
网页表格抓取
网页表格抓取(发明专利技术提供一种网页表格数据抽取的方法及实现步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-03-22 22:06
本发明专利技术提供了一种从网页中提取数据的方法,包括:步骤10、读取网页源代码,根据字符码解析成W3C Document对象,得到任意两个网页表单关键词;Step 20、深度优先遍历Document对象中的所有节点,得到两个关键词所属的两个节点;Step 30、 获取具有唯一属性的两个节点的共同父节点,并使用唯一属性获取网页表定位条件;Step 4 0、使用网页表数据定位条件,过滤网页源代码,提取与网页显示效果相同的网页表。
下载所有详细的技术数据
【技术实现步骤总结】
该专利技术涉及网页
,尤其是涉及。
技术介绍
随着网络技术的不断发展,网页的显示效果和所收录的信息量越来越复杂,网页的结构和内容也在实时更新。但是为了从网页中获取指定的表格数据,需要在大量冗长的网页源码中手动查找表格的位置、标签和属性,从而定位到表格对应的源码并获取表格数据。这不仅需要大量的工作,而且浪费时间和精力。同时,在复杂的网页代码中搜索容易出错,不能满足实时数据的要求。W3C是英文World Wide Web Consortium的缩写,中文意思是W3C委员会或万维网联盟。W3C 组织是制定网络标准的非营利组织。HTML、XHTML、CSS 和 XML 等标准由 W3C 定制。现有技术提供了一种基于DOM树的信息抽取过滤方法,来自《中国学术期刊网络出版总库》,发表日期为2009/9/15,来源中国过滤网,描述了A页面预处理方法,将 HTML 解析为 DOM,利用 DOM 树的特性,不仅可以从大的逻辑单元中提取信息,还可以对更小的单元进行操作,完成信息提取中的页面预处理。这大大提高了信息提取的效率和准确性。该方法还提供了三个过滤器,每个过滤器都可以由用户设置,以完成不同程度的过滤,并以适当的顺序选择和堆叠各个过滤器,形成最佳的预处理组合。该方法的目标不是提取细粒度的数据,而是过滤掉网页中杂乱冗余的信息,比如广告、不相关的链接等,即完成对网页中页面的预处理。网页。
技术实现思路
该专利技术要解决的技术问题是,提供从实时变化的网页中准确、快速地提取出与原网页显示效果相同的表格,并获取指定的行/列数据。专利技术就是这样实现的,其特征在于包括以下步骤: 步骤1 0、读取网页源代码,将网页源代码按照字符编码解析为W3C Document对象,获取任意两个网页表单关键词;步骤20、深度优先遍历Document对象中的所有节点,得到第一个关键词所属的第一个节点,以及第二个关键词所属的第二个节点;步骤 3 0、 获取具有唯一属性的第一节点和第二节点的共同父节点,并使用唯一属性获取网页表单定位条件;Step 4 0、 使用网页表单定位条件遍历Document对象,找到满足定位条件的节点,从而定位表格位置,记录每个单元格数据的正确位置以及字体大小和字体颜色属性,提取与原网页显示效果相同的表格,根据表格位置定位表格。表格行/列值过滤,获取要提取的网页表格的指定行/列数据。进一步地,在步骤20中,对Document对象中的所有节点进行深度优先遍历,得到第一个关键词所属的第一个节点,第二个关键词所属的第二个节点,具体步骤21、获取Document对象的根节点root,记为节点;Step 22、 遍历节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,并转至步骤23,否则遍历查找childNode的每个子节点,如果遍历完成后仍没有关键词节点,则返回到childNode的父节点该节点,继续搜索该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。具体步骤21、获取Document对象的根节点root,记为node;Step 22、 遍历节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,并转至步骤23,否则遍历查找childNode的每个子节点,如果遍历完成后仍没有关键词节点,则返回到childNode的父节点该节点,继续搜索该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。具体步骤21、获取Document对象的根节点root,记为node;Step 22、 遍历节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,并转至步骤23,否则遍历查找childNode的每个子节点,如果遍历完成后仍没有关键词节点,则返回到childNode的父节点该节点,继续搜索该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。遍历节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,并转至步骤23,否则遍历查找childNode的每个子节点,如果遍历完成后仍没有关键词节点,则返回到childNode的父节点该节点,继续搜索该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。遍历节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,并转至步骤23,否则遍历查找childNode的每个子节点,如果遍历完成后仍没有关键词节点,则返回到childNode的父节点该节点,继续搜索该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。遍历完成后的节点,则返回该节点的父节点,继续寻找该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。遍历完成后的节点,则返回该节点的父节点,继续寻找该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。
进一步地,步骤30获取具有唯一属性的第一节点和第二节点的共同父节点,并利用唯一属性获取网页表的定位条件,具体步骤31、分别获取第一个节点node1、第二个节点node2的父节点parentNode1、parentNode2,判断是否相同;如果相同则返回parentNode,如果不同则继续代入parentNode1、parentNode2作为参数,递归搜索,直到距离nodel、node2最近的公共父节点parentNode;Step 32、获取parentNode的唯一属性,并利用唯一属性获取网页表定位条件,具体获取父节点的所有标签属性,并判断是否存在唯一属性,如果有唯一属性,则使用该属性获取父节点的定位条件网页表,即定位条件为“tablel^ath=parentNode标签名”的格式,进入步骤40;如果没有唯一属性,则获取parentNode的父节点targetNode,并搜索其唯一属性,递归搜索直到找到具有唯一属性的父节点targetNode或到达Document的根节点;同时,记录搜索过程的路径标签和parentNode在其父节点targetNode中的相对位置,进行拼接/修改,得到网页表定位条件,即定位条件格式为“tabIePath = targetNode标签名称” /path label 1/path label 2/..., or " tabIePath = Document root node/path label 1/path label 2[relative bit 2]/。. ο 该专利技术具有以下优点。该专利技术只需要网页的源代码、要提取的表格中任意两个关键词以及需要的表格行/列值,就可以从网页中提取出真实变化的原创代码时间。网页展示效果相同的表格,通过过滤获取表格的指定行/列数据,
该专利技术不仅简化了网页的抽取方法,提高了数据抽取的灵活性,满足了数据实时性的要求,而且提高了表格数据抽取的准确性。附图说明图。图1为本发明专利技术方法的流程示意图。1、专利技术包括以下步骤: Step 1 0、读取网页源代码,将网页源代码按照字符编码解析成W3C Document对象,获取网页中的信息桌子。任意两个 关键词; Step 2 0、深度优先遍历Document对象中的所有节点,得到第一个关键词所属的第一个节点,以及第二个关键词所属的第一个节点。两个节点;其中,具体步骤21、获取Document对象的根节点root,记为node;Step 22、遍历该节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,执行步骤23,否则遍历childNode的每个子节点,如果遍历完成后仍然没有关键词节点,则返回node的父节点,并继续搜索其余节点的子节点;step 2 3、判断childNode是否收录关键词,如果是则返回childNode,记为关键词所属的节点;否则,继续搜索判断childNode的兄弟节点。Step 30、 获取具有唯一属性的第一个节点和第二个节点的共同父节点,并使用唯一属性获取网页表定位条件;具体为步骤31、获取第一个节点node1、第二个节点node2的父节点parentNode1、parentNode2,判断是否相同;如果相同则返回parentNode,如果不同则继续代入parentNode1、parentNode2作为参数,递归搜索直到得到距离nodel,即node2最近的公共父节点parentNode;第三步< 继续代入parentNode1、parentNode2作为参数,递归搜索,直到得到距离nodel,即node2最近的公共父节点parentNode;第三步< 继续代入parentNode1、parentNode2作为参数,递归搜索,直到得到距离nodel,即node2最近的公共父节点parentNode;第三步<
【技术保护点】
1.一种从网页中提取数据的方法,其特征在于包括以下步骤: 步骤一0、读取网页源代码,将网页源代码解析成Document对象W3C根据字符编码,获取网页形式的数据。任意两个 关键词; Step 2 0、深度优先遍历Document对象中的所有节点,得到第一个关键词所属的第一个节点,以及第二个关键词所属的第一个节点。两个节点;步骤30、获取具有唯一属性的第一节点和第二节点的共同父节点,并使用唯一属性获取网页表定位条件;Step 40、使用网页表格定位条件,遍历Document对象,
【技术特点总结】
【专利技术性质】
技术研发人员:杨帆、黄健雄、林山、
申请人(专利权)持有人:,
类型:发明
国家、省、市:35
下载所有详细的技术数据 我是该专利的所有者 查看全部
网页表格抓取(发明专利技术提供一种网页表格数据抽取的方法及实现步骤)
本发明专利技术提供了一种从网页中提取数据的方法,包括:步骤10、读取网页源代码,根据字符码解析成W3C Document对象,得到任意两个网页表单关键词;Step 20、深度优先遍历Document对象中的所有节点,得到两个关键词所属的两个节点;Step 30、 获取具有唯一属性的两个节点的共同父节点,并使用唯一属性获取网页表定位条件;Step 4 0、使用网页表数据定位条件,过滤网页源代码,提取与网页显示效果相同的网页表。
下载所有详细的技术数据
【技术实现步骤总结】
该专利技术涉及网页
,尤其是涉及。
技术介绍
随着网络技术的不断发展,网页的显示效果和所收录的信息量越来越复杂,网页的结构和内容也在实时更新。但是为了从网页中获取指定的表格数据,需要在大量冗长的网页源码中手动查找表格的位置、标签和属性,从而定位到表格对应的源码并获取表格数据。这不仅需要大量的工作,而且浪费时间和精力。同时,在复杂的网页代码中搜索容易出错,不能满足实时数据的要求。W3C是英文World Wide Web Consortium的缩写,中文意思是W3C委员会或万维网联盟。W3C 组织是制定网络标准的非营利组织。HTML、XHTML、CSS 和 XML 等标准由 W3C 定制。现有技术提供了一种基于DOM树的信息抽取过滤方法,来自《中国学术期刊网络出版总库》,发表日期为2009/9/15,来源中国过滤网,描述了A页面预处理方法,将 HTML 解析为 DOM,利用 DOM 树的特性,不仅可以从大的逻辑单元中提取信息,还可以对更小的单元进行操作,完成信息提取中的页面预处理。这大大提高了信息提取的效率和准确性。该方法还提供了三个过滤器,每个过滤器都可以由用户设置,以完成不同程度的过滤,并以适当的顺序选择和堆叠各个过滤器,形成最佳的预处理组合。该方法的目标不是提取细粒度的数据,而是过滤掉网页中杂乱冗余的信息,比如广告、不相关的链接等,即完成对网页中页面的预处理。网页。
技术实现思路
该专利技术要解决的技术问题是,提供从实时变化的网页中准确、快速地提取出与原网页显示效果相同的表格,并获取指定的行/列数据。专利技术就是这样实现的,其特征在于包括以下步骤: 步骤1 0、读取网页源代码,将网页源代码按照字符编码解析为W3C Document对象,获取任意两个网页表单关键词;步骤20、深度优先遍历Document对象中的所有节点,得到第一个关键词所属的第一个节点,以及第二个关键词所属的第二个节点;步骤 3 0、 获取具有唯一属性的第一节点和第二节点的共同父节点,并使用唯一属性获取网页表单定位条件;Step 4 0、 使用网页表单定位条件遍历Document对象,找到满足定位条件的节点,从而定位表格位置,记录每个单元格数据的正确位置以及字体大小和字体颜色属性,提取与原网页显示效果相同的表格,根据表格位置定位表格。表格行/列值过滤,获取要提取的网页表格的指定行/列数据。进一步地,在步骤20中,对Document对象中的所有节点进行深度优先遍历,得到第一个关键词所属的第一个节点,第二个关键词所属的第二个节点,具体步骤21、获取Document对象的根节点root,记为节点;Step 22、 遍历节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,并转至步骤23,否则遍历查找childNode的每个子节点,如果遍历完成后仍没有关键词节点,则返回到childNode的父节点该节点,继续搜索该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。具体步骤21、获取Document对象的根节点root,记为node;Step 22、 遍历节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,并转至步骤23,否则遍历查找childNode的每个子节点,如果遍历完成后仍没有关键词节点,则返回到childNode的父节点该节点,继续搜索该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。具体步骤21、获取Document对象的根节点root,记为node;Step 22、 遍历节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,并转至步骤23,否则遍历查找childNode的每个子节点,如果遍历完成后仍没有关键词节点,则返回到childNode的父节点该节点,继续搜索该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。遍历节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,并转至步骤23,否则遍历查找childNode的每个子节点,如果遍历完成后仍没有关键词节点,则返回到childNode的父节点该节点,继续搜索该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。遍历节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,并转至步骤23,否则遍历查找childNode的每个子节点,如果遍历完成后仍没有关键词节点,则返回到childNode的父节点该节点,继续搜索该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。遍历完成后的节点,则返回该节点的父节点,继续寻找该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。遍历完成后的节点,则返回该节点的父节点,继续寻找该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。
进一步地,步骤30获取具有唯一属性的第一节点和第二节点的共同父节点,并利用唯一属性获取网页表的定位条件,具体步骤31、分别获取第一个节点node1、第二个节点node2的父节点parentNode1、parentNode2,判断是否相同;如果相同则返回parentNode,如果不同则继续代入parentNode1、parentNode2作为参数,递归搜索,直到距离nodel、node2最近的公共父节点parentNode;Step 32、获取parentNode的唯一属性,并利用唯一属性获取网页表定位条件,具体获取父节点的所有标签属性,并判断是否存在唯一属性,如果有唯一属性,则使用该属性获取父节点的定位条件网页表,即定位条件为“tablel^ath=parentNode标签名”的格式,进入步骤40;如果没有唯一属性,则获取parentNode的父节点targetNode,并搜索其唯一属性,递归搜索直到找到具有唯一属性的父节点targetNode或到达Document的根节点;同时,记录搜索过程的路径标签和parentNode在其父节点targetNode中的相对位置,进行拼接/修改,得到网页表定位条件,即定位条件格式为“tabIePath = targetNode标签名称” /path label 1/path label 2/..., or " tabIePath = Document root node/path label 1/path label 2[relative bit 2]/。. ο 该专利技术具有以下优点。该专利技术只需要网页的源代码、要提取的表格中任意两个关键词以及需要的表格行/列值,就可以从网页中提取出真实变化的原创代码时间。网页展示效果相同的表格,通过过滤获取表格的指定行/列数据,
该专利技术不仅简化了网页的抽取方法,提高了数据抽取的灵活性,满足了数据实时性的要求,而且提高了表格数据抽取的准确性。附图说明图。图1为本发明专利技术方法的流程示意图。1、专利技术包括以下步骤: Step 1 0、读取网页源代码,将网页源代码按照字符编码解析成W3C Document对象,获取网页中的信息桌子。任意两个 关键词; Step 2 0、深度优先遍历Document对象中的所有节点,得到第一个关键词所属的第一个节点,以及第二个关键词所属的第一个节点。两个节点;其中,具体步骤21、获取Document对象的根节点root,记为node;Step 22、遍历该节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,执行步骤23,否则遍历childNode的每个子节点,如果遍历完成后仍然没有关键词节点,则返回node的父节点,并继续搜索其余节点的子节点;step 2 3、判断childNode是否收录关键词,如果是则返回childNode,记为关键词所属的节点;否则,继续搜索判断childNode的兄弟节点。Step 30、 获取具有唯一属性的第一个节点和第二个节点的共同父节点,并使用唯一属性获取网页表定位条件;具体为步骤31、获取第一个节点node1、第二个节点node2的父节点parentNode1、parentNode2,判断是否相同;如果相同则返回parentNode,如果不同则继续代入parentNode1、parentNode2作为参数,递归搜索直到得到距离nodel,即node2最近的公共父节点parentNode;第三步< 继续代入parentNode1、parentNode2作为参数,递归搜索,直到得到距离nodel,即node2最近的公共父节点parentNode;第三步< 继续代入parentNode1、parentNode2作为参数,递归搜索,直到得到距离nodel,即node2最近的公共父节点parentNode;第三步<
【技术保护点】
1.一种从网页中提取数据的方法,其特征在于包括以下步骤: 步骤一0、读取网页源代码,将网页源代码解析成Document对象W3C根据字符编码,获取网页形式的数据。任意两个 关键词; Step 2 0、深度优先遍历Document对象中的所有节点,得到第一个关键词所属的第一个节点,以及第二个关键词所属的第一个节点。两个节点;步骤30、获取具有唯一属性的第一节点和第二节点的共同父节点,并使用唯一属性获取网页表定位条件;Step 40、使用网页表格定位条件,遍历Document对象,
【技术特点总结】
【专利技术性质】
技术研发人员:杨帆、黄健雄、林山、
申请人(专利权)持有人:,
类型:发明
国家、省、市:35
下载所有详细的技术数据 我是该专利的所有者
网页表格抓取(1.Datapreview预览一下数据的分类及应用方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-03-19 20:21
标签: 更多参数 角度 圆弧类型 网站 保存类型 北京成功
这是简易数据分析系列文章的第11期。
今天我们将讨论如何在 Web 表单中捕获数据。首先我们来分析一下网页中的经典表格是如何组成的。
经典的表格都是关于这些知识点的,没了。让我们编写一个简单的表单 Web Scraper 爬虫。
1.创建站点地图
我们今天的练习 网站 是
%C9%CF%BA%A3&txt道达=%B1%B1%BE%A9
爬虫的内容是爬取上海到北京的所有火车时刻表。
我们首先创建一个收录整个表格的容器,并将Type选择为Table,表示我们要抓取表格。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。如果你看一下,你会发现这些数据实际上是表格数据类型的分类。在这种情况下,他列出了火车、出发站和行驶时间的类别。
在表格列类别中,默认勾选每行内容旁边的选择按钮,这意味着默认捕获这些列的内容。如果您不想爬取某种类型的内容,只需去掉相应的复选框即可。
当你点击保存选择器按钮的时候,你会发现Result键的一些选项报错,说invalid format format无效:
解决这个错误非常简单。一般来说,Result 键名的长度是不够的。您可以添加空格和标点符号。如果仍然出现错误,请尝试更改为英文名称:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程抓取数据了。
2.我为什么不建议你使用 Web Scraper 的表格选择器?
如果按照刚才的教程,感觉会很流畅,但是看数据的时候,就傻眼了。
刚开始爬的时候,我们先用Data preview预览数据,发现数据很完美:
抓取数据后,在浏览器的预览面板中预览,会发现trains一栏的数据为null,表示没有抓取到相关内容:
我们下载捕获的CSV文件并在预览器中打开后,我们会发现出现了列车号的数据,但是出发站的数据又为空了!
这不是傻子!
我已经研究这个问题很长时间了。应该是Web Scraper对中文关键词索引的支持不是很友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表数据,可以使用前面的方案,先创建一个Element类型的容器,然后在容器中手动创建一个子选择器,这样就可以避免这个问题了。
以上只是一个原因,另一个原因是,在现代 网站 中,很少有人再使用 HTML 原创表格了。
HTML 为表格提供了基本的标签,例如 、 、 等,这些标签提供了默认样式。优点是互联网刚开发的时候,可以提供开箱即用的形式;缺点是样式过于简单,不易定制。后来很多网站用其他标签来模拟表格,就像PPT用各种大小的块组合成一个表格,很容易自定义:
正因如此,当你使用Table Selector匹配一个表格的时候,可能会匹配不上,因为从Web Scraper的角度来看,你看到的表格是高仿的,根本不是原装的,自然不是。认可。
3.总结
我们不建议直接使用 Web Scraper 的 Table Selector,因为它对中文支持不是很友好,也不太适合现代网页。如果有抢表的需求,可以使用之前创建父子选择器的方法来做。 查看全部
网页表格抓取(1.Datapreview预览一下数据的分类及应用方法(图))
标签: 更多参数 角度 圆弧类型 网站 保存类型 北京成功

这是简易数据分析系列文章的第11期。
今天我们将讨论如何在 Web 表单中捕获数据。首先我们来分析一下网页中的经典表格是如何组成的。

经典的表格都是关于这些知识点的,没了。让我们编写一个简单的表单 Web Scraper 爬虫。
1.创建站点地图
我们今天的练习 网站 是
%C9%CF%BA%A3&txt道达=%B1%B1%BE%A9
爬虫的内容是爬取上海到北京的所有火车时刻表。
我们首先创建一个收录整个表格的容器,并将Type选择为Table,表示我们要抓取表格。

具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。如果你看一下,你会发现这些数据实际上是表格数据类型的分类。在这种情况下,他列出了火车、出发站和行驶时间的类别。

在表格列类别中,默认勾选每行内容旁边的选择按钮,这意味着默认捕获这些列的内容。如果您不想爬取某种类型的内容,只需去掉相应的复选框即可。
当你点击保存选择器按钮的时候,你会发现Result键的一些选项报错,说invalid format format无效:

解决这个错误非常简单。一般来说,Result 键名的长度是不够的。您可以添加空格和标点符号。如果仍然出现错误,请尝试更改为英文名称:

解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程抓取数据了。
2.我为什么不建议你使用 Web Scraper 的表格选择器?
如果按照刚才的教程,感觉会很流畅,但是看数据的时候,就傻眼了。
刚开始爬的时候,我们先用Data preview预览数据,发现数据很完美:

抓取数据后,在浏览器的预览面板中预览,会发现trains一栏的数据为null,表示没有抓取到相关内容:

我们下载捕获的CSV文件并在预览器中打开后,我们会发现出现了列车号的数据,但是出发站的数据又为空了!

这不是傻子!
我已经研究这个问题很长时间了。应该是Web Scraper对中文关键词索引的支持不是很友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表数据,可以使用前面的方案,先创建一个Element类型的容器,然后在容器中手动创建一个子选择器,这样就可以避免这个问题了。
以上只是一个原因,另一个原因是,在现代 网站 中,很少有人再使用 HTML 原创表格了。
HTML 为表格提供了基本的标签,例如 、 、 等,这些标签提供了默认样式。优点是互联网刚开发的时候,可以提供开箱即用的形式;缺点是样式过于简单,不易定制。后来很多网站用其他标签来模拟表格,就像PPT用各种大小的块组合成一个表格,很容易自定义:

正因如此,当你使用Table Selector匹配一个表格的时候,可能会匹配不上,因为从Web Scraper的角度来看,你看到的表格是高仿的,根本不是原装的,自然不是。认可。
3.总结
我们不建议直接使用 Web Scraper 的 Table Selector,因为它对中文支持不是很友好,也不太适合现代网页。如果有抢表的需求,可以使用之前创建父子选择器的方法来做。
网页表格抓取(一个如何解决三个问题?是怎么爬,第二个的数据如何保存 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-17 19:12
)
所谓爬虫,无非就是通过一些特定的程序,访问一些你想访问的网页,并以自定义的方式保存网页上的内容。
这里我们将使用一个C#小程序,对上交所50个手指的实时信息进行爬取。该程序非常简单。
所谓爬虫就是要解决三个问题:一是爬什么,二是怎么爬,三是爬下来的数据怎么保存。根据个人需要和能力水平,方法有很多。
下面,我们将通过具体的例子来说明如何解决上述三个问题。
一、爬什么
你可以抓取任何你想要的数据,但是这些数据是如何在网页中表示和存储的呢?这时候就需要分析我们要爬取的页面的结构了。
在这个例子中,我们要爬取网页中的表格,如下图所示:
下面通过具体代码来说明:
HtmlDocument doc = web.Document;
HtmlElementCollection tbs = doc.GetElementsByTagName("TABLE");//找到table标签
foreach (HtmlElement tb in tbs)//遍历
{
HtmlElementCollection trs = tb.GetElementsByTagName("TR");//每行
foreach (HtmlElement tr in trs)
{
HtmlElementCollection tds = tr.GetElementsByTagName("TD");//每列
if (tds.Count > 0)
{
DataRow dr = dt.NewRow();
for (int i = 0; i < tds.Count; i++)
{
//找到需要的信息列,并将对应的信息填充到dr
dr["序号"] = tds[0].InnerText;
dr["股票代码"] = tds[1].InnerText;
dr["股票简称"] = tds[2].InnerText;
dr["最新价"] = tds[3].InnerText;
dr["涨跌额"] = tds[4].InnerText;
dr["涨跌幅"] = tds[5].InnerText;
dr["换手率"] = tds[13].InnerText;
}
//将dataReader读取的每一行数据保存到datatable中
dt.Rows.Add(dr);
}
}
最后在Form_load中添加如下代码:
dt.Columns.Add("序号", System.Type.GetType("System.String"));
dt.Columns.Add("股票代码", System.Type.GetType("System.String"));
dt.Columns.Add("股票简称", System.Type.GetType("System.String"));
dt.Columns.Add("最新价", System.Type.GetType("System.String"));
dt.Columns.Add("涨跌额", System.Type.GetType("System.String"));
dt.Columns.Add("涨跌幅", System.Type.GetType("System.String"));
dt.Columns.Add("换手率", System.Type.GetType("System.String"));
web.Url = new System.Uri("http://q.10jqka.com.cn/stock/zs/sz50/");//要爬取的网页URL
最终结果如下所示:
查看全部
网页表格抓取(一个如何解决三个问题?是怎么爬,第二个的数据如何保存
)
所谓爬虫,无非就是通过一些特定的程序,访问一些你想访问的网页,并以自定义的方式保存网页上的内容。
这里我们将使用一个C#小程序,对上交所50个手指的实时信息进行爬取。该程序非常简单。
所谓爬虫就是要解决三个问题:一是爬什么,二是怎么爬,三是爬下来的数据怎么保存。根据个人需要和能力水平,方法有很多。
下面,我们将通过具体的例子来说明如何解决上述三个问题。
一、爬什么
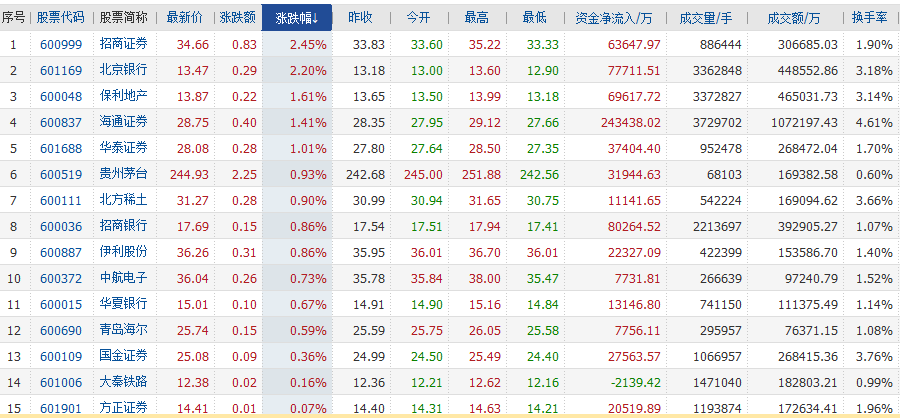
你可以抓取任何你想要的数据,但是这些数据是如何在网页中表示和存储的呢?这时候就需要分析我们要爬取的页面的结构了。
在这个例子中,我们要爬取网页中的表格,如下图所示:
下面通过具体代码来说明:
HtmlDocument doc = web.Document;
HtmlElementCollection tbs = doc.GetElementsByTagName("TABLE");//找到table标签
foreach (HtmlElement tb in tbs)//遍历
{
HtmlElementCollection trs = tb.GetElementsByTagName("TR");//每行
foreach (HtmlElement tr in trs)
{
HtmlElementCollection tds = tr.GetElementsByTagName("TD");//每列
if (tds.Count > 0)
{
DataRow dr = dt.NewRow();
for (int i = 0; i < tds.Count; i++)
{
//找到需要的信息列,并将对应的信息填充到dr
dr["序号"] = tds[0].InnerText;
dr["股票代码"] = tds[1].InnerText;
dr["股票简称"] = tds[2].InnerText;
dr["最新价"] = tds[3].InnerText;
dr["涨跌额"] = tds[4].InnerText;
dr["涨跌幅"] = tds[5].InnerText;
dr["换手率"] = tds[13].InnerText;
}
//将dataReader读取的每一行数据保存到datatable中
dt.Rows.Add(dr);
}
}
最后在Form_load中添加如下代码:
dt.Columns.Add("序号", System.Type.GetType("System.String"));
dt.Columns.Add("股票代码", System.Type.GetType("System.String"));
dt.Columns.Add("股票简称", System.Type.GetType("System.String"));
dt.Columns.Add("最新价", System.Type.GetType("System.String"));
dt.Columns.Add("涨跌额", System.Type.GetType("System.String"));
dt.Columns.Add("涨跌幅", System.Type.GetType("System.String"));
dt.Columns.Add("换手率", System.Type.GetType("System.String"));
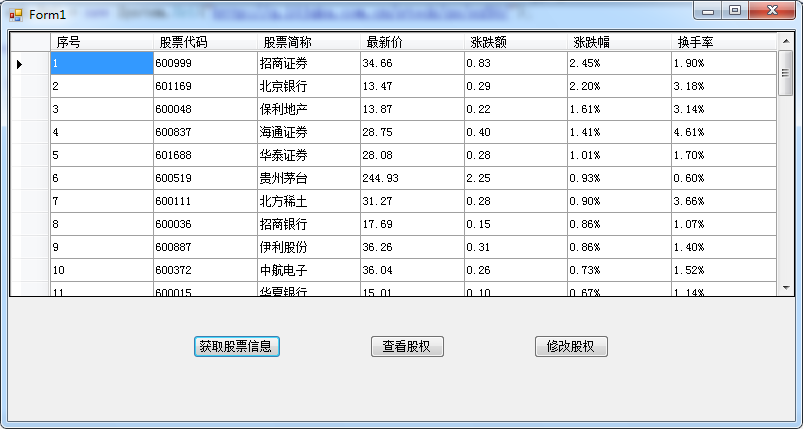
web.Url = new System.Uri("http://q.10jqka.com.cn/stock/zs/sz50/";);//要爬取的网页URL
最终结果如下所示:
网页表格抓取(如何取得网页表格里的数据点击相应的操作?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-17 19:12
目前,一赛奇RPA已经更新到8.0版本,所有用户都可以免费下载试用(复制链接下载)
问题描述
最近很多同学都在问如何获取web表单中的数据?如何根据表格中的数据点击相应的动作?
这两个问题在我们社区其实也有相关的帖子,但是很多人还是问不操作
在实际操作之前,您需要做以下事情:
看看上面两个帖子
了解一些css选择器的知识,我不是专家,这里就不做总结了?也是在百度上搜索信息。每个人也应该培养一些自学的技能。
学习一些审查网页元素的技巧,请参考网页检查/审查技巧
需要了解一些python语言pandas的知识
需求实现声明
好吧,让我们先谈谈要求。我需要在表格中找到产品代码为test120的记录,然后点击对应的删除按钮。下面的截图
所以在解决这个问题的时候,首先是拿到表数据,匹配对应的记录(比如test120),然后找到记录对应的删除按钮点击,这样就可以大致划分了分为两部分,即开头提到的第一和第二个问题的合集。
获取网页表单数据
3.1 领取网页表格
使用pickable组件拾取桌子,这里使用【鼠标点击】组件进行操作
这里需要注意的是,拾取时,要拾取的是整个网页的表格,而不是表格中的某个内容。正确的采摘如下图所示
您还可以通过设计器中的图像预览功能验证您选择的内容是否正确。
3.2 获取web表单的选择器
【鼠标点击】在组件的搜索路径中,选择选择器
7289e87543b148e5b30cbcfa442e6337_E5DA75892CE647CB8DDAE307D2AE570B.png
选择好后编译看看对应的代码
选择器=r'body > DIV:nth-of-type(1) > FORM:nth-of-type(1) > DIV:nth-of-type(2) > DIV: nth-of-type(1) > TABLE:nth-of-type(1)'最后一个 > 后面跟着一个 TABLE 标签,这就是我们想要的。
3.3 获取表中的数据
使用如下代码获取表中的数据,这里不再详述,可以复制使用
可以作为函数或代码块调用
将 ubpa.iie 导入为 iie
重新进口
将熊猫导入为 pd
#将3.2章节selector=后面的代码复制到这里
table_string = iie.get_html(title=r'财务管理',selector=r'body > DIV:nth-of-type(1) > FORM:nth-of-type(1) > DIV: nth-of-type(2) > DIV:nth-of-type(1) > TABLE:nth-of-type(1)')
tb_start = 桩('')
tb_end = 桩('')
last_str = tb_end.sub('', tb_start.sub('', table_string))
#在pandas中调用read_html方法,注意header=0,有些表头不是0
数据 = pd.read_html(last_str, flavor="bs4", header=0)[0]
#此步骤将'product code'列转换为字符串,可以收录None或数字
data['产品代码'] = data['产品代码'].apply(str)
# 打印数据
打印(数据)
打印(' - - - - - - - - - -')
#通过这个可以看到数据有哪些列
打印(数据。列)
其实【鼠标点击】组件的目的是获取web表单的选择器。获取组件后,即可删除组件。
结果如下:
至此,当前web表单中的所有数据已经成功获取,我们要删除的test120的数据记录也在其中
需要注意的是,pandas读出的数据都是dataframe类型的数据集
3.4 过滤和提取数据
使用【数据过滤器】组件对刚刚得到的dataframe类型变量data的数据进行过滤,返回给变量data2
37276cb9b78b4bf08d27f5fd19c6c80c_279E22E4D20E418D847B4D7FB6DCF5AA.png
我们得到了产品代码test120的数据记录
3.5 获取记录的行号
#获取行号,这是一个数组列表,如果有多条记录,列表中会有多个元素
#如果索引中有多个值,也代表多条记录,可以使用循环遍历操作,这里就不赘述了,留给大家
打印(数据2.索引)
#获取数字中的第一个元素单元
打印(数据2.索引[0])
运行结果:
表示这里记录的索引是3
找到记录对应的按钮,点击
4.1 找到模式
通过组件拾取获取组件的选择器并找到规则
先拿起记录test120对应的删除按钮
test120得到的记录的选择器如下
'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(5) > TD:nth-of-type(8) > A:nth-类型(2) > B:nth-of-type(1)'
我们分别获取前三个记录删除按钮的选择器,看看可以遵循哪些规则
#第1⃣️页记录
'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(2) > TD:nth-of-type(8) > A:nth-类型(2) > B:nth-of-type(1)'
#第2⃣️页记录
'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(3) > TD:nth-of-type(8) > A:nth-类型(2) > B:nth-of-type(1)'
#第3⃣️页记录
'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(4) > TD:nth-of-type(8) > A:nth-类型(2) > B:nth-of-type(1)'
#test120 记录
'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(5) > TD:nth-of-type(8) > A:nth-类型(2) > B:nth-of-type(1)'
现在能找到什么?
在这里你会发现 TR:nth-of-type(3) 中的数字是 TR:nth-of-type(2) 中的第 2 条记录发生变化,表示第 n 个- of-type 从 2 开始编号
数据表中test120的索引为3(3.5节)
而对应的删除按钮的 TR:nth-of-type(5) 为 5
那么只要声明一个变量,变量的内容就是index+2,可以把TR:nth-of-type(5)换成变量里面的硬编码值)
4.2 声明变量
根据4.1章节得到的逻辑,先声明一个变量test来存放会变化的值
#在设计器代码窗口中,复制鼠标selector=后面的代码,拾取删除按钮,赋值给测试变量
#可以使用代码块组件来赋值变量
test = r'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(%d) > TD:nth-of-type(8) > A:nth -of-type(2) > B:nth-of-type(1)'%(data2.index[0] + 2)
4.3 鼠标点击删除按钮实现
这一步也是最简单的,只要在【鼠标点击】组件的搜索路径中直接填写测试变量即可
至此,从一个简单的web表单中获取数据,点击对应记录后的按钮操作就完成了。
完全运行后的结果
如果当前页面有多条记录需要删除,则需要使用循环来实现。我这里就不说了,留给学生去做吧。
针对这种场景,我们也会推出操作指导视频和参考项目,但最重要的是让大家自己学习和尝试。? 查看全部
网页表格抓取(如何取得网页表格里的数据点击相应的操作?(图))
目前,一赛奇RPA已经更新到8.0版本,所有用户都可以免费下载试用(复制链接下载)
问题描述
最近很多同学都在问如何获取web表单中的数据?如何根据表格中的数据点击相应的动作?
这两个问题在我们社区其实也有相关的帖子,但是很多人还是问不操作
在实际操作之前,您需要做以下事情:
看看上面两个帖子
了解一些css选择器的知识,我不是专家,这里就不做总结了?也是在百度上搜索信息。每个人也应该培养一些自学的技能。
学习一些审查网页元素的技巧,请参考网页检查/审查技巧
需要了解一些python语言pandas的知识
需求实现声明
好吧,让我们先谈谈要求。我需要在表格中找到产品代码为test120的记录,然后点击对应的删除按钮。下面的截图

所以在解决这个问题的时候,首先是拿到表数据,匹配对应的记录(比如test120),然后找到记录对应的删除按钮点击,这样就可以大致划分了分为两部分,即开头提到的第一和第二个问题的合集。
获取网页表单数据
3.1 领取网页表格
使用pickable组件拾取桌子,这里使用【鼠标点击】组件进行操作
这里需要注意的是,拾取时,要拾取的是整个网页的表格,而不是表格中的某个内容。正确的采摘如下图所示

您还可以通过设计器中的图像预览功能验证您选择的内容是否正确。

3.2 获取web表单的选择器
【鼠标点击】在组件的搜索路径中,选择选择器

7289e87543b148e5b30cbcfa442e6337_E5DA75892CE647CB8DDAE307D2AE570B.png
选择好后编译看看对应的代码

选择器=r'body > DIV:nth-of-type(1) > FORM:nth-of-type(1) > DIV:nth-of-type(2) > DIV: nth-of-type(1) > TABLE:nth-of-type(1)'最后一个 > 后面跟着一个 TABLE 标签,这就是我们想要的。
3.3 获取表中的数据
使用如下代码获取表中的数据,这里不再详述,可以复制使用
可以作为函数或代码块调用
将 ubpa.iie 导入为 iie
重新进口
将熊猫导入为 pd
#将3.2章节selector=后面的代码复制到这里
table_string = iie.get_html(title=r'财务管理',selector=r'body > DIV:nth-of-type(1) > FORM:nth-of-type(1) > DIV: nth-of-type(2) > DIV:nth-of-type(1) > TABLE:nth-of-type(1)')
tb_start = 桩('')
tb_end = 桩('')
last_str = tb_end.sub('', tb_start.sub('', table_string))
#在pandas中调用read_html方法,注意header=0,有些表头不是0
数据 = pd.read_html(last_str, flavor="bs4", header=0)[0]
#此步骤将'product code'列转换为字符串,可以收录None或数字
data['产品代码'] = data['产品代码'].apply(str)
# 打印数据
打印(数据)
打印(' - - - - - - - - - -')
#通过这个可以看到数据有哪些列
打印(数据。列)
其实【鼠标点击】组件的目的是获取web表单的选择器。获取组件后,即可删除组件。
结果如下:

至此,当前web表单中的所有数据已经成功获取,我们要删除的test120的数据记录也在其中
需要注意的是,pandas读出的数据都是dataframe类型的数据集
3.4 过滤和提取数据
使用【数据过滤器】组件对刚刚得到的dataframe类型变量data的数据进行过滤,返回给变量data2

