Power Query 数据编辑
进入Power Query界面后,只会保留序号、评分、电影名称、评论次数四列,其余列将被删除。删除后,四列数据将被重命名。动画显示如下:
设置自定义函数
依次点击【首页】-【高级编辑器】,在弹出的界面中,在字母“let”前输入如下代码:
(p as number) as table =>
然后将第三行代码中的数字["0"]替换为[(Number.ToText(p))],如下图:
(Number.ToText(p))
完成以上两步设置后,点击“确定”,可以发现原来的表1变成了函数样式,fx表1,其中p是函数参数,控件页码,如输入25、可以得到TOP250两页电影列表的数据。
批量调用,批量抓取数据
然后点击【新建源】-【Excel】,选择第一步保存备用Excel表格,导入后点击【添加列】-【调用自定义函数】,下拉函数查询选择【表1】 ,点击确定。
界面会弹出警告框【需要与数据隐私相关的信息】,点击【继续】,勾选【忽略此文件的隐私级别检查】。 ...],点击【保存】后,程序进入页面抓取阶段。
由于爬取的页面较多,程序需要运行一段时间。十多秒后,数据采集完成。总共十页存储在 10 个表中。点击字段【表格1】,勾选【展开】,TOP250信息显示在表格中。
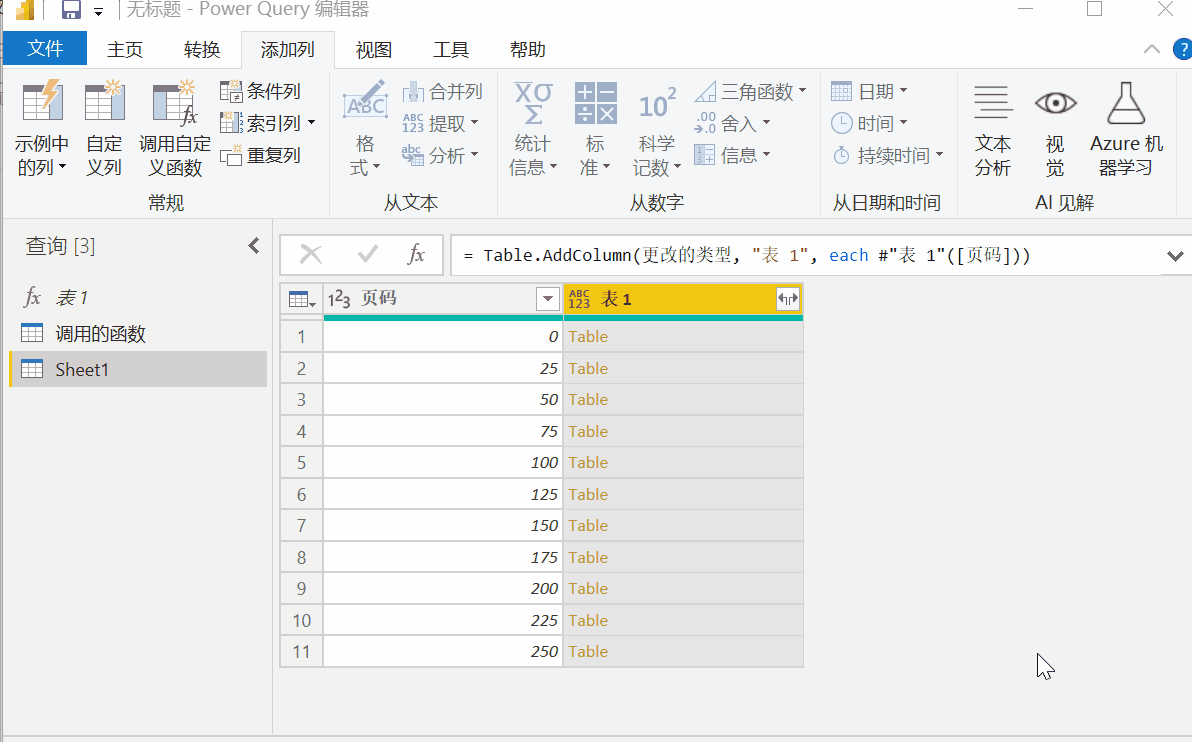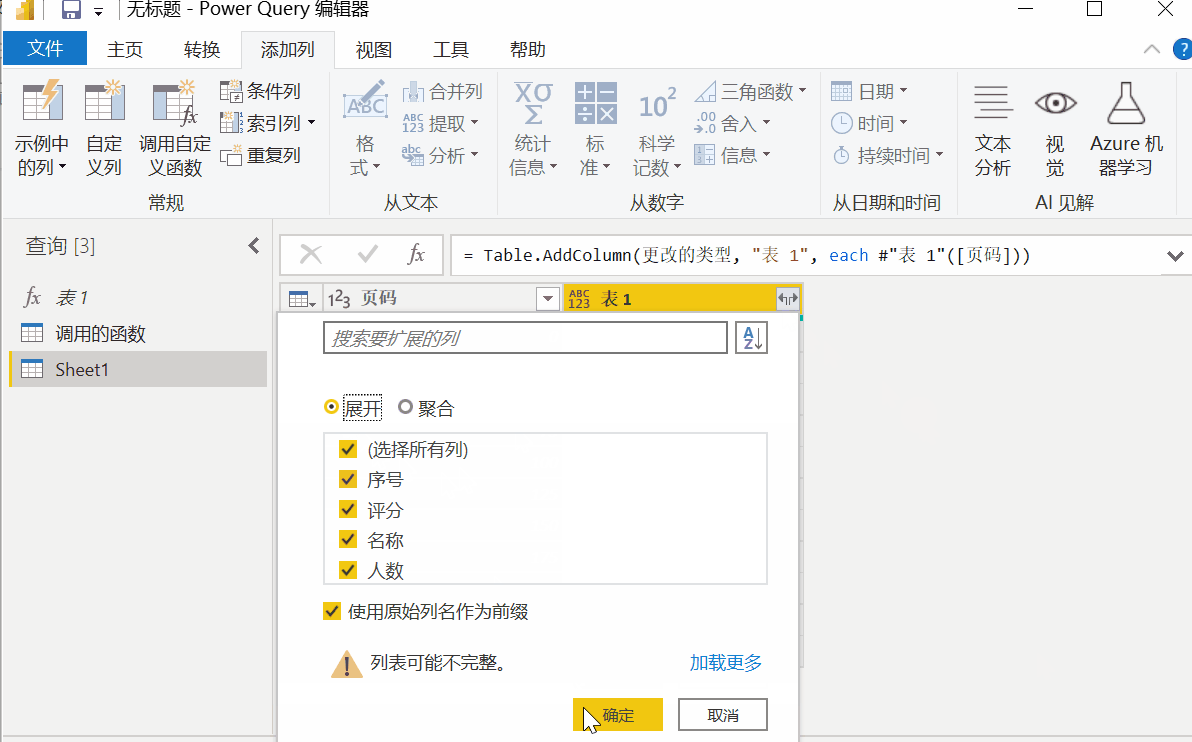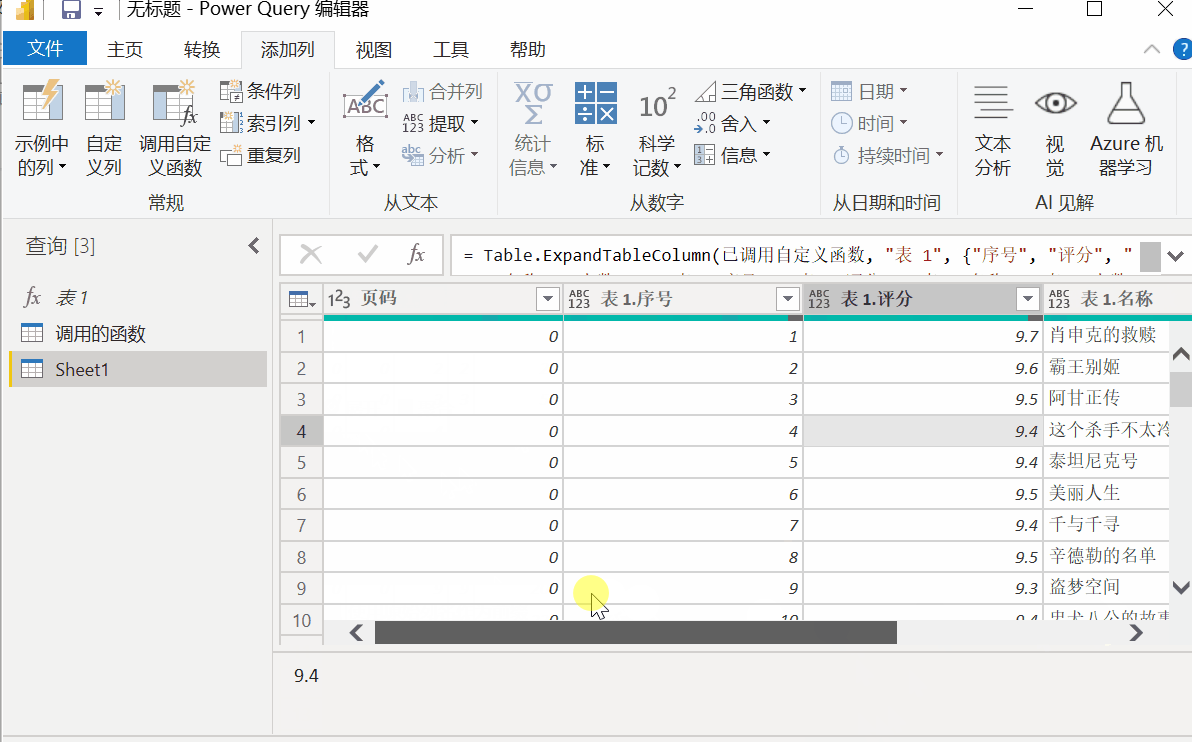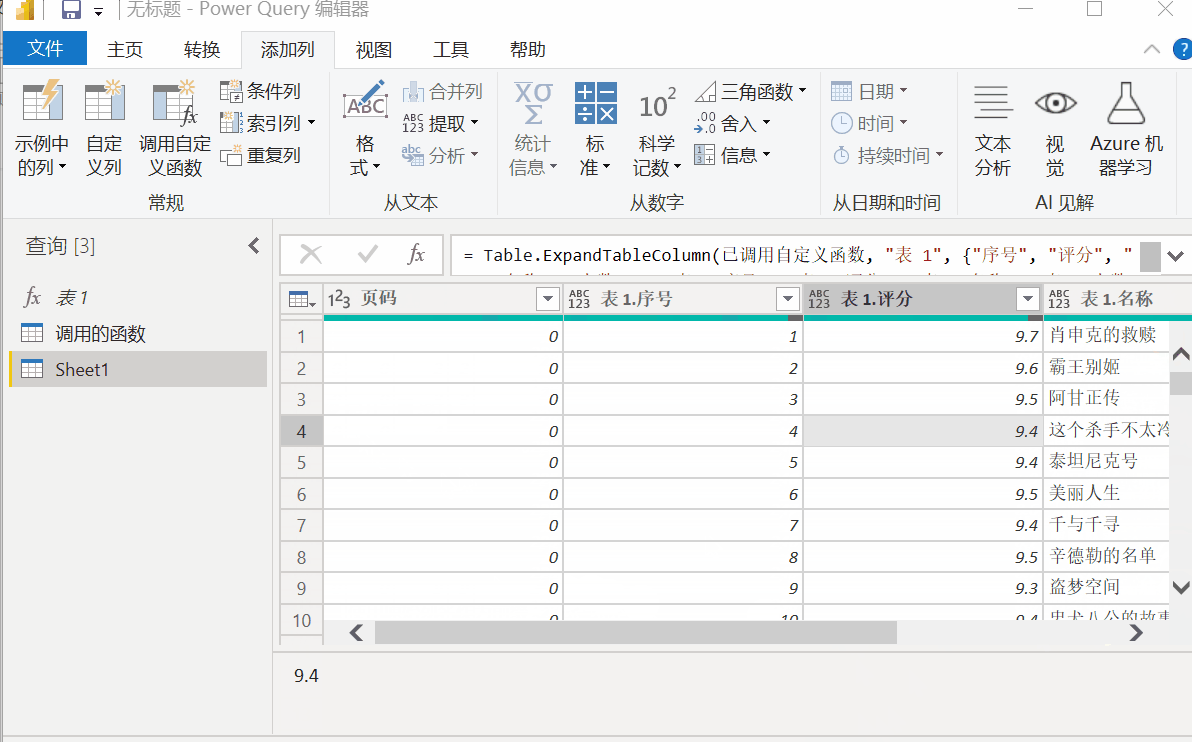
此时数据还在Power Query中,点击【开始】-【关闭并上传】将数据加载到Excel中,完成数据爬取。
总结
我们这些不会编码的人,曾经害怕数据爬行。随着ExcelBI工具的丰富,数据爬取会变得更简单,快来试试吧~
如果您没有更高版本的 Excel,不妨尝试安装 Power BI Desktop。这很方便。您无需注册,只需打开并使用它。您可以从应用商店的 Microsoft 商店下载 Power BI Desktop。
网页表格抓取(Excel教程Excel函数Excel表格信息快速提取实例(33))
网站优化 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-09-10 04:11
背景要求
先说一下问题的背景:
这个网站可以查看深圳各区的空气质量信息,每小时更新一次。
要求:快速提取并保存里面的表单信息。
Excel可以使用data-from网站这个功能来实现简单的网络表格数据爬取,想必很多朋友应该都知道并使用过。
这个方法对于一些简单的网页还是很实用的。但是对于一些网页,比如pm25.in,上面的方法不是很方便,如下图:
直接选择表格顶部的√,无法导入。
如果直接查看整个页面,会提取出很多除了表格之外的无用信息。
效果演示
所以,在这种情况下,你可以灵活地使用VBA来解决这个问题。
第一个效果:点击“更新”直接提取表格信息
然后点击“保存汇总”,将此时提取的信息保存到汇总表中,以备后续使用。
核心代码
整个过程并不难。抓取表格数据的核心函数代码如下。每一行代码的含义都标在背面。
如果你想换到另一个城市,你只需要改变URL地址即可。
With Sheets(1).QueryTables.Add("URL;http://www.pm25.in/shenzhen", Range("A2")) '抓取网站网页地址
.RefreshStyle = xlOverwriteCells '覆盖模式
.WebFormatting = xlWebFormattingAll '包含全部格式
.WebSelectionType = xlSpecifiedTables '指定table模式
.WebTables = "1" '第1张table
.Refresh False
End With
之后的保存和摘要是一些常规的 VBA 代码。
需要说明的是,此代码仅适用于网页源代码中收录表格数据的网页。
如果对本内容感兴趣,可以在公众号回复“网页表单”获取vba文件试用~~
您可能还想看:
VBA 示例(35) – 一键批量 ppt 到 pdf 转换
VBA 示例(34)–– 快速匹配不同名称的数据
VBA示例(33)--一键提取word中的粗体
VBA 示例(32)-batch 替换隐藏的神秘字符
VBA 示例(31) – VBA 代码的自定义快捷键
VBA 示例(30) - 为多个工作表创建目录和超链接 查看全部
网页表格抓取(Excel教程Excel函数Excel表格信息快速提取实例(33))
背景要求
先说一下问题的背景:
这个网站可以查看深圳各区的空气质量信息,每小时更新一次。
 http://www.yhjbox.com/wp-conte ... 3.jpg 300w, http://www.yhjbox.com/wp-conte ... 7.jpg 768w" />
http://www.yhjbox.com/wp-conte ... 3.jpg 300w, http://www.yhjbox.com/wp-conte ... 7.jpg 768w" />要求:快速提取并保存里面的表单信息。
Excel可以使用data-from网站这个功能来实现简单的网络表格数据爬取,想必很多朋友应该都知道并使用过。
 http://www.yhjbox.com/wp-conte ... 3.jpg 300w, http://www.yhjbox.com/wp-conte ... 0.jpg 768w" />
http://www.yhjbox.com/wp-conte ... 3.jpg 300w, http://www.yhjbox.com/wp-conte ... 0.jpg 768w" />这个方法对于一些简单的网页还是很实用的。但是对于一些网页,比如pm25.in,上面的方法不是很方便,如下图:

直接选择表格顶部的√,无法导入。
如果直接查看整个页面,会提取出很多除了表格之外的无用信息。

效果演示
所以,在这种情况下,你可以灵活地使用VBA来解决这个问题。
第一个效果:点击“更新”直接提取表格信息

然后点击“保存汇总”,将此时提取的信息保存到汇总表中,以备后续使用。

核心代码
整个过程并不难。抓取表格数据的核心函数代码如下。每一行代码的含义都标在背面。
如果你想换到另一个城市,你只需要改变URL地址即可。
With Sheets(1).QueryTables.Add("URL;http://www.pm25.in/shenzhen", Range("A2")) '抓取网站网页地址
.RefreshStyle = xlOverwriteCells '覆盖模式
.WebFormatting = xlWebFormattingAll '包含全部格式
.WebSelectionType = xlSpecifiedTables '指定table模式
.WebTables = "1" '第1张table
.Refresh False
End With
之后的保存和摘要是一些常规的 VBA 代码。
需要说明的是,此代码仅适用于网页源代码中收录表格数据的网页。
如果对本内容感兴趣,可以在公众号回复“网页表单”获取vba文件试用~~
您可能还想看:
VBA 示例(35) – 一键批量 ppt 到 pdf 转换
VBA 示例(34)–– 快速匹配不同名称的数据
VBA示例(33)--一键提取word中的粗体
VBA 示例(32)-batch 替换隐藏的神秘字符
VBA 示例(31) – VBA 代码的自定义快捷键
VBA 示例(30) - 为多个工作表创建目录和超链接
网页表格抓取(如何快速获取网页中的表格,并且可以实现自动刷新数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-09-10 04:09
大家好,今天给大家分享一下如何快速获取网页中的表格,并且可以自动刷新数据,他的操作也很简单,不多说,直接开始
我们想在网页中获取2020年GDP预测排名的数据,如下图
一、获取数据
首先我们需要新建一个工作簿,打开它,然后点击数据函数组,点击新建查询,然后从其他源中选择,从网站中选择
此时会弹出一个对话框,直接复制要提取数据的URL,然后点击确定。点击确定后,excel会自动连接并计算数据
计算完成后,会进入powerquery的导航界面。导航器左侧的表格图标是excel检测到的表格数据,当我们点击对应的表格名称时,右侧的数据会显示对应的表格,我们可以点击表格找到我们需要的数据想要获取,这里第一个就是我们想要获取的数据,我们直接点击第一个表格然后点击转换数据
二、处理数据
当您点击转换数据时,您将进入powerquery的数据处理界面,我们可以在此对数据进行相应的处理。比如这里我们要按地区计算每个大洲的GDP总量,以人民币为单位
首先我们在start中点击选择分组基准,然后在分组基准中选择区域,然后在新的列名中命名一个名称,我设置计算方式为sum,然后选择所在的列定位到RMB,点击确定。是的