37276cb9b78b4bf08d27f5fd19c6c80c_279E22E4D20E418D847B4D7FB6DCF5AA.png
我们得到了产品代码test120的数据记录
3.5 获取记录的行号
#获取行号,这是一个数组列表,如果有多条记录,列表中会有多个元素
#如果索引中有多个值,也代表多条记录,可以使用循环遍历操作,这里就不赘述了,留给大家
打印(数据2.索引)
#获取数字中的第一个元素单元
打印(数据2.索引[0])
运行结果:

表示这里记录的索引是3
找到记录对应的按钮,点击
4.1 找到模式
通过组件拾取获取组件的选择器并找到规则
先拿起记录test120对应的删除按钮


test120得到的记录的选择器如下
'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(5) > TD:nth-of-type(8) > A:nth-类型(2) > B:nth-of-type(1)'
我们分别获取前三个记录删除按钮的选择器,看看可以遵循哪些规则
#第1⃣️页记录
'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(2) > TD:nth-of-type(8) > A:nth-类型(2) > B:nth-of-type(1)'
#第2⃣️页记录
'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(3) > TD:nth-of-type(8) > A:nth-类型(2) > B:nth-of-type(1)'
#第3⃣️页记录
'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(4) > TD:nth-of-type(8) > A:nth-类型(2) > B:nth-of-type(1)'
#test120 记录
'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(5) > TD:nth-of-type(8) > A:nth-类型(2) > B:nth-of-type(1)'
现在能找到什么?
在这里你会发现 TR:nth-of-type(3) 中的数字是 TR:nth-of-type(2) 中的第 2 条记录发生变化,表示第 n 个- of-type 从 2 开始编号
数据表中test120的索引为3(3.5节)
而对应的删除按钮的 TR:nth-of-type(5) 为 5
那么只要声明一个变量,变量的内容就是index+2,可以把TR:nth-of-type(5)换成变量里面的硬编码值)
4.2 声明变量
根据4.1章节得到的逻辑,先声明一个变量test来存放会变化的值
#在设计器代码窗口中,复制鼠标selector=后面的代码,拾取删除按钮,赋值给测试变量
#可以使用代码块组件来赋值变量
test = r'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(%d) > TD:nth-of-type(8) > A:nth -of-type(2) > B:nth-of-type(1)'%(data2.index[0] + 2)
4.3 鼠标点击删除按钮实现
这一步也是最简单的,只要在【鼠标点击】组件的搜索路径中直接填写测试变量即可

至此,从一个简单的web表单中获取数据,点击对应记录后的按钮操作就完成了。
完全运行后的结果

如果当前页面有多条记录需要删除,则需要使用循环来实现。我这里就不说了,留给学生去做吧。
针对这种场景,我们也会推出操作指导视频和参考项目,但最重要的是让大家自己学习和尝试。?
网页表格抓取(Python表格型数据获取的准确性是需要考虑的因素? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-17 02:04
)
Python 有许多可以捕获数据的包,例如 selenium、requests、scrapy 和 pandas。每个包都有其适用性。我个人认为在抓数据的时候,代码的简洁性和数据获取的准确性是需要考虑的因素。不要太担心时间的速度。毕竟用python来抓数据可以节省不少时间。使用不同的方法可能是 1 秒和 1 分钟之间的差异。我们在日常生活中总是有抓取表格数据的需求。本文尝试用pandas最简洁的代码来抓取表数据。该代码非常简单且易于使用。
只需选择一个页面:
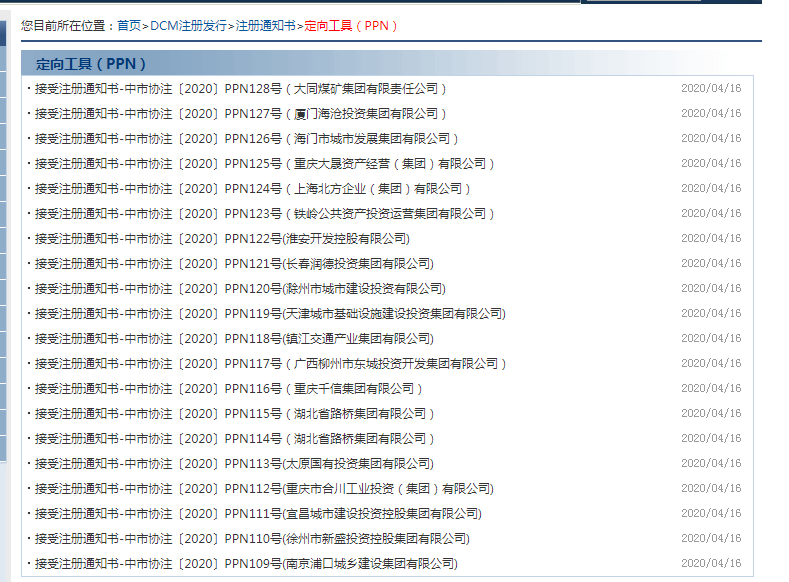
比如爬取下图中定向工具的注册审批文件(当然wind里面有数据,本文只是为了展示如何爬取表格数据)
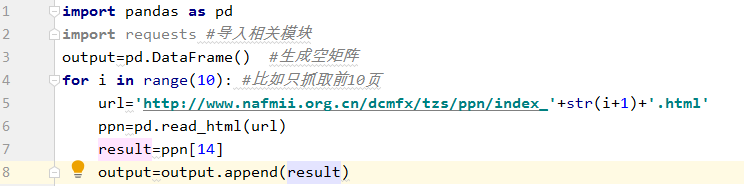
一、爬取当前页面
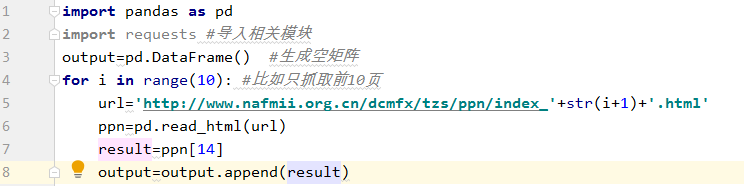
只需要两个密钥代码即可获取它。前两句是导入相关模块,第三句是输入网址,第四句是用pandas读取。由于网页有很多表格,所以会以列表的形式存储在变量ppn中。,点击查看第十四张表格正是我们所需要的。
二、 抓取所有
但是第一部分只抓取第一页,如果要抓取所有页面,也很简单,写个循环就行了。点击下一页可以看到它的 URL 相应地发生了变化:
页码会体现在索引后的数字中,所以可以将url改成变量组合,详见第五句。第一、二句还在导入相关模块,第三句是生成一个空矩阵来存储爬取的结果,第四到第八句是一个简单的循环,每页爬取结果变量。然后将结果连续添加到输出中。最终的输出就是我们想要的结果。
查看全部
网页表格抓取(Python表格型数据获取的准确性是需要考虑的因素?
)
Python 有许多可以捕获数据的包,例如 selenium、requests、scrapy 和 pandas。每个包都有其适用性。我个人认为在抓数据的时候,代码的简洁性和数据获取的准确性是需要考虑的因素。不要太担心时间的速度。毕竟用python来抓数据可以节省不少时间。使用不同的方法可能是 1 秒和 1 分钟之间的差异。我们在日常生活中总是有抓取表格数据的需求。本文尝试用pandas最简洁的代码来抓取表数据。该代码非常简单且易于使用。
只需选择一个页面:
比如爬取下图中定向工具的注册审批文件(当然wind里面有数据,本文只是为了展示如何爬取表格数据)
一、爬取当前页面
只需要两个密钥代码即可获取它。前两句是导入相关模块,第三句是输入网址,第四句是用pandas读取。由于网页有很多表格,所以会以列表的形式存储在变量ppn中。,点击查看第十四张表格正是我们所需要的。

二、 抓取所有
但是第一部分只抓取第一页,如果要抓取所有页面,也很简单,写个循环就行了。点击下一页可以看到它的 URL 相应地发生了变化:
页码会体现在索引后的数字中,所以可以将url改成变量组合,详见第五句。第一、二句还在导入相关模块,第三句是生成一个空矩阵来存储爬取的结果,第四到第八句是一个简单的循环,每页爬取结果变量。然后将结果连续添加到输出中。最终的输出就是我们想要的结果。
网页表格抓取(网页大数据——如何利用互联网收集数据并应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 354 次浏览 • 2022-03-07 23:22
George Gottlob教授是牛津大学计算机科学系数据研究中心主任,也是量化金融研究中心的创始人。他的分享主题是“Web Big Data - How to Get Data and Apply”。
以下为演讲原文
在过去的 10 到 15 年里,数据提取一直是我研究的一个重要领域,今天我将描述如何使用 Internet 来采集数据。
互联网不是数据库
数据存在于我们的日常生活中,数据对当今的发展至关重要。很多人说互联网是最大的数据库,这是不准确的。互联网不是数据库,互联网只是数据的集合。这些数据是非结构化的,非结构化数据以各种形式存在,因此结构化检索是不可能的。
例如,假设我想在网上列出维也纳所有满足一定条件的公寓,条件是他们有阳台,价格低于 50 万美元,附近有很多意大利餐馆,但没有结果在互联网上。因为互联网不是数据库,所以只能搜索数据库。
那么如何将互联网变成一个庞大的数据库呢?数据是结构化的,我们可以创建相应的结构,我们必须为此提取数据。由于今天的时间问题,我不会过多的理论,我会告诉你如何使用它。
一个网页有很多标签,左边展示了网页的结构,但是网页是如何采集信息的呢?我们从标签中得到相应的信息。比如我想采集这个网页上的所有电话号码,网页上会有一个电话号码标记,树形结构上的黄色标记就是电话号码。
此外,还需要研究底层语言和逻辑。对于计算机科学家来说,逻辑非常重要。然后决定你想从网页中挖掘什么样的信息。这些数据记录是一些非常基础的数据源。如果有人想做编程,就需要做这个语言,这个语言可以帮他找到很多网页的特殊性,和其他的网站,属性,图片,JAVA语言都很重要,因此您可以从一种语言跳转到另一种语言。
同时里面有一个逻辑,必须进行可视化处理,同时还需要一个可视化的工具。在设计产品和搜索产品时,有上层和下层,包括大数据、数据库编程和设计。可视化的发展意味着自动化工具可以使挖掘信息的过程更加可视化,并将成为一个自动化的过程。
例如,从 ebay 页面中挖掘相关链接。编程语言如图所示。这些路是单一的数据,表示数据属于哪里,页面数据是什么语言。但是仅仅做这种语言是不够的。我们需要从数万或数百万个页面中爬取和挖掘数据,所以我们将使用云。我们在云中拥有数据,并使用云来做这样的工具。
在数据挖掘方面,我们有本地化的内容挖掘和基于云的内容挖掘。2001 年,我与他人共同创办了一家为客户提供了很多帮助的公司。以下是一些展示数据提取重要性的使用场景。
我们曾经有一些用户是电子产品的零售商。对他们来说,不仅要考虑市场情况,还要考虑竞争对手的情况,包括日常的价格、成本、消费趋势、产品结构信息等。这些数据对他们来说是很难获得的。然而,实现自动数据挖掘是非常重要的。我们得到了一份电子产品清单,该表列出了客户的竞争对手,并且可以显示他们在哪些方面做得更好。因此,客户可以看到可以改进的领域,例如价格或竞争力。
第二个具有代表性的场景是对冲基金。房价指数由国家统计局定期公布。它影响不同行业的股票价格。如果能在国家统计局公布之前预测房价,就可以进行很好的推测。
第三种情况是建筑公司投标。投标人来自世界各地,有关潜在竞争对手的信息既昂贵又不完整。但我们所做的事情对投标人来说是当场的。
全自动数据挖掘
英国有 15,000 多处房产网站,还有少数没有完全覆盖的骨料,这对全自动化挖矿技术的要求很高。因为尽管这些信息很容易获得,但手动或半自动处理数据的成本太高。目前没有完全自动化的采矿工具或技术。所以我和牛津大学的一位教授一起研究固化或形式化的数据挖掘,这样机器就可以自动挖掘数据。
这张图片中的黑点是指向 URL 的链接。这是一个源数据项,我们在其中构建黑盒来更改数据,从数千万页到大型数据集。
上图显示了来自不同来源的两种类型的知识。就像孩子学习知识一样,学校里很多人都会告诉他规则,他学到的就是规则。所以这是从机器学习到基于规则的推理的转变。这对研究人员来说非常重要。右边是通过规则构建的推理,我们将其自动化。有两种类型的规则,标准规则和其他规则。
我们在 2015 年创建了一家公司,为了使用这个系统和规则,我们需要识别和对齐对象、填写表格、块分析和对象丰富以及云支持,以便更有效地提取信息。我们使用上述语言从数千个网页中提取容量信息,规则也需要语言。在二手车、房地产等很多领域都可以实现自动化的数据抽取。如果字段很简单,20天就可以形成相应的规则。但也有一些非常复杂的领域,每个领域都有不同的特点,每个国家都有自己的语言,这些都是需要克服的问题。
当前深耕知识图谱技术
最后介绍一下我们目前的研究工作——知识图谱。知识图谱可以非常清晰地管理大量的知识。它通过识别信息改变了人们的生活,从而形成了一个非常庞大的知识世界。许多公司都追随我们的研究脚步,包括 Facebook、亚马逊等。当然,小公司也希望利用知识图谱来采集员工、客户、竞争对手、价格等信息,从而提高业务质量。
这个知识体系(绿色标记)的核心是推理,其中收录许多规则和许多外部接口。接口之一是外部数据的提取,主要来自互联网。另外有内部知识,数据库之间也有一些关系,可以很方便的接入物联网。事实上,这是一个推理引擎,我们的客户包括中央银行和其他银行。基于此,可以开发许多应用程序,例如信用报告。交易中的欺诈也可以使用基于规则的系统进行检测。它可以用来检测公司贷款的真实性以及是否存在欺诈贷款的倾向。
上图显示了公司的所有权。实际上,公司之间的所有权结构往往非常复杂。该系统可用于理清公司之间的关系,提高公司管理水平。具体可以根据股份数量确定控股公司。此外,如果两家公司共同拥有另一家公司,这些信息很难用SQL进行处理和查询,但使用该方案可以更方便地管理和提高计算速度。 查看全部
网页表格抓取(网页大数据——如何利用互联网收集数据并应用)
George Gottlob教授是牛津大学计算机科学系数据研究中心主任,也是量化金融研究中心的创始人。他的分享主题是“Web Big Data - How to Get Data and Apply”。
以下为演讲原文
在过去的 10 到 15 年里,数据提取一直是我研究的一个重要领域,今天我将描述如何使用 Internet 来采集数据。
互联网不是数据库
数据存在于我们的日常生活中,数据对当今的发展至关重要。很多人说互联网是最大的数据库,这是不准确的。互联网不是数据库,互联网只是数据的集合。这些数据是非结构化的,非结构化数据以各种形式存在,因此结构化检索是不可能的。
例如,假设我想在网上列出维也纳所有满足一定条件的公寓,条件是他们有阳台,价格低于 50 万美元,附近有很多意大利餐馆,但没有结果在互联网上。因为互联网不是数据库,所以只能搜索数据库。
那么如何将互联网变成一个庞大的数据库呢?数据是结构化的,我们可以创建相应的结构,我们必须为此提取数据。由于今天的时间问题,我不会过多的理论,我会告诉你如何使用它。
一个网页有很多标签,左边展示了网页的结构,但是网页是如何采集信息的呢?我们从标签中得到相应的信息。比如我想采集这个网页上的所有电话号码,网页上会有一个电话号码标记,树形结构上的黄色标记就是电话号码。
此外,还需要研究底层语言和逻辑。对于计算机科学家来说,逻辑非常重要。然后决定你想从网页中挖掘什么样的信息。这些数据记录是一些非常基础的数据源。如果有人想做编程,就需要做这个语言,这个语言可以帮他找到很多网页的特殊性,和其他的网站,属性,图片,JAVA语言都很重要,因此您可以从一种语言跳转到另一种语言。
同时里面有一个逻辑,必须进行可视化处理,同时还需要一个可视化的工具。在设计产品和搜索产品时,有上层和下层,包括大数据、数据库编程和设计。可视化的发展意味着自动化工具可以使挖掘信息的过程更加可视化,并将成为一个自动化的过程。
例如,从 ebay 页面中挖掘相关链接。编程语言如图所示。这些路是单一的数据,表示数据属于哪里,页面数据是什么语言。但是仅仅做这种语言是不够的。我们需要从数万或数百万个页面中爬取和挖掘数据,所以我们将使用云。我们在云中拥有数据,并使用云来做这样的工具。
在数据挖掘方面,我们有本地化的内容挖掘和基于云的内容挖掘。2001 年,我与他人共同创办了一家为客户提供了很多帮助的公司。以下是一些展示数据提取重要性的使用场景。
我们曾经有一些用户是电子产品的零售商。对他们来说,不仅要考虑市场情况,还要考虑竞争对手的情况,包括日常的价格、成本、消费趋势、产品结构信息等。这些数据对他们来说是很难获得的。然而,实现自动数据挖掘是非常重要的。我们得到了一份电子产品清单,该表列出了客户的竞争对手,并且可以显示他们在哪些方面做得更好。因此,客户可以看到可以改进的领域,例如价格或竞争力。
第二个具有代表性的场景是对冲基金。房价指数由国家统计局定期公布。它影响不同行业的股票价格。如果能在国家统计局公布之前预测房价,就可以进行很好的推测。
第三种情况是建筑公司投标。投标人来自世界各地,有关潜在竞争对手的信息既昂贵又不完整。但我们所做的事情对投标人来说是当场的。
全自动数据挖掘
英国有 15,000 多处房产网站,还有少数没有完全覆盖的骨料,这对全自动化挖矿技术的要求很高。因为尽管这些信息很容易获得,但手动或半自动处理数据的成本太高。目前没有完全自动化的采矿工具或技术。所以我和牛津大学的一位教授一起研究固化或形式化的数据挖掘,这样机器就可以自动挖掘数据。
这张图片中的黑点是指向 URL 的链接。这是一个源数据项,我们在其中构建黑盒来更改数据,从数千万页到大型数据集。
上图显示了来自不同来源的两种类型的知识。就像孩子学习知识一样,学校里很多人都会告诉他规则,他学到的就是规则。所以这是从机器学习到基于规则的推理的转变。这对研究人员来说非常重要。右边是通过规则构建的推理,我们将其自动化。有两种类型的规则,标准规则和其他规则。
我们在 2015 年创建了一家公司,为了使用这个系统和规则,我们需要识别和对齐对象、填写表格、块分析和对象丰富以及云支持,以便更有效地提取信息。我们使用上述语言从数千个网页中提取容量信息,规则也需要语言。在二手车、房地产等很多领域都可以实现自动化的数据抽取。如果字段很简单,20天就可以形成相应的规则。但也有一些非常复杂的领域,每个领域都有不同的特点,每个国家都有自己的语言,这些都是需要克服的问题。
当前深耕知识图谱技术
最后介绍一下我们目前的研究工作——知识图谱。知识图谱可以非常清晰地管理大量的知识。它通过识别信息改变了人们的生活,从而形成了一个非常庞大的知识世界。许多公司都追随我们的研究脚步,包括 Facebook、亚马逊等。当然,小公司也希望利用知识图谱来采集员工、客户、竞争对手、价格等信息,从而提高业务质量。
这个知识体系(绿色标记)的核心是推理,其中收录许多规则和许多外部接口。接口之一是外部数据的提取,主要来自互联网。另外有内部知识,数据库之间也有一些关系,可以很方便的接入物联网。事实上,这是一个推理引擎,我们的客户包括中央银行和其他银行。基于此,可以开发许多应用程序,例如信用报告。交易中的欺诈也可以使用基于规则的系统进行检测。它可以用来检测公司贷款的真实性以及是否存在欺诈贷款的倾向。
上图显示了公司的所有权。实际上,公司之间的所有权结构往往非常复杂。该系统可用于理清公司之间的关系,提高公司管理水平。具体可以根据股份数量确定控股公司。此外,如果两家公司共同拥有另一家公司,这些信息很难用SQL进行处理和查询,但使用该方案可以更方便地管理和提高计算速度。
网页表格抓取(用excel很难,通过vba编程难度较大,并且数据量不大)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-03-07 08:24
用excel比较难,通过vba编程比较困难,数据量不大。
它可以通过网络蜘蛛通过设置下载。
留个邮箱,我已经下载了,发给你了。
我是通过专门的爬虫程序ninidown下载的。没有代码。只要设置好选项,我就可以下载,但是设置过程极其复杂。而且ninidown的bug很多,调试了差不多3个小时,这个方法不通用。
这个问题没有很好理解。是不是这样:
例子:
Excel工作簿中有两个工作表“Sheet1”和“Sheet2”;当在“Sheet2”的单元格A1中输入项目名称时,工作表“Sheet1”的单元格B1显示相同的名称;其工作表“Sheet1 中的单元格 B1”是对“Sheet2”中的单元格 A1 的引用,其公式应为“=Sheet2!A1”。
你可以在没有 VBA 的情况下做到这一点。
EXCEL本身有数据导入功能
03版本是data-import-from网站
07 版本是数据 - 因为 网站
不知道大家有没有用过,打开网站点击网页上的箭头变成√,然后点击导入。
Web数据可以导入EXCEL表格,打开时自动更新,之后指定时间自动更新。
所以,你只需要设置EXCEL表格,然后在定时任务中添加一个定时器即可打开。
如果不知道提取是什么意思,是指在客户端页面上提取表格吗?这可以完全完成。如果客户端页面中的表格也是直接连接EXCEL显示的,也是可以的,但是如果是后台用SQL语言查询的东西,会发送到客户端页面。如果要提取别人的库,那是不可能的。
如何实现EXCEL自动提取网站中的数据,并将数据累加增加保存-
如何实现EXCEL自动提取网站中的数据
如何实现EXCEL自动提取网站中的数据-...... 用excel比较难,通过vba编程比较难,数据量不大。可以通过设置通过网络蜘蛛下载。留个邮箱,我已经下载了,发给你。
如何实现EXCEL自动提取网站中的数据。- ......其实Excel很好,你只需要输入网址,然后双击单元格,然后看,这个单元格中的网址就变成了一个链接。
EXCEL表格如何自动获取网页数据?- …… excel-数据-导入外部数据-新建网页查询-在对话框中输入网址-输入-选择内容-点击右下角导入-在“数据区属性”中进行设置。
如何实现EXCEL自动定时抽取网站中的数据,并将每次采集到的数据累加向下递增保存。……哇?问题,你必须确保你的文件格式可以被vba的文件读写函数读取。此外,您将创建一个非常大的 Excel,它太大且不稳定。为什么不设置成自动导入到sql数据库中呢?
EXCEL自动提取网页的具体数据...在工具栏中设置链接表=>数据,将网页表导入excel进行处理或VBADim myQuery With ActiveSheet .Cells.Delete .[a1] = "Conneting, Please Wait ..." Set myQuery = ActiveSheet.QueryTables _ .Add(Connection:="URL;URL", _ Destination:=.Cells(1, 1)) 以 myQuery 结束 .Refresh 以
excel如何自动获取网页中的数值--……数据--导入外部数据--新建网页数据--输入数值页所说的URL,然后选择要导入的表格。选择刷新。可以编辑、重新处理等,可以试试
如何让excel自动搜索网页并导出需要的信息?- ...... 这是不可能的。“导出到Excel”是Excel为IE制作的插件添加的菜单项,Word不提供此类插件。但是,如果您使用的是Office2007,并且在安装过程中选择安装OneNote产品,IE工具栏上会多出一个“发送到OneNote”按钮。单击此按钮后,将发送当前网页上的所有图像。将文本内容发送到 OneNote 中的新页面。这个 OneNote 是一个非常方便的工具来记录/组织/共享您的笔记(图像/文本/多媒体)。
如何从07excel中列出的网站中自动获取每个网页中特定位置的信息,并自动抓取到excel中-... Sub 提取网页信息() Dim IE As Object, srg$, brr( 1 To 5) Set IE = CreateObject("Microsoft.XMLHTTP") For i = 1 To 5 a = Right(Cells(i, 1).Value, 9) With IE .Open "get" , "" & a, False .send srg = .... 查看全部
网页表格抓取(用excel很难,通过vba编程难度较大,并且数据量不大)
用excel比较难,通过vba编程比较困难,数据量不大。
它可以通过网络蜘蛛通过设置下载。
留个邮箱,我已经下载了,发给你了。
我是通过专门的爬虫程序ninidown下载的。没有代码。只要设置好选项,我就可以下载,但是设置过程极其复杂。而且ninidown的bug很多,调试了差不多3个小时,这个方法不通用。
这个问题没有很好理解。是不是这样:
例子:
Excel工作簿中有两个工作表“Sheet1”和“Sheet2”;当在“Sheet2”的单元格A1中输入项目名称时,工作表“Sheet1”的单元格B1显示相同的名称;其工作表“Sheet1 中的单元格 B1”是对“Sheet2”中的单元格 A1 的引用,其公式应为“=Sheet2!A1”。
你可以在没有 VBA 的情况下做到这一点。
EXCEL本身有数据导入功能
03版本是data-import-from网站
07 版本是数据 - 因为 网站
不知道大家有没有用过,打开网站点击网页上的箭头变成√,然后点击导入。
Web数据可以导入EXCEL表格,打开时自动更新,之后指定时间自动更新。
所以,你只需要设置EXCEL表格,然后在定时任务中添加一个定时器即可打开。
如果不知道提取是什么意思,是指在客户端页面上提取表格吗?这可以完全完成。如果客户端页面中的表格也是直接连接EXCEL显示的,也是可以的,但是如果是后台用SQL语言查询的东西,会发送到客户端页面。如果要提取别人的库,那是不可能的。
如何实现EXCEL自动提取网站中的数据,并将数据累加增加保存-
如何实现EXCEL自动提取网站中的数据
如何实现EXCEL自动提取网站中的数据-...... 用excel比较难,通过vba编程比较难,数据量不大。可以通过设置通过网络蜘蛛下载。留个邮箱,我已经下载了,发给你。
如何实现EXCEL自动提取网站中的数据。- ......其实Excel很好,你只需要输入网址,然后双击单元格,然后看,这个单元格中的网址就变成了一个链接。
EXCEL表格如何自动获取网页数据?- …… excel-数据-导入外部数据-新建网页查询-在对话框中输入网址-输入-选择内容-点击右下角导入-在“数据区属性”中进行设置。
如何实现EXCEL自动定时抽取网站中的数据,并将每次采集到的数据累加向下递增保存。……哇?问题,你必须确保你的文件格式可以被vba的文件读写函数读取。此外,您将创建一个非常大的 Excel,它太大且不稳定。为什么不设置成自动导入到sql数据库中呢?
EXCEL自动提取网页的具体数据...在工具栏中设置链接表=>数据,将网页表导入excel进行处理或VBADim myQuery With ActiveSheet .Cells.Delete .[a1] = "Conneting, Please Wait ..." Set myQuery = ActiveSheet.QueryTables _ .Add(Connection:="URL;URL", _ Destination:=.Cells(1, 1)) 以 myQuery 结束 .Refresh 以
excel如何自动获取网页中的数值--……数据--导入外部数据--新建网页数据--输入数值页所说的URL,然后选择要导入的表格。选择刷新。可以编辑、重新处理等,可以试试
如何让excel自动搜索网页并导出需要的信息?- ...... 这是不可能的。“导出到Excel”是Excel为IE制作的插件添加的菜单项,Word不提供此类插件。但是,如果您使用的是Office2007,并且在安装过程中选择安装OneNote产品,IE工具栏上会多出一个“发送到OneNote”按钮。单击此按钮后,将发送当前网页上的所有图像。将文本内容发送到 OneNote 中的新页面。这个 OneNote 是一个非常方便的工具来记录/组织/共享您的笔记(图像/文本/多媒体)。
如何从07excel中列出的网站中自动获取每个网页中特定位置的信息,并自动抓取到excel中-... Sub 提取网页信息() Dim IE As Object, srg$, brr( 1 To 5) Set IE = CreateObject("Microsoft.XMLHTTP") For i = 1 To 5 a = Right(Cells(i, 1).Value, 9) With IE .Open "get" , "" & a, False .send srg = ....
网页表格抓取(技术一种可配置化的数据解析方法和网页解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-07 08:18
本发明专利技术涉及一种可配置的数据解析方法,包括以下步骤:解析配置;现场配置;创建空白逻辑表,并将各个字段名写入空白逻辑表;抓取URL对应的URL 对于目标网页,根据解析类型和解析属性提取数据对象,然后依次映射到逻辑表中,与字段名形成对应关系,从而转换目标网页结构化数据文本。本发明的专利技术是一种可配置的数据解析方法。通过配置解析表,可以灵活处理不同格式的网页,完成网页解析,将网页数据转化为结构化数据文本,
一种可配置的数据分析方法和计算机可读存储介质
下载所有详细的技术数据
【技术实现步骤总结】
一种可配置的数据解析方法及计算机可读存储介质
本专利技术涉及一种可配置的数据分析方法及计算机可读存储介质,属于互联网数据爬取领域。
技术介绍
互联网上的信息复杂,信息的类型和表达方式多种多样。显示的信息只是为了方便用户浏览,不是统一的结构化数据显示,所以不考虑机器识别。但是,由于计算机不具备自然语言或类人阅读能力,互联网网页的信息载体所显示的信息不易被计算机识别和分析。在过去的IT技术发展中,积累了大量基于结构化数据的挖掘和分析技术。对于从互联网上抓取的网页的非结构化数据,我们需要先将其从结构化数据中进行转换,以方便机器学习。标识,以方便后续业务单位使用。公开号为CN108959539A的专利技术专利《一种基于规则的可配置网页数据分析方法》公开了网页分析方法如下: S3.网页分析:获取Web中任务配置配置的分析信息,获取采集网页的列表信息进行数据解析,通过Python的BeautifulSoup库解析页面;解析时,根据页面上配置的HTML标签,按标签类型和值提取数据及相关标签;解析结束然后,将数据存入数据库。公开的技术方案使用Python的BeautifulSoup库来解析页面文本数据,但是这种方法有以下两个缺点:1、Python的BeautifulSoup库只能解析HTML或XML格式的文件,并且支持的类型有限,比如不能支持Json格式的网页进行解析;2、Python的BeautifulSoup库是一种封装模式,而对于不同格式的网页一、,它对网页的灵活性有明显的适应作用还不够,尤其是对于一些非常规的特殊处理的网页,或者当用户选择性地过滤过滤相关数据时,封装模式似乎不合适。
技术实现思路
为了解决上述技术问题,专利技术提供了一种可配置的数据分析方法,将捕获的目标网页转换为标准化的结构化数据文本,便于信息的应用和挖掘。该专利技术的第一个技术方案如下:一种可配置的数据解析方法,包括以下步骤:创建解析配置页面,并配置URL、解析类型、解析属性以及保存数据的逻辑表名称解析结果,配置完成后选择提交保存;解析属性包括解析区域和行定位信息,或者解析属性只包括行定位信息;创建一个新的字段配置页面,并在字段配置页面配置必填字段提取的数据对象对应的字段名称;根据逻辑表名称创建一个空白逻辑表,并将每个字段名称写入空白逻辑表;抓取URL对应的目标网页,根据分析类型和分析属性提取数据对象,具体步骤如下:根据解析区域定位待提取数据对象所在区域,然后定位根据行定位信息,从解析区域中提取出待提取数据对象所在的行区域,从这些行中一一提取数据对象,然后依次映射到逻辑表中,与数据对象形成对应关系字段名称,从而将目标网页转换为结构化数据文本;或者只根据行定位信息区域定位待提取数据对象所在的行,从这些行中逐一提取数据对象,然后依次映射到逻辑表中,与字段名称,从而将目标网页转换为结构化数据文本。
更优选地,字段配置还包括配置字段标识,数据分析方法执行以下步骤:新建分析配置页面,配置待爬取目标网页的URL、分析类型、分析属性、以及分析配置页面的分析配置页面信息。保存解析结果的逻辑表名称,配置完成后选择提交保存;解析属性包括解析区域和行定位信息,或者解析属性只包括行定位信息;新建一个字段配置页面,在字段配置页面配置需要的字段提取的数据对象对应的字段名称;根据逻辑表名称创建空白逻辑表,并在空白逻辑表中写入字段名称和对应的字段标识;抓取该URL对应的目标网页,根据解析类型和解析属性提取数据对象,具体步骤如下:根据解析区域定位要提取的数据对象所在的区域,然后根据行定位信息在解析区域中定位待提取数据对象所在的行区域,读取字段配置信息中的字段标识,定位这些行中的字段标识,字段标识对应的属性值是要提取的数据对象,并将提取的字段标识符对应的数据对象写入字段名的取值范围内,依次类推,将解析区的所有字段标识符一一遍历,将所有要提取的数据对象写入逻辑表,并与字段名形成对应关系,从而转换目标网页或根据行定位信息定位待提取数据对象所在行区域,从字段配置信息中读取字段标识,定位这些行中的字段标识符,与字段标识符对应的属性值就是要提取的数据对象。将提取的数据对象写入到字段标识对应的字段名的value字段中,以此类推,一一遍历所有的字段标识,并写入所有需要提取的数据对象。进入逻辑表,并与字段名称形成对应关系,从而将目标网页转换为结构化的数据文本。
更优选地,分析区域的配置包括表格区域标识、表格起始索引和表格结束索引,根据表格起始索引定位分析区域开头的表格区域标识位置,表格区域根据表尾索引定位分析区域的末尾。确定位置。更优选地,行定位信息包括行区域标识、行起始索引和行结束索引,根据行起始索引定位解析区域开头的表区域标识位置,行区域标识位于根据行停止索引定位解析区域的末端。地点。更优选地,目标网页的解析类型为HTMLBYHEAD,解析属性还包括标题定位信息,标题定位信息包括标题行标识、标题行索引和标题列标识,HTMLBYHEAD A类型为在着陆页的表格上方有标题的页面。本专利技术还提供了一种计算机可读存储介质。本专利技术方案二是一种计算机可读存储介质,其上存储有计算机程序,当该程序被处理器执行时,执行以下步骤:创建新的解析配置页面,以及在解析配置页面URL、解析类型、解析属性和用于保存解析结果的逻辑表的名称上配置要爬取的目标网页,完成后提交;解析属性包括解析区域和行定位信息,或者解析属性只包括行定位信息;新建字段配置页面,在字段配置页面配置逻辑表中每个字段的字段名,每个字段名对应要提取的数据对象;根据逻辑表名创建空白逻辑表,将每个字段名写入空白逻辑表,每个字段的排序与解析时数据对象的提取顺序一致;抓取URL对应的目标网页,根据解析类型和解析属性提取数据对象。具体步骤如下:根据解析区域定位要提取的数据对象所在的区域,然后根据行定位信息从分析区域中定位出要提取的数据对象所在的行区域,将这些行中的数据对象一一提取出来,然后依次映射到逻辑表中,所有形成上述字段名称的对应关系,从而将目标网页转换为结构化数据文本;或者根据行定位信息定位要提取的数据对象所在的行区域,将这些行中的数据对象一一提取出来,然后映射到逻辑表中,与字段形成对应关系名称,以便将目标网页转换为结构化数据文本。将这些行中的数据对象一一提取出来,依次映射到逻辑表中,都形成上述字段名的对应关系,从而将目标网页转化为结构化的数据文本;或者根据行定位信息定位要提取的数据对象所在的行区域,将这些行中的数据对象一一提取出来,然后映射到逻辑表中,与字段形成对应关系名称,以便将目标网页转换为结构化数据文本。将这些行中的数据对象一一提取出来,依次映射到逻辑表中,都形成上述字段名的对应关系,从而将目标网页转化为结构化的数据文本;或者根据行定位信息定位要提取的数据对象所在的行区域,将这些行中的数据对象一一提取出来,然后映射到逻辑表中,与字段形成对应关系名称,以便将目标网页转换为结构化数据文本。
更优选地,字段配置还包括配置字段标识,数据分析方法执行以下步骤:新建分析配置页面,配置待爬取目标网页的URL、分析类型、分析属性、以及分析配置页面的分析配置页面信息。保存解析结果的逻辑表名,完成后提交;解析属性包括解析区域和/或行定位信息;新建字段配置页面,在字段配置页面配置逻辑表中各个字段的字段名称和字段标识;根据逻辑表名创建一个空白逻辑表,并在空白逻辑表中写入各个字段名称和对应的字段标识符;抓取该URL对应的目标网页,根据解析类型和解析属性提取数据对象,具体步骤如下:根据解析区域定位待提取数据对象所在的区域,然后根据行定位信息在解析区域中定位待提取数据对象所在行区域,从字段配置信息中读取字段标识,定位在这几行
【技术保护点】
1.一种可配置的数据解析方法,其特征在于包括以下步骤:新建一个解析配置页面,并配置URL、解析类型、解析属性,以及保存解析结果的逻辑表名,配置完成后,选择提交并保存;解析属性包括解析区域和行定位信息,或者解析属性只包括行定位信息;新建一个字段配置页面,在字段配置页面配置需要的字段提取的数据对象对应的字段名称;根据逻辑表名称创建一个空白逻辑表,并将每个字段名称写入空白逻辑表;抓取URL对应的目标网页,根据分析类型和分析属性提取数据对象,具体步骤如下:根据解析区域定位待提取数据对象所在区域,然后定位待提取数据对象所在行区域根据行定位信息从解析区定位,并从这些行中一一提取数据对象,然后依次映射到逻辑表中,与字段名形成对应关系,从而转换目标网页页面转换为结构化数据文本;或者只根据行定位信息区域定位待提取数据对象所在的行,从这些行中逐一提取数据对象,然后依次映射到逻辑表中,与字段名称,
【技术特点总结】
1.一种可配置的数据解析方法,其特征在于包括以下步骤:新建一个解析配置页面,并配置URL、解析类型、解析属性,以及保存解析结果的逻辑表名,配置完成后,选择提交并保存;解析属性包括解析区域和行定位信息,或者解析属性只包括行定位信息;新建一个字段配置页面,在字段配置页面配置需要的字段提取的数据对象对应的字段名称;根据逻辑表名称创建一个空白逻辑表,并将每个字段名称写入空白逻辑表;抓取URL对应的目标网页,根据分析类型和分析属性提取数据对象,具体步骤如下:根据解析区域定位待提取数据对象所在区域,然后定位待提取数据对象所在行区域根据行定位信息从解析区定位,并从这些行中一一提取数据对象,然后依次映射到逻辑表中,与字段名形成对应关系,从而转换目标网页页面转换为结构化数据文本;或者只根据行定位信息区域定位待提取数据对象所在的行,从这些行中逐一提取数据对象,然后依次映射到逻辑表中,与字段名称,从而将目标网页转换为结构化数据文本。2.
3.根据权利要求1所述的一种可配置的数据解析方法,其特征在于,所述解析区域的配置包括表区域标识、表起始索引和表结束索引,根据表起始索引索引定位表区域解析区域开头的标识位置,根据表格终止索引定位解析区域末尾的表格区域标识位置。4.根据权利要求1所述的可配置数据解析方法,其特征在于,所述行定位信息包括行区域标识、行开始索引和行结束索引。根据行起始索引定位解析区开头的表区标识位置,根据行终止索引定位解析区末尾的行区标识位置。5.根据权利要求1所述的一种可配置的数据解析方法,其特征在于,所述目标网页的解析类型为HTMLBYHEAD,解析属性还包括头部定位信息,表头部定位信息包括头部行标识、标题行索引和标题列标识符,HTMLBYHEAD类型是指目标网页中表格上方有标题的网页。6.计算机可读存储... 表头定位信息包括表头行标识、表头行索引和表头列标识,HTMLBYHEAD类型是指目标网页中表头在表上方的网页。6.计算机可读存储... 表头定位信息包括表头行标识、表头行索引和表头列标识,HTMLBYHEAD类型是指目标网页中表头在表上方的网页。6.计算机可读存储...
【专利技术性质】
技术研发人员:邱涛、邱水文、陈成乐、
申请人(专利权)持有人:,
类型:发明
国家、省、市:福建,35
下载所有详细的技术数据 我是该专利的所有者 查看全部
网页表格抓取(技术一种可配置化的数据解析方法和网页解析)
本发明专利技术涉及一种可配置的数据解析方法,包括以下步骤:解析配置;现场配置;创建空白逻辑表,并将各个字段名写入空白逻辑表;抓取URL对应的URL 对于目标网页,根据解析类型和解析属性提取数据对象,然后依次映射到逻辑表中,与字段名形成对应关系,从而转换目标网页结构化数据文本。本发明的专利技术是一种可配置的数据解析方法。通过配置解析表,可以灵活处理不同格式的网页,完成网页解析,将网页数据转化为结构化数据文本,
一种可配置的数据分析方法和计算机可读存储介质
下载所有详细的技术数据
【技术实现步骤总结】
一种可配置的数据解析方法及计算机可读存储介质
本专利技术涉及一种可配置的数据分析方法及计算机可读存储介质,属于互联网数据爬取领域。
技术介绍
互联网上的信息复杂,信息的类型和表达方式多种多样。显示的信息只是为了方便用户浏览,不是统一的结构化数据显示,所以不考虑机器识别。但是,由于计算机不具备自然语言或类人阅读能力,互联网网页的信息载体所显示的信息不易被计算机识别和分析。在过去的IT技术发展中,积累了大量基于结构化数据的挖掘和分析技术。对于从互联网上抓取的网页的非结构化数据,我们需要先将其从结构化数据中进行转换,以方便机器学习。标识,以方便后续业务单位使用。公开号为CN108959539A的专利技术专利《一种基于规则的可配置网页数据分析方法》公开了网页分析方法如下: S3.网页分析:获取Web中任务配置配置的分析信息,获取采集网页的列表信息进行数据解析,通过Python的BeautifulSoup库解析页面;解析时,根据页面上配置的HTML标签,按标签类型和值提取数据及相关标签;解析结束然后,将数据存入数据库。公开的技术方案使用Python的BeautifulSoup库来解析页面文本数据,但是这种方法有以下两个缺点:1、Python的BeautifulSoup库只能解析HTML或XML格式的文件,并且支持的类型有限,比如不能支持Json格式的网页进行解析;2、Python的BeautifulSoup库是一种封装模式,而对于不同格式的网页一、,它对网页的灵活性有明显的适应作用还不够,尤其是对于一些非常规的特殊处理的网页,或者当用户选择性地过滤过滤相关数据时,封装模式似乎不合适。
技术实现思路
为了解决上述技术问题,专利技术提供了一种可配置的数据分析方法,将捕获的目标网页转换为标准化的结构化数据文本,便于信息的应用和挖掘。该专利技术的第一个技术方案如下:一种可配置的数据解析方法,包括以下步骤:创建解析配置页面,并配置URL、解析类型、解析属性以及保存数据的逻辑表名称解析结果,配置完成后选择提交保存;解析属性包括解析区域和行定位信息,或者解析属性只包括行定位信息;创建一个新的字段配置页面,并在字段配置页面配置必填字段提取的数据对象对应的字段名称;根据逻辑表名称创建一个空白逻辑表,并将每个字段名称写入空白逻辑表;抓取URL对应的目标网页,根据分析类型和分析属性提取数据对象,具体步骤如下:根据解析区域定位待提取数据对象所在区域,然后定位根据行定位信息,从解析区域中提取出待提取数据对象所在的行区域,从这些行中一一提取数据对象,然后依次映射到逻辑表中,与数据对象形成对应关系字段名称,从而将目标网页转换为结构化数据文本;或者只根据行定位信息区域定位待提取数据对象所在的行,从这些行中逐一提取数据对象,然后依次映射到逻辑表中,与字段名称,从而将目标网页转换为结构化数据文本。
更优选地,字段配置还包括配置字段标识,数据分析方法执行以下步骤:新建分析配置页面,配置待爬取目标网页的URL、分析类型、分析属性、以及分析配置页面的分析配置页面信息。保存解析结果的逻辑表名称,配置完成后选择提交保存;解析属性包括解析区域和行定位信息,或者解析属性只包括行定位信息;新建一个字段配置页面,在字段配置页面配置需要的字段提取的数据对象对应的字段名称;根据逻辑表名称创建空白逻辑表,并在空白逻辑表中写入字段名称和对应的字段标识;抓取该URL对应的目标网页,根据解析类型和解析属性提取数据对象,具体步骤如下:根据解析区域定位要提取的数据对象所在的区域,然后根据行定位信息在解析区域中定位待提取数据对象所在的行区域,读取字段配置信息中的字段标识,定位这些行中的字段标识,字段标识对应的属性值是要提取的数据对象,并将提取的字段标识符对应的数据对象写入字段名的取值范围内,依次类推,将解析区的所有字段标识符一一遍历,将所有要提取的数据对象写入逻辑表,并与字段名形成对应关系,从而转换目标网页或根据行定位信息定位待提取数据对象所在行区域,从字段配置信息中读取字段标识,定位这些行中的字段标识符,与字段标识符对应的属性值就是要提取的数据对象。将提取的数据对象写入到字段标识对应的字段名的value字段中,以此类推,一一遍历所有的字段标识,并写入所有需要提取的数据对象。进入逻辑表,并与字段名称形成对应关系,从而将目标网页转换为结构化的数据文本。
更优选地,分析区域的配置包括表格区域标识、表格起始索引和表格结束索引,根据表格起始索引定位分析区域开头的表格区域标识位置,表格区域根据表尾索引定位分析区域的末尾。确定位置。更优选地,行定位信息包括行区域标识、行起始索引和行结束索引,根据行起始索引定位解析区域开头的表区域标识位置,行区域标识位于根据行停止索引定位解析区域的末端。地点。更优选地,目标网页的解析类型为HTMLBYHEAD,解析属性还包括标题定位信息,标题定位信息包括标题行标识、标题行索引和标题列标识,HTMLBYHEAD A类型为在着陆页的表格上方有标题的页面。本专利技术还提供了一种计算机可读存储介质。本专利技术方案二是一种计算机可读存储介质,其上存储有计算机程序,当该程序被处理器执行时,执行以下步骤:创建新的解析配置页面,以及在解析配置页面URL、解析类型、解析属性和用于保存解析结果的逻辑表的名称上配置要爬取的目标网页,完成后提交;解析属性包括解析区域和行定位信息,或者解析属性只包括行定位信息;新建字段配置页面,在字段配置页面配置逻辑表中每个字段的字段名,每个字段名对应要提取的数据对象;根据逻辑表名创建空白逻辑表,将每个字段名写入空白逻辑表,每个字段的排序与解析时数据对象的提取顺序一致;抓取URL对应的目标网页,根据解析类型和解析属性提取数据对象。具体步骤如下:根据解析区域定位要提取的数据对象所在的区域,然后根据行定位信息从分析区域中定位出要提取的数据对象所在的行区域,将这些行中的数据对象一一提取出来,然后依次映射到逻辑表中,所有形成上述字段名称的对应关系,从而将目标网页转换为结构化数据文本;或者根据行定位信息定位要提取的数据对象所在的行区域,将这些行中的数据对象一一提取出来,然后映射到逻辑表中,与字段形成对应关系名称,以便将目标网页转换为结构化数据文本。将这些行中的数据对象一一提取出来,依次映射到逻辑表中,都形成上述字段名的对应关系,从而将目标网页转化为结构化的数据文本;或者根据行定位信息定位要提取的数据对象所在的行区域,将这些行中的数据对象一一提取出来,然后映射到逻辑表中,与字段形成对应关系名称,以便将目标网页转换为结构化数据文本。将这些行中的数据对象一一提取出来,依次映射到逻辑表中,都形成上述字段名的对应关系,从而将目标网页转化为结构化的数据文本;或者根据行定位信息定位要提取的数据对象所在的行区域,将这些行中的数据对象一一提取出来,然后映射到逻辑表中,与字段形成对应关系名称,以便将目标网页转换为结构化数据文本。
更优选地,字段配置还包括配置字段标识,数据分析方法执行以下步骤:新建分析配置页面,配置待爬取目标网页的URL、分析类型、分析属性、以及分析配置页面的分析配置页面信息。保存解析结果的逻辑表名,完成后提交;解析属性包括解析区域和/或行定位信息;新建字段配置页面,在字段配置页面配置逻辑表中各个字段的字段名称和字段标识;根据逻辑表名创建一个空白逻辑表,并在空白逻辑表中写入各个字段名称和对应的字段标识符;抓取该URL对应的目标网页,根据解析类型和解析属性提取数据对象,具体步骤如下:根据解析区域定位待提取数据对象所在的区域,然后根据行定位信息在解析区域中定位待提取数据对象所在行区域,从字段配置信息中读取字段标识,定位在这几行
【技术保护点】
1.一种可配置的数据解析方法,其特征在于包括以下步骤:新建一个解析配置页面,并配置URL、解析类型、解析属性,以及保存解析结果的逻辑表名,配置完成后,选择提交并保存;解析属性包括解析区域和行定位信息,或者解析属性只包括行定位信息;新建一个字段配置页面,在字段配置页面配置需要的字段提取的数据对象对应的字段名称;根据逻辑表名称创建一个空白逻辑表,并将每个字段名称写入空白逻辑表;抓取URL对应的目标网页,根据分析类型和分析属性提取数据对象,具体步骤如下:根据解析区域定位待提取数据对象所在区域,然后定位待提取数据对象所在行区域根据行定位信息从解析区定位,并从这些行中一一提取数据对象,然后依次映射到逻辑表中,与字段名形成对应关系,从而转换目标网页页面转换为结构化数据文本;或者只根据行定位信息区域定位待提取数据对象所在的行,从这些行中逐一提取数据对象,然后依次映射到逻辑表中,与字段名称,
【技术特点总结】
1.一种可配置的数据解析方法,其特征在于包括以下步骤:新建一个解析配置页面,并配置URL、解析类型、解析属性,以及保存解析结果的逻辑表名,配置完成后,选择提交并保存;解析属性包括解析区域和行定位信息,或者解析属性只包括行定位信息;新建一个字段配置页面,在字段配置页面配置需要的字段提取的数据对象对应的字段名称;根据逻辑表名称创建一个空白逻辑表,并将每个字段名称写入空白逻辑表;抓取URL对应的目标网页,根据分析类型和分析属性提取数据对象,具体步骤如下:根据解析区域定位待提取数据对象所在区域,然后定位待提取数据对象所在行区域根据行定位信息从解析区定位,并从这些行中一一提取数据对象,然后依次映射到逻辑表中,与字段名形成对应关系,从而转换目标网页页面转换为结构化数据文本;或者只根据行定位信息区域定位待提取数据对象所在的行,从这些行中逐一提取数据对象,然后依次映射到逻辑表中,与字段名称,从而将目标网页转换为结构化数据文本。2.
3.根据权利要求1所述的一种可配置的数据解析方法,其特征在于,所述解析区域的配置包括表区域标识、表起始索引和表结束索引,根据表起始索引索引定位表区域解析区域开头的标识位置,根据表格终止索引定位解析区域末尾的表格区域标识位置。4.根据权利要求1所述的可配置数据解析方法,其特征在于,所述行定位信息包括行区域标识、行开始索引和行结束索引。根据行起始索引定位解析区开头的表区标识位置,根据行终止索引定位解析区末尾的行区标识位置。5.根据权利要求1所述的一种可配置的数据解析方法,其特征在于,所述目标网页的解析类型为HTMLBYHEAD,解析属性还包括头部定位信息,表头部定位信息包括头部行标识、标题行索引和标题列标识符,HTMLBYHEAD类型是指目标网页中表格上方有标题的网页。6.计算机可读存储... 表头定位信息包括表头行标识、表头行索引和表头列标识,HTMLBYHEAD类型是指目标网页中表头在表上方的网页。6.计算机可读存储... 表头定位信息包括表头行标识、表头行索引和表头列标识,HTMLBYHEAD类型是指目标网页中表头在表上方的网页。6.计算机可读存储...
【专利技术性质】
技术研发人员:邱涛、邱水文、陈成乐、
申请人(专利权)持有人:,
类型:发明
国家、省、市:福建,35
下载所有详细的技术数据 我是该专利的所有者
网页表格抓取(Excel抓取并查询网络数据可以使用“获取和转换”+“查找引用函数”的功能组合来实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-05 18:17
Excel抓取和查询网络数据可以通过“获取和转换”+“查找参考功能”的功能组合来实现。
示例:下图是百度百科“奥运”网页中的表格。我们以此为例,将表格抓取到Excel中,我们可以通过输入会话号来查询对应的主办城市。
Step1:使用“获取和转换”功能将网络数据捕获到Excel中
单击数据选项卡、新查询、来自其他来源、来自 Web。
弹出如下窗口,手动将百度百科“奥运”的网址复制粘贴到网址栏,点击确定。
Excel 连接到网页需要一定的时间。稍等片刻,会弹出如下窗口。左侧列表中的每个表代表网页中的一个表。一一点击预览后,发现Table3就是我们需要的数据。
单击下方“加载”旁边的下拉箭头,然后选择“加载到”。
在弹出窗口中,选择“选择如何在工作簿中查看此数据”下的“表”,然后单击“加载”。
如图所示,Web 表单中的数据已经被抓取到 Excel 中。
点击“表格工具”、“设计”,将“表格名称”改为Olympic Games。
Step2:使用“查找和引用”功能实现数据查询
创建一个查询区域,包括“会话数”和“主办城市”,在会话编号中选择一个会话并在下图中输入“第08个会话”,进入主办城市下的vlookup功能,可以得到第08届奥运会的主办城市是巴黎,当届数发生变化时,对应的主办城市也会发生变化。
公式:=VLOOKUP([会话次数],Olympics[#All],4,0)
注意:如果网页中的数据变化频繁,可以设置链接网页的数据定期刷新:
①将鼠标放在导入数据区,切换到【设计】选项卡,点击【刷新】下拉箭头→【链接属性】
②在弹出的【链接属性】对话框中,设置【刷新频率】,例如设置为10分钟刷新一次。这样每10分钟就会刷新一次数据,保证获取到的数据始终是最新的。
《江津Excel》是头条签约作者,关注我,点击任意三篇文章,如果没有你想要的知识,我就是个流氓!
谢谢你的邀请!如何快速使用Excel快速抓取网站中的上万条数据?在日常工作中,我们经常会采取复制->粘贴的方式,但这种方式不仅耗时,而且非常不雅观。今天就跟着视频一起来看看如何实现吧?
{!-- PGC_VIDEO:{"thumb_height": 720, "vposter": "", "thumb_width": 1368, "vid": "v020168e0000bq9bcdrd82dvh4ototbg", "vu": "v020168e0000bq9bcdrd82dvh4ototbg", "duration": 1持续时间”:@>4,“thumb_url”:“tos-cn-p-0000/687d784120b04f1b8f53d7b034ea2565”,“thumb_uri”:“tos-cn-p-0000/687d784120b04f1b8f53d7b034ea2565”,“video_size”:{“high”:持续时间” 190.4, “h”: 720, “w”: 1368}, “超”: {“持续时间”: 190.4, “h”: 720, “w”: 1368},“正常”:{“持续时间”:190.4,“h”:720,“w”:1368}}} --}
希望能帮到你!如需更多应用提示,请查看最近分享的视频,文章。有什么问题可以随时留言! 查看全部
网页表格抓取(Excel抓取并查询网络数据可以使用“获取和转换”+“查找引用函数”的功能组合来实现)
Excel抓取和查询网络数据可以通过“获取和转换”+“查找参考功能”的功能组合来实现。