接下来我们点击close and upload to将数据加载到excel中,如下图
如果不想在powerquery中编辑,可以在导航器界面直接点击加载,数据会直接加载到excel中,我们也可以直接在excel中编辑数据,
powerquery处理的数据是可以刷新的,但是不能直接在excel中点击load and processing来刷新数据。刷新数据,我们只需要在数据功能组中点击刷新即可刷新数据 查看全部
网页表格抓取(如何快速获取网页中的表格,并且可以实现自动刷新数据)
大家好,今天给大家分享一下如何快速获取网页中的表格,并且可以自动刷新数据,他的操作也很简单,不多说,直接开始
我们想在网页中获取2020年GDP预测排名的数据,如下图
一、获取数据
首先我们需要新建一个工作簿,打开它,然后点击数据函数组,点击新建查询,然后从其他源中选择,从网站中选择
此时会弹出一个对话框,直接复制要提取数据的URL,然后点击确定。点击确定后,excel会自动连接并计算数据
计算完成后,会进入powerquery的导航界面。导航器左侧的表格图标是excel检测到的表格数据,当我们点击对应的表格名称时,右侧的数据会显示对应的表格,我们可以点击表格找到我们需要的数据想要获取,这里第一个就是我们想要获取的数据,我们直接点击第一个表格然后点击转换数据
二、处理数据
当您点击转换数据时,您将进入powerquery的数据处理界面,我们可以在此对数据进行相应的处理。比如这里我们要按地区计算每个大洲的GDP总量,以人民币为单位
首先我们在start中点击选择分组基准,然后在分组基准中选择区域,然后在新的列名中命名一个名称,我设置计算方式为sum,然后选择所在的列定位到RMB,点击确定。是的
接下来我们点击close and upload to将数据加载到excel中,如下图
如果不想在powerquery中编辑,可以在导航器界面直接点击加载,数据会直接加载到excel中,我们也可以直接在excel中编辑数据,
powerquery处理的数据是可以刷新的,但是不能直接在excel中点击load and processing来刷新数据。刷新数据,我们只需要在数据功能组中点击刷新即可刷新数据
网页表格抓取(《表》返回数据帧的使用方法分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-10-07 13:10
正如furas所说,您需要提取正确的表格标记(因此请接受他的解决方案)。但我也想补充,考虑使用
方法,因为它为您完成了解析表标签的繁重工作(并在引擎盖下使用了漂亮的汤)。
所以
将返回数据帧列表。我相信你想要的数据框是
, 这是第二个表(在索引位置1):
import pandas as pd
df = pd.read_html('https://www.macrotrends.net/st ... 23x27;)[1]
输出:
print(df)
Tesla Quarterly Revenue(Millions of US $) Tesla Quarterly Revenue(Millions of US $).1
0 2020-12-31 $10,744
1 2020-09-30 $8,771
2 2020-06-30 $6,036
3 2020-03-31 $5,985
4 2019-12-31 $7,384
5 2019-09-30 $6,303
6 2019-06-30 $6,350
7 2019-03-31 $4,541
8 2018-12-31 $7,226
9 2018-09-30 $6,824
10 2018-06-30 $4,002
11 2018-03-31 $3,409
12 2017-12-31 $3,288
13 2017-09-30 $2,985
14 2017-06-30 $2,790
15 2017-03-31 $2,696
16 2016-12-31 $2,285
17 2016-09-30 $2,298
18 2016-06-30 $1,270
19 2016-03-31 $1,147
20 2015-12-31 $1,214
21 2015-09-30 $937
22 2015-06-30 $955
23 2015-03-31 $940
24 2014-12-31 $957
25 2014-09-30 $852
26 2014-06-30 $769
27 2014-03-31 $621
28 2013-12-31 $615
29 2013-09-30 $431
30 2013-06-30 $405
31 2013-03-31 $562
32 2012-12-31 $306
33 2012-09-30 $50
34 2012-06-30 $27
35 2012-03-31 $30
36 2011-12-31 $39
37 2011-09-30 $58
38 2011-06-30 $58
39 2011-03-31 $49
40 2010-12-31 $36
41 2010-09-30 $31
42 2010-06-30 $28
43 2010-03-31 $21
44 2009-12-31 NaN
45 2009-09-30 $46
46 2009-06-30 $27
47 2008-12-31
NaN
CN
正如furas所说,您需要提取正确的表格标记(因此请接受他的解决方案)。但我还想补充一点,考虑如何使用它,因为它为您完成了解析表标签的繁重工作(并且在引擎盖下使用了漂亮的汤)。因此将返回数据帧列表。我相信你想要的数据框是,这是第二个表(在索引位置 1): import panda... 查看全部
网页表格抓取(《表》返回数据帧的使用方法分享)
正如furas所说,您需要提取正确的表格标记(因此请接受他的解决方案)。但我也想补充,考虑使用
方法,因为它为您完成了解析表标签的繁重工作(并在引擎盖下使用了漂亮的汤)。
所以
将返回数据帧列表。我相信你想要的数据框是
, 这是第二个表(在索引位置1):
import pandas as pd
df = pd.read_html('https://www.macrotrends.net/st ... 23x27;)[1]
输出:
print(df)
Tesla Quarterly Revenue(Millions of US $) Tesla Quarterly Revenue(Millions of US $).1
0 2020-12-31 $10,744
1 2020-09-30 $8,771
2 2020-06-30 $6,036
3 2020-03-31 $5,985
4 2019-12-31 $7,384
5 2019-09-30 $6,303
6 2019-06-30 $6,350
7 2019-03-31 $4,541
8 2018-12-31 $7,226
9 2018-09-30 $6,824
10 2018-06-30 $4,002
11 2018-03-31 $3,409
12 2017-12-31 $3,288
13 2017-09-30 $2,985
14 2017-06-30 $2,790
15 2017-03-31 $2,696
16 2016-12-31 $2,285
17 2016-09-30 $2,298
18 2016-06-30 $1,270
19 2016-03-31 $1,147
20 2015-12-31 $1,214
21 2015-09-30 $937
22 2015-06-30 $955
23 2015-03-31 $940
24 2014-12-31 $957
25 2014-09-30 $852
26 2014-06-30 $769
27 2014-03-31 $621
28 2013-12-31 $615
29 2013-09-30 $431
30 2013-06-30 $405
31 2013-03-31 $562
32 2012-12-31 $306
33 2012-09-30 $50
34 2012-06-30 $27
35 2012-03-31 $30
36 2011-12-31 $39
37 2011-09-30 $58
38 2011-06-30 $58
39 2011-03-31 $49
40 2010-12-31 $36
41 2010-09-30 $31
42 2010-06-30 $28
43 2010-03-31 $21
44 2009-12-31 NaN
45 2009-09-30 $46
46 2009-06-30 $27
47 2008-12-31
NaN
CN
正如furas所说,您需要提取正确的表格标记(因此请接受他的解决方案)。但我还想补充一点,考虑如何使用它,因为它为您完成了解析表标签的繁重工作(并且在引擎盖下使用了漂亮的汤)。因此将返回数据帧列表。我相信你想要的数据框是,这是第二个表(在索引位置 1): import panda...
网页表格抓取(如何获取表格信息之前?库怎么用方法?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-10-07 12:11
一、背景
在日常的数据分析工作中,我们经常会寻找数据来源。所以经常会看到网页表格信息,不能直接复制到excel表格中。为了快速获取网页中的表单信息,对其进行分析汇总,最后向上级汇报。所以我们需要思考如何更方便快捷地获取信息。当然,正常的网页爬取也是可行的,但是比较复杂。这里我们使用pandas库来操作,爬表很容易。
二、必备知识
在开始获取表信息之前,需要了解一些pandas的方法。pandas库的文档可以参考:
1、pandas.DataFrame.to_csv 方法:以csv格式保存数据
DataFrame.to_csv(self, path_or_buf=None, sep=', ', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression='infer', quoting=None, quotechar='"', line_terminator=None, chunksize=None, date_format=None, doublequote=True, escapechar=None, decimal='.')
2、pandas.read_html 方法:将HTML网页中的表格解析为DataFrame对象并返回列表。详情:#pandas.read_html
pandas.read_html(io, match='.+', flavor=None, header=None, index_col=None, skiprows=None, attrs=None, parse_dates=False, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None, keep_default_na=True, displayed_only=True)
三、 爬取表数据
1、分析网站
本例的网站地址为:世界大学排名网站,地址见代码。经过分析,网站的请求方式为GET,爬取难度较小。
然后,定位并获取表数据。
最后,代码实现了表格数据的爬取。
import pandas as pd
import requests
from fake_useragent import UserAgent
import random
from lxml import etree
'''请求头函数'''
def agent():
ua = UserAgent()
# 随机选择chrome、ie、firefox请求头
useragent = random.choice([ua.chrome, ua.ie, ua.firefox])
headers = {
'User-Agent': useragent,
'Referer': 'https: // cn.bing.com /'
}
return headers
'''解析网页数据'''
def parse_html(url):
try:
resp = requests.get(url, headers=agent())
# 将编码方式设置为从内容中分析出的响应内容编码方式
resp.encoding = resp.apparent_encoding
if resp.status_code == 200:
tree = etree.HTML(resp.text)
# 定位获取表格信息
tb = tree.xpath('//table[@id="rk"]')
# 将byte类型解码为str类型
tb = etree.tostring(tb[0], encoding='utf8').decode()
return tb
else:
print('爬取失败')
except Exception as e:
print(e)
def main():
url = 'http://www.compassedu.hk/qs_'
tb = parse_html(url)
# 解析表格数据
df = pd.read_html(tb, encoding='utf-8', header=0)[0]
# 转换成列表嵌套字典的格式
result = list(df.T.to_dict().values())
# 保存为csv格式
df.to_csv('university.csv', index=False)
print(result)
if __name__ == '__main__':
main()
结果显示:
四、分析表数据信息
1、编码格式转换
表格数据虽然已经保存到本地.csv文件,但是用excel打开时发现是乱码,用代码编辑器打开时显示正常。是什么原因?事实上,这非常简单。当您按下代码时,您经常会遇到编码问题。只需改变excel的编码方式,保存为excel格式的数据文件即可。
首先,创建一个 university.xlsx 文件,然后打开它。在工具栏“数据”中找到“从text/csv导入数据”,选择数据源文件,即网上爬取的university.csv数据文件。最后点击“导入”
选择文件编码方式,这里是utf-8的编码方式。这里,默认情况下,csv中的数据是用逗号分隔的,所以不需要选择。最后,点击加载。
2、数据分析
现在数据已经全部正常显示在excel表格中了,接下来点击“插入”数据透视表,或者使用快捷键ctrl+q。最后点击确定。
然后,在数据透视表中进行调整,分析数据并得出结论。
最后,对于数据量不是很大的情况,利用excel的数据透视表功能灵活处理、分析、展示数据信息也是一种非常高效的方法。 查看全部
网页表格抓取(如何获取表格信息之前?库怎么用方法?)
一、背景
在日常的数据分析工作中,我们经常会寻找数据来源。所以经常会看到网页表格信息,不能直接复制到excel表格中。为了快速获取网页中的表单信息,对其进行分析汇总,最后向上级汇报。所以我们需要思考如何更方便快捷地获取信息。当然,正常的网页爬取也是可行的,但是比较复杂。这里我们使用pandas库来操作,爬表很容易。
二、必备知识
在开始获取表信息之前,需要了解一些pandas的方法。pandas库的文档可以参考:
1、pandas.DataFrame.to_csv 方法:以csv格式保存数据
DataFrame.to_csv(self, path_or_buf=None, sep=', ', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression='infer', quoting=None, quotechar='"', line_terminator=None, chunksize=None, date_format=None, doublequote=True, escapechar=None, decimal='.')
2、pandas.read_html 方法:将HTML网页中的表格解析为DataFrame对象并返回列表。详情:#pandas.read_html
pandas.read_html(io, match='.+', flavor=None, header=None, index_col=None, skiprows=None, attrs=None, parse_dates=False, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None, keep_default_na=True, displayed_only=True)
三、 爬取表数据
1、分析网站
本例的网站地址为:世界大学排名网站,地址见代码。经过分析,网站的请求方式为GET,爬取难度较小。
然后,定位并获取表数据。
最后,代码实现了表格数据的爬取。
import pandas as pd
import requests
from fake_useragent import UserAgent
import random
from lxml import etree
'''请求头函数'''
def agent():
ua = UserAgent()
# 随机选择chrome、ie、firefox请求头
useragent = random.choice([ua.chrome, ua.ie, ua.firefox])
headers = {
'User-Agent': useragent,
'Referer': 'https: // cn.bing.com /'
}
return headers
'''解析网页数据'''
def parse_html(url):
try:
resp = requests.get(url, headers=agent())
# 将编码方式设置为从内容中分析出的响应内容编码方式
resp.encoding = resp.apparent_encoding
if resp.status_code == 200:
tree = etree.HTML(resp.text)
# 定位获取表格信息
tb = tree.xpath('//table[@id="rk"]')
# 将byte类型解码为str类型
tb = etree.tostring(tb[0], encoding='utf8').decode()
return tb
else:
print('爬取失败')
except Exception as e:
print(e)
def main():
url = 'http://www.compassedu.hk/qs_'
tb = parse_html(url)
# 解析表格数据
df = pd.read_html(tb, encoding='utf-8', header=0)[0]
# 转换成列表嵌套字典的格式
result = list(df.T.to_dict().values())
# 保存为csv格式
df.to_csv('university.csv', index=False)
print(result)
if __name__ == '__main__':
main()
结果显示:
四、分析表数据信息
1、编码格式转换
表格数据虽然已经保存到本地.csv文件,但是用excel打开时发现是乱码,用代码编辑器打开时显示正常。是什么原因?事实上,这非常简单。当您按下代码时,您经常会遇到编码问题。只需改变excel的编码方式,保存为excel格式的数据文件即可。
首先,创建一个 university.xlsx 文件,然后打开它。在工具栏“数据”中找到“从text/csv导入数据”,选择数据源文件,即网上爬取的university.csv数据文件。最后点击“导入”
选择文件编码方式,这里是utf-8的编码方式。这里,默认情况下,csv中的数据是用逗号分隔的,所以不需要选择。最后,点击加载。
2、数据分析
现在数据已经全部正常显示在excel表格中了,接下来点击“插入”数据透视表,或者使用快捷键ctrl+q。最后点击确定。
然后,在数据透视表中进行调整,分析数据并得出结论。
最后,对于数据量不是很大的情况,利用excel的数据透视表功能灵活处理、分析、展示数据信息也是一种非常高效的方法。
网页表格抓取(洛约拉大学(Loyola)网络研讨会演示如何无需编程即可抓取网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-02 13:26
有一些编程语言可以简化这个操作,比如 Python。这是因为 Python 提供了 Scrapy 和 BeautifulSoup 等库,它们比传统的网络爬虫更容易抓取和解析 HTML。
但是,它仍然需要适当的设计以及对编程和 网站 架构的良好理解。
假设您的团队没有编程技能。那没问题!我们团队的一名成员最近在洛约拉大学举办了一场网络研讨会,演示如何在没有编程的情况下抓取网页。相反,Google Sheets 提供了一些有用的功能,可以帮助抓取网络数据。如果您想观看我们的在线讲座视频,请点击下方。如果没有,您可以继续阅读并弄清楚如何使用 Google Sheets 来抓取 网站。
Google表格抓取功能
您可以使用 Google Sheets 进行网络抓取的功能有:
所有这些函数都将根据提供给函数 网站 的不同参数来获取。
使用 ImportFeed 进行网络抓取
ImportFeed Google Sheets 功能是更易于使用的功能之一。它只需要访问 Google 表格和 RSS 提要的 URL。这是通常与博客相关联的提要。
例如,您可以使用我们的 RSS 提要“”。
你如何使用这个功能?下面给出一个例子。
"= ImportFeed(" ")
这就是所需要的!还有其他提示和技巧可以帮助清理数据提要,因为您将拥有不止一列信息。目前,这是网络抓取的良好开端。
Google 表格导入功能会更新吗?
所有这些导入功能每 2 小时自动更新一次数据。可设置触发功能,增加更新节奏。但是,这需要更多的编程。
在这种情况下就是这样!从这里开始,这就是您的团队使用它的方式!确保设计一个可靠的数据采集系统。
上图是使用 ImportFeed 函数的示例。
使用 ImportXML 进行网络爬虫
Google 表格中的 ImportXML 函数用于使用 HTML ID 和类提取特定数据点。这需要对 HTML 和解析 XML 有一定的了解。这可能有点令人沮丧。因此,我们逐渐创建了一个 HTML 网络爬虫。
以下是 EventBrite 页面上的一些示例。
去右键单击并检查元素以找到您感兴趣的 HTML 标记。 我们正在寻找
一些文字,所以这是棘手的部分。您需要从这个 HTML 标记中提取的第一部分是类型。相似
,
,等待。您可以使用“//”,然后使用标签名称来调用第一个。例如“// div”、“// a”或“// span”。现在,如果你真的想要“这里有一些文字”,你需要调用课程。这是在步骤 5 中显示的方法中完成的。您会注意到它使用了“// div”和“[@class =“此处为类名”] 的组合。xml 字符串是“// div [@class ='list-card__body']" 你可能想要获取另一个数据值。我们想要获取所有的 URL。这种情况会涉及到想要提取第一个 HTML 标签本身内部的特定值。例如,点击这里。然后就像 step 7.xml字符串为“//a/@href”ImportXML(URL, XML string)ImportXML(“”,“//div[@class='list-card__body']”)
使用此功能的事实是它需要花费大量时间。因此,它需要规划和设计一个好的 Google 工作表,以确保您从使用中获得最大的收益。否则,您的团队最终将花时间维护它而不是研究新事物。像下面的图片
来自 xkcd
使用 ImportHTML 进行网页抓取
最后,我们将讨论 ImportHTML。这将从网页导入表格或列表。例如,如果您想从 网站 中获取收录股票价格的数据,该怎么办。
我们会用。这个页面上有一张表格,上面有过去几天的股票价格。
与过去的功能类似,您需要使用一个 URL。在 URL 的顶部,您必须提及要在页面上抓取的表格。您可以使用可能的数字来完成此操作。
例如,ImportHTML (" ",6 )。这将从上面的链接中删除股票价格。
在上面的视频中,我们还展示了如何将上述股票数据捕获结合到当天有关股市自动收录设备的新闻中。这可以以更复杂的方式使用。该团队可以创建一个算法,使用过去的股票价格和新的 文章 和 Twitter 信息来选择是买入还是卖出股票。
你有什么使用网页抓取的好主意吗?您需要有关网页抓取项目的帮助吗?让我们知道!