示例:下图是百度百科“奥运”网页中的表格。我们以此为例,将表格抓取到Excel中,我们可以通过输入会话号来查询对应的主办城市。
Step1:使用“获取和转换”功能将网络数据捕获到Excel中
单击数据选项卡、新查询、来自其他来源、来自 Web。
弹出如下窗口,手动将百度百科“奥运”的网址复制粘贴到网址栏,点击确定。
Excel 连接到网页需要一定的时间。稍等片刻,会弹出如下窗口。左侧列表中的每个表代表网页中的一个表。一一点击预览后,发现Table3就是我们需要的数据。
单击下方“加载”旁边的下拉箭头,然后选择“加载到”。
在弹出窗口中,选择“选择如何在工作簿中查看此数据”下的“表”,然后单击“加载”。
如图所示,Web 表单中的数据已经被抓取到 Excel 中。
点击“表格工具”、“设计”,将“表格名称”改为Olympic Games。
Step2:使用“查找和引用”功能实现数据查询
创建一个查询区域,包括“会话数”和“主办城市”,在会话编号中选择一个会话并在下图中输入“第08个会话”,进入主办城市下的vlookup功能,可以得到第08届奥运会的主办城市是巴黎,当届数发生变化时,对应的主办城市也会发生变化。
公式:=VLOOKUP([会话次数],Olympics[#All],4,0)
注意:如果网页中的数据变化频繁,可以设置链接网页的数据定期刷新:
①将鼠标放在导入数据区,切换到【设计】选项卡,点击【刷新】下拉箭头→【链接属性】
②在弹出的【链接属性】对话框中,设置【刷新频率】,例如设置为10分钟刷新一次。这样每10分钟就会刷新一次数据,保证获取到的数据始终是最新的。
《江津Excel》是头条签约作者,关注我,点击任意三篇文章,如果没有你想要的知识,我就是个流氓!
谢谢你的邀请!如何快速使用Excel快速抓取网站中的上万条数据?在日常工作中,我们经常会采取复制->粘贴的方式,但这种方式不仅耗时,而且非常不雅观。今天就跟着视频一起来看看如何实现吧?
{!-- PGC_VIDEO:{"thumb_height": 720, "vposter": "", "thumb_width": 1368, "vid": "v020168e0000bq9bcdrd82dvh4ototbg", "vu": "v020168e0000bq9bcdrd82dvh4ototbg", "duration": 1持续时间”:@>4,“thumb_url”:“tos-cn-p-0000/687d784120b04f1b8f53d7b034ea2565”,“thumb_uri”:“tos-cn-p-0000/687d784120b04f1b8f53d7b034ea2565”,“video_size”:{“high”:持续时间” 190.4, “h”: 720, “w”: 1368}, “超”: {“持续时间”: 190.4, “h”: 720, “w”: 1368},“正常”:{“持续时间”:190.4,“h”:720,“w”:1368}}} --}
希望能帮到你!如需更多应用提示,请查看最近分享的视频,文章。有什么问题可以随时留言!
网页表格抓取(网页中2020年GDP预测排名这个数据,如下图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-03-05 16:12
我们要获取网页中2020年GDP预测排名的数据,如下图
一、获取数据
首先,我们需要新建一个工作簿,打开它,然后点击数据功能组,点击New Query,然后选择from other sources,select from 网站
这种情况下会弹出一个对话框,直接复制你要提取数据的URL,然后点击确定,excel会自动连接计算出来的数据。
计算完成后,进入电量查询导航界面。导航器左侧的表格图标是excel检测到的表格数据,当我们点击对应的表格名称时,右侧会显示对应的数据。,我们可以点击表格找到我们要获取的数据,其中第一个就是我们要获取的数据,我们直接点击第一个表格然后点击转换数据
二、处理数据
点击数据转换后,会进入power query的数据处理界面,我们可以对数据进行相应的处理。例如,这里我们要按地区计算每个大陆的 GDP 总量,单位为人民币。
首先我们点击开始选择group by,然后在group by中选择区域,然后在新的列名中命名,我设置计算方式为sum,然后选择RMB所在的列,然后单击确定。
然后我们点击关闭上传,将数据加载到excel中,如下图
如果不想在power query中编辑,可以直接在导航界面点击加载,这样数据会直接加载到excel中,我们也可以直接在excel中编辑数据,
power query处理后的数据可以刷新,但是直接点击加载在excel中处理是无法刷新数据的。刷新数据,我们只需要在数据功能组中点击刷新即可刷新数据。 查看全部
网页表格抓取(网页中2020年GDP预测排名这个数据,如下图)
我们要获取网页中2020年GDP预测排名的数据,如下图

一、获取数据
首先,我们需要新建一个工作簿,打开它,然后点击数据功能组,点击New Query,然后选择from other sources,select from 网站

这种情况下会弹出一个对话框,直接复制你要提取数据的URL,然后点击确定,excel会自动连接计算出来的数据。

计算完成后,进入电量查询导航界面。导航器左侧的表格图标是excel检测到的表格数据,当我们点击对应的表格名称时,右侧会显示对应的数据。,我们可以点击表格找到我们要获取的数据,其中第一个就是我们要获取的数据,我们直接点击第一个表格然后点击转换数据

二、处理数据
点击数据转换后,会进入power query的数据处理界面,我们可以对数据进行相应的处理。例如,这里我们要按地区计算每个大陆的 GDP 总量,单位为人民币。
首先我们点击开始选择group by,然后在group by中选择区域,然后在新的列名中命名,我设置计算方式为sum,然后选择RMB所在的列,然后单击确定。

然后我们点击关闭上传,将数据加载到excel中,如下图

如果不想在power query中编辑,可以直接在导航界面点击加载,这样数据会直接加载到excel中,我们也可以直接在excel中编辑数据,

power query处理后的数据可以刷新,但是直接点击加载在excel中处理是无法刷新数据的。刷新数据,我们只需要在数据功能组中点击刷新即可刷新数据。
网页表格抓取( Python使用Web抓取有助于的步骤寻找您想要的抓取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-05 16:11
Python使用Web抓取有助于的步骤寻找您想要的抓取数据
)
前言
Crawler 是一种从 网站 中抓取大量数据的自动化方法。甚至在您最喜欢的 网站 上复制和粘贴引号或行也是一种网络抓取形式。大多数网站不允许你在它们网站上保存数据供你使用。所以唯一的选择就是手动复制数据,这会耗费大量时间,甚至可能需要数天才能完成。
网站 上的数据大多是非结构化的。Web 抓取有助于获取这些非结构化数据并将其存储在本地或以自定义和结构化形式存储在数据库中。如果您出于学习目的而抓取网页,那么您不太可能遇到任何问题,那么在不违反服务条款的情况下自己进行一些网页抓取以提高您的技能是一个很好的做法。
爬虫步骤
为什么使用 Python 进行网页抓取?
Python 非常快且更容易进行网络抓取。由于它太容易编码,您可以使用简单的小代码来执行大任务。
如何进行网页抓取?
我们需要运行网页抓取代码来向我们想要抓取的 网站 的 URL 发送请求。服务器发送数据并允许我们读取 HTML 或 XML 页面作为响应。该代码解析 HTML 或 XML 页面,查找数据并提取它们。
以下是使用 Python 使用网络抓取来提取数据的步骤
查找要抓取的 URL 分析网站查找要提取的数据 编写代码 运行代码并从 网站 中提取数据 以所需格式将数据存储在计算机中的库中网页抓取
Requests 是一个允许使用 Python 发送 HTTP 请求的模块。HTTP请求用于返回一个收录所有响应数据(如编码、状态、内容等)的响应对象
BeautifulSoup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。这适用于您最喜欢的解析器,以提供一种惯用的方式来导航、搜索和修改解析树。它专为快速和高度可靠的数据提取而设计。
pandas 是一个开源库,允许我们在 Python Web 开发中执行数据操作。它建立在 Numpy 包之上,其关键数据结构称为 DataFrame。DataFrames 允许我们在观察行和变量列中存储和操作表格数据。
Tqdm 是另一个 python 库,它可以快速让你的循环显示一个智能进度表——你所要做的就是用 Tqdm(iterable) 包装任何可迭代对象。
演示:获取 网站
Step 1. 找到你要抓取的URL
为了演示,我们将抓取网络以提取手机的详细信息。我使用了一个 example() 来展示这个过程。
Stpe 2. 分析网站
数据通常嵌套在标签中。我们要获取的数据被标记在下面的页面是嵌套的。要查看页面,只需右键单击元素并单击“检查”。将打开一个小的复选框。你可以看到网站背后的原创代码。现在您可以找到要抓取的详细信息标签。
您可以在控制台的左上角找到一个箭头符号。如果单击箭头,然后单击产品区域,则特定产品区域的代码将在控制台选项卡中突出显示。
我们应该做的第一件事是回顾和理解 HTML 的结构,因为从 网站 获取数据非常重要。网站 页面上会有很多代码,我们需要收录我们数据的代码。学习 HTML 的基础知识将帮助您熟悉 HTML 标记。
步骤3.找到要提取的数据
我们将提取电话数据,例如产品名称、实际价格、折扣价等。您可以提取任何类型的数据。为此,我们必须找到收录我们数据的标记。
通过检查元素的区域来打开控制台。单击左上角的箭头,然后单击产品。您现在将能够看到我们单击的产品的特定代码。
步骤 4. 编写代码
现在我们必须找出数据和链接的位置。让我们开始编码。
创建一个名为 scrap.py 的文件并在您选择的任何编辑器中打开它。我们将使用 pip 来安装上面提到的四个 Python 库。
第一个也是主要的过程是访问站点数据。我们已经设置了这个 网站 的 URL 并访问了这个 网站。
url = 'https://www.example.com/produc ... aders = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64)' 'AppleWebKit/537.36 (KHTML, like Gecko)' 'Chrome/64.0.3282.167 Safari/537.36' }result = requests.get(url, headers=headers,verify=True)Print(result)
输出:
如果你看到上面的结果,那么你已经成功访问了这个网站。
步骤 5. 运行代码并从 网站 中提取数据
现在,我们将使用 Beautifulsoup 来解析 HTML。
soup = BeautifulSoup(result.content, 'html.parser')
如果我们打印汤,那么我们将能够看到整个 网站 页面的 HTML 内容。我们现在要做的就是过滤收录数据的部分。因此,我们将从汤中提取部分标签。
section=soup.find("section", class_='js-section').find_all("div",{'class':'product-desc-rating})Print(section)
结果如下:
现在,我们可以在 div 的“product-desc-rating”类中提取手机的详细信息。我为手机的每个列详细信息创建了一个列表,并使用 for 循环将其附加到列表中。
Products = []url = []Actual_Price = []Discounted_Price = []Discount = []
产品名称出现在 HTML 中的 p 标签(段落标签)下,product_url 出现在锚标签下。
HTML 锚标记定义将一个页面链接到另一个页面的超链接。它可以创建指向另一个网页以及文件、位置或任何 URL 的超链接。“href”属性是 HTML 标签最重要的属性。以及指向目标页面或 URL 的链接。
然后我们将提取实际价格和折扣价格,它们都出现在 span 标签中。标签用于对内联元素进行分组。标签本身并没有提供任何视觉变化。最后,我们将从 div 标签中提取报价百分比。div 标签是块级标签。它是一个通用容器标签。它用于 HTML 中的各种标签组,以便可以创建部分并将样式应用于它们。
for t in tqdm(section): product_name = t.p.text Products.append(product_name) product_url = t.a['href'] url.append(product_url) original_price = t.span.getText() Actual_Price.append(original_price) discounted_price = t.find('span', class_ = 'lfloat product-price').getText() Discounted_Price.append(discounted_price) try: product_discount = t.find('div', class_ = 'product-discount') Discount.append(product_discount.text) except Exception as e: product_discount = None Discount.append(product_discount)
步骤 6. 以所需格式存储数据
我们已经提取了数据。我们现在要做的就是将数据存储到文件或数据库中。您可以以您想要的格式存储数据。这取决于您的要求。在这里,我们将以 CSV(逗号分隔值)格式存储提取的数据。
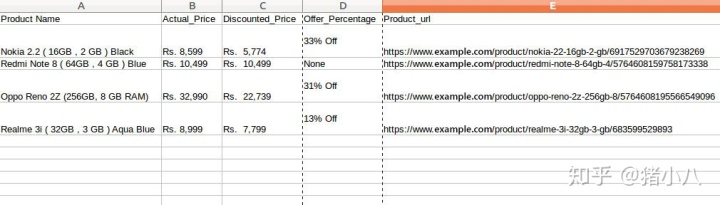
= pd.DataFrame({'Product Name':Products,'Actual_Price':Actual_Price,'Discounted_Price':Discounted_Price,'Offer_Percentage':Discount,'Product_url':url}) df.to_csv(' products.csv', index=False, encoding='utf-8')
查看全部
网页表格抓取(
Python使用Web抓取有助于的步骤寻找您想要的抓取数据
)

前言
Crawler 是一种从 网站 中抓取大量数据的自动化方法。甚至在您最喜欢的 网站 上复制和粘贴引号或行也是一种网络抓取形式。大多数网站不允许你在它们网站上保存数据供你使用。所以唯一的选择就是手动复制数据,这会耗费大量时间,甚至可能需要数天才能完成。
网站 上的数据大多是非结构化的。Web 抓取有助于获取这些非结构化数据并将其存储在本地或以自定义和结构化形式存储在数据库中。如果您出于学习目的而抓取网页,那么您不太可能遇到任何问题,那么在不违反服务条款的情况下自己进行一些网页抓取以提高您的技能是一个很好的做法。
爬虫步骤
为什么使用 Python 进行网页抓取?
Python 非常快且更容易进行网络抓取。由于它太容易编码,您可以使用简单的小代码来执行大任务。
如何进行网页抓取?
我们需要运行网页抓取代码来向我们想要抓取的 网站 的 URL 发送请求。服务器发送数据并允许我们读取 HTML 或 XML 页面作为响应。该代码解析 HTML 或 XML 页面,查找数据并提取它们。
以下是使用 Python 使用网络抓取来提取数据的步骤
查找要抓取的 URL 分析网站查找要提取的数据 编写代码 运行代码并从 网站 中提取数据 以所需格式将数据存储在计算机中的库中网页抓取
Requests 是一个允许使用 Python 发送 HTTP 请求的模块。HTTP请求用于返回一个收录所有响应数据(如编码、状态、内容等)的响应对象
BeautifulSoup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。这适用于您最喜欢的解析器,以提供一种惯用的方式来导航、搜索和修改解析树。它专为快速和高度可靠的数据提取而设计。
pandas 是一个开源库,允许我们在 Python Web 开发中执行数据操作。它建立在 Numpy 包之上,其关键数据结构称为 DataFrame。DataFrames 允许我们在观察行和变量列中存储和操作表格数据。
Tqdm 是另一个 python 库,它可以快速让你的循环显示一个智能进度表——你所要做的就是用 Tqdm(iterable) 包装任何可迭代对象。
演示:获取 网站
Step 1. 找到你要抓取的URL
为了演示,我们将抓取网络以提取手机的详细信息。我使用了一个 example() 来展示这个过程。
Stpe 2. 分析网站
数据通常嵌套在标签中。我们要获取的数据被标记在下面的页面是嵌套的。要查看页面,只需右键单击元素并单击“检查”。将打开一个小的复选框。你可以看到网站背后的原创代码。现在您可以找到要抓取的详细信息标签。
您可以在控制台的左上角找到一个箭头符号。如果单击箭头,然后单击产品区域,则特定产品区域的代码将在控制台选项卡中突出显示。
我们应该做的第一件事是回顾和理解 HTML 的结构,因为从 网站 获取数据非常重要。网站 页面上会有很多代码,我们需要收录我们数据的代码。学习 HTML 的基础知识将帮助您熟悉 HTML 标记。
步骤3.找到要提取的数据
我们将提取电话数据,例如产品名称、实际价格、折扣价等。您可以提取任何类型的数据。为此,我们必须找到收录我们数据的标记。
通过检查元素的区域来打开控制台。单击左上角的箭头,然后单击产品。您现在将能够看到我们单击的产品的特定代码。
步骤 4. 编写代码
现在我们必须找出数据和链接的位置。让我们开始编码。
创建一个名为 scrap.py 的文件并在您选择的任何编辑器中打开它。我们将使用 pip 来安装上面提到的四个 Python 库。
第一个也是主要的过程是访问站点数据。我们已经设置了这个 网站 的 URL 并访问了这个 网站。
url = 'https://www.example.com/produc ... aders = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64)' 'AppleWebKit/537.36 (KHTML, like Gecko)' 'Chrome/64.0.3282.167 Safari/537.36' }result = requests.get(url, headers=headers,verify=True)Print(result)
输出:
如果你看到上面的结果,那么你已经成功访问了这个网站。
步骤 5. 运行代码并从 网站 中提取数据
现在,我们将使用 Beautifulsoup 来解析 HTML。
soup = BeautifulSoup(result.content, 'html.parser')
如果我们打印汤,那么我们将能够看到整个 网站 页面的 HTML 内容。我们现在要做的就是过滤收录数据的部分。因此,我们将从汤中提取部分标签。
section=soup.find("section", class_='js-section').find_all("div",{'class':'product-desc-rating})Print(section)
结果如下:
现在,我们可以在 div 的“product-desc-rating”类中提取手机的详细信息。我为手机的每个列详细信息创建了一个列表,并使用 for 循环将其附加到列表中。
Products = []url = []Actual_Price = []Discounted_Price = []Discount = []
产品名称出现在 HTML 中的 p 标签(段落标签)下,product_url 出现在锚标签下。
HTML 锚标记定义将一个页面链接到另一个页面的超链接。它可以创建指向另一个网页以及文件、位置或任何 URL 的超链接。“href”属性是 HTML 标签最重要的属性。以及指向目标页面或 URL 的链接。
然后我们将提取实际价格和折扣价格,它们都出现在 span 标签中。标签用于对内联元素进行分组。标签本身并没有提供任何视觉变化。最后,我们将从 div 标签中提取报价百分比。div 标签是块级标签。它是一个通用容器标签。它用于 HTML 中的各种标签组,以便可以创建部分并将样式应用于它们。
for t in tqdm(section): product_name = t.p.text Products.append(product_name) product_url = t.a['href'] url.append(product_url) original_price = t.span.getText() Actual_Price.append(original_price) discounted_price = t.find('span', class_ = 'lfloat product-price').getText() Discounted_Price.append(discounted_price) try: product_discount = t.find('div', class_ = 'product-discount') Discount.append(product_discount.text) except Exception as e: product_discount = None Discount.append(product_discount)
步骤 6. 以所需格式存储数据
我们已经提取了数据。我们现在要做的就是将数据存储到文件或数据库中。您可以以您想要的格式存储数据。这取决于您的要求。在这里,我们将以 CSV(逗号分隔值)格式存储提取的数据。
= pd.DataFrame({'Product Name':Products,'Actual_Price':Actual_Price,'Discounted_Price':Discounted_Price,'Offer_Percentage':Discount,'Product_url':url}) df.to_csv(' products.csv', index=False, encoding='utf-8')
网页表格抓取(Python表格型数据获取的准确性是需要考虑的因素? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-03 15:27
)
Python 有许多可以捕获数据的包,例如 selenium、requests、scrapy 和 pandas。每个包都有其适用性。我个人认为在抓数据的时候,代码的简洁性和数据获取的准确性是需要考虑的因素。不要太担心时间的速度。毕竟用python抓数据已经大大节省了时间。使用不同的方法可能是 1 秒和 1 分钟之间的差异。我们在日常生活中总是有抓取表格数据的需求。本文尝试用pandas最简洁的代码来抓取表数据。该代码非常简单且易于使用。
只需选择一个页面:
比如爬取下图中定向工具的注册审批文件(当然wind里面有数据,本文只是为了展示如何爬取表格数据)
一、爬取当前页面
只需要两个密钥代码即可获取它。前两句是导入相关模块,第三句是输入网址,第四句是用pandas读取。由于网页有很多表格,所以会以列表的形式存储在变量ppn中。,点击查看第十四张表格正是我们所需要的。
二、 抓取所有
但是第一部分只抓取第一页,如果要抓取所有页面,也很简单,写个循环就行了。点击下一页可以看到它的 URL 相应地发生了变化:
页码会体现在索引后面的数字中,所以可以把url改成变量组合,详见第五句。第一二句还在导入相关模块,第三句是生成一个空矩阵来存储爬取的结果,第四到第八句是一个简单的循环,每页爬取结果变量。然后将结果连续添加到输出中。最终的输出就是我们想要的结果。
查看全部
网页表格抓取(Python表格型数据获取的准确性是需要考虑的因素?
)
Python 有许多可以捕获数据的包,例如 selenium、requests、scrapy 和 pandas。每个包都有其适用性。我个人认为在抓数据的时候,代码的简洁性和数据获取的准确性是需要考虑的因素。不要太担心时间的速度。毕竟用python抓数据已经大大节省了时间。使用不同的方法可能是 1 秒和 1 分钟之间的差异。我们在日常生活中总是有抓取表格数据的需求。本文尝试用pandas最简洁的代码来抓取表数据。该代码非常简单且易于使用。
只需选择一个页面:
比如爬取下图中定向工具的注册审批文件(当然wind里面有数据,本文只是为了展示如何爬取表格数据)
一、爬取当前页面
只需要两个密钥代码即可获取它。前两句是导入相关模块,第三句是输入网址,第四句是用pandas读取。由于网页有很多表格,所以会以列表的形式存储在变量ppn中。,点击查看第十四张表格正是我们所需要的。