关于数据科学的其他精彩读物:
什么是决策树
算法如何变得不道德和有偏见
如何开发健壮的算法
数据科学家必须具备的 4 项技能
从: 查看全部
网页表格抓取(洛约拉大学(Loyola)网络研讨会演示如何无需编程即可抓取网页)
有一些编程语言可以简化这个操作,比如 Python。这是因为 Python 提供了 Scrapy 和 BeautifulSoup 等库,它们比传统的网络爬虫更容易抓取和解析 HTML。
但是,它仍然需要适当的设计以及对编程和 网站 架构的良好理解。
假设您的团队没有编程技能。那没问题!我们团队的一名成员最近在洛约拉大学举办了一场网络研讨会,演示如何在没有编程的情况下抓取网页。相反,Google Sheets 提供了一些有用的功能,可以帮助抓取网络数据。如果您想观看我们的在线讲座视频,请点击下方。如果没有,您可以继续阅读并弄清楚如何使用 Google Sheets 来抓取 网站。
Google表格抓取功能
您可以使用 Google Sheets 进行网络抓取的功能有:
所有这些函数都将根据提供给函数 网站 的不同参数来获取。
使用 ImportFeed 进行网络抓取
ImportFeed Google Sheets 功能是更易于使用的功能之一。它只需要访问 Google 表格和 RSS 提要的 URL。这是通常与博客相关联的提要。
例如,您可以使用我们的 RSS 提要“”。
你如何使用这个功能?下面给出一个例子。
"= ImportFeed(" ")
这就是所需要的!还有其他提示和技巧可以帮助清理数据提要,因为您将拥有不止一列信息。目前,这是网络抓取的良好开端。
Google 表格导入功能会更新吗?
所有这些导入功能每 2 小时自动更新一次数据。可设置触发功能,增加更新节奏。但是,这需要更多的编程。
在这种情况下就是这样!从这里开始,这就是您的团队使用它的方式!确保设计一个可靠的数据采集系统。
上图是使用 ImportFeed 函数的示例。
使用 ImportXML 进行网络爬虫
Google 表格中的 ImportXML 函数用于使用 HTML ID 和类提取特定数据点。这需要对 HTML 和解析 XML 有一定的了解。这可能有点令人沮丧。因此,我们逐渐创建了一个 HTML 网络爬虫。
以下是 EventBrite 页面上的一些示例。
去右键单击并检查元素以找到您感兴趣的 HTML 标记。 我们正在寻找
一些文字,所以这是棘手的部分。您需要从这个 HTML 标记中提取的第一部分是类型。相似
,
,等待。您可以使用“//”,然后使用标签名称来调用第一个。例如“// div”、“// a”或“// span”。现在,如果你真的想要“这里有一些文字”,你需要调用课程。这是在步骤 5 中显示的方法中完成的。您会注意到它使用了“// div”和“[@class =“此处为类名”] 的组合。xml 字符串是“// div [@class ='list-card__body']" 你可能想要获取另一个数据值。我们想要获取所有的 URL。这种情况会涉及到想要提取第一个 HTML 标签本身内部的特定值。例如,点击这里。然后就像 step 7.xml字符串为“//a/@href”ImportXML(URL, XML string)ImportXML(“”,“//div[@class='list-card__body']”)
使用此功能的事实是它需要花费大量时间。因此,它需要规划和设计一个好的 Google 工作表,以确保您从使用中获得最大的收益。否则,您的团队最终将花时间维护它而不是研究新事物。像下面的图片
来自 xkcd
使用 ImportHTML 进行网页抓取
最后,我们将讨论 ImportHTML。这将从网页导入表格或列表。例如,如果您想从 网站 中获取收录股票价格的数据,该怎么办。
我们会用。这个页面上有一张表格,上面有过去几天的股票价格。
与过去的功能类似,您需要使用一个 URL。在 URL 的顶部,您必须提及要在页面上抓取的表格。您可以使用可能的数字来完成此操作。
例如,ImportHTML (" ",6 )。这将从上面的链接中删除股票价格。
在上面的视频中,我们还展示了如何将上述股票数据捕获结合到当天有关股市自动收录设备的新闻中。这可以以更复杂的方式使用。该团队可以创建一个算法,使用过去的股票价格和新的 文章 和 Twitter 信息来选择是买入还是卖出股票。
你有什么使用网页抓取的好主意吗?您需要有关网页抓取项目的帮助吗?让我们知道!
关于数据科学的其他精彩读物:
什么是决策树
算法如何变得不道德和有偏见
如何开发健壮的算法
数据科学家必须具备的 4 项技能
从:
网页表格抓取(麒麟采集器采集东方财富网数据的方法(组图)!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 267 次浏览 • 2021-10-02 01:13
本文介绍采集使用麒麟采集器采集东方财富网的方法
采集网站:
#10
使用功能点:
lAjax翻页
l 分页信息抽取
东方财富网:东方财富网致力于打造专业、权威、用户至上的财经媒体。东方财富网网站内容涉及金融、股票、基金、期货、债券、外汇、银行、保险等众多金融资讯和财经资讯,全面覆盖金融领域,更新数十篇每天数以千计的最新数据和信息。为用户提供方便的查询。
东方财富网股票数据采集 说明:本文对东方财富网-行情中心-上涨A股股票数据进行了采集。本文仅以《东方财富网-市场中心-A股数据采集》为例。实际操作过程中,您可以根据自己的需要替换东方财富网其他内容为数据。采集。
东方财富网股票数据采集详细描述:股票编号、股票代码、股票名称、股票相关链接、股票最新价格、股票价格波动、股票振幅、股票交易量、股票交易量、股票昨天收盘, 今日开盘,股价最高,股价最低,股价5分钟内涨跌。
第一步:创建采集任务
进入主界面选择,选择自定义模式
将上述网址的网址复制粘贴到网站输入框中,点击“保存网址”
保存 URL 后,页面将在 Kylin采集器 中打开。红框内的评测信息为本次演示的内容。
第 2 步:创建翻页循环
l 找到翻页按钮,设置翻页周期
l 设置ajax翻页时间
将页面下拉到底部,找到下一页按钮,点击鼠标,在右侧的操作提示框中选择“循环点击下一页”
由于页面使用ajax加载技术,需要对点击元素和翻页步骤设置ajax延迟加载(ajax判断方法:打开流程图,找到翻页循环框,手动执行翻页,看看网站 完成加载)在右侧的高级选项框中,勾选Ajax加载数据,选择合适的超时时间,一般设置为2秒;最后点击确定
注:点击右上角“处理”按钮,显示可视化流程图。
第三步:分页表单信息采集
l 选择需要采集的字段信息,创建采集列表
l编辑采集字段名
移动鼠标选中表格中任意空白信息,点击右键,如图,框内的数据将被选中并变为绿色,点击右侧提示中的“TR”
选中数据当前行的数据将全部选中,点击“选择子元素”
在右侧操作提示框中查看提取的字段,删除不需要的字段,点击“全选”
点击“采集以下数据”
注意:提示框中的字段会出现一个“X”,点击删除该字段。
修改采集任务名称和字段名称,在下方提示中点击“保存并启动采集”
根据采集的情况,选择合适的采集方法,这里选择“启动本地采集”
注意:本地采集占用采集的当前计算机资源,如果采集有时间要求或当前计算机长时间无法执行采集你可以使用云采集功能,云采集在网络采集中进行,不需要当前电脑支持,可以关闭电脑,可以设置多个云节点共享任务。10个节点相当于10台电脑分配任务帮你采集,速度降低到原来的十分之一;采集收到的数据可以在云端存储三个月,随时可以导出。
第四步:数据采集并导出
采集 完成后会弹出提示,选择导出数据
选择合适的导出方式,导出采集好的数据 查看全部
网页表格抓取(麒麟采集器采集东方财富网数据的方法(组图)!!)
本文介绍采集使用麒麟采集器采集东方财富网的方法
采集网站:
#10
使用功能点:
lAjax翻页
l 分页信息抽取
东方财富网:东方财富网致力于打造专业、权威、用户至上的财经媒体。东方财富网网站内容涉及金融、股票、基金、期货、债券、外汇、银行、保险等众多金融资讯和财经资讯,全面覆盖金融领域,更新数十篇每天数以千计的最新数据和信息。为用户提供方便的查询。
东方财富网股票数据采集 说明:本文对东方财富网-行情中心-上涨A股股票数据进行了采集。本文仅以《东方财富网-市场中心-A股数据采集》为例。实际操作过程中,您可以根据自己的需要替换东方财富网其他内容为数据。采集。
东方财富网股票数据采集详细描述:股票编号、股票代码、股票名称、股票相关链接、股票最新价格、股票价格波动、股票振幅、股票交易量、股票交易量、股票昨天收盘, 今日开盘,股价最高,股价最低,股价5分钟内涨跌。
第一步:创建采集任务
进入主界面选择,选择自定义模式
将上述网址的网址复制粘贴到网站输入框中,点击“保存网址”
保存 URL 后,页面将在 Kylin采集器 中打开。红框内的评测信息为本次演示的内容。
第 2 步:创建翻页循环
l 找到翻页按钮,设置翻页周期
l 设置ajax翻页时间
将页面下拉到底部,找到下一页按钮,点击鼠标,在右侧的操作提示框中选择“循环点击下一页”
由于页面使用ajax加载技术,需要对点击元素和翻页步骤设置ajax延迟加载(ajax判断方法:打开流程图,找到翻页循环框,手动执行翻页,看看网站 完成加载)在右侧的高级选项框中,勾选Ajax加载数据,选择合适的超时时间,一般设置为2秒;最后点击确定
注:点击右上角“处理”按钮,显示可视化流程图。
第三步:分页表单信息采集
l 选择需要采集的字段信息,创建采集列表
l编辑采集字段名
移动鼠标选中表格中任意空白信息,点击右键,如图,框内的数据将被选中并变为绿色,点击右侧提示中的“TR”
选中数据当前行的数据将全部选中,点击“选择子元素”
在右侧操作提示框中查看提取的字段,删除不需要的字段,点击“全选”
点击“采集以下数据”
注意:提示框中的字段会出现一个“X”,点击删除该字段。
修改采集任务名称和字段名称,在下方提示中点击“保存并启动采集”
根据采集的情况,选择合适的采集方法,这里选择“启动本地采集”
注意:本地采集占用采集的当前计算机资源,如果采集有时间要求或当前计算机长时间无法执行采集你可以使用云采集功能,云采集在网络采集中进行,不需要当前电脑支持,可以关闭电脑,可以设置多个云节点共享任务。10个节点相当于10台电脑分配任务帮你采集,速度降低到原来的十分之一;采集收到的数据可以在云端存储三个月,随时可以导出。
第四步:数据采集并导出
采集 完成后会弹出提示,选择导出数据
选择合适的导出方式,导出采集好的数据
网页表格抓取( 这是简易数据分析系列第11篇文章(图)Datapreview)
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-10-02 00:01
这是简易数据分析系列第11篇文章(图)Datapreview)
这是简单数据分析系列文章的第十一篇。
原文首发于博客园。
今天我们讲讲如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
%C9%CF%BA%A3&txtDaoDa=%B1%B1%BE%A9
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,这意味着这些列的内容会被默认捕获。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的,加一个空格和一个标点符号就可以了。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
我们把抓到的CSV文件下载下来,在预览器中打开后,会发现出现了车次的数据,但是出发站的数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键词索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样我们就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,和其他标签,这些标签提供了默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本就不是原装正品,自然是无法识别的.
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,也不太适合现代网页的匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。 查看全部
网页表格抓取(
这是简易数据分析系列第11篇文章(图)Datapreview)
这是简单数据分析系列文章的第十一篇。
原文首发于博客园。
今天我们讲讲如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
%C9%CF%BA%A3&txtDaoDa=%B1%B1%BE%A9
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,这意味着这些列的内容会被默认捕获。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的,加一个空格和一个标点符号就可以了。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
我们把抓到的CSV文件下载下来,在预览器中打开后,会发现出现了车次的数据,但是出发站的数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键词索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样我们就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,和其他标签,这些标签提供了默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本就不是原装正品,自然是无法识别的.