二、 抓取所有
但是第一部分只抓取第一页,如果要抓取所有页面,也很简单,写个循环就行了。点击下一页可以看到它的 URL 相应地发生了变化:
页码会体现在索引后面的数字中,所以可以把url改成变量组合,详见第五句。第一二句还在导入相关模块,第三句是生成一个空矩阵来存储爬取的结果,第四到第八句是一个简单的循环,每页爬取结果变量。然后将结果连续添加到输出中。最终的输出就是我们想要的结果。
网页表格抓取(如何使用优采云采集器采集单网页上的表格信息? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-03-01 04:10
)
今天小编就给大家介绍一下优采云采集器采集单个网页的表单信息的使用方法。目的是让你知道如何处理表单类型的网页。我们来看看吧。
首先打开优采云采集器→点击快速启动→新建任务进入任务配置页面:
选择任务组,自定义任务名称和备注;
上图配置完成后,选择Next,进入流程配置页面,拖拽一个步骤打开网页进入流程设计器;
选择在浏览器中打开网页的步骤,在右侧页面网址中输入网页网址并点击保存,系统会在软件下方的浏览器中自动打开相应网页:
在上面的浏览器中,可以看到网页都是由同一个区域行组成的。我们需要捕获每个区域行中的数据信息,每个区域块行的格式都是一样的。这时候,我们需要创建一个循环列表来循环遍历每个区域行中的元素。
请注意,最终提取的元素必须收录在循环项中
点击上图中的第一个区域行,可以看到下图浏览器中的红色虚线框选中了整个区域行。如果没有选中,可以在弹出的选择对话框上方的放大选项中进行调整。. 调整好后,选择创建元素列表来处理一组元素;
接下来,在弹出的对话框中,选择添加到列表
添加第一区域行后,选择继续编辑列表。
接下来以相同的方式添加第二个区域行。
当我们添加第二个区域行时,我们可以看上图。此时,页面中的其他元素被添加。这是因为我们在添加两个具有相似特征的元素,系统会在页面中智能添加其他具有相似特征的元素。然后选择创建列表完成→点击下图中的循环
经过以上操作,循环采集列表就完成了。系统会在页面右上角显示该页面添加的所有循环项。
接下来,提取数据字段,点击上图中的第一个循环项,然后在流程设计器中点击提取数据,然后在浏览器中选择要提取的字段,然后在弹出的窗口中选择抓取这个元素选择对话框。文本;
完成上述操作后,系统会在页面右上角显示我们要抓取的字段;
接下来配置页面上需要抓取的其他字段,配置完成后修改字段名称;
修改完成后,点击上图中的保存按钮,然后点击图中的数据字段,可以看到系统会显示最终的采集列表;
点击上图中的Next→Next→Start Standalone采集(调试模式)进入任务检查页面,保证任务的正确性;
点击Start Standalone采集,系统会在本地执行采集进程并显示最终的采集结果;
如果我们需要导出最终的采集数据信息,点击下图中的导出按钮,选择要导出的文件类型,系统会提示保存路径,选择保存路径,系统会自动导出文件。
查看全部
网页表格抓取(如何使用优采云采集器采集单网页上的表格信息?
)
今天小编就给大家介绍一下优采云采集器采集单个网页的表单信息的使用方法。目的是让你知道如何处理表单类型的网页。我们来看看吧。
首先打开优采云采集器→点击快速启动→新建任务进入任务配置页面:

选择任务组,自定义任务名称和备注;

上图配置完成后,选择Next,进入流程配置页面,拖拽一个步骤打开网页进入流程设计器;

选择在浏览器中打开网页的步骤,在右侧页面网址中输入网页网址并点击保存,系统会在软件下方的浏览器中自动打开相应网页:

在上面的浏览器中,可以看到网页都是由同一个区域行组成的。我们需要捕获每个区域行中的数据信息,每个区域块行的格式都是一样的。这时候,我们需要创建一个循环列表来循环遍历每个区域行中的元素。
请注意,最终提取的元素必须收录在循环项中
点击上图中的第一个区域行,可以看到下图浏览器中的红色虚线框选中了整个区域行。如果没有选中,可以在弹出的选择对话框上方的放大选项中进行调整。. 调整好后,选择创建元素列表来处理一组元素;

接下来,在弹出的对话框中,选择添加到列表

添加第一区域行后,选择继续编辑列表。

接下来以相同的方式添加第二个区域行。

当我们添加第二个区域行时,我们可以看上图。此时,页面中的其他元素被添加。这是因为我们在添加两个具有相似特征的元素,系统会在页面中智能添加其他具有相似特征的元素。然后选择创建列表完成→点击下图中的循环

经过以上操作,循环采集列表就完成了。系统会在页面右上角显示该页面添加的所有循环项。

接下来,提取数据字段,点击上图中的第一个循环项,然后在流程设计器中点击提取数据,然后在浏览器中选择要提取的字段,然后在弹出的窗口中选择抓取这个元素选择对话框。文本;
完成上述操作后,系统会在页面右上角显示我们要抓取的字段;

接下来配置页面上需要抓取的其他字段,配置完成后修改字段名称;

修改完成后,点击上图中的保存按钮,然后点击图中的数据字段,可以看到系统会显示最终的采集列表;

点击上图中的Next→Next→Start Standalone采集(调试模式)进入任务检查页面,保证任务的正确性;

点击Start Standalone采集,系统会在本地执行采集进程并显示最终的采集结果;

如果我们需要导出最终的采集数据信息,点击下图中的导出按钮,选择要导出的文件类型,系统会提示保存路径,选择保存路径,系统会自动导出文件。

网页表格抓取(这是简易数据分析系列的第11篇文章(图)制作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-26 11:16
这是简易数据分析系列文章的第11期。
今天我们将讨论如何在 Web 表单中捕获数据。首先我们来分析一下网页中的经典表格是如何组成的。
经典的表格都是关于这些知识点的,没了。让我们编写一个简单的表单 Web Scraper 爬虫。
1.创建站点地图
我们今天的练习 网站 是
�Ϻ�&txt刀大=����
爬虫的内容是爬取上海到北京的所有火车时刻表。
我们首先创建一个收录整个表格的容器,并将Type选择为Table,表示我们要抓取表格。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。如果你看一下,你会发现这些数据实际上是表数据类型的分类。在这种情况下,他列出了火车、出发站和行驶时间的类别。
在表格列类别中,默认勾选每行内容旁边的选择按钮,这意味着默认捕获这些列的内容。如果您不想爬取某种类型的内容,只需去掉相应的复选框即可。
当你点击保存选择器按钮的时候,你会发现Result键的一些选项报错,说invalid format format无效:
解决这个错误非常简单。一般来说,Result 键名的长度是不够的。您可以添加空格和标点符号。如果仍然出现错误,请尝试更改为英文名称:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程抓取数据了。
2.我为什么不建议你使用 Web Scraper 的表格选择器?
如果按照刚才的教程,感觉会很流畅,但是看数据的时候,就傻眼了。
刚开始爬的时候,我们先用Data preview预览数据,发现数据很完美:
抓取数据后,在浏览器的预览面板中预览,会发现trains一栏的数据为null,表示没有抓取到相关内容:
我们下载捕获的CSV文件并在预览器中打开后,我们会发现出现了列车号的数据,但是出发站的数据又为空了!
这不是傻子!
我已经研究这个问题很长时间了。应该是Web Scraper对中文关键词索引的支持不是很友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表数据,可以使用前面的方案,先创建一个Element类型的容器,然后在容器中手动创建一个子选择器,这样就可以避免这个问题了。
以上只是一个原因,另一个原因是,在现代 网站 中,很少有人再使用 HTML 原创表格了。
HTML 为表格提供了基本的标签,例如 、 、 等,这些标签提供了默认样式。优点是互联网刚开发的时候,可以提供开箱即用的形式;缺点是样式过于简单,不易定制。后来很多网站用其他标签来模拟表格,就像PPT用各种大小的块组合成一个表格,很容易自定义:
正因如此,当你使用Table Selector匹配一个表格的时候,可能会匹配不上,因为从Web Scraper的角度来看,你看到的表格是高仿的,根本不是原装的,自然不是。认可。
3.总结
我们不建议直接使用 Web Scraper 的 Table Selector,因为它对中文支持不是很友好,也不太适合现代网页。如果有抢表的需求,可以使用之前创建父子选择器的方法来做。 查看全部
网页表格抓取(这是简易数据分析系列的第11篇文章(图)制作)
这是简易数据分析系列文章的第11期。
今天我们将讨论如何在 Web 表单中捕获数据。首先我们来分析一下网页中的经典表格是如何组成的。

经典的表格都是关于这些知识点的,没了。让我们编写一个简单的表单 Web Scraper 爬虫。
1.创建站点地图
我们今天的练习 网站 是
�Ϻ�&txt刀大=����
爬虫的内容是爬取上海到北京的所有火车时刻表。
我们首先创建一个收录整个表格的容器,并将Type选择为Table,表示我们要抓取表格。

具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。如果你看一下,你会发现这些数据实际上是表数据类型的分类。在这种情况下,他列出了火车、出发站和行驶时间的类别。

在表格列类别中,默认勾选每行内容旁边的选择按钮,这意味着默认捕获这些列的内容。如果您不想爬取某种类型的内容,只需去掉相应的复选框即可。
当你点击保存选择器按钮的时候,你会发现Result键的一些选项报错,说invalid format format无效:

解决这个错误非常简单。一般来说,Result 键名的长度是不够的。您可以添加空格和标点符号。如果仍然出现错误,请尝试更改为英文名称:

解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程抓取数据了。
2.我为什么不建议你使用 Web Scraper 的表格选择器?
如果按照刚才的教程,感觉会很流畅,但是看数据的时候,就傻眼了。
刚开始爬的时候,我们先用Data preview预览数据,发现数据很完美:

抓取数据后,在浏览器的预览面板中预览,会发现trains一栏的数据为null,表示没有抓取到相关内容:

我们下载捕获的CSV文件并在预览器中打开后,我们会发现出现了列车号的数据,但是出发站的数据又为空了!

这不是傻子!
我已经研究这个问题很长时间了。应该是Web Scraper对中文关键词索引的支持不是很友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表数据,可以使用前面的方案,先创建一个Element类型的容器,然后在容器中手动创建一个子选择器,这样就可以避免这个问题了。
以上只是一个原因,另一个原因是,在现代 网站 中,很少有人再使用 HTML 原创表格了。
HTML 为表格提供了基本的标签,例如 、 、 等,这些标签提供了默认样式。优点是互联网刚开发的时候,可以提供开箱即用的形式;缺点是样式过于简单,不易定制。后来很多网站用其他标签来模拟表格,就像PPT用各种大小的块组合成一个表格,很容易自定义:

正因如此,当你使用Table Selector匹配一个表格的时候,可能会匹配不上,因为从Web Scraper的角度来看,你看到的表格是高仿的,根本不是原装的,自然不是。认可。
3.总结
我们不建议直接使用 Web Scraper 的 Table Selector,因为它对中文支持不是很友好,也不太适合现代网页。如果有抢表的需求,可以使用之前创建父子选择器的方法来做。
网页表格抓取( 终端窗口查询全国3400多个区县当日天气信息和近七天信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-12 23:03
终端窗口查询全国3400多个区县当日天气信息和近七天信息)
写一个爬中国天气网的终端版天气预报爬虫
前几篇文章介绍了爬取静态网站的主要方法。今天写一个小项目来练习。本项目可在终端窗口查询全国3400多个区县当天及过去7天的天气信息。实现获取原创链接文件的效果:在公众号Thumbnote后台回复“天气预报”即可获取相关节目和城市id文件。使用方法:在终端窗口运行程序,输入要查询的区县名称(如:丰台、静安等)。相关模块 pandas:读取城市 ID 文件 prettytable:输出 ASC 样式表 bs4:解析网页 天气信息存储在不同的网页中,其 url 如下
现在下载
wiki-scraper:从维基百科中抓取表格和其他信息 - 源代码
Wikicrawler 这是一个简单的脚本,它从 Wikipedia 抓取数据表以安装所需的软件包: pip install beautifulsoup4, pip install pandas 这个例子从一个城市的大都市区抓取人口数据。输出 .dat 文件由双冒号分隔。基于 ADEsquared 的教程::///2013/06/16/using-python-beautifulsoup-to-scrape-a-wikipedia-table/
现在下载
Python 读取文本中的数据并将其转换为 DataFrame 的实例
在一次技术问答中看到这样的问题,觉得比较常见,所以就点开一篇文章文章写下来。从纯文本文件“file_in”中读取数据,格式如下:需要输出到“file_out”,格式如下:数据的原创格式为“category: content”,空行“ \n"作为条目,转换后变成一个条目一行,内容按类别顺序写出。建议看完后使用pandas将数据构建成一个名为DataFrame的表。这使得以后处理数据更容易。但是原创格式不是通常的表格格式,所以先做一些简单的处理。#coding:utf8import sysfrom pandas import DataFrame #DataFrame 通常用于加载二维表导入
现在下载
双色球的单线程爬行网站.py
通过pandas爬表,可供个人测试,爬取双色球网站的所有数据。注意:抓取访问为csv格式,可以在excel中读取,但建议在excel中编辑后保存为xlsx格式,否则会造成混乱。
现在下载
pandas 实现了一种对重复表进行去重并重新转换为表的方法
在python中处理数据时,经常使用DataFrame和set。train=pd.read_csv('XXX.csv')#读取文件 train=train['item_id']#选择要重复的列 train=set(train)#删除数据=pd.DataFrame(list(train) , columns=['item_id'])#因为集合是无序的,所以必须经过列表处理才能成为DataFramedata.to_csv('xxx.csv',index=False)#保存表格记得导入pandas~以上文章Pandas实现了对重复表进行去重再转表的方法。小编分享给大家。
现在下载
Matplotlib图形化分析猪肉价格上涨趋势,pandas数据处理
1.爬取新发地果蔬价格csv,上一张表的内容,爬取新发地果蔬价格并保存为csv格式,筛选出毛猪和白条猪,< @2. 筛选分析猪肉价格,使用matplotlib库制作趋势图#pandasimport pandas as pd #导入数据处理工具pandasimport matplotlib.pyplot as plt#导入图形展示工具matplotlibdataframe = pd.read_csv(新菜价.csv, header=None)#print(dataframe )#获取数据 fei = dataframe[dataframe[0] == 白猪(胖)]shou =
现在下载
300hero_report:300英雄记录查询-源码
300英雄记录查询一个爬虫+一个GUI来下载数据并找到一种显示方式。scrapy PyQt matplotlib 还没有完成。操作方法为python 300hero.pyTODO,防止爬取重复信息数据,存入本地库。查询时,优先从本地库中获取。当你点击某个会话时,会弹出一个对话框,显示该字段的详细数据,并使数据显示更规则(可能你需要pandas和matplotlib)加点图表(组分数变化图表...)多窗口(点击显示详细战况)然后一个网页端具体游戏数据,不再使用爬虫,使用api获取Bug 重复查询会报错 twisted.internet.error 。
现在下载
使用xpath爬取链家租房数据并使用pandas保存到Excel文件
<p>我们的需求是使用xpath爬取链家的租房数据,并通过pandas将数据保存到Excel文件中。我们来看看链家官网的上市信息(以北京为例)。如图,我们通过筛选得到北京。出租信息然后我们需要通过爬虫提取房屋面积、小区名称、户型、面积、朝向、价格等信息。思考步骤:1.通过翻页,我们看到总页数是100页,那么我们需要通过format方法获取100个url地址列表url_list; 查看全部
网页表格抓取(
终端窗口查询全国3400多个区县当日天气信息和近七天信息)

写一个爬中国天气网的终端版天气预报爬虫
前几篇文章介绍了爬取静态网站的主要方法。今天写一个小项目来练习。本项目可在终端窗口查询全国3400多个区县当天及过去7天的天气信息。实现获取原创链接文件的效果:在公众号Thumbnote后台回复“天气预报”即可获取相关节目和城市id文件。使用方法:在终端窗口运行程序,输入要查询的区县名称(如:丰台、静安等)。相关模块 pandas:读取城市 ID 文件 prettytable:输出 ASC 样式表 bs4:解析网页 天气信息存储在不同的网页中,其 url 如下
现在下载

wiki-scraper:从维基百科中抓取表格和其他信息 - 源代码
Wikicrawler 这是一个简单的脚本,它从 Wikipedia 抓取数据表以安装所需的软件包: pip install beautifulsoup4, pip install pandas 这个例子从一个城市的大都市区抓取人口数据。输出 .dat 文件由双冒号分隔。基于 ADEsquared 的教程::///2013/06/16/using-python-beautifulsoup-to-scrape-a-wikipedia-table/
现在下载
Python 读取文本中的数据并将其转换为 DataFrame 的实例
在一次技术问答中看到这样的问题,觉得比较常见,所以就点开一篇文章文章写下来。从纯文本文件“file_in”中读取数据,格式如下:需要输出到“file_out”,格式如下:数据的原创格式为“category: content”,空行“ \n"作为条目,转换后变成一个条目一行,内容按类别顺序写出。建议看完后使用pandas将数据构建成一个名为DataFrame的表。这使得以后处理数据更容易。但是原创格式不是通常的表格格式,所以先做一些简单的处理。#coding:utf8import sysfrom pandas import DataFrame #DataFrame 通常用于加载二维表导入
现在下载

双色球的单线程爬行网站.py
通过pandas爬表,可供个人测试,爬取双色球网站的所有数据。注意:抓取访问为csv格式,可以在excel中读取,但建议在excel中编辑后保存为xlsx格式,否则会造成混乱。
现在下载
pandas 实现了一种对重复表进行去重并重新转换为表的方法
在python中处理数据时,经常使用DataFrame和set。train=pd.read_csv('XXX.csv')#读取文件 train=train['item_id']#选择要重复的列 train=set(train)#删除数据=pd.DataFrame(list(train) , columns=['item_id'])#因为集合是无序的,所以必须经过列表处理才能成为DataFramedata.to_csv('xxx.csv',index=False)#保存表格记得导入pandas~以上文章Pandas实现了对重复表进行去重再转表的方法。小编分享给大家。
现在下载
Matplotlib图形化分析猪肉价格上涨趋势,pandas数据处理
1.爬取新发地果蔬价格csv,上一张表的内容,爬取新发地果蔬价格并保存为csv格式,筛选出毛猪和白条猪,< @2. 筛选分析猪肉价格,使用matplotlib库制作趋势图#pandasimport pandas as pd #导入数据处理工具pandasimport matplotlib.pyplot as plt#导入图形展示工具matplotlibdataframe = pd.read_csv(新菜价.csv, header=None)#print(dataframe )#获取数据 fei = dataframe[dataframe[0] == 白猪(胖)]shou =
现在下载
300hero_report:300英雄记录查询-源码
300英雄记录查询一个爬虫+一个GUI来下载数据并找到一种显示方式。scrapy PyQt matplotlib 还没有完成。操作方法为python 300hero.pyTODO,防止爬取重复信息数据,存入本地库。查询时,优先从本地库中获取。当你点击某个会话时,会弹出一个对话框,显示该字段的详细数据,并使数据显示更规则(可能你需要pandas和matplotlib)加点图表(组分数变化图表...)多窗口(点击显示详细战况)然后一个网页端具体游戏数据,不再使用爬虫,使用api获取Bug 重复查询会报错 twisted.internet.error 。
现在下载
使用xpath爬取链家租房数据并使用pandas保存到Excel文件
<p>我们的需求是使用xpath爬取链家的租房数据,并通过pandas将数据保存到Excel文件中。我们来看看链家官网的上市信息(以北京为例)。如图,我们通过筛选得到北京。出租信息然后我们需要通过爬虫提取房屋面积、小区名称、户型、面积、朝向、价格等信息。思考步骤:1.通过翻页,我们看到总页数是100页,那么我们需要通过format方法获取100个url地址列表url_list;
网页表格抓取(如何用Python爬数据?(第三弹)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-02-12 12:03
阿里云 > 云栖社区 > 主题地图 > R > 如何爬取Web表单数据库
推荐活动:
更多优惠>
当前主题:如何爬取网页表单数据库添加到采集夹
相关话题:
如何抓取网页表单数据库相关的博客查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
如何使用 Python 抓取数据?(一)网页抓取
作者:王淑仪2089 浏览评论:03年前
你期待已久的 Python 网络数据爬虫教程就在这里。本文向您展示了如何从网页中查找感兴趣的链接和描述,并在 Excel 中抓取和存储它们。我需要在公众号后台,经常可以收到读者的消息。许多评论是读者的问题。只要我有时间,我会尝试回答它。但是有些消息乍一看似乎不清楚
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶387人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐人指定歌曲的歌曲名、专辑名、播放链接歌手并在指定页数中排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶397人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐人指定歌曲的歌曲名、专辑名、播放链接歌手并在指定页数中排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
初学者指南 | 使用 Python 进行网页抓取
作者:小旋风柴津2425查看评论:04年前
简介 从网页中提取信息的需求和重要性正在增长。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。
阅读全文
云计算时代企业该如何拥抱大数据?
作者:云栖大讲堂 1408 观众评论:04年前
这篇文章是关于企业在云计算时代应该如何拥抱大数据。随着云计算的实施,“大数据”已经成为业界讨论最广泛的话题之一,许多企业已经在寻找合适的 BI 工具来处理从不同来源采集的大数据,但尽管大数据意识不断增强,只有谷歌和 Facebook 等少数企业能够
阅读全文
云计算时代企业该如何拥抱大数据?
作者:云栖大讲堂 969人浏览评论:04年前
这篇文章是关于企业在云计算时代应该如何拥抱大数据。随着云计算的实施,“大数据”已经成为业界讨论最广泛的话题之一,许多企业已经在寻找合适的 BI 工具来处理从不同来源采集的大数据,但尽管大数据意识不断增强,只有谷歌和 Facebook 等少数企业能够
阅读全文
使用 Scrapy 抓取数据
作者:御客6542 浏览评论:05年前
Scrapy 是一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
《用 Python 编写网络爬虫》——2.2 三种网络爬取方法
作者:异步社区 3748人查看评论:04年前
本节节选自异步社区《Writing Web Crawler in Python》一书第2章第2.2节,作者【澳大利亚】Richard Lawson,李斌翻译,更多章节内容可以参考访问云栖社区“异步社区”公众号查看。2.2 三种网页抓取方式 既然我们了解了网页的结构,以下
阅读全文
如何爬取web表单数据库相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
网页表格抓取(如何用Python爬数据?(第三弹)(组图))
阿里云 > 云栖社区 > 主题地图 > R > 如何爬取Web表单数据库

推荐活动:
更多优惠>
当前主题:如何爬取网页表单数据库添加到采集夹
相关话题:
如何抓取网页表单数据库相关的博客查看更多博客
云数据库产品概述

作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
如何使用 Python 抓取数据?(一)网页抓取


作者:王淑仪2089 浏览评论:03年前
你期待已久的 Python 网络数据爬虫教程就在这里。本文向您展示了如何从网页中查找感兴趣的链接和描述,并在 Excel 中抓取和存储它们。我需要在公众号后台,经常可以收到读者的消息。许多评论是读者的问题。只要我有时间,我会尝试回答它。但是有些消息乍一看似乎不清楚
阅读全文
教你用Python抓取QQ音乐数据(第三弹)


作者:python进阶387人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐人指定歌曲的歌曲名、专辑名、播放链接歌手并在指定页数中排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
教你用Python抓取QQ音乐数据(第三弹)

作者:python进阶397人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐人指定歌曲的歌曲名、专辑名、播放链接歌手并在指定页数中排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
初学者指南 | 使用 Python 进行网页抓取


作者:小旋风柴津2425查看评论:04年前
简介 从网页中提取信息的需求和重要性正在增长。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。
阅读全文
云计算时代企业该如何拥抱大数据?


作者:云栖大讲堂 1408 观众评论:04年前
这篇文章是关于企业在云计算时代应该如何拥抱大数据。随着云计算的实施,“大数据”已经成为业界讨论最广泛的话题之一,许多企业已经在寻找合适的 BI 工具来处理从不同来源采集的大数据,但尽管大数据意识不断增强,只有谷歌和 Facebook 等少数企业能够
阅读全文
云计算时代企业该如何拥抱大数据?

作者:云栖大讲堂 969人浏览评论:04年前
这篇文章是关于企业在云计算时代应该如何拥抱大数据。随着云计算的实施,“大数据”已经成为业界讨论最广泛的话题之一,许多企业已经在寻找合适的 BI 工具来处理从不同来源采集的大数据,但尽管大数据意识不断增强,只有谷歌和 Facebook 等少数企业能够
阅读全文
使用 Scrapy 抓取数据
作者:御客6542 浏览评论:05年前
Scrapy 是一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
《用 Python 编写网络爬虫》——2.2 三种网络爬取方法


作者:异步社区 3748人查看评论:04年前
本节节选自异步社区《Writing Web Crawler in Python》一书第2章第2.2节,作者【澳大利亚】Richard Lawson,李斌翻译,更多章节内容可以参考访问云栖社区“异步社区”公众号查看。2.2 三种网页抓取方式 既然我们了解了网页的结构,以下
阅读全文
如何爬取web表单数据库相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑


作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
网页表格抓取(本文实例讲述Python实现抓取网页生成Excel文件的方法。 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-11 22:07
)
本文中的示例描述了 Python 如何实现爬取网页以生成 Excel 文件。分享给大家,供大家参考,如下:
Python抓取网页,主要使用PyQuery,和jQuery一样,超级强大
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
接下来就是用Notepad++打开gongsi.csv,然后转换成ANSI编码格式保存。然后用Excel软件打开csv文件,保存为Excel文件
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python中Excel表格技巧总结》、《Python文件和目录操作技巧总结》、《Python文本文件操作总结》 《技能》、《Python数据》《结构与算法教程》、《Python函数技巧总结》、《Python字符串操作技巧总结》和《Python入门与进阶经典教程》
希望这篇文章对你的 Python 编程有所帮助。
Python如何实现爬取网页生成Excel文件的例子 查看全部
网页表格抓取(本文实例讲述Python实现抓取网页生成Excel文件的方法。
)
本文中的示例描述了 Python 如何实现爬取网页以生成 Excel 文件。分享给大家,供大家参考,如下:
Python抓取网页,主要使用PyQuery,和jQuery一样,超级强大
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
接下来就是用Notepad++打开gongsi.csv,然后转换成ANSI编码格式保存。然后用Excel软件打开csv文件,保存为Excel文件
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python中Excel表格技巧总结》、《Python文件和目录操作技巧总结》、《Python文本文件操作总结》 《技能》、《Python数据》《结构与算法教程》、《Python函数技巧总结》、《Python字符串操作技巧总结》和《Python入门与进阶经典教程》
希望这篇文章对你的 Python 编程有所帮助。
Python如何实现爬取网页生成Excel文件的例子
网页表格抓取(如何用Python爬数据?(第三弹)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-02-10 21:14
阿里云 > 云栖社区 > 主题地图 > R > 如何爬取Web表单数据库
推荐活动:
更多优惠>
当前主题:如何爬取网页表单数据库添加到采集夹
相关话题:
如何抓取网页表单数据库相关的博客查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
如何使用 Python 抓取数据?(一)网页抓取
作者:王淑仪2089 浏览评论:03年前
你期待已久的 Python 网络数据爬虫教程就在这里。本文向您展示了如何从网页中查找感兴趣的链接和描述,并在 Excel 中抓取和存储它们。我需要在公众号后台,经常可以收到读者的消息。许多评论是读者的问题。只要我有时间,我会尝试回答它。但是有些消息乍一看似乎不清楚
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶387人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐人指定歌曲的歌曲名、专辑名、播放链接歌手并在指定页数中排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶397人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐人指定歌曲的歌曲名、专辑名、播放链接歌手并在指定页数中排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
初学者指南 | 使用 Python 进行网页抓取
作者:小旋风柴津2425查看评论:04年前
简介 从网页中提取信息的需求和重要性正在增长。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。
阅读全文
云计算时代企业该如何拥抱大数据?
作者:云栖大讲堂 1408 观众评论:04年前
这篇文章是关于企业在云计算时代应该如何拥抱大数据。随着云计算的实施,“大数据”已成为业界讨论最广泛的话题之一,许多企业已经在寻找合适的 BI 工具来处理从不同来源采集的大数据,但尽管大数据意识不断增强,只有谷歌和 Facebook 等少数企业能够
阅读全文
云计算时代企业该如何拥抱大数据?
作者:云栖大讲堂 969人浏览评论:04年前
这篇文章是关于企业在云计算时代应该如何拥抱大数据。随着云计算的实施,“大数据”已成为业界讨论最广泛的话题之一,许多企业已经在寻找合适的 BI 工具来处理从不同来源采集的大数据,但尽管大数据意识不断增强,只有谷歌和 Facebook 等少数企业能够
阅读全文
使用 Scrapy 抓取数据
作者:御客6542 浏览评论:05年前
Scrapy 是一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
《用 Python 编写网络爬虫》——2.2 三种网络爬取方法
作者:异步社区 3748人查看评论:04年前
本节节选自异步社区《Writing Web Crawler in Python》一书第2章第2.2节,作者【澳大利亚】Richard Lawson,李斌翻译,更多章节内容可以参考访问云栖社区“异步社区”公众号查看。2.2 三种网页抓取方式 既然我们了解了网页的结构,以下
阅读全文
如何爬取web表单数据库相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
网页表格抓取(如何用Python爬数据?(第三弹)(组图))
阿里云 > 云栖社区 > 主题地图 > R > 如何爬取Web表单数据库
推荐活动:
更多优惠>
当前主题:如何爬取网页表单数据库添加到采集夹
相关话题:
如何抓取网页表单数据库相关的博客查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
如何使用 Python 抓取数据?(一)网页抓取
作者:王淑仪2089 浏览评论:03年前
你期待已久的 Python 网络数据爬虫教程就在这里。本文向您展示了如何从网页中查找感兴趣的链接和描述,并在 Excel 中抓取和存储它们。我需要在公众号后台,经常可以收到读者的消息。许多评论是读者的问题。只要我有时间,我会尝试回答它。但是有些消息乍一看似乎不清楚
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶387人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐人指定歌曲的歌曲名、专辑名、播放链接歌手并在指定页数中排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶397人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐人指定歌曲的歌曲名、专辑名、播放链接歌手并在指定页数中排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
初学者指南 | 使用 Python 进行网页抓取
作者:小旋风柴津2425查看评论:04年前
简介 从网页中提取信息的需求和重要性正在增长。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。
阅读全文
云计算时代企业该如何拥抱大数据?
作者:云栖大讲堂 1408 观众评论:04年前
这篇文章是关于企业在云计算时代应该如何拥抱大数据。随着云计算的实施,“大数据”已成为业界讨论最广泛的话题之一,许多企业已经在寻找合适的 BI 工具来处理从不同来源采集的大数据,但尽管大数据意识不断增强,只有谷歌和 Facebook 等少数企业能够
阅读全文
云计算时代企业该如何拥抱大数据?
作者:云栖大讲堂 969人浏览评论:04年前
这篇文章是关于企业在云计算时代应该如何拥抱大数据。随着云计算的实施,“大数据”已成为业界讨论最广泛的话题之一,许多企业已经在寻找合适的 BI 工具来处理从不同来源采集的大数据,但尽管大数据意识不断增强,只有谷歌和 Facebook 等少数企业能够
阅读全文
使用 Scrapy 抓取数据
作者:御客6542 浏览评论:05年前
Scrapy 是一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
《用 Python 编写网络爬虫》——2.2 三种网络爬取方法
作者:异步社区 3748人查看评论:04年前
本节节选自异步社区《Writing Web Crawler in Python》一书第2章第2.2节,作者【澳大利亚】Richard Lawson,李斌翻译,更多章节内容可以参考访问云栖社区“异步社区”公众号查看。2.2 三种网页抓取方式 既然我们了解了网页的结构,以下
阅读全文
如何爬取web表单数据库相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
网页表格抓取(Google为什么做网站时一定要注意搜索引擎友好(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-02-10 01:21
虽然谷歌已经是爬取页面最多的搜索引擎,但仍然不满足,因为有很多页面和信息很难找到和爬取。这就是为什么在执行 网站 时对 SEO 友好很重要的原因。
现在谷歌开始提供提交表单(form)来发现后续页面。本来想写详细说明的,结果刚看到写了幻灭,直接引用主要内容如下。
我们已经知道Googlebot除了文字、视频、音频、Flash等类型的内容外,还可以通过JS代码抓取链接。而在未来,Googlebot 也有望直接识别图片和视频中的文字。为了进一步抓取互联网,Google 宣布 Googlebot 已经能够通过提交表单抓取更多内容。
据 Google 称,Googlebot 目前正在试验一小部分高质量的 网站 表单提交。当Googlebot在这些网站上找到HTML表格时(即检测到时),会自动从网站中选择一些词进入表格的文本框,然后选择不同的按钮,勾选选项和验证项目,然后提交表格。一旦 Googlebot 在提交表单后认为新内容看起来是合法、有趣和独特的,它可能会将内容抓取到 Google 的搜索结果索引数据库中。这意味着 Googlebot 现在知道如何通过提交表单来获取新内容。
同时谷歌还强调,如果在网站的robots.txt文件中禁止隐藏表单,并且表单提交后生成的链接预计不会被抓取,那么Googlebot不会爬行。此外,目前 Googlebot 仅提交 GET 类型的表单。例如,当表单需要用户个人信息(如密码、用户名、联系人等)时,Googlebot 会自动跳过这些表单。
这种形式的抓取目前是一个小型实验,Google 表示不会影响 网站。既不会影响网站的PR值,也不会影响网站的正常爬取和排名。
Matt Cutts 还写了一篇文章来说明这样做的好处。有很多网站主页只以表格的形式列出公司的子站,并没有以链接的形式列出子站。这种网站不能深入收录之前,因为谷歌不提交表单就找不到隐藏在表单后面的URL。
这当然给一些网站的收录创造了机会,但是否也给一些公司网站带来了一定的安全风险?网站如果你不想被收录屏蔽,请使用robots.txt文件来屏蔽它。 查看全部
网页表格抓取(Google为什么做网站时一定要注意搜索引擎友好(图))
虽然谷歌已经是爬取页面最多的搜索引擎,但仍然不满足,因为有很多页面和信息很难找到和爬取。这就是为什么在执行 网站 时对 SEO 友好很重要的原因。
现在谷歌开始提供提交表单(form)来发现后续页面。本来想写详细说明的,结果刚看到写了幻灭,直接引用主要内容如下。
我们已经知道Googlebot除了文字、视频、音频、Flash等类型的内容外,还可以通过JS代码抓取链接。而在未来,Googlebot 也有望直接识别图片和视频中的文字。为了进一步抓取互联网,Google 宣布 Googlebot 已经能够通过提交表单抓取更多内容。
据 Google 称,Googlebot 目前正在试验一小部分高质量的 网站 表单提交。当Googlebot在这些网站上找到HTML表格时(即检测到时),会自动从网站中选择一些词进入表格的文本框,然后选择不同的按钮,勾选选项和验证项目,然后提交表格。一旦 Googlebot 在提交表单后认为新内容看起来是合法、有趣和独特的,它可能会将内容抓取到 Google 的搜索结果索引数据库中。这意味着 Googlebot 现在知道如何通过提交表单来获取新内容。
同时谷歌还强调,如果在网站的robots.txt文件中禁止隐藏表单,并且表单提交后生成的链接预计不会被抓取,那么Googlebot不会爬行。此外,目前 Googlebot 仅提交 GET 类型的表单。例如,当表单需要用户个人信息(如密码、用户名、联系人等)时,Googlebot 会自动跳过这些表单。
这种形式的抓取目前是一个小型实验,Google 表示不会影响 网站。既不会影响网站的PR值,也不会影响网站的正常爬取和排名。
Matt Cutts 还写了一篇文章来说明这样做的好处。有很多网站主页只以表格的形式列出公司的子站,并没有以链接的形式列出子站。这种网站不能深入收录之前,因为谷歌不提交表单就找不到隐藏在表单后面的URL。
这当然给一些网站的收录创造了机会,但是否也给一些公司网站带来了一定的安全风险?网站如果你不想被收录屏蔽,请使用robots.txt文件来屏蔽它。
网页表格抓取(借助ABBYYFineReader15文字识别软件快速识别为表格数据表格)
网站优化 • 优采云 发表了文章 • 0 个评论 • 328 次浏览 • 2022-02-08 18:35
在一些政府公共信息共享网站或专业数据共享机构网站,会定期公开共享一些社会发展数据或与时事相关的数据。这些数据通常以网页的形式共享,很少提供文件下载。
如果直接复制这些数据,数据排版会耗费大量时间。但借助 ABBYY FineReader PDF 15 文本识别软件,可以快速识别为表格数据,并导出为可编辑的数据表。接下来,让我们看看它是如何工作的。
一、网页表格数据截图
首先打开相关数据网站,对数据表区域进行截图。
图1:打开网页截图
如图2所示,在截屏过程中,建议尽量保持表格边框的完整性,以提高ABBYY FineReader PDF 15的识别准确率。
图 2:完成的表格数据的屏幕截图
二、使用 OCR 编辑器识别表格
接下来,打开ABBYY FineReader PDF 15文本识别软件,使用“在OCR编辑器中打开”功能打开刚刚在网站截取的表格数据。
图 3:在 OCR 编辑器中打开图像
接下来,等待软件完成对图片的文字识别。在识别过程中,为了提高文字识别的准确率,软件会提示图片的分辨率或指定的OCR语言。如果条件允许(如提高图像分辨率),您可以按照建议修改相关设置。
图 4:完成 OCR 识别
完成文本识别程序后,我们首先需要在区域属性面板中检查表格标签的区域属性是否正确。如图 5 所示,可以看出 ABBYY FineReader PDF 15 已正确将此区域标记为表格区域。
图 5:区域属性
接下来,查看软件的文本编辑面板。如图 6 所示,可以看到文本已经以电子表格的形式呈现,并且可以在单元格中编辑文本。
图 6:文本编辑器
三、导出到 Excel
为了方便后续的数据处理,我们可以将识别出来的电子表格保存为Excel文件。如图7所示,在文本编辑面板顶部选择Excel表格的保存格式后,可以将当前文本导出为Excel文件。
图 7:另存为 Excel 工作表
打开导出的Excel文件,可以看到ABBYY FineReader PDF 15不仅可以准确识别数据,还可以“复制”表格的格式,很好地将数据导出到每个单元格。这种形式的导出可以减少排版大量数据所需的时间。
图 8:导出的 Excel 表格
四、总结
通过使用ABBYY文字识别软件的数据表格识别功能,我们可以快速将图片中的表格转换成可编辑的电子表格,提高数据使用效率。这么好用的功能,你学会了吗? 查看全部
网页表格抓取(借助ABBYYFineReader15文字识别软件快速识别为表格数据表格)
在一些政府公共信息共享网站或专业数据共享机构网站,会定期公开共享一些社会发展数据或与时事相关的数据。这些数据通常以网页的形式共享,很少提供文件下载。
如果直接复制这些数据,数据排版会耗费大量时间。但借助 ABBYY FineReader PDF 15 文本识别软件,可以快速识别为表格数据,并导出为可编辑的数据表。接下来,让我们看看它是如何工作的。
一、网页表格数据截图
首先打开相关数据网站,对数据表区域进行截图。
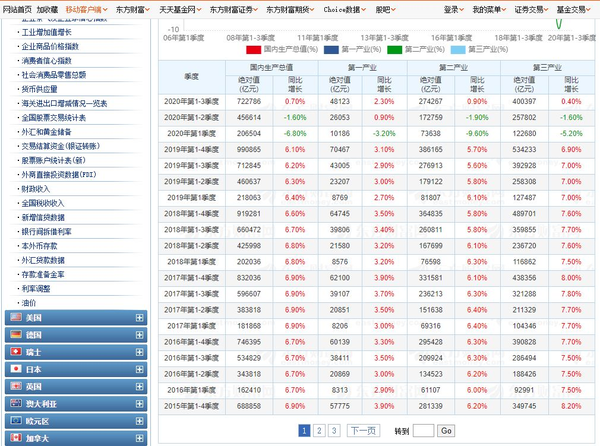
图1:打开网页截图
如图2所示,在截屏过程中,建议尽量保持表格边框的完整性,以提高ABBYY FineReader PDF 15的识别准确率。
图 2:完成的表格数据的屏幕截图
二、使用 OCR 编辑器识别表格
接下来,打开ABBYY FineReader PDF 15文本识别软件,使用“在OCR编辑器中打开”功能打开刚刚在网站截取的表格数据。

图 3:在 OCR 编辑器中打开图像
接下来,等待软件完成对图片的文字识别。在识别过程中,为了提高文字识别的准确率,软件会提示图片的分辨率或指定的OCR语言。如果条件允许(如提高图像分辨率),您可以按照建议修改相关设置。
图 4:完成 OCR 识别
完成文本识别程序后,我们首先需要在区域属性面板中检查表格标签的区域属性是否正确。如图 5 所示,可以看出 ABBYY FineReader PDF 15 已正确将此区域标记为表格区域。
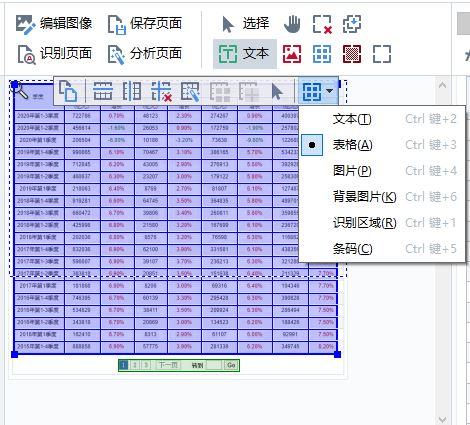
图 5:区域属性
接下来,查看软件的文本编辑面板。如图 6 所示,可以看到文本已经以电子表格的形式呈现,并且可以在单元格中编辑文本。
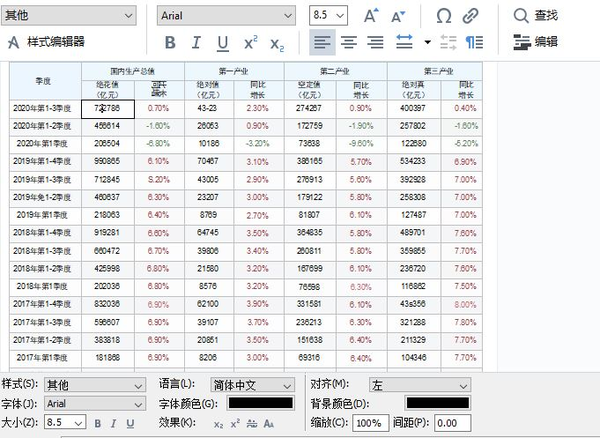
图 6:文本编辑器
三、导出到 Excel
为了方便后续的数据处理,我们可以将识别出来的电子表格保存为Excel文件。如图7所示,在文本编辑面板顶部选择Excel表格的保存格式后,可以将当前文本导出为Excel文件。
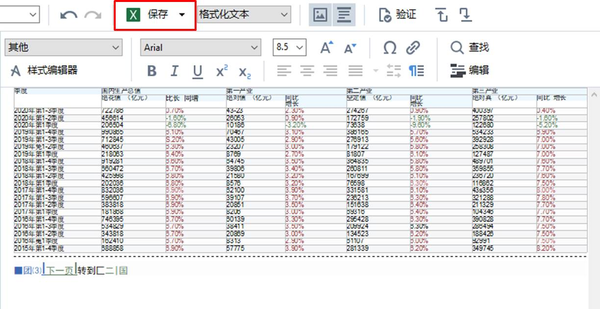
图 7:另存为 Excel 工作表
打开导出的Excel文件,可以看到ABBYY FineReader PDF 15不仅可以准确识别数据,还可以“复制”表格的格式,很好地将数据导出到每个单元格。这种形式的导出可以减少排版大量数据所需的时间。
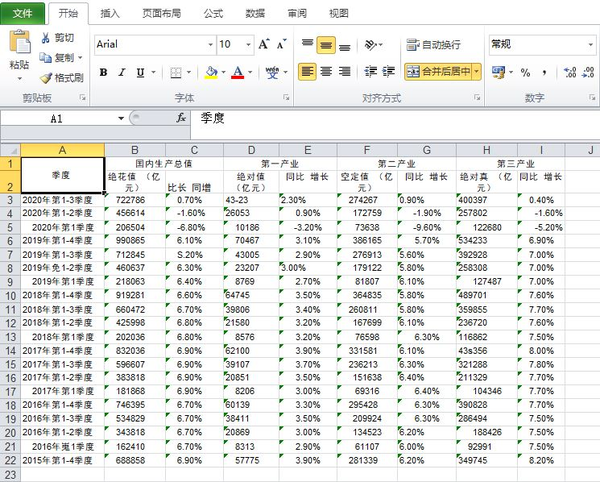
图 8:导出的 Excel 表格
四、总结
通过使用ABBYY文字识别软件的数据表格识别功能,我们可以快速将图片中的表格转换成可编辑的电子表格,提高数据使用效率。这么好用的功能,你学会了吗?
网页表格抓取(发明专利技术提供一种网页表格数据抽取的方法及实现步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-03-22 22:06
本发明专利技术提供了一种从网页中提取数据的方法,包括:步骤10、读取网页源代码,根据字符码解析成W3C Document对象,得到任意两个网页表单关键词;Step 20、深度优先遍历Document对象中的所有节点,得到两个关键词所属的两个节点;Step 30、 获取具有唯一属性的两个节点的共同父节点,并使用唯一属性获取网页表定位条件;Step 4 0、使用网页表数据定位条件,过滤网页源代码,提取与网页显示效果相同的网页表。
下载所有详细的技术数据
【技术实现步骤总结】
该专利技术涉及网页
,尤其是涉及。
技术介绍
随着网络技术的不断发展,网页的显示效果和所收录的信息量越来越复杂,网页的结构和内容也在实时更新。但是为了从网页中获取指定的表格数据,需要在大量冗长的网页源码中手动查找表格的位置、标签和属性,从而定位到表格对应的源码并获取表格数据。这不仅需要大量的工作,而且浪费时间和精力。同时,在复杂的网页代码中搜索容易出错,不能满足实时数据的要求。W3C是英文World Wide Web Consortium的缩写,中文意思是W3C委员会或万维网联盟。W3C 组织是制定网络标准的非营利组织。HTML、XHTML、CSS 和 XML 等标准由 W3C 定制。现有技术提供了一种基于DOM树的信息抽取过滤方法,来自《中国学术期刊网络出版总库》,发表日期为2009/9/15,来源中国过滤网,描述了A页面预处理方法,将 HTML 解析为 DOM,利用 DOM 树的特性,不仅可以从大的逻辑单元中提取信息,还可以对更小的单元进行操作,完成信息提取中的页面预处理。这大大提高了信息提取的效率和准确性。该方法还提供了三个过滤器,每个过滤器都可以由用户设置,以完成不同程度的过滤,并以适当的顺序选择和堆叠各个过滤器,形成最佳的预处理组合。该方法的目标不是提取细粒度的数据,而是过滤掉网页中杂乱冗余的信息,比如广告、不相关的链接等,即完成对网页中页面的预处理。网页。
技术实现思路
该专利技术要解决的技术问题是,提供从实时变化的网页中准确、快速地提取出与原网页显示效果相同的表格,并获取指定的行/列数据。专利技术就是这样实现的,其特征在于包括以下步骤: 步骤1 0、读取网页源代码,将网页源代码按照字符编码解析为W3C Document对象,获取任意两个网页表单关键词;步骤20、深度优先遍历Document对象中的所有节点,得到第一个关键词所属的第一个节点,以及第二个关键词所属的第二个节点;步骤 3 0、 获取具有唯一属性的第一节点和第二节点的共同父节点,并使用唯一属性获取网页表单定位条件;Step 4 0、 使用网页表单定位条件遍历Document对象,找到满足定位条件的节点,从而定位表格位置,记录每个单元格数据的正确位置以及字体大小和字体颜色属性,提取与原网页显示效果相同的表格,根据表格位置定位表格。表格行/列值过滤,获取要提取的网页表格的指定行/列数据。进一步地,在步骤20中,对Document对象中的所有节点进行深度优先遍历,得到第一个关键词所属的第一个节点,第二个关键词所属的第二个节点,具体步骤21、获取Document对象的根节点root,记为节点;Step 22、 遍历节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,并转至步骤23,否则遍历查找childNode的每个子节点,如果遍历完成后仍没有关键词节点,则返回到childNode的父节点该节点,继续搜索该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。具体步骤21、获取Document对象的根节点root,记为node;Step 22、 遍历节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,并转至步骤23,否则遍历查找childNode的每个子节点,如果遍历完成后仍没有关键词节点,则返回到childNode的父节点该节点,继续搜索该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。具体步骤21、获取Document对象的根节点root,记为node;Step 22、 遍历节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,并转至步骤23,否则遍历查找childNode的每个子节点,如果遍历完成后仍没有关键词节点,则返回到childNode的父节点该节点,继续搜索该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。遍历节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,并转至步骤23,否则遍历查找childNode的每个子节点,如果遍历完成后仍没有关键词节点,则返回到childNode的父节点该节点,继续搜索该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。遍历节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,并转至步骤23,否则遍历查找childNode的每个子节点,如果遍历完成后仍没有关键词节点,则返回到childNode的父节点该节点,继续搜索该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。遍历完成后的节点,则返回该节点的父节点,继续寻找该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。遍历完成后的节点,则返回该节点的父节点,继续寻找该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。
进一步地,步骤30获取具有唯一属性的第一节点和第二节点的共同父节点,并利用唯一属性获取网页表的定位条件,具体步骤31、分别获取第一个节点node1、第二个节点node2的父节点parentNode1、parentNode2,判断是否相同;如果相同则返回parentNode,如果不同则继续代入parentNode1、parentNode2作为参数,递归搜索,直到距离nodel、node2最近的公共父节点parentNode;Step 32、获取parentNode的唯一属性,并利用唯一属性获取网页表定位条件,具体获取父节点的所有标签属性,并判断是否存在唯一属性,如果有唯一属性,则使用该属性获取父节点的定位条件网页表,即定位条件为“tablel^ath=parentNode标签名”的格式,进入步骤40;如果没有唯一属性,则获取parentNode的父节点targetNode,并搜索其唯一属性,递归搜索直到找到具有唯一属性的父节点targetNode或到达Document的根节点;同时,记录搜索过程的路径标签和parentNode在其父节点targetNode中的相对位置,进行拼接/修改,得到网页表定位条件,即定位条件格式为“tabIePath = targetNode标签名称” /path label 1/path label 2/..., or " tabIePath = Document root node/path label 1/path label 2[relative bit 2]/。. ο 该专利技术具有以下优点。该专利技术只需要网页的源代码、要提取的表格中任意两个关键词以及需要的表格行/列值,就可以从网页中提取出真实变化的原创代码时间。网页展示效果相同的表格,通过过滤获取表格的指定行/列数据,
该专利技术不仅简化了网页的抽取方法,提高了数据抽取的灵活性,满足了数据实时性的要求,而且提高了表格数据抽取的准确性。附图说明图。图1为本发明专利技术方法的流程示意图。1、专利技术包括以下步骤: Step 1 0、读取网页源代码,将网页源代码按照字符编码解析成W3C Document对象,获取网页中的信息桌子。任意两个 关键词; Step 2 0、深度优先遍历Document对象中的所有节点,得到第一个关键词所属的第一个节点,以及第二个关键词所属的第一个节点。两个节点;其中,具体步骤21、获取Document对象的根节点root,记为node;Step 22、遍历该节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,执行步骤23,否则遍历childNode的每个子节点,如果遍历完成后仍然没有关键词节点,则返回node的父节点,并继续搜索其余节点的子节点;step 2 3、判断childNode是否收录关键词,如果是则返回childNode,记为关键词所属的节点;否则,继续搜索判断childNode的兄弟节点。Step 30、 获取具有唯一属性的第一个节点和第二个节点的共同父节点,并使用唯一属性获取网页表定位条件;具体为步骤31、获取第一个节点node1、第二个节点node2的父节点parentNode1、parentNode2,判断是否相同;如果相同则返回parentNode,如果不同则继续代入parentNode1、parentNode2作为参数,递归搜索直到得到距离nodel,即node2最近的公共父节点parentNode;第三步< 继续代入parentNode1、parentNode2作为参数,递归搜索,直到得到距离nodel,即node2最近的公共父节点parentNode;第三步< 继续代入parentNode1、parentNode2作为参数,递归搜索,直到得到距离nodel,即node2最近的公共父节点parentNode;第三步<
【技术保护点】
1.一种从网页中提取数据的方法,其特征在于包括以下步骤: 步骤一0、读取网页源代码,将网页源代码解析成Document对象W3C根据字符编码,获取网页形式的数据。任意两个 关键词; Step 2 0、深度优先遍历Document对象中的所有节点,得到第一个关键词所属的第一个节点,以及第二个关键词所属的第一个节点。两个节点;步骤30、获取具有唯一属性的第一节点和第二节点的共同父节点,并使用唯一属性获取网页表定位条件;Step 40、使用网页表格定位条件,遍历Document对象,
【技术特点总结】
【专利技术性质】
技术研发人员:杨帆、黄健雄、林山、
申请人(专利权)持有人:,
类型:发明
国家、省、市:35
下载所有详细的技术数据 我是该专利的所有者 查看全部
网页表格抓取(发明专利技术提供一种网页表格数据抽取的方法及实现步骤)
本发明专利技术提供了一种从网页中提取数据的方法,包括:步骤10、读取网页源代码,根据字符码解析成W3C Document对象,得到任意两个网页表单关键词;Step 20、深度优先遍历Document对象中的所有节点,得到两个关键词所属的两个节点;Step 30、 获取具有唯一属性的两个节点的共同父节点,并使用唯一属性获取网页表定位条件;Step 4 0、使用网页表数据定位条件,过滤网页源代码,提取与网页显示效果相同的网页表。
下载所有详细的技术数据
【技术实现步骤总结】
该专利技术涉及网页
,尤其是涉及。
技术介绍
随着网络技术的不断发展,网页的显示效果和所收录的信息量越来越复杂,网页的结构和内容也在实时更新。但是为了从网页中获取指定的表格数据,需要在大量冗长的网页源码中手动查找表格的位置、标签和属性,从而定位到表格对应的源码并获取表格数据。这不仅需要大量的工作,而且浪费时间和精力。同时,在复杂的网页代码中搜索容易出错,不能满足实时数据的要求。W3C是英文World Wide Web Consortium的缩写,中文意思是W3C委员会或万维网联盟。W3C 组织是制定网络标准的非营利组织。HTML、XHTML、CSS 和 XML 等标准由 W3C 定制。现有技术提供了一种基于DOM树的信息抽取过滤方法,来自《中国学术期刊网络出版总库》,发表日期为2009/9/15,来源中国过滤网,描述了A页面预处理方法,将 HTML 解析为 DOM,利用 DOM 树的特性,不仅可以从大的逻辑单元中提取信息,还可以对更小的单元进行操作,完成信息提取中的页面预处理。这大大提高了信息提取的效率和准确性。该方法还提供了三个过滤器,每个过滤器都可以由用户设置,以完成不同程度的过滤,并以适当的顺序选择和堆叠各个过滤器,形成最佳的预处理组合。该方法的目标不是提取细粒度的数据,而是过滤掉网页中杂乱冗余的信息,比如广告、不相关的链接等,即完成对网页中页面的预处理。网页。
技术实现思路
该专利技术要解决的技术问题是,提供从实时变化的网页中准确、快速地提取出与原网页显示效果相同的表格,并获取指定的行/列数据。专利技术就是这样实现的,其特征在于包括以下步骤: 步骤1 0、读取网页源代码,将网页源代码按照字符编码解析为W3C Document对象,获取任意两个网页表单关键词;步骤20、深度优先遍历Document对象中的所有节点,得到第一个关键词所属的第一个节点,以及第二个关键词所属的第二个节点;步骤 3 0、 获取具有唯一属性的第一节点和第二节点的共同父节点,并使用唯一属性获取网页表单定位条件;Step 4 0、 使用网页表单定位条件遍历Document对象,找到满足定位条件的节点,从而定位表格位置,记录每个单元格数据的正确位置以及字体大小和字体颜色属性,提取与原网页显示效果相同的表格,根据表格位置定位表格。表格行/列值过滤,获取要提取的网页表格的指定行/列数据。进一步地,在步骤20中,对Document对象中的所有节点进行深度优先遍历,得到第一个关键词所属的第一个节点,第二个关键词所属的第二个节点,具体步骤21、获取Document对象的根节点root,记为节点;Step 22、 遍历节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,并转至步骤23,否则遍历查找childNode的每个子节点,如果遍历完成后仍没有关键词节点,则返回到childNode的父节点该节点,继续搜索该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。具体步骤21、获取Document对象的根节点root,记为node;Step 22、 遍历节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,并转至步骤23,否则遍历查找childNode的每个子节点,如果遍历完成后仍没有关键词节点,则返回到childNode的父节点该节点,继续搜索该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。具体步骤21、获取Document对象的根节点root,记为node;Step 22、 遍历节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,并转至步骤23,否则遍历查找childNode的每个子节点,如果遍历完成后仍没有关键词节点,则返回到childNode的父节点该节点,继续搜索该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。遍历节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,并转至步骤23,否则遍历查找childNode的每个子节点,如果遍历完成后仍没有关键词节点,则返回到childNode的父节点该节点,继续搜索该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。遍历节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,并转至步骤23,否则遍历查找childNode的每个子节点,如果遍历完成后仍没有关键词节点,则返回到childNode的父节点该节点,继续搜索该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。遍历完成后的节点,则返回该节点的父节点,继续寻找该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。遍历完成后的节点,则返回该节点的父节点,继续寻找该节点剩余的子节点;Step 23、判断childNode是否收录关键词,如果有则返回childNode,记为关键词所属的节点;否则,继续查找判断childNode的兄弟节点。
进一步地,步骤30获取具有唯一属性的第一节点和第二节点的共同父节点,并利用唯一属性获取网页表的定位条件,具体步骤31、分别获取第一个节点node1、第二个节点node2的父节点parentNode1、parentNode2,判断是否相同;如果相同则返回parentNode,如果不同则继续代入parentNode1、parentNode2作为参数,递归搜索,直到距离nodel、node2最近的公共父节点parentNode;Step 32、获取parentNode的唯一属性,并利用唯一属性获取网页表定位条件,具体获取父节点的所有标签属性,并判断是否存在唯一属性,如果有唯一属性,则使用该属性获取父节点的定位条件网页表,即定位条件为“tablel^ath=parentNode标签名”的格式,进入步骤40;如果没有唯一属性,则获取parentNode的父节点targetNode,并搜索其唯一属性,递归搜索直到找到具有唯一属性的父节点targetNode或到达Document的根节点;同时,记录搜索过程的路径标签和parentNode在其父节点targetNode中的相对位置,进行拼接/修改,得到网页表定位条件,即定位条件格式为“tabIePath = targetNode标签名称” /path label 1/path label 2/..., or " tabIePath = Document root node/path label 1/path label 2[relative bit 2]/。. ο 该专利技术具有以下优点。该专利技术只需要网页的源代码、要提取的表格中任意两个关键词以及需要的表格行/列值,就可以从网页中提取出真实变化的原创代码时间。网页展示效果相同的表格,通过过滤获取表格的指定行/列数据,
该专利技术不仅简化了网页的抽取方法,提高了数据抽取的灵活性,满足了数据实时性的要求,而且提高了表格数据抽取的准确性。附图说明图。图1为本发明专利技术方法的流程示意图。1、专利技术包括以下步骤: Step 1 0、读取网页源代码,将网页源代码按照字符编码解析成W3C Document对象,获取网页中的信息桌子。任意两个 关键词; Step 2 0、深度优先遍历Document对象中的所有节点,得到第一个关键词所属的第一个节点,以及第二个关键词所属的第一个节点。两个节点;其中,具体步骤21、获取Document对象的根节点root,记为node;Step 22、遍历该节点的每个子节点childNode,判断childNode是否为叶子节点;如果是,则获取childNode的值,执行步骤23,否则遍历childNode的每个子节点,如果遍历完成后仍然没有关键词节点,则返回node的父节点,并继续搜索其余节点的子节点;step 2 3、判断childNode是否收录关键词,如果是则返回childNode,记为关键词所属的节点;否则,继续搜索判断childNode的兄弟节点。Step 30、 获取具有唯一属性的第一个节点和第二个节点的共同父节点,并使用唯一属性获取网页表定位条件;具体为步骤31、获取第一个节点node1、第二个节点node2的父节点parentNode1、parentNode2,判断是否相同;如果相同则返回parentNode,如果不同则继续代入parentNode1、parentNode2作为参数,递归搜索直到得到距离nodel,即node2最近的公共父节点parentNode;第三步< 继续代入parentNode1、parentNode2作为参数,递归搜索,直到得到距离nodel,即node2最近的公共父节点parentNode;第三步< 继续代入parentNode1、parentNode2作为参数,递归搜索,直到得到距离nodel,即node2最近的公共父节点parentNode;第三步<
【技术保护点】
1.一种从网页中提取数据的方法,其特征在于包括以下步骤: 步骤一0、读取网页源代码,将网页源代码解析成Document对象W3C根据字符编码,获取网页形式的数据。任意两个 关键词; Step 2 0、深度优先遍历Document对象中的所有节点,得到第一个关键词所属的第一个节点,以及第二个关键词所属的第一个节点。两个节点;步骤30、获取具有唯一属性的第一节点和第二节点的共同父节点,并使用唯一属性获取网页表定位条件;Step 40、使用网页表格定位条件,遍历Document对象,
【技术特点总结】
【专利技术性质】
技术研发人员:杨帆、黄健雄、林山、
申请人(专利权)持有人:,
类型:发明
国家、省、市:35
下载所有详细的技术数据 我是该专利的所有者
网页表格抓取(1.Datapreview预览一下数据的分类及应用方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-03-19 20:21
标签: 更多参数 角度 圆弧类型 网站 保存类型 北京成功
这是简易数据分析系列文章的第11期。
今天我们将讨论如何在 Web 表单中捕获数据。首先我们来分析一下网页中的经典表格是如何组成的。
经典的表格都是关于这些知识点的,没了。让我们编写一个简单的表单 Web Scraper 爬虫。
1.创建站点地图
我们今天的练习 网站 是
%C9%CF%BA%A3&txt道达=%B1%B1%BE%A9
爬虫的内容是爬取上海到北京的所有火车时刻表。
我们首先创建一个收录整个表格的容器,并将Type选择为Table,表示我们要抓取表格。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。如果你看一下,你会发现这些数据实际上是表格数据类型的分类。在这种情况下,他列出了火车、出发站和行驶时间的类别。
在表格列类别中,默认勾选每行内容旁边的选择按钮,这意味着默认捕获这些列的内容。如果您不想爬取某种类型的内容,只需去掉相应的复选框即可。
当你点击保存选择器按钮的时候,你会发现Result键的一些选项报错,说invalid format format无效:
解决这个错误非常简单。一般来说,Result 键名的长度是不够的。您可以添加空格和标点符号。如果仍然出现错误,请尝试更改为英文名称:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程抓取数据了。
2.我为什么不建议你使用 Web Scraper 的表格选择器?
如果按照刚才的教程,感觉会很流畅,但是看数据的时候,就傻眼了。
刚开始爬的时候,我们先用Data preview预览数据,发现数据很完美:
抓取数据后,在浏览器的预览面板中预览,会发现trains一栏的数据为null,表示没有抓取到相关内容:
我们下载捕获的CSV文件并在预览器中打开后,我们会发现出现了列车号的数据,但是出发站的数据又为空了!
这不是傻子!
我已经研究这个问题很长时间了。应该是Web Scraper对中文关键词索引的支持不是很友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表数据,可以使用前面的方案,先创建一个Element类型的容器,然后在容器中手动创建一个子选择器,这样就可以避免这个问题了。
以上只是一个原因,另一个原因是,在现代 网站 中,很少有人再使用 HTML 原创表格了。
HTML 为表格提供了基本的标签,例如 、 、 等,这些标签提供了默认样式。优点是互联网刚开发的时候,可以提供开箱即用的形式;缺点是样式过于简单,不易定制。后来很多网站用其他标签来模拟表格,就像PPT用各种大小的块组合成一个表格,很容易自定义:
正因如此,当你使用Table Selector匹配一个表格的时候,可能会匹配不上,因为从Web Scraper的角度来看,你看到的表格是高仿的,根本不是原装的,自然不是。认可。
3.总结
我们不建议直接使用 Web Scraper 的 Table Selector,因为它对中文支持不是很友好,也不太适合现代网页。如果有抢表的需求,可以使用之前创建父子选择器的方法来做。 查看全部
网页表格抓取(1.Datapreview预览一下数据的分类及应用方法(图))
标签: 更多参数 角度 圆弧类型 网站 保存类型 北京成功
这是简易数据分析系列文章的第11期。
今天我们将讨论如何在 Web 表单中捕获数据。首先我们来分析一下网页中的经典表格是如何组成的。
经典的表格都是关于这些知识点的,没了。让我们编写一个简单的表单 Web Scraper 爬虫。
1.创建站点地图
我们今天的练习 网站 是
%C9%CF%BA%A3&txt道达=%B1%B1%BE%A9
爬虫的内容是爬取上海到北京的所有火车时刻表。
我们首先创建一个收录整个表格的容器,并将Type选择为Table,表示我们要抓取表格。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。如果你看一下,你会发现这些数据实际上是表格数据类型的分类。在这种情况下,他列出了火车、出发站和行驶时间的类别。
在表格列类别中,默认勾选每行内容旁边的选择按钮,这意味着默认捕获这些列的内容。如果您不想爬取某种类型的内容,只需去掉相应的复选框即可。
当你点击保存选择器按钮的时候,你会发现Result键的一些选项报错,说invalid format format无效:
解决这个错误非常简单。一般来说,Result 键名的长度是不够的。您可以添加空格和标点符号。如果仍然出现错误,请尝试更改为英文名称:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程抓取数据了。
2.我为什么不建议你使用 Web Scraper 的表格选择器?
如果按照刚才的教程,感觉会很流畅,但是看数据的时候,就傻眼了。
刚开始爬的时候,我们先用Data preview预览数据,发现数据很完美:
抓取数据后,在浏览器的预览面板中预览,会发现trains一栏的数据为null,表示没有抓取到相关内容:
我们下载捕获的CSV文件并在预览器中打开后,我们会发现出现了列车号的数据,但是出发站的数据又为空了!
这不是傻子!
我已经研究这个问题很长时间了。应该是Web Scraper对中文关键词索引的支持不是很友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表数据,可以使用前面的方案,先创建一个Element类型的容器,然后在容器中手动创建一个子选择器,这样就可以避免这个问题了。
以上只是一个原因,另一个原因是,在现代 网站 中,很少有人再使用 HTML 原创表格了。
HTML 为表格提供了基本的标签,例如 、 、 等,这些标签提供了默认样式。优点是互联网刚开发的时候,可以提供开箱即用的形式;缺点是样式过于简单,不易定制。后来很多网站用其他标签来模拟表格,就像PPT用各种大小的块组合成一个表格,很容易自定义:
正因如此,当你使用Table Selector匹配一个表格的时候,可能会匹配不上,因为从Web Scraper的角度来看,你看到的表格是高仿的,根本不是原装的,自然不是。认可。
3.总结
我们不建议直接使用 Web Scraper 的 Table Selector,因为它对中文支持不是很友好,也不太适合现代网页。如果有抢表的需求,可以使用之前创建父子选择器的方法来做。
网页表格抓取(一个如何解决三个问题?是怎么爬,第二个的数据如何保存 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-17 19:12
)
所谓爬虫,无非就是通过一些特定的程序,访问一些你想访问的网页,并以自定义的方式保存网页上的内容。
这里我们将使用一个C#小程序,对上交所50个手指的实时信息进行爬取。该程序非常简单。
所谓爬虫就是要解决三个问题:一是爬什么,二是怎么爬,三是爬下来的数据怎么保存。根据个人需要和能力水平,方法有很多。
下面,我们将通过具体的例子来说明如何解决上述三个问题。
一、爬什么
你可以抓取任何你想要的数据,但是这些数据是如何在网页中表示和存储的呢?这时候就需要分析我们要爬取的页面的结构了。
在这个例子中,我们要爬取网页中的表格,如下图所示:
下面通过具体代码来说明:
HtmlDocument doc = web.Document;
HtmlElementCollection tbs = doc.GetElementsByTagName("TABLE");//找到table标签
foreach (HtmlElement tb in tbs)//遍历
{
HtmlElementCollection trs = tb.GetElementsByTagName("TR");//每行
foreach (HtmlElement tr in trs)
{
HtmlElementCollection tds = tr.GetElementsByTagName("TD");//每列
if (tds.Count > 0)
{
DataRow dr = dt.NewRow();
for (int i = 0; i < tds.Count; i++)
{
//找到需要的信息列,并将对应的信息填充到dr
dr["序号"] = tds[0].InnerText;
dr["股票代码"] = tds[1].InnerText;
dr["股票简称"] = tds[2].InnerText;
dr["最新价"] = tds[3].InnerText;
dr["涨跌额"] = tds[4].InnerText;
dr["涨跌幅"] = tds[5].InnerText;
dr["换手率"] = tds[13].InnerText;
}
//将dataReader读取的每一行数据保存到datatable中
dt.Rows.Add(dr);
}
}
最后在Form_load中添加如下代码:
dt.Columns.Add("序号", System.Type.GetType("System.String"));
dt.Columns.Add("股票代码", System.Type.GetType("System.String"));
dt.Columns.Add("股票简称", System.Type.GetType("System.String"));
dt.Columns.Add("最新价", System.Type.GetType("System.String"));
dt.Columns.Add("涨跌额", System.Type.GetType("System.String"));
dt.Columns.Add("涨跌幅", System.Type.GetType("System.String"));
dt.Columns.Add("换手率", System.Type.GetType("System.String"));
web.Url = new System.Uri("http://q.10jqka.com.cn/stock/zs/sz50/");//要爬取的网页URL
最终结果如下所示:
查看全部
网页表格抓取(一个如何解决三个问题?是怎么爬,第二个的数据如何保存
)
所谓爬虫,无非就是通过一些特定的程序,访问一些你想访问的网页,并以自定义的方式保存网页上的内容。
这里我们将使用一个C#小程序,对上交所50个手指的实时信息进行爬取。该程序非常简单。
所谓爬虫就是要解决三个问题:一是爬什么,二是怎么爬,三是爬下来的数据怎么保存。根据个人需要和能力水平,方法有很多。
下面,我们将通过具体的例子来说明如何解决上述三个问题。
一、爬什么
你可以抓取任何你想要的数据,但是这些数据是如何在网页中表示和存储的呢?这时候就需要分析我们要爬取的页面的结构了。
在这个例子中,我们要爬取网页中的表格,如下图所示:
下面通过具体代码来说明:
HtmlDocument doc = web.Document;
HtmlElementCollection tbs = doc.GetElementsByTagName("TABLE");//找到table标签
foreach (HtmlElement tb in tbs)//遍历
{
HtmlElementCollection trs = tb.GetElementsByTagName("TR");//每行
foreach (HtmlElement tr in trs)
{
HtmlElementCollection tds = tr.GetElementsByTagName("TD");//每列
if (tds.Count > 0)
{
DataRow dr = dt.NewRow();
for (int i = 0; i < tds.Count; i++)
{
//找到需要的信息列,并将对应的信息填充到dr
dr["序号"] = tds[0].InnerText;
dr["股票代码"] = tds[1].InnerText;
dr["股票简称"] = tds[2].InnerText;
dr["最新价"] = tds[3].InnerText;
dr["涨跌额"] = tds[4].InnerText;
dr["涨跌幅"] = tds[5].InnerText;
dr["换手率"] = tds[13].InnerText;
}
//将dataReader读取的每一行数据保存到datatable中
dt.Rows.Add(dr);
}
}
最后在Form_load中添加如下代码:
dt.Columns.Add("序号", System.Type.GetType("System.String"));
dt.Columns.Add("股票代码", System.Type.GetType("System.String"));
dt.Columns.Add("股票简称", System.Type.GetType("System.String"));
dt.Columns.Add("最新价", System.Type.GetType("System.String"));
dt.Columns.Add("涨跌额", System.Type.GetType("System.String"));
dt.Columns.Add("涨跌幅", System.Type.GetType("System.String"));
dt.Columns.Add("换手率", System.Type.GetType("System.String"));
web.Url = new System.Uri("http://q.10jqka.com.cn/stock/zs/sz50/";);//要爬取的网页URL
最终结果如下所示:
网页表格抓取(如何取得网页表格里的数据点击相应的操作?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-17 19:12
目前,一赛奇RPA已经更新到8.0版本,所有用户都可以免费下载试用(复制链接下载)
问题描述
最近很多同学都在问如何获取web表单中的数据?如何根据表格中的数据点击相应的动作?
这两个问题在我们社区其实也有相关的帖子,但是很多人还是问不操作
在实际操作之前,您需要做以下事情:
看看上面两个帖子
了解一些css选择器的知识,我不是专家,这里就不做总结了?也是在百度上搜索信息。每个人也应该培养一些自学的技能。
学习一些审查网页元素的技巧,请参考网页检查/审查技巧
需要了解一些python语言pandas的知识
需求实现声明
好吧,让我们先谈谈要求。我需要在表格中找到产品代码为test120的记录,然后点击对应的删除按钮。下面的截图
所以在解决这个问题的时候,首先是拿到表数据,匹配对应的记录(比如test120),然后找到记录对应的删除按钮点击,这样就可以大致划分了分为两部分,即开头提到的第一和第二个问题的合集。
获取网页表单数据
3.1 领取网页表格
使用pickable组件拾取桌子,这里使用【鼠标点击】组件进行操作
这里需要注意的是,拾取时,要拾取的是整个网页的表格,而不是表格中的某个内容。正确的采摘如下图所示
您还可以通过设计器中的图像预览功能验证您选择的内容是否正确。
3.2 获取web表单的选择器
【鼠标点击】在组件的搜索路径中,选择选择器
7289e87543b148e5b30cbcfa442e6337_E5DA75892CE647CB8DDAE307D2AE570B.png
选择好后编译看看对应的代码
选择器=r'body > DIV:nth-of-type(1) > FORM:nth-of-type(1) > DIV:nth-of-type(2) > DIV: nth-of-type(1) > TABLE:nth-of-type(1)'最后一个 > 后面跟着一个 TABLE 标签,这就是我们想要的。
3.3 获取表中的数据
使用如下代码获取表中的数据,这里不再详述,可以复制使用
可以作为函数或代码块调用
将 ubpa.iie 导入为 iie
重新进口
将熊猫导入为 pd
#将3.2章节selector=后面的代码复制到这里
table_string = iie.get_html(title=r'财务管理',selector=r'body > DIV:nth-of-type(1) > FORM:nth-of-type(1) > DIV: nth-of-type(2) > DIV:nth-of-type(1) > TABLE:nth-of-type(1)')
tb_start = 桩('')
tb_end = 桩('')
last_str = tb_end.sub('', tb_start.sub('', table_string))
#在pandas中调用read_html方法,注意header=0,有些表头不是0
数据 = pd.read_html(last_str, flavor="bs4", header=0)[0]
#此步骤将'product code'列转换为字符串,可以收录None或数字
data['产品代码'] = data['产品代码'].apply(str)
# 打印数据
打印(数据)
打印(' - - - - - - - - - -')
#通过这个可以看到数据有哪些列
打印(数据。列)
其实【鼠标点击】组件的目的是获取web表单的选择器。获取组件后,即可删除组件。
结果如下:
至此,当前web表单中的所有数据已经成功获取,我们要删除的test120的数据记录也在其中
需要注意的是,pandas读出的数据都是dataframe类型的数据集
3.4 过滤和提取数据
使用【数据过滤器】组件对刚刚得到的dataframe类型变量data的数据进行过滤,返回给变量data2
37276cb9b78b4bf08d27f5fd19c6c80c_279E22E4D20E418D847B4D7FB6DCF5AA.png
我们得到了产品代码test120的数据记录
3.5 获取记录的行号
#获取行号,这是一个数组列表,如果有多条记录,列表中会有多个元素
#如果索引中有多个值,也代表多条记录,可以使用循环遍历操作,这里就不赘述了,留给大家
打印(数据2.索引)
#获取数字中的第一个元素单元
打印(数据2.索引[0])
运行结果:
表示这里记录的索引是3
找到记录对应的按钮,点击
4.1 找到模式
通过组件拾取获取组件的选择器并找到规则
先拿起记录test120对应的删除按钮
test120得到的记录的选择器如下
'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(5) > TD:nth-of-type(8) > A:nth-类型(2) > B:nth-of-type(1)'
我们分别获取前三个记录删除按钮的选择器,看看可以遵循哪些规则
#第1⃣️页记录
'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(2) > TD:nth-of-type(8) > A:nth-类型(2) > B:nth-of-type(1)'
#第2⃣️页记录
'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(3) > TD:nth-of-type(8) > A:nth-类型(2) > B:nth-of-type(1)'
#第3⃣️页记录
'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(4) > TD:nth-of-type(8) > A:nth-类型(2) > B:nth-of-type(1)'
#test120 记录
'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(5) > TD:nth-of-type(8) > A:nth-类型(2) > B:nth-of-type(1)'
现在能找到什么?
在这里你会发现 TR:nth-of-type(3) 中的数字是 TR:nth-of-type(2) 中的第 2 条记录发生变化,表示第 n 个- of-type 从 2 开始编号
数据表中test120的索引为3(3.5节)
而对应的删除按钮的 TR:nth-of-type(5) 为 5
那么只要声明一个变量,变量的内容就是index+2,可以把TR:nth-of-type(5)换成变量里面的硬编码值)
4.2 声明变量
根据4.1章节得到的逻辑,先声明一个变量test来存放会变化的值
#在设计器代码窗口中,复制鼠标selector=后面的代码,拾取删除按钮,赋值给测试变量
#可以使用代码块组件来赋值变量