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,也不太适合现代网页的匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。
网页表格抓取( Table表格型数据网页结构?用pd._html)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-01 23:26
Table表格型数据网页结构?用pd._html)
最简单的爬虫程序:用熊猫抓取表数据
让我们承认,使用pandas爬行表数据存在一些限制
它仅适用于捕获表数据。让我们先看看什么样的网页符合条件
什么样的网页结构
当您使用浏览器打开网页并使用F12查看其HTML结构时,您会发现合格的网页结构具有一个共同的功能
如果您发现HTML结构采用下表格式,则可以直接使用pandas
...
...
...
...
...
...
...
这看起来并不直观。它开启了北京空气质量的新篇章网站
F12。左边是网页中的质量索引表。其网页结构完全符合表数据网页结构
它非常适合和熊猫一起攀爬
pd.read uhtml()
Pandas提供了read_html(),to_html()两个函数用于读取和写入html格式的文件。这两个函数非常有用。一种是容易地将复杂的数据结构(如dataframe)转换为HTML表;另一个可以在几行代码中获取表数据,而无需复杂的爬虫程序。这是人工制品![1]
特定pd.read uhtml()参数,可以查看其官方文档:
现在直接把刚才的网页打开
import pandas as pd
df = pd.read_html("http://www.air-level.com/air/beijing/", encoding='utf-8',header=0)[0]
这里只添加了几个参数。Header是指定列标题的行。对于guide包,只需要两行代码
df.head()
对比结果表明,成功地获得了表格数据
多表
在最后一个案例中,我不知道我的朋友是否注意到了
pd.read_html()[0]
对于pd.read uhtml()获得网页结果后,添加[0]。这是因为网页上可能有多个表。在这种情况下,需要使用列表的切片表[x]指定要获取的表
例如,在网站中,空气质量排名页面显然由两个表格组成
此时,如果您使用PD。阅读HTML()以获取右侧的表,只需稍加修改即可
import pandas as pd
df = pd.read_html("http://www.air-level.com/rank", encoding='utf-8',header=0)[1]
相反,您可以看到页面右侧的表已成功获取
以上是PD。阅读uhtml()以简单地抓取静态网页。但是我们使用Python的原因是为了提高效率。但是,如果只有一个网页,则鼠标更容易选择复制。因此,Python操作的最大优势将体现在批处理操作上
批量爬网
让我们向您展示如何使用pandas批量抓取Web表数据
以新浪金融机构持股汇总数据为例:
总共有47个页面,47个网页URL是通过for循环构建的,然后是pd.read uuhtml()循环爬网
df = pd.DataFrame()
for i in range(1, 48):
url = f'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jgcg/index.phtml?p={i}'
df = pd.concat([df, pd.read_html(url)[0]]) # 爬取+合并DataFrame
或者几行代码,很容易解决
共获得47页和1738条数据
通过以上小案例,相信您可以轻松掌握熊猫表数据的批量抓取 查看全部
网页表格抓取(
Table表格型数据网页结构?用pd._html)
最简单的爬虫程序:用熊猫抓取表数据
让我们承认,使用pandas爬行表数据存在一些限制
它仅适用于捕获表数据。让我们先看看什么样的网页符合条件
什么样的网页结构
当您使用浏览器打开网页并使用F12查看其HTML结构时,您会发现合格的网页结构具有一个共同的功能
如果您发现HTML结构采用下表格式,则可以直接使用pandas
...
...
...
...
...
...
...
这看起来并不直观。它开启了北京空气质量的新篇章网站
F12。左边是网页中的质量索引表。其网页结构完全符合表数据网页结构
它非常适合和熊猫一起攀爬
pd.read uhtml()
Pandas提供了read_html(),to_html()两个函数用于读取和写入html格式的文件。这两个函数非常有用。一种是容易地将复杂的数据结构(如dataframe)转换为HTML表;另一个可以在几行代码中获取表数据,而无需复杂的爬虫程序。这是人工制品![1]
特定pd.read uhtml()参数,可以查看其官方文档:
现在直接把刚才的网页打开
import pandas as pd
df = pd.read_html("http://www.air-level.com/air/beijing/", encoding='utf-8',header=0)[0]
这里只添加了几个参数。Header是指定列标题的行。对于guide包,只需要两行代码
df.head()
对比结果表明,成功地获得了表格数据
多表
在最后一个案例中,我不知道我的朋友是否注意到了
pd.read_html()[0]
对于pd.read uhtml()获得网页结果后,添加[0]。这是因为网页上可能有多个表。在这种情况下,需要使用列表的切片表[x]指定要获取的表
例如,在网站中,空气质量排名页面显然由两个表格组成
此时,如果您使用PD。阅读HTML()以获取右侧的表,只需稍加修改即可
import pandas as pd
df = pd.read_html("http://www.air-level.com/rank", encoding='utf-8',header=0)[1]
相反,您可以看到页面右侧的表已成功获取
以上是PD。阅读uhtml()以简单地抓取静态网页。但是我们使用Python的原因是为了提高效率。但是,如果只有一个网页,则鼠标更容易选择复制。因此,Python操作的最大优势将体现在批处理操作上
批量爬网
让我们向您展示如何使用pandas批量抓取Web表数据
以新浪金融机构持股汇总数据为例:
总共有47个页面,47个网页URL是通过for循环构建的,然后是pd.read uuhtml()循环爬网
df = pd.DataFrame()
for i in range(1, 48):
url = f'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jgcg/index.phtml?p={i}'
df = pd.concat([df, pd.read_html(url)[0]]) # 爬取+合并DataFrame
或者几行代码,很容易解决
共获得47页和1738条数据
通过以上小案例,相信您可以轻松掌握熊猫表数据的批量抓取
网页表格抓取( WebScraper翻页——控制链接批量数据上篇文章(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-27 18:14
WebScraper翻页——控制链接批量数据上篇文章(图)
)
这是简单数据分析系列文章的第五篇。
原文首发于博客园:Web Scraper页面翻转-控制链接批量抓取数据
在上一篇文章中,我们爬取了豆瓣电影TOP250前25部电影的数据。今天,我们将对原来的 Web Scraper 配置做一些小改动,让爬虫爬取全部 250 部电影数据。
正如我们前面所说,爬虫的本质是寻找规则。这些程序员在设计网页时,肯定会遵循一些规则。当我们找到规则时,我们就可以预测他们的行为并实现我们的目标。
今天我们就来寻找豆瓣网站的规则,想办法把所有的数据都抓到。今天的规则始于经常被忽视的网络链接。
1.链接分析
我们先来看看第一页的豆瓣网址链接:
/top250?start=0&filter=
这显然是一个豆瓣电影网址。Top250,没什么好说的,就是网页的内容。豆瓣前250电影无话可说?后面有个start=0&filter=,按照英文提示,好像是filtering(filter),从0开始(start)
查看第二页上的 URL 链接。前面一样,只是后面的参数变了,变成start=25,从25开始;
我们再看第三页的链接,参数变成start=50,从50开始;
分析这三个环节,我们可以很容易地画出一个模式:
start=0,表示从排名第一的电影开始,播放1-25部电影
start=25,表示从排名第26的电影开始,播放26-50部电影
start=50,表示从排名第51的电影开始,显示第51-75部电影
...
start=225,表示从排名第226的电影开始,显示226-250部电影
只要技术提供支持,很容易找到规律。深入学习,你会发现Web Scraper的操作并不难,但最重要的还是找到规律。
2.Web Scraper 控制链接参数翻页
Web Scraper为这种通过超链接数字分页获取分页数据的网页提供了非常方便的操作,即范围说明符。
例如,您要抓取的网页链接如下所示:
你可以写/page/[1-3],把链接改成这个,Web Scraper会自动抓取这三个网页的内容。
当然,你也可以写/page/[1-100],这样就可以爬取前100个网页。
那么我们之前分析的豆瓣网页呢?它不是从 1 增加到 100,而是 0 -> 25 -> 50 -> 75 以便它每 25 跳一次。我该怎么办?
事实上,这很简单。这种情况可以用[0-100:25]来表示。每25个是一个网页,100/25=4,抓取前4个网页放到豆瓣电影场景中,我们只需要把链接改成如下即可;
/top250?start=[0-225:25]&filter=
这样,Web Scraper 将抓取 TOP250 的所有网页。
3.获取数据
解决链接问题,下一步就是如何在Web Scraper中修改链接。很简单,鼠标点两下:
1. 点击Stiemaps,在新面板中点击ID为top250的那一列数据;
2. 进入新建面板后,找到Stiemap top250 Tab,点击,然后在下拉菜单中点击Edit metadata;
3.修改原网址,图中红框是区别:
修改超链接后,我们就可以再次抓取网页了。操作同上,这里简单重复一下:
单击站点地图 top250 下拉菜单中的抓取按钮。在新操作面板的两个输入框中输入2000。单击开始抓取蓝色按钮开始抓取数据。抓取结束后,点击面板上的蓝色刷新按钮,检测我们抓取的数据。
如果到了这里抓包成功,你会发现已经抓到了所有的数据,但是顺序是乱的。
这里我们不关心顺序问题,因为这属于数据清洗的内容,我们当前的主题是数据捕获。先完成相关知识点,再攻克下一个知识点,是比较合理的学习方式。
本期讲了通过修改超链接来抓取250部电影的名字。下一期我们会讲一些简单易懂的内容来改变你的想法,说说Web Scraper如何导入别人写的爬虫文件,导出自己写的爬虫软件。
参考阅读:
简单的数据分析04 | 网络爬虫第一款抢食豆瓣高分电影
查看全部
网页表格抓取(
WebScraper翻页——控制链接批量数据上篇文章(图)
)
这是简单数据分析系列文章的第五篇。
原文首发于博客园:Web Scraper页面翻转-控制链接批量抓取数据
在上一篇文章中,我们爬取了豆瓣电影TOP250前25部电影的数据。今天,我们将对原来的 Web Scraper 配置做一些小改动,让爬虫爬取全部 250 部电影数据。
正如我们前面所说,爬虫的本质是寻找规则。这些程序员在设计网页时,肯定会遵循一些规则。当我们找到规则时,我们就可以预测他们的行为并实现我们的目标。
今天我们就来寻找豆瓣网站的规则,想办法把所有的数据都抓到。今天的规则始于经常被忽视的网络链接。
1.链接分析
我们先来看看第一页的豆瓣网址链接:
/top250?start=0&filter=
这显然是一个豆瓣电影网址。Top250,没什么好说的,就是网页的内容。豆瓣前250电影无话可说?后面有个start=0&filter=,按照英文提示,好像是filtering(filter),从0开始(start)
查看第二页上的 URL 链接。前面一样,只是后面的参数变了,变成start=25,从25开始;
我们再看第三页的链接,参数变成start=50,从50开始;
分析这三个环节,我们可以很容易地画出一个模式:
start=0,表示从排名第一的电影开始,播放1-25部电影
start=25,表示从排名第26的电影开始,播放26-50部电影
start=50,表示从排名第51的电影开始,显示第51-75部电影
...
start=225,表示从排名第226的电影开始,显示226-250部电影
只要技术提供支持,很容易找到规律。深入学习,你会发现Web Scraper的操作并不难,但最重要的还是找到规律。
2.Web Scraper 控制链接参数翻页
Web Scraper为这种通过超链接数字分页获取分页数据的网页提供了非常方便的操作,即范围说明符。
例如,您要抓取的网页链接如下所示:
你可以写/page/[1-3],把链接改成这个,Web Scraper会自动抓取这三个网页的内容。
当然,你也可以写/page/[1-100],这样就可以爬取前100个网页。
那么我们之前分析的豆瓣网页呢?它不是从 1 增加到 100,而是 0 -> 25 -> 50 -> 75 以便它每 25 跳一次。我该怎么办?