test = r'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(%d) > TD:nth-of-type(8) > A:nth -of-type(2) > B:nth-of-type(1)'%(data2.index[0] + 2)
4.3 鼠标点击删除按钮实现
这一步也是最简单的,只要在【鼠标点击】组件的搜索路径中直接填写测试变量即可
至此,从一个简单的web表单中获取数据,点击对应记录后的按钮操作就完成了。
完全运行后的结果
如果当前页面有多条记录需要删除,则需要使用循环来实现。我这里就不说了,留给学生去做吧。
针对这种场景,我们也会推出操作指导视频和参考项目,但最重要的是让大家自己学习和尝试。? 查看全部
网页表格抓取(如何取得网页表格里的数据点击相应的操作?(图))
目前,一赛奇RPA已经更新到8.0版本,所有用户都可以免费下载试用(复制链接下载)
问题描述
最近很多同学都在问如何获取web表单中的数据?如何根据表格中的数据点击相应的动作?
这两个问题在我们社区其实也有相关的帖子,但是很多人还是问不操作
在实际操作之前,您需要做以下事情:
看看上面两个帖子
了解一些css选择器的知识,我不是专家,这里就不做总结了?也是在百度上搜索信息。每个人也应该培养一些自学的技能。
学习一些审查网页元素的技巧,请参考网页检查/审查技巧
需要了解一些python语言pandas的知识
需求实现声明
好吧,让我们先谈谈要求。我需要在表格中找到产品代码为test120的记录,然后点击对应的删除按钮。下面的截图
所以在解决这个问题的时候,首先是拿到表数据,匹配对应的记录(比如test120),然后找到记录对应的删除按钮点击,这样就可以大致划分了分为两部分,即开头提到的第一和第二个问题的合集。
获取网页表单数据
3.1 领取网页表格
使用pickable组件拾取桌子,这里使用【鼠标点击】组件进行操作
这里需要注意的是,拾取时,要拾取的是整个网页的表格,而不是表格中的某个内容。正确的采摘如下图所示
您还可以通过设计器中的图像预览功能验证您选择的内容是否正确。
3.2 获取web表单的选择器
【鼠标点击】在组件的搜索路径中,选择选择器
7289e87543b148e5b30cbcfa442e6337_E5DA75892CE647CB8DDAE307D2AE570B.png
选择好后编译看看对应的代码
选择器=r'body > DIV:nth-of-type(1) > FORM:nth-of-type(1) > DIV:nth-of-type(2) > DIV: nth-of-type(1) > TABLE:nth-of-type(1)'最后一个 > 后面跟着一个 TABLE 标签,这就是我们想要的。
3.3 获取表中的数据
使用如下代码获取表中的数据,这里不再详述,可以复制使用
可以作为函数或代码块调用
将 ubpa.iie 导入为 iie
重新进口
将熊猫导入为 pd
#将3.2章节selector=后面的代码复制到这里
table_string = iie.get_html(title=r'财务管理',selector=r'body > DIV:nth-of-type(1) > FORM:nth-of-type(1) > DIV: nth-of-type(2) > DIV:nth-of-type(1) > TABLE:nth-of-type(1)')
tb_start = 桩('')
tb_end = 桩('')
last_str = tb_end.sub('', tb_start.sub('', table_string))
#在pandas中调用read_html方法,注意header=0,有些表头不是0
数据 = pd.read_html(last_str, flavor="bs4", header=0)[0]
#此步骤将'product code'列转换为字符串,可以收录None或数字
data['产品代码'] = data['产品代码'].apply(str)
# 打印数据
打印(数据)
打印(' - - - - - - - - - -')
#通过这个可以看到数据有哪些列
打印(数据。列)
其实【鼠标点击】组件的目的是获取web表单的选择器。获取组件后,即可删除组件。
结果如下:
至此,当前web表单中的所有数据已经成功获取,我们要删除的test120的数据记录也在其中
需要注意的是,pandas读出的数据都是dataframe类型的数据集
3.4 过滤和提取数据
使用【数据过滤器】组件对刚刚得到的dataframe类型变量data的数据进行过滤,返回给变量data2
37276cb9b78b4bf08d27f5fd19c6c80c_279E22E4D20E418D847B4D7FB6DCF5AA.png
我们得到了产品代码test120的数据记录
3.5 获取记录的行号
#获取行号,这是一个数组列表,如果有多条记录,列表中会有多个元素
#如果索引中有多个值,也代表多条记录,可以使用循环遍历操作,这里就不赘述了,留给大家
打印(数据2.索引)
#获取数字中的第一个元素单元
打印(数据2.索引[0])
运行结果:
表示这里记录的索引是3
找到记录对应的按钮,点击
4.1 找到模式
通过组件拾取获取组件的选择器并找到规则
先拿起记录test120对应的删除按钮
test120得到的记录的选择器如下
'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(5) > TD:nth-of-type(8) > A:nth-类型(2) > B:nth-of-type(1)'
我们分别获取前三个记录删除按钮的选择器,看看可以遵循哪些规则
#第1⃣️页记录
'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(2) > TD:nth-of-type(8) > A:nth-类型(2) > B:nth-of-type(1)'
#第2⃣️页记录
'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(3) > TD:nth-of-type(8) > A:nth-类型(2) > B:nth-of-type(1)'
#第3⃣️页记录
'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(4) > TD:nth-of-type(8) > A:nth-类型(2) > B:nth-of-type(1)'
#test120 记录
'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(5) > TD:nth-of-type(8) > A:nth-类型(2) > B:nth-of-type(1)'
现在能找到什么?
在这里你会发现 TR:nth-of-type(3) 中的数字是 TR:nth-of-type(2) 中的第 2 条记录发生变化,表示第 n 个- of-type 从 2 开始编号
数据表中test120的索引为3(3.5节)
而对应的删除按钮的 TR:nth-of-type(5) 为 5
那么只要声明一个变量,变量的内容就是index+2,可以把TR:nth-of-type(5)换成变量里面的硬编码值)
4.2 声明变量
根据4.1章节得到的逻辑,先声明一个变量test来存放会变化的值
#在设计器代码窗口中,复制鼠标selector=后面的代码,拾取删除按钮,赋值给测试变量
#可以使用代码块组件来赋值变量
test = r'#boxTable > TBODY:nth-of-type(1) > TR:nth-of-type(%d) > TD:nth-of-type(8) > A:nth -of-type(2) > B:nth-of-type(1)'%(data2.index[0] + 2)
4.3 鼠标点击删除按钮实现
这一步也是最简单的,只要在【鼠标点击】组件的搜索路径中直接填写测试变量即可
至此,从一个简单的web表单中获取数据,点击对应记录后的按钮操作就完成了。
完全运行后的结果
如果当前页面有多条记录需要删除,则需要使用循环来实现。我这里就不说了,留给学生去做吧。
针对这种场景,我们也会推出操作指导视频和参考项目,但最重要的是让大家自己学习和尝试。?
网页表格抓取(Python表格型数据获取的准确性是需要考虑的因素? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-17 02:04
)
Python 有许多可以捕获数据的包,例如 selenium、requests、scrapy 和 pandas。每个包都有其适用性。我个人认为在抓数据的时候,代码的简洁性和数据获取的准确性是需要考虑的因素。不要太担心时间的速度。毕竟用python来抓数据可以节省不少时间。使用不同的方法可能是 1 秒和 1 分钟之间的差异。我们在日常生活中总是有抓取表格数据的需求。本文尝试用pandas最简洁的代码来抓取表数据。该代码非常简单且易于使用。
只需选择一个页面:
比如爬取下图中定向工具的注册审批文件(当然wind里面有数据,本文只是为了展示如何爬取表格数据)
一、爬取当前页面
只需要两个密钥代码即可获取它。前两句是导入相关模块,第三句是输入网址,第四句是用pandas读取。由于网页有很多表格,所以会以列表的形式存储在变量ppn中。,点击查看第十四张表格正是我们所需要的。
二、 抓取所有
但是第一部分只抓取第一页,如果要抓取所有页面,也很简单,写个循环就行了。点击下一页可以看到它的 URL 相应地发生了变化:
页码会体现在索引后的数字中,所以可以将url改成变量组合,详见第五句。第一、二句还在导入相关模块,第三句是生成一个空矩阵来存储爬取的结果,第四到第八句是一个简单的循环,每页爬取结果变量。然后将结果连续添加到输出中。最终的输出就是我们想要的结果。
查看全部
网页表格抓取(Python表格型数据获取的准确性是需要考虑的因素?
)
Python 有许多可以捕获数据的包,例如 selenium、requests、scrapy 和 pandas。每个包都有其适用性。我个人认为在抓数据的时候,代码的简洁性和数据获取的准确性是需要考虑的因素。不要太担心时间的速度。毕竟用python来抓数据可以节省不少时间。使用不同的方法可能是 1 秒和 1 分钟之间的差异。我们在日常生活中总是有抓取表格数据的需求。本文尝试用pandas最简洁的代码来抓取表数据。该代码非常简单且易于使用。
只需选择一个页面:
比如爬取下图中定向工具的注册审批文件(当然wind里面有数据,本文只是为了展示如何爬取表格数据)
一、爬取当前页面
只需要两个密钥代码即可获取它。前两句是导入相关模块,第三句是输入网址,第四句是用pandas读取。由于网页有很多表格,所以会以列表的形式存储在变量ppn中。,点击查看第十四张表格正是我们所需要的。
二、 抓取所有
但是第一部分只抓取第一页,如果要抓取所有页面,也很简单,写个循环就行了。点击下一页可以看到它的 URL 相应地发生了变化:
页码会体现在索引后的数字中,所以可以将url改成变量组合,详见第五句。第一、二句还在导入相关模块,第三句是生成一个空矩阵来存储爬取的结果,第四到第八句是一个简单的循环,每页爬取结果变量。然后将结果连续添加到输出中。最终的输出就是我们想要的结果。
网页表格抓取(网页大数据——如何利用互联网收集数据并应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 354 次浏览 • 2022-03-07 23:22
George Gottlob教授是牛津大学计算机科学系数据研究中心主任,也是量化金融研究中心的创始人。他的分享主题是“Web Big Data - How to Get Data and Apply”。
以下为演讲原文
在过去的 10 到 15 年里,数据提取一直是我研究的一个重要领域,今天我将描述如何使用 Internet 来采集数据。
互联网不是数据库
数据存在于我们的日常生活中,数据对当今的发展至关重要。很多人说互联网是最大的数据库,这是不准确的。互联网不是数据库,互联网只是数据的集合。这些数据是非结构化的,非结构化数据以各种形式存在,因此结构化检索是不可能的。
例如,假设我想在网上列出维也纳所有满足一定条件的公寓,条件是他们有阳台,价格低于 50 万美元,附近有很多意大利餐馆,但没有结果在互联网上。因为互联网不是数据库,所以只能搜索数据库。
那么如何将互联网变成一个庞大的数据库呢?数据是结构化的,我们可以创建相应的结构,我们必须为此提取数据。由于今天的时间问题,我不会过多的理论,我会告诉你如何使用它。
一个网页有很多标签,左边展示了网页的结构,但是网页是如何采集信息的呢?我们从标签中得到相应的信息。比如我想采集这个网页上的所有电话号码,网页上会有一个电话号码标记,树形结构上的黄色标记就是电话号码。
此外,还需要研究底层语言和逻辑。对于计算机科学家来说,逻辑非常重要。然后决定你想从网页中挖掘什么样的信息。这些数据记录是一些非常基础的数据源。如果有人想做编程,就需要做这个语言,这个语言可以帮他找到很多网页的特殊性,和其他的网站,属性,图片,JAVA语言都很重要,因此您可以从一种语言跳转到另一种语言。
同时里面有一个逻辑,必须进行可视化处理,同时还需要一个可视化的工具。在设计产品和搜索产品时,有上层和下层,包括大数据、数据库编程和设计。可视化的发展意味着自动化工具可以使挖掘信息的过程更加可视化,并将成为一个自动化的过程。
例如,从 ebay 页面中挖掘相关链接。编程语言如图所示。这些路是单一的数据,表示数据属于哪里,页面数据是什么语言。但是仅仅做这种语言是不够的。我们需要从数万或数百万个页面中爬取和挖掘数据,所以我们将使用云。我们在云中拥有数据,并使用云来做这样的工具。
在数据挖掘方面,我们有本地化的内容挖掘和基于云的内容挖掘。2001 年,我与他人共同创办了一家为客户提供了很多帮助的公司。以下是一些展示数据提取重要性的使用场景。
我们曾经有一些用户是电子产品的零售商。对他们来说,不仅要考虑市场情况,还要考虑竞争对手的情况,包括日常的价格、成本、消费趋势、产品结构信息等。这些数据对他们来说是很难获得的。然而,实现自动数据挖掘是非常重要的。我们得到了一份电子产品清单,该表列出了客户的竞争对手,并且可以显示他们在哪些方面做得更好。因此,客户可以看到可以改进的领域,例如价格或竞争力。
第二个具有代表性的场景是对冲基金。房价指数由国家统计局定期公布。它影响不同行业的股票价格。如果能在国家统计局公布之前预测房价,就可以进行很好的推测。
第三种情况是建筑公司投标。投标人来自世界各地,有关潜在竞争对手的信息既昂贵又不完整。但我们所做的事情对投标人来说是当场的。
全自动数据挖掘
英国有 15,000 多处房产网站,还有少数没有完全覆盖的骨料,这对全自动化挖矿技术的要求很高。因为尽管这些信息很容易获得,但手动或半自动处理数据的成本太高。目前没有完全自动化的采矿工具或技术。所以我和牛津大学的一位教授一起研究固化或形式化的数据挖掘,这样机器就可以自动挖掘数据。
这张图片中的黑点是指向 URL 的链接。这是一个源数据项,我们在其中构建黑盒来更改数据,从数千万页到大型数据集。
上图显示了来自不同来源的两种类型的知识。就像孩子学习知识一样,学校里很多人都会告诉他规则,他学到的就是规则。所以这是从机器学习到基于规则的推理的转变。这对研究人员来说非常重要。右边是通过规则构建的推理,我们将其自动化。有两种类型的规则,标准规则和其他规则。
我们在 2015 年创建了一家公司,为了使用这个系统和规则,我们需要识别和对齐对象、填写表格、块分析和对象丰富以及云支持,以便更有效地提取信息。我们使用上述语言从数千个网页中提取容量信息,规则也需要语言。在二手车、房地产等很多领域都可以实现自动化的数据抽取。如果字段很简单,20天就可以形成相应的规则。但也有一些非常复杂的领域,每个领域都有不同的特点,每个国家都有自己的语言,这些都是需要克服的问题。
当前深耕知识图谱技术
最后介绍一下我们目前的研究工作——知识图谱。知识图谱可以非常清晰地管理大量的知识。它通过识别信息改变了人们的生活,从而形成了一个非常庞大的知识世界。许多公司都追随我们的研究脚步,包括 Facebook、亚马逊等。当然,小公司也希望利用知识图谱来采集员工、客户、竞争对手、价格等信息,从而提高业务质量。
这个知识体系(绿色标记)的核心是推理,其中收录许多规则和许多外部接口。接口之一是外部数据的提取,主要来自互联网。另外有内部知识,数据库之间也有一些关系,可以很方便的接入物联网。事实上,这是一个推理引擎,我们的客户包括中央银行和其他银行。基于此,可以开发许多应用程序,例如信用报告。交易中的欺诈也可以使用基于规则的系统进行检测。它可以用来检测公司贷款的真实性以及是否存在欺诈贷款的倾向。
上图显示了公司的所有权。实际上,公司之间的所有权结构往往非常复杂。该系统可用于理清公司之间的关系,提高公司管理水平。具体可以根据股份数量确定控股公司。此外,如果两家公司共同拥有另一家公司,这些信息很难用SQL进行处理和查询,但使用该方案可以更方便地管理和提高计算速度。 查看全部
网页表格抓取(网页大数据——如何利用互联网收集数据并应用)
George Gottlob教授是牛津大学计算机科学系数据研究中心主任,也是量化金融研究中心的创始人。他的分享主题是“Web Big Data - How to Get Data and Apply”。
以下为演讲原文
在过去的 10 到 15 年里,数据提取一直是我研究的一个重要领域,今天我将描述如何使用 Internet 来采集数据。
互联网不是数据库
数据存在于我们的日常生活中,数据对当今的发展至关重要。很多人说互联网是最大的数据库,这是不准确的。互联网不是数据库,互联网只是数据的集合。这些数据是非结构化的,非结构化数据以各种形式存在,因此结构化检索是不可能的。
例如,假设我想在网上列出维也纳所有满足一定条件的公寓,条件是他们有阳台,价格低于 50 万美元,附近有很多意大利餐馆,但没有结果在互联网上。因为互联网不是数据库,所以只能搜索数据库。
那么如何将互联网变成一个庞大的数据库呢?数据是结构化的,我们可以创建相应的结构,我们必须为此提取数据。由于今天的时间问题,我不会过多的理论,我会告诉你如何使用它。
一个网页有很多标签,左边展示了网页的结构,但是网页是如何采集信息的呢?我们从标签中得到相应的信息。比如我想采集这个网页上的所有电话号码,网页上会有一个电话号码标记,树形结构上的黄色标记就是电话号码。
此外,还需要研究底层语言和逻辑。对于计算机科学家来说,逻辑非常重要。然后决定你想从网页中挖掘什么样的信息。这些数据记录是一些非常基础的数据源。如果有人想做编程,就需要做这个语言,这个语言可以帮他找到很多网页的特殊性,和其他的网站,属性,图片,JAVA语言都很重要,因此您可以从一种语言跳转到另一种语言。
同时里面有一个逻辑,必须进行可视化处理,同时还需要一个可视化的工具。在设计产品和搜索产品时,有上层和下层,包括大数据、数据库编程和设计。可视化的发展意味着自动化工具可以使挖掘信息的过程更加可视化,并将成为一个自动化的过程。
例如,从 ebay 页面中挖掘相关链接。编程语言如图所示。这些路是单一的数据,表示数据属于哪里,页面数据是什么语言。但是仅仅做这种语言是不够的。我们需要从数万或数百万个页面中爬取和挖掘数据,所以我们将使用云。我们在云中拥有数据,并使用云来做这样的工具。
在数据挖掘方面,我们有本地化的内容挖掘和基于云的内容挖掘。2001 年,我与他人共同创办了一家为客户提供了很多帮助的公司。以下是一些展示数据提取重要性的使用场景。
我们曾经有一些用户是电子产品的零售商。对他们来说,不仅要考虑市场情况,还要考虑竞争对手的情况,包括日常的价格、成本、消费趋势、产品结构信息等。这些数据对他们来说是很难获得的。然而,实现自动数据挖掘是非常重要的。我们得到了一份电子产品清单,该表列出了客户的竞争对手,并且可以显示他们在哪些方面做得更好。因此,客户可以看到可以改进的领域,例如价格或竞争力。
第二个具有代表性的场景是对冲基金。房价指数由国家统计局定期公布。它影响不同行业的股票价格。如果能在国家统计局公布之前预测房价,就可以进行很好的推测。
第三种情况是建筑公司投标。投标人来自世界各地,有关潜在竞争对手的信息既昂贵又不完整。但我们所做的事情对投标人来说是当场的。
全自动数据挖掘
英国有 15,000 多处房产网站,还有少数没有完全覆盖的骨料,这对全自动化挖矿技术的要求很高。因为尽管这些信息很容易获得,但手动或半自动处理数据的成本太高。目前没有完全自动化的采矿工具或技术。所以我和牛津大学的一位教授一起研究固化或形式化的数据挖掘,这样机器就可以自动挖掘数据。
这张图片中的黑点是指向 URL 的链接。这是一个源数据项,我们在其中构建黑盒来更改数据,从数千万页到大型数据集。
上图显示了来自不同来源的两种类型的知识。就像孩子学习知识一样,学校里很多人都会告诉他规则,他学到的就是规则。所以这是从机器学习到基于规则的推理的转变。这对研究人员来说非常重要。右边是通过规则构建的推理,我们将其自动化。有两种类型的规则,标准规则和其他规则。
我们在 2015 年创建了一家公司,为了使用这个系统和规则,我们需要识别和对齐对象、填写表格、块分析和对象丰富以及云支持,以便更有效地提取信息。我们使用上述语言从数千个网页中提取容量信息,规则也需要语言。在二手车、房地产等很多领域都可以实现自动化的数据抽取。如果字段很简单,20天就可以形成相应的规则。但也有一些非常复杂的领域,每个领域都有不同的特点,每个国家都有自己的语言,这些都是需要克服的问题。
当前深耕知识图谱技术
最后介绍一下我们目前的研究工作——知识图谱。知识图谱可以非常清晰地管理大量的知识。它通过识别信息改变了人们的生活,从而形成了一个非常庞大的知识世界。许多公司都追随我们的研究脚步,包括 Facebook、亚马逊等。当然,小公司也希望利用知识图谱来采集员工、客户、竞争对手、价格等信息,从而提高业务质量。
这个知识体系(绿色标记)的核心是推理,其中收录许多规则和许多外部接口。接口之一是外部数据的提取,主要来自互联网。另外有内部知识,数据库之间也有一些关系,可以很方便的接入物联网。事实上,这是一个推理引擎,我们的客户包括中央银行和其他银行。基于此,可以开发许多应用程序,例如信用报告。交易中的欺诈也可以使用基于规则的系统进行检测。它可以用来检测公司贷款的真实性以及是否存在欺诈贷款的倾向。
上图显示了公司的所有权。实际上,公司之间的所有权结构往往非常复杂。该系统可用于理清公司之间的关系,提高公司管理水平。具体可以根据股份数量确定控股公司。此外,如果两家公司共同拥有另一家公司,这些信息很难用SQL进行处理和查询,但使用该方案可以更方便地管理和提高计算速度。
网页表格抓取(用excel很难,通过vba编程难度较大,并且数据量不大)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-03-07 08:24
用excel比较难,通过vba编程比较困难,数据量不大。
它可以通过网络蜘蛛通过设置下载。
留个邮箱,我已经下载了,发给你了。
我是通过专门的爬虫程序ninidown下载的。没有代码。只要设置好选项,我就可以下载,但是设置过程极其复杂。而且ninidown的bug很多,调试了差不多3个小时,这个方法不通用。
这个问题没有很好理解。是不是这样:
例子:
Excel工作簿中有两个工作表“Sheet1”和“Sheet2”;当在“Sheet2”的单元格A1中输入项目名称时,工作表“Sheet1”的单元格B1显示相同的名称;其工作表“Sheet1 中的单元格 B1”是对“Sheet2”中的单元格 A1 的引用,其公式应为“=Sheet2!A1”。
你可以在没有 VBA 的情况下做到这一点。
EXCEL本身有数据导入功能
03版本是data-import-from网站
07 版本是数据 - 因为 网站
不知道大家有没有用过,打开网站点击网页上的箭头变成√,然后点击导入。
Web数据可以导入EXCEL表格,打开时自动更新,之后指定时间自动更新。
所以,你只需要设置EXCEL表格,然后在定时任务中添加一个定时器即可打开。
如果不知道提取是什么意思,是指在客户端页面上提取表格吗?这可以完全完成。如果客户端页面中的表格也是直接连接EXCEL显示的,也是可以的,但是如果是后台用SQL语言查询的东西,会发送到客户端页面。如果要提取别人的库,那是不可能的。
如何实现EXCEL自动提取网站中的数据,并将数据累加增加保存-
如何实现EXCEL自动提取网站中的数据
如何实现EXCEL自动提取网站中的数据-...... 用excel比较难,通过vba编程比较难,数据量不大。可以通过设置通过网络蜘蛛下载。留个邮箱,我已经下载了,发给你。
如何实现EXCEL自动提取网站中的数据。- ......其实Excel很好,你只需要输入网址,然后双击单元格,然后看,这个单元格中的网址就变成了一个链接。
EXCEL表格如何自动获取网页数据?- …… excel-数据-导入外部数据-新建网页查询-在对话框中输入网址-输入-选择内容-点击右下角导入-在“数据区属性”中进行设置。
如何实现EXCEL自动定时抽取网站中的数据,并将每次采集到的数据累加向下递增保存。……哇?问题,你必须确保你的文件格式可以被vba的文件读写函数读取。此外,您将创建一个非常大的 Excel,它太大且不稳定。为什么不设置成自动导入到sql数据库中呢?
EXCEL自动提取网页的具体数据...在工具栏中设置链接表=>数据,将网页表导入excel进行处理或VBADim myQuery With ActiveSheet .Cells.Delete .[a1] = "Conneting, Please Wait ..." Set myQuery = ActiveSheet.QueryTables _ .Add(Connection:="URL;URL", _ Destination:=.Cells(1, 1)) 以 myQuery 结束 .Refresh 以
excel如何自动获取网页中的数值--……数据--导入外部数据--新建网页数据--输入数值页所说的URL,然后选择要导入的表格。选择刷新。可以编辑、重新处理等,可以试试
如何让excel自动搜索网页并导出需要的信息?- ...... 这是不可能的。“导出到Excel”是Excel为IE制作的插件添加的菜单项,Word不提供此类插件。但是,如果您使用的是Office2007,并且在安装过程中选择安装OneNote产品,IE工具栏上会多出一个“发送到OneNote”按钮。单击此按钮后,将发送当前网页上的所有图像。将文本内容发送到 OneNote 中的新页面。这个 OneNote 是一个非常方便的工具来记录/组织/共享您的笔记(图像/文本/多媒体)。
如何从07excel中列出的网站中自动获取每个网页中特定位置的信息,并自动抓取到excel中-... Sub 提取网页信息() Dim IE As Object, srg$, brr( 1 To 5) Set IE = CreateObject("Microsoft.XMLHTTP") For i = 1 To 5 a = Right(Cells(i, 1).Value, 9) With IE .Open "get" , "" & a, False .send srg = .... 查看全部
网页表格抓取(用excel很难,通过vba编程难度较大,并且数据量不大)
用excel比较难,通过vba编程比较困难,数据量不大。
它可以通过网络蜘蛛通过设置下载。
留个邮箱,我已经下载了,发给你了。
我是通过专门的爬虫程序ninidown下载的。没有代码。只要设置好选项,我就可以下载,但是设置过程极其复杂。而且ninidown的bug很多,调试了差不多3个小时,这个方法不通用。
这个问题没有很好理解。是不是这样:
例子:
Excel工作簿中有两个工作表“Sheet1”和“Sheet2”;当在“Sheet2”的单元格A1中输入项目名称时,工作表“Sheet1”的单元格B1显示相同的名称;其工作表“Sheet1 中的单元格 B1”是对“Sheet2”中的单元格 A1 的引用,其公式应为“=Sheet2!A1”。
你可以在没有 VBA 的情况下做到这一点。
EXCEL本身有数据导入功能
03版本是data-import-from网站
07 版本是数据 - 因为 网站
不知道大家有没有用过,打开网站点击网页上的箭头变成√,然后点击导入。
Web数据可以导入EXCEL表格,打开时自动更新,之后指定时间自动更新。
所以,你只需要设置EXCEL表格,然后在定时任务中添加一个定时器即可打开。
如果不知道提取是什么意思,是指在客户端页面上提取表格吗?这可以完全完成。如果客户端页面中的表格也是直接连接EXCEL显示的,也是可以的,但是如果是后台用SQL语言查询的东西,会发送到客户端页面。如果要提取别人的库,那是不可能的。
如何实现EXCEL自动提取网站中的数据,并将数据累加增加保存-
如何实现EXCEL自动提取网站中的数据
如何实现EXCEL自动提取网站中的数据-...... 用excel比较难,通过vba编程比较难,数据量不大。可以通过设置通过网络蜘蛛下载。留个邮箱,我已经下载了,发给你。
如何实现EXCEL自动提取网站中的数据。- ......其实Excel很好,你只需要输入网址,然后双击单元格,然后看,这个单元格中的网址就变成了一个链接。
EXCEL表格如何自动获取网页数据?- …… excel-数据-导入外部数据-新建网页查询-在对话框中输入网址-输入-选择内容-点击右下角导入-在“数据区属性”中进行设置。
如何实现EXCEL自动定时抽取网站中的数据,并将每次采集到的数据累加向下递增保存。……哇?问题,你必须确保你的文件格式可以被vba的文件读写函数读取。此外,您将创建一个非常大的 Excel,它太大且不稳定。为什么不设置成自动导入到sql数据库中呢?
EXCEL自动提取网页的具体数据...在工具栏中设置链接表=>数据,将网页表导入excel进行处理或VBADim myQuery With ActiveSheet .Cells.Delete .[a1] = "Conneting, Please Wait ..." Set myQuery = ActiveSheet.QueryTables _ .Add(Connection:="URL;URL", _ Destination:=.Cells(1, 1)) 以 myQuery 结束 .Refresh 以
excel如何自动获取网页中的数值--……数据--导入外部数据--新建网页数据--输入数值页所说的URL,然后选择要导入的表格。选择刷新。可以编辑、重新处理等,可以试试
如何让excel自动搜索网页并导出需要的信息?- ...... 这是不可能的。“导出到Excel”是Excel为IE制作的插件添加的菜单项,Word不提供此类插件。但是,如果您使用的是Office2007,并且在安装过程中选择安装OneNote产品,IE工具栏上会多出一个“发送到OneNote”按钮。单击此按钮后,将发送当前网页上的所有图像。将文本内容发送到 OneNote 中的新页面。这个 OneNote 是一个非常方便的工具来记录/组织/共享您的笔记(图像/文本/多媒体)。
如何从07excel中列出的网站中自动获取每个网页中特定位置的信息,并自动抓取到excel中-... Sub 提取网页信息() Dim IE As Object, srg$, brr( 1 To 5) Set IE = CreateObject("Microsoft.XMLHTTP") For i = 1 To 5 a = Right(Cells(i, 1).Value, 9) With IE .Open "get" , "" & a, False .send srg = ....
网页表格抓取(技术一种可配置化的数据解析方法和网页解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-07 08:18
本发明专利技术涉及一种可配置的数据解析方法,包括以下步骤:解析配置;现场配置;创建空白逻辑表,并将各个字段名写入空白逻辑表;抓取URL对应的URL 对于目标网页,根据解析类型和解析属性提取数据对象,然后依次映射到逻辑表中,与字段名形成对应关系,从而转换目标网页结构化数据文本。本发明的专利技术是一种可配置的数据解析方法。通过配置解析表,可以灵活处理不同格式的网页,完成网页解析,将网页数据转化为结构化数据文本,
一种可配置的数据分析方法和计算机可读存储介质
下载所有详细的技术数据
【技术实现步骤总结】
一种可配置的数据解析方法及计算机可读存储介质
本专利技术涉及一种可配置的数据分析方法及计算机可读存储介质,属于互联网数据爬取领域。
技术介绍
互联网上的信息复杂,信息的类型和表达方式多种多样。显示的信息只是为了方便用户浏览,不是统一的结构化数据显示,所以不考虑机器识别。但是,由于计算机不具备自然语言或类人阅读能力,互联网网页的信息载体所显示的信息不易被计算机识别和分析。在过去的IT技术发展中,积累了大量基于结构化数据的挖掘和分析技术。对于从互联网上抓取的网页的非结构化数据,我们需要先将其从结构化数据中进行转换,以方便机器学习。标识,以方便后续业务单位使用。公开号为CN108959539A的专利技术专利《一种基于规则的可配置网页数据分析方法》公开了网页分析方法如下: S3.网页分析:获取Web中任务配置配置的分析信息,获取采集网页的列表信息进行数据解析,通过Python的BeautifulSoup库解析页面;解析时,根据页面上配置的HTML标签,按标签类型和值提取数据及相关标签;解析结束然后,将数据存入数据库。公开的技术方案使用Python的BeautifulSoup库来解析页面文本数据,但是这种方法有以下两个缺点:1、Python的BeautifulSoup库只能解析HTML或XML格式的文件,并且支持的类型有限,比如不能支持Json格式的网页进行解析;2、Python的BeautifulSoup库是一种封装模式,而对于不同格式的网页一、,它对网页的灵活性有明显的适应作用还不够,尤其是对于一些非常规的特殊处理的网页,或者当用户选择性地过滤过滤相关数据时,封装模式似乎不合适。
技术实现思路
为了解决上述技术问题,专利技术提供了一种可配置的数据分析方法,将捕获的目标网页转换为标准化的结构化数据文本,便于信息的应用和挖掘。该专利技术的第一个技术方案如下:一种可配置的数据解析方法,包括以下步骤:创建解析配置页面,并配置URL、解析类型、解析属性以及保存数据的逻辑表名称解析结果,配置完成后选择提交保存;解析属性包括解析区域和行定位信息,或者解析属性只包括行定位信息;创建一个新的字段配置页面,并在字段配置页面配置必填字段提取的数据对象对应的字段名称;根据逻辑表名称创建一个空白逻辑表,并将每个字段名称写入空白逻辑表;抓取URL对应的目标网页,根据分析类型和分析属性提取数据对象,具体步骤如下:根据解析区域定位待提取数据对象所在区域,然后定位根据行定位信息,从解析区域中提取出待提取数据对象所在的行区域,从这些行中一一提取数据对象,然后依次映射到逻辑表中,与数据对象形成对应关系字段名称,从而将目标网页转换为结构化数据文本;或者只根据行定位信息区域定位待提取数据对象所在的行,从这些行中逐一提取数据对象,然后依次映射到逻辑表中,与字段名称,从而将目标网页转换为结构化数据文本。
更优选地,字段配置还包括配置字段标识,数据分析方法执行以下步骤:新建分析配置页面,配置待爬取目标网页的URL、分析类型、分析属性、以及分析配置页面的分析配置页面信息。保存解析结果的逻辑表名称,配置完成后选择提交保存;解析属性包括解析区域和行定位信息,或者解析属性只包括行定位信息;新建一个字段配置页面,在字段配置页面配置需要的字段提取的数据对象对应的字段名称;根据逻辑表名称创建空白逻辑表,并在空白逻辑表中写入字段名称和对应的字段标识;抓取该URL对应的目标网页,根据解析类型和解析属性提取数据对象,具体步骤如下:根据解析区域定位要提取的数据对象所在的区域,然后根据行定位信息在解析区域中定位待提取数据对象所在的行区域,读取字段配置信息中的字段标识,定位这些行中的字段标识,字段标识对应的属性值是要提取的数据对象,并将提取的字段标识符对应的数据对象写入字段名的取值范围内,依次类推,将解析区的所有字段标识符一一遍历,将所有要提取的数据对象写入逻辑表,并与字段名形成对应关系,从而转换目标网页或根据行定位信息定位待提取数据对象所在行区域,从字段配置信息中读取字段标识,定位这些行中的字段标识符,与字段标识符对应的属性值就是要提取的数据对象。将提取的数据对象写入到字段标识对应的字段名的value字段中,以此类推,一一遍历所有的字段标识,并写入所有需要提取的数据对象。进入逻辑表,并与字段名称形成对应关系,从而将目标网页转换为结构化的数据文本。
更优选地,分析区域的配置包括表格区域标识、表格起始索引和表格结束索引,根据表格起始索引定位分析区域开头的表格区域标识位置,表格区域根据表尾索引定位分析区域的末尾。确定位置。更优选地,行定位信息包括行区域标识、行起始索引和行结束索引,根据行起始索引定位解析区域开头的表区域标识位置,行区域标识位于根据行停止索引定位解析区域的末端。地点。更优选地,目标网页的解析类型为HTMLBYHEAD,解析属性还包括标题定位信息,标题定位信息包括标题行标识、标题行索引和标题列标识,HTMLBYHEAD A类型为在着陆页的表格上方有标题的页面。本专利技术还提供了一种计算机可读存储介质。本专利技术方案二是一种计算机可读存储介质,其上存储有计算机程序,当该程序被处理器执行时,执行以下步骤:创建新的解析配置页面,以及在解析配置页面URL、解析类型、解析属性和用于保存解析结果的逻辑表的名称上配置要爬取的目标网页,完成后提交;解析属性包括解析区域和行定位信息,或者解析属性只包括行定位信息;新建字段配置页面,在字段配置页面配置逻辑表中每个字段的字段名,每个字段名对应要提取的数据对象;根据逻辑表名创建空白逻辑表,将每个字段名写入空白逻辑表,每个字段的排序与解析时数据对象的提取顺序一致;抓取URL对应的目标网页,根据解析类型和解析属性提取数据对象。具体步骤如下:根据解析区域定位要提取的数据对象所在的区域,然后根据行定位信息从分析区域中定位出要提取的数据对象所在的行区域,将这些行中的数据对象一一提取出来,然后依次映射到逻辑表中,所有形成上述字段名称的对应关系,从而将目标网页转换为结构化数据文本;或者根据行定位信息定位要提取的数据对象所在的行区域,将这些行中的数据对象一一提取出来,然后映射到逻辑表中,与字段形成对应关系名称,以便将目标网页转换为结构化数据文本。将这些行中的数据对象一一提取出来,依次映射到逻辑表中,都形成上述字段名的对应关系,从而将目标网页转化为结构化的数据文本;或者根据行定位信息定位要提取的数据对象所在的行区域,将这些行中的数据对象一一提取出来,然后映射到逻辑表中,与字段形成对应关系名称,以便将目标网页转换为结构化数据文本。将这些行中的数据对象一一提取出来,依次映射到逻辑表中,都形成上述字段名的对应关系,从而将目标网页转化为结构化的数据文本;或者根据行定位信息定位要提取的数据对象所在的行区域,将这些行中的数据对象一一提取出来,然后映射到逻辑表中,与字段形成对应关系名称,以便将目标网页转换为结构化数据文本。
更优选地,字段配置还包括配置字段标识,数据分析方法执行以下步骤:新建分析配置页面,配置待爬取目标网页的URL、分析类型、分析属性、以及分析配置页面的分析配置页面信息。保存解析结果的逻辑表名,完成后提交;解析属性包括解析区域和/或行定位信息;新建字段配置页面,在字段配置页面配置逻辑表中各个字段的字段名称和字段标识;根据逻辑表名创建一个空白逻辑表,并在空白逻辑表中写入各个字段名称和对应的字段标识符;抓取该URL对应的目标网页,根据解析类型和解析属性提取数据对象,具体步骤如下:根据解析区域定位待提取数据对象所在的区域,然后根据行定位信息在解析区域中定位待提取数据对象所在行区域,从字段配置信息中读取字段标识,定位在这几行
【技术保护点】
1.一种可配置的数据解析方法,其特征在于包括以下步骤:新建一个解析配置页面,并配置URL、解析类型、解析属性,以及保存解析结果的逻辑表名,配置完成后,选择提交并保存;解析属性包括解析区域和行定位信息,或者解析属性只包括行定位信息;新建一个字段配置页面,在字段配置页面配置需要的字段提取的数据对象对应的字段名称;根据逻辑表名称创建一个空白逻辑表,并将每个字段名称写入空白逻辑表;抓取URL对应的目标网页,根据分析类型和分析属性提取数据对象,具体步骤如下:根据解析区域定位待提取数据对象所在区域,然后定位待提取数据对象所在行区域根据行定位信息从解析区定位,并从这些行中一一提取数据对象,然后依次映射到逻辑表中,与字段名形成对应关系,从而转换目标网页页面转换为结构化数据文本;或者只根据行定位信息区域定位待提取数据对象所在的行,从这些行中逐一提取数据对象,然后依次映射到逻辑表中,与字段名称,
【技术特点总结】
1.一种可配置的数据解析方法,其特征在于包括以下步骤:新建一个解析配置页面,并配置URL、解析类型、解析属性,以及保存解析结果的逻辑表名,配置完成后,选择提交并保存;解析属性包括解析区域和行定位信息,或者解析属性只包括行定位信息;新建一个字段配置页面,在字段配置页面配置需要的字段提取的数据对象对应的字段名称;根据逻辑表名称创建一个空白逻辑表,并将每个字段名称写入空白逻辑表;抓取URL对应的目标网页,根据分析类型和分析属性提取数据对象,具体步骤如下:根据解析区域定位待提取数据对象所在区域,然后定位待提取数据对象所在行区域根据行定位信息从解析区定位,并从这些行中一一提取数据对象,然后依次映射到逻辑表中,与字段名形成对应关系,从而转换目标网页页面转换为结构化数据文本;或者只根据行定位信息区域定位待提取数据对象所在的行,从这些行中逐一提取数据对象,然后依次映射到逻辑表中,与字段名称,从而将目标网页转换为结构化数据文本。2.
3.根据权利要求1所述的一种可配置的数据解析方法,其特征在于,所述解析区域的配置包括表区域标识、表起始索引和表结束索引,根据表起始索引索引定位表区域解析区域开头的标识位置,根据表格终止索引定位解析区域末尾的表格区域标识位置。4.根据权利要求1所述的可配置数据解析方法,其特征在于,所述行定位信息包括行区域标识、行开始索引和行结束索引。根据行起始索引定位解析区开头的表区标识位置,根据行终止索引定位解析区末尾的行区标识位置。5.根据权利要求1所述的一种可配置的数据解析方法,其特征在于,所述目标网页的解析类型为HTMLBYHEAD,解析属性还包括头部定位信息,表头部定位信息包括头部行标识、标题行索引和标题列标识符,HTMLBYHEAD类型是指目标网页中表格上方有标题的网页。6.计算机可读存储... 表头定位信息包括表头行标识、表头行索引和表头列标识,HTMLBYHEAD类型是指目标网页中表头在表上方的网页。6.计算机可读存储... 表头定位信息包括表头行标识、表头行索引和表头列标识,HTMLBYHEAD类型是指目标网页中表头在表上方的网页。6.计算机可读存储...
【专利技术性质】
技术研发人员:邱涛、邱水文、陈成乐、
申请人(专利权)持有人:,
类型:发明
国家、省、市:福建,35
下载所有详细的技术数据 我是该专利的所有者 查看全部
网页表格抓取(技术一种可配置化的数据解析方法和网页解析)
本发明专利技术涉及一种可配置的数据解析方法,包括以下步骤:解析配置;现场配置;创建空白逻辑表,并将各个字段名写入空白逻辑表;抓取URL对应的URL 对于目标网页,根据解析类型和解析属性提取数据对象,然后依次映射到逻辑表中,与字段名形成对应关系,从而转换目标网页结构化数据文本。本发明的专利技术是一种可配置的数据解析方法。通过配置解析表,可以灵活处理不同格式的网页,完成网页解析,将网页数据转化为结构化数据文本,
一种可配置的数据分析方法和计算机可读存储介质
下载所有详细的技术数据
【技术实现步骤总结】
一种可配置的数据解析方法及计算机可读存储介质
本专利技术涉及一种可配置的数据分析方法及计算机可读存储介质,属于互联网数据爬取领域。
技术介绍
互联网上的信息复杂,信息的类型和表达方式多种多样。显示的信息只是为了方便用户浏览,不是统一的结构化数据显示,所以不考虑机器识别。但是,由于计算机不具备自然语言或类人阅读能力,互联网网页的信息载体所显示的信息不易被计算机识别和分析。在过去的IT技术发展中,积累了大量基于结构化数据的挖掘和分析技术。对于从互联网上抓取的网页的非结构化数据,我们需要先将其从结构化数据中进行转换,以方便机器学习。标识,以方便后续业务单位使用。公开号为CN108959539A的专利技术专利《一种基于规则的可配置网页数据分析方法》公开了网页分析方法如下: S3.网页分析:获取Web中任务配置配置的分析信息,获取采集网页的列表信息进行数据解析,通过Python的BeautifulSoup库解析页面;解析时,根据页面上配置的HTML标签,按标签类型和值提取数据及相关标签;解析结束然后,将数据存入数据库。公开的技术方案使用Python的BeautifulSoup库来解析页面文本数据,但是这种方法有以下两个缺点:1、Python的BeautifulSoup库只能解析HTML或XML格式的文件,并且支持的类型有限,比如不能支持Json格式的网页进行解析;2、Python的BeautifulSoup库是一种封装模式,而对于不同格式的网页一、,它对网页的灵活性有明显的适应作用还不够,尤其是对于一些非常规的特殊处理的网页,或者当用户选择性地过滤过滤相关数据时,封装模式似乎不合适。
技术实现思路
为了解决上述技术问题,专利技术提供了一种可配置的数据分析方法,将捕获的目标网页转换为标准化的结构化数据文本,便于信息的应用和挖掘。该专利技术的第一个技术方案如下:一种可配置的数据解析方法,包括以下步骤:创建解析配置页面,并配置URL、解析类型、解析属性以及保存数据的逻辑表名称解析结果,配置完成后选择提交保存;解析属性包括解析区域和行定位信息,或者解析属性只包括行定位信息;创建一个新的字段配置页面,并在字段配置页面配置必填字段提取的数据对象对应的字段名称;根据逻辑表名称创建一个空白逻辑表,并将每个字段名称写入空白逻辑表;抓取URL对应的目标网页,根据分析类型和分析属性提取数据对象,具体步骤如下:根据解析区域定位待提取数据对象所在区域,然后定位根据行定位信息,从解析区域中提取出待提取数据对象所在的行区域,从这些行中一一提取数据对象,然后依次映射到逻辑表中,与数据对象形成对应关系字段名称,从而将目标网页转换为结构化数据文本;或者只根据行定位信息区域定位待提取数据对象所在的行,从这些行中逐一提取数据对象,然后依次映射到逻辑表中,与字段名称,从而将目标网页转换为结构化数据文本。
更优选地,字段配置还包括配置字段标识,数据分析方法执行以下步骤:新建分析配置页面,配置待爬取目标网页的URL、分析类型、分析属性、以及分析配置页面的分析配置页面信息。保存解析结果的逻辑表名称,配置完成后选择提交保存;解析属性包括解析区域和行定位信息,或者解析属性只包括行定位信息;新建一个字段配置页面,在字段配置页面配置需要的字段提取的数据对象对应的字段名称;根据逻辑表名称创建空白逻辑表,并在空白逻辑表中写入字段名称和对应的字段标识;抓取该URL对应的目标网页,根据解析类型和解析属性提取数据对象,具体步骤如下:根据解析区域定位要提取的数据对象所在的区域,然后根据行定位信息在解析区域中定位待提取数据对象所在的行区域,读取字段配置信息中的字段标识,定位这些行中的字段标识,字段标识对应的属性值是要提取的数据对象,并将提取的字段标识符对应的数据对象写入字段名的取值范围内,依次类推,将解析区的所有字段标识符一一遍历,将所有要提取的数据对象写入逻辑表,并与字段名形成对应关系,从而转换目标网页或根据行定位信息定位待提取数据对象所在行区域,从字段配置信息中读取字段标识,定位这些行中的字段标识符,与字段标识符对应的属性值就是要提取的数据对象。将提取的数据对象写入到字段标识对应的字段名的value字段中,以此类推,一一遍历所有的字段标识,并写入所有需要提取的数据对象。进入逻辑表,并与字段名称形成对应关系,从而将目标网页转换为结构化的数据文本。
更优选地,分析区域的配置包括表格区域标识、表格起始索引和表格结束索引,根据表格起始索引定位分析区域开头的表格区域标识位置,表格区域根据表尾索引定位分析区域的末尾。确定位置。更优选地,行定位信息包括行区域标识、行起始索引和行结束索引,根据行起始索引定位解析区域开头的表区域标识位置,行区域标识位于根据行停止索引定位解析区域的末端。地点。更优选地,目标网页的解析类型为HTMLBYHEAD,解析属性还包括标题定位信息,标题定位信息包括标题行标识、标题行索引和标题列标识,HTMLBYHEAD A类型为在着陆页的表格上方有标题的页面。本专利技术还提供了一种计算机可读存储介质。本专利技术方案二是一种计算机可读存储介质,其上存储有计算机程序,当该程序被处理器执行时,执行以下步骤:创建新的解析配置页面,以及在解析配置页面URL、解析类型、解析属性和用于保存解析结果的逻辑表的名称上配置要爬取的目标网页,完成后提交;解析属性包括解析区域和行定位信息,或者解析属性只包括行定位信息;新建字段配置页面,在字段配置页面配置逻辑表中每个字段的字段名,每个字段名对应要提取的数据对象;根据逻辑表名创建空白逻辑表,将每个字段名写入空白逻辑表,每个字段的排序与解析时数据对象的提取顺序一致;抓取URL对应的目标网页,根据解析类型和解析属性提取数据对象。具体步骤如下:根据解析区域定位要提取的数据对象所在的区域,然后根据行定位信息从分析区域中定位出要提取的数据对象所在的行区域,将这些行中的数据对象一一提取出来,然后依次映射到逻辑表中,所有形成上述字段名称的对应关系,从而将目标网页转换为结构化数据文本;或者根据行定位信息定位要提取的数据对象所在的行区域,将这些行中的数据对象一一提取出来,然后映射到逻辑表中,与字段形成对应关系名称,以便将目标网页转换为结构化数据文本。将这些行中的数据对象一一提取出来,依次映射到逻辑表中,都形成上述字段名的对应关系,从而将目标网页转化为结构化的数据文本;或者根据行定位信息定位要提取的数据对象所在的行区域,将这些行中的数据对象一一提取出来,然后映射到逻辑表中,与字段形成对应关系名称,以便将目标网页转换为结构化数据文本。将这些行中的数据对象一一提取出来,依次映射到逻辑表中,都形成上述字段名的对应关系,从而将目标网页转化为结构化的数据文本;或者根据行定位信息定位要提取的数据对象所在的行区域,将这些行中的数据对象一一提取出来,然后映射到逻辑表中,与字段形成对应关系名称,以便将目标网页转换为结构化数据文本。
更优选地,字段配置还包括配置字段标识,数据分析方法执行以下步骤:新建分析配置页面,配置待爬取目标网页的URL、分析类型、分析属性、以及分析配置页面的分析配置页面信息。保存解析结果的逻辑表名,完成后提交;解析属性包括解析区域和/或行定位信息;新建字段配置页面,在字段配置页面配置逻辑表中各个字段的字段名称和字段标识;根据逻辑表名创建一个空白逻辑表,并在空白逻辑表中写入各个字段名称和对应的字段标识符;抓取该URL对应的目标网页,根据解析类型和解析属性提取数据对象,具体步骤如下:根据解析区域定位待提取数据对象所在的区域,然后根据行定位信息在解析区域中定位待提取数据对象所在行区域,从字段配置信息中读取字段标识,定位在这几行
【技术保护点】
1.一种可配置的数据解析方法,其特征在于包括以下步骤:新建一个解析配置页面,并配置URL、解析类型、解析属性,以及保存解析结果的逻辑表名,配置完成后,选择提交并保存;解析属性包括解析区域和行定位信息,或者解析属性只包括行定位信息;新建一个字段配置页面,在字段配置页面配置需要的字段提取的数据对象对应的字段名称;根据逻辑表名称创建一个空白逻辑表,并将每个字段名称写入空白逻辑表;抓取URL对应的目标网页,根据分析类型和分析属性提取数据对象,具体步骤如下:根据解析区域定位待提取数据对象所在区域,然后定位待提取数据对象所在行区域根据行定位信息从解析区定位,并从这些行中一一提取数据对象,然后依次映射到逻辑表中,与字段名形成对应关系,从而转换目标网页页面转换为结构化数据文本;或者只根据行定位信息区域定位待提取数据对象所在的行,从这些行中逐一提取数据对象,然后依次映射到逻辑表中,与字段名称,
【技术特点总结】
1.一种可配置的数据解析方法,其特征在于包括以下步骤:新建一个解析配置页面,并配置URL、解析类型、解析属性,以及保存解析结果的逻辑表名,配置完成后,选择提交并保存;解析属性包括解析区域和行定位信息,或者解析属性只包括行定位信息;新建一个字段配置页面,在字段配置页面配置需要的字段提取的数据对象对应的字段名称;根据逻辑表名称创建一个空白逻辑表,并将每个字段名称写入空白逻辑表;抓取URL对应的目标网页,根据分析类型和分析属性提取数据对象,具体步骤如下:根据解析区域定位待提取数据对象所在区域,然后定位待提取数据对象所在行区域根据行定位信息从解析区定位,并从这些行中一一提取数据对象,然后依次映射到逻辑表中,与字段名形成对应关系,从而转换目标网页页面转换为结构化数据文本;或者只根据行定位信息区域定位待提取数据对象所在的行,从这些行中逐一提取数据对象,然后依次映射到逻辑表中,与字段名称,从而将目标网页转换为结构化数据文本。2.
3.根据权利要求1所述的一种可配置的数据解析方法,其特征在于,所述解析区域的配置包括表区域标识、表起始索引和表结束索引,根据表起始索引索引定位表区域解析区域开头的标识位置,根据表格终止索引定位解析区域末尾的表格区域标识位置。4.根据权利要求1所述的可配置数据解析方法,其特征在于,所述行定位信息包括行区域标识、行开始索引和行结束索引。根据行起始索引定位解析区开头的表区标识位置,根据行终止索引定位解析区末尾的行区标识位置。5.根据权利要求1所述的一种可配置的数据解析方法,其特征在于,所述目标网页的解析类型为HTMLBYHEAD,解析属性还包括头部定位信息,表头部定位信息包括头部行标识、标题行索引和标题列标识符,HTMLBYHEAD类型是指目标网页中表格上方有标题的网页。6.计算机可读存储... 表头定位信息包括表头行标识、表头行索引和表头列标识,HTMLBYHEAD类型是指目标网页中表头在表上方的网页。6.计算机可读存储... 表头定位信息包括表头行标识、表头行索引和表头列标识,HTMLBYHEAD类型是指目标网页中表头在表上方的网页。6.计算机可读存储...
【专利技术性质】
技术研发人员:邱涛、邱水文、陈成乐、
申请人(专利权)持有人:,
类型:发明
国家、省、市:福建,35
下载所有详细的技术数据 我是该专利的所有者
网页表格抓取(Excel抓取并查询网络数据可以使用“获取和转换”+“查找引用函数”的功能组合来实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-05 18:17
Excel抓取和查询网络数据可以通过“获取和转换”+“查找参考功能”的功能组合来实现。
示例:下图是百度百科“奥运”网页中的表格。我们以此为例,将表格抓取到Excel中,我们可以通过输入会话号来查询对应的主办城市。
Step1:使用“获取和转换”功能将网络数据捕获到Excel中
单击数据选项卡、新查询、来自其他来源、来自 Web。
弹出如下窗口,手动将百度百科“奥运”的网址复制粘贴到网址栏,点击确定。
Excel 连接到网页需要一定的时间。稍等片刻,会弹出如下窗口。左侧列表中的每个表代表网页中的一个表。一一点击预览后,发现Table3就是我们需要的数据。
单击下方“加载”旁边的下拉箭头,然后选择“加载到”。
在弹出窗口中,选择“选择如何在工作簿中查看此数据”下的“表”,然后单击“加载”。
如图所示,Web 表单中的数据已经被抓取到 Excel 中。
点击“表格工具”、“设计”,将“表格名称”改为Olympic Games。
Step2:使用“查找和引用”功能实现数据查询
创建一个查询区域,包括“会话数”和“主办城市”,在会话编号中选择一个会话并在下图中输入“第08个会话”,进入主办城市下的vlookup功能,可以得到第08届奥运会的主办城市是巴黎,当届数发生变化时,对应的主办城市也会发生变化。
公式:=VLOOKUP([会话次数],Olympics[#All],4,0)
注意:如果网页中的数据变化频繁,可以设置链接网页的数据定期刷新:
①将鼠标放在导入数据区,切换到【设计】选项卡,点击【刷新】下拉箭头→【链接属性】
②在弹出的【链接属性】对话框中,设置【刷新频率】,例如设置为10分钟刷新一次。这样每10分钟就会刷新一次数据,保证获取到的数据始终是最新的。
《江津Excel》是头条签约作者,关注我,点击任意三篇文章,如果没有你想要的知识,我就是个流氓!
谢谢你的邀请!如何快速使用Excel快速抓取网站中的上万条数据?在日常工作中,我们经常会采取复制->粘贴的方式,但这种方式不仅耗时,而且非常不雅观。今天就跟着视频一起来看看如何实现吧?
{!-- PGC_VIDEO:{"thumb_height": 720, "vposter": "", "thumb_width": 1368, "vid": "v020168e0000bq9bcdrd82dvh4ototbg", "vu": "v020168e0000bq9bcdrd82dvh4ototbg", "duration": 1持续时间”:@>4,“thumb_url”:“tos-cn-p-0000/687d784120b04f1b8f53d7b034ea2565”,“thumb_uri”:“tos-cn-p-0000/687d784120b04f1b8f53d7b034ea2565”,“video_size”:{“high”:持续时间” 190.4, “h”: 720, “w”: 1368}, “超”: {“持续时间”: 190.4, “h”: 720, “w”: 1368},“正常”:{“持续时间”:190.4,“h”:720,“w”:1368}}} --}
希望能帮到你!如需更多应用提示,请查看最近分享的视频,文章。有什么问题可以随时留言! 查看全部
网页表格抓取(Excel抓取并查询网络数据可以使用“获取和转换”+“查找引用函数”的功能组合来实现)
Excel抓取和查询网络数据可以通过“获取和转换”+“查找参考功能”的功能组合来实现。
示例:下图是百度百科“奥运”网页中的表格。我们以此为例,将表格抓取到Excel中,我们可以通过输入会话号来查询对应的主办城市。
Step1:使用“获取和转换”功能将网络数据捕获到Excel中
单击数据选项卡、新查询、来自其他来源、来自 Web。
弹出如下窗口,手动将百度百科“奥运”的网址复制粘贴到网址栏,点击确定。
Excel 连接到网页需要一定的时间。稍等片刻,会弹出如下窗口。左侧列表中的每个表代表网页中的一个表。一一点击预览后,发现Table3就是我们需要的数据。
单击下方“加载”旁边的下拉箭头,然后选择“加载到”。
在弹出窗口中,选择“选择如何在工作簿中查看此数据”下的“表”,然后单击“加载”。
如图所示,Web 表单中的数据已经被抓取到 Excel 中。
点击“表格工具”、“设计”,将“表格名称”改为Olympic Games。
Step2:使用“查找和引用”功能实现数据查询
创建一个查询区域,包括“会话数”和“主办城市”,在会话编号中选择一个会话并在下图中输入“第08个会话”,进入主办城市下的vlookup功能,可以得到第08届奥运会的主办城市是巴黎,当届数发生变化时,对应的主办城市也会发生变化。
公式:=VLOOKUP([会话次数],Olympics[#All],4,0)
注意:如果网页中的数据变化频繁,可以设置链接网页的数据定期刷新:
①将鼠标放在导入数据区,切换到【设计】选项卡,点击【刷新】下拉箭头→【链接属性】
②在弹出的【链接属性】对话框中,设置【刷新频率】,例如设置为10分钟刷新一次。这样每10分钟就会刷新一次数据,保证获取到的数据始终是最新的。
《江津Excel》是头条签约作者,关注我,点击任意三篇文章,如果没有你想要的知识,我就是个流氓!
谢谢你的邀请!如何快速使用Excel快速抓取网站中的上万条数据?在日常工作中,我们经常会采取复制->粘贴的方式,但这种方式不仅耗时,而且非常不雅观。今天就跟着视频一起来看看如何实现吧?
{!-- PGC_VIDEO:{"thumb_height": 720, "vposter": "", "thumb_width": 1368, "vid": "v020168e0000bq9bcdrd82dvh4ototbg", "vu": "v020168e0000bq9bcdrd82dvh4ototbg", "duration": 1持续时间”:@>4,“thumb_url”:“tos-cn-p-0000/687d784120b04f1b8f53d7b034ea2565”,“thumb_uri”:“tos-cn-p-0000/687d784120b04f1b8f53d7b034ea2565”,“video_size”:{“high”:持续时间” 190.4, “h”: 720, “w”: 1368}, “超”: {“持续时间”: 190.4, “h”: 720, “w”: 1368},“正常”:{“持续时间”:190.4,“h”:720,“w”:1368}}} --}
希望能帮到你!如需更多应用提示,请查看最近分享的视频,文章。有什么问题可以随时留言!
网页表格抓取(网页中2020年GDP预测排名这个数据,如下图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-03-05 16:12
我们要获取网页中2020年GDP预测排名的数据,如下图
一、获取数据
首先,我们需要新建一个工作簿,打开它,然后点击数据功能组,点击New Query,然后选择from other sources,select from 网站
这种情况下会弹出一个对话框,直接复制你要提取数据的URL,然后点击确定,excel会自动连接计算出来的数据。
计算完成后,进入电量查询导航界面。导航器左侧的表格图标是excel检测到的表格数据,当我们点击对应的表格名称时,右侧会显示对应的数据。,我们可以点击表格找到我们要获取的数据,其中第一个就是我们要获取的数据,我们直接点击第一个表格然后点击转换数据
二、处理数据
点击数据转换后,会进入power query的数据处理界面,我们可以对数据进行相应的处理。例如,这里我们要按地区计算每个大陆的 GDP 总量,单位为人民币。
首先我们点击开始选择group by,然后在group by中选择区域,然后在新的列名中命名,我设置计算方式为sum,然后选择RMB所在的列,然后单击确定。
然后我们点击关闭上传,将数据加载到excel中,如下图
如果不想在power query中编辑,可以直接在导航界面点击加载,这样数据会直接加载到excel中,我们也可以直接在excel中编辑数据,
power query处理后的数据可以刷新,但是直接点击加载在excel中处理是无法刷新数据的。刷新数据,我们只需要在数据功能组中点击刷新即可刷新数据。 查看全部
网页表格抓取(网页中2020年GDP预测排名这个数据,如下图)
我们要获取网页中2020年GDP预测排名的数据,如下图
一、获取数据
首先,我们需要新建一个工作簿,打开它,然后点击数据功能组,点击New Query,然后选择from other sources,select from 网站
这种情况下会弹出一个对话框,直接复制你要提取数据的URL,然后点击确定,excel会自动连接计算出来的数据。
计算完成后,进入电量查询导航界面。导航器左侧的表格图标是excel检测到的表格数据,当我们点击对应的表格名称时,右侧会显示对应的数据。,我们可以点击表格找到我们要获取的数据,其中第一个就是我们要获取的数据,我们直接点击第一个表格然后点击转换数据
二、处理数据
点击数据转换后,会进入power query的数据处理界面,我们可以对数据进行相应的处理。例如,这里我们要按地区计算每个大陆的 GDP 总量,单位为人民币。
首先我们点击开始选择group by,然后在group by中选择区域,然后在新的列名中命名,我设置计算方式为sum,然后选择RMB所在的列,然后单击确定。
然后我们点击关闭上传,将数据加载到excel中,如下图
如果不想在power query中编辑,可以直接在导航界面点击加载,这样数据会直接加载到excel中,我们也可以直接在excel中编辑数据,
power query处理后的数据可以刷新,但是直接点击加载在excel中处理是无法刷新数据的。刷新数据,我们只需要在数据功能组中点击刷新即可刷新数据。
网页表格抓取( Python使用Web抓取有助于的步骤寻找您想要的抓取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-05 16:11
Python使用Web抓取有助于的步骤寻找您想要的抓取数据
)
前言
Crawler 是一种从 网站 中抓取大量数据的自动化方法。甚至在您最喜欢的 网站 上复制和粘贴引号或行也是一种网络抓取形式。大多数网站不允许你在它们网站上保存数据供你使用。所以唯一的选择就是手动复制数据,这会耗费大量时间,甚至可能需要数天才能完成。
网站 上的数据大多是非结构化的。Web 抓取有助于获取这些非结构化数据并将其存储在本地或以自定义和结构化形式存储在数据库中。如果您出于学习目的而抓取网页,那么您不太可能遇到任何问题,那么在不违反服务条款的情况下自己进行一些网页抓取以提高您的技能是一个很好的做法。
爬虫步骤
为什么使用 Python 进行网页抓取?
Python 非常快且更容易进行网络抓取。由于它太容易编码,您可以使用简单的小代码来执行大任务。
如何进行网页抓取?
我们需要运行网页抓取代码来向我们想要抓取的 网站 的 URL 发送请求。服务器发送数据并允许我们读取 HTML 或 XML 页面作为响应。该代码解析 HTML 或 XML 页面,查找数据并提取它们。
以下是使用 Python 使用网络抓取来提取数据的步骤
查找要抓取的 URL 分析网站查找要提取的数据 编写代码 运行代码并从 网站 中提取数据 以所需格式将数据存储在计算机中的库中网页抓取
Requests 是一个允许使用 Python 发送 HTTP 请求的模块。HTTP请求用于返回一个收录所有响应数据(如编码、状态、内容等)的响应对象
BeautifulSoup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。这适用于您最喜欢的解析器,以提供一种惯用的方式来导航、搜索和修改解析树。它专为快速和高度可靠的数据提取而设计。
pandas 是一个开源库,允许我们在 Python Web 开发中执行数据操作。它建立在 Numpy 包之上,其关键数据结构称为 DataFrame。DataFrames 允许我们在观察行和变量列中存储和操作表格数据。
Tqdm 是另一个 python 库,它可以快速让你的循环显示一个智能进度表——你所要做的就是用 Tqdm(iterable) 包装任何可迭代对象。
演示:获取 网站
Step 1. 找到你要抓取的URL
为了演示,我们将抓取网络以提取手机的详细信息。我使用了一个 example() 来展示这个过程。
Stpe 2. 分析网站
数据通常嵌套在标签中。我们要获取的数据被标记在下面的页面是嵌套的。要查看页面,只需右键单击元素并单击“检查”。将打开一个小的复选框。你可以看到网站背后的原创代码。现在您可以找到要抓取的详细信息标签。
您可以在控制台的左上角找到一个箭头符号。如果单击箭头,然后单击产品区域,则特定产品区域的代码将在控制台选项卡中突出显示。
我们应该做的第一件事是回顾和理解 HTML 的结构,因为从 网站 获取数据非常重要。网站 页面上会有很多代码,我们需要收录我们数据的代码。学习 HTML 的基础知识将帮助您熟悉 HTML 标记。
步骤3.找到要提取的数据
我们将提取电话数据,例如产品名称、实际价格、折扣价等。您可以提取任何类型的数据。为此,我们必须找到收录我们数据的标记。
通过检查元素的区域来打开控制台。单击左上角的箭头,然后单击产品。您现在将能够看到我们单击的产品的特定代码。
步骤 4. 编写代码
现在我们必须找出数据和链接的位置。让我们开始编码。
创建一个名为 scrap.py 的文件并在您选择的任何编辑器中打开它。我们将使用 pip 来安装上面提到的四个 Python 库。
第一个也是主要的过程是访问站点数据。我们已经设置了这个 网站 的 URL 并访问了这个 网站。
url = 'https://www.example.com/produc ... aders = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64)' 'AppleWebKit/537.36 (KHTML, like Gecko)' 'Chrome/64.0.3282.167 Safari/537.36' }result = requests.get(url, headers=headers,verify=True)Print(result)
输出:
如果你看到上面的结果,那么你已经成功访问了这个网站。
步骤 5. 运行代码并从 网站 中提取数据
现在,我们将使用 Beautifulsoup 来解析 HTML。
soup = BeautifulSoup(result.content, 'html.parser')
如果我们打印汤,那么我们将能够看到整个 网站 页面的 HTML 内容。我们现在要做的就是过滤收录数据的部分。因此,我们将从汤中提取部分标签。
section=soup.find("section", class_='js-section').find_all("div",{'class':'product-desc-rating})Print(section)
结果如下:
现在,我们可以在 div 的“product-desc-rating”类中提取手机的详细信息。我为手机的每个列详细信息创建了一个列表,并使用 for 循环将其附加到列表中。
Products = []url = []Actual_Price = []Discounted_Price = []Discount = []
产品名称出现在 HTML 中的 p 标签(段落标签)下,product_url 出现在锚标签下。
HTML 锚标记定义将一个页面链接到另一个页面的超链接。它可以创建指向另一个网页以及文件、位置或任何 URL 的超链接。“href”属性是 HTML 标签最重要的属性。以及指向目标页面或 URL 的链接。
然后我们将提取实际价格和折扣价格,它们都出现在 span 标签中。标签用于对内联元素进行分组。标签本身并没有提供任何视觉变化。最后,我们将从 div 标签中提取报价百分比。div 标签是块级标签。它是一个通用容器标签。它用于 HTML 中的各种标签组,以便可以创建部分并将样式应用于它们。
for t in tqdm(section): product_name = t.p.text Products.append(product_name) product_url = t.a['href'] url.append(product_url) original_price = t.span.getText() Actual_Price.append(original_price) discounted_price = t.find('span', class_ = 'lfloat product-price').getText() Discounted_Price.append(discounted_price) try: product_discount = t.find('div', class_ = 'product-discount') Discount.append(product_discount.text) except Exception as e: product_discount = None Discount.append(product_discount)
步骤 6. 以所需格式存储数据
我们已经提取了数据。我们现在要做的就是将数据存储到文件或数据库中。您可以以您想要的格式存储数据。这取决于您的要求。在这里,我们将以 CSV(逗号分隔值)格式存储提取的数据。
= pd.DataFrame({'Product Name':Products,'Actual_Price':Actual_Price,'Discounted_Price':Discounted_Price,'Offer_Percentage':Discount,'Product_url':url}) df.to_csv(' products.csv', index=False, encoding='utf-8')
查看全部
网页表格抓取(
Python使用Web抓取有助于的步骤寻找您想要的抓取数据
)
前言
Crawler 是一种从 网站 中抓取大量数据的自动化方法。甚至在您最喜欢的 网站 上复制和粘贴引号或行也是一种网络抓取形式。大多数网站不允许你在它们网站上保存数据供你使用。所以唯一的选择就是手动复制数据,这会耗费大量时间,甚至可能需要数天才能完成。
网站 上的数据大多是非结构化的。Web 抓取有助于获取这些非结构化数据并将其存储在本地或以自定义和结构化形式存储在数据库中。如果您出于学习目的而抓取网页,那么您不太可能遇到任何问题,那么在不违反服务条款的情况下自己进行一些网页抓取以提高您的技能是一个很好的做法。
爬虫步骤
为什么使用 Python 进行网页抓取?
Python 非常快且更容易进行网络抓取。由于它太容易编码,您可以使用简单的小代码来执行大任务。
如何进行网页抓取?
我们需要运行网页抓取代码来向我们想要抓取的 网站 的 URL 发送请求。服务器发送数据并允许我们读取 HTML 或 XML 页面作为响应。该代码解析 HTML 或 XML 页面,查找数据并提取它们。
以下是使用 Python 使用网络抓取来提取数据的步骤
查找要抓取的 URL 分析网站查找要提取的数据 编写代码 运行代码并从 网站 中提取数据 以所需格式将数据存储在计算机中的库中网页抓取
Requests 是一个允许使用 Python 发送 HTTP 请求的模块。HTTP请求用于返回一个收录所有响应数据(如编码、状态、内容等)的响应对象
BeautifulSoup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。这适用于您最喜欢的解析器,以提供一种惯用的方式来导航、搜索和修改解析树。它专为快速和高度可靠的数据提取而设计。
pandas 是一个开源库,允许我们在 Python Web 开发中执行数据操作。它建立在 Numpy 包之上,其关键数据结构称为 DataFrame。DataFrames 允许我们在观察行和变量列中存储和操作表格数据。
Tqdm 是另一个 python 库,它可以快速让你的循环显示一个智能进度表——你所要做的就是用 Tqdm(iterable) 包装任何可迭代对象。
演示:获取 网站
Step 1. 找到你要抓取的URL
为了演示,我们将抓取网络以提取手机的详细信息。我使用了一个 example() 来展示这个过程。
Stpe 2. 分析网站
数据通常嵌套在标签中。我们要获取的数据被标记在下面的页面是嵌套的。要查看页面,只需右键单击元素并单击“检查”。将打开一个小的复选框。你可以看到网站背后的原创代码。现在您可以找到要抓取的详细信息标签。
您可以在控制台的左上角找到一个箭头符号。如果单击箭头,然后单击产品区域,则特定产品区域的代码将在控制台选项卡中突出显示。
我们应该做的第一件事是回顾和理解 HTML 的结构,因为从 网站 获取数据非常重要。网站 页面上会有很多代码,我们需要收录我们数据的代码。学习 HTML 的基础知识将帮助您熟悉 HTML 标记。
步骤3.找到要提取的数据
我们将提取电话数据,例如产品名称、实际价格、折扣价等。您可以提取任何类型的数据。为此,我们必须找到收录我们数据的标记。
通过检查元素的区域来打开控制台。单击左上角的箭头,然后单击产品。您现在将能够看到我们单击的产品的特定代码。
步骤 4. 编写代码
现在我们必须找出数据和链接的位置。让我们开始编码。
创建一个名为 scrap.py 的文件并在您选择的任何编辑器中打开它。我们将使用 pip 来安装上面提到的四个 Python 库。
第一个也是主要的过程是访问站点数据。我们已经设置了这个 网站 的 URL 并访问了这个 网站。
url = 'https://www.example.com/produc ... aders = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64)' 'AppleWebKit/537.36 (KHTML, like Gecko)' 'Chrome/64.0.3282.167 Safari/537.36' }result = requests.get(url, headers=headers,verify=True)Print(result)
输出:
如果你看到上面的结果,那么你已经成功访问了这个网站。
步骤 5. 运行代码并从 网站 中提取数据
现在,我们将使用 Beautifulsoup 来解析 HTML。
soup = BeautifulSoup(result.content, 'html.parser')
如果我们打印汤,那么我们将能够看到整个 网站 页面的 HTML 内容。我们现在要做的就是过滤收录数据的部分。因此,我们将从汤中提取部分标签。
section=soup.find("section", class_='js-section').find_all("div",{'class':'product-desc-rating})Print(section)
结果如下:
现在,我们可以在 div 的“product-desc-rating”类中提取手机的详细信息。我为手机的每个列详细信息创建了一个列表,并使用 for 循环将其附加到列表中。
Products = []url = []Actual_Price = []Discounted_Price = []Discount = []
产品名称出现在 HTML 中的 p 标签(段落标签)下,product_url 出现在锚标签下。
HTML 锚标记定义将一个页面链接到另一个页面的超链接。它可以创建指向另一个网页以及文件、位置或任何 URL 的超链接。“href”属性是 HTML 标签最重要的属性。以及指向目标页面或 URL 的链接。
然后我们将提取实际价格和折扣价格,它们都出现在 span 标签中。标签用于对内联元素进行分组。标签本身并没有提供任何视觉变化。最后,我们将从 div 标签中提取报价百分比。div 标签是块级标签。它是一个通用容器标签。它用于 HTML 中的各种标签组,以便可以创建部分并将样式应用于它们。
for t in tqdm(section): product_name = t.p.text Products.append(product_name) product_url = t.a['href'] url.append(product_url) original_price = t.span.getText() Actual_Price.append(original_price) discounted_price = t.find('span', class_ = 'lfloat product-price').getText() Discounted_Price.append(discounted_price) try: product_discount = t.find('div', class_ = 'product-discount') Discount.append(product_discount.text) except Exception as e: product_discount = None Discount.append(product_discount)
步骤 6. 以所需格式存储数据
我们已经提取了数据。我们现在要做的就是将数据存储到文件或数据库中。您可以以您想要的格式存储数据。这取决于您的要求。在这里,我们将以 CSV(逗号分隔值)格式存储提取的数据。
= pd.DataFrame({'Product Name':Products,'Actual_Price':Actual_Price,'Discounted_Price':Discounted_Price,'Offer_Percentage':Discount,'Product_url':url}) df.to_csv(' products.csv', index=False, encoding='utf-8')
网页表格抓取(Python表格型数据获取的准确性是需要考虑的因素? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-03 15:27
)
Python 有许多可以捕获数据的包,例如 selenium、requests、scrapy 和 pandas。每个包都有其适用性。我个人认为在抓数据的时候,代码的简洁性和数据获取的准确性是需要考虑的因素。不要太担心时间的速度。毕竟用python抓数据已经大大节省了时间。使用不同的方法可能是 1 秒和 1 分钟之间的差异。我们在日常生活中总是有抓取表格数据的需求。本文尝试用pandas最简洁的代码来抓取表数据。该代码非常简单且易于使用。
只需选择一个页面:
比如爬取下图中定向工具的注册审批文件(当然wind里面有数据,本文只是为了展示如何爬取表格数据)
一、爬取当前页面
只需要两个密钥代码即可获取它。前两句是导入相关模块,第三句是输入网址,第四句是用pandas读取。由于网页有很多表格,所以会以列表的形式存储在变量ppn中。,点击查看第十四张表格正是我们所需要的。
二、 抓取所有
但是第一部分只抓取第一页,如果要抓取所有页面,也很简单,写个循环就行了。点击下一页可以看到它的 URL 相应地发生了变化:
页码会体现在索引后面的数字中,所以可以把url改成变量组合,详见第五句。第一二句还在导入相关模块,第三句是生成一个空矩阵来存储爬取的结果,第四到第八句是一个简单的循环,每页爬取结果变量。然后将结果连续添加到输出中。最终的输出就是我们想要的结果。
查看全部
网页表格抓取(Python表格型数据获取的准确性是需要考虑的因素?
)
Python 有许多可以捕获数据的包,例如 selenium、requests、scrapy 和 pandas。每个包都有其适用性。我个人认为在抓数据的时候,代码的简洁性和数据获取的准确性是需要考虑的因素。不要太担心时间的速度。毕竟用python抓数据已经大大节省了时间。使用不同的方法可能是 1 秒和 1 分钟之间的差异。我们在日常生活中总是有抓取表格数据的需求。本文尝试用pandas最简洁的代码来抓取表数据。该代码非常简单且易于使用。
只需选择一个页面:
比如爬取下图中定向工具的注册审批文件(当然wind里面有数据,本文只是为了展示如何爬取表格数据)
一、爬取当前页面
只需要两个密钥代码即可获取它。前两句是导入相关模块,第三句是输入网址,第四句是用pandas读取。由于网页有很多表格,所以会以列表的形式存储在变量ppn中。,点击查看第十四张表格正是我们所需要的。
二、 抓取所有
但是第一部分只抓取第一页,如果要抓取所有页面,也很简单,写个循环就行了。点击下一页可以看到它的 URL 相应地发生了变化:
页码会体现在索引后面的数字中,所以可以把url改成变量组合,详见第五句。第一二句还在导入相关模块,第三句是生成一个空矩阵来存储爬取的结果,第四到第八句是一个简单的循环,每页爬取结果变量。然后将结果连续添加到输出中。最终的输出就是我们想要的结果。
网页表格抓取(如何使用优采云采集器采集单网页上的表格信息? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-03-01 04:10
)
今天小编就给大家介绍一下优采云采集器采集单个网页的表单信息的使用方法。目的是让你知道如何处理表单类型的网页。我们来看看吧。
首先打开优采云采集器→点击快速启动→新建任务进入任务配置页面:
选择任务组,自定义任务名称和备注;
上图配置完成后,选择Next,进入流程配置页面,拖拽一个步骤打开网页进入流程设计器;
选择在浏览器中打开网页的步骤,在右侧页面网址中输入网页网址并点击保存,系统会在软件下方的浏览器中自动打开相应网页:
在上面的浏览器中,可以看到网页都是由同一个区域行组成的。我们需要捕获每个区域行中的数据信息,每个区域块行的格式都是一样的。这时候,我们需要创建一个循环列表来循环遍历每个区域行中的元素。
请注意,最终提取的元素必须收录在循环项中
点击上图中的第一个区域行,可以看到下图浏览器中的红色虚线框选中了整个区域行。如果没有选中,可以在弹出的选择对话框上方的放大选项中进行调整。. 调整好后,选择创建元素列表来处理一组元素;
接下来,在弹出的对话框中,选择添加到列表
添加第一区域行后,选择继续编辑列表。
接下来以相同的方式添加第二个区域行。
当我们添加第二个区域行时,我们可以看上图。此时,页面中的其他元素被添加。这是因为我们在添加两个具有相似特征的元素,系统会在页面中智能添加其他具有相似特征的元素。然后选择创建列表完成→点击下图中的循环
经过以上操作,循环采集列表就完成了。系统会在页面右上角显示该页面添加的所有循环项。
接下来,提取数据字段,点击上图中的第一个循环项,然后在流程设计器中点击提取数据,然后在浏览器中选择要提取的字段,然后在弹出的窗口中选择抓取这个元素选择对话框。文本;
完成上述操作后,系统会在页面右上角显示我们要抓取的字段;
接下来配置页面上需要抓取的其他字段,配置完成后修改字段名称;
修改完成后,点击上图中的保存按钮,然后点击图中的数据字段,可以看到系统会显示最终的采集列表;
点击上图中的Next→Next→Start Standalone采集(调试模式)进入任务检查页面,保证任务的正确性;
点击Start Standalone采集,系统会在本地执行采集进程并显示最终的采集结果;
如果我们需要导出最终的采集数据信息,点击下图中的导出按钮,选择要导出的文件类型,系统会提示保存路径,选择保存路径,系统会自动导出文件。
查看全部
网页表格抓取(如何使用优采云采集器采集单网页上的表格信息?
)
今天小编就给大家介绍一下优采云采集器采集单个网页的表单信息的使用方法。目的是让你知道如何处理表单类型的网页。我们来看看吧。
首先打开优采云采集器→点击快速启动→新建任务进入任务配置页面:
选择任务组,自定义任务名称和备注;
上图配置完成后,选择Next,进入流程配置页面,拖拽一个步骤打开网页进入流程设计器;
选择在浏览器中打开网页的步骤,在右侧页面网址中输入网页网址并点击保存,系统会在软件下方的浏览器中自动打开相应网页:
在上面的浏览器中,可以看到网页都是由同一个区域行组成的。我们需要捕获每个区域行中的数据信息,每个区域块行的格式都是一样的。这时候,我们需要创建一个循环列表来循环遍历每个区域行中的元素。
请注意,最终提取的元素必须收录在循环项中
点击上图中的第一个区域行,可以看到下图浏览器中的红色虚线框选中了整个区域行。如果没有选中,可以在弹出的选择对话框上方的放大选项中进行调整。. 调整好后,选择创建元素列表来处理一组元素;
接下来,在弹出的对话框中,选择添加到列表
添加第一区域行后,选择继续编辑列表。
接下来以相同的方式添加第二个区域行。
当我们添加第二个区域行时,我们可以看上图。此时,页面中的其他元素被添加。这是因为我们在添加两个具有相似特征的元素,系统会在页面中智能添加其他具有相似特征的元素。然后选择创建列表完成→点击下图中的循环
经过以上操作,循环采集列表就完成了。系统会在页面右上角显示该页面添加的所有循环项。