事实上,这很简单。这种情况可以用[0-100:25]来表示。每25个是一个网页,100/25=4,抓取前4个网页放到豆瓣电影场景中,我们只需要把链接改成如下即可;
/top250?start=[0-225:25]&filter=
这样,Web Scraper 将抓取 TOP250 的所有网页。
3.获取数据
解决链接问题,下一步就是如何在Web Scraper中修改链接。很简单,鼠标点两下:
1. 点击Stiemaps,在新面板中点击ID为top250的那一列数据;
2. 进入新建面板后,找到Stiemap top250 Tab,点击,然后在下拉菜单中点击Edit metadata;
3.修改原网址,图中红框是区别:
修改超链接后,我们就可以再次抓取网页了。操作同上,这里简单重复一下:
单击站点地图 top250 下拉菜单中的抓取按钮。在新操作面板的两个输入框中输入2000。单击开始抓取蓝色按钮开始抓取数据。抓取结束后,点击面板上的蓝色刷新按钮,检测我们抓取的数据。
如果到了这里抓包成功,你会发现已经抓到了所有的数据,但是顺序是乱的。
这里我们不关心顺序问题,因为这属于数据清洗的内容,我们当前的主题是数据捕获。先完成相关知识点,再攻克下一个知识点,是比较合理的学习方式。
本期讲了通过修改超链接来抓取250部电影的名字。下一期我们会讲一些简单易懂的内容来改变你的想法,说说Web Scraper如何导入别人写的爬虫文件,导出自己写的爬虫软件。
参考阅读:
简单的数据分析04 | 网络爬虫第一款抢食豆瓣高分电影
网页表格抓取(我正在尝试使用pythin从每个特定的锻炼中抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-24 14:36
我正在尝试使用 pythin 从 网站 获取一些数据。网站 收录许多不同的练习,每个练习都有自己的数据。我已经弄清楚如何从每个特定练习中获取数据,但要做到这一点,我必须在 url 中提供特定的练习 ID。主页上似乎把所有这些练习ID都列在了一个表格中,但是当我使用beautiful Soup搜索html文档时,返回的表格数据如下:
Name
Location
Instructor
Date
OT Points
Total Calories
(kCal)
{{class.class_name}}
{{class.location}}
{{class.trainer}}
{{class.class_date}} at {{class.class_time}}
{{class.points | number:0}}
{{class.CALORIES | number:0}}
如您所见,没有实际文本,但所有信息似乎都是某种变量(我的 html 知识非常有限)。看来我要的信息都是列表:
class.CLASSID
是否可以使用 python 来获取这些信息?或者它使用了一些我无法访问的 api。
任何帮助表示赞赏。 查看全部
网页表格抓取(我正在尝试使用pythin从每个特定的锻炼中抓取数据)
我正在尝试使用 pythin 从 网站 获取一些数据。网站 收录许多不同的练习,每个练习都有自己的数据。我已经弄清楚如何从每个特定练习中获取数据,但要做到这一点,我必须在 url 中提供特定的练习 ID。主页上似乎把所有这些练习ID都列在了一个表格中,但是当我使用beautiful Soup搜索html文档时,返回的表格数据如下:
Name
Location
Instructor
Date
OT Points
Total Calories
(kCal)
{{class.class_name}}
{{class.location}}
{{class.trainer}}
{{class.class_date}} at {{class.class_time}}
{{class.points | number:0}}
{{class.CALORIES | number:0}}
如您所见,没有实际文本,但所有信息似乎都是某种变量(我的 html 知识非常有限)。看来我要的信息都是列表:
class.CLASSID
是否可以使用 python 来获取这些信息?或者它使用了一些我无法访问的 api。
任何帮助表示赞赏。
网页表格抓取( 基于Web文本挖掘的“创客”热词分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-24 14:32
基于Web文本挖掘的“创客”热词分析)
《表7创客吧860网页讨论内容按频度排序的前80个词列表》
图表编号
B666
发布日期
2019.10.01
作者
夏茂森、姜玲玲
研究课题
基于Web文本挖掘的“创客”热词分析
出版单位
安徽财经大学统计与应用数学学院,安徽财经大学会计学院
下载格式
JPG、GIF(包括无水印/未压缩)
图片大小
20KB~2M(取决于下载方式)
自定义格式
Excel、Word、PDF、PPT
媒体
《表7创客吧860网讨论内容按频度排序的前80个词汇表》
预计下载时间:<2 秒图表描述和下载
在基于Web文本挖掘的“创客”热词分析中,与上述类似,基于创客吧860网页的爬取和排序,对网页讨论内容进行相应的文本分析——去除相关停靠点。词、词频统计、具体词云图和按频次排序的前80个词分别如图7和表7所示:
公告:考虑到您可能需要图表的高清原图或源文本的全套PDF,但由于获取多为付费渠道,为了大家的方便,博主会帮忙获取和分享收到相关求助信息后免费下载。五:YGMTBB
下载图表
并得到词频分布。具体词云图和按频次排序的前60个词分别如图3和表3所示...[ 研究课题:基于Web文本挖掘的“创客”热词分析2019.1< @0.01 原文格式:PDF] 《表6创客吧80字列表中860网页讨论话题Top按频率排序》 在创客吧860网页文字抓取整理的基础上,进行相应的文字分析对网页标题进行-基于去除相关停用词,进行词频数据统计,进行具体词云图,按照频度排序的前80个词如图5、@ >6 …[研究课题:基于Web文本挖掘的“创客”热词分析201< @9.10.01 原文格式:PDF] 《表1“哈萨克斯坦-2050”主要内容》 2014年1月17日,纳扎尔巴耶夫在首都阿斯塔纳独立宫发表了一份关于联盟在2050年对哈萨克斯坦的致辞。充分阐述了发展战略的具体任务和实现方法,简称“哈萨克斯坦-2050”。…[研究课题:哈萨克斯坦绿色经济发展研究——基于“丝绸之路经济带”2019.10.01 原文格式:PDF]》表5题名569其他文档 中文按频次排序前60个词的列表“通过发短信给569篇其他类型文档(包括硕士论文、国内会议、学术期刊、专利和年鉴)的标题<
上表“Table 6 Maker Bar 860 网页讨论主题”
下表“表1学术论文简介”(Swa
相关考研图 《表3 522篇特色期刊文献标题按频度排序的前60个词表》夏茂森、姜玲玲《表4 1780篇报纸文献标题按频度排序的前80个词表》夏茂森,江玲玲,“表6创客吧860网讨论话题排名前80的词汇表”夏茂森和江玲玲“表1“哈萨克斯坦-2050”的主要内容“孙欣,杨静”表1 中国知网“夏茂森、姜玲玲”与“创客”相关的文献数量统计表5 其他569篇文献“夏茂森、姜玲玲”标题中按频次排序前60位的词列表表2 2 977“夏茂森、姜玲玲”期刊文章标题前60词按频次排序表3 522篇特色期刊文章标题前60词按频次排序“夏茂森” ,蒋玲玲,《表1 各种内容生产系统特征新旧对比》 刘华强,吴以娜,《表10 不同犯罪思维水平词汇放置数量及比例》张亚辉,卢仲义吴以娜,《表10不同犯罪思维水平词汇放置数量及比例》张亚辉、陆中义吴以娜,《表10不同犯罪思维水平词汇放置数量及比例》张亚辉、陆中义 查看全部
网页表格抓取(
基于Web文本挖掘的“创客”热词分析)
《表7创客吧860网页讨论内容按频度排序的前80个词列表》
图表编号
B666
发布日期
2019.10.01
作者
夏茂森、姜玲玲
研究课题
基于Web文本挖掘的“创客”热词分析
出版单位
安徽财经大学统计与应用数学学院,安徽财经大学会计学院
下载格式
JPG、GIF(包括无水印/未压缩)
图片大小
20KB~2M(取决于下载方式)
自定义格式
Excel、Word、PDF、PPT
媒体
《表7创客吧860网讨论内容按频度排序的前80个词汇表》
预计下载时间:<2 秒图表描述和下载
在基于Web文本挖掘的“创客”热词分析中,与上述类似,基于创客吧860网页的爬取和排序,对网页讨论内容进行相应的文本分析——去除相关停靠点。词、词频统计、具体词云图和按频次排序的前80个词分别如图7和表7所示:
公告:考虑到您可能需要图表的高清原图或源文本的全套PDF,但由于获取多为付费渠道,为了大家的方便,博主会帮忙获取和分享收到相关求助信息后免费下载。五:YGMTBB
下载图表
并得到词频分布。具体词云图和按频次排序的前60个词分别如图3和表3所示...[ 研究课题:基于Web文本挖掘的“创客”热词分析2019.1< @0.01 原文格式:PDF] 《表6创客吧80字列表中860网页讨论话题Top按频率排序》 在创客吧860网页文字抓取整理的基础上,进行相应的文字分析对网页标题进行-基于去除相关停用词,进行词频数据统计,进行具体词云图,按照频度排序的前80个词如图5、@ >6 …[研究课题:基于Web文本挖掘的“创客”热词分析201< @9.10.01 原文格式:PDF] 《表1“哈萨克斯坦-2050”主要内容》 2014年1月17日,纳扎尔巴耶夫在首都阿斯塔纳独立宫发表了一份关于联盟在2050年对哈萨克斯坦的致辞。充分阐述了发展战略的具体任务和实现方法,简称“哈萨克斯坦-2050”。…[研究课题:哈萨克斯坦绿色经济发展研究——基于“丝绸之路经济带”2019.10.01 原文格式:PDF]》表5题名569其他文档 中文按频次排序前60个词的列表“通过发短信给569篇其他类型文档(包括硕士论文、国内会议、学术期刊、专利和年鉴)的标题<
上表“Table 6 Maker Bar 860 网页讨论主题”
下表“表1学术论文简介”(Swa
相关考研图 《表3 522篇特色期刊文献标题按频度排序的前60个词表》夏茂森、姜玲玲《表4 1780篇报纸文献标题按频度排序的前80个词表》夏茂森,江玲玲,“表6创客吧860网讨论话题排名前80的词汇表”夏茂森和江玲玲“表1“哈萨克斯坦-2050”的主要内容“孙欣,杨静”表1 中国知网“夏茂森、姜玲玲”与“创客”相关的文献数量统计表5 其他569篇文献“夏茂森、姜玲玲”标题中按频次排序前60位的词列表表2 2 977“夏茂森、姜玲玲”期刊文章标题前60词按频次排序表3 522篇特色期刊文章标题前60词按频次排序“夏茂森” ,蒋玲玲,《表1 各种内容生产系统特征新旧对比》 刘华强,吴以娜,《表10 不同犯罪思维水平词汇放置数量及比例》张亚辉,卢仲义吴以娜,《表10不同犯罪思维水平词汇放置数量及比例》张亚辉、陆中义吴以娜,《表10不同犯罪思维水平词汇放置数量及比例》张亚辉、陆中义
网页表格抓取(集搜客网络爬虫软件是一款免费的网页数据抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2021-09-21 17:19
内容捕获–您可以从网站捕获内容,以复制依赖于内容的独特产品或服务优势。例如,yelp等产品依赖于评论。竞争对手可以捕获yelp的所有评论,然后将其复制到他们的网站中,使其网站内容公开
Jisoke web crawler软件是一个免费的网页数据捕获工具,它将网页内容转换为excel表格,用于内容分析、文本分析、策略分析和文献分析。自动分词、社交网络分析和情感分析软件用于毕业设计和行业研究
阿里云为您提供了与网站内容捕获工具相关的8933个产品文档和常见问题解答,以及网站无法打开网页该怎么办、计算机网络技术毕业论文、键值存储kvstore、以下哪一个是数据库等云计算产品
当您打开目标文件夹TPTL时,您将获得图像或内容的网站完整数据,其中保存了HTML文件、PHP文件和JavaScript。网络
阿里云为您提供6415网站产品内容以及与免费网站内容抓取工具相关的常见问题。还有网络简单卡、支付宝API扫描码支付接口文档、it远程操作和监控、计算机网络和什么网络协议。p>
如何抓取不同页面类型的数据网站因为有很多内容,我将在本文的下一节详细介绍它。3.筛选表单网页在网站中很常见。这种网页的最大特点是有很多过滤选项,不同的选项将不会加载
获取网站太多数据或抓取太快等因素通常会导致IP被阻止的风险,但我们可以通过使用PHP构建IP地址来获取数据
爬行web内容的一个例子是通过一个程序自动读取其他网站网页上显示的信息,类似于爬行程序。例如,我们有一个 查看全部
网页表格抓取(集搜客网络爬虫软件是一款免费的网页数据抓取工具)
内容捕获–您可以从网站捕获内容,以复制依赖于内容的独特产品或服务优势。例如,yelp等产品依赖于评论。竞争对手可以捕获yelp的所有评论,然后将其复制到他们的网站中,使其网站内容公开
Jisoke web crawler软件是一个免费的网页数据捕获工具,它将网页内容转换为excel表格,用于内容分析、文本分析、策略分析和文献分析。自动分词、社交网络分析和情感分析软件用于毕业设计和行业研究
阿里云为您提供了与网站内容捕获工具相关的8933个产品文档和常见问题解答,以及网站无法打开网页该怎么办、计算机网络技术毕业论文、键值存储kvstore、以下哪一个是数据库等云计算产品
当您打开目标文件夹TPTL时,您将获得图像或内容的网站完整数据,其中保存了HTML文件、PHP文件和JavaScript。网络
阿里云为您提供6415网站产品内容以及与免费网站内容抓取工具相关的常见问题。还有网络简单卡、支付宝API扫描码支付接口文档、it远程操作和监控、计算机网络和什么网络协议。p>
如何抓取不同页面类型的数据网站因为有很多内容,我将在本文的下一节详细介绍它。3.筛选表单网页在网站中很常见。这种网页的最大特点是有很多过滤选项,不同的选项将不会加载
获取网站太多数据或抓取太快等因素通常会导致IP被阻止的风险,但我们可以通过使用PHP构建IP地址来获取数据
爬行web内容的一个例子是通过一个程序自动读取其他网站网页上显示的信息,类似于爬行程序。例如,我们有一个
网页表格抓取(鱼·云采集服务平台网站内容智能抓取实现及实例详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-17 20:00
当您打开目标文件夹TPTL时,您将获得图像或内容的网站完整数据,其中保存了HTML文件、PHP文件和JavaScript。网络
1.打开网站管理员工具,在网络信息查询中找到要抓取的模拟机器人。2.进入您的网站网站,然后单击查询。此时,您的网站将显示在下面。被捕后会发生什么事。3.在web信息查询中,单击web检测以查看您的关键词密度和网站安全性,以及关键词挖掘
阿里云为您提供了与网站内容捕获工具相关的8933个产品文档和常见问题解答,以及网站无法打开网页该怎么办、计算机网络技术毕业论文、键值存储kvstore、以下哪一个是数据库等云计算产品
Web内容智能抓取的实现和示例细节完全基于Java技术、核心技术、核心技术、XML解析、HTML解析、开源组件应用。该应用程序的开源组件包括:Dom4j:parsing xmljericho-
步骤3:提取内容。在以上两个步骤中,我们使用请求从web页面请求数据,并使用BS4解析页面。现在我们进入最关键的一步:
优采云采集器免费网络爬虫\uuuWeb大数据捕获工具
爬虫是一个自动获取网络内容的程序,如搜索引擎、谷歌、百度等。它每天运行一个巨大的爬虫系统,从网站爬到世界各地