接下来,提取数据字段,点击上图中的第一个循环项,然后在流程设计器中点击提取数据,然后在浏览器中选择要提取的字段,然后在弹出的窗口中选择抓取这个元素选择对话框。文本;
完成上述操作后,系统会在页面右上角显示我们要抓取的字段;
接下来配置页面上需要抓取的其他字段,配置完成后修改字段名称;
修改完成后,点击上图中的保存按钮,然后点击图中的数据字段,可以看到系统会显示最终的采集列表;
点击上图中的Next→Next→Start Standalone采集(调试模式)进入任务检查页面,保证任务的正确性;
点击Start Standalone采集,系统会在本地执行采集进程并显示最终的采集结果;
如果我们需要导出最终的采集数据信息,点击下图中的导出按钮,选择要导出的文件类型,系统会提示保存路径,选择保存路径,系统会自动导出文件。
网页表格抓取(这是简易数据分析系列的第11篇文章(图)制作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-26 11:16
这是简易数据分析系列文章的第11期。
今天我们将讨论如何在 Web 表单中捕获数据。首先我们来分析一下网页中的经典表格是如何组成的。
经典的表格都是关于这些知识点的,没了。让我们编写一个简单的表单 Web Scraper 爬虫。
1.创建站点地图
我们今天的练习 网站 是
�Ϻ�&txt刀大=����
爬虫的内容是爬取上海到北京的所有火车时刻表。
我们首先创建一个收录整个表格的容器,并将Type选择为Table,表示我们要抓取表格。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。如果你看一下,你会发现这些数据实际上是表数据类型的分类。在这种情况下,他列出了火车、出发站和行驶时间的类别。
在表格列类别中,默认勾选每行内容旁边的选择按钮,这意味着默认捕获这些列的内容。如果您不想爬取某种类型的内容,只需去掉相应的复选框即可。
当你点击保存选择器按钮的时候,你会发现Result键的一些选项报错,说invalid format format无效:
解决这个错误非常简单。一般来说,Result 键名的长度是不够的。您可以添加空格和标点符号。如果仍然出现错误,请尝试更改为英文名称:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程抓取数据了。
2.我为什么不建议你使用 Web Scraper 的表格选择器?
如果按照刚才的教程,感觉会很流畅,但是看数据的时候,就傻眼了。
刚开始爬的时候,我们先用Data preview预览数据,发现数据很完美:
抓取数据后,在浏览器的预览面板中预览,会发现trains一栏的数据为null,表示没有抓取到相关内容:
我们下载捕获的CSV文件并在预览器中打开后,我们会发现出现了列车号的数据,但是出发站的数据又为空了!
这不是傻子!
我已经研究这个问题很长时间了。应该是Web Scraper对中文关键词索引的支持不是很友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表数据,可以使用前面的方案,先创建一个Element类型的容器,然后在容器中手动创建一个子选择器,这样就可以避免这个问题了。
以上只是一个原因,另一个原因是,在现代 网站 中,很少有人再使用 HTML 原创表格了。
HTML 为表格提供了基本的标签,例如 、 、 等,这些标签提供了默认样式。优点是互联网刚开发的时候,可以提供开箱即用的形式;缺点是样式过于简单,不易定制。后来很多网站用其他标签来模拟表格,就像PPT用各种大小的块组合成一个表格,很容易自定义:
正因如此,当你使用Table Selector匹配一个表格的时候,可能会匹配不上,因为从Web Scraper的角度来看,你看到的表格是高仿的,根本不是原装的,自然不是。认可。
3.总结
我们不建议直接使用 Web Scraper 的 Table Selector,因为它对中文支持不是很友好,也不太适合现代网页。如果有抢表的需求,可以使用之前创建父子选择器的方法来做。 查看全部
网页表格抓取(这是简易数据分析系列的第11篇文章(图)制作)
这是简易数据分析系列文章的第11期。
今天我们将讨论如何在 Web 表单中捕获数据。首先我们来分析一下网页中的经典表格是如何组成的。
经典的表格都是关于这些知识点的,没了。让我们编写一个简单的表单 Web Scraper 爬虫。
1.创建站点地图
我们今天的练习 网站 是
�Ϻ�&txt刀大=����
爬虫的内容是爬取上海到北京的所有火车时刻表。
我们首先创建一个收录整个表格的容器,并将Type选择为Table,表示我们要抓取表格。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。如果你看一下,你会发现这些数据实际上是表数据类型的分类。在这种情况下,他列出了火车、出发站和行驶时间的类别。
在表格列类别中,默认勾选每行内容旁边的选择按钮,这意味着默认捕获这些列的内容。如果您不想爬取某种类型的内容,只需去掉相应的复选框即可。
当你点击保存选择器按钮的时候,你会发现Result键的一些选项报错,说invalid format format无效:
解决这个错误非常简单。一般来说,Result 键名的长度是不够的。您可以添加空格和标点符号。如果仍然出现错误,请尝试更改为英文名称:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程抓取数据了。
2.我为什么不建议你使用 Web Scraper 的表格选择器?
如果按照刚才的教程,感觉会很流畅,但是看数据的时候,就傻眼了。
刚开始爬的时候,我们先用Data preview预览数据,发现数据很完美:
抓取数据后,在浏览器的预览面板中预览,会发现trains一栏的数据为null,表示没有抓取到相关内容:
我们下载捕获的CSV文件并在预览器中打开后,我们会发现出现了列车号的数据,但是出发站的数据又为空了!
这不是傻子!
我已经研究这个问题很长时间了。应该是Web Scraper对中文关键词索引的支持不是很友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表数据,可以使用前面的方案,先创建一个Element类型的容器,然后在容器中手动创建一个子选择器,这样就可以避免这个问题了。
以上只是一个原因,另一个原因是,在现代 网站 中,很少有人再使用 HTML 原创表格了。
HTML 为表格提供了基本的标签,例如 、 、 等,这些标签提供了默认样式。优点是互联网刚开发的时候,可以提供开箱即用的形式;缺点是样式过于简单,不易定制。后来很多网站用其他标签来模拟表格,就像PPT用各种大小的块组合成一个表格,很容易自定义:
正因如此,当你使用Table Selector匹配一个表格的时候,可能会匹配不上,因为从Web Scraper的角度来看,你看到的表格是高仿的,根本不是原装的,自然不是。认可。
3.总结
我们不建议直接使用 Web Scraper 的 Table Selector,因为它对中文支持不是很友好,也不太适合现代网页。如果有抢表的需求,可以使用之前创建父子选择器的方法来做。
网页表格抓取( 终端窗口查询全国3400多个区县当日天气信息和近七天信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-12 23:03
终端窗口查询全国3400多个区县当日天气信息和近七天信息)
写一个爬中国天气网的终端版天气预报爬虫
前几篇文章介绍了爬取静态网站的主要方法。今天写一个小项目来练习。本项目可在终端窗口查询全国3400多个区县当天及过去7天的天气信息。实现获取原创链接文件的效果:在公众号Thumbnote后台回复“天气预报”即可获取相关节目和城市id文件。使用方法:在终端窗口运行程序,输入要查询的区县名称(如:丰台、静安等)。相关模块 pandas:读取城市 ID 文件 prettytable:输出 ASC 样式表 bs4:解析网页 天气信息存储在不同的网页中,其 url 如下
现在下载
wiki-scraper:从维基百科中抓取表格和其他信息 - 源代码
Wikicrawler 这是一个简单的脚本,它从 Wikipedia 抓取数据表以安装所需的软件包: pip install beautifulsoup4, pip install pandas 这个例子从一个城市的大都市区抓取人口数据。输出 .dat 文件由双冒号分隔。基于 ADEsquared 的教程::///2013/06/16/using-python-beautifulsoup-to-scrape-a-wikipedia-table/
现在下载
Python 读取文本中的数据并将其转换为 DataFrame 的实例
在一次技术问答中看到这样的问题,觉得比较常见,所以就点开一篇文章文章写下来。从纯文本文件“file_in”中读取数据,格式如下:需要输出到“file_out”,格式如下:数据的原创格式为“category: content”,空行“ \n"作为条目,转换后变成一个条目一行,内容按类别顺序写出。建议看完后使用pandas将数据构建成一个名为DataFrame的表。这使得以后处理数据更容易。但是原创格式不是通常的表格格式,所以先做一些简单的处理。#coding:utf8import sysfrom pandas import DataFrame #DataFrame 通常用于加载二维表导入
现在下载
双色球的单线程爬行网站.py
通过pandas爬表,可供个人测试,爬取双色球网站的所有数据。注意:抓取访问为csv格式,可以在excel中读取,但建议在excel中编辑后保存为xlsx格式,否则会造成混乱。
现在下载
pandas 实现了一种对重复表进行去重并重新转换为表的方法
在python中处理数据时,经常使用DataFrame和set。train=pd.read_csv('XXX.csv')#读取文件 train=train['item_id']#选择要重复的列 train=set(train)#删除数据=pd.DataFrame(list(train) , columns=['item_id'])#因为集合是无序的,所以必须经过列表处理才能成为DataFramedata.to_csv('xxx.csv',index=False)#保存表格记得导入pandas~以上文章Pandas实现了对重复表进行去重再转表的方法。小编分享给大家。
现在下载
Matplotlib图形化分析猪肉价格上涨趋势,pandas数据处理
1.爬取新发地果蔬价格csv,上一张表的内容,爬取新发地果蔬价格并保存为csv格式,筛选出毛猪和白条猪,< @2. 筛选分析猪肉价格,使用matplotlib库制作趋势图#pandasimport pandas as pd #导入数据处理工具pandasimport matplotlib.pyplot as plt#导入图形展示工具matplotlibdataframe = pd.read_csv(新菜价.csv, header=None)#print(dataframe )#获取数据 fei = dataframe[dataframe[0] == 白猪(胖)]shou =
现在下载
300hero_report:300英雄记录查询-源码
300英雄记录查询一个爬虫+一个GUI来下载数据并找到一种显示方式。scrapy PyQt matplotlib 还没有完成。操作方法为python 300hero.pyTODO,防止爬取重复信息数据,存入本地库。查询时,优先从本地库中获取。当你点击某个会话时,会弹出一个对话框,显示该字段的详细数据,并使数据显示更规则(可能你需要pandas和matplotlib)加点图表(组分数变化图表...)多窗口(点击显示详细战况)然后一个网页端具体游戏数据,不再使用爬虫,使用api获取Bug 重复查询会报错 twisted.internet.error 。
现在下载
使用xpath爬取链家租房数据并使用pandas保存到Excel文件
<p>我们的需求是使用xpath爬取链家的租房数据,并通过pandas将数据保存到Excel文件中。我们来看看链家官网的上市信息(以北京为例)。如图,我们通过筛选得到北京。出租信息然后我们需要通过爬虫提取房屋面积、小区名称、户型、面积、朝向、价格等信息。思考步骤:1.通过翻页,我们看到总页数是100页,那么我们需要通过format方法获取100个url地址列表url_list; 查看全部
网页表格抓取(
终端窗口查询全国3400多个区县当日天气信息和近七天信息)
写一个爬中国天气网的终端版天气预报爬虫
前几篇文章介绍了爬取静态网站的主要方法。今天写一个小项目来练习。本项目可在终端窗口查询全国3400多个区县当天及过去7天的天气信息。实现获取原创链接文件的效果:在公众号Thumbnote后台回复“天气预报”即可获取相关节目和城市id文件。使用方法:在终端窗口运行程序,输入要查询的区县名称(如:丰台、静安等)。相关模块 pandas:读取城市 ID 文件 prettytable:输出 ASC 样式表 bs4:解析网页 天气信息存储在不同的网页中,其 url 如下
现在下载
wiki-scraper:从维基百科中抓取表格和其他信息 - 源代码
Wikicrawler 这是一个简单的脚本,它从 Wikipedia 抓取数据表以安装所需的软件包: pip install beautifulsoup4, pip install pandas 这个例子从一个城市的大都市区抓取人口数据。输出 .dat 文件由双冒号分隔。基于 ADEsquared 的教程::///2013/06/16/using-python-beautifulsoup-to-scrape-a-wikipedia-table/
现在下载
Python 读取文本中的数据并将其转换为 DataFrame 的实例
在一次技术问答中看到这样的问题,觉得比较常见,所以就点开一篇文章文章写下来。从纯文本文件“file_in”中读取数据,格式如下:需要输出到“file_out”,格式如下:数据的原创格式为“category: content”,空行“ \n"作为条目,转换后变成一个条目一行,内容按类别顺序写出。建议看完后使用pandas将数据构建成一个名为DataFrame的表。这使得以后处理数据更容易。但是原创格式不是通常的表格格式,所以先做一些简单的处理。#coding:utf8import sysfrom pandas import DataFrame #DataFrame 通常用于加载二维表导入
现在下载
双色球的单线程爬行网站.py
通过pandas爬表,可供个人测试,爬取双色球网站的所有数据。注意:抓取访问为csv格式,可以在excel中读取,但建议在excel中编辑后保存为xlsx格式,否则会造成混乱。
现在下载
pandas 实现了一种对重复表进行去重并重新转换为表的方法
在python中处理数据时,经常使用DataFrame和set。train=pd.read_csv('XXX.csv')#读取文件 train=train['item_id']#选择要重复的列 train=set(train)#删除数据=pd.DataFrame(list(train) , columns=['item_id'])#因为集合是无序的,所以必须经过列表处理才能成为DataFramedata.to_csv('xxx.csv',index=False)#保存表格记得导入pandas~以上文章Pandas实现了对重复表进行去重再转表的方法。小编分享给大家。
现在下载
Matplotlib图形化分析猪肉价格上涨趋势,pandas数据处理
1.爬取新发地果蔬价格csv,上一张表的内容,爬取新发地果蔬价格并保存为csv格式,筛选出毛猪和白条猪,< @2. 筛选分析猪肉价格,使用matplotlib库制作趋势图#pandasimport pandas as pd #导入数据处理工具pandasimport matplotlib.pyplot as plt#导入图形展示工具matplotlibdataframe = pd.read_csv(新菜价.csv, header=None)#print(dataframe )#获取数据 fei = dataframe[dataframe[0] == 白猪(胖)]shou =
现在下载
300hero_report:300英雄记录查询-源码
300英雄记录查询一个爬虫+一个GUI来下载数据并找到一种显示方式。scrapy PyQt matplotlib 还没有完成。操作方法为python 300hero.pyTODO,防止爬取重复信息数据,存入本地库。查询时,优先从本地库中获取。当你点击某个会话时,会弹出一个对话框,显示该字段的详细数据,并使数据显示更规则(可能你需要pandas和matplotlib)加点图表(组分数变化图表...)多窗口(点击显示详细战况)然后一个网页端具体游戏数据,不再使用爬虫,使用api获取Bug 重复查询会报错 twisted.internet.error 。
现在下载
使用xpath爬取链家租房数据并使用pandas保存到Excel文件
<p>我们的需求是使用xpath爬取链家的租房数据,并通过pandas将数据保存到Excel文件中。我们来看看链家官网的上市信息(以北京为例)。如图,我们通过筛选得到北京。出租信息然后我们需要通过爬虫提取房屋面积、小区名称、户型、面积、朝向、价格等信息。思考步骤:1.通过翻页,我们看到总页数是100页,那么我们需要通过format方法获取100个url地址列表url_list;
网页表格抓取(如何用Python爬数据?(第三弹)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-02-12 12:03
阿里云 > 云栖社区 > 主题地图 > R > 如何爬取Web表单数据库
推荐活动:
更多优惠>
当前主题:如何爬取网页表单数据库添加到采集夹
相关话题:
如何抓取网页表单数据库相关的博客查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
如何使用 Python 抓取数据?(一)网页抓取
作者:王淑仪2089 浏览评论:03年前
你期待已久的 Python 网络数据爬虫教程就在这里。本文向您展示了如何从网页中查找感兴趣的链接和描述,并在 Excel 中抓取和存储它们。我需要在公众号后台,经常可以收到读者的消息。许多评论是读者的问题。只要我有时间,我会尝试回答它。但是有些消息乍一看似乎不清楚
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶387人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐人指定歌曲的歌曲名、专辑名、播放链接歌手并在指定页数中排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶397人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐人指定歌曲的歌曲名、专辑名、播放链接歌手并在指定页数中排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
初学者指南 | 使用 Python 进行网页抓取
作者:小旋风柴津2425查看评论:04年前
简介 从网页中提取信息的需求和重要性正在增长。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。
阅读全文
云计算时代企业该如何拥抱大数据?
作者:云栖大讲堂 1408 观众评论:04年前
这篇文章是关于企业在云计算时代应该如何拥抱大数据。随着云计算的实施,“大数据”已经成为业界讨论最广泛的话题之一,许多企业已经在寻找合适的 BI 工具来处理从不同来源采集的大数据,但尽管大数据意识不断增强,只有谷歌和 Facebook 等少数企业能够
阅读全文
云计算时代企业该如何拥抱大数据?
作者:云栖大讲堂 969人浏览评论:04年前
这篇文章是关于企业在云计算时代应该如何拥抱大数据。随着云计算的实施,“大数据”已经成为业界讨论最广泛的话题之一,许多企业已经在寻找合适的 BI 工具来处理从不同来源采集的大数据,但尽管大数据意识不断增强,只有谷歌和 Facebook 等少数企业能够
阅读全文
使用 Scrapy 抓取数据
作者:御客6542 浏览评论:05年前
Scrapy 是一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
《用 Python 编写网络爬虫》——2.2 三种网络爬取方法
作者:异步社区 3748人查看评论:04年前
本节节选自异步社区《Writing Web Crawler in Python》一书第2章第2.2节,作者【澳大利亚】Richard Lawson,李斌翻译,更多章节内容可以参考访问云栖社区“异步社区”公众号查看。2.2 三种网页抓取方式 既然我们了解了网页的结构,以下
阅读全文
如何爬取web表单数据库相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
网页表格抓取(如何用Python爬数据?(第三弹)(组图))
阿里云 > 云栖社区 > 主题地图 > R > 如何爬取Web表单数据库
推荐活动:
更多优惠>
当前主题:如何爬取网页表单数据库添加到采集夹
相关话题:
如何抓取网页表单数据库相关的博客查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
如何使用 Python 抓取数据?(一)网页抓取
作者:王淑仪2089 浏览评论:03年前
你期待已久的 Python 网络数据爬虫教程就在这里。本文向您展示了如何从网页中查找感兴趣的链接和描述,并在 Excel 中抓取和存储它们。我需要在公众号后台,经常可以收到读者的消息。许多评论是读者的问题。只要我有时间,我会尝试回答它。但是有些消息乍一看似乎不清楚
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶387人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐人指定歌曲的歌曲名、专辑名、播放链接歌手并在指定页数中排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶397人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐人指定歌曲的歌曲名、专辑名、播放链接歌手并在指定页数中排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
初学者指南 | 使用 Python 进行网页抓取
作者:小旋风柴津2425查看评论:04年前
简介 从网页中提取信息的需求和重要性正在增长。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。
阅读全文
云计算时代企业该如何拥抱大数据?
作者:云栖大讲堂 1408 观众评论:04年前
这篇文章是关于企业在云计算时代应该如何拥抱大数据。随着云计算的实施,“大数据”已经成为业界讨论最广泛的话题之一,许多企业已经在寻找合适的 BI 工具来处理从不同来源采集的大数据,但尽管大数据意识不断增强,只有谷歌和 Facebook 等少数企业能够
阅读全文
云计算时代企业该如何拥抱大数据?
作者:云栖大讲堂 969人浏览评论:04年前
这篇文章是关于企业在云计算时代应该如何拥抱大数据。随着云计算的实施,“大数据”已经成为业界讨论最广泛的话题之一,许多企业已经在寻找合适的 BI 工具来处理从不同来源采集的大数据,但尽管大数据意识不断增强,只有谷歌和 Facebook 等少数企业能够
阅读全文
使用 Scrapy 抓取数据
作者:御客6542 浏览评论:05年前
Scrapy 是一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
《用 Python 编写网络爬虫》——2.2 三种网络爬取方法
作者:异步社区 3748人查看评论:04年前
本节节选自异步社区《Writing Web Crawler in Python》一书第2章第2.2节,作者【澳大利亚】Richard Lawson,李斌翻译,更多章节内容可以参考访问云栖社区“异步社区”公众号查看。2.2 三种网页抓取方式 既然我们了解了网页的结构,以下
阅读全文
如何爬取web表单数据库相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
网页表格抓取(本文实例讲述Python实现抓取网页生成Excel文件的方法。 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-11 22:07
)
本文中的示例描述了 Python 如何实现爬取网页以生成 Excel 文件。分享给大家,供大家参考,如下:
Python抓取网页,主要使用PyQuery,和jQuery一样,超级强大
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
接下来就是用Notepad++打开gongsi.csv,然后转换成ANSI编码格式保存。然后用Excel软件打开csv文件,保存为Excel文件
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python中Excel表格技巧总结》、《Python文件和目录操作技巧总结》、《Python文本文件操作总结》 《技能》、《Python数据》《结构与算法教程》、《Python函数技巧总结》、《Python字符串操作技巧总结》和《Python入门与进阶经典教程》
希望这篇文章对你的 Python 编程有所帮助。
Python如何实现爬取网页生成Excel文件的例子 查看全部
网页表格抓取(本文实例讲述Python实现抓取网页生成Excel文件的方法。
)
本文中的示例描述了 Python 如何实现爬取网页以生成 Excel 文件。分享给大家,供大家参考,如下:
Python抓取网页,主要使用PyQuery,和jQuery一样,超级强大
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
接下来就是用Notepad++打开gongsi.csv,然后转换成ANSI编码格式保存。然后用Excel软件打开csv文件,保存为Excel文件
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python中Excel表格技巧总结》、《Python文件和目录操作技巧总结》、《Python文本文件操作总结》 《技能》、《Python数据》《结构与算法教程》、《Python函数技巧总结》、《Python字符串操作技巧总结》和《Python入门与进阶经典教程》
希望这篇文章对你的 Python 编程有所帮助。
Python如何实现爬取网页生成Excel文件的例子
网页表格抓取(如何用Python爬数据?(第三弹)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-02-10 21:14
阿里云 > 云栖社区 > 主题地图 > R > 如何爬取Web表单数据库
推荐活动:
更多优惠>
当前主题:如何爬取网页表单数据库添加到采集夹
相关话题:
如何抓取网页表单数据库相关的博客查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
如何使用 Python 抓取数据?(一)网页抓取
作者:王淑仪2089 浏览评论:03年前
你期待已久的 Python 网络数据爬虫教程就在这里。本文向您展示了如何从网页中查找感兴趣的链接和描述,并在 Excel 中抓取和存储它们。我需要在公众号后台,经常可以收到读者的消息。许多评论是读者的问题。只要我有时间,我会尝试回答它。但是有些消息乍一看似乎不清楚
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶387人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐人指定歌曲的歌曲名、专辑名、播放链接歌手并在指定页数中排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶397人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐人指定歌曲的歌曲名、专辑名、播放链接歌手并在指定页数中排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
初学者指南 | 使用 Python 进行网页抓取
作者:小旋风柴津2425查看评论:04年前
简介 从网页中提取信息的需求和重要性正在增长。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。
阅读全文
云计算时代企业该如何拥抱大数据?
作者:云栖大讲堂 1408 观众评论:04年前
这篇文章是关于企业在云计算时代应该如何拥抱大数据。随着云计算的实施,“大数据”已成为业界讨论最广泛的话题之一,许多企业已经在寻找合适的 BI 工具来处理从不同来源采集的大数据,但尽管大数据意识不断增强,只有谷歌和 Facebook 等少数企业能够
阅读全文
云计算时代企业该如何拥抱大数据?
作者:云栖大讲堂 969人浏览评论:04年前
这篇文章是关于企业在云计算时代应该如何拥抱大数据。随着云计算的实施,“大数据”已成为业界讨论最广泛的话题之一,许多企业已经在寻找合适的 BI 工具来处理从不同来源采集的大数据,但尽管大数据意识不断增强,只有谷歌和 Facebook 等少数企业能够
阅读全文
使用 Scrapy 抓取数据
作者:御客6542 浏览评论:05年前
Scrapy 是一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
《用 Python 编写网络爬虫》——2.2 三种网络爬取方法
作者:异步社区 3748人查看评论:04年前
本节节选自异步社区《Writing Web Crawler in Python》一书第2章第2.2节,作者【澳大利亚】Richard Lawson,李斌翻译,更多章节内容可以参考访问云栖社区“异步社区”公众号查看。2.2 三种网页抓取方式 既然我们了解了网页的结构,以下
阅读全文
如何爬取web表单数据库相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
网页表格抓取(如何用Python爬数据?(第三弹)(组图))
阿里云 > 云栖社区 > 主题地图 > R > 如何爬取Web表单数据库
推荐活动:
更多优惠>
当前主题:如何爬取网页表单数据库添加到采集夹
相关话题:
如何抓取网页表单数据库相关的博客查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
如何使用 Python 抓取数据?(一)网页抓取
作者:王淑仪2089 浏览评论:03年前
你期待已久的 Python 网络数据爬虫教程就在这里。本文向您展示了如何从网页中查找感兴趣的链接和描述,并在 Excel 中抓取和存储它们。我需要在公众号后台,经常可以收到读者的消息。许多评论是读者的问题。只要我有时间,我会尝试回答它。但是有些消息乍一看似乎不清楚
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶387人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐人指定歌曲的歌曲名、专辑名、播放链接歌手并在指定页数中排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶397人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐人指定歌曲的歌曲名、专辑名、播放链接歌手并在指定页数中排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
初学者指南 | 使用 Python 进行网页抓取
作者:小旋风柴津2425查看评论:04年前
简介 从网页中提取信息的需求和重要性正在增长。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。
阅读全文
云计算时代企业该如何拥抱大数据?
作者:云栖大讲堂 1408 观众评论:04年前
这篇文章是关于企业在云计算时代应该如何拥抱大数据。随着云计算的实施,“大数据”已成为业界讨论最广泛的话题之一,许多企业已经在寻找合适的 BI 工具来处理从不同来源采集的大数据,但尽管大数据意识不断增强,只有谷歌和 Facebook 等少数企业能够
阅读全文
云计算时代企业该如何拥抱大数据?
作者:云栖大讲堂 969人浏览评论:04年前
这篇文章是关于企业在云计算时代应该如何拥抱大数据。随着云计算的实施,“大数据”已成为业界讨论最广泛的话题之一,许多企业已经在寻找合适的 BI 工具来处理从不同来源采集的大数据,但尽管大数据意识不断增强,只有谷歌和 Facebook 等少数企业能够
阅读全文
使用 Scrapy 抓取数据
作者:御客6542 浏览评论:05年前
Scrapy 是一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
《用 Python 编写网络爬虫》——2.2 三种网络爬取方法
作者:异步社区 3748人查看评论:04年前
本节节选自异步社区《Writing Web Crawler in Python》一书第2章第2.2节,作者【澳大利亚】Richard Lawson,李斌翻译,更多章节内容可以参考访问云栖社区“异步社区”公众号查看。2.2 三种网页抓取方式 既然我们了解了网页的结构,以下
阅读全文
如何爬取web表单数据库相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
网页表格抓取(Google为什么做网站时一定要注意搜索引擎友好(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-02-10 01:21
虽然谷歌已经是爬取页面最多的搜索引擎,但仍然不满足,因为有很多页面和信息很难找到和爬取。这就是为什么在执行 网站 时对 SEO 友好很重要的原因。
现在谷歌开始提供提交表单(form)来发现后续页面。本来想写详细说明的,结果刚看到写了幻灭,直接引用主要内容如下。
我们已经知道Googlebot除了文字、视频、音频、Flash等类型的内容外,还可以通过JS代码抓取链接。而在未来,Googlebot 也有望直接识别图片和视频中的文字。为了进一步抓取互联网,Google 宣布 Googlebot 已经能够通过提交表单抓取更多内容。
据 Google 称,Googlebot 目前正在试验一小部分高质量的 网站 表单提交。当Googlebot在这些网站上找到HTML表格时(即检测到时),会自动从网站中选择一些词进入表格的文本框,然后选择不同的按钮,勾选选项和验证项目,然后提交表格。一旦 Googlebot 在提交表单后认为新内容看起来是合法、有趣和独特的,它可能会将内容抓取到 Google 的搜索结果索引数据库中。这意味着 Googlebot 现在知道如何通过提交表单来获取新内容。
同时谷歌还强调,如果在网站的robots.txt文件中禁止隐藏表单,并且表单提交后生成的链接预计不会被抓取,那么Googlebot不会爬行。此外,目前 Googlebot 仅提交 GET 类型的表单。例如,当表单需要用户个人信息(如密码、用户名、联系人等)时,Googlebot 会自动跳过这些表单。
这种形式的抓取目前是一个小型实验,Google 表示不会影响 网站。既不会影响网站的PR值,也不会影响网站的正常爬取和排名。
Matt Cutts 还写了一篇文章来说明这样做的好处。有很多网站主页只以表格的形式列出公司的子站,并没有以链接的形式列出子站。这种网站不能深入收录之前,因为谷歌不提交表单就找不到隐藏在表单后面的URL。
这当然给一些网站的收录创造了机会,但是否也给一些公司网站带来了一定的安全风险?网站如果你不想被收录屏蔽,请使用robots.txt文件来屏蔽它。 查看全部
网页表格抓取(Google为什么做网站时一定要注意搜索引擎友好(图))
虽然谷歌已经是爬取页面最多的搜索引擎,但仍然不满足,因为有很多页面和信息很难找到和爬取。这就是为什么在执行 网站 时对 SEO 友好很重要的原因。
现在谷歌开始提供提交表单(form)来发现后续页面。本来想写详细说明的,结果刚看到写了幻灭,直接引用主要内容如下。
我们已经知道Googlebot除了文字、视频、音频、Flash等类型的内容外,还可以通过JS代码抓取链接。而在未来,Googlebot 也有望直接识别图片和视频中的文字。为了进一步抓取互联网,Google 宣布 Googlebot 已经能够通过提交表单抓取更多内容。
据 Google 称,Googlebot 目前正在试验一小部分高质量的 网站 表单提交。当Googlebot在这些网站上找到HTML表格时(即检测到时),会自动从网站中选择一些词进入表格的文本框,然后选择不同的按钮,勾选选项和验证项目,然后提交表格。一旦 Googlebot 在提交表单后认为新内容看起来是合法、有趣和独特的,它可能会将内容抓取到 Google 的搜索结果索引数据库中。这意味着 Googlebot 现在知道如何通过提交表单来获取新内容。
同时谷歌还强调,如果在网站的robots.txt文件中禁止隐藏表单,并且表单提交后生成的链接预计不会被抓取,那么Googlebot不会爬行。此外,目前 Googlebot 仅提交 GET 类型的表单。例如,当表单需要用户个人信息(如密码、用户名、联系人等)时,Googlebot 会自动跳过这些表单。
这种形式的抓取目前是一个小型实验,Google 表示不会影响 网站。既不会影响网站的PR值,也不会影响网站的正常爬取和排名。
Matt Cutts 还写了一篇文章来说明这样做的好处。有很多网站主页只以表格的形式列出公司的子站,并没有以链接的形式列出子站。这种网站不能深入收录之前,因为谷歌不提交表单就找不到隐藏在表单后面的URL。
这当然给一些网站的收录创造了机会,但是否也给一些公司网站带来了一定的安全风险?网站如果你不想被收录屏蔽,请使用robots.txt文件来屏蔽它。
网页表格抓取(借助ABBYYFineReader15文字识别软件快速识别为表格数据表格)
网站优化 • 优采云 发表了文章 • 0 个评论 • 328 次浏览 • 2022-02-08 18:35
在一些政府公共信息共享网站或专业数据共享机构网站,会定期公开共享一些社会发展数据或与时事相关的数据。这些数据通常以网页的形式共享,很少提供文件下载。
如果直接复制这些数据,数据排版会耗费大量时间。但借助 ABBYY FineReader PDF 15 文本识别软件,可以快速识别为表格数据,并导出为可编辑的数据表。接下来,让我们看看它是如何工作的。
一、网页表格数据截图
首先打开相关数据网站,对数据表区域进行截图。
图1:打开网页截图
如图2所示,在截屏过程中,建议尽量保持表格边框的完整性,以提高ABBYY FineReader PDF 15的识别准确率。
图 2:完成的表格数据的屏幕截图
二、使用 OCR 编辑器识别表格
接下来,打开ABBYY FineReader PDF 15文本识别软件,使用“在OCR编辑器中打开”功能打开刚刚在网站截取的表格数据。
图 3:在 OCR 编辑器中打开图像
接下来,等待软件完成对图片的文字识别。在识别过程中,为了提高文字识别的准确率,软件会提示图片的分辨率或指定的OCR语言。如果条件允许(如提高图像分辨率),您可以按照建议修改相关设置。
图 4:完成 OCR 识别
完成文本识别程序后,我们首先需要在区域属性面板中检查表格标签的区域属性是否正确。如图 5 所示,可以看出 ABBYY FineReader PDF 15 已正确将此区域标记为表格区域。
图 5:区域属性
接下来,查看软件的文本编辑面板。如图 6 所示,可以看到文本已经以电子表格的形式呈现,并且可以在单元格中编辑文本。
图 6:文本编辑器
三、导出到 Excel
为了方便后续的数据处理,我们可以将识别出来的电子表格保存为Excel文件。如图7所示,在文本编辑面板顶部选择Excel表格的保存格式后,可以将当前文本导出为Excel文件。
图 7:另存为 Excel 工作表
打开导出的Excel文件,可以看到ABBYY FineReader PDF 15不仅可以准确识别数据,还可以“复制”表格的格式,很好地将数据导出到每个单元格。这种形式的导出可以减少排版大量数据所需的时间。
图 8:导出的 Excel 表格
四、总结
通过使用ABBYY文字识别软件的数据表格识别功能,我们可以快速将图片中的表格转换成可编辑的电子表格,提高数据使用效率。这么好用的功能,你学会了吗? 查看全部
网页表格抓取(借助ABBYYFineReader15文字识别软件快速识别为表格数据表格)
在一些政府公共信息共享网站或专业数据共享机构网站,会定期公开共享一些社会发展数据或与时事相关的数据。这些数据通常以网页的形式共享,很少提供文件下载。
如果直接复制这些数据,数据排版会耗费大量时间。但借助 ABBYY FineReader PDF 15 文本识别软件,可以快速识别为表格数据,并导出为可编辑的数据表。接下来,让我们看看它是如何工作的。
一、网页表格数据截图
首先打开相关数据网站,对数据表区域进行截图。
图1:打开网页截图
如图2所示,在截屏过程中,建议尽量保持表格边框的完整性,以提高ABBYY FineReader PDF 15的识别准确率。
图 2:完成的表格数据的屏幕截图
二、使用 OCR 编辑器识别表格
接下来,打开ABBYY FineReader PDF 15文本识别软件,使用“在OCR编辑器中打开”功能打开刚刚在网站截取的表格数据。
图 3:在 OCR 编辑器中打开图像
接下来,等待软件完成对图片的文字识别。在识别过程中,为了提高文字识别的准确率,软件会提示图片的分辨率或指定的OCR语言。如果条件允许(如提高图像分辨率),您可以按照建议修改相关设置。
图 4:完成 OCR 识别
完成文本识别程序后,我们首先需要在区域属性面板中检查表格标签的区域属性是否正确。如图 5 所示,可以看出 ABBYY FineReader PDF 15 已正确将此区域标记为表格区域。
图 5:区域属性
接下来,查看软件的文本编辑面板。如图 6 所示,可以看到文本已经以电子表格的形式呈现,并且可以在单元格中编辑文本。
图 6:文本编辑器
三、导出到 Excel
为了方便后续的数据处理,我们可以将识别出来的电子表格保存为Excel文件。如图7所示,在文本编辑面板顶部选择Excel表格的保存格式后,可以将当前文本导出为Excel文件。
图 7:另存为 Excel 工作表
打开导出的Excel文件,可以看到ABBYY FineReader PDF 15不仅可以准确识别数据,还可以“复制”表格的格式,很好地将数据导出到每个单元格。这种形式的导出可以减少排版大量数据所需的时间。
图 8:导出的 Excel 表格
四、总结
通过使用ABBYY文字识别软件的数据表格识别功能,我们可以快速将图片中的表格转换成可编辑的电子表格,提高数据使用效率。这么好用的功能,你学会了吗?