优采云·cloud采集service platform网站内容捕获工具使用网络每天生成大量图形数据。我们如何为您和我使用这些数据,以便这些数据能够为我们的工作带来真正的价值 查看全部
网页表格抓取(鱼·云采集服务平台网站内容智能抓取实现及实例详解)
当您打开目标文件夹TPTL时,您将获得图像或内容的网站完整数据,其中保存了HTML文件、PHP文件和JavaScript。网络
1.打开网站管理员工具,在网络信息查询中找到要抓取的模拟机器人。2.进入您的网站网站,然后单击查询。此时,您的网站将显示在下面。被捕后会发生什么事。3.在web信息查询中,单击web检测以查看您的关键词密度和网站安全性,以及关键词挖掘
阿里云为您提供了与网站内容捕获工具相关的8933个产品文档和常见问题解答,以及网站无法打开网页该怎么办、计算机网络技术毕业论文、键值存储kvstore、以下哪一个是数据库等云计算产品
Web内容智能抓取的实现和示例细节完全基于Java技术、核心技术、核心技术、XML解析、HTML解析、开源组件应用。该应用程序的开源组件包括:Dom4j:parsing xmljericho-
步骤3:提取内容。在以上两个步骤中,我们使用请求从web页面请求数据,并使用BS4解析页面。现在我们进入最关键的一步:
优采云采集器免费网络爬虫\uuuWeb大数据捕获工具
爬虫是一个自动获取网络内容的程序,如搜索引擎、谷歌、百度等。它每天运行一个巨大的爬虫系统,从网站爬到世界各地
优采云·cloud采集service platform网站内容捕获工具使用网络每天生成大量图形数据。我们如何为您和我使用这些数据,以便这些数据能够为我们的工作带来真正的价值
网页表格抓取( 如何用Python快速的抓取一个网页中所有表格的爬虫3.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-13 11:13
如何用Python快速的抓取一个网页中所有表格的爬虫3.)
之前在搜索vscode的快捷键时,发现一个页面以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学了Python爬虫,就形成了惯性思维。当我在网页中看到什么更好,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面简单介绍一下我的一些抢表思路和方法。
1.IE浏览器直接导出EXCLE
微软的设计还是很人性化的。以这种方式访问网页上表格中呈现的内容特别方便。我们只需要在页面上右击选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
2.使用Python从网页中抓取表格
接下来就是本文的重点了,我们先直接上代码。
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'https://segmentfault.com/a/1190000007688656'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
tables = soup.select('table')
df_list = []
for table in tables:
df_list.append(pd.concat(pd.read_html(table.prettify())))
df = pd.concat(df_list)
df.to_excel('vscode快捷键大全.xlsx')
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。我以前这样做过,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址即可。
下面简单介绍一下代码的含义:
这样就完成了一个简单的爬虫,爬取一个网页中的所有表格
3.关于选择方法的建议
最后,我想强调的是,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格最好的方法就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样我们就可以把精力集中在学习vscode快捷键上,而不是获取这种形式。
如果,在另一种场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也很重要。
所以,关键是我们要明确自己的目标,根据相应的目标选择最合适的方法。
下一期:下一篇文章我将介绍使用正则表达式从本地统计公报中抓取结构化数据 查看全部
网页表格抓取(
如何用Python快速的抓取一个网页中所有表格的爬虫3.)
之前在搜索vscode的快捷键时,发现一个页面以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学了Python爬虫,就形成了惯性思维。当我在网页中看到什么更好,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面简单介绍一下我的一些抢表思路和方法。
1.IE浏览器直接导出EXCLE
微软的设计还是很人性化的。以这种方式访问网页上表格中呈现的内容特别方便。我们只需要在页面上右击选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
2.使用Python从网页中抓取表格
接下来就是本文的重点了,我们先直接上代码。
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'https://segmentfault.com/a/1190000007688656'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
tables = soup.select('table')
df_list = []
for table in tables:
df_list.append(pd.concat(pd.read_html(table.prettify())))
df = pd.concat(df_list)
df.to_excel('vscode快捷键大全.xlsx')
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。我以前这样做过,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址即可。
下面简单介绍一下代码的含义:
这样就完成了一个简单的爬虫,爬取一个网页中的所有表格
3.关于选择方法的建议
最后,我想强调的是,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格最好的方法就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样我们就可以把精力集中在学习vscode快捷键上,而不是获取这种形式。
如果,在另一种场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也很重要。
所以,关键是我们要明确自己的目标,根据相应的目标选择最合适的方法。
下一期:下一篇文章我将介绍使用正则表达式从本地统计公报中抓取结构化数据
网页表格抓取(爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-11 05:09
)
爬虫是 Python 的一个重要应用。使用 Python 爬虫,我们可以轻松地从互联网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍 Python爬虫的基本流程。如果您还处于初始爬虫阶段或不了解爬虫的具体工作流程,那么您应该仔细阅读本文!
第一步:尝试请求
首先进入b站首页,点击排行榜复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动 Jupyter notebook 并运行以下代码
import requests
url = 'https://www.bilibili.com/ranki ... 39%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第 2 步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换为Web页面结构化数据,因此您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的。
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用时需要开发一个解析器,这里使用的是html.parser。
然后您可以获得结构化元素之一及其属性。例如,您可以使用soup.title.text 来获取页面标题。你也可以使用soup.body、soup.p等来获取任何需要的元素。
第 3 步:提取内容
在上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
现在我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下面的说明找到
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码就可以这样写了
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
在上面的代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取字段信息我们想要的是以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了encoding='utf-8-sig',否则会出现中文乱码的问题。
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码。
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
总结
到此我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都遵循以上四个步骤。
虽然看起来很简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有各种形式的反爬、加密,以及后续的数据分析、提取甚至存储。许多需要进一步探索和学习。
本文之所以选择B站视频热榜,正是因为它足够简单。希望通过这个案例,大家能够了解爬虫的基本过程,最后附上完整的代码。
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranki ... 39%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig') 查看全部
网页表格抓取(爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取
)
爬虫是 Python 的一个重要应用。使用 Python 爬虫,我们可以轻松地从互联网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍 Python爬虫的基本流程。如果您还处于初始爬虫阶段或不了解爬虫的具体工作流程,那么您应该仔细阅读本文!
第一步:尝试请求
首先进入b站首页,点击排行榜复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动 Jupyter notebook 并运行以下代码
import requests
url = 'https://www.bilibili.com/ranki ... 39%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第 2 步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换为Web页面结构化数据,因此您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的。
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用时需要开发一个解析器,这里使用的是html.parser。
然后您可以获得结构化元素之一及其属性。例如,您可以使用soup.title.text 来获取页面标题。你也可以使用soup.body、soup.p等来获取任何需要的元素。
第 3 步:提取内容
在上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
现在我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下面的说明找到
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码就可以这样写了
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
在上面的代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取字段信息我们想要的是以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了encoding='utf-8-sig',否则会出现中文乱码的问题。
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码。
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
总结
到此我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都遵循以上四个步骤。
虽然看起来很简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有各种形式的反爬、加密,以及后续的数据分析、提取甚至存储。许多需要进一步探索和学习。
本文之所以选择B站视频热榜,正是因为它足够简单。希望通过这个案例,大家能够了解爬虫的基本过程,最后附上完整的代码。
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranki ... 39%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
网页表格抓取(Python批量爬取网页数据的文章,让我们一起看看吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-09-11 05:07
我写过一篇关于Python批量抓取网页数据的文章文章。后来发现随着版本的迭代,Excel已经全面支持多页爬取数据了。您无需编码,只需点击几下鼠标即可抓取数据。一起来看看吧~
网页分析
在抓取数据之前,先对网页进行分析。下图是豆瓣TOP250的初始页面。到最底部,一共10页,每页25部电影,一共250部电影。
我们可以依次获取前三个页面的URL,找出它们之间的规则。除了中间的数字外,每个 URL 都相同。编号从 0/25/50 到 25 递增(每页电影的数量),共 10 页。
发现规律后,我们将10页之间的数字存入一个表格中以备将来使用,如下图A列所示,保存以备将来使用。
数据采集
Excel2016及以上版本内嵌网络批量抓取功能(“数据”-“新建查询”-“其他来源”-“来自网络”),案例演示版本未到,所以我下载了A Power BI Desktop(Excel扩展产品),免安装免使用,效果和Excel一样,不用担心不会用,用Excel来操作就可以了。
打开 Power BI Desktop 或 Excel,点击【获取数据】-【网页】(对于 Excel 2016 及以上版本,在“数据”-“新建查询”-“来自其他来源”-“来自网页”)
界面设置:
点击高级后,在 URL 部分,点击“添加组件”。一共有三个盒子。豆瓣TOP250首页网址以数字0分隔,分为三段,分别放在三个框中,如下图:
你会发现在URL预览框中会自动显示完整的URL。点击确定完成设置。
导航界面
之后程序会进入抓数据状态,稍等片刻,跳出“导航”界面。左侧有一个表“表 1”。查看后,右侧显示屏显示了详细数据,在首页首页可以发现是豆瓣TOP250 25部电影;
一共抓取了9个字段,包括序列号、电影名称、评分、评论数量、电影介绍等信息,部分栏目不需要,我们进入Power Query界面删除,以及点击底部的“数据转换”进入Power Query界面。
Power Query 数据编辑
进入Power Query界面后,只会保留序号、评分、电影名称、评论次数四列,其余列将被删除。删除后,四列数据将被重命名。动画显示如下:
设置自定义函数
依次点击【首页】-【高级编辑器】,在弹出的界面中,在字母“let”前输入如下代码:
(p as number) as table =>
然后将第三行代码中的数字["0"]替换为[(Number.ToText(p))],如下图:
(Number.ToText(p))
完成以上两步设置后,点击“确定”,可以发现原来的表1变成了函数样式,fx表1,其中p是函数参数,控件页码,如输入25、可以得到TOP250两页电影列表的数据。
批量调用,批量抓取数据
然后点击【新建源】-【Excel】,选择第一步保存备用Excel表格,导入后点击【添加列】-【调用自定义函数】,下拉函数查询选择【表1】 ,点击确定。
界面会弹出警告框【需要与数据隐私相关的信息】,点击【继续】,勾选【忽略此文件的隐私级别检查】。 ...],点击【保存】后,程序进入页面抓取阶段。
由于爬取的页面较多,程序需要运行一段时间。十多秒后,数据采集完成。总共十页存储在 10 个表中。点击字段【表格1】,勾选【展开】,TOP250信息显示在表格中。
此时数据还在Power Query中,点击【开始】-【关闭并上传】将数据加载到Excel中,完成数据爬取。
总结
我们这些不会编码的人,曾经害怕数据爬行。随着ExcelBI工具的丰富,数据爬取会变得更简单,快来试试吧~
如果您没有更高版本的 Excel,不妨尝试安装 Power BI Desktop。这很方便。您无需注册,只需打开并使用它。您可以从应用商店的 Microsoft 商店下载 Power BI Desktop。 查看全部
网页表格抓取(Python批量爬取网页数据的文章,让我们一起看看吧)
我写过一篇关于Python批量抓取网页数据的文章文章。后来发现随着版本的迭代,Excel已经全面支持多页爬取数据了。您无需编码,只需点击几下鼠标即可抓取数据。一起来看看吧~
网页分析
在抓取数据之前,先对网页进行分析。下图是豆瓣TOP250的初始页面。到最底部,一共10页,每页25部电影,一共250部电影。
我们可以依次获取前三个页面的URL,找出它们之间的规则。除了中间的数字外,每个 URL 都相同。编号从 0/25/50 到 25 递增(每页电影的数量),共 10 页。
发现规律后,我们将10页之间的数字存入一个表格中以备将来使用,如下图A列所示,保存以备将来使用。
数据采集
Excel2016及以上版本内嵌网络批量抓取功能(“数据”-“新建查询”-“其他来源”-“来自网络”),案例演示版本未到,所以我下载了A Power BI Desktop(Excel扩展产品),免安装免使用,效果和Excel一样,不用担心不会用,用Excel来操作就可以了。
打开 Power BI Desktop 或 Excel,点击【获取数据】-【网页】(对于 Excel 2016 及以上版本,在“数据”-“新建查询”-“来自其他来源”-“来自网页”)
界面设置:
点击高级后,在 URL 部分,点击“添加组件”。一共有三个盒子。豆瓣TOP250首页网址以数字0分隔,分为三段,分别放在三个框中,如下图:
你会发现在URL预览框中会自动显示完整的URL。点击确定完成设置。
导航界面
之后程序会进入抓数据状态,稍等片刻,跳出“导航”界面。左侧有一个表“表 1”。查看后,右侧显示屏显示了详细数据,在首页首页可以发现是豆瓣TOP250 25部电影;
一共抓取了9个字段,包括序列号、电影名称、评分、评论数量、电影介绍等信息,部分栏目不需要,我们进入Power Query界面删除,以及点击底部的“数据转换”进入Power Query界面。
Power Query 数据编辑
进入Power Query界面后,只会保留序号、评分、电影名称、评论次数四列,其余列将被删除。删除后,四列数据将被重命名。动画显示如下:
设置自定义函数
依次点击【首页】-【高级编辑器】,在弹出的界面中,在字母“let”前输入如下代码:
(p as number) as table =>
然后将第三行代码中的数字["0"]替换为[(Number.ToText(p))],如下图:
(Number.ToText(p))
完成以上两步设置后,点击“确定”,可以发现原来的表1变成了函数样式,fx表1,其中p是函数参数,控件页码,如输入25、可以得到TOP250两页电影列表的数据。
批量调用,批量抓取数据
然后点击【新建源】-【Excel】,选择第一步保存备用Excel表格,导入后点击【添加列】-【调用自定义函数】,下拉函数查询选择【表1】 ,点击确定。
界面会弹出警告框【需要与数据隐私相关的信息】,点击【继续】,勾选【忽略此文件的隐私级别检查】。 ...],点击【保存】后,程序进入页面抓取阶段。
由于爬取的页面较多,程序需要运行一段时间。十多秒后,数据采集完成。总共十页存储在 10 个表中。点击字段【表格1】,勾选【展开】,TOP250信息显示在表格中。
此时数据还在Power Query中,点击【开始】-【关闭并上传】将数据加载到Excel中,完成数据爬取。
总结
我们这些不会编码的人,曾经害怕数据爬行。随着ExcelBI工具的丰富,数据爬取会变得更简单,快来试试吧~
如果您没有更高版本的 Excel,不妨尝试安装 Power BI Desktop。这很方便。您无需注册,只需打开并使用它。您可以从应用商店的 Microsoft 商店下载 Power BI Desktop。
网页表格抓取(Excel教程Excel函数Excel表格信息快速提取实例(33))
网站优化 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-09-10 04:11
背景要求
先说一下问题的背景:
这个网站可以查看深圳各区的空气质量信息,每小时更新一次。
要求:快速提取并保存里面的表单信息。
Excel可以使用data-from网站这个功能来实现简单的网络表格数据爬取,想必很多朋友应该都知道并使用过。
这个方法对于一些简单的网页还是很实用的。但是对于一些网页,比如pm25.in,上面的方法不是很方便,如下图:
直接选择表格顶部的√,无法导入。
如果直接查看整个页面,会提取出很多除了表格之外的无用信息。
效果演示
所以,在这种情况下,你可以灵活地使用VBA来解决这个问题。
第一个效果:点击“更新”直接提取表格信息
然后点击“保存汇总”,将此时提取的信息保存到汇总表中,以备后续使用。
核心代码
整个过程并不难。抓取表格数据的核心函数代码如下。每一行代码的含义都标在背面。
如果你想换到另一个城市,你只需要改变URL地址即可。
With Sheets(1).QueryTables.Add("URL;http://www.pm25.in/shenzhen", Range("A2")) '抓取网站网页地址
.RefreshStyle = xlOverwriteCells '覆盖模式
.WebFormatting = xlWebFormattingAll '包含全部格式
.WebSelectionType = xlSpecifiedTables '指定table模式
.WebTables = "1" '第1张table
.Refresh False
End With
之后的保存和摘要是一些常规的 VBA 代码。
需要说明的是,此代码仅适用于网页源代码中收录表格数据的网页。
如果对本内容感兴趣,可以在公众号回复“网页表单”获取vba文件试用~~
您可能还想看:
VBA 示例(35) – 一键批量 ppt 到 pdf 转换
VBA 示例(34)–– 快速匹配不同名称的数据
VBA示例(33)--一键提取word中的粗体
VBA 示例(32)-batch 替换隐藏的神秘字符
VBA 示例(31) – VBA 代码的自定义快捷键
VBA 示例(30) - 为多个工作表创建目录和超链接 查看全部
网页表格抓取(Excel教程Excel函数Excel表格信息快速提取实例(33))
背景要求
先说一下问题的背景:
这个网站可以查看深圳各区的空气质量信息,每小时更新一次。
http://www.yhjbox.com/wp-conte ... 3.jpg 300w, http://www.yhjbox.com/wp-conte ... 7.jpg 768w" />要求:快速提取并保存里面的表单信息。
Excel可以使用data-from网站这个功能来实现简单的网络表格数据爬取,想必很多朋友应该都知道并使用过。
http://www.yhjbox.com/wp-conte ... 3.jpg 300w, http://www.yhjbox.com/wp-conte ... 0.jpg 768w" />这个方法对于一些简单的网页还是很实用的。但是对于一些网页,比如pm25.in,上面的方法不是很方便,如下图:
直接选择表格顶部的√,无法导入。
如果直接查看整个页面,会提取出很多除了表格之外的无用信息。
效果演示
所以,在这种情况下,你可以灵活地使用VBA来解决这个问题。
第一个效果:点击“更新”直接提取表格信息
然后点击“保存汇总”,将此时提取的信息保存到汇总表中,以备后续使用。
核心代码
整个过程并不难。抓取表格数据的核心函数代码如下。每一行代码的含义都标在背面。
如果你想换到另一个城市,你只需要改变URL地址即可。
With Sheets(1).QueryTables.Add("URL;http://www.pm25.in/shenzhen", Range("A2")) '抓取网站网页地址
.RefreshStyle = xlOverwriteCells '覆盖模式
.WebFormatting = xlWebFormattingAll '包含全部格式
.WebSelectionType = xlSpecifiedTables '指定table模式
.WebTables = "1" '第1张table
.Refresh False
End With
之后的保存和摘要是一些常规的 VBA 代码。
需要说明的是,此代码仅适用于网页源代码中收录表格数据的网页。
如果对本内容感兴趣,可以在公众号回复“网页表单”获取vba文件试用~~
您可能还想看:
VBA 示例(35) – 一键批量 ppt 到 pdf 转换
VBA 示例(34)–– 快速匹配不同名称的数据
VBA示例(33)--一键提取word中的粗体
VBA 示例(32)-batch 替换隐藏的神秘字符
VBA 示例(31) – VBA 代码的自定义快捷键
VBA 示例(30) - 为多个工作表创建目录和超链接
网页表格抓取(如何快速获取网页中的表格,并且可以实现自动刷新数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-09-10 04:09
大家好,今天给大家分享一下如何快速获取网页中的表格,并且可以自动刷新数据,他的操作也很简单,不多说,直接开始
我们想在网页中获取2020年GDP预测排名的数据,如下图
一、获取数据
首先我们需要新建一个工作簿,打开它,然后点击数据函数组,点击新建查询,然后从其他源中选择,从网站中选择
此时会弹出一个对话框,直接复制要提取数据的URL,然后点击确定。点击确定后,excel会自动连接并计算数据
计算完成后,会进入powerquery的导航界面。导航器左侧的表格图标是excel检测到的表格数据,当我们点击对应的表格名称时,右侧的数据会显示对应的表格,我们可以点击表格找到我们需要的数据想要获取,这里第一个就是我们想要获取的数据,我们直接点击第一个表格然后点击转换数据
二、处理数据
当您点击转换数据时,您将进入powerquery的数据处理界面,我们可以在此对数据进行相应的处理。比如这里我们要按地区计算每个大洲的GDP总量,以人民币为单位
首先我们在start中点击选择分组基准,然后在分组基准中选择区域,然后在新的列名中命名一个名称,我设置计算方式为sum,然后选择所在的列定位到RMB,点击确定。是的
接下来我们点击close and upload to将数据加载到excel中,如下图
如果不想在powerquery中编辑,可以在导航器界面直接点击加载,数据会直接加载到excel中,我们也可以直接在excel中编辑数据,
powerquery处理的数据是可以刷新的,但是不能直接在excel中点击load and processing来刷新数据。刷新数据,我们只需要在数据功能组中点击刷新即可刷新数据 查看全部
网页表格抓取(如何快速获取网页中的表格,并且可以实现自动刷新数据)
大家好,今天给大家分享一下如何快速获取网页中的表格,并且可以自动刷新数据,他的操作也很简单,不多说,直接开始
我们想在网页中获取2020年GDP预测排名的数据,如下图
一、获取数据
首先我们需要新建一个工作簿,打开它,然后点击数据函数组,点击新建查询,然后从其他源中选择,从网站中选择
此时会弹出一个对话框,直接复制要提取数据的URL,然后点击确定。点击确定后,excel会自动连接并计算数据
计算完成后,会进入powerquery的导航界面。导航器左侧的表格图标是excel检测到的表格数据,当我们点击对应的表格名称时,右侧的数据会显示对应的表格,我们可以点击表格找到我们需要的数据想要获取,这里第一个就是我们想要获取的数据,我们直接点击第一个表格然后点击转换数据
二、处理数据
当您点击转换数据时,您将进入powerquery的数据处理界面,我们可以在此对数据进行相应的处理。比如这里我们要按地区计算每个大洲的GDP总量,以人民币为单位
首先我们在start中点击选择分组基准,然后在分组基准中选择区域,然后在新的列名中命名一个名称,我设置计算方式为sum,然后选择所在的列定位到RMB,点击确定。是的
接下来我们点击close and upload to将数据加载到excel中,如下图
如果不想在powerquery中编辑,可以在导航器界面直接点击加载,数据会直接加载到excel中,我们也可以直接在excel中编辑数据,
powerquery处理的数据是可以刷新的,但是不能直接在excel中点击load and processing来刷新数据。刷新数据,我们只需要在数据功能组中点击刷新即可刷新数据

